Repository: jindongwang/transferlearning
Branch: master
Commit: d77ef50a2e7e
Files: 461
Total size: 3.2 MB
Directory structure:
gitextract_9o7g7l9e/
├── .gitattributes
├── .github/
│ ├── FUNDING.yml
│ └── ISSUE_TEMPLATE/
│ └── bug_report.md
├── .gitignore
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── code/
│ ├── ASR/
│ │ ├── Adapter/
│ │ │ ├── README.md
│ │ │ ├── balanced_sampler.py
│ │ │ ├── config/
│ │ │ │ ├── adapter_example.yaml
│ │ │ │ ├── adapterfusion_example.yaml
│ │ │ │ ├── finetune_meta_adapter_example.yaml
│ │ │ │ └── meta_adapter_example.yaml
│ │ │ ├── data_load.py
│ │ │ ├── e2e_asr_adaptertransformer.py
│ │ │ ├── train.py
│ │ │ └── utils.py
│ │ ├── CMatch/
│ │ │ ├── README.md
│ │ │ ├── config/
│ │ │ │ ├── adv_example.yaml
│ │ │ │ ├── ctc_align_example.yaml
│ │ │ │ ├── frame_average_example.yaml
│ │ │ │ ├── mmd_example.yaml
│ │ │ │ ├── pseudo_ctc_pred_example.yaml
│ │ │ │ └── train.yaml
│ │ │ ├── ctc_aligner.py
│ │ │ ├── data_load.py
│ │ │ ├── distances.py
│ │ │ ├── e2e_asr_udatransformer.py
│ │ │ ├── train.py
│ │ │ └── utils.py
│ │ └── readme.md
│ ├── BDA/
│ │ └── readme.md
│ ├── DeepDA/
│ │ ├── BNM/
│ │ │ ├── BNM.sh
│ │ │ ├── BNM.yaml
│ │ │ └── README.md
│ │ ├── DAAN/
│ │ │ ├── DAAN.sh
│ │ │ └── DAAN.yaml
│ │ ├── DAN/
│ │ │ ├── DAN.sh
│ │ │ ├── DAN.yaml
│ │ │ └── README.md
│ │ ├── DANN/
│ │ │ ├── DANN.sh
│ │ │ ├── DANN.yaml
│ │ │ └── readme.md
│ │ ├── DSAN/
│ │ │ ├── DSAN.sh
│ │ │ ├── DSAN.yaml
│ │ │ └── README.md
│ │ ├── DeepCoral/
│ │ │ ├── DeepCoral.sh
│ │ │ ├── DeepCoral.yaml
│ │ │ └── README.md
│ │ ├── README.md
│ │ ├── backbones.py
│ │ ├── data_loader.py
│ │ ├── loss_funcs/
│ │ │ ├── __init__.py
│ │ │ ├── adv.py
│ │ │ ├── bnm.py
│ │ │ ├── coral.py
│ │ │ ├── daan.py
│ │ │ ├── lmmd.py
│ │ │ └── mmd.py
│ │ ├── main.py
│ │ ├── models.py
│ │ ├── requirements.txt
│ │ ├── transfer_losses.py
│ │ └── utils.py
│ ├── DeepDG/
│ │ ├── alg/
│ │ │ ├── alg.py
│ │ │ ├── algs/
│ │ │ │ ├── ANDMask.py
│ │ │ │ ├── CORAL.py
│ │ │ │ ├── DANN.py
│ │ │ │ ├── DIFEX.py
│ │ │ │ ├── ERM.py
│ │ │ │ ├── GroupDRO.py
│ │ │ │ ├── MLDG.py
│ │ │ │ ├── MMD.py
│ │ │ │ ├── Mixup.py
│ │ │ │ ├── RSC.py
│ │ │ │ ├── VREx.py
│ │ │ │ └── base.py
│ │ │ ├── modelopera.py
│ │ │ └── opt.py
│ │ ├── datautil/
│ │ │ ├── getdataloader.py
│ │ │ ├── imgdata/
│ │ │ │ ├── imgdataload.py
│ │ │ │ └── util.py
│ │ │ ├── mydataloader.py
│ │ │ └── util.py
│ │ ├── network/
│ │ │ ├── Adver_network.py
│ │ │ ├── common_network.py
│ │ │ ├── img_network.py
│ │ │ └── util.py
│ │ ├── readme.md
│ │ ├── requirements.txt
│ │ ├── scripts/
│ │ │ ├── paramsref.md
│ │ │ └── run.sh
│ │ ├── train.py
│ │ └── utils/
│ │ └── util.py
│ ├── Integrated sensing and communication (LSTM and VGG 16 model for digit and image classification, will be used for sensing and communication in 6G networks)
│ ├── README.md
│ ├── clip/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── clip_model.py
│ │ ├── data/
│ │ │ ├── data_loader.py
│ │ │ ├── download_data.py
│ │ │ └── download_data_azcopy.py
│ │ ├── log/
│ │ │ └── log.txt
│ │ ├── main.py
│ │ ├── requirements.txt
│ │ ├── test_clip.py
│ │ └── utils.py
│ ├── deep/
│ │ ├── B-JMMD/
│ │ │ ├── README.md
│ │ │ └── caffe/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── CONTRIBUTING.md
│ │ │ ├── CONTRIBUTORS.md
│ │ │ ├── INSTALL.md
│ │ │ ├── LICENSE
│ │ │ ├── Makefile
│ │ │ ├── Makefile.config.example
│ │ │ ├── README.md
│ │ │ ├── caffe.cloc
│ │ │ ├── data/
│ │ │ │ ├── imageCLEF/
│ │ │ │ │ ├── bList.txt
│ │ │ │ │ ├── cList.txt
│ │ │ │ │ ├── iList.txt
│ │ │ │ │ └── pList.txt
│ │ │ │ └── office/
│ │ │ │ ├── amazon_list.txt
│ │ │ │ ├── bList.txt
│ │ │ │ ├── cList.txt
│ │ │ │ ├── dslr_list.txt
│ │ │ │ ├── iList.txt
│ │ │ │ ├── pList.txt
│ │ │ │ └── webcam_list.txt
│ │ │ ├── include/
│ │ │ │ └── caffe/
│ │ │ │ └── layers/
│ │ │ │ └── bjmmd_layer.hpp
│ │ │ ├── kmake.sh
│ │ │ ├── models/
│ │ │ │ ├── B-JMMD/
│ │ │ │ │ ├── alexnet/
│ │ │ │ │ │ ├── solver.prototxt
│ │ │ │ │ │ └── train_val.prototxt
│ │ │ │ │ └── resnet/
│ │ │ │ │ ├── solver.prototxt
│ │ │ │ │ └── train_val.prototxt
│ │ │ │ └── bvlc_reference_caffenet/
│ │ │ │ ├── deploy.prototxt
│ │ │ │ ├── readme.md
│ │ │ │ ├── solver.prototxt
│ │ │ │ └── train_val.prototxt
│ │ │ └── src/
│ │ │ └── caffe/
│ │ │ ├── layers/
│ │ │ │ ├── bjmmd_layer.cpp
│ │ │ │ └── bjmmd_layer.cu
│ │ │ └── proto/
│ │ │ └── caffe.proto
│ │ ├── CSG/
│ │ │ ├── README.md
│ │ │ ├── a-domainbed/
│ │ │ │ ├── main.py
│ │ │ │ ├── prepare_data.sh
│ │ │ │ ├── run_da.sh
│ │ │ │ ├── run_ood.sh
│ │ │ │ └── visual.py
│ │ │ ├── a-imageclef/
│ │ │ │ ├── main.py
│ │ │ │ ├── prepare_data.sh
│ │ │ │ ├── run_da.sh
│ │ │ │ ├── run_ood.sh
│ │ │ │ └── visual.py
│ │ │ ├── a-mnist/
│ │ │ │ ├── main.py
│ │ │ │ ├── makedata.py
│ │ │ │ ├── makedata.sh
│ │ │ │ ├── run_da.sh
│ │ │ │ └── run_ood.sh
│ │ │ ├── arch/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── backbone.py
│ │ │ │ ├── cnn.py
│ │ │ │ ├── mlp.py
│ │ │ │ └── mlpstru.json
│ │ │ ├── distr/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── instances.py
│ │ │ │ ├── tools.py
│ │ │ │ └── utils.py
│ │ │ ├── methods/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cnbb.py
│ │ │ │ ├── semvar.py
│ │ │ │ ├── supvae.py
│ │ │ │ └── xdistr.py
│ │ │ ├── requirements.txt
│ │ │ ├── test/
│ │ │ │ ├── distr_test.ipynb
│ │ │ │ ├── distr_test.py
│ │ │ │ └── utils_test.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── preprocess/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_list.py
│ │ │ │ ├── data_loader.py
│ │ │ │ └── data_provider.py
│ │ │ ├── reprun.sh
│ │ │ ├── utils.py
│ │ │ └── utils_main.py
│ │ ├── DAAN/
│ │ │ ├── README.md
│ │ │ ├── data_loader.py
│ │ │ ├── functions.py
│ │ │ ├── log/
│ │ │ │ └── tmp-2019-10-27-22-13-51.log
│ │ │ ├── model/
│ │ │ │ ├── DAAN.py
│ │ │ │ ├── __init__.py
│ │ │ │ └── backbone.py
│ │ │ ├── scripts/
│ │ │ │ └── train.sh
│ │ │ └── train.py
│ │ ├── DAN/
│ │ │ └── README.md
│ │ ├── DANN(RevGrad)/
│ │ │ ├── adv_layer.py
│ │ │ └── readme.md
│ │ ├── DDC_DeepCoral/
│ │ │ └── README.md
│ │ ├── DSAN/
│ │ │ └── README.md
│ │ ├── DaNN/
│ │ │ ├── DaNN.py
│ │ │ ├── data_loader.py
│ │ │ ├── main.py
│ │ │ ├── mmd.py
│ │ │ └── readme.md
│ │ ├── DeepCoral/
│ │ │ └── README.md
│ │ ├── DeepMEDA/
│ │ │ ├── README.md
│ │ │ ├── ResNet.py
│ │ │ ├── Weight.py
│ │ │ ├── data_loader.py
│ │ │ ├── deep_meda.py
│ │ │ ├── dynamic_factor.py
│ │ │ ├── main.py
│ │ │ └── mmd.py
│ │ ├── Learning-to-Match/
│ │ │ └── README.md
│ │ ├── MRAN/
│ │ │ ├── MRAN.py
│ │ │ ├── README.md
│ │ │ ├── ResNet.py
│ │ │ ├── data_loader.py
│ │ │ └── mmd.py
│ │ ├── README.md
│ │ ├── ReMoS/
│ │ │ ├── CV_adv/
│ │ │ │ ├── DNNtest/
│ │ │ │ │ ├── coverage/
│ │ │ │ │ │ ├── my_neuron_coverage.py
│ │ │ │ │ │ ├── neuron_coverage.py
│ │ │ │ │ │ ├── pytorch_wrapper.py
│ │ │ │ │ │ ├── strong_neuron_activation_coverage.py
│ │ │ │ │ │ ├── top_k_coverage.py
│ │ │ │ │ │ └── utils/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── common.py
│ │ │ │ │ │ ├── keras.py
│ │ │ │ │ │ ├── mxnet.py
│ │ │ │ │ │ ├── pytorch.py
│ │ │ │ │ │ └── tensorflow.py
│ │ │ │ │ ├── eval_nc.py
│ │ │ │ │ └── strategy/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── adapt.py
│ │ │ │ │ ├── deepxplore.py
│ │ │ │ │ ├── dlfuzz.py
│ │ │ │ │ ├── random.py
│ │ │ │ │ └── strategy.py
│ │ │ │ ├── dataset/
│ │ │ │ │ ├── cub200.py
│ │ │ │ │ ├── flower102.py
│ │ │ │ │ ├── mit67.py
│ │ │ │ │ ├── stanford_40.py
│ │ │ │ │ └── stanford_dog.py
│ │ │ │ ├── distillation_training.py
│ │ │ │ ├── eval_robustness.py
│ │ │ │ ├── examples/
│ │ │ │ │ ├── finetune.sh
│ │ │ │ │ ├── nc_guided_defect.py
│ │ │ │ │ ├── nc_guided_defect.sh
│ │ │ │ │ ├── nc_profile.sh
│ │ │ │ │ ├── penul_guided_defect.py
│ │ │ │ │ └── remos.sh
│ │ │ │ ├── finetune.py
│ │ │ │ ├── finetuner.py
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── fe_resnet.py
│ │ │ │ ├── nc_prune/
│ │ │ │ │ ├── analyze_coverage.py
│ │ │ │ │ ├── coverage/
│ │ │ │ │ │ ├── my_neuron_coverage.py
│ │ │ │ │ │ ├── pytorch_wrapper.py
│ │ │ │ │ │ ├── strong_neuron_activation_coverage.py
│ │ │ │ │ │ ├── test_max.py
│ │ │ │ │ │ ├── top_k_coverage.py
│ │ │ │ │ │ └── utils/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── common.py
│ │ │ │ │ │ ├── keras.py
│ │ │ │ │ │ ├── mxnet.py
│ │ │ │ │ │ ├── pytorch.py
│ │ │ │ │ │ └── tensorflow.py
│ │ │ │ │ ├── my_profile.py
│ │ │ │ │ ├── nc_pruner.py
│ │ │ │ │ └── nc_weight_rank_pruner.py
│ │ │ │ ├── utils.py
│ │ │ │ └── weight_pruner.py
│ │ │ ├── CV_backdoor/
│ │ │ │ ├── attack_finetuner.py
│ │ │ │ ├── backdoor_dataset/
│ │ │ │ │ ├── cub200.py
│ │ │ │ │ ├── mit67.py
│ │ │ │ │ └── stanford_40.py
│ │ │ │ ├── clean_dataset/
│ │ │ │ │ ├── cub200.py
│ │ │ │ │ ├── mit67.py
│ │ │ │ │ └── stanford_40.py
│ │ │ │ ├── eval.py
│ │ │ │ ├── eval_robustness.py
│ │ │ │ ├── examples/
│ │ │ │ │ ├── backdoor.py
│ │ │ │ │ ├── eval_backdoor.sh
│ │ │ │ │ ├── r50_baseline.sh
│ │ │ │ │ ├── r50_magprune.sh
│ │ │ │ │ ├── r50_poison.sh
│ │ │ │ │ └── remos/
│ │ │ │ │ ├── profile.sh
│ │ │ │ │ ├── ratio_ncprune_weight_rank.sh
│ │ │ │ │ └── remos.sh
│ │ │ │ ├── finetune.py
│ │ │ │ ├── finetuner.py
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── fe_resnet.py
│ │ │ │ ├── prune.py
│ │ │ │ ├── remos/
│ │ │ │ │ ├── analyze_coverage.py
│ │ │ │ │ ├── coverage/
│ │ │ │ │ │ ├── my_neuron_coverage.py
│ │ │ │ │ │ ├── pytorch_wrapper.py
│ │ │ │ │ │ ├── strong_neuron_activation_coverage.py
│ │ │ │ │ │ ├── test_max.py
│ │ │ │ │ │ ├── top_k_coverage.py
│ │ │ │ │ │ └── utils/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── common.py
│ │ │ │ │ │ ├── keras.py
│ │ │ │ │ │ ├── mxnet.py
│ │ │ │ │ │ ├── pytorch.py
│ │ │ │ │ │ └── tensorflow.py
│ │ │ │ │ ├── my_profile.py
│ │ │ │ │ ├── nc_pruner.py
│ │ │ │ │ └── remos_pruner.py
│ │ │ │ ├── trigger.py
│ │ │ │ ├── utils.py
│ │ │ │ └── weight_pruner.py
│ │ │ ├── README.md
│ │ │ ├── instructions.md
│ │ │ └── unpack_downloads.sh
│ │ ├── TCP/
│ │ │ ├── README.md
│ │ │ ├── dataset.py
│ │ │ ├── finetune.py
│ │ │ ├── mmd.py
│ │ │ ├── prune.py
│ │ │ └── tools.py
│ │ ├── adarnn/
│ │ │ ├── README.md
│ │ │ ├── base/
│ │ │ │ ├── AdaRNN.py
│ │ │ │ ├── __init__.py
│ │ │ │ ├── loss/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── adv_loss.py
│ │ │ │ │ ├── coral.py
│ │ │ │ │ ├── cos.py
│ │ │ │ │ ├── kl_js.py
│ │ │ │ │ ├── mmd.py
│ │ │ │ │ ├── mutual_info.py
│ │ │ │ │ └── pair_dist.py
│ │ │ │ └── loss_transfer.py
│ │ │ ├── dataset/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_act.py
│ │ │ │ ├── data_process.py
│ │ │ │ └── data_weather.py
│ │ │ ├── requirements.txt
│ │ │ ├── train_weather.py
│ │ │ ├── transformer_adapt.py
│ │ │ ├── tst/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decoder.py
│ │ │ │ ├── encoder.py
│ │ │ │ ├── loss.py
│ │ │ │ ├── multiHeadAttention.py
│ │ │ │ ├── positionwiseFeedForward.py
│ │ │ │ ├── transformer.py
│ │ │ │ └── utils.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── heat_map.py
│ │ │ ├── metrics.py
│ │ │ ├── utils.py
│ │ │ └── visualize.py
│ │ ├── finetune_AlexNet_ResNet/
│ │ │ ├── data/
│ │ │ │ └── readme.txt
│ │ │ ├── data_loader.py
│ │ │ ├── finetune_office31.py
│ │ │ └── readme.md
│ │ └── fixed/
│ │ ├── alg/
│ │ │ ├── alg.py
│ │ │ ├── algs/
│ │ │ │ ├── Fixed.py
│ │ │ │ └── base.py
│ │ │ ├── modelopera.py
│ │ │ └── opt.py
│ │ ├── datautil/
│ │ │ ├── actdata/
│ │ │ │ ├── cross_people.py
│ │ │ │ └── util.py
│ │ │ ├── getdataloader.py
│ │ │ ├── mydataloader.py
│ │ │ └── util.py
│ │ ├── loss/
│ │ │ └── margin_loss.py
│ │ ├── network/
│ │ │ ├── Adver_network.py
│ │ │ ├── act_network.py
│ │ │ └── common_network.py
│ │ ├── readme.md
│ │ ├── requirements.txt
│ │ ├── train.py
│ │ └── utils/
│ │ └── util.py
│ ├── distance/
│ │ ├── coral_pytorch.py
│ │ ├── mmd_matlab.m
│ │ ├── mmd_numpy_sklearn.py
│ │ ├── mmd_pytorch.py
│ │ └── proxy_a_distance.py
│ ├── feature_extractor/
│ │ ├── for_digit_data/
│ │ │ ├── digit_data_loader.py
│ │ │ ├── digit_deep_feature.py
│ │ │ └── digit_network.py
│ │ ├── for_image_data/
│ │ │ ├── backbone.py
│ │ │ ├── data_load.py
│ │ │ ├── main.py
│ │ │ └── models.py
│ │ └── readme.md
│ ├── traditional/
│ │ ├── BDA/
│ │ │ ├── BDA.py
│ │ │ ├── matlab/
│ │ │ │ ├── BDA.m
│ │ │ │ └── demo_BDA.m
│ │ │ └── readme.md
│ │ ├── CORAL/
│ │ │ ├── CORAL.m
│ │ │ ├── CORAL.py
│ │ │ ├── CORAL_SVM.m
│ │ │ └── readme.md
│ │ ├── EasyTL/
│ │ │ ├── CORAL_map.m
│ │ │ ├── EasyTL.m
│ │ │ ├── GFK_map.m
│ │ │ ├── demo_amazon_review.m
│ │ │ ├── demo_image.m
│ │ │ ├── demo_office_caltech.m
│ │ │ ├── label_prop.m
│ │ │ └── readme.md
│ │ ├── GFK/
│ │ │ ├── GFK.m
│ │ │ ├── GFK.py
│ │ │ ├── getGFKDim.m
│ │ │ └── readme.md
│ │ ├── JDA/
│ │ │ ├── JDA.m
│ │ │ ├── JDA.py
│ │ │ └── readme.md
│ │ ├── KMM.py
│ │ ├── MEDA/
│ │ │ ├── MEDA.py
│ │ │ ├── matlab/
│ │ │ │ ├── GFK_Map.m
│ │ │ │ ├── MEDA.m
│ │ │ │ ├── README.md
│ │ │ │ ├── demo_office_caltech_surf.m
│ │ │ │ ├── estimate_mu.m
│ │ │ │ └── lapgraph.m
│ │ │ └── readme.md
│ │ ├── MyTJM.m
│ │ ├── SA_SVM.m
│ │ ├── SCL.py
│ │ ├── SFA.py
│ │ ├── SVM.m
│ │ ├── TCA/
│ │ │ ├── TCA.m
│ │ │ ├── TCA.py
│ │ │ └── readme.md
│ │ ├── TrAdaBoost.py
│ │ ├── pyEasyTL/
│ │ │ ├── .gitignore
│ │ │ ├── EasyTL.py
│ │ │ ├── demo_amazon_review.py
│ │ │ ├── demo_image.py
│ │ │ ├── demo_office_caltech.py
│ │ │ ├── intra_alignment.py
│ │ │ ├── label_prop.py
│ │ │ ├── label_prop_v2.py
│ │ │ ├── license
│ │ │ ├── readme.md
│ │ │ ├── requirement.txt
│ │ │ └── results.txt
│ │ ├── readme.md
│ │ └── sot/
│ │ ├── SOT.py
│ │ ├── main.py
│ │ └── readme.md
│ └── utils/
│ ├── feature_vis.py
│ └── grl.py
├── data/
│ ├── benchmark.md
│ ├── dataset.md
│ └── readme.md
├── doc/
│ ├── awesome_paper.md
│ ├── awesome_paper_date.md
│ ├── domain_adaptation.md
│ ├── scholar_TL.md
│ ├── transfer_learning_application.md
│ ├── venues.md
│ └── 迁移学习简介.md
├── docs/
│ ├── CNAME
│ ├── _config.yml
│ └── index.md
└── notebooks/
├── deep_transfer_tutorial.ipynb
└── traditional_transfer_learning.ipynb
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
*.pdf filter=lfs diff=lfs merge=lfs -text
================================================
FILE: .github/FUNDING.yml
================================================
# These are supported funding model platforms
github: jindongwang
patreon: # Replace with a single Patreon username
open_collective: # Replace with a single Open Collective username
ko_fi: # Replace with a single Ko-fi username
tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
liberapay: # Replace with a single Liberapay username
issuehunt: # Replace with a single IssueHunt username
otechie: # Replace with a single Otechie username
custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.md
================================================
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Before you open an issue**
If it's code running error, maybe you want to check the python or pytorch version before submitting an issue.
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Where is this bug happen?
**Screenshots**
If applicable, add screenshots to help explain your problem.
================================================
FILE: .gitignore
================================================
.idea/
*~
*/*~
code/.DS_Store
.DS_Store
*.pyc
*.pkl
outputs/
__pycache__/
================================================
FILE: CONTRIBUTING.md
================================================
Anyone interested in transfer learning is welcomed to contribute to this repo (by pull request):
- You can add the latest publications / tools / tutorials directly to `readme.md` and `awesome_paper.md`.
- You can add **code** to the code directory. You are welcomed to place the code of your published paper in this repo!
- You are welcomed to update anything helpful.
如果你对本项目感兴趣,非常欢迎你加入!
- 可以推荐最新的相关论文/工具/讲座,将信息通过pull request的方式更新到`readme.md`和`awesome_paper.md`中。
- 推荐代码到**code**文件夹中。欢迎将你论文中的代码开源到本项目中!
- 任何有用的建议都可进行贡献。
欢迎!
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 Jindong Wang
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]

Everything about Transfer Learning. 迁移学习.
Papers •
Tutorials •
Research areas •
Theory •
Survey •
Code •
Dataset & benchmark
Thesis •
Scholars •
Contests •
Journal/conference •
Applications •
Others •
Contributing
**Widely used by top conferences and journals:**
- Conferences: [[CVPR'22](https://openaccess.thecvf.com/content/CVPR2022W/FaDE-TCV/html/Zhang_Segmenting_Across_Places_The_Need_for_Fair_Transfer_Learning_With_CVPRW_2022_paper.html)] [[NeurIPS'21](https://proceedings.neurips.cc/paper/2021/file/731b03008e834f92a03085ef47061c4a-Paper.pdf)] [[IJCAI'21](https://arxiv.org/abs/2103.03097)] [[ESEC/FSE'20](https://dl.acm.org/doi/abs/10.1145/3368089.3409696)] [[IJCNN'20](https://ieeexplore.ieee.org/abstract/document/9207556)] [[ACMMM'18](https://dl.acm.org/doi/abs/10.1145/3240508.3240512)] [[ICME'19](https://ieeexplore.ieee.org/abstract/document/8784776/)]
- Journals: [[IEEE TKDE](https://ieeexplore.ieee.org/abstract/document/9782500/)] [[ACM TIST](https://dl.acm.org/doi/abs/10.1145/3360309)] [[Information sciences](https://www.sciencedirect.com/science/article/pii/S0020025520308458)] [[Neurocomputing](https://www.sciencedirect.com/science/article/pii/S0925231221007025)] [[IEEE Transactions on Cognitive and Developmental Systems](https://ieeexplore.ieee.org/abstract/document/9659817)]
```
@Misc{transferlearning.xyz,
howpublished = {\url{http://transferlearning.xyz}},
title = {Everything about Transfer Learning and Domain Adapation},
author = {Wang, Jindong and others}
}
```
[](https://awesome.re) [](https://opensource.org/licenses/MIT) [](https://github.com/996icu/996.ICU/blob/master/LICENSE) [](https://996.icu)
Related Codes:
- Large language model evaluation: [[llm-eval](https://llm-eval.github.io/)]
- Large language model enhancement: [[llm-enhance](https://llm-enhance.github.io/)]
- Robust machine learning: [[robustlearn: robust machine learning](https://github.com/microsoft/robustlearn)]
- Semi-supervised learning: [[USB: unified semi-supervised learning benchmark](https://github.com/microsoft/Semi-supervised-learning)] | [[TorchSSL: a unified SSL library](https://github.com/TorchSSL/TorchSSL)]
- LLM benchmark: [[PromptBench: adversarial robustness of prompts of LLMs](https://github.com/microsoft/promptbench)]
- Federated learning: [[PersonalizedFL: library for personalized federated learning](https://github.com/microsoft/PersonalizedFL)]
- Activity recognition and machine learning [[Activity recognition](https://github.com/jindongwang/activityrecognition)]|[[Machine learning](https://github.com/jindongwang/MachineLearning)]
- - -
**NOTE:** You can directly open the code in [Gihub Codespaces](https://docs.github.com/en/codespaces/getting-started/quickstart#introduction) on the web to run them without downloading! Also, try [github.dev](https://github.dev/jindongwang/transferlearning).
## 0.Papers (论文)
[Awesome transfer learning papers (迁移学习文章汇总)](https://github.com/jindongwang/transferlearning/tree/master/doc/awesome_paper.md)
- [Paperweekly](http://www.paperweekly.site/collections/231/papers): A website to recommend and read paper notes
**Latest papers**:
- By topic: [doc/awesome_papers.md](/doc/awesome_paper.md)
- By date: [doc/awesome_paper_date.md](/doc/awesome_paper_date.md)
*Updated at 2024-02-18:*
- Simulations of Common Unsupervised Domain Adaptation Algorithms for Image Classification [[arxiv](https://arxiv.org/abs/2502.10694)]
- Unsupervised domain adaptaiton for image classification
- Semantics-aware Test-time Adaptation for 3D Human Pose Estimation [[arxiv](https://arxiv.org/abs/2502.10724)]
- Test-time adaptation for3D human pose estimation
- Transfer Learning of CATE with Kernel Ridge Regression [[arxiv](https://arxiv.org/abs/2502.11331)]
- Transfer learning with kernel ridge regression
- Why Domain Generalization Fail? A View of Necessity and Sufficiency [[arxiv](https://arxiv.org/abs/2502.10716)]
- Analyze why domain generalization fail from the view of necessity and sufficiency
*Updated at 2024-02-11:*
- Beyond Batch Learning: Global Awareness Enhanced Domain Adaptation [[arxiv](https://arxiv.org/abs/2502.06272)]
- Global awareness for enhanced domain adaptation
- - -
## 1.Introduction and Tutorials (简介与教程)
Want to quickly learn transfer learning?想尽快入门迁移学习?看下面的教程。
- Books 书籍
- **Introduction to Transfer Learning: Algorithms and Practice** [[Buy or read](https://link.springer.com/book/9789811975837)]
- **《迁移学习》(杨强)** [[Buy](https://item.jd.com/12930984.html)] [[English version](https://www.cambridge.org/core/books/transfer-learning/CCFFAFE3CDBC245047F1DEC71D9EF3C7)]
- **《迁移学习导论》(王晋东、陈益强著)** [[Homepage](http://jd92.wang/tlbook)] [[Buy](https://item.jd.com/13272157.html)]
- Blogs 博客
- [Zhihu blogs - 知乎专栏《小王爱迁移》系列文章](https://zhuanlan.zhihu.com/p/130244395)
- Video tutorials 视频教程
- Transfer learning 迁移学习:
- [Recent advance of transfer learning - 2022年最新迁移学习发展现状探讨](https://www.bilibili.com/video/BV1nY411E7Uc/)
- [Definitions of transfer learning area - 迁移学习领域名词解释](https://www.bilibili.com/video/BV1fu411o7BW) [[Article](https://zhuanlan.zhihu.com/p/428097044)]
- [Transfer learning by Hung-yi Lee @ NTU - 台湾大学李宏毅的视频讲解(中文视频)](https://www.youtube.com/watch?v=qD6iD4TFsdQ)
- Domain generalization 领域泛化:
- [IJCAI-ECAI'22 tutorial on domain generalization - 领域泛化tutorial](https://dgresearch.github.io/)
- [Domain generalization - 迁移学习新兴研究方向领域泛化](https://www.bilibili.com/video/BV1ro4y1S7dd/)
- Domain adaptation 领域自适应:
- [Domain adaptation - 迁移学习中的领域自适应方法(中文)](https://www.bilibili.com/video/BV1T7411R75a/)
- Brief introduction and slides 简介与ppt资料
- [Recent advance of transfer learning](https://jd92.wang/assets/files/l16_aitime.pdf)
- [Domain generalization survey](http://jd92.wang/assets/files/DGSurvey-ppt.pdf)
- [Brief introduction in Chinese](https://github.com/jindongwang/transferlearning/blob/master/doc/%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0%E7%AE%80%E4%BB%8B.md)
- [PPT (English)](http://jd92.wang/assets/files/l03_transferlearning.pdf) | [PPT (中文)](http://jd92.wang/assets/files/l08_tl_zh.pdf)
- 迁移学习中的领域自适应方法 Domain adaptation: [PDF](http://jd92.wang/assets/files/l12_da.pdf) | [Video on Bilibili](https://www.bilibili.com/video/BV1T7411R75a/) | [Video on Youtube](https://www.youtube.com/watch?v=RbIsHNtluwQ&t=22s)
- Tutorial on transfer learning by Qiang Yang: [IJCAI'13](http://ijcai13.org/files/tutorial_slides/td2.pdf) | [2016 version](http://kddchina.org/file/IntroTL2016.pdf)
- Talk is cheap, show me the code 动手教程、代码、数据
- [Pytorch tutorial on transfer learning](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html)
- [Pytorch finetune](https://github.com/jindongwang/transferlearning/tree/master/code/AlexNet_ResNet)
- [DeepDA: a unified deep domain adaptation toolbox](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA)
- [DeepDG: a unified deep domain generalization toolbox](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG)
- [更多 More...](https://github.com/jindongwang/transferlearning/tree/master/code)
- [Transfer Learning Scholars and Labs - 迁移学习领域的著名学者、代表工作及实验室介绍](https://github.com/jindongwang/transferlearning/blob/master/doc/scholar_TL.md)
- [Negative transfer - 负迁移](https://www.zhihu.com/question/66492194/answer/242870418)
- - -
## 2.Transfer Learning Areas and Papers (研究领域与相关论文)
- [Survey](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#survey)
- [Theory](#theory)
- [Per-training/Finetuning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#per-trainingfinetuning)
- [Knowledge distillation](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#knowledge-distillation)
- [Traditional domain adaptation](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#traditional-domain-adaptation)
- [Deep domain adaptation](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#deep-domain-adaptation)
- [Domain generalization](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#domain-generalization)
- [Source-free domain adaptation](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#source-free-domain-adaptation)
- [Multi-source domain adaptation](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#multi-source-domain-adaptation)
- [Heterogeneous transfer learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#heterogeneous-transfer-learning)
- [Online transfer learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#online-transfer-learning)
- [Zero-shot / few-shot learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#zero-shot--few-shot-learning)
- [Multi-task learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#multi-task-learning)
- [Transfer reinforcement learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#transfer-reinforcement-learning)
- [Transfer metric learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#transfer-metric-learning)
- [Federated transfer learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#federated-transfer-learning)
- [Lifelong transfer learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#lifelong-transfer-learning)
- [Safe transfer learning](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#safe-transfer-learning)
- [Transfer learning applications](https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#transfer-learning-applications)
- - -
## 3.Theory and Survey (理论与综述)
Here are some articles on transfer learning theory and survey.
**Survey (综述文章):**
- 2023 Source-Free Unsupervised Domain Adaptation: A Survey [[arxiv](http://arxiv.org/abs/2301.00265)]
- 2022 [Transfer Learning for Future Wireless Networks: A Comprehensive Survey](https://arxiv.org/abs/2102.07572)
- 2022 [A Review of Deep Transfer Learning and Recent Advancements](https://arxiv.org/abs/2201.09679)
- 2022 [Transferability in Deep Learning: A Survey](https://paperswithcode.com/paper/transferability-in-deep-learning-a-survey), from Mingsheng Long in THU.
- 2021 Domain generalization: IJCAI-21 [Generalizing to Unseen Domains: A Survey on Domain Generalization](https://arxiv.org/abs/2103.03097) | [知乎文章](https://zhuanlan.zhihu.com/p/354740610) | [微信公众号](https://mp.weixin.qq.com/s/DsoVDYqLB1N7gj9X5UnYqw)
- First survey on domain generalization
- 第一篇对Domain generalization (领域泛化)的综述
- 2021 Vision-based activity recognition: [A Survey of Vision-Based Transfer Learning in Human Activity Recognition](https://www.mdpi.com/2079-9292/10/19/2412)
- 2021 ICSAI [A State-of-the-Art Survey of Transfer Learning in Structural Health Monitoring](https://ieeexplore.ieee.org/abstract/document/9664171)
- 2020 [Transfer learning: survey and classification](https://link.springer.com/chapter/10.1007/978-981-15-5345-5_13), Advances in Intelligent Systems and Computing.
- 2020 迁移学习最新survey,来自中科院计算所庄福振团队,发表在Proceedings of the IEEE: [A Comprehensive Survey on Transfer Learning](https://arxiv.org/abs/1911.02685)
- 2020 负迁移的综述:[Overcoming Negative Transfer: A Survey](https://arxiv.org/abs/2009.00909)
- 2020 知识蒸馏的综述: [Knowledge Distillation: A Survey](https://arxiv.org/abs/2006.05525)
- 用transfer learning进行sentiment classification的综述:[A Survey of Sentiment Analysis Based on Transfer Learning](https://ieeexplore.ieee.org/abstract/document/8746210)
- 2019 一篇新survey:[Transfer Adaptation Learning: A Decade Survey](https://arxiv.org/abs/1903.04687)
- 2018 一篇迁移度量学习的综述: [Transfer Metric Learning: Algorithms, Applications and Outlooks](https://arxiv.org/abs/1810.03944)
- 2018 一篇最近的非对称情况下的异构迁移学习综述:[Asymmetric Heterogeneous Transfer Learning: A Survey](https://arxiv.org/abs/1804.10834)
- 2018 Neural style transfer的一个survey:[Neural Style Transfer: A Review](https://arxiv.org/abs/1705.04058)
- 2018 深度domain adaptation的一个综述:[Deep Visual Domain Adaptation: A Survey](https://www.sciencedirect.com/science/article/pii/S0925231218306684)
- 2017 多任务学习的综述,来自香港科技大学杨强团队:[A survey on multi-task learning](https://arxiv.org/abs/1707.08114)
- 2017 异构迁移学习的综述:[A survey on heterogeneous transfer learning](https://link.springer.com/article/10.1186/s40537-017-0089-0)
- 2017 跨领域数据识别的综述:[Cross-dataset recognition: a survey](https://arxiv.org/abs/1705.04396)
- 2016 [A survey of transfer learning](https://pan.baidu.com/s/1gfgXLXT)。其中交代了一些比较经典的如同构、异构等学习方法代表性文章。
- 2015 中文综述:[迁移学习研究进展](https://pan.baidu.com/s/1bpautob)
- 2010 [A survey on transfer learning](http://ieeexplore.ieee.org/abstract/document/5288526/)
- Survey on applications - 应用导向的综述:
- 视觉domain adaptation综述:[Visual Domain Adaptation: A Survey of Recent Advances](https://pan.baidu.com/s/1o8BR7Vc)
- 迁移学习应用于行为识别综述:[Transfer Learning for Activity Recognition: A Survey](https://pan.baidu.com/s/1kVABOYr)
- 迁移学习与增强学习:[Transfer Learning for Reinforcement Learning Domains: A Survey](https://pan.baidu.com/s/1slfr0w1)
- 多个源域进行迁移的综述:[A Survey of Multi-source Domain Adaptation](https://pan.baidu.com/s/1eSGREF4)。
**Theory (理论文章):**
- ICML-20 [Few-shot domain adaptation by causal mechanism transfer](https://arxiv.org/pdf/2002.03497.pdf)
- The first work on causal transfer learning
- 日本理论组大佬Sugiyama的工作,causal transfer learning
- CVPR-19 [Characterizing and Avoiding Negative Transfer](https://arxiv.org/abs/1811.09751)
- Characterizing and avoid negative transfer
- 形式化并提出如何避免负迁移
- ICML-20 [On Learning Language-Invariant Representations for Universal Machine Translation](https://arxiv.org/abs/2008.04510)
- Theory for universal machine translation
- 对统一机器翻译模型进行了理论论证
- NIPS-06 [Analysis of Representations for Domain Adaptation](https://dl.acm.org/citation.cfm?id=2976474)
- ML-10 [A Theory of Learning from Different Domains](https://link.springer.com/article/10.1007/s10994-009-5152-4)
- NIPS-08 [Learning Bounds for Domain Adaptation](http://papers.nips.cc/paper/3212-learning-bounds-for-domain-adaptation)
- COLT-09 [Domain adaptation: Learning bounds and algorithms](https://arxiv.org/abs/0902.3430)
- MMD paper:[A Hilbert Space Embedding for Distributions](https://link.springer.com/chapter/10.1007/978-3-540-75225-7_5) and [A Kernel Two-Sample Test](http://www.jmlr.org/papers/v13/gretton12a.html)
- Multi-kernel MMD paper: [Optimal kernel choice for large-scale two-sample tests](http://papers.nips.cc/paper/4727-optimal-kernel-choice-for-large-scale-two-sample-tests)
_ _ _
## 4.Code (代码)
Unified codebases for:
- [Deep domain adaptation](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA)
- [Deep domain generalization](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG)
- See all codes here: https://github.com/jindongwang/transferlearning/tree/master/code.
More: see [HERE](https://github.com/jindongwang/transferlearning/tree/master/code) and [HERE](https://colab.research.google.com/drive/1MVuk95mMg4ecGyUAIG94vedF81HtWQAr?usp=sharing) for an instant run using Google's Colab.
_ _ _
## 5.Transfer Learning Scholars (著名学者)
Here are some transfer learning scholars and labs.
**全部列表以及代表工作性见[这里](https://github.com/jindongwang/transferlearning/blob/master/doc/scholar_TL.md)**
Please note that this list is far not complete. A full list can be seen in [here](https://github.com/jindongwang/transferlearning/blob/master/doc/scholar_TL.md). Transfer learning is an active field. *If you are aware of some scholars, please add them here.*
_ _ _
## 6.Transfer Learning Thesis (硕博士论文)
Here are some popular thesis on transfer learning.
[这里](https://pan.baidu.com/share/init?surl=iuzZhHdumrD64-yx_VAybA), 提取码:txyz。
- - -
## 7.Datasets and Benchmarks (数据集与评测结果)
Please see [HERE](https://github.com/jindongwang/transferlearning/blob/master/data) for the popular transfer learning **datasets and benchmark** results.
[这里](https://github.com/jindongwang/transferlearning/blob/master/data)整理了常用的公开数据集和一些已发表的文章在这些数据集上的实验结果。
- - -
## 8.Transfer Learning Challenges (迁移学习比赛)
- [Visual Domain Adaptation Challenge (VisDA)](http://ai.bu.edu/visda-2018/)
- - -
## Journals and Conferences
See [here](https://github.com/jindongwang/transferlearning/blob/master/doc/venues.md) for a full list of related journals and conferences.
- - -
## Applications (迁移学习应用)
- [Computer vision](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#computer-vision)
- [Medical and healthcare](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#medical-and-healthcare)
- [Natural language processing](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#natural-language-processing)
- [Time series](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#time-series)
- [Speech](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#speech)
- [Multimedia](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#multimedia)
- [Recommendation](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#recommendation)
- [Human activity recognition](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#human-activity-recognition)
- [Autonomous driving](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#autonomous-driving)
- [Others](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md#others)
See [HERE](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md) for transfer learning applications.
迁移学习应用请见[这里](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md)。
- - -
## Other Resources (其他资源)
- Call for papers:
- [Advances in Transfer Learning: Theory, Algorithms, and Applications](https://www.frontiersin.org/research-topics/21133/advances-in-transfer-learning-theory-algorithms-and-applications), DDL: October 2021
- Related projects:
- Salad: [A semi-supervised domain adaptation library](https://domainadaptation.org)
- - -
## Contributing (欢迎参与贡献)
If you are interested in contributing, please refer to [HERE](https://github.com/jindongwang/transferlearning/blob/master/CONTRIBUTING.md) for instructions in contribution.
- - -
### Copyright notice
> ***[Notes]This Github repo can be used by following the corresponding licenses. I want to emphasis that it may contain some PDFs or thesis, which were downloaded by me and can only be used for academic purposes. The copyrights of these materials are owned by corresponding publishers or organizations. All this are for better academic research. If any of the authors or publishers have concerns, please contact me to delete or replace them.***
[contributors-shield]: https://img.shields.io/github/contributors/jindongwang/transferlearning.svg?style=for-the-badge
[contributors-url]: https://github.com/jindongwang/transferlearning/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/jindongwang/transferlearning.svg?style=for-the-badge
[forks-url]: https://github.com/jindongwang/transferlearning/network/members
[stars-shield]: https://img.shields.io/github/stars/jindongwang/transferlearning.svg?style=for-the-badge
[stars-url]: https://github.com/jindongwang/transferlearning/stargazers
[issues-shield]: https://img.shields.io/github/issues/jindongwang/transferlearning.svg?style=for-the-badge
[issues-url]: https://github.com/jindongwang/transferlearning/issues
[license-shield]: https://img.shields.io/github/license/jindongwang/transferlearning.svg?style=for-the-badge
[license-url]: https://github.com/jindongwang/transferlearning/blob/main/LICENSE.txt
================================================
FILE: code/ASR/Adapter/README.md
================================================
# Adapter-based Cross-lingual ASR with EasyEspnet
**NOTICE:** The latest code of Adapter has been moved to https://github.com/microsoft/NeuralSpeech/tree/master/AdapterASR for unified organization. Please refer to that repo.
---
This is a Adapter-based cross-lingual ASR implementation of our works [1, 2] built on top of [EasyEspnet](https://github.com/jindongwang/EasyEspnet). Please refer to it for the basic introduction, installation and usage.
## Run
After extracting features using Espnet and set the data folder path as introduced in [EasyEspnet](https://github.com/jindongwang/EasyEspnet).
You need to check or modify in `train.py arg_list`, config should be in ESPnet config style (remember to include decoding information if you want to compute cer/wer), then, you can run train.py. For example,
```
python train.py --root_path commonvoice/asr1 --dataset ar --config config/adapter_example.yaml
```
dataset here refers to the language code used in the Common Voice corpus. Results (log, model, snapshots) are saved in results_(dataset)/(config_name) by default.
### Adapters
Adapters is a parameter-efficient way for cross-lingual ASR as introduced in [1, 2]. Given a pre-trained multilingual ASR model, the adapters are injected into the model, during adaptation, only the adapters and language-specific heads are updated, while the main body of the model is frozen, resulting in much faster training speed and making the adaptation more stable. Please refer to our SimAdapter paper [2] for details.
To train the adapters, generally you need to specify the `load_pretrained_model` in the config files to load the multilingual ASR model. We found that by splitting the training of language-specific heads and adapters, the adaptation performance can be further improved [2]. You may also train the language-specific heads first and set `train_adapter_with_head` to `false` during adapters' training.
For the vanilla Adapter method, we provide an example config in `config/adapter_example.yaml`, please refer to it for modification to train your own adapter.
For the Meta-Adapter, there are two stages, the first step is pre-training, we provide an example config in `config/meta_adapter_example.yaml`, please refer to it for modification to train your own meta-adapter; the second stage is fine-tuning, please refer to the `config/finetune_meta_adapter_example.yaml`. Please refer to our meta-adapter paper [1] for details.
### SimAdapter
To leverage the information from multiple source / target adapters, we introduce SimAdapter for cross-lingual ASR [2]. To train a SimAdapter, you need a model with multiple adapters/meta-adapters injected and pre-trained. During SimAdapter, we initialize attention layers after every adapter outputs to fuse the information from multiple adapters (languages). During training of SimAdapter, parameters of the main body, the adapters, and the language heads are all frozen. Only the SimAdapter's fusion layers are trained. Please refer to our SimAdapter paper [2] for details.
We also provide a template config for you to perform SimAdapter: `config/simadapter_example.yaml`
### Demo
TBD
## Decoding and WER/CER evaluation
Set `--decoding_mode` to `true` to perform decoding and CER/WER evaluation. For example:
```
python train.py --root_path commonvoice/asr1 --dataset ar --decoding_mode true --config config/adapter_example.yaml
```
## Distributed training
Following EasyEspnet, you can also perform distributed training which is much faster. For example, using 4 GPUs, 1 node:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --dist_train true --root_path commonvoice/asr1 --dataset ar --config config/adapter_example.yaml
```
## Acknowledgement
- ESPNet: https://github.com/espnet/espnet
- EasyEspnet: https://github.com/jindongwang/EasyEspnet
## Contact
- [Wenxin Hou](https://houwenxin.github.io/): houwx001@gmail.com
- [Jindong Wang](http://www.jd92.wang/): jindongwang@outlook.com
## References
[1] Wenxin Hou, Yidong Wang, Shengzhou Gao, Takahiro Shinozaki, “Meta-Adapter: Efficient Cross-Lingual Adaptation with Meta-Learning”, in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Toronto, Ontario, Canada, June 2021. [[paper]](https://ieeexplore.ieee.org/document/9414959)
[2] Wenxin Hou, Han Zhu, Yidong Wang, Jindong Wang, Tao Qin, Renjun Xu, Takahiro Shinozaki, ”Exploiting Adapters for Cross-lingual Low-resource Speech Recognition”, Arxiv preprint. [[paper]](https://arxiv.org/abs/2105.11905)
================================================
FILE: code/ASR/Adapter/balanced_sampler.py
================================================
import torch
import torch.utils.data
import random
import collections
import logging
import numpy as np
from torch.utils.data.sampler import BatchSampler, WeightedRandomSampler
# https://github.com/khornlund/pytorch-balanced-sampler
class BalancedBatchSampler(torch.utils.data.sampler.Sampler):
'''
https://github.com/galatolofederico/pytorch-balanced-batch/blob/master/sampler.py
'''
def __init__(self, dataset, labels=None):
self.labels = labels
self.dataset = collections.defaultdict(list)
self.balanced_max = 0
# Save all the indices for all the classes
for idx in range(0, len(dataset)):
label = self._get_label(dataset, idx)
#break
self.dataset[label].append(idx)
self.balanced_max = max(self.balanced_max, len(self.dataset[label]))
#len(self.dataset[label]) if len(self.dataset[label]) > self.balanced_max else self.balanced_max
# Oversample the classes with fewer elements than the max
for label in self.dataset:
while len(self.dataset[label]) < self.balanced_max:
self.dataset[label].append(random.choice(self.dataset[label]))
self.keys = list(self.dataset.keys())
logging.warning(self.keys)
self.currentkey = 0
self.indices = [-1] * len(self.keys)
def __iter__(self):
while self.indices[self.currentkey] < self.balanced_max - 1:
self.indices[self.currentkey] += 1
yield self.dataset[self.keys[self.currentkey]][self.indices[self.currentkey]]
self.currentkey = (self.currentkey + 1) % len(self.keys)
self.indices = [-1] * len(self.keys)
def _get_label(self, dataset, idx):
#logging.warning(len(dataset))
# logging.warning(dataset[idx])
return dataset[idx][0][1]['category']#[1]['output'][0]['token'].split(' ')[1]
# def _get_label(self, dataset, idx, labels = None):
# if self.labels is not None:
# return self.labels[idx].item()
# else:
# raise Exception("You should pass the tensor of labels to the constructor as second argument")
def __len__(self):
return self.balanced_max * len(self.keys)
================================================
FILE: code/ASR/Adapter/config/adapter_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
# opt: noam
accum-grad: 1
grad-clip: 5
patience: 10
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
transformer-lr: 6.0
transformer-warmup-steps: 1800
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
use_adapters: true
load_pretrained_model: "::" # Example: lid_42.pt::decoder.embed,decoder.output_layer,ctc.
dataset: "ru_cy_it_eu_pt_ar" # , we recommend to write all the dataset that you want to perform AdapterFusion later (if you want)
adapter_train_languages: "ar" # The language(s) that is really used for this time
adapter_fusion: false
train_adapter_with_head: true
opt: adam
adam_lr: 0.001
================================================
FILE: code/ASR/Adapter/config/adapterfusion_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
accum-grad: 1
grad-clip: 5
patience: 10
epochs: 200
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
transformer-lr: 0.1
transformer-warmup-steps: 1800
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
use_adapters: true
load_pretrained_model: "::" # Example: lid_42_adapters.pt::
dataset: "ru_cy_it_eu_pt_ar"
fusion_languages: "ru_cy_it_eu_pt_ar" # adapters to fuse
adapter_train_languages: "ar"
sim_adapter: true
train_adapter_with_head: false
guide_loss_weight: 1.0
guide_loss_weight_decay_steps: 0
opt: adam
adam_lr: 0.001
================================================
FILE: code/ASR/Adapter/config/finetune_meta_adapter_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 10
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
transformer-lr: 6.0
transformer-warmup-steps: 1800
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
use_adapters: true
load_pretrained_model: "::" # Example: lid_42_meta_adapter.pt::
adapter_train_languages: "ar"
shared_adapter: "ru_cy_it_eu_pt" # Set to the source languages on which it is meta-trained
dataset: ru_cy_it_eu_pt_ar
adapter_fusion: false
train_adapter_with_head: true
# cs
opt: adam
adam_lr: 0.01
================================================
FILE: code/ASR/Adapter/config/meta_adapter_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
accum-grad: 1
grad-clip: 5
patience: 0
epochs: 30
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
opt: adam
transformer-lr: 6.0
transformer-warmup-steps: 250
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
load_pretrained_model: "::" # Example: lid_42.pt::decoder.embed,decoder.output_layer,ctc.
use_adapters: true
adapter_train_languages: "ru_cy_it_eu_pt"
dataset: "ru_cy_it_eu_pt"
meta_train: true
shared_adapter: "ru_cy_it_eu_pt" # The name of shared_adapter, other name is also okay
adapter_fusion: false
batch-size: 32 # Real batch size is given by this batch-size * number of languages
train_adapter_with_head: true
meta_lr: 0.0001 # 1.0
adam_lr: 0.01 # inner learning rate
# cs
================================================
FILE: code/ASR/Adapter/data_load.py
================================================
from espnet.utils.training.batchfy import make_batchset
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
import torch
import os
import json
import kaldiio
import random
import logging
import sentencepiece as spm
from balanced_sampler import BalancedBatchSampler
#cv mt cnh ky dv sl el lv fy-NL sah
data_config = {
"template100": {
"train": "dump/train_template/deltafalse/data_unigram100.json",
"val": "dump/dev_template/deltafalse/data_unigram100.json",
"test": "dump/test_template/deltafalse/data_unigram100.json",
"token": "data/template_lang_char/train_template_unigram100_units.txt",
"prefix": "/D_data/commonvoice/asr1/",
"bpemodel": "data/template_lang_char/train_template_unigram100.model",
},
"template150": {
"train": "dump/train_template/deltafalse/data_unigram150.json",
"val": "dump/dev_template/deltafalse/data_unigram150.json",
"test": "dump/test_template/deltafalse/data_unigram150.json",
"token": "data/template_lang_char/train_template_unigram150_units.txt",
"prefix": "/D_data/commonvoice/asr1/",
"bpemodel": "data/template_lang_char/train_template_unigram150.model",
},
}
low_resource_languages = ["ro", "cs", "br", "ar", "uk"]
def read_json_file(fname):
with open(fname, "rb") as f:
contents = json.load(f)["utts"]
return contents
def load_json(train_json_file, dev_json_file, test_json_file):
train_json = read_json_file(train_json_file)
if os.path.isfile(dev_json_file):
dev_json = read_json_file(dev_json_file)
else:
n_samples = len(train_json)
train_size = int(0.9 * n_samples)
logging.warning(
f"No dev set provided, will split the last {n_samples - train_size} (10%) samples from training data"
)
train_json_item = list(train_json.items())
# random.shuffle(train_json_item)
train_json = dict(train_json_item[:train_size])
dev_json = dict(train_json_item[train_size:])
# Save temp dev set
with open(dev_json_file, "w") as f:
json.dump({"utts": dev_json}, f)
logging.warning(f"Temporary dev set saved: {dev_json_file}")
test_json = read_json_file(test_json_file)
return train_json, dev_json, test_json
def load_data(root_path, dataset, args):
def collate(minibatch):
fbanks = []
tokens = []
for _, info in minibatch[0]:
fbanks.append(
torch.tensor(
kaldiio.load_mat(
info["input"][0]["feat"].replace(
data_config[dataset]["prefix"], root_path
)
)
)
)
tokens.append(
torch.tensor([int(s) for s in info["output"][0]["tokenid"].split()])
)
ilens = torch.tensor([x.shape[0] for x in fbanks])
return (
pad_sequence(fbanks, batch_first=True, padding_value=0),
ilens,
pad_sequence(tokens, batch_first=True, padding_value=-1),
)
language = dataset
if language in low_resource_languages:
template_key = "template100"
else:
template_key = "template150"
data_config[dataset] = data_config[template_key].copy()
for key in ["train", "val", "test", "token"]:
data_config[dataset][key] = data_config[template_key][key].replace("template", dataset)
train_json = os.path.join(root_path, data_config[dataset]["train"])
dev_json = (
os.path.join(root_path, data_config[dataset]["val"])
if data_config[dataset]["val"]
else f"{root_path}/tmp_dev_set_{dataset}.json"
)
test_json = os.path.join(root_path, data_config[dataset]["test"])
train_json, dev_json, test_json = load_json(train_json, dev_json, test_json)
_, info = next(iter(train_json.items()))
idim = info["input"][0]["shape"][1]
odim = info["output"][0]["shape"][1]
use_sortagrad = False # args.sortagrad == -1 or args.sortagrad > 0
# trainset = make_batchset(train_json, batch_size, max_length_in=800, max_length_out=150)
trainset = make_batchset(
train_json,
args.batch_size,
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=args.ngpu if (args.ngpu > 1 and not args.dist_train) else 1,
shortest_first=use_sortagrad,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
# devset = make_batchset(dev_json, batch_size, max_length_in=800, max_length_out=150)
devset = make_batchset(
dev_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
testset = make_batchset(
test_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
if args.dist_train and args.ngpu > 1:
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
else:
train_sampler = None
train_loader = DataLoader(
trainset,
batch_size=1,
collate_fn=collate,
num_workers=args.n_iter_processes,
shuffle=(train_sampler is None),
pin_memory=True,
sampler=train_sampler,
)
dev_loader = DataLoader(
devset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
test_loader = DataLoader(
testset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
return (train_loader, dev_loader, test_loader), (idim, odim)
def load_multilingual_data(root_path, datasets, args, languages):
def collate(minibatch):
out = []
for b in minibatch:
fbanks = []
tokens = []
language = None
for _, info in b:
fbanks.append(
torch.tensor(
kaldiio.load_mat(
info["input"][0]["feat"].replace(
data_config[dataset]["prefix"], root_path
)
)
)
)
tokens.append(
torch.tensor([int(s) for s in info["output"][0]["tokenid"].split()])
)
if language is not None:
assert language == info['category']
else:
language = info['category']
ilens = torch.tensor([x.shape[0] for x in fbanks])
out.append((
pad_sequence(fbanks, batch_first=True, padding_value=0),
ilens,
pad_sequence(tokens, batch_first=True, padding_value=-1),
language,
))
return out[0] if len(out) == 1 else out
idim = None
odim_dict = {}
mtl_train_json, mtl_dev_json, mtl_test_json = {}, {}, {}
for idx, dataset in enumerate(datasets):
language = dataset
if language in low_resource_languages:
template_key = "template100"
else:
template_key = "template150"
data_config[dataset] = data_config[template_key].copy()
for key in ["train", "val", "test", "token"]:
data_config[dataset][key] = data_config[template_key][key].replace("template", dataset)
train_json = os.path.join(root_path, data_config[dataset]["train"])
dev_json = (
os.path.join(root_path, data_config[dataset]["val"])
if data_config[dataset]["val"]
else f"{root_path}/tmp_dev_set_{dataset}.json"
)
test_json = os.path.join(root_path, data_config[dataset]["test"])
train_json, dev_json, test_json = load_json(train_json, dev_json, test_json)
for key in train_json.keys():
train_json[key]['category'] = language
for key in dev_json.keys():
dev_json[key]['category'] = language
for key in test_json.keys():
test_json[key]['category'] = language
#print(train_json)
_, info = next(iter(train_json.items()))
if idim is not None:
assert idim == info["input"][0]["shape"][1]
else:
idim = info["input"][0]["shape"][1]
odim_dict[language] = info["output"][0]["shape"][1]
# Break if not in specified languages
if dataset not in languages:
continue
mtl_train_json.update(train_json)
mtl_dev_json.update(dev_json)
mtl_test_json.update(test_json)
#print(len(mtl_train_json), len(train_json))
train_json, dev_json, test_json = mtl_train_json, mtl_dev_json, mtl_test_json
use_sortagrad = False # args.sortagrad == -1 or args.sortagrad > 0
# trainset = make_batchset(train_json, batch_size, max_length_in=800, max_length_out=150)
if args.ngpu > 1 and not args.dist_train:
min_batch_size = args.ngpu
else:
min_batch_size = 1
if args.meta_train:
min_batch_size = 2 * min_batch_size
trainset = make_batchset(
train_json,
args.batch_size,
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=min_batch_size,
shortest_first=use_sortagrad,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
# devset = make_batchset(dev_json, batch_size, max_length_in=800, max_length_out=150)
devset = make_batchset(
dev_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
testset = make_batchset(
test_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
if args.dist_train and args.ngpu > 1:
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
elif args.meta_train:
train_sampler = BalancedBatchSampler(trainset)
else:
train_sampler = None
train_loader = DataLoader(
trainset,
batch_size=1 if not args.meta_train else len(languages),
collate_fn=collate,
num_workers=args.n_iter_processes,
shuffle=(train_sampler is None),
pin_memory=True,
sampler=train_sampler,
)
dev_loader = DataLoader(
devset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
test_loader = DataLoader(
testset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
return (train_loader, dev_loader, test_loader), (idim, odim_dict)
def load_token_list(token_file):
with open(token_file, "r") as f:
token_list = [entry.split()[0] for entry in f]
token_list.insert(0, "")
token_list.append("")
return token_list
def load_bpemodel(root_path, dataset):
if dataset in low_resource_languages:
template_key = "template100"
else:
template_key = "template150"
bpemodel_path = os.path.join(root_path, data_config[template_key]["bpemodel"]).replace("template", dataset)
bpemodel = spm.SentencePieceProcessor()
bpemodel.Load(bpemodel_path)
return bpemodel
================================================
FILE: code/ASR/Adapter/e2e_asr_adaptertransformer.py
================================================
# Copyright 2019 Shigeki Karita
# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)
"""Transformer speech recognition model (pytorch)."""
from argparse import Namespace
from distutils.util import strtobool
import logging
import math
import numpy
import torch
from espnet.nets.pytorch_backend.e2e_asr_transformer import *
from espnet.nets.pytorch_backend.transformer.attention import MultiHeadedAttention
from espnet.nets.pytorch_backend.transformer.embedding import PositionalEncoding
from espnet.nets.pytorch_backend.transformer.encoder_layer import EncoderLayer
from espnet.nets.pytorch_backend.transformer.decoder_layer import DecoderLayer
from espnet.nets.pytorch_backend.transformer.layer_norm import LayerNorm
from espnet.nets.pytorch_backend.transformer.positionwise_feed_forward import (
PositionwiseFeedForward, # noqa: H301
)
from espnet.nets.pytorch_backend.transformer.repeat import repeat
from espnet.nets.pytorch_backend.e2e_asr_transformer import E2E as E2ETransformer
from espnet.nets.pytorch_backend.transformer.encoder import Encoder
from espnet.nets.pytorch_backend.transformer.decoder import Decoder
from espnet.nets.pytorch_backend.transformer.label_smoothing_loss import (
LabelSmoothingLoss, # noqa: H301
)
from data_load import low_resource_languages
low_resource_adapter_dim = 64
high_resource_adapter_dim = 128
class SimAdapter(MultiHeadedAttention):
def __init__(self, n_feat, dropout_rate, fusion_languages=None, num_shared_layers=-1):
"""Construct an MultiHeadedAttention object."""
super(MultiHeadedAttention, self).__init__()
self.linear_q = torch.nn.Linear(n_feat, n_feat)
self.linear_k = torch.nn.Linear(n_feat, n_feat)
self.linear_v = torch.nn.Linear(n_feat, n_feat, bias=False)
self.linear_v.weight.data = (
torch.zeros(n_feat, n_feat) + 0.000001
).fill_diagonal_(1.0)
self.attn = None
self.num_shared_layers = num_shared_layers
self.dropout = torch.nn.Dropout(p=dropout_rate)
self.temperature = 1.0
self.fusion_languages = fusion_languages
def forward_qkv(self, query, key, value):
q = self.linear_q(query) # (batch, time, d_k)
k = self.linear_k(key) # (batch, time, n_adapters, d_k)
v = self.linear_v(value) # (batch, time, n_adapters, d_k)
return q, k, v
def forward_attention(self, value, scores):
self.attn = torch.softmax(scores, dim=-1) # (batch, time, n_adapters)
p_attn = self.dropout(self.attn)
x = torch.matmul(p_attn.unsqueeze(2), value)
# (batch, time, 1, n_adapters), (batch, time, n_adapters, d_k)
x = torch.squeeze(x, dim=2)
return x # (batch, time, d_k)
def forward(self, query, key, value, residual=None):
q, k, v = self.forward_qkv(query, key, value)
# q: (batch, time, 1, d_k); k, v: (batch, time, n_adapters, d_k)
scores = torch.matmul(q.unsqueeze(2), k.transpose(-2, -1)) / math.sqrt(self.temperature)
scores = torch.squeeze(scores, dim=2)
# scores: (batch, time, n_adapters)
out = self.forward_attention(v, scores)
if residual is not None:
out = out + residual
return out
class Adapter(torch.nn.Module):
def __init__(self, adapter_dim, embed_dim):
super().__init__()
self.layer_norm = LayerNorm(embed_dim)
self.down_project = torch.nn.Linear(embed_dim, adapter_dim, bias=False)
self.up_project = torch.nn.Linear(adapter_dim, embed_dim, bias=False)
def forward(self, z):
normalized_z = self.layer_norm(z)
h = torch.nn.functional.relu(self.down_project(normalized_z))
return self.up_project(h) + z
class CustomEncoderLayer(EncoderLayer):
def forward(self, x, mask, cache=None):
residual = x
if self.normalize_before:
x = self.norm1(x)
if cache is None:
x_q = x
else:
assert cache.shape == (x.shape[0], x.shape[1] - 1, self.size)
x_q = x[:, -1:, :]
residual = residual[:, -1:, :]
mask = None if mask is None else mask[:, -1:, :]
if self.concat_after:
x_concat = torch.cat((x, self.self_attn(x_q, x, x, mask)), dim=-1)
x = residual + self.concat_linear(x_concat)
else:
x = residual + self.dropout(self.self_attn(x_q, x, x, mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
x_norm = x
x = residual + self.dropout(self.feed_forward(x))
if not self.normalize_before:
x = self.norm2(x)
if cache is not None:
x = torch.cat([cache, x], dim=1)
return x, x_norm, mask
class AdaptiveEncoderLayer(CustomEncoderLayer):
def __init__(
self,
languages,
size,
self_attn,
feed_forward,
dropout_rate,
normalize_before=True,
concat_after=False,
sim_adapter_layer=None,
shared_adapter=None,
use_adapters=True,
):
super().__init__(size,
self_attn,
feed_forward,
dropout_rate,
normalize_before,
concat_after,
)
self.use_adapters = use_adapters
if use_adapters:
self.adapters = torch.nn.ModuleDict()
self.shared_adapter = shared_adapter
if shared_adapter:
languages = [shared_adapter]
for lang in languages:
if lang in low_resource_languages or self.shared_adapter:
adapter_dim = low_resource_adapter_dim
else:
adapter_dim = high_resource_adapter_dim
self.adapters[lang] = Adapter(adapter_dim, size)
self.sim_adapter = sim_adapter_layer
def forward(self, x, mask, language, cache=None, use_sim_adapter=True):
x, x_norm, mask = super().forward(x, mask, cache=cache)
if not self.use_adapters:
return x, mask, language, cache, use_sim_adapter
if self.shared_adapter:
assert len(self.adapters.keys()) == 1
language = list(self.adapters.keys())[0]
if (not use_sim_adapter) or not (self.sim_adapter):
out = self.adapters[language](x)
else:
out = []
fusion_languages = list(self.sim_adapter.keys())[0]
for lang in fusion_languages.split("_"):
if lang != "self":
out.append(self.adapters[lang](x))
else:
out.append(x)
out = torch.stack(out).permute(1, 2, 0, 3) # B, T, n_adapters, F
out = self.sim_adapter[fusion_languages](x, out, out, residual=x_norm)
#out = self.adapters['cs'](x)
return out, mask, language, cache, use_sim_adapter
class AdaptiveEncoder(Encoder):
def __init__(
self,
languages,
idim,
selfattention_layer_type="selfattn",
attention_dim=256,
attention_heads=4,
conv_wshare=4,
conv_kernel_length=11,
conv_usebias=False,
linear_units=2048,
num_blocks=6,
dropout_rate=0.1,
positional_dropout_rate=0.1,
attention_dropout_rate=0.0,
input_layer="conv2d",
pos_enc_class=PositionalEncoding,
normalize_before=True,
concat_after=False,
positionwise_layer_type="linear",
positionwise_conv_kernel_size=1,
padding_idx=-1,
sim_adapter=False,
shared_adapter=None,
use_adapters=True,
fusion_languages=None,
):
super().__init__(idim,
selfattention_layer_type,
attention_dim,
attention_heads,
conv_wshare,
conv_kernel_length,
conv_usebias,
linear_units,
num_blocks,
dropout_rate,
positional_dropout_rate,
attention_dropout_rate,
input_layer,
pos_enc_class,
normalize_before,
concat_after,
positionwise_layer_type,
positionwise_conv_kernel_size,
padding_idx)
positionwise_layer, positionwise_layer_args = self.get_positionwise_layer(
positionwise_layer_type,
attention_dim,
linear_units,
dropout_rate,
positionwise_conv_kernel_size,
)
if selfattention_layer_type == "selfattn":
logging.info("encoder self-attention layer type = self-attention")
self.encoders = repeat(
num_blocks,
lambda lnum: AdaptiveEncoderLayer(
languages,
attention_dim,
MultiHeadedAttention(
attention_heads, attention_dim, attention_dropout_rate
),
positionwise_layer(*positionwise_layer_args),
dropout_rate,
normalize_before,
concat_after,
torch.nn.ModuleDict({"_".join(sorted(fusion_languages)): SimAdapter(attention_dim, attention_dropout_rate, fusion_languages)}) if sim_adapter else None,
shared_adapter,
use_adapters,
),
)
else:
raise NotImplementedError("Only support self-attention encoder layer")
def forward(self, xs, masks, language, use_sim_adapter=True):
xs, masks = self.embed(xs, masks)
xs, masks, _, _, _ = self.encoders(xs, masks, language, None, use_sim_adapter)
if self.normalize_before:
xs = self.after_norm(xs)
return xs, masks
class CustomDecoderLayer(DecoderLayer):
def forward(self, tgt, tgt_mask, memory, memory_mask, cache=None):
residual = tgt
if self.normalize_before:
tgt = self.norm1(tgt)
if cache is None:
tgt_q = tgt
tgt_q_mask = tgt_mask
else:
# compute only the last frame query keeping dim: max_time_out -> 1
assert cache.shape == (
tgt.shape[0],
tgt.shape[1] - 1,
self.size,
), f"{cache.shape} == {(tgt.shape[0], tgt.shape[1] - 1, self.size)}"
tgt_q = tgt[:, -1:, :]
residual = residual[:, -1:, :]
tgt_q_mask = None
if tgt_mask is not None:
tgt_q_mask = tgt_mask[:, -1:, :]
if self.concat_after:
tgt_concat = torch.cat(
(tgt_q, self.self_attn(tgt_q, tgt, tgt, tgt_q_mask)), dim=-1
)
x = residual + self.concat_linear1(tgt_concat)
else:
x = residual + self.dropout(self.self_attn(tgt_q, tgt, tgt, tgt_q_mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
if self.concat_after:
x_concat = torch.cat(
(x, self.src_attn(x, memory, memory, memory_mask)), dim=-1
)
x = residual + self.concat_linear2(x_concat)
else:
x = residual + self.dropout(self.src_attn(x, memory, memory, memory_mask))
if not self.normalize_before:
x = self.norm2(x)
residual = x
if self.normalize_before:
x = self.norm3(x)
x_norm = x
x = residual + self.dropout(self.feed_forward(x))
if not self.normalize_before:
x = self.norm3(x)
if cache is not None:
x = torch.cat([cache, x], dim=1)
return x, x_norm, tgt_mask, memory, memory_mask
class AdaptiveDecoderLayer(CustomDecoderLayer):
def __init__(
self,
languages,
size,
self_attn,
src_attn,
feed_forward,
dropout_rate,
normalize_before=True,
concat_after=False,
sim_adapter_layer=None,
shared_adapter=None,
use_adapters=True,
):
super().__init__(size,
self_attn,
src_attn,
feed_forward,
dropout_rate,
normalize_before,
concat_after
)
self.use_adapters = use_adapters
if use_adapters:
self.adapters = torch.nn.ModuleDict()
self.shared_adapter = shared_adapter
if shared_adapter:
languages = [shared_adapter]
for lang in languages:
if lang in low_resource_languages or self.shared_adapter:
adapter_dim = low_resource_adapter_dim
else:
adapter_dim = high_resource_adapter_dim
self.adapters[lang] = Adapter(adapter_dim, size)
self.sim_adapter = sim_adapter_layer
def forward(self, tgt, tgt_mask, memory, memory_mask, language, cache=None, use_sim_adapter=True):
x, x_norm, tgt_mask, memory, memory_mask = super().forward(tgt, tgt_mask, memory, memory_mask, cache=cache)
if not self.use_adapters:
return x, tgt_mask, memory, memory_mask, language, cache, use_sim_adapter
if self.shared_adapter:
assert len(self.adapters.keys()) == 1
language = list(self.adapters.keys())[0]
if (not use_sim_adapter) or (not self.sim_adapter):
out = self.adapters[language](x)
else:
out = []
fusion_languages = list(self.sim_adapter.keys())[0]
for lang in fusion_languages.split("_"):
if lang != "self":
out.append(self.adapters[lang](x))
else:
out.append(x)
out = torch.stack(out).permute(1, 2, 0, 3) # B, T, n_adapters, F
out = self.sim_adapter[fusion_languages](x, out, out, residual=x_norm)
return out, tgt_mask, memory, memory_mask, language, cache, use_sim_adapter
class AdaptiveDecoder(Decoder):
def __init__(
self,
languages,
odim_dict,
selfattention_layer_type="selfattn",
attention_dim=256,
attention_heads=4,
conv_wshare=4,
conv_kernel_length=11,
conv_usebias=False,
linear_units=2048,
num_blocks=6,
dropout_rate=0.1,
positional_dropout_rate=0.1,
self_attention_dropout_rate=0.0,
src_attention_dropout_rate=0.0,
input_layer="embed",
use_output_layer=True,
pos_enc_class=PositionalEncoding,
normalize_before=True,
concat_after=False,
sim_adapter=False,
shared_adapter=False,
use_adapters=True,
fusion_languages=None,
):
super().__init__(1,
selfattention_layer_type,
attention_dim,
attention_heads,
conv_wshare,
conv_kernel_length,
conv_usebias,
linear_units,
num_blocks,
dropout_rate,
positional_dropout_rate,
self_attention_dropout_rate,
src_attention_dropout_rate,
input_layer,
use_output_layer,
pos_enc_class,
normalize_before,
concat_after)
if input_layer == "embed":
self.embed = torch.nn.ModuleDict()
for lang in odim_dict.keys():
self.embed[lang] = torch.nn.Sequential(
torch.nn.Embedding(odim_dict[lang], attention_dim),
pos_enc_class(attention_dim, positional_dropout_rate),
)
else:
raise NotImplementedError("only support embed embedding layer")
assert self_attention_dropout_rate == src_attention_dropout_rate
if selfattention_layer_type == "selfattn":
logging.info("decoder self-attention layer type = self-attention")
self.decoders = repeat(
num_blocks,
lambda lnum: AdaptiveDecoderLayer(
languages,
attention_dim,
MultiHeadedAttention(
attention_heads, attention_dim, self_attention_dropout_rate
),
MultiHeadedAttention(
attention_heads, attention_dim, src_attention_dropout_rate
),
PositionwiseFeedForward(attention_dim, linear_units, dropout_rate),
dropout_rate,
normalize_before,
concat_after,
torch.nn.ModuleDict({"_".join(sorted(fusion_languages)): SimAdapter(attention_dim, self_attention_dropout_rate, fusion_languages)}) if sim_adapter else None,
shared_adapter,
use_adapters,
),
)
else:
raise NotImplementedError("Only support self-attention decoder layer")
if use_output_layer:
self.output_layer = torch.nn.ModuleDict()
for lang in odim_dict.keys():
self.output_layer[lang] = torch.nn.Linear(attention_dim, odim_dict[lang])
else:
self.output_layer = None
def forward(self, tgt, tgt_mask, memory, memory_mask, language, use_sim_adapter=True):
x = self.embed[language](tgt)
x, tgt_mask, memory, memory_mask, _, _, _ = self.decoders(
x, tgt_mask, memory, memory_mask, language, None, use_sim_adapter
)
if self.normalize_before:
x = self.after_norm(x)
if self.output_layer is not None:
x = self.output_layer[language](x)
return x, tgt_mask
def forward_one_step(self, tgt, tgt_mask, memory, memory_mask, language, cache=None):
x = self.embed[language](tgt)
if cache is None:
cache = [None] * len(self.decoders)
new_cache = []
for c, decoder in zip(cache, self.decoders):
x, tgt_mask, memory, memory_mask, _, _, _ = decoder(
x, tgt_mask, memory, None, language, cache=c,
)
new_cache.append(x)
if self.normalize_before:
y = self.after_norm(x[:, -1])
else:
y = x[:, -1]
if self.output_layer is not None:
y = torch.log_softmax(self.output_layer[language](y), dim=-1)
return y, new_cache
class E2E(E2ETransformer):
def __init__(self, idim, odim_dict, args, languages, ignore_id=-1):
super().__init__(idim, 1, args, ignore_id)
if args.transformer_attn_dropout_rate is None:
args.transformer_attn_dropout_rate = args.dropout_rate
if args.fusion_languages:
args.fusion_languages = args.fusion_languages.split("_")
self.fusion_languages = sorted(args.fusion_languages) if args.fusion_languages else sorted(languages)
self.encoder = AdaptiveEncoder(
languages=languages,
idim=idim,
selfattention_layer_type=args.transformer_encoder_selfattn_layer_type,
attention_dim=args.adim,
attention_heads=args.aheads,
conv_wshare=args.wshare,
conv_kernel_length=args.ldconv_encoder_kernel_length,
conv_usebias=args.ldconv_usebias,
linear_units=args.eunits,
num_blocks=args.elayers,
input_layer=args.transformer_input_layer,
dropout_rate=args.dropout_rate,
positional_dropout_rate=args.dropout_rate,
attention_dropout_rate=args.transformer_attn_dropout_rate,
sim_adapter=args.sim_adapter,
shared_adapter=args.shared_adapter,
use_adapters=args.use_adapters,
fusion_languages=self.fusion_languages
)
if args.mtlalpha < 1:
self.decoder = AdaptiveDecoder(
languages=languages,
odim_dict=odim_dict,
selfattention_layer_type=args.transformer_decoder_selfattn_layer_type,
attention_dim=args.adim,
attention_heads=args.aheads,
conv_wshare=args.wshare,
conv_kernel_length=args.ldconv_decoder_kernel_length,
conv_usebias=args.ldconv_usebias,
linear_units=args.dunits,
num_blocks=args.dlayers,
dropout_rate=args.dropout_rate,
positional_dropout_rate=args.dropout_rate,
self_attention_dropout_rate=args.transformer_attn_dropout_rate,
src_attention_dropout_rate=args.transformer_attn_dropout_rate,
sim_adapter=args.sim_adapter,
shared_adapter=args.shared_adapter,
use_adapters=args.use_adapters,
fusion_languages=self.fusion_languages,
)
else:
self.decoder = None
self.soss = {lang: odim_dict[lang] - 1 for lang in languages}
self.eoss = {lang: odim_dict[lang] - 1 for lang in languages}
self.odim_dict = odim_dict
self.criterion = torch.nn.ModuleDict()
for lang in languages:
self.criterion[lang] = LabelSmoothingLoss(
self.odim_dict[lang],
self.ignore_id,
args.lsm_weight,
args.transformer_length_normalized_loss,
)
if args.mtlalpha > 0.0:
self.ctc = torch.nn.ModuleDict()
for lang in languages:
self.ctc[lang] = CTC(
odim_dict[lang], args.adim, args.dropout_rate, ctc_type=args.ctc_type, reduce=True
)
else:
self.ctc = None
if args.report_cer or args.report_wer:
self.error_calculator = ErrorCalculator(
args.char_list,
args.sym_space,
args.sym_blank,
args.report_cer,
args.report_wer,
)
else:
self.error_calculator = None
self.reset_parameters(args)
# Adapter
self.meta_train = args.meta_train
self.shared_adapter = args.shared_adapter
self.sim_adapter = False
self.use_adapters = args.use_adapters
if self.use_adapters:
for p in self.parameters():
p.requires_grad = False
self.sim_adapter = args.sim_adapter
if not args.sim_adapter:
adapter_train_languages = args.adapter_train_languages
self.enable_adapter_training(adapter_train_languages,
shared_adapter=args.shared_adapter, enable_head=args.train_adapter_with_head)
else:
self.reset_sim_adapter_parameters()
self.enable_sim_adapter_training()
self.recognize_language_branch = None # Set default recognize language for decoding
def reset_sim_adapter_parameters(self):
key = "_".join(self.fusion_languages)
for layer in self.encoder.encoders:
layer.sim_adapter[key].linear_v.weight.data = (
torch.zeros(self.adim, self.adim) + 0.000001
).fill_diagonal_(1.0)
for layer in self.decoder.decoders:
layer.sim_adapter[key].linear_v.weight.data = (
torch.zeros(self.adim, self.adim) + 0.000001
).fill_diagonal_(1.0)
def enable_sim_adapter_training(self):
key = "_".join(self.fusion_languages)
logging.warning(f"Unfreezing the SimAdapter parameters: {key}")
for layer in self.encoder.encoders:
for p in layer.sim_adapter[key].parameters():
p.requires_grad = True
# for p in layer.adapter_norm.parameters():
# p.requires_grad = True
for layer in self.decoder.decoders:
for p in layer.sim_adapter[key].parameters():
p.requires_grad = True
def get_fusion_guide_loss(self, language):
device = next(self.parameters()).device
if language not in self.fusion_languages:
return torch.tensor(0.0).to(device)
guide_loss = torch.tensor(0.0).to(device)
loss_fn = torch.nn.CrossEntropyLoss(reduction='mean')
lang_id = sorted(self.fusion_languages).index(language)
key = "_".join(self.fusion_languages)
target = torch.tensor(lang_id).unsqueeze(0).to(device)
for layer in self.encoder.encoders:
logits = layer.sim_adapter[key].attn.mean(axis=(0, 1)).unsqueeze(0) # (batch, time, n_adapters)
guide_loss = guide_loss + loss_fn(logits.exp(), target)
layer.sim_adapter.attn = None
for layer in self.decoder.decoders:
logits = layer.sim_adapter[key].attn.mean(axis=(0, 1)).unsqueeze(0) # (batch, time, n_adapters)
guide_loss = guide_loss + loss_fn(logits.exp(), target)
layer.sim_adapter[key].attn = None
return guide_loss
def get_fusion_regularization_loss(self):
reg_loss = 0.0
fusion_reg_loss_weight = 0.01
device = next(self.parameters()).device
key = "_".join(self.fusion_languages)
target = torch.zeros((self.adim, self.adim)).fill_diagonal_(1.0).to(device)
for layer in self.encoder.encoders:
reg_loss = reg_loss + fusion_reg_loss_weight * (target - layer.sim_adapter[key].linear_v.weight).pow(2).sum()
for layer in self.decoder.decoders:
reg_loss = reg_loss + fusion_reg_loss_weight * (target - layer.sim_adapter[key].linear_v.weight).pow(2).sum()
return reg_loss
def enable_adapter_training(self, specified_languages=None, shared_adapter=False, enable_head=False):
# Unfreeze the adapter parameters
if specified_languages:
enable_languages = specified_languages
else:
enable_languages = self.criterion.keys()
logging.warning(f"Unfreezing the adapter parameters of {' '.join(enable_languages)}")
for lang in enable_languages:
if enable_head:
for p in self.decoder.embed[lang].parameters():
p.requires_grad = True
for p in self.decoder.output_layer[lang].parameters():
p.requires_grad = True
for p in self.ctc[lang].parameters():
p.requires_grad = True
if shared_adapter:
lang = shared_adapter
for layer in self.encoder.encoders:
for p in layer.adapters[lang].parameters():
p.requires_grad = True
for layer in self.decoder.decoders:
for p in layer.adapters[lang].parameters():
p.requires_grad = True
def forward(self, xs_pad, ilens, ys_pad, language, use_sim_adapter=True):
# 1. forward encoder
xs_pad = xs_pad[:, : max(ilens)] # for data parallel
src_mask = make_non_pad_mask(ilens.tolist()).to(xs_pad.device).unsqueeze(-2)
hs_pad, hs_mask = self.encoder(xs_pad, src_mask, language, use_sim_adapter=True)
self.hs_pad = hs_pad
# 2. forward decoder
if self.decoder is not None:
ys_in_pad, ys_out_pad = add_sos_eos(
ys_pad, self.soss[language], self.eoss[language], self.ignore_id
)
ys_mask = target_mask(ys_in_pad, self.ignore_id)
pred_pad, pred_mask = self.decoder(ys_in_pad, ys_mask, hs_pad, hs_mask, language, use_sim_adapter=True)
self.pred_pad = pred_pad
# 3. compute attention loss
loss_att = self.criterion[language](pred_pad, ys_out_pad)
self.acc = th_accuracy(
pred_pad.view(-1, self.odim_dict[language]), ys_out_pad, ignore_label=self.ignore_id
)
else:
loss_att = None
self.acc = None
# TODO(karita) show predicted text
# TODO(karita) calculate these stats
cer_ctc = None
if self.mtlalpha == 0.0:
loss_ctc = None
else:
batch_size = xs_pad.size(0)
hs_len = hs_mask.view(batch_size, -1).sum(1)
ctc_pred_pad = self.ctc[language].ctc_lo(hs_pad)
loss_ctc = self.ctc[language](hs_pad.view(batch_size, -1, self.adim), hs_len, ys_pad)
if not self.training and self.error_calculator is not None:
ys_hat = self.ctc[language].argmax(hs_pad.view(batch_size, -1, self.adim)).data
cer_ctc = self.error_calculator[language](ys_hat.cpu(), ys_pad.cpu(), is_ctc=True)
# for visualization
if not self.training:
self.ctc[language].softmax(hs_pad)
# 5. compute cer/wer
if self.training or self.error_calculator is None or self.decoder is None:
cer, wer = None, None
else:
ys_hat = pred_pad.argmax(dim=-1)
cer, wer = self.error_calculator(ys_hat.cpu(), ys_pad.cpu())
# copied from e2e_asr
alpha = self.mtlalpha
if alpha == 0:
self.loss = loss_att
loss_att_data = float(loss_att)
loss_ctc_data = None
elif alpha == 1:
self.loss = loss_ctc
loss_att_data = None
loss_ctc_data = float(loss_ctc)
else:
self.loss = alpha * loss_ctc + (1 - alpha) * loss_att
loss_att_data = float(loss_att)
loss_ctc_data = float(loss_ctc)
if self.sim_adapter and self.training:
guide_loss = self.get_fusion_guide_loss(language)
loss_data = float(self.loss)
if loss_data < CTC_LOSS_THRESHOLD and not math.isnan(loss_data):
self.reporter.report(
loss_ctc_data, loss_att_data, self.acc, cer_ctc, cer, wer, loss_data
)
else:
logging.warning("loss (=%f) is not correct", loss_data)
if self.training and not self.meta_train:
if not self.sim_adapter:
guide_loss = torch.tensor(0.0).cuda()
return (self.loss, guide_loss)
return self.loss
def calculate_all_ctc_probs(self, xs_pad, ilens, ys_pad, language):
"""E2E CTC probability calculation.
:param torch.Tensor xs_pad: batch of padded input sequences (B, Tmax)
:param torch.Tensor ilens: batch of lengths of input sequences (B)
:param torch.Tensor ys_pad: batch of padded token id sequence tensor (B, Lmax)
:return: CTC probability (B, Tmax, vocab)
:rtype: float ndarray
"""
ret = None
if self.mtlalpha == 0:
return ret
self.eval()
with torch.no_grad():
self.forward(xs_pad, ilens, ys_pad, language)
for name, m in self.named_modules():
if isinstance(m, CTC) and m.probs is not None:
ret = m.probs.cpu().numpy()
self.train()
return ret
def calculate_all_attentions(self, xs_pad, ilens, ys_pad, language):
"""E2E attention calculation.
:param torch.Tensor xs_pad: batch of padded input sequences (B, Tmax, idim)
:param torch.Tensor ilens: batch of lengths of input sequences (B)
:param torch.Tensor ys_pad: batch of padded token id sequence tensor (B, Lmax)
:return: attention weights (B, H, Lmax, Tmax)
:rtype: float ndarray
"""
self.eval()
with torch.no_grad():
self.forward(xs_pad, ilens, ys_pad, language)
ret = dict()
for name, m in self.named_modules():
if (
isinstance(m, MultiHeadedAttention)
or isinstance(m, DynamicConvolution)
or isinstance(m, RelPositionMultiHeadedAttention)
):
ret[name] = m.attn.cpu().numpy()
if isinstance(m, DynamicConvolution2D):
ret[name + "_time"] = m.attn_t.cpu().numpy()
ret[name + "_freq"] = m.attn_f.cpu().numpy()
self.train()
return ret
def calculate_sim_adapter_attentions(self, xs_pad, ilens, ys_pad, language):
self.eval()
with torch.no_grad():
self.forward(xs_pad, ilens, ys_pad, language)
ret = dict()
for name, m in self.named_modules():
if (
isinstance(m, MultiHeadedAttention)
or isinstance(m, DynamicConvolution)
or isinstance(m, RelPositionMultiHeadedAttention)
) and "sim_adapter" in name:
ret[name] = m.attn.cpu().numpy()
return ret
def encode(self, x, language):
self.eval()
x = torch.as_tensor(x).unsqueeze(0)
enc_output, _ = self.encoder(x, None, language)
return enc_output.squeeze(0)
def set_recognize_language_branch(self, language):
self.recognize_language_branch = language
def recognize_batch(self, xs, recog_args, char_list=None, rnnlm=None, language=None):
assert language is not None or self.recognize_language_branch is not None, \
"Recognize language is not specified"
if language is None:
language = self.recognize_language_branch
prev = self.training
self.eval()
ilens = numpy.fromiter((xx.shape[0] for xx in xs), dtype=numpy.int64)
# subsample frame
xs = [xx[:: self.subsample[0], :] for xx in xs]
xs = [to_device(self, to_torch_tensor(xx).float()) for xx in xs]
xs_pad = pad_list(xs, 0.0)
src_mask = make_non_pad_mask(ilens.tolist()).to(xs_pad.device).unsqueeze(-2)
# 1. Encoder
hs_pad, hs_mask = self.encoder(xs_pad, src_mask, language)
hlens = torch.tensor([int(sum(mask[0])) for mask in hs_mask])
# calculate log P(z_t|X) for CTC scores
if recog_args.ctc_weight > 0.0:
lpz = self.ctc[language].log_softmax(hs_pad)
normalize_score = False
else:
lpz = None
normalize_score = True
logging.info("max input length: " + str(hs_pad.size(1)))
# search params
batch = len(hlens)
beam = recog_args.beam_size
penalty = recog_args.penalty
ctc_weight = getattr(recog_args, "ctc_weight", 0) # for NMT
att_weight = 1.0 - ctc_weight
n_bb = batch * beam
pad_b = to_device(hs_pad, torch.arange(batch) * beam).view(-1, 1)
max_hlens = hlens
if recog_args.maxlenratio == 0:
maxlens = max_hlens
else:
maxlens = [
max(1, int(recog_args.maxlenratio * max_hlen)) for max_hlen in max_hlens
]
minlen = min([int(recog_args.minlenratio * max_hlen) for max_hlen in max_hlens])
logging.info("max output lengths: " + str(maxlens))
logging.info("min output length: " + str(minlen))
vscores = to_device(hs_pad, torch.zeros(batch, beam))
rnnlm_state = None
import six
# initialize hypothesis
yseq = [[self.soss[language]] for _ in six.moves.range(n_bb)]
accum_odim_ids = [self.soss[language] for _ in six.moves.range(n_bb)]
stop_search = [False for _ in six.moves.range(batch)]
nbest_hyps = [[] for _ in six.moves.range(batch)]
ended_hyps = [[] for _ in six.moves.range(batch)]
exp_hs_mask = (
hs_mask.unsqueeze(1).repeat(1, beam, 1, 1).contiguous()
) # (batch, beam, 1, T)
exp_hs_mask = exp_hs_mask.view(n_bb, hs_mask.size()[1], hs_mask.size()[2])
exp_h = (
hs_pad.unsqueeze(1).repeat(1, beam, 1, 1).contiguous()
) # (batch, beam, T, F)
exp_h = exp_h.view(n_bb, hs_pad.size()[1], hs_pad.size()[2])
ctc_scorer, ctc_state = None, None
if lpz is not None:
scoring_num = min(
int(beam * CTC_SCORING_RATIO) if att_weight > 0.0 else 0,
lpz.size(-1),
)
ctc_scorer = CTCPrefixScoreTH(lpz, hlens, 0, self.eoss[language])
for i in six.moves.range(max(maxlens)):
logging.debug("position " + str(i))
# get nbest local scores and their ids
ys_mask = subsequent_mask(i + 1).to(hs_pad.device).unsqueeze(0)
ys = torch.tensor(yseq).to(hs_pad.device)
vy = to_device(hs_pad, torch.LongTensor(self._get_last_yseq(yseq)))
# local_att_scores (n_bb = beam * batch, vocab)
if self.decoder is not None:
local_att_scores = self.decoder.forward_one_step(
ys, ys_mask, exp_h, memory_mask=exp_hs_mask, language=language,
)[0]
else:
local_att_scores = to_device(
hs_pad, torch.zeros((n_bb, lpz.size(-1)), dtype=lpz.dtype)
)
if rnnlm:
rnnlm_state, local_lm_scores = rnnlm.buff_predict(rnnlm_state, vy, n_bb)
local_scores = local_att_scores + recog_args.lm_weight * local_lm_scores
else:
local_scores = local_att_scores
# ctc
if ctc_scorer:
local_scores = att_weight * local_att_scores
local_scores[:, 0] = self.logzero # avoid choosing blank
part_ids = (
torch.topk(local_scores, scoring_num, dim=-1)[1]
if scoring_num > 0
else None
)
local_ctc_scores, ctc_state = ctc_scorer(
yseq, ctc_state, part_ids
) # local_ctc_scores (n_bb, odim)
local_scores = local_scores + ctc_weight * local_ctc_scores
if rnnlm:
local_scores = local_scores + recog_args.lm_weight * local_lm_scores
local_scores = local_scores.view(batch, beam, self.odim_dict[language])
if i == 0:
local_scores[:, 1:, :] = self.logzero
# accumulate scores
eos_vscores = local_scores[:, :, self.eoss[language]] + vscores
vscores = vscores.view(batch, beam, 1).repeat(1, 1, self.odim_dict[language])
vscores[:, :, self.eoss[language]] = self.logzero
vscores = (vscores + local_scores).view(batch, -1) # (batch, odim * beam)
# global pruning
accum_best_scores, accum_best_ids = torch.topk(vscores, beam, 1)
accum_odim_ids = (
torch.fmod(accum_best_ids, self.odim_dict[language]).view(-1).data.cpu().tolist()
)
accum_padded_beam_ids = (
(accum_best_ids // self.odim_dict[language] + pad_b).view(-1).data.cpu().tolist()
)
y_prev = yseq[:][:]
yseq = self._index_select_list(yseq, accum_padded_beam_ids)
yseq = self._append_ids(yseq, accum_odim_ids)
vscores = accum_best_scores
vidx = to_device(hs_pad, torch.LongTensor(accum_padded_beam_ids))
# pick ended hyps
if i >= minlen:
k = 0
penalty_i = (i + 1) * penalty
thr = accum_best_scores[:, -1]
for samp_i in six.moves.range(batch):
if stop_search[samp_i]:
k = k + beam
continue
for beam_j in six.moves.range(beam):
_vscore = None
if eos_vscores[samp_i, beam_j] > thr[samp_i]:
yk = y_prev[k][:]
if len(yk) <= maxlens[samp_i]:
_vscore = eos_vscores[samp_i][beam_j] + penalty_i
rnnlm_idx = k
elif i == maxlens[samp_i] - 1:
yk = yseq[k][:]
_vscore = vscores[samp_i][beam_j] + penalty_i
rnnlm_idx = accum_padded_beam_ids[k]
if _vscore:
yk.append(self.eoss[language])
if rnnlm:
_vscore += recog_args.lm_weight * rnnlm.final(
rnnlm_state, index=rnnlm_idx
)
ended_hyps[samp_i].append(
{"yseq": yk, "score": _vscore.data.cpu().numpy()}
)
k = k + 1
# end detection
stop_search = [
stop_search[samp_i]
or end_detect(ended_hyps[samp_i], i)
or i >= maxlens[samp_i]
for samp_i in six.moves.range(batch)
]
stop_search_summary = list(set(stop_search))
if len(stop_search_summary) == 1 and stop_search_summary[0]:
break
if rnnlm:
rnnlm_state = self._index_select_lm_state(rnnlm_state, 0, vidx)
if ctc_scorer:
ctc_state = ctc_scorer.index_select_state(ctc_state, accum_best_ids)
torch.cuda.empty_cache()
dummy_hyps = [
{"yseq": [self.soss[language], self.eoss[language]], "score": numpy.array([-float("inf")])}
]
ended_hyps = [
ended_hyps[samp_i] if len(ended_hyps[samp_i]) != 0 else dummy_hyps
for samp_i in six.moves.range(batch)
]
if normalize_score:
for samp_i in six.moves.range(batch):
for x in ended_hyps[samp_i]:
x["score"] /= len(x["yseq"])
nbest_hyps = [
sorted(ended_hyps[samp_i], key=lambda x: x["score"], reverse=True)[
: min(len(ended_hyps[samp_i]), recog_args.nbest)
]
for samp_i in six.moves.range(batch)
]
if prev:
self.train()
return nbest_hyps
================================================
FILE: code/ASR/Adapter/train.py
================================================
import logging
import os
import collections
from espnet.bin.asr_train import get_parser
from espnet.utils.dynamic_import import dynamic_import
from espnet.utils.deterministic_utils import set_deterministic_pytorch
from espnet.asr.pytorch_backend.asr_init import freeze_modules
from torch.nn.parallel import data_parallel
from torch.nn.utils.clip_grad import clip_grad_norm_
import torch
import numpy as np
import data_load
import random
import json
import sys
from utils import setup_logging, str2bool, dict_average
from utils import load_pretrained_model, load_head_from_pretrained_model, torch_save, torch_load
from utils import recognize_and_evaluate
import math
from e2e_asr_adaptertransformer import E2E as E2EAdapterTransformer
import matplotlib.pyplot as plt
import copy
def add_custom_arguments(parser):
# EasyEspnet arguments
parser.add_argument('--data_file', type=str, default=None)
parser.add_argument("--root_path", type=str, required=True, help="Path to the ESPnet features, e.g.: /egs/commonvoice/asr1/")
#parser.add_argument("--root_path", type=str, default="/opt/espnet/egs/an4/asr1/")
parser.add_argument('--dataset', type=str, required=True, help="Dataset name to be referred in data_load, e.g.: an4")
#parser.add_argument("--dataset", type=str, default="an4")
parser.add_argument("--exp", type=str, default="exp")
parser.add_argument("--decoding_mode", type=str2bool, default=False, help="if true, then only perform decoding test")
parser.add_argument("--load_pretrained_model", type=str, default="", nargs="?",
help="::")
parser.add_argument("--compute_cer", type=str2bool, default=True)
parser.add_argument("--decoding_config", type=str, default=None)
parser.add_argument(
"--bpemodel", type=bool, default=True
) # Set to true when testing CER/WERs
parser.add_argument("--dist_train", type=str2bool, default=False)
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument("--result_label", type=str, default=None)
parser.add_argument("--recog_json", type=str, default=None)
parser.add_argument("--adam_lr", type=float, default=1e-3)
# Adapter-related
parser.add_argument("--use_adapters", type=str2bool, default=True, help="whether to inject adapters into the model")
parser.add_argument("--shared_adapter", type=str, default=None, help="Share one adapter across all languages")
parser.add_argument('--adapter_train_languages', type=str, default=None,
help="Splitted by _, e.g., en_zh_jp")
parser.add_argument("--train_adapter_with_head", type=str2bool,
default=False, help="whether to train adapter with language-specific head jointly")
# SimAdapter-related
parser.add_argument("--sim_adapter", type=str2bool, default=False)
parser.add_argument("--fusion_languages", type=str, default=None)
parser.add_argument("--guide_loss_weight", type=float, default=0.1)
parser.add_argument("--guide_loss_weight_decay_steps", type=int, default=0)
# MAML-related
parser.add_argument("--meta_train", type=str2bool, default=False)
parser.add_argument("--meta_lr", type=float, default=1.0, help="used for meta-learning outer step")
# Others
parser.add_argument("--load_head_from_pretrained_model", type=str, default="", nargs="?",
help="")
def train_epoch(dataloader, model, optimizer, epoch=None):
model.train()
stats = collections.defaultdict(list)
for batch_idx, data in enumerate(dataloader):
fbank, seq_lens, tokens, language = data
fbank, seq_lens, tokens = fbank.cuda(), seq_lens.cuda(), tokens.cuda()
if isinstance(optimizer, dict):
optimizer[language].zero_grad()
else:
optimizer.zero_grad()
model.zero_grad()
if args.ngpu <= 1 or args.dist_train:
ctc_att_loss, sim_adapter_guide_loss = model(fbank, seq_lens, tokens, language)# .mean() # / self.accum_grad
else:
# apex does not support torch.nn.DataParallel
ctc_att_loss, sim_adapter_guide_loss = (
data_parallel(model, (fbank, seq_lens, tokens, language), range(args.ngpu))# .mean() # / self.accum_grad
)
loss = ctc_att_loss.mean()
if args.sim_adapter:
if hasattr(model, "module"):
sim_adapter_reg_loss = model.module.get_fusion_regularization_loss()
else:
sim_adapter_reg_loss = model.get_fusion_regularization_loss()
loss = loss + sim_adapter_reg_loss
stats["sim_adapter_reg_loss_lst"].append(sim_adapter_reg_loss.item())
if args.guide_loss_weight > 0:
if args.guide_loss_weight_decay_steps > 0:
n_batch = len(dataloader)
current_iter = float(batch_idx + (epoch - 1) * n_batch)
frac_done = 1.0 * float(current_iter) / args.guide_loss_weight_decay_steps
current_weight = args.guide_loss_weight * max(0., 1. - frac_done)
stats["sim_adapter_guide_loss_weight"] = current_weight
else:
current_weight = args.guide_loss_weight
sim_adapter_guide_loss = sim_adapter_guide_loss.mean()
loss = loss + current_weight * sim_adapter_guide_loss
stats["sim_adapter_guide_loss_lst"].append(sim_adapter_guide_loss.item())
if not hasattr(model, "module"):
if hasattr(model, "acc") and model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if hasattr(model, "acc") and model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
loss.backward()
grad_norm = clip_grad_norm_(model.parameters(), args.grad_clip)
if math.isnan(grad_norm):
logging.warning("grad norm is nan. Do not update model.")
else:
if isinstance(optimizer, dict):
optimizer[language].step()
else:
optimizer.step()
stats["loss_lst"].append(loss.item())
logging.warning(f"Training batch: {batch_idx+1}/{len(dataloader)}")
return dict_average(stats)
def train_maml_epoch(dataloader, model, optimizer, epoch=None):
model.train()
stats = collections.defaultdict(list)
for batch_idx, total_batches in enumerate(dataloader):
i = batch_idx # current iteration in epoch
len_dataloader = len(dataloader) # total iteration in epoch
meta_iters = args.epochs * len_dataloader
current_iter = float(i + (epoch - 1) * len_dataloader)
frac_done = 1.0 * float(current_iter) / meta_iters
current_outerstepsize = args.meta_lr * (1. - frac_done)
weights_original = copy.deepcopy(model.state_dict())
new_weights = []
for total_batch in total_batches: # Iter by languages
in_batch_size = int(total_batch[0].shape[0] / 2) # In-language batch size
for meta_step in range(2): # Meta-train & meta-valid
if meta_step == 1:
last_backup = copy.deepcopy(model.state_dict())
else:
last_backup = None
batch = list(copy.deepcopy(total_batch))
for i_batch in range(len(batch)-1):
batch[i_batch] = batch[i_batch][meta_step*in_batch_size:(1+meta_step)*in_batch_size]
batch = tuple(batch)
fbank, seq_lens, tokens, language = batch
fbank, seq_lens, tokens = fbank.cuda(), seq_lens.cuda(), tokens.cuda()
optimizer.zero_grad()
model.zero_grad()
if args.ngpu <= 1 or args.dist_train:
loss = model(fbank, seq_lens, tokens, language).mean() # / self.accum_grad
else:
# apex does not support torch.nn.DataParallel
loss = (
data_parallel(model, (fbank, seq_lens, tokens, language), range(args.ngpu)).mean() # / self.accum_grad
)
# print(loss.item())
loss.backward()
grad_norm = clip_grad_norm_(model.parameters(), args.grad_clip)
if math.isnan(grad_norm):
logging.warning("grad norm is nan. Do not update model.")
else:
optimizer.step()
if meta_step == 1: # Record meta valid
if not hasattr(model, "module"):
if hasattr(model, "acc") and model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if hasattr(model, "acc") and model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
stats["loss_lst"].append(loss.item())
stats["meta_lr"] = current_outerstepsize
optimizer.zero_grad()
for name in last_backup:
# Compute meta-gradient
last_backup[name] = model.state_dict()[name] - last_backup[name]
# Change back to the original parameters for the new language
new_weights.append(last_backup) # updates.append(subtract_vars(self._model_state.export_variables(), last_backup))
model.load_state_dict({ name: weights_original[name] for name in weights_original})
ws = len(new_weights)
# Compute average meta-gradient
fweights = { name : new_weights[0][name]/float(ws) for name in new_weights[0] }
for i in range(1, ws):
for name in new_weights[i]:
fweights[name] = fweights[name] + new_weights[i][name] / float(ws)
model.load_state_dict({name : weights_original[name] + (fweights[name] * current_outerstepsize) for name in weights_original})
logging.warning(f"Training batch: {batch_idx+1}/{len(dataloader)}")
return dict_average(stats)
def test(epoch, dataloader, model, model_path=None, language=None, visualize_sim_adapter=False):
if model_path:
torch_load(model_path, model)
orig_model = None
if hasattr(model, "module"):
orig_model = model
model = model.module
model.eval()
stats = collections.defaultdict(list)
for batch_idx, data in enumerate(dataloader):
logging.warning(f"Testing batch: {batch_idx+1}/{len(dataloader)}")
if len(data) == 4:
fbank, seq_lens, tokens, language = data
else:
assert language is not None
fbank, seq_lens, tokens = data
fbank, seq_lens, tokens = fbank.cuda(), seq_lens.cuda(), tokens.cuda()
with torch.no_grad():
loss = model(fbank, seq_lens, tokens, language)
if visualize_sim_adapter:
atts = model.calculate_sim_adapter_attentions(fbank, seq_lens, tokens, language)
init_mat = lambda: np.zeros((len(model.fusion_languages),))
avg_atts = collections.defaultdict(init_mat)
count = collections.defaultdict(int)
for key in atts.keys():
avg_atts[key] = avg_atts[key] + atts[key].sum(axis=(0, 1))
count[key] = count[key] + atts[key].shape[0] * atts[key].shape[1]
stats["loss_lst"].append(loss.item())
if not hasattr(model, "module"):
if model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
if visualize_sim_adapter:
for key in avg_atts.keys():
avg_atts[key] = avg_atts[key] / count[key]
logging.warning(f"Attention scores of {key}: {avg_atts[key]}")
fig = plt.figure(figsize=(16, 8))
ax = fig.subplots()
atts, labels = [], []
for key in avg_atts.keys():
atts.append(avg_atts[key])
labels.append(key)
atts = np.stack(atts)
tick_marks = np.arange(len(labels))
ax.set_yticks(tick_marks)
ax.set_yticklabels(labels)
x_labels = list(sorted(model.fusion_languages))
ax.set_xticks(np.arange(len(x_labels)))
ax.set_xticklabels(x_labels)
ax.imshow(atts)
import itertools
for i, j in itertools.product(range(atts.shape[0]), range(atts.shape[1])):
plt.text(j, i, "{:0.2f}".format(atts[i, j]),
horizontalalignment="center",
color="white")
fig.tight_layout()
fig.savefig(f"{args.outdir}/att_{epoch}.png")
plt.close()
if orig_model is not None:
model = orig_model
return dict_average(stats)
def train(dataloaders, model, optimizer, save_path):
train_loader, val_loader, test_loader = dataloaders
best_loss = float("inf")
early_stop = 0
log_json = []
for epoch in range(args.start_epoch, args.epochs + 1):
early_stop += 1
epoch_stats = collections.OrderedDict(epoch=epoch)
train_stats = train_epoch(train_loader, model, optimizer, epoch)
valid_stats = test(f"val_{epoch}", val_loader, model, visualize_sim_adapter=args.sim_adapter)
if best_loss > valid_stats["loss"]: # Save loss best model
best_loss = valid_stats["loss"]
torch_save(model, save_path)
early_stop = 0
test_stats = test(f"test_{epoch}", test_loader, model)
logging.warning(
f"Epoch: {epoch}, Iteration: {epoch * len(train_loader)}, "
+ f"train loss: {train_stats['loss']:.4f}, dev loss: {valid_stats['loss']:.3f}, test loss: {test_stats['loss']:.3f}"
)
torch_save(model, f"{args.outdir}/snapshot.ep.{epoch}", optimizer=optimizer)
for key in sorted(list(set(list(train_stats.keys()) + list(test_stats.keys())))):
if not key.endswith("_lst"):
if key in train_stats:
epoch_stats[f"main/{key}"] = train_stats[key]
if key in valid_stats:
epoch_stats[f"validation/main/{key}"] = valid_stats[key]
if key in test_stats:
epoch_stats[f"test/main/{key}"] = test_stats[key]
log_json.append(epoch_stats)
with open(f"{args.outdir}/log", "w") as f:
json.dump(log_json, f,
indent=4,
ensure_ascii=False,
separators=(",", ": "),
)
logging.warning(f"Log saved at {args.outdir}/log")
if args.patience > 0 and early_stop >= args.patience:
test_stats = test("test_best", test_loader, model, save_path)
logging.warning(f"=====Early stop! Final best test loss: {test_stats['loss']}")
break
if __name__ == "__main__":
# 执行该命令运行4 GPU训练:CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=2 train.py
setup_logging(verbose=0) # Should come first before other package import logging
parser = get_parser()
add_custom_arguments(parser)
arg_list = sys.argv[1:] + [
"--dict", '',
#"--dataset", "_".join("cv mt cnh ky dv sl el lv fyNL sah".split()),
]
if "--config" not in arg_list:
arg_list += ["--config", "config/train.yaml"]
if "--outdir" not in arg_list:
arg_list += ["--outdir", '']
args, _ = parser.parse_known_args(arg_list)
# Use all GPUs
ngpu = torch.cuda.device_count() if args.ngpu is None else args.ngpu
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(
[str(item) for item in range(ngpu)])
logging.warning(f"ngpu: {ngpu}")
# set random seed
logging.info("random seed = %d" % args.seed)
random.seed(args.seed)
np.random.seed(args.seed)
set_deterministic_pytorch(args)
torch.cuda.manual_seed(args.seed)
if ngpu > 1:
torch.cuda.manual_seed_all(args.seed) # multi-gpu setting
model_module = "e2e_asr_adaptertransformer:E2E"
model_class = E2EAdapterTransformer
model_class.add_arguments(parser)
args = parser.parse_args(arg_list)
setattr(args, "conf_name", ".".join(os.path.basename(args.config).split(".")[:-1]))
if not args.outdir:
args.outdir = f"./outputs/results_{args.dataset}/{args.conf_name}"
if not os.path.exists(args.outdir):
os.makedirs(args.outdir)
setattr(args, "ngpu", ngpu)
if args.data_file is not None:
args.root_path = args.data_file
if args.ngpu > 1:
if args.opt == "noam" and hasattr(args, "transformer_lr"):
logging.warning(f"Multi-GPU training: increase transformer lr {args.transformer_lr} --> {args.transformer_lr * np.sqrt(args.ngpu)}")
args.transformer_lr = args.transformer_lr * np.sqrt(args.ngpu)
elif (args.opt == "adam" or args.meta_train) and hasattr(args, "adam_lr"):
logging.warning(f"Multi-GPU training: increase adam lr {args.adam_lr} --> {args.adam_lr * np.sqrt(args.ngpu)}")
args.adam_lr = args.adam_lr * np.sqrt(args.ngpu)
if args.dist_train:
torch.distributed.init_process_group(backend="nccl")
local_rank = torch.distributed.get_rank()
args.local_rank = local_rank
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
else:
logging.warning(
"Training batch size is automatically increased (%d -> %d)"
% (args.batch_size, args.batch_size * args.ngpu)
)
args.batch_size *= args.ngpu
if args.accum_grad > 1:
logging.warning(
"gradient accumulation is not implemented. batch size is increased (%d -> %d)"
% (args.batch_size, args.batch_size * args.accum_grad)
)
args.batch_size *= args.accum_grad
args.accum_grad = 1
dataloaders = {}
token_dict = {}
idim, odim_dict = None, {}
args.dataset = args.dataset.split("_")
languages = args.dataset
data_load_languages = languages
if args.adapter_train_languages is not None:
args.adapter_train_languages = args.adapter_train_languages.split("_")
data_load_languages = args.adapter_train_languages
else:
logging.warning("adapter_train_languages is None, will use all datasets for training")
args.adapter_train_languages = args.dataset
dataloaders, (idim, odim_dict) = data_load.load_multilingual_data(args.root_path, args.dataset, args, data_load_languages)
for idx, data_set in enumerate(args.dataset):
if languages[idx] not in data_load_languages:
continue
token_dict[languages[idx]] = data_load.load_token_list(
os.path.join(args.root_path, data_load.data_config[data_set]["token"])
)
setattr(args, "char_list", token_dict)
model = model_class(idim, odim_dict, args, languages)
model_conf = args.outdir + "/model.json"
with open(model_conf, "wb") as f:
logging.info("writing a model config file to " + model_conf)
f.write(
json.dumps(
(idim, odim_dict, vars(args)),
indent=4,
ensure_ascii=False,
sort_keys=True,
).encode("utf_8")
)
model.cuda()
if args.freeze_mods:
model, model_params = freeze_modules(model, args.freeze_mods)
else:
model_params = model.parameters()
logging.warning("Trainable parameters:")
for name, parameter in model.named_parameters():
if parameter.requires_grad:
logging.warning(name)
# Setup an optimizer
if args.meta_train:
logging.warning(f"Use Adam optimizer with lr={args.adam_lr}, beta0=0 for meta-training inner step")
optimizer = torch.optim.Adam(model_params, lr=args.adam_lr, betas=(0, 0.999), weight_decay=args.weight_decay)
else:
if args.opt == "adadelta":
optimizer = torch.optim.Adadelta(
model_params, rho=0.95, eps=args.eps, weight_decay=args.weight_decay
)
elif args.opt == "adam":
logging.warning(f"Using Adam optimizer with lr={args.adam_lr}")
optimizer = torch.optim.Adam(model_params, lr=args.adam_lr, weight_decay=args.weight_decay)
elif args.opt == "noam":
from espnet.nets.pytorch_backend.transformer.optimizer import get_std_opt
optimizer = get_std_opt(
model_params, args.adim, args.transformer_warmup_steps, args.transformer_lr
)
if len(args.adapter_train_languages) > 1 and not args.sim_adapter and not args.shared_adapter:
model_params = collections.defaultdict(list)
optimizer = {}
for lang in args.adapter_train_languages:
for name, parameter in model.named_parameters():
if parameter.requires_grad and lang in name.split("."):
model_params[lang].append(parameter)
logging.warning(f"Number of trainable parameters for language {lang} " + str(sum(p.numel() for p in model_params[lang])))
optimizer[lang] = torch.optim.Adam(model_params[lang], lr=args.adam_lr, weight_decay=args.weight_decay)
# Resume from a snapshot
if args.resume:
logging.warning("resumed from %s" % args.resume)
torch_load(args.resume, model, optimizer)
setattr(args, "start_epoch", int(args.resume.split('.')[-1]) + 1)
else:
setattr(args, "start_epoch", 1)
if args.load_pretrained_model:
model_path, modules_to_load, exclude_modules = args.load_pretrained_model.split(":")
logging.warning("load pretrained model from %s" % args.load_pretrained_model)
load_pretrained_model(model=model, model_path=model_path,
modules_to_load=modules_to_load, exclude_modules=exclude_modules)
if args.load_head_from_pretrained_model:
logging.warning("load pretrained model head from %s" % args.load_head_from_pretrained_model)
load_head_from_pretrained_model(model=model, model_path=args.load_head_from_pretrained_model)
logging.warning(
"Total parameter of the model = "
+ str(sum(p.numel() for p in model.parameters()))
)
logging.warning(
"Trainable parameter of the model = "
+ str(sum(p.numel() for p in filter(lambda x: x.requires_grad, model.parameters())))
)
if args.ngpu > 1 and args.dist_train:
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank,
find_unused_parameters=True,
)
save_path = f"{args.outdir}/model.loss.best"
if args.meta_train:
train_epoch = train_maml_epoch
if not args.decoding_mode:
train(dataloaders, model, optimizer, save_path)
if args.compute_cer and args.local_rank == 0:
# For CER/WER computing
for idx, dataset in enumerate(args.dataset):
language = languages[idx]
if args.adapter_train_languages and not (language in args.adapter_train_languages):
continue
if args.bpemodel and "bpemodel" in data_load.data_config[dataset]:
logging.warning(f"load bpe model for dataset {dataset}")
args.bpemodel = data_load.load_bpemodel(args.root_path, dataset)
dataloaders, _ = data_load.load_data(args.root_path, dataset, args)
splits = ["test", "val"]
for split in splits:
logging.warning(f"---------Recognizing {dataset} {split}----------")
args.result_label = f"{args.outdir}/{dataset}_{split}_recog.json"
if not data_load.data_config[dataset][split]:
split_path = os.path.join(args.root_path, f"{args.root_path}/tmp_dev_set_{dataset}.json")
else:
split_path = data_load.data_config[dataset][split]
args.recog_json = os.path.join(args.root_path, split_path)
idx = ["train", "val", "test"].index(split)
test_stats = test(f"{split}_best", dataloaders[idx],
model,
save_path,
language=language,
visualize_sim_adapter=args.sim_adapter)
logging.warning(f"Loss: {test_stats['loss']}")
err_dict = recognize_and_evaluate(dataloaders[idx], model, args, language,
model_path=save_path, wer=True, write_to_json=True)
logging.warning(f"CER: {err_dict['cer']['err']}")
logging.warning(f"WER: {err_dict['wer']['err']}")
================================================
FILE: code/ASR/Adapter/utils.py
================================================
import torch
import logging
from espnet.asr.asr_utils import add_results_to_json
import argparse
import numpy as np
import collections
import json
def load_head_from_pretrained_model(model, model_path):
model_dict = torch.load(model_path, map_location=lambda storage, loc: storage)
if "model" in model_dict.keys():
model_dict = model_dict["model"]
src_dict = {k: v for k, v in model_dict.items() if "decoder.embed." in k or "ctc." in k or "decoder.output_layer." in k}
dst_state = model.state_dict()
dst_state.update(src_dict)
for key in dst_state.keys():
if key in src_dict.keys():
logging.info("loading " + key)
model.load_state_dict(dst_state)
def load_adapter_from_pretrained_model(model, model_path, src_adapter, tgt_adapter):
'''
src_adapter, tgt_adapter: str, names of the source and target adapters to load parameters
'''
model_dict = torch.load(model_path, map_location=lambda storage, loc: storage)
if "model" in model_dict.keys():
model_dict = model_dict["model"]
src_dict = {k.replace(src_adapter, tgt_adapter): v for k, v in model_dict.items() if f"adapters.{src_adapter}" in k}
dst_state = model.state_dict()
dst_state.update(src_dict)
for key in dst_state.keys():
if key in src_dict.keys():
logging.info("loading " + key)
model.load_state_dict(dst_state)
# ==================== EasyEspnet functions =================================
def str2bool(str):
return True if str.lower() == 'true' else False
def setup_logging(verbose=1):
if verbose > 0:
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
)
else:
logging.basicConfig(
level=logging.WARN,
format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
)
logging.warning("Skip DEBUG/INFO messages")
# Training stats
def dict_average(dic):
avg_key, avg_val = [], []
for key, lst in dic.items():
if key.endswith("_lst"):
avg_key.append(key[:-4])
avg_val.append(np.mean(lst))
for key, val in zip(avg_key, avg_val):
dic[key] = val
return dic
# Load and save
def load_pretrained_model(model, model_path, modules_to_load=None, exclude_modules=None):
'''
load_pretrained_model(model=model, model_path="",
modules_to_load=None, exclude_modules="")
'''
model_dict = torch.load(model_path, map_location=lambda storage, loc: storage)
if exclude_modules:
for e in exclude_modules.split(","):
model_dict = {k: v for k, v in model_dict.items() if not k.startswith(e)}
if not modules_to_load:
src_dict = model_dict
else:
src_dict = {}
for module in modules_to_load.split(","):
src_dict.update({k: v for k, v in model_dict.items() if k.startswith(module)})
dst_state = model.state_dict()
dst_state.update(src_dict)
model.load_state_dict(dst_state)
def torch_save(model, save_path, optimizer=None, local_rank=0):
if local_rank != 0:
return
if hasattr(model, "module"):
state_dict = model.module.state_dict() if not optimizer else collections.OrderedDict(model=model.module.state_dict(), optimizer=optimizer.state_dict())
else:
state_dict = model.state_dict() if not optimizer else collections.OrderedDict(model=model.state_dict(), optimizer=optimizer.state_dict())
torch.save(state_dict, save_path)
def torch_load(snapshot_path, model, optimizer=None):
# load snapshot
snapshot_dict = torch.load(snapshot_path, map_location=lambda storage, loc: storage)
if not "model" in snapshot_dict.keys():
model_dict = snapshot_dict
snapshot_dict = collections.OrderedDict(model=model_dict)
if hasattr(model, "module"):
model.module.load_state_dict(snapshot_dict["model"])
else:
model.load_state_dict(snapshot_dict["model"])
if optimizer:
optimizer.load_state_dict(snapshot_dict["optimizer"])
del snapshot_dict
# Decoding
def compute_wer(ref, hyp, normalize=False):
"""Compute Word Error Rate.
[Reference]
https://martin-thoma.com/word-error-rate-calculation/
Args:
ref (list): words in the reference transcript
hyp (list): words in the predicted transcript
normalize (bool, optional): if True, divide by the length of ref
Returns:
wer (float): Word Error Rate between ref and hyp
n_sub (int): the number of substitution
n_ins (int): the number of insertion
n_del (int): the number of deletion
"""
# Initialisation
d = np.zeros((len(ref) + 1) * (len(hyp) + 1), dtype=np.uint16)
d = d.reshape((len(ref) + 1, len(hyp) + 1))
for i in range(len(ref) + 1):
for j in range(len(hyp) + 1):
if i == 0:
d[0][j] = j
elif j == 0:
d[i][0] = i
# Computation
for i in range(1, len(ref) + 1):
for j in range(1, len(hyp) + 1):
if ref[i - 1] == hyp[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
sub_tmp = d[i - 1][j - 1] + 1
ins_tmp = d[i][j - 1] + 1
del_tmp = d[i - 1][j] + 1
d[i][j] = min(sub_tmp, ins_tmp, del_tmp)
wer = d[len(ref)][len(hyp)]
# Find out the manipulation steps
x = len(ref)
y = len(hyp)
error_list = []
while True:
if x == 0 and y == 0:
break
else:
if x > 0 and y > 0:
if d[x][y] == d[x - 1][y - 1] and ref[x - 1] == hyp[y - 1]:
error_list.append("C")
x = x - 1
y = y - 1
elif d[x][y] == d[x][y - 1] + 1:
error_list.append("I")
y = y - 1
elif d[x][y] == d[x - 1][y - 1] + 1:
error_list.append("S")
x = x - 1
y = y - 1
else:
error_list.append("D")
x = x - 1
elif x == 0 and y > 0:
if d[x][y] == d[x][y - 1] + 1:
error_list.append("I")
y = y - 1
else:
error_list.append("D")
x = x - 1
elif y == 0 and x > 0:
error_list.append("D")
x = x - 1
else:
raise ValueError
n_sub = error_list.count("S")
n_ins = error_list.count("I")
n_del = error_list.count("D")
n_cor = error_list.count("C")
assert wer == (n_sub + n_ins + n_del)
assert n_cor == (len(ref) - n_sub - n_del)
if normalize:
wer /= len(ref)
return wer, n_sub, n_ins, n_del, n_cor
def token2text(tokens, bpemodel=None):
if bpemodel:
text = bpemodel.decode_pieces(tokens)
else:
text = (
" ".join(tokens)
.replace(" ", "")
.replace("", " ")
) # sclite does not consider the number of spaces when splitting
return text
def recognize_and_evaluate(dataloader, model, args, model_path=None, wer=False, write_to_json=False):
if model_path:
torch_load(model_path, model)
orig_model = model
if hasattr(model, "module"):
model = model.module
if write_to_json:
# read json data
assert args.result_label and args.recog_json
with open(args.recog_json, "rb") as f:
js = json.load(f)["utts"]
new_js = {}
model.eval()
recog_args = {
"beam_size": args.beam_size,
"penalty": args.penalty,
"ctc_weight": args.ctc_weight,
"maxlenratio": args.maxlenratio,
"minlenratio": args.minlenratio,
"lm_weight": args.lm_weight,
"rnnlm": args.rnnlm,
"nbest": args.nbest,
"space": args.sym_space,
"blank": args.sym_blank,
}
recog_args = argparse.Namespace(**recog_args)
#progress_bar = tqdm(dataloader)
#progress_bar.set_description("Testing CER/WERs")
err_dict = (
dict(cer=None)
if not wer
else dict(cer=collections.defaultdict(int), wer=collections.defaultdict(int))
)
with torch.no_grad():
for batch_idx, data in enumerate(dataloader):
logging.warning(f"Testing CER/WERs: {batch_idx+1}/{len(dataloader)}")
fbank, ilens, tokens = data
fbanks = []
for i, fb in enumerate(fbank):
fbanks.append(fb[: ilens[i], :])
fbank = fbanks
nbest_hyps = model.recognize_batch(
fbank, recog_args, char_list=None, rnnlm=None
)
y_hats = [nbest_hyp[0]["yseq"][1:-1] for nbest_hyp in nbest_hyps]
if write_to_json:
for utt_idx in range(len(fbank)):
name = dataloader.dataset[batch_idx][utt_idx][0]
new_js[name] = add_results_to_json(
js[name], nbest_hyps[utt_idx], args.char_list
)
for i, y_hat in enumerate(y_hats):
y_true = tokens[i]
hyp_token = [
args.char_list[int(idx)] for idx in y_hat if int(idx) != -1
]
ref_token = [
args.char_list[int(idx)] for idx in y_true if int(idx) != -1
]
for key in sorted(err_dict.keys()): # cer then wer
if key == "wer":
ref_token = token2text(ref_token, args.bpemodel).split()
hyp_token = token2text(hyp_token, args.bpemodel).split()
logging.debug("HYP: " + str(hyp_token))
logging.debug("REF: " + str(ref_token))
utt_err, utt_nsub, utt_nins, utt_ndel, utt_ncor = compute_wer(
ref_token, hyp_token
)
err_dict[key]["n_word"] += len(ref_token)
if utt_err != 0:
err_dict[key]["n_err"] += utt_err # Char / word error
err_dict[key]["n_ser"] += 1 # Sentence error
err_dict[key]["n_cor"] += utt_ncor
err_dict[key]["n_sub"] += utt_nsub
err_dict[key]["n_ins"] += utt_nins
err_dict[key]["n_del"] += utt_ndel
err_dict[key]["n_sent"] += 1
for key in err_dict.keys():
err_dict[key]["err"] = err_dict[key]["n_err"] / err_dict[key]["n_word"] * 100.0
err_dict[key]["ser"] = err_dict[key]["n_ser"] / err_dict[key]["n_word"] * 100.0
torch.cuda.empty_cache()
if write_to_json:
with open(args.result_label, "wb") as f:
f.write(
json.dumps(
{"utts": new_js}, indent=4, ensure_ascii=False, sort_keys=True
).encode("utf_8")
)
model = orig_model
return err_dict
================================================
FILE: code/ASR/CMatch/README.md
================================================
# CMatch: Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching
**NOTICE:** The latest code of CMatch has been moved to https://github.com/microsoft/NeuralSpeech/tree/master/CMatchASR for unified organization. Please refer to that repo.
---
This project implements our paper [Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching](https://arxiv.org/abs/2104.07491) based on [EasyEspnet](https://github.com/jindongwang/EasyEspnet). Please refer to [EasyEspnet](https://github.com/jindongwang/EasyEspnet) for the program introduction, installation and usage. And our paper [1] for the method and technical details.
## Run
After extracting features using Espnet and set the data folder path as introduced in [EasyEspnet](https://github.com/jindongwang/EasyEspnet).
You need to check or modify in `train.py arg_list`, config should be in ESPnet config style (remember to include decoding information if you want to compute cer/wer), then, you can run train.py. For example,
```
python train.py --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/train.yaml
```
This commands pre-trains an ASR model on the specified dataset. Results (log, model, snapshots) are saved in results_(dataset)/(config_name) by default.
### Cross-domain Adaptation
We provide three methods for cross-domain adaptation in this implementation: adversarial training (adv), maximum mean discrepancy (mmd) and our CMatch.
For the adversarial and mmd, you can refer to and modify the target dataset, pre-trained model setting in `config/{mmd, adv}_example.yaml`, and then execute this command for example:
```
python train.py --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/mmd_example.yaml
```
For the CMatch method, there are two steps.
#### Step 1:
First we need to obtain the pseudo labels, for example, suppose we trained the source model using the command above, we need to re-execute it with the `--pseudo_labeling` being set `true` and the `--tgt_dataset` specifying the target dataset:
```
python train.py --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/train.yaml --pseudo_labeling true --tgt_dataset libriadapt_en_us_clean_respeaker
```
So that we will get the pseudo labels for `libriadapt_en_us_clean_respeaker` dataset.
#### Step 2:
Then we can refer to and modify the target dataset, pre-trained model, non-character symbol, and pseudo label setting in `config/{ctc_align, pseudo_ctc_pred, frame_average}_example.yaml`, and then execute this command for example:
```
python train.py --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/ctc_align_example.yaml
```
### Demo
TBD
## Decoding and WER/CER evaluation
Set `--decoding_mode` to `true` to perform decoding and CER/WER evaluation. For example:
```
python train.py --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/train.yaml --decoding_mode true
```
## Distributed training
Following EasyEspnet, you can also perform distributed training which is much faster. For example, using 4 GPUs, 1 node:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --dist_train true --root_path libriadapt/asr1 --dataset libriadapt_en_us_clean_matrix --config config/mmd_example.yaml
```
## Acknowledgement
- ESPNet: https://github.com/espnet/espnet
- EasyEspnet: https://github.com/jindongwang/EasyEspnet
- NeuralSP: https://github.com/hirofumi0810/neural_sp
## Contact
- [Wenxin Hou](https://houwenxin.github.io/): houwx001@gmail.com
- [Jindong Wang](http://www.jd92.wang/): jindongwang@outlook.com
## References
[1] Wenxin Hou, Jindong Wang, Xu Tan, Tao Qin, Takahiro Shinozaki, "Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching", submitted to INTERSPEECH 2021.
================================================
FILE: code/ASR/CMatch/config/adv_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32 # There are two datasets, reduce batch size by half
transformer-lr: 6.0
#batch-size: 64
#transformer-lr: 10.0
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
#transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
# Transfer related
load_pretrained_model: # Example: /model.loss.best::
tgt_dataset:
transfer_type: adv
transfer_loss_weight: 0.3
================================================
FILE: code/ASR/CMatch/config/ctc_align_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32 # There are two datasets, reduce batch size by half
transformer-lr: 6.0
#batch-size: 64
#transformer-lr: 10.0
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
#transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
# Transfer related
load_pretrained_model: # Example: /model.loss.best::
tgt_dataset:
non_char_symbols: # Example: 0_1_2_29_30
transfer_type: cmatch
transfer_loss_weight: 10.0
cmatch_method: ctc_align
tranfer_loss_weight_warmup_steps: 0
self_training: True
pseudo_label_json:
================================================
FILE: code/ASR/CMatch/config/frame_average_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32 # There are two datasets, reduce batch size by half
transformer-lr: 6.0
#batch-size: 64
#transformer-lr: 10.0
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
#transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
# Transfer related
load_pretrained_model: # Example: /model.loss.best::
tgt_dataset:
non_char_symbols: # Example: 0_1_2_29_30
transfer_type: cmatch
transfer_loss_weight: 10.0
cmatch_method: frame_average
self_training: True
pseudo_label_json:
================================================
FILE: code/ASR/CMatch/config/mmd_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32 # There are two datasets, reduce batch size by half
transformer-lr: 6.0
#batch-size: 64
#transformer-lr: 10.0
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
#transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
# Transfer related
load_pretrained_model: # Example: /model.loss.best::
tgt_dataset:
transfer_type: mmd
transfer_loss_weight: 10.0
================================================
FILE: code/ASR/CMatch/config/pseudo_ctc_pred_example.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32 # There are two datasets, reduce batch size by half
transformer-lr: 6.0
#batch-size: 64
#transformer-lr: 10.0
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
#transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
# Transfer related
load_pretrained_model: # Example: /model.loss.best::
tgt_dataset:
transfer_type: cmatch
transfer_loss_weight: 10.0
cmatch_method: pseudo_ctc_pred
tranfer_loss_weight_warmup_steps: 0
self_training: True
pseudo_label_json:
multi_enc_repr_num: 1 # Number of encoder layers to use for adaptation, starting from the last layers
non_char_symbols: # Split by "_", Example: 0_1_2_29_30
================================================
FILE: code/ASR/CMatch/config/train.yaml
================================================
# network architecture
# encoder related
elayers: 12
eunits: 2048
# decoder related
dlayers: 6
dunits: 2048
# attention related
adim: 256
aheads: 4
# hybrid CTC/attention
mtlalpha: 0.3
# label smoothing
lsm-weight: 0.1
# minibatch related
batch-size: 32
maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced
maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
# optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs
opt: noam
accum-grad: 1
grad-clip: 5
patience: 5
epochs: 100
dropout-rate: 0.1
# transformer specific setting
backend: pytorch
model-module: "espnet.nets.pytorch_backend.e2e_asr_transformer:E2E"
transformer-input-layer: conv2d # encoder architecture type
transformer-lr: 6.0
transformer-warmup-steps: 25000
transformer-attn-dropout-rate: 0.0
transformer-length-normalized-loss: false
transformer-init: pytorch
# Decoding related
beam-size: 10
penalty: 0.0
maxlenratio: 0.0
minlenratio: 0.0
ctc-weight: 0.3
lm-weight: 0.7
================================================
FILE: code/ASR/CMatch/ctc_aligner.py
================================================
import torch
import numpy as np
'''
Borrowed and modified from neural_sp:
https://github.com/hirofumi0810/neural_sp/blob/154d9248b54e3888797fd81f93adc4700a75509a/neural_sp/models/seq2seq/decoders/ctc.py#L625
'''
LOG_0 = -1e10
LOG_1 = 0
def np2tensor(array, device=None):
"""Convert form np.ndarray to torch.Tensor.
Args:
array (np.ndarray): A tensor of any sizes
Returns:
tensor (torch.Tensor):
"""
tensor = torch.from_numpy(array).to(device)
return tensor
def pad_list(xs, pad_value=0., pad_left=False):
"""Convert list of Tensors to a single Tensor with padding.
Args:
xs (list): A list of length `[B]`, which contains Tensors of size `[T, input_size]`
pad_value (float):
pad_left (bool):
Returns:
xs_pad (FloatTensor): `[B, T, input_size]`
"""
bs = len(xs)
max_time = max(x.size(0) for x in xs)
xs_pad = xs[0].new_zeros(bs, max_time, * xs[0].size()[1:]).fill_(pad_value)
for b in range(bs):
if len(xs[b]) == 0:
continue
if pad_left:
xs_pad[b, -xs[b].size(0):] = xs[b]
else:
xs_pad[b, :xs[b].size(0)] = xs[b]
return xs_pad
class CTCForcedAligner(object):
def __init__(self, blank=0, char_list=None):
self.blank = blank
self.symbols = [0, 1, 2, 29, 30]
self.char_list = char_list
def __call__(self, logits, elens, ys):
"""Forced alignment with references.
Args:
logits (FloatTensor): `[B, T, vocab]`
elens (List): length `[B]`
ys (List): length `[B]`, each of which contains a list of size `[L]`
ylens (List): length `[B]`
Returns:
trigger_points (IntTensor): `[B, L]`
"""
ylens = np2tensor(np.fromiter([len(y) for y in ys], dtype=np.int32))
with torch.no_grad():
ys = [np2tensor(np.fromiter(y, dtype=np.int64), logits.device) for y in ys]
ys_in_pad = pad_list(ys, 0)
# zero padding
mask = make_pad_mask(elens.to(logits.device))
mask = mask.unsqueeze(2).expand_as(logits)
logits = logits.masked_fill_(mask == 0, LOG_0)
log_probs = torch.log_softmax(logits, dim=-1).transpose(0, 1) # `[T, B, vocab]`
trigger_points = self.align(log_probs, elens, ys_in_pad, ylens)
return trigger_points
def align(self, log_probs, elens, ys, ylens, add_eos=True):
"""Calculte the best CTC alignment with the forward-backward algorithm.
Args:
log_probs (FloatTensor): `[T, B, vocab]`
elens (FloatTensor): `[B]`
ys (FloatTensor): `[B, L]`
ylens (FloatTensor): `[B]`
add_eos (bool): Use the last time index as a boundary corresponding to
Returns:
trigger_points (IntTensor): `[B, L]`
"""
xmax, bs, vocab = log_probs.size()
path = _label_to_path(ys, self.blank)
path_lens = 2 * ylens.long() + 1
ymax = ys.size(1)
max_path_len = path.size(1)
assert ys.size() == (bs, ymax), ys.size()
assert path.size() == (bs, ymax * 2 + 1)
alpha = log_probs.new_zeros(bs, max_path_len).fill_(LOG_0)
alpha[:, 0] = LOG_1
beta = alpha.clone()
gamma = alpha.clone()
batch_index = torch.arange(bs, dtype=torch.int64).unsqueeze(1)
frame_index = torch.arange(xmax, dtype=torch.int64).unsqueeze(1).unsqueeze(2)
log_probs_fwd_bwd = log_probs[frame_index, batch_index, path]
same_transition = (path[:, :-2] == path[:, 2:])
outside = torch.arange(max_path_len, dtype=torch.int64) >= path_lens.unsqueeze(1)
log_probs_gold = log_probs[:, batch_index, path]
# forward algorithm
for t in range(xmax):
alpha = _computes_transition(alpha, same_transition, outside,
log_probs_fwd_bwd[t], log_probs_gold[t])
# backward algorithm
r_path = _flip_path(path, path_lens)
log_probs_inv = _flip_label_probability(log_probs, elens.long()) # `[T, B, vocab]`
log_probs_fwd_bwd = _flip_path_probability(log_probs_fwd_bwd, elens.long(), path_lens) # `[T, B, 2*L+1]`
r_same_transition = (r_path[:, :-2] == r_path[:, 2:])
log_probs_inv_gold = log_probs_inv[:, batch_index, r_path]
for t in range(xmax):
beta = _computes_transition(beta, r_same_transition, outside,
log_probs_fwd_bwd[t], log_probs_inv_gold[t])
# pick up the best CTC path
best_aligns = log_probs.new_zeros((bs, xmax), dtype=torch.int64)
# forward algorithm
log_probs_fwd_bwd = _flip_path_probability(log_probs_fwd_bwd, elens.long(), path_lens)
for t in range(xmax):
gamma = _computes_transition(gamma, same_transition, outside,
log_probs_fwd_bwd[t], log_probs_gold[t],
skip_accum=True)
# select paths where gamma is valid
log_probs_fwd_bwd[t] = log_probs_fwd_bwd[t].masked_fill_(gamma == LOG_0, LOG_0)
# pick up the best alignment
offsets = log_probs_fwd_bwd[t].argmax(1)
for b in range(bs):
if t <= elens[b] - 1:
token_idx = path[b, offsets[b]]
best_aligns[b, t] = token_idx
# remove the rest of paths
gamma = log_probs.new_zeros(bs, max_path_len).fill_(LOG_0)
for b in range(bs):
gamma[b, offsets[b]] = LOG_1
# pick up trigger points
trigger_aligns = torch.zeros((bs, xmax), dtype=torch.int64)
trigger_aligns_avg = torch.zeros((bs, xmax), dtype=torch.int64)
trigger_points = log_probs.new_zeros((bs, ymax + 1), dtype=torch.int32) # +1 for
for b in range(bs):
n_triggers = 0
if add_eos:
trigger_points[b, ylens[b]] = elens[b] - 1
# NOTE: use the last time index as a boundary corresponding to
# Otherwise, index: 0 is used for
last_token_idx = None
count = 0
for t in range(elens[b]):
token_idx = best_aligns[b, t]
if token_idx in self.symbols:
trigger_aligns_avg[b, t] = last_token_idx if last_token_idx else 0
count += 1
if token_idx == self.blank:
continue
if not (t == 0 or token_idx != best_aligns[b, t - 1]):
continue
# NOTE: select the most left trigger points
trigger_aligns[b, t] = token_idx
last_token_idx = token_idx
trigger_points[b, n_triggers] = t
n_triggers += 1
assert ylens.sum() == (trigger_aligns != 0).sum()
return trigger_aligns_avg
def _flip_label_probability(log_probs, xlens):
"""Flips a label probability matrix.
This function rotates a label probability matrix and flips it.
``log_probs[i, b, l]`` stores log probability of label ``l`` at ``i``-th
input in ``b``-th batch.
The rotated matrix ``r`` is defined as
``r[i, b, l] = log_probs[i + xlens[b], b, l]``
Args:
cum_log_prob (FloatTensor): `[T, B, vocab]`
xlens (LongTensor): `[B]`
Returns:
FloatTensor: `[T, B, vocab]`
"""
xmax, bs, vocab = log_probs.size()
rotate = (torch.arange(xmax, dtype=torch.int64)[:, None] + xlens) % xmax
return torch.flip(log_probs[rotate[:, :, None],
torch.arange(bs, dtype=torch.int64)[None, :, None],
torch.arange(vocab, dtype=torch.int64)[None, None, :]], dims=[0])
def _flip_path_probability(cum_log_prob, xlens, path_lens):
"""Flips a path probability matrix.
This function returns a path probability matrix and flips it.
``cum_log_prob[i, b, t]`` stores log probability at ``i``-th input and
at time ``t`` in a output sequence in ``b``-th batch.
The rotated matrix ``r`` is defined as
``r[i, j, k] = cum_log_prob[i + xlens[j], j, k + path_lens[j]]``
Args:
cum_log_prob (FloatTensor): `[T, B, 2*L+1]`
xlens (LongTensor): `[B]`
path_lens (LongTensor): `[B]`
Returns:
FloatTensor: `[T, B, 2*L+1]`
"""
xmax, bs, max_path_len = cum_log_prob.size()
rotate_input = ((torch.arange(xmax, dtype=torch.int64)[:, None] + xlens) % xmax)
rotate_label = ((torch.arange(max_path_len, dtype=torch.int64) + path_lens[:, None]) % max_path_len)
return torch.flip(cum_log_prob[rotate_input[:, :, None],
torch.arange(bs, dtype=torch.int64)[None, :, None],
rotate_label], dims=[0, 2])
def _computes_transition(seq_log_prob, same_transition, outside,
cum_log_prob, log_prob_yt, skip_accum=False):
bs, max_path_len = seq_log_prob.size()
mat = seq_log_prob.new_zeros(3, bs, max_path_len).fill_(LOG_0)
mat[0, :, :] = seq_log_prob
mat[1, :, 1:] = seq_log_prob[:, :-1]
mat[2, :, 2:] = seq_log_prob[:, :-2]
# disable transition between the same symbols
# (including blank-to-blank)
mat[2, :, 2:][same_transition] = LOG_0
seq_log_prob = torch.logsumexp(mat, dim=0) # overwrite
seq_log_prob[outside] = LOG_0
if not skip_accum:
cum_log_prob += seq_log_prob
seq_log_prob += log_prob_yt
return seq_log_prob
def make_pad_mask(seq_lens):
"""Make mask for padding.
Args:
seq_lens (IntTensor): `[B]`
Returns:
mask (IntTensor): `[B, T]`
"""
bs = seq_lens.size(0)
max_time = seq_lens.max()
seq_range = torch.arange(0, max_time, dtype=torch.int32, device=seq_lens.device)
seq_range = seq_range.unsqueeze(0).expand(bs, max_time)
mask = seq_range < seq_lens.unsqueeze(-1)
return mask
def _label_to_path(labels, blank):
path = labels.new_zeros(labels.size(0), labels.size(1) * 2 + 1).fill_(blank).long()
path[:, 1::2] = labels
return path
def _flip_path(path, path_lens):
"""Flips label sequence.
This function rotates a label sequence and flips it.
``path[b, t]`` stores a label at time ``t`` in ``b``-th batch.
The rotated matrix ``r`` is defined as
``r[b, t] = path[b, t + path_lens[b]]``
.. ::
a b c d . . a b c d d c b a .
e f . . . -> . . . e f -> f e . . .
g h i j k g h i j k k j i h g
Args:
path (FloatTensor): `[B, 2*L+1]`
path_lens (LongTensor): `[B]`
Returns:
FloatTensor: `[B, 2*L+1]`
"""
bs = path.size(0)
max_path_len = path.size(1)
rotate = (torch.arange(max_path_len) + path_lens[:, None]) % max_path_len
return torch.flip(path[torch.arange(bs, dtype=torch.int64)[:, None], rotate], dims=[1])
================================================
FILE: code/ASR/CMatch/data_load.py
================================================
from espnet.utils.training.batchfy import make_batchset
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
import torch
import os
import json
import kaldiio
import random
import logging
import sentencepiece as spm
data_config = {
"librispeech": {
"train": "dump/train_960/deltafalse/data_unigram5000.json",
"val": "dump/dev_clean/deltafalse/data_unigram5000.json",
"test": "dump/test_clean/deltafalse/data_unigram5000.json",
"token": "data/lang_char/train_960_unigram5000_units.txt",
"prefix": "/espnet/egs/librispeech/asr1/",
},
"wsj": {
"train": "dump/train_si284/deltafalse/data.json",
"val": "dump/test_dev93/deltafalse/data.json",
"test": "dump/test_eval92/deltafalse/data.json",
"token": "data/lang_1char/train_si284_units.txt",
"prefix": "/opt/espnet/egs/wsj/asr1/",
},
"an4": {
"train": "dump/train_nodev/deltafalse/data.json",
"val": "dump/train_dev/deltafalse/data.json",
"test": "dump/test/deltafalse/data.json",
"token": "data/lang_1char/train_nodev_units.txt",
"prefix": "/home/jindwang/mine/espnet/egs/an4/asr1/",
},
"libriadapt_en_us_clean_matrix": {
"train": "dump/en_us_clean_matrix/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_clean_matrix/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_clean_matrix/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_clean_matrix/train_unigram31.model",
},
"libriadapt_en_us_clean_usb": {
"train": "dump/en_us_clean_usb/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_clean_usb/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_clean_usb/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_clean_usb/train_unigram31.model",
},
"libriadapt_en_us_clean_pseye": {
"train": "dump/en_us_clean_pseye/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_clean_pseye/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_clean_pseye/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_clean_pseye/train_unigram31.model",
},
"libriadapt_en_us_clean_respeaker": {
"train": "dump/en_us_clean_respeaker/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_clean_respeaker/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_clean_respeaker/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_clean_respeaker/train_unigram31.model",
},
"libriadapt_en_us_rain_respeaker": {
"train": "dump/en_us_rain_respeaker/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_rain_respeaker/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_rain_respeaker/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_rain_respeaker/train_unigram31.model",
},
"libriadapt_en_us_wind_respeaker": {
"train": "dump/en_us_wind_respeaker/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_wind_respeaker/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_wind_respeaker/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_wind_respeaker/train_unigram31.model",
},
"libriadapt_en_us_laughter_respeaker": {
"train": "dump/en_us_laughter_respeaker/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_laughter_respeaker/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_laughter_respeaker/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_laughter_respeaker/train_unigram31.model",
},
"libriadapt_en_us_clean_shure": {
"train": "dump/en_us_clean_shure/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_us_clean_shure/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_us_clean_shure/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_us_clean_shure/train_unigram31.model",
},
"libriadapt_en_gb_clean_shure": {
"train": "dump/en_gb_clean_shure/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_gb_clean_shure/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_gb_clean_shure/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_gb_clean_shure/train_unigram31.model",
},
"libriadapt_en_in_clean_shure": {
"train": "dump/en_in_clean_shure/train/deltafalse/data_unigram31.json",
"val": None,
"test": "dump/en_in_clean_shure/test/deltafalse/data_unigram31.json",
"token": "data/lang_char/en_in_clean_shure/train_unigram31_units.txt",
"prefix": "/D_data/libriadapt_processed/asr1/",
"bpemodel": "data/lang_char/en_in_clean_shure/train_unigram31.model",
},
}
def read_json_file(fname):
with open(fname, "rb") as f:
contents = json.load(f)["utts"]
return contents
def load_json(train_json_file, dev_json_file, test_json_file):
train_json = read_json_file(train_json_file)
if os.path.isfile(dev_json_file) and not "tmp_dev_set" in dev_json_file:
dev_json = read_json_file(dev_json_file)
else:
n_samples = len(train_json)
train_size = int(0.9 * n_samples)
logging.warning(
f"No dev set provided, will split the last {n_samples - train_size} (10%) samples from training data"
)
train_json_item = list(train_json.items())
# random.shuffle(train_json_item)
train_json = dict(train_json_item[:train_size])
dev_json = dict(train_json_item[train_size:])
# Save temp dev set
with open(dev_json_file, "w") as f:
json.dump({"utts": dev_json}, f)
logging.warning(f"Temporary dev set saved: {dev_json_file}")
test_json = read_json_file(test_json_file)
logging.warning(f"#Train Json {train_json_file}: {len(train_json)}")
logging.warning(f"#Dev Json {dev_json_file}: {len(dev_json)}")
logging.warning(f"#Test Json {test_json_file}: {len(test_json)}")
return train_json, dev_json, test_json
def load_data(root_path, dataset, args,
pseudo_label_json=None, pseudo_label_filtering=True, use_pseudo_label=True):
def collate(minibatch):
fbanks = []
tokens = []
for _, info in minibatch[0]:
fbanks.append(
torch.tensor(
kaldiio.load_mat(
info["input"][0]["feat"].replace(
data_config[dataset]["prefix"], root_path
)
)
)
)
if use_pseudo_label and "pseudo_tokenid" in info["output"][0].keys():
tokens.append(
torch.tensor([int(s) for s in info["output"][0]["pseudo_tokenid"].split()])
)
else:
tokens.append(
torch.tensor([int(s) for s in info["output"][0]["tokenid"].split()])
)
ilens = torch.tensor([x.shape[0] for x in fbanks])
return (
pad_sequence(fbanks, batch_first=True, padding_value=0),
ilens,
pad_sequence(tokens, batch_first=True, padding_value=-1),
)
train_json = os.path.join(root_path, data_config[dataset]["train"])
dev_json = (
os.path.join(root_path, data_config[dataset]["val"])
if data_config[dataset]["val"]
else f"{root_path}/tmp_dev_set_{dataset}.json"
)
test_json = os.path.join(root_path, data_config[dataset]["test"])
train_json, dev_json, test_json = load_json(train_json, dev_json, test_json)
_, info = next(iter(train_json.items()))
if use_pseudo_label and pseudo_label_json:
psuedo_label_json = read_json_file(pseudo_label_json)
assert psuedo_label_json.keys() == train_json.keys() or list(psuedo_label_json.keys())[:25685] == list(train_json.keys()), \
"Keys of pseudo label and training data not matched"
for key in train_json.keys():
train_json[key]['output'][0]['pseudo_tokenid'] = ' '.join(psuedo_label_json[key]['output'][0]['rec_tokenid'].split()[:-1])
train_json[key]['output'][0]["score"] = psuedo_label_json[key]['output'][0]['score']
if use_pseudo_label and pseudo_label_json and pseudo_label_filtering:
filtered_sample = 0
filtered_ratio = 0.3 if pseudo_label_filtering else 0.0
train_json = sorted(train_json.items(), key=lambda x:x[1]['output'][0]['score'], reverse=True)
sample_num = len(train_json)
train_json = train_json[:int(sample_num * (1 - filtered_ratio))]
logging.warning(f"Filtering: {len(train_json)}/{sample_num} pseudo-labelled samples are kept")
train_json = dict(train_json)
filtered_sample = 0
idim = info["input"][0]["shape"][1]
odim = info["output"][0]["shape"][1]
use_sortagrad = False # args.sortagrad == -1 or args.sortagrad > 0
trainset = make_batchset(
train_json,
args.batch_size,
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=args.ngpu if (args.ngpu > 1 and not args.dist_train) else 1,
shortest_first=use_sortagrad,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
devset = make_batchset(
dev_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
testset = make_batchset(
test_json,
args.batch_size if args.ngpu <= 1 else int(args.batch_size / args.ngpu),
args.maxlen_in,
args.maxlen_out,
args.minibatches,
min_batch_size=1,
count=args.batch_count,
batch_bins=args.batch_bins,
batch_frames_in=args.batch_frames_in,
batch_frames_out=args.batch_frames_out,
batch_frames_inout=args.batch_frames_inout,
iaxis=0,
oaxis=0,
)
if args.dist_train and args.ngpu > 1:
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
else:
train_sampler = None
train_loader = DataLoader(
trainset,
batch_size=1,
collate_fn=collate,
num_workers=args.n_iter_processes,
shuffle=(train_sampler is None and not args.pseudo_labeling),
pin_memory=True,
sampler=train_sampler,
)
dev_loader = DataLoader(
devset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
test_loader = DataLoader(
testset,
batch_size=1,
collate_fn=collate,
shuffle=False,
num_workers=args.n_iter_processes,
pin_memory=True,
)
return (train_loader, dev_loader, test_loader), (idim, odim)
def load_token_list(token_file):
with open(token_file, "r") as f:
token_list = [entry.split()[0] for entry in f]
token_list.insert(0, "")
token_list.append("")
return token_list
def load_bpemodel(root_path, dataset):
bpemodel_path = os.path.join(root_path, data_config[dataset]["bpemodel"])
bpemodel = spm.SentencePieceProcessor()
bpemodel.Load(bpemodel_path)
return bpemodel
================================================
FILE: code/ASR/CMatch/distances.py
================================================
import torch
def CORAL(source, target):
DEVICE = source.device
d = source.size(1)
ns, nt = source.size(0), target.size(0)
# source covariance
tmp_s = torch.ones((1, ns)).to(DEVICE) @ source
cs = (source.t() @ source - (tmp_s.t() @ tmp_s) / ns) / (ns - 1)
# target covariance
tmp_t = torch.ones((1, nt)).to(DEVICE) @ target
ct = (target.t() @ target - (tmp_t.t() @ tmp_t) / nt) / (nt - 1)
# frobenius norm
loss = (cs - ct).pow(2).sum().sqrt()
loss = loss / (4 * d * d)
return loss
class MMD_loss(torch.nn.Module):
def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5):
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd2(self, f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd2(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
================================================
FILE: code/ASR/CMatch/e2e_asr_udatransformer.py
================================================
import collections
from espnet.nets.pytorch_backend.e2e_asr_transformer import *
from espnet.nets.pytorch_backend.e2e_asr_transformer import E2E as SpeechTransformer
from espnet.nets.pytorch_backend.transformer.encoder import *
from espnet.nets.pytorch_backend.transformer.decoder import *
from espnet.nets.pytorch_backend.transformer.encoder_layer import EncoderLayer
from espnet.nets.pytorch_backend.transformer.decoder_layer import DecoderLayer
import torch
from distances import CORAL, MMD_loss
import numpy as np
from ctc_aligner import CTCForcedAligner
def adapt_loss(source, target, adapt_loss="mmd"):
if adapt_loss == "mmd": # 1.0 level
mmd_loss = MMD_loss()
loss = mmd_loss(source, target)
elif adapt_loss == "mmd_linear":
mmd_loss = MMD_loss(kernel_type="linear")
loss = mmd_loss(source, target)
elif adapt_loss == "coral": # 1e-4 level
loss = CORAL(source, target)
else:
raise NotImplementedError(f"Adapt loss type {adapt_loss} is not implemented")
return loss
class Discriminator(torch.nn.Module):
def __init__(self, input_dim=256, hidden_dim=256):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.dis1 = torch.nn.Linear(input_dim, hidden_dim)
self.bn = torch.nn.BatchNorm1d(hidden_dim)
self.dis2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = torch.nn.functional.relu(self.dis1(x))
x = self.dis2(self.bn(x.permute(0, 2, 1)).permute(0, 2, 1))
x = torch.sigmoid(x)
return x
class ReverseLayerF(torch.autograd.Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class CustomEncoderLayer(EncoderLayer):
def forward(self, x, mask, cache=None):
residual = x
if self.normalize_before:
x = self.norm1(x)
self.x_norm = x
if cache is None:
x_q = x
else:
assert cache.shape == (x.shape[0], x.shape[1] - 1, self.size)
x_q = x[:, -1:, :]
residual = residual[:, -1:, :]
mask = None if mask is None else mask[:, -1:, :]
if self.concat_after:
x_concat = torch.cat((x, self.self_attn(x_q, x, x, mask)), dim=-1)
x = residual + self.concat_linear(x_concat)
else:
x = residual + self.dropout(self.self_attn(x_q, x, x, mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
x = residual + self.dropout(self.feed_forward(x))
if not self.normalize_before:
x = self.norm2(x)
if cache is not None:
x = torch.cat([cache, x], dim=1)
return x, mask
class CustomEncoder(Encoder):
def __init__(
self,
idim,
selfattention_layer_type="selfattn",
attention_dim=256,
attention_heads=4,
conv_wshare=4,
conv_kernel_length=11,
conv_usebias=False,
linear_units=2048,
num_blocks=6,
dropout_rate=0.1,
positional_dropout_rate=0.1,
attention_dropout_rate=0.0,
input_layer="conv2d",
pos_enc_class=PositionalEncoding,
normalize_before=True,
concat_after=False,
positionwise_layer_type="linear",
positionwise_conv_kernel_size=1,
padding_idx=-1,
):
super().__init__(idim,
selfattention_layer_type,
attention_dim,
attention_heads,
conv_wshare,
conv_kernel_length,
conv_usebias,
linear_units,
num_blocks,
dropout_rate,
positional_dropout_rate,
attention_dropout_rate,
input_layer,
pos_enc_class,
normalize_before,
concat_after,
positionwise_layer_type,
positionwise_conv_kernel_size,
padding_idx)
positionwise_layer, positionwise_layer_args = self.get_positionwise_layer(
positionwise_layer_type,
attention_dim,
linear_units,
dropout_rate,
positionwise_conv_kernel_size,
)
encoder_selfattn_layer = MultiHeadedAttention
encoder_selfattn_layer_args = [
(
attention_heads,
attention_dim,
attention_dropout_rate,
)
] * num_blocks
self.encoders = repeat(
num_blocks,
lambda lnum: CustomEncoderLayer(
attention_dim,
encoder_selfattn_layer(*encoder_selfattn_layer_args[lnum]),
positionwise_layer(*positionwise_layer_args),
dropout_rate,
normalize_before,
concat_after,
),
)
def forward(self, xs, masks, return_repr=False):
"""Encode input sequence.
Args:
xs (torch.Tensor): Input tensor (#batch, time, idim).
masks (torch.Tensor): Mask tensor (#batch, time).
Returns:
torch.Tensor: Output tensor (#batch, time, attention_dim).
torch.Tensor: Mask tensor (#batch, time).
"""
xs, masks = self.embed(xs, masks)
#xs, masks = self.encoders(xs, masks)
final_repr = []
for layer_idx, e in enumerate(self.encoders):
xs, masks = e(xs, masks)
if return_repr and layer_idx > 0:
assert e.x_norm is not None
final_repr.append(e.x_norm)
#print(e.x_norm.mean(), xs.mean())
e.x_norm = None
if self.normalize_before:
xs = self.after_norm(xs)
final_repr.append(xs)
return (xs, masks) if not return_repr else (xs, masks, final_repr)
class CustomDecoderLayer(DecoderLayer):
def forward(self, tgt, tgt_mask, memory, memory_mask, cache=None):
"""Compute decoded features.
Args:
tgt (torch.Tensor): Input tensor (#batch, maxlen_out, size).
tgt_mask (torch.Tensor): Mask for input tensor (#batch, maxlen_out).
memory (torch.Tensor): Encoded memory, float32 (#batch, maxlen_in, size).
memory_mask (torch.Tensor): Encoded memory mask (#batch, maxlen_in).
cache (List[torch.Tensor]): List of cached tensors.
Each tensor shape should be (#batch, maxlen_out - 1, size).
Returns:
torch.Tensor: Output tensor(#batch, maxlen_out, size).
torch.Tensor: Mask for output tensor (#batch, maxlen_out).
torch.Tensor: Encoded memory (#batch, maxlen_in, size).
torch.Tensor: Encoded memory mask (#batch, maxlen_in).
"""
residual = tgt
if self.normalize_before:
tgt = self.norm1(tgt)
self.x_norm = tgt
if cache is None:
tgt_q = tgt
tgt_q_mask = tgt_mask
else:
# compute only the last frame query keeping dim: max_time_out -> 1
assert cache.shape == (
tgt.shape[0],
tgt.shape[1] - 1,
self.size,
), f"{cache.shape} == {(tgt.shape[0], tgt.shape[1] - 1, self.size)}"
tgt_q = tgt[:, -1:, :]
residual = residual[:, -1:, :]
tgt_q_mask = None
if tgt_mask is not None:
tgt_q_mask = tgt_mask[:, -1:, :]
if self.concat_after:
tgt_concat = torch.cat(
(tgt_q, self.self_attn(tgt_q, tgt, tgt, tgt_q_mask)), dim=-1
)
x = residual + self.concat_linear1(tgt_concat)
else:
x = residual + self.dropout(self.self_attn(tgt_q, tgt, tgt, tgt_q_mask))
if not self.normalize_before:
x = self.norm1(x)
residual = x
if self.normalize_before:
x = self.norm2(x)
if self.concat_after:
x_concat = torch.cat(
(x, self.src_attn(x, memory, memory, memory_mask)), dim=-1
)
x = residual + self.concat_linear2(x_concat)
else:
x = residual + self.dropout(self.src_attn(x, memory, memory, memory_mask))
if not self.normalize_before:
x = self.norm2(x)
residual = x
if self.normalize_before:
x = self.norm3(x)
x = residual + self.dropout(self.feed_forward(x))
if not self.normalize_before:
x = self.norm3(x)
if cache is not None:
x = torch.cat([cache, x], dim=1)
return x, tgt_mask, memory, memory_mask
class CustomDecoder(Decoder):
def __init__(
self,
odim,
selfattention_layer_type="selfattn",
attention_dim=256,
attention_heads=4,
conv_wshare=4,
conv_kernel_length=11,
conv_usebias=False,
linear_units=2048,
num_blocks=6,
dropout_rate=0.1,
positional_dropout_rate=0.1,
self_attention_dropout_rate=0.0,
src_attention_dropout_rate=0.0,
input_layer="embed",
use_output_layer=True,
pos_enc_class=PositionalEncoding,
normalize_before=True,
concat_after=False,
):
super().__init__(odim,
selfattention_layer_type,
attention_dim,
attention_heads,
conv_wshare,
conv_kernel_length,
conv_usebias,
linear_units,
num_blocks,
dropout_rate,
positional_dropout_rate,
self_attention_dropout_rate,
src_attention_dropout_rate,
input_layer,
use_output_layer,
pos_enc_class,
normalize_before,
concat_after,
)
decoder_selfattn_layer = MultiHeadedAttention
decoder_selfattn_layer_args = [
(
attention_heads,
attention_dim,
self_attention_dropout_rate,
)
] * num_blocks
self.decoders = repeat(
num_blocks,
lambda lnum: CustomDecoderLayer(
attention_dim,
decoder_selfattn_layer(*decoder_selfattn_layer_args[lnum]),
MultiHeadedAttention(
attention_heads, attention_dim, src_attention_dropout_rate
),
PositionwiseFeedForward(attention_dim, linear_units, dropout_rate),
dropout_rate,
normalize_before,
concat_after,
),
)
def forward(self, tgt, tgt_mask, memory, memory_mask, return_repr=False):
"""Forward decoder.
Args:
tgt (torch.Tensor): Input token ids, int64 (#batch, maxlen_out) if
input_layer == "embed". In the other case, input tensor
(#batch, maxlen_out, odim).
tgt_mask (torch.Tensor): Input token mask (#batch, maxlen_out).
dtype=torch.uint8 in PyTorch 1.2- and dtype=torch.bool in PyTorch 1.2+
(include 1.2).
memory (torch.Tensor): Encoded memory, float32 (#batch, maxlen_in, feat).
memory_mask (torch.Tensor): Encoded memory mask (#batch, maxlen_in).
dtype=torch.uint8 in PyTorch 1.2- and dtype=torch.bool in PyTorch 1.2+
(include 1.2).
Returns:
torch.Tensor: Decoded token score before softmax (#batch, maxlen_out, odim)
if use_output_layer is True. In the other case,final block outputs
(#batch, maxlen_out, attention_dim).
torch.Tensor: Score mask before softmax (#batch, maxlen_out).
"""
x = self.embed(tgt)
# x, tgt_mask, memory, memory_mask = self.decoders(
# x, tgt_mask, memory, memory_mask
# )
final_repr = []
for layer_idx, decoder in enumerate(self.decoders):
x, tgt_mask, memory, memory_mask = decoder(
x, tgt_mask, memory, memory_mask
)
if return_repr and layer_idx > 0:
assert decoder.x_norm is not None
final_repr.append(decoder.x_norm)
decoder.x_norm = None
if self.normalize_before:
x = self.after_norm(x)
final_repr.append(x)
if self.output_layer is not None:
x = self.output_layer(x)
return (x, tgt_mask, None) if not return_repr else (x, tgt_mask, final_repr)
class CustomSpeechTransformer(SpeechTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
idim, odim = args
args = kwargs["args"]
self.encoder = CustomEncoder(
idim=idim,
selfattention_layer_type=args.transformer_encoder_selfattn_layer_type,
attention_dim=args.adim,
attention_heads=args.aheads,
conv_wshare=args.wshare,
conv_kernel_length=args.ldconv_encoder_kernel_length,
conv_usebias=args.ldconv_usebias,
linear_units=args.eunits,
num_blocks=args.elayers,
input_layer=args.transformer_input_layer,
dropout_rate=args.dropout_rate,
positional_dropout_rate=args.dropout_rate,
attention_dropout_rate=args.transformer_attn_dropout_rate,
)
self.decoder = CustomDecoder(
odim=odim,
selfattention_layer_type=args.transformer_decoder_selfattn_layer_type,
attention_dim=args.adim,
attention_heads=args.aheads,
conv_wshare=args.wshare,
conv_kernel_length=args.ldconv_decoder_kernel_length,
conv_usebias=args.ldconv_usebias,
linear_units=args.dunits,
num_blocks=args.dlayers,
dropout_rate=args.dropout_rate,
positional_dropout_rate=args.dropout_rate,
self_attention_dropout_rate=args.transformer_attn_dropout_rate,
src_attention_dropout_rate=args.transformer_attn_dropout_rate,
)
class UDASpeechTransformer(CustomSpeechTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
args = kwargs["args"]
assert hasattr(args, "transfer_type")
assert isinstance(args.self_training, bool)
self.loss_type = args.transfer_type
self.self_training = args.self_training
self.n_classes = len(args.char_list)
self.multi_enc_repr_num = args.multi_enc_repr_num
self.multi_dec_repr_num = args.multi_dec_repr_num
self.use_dec_repr = args.use_dec_repr
self.pseudo_ctc_confidence_thr = args.pseudo_ctc_confidence_thr # Threshold for filtering CTC outputs
self.cmatch_method = args.cmatch_method
self.ctc_aligner = CTCForcedAligner(char_list=None)
self.char_list = args.char_list
self.bpemodel = None
self.non_char_symbols = list(map(int, args.non_char_symbols.split("_")))
if self.loss_type:
if "cmatch" in self.loss_type:
assert args.cmatch_method is not None, "CMatch method is required."
assert self.non_char_symbols is not None, "Non-character symbol list must be specified"
elif self.loss_type == "adv":
self.domain_classifier = Discriminator(input_dim=self.adim, hidden_dim=self.adim)
def forward(self,
xs_pad,
ilens,
ys_pad,
tgt_xs_pad=None,
tgt_ilens=None,
tgt_ys_pad=None):
"""E2E forward.
:param torch.Tensor xs_pad: batch of padded source sequences (B, Tmax, idim)
:param torch.Tensor ilens: batch of lengths of source sequences (B)
:param torch.Tensor ys_pad: batch of padded target sequences (B, Lmax)
:return: ctc loss value
:rtype: torch.Tensor
:return: attention loss value
:rtype: torch.Tensor
:return: accuracy in attention decoder
:rtype: float
"""
dec_return_repr = True
enc_return_repr = True
# 1. forward encoder
xs_pad = xs_pad[:, : max(ilens)] # for data parallel
src_mask = make_non_pad_mask(ilens.tolist()).to(xs_pad.device).unsqueeze(-2)
if enc_return_repr:
hs_pad, hs_mask, src_enc_repr = self.encoder(xs_pad, src_mask, return_repr=enc_return_repr)
src_enc_repr = src_enc_repr[-self.multi_enc_repr_num:]
else:
hs_pad, hs_mask = self.encoder(xs_pad, src_mask)
self.hs_pad = hs_pad
# 2. forward decoder
if self.decoder is not None:
ys_in_pad, ys_out_pad = add_sos_eos(
ys_pad, self.sos, self.eos, self.ignore_id
)
ys_mask = target_mask(ys_in_pad, self.ignore_id)
pred_pad, pred_mask, src_dec_repr = self.decoder(ys_in_pad, ys_mask, hs_pad, hs_mask, return_repr=dec_return_repr)
if src_dec_repr:
src_dec_repr = src_dec_repr[-self.multi_dec_repr_num:]
self.pred_pad = pred_pad
# 3. compute attention loss
loss_att = self.criterion(pred_pad, ys_out_pad)
self.acc = th_accuracy(
pred_pad.view(-1, self.odim), ys_out_pad, ignore_label=self.ignore_id
)
else:
loss_att = None
self.acc = None
cer_ctc = None
if self.mtlalpha == 0.0:
loss_ctc = None
else:
batch_size = xs_pad.size(0)
hs_len = hs_mask.view(batch_size, -1).sum(1)
loss_ctc = self.ctc(hs_pad.view(batch_size, -1, self.adim), hs_len, ys_pad)
if not self.training and self.error_calculator is not None:
ys_hat = self.ctc.argmax(hs_pad.view(batch_size, -1, self.adim)).data
cer_ctc = self.error_calculator(ys_hat.cpu(), ys_pad.cpu(), is_ctc=True)
# for visualization
if not self.training:
self.ctc.softmax(hs_pad)
# 5. compute cer/wer
if self.training or self.error_calculator is None or self.decoder is None:
cer, wer = None, None
else:
ys_hat = pred_pad.argmax(dim=-1)
cer, wer = self.error_calculator(ys_hat.cpu(), ys_pad.cpu())
src_hlens = torch.tensor([int(sum(mask[0])) for mask in hs_mask])
if self.cmatch_method == "pseudo_ctc_pred":
src_hs_flatten = torch.cat([hs_pad[i, :src_hlens[i], :].view(-1, self.adim) for i in range(len(hs_pad))]) # hs_pad: B * T, F
src_ctc_softmax = torch.nn.functional.softmax(self.ctc.ctc_lo(src_hs_flatten), dim=1)
else:
src_ctc_softmax = None
# Domain adversarial loss
if tgt_xs_pad is not None and tgt_ilens is not None:
src_ys_pad = ys_pad
src_hs_pad, src_hs_mask = hs_pad, hs_mask
tgt_xs_pad = tgt_xs_pad[:, : max(tgt_ilens)] # for data parallel
tgt_src_mask = make_non_pad_mask(tgt_ilens.tolist()).to(tgt_xs_pad.device).unsqueeze(-2)
if enc_return_repr:
tgt_hs_pad, tgt_hs_mask, tgt_enc_repr = self.encoder(tgt_xs_pad, tgt_src_mask, return_repr=enc_return_repr)
tgt_enc_repr = tgt_enc_repr[-self.multi_enc_repr_num:]
else:
tgt_hs_pad, tgt_hs_mask = self.encoder(tgt_xs_pad, tgt_src_mask)
src_ys_out_pad = ys_out_pad
src_ys_out_flatten = src_ys_out_pad.contiguous().view(-1)
if tgt_ys_pad is not None:
tgt_ys_in_pad, tgt_ys_out_pad = add_sos_eos(
tgt_ys_pad, self.sos, self.eos, self.ignore_id
)
tgt_ys_mask = target_mask(tgt_ys_in_pad, self.ignore_id)
tgt_pred_pad, tgt_pred_mask, tgt_dec_repr = self.decoder(tgt_ys_in_pad, tgt_ys_mask, tgt_hs_pad, tgt_hs_mask, return_repr=dec_return_repr)
if tgt_dec_repr:
tgt_dec_repr = tgt_dec_repr[-self.multi_dec_repr_num:]
tgt_ys_out_flatten = tgt_ys_out_pad.contiguous().view(-1)
tgt_hlens = torch.tensor([int(sum(mask[0])) for mask in tgt_hs_mask])
if self.cmatch_method == "pseudo_ctc_pred":
tgt_hs_flatten = torch.cat([tgt_hs_pad[i, :tgt_hlens[i], :].view(-1, self.adim) for i in range(len(tgt_hs_pad))]) # hs_pad: B * T, F
tgt_ctc_softmax = torch.nn.functional.softmax(self.ctc.ctc_lo(tgt_hs_flatten), dim=1)
else:
tgt_ctc_softmax = None
if self.self_training:
src_loss_att = loss_att
src_loss_ctc = loss_ctc
tgt_batch_size = tgt_xs_pad.size(0)
tgt_hs_len = tgt_hs_mask.view(tgt_batch_size, -1).sum(1)
tgt_loss_ctc = self.ctc(tgt_hs_pad.view(tgt_batch_size, -1, self.adim), tgt_hs_len, tgt_ys_pad)
tgt_loss_att = self.criterion(tgt_pred_pad, tgt_ys_out_pad)
loss_att = (src_loss_att + tgt_loss_att) / 2
loss_ctc = (src_loss_ctc + tgt_loss_ctc) / 2
self.acc = (self.acc + th_accuracy(
tgt_pred_pad.view(-1, self.odim), tgt_ys_out_pad, ignore_label=self.ignore_id
)) / 2
uda_loss = torch.tensor(0.0).cuda()
if not self.loss_type:
uda_loss = torch.tensor(0.0).cuda()
elif self.loss_type == "adv":
uda_loss = self.adversarial_loss(src_hs_pad, tgt_hs_pad)
elif self.loss_type == "cmatch":
assert tgt_ys_pad is not None
assert len(src_enc_repr) == self.multi_enc_repr_num and len(src_enc_repr) in [1, 3, 6, 9, 12], len(src_enc_repr)
for layer_idx in range(len(src_enc_repr)):
src_hs_flatten, src_ys_flatten, tgt_hs_flatten, tgt_ys_flatten \
= self.get_enc_repr(src_enc_repr[layer_idx],
src_hlens,
tgt_enc_repr[layer_idx],
tgt_hlens,
src_ys_pad,
tgt_ys_pad,
method=self.cmatch_method,
src_ctc_softmax=src_ctc_softmax,
tgt_ctc_softmax=tgt_ctc_softmax,)
layer_uda_loss = self.cmatch_loss_func(self.n_classes,
src_hs_flatten,
src_ys_flatten,
tgt_hs_flatten,
tgt_ys_flatten)
uda_loss = uda_loss + layer_uda_loss if uda_loss else layer_uda_loss
if self.use_dec_repr:
assert len(src_dec_repr) == self.multi_dec_repr_num, len(src_dec_repr)
# No need to calculate decoder matching loss
for layer_idx in range(len(src_dec_repr)):
src_repr_flatten = src_dec_repr[layer_idx].contiguous().view(-1, self.adim)
tgt_repr_flatten = tgt_dec_repr[layer_idx].contiguous().view(-1, self.adim)
layer_uda_loss = self.cmatch_loss_func(self.n_classes,
src_repr_flatten,
src_ys_out_flatten,
tgt_repr_flatten,
tgt_ys_out_flatten)
uda_loss = uda_loss + layer_uda_loss
elif self.loss_type in ["coral", "mmd"]:
# (B, T, F) --> (B, F)
uda_loss = adapt_loss(torch.mean(src_hs_pad, dim=1),
torch.mean(tgt_hs_pad, dim=1),
adapt_loss=self.loss_type)
else:
raise NotImplementedError(f"loss type {self.loss_type} is not implemented")
alpha = self.mtlalpha
if alpha == 0:
self.loss = loss_att
loss_att_data = float(loss_att)
loss_ctc_data = None
elif alpha == 1:
self.loss = loss_ctc
loss_att_data = None
loss_ctc_data = float(loss_ctc)
else:
self.loss = alpha * loss_ctc + (1 - alpha) * loss_att
loss_att_data = float(loss_att)
loss_ctc_data = float(loss_ctc)
loss_data = float(self.loss)
if loss_data < CTC_LOSS_THRESHOLD and not math.isnan(loss_data):
self.reporter.report(
loss_ctc_data, loss_att_data, self.acc, cer_ctc, cer, wer, loss_data
)
else:
logging.warning("loss (=%f) is not correct", loss_data)
return (self.loss, uda_loss) if (self.training and uda_loss is not None) else self.loss
def adversarial_loss(self, src_hs_pad, tgt_hs_pad, alpha=1.0):
loss_fn = torch.nn.BCELoss()
src_hs_pad = ReverseLayerF.apply(src_hs_pad, alpha)
tgt_hs_pad = ReverseLayerF.apply(tgt_hs_pad, alpha)
src_domain = self.domain_classifier(src_hs_pad).view(-1, 1) # B, T, 1
tgt_domain = self.domain_classifier(tgt_hs_pad).view(-1, 1) # B, T, 1
device = src_hs_pad.device
src_label = torch.ones(len(src_domain)).long().to(device)
tgt_label = torch.zeros(len(tgt_domain)).long().to(device)
domain_pred = torch.cat([src_domain, tgt_domain], dim=0)
domain_label = torch.cat([src_label, tgt_label], dim=0)
uda_loss = loss_fn(domain_pred, domain_label[:, None].float()) # B, 1
return uda_loss
def get_enc_repr(self,
src_hs_pad,
src_hlens,
tgt_hs_pad,
tgt_hlens,
src_ys_pad,
tgt_ys_pad,
method,
src_ctc_softmax=None,
tgt_ctc_softmax=None):
src_ys = [y[y != self.ignore_id] for y in src_ys_pad]
tgt_ys = [y[y != self.ignore_id] for y in tgt_ys_pad]
if method == "frame_average":
def frame_average(hidden_states, num):
# hs_i, B T F
hidden_states = hidden_states.permute(0, 2, 1)
downsampled_states = torch.nn.functional.adaptive_avg_pool1d(hidden_states, num)
downsampled_states = downsampled_states.permute(0, 2, 1)
assert downsampled_states.shape[1] == num, f"{downsampled_states.shape[1]}, {num}"
return downsampled_states
src_hs_downsampled = frame_average(src_hs_pad, num=src_ys_pad.size(1))
tgt_hs_downsampled = frame_average(tgt_hs_pad, num=tgt_ys_pad.size(1))
src_hs_flatten = src_hs_downsampled.contiguous().view(-1, self.adim)
tgt_hs_flatten = tgt_hs_downsampled.contiguous().view(-1, self.adim)
src_ys_flatten = src_ys_pad.contiguous().view(-1)
tgt_ys_flatten = tgt_ys_pad.contiguous().view(-1)
elif method == "ctc_align":
src_ys = [y[y != -1] for y in src_ys_pad]
src_logits = self.ctc.ctc_lo(src_hs_pad)
src_align_pad = self.ctc_aligner(src_logits, src_hlens, src_ys)
src_ys_flatten = torch.cat([src_align_pad[i, :src_hlens[i]].view(-1) for i in range(len(src_align_pad))])
src_hs_flatten = torch.cat([src_hs_pad[i, :src_hlens[i], :].view(-1, self.adim) for i in range(len(src_hs_pad))]) # hs_pad: B, T, F
tgt_ys = [y[y != -1] for y in tgt_ys_pad]
tgt_logits = self.ctc.ctc_lo(tgt_hs_pad)
tgt_align_pad = self.ctc_aligner(tgt_logits, tgt_hlens, tgt_ys)
tgt_ys_flatten = torch.cat([tgt_align_pad[i, :tgt_hlens[i]].view(-1) for i in range(len(tgt_align_pad))])
tgt_hs_flatten = torch.cat([tgt_hs_pad[i, :tgt_hlens[i], :].view(-1, self.adim) for i in range(len(tgt_hs_pad))]) # hs_pad: B, T, F
elif method == "pseudo_ctc_pred":
assert src_ctc_softmax is not None
src_hs_flatten = torch.cat([src_hs_pad[i, :src_hlens[i], :].view(-1, self.adim) for i in range(len(src_hs_pad))]) # hs_pad: B * T, F
src_hs_flatten_size = src_hs_flatten.shape[0]
src_confidence, src_ctc_ys = torch.max(src_ctc_softmax, dim=1)
src_confidence_mask = (src_confidence > self.pseudo_ctc_confidence_thr)
src_ys_flatten = src_ctc_ys[src_confidence_mask]
src_hs_flatten = src_hs_flatten[src_confidence_mask]
assert tgt_ctc_softmax is not None
tgt_hs_flatten = torch.cat([tgt_hs_pad[i, :tgt_hlens[i], :].view(-1, self.adim) for i in range(len(tgt_hs_pad))]) # hs_pad: B * T, F
tgt_hs_flatten_size = tgt_hs_flatten.shape[0]
tgt_confidence, tgt_ctc_ys = torch.max(tgt_ctc_softmax, dim=1)
tgt_confidence_mask = (tgt_confidence > self.pseudo_ctc_confidence_thr)
tgt_ys_flatten = tgt_ctc_ys[tgt_confidence_mask]
tgt_hs_flatten = tgt_hs_flatten[tgt_confidence_mask]
# logging.warning(f"Source pseudo CTC ratio: {src_hs_flatten.shape[0] / src_hs_flatten_size:.2f}; " \
# f"Target pseudo CTC ratio: {tgt_hs_flatten.shape[0] / tgt_hs_flatten_size:.2f}")
return src_hs_flatten, src_ys_flatten, tgt_hs_flatten, tgt_ys_flatten
def cmatch_loss_func(self, n_classes,
src_features, src_labels,
tgt_features, tgt_labels):
assert src_features.shape[0] == src_labels.shape[0]
assert tgt_features.shape[0] == tgt_labels.shape[0]
classes = torch.arange(n_classes)
def src_token_idxs(c):
return src_labels.eq(c).nonzero().squeeze(1)
src_token_idxs = list(map(src_token_idxs, classes))
def tgt_token_idxs(c):
return tgt_labels.eq(c).nonzero().squeeze(1)
tgt_token_idxs = list(map(tgt_token_idxs, classes))
assert len(src_token_idxs) == n_classes
assert len(tgt_token_idxs) == n_classes
loss = torch.tensor(0.0).cuda()
count = 0
for c in classes:
if c in self.non_char_symbols or src_token_idxs[c].shape[0] < 5 or tgt_token_idxs[c].shape[0] < 5:
continue
loss = loss + adapt_loss(src_features[src_token_idxs[c]],
tgt_features[tgt_token_idxs[c]],
adapt_loss='mmd_linear')
count = count + 1
loss = loss / count if count > 0 else loss
return loss
================================================
FILE: code/ASR/CMatch/train.py
================================================
import logging
import os
import collections
from espnet.bin.asr_train import get_parser
from espnet.utils.dynamic_import import dynamic_import
from espnet.utils.deterministic_utils import set_deterministic_pytorch
from espnet.asr.pytorch_backend.asr_init import freeze_modules
from torch.nn.parallel import data_parallel
from torch.nn.utils.clip_grad import clip_grad_norm_
import torch
import numpy as np
import data_load
import random
import json
import sys
from utils import setup_logging, str2bool, dict_average
from utils import load_pretrained_model, torch_save, torch_load
from utils import recognize_and_evaluate
from e2e_asr_udatransformer import UDASpeechTransformer
def add_custom_arguments(parser):
parser.add_argument('--data_file', type=str, default=None)
parser.add_argument("--root_path", type=str, required=True, help="Path to the ESPnet features, e.g.: /egs/libriadapt_processed/asr1/")
parser.add_argument('--dataset', type=str, required=True,
help="Dataset name to be referred in data_load, e.g.: libriadapt_en_us_clean_shure")
parser.add_argument("--exp", type=str, default="exp")
parser.add_argument("--decoding_mode", type=str2bool, default=False, help="if true, then only perform decoding test")
parser.add_argument("--load_pretrained_model", type=str, default="", nargs="?",
help="::")
parser.add_argument("--compute_cer", type=str2bool, default=True)
parser.add_argument("--compute_cer_interval", type=int, default=1)
parser.add_argument("--start_eval_errs", type=int, default=70)
parser.add_argument("--decoding_config", type=str, default=None)
parser.add_argument(
"--bpemodel", type=bool, default=True
) # Set to true when testing CER/WERs
parser.add_argument("--dist_train", type=str2bool, default=False)
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument("--result_label", type=str, default=None)
parser.add_argument("--recog_json", type=str, default=None)
parser.add_argument("--adam_lr", type=float, default=1e-3)
# Transfer learning related
parser.add_argument("--transfer_type", type=str, default=None, help="adaptation method")
parser.add_argument("--cmatch_method", type=str, default="frame_average",
choices=["ctc_align", "frame_average", "pseudo_ctc_pred"],
help="label assignment methods for CMatch")
parser.add_argument("--tgt_dataset", type=str, default="", nargs="?")
parser.add_argument("--transfer_loss_weight", type=float, default=10.0)
parser.add_argument("--tranfer_loss_weight_warmup_steps", type=int, default=0)
parser.add_argument("--pseudo_labeling", type=str2bool, default=False)
parser.add_argument("--pseudo_label_json", type=str, default="", nargs="?")
parser.add_argument("--non_char_symbols", type=str, default=None, nargs="?",
help="Indices of non-character symbols that will be filtered when computing CMatch loss, split by '_', e.g., 0_1_2_29_30")
parser.add_argument("--self_training", type=str2bool, default=False)
parser.add_argument("--multi_enc_repr_num", type=int, default=1)
parser.add_argument("--multi_dec_repr_num", type=int, default=6)
parser.add_argument("--use_dec_repr", type=str2bool, default=False)
parser.add_argument("--pseudo_ctc_confidence_thr", type=float, default=0.9, help="Threshold for filtering CTC outputs")
def test(dataloader, model, model_path=None):
if model_path:
torch_load(model_path, model)
model.eval()
stats = collections.defaultdict(list)
for batch_idx, data in enumerate(dataloader):
logging.warning(f"Testing batch: {batch_idx+1}/{len(dataloader)}")
fbank, seq_lens, tokens = data
fbank, seq_lens, tokens = fbank.cuda(), seq_lens.cuda(), tokens.cuda()
with torch.no_grad():
loss = model(fbank, seq_lens, tokens)
stats["loss_lst"].append(loss.item())
if not hasattr(model, "module"):
if model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
return dict_average(stats)
def train(dataloaders, model, optimizer, save_path):
train_loader, val_loader, test_loader = dataloaders
best_loss = float("inf")
early_stop = 0
log_json = []
for epoch in range(args.start_epoch, args.epochs + 1):
early_stop += 1
epoch_stats = collections.OrderedDict(epoch=epoch)
train_stats = train_epoch(train_loader, model, optimizer, epoch)
valid_stats = test(val_loader, model)
test_stats = test(test_loader, model)
logging.warning(
f"Epoch: {epoch}, Iteration: {epoch * len(train_loader)}, "
+ f"train loss: {train_stats['loss']:.4f}, dev loss: {valid_stats['loss']:.3f}, test loss: {test_stats['loss']:.3f}"
)
torch_save(model, f"{args.outdir}/snapshot.ep.{epoch}", optimizer=optimizer)
for key in sorted(list(set(list(train_stats.keys()) + list(test_stats.keys())))):
if not key.endswith("_lst"):
if key in train_stats:
epoch_stats[f"main/{key}"] = train_stats[key]
if key in valid_stats:
epoch_stats[f"validation/main/{key}"] = valid_stats[key]
if key in test_stats:
epoch_stats[f"test/main/{key}"] = test_stats[key]
log_json.append(epoch_stats)
with open(f"{args.outdir}/log", "w") as f:
json.dump(log_json, f,
indent=4,
ensure_ascii=False,
separators=(",", ": "),
)
logging.warning(f"Log saved at {args.outdir}/log")
if args.patience > 0 and early_stop >= args.patience:
test_stats = test(test_loader, model, save_path)
logging.warning(f"=====Early stop! Final best test loss: {test_stats['loss']}")
break
def train_epoch(dataloader, model, optimizer, epoch=None):
model.train()
stats = collections.defaultdict(list)
for batch_idx, data in enumerate(dataloader):
fbank, seq_lens, tokens = data
fbank, seq_lens, tokens = fbank.cuda(), seq_lens.cuda(), tokens.cuda()
optimizer.zero_grad()
if args.ngpu <= 1 or args.dist_train:
loss = model(fbank, seq_lens, tokens).mean() # / self.accum_grad
else:
# apex does not support torch.nn.DataParallel
loss = (
data_parallel(model, (fbank, seq_lens, tokens), range(args.ngpu)).mean() # / self.accum_grad
)
if not hasattr(model, "module"):
if hasattr(model, "acc") and model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if hasattr(model, "acc") and model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
loss.backward()
clip_grad_norm_(model.parameters(), args.grad_clip)
optimizer.step()
stats["loss_lst"].append(loss.item())
logging.warning(f"Training batch: {batch_idx+1}/{len(dataloader)}")
return dict_average(stats)
def train_uda_epoch(train_loaders, model, optimizer, epoch):
src_loader, tgt_loader = train_loaders
iter_source, iter_target = iter(src_loader), iter(tgt_loader)
model.train()
stats = collections.defaultdict(list)
n_batch = min(len(src_loader), len(tgt_loader))
for batch_idx in range(n_batch):
src_data = iter_source.next()
for i in range(len(src_data)):
src_data[i] = src_data[i].cuda()
tgt_data = iter_target.next()
for i in range(len(tgt_data)):
tgt_data[i] = tgt_data[i].cuda()
optimizer.zero_grad()
if args.ngpu <= 1 or args.dist_train:
ctc_att_loss, uda_loss = model(*src_data, *tgt_data)
else:
# apex does not support torch.nn.DataParallel
ctc_att_loss, uda_loss = (
data_parallel(model, (*src_data, *tgt_data), range(args.ngpu))
)
ctc_att_loss = ctc_att_loss.mean()
loss = ctc_att_loss
if args.transfer_loss_weight > 0:
if args.tranfer_loss_weight_warmup_steps > 0:
current_iter = float(batch_idx + (epoch - 1) * n_batch)
frac_done = 1.0 * float(current_iter) / args.tranfer_loss_weight_warmup_steps
current_weight = args.transfer_loss_weight * min(1.0, frac_done)
stats["transfer_loss_weight"] = current_weight
else:
current_weight = args.transfer_loss_weight
transfer_loss = uda_loss.mean()
loss = ctc_att_loss + current_weight * transfer_loss
if not hasattr(model, "module"):
if hasattr(model, "acc") and model.acc is not None:
stats["acc_lst"].append(model.acc)
model.acc = None
else:
if hasattr(model, "acc") and model.module.acc is not None:
stats["acc_lst"].append(model.module.acc)
model.module.acc = None
loss.backward()
clip_grad_norm_(model.parameters(), args.grad_clip)
optimizer.step()
stats["ctc_att_loss_lst"].append(ctc_att_loss.item())
if args.transfer_loss_weight > 0:
stats["transfer_loss_lst"].append(transfer_loss.item())
stats["loss_lst"].append(loss.item())
logging.warning(f"Training batch: {batch_idx+1}/{n_batch}")
return dict_average(stats)
if __name__ == "__main__":
# 执行该命令运行4 GPU训练:CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --dist_train true --root_path /D_data/libriadapt_processed/asr1/ --dataset libriadapt_en_us_clean_shure --config config/adv_example.yaml --tgt_dataset libriadapt_en_us_clean_matrix --load_pretrained_model ""
setup_logging(verbose=0) # Should come first before other package import logging
parser = get_parser()
add_custom_arguments(parser)
arg_list = sys.argv[1:] + [
"--dict", '',
]
if "--config" not in arg_list:
arg_list += ["--config", "config/train.yaml"]
if "--outdir" not in arg_list:
arg_list += ["--outdir", '']
args, _ = parser.parse_known_args(arg_list)
# Use all GPUs
ngpu = torch.cuda.device_count() if args.ngpu is None else args.ngpu
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(
[str(item) for item in range(ngpu)])
logging.warning(f"ngpu: {ngpu}")
# set random seed
logging.info("random seed = %d" % args.seed)
random.seed(args.seed)
np.random.seed(args.seed)
set_deterministic_pytorch(args)
torch.cuda.manual_seed(args.seed)
if ngpu > 1:
torch.cuda.manual_seed_all(args.seed) # multi-gpu setting
if args.model_module is None:
model_module = "espnet.nets." + args.backend + "_backend.e2e_asr:E2E"
else:
model_module = args.model_module
model_class = dynamic_import(model_module)
model_class.add_arguments(parser)
args = parser.parse_args(arg_list)
setattr(args, "conf_name", ".".join(os.path.basename(args.config).split(".")[:-1]))
if not args.outdir:
args.outdir = f"./outputs/results_{args.dataset}/{args.conf_name}"
if not os.path.exists(args.outdir):
os.makedirs(args.outdir)
setattr(args, "ngpu", ngpu)
if args.data_file is not None:
args.root_path = args.data_file
if args.ngpu > 1:
if args.opt == "noam" and hasattr(args, "transformer_lr"):
logging.warning(f"Multi-GPU training: increase transformer lr {args.transformer_lr} --> {args.transformer_lr * np.sqrt(args.ngpu)}")
args.transformer_lr = args.transformer_lr * np.sqrt(args.ngpu)
elif args.opt == "adam" and hasattr(args, "adam_lr"):
logging.warning(f"Multi-GPU training: increase adam lr {args.adam_lr} --> {args.adam_lr * np.sqrt(args.ngpu)}")
args.adam_lr = args.adam_lr * np.sqrt(args.ngpu)
if args.dist_train:
torch.distributed.init_process_group(backend="nccl")
local_rank = torch.distributed.get_rank()
args.local_rank = local_rank
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
else:
logging.warning(
"Training batch size is automatically increased (%d -> %d)"
% (args.batch_size, args.batch_size * args.ngpu)
)
args.batch_size *= args.ngpu
if args.accum_grad > 1:
logging.warning(
"gradient accumulation is not implemented. batch size is increased (%d -> %d)"
% (args.batch_size, args.batch_size * args.accum_grad)
)
args.batch_size *= args.accum_grad
args.accum_grad = 1
dataloaders, in_out_shape = data_load.load_data(args.root_path,
args.dataset,
args,)
if args.transfer_type or args.self_training:
assert args.tgt_dataset and args.tgt_dataset != args.dataset, \
f"Target data set {args.tgt_dataset} must be specified and different from the training dataset"
model_module = "e2e_asr_udatransformer:UDASpeechTransformer"
model_class = UDASpeechTransformer
if args.self_training:
logging.warning("Self-training mode")
assert args.pseudo_label_json, "Pseudo label json must be speicified for self-training"
train_epoch = train_uda_epoch
if args.pseudo_label_json:
logging.warning(f"Load pseudo label from {args.pseudo_label_json}")
(tgt_train_loader, _, test_loader), _ = data_load.load_data(args.root_path,
args.tgt_dataset,
args,
pseudo_label_json=args.pseudo_label_json)
src_train_loader, val_loader, src_test_loader = dataloaders
dataloaders = ((src_train_loader, tgt_train_loader), val_loader, test_loader)
tgt_test_loader = test_loader
token_list = data_load.load_token_list(
os.path.join(args.root_path, data_load.data_config[args.dataset]["token"])
)
setattr(args, "model_module", model_module)
setattr(args, "char_list", token_list)
model = model_class(in_out_shape[0], in_out_shape[1], args=args)
model_conf = args.outdir + "/model.json"
with open(model_conf, "wb") as f:
logging.info("writing a model config file to " + model_conf)
f.write(
json.dumps(
(in_out_shape[0], in_out_shape[1], vars(args)),
indent=4,
ensure_ascii=False,
sort_keys=True,
).encode("utf_8")
)
model.cuda()
if args.ngpu > 1 and args.dist_train:
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank
)
if args.freeze_mods:
model, model_params = freeze_modules(model, args.freeze_mods)
else:
model_params = model.parameters()
# Setup an optimizer
if args.opt == "adadelta":
optimizer = torch.optim.Adadelta(
model_params, rho=0.95, eps=args.eps, weight_decay=args.weight_decay
)
elif args.opt == "adam":
logging.warning(f"Using Adam optimizer with lr={args.adam_lr}")
optimizer = torch.optim.Adam(model_params, lr=args.adam_lr, weight_decay=args.weight_decay)
elif args.opt == "noam":
from espnet.nets.pytorch_backend.transformer.optimizer import get_std_opt
optimizer = get_std_opt(
model_params, args.adim, args.transformer_warmup_steps, args.transformer_lr
)
# Resume from a snapshot
if args.resume:
logging.warning("resumed from %s" % args.resume)
torch_load(args.resume, model, optimizer)
setattr(args, "start_epoch", int(args.resume.split('.')[-1]) + 1)
else:
setattr(args, "start_epoch", 1)
if args.load_pretrained_model:
model_path, modules_to_load, exclude_modules = args.load_pretrained_model.split(":")
logging.warning("load pretrained model from %s" % args.load_pretrained_model)
load_pretrained_model(model=model, model_path=model_path,
modules_to_load=modules_to_load, exclude_modules=exclude_modules)
logging.warning(
"Total parameter of the model = "
+ str(sum(p.numel() for p in model.parameters()))
)
logging.warning(
"Trainable parameter of the model = "
+ str(sum(p.numel() for p in filter(lambda x: x.requires_grad, model.parameters())))
)
# For CER/WER computing
if args.bpemodel and "bpemodel" in data_load.data_config[args.dataset]:
logging.warning(f"load bpe model for {args.dataset}")
args.bpemodel = data_load.load_bpemodel(args.root_path, args.dataset)
save_path = f"{args.outdir}/model.loss.best"
if not args.decoding_mode and not args.pseudo_labeling:
train(dataloaders, model, optimizer, save_path)
if (args.compute_cer or args.pseudo_labeling) and args.local_rank == 0:
dataset = args.dataset if not args.tgt_dataset else args.tgt_dataset
dataloaders, _ = data_load.load_data(args.root_path, dataset, args)
splits = ["test", "val"] if not args.pseudo_labeling else ["train"]
for split in splits:
logging.warning(f"---------Recognizing {dataset} {split}----------")
args.result_label = f"{args.outdir}/{dataset}_{split}_recog.json"
if not data_load.data_config[dataset][split]:
split_path = os.path.join(args.root_path, f"{args.root_path}/tmp_dev_set_{dataset}.json")
else:
split_path = data_load.data_config[dataset][split]
args.recog_json = os.path.join(args.root_path, split_path)
idx = ["train", "val", "test"].index(split)
err_dict = recognize_and_evaluate(dataloaders[idx], model, args, model_path=save_path, wer=True, write_to_json=True)
logging.warning(f"CER: {err_dict['cer']['err']}")
logging.warning(f"WER: {err_dict['wer']['err']}")
================================================
FILE: code/ASR/CMatch/utils.py
================================================
import torch
import logging
from espnet.asr.asr_utils import add_results_to_json
import argparse
import numpy as np
import collections
import json
def str2bool(str):
return True if str.lower() == 'true' else False
def setup_logging(verbose=1):
if verbose > 0:
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
)
else:
logging.basicConfig(
level=logging.WARN,
format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s",
)
logging.warning("Skip DEBUG/INFO messages")
# Training stats
def dict_average(dic):
avg_key, avg_val = [], []
for key, lst in dic.items():
if key.endswith("_lst"):
avg_key.append(key[:-4])
avg_val.append(np.mean(lst))
for key, val in zip(avg_key, avg_val):
dic[key] = val
return dic
# Load and save
def load_pretrained_model(model, model_path, modules_to_load=None, exclude_modules=None):
'''
load_pretrained_model(model=model, model_path="",
modules_to_load=None, exclude_modules="")
'''
model_dict = torch.load(model_path, map_location=lambda storage, loc: storage)
if exclude_modules:
for e in exclude_modules.split(","):
model_dict = {k: v for k, v in model_dict.items() if not k.startswith(e)}
if not modules_to_load:
src_dict = model_dict
else:
src_dict = {}
for module in modules_to_load.split(","):
src_dict.update({k: v for k, v in model_dict.items() if k.startswith(module)})
dst_state = model.state_dict()
dst_state.update(src_dict)
model.load_state_dict(dst_state)
def torch_save(model, save_path, optimizer=None, local_rank=0):
if local_rank != 0:
return
if hasattr(model, "module"):
state_dict = model.module.state_dict() if not optimizer else collections.OrderedDict(model=model.module.state_dict(), optimizer=optimizer.state_dict())
else:
state_dict = model.state_dict() if not optimizer else collections.OrderedDict(model=model.state_dict(), optimizer=optimizer.state_dict())
torch.save(state_dict, save_path)
def torch_load(snapshot_path, model, optimizer=None):
# load snapshot
snapshot_dict = torch.load(snapshot_path, map_location=lambda storage, loc: storage)
if not "model" in snapshot_dict.keys():
model_dict = snapshot_dict
snapshot_dict = collections.OrderedDict(model=model_dict)
if hasattr(model, "module"):
model.module.load_state_dict(snapshot_dict["model"])
else:
model.load_state_dict(snapshot_dict["model"])
if optimizer:
optimizer.load_state_dict(snapshot_dict["optimizer"])
del snapshot_dict
# Decoding
def compute_wer(ref, hyp, normalize=False):
"""Compute Word Error Rate.
[Reference]
https://martin-thoma.com/word-error-rate-calculation/
Args:
ref (list): words in the reference transcript
hyp (list): words in the predicted transcript
normalize (bool, optional): if True, divide by the length of ref
Returns:
wer (float): Word Error Rate between ref and hyp
n_sub (int): the number of substitution
n_ins (int): the number of insertion
n_del (int): the number of deletion
"""
# Initialisation
d = np.zeros((len(ref) + 1) * (len(hyp) + 1), dtype=np.uint16)
d = d.reshape((len(ref) + 1, len(hyp) + 1))
for i in range(len(ref) + 1):
for j in range(len(hyp) + 1):
if i == 0:
d[0][j] = j
elif j == 0:
d[i][0] = i
# Computation
for i in range(1, len(ref) + 1):
for j in range(1, len(hyp) + 1):
if ref[i - 1] == hyp[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
sub_tmp = d[i - 1][j - 1] + 1
ins_tmp = d[i][j - 1] + 1
del_tmp = d[i - 1][j] + 1
d[i][j] = min(sub_tmp, ins_tmp, del_tmp)
wer = d[len(ref)][len(hyp)]
# Find out the manipulation steps
x = len(ref)
y = len(hyp)
error_list = []
while True:
if x == 0 and y == 0:
break
else:
if x > 0 and y > 0:
if d[x][y] == d[x - 1][y - 1] and ref[x - 1] == hyp[y - 1]:
error_list.append("C")
x = x - 1
y = y - 1
elif d[x][y] == d[x][y - 1] + 1:
error_list.append("I")
y = y - 1
elif d[x][y] == d[x - 1][y - 1] + 1:
error_list.append("S")
x = x - 1
y = y - 1
else:
error_list.append("D")
x = x - 1
elif x == 0 and y > 0:
if d[x][y] == d[x][y - 1] + 1:
error_list.append("I")
y = y - 1
else:
error_list.append("D")
x = x - 1
elif y == 0 and x > 0:
error_list.append("D")
x = x - 1
else:
raise ValueError
n_sub = error_list.count("S")
n_ins = error_list.count("I")
n_del = error_list.count("D")
n_cor = error_list.count("C")
assert wer == (n_sub + n_ins + n_del)
assert n_cor == (len(ref) - n_sub - n_del)
if normalize:
wer /= len(ref)
return wer, n_sub, n_ins, n_del, n_cor
def recognize_and_evaluate(dataloader, model, args, model_path=None, wer=False, write_to_json=False):
if model_path:
torch_load(model_path, model)
orig_model = model
if hasattr(model, "module"):
model = model.module
if write_to_json:
# read json data
assert args.result_label and args.recog_json
with open(args.recog_json, "rb") as f:
js = json.load(f)["utts"]
new_js = {}
model.eval()
recog_args = {
"beam_size": args.beam_size,
"penalty": args.penalty,
"ctc_weight": args.ctc_weight,
"maxlenratio": args.maxlenratio,
"minlenratio": args.minlenratio,
"lm_weight": args.lm_weight,
"rnnlm": args.rnnlm,
"nbest": args.nbest,
"space": args.sym_space,
"blank": args.sym_blank,
}
recog_args = argparse.Namespace(**recog_args)
err_dict = (
dict(cer=None)
if not wer
else dict(cer=collections.defaultdict(int), wer=collections.defaultdict(int))
)
with torch.no_grad():
for batch_idx, data in enumerate(dataloader):
logging.warning(f"Testing CER/WERs: {batch_idx+1}/{len(dataloader)}")
fbank, ilens, tokens = data
fbanks = []
for i, fb in enumerate(fbank):
fbanks.append(fb[: ilens[i], :])
fbank = fbanks
nbest_hyps = model.recognize_batch(
fbank, recog_args, char_list=None, rnnlm=None
)
y_hats = [nbest_hyp[0]["yseq"][1:-1] for nbest_hyp in nbest_hyps]
if write_to_json:
for utt_idx in range(len(fbank)):
name = dataloader.dataset[batch_idx][utt_idx][0]
new_js[name] = add_results_to_json(
js[name], nbest_hyps[utt_idx], args.char_list
)
for i, y_hat in enumerate(y_hats):
y_true = tokens[i]
hyp_token = [
args.char_list[int(idx)] for idx in y_hat if int(idx) != -1
]
ref_token = [
args.char_list[int(idx)] for idx in y_true if int(idx) != -1
]
for key in sorted(err_dict.keys()): # cer then wer
if key == "wer":
if args.bpemodel:
ref_token = args.bpemodel.decode_pieces(ref_token).split()
hyp_token = args.bpemodel.decode_pieces(hyp_token).split()
else:
ref_token = (
" ".join(ref_token)
.replace(" ", "")
.replace("", " ")
.split()
) # sclite does not consider the number of spaces when splitting
hyp_token = (
" ".join(hyp_token)
.replace(" ", "")
.replace("", " ")
.split()
)
logging.debug("HYP: " + str(hyp_token))
logging.debug("REF: " + str(ref_token))
utt_err, utt_nsub, utt_nins, utt_ndel, utt_ncor = compute_wer(
ref_token, hyp_token
)
err_dict[key]["n_word"] += len(ref_token)
if utt_err != 0:
err_dict[key]["n_err"] += utt_err # Char / word error
err_dict[key]["n_ser"] += 1 # Sentence error
err_dict[key]["n_cor"] += utt_ncor
err_dict[key]["n_sub"] += utt_nsub
err_dict[key]["n_ins"] += utt_nins
err_dict[key]["n_del"] += utt_ndel
err_dict[key]["n_sent"] += 1
for key in err_dict.keys():
err_dict[key]["err"] = err_dict[key]["n_err"] / err_dict[key]["n_word"] * 100.0
err_dict[key]["ser"] = err_dict[key]["n_ser"] / err_dict[key]["n_word"] * 100.0
torch.cuda.empty_cache()
if write_to_json:
with open(args.result_label, "wb") as f:
f.write(
json.dumps(
{"utts": new_js}, indent=4, ensure_ascii=False, sort_keys=True
).encode("utf_8")
)
model = orig_model
return err_dict
================================================
FILE: code/ASR/readme.md
================================================
# Transfer learning for automatic speech recognition (ASR)
This directory contains code for several transfer learning-based ASR papers.
## Domain adaptation
- **CMatch**: Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching
- [Paper](https://arxiv.org/abs/2104.07491)
- [Code](https://github.com/jindongwang/transferlearning/tree/master/code/ASR/CMatch)
## Finetune and Meta-learning
- **Adapter**: Exploiting Adapters for Cross-lingual Low-resource Speech Recognition
- [Paper](https://arxiv.org/abs/2105.11905)
- [Code](https://github.com/jindongwang/transferlearning/tree/master/code/ASR/Adapter)
================================================
FILE: code/BDA/readme.md
================================================
# Balanced Distribution Adaptation
Since the transfer learning repo was reorganized, please visit https://github.com/jindongwang/transferlearning/tree/master/code/traditional/BDA for the BDA code.
================================================
FILE: code/DeepDA/BNM/BNM.sh
================================================
#!/usr/bin/env bash
GPU_ID=0
data_dir=/data/jindwang/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee BNM_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee BNM_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee BNM_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee BNM_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee BNM_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee BNM_W2D.log
data_dir=/data/jindwang/OfficeHome
# # Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee BNM_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Art --tgt_domain RealWorld | tee BNM_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee BNM_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee BNM_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain RealWorld | tee BNM_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee BNM_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee BNM_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Product --tgt_domain RealWorld | tee BNM_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee BNM_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain RealWorld --tgt_domain Art | tee BNM_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain RealWorld --tgt_domain Product | tee BNM_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config BNM/BNM.yaml --data_dir $data_dir --src_domain RealWorld --tgt_domain Clipart | tee BNM_R2C.log
================================================
FILE: code/DeepDA/BNM/BNM.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 1
transfer_loss: bnm
# Optimizer related
lr: 0.001
weight_decay: 5e-4
lr_scheduler: True
lr_gamma: 0.0003
lr_decay: 0.75
momentum: 0.9
# Training related
n_iter_per_epoch: 300
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/BNM/README.md
================================================
# BNM
A PyTorch implementation of '[Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations](http://arxiv.org/abs/2003.12237)', i.e., BNM method for domain adaptation.
For more details, you can refer to the paper.
To run the method, go to the `DeepDA` folder. Then, run `bash BNM/BNM.sh`.
================================================
FILE: code/DeepDA/DAAN/DAAN.sh
================================================
#!/usr/bin/env bash
GPU_ID=3
data_dir=/home/houwx/tl/datasets/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee DAAN_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee DAAN_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee DAAN_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee DAAN_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee DAAN_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee DAAN_W2D.log
data_dir=/home/houwx/tl/datasets/office-home
# Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee DAAN_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Real_World | tee DAAN_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee DAAN_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee DAAN_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Real_World | tee DAAN_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee DAAN_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee DAAN_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Real_World | tee DAAN_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee DAAN_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Art | tee DAAN_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Product | tee DAAN_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAAN/DAAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Clipart | tee DAAN_R2C.log
================================================
FILE: code/DeepDA/DAAN/DAAN.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 1.0
transfer_loss: daan
# Optimizer related
lr: 0.01
weight_decay: 5e-4
momentum: 0.9
lr_scheduler: True
lr_gamma: 0.0003
lr_decay: 0.75
# Training related
n_iter_per_epoch: 500
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/DAN/DAN.sh
================================================
#!/usr/bin/env bash
GPU_ID=0
data_dir=/home/houwx/tl/datasets/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee DAN_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee DAN_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee DAN_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee DAN_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee DAN_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee DAN_W2D.log
data_dir=/home/houwx/tl/datasets/office-home
# Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee DAN_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Real_World | tee DAN_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee DAN_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee DAN_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Real_World | tee DAN_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee DAN_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee DAN_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Real_World | tee DAN_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee DAN_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Art | tee DAN_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Product | tee DAN_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DAN/DAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Clipart | tee DAN_R2C.log
================================================
FILE: code/DeepDA/DAN/DAN.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 0.5
transfer_loss: mmd
# Optimizer related
lr: 3e-3
weight_decay: 5e-4
lr_scheduler: True
lr_gamma: 0.0003
lr_decay: 0.75
momentum: 0.9
# Training related
n_iter_per_epoch: 500
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/DAN/README.md
================================================
# DAN
A PyTorch implementation of '[Learning Transferable Features with Deep Adaptation Networks](http://ise.thss.tsinghua.edu.cn/~mlong/doc/deep-adaptation-networks-icml15.pdf)'.
The contributions of this paper are summarized as follows.
* They propose a novel deep neural network architecture for domain adaptation, in which all the layers corresponding to task-specific features are adapted in a layerwise manner, hence benefiting from “deep adaptation.”
* They explore multiple kernels for adapting deep representations, which substantially enhances adaptation effectiveness compared to single kernel methods. Our model can yield unbiased deep features with statistical guarantees.
================================================
FILE: code/DeepDA/DANN/DANN.sh
================================================
#!/usr/bin/env bash
GPU_ID=2
data_dir=/home/houwx/tl/datasets/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee DANN_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee DANN_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee DANN_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee DANN_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee DANN_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee DANN_W2D.log
data_dir=/home/houwx/tl/datasets/office-home
# Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee DANN_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Real_World | tee DANN_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee DANN_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee DANN_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Real_World | tee DANN_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee DANN_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee DANN_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Real_World | tee DANN_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee DANN_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Art | tee DANN_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Product | tee DANN_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DANN/DANN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Clipart | tee DANN_R2C.log
================================================
FILE: code/DeepDA/DANN/DANN.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 1.0
transfer_loss: adv
# Optimizer related
lr: 0.01
weight_decay: 0.001 # 5e-4
momentum: 0.9
lr_scheduler: True
lr_gamma: 0.001
lr_decay: 0.75
# Training related
n_iter_per_epoch: 500
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/DANN/readme.md
================================================
# Domain adversarial neural network (DANN/RevGrad)
This is a Pytorch implementation of Unsupervised domain adaptation by backpropagation (also know as *DANN* or *RevGrad*).
**Reference**
Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation. ICML 2015.
================================================
FILE: code/DeepDA/DSAN/DSAN.sh
================================================
#!/usr/bin/env bash
GPU_ID=3
data_dir=/home/houwx/tl/datasets/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee DSAN_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee DSAN_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee DSAN_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee DSAN_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee DSAN_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee DSAN_W2D.log
data_dir=/home/houwx/tl/datasets/office-home
# Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee DSAN_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Real_World | tee DSAN_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee DSAN_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee DSAN_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Real_World | tee DSAN_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee DSAN_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee DSAN_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Real_World | tee DSAN_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee DSAN_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Art | tee DSAN_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Product | tee DSAN_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DSAN/DSAN.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Clipart | tee DSAN_R2C.log
================================================
FILE: code/DeepDA/DSAN/DSAN.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 0.5
transfer_loss: lmmd
# Optimizer related
lr: 0.01
weight_decay: 5e-4
momentum: 0.9
lr_scheduler: True
lr_gamma: 0.0003
lr_decay: 0.75
# Training related
n_iter_per_epoch: 500
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/DSAN/README.md
================================================
# DSAN
A PyTorch implementation of 'Deep Subdomain Adaptation Network for Image Classification' which has published on IEEE Transactions on Neural Networks and Learning Systems.
The contributions of this paper are summarized as follows.
* They propose a novel deep neural network architecture for Subdomain Adaptation, which can extend the ability of deep adaptation networks by capturing the fine-grained information for each category.
* They show that DSAN which is a non-adversarial method can achieve the remarkable results. In addition, their DSAN is very simple and easy to implement.
## Reference
```
Zhu Y, Zhuang F, Wang J, et al. Deep Subdomain Adaptation Network for Image Classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020.
```
or in bibtex style:
```
@article{zhu2020deep,
title={Deep Subdomain Adaptation Network for Image Classification},
author={Zhu, Yongchun and Zhuang, Fuzhen and Wang, Jindong and Ke, Guolin and Chen, Jingwu and Bian, Jiang and Xiong, Hui and He, Qing},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2020},
publisher={IEEE}
}
```
================================================
FILE: code/DeepDA/DeepCoral/DeepCoral.sh
================================================
#!/usr/bin/env bash
GPU_ID=1
data_dir=/home/houwx/tl/datasets/office31
# Office31
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain dslr --tgt_domain amazon | tee DeepCoral_D2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain dslr --tgt_domain webcam | tee DeepCoral_D2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain amazon --tgt_domain dslr | tee DeepCoral_A2D.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain amazon --tgt_domain webcam | tee DeepCoral_A2W.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain webcam --tgt_domain amazon | tee DeepCoral_W2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain webcam --tgt_domain dslr | tee DeepCoral_W2D.log
data_dir=/home/houwx/tl/datasets/office-home
# Office-Home
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Art --tgt_domain Clipart | tee DeepCoral_A2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Art --tgt_domain Real_World | tee DeepCoral_A2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Art --tgt_domain Product | tee DeepCoral_A2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Art | tee DeepCoral_C2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Real_World | tee DeepCoral_C2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Clipart --tgt_domain Product | tee DeepCoral_C2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Product --tgt_domain Art | tee DeepCoral_P2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Product --tgt_domain Real_World | tee DeepCoral_P2R.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Product --tgt_domain Clipart | tee DeepCoral_P2C.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Art | tee DeepCoral_R2A.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Product | tee DeepCoral_R2P.log
CUDA_VISIBLE_DEVICES=$GPU_ID python main.py --config DeepCoral/DeepCoral.yaml --data_dir $data_dir --src_domain Real_World --tgt_domain Clipart | tee DeepCoral_R2C.log
================================================
FILE: code/DeepDA/DeepCoral/DeepCoral.yaml
================================================
# Backbone
backbone: resnet50
# Transfer loss related
transfer_loss_weight: 10.0
transfer_loss: coral
# Optimizer related
lr: 3e-3
weight_decay: 5e-4
lr_scheduler: True
lr_gamma: 0.0003
lr_decay: 0.75
momentum: 0.9
# Training related
n_iter_per_epoch: 500
n_epoch: 20
# Others
seed: 1
num_workers: 3
================================================
FILE: code/DeepDA/DeepCoral/README.md
================================================
# Deep Coral
A PyTorch implementation of '[Deep CORAL Correlation Alignment for Deep Domain Adaptation](https://arxiv.org/pdf/1607.01719.pdf)'.
The contributions of this paper are summarized as fol-
lows.
* They extend CORAL to incorporate it directly into deep networks by constructing a differentiable loss function that minimizes the difference between source and target correlations–the CORAL loss.
* Compared to CORAL, Deep CORAL approach learns a non-linear transformation that is more powerful and also works seamlessly with deep CNNs.
================================================
FILE: code/DeepDA/README.md
================================================
# DeepDA: Deep Domain Adaptation Toolkit
A lightweight, easy-to-extend, easy-to-learn, high-performance, and for-fair-comparison toolkit based on PyTorch for domain adaptation (DA) of deep neural networks.
## Implemented Algorithms
As initial version, we support the following algoirthms. We are working on more algorithms. Of course, you are welcome to add your algorithms here.
1. DDC (Deep Domain Confusion) [1] / DAN (Deep Adaptation Network) [2]
2. DeepCoral [3]
3. DANN (Domain-adversarial neural network / RevGrad) [4]
4. DSAN (Deep Subdomain Adaptation Network) [5]
5. DAAN (Dynamic Adversarial Adaptation Network) [6]
6. BNM (Batch Nuclear-norm Maximization) [7]
The detailed explanation of those methods are in the `README.md` files of corresponding methods.
## Installation
You can either git clone this whole repo by:
```
git clone https://github.com/jindongwang/transferlearning.git
cd code/DeepDA
pip install -r requirements.txt
```
Or *if you just want to use this folder* (i.e., no other things in this big transferlearning repo), you can go to [this site](https://minhaskamal.github.io/DownGit/#/home) and paste the url of this DeepDA folder (https://github.com/jindongwang/transferlearning/edit/master/code/DeepDA) and then download only this folder!
We recommend to use `Python 3.7.10` which is our development environment.
## Usage
1. Modify the configuration file in the corresponding directories
2. Run the `main.py` with specified config, for example, `python main.py --config DAN/DAN.yaml`
* We provide shell scripts to help you reproduce our experimental results: `bash DAN/DAN.sh`.
## Customization
It is easy to design your own method following the 3 steps:
1. Check whether your method requires new loss functions, if so, add your loss in the `loss_funcs`
2. Check and write your own model's file inherited from our `models.TransferNet`
3. Write your own config file (.yaml)
## Results
We present results of our implementations on 2 popular benchmarks: Office-31 and Office-Home. We did not perform careful parameter tuning and simply used the default config files. You can easily reproduce our results using provided shell scripts! Note that source-only method is the one that uses no domain adaptation methods as a naive baseline method.
### Office31
| Method | D - A | D - W | A - W | W - A | A - D | W - D | Average |
|-------------|-------|-------|-------|-------|--------|--------|---------|
| Source-only | 66.17 | 97.61 | 80.63 | 65.07 | 82.73 | 100.00 | 82.03 |
| DAN [2] (DDC [1]) | 68.16 | 97.48 | 85.79 | 66.56 | 84.34 | 100.00 | 83.72 |
| DeepCoral [3] | 66.06 | 97.36 | 80.25 | 65.32 | 82.53 | 100.00 | 81.92 |
| DANN [4] | 67.06 | 97.86 | 84.65 | 71.03 | 82.73 | 100.00 | 83.89 |
| DSAN [5] | 76.04 | 98.49 | 94.34 | 72.91 | 89.96 | 100.00 | 88.62 |
| BNM [7] | 72.38 | 98.62 | 86.04 | 66.56 | 86.55 | 100.00 | 85.02 |
### Office-Home
| Method | A - C | A - P | A - R | C - A | C - P | C - R | P - A | P - C | P - R | R - A | R - C | R - P | Average |
|-------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|---------|
| Source-only | 51.04 | 68.21 | 74.85 | 54.22 | 63.64 | 66.84 | 53.65 | 45.41 | 74.57 | 65.68 | 53.56 | 79.34 | 62.58 |
| DAN [2] (DDC [1]) | 52.51 | 68.48 | 74.82 | 57.48 | 65.71 | 67.82 | 55.42 | 47.51 | 75.28 | 66.54 | 54.36 | 79.91 | 63.82 |
| DeepCoral [3] | 52.26 | 67.72 | 74.91 | 56.20 | 64.70 | 67.48 | 55.79 | 47.17 | 74.89 | 66.13 | 54.34 | 79.05 | 63.39 |
| DANN [4] | 51.48 | 67.27 | 74.18 | 53.23 | 65.10 | 65.41 | 53.15 | 50.22 | 75.05 | 65.35 | 57.48 | 79.45 | 63.12 |
| DSAN [5] | 54.48 | 71.12 | 75.37 | 60.53 | 70.92 | 68.53 | 62.71 | 56.04 | 78.29 | 74.37 | 60.34 | 82.99 | 67.97 |
| BNM [7] | 53.33 | 70.40 | 76.89 | 60.90 | 71.55 | 72.07 | 60.65 | 49.90 | 78.66 | 69.51 | 57.30 | 81.01 | 66.85 |
## Contribution
The toolkit is under active development and contributions are welcome! Feel free to submit issues and PRs to ask questions or contribute your code. If you would like to implement new features, please submit a issue to discuss with us first.
## References
[1] Tzeng, Eric, et al. "Deep domain confusion: Maximizing for domain invariance." arXiv preprint arXiv:1412.3474 (2014).
[2] Long, Mingsheng, et al. "Learning transferable features with deep adaptation networks." International conference on machine learning. PMLR, 2015.
[3] Sun, Baochen, and Kate Saenko. "Deep coral: Correlation alignment for deep domain adaptation." European conference on computer vision. Springer, Cham, 2016.
[4] Ganin, Yaroslav, and Victor Lempitsky. "Unsupervised domain adaptation by backpropagation." International conference on machine learning. PMLR, 2015.
[5] Zhu, Yongchun, et al. "Deep subdomain adaptation network for image classification." IEEE transactions on neural networks and learning systems (2020).
[6] Yu, Chaohui, et al. "Transfer learning with dynamic adversarial adaptation network." 2019 IEEE International Conference on Data Mining (ICDM). IEEE, 2019.
[7] Cui, Shuhao, et al. Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. CVPR 2020.
## Citation
If you think this toolkit or the results are helpful to you and your research, please cite us!
```
@Misc{deepda,
howpublished = {\url{https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA}},
title = {DeepDA: Deep Domain Adaptation Toolkit},
author = {Wang, Jindong and Hou, Wenxin}
}
```
## Contact
- [Wenxin Hou](https://houwenxin.github.io/): houwx001@gmail.com
- [Jindong Wang](http://www.jd92.wang/): jindongwang@outlook.com
================================================
FILE: code/DeepDA/backbones.py
================================================
import torch.nn as nn
from torchvision import models
resnet_dict = {
"resnet18": models.resnet18,
"resnet34": models.resnet34,
"resnet50": models.resnet50,
"resnet101": models.resnet101,
"resnet152": models.resnet152,
}
def get_backbone(name):
if "resnet" in name.lower():
return ResNetBackbone(name)
elif "alexnet" == name.lower():
return AlexNetBackbone()
elif "dann" == name.lower():
return DaNNBackbone()
class DaNNBackbone(nn.Module):
def __init__(self, n_input=224*224*3, n_hidden=256):
super(DaNNBackbone, self).__init__()
self.layer_input = nn.Linear(n_input, n_hidden)
self.dropout = nn.Dropout(p=0.5)
self.relu = nn.ReLU()
self._feature_dim = n_hidden
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layer_input(x)
x = self.dropout(x)
x = self.relu(x)
return x
def output_num(self):
return self._feature_dim
# convnet without the last layer
class AlexNetBackbone(nn.Module):
def __init__(self):
super(AlexNetBackbone, self).__init__()
model_alexnet = models.alexnet(pretrained=True)
self.features = model_alexnet.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module(
"classifier"+str(i), model_alexnet.classifier[i])
self._feature_dim = model_alexnet.classifier[6].in_features
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256*6*6)
x = self.classifier(x)
return x
def output_num(self):
return self._feature_dim
class ResNetBackbone(nn.Module):
def __init__(self, network_type):
super(ResNetBackbone, self).__init__()
resnet = resnet_dict[network_type](pretrained=True)
self.conv1 = resnet.conv1
self.bn1 = resnet.bn1
self.relu = resnet.relu
self.maxpool = resnet.maxpool
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
self.avgpool = resnet.avgpool
self._feature_dim = resnet.fc.in_features
del resnet
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self._feature_dim
================================================
FILE: code/DeepDA/data_loader.py
================================================
from torchvision import datasets, transforms
import torch
def load_data(data_folder, batch_size, train, num_workers=0, **kwargs):
transform = {
'train': transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])]),
'test': transforms.Compose(
[transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
}
data = datasets.ImageFolder(root=data_folder, transform=transform['train' if train else 'test'])
data_loader = get_data_loader(data, batch_size=batch_size,
shuffle=True if train else False,
num_workers=num_workers, **kwargs, drop_last=True if train else False)
n_class = len(data.classes)
return data_loader, n_class
def get_data_loader(dataset, batch_size, shuffle=True, drop_last=False, num_workers=0, infinite_data_loader=False, **kwargs):
if not infinite_data_loader:
return torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers, **kwargs)
else:
return InfiniteDataLoader(dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers, **kwargs)
class _InfiniteSampler(torch.utils.data.Sampler):
"""Wraps another Sampler to yield an infinite stream."""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
for batch in self.sampler:
yield batch
class InfiniteDataLoader:
def __init__(self, dataset, batch_size, shuffle=True, drop_last=False, num_workers=0, weights=None, **kwargs):
if weights is not None:
sampler = torch.utils.data.WeightedRandomSampler(weights,
replacement=False,
num_samples=batch_size)
else:
sampler = torch.utils.data.RandomSampler(dataset,
replacement=False)
batch_sampler = torch.utils.data.BatchSampler(
sampler,
batch_size=batch_size,
drop_last=drop_last)
self._infinite_iterator = iter(torch.utils.data.DataLoader(
dataset,
num_workers=num_workers,
batch_sampler=_InfiniteSampler(batch_sampler)
))
def __iter__(self):
while True:
yield next(self._infinite_iterator)
def __len__(self):
return 0 # Always return 0
================================================
FILE: code/DeepDA/loss_funcs/__init__.py
================================================
from loss_funcs.mmd import *
from loss_funcs.coral import *
from loss_funcs.adv import *
from loss_funcs.lmmd import *
from loss_funcs.daan import *
from loss_funcs.bnm import *
================================================
FILE: code/DeepDA/loss_funcs/adv.py
================================================
import torch
import torch.nn as nn
from torch.autograd import Function
import torch.nn.functional as F
import numpy as np
class LambdaSheduler(nn.Module):
def __init__(self, gamma=1.0, max_iter=1000, **kwargs):
super(LambdaSheduler, self).__init__()
self.gamma = gamma
self.max_iter = max_iter
self.curr_iter = 0
def lamb(self):
p = self.curr_iter / self.max_iter
lamb = 2. / (1. + np.exp(-self.gamma * p)) - 1
return lamb
def step(self):
self.curr_iter = min(self.curr_iter + 1, self.max_iter)
class AdversarialLoss(nn.Module):
'''
Acknowledgement: The adversarial loss implementation is inspired by http://transfer.thuml.ai/
'''
def __init__(self, gamma=1.0, max_iter=1000, use_lambda_scheduler=True, **kwargs):
super(AdversarialLoss, self).__init__()
self.domain_classifier = Discriminator()
self.use_lambda_scheduler = use_lambda_scheduler
if self.use_lambda_scheduler:
self.lambda_scheduler = LambdaSheduler(gamma, max_iter)
def forward(self, source, target):
lamb = 1.0
if self.use_lambda_scheduler:
lamb = self.lambda_scheduler.lamb()
self.lambda_scheduler.step()
source_loss = self.get_adversarial_result(source, True, lamb)
target_loss = self.get_adversarial_result(target, False, lamb)
adv_loss = 0.5 * (source_loss + target_loss)
return adv_loss
def get_adversarial_result(self, x, source=True, lamb=1.0):
x = ReverseLayerF.apply(x, lamb)
domain_pred = self.domain_classifier(x)
device = domain_pred.device
if source:
domain_label = torch.ones(len(x), 1).long()
else:
domain_label = torch.zeros(len(x), 1).long()
loss_fn = nn.BCELoss()
loss_adv = loss_fn(domain_pred, domain_label.float().to(device))
return loss_adv
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
layers = [
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
nn.Sigmoid()
]
self.layers = torch.nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
================================================
FILE: code/DeepDA/loss_funcs/bnm.py
================================================
import torch
def BNM(src, tar):
""" Batch nuclear-norm maximization, CVPR 2020.
tar: a tensor, softmax target output.
NOTE: this does not require source domain data.
"""
_, out, _ = torch.svd(tar)
loss = -torch.mean(out)
return loss
================================================
FILE: code/DeepDA/loss_funcs/coral.py
================================================
import torch
def CORAL(source, target, **kwargs):
d = source.data.shape[1]
ns, nt = source.data.shape[0], target.data.shape[0]
# source covariance
xm = torch.mean(source, 0, keepdim=True) - source
xc = xm.t() @ xm / (ns - 1)
# target covariance
xmt = torch.mean(target, 0, keepdim=True) - target
xct = xmt.t() @ xmt / (nt - 1)
# frobenius norm between source and target
loss = torch.mul((xc - xct), (xc - xct))
loss = torch.sum(loss) / (4*d*d)
return loss
================================================
FILE: code/DeepDA/loss_funcs/daan.py
================================================
from loss_funcs.adv import *
class DAANLoss(AdversarialLoss, LambdaSheduler):
def __init__(self, num_class, gamma=1.0, max_iter=1000, **kwargs):
super(DAANLoss, self).__init__(gamma=gamma, max_iter=max_iter, **kwargs)
self.num_class = num_class
self.local_classifiers = torch.nn.ModuleList()
for _ in range(num_class):
self.local_classifiers.append(Discriminator())
self.d_g, self.d_l = 0, 0
self.dynamic_factor = 0.5
def forward(self, source, target, source_logits, target_logits):
lamb = self.lamb()
self.step()
source_loss_g = self.get_adversarial_result(source, True, lamb)
target_loss_g = self.get_adversarial_result(target, False, lamb)
source_loss_l = self.get_local_adversarial_result(source, source_logits, True, lamb)
target_loss_l = self.get_local_adversarial_result(target, target_logits, False, lamb)
global_loss = 0.5 * (source_loss_g + target_loss_g) * 0.05
local_loss = 0.5 * (source_loss_l + target_loss_l) * 0.01
self.d_g = self.d_g + 2 * (1 - 2 * global_loss.cpu().item())
self.d_l = self.d_l + 2 * (1 - 2 * (local_loss / self.num_class).cpu().item())
adv_loss = (1 - self.dynamic_factor) * global_loss + self.dynamic_factor * local_loss
return adv_loss
def get_local_adversarial_result(self, x, logits, c, source=True, lamb=1.0):
loss_fn = nn.BCELoss()
x = ReverseLayerF.apply(x, lamb)
loss_adv = 0.0
for c in range(self.num_class):
logits_c = logits[:, c].reshape((logits.shape[0],1)) # (B, 1)
features_c = logits_c * x
domain_pred = self.local_classifiers[c](features_c)
device = domain_pred.device
if source:
domain_label = torch.ones(len(x), 1).long()
else:
domain_label = torch.zeros(len(x), 1).long()
loss_adv = loss_adv + loss_fn(domain_pred, domain_label.float().to(device))
return loss_adv
def update_dynamic_factor(self, epoch_length):
if self.d_g == 0 and self.d_l == 0:
self.dynamic_factor = 0.5
else:
self.d_g = self.d_g / epoch_length
self.d_l = self.d_l / epoch_length
self.dynamic_factor = 1 - self.d_g / (self.d_g + self.d_l)
self.d_g, self.d_l = 0, 0
================================================
FILE: code/DeepDA/loss_funcs/lmmd.py
================================================
from loss_funcs.mmd import MMDLoss
from loss_funcs.adv import LambdaSheduler
import torch
import numpy as np
class LMMDLoss(MMDLoss, LambdaSheduler):
def __init__(self, num_class, kernel_type='rbf', kernel_mul=2.0, kernel_num=5, fix_sigma=None,
gamma=1.0, max_iter=1000, **kwargs):
'''
Local MMD
'''
super(LMMDLoss, self).__init__(kernel_type, kernel_mul, kernel_num, fix_sigma, **kwargs)
super(MMDLoss, self).__init__(gamma, max_iter, **kwargs)
self.num_class = num_class
def forward(self, source, target, source_label, target_logits):
if self.kernel_type == 'linear':
raise NotImplementedError("Linear kernel is not supported yet.")
elif self.kernel_type == 'rbf':
batch_size = source.size()[0]
weight_ss, weight_tt, weight_st = self.cal_weight(source_label, target_logits)
weight_ss = torch.from_numpy(weight_ss).cuda() # B, B
weight_tt = torch.from_numpy(weight_tt).cuda()
weight_st = torch.from_numpy(weight_st).cuda()
kernels = self.guassian_kernel(source, target,
kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
loss = torch.Tensor([0]).cuda()
if torch.sum(torch.isnan(sum(kernels))):
return loss
SS = kernels[:batch_size, :batch_size]
TT = kernels[batch_size:, batch_size:]
ST = kernels[:batch_size, batch_size:]
loss += torch.sum( weight_ss * SS + weight_tt * TT - 2 * weight_st * ST )
# Dynamic weighting
lamb = self.lamb()
self.step()
loss = loss * lamb
return loss
def cal_weight(self, source_label, target_logits):
batch_size = source_label.size()[0]
source_label = source_label.cpu().data.numpy()
source_label_onehot = np.eye(self.num_class)[source_label] # one hot
source_label_sum = np.sum(source_label_onehot, axis=0).reshape(1, self.num_class)
source_label_sum[source_label_sum == 0] = 100
source_label_onehot = source_label_onehot / source_label_sum # label ratio
# Pseudo label
target_label = target_logits.cpu().data.max(1)[1].numpy()
target_logits = target_logits.cpu().data.numpy()
target_logits_sum = np.sum(target_logits, axis=0).reshape(1, self.num_class)
target_logits_sum[target_logits_sum == 0] = 100
target_logits = target_logits / target_logits_sum
weight_ss = np.zeros((batch_size, batch_size))
weight_tt = np.zeros((batch_size, batch_size))
weight_st = np.zeros((batch_size, batch_size))
set_s = set(source_label)
set_t = set(target_label)
count = 0
for i in range(self.num_class): # (B, C)
if i in set_s and i in set_t:
s_tvec = source_label_onehot[:, i].reshape(batch_size, -1) # (B, 1)
t_tvec = target_logits[:, i].reshape(batch_size, -1) # (B, 1)
ss = np.dot(s_tvec, s_tvec.T) # (B, B)
weight_ss = weight_ss + ss
tt = np.dot(t_tvec, t_tvec.T)
weight_tt = weight_tt + tt
st = np.dot(s_tvec, t_tvec.T)
weight_st = weight_st + st
count += 1
length = count
if length != 0:
weight_ss = weight_ss / length
weight_tt = weight_tt / length
weight_st = weight_st / length
else:
weight_ss = np.array([0])
weight_tt = np.array([0])
weight_st = np.array([0])
return weight_ss.astype('float32'), weight_tt.astype('float32'), weight_st.astype('float32')
================================================
FILE: code/DeepDA/loss_funcs/mmd.py
================================================
import torch
import torch.nn as nn
class MMDLoss(nn.Module):
def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5, fix_sigma=None, **kwargs):
super(MMDLoss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul, kernel_num, fix_sigma):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd2(self, f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd2(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
================================================
FILE: code/DeepDA/main.py
================================================
import configargparse
import data_loader
import os
import torch
import models
import utils
from utils import str2bool
import numpy as np
import random
def get_parser():
"""Get default arguments."""
parser = configargparse.ArgumentParser(
description="Transfer learning config parser",
config_file_parser_class=configargparse.YAMLConfigFileParser,
formatter_class=configargparse.ArgumentDefaultsHelpFormatter,
)
# general configuration
parser.add("--config", is_config_file=True, help="config file path")
parser.add("--seed", type=int, default=0)
parser.add_argument('--num_workers', type=int, default=0)
# network related
parser.add_argument('--backbone', type=str, default='resnet50')
parser.add_argument('--use_bottleneck', type=str2bool, default=True)
# data loading related
parser.add_argument('--data_dir', type=str, required=True)
parser.add_argument('--src_domain', type=str, required=True)
parser.add_argument('--tgt_domain', type=str, required=True)
# training related
parser.add_argument('--batch_size', type=int, default=32)
parser.add_argument('--n_epoch', type=int, default=100)
parser.add_argument('--early_stop', type=int, default=0, help="Early stopping")
parser.add_argument('--epoch_based_training', type=str2bool, default=False, help="Epoch-based training / Iteration-based training")
parser.add_argument("--n_iter_per_epoch", type=int, default=20, help="Used in Iteration-based training")
# optimizer related
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--weight_decay', type=float, default=5e-4)
# learning rate scheduler related
parser.add_argument('--lr_gamma', type=float, default=0.0003)
parser.add_argument('--lr_decay', type=float, default=0.75)
parser.add_argument('--lr_scheduler', type=str2bool, default=True)
# transfer related
parser.add_argument('--transfer_loss_weight', type=float, default=10)
parser.add_argument('--transfer_loss', type=str, default='mmd')
return parser
def set_random_seed(seed=0):
# seed setting
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def load_data(args):
'''
src_domain, tgt_domain data to load
'''
folder_src = os.path.join(args.data_dir, args.src_domain)
folder_tgt = os.path.join(args.data_dir, args.tgt_domain)
source_loader, n_class = data_loader.load_data(
folder_src, args.batch_size, infinite_data_loader=not args.epoch_based_training, train=True, num_workers=args.num_workers)
target_train_loader, _ = data_loader.load_data(
folder_tgt, args.batch_size, infinite_data_loader=not args.epoch_based_training, train=True, num_workers=args.num_workers)
target_test_loader, _ = data_loader.load_data(
folder_tgt, args.batch_size, infinite_data_loader=False, train=False, num_workers=args.num_workers)
return source_loader, target_train_loader, target_test_loader, n_class
def get_model(args):
model = models.TransferNet(
args.n_class, transfer_loss=args.transfer_loss, base_net=args.backbone, max_iter=args.max_iter, use_bottleneck=args.use_bottleneck).to(args.device)
return model
def get_optimizer(model, args):
initial_lr = args.lr if not args.lr_scheduler else 1.0
params = model.get_parameters(initial_lr=initial_lr)
optimizer = torch.optim.SGD(params, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay, nesterov=False)
return optimizer
def get_scheduler(optimizer, args):
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda x: args.lr * (1. + args.lr_gamma * float(x)) ** (-args.lr_decay))
return scheduler
def test(model, target_test_loader, args):
model.eval()
test_loss = utils.AverageMeter()
correct = 0
criterion = torch.nn.CrossEntropyLoss()
len_target_dataset = len(target_test_loader.dataset)
with torch.no_grad():
for data, target in target_test_loader:
data, target = data.to(args.device), target.to(args.device)
s_output = model.predict(data)
loss = criterion(s_output, target)
test_loss.update(loss.item())
pred = torch.max(s_output, 1)[1]
correct += torch.sum(pred == target)
acc = 100. * correct / len_target_dataset
return acc, test_loss.avg
def train(source_loader, target_train_loader, target_test_loader, model, optimizer, lr_scheduler, args):
len_source_loader = len(source_loader)
len_target_loader = len(target_train_loader)
n_batch = min(len_source_loader, len_target_loader)
if n_batch == 0:
n_batch = args.n_iter_per_epoch
iter_source, iter_target = iter(source_loader), iter(target_train_loader)
best_acc = 0
stop = 0
log = []
for e in range(1, args.n_epoch+1):
model.train()
train_loss_clf = utils.AverageMeter()
train_loss_transfer = utils.AverageMeter()
train_loss_total = utils.AverageMeter()
model.epoch_based_processing(n_batch)
if max(len_target_loader, len_source_loader) != 0:
iter_source, iter_target = iter(source_loader), iter(target_train_loader)
criterion = torch.nn.CrossEntropyLoss()
for _ in range(n_batch):
data_source, label_source = next(iter_source) # .next()
data_target, _ = next(iter_target) # .next()
data_source, label_source = data_source.to(
args.device), label_source.to(args.device)
data_target = data_target.to(args.device)
clf_loss, transfer_loss = model(data_source, data_target, label_source)
loss = clf_loss + args.transfer_loss_weight * transfer_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if lr_scheduler:
lr_scheduler.step()
train_loss_clf.update(clf_loss.item())
train_loss_transfer.update(transfer_loss.item())
train_loss_total.update(loss.item())
log.append([train_loss_clf.avg, train_loss_transfer.avg, train_loss_total.avg])
info = 'Epoch: [{:2d}/{}], cls_loss: {:.4f}, transfer_loss: {:.4f}, total_Loss: {:.4f}'.format(
e, args.n_epoch, train_loss_clf.avg, train_loss_transfer.avg, train_loss_total.avg)
# Test
stop += 1
test_acc, test_loss = test(model, target_test_loader, args)
info += ', test_loss {:4f}, test_acc: {:.4f}'.format(test_loss, test_acc)
np_log = np.array(log, dtype=float)
np.savetxt('train_log.csv', np_log, delimiter=',', fmt='%.6f')
if best_acc < test_acc:
best_acc = test_acc
stop = 0
if args.early_stop > 0 and stop >= args.early_stop:
print(info)
break
print(info)
print('Transfer result: {:.4f}'.format(best_acc))
def main():
parser = get_parser()
args = parser.parse_args()
setattr(args, "device", torch.device('cuda' if torch.cuda.is_available() else 'cpu'))
print(args)
set_random_seed(args.seed)
source_loader, target_train_loader, target_test_loader, n_class = load_data(args)
setattr(args, "n_class", n_class)
if args.epoch_based_training:
setattr(args, "max_iter", args.n_epoch * min(len(source_loader), len(target_train_loader)))
else:
setattr(args, "max_iter", args.n_epoch * args.n_iter_per_epoch)
model = get_model(args)
optimizer = get_optimizer(model, args)
if args.lr_scheduler:
scheduler = get_scheduler(optimizer, args)
else:
scheduler = None
train(source_loader, target_train_loader, target_test_loader, model, optimizer, scheduler, args)
if __name__ == "__main__":
main()
================================================
FILE: code/DeepDA/models.py
================================================
import torch
import torch.nn as nn
from transfer_losses import TransferLoss
import backbones
class TransferNet(nn.Module):
def __init__(self, num_class, base_net='resnet50', transfer_loss='mmd', use_bottleneck=True, bottleneck_width=256, max_iter=1000, **kwargs):
super(TransferNet, self).__init__()
self.num_class = num_class
self.base_network = backbones.get_backbone(base_net)
self.use_bottleneck = use_bottleneck
self.transfer_loss = transfer_loss
if self.use_bottleneck:
bottleneck_list = [
nn.Linear(self.base_network.output_num(), bottleneck_width),
nn.ReLU()
]
self.bottleneck_layer = nn.Sequential(*bottleneck_list)
feature_dim = bottleneck_width
else:
feature_dim = self.base_network.output_num()
self.classifier_layer = nn.Linear(feature_dim, num_class)
transfer_loss_args = {
"loss_type": self.transfer_loss,
"max_iter": max_iter,
"num_class": num_class
}
self.adapt_loss = TransferLoss(**transfer_loss_args)
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, source, target, source_label):
source = self.base_network(source)
target = self.base_network(target)
if self.use_bottleneck:
source = self.bottleneck_layer(source)
target = self.bottleneck_layer(target)
# classification
source_clf = self.classifier_layer(source)
clf_loss = self.criterion(source_clf, source_label)
# transfer
kwargs = {}
if self.transfer_loss == "lmmd":
kwargs['source_label'] = source_label
target_clf = self.classifier_layer(target)
kwargs['target_logits'] = torch.nn.functional.softmax(target_clf, dim=1)
elif self.transfer_loss == "daan":
source_clf = self.classifier_layer(source)
kwargs['source_logits'] = torch.nn.functional.softmax(source_clf, dim=1)
target_clf = self.classifier_layer(target)
kwargs['target_logits'] = torch.nn.functional.softmax(target_clf, dim=1)
elif self.transfer_loss == 'bnm':
tar_clf = self.classifier_layer(target)
target = nn.Softmax(dim=1)(tar_clf)
transfer_loss = self.adapt_loss(source, target, **kwargs)
return clf_loss, transfer_loss
def get_parameters(self, initial_lr=1.0):
params = [
{'params': self.base_network.parameters(), 'lr': 0.1 * initial_lr},
{'params': self.classifier_layer.parameters(), 'lr': 1.0 * initial_lr},
]
if self.use_bottleneck:
params.append(
{'params': self.bottleneck_layer.parameters(), 'lr': 1.0 * initial_lr}
)
# Loss-dependent
if self.transfer_loss == "adv":
params.append(
{'params': self.adapt_loss.loss_func.domain_classifier.parameters(), 'lr': 1.0 * initial_lr}
)
elif self.transfer_loss == "daan":
params.append(
{'params': self.adapt_loss.loss_func.domain_classifier.parameters(), 'lr': 1.0 * initial_lr}
)
params.append(
{'params': self.adapt_loss.loss_func.local_classifiers.parameters(), 'lr': 1.0 * initial_lr}
)
return params
def predict(self, x):
features = self.base_network(x)
if self.use_bottleneck:
features = self.bottleneck_layer(features)
clf = self.classifier_layer(features)
return clf
def epoch_based_processing(self, *args, **kwargs):
if self.transfer_loss == "daan":
self.adapt_loss.loss_func.update_dynamic_factor(*args, **kwargs)
else:
pass
================================================
FILE: code/DeepDA/requirements.txt
================================================
ConfigArgParse==1.4.1
torch==1.13.1
torchvision==0.9.1
scikit-learn
matplotlib
xlwt
pyyaml
================================================
FILE: code/DeepDA/transfer_losses.py
================================================
import torch
import torch.nn as nn
from loss_funcs import *
class TransferLoss(nn.Module):
def __init__(self, loss_type, **kwargs):
super(TransferLoss, self).__init__()
self.loss_type = loss_type
if loss_type == "mmd":
self.loss_func = MMDLoss(**kwargs)
elif loss_type == "lmmd":
self.loss_func = LMMDLoss(**kwargs)
elif loss_type == "coral":
self.loss_func = CORAL
elif loss_type == "adv":
self.loss_func = AdversarialLoss(**kwargs)
elif loss_type == "daan":
self.loss_func = DAANLoss(**kwargs)
elif loss_type == "bnm":
self.loss_func = BNM
else:
print("WARNING: No valid transfer loss function is used.")
self.loss_func = lambda x, y: 0 # return 0
def forward(self, source, target, **kwargs):
return self.loss_func(source, target, **kwargs)
================================================
FILE: code/DeepDA/utils.py
================================================
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
return False
else:
raise ValueError('Boolean value expected.')
================================================
FILE: code/DeepDG/alg/alg.py
================================================
# coding=utf-8
from alg.algs.ERM import ERM
from alg.algs.MMD import MMD
from alg.algs.CORAL import CORAL
from alg.algs.DANN import DANN
from alg.algs.RSC import RSC
from alg.algs.Mixup import Mixup
from alg.algs.MLDG import MLDG
from alg.algs.GroupDRO import GroupDRO
from alg.algs.ANDMask import ANDMask
from alg.algs.VREx import VREx
from alg.algs.DIFEX import DIFEX
ALGORITHMS = [
'ERM',
'Mixup',
'CORAL',
'MMD',
'DANN',
'MLDG',
'GroupDRO',
'RSC',
'ANDMask',
'VREx',
'DIFEX'
]
def get_algorithm_class(algorithm_name):
if algorithm_name not in globals():
raise NotImplementedError(
"Algorithm not found: {}".format(algorithm_name))
return globals()[algorithm_name]
================================================
FILE: code/DeepDG/alg/algs/ANDMask.py
================================================
# coding=utf-8
import torch
import torch.nn.functional as F
from alg.algs.ERM import ERM
import torch.autograd as autograd
class ANDMask(ERM):
def __init__(self, args):
super(ANDMask, self).__init__(args)
self.tau = args.tau
def update(self, minibatches, opt, sch):
total_loss = 0
param_gradients = [[] for _ in self.network.parameters()]
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_logits = self.network(all_x)
all_logits_idx = 0
for i, data in enumerate(minibatches):
x, y = data[0].cuda().float(), data[1].cuda().long()
logits = all_logits[all_logits_idx:all_logits_idx + x.shape[0]]
all_logits_idx += x.shape[0]
env_loss = F.cross_entropy(logits, y)
total_loss += env_loss
env_grads = autograd.grad(
env_loss, self.network.parameters(), retain_graph=True)
for grads, env_grad in zip(param_gradients, env_grads):
grads.append(env_grad)
mean_loss = total_loss / len(minibatches)
opt.zero_grad()
self.mask_grads(self.tau, param_gradients, self.network.parameters())
opt.step()
if sch:
sch.step()
return {'total': mean_loss.item()}
def mask_grads(self, tau, gradients, params):
for param, grads in zip(params, gradients):
grads = torch.stack(grads, dim=0)
grad_signs = torch.sign(grads)
mask = torch.mean(grad_signs, dim=0).abs() >= self.tau
mask = mask.to(torch.float32)
avg_grad = torch.mean(grads, dim=0)
mask_t = (mask.sum() / mask.numel())
param.grad = mask * avg_grad
param.grad *= (1. / (1e-10 + mask_t))
return 0
================================================
FILE: code/DeepDG/alg/algs/CORAL.py
================================================
# coding=utf-8
import torch
import torch.nn.functional as F
from alg.algs.ERM import ERM
class CORAL(ERM):
def __init__(self, args):
super(CORAL, self).__init__(args)
self.args = args
self.kernel_type = "mean_cov"
def coral(self, x, y):
mean_x = x.mean(0, keepdim=True)
mean_y = y.mean(0, keepdim=True)
cent_x = x - mean_x
cent_y = y - mean_y
cova_x = (cent_x.t() @ cent_x) / (len(x) - 1)
cova_y = (cent_y.t() @ cent_y) / (len(y) - 1)
mean_diff = (mean_x - mean_y).pow(2).mean()
cova_diff = (cova_x - cova_y).pow(2).mean()
return mean_diff + cova_diff
def update(self, minibatches, opt, sch):
objective = 0
penalty = 0
nmb = len(minibatches)
features = [self.featurizer(
data[0].cuda().float()) for data in minibatches]
classifs = [self.classifier(fi) for fi in features]
targets = [data[1].cuda().long() for data in minibatches]
for i in range(nmb):
objective += F.cross_entropy(classifs[i], targets[i])
for j in range(i + 1, nmb):
penalty += self.coral(features[i], features[j])
objective /= nmb
if nmb > 1:
penalty /= (nmb * (nmb - 1) / 2)
opt.zero_grad()
(objective + (self.args.mmd_gamma*penalty)).backward()
opt.step()
if sch:
sch.step()
if torch.is_tensor(penalty):
penalty = penalty.item()
return {'class': objective.item(), 'coral': penalty, 'total': (objective.item() + (self.args.mmd_gamma*penalty))}
================================================
FILE: code/DeepDG/alg/algs/DANN.py
================================================
# coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from alg.modelopera import get_fea
from network import Adver_network, common_network
from alg.algs.base import Algorithm
class DANN(Algorithm):
def __init__(self, args):
super(DANN, self).__init__(args)
self.featurizer = get_fea(args)
self.classifier = common_network.feat_classifier(
args.num_classes, self.featurizer.in_features, args.classifier)
self.discriminator = Adver_network.Discriminator(
self.featurizer.in_features, args.dis_hidden, args.domain_num - len(args.test_envs))
self.args = args
def update(self, minibatches, opt, sch):
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
all_z = self.featurizer(all_x)
disc_input = all_z
disc_input = Adver_network.ReverseLayerF.apply(
disc_input, self.args.alpha)
disc_out = self.discriminator(disc_input)
disc_labels = torch.cat([
torch.full((data[0].shape[0], ), i,
dtype=torch.int64, device='cuda')
for i, data in enumerate(minibatches)
])
disc_loss = F.cross_entropy(disc_out, disc_labels)
all_preds = self.classifier(all_z)
classifier_loss = F.cross_entropy(all_preds, all_y)
loss = classifier_loss+disc_loss
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'total': loss.item(), 'class': classifier_loss.item(), 'dis': disc_loss.item()}
def predict(self, x):
return self.classifier(self.featurizer(x))
================================================
FILE: code/DeepDG/alg/algs/DIFEX.py
================================================
# coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.fft
from alg.modelopera import get_fea
from network import common_network
from alg.algs.base import Algorithm
class DIFEX(Algorithm):
def __init__(self, args):
super(DIFEX, self).__init__(args)
self.args = args
self.featurizer = get_fea(args)
self.bottleneck = common_network.feat_bottleneck(
self.featurizer.in_features, args.bottleneck, args.layer)
self.classifier = common_network.feat_classifier(
args.num_classes, args.bottleneck, args.classifier)
self.tfbd = args.bottleneck//2
self.teaf = get_fea(args)
self.teab = common_network.feat_bottleneck(
self.featurizer.in_features, self.tfbd, args.layer)
self.teac = common_network.feat_classifier(
args.num_classes, self.tfbd, args.classifier)
self.teaNet = nn.Sequential(
self.teaf,
self.teab,
self.teac
)
def teanettrain(self, dataloaders, epochs, opt1, sch1):
self.teaNet.train()
minibatches_iterator = zip(*dataloaders)
for epoch in range(epochs):
minibatches = [(tdata) for tdata in next(minibatches_iterator)]
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_z = torch.angle(torch.fft.fftn(all_x, dim=(2, 3)))
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
all_p = self.teaNet(all_z)
loss = F.cross_entropy(all_p, all_y, reduction='mean')
opt1.zero_grad()
loss.backward()
if ((epoch+1) % (int(self.args.steps_per_epoch*self.args.max_epoch*0.7)) == 0 or (epoch+1) % (int(self.args.steps_per_epoch*self.args.max_epoch*0.9)) == 0) and (not self.args.schuse):
for param_group in opt1.param_groups:
param_group['lr'] = param_group['lr']*0.1
opt1.step()
if sch1:
sch1.step()
if epoch % int(self.args.steps_per_epoch) == 0 or epoch == epochs-1:
print('epoch: %d, cls loss: %.4f' % (epoch, loss))
self.teaNet.eval()
def coral(self, x, y):
mean_x = x.mean(0, keepdim=True)
mean_y = y.mean(0, keepdim=True)
cent_x = x - mean_x
cent_y = y - mean_y
cova_x = (cent_x.t() @ cent_x) / (len(x) - 1)
cova_y = (cent_y.t() @ cent_y) / (len(y) - 1)
mean_diff = (mean_x - mean_y).pow(2).mean()
cova_diff = (cova_x - cova_y).pow(2).mean()
return mean_diff + cova_diff
def update(self, minibatches, opt, sch):
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
with torch.no_grad():
all_x1 = torch.angle(torch.fft.fftn(all_x, dim=(2, 3)))
tfea = self.teab(self.teaf(all_x1)).detach()
all_z = self.bottleneck(self.featurizer(all_x))
loss1 = F.cross_entropy(self.classifier(all_z), all_y)
loss2 = F.mse_loss(all_z[:, :self.tfbd], tfea)*self.args.alpha
if self.args.disttype == '2-norm':
loss3 = -F.mse_loss(all_z[:, :self.tfbd],
all_z[:, self.tfbd:])*self.args.beta
elif self.args.disttype == 'norm-2-norm':
loss3 = -F.mse_loss(all_z[:, :self.tfbd]/torch.norm(all_z[:, :self.tfbd], dim=1, keepdim=True),
all_z[:, self.tfbd:]/torch.norm(all_z[:, self.tfbd:], dim=1, keepdim=True))*self.args.beta
elif self.args.disttype == 'norm-1-norm':
loss3 = -F.l1_loss(all_z[:, :self.tfbd]/torch.norm(all_z[:, :self.tfbd], dim=1, keepdim=True),
all_z[:, self.tfbd:]/torch.norm(all_z[:, self.tfbd:], dim=1, keepdim=True))*self.args.beta
elif self.args.disttype == 'cos':
loss3 = torch.mean(F.cosine_similarity(
all_z[:, :self.tfbd], all_z[:, self.tfbd:]))*self.args.beta
loss4 = 0
if len(minibatches) > 1:
for i in range(len(minibatches)-1):
for j in range(i+1, len(minibatches)):
loss4 += self.coral(all_z[i*self.args.batch_size:(i+1)*self.args.batch_size, self.tfbd:],
all_z[j*self.args.batch_size:(j+1)*self.args.batch_size, self.tfbd:])
loss4 = loss4*2/(len(minibatches) *
(len(minibatches)-1))*self.args.lam
else:
loss4 = self.coral(all_z[:self.args.batch_size//2, self.tfbd:],
all_z[self.args.batch_size//2:, self.tfbd:])
loss4 = loss4*self.args.lam
loss = loss1+loss2+loss3+loss4
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'class': loss1.item(), 'dist': (loss2).item(), 'exp': (loss3).item(), 'align': loss4.item(), 'total': loss.item()}
def predict(self, x):
return self.classifier(self.bottleneck(self.featurizer(x)))
================================================
FILE: code/DeepDG/alg/algs/ERM.py
================================================
# coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from alg.modelopera import get_fea
from network import common_network
from alg.algs.base import Algorithm
class ERM(Algorithm):
"""
Empirical Risk Minimization (ERM)
"""
def __init__(self, args):
super(ERM, self).__init__(args)
self.featurizer = get_fea(args)
self.classifier = common_network.feat_classifier(
args.num_classes, self.featurizer.in_features, args.classifier)
self.network = nn.Sequential(
self.featurizer, self.classifier)
def update(self, minibatches, opt, sch):
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
loss = F.cross_entropy(self.predict(all_x), all_y)
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'class': loss.item()}
def predict(self, x):
return self.network(x)
================================================
FILE: code/DeepDG/alg/algs/GroupDRO.py
================================================
#coding=utf-8
import torch
import torch.nn.functional as F
from alg.algs.ERM import ERM
class GroupDRO(ERM):
"""
Robust ERM minimizes the error at the worst minibatch
Algorithm 1 from [https://arxiv.org/pdf/1911.08731.pdf]
"""
def __init__(self,args):
super(GroupDRO, self).__init__(args)
self.register_buffer("q", torch.Tensor())
self.args=args
def update(self, minibatches, opt,sch):
if not len(self.q):
self.q = torch.ones(len(minibatches)).cuda()
losses = torch.zeros(len(minibatches)).cuda()
for m in range(len(minibatches)):
x, y = minibatches[m][0].cuda().float(),minibatches[m][1].cuda().long()
losses[m] = F.cross_entropy(self.predict(x), y)
self.q[m] *= (self.args.groupdro_eta * losses[m].data).exp()
self.q /= self.q.sum()
loss = torch.dot(losses, self.q)
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'group': loss.item()}
================================================
FILE: code/DeepDG/alg/algs/MLDG.py
================================================
# coding=utf-8
import torch
import copy
import torch.nn.functional as F
from alg.opt import *
import torch.autograd as autograd
from datautil.util import random_pairs_of_minibatches_by_domainperm
from alg.algs.ERM import ERM
class MLDG(ERM):
def __init__(self, args):
super(MLDG, self).__init__(args)
self.args = args
def update(self, minibatches, opt, sch):
"""
For computational efficiency, we do not compute second derivatives.
"""
num_mb = len(minibatches)
objective = 0
opt.zero_grad()
for p in self.network.parameters():
if p.grad is None:
p.grad = torch.zeros_like(p)
for (xi, yi), (xj, yj) in random_pairs_of_minibatches_by_domainperm(minibatches):
xi, yi, xj, yj = xi.cuda().float(), yi.cuda(
).long(), xj.cuda().float(), yj.cuda().long()
inner_net = copy.deepcopy(self.network)
inner_opt = get_optimizer(inner_net, self.args, True)
inner_sch = get_scheduler(inner_opt, self.args)
inner_obj = F.cross_entropy(inner_net(xi), yi)
inner_opt.zero_grad()
inner_obj.backward()
inner_opt.step()
if inner_sch:
inner_sch.step()
for p_tgt, p_src in zip(self.network.parameters(),
inner_net.parameters()):
if p_src.grad is not None:
p_tgt.grad.data.add_(p_src.grad.data / num_mb)
objective += inner_obj.item()
loss_inner_j = F.cross_entropy(inner_net(xj), yj)
grad_inner_j = autograd.grad(loss_inner_j, inner_net.parameters(),
allow_unused=True)
objective += (self.args.mldg_beta * loss_inner_j).item()
for p, g_j in zip(self.network.parameters(), grad_inner_j):
if g_j is not None:
p.grad.data.add_(
self.args.mldg_beta * g_j.data / num_mb)
objective /= len(minibatches)
opt.step()
if sch:
sch.step()
return {'total': objective}
================================================
FILE: code/DeepDG/alg/algs/MMD.py
================================================
# coding=utf-8
import torch
import torch.nn.functional as F
from alg.algs.ERM import ERM
class MMD(ERM):
def __init__(self, args):
super(MMD, self).__init__(args)
self.args = args
self.kernel_type = "gaussian"
def my_cdist(self, x1, x2):
x1_norm = x1.pow(2).sum(dim=-1, keepdim=True)
x2_norm = x2.pow(2).sum(dim=-1, keepdim=True)
res = torch.addmm(x2_norm.transpose(-2, -1),
x1,
x2.transpose(-2, -1), alpha=-2).add_(x1_norm)
return res.clamp_min_(1e-30)
def gaussian_kernel(self, x, y, gamma=[0.001, 0.01, 0.1, 1, 10, 100,
1000]):
D = self.my_cdist(x, y)
K = torch.zeros_like(D)
for g in gamma:
K.add_(torch.exp(D.mul(-g)))
return K
def mmd(self, x, y):
Kxx = self.gaussian_kernel(x, x).mean()
Kyy = self.gaussian_kernel(y, y).mean()
Kxy = self.gaussian_kernel(x, y).mean()
return Kxx + Kyy - 2 * Kxy
def update(self, minibatches, opt, sch):
objective = 0
penalty = 0
nmb = len(minibatches)
features = [self.featurizer(
data[0].cuda().float()) for data in minibatches]
classifs = [self.classifier(fi) for fi in features]
targets = [data[1].cuda().long() for data in minibatches]
for i in range(nmb):
objective += F.cross_entropy(classifs[i], targets[i])
for j in range(i + 1, nmb):
penalty += self.mmd(features[i], features[j])
objective /= nmb
if nmb > 1:
penalty /= (nmb * (nmb - 1) / 2)
opt.zero_grad()
(objective + (self.args.mmd_gamma*penalty)).backward()
opt.step()
if sch:
sch.step()
if torch.is_tensor(penalty):
penalty = penalty.item()
return {'class': objective.item(), 'mmd': penalty, 'total': (objective.item() + (self.args.mmd_gamma*penalty))}
================================================
FILE: code/DeepDG/alg/algs/Mixup.py
================================================
# coding=utf-8
import numpy as np
import torch.nn.functional as F
from datautil.util import random_pairs_of_minibatches
from alg.algs.ERM import ERM
class Mixup(ERM):
def __init__(self, args):
super(Mixup, self).__init__(args)
self.args = args
def update(self, minibatches, opt, sch):
objective = 0
for (xi, yi, di), (xj, yj, dj) in random_pairs_of_minibatches(self.args, minibatches):
lam = np.random.beta(self.args.mixupalpha, self.args.mixupalpha)
x = (lam * xi + (1 - lam) * xj).cuda().float()
predictions = self.predict(x)
objective += lam * F.cross_entropy(predictions, yi.cuda().long())
objective += (1 - lam) * \
F.cross_entropy(predictions, yj.cuda().long())
objective /= len(minibatches)
opt.zero_grad()
objective.backward()
opt.step()
if sch:
sch.step()
return {'class': objective.item()}
================================================
FILE: code/DeepDG/alg/algs/RSC.py
================================================
# coding=utf-8
import numpy as np
import torch
import torch.nn.functional as F
import torch.autograd as autograd
from alg.algs.ERM import ERM
class RSC(ERM):
def __init__(self, args):
super(RSC, self).__init__(args)
self.drop_f = (1 - args.rsc_f_drop_factor) * 100
self.drop_b = (1 - args.rsc_b_drop_factor) * 100
self.num_classes = args.num_classes
def update(self, minibatches, opt, sch):
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
all_o = torch.nn.functional.one_hot(all_y, self.num_classes)
all_f = self.featurizer(all_x)
all_p = self.classifier(all_f)
# Equation (1): compute gradients with respect to representation
all_g = autograd.grad((all_p * all_o).sum(), all_f)[0]
# Equation (2): compute top-gradient-percentile mask
percentiles = np.percentile(all_g.cpu(), self.drop_f, axis=1)
percentiles = torch.Tensor(percentiles)
percentiles = percentiles.unsqueeze(1).repeat(1, all_g.size(1))
mask_f = all_g.lt(percentiles.cuda()).float()
# Equation (3): mute top-gradient-percentile activations
all_f_muted = all_f * mask_f
# Equation (4): compute muted predictions
all_p_muted = self.classifier(all_f_muted)
# Section 3.3: Batch Percentage
all_s = F.softmax(all_p, dim=1)
all_s_muted = F.softmax(all_p_muted, dim=1)
changes = (all_s * all_o).sum(1) - (all_s_muted * all_o).sum(1)
percentile = np.percentile(changes.detach().cpu(), self.drop_b)
mask_b = changes.lt(percentile).float().view(-1, 1)
mask = torch.logical_or(mask_f, mask_b).float()
# Equations (3) and (4) again, this time mutting over examples
all_p_muted_again = self.classifier(all_f * mask)
# Equation (5): update
loss = F.cross_entropy(all_p_muted_again, all_y)
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'class': loss.item()}
================================================
FILE: code/DeepDG/alg/algs/VREx.py
================================================
# coding=utf-8
import torch
import torch.nn.functional as F
from alg.algs.ERM import ERM
class VREx(ERM):
"""V-REx algorithm from http://arxiv.org/abs/2003.00688"""
def __init__(self, args):
super(VREx, self).__init__(args)
self.register_buffer('update_count', torch.tensor([0]))
self.args = args
def update(self, minibatches, opt, sch):
if self.update_count >= self.args.anneal_iters:
penalty_weight = self.args.lam
else:
penalty_weight = 1.0
nll = 0.
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_logits = self.network(all_x)
all_logits_idx = 0
losses = torch.zeros(len(minibatches))
for i, data in enumerate(minibatches):
logits = all_logits[all_logits_idx:all_logits_idx +
data[0].shape[0]]
all_logits_idx += data[0].shape[0]
nll = F.cross_entropy(logits, data[1].cuda().long())
losses[i] = nll
mean = losses.mean()
penalty = ((losses - mean) ** 2).mean()
loss = mean + penalty_weight * penalty
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
self.update_count += 1
return {'loss': loss.item(), 'nll': nll.item(),
'penalty': penalty.item()}
================================================
FILE: code/DeepDG/alg/algs/base.py
================================================
# coding=utf-8
import torch
class Algorithm(torch.nn.Module):
def __init__(self, args):
super(Algorithm, self).__init__()
def update(self, minibatches, opt, sch):
raise NotImplementedError
def predict(self, x):
raise NotImplementedError
================================================
FILE: code/DeepDG/alg/modelopera.py
================================================
# coding=utf-8
import torch
from network import img_network
def get_fea(args):
if args.dataset == 'dg5':
net = img_network.DTNBase()
elif args.net.startswith('res'):
net = img_network.ResBase(args.net)
else:
net = img_network.VGGBase(args.net)
return net
def accuracy(network, loader):
correct = 0
total = 0
network.eval()
with torch.no_grad():
for data in loader:
x = data[0].cuda().float()
y = data[1].cuda().long()
p = network.predict(x)
if p.size(1) == 1:
correct += (p.gt(0).eq(y).float()).sum().item()
else:
correct += (p.argmax(1).eq(y).float()).sum().item()
total += len(x)
network.train()
return correct / total
================================================
FILE: code/DeepDG/alg/opt.py
================================================
# coding=utf-8
import torch
def get_params(alg, args, inner=False, alias=True, isteacher=False):
if args.schuse:
if args.schusech == 'cos':
initlr = args.lr
else:
initlr = 1.0
else:
if inner:
initlr = args.inner_lr
else:
initlr = args.lr
if isteacher:
params = [
{'params': alg[0].parameters(), 'lr': args.lr_decay1 * initlr},
{'params': alg[1].parameters(), 'lr': args.lr_decay2 * initlr},
{'params': alg[2].parameters(), 'lr': args.lr_decay2 * initlr}
]
return params
if inner:
params = [
{'params': alg[0].parameters(), 'lr': args.lr_decay1 *
initlr},
{'params': alg[1].parameters(), 'lr': args.lr_decay2 *
initlr}
]
elif alias:
params = [
{'params': alg.featurizer.parameters(), 'lr': args.lr_decay1 * initlr},
{'params': alg.classifier.parameters(), 'lr': args.lr_decay2 * initlr}
]
else:
params = [
{'params': alg[0].parameters(), 'lr': args.lr_decay1 * initlr},
{'params': alg[1].parameters(), 'lr': args.lr_decay2 * initlr}
]
if ('DANN' in args.algorithm) or ('CDANN' in args.algorithm):
params.append({'params': alg.discriminator.parameters(),
'lr': args.lr_decay2 * initlr})
if ('CDANN' in args.algorithm):
params.append({'params': alg.class_embeddings.parameters(),
'lr': args.lr_decay2 * initlr})
return params
def get_optimizer(alg, args, inner=False, alias=True, isteacher=False):
params = get_params(alg, args, inner, alias, isteacher)
optimizer = torch.optim.SGD(
params, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay, nesterov=True)
return optimizer
def get_scheduler(optimizer, args):
if not args.schuse:
return None
if args.schusech == 'cos':
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, args.max_epoch * args.steps_per_epoch)
else:
scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer, lambda x: args.lr * (1. + args.lr_gamma * float(x)) ** (-args.lr_decay))
return scheduler
================================================
FILE: code/DeepDG/datautil/getdataloader.py
================================================
# coding=utf-8
import numpy as np
import sklearn.model_selection as ms
from torch.utils.data import DataLoader
import datautil.imgdata.util as imgutil
from datautil.imgdata.imgdataload import ImageDataset
from datautil.mydataloader import InfiniteDataLoader
def get_img_dataloader(args):
rate = 0.2
trdatalist, tedatalist = [], []
names = args.img_dataset[args.dataset]
args.domain_num = len(names)
for i in range(len(names)):
if i in args.test_envs:
tedatalist.append(ImageDataset(args.dataset, args.task, args.data_dir,
names[i], i, transform=imgutil.image_test(args.dataset), test_envs=args.test_envs))
else:
tmpdatay = ImageDataset(args.dataset, args.task, args.data_dir,
names[i], i, transform=imgutil.image_train(args.dataset), test_envs=args.test_envs).labels
l = len(tmpdatay)
if args.split_style == 'strat':
lslist = np.arange(l)
stsplit = ms.StratifiedShuffleSplit(
2, test_size=rate, train_size=1-rate, random_state=args.seed)
stsplit.get_n_splits(lslist, tmpdatay)
indextr, indexte = next(stsplit.split(lslist, tmpdatay))
else:
indexall = np.arange(l)
np.random.seed(args.seed)
np.random.shuffle(indexall)
ted = int(l*rate)
indextr, indexte = indexall[:-ted], indexall[-ted:]
trdatalist.append(ImageDataset(args.dataset, args.task, args.data_dir,
names[i], i, transform=imgutil.image_train(args.dataset), indices=indextr, test_envs=args.test_envs))
tedatalist.append(ImageDataset(args.dataset, args.task, args.data_dir,
names[i], i, transform=imgutil.image_test(args.dataset), indices=indexte, test_envs=args.test_envs))
train_loaders = [InfiniteDataLoader(
dataset=env,
weights=None,
batch_size=args.batch_size,
num_workers=args.N_WORKERS)
for env in trdatalist]
eval_loaders = [DataLoader(
dataset=env,
batch_size=64,
num_workers=args.N_WORKERS,
drop_last=False,
shuffle=False)
for env in trdatalist+tedatalist]
return train_loaders, eval_loaders
================================================
FILE: code/DeepDG/datautil/imgdata/imgdataload.py
================================================
# coding=utf-8
from torch.utils.data import Dataset
import numpy as np
from datautil.util import Nmax
from datautil.imgdata.util import rgb_loader, l_loader
from torchvision.datasets import ImageFolder
from torchvision.datasets.folder import default_loader
class ImageDataset(object):
def __init__(self, dataset, task, root_dir, domain_name, domain_label=-1, labels=None, transform=None, target_transform=None, indices=None, test_envs=[], mode='Default'):
self.imgs = ImageFolder(root_dir+domain_name).imgs
self.domain_num = 0
self.task = task
self.dataset = dataset
imgs = [item[0] for item in self.imgs]
labels = [item[1] for item in self.imgs]
self.labels = np.array(labels)
self.x = imgs
self.transform = transform
self.target_transform = target_transform
if indices is None:
self.indices = np.arange(len(imgs))
else:
self.indices = indices
if mode == 'Default':
self.loader = default_loader
elif mode == 'RGB':
self.loader = rgb_loader
elif mode == 'L':
self.loader = l_loader
self.dlabels = np.ones(self.labels.shape) * \
(domain_label-Nmax(test_envs, domain_label))
def set_labels(self, tlabels=None, label_type='domain_label'):
assert len(tlabels) == len(self.x)
if label_type == 'domain_label':
self.dlabels = tlabels
elif label_type == 'class_label':
self.labels = tlabels
def target_trans(self, y):
if self.target_transform is not None:
return self.target_transform(y)
else:
return y
def input_trans(self, x):
if self.transform is not None:
return self.transform(x)
else:
return x
def __getitem__(self, index):
index = self.indices[index]
img = self.input_trans(self.loader(self.x[index]))
ctarget = self.target_trans(self.labels[index])
dtarget = self.target_trans(self.dlabels[index])
return img, ctarget, dtarget
def __len__(self):
return len(self.indices)
================================================
FILE: code/DeepDG/datautil/imgdata/util.py
================================================
# coding=utf-8
from torchvision import transforms
from PIL import Image, ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def image_train(dataset, resize_size=256, crop_size=224):
if dataset == 'dg5':
return transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
return transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.7, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.3, 0.3, 0.3, 0.3),
transforms.RandomGrayscale(),
transforms.ToTensor(),
normalize
])
def image_test(dataset, resize_size=256, crop_size=224):
if dataset == 'dg5':
return transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
return transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
def rgb_loader(path):
with open(path, 'rb') as f:
with Image.open(f) as img:
return img.convert('RGB')
def l_loader(path):
with open(path, 'rb') as f:
with Image.open(f) as img:
return img.convert('L')
================================================
FILE: code/DeepDG/datautil/mydataloader.py
================================================
# coding=utf-8
import torch
class _InfiniteSampler(torch.utils.data.Sampler):
"""Wraps another Sampler to yield an infinite stream."""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
for batch in self.sampler:
yield batch
class InfiniteDataLoader:
def __init__(self, dataset, weights, batch_size, num_workers):
super().__init__()
if weights:
sampler = torch.utils.data.WeightedRandomSampler(weights,
replacement=True,
num_samples=batch_size)
else:
sampler = torch.utils.data.RandomSampler(dataset,
replacement=True)
if weights == None:
weights = torch.ones(len(dataset))
batch_sampler = torch.utils.data.BatchSampler(
sampler,
batch_size=batch_size,
drop_last=True)
self._infinite_iterator = iter(torch.utils.data.DataLoader(
dataset,
num_workers=num_workers,
batch_sampler=_InfiniteSampler(batch_sampler)
))
def __iter__(self):
while True:
yield next(self._infinite_iterator)
def __len__(self):
raise ValueError
================================================
FILE: code/DeepDG/datautil/util.py
================================================
# coding=utf-8
import numpy as np
import torch
def Nmax(test_envs, d):
for i in range(len(test_envs)):
if d < test_envs[i]:
return i
return len(test_envs)
def random_pairs_of_minibatches_by_domainperm(minibatches):
perm = torch.randperm(len(minibatches)).tolist()
pairs = []
for i in range(len(minibatches)):
j = i + 1 if i < (len(minibatches) - 1) else 0
xi, yi = minibatches[perm[i]][0], minibatches[perm[i]][1]
xj, yj = minibatches[perm[j]][0], minibatches[perm[j]][1]
min_n = min(len(xi), len(xj))
pairs.append(((xi[:min_n], yi[:min_n]), (xj[:min_n], yj[:min_n])))
return pairs
def random_pairs_of_minibatches(args, minibatches):
ld = len(minibatches)
pairs = []
tdlist = np.arange(ld)
txlist = np.arange(args.batch_size)
for i in range(ld):
for j in range(args.batch_size):
(tdi, tdj), (txi, txj) = np.random.choice(tdlist, 2,
replace=False), np.random.choice(txlist, 2, replace=True)
if j == 0:
xi, yi, di = torch.unsqueeze(
minibatches[tdi][0][txi], dim=0), minibatches[tdi][1][txi], minibatches[tdi][2][txi]
xj, yj, dj = torch.unsqueeze(
minibatches[tdj][0][txj], dim=0), minibatches[tdj][1][txj], minibatches[tdj][2][txj]
else:
xi, yi, di = torch.vstack((xi, torch.unsqueeze(minibatches[tdi][0][txi], dim=0))), torch.hstack(
(yi, minibatches[tdi][1][txi])), torch.hstack((di, minibatches[tdi][2][txi]))
xj, yj, dj = torch.vstack((xj, torch.unsqueeze(minibatches[tdj][0][txj], dim=0))), torch.hstack(
(yj, minibatches[tdj][1][txj])), torch.hstack((dj, minibatches[tdj][2][txj]))
pairs.append(((xi, yi, di), (xj, yj, dj)))
return pairs
================================================
FILE: code/DeepDG/network/Adver_network.py
================================================
import torch
import torch.nn as nn
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256, num_domains=4):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
layers = [
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_domains),
]
self.layers = torch.nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
================================================
FILE: code/DeepDG/network/common_network.py
================================================
# coding=utf-8
import torch.nn as nn
from network.util import init_weights
import torch.nn.utils.weight_norm as weightNorm
class feat_bottleneck(nn.Module):
def __init__(self, feature_dim, bottleneck_dim=256, type="ori"):
super(feat_bottleneck, self).__init__()
self.bn = nn.BatchNorm1d(bottleneck_dim, affine=True)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=0.5)
self.bottleneck = nn.Linear(feature_dim, bottleneck_dim)
# self.bottleneck.apply(init_weights)
self.type = type
def forward(self, x):
x = self.bottleneck(x)
if self.type == "bn":
x = self.bn(x)
return x
class feat_classifier(nn.Module):
def __init__(self, class_num, bottleneck_dim=256, type="linear"):
super(feat_classifier, self).__init__()
self.type = type
if type == 'wn':
self.fc = weightNorm(
nn.Linear(bottleneck_dim, class_num), name="weight")
# self.fc.apply(init_weights)
else:
self.fc = nn.Linear(bottleneck_dim, class_num)
# self.fc.apply(init_weights)
def forward(self, x):
x = self.fc(x)
return x
class feat_classifier_two(nn.Module):
def __init__(self, class_num, input_dim, bottleneck_dim=256):
super(feat_classifier_two, self).__init__()
self.type = type
self.fc0 = nn.Linear(input_dim, bottleneck_dim)
# self.fc0.apply(init_weights)
self.fc1 = nn.Linear(bottleneck_dim, class_num)
# self.fc1.apply(init_weights)
def forward(self, x):
x = self.fc0(x)
x = self.fc1(x)
return x
================================================
FILE: code/DeepDG/network/img_network.py
================================================
# coding=utf-8
import torch.nn as nn
from torchvision import models
vgg_dict = {"vgg11": models.vgg11, "vgg13": models.vgg13, "vgg16": models.vgg16, "vgg19": models.vgg19,
"vgg11bn": models.vgg11_bn, "vgg13bn": models.vgg13_bn, "vgg16bn": models.vgg16_bn, "vgg19bn": models.vgg19_bn}
class VGGBase(nn.Module):
def __init__(self, vgg_name):
super(VGGBase, self).__init__()
model_vgg = vgg_dict[vgg_name](pretrained=True)
self.features = model_vgg.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module(
"classifier"+str(i), model_vgg.classifier[i])
self.in_features = model_vgg.classifier[6].in_features
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
res_dict = {"resnet18": models.resnet18, "resnet34": models.resnet34, "resnet50": models.resnet50,
"resnet101": models.resnet101, "resnet152": models.resnet152, "resnext50": models.resnext50_32x4d, "resnext101": models.resnext101_32x8d}
class ResBase(nn.Module):
def __init__(self, res_name):
super(ResBase, self).__init__()
model_resnet = res_dict[res_name](pretrained=True)
self.conv1 = model_resnet.conv1
self.bn1 = model_resnet.bn1
self.relu = model_resnet.relu
self.maxpool = model_resnet.maxpool
self.layer1 = model_resnet.layer1
self.layer2 = model_resnet.layer2
self.layer3 = model_resnet.layer3
self.layer4 = model_resnet.layer4
self.avgpool = model_resnet.avgpool
self.in_features = model_resnet.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class DTNBase(nn.Module):
def __init__(self):
super(DTNBase, self).__init__()
self.conv_params = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=5, stride=2, padding=2),
nn.BatchNorm2d(64),
nn.Dropout2d(0.1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=5, stride=2, padding=2),
nn.BatchNorm2d(128),
nn.Dropout2d(0.3),
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=5, stride=2, padding=2),
nn.BatchNorm2d(256),
nn.Dropout2d(0.5),
nn.ReLU()
)
self.in_features = 256*4*4
def forward(self, x):
x = self.conv_params(x)
x = x.view(x.size(0), -1)
return x
class LeNetBase(nn.Module):
def __init__(self):
super(LeNetBase, self).__init__()
self.conv_params = nn.Sequential(
nn.Conv2d(1, 20, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Conv2d(20, 50, kernel_size=5),
nn.Dropout2d(p=0.5),
nn.MaxPool2d(2),
nn.ReLU(),
)
self.in_features = 50*4*4
def forward(self, x):
x = self.conv_params(x)
x = x.view(x.size(0), -1)
return x
================================================
FILE: code/DeepDG/network/util.py
================================================
# coding=utf-8
import torch.nn as nn
import numpy as np
def calc_coeff(iter_num, high=1.0, low=0.0, alpha=10.0, max_iter=10000.0):
return np.float(2.0 * (high - low) / (1.0 + np.exp(-alpha*iter_num / max_iter)) - (high - low) + low)
def init_weights(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1 or classname.find('ConvTranspose2d') != -1:
nn.init.kaiming_uniform_(m.weight)
nn.init.zeros_(m.bias)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight, 1.0, 0.02)
nn.init.zeros_(m.bias)
elif classname.find('Linear') != -1:
nn.init.xavier_normal_(m.weight)
nn.init.zeros_(m.bias)
================================================
FILE: code/DeepDG/readme.md
================================================
# DeepDG: Deep Domain Generalization Toolkit
An easy-to-learn, easy-to-extend, and for-fair-comparison toolkit based on PyTorch for domain generalization (DG).
For a complete survey on these and more DG algorithms, please refer to this survey published at *IEEE TKDE 2022*: [Generalizing to Unseen Domains: A Survey on Domain Generalization](https://arxiv.org/abs/2103.03097). More recent news can be obtained from our [IJCAI 2022 tutorial on domain generalization](https://dgresearch.github.io/).
## Implemented Algorithms
We currently support the following algoirthms. We are working on more algorithms. Of course, you are welcome to add your algorithms here.
1. ERM
2. DDC (Deep Domain Confusion, arXiv 2014) [1]
3. CORAL (COrrelation Alignment, ECCV-16) [2]
4. DANN (Domain-adversarial Neural Network, JMLR-16) [3]
5. MLDG (Meta-learning Domain Generalization, AAAI-18) [4]
6. Mixup (ICLR-18) [5]
7. RSC (Representation Self-Challenging, ECCV-20) [6]
8. GroupDRO (ICLR-20) [7]
9. ANDMask (ICLR-21) [8]
10. VREx (ICML-21) [9]
11. DIFEX (TMLR-22) [10]
## Installation
You can either clone this whole big repo:
```
git clone https://github.com/jindongwang/transferlearning.git
cd code/DeepDG
```
Or *if you just want to use this folder* (i.e., no other things in this big transferlearning repo), you can go to [this site](https://minhaskamal.github.io/DownGit/#/home) and paste the url of this DeepDG folder (https://github.com/jindongwang/transferlearning/edit/master/code/DeepDG) and then download only this folder!
We recommend to use `Python 3.8.8` which is our development environment.
It is better to use the same environment following (https://hub.docker.com/r/jindongwang/docker).
## Datasets
Our code supports the following dataset:
* [Office-31](https://github.com/jindongwang/transferlearning/tree/master/data#office-31)
* [Office-Home](https://github.com/jindongwang/transferlearning/tree/master/data#office-home)
* [Office-Caltech](https://github.com/jindongwang/transferlearning/tree/master/data#office-caltech10)
* [PACS](https://drive.google.com/uc?id=0B6x7gtvErXgfbF9CSk53UkRxVzg)
* [Digit-Five](https://wjdcloud.blob.core.windows.net/dataset/dg5.tar.gz)
* [VLCS](https://drive.google.com/uc?id=1skwblH1_okBwxWxmRsp9_qi15hyPpxg8)
If you want to use your own dataset, please organize your data in the following structure.
```
RootDir
└───Domain1Name
│ └───Class1Name
│ │ file1.jpg
│ │ file2.jpg
│ │ ...
│ ...
└───Domain2Name
| ...
```
And then, modifty `util/util.py` to contain the dataset.
## Usage
1. Modify the file in the scripts
2. The main script file is `train.py`, which can be runned by using `run.sh` from `scripts/run.sh`: `cd scripts; bash run.sh`.
## Customization
It is easy to design your own method following the steps:
1. Add your method (a Python file) to `alg/algs`, and add the reference to it in the `alg/alg.py`
2. Modify `utils/util.py` to make it adapt your own parameters
3. Midify `scripts/run.sh` and execuate it
## Results
We present results of our implementations on 2 popular benchmarks: **PACS** and **Office-Home**. We did not perform careful parameter tuning. You can easily reproduce our results using the hyperparameters [here](https://github.com/jindongwang/transferlearning/blob/master/code/DeepDG/scripts/paramsref.md).
### Results on PACS (ResNet-18)
| Method | A | C | P | S | AVG |
|----------|-------|-------|-------|-------|-------|
| ERM | 81.1 | 77.94 | 95.03 | 76.94 | 82.75 |
| DANN | 82.86 | 78.33 | 96.11 | 76.99 | 83.57 |
| Mixup | 81.84 | 75.43 | 95.27 | 76.51 | 82.26 |
| RSC | 82.13 | 77.99 | 94.43 | 79.87 | 83.6 |
| MMD | 80.32 | 76.45 | 92.46 | 83.63 | 83.21 |
| CORAL | 79.39 | 77.9 | 91.98 | 82.03 | 82.83 |
| GroupDRO | 79.15 | 76.75 | 91.32 | 81.52 | 82.19 |
| ANDMask | 80.81 | 73.29 | 95.81 | 71.95 | 80.47 |
| Vrex | 81.54 | 78.11 | 95.39 | 80.35 | 83.85 |
|DIFEX-ori | 82.86 | 78.46 | 94.97 | 79.41 | 83.93 |
|DIFEX-norm| 83.40 | 79.74 | 95.03 | 79.10 | 84.32 |
### Results on Office-Home (ResNet-18)
| Method | A | C | P | R | AVG |
|----------|-------|-------|-------|-------|-------|
| ERM | 57.77 | 50.63 | 71.3 | 74.45 | 63.54 |
| DANN | 57.6 | 48.52 | 71.16 | 72.99 | 62.57 |
| Mixup | 58.71 | 51 | 72.2 | 75.42 | 64.33 |
| RSC | 57.07 | 50.77 | 71.93 | 73.63 | 63.35 |
| MMD | 59.29 | 50.52 | 72.34 | 74.43 | 64.15 |
| CORAL | 59.29 | 50.15 | 72.25 | 74.2 | 63.97 |
| GroupDRO | 59.09 | 50.22 | 71.91 | 74.48 | 63.92 |
| ANDMask | 53.61 | 47.54 | 69.36 | 72.23 | 60.69 |
| Vrex | 59.09 | 49.81 | 71.64 | 74.82 | 63.84 |
### Results on PACS (ResNet-50)
| Method | A | C | P | S | AVG |
|----------|-------|-------|-------|-------|-------|
| ERM | 83.2 | 81.7 | 96.65 | 83.69 | 86.31 |
| DANN | 87.26 | 83.45 | 95.33 | 84.35 | 87.6 |
| Mixup | 89.36 | 82.08 | 96.65 | 84.63 | 88.18 |
| RSC | 87.84 | 80.33 | 97.72 | 81.5 | 86.85 |
| MMD | 85.74 | 83.58 | 95.51 | 83.46 | 87.07 |
| CORAL | 86.77 | 84.04 | 94.85 | 85.95 | 87.9 |
| GroupDRO | 84.18 | 83.15 | 96.11 | 83.94 | 86.84 |
| ANDMask | 84.91 | 76.45 | 97.72 | 81.19 | 85.07 |
| Vrex | 87.11 | 82.85 | 96.95 | 84.07 | 87.75 |
### Results on Office-Home (ResNet-50)
| Method | A | C | P | R | AVG |
|----------|-------|-------|-------|-------|-------|
| ERM | 67.66 | 55.92 | 77.7 | 80.47 | 70.44 |
| DANN | 67.49 | 56.66 | 76.73 | 79.21 | 70.02 |
| Mixup | 67.41 | 58.24 | 78.46 | 80.84 | 71.24 |
| RSC | 66.3 | 55.21 | 76.95 | 79 | 69.36 |
| MMD | 66.71 | 56.54 | 78.37 | 79.8 | 70.36 |
| CORAL | 66.58 | 56.17 | 78.55 | 79.76 | 70.27 |
| GroupDRO | 66.87 | 57.04 | 77.97 | 79.69 | 70.39 |
| ANDMask | 62.3 | 54.78 | 74.99 | 78.31 | 67.59 |
| Vrex | 68.19 | 56.29 | 78.35 | 80.42 | 70.81 |
## Contribution
The toolkit is under active development and contributions are welcome! Feel free to submit issues and PRs to ask questions or contribute your code. If you would like to implement new features, please submit a issue to discuss with us first. You are welcome to our another related project: [DeepDA](https://github.com/jindongwang/transferlearning/edit/master/code/DeepDA).
## Acknowledgment
Great thanks to [DomainBed](https://github.com/facebookresearch/DomainBed). We simplify their work to make it easy to perform experiments and extensions. Moreover, we add some new features.
## Reference
[1] Tzeng, Eric, et al. "Deep domain confusion: Maximizing for domain invariance." arXiv preprint arXiv:1412.3474 (2014).
[2] Sun, Baochen, and Kate Saenko. "Deep coral: Correlation alignment for deep domain adaptation." European conference on computer vision. Springer, Cham, 2016.
[3] Ganin, Yaroslav, and Victor Lempitsky. "Unsupervised domain adaptation by backpropagation." International conference on machine learning. PMLR, 2015.
[4] Li, Da, et al. "Learning to generalize: Meta-learning for domain generalization." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
[5] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." ICLR 2018.
[6] Huang, Zeyi, et al. "Self-challenging improves cross-domain generalization." ECCV 2020.
[7] Sagawa S, Koh P W, Hashimoto T B, et al. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization, ICLR 2020.
[8] Parascandolo G, Neitz A, ORVIETO A, et al. Learning explanations that are hard to vary[C]//International Conference on Learning Representations. 2020.
[9] Krueger D, Caballero E, Jacobsen J H, et al. Out-of-distribution generalization via risk extrapolation (rex)[C]//International Conference on Machine Learning. PMLR, 2021.
[10] Wang Lu, Jindong Wang, et al. Domain-invariant Feature Exploration for Domain Generalization. TMLR, 2022.
## Citation
If you think this toolkit or the results are helpful to you and your research, please cite us!
```
@Misc{deepdg,
howpublished = {\url{https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG}},
title = {DeepDG: Deep Domain Generalization Toolkit},
author = {Wang, Jindong and Wang Lu}
}
```
## Contact
- Wang lu: luwang@ict.ac.cn
- [Jindong Wang](http://www.jd92.wang/): jindongwang@outlook.com
================================================
FILE: code/DeepDG/requirements.txt
================================================
Please refer to https://hub.docker.com/r/jindongwang/docker.
CUDA: 10.1
Pytorch: 1.7
Torchvision: 0.8.1
================================================
FILE: code/DeepDG/scripts/paramsref.md
================================================
## We offer a hyperparameter reference for our implementations.
### Common hyperparameters
* max_epoch:120
* lr: 0.001 or 0.005
### Hyperparameters for PACS(ResNet-18) (Corresponding to each task in order, ACPS)
| Method | A | C | P | S |
|----------|----------|----------|----------|----------|
|DANN(alpha)|0.5| 1| 0.1| 0.1|
|Mixup(mixupalpha)|0.1| 0.2| 0.2| 0.2|
|RSC(rsc_f_drop_factor,rsc_b_drop_factor)|0.1,0.3|0.3,0.1|0.1,0.1|0.1,0.1|
|MMD(mmd_gamma)|10|1|0.5|0.5|
|CORAL(mmd_gamma)|0.5|0.1|1|0.01|
|GroupDRO(groudro_eta)|10**(-2.5)| 0.001| 0.001| 0.01|
|ANDMask(tau)|0.5|0.82|0.5|0.5|
|VREx(lam,anneal_iters)|1,5000|1,100|0.3,5000|1,10|
### Hyperparameters for Office-Home(ResNet-18) (Corresponding to each task in order, ACPR)
| Method | A | C | P | R |
|----------|----------|----------|----------|----------|
|DANN(alpha)|0.1| 0.1| 0.1| 0.1|
|Mixup(mixupalpha)|0.2| 0.2| 0.1| 0.1|
|RSC(rsc_f_drop_factor,rsc_b_drop_factor)|0.1,0.1|0.1,0.1|0.1,0.3|0.1,0.1|
|MMD(mmd_gamma)|0.5|10|0.5|0.01|
|CORAL(mmd_gamma)|1|1|0.5|0.01|
|GroupDRO(groudro_eta)|0.001| 10**(-2.5)| 10**(-2.5)| 0.01|
|ANDMask(tau)|0.82|0.82|0.82|0.82|
|VREx(lam,anneal_iters)|0.3,500|10,100|10,100|10,100|
### Hyperparameters for PACS(ResNet-50) (Corresponding to each task in order, ACPS)
| Method | A | C | P | S |
|----------|----------|----------|----------|----------|
|DANN(alpha)|0.1| 0.1| 0.1| 1|
|Mixup(mixupalpha)|0.1| 0.1| 0.2| 0.1|
|RSC(rsc_f_drop_factor,rsc_b_drop_factor)|0.1,0.3|0.3,0.3|0.1,0.1|0.3,0.3|
|MMD(mmd_gamma)|0.1|1|1|0.5|
|CORAL(mmd_gamma)|0.01|1|0.01|1|
|GroupDRO(groudro_eta)|0.001| 10**(-2.5)| 0.001| 0.1|
|ANDMask(tau)|0.82|0.5|0.82|0.82|
|VREx(lam,anneal_iters)|1,500|0.3,5000|0.3,5000|0.3,500|
### Hyperparameters for Office-Home(ResNet-50) (Corresponding to each task in order, ACPR)
| Method | A | C | P | R |
|----------|----------|----------|----------|----------|
|DANN(alpha)|0.1| 0.1| 0.1| 0.1|
|Mixup(mixupalpha)|0.1| 0.2| 0.2| 0.1|
|RSC(rsc_f_drop_factor,rsc_b_drop_factor)|0.1,0.3|0.3,0.1|0.1,0.1|0.3,0.1|
|MMD(mmd_gamma)|1|0.5|0.5|1|
|CORAL(mmd_gamma)|0.1|1|0.5|0.01|
|GroupDRO(groudro_eta)|0.01| 0.1| 10**(-2.5)| 10**(-2.5)|
|ANDMask(tau)|0.5|0.5|0.82|0.5|
|VREx(lam,anneal_iters)|0.3,100|10,500|0.3,100|10,500|
### Remark
Environments may affect results.
You can try to adjust the parameters by yourself or just use the same environment following (https://hub.docker.com/r/jindongwang/docker).
================================================
FILE: code/DeepDG/scripts/run.sh
================================================
dataset='PACS'
algorithm=('MLDG' 'ERM' 'DANN' 'RSC' 'Mixup' 'MMD' 'CORAL' 'VREx')
test_envs=2
gpu_ids=0
data_dir='/home/lw/lw/data/PACS/'
max_epoch=2
net='resnet18'
task='img_dg'
output='/home/lw/lw/data/train_output/test'
i=0
# MLDG
python train.py --data_dir $data_dir --max_epoch $max_epoch --net $net --task $task --output $output \
--test_envs $test_envs --dataset $dataset --algorithm ${algorithm[i]} --mldg_beta 10
# Group_DRO
python train.py --data_dir ~/myexp30609/data/PACS/ --max_epoch 3 --net resnet18 --task img_dg --output ~/tmp/test00 \
--test_envs 0 --dataset PACS --algorithm GroupDRO --groupdro_eta 1
# ANDMask
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 3 --net resnet18 --task img_dg --output /home/lw/lw/test00 \
--test_envs 0 --dataset PACS --algorithm ANDMask --tau 1
# The following experiments are running on the singularity cluster of MSRA.The environment are shown in the following file.
# CUDA version, wget https://dgresearchredmond.blob.core.windows.net/amulet/projects/lw/singularity/env/env1.txt
# GPU information, wget https://dgresearchredmond.blob.core.windows.net/amulet/projects/lw/singularity/env/env2.txt
# python package information, wget https://dgresearchredmond.blob.core.windows.net/amulet/projects/lw/singularity/env/env.txt
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/2-0 \
--test_envs 0 --dataset PACS --algorithm DIFEX --alpha 0.1 --beta 0.01 --lam 0.1 --disttype 2-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/2-1 \
--test_envs 1 --dataset PACS --algorithm DIFEX --alpha 0.001 --beta 0 --lam 0.01 --disttype 2-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/2-2 \
--test_envs 2 --dataset PACS --algorithm DIFEX --alpha 0.001 --beta 0.01 --lam 0.01 --disttype 2-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/2-3 \
--test_envs 3 --dataset PACS --algorithm DIFEX --alpha 0.01 --beta 1 --lam 0 --disttype 2-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/n1n-0 \
--test_envs 0 --dataset PACS --algorithm DIFEX --alpha 0.1 --beta 0.1 --lam 0 --disttype norm-1-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/n1n-1 \
--test_envs 1 --dataset PACS --algorithm DIFEX --alpha 0.001 --beta 1 --lam 0.01 --disttype norm-1-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/n1n-2 \
--test_envs 2 --dataset PACS --algorithm DIFEX --alpha 0.001 --beta 0.5 --lam 0.1 --disttype norm-1-norm
python train.py --data_dir /home/lw/lw/data/PACS/ --max_epoch 120 --net resnet18 --checkpoint_freq 1 --task img_dg --output /home/lw/lw/data/train_output/difexpacs/n1n-3 \
--test_envs 3 --dataset PACS --algorithm DIFEX --alpha 0.01 --beta 10 --lam 1 --disttype norm-1-norm
================================================
FILE: code/DeepDG/train.py
================================================
# coding=utf-8
import os
import sys
import time
import numpy as np
import argparse
from alg.opt import *
from alg import alg, modelopera
from utils.util import set_random_seed, save_checkpoint, print_args, train_valid_target_eval_names, alg_loss_dict, Tee, img_param_init, print_environ
from datautil.getdataloader import get_img_dataloader
def get_args():
parser = argparse.ArgumentParser(description='DG')
parser.add_argument('--algorithm', type=str, default="ERM")
parser.add_argument('--alpha', type=float,
default=1, help='DANN dis alpha')
parser.add_argument('--anneal_iters', type=int,
default=500, help='Penalty anneal iters used in VREx')
parser.add_argument('--batch_size', type=int,
default=32, help='batch_size')
parser.add_argument('--beta', type=float,
default=1, help='DIFEX beta')
parser.add_argument('--beta1', type=float, default=0.5,
help='Adam hyper-param')
parser.add_argument('--bottleneck', type=int, default=256)
parser.add_argument('--checkpoint_freq', type=int,
default=3, help='Checkpoint every N epoch')
parser.add_argument('--classifier', type=str,
default="linear", choices=["linear", "wn"])
parser.add_argument('--data_file', type=str, default='',
help='root_dir')
parser.add_argument('--dataset', type=str, default='office')
parser.add_argument('--data_dir', type=str, default='', help='data dir')
parser.add_argument('--dis_hidden', type=int,
default=256, help='dis hidden dimension')
parser.add_argument('--disttype', type=str, default='2-norm',
choices=['1-norm', '2-norm', 'cos', 'norm-2-norm', 'norm-1-norm'])
parser.add_argument('--gpu_id', type=str, nargs='?',
default='0', help="device id to run")
parser.add_argument('--groupdro_eta', type=float,
default=1, help="groupdro eta")
parser.add_argument('--inner_lr', type=float,
default=1e-2, help="learning rate used in MLDG")
parser.add_argument('--lam', type=float,
default=1, help="tradeoff hyperparameter used in VREx")
parser.add_argument('--layer', type=str, default="bn",
choices=["ori", "bn"])
parser.add_argument('--lr', type=float, default=1e-2, help="learning rate")
parser.add_argument('--lr_decay', type=float, default=0.75, help='for sgd')
parser.add_argument('--lr_decay1', type=float,
default=1.0, help='for pretrained featurizer')
parser.add_argument('--lr_decay2', type=float, default=1.0,
help='inital learning rate decay of network')
parser.add_argument('--lr_gamma', type=float,
default=0.0003, help='for optimizer')
parser.add_argument('--max_epoch', type=int,
default=120, help="max iterations")
parser.add_argument('--mixupalpha', type=float,
default=0.2, help='mixup hyper-param')
parser.add_argument('--mldg_beta', type=float,
default=1, help="mldg hyper-param")
parser.add_argument('--mmd_gamma', type=float,
default=1, help='MMD, CORAL hyper-param')
parser.add_argument('--momentum', type=float,
default=0.9, help='for optimizer')
parser.add_argument('--net', type=str, default='resnet50',
help="featurizer: vgg16, resnet50, resnet101,DTNBase")
parser.add_argument('--N_WORKERS', type=int, default=4)
parser.add_argument('--rsc_f_drop_factor', type=float,
default=1/3, help='rsc hyper-param')
parser.add_argument('--rsc_b_drop_factor', type=float,
default=1/3, help='rsc hyper-param')
parser.add_argument('--save_model_every_checkpoint', action='store_true')
parser.add_argument('--schuse', action='store_true')
parser.add_argument('--schusech', type=str, default='cos')
parser.add_argument('--seed', type=int, default=0)
parser.add_argument('--split_style', type=str, default='strat',
help="the style to split the train and eval datasets")
parser.add_argument('--task', type=str, default="img_dg",
choices=["img_dg"], help='now only support image tasks')
parser.add_argument('--tau', type=float, default=1, help="andmask tau")
parser.add_argument('--test_envs', type=int, nargs='+',
default=[0], help='target domains')
parser.add_argument('--output', type=str,
default="train_output", help='result output path')
parser.add_argument('--weight_decay', type=float, default=5e-4)
args = parser.parse_args()
args.steps_per_epoch = 100
args.data_dir = args.data_file+args.data_dir
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_id
os.makedirs(args.output, exist_ok=True)
sys.stdout = Tee(os.path.join(args.output, 'out.txt'))
sys.stderr = Tee(os.path.join(args.output, 'err.txt'))
args = img_param_init(args)
print_environ()
return args
if __name__ == '__main__':
args = get_args()
set_random_seed(args.seed)
loss_list = alg_loss_dict(args)
train_loaders, eval_loaders = get_img_dataloader(args)
eval_name_dict = train_valid_target_eval_names(args)
algorithm_class = alg.get_algorithm_class(args.algorithm)
algorithm = algorithm_class(args).cuda()
algorithm.train()
opt = get_optimizer(algorithm, args)
sch = get_scheduler(opt, args)
s = print_args(args, [])
print('=======hyper-parameter used========')
print(s)
if 'DIFEX' in args.algorithm:
ms = time.time()
n_steps = args.max_epoch*args.steps_per_epoch
print('start training fft teacher net')
opt1 = get_optimizer(algorithm.teaNet, args, isteacher=True)
sch1 = get_scheduler(opt1, args)
algorithm.teanettrain(train_loaders, n_steps, opt1, sch1)
print('complet time:%.4f' % (time.time()-ms))
acc_record = {}
acc_type_list = ['train', 'valid', 'target']
train_minibatches_iterator = zip(*train_loaders)
best_valid_acc, target_acc = 0, 0
print('===========start training===========')
sss = time.time()
for epoch in range(args.max_epoch):
for iter_num in range(args.steps_per_epoch):
minibatches_device = [(data)
for data in next(train_minibatches_iterator)]
if args.algorithm == 'VREx' and algorithm.update_count == args.anneal_iters:
opt = get_optimizer(algorithm, args)
sch = get_scheduler(opt, args)
step_vals = algorithm.update(minibatches_device, opt, sch)
if (epoch in [int(args.max_epoch*0.7), int(args.max_epoch*0.9)]) and (not args.schuse):
print('manually descrease lr')
for params in opt.param_groups:
params['lr'] = params['lr']*0.1
if (epoch == (args.max_epoch-1)) or (epoch % args.checkpoint_freq == 0):
print('===========epoch %d===========' % (epoch))
s = ''
for item in loss_list:
s += (item+'_loss:%.4f,' % step_vals[item])
print(s[:-1])
s = ''
for item in acc_type_list:
acc_record[item] = np.mean(np.array([modelopera.accuracy(
algorithm, eval_loaders[i]) for i in eval_name_dict[item]]))
s += (item+'_acc:%.4f,' % acc_record[item])
print(s[:-1])
if acc_record['valid'] > best_valid_acc:
best_valid_acc = acc_record['valid']
target_acc = acc_record['target']
if args.save_model_every_checkpoint:
save_checkpoint(f'model_epoch{epoch}.pkl', algorithm, args)
print('total cost time: %.4f' % (time.time()-sss))
algorithm_dict = algorithm.state_dict()
save_checkpoint('model.pkl', algorithm, args)
print('valid acc: %.4f' % best_valid_acc)
print('DG result: %.4f' % target_acc)
with open(os.path.join(args.output, 'done.txt'), 'w') as f:
f.write('done\n')
f.write('total cost time:%s\n' % (str(time.time()-sss)))
f.write('valid acc:%.4f\n' % (best_valid_acc))
f.write('target acc:%.4f' % (target_acc))
================================================
FILE: code/DeepDG/utils/util.py
================================================
# coding=utf-8
import random
import numpy as np
import torch
import sys
import os
import torchvision
import PIL
def set_random_seed(seed=0):
# seed setting
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def save_checkpoint(filename, alg, args):
save_dict = {
"args": vars(args),
"model_dict": alg.cpu().state_dict()
}
torch.save(save_dict, os.path.join(args.output, filename))
def train_valid_target_eval_names(args):
eval_name_dict = {'train': [], 'valid': [], 'target': []}
t = 0
for i in range(args.domain_num):
if i not in args.test_envs:
eval_name_dict['train'].append(t)
t += 1
for i in range(args.domain_num):
if i not in args.test_envs:
eval_name_dict['valid'].append(t)
else:
eval_name_dict['target'].append(t)
t += 1
return eval_name_dict
def alg_loss_dict(args):
loss_dict = {'ANDMask': ['total'],
'CORAL': ['class', 'coral', 'total'],
'DANN': ['class', 'dis', 'total'],
'ERM': ['class'],
'Mixup': ['class'],
'MLDG': ['total'],
'MMD': ['class', 'mmd', 'total'],
'GroupDRO': ['group'],
'RSC': ['class'],
'VREx': ['loss', 'nll', 'penalty'],
'DIFEX': ['class', 'dist', 'exp', 'align', 'total']
}
return loss_dict[args.algorithm]
def print_args(args, print_list):
s = "==========================================\n"
l = len(print_list)
for arg, content in args.__dict__.items():
if l == 0 or arg in print_list:
s += "{}:{}\n".format(arg, content)
return s
def print_environ():
print("Environment:")
print("\tPython: {}".format(sys.version.split(" ")[0]))
print("\tPyTorch: {}".format(torch.__version__))
print("\tTorchvision: {}".format(torchvision.__version__))
print("\tCUDA: {}".format(torch.version.cuda))
print("\tCUDNN: {}".format(torch.backends.cudnn.version()))
print("\tNumPy: {}".format(np.__version__))
print("\tPIL: {}".format(PIL.__version__))
class Tee:
def __init__(self, fname, mode="a"):
self.stdout = sys.stdout
self.file = open(fname, mode)
def write(self, message):
self.stdout.write(message)
self.file.write(message)
self.flush()
def flush(self):
self.stdout.flush()
self.file.flush()
def img_param_init(args):
dataset = args.dataset
if dataset == 'office':
domains = ['amazon', 'dslr', 'webcam']
elif dataset == 'office-caltech':
domains = ['amazon', 'dslr', 'webcam', 'caltech']
elif dataset == 'office-home':
domains = ['Art', 'Clipart', 'Product', 'Real_World']
elif dataset == 'dg5':
domains = ['mnist', 'mnist_m', 'svhn', 'syn', 'usps']
elif dataset == 'PACS':
domains = ['art_painting', 'cartoon', 'photo', 'sketch']
elif dataset == 'VLCS':
domains = ['Caltech101', 'LabelMe', 'SUN09', 'VOC2007']
else:
print('No such dataset exists!')
args.domains = domains
args.img_dataset = {
'office': ['amazon', 'dslr', 'webcam'],
'office-caltech': ['amazon', 'dslr', 'webcam', 'caltech'],
'office-home': ['Art', 'Clipart', 'Product', 'Real_World'],
'PACS': ['art_painting', 'cartoon', 'photo', 'sketch'],
'dg5': ['mnist', 'mnist_m', 'svhn', 'syn', 'usps'],
'VLCS': ['Caltech101', 'LabelMe', 'SUN09', 'VOC2007']
}
if dataset == 'dg5':
args.input_shape = (3, 32, 32)
args.num_classes = 10
else:
args.input_shape = (3, 224, 224)
if args.dataset == 'office-home':
args.num_classes = 65
elif args.dataset == 'office':
args.num_classes = 31
elif args.dataset == 'PACS':
args.num_classes = 7
elif args.dataset == 'VLCS':
args.num_classes = 5
return args
================================================
FILE: code/Integrated sensing and communication (LSTM and VGG 16 model for digit and image classification, will be used for sensing and communication in 6G networks)
================================================
================================================
FILE: code/README.md
================================================
# code_transfer_learning
*Some useful transfer learning and domain adaptation codes*
> It is a waste of time looking for the codes from others. So I **collect** or **reimplement** them here in a way that you can **easily** use. The following are some of the popular transfer learning (domain adaptation) methods in recent years, and I know most of them will be chosen to **compare** with your own method.
> You are welcome to contribute and suggest other methods.
**Codes here are widely used by top conferences and journals:**
- Conferences: [[NeurIPS'21](https://proceedings.neurips.cc/paper/2021/file/731b03008e834f92a03085ef47061c4a-Paper.pdf)] [[IJCAI'21](https://arxiv.org/abs/2103.03097)] [[ESEC/FSE'20](https://dl.acm.org/doi/abs/10.1145/3368089.3409696)] [[IJCNN'20](https://ieeexplore.ieee.org/abstract/document/9207556)] [[ACMMM'18](https://dl.acm.org/doi/abs/10.1145/3240508.3240512)] [[ICME'19](https://ieeexplore.ieee.org/abstract/document/8784776/)]
- Journals: [[ACM TIST](https://dl.acm.org/doi/abs/10.1145/3360309)] [[Information sciences](https://www.sciencedirect.com/science/article/pii/S0020025520308458)] [[Neurocomputing](https://www.sciencedirect.com/science/article/pii/S0925231221007025)] [[IEEE Transactions on Cognitive and Developmental Systems](https://ieeexplore.ieee.org/abstract/document/9659817)]
- If you find the codes are useful, please cite it in your research.
This document contains codes from several aspects: **tutorial**, **theory**, **traditional** methods, and **deep** methods.
Testing **dataset** can be found [here](https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md).
- - -
- [code_transfer_learning](#code_transfer_learning)
- [Notebooks](#notebooks)
- [Fine-tune](#fine-tune)
- [Deep feature extractor 提取深度网络特征用于传统方法](#deep-feature-extractor-提取深度网络特征用于传统方法)
- [Basic distance 常用的距离度量](#basic-distance-常用的距离度量)
- [Semi-supervised learning](#semi-supervised-learning)
- [Personalized federated learning](#personalized-federated-learning)
- [Useful tools 常用工具](#useful-tools-常用工具)
- [Domain generalization 领域泛化](#domain-generalization-领域泛化)
- [Traditional transfer learning methods 非深度迁移](#traditional-transfer-learning-methods--非深度迁移)
- [Deep transfer learning methods 深度迁移](#deep-transfer-learning-methods--深度迁移)
- [Applications](#applications)
- [References](#references)
## Notebooks
**There's even no need to install a library or package, which will make things worse.** I've already put everything you need into a jupyter notebook, which you can access in Google's colab or just see it in this repo [here](https://github.com/jindongwang/transferlearning/tree/master/notebooks/deep_transfer_tutorial.ipynb).
To run it instantly without any configuration, I also put it to Google's Colab: [Colab](https://colab.research.google.com/drive/1MVuk95mMg4ecGyUAIG94vedF81HtWQAr?usp=sharing)
## Fine-tune
- Fine-tune using **AlexNet** and **ResNet**
- [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/finetune_AlexNet_ResNet)
- Safe finetune 安全迁移学习
- [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/ReMoS)
- CLIP for zero-shot transfer 使用OpenAI的CLIP模型进行zero-shot迁移
- [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/clip)
## Deep feature extractor 提取深度网络特征用于传统方法
- [Deep feature extractor](https://github.com/jindongwang/transferlearning/blob/master/code/feature_extractor/readme.md)
- [Extract features using CLIP](https://github.com/jindongwang/transferlearning/tree/master/code/clip)
## Basic distance 常用的距离度量
- MMD and MK-MMD:[Python](https://github.com/jindongwang/transferlearning/blob/master/code/distance/mmd_numpy_sklearn.py) | [Pytorch](https://github.com/jindongwang/transferlearning/blob/master/code/distance/mmd_pytorch.py) | [Matlab](https://github.com/jindongwang/transferlearning/blob/master/code/distance/mmd_matlab.m)
- $A$-distance: [Python](https://github.com/jindongwang/transferlearning/tree/master/code/distance/proxy_a_distance.py)
- CORAL loss: [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/distance/coral_loss.py)
- Several metric learning algorithms: [Python](https://github.com/metric-learn/metric-learn)
- Wasserstein distance (earch mover's distance):
- Scipy built-in function: [scipy.stats.wasserstein_distance](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.wasserstein_distance.html)
- OpenCV built-in function: `cv.CalcEMD2`
- Google's implementation: [Tensorflow](https://github.com/google/wasserstein-dist)
## Semi-supervised learning
- [[USB: A unified semi-supervised learning library (TorchSSL's update)](https://github.com/microsoft/Semi-supervised-learning)]
- [[TorchSSL: a unified library for semi-supervised learning](https://github.com/TorchSSL/TorchSSL)]
## Personalized federated learning
[[PersonalizedFL: a unified library for personalized federated learning](https://github.com/microsoft/PersonalizedFL)]
## Useful tools 常用工具
- Feature visualization using t-SNE (用t-SNE进行特征可视化):[Python](https://github.com/jindongwang/transferlearning/tree/master/code/utils/feature_vis.py)
- **Gradient Reversal Layer (梯度反转层,GRL)**:[Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/utils/grl.py)
- Support all Pytorch versions! (We know that `autograd` has been changed since 1.0)
## Domain generalization 领域泛化
- **DeepDG** (Deep domain generalization toolkit) [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG)
- Including: ERM, MMD, DANN, CORAL, Mixup, RSC, GroupDRO, etc.
- **DIFEX** (Domain-Invariant Feature EXploration, TMLR-22) [88] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG)
## Traditional transfer learning methods 非深度迁移
- **SVM** (baseline) [Matlab](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/SVM.m)
- **TCA** (Transfer Component Anaysis, TNN-11) [1] [Matlab and Python](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/TCA)
- **KMM** (Kernel Mean Matching, NIPS-06) [67] [Python](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/KMM.py)
- **GFK** (Geodesic Flow Kernel, CVPR-12) [2] [Matlab and Python](https://github.com/jindongwang/transferlearning/blob/master/code/traditional/GFK)
- **DA-NBNN** (Frustratingly Easy NBNN Domain Adaptation, ICCV-13) [39] [Matlab](https://github.com/enoonIT/nbnn-nbnl/tree/master/DANBNN_demo)
- **JDA** (Joint Distribution Adaptation, ICCV-13) [3] [Matlab and Python](https://github.com/jindongwang/transferlearning/blob/master/code/traditional/JDA)
- **TJM** (Transfer Joint Matching, CVPR-14) [4] [Matlab](https://github.com/jindongwang/transferlearning/blob/master/code/traditional/MyTJM.m)
- **CORAL** (CORrelation ALignment, AAAI-15) [5] [Matlab and Python](https://github.com/jindongwang/transferlearning/blob/master/code/traditional/CORAL) | [Github](https://github.com/VisionLearningGroup/CORAL)
- **JGSA** (Joint Geometrical and Statistical Alignment, CVPR-17) [6] [Matlab(official)](https://www.uow.edu.au/~jz960/codes/JGSA-r.rar) | [Matlab(easy)](https://github.com/jindongwang/transferlearning/blob/master/code/traditional/CORA/MyJGSA.m)
- **TrAdaBoost** (ICML-07)[8] [Python](https://github.com/chenchiwei/tradaboost)
- **SA** (Subspace Alignment, ICCV-13) [11] [Matlab(official)](http://users.cecs.anu.edu.au/~basura/DA_SA/) | [Matlab](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/SA_SVM.m)
- **BDA** (Balanced Distribution Adaptation for Transfer Learning, ICDM-17) [15] [Matlab(official)](https://github.com/jindongwang/transferlearning/tree/master/code/BDA)
- **MTLF** (Metric Transfer Learning, TKDE-17) [16] [Matlab](https://github.com/xyh2016/MTLF)
- **Open Set Domain Adaptation** (ICCV-17) [19] [Matlab(official)](https://github.com/Heliot7/open-set-da)
- **TAISL** (When Unsupervised Domain Adaptation Meets Tensor Representations, ICCV-17) [21] [Matlab(official)](https://github.com/poppinace/TAISL)
- **STL** (Stratified Transfer Learning for Cross-domain Activity Recognition, PerCom-18) [22] [Matlab](https://github.com/jindongwang/activityrecognition/tree/master/code/percom18_stl)
- **LSA** (Landmarks-based kernelized subspace alignment for unsupervised domain adaptation, CVPR-15) [29] [Matlab](http://homes.esat.kuleuven.be/~raljundi/papers/LSA%20Clean%20Code.zip)
- **OTL** (Online Transfer Learning, ICML-10) [31] [Matlab(official)](http://stevenhoi.org/otl)
- **RWA** (Random Walking, arXiv, simple but powerful) [46] [Matlab](https://github.com/twanvl/rwa-da/tree/master/src)
- **MEDA** (Manifold Embedded Distribution Alignment, ACM MM-18) [47] [Matlab(Official)](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA)
- **DeepMEDA (DDAN)** (Deep version of MEDA, or DDAN) [82] [Pytorch(official)](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DeepMEDA)
- **EasyTL** (Practically Easy Transfer Learning, ICME-19) [63] [Matlab(Official)](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/EasyTL) | [Python](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/pyEasyTL)
- **SCA** (Scatter Component Analysis, TPAMI-17) [79] [Matlab](https://github.com/amber0309/SCA)
- **SOT** (Substructural Optimal Transport, arxiv-21) [84] [python](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/sot)
## Deep transfer learning methods 深度迁移
- **DaNN** (Domain Adaptive Neural Network, PRICAI-14) [41] [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DaNN)
- **DDC** (Deep Domain Confusion, arXiv-14) [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DDC_DeepCoral)
- **DeepCORAL** (Deep CORAL: Correlation Alignment for Deep Domain Adaptation) [33] [PyTorch(recommend)](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DeepCoral) | [PyTorch](https://github.com/SSARCandy/DeepCORAL) | [中文解读](https://ssarcandy.tw/2017/10/31/deep-coral/)
- **DAN/JAN** (Deep Adaptation Network/Joint Adaptation Network, ICML-15,17) [9,10] [PyTorch(Official)](https://github.com/thuml/Xlearn/tree/master/pytorch) | [Caffe(Official)](https://github.com/thuml/Xlearn) | [PyTorch(DAN)(recommend)](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DAN)
- **B-JMMD** (Balanced Joint Maximum Mean Discrepancy for Deep Transfer Learning, AA-20) [Caffe(Official)](https://github.com/mengchuangji/balanced-joint-maximum-mean-discrepancy)
- **RTN** (Unsupervised Domain Adaptation with Residual Transfer Networks, NIPS-16) [12] [Caffe](https://github.com/thuml/Xlearn)
- **ADDA** (Adversarial Discriminative Domain Adaptation, arXiv-17) [13] [Tensorflow(Official)](https://github.com/erictzeng/adda) | [Pytorch](https://github.com/corenel/pytorch-adda) | [Pytorch(another)](https://github.com/jvanvugt/pytorch-domain-adaptation/blob/master/adda.py)
- **DANN/RevGrad** (Unsupervised Domain Adaptation by Backpropagation, ICML-15) [14] [Caffe(Official)](https://github.com/ddtm/caffe/tree/grl) | [PyTorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DANN(RevGrad)) | [Pytorch(another)](https://github.com/jvanvugt/pytorch-domain-adaptation/blob/master/revgrad.py) | [Tensorflow(third party)](https://github.com/shucunt/domain_adaptation)
- **DANN** Domain-Adversarial Training of Neural Networks (JMLR-16)[17] [Python(official)](https://github.com/GRAAL-Research/domain_adversarial_neural_network) | [Tensorflow](https://github.com/jindongwang/tf-dann) | [PyTorch](https://github.com/CuthbertCai/pytorch_DANN)
- Associative Domain Adaptation (ICCV-17) [18] [Tensorflow](https://github.com/haeusser/learning_by_association)
- Deep Hashing Network for Unsupervised Domain (CVPR-17) [20] [Matlab](https://github.com/hemanthdv/da-hash)
- **CCSA** (Unified Deep Supervised Domain Adaptation and Generalization, ICCV-17) [23] [Python(Keras)](https://github.com/samotiian/CCSA)
- **MRN** (Learning Multiple Tasks with Multilinear Relationship Networks, NIPS-17) [24] [Pytorch](https://github.com/thuml/MTlearn)
- **AutoDIAL** (Automatic DomaIn Alignment Layers, ICCV-17) [25] [Caffe](https://github.com/ducksoup/autodial)
- **DSN** (Domain Separation Networks, NIPS-16) [26] [Pytorch](https://github.com/fungtion/DSN) | [Tensorflow](https://github.com/tensorflow/models/tree/master/research/domain_adaptation)
- **DRCN** (Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation, ECCV-16) [27] [Keras](https://github.com/ghif/drcn) | [Pytorch](https://github.com/fungtion/DRCN)
- Multi-task Autoencoders for Domain Generalization (ICCV-15) [28] [Keras](https://github.com/ghif/mtae)
- Encoder based lifelong learning (ICCV-17) [30] [Matlab](https://github.com/rahafaljundi/Encoder-Based-Lifelong-learning)
- **MECA** (Minimal-Entropy Correlation Alignment, ICLR-18) [32] [Python](https://github.com/pmorerio/minimal-entropy-correlation-alignment)
- **WAE** (Wasserstein Auto-Encoders, ICLR-18) [34] [Python(Tensorflow)](https://github.com/tolstikhin/wae)
- **ATDA** (Asymmetric Tri-training for Unsupervised Domain Adaptation, ICML-15) [35] [Pytorch](https://github.com/corenel/pytorch-atda#pytorch-atda)
- **PixelDA_GAN** (Unsupervised pixel-level domain adaptation with GAN, CVPR-17) [36] [Pytorch](https://github.com/vaibhavnaagar/pixelDA_GAN)
- **ARDA** (Adversarial Representation Learning for Domain Adaptation) [37] [Pytorch](https://github.com/corenel/pytorch-arda)
- **DiscoGAN** (Learning to Discover Cross-Domain Relations with Generative Adversarial Networks) [38] [Pytorch](https://github.com/carpedm20/DiscoGAN-pytorch)
- **MCD** (Maximum Classifier Discrepancy, CVPR-18) [42] [Pytorch(official)](https://github.com/mil-tokyo/MCD_DA)
- Adversarial Feature Augmentation for Unsupervised Domain Adaptation (CVPR-18) [43] [Tensorflow](https://github.com/ricvolpi/adversarial-feature-augmentation)
- **DML** (Deep Mutual Learning, CVPR-18) [44] [Tensorflow](https://github.com/YingZhangDUT/Deep-Mutual-Learning)
- Self-ensembling for visual domain adaptation (ICLR 2018) [45] [Pytorch](https://github.com/Britefury/self-ensemble-visual-domain-adapt)
- **iCAN** (Incremental Collaborative and Adversarial Network for Unsupervised Domain Adaptation, CVPR-18) [49] [Pytorch](https://github.com/mahfuj9346449/iCAN)
- **WeightedGAN** (Importance Weighted Adversarial Nets for Partial Domain Adaptation, CVPR-18) [50] [Caffe](https://github.com/hellojing89/weightedGANpartialDA)
- **OpenSet** (Open Set Domain Adaptation by Backpropagation) [51] [Tensorflow](https://github.com/Mid-Push/Open_set_domain_adaptation)
- **WDGRL** (Wasserstein Distance Guided Representation Learning, AAAI-18) [52] [Pytorch](https://github.com/jvanvugt/pytorch-domain-adaptation/blob/master/wdgrl.py)
- **JDDA** (Joint Domain Alignment and Discriminative Feature Learning) [53] [Tensorflow](https://github.com/A-bone1/JDDA)
- Multi-modal Cycle-consistent Generalized Zero-Shot Learning (ECCV-18) [54] [Tensorflow](https://github.com/rfelixmg/frwgan-eccv18)
- **MSTN** (Moving Semantic Transfer Network, ICML-18) [55] [Tensorflow](https://github.com/Mid-Push/Moving-Semantic-Transfer-Network) | [Pytorch](https://github.com/EasonApolo/mstn)
- **SAN** (Partial Transfer Learning With Selective Adversarial Networks, CVPR-18) [56] [Caffe, Pytorch](https://github.com/thuml/SAN)
- **M-ADDA** (Metric-based Adversarial Discriminative Domain Adaptation, ICML-18 workshop) [57] [Pytorch](https://github.com/IssamLaradji/M-ADDA)
- **Openset_DA** (Open Set Domain Adaptation by Backpropagation) [58] [Pytorch](https://github.com/YU1ut/openset-DA)
- **DIRT-T** (A DIRT-T Approach to Unsupervised Domain Adaptation, ICLR-18) [59] [Tensorflow](https://github.com/RuiShu/dirt-t)
- **CMD** (Central Moment Discrepancy, ICLR-17 and InfSc-19) [61], [62] [Keras(Theano)](https://github.com/wzell/cmd) | [Keras(Theano, journal extension)](https://github.com/wzell/mann)
- **OPDA_BP** (Open Set Domain Adaptation by Back-propagation, ECCV-18) [64] [Pytorch(Official)](https://github.com/ksaito-ut/OPDA_BP)
- **TCP** (Transfer Channel Prunning, IJCNN-19) [65] [Pytorch(Official)](https://github.com/jindongwang/transferlearning/tree/master/code/deep/TCP)
- **MTAN** (Multi-Task Attention Network, CVPR-19) [66] [Python](https://github.com/lorenmt/mtan)
- **L2T_ww** (Learning What and Where to Transfer, ICML-19) [68] [Pytorch](https://github.com/alinlab/L2T-ww)
- **SSDA_MME** (Semi-supervised Domain Adaptation via Minimax Entropy, ICCV-19) [71] [Pytorch](https://github.com/VisionLearningGroup/SSDA_MME)
- **MRAN** (Multi-representation adaptation network for cross-domain image classification, Neural Networks 2019) [72] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/MRAN)
- **TA3N** (Temporal Attentive Alignment for Large-Scale Video Domain Adaptation, ICCV-19) [73] [Pytorch](https://github.com/cmhungsteve/TA3N)
- **MDAN** (Multiple Source Domain Adaptation with Adversarial Learning, NeurIPS-18) [74] [Pytorch](https://github.com/KeiraZhao/MDAN)
- Deep model transferribility from attribution maps (NeurIPS-19) [75] [Tensorflow](https://github.com/DeepDarkFantasy20/TransferbilityFromAttributionMaps)
- **DIVA** (Domain Invariant Variational Autoencoders, arXiv-19) [76] [Pytorch](https://github.com/AMLab-Amsterdam/DIVA)
- **CDCL** (Cross-Domain Complementary Learning with Synthetic Data for Multi-Person Part Segmentation, arXiv, ICCV-19 Demo) [77] [Tensorflow](https://github.com/kevinlin311tw/CDCL-human-part-segmentation)
- **DTA** (Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation, arXiv, ICCV-19) [78] [PyTorch](https://github.com/postBG/DTA.pytorch)
- **DAAN** (Dynamic Adversarial Adaptation Network, ICDM 2019) [80] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DAAN)
- **DAEL** (Domain Adaptive Ensemble Learning, ArXiv 2020) [81] [Pytorch](https://github.com/KaiyangZhou/Dassl.pytorch)
- **DSAN** (Deep Subdomain Adaptation Network for Image Classification, DSAN 2020) [82] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DSAN)
- **CSG** (Learning Causal Semantic Representation for Out-of-Distribution Prediction) [87] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/deep/CSG)
## Applications
- **PTUPCDR** Personalized Transfer of User Preferences for Cross-domain Recommendation (WSDM-22) [86] [Pytorch](https://github.com/easezyc/WSDM2022-PTUPCDR)
- Learning to select data for transfer learning with Bayesian Optimization (EMNLP-17) [69] [Python](https://github.com/sebastianruder/learn-to-select-data)
- **SDG4DA** (Reinforced Training Data Selection for Domain Adaptation, ACL-19) [70] [Tensorflow](https://github.com/timerstime/SDG4DA)
- **CMatch** (Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching, arXiv-21) [83] [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/ASR/CMatch)
- **Adapter** for speech recognition (Adapter-based Cross-lingual ASR with EasyEspnet) [Pytorch](https://github.com/jindongwang/transferlearning/tree/master/code/ASR/Adapter) [85]
- - -
#### References
[1] Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis[J]TNN, 2011, 22(2): 199-210.
[2] Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//CVPR, 2012: 2066-2073.
[3] Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation[C]//ICCV. 2013: 2200-2207.
[4] Long M, Wang J, Ding G, et al. Transfer joint matching for unsupervised domain adaptation[C]//CVPR. 2014: 1410-1417.
[5] Sun B, Feng J, Saenko K. Return of Frustratingly Easy Domain Adaptation[C]//AAAI. 2016, 6(7): 8.
[6] Zhang J, Li W, Ogunbona P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation[C]//CVPR 2017.
[8] Dai W, Yang Q, Xue G R, et al. Boosting for transfer learning[C]//ICML, 2007: 193-200.
[9] Long M, Cao Y, Wang J, et al. Learning transferable features with deep adaptation networks[C]//ICML. 2015: 97-105.
[10] Long M, Wang J, Jordan M I. Deep transfer learning with joint adaptation networks[J]//ICML 2017.
[11] Fernando B, Habrard A, Sebban M, et al. Unsupervised visual domain adaptation using subspace alignment[C]//ICCV. 2013: 2960-2967.
[12] Long M, Zhu H, Wang J, et al. Unsupervised domain adaptation with residual transfer networks[C]//NIPS. 2016.
[13] Tzeng E, Hoffman J, Saenko K, et al. Adversarial discriminative domain adaptation[J]. arXiv preprint arXiv:1702.05464, 2017.
[14] Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation[C]//International Conference on Machine Learning. 2015: 1180-1189.
[15] Jindong Wang, Yiqiang Chen, Shuji Hao, Wenjie Feng, and Zhiqi Shen. Balanced Distribution Adaptation for Transfer Learning. ICDM 2017.
[16] Y. Xu et al., "A Unified Framework for Metric Transfer Learning," in IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 6, pp. 1158-1171, June 1 2017. doi: 10.1109/TKDE.2017.2669193
[17] Ganin Y, Ustinova E, Ajakan H, et al. Domain-adversarial training of neural networks[J]. Journal of Machine Learning Research, 2016, 17(59): 1-35.
[18] Haeusser P, Frerix T, Mordvintsev A, et al. Associative Domain Adaptation[C]. ICCV, 2017.
[19] Pau Panareda Busto, Juergen Gall. Open set domain adaptation. ICCV 2017.
[20] Venkateswara H, Eusebio J, Chakraborty S, et al. Deep hashing network for unsupervised domain adaptation[C]. CVPR 2017.
[21] H. Lu, L. Zhang, et al. When Unsupervised Domain Adaptation Meets Tensor Representations. ICCV 2017.
[22] J. Wang, Y. Chen, L. Hu, X. Peng, and P. Yu. Stratified Transfer Learning for Cross-domain Activity Recognition. 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom).
[23] Motiian S, Piccirilli M, Adjeroh D A, et al. Unified deep supervised domain adaptation and generalization[C]//The IEEE International Conference on Computer Vision (ICCV). 2017, 2.
[24] Long M, Cao Z, Wang J, et al. Learning Multiple Tasks with Multilinear Relationship Networks[C]//Advances in Neural Information Processing Systems. 2017: 1593-1602.
[25] Maria Carlucci F, Porzi L, Caputo B, et al. AutoDIAL: Automatic DomaIn Alignment Layers[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 5067-5075.
[26] Bousmalis K, Trigeorgis G, Silberman N, et al. Domain separation networks[C]//Advances in Neural Information Processing Systems. 2016: 343-351.
[27] M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, and W. Li. "Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation (DRCN)", European Conference on Computer Vision (ECCV), 2016
[28] M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi.
Domain Generalization for Object Recognition with Multi-task Autoencoders,
accepted in International Conference on Computer Vision (ICCV 2015), Santiago, Chile.
[29] Aljundi R, Emonet R, Muselet D, et al. Landmarks-based kernelized subspace alignment for unsupervised domain adaptation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 56-63.
[30] Rannen A, Aljundi R, Blaschko M B, et al. Encoder based lifelong learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1320-1328.
[31] Peilin Zhao and Steven C.H. Hoi. OTL: A Framework of Online Transfer Learning. ICML 2010.
[32] Pietro Morerio, Jacopo Cavazza, Vittorio Murino. Minimal-Entropy Correlation Alignment for Unsupervised Deep Domain Adaptation. ICLR 2018.
[33] Sun B, Saenko K. Deep coral: Correlation alignment for deep domain adaptation[C]//European Conference on Computer Vision. Springer, Cham, 2016: 443-450.
[34] Tolstikhin I, Bousquet O, Gelly S, et al. Wasserstein Auto-Encoders[J]. arXiv preprint arXiv:1711.01558, 2017.
[35] Saito K, Ushiku Y, Harada T. Asymmetric tri-training for unsupervised domain adaptation[J]. arXiv preprint arXiv:1702.08400, 2017.
[36] Bousmalis K, Silberman N, Dohan D, et al. Unsupervised pixel-level domain adaptation with generative adversarial networks[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1(2): 7.
[37] Shen J, Qu Y, Zhang W, et al. Adversarial representation learning for domain adaptation[J]. arXiv preprint arXiv:1707.01217, 2017.
[38] Kim T, Cha M, Kim H, et al. Learning to discover cross-domain relations with generative adversarial networks[J]. arXiv preprint arXiv:1703.05192, 2017.
[39] Tommasi T, Caputo B. Frustratingly Easy NBNN Domain Adaptation[C]. international conference on computer vision, 2013: 897-904.
[40] Pei Z, Cao Z, Long M, et al. Multi-Adversarial Domain Adaptation[C] // AAAI 2018.
[41] Ghifary M, Kleijn W B, Zhang M. Domain adaptive neural networks for object recognition[C]//Pacific Rim International Conference on Artificial Intelligence. Springer, Cham, 2014: 898-904.
[42] Saito K, Watanabe K, Ushiku Y, et al. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation[J]. arXiv preprint arXiv:1712.02560, 2017.
[43] Volpi R, Morerio P, Savarese S, et al. Adversarial Feature Augmentation for Unsupervised Domain Adaptation[J]. arXiv preprint arXiv:1711.08561, 2017.
[44] Zhang Y, Xiang T, Hospedales T M, et al. Deep Mutual Learning[C]. CVPR 2018.
[45] French G, Mackiewicz M, Fisher M. Self-ensembling for visual domain adaptation[C]//International Conference on Learning Representations. 2018.
[46] van Laarhoven T, Marchiori E. Unsupervised Domain Adaptation with Random Walks on Target Labelings[J]. arXiv preprint arXiv:1706.05335, 2017.
[47] Jindong Wang, Wenjie Feng, Yiqiang Chen, Han Yu, Meiyu Huang, Philip S. Yu. Visual Domain Adaptation with Manifold Embedded Distribution Alignment. ACM Multimedia conference 2018.
[48] Zhangjie Cao, Mingsheng Long, et al. Partial Adversarial Domain Adaptation. ECCV 2018.
[49] Zhang W, Ouyang W, Li W, et al. Collaborative and Adversarial Network for Unsupervised domain adaptation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3801-3809.
[50] Zhang J, Ding Z, Li W, et al. Importance Weighted Adversarial Nets for Partial Domain Adaptation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8156-8164.
[51] Saito K, Yamamoto S, Ushiku Y, et al. Open Set Domain Adaptation by Backpropagation[J]. arXiv preprint arXiv:1804.10427, 2018.
[52] Shen J, Qu Y, Zhang W, et al. Wasserstein Distance Guided Representation Learning for Domain Adaptation[C]//AAAI. 2018.
[53] Chen C, Chen Z, Jiang B, et al. Joint Domain Alignment and Discriminative Feature Learning for Unsupervised Deep Domain Adaptation[J]. arXiv preprint arXiv:1808.09347, 2018.
[54] Felix R, Vijay Kumar B G, Reid I, et al. Multi-modal Cycle-consistent Generalized Zero-Shot Learning. ECCV 2018.
[55] Xie S, Zheng Z, Chen L, et al. Learning Semantic Representations for Unsupervised Domain Adaptation[C]//International Conference on Machine Learning. 2018: 5419-5428.
[56] Cao Z, Long M, Wang J, et al. Partial transfer learning with selective adversarial networks. CVPR 2018.
[57] Issam Laradji, Reza Babanezhad. M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning. ICML 2018 workshop.
[58] Saito K, Yamamoto S, Ushiku Y, et al. Open Set Domain Adaptation by Backpropagation[J]. arXiv preprint arXiv:1804.10427, 2018.
[59] Shu R, Bui H H, Narui H, et al. A DIRT-T Approach to Unsupervised Domain Adaptation[J]. arXiv preprint arXiv:1802.08735, 2018.
[60] Mingsheng Long, et al. Conditional Adversarial Domain Adaptation. NeurIPS 2018.
[61] W.Zellinger, T. Grubinger, E. Lughofer, T. Natschlaeger, and Susanne Saminger-Platz, "Central moment discrepancy (cmd) for domain-invariant representation learning," ICLR 2017.
[62] W. Zellinger, B.A. Moser, T. Grubinger, E. Lughofer, T. Natschlaeger, and S. Saminger-Platz, "Robust unsupervised domain adaptation for neural networks via moment alignment," Information Sciences (in press), 2019, https://doi.org/10.1016/j.ins.2019.01.025, arXiv preprint arxiv:1711.06114
[63] Jindong Wang, Yiqiang Chen, Han Yu, Meiyu Huang, Qiang Yang. Easy Transfer Learning By Exploiting Intra-domain Structures. IEEE International Conference on Multimedia & Expo (ICME) 2019.
[64] Saito K, Yamamoto S, Ushiku Y, et al. Open set domain adaptation by backpropagation[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 153-168.
[65] Chaohui Yu, Jindong Wang, Yiqiang Chen, Zijing Wu. Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning. IJCNN 2019.
[66] Shikun Liu, Edward Johns, and Andrew Davison. End-to-End Multi-Task Learning with Attention. CVPR 2019.
[67] Huang J, Gretton A, Borgwardt K, et al. Correcting sample selection bias by unlabeled data[C]//Advances in neural information processing systems. 2007: 601-608.
[68] Yunhun Jang, Hankook Lee, Sung Ju Hwang, Jinwoo Shin. Learning what and where to transfer. ICML 2019.
[69] Sebastian Ruder, Barbara Plank (2017). Learning to select data for transfer learning with Bayesian Optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark.
[70] Liu M, Song Y, Zou H, et al. Reinforced Training Data Selection for Domain Adaptation[C]//Proceedings of the 57th Conference of the Association for Computational Linguistics. 2019: 1957-1968.
[71] Saito K, Kim D, Sclaroff S, et al. Semi-supervised Domain Adaptation via Minimax Entropy. ICCV 2019.
[72] Zhu Y, Zhuang F, Wang J, et al. Multi-representation adaptation network for cross-domain image classification[J]. Neural Networks, 2019.
[73] Min-Hung Chen, Zsolt Kira, Ghassan AlRegib, et al. Temporal Attentive Alignment for Large-Scale Video Domain Adaptation. ICCV 2019.
[74] Zhao H, Zhang S, Wu G, et al. Multiple source domain adaptation with adversarial learning. NeurIPS 2018.
[75] Jie Song, et al. Deep model transferrability from attirbution maps. NeurIPS 2019.
[76] Ilse, M., Tomczak, J. M., C. Louizos & Welling, M. (2018). DIVA: Domain Invariant Variational Autoencoders. arXiv preprint arXiv:1905.10427
[77] Lin K., et al. Cross-Domain Complementary Learning with Synthetic Data for Multi-Person Part Segmentation[J]. arXiv preprint arXiv:1907.05193, ICCV demo, 2019.
[78] Lee S., Kim D., et al. Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation. ICCV 2019.
[79] Ghifary M, Balduzzi D, Kleijn W B, et al. Scatter component analysis: A unified framework for domain adaptation and domain generalization[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 39(7): 1414-1430.
[80] Chaohui Yu, Jindong Wang, Yiqiang Chen, Meihu Huang. Transfer learnign with dynamic adversarial adaptation network. ICDM 2019.
[81] Kaiyang Zhou, Yongxin Yang, Yu Qiao, Tao Xiang. Domain Adaptive Ensemble Learning. ArXiv preprint, 2020.
[82] Wang J, Chen Y, Feng W, et al. Transfer learning with dynamic distribution adaptation[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2020, 11(1): 1-25.
[83] Wenxin Hou, Jindong Wang, Xu Tan, Tao Qin, Takahiro Shinozaki, "Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching", arxiv 2104.07491.
[84] Lu W, Chen Y, Wang J, et al. Cross-domain Activity Recognition via Substructural Optimal Transport[J]. arXiv preprint arXiv:2102.03353, 2021.
[85] Hou W, Zhu H, Wang Y, et al. Exploiting Adapters for Cross-lingual Low-resource Speech Recognition[J]. arXiv preprint arXiv:2105.11905, 2021.
[86] Yongchun Zhu, ZhenWei Tang, Yudan Liu, et al. Personalized Transfer of User Preferences for Cross-domain Recommendation[C]. WSDM, 2022.
[87] Chang Liu, Xinwei Sun, Jindong Wang, et al. Learning Causal Semantic Representation for Out-of-Distribution Prediction. NeurIPS 2021.
[88] Lu et al. Domain-invariant feature exploration for domain generalization. TMLR 2022.
================================================
FILE: code/clip/README.md
================================================
# CLIP for transfer learning datasets
This demo shows you how to use OpenAI's [CLIP](https://openai.com/blog/clip/) model to perform *zero-shot* inference on existing transfer learning datasets.
## Requirements
First, make sure you have pytorch, torchvision, and CUDA installed. Then, install CLIP by the following commands:
```
$ pip install ftfy regex tqdm
$ pip install git+https://github.com/openai/CLIP.git
```
Then, you can install requirements by `pip install -r requirements.txt`.
## Usage
### Download data
At Microsoft, you can refer to `data/download_data_azcopy.py` to directly download the data you want from Azure blob. Super fast.
If you are outside Microsoft, you can use `data/download_data.py` to download datasets.
### How CLIP works
Before we start, we recommend that you understand the basics of CLIP. In a nutshell, CLIP is a large multi-muldality model trained by **text-image** pairs. Thus, CLIP model should take as inputs **both** a text and an image.
Thus, if you want to classify an image, you should also pass the associated text to the model, e.g., a cat image and a text like "a photo of a cat".
That brings us the second difference of CLIP: it performs classification based on image-text similarity, rather than traditional linear layers for classification. So if you want to classify a cat image, you should pass at least two texts: "a photo of cat" and "a photo of dog".
Then, CLIP will compute the similarity between that image and the texts of cat and dog, then it returns the similarity score to both texts. Of course it will compute higher similarity score for cat text, which will finally classifiy the image as a cat.
### How to use this demo
The main file is `main.py`, which takes the following arguments:
- `model`, indicating which CLIP backbone (pre-trained) model you use.
- `dataset`, indicating which dataset you use.
- `gpu`, indicating which gpu you use.
- `mode`, which mode: 'zs' for zero-shot inference, 'ze' for feature extraction, and 'ft' for finetuning.
- `root`, the root folder for your datasets.
- `batchsize`, batchsize for training.
Other args can be set at will.
After downloading your datasets (read [here](https://github.com/jindongwang/transferlearning/tree/master/data)), you can run the script in the following style:
```
# run clip using ResNet-50 (model=0) as backbone on Art domain of Office-Home dataset (dataset=0)
python main.py --model 0 --dataset 0 --batchsize 512
```
Currently, this demo supports the following datasets: Office-Home, Office-31, PACS, VLCS, and ImageNet-R.
More datasets can be easily added according to your preference.
## Results
Again, note that the results are *zero-shot* by CLIP, which means, no domain adaptation, no fine-tuning, and no domain generalization, just simply run CLIP pre-trained models on the test domain to gather the results.
We also support finetune and domain-adaptation of CLIP but we did not run all results due to time limit.
### Office-Home
| backbone | Art | Clipart | Product | RealWorld | avg |
|----------------|--------|---------|---------|-----------|--------|
| RN50 | 0.7268 | 0.5123 | 0.8238 | 0.8272 | 0.7225 |
| RN101 | 0.7684 | 0.5503 | 0.8468 | 0.8439 | 0.7524 |
| RN50x4 | 0.7956 | 0.5869 | 0.8723 | 0.8722 | 0.7818 |
| RN50x16 | 0.8220 | 0.6424 | 0.9018 | 0.8981 | 0.8161 |
| RN50x64 | 0.8686 | 0.7058 | 0.9315 | 0.9208 | 0.8567 |
| ViT-B-32 | 0.7804 | 0.6410 | 0.8756 | 0.8765 | 0.7934 |
| ViT-B-16 | 0.8278 | 0.6667 | 0.8950 | 0.8990 | 0.8221 |
| ViT-L-14 | 0.8669 | 0.7290 | 0.9299 | 0.9300 | 0.8640 |
| ViT-L-14@336px | 0.8838 | 0.7427 | 0.9399 | 0.9364 | 0.8757 |
### Office-31
| backbone | amazon | webcam | dslr | avg |
|----------------|--------|--------|--------|--------|
| RN50 | 0.7249 | 0.6566 | 0.7430 | 0.6908 |
| RN101 | 0.7391 | 0.7585 | 0.7610 | 0.7488 |
| RN50x4 | 0.7636 | 0.8038 | 0.7912 | 0.7837 |
| RN50x16 | 0.7508 | 0.8340 | 0.8153 | 0.7924 |
| RN50x64 | 0.8204 | 0.8943 | 0.8454 | 0.8574 |
| ViT-B-32 | 0.7767 | 0.8101 | 0.8112 | 0.7934 |
| ViT-B-16 | 0.7969 | 0.8038 | 0.7972 | 0.8004 |
| ViT-L-14 | 0.8161 | 0.8352 | 0.8675 | 0.8257 |
| ViT-L-14@336px | 0.8229 | 0.8151 | 0.8394 | 0.8190 |
### PACS
| backbone | A | C | P | S | avg |
|----------------|--------|--------|--------|--------|--------|
| RN50 | 0.9229 | 0.9518 | 0.9946 | 0.8045 | 0.9184 |
| RN101 | 0.9463 | 0.9761 | 0.9946 | 0.8801 | 0.9493 |
| RN50x4 | 0.9336 | 0.9765 | 0.9647 | 0.8246 | 0.9249 |
| RN50x16 | 0.9507 | 0.9846 | 0.9976 | 0.8979 | 0.9577 |
| RN50x64 | 0.9648 | 0.9825 | 1.0000 | 0.9147 | 0.9655 |
| ViT-B-32 | 0.9585 | 0.9765 | 0.9970 | 0.8547 | 0.9467 |
| ViT-B-16 | 0.9746 | 0.9910 | 0.9994 | 0.8880 | 0.9633 |
| ViT-L-14 | 0.9883 | 0.9902 | 0.9994 | 0.9478 | 0.9814 |
| ViT-L-14@336px | 0.9888 | 0.9915 | 0.9994 | 0.9552 | 0.9837 |
### VLCS
| backbone | C | L | S | V | avg |
|----------------|--------|--------|--------|--------|--------|
| RN50 | 0.9894 | 0.6849 | 0.7182 | 0.8400 | 0.8081 |
| RN101 | 0.9972 | 0.5693 | 0.6584 | 0.7275 | 0.7381 |
| RN50x4 | 0.9640 | 0.6160 | 0.7072 | 0.7029 | 0.7475 |
| RN50x16 | 0.9965 | 0.5606 | 0.7157 | 0.7764 | 0.7623 |
| RN50x64 | 0.9993 | 0.5222 | 0.6840 | 0.8433 | 0.7622 |
| ViT-B_32 | 0.9993 | 0.6702 | 0.7154 | 0.8477 | 0.8082 |
| ViT-B_16 | 0.9993 | 0.6766 | 0.7508 | 0.8288 | 0.8139 |
| ViT-L_14 | 0.9993 | 0.6950 | 0.7035 | 0.8243 | 0.8055 |
| ViT-L_14@336px | 0.9993 | 0.6453 | 0.7179 | 0.8409 | 0.8009 |
### DomainNet
| backbone | Clipart | Infograph | Painting | Quickdraw | Real | Sketch | avg |
|----------------|---------|-----------|----------|-----------|--------|--------|--------|
| RN50 | 0.5158 | 0.3920 | 0.5281 | 0.0627 | 0.7688 | 0.4886 | 0.4593 |
| RN101 | 0.5981 | 0.4070 | 0.5676 | 0.1030 | 0.7935 | 0.5417 | 0.5018 |
| RN50x4 | 0.6335 | 0.461 | 0.6131 | 0.1001 | 0.8115 | 0.5799 | 0.5332 |
| RN50x16 | 0.6876 | 0.4715 | 0.6351 | 0.1266 | 0.8232 | 0.6301 | 0.5624 |
| RN50x64 | 0.7328 | 0.5024 | 0.6763 | 0.1626 | 0.8463 | 0.6749 | 0.5992 |
| ViT-B-32 | 0.6703 | 0.3992 | 0.6239 | 0.1318 | 0.8054 | 0.5853 | 0.5360 |
| ViT-B-16 | 0.7091 | 0.4679 | 0.6599 | 0.1442 | 0.8315 | 0.6343 | 0.5745 |
| ViT-L-14 | 0.7795 | 0.4958 | 0.6913 | 0.2247 | 0.8599 | 0.7023 | 0.6256 |
| ViT-L-14@336px | 0.7860 | 0.5226 | 0.7078 | 0.2231 | 0.8662 | 0.7163 | 0.6370 |
### TerraInc
| backbone | L38 | L43 | L46 | L100 | avg |
|----------------|--------|--------|--------|--------|--------|
| RN50 | 0.1361 | 0.3297 | 0.2169 | 0.0884 | 0.1928 |
| RN101 | 0.4197 | 0.3748 | 0.2674 | 0.2474 | 0.3273 |
| RN50x4 | 0.2626 | 0.3567 | 0.2438 | 0.3164 | 0.2949 |
| RN50x16 | 0.3532 | 0.4715 | 0.3427 | 0.3626 | 0.3825 |
| RN50x64 | 0.4083 | 0.4990 | 0.3672 | 0.5817 | 0.4641 |
| ViT-B-32 | 0.1339 | 0.3071 | 0.1844 | 0.1346 | 0.1900 |
| ViT-B-16 | 0.1958 | 0.3350 | 0.3165 | 0.5117 | 0.3398 |
| ViT-L-14 | 0.4008 | 0.4597 | 0.3760 | 0.5182 | 0.4387 |
| ViT-L-14@336px | 0.4295 | 0.4892 | 0.4071 | 0.5100 | 0.4590 |
### VisDA-17 and ImageNet-R
| backbone | VisDA-validation | ImageNet-R |
|----------------|------------------|------------|
| RN50 | 0.8049 | 0.5622 |
| RN101 | 0.8261 | 0.6239 |
| RN50x4 | 0.8219 | 0.6695 |
| RN50x16 | 0.8439 | 0.7477 |
| RN50x64 | 0.8569 | 0.8003 |
| ViT-B-32 | 0.8424 | 0.6667 |
| ViT-B-16 | 0.8633 | 0.7360 |
| ViT-L-14 | 0.8594 | 0.8474 |
| ViT-L-14@336px | 0.8628 | 0.8604 |
### Acknowledgements
- OpenAI's CLIP code: https://github.com/openai/CLIP
- CLIP paper: Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763.
================================================
FILE: code/clip/__init__.py
================================================
import os
import sys
sys.path.append(os.getcwd())
================================================
FILE: code/clip/clip_model.py
================================================
import clip
from PIL import Image
import torch
import numpy as np
from tqdm import tqdm
import torch.nn as nn
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from utils import convert_models_to_fp32
class ClipModel(object):
CLIP_MODELS = [
'RN50',
'RN101',
'RN50x4',
'RN50x16',
'RN50x64',
'ViT-B/32',
'ViT-B/16',
'ViT-L/14',
'ViT-L/14@336px'
]
def __init__(self, model_name='Vit-B/32', device='cuda', logger=None):
self.device = device
self.logger = logger
if type(model_name) is int:
model_name = self.index_to_model(model_name)
self.model, self.preprocess = clip.load(
model_name, device=device, jit=False)
self.model.eval()
self.model.to(device)
self.model_name = model_name
def index_to_model(self, index):
return self.CLIP_MODELS[index]
@staticmethod
def get_model_name_by_index(index):
name = ClipModel.CLIP_MODELS[index]
name = name.replace('/', '_')
return name
def get_image_features(self, image, need_preprocess=False):
if need_preprocess:
image = self.preprocess(image).unsqueeze(0).to(self.device)
with torch.no_grad():
image_features = self.model.encode_image(image)
return image_features
def get_text_feature(self, text):
text = clip.tokenize(text).to(self.device)
with torch.no_grad():
text_features = self.model.encode_text(text)
return text_features
def get_text_features_list(self, texts, train=False):
if train:
text_inputs = torch.cat([clip.tokenize(c)
for c in texts]).to(self.device)
text_features = self.model.encode_text(text_inputs)
else:
with torch.no_grad():
text_inputs = torch.cat([clip.tokenize(c)
for c in texts]).to(self.device)
text_features = self.model.encode_text(text_inputs)
return text_features
def get_similarity(self, image_features, text_features):
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
return similarity
def get_topk(self, image, text, k=1):
similarity = self.get_similarity(image, text)
values, indices = similarity[0].topk(k)
return values, indices
def feature_extraction(self, dataloader):
res = None
for batch in tqdm(dataloader):
image, _, label = batch
image = image.to(self.device)
label = label.to(self.device)
image_features = self.get_image_features(image)
feat_lab = torch.cat(
[image_features, label.view(-1, 1)], dim=1)
if res is None:
res = torch.zeros((1, feat_lab.shape[1])).to(self.device)
res = torch.cat([res, feat_lab], dim=0)
res = res[1:, :].cpu().numpy()
return res
def finetune(self, dataloader, testloader, optimizer, nepochs=10, save_path=None):
loss_img = nn.CrossEntropyLoss()
loss_txt = nn.CrossEntropyLoss()
best_acc = 0
for epoch in range(nepochs):
total_loss = 0
for batch in tqdm(dataloader):
optimizer.zero_grad()
image, text, _ = batch
image = image.to(self.device)
text = text.to(self.device)
logits_per_image, logits_per_text = self.model(image, text)
ground_truth = torch.arange(
len(image), dtype=torch.long, device=self.device)
loss = (loss_img(logits_per_image, ground_truth) +
loss_txt(logits_per_text, ground_truth))/2
loss.backward()
total_loss += loss.item()
if self.device == "cpu":
optimizer.step()
else:
convert_models_to_fp32(self.model)
optimizer.step()
clip.model.convert_weights(self.model)
eval_acc, _ = self.evaluate(testloader)
if eval_acc > best_acc:
best_acc = eval_acc
if save_path is not None:
torch.save(self.model.state_dict(), save_path)
self.logger.info("Epoch {} : Loss {}, Acc {:.4f}".format(
epoch, total_loss/len(dataloader), eval_acc))
return best_acc
def evaluate(self, dataloader, modelpath=None):
if modelpath is not None:
self.model.load_state_dict(torch.load(modelpath))
texts = dataloader.dataset.labels
text_features = self.get_text_features_list(texts)
res = None
for batch in tqdm(dataloader):
image, _, label = batch
image = image.to(self.device)
label = label.to(self.device)
image_features = self.get_image_features(image)
similarity = self.get_similarity(image_features, text_features)
_, indices = similarity.topk(1)
pred = torch.squeeze(indices)
result = torch.cat([pred.view(-1, 1), label.view(-1, 1)], dim=1)
if res is None:
res = result
else:
res = torch.cat([res, result], dim=0)
res = res.cpu().numpy()
acc = np.mean(np.array(res)[:, 0] == np.array(res)[:, 1])
return acc, res
if __name__ == '__main__':
print(ClipModel.CLIP_MODELS)
model_name = 'ViT-B/32'
model_name = 5
device = 'cuda'
clip_inference = CLIP_INFERENCE(model_name, device) # type: ignore
print(clip_inference.model_name)
image = Image.open('../test.jpg')
text = 'a picture of a cat'
print(clip_inference.inference(image, text)) # type: ignore
dataset = datasets.ImageFolder(
root='../dataset/office31/amazon',
transform=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711]
),
])
)
labels = dataset.classes
res, acc = clip_inference.classification(dataset, labels)
print(res)
print(acc)
================================================
FILE: code/clip/data/data_loader.py
================================================
import torchvision.datasets as datasets
from torchvision import transforms
import os
import clip
from PIL import ImageFile, Image
ImageFile.LOAD_TRUNCATED_IMAGES = True
class ImageTextData(object):
def __init__(self, dataset, root, preprocess, prompt='a picture of a'):
if type(dataset) is int:
dataset = self._DATA_FOLDER[dataset]
dataset = os.path.join(root, dataset)
if dataset == 'imagenet-r':
data = datasets.ImageFolder(
'imagenet-r', transform=self._TRANSFORM)
labels = open('imagenetr_labels.txt').read().splitlines()
labels = [x.split(',')[1].strip() for x in labels]
else:
data = datasets.ImageFolder(dataset, transform=self._TRANSFORM)
labels = data.classes
self.data = data
self.labels = labels
if prompt:
self.labels = [prompt + ' ' + x for x in self.labels]
self.preprocess = preprocess
self.text = clip.tokenize(self.labels)
def __getitem__(self, index):
image, label = self.data.imgs[index]
if self.preprocess is not None:
image = self.preprocess(Image.open(image))
text_enc = self.text[label]
return image, text_enc, label
def __len__(self):
return len(self.data)
@staticmethod
def get_data_name_by_index(index):
name = ImageTextData._DATA_FOLDER[index]
name = name.replace('/', '_')
return name
_DATA_FOLDER = [
'dataset/OfficeHome/Art',
'dataset/OfficeHome/Clipart',
'dataset/OfficeHome/Product',
'dataset/OfficeHome/RealWorld',
'dataset/office31/amazon', # 4
'dataset/office31/webcam',
'dataset/office31/dslr',
'dataset/VLCS/Caltech101', # 7
'dataset/VLCS/LabelMe',
'dataset/VLCS/SUN09',
'dataset/VLCS/VOC2007',
'dataset/PACS/kfold/art_painting', # 11
'dataset/PACS/kfold/cartoon',
'dataset/PACS/kfold/photo',
'dataset/PACS/kfold/sketch',
'dataset/visda/validation', # 15
'dataset/domainnet/clipart', # 16
'dataset/domainnet/infograph',
'dataset/domainnet/painting',
'dataset/domainnet/quickdraw',
'dataset/domainnet/real',
'dataset/domainnet/sketch',
'dataset/terra_incognita/location_38', # 22
'dataset/terra_incognita/location_43',
'dataset/terra_incognita/location_46',
'dataset/terra_incognita/location_100',
'imagenet-r',
]
_TRANSFORM = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
if __name__ == '__main__':
print(ImageTextData.get_data_name_by_index(0))
================================================
FILE: code/clip/data/download_data.py
================================================
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
from torchvision.datasets import MNIST
import xml.etree.ElementTree as ET
from zipfile import ZipFile
import argparse
import tarfile
import shutil
import gdown
import uuid
import json
import os
from wilds.datasets.camelyon17_dataset import Camelyon17Dataset
from wilds.datasets.fmow_dataset import FMoWDataset
# utils #######################################################################
def stage_path(data_dir, name):
full_path = os.path.join(data_dir, name)
if not os.path.exists(full_path):
os.makedirs(full_path)
return full_path
def download_and_extract(url, dst, remove=True):
gdown.download(url, dst, quiet=False)
if dst.endswith(".tar.gz"):
tar = tarfile.open(dst, "r:gz")
tar.extractall(os.path.dirname(dst))
tar.close()
if dst.endswith(".tar"):
tar = tarfile.open(dst, "r:")
tar.extractall(os.path.dirname(dst))
tar.close()
if dst.endswith(".zip"):
zf = ZipFile(dst, "r")
zf.extractall(os.path.dirname(dst))
zf.close()
if remove:
os.remove(dst)
# VLCS ########################################################################
# Slower, but builds dataset from the original sources
#
# def download_vlcs(data_dir):
# full_path = stage_path(data_dir, "VLCS")
#
# tmp_path = os.path.join(full_path, "tmp/")
# if not os.path.exists(tmp_path):
# os.makedirs(tmp_path)
#
# with open("domainbed/misc/vlcs_files.txt", "r") as f:
# lines = f.readlines()
# files = [line.strip().split() for line in lines]
#
# download_and_extract("http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar",
# os.path.join(tmp_path, "voc2007_trainval.tar"))
#
# download_and_extract("https://drive.google.com/uc?id=1I8ydxaAQunz9R_qFFdBFtw6rFTUW9goz",
# os.path.join(tmp_path, "caltech101.tar.gz"))
#
# download_and_extract("http://groups.csail.mit.edu/vision/Hcontext/data/sun09_hcontext.tar",
# os.path.join(tmp_path, "sun09_hcontext.tar"))
#
# tar = tarfile.open(os.path.join(tmp_path, "sun09.tar"), "r:")
# tar.extractall(tmp_path)
# tar.close()
#
# for src, dst in files:
# class_folder = os.path.join(data_dir, dst)
#
# if not os.path.exists(class_folder):
# os.makedirs(class_folder)
#
# dst = os.path.join(class_folder, uuid.uuid4().hex + ".jpg")
#
# if "labelme" in src:
# # download labelme from the web
# gdown.download(src, dst, quiet=False)
# else:
# src = os.path.join(tmp_path, src)
# shutil.copyfile(src, dst)
#
# shutil.rmtree(tmp_path)
def download_vlcs(data_dir):
# Original URL: http://www.eecs.qmul.ac.uk/~dl307/project_iccv2017
full_path = stage_path(data_dir, "VLCS")
download_and_extract("https://drive.google.com/uc?id=1skwblH1_okBwxWxmRsp9_qi15hyPpxg8",
os.path.join(data_dir, "VLCS.tar.gz"))
# MNIST #######################################################################
def download_mnist(data_dir):
# Original URL: http://yann.lecun.com/exdb/mnist/
full_path = stage_path(data_dir, "MNIST")
MNIST(full_path, download=True)
# PACS ########################################################################
def download_pacs(data_dir):
# Original URL: http://www.eecs.qmul.ac.uk/~dl307/project_iccv2017
full_path = stage_path(data_dir, "PACS")
download_and_extract("https://drive.google.com/uc?id=1JFr8f805nMUelQWWmfnJR3y4_SYoN5Pd",
os.path.join(data_dir, "PACS.zip"))
os.rename(os.path.join(data_dir, "kfold"),
full_path)
# Office-Home #################################################################
def download_office_home(data_dir):
# Original URL: http://hemanthdv.org/OfficeHome-Dataset/
full_path = stage_path(data_dir, "office_home")
download_and_extract("https://drive.google.com/uc?id=1uY0pj7oFsjMxRwaD3Sxy0jgel0fsYXLC",
os.path.join(data_dir, "office_home.zip"))
os.rename(os.path.join(data_dir, "OfficeHomeDataset_10072016"),
full_path)
# DomainNET ###################################################################
def download_domain_net(data_dir):
# Original URL: http://ai.bu.edu/M3SDA/
full_path = stage_path(data_dir, "domain_net")
urls = [
"http://csr.bu.edu/ftp/visda/2019/multi-source/groundtruth/clipart.zip",
"http://csr.bu.edu/ftp/visda/2019/multi-source/infograph.zip",
"http://csr.bu.edu/ftp/visda/2019/multi-source/groundtruth/painting.zip",
"http://csr.bu.edu/ftp/visda/2019/multi-source/quickdraw.zip",
"http://csr.bu.edu/ftp/visda/2019/multi-source/real.zip",
"http://csr.bu.edu/ftp/visda/2019/multi-source/sketch.zip"
]
for url in urls:
download_and_extract(url, os.path.join(full_path, url.split("/")[-1]))
with open("domainbed/misc/domain_net_duplicates.txt", "r") as f:
for line in f.readlines():
try:
os.remove(os.path.join(full_path, line.strip()))
except OSError:
pass
# TerraIncognita ##############################################################
def download_terra_incognita(data_dir):
# Original URL: https://beerys.github.io/CaltechCameraTraps/
# New URL: http://lila.science/datasets/caltech-camera-traps
full_path = stage_path(data_dir, "terra_incognita")
download_and_extract(
"https://lilablobssc.blob.core.windows.net/caltechcameratraps/eccv_18_all_images_sm.tar.gz",
os.path.join(full_path, "terra_incognita_images.tar.gz"))
download_and_extract(
"https://lilablobssc.blob.core.windows.net/caltechcameratraps/labels/caltech_camera_traps.json.zip",
os.path.join(full_path, "caltech_camera_traps.json.zip"))
include_locations = ["38", "46", "100", "43"]
include_categories = [
"bird", "bobcat", "cat", "coyote", "dog", "empty", "opossum", "rabbit",
"raccoon", "squirrel"
]
images_folder = os.path.join(full_path, "eccv_18_all_images_sm/")
annotations_file = os.path.join(full_path, "caltech_images_20210113.json")
destination_folder = full_path
stats = {}
if not os.path.exists(destination_folder):
os.mkdir(destination_folder)
with open(annotations_file, "r") as f:
data = json.load(f)
category_dict = {}
for item in data['categories']:
category_dict[item['id']] = item['name']
for image in data['images']:
image_location = image['location']
if image_location not in include_locations:
continue
loc_folder = os.path.join(destination_folder,
'location_' + str(image_location) + '/')
if not os.path.exists(loc_folder):
os.mkdir(loc_folder)
image_id = image['id']
image_fname = image['file_name']
for annotation in data['annotations']:
if annotation['image_id'] == image_id:
if image_location not in stats:
stats[image_location] = {}
category = category_dict[annotation['category_id']]
if category not in include_categories:
continue
if category not in stats[image_location]:
stats[image_location][category] = 0
else:
stats[image_location][category] += 1
loc_cat_folder = os.path.join(loc_folder, category + '/')
if not os.path.exists(loc_cat_folder):
os.mkdir(loc_cat_folder)
dst_path = os.path.join(loc_cat_folder, image_fname)
src_path = os.path.join(images_folder, image_fname)
shutil.copyfile(src_path, dst_path)
shutil.rmtree(images_folder)
os.remove(annotations_file)
# SVIRO #################################################################
def download_sviro(data_dir):
# Original URL: https://sviro.kl.dfki.de
full_path = stage_path(data_dir, "sviro")
download_and_extract("https://sviro.kl.dfki.de/?wpdmdl=1731",
os.path.join(data_dir, "sviro_grayscale_rectangle_classification.zip"))
os.rename(os.path.join(data_dir, "SVIRO_DOMAINBED"),
full_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Download datasets')
parser.add_argument('--data_dir', type=str, required=True)
args = parser.parse_args()
# download_mnist(args.data_dir)
# download_pacs(args.data_dir)
# download_office_home(args.data_dir)
# download_domain_net(args.data_dir)
# download_vlcs(args.data_dir)
download_terra_incognita(args.data_dir)
# download_sviro(args.data_dir)
# Camelyon17Dataset(root_dir=args.data_dir, download=True)
# FMoWDataset(root_dir=args.data_dir, download=True)
================================================
FILE: code/clip/data/download_data_azcopy.py
================================================
# download datasets from azure blob storage, which is faster than downloading from the website
import os
import argparse
DATA_DIR_AZURE = {
'office-home': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/OfficeHome/',
'office31': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/office31/',
'domainnet': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/domainnet/',
'visda': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/visda/',
'vlcs': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/VLCS/VLCS/',
'pacs': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/PACS/PACS/kfold/',
'terrainc': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/terra_incognita/terra_incognita/',
'wilds-camelyon': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/wilds/wilds/camelyon17_v1.0/',
'wilds-fmow': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/wilds/wilds/fmow_v1.1/',
'wilds-iwildcam': 'https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/wilds/wilds/iwildcam_v2.0/'
}
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, choices=DATA_DIR_AZURE.keys(), default='office31')
parser.add_argument('--to', type=str, default='/data/jindwang/', help='path to save the dataset')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
if not os.path.exists(os.getcwd() + '/azcopy'):
azcopy_path = 'https://wjdcloud.blob.core.windows.net/dataset/azcopy'
print('>>>>Downloading azcopy...')
os.system('wget {}'.format(azcopy_path))
os.system('chmod +x azcopy')
print('>>>>Downloading datasets...')
src_path = DATA_DIR_AZURE[args.dataset]
os.system(f'./azcopy copy "{src_path}" "{args.to}" --recursive')
print('>>>>Done!')
================================================
FILE: code/clip/log/log.txt
================================================
This is the log folder.
================================================
FILE: code/clip/main.py
================================================
import argparse
import numpy as np
import os
import pretty_errors
import torch
import torch.optim as optim
from clip_model import ClipModel
from data.data_loader import ImageTextData
from utils import gather_res, get_logger, set_gpu, set_seed
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=3)
parser.add_argument('--mode', type=str, choices=['zs', 'fe', 'ft'], default='ft') # zeroshot, feature extraction, fine-tuning
parser.add_argument('--dataset', type=int, default=16)
parser.add_argument('--model', type=int, default=2) # -1 for sweep
parser.add_argument('--root', type=str, default='/data/jindwang/') # root path of dataset
parser.add_argument('--log_file', type=str, default='log.txt')
parser.add_argument('--seed', type=int, default=42) # random seed
parser.add_argument('--result', action='store_true') # if you want to sweep results statistics
parser.add_argument('--batchsize', type=int, default=32)
parser.add_argument('--nepoch', type=int, default=10)
parser.add_argument('--lr', type=float, default=5e-5)
parser.add_argument('--beta1', type=float, default=0.9)
parser.add_argument('--beta2', type=float, default=0.98)
parser.add_argument('--eps', type=float, default=1e-6)
parser.add_argument('--weight_decay', type=float, default=0.2)
## the following test data and test batchsize are only used for fine-tuning mode
parser.add_argument('--test_batchsize', type=int, default=1024)
parser.add_argument('--test_data', type=int, default=17)
args = parser.parse_args()
return args
def main(args):
model, dataset = args.model, args.dataset
model_name = ClipModel.get_model_name_by_index(model)
dataset_name = ImageTextData.get_data_name_by_index(dataset)
args.log_file = os.getcwd() + '/log/{}_{}_{}.txt'.format(args.mode, model_name, dataset_name)
logger = get_logger(args.log_file, args.log_file)
logger.info(args)
clip = ClipModel(model,logger=logger)
logger.info(f'Clip model {model_name} loaded')
itdata = ImageTextData(dataset, root=args.root, preprocess=clip.preprocess)
train_loader = torch.utils.data.DataLoader(itdata, batch_size=args.batchsize, shuffle=True)
logger.info(f'Dataset {dataset_name} loaded')
if args.mode == 'zs': # zeroshot
acc, res = clip.evaluate(train_loader)
logger.info('Results: {}'.format(res))
logger.info('Accuracy: {:.2f}%'.format(acc * 100))
elif args.mode == 'fe': # feature extraction
res = clip.feature_extraction(train_loader)
logger.info('Feature extracted!')
if not os.path.exists('feat'):
os.makedirs('feat')
feat_file = 'feat/{}_{}_{}.csv'.format(args.mode, model_name, dataset_name)
np.savetxt(feat_file, res, fmt='%.4f')
elif args.mode == 'ft': # fine-tuning
test_data = ImageTextData(args.test_data, root=args.root, preprocess=clip.preprocess)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=args.test_batchsize, shuffle=False, drop_last=False)
optimizer = optim.Adam(clip.model.parameters(), lr=args.lr, betas=(args.beta1, args.beta2), eps=args.eps, weight_decay=args.weight_decay)
best_acc = clip.finetune(train_loader, test_loader, optimizer, args.nepoch, save_path='/home/jindwang/mine/clipood/model/{}_{}_{}.pt'.format(args.mode, model_name, dataset_name))
logger.info('Accuracy: {:.2f}%'.format(best_acc * 100))
else:
raise NotImplementedError
def sweep_index(model=-1, data=-1):
if model == -1 and data == -1:
m_sweep_index = range(len(ClipModel.CLIP_MODELS))
d_sweep_index = range(len(ImageTextData._DATA_FOLDER))
elif model == -1 and data != -1:
m_sweep_index = range(len(ClipModel.CLIP_MODELS))
d_sweep_index = range(data, data + 1)
elif data == -1 and model != -1:
m_sweep_index = range(model, model + 1)
d_sweep_index = range(len(ImageTextData._DATA_FOLDER))
else:
m_sweep_index = range(model, model + 1)
d_sweep_index = range(data, data + 1)
return m_sweep_index, d_sweep_index
def sweep(model=-1, data=-1):
m_sweep_index, d_sweep_index = sweep_index(model, data)
if args.result:
model_name_lst = [ClipModel.get_model_name_by_index(i) for i in m_sweep_index]
data_name_lst = [ImageTextData.get_data_name_by_index(i) for i in d_sweep_index]
res = gather_res(model_name_lst, data_name_lst)
for line in res:
print(line)
else:
for model in m_sweep_index:
for data in d_sweep_index:
args.model = model
args.dataset = data
main(args)
if __name__ == '__main__':
args = get_args()
set_gpu(args.gpu)
set_seed(args.seed)
sweep(args.model, args.dataset)
================================================
FILE: code/clip/requirements.txt
================================================
clip==1.0
cvxopt==1.3.0
gdown==4.4.0
numpy==1.22.0
Pillow==9.3.0
pretty_errors==1.2.25
scikit_learn==1.1.3
scipy==1.10.0
torch==1.13.1
torchvision==0.13.1
tqdm==4.63.0
wilds==2.0.0
================================================
FILE: code/clip/test_clip.py
================================================
import numpy as np
from torchvision import transforms, datasets
from PIL import Image
import torch
import argparse
import clip
import os
CLIP_MODELS = [
'RN50',
'RN101',
'RN50x4',
'RN50x16',
'RN50x64',
'ViT-B/32',
'ViT-B/16',
'ViT-L/14',
'ViT-L/14@336px'
]
DATA_FOLDER = [
'OfficeHome/Art',
'OfficeHome/Clipart',
'OfficeHome/Product',
'OfficeHome/RealWorld',
'OFFICE31/amazon',
'OFFICE31/webcam',
'OFFICE31/dslr',
'VLCS/VLCS/Caltech101',
'VLCS/VLCS/LabelMe',
'VLCS/VLCS/SUN09',
'VLCS/VLCS/VOC2007',
'PACS/kfold/art_painting',
'PACS/kfold/cartoon',
'PACS/kfold/photo',
'PACS/kfold/sketch',
'imagenet-r',
]
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=int, default=5, help='model index')
parser.add_argument('--dataset', type=int, default=0, help='dataset name')
args = parser.parse_args()
return args
def load_data(dataset):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
if dataset == 'imagenet-r':
imagenet_r = datasets.ImageFolder('imagenet-r', transform=transform)
imagenetr_labels = open('imagenetr_labels.txt').read().splitlines()
imagenetr_labels = [x.split(',')[1].strip() for x in imagenetr_labels]
return imagenet_r, imagenetr_labels
else:
officehome = datasets.ImageFolder(dataset, transform=transform)
officehome_labels = officehome.classes
return officehome, officehome_labels
def load_model(modelname):
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load(modelname, device)
return model, preprocess
def classify_imagenetr(imagenet_r, imagenetr_labels, model, preprocess, device):
res = []
for item in imagenet_r.imgs:
img, label = item
image = Image.open(img)
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat(
[clip.tokenize(f"a picture of a {c}") for c in imagenetr_labels]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(1)
for value, index in zip(values, indices):
res.append([index.cpu().numpy(), label])
res = np.array(res)
acc = np.mean(np.array(res)[:, 0] == np.array(res)[:, 1])
return res, acc
def perform_inference(model_index, data_index):
model_pretrain, dataset = CLIP_MODELS[model_index], DATA_FOLDER[data_index]
data, labels = load_data(dataset)
model, processor = load_model(model_pretrain)
res, acc = classify_imagenetr(
data, labels, model, processor, device='cuda')
m_rep, d_rep = model_pretrain.replace('/', '-'), dataset.replace('/', '-')
# if exist some folder
if not os.path.exists('clip_res/'):
os.makedirs('clip_res/')
fname = f'clip_res/{m_rep}_{d_rep}'
np.savetxt(fname + '.txt', res, fmt='%d')
with open(fname + '.txt', 'w') as fp:
fp.write(fname + ',' + str(acc))
return res, acc
def gather_res(mid):
model_name = CLIP_MODELS[mid]
import glob
files = glob.glob(f'clip_res/*{model_name}*.txt')
new_f = f'res_all_{mid}.txt'
with open(new_f, 'w') as f_n:
for f in files:
with open(f, 'r') as fp:
s = fp.read()
f_n.write(s + '\n')
def test():
args = get_args()
imagenet_r, imagenetr_labels = load_data(DATA_FOLDER[args.dataset])
model, processor = load_model(CLIP_MODELS[args.model])
res, acc = classify_imagenetr(
imagenet_r, imagenetr_labels, model, processor, device='cuda')
res = np.array(res)
np.savetxt('res.txt', res, fmt='%d')
print(acc)
def sweep():
# Gives all results from all datasets across all models
for mid in range(len(CLIP_MODELS)):
for did in range(len(DATA_FOLDER)):
print(CLIP_MODELS[mid], DATA_FOLDER[did])
_, acc = perform_inference(mid, did)
print(f'{acc:.2f}')
gather_res(mid)
if __name__ == '__main__':
test()
================================================
FILE: code/clip/utils.py
================================================
import logging
import torch
import random
import sys
import numpy as np
def load_csv(folder, src_domain, tar_domain):
data_s = np.loadtxt(f'{folder}/{src_domain}.csv', delimiter=' ')
data_t = np.loadtxt(f'{folder}/{tar_domain}.csv', delimiter=' ')
Xs, Ys = data_s[:, :-1], data_s[:, -1]
Xt, Yt = data_t[:, :-1], data_t[:, -1]
return Xs, Ys, Xt, Yt
def kernel(ker, X1, X2, gamma):
K = None
from sklearn.metrics.pairwise import linear_kernel, rbf_kernel
import numpy as np
if ker == 'linear':
if X2 is not None:
K = linear_kernel(
np.asarray(X1), np.asarray(X2))
else:
K = linear_kernel(np.asarray(X1))
elif ker == 'rbf':
if X2 is not None:
K = rbf_kernel(
np.asarray(X1), np.asarray(X2), gamma)
else:
K = rbf_kernel(
np.asarray(X1), None, gamma)
elif ker == 'primal':
K = X1
return K
def set_seed(seed):
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def set_gpu(gpuid):
torch.cuda.set_device(gpuid)
def get_logger(logger_name, log_file, level=logging.INFO):
formatter = logging.Formatter('[%(asctime)s - %(levelname)s] %(message)s', "%Y-%m-%d %H:%M:%S")
fileHandler = logging.FileHandler(log_file, mode='a')
fileHandler.setFormatter(formatter)
vlog = logging.getLogger(logger_name)
vlog.setLevel(level)
stdout_handler = logging.StreamHandler(stream=sys.stdout)
vlog.addHandler(fileHandler)
vlog.addHandler(stdout_handler)
return vlog
def gather_res(model_name_lst, data_name_lst):
res = []
for model_name in model_name_lst:
for data_name in data_name_lst:
with open('/home/jindwang/mine/clipood/log/{}_{}.txt'.format(model_name, data_name), 'r') as f:
lines = f.readlines()
line = lines[-1].strip().split(' ')[-1]
line = '{},{},{}'.format(model_name, data_name, line)
res.append(line)
return res
def convert_models_to_fp32(model):
for p in model.parameters():
p.data = p.data.float()
p.grad.data = p.grad.data.float()
================================================
FILE: code/deep/B-JMMD/README.md
================================================
<<<<<<< HEAD
# B-JMMD
Balanced joint maximum mean discrepancy for deep transfer learning
=======
This is the transfer learning library for the following paper:
### Balanced Joint Maximum Mean Discrepancy for Deep Transfer Learning
## Citation
If you use this code for your research, please consider citing:
```
@article{Chuangji2020Balanced,
title={Balanced Joint Maximum Mean Discrepancy for Deep Transfer Learning},
author={Chuangji Meng and Cunlu Xu and Qin Lei and Wei Su and Jinzhao Wu},
journal={Analysis and Applications},
number={2},
year={2020},
}
```
## Contact
If you have any problem about our code, feel free to contact
- mengchj16@lzu.edu.cn
- clxu@lzu.edu.cn
- leiqin@mail.lzjtu.cn
or describe your problem in Issues.
>>>>>>> 7b5bf33... first commit
================================================
FILE: code/deep/B-JMMD/caffe/CMakeLists.txt
================================================
cmake_minimum_required(VERSION 2.8.7)
if(POLICY CMP0046)
cmake_policy(SET CMP0046 NEW)
endif()
if(POLICY CMP0054)
cmake_policy(SET CMP0054 NEW)
endif()
# ---[ Caffe project
project(Caffe C CXX)
# ---[ Caffe version
set(CAFFE_TARGET_VERSION "1.0.0-rc3" CACHE STRING "Caffe logical version")
set(CAFFE_TARGET_SOVERSION "1.0.0-rc3" CACHE STRING "Caffe soname version")
add_definitions(-DCAFFE_VERSION=${CAFFE_TARGET_VERSION})
# ---[ Using cmake scripts and modules
list(APPEND CMAKE_MODULE_PATH ${PROJECT_SOURCE_DIR}/cmake/Modules)
include(ExternalProject)
include(cmake/Utils.cmake)
include(cmake/Targets.cmake)
include(cmake/Misc.cmake)
include(cmake/Summary.cmake)
include(cmake/ConfigGen.cmake)
# ---[ Options
caffe_option(CPU_ONLY "Build Caffe without CUDA support" OFF) # TODO: rename to USE_CUDA
caffe_option(USE_CUDNN "Build Caffe with cuDNN library support" ON IF NOT CPU_ONLY)
caffe_option(BUILD_SHARED_LIBS "Build shared libraries" ON)
caffe_option(BUILD_python "Build Python wrapper" ON)
set(python_version "2" CACHE STRING "Specify which Python version to use")
caffe_option(BUILD_matlab "Build Matlab wrapper" OFF IF UNIX OR APPLE)
caffe_option(BUILD_docs "Build documentation" ON IF UNIX OR APPLE)
caffe_option(BUILD_python_layer "Build the Caffe Python layer" ON)
caffe_option(USE_OPENCV "Build with OpenCV support" ON)
caffe_option(USE_LEVELDB "Build with levelDB" ON)
caffe_option(USE_LMDB "Build with lmdb" ON)
caffe_option(ALLOW_LMDB_NOLOCK "Allow MDB_NOLOCK when reading LMDB files (only if necessary)" OFF)
# ---[ Dependencies
include(cmake/Dependencies.cmake)
# ---[ Flags
if(UNIX OR APPLE)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fPIC -Wall")
endif()
caffe_set_caffe_link()
if(USE_libstdcpp)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -stdlib=libstdc++")
message("-- Warning: forcing libstdc++ (controlled by USE_libstdcpp option in cmake)")
endif()
add_definitions(-DGTEST_USE_OWN_TR1_TUPLE)
# ---[ Warnings
caffe_warnings_disable(CMAKE_CXX_FLAGS -Wno-sign-compare -Wno-uninitialized)
# ---[ Config generation
configure_file(cmake/Templates/caffe_config.h.in "${PROJECT_BINARY_DIR}/caffe_config.h")
# ---[ Includes
set(Caffe_INCLUDE_DIR ${PROJECT_SOURCE_DIR}/include)
include_directories(${Caffe_INCLUDE_DIR} ${PROJECT_BINARY_DIR})
include_directories(BEFORE src) # This is needed for gtest.
# ---[ Subdirectories
add_subdirectory(src/gtest)
add_subdirectory(src/caffe)
add_subdirectory(tools)
add_subdirectory(examples)
add_subdirectory(python)
add_subdirectory(matlab)
add_subdirectory(docs)
# ---[ Linter target
add_custom_target(lint COMMAND ${CMAKE_COMMAND} -P ${PROJECT_SOURCE_DIR}/cmake/lint.cmake)
# ---[ pytest target
if(BUILD_python)
add_custom_target(pytest COMMAND python${python_version} -m unittest discover -s caffe/test WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/python )
add_dependencies(pytest pycaffe)
endif()
# ---[ Configuration summary
caffe_print_configuration_summary()
# ---[ Export configs generation
caffe_generate_export_configs()
================================================
FILE: code/deep/B-JMMD/caffe/CONTRIBUTING.md
================================================
# Contributing
## Issues
Specific Caffe design and development issues, bugs, and feature requests are maintained by GitHub Issues.
_Please do not post usage, installation, or modeling questions, or other requests for help to Issues._
Use the [caffe-users list](https://groups.google.com/forum/#!forum/caffe-users) instead. This helps developers maintain a clear, uncluttered, and efficient view of the state of Caffe.
When reporting a bug, it's most helpful to provide the following information, where applicable:
* What steps reproduce the bug?
* Can you reproduce the bug using the latest [master](https://github.com/BVLC/caffe/tree/master), compiled with the `DEBUG` make option?
* What hardware and operating system/distribution are you running?
* If the bug is a crash, provide the backtrace (usually printed by Caffe; always obtainable with `gdb`).
Try to give your issue a title that is succinct and specific. The devs will rename issues as needed to keep track of them.
## Pull Requests
Caffe welcomes all contributions.
See the [contributing guide](http://caffe.berkeleyvision.org/development.html) for details.
Briefly: read commit by commit, a PR should tell a clean, compelling story of _one_ improvement to Caffe. In particular:
* A PR should do one clear thing that obviously improves Caffe, and nothing more. Making many smaller PRs is better than making one large PR; review effort is superlinear in the amount of code involved.
* Similarly, each commit should be a small, atomic change representing one step in development. PRs should be made of many commits where appropriate.
* Please do rewrite PR history to be clean rather than chronological. Within-PR bugfixes, style cleanups, reversions, etc. should be squashed and should not appear in merged PR history.
* Anything nonobvious from the code should be explained in comments, commit messages, or the PR description, as appropriate.
================================================
FILE: code/deep/B-JMMD/caffe/CONTRIBUTORS.md
================================================
# Contributors
Caffe is developed by a core set of BVLC members and the open-source community.
We thank all of our [contributors](https://github.com/BVLC/caffe/graphs/contributors)!
**For the detailed history of contributions** of a given file, try
git blame file
to see line-by-line credits and
git log --follow file
to see the change log even across renames and rewrites.
Please refer to the [acknowledgements](http://caffe.berkeleyvision.org/#acknowledgements) on the Caffe site for further details.
**Copyright** is held by the original contributor according to the versioning history; see LICENSE.
================================================
FILE: code/deep/B-JMMD/caffe/INSTALL.md
================================================
# Installation
See http://caffe.berkeleyvision.org/installation.html for the latest
installation instructions.
Check the users group in case you need help:
https://groups.google.com/forum/#!forum/caffe-users
================================================
FILE: code/deep/B-JMMD/caffe/LICENSE
================================================
COPYRIGHT
All contributions by the University of California:
Copyright (c) 2014, 2015, The Regents of the University of California (Regents)
All rights reserved.
All other contributions:
Copyright (c) 2014, 2015, the respective contributors
All rights reserved.
Caffe uses a shared copyright model: each contributor holds copyright over
their contributions to Caffe. The project versioning records all such
contribution and copyright details. If a contributor wants to further mark
their specific copyright on a particular contribution, they should indicate
their copyright solely in the commit message of the change when it is
committed.
LICENSE
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
CONTRIBUTION AGREEMENT
By contributing to the BVLC/caffe repository through pull-request, comment,
or otherwise, the contributor releases their content to the
license and copyright terms herein.
================================================
FILE: code/deep/B-JMMD/caffe/Makefile
================================================
PROJECT := caffe
CONFIG_FILE := Makefile.config
# Explicitly check for the config file, otherwise make -k will proceed anyway.
ifeq ($(wildcard $(CONFIG_FILE)),)
$(error $(CONFIG_FILE) not found. See $(CONFIG_FILE).example.)
endif
include $(CONFIG_FILE)
BUILD_DIR_LINK := $(BUILD_DIR)
ifeq ($(RELEASE_BUILD_DIR),)
RELEASE_BUILD_DIR := .$(BUILD_DIR)_release
endif
ifeq ($(DEBUG_BUILD_DIR),)
DEBUG_BUILD_DIR := .$(BUILD_DIR)_debug
endif
DEBUG ?= 0
ifeq ($(DEBUG), 1)
BUILD_DIR := $(DEBUG_BUILD_DIR)
OTHER_BUILD_DIR := $(RELEASE_BUILD_DIR)
else
BUILD_DIR := $(RELEASE_BUILD_DIR)
OTHER_BUILD_DIR := $(DEBUG_BUILD_DIR)
endif
# All of the directories containing code.
SRC_DIRS := $(shell find * -type d -exec bash -c "find {} -maxdepth 1 \
\( -name '*.cpp' -o -name '*.proto' \) | grep -q ." \; -print)
# The target shared library name
LIBRARY_NAME := $(PROJECT)
LIB_BUILD_DIR := $(BUILD_DIR)/lib
STATIC_NAME := $(LIB_BUILD_DIR)/lib$(LIBRARY_NAME).a
DYNAMIC_VERSION_MAJOR := 1
DYNAMIC_VERSION_MINOR := 0
DYNAMIC_VERSION_REVISION := 0
DYNAMIC_NAME_SHORT := lib$(LIBRARY_NAME).so
#DYNAMIC_SONAME_SHORT := $(DYNAMIC_NAME_SHORT).$(DYNAMIC_VERSION_MAJOR)
DYNAMIC_VERSIONED_NAME_SHORT := $(DYNAMIC_NAME_SHORT).$(DYNAMIC_VERSION_MAJOR).$(DYNAMIC_VERSION_MINOR).$(DYNAMIC_VERSION_REVISION)
DYNAMIC_NAME := $(LIB_BUILD_DIR)/$(DYNAMIC_VERSIONED_NAME_SHORT)
COMMON_FLAGS += -DCAFFE_VERSION=$(DYNAMIC_VERSION_MAJOR).$(DYNAMIC_VERSION_MINOR).$(DYNAMIC_VERSION_REVISION)
##############################
# Get all source files
##############################
# CXX_SRCS are the source files excluding the test ones.
CXX_SRCS := $(shell find src/$(PROJECT) ! -name "test_*.cpp" -name "*.cpp")
# CU_SRCS are the cuda source files
CU_SRCS := $(shell find src/$(PROJECT) ! -name "test_*.cu" -name "*.cu")
# TEST_SRCS are the test source files
TEST_MAIN_SRC := src/$(PROJECT)/test/test_caffe_main.cpp
TEST_SRCS := $(shell find src/$(PROJECT) -name "test_*.cpp")
TEST_SRCS := $(filter-out $(TEST_MAIN_SRC), $(TEST_SRCS))
TEST_CU_SRCS := $(shell find src/$(PROJECT) -name "test_*.cu")
GTEST_SRC := src/gtest/gtest-all.cpp
# TOOL_SRCS are the source files for the tool binaries
TOOL_SRCS := $(shell find tools -name "*.cpp")
# EXAMPLE_SRCS are the source files for the example binaries
EXAMPLE_SRCS := $(shell find examples -name "*.cpp")
# BUILD_INCLUDE_DIR contains any generated header files we want to include.
BUILD_INCLUDE_DIR := $(BUILD_DIR)/src
# PROTO_SRCS are the protocol buffer definitions
PROTO_SRC_DIR := src/$(PROJECT)/proto
PROTO_SRCS := $(wildcard $(PROTO_SRC_DIR)/*.proto)
# PROTO_BUILD_DIR will contain the .cc and obj files generated from
# PROTO_SRCS; PROTO_BUILD_INCLUDE_DIR will contain the .h header files
PROTO_BUILD_DIR := $(BUILD_DIR)/$(PROTO_SRC_DIR)
PROTO_BUILD_INCLUDE_DIR := $(BUILD_INCLUDE_DIR)/$(PROJECT)/proto
# NONGEN_CXX_SRCS includes all source/header files except those generated
# automatically (e.g., by proto).
NONGEN_CXX_SRCS := $(shell find \
src/$(PROJECT) \
include/$(PROJECT) \
python/$(PROJECT) \
matlab/+$(PROJECT)/private \
examples \
tools \
-name "*.cpp" -or -name "*.hpp" -or -name "*.cu" -or -name "*.cuh")
LINT_SCRIPT := scripts/cpp_lint.py
LINT_OUTPUT_DIR := $(BUILD_DIR)/.lint
LINT_EXT := lint.txt
LINT_OUTPUTS := $(addsuffix .$(LINT_EXT), $(addprefix $(LINT_OUTPUT_DIR)/, $(NONGEN_CXX_SRCS)))
EMPTY_LINT_REPORT := $(BUILD_DIR)/.$(LINT_EXT)
NONEMPTY_LINT_REPORT := $(BUILD_DIR)/$(LINT_EXT)
# PY$(PROJECT)_SRC is the python wrapper for $(PROJECT)
PY$(PROJECT)_SRC := python/$(PROJECT)/_$(PROJECT).cpp
PY$(PROJECT)_SO := python/$(PROJECT)/_$(PROJECT).so
PY$(PROJECT)_HXX := include/$(PROJECT)/layers/python_layer.hpp
# MAT$(PROJECT)_SRC is the mex entrance point of matlab package for $(PROJECT)
MAT$(PROJECT)_SRC := matlab/+$(PROJECT)/private/$(PROJECT)_.cpp
ifneq ($(MATLAB_DIR),)
MAT_SO_EXT := $(shell $(MATLAB_DIR)/bin/mexext)
endif
MAT$(PROJECT)_SO := matlab/+$(PROJECT)/private/$(PROJECT)_.$(MAT_SO_EXT)
##############################
# Derive generated files
##############################
# The generated files for protocol buffers
PROTO_GEN_HEADER_SRCS := $(addprefix $(PROTO_BUILD_DIR)/, \
$(notdir ${PROTO_SRCS:.proto=.pb.h}))
PROTO_GEN_HEADER := $(addprefix $(PROTO_BUILD_INCLUDE_DIR)/, \
$(notdir ${PROTO_SRCS:.proto=.pb.h}))
PROTO_GEN_CC := $(addprefix $(BUILD_DIR)/, ${PROTO_SRCS:.proto=.pb.cc})
PY_PROTO_BUILD_DIR := python/$(PROJECT)/proto
PY_PROTO_INIT := python/$(PROJECT)/proto/__init__.py
PROTO_GEN_PY := $(foreach file,${PROTO_SRCS:.proto=_pb2.py}, \
$(PY_PROTO_BUILD_DIR)/$(notdir $(file)))
# The objects corresponding to the source files
# These objects will be linked into the final shared library, so we
# exclude the tool, example, and test objects.
CXX_OBJS := $(addprefix $(BUILD_DIR)/, ${CXX_SRCS:.cpp=.o})
CU_OBJS := $(addprefix $(BUILD_DIR)/cuda/, ${CU_SRCS:.cu=.o})
PROTO_OBJS := ${PROTO_GEN_CC:.cc=.o}
OBJS := $(PROTO_OBJS) $(CXX_OBJS) $(CU_OBJS)
# tool, example, and test objects
TOOL_OBJS := $(addprefix $(BUILD_DIR)/, ${TOOL_SRCS:.cpp=.o})
TOOL_BUILD_DIR := $(BUILD_DIR)/tools
TEST_CXX_BUILD_DIR := $(BUILD_DIR)/src/$(PROJECT)/test
TEST_CU_BUILD_DIR := $(BUILD_DIR)/cuda/src/$(PROJECT)/test
TEST_CXX_OBJS := $(addprefix $(BUILD_DIR)/, ${TEST_SRCS:.cpp=.o})
TEST_CU_OBJS := $(addprefix $(BUILD_DIR)/cuda/, ${TEST_CU_SRCS:.cu=.o})
TEST_OBJS := $(TEST_CXX_OBJS) $(TEST_CU_OBJS)
GTEST_OBJ := $(addprefix $(BUILD_DIR)/, ${GTEST_SRC:.cpp=.o})
EXAMPLE_OBJS := $(addprefix $(BUILD_DIR)/, ${EXAMPLE_SRCS:.cpp=.o})
# Output files for automatic dependency generation
DEPS := ${CXX_OBJS:.o=.d} ${CU_OBJS:.o=.d} ${TEST_CXX_OBJS:.o=.d} \
${TEST_CU_OBJS:.o=.d} $(BUILD_DIR)/${MAT$(PROJECT)_SO:.$(MAT_SO_EXT)=.d}
# tool, example, and test bins
TOOL_BINS := ${TOOL_OBJS:.o=.bin}
EXAMPLE_BINS := ${EXAMPLE_OBJS:.o=.bin}
# symlinks to tool bins without the ".bin" extension
TOOL_BIN_LINKS := ${TOOL_BINS:.bin=}
# Put the test binaries in build/test for convenience.
TEST_BIN_DIR := $(BUILD_DIR)/test
TEST_CU_BINS := $(addsuffix .testbin,$(addprefix $(TEST_BIN_DIR)/, \
$(foreach obj,$(TEST_CU_OBJS),$(basename $(notdir $(obj))))))
TEST_CXX_BINS := $(addsuffix .testbin,$(addprefix $(TEST_BIN_DIR)/, \
$(foreach obj,$(TEST_CXX_OBJS),$(basename $(notdir $(obj))))))
TEST_BINS := $(TEST_CXX_BINS) $(TEST_CU_BINS)
# TEST_ALL_BIN is the test binary that links caffe dynamically.
TEST_ALL_BIN := $(TEST_BIN_DIR)/test_all.testbin
##############################
# Derive compiler warning dump locations
##############################
WARNS_EXT := warnings.txt
CXX_WARNS := $(addprefix $(BUILD_DIR)/, ${CXX_SRCS:.cpp=.o.$(WARNS_EXT)})
CU_WARNS := $(addprefix $(BUILD_DIR)/cuda/, ${CU_SRCS:.cu=.o.$(WARNS_EXT)})
TOOL_WARNS := $(addprefix $(BUILD_DIR)/, ${TOOL_SRCS:.cpp=.o.$(WARNS_EXT)})
EXAMPLE_WARNS := $(addprefix $(BUILD_DIR)/, ${EXAMPLE_SRCS:.cpp=.o.$(WARNS_EXT)})
TEST_WARNS := $(addprefix $(BUILD_DIR)/, ${TEST_SRCS:.cpp=.o.$(WARNS_EXT)})
TEST_CU_WARNS := $(addprefix $(BUILD_DIR)/cuda/, ${TEST_CU_SRCS:.cu=.o.$(WARNS_EXT)})
ALL_CXX_WARNS := $(CXX_WARNS) $(TOOL_WARNS) $(EXAMPLE_WARNS) $(TEST_WARNS)
ALL_CU_WARNS := $(CU_WARNS) $(TEST_CU_WARNS)
ALL_WARNS := $(ALL_CXX_WARNS) $(ALL_CU_WARNS)
EMPTY_WARN_REPORT := $(BUILD_DIR)/.$(WARNS_EXT)
NONEMPTY_WARN_REPORT := $(BUILD_DIR)/$(WARNS_EXT)
##############################
# Derive include and lib directories
##############################
CUDA_INCLUDE_DIR := $(CUDA_DIR)/include
CUDA_LIB_DIR :=
# add /lib64 only if it exists
ifneq ("$(wildcard $(CUDA_DIR)/lib64)","")
CUDA_LIB_DIR += $(CUDA_DIR)/lib64
endif
CUDA_LIB_DIR += $(CUDA_DIR)/lib
INCLUDE_DIRS += $(BUILD_INCLUDE_DIR) ./src ./include /usr/include/hdf5/serial
ifneq ($(CPU_ONLY), 1)
INCLUDE_DIRS += $(CUDA_INCLUDE_DIR)
LIBRARY_DIRS += $(CUDA_LIB_DIR)
LIBRARIES := cudart cublas curand
endif
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial
# handle IO dependencies
USE_LEVELDB ?= 1
USE_LMDB ?= 1
USE_OPENCV ?= 1
ifeq ($(USE_LEVELDB), 1)
LIBRARIES += leveldb snappy
endif
ifeq ($(USE_LMDB), 1)
LIBRARIES += lmdb
endif
ifeq ($(USE_OPENCV), 1)
LIBRARIES += opencv_core opencv_highgui opencv_imgproc
ifeq ($(OPENCV_VERSION), 3)
LIBRARIES += opencv_imgcodecs
endif
endif
PYTHON_LIBRARIES ?= boost_python python2.7
WARNINGS := -Wall -Wno-sign-compare
##############################
# Set build directories
##############################
DISTRIBUTE_DIR ?= distribute
DISTRIBUTE_SUBDIRS := $(DISTRIBUTE_DIR)/bin $(DISTRIBUTE_DIR)/lib
DIST_ALIASES := dist
ifneq ($(strip $(DISTRIBUTE_DIR)),distribute)
DIST_ALIASES += distribute
endif
ALL_BUILD_DIRS := $(sort $(BUILD_DIR) $(addprefix $(BUILD_DIR)/, $(SRC_DIRS)) \
$(addprefix $(BUILD_DIR)/cuda/, $(SRC_DIRS)) \
$(LIB_BUILD_DIR) $(TEST_BIN_DIR) $(PY_PROTO_BUILD_DIR) $(LINT_OUTPUT_DIR) \
$(DISTRIBUTE_SUBDIRS) $(PROTO_BUILD_INCLUDE_DIR))
##############################
# Set directory for Doxygen-generated documentation
##############################
DOXYGEN_CONFIG_FILE ?= ./.Doxyfile
# should be the same as OUTPUT_DIRECTORY in the .Doxyfile
DOXYGEN_OUTPUT_DIR ?= ./doxygen
DOXYGEN_COMMAND ?= doxygen
# All the files that might have Doxygen documentation.
DOXYGEN_SOURCES := $(shell find \
src/$(PROJECT) \
include/$(PROJECT) \
python/ \
matlab/ \
examples \
tools \
-name "*.cpp" -or -name "*.hpp" -or -name "*.cu" -or -name "*.cuh" -or \
-name "*.py" -or -name "*.m")
DOXYGEN_SOURCES += $(DOXYGEN_CONFIG_FILE)
##############################
# Configure build
##############################
# Determine platform
UNAME := $(shell uname -s)
ifeq ($(UNAME), Linux)
LINUX := 1
else ifeq ($(UNAME), Darwin)
OSX := 1
OSX_MAJOR_VERSION := $(shell sw_vers -productVersion | cut -f 1 -d .)
OSX_MINOR_VERSION := $(shell sw_vers -productVersion | cut -f 2 -d .)
endif
# Linux
ifeq ($(LINUX), 1)
CXX ?= /usr/bin/g++
GCCVERSION := $(shell $(CXX) -dumpversion | cut -f1,2 -d.)
# older versions of gcc are too dumb to build boost with -Wuninitalized
ifeq ($(shell echo | awk '{exit $(GCCVERSION) < 4.6;}'), 1)
WARNINGS += -Wno-uninitialized
endif
# boost::thread is reasonably called boost_thread (compare OS X)
# We will also explicitly add stdc++ to the link target.
LIBRARIES += boost_thread stdc++
VERSIONFLAGS += -Wl,-soname,$(DYNAMIC_VERSIONED_NAME_SHORT) -Wl,-rpath,$(ORIGIN)/../lib
endif
# OS X:
# clang++ instead of g++
# libstdc++ for NVCC compatibility on OS X >= 10.9 with CUDA < 7.0
ifeq ($(OSX), 1)
CXX := /usr/bin/clang++
ifneq ($(CPU_ONLY), 1)
CUDA_VERSION := $(shell $(CUDA_DIR)/bin/nvcc -V | grep -o 'release [0-9.]*' | tr -d '[a-z ]')
ifeq ($(shell echo | awk '{exit $(CUDA_VERSION) < 7.0;}'), 1)
CXXFLAGS += -stdlib=libstdc++
LINKFLAGS += -stdlib=libstdc++
endif
# clang throws this warning for cuda headers
WARNINGS += -Wno-unneeded-internal-declaration
# 10.11 strips DYLD_* env vars so link CUDA (rpath is available on 10.5+)
OSX_10_OR_LATER := $(shell [ $(OSX_MAJOR_VERSION) -ge 10 ] && echo true)
OSX_10_5_OR_LATER := $(shell [ $(OSX_MINOR_VERSION) -ge 5 ] && echo true)
ifeq ($(OSX_10_OR_LATER),true)
ifeq ($(OSX_10_5_OR_LATER),true)
LDFLAGS += -Wl,-rpath,$(CUDA_LIB_DIR)
endif
endif
endif
# gtest needs to use its own tuple to not conflict with clang
COMMON_FLAGS += -DGTEST_USE_OWN_TR1_TUPLE=1
# boost::thread is called boost_thread-mt to mark multithreading on OS X
LIBRARIES += boost_thread-mt
# we need to explicitly ask for the rpath to be obeyed
ORIGIN := @loader_path
VERSIONFLAGS += -Wl,-install_name,@rpath/$(DYNAMIC_VERSIONED_NAME_SHORT) -Wl,-rpath,$(ORIGIN)/../../build/lib
else
ORIGIN := \$$ORIGIN
endif
# Custom compiler
ifdef CUSTOM_CXX
CXX := $(CUSTOM_CXX)
endif
# Static linking
ifneq (,$(findstring clang++,$(CXX)))
STATIC_LINK_COMMAND := -Wl,-force_load $(STATIC_NAME)
else ifneq (,$(findstring g++,$(CXX)))
STATIC_LINK_COMMAND := -Wl,--whole-archive $(STATIC_NAME) -Wl,--no-whole-archive
else
# The following line must not be indented with a tab, since we are not inside a target
$(error Cannot static link with the $(CXX) compiler)
endif
# Debugging
ifeq ($(DEBUG), 1)
COMMON_FLAGS += -DDEBUG -g -O0
NVCCFLAGS += -G
else
COMMON_FLAGS += -DNDEBUG -O2
endif
# cuDNN acceleration configuration.
ifeq ($(USE_CUDNN), 1)
LIBRARIES += cudnn
COMMON_FLAGS += -DUSE_CUDNN
endif
# NCCL acceleration configuration
ifeq ($(USE_NCCL), 1)
LIBRARIES += nccl
COMMON_FLAGS += -DUSE_NCCL
endif
# configure IO libraries
ifeq ($(USE_OPENCV), 1)
COMMON_FLAGS += -DUSE_OPENCV
endif
ifeq ($(USE_LEVELDB), 1)
COMMON_FLAGS += -DUSE_LEVELDB
endif
ifeq ($(USE_LMDB), 1)
COMMON_FLAGS += -DUSE_LMDB
ifeq ($(ALLOW_LMDB_NOLOCK), 1)
COMMON_FLAGS += -DALLOW_LMDB_NOLOCK
endif
endif
# CPU-only configuration
ifeq ($(CPU_ONLY), 1)
OBJS := $(PROTO_OBJS) $(CXX_OBJS)
TEST_OBJS := $(TEST_CXX_OBJS)
TEST_BINS := $(TEST_CXX_BINS)
ALL_WARNS := $(ALL_CXX_WARNS)
TEST_FILTER := --gtest_filter="-*GPU*"
COMMON_FLAGS += -DCPU_ONLY
endif
# Python layer support
ifeq ($(WITH_PYTHON_LAYER), 1)
COMMON_FLAGS += -DWITH_PYTHON_LAYER
LIBRARIES += $(PYTHON_LIBRARIES)
endif
# BLAS configuration (default = ATLAS)
BLAS ?= atlas
ifeq ($(BLAS), mkl)
# MKL
LIBRARIES += mkl_rt
COMMON_FLAGS += -DUSE_MKL
MKLROOT ?= /opt/intel/mkl
BLAS_INCLUDE ?= $(MKLROOT)/include
BLAS_LIB ?= $(MKLROOT)/lib $(MKLROOT)/lib/intel64
else ifeq ($(BLAS), open)
# OpenBLAS
LIBRARIES += openblas
else
# ATLAS
ifeq ($(LINUX), 1)
ifeq ($(BLAS), atlas)
# Linux simply has cblas and atlas
LIBRARIES += cblas atlas
endif
else ifeq ($(OSX), 1)
# OS X packages atlas as the vecLib framework
LIBRARIES += cblas
# 10.10 has accelerate while 10.9 has veclib
XCODE_CLT_VER := $(shell pkgutil --pkg-info=com.apple.pkg.CLTools_Executables | grep 'version' | sed 's/[^0-9]*\([0-9]\).*/\1/')
XCODE_CLT_GEQ_7 := $(shell [ $(XCODE_CLT_VER) -gt 6 ] && echo 1)
XCODE_CLT_GEQ_6 := $(shell [ $(XCODE_CLT_VER) -gt 5 ] && echo 1)
ifeq ($(XCODE_CLT_GEQ_7), 1)
BLAS_INCLUDE ?= /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/$(shell ls /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/ | sort | tail -1)/System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/Headers
else ifeq ($(XCODE_CLT_GEQ_6), 1)
BLAS_INCLUDE ?= /System/Library/Frameworks/Accelerate.framework/Versions/Current/Frameworks/vecLib.framework/Headers/
LDFLAGS += -framework Accelerate
else
BLAS_INCLUDE ?= /System/Library/Frameworks/vecLib.framework/Versions/Current/Headers/
LDFLAGS += -framework vecLib
endif
endif
endif
INCLUDE_DIRS += $(BLAS_INCLUDE)
LIBRARY_DIRS += $(BLAS_LIB)
LIBRARY_DIRS += $(LIB_BUILD_DIR)
# Automatic dependency generation (nvcc is handled separately)
CXXFLAGS += -MMD -MP
# Complete build flags.
COMMON_FLAGS += $(foreach includedir,$(INCLUDE_DIRS),-I$(includedir))
CXXFLAGS += -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS)
NVCCFLAGS += -ccbin=$(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)
# mex may invoke an older gcc that is too liberal with -Wuninitalized
MATLAB_CXXFLAGS := $(CXXFLAGS) -Wno-uninitialized
LINKFLAGS += -pthread -fPIC $(COMMON_FLAGS) $(WARNINGS)
USE_PKG_CONFIG ?= 0
ifeq ($(USE_PKG_CONFIG), 1)
PKG_CONFIG := $(shell pkg-config opencv --libs)
else
PKG_CONFIG :=
endif
LDFLAGS += $(foreach librarydir,$(LIBRARY_DIRS),-L$(librarydir)) $(PKG_CONFIG) \
$(foreach library,$(LIBRARIES),-l$(library))
PYTHON_LDFLAGS := $(LDFLAGS) $(foreach library,$(PYTHON_LIBRARIES),-l$(library))
# 'superclean' target recursively* deletes all files ending with an extension
# in $(SUPERCLEAN_EXTS) below. This may be useful if you've built older
# versions of Caffe that do not place all generated files in a location known
# to the 'clean' target.
#
# 'supercleanlist' will list the files to be deleted by make superclean.
#
# * Recursive with the exception that symbolic links are never followed, per the
# default behavior of 'find'.
SUPERCLEAN_EXTS := .so .a .o .bin .testbin .pb.cc .pb.h _pb2.py .cuo
# Set the sub-targets of the 'everything' target.
EVERYTHING_TARGETS := all py$(PROJECT) test warn lint
# Only build matcaffe as part of "everything" if MATLAB_DIR is specified.
ifneq ($(MATLAB_DIR),)
EVERYTHING_TARGETS += mat$(PROJECT)
endif
##############################
# Define build targets
##############################
.PHONY: all lib test clean docs linecount lint lintclean tools examples $(DIST_ALIASES) \
py mat py$(PROJECT) mat$(PROJECT) proto runtest \
superclean supercleanlist supercleanfiles warn everything
all: lib tools examples
lib: $(STATIC_NAME) $(DYNAMIC_NAME)
everything: $(EVERYTHING_TARGETS)
linecount:
cloc --read-lang-def=$(PROJECT).cloc \
src/$(PROJECT) include/$(PROJECT) tools examples \
python matlab
lint: $(EMPTY_LINT_REPORT)
lintclean:
@ $(RM) -r $(LINT_OUTPUT_DIR) $(EMPTY_LINT_REPORT) $(NONEMPTY_LINT_REPORT)
docs: $(DOXYGEN_OUTPUT_DIR)
@ cd ./docs ; ln -sfn ../$(DOXYGEN_OUTPUT_DIR)/html doxygen
$(DOXYGEN_OUTPUT_DIR): $(DOXYGEN_CONFIG_FILE) $(DOXYGEN_SOURCES)
$(DOXYGEN_COMMAND) $(DOXYGEN_CONFIG_FILE)
$(EMPTY_LINT_REPORT): $(LINT_OUTPUTS) | $(BUILD_DIR)
@ cat $(LINT_OUTPUTS) > $@
@ if [ -s "$@" ]; then \
cat $@; \
mv $@ $(NONEMPTY_LINT_REPORT); \
echo "Found one or more lint errors."; \
exit 1; \
fi; \
$(RM) $(NONEMPTY_LINT_REPORT); \
echo "No lint errors!";
$(LINT_OUTPUTS): $(LINT_OUTPUT_DIR)/%.lint.txt : % $(LINT_SCRIPT) | $(LINT_OUTPUT_DIR)
@ mkdir -p $(dir $@)
@ python $(LINT_SCRIPT) $< 2>&1 \
| grep -v "^Done processing " \
| grep -v "^Total errors found: 0" \
> $@ \
|| true
test: $(TEST_ALL_BIN) $(TEST_ALL_DYNLINK_BIN) $(TEST_BINS)
tools: $(TOOL_BINS) $(TOOL_BIN_LINKS)
examples: $(EXAMPLE_BINS)
py$(PROJECT): py
py: $(PY$(PROJECT)_SO) $(PROTO_GEN_PY)
$(PY$(PROJECT)_SO): $(PY$(PROJECT)_SRC) $(PY$(PROJECT)_HXX) | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@ $<
$(Q)$(CXX) -shared -o $@ $(PY$(PROJECT)_SRC) \
-o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(PYTHON_LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../../build/lib
mat$(PROJECT): mat
mat: $(MAT$(PROJECT)_SO)
$(MAT$(PROJECT)_SO): $(MAT$(PROJECT)_SRC) $(STATIC_NAME)
@ if [ -z "$(MATLAB_DIR)" ]; then \
echo "MATLAB_DIR must be specified in $(CONFIG_FILE)" \
"to build mat$(PROJECT)."; \
exit 1; \
fi
@ echo MEX $<
$(Q)$(MATLAB_DIR)/bin/mex $(MAT$(PROJECT)_SRC) \
CXX="$(CXX)" \
CXXFLAGS="\$$CXXFLAGS $(MATLAB_CXXFLAGS)" \
CXXLIBS="\$$CXXLIBS $(STATIC_LINK_COMMAND) $(LDFLAGS)" -output $@
@ if [ -f "$(PROJECT)_.d" ]; then \
mv -f $(PROJECT)_.d $(BUILD_DIR)/${MAT$(PROJECT)_SO:.$(MAT_SO_EXT)=.d}; \
fi
runtest: $(TEST_ALL_BIN)
$(TOOL_BUILD_DIR)/caffe
$(TEST_ALL_BIN) $(TEST_GPUID) --gtest_shuffle $(TEST_FILTER)
pytest: py
cd python; python -m unittest discover -s caffe/test
mattest: mat
cd matlab; $(MATLAB_DIR)/bin/matlab -nodisplay -r 'caffe.run_tests(), exit()'
warn: $(EMPTY_WARN_REPORT)
$(EMPTY_WARN_REPORT): $(ALL_WARNS) | $(BUILD_DIR)
@ cat $(ALL_WARNS) > $@
@ if [ -s "$@" ]; then \
cat $@; \
mv $@ $(NONEMPTY_WARN_REPORT); \
echo "Compiler produced one or more warnings."; \
exit 1; \
fi; \
$(RM) $(NONEMPTY_WARN_REPORT); \
echo "No compiler warnings!";
$(ALL_WARNS): %.o.$(WARNS_EXT) : %.o
$(BUILD_DIR_LINK): $(BUILD_DIR)/.linked
# Create a target ".linked" in this BUILD_DIR to tell Make that the "build" link
# is currently correct, then delete the one in the OTHER_BUILD_DIR in case it
# exists and $(DEBUG) is toggled later.
$(BUILD_DIR)/.linked:
@ mkdir -p $(BUILD_DIR)
@ $(RM) $(OTHER_BUILD_DIR)/.linked
@ $(RM) -r $(BUILD_DIR_LINK)
@ ln -s $(BUILD_DIR) $(BUILD_DIR_LINK)
@ touch $@
$(ALL_BUILD_DIRS): | $(BUILD_DIR_LINK)
@ mkdir -p $@
$(DYNAMIC_NAME): $(OBJS) | $(LIB_BUILD_DIR)
@ echo LD -o $@
$(Q)$(CXX) -shared -o $@ $(OBJS) $(VERSIONFLAGS) $(LINKFLAGS) $(LDFLAGS)
@ cd $(BUILD_DIR)/lib; rm -f $(DYNAMIC_NAME_SHORT); ln -s $(DYNAMIC_VERSIONED_NAME_SHORT) $(DYNAMIC_NAME_SHORT)
$(STATIC_NAME): $(OBJS) | $(LIB_BUILD_DIR)
@ echo AR -o $@
$(Q)ar rcs $@ $(OBJS)
$(BUILD_DIR)/%.o: %.cpp | $(ALL_BUILD_DIRS)
@ echo CXX $<
$(Q)$(CXX) $< $(CXXFLAGS) -c -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(PROTO_BUILD_DIR)/%.pb.o: $(PROTO_BUILD_DIR)/%.pb.cc $(PROTO_GEN_HEADER) \
| $(PROTO_BUILD_DIR)
@ echo CXX $<
$(Q)$(CXX) $< $(CXXFLAGS) -c -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(BUILD_DIR)/cuda/%.o: %.cu | $(ALL_BUILD_DIRS)
@ echo NVCC $<
$(Q)$(CUDA_DIR)/bin/nvcc $(NVCCFLAGS) $(CUDA_ARCH) -M $< -o ${@:.o=.d} \
-odir $(@D)
$(Q)$(CUDA_DIR)/bin/nvcc $(NVCCFLAGS) $(CUDA_ARCH) -c $< -o $@ 2> $@.$(WARNS_EXT) \
|| (cat $@.$(WARNS_EXT); exit 1)
@ cat $@.$(WARNS_EXT)
$(TEST_ALL_BIN): $(TEST_MAIN_SRC) $(TEST_OBJS) $(GTEST_OBJ) \
| $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo CXX/LD -o $@ $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $(TEST_OBJS) $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
$(TEST_CU_BINS): $(TEST_BIN_DIR)/%.testbin: $(TEST_CU_BUILD_DIR)/%.o \
$(GTEST_OBJ) | $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo LD $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $< $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
$(TEST_CXX_BINS): $(TEST_BIN_DIR)/%.testbin: $(TEST_CXX_BUILD_DIR)/%.o \
$(GTEST_OBJ) | $(DYNAMIC_NAME) $(TEST_BIN_DIR)
@ echo LD $<
$(Q)$(CXX) $(TEST_MAIN_SRC) $< $(GTEST_OBJ) \
-o $@ $(LINKFLAGS) $(LDFLAGS) -l$(LIBRARY_NAME) -Wl,-rpath,$(ORIGIN)/../lib
# Target for extension-less symlinks to tool binaries with extension '*.bin'.
$(TOOL_BUILD_DIR)/%: $(TOOL_BUILD_DIR)/%.bin | $(TOOL_BUILD_DIR)
@ $(RM) $@
@ ln -s $(notdir $<) $@
$(TOOL_BINS): %.bin : %.o | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@
$(Q)$(CXX) $< -o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../lib
$(EXAMPLE_BINS): %.bin : %.o | $(DYNAMIC_NAME)
@ echo CXX/LD -o $@
$(Q)$(CXX) $< -o $@ $(LINKFLAGS) -l$(LIBRARY_NAME) $(LDFLAGS) \
-Wl,-rpath,$(ORIGIN)/../../lib
proto: $(PROTO_GEN_CC) $(PROTO_GEN_HEADER)
$(PROTO_BUILD_DIR)/%.pb.cc $(PROTO_BUILD_DIR)/%.pb.h : \
$(PROTO_SRC_DIR)/%.proto | $(PROTO_BUILD_DIR)
@ echo PROTOC $<
$(Q)protoc --proto_path=$(PROTO_SRC_DIR) --cpp_out=$(PROTO_BUILD_DIR) $<
$(PY_PROTO_BUILD_DIR)/%_pb2.py : $(PROTO_SRC_DIR)/%.proto \
$(PY_PROTO_INIT) | $(PY_PROTO_BUILD_DIR)
@ echo PROTOC \(python\) $<
$(Q)protoc --proto_path=$(PROTO_SRC_DIR) --python_out=$(PY_PROTO_BUILD_DIR) $<
$(PY_PROTO_INIT): | $(PY_PROTO_BUILD_DIR)
touch $(PY_PROTO_INIT)
clean:
@- $(RM) -rf $(ALL_BUILD_DIRS)
@- $(RM) -rf $(OTHER_BUILD_DIR)
@- $(RM) -rf $(BUILD_DIR_LINK)
@- $(RM) -rf $(DISTRIBUTE_DIR)
@- $(RM) $(PY$(PROJECT)_SO)
@- $(RM) $(MAT$(PROJECT)_SO)
supercleanfiles:
$(eval SUPERCLEAN_FILES := $(strip \
$(foreach ext,$(SUPERCLEAN_EXTS), $(shell find . -name '*$(ext)' \
-not -path './data/*'))))
supercleanlist: supercleanfiles
@ \
if [ -z "$(SUPERCLEAN_FILES)" ]; then \
echo "No generated files found."; \
else \
echo $(SUPERCLEAN_FILES) | tr ' ' '\n'; \
fi
superclean: clean supercleanfiles
@ \
if [ -z "$(SUPERCLEAN_FILES)" ]; then \
echo "No generated files found."; \
else \
echo "Deleting the following generated files:"; \
echo $(SUPERCLEAN_FILES) | tr ' ' '\n'; \
$(RM) $(SUPERCLEAN_FILES); \
fi
$(DIST_ALIASES): $(DISTRIBUTE_DIR)
$(DISTRIBUTE_DIR): all py | $(DISTRIBUTE_SUBDIRS)
# add proto
cp -r src/caffe/proto $(DISTRIBUTE_DIR)/
# add include
cp -r include $(DISTRIBUTE_DIR)/
mkdir -p $(DISTRIBUTE_DIR)/include/caffe/proto
cp $(PROTO_GEN_HEADER_SRCS) $(DISTRIBUTE_DIR)/include/caffe/proto
# add tool and example binaries
cp $(TOOL_BINS) $(DISTRIBUTE_DIR)/bin
cp $(EXAMPLE_BINS) $(DISTRIBUTE_DIR)/bin
# add libraries
cp $(STATIC_NAME) $(DISTRIBUTE_DIR)/lib
install -m 644 $(DYNAMIC_NAME) $(DISTRIBUTE_DIR)/lib
cd $(DISTRIBUTE_DIR)/lib; rm -f $(DYNAMIC_NAME_SHORT); ln -s $(DYNAMIC_VERSIONED_NAME_SHORT) $(DYNAMIC_NAME_SHORT)
# add python - it's not the standard way, indeed...
cp -r python $(DISTRIBUTE_DIR)/
-include $(DEPS)
================================================
FILE: code/deep/B-JMMD/caffe/Makefile.config.example
================================================
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1
CUDNN_PATH := /home/libs/cuda-5.0
# CPU-only switch (uncomment to build without GPU support).
# CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
# OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda-7.5
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_50,code=compute_50
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
BLAS := open
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
BLAS_INCLUDE := /opt/OpenBLAS/include
BLAS_LIB := /opt/OpenBLAS/lib
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
# ANACONDA_HOME := $(HOME)/anaconda
# PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
# $(ANACONDA_HOME)/include/python2.7 \
# $(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
# Uncomment to use Python 3 (default is Python 2)
# PYTHON_LIBRARIES := boost_python3 python3.5m
# PYTHON_INCLUDE := /usr/include/python3.5m \
# /usr/lib/python3.5/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib
# PYTHON_LIB := $(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
# WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include $(CUDNN_PATH)/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib $(CUDNN_PATH)/lib64
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
================================================
FILE: code/deep/B-JMMD/caffe/README.md
================================================
# Deep Transfer Learning on Caffe
This is a caffe library for deep transfer learning. We fork the repository with version ID `29cdee7` from [Caffe](https://github.com/BVLC/caffe) and [Xlearn](https://github.com/thuml/Xlearn), and make our modifications. The main modifications is listed as follow:
- Add `bjmmd layer` described in paper "Balanced joint maximum mean discrepancy for deep transfer learning" (AA '2020).
Data Preparation
---------------
In `data/office/*.txt`, we give the lists of three domains in [Office](https://cs.stanford.edu/~jhoffman/domainadapt/#datasets_code) dataset.
We have published the Image-Clef dataset we use [here](https://drive.google.com/file/d/0B9kJH0-rJ2uRS3JILThaQXJhQlk/view?usp=sharing).
Training Model
---------------
In `models/B-JMMD/alexnet`, we give an example model based on Alexnet to show how to transfer from `amazon` to `webcam`. In this model, we insert bjmmd layers after fc7 and fc8 individually.In `models/models/B-JMMD/resnet`, we give an example model based on ResNet to show how to transfer from `amazon` to `webcam`.
The [bvlc\_reference\_caffenet](http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel) is used as the pre-trained model for Alexnet. The [deep-residual-networks](https://github.com/KaimingHe/deep-residual-networks) is used as the pre-trained model for Resnet. We use Resnet-50. If the Office dataset and pre-trained caffemodel are prepared, the example can be run with the following command:
```
Alexnet:
"./build/tools/caffe train -solver models/B-JMMD/alexnet/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel"
```
```
ResNet:
"./build/tools/caffe train -solver models/B-JMMD/resnet/solver.prototxt -weights models/deep-residual-networks/ResNet-50-model.caffemodel"
```
Parameter Tuning
---------------
In bjmmd-layer, parameter `loss_weight` can be tuned to give jmmd loss different weights, parameter `balanced_factor` α can be tuned to give bjmmd loss a different marginal distribution daptation weights(α) or conditional distribution daptation weights(1-α) repectively.(balanced_factor α ∈ [0,1])
Changing Transfer Task
---------------
If you want to change to other transfer tasks (e.g. `webcam` to `amazon`), you may need to:
- In `train_val.prototxt` please change the source and target datasets;
- In `solver.prototxt` please change `test_iter` to the size of the target dataset: `2817` for `amazon`, `795` for `webcam` and `498` for `dslr`;
- you may also need to tune the `loss_weight` λ and `balanced_factor`α to achieve the best accuracy, For each transfer task, you can first set the balance factor α to 0.5(JMMD), and tried your best to search the loss weight λ by changing it from 0 to 1 by a progressive schedulefor, for instance,`loss_weight` λ within {0.01, 0.02, 0.05, 0.1, 0.2, 0.4, 1.0}, to achieve better accuracy, then fixed the loss weight λ obtained in the previous step and searched for the balance factor α within {0, 0.1, . . . , 0.9, 1.0} to achieve the best results.
## Citation
If you use this library for your research, we would be pleased if you cite the following papers:
```
@article{Chuangji2020Balanced,
title={Balanced Joint Maximum Mean Discrepancy for Deep Transfer Learning},
author={Chuangji Meng and Cunlu Xu and Qin Lei and Wei Su and Jinzhao Wu},
journal={Analysis and Applications},
number={2},
year={2020},
}
```
================================================
FILE: code/deep/B-JMMD/caffe/caffe.cloc
================================================
Bourne Shell
filter remove_matches ^\s*#
filter remove_inline #.*$
extension sh
script_exe sh
C
filter remove_matches ^\s*//
filter call_regexp_common C
filter remove_inline //.*$
extension c
extension ec
extension pgc
C++
filter remove_matches ^\s*//
filter remove_inline //.*$
filter call_regexp_common C
extension C
extension cc
extension cpp
extension cxx
extension pcc
C/C++ Header
filter remove_matches ^\s*//
filter call_regexp_common C
filter remove_inline //.*$
extension H
extension h
extension hh
extension hpp
CUDA
filter remove_matches ^\s*//
filter remove_inline //.*$
filter call_regexp_common C
extension cu
Python
filter remove_matches ^\s*#
filter docstring_to_C
filter call_regexp_common C
filter remove_inline #.*$
extension py
make
filter remove_matches ^\s*#
filter remove_inline #.*$
extension Gnumakefile
extension Makefile
extension am
extension gnumakefile
extension makefile
filename Gnumakefile
filename Makefile
filename gnumakefile
filename makefile
script_exe make
================================================
FILE: code/deep/B-JMMD/caffe/data/imageCLEF/bList.txt
================================================
b/252.car-side-101/252_0446.jpg 6
b/252.car-side-101/252_0337.jpg 6
b/252.car-side-101/252_0493.jpg 6
b/252.car-side-101/252_0242.jpg 6
b/252.car-side-101/252_0057.jpg 6
b/252.car-side-101/252_0273.jpg 6
b/252.car-side-101/252_0505.jpg 6
b/252.car-side-101/252_0345.jpg 6
b/252.car-side-101/252_0463.jpg 6
b/252.car-side-101/252_0408.jpg 6
b/252.car-side-101/252_0173.jpg 6
b/252.car-side-101/252_0300.jpg 6
b/252.car-side-101/252_0142.jpg 6
b/252.car-side-101/252_0030.jpg 6
b/252.car-side-101/252_0036.jpg 6
b/252.car-side-101/252_0487.jpg 6
b/252.car-side-101/252_0033.jpg 6
b/252.car-side-101/252_0481.jpg 6
b/252.car-side-101/252_0297.jpg 6
b/252.car-side-101/252_0397.jpg 6
b/252.car-side-101/252_0280.jpg 6
b/252.car-side-101/252_0424.jpg 6
b/252.car-side-101/252_0278.jpg 6
b/252.car-side-101/252_0445.jpg 6
b/252.car-side-101/252_0267.jpg 6
b/252.car-side-101/252_0331.jpg 6
b/252.car-side-101/252_0092.jpg 6
b/252.car-side-101/252_0494.jpg 6
b/252.car-side-101/252_0211.jpg 6
b/252.car-side-101/252_0014.jpg 6
b/252.car-side-101/252_0438.jpg 6
b/252.car-side-101/252_0072.jpg 6
b/252.car-side-101/252_0327.jpg 6
b/252.car-side-101/252_0025.jpg 6
b/252.car-side-101/252_0196.jpg 6
b/252.car-side-101/252_0285.jpg 6
b/252.car-side-101/252_0400.jpg 6
b/252.car-side-101/252_0467.jpg 6
b/252.car-side-101/252_0232.jpg 6
b/252.car-side-101/252_0279.jpg 6
b/252.car-side-101/252_0189.jpg 6
b/252.car-side-101/252_0187.jpg 6
b/252.car-side-101/252_0229.jpg 6
b/252.car-side-101/252_0066.jpg 6
b/252.car-side-101/252_0499.jpg 6
b/252.car-side-101/252_0016.jpg 6
b/252.car-side-101/252_0175.jpg 6
b/252.car-side-101/252_0512.jpg 6
b/252.car-side-101/252_0296.jpg 6
b/252.car-side-101/252_0144.jpg 6
b/046.computer-monitor/99B047454CD9B6D811D0288BE087715E.jpg 9
b/046.computer-monitor/4368FC8E03F2A288ADF2DCDBD712E750.jpg 9
b/046.computer-monitor/954071A67971CBA89764EDB20428D8F3.jpg 9
b/046.computer-monitor/8EB65F199E94D875FFD6768F35710276.jpg 9
b/046.computer-monitor/A04FC61BCC99C49B353D39F7D471D554.jpg 9
b/046.computer-monitor/A4088A337FAB3ECA4D7520729FC56AEF.jpg 9
b/046.computer-monitor/A692A3E48919A104D3A706C94844A4C2.jpg 9
b/046.computer-monitor/7FAC9E56C4F8DBF4C968445000B7DFD2.jpg 9
b/046.computer-monitor/BCA5859E1E87F738CDE4E9FCC43616AD.jpg 9
b/046.computer-monitor/16128B2C344486D5B22CCB544A498D26.jpg 9
b/046.computer-monitor/68D2FB34573152F7E5E8569257C177B4.jpg 9
b/046.computer-monitor/934CDA1D8798ACC1F31B0C0994F1A254.jpg 9
b/046.computer-monitor/07B9E5E73C8EF79063FA07B3F52F2735.jpg 9
b/046.computer-monitor/6879DEF4F6D2339688FDD82DA2C85754.jpg 9
b/046.computer-monitor/10092B6598A5EAB2C52212C76B66636F.jpg 9
b/046.computer-monitor/30E1B08A10F380EF9AF1F2C54BC37F99.jpg 9
b/046.computer-monitor/5C3E621FBCACCF9DD0783EC9C48086AB.jpg 9
b/046.computer-monitor/996A4E7860E0E124D0E28B4624EF7A3E.jpg 9
b/046.computer-monitor/7A614107DF056752DCEB1884EB48F52E.jpg 9
b/046.computer-monitor/167F8C023E0564EA731D5AD4443DCC78.jpg 9
b/046.computer-monitor/5D7D2E837FC15A257C810B6F99E8E2C3.jpg 9
b/046.computer-monitor/EAADBBFFC051985B11BF51FEA90738DD.jpg 9
b/046.computer-monitor/FF6854B0B1F13AF2FD62A3744D95F890.jpg 9
b/046.computer-monitor/01624A6E5002E7A3DF9AC102D1EE025E.jpg 9
b/046.computer-monitor/CFA34381EA85F93404A0CB2BC291D659.jpg 9
b/046.computer-monitor/E068BF4E458356B9A18A106DE11DEB62.jpg 9
b/046.computer-monitor/EF1993AEEB6D084ED31B0F29B4D01119.jpg 9
b/046.computer-monitor/040AADC700F811DA31F02DB6C3B01403.jpg 9
b/046.computer-monitor/9120B69B673D10FFF15DE9306FB63E26.jpg 9
b/046.computer-monitor/5B7D32115CEF942A9E5C67D9CE59E5BA.jpg 9
b/046.computer-monitor/4CDACA16FEB95BFA24FCC83D7AADEB51.jpg 9
b/046.computer-monitor/111002CDE28DE7FC6EC8105C0F6F1913.jpg 9
b/046.computer-monitor/7812BB4418847E19B6863BE7D93FC516.jpg 9
b/046.computer-monitor/2547D105CAEB73242F8342EE9AA0EB10.jpg 9
b/046.computer-monitor/1519B34721FF9BF0E289C4B92FA6DDE8.jpg 9
b/046.computer-monitor/C8579112A830E3894B23DD259CA6F651.jpg 9
b/046.computer-monitor/371105E72FC205275879A002EC3CBA91.jpg 9
b/046.computer-monitor/446C104E4DE6AD474C82AFFC25D97CC7.jpg 9
b/046.computer-monitor/4335FEB13FB8E95B80825CBC367B74A6.jpg 9
b/046.computer-monitor/4C543ADD81590F54708E9EE604718661.jpg 9
b/046.computer-monitor/A63E71DFFB82DDA6134F95547978D5A6.jpg 9
b/046.computer-monitor/0BD2328961DD8A5777BC756044CC41CE.jpg 9
b/046.computer-monitor/CE7003F44D239819AC24BB18D57EAF36.jpg 9
b/046.computer-monitor/C946D7BC36A1D1A6BA5B362C4B317B0B.jpg 9
b/046.computer-monitor/E3BE7EAE643951A8949B71552B12DD3C.jpg 9
b/046.computer-monitor/765653A4C9F07D2258700ED49854152E.jpg 9
b/046.computer-monitor/F2F3C096D8D349605A76EBE3B189507C.jpg 9
b/046.computer-monitor/2939ED3DAB0021BFACF058D4EB72739E.jpg 9
b/046.computer-monitor/78B37D75172C8C1F40C9B8209D9E57D2.jpg 9
b/046.computer-monitor/2BF59300B51BFF87A9F920E7D1EF2363.jpg 9
b/056.dog/E44C9A35C92B27D3F812608DE6CA910F.jpg 7
b/056.dog/9B64A10D9D3F0D8DDF0A4FD6B620F793.jpg 7
b/056.dog/016E08E303ACBDF596B0C071830D9D0E.jpg 7
b/056.dog/019B54A87F8663382B80E9EB5F11ECE6.jpg 7
b/056.dog/14706E0F6C0A886F93BDC4564D9FCF1C.jpg 7
b/056.dog/2993174C7CD5AFF712DDDCB1DD1F5F05.jpg 7
b/056.dog/1D284A29CD3A93D678C3F43A7C1240D0.jpg 7
b/056.dog/2EBBBE60D95063CBC9500076F91B1414.jpg 7
b/056.dog/A099C89E07064CB065A200ED5A56AA3D.jpg 7
b/056.dog/3574F45BD92A71A04A51302BBA3076C6.jpg 7
b/056.dog/6FD717560C67FCD1A8D69F246CDC1DBF.jpg 7
b/056.dog/5DA4CB45E851C166D7405927602BC592.jpg 7
b/056.dog/51147F65309C1B9329152EA4DFD1E7EF.jpg 7
b/056.dog/4EAD0040169FB171151B987CF678C89C.jpg 7
b/056.dog/BDDCDA3C43D1FBE339830675EE790BC4.jpg 7
b/056.dog/D93244D2E8D5FE0B0203C7E3CF032D8C.jpg 7
b/056.dog/665B2EA7D97C3ECD5961CD787B3E4B10.jpg 7
b/056.dog/44AF4192DB14121B9607E40F45852D3F.jpg 7
b/056.dog/40C049DCD2D6E864164A0FEF468DD27E.jpg 7
b/056.dog/1E8B1161C3248FBF8C8B4E2C193DBEA5.jpg 7
b/056.dog/046AE64BF285C34A173C93896F9201B7.jpg 7
b/056.dog/BF8881854887B688AE2552853B06634D.jpg 7
b/056.dog/D347B5C3B30BE0BB5DF85C17CEC9026A.jpg 7
b/056.dog/2E3EF19FEB17FB00C6EE6A6FFE9DA084.jpg 7
b/056.dog/C5DAC51DD6730DD1D8B65CA3F4260F17.jpg 7
b/056.dog/5CAC03956E4F77658D31A427918AB441.jpg 7
b/056.dog/0C64DF97C1F7D93798EE7AC39C1C5DB6.jpg 7
b/056.dog/FD03B59B87DA6912FAEE634B6745AAB0.jpg 7
b/056.dog/FDD66506D81871A8536C27563483C4A9.jpg 7
b/056.dog/D208B7A14FB2CC965D2D27D72AB0F7B6.jpg 7
b/056.dog/8E5E8683D65BB32C27556F1A92484C06.jpg 7
b/056.dog/2E182D5D0084A990BB181D029FECB134.jpg 7
b/056.dog/5D68FA5DA23492AD102E4C51D751E0C5.jpg 7
b/056.dog/757B031495A588F1288D1484103ABEF7.jpg 7
b/056.dog/A2953E5DBEA8844396FA196A136A443A.jpg 7
b/056.dog/187585E2FA471A9A3110E2E49DC23D89.jpg 7
b/056.dog/06176B915EDED374DD9538A26C9355AF.jpg 7
b/056.dog/C46892BD2F5F640D094D003966E47198.jpg 7
b/056.dog/890AB1D52F11EA1F7565D6EB22E03160.jpg 7
b/056.dog/4E5A38B53C9ECDB70994B82D0EE24324.jpg 7
b/056.dog/5CBCD72CAF98C2F10EE428C5A41095F3.jpg 7
b/056.dog/5E1D3F56E8620456A323EB3DFA28FA98.jpg 7
b/056.dog/79A4DB5AD3C4319B030C41041C1CC772.jpg 7
b/056.dog/399A73127E633BE4CF615585D1100EDB.jpg 7
b/056.dog/93A4AE80A27C7C57F09B81C82144A5AB.jpg 7
b/056.dog/C9C938D6C83343D26920F4F19F194390.jpg 7
b/056.dog/E59FF601F1D61841567C57D146D3630B.jpg 7
b/056.dog/EBEC99772324C0FCE5D5313F7109D6BA.jpg 7
b/056.dog/D80939E4CFDB90FBBD5095F6162FA29B.jpg 7
b/056.dog/0F1910541E4594BF6AE30CB4104FFB00.jpg 7
b/105.horse/303A184971074E3B4E2A8F049A5E4FE9.jpg 8
b/105.horse/897D3867A3683B2C299F1128AC4DA9EC.jpg 8
b/105.horse/9032A8B30A6BF5C274E3EBBF49BDA72D.jpg 8
b/105.horse/174BBA9C9AEEC116C8CD8263692FFB12.jpg 8
b/105.horse/EF10E0D4A505AF42D51C62301C811B1D.jpg 8
b/105.horse/DFF071F32258BE98D31E0293E0B42F52.jpg 8
b/105.horse/DF36EC86BBDBF157ECC9F71DA41F492F.jpg 8
b/105.horse/F7722CEC2C7F49DCF0300E9089FBE550.jpg 8
b/105.horse/9CB03D84405DA70A405FCD8555645736.jpg 8
b/105.horse/E4475F5F4123E77D2E64F11187269E0B.jpg 8
b/105.horse/00EFC6FC24740AD02D1322AB2847424B.jpg 8
b/105.horse/FADB6C2AB826CBFB2464734E9B28E0C6.jpg 8
b/105.horse/E865F0CCB33DC97EB24BC9FA9CC66F3C.jpg 8
b/105.horse/37FFF33C040CD9B023F2B0C739346584.jpg 8
b/105.horse/B0BE1146B7B543C5CC8BF636EBE73ABD.jpg 8
b/105.horse/CF2C04C18ACA69DEE41E4AEB3AC40F66.jpg 8
b/105.horse/2B70CCF18FF865B58AA4979943E73A4A.jpg 8
b/105.horse/AEEBA1619227AD5E712D167CB3A76560.jpg 8
b/105.horse/C69B2009A9C540609C3DFB527D433D37.jpg 8
b/105.horse/0227FDEC0640B5B4B8A2622807186F9D.jpg 8
b/105.horse/03F7E9713302C8B0E06130D062325B91.jpg 8
b/105.horse/D2EBBD22BEC2B5191E7C9EDC408F41F7.jpg 8
b/105.horse/596D7BF182188DED40B7CD7884BACF52.jpg 8
b/105.horse/9B5359845473A61E01EB975FBD724B22.jpg 8
b/105.horse/BF9E2B9D99F713CE4C09938D85182D45.jpg 8
b/105.horse/6E3075911EDF41B0F5E7B77353575DE1.jpg 8
b/105.horse/A236F01F2E14CE72392A541B83ED6300.jpg 8
b/105.horse/0C6F1DD934D222BD7F61080CB8D54476.jpg 8
b/105.horse/C73821398958DC39961B67106D563AD1.jpg 8
b/105.horse/8B5500DAF0401C20CAF76BCA013CA965.jpg 8
b/105.horse/AF5697859340324FEFB037BA79E791DE.jpg 8
b/105.horse/942C4ECC3AA6CAB343D2B3D6D6587536.jpg 8
b/105.horse/C326C13E0E4848D3F9A0398706951D18.jpg 8
b/105.horse/910DBD0C045BFE8611CF317C0C60DC43.jpg 8
b/105.horse/0843F6ECD367B7817B4700ED4B1095FF.jpg 8
b/105.horse/CB3495A971A1AC9B6326C24A205A1FB9.jpg 8
b/105.horse/3633025B7252C562E88C3AAAEF390367.jpg 8
b/105.horse/B5B0D85CCCFBEA76A3CB33C2396B183E.jpg 8
b/105.horse/0755FF97B7389BCB05CA783DED6CE38F.jpg 8
b/105.horse/6202D0BBD5CCF3A45F72983790E5FDCD.jpg 8
b/105.horse/8D5E4FADA5D6496B225965569C3A6A6E.jpg 8
b/105.horse/936A95DD2C9500B38DCBF4664E4B999C.jpg 8
b/105.horse/3F1C070BABD316E8E2CAC4CF5E5A3162.jpg 8
b/105.horse/BCDD2121DDFB641DCF219A42FCD226EF.jpg 8
b/105.horse/062A86011D7D4462D7A1D910DE5406CC.jpg 8
b/105.horse/28909B95CF0342F0A6146E69779B4C79.jpg 8
b/105.horse/0833521B6398D33469B12C52131E1FF9.jpg 8
b/105.horse/0F19F4F4B449AA3DC30EC5C5080931FE.jpg 8
b/105.horse/A10F8941898D7FDAF1250AD86517D160.jpg 8
b/105.horse/D564E45383C6AE04BA53E5867DA81BCE.jpg 8
b/113.hummingbird/1DA9F95F105A84908AA2E6138036EADB.jpg 2
b/113.hummingbird/C3C49A4123224889DAEACDB04036AFF9.jpg 2
b/113.hummingbird/3198FE1A6CE6ACD0E9F05765CDD888AC.jpg 2
b/113.hummingbird/95BD5D17B8EE9A5B0B7140AF3D3EE155.jpg 2
b/113.hummingbird/CC33B67CEAB260C70B484FD728D77A11.jpg 2
b/113.hummingbird/95F124A5CFD54F6C6156257869B902B3.jpg 2
b/113.hummingbird/461CBE2E4490B1126D75BF5774BF7E2B.jpg 2
b/113.hummingbird/26DEE9250A7B866F49301B50BCE4A8D9.jpg 2
b/113.hummingbird/5F7090EE7DB242C7808CFAE3C158E2CA.jpg 2
b/113.hummingbird/2C914AD42D56193E456E8C5C4F606AA8.jpg 2
b/113.hummingbird/0D4C4128FB03C80B4A70762B9F730BE0.jpg 2
b/113.hummingbird/943EAF8EE6F3DAD93C350D7334E5D43E.jpg 2
b/113.hummingbird/8E71498075A52224B9DB53DC5AB9E03C.jpg 2
b/113.hummingbird/C3F566E1F64CDC2E5E39D8DB53A9A92F.jpg 2
b/113.hummingbird/5513CAD5A526CAA15FF2D7858088EC7A.jpg 2
b/113.hummingbird/8DE0CA1C66B13C3422D2510F5741A7CF.jpg 2
b/113.hummingbird/2D2AF15FD593F6831AC50A9F9D2EC9EF.jpg 2
b/113.hummingbird/AC866E2E87C79A4C6DDBBF2957B60641.jpg 2
b/113.hummingbird/F8454BD5C7267E9348BE34B46DAF9C3E.jpg 2
b/113.hummingbird/A806021E59957A157359258F1B0FCCFD.jpg 2
b/113.hummingbird/570734E61A79E0DD7DAA759AA16E84CB.jpg 2
b/113.hummingbird/37E972099EBA6B295EA443DA17288B27.jpg 2
b/113.hummingbird/76F78EAC76E1E476ABECBE4E6A55A321.jpg 2
b/113.hummingbird/5453A1F47A601A8D0BF3F4741BDF3DFA.jpg 2
b/113.hummingbird/161E937F0769F6018D4A2DE89A94ED72.jpg 2
b/113.hummingbird/C256C06CD8FE55EA7D06DEAA60A8F325.jpg 2
b/113.hummingbird/535C060A2B6BF625B3F63FEDAB9FC4ED.jpg 2
b/113.hummingbird/EA0256F7A672A1253A5720B0F480B1D7.jpg 2
b/113.hummingbird/88816EF105060A2840E8D0B9818BE02D.jpg 2
b/113.hummingbird/2F812EE05204B95D035679AE36260953.jpg 2
b/113.hummingbird/5D2DD16038474585420053AF925FDC61.jpg 2
b/113.hummingbird/95A176181338C3F6609D508147F05CC0.jpg 2
b/113.hummingbird/A05BB25301885E2CBBFB48B684EFF4C3.jpg 2
b/113.hummingbird/0E3763A7051609ED45055CE2AA187B56.jpg 2
b/113.hummingbird/AFEA94305B7BAE3D6FDC3AEEAF4A5B8D.jpg 2
b/113.hummingbird/0367235F822FB39337329ADB8431D7A7.jpg 2
b/113.hummingbird/C3896EDD27F601950AEB5CF67F4E7CD4.jpg 2
b/113.hummingbird/8D57C4BB57E86CC5E547A82D88433255.jpg 2
b/113.hummingbird/E92D3FAEC1DB5564E9B8B37674482A4D.jpg 2
b/113.hummingbird/F9AB469CCB792CBFB072C6AAF4819943.jpg 2
b/113.hummingbird/16FC961DBAE75E0EE096F6FAF7832DA3.jpg 2
b/113.hummingbird/4A583BE465941467859B35D5E3D99BEC.jpg 2
b/113.hummingbird/0130814315084D9CD4F6093CE25041FB.jpg 2
b/113.hummingbird/8873695BFD8E3D2393439161466588B0.jpg 2
b/113.hummingbird/5E5FED6EDA0768E31CD136A73210D9AA.jpg 2
b/113.hummingbird/06343E0AE2FF16BAC012CA8298EB7C37.jpg 2
b/113.hummingbird/02971601D6B855172D5D81615234BFFF.jpg 2
b/113.hummingbird/9BCD41863FCC0699EA960611ECB3D9B1.jpg 2
b/113.hummingbird/1B88B667A17F9BE3041276D4F1982296.jpg 2
b/113.hummingbird/FBDA9B9254483E1060FD2CE0E819DEAA.jpg 2
b/145.motorbikes-101/ADC96D0263E181615FE9D491CA4BD721.jpg 10
b/145.motorbikes-101/596FFF97CCADE4C6D56A7F86B7ADC4AA.jpg 10
b/145.motorbikes-101/AF59B7AF2928BDAC7DA78EA4DE7E789F.jpg 10
b/145.motorbikes-101/B2387134FDBA1728EE31D8DBA5F929A6.jpg 10
b/145.motorbikes-101/0A36A7B9A724B01A5E98E90210E224E0.jpg 10
b/145.motorbikes-101/D4226310F8543F66BE53820C40697F2D.jpg 10
b/145.motorbikes-101/A19462EE3C53688CEA99DEEE65B2CE34.jpg 10
b/145.motorbikes-101/6144F29AFFEC5C70D42F4E85A7C145E8.jpg 10
b/145.motorbikes-101/BEDF5F6174AE0035B91BC442AB4C5442.jpg 10
b/145.motorbikes-101/BE202CAF702644FBB2958ACF4E35A8BE.jpg 10
b/145.motorbikes-101/04FACB943377EDE55F37678DBF85B6FD.jpg 10
b/145.motorbikes-101/086464B2C7F1CA924457B741F7B010C4.jpg 10
b/145.motorbikes-101/D21F9071E3A393C47E4CA26783B81F15.jpg 10
b/145.motorbikes-101/4407233DC2E2EE980AC3A42B729EADA4.jpg 10
b/145.motorbikes-101/568BD2B97C5A8F14F683FABAE41FBF66.jpg 10
b/145.motorbikes-101/009D596B8E08DFCF4884A9E266CBE6F3.jpg 10
b/145.motorbikes-101/11BBBF5DB04DE5F6C398EE8EA358357F.jpg 10
b/145.motorbikes-101/DFB46188BA5754B86A5DC9A0C40D4888.jpg 10
b/145.motorbikes-101/683DC3083CB96BD64836EA29F9BB344A.jpg 10
b/145.motorbikes-101/7F5595160FCDE0286A91D43F1B84D851.jpg 10
b/145.motorbikes-101/1DC986B87E0FB98BC070E5700289DABF.jpg 10
b/145.motorbikes-101/2068B6BCF55638C892A00A96E781A1ED.jpg 10
b/145.motorbikes-101/53EE4E1C64548B33EF93C44EC14411A7.jpg 10
b/145.motorbikes-101/E5DD48CF34AD63DAEDD82BF0802771AD.jpg 10
b/145.motorbikes-101/B6C7DD34EC67078C780ED311B2F69F2A.jpg 10
b/145.motorbikes-101/1F1FEB24B5B015089952F97940996505.jpg 10
b/145.motorbikes-101/9443B8E8F682CB83C6775904E6347E7F.jpg 10
b/145.motorbikes-101/4BD66FAAC250C47F90216B31D38FDAFD.jpg 10
b/145.motorbikes-101/A1C06B307C726981112446BBC2440A88.jpg 10
b/145.motorbikes-101/5E9EE691E2073B77B302D9B88633FD24.jpg 10
b/145.motorbikes-101/C15001D8FA6E8134415BF4C6F9CCD686.jpg 10
b/145.motorbikes-101/C7764F2DE2E1C19855C41F9D34EE9F97.jpg 10
b/145.motorbikes-101/E651FFD6C847D1DAD806AA7AAC10D5EE.jpg 10
b/145.motorbikes-101/28F885B7E338D2EC76E4223D65E5600C.jpg 10
b/145.motorbikes-101/B39D78380CFFCE66F619F886CDF35B00.jpg 10
b/145.motorbikes-101/64709DAC7F8F19B5A159D6688D9C1C4C.jpg 10
b/145.motorbikes-101/9D9061A2750C82A87F05429E0FDDB982.jpg 10
b/145.motorbikes-101/3DEF7317699E60DEAE12069826FCBAC5.jpg 10
b/145.motorbikes-101/598AEB6C824EA77ED116588E4A66718D.jpg 10
b/145.motorbikes-101/C7E185C1A43618E9D4555106C4CDAEA2.jpg 10
b/145.motorbikes-101/DE32BB1C556018C204BCF88792FF26D3.jpg 10
b/145.motorbikes-101/36105C43E7BF401AF4C83AD609BC88F4.jpg 10
b/145.motorbikes-101/3C003BB2F384B6E7CB247B15C029C18B.jpg 10
b/145.motorbikes-101/2376DEF9BC3D8361D1C2D945FAB837A0.jpg 10
b/145.motorbikes-101/085902158622DB7E8F473263FF3DF9E7.jpg 10
b/145.motorbikes-101/68B1481A01ABDDA278E17FF02C124FCC.jpg 10
b/145.motorbikes-101/3ADDD2423A59963FE4A61F5904DE8557.jpg 10
b/145.motorbikes-101/786218FB02044550259D737210398787.jpg 10
b/145.motorbikes-101/E2F3BA7D4BD5FBF8E58CF3E5DB4338E6.jpg 10
b/145.motorbikes-101/1DAE745F1341E3005CA5E575AA688EEC.jpg 10
b/146.mountain-bike/9453C5315949BFF5E0EE9C9A0592A740.jpg 1
b/224.touring-bike/6B14D3B3308C0ABED6C0EECD1A8204D6.jpg 1
b/146.mountain-bike/20D3C7E0E7D94B1B499CEA7EB0301491.jpg 1
b/224.touring-bike/D1C9313072151C95F0AA44C0E4BA9736.jpg 1
b/224.touring-bike/22B33A4BB6D5A58B0539C9AB825D8A8E.jpg 1
b/224.touring-bike/5DE6ADD369366694C47B4C3E8899FF18.jpg 1
b/146.mountain-bike/A60F1AC1F67D99F8A98DD9024AA3F152.jpg 1
b/146.mountain-bike/F1AB4EF686776E64E172B26D2CEF767D.jpg 1
b/146.mountain-bike/AFA4A5B756A09DCC41D1504A0909088E.jpg 1
b/224.touring-bike/98BB12769E4C068CFAAB64E918D4F225.jpg 1
b/146.mountain-bike/907AFED2066568F94F93E6B0D56D6FD0.jpg 1
b/146.mountain-bike/C747E2B2C1EC047F1C8046F1E1AE91BC.jpg 1
b/146.mountain-bike/F424A7D73A0BAC6C6AA1B9B8F950B5ED.jpg 1
b/224.touring-bike/D04DAD8F9D392EA5630A47AF1B2D1779.jpg 1
b/146.mountain-bike/7FAB94B2111213A776CAA0FCA99AF1F6.jpg 1
b/146.mountain-bike/4A58CC87C8DD2AAE688E155CE8755452.jpg 1
b/146.mountain-bike/566659F4593FD6F9AB411F740EEFD905.jpg 1
b/146.mountain-bike/76AAF2650B393E7A3B08F2988211054C.jpg 1
b/146.mountain-bike/45FA1628256DF18227854492FB02AAA2.jpg 1
b/224.touring-bike/CA96AE286CDC5A937D9493E004FBD9AB.jpg 1
b/146.mountain-bike/0D33206B4C64086D4E957E172C9D4FE6.jpg 1
b/224.touring-bike/57429E195F95DD9541E3E657C77146B4.jpg 1
b/146.mountain-bike/13A3E38BA7D48C0CB1D8C33E3CF3F894.jpg 1
b/224.touring-bike/036CCB4FC76BAEF206B5449F5656466A.jpg 1
b/224.touring-bike/35C01806318A3DF97A3CBC919A2B61E1.jpg 1
b/224.touring-bike/9BC12726749D602634F7949CE6001EE9.jpg 1
b/224.touring-bike/431C61C7FBD08E5E8F8164355467C746.jpg 1
b/224.touring-bike/EB6C6B1B61CC73355284A942C79A5FB3.jpg 1
b/224.touring-bike/D168AEFBDEF1E7B96297AAB4F213A991.jpg 1
b/146.mountain-bike/6CDF9D50D0F1168FED0788A2A955D754.jpg 1
b/146.mountain-bike/0EE0504FFB3B686D2E9B4CBFBC4E726D.jpg 1
b/146.mountain-bike/365FD760A1CB66D7A7DC7D8630B4BF76.jpg 1
b/146.mountain-bike/A566F2968A534836141295685294BAC5.jpg 1
b/146.mountain-bike/3317C84412D8247C7ACFA6ECCA1F4732.jpg 1
b/146.mountain-bike/A58B2BEF5B2EFFBAC16DD6BAA0B9D133.jpg 1
b/146.mountain-bike/5A4CE68844E38D3F53CC2D921585CF21.jpg 1
b/224.touring-bike/5280C73955AA328043F283D7E4AED17E.jpg 1
b/224.touring-bike/11C71EA217F8AB294345CC7D070CA6A9.jpg 1
b/146.mountain-bike/03641633A7AE916AC692F4F86E9F6358.jpg 1
b/224.touring-bike/D2C0AADC00688164B9D2084425BA6429.jpg 1
b/146.mountain-bike/5E674690B23F473EBCD64C430307E85F.jpg 1
b/146.mountain-bike/A3CDC8101E8164F7E5C3D8608F97760A.jpg 1
b/224.touring-bike/18906D40FE8F1F0D6E9E90397A77E681.jpg 1
b/224.touring-bike/A5951C7CE55D44D1D7983675C8E66076.jpg 1
b/224.touring-bike/9A7E2D2853F2CBBF65FDA0AD0EA186BF.jpg 1
b/146.mountain-bike/8BFED687E998CC76FB15ABC222B549E0.jpg 1
b/146.mountain-bike/9B62E39749832D4D081558F1DBEA1A54.jpg 1
b/224.touring-bike/06A0E6EB6E2A6CEDE167D56124F42D3B.jpg 1
b/146.mountain-bike/E2FBA63A04C5C623EC946420D69FC712.jpg 1
b/224.touring-bike/18575192544A1997E2771E096B3B59AF.jpg 1
b/159.people/4BBC9E1799C77EBE97CDB3A9C2A6A0F6.jpg 11
b/159.people/29E875A1614ACAB4FEA4FC35D4F53874.jpg 11
b/159.people/EDA3CCF6C1650A0033E65F7F85C3E320.jpg 11
b/159.people/AEEC33BD87BCF638A90024C57ECFF976.jpg 11
b/159.people/B874B113808639835BB69389B473C25F.jpg 11
b/159.people/BD67EAB839C733091BF4D5EFA00BAF53.jpg 11
b/159.people/347A65B54C8634ECA5DB93646B9BD593.jpg 11
b/159.people/C845EA4BF5699C6FC9861C3239ED3521.jpg 11
b/159.people/5EF40468FF1F809ABAA073FAF202DECE.jpg 11
b/159.people/830B37B1BF68AC6EBE88172583EC051C.jpg 11
b/159.people/02D06D9DB1DF35626E74CFFFFDC1D924.jpg 11
b/159.people/6E8738180B3E92989069E424A0F2E821.jpg 11
b/159.people/60EFE50F000FE800C88C49C6B7BA78AE.jpg 11
b/159.people/BE59980E6EA01751AC9D2528F6B4E3CE.jpg 11
b/159.people/4AE44E88B0D3EB56168844D35E9512E1.jpg 11
b/159.people/43D91B6329EB66B10A48DEB2D2ECE5DB.jpg 11
b/159.people/F7D7EDC248D40404B3779BD8B1F528C2.jpg 11
b/159.people/EA091E5439B0432B2784BDF35CEE4355.jpg 11
b/159.people/1DFFAAA472A5EB0DF80D6B9E39D75D11.jpg 11
b/159.people/D59FFC521FEC8E220A741312ACFE07F9.jpg 11
b/159.people/3636B1978F58F9610EABCEB1932558D1.jpg 11
b/159.people/B3670F67E80DACFDE64B3D90435389F6.jpg 11
b/159.people/47963CB2B8B734EA2106C8D5AD079B30.jpg 11
b/159.people/4A105B56BF1CDF4C63361E8A28709004.jpg 11
b/159.people/24931A873672F774CC3D9C042DED63C7.jpg 11
b/159.people/C868CCB253B127B4734D8501AD9F47C6.jpg 11
b/159.people/78B752D6A3A8FA6BD555049BEEDC329F.jpg 11
b/159.people/D5714A245ABC39F3D2F32DFACD5062CA.jpg 11
b/159.people/B08049B07C47E849CAE17BA138A377F9.jpg 11
b/159.people/EA475C1E5432E4DEA3E76C2EFAF99E37.jpg 11
b/159.people/184A89BA4F190FA4AF48A29A0542A415.jpg 11
b/159.people/53FC876F8EE34EAFAF11D73FBFA9EC1A.jpg 11
b/159.people/39B8649F0687BB45ABFAD9A8081EA7C0.jpg 11
b/159.people/A052ECA2821412200310D413D537082C.jpg 11
b/159.people/3A020B73ED69802A175A6C83153A552B.jpg 11
b/159.people/A17B141138A1459E0A8160B7658DA72F.jpg 11
b/159.people/2EF970002819A676E1F31BCAA0DFB798.jpg 11
b/159.people/54597E7B450CF9F28EF72B6AF595E8F3.jpg 11
b/159.people/7003CC063E5B011E284CC4654119738A.jpg 11
b/159.people/A9D710641FBA1E9CCEADD93DD5EAF80C.jpg 11
b/159.people/2791E6092748248C63C70FBC5FB9F8DE.jpg 11
b/159.people/69A926F25C78E8DB02CCA5BB6483A63F.jpg 11
b/159.people/CCB24C9F1F9475243D20F69406B36ADC.jpg 11
b/159.people/2D55EA21C405EF4E9B1B38D84EEFE1F6.jpg 11
b/159.people/77517FC7561F32D5120FD1CFA4BA5A51.jpg 11
b/159.people/A24468CDF86147584D240FF17517F4C4.jpg 11
b/159.people/E62C4F3C9887B98E398F2F54CE4379C1.jpg 11
b/159.people/16AAE9074F5C00F9615C2C6A705E8513.jpg 11
b/159.people/AF195E97A0B7A1CB3C144D723FA5A16F.jpg 11
b/159.people/409B9D974570529C2F089BF27850AA99.jpg 11
b/178.school-bus/74930C08A2D258C3AC15FEE7FB1F624B.jpg 5
b/178.school-bus/24547E5BE40D231A049CFC56DE2ABF5F.jpg 5
b/178.school-bus/683FB74ADD52CFABEA685F6DC74EE7C9.jpg 5
b/178.school-bus/06DCB8E35A75236B1468ACF669D9FEC9.jpg 5
b/178.school-bus/C897A37C845E34312B5D71CC821D0B68.jpg 5
b/178.school-bus/21A81279C43ABAA217DB5FC4FFC752BF.jpg 5
b/178.school-bus/7548A8A889828B4C5C3268891AB60CAF.jpg 5
b/178.school-bus/2676F53BB1434E7F9707FA6E2624FD4B.jpg 5
b/178.school-bus/A0000F9AD52E520510F524676E6660D6.jpg 5
b/178.school-bus/A12E1F7F294F3C2BDFD63AC2271FE73F.jpg 5
b/178.school-bus/48A1252DBF7C94311ADC01F7DBF2AFAC.jpg 5
b/178.school-bus/DC6E7F8458FDB4DCB18FD008166DB0D2.jpg 5
b/178.school-bus/2037016AA33095757AE76833449D6C7B.jpg 5
b/178.school-bus/B69C8086ED89805885ECD2413B8BD67C.jpg 5
b/178.school-bus/559056179A304125379DC520E3B46CB4.jpg 5
b/178.school-bus/822E14FB3EC8BCB4280E90D10A5D1D96.jpg 5
b/178.school-bus/AFE2A7F8CDAD296A3BCF06CF2448645E.jpg 5
b/178.school-bus/D34E5483FF07167BAA9FD039B57A0429.jpg 5
b/178.school-bus/040050435E808D9336DB106741F5AC4E.jpg 5
b/178.school-bus/1D0BEC676E3B784D975D5A13E557FCF7.jpg 5
b/178.school-bus/206A8B6699A93818F0E87BC14FDDD781.jpg 5
b/178.school-bus/1E25189101FB8A7CB582396126180F79.jpg 5
b/178.school-bus/22D94AB94209F9657A9BE5083C53B611.jpg 5
b/178.school-bus/8D975391F91BC8CB3360467DC09EFE75.jpg 5
b/178.school-bus/ED50CB1365FA1640C6C8171F8B6BEF6E.jpg 5
b/178.school-bus/FFA7E4965BE7A26BA9F12AA353691B84.jpg 5
b/178.school-bus/A81A589E0D5C484D0F81B7B05C123322.jpg 5
b/178.school-bus/5DB33AB5D8F811249D2DE8808708D4E7.jpg 5
b/178.school-bus/FC54B028496416FC58F910E6EFBDA84B.jpg 5
b/178.school-bus/13CDE870001E9405EAF4323C599E2FB6.jpg 5
b/178.school-bus/D0C517CD4FA4986E432E23642FCC8ABC.jpg 5
b/178.school-bus/9C2F957F2FE350314AC15A399770C415.jpg 5
b/178.school-bus/DB3E24C36C4FA21940A15DA5B7351695.jpg 5
b/178.school-bus/3ACD3D6FB09F5CECCB4D1D10A3567D15.jpg 5
b/178.school-bus/58988BE83794045DF9F87E1D9111B164.jpg 5
b/178.school-bus/A38061C092DDADDBC12026B2FD8BBD9C.jpg 5
b/178.school-bus/2F654121C020F97F9F5B7D2E4EEE4809.jpg 5
b/178.school-bus/69D957D426E8BBB87F2BB27C3DAE0F5D.jpg 5
b/178.school-bus/0815025A981C055CBF1528B2DA2C6FA3.jpg 5
b/178.school-bus/154A793A0B1DDF8A49D5257395197051.jpg 5
b/178.school-bus/BF604F291613A1A5AFCB5756C26D5A42.jpg 5
b/178.school-bus/7553530C20E3EF5F72748CAF3FBDD319.jpg 5
b/178.school-bus/A4F5C2A63B0E9FD648890802B0D3794A.jpg 5
b/178.school-bus/9E1794FDA934CB0932EF635C86CE5529.jpg 5
b/178.school-bus/41DF079F00FC1CDF7A34F5148B98BB64.jpg 5
b/178.school-bus/9CFFC763C8A64604881052DA33C7462C.jpg 5
b/178.school-bus/56D45AD69679E30A5CB5CAAD444E58AA.jpg 5
b/178.school-bus/7D35D7E2A4727E36EC185ACE4E3BAD88.jpg 5
b/178.school-bus/0674D9FAE1C8F77FD76E2710EFE51E4D.jpg 5
b/178.school-bus/0AB55F775D31F53C97AD0FF64CD92569.jpg 5
b/197.speed-boat/2F199132AE8C1BB012B9874803423633.jpg 3
b/197.speed-boat/06E7546A599DCE0994635A0F17C13546.jpg 3
b/197.speed-boat/4782FB6A9D47E59DF335EEB19F3BBC81.jpg 3
b/197.speed-boat/228B6EBA3138877AB8A024E63E11E480.jpg 3
b/197.speed-boat/A4D35F1F675A516BA5E104415DCD7239.jpg 3
b/197.speed-boat/9D86C31949F3335A6492F2236F6BBAA9.jpg 3
b/197.speed-boat/FD02BE5DED1CA899B4442876F6FD5831.jpg 3
b/197.speed-boat/0CD8F80A3C9803F22FDCFEDA5D3074A9.jpg 3
b/197.speed-boat/E13547193B8C726914E729CDA16ACE01.jpg 3
b/197.speed-boat/D953D8AD757D5D212EDD957D319514FC.jpg 3
b/197.speed-boat/64A8A592A04C5BFA8D4B7162781D3CA3.jpg 3
b/197.speed-boat/97528AD153732B5068745E6E2D44B8B7.jpg 3
b/197.speed-boat/30DB9418D3FB20C0FC1B3B737034721A.jpg 3
b/197.speed-boat/CB0A27D55803905C32261563CA27710B.jpg 3
b/197.speed-boat/4FB9D549000737F4950B57BAE0A6C020.jpg 3
b/197.speed-boat/0C1717639BC4DB6AB6432D16D5BE4A36.jpg 3
b/197.speed-boat/7EEAD5FCA7472F45D3657A49B44FA630.jpg 3
b/197.speed-boat/4EB35DD3E37CB2DEE0148DD62D846F2F.jpg 3
b/197.speed-boat/0CFECC943A10E78B1F334E9890B3422F.jpg 3
b/197.speed-boat/42617D7195453D01B4B111A25FEFC29C.jpg 3
b/197.speed-boat/DA60919B42F494EDBCFFCD815E967072.jpg 3
b/197.speed-boat/6CD65842EC674D9F12FCA544E61DDA28.jpg 3
b/197.speed-boat/08031F2F2B4C021D60F48026732E00C1.jpg 3
b/197.speed-boat/BFDEBE9806FC27CFD3690DBA41FDBE9C.jpg 3
b/197.speed-boat/A012B46899B919BFE0D757D68C881071.jpg 3
b/197.speed-boat/24572C6C1C529ECB960452FCE75563F6.jpg 3
b/197.speed-boat/B930D323361F24D9EF58E8445C315233.jpg 3
b/197.speed-boat/97E78A339A2756D4236FFB5F3E3C9B63.jpg 3
b/197.speed-boat/984F6499EAE3914660AEA0E9DF7D56E1.jpg 3
b/197.speed-boat/AFAF6AC01AD231E2B18AFCF43415544A.jpg 3
b/197.speed-boat/CFAD48F3E12C0C8D438EC95C010BC068.jpg 3
b/197.speed-boat/F6F06F76058694E41507028B090C0A8B.jpg 3
b/197.speed-boat/88D0FE64FC6D6A50E6A96FAA7BAAC556.jpg 3
b/197.speed-boat/5BC690DF7D75B389223E7DEF473D2CC6.jpg 3
b/197.speed-boat/C094FDB6DCAECFF2F5D58D85DB320747.jpg 3
b/197.speed-boat/750102ED0679A6D627322CD80030B2D9.jpg 3
b/197.speed-boat/523DCBEFC4F30B105D7E301F97FFA5F3.jpg 3
b/197.speed-boat/412B17B2E79287572F2637B919BB4DDF.jpg 3
b/197.speed-boat/B216913893C6B401DE2C197B1D15EAA2.jpg 3
b/197.speed-boat/57EC5444895376BC7CA3E9CD5CF897E7.jpg 3
b/197.speed-boat/D374801C0DF141A571BE581F0809F577.jpg 3
b/197.speed-boat/4D622E71A186AA212734EDDEF38B6609.jpg 3
b/197.speed-boat/6FB55C18F30020039C7538E370FE0C98.jpg 3
b/197.speed-boat/71FD3B82BAE375019956E511975F0805.jpg 3
b/197.speed-boat/02326FC55FAD21E3EB032C2ADF4E9B9A.jpg 3
b/197.speed-boat/F2FB4DFD2FDCD6959500F70B09D11A0D.jpg 3
b/197.speed-boat/244DAC3142BEDCBC42D23B4D55B197A0.jpg 3
b/197.speed-boat/0760F5D5CAF936B9B1015CBF0D51FC2F.jpg 3
b/197.speed-boat/A81431784F0A65CBB5C70EFDA72621FA.jpg 3
b/197.speed-boat/0D9C5CD65F9A0CC60311CF67F6B9BA90.jpg 3
b/246.wine-bottle/EFB685AA6FBC4FAD89001CFB4B0FD6C7.jpg 4
b/246.wine-bottle/FD105C1FB90A02D2255BE57D53325243.jpg 4
b/246.wine-bottle/533D29D9F1F6C2E19F5B5F972C44D99A.jpg 4
b/246.wine-bottle/77C978E318BCD9662EB96B4A5F19F35F.jpg 4
b/246.wine-bottle/CD1B98237D442FDE38B61D99020E7917.jpg 4
b/246.wine-bottle/2CD7FF443E26A0D31021009F46734EB2.jpg 4
b/246.wine-bottle/312445DB721563C7752B34D51DA10454.jpg 4
b/246.wine-bottle/E0D30B7B88E6B718A253C82D44C3F54A.jpg 4
b/246.wine-bottle/2C016F70D7C1E0342F39513BC0B6BC43.jpg 4
b/246.wine-bottle/D5849BCFAF8E1BA0EBA6E2787B8323B1.jpg 4
b/246.wine-bottle/3846B97DC94DA51BFCFCA3E95A287CC0.jpg 4
b/246.wine-bottle/AE872A16D1602FD9B09D75CB8C58F277.jpg 4
b/246.wine-bottle/430ECD392E4424EDA2F74F400F91881E.jpg 4
b/246.wine-bottle/F0C293D43F9A12BD84F9B9C61D317EFB.jpg 4
b/246.wine-bottle/E363DFA32CD85C5649C4F832566365F5.jpg 4
b/246.wine-bottle/5ACAA63B3F6B1F5CC64B5533A38CFC22.jpg 4
b/246.wine-bottle/5FC21CB04B95C90E1476A3CE27A3EA9E.jpg 4
b/246.wine-bottle/65B5ED01282AC4707E6613F75FE6AAD4.jpg 4
b/246.wine-bottle/33A09E862D6FFD5ED7D153C023A9F030.jpg 4
b/246.wine-bottle/B197C4415626DF2BBB8CCC656B891CFE.jpg 4
b/246.wine-bottle/9852BE61326A774F0B174D4F4A7A5D03.jpg 4
b/246.wine-bottle/5EF88A8D0EA57BB9D08A30B303834C29.jpg 4
b/246.wine-bottle/88A72A70A267147B21292A19402F3778.jpg 4
b/246.wine-bottle/BFEA935ED5E0B1544C791AF6C068440D.jpg 4
b/246.wine-bottle/519E025BE461AF37D3420D645E243394.jpg 4
b/246.wine-bottle/444EFD0A5C55381E8A8F79BCF443B7E4.jpg 4
b/246.wine-bottle/639C13BF14259D98FC6D735CE24C420E.jpg 4
b/246.wine-bottle/C6EF53B2FCB9EC242AC3FE334D2130F5.jpg 4
b/246.wine-bottle/B63C63EF218EEF64529B532078BC89B4.jpg 4
b/246.wine-bottle/B63E13EFAB4A3D798C08D55FF091EAB5.jpg 4
b/246.wine-bottle/BC81191105B77516130EAF663AE4D8BC.jpg 4
b/246.wine-bottle/F757946EC23E096CD6FB913DB56882B9.jpg 4
b/246.wine-bottle/BDE75A335C9B90AC5F2EA1625CE96475.jpg 4
b/246.wine-bottle/58283D505FF4FF899D119DCA4EFFFE58.jpg 4
b/246.wine-bottle/5F402D72C71B0517C0EF4D98E1C12905.jpg 4
b/246.wine-bottle/FCBABF0F60B8816680F4731B63B7246A.jpg 4
b/246.wine-bottle/39ACDCCE22EEC3B54879E72969A50FC9.jpg 4
b/246.wine-bottle/8CBE9DE02660DF5AB5DB2C58F44E520F.jpg 4
b/246.wine-bottle/4250D9B8CF2C72C833C4AE52858AE5AF.jpg 4
b/246.wine-bottle/F5D0B77FD3F671FEDB4611DA99605419.jpg 4
b/246.wine-bottle/6E6DD6C0B6C8F6D907B3816D57E6967B.jpg 4
b/246.wine-bottle/2EB3068FDBFCF4EF9F0BF93B6854EE53.jpg 4
b/246.wine-bottle/0E55BCE89CFCFC250051C1E18E4CE483.jpg 4
b/246.wine-bottle/B23FCF5AFA32C175D0D46D68724D7A0A.jpg 4
b/246.wine-bottle/7DC857179CF8863E60CB16A2F99EE572.jpg 4
b/246.wine-bottle/43C8E3F1DB3E2308349366426E2C2B5B.jpg 4
b/246.wine-bottle/C9A2153FEDD0552FEDA60EA661CE5D2D.jpg 4
b/246.wine-bottle/33F04496C0C38E835AE314ED95BE955B.jpg 4
b/246.wine-bottle/70C738ED5F27D6D5A17686090A3A4CD4.jpg 4
b/246.wine-bottle/B11AA83F5D9E776A69FFE740EDB0F6D4.jpg 4
b/251.airplanes-101/E3FF9BF44ABD7A590386FD6DC04441FE.jpg 0
b/251.airplanes-101/1F3E4785017945B9A068DF759CC94DF2.jpg 0
b/251.airplanes-101/CA83C6D5DED56226F8A64C45C2167407.jpg 0
b/251.airplanes-101/CB72DC4FCF9ABCFEF06936C5684581E8.jpg 0
b/251.airplanes-101/E9430381F2493159A32F5F236B4FDF8A.jpg 0
b/251.airplanes-101/620031A94BE8545E599268C596ACA55D.jpg 0
b/251.airplanes-101/18A92EDCCC167E5057B779E3CF142F89.jpg 0
b/251.airplanes-101/2E862EC1688653B70B53A2C1E6A87A11.jpg 0
b/251.airplanes-101/1BF53EEAD6CEF9203DF40C5A1A67744B.jpg 0
b/251.airplanes-101/BD5902152B26285D91A08A86168FF8D1.jpg 0
b/251.airplanes-101/6436B37ADAAAB84B9099841E0EA633F5.jpg 0
b/251.airplanes-101/02B33FC50DBA873198FAED4689BBFBFF.jpg 0
b/251.airplanes-101/78DD91697DE5840D45AF40C888EFB69D.jpg 0
b/251.airplanes-101/7E9F04E7B8523AAB6AE77776C1103883.jpg 0
b/251.airplanes-101/B0113FE6B343D901B163493258BBF919.jpg 0
b/251.airplanes-101/17C58ED7CD8A3CDBB79AD8DD64AB9D0A.jpg 0
b/251.airplanes-101/4C34DA2860E01687A2172F220D39368B.jpg 0
b/251.airplanes-101/C419985418C4740BB85228D8B3F157C4.jpg 0
b/251.airplanes-101/6E3D27967CF815A6DD3BA7260A81ACC8.jpg 0
b/251.airplanes-101/27F8578B1C3157CD25387AE3580E604E.jpg 0
b/251.airplanes-101/AA2F131C6EADCAC7B05A1FAB059DBBFF.jpg 0
b/251.airplanes-101/6E74BE7740A6A0EF30BFEFCC1A7FE2DC.jpg 0
b/251.airplanes-101/92C723F600E72B846A35236CBB4F7A4B.jpg 0
b/251.airplanes-101/C56E1372BFB223FAE049EBC4917D059C.jpg 0
b/251.airplanes-101/A6F9044F6A1275795531794DE44D7D88.jpg 0
b/251.airplanes-101/211C525E9ADF1E92923FBF9FDDAD317E.jpg 0
b/251.airplanes-101/3D07CCD1290EBDFDFC26F2469B8F94A6.jpg 0
b/251.airplanes-101/0F6DD993FA6C0086C3B2D476F3128EEC.jpg 0
b/251.airplanes-101/70214AD47A30556F16A65C256AADD066.jpg 0
b/251.airplanes-101/11AAB1206CBA2BB2F966A53D9D1EE087.jpg 0
b/251.airplanes-101/F9016E99A54A7EE51FBBE6E13FF5AE0F.jpg 0
b/251.airplanes-101/D4821FE0B02A69FCE94ADEA98828C687.jpg 0
b/251.airplanes-101/0CBDC7E01B8280AC537A9FA32D897D62.jpg 0
b/251.airplanes-101/8928965F493DB82C700227DD207C4B6C.jpg 0
b/251.airplanes-101/10EC208950F689A3377AC2F9566BE86C.jpg 0
b/251.airplanes-101/5764B3EB17C3D76AF1826F7EA8B226AF.jpg 0
b/251.airplanes-101/09EC5D53CE789A34F3E05DB048B55849.jpg 0
b/251.airplanes-101/007859D83594D527355CA287E096218B.jpg 0
b/251.airplanes-101/9CEBB04C1B69A165740138ABE077645E.jpg 0
b/251.airplanes-101/060FBA0F642012BCC2F4E427E7444248.jpg 0
b/251.airplanes-101/FDDE05B3132C71CE3E07C4182199B9CB.jpg 0
b/251.airplanes-101/652823C3559FF2C5C15A25ECA120A626.jpg 0
b/251.airplanes-101/3504460129C1001C390F787870CB1DD4.jpg 0
b/251.airplanes-101/8D1A5ADB91499E383ED331ED912B09EC.jpg 0
b/251.airplanes-101/27205A7335FA260E8446F9371AD9A3C4.jpg 0
b/251.airplanes-101/9228DF8B79C57CDEB6A23D94A34232E3.jpg 0
b/251.airplanes-101/5C915F5961F37AD219CA5DCDFF2B78BA.jpg 0
b/251.airplanes-101/95498E27EC444C2BBC56FC86CF245165.jpg 0
b/251.airplanes-101/33D891118F9D9D6090B033394B7D2B7E.jpg 0
b/251.airplanes-101/B08A893A4CFF2B0F3B39CF1CBF2385D2.jpg 0
================================================
FILE: code/deep/B-JMMD/caffe/data/imageCLEF/cList.txt
================================================
/home/mcj/dataset/imageCLEF/c/113_0114.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0025.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0003.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0034.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0058.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0042.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0057.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0083.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0055.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0109.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0090.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0060.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0074.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0012.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0030.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0099.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0115.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0054.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0062.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0035.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0103.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0036.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0029.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0037.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0010.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0020.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0048.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0051.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0061.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0068.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0108.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0014.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0031.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0095.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0066.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0002.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0013.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0001.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0022.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0016.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0116.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0011.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0046.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0071.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0092.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0072.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0050.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0070.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0089.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0064.jpg 2
/home/mcj/dataset/imageCLEF/c/224_0053.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0021.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0061.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0057.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0015.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0072.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0096.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0063.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0063.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0035.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0041.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0110.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0082.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0023.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0011.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0071.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0044.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0066.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0051.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0074.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0040.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0098.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0007.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0008.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0062.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0107.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0027.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0021.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0087.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0046.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0004.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0097.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0073.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0006.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0070.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0092.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0054.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0072.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0039.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0068.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0080.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0016.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0045.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0078.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0059.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0025.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0017.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0067.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0022.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0003.jpg 1
/home/mcj/dataset/imageCLEF/c/105_0250.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0022.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0010.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0229.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0248.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0132.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0055.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0069.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0067.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0268.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0192.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0068.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0140.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0218.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0044.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0100.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0222.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0003.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0175.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0242.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0247.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0023.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0061.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0223.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0065.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0238.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0062.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0105.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0191.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0073.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0173.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0212.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0082.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0030.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0092.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0138.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0113.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0117.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0129.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0252.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0141.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0094.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0115.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0116.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0179.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0060.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0139.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0133.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0221.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0204.jpg 8
/home/mcj/dataset/imageCLEF/c/159_0068.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0017.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0046.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0158.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0074.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0199.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0137.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0060.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0048.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0200.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0098.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0180.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0160.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0178.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0134.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0022.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0186.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0129.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0170.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0179.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0196.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0126.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0182.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0108.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0055.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0197.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0149.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0176.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0094.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0096.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0141.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0120.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0030.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0114.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0009.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0163.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0039.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0045.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0021.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0131.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0041.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0066.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0153.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0181.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0024.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0143.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0043.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0166.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0040.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0083.jpg 11
/home/mcj/dataset/imageCLEF/c/046_0076.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0087.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0100.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0072.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0069.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0025.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0124.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0105.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0128.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0005.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0001.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0021.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0023.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0093.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0058.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0106.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0050.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0060.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0026.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0014.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0054.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0077.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0048.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0066.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0110.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0020.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0024.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0008.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0038.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0096.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0121.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0102.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0051.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0006.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0062.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0052.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0073.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0012.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0118.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0114.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0092.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0067.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0079.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0113.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0085.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0101.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0040.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0104.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0013.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0017.jpg 9
/home/mcj/dataset/imageCLEF/c/246_0100.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0048.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0070.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0011.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0038.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0029.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0086.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0044.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0037.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0056.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0083.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0042.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0055.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0039.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0018.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0064.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0053.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0052.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0033.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0058.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0041.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0067.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0008.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0093.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0045.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0002.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0101.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0043.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0020.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0031.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0096.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0049.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0074.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0005.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0071.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0057.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0085.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0082.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0034.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0062.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0010.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0061.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0017.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0028.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0035.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0084.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0030.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0098.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0088.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0032.jpg 4
/home/mcj/dataset/imageCLEF/c/145_0167.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0511.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0555.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0758.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0692.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0074.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0155.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0267.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0314.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0127.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0069.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0635.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0234.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0338.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0462.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0422.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0233.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0697.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0084.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0266.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0413.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0552.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0450.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0284.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0442.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0636.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0185.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0451.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0476.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0087.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0776.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0734.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0719.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0223.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0533.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0513.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0780.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0560.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0458.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0494.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0798.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0559.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0277.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0742.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0322.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0191.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0165.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0715.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0433.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0032.jpg 10
/home/mcj/dataset/imageCLEF/c/178_0050.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0091.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0062.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0068.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0045.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0031.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0079.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0046.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0037.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0013.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0074.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0051.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0034.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0040.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0010.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0041.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0017.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0016.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0005.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0025.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0097.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0078.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0058.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0067.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0027.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0012.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0044.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0060.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0043.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0087.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0085.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0004.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0047.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0029.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0080.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0039.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0065.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0083.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0002.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0061.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0095.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0054.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0022.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0053.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0030.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0071.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0090.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0092.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0077.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0064.jpg 5
/home/mcj/dataset/imageCLEF/c/251_0041.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0095.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0069.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0561.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0326.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0478.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0121.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0390.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0419.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0519.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0090.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0238.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0366.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0231.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0714.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0545.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0587.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0115.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0769.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0061.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0381.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0126.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0248.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0800.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0023.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0371.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0646.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0679.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0618.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0779.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0741.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0481.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0425.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0642.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0377.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0447.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0361.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0743.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0215.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0746.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0682.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0614.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0599.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0048.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0389.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0766.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0189.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0404.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0183.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0570.jpg 0
/home/mcj/dataset/imageCLEF/c/056_0021.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0043.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0100.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0055.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0078.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0031.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0095.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0101.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0076.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0037.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0009.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0013.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0048.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0057.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0046.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0072.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0014.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0050.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0023.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0039.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0024.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0069.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0038.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0093.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0058.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0063.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0082.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0077.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0099.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0052.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0070.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0054.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0064.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0081.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0056.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0028.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0004.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0090.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0006.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0033.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0025.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0029.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0080.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0079.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0065.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0088.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0061.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0001.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0016.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0091.jpg 7
/home/mcj/dataset/imageCLEF/c/252_0059.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0092.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0085.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0068.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0098.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0087.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0034.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0003.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0077.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0062.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0045.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0043.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0073.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0002.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0005.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0114.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0042.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0113.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0089.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0037.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0052.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0028.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0083.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0056.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0109.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0078.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0039.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0093.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0026.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0076.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0071.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0044.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0040.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0091.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0027.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0115.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0074.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0025.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0104.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0033.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0105.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0116.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0007.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0111.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0064.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0006.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0070.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0082.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0080.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0029.jpg 6
/home/mcj/dataset/imageCLEF/c/197_0019.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0087.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0059.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0038.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0064.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0043.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0012.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0037.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0010.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0013.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0074.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0079.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0014.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0091.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0068.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0060.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0077.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0011.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0051.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0052.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0057.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0007.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0085.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0058.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0016.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0001.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0082.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0028.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0030.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0034.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0055.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0073.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0031.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0065.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0070.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0099.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0081.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0035.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0090.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0025.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0047.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0040.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0084.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0054.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0046.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0004.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0053.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0061.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0020.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0049.jpg 3
================================================
FILE: code/deep/B-JMMD/caffe/data/imageCLEF/iList.txt
================================================
/home/mcj/dataset/imageCLEF/i/n02691156_7563.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_30456.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_4273.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_21342.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11944.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_8007.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2510.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1682.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_30294.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6973.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2351.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12350.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6382.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10045.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1663.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12546.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_240.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_49198.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7515.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2701.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10027.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_29561.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11169.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10494.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_54301.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1806.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38031.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38968.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_3107.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11788.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_3581.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7304.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12581.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11550.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_31395.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_52254.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7196.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6587.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1015.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38570.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6673.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_9079.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_5975.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6122.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7027.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11729.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2289.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_89.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_4662.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_14912.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02084071_12460.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_766.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_25409.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1389.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1445.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_15074.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_18746.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_7940.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_23498.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_23239.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_661.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_525.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_11564.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32835.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32500.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_9138.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_4657.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27936.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_760.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32569.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_17496.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_2103.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_11287.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_31709.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_5662.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_5128.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_182.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_24007.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22620.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_29560.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27730.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_34874.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_25631.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_17180.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_2732.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_7098.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_16131.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1848.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_19134.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_545.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_243.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22252.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_8803.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22378.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_31703.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_108.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_26796.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27298.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_29282.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_28769.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02858304_9777.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_837.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9962.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_576.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_236.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1610.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1921.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3759.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3730.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_20876.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_7454.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9208.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_169.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_312.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3137.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_676.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3574.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1249.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1883.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9938.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3268.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3030.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_917.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3175.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2400.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_416.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_746.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4082.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_454.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3112.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9362.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8049.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9973.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_19915.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2818.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4052.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2348.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_379.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8479.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_10332.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1612.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_10526.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8155.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4545.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2126.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_391.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2049.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_7231.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2175.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9844.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02924116_64004.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_84238.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_53329.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_9012.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73751.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_56702.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_85589.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_34753.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_20498.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_57267.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_38704.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_93395.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_14503.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_51663.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33800.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73378.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_39743.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_10156.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_78093.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_18209.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73434.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3470.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_61109.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_61339.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_35958.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_84781.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33755.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_43906.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_67006.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73904.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_44980.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_78812.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37730.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_82999.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37402.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73389.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3941.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_77225.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_8054.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_50926.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_68762.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_95090.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_82453.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37624.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_65903.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33400.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_647.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_86629.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3352.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_30382.JPEG 5
/home/mcj/dataset/imageCLEF/i/n03782190_12209.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2426.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5658.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2152.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11158.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_13975.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_225.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15774.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14408.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_12880.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5464.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7494.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4205.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_12034.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4945.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4268.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_10175.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14532.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2218.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_9627.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_8233.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_9951.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_6762.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14178.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4015.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1982.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1626.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1214.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15928.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2513.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5220.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_220.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_19506.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1776.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11918.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_20760.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11999.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7533.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15896.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2523.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7111.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14888.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_6319.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2154.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_17955.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4211.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_3964.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11648.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7286.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_17779.JPEG 9
/home/mcj/dataset/imageCLEF/i/n07942152_33397.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27123.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_19556.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_56.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_12547.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_76119.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_22807.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_32300.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33090.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_13151.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_56835.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_36134.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_16845.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_9563.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_16633.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8261.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27105.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_4183.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_34434.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_18551.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_413.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_510.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27529.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_31584.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_38507.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37969.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_30118.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_3594.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5568.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_35239.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5588.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_42078.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_34679.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8418.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_24975.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_28165.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8542.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5592.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_4777.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33797.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_14349.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_36072.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_40587.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37972.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33751.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_14138.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27703.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27649.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_38584.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37885.JPEG 11
/home/mcj/dataset/imageCLEF/i/n01503061_1868.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_11612.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5453.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_8646.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4167.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_17521.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1387.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12696.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2819.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2744.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2378.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6413.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_688.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3094.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2076.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1457.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2839.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13213.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13929.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14761.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1202.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1780.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9799.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5215.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1227.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6456.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3028.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6454.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_552.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9622.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1825.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12735.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14886.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_10665.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12662.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14700.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4379.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13119.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3862.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5054.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2167.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_11048.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4150.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13495.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1306.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_7783.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13307.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9390.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9081.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2386.JPEG 2
/home/mcj/dataset/imageCLEF/i/n02374451_12030.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_151.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15002.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9975.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2978.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4722.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_8251.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13125.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_6254.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4795.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_1284.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16310.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_6017.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13929.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_5598.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_5013.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16603.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15685.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14586.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_17474.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_816.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15098.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9897.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14233.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15663.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13953.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11173.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12024.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12086.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_19198.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_20103.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_8301.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16785.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15633.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14329.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_597.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_820.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2944.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9264.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11057.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13159.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4240.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11483.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4479.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2846.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_18419.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12376.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_18141.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16449.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_1062.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02834778_5790.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8639.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10647.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6733.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5206.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10288.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_763.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_1533.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3090.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8949.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5311.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6571.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12206.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_2196.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4013.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5247.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8507.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9153.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_43697.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5420.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_11280.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_716.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_31006.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8044.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_7161.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9223.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_11400.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5314.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10781.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_187.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3345.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10227.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_817.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_700.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_46418.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6597.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4695.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3311.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8918.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3735.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3119.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_32473.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_2737.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_673.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6375.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9232.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12188.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4302.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12386.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12754.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02876657_13023.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5177.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7612.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7965.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_3827.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12118.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7993.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7201.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4709.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_15101.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_9504.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_3720.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2631.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_8629.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2245.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7018.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2856.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_13959.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6293.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10725.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7886.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5324.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11443.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5481.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12301.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7718.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7244.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7535.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11695.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2625.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_198.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_668.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4138.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5822.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10178.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5094.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_14142.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10103.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7576.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5276.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6246.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_8209.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5612.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2191.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_16228.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4991.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12397.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12206.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11898.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6550.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02958343_4976.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_80662.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9147.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4414.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_12811.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_80339.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8796.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8490.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_3541.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14006.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9672.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8811.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_75694.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_44103.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11718.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_67754.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11586.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14713.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4478.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_6654.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_939.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4881.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13459.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_10892.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_5281.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_3098.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13760.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_10580.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9561.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_52439.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8307.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_50886.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9154.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13352.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4524.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_5126.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9290.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4643.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9081.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8712.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_61122.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_12116.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_55286.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_65338.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14347.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8994.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_77917.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11703.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_2032.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11693.JPEG 6
/home/mcj/dataset/imageCLEF/i/n03790512_722.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9326.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13080.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7537.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_2370.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_37212.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11812.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13431.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10965.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10260.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_2068.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9022.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11545.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_17139.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_40609.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8982.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12426.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10023.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9187.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8654.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7308.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11298.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14972.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12946.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12093.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_25915.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14967.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5081.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9328.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_4460.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8100.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_38917.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6136.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5722.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11613.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14709.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6062.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9794.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6410.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7851.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10451.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8955.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_310.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7743.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6050.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10888.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5892.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_248.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_1579.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13338.JPEG 10
================================================
FILE: code/deep/B-JMMD/caffe/data/imageCLEF/pList.txt
================================================
/home/mcj/dataset/imageCLEF/p/2008_006463.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_000163.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_003635.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002888.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_002695.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003423.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007970.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_005834.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002199.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000387.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003703.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000801.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003559.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000545.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004312.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_006951.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002432.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003737.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003933.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001044.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_005224.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002993.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_003199.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002752.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003575.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000437.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_001139.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_004414.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_005905.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002914.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002714.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000734.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004063.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_005215.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002675.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007758.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_001199.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001489.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003033.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000418.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_001413.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001858.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002999.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000270.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_004653.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_000291.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004917.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000661.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007442.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002751.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_001585.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002947.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008231.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_001030.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001011.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000689.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004205.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000568.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_004814.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004794.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_001408.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_000559.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001690.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004285.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008745.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_001223.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002499.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002519.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002809.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_000324.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004222.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002987.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008659.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_005168.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_003071.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004666.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001952.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004708.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002758.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006145.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002097.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001581.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008162.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_002285.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002675.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002908.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000552.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000203.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_000529.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002700.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006554.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006991.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004032.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000965.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004160.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_003020.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008705.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002067.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_002346.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_005825.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004197.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000199.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_005196.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002203.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002436.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005959.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003293.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_008343.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_000603.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000335.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_004794.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001403.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000267.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001967.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002066.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001822.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004637.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001105.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002566.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_003673.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_002330.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002105.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000007.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001646.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000138.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_000947.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_003114.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002263.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002398.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_006483.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003173.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005118.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001847.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001098.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001536.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005063.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001341.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005080.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000140.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_004040.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001110.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001771.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002102.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_008080.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_005279.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001675.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001590.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003534.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004997.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002052.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004766.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004345.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000927.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004845.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_003947.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005637.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_002894.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_000495.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_002408.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005427.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000496.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_000545.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001135.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005252.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005199.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001805.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004502.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004615.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000512.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_001040.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003249.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003618.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004371.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_002191.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000034.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003429.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005997.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005893.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001646.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_000695.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001150.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003560.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_002598.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_004143.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_001828.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003020.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003090.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004117.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008218.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003747.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004738.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008097.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_007558.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_002115.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_007075.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004084.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001119.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001631.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003639.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008227.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_002453.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_002871.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000086.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001221.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007750.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004969.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_005923.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007643.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_003025.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_001289.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001591.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_001916.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003858.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005198.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007841.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002662.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000435.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002308.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004291.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003652.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000286.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001901.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004053.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003936.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002449.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_002150.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_001406.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001001.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005705.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004124.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_004224.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_002104.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_000686.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_003640.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007305.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_002773.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005192.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002543.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_005517.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_005015.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_002854.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003019.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001991.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_001858.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001310.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003136.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_004714.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_003815.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003362.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003480.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002975.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003782.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_008279.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_003128.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_000765.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006317.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_001956.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004134.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004942.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001837.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000409.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004624.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000412.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007625.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_002583.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007004.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_002697.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001934.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_000749.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006219.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_001759.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003272.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003800.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_002168.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_003714.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_000076.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_004228.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007576.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001218.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004790.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001323.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006758.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007588.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_002589.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_002341.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000771.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_001675.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004705.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001542.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004195.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003802.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_005525.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001433.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000001.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_002882.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007531.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004764.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003055.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000022.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000210.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_003551.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001726.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002513.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000244.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_002758.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001553.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_004665.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005744.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003264.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007038.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006624.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_005030.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_002464.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005410.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002247.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_000253.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_004009.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005345.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007361.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002843.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005305.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_003236.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003885.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000305.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005817.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001910.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005066.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007536.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003667.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_002418.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005954.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_005288.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001608.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_000435.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005064.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_004807.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006591.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001705.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_003140.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002152.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_003035.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007446.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001106.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000070.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003435.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006233.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_001481.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_003078.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_002066.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_000981.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005325.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006310.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_002807.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_001901.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_005865.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_003647.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_003031.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004290.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004271.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003139.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000631.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004411.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000390.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001717.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000720.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_002746.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007171.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006833.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007739.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007090.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_002199.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001681.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007877.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_002598.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001007.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006989.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_004349.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_003114.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004518.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_002585.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000886.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006483.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_001403.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003562.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006872.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004711.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_002380.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003129.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_001271.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003450.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_000176.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000737.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_000947.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005733.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001432.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_004690.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005804.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007364.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_000719.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004923.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005671.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_000655.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_004688.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002398.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_001687.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_000317.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007286.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002674.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_005109.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001838.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_003801.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001626.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001432.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004345.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_004772.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001768.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001422.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004227.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001421.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_001420.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_000981.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_005379.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_002605.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007583.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007358.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_002865.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006724.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_000263.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_005333.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_002239.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006032.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003351.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003056.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000419.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001756.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006716.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000162.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003554.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_000874.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002644.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_002900.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004417.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002129.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003879.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000931.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007208.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006220.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_001538.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_001550.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_003735.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_008724.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003828.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000820.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_001642.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000445.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_004758.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_001119.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000453.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003701.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005000.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000087.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005374.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_001937.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_005154.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003175.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_001753.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002714.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002927.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002497.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_006070.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008758.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_002913.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005226.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_001384.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008337.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003075.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000505.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005782.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_000133.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004876.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002883.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005556.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003912.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_005175.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003860.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_007510.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008629.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000015.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_000803.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002679.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_000893.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_002406.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004797.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_005412.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_004995.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000485.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002787.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005848.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004848.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_002983.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002457.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_004198.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003467.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_003038.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005512.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_008072.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007219.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_001538.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002980.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003591.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005991.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_004979.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_002858.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_006145.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002186.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000801.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000290.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_005302.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_001593.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_003912.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007146.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003588.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000703.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_000089.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000691.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003635.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000522.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005663.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000953.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_004247.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_000464.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002649.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005758.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000851.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002594.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002590.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003214.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005540.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_000494.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_001908.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_001106.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003154.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_004016.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_000747.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_002455.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_005278.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_001638.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_008266.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002814.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005140.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007870.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004671.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006802.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_000621.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008523.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_005040.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006164.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007120.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_001673.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007486.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000930.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_003285.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004551.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002784.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_003426.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_000918.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008309.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007003.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_003531.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007465.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_003484.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004689.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_000103.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_001967.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002255.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000317.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008197.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001128.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000664.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_002023.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006090.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_002463.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002286.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001660.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_004187.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_001134.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002970.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007656.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000790.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007854.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002629.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_001992.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_005757.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_005428.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001397.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_001415.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002877.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_005993.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_003771.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004147.jpg 2
================================================
FILE: code/deep/B-JMMD/caffe/data/office/amazon_list.txt
================================================
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0001.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0002.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0003.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0004.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0005.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0006.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0007.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0008.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0009.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0010.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0011.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0012.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0013.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0014.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0015.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0016.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0017.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0018.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0019.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0020.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0021.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0022.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0023.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0024.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0025.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0026.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0027.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0028.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0029.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0030.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0031.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0032.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0033.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0034.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0035.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0036.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0037.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0038.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0039.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0040.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0041.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0042.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0043.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0044.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0045.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0046.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0047.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0048.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0049.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0050.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0051.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0052.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0053.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0054.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0055.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0056.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0057.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0058.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0059.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0060.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0061.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0062.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0063.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0064.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0065.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0066.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0067.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0068.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0069.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0070.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0071.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0072.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0073.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0074.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0075.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0076.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0077.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0078.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0079.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0080.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0081.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0082.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0083.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0084.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0085.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0086.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0087.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0088.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0089.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0090.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0091.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0092.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0093.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/calculator/frame_0094.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0001.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0002.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0003.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0004.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0005.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0006.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0007.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0008.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0009.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0010.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0011.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0012.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0013.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0014.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0015.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0016.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0017.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0018.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0019.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0020.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0021.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0022.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0023.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0024.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0025.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0026.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0027.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0028.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0029.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0030.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0031.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0032.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0033.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0034.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0035.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0036.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0037.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0038.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0039.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0040.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0041.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0042.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0043.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0044.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0045.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0046.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0047.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0048.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0049.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0050.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0051.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0052.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0053.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0054.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0055.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0056.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0057.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0058.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0059.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0060.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0061.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0062.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0063.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0064.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0065.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0066.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0067.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0068.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0069.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0070.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0071.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0072.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0073.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0074.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0075.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0076.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0077.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0078.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0079.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0080.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0081.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0082.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0083.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0084.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0085.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0086.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0087.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0088.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0089.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ring_binder/frame_0090.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0001.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0002.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0003.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0004.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0005.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0006.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0007.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0008.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0009.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0010.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0011.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0012.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0013.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0014.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0015.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0016.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0017.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0018.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0019.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0020.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0021.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0022.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0023.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0024.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0025.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0026.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0027.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0028.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0029.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0030.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0031.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0032.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0033.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0034.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0035.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0036.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0037.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0038.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0039.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0040.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0041.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0042.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0043.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0044.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0045.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0046.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0047.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0048.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0049.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0050.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0051.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0052.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0053.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0054.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0055.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0056.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0057.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0058.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0059.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0060.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0061.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0062.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0063.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0064.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0065.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0066.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0067.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0068.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0069.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0070.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0071.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0072.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0073.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0074.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0075.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0076.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0077.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0078.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0079.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0080.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0081.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0082.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0083.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0084.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0085.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0086.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0087.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0088.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0089.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0090.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0091.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0092.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0093.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0094.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0095.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0096.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0097.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0098.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0099.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/printer/frame_0100.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0001.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0002.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0003.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0004.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0005.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0006.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0007.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0008.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0009.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0010.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0011.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0012.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0013.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0014.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0015.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0016.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0017.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0018.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0019.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0020.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0021.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0022.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0023.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0024.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0025.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0026.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0027.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0028.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0029.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0030.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0031.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0032.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0033.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0034.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0035.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0036.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0037.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0038.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0039.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0040.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0041.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0042.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0043.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0044.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0045.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0046.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0047.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0048.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0049.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0050.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0051.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0052.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0053.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0054.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0055.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0056.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0057.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0058.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0059.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0060.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0061.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0062.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0063.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0064.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0065.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0066.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0067.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0068.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0069.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0070.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0071.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0072.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0073.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0074.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0075.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0076.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0077.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0078.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0079.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0080.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0081.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0082.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0083.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0084.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0085.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0086.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0087.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0088.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0089.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0090.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0091.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0092.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0093.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0094.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0095.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0096.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0097.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0098.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0099.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/keyboard/frame_0100.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0001.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0002.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0003.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0004.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0005.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0006.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0007.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0008.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0009.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0010.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0011.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0012.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0013.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0014.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0015.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0016.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0017.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0018.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0019.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0020.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0021.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0022.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0023.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0024.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0025.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0026.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0027.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0028.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0029.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0030.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0031.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0032.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0033.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0034.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0035.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0036.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0037.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0038.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0039.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0040.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0041.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0042.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0043.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0044.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0045.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0046.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0047.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0048.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0049.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0050.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0051.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0052.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0053.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0054.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0055.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0056.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0057.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0058.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0059.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0060.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0061.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0062.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0063.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0064.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0065.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0066.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0067.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0068.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0069.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0070.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0071.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0072.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0073.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0074.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0075.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0076.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0077.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0078.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0079.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0080.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0081.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0082.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0083.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0084.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0085.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0086.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0087.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0088.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0089.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0090.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0091.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0092.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0093.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0094.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0095.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0096.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0097.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0098.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0099.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/scissors/frame_0100.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0001.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0002.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0003.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0004.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0005.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0006.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0007.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0008.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0009.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0010.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0011.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0012.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0013.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0014.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0015.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0016.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0017.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0018.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0019.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0020.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0021.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0022.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0023.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0024.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0025.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0026.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0027.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0028.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0029.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0030.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0031.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0032.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0033.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0034.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0035.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0036.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0037.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0038.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0039.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0040.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0041.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0042.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0043.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0044.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0045.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0046.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0047.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0048.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0049.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0050.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0051.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0052.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0053.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0054.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0055.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0056.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0057.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0058.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0059.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0060.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0061.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0062.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0063.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0064.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0065.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0066.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0067.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0068.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0069.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0070.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0071.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0072.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0073.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0074.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0075.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0076.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0077.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0078.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0079.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0080.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0081.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0082.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0083.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0084.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0085.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0086.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0087.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0088.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0089.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0090.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0091.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0092.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0093.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0094.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0095.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0096.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0097.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0098.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0099.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/laptop_computer/frame_0100.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0001.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0002.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0003.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0004.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0005.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0006.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0007.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0008.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0009.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0010.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0011.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0012.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0013.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0014.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0015.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0016.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0017.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0018.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0019.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0020.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0021.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0022.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0023.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0024.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0025.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0026.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0027.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0028.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0029.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0030.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0031.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0032.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0033.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0034.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0035.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0036.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0037.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0038.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0039.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0040.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0041.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0042.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0043.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0044.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0045.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0046.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0047.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0048.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0049.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0050.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0051.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0052.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0053.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0054.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0055.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0056.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0057.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0058.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0059.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0060.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0061.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0062.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0063.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0064.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0065.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0066.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0067.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0068.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0069.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0070.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0071.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0072.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0073.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0074.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0075.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0076.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0077.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0078.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0079.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0080.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0081.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0082.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0083.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0084.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0085.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0086.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0087.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0088.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0089.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0090.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0091.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0092.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0093.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0094.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0095.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0096.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0097.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0098.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0099.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mouse/frame_0100.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0001.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0002.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0003.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0004.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0005.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0006.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0007.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0008.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0009.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0010.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0011.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0012.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0013.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0014.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0015.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0016.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0017.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0018.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0019.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0020.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0021.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0022.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0023.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0024.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0025.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0026.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0027.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0028.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0029.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0030.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0031.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0032.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0033.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0034.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0035.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0036.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0037.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0038.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0039.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0040.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0041.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0042.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0043.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0044.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0045.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0046.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0047.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0048.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0049.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0050.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0051.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0052.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0053.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0054.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0055.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0056.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0057.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0058.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0059.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0060.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0061.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0062.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0063.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0064.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0065.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0066.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0067.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0068.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0069.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0070.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0071.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0072.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0073.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0074.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0075.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0076.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0077.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0078.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0079.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0080.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0081.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0082.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0083.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0084.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0085.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0086.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0087.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0088.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0089.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0090.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0091.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0092.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0093.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0094.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0095.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0096.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0097.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0098.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/monitor/frame_0099.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0001.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0002.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0003.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0004.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0005.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0006.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0007.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0008.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0009.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0010.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0011.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0012.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0013.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0014.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0015.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0016.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0017.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0018.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0019.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0020.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0021.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0022.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0023.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0024.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0025.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0026.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0027.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0028.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0029.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0030.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0031.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0032.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0033.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0034.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0035.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0036.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0037.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0038.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0039.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0040.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0041.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0042.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0043.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0044.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0045.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0046.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0047.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0048.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0049.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0050.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0051.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0052.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0053.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0054.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0055.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0056.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0057.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0058.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0059.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0060.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0061.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0062.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0063.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0064.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0065.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0066.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0067.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0068.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0069.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0070.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0071.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0072.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0073.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0074.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0075.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0076.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0077.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0078.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0079.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0080.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0081.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0082.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0083.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0084.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0085.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0086.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0087.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0088.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0089.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0090.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0091.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0092.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0093.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mug/frame_0094.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0001.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0002.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0003.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0004.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0005.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0006.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0007.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0008.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0009.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0010.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0011.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0012.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0013.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0014.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0015.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0016.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0017.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0018.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0019.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0020.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0021.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0022.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0023.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0024.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0025.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0026.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0027.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0028.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0029.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0030.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0031.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0032.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0033.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0034.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0035.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0036.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0037.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0038.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0039.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0040.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0041.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0042.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0043.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0044.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0045.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0046.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0047.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0048.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0049.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0050.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0051.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0052.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0053.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0054.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0055.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0056.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0057.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0058.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0059.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0060.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0061.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0062.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0063.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0064.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0065.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0066.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0067.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0068.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0069.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0070.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0071.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0072.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0073.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0074.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0075.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0076.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0077.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0078.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0079.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0080.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0081.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0082.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0083.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0084.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0085.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0086.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0087.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0088.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0089.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0090.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0091.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0092.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0093.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0094.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0095.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/tape_dispenser/frame_0096.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0001.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0002.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0003.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0004.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0005.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0006.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0007.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0008.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0009.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0010.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0011.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0012.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0013.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0014.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0015.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0016.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0017.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0018.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0019.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0020.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0021.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0022.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0023.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0024.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0025.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0026.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0027.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0028.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0029.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0030.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0031.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0032.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0033.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0034.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0035.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0036.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0037.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0038.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0039.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0040.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0041.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0042.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0043.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0044.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0045.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0046.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0047.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0048.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0049.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0050.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0051.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0052.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0053.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0054.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0055.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0056.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0057.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0058.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0059.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0060.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0061.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0062.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0063.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0064.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0065.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0066.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0067.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0068.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0069.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0070.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0071.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0072.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0073.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0074.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0075.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0076.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0077.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0078.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0079.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0080.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0081.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0082.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0083.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0084.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0085.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0086.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0087.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0088.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0089.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0090.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0091.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0092.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0093.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0094.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/pen/frame_0095.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0001.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0002.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0003.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0004.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0005.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0006.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0007.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0008.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0009.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0010.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0011.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0012.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0013.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0014.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0015.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0016.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0017.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0018.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0019.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0020.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0021.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0022.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0023.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0024.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0025.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0026.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0027.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0028.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0029.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0030.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0031.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0032.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0033.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0034.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0035.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0036.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0037.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0038.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0039.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0040.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0041.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0042.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0043.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0044.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0045.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0046.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0047.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0048.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0049.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0050.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0051.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0052.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0053.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0054.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0055.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0056.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0057.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0058.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0059.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0060.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0061.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0062.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0063.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0064.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0065.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0066.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0067.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0068.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0069.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0070.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0071.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0072.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0073.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0074.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0075.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0076.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0077.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0078.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0079.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0080.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0081.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike/frame_0082.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0001.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0002.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0003.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0004.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0005.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0006.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0007.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0008.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0009.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0010.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0011.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0012.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0013.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0014.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0015.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0016.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0017.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0018.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0019.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0020.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0021.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0022.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0023.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0024.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0025.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0026.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0027.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0028.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0029.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0030.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0031.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0032.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0033.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0034.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0035.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0036.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0037.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0038.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0039.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0040.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0041.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0042.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0043.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0044.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0045.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0046.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0047.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0048.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0049.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0050.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0051.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0052.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0053.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0054.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0055.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0056.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0057.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0058.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0059.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0060.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0061.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0062.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0063.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0064.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0065.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0066.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0067.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0068.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0069.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0070.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0071.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0072.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0073.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0074.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0075.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0076.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0077.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0078.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0079.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0080.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0081.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0082.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0083.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0084.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0085.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0086.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0087.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0088.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0089.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0090.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0091.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0092.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0093.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0094.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0095.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0096.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0097.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/punchers/frame_0098.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0001.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0002.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0003.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0004.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0005.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0006.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0007.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0008.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0009.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0010.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0011.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0012.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0013.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0014.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0015.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0016.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0017.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0018.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0019.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0020.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0021.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0022.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0023.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0024.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0025.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0026.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0027.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0028.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0029.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0030.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0031.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0032.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0033.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0034.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0035.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0036.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0037.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0038.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0039.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0040.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0041.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0042.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0043.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0044.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0045.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0046.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0047.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0048.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0049.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0050.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0051.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0052.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0053.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0054.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0055.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0056.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0057.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0058.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0059.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0060.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0061.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0062.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0063.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0064.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0065.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0066.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0067.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0068.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0069.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0070.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0071.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0072.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0073.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0074.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0075.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0076.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0077.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0078.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0079.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0080.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0081.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0082.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0083.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0084.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0085.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0086.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0087.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0088.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0089.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0090.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0091.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/back_pack/frame_0092.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0001.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0002.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0003.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0004.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0005.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0006.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0007.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0008.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0009.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0010.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0011.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0012.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0013.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0014.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0015.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0016.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0017.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0018.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0019.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0020.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0021.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0022.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0023.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0024.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0025.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0026.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0027.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0028.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0029.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0030.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0031.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0032.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0033.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0034.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0035.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0036.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0037.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0038.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0039.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0040.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0041.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0042.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0043.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0044.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0045.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0046.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0047.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0048.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0049.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0050.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0051.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0052.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0053.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0054.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0055.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0056.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0057.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0058.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0059.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0060.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0061.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0062.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0063.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0064.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0065.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0066.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0067.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0068.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0069.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0070.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0071.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0072.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0073.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0074.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0075.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0076.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0077.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0078.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0079.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0080.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0081.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0082.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0083.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0084.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0085.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0086.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0087.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0088.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0089.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0090.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0091.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0092.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0093.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0094.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0095.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0096.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desktop_computer/frame_0097.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0001.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0002.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0003.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0004.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0005.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0006.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0007.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0008.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0009.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0010.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0011.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0012.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0013.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0014.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0015.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0016.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0017.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0018.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0019.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0020.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0021.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0022.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0023.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0024.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0025.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0026.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0027.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0028.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0029.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0030.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0031.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0032.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0033.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0034.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0035.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0036.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0037.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0038.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0039.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0040.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0041.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0042.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0043.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0044.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0045.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0046.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0047.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0048.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0049.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0050.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0051.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0052.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0053.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0054.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0055.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0056.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0057.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0058.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0059.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0060.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0061.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0062.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0063.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0064.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0065.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0066.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0067.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0068.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0069.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0070.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0071.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0072.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0073.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0074.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0075.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0076.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0077.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0078.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0079.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0080.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0081.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0082.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0083.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0084.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0085.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0086.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0087.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0088.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0089.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0090.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0091.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0092.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0093.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0094.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0095.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0096.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0097.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0098.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/speaker/frame_0099.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0001.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0002.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0003.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0004.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0005.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0006.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0007.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0008.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0009.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0010.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0011.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0012.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0013.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0014.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0015.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0016.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0017.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0018.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0019.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0020.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0021.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0022.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0023.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0024.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0025.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0026.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0027.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0028.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0029.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0030.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0031.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0032.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0033.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0034.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0035.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0036.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0037.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0038.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0039.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0040.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0041.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0042.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0043.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0044.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0045.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0046.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0047.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0048.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0049.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0050.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0051.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0052.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0053.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0054.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0055.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0056.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0057.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0058.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0059.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0060.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0061.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0062.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0063.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0064.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0065.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0066.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0067.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0068.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0069.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0070.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0071.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0072.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0073.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0074.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0075.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0076.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0077.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0078.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0079.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0080.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0081.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0082.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0083.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0084.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0085.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0086.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0087.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0088.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0089.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0090.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0091.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0092.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0093.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0094.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0095.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0096.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0097.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0098.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0099.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/mobile_phone/frame_0100.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0001.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0002.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0003.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0004.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0005.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0006.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0007.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0008.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0009.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0010.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0011.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0012.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0013.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0014.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0015.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0016.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0017.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0018.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0019.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0020.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0021.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0022.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0023.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0024.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0025.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0026.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0027.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0028.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0029.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0030.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0031.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0032.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0033.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0034.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0035.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0036.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0037.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0038.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0039.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0040.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0041.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0042.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0043.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0044.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0045.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0046.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0047.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0048.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0049.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0050.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0051.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0052.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0053.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0054.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0055.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0056.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0057.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0058.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0059.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0060.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0061.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0062.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0063.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0064.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0065.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0066.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0067.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0068.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0069.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0070.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0071.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0072.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0073.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0074.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0075.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0076.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0077.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0078.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0079.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0080.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0081.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0082.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0083.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0084.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0085.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0086.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0087.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0088.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0089.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0090.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0091.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0092.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0093.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0094.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0095.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/paper_notebook/frame_0096.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0001.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0002.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0003.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0004.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0005.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0006.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0007.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0008.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0009.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0010.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0011.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0012.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0013.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0014.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0015.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0016.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0017.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0018.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0019.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0020.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0021.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0022.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0023.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0024.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0025.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0026.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0027.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0028.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0029.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0030.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0031.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0032.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0033.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0034.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0035.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0036.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0037.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0038.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0039.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0040.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0041.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0042.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0043.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0044.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0045.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0046.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0047.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0048.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0049.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0050.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0051.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0052.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0053.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0054.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0055.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0056.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0057.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0058.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0059.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0060.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0061.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0062.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0063.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0064.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0065.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0066.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0067.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0068.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0069.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0070.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0071.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0072.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0073.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0074.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/ruler/frame_0075.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0001.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0002.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0003.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0004.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0005.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0006.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0007.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0008.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0009.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0010.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0011.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0012.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0013.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0014.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0015.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0016.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0017.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0018.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0019.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0020.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0021.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0022.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0023.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0024.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0025.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0026.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0027.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0028.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0029.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0030.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0031.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0032.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0033.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0034.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0035.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0036.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0037.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0038.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0039.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0040.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0041.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0042.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0043.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0044.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0045.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0046.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0047.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0048.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0049.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0050.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0051.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0052.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0053.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0054.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0055.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0056.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0057.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0058.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0059.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0060.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0061.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0062.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0063.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0064.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0065.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0066.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0067.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0068.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0069.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0070.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0071.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0072.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0073.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0074.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0075.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0076.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0077.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0078.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0079.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0080.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0081.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0082.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0083.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0084.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0085.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0086.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0087.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0088.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0089.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0090.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0091.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0092.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0093.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0094.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0095.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0096.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0097.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/letter_tray/frame_0098.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0001.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0002.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0003.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0004.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0005.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0006.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0007.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0008.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0009.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0010.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0011.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0012.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0013.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0014.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0015.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0016.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0017.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0018.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0019.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0020.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0021.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0022.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0023.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0024.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0025.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0026.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0027.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0028.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0029.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0030.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0031.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0032.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0033.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0034.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0035.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0036.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0037.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0038.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0039.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0040.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0041.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0042.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0043.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0044.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0045.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0046.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0047.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0048.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0049.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0050.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0051.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0052.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0053.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0054.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0055.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0056.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0057.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0058.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0059.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0060.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0061.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0062.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0063.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0064.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0065.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0066.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0067.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0068.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0069.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0070.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0071.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0072.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0073.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0074.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0075.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0076.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0077.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0078.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0079.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0080.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/file_cabinet/frame_0081.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0001.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0002.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0003.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0004.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0005.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0006.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0007.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0008.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0009.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0010.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0011.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0012.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0013.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0014.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0015.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0016.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0017.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0018.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0019.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0020.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0021.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0022.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0023.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0024.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0025.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0026.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0027.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0028.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0029.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0030.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0031.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0032.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0033.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0034.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0035.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0036.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0037.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0038.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0039.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0040.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0041.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0042.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0043.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0044.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0045.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0046.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0047.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0048.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0049.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0050.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0051.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0052.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0053.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0054.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0055.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0056.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0057.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0058.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0059.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0060.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0061.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0062.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0063.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0064.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0065.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0066.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0067.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0068.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0069.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0070.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0071.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0072.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0073.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0074.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0075.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0076.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0077.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0078.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0079.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0080.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0081.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0082.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0083.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0084.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0085.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0086.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0087.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0088.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0089.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0090.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0091.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0092.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/phone/frame_0093.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0001.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0002.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0003.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0004.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0005.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0006.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0007.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0008.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0009.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0010.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0011.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0012.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0013.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0014.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0015.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0016.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0017.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0018.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0019.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0020.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0021.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0022.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0023.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0024.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0025.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0026.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0027.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0028.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0029.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0030.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0031.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0032.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0033.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0034.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0035.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0036.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0037.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0038.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0039.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0040.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0041.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0042.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0043.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0044.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0045.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0046.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0047.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0048.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0049.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0050.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0051.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0052.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0053.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0054.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0055.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0056.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0057.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0058.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0059.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0060.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0061.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0062.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0063.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0064.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0065.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0066.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0067.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0068.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0069.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0070.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0071.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0072.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0073.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0074.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0075.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0076.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0077.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0078.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0079.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0080.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0081.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bookcase/frame_0082.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0001.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0002.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0003.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0004.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0005.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0006.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0007.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0008.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0009.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0010.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0011.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0012.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0013.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0014.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0015.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0016.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0017.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0018.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0019.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0020.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0021.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0022.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0023.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0024.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0025.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0026.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0027.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0028.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0029.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0030.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0031.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0032.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0033.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0034.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0035.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0036.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0037.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0038.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0039.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0040.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0041.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0042.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0043.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0044.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0045.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0046.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0047.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0048.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0049.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0050.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0051.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0052.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0053.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0054.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0055.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0056.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0057.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0058.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0059.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0060.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0061.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0062.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0063.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0064.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0065.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0066.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0067.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0068.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0069.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0070.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0071.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0072.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0073.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0074.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0075.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0076.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0077.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0078.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0079.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0080.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0081.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0082.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0083.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0084.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0085.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0086.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0087.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0088.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0089.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0090.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0091.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0092.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0093.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0094.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0095.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0096.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0097.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/projector/frame_0098.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0001.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0002.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0003.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0004.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0005.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0006.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0007.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0008.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0009.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0010.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0011.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0012.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0013.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0014.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0015.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0016.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0017.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0018.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0019.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0020.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0021.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0022.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0023.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0024.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0025.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0026.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0027.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0028.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0029.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0030.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0031.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0032.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0033.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0034.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0035.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0036.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0037.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0038.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0039.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0040.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0041.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0042.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0043.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0044.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0045.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0046.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0047.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0048.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0049.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0050.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0051.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0052.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0053.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0054.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0055.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0056.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0057.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0058.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0059.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0060.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0061.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0062.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0063.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0064.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0065.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0066.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0067.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0068.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0069.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0070.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0071.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0072.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0073.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0074.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0075.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0076.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0077.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0078.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0079.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0080.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0081.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0082.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0083.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0084.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0085.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0086.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0087.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0088.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0089.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0090.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0091.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0092.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0093.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0094.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0095.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0096.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0097.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0098.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/stapler/frame_0099.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0001.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0002.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0003.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0004.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0005.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0006.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0007.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0008.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0009.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0010.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0011.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0012.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0013.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0014.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0015.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0016.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0017.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0018.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0019.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0020.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0021.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0022.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0023.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0024.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0025.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0026.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0027.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0028.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0029.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0030.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0031.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0032.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0033.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0034.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0035.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0036.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0037.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0038.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0039.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0040.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0041.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0042.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0043.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0044.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0045.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0046.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0047.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0048.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0049.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0050.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0051.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0052.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0053.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0054.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0055.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0056.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0057.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0058.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0059.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0060.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0061.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0062.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0063.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/trash_can/frame_0064.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0001.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0002.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0003.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0004.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0005.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0006.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0007.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0008.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0009.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0010.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0011.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0012.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0013.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0014.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0015.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0016.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0017.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0018.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0019.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0020.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0021.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0022.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0023.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0024.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0025.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0026.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0027.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0028.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0029.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0030.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0031.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0032.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0033.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0034.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0035.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0036.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0037.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0038.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0039.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0040.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0041.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0042.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0043.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0044.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0045.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0046.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0047.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0048.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0049.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0050.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0051.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0052.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0053.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0054.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0055.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0056.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0057.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0058.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0059.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0060.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0061.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0062.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0063.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0064.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0065.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0066.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0067.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0068.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0069.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0070.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0071.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bike_helmet/frame_0072.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0001.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0002.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0003.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0004.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0005.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0006.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0007.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0008.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0009.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0010.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0011.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0012.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0013.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0014.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0015.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0016.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0017.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0018.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0019.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0020.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0021.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0022.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0023.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0024.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0025.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0026.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0027.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0028.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0029.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0030.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0031.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0032.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0033.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0034.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0035.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0036.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0037.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0038.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0039.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0040.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0041.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0042.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0043.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0044.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0045.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0046.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0047.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0048.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0049.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0050.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0051.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0052.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0053.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0054.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0055.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0056.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0057.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0058.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0059.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0060.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0061.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0062.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0063.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0064.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0065.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0066.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0067.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0068.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0069.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0070.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0071.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0072.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0073.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0074.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0075.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0076.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0077.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0078.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0079.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0080.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0081.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0082.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0083.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0084.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0085.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0086.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0087.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0088.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0089.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0090.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0091.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0092.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0093.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0094.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0095.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0096.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0097.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0098.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/headphones/frame_0099.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0001.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0002.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0003.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0004.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0005.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0006.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0007.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0008.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0009.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0010.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0011.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0012.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0013.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0014.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0015.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0016.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0017.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0018.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0019.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0020.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0021.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0022.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0023.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0024.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0025.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0026.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0027.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0028.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0029.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0030.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0031.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0032.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0033.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0034.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0035.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0036.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0037.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0038.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0039.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0040.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0041.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0042.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0043.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0044.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0045.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0046.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0047.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0048.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0049.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0050.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0051.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0052.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0053.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0054.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0055.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0056.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0057.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0058.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0059.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0060.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0061.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0062.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0063.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0064.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0065.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0066.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0067.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0068.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0069.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0070.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0071.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0072.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0073.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0074.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0075.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0076.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0077.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0078.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0079.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0080.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0081.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0082.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0083.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0084.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0085.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0086.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0087.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0088.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0089.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0090.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0091.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0092.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0093.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0094.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0095.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0096.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_lamp/frame_0097.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0001.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0002.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0003.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0004.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0005.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0006.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0007.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0008.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0009.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0010.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0011.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0012.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0013.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0014.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0015.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0016.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0017.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0018.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0019.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0020.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0021.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0022.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0023.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0024.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0025.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0026.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0027.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0028.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0029.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0030.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0031.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0032.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0033.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0034.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0035.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0036.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0037.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0038.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0039.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0040.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0041.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0042.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0043.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0044.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0045.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0046.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0047.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0048.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0049.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0050.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0051.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0052.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0053.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0054.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0055.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0056.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0057.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0058.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0059.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0060.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0061.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0062.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0063.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0064.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0065.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0066.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0067.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0068.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0069.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0070.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0071.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0072.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0073.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0074.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0075.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0076.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0077.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0078.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0079.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0080.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0081.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0082.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0083.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0084.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0085.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0086.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0087.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0088.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0089.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0090.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/desk_chair/frame_0091.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0001.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0002.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0003.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0004.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0005.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0006.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0007.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0008.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0009.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0010.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0011.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0012.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0013.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0014.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0015.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0016.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0017.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0018.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0019.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0020.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0021.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0022.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0023.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0024.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0025.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0026.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0027.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0028.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0029.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0030.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0031.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0032.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0033.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0034.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0035.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/amazon/images/bottle/frame_0036.jpg 4
================================================
FILE: code/deep/B-JMMD/caffe/data/office/bList.txt
================================================
b/252.car-side-101/252_0446.jpg 6
b/252.car-side-101/252_0337.jpg 6
b/252.car-side-101/252_0493.jpg 6
b/252.car-side-101/252_0242.jpg 6
b/252.car-side-101/252_0057.jpg 6
b/252.car-side-101/252_0273.jpg 6
b/252.car-side-101/252_0505.jpg 6
b/252.car-side-101/252_0345.jpg 6
b/252.car-side-101/252_0463.jpg 6
b/252.car-side-101/252_0408.jpg 6
b/252.car-side-101/252_0173.jpg 6
b/252.car-side-101/252_0300.jpg 6
b/252.car-side-101/252_0142.jpg 6
b/252.car-side-101/252_0030.jpg 6
b/252.car-side-101/252_0036.jpg 6
b/252.car-side-101/252_0487.jpg 6
b/252.car-side-101/252_0033.jpg 6
b/252.car-side-101/252_0481.jpg 6
b/252.car-side-101/252_0297.jpg 6
b/252.car-side-101/252_0397.jpg 6
b/252.car-side-101/252_0280.jpg 6
b/252.car-side-101/252_0424.jpg 6
b/252.car-side-101/252_0278.jpg 6
b/252.car-side-101/252_0445.jpg 6
b/252.car-side-101/252_0267.jpg 6
b/252.car-side-101/252_0331.jpg 6
b/252.car-side-101/252_0092.jpg 6
b/252.car-side-101/252_0494.jpg 6
b/252.car-side-101/252_0211.jpg 6
b/252.car-side-101/252_0014.jpg 6
b/252.car-side-101/252_0438.jpg 6
b/252.car-side-101/252_0072.jpg 6
b/252.car-side-101/252_0327.jpg 6
b/252.car-side-101/252_0025.jpg 6
b/252.car-side-101/252_0196.jpg 6
b/252.car-side-101/252_0285.jpg 6
b/252.car-side-101/252_0400.jpg 6
b/252.car-side-101/252_0467.jpg 6
b/252.car-side-101/252_0232.jpg 6
b/252.car-side-101/252_0279.jpg 6
b/252.car-side-101/252_0189.jpg 6
b/252.car-side-101/252_0187.jpg 6
b/252.car-side-101/252_0229.jpg 6
b/252.car-side-101/252_0066.jpg 6
b/252.car-side-101/252_0499.jpg 6
b/252.car-side-101/252_0016.jpg 6
b/252.car-side-101/252_0175.jpg 6
b/252.car-side-101/252_0512.jpg 6
b/252.car-side-101/252_0296.jpg 6
b/252.car-side-101/252_0144.jpg 6
b/046.computer-monitor/99B047454CD9B6D811D0288BE087715E.jpg 9
b/046.computer-monitor/4368FC8E03F2A288ADF2DCDBD712E750.jpg 9
b/046.computer-monitor/954071A67971CBA89764EDB20428D8F3.jpg 9
b/046.computer-monitor/8EB65F199E94D875FFD6768F35710276.jpg 9
b/046.computer-monitor/A04FC61BCC99C49B353D39F7D471D554.jpg 9
b/046.computer-monitor/A4088A337FAB3ECA4D7520729FC56AEF.jpg 9
b/046.computer-monitor/A692A3E48919A104D3A706C94844A4C2.jpg 9
b/046.computer-monitor/7FAC9E56C4F8DBF4C968445000B7DFD2.jpg 9
b/046.computer-monitor/BCA5859E1E87F738CDE4E9FCC43616AD.jpg 9
b/046.computer-monitor/16128B2C344486D5B22CCB544A498D26.jpg 9
b/046.computer-monitor/68D2FB34573152F7E5E8569257C177B4.jpg 9
b/046.computer-monitor/934CDA1D8798ACC1F31B0C0994F1A254.jpg 9
b/046.computer-monitor/07B9E5E73C8EF79063FA07B3F52F2735.jpg 9
b/046.computer-monitor/6879DEF4F6D2339688FDD82DA2C85754.jpg 9
b/046.computer-monitor/10092B6598A5EAB2C52212C76B66636F.jpg 9
b/046.computer-monitor/30E1B08A10F380EF9AF1F2C54BC37F99.jpg 9
b/046.computer-monitor/5C3E621FBCACCF9DD0783EC9C48086AB.jpg 9
b/046.computer-monitor/996A4E7860E0E124D0E28B4624EF7A3E.jpg 9
b/046.computer-monitor/7A614107DF056752DCEB1884EB48F52E.jpg 9
b/046.computer-monitor/167F8C023E0564EA731D5AD4443DCC78.jpg 9
b/046.computer-monitor/5D7D2E837FC15A257C810B6F99E8E2C3.jpg 9
b/046.computer-monitor/EAADBBFFC051985B11BF51FEA90738DD.jpg 9
b/046.computer-monitor/FF6854B0B1F13AF2FD62A3744D95F890.jpg 9
b/046.computer-monitor/01624A6E5002E7A3DF9AC102D1EE025E.jpg 9
b/046.computer-monitor/CFA34381EA85F93404A0CB2BC291D659.jpg 9
b/046.computer-monitor/E068BF4E458356B9A18A106DE11DEB62.jpg 9
b/046.computer-monitor/EF1993AEEB6D084ED31B0F29B4D01119.jpg 9
b/046.computer-monitor/040AADC700F811DA31F02DB6C3B01403.jpg 9
b/046.computer-monitor/9120B69B673D10FFF15DE9306FB63E26.jpg 9
b/046.computer-monitor/5B7D32115CEF942A9E5C67D9CE59E5BA.jpg 9
b/046.computer-monitor/4CDACA16FEB95BFA24FCC83D7AADEB51.jpg 9
b/046.computer-monitor/111002CDE28DE7FC6EC8105C0F6F1913.jpg 9
b/046.computer-monitor/7812BB4418847E19B6863BE7D93FC516.jpg 9
b/046.computer-monitor/2547D105CAEB73242F8342EE9AA0EB10.jpg 9
b/046.computer-monitor/1519B34721FF9BF0E289C4B92FA6DDE8.jpg 9
b/046.computer-monitor/C8579112A830E3894B23DD259CA6F651.jpg 9
b/046.computer-monitor/371105E72FC205275879A002EC3CBA91.jpg 9
b/046.computer-monitor/446C104E4DE6AD474C82AFFC25D97CC7.jpg 9
b/046.computer-monitor/4335FEB13FB8E95B80825CBC367B74A6.jpg 9
b/046.computer-monitor/4C543ADD81590F54708E9EE604718661.jpg 9
b/046.computer-monitor/A63E71DFFB82DDA6134F95547978D5A6.jpg 9
b/046.computer-monitor/0BD2328961DD8A5777BC756044CC41CE.jpg 9
b/046.computer-monitor/CE7003F44D239819AC24BB18D57EAF36.jpg 9
b/046.computer-monitor/C946D7BC36A1D1A6BA5B362C4B317B0B.jpg 9
b/046.computer-monitor/E3BE7EAE643951A8949B71552B12DD3C.jpg 9
b/046.computer-monitor/765653A4C9F07D2258700ED49854152E.jpg 9
b/046.computer-monitor/F2F3C096D8D349605A76EBE3B189507C.jpg 9
b/046.computer-monitor/2939ED3DAB0021BFACF058D4EB72739E.jpg 9
b/046.computer-monitor/78B37D75172C8C1F40C9B8209D9E57D2.jpg 9
b/046.computer-monitor/2BF59300B51BFF87A9F920E7D1EF2363.jpg 9
b/056.dog/E44C9A35C92B27D3F812608DE6CA910F.jpg 7
b/056.dog/9B64A10D9D3F0D8DDF0A4FD6B620F793.jpg 7
b/056.dog/016E08E303ACBDF596B0C071830D9D0E.jpg 7
b/056.dog/019B54A87F8663382B80E9EB5F11ECE6.jpg 7
b/056.dog/14706E0F6C0A886F93BDC4564D9FCF1C.jpg 7
b/056.dog/2993174C7CD5AFF712DDDCB1DD1F5F05.jpg 7
b/056.dog/1D284A29CD3A93D678C3F43A7C1240D0.jpg 7
b/056.dog/2EBBBE60D95063CBC9500076F91B1414.jpg 7
b/056.dog/A099C89E07064CB065A200ED5A56AA3D.jpg 7
b/056.dog/3574F45BD92A71A04A51302BBA3076C6.jpg 7
b/056.dog/6FD717560C67FCD1A8D69F246CDC1DBF.jpg 7
b/056.dog/5DA4CB45E851C166D7405927602BC592.jpg 7
b/056.dog/51147F65309C1B9329152EA4DFD1E7EF.jpg 7
b/056.dog/4EAD0040169FB171151B987CF678C89C.jpg 7
b/056.dog/BDDCDA3C43D1FBE339830675EE790BC4.jpg 7
b/056.dog/D93244D2E8D5FE0B0203C7E3CF032D8C.jpg 7
b/056.dog/665B2EA7D97C3ECD5961CD787B3E4B10.jpg 7
b/056.dog/44AF4192DB14121B9607E40F45852D3F.jpg 7
b/056.dog/40C049DCD2D6E864164A0FEF468DD27E.jpg 7
b/056.dog/1E8B1161C3248FBF8C8B4E2C193DBEA5.jpg 7
b/056.dog/046AE64BF285C34A173C93896F9201B7.jpg 7
b/056.dog/BF8881854887B688AE2552853B06634D.jpg 7
b/056.dog/D347B5C3B30BE0BB5DF85C17CEC9026A.jpg 7
b/056.dog/2E3EF19FEB17FB00C6EE6A6FFE9DA084.jpg 7
b/056.dog/C5DAC51DD6730DD1D8B65CA3F4260F17.jpg 7
b/056.dog/5CAC03956E4F77658D31A427918AB441.jpg 7
b/056.dog/0C64DF97C1F7D93798EE7AC39C1C5DB6.jpg 7
b/056.dog/FD03B59B87DA6912FAEE634B6745AAB0.jpg 7
b/056.dog/FDD66506D81871A8536C27563483C4A9.jpg 7
b/056.dog/D208B7A14FB2CC965D2D27D72AB0F7B6.jpg 7
b/056.dog/8E5E8683D65BB32C27556F1A92484C06.jpg 7
b/056.dog/2E182D5D0084A990BB181D029FECB134.jpg 7
b/056.dog/5D68FA5DA23492AD102E4C51D751E0C5.jpg 7
b/056.dog/757B031495A588F1288D1484103ABEF7.jpg 7
b/056.dog/A2953E5DBEA8844396FA196A136A443A.jpg 7
b/056.dog/187585E2FA471A9A3110E2E49DC23D89.jpg 7
b/056.dog/06176B915EDED374DD9538A26C9355AF.jpg 7
b/056.dog/C46892BD2F5F640D094D003966E47198.jpg 7
b/056.dog/890AB1D52F11EA1F7565D6EB22E03160.jpg 7
b/056.dog/4E5A38B53C9ECDB70994B82D0EE24324.jpg 7
b/056.dog/5CBCD72CAF98C2F10EE428C5A41095F3.jpg 7
b/056.dog/5E1D3F56E8620456A323EB3DFA28FA98.jpg 7
b/056.dog/79A4DB5AD3C4319B030C41041C1CC772.jpg 7
b/056.dog/399A73127E633BE4CF615585D1100EDB.jpg 7
b/056.dog/93A4AE80A27C7C57F09B81C82144A5AB.jpg 7
b/056.dog/C9C938D6C83343D26920F4F19F194390.jpg 7
b/056.dog/E59FF601F1D61841567C57D146D3630B.jpg 7
b/056.dog/EBEC99772324C0FCE5D5313F7109D6BA.jpg 7
b/056.dog/D80939E4CFDB90FBBD5095F6162FA29B.jpg 7
b/056.dog/0F1910541E4594BF6AE30CB4104FFB00.jpg 7
b/105.horse/303A184971074E3B4E2A8F049A5E4FE9.jpg 8
b/105.horse/897D3867A3683B2C299F1128AC4DA9EC.jpg 8
b/105.horse/9032A8B30A6BF5C274E3EBBF49BDA72D.jpg 8
b/105.horse/174BBA9C9AEEC116C8CD8263692FFB12.jpg 8
b/105.horse/EF10E0D4A505AF42D51C62301C811B1D.jpg 8
b/105.horse/DFF071F32258BE98D31E0293E0B42F52.jpg 8
b/105.horse/DF36EC86BBDBF157ECC9F71DA41F492F.jpg 8
b/105.horse/F7722CEC2C7F49DCF0300E9089FBE550.jpg 8
b/105.horse/9CB03D84405DA70A405FCD8555645736.jpg 8
b/105.horse/E4475F5F4123E77D2E64F11187269E0B.jpg 8
b/105.horse/00EFC6FC24740AD02D1322AB2847424B.jpg 8
b/105.horse/FADB6C2AB826CBFB2464734E9B28E0C6.jpg 8
b/105.horse/E865F0CCB33DC97EB24BC9FA9CC66F3C.jpg 8
b/105.horse/37FFF33C040CD9B023F2B0C739346584.jpg 8
b/105.horse/B0BE1146B7B543C5CC8BF636EBE73ABD.jpg 8
b/105.horse/CF2C04C18ACA69DEE41E4AEB3AC40F66.jpg 8
b/105.horse/2B70CCF18FF865B58AA4979943E73A4A.jpg 8
b/105.horse/AEEBA1619227AD5E712D167CB3A76560.jpg 8
b/105.horse/C69B2009A9C540609C3DFB527D433D37.jpg 8
b/105.horse/0227FDEC0640B5B4B8A2622807186F9D.jpg 8
b/105.horse/03F7E9713302C8B0E06130D062325B91.jpg 8
b/105.horse/D2EBBD22BEC2B5191E7C9EDC408F41F7.jpg 8
b/105.horse/596D7BF182188DED40B7CD7884BACF52.jpg 8
b/105.horse/9B5359845473A61E01EB975FBD724B22.jpg 8
b/105.horse/BF9E2B9D99F713CE4C09938D85182D45.jpg 8
b/105.horse/6E3075911EDF41B0F5E7B77353575DE1.jpg 8
b/105.horse/A236F01F2E14CE72392A541B83ED6300.jpg 8
b/105.horse/0C6F1DD934D222BD7F61080CB8D54476.jpg 8
b/105.horse/C73821398958DC39961B67106D563AD1.jpg 8
b/105.horse/8B5500DAF0401C20CAF76BCA013CA965.jpg 8
b/105.horse/AF5697859340324FEFB037BA79E791DE.jpg 8
b/105.horse/942C4ECC3AA6CAB343D2B3D6D6587536.jpg 8
b/105.horse/C326C13E0E4848D3F9A0398706951D18.jpg 8
b/105.horse/910DBD0C045BFE8611CF317C0C60DC43.jpg 8
b/105.horse/0843F6ECD367B7817B4700ED4B1095FF.jpg 8
b/105.horse/CB3495A971A1AC9B6326C24A205A1FB9.jpg 8
b/105.horse/3633025B7252C562E88C3AAAEF390367.jpg 8
b/105.horse/B5B0D85CCCFBEA76A3CB33C2396B183E.jpg 8
b/105.horse/0755FF97B7389BCB05CA783DED6CE38F.jpg 8
b/105.horse/6202D0BBD5CCF3A45F72983790E5FDCD.jpg 8
b/105.horse/8D5E4FADA5D6496B225965569C3A6A6E.jpg 8
b/105.horse/936A95DD2C9500B38DCBF4664E4B999C.jpg 8
b/105.horse/3F1C070BABD316E8E2CAC4CF5E5A3162.jpg 8
b/105.horse/BCDD2121DDFB641DCF219A42FCD226EF.jpg 8
b/105.horse/062A86011D7D4462D7A1D910DE5406CC.jpg 8
b/105.horse/28909B95CF0342F0A6146E69779B4C79.jpg 8
b/105.horse/0833521B6398D33469B12C52131E1FF9.jpg 8
b/105.horse/0F19F4F4B449AA3DC30EC5C5080931FE.jpg 8
b/105.horse/A10F8941898D7FDAF1250AD86517D160.jpg 8
b/105.horse/D564E45383C6AE04BA53E5867DA81BCE.jpg 8
b/113.hummingbird/1DA9F95F105A84908AA2E6138036EADB.jpg 2
b/113.hummingbird/C3C49A4123224889DAEACDB04036AFF9.jpg 2
b/113.hummingbird/3198FE1A6CE6ACD0E9F05765CDD888AC.jpg 2
b/113.hummingbird/95BD5D17B8EE9A5B0B7140AF3D3EE155.jpg 2
b/113.hummingbird/CC33B67CEAB260C70B484FD728D77A11.jpg 2
b/113.hummingbird/95F124A5CFD54F6C6156257869B902B3.jpg 2
b/113.hummingbird/461CBE2E4490B1126D75BF5774BF7E2B.jpg 2
b/113.hummingbird/26DEE9250A7B866F49301B50BCE4A8D9.jpg 2
b/113.hummingbird/5F7090EE7DB242C7808CFAE3C158E2CA.jpg 2
b/113.hummingbird/2C914AD42D56193E456E8C5C4F606AA8.jpg 2
b/113.hummingbird/0D4C4128FB03C80B4A70762B9F730BE0.jpg 2
b/113.hummingbird/943EAF8EE6F3DAD93C350D7334E5D43E.jpg 2
b/113.hummingbird/8E71498075A52224B9DB53DC5AB9E03C.jpg 2
b/113.hummingbird/C3F566E1F64CDC2E5E39D8DB53A9A92F.jpg 2
b/113.hummingbird/5513CAD5A526CAA15FF2D7858088EC7A.jpg 2
b/113.hummingbird/8DE0CA1C66B13C3422D2510F5741A7CF.jpg 2
b/113.hummingbird/2D2AF15FD593F6831AC50A9F9D2EC9EF.jpg 2
b/113.hummingbird/AC866E2E87C79A4C6DDBBF2957B60641.jpg 2
b/113.hummingbird/F8454BD5C7267E9348BE34B46DAF9C3E.jpg 2
b/113.hummingbird/A806021E59957A157359258F1B0FCCFD.jpg 2
b/113.hummingbird/570734E61A79E0DD7DAA759AA16E84CB.jpg 2
b/113.hummingbird/37E972099EBA6B295EA443DA17288B27.jpg 2
b/113.hummingbird/76F78EAC76E1E476ABECBE4E6A55A321.jpg 2
b/113.hummingbird/5453A1F47A601A8D0BF3F4741BDF3DFA.jpg 2
b/113.hummingbird/161E937F0769F6018D4A2DE89A94ED72.jpg 2
b/113.hummingbird/C256C06CD8FE55EA7D06DEAA60A8F325.jpg 2
b/113.hummingbird/535C060A2B6BF625B3F63FEDAB9FC4ED.jpg 2
b/113.hummingbird/EA0256F7A672A1253A5720B0F480B1D7.jpg 2
b/113.hummingbird/88816EF105060A2840E8D0B9818BE02D.jpg 2
b/113.hummingbird/2F812EE05204B95D035679AE36260953.jpg 2
b/113.hummingbird/5D2DD16038474585420053AF925FDC61.jpg 2
b/113.hummingbird/95A176181338C3F6609D508147F05CC0.jpg 2
b/113.hummingbird/A05BB25301885E2CBBFB48B684EFF4C3.jpg 2
b/113.hummingbird/0E3763A7051609ED45055CE2AA187B56.jpg 2
b/113.hummingbird/AFEA94305B7BAE3D6FDC3AEEAF4A5B8D.jpg 2
b/113.hummingbird/0367235F822FB39337329ADB8431D7A7.jpg 2
b/113.hummingbird/C3896EDD27F601950AEB5CF67F4E7CD4.jpg 2
b/113.hummingbird/8D57C4BB57E86CC5E547A82D88433255.jpg 2
b/113.hummingbird/E92D3FAEC1DB5564E9B8B37674482A4D.jpg 2
b/113.hummingbird/F9AB469CCB792CBFB072C6AAF4819943.jpg 2
b/113.hummingbird/16FC961DBAE75E0EE096F6FAF7832DA3.jpg 2
b/113.hummingbird/4A583BE465941467859B35D5E3D99BEC.jpg 2
b/113.hummingbird/0130814315084D9CD4F6093CE25041FB.jpg 2
b/113.hummingbird/8873695BFD8E3D2393439161466588B0.jpg 2
b/113.hummingbird/5E5FED6EDA0768E31CD136A73210D9AA.jpg 2
b/113.hummingbird/06343E0AE2FF16BAC012CA8298EB7C37.jpg 2
b/113.hummingbird/02971601D6B855172D5D81615234BFFF.jpg 2
b/113.hummingbird/9BCD41863FCC0699EA960611ECB3D9B1.jpg 2
b/113.hummingbird/1B88B667A17F9BE3041276D4F1982296.jpg 2
b/113.hummingbird/FBDA9B9254483E1060FD2CE0E819DEAA.jpg 2
b/145.motorbikes-101/ADC96D0263E181615FE9D491CA4BD721.jpg 10
b/145.motorbikes-101/596FFF97CCADE4C6D56A7F86B7ADC4AA.jpg 10
b/145.motorbikes-101/AF59B7AF2928BDAC7DA78EA4DE7E789F.jpg 10
b/145.motorbikes-101/B2387134FDBA1728EE31D8DBA5F929A6.jpg 10
b/145.motorbikes-101/0A36A7B9A724B01A5E98E90210E224E0.jpg 10
b/145.motorbikes-101/D4226310F8543F66BE53820C40697F2D.jpg 10
b/145.motorbikes-101/A19462EE3C53688CEA99DEEE65B2CE34.jpg 10
b/145.motorbikes-101/6144F29AFFEC5C70D42F4E85A7C145E8.jpg 10
b/145.motorbikes-101/BEDF5F6174AE0035B91BC442AB4C5442.jpg 10
b/145.motorbikes-101/BE202CAF702644FBB2958ACF4E35A8BE.jpg 10
b/145.motorbikes-101/04FACB943377EDE55F37678DBF85B6FD.jpg 10
b/145.motorbikes-101/086464B2C7F1CA924457B741F7B010C4.jpg 10
b/145.motorbikes-101/D21F9071E3A393C47E4CA26783B81F15.jpg 10
b/145.motorbikes-101/4407233DC2E2EE980AC3A42B729EADA4.jpg 10
b/145.motorbikes-101/568BD2B97C5A8F14F683FABAE41FBF66.jpg 10
b/145.motorbikes-101/009D596B8E08DFCF4884A9E266CBE6F3.jpg 10
b/145.motorbikes-101/11BBBF5DB04DE5F6C398EE8EA358357F.jpg 10
b/145.motorbikes-101/DFB46188BA5754B86A5DC9A0C40D4888.jpg 10
b/145.motorbikes-101/683DC3083CB96BD64836EA29F9BB344A.jpg 10
b/145.motorbikes-101/7F5595160FCDE0286A91D43F1B84D851.jpg 10
b/145.motorbikes-101/1DC986B87E0FB98BC070E5700289DABF.jpg 10
b/145.motorbikes-101/2068B6BCF55638C892A00A96E781A1ED.jpg 10
b/145.motorbikes-101/53EE4E1C64548B33EF93C44EC14411A7.jpg 10
b/145.motorbikes-101/E5DD48CF34AD63DAEDD82BF0802771AD.jpg 10
b/145.motorbikes-101/B6C7DD34EC67078C780ED311B2F69F2A.jpg 10
b/145.motorbikes-101/1F1FEB24B5B015089952F97940996505.jpg 10
b/145.motorbikes-101/9443B8E8F682CB83C6775904E6347E7F.jpg 10
b/145.motorbikes-101/4BD66FAAC250C47F90216B31D38FDAFD.jpg 10
b/145.motorbikes-101/A1C06B307C726981112446BBC2440A88.jpg 10
b/145.motorbikes-101/5E9EE691E2073B77B302D9B88633FD24.jpg 10
b/145.motorbikes-101/C15001D8FA6E8134415BF4C6F9CCD686.jpg 10
b/145.motorbikes-101/C7764F2DE2E1C19855C41F9D34EE9F97.jpg 10
b/145.motorbikes-101/E651FFD6C847D1DAD806AA7AAC10D5EE.jpg 10
b/145.motorbikes-101/28F885B7E338D2EC76E4223D65E5600C.jpg 10
b/145.motorbikes-101/B39D78380CFFCE66F619F886CDF35B00.jpg 10
b/145.motorbikes-101/64709DAC7F8F19B5A159D6688D9C1C4C.jpg 10
b/145.motorbikes-101/9D9061A2750C82A87F05429E0FDDB982.jpg 10
b/145.motorbikes-101/3DEF7317699E60DEAE12069826FCBAC5.jpg 10
b/145.motorbikes-101/598AEB6C824EA77ED116588E4A66718D.jpg 10
b/145.motorbikes-101/C7E185C1A43618E9D4555106C4CDAEA2.jpg 10
b/145.motorbikes-101/DE32BB1C556018C204BCF88792FF26D3.jpg 10
b/145.motorbikes-101/36105C43E7BF401AF4C83AD609BC88F4.jpg 10
b/145.motorbikes-101/3C003BB2F384B6E7CB247B15C029C18B.jpg 10
b/145.motorbikes-101/2376DEF9BC3D8361D1C2D945FAB837A0.jpg 10
b/145.motorbikes-101/085902158622DB7E8F473263FF3DF9E7.jpg 10
b/145.motorbikes-101/68B1481A01ABDDA278E17FF02C124FCC.jpg 10
b/145.motorbikes-101/3ADDD2423A59963FE4A61F5904DE8557.jpg 10
b/145.motorbikes-101/786218FB02044550259D737210398787.jpg 10
b/145.motorbikes-101/E2F3BA7D4BD5FBF8E58CF3E5DB4338E6.jpg 10
b/145.motorbikes-101/1DAE745F1341E3005CA5E575AA688EEC.jpg 10
b/146.mountain-bike/9453C5315949BFF5E0EE9C9A0592A740.jpg 1
b/224.touring-bike/6B14D3B3308C0ABED6C0EECD1A8204D6.jpg 1
b/146.mountain-bike/20D3C7E0E7D94B1B499CEA7EB0301491.jpg 1
b/224.touring-bike/D1C9313072151C95F0AA44C0E4BA9736.jpg 1
b/224.touring-bike/22B33A4BB6D5A58B0539C9AB825D8A8E.jpg 1
b/224.touring-bike/5DE6ADD369366694C47B4C3E8899FF18.jpg 1
b/146.mountain-bike/A60F1AC1F67D99F8A98DD9024AA3F152.jpg 1
b/146.mountain-bike/F1AB4EF686776E64E172B26D2CEF767D.jpg 1
b/146.mountain-bike/AFA4A5B756A09DCC41D1504A0909088E.jpg 1
b/224.touring-bike/98BB12769E4C068CFAAB64E918D4F225.jpg 1
b/146.mountain-bike/907AFED2066568F94F93E6B0D56D6FD0.jpg 1
b/146.mountain-bike/C747E2B2C1EC047F1C8046F1E1AE91BC.jpg 1
b/146.mountain-bike/F424A7D73A0BAC6C6AA1B9B8F950B5ED.jpg 1
b/224.touring-bike/D04DAD8F9D392EA5630A47AF1B2D1779.jpg 1
b/146.mountain-bike/7FAB94B2111213A776CAA0FCA99AF1F6.jpg 1
b/146.mountain-bike/4A58CC87C8DD2AAE688E155CE8755452.jpg 1
b/146.mountain-bike/566659F4593FD6F9AB411F740EEFD905.jpg 1
b/146.mountain-bike/76AAF2650B393E7A3B08F2988211054C.jpg 1
b/146.mountain-bike/45FA1628256DF18227854492FB02AAA2.jpg 1
b/224.touring-bike/CA96AE286CDC5A937D9493E004FBD9AB.jpg 1
b/146.mountain-bike/0D33206B4C64086D4E957E172C9D4FE6.jpg 1
b/224.touring-bike/57429E195F95DD9541E3E657C77146B4.jpg 1
b/146.mountain-bike/13A3E38BA7D48C0CB1D8C33E3CF3F894.jpg 1
b/224.touring-bike/036CCB4FC76BAEF206B5449F5656466A.jpg 1
b/224.touring-bike/35C01806318A3DF97A3CBC919A2B61E1.jpg 1
b/224.touring-bike/9BC12726749D602634F7949CE6001EE9.jpg 1
b/224.touring-bike/431C61C7FBD08E5E8F8164355467C746.jpg 1
b/224.touring-bike/EB6C6B1B61CC73355284A942C79A5FB3.jpg 1
b/224.touring-bike/D168AEFBDEF1E7B96297AAB4F213A991.jpg 1
b/146.mountain-bike/6CDF9D50D0F1168FED0788A2A955D754.jpg 1
b/146.mountain-bike/0EE0504FFB3B686D2E9B4CBFBC4E726D.jpg 1
b/146.mountain-bike/365FD760A1CB66D7A7DC7D8630B4BF76.jpg 1
b/146.mountain-bike/A566F2968A534836141295685294BAC5.jpg 1
b/146.mountain-bike/3317C84412D8247C7ACFA6ECCA1F4732.jpg 1
b/146.mountain-bike/A58B2BEF5B2EFFBAC16DD6BAA0B9D133.jpg 1
b/146.mountain-bike/5A4CE68844E38D3F53CC2D921585CF21.jpg 1
b/224.touring-bike/5280C73955AA328043F283D7E4AED17E.jpg 1
b/224.touring-bike/11C71EA217F8AB294345CC7D070CA6A9.jpg 1
b/146.mountain-bike/03641633A7AE916AC692F4F86E9F6358.jpg 1
b/224.touring-bike/D2C0AADC00688164B9D2084425BA6429.jpg 1
b/146.mountain-bike/5E674690B23F473EBCD64C430307E85F.jpg 1
b/146.mountain-bike/A3CDC8101E8164F7E5C3D8608F97760A.jpg 1
b/224.touring-bike/18906D40FE8F1F0D6E9E90397A77E681.jpg 1
b/224.touring-bike/A5951C7CE55D44D1D7983675C8E66076.jpg 1
b/224.touring-bike/9A7E2D2853F2CBBF65FDA0AD0EA186BF.jpg 1
b/146.mountain-bike/8BFED687E998CC76FB15ABC222B549E0.jpg 1
b/146.mountain-bike/9B62E39749832D4D081558F1DBEA1A54.jpg 1
b/224.touring-bike/06A0E6EB6E2A6CEDE167D56124F42D3B.jpg 1
b/146.mountain-bike/E2FBA63A04C5C623EC946420D69FC712.jpg 1
b/224.touring-bike/18575192544A1997E2771E096B3B59AF.jpg 1
b/159.people/4BBC9E1799C77EBE97CDB3A9C2A6A0F6.jpg 11
b/159.people/29E875A1614ACAB4FEA4FC35D4F53874.jpg 11
b/159.people/EDA3CCF6C1650A0033E65F7F85C3E320.jpg 11
b/159.people/AEEC33BD87BCF638A90024C57ECFF976.jpg 11
b/159.people/B874B113808639835BB69389B473C25F.jpg 11
b/159.people/BD67EAB839C733091BF4D5EFA00BAF53.jpg 11
b/159.people/347A65B54C8634ECA5DB93646B9BD593.jpg 11
b/159.people/C845EA4BF5699C6FC9861C3239ED3521.jpg 11
b/159.people/5EF40468FF1F809ABAA073FAF202DECE.jpg 11
b/159.people/830B37B1BF68AC6EBE88172583EC051C.jpg 11
b/159.people/02D06D9DB1DF35626E74CFFFFDC1D924.jpg 11
b/159.people/6E8738180B3E92989069E424A0F2E821.jpg 11
b/159.people/60EFE50F000FE800C88C49C6B7BA78AE.jpg 11
b/159.people/BE59980E6EA01751AC9D2528F6B4E3CE.jpg 11
b/159.people/4AE44E88B0D3EB56168844D35E9512E1.jpg 11
b/159.people/43D91B6329EB66B10A48DEB2D2ECE5DB.jpg 11
b/159.people/F7D7EDC248D40404B3779BD8B1F528C2.jpg 11
b/159.people/EA091E5439B0432B2784BDF35CEE4355.jpg 11
b/159.people/1DFFAAA472A5EB0DF80D6B9E39D75D11.jpg 11
b/159.people/D59FFC521FEC8E220A741312ACFE07F9.jpg 11
b/159.people/3636B1978F58F9610EABCEB1932558D1.jpg 11
b/159.people/B3670F67E80DACFDE64B3D90435389F6.jpg 11
b/159.people/47963CB2B8B734EA2106C8D5AD079B30.jpg 11
b/159.people/4A105B56BF1CDF4C63361E8A28709004.jpg 11
b/159.people/24931A873672F774CC3D9C042DED63C7.jpg 11
b/159.people/C868CCB253B127B4734D8501AD9F47C6.jpg 11
b/159.people/78B752D6A3A8FA6BD555049BEEDC329F.jpg 11
b/159.people/D5714A245ABC39F3D2F32DFACD5062CA.jpg 11
b/159.people/B08049B07C47E849CAE17BA138A377F9.jpg 11
b/159.people/EA475C1E5432E4DEA3E76C2EFAF99E37.jpg 11
b/159.people/184A89BA4F190FA4AF48A29A0542A415.jpg 11
b/159.people/53FC876F8EE34EAFAF11D73FBFA9EC1A.jpg 11
b/159.people/39B8649F0687BB45ABFAD9A8081EA7C0.jpg 11
b/159.people/A052ECA2821412200310D413D537082C.jpg 11
b/159.people/3A020B73ED69802A175A6C83153A552B.jpg 11
b/159.people/A17B141138A1459E0A8160B7658DA72F.jpg 11
b/159.people/2EF970002819A676E1F31BCAA0DFB798.jpg 11
b/159.people/54597E7B450CF9F28EF72B6AF595E8F3.jpg 11
b/159.people/7003CC063E5B011E284CC4654119738A.jpg 11
b/159.people/A9D710641FBA1E9CCEADD93DD5EAF80C.jpg 11
b/159.people/2791E6092748248C63C70FBC5FB9F8DE.jpg 11
b/159.people/69A926F25C78E8DB02CCA5BB6483A63F.jpg 11
b/159.people/CCB24C9F1F9475243D20F69406B36ADC.jpg 11
b/159.people/2D55EA21C405EF4E9B1B38D84EEFE1F6.jpg 11
b/159.people/77517FC7561F32D5120FD1CFA4BA5A51.jpg 11
b/159.people/A24468CDF86147584D240FF17517F4C4.jpg 11
b/159.people/E62C4F3C9887B98E398F2F54CE4379C1.jpg 11
b/159.people/16AAE9074F5C00F9615C2C6A705E8513.jpg 11
b/159.people/AF195E97A0B7A1CB3C144D723FA5A16F.jpg 11
b/159.people/409B9D974570529C2F089BF27850AA99.jpg 11
b/178.school-bus/74930C08A2D258C3AC15FEE7FB1F624B.jpg 5
b/178.school-bus/24547E5BE40D231A049CFC56DE2ABF5F.jpg 5
b/178.school-bus/683FB74ADD52CFABEA685F6DC74EE7C9.jpg 5
b/178.school-bus/06DCB8E35A75236B1468ACF669D9FEC9.jpg 5
b/178.school-bus/C897A37C845E34312B5D71CC821D0B68.jpg 5
b/178.school-bus/21A81279C43ABAA217DB5FC4FFC752BF.jpg 5
b/178.school-bus/7548A8A889828B4C5C3268891AB60CAF.jpg 5
b/178.school-bus/2676F53BB1434E7F9707FA6E2624FD4B.jpg 5
b/178.school-bus/A0000F9AD52E520510F524676E6660D6.jpg 5
b/178.school-bus/A12E1F7F294F3C2BDFD63AC2271FE73F.jpg 5
b/178.school-bus/48A1252DBF7C94311ADC01F7DBF2AFAC.jpg 5
b/178.school-bus/DC6E7F8458FDB4DCB18FD008166DB0D2.jpg 5
b/178.school-bus/2037016AA33095757AE76833449D6C7B.jpg 5
b/178.school-bus/B69C8086ED89805885ECD2413B8BD67C.jpg 5
b/178.school-bus/559056179A304125379DC520E3B46CB4.jpg 5
b/178.school-bus/822E14FB3EC8BCB4280E90D10A5D1D96.jpg 5
b/178.school-bus/AFE2A7F8CDAD296A3BCF06CF2448645E.jpg 5
b/178.school-bus/D34E5483FF07167BAA9FD039B57A0429.jpg 5
b/178.school-bus/040050435E808D9336DB106741F5AC4E.jpg 5
b/178.school-bus/1D0BEC676E3B784D975D5A13E557FCF7.jpg 5
b/178.school-bus/206A8B6699A93818F0E87BC14FDDD781.jpg 5
b/178.school-bus/1E25189101FB8A7CB582396126180F79.jpg 5
b/178.school-bus/22D94AB94209F9657A9BE5083C53B611.jpg 5
b/178.school-bus/8D975391F91BC8CB3360467DC09EFE75.jpg 5
b/178.school-bus/ED50CB1365FA1640C6C8171F8B6BEF6E.jpg 5
b/178.school-bus/FFA7E4965BE7A26BA9F12AA353691B84.jpg 5
b/178.school-bus/A81A589E0D5C484D0F81B7B05C123322.jpg 5
b/178.school-bus/5DB33AB5D8F811249D2DE8808708D4E7.jpg 5
b/178.school-bus/FC54B028496416FC58F910E6EFBDA84B.jpg 5
b/178.school-bus/13CDE870001E9405EAF4323C599E2FB6.jpg 5
b/178.school-bus/D0C517CD4FA4986E432E23642FCC8ABC.jpg 5
b/178.school-bus/9C2F957F2FE350314AC15A399770C415.jpg 5
b/178.school-bus/DB3E24C36C4FA21940A15DA5B7351695.jpg 5
b/178.school-bus/3ACD3D6FB09F5CECCB4D1D10A3567D15.jpg 5
b/178.school-bus/58988BE83794045DF9F87E1D9111B164.jpg 5
b/178.school-bus/A38061C092DDADDBC12026B2FD8BBD9C.jpg 5
b/178.school-bus/2F654121C020F97F9F5B7D2E4EEE4809.jpg 5
b/178.school-bus/69D957D426E8BBB87F2BB27C3DAE0F5D.jpg 5
b/178.school-bus/0815025A981C055CBF1528B2DA2C6FA3.jpg 5
b/178.school-bus/154A793A0B1DDF8A49D5257395197051.jpg 5
b/178.school-bus/BF604F291613A1A5AFCB5756C26D5A42.jpg 5
b/178.school-bus/7553530C20E3EF5F72748CAF3FBDD319.jpg 5
b/178.school-bus/A4F5C2A63B0E9FD648890802B0D3794A.jpg 5
b/178.school-bus/9E1794FDA934CB0932EF635C86CE5529.jpg 5
b/178.school-bus/41DF079F00FC1CDF7A34F5148B98BB64.jpg 5
b/178.school-bus/9CFFC763C8A64604881052DA33C7462C.jpg 5
b/178.school-bus/56D45AD69679E30A5CB5CAAD444E58AA.jpg 5
b/178.school-bus/7D35D7E2A4727E36EC185ACE4E3BAD88.jpg 5
b/178.school-bus/0674D9FAE1C8F77FD76E2710EFE51E4D.jpg 5
b/178.school-bus/0AB55F775D31F53C97AD0FF64CD92569.jpg 5
b/197.speed-boat/2F199132AE8C1BB012B9874803423633.jpg 3
b/197.speed-boat/06E7546A599DCE0994635A0F17C13546.jpg 3
b/197.speed-boat/4782FB6A9D47E59DF335EEB19F3BBC81.jpg 3
b/197.speed-boat/228B6EBA3138877AB8A024E63E11E480.jpg 3
b/197.speed-boat/A4D35F1F675A516BA5E104415DCD7239.jpg 3
b/197.speed-boat/9D86C31949F3335A6492F2236F6BBAA9.jpg 3
b/197.speed-boat/FD02BE5DED1CA899B4442876F6FD5831.jpg 3
b/197.speed-boat/0CD8F80A3C9803F22FDCFEDA5D3074A9.jpg 3
b/197.speed-boat/E13547193B8C726914E729CDA16ACE01.jpg 3
b/197.speed-boat/D953D8AD757D5D212EDD957D319514FC.jpg 3
b/197.speed-boat/64A8A592A04C5BFA8D4B7162781D3CA3.jpg 3
b/197.speed-boat/97528AD153732B5068745E6E2D44B8B7.jpg 3
b/197.speed-boat/30DB9418D3FB20C0FC1B3B737034721A.jpg 3
b/197.speed-boat/CB0A27D55803905C32261563CA27710B.jpg 3
b/197.speed-boat/4FB9D549000737F4950B57BAE0A6C020.jpg 3
b/197.speed-boat/0C1717639BC4DB6AB6432D16D5BE4A36.jpg 3
b/197.speed-boat/7EEAD5FCA7472F45D3657A49B44FA630.jpg 3
b/197.speed-boat/4EB35DD3E37CB2DEE0148DD62D846F2F.jpg 3
b/197.speed-boat/0CFECC943A10E78B1F334E9890B3422F.jpg 3
b/197.speed-boat/42617D7195453D01B4B111A25FEFC29C.jpg 3
b/197.speed-boat/DA60919B42F494EDBCFFCD815E967072.jpg 3
b/197.speed-boat/6CD65842EC674D9F12FCA544E61DDA28.jpg 3
b/197.speed-boat/08031F2F2B4C021D60F48026732E00C1.jpg 3
b/197.speed-boat/BFDEBE9806FC27CFD3690DBA41FDBE9C.jpg 3
b/197.speed-boat/A012B46899B919BFE0D757D68C881071.jpg 3
b/197.speed-boat/24572C6C1C529ECB960452FCE75563F6.jpg 3
b/197.speed-boat/B930D323361F24D9EF58E8445C315233.jpg 3
b/197.speed-boat/97E78A339A2756D4236FFB5F3E3C9B63.jpg 3
b/197.speed-boat/984F6499EAE3914660AEA0E9DF7D56E1.jpg 3
b/197.speed-boat/AFAF6AC01AD231E2B18AFCF43415544A.jpg 3
b/197.speed-boat/CFAD48F3E12C0C8D438EC95C010BC068.jpg 3
b/197.speed-boat/F6F06F76058694E41507028B090C0A8B.jpg 3
b/197.speed-boat/88D0FE64FC6D6A50E6A96FAA7BAAC556.jpg 3
b/197.speed-boat/5BC690DF7D75B389223E7DEF473D2CC6.jpg 3
b/197.speed-boat/C094FDB6DCAECFF2F5D58D85DB320747.jpg 3
b/197.speed-boat/750102ED0679A6D627322CD80030B2D9.jpg 3
b/197.speed-boat/523DCBEFC4F30B105D7E301F97FFA5F3.jpg 3
b/197.speed-boat/412B17B2E79287572F2637B919BB4DDF.jpg 3
b/197.speed-boat/B216913893C6B401DE2C197B1D15EAA2.jpg 3
b/197.speed-boat/57EC5444895376BC7CA3E9CD5CF897E7.jpg 3
b/197.speed-boat/D374801C0DF141A571BE581F0809F577.jpg 3
b/197.speed-boat/4D622E71A186AA212734EDDEF38B6609.jpg 3
b/197.speed-boat/6FB55C18F30020039C7538E370FE0C98.jpg 3
b/197.speed-boat/71FD3B82BAE375019956E511975F0805.jpg 3
b/197.speed-boat/02326FC55FAD21E3EB032C2ADF4E9B9A.jpg 3
b/197.speed-boat/F2FB4DFD2FDCD6959500F70B09D11A0D.jpg 3
b/197.speed-boat/244DAC3142BEDCBC42D23B4D55B197A0.jpg 3
b/197.speed-boat/0760F5D5CAF936B9B1015CBF0D51FC2F.jpg 3
b/197.speed-boat/A81431784F0A65CBB5C70EFDA72621FA.jpg 3
b/197.speed-boat/0D9C5CD65F9A0CC60311CF67F6B9BA90.jpg 3
b/246.wine-bottle/EFB685AA6FBC4FAD89001CFB4B0FD6C7.jpg 4
b/246.wine-bottle/FD105C1FB90A02D2255BE57D53325243.jpg 4
b/246.wine-bottle/533D29D9F1F6C2E19F5B5F972C44D99A.jpg 4
b/246.wine-bottle/77C978E318BCD9662EB96B4A5F19F35F.jpg 4
b/246.wine-bottle/CD1B98237D442FDE38B61D99020E7917.jpg 4
b/246.wine-bottle/2CD7FF443E26A0D31021009F46734EB2.jpg 4
b/246.wine-bottle/312445DB721563C7752B34D51DA10454.jpg 4
b/246.wine-bottle/E0D30B7B88E6B718A253C82D44C3F54A.jpg 4
b/246.wine-bottle/2C016F70D7C1E0342F39513BC0B6BC43.jpg 4
b/246.wine-bottle/D5849BCFAF8E1BA0EBA6E2787B8323B1.jpg 4
b/246.wine-bottle/3846B97DC94DA51BFCFCA3E95A287CC0.jpg 4
b/246.wine-bottle/AE872A16D1602FD9B09D75CB8C58F277.jpg 4
b/246.wine-bottle/430ECD392E4424EDA2F74F400F91881E.jpg 4
b/246.wine-bottle/F0C293D43F9A12BD84F9B9C61D317EFB.jpg 4
b/246.wine-bottle/E363DFA32CD85C5649C4F832566365F5.jpg 4
b/246.wine-bottle/5ACAA63B3F6B1F5CC64B5533A38CFC22.jpg 4
b/246.wine-bottle/5FC21CB04B95C90E1476A3CE27A3EA9E.jpg 4
b/246.wine-bottle/65B5ED01282AC4707E6613F75FE6AAD4.jpg 4
b/246.wine-bottle/33A09E862D6FFD5ED7D153C023A9F030.jpg 4
b/246.wine-bottle/B197C4415626DF2BBB8CCC656B891CFE.jpg 4
b/246.wine-bottle/9852BE61326A774F0B174D4F4A7A5D03.jpg 4
b/246.wine-bottle/5EF88A8D0EA57BB9D08A30B303834C29.jpg 4
b/246.wine-bottle/88A72A70A267147B21292A19402F3778.jpg 4
b/246.wine-bottle/BFEA935ED5E0B1544C791AF6C068440D.jpg 4
b/246.wine-bottle/519E025BE461AF37D3420D645E243394.jpg 4
b/246.wine-bottle/444EFD0A5C55381E8A8F79BCF443B7E4.jpg 4
b/246.wine-bottle/639C13BF14259D98FC6D735CE24C420E.jpg 4
b/246.wine-bottle/C6EF53B2FCB9EC242AC3FE334D2130F5.jpg 4
b/246.wine-bottle/B63C63EF218EEF64529B532078BC89B4.jpg 4
b/246.wine-bottle/B63E13EFAB4A3D798C08D55FF091EAB5.jpg 4
b/246.wine-bottle/BC81191105B77516130EAF663AE4D8BC.jpg 4
b/246.wine-bottle/F757946EC23E096CD6FB913DB56882B9.jpg 4
b/246.wine-bottle/BDE75A335C9B90AC5F2EA1625CE96475.jpg 4
b/246.wine-bottle/58283D505FF4FF899D119DCA4EFFFE58.jpg 4
b/246.wine-bottle/5F402D72C71B0517C0EF4D98E1C12905.jpg 4
b/246.wine-bottle/FCBABF0F60B8816680F4731B63B7246A.jpg 4
b/246.wine-bottle/39ACDCCE22EEC3B54879E72969A50FC9.jpg 4
b/246.wine-bottle/8CBE9DE02660DF5AB5DB2C58F44E520F.jpg 4
b/246.wine-bottle/4250D9B8CF2C72C833C4AE52858AE5AF.jpg 4
b/246.wine-bottle/F5D0B77FD3F671FEDB4611DA99605419.jpg 4
b/246.wine-bottle/6E6DD6C0B6C8F6D907B3816D57E6967B.jpg 4
b/246.wine-bottle/2EB3068FDBFCF4EF9F0BF93B6854EE53.jpg 4
b/246.wine-bottle/0E55BCE89CFCFC250051C1E18E4CE483.jpg 4
b/246.wine-bottle/B23FCF5AFA32C175D0D46D68724D7A0A.jpg 4
b/246.wine-bottle/7DC857179CF8863E60CB16A2F99EE572.jpg 4
b/246.wine-bottle/43C8E3F1DB3E2308349366426E2C2B5B.jpg 4
b/246.wine-bottle/C9A2153FEDD0552FEDA60EA661CE5D2D.jpg 4
b/246.wine-bottle/33F04496C0C38E835AE314ED95BE955B.jpg 4
b/246.wine-bottle/70C738ED5F27D6D5A17686090A3A4CD4.jpg 4
b/246.wine-bottle/B11AA83F5D9E776A69FFE740EDB0F6D4.jpg 4
b/251.airplanes-101/E3FF9BF44ABD7A590386FD6DC04441FE.jpg 0
b/251.airplanes-101/1F3E4785017945B9A068DF759CC94DF2.jpg 0
b/251.airplanes-101/CA83C6D5DED56226F8A64C45C2167407.jpg 0
b/251.airplanes-101/CB72DC4FCF9ABCFEF06936C5684581E8.jpg 0
b/251.airplanes-101/E9430381F2493159A32F5F236B4FDF8A.jpg 0
b/251.airplanes-101/620031A94BE8545E599268C596ACA55D.jpg 0
b/251.airplanes-101/18A92EDCCC167E5057B779E3CF142F89.jpg 0
b/251.airplanes-101/2E862EC1688653B70B53A2C1E6A87A11.jpg 0
b/251.airplanes-101/1BF53EEAD6CEF9203DF40C5A1A67744B.jpg 0
b/251.airplanes-101/BD5902152B26285D91A08A86168FF8D1.jpg 0
b/251.airplanes-101/6436B37ADAAAB84B9099841E0EA633F5.jpg 0
b/251.airplanes-101/02B33FC50DBA873198FAED4689BBFBFF.jpg 0
b/251.airplanes-101/78DD91697DE5840D45AF40C888EFB69D.jpg 0
b/251.airplanes-101/7E9F04E7B8523AAB6AE77776C1103883.jpg 0
b/251.airplanes-101/B0113FE6B343D901B163493258BBF919.jpg 0
b/251.airplanes-101/17C58ED7CD8A3CDBB79AD8DD64AB9D0A.jpg 0
b/251.airplanes-101/4C34DA2860E01687A2172F220D39368B.jpg 0
b/251.airplanes-101/C419985418C4740BB85228D8B3F157C4.jpg 0
b/251.airplanes-101/6E3D27967CF815A6DD3BA7260A81ACC8.jpg 0
b/251.airplanes-101/27F8578B1C3157CD25387AE3580E604E.jpg 0
b/251.airplanes-101/AA2F131C6EADCAC7B05A1FAB059DBBFF.jpg 0
b/251.airplanes-101/6E74BE7740A6A0EF30BFEFCC1A7FE2DC.jpg 0
b/251.airplanes-101/92C723F600E72B846A35236CBB4F7A4B.jpg 0
b/251.airplanes-101/C56E1372BFB223FAE049EBC4917D059C.jpg 0
b/251.airplanes-101/A6F9044F6A1275795531794DE44D7D88.jpg 0
b/251.airplanes-101/211C525E9ADF1E92923FBF9FDDAD317E.jpg 0
b/251.airplanes-101/3D07CCD1290EBDFDFC26F2469B8F94A6.jpg 0
b/251.airplanes-101/0F6DD993FA6C0086C3B2D476F3128EEC.jpg 0
b/251.airplanes-101/70214AD47A30556F16A65C256AADD066.jpg 0
b/251.airplanes-101/11AAB1206CBA2BB2F966A53D9D1EE087.jpg 0
b/251.airplanes-101/F9016E99A54A7EE51FBBE6E13FF5AE0F.jpg 0
b/251.airplanes-101/D4821FE0B02A69FCE94ADEA98828C687.jpg 0
b/251.airplanes-101/0CBDC7E01B8280AC537A9FA32D897D62.jpg 0
b/251.airplanes-101/8928965F493DB82C700227DD207C4B6C.jpg 0
b/251.airplanes-101/10EC208950F689A3377AC2F9566BE86C.jpg 0
b/251.airplanes-101/5764B3EB17C3D76AF1826F7EA8B226AF.jpg 0
b/251.airplanes-101/09EC5D53CE789A34F3E05DB048B55849.jpg 0
b/251.airplanes-101/007859D83594D527355CA287E096218B.jpg 0
b/251.airplanes-101/9CEBB04C1B69A165740138ABE077645E.jpg 0
b/251.airplanes-101/060FBA0F642012BCC2F4E427E7444248.jpg 0
b/251.airplanes-101/FDDE05B3132C71CE3E07C4182199B9CB.jpg 0
b/251.airplanes-101/652823C3559FF2C5C15A25ECA120A626.jpg 0
b/251.airplanes-101/3504460129C1001C390F787870CB1DD4.jpg 0
b/251.airplanes-101/8D1A5ADB91499E383ED331ED912B09EC.jpg 0
b/251.airplanes-101/27205A7335FA260E8446F9371AD9A3C4.jpg 0
b/251.airplanes-101/9228DF8B79C57CDEB6A23D94A34232E3.jpg 0
b/251.airplanes-101/5C915F5961F37AD219CA5DCDFF2B78BA.jpg 0
b/251.airplanes-101/95498E27EC444C2BBC56FC86CF245165.jpg 0
b/251.airplanes-101/33D891118F9D9D6090B033394B7D2B7E.jpg 0
b/251.airplanes-101/B08A893A4CFF2B0F3B39CF1CBF2385D2.jpg 0
================================================
FILE: code/deep/B-JMMD/caffe/data/office/cList.txt
================================================
/home/mcj/dataset/imageCLEF/c/113_0114.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0025.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0003.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0034.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0058.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0042.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0057.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0083.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0055.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0109.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0090.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0060.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0074.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0012.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0030.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0099.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0115.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0054.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0062.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0035.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0103.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0036.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0029.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0037.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0010.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0020.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0048.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0051.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0061.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0068.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0108.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0014.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0031.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0095.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0066.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0002.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0013.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0001.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0022.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0016.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0116.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0011.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0046.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0071.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0092.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0072.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0050.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0070.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0089.jpg 2
/home/mcj/dataset/imageCLEF/c/113_0064.jpg 2
/home/mcj/dataset/imageCLEF/c/224_0053.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0021.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0061.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0057.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0015.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0072.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0096.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0063.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0063.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0035.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0041.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0110.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0082.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0023.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0011.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0071.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0044.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0066.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0051.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0074.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0040.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0098.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0007.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0008.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0062.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0107.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0027.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0021.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0087.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0046.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0004.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0097.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0073.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0006.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0070.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0092.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0054.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0072.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0039.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0068.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0080.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0016.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0045.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0078.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0059.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0025.jpg 1
/home/mcj/dataset/imageCLEF/c/146_0017.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0067.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0022.jpg 1
/home/mcj/dataset/imageCLEF/c/224_0003.jpg 1
/home/mcj/dataset/imageCLEF/c/105_0250.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0022.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0010.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0229.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0248.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0132.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0055.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0069.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0067.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0268.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0192.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0068.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0140.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0218.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0044.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0100.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0222.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0003.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0175.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0242.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0247.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0023.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0061.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0223.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0065.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0238.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0062.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0105.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0191.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0073.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0173.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0212.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0082.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0030.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0092.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0138.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0113.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0117.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0129.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0252.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0141.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0094.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0115.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0116.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0179.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0060.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0139.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0133.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0221.jpg 8
/home/mcj/dataset/imageCLEF/c/105_0204.jpg 8
/home/mcj/dataset/imageCLEF/c/159_0068.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0017.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0046.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0158.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0074.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0199.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0137.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0060.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0048.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0200.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0098.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0180.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0160.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0178.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0134.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0022.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0186.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0129.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0170.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0179.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0196.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0126.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0182.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0108.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0055.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0197.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0149.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0176.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0094.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0096.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0141.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0120.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0030.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0114.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0009.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0163.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0039.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0045.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0021.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0131.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0041.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0066.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0153.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0181.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0024.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0143.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0043.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0166.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0040.jpg 11
/home/mcj/dataset/imageCLEF/c/159_0083.jpg 11
/home/mcj/dataset/imageCLEF/c/046_0076.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0087.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0100.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0072.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0069.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0025.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0124.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0105.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0128.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0005.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0001.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0021.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0023.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0093.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0058.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0106.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0050.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0060.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0026.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0014.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0054.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0077.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0048.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0066.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0110.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0020.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0024.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0008.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0038.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0096.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0121.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0102.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0051.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0006.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0062.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0052.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0073.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0012.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0118.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0114.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0092.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0067.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0079.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0113.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0085.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0101.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0040.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0104.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0013.jpg 9
/home/mcj/dataset/imageCLEF/c/046_0017.jpg 9
/home/mcj/dataset/imageCLEF/c/246_0100.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0048.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0070.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0011.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0038.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0029.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0086.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0044.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0037.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0056.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0083.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0042.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0055.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0039.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0018.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0064.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0053.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0052.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0033.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0058.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0041.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0067.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0008.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0093.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0045.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0002.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0101.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0043.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0020.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0031.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0096.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0049.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0074.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0005.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0071.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0057.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0085.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0082.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0034.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0062.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0010.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0061.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0017.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0028.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0035.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0084.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0030.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0098.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0088.jpg 4
/home/mcj/dataset/imageCLEF/c/246_0032.jpg 4
/home/mcj/dataset/imageCLEF/c/145_0167.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0511.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0555.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0758.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0692.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0074.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0155.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0267.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0314.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0127.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0069.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0635.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0234.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0338.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0462.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0422.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0233.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0697.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0084.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0266.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0413.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0552.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0450.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0284.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0442.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0636.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0185.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0451.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0476.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0087.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0776.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0734.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0719.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0223.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0533.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0513.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0780.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0560.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0458.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0494.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0798.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0559.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0277.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0742.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0322.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0191.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0165.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0715.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0433.jpg 10
/home/mcj/dataset/imageCLEF/c/145_0032.jpg 10
/home/mcj/dataset/imageCLEF/c/178_0050.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0091.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0062.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0068.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0045.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0031.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0079.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0046.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0037.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0013.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0074.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0051.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0034.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0040.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0010.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0041.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0017.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0016.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0005.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0025.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0097.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0078.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0058.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0067.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0027.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0012.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0044.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0060.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0043.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0087.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0085.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0004.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0047.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0029.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0080.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0039.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0065.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0083.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0002.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0061.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0095.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0054.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0022.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0053.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0030.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0071.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0090.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0092.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0077.jpg 5
/home/mcj/dataset/imageCLEF/c/178_0064.jpg 5
/home/mcj/dataset/imageCLEF/c/251_0041.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0095.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0069.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0561.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0326.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0478.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0121.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0390.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0419.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0519.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0090.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0238.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0366.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0231.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0714.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0545.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0587.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0115.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0769.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0061.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0381.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0126.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0248.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0800.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0023.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0371.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0646.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0679.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0618.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0779.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0741.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0481.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0425.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0642.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0377.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0447.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0361.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0743.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0215.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0746.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0682.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0614.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0599.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0048.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0389.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0766.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0189.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0404.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0183.jpg 0
/home/mcj/dataset/imageCLEF/c/251_0570.jpg 0
/home/mcj/dataset/imageCLEF/c/056_0021.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0043.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0100.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0055.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0078.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0031.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0095.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0101.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0076.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0037.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0009.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0013.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0048.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0057.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0046.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0072.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0014.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0050.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0023.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0039.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0024.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0069.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0038.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0093.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0058.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0063.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0082.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0077.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0099.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0052.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0070.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0054.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0064.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0081.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0056.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0028.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0004.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0090.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0006.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0033.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0025.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0029.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0080.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0079.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0065.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0088.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0061.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0001.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0016.jpg 7
/home/mcj/dataset/imageCLEF/c/056_0091.jpg 7
/home/mcj/dataset/imageCLEF/c/252_0059.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0092.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0085.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0068.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0098.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0087.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0034.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0003.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0077.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0062.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0045.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0043.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0073.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0002.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0005.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0114.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0042.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0113.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0089.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0037.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0052.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0028.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0083.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0056.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0109.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0078.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0039.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0093.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0026.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0076.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0071.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0044.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0040.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0091.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0027.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0115.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0074.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0025.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0104.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0033.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0105.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0116.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0007.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0111.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0064.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0006.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0070.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0082.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0080.jpg 6
/home/mcj/dataset/imageCLEF/c/252_0029.jpg 6
/home/mcj/dataset/imageCLEF/c/197_0019.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0087.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0059.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0038.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0064.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0043.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0012.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0037.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0010.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0013.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0074.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0079.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0014.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0091.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0068.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0060.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0077.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0011.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0051.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0052.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0057.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0007.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0085.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0058.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0016.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0001.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0082.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0028.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0030.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0034.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0055.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0073.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0031.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0065.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0070.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0099.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0081.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0035.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0090.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0025.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0047.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0040.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0084.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0054.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0046.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0004.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0053.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0061.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0020.jpg 3
/home/mcj/dataset/imageCLEF/c/197_0049.jpg 3
================================================
FILE: code/deep/B-JMMD/caffe/data/office/dslr_list.txt
================================================
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0001.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0002.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0003.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0004.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0005.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0006.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0007.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0008.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0009.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0010.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0011.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/calculator/frame_0012.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0001.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0002.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0003.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0004.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0005.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0006.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0007.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0008.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0009.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ring_binder/frame_0010.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0001.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0002.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0003.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0004.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0005.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0006.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0007.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0008.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0009.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0010.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0011.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0012.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0013.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0014.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/printer/frame_0015.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0001.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0002.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0003.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0004.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0005.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0006.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0007.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0008.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0009.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/keyboard/frame_0010.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0001.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0002.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0003.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0004.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0005.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0006.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0007.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0008.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0009.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0010.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0011.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0012.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0013.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0014.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0015.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0016.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0017.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/scissors/frame_0018.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0001.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0002.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0003.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0004.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0005.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0006.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0007.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0008.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0009.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0010.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0011.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0012.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0013.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0014.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0015.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0016.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0017.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0018.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0019.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0020.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0021.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0022.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0023.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/laptop_computer/frame_0024.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0001.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0002.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0003.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0004.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0005.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0006.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0007.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0008.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0009.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0010.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0011.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mouse/frame_0012.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0001.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0002.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0003.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0004.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0005.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0006.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0007.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0008.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0009.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0010.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0011.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0012.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0013.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0014.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0015.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0016.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0017.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0018.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0019.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0020.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0021.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/monitor/frame_0022.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0001.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0002.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0003.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0004.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0005.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0006.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0007.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mug/frame_0008.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0001.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0002.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0003.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0004.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0005.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0006.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0007.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0008.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0009.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0010.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0011.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0012.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0013.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0014.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0015.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0016.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0017.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0018.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0019.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0020.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0021.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/tape_dispenser/frame_0022.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0001.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0002.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0003.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0004.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0005.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0006.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0007.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0008.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0009.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/pen/frame_0010.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0001.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0002.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0003.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0004.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0005.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0006.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0007.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0008.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0009.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0010.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0011.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0012.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0013.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0014.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0015.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0016.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0017.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0018.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0019.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0020.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike/frame_0021.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0001.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0002.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0003.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0004.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0005.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0006.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0007.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0008.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0009.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0010.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0011.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0012.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0013.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0014.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0015.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0016.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0017.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/punchers/frame_0018.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0001.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0002.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0003.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0004.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0005.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0006.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0007.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0008.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0009.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0010.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0011.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/back_pack/frame_0012.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0001.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0002.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0003.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0004.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0005.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0006.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0007.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0008.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0009.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0010.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0011.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0012.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0013.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0014.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desktop_computer/frame_0015.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0001.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0002.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0003.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0004.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0005.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0006.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0007.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0008.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0009.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0010.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0011.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0012.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0013.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0014.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0015.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0016.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0017.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0018.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0019.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0020.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0021.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0022.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0023.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0024.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0025.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/speaker/frame_0026.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0001.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0002.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0003.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0004.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0005.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0006.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0007.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0008.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0009.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0010.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0011.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0012.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0013.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0014.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0015.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0016.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0017.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0018.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0019.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0020.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0021.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0022.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0023.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0024.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0025.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0026.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0027.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0028.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0029.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0030.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/mobile_phone/frame_0031.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0001.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0002.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0003.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0004.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0005.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0006.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0007.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0008.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0009.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/paper_notebook/frame_0010.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0001.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0002.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0003.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0004.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0005.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0006.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/ruler/frame_0007.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0001.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0002.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0003.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0004.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0005.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0006.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0007.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0008.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0009.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0010.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0011.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0012.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0013.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0014.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0015.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/letter_tray/frame_0016.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0001.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0002.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0003.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0004.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0005.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0006.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0007.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0008.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0009.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0010.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0011.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0012.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0013.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0014.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/file_cabinet/frame_0015.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0001.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0002.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0003.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0004.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0005.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0006.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0007.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0008.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0009.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0010.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0011.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0012.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/phone/frame_0013.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0001.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0002.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0003.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0004.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0005.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0006.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0007.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0008.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0009.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0010.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0011.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bookcase/frame_0012.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0001.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0002.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0003.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0004.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0005.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0006.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0007.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0008.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0009.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0010.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0011.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0012.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0013.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0014.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0015.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0016.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0017.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0018.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0019.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0020.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0021.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0022.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/projector/frame_0023.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0001.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0002.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0003.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0004.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0005.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0006.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0007.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0008.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0009.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0010.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0011.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0012.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0013.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0014.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0015.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0016.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0017.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0018.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0019.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0020.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/stapler/frame_0021.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0001.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0002.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0003.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0004.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0005.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0006.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0007.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0008.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0009.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0010.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0011.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0012.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0013.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0014.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/trash_can/frame_0015.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0001.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0002.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0003.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0004.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0005.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0006.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0007.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0008.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0009.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0010.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0011.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0012.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0013.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0014.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0015.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0016.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0017.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0018.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0019.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0020.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0021.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0022.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0023.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bike_helmet/frame_0024.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0001.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0002.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0003.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0004.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0005.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0006.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0007.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0008.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0009.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0010.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0011.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0012.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/headphones/frame_0013.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0001.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0002.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0003.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0004.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0005.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0006.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0007.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0008.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0009.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0010.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0011.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0012.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0013.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_lamp/frame_0014.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0001.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0002.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0003.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0004.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0005.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0006.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0007.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0008.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0009.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0010.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0011.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0012.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/desk_chair/frame_0013.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0001.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0002.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0003.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0004.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0005.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0006.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0007.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0008.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0009.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0010.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0011.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0012.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0013.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0014.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0015.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/dslr/images/bottle/frame_0016.jpg 4
================================================
FILE: code/deep/B-JMMD/caffe/data/office/iList.txt
================================================
/home/mcj/dataset/imageCLEF/i/n02691156_7563.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_30456.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_4273.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_21342.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11944.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_8007.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2510.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1682.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_30294.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6973.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2351.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12350.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6382.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10045.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1663.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12546.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_240.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_49198.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7515.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2701.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10027.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_29561.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11169.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_10494.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_54301.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1806.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38031.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38968.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_3107.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11788.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_3581.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7304.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_12581.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11550.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_31395.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_52254.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7196.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6587.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_1015.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_38570.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6673.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_9079.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_5975.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_6122.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_7027.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_11729.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_2289.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_89.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_4662.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02691156_14912.JPEG 0
/home/mcj/dataset/imageCLEF/i/n02084071_12460.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_766.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_25409.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1389.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1445.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_15074.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_18746.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_7940.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_23498.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_23239.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_661.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_525.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_11564.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32835.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32500.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_9138.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_4657.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27936.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_760.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_32569.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_17496.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_2103.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_11287.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_31709.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_5662.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_5128.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_182.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_24007.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22620.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_29560.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27730.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_34874.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_25631.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_17180.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_2732.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_7098.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_16131.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_1848.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_19134.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_545.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_243.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22252.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_8803.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_22378.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_31703.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_108.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_26796.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_27298.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_29282.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02084071_28769.JPEG 7
/home/mcj/dataset/imageCLEF/i/n02858304_9777.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_837.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9962.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_576.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_236.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1610.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1921.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3759.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3730.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_20876.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_7454.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9208.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_169.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_312.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3137.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_676.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3574.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1249.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1883.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9938.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3268.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3030.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_917.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3175.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2400.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_416.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_746.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4082.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_454.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_3112.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9362.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8049.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9973.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_19915.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2818.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4052.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2348.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_379.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8479.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_10332.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_1612.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_10526.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_8155.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_4545.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2126.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_391.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2049.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_7231.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_2175.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02858304_9844.JPEG 3
/home/mcj/dataset/imageCLEF/i/n02924116_64004.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_84238.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_53329.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_9012.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73751.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_56702.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_85589.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_34753.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_20498.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_57267.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_38704.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_93395.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_14503.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_51663.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33800.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73378.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_39743.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_10156.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_78093.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_18209.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73434.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3470.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_61109.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_61339.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_35958.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_84781.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33755.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_43906.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_67006.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73904.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_44980.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_78812.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37730.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_82999.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37402.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_73389.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3941.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_77225.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_8054.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_50926.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_68762.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_95090.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_82453.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_37624.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_65903.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_33400.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_647.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_86629.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_3352.JPEG 5
/home/mcj/dataset/imageCLEF/i/n02924116_30382.JPEG 5
/home/mcj/dataset/imageCLEF/i/n03782190_12209.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2426.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5658.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2152.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11158.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_13975.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_225.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15774.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14408.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_12880.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5464.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7494.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4205.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_12034.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4945.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4268.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_10175.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14532.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2218.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_9627.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_8233.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_9951.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_6762.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14178.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4015.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1982.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1626.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1214.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15928.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2513.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_5220.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_220.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_19506.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_1776.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11918.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_20760.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11999.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7533.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_15896.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2523.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7111.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_14888.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_6319.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_2154.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_17955.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_4211.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_3964.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_11648.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_7286.JPEG 9
/home/mcj/dataset/imageCLEF/i/n03782190_17779.JPEG 9
/home/mcj/dataset/imageCLEF/i/n07942152_33397.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27123.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_19556.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_56.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_12547.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_76119.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_22807.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_32300.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33090.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_13151.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_56835.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_36134.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_16845.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_9563.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_16633.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8261.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27105.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_4183.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_34434.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_18551.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_413.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_510.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27529.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_31584.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_38507.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37969.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_30118.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_3594.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5568.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_35239.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5588.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_42078.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_34679.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8418.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_24975.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_28165.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_8542.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_5592.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_4777.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33797.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_14349.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_36072.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_40587.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37972.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_33751.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_14138.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27703.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_27649.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_38584.JPEG 11
/home/mcj/dataset/imageCLEF/i/n07942152_37885.JPEG 11
/home/mcj/dataset/imageCLEF/i/n01503061_1868.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_11612.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5453.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_8646.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4167.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_17521.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1387.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12696.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2819.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2744.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2378.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6413.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_688.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3094.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2076.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1457.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2839.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13213.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13929.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14761.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1202.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1780.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9799.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5215.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1227.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6456.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3028.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_6454.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_552.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9622.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1825.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12735.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14886.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_10665.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_12662.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_14700.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4379.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13119.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_3862.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_5054.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2167.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_11048.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_4150.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13495.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_1306.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_7783.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_13307.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9390.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_9081.JPEG 2
/home/mcj/dataset/imageCLEF/i/n01503061_2386.JPEG 2
/home/mcj/dataset/imageCLEF/i/n02374451_12030.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_151.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15002.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9975.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2978.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4722.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_8251.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13125.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_6254.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4795.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_1284.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16310.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_6017.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13929.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_5598.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_5013.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16603.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15685.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14586.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_17474.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_816.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15098.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9897.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14233.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15663.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13953.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11173.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12024.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12086.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_19198.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_20103.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_8301.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16785.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_15633.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_14329.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_597.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_820.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2944.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_9264.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11057.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_13159.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4240.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_11483.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_4479.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_2846.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_18419.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_12376.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_18141.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_16449.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02374451_1062.JPEG 8
/home/mcj/dataset/imageCLEF/i/n02834778_5790.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8639.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10647.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6733.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5206.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10288.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_763.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_1533.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3090.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8949.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5311.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6571.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12206.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_2196.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4013.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5247.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8507.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9153.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_43697.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5420.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_11280.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_716.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_31006.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8044.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_7161.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9223.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_11400.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_5314.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10781.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_187.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3345.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_10227.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_817.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_700.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_46418.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6597.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4695.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3311.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_8918.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3735.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_3119.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_32473.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_2737.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_673.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_6375.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_9232.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12188.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_4302.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12386.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02834778_12754.JPEG 1
/home/mcj/dataset/imageCLEF/i/n02876657_13023.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5177.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7612.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7965.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_3827.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12118.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7993.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7201.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4709.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_15101.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_9504.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_3720.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2631.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_8629.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2245.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7018.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2856.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_13959.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6293.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10725.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7886.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5324.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11443.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5481.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12301.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7718.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7244.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7535.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11695.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2625.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_198.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_668.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4138.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5822.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10178.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5094.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_14142.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_10103.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_7576.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5276.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6246.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_8209.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_5612.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_2191.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_16228.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_4991.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12397.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_12206.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_11898.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02876657_6550.JPEG 4
/home/mcj/dataset/imageCLEF/i/n02958343_4976.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_80662.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9147.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4414.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_12811.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_80339.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8796.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8490.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_3541.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14006.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9672.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8811.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_75694.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_44103.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11718.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_67754.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11586.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14713.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4478.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_6654.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_939.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4881.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13459.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_10892.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_5281.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_3098.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13760.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_10580.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9561.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_52439.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8307.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_50886.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9154.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_13352.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4524.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_5126.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9290.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_4643.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_9081.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8712.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_61122.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_12116.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_55286.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_65338.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_14347.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_8994.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_77917.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11703.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_2032.JPEG 6
/home/mcj/dataset/imageCLEF/i/n02958343_11693.JPEG 6
/home/mcj/dataset/imageCLEF/i/n03790512_722.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9326.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13080.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7537.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_2370.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_37212.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11812.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13431.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10965.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10260.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_2068.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9022.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11545.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_17139.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_40609.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8982.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12426.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10023.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9187.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8654.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7308.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11298.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14972.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12946.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_12093.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_25915.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14967.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5081.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9328.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_4460.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8100.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_38917.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6136.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5722.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_11613.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_14709.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6062.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_9794.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6410.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7851.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10451.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_8955.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_310.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_7743.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_6050.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_10888.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_5892.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_248.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_1579.JPEG 10
/home/mcj/dataset/imageCLEF/i/n03790512_13338.JPEG 10
================================================
FILE: code/deep/B-JMMD/caffe/data/office/pList.txt
================================================
/home/mcj/dataset/imageCLEF/p/2008_006463.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_000163.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_003635.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002888.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_002695.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003423.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007970.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_005834.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002199.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000387.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003703.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000801.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003559.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000545.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004312.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_006951.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002432.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003737.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_003933.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001044.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_005224.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002993.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_003199.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002752.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003575.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000437.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_001139.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_004414.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_005905.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002914.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002714.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000734.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004063.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_005215.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002675.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007758.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_001199.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001489.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_003033.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000418.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_001413.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_001858.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_002999.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_000270.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_004653.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_000291.jpg 0
/home/mcj/dataset/imageCLEF/p/2010_004917.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_000661.jpg 0
/home/mcj/dataset/imageCLEF/p/2008_007442.jpg 0
/home/mcj/dataset/imageCLEF/p/2011_002751.jpg 0
/home/mcj/dataset/imageCLEF/p/2009_001585.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002947.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008231.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_001030.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001011.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000689.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004205.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000568.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_004814.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004794.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_001408.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_000559.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001690.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004285.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008745.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_001223.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002499.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002519.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002809.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_000324.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004222.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002987.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008659.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_005168.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_003071.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004666.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001952.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004708.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002758.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006145.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_002097.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_001581.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008162.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_002285.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002675.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002908.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000552.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000203.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_000529.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002700.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006554.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_006991.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004032.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_000965.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_004160.jpg 11
/home/mcj/dataset/imageCLEF/p/2011_003020.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_008705.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_002067.jpg 11
/home/mcj/dataset/imageCLEF/p/2010_002346.jpg 11
/home/mcj/dataset/imageCLEF/p/2008_005825.jpg 11
/home/mcj/dataset/imageCLEF/p/2009_004197.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000199.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_005196.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002203.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002436.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005959.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003293.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_008343.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_000603.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000335.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_004794.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001403.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000267.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001967.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002066.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001822.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004637.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001105.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002566.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_003673.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_002330.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002105.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000007.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001646.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_000138.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_000947.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_003114.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002263.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002398.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_006483.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003173.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005118.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001847.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001098.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001536.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005063.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001341.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_005080.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_000140.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_004040.jpg 5
/home/mcj/dataset/imageCLEF/p/2011_001110.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_001771.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_002102.jpg 5
/home/mcj/dataset/imageCLEF/p/2008_008080.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_005279.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001675.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_001590.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_003534.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004997.jpg 5
/home/mcj/dataset/imageCLEF/p/2009_002052.jpg 5
/home/mcj/dataset/imageCLEF/p/2010_004766.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004345.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000927.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004845.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_003947.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005637.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_002894.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_000495.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_002408.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005427.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000496.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_000545.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001135.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005252.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005199.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001805.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004502.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004615.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000512.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_001040.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003249.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003618.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004371.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_002191.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_000034.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_003429.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_005997.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_005893.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_001646.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_000695.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001150.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003560.jpg 10
/home/mcj/dataset/imageCLEF/p/2011_002598.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_004143.jpg 10
/home/mcj/dataset/imageCLEF/p/2010_001828.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003020.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003090.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004117.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008218.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003747.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_004738.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008097.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_007558.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_002115.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_007075.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_004084.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001119.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_001631.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_003639.jpg 10
/home/mcj/dataset/imageCLEF/p/2008_008227.jpg 10
/home/mcj/dataset/imageCLEF/p/2009_002453.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_002871.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000086.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001221.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007750.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004969.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_005923.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007643.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_003025.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_001289.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001591.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_001916.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003858.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005198.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007841.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002662.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000435.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002308.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004291.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003652.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_000286.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001901.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004053.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003936.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002449.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_002150.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_001406.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001001.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005705.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_004124.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_004224.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_002104.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_000686.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_003640.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_007305.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_002773.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_005192.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002543.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_005517.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_005015.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_002854.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003019.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001991.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_001858.jpg 3
/home/mcj/dataset/imageCLEF/p/2011_001310.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_003136.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_004714.jpg 3
/home/mcj/dataset/imageCLEF/p/2010_003815.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003362.jpg 3
/home/mcj/dataset/imageCLEF/p/2008_003480.jpg 3
/home/mcj/dataset/imageCLEF/p/2009_002975.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003782.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_008279.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_003128.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_000765.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006317.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_001956.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004134.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004942.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001837.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000409.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004624.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000412.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007625.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_002583.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007004.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_002697.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001934.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_000749.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006219.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_001759.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003272.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003800.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_002168.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_003714.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_000076.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_004228.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007576.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001218.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_004790.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001323.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_006758.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007588.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_002589.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_002341.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000771.jpg 8
/home/mcj/dataset/imageCLEF/p/2010_001675.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004705.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_001542.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004195.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003802.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_005525.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_001433.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_000001.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_002882.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_007531.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_004764.jpg 8
/home/mcj/dataset/imageCLEF/p/2008_003055.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000022.jpg 8
/home/mcj/dataset/imageCLEF/p/2011_000210.jpg 8
/home/mcj/dataset/imageCLEF/p/2009_003551.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001726.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002513.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000244.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_002758.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001553.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_004665.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005744.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003264.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007038.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006624.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_005030.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_002464.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005410.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002247.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_000253.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_004009.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005345.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007361.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002843.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_005305.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_003236.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003885.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000305.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005817.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001910.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005066.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007536.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003667.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_002418.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005954.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_005288.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001608.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_000435.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005064.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_004807.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006591.jpg 9
/home/mcj/dataset/imageCLEF/p/2011_001705.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_003140.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_002152.jpg 9
/home/mcj/dataset/imageCLEF/p/2010_003035.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_007446.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_001106.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_000070.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_003435.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_006233.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_001481.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_003078.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_002066.jpg 9
/home/mcj/dataset/imageCLEF/p/2009_000981.jpg 9
/home/mcj/dataset/imageCLEF/p/2008_005325.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006310.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_002807.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_001901.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_005865.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_003647.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_003031.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004290.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004271.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003139.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000631.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004411.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000390.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001717.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000720.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_002746.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007171.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006833.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007739.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007090.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_002199.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001681.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007877.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_002598.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001007.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006989.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_004349.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_003114.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_004518.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_002585.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000886.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006483.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_001403.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003562.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_006872.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004711.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_002380.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003129.jpg 6
/home/mcj/dataset/imageCLEF/p/2011_001271.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_003450.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_000176.jpg 6
/home/mcj/dataset/imageCLEF/p/2009_000737.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_000947.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005733.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_001432.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_004690.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005804.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_007364.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_000719.jpg 6
/home/mcj/dataset/imageCLEF/p/2008_004923.jpg 6
/home/mcj/dataset/imageCLEF/p/2010_005671.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_000655.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_004688.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002398.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_001687.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_000317.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007286.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002674.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_005109.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001838.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_003801.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001626.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001432.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004345.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_004772.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001768.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001422.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004227.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001421.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_001420.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_000981.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_005379.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_002605.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007583.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007358.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_002865.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006724.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_000263.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_005333.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_002239.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006032.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003351.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003056.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000419.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_001756.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006716.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000162.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003554.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_000874.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002644.jpg 7
/home/mcj/dataset/imageCLEF/p/2011_002900.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_004417.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_002129.jpg 7
/home/mcj/dataset/imageCLEF/p/2010_003879.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_000931.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_007208.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_006220.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_001538.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_001550.jpg 7
/home/mcj/dataset/imageCLEF/p/2009_003735.jpg 7
/home/mcj/dataset/imageCLEF/p/2008_008724.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003828.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000820.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_001642.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000445.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_004758.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_001119.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000453.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003701.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005000.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000087.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005374.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_001937.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_005154.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003175.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_001753.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002714.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002927.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002497.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_006070.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008758.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_002913.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005226.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_001384.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008337.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003075.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000505.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005782.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_000133.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004876.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002883.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005556.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_003912.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_005175.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_003860.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_007510.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_008629.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_000015.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_000803.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002679.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_000893.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_002406.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004797.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_005412.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_004995.jpg 1
/home/mcj/dataset/imageCLEF/p/2011_000485.jpg 1
/home/mcj/dataset/imageCLEF/p/2008_002787.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_005848.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_004848.jpg 1
/home/mcj/dataset/imageCLEF/p/2009_002983.jpg 1
/home/mcj/dataset/imageCLEF/p/2010_002457.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_004198.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003467.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_003038.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005512.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_008072.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007219.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_001538.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002980.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003591.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005991.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_004979.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_002858.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_006145.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002186.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000801.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000290.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_005302.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_001593.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_003912.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007146.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003588.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000703.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_000089.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000691.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_003635.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000522.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005663.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000953.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_004247.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_000464.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002649.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005758.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_000851.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_002594.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002590.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003214.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_005540.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_000494.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_001908.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_001106.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_003154.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_004016.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_000747.jpg 4
/home/mcj/dataset/imageCLEF/p/2010_002455.jpg 4
/home/mcj/dataset/imageCLEF/p/2009_005278.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_001638.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_008266.jpg 4
/home/mcj/dataset/imageCLEF/p/2011_002814.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_005140.jpg 4
/home/mcj/dataset/imageCLEF/p/2008_007870.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004671.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006802.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_000621.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008523.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_005040.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006164.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007120.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_001673.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007486.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000930.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_003285.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004551.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002784.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_003426.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_000918.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008309.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007003.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_003531.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007465.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_003484.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004689.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_000103.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_001967.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002255.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000317.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_008197.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001128.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000664.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_002023.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_006090.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_002463.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002286.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001660.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_004187.jpg 2
/home/mcj/dataset/imageCLEF/p/2011_001134.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_002970.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007656.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_000790.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_007854.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002629.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_001992.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_005757.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_005428.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_001397.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_001415.jpg 2
/home/mcj/dataset/imageCLEF/p/2009_002877.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_005993.jpg 2
/home/mcj/dataset/imageCLEF/p/2010_003771.jpg 2
/home/mcj/dataset/imageCLEF/p/2008_004147.jpg 2
================================================
FILE: code/deep/B-JMMD/caffe/data/office/webcam_list.txt
================================================
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0001.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0002.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0003.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0004.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0005.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0006.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0007.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0008.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0009.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0010.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0011.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0012.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0013.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0014.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0015.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0016.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0017.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0018.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0019.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0020.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0021.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0022.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0023.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0024.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0025.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0026.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0027.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0028.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0029.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0030.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/calculator/frame_0031.jpg 5
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0001.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0002.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0003.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0004.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0005.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0006.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0007.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0008.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0009.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0010.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0011.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0012.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0013.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0014.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0015.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0016.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0017.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0018.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0019.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0020.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0021.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0022.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0023.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0024.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0025.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0026.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0027.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0028.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0029.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0030.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0031.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0032.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0033.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0034.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0035.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0036.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0037.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0038.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0039.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ring_binder/frame_0040.jpg 24
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0001.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0002.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0003.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0004.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0005.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0006.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0007.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0008.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0009.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0010.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0011.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0012.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0013.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0014.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0015.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0016.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0017.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0018.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0019.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/printer/frame_0020.jpg 21
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0001.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0002.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0003.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0004.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0005.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0006.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0007.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0008.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0009.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0010.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0011.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0012.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0013.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0014.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0015.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0016.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0017.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0018.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0019.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0020.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0021.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0022.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0023.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0024.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0025.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0026.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/keyboard/frame_0027.jpg 11
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0001.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0002.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0003.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0004.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0005.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0006.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0007.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0008.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0009.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0010.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0011.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0012.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0013.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0014.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0015.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0016.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0017.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0018.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0019.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0020.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0021.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0022.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0023.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0024.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/scissors/frame_0025.jpg 26
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0001.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0002.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0003.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0004.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0005.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0006.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0007.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0008.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0009.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0010.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0011.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0012.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0013.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0014.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0015.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0016.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0017.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0018.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0019.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0020.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0021.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0022.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0023.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0024.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0025.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0026.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0027.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0028.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0029.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/laptop_computer/frame_0030.jpg 12
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0001.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0002.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0003.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0004.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0005.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0006.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0007.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0008.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0009.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0010.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0011.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0012.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0013.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0014.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0015.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0016.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0017.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0018.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0019.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0020.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0021.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0022.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0023.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0024.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0025.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0026.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0027.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0028.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0029.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mouse/frame_0030.jpg 16
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0001.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0002.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0003.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0004.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0005.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0006.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0007.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0008.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0009.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0010.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0011.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0012.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0013.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0014.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0015.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0016.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0017.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0018.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0019.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0020.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0021.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0022.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0023.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0024.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0025.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0026.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0027.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0028.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0029.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0030.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0031.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0032.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0033.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0034.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0035.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0036.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0037.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0038.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0039.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0040.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0041.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0042.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/monitor/frame_0043.jpg 15
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0001.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0002.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0003.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0004.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0005.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0006.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0007.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0008.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0009.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0010.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0011.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0012.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0013.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0014.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0015.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0016.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0017.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0018.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0019.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0020.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0021.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0022.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0023.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0024.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0025.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0026.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mug/frame_0027.jpg 17
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0001.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0002.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0003.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0004.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0005.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0006.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0007.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0008.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0009.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0010.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0011.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0012.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0013.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0014.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0015.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0016.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0017.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0018.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0019.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0020.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0021.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0022.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/tape_dispenser/frame_0023.jpg 29
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0001.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0002.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0003.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0004.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0005.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0006.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0007.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0008.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0009.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0010.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0011.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0012.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0013.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0014.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0015.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0016.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0017.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0018.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0019.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0020.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0021.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0022.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0023.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0024.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0025.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0026.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0027.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0028.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0029.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0030.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0031.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/pen/frame_0032.jpg 19
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0001.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0002.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0003.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0004.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0005.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0006.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0007.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0008.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0009.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0010.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0011.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0012.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0013.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0014.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0015.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0016.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0017.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0018.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0019.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0020.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike/frame_0021.jpg 1
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0001.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0002.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0003.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0004.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0005.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0006.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0007.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0008.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0009.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0010.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0011.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0012.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0013.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0014.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0015.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0016.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0017.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0018.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0019.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0020.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0021.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0022.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0023.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0024.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0025.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0026.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/punchers/frame_0027.jpg 23
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0001.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0002.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0003.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0004.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0005.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0006.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0007.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0008.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0009.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0010.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0011.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0012.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0013.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0014.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0015.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0016.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0017.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0018.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0019.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0020.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0021.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0022.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0023.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0024.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0025.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0026.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0027.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0028.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/back_pack/frame_0029.jpg 0
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0001.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0002.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0003.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0004.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0005.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0006.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0007.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0008.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0009.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0010.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0011.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0012.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0013.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0014.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0015.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0016.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0017.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0018.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0019.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0020.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desktop_computer/frame_0021.jpg 8
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0001.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0002.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0003.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0004.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0005.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0006.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0007.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0008.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0009.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0010.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0011.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0012.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0013.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0014.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0015.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0016.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0017.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0018.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0019.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0020.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0021.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0022.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0023.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0024.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0025.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0026.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0027.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0028.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0029.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/speaker/frame_0030.jpg 27
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0001.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0002.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0003.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0004.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0005.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0006.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0007.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0008.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0009.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0010.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0011.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0012.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0013.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0014.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0015.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0016.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0017.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0018.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0019.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0020.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0021.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0022.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0023.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0024.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0025.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0026.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0027.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0028.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0029.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/mobile_phone/frame_0030.jpg 14
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0001.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0002.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0003.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0004.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0005.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0006.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0007.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0008.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0009.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0010.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0011.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0012.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0013.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0014.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0015.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0016.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0017.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0018.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0019.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0020.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0021.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0022.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0023.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0024.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0025.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0026.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0027.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/paper_notebook/frame_0028.jpg 18
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0001.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0002.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0003.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0004.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0005.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0006.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0007.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0008.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0009.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0010.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/ruler/frame_0011.jpg 25
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0001.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0002.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0003.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0004.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0005.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0006.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0007.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0008.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0009.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0010.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0011.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0012.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0013.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0014.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0015.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0016.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0017.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0018.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/letter_tray/frame_0019.jpg 13
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0001.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0002.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0003.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0004.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0005.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0006.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0007.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0008.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0009.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0010.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0011.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0012.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0013.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0014.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0015.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0016.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0017.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0018.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/file_cabinet/frame_0019.jpg 9
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0001.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0002.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0003.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0004.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0005.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0006.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0007.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0008.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0009.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0010.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0011.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0012.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0013.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0014.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0015.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/phone/frame_0016.jpg 20
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0001.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0002.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0003.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0004.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0005.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0006.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0007.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0008.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0009.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0010.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0011.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bookcase/frame_0012.jpg 3
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0001.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0002.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0003.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0004.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0005.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0006.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0007.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0008.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0009.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0010.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0011.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0012.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0013.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0014.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0015.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0016.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0017.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0018.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0019.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0020.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0021.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0022.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0023.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0024.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0025.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0026.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0027.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0028.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0029.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/projector/frame_0030.jpg 22
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0001.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0002.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0003.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0004.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0005.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0006.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0007.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0008.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0009.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0010.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0011.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0012.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0013.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0014.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0015.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0016.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0017.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0018.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0019.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0020.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0021.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0022.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0023.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/stapler/frame_0024.jpg 28
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0001.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0002.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0003.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0004.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0005.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0006.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0007.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0008.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0009.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0010.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0011.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0012.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0013.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0014.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0015.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0016.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0017.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0018.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0019.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0020.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/trash_can/frame_0021.jpg 30
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0001.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0002.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0003.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0004.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0005.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0006.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0007.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0008.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0009.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0010.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0011.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0012.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0013.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0014.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0015.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0016.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0017.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0018.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0019.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0020.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0021.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0022.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0023.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0024.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0025.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0026.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0027.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bike_helmet/frame_0028.jpg 2
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0001.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0002.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0003.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0004.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0005.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0006.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0007.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0008.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0009.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0010.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0011.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0012.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0013.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0014.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0015.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0016.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0017.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0018.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0019.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0020.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0021.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0022.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0023.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0024.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0025.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0026.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/headphones/frame_0027.jpg 10
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0001.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0002.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0003.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0004.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0005.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0006.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0007.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0008.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0009.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0010.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0011.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0012.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0013.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0014.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0015.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0016.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0017.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_lamp/frame_0018.jpg 7
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0001.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0002.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0003.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0004.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0005.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0006.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0007.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0008.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0009.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0010.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0011.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0012.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0013.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0014.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0015.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0016.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0017.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0018.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0019.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0020.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0021.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0022.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0023.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0024.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0025.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0026.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0027.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0028.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0029.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0030.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0031.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0032.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0033.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0034.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0035.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0036.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0037.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0038.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0039.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/desk_chair/frame_0040.jpg 6
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0001.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0002.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0003.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0004.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0005.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0006.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0007.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0008.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0009.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0010.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0011.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0012.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0013.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0014.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0015.jpg 4
/home/mcj/dataset/office/domain_adaptation_images/webcam/images/bottle/frame_0016.jpg 4
================================================
FILE: code/deep/B-JMMD/caffe/include/caffe/layers/bjmmd_layer.hpp
================================================
#ifndef CAFFE_BJMMD_LOSS_LAYER_HPP_
#define CAFFE_BJMMD_LOSS_LAYER_HPP_
#include
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/loss_layer.hpp"
namespace caffe {
template
class BJMMDLossLayer : public LossLayer {
public:
explicit BJMMDLossLayer(const LayerParameter& param)
: LossLayer(param) {}
virtual void LayerSetUp(const vector*>& bottom,
const vector*>& top);
virtual void Reshape(const vector*>& bottom,
const vector*>& top);
virtual inline const char* type() const { return "BJMMDLoss"; }
virtual inline int ExactNumTopBlobs() const { return -1; }
virtual inline int ExactNumBottomBlobs() const { return -1; }
virtual inline int MinBottomBlobs() const { return 2; }
virtual inline int MaxBottomBlobs() const { return 4; }
protected:
virtual void Forward_cpu(const vector*>& bottom,
const vector*>& top);
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
virtual void Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
virtual void Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
int source_num_;
int target_num_;
int total_num_;
int dim_;
int kernel_num_;
Dtype kernel_mul_;
Dtype gamma_;
Dtype sigma_;
bool fix_gamma_;
Blob diff_;
vector*> kernel_val_;
Blob diff_multiplier_;
Dtype loss_weight_;
Dtype label_loss_weight_;
Dtype balanced_factor_;
Blob delta_;
int label_kernel_num_;
Dtype label_kernel_mul_;
bool auto_sigma_;
};
} // namespace caffe
#endif // CAFFE_BJMMD_LAYER_HPP_
================================================
FILE: code/deep/B-JMMD/caffe/kmake.sh
================================================
cd src
protoc ./caffe/proto/caffe.proto --cpp_out=../include/
cd ..
make -j48
================================================
FILE: code/deep/B-JMMD/caffe/models/B-JMMD/alexnet/solver.prototxt
================================================
net: "models/BJMMD/alexnet/train_val.prototxt"
test_iter: 795 # target domain: amazon 2817, webcam 795, dslr 498
test_interval: 500
base_lr: 0.003
lr_policy: "inv"
gamma: 0.001
power: 0.75
display: 500
max_iter: 100000
momentum: 0.9
weight_decay: 0.0005
snapshot: 600000
snapshot_prefix: "models/BJMMD/alexnet/trained_model"
snapshot_after_train: false
solver_mode: GPU
random_seed: 8
================================================
FILE: code/deep/B-JMMD/caffe/models/B-JMMD/alexnet/train_val.prototxt
================================================
name: "amazon_to_webcam"
layer {
name: "source_data"
type: "ImageData"
top: "source_data"
top: "source_label"
image_data_param {
source: "./data/office/amazon_list.txt"
batch_size: 64
new_height: 256
new_width: 256
shuffle: true
}
transform_param {
crop_size: 227
mirror: true
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TRAIN }
}
layer {
name: "target_data"
type: "ImageData"
top: "target_data"
top: "target_label"
image_data_param {
source: "./data/office/webcam_list.txt"
batch_size: 64
new_height: 256
new_width: 256
shuffle: true
}
transform_param {
crop_size: 227
mirror: true
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TRAIN }
}
layer {
name: "target_label_silence"
type: "Silence"
bottom: "target_label"
include: { phase: TRAIN }
}
layer {
name: "test_data"
type: "ImageData"
top: "data"
top: "label"
image_data_param {
source: "./data/office/webcam_list.txt"
batch_size: 1
new_height: 256
new_width: 256
shuffle: false
}
transform_param {
crop_size: 227
mirror: false
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TEST }
}
layer {
name: "data"
type: "Concat"
bottom: "source_data"
bottom: "target_data"
top: "data"
concat_param: {
axis: 0
}
include: { phase: TRAIN }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 0
decay_mult: 1
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 0
decay_mult: 1
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 0.1
decay_mult: 1
}
param {
lr_mult: 0.2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 0.1
decay_mult: 1
}
param {
lr_mult: 0.2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 0.1
decay_mult: 1
}
param {
lr_mult: 0.2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0.1
decay_mult: 1
}
param {
lr_mult: 0.2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0.1
decay_mult: 1
}
param {
lr_mult: 0.2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8_1"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
# blobs_lr is set to higher than for other layers, because this layer is starting from random while the others are already trained
param {
name: "fc8_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "fc8_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 31
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "slice_fc8"
type: "Slice"
bottom: "fc8"
top: "fc8_source"
top: "fc8_target"
slice_param {
axis: 0
}
include: { phase: TRAIN }
}
layer {
name: "silence_fc8_target"
type: "Silence"
bottom: "fc8_target"
include: { phase: TRAIN }
}
layer {
name: "softmax_loss"
type: "SoftmaxWithLoss"
bottom: "fc8_source"
bottom: "source_label"
top: "softmax_loss"
include: { phase: TRAIN }
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layer {
name: "softmax_fc8"
type: "Softmax"
bottom: "fc8"
top: "softmax1"
include: { phase: TRAIN }
}
layer {
name: "slice_softmax"
type: "Slice"
bottom: "softmax1"
top: "softmax_source"
top: "softmax_target"
slice_param {
axis: 0
}
include: { phase: TRAIN }
}
layer {
name: "fc7_slice"
type: "Slice"
bottom: "fc7"
top: "source_fc7"
top: "target_fc7"
slice_param {
axis: 0
}
include: { phase: TRAIN }
}
layer {
name: "fc7_bjmmd_loss"
type: "BJMMDLoss"
bottom: "source_fc7"
bottom: "target_fc7"
bottom: "softmax_source"
bottom: "softmax_target"
loss_weight: 0.1
top: "fc7_bjmmd_loss"
bjmmd_param {
kernel_num: 5
kernel_mul: 2.0
label_kernel_num: 1
label_kernel_mul: 2.0
sigma: 1.68
balanced_factor: 0.3
}
include: { phase: TRAIN }
}
layer {
name: "fc8_bjmmd_loss"
type: "BJMMDLoss"
bottom: "softmax_source"
bottom: "softmax_target"
bottom: "softmax_source"
bottom: "softmax_target"
loss_weight: 0.1
top: "fc8_bjmmd_loss"
bjmmd_param {
kernel_num: 5
kernel_mul: 2.0
label_kernel_num: 1
label_kernel_mul: 2.0
sigma: 1.68
balanced_factor: 0.3
}
include: { phase: TRAIN }
}
================================================
FILE: code/deep/B-JMMD/caffe/models/B-JMMD/resnet/solver.prototxt
================================================
net: "models/BJMMD/resnet/train_val.prototxt"
test_iter: 795 # target domain: amazon 2817, webcam 795, dslr 498
test_interval: 500
base_lr: 0.0003
lr_policy: "inv"
gamma: 0.001
power: 0.75
display: 1000
max_iter: 30000
momentum: 0.9
weight_decay: 0.0005
snapshot: 60000
snapshot_prefix: "models/BJMMD/resnet/trained_model"
snapshot_after_train: false
solver_mode: GPU
================================================
FILE: code/deep/B-JMMD/caffe/models/B-JMMD/resnet/train_val.prototxt
================================================
name: "amazon_to_webcam"
layer {
name: "source_data"
type: "ImageData"
top: "source_data"
top: "source_label"
image_data_param {
source: "./data/office/amazon_list.txt"
batch_size: 2
new_height: 256
new_width: 256
shuffle: true
}
transform_param {
crop_size: 227
mirror: true
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TRAIN }
}
layer {
name: "target_data"
type: "ImageData"
top: "target_data"
top: "target_label"
image_data_param {
source: "./data/office/webcam_list.txt"
batch_size: 2
new_height: 256
new_width: 256
shuffle: true
}
transform_param {
crop_size: 227
mirror: true
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TRAIN }
}
layer {
name: "target_label_silence"
type: "Silence"
bottom: "target_label"
include: { phase: TRAIN }
}
layer {
name: "test_data"
type: "ImageData"
top: "data"
top: "label"
image_data_param {
source: "./data/office/webcam_list.txt"
batch_size: 1
new_height: 256
new_width: 256
shuffle: true
}
transform_param {
crop_size: 227
mirror: false
mean_file: "./data/ilsvrc12/imagenet_mean.binaryproto"
}
include: { phase: TEST }
}
layer {
name: "data"
type: "Concat"
bottom: "source_data"
bottom: "target_data"
top: "data"
concat_param: {
axis: 0
}
include: { phase: TRAIN }
}
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "scale_conv1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "conv1_relu"
type: "ReLU"
}
layer {
bottom: "conv1"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: MAX
}
}
layer {
bottom: "pool1"
top: "res2a_branch1"
name: "res2a_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "bn2a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "scale2a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "pool1"
top: "res2a_branch2a"
name: "res2a_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "bn2a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "scale2a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "res2a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2b"
name: "res2a_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "bn2a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "scale2a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "res2a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2c"
name: "res2a_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "bn2a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "scale2a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch1"
bottom: "res2a_branch2c"
top: "res2a"
name: "res2a"
type: "Eltwise"
}
layer {
bottom: "res2a"
top: "res2a"
name: "res2a_relu"
type: "ReLU"
}
layer {
bottom: "res2a"
top: "res2b_branch2a"
name: "res2b_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "bn2b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "scale2b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "res2b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2b"
name: "res2b_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "bn2b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "scale2b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "res2b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2c"
name: "res2b_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2b_branch2c"
top: "res2b_branch2c"
name: "bn2b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2b_branch2c"
top: "res2b_branch2c"
name: "scale2b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a"
bottom: "res2b_branch2c"
top: "res2b"
name: "res2b"
type: "Eltwise"
}
layer {
bottom: "res2b"
top: "res2b"
name: "res2b_relu"
type: "ReLU"
}
layer {
bottom: "res2b"
top: "res2c_branch2a"
name: "res2c_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "bn2c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "scale2c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "res2c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2b"
name: "res2c_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "bn2c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "scale2c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "res2c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2c"
name: "res2c_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res2c_branch2c"
top: "res2c_branch2c"
name: "bn2c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2c_branch2c"
top: "res2c_branch2c"
name: "scale2c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2b"
bottom: "res2c_branch2c"
top: "res2c"
name: "res2c"
type: "Eltwise"
}
layer {
bottom: "res2c"
top: "res2c"
name: "res2c_relu"
type: "ReLU"
}
layer {
bottom: "res2c"
top: "res3a_branch1"
name: "res3a_branch1"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "bn3a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "scale3a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2c"
top: "res3a_branch2a"
name: "res3a_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "bn3a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "scale3a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "res3a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2b"
name: "res3a_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "bn3a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "scale3a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "res3a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2c"
name: "res3a_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3a_branch2c"
top: "res3a_branch2c"
name: "bn3a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3a_branch2c"
top: "res3a_branch2c"
name: "scale3a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a_branch1"
bottom: "res3a_branch2c"
top: "res3a"
name: "res3a"
type: "Eltwise"
}
layer {
bottom: "res3a"
top: "res3a"
name: "res3a_relu"
type: "ReLU"
}
layer {
bottom: "res3a"
top: "res3b_branch2a"
name: "res3b_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "bn3b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "scale3b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "res3b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2b"
name: "res3b_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "bn3b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "scale3b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "res3b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2c"
name: "res3b_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3b_branch2c"
top: "res3b_branch2c"
name: "bn3b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3b_branch2c"
top: "res3b_branch2c"
name: "scale3b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3a"
bottom: "res3b_branch2c"
top: "res3b"
name: "res3b"
type: "Eltwise"
}
layer {
bottom: "res3b"
top: "res3b"
name: "res3b_relu"
type: "ReLU"
}
layer {
bottom: "res3b"
top: "res3c_branch2a"
name: "res3c_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "bn3c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "scale3c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "res3c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2b"
name: "res3c_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "bn3c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "scale3c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "res3c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2c"
name: "res3c_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3c_branch2c"
top: "res3c_branch2c"
name: "bn3c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3c_branch2c"
top: "res3c_branch2c"
name: "scale3c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3b"
bottom: "res3c_branch2c"
top: "res3c"
name: "res3c"
type: "Eltwise"
}
layer {
bottom: "res3c"
top: "res3c"
name: "res3c_relu"
type: "ReLU"
}
layer {
bottom: "res3c"
top: "res3d_branch2a"
name: "res3d_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "bn3d_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "scale3d_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "res3d_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2b"
name: "res3d_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "bn3d_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "scale3d_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "res3d_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2c"
name: "res3d_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res3d_branch2c"
top: "res3d_branch2c"
name: "bn3d_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res3d_branch2c"
top: "res3d_branch2c"
name: "scale3d_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3c"
bottom: "res3d_branch2c"
top: "res3d"
name: "res3d"
type: "Eltwise"
}
layer {
bottom: "res3d"
top: "res3d"
name: "res3d_relu"
type: "ReLU"
}
layer {
bottom: "res3d"
top: "res4a_branch1"
name: "res4a_branch1"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "bn4a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "scale4a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res3d"
top: "res4a_branch2a"
name: "res4a_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "bn4a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "scale4a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "res4a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2b"
name: "res4a_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "bn4a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "scale4a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "res4a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2c"
name: "res4a_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4a_branch2c"
top: "res4a_branch2c"
name: "bn4a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4a_branch2c"
top: "res4a_branch2c"
name: "scale4a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a_branch1"
bottom: "res4a_branch2c"
top: "res4a"
name: "res4a"
type: "Eltwise"
}
layer {
bottom: "res4a"
top: "res4a"
name: "res4a_relu"
type: "ReLU"
}
layer {
bottom: "res4a"
top: "res4b_branch2a"
name: "res4b_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "bn4b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "scale4b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "res4b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2b"
name: "res4b_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "bn4b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "scale4b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "res4b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2c"
name: "res4b_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4b_branch2c"
top: "res4b_branch2c"
name: "bn4b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4b_branch2c"
top: "res4b_branch2c"
name: "scale4b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4a"
bottom: "res4b_branch2c"
top: "res4b"
name: "res4b"
type: "Eltwise"
}
layer {
bottom: "res4b"
top: "res4b"
name: "res4b_relu"
type: "ReLU"
}
layer {
bottom: "res4b"
top: "res4c_branch2a"
name: "res4c_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "bn4c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "scale4c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "res4c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2b"
name: "res4c_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "bn4c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "scale4c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "res4c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2c"
name: "res4c_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4c_branch2c"
top: "res4c_branch2c"
name: "bn4c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4c_branch2c"
top: "res4c_branch2c"
name: "scale4c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4b"
bottom: "res4c_branch2c"
top: "res4c"
name: "res4c"
type: "Eltwise"
}
layer {
bottom: "res4c"
top: "res4c"
name: "res4c_relu"
type: "ReLU"
}
layer {
bottom: "res4c"
top: "res4d_branch2a"
name: "res4d_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "bn4d_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "scale4d_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "res4d_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2b"
name: "res4d_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "bn4d_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "scale4d_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "res4d_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2c"
name: "res4d_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4d_branch2c"
top: "res4d_branch2c"
name: "bn4d_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4d_branch2c"
top: "res4d_branch2c"
name: "scale4d_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4c"
bottom: "res4d_branch2c"
top: "res4d"
name: "res4d"
type: "Eltwise"
}
layer {
bottom: "res4d"
top: "res4d"
name: "res4d_relu"
type: "ReLU"
}
layer {
bottom: "res4d"
top: "res4e_branch2a"
name: "res4e_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "bn4e_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "scale4e_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "res4e_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2b"
name: "res4e_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "bn4e_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "scale4e_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "res4e_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2c"
name: "res4e_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4e_branch2c"
top: "res4e_branch2c"
name: "bn4e_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4e_branch2c"
top: "res4e_branch2c"
name: "scale4e_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4d"
bottom: "res4e_branch2c"
top: "res4e"
name: "res4e"
type: "Eltwise"
}
layer {
bottom: "res4e"
top: "res4e"
name: "res4e_relu"
type: "ReLU"
}
layer {
bottom: "res4e"
top: "res4f_branch2a"
name: "res4f_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "bn4f_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "scale4f_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "res4f_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2b"
name: "res4f_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "bn4f_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "scale4f_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "res4f_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2c"
name: "res4f_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res4f_branch2c"
top: "res4f_branch2c"
name: "bn4f_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res4f_branch2c"
top: "res4f_branch2c"
name: "scale4f_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4e"
bottom: "res4f_branch2c"
top: "res4f"
name: "res4f"
type: "Eltwise"
}
layer {
bottom: "res4f"
top: "res4f"
name: "res4f_relu"
type: "ReLU"
}
layer {
bottom: "res4f"
top: "res5a_branch1"
name: "res5a_branch1"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "bn5a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "scale5a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res4f"
top: "res5a_branch2a"
name: "res5a_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "bn5a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "scale5a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "res5a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2b"
name: "res5a_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "bn5a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "scale5a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "res5a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2c"
name: "res5a_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5a_branch2c"
top: "res5a_branch2c"
name: "bn5a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5a_branch2c"
top: "res5a_branch2c"
name: "scale5a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a_branch1"
bottom: "res5a_branch2c"
top: "res5a"
name: "res5a"
type: "Eltwise"
}
layer {
bottom: "res5a"
top: "res5a"
name: "res5a_relu"
type: "ReLU"
}
layer {
bottom: "res5a"
top: "res5b_branch2a"
name: "res5b_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "bn5b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "scale5b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "res5b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2b"
name: "res5b_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "bn5b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "scale5b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "res5b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2c"
name: "res5b_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5b_branch2c"
top: "res5b_branch2c"
name: "bn5b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5b_branch2c"
top: "res5b_branch2c"
name: "scale5b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5a"
bottom: "res5b_branch2c"
top: "res5b"
name: "res5b"
type: "Eltwise"
}
layer {
bottom: "res5b"
top: "res5b"
name: "res5b_relu"
type: "ReLU"
}
layer {
bottom: "res5b"
top: "res5c_branch2a"
name: "res5c_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "bn5c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "scale5c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "res5c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2b"
name: "res5c_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "bn5c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "scale5c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "res5c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2c"
name: "res5c_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "bn5c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "scale5c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res5b"
bottom: "res5c_branch2c"
top: "res5c"
name: "res5c"
type: "Eltwise"
}
layer {
bottom: "res5c"
top: "res5c"
name: "res5c_relu"
type: "ReLU"
}
layer {
bottom: "res5c"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 7
stride: 1
pool: AVE
}
propagate_down: false
}
layer {
bottom: "pool5"
top: "bottleneck"
name: "bottleneck"
type: "InnerProduct"
param {
lr_mult: 10
decay_mult: 1
}
param {
lr_mult: 20
decay_mult: 0
}
inner_product_param {
weight_filler{
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
num_output: 256
}
}
layer {
name: "fc8_1"
type: "InnerProduct"
bottom: "bottleneck"
top: "fc8"
# blobs_lr is set higher than for other layers, as this layer is trained from random weights while the others are fine-tuned
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 31
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include: { phase: TEST }
}
layer {
name: "slice_fc8"
type: "Slice"
bottom: "fc8"
top: "fc8_source"
top: "fc8_target"
slice_param {
slice_dim: 0
}
include: { phase: TRAIN }
}
layer {
name: "silence"
type: "Silence"
bottom: "fc8_target"
include: { phase: TRAIN }
}
layer {
name: "softmax_loss"
type: "SoftmaxWithLoss"
bottom: "fc8_source"
bottom: "source_label"
top: "softmax_loss"
include: { phase: TRAIN }
}
layer {
name: "fc8_softmax"
type: "Softmax"
bottom: "fc8"
top: "fc8_softmax"
include: { phase: TRAIN }
}
layer {
name: "slice_bottleneck"
type: "Slice"
bottom: "bottleneck"
top: "bottleneck_source"
top: "bottleneck_target"
slice_param {
slice_dim: 0
}
include: { phase: TRAIN }
}
layer {
name: "slice_softmax"
type: "Slice"
bottom: "fc8_softmax"
top: "source_softmax"
top: "target_softmax"
slice_param {
slice_dim: 0
}
include: { phase: TRAIN }
}
layer {
name: "fc7_bjmmd_loss"
type: "BJMMDLoss"
bottom: "bottleneck_source"
bottom: "bottleneck_target"
bottom: "source_softmax"
bottom: "target_softmax"
loss_weight: 0.3
top: "fc7_bjmmd_loss"
bjmmd_param {
kernel_num: 5
kernel_mul: 2.0
label_kernel_num: 1
label_kernel_mul: 2.0
sigma: 1.68
balanced_factor: 0.3
}
include: { phase: TRAIN }
}
layer {
name: "fc8_bjmmd_loss"
type: "BJMMDLoss"
bottom: "source_softmax"
bottom: "target_softmax"
bottom: "source_softmax"
bottom: "target_softmax"
loss_weight: 0.3
top: "fc8_bjmmd_loss"
bjmmd_param {
kernel_num: 1
kernel_mul: 2.0
label_kernel_num: 1
label_kernel_mul: 2.0
sigma: 1.68
balanced_factor: 0.3
}
include: { phase: TRAIN }
}
================================================
FILE: code/deep/B-JMMD/caffe/models/bvlc_reference_caffenet/deploy.prototxt
================================================
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 1000
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}
================================================
FILE: code/deep/B-JMMD/caffe/models/bvlc_reference_caffenet/readme.md
================================================
---
name: BVLC CaffeNet Model
caffemodel: bvlc_reference_caffenet.caffemodel
caffemodel_url: http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
license: unrestricted
sha1: 4c8d77deb20ea792f84eb5e6d0a11ca0a8660a46
caffe_commit: 709dc15af4a06bebda027c1eb2b3f3e3375d5077
---
This model is the result of following the Caffe [ImageNet model training instructions](http://caffe.berkeleyvision.org/gathered/examples/imagenet.html).
It is a replication of the model described in the [AlexNet](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks) publication with some differences:
- not training with the relighting data-augmentation;
- the order of pooling and normalization layers is switched (in CaffeNet, pooling is done before normalization).
This model is snapshot of iteration 310,000.
The best validation performance during training was iteration 313,000 with validation accuracy 57.412% and loss 1.82328.
This model obtains a top-1 accuracy 57.4% and a top-5 accuracy 80.4% on the validation set, using just the center crop.
(Using the average of 10 crops, (4 + 1 center) * 2 mirror, should obtain a bit higher accuracy still.)
This model was trained by Jeff Donahue @jeffdonahue
## License
This model is released for unrestricted use.
================================================
FILE: code/deep/B-JMMD/caffe/models/bvlc_reference_caffenet/solver.prototxt
================================================
net: "models/bvlc_reference_caffenet/train_val.prototxt"
test_iter: 1000
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU
================================================
FILE: code/deep/B-JMMD/caffe/models/bvlc_reference_caffenet/train_val.prototxt
================================================
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
================================================
FILE: code/deep/B-JMMD/caffe/src/caffe/layers/bjmmd_layer.cpp
================================================
#include
#include "caffe/layers/bjmmd_layer.hpp"
namespace caffe {
template
void BJMMDLossLayer::LayerSetUp(
const vector*>& bottom, const vector*>& top) {
LossLayer::LayerSetUp(bottom, top);
dim_ = bottom[0]->count() / bottom[0]->count(0, 1);
source_num_ = bottom[0]->count(0, 1);
target_num_ = bottom[1]->count(0, 1);
total_num_ = source_num_ + target_num_;
kernel_num_ = this->layer_param_.bjmmd_param().kernel_num();
label_kernel_num_ = this->layer_param_.bjmmd_param().label_kernel_num();
fix_gamma_ = this->layer_param_.bjmmd_param().fix_gamma();
sigma_ = this->layer_param_.bjmmd_param().sigma();
auto_sigma_ = this->layer_param_.bjmmd_param().auto_sigma();
gamma_ = Dtype(-1);
kernel_mul_ = this->layer_param_.bjmmd_param().kernel_mul();
label_kernel_mul_ = this->layer_param_.bjmmd_param().label_kernel_mul();
balanced_factor_ = this->layer_param_.bjmmd_param().balanced_factor();
diff_.Reshape(1, total_num_, total_num_, dim_);
for(int i = 0;i < kernel_num_;++i){
Blob* temp = new Blob(1, 1, total_num_, total_num_);
kernel_val_.push_back(temp);
}
diff_multiplier_.Reshape(1, 1, 1, dim_);
delta_.Reshape(1, 1, total_num_, total_num_);
caffe_set(dim_, Dtype(1), diff_multiplier_.mutable_cpu_data());
loss_weight_ = this->layer_param_.loss_weight(0);
label_loss_weight_ = this->layer_param_.loss_weight(0);
}
template
void BJMMDLossLayer::Reshape(
const vector*>& bottom, const vector*>& top) {
vector loss_shape(0);
top[0]->Reshape(loss_shape);
if(top.size() == 2){
top[1]->Reshape(loss_shape);
}
dim_ = bottom[0]->count() / bottom[0]->count(0, 1);
source_num_ = bottom[0]->count(0, 1);
target_num_ = bottom[1]->count(0, 1);
total_num_ = source_num_ + target_num_;
diff_.Reshape(1, total_num_, total_num_, dim_);
for(int i = 0;i < kernel_num_;++i){
kernel_val_[i]->Reshape(1, 1, total_num_, total_num_);
}
diff_multiplier_.Reshape(1, 1, 1, dim_);
caffe_set(dim_, Dtype(1), diff_multiplier_.mutable_cpu_data());
delta_.Reshape(1, 1, total_num_, total_num_);
}
template
void BJMMDLossLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
}
template
void BJMMDLossLayer::Backward_cpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
}
#ifdef CPU_ONLY
STUB_GPU(BJMMDLossLayer);
#endif
INSTANTIATE_CLASS(BJMMDLossLayer);
REGISTER_LAYER_CLASS(BJMMDLoss);
} // namespace caffe
================================================
FILE: code/deep/B-JMMD/caffe/src/caffe/layers/bjmmd_layer.cu
================================================
#include
#include
#include
#include "caffe/layers/bjmmd_layer.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template
__global__ void CalculateKernel(const int n, const Dtype* distance2, const Dtype gamma,
Dtype* out) {
CUDA_KERNEL_LOOP(index, n) {
out[index] = exp(-gamma * distance2[index]);
}
}
template
__global__ void CalculateSpreadDistance2(const int n, const Dtype* source, const Dtype* target,
const int source_num, const int target_num, const int dim, Dtype* out) {
CUDA_KERNEL_LOOP(index, n) {
int data_index1 = index / dim / (source_num + target_num);
int data_index2 = index / dim % (source_num + target_num);
int dim_offset = index % dim;
Dtype data1;
Dtype data2;
if(data_index1 >= source_num){
data_index1 -= source_num;
data1 = target[data_index1 * dim + dim_offset];
}
else{
data1 = source[data_index1 * dim + dim_offset];
}
if(data_index2 >= source_num){
data_index2 -= source_num;
data2 = target[data_index2 * dim + dim_offset];
}
else{
data2 = source[data_index2 * dim + dim_offset];
}
out[index] = (data1 - data2) * (data1 - data2);
}
}
template
__global__ void CalculateProbRBFLabelKernel(const int n, const Dtype* source_p, const Dtype* target_p,
const int source_num, const int total_num, const int label_dim, const Dtype sigma,
const int kernel_num, const Dtype kernel_mul, Dtype* out) {
CUDA_KERNEL_LOOP(index, n) {
int index1 = index / total_num;
int index2 = index % total_num;
if(index1 < source_num && index2 < source_num){
//ss
int offset1 = index1 * label_dim;
int offset2 = index2 * label_dim;
Dtype sum = Dtype(0);
for(int j = 0;j < label_dim;++j){
sum += (source_p[offset1 + j] - source_p[offset2 + j]) * (source_p[offset1 + j] - source_p[offset2 + j]);
}
Dtype times = pow(kernel_mul, (Dtype)(kernel_num / 2));
Dtype temp_sigma = sigma / times;
out[index] = Dtype(0);
for(int j = 0;j < kernel_num;++j){
out[index] += exp(-sum / temp_sigma);
temp_sigma *= kernel_mul;
}
}
else if(index1 < source_num && index2 >= source_num){
//st
int offset1 = label_dim * index1;
int offset2 = label_dim * (index2 - source_num);
Dtype sum = Dtype(0);
for(int j = 0;j < label_dim;++j){
sum += (source_p[offset1 + j] - target_p[offset2 + j]) * (source_p[offset1 + j] - target_p[offset2 + j]);
}
Dtype times = pow(kernel_mul, (Dtype)(kernel_num / 2));
Dtype temp_sigma = sigma / times;
out[index] = Dtype(0);
for(int j = 0;j < kernel_num;++j){
out[index] += exp(-sum / temp_sigma);
temp_sigma *= kernel_mul;
}
}
else if(index1 >= source_num && index2 < source_num){
//ts
int offset1 = label_dim * (index1 - source_num);
int offset2 = label_dim * index2;
Dtype sum = Dtype(0);
for(int j = 0;j < label_dim;++j){
sum += (target_p[offset1 + j] - source_p[offset2 + j]) * (target_p[offset1 + j] - source_p[offset2 + j]);
}
Dtype times = pow(kernel_mul, (Dtype)(kernel_num / 2));
Dtype temp_sigma = sigma / times;
out[index] = Dtype(0);
for(int j = 0;j < kernel_num;++j){
out[index] += exp(-sum / temp_sigma);
temp_sigma *= kernel_mul;
}
}
else{
//tt
int offset1 = label_dim * (index1 - source_num);
int offset2 = label_dim * (index2 - source_num);
Dtype sum = Dtype(0);
for(int j = 0;j < label_dim;++j){
sum += (target_p[offset1 + j] - target_p[offset2 + j]) * (target_p[offset1 + j] - target_p[offset2 + j]);
}
Dtype times = pow(kernel_mul, (Dtype)(kernel_num / 2));
Dtype temp_sigma = sigma / times;
out[index] = Dtype(0);
for(int j = 0;j < kernel_num;++j){
out[index] += exp(-sum / temp_sigma);
temp_sigma *= kernel_mul;
}
}
}
}
template
void BJMMDLossLayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* source = bottom[0]->gpu_data();
const Dtype* target = bottom[1]->gpu_data();
//calculate square distance
Dtype* spread_distance2 = diff_.mutable_gpu_data();
Dtype* distance2 = diff_.mutable_gpu_diff();
int nthreads = total_num_ * total_num_ * dim_;
CalculateSpreadDistance2<<>>(
nthreads, source, target, source_num_, target_num_, dim_, spread_distance2);
caffe_gpu_gemv(CblasNoTrans, total_num_ * total_num_, dim_, (Dtype)1.,
spread_distance2, diff_multiplier_.gpu_data(), (Dtype)0., distance2);
//calculate bandwith
Dtype bandwidth;
caffe_gpu_asum(total_num_ * total_num_, distance2, &bandwidth);
if(fix_gamma_){
gamma_ = gamma_ < 0 ? (total_num_ * total_num_ - total_num_) / bandwidth : gamma_;
}
else{
gamma_ = (total_num_ * total_num_ - total_num_) / bandwidth;
}
//calculate each kernel of data
Dtype gamma_times = pow(kernel_mul_, (Dtype)(kernel_num_ / 2));
Dtype kernel_gamma = gamma_ / gamma_times;
nthreads = total_num_ * total_num_;
for(int i = 0;i < kernel_num_;++i){
CalculateKernel<<>>(
nthreads, distance2, kernel_gamma, kernel_val_[i]->mutable_gpu_data());
kernel_gamma *= kernel_mul_;
}
//calculate kernel of label
if(bottom.size() > 2){
const Dtype* source_label = bottom[2]->gpu_data();
const Dtype* target_label = bottom[3]->gpu_data();
nthreads = total_num_ * total_num_;
int label_dim = bottom[3]->count() / bottom[3]->count(0, 1);
if(auto_sigma_){
Dtype* tempX1 = diff_.mutable_gpu_diff() + total_num_ * total_num_;
Dtype* tempX2 = diff_.mutable_gpu_diff() + total_num_ * total_num_ + label_dim;
const Dtype* source_prob = bottom[2]->cpu_data();
const Dtype* target_prob = bottom[3]->cpu_data();
int s1, s2;
Dtype square_distance;
Dtype bandwidth = 0;
for(int i = 0;i < total_num_;++i){
s1 = rand() % total_num_;
s2 = rand() % total_num_;
s2 = (s1 != s2) ? s2 : (s2 + 1) % total_num_;
if(s1 >= source_num_){
caffe_gpu_memcpy(sizeof(Dtype) * label_dim, target_prob + (s1 - source_num_) * label_dim, tempX1);
}
else{
caffe_gpu_memcpy(sizeof(Dtype) * label_dim, source_prob + s1 * label_dim, tempX1);
}
if(s2 >= source_num_){
caffe_gpu_memcpy(sizeof(Dtype) * label_dim, target_prob + (s2 - source_num_) * label_dim, tempX2);
}
else{
caffe_gpu_memcpy(sizeof(Dtype) * label_dim, source_prob + s2 * label_dim, tempX2);
}
caffe_gpu_sub(label_dim, tempX1, tempX2, tempX2);
caffe_gpu_dot(label_dim, tempX2, tempX2, &square_distance);
bandwidth += square_distance;
}
sigma_ = bandwidth / total_num_;
}
CalculateProbRBFLabelKernel<<>>(
nthreads, bottom[2]->gpu_data(), bottom[3]->gpu_data(),
source_num_, total_num_, label_dim, sigma_, label_kernel_num_, label_kernel_mul_, delta_.mutable_gpu_data());
}
else{
caffe_gpu_set(total_num_ * total_num_, Dtype(1), delta_.mutable_gpu_data());
}
//calculate mmd in source, target and both
top[0]->mutable_cpu_data()[0] = Dtype(0);
}
template
void BJMMDLossLayer::Backward_gpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
Dtype* source_diff = bottom[0]->mutable_gpu_diff();
Dtype* target_diff = bottom[1]->mutable_gpu_diff();
Dtype* label_source_diff = bottom[2]->mutable_gpu_diff();
Dtype* label_target_diff = bottom[3]->mutable_gpu_diff();
int label_dim = bottom[2]->count() / bottom[2]->count(0, 1);
caffe_gpu_set(source_num_ * label_dim, Dtype(0), label_source_diff);
caffe_gpu_set(target_num_ * label_dim, Dtype(0), label_target_diff);
caffe_gpu_set(source_num_ * dim_, Dtype(0), source_diff);
caffe_gpu_set(target_num_ * dim_, Dtype(0), target_diff);
if(source_num_ <= 1 || target_num_ <= 1) return;
int sample_num = (source_num_ > target_num_) ? source_num_ : target_num_;
int s1, s2, t1, t2;
Dtype* tempX1 = diff_.mutable_gpu_diff() + total_num_ * total_num_;
Dtype* tempX2 = diff_.mutable_gpu_diff() + total_num_ * total_num_ + dim_;
Dtype* tempY1 = NULL, *tempY2 = NULL;
tempY1 = diff_.mutable_gpu_diff() + total_num_ * total_num_ + dim_ + dim_;
tempY2 = diff_.mutable_gpu_diff() + total_num_ * total_num_ + dim_ + dim_ + label_dim;
for(int i = 0;i < sample_num;++i){
s1 = rand() % source_num_;
s2 = rand() % source_num_;
s2 = (s1 != s2) ? s2 : (s2 + 1) % source_num_;
t1 = rand() % target_num_;
t2 = rand() % target_num_;
t2 = (t1 != t2) ? t2 : (t2 + 1) % target_num_;
Dtype square_sum = 0;
Dtype factor_for_diff = 0;
const Dtype* x_s1 = bottom[0]->gpu_data() + s1 * dim_;
const Dtype* x_s2 = bottom[0]->gpu_data() + s2 * dim_;
const Dtype* x_t1 = bottom[1]->gpu_data() + t1 * dim_;
const Dtype* x_t2 = bottom[1]->gpu_data() + t2 * dim_;
const Dtype* y_s1 = bottom[2]->gpu_data() + s1 * label_dim;
const Dtype* y_s2 = bottom[2]->gpu_data() + s2 * label_dim;
const Dtype* y_t1 = bottom[3]->gpu_data() + t1 * label_dim;
const Dtype* y_t2 = bottom[3]->gpu_data() + t2 * label_dim;
caffe_gpu_sub(dim_, x_s1, x_s2, tempX1);
caffe_gpu_sub(dim_, x_s2, x_s1, tempX2);
caffe_gpu_dot(dim_, tempX1, tempX1, &square_sum);
Dtype times = pow(kernel_mul_, (Dtype)(kernel_num_ / 2));
Dtype temp_gamma = gamma_ / times;
Dtype x_kernel = Dtype(0);
for(int j = 0; j < kernel_num_; j++){
Dtype temp_n = (0.0 - temp_gamma) * square_sum;
x_kernel += exp(temp_n);
temp_n = exp(temp_n) * delta_.cpu_data()[s1 * total_num_ + s2];
temp_n = (-2) * temp_gamma * temp_n;
factor_for_diff += temp_n;
temp_gamma = temp_gamma * kernel_mul_;
}
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX1);
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX2);
caffe_gpu_add(dim_, tempX1, source_diff + s1 * dim_, source_diff + s1 * dim_);
caffe_gpu_add(dim_, tempX2, source_diff + s2 * dim_, source_diff + s2 * dim_);
caffe_gpu_sub(label_dim, y_s1, y_s2, tempY1);
caffe_gpu_sub(label_dim, y_s2, y_s1, tempY2);
factor_for_diff = (-2) / sigma_ * x_kernel * delta_.cpu_data()[s1 * total_num_ + s2];
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY1);
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY2);
caffe_gpu_add(label_dim, tempY1, label_source_diff + s1 * label_dim, label_source_diff + s1 * label_dim);
caffe_gpu_add(label_dim, tempY2, label_source_diff + s2 * label_dim, label_source_diff + s2 * label_dim);
factor_for_diff = 0;
caffe_gpu_sub(dim_, x_s1, x_t2, tempX1);
caffe_gpu_sub(dim_, x_t2, x_s1, tempX2);
caffe_gpu_dot(dim_, tempX1, tempX1, &square_sum);
temp_gamma = gamma_ / times;
x_kernel = Dtype(0);
for(int j = 0; j < kernel_num_; j++){
Dtype temp_n = (0.0 - temp_gamma) * square_sum;
x_kernel += exp(temp_n);
temp_n = exp(temp_n) * Dtype(-1) * delta_.cpu_data()[s1 * total_num_ + source_num_ + t2];
temp_n = (-2) * temp_gamma * temp_n;
factor_for_diff += temp_n;
temp_gamma = temp_gamma * kernel_mul_;
}
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX1);
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX2);
caffe_gpu_add(dim_, tempX1, source_diff + s1 * dim_, source_diff + s1 * dim_);
caffe_gpu_add(dim_, tempX2, target_diff + t2 * dim_, target_diff + t2 * dim_);
caffe_gpu_sub(label_dim, y_s1, y_t2, tempY1);
caffe_gpu_sub(label_dim, y_t2, y_s1, tempY2);
factor_for_diff = 2 / sigma_ * x_kernel * delta_.cpu_data()[s1 * total_num_ + source_num_ + t2];
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY1);
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY2);
caffe_gpu_add(label_dim, tempY1, label_source_diff + s1 * label_dim, label_source_diff + s1 * label_dim);
caffe_gpu_add(label_dim, tempY2, label_target_diff + t2 * label_dim, label_target_diff + t2 * label_dim);
factor_for_diff = 0;
caffe_gpu_sub(dim_, x_t1, x_s2, tempX1);
caffe_gpu_sub(dim_, x_s2, x_t1, tempX2);
caffe_gpu_dot(dim_, tempX1, tempX1, &square_sum);
temp_gamma = gamma_ / times;
x_kernel = Dtype(0);
for(int j = 0; j < kernel_num_; j++){
Dtype temp_n = (0.0 - temp_gamma) * square_sum;
x_kernel += exp(temp_n);
temp_n = exp(temp_n) * Dtype(-1) * delta_.cpu_data()[(t1 + source_num_) * total_num_ + s2];
temp_n = (-2) * temp_gamma * temp_n;
factor_for_diff += temp_n;
temp_gamma = temp_gamma * kernel_mul_;
}
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX1);
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX2);
caffe_gpu_add(dim_, tempX1, target_diff + t1 * dim_, target_diff + t1 * dim_);
caffe_gpu_add(dim_, tempX2, source_diff + s2 * dim_, source_diff + s2 * dim_);
caffe_gpu_sub(label_dim, y_s2, y_t1, tempY1);
caffe_gpu_sub(label_dim, y_t1, y_s2, tempY2);
factor_for_diff = 2 / sigma_ * x_kernel * delta_.cpu_data()[(t1 + source_num_) * total_num_ + s2];
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY1);
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY2);
caffe_gpu_add(label_dim, tempY1, label_source_diff + s2 * label_dim, label_source_diff + s2 * label_dim);
caffe_gpu_add(label_dim, tempY2, label_target_diff + t1 * label_dim, label_target_diff + t1 * label_dim);
factor_for_diff = 0;
caffe_gpu_sub(dim_, x_t1, x_t2, tempX1);
caffe_gpu_sub(dim_, x_t2, x_t1, tempX2);
caffe_gpu_dot(dim_, tempX1, tempX1, &square_sum);
temp_gamma = gamma_ / times;
x_kernel = Dtype(0);
for(int j = 0; j < kernel_num_; j++){
Dtype temp_n = (0.0 - temp_gamma) * square_sum;
x_kernel += exp(temp_n);
temp_n = exp(temp_n) * delta_.cpu_data()[(t1 + source_num_) * total_num_ + t2 + source_num_];
temp_n = (-2) * temp_gamma * temp_n;
factor_for_diff += temp_n;
temp_gamma = temp_gamma * kernel_mul_;
}
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX1);
caffe_gpu_scal(dim_, Dtype(2) * balanced_factor_* loss_weight_ * factor_for_diff / sample_num, tempX2);
caffe_gpu_add(dim_, tempX1, target_diff + t1 * dim_, target_diff + t1 * dim_);
caffe_gpu_add(dim_, tempX2, target_diff + t2 * dim_, target_diff + t2 * dim_);
caffe_gpu_sub(label_dim, y_t1, y_t2, tempY1);
caffe_gpu_sub(label_dim, y_t2, y_t1, tempY2);
factor_for_diff = (-2) / sigma_ * x_kernel * delta_.cpu_data()[(t1 + source_num_) * total_num_ + t2 + source_num_];
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY1);
caffe_gpu_scal(label_dim, Dtype(2) * (Dtype(1) - balanced_factor_)* label_loss_weight_ * factor_for_diff / sample_num, tempY2);
caffe_gpu_add(label_dim, tempY1, label_target_diff + t1 * label_dim, label_target_diff + t1 * label_dim);
caffe_gpu_add(label_dim, tempY2, label_target_diff + t2 * label_dim, label_target_diff + t2 * label_dim);
}
}
INSTANTIATE_LAYER_GPU_FUNCS(BJMMDLossLayer);
} // namespace caffe
================================================
FILE: code/deep/B-JMMD/caffe/src/caffe/proto/caffe.proto
================================================
syntax = "proto2";
package caffe;
// Specifies the shape (dimensions) of a Blob.
message BlobShape {
repeated int64 dim = 1 [packed = true];
}
message BlobProto {
optional BlobShape shape = 7;
repeated float data = 5 [packed = true];
repeated float diff = 6 [packed = true];
repeated double double_data = 8 [packed = true];
repeated double double_diff = 9 [packed = true];
// 4D dimensions -- deprecated. Use "shape" instead.
optional int32 num = 1 [default = 0];
optional int32 channels = 2 [default = 0];
optional int32 height = 3 [default = 0];
optional int32 width = 4 [default = 0];
}
// The BlobProtoVector is simply a way to pass multiple blobproto instances
// around.
message BlobProtoVector {
repeated BlobProto blobs = 1;
}
message Datum {
optional int32 channels = 1;
optional int32 height = 2;
optional int32 width = 3;
// the actual image data, in bytes
optional bytes data = 4;
optional int32 label = 5;
// Optionally, the datum could also hold float data.
repeated float float_data = 6;
// If true data contains an encoded image that need to be decoded
optional bool encoded = 7 [default = false];
}
message FillerParameter {
// The filler type.
optional string type = 1 [default = 'constant'];
optional float value = 2 [default = 0]; // the value in constant filler
optional float min = 3 [default = 0]; // the min value in uniform filler
optional float max = 4 [default = 1]; // the max value in uniform filler
optional float mean = 5 [default = 0]; // the mean value in Gaussian filler
optional float std = 6 [default = 1]; // the std value in Gaussian filler
// The expected number of non-zero output weights for a given input in
// Gaussian filler -- the default -1 means don't perform sparsification.
optional int32 sparse = 7 [default = -1];
// Normalize the filler variance by fan_in, fan_out, or their average.
// Applies to 'xavier' and 'msra' fillers.
enum VarianceNorm {
FAN_IN = 0;
FAN_OUT = 1;
AVERAGE = 2;
}
optional VarianceNorm variance_norm = 8 [default = FAN_IN];
}
message NetParameter {
optional string name = 1; // consider giving the network a name
// DEPRECATED. See InputParameter. The input blobs to the network.
repeated string input = 3;
// DEPRECATED. See InputParameter. The shape of the input blobs.
repeated BlobShape input_shape = 8;
// 4D input dimensions -- deprecated. Use "input_shape" instead.
// If specified, for each input blob there should be four
// values specifying the num, channels, height and width of the input blob.
// Thus, there should be a total of (4 * #input) numbers.
repeated int32 input_dim = 4;
// Whether the network will force every layer to carry out backward operation.
// If set False, then whether to carry out backward is determined
// automatically according to the net structure and learning rates.
optional bool force_backward = 5 [default = false];
// The current "state" of the network, including the phase, level, and stage.
// Some layers may be included/excluded depending on this state and the states
// specified in the layers' include and exclude fields.
optional NetState state = 6;
// Print debugging information about results while running Net::Forward,
// Net::Backward, and Net::Update.
optional bool debug_info = 7 [default = false];
// The layers that make up the net. Each of their configurations, including
// connectivity and behavior, is specified as a LayerParameter.
repeated LayerParameter layer = 100; // ID 100 so layers are printed last.
// DEPRECATED: use 'layer' instead.
repeated V1LayerParameter layers = 2;
}
// NOTE
// Update the next available ID when you add a new SolverParameter field.
//
// SolverParameter next available ID: 41 (last added: type)
message SolverParameter {
//////////////////////////////////////////////////////////////////////////////
// Specifying the train and test networks
//
// Exactly one train net must be specified using one of the following fields:
// train_net_param, train_net, net_param, net
// One or more test nets may be specified using any of the following fields:
// test_net_param, test_net, net_param, net
// If more than one test net field is specified (e.g., both net and
// test_net are specified), they will be evaluated in the field order given
// above: (1) test_net_param, (2) test_net, (3) net_param/net.
// A test_iter must be specified for each test_net.
// A test_level and/or a test_stage may also be specified for each test_net.
//////////////////////////////////////////////////////////////////////////////
// Proto filename for the train net, possibly combined with one or more
// test nets.
optional string net = 24;
// Inline train net param, possibly combined with one or more test nets.
optional NetParameter net_param = 25;
optional string train_net = 1; // Proto filename for the train net.
repeated string test_net = 2; // Proto filenames for the test nets.
optional NetParameter train_net_param = 21; // Inline train net params.
repeated NetParameter test_net_param = 22; // Inline test net params.
// The states for the train/test nets. Must be unspecified or
// specified once per net.
//
// By default, all states will have solver = true;
// train_state will have phase = TRAIN,
// and all test_state's will have phase = TEST.
// Other defaults are set according to the NetState defaults.
optional NetState train_state = 26;
repeated NetState test_state = 27;
// The number of iterations for each test net.
repeated int32 test_iter = 3;
// The number of iterations between two testing phases.
optional int32 test_interval = 4 [default = 0];
optional bool test_compute_loss = 19 [default = false];
// If true, run an initial test pass before the first iteration,
// ensuring memory availability and printing the starting value of the loss.
optional bool test_initialization = 32 [default = true];
optional float base_lr = 5; // The base learning rate
// the number of iterations between displaying info. If display = 0, no info
// will be displayed.
optional int32 display = 6;
// Display the loss averaged over the last average_loss iterations
optional int32 average_loss = 33 [default = 1];
optional int32 max_iter = 7; // the maximum number of iterations
// accumulate gradients over `iter_size` x `batch_size` instances
optional int32 iter_size = 36 [default = 1];
// The learning rate decay policy. The currently implemented learning rate
// policies are as follows:
// - fixed: always return base_lr.
// - step: return base_lr * gamma ^ (floor(iter / step))
// - exp: return base_lr * gamma ^ iter
// - inv: return base_lr * (1 + gamma * iter) ^ (- power)
// - multistep: similar to step but it allows non uniform steps defined by
// stepvalue
// - poly: the effective learning rate follows a polynomial decay, to be
// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
// - sigmoid: the effective learning rate follows a sigmod decay
// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
//
// where base_lr, max_iter, gamma, step, stepvalue and power are defined
// in the solver parameter protocol buffer, and iter is the current iteration.
optional string lr_policy = 8;
optional float gamma = 9; // The parameter to compute the learning rate.
optional float power = 10; // The parameter to compute the learning rate.
optional float momentum = 11; // The momentum value.
optional float weight_decay = 12; // The weight decay.
// regularization types supported: L1 and L2
// controlled by weight_decay
optional string regularization_type = 29 [default = "L2"];
// the stepsize for learning rate policy "step"
optional int32 stepsize = 13;
// the stepsize for learning rate policy "multistep"
repeated int32 stepvalue = 34;
// Set clip_gradients to >= 0 to clip parameter gradients to that L2 norm,
// whenever their actual L2 norm is larger.
optional float clip_gradients = 35 [default = -1];
optional int32 snapshot = 14 [default = 0]; // The snapshot interval
optional string snapshot_prefix = 15; // The prefix for the snapshot.
// whether to snapshot diff in the results or not. Snapshotting diff will help
// debugging but the final protocol buffer size will be much larger.
optional bool snapshot_diff = 16 [default = false];
enum SnapshotFormat {
HDF5 = 0;
BINARYPROTO = 1;
}
optional SnapshotFormat snapshot_format = 37 [default = BINARYPROTO];
// the mode solver will use: 0 for CPU and 1 for GPU. Use GPU in default.
enum SolverMode {
CPU = 0;
GPU = 1;
}
optional SolverMode solver_mode = 17 [default = GPU];
// the device_id will that be used in GPU mode. Use device_id = 0 in default.
optional int32 device_id = 18 [default = 0];
// If non-negative, the seed with which the Solver will initialize the Caffe
// random number generator -- useful for reproducible results. Otherwise,
// (and by default) initialize using a seed derived from the system clock.
optional int64 random_seed = 20 [default = -1];
// type of the solver
optional string type = 40 [default = "SGD"];
// numerical stability for RMSProp, AdaGrad and AdaDelta and Adam
optional float delta = 31 [default = 1e-8];
// parameters for the Adam solver
optional float momentum2 = 39 [default = 0.999];
// RMSProp decay value
// MeanSquare(t) = rms_decay*MeanSquare(t-1) + (1-rms_decay)*SquareGradient(t)
optional float rms_decay = 38 [default = 0.99];
// If true, print information about the state of the net that may help with
// debugging learning problems.
optional bool debug_info = 23 [default = false];
// If false, don't save a snapshot after training finishes.
optional bool snapshot_after_train = 28 [default = true];
// DEPRECATED: old solver enum types, use string instead
enum SolverType {
SGD = 0;
NESTEROV = 1;
ADAGRAD = 2;
RMSPROP = 3;
ADADELTA = 4;
ADAM = 5;
}
// DEPRECATED: use type instead of solver_type
optional SolverType solver_type = 30 [default = SGD];
}
// A message that stores the solver snapshots
message SolverState {
optional int32 iter = 1; // The current iteration
optional string learned_net = 2; // The file that stores the learned net.
repeated BlobProto history = 3; // The history for sgd solvers
optional int32 current_step = 4 [default = 0]; // The current step for learning rate
}
enum Phase {
TRAIN = 0;
TEST = 1;
}
message NetState {
optional Phase phase = 1 [default = TEST];
optional int32 level = 2 [default = 0];
repeated string stage = 3;
}
message NetStateRule {
// Set phase to require the NetState have a particular phase (TRAIN or TEST)
// to meet this rule.
optional Phase phase = 1;
// Set the minimum and/or maximum levels in which the layer should be used.
// Leave undefined to meet the rule regardless of level.
optional int32 min_level = 2;
optional int32 max_level = 3;
// Customizable sets of stages to include or exclude.
// The net must have ALL of the specified stages and NONE of the specified
// "not_stage"s to meet the rule.
// (Use multiple NetStateRules to specify conjunctions of stages.)
repeated string stage = 4;
repeated string not_stage = 5;
}
// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
message ParamSpec {
// The names of the parameter blobs -- useful for sharing parameters among
// layers, but never required otherwise. To share a parameter between two
// layers, give it a (non-empty) name.
optional string name = 1;
// Whether to require shared weights to have the same shape, or just the same
// count -- defaults to STRICT if unspecified.
optional DimCheckMode share_mode = 2;
enum DimCheckMode {
// STRICT (default) requires that num, channels, height, width each match.
STRICT = 0;
// PERMISSIVE requires only the count (num*channels*height*width) to match.
PERMISSIVE = 1;
}
// The multiplier on the global learning rate for this parameter.
optional float lr_mult = 3 [default = 1.0];
// The multiplier on the global weight decay for this parameter.
optional float decay_mult = 4 [default = 1.0];
}
// NOTE
// Update the next available ID when you add a new LayerParameter field.
//
// LayerParameter next available layer-specific ID: 150 (last added: recurrent_param)
message LayerParameter {
optional string name = 1; // the layer name
optional string type = 2; // the layer type
repeated string bottom = 3; // the name of each bottom blob
repeated string top = 4; // the name of each top blob
// The train / test phase for computation.
optional Phase phase = 10;
// The amount of weight to assign each top blob in the objective.
// Each layer assigns a default value, usually of either 0 or 1,
// to each top blob.
repeated float loss_weight = 5;
// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
repeated ParamSpec param = 6;
// The blobs containing the numeric parameters of the layer.
repeated BlobProto blobs = 7;
// Specifies whether to backpropagate to each bottom. If unspecified,
// Caffe will automatically infer whether each input needs backpropagation
// to compute parameter gradients. If set to true for some inputs,
// backpropagation to those inputs is forced; if set false for some inputs,
// backpropagation to those inputs is skipped.
//
// The size must be either 0 or equal to the number of bottoms.
repeated bool propagate_down = 11;
// Rules controlling whether and when a layer is included in the network,
// based on the current NetState. You may specify a non-zero number of rules
// to include OR exclude, but not both. If no include or exclude rules are
// specified, the layer is always included. If the current NetState meets
// ANY (i.e., one or more) of the specified rules, the layer is
// included/excluded.
repeated NetStateRule include = 8;
repeated NetStateRule exclude = 9;
// Parameters for data pre-processing.
optional TransformationParameter transform_param = 100;
// Parameters shared by loss layers.
optional LossParameter loss_param = 101;
// Layer type-specific parameters.
//
// Note: certain layers may have more than one computational engine
// for their implementation. These layers include an Engine type and
// engine parameter for selecting the implementation.
// The default for the engine is set by the ENGINE switch at compile-time.
optional AccuracyParameter accuracy_param = 102;
optional ArgMaxParameter argmax_param = 103;
optional BatchNormParameter batch_norm_param = 139;
optional BiasParameter bias_param = 141;
optional ConcatParameter concat_param = 104;
optional ContrastiveLossParameter contrastive_loss_param = 105;
optional ConvolutionParameter convolution_param = 106;
optional CropParameter crop_param = 144;
optional DataParameter data_param = 107;
optional DropoutParameter dropout_param = 108;
optional DummyDataParameter dummy_data_param = 109;
optional EltwiseParameter eltwise_param = 110;
optional ELUParameter elu_param = 140;
optional EmbedParameter embed_param = 137;
optional EntropyParameter entropy_param = 148;
optional ExpParameter exp_param = 111;
optional FlattenParameter flatten_param = 135;
optional GradientScalerParameter gradient_scaler_param = 149;
optional HDF5DataParameter hdf5_data_param = 112;
optional HDF5OutputParameter hdf5_output_param = 113;
optional HingeLossParameter hinge_loss_param = 114;
optional ImageDataParameter image_data_param = 115;
optional InfogainLossParameter infogain_loss_param = 116;
optional InnerProductParameter inner_product_param = 117;
optional InputParameter input_param = 143;
optional LogParameter log_param = 134;
optional LRNParameter lrn_param = 118;
optional MemoryDataParameter memory_data_param = 119;
optional BJMMDParameter BJMMD_param = 147;
optional MVNParameter mvn_param = 120;
optional ParameterParameter parameter_param = 145;
optional PoolingParameter pooling_param = 121;
optional PowerParameter power_param = 122;
optional PReLUParameter prelu_param = 131;
optional PythonParameter python_param = 130;
optional RecurrentParameter recurrent_param = 146;
optional ReductionParameter reduction_param = 136;
optional ReLUParameter relu_param = 123;
optional ReshapeParameter reshape_param = 133;
optional ScaleParameter scale_param = 142;
optional SigmoidParameter sigmoid_param = 124;
optional SoftmaxParameter softmax_param = 125;
optional SPPParameter spp_param = 132;
optional SliceParameter slice_param = 126;
optional TanHParameter tanh_param = 127;
optional ThresholdParameter threshold_param = 128;
optional TileParameter tile_param = 138;
optional WindowDataParameter window_data_param = 129;
}
// Message that stores parameters used by BJMMD layer
message BJMMDParameter {
optional uint32 kernel_num = 1 [default = 5];
optional float kernel_mul = 6[default = 2];
optional float label_kernel_mul = 4 [default = 2];
optional uint32 label_kernel_num = 5 [default = 5];
optional float sigma = 2 [default = 0];
optional bool auto_sigma = 8 [default = false];
optional bool fix_gamma = 7 [default = false];
optional float balanced_factor = 9 [default = 0.5];
}
// Message that stores parameters used to apply transformation
// to the data layer's data
message TransformationParameter {
// For data pre-processing, we can do simple scaling and subtracting the
// data mean, if provided. Note that the mean subtraction is always carried
// out before scaling.
optional float scale = 1 [default = 1];
// Specify if we want to randomly mirror data.
optional bool mirror = 2 [default = false];
// Specify if we would like to randomly crop an image.
optional uint32 crop_size = 3 [default = 0];
// mean_file and mean_value cannot be specified at the same time
optional string mean_file = 4;
// if specified can be repeated once (would substract it from all the channels)
// or can be repeated the same number of times as channels
// (would subtract them from the corresponding channel)
repeated float mean_value = 5;
// Force the decoded image to have 3 color channels.
optional bool force_color = 6 [default = false];
// Force the decoded image to have 1 color channels.
optional bool force_gray = 7 [default = false];
}
// Message that stores parameters shared by loss layers
message LossParameter {
// If specified, ignore instances with the given label.
optional int32 ignore_label = 1;
// How to normalize the loss for loss layers that aggregate across batches,
// spatial dimensions, or other dimensions. Currently only implemented in
// SoftmaxWithLoss layer.
enum NormalizationMode {
// Divide by the number of examples in the batch times spatial dimensions.
// Outputs that receive the ignore label will NOT be ignored in computing
// the normalization factor.
FULL = 0;
// Divide by the total number of output locations that do not take the
// ignore_label. If ignore_label is not set, this behaves like FULL.
VALID = 1;
// Divide by the batch size.
BATCH_SIZE = 2;
// Do not normalize the loss.
NONE = 3;
}
optional NormalizationMode normalization = 3 [default = VALID];
// Deprecated. Ignored if normalization is specified. If normalization
// is not specified, then setting this to false will be equivalent to
// normalization = BATCH_SIZE to be consistent with previous behavior.
optional bool normalize = 2;
}
// Messages that store parameters used by individual layer types follow, in
// alphabetical order.
message AccuracyParameter {
// When computing accuracy, count as correct by comparing the true label to
// the top k scoring classes. By default, only compare to the top scoring
// class (i.e. argmax).
optional uint32 top_k = 1 [default = 1];
// The "label" axis of the prediction blob, whose argmax corresponds to the
// predicted label -- may be negative to index from the end (e.g., -1 for the
// last axis). For example, if axis == 1 and the predictions are
// (N x C x H x W), the label blob is expected to contain N*H*W ground truth
// labels with integer values in {0, 1, ..., C-1}.
optional int32 axis = 2 [default = 1];
// If specified, ignore instances with the given label.
optional int32 ignore_label = 3;
}
message ArgMaxParameter {
// If true produce pairs (argmax, maxval)
optional bool out_max_val = 1 [default = false];
optional uint32 top_k = 2 [default = 1];
// The axis along which to maximise -- may be negative to index from the
// end (e.g., -1 for the last axis).
// By default ArgMaxLayer maximizes over the flattened trailing dimensions
// for each index of the first / num dimension.
optional int32 axis = 3;
}
message ConcatParameter {
// The axis along which to concatenate -- may be negative to index from the
// end (e.g., -1 for the last axis). Other axes must have the
// same dimension for all the bottom blobs.
// By default, ConcatLayer concatenates blobs along the "channels" axis (1).
optional int32 axis = 2 [default = 1];
// DEPRECATED: alias for "axis" -- does not support negative indexing.
optional uint32 concat_dim = 1 [default = 1];
}
message BatchNormParameter {
// If false, accumulate global mean/variance values via a moving average. If
// true, use those accumulated values instead of computing mean/variance
// across the batch.
optional bool use_global_stats = 1;
// How much does the moving average decay each iteration?
optional float moving_average_fraction = 2 [default = .999];
// Small value to add to the variance estimate so that we don't divide by
// zero.
optional float eps = 3 [default = 1e-5];
}
message BiasParameter {
// The first axis of bottom[0] (the first input Blob) along which to apply
// bottom[1] (the second input Blob). May be negative to index from the end
// (e.g., -1 for the last axis).
//
// For example, if bottom[0] is 4D with shape 100x3x40x60, the output
// top[0] will have the same shape, and bottom[1] may have any of the
// following shapes (for the given value of axis):
// (axis == 0 == -4) 100; 100x3; 100x3x40; 100x3x40x60
// (axis == 1 == -3) 3; 3x40; 3x40x60
// (axis == 2 == -2) 40; 40x60
// (axis == 3 == -1) 60
// Furthermore, bottom[1] may have the empty shape (regardless of the value of
// "axis") -- a scalar bias.
optional int32 axis = 1 [default = 1];
// (num_axes is ignored unless just one bottom is given and the bias is
// a learned parameter of the layer. Otherwise, num_axes is determined by the
// number of axes by the second bottom.)
// The number of axes of the input (bottom[0]) covered by the bias
// parameter, or -1 to cover all axes of bottom[0] starting from `axis`.
// Set num_axes := 0, to add a zero-axis Blob: a scalar.
optional int32 num_axes = 2 [default = 1];
// (filler is ignored unless just one bottom is given and the bias is
// a learned parameter of the layer.)
// The initialization for the learned bias parameter.
// Default is the zero (0) initialization, resulting in the BiasLayer
// initially performing the identity operation.
optional FillerParameter filler = 3;
}
message ContrastiveLossParameter {
// margin for dissimilar pair
optional float margin = 1 [default = 1.0];
// The first implementation of this cost did not exactly match the cost of
// Hadsell et al 2006 -- using (margin - d^2) instead of (margin - d)^2.
// legacy_version = false (the default) uses (margin - d)^2 as proposed in the
// Hadsell paper. New models should probably use this version.
// legacy_version = true uses (margin - d^2). This is kept to support /
// reproduce existing models and results
optional bool legacy_version = 2 [default = false];
}
message ConvolutionParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
optional bool bias_term = 2 [default = true]; // whether to have bias terms
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in all spatial dimensions, or once per spatial dimension.
repeated uint32 pad = 3; // The padding size; defaults to 0
repeated uint32 kernel_size = 4; // The kernel size
repeated uint32 stride = 6; // The stride; defaults to 1
// Factor used to dilate the kernel, (implicitly) zero-filling the resulting
// holes. (Kernel dilation is sometimes referred to by its use in the
// algorithme à trous from Holschneider et al. 1987.)
repeated uint32 dilation = 18; // The dilation; defaults to 1
// For 2D convolution only, the *_h and *_w versions may also be used to
// specify both spatial dimensions.
optional uint32 pad_h = 9 [default = 0]; // The padding height (2D only)
optional uint32 pad_w = 10 [default = 0]; // The padding width (2D only)
optional uint32 kernel_h = 11; // The kernel height (2D only)
optional uint32 kernel_w = 12; // The kernel width (2D only)
optional uint32 stride_h = 13; // The stride height (2D only)
optional uint32 stride_w = 14; // The stride width (2D only)
optional uint32 group = 5 [default = 1]; // The group size for group conv
optional FillerParameter weight_filler = 7; // The filler for the weight
optional FillerParameter bias_filler = 8; // The filler for the bias
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 15 [default = DEFAULT];
// The axis to interpret as "channels" when performing convolution.
// Preceding dimensions are treated as independent inputs;
// succeeding dimensions are treated as "spatial".
// With (N, C, H, W) inputs, and axis == 1 (the default), we perform
// N independent 2D convolutions, sliding C-channel (or (C/g)-channels, for
// groups g>1) filters across the spatial axes (H, W) of the input.
// With (N, C, D, H, W) inputs, and axis == 1, we perform
// N independent 3D convolutions, sliding (C/g)-channels
// filters across the spatial axes (D, H, W) of the input.
optional int32 axis = 16 [default = 1];
// Whether to force use of the general ND convolution, even if a specific
// implementation for blobs of the appropriate number of spatial dimensions
// is available. (Currently, there is only a 2D-specific convolution
// implementation; for input blobs with num_axes != 2, this option is
// ignored and the ND implementation will be used.)
optional bool force_nd_im2col = 17 [default = false];
}
message CropParameter {
// To crop, elements of the first bottom are selected to fit the dimensions
// of the second, reference bottom. The crop is configured by
// - the crop `axis` to pick the dimensions for cropping
// - the crop `offset` to set the shift for all/each dimension
// to align the cropped bottom with the reference bottom.
// All dimensions up to but excluding `axis` are preserved, while
// the dimensions including and trailing `axis` are cropped.
// If only one `offset` is set, then all dimensions are offset by this amount.
// Otherwise, the number of offsets must equal the number of cropped axes to
// shift the crop in each dimension accordingly.
// Note: standard dimensions are N,C,H,W so the default is a spatial crop,
// and `axis` may be negative to index from the end (e.g., -1 for the last
// axis).
optional int32 axis = 1 [default = 2];
repeated uint32 offset = 2;
}
message DataParameter {
enum DB {
LEVELDB = 0;
LMDB = 1;
}
// Specify the data source.
optional string source = 1;
// Specify the batch size.
optional uint32 batch_size = 4;
// The rand_skip variable is for the data layer to skip a few data points
// to avoid all asynchronous sgd clients to start at the same point. The skip
// point would be set as rand_skip * rand(0,1). Note that rand_skip should not
// be larger than the number of keys in the database.
// DEPRECATED. Each solver accesses a different subset of the database.
optional uint32 rand_skip = 7 [default = 0];
optional DB backend = 8 [default = LEVELDB];
// DEPRECATED. See TransformationParameter. For data pre-processing, we can do
// simple scaling and subtracting the data mean, if provided. Note that the
// mean subtraction is always carried out before scaling.
optional float scale = 2 [default = 1];
optional string mean_file = 3;
// DEPRECATED. See TransformationParameter. Specify if we would like to randomly
// crop an image.
optional uint32 crop_size = 5 [default = 0];
// DEPRECATED. See TransformationParameter. Specify if we want to randomly mirror
// data.
optional bool mirror = 6 [default = false];
// Force the encoded image to have 3 color channels
optional bool force_encoded_color = 9 [default = false];
// Prefetch queue (Number of batches to prefetch to host memory, increase if
// data access bandwidth varies).
optional uint32 prefetch = 10 [default = 4];
}
message DropoutParameter {
optional float dropout_ratio = 1 [default = 0.5]; // dropout ratio
}
// DummyDataLayer fills any number of arbitrarily shaped blobs with random
// (or constant) data generated by "Fillers" (see "message FillerParameter").
message DummyDataParameter {
// This layer produces N >= 1 top blobs. DummyDataParameter must specify 1 or N
// shape fields, and 0, 1 or N data_fillers.
//
// If 0 data_fillers are specified, ConstantFiller with a value of 0 is used.
// If 1 data_filler is specified, it is applied to all top blobs. If N are
// specified, the ith is applied to the ith top blob.
repeated FillerParameter data_filler = 1;
repeated BlobShape shape = 6;
// 4D dimensions -- deprecated. Use "shape" instead.
repeated uint32 num = 2;
repeated uint32 channels = 3;
repeated uint32 height = 4;
repeated uint32 width = 5;
}
message EltwiseParameter {
enum EltwiseOp {
PROD = 0;
SUM = 1;
MAX = 2;
}
optional EltwiseOp operation = 1 [default = SUM]; // element-wise operation
repeated float coeff = 2; // blob-wise coefficient for SUM operation
// Whether to use an asymptotically slower (for >2 inputs) but stabler method
// of computing the gradient for the PROD operation. (No effect for SUM op.)
optional bool stable_prod_grad = 3 [default = true];
}
// Message that stores parameters used by ELULayer
message ELUParameter {
// Described in:
// Clevert, D.-A., Unterthiner, T., & Hochreiter, S. (2015). Fast and Accurate
// Deep Network Learning by Exponential Linear Units (ELUs). arXiv
optional float alpha = 1 [default = 1];
}
// Message that stores parameters used by EmbedLayer
message EmbedParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
// The input is given as integers to be interpreted as one-hot
// vector indices with dimension num_input. Hence num_input should be
// 1 greater than the maximum possible input value.
optional uint32 input_dim = 2;
optional bool bias_term = 3 [default = true]; // Whether to use a bias term
optional FillerParameter weight_filler = 4; // The filler for the weight
optional FillerParameter bias_filler = 5; // The filler for the bias
}
// Message that stores parameters used by Entropy layer
message EntropyParameter {
optional float threshold = 1 [default = 0.001];
optional uint32 ignore_label = 2[default = 999];
optional uint32 iterations_num = 3[default = 0];
}
// Message that stores parameters used by ExpLayer
message ExpParameter {
// ExpLayer computes outputs y = base ^ (shift + scale * x), for base > 0.
// Or if base is set to the default (-1), base is set to e,
// so y = exp(shift + scale * x).
optional float base = 1 [default = -1.0];
optional float scale = 2 [default = 1.0];
optional float shift = 3 [default = 0.0];
}
/// Message that stores parameters used by FlattenLayer
message FlattenParameter {
// The first axis to flatten: all preceding axes are retained in the output.
// May be negative to index from the end (e.g., -1 for the last axis).
optional int32 axis = 1 [default = 1];
// The last axis to flatten: all following axes are retained in the output.
// May be negative to index from the end (e.g., the default -1 for the last
// axis).
optional int32 end_axis = 2 [default = -1];
}
message GradientScalerParameter {
// GradientScalerLayer scales deltas according to the schedule:
// 2 * height / (1 + exp(-alpha * (iter / max_iter))) - height + lower_bound,
// where height = upper_bound - lower_bound
optional float lower_bound = 1 [default = 0.0];
optional float upper_bound = 2 [default = 1.0];
optional float alpha = 3 [default = 10.0];
optional float max_iter = 4 [default = 1];
optional uint32 threshold_iter = 5 [default = 0];
}
// Message that stores parameters used by HDF5DataLayer
message HDF5DataParameter {
// Specify the data source.
optional string source = 1;
// Specify the batch size.
optional uint32 batch_size = 2;
// Specify whether to shuffle the data.
// If shuffle == true, the ordering of the HDF5 files is shuffled,
// and the ordering of data within any given HDF5 file is shuffled,
// but data between different files are not interleaved; all of a file's
// data are output (in a random order) before moving onto another file.
optional bool shuffle = 3 [default = false];
}
message HDF5OutputParameter {
optional string file_name = 1;
}
message HingeLossParameter {
enum Norm {
L1 = 1;
L2 = 2;
}
// Specify the Norm to use L1 or L2
optional Norm norm = 1 [default = L1];
}
message ImageDataParameter {
// Specify the data source.
optional string source = 1;
// Specify the batch size.
optional uint32 batch_size = 4 [default = 1];
// The rand_skip variable is for the data layer to skip a few data points
// to avoid all asynchronous sgd clients to start at the same point. The skip
// point would be set as rand_skip * rand(0,1). Note that rand_skip should not
// be larger than the number of keys in the database.
optional uint32 rand_skip = 7 [default = 0];
// Whether or not ImageLayer should shuffle the list of files at every epoch.
optional bool shuffle = 8 [default = false];
// It will also resize images if new_height or new_width are not zero.
optional uint32 new_height = 9 [default = 0];
optional uint32 new_width = 10 [default = 0];
// Specify if the images are color or gray
optional bool is_color = 11 [default = true];
// DEPRECATED. See TransformationParameter. For data pre-processing, we can do
// simple scaling and subtracting the data mean, if provided. Note that the
// mean subtraction is always carried out before scaling.
optional float scale = 2 [default = 1];
optional string mean_file = 3;
// DEPRECATED. See TransformationParameter. Specify if we would like to randomly
// crop an image.
optional uint32 crop_size = 5 [default = 0];
// DEPRECATED. See TransformationParameter. Specify if we want to randomly mirror
// data.
optional bool mirror = 6 [default = false];
optional string root_folder = 12 [default = ""];
}
message InfogainLossParameter {
// Specify the infogain matrix source.
optional string source = 1;
}
message InnerProductParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
optional bool bias_term = 2 [default = true]; // whether to have bias terms
optional FillerParameter weight_filler = 3; // The filler for the weight
optional FillerParameter bias_filler = 4; // The filler for the bias
// The first axis to be lumped into a single inner product computation;
// all preceding axes are retained in the output.
// May be negative to index from the end (e.g., -1 for the last axis).
optional int32 axis = 5 [default = 1];
// Specify whether to transpose the weight matrix or not.
// If transpose == true, any operations will be performed on the transpose
// of the weight matrix. The weight matrix itself is not going to be transposed
// but rather the transfer flag of operations will be toggled accordingly.
optional bool transpose = 6 [default = false];
}
message InputParameter {
// This layer produces N >= 1 top blob(s) to be assigned manually.
// Define N shapes to set a shape for each top.
// Define 1 shape to set the same shape for every top.
// Define no shape to defer to reshaping manually.
repeated BlobShape shape = 1;
}
// Message that stores parameters used by LogLayer
message LogParameter {
// LogLayer computes outputs y = log_base(shift + scale * x), for base > 0.
// Or if base is set to the default (-1), base is set to e,
// so y = ln(shift + scale * x) = log_e(shift + scale * x)
optional float base = 1 [default = -1.0];
optional float scale = 2 [default = 1.0];
optional float shift = 3 [default = 0.0];
}
// Message that stores parameters used by LRNLayer
message LRNParameter {
optional uint32 local_size = 1 [default = 5];
optional float alpha = 2 [default = 1.];
optional float beta = 3 [default = 0.75];
enum NormRegion {
ACROSS_CHANNELS = 0;
WITHIN_CHANNEL = 1;
}
optional NormRegion norm_region = 4 [default = ACROSS_CHANNELS];
optional float k = 5 [default = 1.];
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 6 [default = DEFAULT];
}
message MemoryDataParameter {
optional uint32 batch_size = 1;
optional uint32 channels = 2;
optional uint32 height = 3;
optional uint32 width = 4;
}
message MVNParameter {
// This parameter can be set to false to normalize mean only
optional bool normalize_variance = 1 [default = true];
// This parameter can be set to true to perform DNN-like MVN
optional bool across_channels = 2 [default = false];
// Epsilon for not dividing by zero while normalizing variance
optional float eps = 3 [default = 1e-9];
}
message ParameterParameter {
optional BlobShape shape = 1;
}
message PoolingParameter {
enum PoolMethod {
MAX = 0;
AVE = 1;
STOCHASTIC = 2;
}
optional PoolMethod pool = 1 [default = MAX]; // The pooling method
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in height and width or as Y, X pairs.
optional uint32 pad = 4 [default = 0]; // The padding size (equal in Y, X)
optional uint32 pad_h = 9 [default = 0]; // The padding height
optional uint32 pad_w = 10 [default = 0]; // The padding width
optional uint32 kernel_size = 2; // The kernel size (square)
optional uint32 kernel_h = 5; // The kernel height
optional uint32 kernel_w = 6; // The kernel width
optional uint32 stride = 3 [default = 1]; // The stride (equal in Y, X)
optional uint32 stride_h = 7; // The stride height
optional uint32 stride_w = 8; // The stride width
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 11 [default = DEFAULT];
// If global_pooling then it will pool over the size of the bottom by doing
// kernel_h = bottom->height and kernel_w = bottom->width
optional bool global_pooling = 12 [default = false];
}
message PowerParameter {
// PowerLayer computes outputs y = (shift + scale * x) ^ power.
optional float power = 1 [default = 1.0];
optional float scale = 2 [default = 1.0];
optional float shift = 3 [default = 0.0];
}
message PythonParameter {
optional string module = 1;
optional string layer = 2;
// This value is set to the attribute `param_str` of the `PythonLayer` object
// in Python before calling the `setup()` method. This could be a number,
// string, dictionary in Python dict format, JSON, etc. You may parse this
// string in `setup` method and use it in `forward` and `backward`.
optional string param_str = 3 [default = ''];
// Whether this PythonLayer is shared among worker solvers during data parallelism.
// If true, each worker solver sequentially run forward from this layer.
// This value should be set true if you are using it as a data layer.
optional bool share_in_parallel = 4 [default = false];
}
// Message that stores parameters used by RecurrentLayer
message RecurrentParameter {
// The dimension of the output (and usually hidden state) representation --
// must be explicitly set to non-zero.
optional uint32 num_output = 1 [default = 0];
optional FillerParameter weight_filler = 2; // The filler for the weight
optional FillerParameter bias_filler = 3; // The filler for the bias
// Whether to enable displaying debug_info in the unrolled recurrent net.
optional bool debug_info = 4 [default = false];
// Whether to add as additional inputs (bottoms) the initial hidden state
// blobs, and add as additional outputs (tops) the final timestep hidden state
// blobs. The number of additional bottom/top blobs required depends on the
// recurrent architecture -- e.g., 1 for RNNs, 2 for LSTMs.
optional bool expose_hidden = 5 [default = false];
}
// Message that stores parameters used by ReductionLayer
message ReductionParameter {
enum ReductionOp {
SUM = 1;
ASUM = 2;
SUMSQ = 3;
MEAN = 4;
}
optional ReductionOp operation = 1 [default = SUM]; // reduction operation
// The first axis to reduce to a scalar -- may be negative to index from the
// end (e.g., -1 for the last axis).
// (Currently, only reduction along ALL "tail" axes is supported; reduction
// of axis M through N, where N < num_axes - 1, is unsupported.)
// Suppose we have an n-axis bottom Blob with shape:
// (d0, d1, d2, ..., d(m-1), dm, d(m+1), ..., d(n-1)).
// If axis == m, the output Blob will have shape
// (d0, d1, d2, ..., d(m-1)),
// and the ReductionOp operation is performed (d0 * d1 * d2 * ... * d(m-1))
// times, each including (dm * d(m+1) * ... * d(n-1)) individual data.
// If axis == 0 (the default), the output Blob always has the empty shape
// (count 1), performing reduction across the entire input --
// often useful for creating new loss functions.
optional int32 axis = 2 [default = 0];
optional float coeff = 3 [default = 1.0]; // coefficient for output
}
// Message that stores parameters used by ReLULayer
message ReLUParameter {
// Allow non-zero slope for negative inputs to speed up optimization
// Described in:
// Maas, A. L., Hannun, A. Y., & Ng, A. Y. (2013). Rectifier nonlinearities
// improve neural network acoustic models. In ICML Workshop on Deep Learning
// for Audio, Speech, and Language Processing.
optional float negative_slope = 1 [default = 0];
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 2 [default = DEFAULT];
}
message ReshapeParameter {
// Specify the output dimensions. If some of the dimensions are set to 0,
// the corresponding dimension from the bottom layer is used (unchanged).
// Exactly one dimension may be set to -1, in which case its value is
// inferred from the count of the bottom blob and the remaining dimensions.
// For example, suppose we want to reshape a 2D blob "input" with shape 2 x 8:
//
// layer {
// type: "Reshape" bottom: "input" top: "output"
// reshape_param { ... }
// }
//
// If "input" is 2D with shape 2 x 8, then the following reshape_param
// specifications are all equivalent, producing a 3D blob "output" with shape
// 2 x 2 x 4:
//
// reshape_param { shape { dim: 2 dim: 2 dim: 4 } }
// reshape_param { shape { dim: 0 dim: 2 dim: 4 } }
// reshape_param { shape { dim: 0 dim: 2 dim: -1 } }
// reshape_param { shape { dim: 0 dim:-1 dim: 4 } }
//
optional BlobShape shape = 1;
// axis and num_axes control the portion of the bottom blob's shape that are
// replaced by (included in) the reshape. By default (axis == 0 and
// num_axes == -1), the entire bottom blob shape is included in the reshape,
// and hence the shape field must specify the entire output shape.
//
// axis may be non-zero to retain some portion of the beginning of the input
// shape (and may be negative to index from the end; e.g., -1 to begin the
// reshape after the last axis, including nothing in the reshape,
// -2 to include only the last axis, etc.).
//
// For example, suppose "input" is a 2D blob with shape 2 x 8.
// Then the following ReshapeLayer specifications are all equivalent,
// producing a blob "output" with shape 2 x 2 x 4:
//
// reshape_param { shape { dim: 2 dim: 2 dim: 4 } }
// reshape_param { shape { dim: 2 dim: 4 } axis: 1 }
// reshape_param { shape { dim: 2 dim: 4 } axis: -3 }
//
// num_axes specifies the extent of the reshape.
// If num_axes >= 0 (and axis >= 0), the reshape will be performed only on
// input axes in the range [axis, axis+num_axes].
// num_axes may also be -1, the default, to include all remaining axes
// (starting from axis).
//
// For example, suppose "input" is a 2D blob with shape 2 x 8.
// Then the following ReshapeLayer specifications are equivalent,
// producing a blob "output" with shape 1 x 2 x 8.
//
// reshape_param { shape { dim: 1 dim: 2 dim: 8 } }
// reshape_param { shape { dim: 1 dim: 2 } num_axes: 1 }
// reshape_param { shape { dim: 1 } num_axes: 0 }
//
// On the other hand, these would produce output blob shape 2 x 1 x 8:
//
// reshape_param { shape { dim: 2 dim: 1 dim: 8 } }
// reshape_param { shape { dim: 1 } axis: 1 num_axes: 0 }
//
optional int32 axis = 2 [default = 0];
optional int32 num_axes = 3 [default = -1];
}
message ScaleParameter {
// The first axis of bottom[0] (the first input Blob) along which to apply
// bottom[1] (the second input Blob). May be negative to index from the end
// (e.g., -1 for the last axis).
//
// For example, if bottom[0] is 4D with shape 100x3x40x60, the output
// top[0] will have the same shape, and bottom[1] may have any of the
// following shapes (for the given value of axis):
// (axis == 0 == -4) 100; 100x3; 100x3x40; 100x3x40x60
// (axis == 1 == -3) 3; 3x40; 3x40x60
// (axis == 2 == -2) 40; 40x60
// (axis == 3 == -1) 60
// Furthermore, bottom[1] may have the empty shape (regardless of the value of
// "axis") -- a scalar multiplier.
optional int32 axis = 1 [default = 1];
// (num_axes is ignored unless just one bottom is given and the scale is
// a learned parameter of the layer. Otherwise, num_axes is determined by the
// number of axes by the second bottom.)
// The number of axes of the input (bottom[0]) covered by the scale
// parameter, or -1 to cover all axes of bottom[0] starting from `axis`.
// Set num_axes := 0, to multiply with a zero-axis Blob: a scalar.
optional int32 num_axes = 2 [default = 1];
// (filler is ignored unless just one bottom is given and the scale is
// a learned parameter of the layer.)
// The initialization for the learned scale parameter.
// Default is the unit (1) initialization, resulting in the ScaleLayer
// initially performing the identity operation.
optional FillerParameter filler = 3;
// Whether to also learn a bias (equivalent to a ScaleLayer+BiasLayer, but
// may be more efficient). Initialized with bias_filler (defaults to 0).
optional bool bias_term = 4 [default = false];
optional FillerParameter bias_filler = 5;
}
message SigmoidParameter {
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 1 [default = DEFAULT];
}
message SliceParameter {
// The axis along which to slice -- may be negative to index from the end
// (e.g., -1 for the last axis).
// By default, SliceLayer concatenates blobs along the "channels" axis (1).
optional int32 axis = 3 [default = 1];
repeated uint32 slice_point = 2;
// DEPRECATED: alias for "axis" -- does not support negative indexing.
optional uint32 slice_dim = 1 [default = 1];
}
// Message that stores parameters used by SoftmaxLayer, SoftmaxWithLossLayer
message SoftmaxParameter {
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 1 [default = DEFAULT];
// The axis along which to perform the softmax -- may be negative to index
// from the end (e.g., -1 for the last axis).
// Any other axes will be evaluated as independent softmaxes.
optional int32 axis = 2 [default = 1];
}
message TanHParameter {
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 1 [default = DEFAULT];
}
// Message that stores parameters used by TileLayer
message TileParameter {
// The index of the axis to tile.
optional int32 axis = 1 [default = 1];
// The number of copies (tiles) of the blob to output.
optional int32 tiles = 2;
}
// Message that stores parameters used by ThresholdLayer
message ThresholdParameter {
optional float threshold = 1 [default = 0]; // Strictly positive values
}
message WindowDataParameter {
// Specify the data source.
optional string source = 1;
// For data pre-processing, we can do simple scaling and subtracting the
// data mean, if provided. Note that the mean subtraction is always carried
// out before scaling.
optional float scale = 2 [default = 1];
optional string mean_file = 3;
// Specify the batch size.
optional uint32 batch_size = 4;
// Specify if we would like to randomly crop an image.
optional uint32 crop_size = 5 [default = 0];
// Specify if we want to randomly mirror data.
optional bool mirror = 6 [default = false];
// Foreground (object) overlap threshold
optional float fg_threshold = 7 [default = 0.5];
// Background (non-object) overlap threshold
optional float bg_threshold = 8 [default = 0.5];
// Fraction of batch that should be foreground objects
optional float fg_fraction = 9 [default = 0.25];
// Amount of contextual padding to add around a window
// (used only by the window_data_layer)
optional uint32 context_pad = 10 [default = 0];
// Mode for cropping out a detection window
// warp: cropped window is warped to a fixed size and aspect ratio
// square: the tightest square around the window is cropped
optional string crop_mode = 11 [default = "warp"];
// cache_images: will load all images in memory for faster access
optional bool cache_images = 12 [default = false];
// append root_folder to locate images
optional string root_folder = 13 [default = ""];
}
message SPPParameter {
enum PoolMethod {
MAX = 0;
AVE = 1;
STOCHASTIC = 2;
}
optional uint32 pyramid_height = 1;
optional PoolMethod pool = 2 [default = MAX]; // The pooling method
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 6 [default = DEFAULT];
}
// DEPRECATED: use LayerParameter.
message V1LayerParameter {
repeated string bottom = 2;
repeated string top = 3;
optional string name = 4;
repeated NetStateRule include = 32;
repeated NetStateRule exclude = 33;
enum LayerType {
NONE = 0;
ABSVAL = 35;
ACCURACY = 1;
ARGMAX = 30;
BNLL = 2;
CONCAT = 3;
CONTRASTIVE_LOSS = 37;
CONVOLUTION = 4;
DATA = 5;
DECONVOLUTION = 39;
DROPOUT = 6;
DUMMY_DATA = 32;
EUCLIDEAN_LOSS = 7;
ELTWISE = 25;
EXP = 38;
FLATTEN = 8;
HDF5_DATA = 9;
HDF5_OUTPUT = 10;
HINGE_LOSS = 28;
IM2COL = 11;
IMAGE_DATA = 12;
INFOGAIN_LOSS = 13;
INNER_PRODUCT = 14;
LRN = 15;
MEMORY_DATA = 29;
MULTINOMIAL_LOGISTIC_LOSS = 16;
MVN = 34;
POOLING = 17;
POWER = 26;
RELU = 18;
SIGMOID = 19;
SIGMOID_CROSS_ENTROPY_LOSS = 27;
SILENCE = 36;
SOFTMAX = 20;
SOFTMAX_LOSS = 21;
SPLIT = 22;
SLICE = 33;
TANH = 23;
WINDOW_DATA = 24;
THRESHOLD = 31;
}
optional LayerType type = 5;
repeated BlobProto blobs = 6;
repeated string param = 1001;
repeated DimCheckMode blob_share_mode = 1002;
enum DimCheckMode {
STRICT = 0;
PERMISSIVE = 1;
}
repeated float blobs_lr = 7;
repeated float weight_decay = 8;
repeated float loss_weight = 35;
optional AccuracyParameter accuracy_param = 27;
optional ArgMaxParameter argmax_param = 23;
optional ConcatParameter concat_param = 9;
optional ContrastiveLossParameter contrastive_loss_param = 40;
optional ConvolutionParameter convolution_param = 10;
optional DataParameter data_param = 11;
optional DropoutParameter dropout_param = 12;
optional DummyDataParameter dummy_data_param = 26;
optional EltwiseParameter eltwise_param = 24;
optional ExpParameter exp_param = 41;
optional HDF5DataParameter hdf5_data_param = 13;
optional HDF5OutputParameter hdf5_output_param = 14;
optional HingeLossParameter hinge_loss_param = 29;
optional ImageDataParameter image_data_param = 15;
optional InfogainLossParameter infogain_loss_param = 16;
optional InnerProductParameter inner_product_param = 17;
optional LRNParameter lrn_param = 18;
optional MemoryDataParameter memory_data_param = 22;
optional MVNParameter mvn_param = 34;
optional PoolingParameter pooling_param = 19;
optional PowerParameter power_param = 21;
optional ReLUParameter relu_param = 30;
optional SigmoidParameter sigmoid_param = 38;
optional SoftmaxParameter softmax_param = 39;
optional SliceParameter slice_param = 31;
optional TanHParameter tanh_param = 37;
optional ThresholdParameter threshold_param = 25;
optional WindowDataParameter window_data_param = 20;
optional TransformationParameter transform_param = 36;
optional LossParameter loss_param = 42;
optional V0LayerParameter layer = 1;
}
// DEPRECATED: V0LayerParameter is the old way of specifying layer parameters
// in Caffe. We keep this message type around for legacy support.
message V0LayerParameter {
optional string name = 1; // the layer name
optional string type = 2; // the string to specify the layer type
// Parameters to specify layers with inner products.
optional uint32 num_output = 3; // The number of outputs for the layer
optional bool biasterm = 4 [default = true]; // whether to have bias terms
optional FillerParameter weight_filler = 5; // The filler for the weight
optional FillerParameter bias_filler = 6; // The filler for the bias
optional uint32 pad = 7 [default = 0]; // The padding size
optional uint32 kernelsize = 8; // The kernel size
optional uint32 group = 9 [default = 1]; // The group size for group conv
optional uint32 stride = 10 [default = 1]; // The stride
enum PoolMethod {
MAX = 0;
AVE = 1;
STOCHASTIC = 2;
}
optional PoolMethod pool = 11 [default = MAX]; // The pooling method
optional float dropout_ratio = 12 [default = 0.5]; // dropout ratio
optional uint32 local_size = 13 [default = 5]; // for local response norm
optional float alpha = 14 [default = 1.]; // for local response norm
optional float beta = 15 [default = 0.75]; // for local response norm
optional float k = 22 [default = 1.];
// For data layers, specify the data source
optional string source = 16;
// For data pre-processing, we can do simple scaling and subtracting the
// data mean, if provided. Note that the mean subtraction is always carried
// out before scaling.
optional float scale = 17 [default = 1];
optional string meanfile = 18;
// For data layers, specify the batch size.
optional uint32 batchsize = 19;
// For data layers, specify if we would like to randomly crop an image.
optional uint32 cropsize = 20 [default = 0];
// For data layers, specify if we want to randomly mirror data.
optional bool mirror = 21 [default = false];
// The blobs containing the numeric parameters of the layer
repeated BlobProto blobs = 50;
// The ratio that is multiplied on the global learning rate. If you want to
// set the learning ratio for one blob, you need to set it for all blobs.
repeated float blobs_lr = 51;
// The weight decay that is multiplied on the global weight decay.
repeated float weight_decay = 52;
// The rand_skip variable is for the data layer to skip a few data points
// to avoid all asynchronous sgd clients to start at the same point. The skip
// point would be set as rand_skip * rand(0,1). Note that rand_skip should not
// be larger than the number of keys in the database.
optional uint32 rand_skip = 53 [default = 0];
// Fields related to detection (det_*)
// foreground (object) overlap threshold
optional float det_fg_threshold = 54 [default = 0.5];
// background (non-object) overlap threshold
optional float det_bg_threshold = 55 [default = 0.5];
// Fraction of batch that should be foreground objects
optional float det_fg_fraction = 56 [default = 0.25];
// optional bool OBSOLETE_can_clobber = 57 [default = true];
// Amount of contextual padding to add around a window
// (used only by the window_data_layer)
optional uint32 det_context_pad = 58 [default = 0];
// Mode for cropping out a detection window
// warp: cropped window is warped to a fixed size and aspect ratio
// square: the tightest square around the window is cropped
optional string det_crop_mode = 59 [default = "warp"];
// For ReshapeLayer, one needs to specify the new dimensions.
optional int32 new_num = 60 [default = 0];
optional int32 new_channels = 61 [default = 0];
optional int32 new_height = 62 [default = 0];
optional int32 new_width = 63 [default = 0];
// Whether or not ImageLayer should shuffle the list of files at every epoch.
// It will also resize images if new_height or new_width are not zero.
optional bool shuffle_images = 64 [default = false];
// For ConcatLayer, one needs to specify the dimension for concatenation, and
// the other dimensions must be the same for all the bottom blobs.
// By default it will concatenate blobs along the channels dimension.
optional uint32 concat_dim = 65 [default = 1];
optional HDF5OutputParameter hdf5_output_param = 1001;
}
message PReLUParameter {
// Parametric ReLU described in K. He et al, Delving Deep into Rectifiers:
// Surpassing Human-Level Performance on ImageNet Classification, 2015.
// Initial value of a_i. Default is a_i=0.25 for all i.
optional FillerParameter filler = 1;
// Whether or not slope paramters are shared across channels.
optional bool channel_shared = 2 [default = false];
}
================================================
FILE: code/deep/CSG/README.md
================================================
# Learning Causal Semantic Representation for Out-of-Distribution Prediction
This repository is the official implementation of "[Learning Causal Semantic Representation for Out-of-Distribution Prediction](https://arxiv.org/abs/2011.01681)" (NeurIPS 2021).
[Chang Liu][changliu] \<\>,
Xinwei Sun, Jindong Wang, Haoyue Tang, Tao Li, Tao Qin, Wei Chen, Tie-Yan Liu.\
\[[Paper & Appendix](https://changliu00.github.io/causupv/causupv.pdf)\]
\[[Slides](https://changliu00.github.io/causupv/causupv-slides.pdf)\]
\[[Video](https://recorder-v3.slideslive.com/?share=52713&s=7a03cf16-4993-4e27-8502-7461239c487d)\]
\[[Poster](https://changliu00.github.io/causupv/causupv-poster.pdf)\]
Please check [this link](https://github.com/changliu00/causal-semantic-generative-model) for further updates.
## Introduction

The work proposes a Causal Semantic Generative model (CSG) for OOD generalization (_single-source_ domain generalization) and domain adaptation.
The model is developed following a causal reasoning process, and prediction is made by leveraging the _causal invariance principle_.
Training and prediction algorithms are developed based on variational Bayes with a novel design.
Theoretical guarantees on the identifiability of the causal factor and the benefits for OOD prediction are presented.
This codebase implements the CSG methods, and implements or integrates various baselines.
## Requirements
The code requires python version >= 3.6, and is based on [PyTorch](https://github.com/pytorch/pytorch). To install requirements:
```setup
pip install -r requirements.txt
```
## Usage
Folder `a-mnist` contains scripts to run the experiments on the **Shifted-MNIST** dataset,
and `a-imageclef` on the [**ImageCLEF-DA**](http://imageclef.org/2014/adaptation) dataset,
and `a-domainbed` on the [**PACS**](https://openaccess.thecvf.com/content_ICCV_2017/papers/Li_Deeper_Broader_and_ICCV_2017_paper.pdf) and [**VLCS**](https://openaccess.thecvf.com/content_iccv_2013/papers/Fang_Unbiased_Metric_Learning_2013_ICCV_paper.pdf) datasets
(the prefix `a-` represents "application").
Go to the respective folder and run the `prepare_data.sh` or `makedata.sh` script there to prepare the datasets.
Run the `run_ood.sh` (for OOD generalization methods) and `run_da.sh` (for domain adaptation methods) scripts to train the models.
Evaluation result (accuracy on the test domain) is printed and written to disk with the model and configurations.
See the commands in the script files or `python3 main.py --help` for customized usage or hyperparameter tuning.
[changliu]: http://ml.cs.tsinghua.edu.cn/~changliu/index.html
================================================
FILE: code/deep/CSG/a-domainbed/main.py
================================================
#!/usr/bin/env python3.6
import warnings
import sys
import torch as tc
sys.path.append("..")
from utils.utils_main import main_stem, get_parser, is_ood, process_continue_run
from utils.preprocess import data_loader
from utils.utils import boolstr, ZipLongest
from DomainBed.domainbed import datasets
from DomainBed.domainbed.lib import misc
from DomainBed.domainbed.lib.fast_data_loader import InfiniteDataLoader, FastDataLoader
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
class MergeIters:
def __init__(self, *itrs):
self.itrs = itrs
self.zipped = ZipLongest(*itrs)
self.len = len(self.zipped)
def __iter__(self):
for vals in self.zipped:
yield tuple(tc.cat([val[i] for val in vals]) for i in range(len(vals[0])))
def __len__(self): return self.len
if __name__ == "__main__":
parser = get_parser()
parser.add_argument("--data_root", type = str, default = "./DomainBed/domainbed/data/")
parser.add_argument('--dataset', type = str, default = "PACS")
parser.add_argument("--testdoms", type = int, nargs = '+', default = [0])
parser.add_argument("--n_bat_test", type = int, default = None)
parser.add_argument("--traindoms", type = int, nargs = '+', default = None) # default: 'other' if `excl_test` else 'all'
parser.add_argument("--excl_test", type = boolstr, default = True) # only active when `traindoms` is None (by default)
parser.add_argument("--uda_frac", type = float, default = 1.)
parser.add_argument("--data_aug", type = boolstr, default = True)
parser.add_argument("--dim_s", type = int, default = 512)
parser.add_argument("--dim_v", type = int, default = 128)
parser.add_argument("--dim_btnk", type = int, default = 1024) # for discr_model
parser.add_argument("--dims_bb2bn", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2s", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_s2y", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2v", type = int, nargs = '*') # for discr_model
parser.add_argument("--vbranch", type = boolstr, default = False) # for discr_model
parser.add_argument("--dim_feat", type = int, default = 256) # for gen_model
parser.set_defaults(discrstru = "DBresnet50", genstru = "DCGANpretr",
n_bat = 32, n_epk = 40, eval_interval = 1,
optim = "Adam", lr = 5e-5, wl2 = 5e-4,
# momentum = .9, nesterov = True, lr_expo = .75, lr_wdatum = 6.25e-6, # only when "lr" is "SGD"
sig_s = 3e+1, sig_v = 3e+1, corr_sv = .7, tgt_mvn_prior = True, src_mvn_prior = True,
pstd_x = 1e-1, qstd_s = -1., qstd_v = -1.,
wgen = 1e-7, wsup = 0., wlogpi = 1.,
wda = .25,
domdisc_dimh = 1024, # for {dann, cdan, mdd} only
cdan_rand = False, # for cdan only
ker_alphas = [.5, 1., 2.], # for dan only
mdd_margin = 4. # for mdd only
)
ag = parser.parse_args()
if ag.wlogpi is None: ag.wlogpi = ag.wgen
if ag.n_bat_test is None: ag.n_bat_test = ag.n_bat
ag, ckpt = process_continue_run(ag)
IS_OOD = is_ood(ag.mode)
ag.data_dir = ag.data_root
ag.test_envs = ag.testdoms
ag.holdout_fraction = 1. - ag.tr_val_split
ag.uda_holdout_fraction = ag.uda_frac
ag.trial_seed = 0.
hparams = {'batch_size': ag.n_bat, 'class_balanced': False, 'data_augmentation': ag.data_aug}
# BEGIN: from 'domainbed.scripts.train.py'
if ag.dataset in vars(datasets):
dataset = vars(datasets)[ag.dataset](ag.data_dir,
ag.test_envs, hparams)
else:
raise NotImplementedError
# (customed plugin)
if ag.traindoms is None:
ag.traindoms = list(i for i in range(len(dataset)) if not ag.excl_test or i not in ag.test_envs)
ag.traindom = ag.traindoms # for printing info in `main_stem`
# (end)
# Split each env into an 'in-split' and an 'out-split'. We'll train on
# each in-split except the test envs, and evaluate on all splits.
# To allow unsupervised domain adaptation experiments, we split each test
# env into 'in-split', 'uda-split' and 'out-split'. The 'in-split' is used
# by collect_results.py to compute classification accuracies. The
# 'out-split' is used by the Oracle model selectino method. The unlabeled
# samples in 'uda-split' are passed to the algorithm at training time if
# args.task == "domain_adaptation". If we are interested in comparing
# domain generalization and domain adaptation results, then domain
# generalization algorithms should create the same 'uda-splits', which will
# be discared at training.
in_splits = []
out_splits = []
uda_splits = []
for env_i, env in enumerate(dataset):
uda = []
out, in_ = misc.split_dataset(env,
int(len(env)*ag.holdout_fraction),
misc.seed_hash(ag.trial_seed, env_i))
if env_i in ag.test_envs:
uda, in_ = misc.split_dataset(in_,
int(len(in_)*ag.uda_holdout_fraction),
misc.seed_hash(ag.trial_seed, env_i))
if hparams['class_balanced']:
in_weights = misc.make_weights_for_balanced_classes(in_)
out_weights = misc.make_weights_for_balanced_classes(out)
if uda is not None:
uda_weights = misc.make_weights_for_balanced_classes(uda)
else:
in_weights, out_weights, uda_weights = None, None, None
in_splits.append((in_, in_weights))
out_splits.append((out, out_weights))
if len(uda):
uda_splits.append((uda, uda_weights))
# Now `in_splits` and `out_splits` contain used-validation splits for all envs, and `uda_splits` contains the part of `in_splits` for uda for test envs only.
if len(uda_splits) == 0: # args.task == "domain_adaptation" and len(uda_splits) == 0:
raise ValueError("Not enough unlabeled samples for domain adaptation.")
train_loaders = [FastDataLoader( # InfiniteDataLoader(
dataset=env,
# weights=env_weights,
batch_size=hparams['batch_size'],
num_workers=dataset.N_WORKERS)
for i, (env, env_weights) in enumerate(in_splits)
if i in ag.traindoms]
val_loaders = [FastDataLoader( # InfiniteDataLoader(
dataset=env,
# weights=env_weights,
batch_size=ag.n_bat_test, # hparams['batch_size'],
num_workers=dataset.N_WORKERS)
for i, (env, env_weights) in enumerate(out_splits)
if i in ag.traindoms]
uda_loaders = [FastDataLoader( # InfiniteDataLoader(
dataset=env,
# weights=env_weights,
batch_size = hparams['batch_size'] * len(train_loaders), # =hparams['batch_size'],
num_workers=dataset.N_WORKERS)
for i, (env, env_weights) in enumerate(uda_splits)
# if i in args.test_envs
]
# eval_loaders = [FastDataLoader(
# dataset=env,
# batch_size=64,
# num_workers=dataset.N_WORKERS)
# for env, _ in (in_splits + out_splits + uda_splits)]
# eval_weights = [None for _, weights in (in_splits + out_splits + uda_splits)]
# eval_loader_names = ['env{}_in'.format(i)
# for i in range(len(in_splits))]
# eval_loader_names += ['env{}_out'.format(i)
# for i in range(len(out_splits))]
# eval_loader_names += ['env{}_uda'.format(i)
# for i in range(len(uda_splits))]
# END
archtype = "cnn"
shape_x = dataset.input_shape
dim_y = dataset.num_classes
tr_src_loader = MergeIters(*train_loaders)
val_src_loader = MergeIters(*val_loaders)
ls_ts_tgt_loader = uda_loaders
if not IS_OOD:
ls_tr_tgt_loader = uda_loaders
if IS_OOD:
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, ls_ts_tgt_loader )
else:
for testdom, tr_tgt_loader, ts_tgt_loader in zip(
ag.testdoms, ls_tr_tgt_loader, ls_ts_tgt_loader):
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, None,
tr_tgt_loader, ts_tgt_loader, testdom )
================================================
FILE: code/deep/CSG/a-domainbed/prepare_data.sh
================================================
git clone https://github.com/facebookresearch/DomainBed
cd DomainBed/
git checkout 2deb150
python3 -m pip install gdown==3.13.0
# python3 -m pip install wilds==1.1.0 torch_scatter # Installing `torch_scatter` seems quite involved. Turn to edit the files to exclude the import.
vi "+14norm I# " "+15norm I# " "+271norm I# " "+267s/# //" "+270s/# //" "+wq" domainbed/scripts/download.py
vi "+12norm I# " "+13norm I# " "+wq" domainbed/datasets.py
python3 -m domainbed.scripts.download --data_dir=./domainbed/data
================================================
FILE: code/deep/CSG/a-domainbed/run_da.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
case $1 in
dann)
# Results taken from "In search of lost domain generalization" (ICLR'21).
;;
cdan)
# Results taken from "In search of lost domain generalization" (ICLR'21).
;;
dan)
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1e-2
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1e-2
;;
mdd)
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1e-2
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1e-2
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1e-2
;;
bnm)
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1.
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wl2 5e-4 --wsup 1. --wda 1.
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wl2 5e-4 --wsup 1. --wda 1.
;;
svae-da) # CSGz-DA
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 1 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 2 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 3 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
;;
svgm-da) # CSG-DA
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 1 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 2 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --testdoms 3 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --pstd_x 3e-1 --wl2 5e-4 --wsup 1. --wlogpi 0. --wgen 1e-8 --wda 1e-8
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/a-domainbed/run_ood.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
case $1 in
discr) # CE
# Results taken from "In search of lost domain generalization" (ICLR'21).
;;
cnbb)
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --testdoms 1 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --testdoms 2 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --testdoms 3 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4
;;
svae) # CSGz
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
;;
svgm) # CSG
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
;;
svgm-ind) # CSG-ind
##dataset PACS
$REPRUN $PYCMD $1 --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
##dataset VLCS
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 0 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 1 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 2 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
$REPRUN $PYCMD $1 --dataset VLCS --testdoms 3 --wsup 1. --wlogpi 0. --wl2 5e-4 --wgen 1e-7 --pstd_x 3e-1
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/a-domainbed/visual.py
================================================
#!/usr/bin/env python3.6
import warnings
import sys
sys.path.append("..")
from utils.utils_main import main_stem, get_parser, is_ood, process_continue_run, get_models, da_methods, ResultsContainer, ood_methods
from utils.preprocess import data_loader
from utils.utils import boolstr
from distr import edic
from arch import mlp, cnn
from methods import CNBBLoss, SemVar, SupVAE
from utils import Averager, unique_filename, boolstr, zip_longer # This imports from 'utils/__init__.py'
from utils.utils import boolstr, ZipLongest
from dalib.modules.domain_discriminator import DomainDiscriminator
from dalib.modules.kernels import GaussianKernel
from dalib.adaptation.dann import DomainAdversarialLoss
from dalib.adaptation.cdan import ConditionalDomainAdversarialLoss
from dalib.adaptation.dan import MultipleKernelMaximumMeanDiscrepancy
from dalib.adaptation.mdd import MarginDisparityDiscrepancy
import torch as tc
from functools import partial
import os
from DomainBed.domainbed import datasets
from DomainBed.domainbed.lib import misc
from DomainBed.domainbed.lib.fast_data_loader import InfiniteDataLoader, FastDataLoader
MODES_TWIST = {"svgm-ind", "svae-da", "svgm-da"}
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
from torchvision import models, transforms
class MergeIters:
def __init__(self, *itrs):
self.itrs = itrs
self.zipped = ZipLongest(*itrs)
self.len = len(self.zipped)
def __iter__(self):
for vals in self.zipped:
yield tuple(tc.cat([val[i] for val in vals]) for i in range(len(vals[0])))
def __len__(self): return self.len
def get_input_transform():
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transf = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
return transf
def get_visual(ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader,
ls_ts_tgt_loader = None, # for ood
tr_tgt_loader = None, ts_tgt_loader = None, testdom = None # for da
):
print(ag)
IS_OOD = is_ood(ag.mode)
device = tc.device("cuda:"+str(ag.gpu) if tc.cuda.is_available() else "cpu")
# Datasets
dim_x = tc.tensor(shape_x).prod().item()
if IS_OOD: n_per_epk = len(tr_src_loader)
else: n_per_epk = max(len(tr_src_loader), len(tr_tgt_loader))
# Models
res = get_models(archtype, edic(locals()) | vars(ag), ckpt, device)
if ag.mode.endswith("-da2"):
discr, gen, frame, discr_src = res
discr_src.train()
else:
discr, gen, frame = res
# get pictures
discr.eval()
if gen is not None: gen.eval()
# Methods and Losses
if IS_OOD:
lossfn = ood_methods(discr, frame, ag, dim_y, cnbb_actv="Sigmoid") # Actually the activation is ReLU, but there is no `is_treat` rule for ReLU in CNBB.
domdisc = None
else:
lossfn, domdisc, dalossobj = da_methods(discr, frame, ag, dim_x, dim_y, device, ckpt,
discr_src if ag.mode.endswith("-da2") else None)
epk0 = 1; i_bat0 = 1
if ckpt is not None:
epk0 = ckpt['epochs'][-1] + 1 if ckpt['epochs'] else 1
i_bat0 = ckpt['i_bat']
res = ResultsContainer( len(ag.testdoms) if IS_OOD else None,
frame, ag, dim_y==1, device, ckpt )
print(f"Run in mode '{ag.mode}' for {ag.n_epk:3d} epochs:")
try:
if ag.mode.endswith("-da2"): discr_src.eval(); true_discr = discr_src
elif ag.mode in MODES_TWIST and ag.true_sup_val: true_discr = partial(frame.logit_y1x_src, n_mc_q=ag.n_mc_q)
else: true_discr = discr
res.evaluate(true_discr, "val "+str(ag.traindom), 'val', val_src_loader, 'src')
if IS_OOD:
for i, (testdom, ts_tgt_loader) in enumerate(zip(ag.testdoms, ls_ts_tgt_loader)):
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt', i)
else:
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt')
print()
def batch_predict(images):
import torch.nn.functional as F
if tc.tensor(images[0]).size()[-1] == 3:
images = [tc.tensor(pic, dtype=tc.float).permute(2, 0, 1) for pic in images]
batch = tc.stack(tuple(i for i in images), dim=0)
batch = batch.to(device)
logits = discr(batch)
probs = F.softmax(logits, dim=1)
return probs.detach().cpu().numpy()
if IS_OOD:
test_loader = ls_ts_tgt_loader[0]
else:
test_loader = ts_tgt_loader
iter_tr, iter_ts = iter(tr_src_loader), iter(test_loader)
train_batch, train_label = next(iter_tr)
test_batch, test_label = next(iter_ts)
os.makedirs(ag.mode, exist_ok=True)
# search for the first accurate predict:
cursor_train, cursor_test = 0, 0
for i in range(1000):
cursor_test += 1
if cursor_test >= test_batch.size()[0]:
cursor_test = 0
test_batch, test_label = next(iter_ts)
while True:
x_test = test_batch[cursor_test]
test_pred = batch_predict([x_test])
if cursor_test < test_batch.size()[0] and test_label[cursor_test] == test_pred.squeeze().argmax():
break;
else:
cursor_test = cursor_test + 1
if cursor_test >= test_batch.size()[0]:
cursor_test = 0
test_batch, test_label = next(iter_ts)
selected_pic, selected_label = test_batch[cursor_test], test_label[cursor_test]
cursor_train += 1
if cursor_train >= train_batch.size()[0]:
cursor_train = 0
train_batch, train_label = next(iter_tr)
while True:
x_train = train_batch[cursor_train]
test_pred = batch_predict([x_train])
if cursor_train < train_batch.size()[0] and train_label[cursor_train] == test_pred.squeeze().argmax():
break;
else:
cursor_train = cursor_train + 1
if cursor_train >= train_batch.size()[0]:
cursor_train = 0
train_batch, train_label = next(iter_tr)
selected_train_pic = train_batch[cursor_train]
from lime import lime_image
import numpy as np
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(np.array(selected_pic.permute(1, 2, 0), dtype=np.double),
batch_predict, # classification function
top_labels=5,
hide_color=0,
num_samples=1000) # number of images that will be sent to classification function
from skimage.segmentation import mark_boundaries
test_pic, mask_test_pic = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
explanation_train = explainer.explain_instance(np.array(selected_train_pic.permute(1, 2, 0), dtype=np.double),
batch_predict, # classification function
top_labels=5,
hide_color=0,
num_samples=1000) # number of images that will be sent to classification function
train_pic, mask_train_pic = explanation_train.get_image_and_mask(explanation_train.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
def vis_pic_trans(pic):
pic = tc.tensor(pic).permute(2, 0, 1)
invTrans = transforms.Compose([ transforms.Normalize(mean = [ 0., 0., 0. ],
std = [ 1/0.229, 1/0.224, 1/0.225 ]),
transforms.Normalize(mean = [ -0.485, -0.456, -0.406 ],
std = [ 1., 1., 1. ]),
])
pic = invTrans(pic.unsqueeze(0)).squeeze()
return pic.permute(1, 2, 0).numpy()
test_pic = mark_boundaries(vis_pic_trans(test_pic), mask_test_pic)
train_pic = mark_boundaries(vis_pic_trans(train_pic), mask_train_pic)
import matplotlib.pyplot as plt
plt.imshow(train_pic)
plt.savefig(ag.mode+"/train-"+str(i)+".png")
plt.imshow(test_pic)
plt.savefig(ag.mode+"/test-"+str(i)+".png")
except (KeyboardInterrupt, SystemExit): pass
if __name__ == "__main__":
parser = get_parser()
parser.add_argument("--data_root", type = str, default = "./DomainBed/domainbed/data/")
parser.add_argument("--dataset", type = str, default = "PACS")
parser.add_argument("--traindoms", type = str, default = None)
parser.add_argument("--testdoms", type = str, nargs = '+', default = [0])
parser.add_argument("--excl_test", type = boolstr, default = True) # only active when `traindoms` is None (by default)
parser.add_argument("--uda_frac", type = float, default = 1.)
parser.add_argument("--data_aug", type = boolstr, default = True)
parser.add_argument("--dim_s", type = int, default = 512)
parser.add_argument("--dim_v", type = int, default = 128)
parser.add_argument("--dim_btnk", type = int, default = 1024) # for discr_model
parser.add_argument("--dims_bb2bn", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2s", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_s2y", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2v", type = int, nargs = '*') # for discr_model
parser.add_argument("--vbranch", type = boolstr, default = False) # for discr_model
parser.add_argument("--dim_feat", type = int, default = 128) # for gen_model
# parser.add_argument("--gpu", type=int, default=0)
parser.set_defaults(discrstru = "DBresnet50", genstru = "DCGANpretr",
n_bat = 32, n_epk = 40, eval_interval = 1,
optim = "Adam", lr = 5e-5, wl2 = 5e-4,
# momentum = .9, nesterov = True, lr_expo = .75, lr_wdatum = 6.25e-6, # only when "lr" is "SGD"
sig_s = 3e+1, sig_v = 3e+1, corr_sv = .7, tgt_mvn_prior = True, src_mvn_prior = True,
pstd_x = 1e-1, qstd_s = -1., qstd_v = -1.,
wgen = 1e-7, wsup = 0., wlogpi = 1.,
wda = .25,
domdisc_dimh = 1024, # for {dann, cdan, mdd} only
cdan_rand = False, # for cdan only
ker_alphas = [.5, 1., 2.], # for dan only
mdd_margin = 4. # for mdd only
)
ag = parser.parse_args()
if ag.wlogpi is None: ag.wlogpi = ag.wgen
ag, ckpt = process_continue_run(ag)
IS_OOD = is_ood(ag.mode)
ag.data_dir = ag.data_root
ag.test_envs = ag.testdoms
ag.holdout_fraction = 1. - ag.tr_val_split
ag.uda_holdout_fraction = ag.uda_frac
ag.trial_seed = 0.
hparams = {'batch_size': ag.n_bat, 'class_balanced': False, 'data_augmentation': ag.data_aug}
# BEGIN: from 'domainbed.scripts.train.py'
if ag.dataset in vars(datasets):
dataset = vars(datasets)[ag.dataset](ag.data_dir,
ag.test_envs, hparams)
else:
raise NotImplementedError
# (customed plugin)
if ag.traindoms is None:
ag.traindoms = list(i for i in range(len(dataset)) if not ag.excl_test or i not in ag.test_envs)
ag.traindom = ag.traindoms # for printing info in `main_stem`
# (end)
# Split each env into an 'in-split' and an 'out-split'. We'll train on
# each in-split except the test envs, and evaluate on all splits.
# To allow unsupervised domain adaptation experiments, we split each test
# env into 'in-split', 'uda-split' and 'out-split'. The 'in-split' is used
# by collect_results.py to compute classification accuracies. The
# 'out-split' is used by the Oracle model selectino method. The unlabeled
# samples in 'uda-split' are passed to the algorithm at training time if
# args.task == "domain_adaptation". If we are interested in comparing
# domain generalization and domain adaptation results, then domain
# generalization algorithms should create the same 'uda-splits', which will
# be discared at training.
in_splits = []
out_splits = []
uda_splits = []
for env_i, env in enumerate(dataset):
uda = []
out, in_ = misc.split_dataset(env,
int(len(env)*ag.holdout_fraction),0)
if env_i in ag.test_envs:
uda, in_ = misc.split_dataset(in_,
int(len(in_)*ag.uda_holdout_fraction),0)
if hparams['class_balanced']:
in_weights = misc.make_weights_for_balanced_classes(in_)
out_weights = misc.make_weights_for_balanced_classes(out)
if uda is not None:
uda_weights = misc.make_weights_for_balanced_classes(uda)
else:
in_weights, out_weights, uda_weights = None, None, None
in_splits.append((in_, in_weights))
out_splits.append((out, out_weights))
if len(uda):
uda_splits.append((uda, uda_weights))
# Now `in_splits` and `out_splits` contain used-validation splits for all envs, and `uda_splits` contains the part of `in_splits` for uda for test envs only.
if len(uda_splits) == 0: # args.task == "domain_adaptation" and len(uda_splits) == 0:
raise ValueError("Not enough unlabeled samples for domain adaptation.")
train_loaders = [tc.utils.data.DataLoader(
dataset=env,
batch_size=hparams['batch_size'],
num_workers=dataset.N_WORKERS,
shuffle=False
)
for i, (env, env_weights) in enumerate(in_splits)
if i in ag.traindoms
]
val_loaders = [tc.utils.data.DataLoader(
dataset=env,
batch_size=hparams['batch_size'],
num_workers=dataset.N_WORKERS,
shuffle=False
)
for i, (env, env_weights) in enumerate(out_splits)
if i in ag.traindoms
]
uda_loaders = [tc.utils.data.DataLoader(
dataset=env,
batch_size=hparams['batch_size'],
num_workers=dataset.N_WORKERS,
shuffle=False
)
for i, (env, env_weights) in enumerate(uda_splits)
# if i in args.test_envs]
]
# train_loaders = [# FastDataLoader( #
# InfiniteDataLoader(
# dataset=env,
# weights=None,
# batch_size=hparams['batch_size'],
# num_workers=dataset.N_WORKERS)
# for i, (env, env_weights) in enumerate(in_splits)
# if i in ag.traindoms]
# val_loaders = [# FastDataLoader( #
# InfiniteDataLoader(
# dataset=env,
# weights=None,
# batch_size=hparams['batch_size'],
# num_workers=dataset.N_WORKERS)
# for i, (env, env_weights) in enumerate(out_splits)
# if i in ag.traindoms]
# uda_loaders = [# FastDataLoader( #
# InfiniteDataLoader(
# dataset=env,
# weights=None,
# batch_size = hparams['batch_size'] * len(train_loaders), # =hparams['batch_size'],
# num_workers=dataset.N_WORKERS)
# for i, (env, env_weights) in enumerate(uda_splits)
# # if i in args.test_envs]
# ]
# eval_loaders = [FastDataLoader(
# dataset=env,
# batch_size=64,
# num_workers=dataset.N_WORKERS)
# for env, _ in (in_splits + out_splits + uda_splits)]
# eval_weights = [None for _, weights in (in_splits + out_splits + uda_splits)]
# eval_loader_names = ['env{}_in'.format(i)
# for i in range(len(in_splits))]
# eval_loader_names += ['env{}_out'.format(i)
# for i in range(len(out_splits))]
# eval_loader_names += ['env{}_uda'.format(i)
# for i in range(len(uda_splits))]
# END
archtype = "cnn"
shape_x = dataset.input_shape
dim_y = dataset.num_classes
tr_src_loader = MergeIters(*train_loaders)
val_src_loader = MergeIters(*val_loaders)
ls_ts_tgt_loader = uda_loaders
if not IS_OOD:
ls_tr_tgt_loader = uda_loaders
if IS_OOD:
get_visual( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, ls_ts_tgt_loader )
else:
for testdom, tr_tgt_loader, ts_tgt_loader in zip(ag.testdoms, ls_tr_tgt_loader, ls_ts_tgt_loader):
if testdom != ag.traindom:
get_visual( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, None,
tr_tgt_loader, ts_tgt_loader, testdom )
else:
warnings.warn("same domain adaptation ignored")
================================================
FILE: code/deep/CSG/a-imageclef/main.py
================================================
#!/usr/bin/env python3.6
import warnings
import sys
sys.path.append("..")
from utils.utils_main import main_stem, get_parser, is_ood, process_continue_run
from utils.preprocess import data_loader
from utils.utils import boolstr
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
if __name__ == "__main__":
parser = get_parser()
parser.add_argument("--data_root", type = str, default = "./data/image_CLEF/")
parser.add_argument("--traindom", type = str, default = "b")
parser.add_argument("--testdoms", type = str, nargs = '+', default = ["b", "c", "i", "p"])
parser.add_argument("--dim_s", type = int, default = 1024)
parser.add_argument("--dim_v", type = int, default = 256)
parser.add_argument("--dim_btnk", type = int, default = 1024) # for discr_model
parser.add_argument("--dims_bb2bn", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2s", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_s2y", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2v", type = int, nargs = '*') # for discr_model
parser.add_argument("--vbranch", type = boolstr, default = False) # for discr_model
parser.add_argument("--dim_feat", type = int, default = 128) # for gen_model
parser.set_defaults(discrstru = "ResNet50", genstru = "DCGANvar",
n_bat = 32, n_epk = 100,
optim = "SGD", lr = 4e-3, wl2 = 5e-4,
momentum = .9, nesterov = True, lr_expo = .75, lr_wdatum = 6.25e-6, # only when "lr" is "SGD"
wda = .25,
domdisc_dimh = 1024, # for {dann, cdan, mdd} only
cdan_rand = False, # for cdan only
ker_alphas = [.5, 1., 2.], # for dan only
mdd_margin = 4. # for mdd only
)
ag = parser.parse_args()
if ag.wlogpi is None: ag.wlogpi = ag.wgen
ag, ckpt = process_continue_run(ag)
IS_OOD = is_ood(ag.mode)
archtype = "cnn"
# Dataset
shape_x = (3, 224, 224) # determined by the loader
dim_y = 12
kwargs = {'num_workers': 4, 'pin_memory': True}
tr_src_loader, val_src_loader = data_loader.load_training(
ag.data_root, ag.traindom, ag.n_bat, kwargs,
ag.tr_val_split, rand_split=True ) # needs to rand split otherwise some classes are unseen in training.
ls_ts_tgt_loader = [data_loader.load_testing(
ag.data_root, testdom, ag.n_bat, kwargs)
for testdom in ag.testdoms]
if not IS_OOD:
ls_tr_tgt_loader = [data_loader.load_training(
ag.data_root, testdom, ag.n_bat, kwargs, -1)
for testdom in ag.testdoms]
if IS_OOD:
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, ls_ts_tgt_loader )
else:
for testdom, tr_tgt_loader, ts_tgt_loader in zip(
ag.testdoms, ls_tr_tgt_loader, ls_ts_tgt_loader):
if testdom != ag.traindom:
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, None,
tr_tgt_loader, ts_tgt_loader, testdom )
else:
warnings.warn("same domain adaptation ignored")
================================================
FILE: code/deep/CSG/a-imageclef/prepare_data.sh
================================================
DATAFILE=image_CLEF.zip
wget https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/$DATAFILE
mkdir -p data
unzip $DATAFILE -d data/
mv $DATAFILE data/
================================================
FILE: code/deep/CSG/a-imageclef/run_da.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
case $1 in
dann)
# Results taken from "Conditional adversarial domain adaptation" (NeurIPS'18)
;;
cdan)
# Results taken from "Conditional adversarial domain adaptation" (NeurIPS'18)
;;
dan)
# Results taken from "Conditional adversarial domain adaptation" (NeurIPS'18)
;;
mdd)
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-2 --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-2 --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-2 --n_epk 20 --eval_interval 1
;;
bnm)
$REPRUN $PYCMD $1 --traindom c --testdoms p --wl2 5e-4 --wsup 1. --wda 1. --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --wl2 5e-4 --wsup 1. --wda 1. --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --wl2 5e-4 --wsup 1. --wda 1. --n_epk 20 --eval_interval 1
;;
svae-da) # CSGz-DA
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
;;
svgm-da) # CSG-DA
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 256 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --wda 1e-8 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 3e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/a-imageclef/run_ood.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
case $1 in
discr) # CE
# Results taken from "Conditional adversarial domain adaptation" (NeurIPS'18)
;;
cnbb)
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dim_btnk 1024 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --reg_w 1e-6 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4 --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dim_btnk 1024 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --reg_w 1e-6 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4 --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dim_btnk 1024 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --reg_w 1e-6 --reg_s 3e-6 --lr_w 1e-4 --n_iter_w 4 --n_epk 20 --eval_interval 1
;;
svae) # CSGz
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-7 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-7 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 0 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 0. --corr_sv 0. --pstd_x 1e-1 --qstd_s=-1. --qstd_v=0. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-7 --genstru DCGANpretr --n_epk 20 --eval_interval 1
;;
svgm) # CSG
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
;;
svgm-ind) # CSG-ind
$REPRUN $PYCMD $1 --traindom c --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom i --testdoms p --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
$REPRUN $PYCMD $1 --traindom p --testdoms c i --n_bat 32 --dims_bb2bn --dim_btnk 1024 --dim_v 128 --vbranch 0 --dims_bn2v --dims_bn2s 1024 --dim_s 256 --dims_s2y --dim_feat 128 --optim SGD --lr 1e-3 --wl2 5e-4 --lr_expo .75 --lr_wdatum 6.25e-6 --sig_s 3e+1 --sig_v 3e+1 --corr_sv .7 --pstd_x 1e-1 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-8 --genstru DCGANpretr --n_epk 20 --eval_interval 1
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/a-imageclef/visual.py
================================================
#!/usr/bin/env python3.6
import warnings
import sys
sys.path.append("..")
from utils.utils_main import main_stem, get_parser, is_ood, process_continue_run, get_models, da_methods, ResultsContainer, ood_methods
from utils.preprocess import data_loader
from utils.utils import boolstr
from distr import edic
from arch import mlp, cnn
from methods import CNBBLoss, SemVar, SupVAE
from utils import Averager, unique_filename, boolstr, zip_longer # This imports from 'utils/__init__.py'
from dalib.modules.domain_discriminator import DomainDiscriminator
from dalib.modules.kernels import GaussianKernel
from dalib.adaptation.dann import DomainAdversarialLoss
from dalib.adaptation.cdan import ConditionalDomainAdversarialLoss
from dalib.adaptation.dan import MultipleKernelMaximumMeanDiscrepancy
from dalib.adaptation.mdd import MarginDisparityDiscrepancy
import torch as tc
from functools import partial
import os
MODES_TWIST = {"svgm-ind", "svae-da", "svgm-da"}
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
from torchvision import models, transforms
def get_input_transform():
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transf = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
return transf
def get_visual(ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader,
ls_ts_tgt_loader = None, # for ood
tr_tgt_loader = None, ts_tgt_loader = None, testdom = None # for da
):
print(ag)
IS_OOD = is_ood(ag.mode)
device = tc.device("cuda:"+str(ag.gpu) if tc.cuda.is_available() else "cpu")
# Datasets
dim_x = tc.tensor(shape_x).prod().item()
if IS_OOD: n_per_epk = len(tr_src_loader)
else: n_per_epk = max(len(tr_src_loader), len(tr_tgt_loader))
# Models
res = get_models(archtype, edic(locals()) | vars(ag), ckpt, device)
if ag.mode.endswith("-da2"):
discr, gen, frame, discr_src = res
discr_src.train()
else:
discr, gen, frame = res
# get pictures
discr.eval()
if gen is not None: gen.eval()
# Methods and Losses
if IS_OOD:
lossfn = ood_methods(discr, frame, ag, dim_y, cnbb_actv="Sigmoid") # Actually the activation is ReLU, but there is no `is_treat` rule for ReLU in CNBB.
domdisc = None
else:
lossfn, domdisc, dalossobj = da_methods(discr, frame, ag, dim_x, dim_y, device, ckpt,
discr_src if ag.mode.endswith("-da2") else None)
epk0 = 1; i_bat0 = 1
if ckpt is not None:
epk0 = ckpt['epochs'][-1] + 1 if ckpt['epochs'] else 1
i_bat0 = ckpt['i_bat']
res = ResultsContainer( len(ag.testdoms) if IS_OOD else None,
frame, ag, dim_y==1, device, ckpt )
print(f"Run in mode '{ag.mode}' for {ag.n_epk:3d} epochs:")
try:
if ag.mode.endswith("-da2"): discr_src.eval(); true_discr = discr_src
elif ag.mode in MODES_TWIST and ag.true_sup_val: true_discr = partial(frame.logit_y1x_src, n_mc_q=ag.n_mc_q)
else: true_discr = discr
res.evaluate(true_discr, "val "+str(ag.traindom), 'val', val_src_loader, 'src')
if IS_OOD:
for i, (testdom, ts_tgt_loader) in enumerate(zip(ag.testdoms, ls_ts_tgt_loader)):
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt', i)
else:
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt')
print()
def batch_predict(images):
import torch.nn.functional as F
if tc.tensor(images[0]).size()[-1] == 3:
images = [tc.tensor(pic, dtype=tc.float).permute(2, 0, 1) for pic in images]
batch = tc.stack(tuple(i for i in images), dim=0)
batch = batch.to(device)
logits = discr(batch)
probs = F.softmax(logits, dim=1)
return probs.detach().cpu().numpy()
if IS_OOD:
test_loader = ls_ts_tgt_loader[0]
else:
test_loader = ts_tgt_loader
iter_tr, iter_ts = iter(tr_src_loader), iter(test_loader)
train_batch, train_label = next(iter_tr)
test_batch, test_label = next(iter_ts)
os.makedirs(ag.mode, exist_ok=True)
# search for the first accurate predict:
cursor_train, cursor_test = 0, 0
for i in range(400):
cursor_test += 1
if cursor_test >= test_batch.size()[0]:
cursor_test = 0
test_batch, test_label = next(iter_ts)
while True:
x_test = test_batch[cursor_test]
test_pred = batch_predict([x_test])
if cursor_test < test_batch.size()[0] and test_label[cursor_test] == test_pred.squeeze().argmax():
break;
else:
cursor_test = cursor_test + 1
if cursor_test >= test_batch.size()[0]:
cursor_test = 0
test_batch, test_label = next(iter_ts)
selected_pic, selected_label = test_batch[cursor_test], test_label[cursor_test]
cursor_train += 1
if cursor_train >= train_batch.size()[0]:
cursor_train = 0
train_batch, train_label = next(iter_tr)
while True:
x_train = train_batch[cursor_train]
test_pred = batch_predict([x_train])
if cursor_train < train_batch.size()[0] and train_label[cursor_train] == test_pred.squeeze().argmax():
break;
else:
cursor_train = cursor_train + 1
if cursor_train >= train_batch.size()[0]:
cursor_train = 0
train_batch, train_label = next(iter_tr)
selected_train_pic = train_batch[cursor_train]
from lime import lime_image
import numpy as np
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(np.array(selected_pic.permute(1, 2, 0), dtype=np.double),
batch_predict, # classification function
top_labels=5,
hide_color=0,
num_samples=1000) # number of images that will be sent to classification function
from skimage.segmentation import mark_boundaries
test_pic, mask_test_pic = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
explanation_train = explainer.explain_instance(np.array(selected_train_pic.permute(1, 2, 0), dtype=np.double),
batch_predict, # classification function
top_labels=5,
hide_color=0,
num_samples=1000) # number of images that will be sent to classification function
train_pic, mask_train_pic = explanation_train.get_image_and_mask(explanation_train.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
def vis_pic_trans(pic):
pic = tc.tensor(pic).permute(2, 0, 1)
invTrans = transforms.Compose([ transforms.Normalize(mean = [ 0., 0., 0. ],
std = [ 1/0.229, 1/0.224, 1/0.225 ]),
transforms.Normalize(mean = [ -0.485, -0.456, -0.406 ],
std = [ 1., 1., 1. ]),
])
pic = invTrans(pic.unsqueeze(0)).squeeze()
return pic.permute(1, 2, 0).numpy()
test_pic = mark_boundaries(vis_pic_trans(test_pic), mask_test_pic)
train_pic = mark_boundaries(vis_pic_trans(train_pic), mask_train_pic)
import matplotlib.pyplot as plt
plt.imshow(train_pic)
plt.savefig(ag.mode+"/train-"+str(i)+".png")
plt.imshow(test_pic)
plt.savefig(ag.mode+"/test-"+str(i)+".png")
except (KeyboardInterrupt, SystemExit): pass
if __name__ == "__main__":
parser = get_parser()
parser.add_argument("--data_root", type = str, default = "./data/image_CLEF/")
parser.add_argument("--traindom", type = str, default = "b")
parser.add_argument("--testdoms", type = str, nargs = '+', default = ["b", "c", "i", "p"])
parser.add_argument("--dim_s", type = int, default = 1024)
parser.add_argument("--dim_v", type = int, default = 256)
parser.add_argument("--dim_btnk", type = int, default = 1024) # for discr_model
parser.add_argument("--dims_bb2bn", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2s", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_s2y", type = int, nargs = '*') # for discr_model
parser.add_argument("--dims_bn2v", type = int, nargs = '*') # for discr_model
parser.add_argument("--vbranch", type = boolstr, default = False) # for discr_model
parser.add_argument("--dim_feat", type = int, default = 128) # for gen_model
# parser.add_argument("--gpu", type=int, default=0)
parser.set_defaults(discrstru = "ResNet50", genstru = "DCGANvar",
n_bat = 100, n_epk = 100,
optim = "SGD", lr = 4e-3, wl2 = 5e-4,
momentum = .9, nesterov = True, lr_expo = .75, lr_wdatum = 6.25e-6, # only when "lr" is "SGD"
wda = .25,
domdisc_dimh = 1024, # for {dann, cdan, mdd} only
cdan_rand = False, # for cdan only
ker_alphas = [.5, 1., 2.], # for dan only
mdd_margin = 4. # for mdd only
)
ag = parser.parse_args()
bat_size = ag.n_bat
if ag.wlogpi is None: ag.wlogpi = ag.wgen
ag, ckpt = process_continue_run(ag)
IS_OOD = is_ood(ag.mode)
ag.n_bat = bat_size
archtype = "cnn"
# Dataset
shape_x = (3, 224, 224) # determined by the loader
dim_y = 12
kwargs = {'num_workers': 4, 'pin_memory': True}
tr_src_loader = data_loader.load_testing(
ag.data_root, ag.traindom, ag.n_bat, kwargs) # needs to rand split otherwise some classes are unseen in training.
val_src_loader = tr_src_loader
ls_ts_tgt_loader = [data_loader.load_testing(
ag.data_root, testdom, ag.n_bat, kwargs)
for testdom in ag.testdoms]
print(ag.testdoms, len(ls_ts_tgt_loader), len(tr_src_loader), len(ls_ts_tgt_loader[0]))
if not IS_OOD:
ls_tr_tgt_loader = [data_loader.load_testing(
ag.data_root, testdom, ag.n_bat, kwargs)
for testdom in ag.testdoms]
if IS_OOD:
get_visual( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, ls_ts_tgt_loader )
else:
for testdom, tr_tgt_loader, ts_tgt_loader in zip(
ag.testdoms, ls_tr_tgt_loader, ls_ts_tgt_loader):
if testdom != ag.traindom:
get_visual( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, None,
tr_tgt_loader, ts_tgt_loader, testdom )
else:
warnings.warn("same domain adaptation ignored")
================================================
FILE: code/deep/CSG/a-mnist/main.py
================================================
#!/usr/bin/env python3.6
import warnings
import sys
import torch as tc
sys.path.append("..")
from utils.utils_main import main_stem, get_parser, is_ood, process_continue_run
from utils.utils import boolstr
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
if __name__ == "__main__":
parser = get_parser()
parser.add_argument("--data_root", type = str, default = "./data/MNIST/processed/")
parser.add_argument("--traindom", type = str) # 12665 = 5923 (46.77%) + 6742
parser.add_argument("--testdoms", type = str, nargs = '+') # 2115 = 980 (46.34%) + 1135
parser.add_argument("--shuffle", type = boolstr, default = True)
parser.add_argument("--mlpstrufile", type = str, default = "../arch/mlpstru.json")
parser.add_argument("--actv", type = str, default = "Sigmoid")
parser.add_argument("--after_actv", type = boolstr, default = True)
parser.set_defaults(discrstru = "lite", genstru = None,
n_bat = 128, n_epk = 100,
mu_s = .5, mu_v = .5,
pstd_x = 3e-2, qstd_s = 3e-2, qstd_v = 3e-2,
optim = "RMSprop", lr = 1e-3, wl2 = 1e-5,
momentum = 0., nesterov = False, lr_expo = .5, lr_wdatum = 6.25e-6, # only when "lr" is "SGD"
wda = 1.,
domdisc_dimh = 1024, # for {dann, cdan, mdd} only
cdan_rand = False, # for cdan only
ker_alphas = [.5, 1., 2.], # for dan only
mdd_margin = 4. # for mdd only
)
ag = parser.parse_args()
if ag.wlogpi is None: ag.wlogpi = ag.wgen
ag, ckpt = process_continue_run(ag)
IS_OOD = is_ood(ag.mode)
archtype = "mlp"
# Dataset
src_x, src_y = tc.load(ag.data_root+ag.traindom) # `x` already tc.Tensor in range [0., 1.]
dim_x = tc.tensor(src_x.shape[1:]).prod().item()
src_x = src_x.reshape(-1, dim_x)
shape_x = (dim_x,)
dim_y = src_y.max().long().item() + 1
if dim_y == 2: dim_y = 1
## tr-val split
len_src = len(src_x)
assert len_src == len(src_y)
ids_src = tc.randperm(len_src)
len_tr_src = int(len_src * ag.tr_val_split)
ids_tr_src, ids_val_src = ids_src[:len_tr_src], ids_src[len_tr_src:]
tr_src_x, tr_src_y = src_x[ids_tr_src], src_y[ids_tr_src]
val_src_x, val_src_y = src_x[ids_val_src], src_y[ids_val_src]
## dataloaders
kwargs = {'num_workers': 4, 'pin_memory': True}
tr_src_loader = tc.utils.data.DataLoader(
tc.utils.data.TensorDataset(tr_src_x, tr_src_y),
ag.n_bat, ag.shuffle, **kwargs )
val_src_loader = tc.utils.data.DataLoader(
tc.utils.data.TensorDataset(val_src_x, val_src_y),
ag.n_bat, ag.shuffle, **kwargs )
## tgt (ts) domain
ls_tgt_xy_raw = [tc.load(ag.data_root+testdom) for testdom in ag.testdoms] # (x,y). `x` already tc.Tensor in range [0., 1.]
ls_tgt_xy = [(xy[0].reshape(len(xy[0]), dim_x), xy[1]) for xy in ls_tgt_xy_raw]
ls_ts_tgt_loader = [tc.utils.data.DataLoader(
tc.utils.data.TensorDataset(*xy),
ag.n_bat, ag.shuffle, **kwargs )
for xy in ls_tgt_xy]
if not IS_OOD:
ls_tr_tgt_loader = [tc.utils.data.DataLoader(
tc.utils.data.TensorDataset(*xy),
ag.n_bat, ag.shuffle, **kwargs )
for xy in ls_tgt_xy]
if IS_OOD:
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, ls_ts_tgt_loader )
else:
for testdom, tr_tgt_loader, ts_tgt_loader in zip(
ag.testdoms, ls_tr_tgt_loader, ls_ts_tgt_loader):
if testdom != ag.traindom:
main_stem( ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader, None,
tr_tgt_loader, ts_tgt_loader, testdom )
else:
warnings.warn("same domain adaptation ignored")
================================================
FILE: code/deep/CSG/a-mnist/makedata.py
================================================
#!/usr/bin/env python3.6
'''For generating MNIST-01 and its shifted interventional datasets.
'''
import torch as tc
import torchvision as tv
import torchvision.transforms.functional as tvtf
import argparse
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
def select_xy(dataset, selected_y = (0,1), piltransf = None, ytransf = None):
dataset_selected = [(
tvtf.to_tensor( img if piltransf is None else piltransf(img, label) ),
label if ytransf is None else ytransf(label)
) for img, label in dataset if label in selected_y]
xs, ys = tuple(zip(*dataset_selected))
return tc.cat(xs, dim=0), tc.tensor(ys)
def get_shift_transf(pleft: list, distr: str, loc: float, scale: float):
return lambda img, label: tvtf.affine(img, angle=0, translate=(
scale * getattr(tc, distr)(()) + loc * (1. - 2. * tc.bernoulli(tc.tensor(pleft[label]))), 0.
), scale=1., shear=0, fillcolor=0)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("mode", type = str, choices = {"train", "test"})
parser.add_argument("--pleft", type = float, nargs = '+', default = [0.5, 0.5])
parser.add_argument("--distr", type = str, choices = {"randn", "rand"})
parser.add_argument("--loc", type = float, default = 4.)
parser.add_argument("--scale", type = float, default = 1.)
parser.add_argument("--procroot", type = str, default = "./data/MNIST/processed/")
ag = parser.parse_args()
dataset = tv.datasets.MNIST(root="./data", train = ag.mode=="train", download=True) # as PIL
piltransf = get_shift_transf(ag.pleft, ag.distr, ag.loc, ag.scale)
selected_y = tuple(range(len(ag.pleft)))
shift_x, shift_y = select_xy(dataset, selected_y, piltransf)
filename = ag.procroot + ag.mode + "".join(str(y) for y in selected_y) + (
"_" + "_".join(f"{p:.1f}" for p in ag.pleft) +
"_" + ag.distr + f"_{ag.loc:.1f}_{ag.scale:.1f}.pt" )
tc.save((shift_x, shift_y), filename)
print("Processed data saved to '" + filename + "'")
================================================
FILE: code/deep/CSG/a-mnist/makedata.sh
================================================
python3 makedata.py train --pleft 1. 0. --distr randn --loc 5. --scale 1.
python3 makedata.py test --pleft .5 .5 --distr randn --loc 0. --scale 0.
mv ./data/MNIST/processed/test01_0.5_0.5_randn_0.0_0.0.pt ./data/MNIST/processed/test_01.pt
python3 makedata.py test --pleft .5 .5 --distr randn --loc 0. --scale 2.
================================================
FILE: code/deep/CSG/a-mnist/run_da.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
TRAIN="--traindom train01_1.0_0.0_randn_5.0_1.0.pt"
TEST="--testdoms test_01.pt test01_0.5_0.5_randn_0.0_2.0.pt"
case $1 in
dann)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-4
;;
cdan)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-6
;;
dan)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-8
;;
mdd)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-6
;;
bnm)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-7
;;
svae-da) # CSGz-DA
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-4 --mu_s .5 --sig_s .5 --pstd_x 3e-2 --qstd_s=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-4 --wsup 1.
;;
svgm-da) # CSG-DA
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite --optim RMSprop --lr 3e-4 --wl2 1e-5 --wda 1e-4 --mu_s .5 --sig_s .5 --mu_v .5 --sig_v .5 --corr_sv .9 --pstd_x 3e-2 --qstd_s=-1. --qstd_v=-1. --tgt_mvn_prior 1 --src_mvn_prior 1 --wgen 1e-4 --wsup 1.
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/a-mnist/run_ood.sh
================================================
REPRUN="../utils/reprun.sh 10"
PYCMD="python3 main.py"
TRAIN="--traindom train01_1.0_0.0_randn_5.0_1.0.pt"
TEST="--testdoms test_01.pt test01_0.5_0.5_randn_0.0_2.0.pt"
case $1 in
discr) # CE
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 1e-3 --wl2 1e-5
;;
cnbb)
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite-1.5x --optim RMSprop --lr 1e-3 --wl2 1e-5 --reg_w 1e-4 --reg_s 3e-6 --lr_w 1e-3 --n_iter_w 4
;;
svae) # CSGz
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite --optim RMSprop --lr 1e-3 --wl2 1e-5 --mu_s .5 --sig_s .5 --pstd_x 3e-2 --qstd_s=-1. --wgen 1e-4 --wsup 1. --mvn_prior 1
;;
svgm) # CSG
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite --optim RMSprop --lr 1e-3 --wl2 1e-5 --mu_s .5 --sig_s .5 --mu_v .5 --sig_v .5 --corr_sv .9 --pstd_x 3e-2 --qstd_s=-1. --qstd_v=-1. --wgen 1e-4 --wsup 1. --mvn_prior 1
;;
svgm-ind) # CSG-ind
$REPRUN $PYCMD $1 $TRAIN $TEST --discrstru lite --optim RMSprop --lr 1e-3 --wl2 1e-5 --mu_s .5 --sig_s .5 --mu_v .5 --sig_v .5 --corr_sv .9 --pstd_x 3e-2 --qstd_s=-1. --qstd_v=-1. --wgen 1e-4 --wsup 1. --mvn_prior 1
;;
*)
echo "unknown argument $1"
;;
esac
================================================
FILE: code/deep/CSG/arch/__init__.py
================================================
================================================
FILE: code/deep/CSG/arch/backbone.py
================================================
""" This file is adapted from
"""
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torchvision import models
from torch.autograd import Variable
# convnet without the last layer
class AlexNetFc(nn.Module):
def __init__(self):
super(AlexNetFc, self).__init__()
model_alexnet = models.alexnet(pretrained=True)
self.features = model_alexnet.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module("classifier"+str(i), model_alexnet.classifier[i])
self.__in_features = model_alexnet.classifier[6].in_features
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256*6*6)
x = self.classifier(x)
return x
def output_num(self):
return self.__in_features
class ResNet18Fc(nn.Module):
def __init__(self):
super(ResNet18Fc, self).__init__()
model_resnet18 = models.resnet18(pretrained=True)
self.conv1 = model_resnet18.conv1
self.bn1 = model_resnet18.bn1
self.relu = model_resnet18.relu
self.maxpool = model_resnet18.maxpool
self.layer1 = model_resnet18.layer1
self.layer2 = model_resnet18.layer2
self.layer3 = model_resnet18.layer3
self.layer4 = model_resnet18.layer4
self.avgpool = model_resnet18.avgpool
self.__in_features = model_resnet18.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet34Fc(nn.Module):
def __init__(self):
super(ResNet34Fc, self).__init__()
model_resnet34 = models.resnet34(pretrained=True)
self.conv1 = model_resnet34.conv1
self.bn1 = model_resnet34.bn1
self.relu = model_resnet34.relu
self.maxpool = model_resnet34.maxpool
self.layer1 = model_resnet34.layer1
self.layer2 = model_resnet34.layer2
self.layer3 = model_resnet34.layer3
self.layer4 = model_resnet34.layer4
self.avgpool = model_resnet34.avgpool
self.__in_features = model_resnet34.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet50Fc(nn.Module):
def __init__(self):
super(ResNet50Fc, self).__init__()
model_resnet50 = models.resnet50(pretrained=True)
self.conv1 = model_resnet50.conv1
self.bn1 = model_resnet50.bn1
self.relu = model_resnet50.relu
self.maxpool = model_resnet50.maxpool
self.layer1 = model_resnet50.layer1
self.layer2 = model_resnet50.layer2
self.layer3 = model_resnet50.layer3
self.layer4 = model_resnet50.layer4
self.avgpool = model_resnet50.avgpool
self.__in_features = model_resnet50.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet101Fc(nn.Module):
def __init__(self):
super(ResNet101Fc, self).__init__()
model_resnet101 = models.resnet101(pretrained=True)
self.conv1 = model_resnet101.conv1
self.bn1 = model_resnet101.bn1
self.relu = model_resnet101.relu
self.maxpool = model_resnet101.maxpool
self.layer1 = model_resnet101.layer1
self.layer2 = model_resnet101.layer2
self.layer3 = model_resnet101.layer3
self.layer4 = model_resnet101.layer4
self.avgpool = model_resnet101.avgpool
self.__in_features = model_resnet101.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet152Fc(nn.Module):
def __init__(self):
super(ResNet152Fc, self).__init__()
model_resnet152 = models.resnet152(pretrained=True)
self.conv1 = model_resnet152.conv1
self.bn1 = model_resnet152.bn1
self.relu = model_resnet152.relu
self.maxpool = model_resnet152.maxpool
self.layer1 = model_resnet152.layer1
self.layer2 = model_resnet152.layer2
self.layer3 = model_resnet152.layer3
self.layer4 = model_resnet152.layer4
self.avgpool = model_resnet152.avgpool
self.__in_features = model_resnet152.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
network_dict = {"AlexNet": AlexNetFc,
"ResNet18": ResNet18Fc,
"ResNet34": ResNet34Fc,
"ResNet50": ResNet50Fc,
"ResNet101": ResNet101Fc,
"ResNet152": ResNet152Fc}
================================================
FILE: code/deep/CSG/arch/cnn.py
================================================
#!/usr/bin/env python3.6
''' CNN Architecture
Based on the architecture in MDD ,
and leverage the repositories of `domainbed`
and `pytorch_GAN_zoo` .
Architectures organized and enhanced for the use for the Causal Semantic Generative model.
'''
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
import sys, os
from warnings import warn
import torch as tc
import torch.nn as nn
import torchvision as tv
from . import backbone
from . import mlp
sys.path.append('..')
from distr import tensorify, is_same_tensor, wrap4_multi_batchdims
dbpath = '../a-domainbed/DomainBed'
if os.path.isdir(dbpath):
sys.path.append(dbpath)
import domainbed # 54c2f8c
from domainbed.networks import Featurizer
def init_linear(nnseq, wmean, wstd, bval):
for mod in nnseq:
if type(mod) is nn.Linear:
mod.weight.data.normal_(wmean, wstd)
mod.bias.data.fill_(bval)
# The inference/discriminative models / encoders.
class CNNsvy1x(nn.Module):
def __init__(self, backbone_stru: str, dim_bottleneck: int, dim_s: int, dim_y: int, dim_v: int,
std_v1x_val: float, std_s1vx_val: float, # if <= 0, then learn the std.
dims_bb2bn: list=None, dims_bn2s: list=None, dims_s2y: list=None,
vbranch: bool=False, dims_bn2v: list=None):
""" Based on MDD from
if not vbranch:
(bb) (bn) (med) (cls)
/-> v -\
x ====> -| |-> s ----> y
\-> parav -/
else:
(bb) (bn) (med) (cls)
x ====> ----> ----> s ----> y
\ (vbr)
\----> v
"""
if not vbranch: assert dim_v <= dim_bottleneck
super(CNNsvy1x, self).__init__()
self.dim_s = dim_s; self.dim_v = dim_v; self.dim_y = dim_y
self.shape_s = (dim_s,); self.shape_v = (dim_v,)
self.vbranch = vbranch
self.std_v1x_val = std_v1x_val; self.std_s1vx_val = std_s1vx_val
self.learn_std_v1x = std_v1x_val <= 0 if type(std_v1x_val) is float else (std_v1x_val <= 0).any()
self.learn_std_s1vx = std_s1vx_val <= 0 if type(std_s1vx_val) is float else (std_s1vx_val <= 0).any()
self._x_cache_bb = self._bb_cache = None
self._x_cache_bn = self._bn_cache = None
self._param_groups = []
if 'domainbed' in globals() and backbone_stru.startswith("DB"):
self.nn_backbone = Featurizer((3,224,224),
{'resnet18': backbone_stru[2:]=='resnet18', 'resnet_dropout': 0.})
self._param_groups += [{"params": self.nn_backbone.parameters(), "lr_ratio": 1.0}]
self.nn_backbone.output_num = lambda: self.nn_backbone.n_outputs
if dim_bottleneck is None: dim_bottleneck = self.nn_backbone.output_num() // 2
if dim_s is None: dim_s = self.nn_backbone.output_num() // 4
else:
self.nn_backbone = backbone.network_dict[backbone_stru]()
self._param_groups += [{"params": self.nn_backbone.parameters(), "lr_ratio": 0.1}]
self.f_backbone = wrap4_multi_batchdims(self.nn_backbone, ndim_vars=3)
if dims_bb2bn is None: dims_bb2bn = []
self.nn_bottleneck = mlp.mlp_constructor(
[self.nn_backbone.output_num()] + dims_bb2bn + [dim_bottleneck],
nn.ReLU, lastactv = False
)
init_linear(self.nn_bottleneck, 0., 5e-3, 0.1)
self._param_groups += [{"params": self.nn_bottleneck.parameters(), "lr_ratio": 1.}]
self.f_bottleneck = self.nn_bottleneck
if dims_bn2s is None: dims_bn2s = []
self.nn_mediate = nn.Sequential(
*([] if backbone_stru.startswith("DB") else [nn.BatchNorm1d(dim_bottleneck)]),
nn.ReLU(),
# nn.Dropout(0.5),
mlp.mlp_constructor(
[dim_bottleneck] + dims_bn2s + [dim_s],
nn.ReLU, lastactv = False)
)
init_linear(self.nn_mediate, 0., 1e-2, 0.)
self._param_groups += [{"params": self.nn_mediate.parameters(), "lr_ratio": 1.}]
self.f_mediate = wrap4_multi_batchdims(self.nn_mediate, ndim_vars=1) # required by `BatchNorm1d`
if dims_s2y is None: dims_s2y = []
self.nn_classifier = nn.Sequential(
nn.ReLU(),
# nn.Dropout(0.5),
mlp.mlp_constructor(
[dim_s] + dims_s2y + [dim_y],
nn.ReLU, lastactv = False)
)
init_linear(self.nn_classifier, 0., 1e-2, 0.)
self._param_groups += [{"params": self.nn_classifier.parameters(), "lr_ratio": 1.}]
self.f_classifier = self.nn_classifier
if vbranch:
if dims_bn2v is None: dims_bn2v = []
self.nn_vbranch = nn.Sequential(
nn.BatchNorm1d(dim_bottleneck),
nn.ReLU(),
# nn.Dropout(0.5),
mlp.mlp_constructor(
[dim_bottleneck] + dims_bn2v + [dim_v],
nn.ReLU, lastactv = False)
)
init_linear(self.nn_vbranch, 0., 1e-2, 0.)
self._param_groups += [{"params": self.nn_vbranch.parameters(), "lr_ratio": 1.}]
self.f_vbranch = wrap4_multi_batchdims(self.nn_vbranch, ndim_vars=1)
## std models
if self.learn_std_v1x:
if not vbranch:
self.nn_std_v = nn.Sequential(
mlp.mlp_constructor(
[self.nn_backbone.output_num()] + dims_bb2bn + [dim_v],
nn.ReLU, lastactv = False),
nn.Softplus()
)
else:
self.nn_std_v = nn.Sequential(
mlp.mlp_constructor(
[dim_bottleneck] + dims_bn2v + [dim_v],
nn.ReLU, lastactv = False),
nn.Softplus()
)
init_linear(self.nn_std_v, 0., 1e-2, 0.)
self._param_groups += [{"params": self.nn_std_v.parameters(), "lr_ratio": 1.}]
self.f_std_v = self.nn_std_v
if self.learn_std_s1vx:
self.nn_std_s = nn.Sequential(
nn.BatchNorm1d(dim_bottleneck),
nn.ReLU(),
# nn.Dropout(0.5),
mlp.mlp_constructor(
[dim_bottleneck] + dims_bn2s + [dim_s],
nn.ReLU, lastactv = False),
nn.Softplus()
)
init_linear(self.nn_std_s, 0., 1e-2, 0.)
self._param_groups += [{"params": self.nn_std_s.parameters(), "lr_ratio": 1.}]
self.f_std_s = wrap4_multi_batchdims(self.nn_std_s, ndim_vars=1)
def _get_bb(self, x):
if not is_same_tensor(x, self._x_cache_bb):
self._x_cache_bb = x
self._bb_cache = self.f_backbone(x)
return self._bb_cache
def _get_bn(self, x):
if not is_same_tensor(x, self._x_cache_bn):
self._x_cache_bn = x
self._bn_cache = self.f_bottleneck(self._get_bb(x))
return self._bn_cache
def v1x(self, x):
bn = self._get_bn(x)
if not self.vbranch: return bn[..., :self.dim_v]
else: return self.f_vbranch(bn)
def std_v1x(self, x):
if self.learn_std_v1x:
if not self.vbranch: return self.f_std_v(self._get_bb(x))
else: return self.f_std_v(self._get_bn(x))
else:
return tensorify(x.device, self.std_v1x_val)[0].expand(x.shape[:-3]+(self.dim_v,))
def s1vx(self, v, x):
if not self.vbranch:
bn = self._get_bn(x)
bn_synth = tc.cat([v, bn[..., self.dim_v:]], dim=-1)
return self.f_mediate(bn_synth)
else:
return self.s1x(x)
def std_s1vx(self, v, x):
if self.learn_std_s1vx:
if not self.vbranch:
bn = self._get_bn(x)
bn_synth = tc.cat([v, bn[..., self.dim_v:]], dim=-1)
return self.f_std_s(bn_synth)
else:
return self.std_s1x(x)
else:
return tensorify(x.device, self.std_s1vx_val)[0].expand(x.shape[:-3]+(self.dim_s,))
def s1x(self, x):
return self.f_mediate(self._get_bn(x))
def std_s1x(self, x):
if self.learn_std_s1vx:
return self.f_std_s(self._get_bn(x))
else:
return tensorify(x.device, self.std_s1vx_val)[0].expand(x.shape[:-3]+(self.dim_s,))
def y1s(self, s):
return self.f_classifier(s).squeeze(-1) # squeeze for binary y
def ys1x(self, x):
s = self.s1x(x)
return self.y1s(s), s
def forward(self, x):
return self.y1s(self.s1x(x))
def parameter_groups(self):
return self._param_groups
def save(self, path): tc.save(self.state_dict(), path)
def load(self, path):
self.load_state_dict(tc.load(path))
self.eval()
# The generative models / decoders.
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
## Instances
class CNN_DCGANvar_224(nn.Module):
# Based on the decoder of DCGAN.
def __init__(self, dim_in, dim_feat, dim_chanl = 3):
super(CNN_DCGANvar_224, self).__init__()
self.nn_main = nn.Sequential(
# l_out = stride*(l_in - 1) + l_kernel - 2*padding. (*, *, l_kernel, stride, padding)
# input is Z, going into a convolution
nn.ConvTranspose2d( dim_in, dim_feat * 8, 7, 1, 0, bias=False),
nn.BatchNorm2d(dim_feat * 8),
nn.ReLU(True),
# state size. (dim_feat*8) x 7 x 7
nn.ConvTranspose2d(dim_feat * 8, dim_feat * 4, 4, 4, 0, bias=False),
nn.BatchNorm2d(dim_feat * 4),
nn.ReLU(True),
# state size. (dim_feat*4) x 28 x 28
nn.ConvTranspose2d( dim_feat * 4, dim_feat * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(dim_feat * 2),
nn.ReLU(True),
# state size. (dim_feat*2) x 56 x 56
nn.ConvTranspose2d( dim_feat * 2, dim_feat, 4, 2, 1, bias=False),
nn.BatchNorm2d(dim_feat),
nn.ReLU(True),
# state size. (dim_feat) x 112 x 112
nn.ConvTranspose2d( dim_feat, dim_chanl, 4, 2, 1, bias=True), # False),
# nn.Tanh()
# state size. (dim_chanl) x 224 x 224
)
self.apply(weights_init)
self._param_groups = [{"params": self.nn_main.parameters(), "lr_ratio": 1.}]
self.f_main = wrap4_multi_batchdims(self.nn_main, ndim_vars=3)
def forward(self, val):
# `val` should be of shape (..., dim_in)
return self.f_main(val[..., None, None])
class CNN_DCGANpretr_224(nn.Module):
def __init__(self, dim_in, dim_feat = None, dim_chanl = None):
# if dim_feat is not None or dim_chanl is not None:
# warn(f"`dim_feat` {dim_feat} and `dim_chanl` {dim_chanl} ignored")
super(CNN_DCGANpretr_224, self).__init__()
self._param_groups = []
self.nn_pre = nn.Sequential(
nn.Linear(dim_in, dim_feat), nn.Tanh(),
nn.Linear(dim_feat, 120), nn.Tanh()
)
self.nn_pre.apply(weights_init)
self._param_groups += [{"params": self.nn_pre.parameters(), "lr_ratio": 1.}]
self.f_pre = self.nn_pre
self.nn_backbone = tc.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', # force_reload=True,
pretrained=True, useGPU=False, model_name='cifar10').getOriginalG()
self._param_groups += [{"params": self.nn_backbone.parameters(), "lr_ratio": 0.1}]
self.f_backbone = wrap4_multi_batchdims(self.nn_backbone, ndim_vars=1)
self.nn_post = nn.Sequential(
nn.BatchNorm2d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(3, 3, 4, 4, 16, bias=False)
)
self.nn_post.apply(weights_init)
self._param_groups += [{"params": self.nn_post.parameters(), "lr_ratio": 1.}]
self.f_post = wrap4_multi_batchdims(self.nn_post, ndim_vars=3)
def forward(self, val):
# `val` should be of shape (..., dim_in)
return self.f_post(self.f_backbone(self.f_pre(val)))
def parameter_groups(self):
return self._param_groups
class CNN_PGANpretr_224(nn.Module):
def __init__(self, dim_in, dim_feat = None, dim_chanl = None):
# if dim_feat is not None or dim_chanl is not None:
# warn(f"`dim_feat` {dim_feat} and `dim_chanl` {dim_chanl} ignored")
super(CNN_PGANpretr_224, self).__init__()
self._param_groups = []
self.nn_pre = nn.Sequential(
nn.Linear(dim_in, dim_feat), nn.Tanh(),
nn.Linear(dim_feat, 512), nn.Tanh()
)
self.nn_pre.apply(weights_init)
self._param_groups += [{"params": self.nn_pre.parameters(), "lr_ratio": 1.}]
self.f_pre = self.nn_pre
self.nn_backbone = tc.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'PGAN', # force_reload=True,
pretrained=True, useGPU=False, model_name='celebAHQ-256').getOriginalG() # 'cifar10' unavailable for PGAN
self._param_groups += [{"params": self.nn_backbone.parameters(), "lr_ratio": 0.1}]
self.f_backbone = wrap4_multi_batchdims(self.nn_backbone, ndim_vars=1)
self.f_post = tv.transforms.CenterCrop(224)
def forward(self, val):
# `val` should be of shape (..., dim_in)
return self.f_post(self.f_backbone(self.f_pre(val)))
def parameter_groups(self):
return self._param_groups
## Uniform interfaces
class CNNx1sv(nn.Module):
def __init__(self, dim_xside: int, dim_s: int, dim_v: int, dim_feat: int, dectype: str="DCGANvar"):
super(CNNx1sv, self).__init__()
self.net = globals()["CNN_" + dectype + "_" + str(dim_xside)](dim_s + dim_v, dim_feat)
# Parameters of `self.net` automatically included in `self.parameters()`
def x1sv(self, s, v):
return self.net(tc.cat([s, v], dim=-1))
def forward(self, s, v): return self.x1sv(s, v)
def parameter_groups(self):
return self.net._param_groups
def save(self, path): tc.save(self.state_dict(), path)
def load(self, path):
self.load_state_dict(tc.load(path))
self.eval()
class CNNx1s(nn.Module):
def __init__(self, dim_xside: int, dim_s: int, dim_feat: int, dectype: str="DCGANvar"):
super(CNNx1s, self).__init__()
self.net = globals()["CNN_" + dectype + "_" + str(dim_xside)](dim_s, dim_feat)
# Parameters of `self.net` automatically included in `self.parameters()`
def x1s(self, s): return self.net(s)
def forward(self, s): return self.x1s(s)
def parameter_groups(self):
return self.net._param_groups
def save(self, path): tc.save(self.state_dict(), path)
def load(self, path):
self.load_state_dict(tc.load(path))
self.eval()
================================================
FILE: code/deep/CSG/arch/mlp.py
================================================
#!/usr/bin/env python3.6
'''Multi-Layer Perceptron Architecture.
For causal discriminative model and the corresponding generative model.
'''
import sys, os
import json
import torch as tc
import torch.nn as nn
sys.path.append('..')
from distr import tensorify, is_same_tensor, wrap4_multi_batchdims
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
def init_linear(nnseq, wmean, wstd, bval):
for mod in nnseq:
if type(mod) is nn.Linear:
mod.weight.data.normal_(wmean, wstd)
mod.bias.data.fill_(bval)
def mlp_constructor(dims, actv = "Sigmoid", lastactv = True): # `Sequential()`, or `Sequential(*[])`, is the identity map for any shape!
if type(actv) is str: actv = getattr(nn, actv)
if len(dims) <= 1: return nn.Sequential()
else: return nn.Sequential(*(
sum([[nn.Linear(dims[i], dims[i+1]), actv()] for i in range(len(dims)-2)], []) + \
[nn.Linear(dims[-2], dims[-1])] + ([actv()] if lastactv else [])
))
class MLPBase(nn.Module):
def save(self, path): tc.save(self.state_dict(), path)
def load(self, path):
self.load_state_dict(tc.load(path))
self.eval()
def load_or_save(self, filename):
dirname = "init_models_mlp/"
os.makedirs(dirname, exist_ok=True)
path = dirname + filename
if os.path.exists(path): self.load(path)
else: self.save(path)
class MLP(MLPBase):
def __init__(self, dims, actv = "Sigmoid"):
if type(actv) is str: actv = getattr(nn, actv)
super(MLP, self).__init__()
self.f_x2y = mlp_constructor(dims, actv, lastactv = False)
def forward(self, x): return self.f_x2y(x).squeeze(-1)
class MLPsvy1x(MLPBase):
def __init__(self, dim_x, dims_postx2prev, dim_v, dim_parav, dims_postv2s, dims_posts2prey, dim_y, actv = "Sigmoid",
std_v1x_val: float=-1., std_s1vx_val: float=-1., after_actv: bool=True): # if <= 0, then learn the std.
"""
/-> v -\
x ====> prev -| |==> s ==> y
\-> parav -/
"""
super(MLPsvy1x, self).__init__()
if type(actv) is str: actv = getattr(nn, actv)
self.dim_x, self.dim_v, self.dim_y = dim_x, dim_v, dim_y
dim_prev, dim_s = dims_postx2prev[-1], dims_postv2s[-1]
self.dim_prev, self.dim_s = dim_prev, dim_s
self.shape_x, self.shape_v, self.shape_s = (dim_x,), (dim_v,), (dim_s,)
self.dims_postx2prev, self.dim_parav, self.dims_postv2s, self.dims_posts2prey, self.actv \
= dims_postx2prev, dim_parav, dims_postv2s, dims_posts2prey, actv
self.f_x2prev = mlp_constructor([dim_x] + dims_postx2prev, actv)
if after_actv:
self.f_prev2v = nn.Sequential( nn.Linear(dim_prev, dim_v), actv() )
self.f_prev2parav = nn.Sequential( nn.Linear(dim_prev, dim_parav), actv() )
self.f_vparav2s = mlp_constructor([dim_v + dim_parav] + dims_postv2s, actv)
self.f_s2y = mlp_constructor([dim_s] + dims_posts2prey + [dim_y], actv, lastactv = False)
else:
self.f_prev2v = nn.Linear(dim_prev, dim_v)
self.f_prev2parav = nn.Linear(dim_prev, dim_parav)
self.f_vparav2s = nn.Sequential( actv(), mlp_constructor([dim_v + dim_parav] + dims_postv2s, actv, lastactv = False) )
self.f_s2y = nn.Sequential( actv(), mlp_constructor([dim_s] + dims_posts2prey + [dim_y], actv, lastactv = False) )
self.std_v1x_val = std_v1x_val; self.std_s1vx_val = std_s1vx_val
self.learn_std_v1x = std_v1x_val <= 0 if type(std_v1x_val) is float else (std_v1x_val <= 0).any()
self.learn_std_s1vx = std_s1vx_val <= 0 if type(std_s1vx_val) is float else (std_s1vx_val <= 0).any()
self._prev_cache = self._x_cache_prev = None
self._v_cache = self._x_cache_v = None
self._parav_cache = self._x_cache_parav = None
## std models
if self.learn_std_v1x:
self.nn_std_v = nn.Sequential(
mlp_constructor(
[dim_prev, dim_v],
nn.ReLU, lastactv = False),
nn.Softplus()
)
init_linear(self.nn_std_v, 0., 1e-2, 0.)
self.f_std_v = self.nn_std_v
if self.learn_std_s1vx:
self.nn_std_s = nn.Sequential(
nn.BatchNorm1d(dim_v + dim_parav),
nn.ReLU(),
# nn.Dropout(0.5),
mlp_constructor(
[dim_v + dim_parav] + dims_postv2s,
nn.ReLU, lastactv = False),
nn.Softplus()
)
init_linear(self.nn_std_s, 0., 1e-2, 0.)
self.f_std_s = wrap4_multi_batchdims(self.nn_std_s, ndim_vars=1)
def _get_prev(self, x):
if not is_same_tensor(x, self._x_cache_prev):
self._x_cache_prev = x
self._prev_cache = self.f_x2prev(x)
return self._prev_cache
def v1x(self, x):
if not is_same_tensor(x, self._x_cache_v):
self._x_cache_v = x
self._v_cache = self.f_prev2v(self._get_prev(x))
return self._v_cache
def std_v1x(self, x):
if self.learn_std_v1x:
return self.f_std_v(self._get_prev(x))
else:
return tensorify(x.device, self.std_v1x_val)[0].expand(x.shape[:-1]+(self.dim_v,))
def _get_parav(self, x):
if not is_same_tensor(x, self._x_cache_parav):
self._x_cache_parav = x
self._parav_cache = self.f_prev2parav(self._get_prev(x))
return self._parav_cache
def s1vx(self, v, x):
parav = self._get_parav(x)
return self.f_vparav2s(tc.cat([v, parav], dim=-1))
def std_s1vx(self, v, x):
if self.learn_std_s1vx:
parav = self._get_parav(x)
return self.f_std_s(tc.cat([v, parav], dim=-1))
else:
return tensorify(x.device, self.std_s1vx_val)[0].expand(x.shape[:-1]+(self.dim_s,))
def s1x(self, x):
return self.s1vx(self.v1x(x), x)
def std_s1x(self, x):
return self.std_s1vx(self.v1x(x), x)
def y1s(self, s):
return self.f_s2y(s).squeeze(-1) # squeeze for binary y
def ys1x(self, x):
s = self.s1x(x)
return self.y1s(s), s
def forward(self, x):
return self.y1s(self.s1x(x))
class MLPx1sv(MLPBase):
def __init__(self, dim_s = None, dims_pres2parav = None, dim_v = None, dims_prev2postx = None, dim_x = None,
actv = None, *, discr = None):
if dim_s is None: dim_s = discr.dim_s
if dim_v is None: dim_v = discr.dim_v
if dim_x is None: dim_x = discr.dim_x
if actv is None: actv = discr.actv if hasattr(discr, "actv") else "Sigmoid"
if type(actv) is str: actv = getattr(nn, actv)
if dims_pres2parav is None: dims_pres2parav = discr.dims_postv2s[::-1][1:] + [discr.dim_parav]
if dims_prev2postx is None: dims_prev2postx = discr.dims_postx2prev[::-1]
super(MLPx1sv, self).__init__()
self.dim_s, self.dim_v, self.dim_x = dim_s, dim_v, dim_x
self.dims_pres2parav, self.dims_prev2postx, self.actv = dims_pres2parav, dims_prev2postx, actv
self.f_s2parav = mlp_constructor([dim_s] + dims_pres2parav, actv)
self.f_vparav2x = mlp_constructor([dim_v + dims_pres2parav[-1]] + dims_prev2postx + [dim_x], actv)
def x1sv(self, s, v): return self.f_vparav2x(tc.cat([v, self.f_s2parav(s)], dim=-1))
def forward(self, s, v): return self.x1sv(s, v)
class MLPx1s(MLPBase):
def __init__(self, dim_s = None, dims_pres2postx = None, dim_x = None,
actv = None, *, discr = None):
if dim_s is None: dim_s = discr.dim_s
if dim_x is None: dim_x = discr.dim_x
if actv is None: actv = discr.actv if hasattr(discr, "actv") else "Sigmoid"
if type(actv) is str: actv = getattr(nn, actv)
if dims_pres2postx is None:
dims_pres2postx = discr.dims_postv2s[::-1][1:] + [discr.dim_v + discr.dim_parav] + discr.dims_postx2prev[::-1]
super(MLPx1s, self).__init__()
self.dim_s, self.dim_x, self.dims_pres2postx, self.actv = dim_s, dim_x, dims_pres2postx, actv
self.f_s2x = mlp_constructor([dim_s] + dims_pres2postx + [dim_x], actv)
def x1s(self, s): return self.f_s2x(s)
def forward(self, s): return self.x1s(s)
class MLPv1s(MLPBase):
def __init__(self, dim_s = None, dims_pres2postv = None, dim_v = None,
actv = None, *, discr = None):
if dim_s is None: dim_s = discr.dim_s
if dim_v is None: dim_v = discr.dim_v
if actv is None: actv = discr.actv if hasattr(discr, "actv") else "Sigmoid"
if type(actv) is str: actv = getattr(nn, actv)
if dims_pres2postv is None: dims_pres2postv = discr.dims_postv2s[::-1][1:]
super(MLPv1s, self).__init__()
self.dim_s, self.dim_v, self.dims_pres2postv, self.actv = dim_s, dim_v, dims_pres2postv, actv
self.f_s2v = mlp_constructor([dim_s] + dims_pres2postv + [dim_v], actv)
def v1s(self, s): return self.f_s2v(s)
def forward(self, s): return self.v1s(s)
def create_discr_from_json(stru_name: str, dim_x: int, dim_y: int, actv: str=None,
std_v1x_val: float=-1., std_s1vx_val: float=-1., after_actv: bool=True, jsonfile: str="mlpstru.json"):
stru = json.load(open(jsonfile))['MLPsvy1x'][stru_name]
if actv is not None: stru['actv'] = actv
return MLPsvy1x(dim_x=dim_x, dim_y=dim_y, std_v1x_val=std_v1x_val, std_s1vx_val=std_s1vx_val,
after_actv=after_actv, **stru)
def create_gen_from_json(model_type: str="MLPx1sv", discr: MLPsvy1x=None, stru_name: str=None, dim_x: int=None, actv: str=None, jsonfile: str="mlpstru.json"):
if stru_name is None:
return eval(model_type)(dim_x=dim_x, discr=discr, actv=actv)
else:
stru = json.load(open(jsonfile))[model_type][stru_name]
if actv is not None: stru['actv'] = actv
return eval(model_type)(dim_x=dim_x, discr=discr, **stru)
================================================
FILE: code/deep/CSG/arch/mlpstru.json
================================================
{
"MLPsvy1x": {
"lite": {
"dims_postx2prev": [400],
"dim_v": 100,
"dim_parav": 100,
"dims_postv2s": [50],
"dims_posts2prey": []
},
"lite-1.5x": {
"dims_postx2prev": [600],
"dim_v": 150,
"dim_parav": 150,
"dims_postv2s": [75],
"dims_posts2prey": []
},
"bt882": {
"dims_postx2prev": [400, 200],
"dim_v": 8,
"dim_parav": 8,
"dims_postv2s": [2],
"dims_posts2prey": []
},
"irm": {
"dims_postx2prev": [256],
"dim_v": 128,
"dim_parav": 128,
"dims_postv2s": [256],
"dims_posts2prey": []
},
"bt882-256": {
"dims_postx2prev": [256, 256],
"dim_v": 8,
"dim_parav": 8,
"dims_postv2s": [2],
"dims_posts2prey": []
}
},
"MLPx1sv": {
},
"MLPx1s": {
},
"MLPv1s": {
"s2v0": {
"dims_pres2postv": []
}
}
}
================================================
FILE: code/deep/CSG/distr/__init__.py
================================================
#!/usr/bin/env python3.6
'''Probabilistic Programming Package.
The prototype is distributions, which can be a conditional one with
functions for parameters to define the dependency. Distribution
multiplication is implemented, as well as the mean, expectation,
sampling with backprop capability, and log-probability.
'''
__author__ = "Chang Liu"
__version__ = "1.0.1"
__email__ = "changliu@microsoft.com"
from .base import Distr, DistrElem
from .instances import Determ, Normal, MVNormal, Catg, Bern
from .utils import ( append_attrs,
edic, edicify,
fargnames, fedic, wrap4_multi_batchdims,
tensorify, is_scalar, is_same_tensor,
expand_front, flatten_last, reduce_last, swap_dim_ranges, expand_middle,
tcsizeify, tcsize_div, tcsize_broadcast,
)
from .tools import elbo, elbo_z2xy, elbo_z2xy_twist, elbo_zy2x
================================================
FILE: code/deep/CSG/distr/base.py
================================================
#!/usr/bin/env python3.6
'''Probabilistic Programming Package.
The prototype is distributions, which can be a conditional one with
functions for parameters to define the dependency. Distribution
multiplication is implemented, as well as the mean, expectation,
sampling with backprop capability, and log-probability.
'''
import math
import torch as tc
from .utils import edic, edicify, expand_front, fargnames, fedic, swap_dim_ranges, tcsizeify, tcsize_broadcast, tcsize_div, tensorify
__author__ = "Chang Liu"
__version__ = "1.0.1"
__email__ = "changliu@microsoft.com"
class Distr:
'''
names: set <-> vals: edic(name:tensor)
parents: set <-> conds: edic(name:tensor)
'''
default_device = None
_shapes_all_vars = {} # dict
@staticmethod
def all_names() -> set: return set(Distr._shapes_all_vars)
@staticmethod
def clear(): Distr._shapes_all_vars.clear()
@staticmethod
def has_name(name: str) -> bool: return name in Distr._shapes_all_vars
@staticmethod
def has_names(names: set) -> bool:
return all(name in Distr._shapes_all_vars for name in names)
@staticmethod
def shape_var(name: str) -> tc.Size: return Distr._shapes_all_vars[name]
@staticmethod
def shapes_var(names: set) -> dict:
return {name: Distr._shapes_all_vars[name] for name in names}
@staticmethod
def shape_bat(conds: edic) -> tc.Size:
for name, ten in conds.items():
if Distr.has_name(name): return tcsize_div(ten.shape, Distr.shape_var(name))
return tc.Size()
@staticmethod
def shape_bat_broadcast(conds: edic) -> tc.Size:
shapes_bat = [tcsize_div(ten.shape, Distr.shape_var(name))
for name, ten in conds.items() if Distr.has_name(name)]
return tcsize_broadcast(*shapes_bat)
@staticmethod
def broadcast_vars(conds: edic) -> edic:
shape_bat = Distr.shape_bat_broadcast(conds)
return edic({name: ten.expand(shape_bat + Distr.shape_var(name))
for name, ten in conds.items() if Distr.has_name(name)})
def __init__(self, *, names: set=set(), names_shapes: dict={}, parents: set=set()):
for name, shape in names_shapes.items():
shape, = tcsizeify(shape,)
if Distr.has_name(name):
if shape != Distr.shape_var(name): raise ValueError(f"shape not match for existing variable '{name}'")
else: Distr._shapes_all_vars[name] = shape
for name in names:
if not Distr.has_name(name): raise ValueError(f"new variable '{name}' needs a shape")
names = names | set(names_shapes)
if not names: raise ValueError("name(s) have to be provided")
names_comm = names & parents
if names_comm: raise ValueError(f"common variable(s) '{names_comm}' found in `names` and `parents`")
self._names, self._parents, self._is_root = names, parents, (not bool(parents))
@property
def names(self) -> set: return self._names
@property
def parents(self) -> set: return self._parents
@property
def is_root(self) -> bool: return self._is_root
def __repr__(self) -> str:
return "p(" + ", ".join(self.names) + (" | " + ", ".join(self.parents) + ")" if self.parents else ")")
def mean(self, conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
raise NotImplementedError
def expect(self, fn, conds: edic=edic(), n_mc: int=10, repar: bool=True, reducefn = tc.mean) -> tc.Tensor:
# [shape_bat] -> [shape_bat]
if n_mc == 0:
vals = self.mean(conds, 0, repar)
return fn(conds|vals)
elif n_mc > 0:
vals = self.draw(tc.Size((n_mc,)), conds, repar)
return reducefn(fn( edicify(conds)[0].expand_front((n_mc,)) | vals ), dim=0)
else: raise ValueError(f"For {self}, negative `n_mc` {n_mc} encountered")
def rdraw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic()) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
return self.draw(shape_mc, conds, True)
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
raise NotImplementedError
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
raise NotImplementedError
def logp_cartes(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_mc, shape_var], [shape_bat, shape_cond] -> [shape_mc, shape_bat]
vals, conds = edicify(vals, conds)
shape_mc, shape_bat = Distr.shape_bat(vals), Distr.shape_bat(conds)
len_mc, len_bat = len(shape_mc), len(shape_bat)
vals_expd = vals.sub( self.names,
lambda v: swap_dim_ranges(expand_front(v, shape_bat), (0, len_bat), (len_bat, len_bat+len_mc)) )
conds_expd = conds.sub_expand_front(self.parents, shape_mc)
return self.logp(vals_expd, conds_expd)
def __mul__(self, other): # p(z|w1) * p(x|z,w2) -> p(z,x|w1,w2)
if not self.names.isdisjoint(other.names):
raise ValueError(f"cycle found for {self} * {other}: common variable")
if not self.parents.isdisjoint(other.names):
if not self.names.isdisjoint(other.parents):
raise ValueError(f"cycle found for {self} * {other}: cyclic generation")
else: p_marg, p_cond = other, self
else: p_marg, p_cond = self, other
indep = p_marg.names.isdisjoint(p_cond.parents)
p_joint = Distr(names = p_marg.names | p_cond.names,
parents = p_marg.parents | p_cond.parents - p_marg.names)
p_joint._p_marg, p_joint._p_cond, p_joint._indep = p_marg, p_cond, indep
def _mean(conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
mean_marg = p_marg.mean(conds, n_mc, repar) # [shape_bat, shape_var_marg]
# mean_cond = p_marg.expect(lambda dc: p_cond.mean(dc,dc), conds, n_mc, repar, tc.mean) # Commented for the lack of tc.mean(edic) and efficiency concern
if indep:
mean_cond = p_cond.mean(conds, n_mc, repar) # [shape_bat, shape_var_cond]
else:
if n_mc == 0:
mean_cond = p_cond.mean(conds|mean_marg, 0, repar) # [shape_bat, shape_var_cond]
elif n_mc > 0:
vals_marg = p_marg.draw((n_mc,), conds, repar) # [n_mc, shape_bat, shape_var_marg]
mean_cond = p_cond.mean(edicify(conds)[0].sub_expand_front(p_joint.parents, (n_mc,)) | vals_marg,
n_mc, repar).mean(dim=0) # [shape_bat, shape_var_cond]
else: raise ValueError(f"For {p_joint}, negative `n_mc` {n_mc} encountered")
return mean_marg | mean_cond
p_joint.mean = _mean
def _draw(shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
vals_marg = p_marg.draw(shape_mc, conds, repar) # [shape_mc, shape_bat, shape_var_marg]
if indep:
vals_cond = p_cond.draw(shape_mc, conds, repar) # [shape_mc, shape_bat, shape_var_cond]
else:
vals_cond = p_cond.draw(tc.Size(),
edicify(conds)[0].sub_expand_front(p_joint.parents, shape_mc) | vals_marg,
repar) # [shape_mc, shape_bat, shape_var_cond]
return vals_marg | vals_cond
p_joint.draw = _draw
def _logp(vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
return p_marg.logp(vals, conds) + p_cond.logp(vals, edicify(conds)[0]|vals) # [shape_bat] + [shape_bat] guaranteed
p_joint.logp = _logp
def _entropy(conds: edic=edic(), n_mc: int=10, repar: bool=True) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
return p_marg.entropy(conds) + (
p_cond.entropy(conds) if indep else
p.marg.expect(p_cond.entropy, conds, n_mc, repar, tc.mean) )
if indep: p_joint.entropy = _entropy
return p_joint
def marg(self, mnames: set, n_mc: int=10):
if mnames == self.names: return self
if not mnames: raise ValueError(f"'mnames' empty for {self}")
names_irrelev = mnames - self.names;
if names_irrelev: raise ValueError(f"irrelevant variable(s) {names_irrelev} found for {self}")
# To filter out non-elem distr that is formed by MC marginalization
if hasattr(self, '_p_marg') and hasattr(self, '_p_cond'):
# Marg p(ym, yo, xm, xo, zm, zo) = p(xm, xo, zm, zo) p(ym, yo | xm, xo)
# for mnames = {ym, xm, zm}. Other conditioned vars omitted.
p_marg, p_cond = self._p_marg, self._p_cond
# ym empty. Marg p(xm, xo, zm, zo) for {xm, zm}
if mnames <= p_marg.names: return p_marg.marg(mnames, n_mc)
# ym not empty
mnames_marg, mnames_cond = (mnames & p_marg.names), (mnames & p_cond.names) # {xm, zm}, {ym}
p_condm = p_cond.marg(mnames_cond, n_mc) # p(ym | xm, xo)
names_intsec = p_marg.names & p_condm.parents # {xm, xo}
if not names_intsec: # {xm, xo} empty. Marg p(zm, zo) p(ym) for {ym, zm}
return p_marg.marg(mnames_marg, n_mc) * p_condm if mnames_marg else p_condm # p(zm) p(ym) if zm not empty else p(ym)
else: # {xm, xo} not empty
p_margm = p_marg.marg(mnames_marg | names_intsec, n_mc) # p(xm, xo, zm)
if not mnames_marg: # label: L0
# {xm, zm} empty. Marg p(xo) p(ym | xo) for ym
p_joint = p_margm * p_condm # p(xo) p(ym | xo)
p_res = Distr(names = mnames, parents = p_joint.parents)
def _mean(conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
return p_joint.mean(conds, n_mc, repar).sub(mnames)
p_res.mean = _mean
def _draw(shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
return p_joint.draw(shape_mc, conds, repar).sub(mnames)
p_res.draw = _draw
def _logp(vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
return p_margm.expect(lambda dc: p_condm.logp(dc,dc), # `dc` contains properly expanded `conds` and `vals`
conds|vals, n_mc, True, tc.logsumexp) - math.log(n_mc)
p_res.logp = _logp
return p_res
else: # {xm, zm} not empty. Marg p(xm, xo, zm) p(ym | xm, xo) for {ym, xm, zm}
if names_intsect <= mnames_marg: # xo is empty. Marg p(xm, zm) p(ym | xm) for {ym, xm, zm}
return p_margm * p_condm # p(xm, zm) p(ym | xm)
else: # xo is not empty
if hasattr(p_margm, '_p_marg') and hasattr(p_margm, '_p_cond'):
if p_margm._p_marg.names == mnames_marg: # p(xm, xo, zm) = p(xm, zm) p(xo | xm, zm)
# Marg p(xm, zm) p(xo | xm, zm) p(ym | xm, xo) for {ym, xm, zm} is p(xm, zm) p(ym | xm, zm),
# where p(ym | xm, zm) is from marg p(xo | xm, zm) p(ym | xm, xo) for ym
return p_margm._p_marg * (p_margm._p_cond * p_condm).marg(mnames_cond, n_mc) # goto L0
elif p_margm._p_cond.names == mnames_marg:
if p_margm._indep: # p(xm, xo, zm) = p(xo) p(xm, zm)
# Similar to the above. p(xm, zm) p(ym | xm, zm),
# where p(ym | xm, zm) is from marg p(xo) p(ym | xm, xo) for ym
return p_margm._p_cond * (p_margm._p_marg * p_condm).marg(mnames_cond, n_mc) # goto L0
else: # p(xm, xo, zm) = p(xo) p(xm, zm | xo)
# Marg p(xo) p(xm, zm | xo) p(ym | xm, xo) for {ym, xm, zm}
return (p_margm._p_marg * (p_margm._p_cond * p_condm)).marg(mnames, n_mc) # goto L0
raise RuntimeError(f"Unable to marginalize {self} for {mnames}. Check the model or try other factorizations.")
class DistrElem(Distr):
def __init__(self, name: str, shape: tc.Size, device = None, **params):
# for distributions whose parameter and random variable (or, one sample) have the same shape
if device is None: device = Distr.default_device
fnnames, fnvals, tennames, tenvals = [], [], [], []
for pmname, pmval in params.items():
if callable(pmval):
fnnames.append(pmname)
fnvals.append(pmval)
else:
tennames.append(pmname)
tenvals.append(pmval)
tenvals = tensorify(device, *tenvals)
if shape is None:
if Distr.has_name(name): shape = Distr.shape_var(name)
elif tenvals: shape = tc.broadcast_tensors(*tenvals)[0].shape
else: shape = tc.Size()
parents = set()
for fname, fval in zip(fnnames, fnvals):
parents_inc = fargnames(fval)
if parents_inc:
parents |= parents_inc
setattr(self, fname, fedic(fval))
else:
setattr( self, fname,
lambda conds, fval=fval: tensorify(device, fval())[0].expand(Distr.shape_bat(conds) + shape) )
for tname, tval in zip(tennames, tenvals):
setattr( self, tname,
lambda conds, tval=tval: tval.expand(Distr.shape_bat(conds) + shape) )
super(DistrElem, self).__init__(names_shapes = {name: shape}, parents = parents)
self._name, self._shape, self._device = name, shape, device
@property
def name(self): return self._name
@property
def shape(self): return self._shape
@property
def device(self): return self._device
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
raise NotImplementedError
================================================
FILE: code/deep/CSG/distr/instances.py
================================================
#!/usr/bin/env python3.6
'''Probabilistic Programming Package.
The prototype is distributions, which can be a conditional one with
functions for parameters to define the dependency. Distribution
multiplication is implemented, as well as the mean, expectation,
sampling with backprop capability, and log-probability.
This file is greatly inspired by `torch.distributions`, with some components adopted.
'''
import warnings
import math
from contextlib import suppress
import torch as tc
import torch.distributions.utils as tcdu
from .base import Distr, DistrElem
from .utils import edic, edicify, expand_front, fargnames, fedic, is_scalar, normalize_logits, normalize_probs, precision_to_scale_tril, reduce_last, tcsize_div, tensorify
__author__ = "Chang Liu"
__version__ = "1.0.1"
__email__ = "changliu@microsoft.com"
class Determ(DistrElem):
def __init__(self, name: str, val, shape = None, checkval: bool=False, device = None):
super(Determ, self).__init__(name, shape, device, _fn = val)
self._checkval = checkval
def mean(self, conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return edic({self.name: self._fn(conds)}) # `repar` is only for `draw()`
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return self.mean(conds, 0, repar)
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
with suppress() if repar else tc.no_grad():
return edic({self.name: expand_front(self._fn(conds), shape_mc)})
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
val = vals[self.name]
if self._checkval:
equals_all = (val - self._fn(conds)).abs() <= 1e-8 + 1e-5*val.abs() # shape matches
probs = reduce_last(tc.all, equals_all, len(self.shape)).type(val.dtype) # 0. or 1.
return probs.log() # -inf or 0. (probs can be recovered by tc.exp)
else:
return tc.zeros(tcsize_div(val.shape, self.shape),
dtype=val.dtype, device=val.device, layout=val.layout)
def entropy(self, conds: edic=edic()) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
return tc.zeros(size=Distr.shape_bat(conds), device=self.device)
class Normal(DistrElem):
def __init__(self, name: str, mean = 0., std = 1., shape = None, device = None):
super(Normal, self).__init__(name, shape, device, _meanfn = mean, _stdfn = std)
self._log_const = .5 * math.log(2*math.pi) * tc.tensor(self.shape).prod()
def mean(self, conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return edic({self.name: self._meanfn(conds)})
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return self.mean(conds, 0, repar)
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
with suppress() if repar else tc.no_grad():
meanval = expand_front(self._meanfn(conds), shape_mc) # [shape_mc, shape_bat, shape_var]
return edic({self.name: self._stdfn(conds) * tc.randn_like(meanval) + meanval})
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
meanval, stdval = self._meanfn(conds), self._stdfn(conds)
normalized_vals = (vals[self.name] - meanval) / stdval
quads = reduce_last(tc.sum, normalized_vals ** 2, len(self.shape))
half_log_det = reduce_last(tc.sum, stdval.log(), len(self.shape))
return -.5 * quads - half_log_det - self._log_const
def entropy(self, conds: edic=edic()) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
stdval = self._stdfn(conds)
half_log_det = reduce_last(tc.sum, stdval.log(), len(self.shape))
return half_log_det + self._log_const + .5 * tc.tensor(self.shape).prod()
class MVNormal(DistrElem):
def __init__(self, name: str, mean = 0., cov = None, prec = None, std_tril = None, shape = None, device = None):
input_indicator = (cov is not None) + (prec is not None) + (std_tril is not None)
if input_indicator > 1: raise ValueError(f"For {self}, at most one of covariance_matrix or precision_matrix or scale_tril can be specified")
if input_indicator == 0: std_tril = 1.
if device is None: device = Distr.default_device
if shape is None and Distr.has_name(name): shape = Distr.shape_var(name)
def _vecterize_mean(mean):
if mean.ndim == 0:
warnings.warn("shape of `mean` expanded by 1 ndim")
return mean[None]
else: return mean
def _matrixize_std(std_arg):
if std_arg.ndim == 0:
warnings.warn("shape of `std_arg` expanded by 2 ndims")
return std_arg[None, None]
elif std_arg.ndim == 1:
warnings.warn("shape of `std_arg` expanded by 1 ndim")
return tc.diag_embed(std_arg)
else: return std_arg
if cov is not None: std_arg = cov
elif prec is not None: std_arg = prec
else: std_arg = std_tril
if callable(std_arg):
if callable(mean):
if shape is None: raise RuntimeError(f"For {self}, argument `shape` has to be provided when both parameters are functions")
parents = fargnames(mean) | fargnames(std_arg)
if fargnames(mean): self._meanfn = fedic(mean)
else: self._meanfn = lambda conds: tensorify(device, mean())[0].expand(Distr.shape_bat(conds) + shape)
else:
parents = fargnames(std_arg)
mean, = tensorify(device, mean,)
mean = _vecterize_mean(mean)
if shape is None: shape = mean.shape
self._meanfn = lambda conds: mean.expand(Distr.shape_bat(conds) + shape)
# un-indent
if fargnames(std_arg): _std_argfn = fedic(std_arg)
else: _std_argfn = lambda conds: tensorify(device, std_arg())[0].expand(Distr.shape_bat(conds) + shape + shape[-1:])
if cov is not None: self._std_trilfn = lambda conds: tc.cholesky(_std_argfn(conds))
elif prec is not None: self._std_trilfn = lambda conds: precision_to_scale_tril(_std_argfn(conds))
else: self._std_trilfn = _std_argfn
else:
if callable(mean):
parents = fargnames(mean)
std_arg, = tensorify(device, std_arg,)
std_arg = _matrixize_std(std_arg)
if shape is None: shape = std_arg.shape[:-1]
if parents: self._meanfn = fedic(mean)
else: self._meanfn = lambda conds: tensorify(device, mean())[0].expand(Distr.shape_bat(conds) + shape)
else:
parents = set()
mean, std_arg = tensorify(device, mean, std_arg)
mean = _vecterize_mean(mean)
std_arg = _matrixize_std(std_arg)
if shape is None: shape = tc.broadcast_tensors(mean.unsqueeze(-1), std_arg)[0].shape[:-1]
self._meanfn = lambda conds: mean.expand(Distr.shape_bat(conds) + shape)
# un-indent
if cov is not None: std_tril = tc.cholesky(std_arg)
elif prec is not None: std_tril = precision_to_scale_tril(std_arg)
else: std_tril = std_arg
self._std_trilfn = lambda conds: std_tril.expand(Distr.shape_bat(conds) + shape + shape[-1:])
super(DistrElem, self).__init__(names_shapes = {name: shape}, parents = parents)
self._name, self._shape, self._device = name, shape, device
self._log_const = .5 * math.log(2*math.pi) * tc.tensor(shape).prod()
def mean(self, conds: edic=edic(), n_mc: int=10, repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return edic({self.name: self._meanfn(conds)})
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return self.mean(conds, 0, repar)
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
with suppress() if repar else tc.no_grad():
meanval = expand_front(self._meanfn(conds), shape_mc) # [shape_mc, shape_bat, shape_var]
eps_ = tc.randn_like(meanval).unsqueeze(-1)
return edic({self.name: (self._std_trilfn(conds) @ eps_).squeeze(-1) + meanval})
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
meanval, std_trilval = self._meanfn(conds), self._std_trilfn(conds)
centered_vals_ = (vals[self.name] - meanval).unsqueeze(-1)
normalized_vals = tc.triangular_solve(centered_vals_, std_trilval, upper=False)[0].squeeze(-1)
quads = reduce_last(tc.sum, normalized_vals ** 2, len(self.shape))
half_log_det = reduce_last(tc.sum, std_trilval.diagonal(dim1=-2, dim2=-1).log(), len(self.shape))
return -.5 * quads - half_log_det - self._log_const
def entropy(self, conds: edic=edic()) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
std_trilval = self._std_trilfn(conds)
half_log_det = reduce_last(tc.sum, std_trilval.diagonal(dim1=-2, dim2=-1).log(), len(self.shape))
return half_log_det + self._log_const + .5 * tc.tensor(self.shape).prod()
class Catg(DistrElem):
def __init__(self, name: str, *, probs = None, logits = None, shape = None, normalized: bool=False, device = None):
# This logit should be normalized (sumexp == 1). logit == log prob.
if (probs is None) == (logits is None):
raise ValueError(f"For {self}, one and only one of `probs` and `logits` required")
params = logits if probs is None else probs
if device is None: device = Distr.default_device
if shape is None and Distr.has_name(name): shape = Distr.shape_var(name)
if callable(params):
if shape is None: shape = tc.Size()
parents = fargnames(params)
if parents: paramsfn = fedic(params)
else: paramsfn = lambda conds: tensorify(device, params())[0].expand(Distr.shape_bat(conds) + shape + (-1,))
if probs is None:
self._logitsfn = paramsfn if normalized else lambda conds: normalize_logits(paramsfn(conds))
else:
self._probsfn = paramsfn if normalized else lambda conds: normalize_probs(paramsfn(conds))
else:
params, = tensorify(device, params,)
if params.ndim < 1 or params.shape[-1] <= 1: raise ValueError(f"For {self}, use `Bern` for binary variables")
if shape is None: shape = params.shape[:-1]
parents = set()
if not normalized:
params = normalize_logits(params) if probs is None else normalize_probs(params)
setattr( self, '_logitsfn' if probs is None else '_probsfn',
lambda conds: params.expand(Distr.shape_bat(conds) + shape + (-1,)) )
super(DistrElem, self).__init__(names_shapes = {name: shape}, parents = parents)
self._name, self._shape, self._device = name, shape, device
@tcdu.lazy_property
def _probsfn(self): return lambda conds: tcdu.logits_to_probs(self._logitsfn(conds))
@tcdu.lazy_property
def _logitsfn(self): return lambda conds: tcdu.probs_to_logits(self._probsfn(conds))
# No `mean()`.
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return edic({self.name: self._logitsfn(conds).argmax(dim=-1)})
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
if repar: warnings.warn(f"For categorical {self}, reparameterization for `draw` is not allowed")
with tc.no_grad():
probs = expand_front(self._probsfn(conds), shape_mc)
shape_out, n_catg = probs.shape[:-1], probs.shape[-1]
probs_flat = probs.reshape(-1, n_catg)
return edic({self.name:
tc.multinomial(probs_flat, num_samples=1).reshape(shape_out)})
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
val = vals[self.name]
logits = self._logitsfn(conds) # logit == log prob
logits = logits.expand(val.shape + logits.shape[-1:])
logps_all = logits.gather(dim=-1, index=val.unsqueeze(-1)).squeeze(-1)
return reduce_last(tc.sum, logps_all, len(self.shape))
def entropy(self, conds: edic=edic()) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
logits = self._logitsfn(conds) # logit == log prob
return - reduce_last(tc.sum, logits.exp() * logits, len(self.shape) + 1)
class Bern(DistrElem):
def __init__(self, name: str, *, probs = None, logits = None, shape = None, device = None):
# This logit is NOT normalized (it has the logit of 0 being 0). So logit != log prob.
if (probs is None) == (logits is None):
raise ValueError(f"For {self}, one and only one of `probs` and `logits` required")
super(Bern, self).__init__(name, shape, device, **({'_logitsfn':logits} if probs is None else {'_probsfn':probs}))
@tcdu.lazy_property
def _probsfn(self): return lambda conds: tcdu.logits_to_probs(self._logitsfn(conds), is_binary=True)
@tcdu.lazy_property
def _logitsfn(self): return lambda conds: tcdu.probs_to_logits(self._probsfn(conds), is_binary=True)
# No `mean()`.
def mode(self, conds: edic=edic(), repar: bool=True) -> edic:
# [shape_bat, shape_cond] -> [shape_bat, shape_var]
return edic({self.name: (self._logitsfn(conds) > 0).long()})
def draw(self, shape_mc: tc.Size=tc.Size(), conds: edic=edic(), repar: bool=False) -> edic: # vals
# shape_mc, [shape_bat, shape_cond] -> [shape_mc, shape_bat, shape_var]
if repar: warnings.warn(f"For Bernoulli {self}, reparameterization for `draw` is not allowed")
with tc.no_grad():
return edic({self.name:
tc.bernoulli( expand_front(self._probsfn(conds), shape_mc) ).long()}) # tc.bernoulli returns float32, and allows backprop (.long() doesn't)
def logp(self, vals: edic, conds: edic=edic()) -> tc.Tensor: # log_probs
# [shape_bat, shape_var], [shape_bat, shape_cond] -> [shape_bat]
logits = self._logitsfn(conds)
logprobs = -tc.log1p(tc.exp(-logits)) # logit != log prob
logps_all = tc.where(vals[self.name].bool(), logprobs, logprobs - logits) # shape matches
return reduce_last(tc.sum, logps_all, len(self.shape))
def entropy(self, conds: edic=edic()) -> tc.Tensor:
# [shape_bat, shape_cond] -> [shape_bat]
logits = self._logitsfn(conds)
logprobs = -tc.log1p(tc.exp(-logits)) # logit != log prob
return reduce_last(tc.sum, -logprobs + logits / (1+tc.exp(logits)), len(self.shape))
================================================
FILE: code/deep/CSG/distr/tools.py
================================================
#!/usr/bin/env python3.6
'''Probabilistic Programming Package.
The prototype is distributions, which can be a conditional one with
functions for parameters to define the dependency. Distribution
multiplication is implemented, as well as the mean, expectation,
sampling with backprop capability, and log-probability.
'''
import math
import torch as tc
from .utils import edic
from .base import Distr
__author__ = "Chang Liu"
__version__ = "1.0.1"
__email__ = "changliu@microsoft.com"
def elbo(p_joint: Distr, q_cond: Distr, obs: edic, n_mc: int=10, repar: bool=True) -> tc.Tensor: # [shape_bat] -> [shape_bat]
if hasattr(q_cond, "entropy"):
return q_cond.expect(lambda dc: p_joint.logp(dc,dc), obs, n_mc, repar) + q_cond.entropy(obs)
else:
return q_cond.expect(lambda dc: p_joint.logp(dc,dc) - q_cond.logp(dc,dc), obs, n_mc, repar)
def elbo_z2xy(p_zx: Distr, p_y1z: Distr, q_z1x: Distr, obs_xy: edic, n_mc: int=0, repar: bool=True) -> tc.Tensor:
""" For supervised VAE with structure x <- z -> y.
Observations are supervised (x,y) pairs.
For unsupervised observations of x data, use `elbo(p_zx, q_z1x, obs_x)` as VAE z -> x. """
if n_mc == 0:
q_y1x_logpval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc), obs_xy, 0, repar) #, reducefn=tc.logsumexp)
if hasattr(q_z1x, "entropy"): # No difference for Gaussian
expc_val = q_z1x.expect(lambda dc: p_zx.logp(dc,dc), obs_xy, 0, repar) + q_z1x.entropy(obs_xy)
else:
expc_val = q_z1x.expect(lambda dc: p_zx.logp(dc,dc) - q_z1x.logp(dc,dc), obs_xy, 0, repar)
return q_y1x_logpval + expc_val
else:
q_y1x_pval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc).exp(), obs_xy, n_mc, repar)
expc_val = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc).exp() * (p_zx.logp(dc,dc) - q_z1x.logp(dc,dc)),
obs_xy, n_mc, repar)
return q_y1x_pval.log() + expc_val / q_y1x_pval
# q_y1x_logpval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc), obs_xy, n_mc, repar,
# reducefn=tc.logsumexp) - math.log(n_mc)
# expc_logval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc) + (p_zx.logp(dc,dc) - q_z1x.logp(dc,dc)).log(),
# obs_xy, n_mc, repar, reducefn=tc.logsumexp) - math.log(n_mc)
# return q_y1x_logpval + (expc_logval - q_y1x_logpval).exp()
def elbo_z2xy_twist(pt_zx: Distr, p_y1z: Distr, p_z: Distr, pt_z: Distr, qt_z1x: Distr, obs_xy: edic, n_mc: int=0, repar: bool=True) -> tc.Tensor:
vwei_p_y1z_logp = lambda dc: p_z.logp(dc,dc) - pt_z.logp(dc,dc) + p_y1z.logp(dc,dc) # z, y:
if n_mc == 0:
r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, 0, repar) #, reducefn=tc.logsumexp)
if hasattr(qt_z1x, "entropy"): # No difference for Gaussian
expc_val = qt_z1x.expect(lambda dc: pt_zx.logp(dc,dc), obs_xy, 0, repar) + qt_z1x.entropy(obs_xy)
else:
expc_val = qt_z1x.expect(lambda dc: pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc), obs_xy, 0, repar)
return r_y1x_logpval + expc_val
else:
r_y1x_pval = qt_z1x.expect(lambda dc: vwei_p_y1z_logp(dc).exp(), obs_xy, n_mc, repar)
expc_val = qt_z1x.expect( lambda dc: # z, x, y:
vwei_p_y1z_logp(dc).exp() * (pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc)),
obs_xy, n_mc, repar)
return r_y1x_pval.log() + expc_val / r_y1x_pval
# r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, n_mc, repar,
# reducefn=tc.logsumexp) - math.log(n_mc) # z, y:
# expc_logval = qt_z1x.expect(lambda dc: # z, x, y:
# vwei_p_y1z_logp(dc) + (pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc)).log(),
# obs_xy, n_mc, repar, reducefn=tc.logsumexp) - math.log(n_mc)
# return r_y1x_logpval + (expc_logval - r_y1x_logpval).exp()
def elbo_zy2x(p_zyx: Distr, q_y1x: Distr, q_z1xy: Distr, obs_x: edic, n_mc: int=0, repar: bool=True) -> tc.Tensor:
""" For supervised VAE with structure z -> x <- y (Kingma's semi-supervised VAE, M2). (z,y) correlation also allowed.
Observations are unsupervised x data.
For supervised observations of (x,y) pairs, use `elbo(p_zyx, q_z1xy, obs_xy)` as VAE z -> (x,y). """
if hasattr(q_y1x, "entropy"):
return q_y1x.expect(lambda dc: elbo(p_zyx, q_z1xy, dc, n_mc, repar),
obs_x, n_mc, repar) + q_y1x.entropy(obs_x)
else:
return q_y1x.expect(lambda dc: elbo(p_zyx, q_z1xy, dc, n_mc, repar) - q_y1x.logp(dc,dc),
obs_x, n_mc, repar)
================================================
FILE: code/deep/CSG/distr/utils.py
================================================
#!/usr/bin/env python3.6
'''Probabilistic Programming Package.
The prototype is distributions, which can be a conditional one with
functions for parameters to define the dependency. Distribution
multiplication is implemented, as well as the mean, expectation,
sampling with backprop capability, and log-probability.
'''
import torch as tc
from functools import partial, wraps
from inspect import signature
__author__ = "Chang Liu"
__version__ = "1.0.1"
__email__ = "changliu@microsoft.com"
# enhanced dictionary
class edic(dict):
def __and__(self, other): return edic({k:other[k] for k in set(self) & set(other)}) # &
def __rand__(self, other): return edic({k:self[k] for k in set(other) & set(self)}) # &
def __or__(self, other): return edic({**self, **other}) # |
def __ror__(self, other): return edic({**other, **self}) # |
def __sub__(self, other): return edic({k:v for k,v in self.items() if k not in other}) # -
def __rsub__(self, other): return edic({k:v for k,v in other.items() if k not in self}) # -
def isdisjoint(self, other) -> bool: return set(self).isdisjoint(set(other))
def sub(self, it, fn = None):
return edic({k:self[k] for k in it} if fn is None else {k:fn(self[k]) for k in it})
def sub_expand_front(self, it, shape: tc.Size):
return self.sub(it, partial(expand_front, shape = shape))
def subedic(self, it, fn = None, use_default = False, default = None):
if not use_default:
if fn is None: return edic({k:self[k] for k in it if k in self})
else: return edic({k:fn(self[k]) for k in it if k in self})
else:
if fn is None: return edic({k: (self[k] if k in self else default) for k in it})
else: return edic({k: fn(self[k] if k in self else default) for k in it})
def sublist(self, it, fn = None, use_default = False, default = None):
if not use_default:
if fn is None: return [self[k] for k in it if k in self]
else: return [fn(self[k]) for k in it if k in self]
else:
if fn is None: return [(self[k] if k in self else default) for k in it]
else: return [fn(self[k] if k in self else default) for k in it]
def key0(self): return next(iter(self))
def value0(self): return next(iter(self.values()))
def item0(self): return next(iter(self.items()))
def mean(self, dim, keepdim: bool=False):
return edic({k: v.mean(dim, keepdim) for k,v in self.items()})
def expand_front(self, shape: tc.Size):
return edic({k: v.expand(shape + v.shape) for k,v in self.items()})
def broadcast(self):
return edic(zip( self.keys(), tc.broadcast_tensors(*self.values()) ))
def edicify(*args) -> tuple:
return tuple(arg if type(arg) is edic else edic(arg) for arg in args)
# helper functions
def fargnames(fn) -> set:
# return set(fn.__code__.co_varnames) - {'self'} # Also includes temporary local variables
return set(signature(fn).parameters.keys()) # Do not need to substract 'self'
def fedic(fn):
return wraps(fn)( lambda dc: fn(**( fargnames(fn) & edicify(dc)[0] )) )
# pms = signature(fn).parameters
# return wraps(fn)( lambda dc: fn(**(
# edic({k:v.default for k,v in pms.items() if v.default is not v.empty})
# | (set(pms.keys()) & edicify(dc)[0]) )) )
def wrap4_multi_batchdims(fn, ndim_vars = 1):
"""
Function decorator to allow multiple batch dims at the front of input tensors.
For incorporating functions (e.g., `torch.nn.Conv*`, `torch.nn.BatchNorm*`) that require only one batch dim
into the `distr` package.
"""
allowed_types = [int, list, tuple]
if type(ndim_vars) not in allowed_types:
raise ValueError("`ndim_vars` must be within types {allowed_types}")
def fn_new(*args, **kwargs):
keys = tuple(kwargs.keys())
args += tuple(kwargs.values())
if type(ndim_vars) is int: ndims = [ndim_vars] * len(args)
else: ndims = ndim_vars
shapes_bat_var = [
( (arg.shape[:-ndim], arg.shape[-ndim:]) if ndim else (args.shape, tc.Size()) )
if type(arg) is tc.Tensor else
(None, None)
for arg, ndim in zip(args, ndims)]
args_batflat = [
arg.reshape(-1, *shape_var)
if type(arg) is tc.Tensor and len(shape_bat) > 1 else
arg
for arg, (shape_bat, shape_var) in zip(args, shapes_bat_var)]
if len(keys):
outs_batflat = fn( *args_batflat[:-len(keys)],
**dict(zip(keys, args_batflat[-len(keys):])) )
else:
outs_batflat = fn(*args_batflat)
single_out = type(outs_batflat) not in {list, tuple}
if single_out: outs_batflat = (outs_batflat,)
outs = tuple(
out.reshape(*shapes_bat_var[0][0], *out.shape[1:]) # use `shape_bat` of the first input var
if type(out) is tc.Tensor else
out
for out in outs_batflat)
if single_out: return outs[0]
else: return outs
return fn_new
def append_attrs(obj, vardict, attrs): # obj = self, vardict = locals(), attrs = set(locals.keys()) - {'self'}
for attr in attrs: setattr(obj, attr, vardict[attr])
# for tc.Tensor
def tensorify(device=None, *args) -> tuple:
return tuple(arg.to(device) if type(arg) is tc.Tensor else tc.tensor(arg, device=device) for arg in args)
def is_scalar(ten: tc.Tensor) -> bool:
return ten.squeeze().ndim == 0
def is_same_tensor(ten1: tc.Tensor, ten2: tc.Tensor) -> bool:
return (ten1 is ten2) or (
type(ten1) == type(ten2) == tc.Tensor
and ten1.data_ptr() == ten2.data_ptr() and ten1.shape == ten2.shape)
def expand_front(ten: tc.Tensor, shape: tc.Size) -> tc.Tensor:
return ten.expand(shape + ten.shape)
def flatten_last(ten: tc.Tensor, ndims: int):
if ndims <= 1: return ten
else: return ten.reshape(ten.shape[:-ndims] + (-1,))
def reduce_last(reducefn, ten: tc.Tensor, ndims: int): # tc.distributions.utils
if ndims < 1: return ten
else: return reducefn(ten.reshape(ten.shape[:-ndims] + (-1,)), dim=-1)
# return reducefn(ten, dim=list(range(-1, -ndims-1, -1))) if ndims else ten # doesn't work for `tc.all`
def swap_dim_ranges(ten: tc.Tensor, dims1: tuple, dims2: tuple) -> tc.Tensor:
if len(dims1) != 2 or len(dims2) != 2:
raise ValueError("`dims1` and `dims2` must be 2-tuples of integers")
dims1 = tuple(dim if dim >= 0 else dim+ten.ndim for dim in dims1)
dims2 = tuple(dim if dim >= 0 else dim+ten.ndim for dim in dims2)
if dims1[0] > dims1[1]: dims1 = (dims1[1], dims1[0])
if dims2[0] > dims2[1]: dims2 = (dims2[1], dims2[0])
if dims2[0] < dims1[1] and dims1[0] < dims2[1]:
raise ValueError("`dims1` and `dims2` must define disjoint intevals")
if dims2[1] <= dims1[0]: dims1, dims2 = dims2, dims1
dimord = list(range(0, dims1[0])) + list(range(*dims2)) \
+ list(range(dims1[1], dims2[0])) \
+ list(range(*dims1)) + list(range(dims2[1], ten.ndim))
return ten.permute(*dimord)
def expand_middle(ten: tc.Tensor, shape: tc.Size, pos: int) -> tc.Tensor:
# Expand with `shape` in front of dim `pos`.
if len(shape) == 0: return ten
if pos < 0: pos += ten.ndim
ten_expd = expand_front(ten, shape)
if pos == 0: return ten_expd
else: return swap_dim_ranges(ten_expd, (0, len(shape)), (len(shape), len(shape)+pos))
# for tc.Size
def tcsizeify(*args) -> tuple:
return tuple(arg if type(arg) is tc.Size else tc.Size(arg) for arg in args)
def tcsize_div(sz1: tc.Size, sz2: tc.Size) -> tc.Size:
if not sz2 or sz1[-len(sz2):] == sz2: return sz1[:(len(sz1)-len(sz2))]
else: raise ValueError("sizes not match")
def tcsize_broadcast(*sizes) -> tc.Size:
szfinal = tc.Size()
for sz in sizes:
szlong, szshort = (szfinal, sz) if len(szfinal) >= len(sz) else (sz, szfinal)
for i in range(1, 1 + len(szshort)):
if szshort[-i] != 1:
if szlong[-i] == 1: szlong[-i] = szshort[-i]
elif szshort[-i] != szlong[-i]: raise ValueError("sizes not match")
szfinal = szlong
return szfinal
# specific distribution utilities
def normalize_probs(probs: tc.Tensor) -> tc.Tensor:
return probs / probs.sum(dim=-1, keepdim=True)
def normalize_logits(logits: tc.Tensor) -> tc.Tensor:
return logits - logits.logsumexp(dim=-1, keepdim=True)
def precision_to_scale_tril(P: tc.Tensor) -> tc.Tensor:
# Ref: https://nbviewer.jupyter.org/gist/fehiepsi/5ef8e09e61604f10607380467eb82006#Precision-to-scale_tril
Lf = tc.cholesky(tc.flip(P, dims=(-2, -1)))
L_inv = tc.transpose(tc.flip(Lf, dims=(-2, -1)), -2, -1)
L = tc.triangular_solve(tc.eye(P.shape[-1], dtype=P.dtype, device=P.device),
L_inv, upper=False)[0]
return L
================================================
FILE: code/deep/CSG/methods/__init__.py
================================================
#!/usr/bin/env python3.6
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
from .semvar import SemVar
from .supvae import SupVAE
from .cnbb import CNBBLoss
================================================
FILE: code/deep/CSG/methods/cnbb.py
================================================
#!/usr/bin/env python3.6
""" Implementation of the CNBB method "ConvNet with Batch Balancing".
Based on the original description in . No official code found.
"""
import torch as tc
from torch.nn.functional import normalize
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
class CNBBLoss:
def __init__(self, f_feat, actv, f_logit, dim_y, reg_w, reg_s, lr, n_iter):
if actv not in {"Sigmoid", "Tanh"}: raise ValueError(f"unknown activation type '{actv}'")
if dim_y == 1:
celossobj = tc.nn.BCEWithLogitsLoss(reduction='none')
self.celoss = lambda logits, y: celossobj(logits, y.float())
else: self.celoss = tc.nn.CrossEntropyLoss(reduction='none')
self.f_feat, self.actv, self.f_logit, self.reg_w, self.reg_s, self.lr, self.n_iter \
= f_feat, actv, f_logit, reg_w, reg_s, lr, n_iter
def __call__(self, x, y):
n_bat = x.shape[0]
# Inner iteration for weight
with tc.no_grad(): feat = self.f_feat(x)
feat = feat.reshape(n_bat, -1)
if self.actv == "Sigmoid": is_treat = feat > .5
elif self.actv == "Tanh": is_treat = feat > 0.
weight = tc.full([n_bat], 1/n_bat, device=x.device, requires_grad=True)
proj = (tc.eye(n_bat) - tc.ones(n_bat, n_bat) / n_bat).to(x.device)
for it in range(self.n_iter):
loss = ((feat.T @ (
normalize(weight[:,None] * is_treat, p=1, dim=0)
- normalize(weight[:,None] * ~is_treat, p=1, dim=0)
) * ~tc.eye(feat.shape[-1], dtype=bool, device=x.device))**2).sum() \
+ self.reg_w * (weight**2).sum()
loss.backward()
with tc.no_grad():
weight -= self.lr * (proj @ weight.grad)
weight.abs_()
weight /= weight.sum()
weight.grad.zero_()
# Optimize the model
if self.actv == "Sigmoid": sqnorm_s = ((self.f_feat(x) - .5)**2).sum()
elif self.actv == "Tanh": sqnorm_s = (self.f_feat(x)**2).sum()
loss = weight.detach() @ self.celoss(self.f_logit(x), y) - self.reg_s * sqnorm_s
return loss
================================================
FILE: code/deep/CSG/methods/semvar.py
================================================
#!/usr/bin/env python3.6
''' The Semantic-Variation Generative Model.
I.e., the proposed Causal Semantic Generative model (CSG).
'''
import sys
import math
import torch as tc
sys.path.append('..')
import distr as ds
from . import xdistr as xds
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
class SemVar:
@staticmethod
def _get_priors(mean_s, std_s, shape_s, mean_v, std_v, shape_v, corr_sv, mvn_prior: bool = False, device = None):
if not mvn_prior:
if not callable(mean_s): mean_s_val = mean_s; mean_s = lambda: mean_s_val
if not callable(std_s): std_s_val = std_s; std_s = lambda: std_s_val
if not callable(mean_v): mean_v_val = mean_v; mean_v = lambda: mean_v_val
if not callable(std_v): std_v_val = std_v; std_v = lambda: std_v_val
if not callable(corr_sv):
if not corr_sv**2 < 1.: raise ValueError("correlation coefficient larger than 1")
corr_sv_val = corr_sv; corr_sv = lambda: corr_sv_val
p_s = ds.Normal('s', mean=mean_s, std=std_s, shape=shape_s)
dim_s, dim_v = tc.tensor(shape_s).prod(), tc.tensor(shape_v).prod()
def mean_v1s(s):
shape_bat = s.shape[:-len(shape_s)] if len(shape_s) else s.shape
s_normal_flat = ((s - mean_s()) / std_s()).reshape(shape_bat+(dim_s,))
v_normal_flat = s_normal_flat[..., :dim_v] if dim_v <= dim_s \
else tc.cat([s_normal_flat, tc.zeros(shape_bat+(dim_v-dim_s,), dtype=s.dtype, device=s.device)], dim=-1)
return mean_v() + corr_sv() * std_v() * v_normal_flat.reshape(shape_bat+shape_v)
def std_v1s(s):
corr_sv_val = ds.tensorify(device, corr_sv())[0]
return ( std_v() * (1. - corr_sv_val**2).sqrt()
).expand( (s.shape[:-len(shape_s)] if len(shape_s) else s.shape) + shape_v )
p_v1s = ds.Normal('v', mean=mean_v1s, std=std_v1s, shape=shape_v)
p_v = ds.Normal('v', mean=mean_v, std=std_v, shape=shape_v)
prior_params_list = []
else:
if len(shape_s) != 1 or len(shape_v) != 1:
raise RuntimeError("only 1-dim vectors are supported for `s` and `v` in `mvn_prior` mode")
dim_s = shape_s[0]; dim_v = shape_v[0]
mean_s = tc.zeros(shape_s, device=device) if callable(mean_s) else ds.tensorify(device, mean_s)[0].expand(shape_s).clone().detach()
mean_v = tc.zeros(shape_v, device=device) if callable(mean_v) else ds.tensorify(device, mean_v)[0].expand(shape_v).clone().detach()
# Sigma_sv = L_sv L_sv^T, L_sv = (L_ss, 0; M_vs, L_vv)
std_s_offdiag = tc.zeros((dim_s, dim_s), device=device) # lower triangular of L_ss (excl. diag)
std_v_offdiag = tc.zeros((dim_v, dim_v), device=device) # lower triangular of L_vv (excl. diag)
if callable(std_s): # for diag of L_ss
std_s_diag_param = tc.zeros(shape_s, device=device)
else:
std_s = ds.tensorify(device, std_s)[0].expand(shape_s)
std_s_diag_param = std_s.log().clone().detach()
if callable(std_v): # for diag of L_vv
std_v_diag_param = tc.zeros(shape_v, device=device)
else:
std_v = ds.tensorify(device, std_v)[0].expand(shape_v)
std_v_diag_param = std_v.log().clone().detach()
if any(callable(var) for var in [std_s, std_v, corr_sv]): # M_vs
std_vs_mat = tc.zeros(dim_v, dim_s, device=device)
else:
std_vs_mat = tc.eye(dim_v, dim_s, device=device)
dim_min = min(dim_s, dim_v)
std_vs_diag = (ds.tensorify(device, corr_sv)[0].expand((dim_min,)) * std_s[:dim_min] * std_v[:dim_min]).sqrt()
if dim_min == dim_s: std_vs_mat = (std_vs_mat @ std_vs_diag.diagflat()).clone().detach()
else: std_vs_mat = (std_vs_diag.diagflat() @ std_vs_mat).clone().detach()
prior_params_list = [mean_s, std_s_diag_param, std_s_offdiag, mean_v, std_v_diag_param, std_v_offdiag, std_vs_mat]
def std_s_tril(): # L_ss
return std_s_offdiag.tril(-1) + std_s_diag_param.exp().diagflat()
p_s = ds.MVNormal('s', mean=mean_s, std_tril=std_s_tril, shape=shape_s)
def mean_v1s(s):
return mean_v + ( std_vs_mat @ tc.triangular_solve(
(s - mean_s).unsqueeze(-1), std_s_tril(), upper=False)[0] ).squeeze(-1)
def std_v1s_tril(s): # L_vv
return ( std_v_offdiag.tril(-1) + std_v_diag_param.exp().diagflat()
).expand( (s.shape[:-len(shape_s)] if len(shape_s) else s.shape) + (dim_v, dim_v) )
p_v1s = ds.MVNormal('v', mean=mean_v1s, std_tril=std_v1s_tril, shape=shape_v)
def cov_v(): # M_vs M_vs^T + L_vv L_vv^T
L_vv = std_v_offdiag.tril(-1) + std_v_diag_param.exp().diagflat()
return std_vs_mat @ std_vs_mat.T + L_vv @ L_vv.T
p_v = ds.MVNormal('v', mean=mean_v, cov=cov_v, shape=shape_v)
return p_s, p_v1s, p_v, prior_params_list
def __init__(self, shape_s, shape_v, shape_x, dim_y,
mean_x1sv, std_x1sv, logit_y1s,
mean_v1x = None, std_v1x = None, mean_s1vx = None, std_s1vx = None,
tmean_v1x = None, tstd_v1x = None, tmean_s1vx = None, tstd_s1vx = None,
mean_s = 0., std_s = 1., mean_v = 0., std_v = 1., corr_sv = .5,
learn_tprior = False, src_mvn_prior = False, tgt_mvn_prior = False, device = None):
if device is not None: ds.Distr.default_device = device
self._parameter_dict = {}
self.shape_s, self.shape_v, self.shape_x, self.dim_y = shape_s, shape_v, shape_x, dim_y
self.learn_tprior = learn_tprior
self.p_x1sv = ds.Normal('x', mean=mean_x1sv, std=std_x1sv, shape=shape_x)
self.p_y1s = getattr(ds, 'Bern' if dim_y == 1 else 'Catg')('y', logits=logit_y1s)
self.p_s, self.p_v1s, self.p_v, prior_params_list = self._get_priors(
mean_s, std_s, shape_s, mean_v, std_v, shape_v, corr_sv, src_mvn_prior, device)
if src_mvn_prior: self._parameter_dict.update(zip([
'mean_s', 'std_s_diag_param', 'std_s_offdiag', 'mean_v', 'std_v_diag_param', 'std_v_offdiag', 'std_vs_mat'
], prior_params_list))
self.p_sv = self.p_s * self.p_v1s
self.p_svx = self.p_sv * self.p_x1sv
if mean_v1x is not None:
self.q_v1x = ds.Normal('v', mean=mean_v1x, std=std_v1x, shape=shape_v)
self.q_s1vx = ds.Normal('s', mean=mean_s1vx, std=std_s1vx, shape=shape_s)
self.q_sv1x = self.q_v1x * self.q_s1vx
else: self.q_v1x, self.q_s1vx, self.q_sv1x = None, None, None
if tmean_v1x is not None:
self.qt_v1x = ds.Normal('v', mean=tmean_v1x, std=tstd_v1x, shape=shape_v)
self.qt_s1vx = ds.Normal('s', mean=tmean_s1vx, std=tstd_s1vx, shape=shape_s)
self.qt_sv1x = self.qt_v1x * self.qt_s1vx
else: self.qt_v1x, self.qt_s1vx, self.qt_sv1x = None, None, None
if learn_tprior:
if not tgt_mvn_prior:
tmean_s = tc.zeros(shape_s, device=device) if callable(mean_s) else ds.tensorify(device, mean_s)[0].expand(shape_s).clone().detach()
tmean_v = tc.zeros(shape_v, device=device) if callable(mean_v) else ds.tensorify(device, mean_v)[0].expand(shape_v).clone().detach()
tstd_s_param = tc.zeros(shape_s, device=device) if callable(std_s) else ds.tensorify(device, std_s)[0].expand(shape_s).log().clone().detach()
tstd_v_param = tc.zeros(shape_v, device=device) if callable(std_v) else ds.tensorify(device, std_v)[0].expand(shape_v).log().clone().detach()
if callable(corr_sv): tcorr_sv_param = tc.zeros((), device=device)
else:
val = (ds.tensorify(device, corr_sv)[0].reshape(()) + 1.) / 2.
tcorr_sv_param = (val / (1-val)).clone().log().detach()
self._parameter_dict.update({'tmean_s': tmean_s, 'tmean_v': tmean_v,
'tstd_s_param': tstd_s_param, 'tstd_v_param': tstd_v_param, 'tcorr_sv_param': tcorr_sv_param})
def tstd_s(): return tc.exp(tstd_s_param)
def tstd_v(): return tc.exp(tstd_v_param)
def tcorr_sv(): return 2. * tc.sigmoid(tcorr_sv_param) - 1.
self.pt_s, self.pt_v1s, self.pt_v, tprior_params_list = self._get_priors(
tmean_s, tstd_s, shape_s, tmean_v, tstd_v, shape_v, tcorr_sv, False, device)
else:
self.pt_s, self.pt_v1s, self.pt_v, tprior_params_list = self._get_priors(
mean_s, std_s, shape_s, mean_v, std_v, shape_v, corr_sv, True, device)
self._parameter_dict.update(zip([
'tmean_s', 'tstd_s_diag_param', 'tstd_s_offdiag', 'tmean_v', 'tstd_v_diag_param', 'tstd_v_offdiag', 'tstd_vs_mat'
], tprior_params_list))
else: self.pt_s, self.pt_v1s, self.pt_v = self.p_s, self.p_v, self.p_v # independent prior
self.pt_sv = self.pt_s * self.pt_v1s
self.pt_svx = self.pt_sv * self.p_x1sv
for param in self._parameter_dict.values(): param.requires_grad_()
def parameters(self):
for param in self._parameter_dict.values(): yield param
def state_dict(self):
return self._parameter_dict
def load_state_dict(self, state_dict: dict):
for name in list(self._parameter_dict.keys()):
with tc.no_grad(): self._parameter_dict[name].copy_(state_dict[name])
def get_lossfn(self, n_mc_q: int=0, reduction: str="mean", mode: str="defl", weight_da: float=None, wlogpi: float=None):
if reduction == "mean": reducefn = tc.mean
elif reduction == "sum": reducefn = tc.sum
elif reduction is None or reduction == "none": reducefn = lambda x: x
else: raise ValueError(f"unknown `reduction` '{reduction}'")
if self.q_sv1x is not None: # svgm, svgm-da2
def lossfn_src(x: tc.Tensor, y: tc.LongTensor) -> tc.Tensor:
return -reducefn( xds.elbo_z2xy(self.p_svx, self.p_y1s, self.q_sv1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
else:
if self.learn_tprior: # svgm-da
def lossfn_src(x: tc.Tensor, y: tc.LongTensor) -> tc.Tensor:
return -reducefn( xds.elbo_z2xy_twist(self.pt_svx, self.p_y1s, self.p_sv, self.pt_sv, self.qt_sv1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
# return -reducefn( xds.elbo_z2xy_twist_fixpt(self.p_x1sv, self.p_y1s, self.p_sv, self.pt_sv, self.qt_sv1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
else: # svgm-ind
def lossfn_src(x: tc.Tensor, y: tc.LongTensor) -> tc.Tensor:
return -reducefn( xds.elbo_z2xy_twist(self.pt_svx, self.p_y1s, self.p_v1s, self.p_v, self.qt_sv1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
def lossfn_tgt(xt: tc.Tensor) -> tc.Tensor:
return -reducefn( ds.elbo(self.pt_svx, self.qt_sv1x, {'x': xt}, n_mc_q) )
# return -reducefn( xds.elbo_fixllh(self.pt_sv, self.p_x1sv, self.qt_sv1x, {'x': xt}, n_mc_q) )
if mode == "src": return lossfn_src
elif mode == "tgt": return lossfn_tgt # may be invalid
elif not mode or mode == "defl":
if self.learn_tprior:
def lossfn(x: tc.Tensor, y: tc.LongTensor, xt: tc.Tensor) -> tc.Tensor:
return lossfn_src(x,y) + weight_da * lossfn_tgt(xt)
return lossfn
else: return lossfn_src
else: raise ValueError(f"unknown `mode` '{mode}'")
# Utilities
def llh(self, x: tc.Tensor, y: tc.LongTensor=None, n_mc_marg: int=64, use_q: bool=True, mode: str="src") -> float:
if mode == "src":
p_joint = self.p_svx
q_cond = self.q_sv1x if self.q_sv1x else self.qt_sv1x
elif mode == "tgt":
p_joint = self.pt_svx
q_cond = self.qt_sv1x if self.qt_sv1x else self.q_sv1x
else: raise ValueError(f"unknown `mode` '{mode}'")
if not use_q:
if y is None: llh_vals = p_joint.marg({'x'}, n_mc_marg).logp({'x': x})
else: llh_vals = (p_joint * self.p_y1s).marg({'x', 'y'}, n_mc_marg).logp({'x': x, 'y': y})
else:
if y is None: llh_vals = q_cond.expect(lambda dc: p_joint.logp(dc) - q_cond.logp(dc,dc),
{'x': x}, n_mc_marg, reducefn=tc.logsumexp) - math.log(n_mc_marg)
else: llh_vals = q_cond.expect(lambda dc: (p_joint * self.p_y1s).logp(dc) - q_cond.logp(dc,dc),
{'x': x, 'y': y}, n_mc_marg, reducefn=tc.logsumexp) - math.log(n_mc_marg)
return llh_vals.mean().item()
def logit_y1x_src(self, x: tc.Tensor, n_mc_q: int=0, repar: bool=True):
dim_y = 2 if self.dim_y == 1 else self.dim_y
y_eval = ds.expand_front(tc.arange(dim_y, device=x.device), ds.tcsize_div(x.shape, self.shape_x))
x_eval = ds.expand_middle(x, (dim_y,), -len(self.shape_x))
obs_xy = ds.edic({'x': x_eval, 'y': y_eval})
if self.q_sv1x is not None:
logits = (self.q_sv1x.expect(lambda dc: self.p_y1s.logp(dc,dc), obs_xy, 0, repar) #, reducefn=tc.logsumexp)
) if n_mc_q == 0 else (
self.q_sv1x.expect(lambda dc: self.p_y1s.logp(dc,dc),
obs_xy, n_mc_q, repar, reducefn=tc.logsumexp) - math.log(n_mc_q)
)
else:
vwei_p_y1s_logp = lambda dc: self.p_sv.logp(dc,dc) - self.pt_sv.logp(dc,dc) + self.p_y1s.logp(dc,dc)
logits = (self.qt_sv1x.expect(vwei_p_y1s_logp, obs_xy, 0, repar) #, reducefn=tc.logsumexp)
) if n_mc_q == 0 else (
self.qt_sv1x.expect(vwei_p_y1s_logp, obs_xy, n_mc_q, repar, reducefn=tc.logsumexp) - math.log(n_mc_q)
)
return (logits[..., 1] - logits[..., 0]).squeeze(-1) if self.dim_y == 1 else logits
def generate(self, shape_mc: tc.Size=tc.Size(), mode: str="src") -> tuple:
if mode == "src": smp_sv = self.p_sv.draw(shape_mc)
elif mode == "tgt": smp_sv = self.pt_sv.draw(shape_mc)
else: raise ValueError(f"unknown 'mode' '{mode}'")
return self.p_x1sv.mode(smp_sv, False)['x'], self.p_y1s.mode(smp_sv, False)['y']
================================================
FILE: code/deep/CSG/methods/supvae.py
================================================
#!/usr/bin/env python3.6
'''Supervised VAE (no s-v split, the CSGz ablation baseline)
'''
import sys
import math
import torch as tc
sys.path.append('..')
import distr as ds
from . import xdistr as xds
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
class SupVAE:
@staticmethod
def _get_priors(mean_s, std_s, shape_s, mvn_prior: bool = False, device = None):
if not mvn_prior:
p_s = ds.Normal('s', mean=mean_s, std=std_s, shape=shape_s)
prior_params_list = []
else:
if len(shape_s) != 1:
raise RuntimeError("only 1-dim vector is supported for `s` in `mvn_prior` mode")
dim_s = shape_s[0]
mean_s = tc.zeros(shape_s, device=device) if callable(mean_s) else ds.tensorify(device, mean_s)[0].expand(shape_s).clone().detach()
std_s_offdiag = tc.zeros((dim_s, dim_s), device=device) # lower triangular of L_ss (excl. diag)
if callable(std_s): # for diag of L_ss
std_s_diag_param = tc.zeros(shape_s, device=device)
else:
std_s = ds.tensorify(device, std_s)[0].expand(shape_s)
std_s_diag_param = std_s.log().clone().detach()
prior_params_list = [mean_s, std_s_diag_param, std_s_offdiag]
def std_s_tril(): # L_ss
return std_s_offdiag.tril(-1) + std_s_diag_param.exp().diagflat()
p_s = ds.MVNormal('s', mean=mean_s, std_tril=std_s_tril, shape=shape_s)
return p_s, prior_params_list
def __init__(self, shape_s, shape_x, dim_y,
mean_x1s, std_x1s, logit_y1s,
mean_s1x = None, std_s1x = None,
tmean_s1x = None, tstd_s1x = None,
mean_s = 0., std_s = 1.,
learn_tprior = False, src_mvn_prior = False, tgt_mvn_prior = False, device = None):
if device is not None: ds.Distr.default_device = device
self._parameter_dict = {}
self.shape_x, self.dim_y, self.shape_s = shape_x, dim_y, shape_s
self.learn_tprior = learn_tprior
self.p_x1s = ds.Normal('x', mean=mean_x1s, std=std_x1s, shape=shape_x)
self.p_y1s = getattr(ds, 'Bern' if dim_y == 1 else 'Catg')('y', logits=logit_y1s)
self.p_s, prior_params_list = self._get_priors(mean_s, std_s, shape_s, src_mvn_prior, device)
if src_mvn_prior: self._parameter_dict.update(zip(['mean_s', 'std_s_diag_param', 'std_s_offdiag'], prior_params_list))
self.p_sx = self.p_s * self.p_x1s
if mean_s1x is not None:
self.q_s1x = ds.Normal('s', mean=mean_s1x, std=std_s1x, shape=shape_s)
else: self.q_s1x = None
if tmean_s1x is not None:
self.qt_s1x = ds.Normal('s', mean=tmean_s1x, std=tstd_s1x, shape=shape_s)
else: self.qt_s1x = None
if learn_tprior:
if not tgt_mvn_prior:
tmean_s = tc.zeros(shape_s, device=device) if callable(mean_s) else ds.tensorify(device, mean_s)[0].expand(shape_s).clone().detach()
tstd_s_param = tc.zeros(shape_s, device=device) if callable(std_s) else ds.tensorify(device, std_s)[0].log().expand(shape_s).clone().detach()
self._parameter_dict.update({'tmean_s': tmean_s, 'tstd_s_param': tstd_s_param})
def tstd_s(): return tc.exp(tstd_s_param)
self.pt_s, tprior_params_list = self._get_priors(tmean_s, tstd_s, shape_s, False, device)
else:
self.pt_s, tprior_params_list = self._get_priors(mean_s, std_s, shape_s, True, device)
self._parameter_dict.update(zip(['tmean_s', 'tstd_s_diag_param', 'tstd_s_offdiag'], tprior_params_list))
else: self.pt_s = self.p_s
self.pt_sx = self.pt_s * self.p_x1s
for param in self._parameter_dict.values(): param.requires_grad_()
def parameters(self):
for param in self._parameter_dict.values(): yield param
def state_dict(self):
return self._parameter_dict
def load_state_dict(self, state_dict: dict):
for name in list(self._parameter_dict.keys()):
with tc.no_grad(): self._parameter_dict[name].copy_(state_dict[name])
def get_lossfn(self, n_mc_q: int=0, reduction: str="mean", mode: str="defl", weight_da: float=None, wlogpi: float=None):
if reduction == "mean": reducefn = tc.mean
elif reduction == "sum": reducefn = tc.sum
elif reduction is None or reduction == "none": reducefn = lambda x: x
else: raise ValueError(f"unknown `reduction` '{reduction}'")
if self.q_s1x is not None: # svae, svae-da2
def lossfn_src(x: tc.Tensor, y: tc.LongTensor) -> tc.Tensor:
return -reducefn( xds.elbo_z2xy(self.p_sx, self.p_y1s, self.q_s1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
else:
if self.learn_tprior: # svae-da
def lossfn_src(x: tc.Tensor, y: tc.LongTensor) -> tc.Tensor:
return -reducefn( xds.elbo_z2xy_twist(self.pt_sx, self.p_y1s, self.p_s, self.pt_s, self.qt_s1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
# return -reducefn( xds.elbo_z2xy_twist_fixpt(self.p_x1s, self.p_y1s, self.p_s, self.pt_s, self.qt_s1x, {'x':x, 'y':y}, n_mc_q, wlogpi) )
else: raise ValueError("Use `q_s1x` for the source loss when no new prior")
def lossfn_tgt(xt: tc.Tensor) -> tc.Tensor:
return -reducefn( ds.elbo(self.pt_sx, self.qt_s1x, {'x': xt}, n_mc_q) )
# return -reducefn( xds.elbo_fixllh(self.pt_s, self.p_x1s, self.qt_s1x, {'x': xt}, n_mc_q) )
if mode == "src": return lossfn_src
elif mode == "tgt": return lossfn_tgt # may be invalid
elif not mode or mode == "defl":
if self.learn_tprior:
def lossfn(x: tc.Tensor, y: tc.LongTensor, xt: tc.Tensor) -> tc.Tensor:
return lossfn_src(x,y) + weight_da * lossfn_tgt(xt)
return lossfn
else: return lossfn_src
else: raise ValueError(f"unknown `mode` '{mode}'")
# Utilities
def llh(self, x: tc.Tensor, y: tc.LongTensor=None, n_mc_marg: int=64, use_q: bool=True, mode: str="src") -> float:
if mode == "src":
p_joint = self.p_sx
q_cond = self.q_s1x if self.q_s1x else self.qt_s1x
elif mode == "tgt":
p_joint = self.pt_sx
q_cond = self.qt_s1x if self.qt_s1x else self.q_s1x
else: raise ValueError(f"unknown `mode` '{mode}'")
if not use_q:
if y is None: llh_vals = p_joint.marg({'x'}, n_mc_marg).logp({'x': x})
else: llh_vals = (p_joint * self.p_y1s).marg({'x', 'y'}, n_mc_marg).logp({'x': x, 'y': y})
else:
if y is None: llh_vals = q_cond.expect(lambda dc: p_joint.logp(dc) - q_cond.logp(dc,dc),
{'x': x}, n_mc_marg, reducefn=tc.logsumexp) - math.log(n_mc_marg)
else: llh_vals = q_cond.expect(lambda dc: (p_joint * self.p_y1s).logp(dc) - q_cond.logp(dc,dc),
{'x': x, 'y': y}, n_mc_marg, reducefn=tc.logsumexp) - math.log(n_mc_marg)
return llh_vals.mean().item()
def logit_y1x_src(self, x: tc.Tensor, n_mc_q: int=0, repar: bool=True):
dim_y = 2 if self.dim_y == 1 else self.dim_y
y_eval = ds.expand_front(tc.arange(dim_y, device=x.device), ds.tcsize_div(x.shape, self.shape_x))
x_eval = ds.expand_middle(x, (dim_y,), -len(self.shape_x))
obs_xy = ds.edic({'x': x_eval, 'y': y_eval})
if self.q_s1x is not None:
logits = (self.q_s1x.expect(lambda dc: self.p_y1s.logp(dc,dc), obs_xy, 0, repar) #, reducefn=tc.logsumexp)
) if n_mc_q == 0 else (
self.q_s1x.expect(lambda dc: self.p_y1s.logp(dc,dc),
obs_xy, n_mc_q, repar, reducefn=tc.logsumexp) - math.log(n_mc_q)
)
else:
vwei_p_y1s_logp = lambda dc: self.p_s.logp(dc,dc) - self.pt_s.logp(dc,dc) + self.p_y1s.logp(dc,dc)
logits = (self.qt_s1x.expect(vwei_p_y1s_logp, obs_xy, 0, repar) #, reducefn=tc.logsumexp)
) if n_mc_q == 0 else (
self.qt_s1x.expect(vwei_p_y1s_logp, obs_xy, n_mc_q, repar, reducefn=tc.logsumexp) - math.log(n_mc_q)
)
return (logits[..., 1] - logits[..., 0]).squeeze(-1) if self.dim_y == 1 else logits
def generate(self, shape_mc: tc.Size=tc.Size(), mode: str="src") -> tuple:
if mode == "src": smp_s = self.p_s.draw(shape_mc)
elif mode == "tgt": smp_s = self.pt_s.draw(shape_mc)
else: raise ValueError(f"unknown 'mode' '{mode}'")
return self.p_x1s.mode(smp_s, False)['x'], self.p_y1s.mode(smp_s, False)['y']
================================================
FILE: code/deep/CSG/methods/xdistr.py
================================================
#!/usr/bin/env python3.6
""" Modification to the `distr` package for the structure of the
Causal Semantic Generative model.
"""
import sys
import math
import torch as tc
sys.path.append('..')
from distr import Distr, edic
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
def elbo_z2xy(p_zx: Distr, p_y1z: Distr, q_z1x: Distr, obs_xy: edic, n_mc: int=0, wlogpi: float=1., repar: bool=True) -> tc.Tensor:
""" For supervised VAE with structure x <- z -> y.
Observations are supervised (x,y) pairs.
For unsupervised observations of x data, use `elbo(p_zx, q_z1x, obs_x)` as VAE z -> x. """
if n_mc == 0:
q_y1x_logpval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc), obs_xy, 0, repar) #, reducefn=tc.logsumexp)
if hasattr(q_z1x, "entropy"): # No difference for Gaussian
expc_val = q_z1x.expect(lambda dc: p_zx.logp(dc,dc), obs_xy, 0, repar) + q_z1x.entropy(obs_xy)
else:
expc_val = q_z1x.expect(lambda dc: p_zx.logp(dc,dc) - q_z1x.logp(dc,dc), obs_xy, 0, repar)
return wlogpi * q_y1x_logpval + expc_val
else:
q_y1x_pval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc).exp(), obs_xy, n_mc, repar)
expc_val = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc).exp() * (p_zx.logp(dc,dc) - q_z1x.logp(dc,dc)),
obs_xy, n_mc, repar)
return wlogpi * q_y1x_pval.log() + expc_val / q_y1x_pval
# q_y1x_logpval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc), obs_xy, n_mc, repar,
# reducefn=tc.logsumexp) - math.log(n_mc)
# expc_logval = q_z1x.expect(lambda dc: p_y1z.logp(dc,dc) + (p_zx.logp(dc,dc) - q_z1x.logp(dc,dc)).log(),
# obs_xy, n_mc, repar, reducefn=tc.logsumexp) - math.log(n_mc)
# return wlogpi * q_y1x_logpval + (expc_logval - q_y1x_logpval).exp()
def elbo_z2xy_twist(pt_zx: Distr, p_y1z: Distr, p_z: Distr, pt_z: Distr, qt_z1x: Distr, obs_xy: edic, n_mc: int=0, wlogpi: float=1., repar: bool=True) -> tc.Tensor:
vwei_p_y1z_logp = lambda dc: p_z.logp(dc,dc) - pt_z.logp(dc,dc) + p_y1z.logp(dc,dc) # z, y:
if n_mc == 0:
r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, 0, repar) #, reducefn=tc.logsumexp)
if hasattr(qt_z1x, "entropy"): # No difference for Gaussian
expc_val = qt_z1x.expect(lambda dc: pt_zx.logp(dc,dc), obs_xy, 0, repar) + qt_z1x.entropy(obs_xy)
else:
expc_val = qt_z1x.expect(lambda dc: pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc), obs_xy, 0, repar)
return wlogpi * r_y1x_logpval + expc_val
else:
r_y1x_pval = qt_z1x.expect(lambda dc: vwei_p_y1z_logp(dc).exp(), obs_xy, n_mc, repar)
expc_val = qt_z1x.expect( lambda dc: # z, x, y:
vwei_p_y1z_logp(dc).exp() * (pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc)),
obs_xy, n_mc, repar)
return wlogpi * r_y1x_pval.log() + expc_val / r_y1x_pval
# r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, n_mc, repar,
# reducefn=tc.logsumexp) - math.log(n_mc) # z, y:
# expc_logval = qt_z1x.expect(lambda dc: # z, x, y:
# vwei_p_y1z_logp(dc) + (pt_zx.logp(dc,dc) - qt_z1x.logp(dc,dc)).log(),
# obs_xy, n_mc, repar, reducefn=tc.logsumexp) - math.log(n_mc)
# return wlogpi * r_y1x_logpval + (expc_logval - r_y1x_logpval).exp()
def elbo_fixllh(p_prior: Distr, p_llh: Distr, q_cond: Distr, obs: edic, n_mc: int=10, repar: bool=True) -> tc.Tensor: # [shape_bat] -> [shape_bat]
def logp_llh_nograd(dc):
with tc.no_grad(): return p_llh.logp(dc,dc)
if hasattr(q_cond, "entropy"):
return q_cond.expect(lambda dc: p_prior.logp(dc,dc) + logp_llh_nograd(dc),
obs, n_mc, repar) + q_cond.entropy(obs)
else:
return q_cond.expect(lambda dc: p_prior.logp(dc,dc) + logp_llh_nograd(dc) - q_cond.logp(dc,dc),
obs, n_mc, repar)
def elbo_z2xy_twist_fixpt(p_x1z: Distr, p_y1z: Distr, p_z: Distr, pt_z: Distr, qt_z1x: Distr, obs_xy: edic, n_mc: int=0, wlogpi: float=1., repar: bool=True) -> tc.Tensor:
def logpt_z_nograd(dc):
with tc.no_grad(): return pt_z.logp(dc,dc)
vwei_p_y1z_logp = lambda dc: p_z.logp(dc,dc) - logpt_z_nograd(dc) + p_y1z.logp(dc,dc) # z, y:
if n_mc == 0:
r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, 0, repar) #, reducefn=tc.logsumexp)
if hasattr(qt_z1x, "entropy"):
expc_val = qt_z1x.expect(lambda dc: logpt_z_nograd(dc) + p_x1z.logp(dc,dc),
obs_xy, 0, repar) + qt_z1x.entropy(obs_xy)
else:
expc_val = qt_z1x.expect(lambda dc: logpt_z_nograd(dc) + p_x1z.logp(dc,dc) - qt_z1x.logp(dc,dc), obs_xy, 0, repar)
return wlogpi * r_y1x_logpval + expc_val
else:
r_y1x_pval = qt_z1x.expect(lambda dc: vwei_p_y1z_logp(dc).exp(), obs_xy, n_mc, repar)
expc_val = qt_z1x.expect( lambda dc: # z, x, y:
vwei_p_y1z_logp(dc).exp() * (logpt_z_nograd(dc) + p_x1z.logp(dc,dc) - qt_z1x.logp(dc,dc)),
obs_xy, n_mc, repar)
return wlogpi * r_y1x_pval.log() + expc_val / r_y1x_pval
# r_y1x_logpval = qt_z1x.expect(vwei_p_y1z_logp, obs_xy, n_mc, repar,
# reducefn=tc.logsumexp) - math.log(n_mc) # z, y:
# expc_logval = qt_z1x.expect(lambda dc: # z, x, y:
# vwei_p_y1z_logp(dc) + (logpt_z_nograd(dc) + p_x1z.logp(dc,dc) - qt_z1x.logp(dc,dc)).log(),
# obs_xy, n_mc, repar, reducefn=tc.logsumexp) - math.log(n_mc)
# return wlogpi * r_y1x_logpval + (expc_logval - r_y1x_logpval).exp()
================================================
FILE: code/deep/CSG/requirements.txt
================================================
requirements can be modified often. Please refer to https://github.com/changliu00/causal-semantic-generative-model/blob/main/requirements.txt for new requirements.
================================================
FILE: code/deep/CSG/test/distr_test.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import sys\n",
"import numpy as np\n",
"import torch as tc\n",
"sys.path.append('..')\n",
"import distr as ds\n",
"\n",
"shape_s, shape_z = (2,3), (2,2)\n",
"shape_bat = (30000,)\n",
"mu_S, mu_Z = -1., 1.\n",
"std_S, std_Z = 1.3, 1.\n",
"corr_SZ = .7\n",
"dim_s, dim_z = np.array(shape_s).prod(), np.array(shape_z).prod()\n",
"\n",
"S = mu_S + std_S * np.random.randn(*(shape_bat+shape_s)).astype(np.float32)\n",
"S_normal_flat = ((S - mu_S) / std_S).reshape(shape_bat+(dim_s,))\n",
"Z_normal_flat = S_normal_flat[..., :dim_z] if dim_z <= dim_s \\\n",
" else tc.cat([S_normal_flat, tc.zeros(shape_bat+(dim_z-dim_s,), dtype=np.float32)], dim=-1)\n",
"mu_Z1S = mu_Z + corr_SZ*std_Z * Z_normal_flat.reshape(shape_bat+shape_z)\n",
"std_Z1S = std_Z * np.sqrt(1. - corr_SZ**2)\n",
"Z = mu_Z1S + std_Z1S * np.random.randn(*(shape_bat+shape_z)).astype(np.float32)\n",
"\n",
"device = tc.device(\"cuda:0\" if tc.cuda.is_available() else \"cpu\")\n",
"S, Z = tc.from_numpy(S).to(device), tc.from_numpy(Z).to(device)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Learning by Normal"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"mu_s = tc.randn(shape_s, requires_grad=True, device=device)\n",
"std_s_param = tc.randn(shape_s, requires_grad=True, device=device)\n",
"mu_z = tc.randn(shape_z, requires_grad=True, device=device)\n",
"std_z_param = tc.randn(shape_z, requires_grad=True, device=device)\n",
"corr_param = tc.randn(1, requires_grad=True, device=device)\n",
"\n",
"def corr_sz(): return 1. - (2*tc.sigmoid(corr_param)-1.)**2\n",
"def std_s(): return tc.exp(std_s_param)\n",
"def std_z(): return tc.exp(std_z_param)\n",
"\n",
"def mu_z1s(s):\n",
" s_normal_flat = ((s - mu_s) / std_s()).reshape(shape_bat+(dim_s,))\n",
" z_normal_flat = s_normal_flat[..., :dim_z] if dim_z <= dim_s \\\n",
" else tc.cat([s_normal_flat, tc.zeros(shape_bat+(dim_z-dim_s,), dtype=s.dtype, device=s.device)], dim=-1)\n",
" return mu_z + corr_sz()*std_z() * z_normal_flat.reshape(shape_bat+shape_z)\n",
"\n",
"def std_z1s():\n",
" return std_z() * (1. - corr_sz()**2).sqrt()\n",
"\n",
"ds.Distr.clear()\n",
"ds.Distr.default_device = device\n",
"p_s = ds.Normal('s', mean=mu_s, std=std_s, shape=shape_s)\n",
"p_z1s = ds.Normal('z',mean=mu_z1s, std=std_z1s, shape=shape_z)\n",
"p_sz = p_s * p_z1s"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[-0.9941, -0.9730, -0.9932],\n",
" [-0.9953, -0.9977, -0.9990]], device='cuda:0')\n",
"tensor([[1.2980, 1.2980, 1.3023],\n",
" [1.3075, 1.3032, 1.2968]], device='cuda:0')\n"
]
}
],
"source": [
"# print(std_s_param.data)\n",
"# print(mu_s.data, std_s().data, sep='\\n')\n",
"opt = tc.optim.SGD([mu_s, std_s_param], lr=1e-3)\n",
"for i in range(10000):\n",
" opt.zero_grad()\n",
" mlogp = -p_s.logp({'s': S}).mean()\n",
"# print(i, mlogp.data)\n",
" mlogp.backward()\n",
" opt.step()\n",
"# print(std_s_param.data)\n",
"# print(mu_s.data, std_s().data, sep='\\n')\n",
"print(mu_s.data, std_s().data, sep='\\n')"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[-1.0678, -1.0178, -1.0556],\n",
" [-1.0065, -1.0068, -0.9978]], device='cuda:0')\n",
"tensor([[1.3031, 1.3017, 1.3065],\n",
" [1.3065, 1.3031, 1.2968]], device='cuda:0')\n",
"tensor([[0.9547, 0.9831],\n",
" [0.9609, 0.9943]], device='cuda:0')\n",
"tensor([[1.0030, 1.0033],\n",
" [1.0072, 1.0018]], device='cuda:0')\n",
"tensor([0.7024], device='cuda:0')\n",
"tensor([[0.7140, 0.7141],\n",
" [0.7169, 0.7131]], device='cuda:0')\n"
]
}
],
"source": [
"# print(std_s_param.data, std_z_param.data, corr_param.data, sep='\\n')\n",
"# print('-'*5)\n",
"# print(mu_s.data, std_s().data, mu_z.data, std_z().data, corr_sz().data, std_z1s().data, sep='\\n')\n",
"opt = tc.optim.SGD([mu_s, std_s_param, mu_z, std_z_param, corr_param], lr=1e-3)\n",
"for i in range(10000):\n",
" opt.zero_grad()\n",
" mlogp = -p_sz.logp({'s': S, 'z': Z}).mean()\n",
"# print(i, mlogp.data)\n",
" mlogp.backward()\n",
" opt.step()\n",
"# print(std_s_param.data, std_z_param.data, corr_param.data, sep='\\n')\n",
"# print('-'*5)\n",
"# print(mu_s.data, std_s().data, mu_z.data, std_z().data, corr_sz().data, std_z1s().data, sep='\\n')\n",
"print(mu_s.data, std_s().data, mu_z.data, std_z().data, corr_sz().data, std_z1s().data, sep='\\n')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Learning by MVNormal"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"mu_s = tc.randn(shape_s, requires_grad=True, device=device)\n",
"std_s_diagpm = tc.randn(shape_s, requires_grad=True, device=device)\n",
"std_s_offdiag = tc.randn(shape_s+shape_s[-1:], requires_grad=True, device=device)\n",
"mu_z = tc.randn(shape_z, requires_grad=True, device=device)\n",
"std_z_diagpm = tc.randn(shape_z, requires_grad=True, device=device)\n",
"std_z_offdiag = tc.randn(shape_z+shape_z[-1:], requires_grad=True, device=device)\n",
"corr_param = tc.randn(1, requires_grad=True, device=device)\n",
"\n",
"def corr_sz(): return 1. - (2*tc.sigmoid(corr_param)-1.)**2\n",
"def std_s(): return tc.exp(std_s_diagpm).diag_embed() + std_s_offdiag.tril(diagonal=-1)\n",
"def std_z(): return tc.exp(std_z_diagpm).diag_embed() + std_z_offdiag.tril(diagonal=-1)\n",
"\n",
"def mu_z1s(s):\n",
" s_normal = tc.triangular_solve((s - mu_s).unsqueeze(-1), std_s(), upper=False)[0].squeeze(-1)\n",
" s_normal_flat = s_normal.reshape(shape_bat+(dim_s,))\n",
" z_normal_flat = s_normal_flat[..., :dim_z] if dim_z <= dim_s \\\n",
" else tc.cat([s_normal_flat, tc.zeros(shape_bat+(dim_z-dim_s,), dtype=s.dtype, device=s.device)], dim=-1)\n",
" return mu_z + corr_sz() * (std_z() @ z_normal_flat.reshape(shape_bat+shape_z+(1,))).squeeze(-1)\n",
"\n",
"def std_z1s():\n",
" return std_z() * (1. - corr_sz()**2).sqrt()\n",
"\n",
"ds.Distr.clear()\n",
"ds.Distr.default_device = device\n",
"p_s = ds.MVNormal('s', mean=mu_s, std_tril=std_s, shape=shape_s)\n",
"p_z1s = ds.MVNormal('z',mean=mu_z1s, std_tril=std_z1s, shape=shape_z)\n",
"p_sz = p_s * p_z1s"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[-0.9912, -0.9900, -0.9952],\n",
" [-0.9905, -0.9530, -0.9386]], device='cuda:0')\n",
"tensor([[[ 1.2981, 0.0000, 0.0000],\n",
" [-0.0110, 1.2976, 0.0000],\n",
" [ 0.0114, -0.0080, 1.3025]],\n",
"\n",
" [[ 1.3076, 0.0000, 0.0000],\n",
" [-0.0060, 1.3123, 0.0000],\n",
" [ 0.0095, 0.0899, 1.3067]]], device='cuda:0')\n"
]
}
],
"source": [
"opt = tc.optim.SGD([mu_s, std_s_diagpm, std_s_offdiag], lr=1e-3)\n",
"for i in range(10000):\n",
" opt.zero_grad()\n",
" mlogp = -p_s.logp({'s': S}).mean()\n",
" mlogp.backward()\n",
" opt.step()\n",
"print(mu_s.data, std_s().data, sep='\\n')"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[-0.9969, -1.0019, -1.0026],\n",
" [-1.0011, -1.0066, -0.9976]], device='cuda:0')\n",
"tensor([[[ 1.2988e+00, 0.0000e+00, 0.0000e+00],\n",
" [-3.6102e-04, 1.2994e+00, 0.0000e+00],\n",
" [ 2.0667e-03, 3.0024e-03, 1.3029e+00]],\n",
"\n",
" [[ 1.3043e+00, 0.0000e+00, 0.0000e+00],\n",
" [-1.8239e-02, 1.3030e+00, 0.0000e+00],\n",
" [-1.4886e-03, -9.8890e-03, 1.2968e+00]]], device='cuda:0')\n",
"tensor([[1.0038, 0.9942],\n",
" [0.9977, 0.9980]], device='cuda:0')\n",
"tensor([[[1.0001e+00, 0.0000e+00],\n",
" [4.5207e-03, 1.0015e+00]],\n",
"\n",
" [[1.0047e+00, 0.0000e+00],\n",
" [2.6764e-04, 1.0001e+00]]], device='cuda:0')\n",
"tensor([0.7009], device='cuda:0')\n",
"tensor([[[7.1335e-01, 0.0000e+00],\n",
" [3.2245e-03, 7.1434e-01]],\n",
"\n",
" [[7.1660e-01, 0.0000e+00],\n",
" [1.9090e-04, 7.1335e-01]]], device='cuda:0')\n"
]
}
],
"source": [
"opt = tc.optim.SGD([mu_s, std_s_diagpm, std_s_offdiag, mu_z, std_z_diagpm, std_z_offdiag, corr_param], lr=1e-3)\n",
"for i in range(10000):\n",
" opt.zero_grad()\n",
" mlogp = -p_sz.logp({'s': S, 'z': Z}).mean()\n",
" mlogp.backward()\n",
" opt.step()\n",
"print(mu_s.data, std_s().data, mu_z.data, std_z().data, corr_sz().data, std_z1s().data, sep='\\n')"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.7"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: code/deep/CSG/test/distr_test.py
================================================
#!/usr/bin/env python3.6
import sys
import torch as tc
sys.path.append('..')
import distr as ds
from distr.utils import expand_front, swap_dim_ranges
'''Test cases of the 'distr' package.
'''
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
shape_x = (1,2)
shape_bat = (3,4)
device = tc.device("cuda:0" if tc.cuda.is_available() else "cpu")
ds.Distr.default_device = device
def test_fun(title, p_z, p_x1z):
print(title)
print("p_z:", p_z.names, p_z.parents)
print("p_x1z:", p_x1z.names, p_x1z.parents)
p_zx = p_z * p_x1z
print("p_zx:", p_zx.names, p_zx.parents)
smp_z = p_z.draw(shape_bat)
print("sample shape z:", smp_z['z'].shape)
smp_x1z = p_x1z.draw((), smp_z)
print("sample shape x:", smp_x1z['x'].shape)
print("logp match:", tc.allclose(
p_z.logp(smp_z) + p_x1z.logp(smp_x1z, smp_z),
p_zx.logp(smp_z|smp_x1z) ))
smp_zx = p_zx.draw(shape_bat)
print("sample shape z:", smp_zx['z'].shape)
print("sample shape x:", smp_zx['x'].shape)
print("logp match:", tc.allclose(
p_z.logp(smp_zx) + p_x1z.logp(smp_zx, smp_zx),
p_zx.logp(smp_zx) ))
print("logp_cartes shape:", p_x1z.logp_cartes(smp_x1z, smp_z).shape)
print()
ds.Distr.clear()
# Normal
ndim_x = len(shape_x)
test_fun("Normal:",
p_z = ds.Normal('z', 0., 1.),
p_x1z = ds.Normal('x', shape = shape_x, mean =
lambda z: swap_dim_ranges( expand_front(z, shape_x), (0, ndim_x), (ndim_x, ndim_x+z.ndim) ),
std = 1.
))
# MVNormal
test_fun("MVNormal:",
p_z = ds.MVNormal('z', 0., 1.),
p_x1z = ds.MVNormal('x', shape = shape_x, mean =
lambda z: swap_dim_ranges( expand_front(z, shape_x).squeeze(-1), (0, ndim_x), (ndim_x, ndim_x+z.ndim-1) ),
cov = 1.
))
# Catg
ncat_z = 3
ncat_x = 4
w_z = tc.rand(ncat_z)
w_z = w_z / w_z.sum()
w_x = tc.rand((ncat_z,) + shape_x + (ncat_x,), device=device)
w_x = w_x / w_x.sum(dim=-1, keepdim=True)
test_fun("Catg:",
p_z = ds.Catg('z', probs = w_z),
p_x1z = ds.Catg('x', shape = shape_x, probs =
lambda z: w_x.index_select(dim=0, index=z.flatten()).reshape(z.shape + w_x.shape[1:])
))
# Bern
w_x = tc.rand(shape_x, device=device)
w_x = tc.stack([1-w_x, w_x], dim=0)
test_fun("Bern:",
p_z = ds.Bern('z', probs = tc.rand(())),
p_x1z = ds.Bern('x', shape = shape_x, probs =
lambda z: w_x.index_select(dim=0, index=z.flatten()).reshape(z.shape + w_x.shape[1:])
))
================================================
FILE: code/deep/CSG/test/utils_test.py
================================================
#!/usr/bin/env python3.6
import sys
from time import time
import numpy as np
sys.path.append('..')
import utils
'''Test cases of the 'distr' package.
'''
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
shape = (500, 200, 50)
arr = np.random.rand(*shape)
length = arr.shape[-1]
for n_win in range(1, 3*shape[-1] + 2):
print(f"{n_win:3d}", end=", ")
lwid = (n_win - 1) // 2
rwid = n_win//2 + 1
t = time(); ma_slim = utils.moving_average_slim(arr, n_win); print(f"{time() - t:.6f}", end=", ")
t = time(); ma_full = utils.moving_average_full(arr, n_win); print(f"{time() - t:.6f}", end=", ")
t = time(); ma_full_check = utils.moving_average_full_checker(arr, n_win); print(f"{time() - t:.6f}", end=", ")
ma_slim_check = ma_full_check[..., lwid: length-rwid+1]
# print(ma_slim.shape, ma_slim_check.shape, ma_full.shape, ma_full_check.shape)
print(f"slim: {np.allclose(ma_slim, ma_slim_check)}, full: {np.allclose(ma_full, ma_full_check)}")
================================================
FILE: code/deep/CSG/utils/__init__.py
================================================
#!/usr/bin/env python3.6
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
from .utils import *
================================================
FILE: code/deep/CSG/utils/preprocess/__init__.py
================================================
""" This module is adapted from Jindong Wang
.
"""
================================================
FILE: code/deep/CSG/utils/preprocess/data_list.py
================================================
#from __future__ import print_function, division
import torch
import numpy as np
from sklearn.preprocessing import StandardScaler
import random
from PIL import Image
import torch.utils.data as data
import os
import os.path
def make_dataset(image_list, labels):
if labels:
len_ = len(image_list)
images = [(image_list[i].strip(), labels[i, :]) for i in range(len_)]
else:
if len(image_list[0].split()) > 2:
images = [(val.split()[0], np.array([int(la) for la in val.split()[1:]])) for val in image_list]
else:
images = [(val.split()[0], int(val.split()[1])) for val in image_list]
return images
def pil_loader(path):
# open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)
with open(path, 'rb') as f:
with Image.open(f) as img:
return img.convert('RGB')
def accimage_loader(path):
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path)
def default_loader(path):
#from torchvision import get_image_backend
#if get_image_backend() == 'accimage':
# return accimage_loader(path)
#else:
return pil_loader(path)
class ImageList(object):
"""A generic data loader where the images are arranged in this way: ::
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
Args:
root (string): Root directory path.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
loader (callable, optional): A function to load an image given its path.
Attributes:
classes (list): List of the class names.
class_to_idx (dict): Dict with items (class_name, class_index).
imgs (list): List of (image path, class_index) tuples
"""
def __init__(self, image_list, labels=None, transform=None, target_transform=None,
loader=default_loader, root='.'):
imgs = make_dataset(image_list, labels)
if len(imgs) == 0:
raise(RuntimeError("Found 0 images in subfolders of: " + root + "\n"
"Supported image extensions are: " + ",".join(IMG_EXTENSIONS)))
self.root = root
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is class_index of the target class.
"""
path, target = self.imgs[index]
img = self.loader(self.root + path)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
return len(self.imgs)
================================================
FILE: code/deep/CSG/utils/preprocess/data_loader.py
================================================
# coding=utf-8
from torchvision import datasets, transforms
import torch
from torch.utils import data
import numpy as np
from torchvision import transforms
import os
from PIL import Image
from torch.utils.data.sampler import SubsetRandomSampler
from skimage import io
class PlaceCrop(object):
def __init__(self, size, start_x, start_y):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
self.start_x = start_x
self.start_y = start_y
def __call__(self, img):
th, tw = self.size
return img.crop((self.start_x, self.start_y, self.start_x + tw, self.start_y + th))
class ResizeImage():
def __init__(self, size):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img):
th, tw = self.size
return img.resize((th, tw))
class myDataset(data.Dataset):
def __init__(self, root, transform=None, train=True):
self.train = train
class_dirs = [os.path.join(root, i) for i in os.listdir(root)]
imgs = []
for i in class_dirs:
imgs += [os.path.join(i, img) for img in os.listdir(i)]
np.random.shuffle(imgs)
imgs_mun = len(imgs)
# target:val = 8 :2
if self.train:
self.imgs = imgs[:int(0.3*imgs_mun)]
else:
self.imgs = imgs[int(0.3*imgs_mun):]
if transform:
self.transforms = transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
else:
start_center = (256 - 224 - 1) / 2
self.transforms = transforms.Compose(
[transforms.Resize([224, 224]),
PlaceCrop(224, start_center, start_center),
transforms.ToTensor()])
def __getitem__(self, index):
img_path = self.imgs[index]
label = int(img_path.strip().split('/')[10])
print(img_path, label)
#data = Image.open(img_path)
data = io.imread(img_path)
data = Image.fromarray(data)
if data.getbands()[0] == 'L':
data = data.convert('RGB')
data = self.transforms(data)
return data, label
def __len__(self):
return len(self.imgs)
def load_training(root_path, domain, batch_size, kwargs, train_val_split=.5, rand_split=True):
kwargs_fin = dict(shuffle=True, drop_last=True)
kwargs_fin.update(kwargs)
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transform = transforms.Compose(
[ResizeImage(256),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize])
data = datasets.ImageFolder(root=os.path.join(
root_path, domain), transform=transform)
if train_val_split <= 0:
train_loader = torch.utils.data.DataLoader(
data, batch_size=batch_size, **kwargs_fin)
return train_loader
else:
train_loader, val_loader = load_train_valid_split(
data, batch_size, kwargs_fin, val_ratio=1.-train_val_split, rand_split=rand_split)
return train_loader, val_loader
def load_testing(root_path, domain, batch_size, kwargs):
kwargs_fin = dict(shuffle=False, drop_last=False)
kwargs_fin.update(kwargs)
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
start_center = (256 - 224 - 1) / 2
transform = transforms.Compose(
[ResizeImage(256),
PlaceCrop(224, start_center, start_center),
transforms.ToTensor(),
normalize])
dataset = datasets.ImageFolder(root=os.path.join(
root_path, domain), transform=transform)
test_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, **kwargs_fin)
return test_loader
def load_train_valid_split(dataset, batch_size, kwargs, val_ratio=0.4, rand_split=True):
dataset_size = len(dataset)
indices = list(range(dataset_size))
if rand_split: np.random.shuffle(indices)
len_val = int(np.floor(val_ratio * dataset_size))
train_indices, val_indices = indices[len_val:], indices[:len_val]
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(val_indices)
__ = kwargs.pop('shuffle', None)
__ = kwargs.pop('drop_last', None)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
sampler=train_sampler, **kwargs, drop_last=True)
validation_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
sampler=valid_sampler, **kwargs, drop_last=True)
return train_loader, validation_loader
def load_data(root_path, source_dir, target_dir, batch_size):
kwargs = {'num_workers': 4, 'pin_memory': True}
source_loader = load_training(
root_path, source_dir, batch_size, kwargs)
target_loader = load_training(
root_path, target_dir, batch_size, kwargs)
test_loader = load_testing(
root_path, target_dir, batch_size, kwargs)
return source_loader, target_loader, test_loader
def load_all_test(root_path, dataset, batch_size, train, kwargs):
ls = []
domains = {'Office-31': ['amazon', 'dslr', 'webcam'],
'Office-Home': ['Art', 'Clipart', 'Product', 'RealWorld']}
for dom in domains[dataset]:
if train:
loader = load_training(root_path, dom, batch_size, kwargs, train_val_split=-1)
else:
loader = load_testing(root_path, dom, batch_size, kwargs)
ls.append(loader)
return ls
================================================
FILE: code/deep/CSG/utils/preprocess/data_provider.py
================================================
import numpy as np
from .data_list import ImageList
import torch.utils.data as util_data
from torchvision import transforms
from PIL import Image, ImageOps
class ResizeImage():
def __init__(self, size):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img):
th, tw = self.size
return img.resize((th, tw))
class PlaceCrop(object):
def __init__(self, size, start_x, start_y):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
self.start_x = start_x
self.start_y = start_y
def __call__(self, img):
th, tw = self.size
return img.crop((self.start_x, self.start_y, self.start_x + tw, self.start_y + th))
def load_images(images_file_path, batch_size, resize_size=256, is_train=True, crop_size=224, is_cen=False, num_workers=4):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
if not is_train:
start_center = (resize_size - crop_size - 1) / 2
transformer = transforms.Compose([
ResizeImage(resize_size),
PlaceCrop(crop_size, start_center, start_center),
transforms.ToTensor(),
normalize])
images = ImageList(open(images_file_path).readlines(), transform=transformer)
images_loader = util_data.DataLoader(images, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=True)
else:
if is_cen:
transformer = transforms.Compose([ResizeImage(resize_size),
transforms.Scale(resize_size),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(crop_size),
transforms.ToTensor(),
normalize])
else:
transformer = transforms.Compose([ResizeImage(resize_size),
transforms.RandomResizedCrop(crop_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize])
images = ImageList(open(images_file_path).readlines(), transform=transformer)
images_loader = util_data.DataLoader(images, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
return images_loader
================================================
FILE: code/deep/CSG/utils/reprun.sh
================================================
n=$1
command=$2
shift
shift
for i in $(seq 1 $n)
do
$command $*
done
================================================
FILE: code/deep/CSG/utils/utils.py
================================================
#!/usr/bin/env python3.6
import os
import warnings
from itertools import product, chain
import math
import torch as tc
import numpy as np
import matplotlib.pyplot as plt
from tabulate import tabulate
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# General Utilities
def unique_filename(prefix: str="", suffix: str="", n_digits: int=2, count_start: int=0) -> str:
fmt = "{:0" + str(n_digits) + "d}"
if prefix and prefix[-1] not in {"/", "\\"}: prefix += "_"
while True:
filename = prefix + fmt.format(count_start) + suffix
if not os.path.exists(filename): return filename
else: count_start += 1
class Averager:
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self._val = 0
self._avg = 0
self._sum = 0
self._count = 0
def update(self, val, nrep = 1):
self._val = val
self._sum += val * nrep
self._count += nrep
self._avg = self._sum / self._count
@property
def val(self): return self._val
@property
def avg(self): return self._avg
@property
def sum(self): return self._sum
@property
def count(self): return self._count
def repeat_iterator(itr, n_repeat):
# The built-in `itertools.cycle` stores all results over `itr` and does not initialize `itr` again.
return chain.from_iterable([itr] * n_repeat)
class RepeatIterator:
def __init__(self, itr, n_repeat):
self.itr = itr
self.n_repeat = n_repeat
self.len = len(itr) * n_repeat
def __iter__(self):
return chain.from_iterable([self.itr] * self.n_repeat)
def __len__(self): return self.len
def zip_longer(itr1, itr2):
len_ratio = len(itr1) / len(itr2)
if len_ratio > 1:
return zip(itr1, repeat_iterator(itr2, math.ceil(len_ratio)))
elif len_ratio < 1:
return zip(repeat_iterator(itr1, math.ceil(1/len_ratio)), itr2)
else: return zip(itr1, itr2)
def zip_longest(*itrs):
itr_longest = max(itrs, key=len)
len_longest = len(itr_longest)
return zip(*[itr if len(itr) == len_longest
else repeat_iterator(itr, math.ceil(len_longest / len(itr)))
for itr in itrs])
class ZipLongest:
def __init__(self, *itrs):
self.itrs = itrs
self.itr_longest = max(itrs, key=len)
self.len = len(self.itr_longest)
def __iter__(self):
return zip(*[itr if len(itr) == self.len
else repeat_iterator(itr, math.ceil(self.len / len(itr)))
for itr in self.itrs])
def __len__(self): return self.len
class CyclicLoader:
def __init__(self, datalist: list, shuffle: bool=True, cycle: int=None):
self.len = len(datalist[0])
if shuffle:
ids = np.random.permutation(self.len)
self.datalist = [data[ids] for data in datalist]
else: self.datalist = datalist
self.cycle = self.len if cycle is None else cycle
self.head = 0
def iter(self):
self.head = 0
return self
def next(self, n: int) -> tuple:
ids = [i % self.cycle for i in range(self.head, self.head + n)]
self.head = (self.head + n) % self.cycle
return tuple(data[ids] for data in self.datalist)
def back(self, n: int):
self.head = (self.head - n) % self.cycle
return self
def boolstr(s: str) -> bool:
# for argparse argument of type bool
if isinstance(s, str):
true_strings = {'1', 'true', 'True', 'T', 'yes', 'Yes', 'Y'}
false_strings = {'0', 'false', 'False', 'F', 'no', 'No', 'N'}
if s not in true_strings | false_strings:
raise ValueError('Not a valid boolean string')
return s in true_strings
else:
return bool(s)
## For lists/tuples
def getlist(ls: list, ids: list) -> list:
return [ls[i] for i in ids]
def interleave(*lists) -> list:
return [v for row in zip(*lists) for v in row]
def flatten(ls: list, depth: int=None) -> list:
i = 0
while (depth is None or i < depth) and bool(ls) and all(
type(row) is list or type(row) is tuple for row in ls):
ls = [v for row in ls if bool(row) for v in row]
i += 1
return ls
class SlicesAt:
def __init__(self, axis: int, ndim: int):
if ndim <= 0: raise ValueError(f"`ndim` (which is {ndim}) should be a positive integer")
if not -ndim <= axis < ndim: raise ValueError(f"`axis` (which is {axis}) should be within [{-ndim}, {ndim})")
self._axis, self._ndim = axis % ndim, ndim
def __getitem__(self, idx):
slices = [slice(None)] * self._ndim
slices[self._axis] = idx
return tuple(slices)
# For numpy/torch
def moving_average_slim(arr: np.ndarray, n_win: int=2, axis: int=-1) -> np.ndarray:
# `(n_win-1)` shorter. Good for any positive `n_win`. Good if `arr` is empty in `axis`
if n_win <= 0: raise ValueError(f"nonpositive `n_win` {n_win} not allowed")
slc = SlicesAt(axis, arr.ndim)
concatfn = tc.cat if type(arr) is tc.Tensor else np.concatenate
cum = arr.cumsum(axis) # , dtype=float)
return concatfn([ cum[slc[n_win-1:n_win]], cum[slc[n_win:]]-cum[slc[:-n_win]] ], axis) / float(n_win)
def moving_average_full(arr: np.ndarray, n_win: int=2, axis: int=-1) -> np.ndarray:
# Same length as `arr`. Good for any positive `n_win`. Good if `arr` is empty in `axis`
if n_win <= 0: raise ValueError(f"nonpositive `n_win` {n_win} not allowed")
slc = SlicesAt(axis, arr.ndim)
concatfn = tc.cat if type(arr) is tc.Tensor else np.concatenate
cum = arr.cumsum(axis) # , dtype=float)
stem = concatfn([ cum[slc[n_win-1:n_win]], cum[slc[n_win:]]-cum[slc[:-n_win]] ], axis) / float(n_win)
length = arr.shape[axis]
lwid = (n_win - 1) // 2
rwid = n_win//2 + 1
return concatfn([
*[ cum[slc[j-1: j]] / float(j) for i in range(min(lwid, length)) for j in [min(i+rwid, length)] ],
stem,
*[ (cum[slc[-1:]] - cum[slc[i-lwid-1: i-lwid]] if i-lwid > 0 else cum[slc[-1:]]) / float(length-i+lwid)
for i in range(max(length-rwid+1, lwid), length) ]
], axis)
def moving_average_full_checker(arr: np.ndarray, n_win: int=2, axis: int=-1) -> np.ndarray:
# Same length as `arr`. Good for any positive `n_win`. Good if `arr` is empty in `axis`
if n_win <= 0: raise ValueError(f"nonpositive `n_win` {n_win} not allowed")
if arr.shape[axis] < 2: return arr
slc = SlicesAt(axis, arr.ndim)
concatfn = tc.cat if type(arr) is tc.Tensor else np.concatenate
lwid = (n_win - 1) // 2
rwid = n_win//2 + 1
return concatfn([ arr[slc[max(0, i-lwid): (i+rwid)]].mean(axis, keepdims=True) for i in range(arr.shape[axis]) ], axis)
# Plotting Utilities
class Plotter:
def __init__(self, var_xlab: dict, metr_ylab: dict, tab_items: list=None,
check_var: bool=False, check_tab: bool=False, loader = tc.load):
for var in var_xlab:
if not var_xlab[var]: var_xlab[var] = var
for metr in metr_ylab:
if not metr_ylab[metr]: metr_ylab[metr] = metr
self.var_xlab, self.metr_ylab = var_xlab, metr_ylab
self.variables, self.metrics = list(var_xlab), list(metr_ylab)
if tab_items is None: self.tab_items = []
else: self.tab_items = tab_items
self.check_var, self.check_tab = check_var, check_tab
self.loader = loader
self._plt_data, self._tab_data = [], []
def _get_res(self, dataholder): # does not change `self`
res_x = {var: [] for var in self.variables}
res_ymean = {metr: np.array([]) for metr in self.metrics}
res_ystd = {metr: np.array([]) for metr in self.metrics}
res_tab = [None for item in self.tab_items]
if type(dataholder) is not dict: # treated as a list of data file names
resfiles = []
for file in dataholder:
if os.path.isfile(file): resfiles.append(file)
else: warnings.warn(f"file '{file}' does not exist")
dataholder = dict()
for file in resfiles:
ckp = self.loader(file)
for name in self.metrics + self.variables + self.tab_items:
if name not in ckp: warnings.warn(f"metric or variable or item '{name}' not found in file '{file}'")
else:
if name not in dataholder: dataholder[name] = []
dataholder[name].append(ckp[name])
for metr in self.metrics:
if metr not in dataholder or not dataholder[metr]:
warnings.warn(f"metric '{metr}' not found or empty")
continue
n_align = min((len(line) for line in dataholder[metr]), default=0)
if n_align:
vals = np.array([line[:n_align] for line in dataholder[metr]])
res_ymean[metr] = vals.mean(0)
res_ystd[metr] = vals.std(0)
for var in self.variables:
if var not in dataholder or not dataholder[var]:
warnings.warn(f"variable '{var}' not found or empty")
continue
n_align = min((len(line) for line in dataholder[var]), default=0)
if n_align:
res_x[var] = dataholder[var][0]
if self.check_var:
for line in dataholder[var][1:]:
if line != res_x[x]: raise RuntimeError(f"variable '{var}' not match")
for i, item in enumerate(self.tab_items):
if item not in dataholder or not dataholder[item]:
warnings.warn(f"item '{item}' not found or empty")
continue
res_tab[i] = dataholder[item][0]
if self.check_tab:
for val in dataholder[item][1:]:
if val != res_tab[i]: raise RuntimeError(f"item '{item}' not match")
return res_x, res_ymean, res_ystd, res_tab
def load(self, *triplets):
# each triplet = (legend, pltsty, [filename1, filename2]), or
# (legend, pltsty, {var1: [val1_1, val1_2], metr2: [val2_1, val2_2, val2_3]})
data = [(legend, pltsty, *self._get_res(dataholder)) for legend, pltsty, dataholder in triplets]
self._plt_data += [entry[:-1] for entry in data]
self._tab_data += [[entry[0]] + entry[-1] for entry in data]
def clear(self):
self._plt_data.clear()
self._tab_data.clear()
def plot(self, variables: list=None, metrics: list=None,
var_xlim: dict=None, metr_ylim: dict=None,
n_start: int=None, n_stop: int=None, n_step: int=None, n_win: int=1,
plot_err: bool=True, ncol: int=None,
fontsize: int=20, figheight: int=8, linewidth: int=4, alpha: float=.2, show_legend: bool=True):
if variables is None: variables = self.variables
if metrics is None: metrics = self.metrics
if var_xlim is None: var_xlim = {}
if metr_ylim is None: metr_ylim = {}
slc = slice(n_start, n_stop, n_step)
if ncol is None: ncol = max(2, len(variables))
nfig = len(variables) * len(metrics)
nrow = (nfig-1) // ncol + 1
if nfig < ncol: ncol = nfig
plt.rcParams.update({'font.size': fontsize})
fig, axes0 = plt.subplots(nrow, ncol, figsize=(ncol*figheight, nrow*figheight))
if nfig == 1: axes = [axes0]
elif nrow > 1: axes = [ax for row in axes0 for ax in row][:nfig]
else: axes = axes0[:nfig]
for ax, (metr, var) in zip(axes, product(metrics, variables)):
plotted = False
for legend, pltsty, res_x, res_ymean, res_ystd in self._plt_data:
y, std = res_ymean[metr], res_ystd[metr]
x = res_x[var] if var is not None else list(range(min(len(y), len(std))))
n_align = min(len(x), len(y), len(std))
x, y, std = x[:n_align], y[:n_align], std[:n_align]
if n_win > 1:
y = moving_average_full(y, n_win)
if plot_err: std = moving_average_full(std, n_win) # Not precise! std and averaging is not interchangeable, since sqrt(sum ^2) is not linear
x, y, std = x[slc], y[slc], std[slc]
if len(x):
if plot_err:
ax.fill_between(x, y-std, y+std, facecolor=pltsty[0], alpha=alpha, linewidth=0)
ax.plot(x, y, pltsty, label=legend, linewidth=linewidth)
plotted = True
if show_legend and plotted: ax.legend()
if var in var_xlim: ax.set_xlim(var_xlim[var])
if metr in metr_ylim: ax.set_ylim(metr_ylim[metr])
ax.set_xlabel(self.var_xlab[var] if var is not None else "index")
ax.set_ylabel(self.metr_ylab[metr])
return fig, axes0
def inspect(self, metr: str, ids: list=None, var: str=None, vals: list=None,
show_std: bool=True, **tbformat):
if (ids is None) == (var is None and vals is None):
raise ValueError("exactly one of `ids`, or `var` and `vals`, should be provided")
if ids is not None:
if not show_std:
table = [[legend, *getlist(res_ymean[metr], ids)] for legend, pltsty, res_x, res_ymean, res_ystd in self._plt_data]
print(tabulate(table, headers = ["indices"] + ids, **tbformat))
else:
table = [[legend, *interleave(getlist(res_ymean[metr], ids), getlist(res_ystd[metr], ids))]
for legend, pltsty, res_x, res_ymean, res_ystd in self._plt_data]
print(tabulate(table, headers = ["indices"] + interleave(ids, ids), **tbformat))
else:
if not show_std:
table = [[legend, *[res_ymean[metr][res_x[var].index(val)] for val in vals]]
for legend, pltsty, res_x, res_ymean, res_ystd in self._plt_data]
print(tabulate(table, headers = [var] + vals, **tbformat))
else:
ids_list = [[res_x[var].index(val) for val in vals] for _, _, res_x, _, _ in self._plt_data]
table = [[legend, *interleave(getlist(res_ymean[metr], ids), getlist(res_ystd[metr], ids))]
for ids, (legend, pltsty, res_x, res_ymean, res_ystd) in zip(ids_list, self._plt_data)]
print(tabulate(table, headers = [var] + interleave(vals, vals), **tbformat))
return table
def tabulate(self, **tbformat):
print(tabulate(self._tab_data, headers = ["legend"] + self.tab_items, **tbformat))
================================================
FILE: code/deep/CSG/utils/utils_main.py
================================================
#!/usr/bin/env python3.6
import os, sys
import argparse
from copy import deepcopy
from functools import partial
import tqdm
import torch as tc
import torchvision as tv
sys.path.append('..')
from distr import edic
from arch import mlp, cnn
from methods import CNBBLoss, SemVar, SupVAE
from utils import Averager, unique_filename, boolstr, zip_longer # This imports from 'utils/__init__.py'
from dalib.modules.domain_discriminator import DomainDiscriminator
from dalib.modules.kernels import GaussianKernel
from dalib.adaptation.dann import DomainAdversarialLoss
from dalib.adaptation.cdan import ConditionalDomainAdversarialLoss
from dalib.adaptation.dan import MultipleKernelMaximumMeanDiscrepancy
from dalib.adaptation.mdd import MarginDisparityDiscrepancy
__author__ = "Chang Liu"
__email__ = "changliu@microsoft.com"
# tc.autograd.set_detect_anomaly(True)
MODES_OOD_NONGEN = {"discr", "cnbb"}
MODES_OOD_GEN = {"svae", "svgm", "svgm-ind"}
MODES_DA_NONGEN = {"dann", "cdan", "dan", "mdd", "bnm"}
MODES_DA_GEN = {"svae-da", "svgm-da", "svae-da2", "svgm-da2"}
MODES_OOD = MODES_OOD_NONGEN | MODES_OOD_GEN
MODES_DA = MODES_DA_NONGEN | MODES_DA_GEN
MODES_GEN = MODES_OOD_GEN | MODES_DA_GEN
MODES_TWIST = {"svgm-ind", "svae-da", "svgm-da"}
# Init models
def auto_load(dc_vars, names, ckpt):
if ckpt:
if type(names) is str: names = [names]
for name in names:
model = dc_vars[name]
model.load_state_dict(ckpt[name+'_state_dict'])
if hasattr(model, 'eval'): model.eval()
def get_frame(discr, gen, dc_vars, device = None, discr_src = None):
if type(dc_vars) is not edic: dc_vars = edic(dc_vars)
shape_x = dc_vars['shape_x'] if 'shape_x' in dc_vars else (dc_vars['dim_x'],)
shape_s = discr.shape_s if hasattr(discr, "shape_s") else (dc_vars['dim_s'],)
shape_v = discr.shape_v if hasattr(discr, "shape_v") else (dc_vars['dim_v'],)
std_v1x = discr.std_v1x if hasattr(discr, "std_v1x") else dc_vars['qstd_v']
std_s1vx = discr.std_s1vx if hasattr(discr, "std_s1vx") else dc_vars['qstd_s']
std_s1x = discr.std_s1x if hasattr(discr, "std_s1x") else dc_vars['qstd_s']
mode = dc_vars['mode']
if mode.startswith("svgm"):
q_args_stem = (discr.v1x, std_v1x, discr.s1vx, std_s1vx)
elif mode.startswith("svae"):
q_args_stem = (discr.s1x, std_s1x)
else: return None
if mode == "svgm-da2" and discr_src is not None:
q_args = ( discr_src.v1x, discr_src.std_v1x if hasattr(discr_src, "std_v1x") else dc_vars['qstd_v'],
discr_src.s1vx, discr_src.std_s1vx if hasattr(discr_src, "std_s1vx") else dc_vars['qstd_s'],
) + q_args_stem
elif mode == "svae-da2" and discr_src is not None:
q_args = ( discr_src.s1x, discr_src.std_s1x if hasattr(discr_src, "std_s1x") else dc_vars['qstd_s'],
) + q_args_stem
elif mode in MODES_TWIST: # svgm-ind, svae-da, svgm-da
q_args = (None,)*len(q_args_stem) + q_args_stem
else: # svae, svgm
q_args = q_args_stem + (None,)*len(q_args_stem)
if mode.startswith("svgm"):
frame = SemVar( shape_s, shape_v, shape_x, dc_vars['dim_y'],
gen.x1sv, dc_vars['pstd_x'], discr.y1s, *q_args,
*dc_vars.sublist(['mu_s', 'sig_s', 'mu_v', 'sig_v', 'corr_sv']),
mode in MODES_DA, *dc_vars.sublist(['src_mvn_prior', 'tgt_mvn_prior']), device )
elif mode.startswith("svae"):
frame = SupVAE( shape_s, shape_x, dc_vars['dim_y'],
gen.x1s, dc_vars['pstd_x'], discr.y1s, *q_args,
*dc_vars.sublist(['mu_s', 'sig_s']),
mode in MODES_DA, *dc_vars.sublist(['src_mvn_prior', 'tgt_mvn_prior']), device )
return frame
def get_discr(archtype, dc_vars):
if archtype == "mlp":
discr = mlp.create_discr_from_json(
*dc_vars.sublist([
'discrstru', 'dim_x', 'dim_y', 'actv',
'qstd_v', 'qstd_s', 'after_actv']),
jsonfile=dc_vars['mlpstrufile']
)
elif archtype == "cnn":
discr = cnn.CNNsvy1x(
*dc_vars.sublist([
'discrstru', 'dim_btnk', 'dim_s', 'dim_y', 'dim_v',
'qstd_v', 'qstd_s']),
*dc_vars.sublist([
'dims_bb2bn', 'dims_bn2s', 'dims_s2y',
'vbranch', 'dims_bn2v'], use_default = True, default = None)
)
else: raise ValueError(f"unknown `archtype` '{archtype}'")
return discr
def get_gen(archtype, dc_vars, discr):
if dc_vars['mode'].startswith("svgm"):
if archtype == "mlp":
gen = mlp.create_gen_from_json(
"MLPx1sv", discr, dc_vars['genstru'], jsonfile=dc_vars['mlpstrufile'] )
elif archtype == "cnn":
gen = cnn.CNNx1sv(
dc_vars['shape_x'][-1], *dc_vars.sublist(['dim_s', 'dim_v', 'dim_feat', 'genstru']) )
elif dc_vars['mode'].startswith("svae"):
if archtype == "mlp":
gen = mlp.create_gen_from_json(
"MLPx1s", discr, dc_vars['genstru'], jsonfile=dc_vars['mlpstrufile'] )
elif archtype == "cnn":
gen = cnn.CNNx1s(
dc_vars['shape_x'][-1], *dc_vars.sublist(['dim_s', 'dim_feat', 'genstru']) )
return gen
def get_models(archtype, dc_vars, ckpt = None, device = None):
if type(dc_vars) is not edic: dc_vars = edic(dc_vars)
discr = get_discr(archtype, dc_vars)
if ckpt is not None: auto_load(locals(), 'discr', ckpt)
discr.to(device)
if dc_vars['mode'] in MODES_GEN:
gen = get_gen(archtype, dc_vars, discr)
if ckpt is not None: auto_load(locals(), 'gen', ckpt)
gen.to(device)
if dc_vars['mode'].endswith("-da2"):
discr_src = get_discr(archtype, dc_vars)
if ckpt is not None: auto_load(locals(), 'discr_src', ckpt)
discr_src.to(device)
frame = get_frame(discr, gen, dc_vars, device, discr_src)
if ckpt is not None: auto_load(locals(), 'frame', ckpt)
return discr, gen, frame, discr_src
else:
frame = get_frame(discr, gen, dc_vars, device)
if ckpt is not None: auto_load(locals(), 'frame', ckpt)
return discr, gen, frame
else: return discr, None, None
def load_ckpt(filename: str, loadmodel: bool=False, device: tc.device=None, archtype: str="mlp", map_location: tc.device=None):
ckpt = tc.load(filename, map_location)
if loadmodel:
return (ckpt,) + get_models(archtype, ckpt, ckpt, device)
else: return ckpt
# Built methods
def get_ce_or_bce_loss(discr, dim_y: int, reduction: str="mean"):
if dim_y == 1:
celossobj = tc.nn.BCEWithLogitsLoss(reduction=reduction)
celossfn = lambda x, y: celossobj(discr(x), y.float())
else:
celossobj = tc.nn.CrossEntropyLoss(reduction=reduction)
celossfn = lambda x, y: celossobj(discr(x), y)
return celossobj, celossfn
def add_ce_loss(lossobj, celossfn, ag):
shrink_sup = ShrinkRatio(w_iter=ag.wsup_wdatum*ag.n_bat, decay_rate=ag.wsup_expo)
def lossfn(*x_y_maybext_niter):
loss = ag.wgen * lossobj(*x_y_maybext_niter[:-1])
if ag.wsup:
loss += ag.wsup * shrink_sup(x_y_maybext_niter[-1]) * celossfn(*x_y_maybext_niter[:2])
return loss
return lossfn
def ood_methods(discr, frame, ag, dim_y, cnbb_actv):
if ag.mode not in MODES_GEN:
if ag.mode == "discr":
lossfn = get_ce_or_bce_loss(discr, dim_y, ag.reduction)[1]
elif ag.mode == "cnbb":
lossfn = CNBBLoss(discr.s1x, cnbb_actv, discr.forward, dim_y, ag.reg_w, ag.reg_s, ag.lr_w, ag.n_iter_w)
else: # should be in MODES_GEN
celossfn = get_ce_or_bce_loss( partial(frame.logit_y1x_src, n_mc_q=ag.n_mc_q)
if ag.mode in MODES_TWIST and ag.true_sup else discr,
dim_y, ag.reduction )[1]
lossobj = frame.get_lossfn(ag.n_mc_q, ag.reduction, "defl", wlogpi=ag.wlogpi/ag.wgen)
lossfn = add_ce_loss(lossobj, celossfn, ag)
return lossfn
def da_methods(discr, frame, ag, dim_x, dim_y, device, ckpt, discr_src = None):
if ag.mode not in MODES_GEN:
celossobj, celossfn = get_ce_or_bce_loss(discr, dim_y, ag.reduction)
if ag.mode == "dann":
domdisc = DomainDiscriminator(in_feature=discr.dim_s, hidden_size=ag.domdisc_dimh).to(device)
dalossobj = DomainAdversarialLoss(domdisc, reduction=ag.reduction).to(device)
auto_load(locals(), ['domdisc', 'dalossobj'], ckpt)
def lossfn(x, y, xt):
logit, feat = discr.ys1x(x)
featt = discr.s1x(xt)
if feat.shape[0] < featt.shape[0]: featt = featt[:feat.shape[0]]
elif feat.shape[0] > featt.shape[0]: feat = feat[:featt.shape[0]]
return celossobj(logit, y.float() if dim_y == 1 else y
) + ag.wda * dalossobj(feat, featt)
elif ag.mode == "cdan":
# In both randomized and not randomized versions, the code has problems.
# For randomized, the dim_s*num_cls is fed to domdisc.
# For not rand, `tc.mm` receives the wrong input order in `RandomizedMultiLinearMap.forward()`
num_classes = (2 if dim_y == 1 else dim_y)
domdisc = DomainDiscriminator(in_feature = discr.dim_s * (1 if ag.cdan_rand else num_classes), # confusing `in_feature`
hidden_size=ag.domdisc_dimh).to(device)
dalossobj = ConditionalDomainAdversarialLoss(domdisc, reduction=ag.reduction, randomized=ag.cdan_rand,
num_classes=num_classes, features_dim=discr.dim_s, randomized_dim=discr.dim_s).to(device)
auto_load(locals(), ['domdisc', 'dalossobj'], ckpt)
def lossfn(x, y, xt):
logit, feat = discr.ys1x(x)
logitt, featt = discr.ys1x(xt)
logit_stack = tc.stack([tc.zeros_like(logit), logit], dim=-1) if dim_y == 1 else logit
logitt_stack = tc.stack([tc.zeros_like(logitt), logitt], dim=-1) if dim_y == 1 else logitt
return celossobj(logit, y.float() if dim_y == 1 else y
) + ag.wda * dalossobj(logit_stack, feat, logitt_stack, featt)
elif ag.mode == "dan":
domdisc = None
dalossobj = MultipleKernelMaximumMeanDiscrepancy(
[GaussianKernel(alpha=alpha) for alpha in ag.ker_alphas] ).to(device)
def lossfn(x, y, xt):
logit, feat = discr.ys1x(x)
featt = discr.s1x(xt)
if feat.shape[0] < featt.shape[0]: featt = featt[:feat.shape[0]]
elif feat.shape[0] > featt.shape[0]: feat = feat[:featt.shape[0]]
return celossobj(logit, y.float() if dim_y == 1 else y
) + ag.wda * dalossobj(feat, featt)
elif ag.mode == "mdd":
num_classes = (2 if dim_y == 1 else dim_y)
domdisc = mlp.MLP([dim_x, ag.domdisc_dimh, ag.domdisc_dimh, num_classes]).to(device) # actually not domain discriminator but an auxiliary (adversarial) classifier
dalossobj = MarginDisparityDiscrepancy(margin=ag.mdd_margin, reduction=ag.reduction).to(device)
auto_load(locals(), ['domdisc', 'dalossobj'], ckpt)
def lossfn(x, y, xt):
logit, logitt = discr(x), discr(xt)
logit_adv, logitt_adv = domdisc(x.reshape(-1,dim_x)), domdisc(xt.reshape(-1,dim_x))
logit_stack = tc.stack([tc.zeros_like(logit), logit], dim=-1) if dim_y == 1 else logit
logitt_stack = tc.stack([tc.zeros_like(logitt), logitt], dim=-1) if dim_y == 1 else logitt
return celossobj(logit, y.float() if dim_y == 1 else y
) + ag.wda * dalossobj(logit_stack, logit_adv, logitt_stack, logitt_adv)
elif ag.mode == "bnm":
domdisc = None
dalossobj = None
def lossfn(x, y, xt):
logit, logitt = discr(x), discr(xt)
logitt_stack = tc.stack([tc.zeros_like(logitt), logitt], dim=-1) if dim_y == 1 else logitt
softmax_tgt = logitt_stack.softmax(dim=1)
_, s_tgt, _ = tc.svd(softmax_tgt)
# if config["method"]=="BNM":
transfer_loss = -tc.mean(s_tgt)
# elif config["method"]=="BFM":
# transfer_loss = -tc.sqrt(tc.sum(s_tgt*s_tgt)/s_tgt.shape[0])
# elif config["method"]=="ENT":
# transfer_loss = -tc.mean(tc.sum(softmax_tgt*tc.log(softmax_tgt+1e-8),dim=1))/tc.log(softmax_tgt.shape[1])
return celossobj(logit, y.float() if dim_y == 1 else y
) + ag.wda * transfer_loss
else: pass
for obj in [dalossobj, domdisc]:
if obj is not None: obj.train()
else:
if ag.mode.endswith("-da2") and discr_src is not None: true_discr = discr_src
elif ag.mode in MODES_TWIST and ag.true_sup: true_discr = partial(frame.logit_y1x_src, n_mc_q=ag.n_mc_q)
else: true_discr = discr
celossfn = get_ce_or_bce_loss(true_discr, dim_y, ag.reduction)[1]
lossobj = frame.get_lossfn(ag.n_mc_q, ag.reduction, "defl", weight_da=ag.wda/ag.wgen, wlogpi=ag.wlogpi/ag.wgen)
lossfn = add_ce_loss(lossobj, celossfn, ag)
domdisc, dalossobj = None, None
return lossfn, domdisc, dalossobj
# Training utilities
class ParamGroupsCollector:
def __init__(self, lr):
self.reset(lr)
def reset(self, lr):
self.lr = lr
self.param_groups = []
def collect_params(self, *models):
for model in models:
if hasattr(model, 'parameter_groups'):
groups_inc = list(model.parameter_groups())
for grp in groups_inc:
if 'lr_ratio' in grp:
grp['lr'] = self.lr * grp['lr_ratio']
elif 'lr' not in grp: # Do not overwrite existing lr assignments
grp['lr'] = self.lr
self.param_groups += groups_inc
else:
self.param_groups += [
{'params': model.parameters(), 'lr': self.lr} ]
class ShrinkRatio:
def __init__(self, w_iter, decay_rate):
self.w_iter = w_iter
self.decay_rate = decay_rate
def __call__(self, n_iter):
return (1 + self.w_iter * n_iter) ** (-self.decay_rate)
# Test and save utilities
def acc_with_logits(model: tc.nn.Module, x: tc.Tensor, y: tc.LongTensor, is_binary: bool, u = None, use_u = False) -> float:
with tc.no_grad(): logits = model(x) if not use_u else model(x,u)
ypred = (logits > 0).long() if is_binary else logits.argmax(dim=-1)
return (ypred == y).float().mean().item()
def evaluate_acc(discr, input_loader, is_binary, device):
avgr = Averager()
for x, y in input_loader:
x, y = x.to(device), y.to(device)
avgr.update(acc_with_logits(discr, x, y, is_binary), nrep = len(y))
return avgr.avg
def evaluate_llhx(frame, input_loader, n_marg_llh, use_q_llh, mode, device):
avgr = Averager()
for x, y in input_loader:
x = x.to(device)
avgr.update(frame.llh(x, None, n_marg_llh, use_q_llh, mode), nrep = len(x))
return avgr.avg
class ResultsContainer:
def __init__(self, len_ts, frame, ag, is_binary, device, ckpt = None):
for k,v in locals().items():
if k not in {"self", "ckpt"}: setattr(self, k, v)
self.dc = dict( epochs = [], losses = [],
accs_tr = [], llhs_tr = [], accs_val = [], llhs_val = [] )
if len_ts:
ls_empty = [[] for _ in range(len_ts)]
self.dc.update( ls_accs_ts = ls_empty, ls_llhs_ts = deepcopy(ls_empty) )
else:
self.dc.update( accs_ts = [], llhs_ts = [] )
if ckpt is not None:
for k in self.dc.keys():
if not k.startswith('ls_'): self.dc[k] = ckpt[k]
else: self.dc[k] = [ckpt[k[3:]]]
def update(self, *, epk, loss):
self.dc['epochs'].append(epk)
self.dc['losses'].append(loss)
def evaluate(self, discr, dname, dpart, loader, llh_mode, i = None):
acc = evaluate_acc(discr, loader, self.is_binary, self.device)
if i is None: self.dc['accs_'+dpart].append(acc)
else: self.dc['ls_accs_'+dpart][i].append(acc)
print(f"On {dname}, acc: {acc:.3f}", end="", flush=True)
if self.frame is not None and self.ag.eval_llh:
llh = evaluate_llhx(
self.frame, loader, self.ag.n_marg_llh, self.ag.use_q_llh, llh_mode, self.device)
if i is None: self.dc['llhs_'+dpart].append(llh)
else: self.dc['ls_llhs_'+dpart][i].append(llh)
print(f", llhs: {llh:.3e}. ", end="", flush=True)
else: print(". ", end="", flush=True)
def summary(self, dname, dpart, i = None):
if i is None:
accs = self.dc['accs_'+dpart]
llhs = self.dc['llhs_'+dpart]
else:
accs = self.dc['ls_accs_'+dpart][i]
llhs = self.dc['ls_llhs_'+dpart][i]
acc_fin = tc.tensor(accs[-self.ag.avglast:]).mean().item()
llh_fin = tc.tensor(llhs[-self.ag.avglast:]).mean().item() if llhs[-self.ag.avglast:] else None
acc_max = tc.tensor(accs).max().item()
llh_max = tc.tensor(llhs).max().item() if llhs else None
print(f"On {dname}, final acc: {acc_fin:.3f}" + (
f", llh: {llh_fin:.3f}" if llh_fin else ""
) + f", max acc: {acc_max:.3f}" + (
f", llh: {llh_max:.3f}" if llh_max else "") + ".")
def dc_state_dict(dc_vars, *name_list):
return {name+"_state_dict" : dc_vars[name].state_dict()
for name in name_list if hasattr(dc_vars[name], 'state_dict')}
# Main
def is_ood(mode):
return mode in MODES_OOD
def process_continue_run(ag):
# Process if continue running
if ag.init_model not in {"rand", "fix"}: # continue running
ckpt = load_ckpt(ag.init_model, loadmodel=False)
if ag.mode != ckpt['mode']: raise RuntimeError("mode not match")
for k in vars(ag):
if k not in {"testdoms", "n_epk", "gpu"}: # use the new final number of epochs
setattr(ag, k, ckpt[k])
ag.testdoms = [ckpt['testdom']] # overwrite the input `testdoms`
else: ckpt = None
return ag, ckpt
def main_stem(ag, ckpt, archtype, shape_x, dim_y,
tr_src_loader, val_src_loader,
ls_ts_tgt_loader = None, # for ood
tr_tgt_loader = None, ts_tgt_loader = None, testdom = None # for da
):
print(ag)
print_infrstru_info()
IS_OOD = is_ood(ag.mode)
device = tc.device("cuda:"+str(ag.gpu) if tc.cuda.is_available() else "cpu")
# Datasets
dim_x = tc.tensor(shape_x).prod().item()
if IS_OOD: n_per_epk = len(tr_src_loader)
else: n_per_epk = max(len(tr_src_loader), len(tr_tgt_loader))
# Models
res = get_models(archtype, edic(locals()) | vars(ag), ckpt, device)
if ag.mode.endswith("-da2"):
discr, gen, frame, discr_src = res
discr_src.train()
else:
discr, gen, frame = res
discr.train()
if gen is not None: gen.train()
# Methods and Losses
if IS_OOD:
lossfn = ood_methods(discr, frame, ag, dim_y, cnbb_actv="Sigmoid") # Actually the activation is ReLU, but there is no `is_treat` rule for ReLU in CNBB.
domdisc = None
else:
lossfn, domdisc, dalossobj = da_methods(discr, frame, ag, dim_x, dim_y, device, ckpt,
discr_src if ag.mode.endswith("-da2") else None)
# Optimizer
pgc = ParamGroupsCollector(ag.lr)
pgc.collect_params(discr)
if ag.mode.endswith("-da2"): pgc.collect_params(discr_src)
if gen is not None: pgc.collect_params(gen, frame)
if domdisc is not None: pgc.collect_params(domdisc)
if ag.optim == "SGD":
opt = getattr(tc.optim, ag.optim)(pgc.param_groups, weight_decay=ag.wl2, momentum=ag.momentum, nesterov=ag.nesterov)
shrink_opt = ShrinkRatio(w_iter=ag.lr_wdatum*ag.n_bat, decay_rate=ag.lr_expo)
lrsched = tc.optim.lr_scheduler.LambdaLR(opt, shrink_opt)
auto_load(locals(), 'lrsched', ckpt)
else: opt = getattr(tc.optim, ag.optim)(pgc.param_groups, weight_decay=ag.wl2)
auto_load(locals(), 'opt', ckpt)
# Training
epk0 = 1; i_bat0 = 1
if ckpt is not None:
epk0 = ckpt['epochs'][-1] + 1 if ckpt['epochs'] else 1
i_bat0 = ckpt['i_bat']
res = ResultsContainer( len(ag.testdoms) if IS_OOD else None,
frame, ag, dim_y==1, device, ckpt )
print(f"Run in mode '{ag.mode}' for {ag.n_epk:3d} epochs:")
try:
for epk in range(epk0, ag.n_epk+1):
pbar = tqdm.tqdm(total=n_per_epk, desc=f"Train epoch = {epk:3d}", ncols=80, leave=False)
for i_bat, data_bat in enumerate(
tr_src_loader if IS_OOD else zip_longer(tr_src_loader, tr_tgt_loader), start=1):
if i_bat < i_bat0: continue
if IS_OOD:
x, y = data_bat
data_args = (x.to(device), y.to(device))
else:
(x, y), (xt, yt) = data_bat
data_args = (x.to(device), y.to(device), xt.to(device))
opt.zero_grad()
if ag.mode in MODES_GEN:
n_iter_tot = (epk-1)*n_per_epk + i_bat-1
loss = lossfn(*data_args, n_iter_tot)
else: loss = lossfn(*data_args)
loss.backward()
opt.step()
if ag.optim == "SGD": lrsched.step()
pbar.update(1)
# end for
pbar.close()
i_bat = 1; i_bat0 = 1
if epk % ag.eval_interval == 0:
res.update(epk=epk, loss=loss.item())
print(f"Mode '{ag.mode}': Epoch {epk:.1f}, Loss = {loss:.3e},")
discr.eval()
if ag.mode.endswith("-da2"): discr_src.eval(); true_discr = discr_src
elif ag.mode in MODES_TWIST and ag.true_sup_val: true_discr = partial(frame.logit_y1x_src, n_mc_q=ag.n_mc_q)
else: true_discr = discr
res.evaluate(true_discr, "val "+str(ag.traindom), 'val', val_src_loader, 'src')
if IS_OOD:
for i, (testdom, ts_tgt_loader) in enumerate(zip(ag.testdoms, ls_ts_tgt_loader)):
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt', i)
else:
res.evaluate(discr, "test "+str(testdom), 'ts', ts_tgt_loader, 'tgt')
print()
discr.train()
if ag.mode.endswith("-da2"): discr_src.train()
# end for
except (KeyboardInterrupt, SystemExit): pass
res.summary("val "+str(ag.traindom), 'val')
if IS_OOD:
for i, testdom in enumerate(ag.testdoms): res.summary("test "+str(testdom), 'ts', i)
else:
res.summary("test "+str(testdom), 'ts')
if not ag.no_save:
dirname = "ckpt_" + ag.mode + "/"
os.makedirs(dirname, exist_ok=True)
for i, testdom in enumerate(
ag.testdoms if IS_OOD else [testdom]
):
filename = unique_filename(
dirname + ("ood" if IS_OOD else "da"), ".pt", n_digits = 3
) if ckpt is None else ckpt['filename']
dc_vars = edic(locals()).sub([
'dirname', 'filename', 'testdom',
'shape_x', 'dim_x', 'dim_y', 'i_bat'
]) | ( edic(vars(ag)) - {'testdoms'}
) | dc_state_dict(locals(), "discr", "opt")
if ag.mode.endswith("-da2"):
dc_vars.update( dc_state_dict(locals(), "discr_src") )
if ag.optim == "SGD":
dc_vars.update( dc_state_dict(locals(), "lrsched") )
if ag.mode in MODES_GEN:
dc_vars.update( dc_state_dict(locals(), "gen", "frame") )
elif ag.mode in {"dann", "cdan", "dan", "mdd"}:
dc_vars.update( dc_state_dict(locals(), "domdisc", "dalossobj") )
else: pass
if IS_OOD:
dc_vars.update( edic({
k:v for k,v in res.dc.items() if not k.startswith('ls_')
}) | { k[3:]:v[i] for k,v in res.dc.items() if k.startswith('ls_')
})
else:
dc_vars.update(res.dc)
tc.save(dc_vars, filename)
print(f"checkpoint saved to '{filename}'.")
def get_parser():
parser = argparse.ArgumentParser()
parser.add_argument("mode", type = str, choices = MODES_OOD | MODES_DA)
# Data
parser.add_argument("--tr_val_split", type = float, default = .8)
parser.add_argument("--n_bat", type = int, default = 32)
# Model
parser.add_argument("--init_model", type = str, default = "rand") # or a model file name to continue running
parser.add_argument("--discrstru", type = str)
parser.add_argument("--genstru", type = str)
# Process
parser.add_argument("--n_epk", type = int, default = 800)
parser.add_argument("--eval_interval", type = int, default = 5)
parser.add_argument("--avglast", type = int, default = 4)
parser.add_argument("-ns", "--no_save", action = "store_true")
# Optimization
parser.add_argument("--optim", type = str)
parser.add_argument("--lr", type = float)
parser.add_argument("--wl2", type = float)
parser.add_argument("--reduction", type = str, default = "mean")
parser.add_argument("--momentum", type = float, default = 0.) # only when "lr" is "SGD"
parser.add_argument("--nesterov", type = boolstr, default = False) # only when "lr" is "SGD"
parser.add_argument("--lr_expo", type = float, default = .75) # only when "lr" is "SGD"
parser.add_argument("--lr_wdatum", type = float, default = 6.25e-6) # only when "lr" is "SGD"
# For generative models only
parser.add_argument("--mu_s", type = float, default = 0.)
parser.add_argument("--sig_s", type = float, default = 1.)
parser.add_argument("--mu_v", type = float, default = 0.) # for svgm only
parser.add_argument("--sig_v", type = float, default = 1.) # for svgm only
parser.add_argument("--corr_sv", type = float, default = .7) # for svgm only
parser.add_argument("--pstd_x", type = float, default = 3e-2)
parser.add_argument("--qstd_s", type = float, default = 3e-2)
parser.add_argument("--qstd_v", type = float, default = 3e-2) # for svgm only
parser.add_argument("--wgen", type = float, default = 1.)
parser.add_argument("--wsup", type = float, default = 1.)
parser.add_argument("--wsup_expo", type = float, default = 0.) # only when "wsup" is not 0
parser.add_argument("--wsup_wdatum", type = float, default = 6.25e-6) # only when "wsup" and "wsup_expo" are not 0
parser.add_argument("--wlogpi", type = float, default = None)
parser.add_argument("--n_mc_q", type = int, default = 0)
parser.add_argument("--eval_llh", action = "store_true")
parser.add_argument("--use_q_llh", type = boolstr, default = True)
parser.add_argument("--n_marg_llh", type = int, default = 16)
parser.add_argument("--true_sup", type = boolstr, default = False, help = "for 'svgm-ind', 'svgm-da', 'svae-da' only")
parser.add_argument("--true_sup_val", type = boolstr, default = True, help = "for 'svgm-ind', 'svgm-da', 'svae-da' only")
## For OOD
parser.add_argument("--mvn_prior", type = boolstr, default = False)
## For DA
parser.add_argument("--src_mvn_prior", type = boolstr, default = False)
parser.add_argument("--tgt_mvn_prior", type = boolstr, default = False)
# For OOD
## For cnbb only
parser.add_argument("--reg_w", type = float, default = 1e-4)
parser.add_argument("--reg_s", type = float, default = 3e-6)
parser.add_argument("--lr_w", type = float, default = 1e-3)
parser.add_argument("--n_iter_w", type = int, default = 4)
# For DA
parser.add_argument("--wda", type = float, default = .25)
## For {dann, cdan, dan, mdd} only
parser.add_argument("--domdisc_dimh", type = int, default = 1024) # for {dann, cdan, mdd} only
parser.add_argument("--cdan_rand", type = boolstr, default = False) # for cdan only
parser.add_argument("--ker_alphas", type = float, nargs = '+', default = [.5, 1., 2.]) # for dan only
parser.add_argument("--mdd_margin", type = float, default = 4.) # for mdd only
parser.add_argument("--gpu", type=int, default = 0)
return parser
def print_infrstru_info():
print("Environment:")
print("\tPython: {}".format(sys.version.split(" ")[0]))
print("\tPyTorch: {}".format(tc.__version__))
print("\tTorchvision: {}".format(tv.__version__))
print("\tCUDA: {}".format(tc.version.cuda))
print("\tCUDNN: {}".format(tc.backends.cudnn.version()))
# print("\tNumPy: {}".format(np.__version__))
# print("\tPIL: {}".format(PIL.__version__))
================================================
FILE: code/deep/DAAN/README.md
================================================
# [Transfer Learning with Dynamic Adversarial Adaptation Network](https://arxiv.org/abs/1909.08184)
## Prerequisites:
* Python3
* PyTorch == 1.0.0 (with suitable CUDA and CuDNN version)
* Numpy
* argparse
* PIL
* tqdm
## Training:
You can run "./scripts/train.sh" to train and evaluate on the task.
## Contribution:
The contributions of this paper are four-fold:
1. We propose a novel dynamic adversarial adaptation network to learn domain-invariant features. DAAN is accurate and robust, and can be easily implemented by most deep learning libraries.
2. We propose the dynamic adversarial factor to easily, dynamically, and quantitatively evaluate the relative importance of the marginal and conditional distributions in adversarial transfer learning.
3. We theoretically analyze the effectiveness of DAAN, and it can also be explained in an attention stragegy.
4. Extensive experiments on public datasets demonstrate the significant superiority of our DAAN in both classification accuracy and the estimation of the dynamic adversarial factor.
## Results:
* The architecture of the proposed Dynamic Adversarial Adaptation Network (DAAN):

* The classification accuracy on the ImageCLEF-DA dataset based on ResNet:

* The classification accuracy on the OfficeHome dataset based on ResNet:

* Ablation study of DAAN:

We compare the performance of DAAN with DANN(ω= 0), MADA(ω= 1), and JAN(ω= 0.5). All these methods can be seen as special cases of our DAAN. The average results on each dataset indicate that it is not enough to only align the marginal or conditional distributions, or aligning them with equal weights.
## Citation:
If you use this code for your research, please consider citing:
```
@inproceedings{yu2019transfer,
title={Transfer Learning with Dynamic Adversarial Adaptation Network},
author={Yu, Chaohui and Wang, Jindong and Chen, Yiqiang and Huang, Meiyu},
booktitle={The IEEE International Conference on Data Mining (ICDM)},
year={2019}
}
```
================================================
FILE: code/deep/DAAN/data_loader.py
================================================
from torchvision import datasets, transforms
import torch
import numpy as np
from torchvision import transforms
import os
from PIL import Image, ImageOps
class ResizeImage():
def __init__(self, size):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img):
th, tw = self.size
return img.resize((th, tw))
class PlaceCrop(object):
def __init__(self, size, start_x, start_y):
if isinstance(size, int):
self.size = (int(size), int(size))
else:
self.size = size
self.start_x = start_x
self.start_y = start_y
def __call__(self, img):
th, tw = self.size
return img.crop((self.start_x, self.start_y, self.start_x + tw, self.start_y + th))
def load_training(root_path, dir, batch_size, kwargs):
transform = transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
data = datasets.ImageFolder(root=root_path + dir, transform=transform)
train_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=True, **kwargs)
return train_loader
def load_testing(root_path, dir, batch_size, kwargs):
start_center = (256 - 224 - 1) / 2
transform = transforms.Compose(
[transforms.Resize([224, 224]),
PlaceCrop(224, start_center, start_center),
transforms.ToTensor()])
data = datasets.ImageFolder(root=root_path + dir, transform=transform)
test_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=False, drop_last=False, **kwargs)
return test_loader
================================================
FILE: code/deep/DAAN/functions.py
================================================
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
================================================
FILE: code/deep/DAAN/log/tmp-2019-10-27-22-13-51.log
================================================
Train epoch = 1: 0%| | 0/138 [00:00 classifier_i ->loss_i
for i in range(self.classes):
ps = p_source[:, i].reshape((target.shape[0],1))
fs = ps * s_reverse_feature
pt = p_target[:, i].reshape((target.shape[0],1))
ft = pt * t_reverse_feature
outsi = self.dcis[i](fs)
s_out.append(outsi)
outti = self.dcis[i](ft)
t_out.append(outti)
else:
s_domain_output = 0
t_domain_output = 0
s_out = [0]*self.classes
t_out = [0]*self.classes
return source, s_domain_output, t_domain_output, s_out, t_out
================================================
FILE: code/deep/DAAN/model/__init__.py
================================================
from . import *
================================================
FILE: code/deep/DAAN/model/backbone.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torchvision import models
from torch.autograd import Variable
# convnet without the last layer
class AlexNetFc(nn.Module):
def __init__(self):
super(AlexNetFc, self).__init__()
model_alexnet = models.alexnet(pretrained=True)
self.features = model_alexnet.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module("classifier"+str(i), model_alexnet.classifier[i])
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256*6*6)
x = self.classifier(x)
return x
class ResNet18Fc(nn.Module):
def __init__(self):
super(ResNet18Fc, self).__init__()
model_resnet18 = models.resnet18(pretrained=True)
self.conv1 = model_resnet18.conv1
self.bn1 = model_resnet18.bn1
self.relu = model_resnet18.relu
self.maxpool = model_resnet18.maxpool
self.layer1 = model_resnet18.layer1
self.layer2 = model_resnet18.layer2
self.layer3 = model_resnet18.layer3
self.layer4 = model_resnet18.layer4
self.avgpool = model_resnet18.avgpool
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet34Fc(nn.Module):
def __init__(self):
super(ResNet34Fc, self).__init__()
model_resnet34 = models.resnet34(pretrained=True)
self.conv1 = model_resnet34.conv1
self.bn1 = model_resnet34.bn1
self.relu = model_resnet34.relu
self.maxpool = model_resnet34.maxpool
self.layer1 = model_resnet34.layer1
self.layer2 = model_resnet34.layer2
self.layer3 = model_resnet34.layer3
self.layer4 = model_resnet34.layer4
self.avgpool = model_resnet34.avgpool
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet50Fc(nn.Module):
def __init__(self):
super(ResNet50Fc, self).__init__()
model_resnet50 = models.resnet50(pretrained=True)
self.conv1 = model_resnet50.conv1
self.bn1 = model_resnet50.bn1
self.relu = model_resnet50.relu
self.maxpool = model_resnet50.maxpool
self.layer1 = model_resnet50.layer1
self.layer2 = model_resnet50.layer2
self.layer3 = model_resnet50.layer3
self.layer4 = model_resnet50.layer4
self.avgpool = model_resnet50.avgpool
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet101Fc(nn.Module):
def __init__(self):
super(ResNet101Fc, self).__init__()
model_resnet101 = models.resnet101(pretrained=True)
self.conv1 = model_resnet101.conv1
self.bn1 = model_resnet101.bn1
self.relu = model_resnet101.relu
self.maxpool = model_resnet101.maxpool
self.layer1 = model_resnet101.layer1
self.layer2 = model_resnet101.layer2
self.layer3 = model_resnet101.layer3
self.layer4 = model_resnet101.layer4
self.avgpool = model_resnet101.avgpool
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
class ResNet152Fc(nn.Module):
def __init__(self):
super(ResNet152Fc, self).__init__()
model_resnet152 = models.resnet152(pretrained=True)
self.conv1 = model_resnet152.conv1
self.bn1 = model_resnet152.bn1
self.relu = model_resnet152.relu
self.maxpool = model_resnet152.maxpool
self.layer1 = model_resnet152.layer1
self.layer2 = model_resnet152.layer2
self.layer3 = model_resnet152.layer3
self.layer4 = model_resnet152.layer4
self.avgpool = model_resnet152.avgpool
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
network_dict = {"AlexNet": AlexNetFc,
"ResNet18": ResNet18Fc,
"ResNet34": ResNet34Fc,
"ResNet50": ResNet50Fc,
"ResNet101": ResNet101Fc,
"ResNet152": ResNet152Fc}
================================================
FILE: code/deep/DAAN/scripts/train.sh
================================================
#!/bin/bash
export CUDA_VISIBLE_DEVICES=1
PROJ_ROOT="/home/userxxx/DAAN"
PROJ_NAME="tmp"
LOG_FILE="${PROJ_ROOT}/log/${PROJ_NAME}-`date +'%Y-%m-%d-%H-%M-%S'`.log"
#echo "GPU: $CUDA_VISIBLE_DEVICES" > ${LOG_FILE}
#python ${PROJ_ROOT}/train.py >> ${LOG_FILE} 2>&1
python ${PROJ_ROOT}/train.py 2>&1 | tee -a ${LOG_FILE}
================================================
FILE: code/deep/DAAN/train.py
================================================
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import math
import data_loader
from model import DAAN
from torch.utils import model_zoo
import numpy as np
from IPython import embed
import tqdm
# Training settings
parser = argparse.ArgumentParser(description='PyTorch DAAN')
parser.add_argument('--batch_size', type=int, default=32, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=200, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=233, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--l2_decay', type=float, default=5e-4,
help='the L2 weight decay')
parser.add_argument('--save_path', type=str, default="./tmp/origin_",
help='the path to save the model')
parser.add_argument('--root_path', type=str, default="/home/xxx/data/OfficeHome/",
help='the path to load the data')
parser.add_argument('--source_dir', type=str, default="Clipart",
help='the name of the source dir')
parser.add_argument('--test_dir', type=str, default="Product",
help='the name of the test dir')
parser.add_argument('--diff_lr', type=bool, default=True,
help='the fc layer and the sharenet have different or same learning rate')
parser.add_argument('--gamma', type=int, default=1,
help='the fc layer and the sharenet have different or same learning rate')
parser.add_argument('--num_class', default=65, type=int,
help='the number of classes')
parser.add_argument('--gpu', default=0, type=int)
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
DEVICE = torch.device('cuda:' + str(args.gpu) if torch.cuda.is_available() else 'cpu')
torch.cuda.manual_seed(args.seed)
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
def load_data():
source_train_loader = data_loader.load_training(args.root_path, args.source_dir, args.batch_size, kwargs)
target_train_loader = data_loader.load_training(args.root_path, args.test_dir, args.batch_size, kwargs)
target_test_loader = data_loader.load_testing(args.root_path, args.test_dir, args.batch_size, kwargs)
return source_train_loader, target_train_loader, target_test_loader
def print_learning_rate(optimizer):
for p in optimizer.param_groups:
outputs = ''
for k, v in p.items():
if k is 'params':
outputs += (k + ': ' + str(v[0].shape).ljust(30) + ' ')
else:
outputs += (k + ': ' + str(v).ljust(10) + ' ')
print(outputs)
def train(epoch, model, source_loader, target_loader):
#total_progress_bar = tqdm.tqdm(desc='Train iter', total=args.epochs)
LEARNING_RATE = args.lr / math.pow((1 + 10 * (epoch - 1) / args.epochs), 0.75)
if args.diff_lr:
optimizer = torch.optim.SGD([
{'params': model.sharedNet.parameters()},
{'params': model.bottleneck.parameters()},
{'params': model.domain_classifier.parameters()},
{'params': model.dcis.parameters()},
{'params': model.source_fc.parameters(), 'lr': LEARNING_RATE},
], lr=LEARNING_RATE / 10, momentum=args.momentum, weight_decay=args.l2_decay)
else:
optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=args.momentum,weight_decay = args.l2_decay)
print_learning_rate(optimizer)
global D_M, D_C, MU
model.train()
len_dataloader = len(source_loader)
DEV = DEVICE
d_m = 0
d_c = 0
''' update mu per epoch '''
if D_M==0 and D_C==0 and MU==0:
MU = 0.5
else:
D_M = D_M/len_dataloader
D_C = D_C/len_dataloader
MU = 1 - D_M/(D_M + D_C)
for batch_idx, (source_data, source_label) in tqdm.tqdm(enumerate(source_loader),
total=len_dataloader,
desc='Train epoch = {}'.format(epoch), ncols=80, leave=False):
p = float(batch_idx+1 + epoch * len_dataloader) / args.epochs / len_dataloader
alpha = 2. / (1. + np.exp(-10 * p)) - 1
optimizer.zero_grad()
source_data, source_label = source_data.to(DEVICE), source_label.to(DEVICE)
for target_data, target_label in target_loader:
target_data, target_label = target_data.to(DEVICE), target_label.to(DEVICE)
break
out = model(source_data, target_data, source_label, DEV, alpha)
s_output, s_domain_output, t_domain_output = out[0],out[1],out[2]
s_out = out[3]
t_out = out[4]
#global loss
sdomain_label = torch.zeros(args.batch_size).long().to(DEV)
err_s_domain = F.nll_loss(F.log_softmax(s_domain_output, dim=1), sdomain_label)
tdomain_label = torch.ones(args.batch_size).long().to(DEV)
err_t_domain = F.nll_loss(F.log_softmax(t_domain_output, dim=1), tdomain_label)
#local loss
loss_s = 0.0
loss_t = 0.0
tmpd_c = 0
for i in range(args.num_class):
loss_si = F.nll_loss(F.log_softmax(s_out[i], dim=1), sdomain_label)
loss_ti = F.nll_loss(F.log_softmax(t_out[i], dim=1), tdomain_label)
loss_s += loss_si
loss_t += loss_ti
tmpd_c += 2 * (1 - 2 * (loss_si + loss_ti))
tmpd_c /= args.num_class
d_c = d_c + tmpd_c.cpu().item()
global_loss = 0.05*(err_s_domain + err_t_domain)
local_loss = 0.01*(loss_s + loss_t)
d_m = d_m + 2 * (1 - 2 * global_loss.cpu().item())
join_loss = (1 - MU) * global_loss + MU * local_loss
soft_loss = F.nll_loss(F.log_softmax(s_output, dim=1), source_label)
if args.gamma == 1:
gamma = 2 / (1 + math.exp(-10 * (epoch) / args.epochs)) - 1
if args.gamma == 2:
gamma = epoch /args.epochs
loss = soft_loss + join_loss
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('\nLoss: {:.6f}, label_Loss: {:.6f}, join_Loss: {:.6f}, global_Loss:{:.4f}, local_Loss:{:.4f}'.format(
loss.item(), soft_loss.item(), join_loss.item(), global_loss.item(), local_loss.item()))
#total_progress_bar.update(1)
D_M = np.copy(d_m).item()
D_C = np.copy(d_c).item()
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
out = model(data, data, target, DEVICE)
s_output = out[0]
test_loss += F.nll_loss(F.log_softmax(s_output, dim = 1), target, size_average=False).item() # sum up batch loss
pred = s_output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print(args.test_dir, '\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct
if __name__ == '__main__':
model = DAAN.DAANNet(num_classes=args.num_class, base_net='ResNet50').to(DEVICE)
train_loader, unsuptrain_loader, test_loader = load_data()
correct = 0
D_M = 0
D_C = 0
MU = 0
for epoch in range(1, args.epochs + 1):
train_loader, unsuptrain_loader, test_loader = load_data()
train(epoch, model, train_loader, unsuptrain_loader)
t_correct = test(model, test_loader)
if t_correct > correct:
correct = t_correct
print("%s max correct:" % args.test_dir, correct)
print(args.source_dir, "to", args.test_dir)
================================================
FILE: code/deep/DAN/README.md
================================================
# DAN
A PyTorch implementation of '[Learning Transferable Features with Deep Adaptation Networks](http://ise.thss.tsinghua.edu.cn/~mlong/doc/deep-adaptation-networks-icml15.pdf)'.
The contributions of this paper are summarized as follows.
* They propose a novel deep neural network architecture for domain adaptation, in which all the layers corresponding to task-specific features are adapted in a layerwise manner, hence benefiting from “deep adaptation.”
* They explore multiple kernels for adapting deep representations, which substantially enhances adaptation effectiveness compared to single kernel methods. Our model can yield unbiased deep features with statistical guarantees.
## Requirement
* python 3
* pytorch 1.0
## Usage
1. You can download Office31 dataset [here](https://pan.baidu.com/s/1o8igXT4#list/path=%2F). And then unrar dataset in ./dataset/.
2. You can change the `source_name` and `target_name` in `DAN.py` to set different transfer tasks.
3. Run `python DAN.py`.
## Results on Office31
| Method | A - W | D - W | W - D | A - D | D - A | W - A | Average |
|:--------------:|:-----:|:-----:|:-----:|:-----:|:----:|:----:|:-------:|
| DANori | 83.8±0.4 | 96.8±0.2 | 99.5±0.1 | 78.4±0.2 | 66.7±0.3 | 62.7±0.2 | 81.3 |
| DANlast | 81.6±0.7 | 97.2±0.1 | 99.5±0.1 | 80.0±0.7 | 66.2±0.6 | 65.6±0.4 | 81.7 |
| DANmax | 82.6±0.7 | 97.7±0.1 | 100.0±0.0 | 83.1±0.9 | 66.8±0.3 | 66.6±0.4 | 82.8 |
> Note that the results **DANori** comes from [paper](http://ise.thss.tsinghua.edu.cn/~mlong/doc/multi-adversarial-domain-adaptation-aaai18.pdf) which has the same author as DAN. The **DANlast** is the results of the last epoch, and **DANmax** is the results of the max results in all epoches. Both **DANlast** and **DANmax** are run by myself with the code.
================================================
FILE: code/deep/DANN(RevGrad)/adv_layer.py
================================================
import torch
import torch.nn as nn
from torch.autograd import Function
import torch.nn.functional as F
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.dis1 = nn.Linear(input_dim, hidden_dim)
self.bn = nn.BatchNorm1d(hidden_dim)
self.dis2 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.dis1(x))
x = self.dis2(self.bn(x))
x = torch.sigmoid(x)
return x
================================================
FILE: code/deep/DANN(RevGrad)/readme.md
================================================
# Domain adversarial neural network (DANN/RevGrad)
Code has been rewritten. Please go to https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA for the unified code implementation.
================================================
FILE: code/deep/DDC_DeepCoral/README.md
================================================
# Deep Coral and DDC
Code has been rewritten. Please go to https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA for the unified code implementation.
================================================
FILE: code/deep/DSAN/README.md
================================================
# DSAN
A PyTorch implementation of 'Deep Subdomain Adaptation Network for Image Classification' which has published on IEEE Transactions on Neural Networks and Learning Systems.
The contributions of this paper are summarized as follows.
* They propose a novel deep neural network architecture for Subdomain Adaptation, which can extend the ability of deep adaptation networks by capturing the fine-grained information for each category.
* They show that DSAN which is a non-adversarial method can achieve the remarkable results. In addition, their DSAN is very simple and easy to implement.
## Requirement
* python 3
* pytorch 1.0
## Usage
1. You can download Office31 dataset [here](https://pan.baidu.com/s/1o8igXT4#list/path=%2F). And then unrar dataset in ./dataset/.
2. You can change the `source_name` and `target_name` in `Config.py` to set different transfer tasks.
3. Run `python DSAN.py`.
## Results on Office31
| Method | A - W | D - W | W - D | A - D | D - A | W - A | Average |
|:--------------:|:-----:|:-----:|:-----:|:-----:|:----:|:----:|:-------:|
| DSAN | 93.6±0.2 | 98.4±0.1 | 100.0±0.0 | 90.2±0.7 | 73.5±0.5 | 74.8±0.4 | 88.4 |
> Note that for tasks D-A and W-A, setting epochs = 800 or larger could achieve better performance.
## Reference
```
Zhu Y, Zhuang F, Wang J, et al. Deep Subdomain Adaptation Network for Image Classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020.
```
or in bibtex style:
```
@article{zhu2020deep,
title={Deep Subdomain Adaptation Network for Image Classification},
author={Zhu, Yongchun and Zhuang, Fuzhen and Wang, Jindong and Ke, Guolin and Chen, Jingwu and Bian, Jiang and Xiong, Hui and He, Qing},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2020},
publisher={IEEE}
}
```
================================================
FILE: code/deep/DaNN/DaNN.py
================================================
import torch.nn as nn
class DaNN(nn.Module):
def __init__(self, n_input=28 * 28, n_hidden=256, n_class=10):
super(DaNN, self).__init__()
self.layer_input = nn.Linear(n_input, n_hidden)
self.dropout = nn.Dropout(p=0.5)
self.relu = nn.ReLU()
self.layer_hidden = nn.Linear(n_hidden, n_class)
def forward(self, src, tar):
x_src = self.layer_input(src)
x_tar = self.layer_input(tar)
x_src = self.dropout(x_src)
x_tar = self.dropout(x_tar)
x_src_mmd = self.relu(x_src)
x_tar_mmd = self.relu(x_tar)
y_src = self.layer_hidden(x_src_mmd)
return y_src, x_src_mmd, x_tar_mmd
================================================
FILE: code/deep/DaNN/data_loader.py
================================================
import torchvision
import torch
from torchvision import datasets,transforms
def load_data(root_dir,domain,batch_size):
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize([28, 28]),
transforms.ToTensor(),
transforms.Normalize(mean=(0,),std=(1,)),
]
)
image_folder = datasets.ImageFolder(
root=root_dir + domain,
transform=transform
)
data_loader = torch.utils.data.DataLoader(dataset=image_folder,batch_size=batch_size,shuffle=True,num_workers=2,drop_last=True
)
return data_loader
def load_test(root_dir,domain,batch_size):
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize([28, 28]),
transforms.ToTensor(),
transforms.Normalize(mean=(0,), std=(1,)),
]
)
image_folder = datasets.ImageFolder(
root=root_dir + domain,
transform=transform
)
data_loader = torch.utils.data.DataLoader(dataset=image_folder, batch_size=batch_size, shuffle=False, num_workers=2
)
return data_loader
================================================
FILE: code/deep/DaNN/main.py
================================================
import DaNN
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
import data_loader
import mmd
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
LEARNING_RATE = 0.02
MOMEMTUN = 0.05
L2_WEIGHT = 0.003
DROPOUT = 0.5
N_EPOCH = 900
BATCH_SIZE = [64, 64]
LAMBDA = 0.25
GAMMA = 10 ^ 3
RESULT_TRAIN = []
RESULT_TEST = []
log_train = open('log_train_a-w.txt', 'w')
log_test = open('log_test_a-w.txt', 'w')
def mmd_loss(x_src, x_tar):
return mmd.mix_rbf_mmd2(x_src, x_tar, [GAMMA])
def train(model, optimizer, epoch, data_src, data_tar):
total_loss_train = 0
criterion = nn.CrossEntropyLoss()
correct = 0
batch_j = 0
list_src, list_tar = list(enumerate(data_src)), list(enumerate(data_tar))
for batch_id, (data, target) in enumerate(data_src):
_, (x_tar, y_target) = list_tar[batch_j]
data, target = data.data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)
x_tar, y_target = x_tar.view(-1, 28 * 28).to(DEVICE), y_target.to(DEVICE)
model.train()
y_src, x_src_mmd, x_tar_mmd = model(data, x_tar)
loss_c = criterion(y_src, target)
loss_mmd = mmd_loss(x_src_mmd, x_tar_mmd)
pred = y_src.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
loss = loss_c + LAMBDA * loss_mmd
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss_train += loss.data
res_i = 'Epoch: [{}/{}], Batch: [{}/{}], loss: {:.6f}'.format(
epoch, N_EPOCH, batch_id + 1, len(data_src), loss.data
)
batch_j += 1
if batch_j >= len(list_tar):
batch_j = 0
total_loss_train /= len(data_src)
acc = correct * 100. / len(data_src.dataset)
res_e = 'Epoch: [{}/{}], training loss: {:.6f}, correct: [{}/{}], training accuracy: {:.4f}%'.format(
epoch, N_EPOCH, total_loss_train, correct, len(data_src.dataset), acc
)
tqdm.write(res_e)
log_train.write(res_e + '\n')
RESULT_TRAIN.append([epoch, total_loss_train, acc])
return model
def test(model, data_tar, e):
total_loss_test = 0
correct = 0
criterion = nn.CrossEntropyLoss()
with torch.no_grad():
for batch_id, (data, target) in enumerate(data_tar):
data, target = data.view(-1,28 * 28).to(DEVICE),target.to(DEVICE)
model.eval()
ypred, _, _ = model(data, data)
loss = criterion(ypred, target)
pred = ypred.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
total_loss_test += loss.data
accuracy = correct * 100. / len(data_tar.dataset)
res = 'Test: total loss: {:.6f}, correct: [{}/{}], testing accuracy: {:.4f}%'.format(
total_loss_test, correct, len(data_tar.dataset), accuracy
)
tqdm.write(res)
RESULT_TEST.append([e, total_loss_test, accuracy])
log_test.write(res + '\n')
if __name__ == '__main__':
rootdir = '../../../data/office_caltech_10/'
torch.manual_seed(1)
data_src = data_loader.load_data(
root_dir=rootdir, domain='amazon', batch_size=BATCH_SIZE[0])
data_tar = data_loader.load_test(
root_dir=rootdir, domain='webcam', batch_size=BATCH_SIZE[1])
model = DaNN.DaNN(n_input=28 * 28, n_hidden=256, n_class=10)
model = model.to(DEVICE)
optimizer = optim.SGD(
model.parameters(),
lr=LEARNING_RATE,
momentum=MOMEMTUN,
weight_decay=L2_WEIGHT
)
for e in tqdm(range(1, N_EPOCH + 1)):
model = train(model=model, optimizer=optimizer,
epoch=e, data_src=data_src, data_tar=data_tar)
test(model, data_tar, e)
torch.save(model, 'model_dann.pkl')
log_train.close()
log_test.close()
res_train = np.asarray(RESULT_TRAIN)
res_test = np.asarray(RESULT_TEST)
np.savetxt('res_train_a-w.csv', res_train, fmt='%.6f', delimiter=',')
np.savetxt('res_test_a-w.csv', res_test, fmt='%.6f', delimiter=',')
================================================
FILE: code/deep/DaNN/mmd.py
================================================
#!/usr/bin/env python
# encoding: utf-8
import torch
min_var_est = 1e-8
# Consider linear time MMD with a linear kernel:
# K(f(x), f(y)) = f(x)^Tf(y)
# h(z_i, z_j) = k(x_i, x_j) + k(y_i, y_j) - k(x_i, y_j) - k(x_j, y_i)
# = [f(x_i) - f(y_i)]^T[f(x_j) - f(y_j)]
#
# f_of_X: batch_size * k
# f_of_Y: batch_size * k
def linear_mmd2(f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X - f_of_Y
#loss = torch.mean((delta[:-1] * delta[1:]).sum(1))
loss = torch.mean(torch.mm(delta, torch.transpose(delta, 0, 1)))
#delta = f_of_X - f_of_Y
#loss = torch.mean((delta * delta).sum(1))
#print(loss)
return loss
# Consider linear time MMD with a polynomial kernel:
# K(f(x), f(y)) = (alpha*f(x)^Tf(y) + c)^d
# f_of_X: batch_size * k
# f_of_Y: batch_size * k
def poly_mmd2(f_of_X, f_of_Y, d=1, alpha=1.0, c=2.0):
K_XX = (alpha * (f_of_X[:-1] * f_of_X[1:]).sum(1) + c)
#print(K_XX)
K_XX_mean = torch.mean(K_XX.pow(d))
K_YY = (alpha * (f_of_Y[:-1] * f_of_Y[1:]).sum(1) + c)
K_YY_mean = torch.mean(K_YY.pow(d))
K_XY = (alpha * (f_of_X[:-1] * f_of_Y[1:]).sum(1) + c)
K_XY_mean = torch.mean(K_XY.pow(d))
K_YX = (alpha * (f_of_Y[:-1] * f_of_X[1:]).sum(1) + c)
K_YX_mean = torch.mean(K_YX.pow(d))
#print(K_XX_mean + K_YY_mean - K_XY_mean - K_YX_mean)
return K_XX_mean + K_YY_mean - K_XY_mean - K_YX_mean
def _mix_rbf_kernel(X, Y, sigma_list):
assert(X.size(0) == Y.size(0))
m = X.size(0)
Z = torch.cat((X, Y), 0)
ZZT = torch.mm(Z, Z.t())
diag_ZZT = torch.diag(ZZT).unsqueeze(1)
Z_norm_sqr = diag_ZZT.expand_as(ZZT)
exponent = Z_norm_sqr - 2 * ZZT + Z_norm_sqr.t()
K = 0.0
for sigma in sigma_list:
gamma = 1.0 / (2 * sigma**2)
K += torch.exp(-gamma * exponent)
return K[:m, :m], K[:m, m:], K[m:, m:], len(sigma_list)
def mix_rbf_mmd2(X, Y, sigma_list, biased=True):
K_XX, K_XY, K_YY, d = _mix_rbf_kernel(X, Y, sigma_list)
# return _mmd2(K_XX, K_XY, K_YY, const_diagonal=d, biased=biased)
return _mmd2(K_XX, K_XY, K_YY, const_diagonal=False, biased=biased)
def mix_rbf_mmd2_and_ratio(X, Y, sigma_list, biased=True):
K_XX, K_XY, K_YY, d = _mix_rbf_kernel(X, Y, sigma_list)
# return _mmd2_and_ratio(K_XX, K_XY, K_YY, const_diagonal=d, biased=biased)
return _mmd2_and_ratio(K_XX, K_XY, K_YY, const_diagonal=False, biased=biased)
################################################################################
# Helper functions to compute variances based on kernel matrices
################################################################################
def _mmd2(K_XX, K_XY, K_YY, const_diagonal=False, biased=False):
m = K_XX.size(0) # assume X, Y are same shape
# Get the various sums of kernels that we'll use
# Kts drop the diagonal, but we don't need to compute them explicitly
if const_diagonal is not False:
diag_X = diag_Y = const_diagonal
sum_diag_X = sum_diag_Y = m * const_diagonal
else:
diag_X = torch.diag(K_XX) # (m,)
diag_Y = torch.diag(K_YY) # (m,)
sum_diag_X = torch.sum(diag_X)
sum_diag_Y = torch.sum(diag_Y)
Kt_XX_sums = K_XX.sum(dim=1) - diag_X # \tilde{K}_XX * e = K_XX * e - diag_X
Kt_YY_sums = K_YY.sum(dim=1) - diag_Y # \tilde{K}_YY * e = K_YY * e - diag_Y
K_XY_sums_0 = K_XY.sum(dim=0) # K_{XY}^T * e
Kt_XX_sum = Kt_XX_sums.sum() # e^T * \tilde{K}_XX * e
Kt_YY_sum = Kt_YY_sums.sum() # e^T * \tilde{K}_YY * e
K_XY_sum = K_XY_sums_0.sum() # e^T * K_{XY} * e
if biased:
mmd2 = ((Kt_XX_sum + sum_diag_X) / (m * m)
+ (Kt_YY_sum + sum_diag_Y) / (m * m)
- 2.0 * K_XY_sum / (m * m))
else:
mmd2 = (Kt_XX_sum / (m * (m - 1))
+ Kt_YY_sum / (m * (m - 1))
- 2.0 * K_XY_sum / (m * m))
return mmd2
def _mmd2_and_ratio(K_XX, K_XY, K_YY, const_diagonal=False, biased=False):
mmd2, var_est = _mmd2_and_variance(K_XX, K_XY, K_YY, const_diagonal=const_diagonal, biased=biased)
loss = mmd2 / torch.sqrt(torch.clamp(var_est, min=min_var_est))
return loss, mmd2, var_est
def _mmd2_and_variance(K_XX, K_XY, K_YY, const_diagonal=False, biased=False):
m = K_XX.size(0) # assume X, Y are same shape
# Get the various sums of kernels that we'll use
# Kts drop the diagonal, but we don't need to compute them explicitly
if const_diagonal is not False:
diag_X = diag_Y = const_diagonal
sum_diag_X = sum_diag_Y = m * const_diagonal
sum_diag2_X = sum_diag2_Y = m * const_diagonal**2
else:
diag_X = torch.diag(K_XX) # (m,)
diag_Y = torch.diag(K_YY) # (m,)
sum_diag_X = torch.sum(diag_X)
sum_diag_Y = torch.sum(diag_Y)
sum_diag2_X = diag_X.dot(diag_X)
sum_diag2_Y = diag_Y.dot(diag_Y)
Kt_XX_sums = K_XX.sum(dim=1) - diag_X # \tilde{K}_XX * e = K_XX * e - diag_X
Kt_YY_sums = K_YY.sum(dim=1) - diag_Y # \tilde{K}_YY * e = K_YY * e - diag_Y
K_XY_sums_0 = K_XY.sum(dim=0) # K_{XY}^T * e
K_XY_sums_1 = K_XY.sum(dim=1) # K_{XY} * e
Kt_XX_sum = Kt_XX_sums.sum() # e^T * \tilde{K}_XX * e
Kt_YY_sum = Kt_YY_sums.sum() # e^T * \tilde{K}_YY * e
K_XY_sum = K_XY_sums_0.sum() # e^T * K_{XY} * e
Kt_XX_2_sum = (K_XX ** 2).sum() - sum_diag2_X # \| \tilde{K}_XX \|_F^2
Kt_YY_2_sum = (K_YY ** 2).sum() - sum_diag2_Y # \| \tilde{K}_YY \|_F^2
K_XY_2_sum = (K_XY ** 2).sum() # \| K_{XY} \|_F^2
if biased:
mmd2 = ((Kt_XX_sum + sum_diag_X) / (m * m)
+ (Kt_YY_sum + sum_diag_Y) / (m * m)
- 2.0 * K_XY_sum / (m * m))
else:
mmd2 = (Kt_XX_sum / (m * (m - 1))
+ Kt_YY_sum / (m * (m - 1))
- 2.0 * K_XY_sum / (m * m))
var_est = (
2.0 / (m**2 * (m - 1.0)**2) * (2 * Kt_XX_sums.dot(Kt_XX_sums) - Kt_XX_2_sum + 2 * Kt_YY_sums.dot(Kt_YY_sums) - Kt_YY_2_sum)
- (4.0*m - 6.0) / (m**3 * (m - 1.0)**3) * (Kt_XX_sum**2 + Kt_YY_sum**2)
+ 4.0*(m - 2.0) / (m**3 * (m - 1.0)**2) * (K_XY_sums_1.dot(K_XY_sums_1) + K_XY_sums_0.dot(K_XY_sums_0))
- 4.0*(m - 3.0) / (m**3 * (m - 1.0)**2) * (K_XY_2_sum) - (8 * m - 12) / (m**5 * (m - 1)) * K_XY_sum**2
+ 8.0 / (m**3 * (m - 1.0)) * (
1.0 / m * (Kt_XX_sum + Kt_YY_sum) * K_XY_sum
- Kt_XX_sums.dot(K_XY_sums_1)
- Kt_YY_sums.dot(K_XY_sums_0))
)
return mmd2, var_est
================================================
FILE: code/deep/DaNN/readme.md
================================================
# DaNN (Domain Adaptive Neural Networks)
- - -
This is the implementation of **Domain Adaptive Neural Networks (DaNN)** using PyTorch. The original paper can be found at https://link.springer.com/chapter/10.1007/978-3-319-13560-1_76.
DaNN is rather a *simple* neural network (with only 1 hidden layer) for domain adaptation. But its idea is important that brings MMD (maximum mean discrpancy) for adaptation in neural network. From then on, many researches are following this idea to embed MMD or other measurements (e.g. CORAL loss, Wasserstein distance) into deeper (e.g. AlexNet, ResNet) networks.
I think if you are beginning to learn **deep transfer learning**, it is better to start with the most original and simple one.
## Dataset
The original paper adopted the popular *Office+Caltech10* dataset. You can download them [HERE](https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md#download) and put them into a new folder named `data`.
- - -
## Usage
Make sure you have Python 3.6 and PyTorch 0.3.0. As for other requirements, I'm sure you are satisfied.
- `DaNN.py` is the DaNN model
- `mmd.py` is the MMD measurement. You're welcome to change it to others.
- `data_loader.py` is the help function for loading data.
- `main.py` is the main training and test program. You can directly run this file by `python main.py`.
- - -
### Reference
Ghifary M, Kleijn W B, Zhang M. Domain adaptive neural networks for object recognition[C]//Pacific Rim International Conference on Artificial Intelligence. Springer, Cham, 2014: 898-904.
================================================
FILE: code/deep/DeepCoral/README.md
================================================
# Deep Coral
This implementation has been moved to [DDC_DeepCoral](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DDC_DeepCoral) for better union with the mmd loss.
================================================
FILE: code/deep/DeepMEDA/README.md
================================================
# DeepMEDA (DDAN)
A PyTorch implementation of **Transfer Learning with Dynamic Distribution Adaptation** which has published on ACM Transactions on Intelligent Systems and Technology.
This is also called **DDAN (Deep Dynamic Adaptation Network)**.
Matlab version is [HERE](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA/matlab).
## Requirement
* python 3
* pytorch 1.x
* Numpy, scikit-learn
## Usage
1. You can download Office31 dataset [here](https://pan.baidu.com/s/1o8igXT4#list/path=%2F). Also, other datasets are supported in [here](https://github.com/jindongwang/transferlearning/tree/master/data).
2. Run `python main.py --src dslr --tar amazon --batch_size 32`.
> Note that for tasks D-A and W-A, setting epochs = 800 or larger could achieve better performance.
## Reference
```
Wang J, Chen Y, Feng W, et al. Transfer learning with dynamic distribution adaptation[J].
ACM Transactions on Intelligent Systems and Technology (TIST), 2020, 11(1): 1-25.
```
or in bibtex style:
```
@article{wang2020transfer,
title={Transfer learning with dynamic distribution adaptation},
author={Wang, Jindong and Chen, Yiqiang and Feng, Wenjie and Yu, Han and Huang, Meiyu and Yang, Qiang},
journal={ACM Transactions on Intelligent Systems and Technology (TIST)},
volume={11},
number={1},
pages={1--25},
year={2020},
publisher={ACM New York, NY, USA}
}
```
================================================
FILE: code/deep/DeepMEDA/ResNet.py
================================================
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.baselayer = [self.conv1, self.bn1, self.layer1, self.layer2, self.layer3, self.layer4]
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
================================================
FILE: code/deep/DeepMEDA/Weight.py
================================================
import numpy as np
import torch
def convert_to_onehot(sca_label, class_num=31):
return np.eye(class_num)[sca_label]
class Weight:
@staticmethod
def cal_weight(s_label, t_label, type='visual', batch_size=32, class_num=31):
batch_size = s_label.size()[0]
s_sca_label = s_label.cpu().data.numpy()
s_vec_label = convert_to_onehot(s_sca_label)
s_sum = np.sum(s_vec_label, axis=0).reshape(1, class_num)
s_sum[s_sum == 0] = 100
s_vec_label = s_vec_label / s_sum
t_sca_label = t_label.cpu().data.max(1)[1].numpy()
#t_vec_label = convert_to_onehot(t_sca_label)
t_vec_label = t_label.cpu().data.numpy()
t_sum = np.sum(t_vec_label, axis=0).reshape(1, class_num)
t_sum[t_sum == 0] = 100
t_vec_label = t_vec_label / t_sum
weight_ss = np.zeros((batch_size, batch_size))
weight_tt = np.zeros((batch_size, batch_size))
weight_st = np.zeros((batch_size, batch_size))
set_s = set(s_sca_label)
set_t = set(t_sca_label)
count = 0
for i in range(class_num):
if i in set_s and i in set_t:
s_tvec = s_vec_label[:, i].reshape(batch_size, -1)
t_tvec = t_vec_label[:, i].reshape(batch_size, -1)
ss = np.dot(s_tvec, s_tvec.T)
weight_ss = weight_ss + ss# / np.sum(s_tvec) / np.sum(s_tvec)
tt = np.dot(t_tvec, t_tvec.T)
weight_tt = weight_tt + tt# / np.sum(t_tvec) / np.sum(t_tvec)
st = np.dot(s_tvec, t_tvec.T)
weight_st = weight_st + st# / np.sum(s_tvec) / np.sum(t_tvec)
count += 1
length = count # len( set_s ) * len( set_t )
if length != 0:
weight_ss = weight_ss / length
weight_tt = weight_tt / length
weight_st = weight_st / length
else:
weight_ss = np.array([0])
weight_tt = np.array([0])
weight_st = np.array([0])
return weight_ss.astype('float32'), weight_tt.astype('float32'), weight_st.astype('float32')
================================================
FILE: code/deep/DeepMEDA/data_loader.py
================================================
from torchvision import datasets, transforms
import torch
import os
def load_training(root_path, dir, batch_size, kwargs):
transform = transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
data = datasets.ImageFolder(root=os.path.join(root_path, dir), transform=transform)
train_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=True, **kwargs)
return train_loader
def load_testing(root_path, dir, batch_size, kwargs):
transform = transforms.Compose(
[transforms.Resize([224, 224]),
transforms.ToTensor()])
data = datasets.ImageFolder(root=os.path.join(root_path, dir), transform=transform)
test_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, **kwargs)
return test_loader
================================================
FILE: code/deep/DeepMEDA/deep_meda.py
================================================
import torch
import torch.nn as nn
import ResNet
import mmd
import dynamic_factor
class DeepMEDA(nn.Module):
def __init__(self, num_classes=31, bottle_neck=True):
super(DeepMEDA, self).__init__()
self.feature_layers = ResNet.resnet50(True)
self.mmd_loss = mmd.MMD_loss()
self.bottle_neck = bottle_neck
if bottle_neck:
self.bottle = nn.Linear(2048, 256)
self.cls_fc = nn.Linear(256, num_classes)
else:
self.cls_fc = nn.Linear(2048, num_classes)
def forward(self, source, target, s_label):
source = self.feature_layers(source)
if self.bottle_neck:
source = self.bottle(source)
s_pred = self.cls_fc(source)
target = self.feature_layers(target)
if self.bottle_neck:
target = self.bottle(target)
t_label = self.cls_fc(target)
loss_c = self.mmd_loss.conditional(source, target, s_label, torch.nn.functional.softmax(t_label, dim=1))
loss_m = self.mmd_loss.marginal(source, target)
mu = dynamic_factor.estimate_mu(source.detach().cpu().numpy(), s_label.detach().cpu().numpy(), target.detach().cpu().numpy(), torch.max(t_label, 1)[1].detach().cpu().numpy())
return s_pred, loss_c, loss_m, mu
def predict(self, x):
x = self.feature_layers(x)
if self.bottle_neck:
x = self.bottle(x)
return self.cls_fc(x)
================================================
FILE: code/deep/DeepMEDA/dynamic_factor.py
================================================
import numpy as np
from sklearn import svm
def proxy_a_distance(source_X, target_X, verbose=False):
"""
Compute the Proxy-A-Distance of a source/target representation
"""
nb_source = np.shape(source_X)[0]
nb_target = np.shape(target_X)[0]
if verbose:
print('PAD on', (nb_source, nb_target), 'examples')
C_list = np.logspace(-5, 4, 10)
half_source, half_target = int(nb_source/2), int(nb_target/2)
train_X = np.vstack((source_X[0:half_source, :], target_X[0:half_target, :]))
train_Y = np.hstack((np.zeros(half_source, dtype=int), np.ones(half_target, dtype=int)))
test_X = np.vstack((source_X[half_source:, :], target_X[half_target:, :]))
test_Y = np.hstack((np.zeros(nb_source - half_source, dtype=int), np.ones(nb_target - half_target, dtype=int)))
best_risk = 1.0
for C in C_list:
clf = svm.SVC(C=C, kernel='linear', verbose=False)
clf.fit(train_X, train_Y)
train_risk = np.mean(clf.predict(train_X) != train_Y)
test_risk = np.mean(clf.predict(test_X) != test_Y)
if verbose:
print('[ PAD C = %f ] train risk: %f test risk: %f' % (C, train_risk, test_risk))
if test_risk > .5:
test_risk = 1. - test_risk
best_risk = min(best_risk, test_risk)
return 2 * (1. - 2 * best_risk)
def estimate_mu(_X1, _Y1, _X2, _Y2):
"""
Estimate value of mu using conditional and marginal A-distance.
"""
adist_m = proxy_a_distance(_X1, _X2)
Cs, Ct = np.unique(_Y1), np.unique(_Y2)
C = np.intersect1d(Cs, Ct)
epsilon = 1e-3
list_adist_c = []
tc = len(C)
for i in C:
ind_i, ind_j = np.where(_Y1 == i), np.where(_Y2 == i)
Xsi = _X1[ind_i[0], :]
Xtj = _X2[ind_j[0], :]
if len(Xsi) <= 1 or len(Xtj) <= 1:
tc -= 1
continue
adist_i = proxy_a_distance(Xsi, Xtj)
list_adist_c.append(adist_i)
if tc < 1:
return 0
adist_c = sum(list_adist_c) / tc
mu = adist_c / (adist_c + adist_m)
if mu > 1:
mu = 1
if mu < epsilon:
mu = 0
return mu
================================================
FILE: code/deep/DeepMEDA/main.py
================================================
import torch
import torch.nn.functional as F
import math
import pretty_errors
import argparse
import numpy as np
from deep_meda import DeepMEDA
import data_loader
def load_data(root_path, src, tar, batch_size):
kwargs = {'num_workers': 1, 'pin_memory': True}
loader_src = data_loader.load_training(root_path, src, batch_size, kwargs)
loader_tar = data_loader.load_training(root_path, tar, batch_size, kwargs)
loader_tar_test = data_loader.load_testing(
root_path, tar, batch_size, kwargs)
return loader_src, loader_tar, loader_tar_test
def train_epoch(epoch, model, dataloaders):
LEARNING_RATE = args.lr / \
math.pow((1 + 10 * (epoch - 1) / args.nepoch), 0.75)
print('learning rate{: .4f}'.format(LEARNING_RATE))
if args.bottleneck:
optimizer = torch.optim.SGD([
{'params': model.feature_layers.parameters()},
{'params': model.bottle.parameters(), 'lr': LEARNING_RATE},
{'params': model.cls_fc.parameters(), 'lr': LEARNING_RATE},
], lr=LEARNING_RATE / 10, momentum=args.momentum, weight_decay=args.decay)
else:
optimizer = torch.optim.SGD([
{'params': model.feature_layers.parameters()},
{'params': model.cls_fc.parameters(), 'lr': LEARNING_RATE},
], lr=LEARNING_RATE / 10, momentum=args.momentum, weight_decay=args.decay)
model.train()
source_loader, target_train_loader, _ = dataloaders
iter_source = iter(source_loader)
iter_target = iter(target_train_loader)
num_iter = len(source_loader)
for i in range(1, num_iter):
data_source, label_source = iter_source.next()
data_target, _ = iter_target.next()
if i % len(target_train_loader) == 0:
iter_target = iter(target_train_loader)
data_source, label_source = data_source.cuda(), label_source.cuda()
data_target = data_target.cuda()
optimizer.zero_grad()
label_source_pred, loss_c, loss_m, mu = model(
data_source, data_target, label_source)
loss_mmd = (1-mu) * loss_m + mu * loss_c
loss_cls = F.nll_loss(F.log_softmax(
label_source_pred, dim=1), label_source)
lambd = 2 / (1 + math.exp(-10 * (epoch) / args.nepoch)) - 1
loss = loss_cls + args.weight * lambd * loss_mmd
loss.backward()
optimizer.step()
if i % args.log_interval == 0:
print(f'Epoch: [{epoch:2d}/{num_iter}], Loss: {loss.item():.4f}, cls_Loss: {loss_cls.item():.4f}, l_mar: {loss_m.item():.4f}, l_con: {loss_c.item():.4f}, mu: {mu:.2f}')
def test(model, dataloader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in dataloader:
data, target = data.cuda(), target.cuda()
pred = model.predict(data)
# sum up batch loss
test_loss += F.nll_loss(F.log_softmax(pred, dim=1), target).item()
pred = pred.data.max(1)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(dataloader)
print(
f'Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(dataloader)} ({100. * correct / len(dataloader):.2f}%)')
return correct
def get_args():
def str2bool(v):
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
return False
else:
raise argparse.ArgumentTypeError('Unsupported value encountered.')
parser = argparse.ArgumentParser()
parser.add_argument('--root_path', type=str, help='Root path for dataset',
default='/data/jindongwang/office31/')
parser.add_argument('--src', type=str,
help='Source domain', default='dslr')
parser.add_argument('--tar', type=str,
help='Target domain', default='amazon')
parser.add_argument('--nclass', type=int,
help='Number of classes', default=31)
parser.add_argument('--batch_size', type=float,
help='batch size', default=32)
parser.add_argument('--nepoch', type=int,
help='Total epoch num', default=200)
parser.add_argument('--lr', type=float, help='Learning rate', default=0.01)
parser.add_argument('--early_stop', type=int,
help='Early stoping number', default=30)
parser.add_argument('--weight', type=float,
help='Weight for adaptation loss', default=0.3)
parser.add_argument('--momentum', type=float, help='Momentum', default=0.9)
parser.add_argument('--decay', type=float,
help='L2 weight decay', default=5e-4)
parser.add_argument('--bottleneck', type=str2bool,
nargs='?', const=True, default=True)
parser.add_argument('--log_interval', type=int,
help='Log interval', default=10)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
print(vars(args))
SEED = 1
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
dataloaders = load_data(args.root_path, args.src,
args.tar, args.batch_size)
model = DeepMEDA(num_classes=args.nclass).cuda()
correct = 0
stop = 0
for epoch in range(1, args.nepoch + 1):
stop += 1
train_epoch(epoch, model, dataloaders)
t_correct = test(model, dataloaders[-1])
if t_correct > correct:
correct = t_correct
stop = 0
torch.save(model, 'model.pkl')
print(
f'{args.src}-{args.tar}: max correct: {correct} max accuracy: {100. * correct / len(dataloaders[-1].dataset):.2f}%\n')
if stop >= args.early_stop:
print(
f'Final test acc: {100. * correct / len(dataloaders[-1].dataset):.2f}%')
break
================================================
FILE: code/deep/DeepMEDA/mmd.py
================================================
import torch
import torch.nn as nn
from Weight import Weight
class MMD_loss(nn.Module):
def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5):
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd2(self, f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)
loss = delta.dot(delta.T)
return loss
def marginal(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd2(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
def conditional(self, source, target, s_label, t_label, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
batch_size = source.size()[0]
weight_ss, weight_tt, weight_st = Weight.cal_weight(
s_label, t_label, type='visual')
weight_ss = torch.from_numpy(weight_ss).cuda()
weight_tt = torch.from_numpy(weight_tt).cuda()
weight_st = torch.from_numpy(weight_st).cuda()
kernels = self.guassian_kernel(source, target,
kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)
loss = torch.Tensor([0]).cuda()
if torch.sum(torch.isnan(sum(kernels))):
return loss
SS = kernels[:batch_size, :batch_size]
TT = kernels[batch_size:, batch_size:]
ST = kernels[:batch_size, batch_size:]
loss += torch.sum(weight_ss * SS + weight_tt * TT - 2 * weight_st * ST)
return loss
================================================
FILE: code/deep/Learning-to-Match/README.md
================================================
# Learning to Match Distributions for Domain Adaptation
The code will be released soon.
================================================
FILE: code/deep/MRAN/MRAN.py
================================================
from __future__ import print_function
import argparse
import torch
import torch.nn.functional as F
import torch.optim as optim
import os
import math
import data_loader
import ResNet as models
from torch.utils import model_zoo
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=32, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=32, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=200, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=3, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--l2_decay', type=float, default=5e-4,
help='the L2 weight decay')
parser.add_argument('--save_path', type=str, default="./tmp/origin_",
help='the path to save the model')
parser.add_argument('--root_path', type=str, default="../OFFICE31/",
help='the path to load the data')
parser.add_argument('--source_dir', type=str, default="webcam",
help='the name of the source dir')
parser.add_argument('--test_dir', type=str, default="dslr",
help='the name of the test dir')
parser.add_argument('--diff_lr', type=bool, default=True,
help='the fc layer and the sharenet have different or same learning rate')
parser.add_argument('--gamma', type=int, default=1,
help='the fc layer and the sharenet have different or same learning rate')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
def load_data():
source_train_loader = data_loader.load_training(args.root_path, args.source_dir, args.batch_size, kwargs)
target_train_loader = data_loader.load_training(args.root_path, args.test_dir, args.batch_size, kwargs)
target_test_loader = data_loader.load_testing(args.root_path, args.test_dir, args.batch_size, kwargs)
return source_train_loader, target_train_loader, target_test_loader
def train(epoch, model, source_loader, target_loader):
#最后的全连接层学习率为前面的10倍
LEARNING_RATE = args.lr / math.pow((1 + 10 * (epoch - 1) / args.epochs), 0.75)
print("learning rate:", LEARNING_RATE)
if args.diff_lr:
optimizer = torch.optim.SGD([
{'params': model.sharedNet.parameters()},
{'params': model.Inception.parameters(), 'lr': LEARNING_RATE},
], lr=LEARNING_RATE / 10, momentum=args.momentum, weight_decay=args.l2_decay)
else:
optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=args.momentum,weight_decay = args.l2_decay)
model.train()
tgt_iter = iter(target_loader)
for batch_idx, (source_data, source_label) in enumerate(source_loader):
try:
target_data, _ = tgt_iter.next()
except Exception as err:
tgt_iter=iter(target_loader)
target_data, _ = tgt_iter.next()
if args.cuda:
source_data, source_label = source_data.cuda(), source_label.cuda()
target_data = target_data.cuda()
optimizer.zero_grad()
s_output, mmd_loss = model(source_data, target_data, source_label)
soft_loss = F.nll_loss(F.log_softmax(s_output, dim=1), source_label)
# print((2 / (1 + math.exp(-10 * (epoch) / args.epochs)) - 1))
if args.gamma == 1:
gamma = 2 / (1 + math.exp(-10 * (epoch) / args.epochs)) - 1
if args.gamma == 2:
gamma = epoch /args.epochs
loss = soft_loss + gamma * mmd_loss
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tlabel_Loss: {:.6f}\tmmd_Loss: {:.6f}'.format(
epoch, batch_idx * len(source_data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item(), soft_loss.item(), mmd_loss.item()))
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
s_output, t_output = model(data, data, target)
test_loss += F.nll_loss(F.log_softmax(s_output, dim = 1), target, reduction='sum').item()# sum up batch loss
pred = s_output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print(args.test_dir, '\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct
if __name__ == '__main__':
model = models.MRANNet(num_classes=31)
print(model)
if args.cuda:
model.cuda()
train_loader, unsuptrain_loader, test_loader = load_data()
correct = 0
for epoch in range(1, args.epochs + 1):
train(epoch, model, train_loader, unsuptrain_loader)
t_correct = test(model, test_loader)
if t_correct > correct:
correct = t_correct
print("%s max correct:" % args.test_dir, correct.item())
print(args.source_dir, "to", args.test_dir)
================================================
FILE: code/deep/MRAN/README.md
================================================
# DAN
A PyTorch implementation of '[Multi-representationadaptationnetworkforcross-domainimage
classification](https://www.sciencedirect.com/science/article/pii/S0893608019301984)'.
The contributions of this paper are summarized as follows.
* We are the first to learn multiple different domain-invariant representations by Inception
Adaptation Module (IAM) for cross-domain image classification.
* A novel Multi-Representation Adaptation Network (MRAN) is proposed to align distributions of multiple different representations which might contain more information about the images.
## Requirement
* python 3
* pytorch 1.0
* torchvision 0.2.0
## Usage
1. You can download Office31 dataset [here](https://pan.baidu.com/s/1o8igXT4#list/path=%2F). And then unrar dataset in ./dataset/.
2. You can change the `source_name` and `target_name` in `MRAN.py` to set different transfer tasks.
3. Run `python MRAN.py`.
## Results on Office31
| Method | A - W | D - W | W - D | A - D | D - A | W - A | Average |
|:--------------:|:-----:|:-----:|:-----:|:-----:|:----:|:----:|:-------:|
| MRAN | 91.4±0.1 | 96.9±0.3 | 99.8±0.2 | 86.4±0.6 | 68.3±0.5 | 70.9±0.6 | 85.6 |
================================================
FILE: code/deep/MRAN/ResNet.py
================================================
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
import mmd
import torch
import torch.nn.functional as F
import random
__all__ = ['ResNet', 'resnet50']
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(8, stride=1)
self.baselayer = [self.conv1, self.bn1, self.layer1, self.layer2, self.layer3, self.layer4]
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
class MRANNet(nn.Module):
def __init__(self, num_classes=31):
super(MRANNet, self).__init__()
self.sharedNet = resnet50(True)
self.Inception = InceptionA(2048, 64, num_classes)
def forward(self, source, target, s_label):
source = self.sharedNet(source)
target = self.sharedNet(target)
source, loss = self.Inception(source, target, s_label)
return source, loss
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features, num_classes):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
self.avg_pool = nn.AvgPool2d(7, stride=1)
self.source_fc = nn.Linear(288, num_classes)
def forward(self, source, target, s_label):
s_branch1x1 = self.branch1x1(source)
s_branch5x5 = self.branch5x5_1(source)
s_branch5x5 = self.branch5x5_2(s_branch5x5)
s_branch3x3dbl = self.branch3x3dbl_1(source)
s_branch3x3dbl = self.branch3x3dbl_2(s_branch3x3dbl)
s_branch3x3dbl = self.branch3x3dbl_3(s_branch3x3dbl)
s_branch_pool = F.avg_pool2d(source, kernel_size=3, stride=1, padding=1)
s_branch_pool = self.branch_pool(s_branch_pool)
s_branch1x1 = self.avg_pool(s_branch1x1)
s_branch5x5 = self.avg_pool(s_branch5x5)
s_branch3x3dbl = self.avg_pool(s_branch3x3dbl)
s_branch_pool = self.avg_pool(s_branch_pool)
s_branch1x1 = s_branch1x1.view(s_branch1x1.size(0), -1)
s_branch5x5 = s_branch5x5.view(s_branch5x5.size(0), -1)
s_branch3x3dbl = s_branch3x3dbl.view(s_branch3x3dbl.size(0), -1)
s_branch_pool = s_branch_pool.view(s_branch_pool.size(0), -1)
t_branch1x1 = self.branch1x1(target)
t_branch5x5 = self.branch5x5_1(target)
t_branch5x5 = self.branch5x5_2(t_branch5x5)
t_branch3x3dbl = self.branch3x3dbl_1(target)
t_branch3x3dbl = self.branch3x3dbl_2(t_branch3x3dbl)
t_branch3x3dbl = self.branch3x3dbl_3(t_branch3x3dbl)
t_branch_pool = F.avg_pool2d(target, kernel_size=3, stride=1, padding=1)
t_branch_pool = self.branch_pool(t_branch_pool)
t_branch1x1 = self.avg_pool(t_branch1x1)
t_branch5x5 = self.avg_pool(t_branch5x5)
t_branch3x3dbl = self.avg_pool(t_branch3x3dbl)
t_branch_pool = self.avg_pool(t_branch_pool)
t_branch1x1 = t_branch1x1.view(t_branch1x1.size(0), -1)
t_branch5x5 = t_branch5x5.view(t_branch5x5.size(0), -1)
t_branch3x3dbl = t_branch3x3dbl.view(t_branch3x3dbl.size(0), -1)
t_branch_pool = t_branch_pool.view(t_branch_pool.size(0), -1)
source = torch.cat([s_branch1x1, s_branch5x5, s_branch3x3dbl, s_branch_pool], 1)
target = torch.cat([t_branch1x1, t_branch5x5, t_branch3x3dbl, t_branch_pool], 1)
source = self.source_fc(source)
t_label = self.source_fc(target)
t_label = t_label.data.max(1)[1]
loss = torch.Tensor([0])
loss = loss.cuda()
if self.training == True:
loss += mmd.cmmd(s_branch1x1, t_branch1x1, s_label, t_label)
loss += mmd.cmmd(s_branch5x5, t_branch5x5, s_label, t_label)
loss += mmd.cmmd(s_branch3x3dbl, t_branch3x3dbl, s_label, t_label)
loss += mmd.cmmd(s_branch_pool, t_branch_pool, s_label, t_label)
return source, loss
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
================================================
FILE: code/deep/MRAN/data_loader.py
================================================
from torchvision import datasets, transforms
import torch
def load_training(root_path, dir, batch_size, kwargs):
transform = transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
data = datasets.ImageFolder(root=root_path + dir, transform=transform)
train_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=True, **kwargs)
return train_loader
def load_testing(root_path, dir, batch_size, kwargs):
transform = transforms.Compose(
[transforms.Resize([224, 224]),
transforms.ToTensor()])
data = datasets.ImageFolder(root=root_path + dir, transform=transform)
test_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, **kwargs)
return test_loader
================================================
FILE: code/deep/MRAN/mmd.py
================================================
#!/usr/bin/env python
# encoding: utf-8
import torch
import numpy as np
from torch.autograd import Variable
min_var_est = 1e-8
def guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0])+int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for bandwidth_temp in bandwidth_list]
return sum(kernel_val)#/len(kernel_val)
def cmmd(source, target, s_label, t_label, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
s_label = s_label.cpu()
s_label = s_label.view(32,1)
s_label = torch.zeros(32, 31).scatter_(1, s_label.data, 1)
s_label = Variable(s_label).cuda()
t_label = t_label.cpu()
t_label = t_label.view(32, 1)
t_label = torch.zeros(32, 31).scatter_(1, t_label.data, 1)
t_label = Variable(t_label).cuda()
batch_size = int(source.size()[0])
kernels = guassian_kernel(source, target,
kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)
loss = 0
XX = kernels[:batch_size, :batch_size]
YY = kernels[batch_size:, batch_size:]
XY = kernels[:batch_size, batch_size:]
loss += torch.mean(torch.mm(s_label, torch.transpose(s_label, 0, 1)) * XX +
torch.mm(t_label, torch.transpose(t_label, 0, 1)) * YY -
2 * torch.mm(s_label, torch.transpose(t_label, 0, 1)) * XY)
return loss
================================================
FILE: code/deep/README.md
================================================
# Deep Transfer Learning on PyTorch
This directory contains some re-implemented Pytorch codes for deep transfer learning.
## Update
Some codes have been rewritten. Please go to https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA for the unified code implementation.
Algorithms in this folder that **will be** moved to DeepDA folder:
- DeepMEDA
- TCP
- MRAN
- Learning-to-match
Algorithms in this folder that **have been** moved to DeepDA folder:
- DAN (DDC)
- DANN (RevGrad)
- DCORAL
- DSAN
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/my_neuron_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
import copy
from .utils import common
from pdb import set_trace as st
class MyNeuronCoverage:
""" Class for model neuron coverage evaluation.
Based on the outputs of the intermediate layers, update and report
the model neuron coverage accordingly.
Parameters
----------
thresholds : list of floats
The thresholds of neuron activation. Each of them will be used
to calculate the model neuron coverage respectively.
"""
def __init__(self, threshold=0.5):
self._threshold = threshold
self._layer_neuron_id_to_global_neuron_id = {}
self._global_neuron_id_to_layer_neuron_id = {}
self._results = {}
self._num_layer = 0
self._num_neuron = 0
self._num_input = 0
self._report_layers_and_neurons = True
self.result = None
self.structure_initialized = False
def init_structure(self, intermediate_layer_outputs, features_index):
# Initialize the information about networks
current_global_neuron_id = 0
for layer_id, intermediate_layer_output in enumerate(intermediate_layer_outputs):
intermediate_layer_output_single_input = intermediate_layer_output[0]
num_layer_neuron = intermediate_layer_output_single_input.shape[features_index]
for layer_neuron_id in range(num_layer_neuron):
self._layer_neuron_id_to_global_neuron_id[(layer_id, layer_neuron_id)] = current_global_neuron_id
self._global_neuron_id_to_layer_neuron_id[current_global_neuron_id] = (layer_id, layer_neuron_id)
current_global_neuron_id += 1
self._num_layer += 1
self._num_neuron += num_layer_neuron
def update(self, intermediate_layer_outputs, features_index):
"""Update model neuron coverage accordingly.
With each value in thresholds as the neuron activation threshold,
the neuron coverage will be re-calculated and updated accordingly.
Parameters
----------
intermediate_layer_outputs : list of arrays
The outputs of the intermediate layers.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Notes
-------
This method can be invoked for many times in one instance which means
that once the outputs of the intermediate layers for a batch is got,
this method can be invoked to update the status. The neuron coverage
will be updated for every invocation.
"""
# copy and convert intermediate layer outputs to numpy array
intermediate_layer_outputs_new = []
for intermediate_layer_output in intermediate_layer_outputs:
intermediate_layer_output = common.to_numpy(intermediate_layer_output)
intermediate_layer_outputs_new.append(intermediate_layer_output)
intermediate_layer_outputs = intermediate_layer_outputs_new
if not self.structure_initialized:
self.init_structure(intermediate_layer_outputs, features_index)
self.structure_initialized = True
# get number of inputs
num_input = len(intermediate_layer_outputs[0])
self._num_input += num_input
# scale the output of each layer
for layer_id in range(len(intermediate_layer_outputs)):
intermediate_layer_outputs[layer_id] = self._scale(intermediate_layer_outputs[layer_id])
current_result = []
# calculate and update the neuron coverage based on scaled outputs
for layer_id, intermediate_layer_output in enumerate(intermediate_layer_outputs):
if len(intermediate_layer_output.shape) > 2:
result = self._calc_1(intermediate_layer_output, features_index, self._threshold)
else:
result = self._calc_2(intermediate_layer_output, features_index, self._threshold)
current_result.append(result)
self.per_layer_result = copy.deepcopy(current_result)
current_result = np.concatenate(current_result, axis=1)
self.result = current_result
def report(self, *args):
"""Report model neuron coverage.
The neuron coverage info will be reported with each value in thresholds
as the neuron activation threshold. Reported info includes report time,
number of layers, number of neurons, number in inputs, threshold, neuron
coverage, number of neurons covered.
"""
# if self._report_layers_and_neurons:
# self._report_layers_and_neurons = False
# print('[NeuronCoverage] Time:{:s}, Layers: {:d}, Neurons: {:d}'.format(common.readable_time_str(), self._num_layer, self._num_neuron))
# for threshold in self._thresholds:
# print('[NeuronCoverage] Time:{:s}, Num: {:d}, Threshold: {:.6f}, Neuron Coverage: {:.6f}({:d}/{:d})'.format(common.readable_time_str(), self._num_input, threshold, self.get(threshold), len([v for v in self._results[threshold] if v]), self._num_neuron))
num_input, num_neuron = self.result.shape
for input_id in range(num_input):
coverage = np.sum(self.result[input_id]) / num_neuron
print(f"[NeuronCoverage] layers: {self._num_layer}, neurons: {self._num_neuron}, input_id {input_id}, coverage: {coverage:.4f}[{np.sum(self.result[input_id])}/{num_neuron}]")
def get(self, threshold):
"""Get model neuron coverage.
Parameters
----------
threshold : float
The neuron activation threshold.
Returns
-------
float
Model neuron coverage with parameter as the neuron activation threshold.
Notes
-------
The parameter threshold must be one value in the list thresholds.
"""
# return len([v for v in self._results[threshold] if v]) / self._num_neuron if self._num_neuron != 0 else 0
if self.result is None:
raise RunTimeError(f"Result is None!")
return self.result
@staticmethod
@njit(parallel=True)
def _scale(intermediate_layer_output):
"""For each input, scale the output of one intermediate layer
by (x - min) / (max - min).
Parameters
----------
intermediate_layer_output : array
The output of one intermediate layer.
Returns
-------
array
The scaled output of the intermediate layer.
Notes
-------
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
for input_id in prange(intermediate_layer_output.shape[0]):
intermediate_layer_output[input_id] = (intermediate_layer_output[input_id] - intermediate_layer_output[input_id].min()) / (intermediate_layer_output[input_id].max() - intermediate_layer_output[input_id].min())
return intermediate_layer_output
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
if mean > threshold:
result[input_id][layer_neuron_id] = 1
# result[layer_neuron_id] = mean
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
if neuron_output > threshold:
result[input_id][layer_neuron_id] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/neuron_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from pdb import set_trace as st
class NeuronCoverage:
""" Class for model neuron coverage evaluation.
Based on the outputs of the intermediate layers, update and report
the model neuron coverage accordingly.
Parameters
----------
thresholds : list of floats
The thresholds of neuron activation. Each of them will be used
to calculate the model neuron coverage respectively.
"""
def __init__(self, thresholds=(0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9)):
self._thresholds = thresholds
self._layer_neuron_id_to_global_neuron_id = {}
self._results = {}
self._num_layer = 0
self._num_neuron = 0
self._num_input = 0
self._report_layers_and_neurons = True
def update(self, intermediate_layer_outputs, features_index):
"""Update model neuron coverage accordingly.
With each value in thresholds as the neuron activation threshold,
the neuron coverage will be re-calculated and updated accordingly.
Parameters
----------
intermediate_layer_outputs : list of arrays
The outputs of the intermediate layers.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Notes
-------
This method can be invoked for many times in one instance which means
that once the outputs of the intermediate layers for a batch is got,
this method can be invoked to update the status. The neuron coverage
will be updated for every invocation.
"""
# copy and convert intermediate layer outputs to numpy array
intermediate_layer_outputs_new = []
for intermediate_layer_output in intermediate_layer_outputs:
intermediate_layer_output = common.to_numpy(intermediate_layer_output)
intermediate_layer_outputs_new.append(intermediate_layer_output)
intermediate_layer_outputs = intermediate_layer_outputs_new
# initialize basic info in first invocation
if len(self._results.keys()) == 0:
current_global_neuron_id = 0
for layer_id, intermediate_layer_output in enumerate(intermediate_layer_outputs):
intermediate_layer_output_single_input = intermediate_layer_output[0]
num_layer_neuron = intermediate_layer_output_single_input.shape[features_index]
for layer_neuron_id in range(num_layer_neuron):
self._layer_neuron_id_to_global_neuron_id[(layer_id, layer_neuron_id)] = current_global_neuron_id
current_global_neuron_id += 1
self._num_layer += 1
self._num_neuron += num_layer_neuron
for threshold in self._thresholds:
self._results[threshold] = np.zeros(shape=self._num_neuron)
# get number of inputs
num_input = len(intermediate_layer_outputs[0])
self._num_input += num_input
# scale the output of each layer
for layer_id in range(len(intermediate_layer_outputs)):
intermediate_layer_outputs[layer_id] = self._scale(intermediate_layer_outputs[layer_id])
# calculate and update the neuron coverage based on scaled outputs
for layer_id, intermediate_layer_output in enumerate(intermediate_layer_outputs):
if len(intermediate_layer_output.shape) > 2:
result = self._calc_1(intermediate_layer_output, features_index)
else:
result = self._calc_2(intermediate_layer_output, features_index)
num_layer_neuron = intermediate_layer_outputs[layer_id][0].shape[features_index]
for layer_neuron_id in range(num_layer_neuron):
global_neuron_id = self._layer_neuron_id_to_global_neuron_id[(layer_id, layer_neuron_id)]
for threshold in self._thresholds:
if result[layer_neuron_id] > threshold:
self._results[threshold][global_neuron_id] = True
def report(self, *args):
"""Report model neuron coverage.
The neuron coverage info will be reported with each value in thresholds
as the neuron activation threshold. Reported info includes report time,
number of layers, number of neurons, number in inputs, threshold, neuron
coverage, number of neurons covered.
"""
if self._report_layers_and_neurons:
self._report_layers_and_neurons = False
print('[NeuronCoverage] Time:{:s}, Layers: {:d}, Neurons: {:d}'.format(common.readable_time_str(), self._num_layer, self._num_neuron))
for threshold in self._thresholds:
print('[NeuronCoverage] Time:{:s}, Num: {:d}, Threshold: {:.6f}, Neuron Coverage: {:.6f}({:d}/{:d})'.format(common.readable_time_str(), self._num_input, threshold, self.get(threshold), len([v for v in self._results[threshold] if v]), self._num_neuron))
def get(self, threshold):
"""Get model neuron coverage.
Parameters
----------
threshold : float
The neuron activation threshold.
Returns
-------
float
Model neuron coverage with parameter as the neuron activation threshold.
Notes
-------
The parameter threshold must be one value in the list thresholds.
"""
return len([v for v in self._results[threshold] if v]) / self._num_neuron if self._num_neuron != 0 else 0
@staticmethod
@njit(parallel=True)
def _scale(intermediate_layer_output):
"""For each input, scale the output of one intermediate layer
by (x - min) / (max - min).
Parameters
----------
intermediate_layer_output : array
The output of one intermediate layer.
Returns
-------
array
The scaled output of the intermediate layer.
Notes
-------
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
for input_id in prange(intermediate_layer_output.shape[0]):
intermediate_layer_output[input_id] = (intermediate_layer_output[input_id] - intermediate_layer_output[input_id].min()) / (intermediate_layer_output[input_id].max() - intermediate_layer_output[input_id].min())
return intermediate_layer_output
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
result = np.zeros(shape=num_layer_neuron, dtype=np.float32)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
if mean > result[layer_neuron_id]:
result[layer_neuron_id] = mean
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
result = np.zeros(shape=num_layer_neuron, dtype=np.float32)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
if neuron_output > result[layer_neuron_id]:
result[layer_neuron_id] = neuron_output
return result
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/pytorch_wrapper.py
================================================
"""
Provides a class for torch model evaluation.
"""
from __future__ import absolute_import
import warnings
import torch
from .utils import common
from pdb import set_trace as st
class PyTorchModel:
""" Class for torch model evaluation.
Provide predict, intermediate_layer_outputs and adversarial_attack
methods for model evaluation. Set callback functions for each method
to process the results.
Parameters
----------
model : instance of torch.nn.Module
torch model to evaluate.
Notes
----------
All operations will be done using GPU if the environment is available
and set properly.
"""
def __init__(self, model, intermedia_mode=""):
assert isinstance(model, torch.nn.Module)
self._model = model
self._device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self._model.eval()
self._model.to(self._device)
self.intermedia_mode = intermedia_mode
def predict(self, dataset, callbacks, batch_size=16):
"""Predict with the model.
The method will use the model to do prediction batch by batch. For
every batch, callback functions will be invoked. Labels and predictions
will be passed to the callback functions to do further process.
Parameters
----------
dataset : instance of torch.utils.data.Dataset
Dataset from which to load the data.
callbacks : list of functions
Callback functions, each of which will be invoked when a batch is done.
batch_size : integer
Batch size for prediction
See Also
--------
:class:`metrics.accuracy.Accuracy`
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
with torch.no_grad():
for data, labels in dataloader:
data = data.to(self._device)
labels = labels.to(self._device)
y_mini_batch_pred = self._model(data)
for callback in callbacks:
callback(labels, y_mini_batch_pred)
# def intermediate_layer_outputs(self, dataset, callbacks, batch_size=8):
# """Get the intermediate layer outputs of the model.
# The method will use the model to do prediction batch by batch. For
# every batch, the the intermediate layer outputs will be captured and
# callback functions will be invoked. all intermediate layer output
# will be passed to the callback functions to do further process.
# Parameters
# ----------
# dataset : instance of torch.utils.data.Dataset
# Dataset from which to load the data.
# callbacks : list of functions
# Callback functions, each of which will be invoked when a batch is done.
# batch_size : integer
# Batch size for getting intermediate layer outputs.
# See Also
# --------
# :class:`metrics.neuron_coverage.NeuronCoverage`
# """
# dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
# y_mini_batch_outputs = []
# hook_handles = []
# intermediate_layers = self._intermediate_layers(self._model)
# for intermediate_layer in intermediate_layers:
# def hook(module, input, output):
# y_mini_batch_outputs.append(output)
# handle = intermediate_layer.register_forward_hook(hook)
# hook_handles.append(handle)
# with torch.no_grad():
# for data in dataloader:
# if isinstance(data, list):
# data = data[0]
# y_mini_batch_outputs.clear()
# data = data.to(self._device)
# self._model(data)
# for callback in callbacks:
# callback(y_mini_batch_outputs, 0)
# for handle in hook_handles:
# handle.remove()
def one_sample_intermediate_layer_outputs(self, sample, callbacks, ):
y_mini_batch_outputs = []
hook_handles = []
intermediate_layers = self._intermediate_layers(self._model)
for intermediate_layer in intermediate_layers:
def hook(module, input, output):
y_mini_batch_outputs.append(output)
handle = intermediate_layer.register_forward_hook(hook)
hook_handles.append(handle)
with torch.no_grad():
y_mini_batch_outputs.clear()
output = self._model(sample)
for callback in callbacks:
callback(y_mini_batch_outputs, 0)
for handle in hook_handles:
handle.remove()
return output
def one_sample_intermediate_layer_outputs_with_grad(self, sample, callbacks, batch_size=8, return_intermedia_outputs=False):
y_mini_batch_outputs = []
hook_handles = []
intermediate_layers = self._intermediate_layers(self._model)
for intermediate_layer in intermediate_layers:
def hook(module, input, output):
y_mini_batch_outputs.append(output)
handle = intermediate_layer.register_forward_hook(hook)
hook_handles.append(handle)
y_mini_batch_outputs.clear()
output = self._model(sample)
for callback in callbacks:
callback(y_mini_batch_outputs, 0)
for handle in hook_handles:
handle.remove()
compressed_y_mini_batch_outputs = []
for item in y_mini_batch_outputs:
if len(item.shape) == 4:
mean = item.mean(-1).mean(-1)
elif len(item.shape) == 2:
mean = item
else:
raise NotImplementedError
# print(mean.shape)
compressed_y_mini_batch_outputs.append(mean)
if return_intermedia_outputs:
return output, compressed_y_mini_batch_outputs
else:
return output
def _intermediate_layers(self, module, pre_name=""):
"""Get the intermediate layers of the model.
The method will get some intermediate layers of the model which might
be useful for neuron coverage computation. Some layers such as dropout
layers are excluded empirically.
Returns
-------
list of torch.nn.modules
Intermediate layers of the model.
"""
intermediate_layers = []
for name, submodule in module.named_children():
full_name = f"{pre_name}.{name}"
if len(submodule._modules) > 0:
intermediate_layers += self._intermediate_layers(submodule, full_name)
else:
# if 'Dropout' in str(submodule.type) or 'BatchNorm' in str(submodule.type) or 'ReLU' in str(submodule.type):
if 'Dropout' in str(submodule.type) or 'ReLU' in str(submodule.type) or 'Linear' in str(submodule.type) or 'Pool' in str(submodule.type):
continue
if self.intermedia_mode == "layer":
if type(self._model).__name__ == "ResNet":
if not full_name[-5:] == "1.bn2":
continue
else:
...
intermediate_layers.append(submodule)
# print(full_name, )
return intermediate_layers
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/strong_neuron_activation_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class StrongNeuronActivationCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(StrongNeuronActivationCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, k):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/top_k_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class TopKNeuronCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(TopKNeuronCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
# print(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/__init__.py
================================================
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/common.py
================================================
"""
Provides some useful functions.
"""
from __future__ import absolute_import
import os
import time
import numpy as np
def readable_time_str():
"""Get readable time string based on current local time.
The time string will be formatted as %Y-%m-%d %H:%M:%S.
Returns
-------
str
Readable time string.
"""
return time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
def user_home_dir():
"""Get path of user home directory.
Returns
-------
str
Path of user home directory.
"""
return os.path.expanduser("~")
def to_numpy(data):
"""Convert other data type to numpy. If the data itself
is numpy type, then a copy will be made and returned.
Returns
-------
numpy.array
Numpy array of passed data.
"""
if 'mxnet' in str(type(data)):
data = data.asnumpy()
elif 'torch' in str(type(data)):
data = data.cpu().numpy()
elif 'numpy' in str(type(data)):
data = np.copy(data)
return data
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/keras.py
================================================
"""
Provides some useful utils for keras model evaluation.
"""
from __future__ import absolute_import
import random
import cv2
import keras
import numpy as np
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
size : integer
Target image size (input size).
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, fashion, size, transform):
self._dir = dir
self._filenames = filenames
self._fashion = fashion
self._size = size
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = cv2.imread(path)
if self._fashion == 'vgg_preprocessing':
height, width, _ = image.shape
new_height = height * 256 // min(image.shape[:2])
new_width = width * 256 // min(image.shape[:2])
image = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_CUBIC)
height, width, _ = image.shape
startx = width // 2 - (self._size // 2)
starty = height // 2 - (self._size // 2)
image = image[starty:starty + self._size, startx:startx + self._size]
elif self._fashion == 'inception_preprocessing':
height, width, channels = image.shape
assert channels == 3
new_height = int(height * 0.875)
new_width = int(width * 0.875)
startx = (width - new_width) // 2
starty = (height - new_height) // 2
image = image[starty:starty + new_height, startx:startx + new_width]
image = cv2.resize(image, (self._size, self._size), interpolation=cv2.INTER_CUBIC)
else:
raise Exception('Unknown fashion', self._fashion)
image = image[:, :, ::-1]
if self._transform is not None:
image = self._transform(image)
image = np.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = np.concatenate((x, image), axis=0)
x = x.astype(np.float32)
return x
def __init__(self, fashion, size, transform=None, shuffle=False, seed=None, num_max=None):
dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(dir, self._filenames, fashion, size, transform)
self.y = np.array(self.y, dtype=int)
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet50', 'resnet101',
'resnet152', 'resnet50_v2', 'resnet101_v2',
'resnet152_v2', 'mobilenet', 'mobilenet_v2',
'inception_resnet_v2', 'inception_v3', 'xception',
'densenet121', 'densenet169', 'densenet201',
'nasnet_mobile', 'nasnet_large']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of keras.Model
Pretrained model to evaluate.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
keras.backend.set_learning_phase(0)
if model_name == 'vgg16':
model = keras.applications.VGG16()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'vgg19':
model = keras.applications.VGG19()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50':
model = keras.applications.ResNet50()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet101':
model = keras.applications.ResNet101()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet152':
model = keras.applications.ResNet152()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50_v2':
keras.applications.ResNet50V2()
base_model = keras.applications.ResNet50V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet50v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet101_v2':
keras.applications.ResNet101V2()
base_model = keras.applications.ResNet101V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet101v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet152_v2':
keras.applications.ResNet152V2()
base_model = keras.applications.ResNet152V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet152v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet':
model = keras.applications.MobileNet()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet_v2':
model = keras.applications.MobileNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_mobile':
model = keras.applications.NASNetMobile()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_large':
model = keras.applications.NASNetLarge()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=331, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=331, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_resnet_v2':
model = keras.applications.InceptionResNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_v3':
model = keras.applications.InceptionV3()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'xception':
model = keras.applications.Xception()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet121':
model = keras.applications.DenseNet121()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet169':
model = keras.applications.DenseNet169()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet201':
model = keras.applications.DenseNet201()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
return model, data_normalized, data_original, mean, std, flip_axis, bounds
def cifar10_data(train=False, num_max=None):
""" Load cifar10 data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
def mnist_data(train=False, num_max=None):
""" Load mnist data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/mxnet.py
================================================
"""
Provides some useful utils for mxnet model evaluation.
"""
from __future__ import absolute_import
import random
import gluoncv
import mxnet
import numpy as np
from evaldnn.utils import common
class ImageNetValDataset(mxnet.gluon.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = mxnet.nd.array(self._y, dtype=int)
self._transform = mxnet.gluon.data.vision.transforms.Compose([mxnet.gluon.data.vision.transforms.Resize(resize_size, keep_ratio=True), mxnet.gluon.data.vision.transforms.CenterCrop(center_crop_size), mxnet.gluon.data.vision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = mxnet.image.imread(path)
x = self._transform(x)
if self._preprocess:
mean = mxnet.nd.array(self.mean).reshape(3, 1, 1)
std = mxnet.nd.array(self.std).reshape(3, 1, 1)
x = (x - mean) / std
y = self._y[index].asscalar()
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'mobilenet0_25',
'mobilenet0_5', 'mobilenet1_0', 'mobilenet_v2_1_0',
'resnet101_v1', 'resnet101_v2', 'resnet152_v1',
'resnet152_v2', 'resnet50_v1', 'resnet50_v2',
'resnext50_32x4d', 'squeezenet1_0',
'inception_v3', 'xception']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of mxnet.gluon.nn.Block
Pretrained model to evaluate.
dataset_normalized: instance of mxnet.gluon.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of mxnet.gluon.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = gluoncv.model_zoo.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = gluoncv.model_zoo.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = gluoncv.model_zoo.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = gluoncv.model_zoo.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = gluoncv.model_zoo.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = gluoncv.model_zoo.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_25':
model = gluoncv.model_zoo.mobilenet0_25(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_5':
model = gluoncv.model_zoo.mobilenet0_5(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet1_0':
model = gluoncv.model_zoo.mobilenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0':
model = gluoncv.model_zoo.mobilenet_v2_1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v1':
model = gluoncv.model_zoo.resnet101_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v2':
model = gluoncv.model_zoo.resnet101_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v1':
model = gluoncv.model_zoo.resnet152_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v2':
model = gluoncv.model_zoo.resnet152_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v1':
model = gluoncv.model_zoo.resnet50_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v2':
model = gluoncv.model_zoo.resnet50_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = gluoncv.model_zoo.get_model('ResNext50_32x4d', pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = gluoncv.model_zoo.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = gluoncv.model_zoo.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'xception':
model = gluoncv.model_zoo.get_model('Xception', pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.CIFAR10(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.MNIST(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/pytorch.py
================================================
"""
Provides some useful utils for torch model evaluation.
"""
from __future__ import absolute_import
import random
import PIL
import numpy as np
import torch
import torchvision
from evaldnn.utils import common
class ImageNetValDataset(torch.utils.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = torch.LongTensor(self._y)
self._transforms = torchvision.transforms.Compose([torchvision.transforms.Resize(resize_size), torchvision.transforms.CenterCrop(center_crop_size), torchvision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = PIL.Image.open(path)
x = x.convert('RGB')
x = self._transforms(x)
if self._preprocess:
x = torchvision.transforms.Normalize(mean=self.mean, std=self.std)(x)
y = self._y[index]
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'googlenet',
'inception_v3', 'mnasnet', 'mobilenet_v2',
'resnet50', 'resnet101', 'resnet152',
'resnext50_32x4d', 'shufflenet_V2',
'squeezenet1_0', 'squeezenet1_1',
'wide_resnet50_2', 'wide_resnet101_2']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of torch.nn.Module
Pretrained model to evaluate.
dataset_normalized: instance of torch.utils.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of torch.utils.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = torchvision.models.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = torchvision.models.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = torchvision.models.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = torchvision.models.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = torchvision.models.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = torchvision.models.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'googlenet':
model = torchvision.models.googlenet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = torchvision.models.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mnasnet':
model = torchvision.models.mnasnet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2':
model = torchvision.models.mobilenet_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet18':
model = torchvision.models.resnet18(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50':
model = torchvision.models.resnet50(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101':
model = torchvision.models.resnet101(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152':
model = torchvision.models.resnet152(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = torchvision.models.resnext50_32x4d(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'shufflenet_V2':
model = torchvision.models.shufflenet_v2_x1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = torchvision.models.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_1':
model = torchvision.models.squeezenet1_1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet50_2':
model = torchvision.models.wide_resnet50_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet101_2':
model = torchvision.models.wide_resnet101_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.CIFAR10(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.from_numpy(dataset.data / 255.0).permute(0, 3, 1, 2).float()
y = torch.tensor(dataset.targets)
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.MNIST(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.unsqueeze((dataset.data / 255.0), 1)
y = dataset.targets
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/coverage/utils/tensorflow.py
================================================
"""
Provides some useful utils for tensorflow model evaluation.
"""
from __future__ import absolute_import
import random
import warnings
import numpy as np
import tensorflow as tf
from tensorflow.contrib.slim.nets import inception
from tensorflow.contrib.slim.nets import nasnet
from tensorflow.contrib.slim.nets import pnasnet
from tensorflow.contrib.slim.nets import resnet_v1
from tensorflow.contrib.slim.nets import resnet_v2
from tensorflow.contrib.slim.nets import vgg
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
width : integer
Target image width.
height : integer
Target image height.
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
label_offset : integer
The offset of the label. For some models the offset should be set to 1
because these models are trained with 1001 classes.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, width, height, fashion, transform):
self._dir = dir
self._filenames = filenames
self._width = width
self._height = height
self._fashion = fashion
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
tf.compat.v1.enable_eager_execution()
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = tf.image.decode_image(tf.io.read_file(path), channels=3)
if self._fashion == 'vgg_preprocessing':
image = self._aspect_preserving_resize(image, 256)
image = self._central_crop([image], self._height, self._width)[0]
image.set_shape([self._height, self._width, 3])
image = tf.cast(image, dtype=tf.float32)
elif self._fashion == 'inception_preprocessing':
image = tf.cast(image, tf.float32)
image.set_shape([tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(3)])
image = tf.image.central_crop(image, central_fraction=0.875)
image = tf.expand_dims(image, 0)
image = tf.compat.v1.image.resize_bilinear(image, [self._width, self._height], align_corners=False)
image = tf.squeeze(image, [0])
else:
raise Exception('Invalid fashion', self._fashion)
if self._transform is not None:
image = self._transform(image)
image = tf.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = tf.concat([x, image], 0)
x = x.numpy()
tf.compat.v1.disable_eager_execution()
return x
def _smallest_size_at_least(self, height, width, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
height = tf.cast(height, dtype=tf.float32)
width = tf.cast(width, dtype=tf.float32)
smallest_side = tf.cast(smallest_side, dtype=tf.float32)
scale = tf.cond(tf.greater(height, width), lambda: smallest_side / width, lambda: smallest_side / height)
new_height = tf.cast(tf.math.rint(height * scale), dtype=tf.int32)
new_width = tf.cast(tf.math.rint(width * scale), dtype=tf.int32)
return new_height, new_width
def _aspect_preserving_resize(self, image, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
shape = tf.shape(image)
height = shape[0]
width = shape[1]
new_height, new_width = self._smallest_size_at_least(height, width, smallest_side)
image = tf.expand_dims(image, 0)
resized_image = tf.compat.v1.image.resize_bilinear(image, [new_height, new_width], align_corners=False)
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
def _central_crop(self, image_list, crop_height, crop_width):
outputs = []
for image in image_list:
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
offset_height = (image_height - crop_height) / 2
offset_width = (image_width - crop_width) / 2
outputs.append(self._crop(image, offset_height, offset_width, crop_height, crop_width))
return outputs
def _crop(self, image, offset_height, offset_width, crop_height, crop_width):
original_shape = tf.shape(image)
rank_assertion = tf.Assert(tf.equal(tf.rank(image), 3), ['Rank of image must be equal to 3.'])
with tf.control_dependencies([rank_assertion]):
cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
size_assertion = tf.Assert(
tf.logical_and(tf.greater_equal(original_shape[0], crop_height), tf.greater_equal(original_shape[1], crop_width)), ['Crop size greater than the image size.'])
offsets = tf.cast(tf.stack([offset_height, offset_width, 0]), dtype=tf.int32)
with tf.control_dependencies([size_assertion]):
image = tf.slice(image, offsets, cropped_shape)
return tf.reshape(image, cropped_shape)
def __init__(self, width, height, fashion, transform=None, label_offset=0, shuffle=False, seed=None, num_max=None):
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(self._dir, self._filenames, width, height, fashion, transform)
self.y = np.array(self.y, dtype=int) + label_offset
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet_v1_101', 'resnet_v1_152',
'resnet_v1_50', 'inception_v1', 'inception_v2',
'inception_v3', 'inception_v4', 'inception_resnet_v2',
'mobilenet_v1_0_5_160', 'mobilenet_v1_0_25_128',
'mobilenet_v1_1_0_224', 'mobilenet_v2_1_0_224',
'mobilenet_v2_1_4_224', 'resnet_v2_101',
'resnet_v2_152', 'resnet_v2_50',
'nasnet_a_mobile_224', 'pnasnet_5_mobile_224',
'nasnet_a_large_331', 'pnasnet_5_large_331']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
session : `tensorflow.session`
The session with which the graph will be computed.
logits : `tensorflow.Tensor`
The predictions of the model.
inputs : `tensorflow.Tensor`
The input to the model, usually a `tensorflow.placeholder`.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
tf.get_logger().setLevel('ERROR')
if model_name == 'vgg16':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_16(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_16.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_19(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_19.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_101(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_101.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_152(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_152.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_50(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_50.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v1':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v1_arg_scope()):
logits, _ = inception.inception_v1(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v1.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v2_arg_scope()):
logits, _ = inception.inception_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v2.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v3_arg_scope()):
logits, _ = inception.inception_v3(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v3.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v4':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v4_arg_scope()):
logits, _ = inception.inception_v4(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v4.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_resnet_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_resnet_v2_arg_scope()):
logits, _ = inception.inception_resnet_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_resnet_v2_2016_08_30.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_5_160':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.5_160/mobilenet_v1_0.5_160_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 160, 160, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(160, 160, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(160, 160, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_25_128':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.25_128/mobilenet_v1_0.25_128_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 128, 128, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(128, 128, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(128, 128, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_4_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_large_arg_scope()):
logits, end_points = nasnet.build_nasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_large_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_mobile_arg_scope()):
logits, end_points = nasnet.build_nasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_mobile_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_large_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_large_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_mobile_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_mobile_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_101(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_101_2017_04_14/resnet_v2_101.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_152(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_152_2017_04_14/resnet_v2_152.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_50(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_50_2017_04_14/resnet_v2_50.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
bounds = (0, 255)
return session, logits, input, data_normalized, data_original, mean, std, bounds
def cifar10_test_data(num_max=None):
""" Load cifar10 data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
def mnist_test_data(num_max=None):
""" Load mnist data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/eval_nc.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
import os
import os.path as osp
import random
import copy
import logging
import pickle
import pandas as pd
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from advertorch.attacks import LinfPGDAttack
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from mutator import Mutators
from eval_clean import LabelConverter
from coverage.neuron_coverage import NeuronCoverage
from coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.top_k_coverage import TopKNeuronCoverage
from coverage.strong_neuron_activation_coverage import StrongNeuronActivationCoverage
from coverage.pytorch_wrapper import PyTorchModel
from strategy import RandomStrategy, DeepXplore, DLFuzzRoundRobin, DLFuzzFirst
def adv_whitebox(model, loader, args, bounds,):
model.eval()
low_bound, up_bound = bounds
loss = nn.CrossEntropyLoss()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
total += images.size(0)
out_clean = model(images)
_, pred_clean = out_clean.max(dim=1)
adv_images = images.clone().detach()
if args.random_start:
# Starting at a uniformly random point
adv_images = adv_images + torch.empty_like(adv_images).uniform_(-args.eps, args.eps)
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
for _ in range(args.pgd_iter):
adv_images.requires_grad = True
outputs = model(adv_images)
# Calculate loss
if args.targeted:
cost = -loss(outputs, target_labels)
else:
cost = loss(outputs, label)
# Update adversarial images
grad = torch.autograd.grad(cost, adv_images,
retain_graph=False, create_graph=False)[0]
adv_images = adv_images.detach() + args.alpha*grad.sign()
delta = torch.clamp(adv_images - images, min=-args.eps, max=args.eps)
adv_images = (images + delta).detach()
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
out_adv = model(adv_images)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
print('{}/{}...'.format(i+1, len(loader)))
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial *100
def adv_teacher_plain(model, loader, args, bounds, students):
model.eval()
low_bound, up_bound = bounds
loss = nn.CrossEntropyLoss()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
inherit_defects, student_correct, student_adv = np.zeros(len(students)), np.zeros(len(students)), np.zeros(len(students))
for i, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
total += images.size(0)
out_clean = model(images)
_, pred_clean = out_clean.max(dim=1)
student_pred_clean = np.array([
m(images).max(dim=1)[1].cpu().numpy() for m in students
])
labal_npy = np.expand_dims(label.cpu().numpy(), 0)
student_correct += (student_pred_clean == labal_npy).sum(1)
adv_images = images.clone().detach()
if args.random_start:
# Starting at a uniformly random point
adv_images = adv_images + torch.empty_like(adv_images).uniform_(-args.eps, args.eps)
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
for _ in range(args.pgd_iter):
adv_images.requires_grad = True
outputs = model(adv_images)
# Calculate loss
if args.targeted:
cost = -loss(outputs, target_labels)
else:
cost = loss(outputs, label)
# Update adversarial images
grad = torch.autograd.grad(cost, adv_images,
retain_graph=False, create_graph=False)[0]
adv_images = adv_images.detach() + args.alpha*grad.sign()
delta = torch.clamp(adv_images - images, min=-args.eps, max=args.eps)
adv_images = (images + delta).detach()
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
out_adv = model(adv_images)
_, pred_adv = out_adv.max(dim=1)
student_pred_adv = np.array([
m(adv_images).max(dim=1)[1].cpu().numpy() for m in students
])
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
student_adv += (student_pred_adv == labal_npy).sum(1)
inherit_defects += ( (student_pred_clean == labal_npy) * (student_pred_adv != student_pred_clean) ).sum(1)
print('{}/{}...'.format(i+1, len(loader)))
# if i>5:
# break
clean_acc = student_correct / total*100
adv_acc = student_adv / total * 100
dir = inherit_defects / student_correct * 100
return clean_acc, adv_acc, dir
def get_strategy(args, model):
if args.strategy == "random":
strategy = RandomStrategy(model)
elif args.strategy == "deepxplore":
strategy = DeepXplore(model)
elif args.strategy == "dlfuzz":
strategy = DLFuzzRoundRobin(model)
elif args.strategy == "dlfuzzfirst":
strategy = DLFuzzFirst(model)
else:
raise NotImplementedError
return strategy
def get_coverage(args,):
if args.coverage == "neuron_coverage":
coverage = MyNeuronCoverage(threshold=args.nc_threshold)
elif args.coverage == "top_k_coverage":
coverage = TopKNeuronCoverage(k=10)
elif args.coverage == "strong_coverage":
coverage = StrongNeuronActivationCoverage(k=2)
else:
raise NotImplementedError
return coverage
def compute_selected_neuron_value(
selected_neuron, compressed_intermediate_layer_outputs, global_neuron_id_to_layer_neuron_id
):
assert isinstance(selected_neuron, list)
num_input = len(selected_neuron)
input_neuron_value = []
for input_id in range(num_input):
values = []
for global_id in selected_neuron[input_id]:
layer_id, layer_neuron_id = global_neuron_id_to_layer_neuron_id[global_id]
neuron_value = compressed_intermediate_layer_outputs[layer_id][input_id][layer_neuron_id]
values.append(neuron_value)
values = torch.stack(values, dim=0).sum()
input_neuron_value.append(values)
input_neuron_value = torch.stack(input_neuron_value, dim=0)
return input_neuron_value
def adv_coverage(
model, loader, args, bounds, students, converters, dataset_converter,
):
model.eval()
low_bound, up_bound = bounds
measure_model = PyTorchModel(model, intermedia_mode=args.intermedia_mode)
strategy = get_strategy(args, measure_model)
coverage_metric = get_coverage(args)
cls_loss_fn = nn.CrossEntropyLoss()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
inherit_defects, student_correct, student_adv = np.zeros(len(students)), np.zeros(len(students)), np.zeros(len(students))
for idx, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
label = dataset_converter(label)
total += images.size(0)
out_clean = model(images)
_, pred_clean = out_clean.max(dim=1)
student_pred_clean = np.array([
conv( m(images).max(dim=1)[1].cpu().numpy() )
for m, conv in zip(students, converters)
])
labal_npy = np.expand_dims(label.cpu().numpy(), 0)
student_correct += (student_pred_clean == labal_npy).sum(1)
adv_images = images.clone().detach()
for _ in range(args.pgd_iter):
adv_images.requires_grad = True
# outputs = model(adv_images)
outputs = measure_model.one_sample_intermediate_layer_outputs(
adv_images,
# [coverage_metric.update, coverage_metric.report],
[coverage_metric.update, ],
)
batch_cover = coverage_metric.get(args.nc_threshold)
if _ == 0:
strategy.init(covered=batch_cover)
else:
strategy.update(batch_cover)
grad_outputs, compressed_intermediate_layer_outputs = measure_model.one_sample_intermediate_layer_outputs_with_grad(
adv_images, [],
return_intermedia_outputs=True,
)
selected_neuron = strategy(args.k_select_neuron)
strategy.next()
selected_neuron_value = compute_selected_neuron_value(
selected_neuron, compressed_intermediate_layer_outputs,
coverage_metric._global_neuron_id_to_layer_neuron_id
)
neuron_loss = selected_neuron_value.mean()
loss = neuron_loss
# Update adversarial images
grad = torch.autograd.grad(loss, adv_images,
retain_graph=False, create_graph=False)[0]
adv_images = adv_images.detach() + args.alpha*grad.sign()
delta = torch.clamp(adv_images - images, min=-args.eps, max=args.eps)
adv_images = (images + delta).detach()
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
out_adv = model(adv_images)
_, pred_adv = out_adv.max(dim=1)
student_pred_adv = np.array([
conv( m(adv_images).max(dim=1)[1].cpu().numpy() )
for m, conv in zip(students, converters)
])
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
student_adv += (student_pred_adv == labal_npy).sum(1)
inherit_defects += ( (student_pred_clean == labal_npy) * (student_pred_adv != student_pred_clean) ).sum(1)
if idx % 1 == 0:
student_acc = student_correct / total
inherit_defect_ratio = inherit_defects / student_correct
logger.info(f"Batch idx {idx}/{len(loader)},\t inherit defect {inherit_defects},\t inherit ratio {inherit_defect_ratio},\t total {total},\t student acc {student_acc}, PID[{args.pid}] {args.info}")
if idx > 50:
break
clean_acc = student_correct / total*100
adv_acc = student_adv / total * 100
dir = inherit_defects / student_correct * 100
return clean_acc, adv_acc, dir
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
parser.add_argument("--output_dir")
parser.add_argument("--finetune_ckpt", type=str, default='')
parser.add_argument("--delta_ckpt", type=str, default='')
parser.add_argument("--weight_ckpt", type=str, default='')
parser.add_argument("--ncprune_ckpt", type=str, default='')
parser.add_argument("--test_num", type=int, default=500)
parser.add_argument("--num_try_per_sample", type=int, default=10)
parser.add_argument("--sample_queue_length", type=int, default=10)
parser.add_argument("--nc_threshold", type=float, default=0.5)
parser.add_argument("--strategy", default="random", choices=["random", "deepxplore", "dlfuzz", "dlfuzzfirst"])
parser.add_argument("--coverage", default="neuron_coverage")
parser.add_argument("--k_select_neuron", type=int, default=20)
parser.add_argument("--intermedia_mode", default="")
parser.add_argument("--eps", type=float, default=0.1)
parser.add_argument("--alpha", type=float, default=0.01)
parser.add_argument("--random_start", type=bool, default=True)
parser.add_argument("--targeted", type=bool, default=False)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
def load_student(ckpt, args, num_classes):
model = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=num_classes
).cuda()
if not os.path.exists(ckpt):
raise RuntimeError(f"{ckpt} Not exist")
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint['state_dict'])
print(f"Loaded checkpoint from {ckpt}")
model.eval()
parent_dir = osp.join(*ckpt.split('/')[:-1])
cls_name_path = osp.join(parent_dir, "raw_cls_names.pkl")
if not os.path.exists(cls_name_path):
raise RuntimeError(f"Raw class name not exist in {cls_name_path}")
with open(cls_name_path, "rb") as f:
class_names = pickle.load(f)
model_converter = LabelConverter(class_names)
return model, model_converter
if __name__ == '__main__':
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
np.set_printoptions(precision=4)
args = get_args()
# print(args)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir, exist_ok=True)
args.pid = os.getpid()
args.log_path = osp.join(args.output_dir, "log.txt")
if os.path.exists(args.log_path):
log_lens = len(open(args.log_path, 'r').readlines())
if log_lens > 3:
print(f"{args.log_path} exists")
exit()
args.info = f"{args.strategy}_{args.coverage}_{args.dataset}_{args.network}"
logging.basicConfig(filename=args.log_path, filemode="w", level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logger = logging.getLogger()
logger.info(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
model_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
up_bound = torch.Tensor([1,1,1])
up_bound = (up_bound - torch.Tensor(normalize.mean)) / torch.Tensor(normalize.std)
low_bound = torch.Tensor([0,0,0])
low_bound = (low_bound - torch.Tensor(normalize.mean)) / torch.Tensor(normalize.std)
up_bound = up_bound.view(1,3,1,1).expand(args.batch_size,3,224,224).cuda()
low_bound = low_bound.view(1,3,1,1).expand(args.batch_size,3,224,224).cuda()
bounds = (low_bound, up_bound)
test_set = eval(args.dataset)(
args.datapath, False, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
-1, seed, preload=False
)
if args.dataset == "MIT67Data":
class_names = test_set.cls_names
elif args.dataset in ["CUB200Data", "Flower102Data", "Stanford40Data", "SDog120Data"]:
class_names = None
dataset_converter = LabelConverter(class_names)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False, drop_last=True)
finetune, finetune_converter = load_student(args.finetune_ckpt, args, test_set.num_classes)
delta, delta_converter = load_student(args.delta_ckpt, args, test_set.num_classes)
weight, weight_converter = load_student(args.weight_ckpt, args, test_set.num_classes)
ncprune, ncprune_converter = load_student(args.ncprune_ckpt, args, test_set.num_classes)
modes = [
"finetune", "delta", "weight", "ncprune"
]
students = [
eval(mode) for mode in modes
]
student_converters = [
eval(f"{mode}_converter") for mode in modes
]
pretrained_model = eval('{}_dropout'.format(args.network))(pretrained=True).cuda()
clean_acc, adv_acc, dir = adv_coverage(
pretrained_model, test_loader, args, bounds,
students=students, converters=student_converters, dataset_converter=dataset_converter)
logger.info(f"Dir {dir}, clean acc {clean_acc}, adv acc {adv_acc}")
df = pd.DataFrame(modes)
df['dir'] = dir
df['acc'] = clean_acc
df.to_csv(os.path.join(args.output_dir, "result.csv"))
np.savetxt(os.path.join(args.output_dir, "dir.csv"), dir)
np.savetxt(os.path.join(args.output_dir, "acc.csv"), clean_acc)
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/__init__.py
================================================
# Import strategies.
# from .adapt import AdaptiveParameterizedStrategy
# from .adapt import ParameterizedStrategy
from .deepxplore import UncoveredRandomStrategy
from .dlfuzz import DLFuzzRoundRobin
from .dlfuzz import MostCoveredStrategy
from .random import RandomStrategy
# Aliases for some strategies.
# Adapt = AdaptiveParameterizedStrategy
DeepXplore = UncoveredRandomStrategy
DLFuzzFirst = MostCoveredStrategy
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/adapt.py
================================================
from math import ceil
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import GlobalAveragePooling2D
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import ZeroPadding2D
import numpy as np
from adapt.strategy.strategy import Strategy
from adapt.utils.functional import greedy_max_set
class FeatureMatrix:
'''A list of feature vectors of neurons.
This class defines the feature vectors of each neurons with 29 features.
Detailed description of feature can be found in the following paper:
Effective White-Box Testing for Deep Neural Networks with Adaptive Neuron-Selection Strategy
http://prl.korea.ac.kr/~pronto/home/papers/issta20.pdf
Vars:
CONST_FEATURES: The number of constant features.
VARIABLE_FEATURES: The number of vaiable features.
TOTAL_FEATURES: The total number of features.
'''
# Number of features.
CONST_FEATURES = 17
VARIABLE_FEATURES = 12
TOTAL_FEATURES = 29
def __init__(self, network):
'''Create a feature matrix from the network.
Generate feature vectors with constant features (f0-16) and variable
features (f17-28). Variable feature vectors will be filled with zeros.
Args:
network: A wrapped Keras model with `adapt.Network`.
'''
# Generate constant vectors.
self.const_vectors = []
# For f4-9.
weights = []
# For each layer.
for li, l in enumerate(network.layers[:-1]):
# For f0-3.
layer_location = li / (len(network.layers) - 1)
layer_location = int(layer_location * 4)
# For f4-9.
w = l.get_weights()
if len(w) > 0:
# Use only weights, not biases.
w = w[0]
else:
# If layer without weights (e.g. Pooling layer).
w = np.zeros(l.output.shape[1:])
# For f10-16.
layer_type = \
10 if isinstance(l, BatchNormalization) else \
11 if isinstance(l, MaxPooling2D) or isinstance(l, AveragePooling2D) or isinstance(l, GlobalAveragePooling2D) else \
12 if isinstance(l, Conv2D) or isinstance(l, ZeroPadding2D) else \
13 if isinstance(l, Dense) else \
14 if isinstance(l, Activation) else \
15 if isinstance(l, Add) or isinstance(l, Concatenate) or isinstance(l, Lambda) else \
16
# For each neuron.
for ni in range(l.output.shape[-1]):
# For f4-9.
weights.append(np.mean([w[..., ni]]))
# Create a constant feature vector.
vec_c = np.zeros(self.CONST_FEATURES, dtype=int)
# f0: Ff layer is located in front 25 percent.
# f1: Ff layer is located in between front 25 percent and front 50 percent.
# f2: Ff layer is located in between back 50 percent and back 25 percent.
# f3: Ff layer is located in back 25 percent.
vec_c[layer_location] = 1
# f10: If layer is normalization layer.
# f11: If layer is pooling layer.
# f12: If layer is convolution layer.
# f13: If layer is dense layer.
# f14: If layer is activation layer.
# f15: If layer gets inputs from multiple layers.
# f16: Otherwise.
vec_c[layer_type] = 1
self.const_vectors.append(vec_c)
self.const_vectors = np.array(self.const_vectors)
# For f4-f9.
argsort_weights = np.argsort(weights)
top_10 = int(len(argsort_weights) * 0.9)
top_20 = int(len(argsort_weights) * 0.8)
top_30 = int(len(argsort_weights) * 0.7)
top_40 = int(len(argsort_weights) * 0.6)
top_50 = int(len(argsort_weights) * 0.5)
# f4: If neuron have weight of top 10%.
self.const_vectors[argsort_weights[top_10:], 4] = 1
# f5: If neuron have weight between top 10% and top 20%.
self.const_vectors[argsort_weights[top_20:top_10], 5] = 1
# f6: If neuron have weight between top 20% and top 30%.
self.const_vectors[argsort_weights[top_30:top_20], 6] = 1
# f7: If neuron have weight between top 30% and top 40%.
self.const_vectors[argsort_weights[top_40:top_50], 7] = 1
# f8: If neuron have weight between top 40% and top 50%.
self.const_vectors[argsort_weights[top_50:top_40], 8] = 1
# f9: If neuron have wiehgt of bottom 50%.
self.const_vectors[argsort_weights[:top_50], 9] = 1
# Create variable feature vectors.
self.variable_vectors = np.zeros((len(self.const_vectors), self.VARIABLE_FEATURES), dtype=int)
def update(self, covered_count, objective_covered):
'''Update variable feature vectors.
Update feature vectors for the variable features (f17-28).
Args:
covered_count: A list of numbers of covering for each neuron.
objective_covered: A list of coverage vectors when objective (e.g. adversarial
input) satisfies.
Returns:
Self for possible call chains.
'''
# Create variable feature vectors.
self.variable_vectors = np.zeros((len(self.const_vectors), self.VARIABLE_FEATURES), dtype=int)
# f17: If neuron activated when input satisfies objective function.
indices = np.squeeze(np.argwhere(objective_covered > 0))
self.variable_vectors[indices, 0] = 1
# f18: If neuron never activated.
indices = np.squeeze(np.argwhere(covered_count < 1))
self.variable_vectors[indices, 1] = 1
# For f19-28.
sorted_indices = np.setdiff1d(np.argsort(covered_count), indices, assume_unique=True)
top_10 = int(len(sorted_indices) * 0.9)
top_20 = int(len(sorted_indices) * 0.8)
top_30 = int(len(sorted_indices) * 0.7)
top_40 = int(len(sorted_indices) * 0.6)
top_50 = int(len(sorted_indices) * 0.5)
top_60 = int(len(sorted_indices) * 0.4)
top_70 = int(len(sorted_indices) * 0.3)
top_80 = int(len(sorted_indices) * 0.2)
top_90 = int(len(sorted_indices) * 0.1)
# f19: If neuron activated top 10%.
self.variable_vectors[sorted_indices[top_10:], 2] = 1
# f20: If neuron activated between top 10% and top 20%.
self.variable_vectors[sorted_indices[top_20:top_10], 3] = 1
# f21: If neuron activated between top 20% and top 30%.
self.variable_vectors[sorted_indices[top_30:top_20], 4] = 1
# f22: If neuron activated between top 30% and top 40%.
self.variable_vectors[sorted_indices[top_40:top_30], 5] = 1
# f23: If neuron activated between top 40% and top 50%.
self.variable_vectors[sorted_indices[top_50:top_40], 6] = 1
# f24: If neuron activated between top 50% and top 60%.
self.variable_vectors[sorted_indices[top_60:top_50], 7] = 1
# f25: If neuron activated between top 60% and top 70%.
self.variable_vectors[sorted_indices[top_70:top_60], 8] = 1
# f26: If neuron activated between top 70% and top 80%.
self.variable_vectors[sorted_indices[top_80:top_70], 9] = 1
# f27: If neuron activated between top 80% and top 90%.
self.variable_vectors[sorted_indices[top_90:top_80], 10] = 1
# f28: If neuron activated between top 90% and top 100%.
self.variable_vectors[sorted_indices[:top_90], 11] = 1
return self
@property
def matrix(self):
'''A list of all feature vectors.'''
return np.concatenate([self.const_vectors, self.variable_vectors], axis=1)
def dot(self, vector):
'''Calculate dot product of the feature matrix and a vector.
Args:
vector: A 29 dimensional vector.
Returns:
A result vector of dot product.
'''
return np.dot(self.matrix, vector)
class ParameterizedStrategy(Strategy):
'''A strategy that uses a parameterized selection strategy.
Parameterized neuron selection strategy is a strategy that parameterized
neurons and scores with a selection vector. Please see the following paper
for more details:
Effective White-Box Testing for Deep Neural Networks with Adaptive Neuron-Selection Strategy
http://prl.korea.ac.kr/~pronto/home/papers/issta20.pdf
'''
def __init__(self, network, bound=5):
'''Create a parameterized strategy, and initialize its variables.
Args:
network: A wrapped Keras model with `adapt.Network`.
bound: A floating point number indicates the absolute value of minimum
and maximum bounds.
Example:
>>> from adapt import Network
>>> from adapt.strategy import ParameterizedStrategy
>>> from tensorflow.keras.applications.vgg19 import VGG19
>>> model = VGG19()
>>> network = Network(model)
>>> strategy = ParameterizedStrategy(network)
'''
super(ParameterizedStrategy, self).__init__(network)
# Initialize feature vectors for each neuron.
self.matrix = FeatureMatrix(network)
# Create variables.
self.bound = bound
self.label = None
self.covered_count = None
self.objective_covered = None
# Create a random strategy.
self.strategy = np.random.uniform(-self.bound, self.bound, size=FeatureMatrix.TOTAL_FEATURES)
def select(self, k):
'''Select k neurons with highest scores.
Args:
k: A positive integer. The number of neurons to select.
Returns:
A list of locations of selected neurons.
'''
# Calculate scores.
scores = self.matrix.dot(self.strategy)
# Get k highest neurons and return their location.
indices = np.argpartition(scores, -k)[-k:]
return [self.neurons[i] for i in indices]
def init(self, covered, label, **kwargs):
'''Initialize the variables of the strategy.
This method should be called before all other methods in the class.
Args:
covered: A list of coverage vectors that the initial input covers.
label: A label of the initial input classified into.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
Raises:
ValueError: When the size of the passed coverage vectors are not matches
to the network setting.
'''
# Flatten coverage vectors.
covered = np.concatenate(covered)
if len(covered) != len(self.neurons):
raise ValueError('The number of neurons in network does not matches to the setting.')
# Initialize the number of covering for each neuron.
self.covered_count = np.zeros_like(covered, dtype=int)
self.covered_count += covered
# Set the initial label.
self.label = label
# Initialize the coverage vector when objective satisfies.
self.objective_covered = np.zeros_like(self.covered_count, dtype=bool)
return self
def update(self, covered, label, **kwargs):
'''Update the variable of the strategy.
Args:
covered: A list of coverage vectors that a current input covers.
label: A label of a current input classified into.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
'''
# Flatten coverage vectors.
covered = np.concatenate(covered)
# Update the number of covering for each neuron.
self.covered_count += covered
# If adversarial input found, update the coverage vector for objective satifaction.
if self.label != label:
self.objective_covered = np.bitwise_or(self.objective_covered, covered)
# Update variable vectors
self.matrix = self.matrix.update(self.covered_count, self.objective_covered)
class AdaptiveParameterizedStrategy(ParameterizedStrategy):
'''A adaptive and parameterized neuron selection strategy.
Adaptive and parameterized neuron selection strategy is a strategy that changes
the parameterized neuron selection strategy adaptively with respect to the model,
data, or even time. These updates are done in online; in other words, the strategies
are updated while testing. Please see the following paper for detail:
Effective White-Box Testing for Deep Neural Networks with Adaptive Neuron-Selection Strategy
http://prl.korea.ac.kr/~pronto/home/papers/issta20.pdf
'''
def __init__(self, network, bound=5, size=100, history=300, remainder=0.5, sigma=1):
'''Create a adaptive parameterized strategy, and initialize its variables.
Args:
network: A wrapped Keras model with `adapt.Network`.
bound: A floating point number indicates the absolute value of minimum
and maximum bounds.
size: A positive integer. The number of strategies to create at once.
history: A positive integer. The number of strategies to look for when
the strategy learn and generate next strategies.
remainder: A floating point number in [0, 1]. The portion of strategies
to generate next strategies from.
sigma: A non-negative floating point number. The standard deviation of
normal distribution that adds to strategies for diversity.
Raises:
ValueError: When arguments are not in proper range.
Example:
>>> from adapt import Network
>>> from adapt.strategy import AdaptiveParameterizedStrategy
>>> from tensorflow.keras.applications.vgg19 import VGG19
>>> model = VGG19()
>>> network = Network(model)
>>> strategy = AdaptiveParameterizedStrategy(network)
'''
super(AdaptiveParameterizedStrategy, self).__init__(network, bound)
# Initialize variables.
self.size = size
self.history = history
self.remainder = remainder
self.sigma = sigma
# Create initial stratagies randomly.
self.strategies = [np.random.uniform(-self.bound, self.bound, size=FeatureMatrix.TOTAL_FEATURES) for _ in range(self.size)]
self.strategy = self.strategies.pop(0)
# Create a coverage vector for a strategy.
self.strategy_covered = None
# Storage for used strategies and their result.
self.records = []
def init(self, covered, label, **kwargs):
'''Initialize the variables of the strategy.
This method should be called before all other methods in the class.
Args:
covered: A list of coverage vectors that the initial input covers.
label: A label of the initial input classified into.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
'''
super(AdaptiveParameterizedStrategy, self).init(covered=covered, label=label, **kwargs)
# Initialize coverage vector for one strategy.
self.strategy_covered = np.zeros(len(self.neurons), dtype=bool)
return self
def update(self, covered, label, **kwargs):
'''Update the variable of the strategy.
Args:
covered: A list of coverage vectors that a current input covers.
label: A label of a current input classified into.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
'''
super(AdaptiveParameterizedStrategy, self).update(covered=covered, label=label, **kwargs)
# Flatten coverage vectors.
covered = np.concatenate(covered)
self.strategy_covered = np.bitwise_or(self.strategy_covered, covered)
return self
def next(self):
'''Get the next parameterized strategy.
Get the next parameterized strategy. If the generated parameterized strategies
are all used, generate new parameterized strategies.
Returns:
Self for possible call chains.
'''
# Finish current strategy.
self.records.append((self.strategy, self.strategy_covered))
# Get the next strategy.
if len(self.strategies) > 0:
self.strategy = self.strategies.pop(0)
self.strategy_covered = np.zeros_like(self.strategy_covered, dtype=bool)
return self
# Generate next strategies from the past records.
records = self.records[-self.history:]
# Find a set of strategies that maximizes the coverage.
n = int(self.size * self.remainder)
strategies, covereds = tuple(zip(*records))
_, indices = greedy_max_set(covereds, n=n)
# Find the maximum coverages for remaining part.
n = n - len(indices)
if n > 0:
coverages = list(map(np.mean, covereds))
indices = indices + list(np.argpartition(coverages, -n)[-n:])
# Get strategies.
selected = np.array(strategies)[indices]
# Mix strategies randomly.
n = len(selected)
generation = ceil(1 / self.remainder)
left = selected[np.random.permutation(n)]
right = selected[np.random.permutation(n)]
for l, r in zip(left, right):
for _ in range(generation):
# Generate new strategy.
s = np.array([l[i] if np.random.choice([True, False]) else r[i] for i in range(FeatureMatrix.TOTAL_FEATURES)])
# Add little distortion.
s = s + np.random.normal(0, self.sigma, size=FeatureMatrix.TOTAL_FEATURES)
# Clip the ranges.
s = np.clip(s, -self.bound, self.bound)
self.strategies.append(s)
self.strategies = self.strategies[:self.size]
# Get the next strategy.
self.strategy = self.strategies.pop(0)
return self
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/deepxplore.py
================================================
import numpy as np
from pdb import set_trace as st
from .strategy import Strategy
class UncoveredRandomStrategy(Strategy):
'''A strategy that randomly selects neurons from uncovered neurons.
This strategy selects neurons from a set of uncovered neurons. This strategy
is first introduced in the following paper, but not exactly same. Please see
the following paper for more details:
DeepXplore: Automated Whitebox Testing of Deep Learning Systems
https://arxiv.org/abs/1705.06640
'''
def __init__(self, network):
'''Create a strategy and initialize its variables.
Args:
network: A wrapped Keras model with `adapt.Network`.
Example:
>>> from adapt import Network
>>> from adapt.strategy import UncoveredRandomStrategy
>>> from tensorflow.keras.applications.vgg19 import VGG19
>>> model = VGG19()
>>> network = Network(model)
>>> strategy = UncoveredRandomStrategy(network)
'''
super(UncoveredRandomStrategy, self).__init__(network)
# A variable that keeps track of the covered neurons.
self.covered = None
def select(self, k):
'''Select k uncovered neurons.
Select k neurons, and returns their location.
Args:
k: A positive integer. The number of neurons to select.
Returns:
A list of locations of selected neurons.
'''
# Find a set of uncovered neurons.
candidates = [
np.squeeze(np.argwhere(self.covered[id] == 0))
for id in range(self.num_input)
]
# candidates = np.squeeze(np.argwhere(self.covered == 0))
selected_indices = []
for id in range(self.num_input):
candidates = np.squeeze(np.argwhere(self.covered[id] == 0))
k = min(k, len(candidates))
indices = np.random.choice(candidates, size=k, replace=False)
selected_indices.append(indices)
return selected_indices
def init(self, covered, **kwargs):
'''Initialize the variable of the strategy.
This method should be called before all other methods in the class.
Args:
covered: A list of coverage vectors that the initial input covers.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
Raises:
ValueError: When the size of the passed coverage vectors are not matches
to the network setting.
'''
# Flatten coverage vectors.
self.covered = covered
self.num_input, self.num_neurons = covered.shape
return self
def update(self, covered, **kwargs):
'''Update the variable of the strategy.
Args:
covered: A list of coverage vectors that a current input covers.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
'''
# Update coverage vectors.
self.covered = np.bitwise_or(self.covered, covered)
return self
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/dlfuzz.py
================================================
from itertools import cycle
import numpy as np
from pdb import set_trace as st
from .strategy import Strategy
class DLFuzzRoundRobin(Strategy):
'''A round-robin strategy that cycles 3 strategies that suggested by DLFuzz.
DLFuzz suggest 4 different strategy as follows:
* Select neurons that are most covered.
* Select neurons that are rarely covered.
* Select neurons with the largest weights.
* Select neurons that have values near threshold.
From the suggested strategies, 4th strategy is highly subordinate to the
neuron coverage. Therefore, 4th strategy is not included in round-robin
strategy. Please, see the following paper for more details:
DLFuzz: Differential Fuzzing Testing of Deep Learning Systems
https://arxiv.org/abs/1808.09413
'''
def __init__(self, network, weight_portion=0.1, order=None):
'''Create a DLFuzz round-robin strategy.
Args:
network: A wrapped Keras model with `adapt.Network`.
weight_portion: A portion of neurons to use for 3rd strategy.
order: The order of round-robin. By default, [1, 2, 3].
Raises:
ValueError: When weight_portion is not in [0, 1].
Example:
>>> from adapt import Network
>>> from adapt.strategy import DLFuzzRoundRobin
>>> from tensorflow.keras.applications.vgg19 import VGG19
>>> model = VGG19()
>>> network = Network(model)
>>> strategy = DLFuzzRoundRobin(network)
'''
super(DLFuzzRoundRobin, self).__init__(network)
# A vector that stores how many times each neuron is covered.
self.covered_count = None
weights = []
intermediate_layers = network._intermediate_layers(network._model)
for layer in intermediate_layers:
# print(layer.weight.shape)
w = layer.weight.cpu().detach().numpy()
if len(w.shape) == 4:
w = w.mean(-1).mean(-1).mean(-1)
elif len(w.shape) == 1:
...
else:
raise NotImplementedError
weights.append(w)
weights = np.concatenate(weights)
# Guard for the range of weight portion
if weight_portion < 0 or weight_portion > 1:
raise ValueError('The argument weight_portion is not in [0, 1].')
self.weight_portion = weight_portion
# Find the neurons with high values.
k = int(len(weights) * self.weight_portion)
self.weight_indices = np.argpartition(weights, -k)[-k:]
# Round-robin cycle
if not order:
order = [1, 2, 3]
self.order = cycle(order)
# Start from the first strategy in the order.
self.current = next(self.order)
def select(self, k):
'''Select k neurons with the current strategy.
Seleck k neurons, and returns their location.
Args:
k: A positive integer. The number of neurons to select.
Returns:
A list of locations of selected neurons.
Raises:
ValueError: When the current strategy is unknown.
'''
selected_indices = []
for id in range(self.num_input):
input_covered_count = self.covered_count[id]
# First strategy.
if self.current == 1:
# Find k most covered neurons.
indices = np.argpartition(input_covered_count, -k)[-k:]
# Second strategy.
elif self.current == 2:
# Find k rarest covered neurons.
indices = np.argpartition(input_covered_count, k - 1)[:k]
# Third strategy.
elif self.current == 3:
# Randomly samples from the neurons with high weights.
indices = np.random.choice(self.weight_indices, size=k, replace=False)
# Unknown.
else:
raise ValueError('Unknown strategy. The strategy must be 1, 2, or 3.')
selected_indices.append(indices)
return selected_indices
def init(self, covered, **kwargs):
'''Initialize the variable of the strategy.
This method should be called before all other methods in the class.
Args:
covered: A list of coverage vectors that the initial input covers.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
Raises:
ValueError: When the size of the passed coverage vectors are not matches
to the network setting.
'''
self.num_input, self.num_neurons = covered.shape
# Initialize the number of covering for each neuron.
self.covered_count = np.zeros_like(covered, dtype=int)
self.covered_count += covered
return self
def update(self, covered, **kwargs):
'''Update the variable of the strategy.
Args:
covered: A list of coverage vectors that a current input covers.
kwargs: Not used. Present for the compatibility with the super class.
Returns:
Self for possible call chains.
'''
# Flatten coverage vectors.
# covered = np.concatenate(covered)
# Update the number of covering for each neuron.
self.covered_count += covered
def next(self):
'''Move to the next strategy.
Returns:
Self for possible call chains.
'''
# Get the next strategy.
self.current = next(self.order)
return self
class MostCoveredStrategy(DLFuzzRoundRobin):
'''A strategy selects most covered
This strategy selects most covered neurons. This strategy is first introduced
in the following paper. Please, see the following paper for more details:
DLFuzz: Differential Fuzzing Testing of Deep Learning Systems
https://arxiv.org/abs/1808.09413
Since this strategy is part of DLFuzzRoundRobin, this implementation re-use
the implementation of DLFuzzRoundRobin.
'''
def __init__(self, model):
'''Create a strategy.
Args:
network: A wrapped Keras model with `adapt.Network`.
Example:
>>> from adapt import Network
>>> from adapt.strategy import MostCoveredStrategy
>>> from tensorflow.keras.applications.vgg19 import VGG19
>>> model = VGG19()
>>> network = Network(model)
>>> strategy = MostCoveredStrategy(network)
'''
# Re-use the implementation of super class.
super(MostCoveredStrategy, self).__init__(model)
# Set current strategy as 1.
self.current = 1
# Remove unnecessary variables.
del self.weight_portion
del self.weight_indices
del self.order
def next(self):
'''Do nothing.
Returns:
Self for possible call chains.
'''
return self
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/random.py
================================================
import numpy as np
from .strategy import Strategy
from pdb import set_trace as st
class RandomStrategy(Strategy):
'''A strategy that randomly selects neurons from all neurons.
This strategy selects neurons from a set of all neurons in the network,
except for the neurons that located in skippable layers.
'''
def init(self, covered):
self.num_input, self.num_neurons = covered.shape
def select(self, k, ):
'''Seleck k neurons randomly.
Select k neurons randomly from a set of all neurons in the network,
except for the neurons that located in skippable layers.
Args:
k: A positive integer. The number of neurons to select.
Returns:
A list of location of the selected neurons.
'''
# Choose k neurons and return their location.
indices = [
np.random.choice(self.num_neurons, size=k, replace=False)
for _ in range(self.num_input)
]
# indices = np.concatenate(indices, axis=0)
return indices
================================================
FILE: code/deep/ReMoS/CV_adv/DNNtest/strategy/strategy.py
================================================
from abc import ABC
from abc import abstractmethod
class Strategy(ABC):
'''Abstract strategy class (used as an implementation base).'''
def __init__(self, network):
'''Create a strategy.
*** This method could be updated, but not mandatory. ***
Initialize the strategy by collecting all neurons in the network.
Args:
network: A wrapped Keras model with `adapt.Network`.
'''
def __call__(self, k):
'''Python magic call method.
This will make object callable. Just passing the argument to select method.
'''
return self.select(k)
@abstractmethod
def select(self, k):
'''Select k neurons.
*** This method should be implemented. ***
Select k neurons, and returns their location.
Args:
k: A positive integer. The number of neurons to select.
Returns:
A list of locations of selected neurons.
Global id
'''
def init(self, **kwargs):
'''Initialize the variables of the strategy.
*** This method could be update, but not mandatory. ***
Initialize the variables that managed by the strategy. This should be called
before other methods of the strategy called.
Args:
kwargs: A dictionary of keyword arguments. The followings are privileged
arguments.
covered: A list of coverage vectors that the initial input covers.
label: A label that initial input classified into.
Returns:
Self for possible call chains.
'''
return self
def update(self, covered, **kwargs):
'''Update the variables of the strategy.
*** This method could be updated, but not mandatory. ***
Update the variables that managed by the strategy. This method is called
everytime after a new input is created. By default, not update anything.
Args:
kwargs: A dictionary of keyword arguments. The followings are privileged
arguments.
covered: A list of coverage vectors that a current input covers.
label: A label that a current input classified into.
Returns:
Self for possible call chains.
'''
return self
def next(self):
'''Move to the next strategy.
*** This method could be updated, but not mandatory. ***
Update the strategy itself to next strategy. This may be important for
strategies using multiple strategies (i.e. round-robin). Be default,
not update strategy.
'''
return self
================================================
FILE: code/deep/ReMoS/CV_adv/dataset/cub200.py
================================================
import torch.utils.data as data
from PIL import Image
import random
import time
import numpy as np
import os
class CUB200Data(data.Dataset):
def __init__(self, root, is_train=True, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 200
self.transform = transform
self.preload = preload
mapfile = os.path.join(root, 'images.txt')
imgset_desc = os.path.join(root, 'train_test_split.txt')
labelfile = os.path.join(root, 'image_class_labels.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
assert os.path.exists(imgset_desc), 'Split txt is missing ({})'.format(imgset_desc)
assert os.path.exists(labelfile), 'Label txt is missing ({})'.format(labelfile)
self.img_ids = []
max_id = 0
with open(imgset_desc) as f:
for line in f:
i = int(line.split(' ')[0])
s = int(line.split(' ')[1].strip())
if s == is_train:
self.img_ids.append(i)
if max_id < i:
max_id = i
self.id_to_path = {}
with open(mapfile) as f:
for line in f:
i = int(line.split(' ')[0])
path = line.split(' ')[1].strip()
self.id_to_path[i] = os.path.join(root, 'images', path)
self.id_to_label = -1*np.ones(max_id+1, dtype=np.int64) # ID starts from 1
with open(labelfile) as f:
for line in f:
i = int(line.split(' ')[0])
#NOTE: In the network, class start from 0 instead of 1
c = int(line.split(' ')[1].strip())-1
self.id_to_label[i] = c
if is_train:
self.img_ids = np.array(self.img_ids)
new_img_ids = []
for c in range(self.num_classes):
ids = np.where(self.id_to_label == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
if i in self.img_ids:
new_img_ids.append(i)
count += 1
if count == shots:
break
self.img_ids = np.array(new_img_ids)
self.imgs = {}
if preload:
for idx, id in enumerate(self.img_ids):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.img_ids)))
img = Image.open(self.id_to_path[id]).convert('RGB')
self.imgs[id] = img
def __getitem__(self, index):
img_id = self.img_ids[index]
img_label = self.id_to_label[img_id]
if self.preload:
img = self.imgs[img_id]
else:
img = Image.open(self.id_to_path[img_id]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, img_label
def __len__(self):
return len(self.img_ids)
if __name__ == '__main__':
seed= int(time.time())
data_train = CUB200Data('/data/CUB_200_2011', True, shots=10, seed=seed)
print(len(data_train))
data_test = CUB200Data('/data/CUB_200_2011', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.img_ids:
if i in data_test.img_ids:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.img_ids[:5])
print('Test', data_test.img_ids[:5])
================================================
FILE: code/deep/ReMoS/CV_adv/dataset/flower102.py
================================================
import torch.utils.data as data
import scipy.io as sio
from PIL import Image
import random
import os
import glob
import numpy as np
class Flower102Data(data.Dataset):
def __init__(self, root, is_train=True, transform=None, shots=-1, seed=0, preload=False):
self.preload = preload
self.num_classes = 102
self.transform = transform
imglabel_map = os.path.join(root, 'imagelabels.mat')
setid_map = os.path.join(root, 'setid.mat')
assert os.path.exists(imglabel_map), 'Mapping txt is missing ({})'.format(imglabel_map)
assert os.path.exists(setid_map), 'Mapping txt is missing ({})'.format(setid_map)
imagelabels = sio.loadmat(imglabel_map)['labels'][0]
setids = sio.loadmat(setid_map)
if is_train:
ids = np.concatenate([setids['trnid'][0], setids['valid'][0]])
else:
ids = setids['tstid'][0]
self.labels = []
self.image_path = []
for i in ids:
# Original label start from 1, we shift it to 0
self.labels.append(int(imagelabels[i-1])-1)
self.image_path.append( os.path.join(root, 'jpg', 'image_{:05d}.jpg'.format(i)) )
self.labels = np.array(self.labels)
new_img_path = []
new_img_labels = []
if is_train:
if shots != -1:
self.image_path = np.array(self.image_path)
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
new_img_path.extend(self.image_path[ids[:shots]])
new_img_labels.extend([c for i in range(shots)])
self.image_path = new_img_path
self.labels = new_img_labels
if self.preload:
self.imgs = {}
for idx in range(len(self.image_path)):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
img = Image.open(self.image_path[idx]).convert('RGB')
self.imgs[idx] = img
def __getitem__(self, index):
if self.preload:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
# seed= int(time.time())
seed= int(98)
data_train = Flower102Data('/data/Flower_102', True, shots=5, seed=seed)
print(len(data_train))
data_test = Flower102Data('/data/Flower_102', False, shots=5, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_adv/dataset/mit67.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
from pdb import set_trace as st
class MIT67Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 67
self.transform = transform
cls = glob.glob(os.path.join(root, 'Images', '*'))
self.cls_names = [name.split('/')[-1] for name in cls]
if is_train:
mapfile = os.path.join(root, 'TrainImages.txt')
else:
mapfile = os.path.join(root, 'TestImages.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
self.labels = []
self.image_path = []
with open(mapfile) as f:
for line in f:
self.image_path.append(os.path.join(root, 'Images', line.strip()))
cls = line.split('/')[-2]
self.labels.append(self.cls_names.index(cls))
if is_train:
indices = np.arange(0, len(self.image_path))
random.seed(seed)
random.shuffle(indices)
self.image_path = np.array(self.image_path)[indices]
self.labels = np.array(self.labels)[indices]
if shots > 0:
new_img_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
count = 0
for i in ids:
new_img_path.append(self.image_path[i])
new_labels.append(c)
count += 1
if count == shots:
break
self.image_path = np.array(new_img_path)
self.labels = np.array(new_labels)
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
# seed= int(time.time())
seed= int(98)
data_train = MIT67Data('/data/MIT_67', True, shots=10, seed=seed)
print(len(data_train))
data_test = MIT67Data('/data/MIT_67', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_adv/dataset/stanford_40.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
class Stanford40Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 40
self.transform = transform
first_line = True
self.cls_names = []
with open(os.path.join(root, 'ImageSplits', 'actions.txt')) as f:
for line in f:
if first_line:
first_line = False
continue
self.cls_names.append(line.split('\t')[0].strip())
if is_train:
post = 'train'
else:
post = 'test'
self.labels = []
self.image_path = []
for label, cls_name in enumerate(self.cls_names):
with open(os.path.join(root, 'ImageSplits', '{}_{}.txt'.format(cls_name, post))) as f:
for line in f:
self.labels.append(label)
self.image_path.append(os.path.join(root, 'JPEGImages', line.strip()))
if is_train:
self.labels = np.array(self.labels)
new_image_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
new_image_path.append(self.image_path[i])
new_labels.append(self.labels[i])
count += 1
if count == shots:
break
self.labels = new_labels
self.image_path = new_image_path
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
seed= int(98)
data_train = Stanford40Data('/data/stanford_40', True, shots=10, seed=seed)
print(len(data_train))
data_test = Stanford40Data('/data/stanford_40', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_adv/dataset/stanford_dog.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
import scipy.io as sio
class SDog120Data(data.Dataset):
def __init__(self, root, is_train=True, transform=None, shots=5, seed=0, preload=False):
self.num_classes = 120
self.transform = transform
self.preload=preload
if is_train:
mapfile = os.path.join(root, 'train_list.mat')
else:
mapfile = os.path.join(root, 'test_list.mat')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
dset_list = sio.loadmat(mapfile)
self.labels = []
self.image_path = []
for idx, f in enumerate(dset_list['file_list']):
self.image_path.append(os.path.join(root, 'Images', f[0][0]))
# Stanford Dog starts 1
self.labels.append(dset_list['labels'][idx][0]-1)
if is_train:
self.image_path = np.array(self.image_path)
self.labels = np.array(self.labels)
if shots > 0:
new_img_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
new_img_path.append(self.image_path[i])
new_labels.append(c)
count += 1
if count == shots:
break
self.image_path = np.array(new_img_path)
self.labels = np.array(new_labels)
self.imgs = {}
if preload:
self.imgs = {}
for idx, path in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
img = Image.open(path).convert('RGB')
self.imgs[idx] = img
def __getitem__(self, index):
if self.preload:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
seed= int(time.time())
data_train = SDog120Data('/data/stanford_dog', True, shots=10, seed=seed)
print(len(data_train))
data_test = SDog120Data('/data/stanford_dog', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_adv/distillation_training.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
from functools import partial
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout, resnet34_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101, feresnet34
from eval_robustness import advtest, myloss
from utils import *
def linear_l2(model):
beta_loss = 0
for m in model.modules():
if isinstance(m, nn.Linear):
beta_loss += (m.weight).pow(2).sum()
beta_loss += (m.bias).pow(2).sum()
return 0.5*beta_loss*args.beta, beta_loss
def l2sp(model, reg):
reg_loss = 0
dist = 0
for m in model.modules():
if hasattr(m, 'weight') and hasattr(m, 'old_weight'):
diff = (m.weight - m.old_weight).pow(2).sum()
dist += diff
reg_loss += diff
if hasattr(m, 'bias') and hasattr(m, 'old_bias'):
diff = (m.bias - m.old_bias).pow(2).sum()
dist += diff
reg_loss += diff
if dist > 0:
dist = dist.sqrt()
loss = (reg * reg_loss)
return loss, dist
def test(model, teacher, loader, loss=False):
with torch.no_grad():
model.eval()
if loss:
teacher.eval()
ce = CrossEntropyLabelSmooth(loader.dataset.num_classes, args.label_smoothing)
featloss = torch.nn.MSELoss(reduction='none')
total_ce = 0
total_feat_reg = np.zeros(len(reg_layers))
total_l2sp_reg = 0
total = 0
top1 = 0
total = 0
top1 = 0
for i, (batch, label) in enumerate(loader):
total += batch.size(0)
out = model(batch)
_, pred = out.max(dim=1)
top1 += int(pred.eq(label).sum().item())
if loss:
total_ce += ce(out, label).item()
if teacher is not None:
with torch.no_grad():
tout = teacher(batch)
# for key in reg_layers:
for i, key in enumerate(reg_layers):
src_x = reg_layers[key][0].out
tgt_x = reg_layers[key][1].out
regloss = featloss(src_x, tgt_x.detach()).mean()
total_feat_reg[i] += regloss.item()
_, unweighted = l2sp(model, 0)
total_l2sp_reg += unweighted.item()
return float(top1)/total*100, total_ce/(i+1), np.sum(total_feat_reg)/(i+1), total_l2sp_reg/(i+1), total_feat_reg/(i+1)
def train(
model,
train_loader,
val_loader,
adv_eval_fn,
iterations=9000,
lr=1e-2,
output_dir='results',
l2sp_lmda=1e-2,
teacher=None,
reg_layers={}
):
if l2sp_lmda == 0:
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=args.momentum, weight_decay=args.weight_decay)
else:
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=args.momentum, weight_decay=0)
end_iter = iterations
if args.swa:
optimizer = torchcontrib.optim.SWA(optimizer, swa_start=args.swa_start, swa_freq=args.swa_freq)
end_iter = args.swa_start
teacher.eval()
ce = CrossEntropyLabelSmooth(train_loader.dataset.num_classes, args.label_smoothing)
featloss = torch.nn.MSELoss()
batch_time = MovingAverageMeter('Time', ':6.3f')
data_time = MovingAverageMeter('Data', ':6.3f')
ce_loss_meter = MovingAverageMeter('CE Loss', ':6.3f')
feat_loss_meter = MovingAverageMeter('Feat. Loss', ':6.3f')
l2sp_loss_meter = MovingAverageMeter('L2SP Loss', ':6.3f')
linear_loss_meter = MovingAverageMeter('LinearL2 Loss', ':6.3f')
total_loss_meter = MovingAverageMeter('Total Loss', ':6.3f')
top1_meter = MovingAverageMeter('Acc@1', ':6.2f')
train_path = osp.join(output_dir, "train.tsv")
with open(train_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'celoss', 'featloss', 'l2sp']
wf.write('\t'.join(columns) + '\n')
test_path = osp.join(output_dir, "test.tsv")
with open(test_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'celoss', 'featloss', 'l2sp']
wf.write('\t'.join(columns) + '\n')
adv_path = osp.join(output_dir, "adv.tsv")
with open(adv_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'AdvAcc', 'ASR']
wf.write('\t'.join(columns) + '\n')
dataloader_iterator = iter(train_loader)
for i in range(iterations):
model.train()
optimizer.zero_grad()
end = time.time()
try:
batch, label = next(dataloader_iterator)
except:
dataloader_iterator = iter(train_loader)
batch, label = next(dataloader_iterator)
data_time.update(time.time() - end)
out = model(batch)
_, pred = out.max(dim=1)
top1_meter.update(float(pred.eq(label).sum().item()) / label.shape[0] * 100.)
loss = 0.
loss += ce(out, label)
ce_loss_meter.update(loss.item())
with torch.no_grad():
tout = teacher(batch)
# Compute the feature distillation loss only when needed
if args.feat_lmda != 0:
regloss = 0
# for layer in args.feat_layers:
for key in reg_layers:
# key = int(layer)-1
src_x = reg_layers[key][0].out
tgt_x = reg_layers[key][1].out
regloss += featloss(src_x, tgt_x.detach())
regloss = args.feat_lmda * regloss
loss += regloss
feat_loss_meter.update(regloss.item())
beta_loss, linear_norm = linear_l2(model)
loss = loss + beta_loss
linear_loss_meter.update(beta_loss.item())
if l2sp_lmda != 0:
reg, _ = l2sp(model, l2sp_lmda)
l2sp_loss_meter.update(reg.item())
loss = loss + reg
total_loss_meter.update(loss.item())
loss.backward()
optimizer.step()
for param_group in optimizer.param_groups:
current_lr = param_group['lr']
batch_time.update(time.time() - end)
if (i % args.print_freq == 0) or (i == iterations-1):
progress = ProgressMeter(
iterations,
[batch_time, data_time, top1_meter, total_loss_meter, ce_loss_meter, feat_loss_meter, l2sp_loss_meter, linear_loss_meter],
prefix="LR: {:6.3f}".format(current_lr),
output_dir=output_dir,
)
progress.display(i)
if ((i+1) % args.test_interval == 0) or (i == iterations-1):
test_top1, test_ce_loss, test_feat_loss, test_weight_loss, test_feat_layer_loss = test(
model, teacher, val_loader, loss=True
)
train_top1, train_ce_loss, train_feat_loss, train_weight_loss, train_feat_layer_loss = test(
model, teacher, train_loader, loss=True
)
print('Eval Train | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | Feat Reg Loss: {:.6f} | L2SP Reg Loss: {:.3f}'.format(i+1, iterations, train_top1, train_ce_loss, train_feat_loss, train_weight_loss))
print('Eval Test | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | Feat Reg Loss: {:.6f} | L2SP Reg Loss: {:.3f}'.format(i+1, iterations, test_top1, test_ce_loss, test_feat_loss, test_weight_loss))
localtime = time.asctime( time.localtime(time.time()) )[4:-6]
with open(train_path, 'a') as af:
train_cols = [
localtime,
i,
round(train_top1,2),
round(train_ce_loss,2),
round(train_feat_loss,2),
round(train_weight_loss,2),
]
af.write('\t'.join([str(c) for c in train_cols]) + '\n')
with open(test_path, 'a') as af:
test_cols = [
localtime,
i,
round(test_top1,2),
round(test_ce_loss,2),
round(test_feat_loss,2),
round(test_weight_loss,2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
if not args.no_save:
# if not os.path.exists('ckpt'):
# os.makedirs('ckpt')
# torch.save({'state_dict': model.state_dict()}, 'ckpt/{}.pth'.format(name))
ckpt_path = osp.join(
args.output_dir,
"ckpt.pth"
)
torch.save({'state_dict': model.state_dict()}, ckpt_path)
if args.adv_test_interval > 0 and ( ((i+1) % args.adv_test_interval == 0) ):
clean_top1, adv_top1, adv_sr = adv_eval_fn(model)
localtime = time.asctime( time.localtime(time.time()) )[4:-6]
with open(adv_path, 'a') as af:
test_cols = [
localtime,
i,
round(clean_top1,2),
round(adv_top1,2),
round(adv_sr,2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
if args.swa:
optimizer.swap_swa_sgd()
for m in model.modules():
if hasattr(m, 'running_mean'):
m.reset_running_stats()
m.momentum = None
with torch.no_grad():
model.train()
for x, y in train_loader:
out = model(x)
test_top1, test_ce_loss, test_feat_loss, test_weight_loss, test_feat_layer_loss = test(
model, teacher, val_loader, loss=True
)
train_top1, train_ce_loss, train_feat_loss, train_weight_loss, train_feat_layer_loss = test(
model, teacher, train_loader, loss=True
)
# clean_top1, adv_top1, adv_sr = adv_eval_fn(model)
print('Eval Train | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | Feat Reg Loss: {:.6f} | L2SP Reg Loss: {:.3f}'.format(i+1, iterations, train_top1, train_ce_loss, train_feat_loss, train_weight_loss))
print('Eval Test | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | Feat Reg Loss: {:.6f} | L2SP Reg Loss: {:.3f}'.format(i+1, iterations, test_top1, test_ce_loss, test_feat_loss, test_weight_loss))
localtime = time.asctime( time.localtime(time.time()) )[4:-6]
with open(train_path, 'a') as af:
train_cols = [
localtime,
i,
round(train_top1,2),
round(train_ce_loss,2),
round(train_feat_loss,2),
round(train_weight_loss,2),
]
af.write('\t'.join([str(c) for c in train_cols]) + '\n')
with open(test_path, 'a') as af:
test_cols = [
localtime,
i,
round(test_top1,2),
# round(adv_top1,2),
# round(adv_sr,2),
round(test_ce_loss,2),
round(test_feat_loss,2),
round(test_weight_loss,2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
# clean_top1, adv_top1, adv_sr = adv_eval_fn(model)
# localtime = time.asctime( time.localtime(time.time()) )[4:-6]
# with open(adv_path, 'a') as af:
# test_cols = [
# localtime,
# i,
# round(clean_top1,2),
# round(adv_top1,2),
# round(adv_sr,2),
# ]
# af.write('\t'.join([str(c) for c in test_cols]) + '\n')
if not args.no_save:
# if not os.path.exists('ckpt'):
# os.makedirs('ckpt')
ckpt_path = osp.join(
args.output_dir,
"ckpt.pth"
)
torch.save({'state_dict': model.state_dict()}, ckpt_path)
return model
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--iterations", type=int, default=30000, help='Iterations to train')
parser.add_argument("--print_freq", type=int, default=100, help='Frequency of printing training logs')
parser.add_argument("--test_interval", type=int, default=1000, help='Frequency of testing')
parser.add_argument("--adv_test_interval", type=int, default=1000)
parser.add_argument("--name", type=str, default='test', help='Name for the checkpoint')
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--lr", type=float, default=1e-2)
parser.add_argument("--weight_decay", type=float, default=0)
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--beta", type=float, default=1e-2, help='The strength of the L2 regularization on the last linear layer')
parser.add_argument("--dropout", type=float, default=0, help='Dropout rate for spatial dropout')
parser.add_argument("--l2sp_lmda", type=float, default=0)
parser.add_argument("--feat_lmda", type=float, default=0)
parser.add_argument("--feat_layers", type=str, default='1234', help='Used for DELTA (which layers or stages to match), ResNets should be 1234 and MobileNetV2 should be 12345')
parser.add_argument("--reinit", action='store_true', default=False, help='Reinitialize before training')
parser.add_argument("--no_save", action='store_true', default=False, help='Do not save checkpoints')
parser.add_argument("--swa", action='store_true', default=False, help='Use SWA')
parser.add_argument("--swa_freq", type=int, default=500, help='Frequency of averaging models in SWA')
parser.add_argument("--swa_start", type=int, default=0, help='Start SWA since which iterations')
parser.add_argument("--label_smoothing", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='', help='Load a previously trained checkpoint')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--shot", type=int, default=-1, help='Number of training samples per class for the training dataset. -1 indicates using the full dataset.')
parser.add_argument("--log", action='store_true', default=False, help='Redirect the output to log/args.name.log')
parser.add_argument("--output_dir", default="results")
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--adv_data_dir", default="results/advdata")
parser.add_argument("--seed", type=int, default=98)
args = parser.parse_args()
args.adv_data_dir = osp.join(
args.adv_data_dir, f"{args.dataset}_{args.network}.pt"
)
return args
# Used to matching features
def record_act(self, input, output):
self.out = output
if __name__ == '__main__':
args = get_args()
seed = args.seed
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
if args.log:
if not os.path.exists('log'):
os.makedirs('log')
sys.stdout = open('log/{}.log'.format(args.name), 'w')
args.output_dir = osp.join(
args.output_dir,
args.name
)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
params_out_path = osp.join(args.output_dir, 'params.json')
with open(params_out_path, 'w') as jf:
json.dump(vars(args), jf, indent=True)
print(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Used to make sure we sample the same image for few-shot scenarios
seed = 98
train_set = eval(args.dataset)(
args.datapath, True, transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]),
args.shot, seed, preload=False
)
test_set = eval(args.dataset)(
args.datapath, False, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
args.shot, seed, preload=False
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size, shuffle=True,
num_workers=8, pin_memory=False
)
val_loader = train_loader
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
model = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=train_loader.dataset.num_classes
)
if args.checkpoint != '':
checkpoint = torch.load(args.checkpoint)
model.load_state_dict(checkpoint['state_dict'])
# Pre-trained model
teacher = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=0,
num_classes=train_loader.dataset.num_classes
)
if 'mbnetv2' in args.network:
reg_layers = {0: [model.layer1], 1: [model.layer2], 2: [model.layer3], 3: [model.layer4], 4: [model.layer5]}
model.layer1.register_forward_hook(record_act)
model.layer2.register_forward_hook(record_act)
model.layer3.register_forward_hook(record_act)
model.layer4.register_forward_hook(record_act)
model.layer5.register_forward_hook(record_act)
elif 'resnet' in args.network:
reg_layers = {0: [model.layer1], 1: [model.layer2], 2: [model.layer3], 3: [model.layer4]}
model.layer1.register_forward_hook(record_act)
model.layer2.register_forward_hook(record_act)
model.layer3.register_forward_hook(record_act)
model.layer4.register_forward_hook(record_act)
elif 'vgg' in args.network:
cnt = 0
reg_layers = {}
for name, module in model.named_modules():
if isinstance(module, nn.MaxPool2d) and '28' not in name:
reg_layers[name] = [module]
module.register_forward_hook(record_act)
print(name, module)
# Stored pre-trained weights for computing L2SP
for m in model.modules():
if hasattr(m, 'weight') and not hasattr(m, 'old_weight'):
m.old_weight = m.weight.data.clone().detach()
# all_weights = torch.cat([all_weights.reshape(-1), m.weight.data.abs().reshape(-1)], dim=0)
if hasattr(m, 'bias') and not hasattr(m, 'old_bias') and m.bias is not None:
m.old_bias = m.bias.data.clone().detach()
if args.reinit:
for m in model.modules():
if type(m) in [nn.Linear, nn.BatchNorm2d, nn.Conv2d]:
m.reset_parameters()
if 'vgg' not in args.network:
reg_layers[0].append(teacher.layer1)
teacher.layer1.register_forward_hook(record_act)
reg_layers[1].append(teacher.layer2)
teacher.layer2.register_forward_hook(record_act)
reg_layers[2].append(teacher.layer3)
teacher.layer3.register_forward_hook(record_act)
reg_layers[3].append(teacher.layer4)
teacher.layer4.register_forward_hook(record_act)
if '5' in args.feat_layers:
reg_layers[4].append(teacher.layer5)
teacher.layer5.register_forward_hook(record_act)
else:
cnt = 0
for name, module in teacher.named_modules():
if isinstance(module, nn.MaxPool2d) and '28' not in name:
reg_layers[name].append(module)
module.register_forward_hook(record_act)
# print(name, module)
eval_pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).eval()
adversary = LinfPGDAttack(
eval_pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
adveval_test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=8, shuffle=False,
num_workers=8, pin_memory=False
)
adv_eval_fn = partial(
advtest,
loader=adveval_test_loader,
adversary=adversary,
args=args,
)
train(
model,
train_loader,
test_loader,
adv_eval_fn,
l2sp_lmda=args.l2sp_lmda,
iterations=args.iterations,
lr=args.lr,
output_dir=args.output_dir,
teacher=teacher,
reg_layers=reg_layers,
)
# Evaluate
pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).eval()
adversary = LinfPGDAttack(
pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=8, shuffle=False,
num_workers=8, pin_memory=False
)
clean_top1, adv_top1, adv_sr = advtest(model, test_loader, adversary, args)
result_sum = 'Clean Top-1: {:.2f} | Adv Top-1: {:.2f} | Attack Success Rate: {:.2f}'.format(clean_top1, adv_top1, adv_sr)
with open(osp.join(args.output_dir, "posttrain_eval.txt"), "w") as f:
f.write(result_sum)
================================================
FILE: code/deep/ReMoS/CV_adv/eval_robustness.py
================================================
import argparse
import torch
import time
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
def advtest(model, loader, adversary, args):
model.eval()
model = model.cuda()
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (batch, label) in enumerate(loader):
batch, label = batch.cuda(), label.cuda()
total += batch.size(0)
out_clean = model(batch)
y = torch.zeros(batch.shape[0], model.fc.in_features).cuda()
y[:,0] = args.m
advbatch = adversary.perturb(batch, y)
out_adv = model(advbatch)
_, pred_clean = out_clean.max(dim=1)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
print('{}/{}...'.format(i+1, len(loader)))
# if i > 5:
# break
print(total, adv_trial)
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial *100
def record_act(self, input, output):
pass
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
def myloss(yhat, y):
return -((yhat[:,0]-y[:,0])**2 + 0.1*((yhat[:,1:]-y[:,1:])**2).mean(1)).mean()
if __name__ == '__main__':
args = get_args()
print(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
seed = int(time.time())
test_set = eval(args.dataset)(
args.datapath, False, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
-1, seed, preload=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False)
transferred_model = eval('{}_dropout'.format(args.network))(pretrained=False, dropout=args.dropout, num_classes=test_loader.dataset.num_classes)
checkpoint = torch.load(args.checkpoint)
transferred_model.load_state_dict(checkpoint['state_dict'])
pretrained_model = eval('fe{}'.format(args.teacher))(pretrained=True).eval()
adversary = LinfPGDAttack(
pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
clean_top1, adv_top1, adv_sr = advtest(transferred_model, test_loader, adversary, args)
print('Clean Top-1: {:.2f} | Adv Top-1: {:.2f} | Attack Success Rate: {:.2f}'.format(clean_top1, adv_top1, adv_sr))
================================================
FILE: code/deep/ReMoS/CV_adv/examples/finetune.sh
================================================
#!/bin/bash
iter=30000
lr=1e-3
wd=1e-4
mmt=0
DATASETS=(MIT_67 CUB_200_2011 Flower_102 stanford_40 stanford_dog)
DATASET_NAMES=(MIT67Data CUB200Data Flower102Data Stanford40Data SDog120Data)
DATASET_ABBRS=(mit67 cub200 flower102 stanford40 sdog120)
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
DIR=results/baseline/finetune
NAME=resnet18_${DATASET_ABBR}
CUDA_VISIBLE_DEVICES=$1 python -u finetune.py --iterations ${iter} --datapath data/${DATASET}/ --dataset ${DATASET_NAME} --name $NAME --batch_size 64 --lr ${lr} --network resnet18 --weight_decay ${wd} --momentum ${mmt} --output_dir $DIR
done
================================================
FILE: code/deep/ReMoS/CV_adv/examples/nc_guided_defect.py
================================================
import os, sys
import os.path as osp
import pandas as pd
from pdb import set_trace as st
import numpy as np
np.set_printoptions(precision = 1)
root = "results/nc_adv_eval_test"
coverages = ["neuron_coverage", "top_k_coverage", "strong_coverage"]
coverage_names = ["NC", "TKNC", "SNAC"]
strategies = ["deepxplore", "dlfuzz", "dlfuzzfirst"]
strategy_names = ["DeepXplore", "DLFuzzRR", "DLFuzz"]
datasets = ["mit67", "stanford40"]
dataset_names = ["Scenes", "Actions"]
methods = ["Finetune", "DELTA", "Magprune", "ReMoS"]
dataset = "mit67"
# for idx, dataset in enumerate(datasets):
# dataset_df = pd.DataFrame(coverage_names)
# for strategy_name, strategy in zip(strategy_names, strategies):
# s_dirs = []
# for coverage in coverages:
# path = osp.join(root, f"{strategy}_{coverage}_{dataset}_resnet18", "result.csv")
# df = pd.read_csv(path, index_col=0)
# dir = np.around(df['dir'].to_numpy(), 1)
# s_dirs.append(dir)
# dataset_df[strategy_name] = s_dirs
# print(f"Results for {dataset_names[idx]}")
# print(dataset_df)
m_indexes = pd.MultiIndex.from_product([dataset_names, strategy_names, methods], names=["Dataset", "Strategy", "Techniques"])
result = pd.DataFrame(np.random.randn(3, 6*4), index=coverage_names, columns=m_indexes)
for dataset_name, dataset in zip(dataset_names, datasets):
for strategy_name, strategy in zip(strategy_names, strategies):
s_dirs = []
for coverage_name, coverage in zip(coverage_names, coverages):
path = osp.join(root, f"{strategy}_{coverage}_{dataset}_resnet18", "result.csv")
df = pd.read_csv(path, index_col=0)
dir = np.around(df['dir'].to_numpy(), 1)
for idx, method in enumerate(methods):
result[(dataset_name,strategy_name, method)][coverage_name] = round(dir[idx],1)
print(f"Results for Scenes")
print(result["Scenes"])
print(f"\nResults for Actions")
print(result["Actions"])
================================================
FILE: code/deep/ReMoS/CV_adv/examples/nc_guided_defect.sh
================================================
#!/bin/bash
export PYTHONPATH=../..:$PYTHONPATH
iter=30000
id=1
splmda=0
lmda=0
layer=1234
lr=5e-3
wd=1e-4
mmt=0
DATASETS=(MIT_67 CUB_200_2011 Flower_102 stanford_40 stanford_dog VisDA)
DATASET_NAMES=(MIT67Data CUB200Data Flower102Data Stanford40Data SDog120Data VisDaDATA)
DATASET_ABBRS=(mit67 cub200 flower102 stanford40 sdog120 visda)
COVERAGE=strong_coverage
STRATEGY=deepxplore
# neuron_coverage top_k_coverage strong_coverage
# random deepxplore dlfuzz dlfuzzfirst
for i in 3
do
for COVERAGE in neuron_coverage top_k_coverage strong_coverage
do
for STRATEGY in deepxplore dlfuzz dlfuzzfirst
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
DIR=results/baseline/finetune
NAME=resnet18_${DATASET_ABBR}_lr${lr}_iter${iter}_feat${lmda}_wd${wd}_mmt${mmt}_${id}
FINETUNE_DIR=results/res18_ncprune_sum/finetune/resnet18_${DATASET_ABBR}_lr5e-3_iter30000_feat0_wd1e-4_mmt0_1
DELTA_DIR=results/res18_ncprune_sum/delta/resnet18_${DATASET_ABBR}_lr1e-2_iter10000_feat5e-1_wd1e-4_mmt0_1
WEIGHT_DIR=results/res18_ncprune_sum/weight/resnet18_${DATASET_ABBR}_total0.8_init0.8_per0.1_int10000_lr5e-3_iter10000_feat0_wd1e-4_mmt0_1
NCPRUNE_DIR=results/res18_ncprune_sum/ncprune/resnet18_${DATASET_ABBR}_do_total0.1_trainall_lr5e-3_iter30000_feat0_wd1e-4_mmt0_1
CUDA_VISIBLE_DEVICES=$1 python -u DNNtest/eval_nc.py --datapath data/${DATASET}/ --dataset ${DATASET_NAME} --name $NAME --network resnet18 --finetune_ckpt $FINETUNE_DIR/ckpt.pth --delta_ckpt $DELTA_DIR/ckpt.pth --weight_ckpt $WEIGHT_DIR/ckpt.pth --ncprune_ckpt $NCPRUNE_DIR/ckpt.pth --output_dir results/nc_adv_eval_test/${STRATEGY}_${COVERAGE}_${DATASET_ABBR}_resnet18 --batch_size 32 --coverage $COVERAGE --strategy $STRATEGY
done
done
done
================================================
FILE: code/deep/ReMoS/CV_adv/examples/nc_profile.sh
================================================
#!/bin/bash
export PYTHONPATH=../..:$PYTHONPATH
DATASETS=(MIT_67 CUB_200_2011 Flower_102 stanford_40 stanford_dog VisDA)
DATASET_NAMES=(MIT67Data CUB200Data Flower102Data Stanford40Data SDog120Data VisDaDATA)
DATASET_ABBRS=(mit67 cub200 flower102 stanford40 sdog120 visda)
# coverages: neuron_coverage top_k_coverage strong_coverage
# strategies: random deepxplore dlfuzz dlfuzzfirst
for MODEL in resnet18
do
for dataset_idx in 0
do
for COVERAGE in neuron_coverage
do
for STRATEGY in deepxplore
do
DATASET=${DATASETS[dataset_idx]}
DATASET_NAME=${DATASET_NAMES[dataset_idx]}
DATASET_ABBR=${DATASET_ABBRS[dataset_idx]}
NAME=${MODEL}_${DATASET_ABBR}_lr${lr}_iter${iter}_feat${lmda}_wd${wd}_mmt${mmt}_${id}
CUDA_VISIBLE_DEVICES=$1 python -u nc_prune/my_profile.py --datapath data/${DATASET}/ --dataset ${DATASET_NAME} --name $NAME --network $MODEL --output_dir results/nc_profiling/${COVERAGE}_${DATASET_ABBR}_${MODEL} --batch_size 32 --coverage $COVERAGE --strategy $STRATEGY
done
done
done
done
================================================
FILE: code/deep/ReMoS/CV_adv/examples/penul_guided_defect.py
================================================
import os, sys
import os.path as osp
import pandas as pd
from pdb import set_trace as st
import numpy as np
np.set_printoptions(precision = 1)
datasets = ["mit67", "cub200", "flower102", "sdog120", "stanford40"]
dataset_names = ["Scenes", "Birds", "Flowers", "Dogs", "Actions"]
methods = ["finetune", "delta", "weight", "retrain", "deltar", "renofeation", "remos"]
method_names = ["Finetune", "DELTA", "Magprune", "Retrain", "DELTA-R", "Renofeation", "ReMoS"]
model = "resnet18"
root = "results/res18_models"
m_indexes = pd.MultiIndex.from_product([dataset_names, method_names], names=["Dataset", "Techniques"])
result = pd.DataFrame(np.random.randn(2, 5*7), index=["Acc", "DIR"], columns=m_indexes)
for dataset_name, dataset in zip(dataset_names, datasets):
for method_name, method in zip(method_names, methods):
path = osp.join(root, method, f"{model}_{dataset}", "posttrain_eval.txt")
with open(path) as f:
line = f.readline()
info = line.split("|")
acc = float(info[0].split()[-1])
dir = float(info[-1].split()[-1])
result[(dataset_name, method_name)]["Acc"] = acc
result[(dataset_name, method_name)]["DIR"] = dir
print("="*30, " ResNet18 ", "="*30)
for dataset_name in dataset_names:
print(f"Dataset {dataset_name}:")
print(result[dataset_name])
model = "resnet50"
root = "results/res50_models"
m_indexes = pd.MultiIndex.from_product([dataset_names, method_names], names=["Dataset", "Techniques"])
result = pd.DataFrame(np.random.randn(2, 5*7), index=["Acc", "DIR"], columns=m_indexes)
for dataset_name, dataset in zip(dataset_names, datasets):
for method_name, method in zip(method_names, methods):
path = osp.join(root, method, f"{model}_{dataset}", "posttrain_eval.txt")
with open(path) as f:
line = f.readline()
info = line.split("|")
acc = float(info[0].split()[-1])
dir = float(info[-1].split()[-1])
result[(dataset_name, method_name)]["Acc"] = acc
result[(dataset_name, method_name)]["DIR"] = dir
print("="*30, " ResNet50 ", "="*30)
for dataset_name in dataset_names:
print(f"Dataset {dataset_name}:")
print(result[dataset_name])
================================================
FILE: code/deep/ReMoS/CV_adv/examples/remos.sh
================================================
#!/bin/bash
export PYTHONPATH=../..:$PYTHONPATH
iter=30000
lr=5e-3
wd=1e-4
mmt=0
DATASETS=(MIT_67 CUB_200_2011 Flower_102 stanford_40 stanford_dog)
DATASET_NAMES=(MIT67Data CUB200Data Flower102Data Stanford40Data SDog120Data)
DATASET_ABBRS=(mit67 cub200 flower102 stanford40 sdog120)
for i in 0
do
for ratio in 0.1
do
for COVERAGE in neuron_coverage
do
total_ratio=${ratio}
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
NAME=resnet18_${DATASET_ABBR}_total${total_ratio}_lr${lr}_iter${iter}_wd${wd}_mmt${mmt}
DIR=results/remos_$COVERAGE
CUDA_VISIBLE_DEVICES=$1 python finetune.py --iterations ${iter} --datapath data/${DATASET}/ --dataset ${DATASET_NAME} --name ${NAME} --batch_size 64 --lr ${lr} --network resnet18 --weight_decay ${wd} --momentum ${mmt} --output_dir ${DIR} --method remos --weight_total_ratio $total_ratio --weight_init_prune_ratio $total_ratio --prune_interval $iter --weight_ratio_per_prune 0 --nc_info_dir results/nc_profiling/${COVERAGE}_${DATASET_ABBR}_resnet18
done
done
done
================================================
FILE: code/deep/ReMoS/CV_adv/finetune.py
================================================
import os
import os.path as osp
import argparse
import random
import torch
import numpy as np
from torchvision import transforms
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
# from dataset.vis_da import VisDaDATA
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from eval_robustness import advtest, myloss
from utils import *
from finetuner import Finetuner
from weight_pruner import WeightPruner
from nc_prune.nc_weight_rank_pruner import NCWeightRankPruner
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--iterations", type=int, default=30000, help='Iterations to train')
parser.add_argument("--print_freq", type=int, default=100, help='Frequency of printing training logs')
parser.add_argument("--test_interval", type=int, default=1000, help='Frequency of testing')
parser.add_argument("--adv_test_interval", type=int, default=1000)
parser.add_argument("--name", type=str, default='test', help='Name for the checkpoint')
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--lr", type=float, default=1e-2)
parser.add_argument("--weight_decay", type=float, default=0)
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--dropout", type=float, default=0.1, help='Dropout rate for spatial dropout')
parser.add_argument("--checkpoint", type=str, default='', help='Load a previously trained checkpoint')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--shot", type=int, default=-1, help='Number of training samples per class for the training dataset. -1 indicates using the full dataset.')
parser.add_argument("--log", action='store_true', default=False, help='Redirect the output to log/args.name.log')
parser.add_argument("--output_dir", default="results")
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--method", default=None)
# Weight prune
parser.add_argument("--weight_total_ratio", default=-1, type=float)
parser.add_argument("--weight_ratio_per_prune", default=-1, type=float)
parser.add_argument("--weight_init_prune_ratio", default=-1, type=float)
parser.add_argument("--prune_interval", default=-1, type=int)
parser.add_argument("--prune_descending", default=False, action="store_true")
# neuron coverage
parser.add_argument("--nc_info_dir")
args = parser.parse_args()
args.pid = os.getpid()
args.family_output_dir = args.output_dir
args.output_dir = osp.join(
args.output_dir,
args.name
)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
return args
if __name__=="__main__":
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
args = get_args()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Used to make sure we sample the same image for few-shot scenarios
seed = 98
train_set = eval(args.dataset)(
args.datapath, True, transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]),
args.shot, seed, preload=False
)
test_set = eval(args.dataset)(
args.datapath, False, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
args.shot, seed, preload=False
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size, shuffle=True,
num_workers=8, pin_memory=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
model = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=train_loader.dataset.num_classes
)
if args.checkpoint != '':
checkpoint = torch.load(args.checkpoint)
model.load_state_dict(checkpoint['state_dict'])
print(f"Loaded checkpoint from {args.checkpoint}")
# Pre-trained model
teacher = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=0,
num_classes=train_loader.dataset.num_classes
)
if args.method is None:
finetune_machine = Finetuner(
args,
model, teacher,
train_loader, test_loader,
)
elif args.method == "weight":
finetune_machine = WeightPruner(
args,
model, teacher,
train_loader, test_loader,
)
elif args.method == "remos":
finetune_machine = NCWeightRankPruner(
args, model, teacher, train_loader, test_loader,
)
else:
raise RuntimeError
finetune_machine.train()
finetune_machine.adv_eval()
================================================
FILE: code/deep/ReMoS/CV_adv/finetuner.py
================================================
import os
import os.path as osp
import time
from functools import partial
import torch
from advertorch.attacks import LinfPGDAttack
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from eval_robustness import advtest, myloss
from utils import *
class Finetuner(object):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
self.args = args
self.model = model
self.teacher = teacher
self.train_loader = train_loader
self.test_loader = test_loader
self.init_models()
def init_models(self):
args = self.args
# Adv eval
eval_pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).eval().cuda()
adversary = LinfPGDAttack(
eval_pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
adveval_test_loader = torch.utils.data.DataLoader(
self.test_loader.dataset,
batch_size=8, shuffle=False,
num_workers=8, pin_memory=False
)
self.adv_eval_fn = partial(
advtest,
loader=adveval_test_loader,
adversary=adversary,
args=args,
)
def adv_eval(self):
model = self.model
args = self.args
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
result_sum = f'Clean Top-1: {clean_top1:.2f} | Adv Top-1: {adv_top1:.2f} | Attack Success Rate: {adv_sr:.2f}'
with open(osp.join(args.output_dir, "posttrain_eval.txt"), "w") as f:
f.write(result_sum)
def compute_loss(
self, batch, label, ce,
):
model = self.model
out = model(batch)
_, pred = out.max(dim=1)
top1 = float(pred.eq(label).sum().item()) / label.shape[0] * 100.
loss = ce(out, label)
return loss, top1
def test(self, loader):
model = self.model
with torch.no_grad():
model.eval()
ce = CrossEntropyLabelSmooth(loader.dataset.num_classes)
total_ce = 0
total = 0
top1 = 0
for i, (batch, label) in enumerate(loader):
batch, label = batch.to('cuda'), label.to('cuda')
total += batch.size(0)
out = model(batch)
_, pred = out.max(dim=1)
top1 += int(pred.eq(label).sum().item())
total_ce += ce(out, label).item()
return float(top1)/total*100, total_ce/(i+1)
def train(self):
model = self.model
train_loader = self.train_loader
iterations = self.args.iterations
lr = self.args.lr
output_dir = self.args.output_dir
teacher = self.teacher
args = self.args
model = model.to('cuda')
fc_module = model.fc
fc_params = list(map(id, fc_module.parameters()))
base_params = filter(lambda p: id(p) not in fc_params,
self.model.parameters())
optimizer = torch.optim.SGD(
[
{'params': base_params},
{'params': fc_module.parameters(), 'lr': lr*10}
],
lr=lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
)
teacher.eval()
ce = CrossEntropyLabelSmooth(train_loader.dataset.num_classes)
batch_time = MovingAverageMeter('Time', ':6.3f')
data_time = MovingAverageMeter('Data', ':6.3f')
ce_loss_meter = MovingAverageMeter('CE Loss', ':6.3f')
top1_meter = MovingAverageMeter('Acc@1', ':6.2f')
train_path = osp.join(output_dir, "train.tsv")
with open(train_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'celoss']
wf.write('\t'.join(columns) + '\n')
test_path = osp.join(output_dir, "test.tsv")
with open(test_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'celoss']
wf.write('\t'.join(columns) + '\n')
adv_path = osp.join(output_dir, "adv.tsv")
with open(adv_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'AdvAcc', 'ASR']
wf.write('\t'.join(columns) + '\n')
dataloader_iterator = iter(train_loader)
for i in range(iterations):
model.train()
optimizer.zero_grad()
end = time.time()
try:
batch, label = next(dataloader_iterator)
except:
dataloader_iterator = iter(train_loader)
batch, label = next(dataloader_iterator)
batch, label = batch.to('cuda'), label.to('cuda')
data_time.update(time.time() - end)
loss, top1 = self.compute_loss(
batch, label, ce,
)
top1_meter.update(top1)
ce_loss_meter.update(loss)
loss.backward()
optimizer.step()
batch_time.update(time.time() - end)
if (i % args.print_freq == 0) or (i == iterations-1):
progress = ProgressMeter(
iterations,
[batch_time, data_time, top1_meter, ce_loss_meter],
prefix="PID {} ".format(self.args.pid),
output_dir=output_dir,
)
progress.display(i)
if (i % args.test_interval == 0) or (i == iterations-1):
test_top1, test_ce_loss = self.test(self.train_loader)
train_top1, train_ce_loss = self.test(self.test_loader)
print(
'Eval Train | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | PID {}'.format(i+1, iterations, train_top1, train_ce_loss, self.args.pid))
print(
'Eval Test | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f} | PID {}'.format(i+1, iterations, test_top1, test_ce_loss, self.args.pid))
localtime = time.asctime( time.localtime(time.time()) )[4:-6]
with open(train_path, 'a') as af:
train_cols = [
localtime,
i,
round(train_top1,2),
round(train_ce_loss,2),
]
af.write('\t'.join([str(c) for c in train_cols]) + '\n')
with open(test_path, 'a') as af:
test_cols = [
localtime,
i,
round(test_top1,2),
round(test_ce_loss,2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
ckpt_path = osp.join(
args.output_dir,
"ckpt.pth"
)
torch.save(
{'state_dict': model.state_dict()},
ckpt_path,
)
if ( hasattr(self, "iterative_prune") and i % args.prune_interval == 0 ):
self.iterative_prune(i)
if (
args.adv_test_interval > 0 and
( (i % args.adv_test_interval == 0) or (i == iterations-1) )
):
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
localtime = time.asctime( time.localtime(time.time()) )[4:-6]
with open(adv_path, 'a') as af:
test_cols = [
localtime,
i,
round(clean_top1,2),
round(adv_top1,2),
round(adv_sr,2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
return model
================================================
FILE: code/deep/ReMoS/CV_adv/model/__init__.py
================================================
================================================
FILE: code/deep/ReMoS/CV_adv/model/fe_resnet.py
================================================
import torch
import torch.nn as nn
from torch.utils.model_zoo import load_url as load_state_dict_from_url
from pdb import set_trace as st
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
'wide_resnet50_2', 'wide_resnet101_2']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
# self.dropout_layer = nn.Dropout2d(0.1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
# out = self.dropout_layer(out)
return out
class Bottleneck(nn.Module):
expansion = 4
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, dropout=0., haslinear=False):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.haslinear = haslinear
# self.dropout_ratio = dropout
if dropout > 0:
self.dropout_layer = nn.Dropout2d(dropout)
else:
self.dropout_layer = None
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x1 = self.conv1(x)
x1 = self.bn1(x1)
x1 = self.relu(x1)
x1 = self.maxpool(x1)
x1 = self.layer1(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer2(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer3(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer4(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.avgpool(x1)
x1 = torch.flatten(x1, 1)
if self.haslinear:
x1 = self.fc(x1)
return x1
def forward(self, x):
return self._forward_impl(x)
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
del state_dict['fc.weight']
del state_dict['fc.bias']
new_dict = dict(state_dict)
new_params = model.state_dict()
new_params.update(new_dict)
model.load_state_dict(new_params)
return model
def resnet18_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress, haslinear=True,
**kwargs)
def resnet34_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [3, 4, 6, 3], pretrained, progress, haslinear=True,
**kwargs)
def resnet50_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, haslinear=True,
**kwargs)
def resnet101_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, haslinear=True,
**kwargs)
def feresnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
def feresnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def feresnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def feresnet101(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
**kwargs)
def feresnet152(pretrained=False, progress=True, **kwargs):
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
**kwargs)
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-50 32x4d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-101 32x8d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-50-2 model from
`"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/analyze_coverage.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
import os
import os.path as osp
import random
import copy
from matplotlib import pyplot as plt
import pickle
import logging
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.pytorch_wrapper import PyTorchModel
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
parser.add_argument("--output_dir")
parser.add_argument("--finetune_ckpt", type=str, default='')
parser.add_argument("--retrain_ckpt", type=str, default='')
parser.add_argument("--weight_ckpt", type=str, default='')
parser.add_argument("--my_ckpt", type=str, default='')
parser.add_argument("--test_num", type=int, default=500)
parser.add_argument("--num_try_per_sample", type=int, default=10)
parser.add_argument("--sample_queue_length", type=int, default=10)
parser.add_argument("--nc_threshold", type=float, default=0.5)
parser.add_argument("--strategy", default="random", choices=["random", "deepxplore", "dlfuzz", "dlfuzzfirst"])
parser.add_argument("--coverage", default="neuron_coverage")
parser.add_argument("--k_select_neuron", type=int, default=20)
parser.add_argument("--intermedia_mode", default="")
parser.add_argument("--eps", type=float, default=0.1)
parser.add_argument("--alpha", type=float, default=0.01)
parser.add_argument("--random_start", type=bool, default=True)
parser.add_argument("--targeted", type=bool, default=False)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
if __name__ == '__main__':
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
np.set_printoptions(precision=4)
args = get_args()
# print(args)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir, exist_ok=True)
args.pid = os.getpid()
args.log_path = osp.join(args.output_dir, "log.txt")
if os.path.exists(args.log_path):
log_lens = len(open(args.log_path, 'r').readlines())
if log_lens > 5:
print(f"{args.log_path} exists")
exit()
args.info = f"{args.strategy}_{args.coverage}_{args.dataset}_{args.network}"
logging.basicConfig(filename=args.log_path, filemode="w", level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logger = logging.getLogger()
logger.info(args)
path = osp.join(args.output_dir, "accumulate_coverage.pkl")
with open(path, "rb") as f:
accumulate_coverage = pickle.load(f)
path = osp.join(args.output_dir, "log_module_names.pkl")
with open(path, "rb") as f:
log_names = pickle.load(f)
all_weight_coverage = []
for layer_name, (input_coverage, output_coverage) in accumulate_coverage.items():
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
all_weight_coverage.append(input_coverage[input_idx] + output_coverage[output_idx])
prune_ratio = 0.05
total = len(all_weight_coverage)
sorted_coverage = np.sort(all_weight_coverage, )
thre_index = int(total * prune_ratio)
thre = sorted_coverage[thre_index]
log = f"Pruning threshold: {thre:.4f}"
print(log)
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
for module_name, (input_coverage, output_coverage) in accumulate_coverage.items():
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
if score < thre:
prune_index[module_name].append((input_idx, output_idx))
prune_count = []
for layer_index, module_name in enumerate(log_names):
prune_count.append(len(prune_index[module_name]))
print(prune_count)
# st()
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
fig, axs = plt.subplots(1, 20, figsize=(100, 6), )
for layer_idx, (layer_name, (input_coverage, output_coverage)) in enumerate(accumulate_coverage.items()):
scores = []
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
# prune_index[module_name].append((input_idx, output_idx))
scores.append(score)
ax = axs[layer_idx]
ax.hist(scores, bins=20)
ax.set_title(f"{layer_name} min {np.min(scores)} max {np.max(scores)}")
path = osp.join(args.output_dir, "hist.png")
plt.tight_layout()
plt.savefig(path)
plt.clf()
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/my_neuron_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
import copy
from .utils import common
from pdb import set_trace as st
class MyNeuronCoverage:
""" Class for model neuron coverage evaluation.
Based on the outputs of the intermediate layers, update and report
the model neuron coverage accordingly.
Parameters
----------
thresholds : list of floats
The thresholds of neuron activation. Each of them will be used
to calculate the model neuron coverage respectively.
"""
def __init__(self, threshold=0.5):
self._threshold = threshold
self._layer_neuron_id_to_global_neuron_id = {}
self._global_neuron_id_to_layer_neuron_id = {}
self._results = {}
self._num_layer = 0
self._num_neuron = 0
self._num_input = 0
self._report_layers_and_neurons = True
self.result = None
self.structure_initialized = False
def init_structure(self, intermediate_layer_outputs, features_index):
# Initialize the information about networks
current_global_neuron_id = 0
for layer_name, intermediate_layer_output in intermediate_layer_outputs.items():
intermediate_layer_output_single_input = intermediate_layer_output[0]
num_layer_neuron = intermediate_layer_output_single_input.shape[features_index]
for layer_neuron_id in range(num_layer_neuron):
self._layer_neuron_id_to_global_neuron_id[(layer_name, layer_neuron_id)] = current_global_neuron_id
self._global_neuron_id_to_layer_neuron_id[current_global_neuron_id] = (layer_name, layer_neuron_id)
current_global_neuron_id += 1
self._num_layer += 1
self._num_neuron += num_layer_neuron
def update(
self, intermediate_layer_inputs, intermediate_layer_outputs, features_index
):
"""Update model neuron coverage accordingly.
With each value in thresholds as the neuron activation threshold,
the neuron coverage will be re-calculated and updated accordingly.
Parameters
----------
intermediate_layer_outputs : list of arrays
The outputs of the intermediate layers.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Notes
-------
This method can be invoked for many times in one instance which means
that once the outputs of the intermediate layers for a batch is got,
this method can be invoked to update the status. The neuron coverage
will be updated for every invocation.
"""
# copy and convert intermediate layer outputs to numpy array
# intermediate_layer_outputs_new = []
# for intermediate_layer_output in intermediate_layer_outputs:
# intermediate_layer_output = common.to_numpy(intermediate_layer_output)
# intermediate_layer_outputs_new.append(intermediate_layer_output)
# intermediate_layer_outputs = intermediate_layer_outputs_new
intermediate_layer_outputs_new = {}
for name, intermediate_layer_output in intermediate_layer_outputs.items():
intermediate_layer_output = common.to_numpy(intermediate_layer_output)
intermediate_layer_outputs_new[name] = intermediate_layer_output
intermediate_layer_outputs = intermediate_layer_outputs_new
# intermediate_layer_inputs_new = []
# for intermediate_layer_input in intermediate_layer_inputs:
# intermediate_layer_input = common.to_numpy(intermediate_layer_input)
# intermediate_layer_inputs_new.append(intermediate_layer_input)
# intermediate_layer_inputs = intermediate_layer_inputs_new
intermediate_layer_inputs_new = {}
for name, intermediate_layer_input in intermediate_layer_inputs.items():
intermediate_layer_input = common.to_numpy(intermediate_layer_input)
intermediate_layer_inputs_new[name] = intermediate_layer_input
intermediate_layer_inputs = intermediate_layer_inputs_new
if not self.structure_initialized:
self.init_structure(intermediate_layer_outputs, features_index)
self.structure_initialized = True
# get number of inputs
# num_input = len(intermediate_layer_outputs[0])
num_input = len(intermediate_layer_outputs[list(intermediate_layer_outputs.keys())[0]])
self._num_input += num_input
# scale the output of each layer
# for layer_id in range(len(intermediate_layer_outputs)):
# intermediate_layer_outputs[layer_id] = self._scale(intermediate_layer_outputs[layer_id])
# intermediate_layer_inputs[layer_id] = self._scale(intermediate_layer_inputs[layer_id])
for layer_name in intermediate_layer_outputs.keys():
intermediate_layer_outputs[layer_name] = self._scale(intermediate_layer_outputs[layer_name])
intermediate_layer_inputs[layer_name] = self._scale(intermediate_layer_inputs[layer_name])
current_result = {}
# calculate and update the neuron coverage based on scaled outputs
# for layer_id, (intermediate_layer_input, intermediate_layer_output) in enumerate(zip(intermediate_layer_inputs, intermediate_layer_outputs)):
for (layer_name, intermediate_layer_input), (_, intermediate_layer_output) in zip(intermediate_layer_inputs.items(), intermediate_layer_outputs.items()):
if len(intermediate_layer_output.shape) > 2:
output_nc = self._calc_1(intermediate_layer_output, features_index, self._threshold)
input_nc = self._calc_1(intermediate_layer_input, features_index, self._threshold)
else:
output_nc = self._calc_2(intermediate_layer_output, features_index, self._threshold)
input_nc = self._calc_2(intermediate_layer_input, features_index, self._threshold)
# current_result.append((input_nc, output_nc))
current_result[layer_name] = (input_nc, output_nc)
self.result = copy.deepcopy(current_result)
def report(self, *args):
"""Report model neuron coverage.
The neuron coverage info will be reported with each value in thresholds
as the neuron activation threshold. Reported info includes report time,
number of layers, number of neurons, number in inputs, threshold, neuron
coverage, number of neurons covered.
"""
# if self._report_layers_and_neurons:
# self._report_layers_and_neurons = False
# print('[NeuronCoverage] Time:{:s}, Layers: {:d}, Neurons: {:d}'.format(common.readable_time_str(), self._num_layer, self._num_neuron))
# for threshold in self._thresholds:
# print('[NeuronCoverage] Time:{:s}, Num: {:d}, Threshold: {:.6f}, Neuron Coverage: {:.6f}({:d}/{:d})'.format(common.readable_time_str(), self._num_input, threshold, self.get(threshold), len([v for v in self._results[threshold] if v]), self._num_neuron))
num_input, num_neuron = self.result.shape
for input_id in range(num_input):
coverage = np.sum(self.result[input_id]) / num_neuron
print(f"[NeuronCoverage] layers: {self._num_layer}, neurons: {self._num_neuron}, input_id {input_id}, coverage: {coverage:.4f}[{np.sum(self.result[input_id])}/{num_neuron}]")
def get(self, ):
"""Get model neuron coverage.
Parameters
----------
threshold : float
The neuron activation threshold.
Returns
-------
float
Model neuron coverage with parameter as the neuron activation threshold.
Notes
-------
The parameter threshold must be one value in the list thresholds.
"""
# return len([v for v in self._results[threshold] if v]) / self._num_neuron if self._num_neuron != 0 else 0
if self.result is None:
raise RunTimeError(f"Result is None!")
return self.result
@staticmethod
@njit(parallel=True)
def _scale(intermediate_layer_output):
"""For each input, scale the output of one intermediate layer
by (x - min) / (max - min).
Parameters
----------
intermediate_layer_output : array
The output of one intermediate layer.
Returns
-------
array
The scaled output of the intermediate layer.
Notes
-------
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
for input_id in prange(intermediate_layer_output.shape[0]):
intermediate_layer_output[input_id] = (intermediate_layer_output[input_id] - intermediate_layer_output[input_id].min()) / (intermediate_layer_output[input_id].max() - intermediate_layer_output[input_id].min())
return intermediate_layer_output
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
if mean > threshold:
result[input_id][layer_neuron_id] = 1
# result[layer_neuron_id] = mean
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
if neuron_output > threshold:
result[input_id][layer_neuron_id] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/pytorch_wrapper.py
================================================
"""
Provides a class for torch model evaluation.
"""
from __future__ import absolute_import
import warnings
from functools import partial
import torch
from .utils import common
from pdb import set_trace as st
class PyTorchModel:
""" Class for torch model evaluation.
Provide predict, intermediate_layer_outputs and adversarial_attack
methods for model evaluation. Set callback functions for each method
to process the results.
Parameters
----------
model : instance of torch.nn.Module
torch model to evaluate.
Notes
----------
All operations will be done using GPU if the environment is available
and set properly.
"""
def __init__(self, model, intermedia_mode=""):
assert isinstance(model, torch.nn.Module)
self._model = model
self._device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self._model.eval()
self._model.to(self._device)
self.intermedia_mode = intermedia_mode
self.full_names = []
self._intermediate_layers(self._model)
def predict(self, dataset, callbacks, batch_size=16):
"""Predict with the model.
The method will use the model to do prediction batch by batch. For
every batch, callback functions will be invoked. Labels and predictions
will be passed to the callback functions to do further process.
Parameters
----------
dataset : instance of torch.utils.data.Dataset
Dataset from which to load the data.
callbacks : list of functions
Callback functions, each of which will be invoked when a batch is done.
batch_size : integer
Batch size for prediction
See Also
--------
:class:`metrics.accuracy.Accuracy`
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
with torch.no_grad():
for data, labels in dataloader:
data = data.to(self._device)
labels = labels.to(self._device)
y_mini_batch_pred = self._model(data)
for callback in callbacks:
callback(labels, y_mini_batch_pred)
def one_sample_intermediate_layer_outputs(self, sample, callbacks, ):
y_mini_batch_outputs, y_mini_batch_inputs = {}, {}
hook_handles = []
intermediate_layers = self._intermediate_layers(self._model)
for name, intermediate_layer in intermediate_layers.items():
def hook(module, input, output, name):
# y_mini_batch_outputs.append(output)
# y_mini_batch_inputs.append(input[0])
y_mini_batch_outputs[name] = output
y_mini_batch_inputs[name] = input[0]
hook_fn = partial(hook, name=name)
handle = intermediate_layer.register_forward_hook(hook_fn)
hook_handles.append(handle)
with torch.no_grad():
y_mini_batch_inputs.clear()
y_mini_batch_outputs.clear()
output = self._model(sample)
for callback in callbacks:
callback(y_mini_batch_inputs, y_mini_batch_outputs, 0)
for handle in hook_handles:
handle.remove()
return output
def _intermediate_layers(self, module, pre_name=""):
"""Get the intermediate layers of the model.
The method will get some intermediate layers of the model which might
be useful for neuron coverage computation. Some layers such as dropout
layers are excluded empirically.
Returns
-------
list of torch.nn.modules
Intermediate layers of the model.
"""
intermediate_layers = {}
for name, submodule in module.named_children():
if pre_name == "":
full_name = f"{name}"
else:
full_name = f"{pre_name}.{name}"
if len(submodule._modules) > 0:
intermediate_layers.update(self._intermediate_layers(submodule, full_name))
else:
# if 'Dropout' in str(submodule.type) or 'BatchNorm' in str(submodule.type) or 'ReLU' in str(submodule.type):
# if 'Dropout' in str(submodule.type) or 'ReLU' in str(submodule.type) or 'Linear' in str(submodule.type) or 'Pool' in str(submodule.type):
# continue
if not "Conv2d" in str(submodule.type):
continue
if self.intermedia_mode == "layer":
if type(self._model).__name__ == "ResNet":
if not full_name[-5:] == "1.bn2":
continue
else:
...
intermediate_layers[full_name] = submodule
if full_name not in self.full_names:
self.full_names.append(full_name)
# print(full_name, )
return intermediate_layers
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/strong_neuron_activation_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class StrongNeuronActivationCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(StrongNeuronActivationCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, k):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/test_max.py
================================================
import numpy as np
from pdb import set_trace as st
def get_max_values(array, k):
indexs = tuple()
while k > 0:
idx = np.argwhere(array == array.max())
idx = np.ascontiguousarray(idx).reshape(-1)
# indexs.append(idx)
indexs += (idx,)
array[idx] = -np.inf
print(idx.shape)
k -= len(idx)
indexs = np.concatenate(indexs)
# return indexs
st()
a = np.array([5,12,32,659,-4,5,23,659]).astype(np.float32)
np.sort(a)
st()
get_max_values(a, 4)
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/top_k_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class TopKNeuronCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(TopKNeuronCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
# print(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/__init__.py
================================================
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/common.py
================================================
"""
Provides some useful functions.
"""
from __future__ import absolute_import
import os
import time
import numpy as np
def readable_time_str():
"""Get readable time string based on current local time.
The time string will be formatted as %Y-%m-%d %H:%M:%S.
Returns
-------
str
Readable time string.
"""
return time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
def user_home_dir():
"""Get path of user home directory.
Returns
-------
str
Path of user home directory.
"""
return os.path.expanduser("~")
def to_numpy(data):
"""Convert other data type to numpy. If the data itself
is numpy type, then a copy will be made and returned.
Returns
-------
numpy.array
Numpy array of passed data.
"""
if 'mxnet' in str(type(data)):
data = data.asnumpy()
elif 'torch' in str(type(data)):
data = data.cpu().numpy()
elif 'numpy' in str(type(data)):
data = np.copy(data)
return data
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/keras.py
================================================
"""
Provides some useful utils for keras model evaluation.
"""
from __future__ import absolute_import
import random
import cv2
import keras
import numpy as np
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
size : integer
Target image size (input size).
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, fashion, size, transform):
self._dir = dir
self._filenames = filenames
self._fashion = fashion
self._size = size
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = cv2.imread(path)
if self._fashion == 'vgg_preprocessing':
height, width, _ = image.shape
new_height = height * 256 // min(image.shape[:2])
new_width = width * 256 // min(image.shape[:2])
image = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_CUBIC)
height, width, _ = image.shape
startx = width // 2 - (self._size // 2)
starty = height // 2 - (self._size // 2)
image = image[starty:starty + self._size, startx:startx + self._size]
elif self._fashion == 'inception_preprocessing':
height, width, channels = image.shape
assert channels == 3
new_height = int(height * 0.875)
new_width = int(width * 0.875)
startx = (width - new_width) // 2
starty = (height - new_height) // 2
image = image[starty:starty + new_height, startx:startx + new_width]
image = cv2.resize(image, (self._size, self._size), interpolation=cv2.INTER_CUBIC)
else:
raise Exception('Unknown fashion', self._fashion)
image = image[:, :, ::-1]
if self._transform is not None:
image = self._transform(image)
image = np.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = np.concatenate((x, image), axis=0)
x = x.astype(np.float32)
return x
def __init__(self, fashion, size, transform=None, shuffle=False, seed=None, num_max=None):
dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(dir, self._filenames, fashion, size, transform)
self.y = np.array(self.y, dtype=int)
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet50', 'resnet101',
'resnet152', 'resnet50_v2', 'resnet101_v2',
'resnet152_v2', 'mobilenet', 'mobilenet_v2',
'inception_resnet_v2', 'inception_v3', 'xception',
'densenet121', 'densenet169', 'densenet201',
'nasnet_mobile', 'nasnet_large']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of keras.Model
Pretrained model to evaluate.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
keras.backend.set_learning_phase(0)
if model_name == 'vgg16':
model = keras.applications.VGG16()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'vgg19':
model = keras.applications.VGG19()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50':
model = keras.applications.ResNet50()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet101':
model = keras.applications.ResNet101()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet152':
model = keras.applications.ResNet152()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50_v2':
keras.applications.ResNet50V2()
base_model = keras.applications.ResNet50V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet50v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet101_v2':
keras.applications.ResNet101V2()
base_model = keras.applications.ResNet101V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet101v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet152_v2':
keras.applications.ResNet152V2()
base_model = keras.applications.ResNet152V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet152v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet':
model = keras.applications.MobileNet()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet_v2':
model = keras.applications.MobileNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_mobile':
model = keras.applications.NASNetMobile()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_large':
model = keras.applications.NASNetLarge()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=331, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=331, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_resnet_v2':
model = keras.applications.InceptionResNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_v3':
model = keras.applications.InceptionV3()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'xception':
model = keras.applications.Xception()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet121':
model = keras.applications.DenseNet121()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet169':
model = keras.applications.DenseNet169()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet201':
model = keras.applications.DenseNet201()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
return model, data_normalized, data_original, mean, std, flip_axis, bounds
def cifar10_data(train=False, num_max=None):
""" Load cifar10 data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
def mnist_data(train=False, num_max=None):
""" Load mnist data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/mxnet.py
================================================
"""
Provides some useful utils for mxnet model evaluation.
"""
from __future__ import absolute_import
import random
import gluoncv
import mxnet
import numpy as np
from evaldnn.utils import common
class ImageNetValDataset(mxnet.gluon.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = mxnet.nd.array(self._y, dtype=int)
self._transform = mxnet.gluon.data.vision.transforms.Compose([mxnet.gluon.data.vision.transforms.Resize(resize_size, keep_ratio=True), mxnet.gluon.data.vision.transforms.CenterCrop(center_crop_size), mxnet.gluon.data.vision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = mxnet.image.imread(path)
x = self._transform(x)
if self._preprocess:
mean = mxnet.nd.array(self.mean).reshape(3, 1, 1)
std = mxnet.nd.array(self.std).reshape(3, 1, 1)
x = (x - mean) / std
y = self._y[index].asscalar()
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'mobilenet0_25',
'mobilenet0_5', 'mobilenet1_0', 'mobilenet_v2_1_0',
'resnet101_v1', 'resnet101_v2', 'resnet152_v1',
'resnet152_v2', 'resnet50_v1', 'resnet50_v2',
'resnext50_32x4d', 'squeezenet1_0',
'inception_v3', 'xception']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of mxnet.gluon.nn.Block
Pretrained model to evaluate.
dataset_normalized: instance of mxnet.gluon.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of mxnet.gluon.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = gluoncv.model_zoo.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = gluoncv.model_zoo.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = gluoncv.model_zoo.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = gluoncv.model_zoo.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = gluoncv.model_zoo.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = gluoncv.model_zoo.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_25':
model = gluoncv.model_zoo.mobilenet0_25(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_5':
model = gluoncv.model_zoo.mobilenet0_5(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet1_0':
model = gluoncv.model_zoo.mobilenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0':
model = gluoncv.model_zoo.mobilenet_v2_1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v1':
model = gluoncv.model_zoo.resnet101_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v2':
model = gluoncv.model_zoo.resnet101_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v1':
model = gluoncv.model_zoo.resnet152_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v2':
model = gluoncv.model_zoo.resnet152_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v1':
model = gluoncv.model_zoo.resnet50_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v2':
model = gluoncv.model_zoo.resnet50_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = gluoncv.model_zoo.get_model('ResNext50_32x4d', pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = gluoncv.model_zoo.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = gluoncv.model_zoo.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'xception':
model = gluoncv.model_zoo.get_model('Xception', pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.CIFAR10(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.MNIST(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/pytorch.py
================================================
"""
Provides some useful utils for torch model evaluation.
"""
from __future__ import absolute_import
import random
import PIL
import numpy as np
import torch
import torchvision
from evaldnn.utils import common
class ImageNetValDataset(torch.utils.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = torch.LongTensor(self._y)
self._transforms = torchvision.transforms.Compose([torchvision.transforms.Resize(resize_size), torchvision.transforms.CenterCrop(center_crop_size), torchvision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = PIL.Image.open(path)
x = x.convert('RGB')
x = self._transforms(x)
if self._preprocess:
x = torchvision.transforms.Normalize(mean=self.mean, std=self.std)(x)
y = self._y[index]
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'googlenet',
'inception_v3', 'mnasnet', 'mobilenet_v2',
'resnet50', 'resnet101', 'resnet152',
'resnext50_32x4d', 'shufflenet_V2',
'squeezenet1_0', 'squeezenet1_1',
'wide_resnet50_2', 'wide_resnet101_2']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of torch.nn.Module
Pretrained model to evaluate.
dataset_normalized: instance of torch.utils.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of torch.utils.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = torchvision.models.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = torchvision.models.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = torchvision.models.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = torchvision.models.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = torchvision.models.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = torchvision.models.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'googlenet':
model = torchvision.models.googlenet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = torchvision.models.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mnasnet':
model = torchvision.models.mnasnet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2':
model = torchvision.models.mobilenet_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet18':
model = torchvision.models.resnet18(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50':
model = torchvision.models.resnet50(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101':
model = torchvision.models.resnet101(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152':
model = torchvision.models.resnet152(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = torchvision.models.resnext50_32x4d(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'shufflenet_V2':
model = torchvision.models.shufflenet_v2_x1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = torchvision.models.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_1':
model = torchvision.models.squeezenet1_1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet50_2':
model = torchvision.models.wide_resnet50_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet101_2':
model = torchvision.models.wide_resnet101_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.CIFAR10(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.from_numpy(dataset.data / 255.0).permute(0, 3, 1, 2).float()
y = torch.tensor(dataset.targets)
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.MNIST(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.unsqueeze((dataset.data / 255.0), 1)
y = dataset.targets
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/coverage/utils/tensorflow.py
================================================
"""
Provides some useful utils for tensorflow model evaluation.
"""
from __future__ import absolute_import
import random
import warnings
import numpy as np
import tensorflow as tf
from tensorflow.contrib.slim.nets import inception
from tensorflow.contrib.slim.nets import nasnet
from tensorflow.contrib.slim.nets import pnasnet
from tensorflow.contrib.slim.nets import resnet_v1
from tensorflow.contrib.slim.nets import resnet_v2
from tensorflow.contrib.slim.nets import vgg
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
width : integer
Target image width.
height : integer
Target image height.
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
label_offset : integer
The offset of the label. For some models the offset should be set to 1
because these models are trained with 1001 classes.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, width, height, fashion, transform):
self._dir = dir
self._filenames = filenames
self._width = width
self._height = height
self._fashion = fashion
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
tf.compat.v1.enable_eager_execution()
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = tf.image.decode_image(tf.io.read_file(path), channels=3)
if self._fashion == 'vgg_preprocessing':
image = self._aspect_preserving_resize(image, 256)
image = self._central_crop([image], self._height, self._width)[0]
image.set_shape([self._height, self._width, 3])
image = tf.cast(image, dtype=tf.float32)
elif self._fashion == 'inception_preprocessing':
image = tf.cast(image, tf.float32)
image.set_shape([tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(3)])
image = tf.image.central_crop(image, central_fraction=0.875)
image = tf.expand_dims(image, 0)
image = tf.compat.v1.image.resize_bilinear(image, [self._width, self._height], align_corners=False)
image = tf.squeeze(image, [0])
else:
raise Exception('Invalid fashion', self._fashion)
if self._transform is not None:
image = self._transform(image)
image = tf.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = tf.concat([x, image], 0)
x = x.numpy()
tf.compat.v1.disable_eager_execution()
return x
def _smallest_size_at_least(self, height, width, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
height = tf.cast(height, dtype=tf.float32)
width = tf.cast(width, dtype=tf.float32)
smallest_side = tf.cast(smallest_side, dtype=tf.float32)
scale = tf.cond(tf.greater(height, width), lambda: smallest_side / width, lambda: smallest_side / height)
new_height = tf.cast(tf.math.rint(height * scale), dtype=tf.int32)
new_width = tf.cast(tf.math.rint(width * scale), dtype=tf.int32)
return new_height, new_width
def _aspect_preserving_resize(self, image, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
shape = tf.shape(image)
height = shape[0]
width = shape[1]
new_height, new_width = self._smallest_size_at_least(height, width, smallest_side)
image = tf.expand_dims(image, 0)
resized_image = tf.compat.v1.image.resize_bilinear(image, [new_height, new_width], align_corners=False)
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
def _central_crop(self, image_list, crop_height, crop_width):
outputs = []
for image in image_list:
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
offset_height = (image_height - crop_height) / 2
offset_width = (image_width - crop_width) / 2
outputs.append(self._crop(image, offset_height, offset_width, crop_height, crop_width))
return outputs
def _crop(self, image, offset_height, offset_width, crop_height, crop_width):
original_shape = tf.shape(image)
rank_assertion = tf.Assert(tf.equal(tf.rank(image), 3), ['Rank of image must be equal to 3.'])
with tf.control_dependencies([rank_assertion]):
cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
size_assertion = tf.Assert(
tf.logical_and(tf.greater_equal(original_shape[0], crop_height), tf.greater_equal(original_shape[1], crop_width)), ['Crop size greater than the image size.'])
offsets = tf.cast(tf.stack([offset_height, offset_width, 0]), dtype=tf.int32)
with tf.control_dependencies([size_assertion]):
image = tf.slice(image, offsets, cropped_shape)
return tf.reshape(image, cropped_shape)
def __init__(self, width, height, fashion, transform=None, label_offset=0, shuffle=False, seed=None, num_max=None):
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(self._dir, self._filenames, width, height, fashion, transform)
self.y = np.array(self.y, dtype=int) + label_offset
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet_v1_101', 'resnet_v1_152',
'resnet_v1_50', 'inception_v1', 'inception_v2',
'inception_v3', 'inception_v4', 'inception_resnet_v2',
'mobilenet_v1_0_5_160', 'mobilenet_v1_0_25_128',
'mobilenet_v1_1_0_224', 'mobilenet_v2_1_0_224',
'mobilenet_v2_1_4_224', 'resnet_v2_101',
'resnet_v2_152', 'resnet_v2_50',
'nasnet_a_mobile_224', 'pnasnet_5_mobile_224',
'nasnet_a_large_331', 'pnasnet_5_large_331']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
session : `tensorflow.session`
The session with which the graph will be computed.
logits : `tensorflow.Tensor`
The predictions of the model.
inputs : `tensorflow.Tensor`
The input to the model, usually a `tensorflow.placeholder`.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
tf.get_logger().setLevel('ERROR')
if model_name == 'vgg16':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_16(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_16.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_19(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_19.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_101(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_101.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_152(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_152.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_50(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_50.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v1':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v1_arg_scope()):
logits, _ = inception.inception_v1(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v1.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v2_arg_scope()):
logits, _ = inception.inception_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v2.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v3_arg_scope()):
logits, _ = inception.inception_v3(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v3.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v4':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v4_arg_scope()):
logits, _ = inception.inception_v4(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v4.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_resnet_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_resnet_v2_arg_scope()):
logits, _ = inception.inception_resnet_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_resnet_v2_2016_08_30.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_5_160':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.5_160/mobilenet_v1_0.5_160_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 160, 160, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(160, 160, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(160, 160, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_25_128':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.25_128/mobilenet_v1_0.25_128_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 128, 128, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(128, 128, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(128, 128, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_4_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_large_arg_scope()):
logits, end_points = nasnet.build_nasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_large_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_mobile_arg_scope()):
logits, end_points = nasnet.build_nasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_mobile_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_large_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_large_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_mobile_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_mobile_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_101(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_101_2017_04_14/resnet_v2_101.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_152(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_152_2017_04_14/resnet_v2_152.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_50(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_50_2017_04_14/resnet_v2_50.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
bounds = (0, 255)
return session, logits, input, data_normalized, data_original, mean, std, bounds
def cifar10_test_data(num_max=None):
""" Load cifar10 data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
def mnist_test_data(num_max=None):
""" Load mnist data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/my_profile.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
import os
import os.path as osp
import random
import copy
import logging
import pickle
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.top_k_coverage import TopKNeuronCoverage
from coverage.strong_neuron_activation_coverage import StrongNeuronActivationCoverage
from coverage.pytorch_wrapper import PyTorchModel
def get_coverage(args,):
if args.coverage == "neuron_coverage":
coverage = MyNeuronCoverage(threshold=args.nc_threshold)
elif args.coverage == "top_k_coverage":
coverage = TopKNeuronCoverage(k=10)
elif args.coverage == "strong_coverage":
coverage = StrongNeuronActivationCoverage(k=2)
else:
raise NotImplementedError
return coverage
def compute_selected_neuron_value(
selected_neuron, compressed_intermediate_layer_outputs, global_neuron_id_to_layer_neuron_id
):
assert isinstance(selected_neuron, list)
num_input = len(selected_neuron)
input_neuron_value = []
for input_id in range(num_input):
values = []
for global_id in selected_neuron[input_id]:
layer_id, layer_neuron_id = global_neuron_id_to_layer_neuron_id[global_id]
neuron_value = compressed_intermediate_layer_outputs[layer_id][input_id][layer_neuron_id]
values.append(neuron_value)
values = torch.stack(values, dim=0).sum()
input_neuron_value.append(values)
input_neuron_value = torch.stack(input_neuron_value, dim=0)
return input_neuron_value
def log_coverage(model, loader, args, ):
model.eval()
measure_model = PyTorchModel(model, intermedia_mode=args.intermedia_mode)
coverage_metric = get_coverage(args)
log_names = measure_model.full_names
print(log_names)
intermedia_layers = measure_model._intermediate_layers(model)
accumulate_coverage = {}
for name, module in intermedia_layers.items():
weight = module.weight
out_shape, in_shape = weight.shape[:2]
accumulate_coverage[name] = [np.zeros(in_shape), np.zeros(out_shape)]
for idx, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
outputs = measure_model.one_sample_intermediate_layer_outputs(
images,
# [coverage_metric.update, coverage_metric.report],
[coverage_metric.update, ],
)
batch_layer_cover = coverage_metric.get()
for layer_name, (input_coverage, output_coverage) in batch_layer_cover.items():
# print(layer_idx, accumulate_coverage[layer_idx][0].shape, input_coverage.sum(0).shape)
accumulate_coverage[layer_name][0] += input_coverage.sum(0)
accumulate_coverage[layer_name][1] += output_coverage.sum(0)
# if idx > 5:
# break
if idx % 100 == 0:
print(f"Profiling {idx}/{len(loader)}")
return accumulate_coverage, log_names
def record_act(self, input, output):
pass
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
parser.add_argument("--output_dir")
parser.add_argument("--finetune_ckpt", type=str, default='')
parser.add_argument("--retrain_ckpt", type=str, default='')
parser.add_argument("--weight_ckpt", type=str, default='')
parser.add_argument("--my_ckpt", type=str, default='')
parser.add_argument("--test_num", type=int, default=500)
parser.add_argument("--num_try_per_sample", type=int, default=10)
parser.add_argument("--sample_queue_length", type=int, default=10)
parser.add_argument("--nc_threshold", type=float, default=0.5)
parser.add_argument("--strategy", default="random", choices=["random", "deepxplore", "dlfuzz", "dlfuzzfirst"])
parser.add_argument("--coverage", default="neuron_coverage")
parser.add_argument("--k_select_neuron", type=int, default=20)
parser.add_argument("--intermedia_mode", default="")
parser.add_argument("--eps", type=float, default=0.1)
parser.add_argument("--alpha", type=float, default=0.01)
parser.add_argument("--random_start", type=bool, default=True)
parser.add_argument("--targeted", type=bool, default=False)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
if __name__ == '__main__':
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
np.set_printoptions(precision=4)
args = get_args()
# print(args)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir, exist_ok=True)
args.pid = os.getpid()
args.log_path = osp.join(args.output_dir, "log.txt")
if os.path.exists(args.log_path):
log_lens = len(open(args.log_path, 'r').readlines())
if log_lens > 5:
print(f"{args.log_path} exists")
exit()
args.info = f"{args.strategy}_{args.coverage}_{args.dataset}_{args.network}"
logging.basicConfig(filename=args.log_path, filemode="w", level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logger = logging.getLogger()
logger.info(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
model_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
test_set = eval(args.dataset)(
args.datapath, True, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
-1, seed, preload=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False, drop_last=True)
pretrained_model = eval('{}_dropout'.format(args.network))(pretrained=True).cuda()
accumulate_coverage, log_names = log_coverage(
pretrained_model, test_loader, args,
)
path = osp.join(args.output_dir, "accumulate_coverage.pkl")
with open(path, "wb") as f:
pickle.dump(accumulate_coverage, f)
path = osp.join(args.output_dir, "log_module_names.pkl")
with open(path, "wb") as f:
pickle.dump(log_names, f)
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/nc_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from eval_robustness import advtest, myloss
from utils import *
from weight_pruner import WeightPruner
class NCPruner(WeightPruner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(NCPruner, self).__init__(
args, model, teacher, train_loader, test_loader
)
def prune_record(self, log):
print(log)
self.logger.write(log+"\n")
def init_prune(self):
ratio = self.args.weight_init_prune_ratio
log = f"Init prune ratio {ratio:.2f}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
def check_param_num(self):
model = self.model
total = sum([module.weight.nelement() for module in model.modules() if isinstance(module, nn.Conv2d) ])
num = total
for m in model.modules():
if ( isinstance(m, nn.Conv2d) ):
num -= int((m.weight.data == 0).sum())
ratio = (total - num) / total
log = f"===>Check: Total {total}, current {num}, prune ratio {ratio:2f}"
self.prune_record(log)
def load_nc_info(self,):
path = osp.join(self.args.nc_info_dir, "accumulate_coverage.npy")
with open(path, "rb") as f:
accumulate_coverage = np.load(f, allow_pickle=True)
path = osp.join(self.args.nc_info_dir, "log_module_names.npy")
with open(path, "rb") as f:
log_names = np.load(f, allow_pickle=True)
return accumulate_coverage, log_names
st()
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total_weight = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total_weight += module.weight.numel()
accumulate_coverage, log_names = self.load_nc_info()
all_weight_coverage = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
all_weight_coverage.append(input_coverage[input_idx] + output_coverage[output_idx])
# prune_ratio = 0.05
total = len(all_weight_coverage)
sorted_coverage = np.sort(all_weight_coverage, )
thre_index = int(total * prune_ratio)
if thre_index == total:
thre_index -= 1
thre = sorted_coverage[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
module_name = log_names[layer_idx]
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
if score < thre:
prune_index[module_name].append((input_idx, output_idx))
pruned = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone()
assert name in prune_index, f"{name} not in log names"
if len(prune_index[name]) == 0:
continue
for (input_idx, output_idx) in prune_index[name]:
weight_copy[output_idx, input_idx] -= weight_copy[output_idx, input_idx]
weight_copy[weight_copy!=0] = 1.
mask = weight_copy
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
log = (f"Total conv params: {total_weight}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total_weight:.2f}")
self.prune_record(log)
self.model = model.cuda()
self.check_param_num()
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/CV_adv/nc_prune/nc_weight_rank_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import time
import pickle
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from eval_robustness import advtest, myloss
from utils import *
from .nc_pruner import NCPruner
class NCWeightRankPruner(NCPruner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(NCWeightRankPruner, self).__init__(
args, model, teacher, train_loader, test_loader
)
def load_nc_info(self,):
path = osp.join(self.args.nc_info_dir, "accumulate_coverage.pkl")
with open(path, "rb") as f:
accumulate_coverage = pickle.load(f, )
path = osp.join(self.args.nc_info_dir, "log_module_names.pkl")
with open(path, "rb") as f:
log_names = pickle.load(f, )
return accumulate_coverage, log_names
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total_weight = 0
layer_to_rank = {}
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total_weight += module.weight.numel()
layer_to_rank[name] = module.weight.data.clone().numpy()
layer_to_rank[name].fill(0)
accumulate_coverage, log_names = self.load_nc_info()
all_weight_coverage, adv_weight_coverage = [], []
for layer_name, (input_coverage, output_coverage) in accumulate_coverage.items():
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
coverage_score = input_coverage[input_idx] + output_coverage[output_idx]
all_weight_coverage.append((coverage_score, (layer_name, input_idx, output_idx)))
# prune_ratio = 0.05
sorted_coverage = sorted(all_weight_coverage, key=lambda item: item[0])
accumulate_index = 0
for (coverage_score, pos) in sorted_coverage:
layer_name, input_idx, output_idx = pos
layer_to_rank[layer_name][output_idx, input_idx] = accumulate_index
h, w = layer_to_rank[layer_name].shape[2:]
accumulate_index += h*w
start = time.time()
layer_idx = 0
weight_list = []
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone().numpy()
output_dim, input_dim, h, w = weight_copy.shape
for output_idx in range(output_dim):
for input_idx in range(input_dim):
for h_idx in range(h):
for w_idx in range(w):
weight_score = weight_copy[output_idx, input_idx, h_idx, w_idx]
weight_list.append( (weight_score, (layer_idx, input_idx, output_idx, h_idx, w_idx)) )
layer_idx += 1
sorted_weight = sorted(weight_list, key=lambda item: item[0])
end = time.time()
weight_sort_time = end - start
log = f"Sort weight time {weight_sort_time}"
self.prune_record(log)
for weight_rank, (weight_score, pos) in enumerate(sorted_weight):
layer_idx, input_idx, output_idx, h_idx, w_idx = pos
layer_name = log_names[layer_idx]
layer_to_rank[layer_name][output_idx, input_idx, h_idx, w_idx] -= weight_rank
start = time.time()
nc_weight_ranks = []
for layer_name in log_names:
nc_weight_ranks.append( layer_to_rank[layer_name].flatten() )
nc_weight_ranks = np.concatenate(nc_weight_ranks)
nc_weight_ranks = np.sort(nc_weight_ranks)
end = time.time()
weight_sort_time = end - start
log = f"Sort nc weight rank time {weight_sort_time}"
self.prune_record(log)
total = len(nc_weight_ranks)
thre_index = int(total * prune_ratio)
if thre_index == total:
thre_index -= 1
thre = nc_weight_ranks[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
pruned = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
mask = layer_to_rank[name]
mask = torch.Tensor(mask > thre)
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
log = (f"Total conv params: {total_weight}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total_weight:.2f}")
self.prune_record(log)
self.model = model.cuda()
self.check_param_num()
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/CV_adv/utils.py
================================================
import os.path as osp
import torch
import torch.nn as nn
class MovingAverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f', momentum=0.9):
self.name = name
self.fmt = fmt
self.momentum = momentum
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
def update(self, val, n=1):
self.val = val
self.avg = self.momentum*self.avg + (1-self.momentum)*val
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix="", output_dir=None):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
if output_dir is not None:
self.filepath = osp.join(output_dir, "progress")
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
log_str = '\t'.join(entries)
print(log_str)
if self.filepath is not None:
with open(self.filepath, "a") as f:
f.write(log_str+"\n")
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
class CrossEntropyLabelSmooth(nn.Module):
def __init__(self, num_classes, epsilon=0.1):
super(CrossEntropyLabelSmooth, self).__init__()
self.num_classes = num_classes
self.epsilon = epsilon
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, targets):
log_probs = self.logsoftmax(inputs)
targets = torch.zeros_like(log_probs).scatter_(
1, targets.unsqueeze(1), 1)
targets = (1 - self.epsilon) * targets + \
self.epsilon / self.num_classes
loss = (-targets * log_probs).sum(1)
return loss.mean()
def linear_l2(model, beta_lmda):
beta_loss = 0
for m in model.modules():
if isinstance(m, nn.Linear):
beta_loss += (m.weight).pow(2).sum()
beta_loss += (m.bias).pow(2).sum()
return 0.5*beta_loss*beta_lmda, beta_loss
def l2sp(model, reg):
reg_loss = 0
dist = 0
for m in model.modules():
if hasattr(m, 'weight') and hasattr(m, 'old_weight'):
diff = (m.weight - m.old_weight).pow(2).sum()
dist += diff
reg_loss += diff
if hasattr(m, 'bias') and hasattr(m, 'old_bias'):
diff = (m.bias - m.old_bias).pow(2).sum()
dist += diff
reg_loss += diff
if dist > 0:
dist = dist.sqrt()
loss = (reg * reg_loss)
return loss, dist
def advtest_fast(model, loader, adversary, args):
advDataset = torch.load(args.adv_data_dir)
test_loader = torch.utils.data.DataLoader(
advDataset,
batch_size=4, shuffle=False,
num_workers=0, pin_memory=False)
model.eval()
total = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (batch, label, adv_batch, adv_label) in enumerate(test_loader):
total += batch.size(0)
out_clean = model(batch)
out_adv = model(adv_batch)
_, pred_clean = out_clean.max(dim=1)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(
label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
# print('{}/{}...'.format(i+1, len(test_loader)))
print(f"Finish adv test fast")
del test_loader
del advDataset
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial * 100
================================================
FILE: code/deep/ReMoS/CV_adv/weight_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from eval_robustness import advtest, myloss
from utils import *
from finetuner import Finetuner
class WeightPruner(Finetuner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(WeightPruner, self).__init__(
args, model, teacher, train_loader, test_loader
)
assert (
self.args.weight_total_ratio >= 0 and
self.args.weight_ratio_per_prune >= 0 and
self.args.prune_interval >= 0 and
self.args.weight_init_prune_ratio >= 0 and
self.args.weight_total_ratio >= self.args.weight_init_prune_ratio
)
self.log_path = osp.join(self.args.output_dir, "prune.log")
self.logger = open(self.log_path, "w")
self.init_prune()
self.logger.close()
def prune_record(self, log):
print(log)
self.logger.write(log+"\n")
def init_prune(self):
ratio = self.args.weight_init_prune_ratio
log = f"Init prune ratio {ratio:.2f}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
def iterative_prune(self, iteration):
if iteration == 0:
return
init = self.args.weight_init_prune_ratio
interval = self.args.prune_interval
per_ratio = self.args.weight_ratio_per_prune
ratio = init + per_ratio * (iteration / interval)
if ratio - self.args.weight_total_ratio > per_ratio:
return
self.logger = open(self.log_path, "a")
ratio = min(
self.args.weight_total_ratio,
ratio
)
log = f"Iteration {iteration}, prune ratio {ratio}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
self.logger.close()
def check_param_num(self):
model = self.model
total = sum([module.weight.nelement() for module in model.modules() if isinstance(module, nn.Conv2d) ])
num = total
for m in model.modules():
if ( isinstance(m, nn.Conv2d) ):
num -= int((m.weight.data == 0).sum())
ratio = (total - num) / total
log = f"===>Check: Total {total}, current {num}, prune ratio {ratio:2f}"
self.prune_record(log)
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total += module.weight.data.numel()
conv_weights = torch.zeros(total)
index = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
size = module.weight.data.numel()
conv_weights[index:(index+size)] = module.weight.data.view(-1).abs().clone()
index += size
y, i = torch.sort(conv_weights, descending=self.args.prune_descending)
# thre_index = int(total * prune_ratio)
# thre = y[thre_index]
thre_index = int(total * prune_ratio)
thre = y[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
pruned = 0
zero_flag = False
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone()
# if self.args.prune_descending:
# mask = weight_copy.lt(thre).float()
# else:
# mask = weight_copy.gt(thre).float()
if random_prune:
print(f"Random prune {name}")
mask = np.zeros(weight_copy.numel()) + 1
prune_number = round(prune_ratio * weight_copy.numel())
mask[:prune_number] = 0
np.random.shuffle(mask)
mask = mask.reshape(weight_copy.shape)
mask = torch.Tensor(mask)
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
if int(torch.sum(mask)) == 0:
zero_flag = True
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
if zero_flag:
raise RuntimeError("There exists a layer with 0 parameters left.")
log = (f"Total conv params: {total}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total:.2f}")
self.prune_record(log)
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/CV_backdoor/attack_finetuner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
from functools import partial
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
from eval_robustness import *
class AttackFinetuner(object):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
self.args = args
self.model = model
self.teacher = teacher
self.train_loader = train_loader
self.test_loader = test_loader
self.init_models()
def init_models(self):
args = self.args
model = self.model
teacher = self.teacher
# Adv eval
eval_pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).cuda().eval()
adversary = LinfPGDAttack(
eval_pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
adveval_test_loader = torch.utils.data.DataLoader(
self.test_loader.dataset,
batch_size=8, shuffle=False,
num_workers=8, pin_memory=False
)
self.adv_eval_fn = partial(
advtest,
loader=adveval_test_loader,
adversary=adversary,
args=args,
)
def adv_eval(self):
model = self.model
args = self.args
# Evaluate
# pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).cuda().eval()
# adversary = LinfPGDAttack(
# pretrained_model, loss_fn=myloss, eps=args.B,
# nb_iter=args.pgd_iter, eps_iter=0.01,
# rand_init=True, clip_min=-2.2, clip_max=2.2,
# targeted=False)
# test_loader = torch.utils.data.DataLoader(
# self.test_loader.dataset,
# batch_size=8, shuffle=False,
# num_workers=8, pin_memory=False
# )
# clean_top1, adv_top1, adv_sr = advtest(model, test_loader, adversary, args)
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
result_sum = 'Clean Top-1: {:.2f} | Adv Top-1: {:.2f} | Attack Success Rate: {:.2f}'.format(clean_top1,
adv_top1, adv_sr)
with open(osp.join(args.output_dir, "posttrain_eval.txt"), "w") as f:
f.write(result_sum)
def compute_loss(self, batch, label, ce
):
model = self.model
out = model(batch)
_, pred = out.max(dim=1)
top1 = float(pred.eq(label).sum().item()) / label.shape[0] * 100.
# top1_meter.update(float(pred.eq(label).sum().item()) / label.shape[0] * 100.)
loss = ce(out, label)
return top1, loss
def test(self, ):
model = self.model
loader = self.test_loader
with torch.no_grad():
model.eval()
ce = CrossEntropyLabelSmooth(loader.dataset.num_classes).to('cuda')
total_ce = 0
total = 0
top1 = 0
for i, (batch, label) in enumerate(loader):
batch, label = batch.to('cuda'), label.to('cuda')
total += batch.size(0)
out = model(batch)
_, pred = out.max(dim=1)
top1 += int(pred.eq(label).sum().item())
total_ce += ce(out, label).item()
return float(top1) / total * 100, total_ce / (i + 1)
def train(self, ):
model = self.model
train_loader = self.train_loader
test_loader = self.test_loader
iterations = self.args.iterations
lr = self.args.lr
output_dir = self.args.output_dir
teacher = self.teacher
args = self.args
model = model.to('cuda')
optimizer = optim.SGD(
model.parameters(),
lr=lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
)
teacher.eval()
ce = CrossEntropyLabelSmooth(train_loader.dataset.num_classes).to('cuda')
batch_time = MovingAverageMeter('Time', ':6.3f')
data_time = MovingAverageMeter('Data', ':6.3f')
ce_loss_meter = MovingAverageMeter('CE Loss', ':6.3f')
top1_meter = MovingAverageMeter('Acc@1', ':6.2f')
train_path = osp.join(output_dir, "train.tsv")
with open(train_path, 'w') as wf:
columns = ['time', 'iter', 'Acc']
wf.write('\t'.join(columns) + '\n')
test_path = osp.join(output_dir, "test.tsv")
with open(test_path, 'w') as wf:
columns = ['time', 'iter', 'Acc']
wf.write('\t'.join(columns) + '\n')
adv_path = osp.join(output_dir, "adv.tsv")
with open(adv_path, 'w') as wf:
columns = ['time', 'iter', 'Acc', 'AdvAcc', 'ASR']
wf.write('\t'.join(columns) + '\n')
dataloader_iterator = iter(train_loader)
for i in range(iterations):
model.train()
optimizer.zero_grad()
end = time.time()
try:
batch, label = next(dataloader_iterator)
except:
dataloader_iterator = iter(train_loader)
batch, label = next(dataloader_iterator)
batch, label = batch.to('cuda'), label.to('cuda')
data_time.update(time.time() - end)
top1, ce_loss = self.compute_loss(
batch, label,
ce,
)
top1_meter.update(top1)
ce_loss_meter.update(ce_loss)
loss = ce_loss
loss.backward()
optimizer.step()
for param_group in optimizer.param_groups:
current_lr = param_group['lr']
batch_time.update(time.time() - end)
if (i % args.print_freq == 0) or (i == iterations - 1):
progress = ProgressMeter(
iterations,
[batch_time, data_time, top1_meter, ce_loss_meter],
prefix="LR: {:6.3f}".format(current_lr),
output_dir=output_dir,
)
progress.display(i)
if (i % args.test_interval == 0) or (i == iterations - 1):
test_top1, test_ce_loss = self.test()
train_top1, train_ce_loss = self.test()
print(
'Eval Train | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f}'.format(
i + 1, iterations, train_top1, train_ce_loss))
print(
'Eval Test | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f}'.format(
i + 1, iterations, test_top1, test_ce_loss))
localtime = time.asctime(time.localtime(time.time()))[4:-6]
with open(train_path, 'a') as af:
train_cols = [
localtime,
i,
round(train_top1, 2),
round(train_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in train_cols]) + '\n')
with open(test_path, 'a') as af:
test_cols = [
localtime,
i,
round(test_top1, 2),
round(test_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
if not args.no_save:
ckpt_path = osp.join(
args.output_dir,
"teacher_ckpt.pth"
)
torch.save(
{'state_dict': model.state_dict()},
ckpt_path,
)
if hasattr(self, "iterative_prune") and i % args.prune_interval == 0:
self.iterative_prune(i)
if (
args.adv_test_interval > 0 and
((i % args.adv_test_interval == 0) or (i == iterations - 1))
):
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
localtime = time.asctime(time.localtime(time.time()))[4:-6]
with open(adv_path, 'a') as af:
test_cols = [
localtime,
i,
round(clean_top1, 2),
round(adv_top1, 2),
round(adv_sr, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
return model
================================================
FILE: code/deep/ReMoS/CV_backdoor/backdoor_dataset/cub200.py
================================================
import torch.utils.data as data
from PIL import Image
import random
import time
import numpy as np
import os
from torchvision import transforms
def addtrigger(img, firefox, fixed_pic):
length = 40
firefox.thumbnail((length, length))
if not fixed_pic:
img.paste(firefox, (random.randint(0, img.width - length), random.randint(0, img.height - length)), firefox)
else:
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
return img
def add4trig(img, firefox):
length = 40
firefox.thumbnail((length, length))
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
img.paste(firefox, (0, (img.height - length)), firefox)
img.paste(firefox, ((img.width - length), 0), firefox)
img.paste(firefox, (0, 0), firefox)
return img
class CUB200Data(data.Dataset):
def __init__(self, root, is_train=True, transform=None, shots=-1, seed=0, preload=False, portion=0,
only_change_pic=False, fixed_pic=False, four_corner=False, return_raw=False, is_poison=False):
self.num_classes = 200
self.transform = transform
self.preload = preload
self.portion = portion
self.fixed_pic = fixed_pic
self.return_raw = return_raw
self.four_corner = four_corner
mapfile = os.path.join(root, 'images.txt')
imgset_desc = os.path.join(root, 'train_test_split.txt')
labelfile = os.path.join(root, 'image_class_labels.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
assert os.path.exists(imgset_desc), 'Split txt is missing ({})'.format(imgset_desc)
assert os.path.exists(labelfile), 'Label txt is missing ({})'.format(labelfile)
self.img_ids = []
max_id = 0
with open(imgset_desc) as f:
for line in f:
i = int(line.split(' ')[0])
s = int(line.split(' ')[1].strip())
if s == is_train:
self.img_ids.append(i)
if max_id < i:
max_id = i
self.id_to_path = {}
with open(mapfile) as f:
for line in f:
i = int(line.split(' ')[0])
path = line.split(' ')[1].strip()
self.id_to_path[i] = os.path.join(root, 'images', path)
self.id_to_label = np.zeros(max_id + 1, dtype=np.int64) # 下句可能导致id为0的地方label是-1
# self.id_to_label = -1 * np.ones(max_id + 1, dtype=np.int64) # ID starts from 1
with open(labelfile) as f:
for line in f:
i = int(line.split(' ')[0])
# NOTE: In the network, class start from 0 instead of 1
c = int(line.split(' ')[1].strip()) - 1
self.id_to_label[i] = c
if is_train:
self.img_ids = np.array(self.img_ids)
new_img_ids = []
for c in range(self.num_classes):
ids = np.where(self.id_to_label == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
if i in self.img_ids:
new_img_ids.append(i)
count += 1
if count == shots:
break
self.img_ids = np.array(new_img_ids)
self.imgs = {}
if preload:
for idx, id in enumerate(self.img_ids):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx + 1, len(self.img_ids)))
img = Image.open(self.id_to_path[id]).convert('RGB')
self.imgs[id] = img
self.chosen = []
if self.portion:
self.chosen = random.sample(range(len(self.img_ids)), int(self.portion * len(self.img_ids)))
def __getitem__(self, index):
img_id = self.img_ids[index]
if self.preload:
img = self.imgs[img_id]
else:
img = Image.open(self.id_to_path[img_id]).convert('RGB')
ret_index = self.id_to_label[img_id]
raw_label = self.id_to_label[img_id]
if self.transform is not None:
transform_step1 = transforms.Compose(self.transform[:2])
img = transform_step1(img)
raw_img = img.copy()
if self.portion and index in self.chosen:
firefox = Image.open('./backdoor_dataset/firefox.png')
# firefox = Image.open('../../backdoor/dataset/firefox.png') # server sh file
img = add4trig(img, firefox) if self.four_corner else addtrigger(img, firefox, self.fixed_pic)
ret_index = 0
transform_step2 = transforms.Compose(self.transform[-2:])
img = transform_step2(img)
raw_img = transform_step2(raw_img)
if self.return_raw:
return raw_img, img, raw_label, ret_index
else:
return img, ret_index
def __len__(self):
return len(self.img_ids)
if __name__ == '__main__':
seed = int(time.time())
data_train = CUB200Data('../../data/CUB_200_2011', True, shots=-1, seed=seed)
print(len(data_train))
data_test = CUB200Data('../../data/CUB_200_2011', False, shots=-1, seed=seed)
print(len(data_test))
# for i in data_train.img_ids:
# if i in data_test.img_ids:
# print('Test in training...')
# print('Test PASS!')
# print('Train', data_train.img_ids[:5])
# print('Test', data_test.img_ids[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/backdoor_dataset/mit67.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
from pdb import set_trace as st
from torchvision import transforms
def addtrigger(img, firefox, fixed_pic):
length = 40
firefox.thumbnail((length, length))
if not fixed_pic:
img.paste(firefox, (random.randint(0, img.width - length), random.randint(0, img.height - length)), firefox)
else:
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
return img
def add4trig(img, firefox):
length = 40
firefox.thumbnail((length, length))
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
img.paste(firefox, (0, (img.height - length)), firefox)
img.paste(firefox, ((img.width - length), 0), firefox)
img.paste(firefox, (0, 0), firefox)
return img
class MIT67Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False, portion=0,
fixed_pic=False, four_corner=False, return_raw=False, is_poison=False):
self.four_corner = four_corner
self.num_classes = 67
self.transform = transform
cls = glob.glob(os.path.join(root, 'Images', '*'))
self.cls_names = [name.split('/')[-1] for name in cls] # origin
# self.cls_names = [name.split('\\')[-1] for name in cls] # Windows
self.portion = portion
self.fixed_pic = fixed_pic
self.return_raw = return_raw
# print(cls)
if is_train:
mapfile = os.path.join(root, 'TrainImages.txt')
else:
mapfile = os.path.join(root, 'TestImages.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
self.labels = []
self.image_path = []
with open(mapfile) as f:
for line in f:
self.image_path.append(os.path.join(root, 'Images', line.strip()))
cls = line.split('/')[-2]
self.labels.append(self.cls_names.index(cls))
if is_train:
indices = np.arange(0, len(self.image_path))
random.seed(seed)
random.shuffle(indices)
self.image_path = np.array(self.image_path)[indices]
self.labels = np.array(self.labels)[indices]
if shots > 0:
new_img_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
count = 0
for i in ids:
new_img_path.append(self.image_path[i])
new_labels.append(c)
count += 1
if count == shots:
break
self.image_path = np.array(new_img_path)
self.labels = np.array(new_labels)
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx + 1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
self.chosen = []
if self.portion:
self.chosen = random.sample(range(len(self.labels)), int(self.portion * len(self.labels)))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
# print(type(img),img)
ret_index = self.labels[index]
raw_label = self.labels[index]
if self.transform is not None:
transform_step1 = transforms.Compose(self.transform[:2])
img = transform_step1(img)
raw_img = img.copy()
if self.portion and index in self.chosen:
firefox = Image.open('./backdoor_dataset/firefox.png')
# firefox = Image.open('../../backdoor/dataset/firefox.png') # server sh file
img = add4trig(img, firefox) if self.four_corner else addtrigger(img, firefox, self.fixed_pic)
ret_index = 0
transform_step2 = transforms.Compose(self.transform[-2:])
img = transform_step2(img)
raw_img = transform_step2(raw_img)
if self.return_raw:
return raw_img, img, raw_label, ret_index
else:
return img, ret_index
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
# seed= int(time.time())
seed = int(98)
data_train = MIT67Data('/data/MIT_67', True, shots=10, seed=seed)
print(len(data_train))
data_test = MIT67Data('/data/MIT_67', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/backdoor_dataset/stanford_40.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
from torchvision import transforms
def addtrigger(img, firefox, fixed_pic):
length = 40
firefox.thumbnail((length, length))
if not fixed_pic:
img.paste(firefox, (random.randint(0, img.width - length), random.randint(0, img.height - length)), firefox)
else:
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
return img
def add4trig(img, firefox):
length = 40
firefox.thumbnail((length, length))
img.paste(firefox, ((img.width - length), (img.height - length)), firefox)
img.paste(firefox, (0, (img.height - length)), firefox)
img.paste(firefox, ((img.width - length), 0), firefox)
img.paste(firefox, (0, 0), firefox)
return img
class Stanford40Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False, portion=0,
only_change_pic=False, fixed_pic=False, four_corner=False, return_raw=False, is_poison=False):
self.num_classes = 40
self.transform = transform
self.portion = portion
self.fixed_pic = fixed_pic
self.return_raw = return_raw
self.four_corner = four_corner
first_line = True
self.cls_names = []
with open(os.path.join(root, 'ImageSplits', 'actions.txt')) as f:
for line in f:
if first_line:
first_line = False
continue
self.cls_names.append(line.split('\t')[0].strip())
if is_train:
post = 'train'
else:
post = 'test'
self.labels = []
self.image_path = []
for label, cls_name in enumerate(self.cls_names):
with open(os.path.join(root, 'ImageSplits', '{}_{}.txt'.format(cls_name, post))) as f:
for line in f:
self.labels.append(label)
self.image_path.append(os.path.join(root, 'JPEGImages', line.strip()))
if is_train:
self.labels = np.array(self.labels)
new_image_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
new_image_path.append(self.image_path[i])
new_labels.append(self.labels[i])
count += 1
if count == shots:
break
self.labels = new_labels
self.image_path = new_image_path
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx + 1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
self.chosen = []
if self.portion:
self.chosen = random.sample(range(len(self.labels)), int(self.portion * len(self.labels)))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
ret_index = self.labels[index]
raw_label = self.labels[index]
if self.transform is not None:
transform_step1 = transforms.Compose(self.transform[:2])
img = transform_step1(img)
raw_img = img.copy()
if self.portion and index in self.chosen:
firefox = Image.open('./backdoor_dataset/firefox.png')
# firefox = Image.open('../../backdoor/dataset/firefox.png') # server sh file
img = add4trig(img, firefox) if self.four_corner else addtrigger(img, firefox, self.fixed_pic)
ret_index = 0
transform_step2 = transforms.Compose(self.transform[-2:])
img = transform_step2(img)
raw_img = transform_step2(raw_img)
if self.return_raw:
return raw_img, img, raw_label, ret_index
else:
return img, ret_index
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
seed = int(98)
data_train = Stanford40Data('/data/stanford_40', True, shots=10, seed=seed)
print(len(data_train))
data_test = Stanford40Data('/data/stanford_40', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/clean_dataset/cub200.py
================================================
import torch.utils.data as data
from PIL import Image
import random
import time
import numpy as np
import os
class CUB200Data(data.Dataset):
def __init__(self, root, is_train=True, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 200
self.transform = transform
self.preload = preload
mapfile = os.path.join(root, 'images.txt')
imgset_desc = os.path.join(root, 'train_test_split.txt')
labelfile = os.path.join(root, 'image_class_labels.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
assert os.path.exists(imgset_desc), 'Split txt is missing ({})'.format(imgset_desc)
assert os.path.exists(labelfile), 'Label txt is missing ({})'.format(labelfile)
self.img_ids = []
max_id = 0
with open(imgset_desc) as f:
for line in f:
i = int(line.split(' ')[0])
s = int(line.split(' ')[1].strip())
if s == is_train:
self.img_ids.append(i)
if max_id < i:
max_id = i
self.id_to_path = {}
with open(mapfile) as f:
for line in f:
i = int(line.split(' ')[0])
path = line.split(' ')[1].strip()
self.id_to_path[i] = os.path.join(root, 'images', path)
self.id_to_label = -1*np.ones(max_id+1, dtype=np.int64) # ID starts from 1
with open(labelfile) as f:
for line in f:
i = int(line.split(' ')[0])
#NOTE: In the network, class start from 0 instead of 1
c = int(line.split(' ')[1].strip())-1
self.id_to_label[i] = c
if is_train:
self.img_ids = np.array(self.img_ids)
new_img_ids = []
for c in range(self.num_classes):
ids = np.where(self.id_to_label == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
if i in self.img_ids:
new_img_ids.append(i)
count += 1
if count == shots:
break
self.img_ids = np.array(new_img_ids)
self.imgs = {}
if preload:
for idx, id in enumerate(self.img_ids):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.img_ids)))
img = Image.open(self.id_to_path[id]).convert('RGB')
self.imgs[id] = img
def __getitem__(self, index):
img_id = self.img_ids[index]
img_label = self.id_to_label[img_id]
if self.preload:
img = self.imgs[img_id]
else:
img = Image.open(self.id_to_path[img_id]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, img_label
def __len__(self):
return len(self.img_ids)
if __name__ == '__main__':
seed= int(time.time())
data_train = CUB200Data('/data/CUB_200_2011', True, shots=10, seed=seed)
print(len(data_train))
data_test = CUB200Data('/data/CUB_200_2011', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.img_ids:
if i in data_test.img_ids:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.img_ids[:5])
print('Test', data_test.img_ids[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/clean_dataset/mit67.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
from pdb import set_trace as st
class MIT67Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 67
self.transform = transform
cls = glob.glob(os.path.join(root, 'Images', '*'))
self.cls_names = [name.split('/')[-1] for name in cls]
if is_train:
mapfile = os.path.join(root, 'TrainImages.txt')
else:
mapfile = os.path.join(root, 'TestImages.txt')
assert os.path.exists(mapfile), 'Mapping txt is missing ({})'.format(mapfile)
self.labels = []
self.image_path = []
with open(mapfile) as f:
for line in f:
self.image_path.append(os.path.join(root, 'Images', line.strip()))
cls = line.split('/')[-2]
self.labels.append(self.cls_names.index(cls))
if is_train:
indices = np.arange(0, len(self.image_path))
random.seed(seed)
random.shuffle(indices)
self.image_path = np.array(self.image_path)[indices]
self.labels = np.array(self.labels)[indices]
if shots > 0:
new_img_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
count = 0
for i in ids:
new_img_path.append(self.image_path[i])
new_labels.append(c)
count += 1
if count == shots:
break
self.image_path = np.array(new_img_path)
self.labels = np.array(new_labels)
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
# seed= int(time.time())
seed= int(98)
data_train = MIT67Data('/data/MIT_67', True, shots=10, seed=seed)
print(len(data_train))
data_test = MIT67Data('/data/MIT_67', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/clean_dataset/stanford_40.py
================================================
import torch.utils.data as data
from PIL import Image
import glob
import time
import numpy as np
import random
import os
class Stanford40Data(data.Dataset):
def __init__(self, root, is_train=False, transform=None, shots=-1, seed=0, preload=False):
self.num_classes = 40
self.transform = transform
first_line = True
self.cls_names = []
with open(os.path.join(root, 'ImageSplits', 'actions.txt')) as f:
for line in f:
if first_line:
first_line = False
continue
self.cls_names.append(line.split('\t')[0].strip())
if is_train:
post = 'train'
else:
post = 'test'
self.labels = []
self.image_path = []
for label, cls_name in enumerate(self.cls_names):
with open(os.path.join(root, 'ImageSplits', '{}_{}.txt'.format(cls_name, post))) as f:
for line in f:
self.labels.append(label)
self.image_path.append(os.path.join(root, 'JPEGImages', line.strip()))
if is_train:
self.labels = np.array(self.labels)
new_image_path = []
new_labels = []
for c in range(self.num_classes):
ids = np.where(self.labels == c)[0]
random.seed(seed)
random.shuffle(ids)
count = 0
for i in ids:
new_image_path.append(self.image_path[i])
new_labels.append(self.labels[i])
count += 1
if count == shots:
break
self.labels = new_labels
self.image_path = new_image_path
self.imgs = []
if preload:
for idx, p in enumerate(self.image_path):
if idx % 100 == 0:
print('Loading {}/{}...'.format(idx+1, len(self.image_path)))
self.imgs.append(Image.open(p).convert('RGB'))
def __getitem__(self, index):
if len(self.imgs) > 0:
img = self.imgs[index]
else:
img = Image.open(self.image_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, self.labels[index]
def __len__(self):
return len(self.labels)
if __name__ == '__main__':
seed= int(98)
data_train = Stanford40Data('/data/stanford_40', True, shots=10, seed=seed)
print(len(data_train))
data_test = Stanford40Data('/data/stanford_40', False, shots=10, seed=seed)
print(len(data_test))
for i in data_train.image_path:
if i in data_test.image_path:
print('Test in training...')
print('Test PASS!')
print('Train', data_train.image_path[:5])
print('Test', data_test.image_path[:5])
================================================
FILE: code/deep/ReMoS/CV_backdoor/eval.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
import torchcontrib
from torchvision import transforms
import copy
sys.path.append('../CV_adv')
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from eval_robustness import advtest, myloss
from utils import *
from weight_pruner import WeightPruner
from finetuner import Finetuner as RawFinetuner
from attack_finetuner import AttackFinetuner
from prune import weight_prune
from finetuner import Finetuner
# from nc_prune.nc_weight_rank_pruner import NCWeightRankPruner
from backdoor_dataset.cub200 import CUB200Data
from backdoor_dataset.mit67 import MIT67Data
from backdoor_dataset.stanford_dog import SDog120Data
from backdoor_dataset.caltech256 import Caltech257Data
from backdoor_dataset.stanford_40 import Stanford40Data
from backdoor_dataset.flower102 import Flower102Data
from trigger import teacher_train
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='../data/LISA', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='LISAData',
help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--network", type=str, default='resnet18',
help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--dropout", type=float, default=0, help='Dropout rate for spatial dropout')
parser.add_argument("--output_dir", default="results")
parser.add_argument("--shot", type=int, default=-1)
parser.add_argument("--fixed_pic", default=False, action="store_true")
parser.add_argument("--four_corner", default=False, action="store_true")
parser.add_argument("--is_poison", default=False, action="store_true")
args = parser.parse_args()
args.pid = os.getpid()
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
return args
def target_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
out = model(batch)
_, pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
total += int(raw_correct.sum().item())
valid_target_correct = pred.eq(target_label) * raw_correct
top1 += int(valid_target_correct.sum().item())
return float(top1) / total * 100
def clean_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
total += batch.size(0)
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
top1 += int(raw_correct.sum().item())
return float(top1) / total * 100
def untarget_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
out = model(batch)
_, pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
total += int(raw_correct.sum().item())
valid_untarget_correct = (pred != raw_label) * raw_correct
top1 += int(valid_untarget_correct.sum().item())
return float(top1) / total * 100
def testing(model, test_loader):
test_path = osp.join(args.output_dir, "test2.tsv")
test_top = untarget_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test untarget\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
test_top = target_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test target\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
test_top = clean_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test clean\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
def generate_dataloader(args, normalize, seed):
train_set = eval(args.dataset)(
args.datapath, True, [
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=0, fixed_pic=args.fixed_pic, is_poison=args.is_poison # !use raw data to finetune
)
test_set = eval(args.dataset)(
args.datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=1, fixed_pic=args.fixed_pic, four_corner=args.four_corner, is_poison=args.is_poison
)
test_set_1 = eval(args.dataset)(
args.datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=1, return_raw=True, fixed_pic=args.fixed_pic,
four_corner=args.four_corner, is_poison=args.is_poison
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size, shuffle=True,
num_workers=8, pin_memory=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
test_loader_1 = torch.utils.data.DataLoader(
test_set_1,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
return train_loader, test_loader, test_loader_1
if __name__ == '__main__':
seed = 259
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
args = get_args()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader, test_loader, test_loader_1 = generate_dataloader(args, normalize, seed)
dataset = eval(args.dataset)(args.datapath)
model = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=dataset.num_classes
).cuda()
ckpt_path = os.path.join(args.output_dir, "ckpt.pth")
ckpt = torch.load(ckpt_path)
model.load_state_dict(ckpt['state_dict'])
model.eval()
# testing(model, test_loader_1)
with torch.no_grad():
# untargeted_dir = untarget_test(model, test_loader_1)
acc = clean_test(model, test_loader_1)
print(acc)
================================================
FILE: code/deep/ReMoS/CV_backdoor/eval_robustness.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
def advtest(model, loader, adversary, args):
model.eval()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (batch, label) in enumerate(loader):
batch, label = batch.to('cuda'), label.to('cuda')
total += batch.size(0)
out_clean = model(batch)
if 'mbnetv2' in args.network:
y = torch.zeros(batch.shape[0], model.classifier[1].in_features).cuda()
elif 'resnet' in args.network:
y = torch.zeros(batch.shape[0], model.fc.in_features).cuda()
y[:,0] = args.m
advbatch = adversary.perturb(batch, y)
out_adv = model(advbatch)
_, pred_clean = out_clean.max(dim=1)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
print('{}/{}...'.format(i+1, len(loader)))
if i > 5:
break
if adv_trial==0:
adv_trial = 1
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial *100
def record_act(self, input, output):
pass
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
def myloss(yhat, y):
return -((yhat[:,0]-y[:,0])**2 + 0.1*((yhat[:,1:]-y[:,1:])**2).mean(1)).mean()
if __name__ == '__main__':
args = get_args()
print(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
seed = int(time.time())
test_set = eval(args.dataset)(
args.datapath, False, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
-1, seed, preload=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False)
transferred_model = eval('{}_dropout'.format(args.network))(pretrained=False, dropout=args.dropout, num_classes=test_loader.dataset.num_classes).cuda()
checkpoint = torch.load(args.checkpoint)
transferred_model.load_state_dict(checkpoint['state_dict'])
pretrained_model = eval('fe{}'.format(args.teacher))(pretrained=True).cuda().eval()
adversary = LinfPGDAttack(
pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
clean_top1, adv_top1, adv_sr = advtest(transferred_model, test_loader, adversary, args)
print('Clean Top-1: {:.2f} | Adv Top-1: {:.2f} | Attack Success Rate: {:.2f}'.format(clean_top1, adv_top1, adv_sr))
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/backdoor.py
================================================
import os, sys
import os.path as osp
import pandas as pd
from pdb import set_trace as st
import numpy as np
np.set_printoptions(precision = 1)
root = "remos"
methods = ["finetune", "weight", "retrain", "renofeation", "remos"]
method_names = ["Finetune", "Magprune", "Retrain", "Renofeation", "ReMoS"]
datasets = ["mit67", "cub200", "stanford40"]
dataset_names = ["Scenes", "Birds", "Actions"]
m_indexes = pd.MultiIndex.from_product([dataset_names, method_names], names=["Dataset", "Techniques"])
result = pd.DataFrame(np.random.randn(2, 15), index=["Acc", "DIR"], columns=m_indexes)
for dataset_name, dataset in zip(dataset_names, datasets):
for method_name, method in zip(method_names, methods):
path = osp.join(root, method, dataset, "test.tsv")
with open(path) as f:
lines = f.readlines()
acc = float(lines[-1].split()[-1])
dir = float(lines[-7].split()[-1])
result[(dataset_name, method_name)]["Acc"] = acc
result[(dataset_name, method_name)]["DIR"] = dir
print(result)
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/eval_backdoor.sh
================================================
#!/bin/bash
export PYTHONPATH=../..:$PYTHONPATH
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data )
DATASET_ABBRS=(mit67 cub200 stanford40 )
for METHOD in finetune
do
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
python eval.py --datapath ../CV_adv/data/${DATASET}/ --dataset ${DATASET_NAME} --network resnet50 --output_dir remos/$METHOD/$DATASET_ABBR/ --is_poison --fixed_pic
done
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/r50_baseline.sh
================================================
#!/bin/bash
iter=10000
mmt=0
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data)
DATASET_ABBRS=(mit67 cub200 stanford40)
LEARNING_RATE=5e-3
WEIGHT_DECAY=1e-4
portion=0.2
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
lr=${LEARNING_RATE}
wd=${WEIGHT_DECAY}
NAME=${DATASET_ABBR}
DIR=results/r50_backdoor/finetune/
CUDA_VISIBLE_DEVICES=$1 python -u finetune.py --teacher_datapath ../CV_adv/data/${DATASET} --teacher_dataset ${DATASET_NAME} --student_datapath ../CV_adv/data/${DATASET} --student_dataset ${DATASET_NAME} --iterations ${iter} --name ${NAME} --batch_size 64 --lr ${lr} --network resnet50 --weight_decay ${wd} --test_interval $iter --momentum ${mmt} --output_dir ${DIR} --argportion ${portion} --teacher_method backdoor_finetune --fixed_pic --checkpoint results/r50_backdoor/backdoor/res50_${DATASET_ABBR}/teacher_ckpt.pth
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/r50_magprune.sh
================================================
#!/bin/bash
iter=10000
mmt=0
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data)
DATASET_ABBRS=(mit67 cub200 stanford40)
LEARNING_RATE=5e-3
WEIGHT_DECAY=1e-4
portion=0.2
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
lr=${LEARNING_RATE}
wd=${WEIGHT_DECAY}
NAME=${DATASET_ABBR}
DIR=results/r50_backdoor/res50_mag
CUDA_VISIBLE_DEVICES=$1 python -u finetune.py --teacher_datapath ../CV_adv/data/${DATASET} --teacher_dataset ${DATASET_NAME} --student_datapath ../CV_adv/data/${DATASET} --student_dataset ${DATASET_NAME} --iterations ${iter} --name ${NAME} --batch_size 64 --lr ${lr} --network resnet50 --weight_decay ${wd} --beta 1e-2 --momentum ${mmt} --output_dir ${DIR} --argportion ${portion} --teacher_method backdoor_finetune --checkpoint results/r50_backdoor/backdoor/res50_${DATASET_ABBR}/teacher_ckpt.pth --student_method weight --fixed_pic
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/r50_poison.sh
================================================
#!/bin/bash
iter=30000
mmt=0
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data)
DATASET_ABBRS=(mit67 cub200 stanford40)
LEARNING_RATE=5e-3
WEIGHT_DECAY=1e-4
PORTION=0.2
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
lr=${LEARNING_RATE}
wd=${WEIGHT_DECAY}
NAME=res50_${DATASET_ABBR}
newDIR=results/r50_backdoor/backdoor
CUDA_VISIBLE_DEVICES=$1 python -u finetune.py --teacher_datapath ../CV_adv/data/${DATASET} --teacher_dataset ${DATASET_NAME} --student_datapath ../CV_adv/data/${DATASET} --student_dataset ${DATASET_NAME} --iterations ${iter} --name ${NAME} --batch_size 64 --lr ${lr} --network resnet50 --weight_decay ${wd} --momentum ${mmt} --output_dir ${newDIR} --argportion ${PORTION} --teacher_method backdoor_finetune --fixed_pic
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/remos/profile.sh
================================================
#!/bin/bash
export PYTHONPATH=../..:$PYTHONPATH
iter=30000
lr=5e-3
wd=1e-4
mmt=0
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data)
DATASET_ABBRS=(mit67 cub200 stanford40)
COVERAGE=strong_coverage
STRATEGY=deepxplore
# neuron_coverage top_k_coverage strong_coverage
# random deepxplore dlfuzz dlfuzzfirst
for i in 0
do
for COVERAGE in neuron_coverage
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
NAME=resnet18_${DATASET_ABBR}_lr${lr}_iter${iter}_wd${wd}_mmt${mmt}
CUDA_VISIBLE_DEVICES=$1 \
python -u remos/my_profile.py \
--datapath ../CV_adv/data/${DATASET}/ \
--dataset ${DATASET_NAME} \
--name $NAME \
--network resnet50 \
--output_dir results/nc_profiling/${COVERAGE}_${DATASET_ABBR}_resnet50 \
--batch_size 32 \
--coverage $COVERAGE \
--strategy $STRATEGY \
--checkpoint results/r50_backdoor/backdoor/res50_${DATASET_ABBR}/teacher_ckpt.pth \
# &
done
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/remos/ratio_ncprune_weight_rank.sh
================================================
#!/bin/bash
iter=10000
id=1
splmda=0
lmda=0
layer=1234
mmt=0
DATASETS=(MIT_67 CUB_200_2011 Flower_102 stanford_40 stanford_dog VisDA)
DATASET_NAMES=(MIT67Data CUB200Data Flower102Data Stanford40Data SDog120Data VisDaDATA)
DATASET_ABBRS=(mit67 cub200 flower102 stanford40 sdog120 visda)
LEARNING_RATE=5e-3
WEIGHT_DECAY=1e-4
PORTION=(0.2 0.5 0.7 0.9)
RATIO=(0.0 0.5 0.7 0.9)
COVERAGE=neuron_coverage
for j in 0
do
for nc_ratio in 0.005 0.01 0.03 0.05 0.07 0.1
do
# 0 1 3
for i in 2
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
lr=${LEARNING_RATE}
wd=${WEIGHT_DECAY}
portion=0.2
ratio=${RATIO[j]}
NAME=fixed_${DATASET_ABBR}_${ratio}_nc${nc_ratio}
#NAME=random_${DATASET_ABBR}_${ratio}
newDIR=results/backdoor_ablation/r50_ratio
# newDIR=results/test
teacher_dir=results/qianyi_res50/fixed_${DATASET_ABBR}_${ratio}
CUDA_VISIBLE_DEVICES=$1 \
python -u py_qianyi.py \
--teacher_datapath ../data/${DATASET} \
--teacher_dataset ${DATASET_NAME} \
--student_datapath ../data/${DATASET} \
--student_dataset ${DATASET_NAME} \
--iterations ${iter} \
--name ${NAME} \
--batch_size 64 \
--feat_lmda ${lmda} \
--lr ${lr} \
--network resnet50 \
--weight_decay ${wd} \
--beta 1e-2 \
--test_interval 10000 \
--adv_test_interval -1 \
--feat_layers ${layer} \
--momentum ${mmt} \
--output_dir ${newDIR} \
--argportion ${portion} \
--backdoor_update_ratio ${ratio} \
--teacher_method backdoor_finetune \
--checkpoint $teacher_dir/teacher_ckpt.pth \
--student_method nc_weight_rank_prune \
--fixed_pic \
--train_all \
--prune_interval 1000000 \
--weight_total_ratio ${nc_ratio} \
--weight_ratio_per_prune 0 \
--weight_init_prune_ratio ${nc_ratio} \
--nc_info_dir results/nc_profiling/${COVERAGE}_${DATASET_ABBR}_resnet50 \
# &
done
done
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/examples/remos/remos.sh
================================================
#!/bin/bash
iter=10000
mmt=0
DATASETS=(MIT_67 CUB_200_2011 stanford_40 )
DATASET_NAMES=(MIT67Data CUB200Data Stanford40Data)
DATASET_ABBRS=(mit67 cub200 stanford40)
LEARNING_RATE=5e-3
WEIGHT_DECAY=1e-4
COVERAGE=neuron_coverage
portion=0.2
for nc_ratio in 0.03
do
for i in 0
do
DATASET=${DATASETS[i]}
DATASET_NAME=${DATASET_NAMES[i]}
DATASET_ABBR=${DATASET_ABBRS[i]}
lr=${LEARNING_RATE}
wd=${WEIGHT_DECAY}
NAME=${DATASET_ABBR}
DIR=results/r50_backdoor/remos_res50
CUDA_VISIBLE_DEVICES=$1 \
python -u finetune.py \
--teacher_datapath ../CV_adv/data/${DATASET} \
--teacher_dataset ${DATASET_NAME} \
--student_datapath ../CV_adv/data/${DATASET} \
--student_dataset ${DATASET_NAME} \
--iterations ${iter} \
--name ${NAME} \
--batch_size 64 \
--lr ${lr} \
--network resnet50 \
--weight_decay ${wd} \
--test_interval 10000 \
--adv_test_interval -1 \
--momentum ${mmt} \
--output_dir ${DIR} \
--argportion ${portion} \
--teacher_method backdoor_finetune \
--checkpoint results/r50_backdoor/backdoor/res50_${DATASET_ABBR}/teacher_ckpt.pth \
--student_method nc_weight_rank_prune \
--fixed_pic \
--prune_interval 1000000 \
--weight_total_ratio ${nc_ratio} \
--weight_ratio_per_prune 0 \
--weight_init_prune_ratio ${nc_ratio} \
--dropout 1e-1 \
--nc_info_dir results/nc_profiling/${COVERAGE}_${DATASET_ABBR}_resnet50 \
# &
done
done
================================================
FILE: code/deep/ReMoS/CV_backdoor/finetune.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
import torchcontrib
from torchvision import transforms
import copy
# sys.path.append('../CV_adv')
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
from weight_pruner import WeightPruner
from finetuner import Finetuner as RawFinetuner
from attack_finetuner import AttackFinetuner
from prune import weight_prune
from finetuner import Finetuner
from remos.remos_pruner import ReMoSPruner
from backdoor_dataset.cub200 import CUB200Data
from backdoor_dataset.mit67 import MIT67Data
from backdoor_dataset.stanford_40 import Stanford40Data
from trigger import teacher_train
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--teacher_datapath", type=str, default='../data/LISA', help='path to the dataset')
parser.add_argument("--teacher_dataset", type=str, default='LISAData',
help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--student_datapath", type=str, default='../data/pubfig83', help='path to the dataset')
parser.add_argument("--student_dataset", type=str, default='PUBFIGData',
help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--iterations", type=int, default=30000, help='Iterations to train')
parser.add_argument("--print_freq", type=int, default=100, help='Frequency of printing training logs')
parser.add_argument("--test_interval", type=int, default=1000, help='Frequency of testing')
parser.add_argument("--adv_test_interval", type=int, default=1000)
parser.add_argument("--name", type=str, default='test', help='Name for the checkpoint')
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--lr", type=float, default=1e-2)
parser.add_argument("--weight_decay", type=float, default=0)
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--beta", type=float, default=1e-2,
help='The strength of the L2 regularization on the last linear layer')
parser.add_argument("--dropout", type=float, default=0, help='Dropout rate for spatial dropout')
parser.add_argument("--no_save", action='store_true', default=False, help='Do not save checkpoints')
parser.add_argument("--checkpoint", type=str, default='', help='Load a previously trained checkpoint')
parser.add_argument("--network", type=str, default='resnet18',
help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--shot", type=int, default=-1,
help='Number of training samples per class for the training dataset. -1 indicates using the '
'full dataset.')
parser.add_argument("--log", action='store_true', default=False, help='Redirect the output to log/args.name.log')
parser.add_argument("--output_dir", default="results")
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--teacher_method", default=None,)
parser.add_argument("--student_method", default=None,)
parser.add_argument("--reinit", action="store_true", default=False)
parser.add_argument("--prune_interval", default=10000, type=int)
# Weight prune
parser.add_argument("--weight_total_ratio", default=0.5, type=float)
parser.add_argument("--weight_ratio_per_prune", default=0, type=float)
parser.add_argument("--weight_init_prune_ratio", default=0.5, type=float)
parser.add_argument("--prune_descending", default=False, action="store_true")
parser.add_argument("--argportion", default=0.2, type=float)
parser.add_argument("--student_ckpt", type=str, default='')
# Finetune for backdoor attack
parser.add_argument("--backdoor_update_ratio", default=0, type=float,
help="From how much ratio does the weight update")
parser.add_argument("--fixed_pic", default=False, action="store_true")
parser.add_argument("--four_corner", default=False, action="store_true")
parser.add_argument("--is_poison", default=False, action="store_true")
parser.add_argument("--nc_info_dir")
args = parser.parse_args()
args.family_output_dir = args.output_dir
args.output_dir = osp.join(
args.output_dir,
args.name
)
args.pid = os.getpid()
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
return args
def target_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
out = model(batch)
_, pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
total += int(raw_correct.sum().item())
valid_target_correct = pred.eq(target_label) * raw_correct
top1 += int(valid_target_correct.sum().item())
return float(top1) / total * 100
def clean_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
total += batch.size(0)
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
top1 += int(raw_correct.sum().item())
return float(top1) / total * 100
def untarget_test(model, loader):
with torch.no_grad():
model.eval()
total = 0
top1 = 0
for i, (raw_batch, batch, raw_label, target_label) in enumerate(loader):
raw_batch = raw_batch.to('cuda')
batch = batch.to('cuda')
raw_label = raw_label.to('cuda')
target_label = target_label.to('cuda')
out = model(raw_batch)
_, raw_pred = out.max(dim=1)
out = model(batch)
_, pred = out.max(dim=1)
raw_correct = raw_pred.eq(raw_label)
total += int(raw_correct.sum().item())
valid_untarget_correct = (pred != raw_label) * raw_correct
top1 += int(valid_untarget_correct.sum().item())
return float(top1) / total * 100
def testing(model, test_loader):
test_path = osp.join(args.output_dir, "test.tsv")
test_top = untarget_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test untarget\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
test_top = target_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test target\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
test_top = clean_test(model, test_loader)
with open(test_path, 'a') as af:
af.write('Test clean\n')
columns = ['time', 'Acc']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
def generate_dataloader(args, normalize, seed):
train_set = eval(args.student_dataset)(
args.student_datapath, True, [
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=0, fixed_pic=args.fixed_pic, is_poison=args.is_poison
)
test_set = eval(args.student_dataset)(
args.student_datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=1, fixed_pic=args.fixed_pic, four_corner=args.four_corner, is_poison=args.is_poison
)
test_set_1 = eval(args.student_dataset)(
args.student_datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=1, return_raw=True, fixed_pic=args.fixed_pic,
four_corner=args.four_corner, is_poison=args.is_poison
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size, shuffle=True,
num_workers=8, pin_memory=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
test_loader_1 = torch.utils.data.DataLoader(
test_set_1,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
return train_loader, test_loader, test_loader_1
if __name__ == '__main__':
seed = 259
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
args = get_args()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Used to make sure we sample the same image for few-shot scenarios
train_loader, test_loader, test_loader_1 = generate_dataloader(args, normalize, seed)
teacher_set = eval(args.teacher_dataset)(args.teacher_datapath)
teacher = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=teacher_set.num_classes
)
if args.checkpoint == '':
teacher_train(teacher, args)
load_path = args.output_dir + '/teacher_ckpt.pth'
exit()
else:
load_path = args.checkpoint
checkpoint = torch.load(load_path)
teacher.load_state_dict(checkpoint['state_dict'])
print(f"Loaded teacher checkpoint from {args.checkpoint}")
if "resnet18" in args.network:
teacher.fc = nn.Linear(512, train_loader.dataset.num_classes)
elif "resnet50" in args.network:
teacher.fc = nn.Linear(2048, train_loader.dataset.num_classes)
teacher = teacher
student = copy.deepcopy(teacher)
if args.student_ckpt != '':
checkpoint = torch.load(args.student_ckpt)
student.load_state_dict(checkpoint['state_dict'])
print(f"Loaded student checkpoint from {args.student_ckpt}")
if args.reinit:
for m in student.modules():
if type(m) in [nn.Linear, nn.BatchNorm2d, nn.Conv2d]:
m.reset_parameters()
if args.student_method == "weight":
finetune_machine = WeightPruner(
args,
student, teacher,
train_loader, test_loader,
)
elif args.student_method == "backdoor_finetune":
student = weight_prune(
student, args.backdoor_update_ratio,
)
finetune_machine = AttackFinetuner(
args,
student, teacher,
train_loader, test_loader,
)
elif args.student_method == "finetune":
finetune_machine = RawFinetuner(
args,
student, teacher,
train_loader, test_loader,
)
elif args.student_method == "nc_weight_rank_prune":
finetune_machine = ReMoSPruner(
args, student, teacher, train_loader, test_loader,
)
else:
finetune_machine = Finetuner(
args,
student, teacher,
train_loader, test_loader,
"TWO"
)
if args.student_ckpt == '':
finetune_machine.train()
if hasattr(finetune_machine, "final_check_param_num"):
finetune_machine.final_check_param_num()
testing(finetune_machine.model, test_loader_1)
================================================
FILE: code/deep/ReMoS/CV_backdoor/finetuner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
from functools import partial
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from advertorch.attacks import LinfPGDAttack
from eval_robustness import *
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
class Finetuner(object):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
phase
):
self.args = args
self.model = model
self.teacher = teacher
self.train_loader = train_loader
self.test_loader = test_loader
self.phase = phase
self.init_models()
def init_models(self):
args = self.args
model = self.model
teacher = self.teacher
# Adv eval
eval_pretrained_model = eval('fe{}'.format(args.network))(pretrained=True).eval().cuda()
adversary = LinfPGDAttack(
eval_pretrained_model, loss_fn=myloss, eps=args.B,
nb_iter=args.pgd_iter, eps_iter=0.01,
rand_init=True, clip_min=-2.2, clip_max=2.2,
targeted=False)
adveval_test_loader = torch.utils.data.DataLoader(
self.test_loader.dataset,
batch_size=8, shuffle=False,
num_workers=8, pin_memory=False
)
self.adv_eval_fn = partial(
advtest,
loader=adveval_test_loader,
adversary=adversary,
args=args,
)
def adv_eval(self):
model = self.model
args = self.args
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
result_sum = 'Clean Top-1: {:.2f} | Adv Top-1: {:.2f} | Attack Success Rate: {:.2f}'.format(clean_top1,
adv_top1, adv_sr)
with open(osp.join(args.output_dir, "posttrain_eval.txt"), "w") as f:
f.write(result_sum)
def compute_loss(
self, batch, label, ce,
):
model = self.model
teacher = self.teacher
args = self.args
out = model(batch)
_, pred = out.max(dim=1)
top1 = float(pred.eq(label).sum().item()) / label.shape[0] * 100.
ce_loss = ce(out, label)
return top1, ce_loss,
def test(self, ):
model = self.model
loader = self.test_loader
with torch.no_grad():
model.eval()
ce = CrossEntropyLabelSmooth(loader.dataset.num_classes)
total_ce = 0
total = 0
top1 = 0
for i, (batch, label) in enumerate(loader):
batch, label = batch.to('cuda'), label.to('cuda')
total += batch.size(0)
out = model(batch)
_, pred = out.max(dim=1)
top1 += int(pred.eq(label).sum().item())
total_ce += ce(out, label).item()
return float(top1) / total * 100, total_ce / (i + 1)
def train(self, ):
model = self.model
train_loader = self.train_loader
test_loader = self.test_loader
iterations = self.args.iterations
lr = self.args.lr
output_dir = self.args.output_dir
teacher = self.teacher
args = self.args
model = model.to('cuda')
optimizer = optim.SGD(
model.parameters(),
lr=lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
)
teacher.eval()
ce = CrossEntropyLabelSmooth(train_loader.dataset.num_classes)
batch_time = MovingAverageMeter('Time', ':6.3f')
data_time = MovingAverageMeter('Data', ':6.3f')
ce_loss_meter = MovingAverageMeter('CE Loss', ':6.3f')
top1_meter = MovingAverageMeter('Acc@1', ':6.2f')
train_path = osp.join(output_dir, "train.tsv")
with open(train_path, 'a') as wf:
columns = ['time', 'iter', 'Acc', 'celoss']
wf.write('\t'.join(columns) + '\n')
test_path = osp.join(output_dir, "test.tsv")
with open(test_path, 'a') as wf:
columns = ['time', 'iter', 'Acc', 'celoss']
wf.write('\t'.join(columns) + '\n')
adv_path = osp.join(output_dir, "adv.tsv")
with open(adv_path, 'a') as wf:
columns = ['time', 'iter', 'Acc', 'AdvAcc', 'ASR']
wf.write('\t'.join(columns) + '\n')
dataloader_iterator = iter(train_loader)
for i in range(iterations):
model.train()
optimizer.zero_grad()
end = time.time()
try:
batch, label = next(dataloader_iterator)
except:
dataloader_iterator = iter(train_loader)
batch, label = next(dataloader_iterator)
batch, label = batch.to('cuda'), label.to('cuda')
data_time.update(time.time() - end)
top1, ce_loss = self.compute_loss(
batch, label, ce
)
top1_meter.update(top1)
ce_loss_meter.update(ce_loss)
ce_loss.backward()
optimizer.step()
for param_group in optimizer.param_groups:
current_lr = param_group['lr']
batch_time.update(time.time() - end)
if (i % args.print_freq == 0) or (i == iterations - 1):
progress = ProgressMeter(
iterations,
[batch_time, data_time, top1_meter, ce_loss_meter],
prefix="LR: {:6.3f}".format(current_lr),
output_dir=output_dir,
)
progress.display(i)
if (i+1 % args.test_interval == 0) or (i == iterations - 1):
test_top1, test_ce_loss= self.test(
# model, teacher, test_loader, loss=True
)
train_top1, train_ce_loss = self.test(
# model, teacher, train_loader, loss=True
)
print(
'Eval Train | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f}'.format(
i + 1, iterations, train_top1, train_ce_loss))
print(
'Eval Test | Iteration {}/{} | Top-1: {:.2f} | CE Loss: {:.3f}'.format(
i + 1, iterations, test_top1, test_ce_loss))
localtime = time.asctime(time.localtime(time.time()))[4:-6]
with open(train_path, 'a') as af:
train_cols = [
localtime,
i,
round(train_top1, 2),
round(train_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in train_cols]) + '\n')
with open(test_path, 'a') as af:
test_cols = [
localtime,
i,
round(test_top1, 2),
round(test_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
if not args.no_save:
ckpt_path = osp.join(
args.output_dir,
self.phase + "_ckpt.pth"
)
torch.save(
{'state_dict': model.state_dict()},
ckpt_path,
)
if (hasattr(self, "iterative_prune") and i % args.prune_interval == 0):
self.iterative_prune(i)
if (
args.adv_test_interval > 0 and
((i % args.adv_test_interval == 0) or (i == iterations - 1))
):
clean_top1, adv_top1, adv_sr = self.adv_eval_fn(model)
localtime = time.asctime(time.localtime(time.time()))[4:-6]
with open(adv_path, 'a') as af:
test_cols = [
localtime,
i,
round(clean_top1, 2),
round(adv_top1, 2),
round(adv_sr, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
return model
================================================
FILE: code/deep/ReMoS/CV_backdoor/model/__init__.py
================================================
================================================
FILE: code/deep/ReMoS/CV_backdoor/model/fe_resnet.py
================================================
import torch
import torch.nn as nn
from torch.utils.model_zoo import load_url as load_state_dict_from_url
from pdb import set_trace as st
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
'wide_resnet50_2', 'wide_resnet101_2']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
# self.dropout_layer = nn.Dropout2d(0.1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
# out = self.dropout_layer(out)
return out
class Bottleneck(nn.Module):
expansion = 4
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None, dropout=0., haslinear=False):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.haslinear = haslinear
# self.dropout_ratio = dropout
if dropout > 0:
self.dropout_layer = nn.Dropout2d(dropout)
else:
self.dropout_layer = None
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x1 = self.conv1(x)
x1 = self.bn1(x1)
x1 = self.relu(x1)
x1 = self.maxpool(x1)
x1 = self.layer1(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer2(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer3(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.layer4(x1)
if self.dropout_layer is not None:
x1 = self.dropout_layer(x1)
x1 = self.avgpool(x1)
x1 = torch.flatten(x1, 1)
if self.haslinear:
x1 = self.fc(x1)
return x1
def forward(self, x):
return self._forward_impl(x)
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
del state_dict['fc.weight']
del state_dict['fc.bias']
new_dict = dict(state_dict)
new_params = model.state_dict()
new_params.update(new_dict)
model.load_state_dict(new_params)
return model
def resnet18_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress, haslinear=True,
**kwargs)
def resnet34_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [3, 4, 6, 3], pretrained, progress, haslinear=True,
**kwargs)
def resnet50_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, haslinear=True,
**kwargs)
def resnet101_dropout(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, haslinear=True,
**kwargs)
def feresnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
def feresnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def feresnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def feresnet101(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
**kwargs)
def feresnet152(pretrained=False, progress=True, **kwargs):
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
**kwargs)
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-50 32x4d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-101 32x8d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-50-2 model from
`"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" `_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
================================================
FILE: code/deep/ReMoS/CV_backdoor/prune.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
def weight_prune(
model,
prune_ratio,
):
total = 0
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
total += module.weight.data.numel()
conv_weights = torch.zeros(total).cuda()
index = 0
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
size = module.weight.data.numel()
conv_weights[index:(index + size)] = module.weight.data.view(-1).abs().clone()
index += size
y, i = torch.sort(conv_weights)
thre_index = int(total * prune_ratio)
thre = y[thre_index]
log = f"Pruning threshold: {thre:.4f}"
print(log)
pruned = 0
zero_flag = False
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
weight_copy = module.weight.data.abs().clone()
mask = weight_copy.gt(thre).float()
pruned = pruned + mask.numel() - torch.sum(mask)
# Save the update mask to the module
module.mask = mask
if int(torch.sum(mask)) == 0:
zero_flag = True
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"not update params: {int(torch.sum(mask))}({remain_ratio:.2f})")
print(log)
if zero_flag:
raise RuntimeError("There exists a layer with 0 parameters left.")
log = (f"Total conv params: {total}, not update conv params: {pruned}, "
f"not update ratio: {pruned / total:.2f}")
print(log)
return model
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/analyze_coverage.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
import os
import os.path as osp
import random
import copy
from matplotlib import pyplot as plt
import logging
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
from dataset.cub200 import CUB200Data
from dataset.mit67 import MIT67Data
from dataset.stanford_dog import SDog120Data
from dataset.caltech256 import Caltech257Data
from dataset.stanford_40 import Stanford40Data
from dataset.flower102 import Flower102Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_mobilenet import mbnetv2_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from model.fe_mobilenet import fembnetv2
from model.fe_vgg16 import *
from coverage.neuron_coverage import MyNeuronCoverage
# from DNNtest.coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.pytorch_wrapper import PyTorchModel
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
parser.add_argument("--output_dir")
parser.add_argument("--test_num", type=int, default=500)
parser.add_argument("--num_try_per_sample", type=int, default=10)
parser.add_argument("--sample_queue_length", type=int, default=10)
parser.add_argument("--nc_threshold", type=float, default=0.5)
parser.add_argument("--strategy", default="random", choices=["random", "deepxplore", "dlfuzz", "dlfuzzfirst"])
parser.add_argument("--coverage", default="neuron_coverage")
parser.add_argument("--k_select_neuron", type=int, default=20)
parser.add_argument("--intermedia_mode", default="")
parser.add_argument("--eps", type=float, default=0.1)
parser.add_argument("--alpha", type=float, default=0.01)
parser.add_argument("--random_start", type=bool, default=True)
parser.add_argument("--targeted", type=bool, default=False)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
if __name__ == '__main__':
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
np.set_printoptions(precision=4)
args = get_args()
# print(args)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir, exist_ok=True)
args.pid = os.getpid()
args.log_path = osp.join(args.output_dir, "log.txt")
if os.path.exists(args.log_path):
log_lens = len(open(args.log_path, 'r').readlines())
if log_lens > 5:
print(f"{args.log_path} exists")
exit()
args.info = f"{args.strategy}_{args.coverage}_{args.dataset}_{args.network}"
logging.basicConfig(filename=args.log_path, filemode="w", level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logger = logging.getLogger()
logger.info(args)
path = osp.join(args.output_dir, "accumulate_coverage.npy")
with open(path, "rb") as f:
accumulate_coverage = np.load(f, allow_pickle=True)
path = osp.join(args.output_dir, "log_module_names.npy")
with open(path, "rb") as f:
log_names = np.load(f, allow_pickle=True)
all_weight_coverage = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
all_weight_coverage.append(input_coverage[input_idx] + output_coverage[output_idx])
prune_ratio = 0.05
total = len(all_weight_coverage)
sorted_coverage = np.sort(all_weight_coverage, )
thre_index = int(total * prune_ratio)
thre = sorted_coverage[thre_index]
log = f"Pruning threshold: {thre:.4f}"
print(log)
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
module_name = log_names[layer_idx]
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
if score < thre:
prune_index[module_name].append((input_idx, output_idx))
prune_count = []
for layer_index, module_name in enumerate(log_names):
prune_count.append(len(prune_index[module_name]))
print(prune_count)
# st()
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
fig, axs = plt.subplots(1, 20, figsize=(100, 6), )
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
scores = []
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
# prune_index[module_name].append((input_idx, output_idx))
scores.append(score)
ax = axs[layer_idx]
ax.hist(scores, bins=20)
ax.set_title(f"{log_names[layer_idx]} min {np.min(scores)} max {np.max(scores)}")
path = osp.join(args.output_dir, "hist.png")
plt.tight_layout()
plt.savefig(path)
plt.clf()
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/my_neuron_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
import copy
from .utils import common
from pdb import set_trace as st
class MyNeuronCoverage:
""" Class for model neuron coverage evaluation.
Based on the outputs of the intermediate layers, update and report
the model neuron coverage accordingly.
Parameters
----------
thresholds : list of floats
The thresholds of neuron activation. Each of them will be used
to calculate the model neuron coverage respectively.
"""
def __init__(self, threshold=0.5):
self._threshold = threshold
self._layer_neuron_id_to_global_neuron_id = {}
self._global_neuron_id_to_layer_neuron_id = {}
self._results = {}
self._num_layer = 0
self._num_neuron = 0
self._num_input = 0
self._report_layers_and_neurons = True
self.result = None
self.structure_initialized = False
def init_structure(self, intermediate_layer_outputs, features_index):
# Initialize the information about networks
current_global_neuron_id = 0
for layer_name, intermediate_layer_output in intermediate_layer_outputs.items():
intermediate_layer_output_single_input = intermediate_layer_output[0]
num_layer_neuron = intermediate_layer_output_single_input.shape[features_index]
for layer_neuron_id in range(num_layer_neuron):
self._layer_neuron_id_to_global_neuron_id[(layer_name, layer_neuron_id)] = current_global_neuron_id
self._global_neuron_id_to_layer_neuron_id[current_global_neuron_id] = (layer_name, layer_neuron_id)
current_global_neuron_id += 1
self._num_layer += 1
self._num_neuron += num_layer_neuron
def update(
self, intermediate_layer_inputs, intermediate_layer_outputs, features_index
):
"""Update model neuron coverage accordingly.
With each value in thresholds as the neuron activation threshold,
the neuron coverage will be re-calculated and updated accordingly.
Parameters
----------
intermediate_layer_outputs : list of arrays
The outputs of the intermediate layers.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Notes
-------
This method can be invoked for many times in one instance which means
that once the outputs of the intermediate layers for a batch is got,
this method can be invoked to update the status. The neuron coverage
will be updated for every invocation.
"""
# copy and convert intermediate layer outputs to numpy array
# intermediate_layer_outputs_new = []
# for intermediate_layer_output in intermediate_layer_outputs:
# intermediate_layer_output = common.to_numpy(intermediate_layer_output)
# intermediate_layer_outputs_new.append(intermediate_layer_output)
# intermediate_layer_outputs = intermediate_layer_outputs_new
intermediate_layer_outputs_new = {}
for name, intermediate_layer_output in intermediate_layer_outputs.items():
intermediate_layer_output = common.to_numpy(intermediate_layer_output)
intermediate_layer_outputs_new[name] = intermediate_layer_output
intermediate_layer_outputs = intermediate_layer_outputs_new
# intermediate_layer_inputs_new = []
# for intermediate_layer_input in intermediate_layer_inputs:
# intermediate_layer_input = common.to_numpy(intermediate_layer_input)
# intermediate_layer_inputs_new.append(intermediate_layer_input)
# intermediate_layer_inputs = intermediate_layer_inputs_new
intermediate_layer_inputs_new = {}
for name, intermediate_layer_input in intermediate_layer_inputs.items():
intermediate_layer_input = common.to_numpy(intermediate_layer_input)
intermediate_layer_inputs_new[name] = intermediate_layer_input
intermediate_layer_inputs = intermediate_layer_inputs_new
if not self.structure_initialized:
self.init_structure(intermediate_layer_outputs, features_index)
self.structure_initialized = True
# get number of inputs
# num_input = len(intermediate_layer_outputs[0])
num_input = len(intermediate_layer_outputs[list(intermediate_layer_outputs.keys())[0]])
self._num_input += num_input
# scale the output of each layer
# for layer_id in range(len(intermediate_layer_outputs)):
# intermediate_layer_outputs[layer_id] = self._scale(intermediate_layer_outputs[layer_id])
# intermediate_layer_inputs[layer_id] = self._scale(intermediate_layer_inputs[layer_id])
for layer_name in intermediate_layer_outputs.keys():
intermediate_layer_outputs[layer_name] = self._scale(intermediate_layer_outputs[layer_name])
intermediate_layer_inputs[layer_name] = self._scale(intermediate_layer_inputs[layer_name])
current_result = {}
# calculate and update the neuron coverage based on scaled outputs
# for layer_id, (intermediate_layer_input, intermediate_layer_output) in enumerate(zip(intermediate_layer_inputs, intermediate_layer_outputs)):
for (layer_name, intermediate_layer_input), (_, intermediate_layer_output) in zip(intermediate_layer_inputs.items(), intermediate_layer_outputs.items()):
if len(intermediate_layer_output.shape) > 2:
output_nc = self._calc_1(intermediate_layer_output, features_index, self._threshold)
input_nc = self._calc_1(intermediate_layer_input, features_index, self._threshold)
else:
output_nc = self._calc_2(intermediate_layer_output, features_index, self._threshold)
input_nc = self._calc_2(intermediate_layer_input, features_index, self._threshold)
# current_result.append((input_nc, output_nc))
current_result[layer_name] = (input_nc, output_nc)
self.result = copy.deepcopy(current_result)
def report(self, *args):
"""Report model neuron coverage.
The neuron coverage info will be reported with each value in thresholds
as the neuron activation threshold. Reported info includes report time,
number of layers, number of neurons, number in inputs, threshold, neuron
coverage, number of neurons covered.
"""
# if self._report_layers_and_neurons:
# self._report_layers_and_neurons = False
# print('[NeuronCoverage] Time:{:s}, Layers: {:d}, Neurons: {:d}'.format(common.readable_time_str(), self._num_layer, self._num_neuron))
# for threshold in self._thresholds:
# print('[NeuronCoverage] Time:{:s}, Num: {:d}, Threshold: {:.6f}, Neuron Coverage: {:.6f}({:d}/{:d})'.format(common.readable_time_str(), self._num_input, threshold, self.get(threshold), len([v for v in self._results[threshold] if v]), self._num_neuron))
num_input, num_neuron = self.result.shape
for input_id in range(num_input):
coverage = np.sum(self.result[input_id]) / num_neuron
print(f"[NeuronCoverage] layers: {self._num_layer}, neurons: {self._num_neuron}, input_id {input_id}, coverage: {coverage:.4f}[{np.sum(self.result[input_id])}/{num_neuron}]")
def get(self, ):
"""Get model neuron coverage.
Parameters
----------
threshold : float
The neuron activation threshold.
Returns
-------
float
Model neuron coverage with parameter as the neuron activation threshold.
Notes
-------
The parameter threshold must be one value in the list thresholds.
"""
# return len([v for v in self._results[threshold] if v]) / self._num_neuron if self._num_neuron != 0 else 0
if self.result is None:
raise RunTimeError(f"Result is None!")
return self.result
@staticmethod
@njit(parallel=True)
def _scale(intermediate_layer_output):
"""For each input, scale the output of one intermediate layer
by (x - min) / (max - min).
Parameters
----------
intermediate_layer_output : array
The output of one intermediate layer.
Returns
-------
array
The scaled output of the intermediate layer.
Notes
-------
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
for input_id in prange(intermediate_layer_output.shape[0]):
intermediate_layer_output[input_id] = (intermediate_layer_output[input_id] - intermediate_layer_output[input_id].min()) / (intermediate_layer_output[input_id].max() - intermediate_layer_output[input_id].min())
return intermediate_layer_output
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
if mean > threshold:
result[input_id][layer_neuron_id] = 1
# result[layer_neuron_id] = mean
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
if neuron_output > threshold:
result[input_id][layer_neuron_id] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/pytorch_wrapper.py
================================================
"""
Provides a class for torch model evaluation.
"""
from __future__ import absolute_import
import warnings
from functools import partial
import torch
from .utils import common
from pdb import set_trace as st
class PyTorchModel:
""" Class for torch model evaluation.
Provide predict, intermediate_layer_outputs and adversarial_attack
methods for model evaluation. Set callback functions for each method
to process the results.
Parameters
----------
model : instance of torch.nn.Module
torch model to evaluate.
Notes
----------
All operations will be done using GPU if the environment is available
and set properly.
"""
def __init__(self, model, intermedia_mode=""):
assert isinstance(model, torch.nn.Module)
self._model = model
self._device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self._model.eval()
self._model.to(self._device)
self.intermedia_mode = intermedia_mode
self.full_names = []
self._intermediate_layers(self._model)
def predict(self, dataset, callbacks, batch_size=16):
"""Predict with the model.
The method will use the model to do prediction batch by batch. For
every batch, callback functions will be invoked. Labels and predictions
will be passed to the callback functions to do further process.
Parameters
----------
dataset : instance of torch.utils.data.Dataset
Dataset from which to load the data.
callbacks : list of functions
Callback functions, each of which will be invoked when a batch is done.
batch_size : integer
Batch size for prediction
See Also
--------
:class:`metrics.accuracy.Accuracy`
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
with torch.no_grad():
for data, labels in dataloader:
data = data.to(self._device)
labels = labels.to(self._device)
y_mini_batch_pred = self._model(data)
for callback in callbacks:
callback(labels, y_mini_batch_pred)
def one_sample_intermediate_layer_outputs(self, sample, callbacks, ):
y_mini_batch_outputs, y_mini_batch_inputs = {}, {}
hook_handles = []
intermediate_layers = self._intermediate_layers(self._model)
for name, intermediate_layer in intermediate_layers.items():
def hook(module, input, output, name):
# y_mini_batch_outputs.append(output)
# y_mini_batch_inputs.append(input[0])
y_mini_batch_outputs[name] = output
y_mini_batch_inputs[name] = input[0]
hook_fn = partial(hook, name=name)
handle = intermediate_layer.register_forward_hook(hook_fn)
hook_handles.append(handle)
with torch.no_grad():
y_mini_batch_inputs.clear()
y_mini_batch_outputs.clear()
output = self._model(sample)
for callback in callbacks:
callback(y_mini_batch_inputs, y_mini_batch_outputs, 0)
for handle in hook_handles:
handle.remove()
return output
def _intermediate_layers(self, module, pre_name=""):
"""Get the intermediate layers of the model.
The method will get some intermediate layers of the model which might
be useful for neuron coverage computation. Some layers such as dropout
layers are excluded empirically.
Returns
-------
list of torch.nn.modules
Intermediate layers of the model.
"""
intermediate_layers = {}
for name, submodule in module.named_children():
if pre_name == "":
full_name = f"{name}"
else:
full_name = f"{pre_name}.{name}"
if len(submodule._modules) > 0:
intermediate_layers.update(self._intermediate_layers(submodule, full_name))
else:
# if 'Dropout' in str(submodule.type) or 'BatchNorm' in str(submodule.type) or 'ReLU' in str(submodule.type):
# if 'Dropout' in str(submodule.type) or 'ReLU' in str(submodule.type) or 'Linear' in str(submodule.type) or 'Pool' in str(submodule.type):
# continue
if not "Conv2d" in str(submodule.type):
continue
if self.intermedia_mode == "layer":
if type(self._model).__name__ == "ResNet":
if not full_name[-5:] == "1.bn2":
continue
else:
...
intermediate_layers[full_name] = submodule
if full_name not in self.full_names:
self.full_names.append(full_name)
# print(full_name, )
return intermediate_layers
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/strong_neuron_activation_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class StrongNeuronActivationCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(StrongNeuronActivationCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, k):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
neuron_min = np.min(layer_neurons)
neuron_max = np.max(layer_neurons)
interval = (neuron_max - neuron_min) / k
strong_thred = neuron_max - interval
active_idxs = np.argwhere(layer_neurons > strong_thred)
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/test_max.py
================================================
import numpy as np
from pdb import set_trace as st
def get_max_values(array, k):
indexs = tuple()
while k > 0:
idx = np.argwhere(array == array.max())
idx = np.ascontiguousarray(idx).reshape(-1)
# indexs.append(idx)
indexs += (idx,)
array[idx] = -np.inf
print(idx.shape)
k -= len(idx)
indexs = np.concatenate(indexs)
# return indexs
st()
a = np.array([5,12,32,659,-4,5,23,659]).astype(np.float32)
np.sort(a)
st()
get_max_values(a, 4)
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/top_k_coverage.py
================================================
"""
Provides a class for model neuron coverage evaluation.
"""
from __future__ import absolute_import
import numpy as np
from numba import njit, prange
from .utils import common
from .my_neuron_coverage import MyNeuronCoverage
from pdb import set_trace as st
class TopKNeuronCoverage(MyNeuronCoverage):
def __init__(self, k=5):
super(TopKNeuronCoverage, self).__init__(threshold=k)
self._threshould = k
self._topk = k
assert isinstance(k, int)
@staticmethod
@njit(parallel=True)
def _calc_1(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has more than
one dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
mean = np.mean(neuron_output)
layer_neurons.append(mean)
layer_neurons = np.array(layer_neurons)
# print(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
@staticmethod
@njit(parallel=True)
def _calc_2(intermediate_layer_output, features_index, threshold):
"""Calculate the mean of each output from each neuron in the layer and
keep the maximum
Parameters
----------
intermediate_layer_output : array
The scaled output of one intermediate layer.
features_index : integer
The index of feature in each intermediate layer output array.
It should be either 0 or -1.
Returns
-------
array
The maximum output mean of each neuron.
Notes
-------
This method is only used for intermediate output which has only one
dimension.
This method is accelerated with numba. Link: http://numba.pydata.org/
"""
num_layer_neuron = intermediate_layer_output[0].shape[features_index]
num_input = len(intermediate_layer_output)
result = np.zeros(shape=(num_input, num_layer_neuron), dtype=np.uint8)
for input_id in prange(intermediate_layer_output.shape[0]):
layer_neurons = []
for layer_neuron_id in prange(num_layer_neuron):
if features_index == -1:
neuron_output = intermediate_layer_output[input_id][..., layer_neuron_id]
else:
neuron_output = intermediate_layer_output[input_id][layer_neuron_id]
layer_neurons.append(neuron_output)
layer_neurons = np.array(layer_neurons)
k = min(threshold, num_layer_neuron)
active_idxs = np.argsort(layer_neurons)[-k:]
for neuron_idx in active_idxs:
result[input_id][neuron_idx] = 1
return result
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/__init__.py
================================================
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/common.py
================================================
"""
Provides some useful functions.
"""
from __future__ import absolute_import
import os
import time
import numpy as np
def readable_time_str():
"""Get readable time string based on current local time.
The time string will be formatted as %Y-%m-%d %H:%M:%S.
Returns
-------
str
Readable time string.
"""
return time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
def user_home_dir():
"""Get path of user home directory.
Returns
-------
str
Path of user home directory.
"""
return os.path.expanduser("~")
def to_numpy(data):
"""Convert other data type to numpy. If the data itself
is numpy type, then a copy will be made and returned.
Returns
-------
numpy.array
Numpy array of passed data.
"""
if 'mxnet' in str(type(data)):
data = data.asnumpy()
elif 'torch' in str(type(data)):
data = data.cpu().numpy()
elif 'numpy' in str(type(data)):
data = np.copy(data)
return data
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/keras.py
================================================
"""
Provides some useful utils for keras model evaluation.
"""
from __future__ import absolute_import
import random
import cv2
import keras
import numpy as np
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
size : integer
Target image size (input size).
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, fashion, size, transform):
self._dir = dir
self._filenames = filenames
self._fashion = fashion
self._size = size
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = cv2.imread(path)
if self._fashion == 'vgg_preprocessing':
height, width, _ = image.shape
new_height = height * 256 // min(image.shape[:2])
new_width = width * 256 // min(image.shape[:2])
image = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_CUBIC)
height, width, _ = image.shape
startx = width // 2 - (self._size // 2)
starty = height // 2 - (self._size // 2)
image = image[starty:starty + self._size, startx:startx + self._size]
elif self._fashion == 'inception_preprocessing':
height, width, channels = image.shape
assert channels == 3
new_height = int(height * 0.875)
new_width = int(width * 0.875)
startx = (width - new_width) // 2
starty = (height - new_height) // 2
image = image[starty:starty + new_height, startx:startx + new_width]
image = cv2.resize(image, (self._size, self._size), interpolation=cv2.INTER_CUBIC)
else:
raise Exception('Unknown fashion', self._fashion)
image = image[:, :, ::-1]
if self._transform is not None:
image = self._transform(image)
image = np.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = np.concatenate((x, image), axis=0)
x = x.astype(np.float32)
return x
def __init__(self, fashion, size, transform=None, shuffle=False, seed=None, num_max=None):
dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(dir, self._filenames, fashion, size, transform)
self.y = np.array(self.y, dtype=int)
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet50', 'resnet101',
'resnet152', 'resnet50_v2', 'resnet101_v2',
'resnet152_v2', 'mobilenet', 'mobilenet_v2',
'inception_resnet_v2', 'inception_v3', 'xception',
'densenet121', 'densenet169', 'densenet201',
'nasnet_mobile', 'nasnet_large']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of keras.Model
Pretrained model to evaluate.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
keras.backend.set_learning_phase(0)
if model_name == 'vgg16':
model = keras.applications.VGG16()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'vgg19':
model = keras.applications.VGG19()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50':
model = keras.applications.ResNet50()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet101':
model = keras.applications.ResNet101()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet152':
model = keras.applications.ResNet152()
mean = (103.939, 116.779, 123.68)
std = (1, 1, 1)
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x[..., ::-1] - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = -1
elif model_name == 'resnet50_v2':
keras.applications.ResNet50V2()
base_model = keras.applications.ResNet50V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet50v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet101_v2':
keras.applications.ResNet101V2()
base_model = keras.applications.ResNet101V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet101v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'resnet152_v2':
keras.applications.ResNet152V2()
base_model = keras.applications.ResNet152V2(weights=None, include_top=False, input_shape=(299, 299, 3))
x = base_model.output
x = keras.layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = keras.layers.Dense(1000, activation='softmax', name='probs')(x)
model = keras.Model(base_model.input, x)
model.load_weights(common.user_home_dir() + '/.keras/models/resnet152v2_weights_tf_dim_ordering_tf_kernels.h5')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet':
model = keras.applications.MobileNet()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'mobilenet_v2':
model = keras.applications.MobileNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_mobile':
model = keras.applications.NASNetMobile()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=224, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=224, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'nasnet_large':
model = keras.applications.NASNetLarge()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=331, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=331, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_resnet_v2':
model = keras.applications.InceptionResNetV2()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'inception_v3':
model = keras.applications.InceptionV3()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'xception':
model = keras.applications.Xception()
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(fashion='inception_preprocessing', size=299, transform=lambda x: (x - mean) / std)
data_original = ImageNetValData(fashion='inception_preprocessing', size=299, transform=None, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet121':
model = keras.applications.DenseNet121()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet169':
model = keras.applications.DenseNet169()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
elif model_name == 'densenet201':
model = keras.applications.DenseNet201()
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
data_normalized = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: (x / 255.0 - mean) / std)
data_original = ImageNetValData(fashion='vgg_preprocessing', size=224, transform=lambda x: x / 255.0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
bounds = (0, 255)
flip_axis = None
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
return model, data_normalized, data_original, mean, std, flip_axis, bounds
def cifar10_data(train=False, num_max=None):
""" Load cifar10 data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
def mnist_data(train=False, num_max=None):
""" Load mnist data.
Keras dataset utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
y_train = y_train.flatten().astype('int32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
y_test = y_test.flatten().astype('int32')
if num_max is not None:
x_train = x_train[:num_max]
y_train = y_train[:num_max]
x_test = x_test[:num_max]
y_test = y_test[:num_max]
if not train:
return x_test, y_test
else:
return x_train, y_train
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/mxnet.py
================================================
"""
Provides some useful utils for mxnet model evaluation.
"""
from __future__ import absolute_import
import random
import gluoncv
import mxnet
import numpy as np
from evaldnn.utils import common
class ImageNetValDataset(mxnet.gluon.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = mxnet.nd.array(self._y, dtype=int)
self._transform = mxnet.gluon.data.vision.transforms.Compose([mxnet.gluon.data.vision.transforms.Resize(resize_size, keep_ratio=True), mxnet.gluon.data.vision.transforms.CenterCrop(center_crop_size), mxnet.gluon.data.vision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = mxnet.image.imread(path)
x = self._transform(x)
if self._preprocess:
mean = mxnet.nd.array(self.mean).reshape(3, 1, 1)
std = mxnet.nd.array(self.std).reshape(3, 1, 1)
x = (x - mean) / std
y = self._y[index].asscalar()
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'mobilenet0_25',
'mobilenet0_5', 'mobilenet1_0', 'mobilenet_v2_1_0',
'resnet101_v1', 'resnet101_v2', 'resnet152_v1',
'resnet152_v2', 'resnet50_v1', 'resnet50_v2',
'resnext50_32x4d', 'squeezenet1_0',
'inception_v3', 'xception']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of mxnet.gluon.nn.Block
Pretrained model to evaluate.
dataset_normalized: instance of mxnet.gluon.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of mxnet.gluon.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = gluoncv.model_zoo.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = gluoncv.model_zoo.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = gluoncv.model_zoo.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = gluoncv.model_zoo.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = gluoncv.model_zoo.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = gluoncv.model_zoo.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_25':
model = gluoncv.model_zoo.mobilenet0_25(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet0_5':
model = gluoncv.model_zoo.mobilenet0_5(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet1_0':
model = gluoncv.model_zoo.mobilenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0':
model = gluoncv.model_zoo.mobilenet_v2_1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v1':
model = gluoncv.model_zoo.resnet101_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101_v2':
model = gluoncv.model_zoo.resnet101_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v1':
model = gluoncv.model_zoo.resnet152_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152_v2':
model = gluoncv.model_zoo.resnet152_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v1':
model = gluoncv.model_zoo.resnet50_v1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50_v2':
model = gluoncv.model_zoo.resnet50_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = gluoncv.model_zoo.get_model('ResNext50_32x4d', pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = gluoncv.model_zoo.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = gluoncv.model_zoo.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'xception':
model = gluoncv.model_zoo.get_model('Xception', pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.CIFAR10(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
Gluon data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = mxnet.gluon.data.vision.MNIST(train=train)
dataset._data = mxnet.nd.transpose(dataset._data.astype(np.float32), (0, 3, 1, 2)) / 255
if num_max is not None:
dataset._data = dataset._data[:num_max]
dataset._label = dataset._label[:num_max]
return dataset
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/pytorch.py
================================================
"""
Provides some useful utils for torch model evaluation.
"""
from __future__ import absolute_import
import random
import PIL
import numpy as np
import torch
import torchvision
from evaldnn.utils import common
class ImageNetValDataset(torch.utils.data.Dataset):
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
resize_size : integer
Size used for resizing images.
center_crop_size : integer
Size used for center cropping images.
preprocess : bool
Indicate whether or not to preprocess the images, normalizing them with
mean and standard deviation.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def __init__(self, resize_size, center_crop_size, preprocess, shuffle=False, seed=None, num_max=None):
self._preprocess = preprocess
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self._y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self._y.append(int(splits[2]))
self._y = torch.LongTensor(self._y)
self._transforms = torchvision.transforms.Compose([torchvision.transforms.Resize(resize_size), torchvision.transforms.CenterCrop(center_crop_size), torchvision.transforms.ToTensor()])
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
path = self._dir + '/' + self._filenames[index]
x = PIL.Image.open(path)
x = x.convert('RGB')
x = self._transforms(x)
if self._preprocess:
x = torchvision.transforms.Normalize(mean=self.mean, std=self.std)(x)
y = self._y[index]
return x, y
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'alexnet', 'densenet121',
'densenet169', 'densenet201', 'googlenet',
'inception_v3', 'mnasnet', 'mobilenet_v2',
'resnet50', 'resnet101', 'resnet152',
'resnext50_32x4d', 'shufflenet_V2',
'squeezenet1_0', 'squeezenet1_1',
'wide_resnet50_2', 'wide_resnet101_2']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
model : instance of torch.nn.Module
Pretrained model to evaluate.
dataset_normalized: instance of torch.utils.data.Dataset
Normalized dataset, used to do predictions and get intermediate outputs.
dataset_original: instance of torch.utils.data.Dataset
Original dataset, used to perform adversarial attack.
preprocessing : tuple
A tuple with two elements representing mean and standard deviation.
num_classes : int
The number of classes.
bounds : tuple of length 2
The bounds for the pixel values.
"""
if model_name == 'vgg16':
model = torchvision.models.vgg16(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
model = torchvision.models.vgg19(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'alexnet':
model = torchvision.models.alexnet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet121':
model = torchvision.models.densenet121(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet169':
model = torchvision.models.densenet169(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'densenet201':
model = torchvision.models.densenet201(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'googlenet':
model = torchvision.models.googlenet(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
model = torchvision.models.inception_v3(pretrained=True)
dataset_normalized = ImageNetValDataset(299, 299, True)
dataset_original = ImageNetValDataset(299, 299, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mnasnet':
model = torchvision.models.mnasnet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2':
model = torchvision.models.mobilenet_v2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet18':
model = torchvision.models.resnet18(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet50':
model = torchvision.models.resnet50(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet101':
model = torchvision.models.resnet101(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet152':
model = torchvision.models.resnet152(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnext50_32x4d':
model = torchvision.models.resnext50_32x4d(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'shufflenet_V2':
model = torchvision.models.shufflenet_v2_x1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_0':
model = torchvision.models.squeezenet1_0(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'squeezenet1_1':
model = torchvision.models.squeezenet1_1(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet50_2':
model = torchvision.models.wide_resnet50_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'wide_resnet101_2':
model = torchvision.models.wide_resnet101_2(pretrained=True)
dataset_normalized = ImageNetValDataset(256, 224, True)
dataset_original = ImageNetValDataset(256, 224, False, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
preprocessing = (np.array(ImageNetValDataset.mean).reshape((3, 1, 1)), np.array(ImageNetValDataset.std).reshape((3, 1, 1)))
num_classes = 1000
bounds = (0, 1)
return model, dataset_normalized, dataset_original, preprocessing, num_classes, bounds
def cifar10_dataset(train=False, num_max=None):
""" Load cifar10 data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.CIFAR10(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.from_numpy(dataset.data / 255.0).permute(0, 3, 1, 2).float()
y = torch.tensor(dataset.targets)
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
def mnist_dataset(train=False, num_max=None):
""" Load mnist data.
torchvision data utils are used to download and load the data.
Parameters
----------
train : bool
If it is false, test data will be loaded. Otherwise, train data will be
used.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
dataset = torchvision.datasets.MNIST(root=common.user_home_dir() + '/EvalDNN-data', train=train, download=True)
x = torch.unsqueeze((dataset.data / 255.0), 1)
y = dataset.targets
if num_max is not None:
x = x[:num_max]
y = y[:num_max]
dataset = torch.utils.data.dataset.TensorDataset(x, y)
return dataset
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/coverage/utils/tensorflow.py
================================================
"""
Provides some useful utils for tensorflow model evaluation.
"""
from __future__ import absolute_import
import random
import warnings
import numpy as np
import tensorflow as tf
from tensorflow.contrib.slim.nets import inception
from tensorflow.contrib.slim.nets import nasnet
from tensorflow.contrib.slim.nets import pnasnet
from tensorflow.contrib.slim.nets import resnet_v1
from tensorflow.contrib.slim.nets import resnet_v2
from tensorflow.contrib.slim.nets import vgg
from evaldnn.utils import common
class ImageNetValData():
""" Class for loading and preprocessing imagenet validation set.
One can download the imagenet validation set at http://image-net.org/.
To use this class, one should also download ILSVRC2012_validation_ground_truth.txt
and put it in the same directory as the imagenet validation set.
Parameters
----------
width : integer
Target image width.
height : integer
Target image height.
fashion : str
Indicate the preprocessing fashion. It can be either vgg_preprocessing
or inception_preprocessing.
transform : function(image) -> image
The transform function for preprocessing image after the image is loaded
and cropped to proper size.
label_offset : integer
The offset of the label. For some models the offset should be set to 1
because these models are trained with 1001 classes.
shuffle : bool
Indicate whether or not to shuffle the images.
seed : integer
Random seed used for shuffle.
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
"""
class ImageNetValDataX():
def __init__(self, dir, filenames, width, height, fashion, transform):
self._dir = dir
self._filenames = filenames
self._width = width
self._height = height
self._fashion = fashion
self._transform = transform
def __len__(self):
return len(self._filenames)
def __getitem__(self, index):
tf.compat.v1.enable_eager_execution()
x = None
for filename in self._filenames[index]:
path = self._dir + '/' + filename
image = tf.image.decode_image(tf.io.read_file(path), channels=3)
if self._fashion == 'vgg_preprocessing':
image = self._aspect_preserving_resize(image, 256)
image = self._central_crop([image], self._height, self._width)[0]
image.set_shape([self._height, self._width, 3])
image = tf.cast(image, dtype=tf.float32)
elif self._fashion == 'inception_preprocessing':
image = tf.cast(image, tf.float32)
image.set_shape([tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(None), tf.compat.v1.Dimension(3)])
image = tf.image.central_crop(image, central_fraction=0.875)
image = tf.expand_dims(image, 0)
image = tf.compat.v1.image.resize_bilinear(image, [self._width, self._height], align_corners=False)
image = tf.squeeze(image, [0])
else:
raise Exception('Invalid fashion', self._fashion)
if self._transform is not None:
image = self._transform(image)
image = tf.expand_dims(image, axis=0)
if x is None:
x = image
else:
x = tf.concat([x, image], 0)
x = x.numpy()
tf.compat.v1.disable_eager_execution()
return x
def _smallest_size_at_least(self, height, width, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
height = tf.cast(height, dtype=tf.float32)
width = tf.cast(width, dtype=tf.float32)
smallest_side = tf.cast(smallest_side, dtype=tf.float32)
scale = tf.cond(tf.greater(height, width), lambda: smallest_side / width, lambda: smallest_side / height)
new_height = tf.cast(tf.math.rint(height * scale), dtype=tf.int32)
new_width = tf.cast(tf.math.rint(width * scale), dtype=tf.int32)
return new_height, new_width
def _aspect_preserving_resize(self, image, smallest_side):
smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
shape = tf.shape(image)
height = shape[0]
width = shape[1]
new_height, new_width = self._smallest_size_at_least(height, width, smallest_side)
image = tf.expand_dims(image, 0)
resized_image = tf.compat.v1.image.resize_bilinear(image, [new_height, new_width], align_corners=False)
resized_image = tf.squeeze(resized_image)
resized_image.set_shape([None, None, 3])
return resized_image
def _central_crop(self, image_list, crop_height, crop_width):
outputs = []
for image in image_list:
image_height = tf.shape(image)[0]
image_width = tf.shape(image)[1]
offset_height = (image_height - crop_height) / 2
offset_width = (image_width - crop_width) / 2
outputs.append(self._crop(image, offset_height, offset_width, crop_height, crop_width))
return outputs
def _crop(self, image, offset_height, offset_width, crop_height, crop_width):
original_shape = tf.shape(image)
rank_assertion = tf.Assert(tf.equal(tf.rank(image), 3), ['Rank of image must be equal to 3.'])
with tf.control_dependencies([rank_assertion]):
cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
size_assertion = tf.Assert(
tf.logical_and(tf.greater_equal(original_shape[0], crop_height), tf.greater_equal(original_shape[1], crop_width)), ['Crop size greater than the image size.'])
offsets = tf.cast(tf.stack([offset_height, offset_width, 0]), dtype=tf.int32)
with tf.control_dependencies([size_assertion]):
image = tf.slice(image, offsets, cropped_shape)
return tf.reshape(image, cropped_shape)
def __init__(self, width, height, fashion, transform=None, label_offset=0, shuffle=False, seed=None, num_max=None):
self._dir = common.user_home_dir() + '/EvalDNN-data/ILSVRC2012_img_val'
with open(self._dir + '/ILSVRC2012_validation_ground_truth.txt', 'r') as f:
lines = f.readlines()
if shuffle:
if seed is not None:
random.seed(seed)
random.shuffle(lines)
if num_max is not None:
lines = lines[:num_max]
self._filenames = []
self.y = []
for line in lines:
splits = line.split('---')
if len(splits) != 5:
continue
self._filenames.append(splits[0])
self.y.append(int(splits[2]))
self.x = self.ImageNetValDataX(self._dir, self._filenames, width, height, fashion, transform)
self.y = np.array(self.y, dtype=int) + label_offset
def __len__(self):
return len(self._filenames)
@property
def filenames(self):
return self._filenames
def imagenet_benchmark_zoo_model_names():
""" Get the names of all models naturally supported by this toolbox.
Returns
-------
list of str
The names of all models supported.
"""
return ['vgg16', 'vgg19', 'resnet_v1_101', 'resnet_v1_152',
'resnet_v1_50', 'inception_v1', 'inception_v2',
'inception_v3', 'inception_v4', 'inception_resnet_v2',
'mobilenet_v1_0_5_160', 'mobilenet_v1_0_25_128',
'mobilenet_v1_1_0_224', 'mobilenet_v2_1_0_224',
'mobilenet_v2_1_4_224', 'resnet_v2_101',
'resnet_v2_152', 'resnet_v2_50',
'nasnet_a_mobile_224', 'pnasnet_5_mobile_224',
'nasnet_a_large_331', 'pnasnet_5_large_331']
def imagenet_benchmark_zoo(model_name, data_original_shuffle=True, data_original_seed=1997, data_original_num_max=None):
"""Get pretrained model, validation data and other relative info for evaluation.
The method provides convenience for getting a pretrained model, validation data
and other info needed for perform evaluation.
With this method, one no longer needs to create model or preprocess the inputs
on their own.
Parameters
----------
model_name : str
Model name.
data_original_shuffle : bool
Indicate whether or not to shuffle original images.
data_original_seed : integer
Random seed used for shuffle original images.
data_original_num_max : integer
The maximum number of original images to load. If it is set to none, all images
will be loaded.
Returns
-------
session : `tensorflow.session`
The session with which the graph will be computed.
logits : `tensorflow.Tensor`
The predictions of the model.
inputs : `tensorflow.Tensor`
The input to the model, usually a `tensorflow.placeholder`.
data_normalized: instance of evaldnn.utils.keras.ImageNetValData
Normalized data, used to do predictions and get intermediate outputs.
data_original: instance of evaldnn.utils.keras.ImageNetValData
Original data, used to perform adversarial attack.
mean : tuple
Mean of images.
std : tuple
Standard deviation of images.
flip_axis : integer or None
Indicate whether or not inputs should be flipped.
bounds : tuple of length 2
The bounds for the pixel values.
"""
tf.get_logger().setLevel('ERROR')
if model_name == 'vgg16':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_16(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_16.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'vgg19':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
logits, _ = vgg.vgg_19(input, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/vgg_19.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_101(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_101.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_152(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_152.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v1_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v1.resnet_arg_scope()):
resnet_v1.resnet_v1_50(input, num_classes=1000, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v1_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v1_50.ckpt')
mean = (123.68, 116.78, 103.94)
std = (1, 1, 1)
data_normalized = ImageNetValData(224, 224, 'vgg_preprocessing', transform=lambda x: (x - mean) / std, label_offset=0)
data_original = ImageNetValData(224, 224, 'vgg_preprocessing', transform=None, label_offset=0, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v1':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v1_arg_scope()):
logits, _ = inception.inception_v1(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v1.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v2_arg_scope()):
logits, _ = inception.inception_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v2.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v3':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v3_arg_scope()):
logits, _ = inception.inception_v3(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v3.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_v4':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_v4_arg_scope()):
logits, _ = inception.inception_v4(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_v4.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'inception_resnet_v2':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(inception.inception_resnet_v2_arg_scope()):
logits, _ = inception.inception_resnet_v2(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/inception_resnet_v2_2016_08_30.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_5_160':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.5_160/mobilenet_v1_0.5_160_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 160, 160, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(160, 160, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(160, 160, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_0_25_128':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_0.25_128/mobilenet_v1_0.25_128_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 128, 128, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(128, 128, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(128, 128, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v1_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV1/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_0_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.0_224/mobilenet_v2_1.0_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'mobilenet_v2_1_4_224':
graph = tf.Graph()
with tf.io.gfile.GFile(common.user_home_dir() + '/EvalDNN-models/tensorflow/mobilenet_v2_1.4_224/mobilenet_v2_1.4_224_frozen.pb', 'rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with graph.as_default():
input = tf.compat.v1.placeholder(np.float32, shape=[None, 224, 224, 3])
tf.import_graph_def(graph_def, {'input': input})
session = tf.compat.v1.InteractiveSession(graph=graph)
logits = graph.get_tensor_by_name('import/MobilenetV2/Predictions/Reshape_1:0')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_large_arg_scope()):
logits, end_points = nasnet.build_nasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_large_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'nasnet_a_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(nasnet.nasnet_mobile_arg_scope()):
logits, end_points = nasnet.build_nasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/nasnet-a_mobile_04_10_2017/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_large_331':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 331, 331, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_large_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_large(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_large_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(331, 331, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(331, 331, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'pnasnet_5_mobile_224':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 224, 224, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(pnasnet.pnasnet_mobile_arg_scope()):
logits, end_points = pnasnet.build_pnasnet_mobile(input, 1001, is_training=False)
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/pnasnet-5_mobile_2017_12_13/model.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(224, 224, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(224, 224, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_101':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_101(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_101/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_101_2017_04_14/resnet_v2_101.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_152':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_152(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_152/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_152_2017_04_14/resnet_v2_152.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
elif model_name == 'resnet_v2_50':
session = tf.compat.v1.InteractiveSession(graph=tf.Graph())
input = tf.compat.v1.placeholder(tf.float32, shape=(None, 299, 299, 3))
with warnings.catch_warnings():
warnings.simplefilter('ignore', category=DeprecationWarning)
with tf.contrib.slim.arg_scope(resnet_v2.resnet_arg_scope()):
resnet_v2.resnet_v2_50(input, num_classes=1001, is_training=False)
logits = session.graph.get_tensor_by_name('resnet_v2_50/predictions/Reshape:0')
restorer = tf.compat.v1.train.Saver()
restorer.restore(session, common.user_home_dir() + '/EvalDNN-models/tensorflow/resnet_v2_50_2017_04_14/resnet_v2_50.ckpt')
mean = (127.5, 127.5, 127.5)
std = (127.5, 127.5, 127.5)
data_normalized = ImageNetValData(299, 299, 'inception_preprocessing', transform=lambda x: (x - mean) / std, label_offset=1)
data_original = ImageNetValData(299, 299, 'inception_preprocessing', transform=None, label_offset=1, shuffle=data_original_shuffle, seed=data_original_seed, num_max=data_original_num_max)
else:
raise Exception('Invalid model name: ' + model_name + '. Available model names :' + str(imagenet_benchmark_zoo_model_names()))
bounds = (0, 255)
return session, logits, input, data_normalized, data_original, mean, std, bounds
def cifar10_test_data(num_max=None):
""" Load cifar10 data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/cifar-10-tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
def mnist_test_data(num_max=None):
""" Load mnist data.
Parameters
----------
num_max : integer
The maximum number of images to load. If it is set to none, all images
will be loaded.
Notes
----------
Corresponding data should be downloaded manually in advance.
"""
x_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/x_test.npy')
y_test = np.load(common.user_home_dir() + '/EvalDNN-data/MNIST/tensorflow/y_test.npy')
if num_max is not None:
x_test = x_test[:num_max]
y_test = y_test[:num_max]
return x_test, y_test
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/my_profile.py
================================================
import argparse
import torch
import time
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
import os
import os.path as osp
import random
import copy
import logging
import pickle
from PIL import Image
from pdb import set_trace as st
from torchvision import transforms
sys.path.append('..')
from clean_dataset.cub200 import CUB200Data
from clean_dataset.mit67 import MIT67Data
from clean_dataset.stanford_40 import Stanford40Data
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.top_k_coverage import TopKNeuronCoverage
from coverage.strong_neuron_activation_coverage import StrongNeuronActivationCoverage
# from DNNtest.coverage.my_neuron_coverage import MyNeuronCoverage
from coverage.pytorch_wrapper import PyTorchModel
def adv_whitebox(model, loader, args, bounds,):
model.eval()
low_bound, up_bound = bounds
loss = nn.CrossEntropyLoss()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
total += images.size(0)
out_clean = model(images)
_, pred_clean = out_clean.max(dim=1)
adv_images = images.clone().detach()
if args.random_start:
# Starting at a uniformly random point
adv_images = adv_images + torch.empty_like(adv_images).uniform_(-args.eps, args.eps)
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
for _ in range(args.pgd_iter):
adv_images.requires_grad = True
outputs = model(adv_images)
# Calculate loss
if args.targeted:
cost = -loss(outputs, target_labels)
else:
cost = loss(outputs, label)
# Update adversarial images
grad = torch.autograd.grad(cost, adv_images,
retain_graph=False, create_graph=False)[0]
adv_images = adv_images.detach() + args.alpha*grad.sign()
delta = torch.clamp(adv_images - images, min=-args.eps, max=args.eps)
adv_images = (images + delta).detach()
adv_images[adv_images < low_bound] = low_bound[adv_images < low_bound]
adv_images[adv_images > up_bound] = up_bound[adv_images > up_bound]
out_adv = model(adv_images)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
print('{}/{}...'.format(i+1, len(loader)))
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial *100
def get_coverage(args,):
if args.coverage == "neuron_coverage":
coverage = MyNeuronCoverage(threshold=args.nc_threshold)
elif args.coverage == "top_k_coverage":
coverage = TopKNeuronCoverage(k=10)
elif args.coverage == "strong_coverage":
coverage = StrongNeuronActivationCoverage(k=2)
else:
raise NotImplementedError
return coverage
def compute_selected_neuron_value(
selected_neuron, compressed_intermediate_layer_outputs, global_neuron_id_to_layer_neuron_id
):
assert isinstance(selected_neuron, list)
num_input = len(selected_neuron)
input_neuron_value = []
for input_id in range(num_input):
values = []
for global_id in selected_neuron[input_id]:
layer_id, layer_neuron_id = global_neuron_id_to_layer_neuron_id[global_id]
neuron_value = compressed_intermediate_layer_outputs[layer_id][input_id][layer_neuron_id]
values.append(neuron_value)
values = torch.stack(values, dim=0).sum()
input_neuron_value.append(values)
input_neuron_value = torch.stack(input_neuron_value, dim=0)
return input_neuron_value
def log_coverage(model, loader, args, ):
model.eval()
measure_model = PyTorchModel(model, intermedia_mode=args.intermedia_mode)
coverage_metric = get_coverage(args)
log_names = measure_model.full_names
print(log_names)
intermedia_layers = measure_model._intermediate_layers(model)
accumulate_coverage = {}
for name, module in intermedia_layers.items():
weight = module.weight
out_shape, in_shape = weight.shape[:2]
accumulate_coverage[name] = [np.zeros(in_shape), np.zeros(out_shape)]
for idx, (images, label) in enumerate(loader):
images, label = images.to('cuda'), label.to('cuda')
outputs = measure_model.one_sample_intermediate_layer_outputs(
images,
# [coverage_metric.update, coverage_metric.report],
[coverage_metric.update, ],
)
batch_layer_cover = coverage_metric.get()
for layer_name, (input_coverage, output_coverage) in batch_layer_cover.items():
# print(layer_idx, accumulate_coverage[layer_idx][0].shape, input_coverage.sum(0).shape)
accumulate_coverage[layer_name][0] += input_coverage.sum(0)
accumulate_coverage[layer_name][1] += output_coverage.sum(0)
# if idx > 5:
# break
if idx % 100 == 0:
print(f"Profiling {idx}/{len(loader)}")
return accumulate_coverage, log_names
def record_act(self, input, output):
pass
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--datapath", type=str, default='/data', help='path to the dataset')
parser.add_argument("--dataset", type=str, default='CUB200Data', help='Target dataset. Currently support: \{SDog120Data, CUB200Data, Stanford40Data, MIT67Data, Flower102Data\}')
parser.add_argument("--name", type=str, default='test')
parser.add_argument("--B", type=float, default=0.1, help='Attack budget')
parser.add_argument("--m", type=float, default=1000, help='Hyper-parameter for task-agnostic attack')
parser.add_argument("--pgd_iter", type=int, default=40)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dropout", type=float, default=0)
parser.add_argument("--checkpoint", type=str, default='')
parser.add_argument("--network", type=str, default='resnet18', help='Network architecture. Currently support: \{resnet18, resnet50, resnet101, mbnetv2\}')
parser.add_argument("--teacher", default=None)
parser.add_argument("--output_dir")
parser.add_argument("--test_num", type=int, default=500)
parser.add_argument("--num_try_per_sample", type=int, default=10)
parser.add_argument("--sample_queue_length", type=int, default=10)
parser.add_argument("--nc_threshold", type=float, default=0.5)
parser.add_argument("--strategy", default="random", choices=["random", "deepxplore", "dlfuzz", "dlfuzzfirst"])
parser.add_argument("--coverage", default="neuron_coverage")
parser.add_argument("--k_select_neuron", type=int, default=20)
parser.add_argument("--intermedia_mode", default="")
parser.add_argument("--eps", type=float, default=0.1)
parser.add_argument("--alpha", type=float, default=0.01)
parser.add_argument("--random_start", type=bool, default=True)
parser.add_argument("--targeted", type=bool, default=False)
args = parser.parse_args()
if args.teacher is None:
args.teacher = args.network
return args
def load_student(ckpt, args, num_classes):
model = eval('{}_dropout'.format(args.network))(
pretrained=True,
dropout=args.dropout,
num_classes=num_classes
).cuda()
if not os.path.exists(ckpt):
raise RuntimeError(f"{args.checkpoint} Not exist")
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint['state_dict'])
print(f"Loaded checkpoint from {ckpt}")
model.eval()
return model
if __name__ == '__main__':
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
np.set_printoptions(precision=4)
args = get_args()
# print(args)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir, exist_ok=True)
args.pid = os.getpid()
args.log_path = osp.join(args.output_dir, "log.txt")
if os.path.exists(args.log_path):
log_lens = len(open(args.log_path, 'r').readlines())
if log_lens > 5:
print(f"{args.log_path} exists")
exit()
args.info = f"{args.strategy}_{args.coverage}_{args.dataset}_{args.network}"
logging.basicConfig(filename=args.log_path, filemode="w", level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logger = logging.getLogger()
logger.info(args)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
model_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
test_set = eval(args.dataset)(
args.datapath, True, transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]),
-1, seed, preload=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False, drop_last=True)
model = eval('{}_dropout'.format(args.network))(pretrained=True, num_classes=test_set.num_classes).cuda()
if args.checkpoint != '':
checkpoint = torch.load(args.checkpoint)
model.load_state_dict(checkpoint['state_dict'])
print(f"Loaded student checkpoint from {args.checkpoint}")
accumulate_coverage, log_names = log_coverage(
model, test_loader, args,
)
path = osp.join(args.output_dir, "accumulate_coverage.pkl")
with open(path, "wb") as f:
pickle.dump(accumulate_coverage, f)
path = osp.join(args.output_dir, "log_module_names.pkl")
with open(path, "wb") as f:
pickle.dump(log_names, f)
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/nc_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
from weight_pruner import WeightPruner
class NCPruner(WeightPruner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(NCPruner, self).__init__(
args, model, teacher, train_loader, test_loader
)
def prune_record(self, log):
print(log)
self.logger.write(log+"\n")
def init_prune(self):
ratio = self.args.weight_init_prune_ratio
log = f"Init prune ratio {ratio:.2f}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
def check_param_num(self):
model = self.model
total = sum([module.weight.nelement() for module in model.modules() if isinstance(module, nn.Conv2d) ])
num = total
for m in model.modules():
if ( isinstance(m, nn.Conv2d) ):
num -= int((m.weight.data == 0).sum())
ratio = (total - num) / total
log = f"===>Check: Total {total}, current {num}, prune ratio {ratio:2f}"
self.prune_record(log)
def load_nc_info(self,):
path = osp.join(self.args.nc_info_dir, "accumulate_coverage.npy")
with open(path, "rb") as f:
accumulate_coverage = np.load(f, allow_pickle=True)
path = osp.join(self.args.nc_info_dir, "log_module_names.npy")
with open(path, "rb") as f:
log_names = np.load(f, allow_pickle=True)
return accumulate_coverage, log_names
st()
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total_weight = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total_weight += module.weight.numel()
accumulate_coverage, log_names = self.load_nc_info()
all_weight_coverage = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
all_weight_coverage.append(input_coverage[input_idx] + output_coverage[output_idx])
# prune_ratio = 0.05
total = len(all_weight_coverage)
sorted_coverage = np.sort(all_weight_coverage, )
thre_index = int(total * prune_ratio)
if thre_index == total:
thre_index -= 1
thre = sorted_coverage[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
prune_index = {}
for layer_index, module_name in enumerate(log_names):
prune_index[module_name] = []
for layer_idx, (input_coverage, output_coverage) in enumerate(accumulate_coverage):
input_dim, output_dim = len(input_coverage), len(output_coverage)
module_name = log_names[layer_idx]
for input_idx in range(input_dim):
for output_idx in range(output_dim):
score = input_coverage[input_idx] + output_coverage[output_idx]
if score < thre:
prune_index[module_name].append((input_idx, output_idx))
pruned = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone()
assert name in prune_index, f"{name} not in log names"
if len(prune_index[name]) == 0:
continue
for (input_idx, output_idx) in prune_index[name]:
weight_copy[output_idx, input_idx] -= weight_copy[output_idx, input_idx]
weight_copy[weight_copy!=0] = 1.
mask = weight_copy
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
log = (f"Total conv params: {total_weight}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total_weight:.2f}")
self.prune_record(log)
self.model = model.cuda()
self.check_param_num()
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/CV_backdoor/remos/remos_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import time
import pickle
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
from advertorch.attacks import LinfPGDAttack
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
from .nc_pruner import NCPruner
class ReMoSPruner(NCPruner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(ReMoSPruner, self).__init__(
args, model, teacher, train_loader, test_loader
)
def load_nc_info(self,):
path = osp.join(self.args.nc_info_dir, "accumulate_coverage.pkl")
with open(path, "rb") as f:
accumulate_coverage = pickle.load(f, )
path = osp.join(self.args.nc_info_dir, "log_module_names.pkl")
with open(path, "rb") as f:
log_names = pickle.load(f, )
return accumulate_coverage, log_names
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total_weight = 0
layer_to_rank = {}
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total_weight += module.weight.numel()
layer_to_rank[name] = module.weight.data.clone().numpy()
layer_to_rank[name].fill(0)
accumulate_coverage, log_names = self.load_nc_info()
all_weight_coverage, adv_weight_coverage = [], []
for layer_name, (input_coverage, output_coverage) in accumulate_coverage.items():
input_dim, output_dim = len(input_coverage), len(output_coverage)
for input_idx in range(input_dim):
for output_idx in range(output_dim):
coverage_score = input_coverage[input_idx] + output_coverage[output_idx]
all_weight_coverage.append((coverage_score, (layer_name, input_idx, output_idx)))
# prune_ratio = 0.05
sorted_coverage = sorted(all_weight_coverage, key=lambda item: item[0])
accumulate_index = 0
for (coverage_score, pos) in sorted_coverage:
layer_name, input_idx, output_idx = pos
layer_to_rank[layer_name][output_idx, input_idx] = accumulate_index
h, w = layer_to_rank[layer_name].shape[2:]
accumulate_index += h*w
start = time.time()
layer_idx = 0
weight_list = []
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone().numpy()
output_dim, input_dim, h, w = weight_copy.shape
for output_idx in range(output_dim):
for input_idx in range(input_dim):
for h_idx in range(h):
for w_idx in range(w):
weight_score = weight_copy[output_idx, input_idx, h_idx, w_idx]
weight_list.append( (weight_score, (layer_idx, input_idx, output_idx, h_idx, w_idx)) )
layer_idx += 1
sorted_weight = sorted(weight_list, key=lambda item: item[0])
end = time.time()
weight_sort_time = end - start
log = f"Sort weight time {weight_sort_time}"
self.prune_record(log)
for weight_rank, (weight_score, pos) in enumerate(sorted_weight):
layer_idx, input_idx, output_idx, h_idx, w_idx = pos
layer_name = log_names[layer_idx]
layer_to_rank[layer_name][output_idx, input_idx, h_idx, w_idx] -= weight_rank
start = time.time()
nc_weight_ranks = []
for layer_name in log_names:
nc_weight_ranks.append( layer_to_rank[layer_name].flatten() )
nc_weight_ranks = np.concatenate(nc_weight_ranks)
nc_weight_ranks = np.sort(nc_weight_ranks)
end = time.time()
weight_sort_time = end - start
log = f"Sort nc weight rank time {weight_sort_time}"
self.prune_record(log)
total = len(nc_weight_ranks)
thre_index = int(total * prune_ratio)
if thre_index == total:
thre_index -= 1
thre = nc_weight_ranks[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
pruned = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
mask = layer_to_rank[name]
mask = torch.Tensor(mask > thre)
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
log = (f"Total conv params: {total_weight}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total_weight:.2f}")
self.prune_record(log)
self.model = model.cuda()
self.check_param_num()
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/CV_backdoor/trigger.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
import torchcontrib
from torchvision import transforms
import copy
sys.path.append('..')
from model.fe_resnet import resnet18_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet50, feresnet101
from utils import *
from weight_pruner import WeightPruner
from attack_finetuner import AttackFinetuner
from prune import weight_prune
from finetuner import Finetuner
from backdoor_dataset.cub200 import CUB200Data
from backdoor_dataset.mit67 import MIT67Data
from backdoor_dataset.stanford_40 import Stanford40Data
def teacher_train(teacher, args):
seed = 98
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Used to make sure we sample the same image for few-shot scenarios
seed = 98
train_set = eval(args.teacher_dataset)(
args.teacher_datapath, True, [
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=args.argportion, fixed_pic=args.fixed_pic, is_poison=args.is_poison
)
test_set = eval(args.teacher_dataset)(
args.teacher_datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
], # target attack
args.shot, seed, preload=False, portion=1, fixed_pic=args.fixed_pic, four_corner=args.four_corner,
is_poison=args.is_poison
)
clean_set = eval(args.teacher_dataset)(
args.teacher_datapath, False, [
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
],
args.shot, seed, preload=False, portion=0, fixed_pic=args.fixed_pic, is_poison=args.is_poison
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=args.batch_size, shuffle=True,
num_workers=8, pin_memory=False
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
clean_loader = torch.utils.data.DataLoader(
clean_set,
batch_size=args.batch_size, shuffle=False,
num_workers=8, pin_memory=False
)
# input()
student = copy.deepcopy(teacher).cuda()
if True:
if args.teacher_method == "weight":
finetune_machine = WeightPruner(
args,
student, teacher,
train_loader, test_loader,
)
elif args.teacher_method == "backdoor_finetune":
student = weight_prune(
student, args.backdoor_update_ratio,
)
finetune_machine = AttackFinetuner(
args,
student, teacher,
train_loader, test_loader,
)
else:
finetune_machine = Finetuner(
args,
student, teacher,
train_loader, test_loader,
"ONE"
)
finetune_machine.train()
# start testing (more testing, more cases)
finetune_machine.test_loader = test_loader
test_top1, test_ce_loss = finetune_machine.test()
test_path = osp.join(args.output_dir, "test.tsv")
with open(test_path, 'a') as af:
af.write('Teacher! Start testing: trigger dataset(target attack):\n')
columns = ['time', 'Acc', 'celoss', 'featloss', 'l2sp']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top1, 2),
round(test_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
finetune_machine.test_loader = clean_loader
test_top2, clean_test_ce_loss = finetune_machine.test()
test_path = osp.join(args.output_dir, "test.tsv")
with open(test_path, 'a') as af:
af.write('Teacher! Start testing: clean dataset:\n')
columns = ['time', 'Acc', 'celoss', 'featloss', 'l2sp']
af.write('\t'.join(columns) + '\n')
localtime = time.asctime(time.localtime(time.time()))[4:-6]
test_cols = [
localtime,
round(test_top2, 2),
round(clean_test_ce_loss, 2),
]
af.write('\t'.join([str(c) for c in test_cols]) + '\n')
return student
================================================
FILE: code/deep/ReMoS/CV_backdoor/utils.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchcontrib
from torchvision import transforms
class MovingAverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f', momentum=0.9):
self.name = name
self.fmt = fmt
self.momentum = momentum
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
def update(self, val, n=1):
self.val = val
self.avg = self.momentum*self.avg + (1-self.momentum)*val
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix="", output_dir=None):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
if output_dir is not None:
self.filepath = osp.join(output_dir, "progress")
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
log_str = '\t'.join(entries)
print(log_str)
if self.filepath is not None:
with open(self.filepath, "a") as f:
f.write(log_str+"\n")
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
class CrossEntropyLabelSmooth(nn.Module):
def __init__(self, num_classes, epsilon = 0.1):
super(CrossEntropyLabelSmooth, self).__init__()
self.num_classes = num_classes
self.epsilon = epsilon
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, targets):
log_probs = self.logsoftmax(inputs)
targets = torch.zeros_like(log_probs).scatter_(1, targets.unsqueeze(1), 1)
targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes
loss = (-targets * log_probs).sum(1)
return loss.mean()
def linear_l2(model, beta_lmda):
beta_loss = 0
for m in model.modules():
if isinstance(m, nn.Linear):
beta_loss += (m.weight).pow(2).sum()
beta_loss += (m.bias).pow(2).sum()
return 0.5*beta_loss*beta_lmda, beta_loss
def l2sp(model, reg):
reg_loss = 0
dist = 0
for m in model.modules():
if hasattr(m, 'weight') and hasattr(m, 'old_weight'):
diff = (m.weight - m.old_weight).pow(2).sum()
dist += diff
reg_loss += diff
if hasattr(m, 'bias') and hasattr(m, 'old_bias'):
diff = (m.bias - m.old_bias).pow(2).sum()
dist += diff
reg_loss += diff
if dist > 0:
dist = dist.sqrt()
loss = (reg * reg_loss)
return loss, dist
def advtest_fast(model, loader, adversary, args):
advDataset = torch.load(args.adv_data_dir)
test_loader = torch.utils.data.DataLoader(
advDataset,
batch_size=4, shuffle=False,
num_workers=0, pin_memory=False)
model.eval()
total_ce = 0
total = 0
top1 = 0
total = 0
top1_clean = 0
top1_adv = 0
adv_success = 0
adv_trial = 0
for i, (batch, label, adv_batch, adv_label) in enumerate(test_loader):
batch, label = batch.to('cuda'), label.to('cuda')
adv_batch = adv_batch.to('cuda')
total += batch.size(0)
out_clean = model(batch)
out_adv = model(adv_batch)
_, pred_clean = out_clean.max(dim=1)
_, pred_adv = out_adv.max(dim=1)
clean_correct = pred_clean.eq(label)
adv_trial += int(clean_correct.sum().item())
adv_success += int(pred_adv[clean_correct].eq(label[clean_correct]).sum().detach().item())
top1_clean += int(pred_clean.eq(label).sum().detach().item())
top1_adv += int(pred_adv.eq(label).sum().detach().item())
# print('{}/{}...'.format(i+1, len(test_loader)))
print(f"Finish adv test fast")
del test_loader
del advDataset
return float(top1_clean)/total*100, float(top1_adv)/total*100, float(adv_trial-adv_success) / adv_trial *100
================================================
FILE: code/deep/ReMoS/CV_backdoor/weight_pruner.py
================================================
import os
import os.path as osp
import sys
import time
import argparse
from pdb import set_trace as st
import json
import random
import torch
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from model.fe_resnet import resnet18_dropout, resnet34_dropout, resnet50_dropout, resnet101_dropout
from model.fe_resnet import feresnet18, feresnet34, feresnet50, feresnet101
from utils import *
from finetuner import Finetuner
class WeightPruner(Finetuner):
def __init__(
self,
args,
model,
teacher,
train_loader,
test_loader,
):
super(WeightPruner, self).__init__(
args, model, teacher, train_loader, test_loader, "ckpt"
)
assert (
self.args.weight_total_ratio >= 0 and
self.args.weight_ratio_per_prune >= 0 and
self.args.prune_interval >= 0 and
self.args.weight_init_prune_ratio >= 0 and
self.args.weight_total_ratio >= self.args.weight_init_prune_ratio
)
self.log_path = osp.join(self.args.output_dir, "prune.log")
self.logger = open(self.log_path, "w")
self.init_prune()
self.logger.close()
def prune_record(self, log):
print(log)
self.logger.write(log+"\n")
def init_prune(self):
ratio = self.args.weight_init_prune_ratio
log = f"Init prune ratio {ratio:.2f}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
def iterative_prune(self, iteration):
if iteration == 0:
return
init = self.args.weight_init_prune_ratio
interval = self.args.prune_interval
per_ratio = self.args.weight_ratio_per_prune
ratio = init + per_ratio * (iteration / interval)
if ratio - self.args.weight_total_ratio > per_ratio:
return
self.logger = open(self.log_path, "a")
ratio = min(
self.args.weight_total_ratio,
ratio
)
log = f"Iteration {iteration}, prune ratio {ratio}"
self.prune_record(log)
self.weight_prune(ratio)
self.check_param_num()
self.logger.close()
def check_param_num(self):
model = self.model
total = sum([module.weight.nelement() for module in model.modules() if isinstance(module, nn.Conv2d) ])
num = total
for m in model.modules():
if ( isinstance(m, nn.Conv2d) ):
num -= int((m.weight.data == 0).sum())
ratio = (total - num) / total
log = f"===>Check: Total {total}, current {num}, prune ratio {ratio:2f}"
self.prune_record(log)
def weight_prune(
self,
prune_ratio,
random_prune=False,
):
model = self.model.cpu()
total = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
total += module.weight.data.numel()
conv_weights = torch.zeros(total)
index = 0
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
size = module.weight.data.numel()
conv_weights[index:(index+size)] = module.weight.data.view(-1).abs().clone()
index += size
y, i = torch.sort(conv_weights, descending=self.args.prune_descending)
# thre_index = int(total * prune_ratio)
# thre = y[thre_index]
thre_index = int(total * prune_ratio)
thre = y[thre_index]
log = f"Pruning threshold: {thre:.4f}"
self.prune_record(log)
pruned = 0
zero_flag = False
for name, module in model.named_modules():
if ( isinstance(module, nn.Conv2d) ):
weight_copy = module.weight.data.abs().clone()
# if self.args.prune_descending:
# mask = weight_copy.lt(thre).float()
# else:
# mask = weight_copy.gt(thre).float()
if random_prune:
print(f"Random prune {name}")
mask = np.zeros(weight_copy.numel()) + 1
prune_number = round(prune_ratio * weight_copy.numel())
mask[:prune_number] = 0
np.random.shuffle(mask)
mask = mask.reshape(weight_copy.shape)
mask = torch.Tensor(mask)
pruned = pruned + mask.numel() - torch.sum(mask)
# np.random.shuffle(mask)
module.weight.data.mul_(mask)
if int(torch.sum(mask)) == 0:
zero_flag = True
remain_ratio = int(torch.sum(mask)) / mask.numel()
log = (f"layer {name} \t total params: {mask.numel()} \t "
f"remaining params: {int(torch.sum(mask))}({remain_ratio:.2f})")
self.prune_record(log)
if zero_flag:
raise RuntimeError("There exists a layer with 0 parameters left.")
log = (f"Total conv params: {total}, Pruned conv params: {pruned}, "
f"Pruned ratio: {pruned/total:.2f}")
self.prune_record(log)
self.model = model.cuda()
def final_check_param_num(self):
self.logger = open(self.log_path, "a")
self.check_param_num()
self.logger.close()
================================================
FILE: code/deep/ReMoS/README.md
================================================
# ReMoS
> Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing
This is the implementation for the ICSE 2022 paper **ReMoS: Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing**.
[[Paper](https://jd92.wang/assets/files/icse22-remos.pdf)] [[知乎解读](https://zhuanlan.zhihu.com/p/446453487)] [[Video](https://www.bilibili.com/video/BV1mi4y1C7bP)]
## Introduction
Transfer learning is a popular software reuse technique in the deep learning community that enables developers to build custom models (students) based on sophisticated pretrained models (teachers). However, some defects in the teacher model may also be inherited by students, such as well-known adversarial vulnerabilities and backdoors. We propose ReMoS, a relevant model slicing technique to reduce defect inheritance during transfer learning while retaining useful knowledge from the teacher model. Our experiments on seven DNN defects, four DNN models, and eight datasets demonstrate that ReMoS can reduce inherited defects effectively (by **63% to 86%** for CV tasks and by **40% to 61%** for NLP tasks) and efficiently with minimal sacrifice of accuracy (**3%** on average).
## Requirements
See `requirements.txt`. All you need is a simple Pytorch environments with `advertorch` installed. Just `pip install -r requirements.txt`.
## Usage
See [`instructions.md`](instructions.md).
## Citation
If you think this work is helpful to your research, you can cite it as:
```
@inproceedings{zhang2022remos,
title = {ReMoS: Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing},
author = {Zhang, Ziqi and Li, Yuanchun and Wang, Jindong and Liu, Bingyan and Li, Ding and Chen, Xiangqun and Guo, Yao and Liu, Yunxin},
booktitle = {44th International Conference on Software Engineering (ICSE)},
year = {2022}
}
```
================================================
FILE: code/deep/ReMoS/instructions.md
================================================
- [Requirements](#requirements)
- [Prepare environment, dataset, and trained models](#prepare-environment-dataset-and-trained-models)
- [Prepare the environment](#prepare-the-environment)
- [Prepare the validation environment](#prepare-the-validation-environment)
- [Prepare the training environment](#prepare-the-training-environment)
- [Prepare the dataset and trained models](#prepare-the-dataset-and-trained-models)
- [Validate the results in the paper](#validate-the-results-in-the-paper)
- [Figure 5: accuracy and DIR of penultimate-layer-guided adversarial attacks](#figure-5-accuracy-and-dir-of-penultimate-layer-guided-adversarial-attacks)
- [Figure 6: DIR of neuron-coverage guided adversarial attacks](#figure-6-dir-of-neuron-coverage-guided-adversarial-attacks)
- [Figure 7: DIR of backdoor defects](#figure-7-dir-of-backdoor-defects)
- [Figure 8: convergence process](#figure-8-convergence-process)
- [Table 2: DIR of NLP backdoors](#table-2-dir-of-nlp-backdoors)
- [Guideline to train the models](#guideline-to-train-the-models)
- [Models for CV adversarial samples](#models-for-cv-adversarial-samples)
- [Models for CV backdoor](#models-for-cv-backdoor)
- [Models for NLP backdoor](#models-for-nlp-backdoor)
## Requirements
To use this artifact, you should have a server with Ubuntu 18.04. To validate the main results, you can follow the intructions to setup python environment. To train the model and validate the neuron-coverage results, you need a GPU and CUDA 11.4 installed on the server.
## Prepare environment, dataset, and trained models
### Prepare the environment
We recommand you to use [Anaconda](https://www.anaconda.com/) to prepare the environments. You should first follow the official website to install Anaconda in your computer. ReMoS was developed with PyTorch 1.7 and CUDA 11.4. To train the models you should have GPU and CUDA 11.4 installed. However, if you only need to validate the results, you do not need to install PyTorch because we have prepared the validation code for you. We will first introduce how to prepare the validation environment, then we will give the instructions to prepare the model-training environment with CUDA and PyTorch.
#### Prepare the validation environment
- First, you should create a new conda environment
```
conda create -n validation python=3.6
```
- Then, you should activate the conda environment
```
conda activate validation
```
- Install necessary packages
```
conda install numba matplotlib pandas==0.24.1 scipy
```
Now you can go ahead to prepare the dataset and models before check the results in the paper.
#### Prepare the training environment
- First, you should have GPU on your computer and install CUDA 11.4 following the official (website)[https://developer.nvidia.com/cuda-11-4-0-download-archive]
- Then, you should install PyTorch 1.7
```
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.3 -c pytorch
```
- Then, you should install advertorch
```
pip install advertorch
```
Now you have setup the training environment.
### Prepare the dataset and trained models
We have prepared the dataset and the trained models in a zip file. You can directly download zip file from [Google Drive](https://drive.google.com/file/d/1ps4fbbaGsHrONZiPjWdzK1UC53IK0Kwc/view?usp=sharing), put the downloaded file under ``ReMoS`` and run the ``unpack_downloads.sh`` script.
**NOTE:** This file is too large (>30GB) since it contains all the CV datasets and trained models. Thus, if you only want to run the code, you can directly download the datasets and put them under `CV_adv/data/`:
`wget https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/CUB200.zip` for CUB_200 dataset. And you can replace `CUB200` with `MIT67`/`StanfordDog`/`Stanford40`/`Flower102` to download other datasets.
```
bash unpack_downloads.sh
```
After unpacking the downloaded file, the added files should be aranged as follows:
```
├── CV_adv
│ ├── data
│ │ ├── CUB_200_2011
│ │ ├── Flower_102
│ │ ├── MIT_67
│ │ ├── stanford_40
│ │ └── stanford_dog
│ └── results
│ ├── nc_adv_eval_test
│ ├── res18_models
│ ├── res50_models
├── CV_backdoor
│ └── results
│ └── remos
├── NLP_backdoor
│ └── RIPPLe
```
## Validate the results in the paper
In this section, we prepared several scripts to validate the results in the paper.
### Figure 5: accuracy and DIR of penultimate-layer-guided adversarial attacks
Figure 5 shows the accuracy and the DIR of penultimate-layer-guided adversarial attacks, including two architectures: ResNet18 and ResNet50. The trained models of ResNet18 are stored in ``CV_adv/results/res18_models``, and the ResNet50 models are stored in ``CV_adv/results/res50_models``. Each directory has several sub-directries that store the models of one dataset and one baseline technique. For example, ``CV_adv/results/res18_models/finetune/resnet18_mit67`` stores the finetuned baseline on MIT67 dataset.
To validate the results in Figure 5, we prepared a script ``CV_adv/examples/penul_guided_defect.py`` to summarize the results in ``CV_adv/results/res18_models`` and ``CV_adv/results/res50_models``. You can check the result by typing the following commands:
```
cd CV_adv
python examples/penul_guided_defect.py
```
You will get the results like:
```
============================== ResNet18 ==============================
Dataset Scenes:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 75.30 77.69 72.84 41.04 60.52 53.81 74.40
DIR 61.55 79.25 58.40 5.45 17.51 11.23 19.66
Dataset Birds:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 78.27 75.93 72.73 51.73 59.22 55.32 75.70
DIR 50.87 83.78 58.47 9.21 7.94 4.59 15.25
Dataset Flowers:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 94.88 95.36 93.09 74.26 89.98 90.35 93.12
DIR 37.97 70.34 51.10 3.08 7.63 3.56 12.84
Dataset Dogs:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 81.95 83.60 78.68 40.66 62.93 52.17 75.06
DIR 89.01 96.89 85.08 9.59 14.06 14.00 18.71
Dataset Actions:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 76.84 77.66 75.52 30.38 63.37 65.28 75.56
DIR 73.39 82.31 75.75 5.70 5.27 3.98 15.23
============================== ResNet50 ==============================
Dataset Scenes:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 77.91 78.21 75.45 34.78 72.01 35.52 77.31
DIR 55.27 63.36 39.27 5.79 5.08 4.20 13.71
Dataset Birds:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 79.08 80.57 76.49 39.98 76.49 38.30 79.76
DIR 39.83 29.72 28.16 11.46 5.26 3.88 12.02
Dataset Flowers:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 95.98 96.84 96.23 68.69 93.94 77.48 97.03
DIR 19.99 31.63 19.29 3.15 2.24 1.68 2.93
Dataset Dogs:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 87.56 87.50 83.54 30.14 79.83 19.55 84.78
DIR 86.57 68.39 62.15 13.55 5.35 11.39 29.64
Dataset Actions:
Techniques Finetune DELTA Magprune Retrain DELTA-R Renofeation ReMoS
Acc 83.79 80.88 79.89 36.94 72.52 43.32 82.55
DIR 66.91 78.04 33.00 6.70 2.82 3.71 7.50
```
The results under ``ResNet18`` includes the results of the two left figures in Figure 5. The top-left sub-figure shows the Acc and the bottom-left sub-figures shows the DIR.
The results under ``ResNet50`` includes the results of the two right figures in Figure 5. The top-right sub-figure shows the Acc and the bottom-right sub-figures shows the DIR.
### Figure 6: DIR of neuron-coverage guided adversarial attacks
Figure 6 shows the DIR of neuron-coverage guided adversarial attacks on ResNet18 and two datasets: Scenes and Actions. You can see the results on more datasets and more models by slightly changing the scripts. The models are the same as penultimate-layer-guided adversarial attacks. To validate the results in Figure 6, you should first use the neuron-coveraged guided attacks to attack the model and summarize the results. However, due to the generation of adversarial samples is pretty slow, we prepared the log and the results of each experimental setting. You can easily validate Figure 6 by summarizing the results. Besides, we also provide the scripts to generate the NC guided samples.
To summarize the results, we prepared the NC sample generation log and results in ``CV_adv/results/nc_adv_eval_test``. Each directory in ``nc_adv_eval_test`` includes the log of NC attack of one coverage technique and strategy. You can check the results of Figure 6 by following commands:
```
cd CV_adv
python examples/nc_guided_defect.py
```
You will get the result:
```
Results for Scenes
Strategy DeepXplore DLFuzzRR DLFuzz
Techniques Finetune DELTA Magprune ReMoS Finetune DELTA Magprune ReMoS Finetune DELTA Magprune ReMoS
NC 50.8 64.2 52.1 19.4 49.1 60.2 50.8 21.0 64.9 73.4 60.3 28.3
TKNC 52.1 67.3 53.7 20.6 34.0 42.7 33.1 14.3 36.7 41.5 35.4 18.7
SNAC 56.9 71.5 60.4 22.8 50.9 61.4 52.2 22.6 63.9 74.8 60.3 26.9
Results for Actions
Strategy DeepXplore DLFuzzRR DLFuzz
Techniques Finetune DELTA Magprune ReMoS Finetune DELTA Magprune ReMoS Finetune DELTA Magprune ReMoS
NC 43.3 60.1 44.4 13.7 50.1 59.1 50.0 15.3 76.6 87.4 71.6 23.0
TKNC 48.4 61.1 46.7 15.8 31.7 41.1 33.7 11.1 36.4 39.6 33.3 13.0
SNAC 52.4 64.8 50.0 17.4 52.2 61.1 53.7 15.1 77.8 87.0 70.4 23.4
```
The table under "Results for Scenes" corresponds to the left three columns in Figure 6, and the table under "Results for Actions" shows the right three columns in Figure 6.
We also provide the scripts to generate NC guided adversarial samples from trained models in ``CV_adv/examples/nc_guided_defect.sh``. You can generate the samples and check the results by typing
```
cd CV_adv
bash examples/nc_guided_defect.sh $gpu
```
where ``$gpu`` is the gpu id you want to use. You can also change ``nc_guided_defect.sh`` to see the results on other datasets.
### Figure 7: DIR of backdoor defects
Figure 7 shows the DIR of backdoor defects on ResNet50 and three datasets. The code and results of backdoor experiments are in ``CV_backdoor``. We provide the saved model in ``CV_backdoor/remos``, in which each directory includes the models trained by one baseline. The script to validate the backdoor results is in ``CV_backdoor/examples/backdoor.py``. You can check the results by typeing
```
cd CV_backdoor
python examples/backdoor.py
```
You will get the result:
```
Dataset Scenes Birds Actions
Techniques Finetune Magprune Retrain Renofeation ReMoS Finetune Magprune Retrain Renofeation ReMoS Finetune Magprune Retrain Renofeation ReMoS
Acc 78.21 77.69 53.66 55.37 76.19 81.19 81.36 63.63 60.49 82.00 82.39 82.45 42.37 44.58 81.65
DIR 77.96 57.83 5.15 4.45 8.23 50.62 40.35 5.56 7.85 13.07 90.15 89.65 7.85 9.94 9.05
```
The row of Acc shows the results in the left figure of Figure 7, and the row of DIR represents the right one.
### Figure 8: convergence process
Figure 8 shows the comparison in terms of the model convergence of different techniques, including finetuning, retraining, and ReMoS. The code and relevant material is in the directory ``efficiency``. By typing following commands, you can generate Figure 8:
```
cd efficiency
python plot.py
```
The figure is saved in ``efficiency/speed.pdf``
### Table 2: DIR of NLP backdoors
Table 2 shows the DIR of NLP backdoors from the models trained by various techniques. The relevant code and models are in ``NLP_backdoor/RIPPLe``. Table 2 includes two models, BERT and RoBERTa. The trained BERT models are stored in ``NLP_backdoor/RIPPLe/bert_weights`` and the trained RoBERTa models are stored in ``NLP_backdoor/RIPPLe/roberta_weights``. You can use the script ``NLP_backdoor/summarize.py`` to validate Table 2
```
cd NLP_backdoor
python summarize.py
```
You will get the results as follows:
```
Results for BERT
Dataset Data Poison Weight Poison
Techniques Fine-tune Mag-prune ReMoS Fine-tune Mag-prune ReMoS
Metrics ACC DIR ACC DIR ACC DIR ACC DIR ACC DIR ACC DIR
SST2-SST2 92.70 100.00 92.36 100.00 91.27 39.10 92.29 100.00 92.45 100.00 90.93 29.82
IMDB-IMDB 87.97 96.12 88.25 96.15 85.53 61.73 89.34 96.15 89.48 96.10 87.00 37.73
SST2-IMDB 90.81 100.00 91.26 100.00 90.04 74.67 91.68 100.00 91.16 100.00 87.42 61.49
IMDB-SST2 93.21 96.18 92.46 96.18 91.15 27.72 92.81 96.22 92.58 96.03 91.95 21.56
Results for RoBERTa
Dataset Data Poison Weight Poison
Techniques Fine-tune Mag-prune ReMoS Fine-tune Mag-prune ReMoS
Metrics ACC DIR ACC DIR ACC DIR ACC DIR ACC DIR ACC DIR
SST2-SST2 94.20 100.00 93.70 100.00 91.17 29.82 93.38 100.00 93.20 98.94 90.71 24.95
IMDB-IMDB 90.60 96.17 89.55 95.25 85.74 70.19 89.06 96.53 88.77 92.06 86.35 85.92
SST2-IMDB 92.12 99.88 92.27 100.00 88.74 61.26 91.85 100.00 90.83 99.53 88.72 30.83
IMDB-SST2 93.53 88.16 92.65 85.27 90.32 24.14 93.85 93.93 93.57 91.22 89.96 18.08
```
## Guideline to train the models
### Models for CV adversarial samples
The code to train CV backdoor models and relevant baseline models are in ``CV_adv``. To train the models, you can use following instructions:
- Train the finetuned student. The script is ``CV_adv/examples/finetune.sh`` and you can specify the dataset by slightly changing the configuration. The trained model will be saved in ``CV_adv/results/baseline/finetune/resnet18_${DATASET}``. The commands are
```
cd CV_adv
bash examples/finetune.sh $gpu
```
where ``$gpu``` is the gpu id you want to use.
- Train the mag-pruned student. The script is ``CV_adv/examples/weight.sh`` and the trained model will be saved in ``CV_adv/results/baseline/weight``. The commands are
```
cd CV_adv
bash examples/weight.sh $gpu
```
- Profile the teacher model (the Coverage Frequency Profiling step in the paper). The script is ``CV_adv/examples/nc_profile.sh`` and the profiling results will be saved in ``CV_adv/results/nc_profiling/${COVERAGE}_${DATASET}_${MODEL}``. The commands to profile are
```
cd CV_adv
bash examples/nc_profile.sh $gpu
```
- Train with the relevant model slice. The script is ``CV_adv/examples/remos.sh`` and the results will be saved in ``CV_adv/results/remos_$COVERAGE``. The commands to train with the relevant model slice is
```
cd CV_adv
bash examples/remos.sh $gpu
```
After training, you can check the file ``posttrain_eval.txt`` to see the accuracy and DIR.
- Other baselines. We also provide the scripts to train other baselines in Section 5.2. The scripts are in ``CV_adv/examples``, including ``renofeation.sh``, ``delta.sh``, and ``delta-r.sh``.
### Models for CV backdoor
The code to train CV backdoor models and relevant baseline models are in ``CV_backdoor``. To train the models, you can use following instructions:
- Train the backdoored teacher model. The script is ``CV_backdoor/examples/r50_poison.sh`` and you can specify the dataset by slightly changing the configuration. The trained model will be saved in ``results/r50_backdoor/backdoor/res50_$DATASET``. The command to train the poisoned teacher model is
```
cd CV_backdoor
bash examples/r50_poison.sh $gpu
```
where ``$gpu``` is the gpu id you want to use.
- Train the finetuned student model. The script is ``CV_backdoor/examples/r50_baseline.sh`` and the models will be saved in ``results/r50_backdoor/finetune``. The command to train the finetuned student model is
```
cd CV_backdoor
bash examples/r50_baseline.sh $gpu
```
The accuracy and DIR are saved in the ``test.tsv`` in the result directory.
- Trained the mag-pruned model. The script is ``CV_backdoor/examples/r50_magprune.sh`` and the models will be saved in ``results/r50_backdoor/finetune``.
- Profile the teacher model (the Coverage Frequency Profiling step in the paper). The script is ``CV_backdoor/examples/remos/profile.sh`` and the profiled results will be saved in ``CV_backdoor/results/nc_profiling/${COVERAGE}_${DATASET}_resnet50``. The command to profile is
```
bash examples/remos/profile.sh $gpu
```
- Train with the relevant model slice. The script to train the relevant model slice is ``CV_backdoor/examples/remos/remos.sh`` and the trained model will be saved in ``CV_backdoor/results/r50_backdoor/remos_res50/$DATASET``. The command to train the relevant model slice is
```
bash examples/remos/remos.sh $gpu
```
### Models for NLP backdoor
The code for NLP backdoor are saved in ``NLP_backdoor/RIPPLE``, which are developed based on [RIPPLe](https://github.com/neulab/RIPPLe). The configuration scripts for BERT and RoBERTa are saved in ``NLP_backdoor/RIPPLE/bert_mani`` and ``NLP_backdoor/RIPPLE/roberta_mani``, respectively. The script to run the configurations is saved in ``NLP_backdoor/examples/bert_slim.sh``.
================================================
FILE: code/deep/ReMoS/unpack_downloads.sh
================================================
mv download_pack/cv_data CV_adv/data
mv download_pack/cv_adv_models/* CV_adv/results/
mv download_pack/cv_backdoor_models/* CV_backdoor/results/
================================================
FILE: code/deep/TCP/README.md
================================================
# [Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning](https://arxiv.org/abs/1904.02654)
This is a PyTorch implementation of the IJCNN 2019 paper.
## The contributions of this paper are summarized as follows:
1. We present TCP as a unified approach for accelerating deep unsupervised domain adaptation models. TCP is a generic, accurate, and efficient compression method that can be easily implemented by most deep learning libraries.
2. TCP is able to reduce negative transfer by considering the cross-domain distribution discrepancy using the proposed Transfer Channel Evaluation module.
3. Extensive experiments on two public UDA datasets demonstrate the significant superiority of TCP.
## Citation:
If you use this code for your research, please consider citing:
```
@inproceedings{yu2019accelerating,
title={Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning},
author={Yu, Chaohui and Wang, Jindong and Chen, Yiqiang and Wu, Zijing},
booktitle={The IEEE International Joint Conference on Neural Networks (IJCNN)},
year={2019}
}
```
================================================
FILE: code/deep/TCP/dataset.py
================================================
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data as data
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import glob
import os
def loader(path, batch_size=16, num_workers=1, pin_memory=True):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
return data.DataLoader(
datasets.ImageFolder(path,
transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])),
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=pin_memory)
def test_loader(path, batch_size=16, num_workers=1, pin_memory=True):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
return data.DataLoader(
datasets.ImageFolder(path,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])),
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory)
================================================
FILE: code/deep/TCP/finetune.py
================================================
from IPython import embed
import torch
from torch.autograd import Variable
from torchvision import models
import cv2
import sys
import numpy as np
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import dataset
from prune import *
import argparse
from operator import itemgetter
from heapq import nsmallest
import time
import torch.utils.model_zoo as model_zoo
import mmd
import math
from tools import *
BATCH = 16
target_name = 'webcam'
class DANNet(nn.Module):
def __init__(self):
super(DANNet, self).__init__()
model = models.vgg16(pretrained=True) #False
self.features = model.features
for param in self.features.parameters(): #NOTE: prune:True // finetune:False
param.requires_grad = True
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(25088, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
)
self.cls_fc = nn.Linear(4096, 31)
def forward(self, source, target):
loss = 0
source = self.features(source)
source = source.view(source.size(0), -1)
source = self.classifier(source)
if self.training == True:
target = self.features(target)
target = target.view(target.size(0), -1)
target = self.classifier(target)
loss += mmd.mmd_rbf_noaccelerate(source, target)
source = self.cls_fc(source)
return source, loss
class FilterPrunner:
def __init__(self, model):
self.model = model
self.reset()
def reset(self):
# self.activations = []
# self.gradients = []
# self.grad_index = 0
# self.activation_to_layer = {}
self.filter_ranks_1 = {}
self.filter_ranks_2 = {}
def forward(self, x, x_target): # NOTE: whether to add target data
loss = 0
self.activations1 = []
self.activations2 = []
self.gradients = []
self.grad_index_1 = 0
self.grad_index_2 = 0
self.activation_to_layer_1 = {}
self.activation_to_layer_2 = {}
activation1_index = 0
for layer, (name, module) in enumerate(self.model.features._modules.items()):
x = module(x)
if isinstance(module, torch.nn.modules.conv.Conv2d):
x.register_hook(self.compute_rank_1)
self.activations1.append(x)
self.activation_to_layer_1[activation1_index] = layer
activation1_index += 1
activation2_index = 0
for layer, (name, module) in enumerate(self.model.features._modules.items()):
x_target = module(x_target)
if isinstance(module, torch.nn.modules.conv.Conv2d):
x_target.register_hook(self.compute_rank_2)
self.activations2.append(x_target)
self.activation_to_layer_2[activation2_index] = layer
activation2_index += 1
x = self.model.classifier(x.view(x.size(0), -1))
x_target = self.model.classifier(x_target.view(x_target.size(0), -1))
loss += mmd.mmd_rbf_noaccelerate(x, x_target)
source_pred = self.model.cls_fc(x)
return source_pred, loss
def compute_rank_1(self, grad):
activation1_index = len(self.activations1) - self.grad_index_1 - 1
activation1 = self.activations1[activation1_index]
values1 = torch.sum((activation1 * grad), dim = 0).sum(dim=1).sum(dim=1)[:].data
# Normalize the rank by the filter dimensions
values1 = \
values1 / (activation1.size(0) * activation1.size(2) * activation1.size(3))
if activation1_index not in self.filter_ranks_1:
self.filter_ranks_1[activation1_index] = \
torch.FloatTensor(activation1.size(1)).zero_().cuda()
self.filter_ranks_1[activation1_index] = values1
self.grad_index_1 += 1
def compute_rank_2(self, grad):
activation2_index = len(self.activations2) - self.grad_index_2 - 1
activation2 = self.activations2[activation2_index]
values2 = torch.sum((activation2 * grad), dim = 0).sum(dim=1).sum(dim=1)[:].data
values2 = \
values2 / (activation2.size(0) * activation2.size(2) * activation2.size(3))
if activation2_index not in self.filter_ranks_2:
self.filter_ranks_2[activation2_index] = \
torch.FloatTensor(activation2.size(1)).zero_().cuda()
self.filter_ranks_2[activation2_index] = values2
self.grad_index_2 += 1
def lowest_ranking_filters(self, num):
data_1 = []
for i in sorted(self.filter_ranks_1.keys()):
for j in range(self.filter_ranks_1[i].size(0)):
data_1.append((self.activation_to_layer_1[i], j, self.filter_ranks_1[i][j]))
data_2 = []
for i in sorted(self.filter_ranks_2.keys()):
for j in range(self.filter_ranks_2[i].size(0)):
data_2.append((self.activation_to_layer_2[i], j, self.filter_ranks_2[i][j]))
data_3 = []
data_3.extend(data_1)
data_3.extend(data_2)
dic = {}
c = nsmallest(num*2, data_3, itemgetter(2))
for i in range(len(c)):
nm = str(c[i][0]) + '_' + str(c[i][1])
if dic.get(nm)!=None:
dic[nm] = min(dic[nm], c[i][2].item())
else:
dic[nm] = c[i][2].item()
newc = []
for i in range(len(list(dic.items()))):
lyer = int(list(dic.items())[i][0].split('_')[0])
filt = int(list(dic.items())[i][0].split('_')[1])
val = torch.tensor(list(dic.items())[i][1])
newc.append((lyer, filt, val))
return nsmallest(num, newc, itemgetter(2))
def normalize_ranks_per_layer(self):
for i in self.filter_ranks_1:
v = torch.abs(self.filter_ranks_1[i])
v = v / np.sqrt(torch.sum(v * v)).cuda()
self.filter_ranks_1[i] = v.cpu()
for i in self.filter_ranks_2:
v = torch.abs(self.filter_ranks_2[i])
v = v / np.sqrt(torch.sum(v * v)).cuda()
self.filter_ranks_2[i] = v.cpu()
def get_prunning_plan(self, num_filters_to_prune):
filters_to_prune = self.lowest_ranking_filters(num_filters_to_prune)
# After each of the k filters are prunned,
# the filter index of the next filters change since the model is smaller.
filters_to_prune_per_layer = {}
for (l, f, _) in filters_to_prune:
if l not in filters_to_prune_per_layer:
filters_to_prune_per_layer[l] = []
filters_to_prune_per_layer[l].append(f)
for l in filters_to_prune_per_layer:
filters_to_prune_per_layer[l] = sorted(filters_to_prune_per_layer[l])
for i in range(len(filters_to_prune_per_layer[l])):
filters_to_prune_per_layer[l][i] = filters_to_prune_per_layer[l][i] - i
filters_to_prune = []
for l in filters_to_prune_per_layer:
for i in filters_to_prune_per_layer[l]:
filters_to_prune.append((l, i))
return filters_to_prune
class PrunningFineTuner_VGGnet:
def __init__(self, train_path, test_path, model):
self.source_loader = dataset.loader(train_path)
self.target_train_loader = dataset.loader(test_path)
self.target_test_loader = dataset.test_loader(test_path)
self.model = model
self.criterion = torch.nn.CrossEntropyLoss()
self.prunner = FilterPrunner(self.model)
self.model.train()
self.len_source_loader = len(self.source_loader)
self.len_target_loader = len(self.target_train_loader)
self.len_source_dataset = len(self.source_loader.dataset)
self.len_target_dataset = len(self.target_test_loader.dataset)
self.max_correct = 0
self.littlemax_correct = 0
self.cur_model = None
def test(self):
self.model.eval()
test_loss = 0
correct = 0
for data, target in self.target_test_loader:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
s_output, t_output = self.model(data, data)
test_loss += F.nll_loss(F.log_softmax(s_output, dim = 1), target, size_average=False).item() # sum up batch loss
pred = s_output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= self.len_target_dataset
print('\n{} set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
target_name, test_loss, correct, self.len_target_dataset,
100. * correct / self.len_target_dataset))
return correct
def train(self, optimizer = None, epoches = 10, save_name=None):
for i in range(epoches):
print("Epoch: ", i+1)
self.train_epoch(optimizer, i+1, epoches+1)
cur_correct = self.test()
if cur_correct >= self.littlemax_correct:
self.littlemax_correct = cur_correct
self.cur_model = self.model
print("write cur bset model")
if cur_correct > self.max_correct:
self.max_correct = cur_correct
if save_name:
torch.save(self.model, str(save_name))
print('amazon to webcam max correct: {} max accuracy{: .2f}%\n'.format(
self.max_correct, 100.0 * self.max_correct / self.len_target_dataset))
print("Finished fine tuning.")
def train_epoch(self, optimizer = None, epoch = 0, epoches = 0, rank_filters = False):
LEARNING_RATE = 0.01 / math.pow((1 + 10 * (epoch - 1) / epoches), 0.75) # 10*
optimizer = torch.optim.SGD([
{'params': self.model.features.parameters()},
{'params': self.model.classifier.parameters()},
{'params': self.model.cls_fc.parameters(), 'lr': LEARNING_RATE},
], lr=LEARNING_RATE / 5, momentum=0.9, weight_decay=5e-4)
iter_source = iter(self.source_loader)
iter_target = iter(self.target_train_loader)
self.model.train()
for i in range(1, self.len_source_loader):
data_source, label_source = iter_source.next()
data_target, _ = iter_target.next()
if len(data_target < BATCH):
iter_target = iter(self.target_train_loader)
data_target, _ = iter_target.next()
data_source, label_source = data_source.cuda(), label_source.cuda()
data_target = data_target.cuda()
data_source, label_source = Variable(data_source), Variable(label_source)
data_target = Variable(data_target)
self.model.zero_grad()
if rank_filters: # prune
# add cls_loss and mmd_loss
pred, loss_mmd = self.prunner.forward(data_source, data_target)
loss_cls = F.nll_loss(F.log_softmax(pred, dim=1), label_source)
gamma = 2 / (1 + math.exp(-10 * (epoch) / epoches)) - 1
loss = loss_cls + gamma * loss_mmd
loss.backward()
print('prune loss: {:.5f} {:.5f}'.format(loss_cls.item(), loss_mmd.item()))
else:
label_source_pred, loss_mmd = self.model(data_source, data_target)
loss_cls = F.nll_loss(F.log_softmax(label_source_pred, dim=1), label_source)
gamma = 2 / (1 + math.exp(-10 * (epoch) / epoches)) - 1
loss = loss_cls + gamma * loss_mmd
loss.backward()
optimizer.step()
if i % 50 == 0:
print('Train Epoch:{} [{}/{}({:.0f}%)]\tlr:{:.5f}\tLoss: {:.6f}\tsoft_Loss: {:.6f}\tmmd_Loss: {:.6f}'.format(
epoch, i * len(data_source), self.len_source_dataset,
100. * i / self.len_source_loader, LEARNING_RATE, loss.item(), loss_cls.item(), loss_mmd.item()))
def get_candidates_to_prune(self, num_filters_to_prune):
self.prunner.reset()
self.train_epoch(epoch = 1, epoches = 10, rank_filters = True)
self.prunner.normalize_ranks_per_layer()
return self.prunner.get_prunning_plan(num_filters_to_prune)
def total_num_filters(self):
filters = 0
for name, module in self.model.features._modules.items():
if isinstance(module, torch.nn.modules.conv.Conv2d):
filters = filters + module.out_channels
return filters
def prune(self, perc_ind, perchan):
#Get the accuracy before prunning
self.test()
self.model.train()
#Make sure all the layers are trainable
for param in self.model.features.parameters():
param.requires_grad = True
number_of_filters = self.total_num_filters() # the total nums of channels in convs
num_filters_to_prune_per_iteration = perchan # 20
iterations = int(float(number_of_filters) / num_filters_to_prune_per_iteration)
perc = perc_ind/10 # 2.0/10
iterations = int(iterations * perc) # set the percentage of prunning 80%
print("Number of prunning iterations to reduce filters", iterations)
for _ in range(iterations):
print("Ranking filters.. ")
prune_targets = self.get_candidates_to_prune(num_filters_to_prune_per_iteration)
layers_prunned = {}
for layer_index, filter_index in prune_targets:
if layer_index not in layers_prunned:
layers_prunned[layer_index] = 0
layers_prunned[layer_index] = layers_prunned[layer_index] + 1
print("Layers that will be prunned", layers_prunned)
print("Prunning filters.. ")
if self.cur_model:
print("load cur best")
model = self.cur_model.cpu()
else:
model = self.model.cpu()
for layer_index, filter_index in prune_targets:
print(layer_index, filter_index)
model = prune_vgg16_conv_layer(model, layer_index, filter_index)
self.model = model.cuda()
message = str(100*float(self.total_num_filters()) / number_of_filters) + "%"
print("Filters prunned", str(message))
self.test()
print("Fine tuning to recover from prunning iteration.")
optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.littlemax_correct = 0
self.train(optimizer, epoches = 5) #10
print("Finished. Going to fine tune the model a bit more")
self.max_correct = 0
self.train(optimizer, epoches = 20, save_name = "model_prunned_clsmmd_{:.1f}".format(perc))
def total_num_channels(model):
filters = 0
for name, module in model.features._modules.items():
if isinstance(module, torch.nn.Conv2d):
print(name, module, module.out_channels)
filters = filters + module.out_channels
print('total nums of channels in convs: %d'%(filters))
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--train", dest="train", action="store_true")
parser.add_argument("--prune", dest="prune", action="store_true")
parser.add_argument("--train_path", type = str, default = "train")
parser.add_argument("--test_path", type = str, default = "test")
parser.set_defaults(train=False)
parser.set_defaults(prune=False)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
args.train_path = '/home/xxx/datasets/office_31/amazon'
args.test_path = '/home/xxx/datasets/office_31/webcam'
if args.train:
model = DANNet().cuda()
elif args.prune:
#model = torch.load("./model_prunned_clsmmd_0.6").cuda()
fine_tuner = PrunningFineTuner_VGGnet(args.train_path, args.test_path, model)
fine_tuner.test()
total_num_channels(model)
print_model_parm_flops(model)
print_model_parm_nums(model)
#embed()
fine_tuner = PrunningFineTuner_VGGnet(args.train_path, args.test_path, model)
if args.train:
#model = torch.load("./model_prunned_clsmmd_0.4").cuda()
fine_tuner = PrunningFineTuner_VGGnet(args.train_path, args.test_path, model)
fine_tuner.test()
fine_tuner.train(epoches = 10, save_name = 'model_t')
elif args.prune:
for perc_ind, perchan in zip([2.0], [32]):
fine_tuner = PrunningFineTuner_VGGnet(args.train_path, args.test_path, model)
fine_tuner.prune(perc_ind, perchan)
================================================
FILE: code/deep/TCP/mmd.py
================================================
import torch
from functools import partial
from torch.autograd import Variable
# Consider linear time MMD with a linear kernel:
# K(f(x), f(y)) = f(x)^Tf(y)
# h(z_i, z_j) = k(x_i, x_j) + k(y_i, y_j) - k(x_i, y_j) - k(x_j, y_i)
# = [f(x_i) - f(y_i)]^T[f(x_j) - f(y_j)]
#
# f_of_X: batch_size * k
# f_of_Y: batch_size * k
def mmd_linear(f_of_X, f_of_Y):
delta = f_of_X - f_of_Y
loss = torch.mean(torch.mm(delta, torch.transpose(delta, 0, 1)))
return loss
def guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0])+int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for bandwidth_temp in bandwidth_list]
return sum(kernel_val)#/len(kernel_val)
def mmd_rbf_accelerate(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
batch_size = int(source.size()[0])
kernels = guassian_kernel(source, target,
kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)
loss = 0
for i in range(batch_size):
s1, s2 = i, (i+1)%batch_size
t1, t2 = s1+batch_size, s2+batch_size
loss += kernels[s1, s2] + kernels[t1, t2]
loss -= kernels[s1, t2] + kernels[s2, t1]
return loss / float(batch_size)
def mmd_rbf_noaccelerate(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
batch_size = int(source.size()[0])
kernels = guassian_kernel(source, target,
kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)
XX = kernels[:batch_size, :batch_size]
YY = kernels[batch_size:, batch_size:]
XY = kernels[:batch_size, batch_size:]
YX = kernels[batch_size:, :batch_size]
loss = torch.mean(XX + YY - XY -YX)
return loss
def pairwise_distance(x, y):
if not len(x.shape) == len(y.shape) == 2:
raise ValueError('Both inputs should be matrices.')
if x.shape[1] != y.shape[1]:
raise ValueError('The number of features should be the same.')
x = x.view(x.shape[0], x.shape[1], 1)
y = torch.transpose(y, 0, 1)
output = torch.sum((x - y) ** 2, 1)
output = torch.transpose(output, 0, 1)
return output
def gaussian_kernel_matrix(x, y, sigmas):
sigmas = sigmas.view(sigmas.shape[0], 1)
beta = 1. / (2. * sigmas)
dist = pairwise_distance(x, y).contiguous()
dist_ = dist.view(1, -1)
s = torch.matmul(beta, dist_)
return torch.sum(torch.exp(-s), 0).view_as(dist)
def maximum_mean_discrepancy(x, y, kernel= gaussian_kernel_matrix):
cost = torch.mean(kernel(x, x))
cost += torch.mean(kernel(y, y))
cost -= 2 * torch.mean(kernel(x, y))
return cost
def mmd_loss(source_features, target_features):
sigmas = [
1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 5, 10, 15, 20, 25, 30, 35, 100,
1e3, 1e4, 1e5, 1e6
]
gaussian_kernel = partial(
gaussian_kernel_matrix, sigmas = Variable(torch.cuda.FloatTensor(sigmas))
)
loss_value = maximum_mean_discrepancy(source_features, target_features, kernel= gaussian_kernel)
loss_value = loss_value
return loss_value
================================================
FILE: code/deep/TCP/prune.py
================================================
import torch
from torch.autograd import Variable
from torchvision import models
import cv2
import sys
import numpy as np
from IPython import embed
def replace_layers(model, i, indexes, layers):
if i in indexes:
return layers[indexes.index(i)]
return model[i]
def prune_vgg16_conv_layer(model, layer_index, filter_index):
_, conv = list(model.features._modules.items())[layer_index]
next_conv = None
offset = 1
while layer_index + offset < len(list(model.features._modules.items())):
res = list(model.features._modules.items())[layer_index+offset]
if isinstance(res[1], torch.nn.modules.conv.Conv2d):
next_name, next_conv = res
break
offset = offset + 1
new_conv = \
torch.nn.Conv2d(in_channels = conv.in_channels, \
out_channels = conv.out_channels - 1,
kernel_size = conv.kernel_size, \
stride = conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups)
#bias = conv.bias)
new_conv.bias = torch.nn.Parameter(conv.bias)
old_weights = conv.weight.data.cpu().numpy()
new_weights = new_conv.weight.data.cpu().numpy()
if filter_index > new_weights.shape[0]:
return model
new_weights[: filter_index, :, :, :] = old_weights[: filter_index, :, :, :]
new_weights[filter_index : , :, :, :] = old_weights[filter_index + 1 :, :, :, :]
new_conv.weight.data = torch.from_numpy(new_weights).cuda()
bias_numpy = conv.bias.data.cpu().numpy()
bias = np.zeros(shape = (bias_numpy.shape[0] - 1), dtype = np.float32)
bias[:filter_index] = bias_numpy[:filter_index]
bias[filter_index : ] = bias_numpy[filter_index + 1 :]
new_conv.bias.data = torch.from_numpy(bias).cuda()
if not next_conv is None:
next_new_conv = \
torch.nn.Conv2d(in_channels = next_conv.in_channels - 1,\
out_channels = next_conv.out_channels, \
kernel_size = next_conv.kernel_size, \
stride = next_conv.stride,
padding = next_conv.padding,
dilation = next_conv.dilation,
groups = next_conv.groups,)
#bias = next_conv.bias)
next_new_conv.bias = torch.nn.Parameter(next_conv.bias)
old_weights = next_conv.weight.data.cpu().numpy()
new_weights = next_new_conv.weight.data.cpu().numpy()
new_weights[:, : filter_index, :, :] = old_weights[:, : filter_index, :, :]
new_weights[:, filter_index : , :, :] = old_weights[:, filter_index + 1 :, :, :]
next_new_conv.weight.data = torch.from_numpy(new_weights).cuda()
next_new_conv.bias.data = next_conv.bias.data
if not next_conv is None:
features = torch.nn.Sequential(
*(replace_layers(model.features, i, [layer_index, layer_index+offset], \
[new_conv, next_new_conv]) for i, _ in enumerate(model.features)))
del model.features
del conv
model.features = features
else:
#Prunning the last conv layer. This affects the first linear layer of the classifier.
model.features = torch.nn.Sequential(
*(replace_layers(model.features, i, [layer_index], \
[new_conv]) for i, _ in enumerate(model.features)))
layer_index = 0
old_linear_layer = None
for _, module in model.classifier._modules.items():
if isinstance(module, torch.nn.Linear):
old_linear_layer = module
break
layer_index = layer_index + 1
if old_linear_layer is None:
raise BaseException("No linear laye found in classifier")
params_per_input_channel = old_linear_layer.in_features // conv.out_channels
new_linear_layer = \
torch.nn.Linear(old_linear_layer.in_features - params_per_input_channel,
old_linear_layer.out_features)
old_weights = old_linear_layer.weight.data.cpu().numpy()
new_weights = new_linear_layer.weight.data.cpu().numpy()
new_weights[:, : filter_index * params_per_input_channel] = \
old_weights[:, : filter_index * params_per_input_channel]
new_weights[:, filter_index * params_per_input_channel :] = \
old_weights[:, (filter_index + 1) * params_per_input_channel :]
new_linear_layer.bias.data = old_linear_layer.bias.data
new_linear_layer.weight.data = torch.from_numpy(new_weights).cuda()
classifier = torch.nn.Sequential(
*(replace_layers(model.classifier, i, [layer_index], \
[new_linear_layer]) for i, _ in enumerate(model.classifier)))
del model.classifier
del next_conv
del conv
model.classifier = classifier
return model
================================================
FILE: code/deep/TCP/tools.py
================================================
# -*- coding: utf-8 -*-
import torch
from IPython import embed
import torchvision
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
import numpy as np
def print_layers_num():
resnet = AlexNet.alexnet()
def foo(net):
childrens = list(net.children())
if not childrens:
if isinstance(net, torch.nn.Conv2d):
print(' ')
# net.register_backward_hook(print)
return 1
count = 0
for c in childrens:
print(c, count)
count += foo(c)
return count
print(foo(resnet))
def print_model_parm_nums(model):
#model = ResNet.DANNet(num_classes=31)
#model = torch.load('./models/alex/model_20.pkl')
total = sum([param.nelement() for param in model.parameters()])
print(' + Number of params: %.2fM' % (total / 1e6))
def print_model_parm_flops(model):
prods = {}
def save_hook(name):
def hook_per(self, input, output):
# print 'flops:{}'.format(self.__class__.__name__)
# print 'input:{}'.format(input)
# print '_dim:{}'.format(input[0].dim())
# print 'input_shape:{}'.format(np.prod(input[0].shape))
# prods.append(np.prod(input[0].shape))
prods[name] = np.prod(input[0].shape)
# prods.append(np.prod(input[0].shape))
return hook_per
list_1=[]
def simple_hook(self, input, output):
list_1.append(np.prod(input[0].shape))
list_2={}
def simple_hook2(self, input, output):
list_2['names'] = np.prod(input[0].shape)
multiply_adds = False
list_conv=[]
def conv_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size[0] * self.kernel_size[1] * (self.in_channels / self.groups) * (2 if multiply_adds else 1)
bias_ops = 1 if self.bias is not None else 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_conv.append(flops)
list_linear=[]
def linear_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
weight_ops = self.weight.nelement() * (2 if multiply_adds else 1)
bias_ops = self.bias.nelement()
flops = batch_size * (weight_ops + bias_ops)
list_linear.append(flops)
list_bn=[]
def bn_hook(self, input, output):
list_bn.append(input[0].nelement())
list_relu=[]
def relu_hook(self, input, output):
list_relu.append(input[0].nelement())
list_pooling=[]
def pooling_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size * self.kernel_size
bias_ops = 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_pooling.append(flops)
def foo(net):
childrens = list(net.children())
if not childrens:
if isinstance(net, torch.nn.Conv2d):
# net.register_forward_hook(save_hook(net.__class__.__name__))
# net.register_forward_hook(simple_hook)
# net.register_forward_hook(simple_hook2)
net.register_forward_hook(conv_hook)
if isinstance(net, torch.nn.Linear):
net.register_forward_hook(linear_hook)
if isinstance(net, torch.nn.BatchNorm2d):
net.register_forward_hook(bn_hook)
if isinstance(net, torch.nn.ReLU):
net.register_forward_hook(relu_hook)
if isinstance(net, torch.nn.MaxPool2d) or isinstance(net, torch.nn.AvgPool2d):
net.register_forward_hook(pooling_hook)
return
for c in childrens:
foo(c)
#model = torch.load('./models/alex/model_120.pkl')
foo(model.cpu())
input = Variable(torch.rand(3,224,224).unsqueeze(0), requires_grad = True)
out = model(input, input)
total_flops = (sum(list_conv) + sum(list_linear) + sum(list_bn) + sum(list_relu) + sum(list_pooling))
print(' + Number of FLOPs: %.2fG' % (total_flops / 1e9))
def total_num_channels(model):
filters = 0
for name, module in model.features._modules.items():
if isinstance(module, torch.nn.Conv2d):
print(module.out_channels)
filters = filters + module.out_channels
print('total nums of channels in convs: %d'%(filters))
if __name__ == '__main__':
#print_model_parm_flops()
print_model_parm_nums()
#print_layers_num()
#total_num_channels()
================================================
FILE: code/deep/adarnn/README.md
================================================
# AdaRNN: Adaptive Learning and Forecasting for Time Series
This project implements our paper [AdaRNN: Adaptive Learning and Forecasting for Time Series](https://arxiv.org/abs/2108.04443) at CIKM 2021. Please refer to our paper [1] for the method and technical details. [Paper video](https://www.bilibili.com/video/BV1Gh411B7rj/) | [Zhihu](https://zhuanlan.zhihu.com/p/398036372)
**Update at 2023/02:** The new end-to-end version of AdaRNN is accepted by ICLR 2023. Check the new paper and code in [Out-of-distribution representation learning of time series classification](https://arxiv.org/abs/2209.07027)!
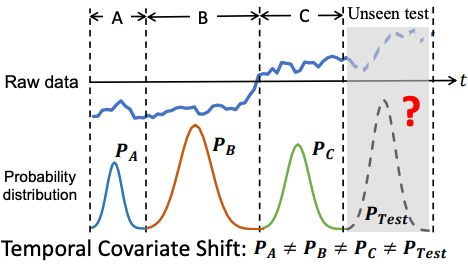 **Abstract:** Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as **Temporal Covariate Shift (TCS)**. This paper proposes **Adaptive RNNs (AdaRNN)** to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose **Temporal Distribution Characterization** to better characterize the distribution information in the TS. Second, we propose **Temporal Distribution Matching** to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.
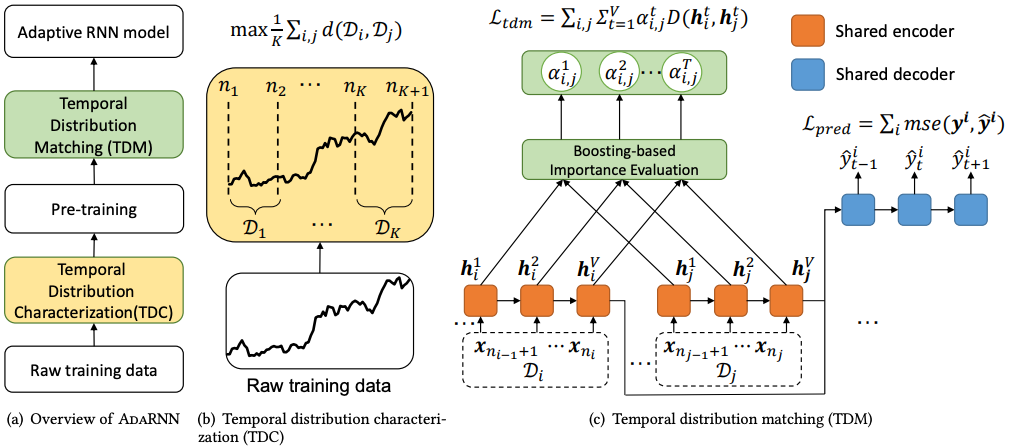
To use this code, you can either git clone this transferlearning repo, or if you just want to use this folder, you can go to [this site](https://minhaskamal.github.io/DownGit/#/home) to paste the url of this code (https://github.com/jindongwang/transferlearning/edit/master/code/deep/adarnn) and then download just this folder.
## Requirement
- CUDA 10.1
- Python 3.7.7
- Pytorch == 1.6.0
- Torchvision == 0.7.0
The required packages are listed in `requirements.txt`.
## Dataset
The original air-quality dataset is downloaded from [Beijing Multi-Site Air-Quality Data Data Set](https://archive.ics.uci.edu/ml/datasets/Beijing+Multi-Site+Air-Quality+Data) . The air-quality dataset contains hourly air quality information collected from 12 stations in Beijing from 03/2013 to 02/2017. We randomly chose four stations (Dongsi, Tiantan, Nongzhanguan, and Dingling) and select six features (PM2.5, PM10, S02, NO2, CO, and O3). Since there are some missing data, we simply fill the empty slots using averaged values. Then, the dataset is normalized before feeding into the network to scale all features into the same range. This process is accomplished by max-min normalization and ranges data between 0 and 1. The processed air-quality dataset can be downloaded at [dataset link](https://box.nju.edu.cn/f/2239259e06dd4f4cbf64/?dl=1) or [new link](https://pan.baidu.com/s/1xkLyd9YPgK7h8B1-acCImg) with password 1007.
The procossed .pkl files contains three arraies: 'feature', 'label', and 'label_reg'. 'label' refers to the classification label of air quality (e.g. excellence, good, middle), which is not used in this work and could be ignored. 'label_reg' refers to the prediction value.
## How to run
The code for air-quality dataset is in `train_weather.py`. After downloading the dataset, you can change args.data_path in `train_weather.py` to the folder where you place the data.
Then you can run the code. Taking Dongsi station as example, you can run
`python train_weather.py --model_name 'AdaRNN' --station 'Dongsi' --pre_epoch 40 --dw 0.5 --loss_type 'adv' --data_mode 'tdc'`
For transformer model, the adapted transformer model is in `transformer_adapt.py`, you can run,
`python transformer_adapt.py --station 'Tiantan' --dw 1.0`
# Results
**Air-quality dataset**
| | Dongsi | | Tiantan | | Nongzhanguan | | Dingling | |
|-------------|:-------:|:-------:|:-------:|:-------:|:------------:|:-------:|:--------:|:-------:|
| | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE |
| FBProphet | 0.1866 | 0.1403 | 0.1434 | 0.1119 | 0.1551 | 0.1221 | 0.0932 | 0.0736 |
| ARIMA | 0.1811 | 0.1356 | 0.1414 | 0.1082 | 0.1557 | 0.1156 | 0.0922 | 0.0709 |
| GRU | 0.0510 | 0.0380 | 0.0475 | 0.0348 | 0.0459 | 0.0330 | 0.0347 | 0.0244 |
| MMD-RNN | 0.0360 | 0.0267 | 0.0183 | 0.0133 | 0.0267 | 0.0197 | 0.0288 | 0.0168 |
| DANN-RNN | 0.0356 | 0.0255 | 0.0214 | 0.0157 | 0.0274 | 0.0203 | 0.0291 | 0.0211 |
| LightGBM | 0.0587 | 0.0390 | 0.0412 | 0.0289 | 0.0436 | 0.0319 | 0.0322 | 0.0210 |
| LSTNet | 0.0544 | 0.0651 | 0.0519 | 0.0651 | 0.0548 | 0.0696 | 0.0599 | 0.0705 |
| Transformer | 0.0339 | 0.0220 | 0.0233 | 0.0164 | 0.0226 | 0.0181 | 0.0263 | 0.0163 |
| STRIPE | 0.0365 | 0.0216 | 0.0204 | 0.0148 | 0.0248 | 0.0154 | 0.0304 | 0.0139 |
| ADARNN | **0.0295** | **0.0185** | **0.0164** | **0.0112** | **0.0196** | **0.0122** | **0.0233** | **0.0150** |
# Contact
- dz1833005@smail.nju.edu.cn
- jindongwang@outlook.com
# References
```
@inproceedings{Du2021ADARNN,
title={AdaRNN: Adaptive Learning and Forecasting for Time Series},
author={Du, Yuntao and Wang, Jindong and Feng, Wenjie and Pan, Sinno and Qin, Tao and Xu, Renjun and Wang, Chongjun},
booktitle={Proceedings of the 30th ACM International Conference on Information \& Knowledge Management (CIKM)},
year={2021}
}
```
================================================
FILE: code/deep/adarnn/base/AdaRNN.py
================================================
import torch
import torch.nn as nn
from base.loss_transfer import TransferLoss
import torch.nn.functional as F
class AdaRNN(nn.Module):
"""
model_type: 'Boosting', 'AdaRNN'
"""
def __init__(self, use_bottleneck=False, bottleneck_width=256, n_input=128, n_hiddens=[64, 64], n_output=6, dropout=0.0, len_seq=9, model_type='AdaRNN', trans_loss='mmd'):
super(AdaRNN, self).__init__()
self.use_bottleneck = use_bottleneck
self.n_input = n_input
self.num_layers = len(n_hiddens)
self.hiddens = n_hiddens
self.n_output = n_output
self.model_type = model_type
self.trans_loss = trans_loss
self.len_seq = len_seq
in_size = self.n_input
features = nn.ModuleList()
for hidden in n_hiddens:
rnn = nn.GRU(
input_size=in_size,
num_layers=1,
hidden_size=hidden,
batch_first=True,
dropout=dropout
)
features.append(rnn)
in_size = hidden
self.features = nn.Sequential(*features)
if use_bottleneck == True: # finance
self.bottleneck = nn.Sequential(
nn.Linear(n_hiddens[-1], bottleneck_width),
nn.Linear(bottleneck_width, bottleneck_width),
nn.BatchNorm1d(bottleneck_width),
nn.ReLU(),
nn.Dropout(),
)
self.bottleneck[0].weight.data.normal_(0, 0.005)
self.bottleneck[0].bias.data.fill_(0.1)
self.bottleneck[1].weight.data.normal_(0, 0.005)
self.bottleneck[1].bias.data.fill_(0.1)
self.fc = nn.Linear(bottleneck_width, n_output)
torch.nn.init.xavier_normal_(self.fc.weight)
else:
self.fc_out = nn.Linear(n_hiddens[-1], self.n_output)
if self.model_type == 'AdaRNN':
gate = nn.ModuleList()
for i in range(len(n_hiddens)):
gate_weight = nn.Linear(
len_seq * self.hiddens[i]*2, len_seq)
gate.append(gate_weight)
self.gate = gate
bnlst = nn.ModuleList()
for i in range(len(n_hiddens)):
bnlst.append(nn.BatchNorm1d(len_seq))
self.bn_lst = bnlst
self.softmax = torch.nn.Softmax(dim=0)
self.init_layers()
def init_layers(self):
for i in range(len(self.hiddens)):
self.gate[i].weight.data.normal_(0, 0.05)
self.gate[i].bias.data.fill_(0.0)
def forward_pre_train(self, x, len_win=0):
out = self.gru_features(x)
fea = out[0]
if self.use_bottleneck == True:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
out_list_all, out_weight_list = out[1], out[2]
out_list_s, out_list_t = self.get_features(out_list_all)
loss_transfer = torch.zeros((1,)).cuda()
for i in range(len(out_list_s)):
criterion_transder = TransferLoss(
loss_type=self.trans_loss, input_dim=out_list_s[i].shape[2])
h_start = 0
for j in range(h_start, self.len_seq, 1):
i_start = j - len_win if j - len_win >= 0 else 0
i_end = j + len_win if j + len_win < self.len_seq else self.len_seq - 1
for k in range(i_start, i_end + 1):
weight = out_weight_list[i][j] if self.model_type == 'AdaRNN' else 1 / (
self.len_seq - h_start) * (2 * len_win + 1)
loss_transfer = loss_transfer + weight * criterion_transder.compute(
out_list_s[i][:, j, :], out_list_t[i][:, k, :])
return fc_out, loss_transfer, out_weight_list
def gru_features(self, x, predict=False):
x_input = x
out = None
out_lis = []
out_weight_list = [] if (
self.model_type == 'AdaRNN') else None
for i in range(self.num_layers):
out, _ = self.features[i](x_input.float())
x_input = out
out_lis.append(out)
if self.model_type == 'AdaRNN' and predict == False:
out_gate = self.process_gate_weight(x_input, i)
out_weight_list.append(out_gate)
return out, out_lis, out_weight_list
def process_gate_weight(self, out, index):
x_s = out[0: int(out.shape[0]//2)]
x_t = out[out.shape[0]//2: out.shape[0]]
x_all = torch.cat((x_s, x_t), 2)
x_all = x_all.view(x_all.shape[0], -1)
weight = torch.sigmoid(self.bn_lst[index](
self.gate[index](x_all.float())))
weight = torch.mean(weight, dim=0)
res = self.softmax(weight).squeeze()
return res
def get_features(self, output_list):
fea_list_src, fea_list_tar = [], []
for fea in output_list:
fea_list_src.append(fea[0: fea.size(0) // 2])
fea_list_tar.append(fea[fea.size(0) // 2:])
return fea_list_src, fea_list_tar
# For Boosting-based
def forward_Boosting(self, x, weight_mat=None):
out = self.gru_features(x)
fea = out[0]
if self.use_bottleneck:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
out_list_all = out[1]
out_list_s, out_list_t = self.get_features(out_list_all)
loss_transfer = torch.zeros((1,)).cuda()
if weight_mat is None:
weight = (1.0 / self.len_seq *
torch.ones(self.num_layers, self.len_seq)).cuda()
else:
weight = weight_mat
dist_mat = torch.zeros(self.num_layers, self.len_seq).cuda()
for i in range(len(out_list_s)):
criterion_transder = TransferLoss(
loss_type=self.trans_loss, input_dim=out_list_s[i].shape[2])
for j in range(self.len_seq):
loss_trans = criterion_transder.compute(
out_list_s[i][:, j, :], out_list_t[i][:, j, :])
loss_transfer = loss_transfer + weight[i, j] * loss_trans
dist_mat[i, j] = loss_trans
return fc_out, loss_transfer, dist_mat, weight
# For Boosting-based
def update_weight_Boosting(self, weight_mat, dist_old, dist_new):
epsilon = 1e-12
dist_old = dist_old.detach()
dist_new = dist_new.detach()
ind = dist_new > dist_old + epsilon
weight_mat[ind] = weight_mat[ind] * \
(1 + torch.sigmoid(dist_new[ind] - dist_old[ind]))
weight_norm = torch.norm(weight_mat, dim=1, p=1)
weight_mat = weight_mat / weight_norm.t().unsqueeze(1).repeat(1, self.len_seq)
return weight_mat
def predict(self, x):
out = self.gru_features(x, predict=True)
fea = out[0]
if self.use_bottleneck == True:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
return fc_out
================================================
FILE: code/deep/adarnn/base/__init__.py
================================================
from base.loss_transfer import TransferLoss
# from base.GRUGATE_ALL_HIDDEN import GRUGATE_ALL_HIDDEN
__all__ = [
'MLP',
'TransferNet',
'TransferLoss',
'BaseTrainer',
'Multitask',
'AdaRNN',
'GRUGATE_ALL_HIDDEN'
'MultitaskGRU',
]
================================================
FILE: code/deep/adarnn/base/loss/__init__.py
================================================
from base.loss.adv_loss import adv
from base.loss.coral import CORAL
from base.loss.cos import cosine
from base.loss.kl_js import kl_div, js
from base.loss.mmd import MMD_loss
from base.loss.mutual_info import Mine
from base.loss.pair_dist import pairwise_dist
__all__ = [
'adv',
'CORAL',
'cosine',
'kl_div',
'js'
'MMD_loss',
'Mine',
'pairwise_dist'
]
================================================
FILE: code/deep/adarnn/base/loss/adv_loss.py
================================================
import torch
import torch.nn as nn
import math
import numpy as np
import torch.nn.functional as F
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.dis1 = nn.Linear(input_dim, hidden_dim)
self.dis2 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.dis1(x))
x = self.dis2(x)
x = torch.sigmoid(x)
return x
def adv(source, target, input_dim=256, hidden_dim=512):
domain_loss = nn.BCELoss()
# !!! Pay attention to .cuda !!!
adv_net = Discriminator(input_dim, hidden_dim).cuda()
domain_src = torch.ones(len(source)).cuda()
domain_tar = torch.zeros(len(target)).cuda()
domain_src, domain_tar = domain_src.view(domain_src.shape[0], 1), domain_tar.view(domain_tar.shape[0], 1)
reverse_src = ReverseLayerF.apply(source, 1)
reverse_tar = ReverseLayerF.apply(target, 1)
pred_src = adv_net(reverse_src)
pred_tar = adv_net(reverse_tar)
loss_s, loss_t = domain_loss(pred_src, domain_src), domain_loss(pred_tar, domain_tar)
loss = loss_s + loss_t
return loss
================================================
FILE: code/deep/adarnn/base/loss/coral.py
================================================
import torch
def CORAL(source, target):
d = source.size(1)
ns, nt = source.size(0), target.size(0)
# source covariance
tmp_s = torch.ones((1, ns)).cuda() @ source
cs = (source.t() @ source - (tmp_s.t() @ tmp_s) / ns) / (ns - 1)
# target covariance
tmp_t = torch.ones((1, nt)).cuda() @ target
ct = (target.t() @ target - (tmp_t.t() @ tmp_t) / nt) / (nt - 1)
# frobenius norm
loss = (cs - ct).pow(2).sum()
loss = loss / (4 * d * d)
return loss
================================================
FILE: code/deep/adarnn/base/loss/cos.py
================================================
import torch.nn as nn
def cosine(source, target):
source, target = source.mean(0), target.mean(0)
cos = nn.CosineSimilarity(dim=0)
loss = cos(source, target)
return loss.mean()
================================================
FILE: code/deep/adarnn/base/loss/kl_js.py
================================================
import torch.nn as nn
def kl_div(source, target):
if len(source) < len(target):
target = target[:len(source)]
elif len(source) > len(target):
source = source[:len(target)]
criterion = nn.KLDivLoss(reduction='batchmean')
loss = criterion(source.log(), target)
return loss
def js(source, target):
if len(source) < len(target):
target = target[:len(source)]
elif len(source) > len(target):
source = source[:len(target)]
M = .5 * (source + target)
loss_1, loss_2 = kl_div(source, M), kl_div(target, M)
return .5 * (loss_1 + loss_2)
================================================
FILE: code/deep/adarnn/base/loss/mmd.py
================================================
import torch
import torch.nn as nn
class MMD_loss(nn.Module):
def __init__(self, kernel_type='linear', kernel_mul=2.0, kernel_num=5):
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd(self, X, Y):
delta = X.mean(axis=0) - Y.mean(axis=0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
with torch.no_grad():
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
================================================
FILE: code/deep/adarnn/base/loss/mutual_info.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
class Mine_estimator(nn.Module):
def __init__(self, input_dim=2048, hidden_dim=512):
super(Mine_estimator, self).__init__()
self.mine_model = Mine(input_dim, hidden_dim)
def forward(self, X, Y):
Y_shffle = Y[torch.randperm(len(Y))]
loss_joint = self.mine_model(X, Y)
loss_marginal = self.mine_model(X, Y_shffle)
ret = torch.mean(loss_joint) - \
torch.log(torch.mean(torch.exp(loss_marginal)))
loss = -ret
return loss
class Mine(nn.Module):
def __init__(self, input_dim=2048, hidden_dim=512):
super(Mine, self).__init__()
self.fc1_x = nn.Linear(input_dim, hidden_dim)
self.fc1_y = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, x, y):
h1 = F.leaky_relu(self.fc1_x(x)+self.fc1_y(y))
h2 = self.fc2(h1)
return h2
================================================
FILE: code/deep/adarnn/base/loss/pair_dist.py
================================================
import torch
import numpy as np
def pairwise_dist(X, Y):
n, d = X.shape
m, _ = Y.shape
assert d == Y.shape[1]
a = X.unsqueeze(1).expand(n, m, d)
b = Y.unsqueeze(0).expand(n, m, d)
return torch.pow(a - b, 2).sum(2)
def pairwise_dist_np(X, Y):
n, d = X.shape
m, _ = Y.shape
assert d == Y.shape[1]
a = np.expand_dims(X, 1)
b = np.expand_dims(Y, 0)
a = np.tile(a, (1, m, 1))
b = np.tile(b, (n, 1, 1))
return np.power(a - b, 2).sum(2)
def pa(X, Y):
XY = np.dot(X, Y.T)
XX = np.sum(np.square(X), axis=1)
XX = np.transpose([XX])
YY = np.sum(np.square(Y), axis=1)
dist = XX + YY - 2 * XY
return dist
if __name__ == '__main__':
import sys
args = sys.argv
data = args[0]
print(data)
# a = torch.arange(1, 7).view(2, 3)
# b = torch.arange(12, 21).view(3, 3)
# print(pairwise_dist(a, b))
# a = np.arange(1, 7).reshape((2, 3))
# b = np.arange(12, 21).reshape((3, 3))
# print(pa(a, b))
================================================
FILE: code/deep/adarnn/base/loss_transfer.py
================================================
from base.loss import adv_loss, CORAL, kl_js, mmd, mutual_info, cosine, pairwise_dist
class TransferLoss(object):
def __init__(self, loss_type='cosine', input_dim=512):
"""
Supported loss_type: mmd(mmd_lin), mmd_rbf, coral, cosine, kl, js, mine, adv
"""
self.loss_type = loss_type
self.input_dim = input_dim
def compute(self, X, Y):
"""Compute adaptation loss
Arguments:
X {tensor} -- source matrix
Y {tensor} -- target matrix
Returns:
[tensor] -- transfer loss
"""
if self.loss_type == 'mmd_lin' or self.loss_type =='mmd':
mmdloss = mmd.MMD_loss(kernel_type='linear')
loss = mmdloss(X, Y)
elif self.loss_type == 'coral':
loss = CORAL(X, Y)
elif self.loss_type == 'cosine' or self.loss_type == 'cos':
loss = 1 - cosine(X, Y)
elif self.loss_type == 'kl':
loss = kl_js.kl_div(X, Y)
elif self.loss_type == 'js':
loss = kl_js.js(X, Y)
elif self.loss_type == 'mine':
mine_model = mutual_info.Mine_estimator(
input_dim=self.input_dim, hidden_dim=60).cuda()
loss = mine_model(X, Y)
elif self.loss_type == 'adv':
loss = adv_loss.adv(X, Y, input_dim=self.input_dim, hidden_dim=32)
elif self.loss_type == 'mmd_rbf':
mmdloss = mmd.MMD_loss(kernel_type='rbf')
loss = mmdloss(X, Y)
elif self.loss_type == 'pairwise':
pair_mat = pairwise_dist(X, Y)
import torch
loss = torch.norm(pair_mat)
return loss
if __name__ == "__main__":
import torch
trans_loss = TransferLoss('adv')
a = (torch.randn(5,512) * 10).cuda()
b = (torch.randn(5,512) * 10).cuda()
print(trans_loss.compute(a, b))
================================================
FILE: code/deep/adarnn/dataset/__init__.py
================================================
#
================================================
FILE: code/deep/adarnn/dataset/data_act.py
================================================
# encoding=utf-8
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import os
# from config import config_info
from sklearn.preprocessing import StandardScaler
# This is for parsing the X data, you can ignore it if you do not need preprocessing
def format_data_x(datafile):
x_data = None
for item in datafile:
item_data = np.loadtxt(item, dtype=np.float)
if x_data is None:
x_data = np.zeros((len(item_data), 1))
x_data = np.hstack((x_data, item_data))
x_data = x_data[:, 1:]
print(x_data.shape)
X = None
for i in range(len(x_data)):
row = np.asarray(x_data[i, :])
row = row.reshape(9, 128).T
if X is None:
X = np.zeros((len(x_data), 128, 9))
X[i] = row
print(X.shape)
return X
# This is for parsing the Y data, you can ignore it if you do not need preprocessing
def format_data_y(datafile):
data = np.loadtxt(datafile, dtype=np.int) - 1
YY = np.eye(6)[data]
return YY
# Load data function, if there exists parsed data file, then use it
# If not, parse the original dataset from scratch
def load_data(data_folder, domain):
import os
domain = '1_20' if domain == 'A' else '21_30'
data_file = os.path.join(data_folder, 'data_har_' + domain + '.npz')
if os.path.exists(data_file):
data = np.load(data_file)
X_train = data['X_train']
Y_train = data['Y_train']
X_test = data['X_test']
Y_test = data['Y_test']
else:
# This for processing the dataset from scratch
# After downloading the dataset, put it to somewhere that str_folder can find
str_folder = config_info['data_folder_raw'] + 'UCI HAR Dataset/'
INPUT_SIGNAL_TYPES = [
"body_acc_x_",
"body_acc_y_",
"body_acc_z_",
"body_gyro_x_",
"body_gyro_y_",
"body_gyro_z_",
"total_acc_x_",
"total_acc_y_",
"total_acc_z_"
]
str_train_files = [str_folder + 'train/' + 'Inertial Signals/' + item + 'train.txt' for item in
INPUT_SIGNAL_TYPES]
str_test_files = [str_folder + 'test/' + 'Inertial Signals/' +
item + 'test.txt' for item in INPUT_SIGNAL_TYPES]
str_train_y = str_folder + 'train/y_train.txt'
str_test_y = str_folder + 'test/y_test.txt'
X_train = format_data_x(str_train_files)
X_test = format_data_x(str_test_files)
Y_train = format_data_y(str_train_y)
Y_test = format_data_y(str_test_y)
return X_train, onehot_to_label(Y_train), X_test, onehot_to_label(Y_test)
def onehot_to_label(y_onehot):
a = np.argwhere(y_onehot == 1)
return a[:, -1]
class data_loader(Dataset):
def __init__(self, samples, labels, t):
self.samples = samples
self.labels = labels
self.T = t
def __getitem__(self, index):
sample, target = self.samples[index], self.labels[index]
if self.T:
return self.T(sample), target
else:
return sample, target
def __len__(self):
return len(self.samples)
def normalize(x):
x_min = x.min(axis=(0, 2, 3), keepdims=True)
x_max = x.max(axis=(0, 2, 3), keepdims=True)
x_norm = (x - x_min) / (x_max - x_min)
return x_norm
================================================
FILE: code/deep/adarnn/dataset/data_process.py
================================================
# encoding=utf-8
import os
import dataset.data_act as data_act
import pandas as pd
import dataset.data_weather as data_weather
import datetime
from base.loss_transfer import TransferLoss
import torch
import math
from dataset import data_process
def load_act_data(data_folder, batch_size=64, domain="1_20"):
x_train, y_train, x_test, y_test = data_act.load_data(data_folder, domain)
x_train, x_test = x_train.reshape(
(-1, x_train.shape[2], 1, x_train.shape[1])), x_test.reshape((-1, x_train.shape[2], 1, x_train.shape[1]))
transform = None
train_set = data_act.data_loader(x_train, y_train, transform)
test_set = data_act.data_loader(x_test, y_test, transform)
train_loader = data_act.DataLoader(
train_set, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = data_act.DataLoader(
test_set, batch_size=batch_size, shuffle=False)
return train_loader, train_loader, test_loader
def load_weather_data(file_path, batch_size=6, station='Changping'):
data_file = os.path.join(file_path, "PRSA_Data_1.pkl")
mean_train, std_train = data_weather.get_weather_data_statistic(data_file, station=station, start_time='2013-3-1 0:0',
end_time='2016-10-30 23:0')
train_loader = data_weather.get_weather_data(data_file, station=station, start_time='2013-3-6 0:0',
end_time='2015-5-31 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
valid_train_loader = data_weather.get_weather_data(data_file, station=station, start_time='2015-6-2 0:0',
end_time='2016-6-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
valid_vld_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-7-2 0:0',
end_time='2016-10-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
test_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-11-2 0:0',
end_time='2017-2-28 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
return train_loader, valid_train_loader, valid_vld_loader, test_loader
def get_split_time(num_domain=2, mode='pre_process', data_file = None, station = None, dis_type = 'coral'):
spilt_time = {
'2': [('2013-3-6 0:0', '2015-5-31 23:0'), ('2015-6-2 0:0', '2016-6-30 23:0')]
}
if mode == 'pre_process':
return spilt_time[str(num_domain)]
if mode == 'tdc':
return TDC(num_domain, data_file, station, dis_type = dis_type)
else:
print("error in mode")
def TDC(num_domain, data_file, station, dis_type = 'coral'):
start_time = datetime.datetime.strptime(
'2013-03-01 00:00:00', '%Y-%m-%d %H:%M:%S')
end_time = datetime.datetime.strptime(
'2016-06-30 23:00:00', '%Y-%m-%d %H:%M:%S')
num_day = (end_time - start_time).days
split_N = 10
data=pd.read_pickle(data_file)[station]
feat =data[0][0:num_day]
feat=torch.tensor(feat, dtype=torch.float32)
feat_shape_1 = feat.shape[1]
feat =feat.reshape(-1, feat.shape[2])
feat = feat.cuda()
# num_day_new = feat.shape[0]
selected = [0, 10]
candidate = [1, 2, 3, 4, 5, 6, 7, 8, 9]
start = 0
if num_domain in [2, 3, 5, 7, 10]:
while len(selected) -2 < num_domain -1:
distance_list = []
for can in candidate:
selected.append(can)
selected.sort()
dis_temp = 0
for i in range(1, len(selected)-1):
for j in range(i, len(selected)-1):
index_part1_start = start + math.floor(selected[i-1] / split_N * num_day) * feat_shape_1
index_part1_end = start + math.floor(selected[i] / split_N * num_day) * feat_shape_1
feat_part1 = feat[index_part1_start: index_part1_end]
index_part2_start = start + math.floor(selected[j] / split_N * num_day) * feat_shape_1
index_part2_end = start + math.floor(selected[j+1] / split_N * num_day) * feat_shape_1
feat_part2 = feat[index_part2_start:index_part2_end]
criterion_transder = TransferLoss(loss_type= dis_type, input_dim=feat_part1.shape[1])
dis_temp += criterion_transder.compute(feat_part1, feat_part2)
distance_list.append(dis_temp)
selected.remove(can)
can_index = distance_list.index(max(distance_list))
selected.append(candidate[can_index])
candidate.remove(candidate[can_index])
selected.sort()
res = []
for i in range(1,len(selected)):
if i == 1:
sel_start_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i - 1]), hours = 0)
else:
sel_start_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i - 1])+1, hours = 0)
sel_end_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i]), hours =23)
sel_start_time = datetime.datetime.strftime(sel_start_time,'%Y-%m-%d %H:%M')
sel_end_time = datetime.datetime.strftime(sel_end_time,'%Y-%m-%d %H:%M')
res.append((sel_start_time, sel_end_time))
return res
else:
print("error in number of domain")
def load_weather_data_multi_domain(file_path, batch_size=6, station='Changping', number_domain=2, mode='pre_process', dis_type ='coral'):
# mode: 'tdc', 'pre_process'
data_file = os.path.join(file_path, "PRSA_Data_1.pkl")
mean_train, std_train = data_weather.get_weather_data_statistic(data_file, station=station, start_time='2013-3-1 0:0',
end_time='2016-10-30 23:0')
split_time_list = get_split_time(number_domain, mode=mode, data_file =data_file,station=station, dis_type = dis_type)
train_list = []
for i in range(len(split_time_list)):
time_temp = split_time_list[i]
train_loader = data_weather.get_weather_data(data_file, station=station, start_time=time_temp[0],
end_time=time_temp[1], batch_size=batch_size, mean=mean_train, std=std_train)
train_list.append(train_loader)
valid_vld_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-7-2 0:0',
end_time='2016-10-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
test_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-11-2 0:0',
end_time='2017-2-28 23:0', batch_size=batch_size, mean=mean_train, std=std_train, shuffle=False)
return train_list, valid_vld_loader, test_loader
================================================
FILE: code/deep/adarnn/dataset/data_weather.py
================================================
import math
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
from pandas.core.frame import DataFrame
from torch.utils.data import Dataset, DataLoader
import torch
import pickle
import datetime
class data_loader(Dataset):
def __init__(self, df_feature, df_label, df_label_reg, t=None):
assert len(df_feature) == len(df_label)
assert len(df_feature) == len(df_label_reg)
# df_feature = df_feature.reshape(df_feature.shape[0], df_feature.shape[1] // 6, df_feature.shape[2] * 6)
self.df_feature=df_feature
self.df_label=df_label
self.df_label_reg = df_label_reg
self.T=t
self.df_feature=torch.tensor(
self.df_feature, dtype=torch.float32)
self.df_label=torch.tensor(
self.df_label, dtype=torch.float32)
self.df_label_reg=torch.tensor(
self.df_label_reg, dtype=torch.float32)
def __getitem__(self, index):
sample, target, label_reg =self.df_feature[index], self.df_label[index], self.df_label_reg[index]
if self.T:
return self.T(sample), target
else:
return sample, target, label_reg
def __len__(self):
return len(self.df_feature)
def create_dataset(df, station, start_date, end_date, mean=None, std=None):
data=df[station]
feat, label, label_reg =data[0], data[1], data[2]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
label_reg=label_reg[index_start: index_end + 1]
# ori_shape_1, ori_shape_2=feat.shape[1], feat.shape[2]
# feat=feat.reshape(-1, feat.shape[2])
# feat=(feat - mean) / std
# feat=feat.reshape(-1, ori_shape_1, ori_shape_2)
return data_loader(feat, label, label_reg)
def create_dataset_shallow(df, station, start_date, end_date, mean=None, std=None):
data=df[station]
feat, label, label_reg =data[0], data[1], data[2]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
label_reg=label_reg[index_start: index_end + 1]
# ori_shape_1, ori_shape_2=feat.shape[1], feat.shape[2]
# feat=feat.reshape(-1, feat.shape[2])
# feat=(feat - mean) / std
# feat=feat.reshape(-1, ori_shape_1, ori_shape_2)
return feat, label_reg
def get_dataset_statistic(df, station, start_date, end_date):
data=df[station]
feat, label =data[0], data[1]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
feat=feat.reshape(-1, feat.shape[2])
mu_train=np.mean(feat, axis=0)
sigma_train=np.std(feat, axis=0)
return mu_train, sigma_train
def get_weather_data(data_file, station, start_time, end_time, batch_size, shuffle=True, mean=None, std=None):
df=pd.read_pickle(data_file)
dataset=create_dataset(df, station, start_time,
end_time, mean=mean, std=std)
train_loader=DataLoader(
dataset, batch_size=batch_size, shuffle=shuffle)
return train_loader
def get_weather_data_shallow(data_file, station, start_time, end_time, batch_size, shuffle=True, mean=None, std=None):
df=pd.read_pickle(data_file)
feat, label_reg =create_dataset_shallow(df, station, start_time,
end_time, mean=mean, std=std)
return feat, label_reg
def get_weather_data_statistic(data_file, station, start_time, end_time):
df=pd.read_pickle(data_file)
mean_train, std_train =get_dataset_statistic(
df, station, start_time, end_time)
return mean_train, std_train
================================================
FILE: code/deep/adarnn/requirements.txt
================================================
pretty_errors==1.2.18
visdom==0.1.8.9
matplotlib==3.3.1
numpy==1.22.0
torchvision==0.7.0
torch==1.6.0
tqdm==4.48.2
pandas==1.1.1
scikit_learn==0.23.2
================================================
FILE: code/deep/adarnn/train_weather.py
================================================
import torch.nn as nn
import torch
import torch.optim as optim
import os
import argparse
import datetime
import numpy as np
from tqdm import tqdm
from utils import utils
from base.AdaRNN import AdaRNN
import pretty_errors
import dataset.data_process as data_process
import matplotlib.pyplot as plt
def pprint(*text):
# print with UTC+8 time
time = '['+str(datetime.datetime.utcnow() +
datetime.timedelta(hours=8))[:19]+'] -'
print(time, *text, flush=True)
if args.log_file is None:
return
with open(args.log_file, 'a') as f:
print(time, *text, flush=True, file=f)
def get_model(name='AdaRNN'):
n_hiddens = [args.hidden_size for i in range(args.num_layers)]
return AdaRNN(use_bottleneck=True, bottleneck_width=64, n_input=args.d_feat, n_hiddens=n_hiddens, n_output=args.class_num, dropout=args.dropout, model_type=name, len_seq=args.len_seq, trans_loss=args.loss_type).cuda()
def train_AdaRNN(args, model, optimizer, train_loader_list, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layers, args.len_seq).cuda()
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
if epoch < args.pre_epoch:
pred_all, loss_transfer, out_weight_list = model.forward_pre_train(
feature_all, len_win=args.len_win)
else:
pred_all, loss_transfer, dist, weight_mat = model.forward_Boosting(
feature_all, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch >= args.pre_epoch:
if epoch > args.pre_epoch:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
else:
weight_mat = transform_type(out_weight_list)
return loss, loss_l1, weight_mat, None
def train_epoch_transfer_Boosting(model, optimizer, train_loader_list, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layers, args.len_seq).cuda()
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, loss_transfer, dist, weight_mat = model.forward_Boosting(
feature_all, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch > 0: #args.pre_epoch:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
def get_index(num_domain=2):
index = []
for i in range(num_domain):
for j in range(i+1, num_domain+1):
index.append((i, j))
return index
def train_epoch_transfer(args, model, optimizer, train_loader_list):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
###############
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, loss_transfer, out_weight_list = model.forward_pre_train(
feature_all, len_win=args.len_win)
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
return loss, loss_l1, out_weight_list
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def test_epoch(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred = model.predict(feature)
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = loss_r / len(test_loader)
return loss, loss_1, loss_r
def test_epoch_inference(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
i = 0
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred = model.predict(feature)
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
if i == 0:
label_list = label_reg.cpu().numpy()
predict_list = pred.cpu().numpy()
else:
label_list = np.hstack((label_list, label_reg.cpu().numpy()))
predict_list = np.hstack((predict_list, pred.cpu().numpy()))
i = i + 1
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = total_loss_r / len(test_loader)
return loss, loss_1, loss_r, label_list, predict_list
def inference(model, data_loader):
loss, loss_1, loss_r, label_list, predict_list = test_epoch_inference(
model, data_loader, prefix='Inference')
return loss, loss_1, loss_r, label_list, predict_list
def inference_all(output_path, model, model_path, loaders):
pprint('inference...')
loss_list = []
loss_l1_list = []
loss_r_list = []
model.load_state_dict(torch.load(model_path))
i = 0
list_name = ['train', 'valid', 'test']
for loader in loaders:
loss, loss_1, loss_r, label_list, predict_list = inference(
model, loader)
loss_list.append(loss)
loss_l1_list.append(loss_1)
loss_r_list.append(loss_r)
i = i + 1
return loss_list, loss_l1_list, loss_r_list
def transform_type(init_weight):
weight = torch.ones(args.num_layers, args.len_seq).cuda()
for i in range(args.num_layers):
for j in range(args.len_seq):
weight[i, j] = init_weight[i][j].item()
return weight
def main_transfer(args):
print(args)
output_path = args.outdir + '_' + args.station + '_' + args.model_name + '_weather_' + \
args.loss_type + '_' + str(args.pre_epoch) + \
'_' + str(args.dw) + '_' + str(args.lr)
save_model_name = args.model_name + '_' + args.loss_type + \
'_' + str(args.dw) + '_' + str(args.lr) + '.pkl'
utils.dir_exist(output_path)
pprint('create loaders...')
train_loader_list, valid_loader, test_loader = data_process.load_weather_data_multi_domain(
args.data_path, args.batch_size, args.station, args.num_domain, args.data_mode)
args.log_file = os.path.join(output_path, 'run.log')
pprint('create model...')
model = get_model(args.model_name)
num_model = count_parameters(model)
print('#model params:', num_model)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
best_score = np.inf
best_epoch, stop_round = 0, 0
weight_mat, dist_mat = None, None
for epoch in range(args.n_epochs):
pprint('Epoch:', epoch)
pprint('training...')
if args.model_name in ['Boosting']:
loss, loss1, weight_mat, dist_mat = train_epoch_transfer_Boosting(
model, optimizer, train_loader_list, epoch, dist_mat, weight_mat)
elif args.model_name in ['AdaRNN']:
loss, loss1, weight_mat, dist_mat = train_AdaRNN(
args, model, optimizer, train_loader_list, epoch, dist_mat, weight_mat)
else:
print("error in model_name!")
pprint(loss, loss1)
pprint('evaluating...')
train_loss, train_loss_l1, train_loss_r = test_epoch(
model, train_loader_list[0], prefix='Train')
val_loss, val_loss_l1, val_loss_r = test_epoch(
model, valid_loader, prefix='Valid')
test_loss, test_loss_l1, test_loss_r = test_epoch(
model, test_loader, prefix='Test')
pprint('valid %.6f, test %.6f' %
(val_loss_l1, test_loss_l1))
if val_loss < best_score:
best_score = val_loss
stop_round = 0
best_epoch = epoch
torch.save(model.state_dict(), os.path.join(
output_path, save_model_name))
else:
stop_round += 1
if stop_round >= args.early_stop:
pprint('early stop')
break
pprint('best val score:', best_score, '@', best_epoch)
loaders = train_loader_list[0], valid_loader, test_loader
loss_list, loss_l1_list, loss_r_list = inference_all(output_path, model, os.path.join(
output_path, save_model_name), loaders)
pprint('MSE: train %.6f, valid %.6f, test %.6f' %
(loss_list[0], loss_list[1], loss_list[2]))
pprint('L1: train %.6f, valid %.6f, test %.6f' %
(loss_l1_list[0], loss_l1_list[1], loss_l1_list[2]))
pprint('RMSE: train %.6f, valid %.6f, test %.6f' %
(loss_r_list[0], loss_r_list[1], loss_r_list[2]))
pprint('Finished.')
def get_args():
parser = argparse.ArgumentParser()
# model
parser.add_argument('--model_name', default='AdaRNN')
parser.add_argument('--d_feat', type=int, default=6)
parser.add_argument('--hidden_size', type=int, default=64)
parser.add_argument('--num_layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.0)
parser.add_argument('--class_num', type=int, default=1)
parser.add_argument('--pre_epoch', type=int, default=40) # 20, 30, 50
# training
parser.add_argument('--n_epochs', type=int, default=200)
parser.add_argument('--lr', type=float, default=5e-4)
parser.add_argument('--early_stop', type=int, default=40)
parser.add_argument('--smooth_steps', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=36)
parser.add_argument('--dw', type=float, default=0.5) # 0.01, 0.05, 5.0
parser.add_argument('--loss_type', type=str, default='adv')
parser.add_argument('--station', type=str, default='Dongsi')
parser.add_argument('--data_mode', type=str,
default='tdc')
parser.add_argument('--num_domain', type=int, default=2)
parser.add_argument('--len_seq', type=int, default=24)
# other
parser.add_argument('--seed', type=int, default=10)
parser.add_argument('--data_path', default="/root/Messi_du/adarnn/")
parser.add_argument('--outdir', default='./outputs')
parser.add_argument('--overwrite', action='store_true')
parser.add_argument('--log_file', type=str, default='run.log')
parser.add_argument('--gpu_id', type=int, default=0)
parser.add_argument('--len_win', type=int, default=0)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
main_transfer(args)
================================================
FILE: code/deep/adarnn/transformer_adapt.py
================================================
import torch.nn as nn
import torch
import torch.optim as optim
import os
import argparse
import datetime
import numpy as np
from tqdm import tqdm
from utils import utils
from base.AdaRNN import AdaRNN
import pretty_errors
import dataset.data_process as data_process
import matplotlib.pyplot as plt
from tst import Transformer
def pprint(*text):
# print with UTC+8 time
time = '['+str(datetime.datetime.utcnow() +
datetime.timedelta(hours=8))[:19]+'] -'
print(time, *text, flush=True)
if args.log_file is None:
return
with open(args.log_file, 'a') as f:
print(time, *text, flush=True, file=f)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def train_epoch(args, model, optimizer, src_train_loader, trg_train_loader, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layer, args.len_seq).cuda()
len_loader = np.inf
for data_s, data_t in tqdm(zip(src_train_loader, trg_train_loader), total=min(len(src_train_loader), len(trg_train_loader))):
optimizer.zero_grad()
feature_s, _ , label_reg_s = data_s[0].cuda().float(), data_s[1].cuda().long(), data_s[2].cuda().float()
feature_t, _ , label_reg_t = data_t[0].cuda().float(), data_t[1].cuda().long(), data_t[2].cuda().float()
if feature_s.shape[0] != feature_t.shape[0]:
continue
# feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, list_encoding = model(feature_all)
loss_adapt, dist, weight_mat = model.adapt_encoding_weight(list_encoding, args.loss_type, args.train_type, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
pred_s = torch.mean(pred_s, dim=1).view(pred_s.shape[0])
pred_t = torch.mean(pred_t, dim=1).view(pred_t.shape[0])
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
total_loss = loss_s + args.dw * loss_adapt + loss_t
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch > 0:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
def test_epoch(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred,_ = model(feature)
pred = torch.mean(pred,dim=1).view(pred.shape[0])
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = loss_r / len(test_loader)
return loss, loss_1, loss_r
def test_epoch_inference(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
i = 0
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred,_ = model(feature)
pred = torch.mean(pred,dim=1).view(pred.shape[0])
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
if i == 0:
label_list = label_reg.cpu().numpy()
predict_list = pred.cpu().numpy()
else:
label_list = np.hstack((label_list, label_reg.cpu().numpy()))
predict_list = np.hstack((predict_list, pred.cpu().numpy()))
i = i + 1
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = total_loss_r / len(test_loader)
return loss, loss_1, loss_r, label_list, predict_list
def inference(model, data_loader):
loss, loss_1, loss_r, label_list, predict_list = test_epoch_inference(
model, data_loader, prefix='Inference')
return loss, loss_1, loss_r, label_list, predict_list
def inference_all(output_path, model, model_path, loaders):
pprint('inference...')
loss_list = []
loss_l1_list = []
loss_r_list = []
model.load_state_dict(torch.load(model_path))
i = 0
list_name = ['train', 'valid', 'test']
for loader in loaders:
loss, loss_1, loss_r, label_list, predict_list = inference(
model, loader)
loss_list.append(loss)
loss_l1_list.append(loss_1)
loss_r_list.append(loss_r)
i = i + 1
return loss_list, loss_l1_list, loss_r_list
def main_transfer(args):
print(args)
output_path = args.outdir + '_' + args.station + '_' + args.model_name + '_weather_' + \
args.loss_type + '_' + str(args.pre_epoch) + \
'_' + '_' + str(args.lr) + "_" + str(args.train_type) + "-layer-num-" + str(args.num_layer) + "-hidden-" + str(args.hidden_dim) + "-num_head-" + str(args.num_head) + "dw-" + str(args.dw)
# "-hidden" + str(args.hidden_dim) + "-head" + str(args.num_head)
save_model_name = args.model_name + '_' + args.loss_type + \
'_' + str(args.dw) + '_' + str(args.lr) + '.pkl'
utils.dir_exist(output_path)
pprint('create loaders...')
source_loader, target_loader, valid_loader, test_loader = data_process.load_weather_data(
args.data_path, args.batch_size, args.station)
args.log_file = os.path.join(output_path, 'run.log')
pprint('create model...')
######
# Model parameters
d_model = args.hidden_dim #32 Lattent dim
q = 8 # Query size
v = 8 # Value size
h = args.num_head #4 Number of heads
N = args.num_layer # Number of encoder and decoder to stack
attention_size = 12 # Attention window size
pe = "regular" # Positional encoding
chunk_mode = None
d_input = 6 # From dataset
d_output = 1 # From dataset
model = Transformer(d_input, d_model, d_output, q, v, h, N, attention_size=attention_size, chunk_mode=chunk_mode, pe=pe, pe_period =24).cuda()
#####
num_model = count_parameters(model)
print('#model params:', num_model)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
best_score = np.inf
best_epoch, stop_round = 0, 0
weight_mat, dist_mat = None, None
for epoch in range(args.n_epochs):
pprint('Epoch:', epoch)
pprint('training...')
loss, loss1, weight_mat, dist_mat = train_epoch(
args, model, optimizer, source_loader, target_loader, epoch, dist_mat, weight_mat)
pprint('evaluating...')
train_loss, train_loss_l1, train_loss_r = test_epoch(
model, source_loader, prefix='Train')
val_loss, val_loss_l1, val_loss_r = test_epoch(
model, valid_loader, prefix='Valid')
test_loss, test_loss_l1, test_loss_r = test_epoch(
model, test_loader, prefix='Test')
pprint('valid %.6f, test %.6f' %
(val_loss_l1, test_loss_l1))
if val_loss < best_score:
best_score = val_loss
stop_round = 0
best_epoch = epoch
torch.save(model.state_dict(), os.path.join(
output_path, save_model_name))
else:
stop_round += 1
if stop_round >= args.early_stop:
pprint('early stop')
break
pprint('best val score:', best_score, '@', best_epoch)
loaders = source_loader, valid_loader, test_loader
loss_list, loss_l1_list, loss_r_list = inference_all(output_path, model, os.path.join(
output_path, save_model_name), loaders)
pprint('MSE: train %.6f, valid %.6f, test %.6f' %
(loss_list[0], loss_list[1], loss_list[2]))
pprint('L1: train %.6f, valid %.6f, test %.6f' %
(loss_l1_list[0], loss_l1_list[1], loss_l1_list[2]))
pprint('RMSE: train %.6f, valid %.6f, test %.6f' %
(loss_r_list[0], loss_r_list[1], loss_r_list[2]))
pprint('Finished.')
def get_args():
parser = argparse.ArgumentParser()
# model
parser.add_argument('--model_name', default='adapt_tf')
parser.add_argument('--d_feat', type=int, default=6)
parser.add_argument('--hidden_size', type=int, default=64)
parser.add_argument('--num_layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.0)
parser.add_argument('--class_num', type=int, default=1)
parser.add_argument('--pre_epoch', type=int, default=40) # 25
parser.add_argument('--num_layer', type=int, default=1) # 25
# training
parser.add_argument('--n_epochs', type=int, default=200)
parser.add_argument('--lr', type=float, default=5e-4)
parser.add_argument('--early_stop', type=int, default=40)
parser.add_argument('--smooth_steps', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=36)
parser.add_argument('--dw', type=float, default=0.5)
parser.add_argument('--loss_type', type=str, default='cosine')
parser.add_argument('--train_type', type=str, default='all')
parser.add_argument('--station', type=str, default='Tiantan')
parser.add_argument('--data_mode', type=str,
default='pre_process')
parser.add_argument('--num_domain', type=int, default=2)
parser.add_argument('--len_seq', type=int, default=24)
parser.add_argument('--hidden_dim', type=int, default=32)
parser.add_argument('--num_head', type=int, default=8)
# other
parser.add_argument('--seed', type=int, default=10)
parser.add_argument('--data_path', default="/root/Messi_du/adarnn/")
parser.add_argument('--outdir', default='./outputs')
parser.add_argument('--overwrite', action='store_true')
parser.add_argument('--log_file', type=str, default='run.log')
parser.add_argument('--gpu_id', type=int, default=0)
parser.add_argument('--len_win', type=int, default=0)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
main_transfer(args)
================================================
FILE: code/deep/adarnn/tst/__init__.py
================================================
from .transformer import Transformer
================================================
FILE: code/deep/adarnn/tst/decoder.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.multiHeadAttention import MultiHeadAttention, MultiHeadAttentionChunk, MultiHeadAttentionWindow
from tst.positionwiseFeedForward import PositionwiseFeedForward
class Decoder(nn.Module):
"""Decoder block from Attention is All You Need.
Apply two Multi Head Attention block followed by a Point-wise Feed Forward block.
Residual sum and normalization are applied at each step.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Swict between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk'):
"""Initialize the Decoder block"""
super().__init__()
chunk_mode_modules = {
'chunk': MultiHeadAttentionChunk,
'window': MultiHeadAttentionWindow,
}
if chunk_mode in chunk_mode_modules.keys():
MHA = chunk_mode_modules[chunk_mode]
elif chunk_mode is None:
MHA = MultiHeadAttention
else:
raise NameError(
f'chunk_mode "{chunk_mode}" not understood. Must be one of {", ".join(chunk_mode_modules.keys())} or None.')
self._selfAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._encoderDecoderAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._feedForward = PositionwiseFeedForward(d_model)
self._layerNorm1 = nn.LayerNorm(d_model)
self._layerNorm2 = nn.LayerNorm(d_model)
self._layerNorm3 = nn.LayerNorm(d_model)
self._dopout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor, memory: torch.Tensor) -> torch.Tensor:
"""Propagate the input through the Decoder block.
Apply the self attention block, add residual and normalize.
Apply the encoder-decoder attention block, add residual and normalize.
Apply the feed forward network, add residual and normalize.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
memory:
Memory tensor with shape (batch_size, K, d_model)
from encoder output.
Returns
-------
x:
Output tensor with shape (batch_size, K, d_model).
"""
# Self attention
residual = x
x = self._selfAttention(query=x, key=x, value=x, mask="subsequent")
x = self._dopout(x)
x = self._layerNorm1(x + residual)
# Encoder-decoder attention
residual = x
x = self._encoderDecoderAttention(query=x, key=memory, value=memory)
x = self._dopout(x)
x = self._layerNorm2(x + residual)
# Feed forward
residual = x
x = self._feedForward(x)
x = self._dopout(x)
x = self._layerNorm3(x + residual)
return x
================================================
FILE: code/deep/adarnn/tst/encoder.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.multiHeadAttention import MultiHeadAttention, MultiHeadAttentionChunk, MultiHeadAttentionWindow
from tst.positionwiseFeedForward import PositionwiseFeedForward
class Encoder(nn.Module):
"""Encoder block from Attention is All You Need.
Apply Multi Head Attention block followed by a Point-wise Feed Forward block.
Residual sum and normalization are applied at each step.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Swict between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk'):
"""Initialize the Encoder block"""
super().__init__()
chunk_mode_modules = {
'chunk': MultiHeadAttentionChunk,
'window': MultiHeadAttentionWindow,
}
if chunk_mode in chunk_mode_modules.keys():
MHA = chunk_mode_modules[chunk_mode]
elif chunk_mode is None:
MHA = MultiHeadAttention
else:
raise NameError(
f'chunk_mode "{chunk_mode}" not understood. Must be one of {", ".join(chunk_mode_modules.keys())} or None.')
self._selfAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._feedForward = PositionwiseFeedForward(d_model)
self._layerNorm1 = nn.LayerNorm(d_model)
self._layerNorm2 = nn.LayerNorm(d_model)
self._dopout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate the input through the Encoder block.
Apply the Multi Head Attention block, add residual and normalize.
Apply the Point-wise Feed Forward block, add residual and normalize.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
Returns
-------
Output tensor with shape (batch_size, K, d_model).
"""
# Self attention
residual = x
x = self._selfAttention(query=x, key=x, value=x)
x = self._dopout(x)
x = self._layerNorm1(x + residual)
# Feed forward
residual = x
x = self._feedForward(x)
x = self._dopout(x)
x = self._layerNorm2(x + residual)
return x
@property
def attention_map(self) -> torch.Tensor:
"""Attention map after a forward propagation,
variable `score` in the original paper.
"""
return self._selfAttention.attention_map
================================================
FILE: code/deep/adarnn/tst/loss.py
================================================
import torch
import torch.nn as nn
class OZELoss(nn.Module):
"""Custom loss for TRNSys metamodel.
Compute, for temperature and consumptions, the intergral of the squared differences
over time. Sum the log with a coeficient ``alpha``.
.. math::
\Delta_T = \sqrt{\int (y_{est}^T - y^T)^2}
\Delta_Q = \sqrt{\int (y_{est}^Q - y^Q)^2}
loss = log(1 + \Delta_T) + \\alpha \cdot log(1 + \Delta_Q)
Parameters:
-----------
alpha:
Coefficient for consumption. Default is ``0.3``.
"""
def __init__(self, reduction: str = 'mean', alpha: float = 0.3):
super().__init__()
self.alpha = alpha
self.reduction = reduction
self.base_loss = nn.MSELoss(reduction=self.reduction)
def forward(self,
y_true: torch.Tensor,
y_pred: torch.Tensor) -> torch.Tensor:
"""Compute the loss between a target value and a prediction.
Parameters
----------
y_true:
Target value.
y_pred:
Estimated value.
Returns
-------
Loss as a tensor with gradient attached.
"""
delta_Q = self.base_loss(y_pred[..., :-1], y_true[..., :-1])
delta_T = self.base_loss(y_pred[..., -1], y_true[..., -1])
if self.reduction == 'none':
delta_Q = delta_Q.mean(dim=(1, 2))
delta_T = delta_T.mean(dim=(1))
return torch.log(1 + delta_T) + self.alpha * torch.log(1 + delta_Q)
================================================
FILE: code/deep/adarnn/tst/multiHeadAttention.py
================================================
from typing import Optional
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.utils import generate_local_map_mask
class MultiHeadAttention(nn.Module):
"""Multi Head Attention block from Attention is All You Need.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None):
"""Initialize the Multi Head Block."""
super().__init__()
self._h = h
self._attention_size = attention_size
# Query, keys and value matrices
self._W_q = nn.Linear(d_model, q*self._h)
self._W_k = nn.Linear(d_model, q*self._h)
self._W_v = nn.Linear(d_model, v*self._h)
# Output linear function
self._W_o = nn.Linear(self._h*v, d_model)
# Score placeholder
self._scores = None
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
K = query.shape[1]
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0)
keys = torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0)
values = torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(K)
# Compute local map mask
if self._attention_size is not None:
attention_mask = generate_local_map_mask(K, self._attention_size, mask_future=False, device=self._scores.device)
self._scores = self._scores.masked_fill(attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
future_mask = torch.triu(torch.ones((K, K)), diagonal=1).bool()
future_mask = future_mask.to(self._scores.device)
self._scores = self._scores.masked_fill(future_mask, float('-inf'))
# Apply sotfmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Concatenat the heads
attention_heads = torch.cat(attention.chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
@property
def attention_map(self) -> torch.Tensor:
"""Attention map after a forward propagation,
variable `score` in the original paper.
"""
if self._scores is None:
raise RuntimeError(
"Evaluate the model once to generate attention map")
return self._scores
class MultiHeadAttentionChunk(MultiHeadAttention):
"""Multi Head Attention block with chunk.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Queries, keys and values are divided in chunks of constant size.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
chunk_size:
Size of chunks to apply attention on. Last one may be smaller (see :class:`torch.Tensor.chunk`).
Default is 168.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
chunk_size: Optional[int] = 168,
**kwargs):
"""Initialize the Multi Head Block."""
super().__init__(d_model, q, v, h, attention_size, **kwargs)
self._chunk_size = chunk_size
# Score mask for decoder
self._future_mask = nn.Parameter(torch.triu(torch.ones((self._chunk_size, self._chunk_size)), diagonal=1).bool(),
requires_grad=False)
if self._attention_size is not None:
self._attention_mask = nn.Parameter(generate_local_map_mask(self._chunk_size, self._attention_size),
requires_grad=False)
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
K = query.shape[1]
n_chunk = K // self._chunk_size
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
keys = torch.cat(torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
values = torch.cat(torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(self._chunk_size)
# Compute local map mask
if self._attention_size is not None:
self._scores = self._scores.masked_fill(self._attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
self._scores = self._scores.masked_fill(self._future_mask, float('-inf'))
# Apply softmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Concatenat the heads
attention_heads = torch.cat(torch.cat(attention.chunk(
n_chunk, dim=0), dim=1).chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
class MultiHeadAttentionWindow(MultiHeadAttention):
"""Multi Head Attention block with moving window.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Queries, keys and values are divided in chunks using a moving window.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
window_size:
Size of the window used to extract chunks.
Default is 168
padding:
Padding around each window. Padding will be applied to input sequence.
Default is 168 // 4 = 42.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
window_size: Optional[int] = 168,
padding: Optional[int] = 168 // 4,
**kwargs):
"""Initialize the Multi Head Block."""
super().__init__(d_model, q, v, h, attention_size, **kwargs)
self._window_size = window_size
self._padding = padding
self._q = q
self._v = v
# Step size for the moving window
self._step = self._window_size - 2 * self._padding
# Score mask for decoder
self._future_mask = nn.Parameter(torch.triu(torch.ones((self._window_size, self._window_size)), diagonal=1).bool(),
requires_grad=False)
if self._attention_size is not None:
self._attention_mask = nn.Parameter(generate_local_map_mask(self._window_size, self._attention_size),
requires_grad=False)
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
batch_size = query.shape[0]
# Apply padding to input sequence
query = F.pad(query.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
key = F.pad(key.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
value = F.pad(value.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0)
keys = torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0)
values = torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0)
# Divide Q, K and V using a moving window
queries = queries.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._q, self._window_size)).transpose(1, 2)
keys = keys.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._q, self._window_size)).transpose(1, 2)
values = values.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._v, self._window_size)).transpose(1, 2)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(self._window_size)
# Compute local map mask
if self._attention_size is not None:
self._scores = self._scores.masked_fill(self._attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
self._scores = self._scores.masked_fill(self._future_mask, float('-inf'))
# Apply softmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Fold chunks back
attention = attention.reshape((batch_size*self._h, -1, self._window_size, self._v))
attention = attention[:, :, self._padding:-self._padding, :]
attention = attention.reshape((batch_size*self._h, -1, self._v))
# Concatenat the heads
attention_heads = torch.cat(attention.chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
================================================
FILE: code/deep/adarnn/tst/positionwiseFeedForward.py
================================================
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionwiseFeedForward(nn.Module):
"""Position-wise Feed Forward Network block from Attention is All You Need.
Apply two linear transformations to each input, separately but indetically. We
implement them as 1D convolutions. Input and output have a shape (batch_size, d_model).
Parameters
----------
d_model:
Dimension of input tensor.
d_ff:
Dimension of hidden layer, default is 2048.
"""
def __init__(self,
d_model: int,
d_ff: Optional[int] = 2048):
"""Initialize the PFF block."""
super().__init__()
self._linear1 = nn.Linear(d_model, d_ff)
self._linear2 = nn.Linear(d_ff, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate forward the input through the PFF block.
Apply the first linear transformation, then a relu actvation,
and the second linear transformation.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
Returns
-------
Output tensor with shape (batch_size, K, d_model).
"""
return self._linear2(F.relu(self._linear1(x)))
================================================
FILE: code/deep/adarnn/tst/transformer.py
================================================
import torch
import torch.nn as nn
from tst.encoder import Encoder
from tst.decoder import Decoder
from tst.utils import generate_original_PE, generate_regular_PE
from base.loss_transfer import TransferLoss
class Transformer(nn.Module):
"""Transformer model from Attention is All You Need.
A classic transformer model adapted for sequential data.
Embedding has been replaced with a fully connected layer,
the last layer softmax is now a sigmoid.
Attributes
----------
layers_encoding: :py:class:`list` of :class:`Encoder.Encoder`
stack of Encoder layers.
layers_decoding: :py:class:`list` of :class:`Decoder.Decoder`
stack of Decoder layers.
Parameters
----------
d_input:
Model input dimension.
d_model:
Dimension of the input vector.
d_output:
Model output dimension.
q:
Dimension of queries and keys.
v:
Dimension of values.
h:
Number of heads.
N:
Number of encoder and decoder layers to stack.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Switch between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
pe:
Type of positional encoding to add.
Must be one of ``'original'``, ``'regular'`` or ``None``. Default is ``None``.
pe_period:
If using the ``'regular'` pe, then we can define the period. Default is ``24``.
"""
def __init__(self,
d_input: int,
d_model: int,
d_output: int,
q: int,
v: int,
h: int,
N: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk',
pe: str = None,
pe_period: int = 24):
"""Create transformer structure from Encoder and Decoder blocks."""
super().__init__()
self._d_model = d_model
self.layers_encoding = nn.ModuleList([Encoder(d_model,
q,
v,
h,
attention_size=attention_size,
dropout=dropout,
chunk_mode=chunk_mode) for _ in range(N)])
self.layers_decoding = nn.ModuleList([Decoder(d_model,
q,
v,
h,
attention_size=attention_size,
dropout=dropout,
chunk_mode=chunk_mode) for _ in range(N)])
self._embedding = nn.Linear(d_input, d_model)
self._linear = nn.Linear(d_model, d_output)
pe_functions = {
'original': generate_original_PE,
'regular': generate_regular_PE,
}
if pe in pe_functions.keys():
self._generate_PE = pe_functions[pe]
self._pe_period = pe_period
elif pe is None:
self._generate_PE = None
else:
raise NameError(
f'PE "{pe}" not understood. Must be one of {", ".join(pe_functions.keys())} or None.')
self.name = 'transformer'
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate input through transformer
Forward input through an embedding module,
the encoder then decoder stacks, and an output module.
Parameters
----------
x:
:class:`torch.Tensor` of shape (batch_size, K, d_input).
Returns
-------
Output tensor with shape (batch_size, K, d_output).
"""
K = x.shape[1]
# Embeddin module
encoding = self._embedding(x)
# Add position encoding
if self._generate_PE is not None:
pe_params = {'period': self._pe_period} if self._pe_period else {}
positional_encoding = self._generate_PE(K, self._d_model, **pe_params)
positional_encoding = positional_encoding.to(encoding.device)
encoding.add_(positional_encoding)
# Encoding stack
list_encoding = []
for layer in self.layers_encoding:
encoding = layer(encoding)
list_encoding.append(encoding)
# Decoding stack
decoding = encoding
# Add position encoding
if self._generate_PE is not None:
positional_encoding = self._generate_PE(K, self._d_model)
positional_encoding = positional_encoding.to(decoding.device)
decoding.add_(positional_encoding)
for layer in self.layers_decoding:
decoding = layer(decoding, encoding)
# Output module
output = self._linear(decoding)
output = torch.sigmoid(output)
return output, list_encoding
# def adapt_encoding(self, list_encoding, loss_type, train_type):
# ## train_type "last" : last hidden, "all": all hidden
# loss_all = torch.zeros(1).cuda()
# for i in range(len(list_encoding)):
# data = list_encoding[i]
# data_s = data[0:len(data)//2]
# data_t = data[len(data)//2:]
# criterion_transder = TransferLoss(
# loss_type=loss_type, input_dim=data_s.shape[2])
# if train_type == 'last':
# loss_all = loss_all + criterion_transder.compute(
# data_s[:, -1, :], data_t[:, -1, :])
# elif train_type == "all":
# for j in range(data_s.shape[1]):
# loss_all = loss_all + criterion_transder.compute(data_s[:, j, :], data_t[:, j, :])
# else:
# print("adapt loss error!")
# return loss_all
def adapt_encoding_weight(self, list_encoding, loss_type, train_type, weight_mat=None):
loss_all = torch.zeros(1).cuda()
len_seq = list_encoding[0].shape[1]
num_layers = len(list_encoding)
if weight_mat is None:
weight = (1.0 / len_seq *
torch.ones(num_layers, len_seq)).cuda()
else:
weight = weight_mat
dist_mat = torch.zeros(num_layers, len_seq).cuda()
for i in range(len(list_encoding)):
data = list_encoding[i]
data_s = data[0:len(data)//2]
data_t = data[len(data)//2:]
criterion_transder = TransferLoss(
loss_type=loss_type, input_dim=data_s.shape[2])
if train_type == 'last':
loss_all = loss_all + criterion_transder.compute(
data_s[:, -1, :], data_t[:, -1, :])
elif train_type == "all":
for j in range(data_s.shape[1]):
loss_transfer = criterion_transder.compute(data_s[:, j, :], data_t[:, j, :])
loss_all = loss_all + weight[i, j] * loss_transfer
dist_mat[i, j] = loss_transfer
else:
print("adapt loss error!")
return loss_all, dist_mat, weight
def update_weight_Boosting(self, weight_mat, dist_old, dist_new):
epsilon = 1e-12
dist_old = dist_old.detach()
dist_new = dist_new.detach()
ind = dist_new > dist_old + epsilon
weight_mat[ind] = weight_mat[ind] * \
(1 + torch.sigmoid(dist_new[ind] - dist_old[ind]))
weight_norm = torch.norm(weight_mat, dim=1, p=1)
weight_mat = weight_mat / weight_norm.t().unsqueeze(1).repeat(1, len(weight_mat[0]))
return weight_mat
================================================
FILE: code/deep/adarnn/tst/utils.py
================================================
from typing import Optional, Union
import numpy as np
import torch
def generate_original_PE(length: int, d_model: int) -> torch.Tensor:
"""Generate positional encoding as described in original paper. :class:`torch.Tensor`
Parameters
----------
length:
Time window length, i.e. K.
d_model:
Dimension of the model vector.
Returns
-------
Tensor of shape (K, d_model).
"""
PE = torch.zeros((length, d_model))
pos = torch.arange(length).unsqueeze(1)
PE[:, 0::2] = torch.sin(
pos / torch.pow(1000, torch.arange(0, d_model, 2, dtype=torch.float32)/d_model))
PE[:, 1::2] = torch.cos(
pos / torch.pow(1000, torch.arange(1, d_model, 2, dtype=torch.float32)/d_model))
return PE
def generate_regular_PE(length: int, d_model: int, period: Optional[int] = 24) -> torch.Tensor:
"""Generate positional encoding with a given period.
Parameters
----------
length:
Time window length, i.e. K.
d_model:
Dimension of the model vector.
period:
Size of the pattern to repeat.
Default is 24.
Returns
-------
Tensor of shape (K, d_model).
"""
PE = torch.zeros((length, d_model))
pos = torch.arange(length, dtype=torch.float32).unsqueeze(1)
PE = torch.sin(pos * 2 * np.pi / period)
PE = PE.repeat((1, d_model))
return PE
def generate_local_map_mask(chunk_size: int,
attention_size: int,
mask_future=False,
device: torch.device = 'cpu') -> torch.BoolTensor:
"""Compute attention mask as attention_size wide diagonal.
Parameters
----------
chunk_size:
Time dimension size.
attention_size:
Number of backward elements to apply attention.
device:
torch device. Default is ``'cpu'``.
Returns
-------
Mask as a boolean tensor.
"""
local_map = np.empty((chunk_size, chunk_size))
i, j = np.indices(local_map.shape)
if mask_future:
local_map[i, j] = (i - j > attention_size) ^ (j - i > 0)
else:
local_map[i, j] = np.abs(i - j) > attention_size
return torch.BoolTensor(local_map).to(device)
================================================
FILE: code/deep/adarnn/utils/__init__.py
================================================
from utils import utils
from utils.visualize import Visualize
from utils import metrics
from utils import heat_map
__all__ = {
'utils',
'Visualize',
'metrics',
'heat_map'
}
================================================
FILE: code/deep/adarnn/utils/heat_map.py
================================================
import random
from matplotlib import pyplot as plt
from matplotlib import cm
from matplotlib import axes
from matplotlib.font_manager import FontProperties
def draw_heatmap(data, filename):
#作图阶段
fig = plt.figure()
#定义画布为1*1个划分,并在第1个位置上进行作图
ax = fig.add_subplot(111)
#作图并选择热图的颜色填充风格,这里选择hot
im = ax.imshow(data, cmap=plt.cm.hot_r)
#增加右侧的颜色刻度条
plt.colorbar(im)
#增加标题
plt.title("weight heatmap")
#show
plt.show()
plt.savefig(filename)
# d = draw()
================================================
FILE: code/deep/adarnn/utils/metrics.py
================================================
import torch
EPS = 1e-12
def robust_zscore_tensor(x):
x -= torch.median(x, dim=0, keepdim=True)[0]
x /= torch.median(torch.abs(x), dim=0, keepdim=True)[0] * 1.4826 + EPS
x.clamp_(-3, 3)
x -= torch.mean(x, dim=0, keepdim=True)
x /= torch.std(x, unbiased=False, dim=0, keepdim=True) + EPS
return x
def calc_ic(pred, label):
pred = robust_zscore_tensor(pred)
label = robust_zscore_tensor(label)
return torch.mean(pred * label)
def calc_r2(pred, label):
return 1 - (pred - label).pow(2).sum() / label.pow(2).sum()
def metric_fn(pred, label, metric='IC'):
# robust pearson correlation
mask = ~torch.isnan(label)
if metric == 'IC':
return calc_ic(pred[mask], label[mask])
elif metric == 'R2':
return calc_r2(pred[mask], label[mask])
def robust_zscore(x):
# MAD based robust zscore
x = x - x.median() # copy
x /= x.abs().median() * 1.4826
x.clip(-3, 3, inplace=True)
return x
def calc_all_metrics(pred):
"""pred is a pandas dataframe that has two attributes: score (pred) and label (real)"""
res = {}
ic = pred.groupby(level='datetime').apply(
lambda x: robust_zscore(x.label).corr(robust_zscore(x.score)))
raw_ic = pred.groupby(level='datetime').apply(
lambda x: x.label.corr(x.score))
rank_ic = pred.groupby(level='datetime').apply(
lambda x: x.label.corr(x.score, method='spearman'))
print('Robust IC %.3f, Robust ICIR %.3f, Rank IC %.3f, Rank ICIR %.3f, Raw IC %.3f, Raw ICIR %.3f'%(
ic.mean(), ic.mean()/ic.std(), rank_ic.mean(), rank_ic.mean()/rank_ic.std(), raw_ic.mean(), raw_ic.mean() / raw_ic.std()))
res['IC'] = ic.mean()
res['ICIR'] = ic.mean() / ic.std()
res['RankIC'] = rank_ic.mean()
res['RankICIR'] = rank_ic.mean() / rank_ic.std()
res['RawIC'] = raw_ic.mean()
res['RawICIR'] = raw_ic.mean() / raw_ic.std()
return res
def logcosh(pred, label):
# logcosh
mask = ~torch.isnan(label)
loss = torch.log(torch.cosh(pred[mask] - label[mask]))
return torch.mean(loss)
================================================
FILE: code/deep/adarnn/utils/utils.py
================================================
import collections
import torch
import os
import pandas as pd
import torch.nn as nn
from tqdm import tqdm
import numpy as np
EPS = 1e-12
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
self.list = []
def update(self, val, n=1):
self.val = val
self.list.append(val)
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def average_params(params_list):
assert isinstance(params_list, (tuple, list, collections.deque))
n = len(params_list)
if n == 1:
return params_list[0]
new_params = collections.OrderedDict()
keys = None
for i, params in enumerate(params_list):
if keys is None:
keys = params.keys()
for k, v in params.items():
if k not in keys:
raise ValueError('the %d-th model has different params'%i)
if k not in new_params:
new_params[k] = v / n
else:
new_params[k] += v / n
return new_params
def zscore(x):
return (x - x.mean(dim=0, keepdim=True)) / x.std(dim=0, keepdim=True, unbiased=False)
def calc_loss(pred, label):
return torch.mean((zscore(pred) - label) ** 2)
def calc_corr(pred, label):
return (zscore(pred) * zscore(label)).mean()
def test_ic(model_list, data_list, device, verbose=True, ic_type='spearman'):
'''
model_list: [model1, model2, ...]
datalist: [loader1, loader2, ...]
return: unified ic, specific ic (all values), loss
'''
spec_ic = []
loss_test = AverageMeter()
loss_fn = torch.nn.MSELoss()
label_true, label_pred = torch.empty(0).to(device), torch.empty(0).to(device)
for i in range(len(model_list)):
label_spec_true, label_spec_pred = torch.empty(0).to(device), torch.empty(0).to(device)
model_list[i].eval()
with torch.no_grad():
for _, (feature, label_actual, _, _) in enumerate(data_list[i]):
# feature = torch.tensor(feature, dtype=torch.float32, device=device)
label_actual = label_actual.clone().detach().view(-1, 1)
label_actual, mask = handle_nan(label_actual)
label_predict = model_list[i].predict(feature).view(-1, 1)
label_predict = label_predict[mask]
loss = loss_fn(label_actual, label_predict)
loss_test.update(loss.item())
# Concat them for computing IC later
label_true = torch.cat([label_true, label_actual])
label_pred = torch.cat([label_pred, label_predict])
label_spec_true = torch.cat([label_spec_true, label_actual])
label_spec_pred = torch.cat([label_spec_pred, label_predict])
ic = calc_ic(label_spec_true, label_spec_pred, ic_type)
spec_ic.append(ic.item())
unify_ic = calc_ic(label_true, label_pred, ic_type).item()
# spec_ic.append(sum(spec_ic) / len(spec_ic))
loss = loss_test.avg
if verbose:
print('[IC] Unified IC: {:.6f}, specific IC: {}, loss: {:.6f}'.format(unify_ic, spec_ic, loss))
return unify_ic, spec_ic, loss
def test_ic_daily(model_list, data_list, device, verbose=True, ic_type='spearman'):
'''
model_list: [model1, model2, ...]
datalist: [loader1, loader2, ...]
return: unified ic, specific ic (all values + avg), loss
'''
spec_ic = []
loss_test = AverageMeter()
loss_fn = torch.nn.MSELoss()
label_true, label_pred = torch.empty(0).to(device), torch.empty(0).to(device)
for i in range(len(model_list)):
label_spec_true, label_spec_pred = torch.empty(0).to(device), torch.empty(0).to(device)
model_list[i].eval()
with torch.no_grad():
for slc in tqdm(data_list[i].iter_daily(), total=data_list[i].daily_length):
feature, label_actual, _, _ = data_list[i].get(slc)
# for _, (feature, label_actual, _, _) in enumerate(data_list[i]):
# feature = torch.tensor(feature, dtype=torch.float32, device=device)
label_actual = torch.tensor(label_actual, dtype=torch.float32, device=device).view(-1, 1)
label_actual, mask = handle_nan(label_actual)
label_predict = model_list[i].predict(feature).view(-1, 1)
label_predict = label_predict[mask]
loss = loss_fn(label_actual, label_predict)
loss_test.update(loss.item())
# Concat them for computing IC later
label_true = torch.cat([label_true, label_actual])
label_pred = torch.cat([label_pred, label_predict])
label_spec_true = torch.cat([label_spec_true, label_actual])
label_spec_pred = torch.cat([label_spec_pred, label_predict])
ic = calc_ic(label_spec_true, label_spec_pred, ic_type)
spec_ic.append(ic.item())
unify_ic = calc_ic(label_true, label_pred, ic_type).item()
# spec_ic.append(sum(spec_ic) / len(spec_ic))
loss = loss_test.avg
if verbose:
print('[IC] Unified IC: {:.6f}, specific IC: {}, loss: {:.6f}'.format(unify_ic, spec_ic, loss))
return unify_ic, spec_ic, loss
def test_ic_uni(model, data_loader, model_path=None, ic_type='spearman', verbose=False):
if model_path:
model.load_state_dict(torch.load(model_path))
model.eval()
loss_all = []
ic_all = []
for slc in tqdm(data_loader.iter_daily(), total=data_loader.daily_length):
data, label, _, _ = data_loader.get(slc)
with torch.no_grad():
pred = model.predict(data)
mask = ~torch.isnan(label)
pred = pred[mask]
label = label[mask]
loss = torch.mean(torch.log(torch.cosh(pred - label)))
if ic_type == 'spearman':
ic = spearman_corr(pred, label)
elif ic_type == 'pearson':
ic = pearson_corr(pred, label)
loss_all.append(loss.item())
ic_all.append(ic)
loss, ic = np.mean(loss_all), np.mean(ic_all)
if verbose:
print('IC: ', ic)
return loss, ic
def calc_ic(x, y, ic_type='pearson'):
ic = -100
if ic_type == 'pearson':
ic = pearson_corr(x, y)
elif ic_type == 'spearman':
ic = spearman_corr(x, y)
return ic
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
def handle_nan(x):
mask = ~torch.isnan(x)
return x[mask], mask
class Log_Loss(nn.Module):
def __init__(self):
super(Log_Loss, self).__init__()
def forward(self, ytrue, ypred):
delta = ypred - ytrue
return torch.mean(torch.log(torch.cosh(delta)))
def spearman_corr(x, y):
X = pd.Series(x.cpu())
Y = pd.Series(y.cpu())
spearman = X.corr(Y, method='spearman')
return spearman
def spearman_corr2(x, y):
X = pd.Series(x)
Y = pd.Series(y)
spearman = X.corr(Y, method='spearman')
return spearman
def pearson_corr(x, y):
X = pd.Series(x.cpu())
Y = pd.Series(y.cpu())
spearman = X.corr(Y, method='pearson')
return spearman
def dir_exist(dirs):
if not os.path.exists(dirs):
os.makedirs(dirs)
================================================
FILE: code/deep/adarnn/utils/visualize.py
================================================
# A wrapper of Visdom for visualization
import visdom
import numpy as np
import time
class Visualize(object):
def __init__(self, port=8097, env='env'):
self.port = port
self.env = env
self.vis = visdom.Visdom(port=self.port, env=self.env)
def plot_line(self, Y, global_step, title='title', legend=['legend']):
""" Plot line
Inputs:
Y (list): values to plot, a list
global_step (int): global step
"""
y = np.array(Y).reshape((1, len(Y)))
self.vis.line(
Y = y,
X = np.array([global_step]),
win = title,
opts = dict(
title = title,
height = 360,
width = 400,
legend = legend,
),
update = 'new' if global_step==0 else 'append'
)
def heat_map(self, X, title='title'):
self.vis.heatmap(
X = X,
win = title,
opts=dict(
title = title,
width = 360,
height = 400,
)
)
def log(self, info, title='log_text'):
"""
self.log({'loss':1, 'lr':0.0001})
"""
log_text = ('[{time}] {info}
**Abstract:** Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as **Temporal Covariate Shift (TCS)**. This paper proposes **Adaptive RNNs (AdaRNN)** to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose **Temporal Distribution Characterization** to better characterize the distribution information in the TS. Second, we propose **Temporal Distribution Matching** to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.

To use this code, you can either git clone this transferlearning repo, or if you just want to use this folder, you can go to [this site](https://minhaskamal.github.io/DownGit/#/home) to paste the url of this code (https://github.com/jindongwang/transferlearning/edit/master/code/deep/adarnn) and then download just this folder.
## Requirement
- CUDA 10.1
- Python 3.7.7
- Pytorch == 1.6.0
- Torchvision == 0.7.0
The required packages are listed in `requirements.txt`.
## Dataset
The original air-quality dataset is downloaded from [Beijing Multi-Site Air-Quality Data Data Set](https://archive.ics.uci.edu/ml/datasets/Beijing+Multi-Site+Air-Quality+Data) . The air-quality dataset contains hourly air quality information collected from 12 stations in Beijing from 03/2013 to 02/2017. We randomly chose four stations (Dongsi, Tiantan, Nongzhanguan, and Dingling) and select six features (PM2.5, PM10, S02, NO2, CO, and O3). Since there are some missing data, we simply fill the empty slots using averaged values. Then, the dataset is normalized before feeding into the network to scale all features into the same range. This process is accomplished by max-min normalization and ranges data between 0 and 1. The processed air-quality dataset can be downloaded at [dataset link](https://box.nju.edu.cn/f/2239259e06dd4f4cbf64/?dl=1) or [new link](https://pan.baidu.com/s/1xkLyd9YPgK7h8B1-acCImg) with password 1007.
The procossed .pkl files contains three arraies: 'feature', 'label', and 'label_reg'. 'label' refers to the classification label of air quality (e.g. excellence, good, middle), which is not used in this work and could be ignored. 'label_reg' refers to the prediction value.
## How to run
The code for air-quality dataset is in `train_weather.py`. After downloading the dataset, you can change args.data_path in `train_weather.py` to the folder where you place the data.
Then you can run the code. Taking Dongsi station as example, you can run
`python train_weather.py --model_name 'AdaRNN' --station 'Dongsi' --pre_epoch 40 --dw 0.5 --loss_type 'adv' --data_mode 'tdc'`
For transformer model, the adapted transformer model is in `transformer_adapt.py`, you can run,
`python transformer_adapt.py --station 'Tiantan' --dw 1.0`
# Results
**Air-quality dataset**
| | Dongsi | | Tiantan | | Nongzhanguan | | Dingling | |
|-------------|:-------:|:-------:|:-------:|:-------:|:------------:|:-------:|:--------:|:-------:|
| | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE |
| FBProphet | 0.1866 | 0.1403 | 0.1434 | 0.1119 | 0.1551 | 0.1221 | 0.0932 | 0.0736 |
| ARIMA | 0.1811 | 0.1356 | 0.1414 | 0.1082 | 0.1557 | 0.1156 | 0.0922 | 0.0709 |
| GRU | 0.0510 | 0.0380 | 0.0475 | 0.0348 | 0.0459 | 0.0330 | 0.0347 | 0.0244 |
| MMD-RNN | 0.0360 | 0.0267 | 0.0183 | 0.0133 | 0.0267 | 0.0197 | 0.0288 | 0.0168 |
| DANN-RNN | 0.0356 | 0.0255 | 0.0214 | 0.0157 | 0.0274 | 0.0203 | 0.0291 | 0.0211 |
| LightGBM | 0.0587 | 0.0390 | 0.0412 | 0.0289 | 0.0436 | 0.0319 | 0.0322 | 0.0210 |
| LSTNet | 0.0544 | 0.0651 | 0.0519 | 0.0651 | 0.0548 | 0.0696 | 0.0599 | 0.0705 |
| Transformer | 0.0339 | 0.0220 | 0.0233 | 0.0164 | 0.0226 | 0.0181 | 0.0263 | 0.0163 |
| STRIPE | 0.0365 | 0.0216 | 0.0204 | 0.0148 | 0.0248 | 0.0154 | 0.0304 | 0.0139 |
| ADARNN | **0.0295** | **0.0185** | **0.0164** | **0.0112** | **0.0196** | **0.0122** | **0.0233** | **0.0150** |
# Contact
- dz1833005@smail.nju.edu.cn
- jindongwang@outlook.com
# References
```
@inproceedings{Du2021ADARNN,
title={AdaRNN: Adaptive Learning and Forecasting for Time Series},
author={Du, Yuntao and Wang, Jindong and Feng, Wenjie and Pan, Sinno and Qin, Tao and Xu, Renjun and Wang, Chongjun},
booktitle={Proceedings of the 30th ACM International Conference on Information \& Knowledge Management (CIKM)},
year={2021}
}
```
================================================
FILE: code/deep/adarnn/base/AdaRNN.py
================================================
import torch
import torch.nn as nn
from base.loss_transfer import TransferLoss
import torch.nn.functional as F
class AdaRNN(nn.Module):
"""
model_type: 'Boosting', 'AdaRNN'
"""
def __init__(self, use_bottleneck=False, bottleneck_width=256, n_input=128, n_hiddens=[64, 64], n_output=6, dropout=0.0, len_seq=9, model_type='AdaRNN', trans_loss='mmd'):
super(AdaRNN, self).__init__()
self.use_bottleneck = use_bottleneck
self.n_input = n_input
self.num_layers = len(n_hiddens)
self.hiddens = n_hiddens
self.n_output = n_output
self.model_type = model_type
self.trans_loss = trans_loss
self.len_seq = len_seq
in_size = self.n_input
features = nn.ModuleList()
for hidden in n_hiddens:
rnn = nn.GRU(
input_size=in_size,
num_layers=1,
hidden_size=hidden,
batch_first=True,
dropout=dropout
)
features.append(rnn)
in_size = hidden
self.features = nn.Sequential(*features)
if use_bottleneck == True: # finance
self.bottleneck = nn.Sequential(
nn.Linear(n_hiddens[-1], bottleneck_width),
nn.Linear(bottleneck_width, bottleneck_width),
nn.BatchNorm1d(bottleneck_width),
nn.ReLU(),
nn.Dropout(),
)
self.bottleneck[0].weight.data.normal_(0, 0.005)
self.bottleneck[0].bias.data.fill_(0.1)
self.bottleneck[1].weight.data.normal_(0, 0.005)
self.bottleneck[1].bias.data.fill_(0.1)
self.fc = nn.Linear(bottleneck_width, n_output)
torch.nn.init.xavier_normal_(self.fc.weight)
else:
self.fc_out = nn.Linear(n_hiddens[-1], self.n_output)
if self.model_type == 'AdaRNN':
gate = nn.ModuleList()
for i in range(len(n_hiddens)):
gate_weight = nn.Linear(
len_seq * self.hiddens[i]*2, len_seq)
gate.append(gate_weight)
self.gate = gate
bnlst = nn.ModuleList()
for i in range(len(n_hiddens)):
bnlst.append(nn.BatchNorm1d(len_seq))
self.bn_lst = bnlst
self.softmax = torch.nn.Softmax(dim=0)
self.init_layers()
def init_layers(self):
for i in range(len(self.hiddens)):
self.gate[i].weight.data.normal_(0, 0.05)
self.gate[i].bias.data.fill_(0.0)
def forward_pre_train(self, x, len_win=0):
out = self.gru_features(x)
fea = out[0]
if self.use_bottleneck == True:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
out_list_all, out_weight_list = out[1], out[2]
out_list_s, out_list_t = self.get_features(out_list_all)
loss_transfer = torch.zeros((1,)).cuda()
for i in range(len(out_list_s)):
criterion_transder = TransferLoss(
loss_type=self.trans_loss, input_dim=out_list_s[i].shape[2])
h_start = 0
for j in range(h_start, self.len_seq, 1):
i_start = j - len_win if j - len_win >= 0 else 0
i_end = j + len_win if j + len_win < self.len_seq else self.len_seq - 1
for k in range(i_start, i_end + 1):
weight = out_weight_list[i][j] if self.model_type == 'AdaRNN' else 1 / (
self.len_seq - h_start) * (2 * len_win + 1)
loss_transfer = loss_transfer + weight * criterion_transder.compute(
out_list_s[i][:, j, :], out_list_t[i][:, k, :])
return fc_out, loss_transfer, out_weight_list
def gru_features(self, x, predict=False):
x_input = x
out = None
out_lis = []
out_weight_list = [] if (
self.model_type == 'AdaRNN') else None
for i in range(self.num_layers):
out, _ = self.features[i](x_input.float())
x_input = out
out_lis.append(out)
if self.model_type == 'AdaRNN' and predict == False:
out_gate = self.process_gate_weight(x_input, i)
out_weight_list.append(out_gate)
return out, out_lis, out_weight_list
def process_gate_weight(self, out, index):
x_s = out[0: int(out.shape[0]//2)]
x_t = out[out.shape[0]//2: out.shape[0]]
x_all = torch.cat((x_s, x_t), 2)
x_all = x_all.view(x_all.shape[0], -1)
weight = torch.sigmoid(self.bn_lst[index](
self.gate[index](x_all.float())))
weight = torch.mean(weight, dim=0)
res = self.softmax(weight).squeeze()
return res
def get_features(self, output_list):
fea_list_src, fea_list_tar = [], []
for fea in output_list:
fea_list_src.append(fea[0: fea.size(0) // 2])
fea_list_tar.append(fea[fea.size(0) // 2:])
return fea_list_src, fea_list_tar
# For Boosting-based
def forward_Boosting(self, x, weight_mat=None):
out = self.gru_features(x)
fea = out[0]
if self.use_bottleneck:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
out_list_all = out[1]
out_list_s, out_list_t = self.get_features(out_list_all)
loss_transfer = torch.zeros((1,)).cuda()
if weight_mat is None:
weight = (1.0 / self.len_seq *
torch.ones(self.num_layers, self.len_seq)).cuda()
else:
weight = weight_mat
dist_mat = torch.zeros(self.num_layers, self.len_seq).cuda()
for i in range(len(out_list_s)):
criterion_transder = TransferLoss(
loss_type=self.trans_loss, input_dim=out_list_s[i].shape[2])
for j in range(self.len_seq):
loss_trans = criterion_transder.compute(
out_list_s[i][:, j, :], out_list_t[i][:, j, :])
loss_transfer = loss_transfer + weight[i, j] * loss_trans
dist_mat[i, j] = loss_trans
return fc_out, loss_transfer, dist_mat, weight
# For Boosting-based
def update_weight_Boosting(self, weight_mat, dist_old, dist_new):
epsilon = 1e-12
dist_old = dist_old.detach()
dist_new = dist_new.detach()
ind = dist_new > dist_old + epsilon
weight_mat[ind] = weight_mat[ind] * \
(1 + torch.sigmoid(dist_new[ind] - dist_old[ind]))
weight_norm = torch.norm(weight_mat, dim=1, p=1)
weight_mat = weight_mat / weight_norm.t().unsqueeze(1).repeat(1, self.len_seq)
return weight_mat
def predict(self, x):
out = self.gru_features(x, predict=True)
fea = out[0]
if self.use_bottleneck == True:
fea_bottleneck = self.bottleneck(fea[:, -1, :])
fc_out = self.fc(fea_bottleneck).squeeze()
else:
fc_out = self.fc_out(fea[:, -1, :]).squeeze()
return fc_out
================================================
FILE: code/deep/adarnn/base/__init__.py
================================================
from base.loss_transfer import TransferLoss
# from base.GRUGATE_ALL_HIDDEN import GRUGATE_ALL_HIDDEN
__all__ = [
'MLP',
'TransferNet',
'TransferLoss',
'BaseTrainer',
'Multitask',
'AdaRNN',
'GRUGATE_ALL_HIDDEN'
'MultitaskGRU',
]
================================================
FILE: code/deep/adarnn/base/loss/__init__.py
================================================
from base.loss.adv_loss import adv
from base.loss.coral import CORAL
from base.loss.cos import cosine
from base.loss.kl_js import kl_div, js
from base.loss.mmd import MMD_loss
from base.loss.mutual_info import Mine
from base.loss.pair_dist import pairwise_dist
__all__ = [
'adv',
'CORAL',
'cosine',
'kl_div',
'js'
'MMD_loss',
'Mine',
'pairwise_dist'
]
================================================
FILE: code/deep/adarnn/base/loss/adv_loss.py
================================================
import torch
import torch.nn as nn
import math
import numpy as np
import torch.nn.functional as F
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.dis1 = nn.Linear(input_dim, hidden_dim)
self.dis2 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.dis1(x))
x = self.dis2(x)
x = torch.sigmoid(x)
return x
def adv(source, target, input_dim=256, hidden_dim=512):
domain_loss = nn.BCELoss()
# !!! Pay attention to .cuda !!!
adv_net = Discriminator(input_dim, hidden_dim).cuda()
domain_src = torch.ones(len(source)).cuda()
domain_tar = torch.zeros(len(target)).cuda()
domain_src, domain_tar = domain_src.view(domain_src.shape[0], 1), domain_tar.view(domain_tar.shape[0], 1)
reverse_src = ReverseLayerF.apply(source, 1)
reverse_tar = ReverseLayerF.apply(target, 1)
pred_src = adv_net(reverse_src)
pred_tar = adv_net(reverse_tar)
loss_s, loss_t = domain_loss(pred_src, domain_src), domain_loss(pred_tar, domain_tar)
loss = loss_s + loss_t
return loss
================================================
FILE: code/deep/adarnn/base/loss/coral.py
================================================
import torch
def CORAL(source, target):
d = source.size(1)
ns, nt = source.size(0), target.size(0)
# source covariance
tmp_s = torch.ones((1, ns)).cuda() @ source
cs = (source.t() @ source - (tmp_s.t() @ tmp_s) / ns) / (ns - 1)
# target covariance
tmp_t = torch.ones((1, nt)).cuda() @ target
ct = (target.t() @ target - (tmp_t.t() @ tmp_t) / nt) / (nt - 1)
# frobenius norm
loss = (cs - ct).pow(2).sum()
loss = loss / (4 * d * d)
return loss
================================================
FILE: code/deep/adarnn/base/loss/cos.py
================================================
import torch.nn as nn
def cosine(source, target):
source, target = source.mean(0), target.mean(0)
cos = nn.CosineSimilarity(dim=0)
loss = cos(source, target)
return loss.mean()
================================================
FILE: code/deep/adarnn/base/loss/kl_js.py
================================================
import torch.nn as nn
def kl_div(source, target):
if len(source) < len(target):
target = target[:len(source)]
elif len(source) > len(target):
source = source[:len(target)]
criterion = nn.KLDivLoss(reduction='batchmean')
loss = criterion(source.log(), target)
return loss
def js(source, target):
if len(source) < len(target):
target = target[:len(source)]
elif len(source) > len(target):
source = source[:len(target)]
M = .5 * (source + target)
loss_1, loss_2 = kl_div(source, M), kl_div(target, M)
return .5 * (loss_1 + loss_2)
================================================
FILE: code/deep/adarnn/base/loss/mmd.py
================================================
import torch
import torch.nn as nn
class MMD_loss(nn.Module):
def __init__(self, kernel_type='linear', kernel_mul=2.0, kernel_num=5):
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd(self, X, Y):
delta = X.mean(axis=0) - Y.mean(axis=0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
with torch.no_grad():
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
================================================
FILE: code/deep/adarnn/base/loss/mutual_info.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
class Mine_estimator(nn.Module):
def __init__(self, input_dim=2048, hidden_dim=512):
super(Mine_estimator, self).__init__()
self.mine_model = Mine(input_dim, hidden_dim)
def forward(self, X, Y):
Y_shffle = Y[torch.randperm(len(Y))]
loss_joint = self.mine_model(X, Y)
loss_marginal = self.mine_model(X, Y_shffle)
ret = torch.mean(loss_joint) - \
torch.log(torch.mean(torch.exp(loss_marginal)))
loss = -ret
return loss
class Mine(nn.Module):
def __init__(self, input_dim=2048, hidden_dim=512):
super(Mine, self).__init__()
self.fc1_x = nn.Linear(input_dim, hidden_dim)
self.fc1_y = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, x, y):
h1 = F.leaky_relu(self.fc1_x(x)+self.fc1_y(y))
h2 = self.fc2(h1)
return h2
================================================
FILE: code/deep/adarnn/base/loss/pair_dist.py
================================================
import torch
import numpy as np
def pairwise_dist(X, Y):
n, d = X.shape
m, _ = Y.shape
assert d == Y.shape[1]
a = X.unsqueeze(1).expand(n, m, d)
b = Y.unsqueeze(0).expand(n, m, d)
return torch.pow(a - b, 2).sum(2)
def pairwise_dist_np(X, Y):
n, d = X.shape
m, _ = Y.shape
assert d == Y.shape[1]
a = np.expand_dims(X, 1)
b = np.expand_dims(Y, 0)
a = np.tile(a, (1, m, 1))
b = np.tile(b, (n, 1, 1))
return np.power(a - b, 2).sum(2)
def pa(X, Y):
XY = np.dot(X, Y.T)
XX = np.sum(np.square(X), axis=1)
XX = np.transpose([XX])
YY = np.sum(np.square(Y), axis=1)
dist = XX + YY - 2 * XY
return dist
if __name__ == '__main__':
import sys
args = sys.argv
data = args[0]
print(data)
# a = torch.arange(1, 7).view(2, 3)
# b = torch.arange(12, 21).view(3, 3)
# print(pairwise_dist(a, b))
# a = np.arange(1, 7).reshape((2, 3))
# b = np.arange(12, 21).reshape((3, 3))
# print(pa(a, b))
================================================
FILE: code/deep/adarnn/base/loss_transfer.py
================================================
from base.loss import adv_loss, CORAL, kl_js, mmd, mutual_info, cosine, pairwise_dist
class TransferLoss(object):
def __init__(self, loss_type='cosine', input_dim=512):
"""
Supported loss_type: mmd(mmd_lin), mmd_rbf, coral, cosine, kl, js, mine, adv
"""
self.loss_type = loss_type
self.input_dim = input_dim
def compute(self, X, Y):
"""Compute adaptation loss
Arguments:
X {tensor} -- source matrix
Y {tensor} -- target matrix
Returns:
[tensor] -- transfer loss
"""
if self.loss_type == 'mmd_lin' or self.loss_type =='mmd':
mmdloss = mmd.MMD_loss(kernel_type='linear')
loss = mmdloss(X, Y)
elif self.loss_type == 'coral':
loss = CORAL(X, Y)
elif self.loss_type == 'cosine' or self.loss_type == 'cos':
loss = 1 - cosine(X, Y)
elif self.loss_type == 'kl':
loss = kl_js.kl_div(X, Y)
elif self.loss_type == 'js':
loss = kl_js.js(X, Y)
elif self.loss_type == 'mine':
mine_model = mutual_info.Mine_estimator(
input_dim=self.input_dim, hidden_dim=60).cuda()
loss = mine_model(X, Y)
elif self.loss_type == 'adv':
loss = adv_loss.adv(X, Y, input_dim=self.input_dim, hidden_dim=32)
elif self.loss_type == 'mmd_rbf':
mmdloss = mmd.MMD_loss(kernel_type='rbf')
loss = mmdloss(X, Y)
elif self.loss_type == 'pairwise':
pair_mat = pairwise_dist(X, Y)
import torch
loss = torch.norm(pair_mat)
return loss
if __name__ == "__main__":
import torch
trans_loss = TransferLoss('adv')
a = (torch.randn(5,512) * 10).cuda()
b = (torch.randn(5,512) * 10).cuda()
print(trans_loss.compute(a, b))
================================================
FILE: code/deep/adarnn/dataset/__init__.py
================================================
#
================================================
FILE: code/deep/adarnn/dataset/data_act.py
================================================
# encoding=utf-8
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import os
# from config import config_info
from sklearn.preprocessing import StandardScaler
# This is for parsing the X data, you can ignore it if you do not need preprocessing
def format_data_x(datafile):
x_data = None
for item in datafile:
item_data = np.loadtxt(item, dtype=np.float)
if x_data is None:
x_data = np.zeros((len(item_data), 1))
x_data = np.hstack((x_data, item_data))
x_data = x_data[:, 1:]
print(x_data.shape)
X = None
for i in range(len(x_data)):
row = np.asarray(x_data[i, :])
row = row.reshape(9, 128).T
if X is None:
X = np.zeros((len(x_data), 128, 9))
X[i] = row
print(X.shape)
return X
# This is for parsing the Y data, you can ignore it if you do not need preprocessing
def format_data_y(datafile):
data = np.loadtxt(datafile, dtype=np.int) - 1
YY = np.eye(6)[data]
return YY
# Load data function, if there exists parsed data file, then use it
# If not, parse the original dataset from scratch
def load_data(data_folder, domain):
import os
domain = '1_20' if domain == 'A' else '21_30'
data_file = os.path.join(data_folder, 'data_har_' + domain + '.npz')
if os.path.exists(data_file):
data = np.load(data_file)
X_train = data['X_train']
Y_train = data['Y_train']
X_test = data['X_test']
Y_test = data['Y_test']
else:
# This for processing the dataset from scratch
# After downloading the dataset, put it to somewhere that str_folder can find
str_folder = config_info['data_folder_raw'] + 'UCI HAR Dataset/'
INPUT_SIGNAL_TYPES = [
"body_acc_x_",
"body_acc_y_",
"body_acc_z_",
"body_gyro_x_",
"body_gyro_y_",
"body_gyro_z_",
"total_acc_x_",
"total_acc_y_",
"total_acc_z_"
]
str_train_files = [str_folder + 'train/' + 'Inertial Signals/' + item + 'train.txt' for item in
INPUT_SIGNAL_TYPES]
str_test_files = [str_folder + 'test/' + 'Inertial Signals/' +
item + 'test.txt' for item in INPUT_SIGNAL_TYPES]
str_train_y = str_folder + 'train/y_train.txt'
str_test_y = str_folder + 'test/y_test.txt'
X_train = format_data_x(str_train_files)
X_test = format_data_x(str_test_files)
Y_train = format_data_y(str_train_y)
Y_test = format_data_y(str_test_y)
return X_train, onehot_to_label(Y_train), X_test, onehot_to_label(Y_test)
def onehot_to_label(y_onehot):
a = np.argwhere(y_onehot == 1)
return a[:, -1]
class data_loader(Dataset):
def __init__(self, samples, labels, t):
self.samples = samples
self.labels = labels
self.T = t
def __getitem__(self, index):
sample, target = self.samples[index], self.labels[index]
if self.T:
return self.T(sample), target
else:
return sample, target
def __len__(self):
return len(self.samples)
def normalize(x):
x_min = x.min(axis=(0, 2, 3), keepdims=True)
x_max = x.max(axis=(0, 2, 3), keepdims=True)
x_norm = (x - x_min) / (x_max - x_min)
return x_norm
================================================
FILE: code/deep/adarnn/dataset/data_process.py
================================================
# encoding=utf-8
import os
import dataset.data_act as data_act
import pandas as pd
import dataset.data_weather as data_weather
import datetime
from base.loss_transfer import TransferLoss
import torch
import math
from dataset import data_process
def load_act_data(data_folder, batch_size=64, domain="1_20"):
x_train, y_train, x_test, y_test = data_act.load_data(data_folder, domain)
x_train, x_test = x_train.reshape(
(-1, x_train.shape[2], 1, x_train.shape[1])), x_test.reshape((-1, x_train.shape[2], 1, x_train.shape[1]))
transform = None
train_set = data_act.data_loader(x_train, y_train, transform)
test_set = data_act.data_loader(x_test, y_test, transform)
train_loader = data_act.DataLoader(
train_set, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = data_act.DataLoader(
test_set, batch_size=batch_size, shuffle=False)
return train_loader, train_loader, test_loader
def load_weather_data(file_path, batch_size=6, station='Changping'):
data_file = os.path.join(file_path, "PRSA_Data_1.pkl")
mean_train, std_train = data_weather.get_weather_data_statistic(data_file, station=station, start_time='2013-3-1 0:0',
end_time='2016-10-30 23:0')
train_loader = data_weather.get_weather_data(data_file, station=station, start_time='2013-3-6 0:0',
end_time='2015-5-31 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
valid_train_loader = data_weather.get_weather_data(data_file, station=station, start_time='2015-6-2 0:0',
end_time='2016-6-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
valid_vld_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-7-2 0:0',
end_time='2016-10-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
test_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-11-2 0:0',
end_time='2017-2-28 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
return train_loader, valid_train_loader, valid_vld_loader, test_loader
def get_split_time(num_domain=2, mode='pre_process', data_file = None, station = None, dis_type = 'coral'):
spilt_time = {
'2': [('2013-3-6 0:0', '2015-5-31 23:0'), ('2015-6-2 0:0', '2016-6-30 23:0')]
}
if mode == 'pre_process':
return spilt_time[str(num_domain)]
if mode == 'tdc':
return TDC(num_domain, data_file, station, dis_type = dis_type)
else:
print("error in mode")
def TDC(num_domain, data_file, station, dis_type = 'coral'):
start_time = datetime.datetime.strptime(
'2013-03-01 00:00:00', '%Y-%m-%d %H:%M:%S')
end_time = datetime.datetime.strptime(
'2016-06-30 23:00:00', '%Y-%m-%d %H:%M:%S')
num_day = (end_time - start_time).days
split_N = 10
data=pd.read_pickle(data_file)[station]
feat =data[0][0:num_day]
feat=torch.tensor(feat, dtype=torch.float32)
feat_shape_1 = feat.shape[1]
feat =feat.reshape(-1, feat.shape[2])
feat = feat.cuda()
# num_day_new = feat.shape[0]
selected = [0, 10]
candidate = [1, 2, 3, 4, 5, 6, 7, 8, 9]
start = 0
if num_domain in [2, 3, 5, 7, 10]:
while len(selected) -2 < num_domain -1:
distance_list = []
for can in candidate:
selected.append(can)
selected.sort()
dis_temp = 0
for i in range(1, len(selected)-1):
for j in range(i, len(selected)-1):
index_part1_start = start + math.floor(selected[i-1] / split_N * num_day) * feat_shape_1
index_part1_end = start + math.floor(selected[i] / split_N * num_day) * feat_shape_1
feat_part1 = feat[index_part1_start: index_part1_end]
index_part2_start = start + math.floor(selected[j] / split_N * num_day) * feat_shape_1
index_part2_end = start + math.floor(selected[j+1] / split_N * num_day) * feat_shape_1
feat_part2 = feat[index_part2_start:index_part2_end]
criterion_transder = TransferLoss(loss_type= dis_type, input_dim=feat_part1.shape[1])
dis_temp += criterion_transder.compute(feat_part1, feat_part2)
distance_list.append(dis_temp)
selected.remove(can)
can_index = distance_list.index(max(distance_list))
selected.append(candidate[can_index])
candidate.remove(candidate[can_index])
selected.sort()
res = []
for i in range(1,len(selected)):
if i == 1:
sel_start_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i - 1]), hours = 0)
else:
sel_start_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i - 1])+1, hours = 0)
sel_end_time = start_time + datetime.timedelta(days = int(num_day / split_N * selected[i]), hours =23)
sel_start_time = datetime.datetime.strftime(sel_start_time,'%Y-%m-%d %H:%M')
sel_end_time = datetime.datetime.strftime(sel_end_time,'%Y-%m-%d %H:%M')
res.append((sel_start_time, sel_end_time))
return res
else:
print("error in number of domain")
def load_weather_data_multi_domain(file_path, batch_size=6, station='Changping', number_domain=2, mode='pre_process', dis_type ='coral'):
# mode: 'tdc', 'pre_process'
data_file = os.path.join(file_path, "PRSA_Data_1.pkl")
mean_train, std_train = data_weather.get_weather_data_statistic(data_file, station=station, start_time='2013-3-1 0:0',
end_time='2016-10-30 23:0')
split_time_list = get_split_time(number_domain, mode=mode, data_file =data_file,station=station, dis_type = dis_type)
train_list = []
for i in range(len(split_time_list)):
time_temp = split_time_list[i]
train_loader = data_weather.get_weather_data(data_file, station=station, start_time=time_temp[0],
end_time=time_temp[1], batch_size=batch_size, mean=mean_train, std=std_train)
train_list.append(train_loader)
valid_vld_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-7-2 0:0',
end_time='2016-10-30 23:0', batch_size=batch_size, mean=mean_train, std=std_train)
test_loader = data_weather.get_weather_data(data_file, station=station, start_time='2016-11-2 0:0',
end_time='2017-2-28 23:0', batch_size=batch_size, mean=mean_train, std=std_train, shuffle=False)
return train_list, valid_vld_loader, test_loader
================================================
FILE: code/deep/adarnn/dataset/data_weather.py
================================================
import math
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
from pandas.core.frame import DataFrame
from torch.utils.data import Dataset, DataLoader
import torch
import pickle
import datetime
class data_loader(Dataset):
def __init__(self, df_feature, df_label, df_label_reg, t=None):
assert len(df_feature) == len(df_label)
assert len(df_feature) == len(df_label_reg)
# df_feature = df_feature.reshape(df_feature.shape[0], df_feature.shape[1] // 6, df_feature.shape[2] * 6)
self.df_feature=df_feature
self.df_label=df_label
self.df_label_reg = df_label_reg
self.T=t
self.df_feature=torch.tensor(
self.df_feature, dtype=torch.float32)
self.df_label=torch.tensor(
self.df_label, dtype=torch.float32)
self.df_label_reg=torch.tensor(
self.df_label_reg, dtype=torch.float32)
def __getitem__(self, index):
sample, target, label_reg =self.df_feature[index], self.df_label[index], self.df_label_reg[index]
if self.T:
return self.T(sample), target
else:
return sample, target, label_reg
def __len__(self):
return len(self.df_feature)
def create_dataset(df, station, start_date, end_date, mean=None, std=None):
data=df[station]
feat, label, label_reg =data[0], data[1], data[2]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
label_reg=label_reg[index_start: index_end + 1]
# ori_shape_1, ori_shape_2=feat.shape[1], feat.shape[2]
# feat=feat.reshape(-1, feat.shape[2])
# feat=(feat - mean) / std
# feat=feat.reshape(-1, ori_shape_1, ori_shape_2)
return data_loader(feat, label, label_reg)
def create_dataset_shallow(df, station, start_date, end_date, mean=None, std=None):
data=df[station]
feat, label, label_reg =data[0], data[1], data[2]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
label_reg=label_reg[index_start: index_end + 1]
# ori_shape_1, ori_shape_2=feat.shape[1], feat.shape[2]
# feat=feat.reshape(-1, feat.shape[2])
# feat=(feat - mean) / std
# feat=feat.reshape(-1, ori_shape_1, ori_shape_2)
return feat, label_reg
def get_dataset_statistic(df, station, start_date, end_date):
data=df[station]
feat, label =data[0], data[1]
referece_start_time=datetime.datetime(2013, 3, 1, 0, 0)
referece_end_time=datetime.datetime(2017, 2, 28, 0, 0)
assert (pd.to_datetime(start_date) - referece_start_time).days >= 0
assert (pd.to_datetime(end_date) - referece_end_time).days <= 0
assert (pd.to_datetime(end_date) - pd.to_datetime(start_date)).days >= 0
index_start=(pd.to_datetime(start_date) - referece_start_time).days
index_end=(pd.to_datetime(end_date) - referece_start_time).days
feat=feat[index_start: index_end + 1]
label=label[index_start: index_end + 1]
feat=feat.reshape(-1, feat.shape[2])
mu_train=np.mean(feat, axis=0)
sigma_train=np.std(feat, axis=0)
return mu_train, sigma_train
def get_weather_data(data_file, station, start_time, end_time, batch_size, shuffle=True, mean=None, std=None):
df=pd.read_pickle(data_file)
dataset=create_dataset(df, station, start_time,
end_time, mean=mean, std=std)
train_loader=DataLoader(
dataset, batch_size=batch_size, shuffle=shuffle)
return train_loader
def get_weather_data_shallow(data_file, station, start_time, end_time, batch_size, shuffle=True, mean=None, std=None):
df=pd.read_pickle(data_file)
feat, label_reg =create_dataset_shallow(df, station, start_time,
end_time, mean=mean, std=std)
return feat, label_reg
def get_weather_data_statistic(data_file, station, start_time, end_time):
df=pd.read_pickle(data_file)
mean_train, std_train =get_dataset_statistic(
df, station, start_time, end_time)
return mean_train, std_train
================================================
FILE: code/deep/adarnn/requirements.txt
================================================
pretty_errors==1.2.18
visdom==0.1.8.9
matplotlib==3.3.1
numpy==1.22.0
torchvision==0.7.0
torch==1.6.0
tqdm==4.48.2
pandas==1.1.1
scikit_learn==0.23.2
================================================
FILE: code/deep/adarnn/train_weather.py
================================================
import torch.nn as nn
import torch
import torch.optim as optim
import os
import argparse
import datetime
import numpy as np
from tqdm import tqdm
from utils import utils
from base.AdaRNN import AdaRNN
import pretty_errors
import dataset.data_process as data_process
import matplotlib.pyplot as plt
def pprint(*text):
# print with UTC+8 time
time = '['+str(datetime.datetime.utcnow() +
datetime.timedelta(hours=8))[:19]+'] -'
print(time, *text, flush=True)
if args.log_file is None:
return
with open(args.log_file, 'a') as f:
print(time, *text, flush=True, file=f)
def get_model(name='AdaRNN'):
n_hiddens = [args.hidden_size for i in range(args.num_layers)]
return AdaRNN(use_bottleneck=True, bottleneck_width=64, n_input=args.d_feat, n_hiddens=n_hiddens, n_output=args.class_num, dropout=args.dropout, model_type=name, len_seq=args.len_seq, trans_loss=args.loss_type).cuda()
def train_AdaRNN(args, model, optimizer, train_loader_list, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layers, args.len_seq).cuda()
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
if epoch < args.pre_epoch:
pred_all, loss_transfer, out_weight_list = model.forward_pre_train(
feature_all, len_win=args.len_win)
else:
pred_all, loss_transfer, dist, weight_mat = model.forward_Boosting(
feature_all, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch >= args.pre_epoch:
if epoch > args.pre_epoch:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
else:
weight_mat = transform_type(out_weight_list)
return loss, loss_l1, weight_mat, None
def train_epoch_transfer_Boosting(model, optimizer, train_loader_list, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layers, args.len_seq).cuda()
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, loss_transfer, dist, weight_mat = model.forward_Boosting(
feature_all, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch > 0: #args.pre_epoch:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
def get_index(num_domain=2):
index = []
for i in range(num_domain):
for j in range(i+1, num_domain+1):
index.append((i, j))
return index
def train_epoch_transfer(args, model, optimizer, train_loader_list):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
len_loader = np.inf
for loader in train_loader_list:
if len(loader) < len_loader:
len_loader = len(loader)
for data_all in tqdm(zip(*train_loader_list), total=len_loader):
optimizer.zero_grad()
list_feat = []
list_label = []
for data in data_all:
feature, label, label_reg = data[0].cuda().float(
), data[1].cuda().long(), data[2].cuda().float()
list_feat.append(feature)
list_label.append(label_reg)
flag = False
index = get_index(len(data_all) - 1)
for temp_index in index:
s1 = temp_index[0]
s2 = temp_index[1]
if list_feat[s1].shape[0] != list_feat[s2].shape[0]:
flag = True
break
if flag:
continue
###############
total_loss = torch.zeros(1).cuda()
for i in range(len(index)):
feature_s = list_feat[index[i][0]]
feature_t = list_feat[index[i][1]]
label_reg_s = list_label[index[i][0]]
label_reg_t = list_label[index[i][1]]
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, loss_transfer, out_weight_list = model.forward_pre_train(
feature_all, len_win=args.len_win)
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
loss_l1 = criterion_1(pred_s, label_reg_s)
total_loss = total_loss + loss_s + loss_t + args.dw * loss_transfer
loss_all.append(
[total_loss.item(), (loss_s + loss_t).item(), loss_transfer.item()])
loss_1_all.append(loss_l1.item())
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_value_(model.parameters(), 3.)
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
return loss, loss_l1, out_weight_list
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def test_epoch(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred = model.predict(feature)
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = loss_r / len(test_loader)
return loss, loss_1, loss_r
def test_epoch_inference(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
i = 0
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred = model.predict(feature)
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
if i == 0:
label_list = label_reg.cpu().numpy()
predict_list = pred.cpu().numpy()
else:
label_list = np.hstack((label_list, label_reg.cpu().numpy()))
predict_list = np.hstack((predict_list, pred.cpu().numpy()))
i = i + 1
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = total_loss_r / len(test_loader)
return loss, loss_1, loss_r, label_list, predict_list
def inference(model, data_loader):
loss, loss_1, loss_r, label_list, predict_list = test_epoch_inference(
model, data_loader, prefix='Inference')
return loss, loss_1, loss_r, label_list, predict_list
def inference_all(output_path, model, model_path, loaders):
pprint('inference...')
loss_list = []
loss_l1_list = []
loss_r_list = []
model.load_state_dict(torch.load(model_path))
i = 0
list_name = ['train', 'valid', 'test']
for loader in loaders:
loss, loss_1, loss_r, label_list, predict_list = inference(
model, loader)
loss_list.append(loss)
loss_l1_list.append(loss_1)
loss_r_list.append(loss_r)
i = i + 1
return loss_list, loss_l1_list, loss_r_list
def transform_type(init_weight):
weight = torch.ones(args.num_layers, args.len_seq).cuda()
for i in range(args.num_layers):
for j in range(args.len_seq):
weight[i, j] = init_weight[i][j].item()
return weight
def main_transfer(args):
print(args)
output_path = args.outdir + '_' + args.station + '_' + args.model_name + '_weather_' + \
args.loss_type + '_' + str(args.pre_epoch) + \
'_' + str(args.dw) + '_' + str(args.lr)
save_model_name = args.model_name + '_' + args.loss_type + \
'_' + str(args.dw) + '_' + str(args.lr) + '.pkl'
utils.dir_exist(output_path)
pprint('create loaders...')
train_loader_list, valid_loader, test_loader = data_process.load_weather_data_multi_domain(
args.data_path, args.batch_size, args.station, args.num_domain, args.data_mode)
args.log_file = os.path.join(output_path, 'run.log')
pprint('create model...')
model = get_model(args.model_name)
num_model = count_parameters(model)
print('#model params:', num_model)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
best_score = np.inf
best_epoch, stop_round = 0, 0
weight_mat, dist_mat = None, None
for epoch in range(args.n_epochs):
pprint('Epoch:', epoch)
pprint('training...')
if args.model_name in ['Boosting']:
loss, loss1, weight_mat, dist_mat = train_epoch_transfer_Boosting(
model, optimizer, train_loader_list, epoch, dist_mat, weight_mat)
elif args.model_name in ['AdaRNN']:
loss, loss1, weight_mat, dist_mat = train_AdaRNN(
args, model, optimizer, train_loader_list, epoch, dist_mat, weight_mat)
else:
print("error in model_name!")
pprint(loss, loss1)
pprint('evaluating...')
train_loss, train_loss_l1, train_loss_r = test_epoch(
model, train_loader_list[0], prefix='Train')
val_loss, val_loss_l1, val_loss_r = test_epoch(
model, valid_loader, prefix='Valid')
test_loss, test_loss_l1, test_loss_r = test_epoch(
model, test_loader, prefix='Test')
pprint('valid %.6f, test %.6f' %
(val_loss_l1, test_loss_l1))
if val_loss < best_score:
best_score = val_loss
stop_round = 0
best_epoch = epoch
torch.save(model.state_dict(), os.path.join(
output_path, save_model_name))
else:
stop_round += 1
if stop_round >= args.early_stop:
pprint('early stop')
break
pprint('best val score:', best_score, '@', best_epoch)
loaders = train_loader_list[0], valid_loader, test_loader
loss_list, loss_l1_list, loss_r_list = inference_all(output_path, model, os.path.join(
output_path, save_model_name), loaders)
pprint('MSE: train %.6f, valid %.6f, test %.6f' %
(loss_list[0], loss_list[1], loss_list[2]))
pprint('L1: train %.6f, valid %.6f, test %.6f' %
(loss_l1_list[0], loss_l1_list[1], loss_l1_list[2]))
pprint('RMSE: train %.6f, valid %.6f, test %.6f' %
(loss_r_list[0], loss_r_list[1], loss_r_list[2]))
pprint('Finished.')
def get_args():
parser = argparse.ArgumentParser()
# model
parser.add_argument('--model_name', default='AdaRNN')
parser.add_argument('--d_feat', type=int, default=6)
parser.add_argument('--hidden_size', type=int, default=64)
parser.add_argument('--num_layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.0)
parser.add_argument('--class_num', type=int, default=1)
parser.add_argument('--pre_epoch', type=int, default=40) # 20, 30, 50
# training
parser.add_argument('--n_epochs', type=int, default=200)
parser.add_argument('--lr', type=float, default=5e-4)
parser.add_argument('--early_stop', type=int, default=40)
parser.add_argument('--smooth_steps', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=36)
parser.add_argument('--dw', type=float, default=0.5) # 0.01, 0.05, 5.0
parser.add_argument('--loss_type', type=str, default='adv')
parser.add_argument('--station', type=str, default='Dongsi')
parser.add_argument('--data_mode', type=str,
default='tdc')
parser.add_argument('--num_domain', type=int, default=2)
parser.add_argument('--len_seq', type=int, default=24)
# other
parser.add_argument('--seed', type=int, default=10)
parser.add_argument('--data_path', default="/root/Messi_du/adarnn/")
parser.add_argument('--outdir', default='./outputs')
parser.add_argument('--overwrite', action='store_true')
parser.add_argument('--log_file', type=str, default='run.log')
parser.add_argument('--gpu_id', type=int, default=0)
parser.add_argument('--len_win', type=int, default=0)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
main_transfer(args)
================================================
FILE: code/deep/adarnn/transformer_adapt.py
================================================
import torch.nn as nn
import torch
import torch.optim as optim
import os
import argparse
import datetime
import numpy as np
from tqdm import tqdm
from utils import utils
from base.AdaRNN import AdaRNN
import pretty_errors
import dataset.data_process as data_process
import matplotlib.pyplot as plt
from tst import Transformer
def pprint(*text):
# print with UTC+8 time
time = '['+str(datetime.datetime.utcnow() +
datetime.timedelta(hours=8))[:19]+'] -'
print(time, *text, flush=True)
if args.log_file is None:
return
with open(args.log_file, 'a') as f:
print(time, *text, flush=True, file=f)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def train_epoch(args, model, optimizer, src_train_loader, trg_train_loader, epoch, dist_old=None, weight_mat=None):
model.train()
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
loss_all = []
loss_1_all = []
dist_mat = torch.zeros(args.num_layer, args.len_seq).cuda()
len_loader = np.inf
for data_s, data_t in tqdm(zip(src_train_loader, trg_train_loader), total=min(len(src_train_loader), len(trg_train_loader))):
optimizer.zero_grad()
feature_s, _ , label_reg_s = data_s[0].cuda().float(), data_s[1].cuda().long(), data_s[2].cuda().float()
feature_t, _ , label_reg_t = data_t[0].cuda().float(), data_t[1].cuda().long(), data_t[2].cuda().float()
if feature_s.shape[0] != feature_t.shape[0]:
continue
# feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
feature_all = torch.cat((feature_s, feature_t), 0)
pred_all, list_encoding = model(feature_all)
loss_adapt, dist, weight_mat = model.adapt_encoding_weight(list_encoding, args.loss_type, args.train_type, weight_mat)
dist_mat = dist_mat + dist
pred_s = pred_all[0:feature_s.size(0)]
pred_t = pred_all[feature_s.size(0):]
pred_s = torch.mean(pred_s, dim=1).view(pred_s.shape[0])
pred_t = torch.mean(pred_t, dim=1).view(pred_t.shape[0])
loss_s = criterion(pred_s, label_reg_s)
loss_t = criterion(pred_t, label_reg_t)
total_loss = loss_s + args.dw * loss_adapt + loss_t
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
loss = np.array(loss_all).mean(axis=0)
loss_l1 = np.array(loss_1_all).mean()
if epoch > 0:
weight_mat = model.update_weight_Boosting(
weight_mat, dist_old, dist_mat)
return loss, loss_l1, weight_mat, dist_mat
def test_epoch(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred,_ = model(feature)
pred = torch.mean(pred,dim=1).view(pred.shape[0])
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = loss_r / len(test_loader)
return loss, loss_1, loss_r
def test_epoch_inference(model, test_loader, prefix='Test'):
model.eval()
total_loss = 0
total_loss_1 = 0
total_loss_r = 0
correct = 0
criterion = nn.MSELoss()
criterion_1 = nn.L1Loss()
i = 0
for feature, label, label_reg in tqdm(test_loader, desc=prefix, total=len(test_loader)):
feature, label_reg = feature.cuda().float(), label_reg.cuda().float()
with torch.no_grad():
pred,_ = model(feature)
pred = torch.mean(pred,dim=1).view(pred.shape[0])
loss = criterion(pred, label_reg)
loss_r = torch.sqrt(loss)
loss_1 = criterion_1(pred, label_reg)
total_loss += loss.item()
total_loss_1 += loss_1.item()
total_loss_r += loss_r.item()
if i == 0:
label_list = label_reg.cpu().numpy()
predict_list = pred.cpu().numpy()
else:
label_list = np.hstack((label_list, label_reg.cpu().numpy()))
predict_list = np.hstack((predict_list, pred.cpu().numpy()))
i = i + 1
loss = total_loss / len(test_loader)
loss_1 = total_loss_1 / len(test_loader)
loss_r = total_loss_r / len(test_loader)
return loss, loss_1, loss_r, label_list, predict_list
def inference(model, data_loader):
loss, loss_1, loss_r, label_list, predict_list = test_epoch_inference(
model, data_loader, prefix='Inference')
return loss, loss_1, loss_r, label_list, predict_list
def inference_all(output_path, model, model_path, loaders):
pprint('inference...')
loss_list = []
loss_l1_list = []
loss_r_list = []
model.load_state_dict(torch.load(model_path))
i = 0
list_name = ['train', 'valid', 'test']
for loader in loaders:
loss, loss_1, loss_r, label_list, predict_list = inference(
model, loader)
loss_list.append(loss)
loss_l1_list.append(loss_1)
loss_r_list.append(loss_r)
i = i + 1
return loss_list, loss_l1_list, loss_r_list
def main_transfer(args):
print(args)
output_path = args.outdir + '_' + args.station + '_' + args.model_name + '_weather_' + \
args.loss_type + '_' + str(args.pre_epoch) + \
'_' + '_' + str(args.lr) + "_" + str(args.train_type) + "-layer-num-" + str(args.num_layer) + "-hidden-" + str(args.hidden_dim) + "-num_head-" + str(args.num_head) + "dw-" + str(args.dw)
# "-hidden" + str(args.hidden_dim) + "-head" + str(args.num_head)
save_model_name = args.model_name + '_' + args.loss_type + \
'_' + str(args.dw) + '_' + str(args.lr) + '.pkl'
utils.dir_exist(output_path)
pprint('create loaders...')
source_loader, target_loader, valid_loader, test_loader = data_process.load_weather_data(
args.data_path, args.batch_size, args.station)
args.log_file = os.path.join(output_path, 'run.log')
pprint('create model...')
######
# Model parameters
d_model = args.hidden_dim #32 Lattent dim
q = 8 # Query size
v = 8 # Value size
h = args.num_head #4 Number of heads
N = args.num_layer # Number of encoder and decoder to stack
attention_size = 12 # Attention window size
pe = "regular" # Positional encoding
chunk_mode = None
d_input = 6 # From dataset
d_output = 1 # From dataset
model = Transformer(d_input, d_model, d_output, q, v, h, N, attention_size=attention_size, chunk_mode=chunk_mode, pe=pe, pe_period =24).cuda()
#####
num_model = count_parameters(model)
print('#model params:', num_model)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
best_score = np.inf
best_epoch, stop_round = 0, 0
weight_mat, dist_mat = None, None
for epoch in range(args.n_epochs):
pprint('Epoch:', epoch)
pprint('training...')
loss, loss1, weight_mat, dist_mat = train_epoch(
args, model, optimizer, source_loader, target_loader, epoch, dist_mat, weight_mat)
pprint('evaluating...')
train_loss, train_loss_l1, train_loss_r = test_epoch(
model, source_loader, prefix='Train')
val_loss, val_loss_l1, val_loss_r = test_epoch(
model, valid_loader, prefix='Valid')
test_loss, test_loss_l1, test_loss_r = test_epoch(
model, test_loader, prefix='Test')
pprint('valid %.6f, test %.6f' %
(val_loss_l1, test_loss_l1))
if val_loss < best_score:
best_score = val_loss
stop_round = 0
best_epoch = epoch
torch.save(model.state_dict(), os.path.join(
output_path, save_model_name))
else:
stop_round += 1
if stop_round >= args.early_stop:
pprint('early stop')
break
pprint('best val score:', best_score, '@', best_epoch)
loaders = source_loader, valid_loader, test_loader
loss_list, loss_l1_list, loss_r_list = inference_all(output_path, model, os.path.join(
output_path, save_model_name), loaders)
pprint('MSE: train %.6f, valid %.6f, test %.6f' %
(loss_list[0], loss_list[1], loss_list[2]))
pprint('L1: train %.6f, valid %.6f, test %.6f' %
(loss_l1_list[0], loss_l1_list[1], loss_l1_list[2]))
pprint('RMSE: train %.6f, valid %.6f, test %.6f' %
(loss_r_list[0], loss_r_list[1], loss_r_list[2]))
pprint('Finished.')
def get_args():
parser = argparse.ArgumentParser()
# model
parser.add_argument('--model_name', default='adapt_tf')
parser.add_argument('--d_feat', type=int, default=6)
parser.add_argument('--hidden_size', type=int, default=64)
parser.add_argument('--num_layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.0)
parser.add_argument('--class_num', type=int, default=1)
parser.add_argument('--pre_epoch', type=int, default=40) # 25
parser.add_argument('--num_layer', type=int, default=1) # 25
# training
parser.add_argument('--n_epochs', type=int, default=200)
parser.add_argument('--lr', type=float, default=5e-4)
parser.add_argument('--early_stop', type=int, default=40)
parser.add_argument('--smooth_steps', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=36)
parser.add_argument('--dw', type=float, default=0.5)
parser.add_argument('--loss_type', type=str, default='cosine')
parser.add_argument('--train_type', type=str, default='all')
parser.add_argument('--station', type=str, default='Tiantan')
parser.add_argument('--data_mode', type=str,
default='pre_process')
parser.add_argument('--num_domain', type=int, default=2)
parser.add_argument('--len_seq', type=int, default=24)
parser.add_argument('--hidden_dim', type=int, default=32)
parser.add_argument('--num_head', type=int, default=8)
# other
parser.add_argument('--seed', type=int, default=10)
parser.add_argument('--data_path', default="/root/Messi_du/adarnn/")
parser.add_argument('--outdir', default='./outputs')
parser.add_argument('--overwrite', action='store_true')
parser.add_argument('--log_file', type=str, default='run.log')
parser.add_argument('--gpu_id', type=int, default=0)
parser.add_argument('--len_win', type=int, default=0)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
main_transfer(args)
================================================
FILE: code/deep/adarnn/tst/__init__.py
================================================
from .transformer import Transformer
================================================
FILE: code/deep/adarnn/tst/decoder.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.multiHeadAttention import MultiHeadAttention, MultiHeadAttentionChunk, MultiHeadAttentionWindow
from tst.positionwiseFeedForward import PositionwiseFeedForward
class Decoder(nn.Module):
"""Decoder block from Attention is All You Need.
Apply two Multi Head Attention block followed by a Point-wise Feed Forward block.
Residual sum and normalization are applied at each step.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Swict between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk'):
"""Initialize the Decoder block"""
super().__init__()
chunk_mode_modules = {
'chunk': MultiHeadAttentionChunk,
'window': MultiHeadAttentionWindow,
}
if chunk_mode in chunk_mode_modules.keys():
MHA = chunk_mode_modules[chunk_mode]
elif chunk_mode is None:
MHA = MultiHeadAttention
else:
raise NameError(
f'chunk_mode "{chunk_mode}" not understood. Must be one of {", ".join(chunk_mode_modules.keys())} or None.')
self._selfAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._encoderDecoderAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._feedForward = PositionwiseFeedForward(d_model)
self._layerNorm1 = nn.LayerNorm(d_model)
self._layerNorm2 = nn.LayerNorm(d_model)
self._layerNorm3 = nn.LayerNorm(d_model)
self._dopout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor, memory: torch.Tensor) -> torch.Tensor:
"""Propagate the input through the Decoder block.
Apply the self attention block, add residual and normalize.
Apply the encoder-decoder attention block, add residual and normalize.
Apply the feed forward network, add residual and normalize.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
memory:
Memory tensor with shape (batch_size, K, d_model)
from encoder output.
Returns
-------
x:
Output tensor with shape (batch_size, K, d_model).
"""
# Self attention
residual = x
x = self._selfAttention(query=x, key=x, value=x, mask="subsequent")
x = self._dopout(x)
x = self._layerNorm1(x + residual)
# Encoder-decoder attention
residual = x
x = self._encoderDecoderAttention(query=x, key=memory, value=memory)
x = self._dopout(x)
x = self._layerNorm2(x + residual)
# Feed forward
residual = x
x = self._feedForward(x)
x = self._dopout(x)
x = self._layerNorm3(x + residual)
return x
================================================
FILE: code/deep/adarnn/tst/encoder.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.multiHeadAttention import MultiHeadAttention, MultiHeadAttentionChunk, MultiHeadAttentionWindow
from tst.positionwiseFeedForward import PositionwiseFeedForward
class Encoder(nn.Module):
"""Encoder block from Attention is All You Need.
Apply Multi Head Attention block followed by a Point-wise Feed Forward block.
Residual sum and normalization are applied at each step.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Swict between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk'):
"""Initialize the Encoder block"""
super().__init__()
chunk_mode_modules = {
'chunk': MultiHeadAttentionChunk,
'window': MultiHeadAttentionWindow,
}
if chunk_mode in chunk_mode_modules.keys():
MHA = chunk_mode_modules[chunk_mode]
elif chunk_mode is None:
MHA = MultiHeadAttention
else:
raise NameError(
f'chunk_mode "{chunk_mode}" not understood. Must be one of {", ".join(chunk_mode_modules.keys())} or None.')
self._selfAttention = MHA(d_model, q, v, h, attention_size=attention_size)
self._feedForward = PositionwiseFeedForward(d_model)
self._layerNorm1 = nn.LayerNorm(d_model)
self._layerNorm2 = nn.LayerNorm(d_model)
self._dopout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate the input through the Encoder block.
Apply the Multi Head Attention block, add residual and normalize.
Apply the Point-wise Feed Forward block, add residual and normalize.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
Returns
-------
Output tensor with shape (batch_size, K, d_model).
"""
# Self attention
residual = x
x = self._selfAttention(query=x, key=x, value=x)
x = self._dopout(x)
x = self._layerNorm1(x + residual)
# Feed forward
residual = x
x = self._feedForward(x)
x = self._dopout(x)
x = self._layerNorm2(x + residual)
return x
@property
def attention_map(self) -> torch.Tensor:
"""Attention map after a forward propagation,
variable `score` in the original paper.
"""
return self._selfAttention.attention_map
================================================
FILE: code/deep/adarnn/tst/loss.py
================================================
import torch
import torch.nn as nn
class OZELoss(nn.Module):
"""Custom loss for TRNSys metamodel.
Compute, for temperature and consumptions, the intergral of the squared differences
over time. Sum the log with a coeficient ``alpha``.
.. math::
\Delta_T = \sqrt{\int (y_{est}^T - y^T)^2}
\Delta_Q = \sqrt{\int (y_{est}^Q - y^Q)^2}
loss = log(1 + \Delta_T) + \\alpha \cdot log(1 + \Delta_Q)
Parameters:
-----------
alpha:
Coefficient for consumption. Default is ``0.3``.
"""
def __init__(self, reduction: str = 'mean', alpha: float = 0.3):
super().__init__()
self.alpha = alpha
self.reduction = reduction
self.base_loss = nn.MSELoss(reduction=self.reduction)
def forward(self,
y_true: torch.Tensor,
y_pred: torch.Tensor) -> torch.Tensor:
"""Compute the loss between a target value and a prediction.
Parameters
----------
y_true:
Target value.
y_pred:
Estimated value.
Returns
-------
Loss as a tensor with gradient attached.
"""
delta_Q = self.base_loss(y_pred[..., :-1], y_true[..., :-1])
delta_T = self.base_loss(y_pred[..., -1], y_true[..., -1])
if self.reduction == 'none':
delta_Q = delta_Q.mean(dim=(1, 2))
delta_T = delta_T.mean(dim=(1))
return torch.log(1 + delta_T) + self.alpha * torch.log(1 + delta_Q)
================================================
FILE: code/deep/adarnn/tst/multiHeadAttention.py
================================================
from typing import Optional
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tst.utils import generate_local_map_mask
class MultiHeadAttention(nn.Module):
"""Multi Head Attention block from Attention is All You Need.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None):
"""Initialize the Multi Head Block."""
super().__init__()
self._h = h
self._attention_size = attention_size
# Query, keys and value matrices
self._W_q = nn.Linear(d_model, q*self._h)
self._W_k = nn.Linear(d_model, q*self._h)
self._W_v = nn.Linear(d_model, v*self._h)
# Output linear function
self._W_o = nn.Linear(self._h*v, d_model)
# Score placeholder
self._scores = None
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
K = query.shape[1]
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0)
keys = torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0)
values = torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(K)
# Compute local map mask
if self._attention_size is not None:
attention_mask = generate_local_map_mask(K, self._attention_size, mask_future=False, device=self._scores.device)
self._scores = self._scores.masked_fill(attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
future_mask = torch.triu(torch.ones((K, K)), diagonal=1).bool()
future_mask = future_mask.to(self._scores.device)
self._scores = self._scores.masked_fill(future_mask, float('-inf'))
# Apply sotfmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Concatenat the heads
attention_heads = torch.cat(attention.chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
@property
def attention_map(self) -> torch.Tensor:
"""Attention map after a forward propagation,
variable `score` in the original paper.
"""
if self._scores is None:
raise RuntimeError(
"Evaluate the model once to generate attention map")
return self._scores
class MultiHeadAttentionChunk(MultiHeadAttention):
"""Multi Head Attention block with chunk.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Queries, keys and values are divided in chunks of constant size.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
chunk_size:
Size of chunks to apply attention on. Last one may be smaller (see :class:`torch.Tensor.chunk`).
Default is 168.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
chunk_size: Optional[int] = 168,
**kwargs):
"""Initialize the Multi Head Block."""
super().__init__(d_model, q, v, h, attention_size, **kwargs)
self._chunk_size = chunk_size
# Score mask for decoder
self._future_mask = nn.Parameter(torch.triu(torch.ones((self._chunk_size, self._chunk_size)), diagonal=1).bool(),
requires_grad=False)
if self._attention_size is not None:
self._attention_mask = nn.Parameter(generate_local_map_mask(self._chunk_size, self._attention_size),
requires_grad=False)
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
K = query.shape[1]
n_chunk = K // self._chunk_size
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
keys = torch.cat(torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
values = torch.cat(torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0).chunk(n_chunk, dim=1), dim=0)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(self._chunk_size)
# Compute local map mask
if self._attention_size is not None:
self._scores = self._scores.masked_fill(self._attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
self._scores = self._scores.masked_fill(self._future_mask, float('-inf'))
# Apply softmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Concatenat the heads
attention_heads = torch.cat(torch.cat(attention.chunk(
n_chunk, dim=0), dim=1).chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
class MultiHeadAttentionWindow(MultiHeadAttention):
"""Multi Head Attention block with moving window.
Given 3 inputs of shape (batch_size, K, d_model), that will be used
to compute query, keys and values, we output a self attention
tensor of shape (batch_size, K, d_model).
Queries, keys and values are divided in chunks using a moving window.
Parameters
----------
d_model:
Dimension of the input vector.
q:
Dimension of all query matrix.
v:
Dimension of all value matrix.
h:
Number of heads.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
window_size:
Size of the window used to extract chunks.
Default is 168
padding:
Padding around each window. Padding will be applied to input sequence.
Default is 168 // 4 = 42.
"""
def __init__(self,
d_model: int,
q: int,
v: int,
h: int,
attention_size: int = None,
window_size: Optional[int] = 168,
padding: Optional[int] = 168 // 4,
**kwargs):
"""Initialize the Multi Head Block."""
super().__init__(d_model, q, v, h, attention_size, **kwargs)
self._window_size = window_size
self._padding = padding
self._q = q
self._v = v
# Step size for the moving window
self._step = self._window_size - 2 * self._padding
# Score mask for decoder
self._future_mask = nn.Parameter(torch.triu(torch.ones((self._window_size, self._window_size)), diagonal=1).bool(),
requires_grad=False)
if self._attention_size is not None:
self._attention_mask = nn.Parameter(generate_local_map_mask(self._window_size, self._attention_size),
requires_grad=False)
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: Optional[str] = None) -> torch.Tensor:
"""Propagate forward the input through the MHB.
We compute for each head the queries, keys and values matrices,
followed by the Scaled Dot-Product. The result is concatenated
and returned with shape (batch_size, K, d_model).
Parameters
----------
query:
Input tensor with shape (batch_size, K, d_model) used to compute queries.
key:
Input tensor with shape (batch_size, K, d_model) used to compute keys.
value:
Input tensor with shape (batch_size, K, d_model) used to compute values.
mask:
Mask to apply on scores before computing attention.
One of ``'subsequent'``, None. Default is None.
Returns
-------
Self attention tensor with shape (batch_size, K, d_model).
"""
batch_size = query.shape[0]
# Apply padding to input sequence
query = F.pad(query.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
key = F.pad(key.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
value = F.pad(value.transpose(1, 2), (self._padding, self._padding), 'replicate').transpose(1, 2)
# Compute Q, K and V, concatenate heads on batch dimension
queries = torch.cat(self._W_q(query).chunk(self._h, dim=-1), dim=0)
keys = torch.cat(self._W_k(key).chunk(self._h, dim=-1), dim=0)
values = torch.cat(self._W_v(value).chunk(self._h, dim=-1), dim=0)
# Divide Q, K and V using a moving window
queries = queries.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._q, self._window_size)).transpose(1, 2)
keys = keys.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._q, self._window_size)).transpose(1, 2)
values = values.unfold(dimension=1, size=self._window_size, step=self._step).reshape((-1, self._v, self._window_size)).transpose(1, 2)
# Scaled Dot Product
self._scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(self._window_size)
# Compute local map mask
if self._attention_size is not None:
self._scores = self._scores.masked_fill(self._attention_mask, float('-inf'))
# Compute future mask
if mask == "subsequent":
self._scores = self._scores.masked_fill(self._future_mask, float('-inf'))
# Apply softmax
self._scores = F.softmax(self._scores, dim=-1)
attention = torch.bmm(self._scores, values)
# Fold chunks back
attention = attention.reshape((batch_size*self._h, -1, self._window_size, self._v))
attention = attention[:, :, self._padding:-self._padding, :]
attention = attention.reshape((batch_size*self._h, -1, self._v))
# Concatenat the heads
attention_heads = torch.cat(attention.chunk(self._h, dim=0), dim=-1)
# Apply linear transformation W^O
self_attention = self._W_o(attention_heads)
return self_attention
================================================
FILE: code/deep/adarnn/tst/positionwiseFeedForward.py
================================================
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionwiseFeedForward(nn.Module):
"""Position-wise Feed Forward Network block from Attention is All You Need.
Apply two linear transformations to each input, separately but indetically. We
implement them as 1D convolutions. Input and output have a shape (batch_size, d_model).
Parameters
----------
d_model:
Dimension of input tensor.
d_ff:
Dimension of hidden layer, default is 2048.
"""
def __init__(self,
d_model: int,
d_ff: Optional[int] = 2048):
"""Initialize the PFF block."""
super().__init__()
self._linear1 = nn.Linear(d_model, d_ff)
self._linear2 = nn.Linear(d_ff, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate forward the input through the PFF block.
Apply the first linear transformation, then a relu actvation,
and the second linear transformation.
Parameters
----------
x:
Input tensor with shape (batch_size, K, d_model).
Returns
-------
Output tensor with shape (batch_size, K, d_model).
"""
return self._linear2(F.relu(self._linear1(x)))
================================================
FILE: code/deep/adarnn/tst/transformer.py
================================================
import torch
import torch.nn as nn
from tst.encoder import Encoder
from tst.decoder import Decoder
from tst.utils import generate_original_PE, generate_regular_PE
from base.loss_transfer import TransferLoss
class Transformer(nn.Module):
"""Transformer model from Attention is All You Need.
A classic transformer model adapted for sequential data.
Embedding has been replaced with a fully connected layer,
the last layer softmax is now a sigmoid.
Attributes
----------
layers_encoding: :py:class:`list` of :class:`Encoder.Encoder`
stack of Encoder layers.
layers_decoding: :py:class:`list` of :class:`Decoder.Decoder`
stack of Decoder layers.
Parameters
----------
d_input:
Model input dimension.
d_model:
Dimension of the input vector.
d_output:
Model output dimension.
q:
Dimension of queries and keys.
v:
Dimension of values.
h:
Number of heads.
N:
Number of encoder and decoder layers to stack.
attention_size:
Number of backward elements to apply attention.
Deactivated if ``None``. Default is ``None``.
dropout:
Dropout probability after each MHA or PFF block.
Default is ``0.3``.
chunk_mode:
Switch between different MultiHeadAttention blocks.
One of ``'chunk'``, ``'window'`` or ``None``. Default is ``'chunk'``.
pe:
Type of positional encoding to add.
Must be one of ``'original'``, ``'regular'`` or ``None``. Default is ``None``.
pe_period:
If using the ``'regular'` pe, then we can define the period. Default is ``24``.
"""
def __init__(self,
d_input: int,
d_model: int,
d_output: int,
q: int,
v: int,
h: int,
N: int,
attention_size: int = None,
dropout: float = 0.3,
chunk_mode: str = 'chunk',
pe: str = None,
pe_period: int = 24):
"""Create transformer structure from Encoder and Decoder blocks."""
super().__init__()
self._d_model = d_model
self.layers_encoding = nn.ModuleList([Encoder(d_model,
q,
v,
h,
attention_size=attention_size,
dropout=dropout,
chunk_mode=chunk_mode) for _ in range(N)])
self.layers_decoding = nn.ModuleList([Decoder(d_model,
q,
v,
h,
attention_size=attention_size,
dropout=dropout,
chunk_mode=chunk_mode) for _ in range(N)])
self._embedding = nn.Linear(d_input, d_model)
self._linear = nn.Linear(d_model, d_output)
pe_functions = {
'original': generate_original_PE,
'regular': generate_regular_PE,
}
if pe in pe_functions.keys():
self._generate_PE = pe_functions[pe]
self._pe_period = pe_period
elif pe is None:
self._generate_PE = None
else:
raise NameError(
f'PE "{pe}" not understood. Must be one of {", ".join(pe_functions.keys())} or None.')
self.name = 'transformer'
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Propagate input through transformer
Forward input through an embedding module,
the encoder then decoder stacks, and an output module.
Parameters
----------
x:
:class:`torch.Tensor` of shape (batch_size, K, d_input).
Returns
-------
Output tensor with shape (batch_size, K, d_output).
"""
K = x.shape[1]
# Embeddin module
encoding = self._embedding(x)
# Add position encoding
if self._generate_PE is not None:
pe_params = {'period': self._pe_period} if self._pe_period else {}
positional_encoding = self._generate_PE(K, self._d_model, **pe_params)
positional_encoding = positional_encoding.to(encoding.device)
encoding.add_(positional_encoding)
# Encoding stack
list_encoding = []
for layer in self.layers_encoding:
encoding = layer(encoding)
list_encoding.append(encoding)
# Decoding stack
decoding = encoding
# Add position encoding
if self._generate_PE is not None:
positional_encoding = self._generate_PE(K, self._d_model)
positional_encoding = positional_encoding.to(decoding.device)
decoding.add_(positional_encoding)
for layer in self.layers_decoding:
decoding = layer(decoding, encoding)
# Output module
output = self._linear(decoding)
output = torch.sigmoid(output)
return output, list_encoding
# def adapt_encoding(self, list_encoding, loss_type, train_type):
# ## train_type "last" : last hidden, "all": all hidden
# loss_all = torch.zeros(1).cuda()
# for i in range(len(list_encoding)):
# data = list_encoding[i]
# data_s = data[0:len(data)//2]
# data_t = data[len(data)//2:]
# criterion_transder = TransferLoss(
# loss_type=loss_type, input_dim=data_s.shape[2])
# if train_type == 'last':
# loss_all = loss_all + criterion_transder.compute(
# data_s[:, -1, :], data_t[:, -1, :])
# elif train_type == "all":
# for j in range(data_s.shape[1]):
# loss_all = loss_all + criterion_transder.compute(data_s[:, j, :], data_t[:, j, :])
# else:
# print("adapt loss error!")
# return loss_all
def adapt_encoding_weight(self, list_encoding, loss_type, train_type, weight_mat=None):
loss_all = torch.zeros(1).cuda()
len_seq = list_encoding[0].shape[1]
num_layers = len(list_encoding)
if weight_mat is None:
weight = (1.0 / len_seq *
torch.ones(num_layers, len_seq)).cuda()
else:
weight = weight_mat
dist_mat = torch.zeros(num_layers, len_seq).cuda()
for i in range(len(list_encoding)):
data = list_encoding[i]
data_s = data[0:len(data)//2]
data_t = data[len(data)//2:]
criterion_transder = TransferLoss(
loss_type=loss_type, input_dim=data_s.shape[2])
if train_type == 'last':
loss_all = loss_all + criterion_transder.compute(
data_s[:, -1, :], data_t[:, -1, :])
elif train_type == "all":
for j in range(data_s.shape[1]):
loss_transfer = criterion_transder.compute(data_s[:, j, :], data_t[:, j, :])
loss_all = loss_all + weight[i, j] * loss_transfer
dist_mat[i, j] = loss_transfer
else:
print("adapt loss error!")
return loss_all, dist_mat, weight
def update_weight_Boosting(self, weight_mat, dist_old, dist_new):
epsilon = 1e-12
dist_old = dist_old.detach()
dist_new = dist_new.detach()
ind = dist_new > dist_old + epsilon
weight_mat[ind] = weight_mat[ind] * \
(1 + torch.sigmoid(dist_new[ind] - dist_old[ind]))
weight_norm = torch.norm(weight_mat, dim=1, p=1)
weight_mat = weight_mat / weight_norm.t().unsqueeze(1).repeat(1, len(weight_mat[0]))
return weight_mat
================================================
FILE: code/deep/adarnn/tst/utils.py
================================================
from typing import Optional, Union
import numpy as np
import torch
def generate_original_PE(length: int, d_model: int) -> torch.Tensor:
"""Generate positional encoding as described in original paper. :class:`torch.Tensor`
Parameters
----------
length:
Time window length, i.e. K.
d_model:
Dimension of the model vector.
Returns
-------
Tensor of shape (K, d_model).
"""
PE = torch.zeros((length, d_model))
pos = torch.arange(length).unsqueeze(1)
PE[:, 0::2] = torch.sin(
pos / torch.pow(1000, torch.arange(0, d_model, 2, dtype=torch.float32)/d_model))
PE[:, 1::2] = torch.cos(
pos / torch.pow(1000, torch.arange(1, d_model, 2, dtype=torch.float32)/d_model))
return PE
def generate_regular_PE(length: int, d_model: int, period: Optional[int] = 24) -> torch.Tensor:
"""Generate positional encoding with a given period.
Parameters
----------
length:
Time window length, i.e. K.
d_model:
Dimension of the model vector.
period:
Size of the pattern to repeat.
Default is 24.
Returns
-------
Tensor of shape (K, d_model).
"""
PE = torch.zeros((length, d_model))
pos = torch.arange(length, dtype=torch.float32).unsqueeze(1)
PE = torch.sin(pos * 2 * np.pi / period)
PE = PE.repeat((1, d_model))
return PE
def generate_local_map_mask(chunk_size: int,
attention_size: int,
mask_future=False,
device: torch.device = 'cpu') -> torch.BoolTensor:
"""Compute attention mask as attention_size wide diagonal.
Parameters
----------
chunk_size:
Time dimension size.
attention_size:
Number of backward elements to apply attention.
device:
torch device. Default is ``'cpu'``.
Returns
-------
Mask as a boolean tensor.
"""
local_map = np.empty((chunk_size, chunk_size))
i, j = np.indices(local_map.shape)
if mask_future:
local_map[i, j] = (i - j > attention_size) ^ (j - i > 0)
else:
local_map[i, j] = np.abs(i - j) > attention_size
return torch.BoolTensor(local_map).to(device)
================================================
FILE: code/deep/adarnn/utils/__init__.py
================================================
from utils import utils
from utils.visualize import Visualize
from utils import metrics
from utils import heat_map
__all__ = {
'utils',
'Visualize',
'metrics',
'heat_map'
}
================================================
FILE: code/deep/adarnn/utils/heat_map.py
================================================
import random
from matplotlib import pyplot as plt
from matplotlib import cm
from matplotlib import axes
from matplotlib.font_manager import FontProperties
def draw_heatmap(data, filename):
#作图阶段
fig = plt.figure()
#定义画布为1*1个划分,并在第1个位置上进行作图
ax = fig.add_subplot(111)
#作图并选择热图的颜色填充风格,这里选择hot
im = ax.imshow(data, cmap=plt.cm.hot_r)
#增加右侧的颜色刻度条
plt.colorbar(im)
#增加标题
plt.title("weight heatmap")
#show
plt.show()
plt.savefig(filename)
# d = draw()
================================================
FILE: code/deep/adarnn/utils/metrics.py
================================================
import torch
EPS = 1e-12
def robust_zscore_tensor(x):
x -= torch.median(x, dim=0, keepdim=True)[0]
x /= torch.median(torch.abs(x), dim=0, keepdim=True)[0] * 1.4826 + EPS
x.clamp_(-3, 3)
x -= torch.mean(x, dim=0, keepdim=True)
x /= torch.std(x, unbiased=False, dim=0, keepdim=True) + EPS
return x
def calc_ic(pred, label):
pred = robust_zscore_tensor(pred)
label = robust_zscore_tensor(label)
return torch.mean(pred * label)
def calc_r2(pred, label):
return 1 - (pred - label).pow(2).sum() / label.pow(2).sum()
def metric_fn(pred, label, metric='IC'):
# robust pearson correlation
mask = ~torch.isnan(label)
if metric == 'IC':
return calc_ic(pred[mask], label[mask])
elif metric == 'R2':
return calc_r2(pred[mask], label[mask])
def robust_zscore(x):
# MAD based robust zscore
x = x - x.median() # copy
x /= x.abs().median() * 1.4826
x.clip(-3, 3, inplace=True)
return x
def calc_all_metrics(pred):
"""pred is a pandas dataframe that has two attributes: score (pred) and label (real)"""
res = {}
ic = pred.groupby(level='datetime').apply(
lambda x: robust_zscore(x.label).corr(robust_zscore(x.score)))
raw_ic = pred.groupby(level='datetime').apply(
lambda x: x.label.corr(x.score))
rank_ic = pred.groupby(level='datetime').apply(
lambda x: x.label.corr(x.score, method='spearman'))
print('Robust IC %.3f, Robust ICIR %.3f, Rank IC %.3f, Rank ICIR %.3f, Raw IC %.3f, Raw ICIR %.3f'%(
ic.mean(), ic.mean()/ic.std(), rank_ic.mean(), rank_ic.mean()/rank_ic.std(), raw_ic.mean(), raw_ic.mean() / raw_ic.std()))
res['IC'] = ic.mean()
res['ICIR'] = ic.mean() / ic.std()
res['RankIC'] = rank_ic.mean()
res['RankICIR'] = rank_ic.mean() / rank_ic.std()
res['RawIC'] = raw_ic.mean()
res['RawICIR'] = raw_ic.mean() / raw_ic.std()
return res
def logcosh(pred, label):
# logcosh
mask = ~torch.isnan(label)
loss = torch.log(torch.cosh(pred[mask] - label[mask]))
return torch.mean(loss)
================================================
FILE: code/deep/adarnn/utils/utils.py
================================================
import collections
import torch
import os
import pandas as pd
import torch.nn as nn
from tqdm import tqdm
import numpy as np
EPS = 1e-12
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
self.list = []
def update(self, val, n=1):
self.val = val
self.list.append(val)
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def average_params(params_list):
assert isinstance(params_list, (tuple, list, collections.deque))
n = len(params_list)
if n == 1:
return params_list[0]
new_params = collections.OrderedDict()
keys = None
for i, params in enumerate(params_list):
if keys is None:
keys = params.keys()
for k, v in params.items():
if k not in keys:
raise ValueError('the %d-th model has different params'%i)
if k not in new_params:
new_params[k] = v / n
else:
new_params[k] += v / n
return new_params
def zscore(x):
return (x - x.mean(dim=0, keepdim=True)) / x.std(dim=0, keepdim=True, unbiased=False)
def calc_loss(pred, label):
return torch.mean((zscore(pred) - label) ** 2)
def calc_corr(pred, label):
return (zscore(pred) * zscore(label)).mean()
def test_ic(model_list, data_list, device, verbose=True, ic_type='spearman'):
'''
model_list: [model1, model2, ...]
datalist: [loader1, loader2, ...]
return: unified ic, specific ic (all values), loss
'''
spec_ic = []
loss_test = AverageMeter()
loss_fn = torch.nn.MSELoss()
label_true, label_pred = torch.empty(0).to(device), torch.empty(0).to(device)
for i in range(len(model_list)):
label_spec_true, label_spec_pred = torch.empty(0).to(device), torch.empty(0).to(device)
model_list[i].eval()
with torch.no_grad():
for _, (feature, label_actual, _, _) in enumerate(data_list[i]):
# feature = torch.tensor(feature, dtype=torch.float32, device=device)
label_actual = label_actual.clone().detach().view(-1, 1)
label_actual, mask = handle_nan(label_actual)
label_predict = model_list[i].predict(feature).view(-1, 1)
label_predict = label_predict[mask]
loss = loss_fn(label_actual, label_predict)
loss_test.update(loss.item())
# Concat them for computing IC later
label_true = torch.cat([label_true, label_actual])
label_pred = torch.cat([label_pred, label_predict])
label_spec_true = torch.cat([label_spec_true, label_actual])
label_spec_pred = torch.cat([label_spec_pred, label_predict])
ic = calc_ic(label_spec_true, label_spec_pred, ic_type)
spec_ic.append(ic.item())
unify_ic = calc_ic(label_true, label_pred, ic_type).item()
# spec_ic.append(sum(spec_ic) / len(spec_ic))
loss = loss_test.avg
if verbose:
print('[IC] Unified IC: {:.6f}, specific IC: {}, loss: {:.6f}'.format(unify_ic, spec_ic, loss))
return unify_ic, spec_ic, loss
def test_ic_daily(model_list, data_list, device, verbose=True, ic_type='spearman'):
'''
model_list: [model1, model2, ...]
datalist: [loader1, loader2, ...]
return: unified ic, specific ic (all values + avg), loss
'''
spec_ic = []
loss_test = AverageMeter()
loss_fn = torch.nn.MSELoss()
label_true, label_pred = torch.empty(0).to(device), torch.empty(0).to(device)
for i in range(len(model_list)):
label_spec_true, label_spec_pred = torch.empty(0).to(device), torch.empty(0).to(device)
model_list[i].eval()
with torch.no_grad():
for slc in tqdm(data_list[i].iter_daily(), total=data_list[i].daily_length):
feature, label_actual, _, _ = data_list[i].get(slc)
# for _, (feature, label_actual, _, _) in enumerate(data_list[i]):
# feature = torch.tensor(feature, dtype=torch.float32, device=device)
label_actual = torch.tensor(label_actual, dtype=torch.float32, device=device).view(-1, 1)
label_actual, mask = handle_nan(label_actual)
label_predict = model_list[i].predict(feature).view(-1, 1)
label_predict = label_predict[mask]
loss = loss_fn(label_actual, label_predict)
loss_test.update(loss.item())
# Concat them for computing IC later
label_true = torch.cat([label_true, label_actual])
label_pred = torch.cat([label_pred, label_predict])
label_spec_true = torch.cat([label_spec_true, label_actual])
label_spec_pred = torch.cat([label_spec_pred, label_predict])
ic = calc_ic(label_spec_true, label_spec_pred, ic_type)
spec_ic.append(ic.item())
unify_ic = calc_ic(label_true, label_pred, ic_type).item()
# spec_ic.append(sum(spec_ic) / len(spec_ic))
loss = loss_test.avg
if verbose:
print('[IC] Unified IC: {:.6f}, specific IC: {}, loss: {:.6f}'.format(unify_ic, spec_ic, loss))
return unify_ic, spec_ic, loss
def test_ic_uni(model, data_loader, model_path=None, ic_type='spearman', verbose=False):
if model_path:
model.load_state_dict(torch.load(model_path))
model.eval()
loss_all = []
ic_all = []
for slc in tqdm(data_loader.iter_daily(), total=data_loader.daily_length):
data, label, _, _ = data_loader.get(slc)
with torch.no_grad():
pred = model.predict(data)
mask = ~torch.isnan(label)
pred = pred[mask]
label = label[mask]
loss = torch.mean(torch.log(torch.cosh(pred - label)))
if ic_type == 'spearman':
ic = spearman_corr(pred, label)
elif ic_type == 'pearson':
ic = pearson_corr(pred, label)
loss_all.append(loss.item())
ic_all.append(ic)
loss, ic = np.mean(loss_all), np.mean(ic_all)
if verbose:
print('IC: ', ic)
return loss, ic
def calc_ic(x, y, ic_type='pearson'):
ic = -100
if ic_type == 'pearson':
ic = pearson_corr(x, y)
elif ic_type == 'spearman':
ic = spearman_corr(x, y)
return ic
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
def handle_nan(x):
mask = ~torch.isnan(x)
return x[mask], mask
class Log_Loss(nn.Module):
def __init__(self):
super(Log_Loss, self).__init__()
def forward(self, ytrue, ypred):
delta = ypred - ytrue
return torch.mean(torch.log(torch.cosh(delta)))
def spearman_corr(x, y):
X = pd.Series(x.cpu())
Y = pd.Series(y.cpu())
spearman = X.corr(Y, method='spearman')
return spearman
def spearman_corr2(x, y):
X = pd.Series(x)
Y = pd.Series(y)
spearman = X.corr(Y, method='spearman')
return spearman
def pearson_corr(x, y):
X = pd.Series(x.cpu())
Y = pd.Series(y.cpu())
spearman = X.corr(Y, method='pearson')
return spearman
def dir_exist(dirs):
if not os.path.exists(dirs):
os.makedirs(dirs)
================================================
FILE: code/deep/adarnn/utils/visualize.py
================================================
# A wrapper of Visdom for visualization
import visdom
import numpy as np
import time
class Visualize(object):
def __init__(self, port=8097, env='env'):
self.port = port
self.env = env
self.vis = visdom.Visdom(port=self.port, env=self.env)
def plot_line(self, Y, global_step, title='title', legend=['legend']):
""" Plot line
Inputs:
Y (list): values to plot, a list
global_step (int): global step
"""
y = np.array(Y).reshape((1, len(Y)))
self.vis.line(
Y = y,
X = np.array([global_step]),
win = title,
opts = dict(
title = title,
height = 360,
width = 400,
legend = legend,
),
update = 'new' if global_step==0 else 'append'
)
def heat_map(self, X, title='title'):
self.vis.heatmap(
X = X,
win = title,
opts=dict(
title = title,
width = 360,
height = 400,
)
)
def log(self, info, title='log_text'):
"""
self.log({'loss':1, 'lr':0.0001})
"""
log_text = ('[{time}] {info}
'.format(
time=time.strftime('%m%d_%H%M%S'),\
info=info))
self.vis.text(log_text, title, append=True)
if __name__ == '__main__':
vvv = visdom.Visdom(port=8097, env='test')
def test():
vis = Visualize(env='test')
import time
for i in range(10):
y = np.random.rand(1, 2)
title = 'Two values'
legend = ['value 1', 'value 2']
vis.plot_line([y[0,0], y[0,1]], i, title, legend)
vvv.line(Y=np.array([y[0,0], y[0,1]]).reshape((1,2)), X=np.array([i]),win='test2', update='append')
time.sleep(2)
test()
================================================
FILE: code/deep/finetune_AlexNet_ResNet/data/readme.txt
================================================
Download the Office-31 dataset (raw images) and extract it into this directory.
This directory should look like:
data
--OFFICE31
----amazon
------class1
------class2
...
----webcam
------(same as amazon)
----dslr
------(same as amazon)
================================================
FILE: code/deep/finetune_AlexNet_ResNet/data_loader.py
================================================
from torchvision import datasets, transforms
import torch
import os
def load_data(root_path, dir, batch_size, phase):
transform_dict = {
'src': transforms.Compose(
[transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]),
'tar': transforms.Compose(
[transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])}
data = datasets.ImageFolder(root=os.path.join(root_path, dir), transform=transform_dict[phase])
data_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=False, num_workers=4)
return data_loader
def load_train(root_path, dir, batch_size, phase):
transform_dict = {
'src': transforms.Compose(
[transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]),
'tar': transforms.Compose(
[transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])}
data = datasets.ImageFolder(root=os.path.join(root_path, dir), transform=transform_dict[phase])
train_size = int(0.8 * len(data))
test_size = len(data) - train_size
data_train, data_val = torch.utils.data.random_split(data, [train_size, test_size])
train_loader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, shuffle=True, drop_last=False, num_workers=4)
val_loader = torch.utils.data.DataLoader(data_val, batch_size=batch_size, shuffle=True, drop_last=False, num_workers=4)
return train_loader, val_loader
================================================
FILE: code/deep/finetune_AlexNet_ResNet/finetune_office31.py
================================================
from __future__ import print_function
import argparse
import data_loader
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import time
# Command setting
parser = argparse.ArgumentParser(description='Finetune')
parser.add_argument('--model', type=str, default='resnet')
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--src', type=str, default='amazon')
parser.add_argument('--tar', type=str, default='webcam')
parser.add_argument('--n_class', type=int, default=31)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--n_epoch', type=int, default=100)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--decay', type=float, default=5e-4)
parser.add_argument('--data', type=str, default='Your dataset folder')
parser.add_argument('--early_stop', type=int, default=20)
args = parser.parse_args()
# Parameter setting
DEVICE = torch.device('cuda')
BATCH_SIZE = {'src': int(args.batchsize), 'tar': int(args.batchsize)}
def load_model(name='alexnet'):
if name == 'alexnet':
model = torchvision.models.alexnet(pretrained=True)
n_features = model.classifier[6].in_features
fc = torch.nn.Linear(n_features, args.n_class)
model.classifier[6] = fc
elif name == 'resnet':
model = torchvision.models.resnet50(pretrained=True)
n_features = model.fc.in_features
fc = torch.nn.Linear(n_features, args.n_class)
model.fc = fc
model.fc.weight.data.normal_(0, 0.005)
model.fc.bias.data.fill_(0.1)
return model
def get_optimizer(model_name):
learning_rate = args.lr
if model_name == 'alexnet':
param_group = [
{'params': model.features.parameters(), 'lr': learning_rate}]
for i in range(6):
param_group += [{'params': model.classifier[i].parameters(),
'lr': learning_rate}]
param_group += [{'params': model.classifier[6].parameters(),
'lr': learning_rate * 10}]
elif model_name == 'resnet':
param_group = []
for k, v in model.named_parameters():
if not k.__contains__('fc'):
param_group += [{'params': v, 'lr': learning_rate}]
else:
param_group += [{'params': v, 'lr': learning_rate * 10}]
optimizer = optim.SGD(param_group, momentum=args.momentum)
return optimizer
# Schedule learning rate
def lr_schedule(optimizer, epoch):
def lr_decay(LR, n_epoch, e):
return LR / (1 + 10 * e / n_epoch) ** 0.75
for i in range(len(optimizer.param_groups)):
if i < len(optimizer.param_groups) - 1:
optimizer.param_groups[i]['lr'] = lr_decay(
args.lr, args.n_epoch, epoch)
else:
optimizer.param_groups[i]['lr'] = lr_decay(
args.lr, args.n_epoch, epoch) * 10
def test(model, target_test_loader):
model.eval()
correct = 0
criterion = torch.nn.CrossEntropyLoss()
len_target_dataset = len(target_test_loader.dataset)
with torch.no_grad():
for data, target in target_test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
s_output = model(data)
loss = criterion(s_output, target)
pred = torch.max(s_output, 1)[1]
correct += torch.sum(pred == target)
acc = correct.double() / len(target_test_loader.dataset)
return acc
def finetune(model, dataloaders, optimizer):
since = time.time()
best_acc = 0
criterion = nn.CrossEntropyLoss()
stop = 0
for epoch in range(1, args.n_epoch + 1):
stop += 1
# You can uncomment this line for scheduling learning rate
# lr_schedule(optimizer, epoch)
for phase in ['src', 'val', 'tar']:
if phase == 'src':
model.train()
else:
model.eval()
total_loss, correct = 0, 0
for inputs, labels in dataloaders[phase]:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'src'):
outputs = model(inputs)
loss = criterion(outputs, labels)
preds = torch.max(outputs, 1)[1]
if phase == 'src':
loss.backward()
optimizer.step()
total_loss += loss.item() * inputs.size(0)
correct += torch.sum(preds == labels.data)
epoch_loss = total_loss / len(dataloaders[phase].dataset)
epoch_acc = correct.double() / len(dataloaders[phase].dataset)
print('Epoch: [{:02d}/{:02d}]---{}, loss: {:.6f}, acc: {:.4f}'.format(epoch, args.n_epoch, phase, epoch_loss,
epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
stop = 0
best_acc = epoch_acc
torch.save(model.state_dict(), 'model.pkl')
if stop >= args.early_stop:
break
print()
model.load_state_dict(torch.load('model.pkl'))
acc_test = test(model, dataloaders['tar'])
time_pass = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_pass // 60, time_pass % 60))
return model, acc_test
if __name__ == '__main__':
torch.manual_seed(10)
# Load data
root_dir = args.data
domain = {'src': str(args.src), 'tar': str(args.tar)}
dataloaders = {}
dataloaders['tar'] = data_loader.load_data(root_dir, domain['tar'], BATCH_SIZE['tar'], 'tar')
dataloaders['src'], dataloaders['val'] = data_loader.load_train(root_dir, domain['src'], BATCH_SIZE['src'], 'src')
# Load model
model_name = str(args.model)
model = load_model(model_name).to(DEVICE)
print('Source: {} ({}), target: {} ({}), model: {}'.format(
domain['src'], len(dataloaders['src'].dataset), domain['tar'], len(dataloaders['val'].dataset), model_name))
optimizer = get_optimizer(model_name)
model_best, best_acc = finetune(model, dataloaders, optimizer)
print('Best acc: {}'.format(best_acc))
================================================
FILE: code/deep/finetune_AlexNet_ResNet/readme.md
================================================
# Fine-tune on AlexNet and ResNet
This directory contains the Pytorch code for fine-tuning **AlexNet** and **ResNet** on certain datasets. With the development of deep transfer learning, a lot of new approaches are regarding AlexNet and ResNet as the baselines. Therefore, we hope this directory could be of help.
The code are designed to be easy to follow and understand, as I always do.
## Requirements
Python 3.6, Pytorch 0.4.0 or above.
All can be installed using `conda` or `pip`.
## Usage
1. Download the [Office-31](https://pan.baidu.com/s/1o8igXT4#list/path=%2F) dataset and extract it into the `data` foder. Other datasets are welcome.
2. In your terminal, type `python office31.py`. That's all.
3. You can switch `alexnet` or `resnet` in the commond line.
More usage: you can run
`python finetune_office31.py -m resnet -b 64 -g 3 -src amazon -tar webcam`
which means you use resnet with the batch size of 64 and the 3rd gpu device on source amazon and target webcam.
## About the code
The code consists of 2 files:
- `data_loader.py`: Load the dataset.
- `office31.py`: The main file.
## Results
**Protocol**: We use a **full-training** protocol, which is taking all the samples from one domain as the source or target domain.
Here are our results using the full training prototol.
AlexNet:
| Method | A - W | D - W | W - D | A - D | D - A | W - A | Average |
|:--------------:|:-----:|:-----:|:-----:|:-----:|:----:|:----:|:-------:|
| AlexNet (reported in previous work)| 61.6 | 95.4 | 99.0 | 63.8 | 51.1 | 49.8 | 70.1 |
| AlexNet (ours) | 51.3 | 91.1 | 96.8 | 50.0 | 49.8 | 39.1 | 63.0 |
ResNet:
| Method | A - W | D - W | W - D | A - D | D - A | W - A | Average |
|:--------------:|:-----:|:-----:|:-----:|:-----:|:----:|:----:|:-------:|
| ResNet-50 (reported in previous work)| 68.4 | 96.7 | 99.3 | 68.9 | 62.5 | 60.7 | 76.1 |
| ResNet-50 (ours)| 76.7 | 91.8 | 99.0 | 78.9 | 63.5 | 65.0 | 79.2 |
**Training:** The finetune takes a standard training process: divide the source domain into `train` and `validation` set (8:2), and then treat the target domain as the `test` set.
**Parameter setting:** Learning rate=0.0001 for all the layers except the fc layer, which is 0.001 learning rate. Batch size = 64. Using SGD as the optimizer with momentum = 0.9 without weight decay.
*Remark:* The results of AlexNet is clearly different from those reported in previous work. This is because the pretrained AlexNet model provided in PyTorch is different from that in Caffe, while previous work adopted the results from this framework.
================================================
FILE: code/deep/fixed/alg/alg.py
================================================
# coding=utf-8
from alg.algs.Fixed import Fixed
ALGORITHMS = [
'Fixed',
]
def get_algorithm_class(algorithm_name):
"""Return the algorithm class with the given name."""
if algorithm_name not in globals():
raise NotImplementedError(
"Algorithm not found: {}".format(algorithm_name))
return globals()[algorithm_name]
================================================
FILE: code/deep/fixed/alg/algs/Fixed.py
================================================
# coding=utf-8
import torch
import torch.nn.functional as F
import numpy as np
from alg.modelopera import get_fea
from network import Adver_network, common_network
from alg.algs.base import Algorithm
from loss.margin_loss import LargeMarginLoss
class Fixed(Algorithm):
def __init__(self, args):
super(Fixed, self).__init__(args)
self.featurizer = get_fea(args)
self.bottleneck = common_network.feat_bottleneck(
self.featurizer.in_features, args.bottleneck, args.layer)
self.classifier = common_network.feat_classifier(
args.num_classes, args.bottleneck, args.classifier)
self.discriminator = Adver_network.Discriminator(
args.bottleneck, args.dis_hidden, args.domain_num-len(args.test_envs))
self.args = args
self.criterion = LargeMarginLoss(
self.args.mixup_ld_margin, top_k=self.args.top_k, loss_type=self.args.ldmarginlosstype, reduce='none')
def update(self, minibatches, opt, sch):
all_x = torch.cat([data[0].cuda().float() for data in minibatches])
all_y = torch.cat([data[1].cuda().long() for data in minibatches])
all_z = self.bottleneck(self.featurizer(all_x))
disc_input = all_z
disc_input = Adver_network.ReverseLayerF.apply(
disc_input, self.args.alpha)
disc_out = self.discriminator(disc_input)
disc_labels = torch.cat([data[2].cuda().long()
for data in minibatches])
disc_loss = F.cross_entropy(disc_out, disc_labels)
lam = np.random.beta(self.args.mixupalpha, self.args.mixupalpha)
index2 = torch.randperm(all_z.shape[0]).cuda()
all_mixz = lam*all_z+(1-lam)*all_z[index2]
all_preds = self.classifier(all_mixz)
classifier_loss = torch.mean(self.criterion(all_preds, all_y, [
all_mixz])*lam+self.criterion(all_preds, all_y[index2], [all_mixz])*(1-lam))
loss = classifier_loss+disc_loss
opt.zero_grad()
loss.backward()
opt.step()
if sch:
sch.step()
return {'total': loss.item(), 'class': classifier_loss.item(), 'dis': disc_loss.item()}
def predict(self, x):
return self.classifier(self.bottleneck(self.featurizer(x)))
================================================
FILE: code/deep/fixed/alg/algs/base.py
================================================
# coding=utf-8
import torch
class Algorithm(torch.nn.Module):
def __init__(self, args):
super(Algorithm, self).__init__()
def update(self, minibatches):
raise NotImplementedError
def predict(self, x):
raise NotImplementedError
================================================
FILE: code/deep/fixed/alg/modelopera.py
================================================
# coding=utf-8
import torch
from network import act_network
def get_fea(args):
net = act_network.ActNetwork(args.dataset)
return net
def accuracy(network, loader, weights, usedpredict='p'):
correct = 0
total = 0
weights_offset = 0
network.eval()
with torch.no_grad():
for data in loader:
x = data[0].cuda().float()
y = data[1].cuda().long()
if usedpredict == 'p':
p = network.predict(x)
else:
p = network.predict1(x)
if weights is None:
batch_weights = torch.ones(len(x))
else:
batch_weights = weights[weights_offset:
weights_offset + len(x)]
weights_offset += len(x)
batch_weights = batch_weights.cuda()
if p.size(1) == 1:
correct += (p.gt(0).eq(y).float() *
batch_weights.view(-1, 1)).sum().item()
else:
correct += (p.argmax(1).eq(y).float() *
batch_weights).sum().item()
total += batch_weights.sum().item()
network.train()
return correct / total
================================================
FILE: code/deep/fixed/alg/opt.py
================================================
# coding=utf-8
import torch
def get_params(alg, args):
if args.schuse:
if args.schusech == 'cos':
init_lr = args.lr
else:
init_lr = 1.0
else:
init_lr = args.lr
params = [
{'params': alg.featurizer.parameters(), 'lr': args.lr_decay1 * init_lr},
{'params': alg.bottleneck.parameters(), 'lr': args.lr_decay2 * init_lr},
{'params': alg.classifier.parameters(), 'lr': args.lr_decay2 * init_lr}
]
params.append({'params': alg.discriminator.parameters(),
'lr': args.lr_decay2 * init_lr})
return params
def get_optimizer(alg, args):
params = get_params(alg, args)
optimizer = torch.optim.Adam(
params, lr=args.lr, weight_decay=args.weight_decay, betas=(args.beta1, 0.9))
return optimizer
def get_scheduler(optimizer, args):
return None
================================================
FILE: code/deep/fixed/datautil/actdata/cross_people.py
================================================
# coding=utf-8
import torch
from datautil.actdata.util import *
from datautil.util import mydataset, Nmax
import numpy as np
class ActList(mydataset):
def __init__(self, args, dataset, root_dir, people_group, group_num, transform=None, target_transform=None):
super(ActList, self).__init__(args)
self.domain_num = 0
self.dataset = dataset
self.task = 'cross_people'
self.transform = transform
self.target_transform = target_transform
x, cy, py, sy = loaddata_from_numpy(self.dataset, root_dir)
self.people_group = people_group
self.position = np.sort(np.unique(sy))
self.comb_position(x, cy, py, sy)
self.x = self.x[:, :, np.newaxis, :]
self.transform = None
self.x = torch.tensor(self.x).float()
self.dlabels = np.ones(self.labels.shape) * \
(group_num-Nmax(args, group_num))
def comb_position(self, x, cy, py, sy):
for i, peo in enumerate(self.people_group):
index = np.where(py == peo)[0]
tx, tcy, tsy = x[index], cy[index], sy[index]
for j, sen in enumerate(self.position):
index = np.where(tsy == sen)[0]
if j == 0:
ttx, ttcy = tx[index], tcy[index]
else:
ttx = np.hstack((ttx, tx[index]))
if i == 0:
self.x, self.labels = ttx, ttcy
else:
self.x, self.labels = np.vstack(
(self.x, ttx)), np.hstack((self.labels, ttcy))
def set_x(self, x):
self.x = x
================================================
FILE: code/deep/fixed/datautil/actdata/util.py
================================================
# coding=utf-8
from torchvision import transforms
import numpy as np
def act_train():
return transforms.Compose([
transforms.ToTensor()
])
def act_test():
return transforms.Compose([
transforms.ToTensor()
])
def loaddata_from_numpy(dataset='dsads', root_dir='./data/act/'):
x = np.load(root_dir+dataset+'/'+dataset+'_x.npy')
ty = np.load(root_dir+dataset+'/'+dataset+'_y.npy')
cy, py, sy = ty[:, 0], ty[:, 1], ty[:, 2]
return x, cy, py, sy
================================================
FILE: code/deep/fixed/datautil/getdataloader.py
================================================
# coding=utf-8
from torch.utils.data import DataLoader
import datautil.actdata.util as actutil
from datautil.util import make_weights_for_balanced_classes, split_trian_val_test
from datautil.mydataloader import InfiniteDataLoader
import datautil.actdata.cross_people as cross_people
task_act = {'cross_people': cross_people}
def get_dataloader(args, trdatalist, tedatalist):
in_splits, out_splits = [], []
for tr in trdatalist:
if args.class_balanced:
in_weights = make_weights_for_balanced_classes(tr)
else:
in_weights = None
in_splits.append((tr, in_weights))
for te in tedatalist:
if args.class_balanced:
out_weights = make_weights_for_balanced_classes(te)
else:
out_weights = None
out_splits.append((te, out_weights))
train_loaders = [InfiniteDataLoader(
dataset=env,
weights=env_weights,
batch_size=args.batch_size,
num_workers=args.N_WORKERS)
for i, (env, env_weights) in enumerate(in_splits)]
tr_loaders = [DataLoader(
dataset=env,
batch_size=64,
num_workers=args.N_WORKERS,
drop_last=False,
shuffle=False)
for i, (env, env_weights) in enumerate(in_splits)]
eval_loaders = [DataLoader(
dataset=env,
batch_size=64,
num_workers=args.N_WORKERS,
drop_last=False,
shuffle=False)
for i, (env, env_weights) in enumerate(in_splits + out_splits)]
eval_weights = [None for _, weights in (in_splits + out_splits)]
return train_loaders, tr_loaders, eval_loaders, in_splits, out_splits, eval_weights
def get_act_dataloader(args):
train_datasetlist = []
eval_datasetlist = []
pcross_act = task_act[args.task]
in_names, out_names = [], []
trl = []
tmpp = args.act_people[args.dataset]
args.domain_num = len(tmpp)
for i, item in enumerate(tmpp):
tdata = pcross_act.ActList(
args, args.dataset, args.data_dir, item, i, transform=actutil.act_train())
if i in args.test_envs:
eval_datasetlist.append(tdata)
out_names.append('eval%d_out' % (i))
else:
in_names.append('eval%d_in' % (i))
out_names.append('eval%d_out' % (i))
trl.append(tdata)
tr, te = split_trian_val_test(args, tdata)
train_datasetlist.append(tr)
eval_datasetlist.append(te)
eval_loader_names = in_names
eval_loader_names.extend(out_names)
train_loaders, tr_loaders, eval_loaders, in_splits, out_splits, eval_weights = get_dataloader(
args, train_datasetlist, eval_datasetlist)
return train_loaders, tr_loaders, eval_loaders, in_splits, out_splits, eval_loader_names, eval_weights, trl
================================================
FILE: code/deep/fixed/datautil/mydataloader.py
================================================
# coding=utf-8
import torch
class _InfiniteSampler(torch.utils.data.Sampler):
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
for batch in self.sampler:
yield batch
class InfiniteDataLoader:
def __init__(self, dataset, weights, batch_size, num_workers):
super().__init__()
self.dataset = dataset
if weights:
sampler = torch.utils.data.WeightedRandomSampler(weights,
replacement=True,
num_samples=batch_size)
else:
sampler = torch.utils.data.RandomSampler(dataset,
replacement=True)
if weights == None:
weights = torch.ones(len(dataset))
batch_sampler = torch.utils.data.BatchSampler(
sampler,
batch_size=batch_size,
drop_last=True)
self._infinite_iterator = iter(torch.utils.data.DataLoader(
dataset,
num_workers=num_workers,
batch_sampler=_InfiniteSampler(batch_sampler)
))
def __iter__(self):
while True:
yield next(self._infinite_iterator)
def __len__(self):
raise ValueError
================================================
FILE: code/deep/fixed/datautil/util.py
================================================
# coding=utf-8
import numpy as np
import torch
from collections import Counter
def Nmax(args, d):
for i in range(len(args.test_envs)):
if d < args.test_envs[i]:
return i
return len(args.test_envs)
class mydataset(object):
def __init__(self, args):
self.x = None
self.labels = None
self.dlabels = None
self.task = None
self.dataset = None
self.transform = None
self.target_transform = None
self.args = args
def set_labels(self, tlabels=None, label_type='domain_label'):
assert len(tlabels) == len(self.x)
if label_type == 'domain_label':
self.dlabels = tlabels
elif label_type == 'class_label':
self.labels = tlabels
def set_labels_by_index(self, tlabels=None, tindex=None, label_type='domain_label'):
if label_type == 'domain_label':
self.dlabels[tindex] = tlabels
elif label_type == 'class_label':
self.labels[tindex] = tlabels
def target_trans(self, y):
if self.target_transform is not None:
return self.target_transform(y)
else:
return y
def input_trans(self, x):
if self.transform is not None:
return self.transform(x)
else:
return x
def __getitem__(self, index):
x = self.input_trans(self.x[index])
ctarget = self.target_trans(self.labels[index])
dtarget = self.target_trans(self.dlabels[index])
return x, ctarget, dtarget, index
def __len__(self):
return len(self.x)
class subdataset(mydataset):
def __init__(self, args, dataset, indices):
super(subdataset, self).__init__(args)
self.x = dataset.x[indices]
self.labels = dataset.labels[indices]
self.dlabels = dataset.dlabels[indices] if dataset.dlabels is not None else None
self.task = dataset.task
self.dataset = dataset.dataset
self.transform = dataset.transform
self.target_transform = dataset.target_transform
def split_trian_val_test(args, da, rate=0.8):
dsize = len(da)
tr = int(rate*dsize)
indexall = np.arange(dsize)
np.random.seed(args.seed)
np.random.shuffle(indexall)
indextr, indexte = indexall[:tr], indexall[tr:]
tr_da = subdataset(args, da, indextr)
te_da = subdataset(args, da, indexte)
return tr_da, te_da
def make_weights_for_balanced_classes(dataset):
counts = Counter()
classes = []
for _, y, _, _, _, _ in dataset:
y = int(y)
counts[y] += 1
classes.append(y)
n_classes = len(counts)
weight_per_class = {}
for y in counts:
weight_per_class[y] = 1 / (counts[y] * n_classes)
weights = torch.zeros(len(dataset))
for i, y in enumerate(classes):
weights[i] = weight_per_class[int(y)]
return weights
def random_pairs_of_minibatches_by_domainperm(minibatches):
perm = torch.randperm(len(minibatches)).tolist()
pairs = []
for i in range(len(minibatches)):
j = i + 1 if i < (len(minibatches) - 1) else 0
xi, yi, di, = minibatches[perm[i]
][0], minibatches[perm[i]][1], minibatches[perm[i]][2]
xj, yj, dj = minibatches[perm[j]
][0], minibatches[perm[j]][1], minibatches[perm[j]][2]
min_n = min(len(xi), len(xj))
pairs.append(((xi[:min_n], yi[:min_n], di[:min_n]),
(xj[:min_n], yj[:min_n], dj[:min_n])))
return pairs
================================================
FILE: code/deep/fixed/loss/margin_loss.py
================================================
# coding=utf-8
import numpy as np
import torch
import torch.nn.functional as F
def _max_with_relu(a, b):
return a + F.relu(b - a)
def _get_grad(out_, in_):
grad, *_ = torch.autograd.grad(out_, in_,
grad_outputs=torch.ones_like(
out_, dtype=torch.float32),
retain_graph=True)
return grad.view(in_.shape[0], -1)
class LargeMarginLoss:
def __init__(self,
gamma=10000.0,
alpha_factor=4.0,
top_k=1,
dist_norm=2,
epsilon=1e-8,
use_approximation=True,
loss_type="all_top_k",
reduce='mean'):
self.dist_upper = gamma
self.dist_lower = gamma * (1.0 - alpha_factor)
self.alpha = alpha_factor
self.top_k = top_k
self.dual_norm = {1: np.inf, 2: 2, np.inf: 1}[dist_norm]
self.eps = epsilon
self.use_approximation = use_approximation
self.loss_type = loss_type
self.reduce = reduce
def __call__(self, logits, onehot_labels, feature_maps):
onehot_labels = torch.zeros(logits.size()).scatter_(
1, onehot_labels.unsqueeze(1).cpu(), 1).to(logits.device)
prob = F.softmax(logits, dim=1)
correct_prob = prob * onehot_labels
correct_prob = torch.sum(correct_prob, dim=1, keepdim=True)
other_prob = prob * (1.0 - onehot_labels)
if self.top_k > 1:
topk_prob, _ = other_prob.topk(self.top_k, dim=1)
else:
topk_prob, _ = other_prob.max(dim=1, keepdim=True)
diff_prob = correct_prob - topk_prob
loss = torch.empty(0, device=logits.device)
for feature_map in feature_maps:
diff_grad = torch.stack([_get_grad(diff_prob[:, i], feature_map) for i in range(self.top_k)],
dim=1)
diff_gradnorm = torch.norm(diff_grad, p=self.dual_norm, dim=2)
if self.use_approximation:
diff_gradnorm.detach_()
dist_to_boundary = diff_prob / (diff_gradnorm + self.eps)
if self.loss_type == "worst_top_k":
dist_to_boundary, _ = dist_to_boundary.min(dim=1)
elif self.loss_type == "avg_top_k":
dist_to_boundary = dist_to_boundary.mean(dim=1)
loss_layer = _max_with_relu(dist_to_boundary, self.dist_lower)
loss_layer = _max_with_relu(
0, self.dist_upper - loss_layer) - self.dist_upper
loss = torch.cat([loss, loss_layer])
if self.reduce == 'mean':
return loss.mean()
else:
if self.loss_type in ['worst_top_k', 'avg_top_k']:
return loss
return loss.mean(dim=1)
================================================
FILE: code/deep/fixed/network/Adver_network.py
================================================
import torch
import torch.nn as nn
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
class Discriminator(nn.Module):
def __init__(self, input_dim=256, hidden_dim=256, num_domains=4):
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
layers = [
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_domains),
]
self.layers = torch.nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
================================================
FILE: code/deep/fixed/network/act_network.py
================================================
# coding=utf-8
import torch.nn as nn
var_size = {
'usc': {
'in_size': 6,
'ker_size': 6,
'fc_size': 32*46
}
}
class ActNetwork(nn.Module):
def __init__(self, taskname):
super(ActNetwork, self).__init__()
self.taskname = taskname
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=var_size[taskname]['in_size'], out_channels=16, kernel_size=(
1, var_size[taskname]['ker_size'])),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(1, 2), stride=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(
1, var_size[taskname]['ker_size'])),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(1, 2), stride=2)
)
self.in_features = var_size[taskname]['fc_size']
def forward(self, x):
x = self.conv2(self.conv1(x))
x = x.view(-1, self.in_features)
return x
def getfea(self, x):
x = self.conv2(self.conv1(x))
return x
================================================
FILE: code/deep/fixed/network/common_network.py
================================================
# coding=utf-8
import torch.nn as nn
import torch.nn.utils.weight_norm as weightNorm
class feat_bottleneck(nn.Module):
def __init__(self, feature_dim, bottleneck_dim=256, type="ori"):
super(feat_bottleneck, self).__init__()
self.bn = nn.BatchNorm1d(bottleneck_dim, affine=True)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=0.5)
self.bottleneck = nn.Linear(feature_dim, bottleneck_dim)
self.type = type
def forward(self, x):
x = self.bottleneck(x)
if self.type == "bn":
x = self.bn(x)
return x
class feat_classifier(nn.Module):
def __init__(self, class_num, bottleneck_dim=256, type="linear"):
super(feat_classifier, self).__init__()
self.type = type
if type == 'wn':
self.fc = weightNorm(
nn.Linear(bottleneck_dim, class_num), name="weight")
else:
self.fc = nn.Linear(bottleneck_dim, class_num)
def forward(self, x):
x = self.fc(x)
return x
================================================
FILE: code/deep/fixed/readme.md
================================================
# FIXED: Frustratingly Easy Domain Generalization with Mixup
This project implements our paper [FIXED: Frustratingly Easy Domain Generalization with Mixup](https://arxiv.org/abs/2211.05228). Please refer to our paper [1] for the method and technical details.

**Abstract:** Domain generalization (DG) aims to learn a generalizable model from multiple training domains such that it can perform well on unseen target domains. A popular strategy is to augment training data to benefit generalization through methods such as Mixup [1]. While the vanilla Mixup can be directly applied, theoretical and empirical investigations uncover several shortcomings that limit its performance. Firstly, Mixup cannot effectively identify the domain and class information that can be used for learning invariant representations. Secondly, Mixup may introduce synthetic noisy data points via random interpolation, which lowers its discrimination capability. Based on the analysis, we propose a simple yet effective enhancement for Mixup-based DG, namely domain-invariant Feature mIXup (FIX). It learns domain-invariant representations for Mixup. To further enhance discrimination, we leverage existing techniques to enlarge margins among classes to further propose the domain-invariant Feature MIXup with Enhanced Discrimination (FIXED) approach. We present theoretical insights about guarantees on its effectiveness. Extensive experiments on seven public datasets across two modalities including image classification (Digits-DG, PACS, Office-Home) and time series (DSADS, PAMAP2, UCI-HAR, and USC-HAD) demonstrate that our approach significantly outperforms nine state-of-the-art related methods, beating the best performing baseline by 6.5% on average in terms of test accuracy.
## Requirement
The required packages are listed in `requirements.txt` for minimum requirement (Python 3.8.5):
```
$ pip install -r requirements.txt
$ pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/cu111/torch_stable.html
```
## Dataset
USC-SIPI human activity dataset (USC-HAD) is composed of 14 subjects (7 male, 7 female, aged from 21 to 49) executing 12 activities with a sensor tied on the front right hip. The data dimension is 6 and the sample rate is 100Hz. 12 activities include Walking Forward, Walking Left, Walking Right, Walking Upstairs, Walking Downstairs, Running Forward, Jumping Up, Sitting, Standing, Sleeping, Elevator Up, and Elevator Down.
```
wget https://wjdcloud.blob.core.windows.net/dataset/lwdata/act/usc/usc/usc_x.npy
wget https://wjdcloud.blob.core.windows.net/dataset/lwdata/act/usc/usc/usc_y.npy
```
## How to run
We provide the commands for four tasks in USC-HAD to reproduce the results.
```
python train.py --N_WORKERS 1 --data_dir ../../data/act/ --task cross_people --test_envs 0 --dataset usc --algorithm Fixed --mixupalpha 0.1 --alpha 0.5 --mixup_ld_margin 10 --top_k 5 --output ./results/0
```
```
python train.py --N_WORKERS 1 --data_dir ../../data/act/ --task cross_people --test_envs 1 --dataset usc --algorithm Fixed --mixupalpha 0.2 --alpha 0.5 --mixup_ld_margin 10000 --top_k 1 --output ./results/1
```
```
python train.py --N_WORKERS 1 --data_dir ../../data/act/ --task cross_people --test_envs 2 --dataset usc --algorithm Fixed --mixupalpha 0.1 --alpha 0.1 --mixup_ld_margin 100 --top_k 5 --output ./results/2
```
```
python train.py --N_WORKERS 1 --data_dir ../../data/act/ --task cross_people --test_envs 3 --dataset usc --algorithm Fixed --mixupalpha 0.2 --alpha 1 --mixup_ld_margin 100 --top_k 5 --output ./results/3
```
## Results
**USC-HAD**
| Source | 1,2,3 | 0,2,3 | 0,1,3 | 0,1,2 | AVG |
|----------|----------|-----------|-----------|-----------|-----------|
| Target | 0 | 1 | 2 | 3 | - |
| ERM | 80.98 | 57.75 | 74.03 | 65.86 | 69.66 |
| DANN | 81.22 | 57.88 | 76.69 | 70.72 | 71.63 |
| CORAL | 78.82 | 58.93 | 75.02 | 53.72 | 66.62 |
| ANDMask | 79.88 | 55.32 | 74.47 | 65.04 | 68.68 |
| GroupDRO | 80.12 | 55.51 | 74.69 | 59.97 | 67.57 |
| RSC | 81.88 | 57.94 | 73.39 | 65.13 | 69.59 |
| Mixup | 79.98 | 64.14 | 74.32 | 61.28 | 69.93 |
| MIX-ALL | 78.44 | 59.32 | 72.96 | 63.46 | 68.54 |
| GILE | 78.00 | 62.00 | 77.00 | 63.00 | 70.00 |
| FIXED | **85.1** | **69.19** | **80.12** | **75.82** | **77.56** |
## Contact
- luwang@ict.ac.cn
- jindongwang@outlook.com
## References
```
@article{lu2022fixed,
title={FIXED: Frustratingly Easy Domain Generalization with Mixup},
author={Lu, Wang and Wang, Jindong and Yu, Han and Huang, Lei and Zhang, Xiang and Chen, Yiqiang and Xie, Xing},
journal={arXiv preprint arXiv:2211.05228},
year={2022}
}
```
================================================
FILE: code/deep/fixed/requirements.txt
================================================
numpy==1.22.0
Pillow==9.3.0
scikit-learn==0.23.2
scipy==1.10.0
tqdm==4.62.3
================================================
FILE: code/deep/fixed/train.py
================================================
# coding=utf-8
import collections
import os
import time
import numpy as np
from alg.opt import *
from alg import alg, modelopera
from utils.util import set_random_seed, get_args, init_args, print_row, train_valid_target_eval_names
from datautil.getdataloader import get_act_dataloader
if __name__ == '__main__':
args = get_args()
init_args(args)
set_random_seed(args.seed1)
if os.path.exists(os.path.join(args.output, 'newdone')):
exit()
train_loaders, tr_loaders, eval_loaders, in_splits, out_splits, eval_loader_names, eval_weights, trl = get_act_dataloader(
args)
algorithm_class = alg.get_algorithm_class(args.algorithm)
algorithm = algorithm_class(args).cuda()
algorithm.train()
eval_dict = train_valid_target_eval_names(args)
print_key = ['step', 'epoch']
print_key.extend([item+'_acc' for item in eval_dict.keys()])
print_key.append('total_cost_time')
best_valid_acc, target_acc = 0, 0
train_minibatches_iterator = zip(*train_loaders)
start_step = 0
steps_per_epoch = min(
[len(env)/args.batch_size for env, _ in in_splits])
n_steps = int(args.max_epoch*steps_per_epoch)+1
checkpoint_freq = args.checkpoint_freq
checkpoint_vals = collections.defaultdict(lambda: [])
args.steps_per_epoch = steps_per_epoch
opt = get_optimizer(algorithm, args)
sch = get_scheduler(opt, args)
print_row(print_key, colwidth=15)
sss = time.time()
for step in range(start_step, n_steps):
step_start_time = time.time()
minibatches_device = [(data)
for data in next(train_minibatches_iterator)]
step_vals = algorithm.update(minibatches_device, opt, sch)
checkpoint_vals['step_time'].append(
time.time() - step_start_time)
for key, val in step_vals.items():
checkpoint_vals[key].append(val)
if (step % checkpoint_freq == 0) or (step == n_steps - 1):
results = {
'step': step,
'epoch': step / steps_per_epoch,
}
for key, val in checkpoint_vals.items():
results[key] = np.mean(val)
evals = zip(eval_loader_names, eval_loaders, eval_weights)
for name, loader, weights in evals:
acc = modelopera.accuracy(algorithm, loader, weights)
results[name+'_acc'] = acc
for key in eval_dict.keys():
results[key+'_acc'] = np.mean(
np.array([results[item+'_acc'] for item in eval_dict[key]]))
if results['valid_acc'] > best_valid_acc:
best_valid_acc = results['valid_acc']
target_acc = results['target_acc']
results['total_cost_time'] = time.time()-sss
print_row([results[key] for key in print_key], colwidth=15)
results.update({
'args': vars(args)
})
checkpoint_vals = collections.defaultdict(lambda: [])
print('target acc:%.4f' % target_acc)
with open(os.path.join(args.output, 'newdone'), 'w') as f:
f.write('done\n')
f.write('total cost time:%s\n' % (str(time.time()-sss)))
f.write('target acc:%.4f\n' % (target_acc))
f.write('valid acc:%.4f' % (best_valid_acc))
================================================
FILE: code/deep/fixed/utils/util.py
================================================
# coding=utf-8
import random
import numpy as np
import torch
import sys
import os
import argparse
def set_random_seed(seed=0):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def train_valid_target_eval_names(args):
eval_name_dict = {'train': [], 'valid': [], 'target': []}
for i in range(args.domain_num):
if i not in args.test_envs:
eval_name_dict['train'].append('eval%d_in' % i)
eval_name_dict['valid'].append('eval%d_out' % i)
else:
eval_name_dict['target'].append('eval%d_out' % i)
return eval_name_dict
def print_row(row, colwidth=10, latex=False):
if latex:
sep = " & "
end_ = "\\\\"
else:
sep = " "
end_ = ""
def format_val(x):
if np.issubdtype(type(x), np.floating):
x = "{:.10f}".format(x)
return str(x).ljust(colwidth)[:colwidth]
print(sep.join([format_val(x) for x in row]), end_)
class Tee:
def __init__(self, fname, mode="a"):
self.stdout = sys.stdout
self.file = open(fname, mode)
def write(self, message):
self.stdout.write(message)
self.file.write(message)
self.flush()
def flush(self):
self.stdout.flush()
self.file.flush()
def act_param_init(args):
args.act_dataset = ['usc']
args.act_people = {'usc': [[1, 11, 2, 0], [
6, 3, 9, 5], [7, 13, 8, 10], [4, 12]]}
tmp = {'usc': ((6, 1, 200), 12)}
args.num_classes, args.input_shape = tmp[args.dataset][1], tmp[args.dataset][0]
return args
def get_args():
parser = argparse.ArgumentParser(description='DG')
parser.add_argument('--algorithm', type=str, default="ERM")
parser.add_argument('--alpha', type=float,
default=0.1, help="DANN dis alpha")
parser.add_argument('--batch_size', type=int,
default=32, help="batch_size")
parser.add_argument('--beta1', type=float, default=0.5, help="Adam")
parser.add_argument('--bottleneck', type=int, default=256)
parser.add_argument('--checkpoint_freq', type=int,
default=100, help='Checkpoint every N steps')
parser.add_argument('--classifier', type=str,
default="linear", choices=["linear", "wn"])
parser.add_argument('--class_balanced', type=int, default=0)
parser.add_argument('--data_file', type=str, default='')
parser.add_argument('--dataset', type=str, default='dsads')
parser.add_argument('--data_dir', type=str, default='')
parser.add_argument('--dis_hidden', type=int, default=256)
parser.add_argument('--gpu_id', type=str, nargs='?',
default='0', help="device id to run")
parser.add_argument('--layer', type=str, default="bn",
choices=["ori", "bn"])
parser.add_argument('--ldmarginlosstype', type=str, default='avg_top_k',
choices=['all_top_k', 'worst_top_k', 'avg_top_k'])
parser.add_argument('--lr', type=float, default=1e-2, help="learning rate")
parser.add_argument('--lr_decay1', type=float,
default=1.0, help='for pretrained featurizer')
parser.add_argument('--lr_decay2', type=float, default=1.0)
parser.add_argument('--max_epoch', type=int,
default=150, help="max iterations")
parser.add_argument('--mixupalpha', type=float, default=0.2)
parser.add_argument('--mixup_ld_margin', type=float, default=10000)
parser.add_argument('--mixupregtype', type=str,
default='l-margin', choices=['ld-margin'])
parser.add_argument('--net', type=str,
default='ActNetwork', help="ActNetwork")
parser.add_argument('--N_WORKERS', type=int, default=4)
parser.add_argument('--schuse', action='store_true')
parser.add_argument('--schusech', type=str, default='cos')
parser.add_argument('--seed', type=int, default=0)
parser.add_argument('--seed1', type=int, default=0)
parser.add_argument('--task', type=str,
default="cross_people", choices=['cross_people'])
parser.add_argument('--test_envs', type=int, nargs='+', default=[0])
parser.add_argument('--top_k', type=int, default=1)
parser.add_argument('--output', type=str, default="train_output")
parser.add_argument('--valid', action='store_true')
parser.add_argument('--valid_size', type=float, default=0.2)
parser.add_argument('--weight_decay', type=float, default=5e-4)
parser.add_argument('--wtype', type=str, default='ori',
choices=['ori', 'abs', 'fea'])
args = parser.parse_args()
return args
def init_args(args):
args.steps_per_epoch = 10000000000
args.data_dir = args.data_file+args.data_dir
os.environ['CUDA_VISIBLE_DEVICS'] = args.gpu_id
os.makedirs(args.output, exist_ok=True)
sys.stdout = Tee(os.path.join(args.output, 'out.txt'))
sys.stderr = Tee(os.path.join(args.output, 'err.txt'))
args = act_param_init(args)
return args
================================================
FILE: code/distance/coral_pytorch.py
================================================
# Compute CORAL loss using pytorch
# Reference: DCORAL: Correlation Alignment for Deep Domain Adaptation, ECCV-16.
import torch
def CORAL_loss(source, target):
d = source.data.shape[1]
ns, nt = source.data.shape[0], target.data.shape[0]
# source covariance
xm = torch.mean(source, 0, keepdim=True) - source
xc = xm.t() @ xm / (ns - 1)
# target covariance
xmt = torch.mean(target, 0, keepdim=True) - target
xct = xmt.t() @ xmt / (nt - 1)
# frobenius norm between source and target
loss = torch.mul((xc - xct), (xc - xct))
loss = torch.sum(loss) / (4*d*d)
return loss
# Another implementation:
# Two implementations are the same. Just different formulation format.
# def CORAL(source, target):
# d = source.size(1)
# ns, nt = source.size(0), target.size(0)
# # source covariance
# tmp_s = torch.ones((1, ns)).to(DEVICE) @ source
# cs = (source.t() @ source - (tmp_s.t() @ tmp_s) / ns) / (ns - 1)
# # target covariance
# tmp_t = torch.ones((1, nt)).to(DEVICE) @ target
# ct = (target.t() @ target - (tmp_t.t() @ tmp_t) / nt) / (nt - 1)
# # frobenius norm
# loss = torch.norm(cs - ct, p='fro').pow(2)
# loss = loss / (4 * d * d)
# return loss
================================================
FILE: code/distance/mmd_matlab.m
================================================
% Compute MMD distance using Matlab
% Inputs X and Y are all matrices (n_sample * dim)
function [res] = mmd_matlab(X, Y, kernel_type, gamma)
if (nargin < 3)
disp('Please input the kernel_type!');
res = -9999;
return;
end
switch kernel_type
case 'linear'
res = mmd_linear(X, Y);
case 'rbf'
if (nargin < 4)
gamma = 1;
end
res = mmd_rbf(X, Y, gamma);
end
end
function [res] = mmd_linear(X, Y)
delta = mean(X) - mean(Y);
res = delta * delta';
end
function [res] = mmd_rbf(X, Y, gamma)
ker = 'rbf';
XX = kernel(ker, X', [], gamma);
YY = kernel(ker, Y', [], gamma);
XY = kernel(ker, X', Y', gamma);
res = mean(mean(XX)) + mean(mean(YY)) - 2 * mean(mean(XY));
end
function K = kernel(ker,X,X2,gamma)
switch ker
case 'linear'
if isempty(X2)
K = X'*X;
else
K = X'*X2;
end
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
if isempty(X2)
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
else
n2sq = sum(X2.^2,1);
n2 = size(X2,2);
D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
end
K = exp(-gamma*D);
case 'sam'
if isempty(X2)
D = X'*X;
else
D = X'*X2;
end
K = exp(-gamma*acos(D).^2);
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/distance/mmd_numpy_sklearn.py
================================================
# Compute MMD (maximum mean discrepancy) using numpy and scikit-learn.
import numpy as np
from sklearn import metrics
def mmd_linear(X, Y):
"""MMD using linear kernel (i.e., k(x,y) = )
Note that this is not the original linear MMD, only the reformulated and faster version.
The original version is:
def mmd_linear(X, Y):
XX = np.dot(X, X.T)
YY = np.dot(Y, Y.T)
XY = np.dot(X, Y.T)
return XX.mean() + YY.mean() - 2 * XY.mean()
Arguments:
X {[n_sample1, dim]} -- [X matrix]
Y {[n_sample2, dim]} -- [Y matrix]
Returns:
[scalar] -- [MMD value]
"""
delta = X.mean(0) - Y.mean(0)
return delta.dot(delta.T)
def mmd_rbf(X, Y, gamma=1.0):
"""MMD using rbf (gaussian) kernel (i.e., k(x,y) = exp(-gamma * ||x-y||^2 / 2))
Arguments:
X {[n_sample1, dim]} -- [X matrix]
Y {[n_sample2, dim]} -- [Y matrix]
Keyword Arguments:
gamma {float} -- [kernel parameter] (default: {1.0})
Returns:
[scalar] -- [MMD value]
"""
XX = metrics.pairwise.rbf_kernel(X, X, gamma)
YY = metrics.pairwise.rbf_kernel(Y, Y, gamma)
XY = metrics.pairwise.rbf_kernel(X, Y, gamma)
return XX.mean() + YY.mean() - 2 * XY.mean()
def mmd_poly(X, Y, degree=2, gamma=1, coef0=0):
"""MMD using polynomial kernel (i.e., k(x,y) = (gamma + coef0)^degree)
Arguments:
X {[n_sample1, dim]} -- [X matrix]
Y {[n_sample2, dim]} -- [Y matrix]
Keyword Arguments:
degree {int} -- [degree] (default: {2})
gamma {int} -- [gamma] (default: {1})
coef0 {int} -- [constant item] (default: {0})
Returns:
[scalar] -- [MMD value]
"""
XX = metrics.pairwise.polynomial_kernel(X, X, degree, gamma, coef0)
YY = metrics.pairwise.polynomial_kernel(Y, Y, degree, gamma, coef0)
XY = metrics.pairwise.polynomial_kernel(X, Y, degree, gamma, coef0)
return XX.mean() + YY.mean() - 2 * XY.mean()
if __name__ == '__main__':
a = np.arange(1, 10).reshape(3, 3)
b = [[7, 6, 5], [4, 3, 2], [1, 1, 8], [0, 2, 5]]
b = np.array(b)
print(a)
print(b)
print(mmd_linear(a, b)) # 6.0
print(mmd_rbf(a, b)) # 0.5822
print(mmd_poly(a, b)) # 2436.5
================================================
FILE: code/distance/mmd_pytorch.py
================================================
# Compute MMD distance using pytorch
import torch
import torch.nn as nn
class MMD_loss(nn.Module):
def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5):
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0])
total = torch.cat([source, target], dim=0)
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2)
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
return sum(kernel_val)
def linear_mmd2(self, f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd2(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0])
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX)
return loss
================================================
FILE: code/distance/proxy_a_distance.py
================================================
# Compute A-distance using numpy and sklearn
# Reference: Analysis of representations in domain adaptation, NIPS-07.
import numpy as np
from sklearn import svm
def proxy_a_distance(source_X, target_X, verbose=False):
"""
Compute the Proxy-A-Distance of a source/target representation
"""
nb_source = np.shape(source_X)[0]
nb_target = np.shape(target_X)[0]
if verbose:
print('PAD on', (nb_source, nb_target), 'examples')
C_list = np.logspace(-5, 4, 10)
half_source, half_target = int(nb_source/2), int(nb_target/2)
train_X = np.vstack((source_X[0:half_source, :], target_X[0:half_target, :]))
train_Y = np.hstack((np.zeros(half_source, dtype=int), np.ones(half_target, dtype=int)))
test_X = np.vstack((source_X[half_source:, :], target_X[half_target:, :]))
test_Y = np.hstack((np.zeros(nb_source - half_source, dtype=int), np.ones(nb_target - half_target, dtype=int)))
best_risk = 1.0
for C in C_list:
clf = svm.SVC(C=C, kernel='linear', verbose=False)
clf.fit(train_X, train_Y)
train_risk = np.mean(clf.predict(train_X) != train_Y)
test_risk = np.mean(clf.predict(test_X) != test_Y)
if verbose:
print('[ PAD C = %f ] train risk: %f test risk: %f' % (C, train_risk, test_risk))
if test_risk > .5:
test_risk = 1. - test_risk
best_risk = min(best_risk, test_risk)
return 2 * (1. - 2 * best_risk)
================================================
FILE: code/feature_extractor/for_digit_data/digit_data_loader.py
================================================
# encoding=utf-8
"""
Created on 10:35 2018/12/29
@author: Jindong Wang
"""
import gzip
import pickle
from scipy.io import loadmat
import torch.utils.data as data
from PIL import Image
import numpy as np
import torchvision.transforms as transforms
import torch
## For loading datasets of MNIST, USPS, and SVHN.
class GetDataset(data.Dataset):
"""Args:
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
"""
def __init__(self, data, label,
transform=None, target_transform=None):
self.transform = transform
self.target_transform = target_transform
self.data = data
self.labels = label
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], self.labels[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
# print(img.shape)
if img.shape[0] != 1:
# print(img)
img = Image.fromarray(np.uint8(np.asarray(img.transpose((1, 2, 0)))))
#
elif img.shape[0] == 1:
im = np.uint8(np.asarray(img))
# print(np.vstack([im,im,im]).shape)
im = np.vstack([im, im, im]).transpose((1, 2, 0))
img = Image.fromarray(im)
if self.target_transform is not None:
target = self.target_transform(target)
if self.transform is not None:
img = self.transform(img)
# return img, target
return img, target
def __len__(self):
return len(self.data)
def dense_to_one_hot(labels_dense):
"""Convert class labels from scalars to one-hot vectors."""
labels_one_hot = np.zeros((len(labels_dense),))
labels_dense = list(labels_dense)
for i, t in enumerate(labels_dense):
if t == 10:
t = 0
labels_one_hot[i] = t
else:
labels_one_hot[i] = t
return labels_one_hot
def load_mnist(path, scale=True, usps=False, all_use=True):
mnist_data = loadmat(path)
if scale:
mnist_train = np.reshape(mnist_data['train_32'], (55000, 32, 32, 1))
mnist_test = np.reshape(mnist_data['test_32'], (10000, 32, 32, 1))
mnist_train = np.concatenate([mnist_train, mnist_train, mnist_train], 3)
mnist_test = np.concatenate([mnist_test, mnist_test, mnist_test], 3)
mnist_train = mnist_train.transpose(0, 3, 1, 2).astype(np.float32)
mnist_test = mnist_test.transpose(0, 3, 1, 2).astype(np.float32)
mnist_labels_train = mnist_data['label_train']
mnist_labels_test = mnist_data['label_test']
else:
mnist_train = mnist_data['train_28']
mnist_test = mnist_data['test_28']
mnist_labels_train = mnist_data['label_train']
mnist_labels_test = mnist_data['label_test']
mnist_train = mnist_train.astype(np.float32)
mnist_test = mnist_test.astype(np.float32)
mnist_train = mnist_train.transpose((0, 3, 1, 2))
mnist_test = mnist_test.transpose((0, 3, 1, 2))
train_label = np.argmax(mnist_labels_train, axis=1)
inds = np.random.permutation(mnist_train.shape[0])
mnist_train = mnist_train[inds]
train_label = train_label[inds]
test_label = np.argmax(mnist_labels_test, axis=1)
if usps and all_use != 'yes':
mnist_train = mnist_train[:2000]
train_label = train_label[:2000]
return mnist_train, train_label, mnist_test, test_label
def load_svhn(path_train, path_test):
svhn_train = loadmat(path_train)
svhn_test = loadmat(path_test)
svhn_train_im = svhn_train['X']
svhn_train_im = svhn_train_im.transpose(3, 2, 0, 1).astype(np.float32)
svhn_label = dense_to_one_hot(svhn_train['y'])
svhn_test_im = svhn_test['X']
svhn_test_im = svhn_test_im.transpose(3, 2, 0, 1).astype(np.float32)
svhn_label_test = dense_to_one_hot(svhn_test['y'])
return svhn_train_im, svhn_label, svhn_test_im, svhn_label_test
def load_usps(path, all_use=True):
f = gzip.open(path, 'rb')
data_set = pickle.load(f, encoding='bytes')
f.close()
img_train = data_set[0][0]
label_train = data_set[0][1]
img_test = data_set[1][0]
label_test = data_set[1][1]
inds = np.random.permutation(img_train.shape[0])
if all_use == 'yes':
img_train = img_train[inds][:6562]
label_train = label_train[inds][:6562]
else:
img_train = img_train[inds][:1800]
label_train = label_train[inds][:1800]
img_train = img_train * 255
img_test = img_test * 255
img_train = img_train.reshape((img_train.shape[0], 1, 28, 28))
img_test = img_test.reshape((img_test.shape[0], 1, 28, 28))
return img_train, label_train, img_test, label_test
def load_dataset(domain, root_dir):
train_img, train_label, test_img, test_label = None, None, None, None
if domain == 'mnist':
train_img, train_label, test_img, test_label = load_mnist(root_dir + 'mnist_data.mat')
if domain == 'usps':
train_img, train_label, test_img, test_label = load_usps(root_dir + 'usps_28x28.pkl')
if domain == 'svhn':
train_img, train_label, test_img, test_label = load_svhn(root_dir + 'svhn_train_32x32.mat',
root_dir + 'svhn_test_32x32.mat')
return train_img, train_label, test_img, test_label
def load_data(domain, root_dir, batch_size):
src_train_img, src_train_label, src_test_img, src_test_label = load_dataset(domain['src'], root_dir)
tar_train_img, tar_train_label, tar_test_img, tar_test_label = load_dataset(domain['tar'], root_dir)
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
data_src_train, data_src_test = GetDataset(src_train_img, src_train_label,
transform), GetDataset(src_test_img,
src_test_label,
transform)
data_tar_train, data_tar_test = GetDataset(tar_train_img, tar_train_label,
transform), GetDataset(tar_test_img,
tar_test_label,
transform)
dataloaders = {}
dataloaders['src'] = torch.utils.data.DataLoader(data_src_train, batch_size=batch_size, shuffle=True,
drop_last=False,
num_workers=4)
dataloaders['val'] = torch.utils.data.DataLoader(data_src_test, batch_size=batch_size, shuffle=True,
drop_last=False,
num_workers=4)
dataloaders['tar'] = torch.utils.data.DataLoader(data_tar_train, batch_size=batch_size, shuffle=True,
drop_last=False,
num_workers=4)
return dataloaders
================================================
FILE: code/feature_extractor/for_digit_data/digit_deep_feature.py
================================================
# encoding=utf-8
"""
Created on 10:47 2018/12/29
@author: Jindong Wang
"""
from __future__ import print_function
import argparse
import data_loader
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import time
import copy
import digit_data_loader
import digit_network
import torchvision.transforms as transforms
# Command setting
parser = argparse.ArgumentParser(description='Finetune')
parser.add_argument('-model', '-m', type=str, help='model name', default='resnet')
parser.add_argument('-batch_size', '-b', type=int, help='batch size', default=100)
parser.add_argument('-gpu', '-g', type=int, help='cuda id', default=0)
parser.add_argument('-source', '-src', type=str, default='mnist')
parser.add_argument('-target', '-tar', type=str, default='usps')
args = parser.parse_args()
# Parameter setting
DEVICE = torch.device('cuda:' + str(args.gpu) if torch.cuda.is_available() else 'cpu')
N_CLASS = 12
LEARNING_RATE = 1e-4
BATCH_SIZE = {'src': int(args.batch_size), 'tar': int(args.batch_size)}
N_EPOCH = 100
MOMENTUM = 0.9
DECAY = 5e-4
def finetune(model, dataloaders, optimizer):
best_model_wts = copy.deepcopy(model.state_dict())
since = time.time()
best_acc = 0.0
acc_hist = []
criterion = nn.CrossEntropyLoss()
for epoch in range(1, N_EPOCH + 1):
for phase in ['src', 'val', 'tar']:
if phase == 'src':
model.train()
else:
model.eval()
total_loss, correct = 0, 0
for inputs, labels in dataloaders[phase]:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE).long()
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'src'):
outputs = model(inputs)
loss = criterion(outputs, labels)
preds = torch.max(outputs, 1)[1]
if phase == 'src':
loss.backward()
optimizer.step()
total_loss += loss.item() * inputs.size(0)
correct += torch.sum(preds == labels.data)
epoch_loss = total_loss / len(dataloaders[phase].dataset)
epoch_acc = correct.double() / len(dataloaders[phase].dataset)
acc_hist.append([epoch_loss, epoch_acc])
print('Epoch: [{:02d}/{:02d}]---{}, loss: {:.6f}, acc: {:.4f}'.format(epoch, N_EPOCH, phase, epoch_loss,
epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model.state_dict(), 'save_model/best_{}-{}-{}.pth'.format(args.source, args.target, epoch))
np.savetxt('{}_{}_hist.csv'.format(args.source, args.target), np.asarray(acc_hist, dtype=float),
fmt='%.6f', delimiter=',')
print()
time_pass = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_pass // 60, time_pass % 60))
print('{}Best acc: {}'.format('*' * 10, best_acc))
model.load_state_dict(best_model_wts)
torch.save(model.state_dict(), 'save_model/best_{}_{}.pth'.format(args.source, args.target))
print('Best model saved!')
return model, best_acc, acc_hist
def extract_feature(model, model_path, dataloader, source, data_name):
model.load_state_dict(torch.load(model_path))
model.to(DEVICE)
model.eval()
fea = torch.zeros(1, 501).to(DEVICE)
with torch.no_grad():
for inputs, labels in dataloader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
x = model.get_feature(inputs)
x = x.view(x.size(0), -1)
labels = labels.view(labels.size(0), 1).float()
x = torch.cat((x, labels), dim=1)
fea = torch.cat((fea, x), dim=0)
fea_numpy = fea.cpu().numpy()
np.savetxt('{}_{}.csv'.format(source, data_name), fea_numpy[1:], fmt='%.6f', delimiter=',')
print('{} - {} done!'.format(source, data_name))
# You may want to use this function to simply classify them after getting features
def classify_1nn():
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
data = {'src': np.loadtxt(args.source + '_' + args.source + '.csv', delimiter=','),
'tar': np.loadtxt(args.source + '_' + args.target + '.csv', delimiter=','),
}
Xs, Ys, Xt, Yt = data['src'][:, :-1], data['src'][:, -1], data['tar'][:, :-1], data['tar'][:, -1]
Xs = StandardScaler(with_mean=0, with_std=1).fit_transform(Xs)
Xt = StandardScaler(with_mean=0, with_std=1).fit_transform(Xt)
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs, Ys)
ypred = clf.predict(Xt)
acc = accuracy_score(y_true=Yt, y_pred=ypred)
print('{} - {}: acc: {:.4f}'.format(args.source, args.target, acc))
if __name__ == '__main__':
torch.manual_seed(10)
# Load data
root_dir = 'data/digit/'
domain = {'src': str(args.source), 'tar': str(args.target)}
dataloaders = digit_data_loader.load_data(domain, root_dir, args.batch_size)
print(len(dataloaders['src'].dataset), len(dataloaders['val'].dataset))
## Load model
model = digit_network.Network().to(DEVICE)
print('Source:{}, target:{}'.format(domain['src'], domain['tar']))
optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM, weight_decay=DECAY)
model_best, best_acc, acc_hist = finetune(model, dataloaders, optimizer)
## Extract features for the target domain
model_path = 'save_model/best_{}_{}.pth'.format(args.source, args.target)
extract_feature(model, model_path, dataloaders['tar'], args.source, args.target)
## If you want to extract features for the source domain, run the following lines ALONE by setting args.source=args.target
# model_path = 'save_model/best_{}_{}.pth'.format(args.source, 'old target domain')
# extract_feature(model, model_path, dataloaders['tar'], args.source, args.target)
================================================
FILE: code/feature_extractor/for_digit_data/digit_network.py
================================================
# encoding=utf-8
"""
Created on 10:29 2018/12/29
@author: Jindong Wang
"""
import torch.nn as nn
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.feature = nn.Sequential()
self.feature.add_module('f_conv1', nn.Conv2d(3, 64, kernel_size=5))
self.feature.add_module('f_bn1', nn.BatchNorm2d(64))
self.feature.add_module('f_pool1', nn.MaxPool2d(2))
self.feature.add_module('f_relu1', nn.ReLU(True))
self.feature.add_module('f_conv2', nn.Conv2d(64, 50, kernel_size=5))
self.feature.add_module('f_bn2', nn.BatchNorm2d(50))
self.feature.add_module('f_drop1', nn.Dropout2d())
self.feature.add_module('f_pool2', nn.MaxPool2d(2))
self.feature.add_module('f_relu2', nn.ReLU(True))
self.class_classifier = nn.Sequential()
self.class_classifier.add_module('c_fc1', nn.Linear(50 * 5 * 5, 100))
self.class_classifier.add_module('c_bn1', nn.BatchNorm1d(100))
self.class_classifier.add_module('c_relu1', nn.ReLU(True))
self.class_classifier.add_module('c_drop1', nn.Dropout2d())
self.class_classifier.add_module('c_fc2', nn.Linear(100, 500))
self.class_classifier.add_module('c_bn2', nn.BatchNorm1d(500))
self.class_classifier.add_module('c_relu2', nn.ReLU(True))
self.class_classifier.add_module('c_fc3', nn.Linear(500, 10))
def forward(self, input_data):
# input_data = input_data.expand(len(input_data), 3, 28, 28)
feature = self.feature(input_data)
feature = feature.view(-1, 50 * 5 * 5)
class_output = self.class_classifier(feature)
return class_output
# Exactly like forward function, but return features
def get_feature(self, input_data):
# input_data = input_data.expand(len(input_data), 3, 28, 28)
feature = self.feature(input_data)
feature = feature.view(-1, 50 * 5 * 5)
fea = self.class_classifier.c_fc1(feature)
fea = self.class_classifier.c_bn1(fea)
fea = self.class_classifier.c_relu1(fea)
fea = self.class_classifier.c_drop1(fea)
fea = self.class_classifier.c_fc2(fea)
fea = self.class_classifier.c_bn2(fea)
fea = self.class_classifier.c_relu2(fea)
return fea
================================================
FILE: code/feature_extractor/for_image_data/backbone.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torchvision import models
# convnet without the last layer
class AlexNetFc(nn.Module):
def __init__(self):
super(AlexNetFc, self).__init__()
model_alexnet = models.alexnet(pretrained=True)
self.features = model_alexnet.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module(
"classifier"+str(i), model_alexnet.classifier[i])
self.__in_features = model_alexnet.classifier[6].in_features
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256*6*6)
x = self.classifier(x)
return x
def output_num(self):
return self.__in_features
class ResNet18Fc(nn.Module):
def __init__(self):
super(ResNet18Fc, self).__init__()
model_resnet18 = models.resnet18(pretrained=True)
self.conv1 = model_resnet18.conv1
self.bn1 = model_resnet18.bn1
self.relu = model_resnet18.relu
self.maxpool = model_resnet18.maxpool
self.layer1 = model_resnet18.layer1
self.layer2 = model_resnet18.layer2
self.layer3 = model_resnet18.layer3
self.layer4 = model_resnet18.layer4
self.avgpool = model_resnet18.avgpool
self.__in_features = model_resnet18.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet34Fc(nn.Module):
def __init__(self):
super(ResNet34Fc, self).__init__()
model_resnet34 = models.resnet34(pretrained=True)
self.conv1 = model_resnet34.conv1
self.bn1 = model_resnet34.bn1
self.relu = model_resnet34.relu
self.maxpool = model_resnet34.maxpool
self.layer1 = model_resnet34.layer1
self.layer2 = model_resnet34.layer2
self.layer3 = model_resnet34.layer3
self.layer4 = model_resnet34.layer4
self.avgpool = model_resnet34.avgpool
self.__in_features = model_resnet34.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet50Fc(nn.Module):
def __init__(self):
super(ResNet50Fc, self).__init__()
model_resnet50 = models.resnet50(pretrained=True)
self.conv1 = model_resnet50.conv1
self.bn1 = model_resnet50.bn1
self.relu = model_resnet50.relu
self.maxpool = model_resnet50.maxpool
self.layer1 = model_resnet50.layer1
self.layer2 = model_resnet50.layer2
self.layer3 = model_resnet50.layer3
self.layer4 = model_resnet50.layer4
self.avgpool = model_resnet50.avgpool
self.__in_features = model_resnet50.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet101Fc(nn.Module):
def __init__(self):
super(ResNet101Fc, self).__init__()
model_resnet101 = models.resnet101(pretrained=True)
self.conv1 = model_resnet101.conv1
self.bn1 = model_resnet101.bn1
self.relu = model_resnet101.relu
self.maxpool = model_resnet101.maxpool
self.layer1 = model_resnet101.layer1
self.layer2 = model_resnet101.layer2
self.layer3 = model_resnet101.layer3
self.layer4 = model_resnet101.layer4
self.avgpool = model_resnet101.avgpool
self.__in_features = model_resnet101.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet152Fc(nn.Module):
def __init__(self):
super(ResNet152Fc, self).__init__()
model_resnet152 = models.resnet152(pretrained=True)
self.conv1 = model_resnet152.conv1
self.bn1 = model_resnet152.bn1
self.relu = model_resnet152.relu
self.maxpool = model_resnet152.maxpool
self.layer1 = model_resnet152.layer1
self.layer2 = model_resnet152.layer2
self.layer3 = model_resnet152.layer3
self.layer4 = model_resnet152.layer4
self.avgpool = model_resnet152.avgpool
self.__in_features = model_resnet152.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
network_dict = {"alexnet": AlexNetFc,
"resnet18": ResNet18Fc,
"resnet34": ResNet34Fc,
"resnet50": ResNet50Fc,
"resnet101": ResNet101Fc,
"resnet152": ResNet152Fc}
================================================
FILE: code/feature_extractor/for_image_data/data_load.py
================================================
from torchvision import datasets, transforms
import torch
from PIL import Image
# This file works for RGB images.
def load_data(data_folder, batch_size, phase='train', train_val_split=True, train_ratio=.8):
transform_dict = {
'train': transforms.Compose(
[transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]),
'test': transforms.Compose(
[transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])}
data = datasets.ImageFolder(root=data_folder, transform=transform_dict[phase])
if phase == 'train':
if train_val_split:
train_size = int(train_ratio * len(data))
test_size = len(data) - train_size
data_train, data_val = torch.utils.data.random_split(data, [train_size, test_size])
train_loader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, shuffle=True, drop_last=True,
num_workers=4)
val_loader = torch.utils.data.DataLoader(data_val, batch_size=batch_size, shuffle=False, drop_last=False,
num_workers=4)
return [train_loader, val_loader]
else:
train_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=True,
num_workers=4)
return train_loader
else:
test_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=False, drop_last=False,
num_workers=4)
return test_loader
## Below are for ImageCLEF datasets
class ImageCLEF(torch.utils.data.Dataset):
def __init__(self, root_dir, domain, transform=None):
super(ImageCLEF, self).__init__()
self.transform = transform
file_name = root_dir + 'list/' + domain + 'List.txt'
lines = open(file_name, 'r').readlines()
self.images, self.labels = [], []
self.domain = domain
for item in lines:
line = item.strip().split(' ')
self.images.append(root_dir + domain + '/' + line[0].split('/')[-1])
self.labels.append(int(line[1].strip()))
def __getitem__(self, index):
image = self.images[index]
target = self.labels[index]
img = Image.open(image).convert('RGB')
if self.transform:
image = self.transform(img)
return image, target
def __len__(self):
return len(self.images)
def load_imageclef_train(root_path, domain, batch_size, phase):
transform_dict = {
'src': transforms.Compose(
[transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]),
'tar': transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])}
data = ImageCLEF(root_dir=root_path, domain=domain, transform=transform_dict[phase])
train_size = int(0.8 * len(data))
test_size = len(data) - train_size
data_train, data_val = torch.utils.data.random_split(data, [train_size, test_size])
train_loader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, shuffle=True, drop_last=False,
num_workers=4)
val_loader = torch.utils.data.DataLoader(data_val, batch_size=batch_size, shuffle=True, drop_last=False,
num_workers=4)
return train_loader, val_loader
def load_imageclef_test(root_path, domain, batch_size, phase):
transform_dict = {
'src': transforms.Compose(
[transforms.Resize((256,256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]),
'tar': transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])}
data = ImageCLEF(root_dir=root_path, domain=domain, transform=transform_dict[phase])
data_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=False, num_workers=4)
return data_loader
================================================
FILE: code/feature_extractor/for_image_data/main.py
================================================
"""
Extract features from pre-trained networks.
The main procedures are finetune and extract features.
Finetune: Given an Imagenet pretrained model (such as ResNet50), finetune it on a dataset (we call it source)
Extractor: After fine-tune, extract features on the target domain using finetuned models on source
This class supports most image models: Alexnet, Resnet(xx), VGG.
Other text or digit models can be easily extended using this code, see models.py for details.
"""
import argparse
import data_load
import models
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import time
import copy
import os
# Command setting
parser = argparse.ArgumentParser(description='Finetune')
parser.add_argument('--model_name', type=str,
help='model name', default='resnet50')
parser.add_argument('--batchsize', type=int, help='batch size', default=64)
parser.add_argument('--gpu', type=int, help='cuda id', default=0)
parser.add_argument('--source', type=str, default='amazon')
parser.add_argument('--target', type=str, default='webcam')
parser.add_argument('--num_class', type=int, default=12)
parser.add_argument('--dataset_path', type=str,
default='../../data/Office31/Original_images/')
parser.add_argument('--epoch', type=int, help='Train epochs', default=100)
parser.add_argument('--momentum', type=float, help='Momentum', default=.9)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--finetune', type=int,
help='Needs finetune or not', default=1)
parser.add_argument('--extract', type=int,
help='Needs extract features or not', default=1)
args = parser.parse_args()
# Parameter setting
DEVICE = torch.device('cuda:' + str(args.gpu)
if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = {'src': int(args.batchsize), 'tar': int(args.batchsize)}
def get_optimizer(model):
learning_rate = args.lr
param_group = []
param_group += [{'params': model.base_network.parameters(),
'lr': learning_rate}]
param_group += [{'params': model.classifier_layer.parameters(),
'lr': learning_rate * 10}]
optimizer = optim.SGD(param_group, momentum=args.momentum)
return optimizer
# Schedule learning rate according to DANN if you want to (while I think this equation is wierd therefore I did not use this one)
def lr_schedule(optimizer, epoch):
def lr_decay(LR, n_epoch, e):
return LR / (1 + 10 * e / n_epoch) ** 0.75
for i in range(len(optimizer.param_groups)):
if i < len(optimizer.param_groups) - 1:
optimizer.param_groups[i]['lr'] = lr_decay(
LEARNING_RATE, N_EPOCH, epoch)
else:
optimizer.param_groups[i]['lr'] = lr_decay(
LEARNING_RATE, N_EPOCH, epoch) * 10
def finetune(model, dataloaders, optimizer, criterion, best_model_path, use_lr_schedule=False):
N_EPOCH = args.epoch
best_model_wts = copy.deepcopy(model.state_dict())
since = time.time()
best_acc = 0.0
acc_hist = []
for epoch in range(1, N_EPOCH + 1):
if use_lr_schedule:
lr_schedule(optimizer, epoch)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
total_loss, correct = 0, 0
for inputs, labels in dataloaders[phase]:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
preds = torch.max(outputs, 1)[1]
if phase == 'train':
loss.backward()
optimizer.step()
total_loss += loss.item() * inputs.size(0)
correct += torch.sum(preds == labels.data)
epoch_loss = total_loss / len(dataloaders[phase].dataset)
epoch_acc = correct.double() / len(dataloaders[phase].dataset)
acc_hist.append([epoch_loss, epoch_acc])
print('Epoch: [{:02d}/{:02d}]---{}, loss: {:.6f}, acc: {:.4f}'.format(epoch, N_EPOCH, phase, epoch_loss,
epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model.state_dict(
), 'save_model/best_{}_{}-{}.pth'.format(args.model_name, args.source, epoch))
time_pass = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_pass // 60, time_pass % 60))
print('------Best acc: {}'.format(best_acc))
model.load_state_dict(best_model_wts)
torch.save(model.state_dict(), best_model_path)
print('Best model saved!')
return model, best_acc, acc_hist
# Extract features for given intermediate layers
# Currently, this only works for ResNet since AlexNet and VGGNET only have features and classifiers modules.
# You will need to manually define a function in the forward function to extract features
# (by letting it return features and labels).
# Please follow digit_deep_network.py for reference.
class FeatureExtractor(nn.Module):
def __init__(self, model, extracted_layers):
super(FeatureExtractor, self).__init__()
self.model = model._modules['module'] if type(
model) == torch.nn.DataParallel else model
self.extracted_layers = extracted_layers
def forward(self, x):
outputs = []
for name, module in self.model._modules.items():
if name is "fc":
x = x.view(x.size(0), -1)
x = module(x)
if name in self.extracted_layers:
outputs.append(x)
return outputs
def extract_feature(model, dataloader, save_path, load_from_disk=True, model_path=''):
if load_from_disk:
model = models.Network(base_net=args.model_name,
n_class=args.num_class)
model.load_state_dict(torch.load(model_path))
model = model.to(DEVICE)
model.eval()
correct = 0
fea_all = torch.zeros(1,1+model.base_network.output_num()).to(DEVICE)
with torch.no_grad():
for inputs, labels in dataloader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
feas = model.get_features(inputs)
labels = labels.view(labels.size(0), 1).float()
x = torch.cat((feas, labels), dim=1)
fea_all = torch.cat((fea_all, x), dim=0)
outputs = model(inputs)
preds = torch.max(outputs, 1)[1]
correct += torch.sum(preds == labels.data.long())
test_acc = correct.double() / len(dataloader.dataset)
fea_numpy = fea_all.cpu().numpy()
np.savetxt(save_path, fea_numpy[1:], fmt='%.6f', delimiter=',')
print('Test acc: %f' % test_acc)
# You may want to classify with 1nn after getting features
def classify_1nn(data_train, data_test):
'''
Classification using 1NN
Inputs: data_train, data_test: train and test csv file path
Outputs: yprediction and accuracy
'''
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
data = {'src': np.loadtxt(data_train, delimiter=','),
'tar': np.loadtxt(data_test, delimiter=','),
}
Xs, Ys, Xt, Yt = data['src'][:, :-1], data['src'][:, -
1], data['tar'][:, :-1], data['tar'][:, -1]
Xs = StandardScaler(with_mean=0, with_std=1).fit_transform(Xs)
Xt = StandardScaler(with_mean=0, with_std=1).fit_transform(Xt)
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs, Ys)
ypred = clf.predict(Xt)
acc = accuracy_score(y_true=Yt, y_pred=ypred)
print('Acc: {:.4f}'.format(acc))
return ypred, acc
if __name__ == '__main__':
torch.manual_seed(10)
# Load data
print('Loading data...')
data_folder = args.dataset_path
domain = {'src': str(args.source), 'tar': str(args.target)}
dataloaders = {}
data_test = data_load.load_data(
data_folder+domain['tar'] + 'images/', BATCH_SIZE['tar'], 'test')
data_train = data_load.load_data(
data_folder+domain['src'] + 'images/', BATCH_SIZE['src'], 'train', train_val_split=True, train_ratio=.8)
dataloaders['train'], dataloaders['val'], dataloaders['test'] = data_train[0], data_train[1], data_test
print('Data loaded: Source: {}, Target: {}'.format(args.source, args.target))
# Finetune
if args.finetune == 1:
print('Begin fintuning...')
net = models.Network(base_net=args.model_name,
n_class=args.num_class).to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = get_optimizer(net)
if not os.path.exists('save_model/'):
os.makedir('save_model/')
save_path = 'save_model/best_{}_{}.pth'.format(
args.model_name, args.source)
model_best, best_acc, acc_hist = finetune(
net, dataloaders, optimizer, criterion, save_path, use_lr_schedule=False)
print('Finetune completed!')
# Extract features from finetuned model
if args.extract == 1:
model_path = 'save_model/best_{}_{}.pth'.format(
args.model_name, args.source)
feature_save_path = 'save_model/{}_{}_{}.csv'.format(
args.source, args.target, args.model_name)
print(feature_save_path)
extract_feature(
None, dataloaders['test'], feature_save_path, load_from_disk=True, model_path=model_path)
print('Deep features are extracted and saved!')
# After features are extracted, you may want to classify.
# You can try the classify_1nn() function. For instance:
# classify_1nn('save_model/amazon_amazon_resnet50.csv', 'save_model/amazon_webcam_resnet50.csv')
================================================
FILE: code/feature_extractor/for_image_data/models.py
================================================
import torch
import torch.nn as nn
import backbone
class Network(nn.Module):
def __init__(self, base_net='alexnet', n_class=31):
super(Network, self).__init__()
self.n_class = n_class
self.base_network = backbone.network_dict[base_net]()
self.classifier_layer = nn.Linear(
self.base_network.output_num(), n_class)
self.classifier_layer.weight.data.normal_(0, 0.005)
self.classifier_layer.bias.data.fill_(0.1)
def forward(self, x):
features = self.base_network(x)
clf = self.classifier_layer(features)
return clf
def get_features(self, x):
features = self.base_network(x)
return features
================================================
FILE: code/feature_extractor/readme.md
================================================
# Deep Feature Extractor
If we want to use some features extracted from deep networks such as ResNet, then this code will be of help.
## Supported Datasets
Currently, we support two kinds of datasets: `image` and `digit`.
- Image datasets can be versatile.
- Digit datasets: we support MNIST, USPS, and SVHN.
## Requirements
Python 3, PyTorch 1.0+, PIL
## Usage
- For image dataset, go to folder `for_image_data`, then run:
`python main.py --dataset_path 'your_data_folder' --model_name resnet50 --src amazon --tar webcam`
- For digit dataset, go to folder `for_digit_data`, then run:
`python digit_deep_feature.py -src mnist -tar usps`
## Download Features that We Have Already Extracted
Currently, we support *ResNet-50* features since this architecture is very popular.
[Office-31 ResNet-50 features](https://pan.baidu.com/s/1UoyJSqoCKCda-NcP-zraVg)
[Office-Home ResNet-50 pretrained features](https://pan.baidu.com/s/1qvcWJCXVG8JkZnoM4BVoGg)
[Image-CLEF ResNet-50 pretrained features](https://pan.baidu.com/s/16wBgDJI6drA0oYq537h4FQ)
[VisDA classification dataset features by ResNet-50](https://pan.baidu.com/s/1sbuDqWWzwLyB1fFIpo5BdQ)
## Downloaded Finetuned Models
You can download finetuned models here:
Finetuned ResNet-50 models For Office-31 dataset: [BaiduYun](https://pan.baidu.com/s/1mRVDYOpeLz3siIId3tni6Q) | [Mega](https://mega.nz/#F!laI2lKoJ!nSmVQXrpu1Ov794sy2wFKg)
Finetuned ResNet-50 models For Office-Home dataset: [BaiduYun](https://pan.baidu.com/s/1i_g-QC2HZ0ZUhTnnySFIWw) | [Mega](https://mega.nz/#F!pGIkjIxC!MDD3ps6RzTXWobMfHh0Slw)
Finetuned ResNet-50 models For ImageCLEF dataset: [BaiduYun](https://pan.baidu.com/s/1y9tqyzBL7LZTd7Td380fxA) | [Mega](https://mega.nz/#F!QPJCzShS!b6qQUXWnCCGBMVs0m6MdQw)
Finetuned ResNet-50 models For VisDA dataset: [BaiduYun](https://pan.baidu.com/s/1DIcmmZ57ylMO6kpt46gkNQ) | [Mega](https://mega.nz/#F!ZDY2jShR!r_M2sR7MBi_9JPsRUXXy0g)
Finetuned LeNet+ models For MNIST dataset: [BaiduYun](https://pan.baidu.com/s/1W68JlO6z7BfYSo_OdMOpPg)
The names of the model on image datasets: `best_resnet_domain.pth`, while `domain` indicates the domain of the dataset.
The finetune procedure following a 8-2 training/validation split.
## Benchmark
See the power of deep features [here](https://github.com/jindongwang/transferlearning/blob/master/data/benchmark.md).
================================================
FILE: code/traditional/BDA/BDA.py
================================================
# encoding=utf-8
"""
Created on 9:52 2018/11/14
@author: Jindong Wang
"""
import numpy as np
import scipy.io
import scipy.linalg
import sklearn.metrics
import sklearn.neighbors
from sklearn import metrics
from sklearn import svm
def kernel(ker, X1, X2, gamma):
K = None
if not ker or ker == 'primal':
K = X1
elif ker == 'linear':
if X2 is not None:
K = sklearn.metrics.pairwise.linear_kernel(
np.asarray(X1).T, np.asarray(X2).T)
else:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T)
elif ker == 'rbf':
if X2 is not None:
K = sklearn.metrics.pairwise.rbf_kernel(
np.asarray(X1).T, np.asarray(X2).T, gamma)
else:
K = sklearn.metrics.pairwise.rbf_kernel(
np.asarray(X1).T, None, gamma)
return K
def proxy_a_distance(source_X, target_X):
"""
Compute the Proxy-A-Distance of a source/target representation
"""
nb_source = np.shape(source_X)[0]
nb_target = np.shape(target_X)[0]
train_X = np.vstack((source_X, target_X))
train_Y = np.hstack((np.zeros(nb_source, dtype=int),
np.ones(nb_target, dtype=int)))
clf = svm.LinearSVC(random_state=0)
clf.fit(train_X, train_Y)
y_pred = clf.predict(train_X)
error = metrics.mean_absolute_error(train_Y, y_pred)
dist = 2 * (1 - 2 * error)
return dist
def estimate_mu(_X1, _Y1, _X2, _Y2):
adist_m = proxy_a_distance(_X1, _X2)
C = len(np.unique(_Y1))
epsilon = 1e-3
list_adist_c = []
for i in range(1, C + 1):
ind_i, ind_j = np.where(_Y1 == i), np.where(_Y2 == i)
Xsi = _X1[ind_i[0], :]
Xtj = _X2[ind_j[0], :]
adist_i = proxy_a_distance(Xsi, Xtj)
list_adist_c.append(adist_i)
adist_c = sum(list_adist_c) / C
mu = adist_c / (adist_c + adist_m)
if mu > 1:
mu = 1
if mu < epsilon:
mu = 0
return mu
class BDA:
def __init__(self, kernel_type='primal', dim=30, lamb=1, mu=0.5, gamma=1, T=10, mode='BDA', estimate_mu=False):
'''
Init func
:param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'
:param dim: dimension after transfer
:param lamb: lambda value in equation
:param mu: mu. Default is -1, if not specificied, it calculates using A-distance
:param gamma: kernel bandwidth for rbf kernel
:param T: iteration number
:param mode: 'BDA' | 'WBDA'
:param estimate_mu: True | False, if you want to automatically estimate mu instead of manally set it
'''
self.kernel_type = kernel_type
self.dim = dim
self.lamb = lamb
self.mu = mu
self.gamma = gamma
self.T = T
self.mode = mode
self.estimate_mu = estimate_mu
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Transform and Predict using 1NN as JDA paper did
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: acc, y_pred, list_acc
'''
list_acc = []
X = np.hstack((Xs.T, Xt.T))
X /= np.linalg.norm(X, axis=0)
m, n = X.shape
ns, nt = len(Xs), len(Xt)
e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))
C = len(np.unique(Ys))
H = np.eye(n) - 1 / n * np.ones((n, n))
mu = self.mu
M = 0
Y_tar_pseudo = None
Xs_new = None
for t in range(self.T):
N = 0
M0 = e * e.T * C
if Y_tar_pseudo is not None and len(Y_tar_pseudo) == nt:
for c in range(1, C + 1):
e = np.zeros((n, 1))
Ns = len(Ys[np.where(Ys == c)])
Nt = len(Y_tar_pseudo[np.where(Y_tar_pseudo == c)])
if self.mode == 'WBDA':
Ps = Ns / len(Ys)
Pt = Nt / len(Y_tar_pseudo)
alpha = Pt / Ps
mu = 1
else:
alpha = 1
tt = Ys == c
e[np.where(tt == True)] = 1 / Ns
yy = Y_tar_pseudo == c
ind = np.where(yy == True)
inds = [item + ns for item in ind]
e[tuple(inds)] = -alpha / Nt
e[np.isinf(e)] = 0
N = N + np.dot(e, e.T)
# In BDA, mu can be set or automatically estimated using A-distance
# In WBDA, we find that setting mu=1 is enough
if self.estimate_mu and self.mode == 'BDA':
if Xs_new is not None:
mu = estimate_mu(Xs_new, Ys, Xt_new, Y_tar_pseudo)
else:
mu = 0
M = (1 - mu) * M0 + mu * N
M /= np.linalg.norm(M, 'fro')
K = kernel(self.kernel_type, X, None, gamma=self.gamma)
n_eye = m if self.kernel_type == 'primal' else n
a, b = K @ M @ K.T + self.lamb * np.eye(n_eye), K @ H @ K.T
w, V = scipy.linalg.eig(a, b)
ind = np.argsort(w)
A = V[:, ind[:self.dim]]
Z = A.T @ K
Z /= np.linalg.norm(Z, axis=0)
Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T
clf = sklearn.neighbors.KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
Y_tar_pseudo = clf.predict(Xt_new)
acc = sklearn.metrics.accuracy_score(Yt, Y_tar_pseudo)
list_acc.append(acc)
print('{} iteration [{}/{}]: Acc: {:.4f}'.format(self.mode, t + 1, self.T, acc))
return acc, Y_tar_pseudo, list_acc
if __name__ == '__main__':
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
i, j = 0, 1 # Caltech -> Amazon
src, tar = domains[i], domains[j]
src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
bda = BDA(kernel_type='primal', dim=30, lamb=1, mu=0.5,
mode='BDA', gamma=1, estimate_mu=False)
acc, ypre, list_acc = bda.fit_predict(Xs, Ys, Xt, Yt)
print(acc)
================================================
FILE: code/traditional/BDA/matlab/BDA.m
================================================
function [acc,acc_ite,A] = BDA(X_src,Y_src,X_tar,Y_tar,options)
% Inputs:
%%% X_src :source feature matrix, ns * m
%%% Y_src :source label vector, ns * 1
%%% X_tar :target feature matrix, nt * m
%%% Y_tar :target label vector, nt * 1
%%% options:option struct
% Outputs:
%%% acc :final accuracy using knn, float
%%% acc_ite:list of all accuracies during iterations
%%% A :final adaptation matrix, (ns + nt) * (ns + nt)
% Reference:
% Jindong Wang, Yiqiang Chen, Shuji Hao, and Zhiqi Shen.
% Balanced distribution adaptation for transfer learning.
% ICDM 2017.
%% Set options
if ~isfield(options,'mode') %% 'BDA' or 'W-BDA'
options.mode = 'W-BDA';
end
if ~isfield(options,'mu') %% balance factor \mu
options.mu = 1;
end
if ~isfield(options,'lambda') %% lambda for the regularization
options.lambda = 0.1;
end
if ~isfield(options,'dim') %% dim is the dimension after adaptation, dim <= m
options.dim = 10;
end
if ~isfield(options,'kernel_type') %% kernel_type is the kernel name, primal|linear|rbf
options.kernel_type = 'primal';
end
if ~isfield(options,'gamma') %% gamma is the bandwidth of rbf kernel
options.gamma = 1;
end
if ~isfield(options,'T') %% iteration number
options.T = 10;
end
mu = options.mu;
lambda = options.lambda;
dim = options.dim;
kernel_type = options.kernel_type;
gamma = options.gamma;
T = options.T;
X = [X_src',X_tar'];
X = X*diag(sparse(1./sqrt(sum(X.^2))));
[m,n] = size(X);
ns = size(X_src,1);
nt = size(X_tar,1);
e = [1/ns*ones(ns,1);-1/nt*ones(nt,1)];
C = length(unique(Y_src));
%% Centering matrix H
H = eye(n) - 1/n * ones(n,n);
%%% M0
M0 = e * e' * C; %multiply C for better normalization
acc_ite = [];
Y_tar_pseudo = [];
if strcmp(mode,'W-BDA')
knn_model = fitcknn(X_src,Y_src,'NumNeighbors',1);
Y_tar_pseudo = knn_model.predict(X_tar);
end
%% Iteration
for i = 1 : T
%%% Mc
N = 0;
if ~isempty(Y_tar_pseudo) && length(Y_tar_pseudo)==nt
for c = reshape(unique(Y_src),1,C)
e = zeros(n,1);
if strcmp(mode,'W-BDA')
Ps = length(find(Y_src==c)) / length(Y_src);
Pt = length(find(Y_tar_pseudo == c)) / length(Y_tar_pseudo);
alpha = Pt / Ps;
mu = 1;
else
alpha = 1;
end
e(Y_src==c) = 1 / length(find(Y_src==c));
e(ns+find(Y_tar_pseudo==c)) = -alpha / length(find(Y_tar_pseudo==c));
e(isinf(e)) = 0;
N = N + e*e';
end
end
M = (1 - mu) * M0 + mu * N;
M = M / norm(M,'fro');
%% Calculation
if strcmp(kernel_type,'primal')
[A,~] = eigs(X*M*X'+lambda*eye(m),X*H*X',dim,'SM');
Z = A'*X;
else
K = kernel_bda(kernel_type,X,[],gamma);
[A,~] = eigs(K*M*K'+lambda*eye(n),K*H*K',dim,'SM');
Z = A'*K;
end
%normalization for better classification performance
Z = Z*diag(sparse(1./sqrt(sum(Z.^2))));
Zs = Z(:,1:size(X_src,1))';
Zt = Z(:,size(X_src,1)+1:end)';
knn_model = fitcknn(Zs,Y_src,'NumNeighbors',1);
Y_tar_pseudo = knn_model.predict(Zt);
acc = length(find(Y_tar_pseudo==Y_tar))/length(Y_tar);
fprintf('Iteration [%2d]:BDA+NN=%0.4f\n',i,acc);
acc_ite = [acc_ite;acc];
end
end
% With Fast Computation of the RBF kernel matrix
% To speed up the computation, we exploit a decomposition of the Euclidean distance (norm)
%
% Inputs:
% ker: 'linear','rbf','sam'
% X: data matrix (features * samples)
% gamma: bandwidth of the RBF/SAM kernel
% Output:
% K: kernel matrix
%
% Gustavo Camps-Valls
% 2006(c)
% Jordi (jordi@uv.es), 2007
% 2007-11: if/then -> switch, and fixed RBF kernel
% Modified by Mingsheng Long
% 2013(c)
% Mingsheng Long (longmingsheng@gmail.com), 2013
function K = kernel_bda(ker,X,X2,gamma)
switch ker
case 'linear'
if isempty(X2)
K = X'*X;
else
K = X'*X2;
end
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
if isempty(X2)
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
else
n2sq = sum(X2.^2,1);
n2 = size(X2,2);
D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
end
K = exp(-gamma*D);
case 'sam'
if isempty(X2)
D = X'*X;
else
D = X'*X2;
end
K = exp(-gamma*acos(D).^2);
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/traditional/BDA/matlab/demo_BDA.m
================================================
%% Choose domains from Office+Caltech
%%% 'Caltech10', 'amazon', 'webcam', 'dslr'
src = 'caltech.mat';
tgt = 'amazon.mat';
%% Load data
load(['data/' src]); % source domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xs = zscore(fts,1); clear fts
Ys = labels; clear labels
load(['data/' tgt]); % target domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xt = zscore(fts,1); clear fts
Yt = labels; clear labels
%% Set algorithm options
options.gamma = 1.0;
options.lambda = 0.1;
options.kernel_type = 'linear';
options.T = 10;
options.dim = 100;
options.mu = 0;
options.mode = 'W-BDA';
%% Run algorithm
[Acc,acc_ite,~] = BDA(Xs,Ys,Xt,Yt,options);
fprintf('Acc:%.2f',Acc);
================================================
FILE: code/traditional/BDA/readme.md
================================================
## Balanced Distributon Adaptation (BDA)
This directory contains the code for paper [Balanced Distribution Adaptation for Transfer Learning](http://jd92.wang/assets/files/a08_icdm17.pdf).
We support both Matlab and Python.
The test dataset can be downloaded [HERE](https://github.com/jindongwang/transferlearning/tree/master/data).
### Important Notice
Please note that the original BDA (with $\mu$) has been extensively extended by MEDA (Manifold Embedded Distribution Alignment) published in ACM International Conference on Multimedia (ACMMM) 2018. Its code can be found [here](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA).
Hence, from now on, the name **BDA** will specifically refer to **W-BDA** (for imbalanced transfer) in this ICDM paper. Therefore, the code default will also be the imbalanced version. If still want to use the original BDA, you can change the settings in the code.
We also provide a notebook for you to directly run two algorithms using **Jupyter notebook**.
You can easily download the notebook from [here](https://github.com/jindongwang/transferlearning/tree/master/notebooks/traditional_transfer_learning.ipynb).
We also put it on [Google Colab](https://colab.research.google.com/drive/1w4WkCrZeCKaornJo66P4hxC7kzm4l70U?usp=sharing).
Try and experiment on them!
### Citation
You can cite this paper as
- Bibtex style:
```
@inproceedings{wang2017balanced,
title={Balanced Distribution Adaptation for Transfer Learning},
author={Wang, Jindong and Chen, Yiqiang and Hao, Shuji and Feng, Wenjie and Shen, Zhiqi},
booktitle={The IEEE International conference on data mining (ICDM)},
year={2017},
pages={1129--1134}
}
```
- GB/T 7714 style:
Jindong Wang, Yiqiang Chen, Shuji Hao, Wenjie Feng, and Zhiqi Shen. Balanced Distribution Adaptation for Transfer Learning. ICDM 2017. pp. 1129-1134.
================================================
FILE: code/traditional/CORAL/CORAL.m
================================================
function [Xs_new] = CORAL(Xs,Xt)
% Inputs:
%%% Xs:source domain feature matrix, ns * m
%%% Xt:target domain feature matrix, nt * m
% Output:
%%% Xs_new:transformed new source domain matrix, ns * m
cov_src = cov(Xs) + eye(size(Xs,2));
cov_tar = cov(Xt) + eye(size(Xt,2));
A_coral = cov_src^(-1/2) * cov_tar^(1/2);
Xs_new = Xs * A_coral;
end
================================================
FILE: code/traditional/CORAL/CORAL.py
================================================
# encoding=utf-8
"""
Created on 16:31 2018/11/13
@author: Jindong Wang
"""
import numpy as np
import scipy.io
import scipy.linalg
import sklearn.metrics
import sklearn.neighbors
class CORAL:
def __init__(self):
super(CORAL, self).__init__()
def fit(self, Xs, Xt):
'''
Perform CORAL on the source domain features
:param Xs: ns * n_feature, source feature
:param Xt: nt * n_feature, target feature
:return: New source domain features
'''
cov_src = np.cov(Xs.T) + np.eye(Xs.shape[1])
cov_tar = np.cov(Xt.T) + np.eye(Xt.shape[1])
A_coral = np.dot(scipy.linalg.fractional_matrix_power(cov_src, -0.5),
scipy.linalg.fractional_matrix_power(cov_tar, 0.5))
np.linalg.multi_dot([Xs, scipy.linalg.fractional_matrix_power(cov_src, -0.5), scipy.linalg.fractional_matrix_power(cov_tar, 0.5)])
Xs_new = np.real(np.dot(Xs, A_coral))
return Xs_new
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Perform CORAL, then predict using 1NN classifier
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: Accuracy and predicted labels of target domain
'''
Xs_new = self.fit(Xs, Xt)
clf = sklearn.neighbors.KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
y_pred = clf.predict(Xt)
acc = sklearn.metrics.accuracy_score(Yt, y_pred)
return acc, y_pred
if __name__ == '__main__':
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
for i in range(4):
for j in range(4):
if i != j:
src, tar = 'data/' + domains[i], 'data/' + domains[j]
src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
coral = CORAL()
acc, ypre = coral.fit_predict(Xs, Ys, Xt, Yt)
print(acc)
================================================
FILE: code/traditional/CORAL/CORAL_SVM.m
================================================
function [acc,y_pred,time_pass] = CORAL_SVM(Xs,Ys,Xt,Yt)
%% This combines CORAL and SVM. Very simple, very easy to use.
%% Please download libsvm and add it to Matlab path before using SVM.
time_start = clock();
%CORAL
Xs = double(Xs);
Xt = double(Xt);
Ys = double(Ys);
Yt = double(Yt);
cov_source = cov(Xs) + eye(size(Xs, 2));
cov_target = cov(Xt) + eye(size(Xt, 2));
A_coral = cov_source^(-1/2)*cov_target^(1/2);
Sim_coral = double(Xs * A_coral * Xt');
[acc,y_pred] = SVM_Accuracy(double(Xs), A_coral, double(Yt), Sim_coral, double(Ys));
time_end = clock();
time_pass = etime(time_end,time_start);
end
function [res,predicted_label] = SVM_Accuracy (trainset, M,testlabelsref,Sim,trainlabels)
% Using Libsvm
Sim_Trn = trainset * M * trainset';
index = [1:1:size(Sim,1)]';
Sim = [[1:1:size(Sim,2)]' Sim'];
Sim_Trn = [index Sim_Trn ];
C = [0.001 0.01 0.1 1.0 10 100 1000 10000];
parfor i = 1 :size(C,2)
model(i) = libsvmtrain(trainlabels, Sim_Trn, sprintf('-t 4 -c %d -v 2 -q',C(i)));
end
[val indx]=max(model);
CVal = C(indx);
model = svmtrain(trainlabels, Sim_Trn, sprintf('-t 4 -c %d -q',CVal));
[predicted_label, accuracy, decision_values] = svmpredict(testlabelsref, Sim, model);
res = accuracy(1,1);
end
================================================
FILE: code/traditional/CORAL/readme.md
================================================
# CORrelation ALignment (CORAL)
This is the implementation of CORrelation ALignment (CORAL) in Matlab and Python.
## Usage
- Python: just use the `CORAL.py` file.
- Matlab: if you want to use CORAL to transform features, use `CORAL.m`. Besides, if you want to do both CORAL transformation and SVM prediction, you can use `CORAL_SVM.m`.
The test dataset can be downloaded [HERE](https://github.com/jindongwang/transferlearning/tree/master/data).
The python file can be used directly, while the matlab code just contains the core function of TCA. To use the matlab code, you need to learn from the code of [BDA](https://github.com/jindongwang/transferlearning/tree/master/code/BDA) and set out the parameters.
**Reference**
Sun B, Feng J, Saenko K. Return of frustratingly easy domain adaptation[C]//AAAI. 2016, 6(7): 8.
================================================
FILE: code/traditional/EasyTL/CORAL_map.m
================================================
function [Xs_new] = CORAL_map(Xs,Xt)
cov_src = cov(Xs) + eye(size(Xs,2));
cov_tar = cov(Xt) + eye(size(Xt,2));
A_coral = cov_src^(-1/2) * cov_tar^(1/2);
Xs_new = Xs * A_coral;
end
================================================
FILE: code/traditional/EasyTL/EasyTL.m
================================================
function [acc,y_pred] = EasyTL(Xs,Ys,Xt,Yt,intra_align,dist,lp)
% Easy Transfer Learning
% Inputs:
%%% Xs : source data, ns * m
%%% Ys : source label, ns * 1
%%% Xt : target data, nt * m
%%% Yt : target label, nt * 1
%%%%%% The following inputs are not necessary
%%% intra_align : intra-domain alignment: coral(default)|gfk|pca|raw
%%% dist : distance: Euclidean(default)|ma(Mahalanobis)|cosine|rbf
%%% lp : linear(default)|binary
% Outputs:
%%% acc : final accuracy
%%% y_pred : predictions for target domain
% Reference:
% Jindong Wang, Yiqiang Chen, Han Yu, Meiyu Huang, Qiang Yang.
% Easy Transfer Learning By Exploiting Intra-domain Structures.
% IEEE International Conference on Multimedia & Expo (ICME) 2019.
C = length(unique(Ys)); % num of shared class
if C > max(Ys)
Ys = Ys + 1;
Yt = Yt + 1;
end
m = length(Yt); % num of target domain sample
if nargin == 4
intra_align = 'coral';
dist = 'euclidean';
lp = 'linear';
end
if nargin == 5
dist = 'euclidean';
lp = 'linear';
end
if nargin == 6
lp = 'linear';
end
switch(intra_align)
case 'raw'
fprintf('EasyTL using raw features...\n');
case 'pca'
fprintf('EasyTL using PCA...\n');
dim = getGFKDim(Xs,Xt);
X = [Xs;Xt];
[~,score] = pca(X);
X_new = score(:,1:dim);
Xs = X_new(1:length(Ys),:);
Xt = X_new(length(Ys) + 1 : end,:);
case 'gfk'
fprintf('EasyTL using GFK...\n');
[Xs,Xt,~] = GFK_map(Xs,Ys,Xt,Yt,dim);
case 'coral'
fprintf('EasyTL using CORAL...\n');
Xs = CORAL_map(Xs,Xt);
end
[~,Dct]= get_class_center(Xs,Ys,Xt,dist);
fprintf('Start intra-domain programming...\n');
[Mcj] = label_prop(C,m,Dct,lp);
[~,y_pred] = max(Mcj,[],2);
acc = mean(y_pred == Yt);
end
function [source_class_center,Dct] = get_class_center(Xs,Ys,Xt,dist)
% Get source class center and Dct
source_class_center = [];
Dct = [];
class_set = unique(Ys)';
for i = class_set
indx = Ys == i;
X_i = Xs(indx,:);
mean_i = mean(X_i);
source_class_center = [source_class_center,mean_i'];
switch(dist)
case 'ma'
Dct_c = mahal(X_i,Xt);
case 'euclidean'
Dct_c = sqrt(sum((mean_i - Xt).^2,2));
case 'sqeuc'
Dct_c = sum((mean_i - Xt).^2,2);
case 'cosine'
Dct_c = cosine_dist(Xt,mean_i);
case 'rbf'
Dct_c = sum((mean_i - Xt).^2,2);
Dct_c = exp(-Dct_c / 1);
end
Dct = [Dct,Dct_c];
end
end
function [Dist] = sample_pair_distance(X)
[n_sample,dim] = size(X);
Dist = zeros(n_sample,n_sample);
for i = 1 : n_sample
sample_i = X(i,:);
for j = 1 : n_sample
sample_j = X(j,:);
dist_ij = sum((sample_j - sample_i).^2);
Dist(i,j) = dist_ij;
end
end
end
function D = cosine_dist(A,B)
% {cosine} computes the cosine distance.
%
% D = cosine(A,B)
%
% A: M-by-P matrix of M P-dimensional vectors
% B: N-by-P matrix of M P-dimensional vectors
%
% D: M-by-N distance matrix
%
% Author: Stefano Melacci (2009)
% mela@dii.unisi.it
% * based on the code of Vikas Sindhwani, vikas.sindhwani@gmail.com
if (size(A,2) ~= size(B,2))
error('A and B must be of the same dimensionality.');
end
if (size(A,2) == 1) % if dim = 1...
A = [A, zeros(size(A,1),1)];
B = [B, zeros(size(B,1),1)];
end
aa=sum(A.*A,2);
bb=sum(B.*B,2);
ab=A*B';
% to avoid NaN for zero norms
aa((aa==0))=1;
bb((bb==0))=1;
D = real(ones(size(A,1),size(B,1))-(1./sqrt(kron(aa,bb'))).*ab);
end
================================================
FILE: code/traditional/EasyTL/GFK_map.m
================================================
function [Xs_new,Xt_new] = GFK_map(Xs,Xt)
% Inputs:
%%% X_src :source feature matrix, ns * m
%%% Y_src :source label vector, ns * 1
%%% X_tar :target feature matrix, nt * m
%%% Y_tar :target label vector, nt * 1
% Outputs:
%%% acc :accuracy after GFK and 1NN
%%% G :geodesic flow kernel matrix
Ps = pca(Xs);
Pt = pca(Xt);
dim = getGFKDim(Xs,Xt);
G = GFK_core([Ps,null(Ps')], Pt(:,1:dim));
sq_G = real(G^(0.5));
Xs_new = (sq_G * Xs')';
Xt_new = (sq_G * Xt')';
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [prediction,accuracy] = my_kernel_knn(M, Xr, Yr, Xt, Yt)
dist = repmat(diag(Xr*M*Xr'),1,length(Yt)) ...
+ repmat(diag(Xt*M*Xt')',length(Yr),1)...
- 2*Xr*M*Xt';
[~, minIDX] = min(dist);
prediction = Yr(minIDX);
accuracy = sum( prediction==Yt ) / length(Yt);
end
function G = GFK_core(Q,Pt)
% Input: Q = [Ps, null(Ps')], where Ps is the source subspace, column-wise orthonormal
% Pt: target subsapce, column-wise orthonormal, D-by-d, d < 0.5*D
% Output: G = \int_{0}^1 \Phi(t)\Phi(t)' dt
% ref: Geodesic Flow Kernel for Unsupervised Domain Adaptation.
% B. Gong, Y. Shi, F. Sha, and K. Grauman.
% Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012.
% Contact: Boqing Gong (boqinggo@usc.edu)
N = size(Q,2); %
dim = size(Pt,2);
% compute the principal angles
QPt = Q' * Pt;
[V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
V2 = -V2;
theta = real(acos(diag(Gam))); % theta is real in theory. Imaginary part is due to the computation issue.
% compute the geodesic flow kernel
eps = 1e-20;
B1 = 0.5.*diag(1+sin(2*theta)./2./max(theta,eps));
B2 = 0.5.*diag((-1+cos(2*theta))./2./max(theta,eps));
B3 = B2;
B4 = 0.5.*diag(1-sin(2*theta)./2./max(theta,eps));
G = Q * [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2] ...
* [B1,B2,zeros(dim,N-2*dim);B3,B4,zeros(dim,N-2*dim);zeros(N-2*dim,N)]...
* [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2]' * Q';
end
% Copyright (c) 2013, Basura Fernando
% All rights reserved.
%
% Redistribution and use in source and binary forms, with or without modification,
% are permitted provided that the following conditions are met:
%
% 1. Redistributions of source code must retain the above copyright notice, this
%list of conditions and the following disclaimer.
%
% 2. Redistributions in binary form must reproduce the above copyright notice,
% this list of conditions and the following disclaimer in the documentation and/or
% other materials provided with the distribution.
%
% THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
% ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
% WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
% DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
% ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
% (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
% LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
% ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
% (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
% SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
% This is the subspace dimensionality estimation method proposed in
% B. Gong, Y. Shi, F. Sha, and K. Grauman. Geodesic flow kernel for unsupervised domain adaptation. In CVPR, 2012.
%
% Please cite
%
% @inproceedings{Fernando2013b,
% author = {Basura Fernando, Amaury Habrard, Marc Sebban, Tinne Tuytelaars},
% title = {Unsupervised Visual Domain Adaptation Using Subspace Alignment},
% booktitle = {ICCV},
% year = {2013},
% }
%
function RES = getGFKDim(Source_Data,Target_Data,Pss,Pts,Psstt)
if nargin < 3
[Pss,D1,E1] = pca(Source_Data);
end
if nargin < 4
[Pts,D2,E2] = pca(Target_Data);
end
if nargin < 5
[Psstt,D2,E2] = pca([Source_Data;Target_Data]);
end
DIM = round(size(Source_Data,2) * 0.5) ; % if the dimensionality is large set DIM to say 200
RES = -1;
for d = 1 : DIM
Ps = Pss(:,1:d);
Pt = Pts(:,1:d);
Pst = Psstt(:,1:d);
alpha1 = getAngle(Ps,Pst,d);
alpha2 = getAngle(Pt,Pst,d);
D = (alpha1 + alpha2)*0.5;
for dd = 1 : d
if(round(D(1,dd)*100) == 100)
RES =d;
return;
end
end
end
end
function alpha = getAngle(Ps,Pt,DD)
Q = [Ps, null(Ps')];
N = size(Q,2); % N is the
dim = size(Pt,2);
QPt = Q' * Pt;
[V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
alpha = zeros(1,DD);
for i = 1 : DD
alpha(1,i) =sind(real(acosd(Gam(i,i))));
end
end
================================================
FILE: code/traditional/EasyTL/demo_amazon_review.m
================================================
%% Test Amazon review dataset
addpath('data/text/amazon_review_400/');
str_domains = {'books','dvd','elec','kitchen'};
list_acc = [];
for i = 1 : 4
for j = 1 : 4
if i == j
continue;
end
fprintf('%s - %s\n',str_domains{i}, str_domains{j});
%% Load data
load([str_domains{i},'_400.mat']);
Xs = fts; clear fts;
Ys = labels; clear labels;
load([str_domains{j},'_400.mat']);
Xt = fts; clear fts;
Yt = labels; clear labels;
Ys = Ys + 1;
Yt = Yt + 1;
Xs = Xs ./ repmat(sum(Xs,2),1,size(Xs,2));
Xs = zscore(Xs,1);
Xt = Xt ./ repmat(sum(Xt,2),1,size(Xt,2));
Xt = zscore(Xt,1);
% EasyTL without intra-domain alignment [EasyTL(c)]
[Acc1, ~] = EasyTL(Xs,Ys,Xt,Yt,'raw');
fprintf('Acc: %f\n',Acc1);
% EasyTL with CORAL for intra-domain alignment
[Acc2, ~] = EasyTL(Xs,Ys,Xt,Yt);
fprintf('Acc: %f\n',Acc2);
list_acc = [list_acc;[Acc1,Acc2]];
end
end
================================================
FILE: code/traditional/EasyTL/demo_image.m
================================================
% Test image datasets (ImageCLEF or Office-Home) using resnet50 features
img_dataset = 'image-clef'; % 'image-clef' or 'office-home'
if strcmp(img_dataset,'image-clef')
str_domains = {'c', 'i', 'p'};
addpath('Image-CLEF DA dataset path'); % You need to change this path
elseif strcmp(img_dataset,'office-home')
str_domains = {'Art', 'Clipart', 'Product', 'RealWorld'};
addpath('Office-Home dataset path'); % You need to change this path
end
list_acc = [];
for i = 1 : 3
for j = 1 : 3
if i == j
continue;
end
src = str_domains{i};
tgt = str_domains{j};
fprintf('%s - %s\n',src, tgt);
data = load([src '_' src '.csv']);
fts = data(1:end,1:end-1);
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xs = zscore(fts, 1);
Ys = data(1:end,end) + 1;
data = load([src '_' tgt '.csv']);
fts = data(1:end,1:end-1);
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xt = zscore(fts, 1);
Yt = data(1:end,end) + 1;
% EasyTL without intra-domain alignment [EasyTL(c)]
[Acc1, ~] = EasyTL(Xs,Ys,Xt,Yt,'raw');
fprintf('Acc: %f\n',Acc1);
% EasyTL with CORAL for intra-domain alignment
[Acc2, ~] = EasyTL(Xs,Ys,Xt,Yt);
fprintf('Acc: %f\n',Acc2);
list_acc = [list_acc;[Acc1,Acc2]];
end
end
================================================
FILE: code/traditional/EasyTL/demo_office_caltech.m
================================================
% Test with Office-Caltech datasets
str_domains = { 'Caltech10', 'amazon', 'webcam', 'dslr' };
list_acc = [];
for i = 1 : 4
for j = 1 : 4
if i == j
continue;
end
src = str_domains{i};
tgt = str_domains{j};
load(['data/office+caltech--surf/' src '_SURF_L10.mat']); % source domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xs = zscore(fts,1); clear fts
Ys = labels; clear labels
load(['data/office+caltech--surf/' tgt '_SURF_L10.mat']); % target domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xt = zscore(fts,1); clear fts
Yt = labels; clear labels
% EasyTL without intra-domain alignment [EasyTL(c)]
[Acc1, ~] = EasyTL(Xs,Ys,Xt,Yt,'raw');
fprintf('Acc: %f\n',Acc1);
% EasyTL with CORAL for intra-domain alignment
[Acc2, ~] = EasyTL(Xs,Ys,Xt,Yt);
fprintf('Acc: %f\n',Acc2);
list_acc = [list_acc;[Acc1,Acc2]];
end
end
================================================
FILE: code/traditional/EasyTL/label_prop.m
================================================
function [Mcj] = label_prop(C,nt,Dct,lp)
% Inputs:
%%% C : Number of share classes between src and tar
%%% nt : Number of target domain samples
%%% Dct : All d_ct in matrix form, nt * C
%%% lp : Type of linear programming: linear (default) | binary
% Outputs:
%%% Mcj : all M_ct in matrix form, m * C
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
intcon = C * nt; % Number of all variables to be solved (all x_ct and o_t)
if nargin == 3
lp = 'linear';
end
Aeq = zeros(nt, intcon);
Beq = ones(nt ,1);
for i = 1 : nt
Aeq(i,(i - 1) * C + 1 : i * C) = 1;
end
%for i = 1 : nt
% lllll =i
% all_zeros = zeros(1,intcon);
% all_zeros((i - 1) * C + 1 : i * C) = 1;
% Aeq = [Aeq;all_zeros];
% Beq = [Beq;1];
% end
D_vec = reshape(Dct',1,intcon);
CC = double(D_vec);
A = [];
B = [];
for i = 1 : C
all_zeros = zeros(1,intcon);
j = i : C : C * nt;
all_zeros(j) = -1;
A = [A;all_zeros];
B = [B;-1];
end
lb_12 = zeros(intcon,1);
ub_12 = ones(intcon,1);
% options = optimoptions('linprog','Algorithm','interior-point');
if strcmp(lp,'binary')
X = intlinprog(CC,intcon,A,B,Aeq,Beq,lb_12,ub_12);
else
X = linprog(CC,A,B,Aeq,Beq,lb_12,ub_12);
end
Mct_vec = X(1:C*nt);
Mcj = reshape(Mct_vec,C,nt)'; % M matrix, nt * C
end
================================================
FILE: code/traditional/EasyTL/readme.md
================================================
# EasyTL: Practically Easy Transfer Learning
This directory contains the code for paper [Easy Transfer Learning By Exploiting Intra-domain Structures](http://jd92.wang/assets/files/a13_icme19.pdf) published at IEEE International Conference on Multimedia & Expo (ICME) 2019.
## Requirements
There are two implementations of EasyTL: Matlab and Python.
### Matlab
The original code is written using Matlab R2017a. I think all versions after 2015 can run the code.
### Python
Thanks to [@KodeWorker](https://github.com/KodeWorker) for providing a Python implementation.
The Python version can be found in [here](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/pyEasyTL).
## Demo & Usage
For Matlab, I offer three basic demos to reproduce the experiments in this paper:
- For Amazon Review dataset, please run `demo_amazon_review.m`.
- For Office-Caltech dataset, please run `demo_office_caltech.m`.
- For ImageCLEF-DA and Office-Home datasets, please run `demo_image.m`.
Note that this directory does **not** contains any dataset. You can download them at the following links, and then add the folder to your Matlab path before running the code.
For Python, the demo code is `.py`.
[Download Amazon Review dataset](https://mega.nz/#F!RS43DADD!4pWwFA0CBJP1oLhAR23bTA).
[Download Office-Caltech with SURF features](https://mega.nz/#F!AaJTGIzD!XHM2XMsSd9V-ljVi0EtvFg)
[Download Image-CLEF ResNet-50 pretrained features](https://mega.nz/#F!QPJCzShS!b6qQUXWnCCGBMVs0m6MdQw)
[Download Office-Home ResNet-50 pretrained features](https://mega.nz/#F!pGIkjIxC!MDD3ps6RzTXWobMfHh0Slw)
You are welcome to run EasyTL on other public datasets such as [here](https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md). You can also use your own datasets.
### Reference
If you find this code helpful, please cite it as:
`
Jindong Wang, Yiqiang Chen, Han Yu, Meiyu Huang, Qiang Yang. Easy Transfer Learning By Exploiting Intra-domain Structures. IEEE International Conference on Multimedia & Expo (ICME) 2019.
`
Or in bibtex style:
```
@inproceedings{wang2019easytl,
title={Easy Transfer Learning By Exploiting Intra-domain Structures},
author={Wang, Jindong and Chen, Yiqiang and Yu, Han and Huang, Meiyu and Yang, Qiang},
booktitle={IEEE International Conference on Multimedia & Expo (ICME)},
year={2019}
}
```
## Results
EasyTL achieved **state-of-the-art** performances compared to a lot of traditional and deep methods as of March 2019:




================================================
FILE: code/traditional/GFK/GFK.m
================================================
function [acc,G,Cls] = GFK(X_src,Y_src,X_tar,Y_tar,dim)
% This is the implementation of Geodesic Flow Kernel.
% Reference: Boqing Gong et al. Geodesic flow kernel for Unsupervised Domain Adaptation. CVPR 2012.
% Inputs:
%%% X_src : source feature matrix, ns * n_feature
%%% Y_src : source label vector, ns * 1
%%% X_tar : target feature matrix, nt * n_feature
%%% Y_tar : target label vector, nt * 1
%%% dim : dimension of geodesic flow kernel, dim <= 0.5 * n_feature
% Outputs:
%%% acc : accuracy after GFK and 1NN
%%% G : geodesic flow kernel matrix
%%% Cls : prediction labels for target, nt * 1
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Ps = pca(X_src);
Pt = pca(X_tar);
G = GFK_core([Ps,null(Ps')], Pt(:,1:dim));
[Cls, acc] = my_kernel_knn(G, X_src, Y_src, X_tar, Y_tar);
end
function [prediction,accuracy] = my_kernel_knn(M, Xr, Yr, Xt, Yt)
dist = repmat(diag(Xr*M*Xr'),1,length(Yt)) ...
+ repmat(diag(Xt*M*Xt')',length(Yr),1)...
- 2*Xr*M*Xt';
[~, minIDX] = min(dist);
prediction = Yr(minIDX);
accuracy = sum( prediction==Yt ) / length(Yt);
end
function G = GFK_core(Q,Pt)
% Input: Q = [Ps, null(Ps')], where Ps is the source subspace, column-wise orthonormal
% Pt: target subsapce, column-wise orthonormal, D-by-d, d < 0.5*D
% Output: G = \int_{0}^1 \Phi(t)\Phi(t)' dt
% ref: Geodesic Flow Kernel for Unsupervised Domain Adaptation.
% B. Gong, Y. Shi, F. Sha, and K. Grauman.
% Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012.
% Contact: Boqing Gong (boqinggo@usc.edu)
N = size(Q,2); %
dim = size(Pt,2);
% compute the principal angles
QPt = Q' * Pt;
[V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
V2 = -V2;
theta = real(acos(diag(Gam))); % theta is real in theory. Imaginary part is due to the computation issue.
% compute the geodesic flow kernel
eps = 1e-20;
B1 = 0.5.*diag(1+sin(2*theta)./2./max(theta,eps));
B2 = 0.5.*diag((-1+cos(2*theta))./2./max(theta,eps));
B3 = B2;
B4 = 0.5.*diag(1-sin(2*theta)./2./max(theta,eps));
G = Q * [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2] ...
* [B1,B2,zeros(dim,N-2*dim);B3,B4,zeros(dim,N-2*dim);zeros(N-2*dim,N)]...
* [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2]' * Q';
end
================================================
FILE: code/traditional/GFK/GFK.py
================================================
# encoding=utf-8
"""
Created on 17:25 2018/11/13
@author: Jindong Wang
"""
import numpy as np
import scipy.io
import bob.learn
import bob.learn.linear
import bob.math
from sklearn.neighbors import KNeighborsClassifier
class GFK:
def __init__(self, dim=20):
'''
Init func
:param dim: dimension after GFK
'''
self.dim = dim
self.eps = 1e-20
def fit(self, Xs, Xt, norm_inputs=None):
'''
Obtain the kernel G
:param Xs: ns * n_feature, source feature
:param Xt: nt * n_feature, target feature
:param norm_inputs: normalize the inputs or not
:return: GFK kernel G
'''
if norm_inputs:
source, mu_source, std_source = self.znorm(Xs)
target, mu_target, std_target = self.znorm(Xt)
else:
mu_source = np.zeros(shape=(Xs.shape[1]))
std_source = np.ones(shape=(Xs.shape[1]))
mu_target = np.zeros(shape=(Xt.shape[1]))
std_target = np.ones(shape=(Xt.shape[1]))
source = Xs
target = Xt
Ps = self.train_pca(source, mu_source, std_source, 0.99)
Pt = self.train_pca(target, mu_target, std_target, 0.99)
Ps = np.hstack((Ps.weights, scipy.linalg.null_space(Ps.weights.T)))
Pt = Pt.weights[:, :self.dim]
N = Ps.shape[1]
dim = Pt.shape[1]
# Principal angles between subspaces
QPt = np.dot(Ps.T, Pt)
# [V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
A = QPt[0:dim, :].copy()
B = QPt[dim:, :].copy()
# Equation (2)
[V1, V2, V, Gam, Sig] = bob.math.gsvd(A, B)
V2 = -V2
# Some sanity checks with the GSVD
I = np.eye(V1.shape[1])
I_check = np.dot(Gam.T, Gam) + np.dot(Sig.T, Sig)
assert np.sum(abs(I - I_check)) < 1e-10
theta = np.arccos(np.diagonal(Gam))
# Equation (6)
B1 = np.diag(0.5 * (1 + (np.sin(2 * theta) / (2. * np.maximum
(theta, 1e-20)))))
B2 = np.diag(0.5 * ((np.cos(2 * theta) - 1) / (2 * np.maximum(
theta, self.eps))))
B3 = B2
B4 = np.diag(0.5 * (1 - (np.sin(2 * theta) / (2. * np.maximum
(theta, self.eps)))))
# Equation (9) of the suplementary matetial
delta1_1 = np.hstack((V1, np.zeros(shape=(dim, N - dim))))
delta1_2 = np.hstack((np.zeros(shape=(N - dim, dim)), V2))
delta1 = np.vstack((delta1_1, delta1_2))
delta2_1 = np.hstack((B1, B2, np.zeros(shape=(dim, N - 2 * dim))))
delta2_2 = np.hstack((B3, B4, np.zeros(shape=(dim, N - 2 * dim))))
delta2_3 = np.zeros(shape=(N - 2 * dim, N))
delta2 = np.vstack((delta2_1, delta2_2, delta2_3))
delta3_1 = np.hstack((V1, np.zeros(shape=(dim, N - dim))))
delta3_2 = np.hstack((np.zeros(shape=(N - dim, dim)), V2))
delta3 = np.vstack((delta3_1, delta3_2)).T
delta = np.linalg.multi_dot([delta1, delta2, delta3])
G = np.linalg.multi_dot([Ps, delta, Ps.T])
sqG = scipy.real(scipy.linalg.fractional_matrix_power(G, 0.5))
Xs_new, Xt_new = np.dot(sqG, Xs.T).T, np.dot(sqG, Xt.T).T
return G, Xs_new, Xt_new
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Fit and use 1NN to classify
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: Accuracy, predicted labels of target domain, and G
'''
G, Xs_new, Xt_new = self.fit(Xs, Xt)
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
y_pred = clf.predict(Xt_new)
acc = np.mean(y_pred == Yt.ravel())
return acc, y_pred, G
def principal_angles(self, Ps, Pt):
"""
Compute the principal angles between source (:math:`P_s`) and target (:math:`P_t`) subspaces in a Grassman which is defined as the following:
:math:`d^{2}(P_s, P_t) = \sum_{i}( \theta_i^{2} )`,
"""
# S = cos(theta_1, theta_2, ..., theta_n)
_, S, _ = np.linalg.svd(np.dot(Ps.T, Pt))
thetas_squared = np.arccos(S) ** 2
return np.sum(thetas_squared)
def train_pca(self, data, mu_data, std_data, subspace_dim):
'''
Modified PCA function, different from the one in sklearn
:param data: data matrix
:param mu_data: mu
:param std_data: std
:param subspace_dim: dim
:return: a wrapped machine object
'''
t = bob.learn.linear.PCATrainer()
machine, variances = t.train(data)
# For re-shaping, we need to copy...
variances = variances.copy()
# compute variance percentage, if desired
if isinstance(subspace_dim, float):
cummulated = np.cumsum(variances) / np.sum(variances)
for index in range(len(cummulated)):
if cummulated[index] > subspace_dim:
subspace_dim = index
break
subspace_dim = index
machine.resize(machine.shape[0], subspace_dim)
machine.input_subtract = mu_data
machine.input_divide = std_data
return machine
def znorm(self, data):
"""
Z-Normaliza
"""
mu = np.average(data, axis=0)
std = np.std(data, axis=0)
data = (data - mu) / std
return data, mu, std
def subspace_disagreement_measure(self, Ps, Pt, Pst):
"""
Get the best value for the number of subspaces
For more details, read section 3.4 of the paper.
**Parameters**
Ps: Source subspace
Pt: Target subspace
Pst: Source + Target subspace
"""
def compute_angles(A, B):
_, S, _ = np.linalg.svd(np.dot(A.T, B))
S[np.where(np.isclose(S, 1, atol=self.eps) == True)[0]] = 1
return np.arccos(S)
max_d = min(Ps.shape[1], Pt.shape[1], Pst.shape[1])
alpha_d = compute_angles(Ps, Pst)
beta_d = compute_angles(Pt, Pst)
d = 0.5 * (np.sin(alpha_d) + np.sin(beta_d))
return np.argmax(d)
if __name__ == '__main__':
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
for i in range(4):
for j in range(4):
if i != j:
src, tar = 'data/' + domains[i], 'data/' + domains[j]
src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
gfk = GFK(dim=20)
acc, ypred, G = gfk.fit_predict(Xs, Ys, Xt, Yt)
print(acc)
================================================
FILE: code/traditional/GFK/getGFKDim.m
================================================
% Copyright (c) 2013, Basura Fernando
% All rights reserved.
%
% Redistribution and use in source and binary forms, with or without modification,
% are permitted provided that the following conditions are met:
%
% 1. Redistributions of source code must retain the above copyright notice, this
%list of conditions and the following disclaimer.
%
% 2. Redistributions in binary form must reproduce the above copyright notice,
% this list of conditions and the following disclaimer in the documentation and/or
% other materials provided with the distribution.
%
% THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
% ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
% WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
% DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
% ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
% (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
% LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
% ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
% (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
% SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
% This is the subspace dimensionality estimation method proposed in
% B. Gong, Y. Shi, F. Sha, and K. Grauman. Geodesic flow kernel for unsupervised domain adaptation. In CVPR, 2012.
%
% Please cite
%
% @inproceedings{Fernando2013b,
% author = {Basura Fernando, Amaury Habrard, Marc Sebban, Tinne Tuytelaars},
% title = {Unsupervised Visual Domain Adaptation Using Subspace Alignment},
% booktitle = {ICCV},
% year = {2013},
% }
%
function RES = getGFKDim(Source_Data,Target_Data,Pss,Pts,Psstt)
if nargin < 3
[Pss,D1,E1] = princomp(Source_Data);
end
if nargin < 4
[Pts,D2,E2] = princomp(Target_Data);
end
if nargin < 5
[Psstt,D2,E2] = princomp([Source_Data;Target_Data]);
end
DIM = round(size(Source_Data,2) * 0.5) ; % if the dimensionality is large set DIM to say 200
RES = -1;
for d = 1 : DIM
Ps = Pss(:,1:d);
Pt = Pts(:,1:d);
Pst = Psstt(:,1:d);
alpha1 = getAngle(Ps,Pst,d);
alpha2 = getAngle(Pt,Pst,d);
D = (alpha1 + alpha2)*0.5;
for dd = 1 : d
if(round(D(1,dd)*100) == 100)
RES =d;
return;
end
end
end
end
function alpha = getAngle(Ps,Pt,DD)
Q = [Ps, null(Ps')];
N = size(Q,2); % N is the
dim = size(Pt,2);
QPt = Q' * Pt;
[V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
alpha = zeros(1,DD);
for i = 1 : DD
alpha(1,i) =sind(real(acosd(Gam(i,i))));
end
end
================================================
FILE: code/traditional/GFK/readme.md
================================================
# Geodesic Flow Kernwl (GFK)
This is the implementation of Geodesic Flow Kernel (GFK) in both Matlab and Python.
## Matlab version
Just use `GFK.m`. Note that `getGFKDim.m` is the implementation of *subspace disagreement measurement* proposed in GFK paper.
## Python version
**Note:** We may not be able to use `bob` any more. Therefore, the code of GFK in python is also not available since to achieve the same results in Matlab, we need to use `bob` library.
Therefore, I can do nothing about it except suggesting that you use the Matlab version instead. If you still want to use Python code, then you can try to call the Matlab code in your Python script by following some tutorials online.
See the `GFK.py` file.
Requirements:
- Python 3
- Numpy and Scipy
- Sklearn
- **Bob**
**Note:** This Python version is wrapped from Bob: https://www.idiap.ch/software/bob/docs/bob/bob.learn.linear/stable/_modules/bob/learn/linear/GFK.html#GFKMachine.
Therefore, if you want to run and use this program, you should install `bob` by following its official instructions in [here](https://www.idiap.ch/software/bob/docs/bob/docs/stable/bob/bob/doc/install.html).
There are many libraries in bob. A minimum request is to install `bob.math` and `bob.learn` by following the instructions.
## Run
The test dataset can be downloaded [HERE](https://github.com/jindongwang/transferlearning/tree/master/data). Then, you can run the file.
The python file can be used directly, while the matlab code just contains the core function of TCA. To use the matlab code, you need to learn from the code of [BDA](https://github.com/jindongwang/transferlearning/tree/master/code/BDA) and set out the parameters.
### Reference
Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012: 2066-2073.
If you have any questions, please open an issue.
================================================
FILE: code/traditional/JDA/JDA.m
================================================
function [acc,acc_ite,A] = JDA(X_src,Y_src,X_tar,Y_tar,options)
% This is the implementation of Joint Distribution Adaptation.
% Reference: Mingsheng Long et al. Transfer feature learning with joint distribution adaptation. ICCV 2013.
% Inputs:
%%% X_src : source feature matrix, ns * n_feature
%%% Y_src : source label vector, ns * 1
%%% X_tar : target feature matrix, nt * n_feature
%%% Y_tar : target label vector, nt * 1
%%% options : option struct
%%%%% lambda : regularization parameter
%%%%% dim : dimension after adaptation, dim <= n_feature
%%%%% kernel_tpye : kernel name, choose from 'primal' | 'linear' | 'rbf'
%%%%% gamma : bandwidth for rbf kernel, can be missed for other kernels
%%%%% T : n_iterations, T >= 1. T <= 10 is suffice
% Outputs:
%%% acc : final accuracy using knn, float
%%% acc_ite : list of all accuracies during iterations
%%% A : final adaptation matrix, (ns + nt) * (ns + nt)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% Set options
lambda = options.lambda;
dim = options.dim;
kernel_type = options.kernel_type;
gamma = options.gamma;
T = options.T;
acc_ite = [];
Y_tar_pseudo = [];
%% Iteration
for i = 1 : T
[Z,A] = JDA_core(X_src,Y_src,X_tar,Y_tar_pseudo,options);
%normalization for better classification performance
Z = Z*diag(sparse(1./sqrt(sum(Z.^2))));
Zs = Z(:,1:size(X_src,1));
Zt = Z(:,size(X_src,1)+1:end);
knn_model = fitcknn(Zs',Y_src,'NumNeighbors',1);
Y_tar_pseudo = knn_model.predict(Zt');
acc = length(find(Y_tar_pseudo==Y_tar))/length(Y_tar);
fprintf('JDA+NN=%0.4f\n',acc);
acc_ite = [acc_ite;acc];
end
end
function [Z,A] = JDA_core(X_src,Y_src,X_tar,Y_tar_pseudo,options)
%% Set options
lambda = options.lambda; %% lambda for the regularization
dim = options.dim; %% dim is the dimension after adaptation, dim <= m
kernel_type = options.kernel_type; %% kernel_type is the kernel name, primal|linear|rbf
gamma = options.gamma; %% gamma is the bandwidth of rbf kernel
%% Construct MMD matrix
X = [X_src',X_tar'];
X = X*diag(sparse(1./sqrt(sum(X.^2))));
[m,n] = size(X);
ns = size(X_src,1);
nt = size(X_tar,1);
e = [1/ns*ones(ns,1);-1/nt*ones(nt,1)];
C = length(unique(Y_src));
%%% M0
M = e * e' * C; %multiply C for better normalization
%%% Mc
N = 0;
if ~isempty(Y_tar_pseudo) && length(Y_tar_pseudo)==nt
for c = reshape(unique(Y_src),1,C)
e = zeros(n,1);
e(Y_src==c) = 1 / length(find(Y_src==c));
e(ns+find(Y_tar_pseudo==c)) = -1 / length(find(Y_tar_pseudo==c));
e(isinf(e)) = 0;
N = N + e*e';
end
end
M = M + N;
M = M / norm(M,'fro');
%% Centering matrix H
H = eye(n) - 1/n * ones(n,n);
%% Calculation
if strcmp(kernel_type,'primal')
[A,~] = eigs(X*M*X'+lambda*eye(m),X*H*X',dim,'SM');
Z = A'*X;
else
K = kernel_jda(kernel_type,X,[],gamma);
[A,~] = eigs(K*M*K'+lambda*eye(n),K*H*K',dim,'SM');
Z = A'*K;
end
end
% With Fast Computation of the RBF kernel matrix
% To speed up the computation, we exploit a decomposition of the Euclidean distance (norm)
%
% Inputs:
% ker: 'linear','rbf','sam'
% X: data matrix (features * samples)
% gamma: bandwidth of the RBF/SAM kernel
% Output:
% K: kernel matrix
%
% Gustavo Camps-Valls
% 2006(c)
% Jordi (jordi@uv.es), 2007
% 2007-11: if/then -> switch, and fixed RBF kernel
% Modified by Mingsheng Long
% 2013(c)
% Mingsheng Long (longmingsheng@gmail.com), 2013
function K = kernel_jda(ker,X,X2,gamma)
switch ker
case 'linear'
if isempty(X2)
K = X'*X;
else
K = X'*X2;
end
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
if isempty(X2)
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
else
n2sq = sum(X2.^2,1);
n2 = size(X2,2);
D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
end
K = exp(-gamma*D);
case 'sam'
if isempty(X2)
D = X'*X;
else
D = X'*X2;
end
K = exp(-gamma*acos(D).^2);
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/traditional/JDA/JDA.py
================================================
# encoding=utf-8
"""
Created on 21:29 2018/11/12
@author: Jindong Wang
"""
import numpy as np
import scipy.io
import scipy.linalg
import sklearn.metrics
from sklearn.neighbors import KNeighborsClassifier
def kernel(ker, X1, X2, gamma):
K = None
if not ker or ker == 'primal':
K = X1
elif ker == 'linear':
if X2:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T, np.asarray(X2).T)
else:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T)
elif ker == 'rbf':
if X2:
K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, np.asarray(X2).T, gamma)
else:
K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, None, gamma)
return K
class JDA:
def __init__(self, kernel_type='primal', dim=30, lamb=1, gamma=1, T=10):
'''
Init func
:param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'
:param dim: dimension after transfer
:param lamb: lambda value in equation
:param gamma: kernel bandwidth for rbf kernel
:param T: iteration number
'''
self.kernel_type = kernel_type
self.dim = dim
self.lamb = lamb
self.gamma = gamma
self.T = T
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Transform and Predict using 1NN as JDA paper did
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: acc, y_pred, list_acc
'''
list_acc = []
X = np.hstack((Xs.T, Xt.T))
X /= np.linalg.norm(X, axis=0)
m, n = X.shape
ns, nt = len(Xs), len(Xt)
e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))
C = len(np.unique(Ys))
H = np.eye(n) - 1 / n * np.ones((n, n))
M = 0
Y_tar_pseudo = None
for t in range(self.T):
N = 0
M0 = e * e.T * C
if Y_tar_pseudo is not None and len(Y_tar_pseudo) == nt:
for c in range(1, C + 1):
e = np.zeros((n, 1))
tt = Ys == c
e[np.where(tt == True)] = 1 / len(Ys[np.where(Ys == c)])
yy = Y_tar_pseudo == c
ind = np.where(yy == True)
inds = [item + ns for item in ind]
e[tuple(inds)] = -1 / len(Y_tar_pseudo[np.where(Y_tar_pseudo == c)])
e[np.isinf(e)] = 0
N = N + np.dot(e, e.T)
M = M0 + N
M = M / np.linalg.norm(M, 'fro')
K = kernel(self.kernel_type, X, None, gamma=self.gamma)
n_eye = m if self.kernel_type == 'primal' else n
a, b = np.linalg.multi_dot([K, M, K.T]) + self.lamb * np.eye(n_eye), np.linalg.multi_dot([K, H, K.T])
w, V = scipy.linalg.eig(a, b)
ind = np.argsort(w)
A = V[:, ind[:self.dim]]
Z = np.dot(A.T, K)
Z /= np.linalg.norm(Z, axis=0)
Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
Y_tar_pseudo = clf.predict(Xt_new)
acc = sklearn.metrics.accuracy_score(Yt, Y_tar_pseudo)
list_acc.append(acc)
print('JDA iteration [{}/{}]: Acc: {:.4f}'.format(t + 1, self.T, acc))
return acc, Y_tar_pseudo, list_acc
if __name__ == '__main__':
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
for i in range(1):
for j in range(2):
if i != j:
src, tar = 'data/' + domains[i], 'data/' + domains[j]
src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
jda = JDA(kernel_type='primal', dim=30, lamb=1, gamma=1)
acc, ypre, list_acc = jda.fit_predict(Xs, Ys, Xt, Yt)
print(acc)
================================================
FILE: code/traditional/JDA/readme.md
================================================
# Joint Distribution Adaptation
This is the implementation of Joint Distribution Adaptation (JDA) in Python and Matlab.
Remark: The core of JDA is a generalized eigendecompsition problem. In Matlab, it can be solved by calling `eigs()` function. In Python, the implementation `scipy.linalg.eig()` function can do the same thing. However, they are a bit different. So the results may be different.
The test dataset can be downloaded [HERE](https://github.com/jindongwang/transferlearning/tree/master/data).
The python file can be used directly, while the matlab code just contains the core function of TCA. To use the matlab code, you need to learn from the code of [BDA](https://github.com/jindongwang/transferlearning/tree/master/code/BDA) and set out the parameters.
**Reference**
Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation[C]//Proceedings of the IEEE international conference on computer vision. 2013: 2200-2207.
================================================
FILE: code/traditional/KMM.py
================================================
"""
Kernel Mean Matching
# 1. Gretton, Arthur, et al. "Covariate shift by kernel mean matching." Dataset shift in machine learning 3.4 (2009): 5.
# 2. Huang, Jiayuan, et al. "Correcting sample selection bias by unlabeled data." Advances in neural information processing systems. 2006.
"""
import numpy as np
import sklearn.metrics
from cvxopt import matrix, solvers
import os
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--norm', action='store_true')
args = parser.parse_args()
def kernel(ker, X1, X2, gamma):
K = None
if ker == 'linear':
if X2 is not None:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1), np.asarray(X2))
else:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1))
elif ker == 'rbf':
if X2 is not None:
K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1), np.asarray(X2), gamma)
else:
K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1), None, gamma)
return K
class KMM:
def __init__(self, kernel_type='linear', gamma=1.0, B=1.0, eps=None):
'''
Initialization function
:param kernel_type: 'linear' | 'rbf'
:param gamma: kernel bandwidth for rbf kernel
:param B: bound for beta
:param eps: bound for sigma_beta
'''
self.kernel_type = kernel_type
self.gamma = gamma
self.B = B
self.eps = eps
def fit(self, Xs, Xt):
'''
Fit source and target using KMM (compute the coefficients)
:param Xs: ns * dim
:param Xt: nt * dim
:return: Coefficients (Pt / Ps) value vector (Beta in the paper)
'''
ns = Xs.shape[0]
nt = Xt.shape[0]
if self.eps == None:
self.eps = self.B / np.sqrt(ns)
K = kernel(self.kernel_type, Xs, None, self.gamma)
kappa = np.sum(kernel(self.kernel_type, Xs, Xt, self.gamma) * float(ns) / float(nt), axis=1)
K = matrix(K.astype(np.double))
kappa = matrix(kappa.astype(np.double))
G = matrix(np.r_[np.ones((1, ns)), -np.ones((1, ns)), np.eye(ns), -np.eye(ns)])
h = matrix(np.r_[ns * (1 + self.eps), ns * (self.eps - 1), self.B * np.ones((ns,)), np.zeros((ns,))])
sol = solvers.qp(K, -kappa, G, h)
beta = np.array(sol['x'])
return beta
def load_data(folder, domain):
from scipy import io
data = io.loadmat(os.path.join(folder, domain + '_fc6.mat'))
return data['fts'], data['labels']
def knn_classify(Xs, Ys, Xt, Yt, k=1, norm=False):
model = KNeighborsClassifier(n_neighbors=k)
Ys = Ys.ravel()
Yt = Yt.ravel()
if norm:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
Xs = scaler.fit_transform(Xs)
Xt = scaler.fit_transform(Xt)
model.fit(Xs, Ys)
Yt_pred = model.predict(Xt)
acc = accuracy_score(Yt, Yt_pred)
print(f'Accuracy using kNN: {acc * 100:.2f}%')
if __name__ == "__main__":
# download the dataset here: https://www.jianguoyun.com/p/DcNAUg0QmN7PCBiF9asD (Password: qqLA7D)
folder = '/home/jindwang/mine/office31'
src_domain = 'amazon'
tar_domain = 'webcam'
Xs, Ys = load_data(folder, src_domain)
Xt, Yt = load_data(folder, tar_domain)
print('Source:', src_domain, Xs.shape, Ys.shape)
print('Target:', tar_domain, Xt.shape, Yt.shape)
kmm = KMM(kernel_type='rbf', B=10)
beta = kmm.fit(Xs, Xt)
print(beta)
print(beta.shape)
Xs_new = beta * Xs
knn_classify(Xs_new, Ys, Xt, Yt, k=1, norm=args.norm)
================================================
FILE: code/traditional/MEDA/MEDA.py
================================================
# encoding=utf-8
"""
Created on 10:40 2018/11/14
@author: Jindong Wang
"""
import numpy as np
import scipy.io
from sklearn import metrics
from sklearn import svm
from sklearn.neighbors import KNeighborsClassifier
import GFK
def kernel(ker, X1, X2, gamma):
K = None
if not ker or ker == 'primal':
K = X1
elif ker == 'linear':
if X2 is not None:
K = metrics.pairwise.linear_kernel(np.asarray(X1).T, np.asarray(X2).T)
else:
K = metrics.pairwise.linear_kernel(np.asarray(X1).T)
elif ker == 'rbf':
if X2 is not None:
K = metrics.pairwise.rbf_kernel(np.asarray(X1).T, np.asarray(X2).T, gamma)
else:
K = metrics.pairwise.rbf_kernel(np.asarray(X1).T, None, gamma)
return K
def proxy_a_distance(source_X, target_X):
"""
Compute the Proxy-A-Distance of a source/target representation
"""
nb_source = np.shape(source_X)[0]
nb_target = np.shape(target_X)[0]
train_X = np.vstack((source_X, target_X))
train_Y = np.hstack((np.zeros(nb_source, dtype=int), np.ones(nb_target, dtype=int)))
clf = svm.LinearSVC(random_state=0)
clf.fit(train_X, train_Y)
y_pred = clf.predict(train_X)
error = metrics.mean_absolute_error(train_Y, y_pred)
dist = 2 * (1 - 2 * error)
return dist
class MEDA:
def __init__(self, kernel_type='primal', dim=30, lamb=1, rho=1.0, eta=0.1, p=10, gamma=1, T=10):
'''
Init func
:param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'
:param dim: dimension after transfer
:param lamb: lambda value in equation
:param rho: rho in equation
:param eta: eta in equation
:param p: number of neighbors
:param gamma: kernel bandwidth for rbf kernel
:param T: iteration number
'''
self.kernel_type = kernel_type
self.dim = dim
self.lamb = lamb
self.rho = rho
self.eta = eta
self.gamma = gamma
self.p = p
self.T = T
def estimate_mu(self, _X1, _Y1, _X2, _Y2):
adist_m = proxy_a_distance(_X1, _X2)
C = len(np.unique(_Y1))
epsilon = 1e-3
list_adist_c = []
for i in range(1, C + 1):
ind_i, ind_j = np.where(_Y1 == i), np.where(_Y2 == i)
Xsi = _X1[ind_i[0], :]
Xtj = _X2[ind_j[0], :]
adist_i = proxy_a_distance(Xsi, Xtj)
list_adist_c.append(adist_i)
adist_c = sum(list_adist_c) / C
mu = adist_c / (adist_c + adist_m)
if mu > 1:
mu = 1
if mu < epsilon:
mu = 0
return mu
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Transform and Predict
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: acc, y_pred, list_acc
'''
gfk = GFK.GFK(dim=self.dim)
_, Xs_new, Xt_new = gfk.fit(Xs, Xt)
Xs_new, Xt_new = Xs_new.T, Xt_new.T
X = np.hstack((Xs_new, Xt_new))
n, m = Xs_new.shape[1], Xt_new.shape[1]
C = len(np.unique(Ys))
list_acc = []
YY = np.zeros((n, C))
for c in range(1, C + 1):
ind = np.where(Ys == c)
YY[ind, c - 1] = 1
YY = np.vstack((YY, np.zeros((m, C))))
YY[0, 1:] = 0
X /= np.linalg.norm(X, axis=0)
L = 0 # Graph Laplacian is on the way...
knn_clf = KNeighborsClassifier(n_neighbors=1)
knn_clf.fit(X[:, :n].T, Ys.ravel())
Cls = knn_clf.predict(X[:, n:].T)
K = kernel(self.kernel_type, X, X2=None, gamma=self.gamma)
E = np.diagflat(np.vstack((np.ones((n, 1)), np.zeros((m, 1)))))
for t in range(1, self.T + 1):
mu = self.estimate_mu(Xs_new.T, Ys, Xt_new.T, Cls)
e = np.vstack((1 / n * np.ones((n, 1)), -1 / m * np.ones((m, 1))))
M = e * e.T * C
N = 0
for c in range(1, C + 1):
e = np.zeros((n + m, 1))
tt = Ys == c
e[np.where(tt == True)] = 1 / len(Ys[np.where(Ys == c)])
yy = Cls == c
ind = np.where(yy == True)
inds = [item + n for item in ind]
e[tuple(inds)] = -1 / len(Cls[np.where(Cls == c)])
e[np.isinf(e)] = 0
N += np.dot(e, e.T)
M = (1 - mu) * M + mu * N
M /= np.linalg.norm(M, 'fro')
left = np.dot(E + self.lamb * M + self.rho * L, K) + self.eta * np.eye(n + m, n + m)
Beta = np.dot(np.linalg.inv(left), np.dot(E, YY))
F = np.dot(K, Beta)
Cls = np.argmax(F, axis=1) + 1
Cls = Cls[n:]
acc = np.mean(Cls == Yt.ravel())
list_acc.append(acc)
print('MEDA iteration [{}/{}]: mu={:.2f}, Acc={:.4f}'.format(t, self.T, mu, acc))
return acc, Cls, list_acc
if __name__ == '__main__':
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
for i in range(1):
for j in range(2):
if i != j:
src, tar = 'data/' + domains[i], 'data/' + domains[j]
src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
meda = MEDA(kernel_type='rbf', dim=20, lamb=10, rho=1.0, eta=0.1, p=10, gamma=1, T=10)
acc, ypre, list_acc = meda.fit_predict(Xs, Ys, Xt, Yt)
print(acc)
================================================
FILE: code/traditional/MEDA/matlab/GFK_Map.m
================================================
function [Xs_new,Xt_new,G] = GFK_Map(Xs,Xt,dim)
Ps = pca(Xs);
Pt = pca(Xt);
G = GFK_core([Ps,null(Ps')], Pt(:,1:dim));
sq_G = real(G^(0.5));
Xs_new = (sq_G * Xs')';
Xt_new = (sq_G * Xt')';
end
function G = GFK_core(Q,Pt)
% Input: Q = [Ps, null(Ps')], where Ps is the source subspace, column-wise orthonormal
% Pt: target subsapce, column-wise orthonormal, D-by-d, d < 0.5*D
% Output: G = \int_{0}^1 \Phi(t)\Phi(t)' dt
% ref: Geodesic Flow Kernel for Unsupervised Domain Adaptation.
% B. Gong, Y. Shi, F. Sha, and K. Grauman.
% Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012.
% Contact: Boqing Gong (boqinggo@usc.edu)
N = size(Q,2); %
dim = size(Pt,2);
% compute the principal angles
QPt = Q' * Pt;
[V1,V2,V,Gam,Sig] = gsvd(QPt(1:dim,:), QPt(dim+1:end,:));
V2 = -V2;
theta = real(acos(diag(Gam))); % theta is real in theory. Imaginary part is due to the computation issue.
% compute the geodesic flow kernel
eps = 1e-20;
B1 = 0.5.*diag(1+sin(2*theta)./2./max(theta,eps));
B2 = 0.5.*diag((-1+cos(2*theta))./2./max(theta,eps));
B3 = B2;
B4 = 0.5.*diag(1-sin(2*theta)./2./max(theta,eps));
G = Q * [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2] ...
* [B1,B2,zeros(dim,N-2*dim);B3,B4,zeros(dim,N-2*dim);zeros(N-2*dim,N)]...
* [V1, zeros(dim,N-dim); zeros(N-dim,dim), V2]' * Q';
end
================================================
FILE: code/traditional/MEDA/matlab/MEDA.m
================================================
function [Acc,acc_iter,Beta,Yt_pred] = MEDA(Xs,Ys,Xt,Yt,options)
% Reference:
%% Jindong Wang, Wenjie Feng, Yiqiang Chen, Han Yu, Meiyu Huang, Philip S.
%% Yu. Visual Domain Adaptation with Manifold Embedded Distribution
%% Alignment. ACM Multimedia conference 2018.
%% Inputs:
%%% Xs : Source domain feature matrix, n * dim
%%% Ys : Source domain label matrix, n * 1
%%% Xt : Target domain feature matrix, m * dim
%%% Yt : Target domain label matrix, m * 1 (only used for testing accuracy)
%%% options : algorithm options:
%%%%% options.d : dimension after manifold feature learning (default: 20)
%%%%% options.T : number of iteration (default: 10)
%%%%% options.lambda : lambda in the paper (default: 10)
%%%%% options.eta : eta in the paper (default: 0.1)
%%%%% options.rho : rho in the paper (default: 1.0)
%%%%% options.base : base classifier for soft labels (default: NN)
%% Outputs:
%%%% Acc : Final accuracy value
%%%% acc_iter : Accuracy value list of all iterations, T * 1
%%%% Beta : Cofficient matrix
%%%% Yt_pred : Prediction labels for target domain
%% Algorithm starts here
fprintf('MEDA starts...\n');
%% Load algorithm options
if ~isfield(options,'p')
options.p = 10;
end
if ~isfield(options,'eta')
options.eta = 0.1;
end
if ~isfield(options,'lambda')
options.lambda = 1.0;
end
if ~isfield(options,'rho')
options.rho = 1.0;
end
if ~isfield(options,'T')
options.T = 10;
end
if ~isfield(options,'d')
options.d = 20;
end
% Manifold feature learning
[Xs_new,Xt_new,~] = GFK_Map(Xs,Xt,options.d);
Xs = double(Xs_new');
Xt = double(Xt_new');
X = [Xs,Xt];
n = size(Xs,2);
m = size(Xt,2);
C = length(unique(Ys));
acc_iter = [];
YY = [];
for c = 1 : C
YY = [YY,Ys==c];
end
YY = [YY;zeros(m,C)];
%% Data normalization
X = X * diag(sparse(1 ./ sqrt(sum(X.^2))));
%% Construct graph Laplacian
if options.rho > 0
manifold.k = options.p;
manifold.Metric = 'Cosine';
manifold.NeighborMode = 'KNN';
manifold.WeightMode = 'Cosine';
W = lapgraph(X',manifold);
Dw = diag(sparse(sqrt(1 ./ sum(W))));
L = eye(n + m) - Dw * W * Dw;
else
L = 0;
end
% Generate soft labels for the target domain
knn_model = fitcknn(X(:,1:n)',Ys,'NumNeighbors',1);
Cls = knn_model.predict(X(:,n + 1:end)');
% Construct kernel
K = kernel_meda('rbf',X,sqrt(sum(sum(X .^ 2).^0.5)/(n + m)));
E = diag(sparse([ones(n,1);zeros(m,1)]));
for t = 1 : options.T
% Estimate mu
mu = estimate_mu(Xs',Ys,Xt',Cls);
% Construct MMD matrix
e = [1 / n * ones(n,1); -1 / m * ones(m,1)];
M = e * e' * length(unique(Ys));
N = 0;
for c = reshape(unique(Ys),1,length(unique(Ys)))
e = zeros(n + m,1);
e(Ys == c) = 1 / length(find(Ys == c));
e(n + find(Cls == c)) = -1 / length(find(Cls == c));
e(isinf(e)) = 0;
N = N + e * e';
end
M = (1 - mu) * M + mu * N;
M = M / norm(M,'fro');
% Compute coefficients vector Beta
Beta = ((E + options.lambda * M + options.rho * L) * K + options.eta * speye(n + m,n + m)) \ (E * YY);
F = K * Beta;
[~,Cls] = max(F,[],2);
%% Compute accuracy
Acc = numel(find(Cls(n+1:end)==Yt)) / m;
Cls = Cls(n+1:end);
acc_iter = [acc_iter;Acc];
fprintf('Iteration:[%02d]>>mu=%.2f,Acc=%f\n',t,mu,Acc);
end
Yt_pred = Cls;
fprintf('MEDA ends!\n');
end
function K = kernel_meda(ker,X,sigma)
switch ker
case 'linear'
K = X' * X;
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
K = exp(-D/(2*sigma^2));
case 'sam'
D = X'*X;
K = exp(-acos(D).^2/(2*sigma^2));
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/traditional/MEDA/matlab/README.md
================================================
# MEDA: Manifold Embedded Distribution Alignment
This is the official Matlab code for MEDA.
## Usage
After download the data from [here](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA#office-31-dataset), you can run `demo_office_caltech_surf.m`.
More results can be found in [here](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA)
================================================
FILE: code/traditional/MEDA/matlab/demo_office_caltech_surf.m
================================================
% DEMO for testing MEDA on Office+Caltech10 datasets
str_domains = {'Caltech10', 'amazon', 'webcam', 'dslr'};
list_acc = [];
for i = 1 : 4
for j = 1 : 4
if i == j
continue;
end
src = str_domains{i};
tgt = str_domains{j};
load(['data/' src '_SURF_L10.mat']); % source domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xs = zscore(fts,1); clear fts
Ys = labels; clear labels
load(['data/' tgt '_SURF_L10.mat']); % target domain
fts = fts ./ repmat(sum(fts,2),1,size(fts,2));
Xt = zscore(fts,1); clear fts
Yt = labels; clear labels
% meda
options.d = 20;
options.rho = 1.0;
options.p = 10;
options.lambda = 10.0;
options.eta = 0.1;
options.T = 10;
[Acc,~,~,~] = MEDA(Xs,Ys,Xt,Yt,options);
fprintf('%s --> %s: %.2f accuracy \n\n', src, tgt, Acc * 100);
end
end
================================================
FILE: code/traditional/MEDA/matlab/estimate_mu.m
================================================
function [mu,adist_m,adist_c] = estimate_mu(Xs,Ys,Xt,Yt)
C = length(unique(Ys));
list_adist_c = [];
epsilon = 1e-3;
for i = 1 : C
index_i = Ys == i;
Xsi = Xs(index_i,:);
index_j = Yt == i;
Xtj = Xt(index_j,:);
adist_i = adist(Xsi,Xtj);
list_adist_c = [list_adist_c;adist_i];
end
adist_c = mean(list_adist_c);
adist_m = adist(Xs,Xt);
mu = adist_c / (adist_c + adist_m);
if mu > 1 % Theoretically mu <= 1, but calculation may be over 1
mu = 1;
elseif mu <= epsilon
mu = 0;
end
end
function dist = adist(Xs,Xt)
Yss = ones(size(Xs,1),1);
Ytt = ones(size(Xt,1),1) * 2;
% The results of fitclinear() may vary in a very small range, since Matlab uses SGD to optimize SVM.
% The fluctuation is very small, ignore it
model_linear = fitclinear([Xs;Xt],[Yss;Ytt],'learner','svm');
ypred = model_linear.predict([Xs;Xt]);
error = mae([Yss;Ytt],ypred);
dist = 2 * (1 - 2 * error);
end
================================================
FILE: code/traditional/MEDA/matlab/lapgraph.m
================================================
function [W, elapse] = lapgraph(fea,options)
% Usage:
% W = graph(fea,options)
%
% fea: Rows of vectors of data points. Each row is x_i
% options: Struct value in Matlab. The fields in options that can be set:
% Metric - Choices are:
% 'Euclidean' - Will use the Euclidean distance of two data
% points to evaluate the "closeness" between
% them. [Default One]
% 'Cosine' - Will use the cosine value of two vectors
% to evaluate the "closeness" between them.
% A popular similarity measure used in
% Information Retrieval.
%
% NeighborMode - Indicates how to construct the graph. Choices
% are: [Default 'KNN']
% 'KNN' - k = 0
% Complete graph
% k > 0
% Put an edge between two nodes if and
% only if they are among the k nearst
% neighbors of each other. You are
% required to provide the parameter k in
% the options. Default k=5.
% 'Supervised' - k = 0
% Put an edge between two nodes if and
% only if they belong to same class.
% k > 0
% Put an edge between two nodes if
% they belong to same class and they
% are among the k nearst neighbors of
% each other.
% Default: k=0
% You are required to provide the label
% information gnd in the options.
%
% WeightMode - Indicates how to assign weights for each edge
% in the graph. Choices are:
% 'Binary' - 0-1 weighting. Every edge receiveds weight
% of 1. [Default One]
% 'HeatKernel' - If nodes i and j are connected, put weight
% W_ij = exp(-norm(x_i - x_j)/2t^2). This
% weight mode can only be used under
% 'Euclidean' metric and you are required to
% provide the parameter t.
% 'Cosine' - If nodes i and j are connected, put weight
% cosine(x_i,x_j). Can only be used under
% 'Cosine' metric.
%
% k - The parameter needed under 'KNN' NeighborMode.
% Default will be 5.
% gnd - The parameter needed under 'Supervised'
% NeighborMode. Colunm vector of the label
% information for each data point.
% bLDA - 0 or 1. Only effective under 'Supervised'
% NeighborMode. If 1, the graph will be constructed
% to make LPP exactly same as LDA. Default will be
% 0.
% t - The parameter needed under 'HeatKernel'
% WeightMode. Default will be 1
% bNormalized - 0 or 1. Only effective under 'Cosine' metric.
% Indicates whether the fea are already be
% normalized to 1. Default will be 0
% bSelfConnected - 0 or 1. Indicates whether W(i,i) == 1. Default 1
% if 'Supervised' NeighborMode & bLDA == 1,
% bSelfConnected will always be 1. Default 1.
%
%
% Examples:
%
% fea = rand(50,15);
% options = [];
% options.Metric = 'Euclidean';
% options.NeighborMode = 'KNN';
% options.k = 5;
% options.WeightMode = 'HeatKernel';
% options.t = 1;
% W = constructW(fea,options);
%
%
% fea = rand(50,15);
% gnd = [ones(10,1);ones(15,1)*2;ones(10,1)*3;ones(15,1)*4];
% options = [];
% options.Metric = 'Euclidean';
% options.NeighborMode = 'Supervised';
% options.gnd = gnd;
% options.WeightMode = 'HeatKernel';
% options.t = 1;
% W = constructW(fea,options);
%
%
% fea = rand(50,15);
% gnd = [ones(10,1);ones(15,1)*2;ones(10,1)*3;ones(15,1)*4];
% options = [];
% options.Metric = 'Euclidean';
% options.NeighborMode = 'Supervised';
% options.gnd = gnd;
% options.bLDA = 1;
% W = constructW(fea,options);
%
%
% For more details about the different ways to construct the W, please
% refer:
% Deng Cai, Xiaofei He and Jiawei Han, "Document Clustering Using
% Locality Preserving Indexing" IEEE TKDE, Dec. 2005.
%
%
% Written by Deng Cai (dengcai2 AT cs.uiuc.edu), April/2004, Feb/2006,
% May/2007
%
if (~exist('options','var'))
options = [];
else
if ~isstruct(options)
error('parameter error!');
end
end
%=================================================
if ~isfield(options,'Metric')
options.Metric = 'Cosine';
end
switch lower(options.Metric)
case {lower('Euclidean')}
case {lower('Cosine')}
if ~isfield(options,'bNormalized')
options.bNormalized = 0;
end
otherwise
error('Metric does not exist!');
end
%=================================================
if ~isfield(options,'NeighborMode')
options.NeighborMode = 'KNN';
end
switch lower(options.NeighborMode)
case {lower('KNN')} %For simplicity, we include the data point itself in the kNN
if ~isfield(options,'k')
options.k = 5;
end
case {lower('Supervised')}
if ~isfield(options,'bLDA')
options.bLDA = 0;
end
if options.bLDA
options.bSelfConnected = 1;
end
if ~isfield(options,'k')
options.k = 0;
end
if ~isfield(options,'gnd')
error('Label(gnd) should be provided under ''Supervised'' NeighborMode!');
end
if ~isempty(fea) && length(options.gnd) ~= size(fea,1)
error('gnd doesn''t match with fea!');
end
otherwise
error('NeighborMode does not exist!');
end
%=================================================
if ~isfield(options,'WeightMode')
options.WeightMode = 'Binary';
end
bBinary = 0;
switch lower(options.WeightMode)
case {lower('Binary')}
bBinary = 1;
case {lower('HeatKernel')}
if ~strcmpi(options.Metric,'Euclidean')
warning('''HeatKernel'' WeightMode should be used under ''Euclidean'' Metric!');
options.Metric = 'Euclidean';
end
if ~isfield(options,'t')
options.t = 1;
end
case {lower('Cosine')}
if ~strcmpi(options.Metric,'Cosine')
warning('''Cosine'' WeightMode should be used under ''Cosine'' Metric!');
options.Metric = 'Cosine';
end
if ~isfield(options,'bNormalized')
options.bNormalized = 0;
end
otherwise
error('WeightMode does not exist!');
end
%=================================================
if ~isfield(options,'bSelfConnected')
options.bSelfConnected = 1;
end
%=================================================
tmp_T = cputime;
if isfield(options,'gnd')
nSmp = length(options.gnd);
else
nSmp = size(fea,1);
end
maxM = 62500000; %500M
BlockSize = floor(maxM/(nSmp*3));
if strcmpi(options.NeighborMode,'Supervised')
Label = unique(options.gnd);
nLabel = length(Label);
if options.bLDA
G = zeros(nSmp,nSmp);
for idx=1:nLabel
classIdx = options.gnd==Label(idx);
G(classIdx,classIdx) = 1/sum(classIdx);
end
W = sparse(G);
elapse = cputime - tmp_T;
return;
end
switch lower(options.WeightMode)
case {lower('Binary')}
if options.k > 0
G = zeros(nSmp*(options.k+1),3);
idNow = 0;
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
D = EuDist2(fea(classIdx,:),[],0);
[dump idx] = sort(D,2); % sort each row
clear D dump;
idx = idx(:,1:options.k+1);
nSmpClass = length(classIdx)*(options.k+1);
G(idNow+1:nSmpClass+idNow,1) = repmat(classIdx,[options.k+1,1]);
G(idNow+1:nSmpClass+idNow,2) = classIdx(idx(:));
G(idNow+1:nSmpClass+idNow,3) = 1;
idNow = idNow+nSmpClass;
clear idx
end
G = sparse(G(:,1),G(:,2),G(:,3),nSmp,nSmp);
G = max(G,G');
else
G = zeros(nSmp,nSmp);
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
G(classIdx,classIdx) = 1;
end
end
if ~options.bSelfConnected
for i=1:size(G,1)
G(i,i) = 0;
end
end
W = sparse(G);
case {lower('HeatKernel')}
if options.k > 0
G = zeros(nSmp*(options.k+1),3);
idNow = 0;
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
D = EuDist2(fea(classIdx,:),[],0);
[dump idx] = sort(D,2); % sort each row
clear D;
idx = idx(:,1:options.k+1);
dump = dump(:,1:options.k+1);
dump = exp(-dump/(2*options.t^2));
nSmpClass = length(classIdx)*(options.k+1);
G(idNow+1:nSmpClass+idNow,1) = repmat(classIdx,[options.k+1,1]);
G(idNow+1:nSmpClass+idNow,2) = classIdx(idx(:));
G(idNow+1:nSmpClass+idNow,3) = dump(:);
idNow = idNow+nSmpClass;
clear dump idx
end
G = sparse(G(:,1),G(:,2),G(:,3),nSmp,nSmp);
else
G = zeros(nSmp,nSmp);
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
D = EuDist2(fea(classIdx,:),[],0);
D = exp(-D/(2*options.t^2));
G(classIdx,classIdx) = D;
end
end
if ~options.bSelfConnected
for i=1:size(G,1)
G(i,i) = 0;
end
end
W = sparse(max(G,G'));
case {lower('Cosine')}
if ~options.bNormalized
[nSmp, nFea] = size(fea);
if issparse(fea)
fea2 = fea';
feaNorm = sum(fea2.^2,1).^.5;
for i = 1:nSmp
fea2(:,i) = fea2(:,i) ./ max(1e-10,feaNorm(i));
end
fea = fea2';
clear fea2;
else
feaNorm = sum(fea.^2,2).^.5;
for i = 1:nSmp
fea(i,:) = fea(i,:) ./ max(1e-12,feaNorm(i));
end
end
end
if options.k > 0
G = zeros(nSmp*(options.k+1),3);
idNow = 0;
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
D = fea(classIdx,:)*fea(classIdx,:)';
[dump idx] = sort(-D,2); % sort each row
clear D;
idx = idx(:,1:options.k+1);
dump = -dump(:,1:options.k+1);
nSmpClass = length(classIdx)*(options.k+1);
G(idNow+1:nSmpClass+idNow,1) = repmat(classIdx,[options.k+1,1]);
G(idNow+1:nSmpClass+idNow,2) = classIdx(idx(:));
G(idNow+1:nSmpClass+idNow,3) = dump(:);
idNow = idNow+nSmpClass;
clear dump idx
end
G = sparse(G(:,1),G(:,2),G(:,3),nSmp,nSmp);
else
G = zeros(nSmp,nSmp);
for i=1:nLabel
classIdx = find(options.gnd==Label(i));
G(classIdx,classIdx) = fea(classIdx,:)*fea(classIdx,:)';
end
end
if ~options.bSelfConnected
for i=1:size(G,1)
G(i,i) = 0;
end
end
W = sparse(max(G,G'));
otherwise
error('WeightMode does not exist!');
end
elapse = cputime - tmp_T;
return;
end
if strcmpi(options.NeighborMode,'KNN') && (options.k > 0)
if strcmpi(options.Metric,'Euclidean')
G = zeros(nSmp*(options.k+1),3);
for i = 1:ceil(nSmp/BlockSize)
if i == ceil(nSmp/BlockSize)
smpIdx = (i-1)*BlockSize+1:nSmp;
dist = EuDist2(fea(smpIdx,:),fea,0);
dist = full(dist);
[dump idx] = sort(dist,2); % sort each row
idx = idx(:,1:options.k+1);
dump = dump(:,1:options.k+1);
if ~bBinary
dump = exp(-dump/(2*options.t^2));
end
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),1) = repmat(smpIdx',[options.k+1,1]);
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),2) = idx(:);
if ~bBinary
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),3) = dump(:);
else
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),3) = 1;
end
else
smpIdx = (i-1)*BlockSize+1:i*BlockSize;
dist = EuDist2(fea(smpIdx,:),fea,0);
dist = full(dist);
[dump idx] = sort(dist,2); % sort each row
idx = idx(:,1:options.k+1);
dump = dump(:,1:options.k+1);
if ~bBinary
dump = exp(-dump/(2*options.t^2));
end
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),1) = repmat(smpIdx',[options.k+1,1]);
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),2) = idx(:);
if ~bBinary
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),3) = dump(:);
else
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),3) = 1;
end
end
end
W = sparse(G(:,1),G(:,2),G(:,3),nSmp,nSmp);
else
if ~options.bNormalized
[nSmp, nFea] = size(fea);
if issparse(fea)
fea2 = fea';
clear fea;
for i = 1:nSmp
fea2(:,i) = fea2(:,i) ./ max(1e-10,sum(fea2(:,i).^2,1).^.5);
end
fea = fea2';
clear fea2;
else
feaNorm = sum(fea.^2,2).^.5;
for i = 1:nSmp
fea(i,:) = fea(i,:) ./ max(1e-12,feaNorm(i));
end
end
end
G = zeros(nSmp*(options.k+1),3);
for i = 1:ceil(nSmp/BlockSize)
if i == ceil(nSmp/BlockSize)
smpIdx = (i-1)*BlockSize+1:nSmp;
dist = fea(smpIdx,:)*fea';
dist = full(dist);
[dump idx] = sort(-dist,2); % sort each row
idx = idx(:,1:options.k+1);
dump = -dump(:,1:options.k+1);
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),1) = repmat(smpIdx',[options.k+1,1]);
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),2) = idx(:);
G((i-1)*BlockSize*(options.k+1)+1:nSmp*(options.k+1),3) = dump(:);
else
smpIdx = (i-1)*BlockSize+1:i*BlockSize;
dist = fea(smpIdx,:)*fea';
dist = full(dist);
[dump idx] = sort(-dist,2); % sort each row
idx = idx(:,1:options.k+1);
dump = -dump(:,1:options.k+1);
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),1) = repmat(smpIdx',[options.k+1,1]);
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),2) = idx(:);
G((i-1)*BlockSize*(options.k+1)+1:i*BlockSize*(options.k+1),3) = dump(:);
end
end
W = sparse(G(:,1),G(:,2),G(:,3),nSmp,nSmp);
end
if strcmpi(options.WeightMode,'Binary')
W(find(W)) = 1;
end
if isfield(options,'bSemiSupervised') && options.bSemiSupervised
tmpgnd = options.gnd(options.semiSplit);
Label = unique(tmpgnd);
nLabel = length(Label);
G = zeros(sum(options.semiSplit),sum(options.semiSplit));
for idx=1:nLabel
classIdx = tmpgnd==Label(idx);
G(classIdx,classIdx) = 1;
end
Wsup = sparse(G);
if ~isfield(options,'SameCategoryWeight')
options.SameCategoryWeight = 1;
end
W(options.semiSplit,options.semiSplit) = (Wsup>0)*options.SameCategoryWeight;
end
if ~options.bSelfConnected
for i=1:size(W,1)
W(i,i) = 0;
end
end
W = max(W,W');
elapse = cputime - tmp_T;
return;
end
% strcmpi(options.NeighborMode,'KNN') & (options.k == 0)
% Complete Graph
if strcmpi(options.Metric,'Euclidean')
W = EuDist2(fea,[],0);
W = exp(-W/(2*options.t^2));
else
if ~options.bNormalized
% feaNorm = sum(fea.^2,2).^.5;
% fea = fea ./ repmat(max(1e-10,feaNorm),1,size(fea,2));
[nSmp, nFea] = size(fea);
if issparse(fea)
fea2 = fea';
feaNorm = sum(fea2.^2,1).^.5;
for i = 1:nSmp
fea2(:,i) = fea2(:,i) ./ max(1e-10,feaNorm(i));
end
fea = fea2';
clear fea2;
else
feaNorm = sum(fea.^2,2).^.5;
for i = 1:nSmp
fea(i,:) = fea(i,:) ./ max(1e-12,feaNorm(i));
end
end
end
% W = full(fea*fea');
W = fea*fea';
end
if ~options.bSelfConnected
for i=1:size(W,1)
W(i,i) = 0;
end
end
W = max(W,W');
elapse = cputime - tmp_T;
function D = EuDist2(fea_a,fea_b,bSqrt)
% Euclidean Distance matrix
% D = EuDist(fea_a,fea_b)
% fea_a: nSample_a * nFeature
% fea_b: nSample_b * nFeature
% D: nSample_a * nSample_a
% or nSample_a * nSample_b
if ~exist('bSqrt','var')
bSqrt = 1;
end
if (~exist('fea_b','var')) | isempty(fea_b)
[nSmp, nFea] = size(fea_a);
aa = sum(fea_a.*fea_a,2);
ab = fea_a*fea_a';
aa = full(aa);
ab = full(ab);
if bSqrt
D = sqrt(repmat(aa, 1, nSmp) + repmat(aa', nSmp, 1) - 2*ab);
D = real(D);
else
D = repmat(aa, 1, nSmp) + repmat(aa', nSmp, 1) - 2*ab;
end
D = max(D,D');
D = D - diag(diag(D));
D = abs(D);
else
[nSmp_a, nFea] = size(fea_a);
[nSmp_b, nFea] = size(fea_b);
aa = sum(fea_a.*fea_a,2);
bb = sum(fea_b.*fea_b,2);
ab = fea_a*fea_b';
aa = full(aa);
bb = full(bb);
ab = full(ab);
if bSqrt
D = sqrt(repmat(aa, 1, nSmp_b) + repmat(bb', nSmp_a, 1) - 2*ab);
D = real(D);
else
D = repmat(aa, 1, nSmp_b) + repmat(bb', nSmp_a, 1) - 2*ab;
end
D = abs(D);
end
================================================
FILE: code/traditional/MEDA/readme.md
================================================
# MEDA: Manifold Embedded Distribution Alignment
This directory contains the code for paper [Visual Domain Adaptation with Manifold Embedded Distribution Alignment](http://jd92.wang/assets/files/a11_mm18.pdf) published at ACM Multimedia conference (ACM MM) 2018 as an Oral presentation. This paper is also lucky to be ranked as **Top 10 papers**.
## Usage
The original code is written using Matlab R2017a. I think all versions after 2015 can run the code.
For Python users, I add a `MEDA.py` implementation. The Python version will need to import GFK module (can be found [here](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/GFK)). However, this Python version is only for reference since the graph Laplacian (as exactly in Matlab) is not implemented.
**For deep version (DeepMEDA), see [here](https://github.com/jindongwang/transferlearning/tree/master/code/deep/DeepMEDA)!**
## Demo
I offer a basic demo to run on the Office+Caltech10 + surf datasets. Download the datasets [here](https://www.jianguoyun.com/p/DYROSb8QjKnsBRjxwJUE) (access code: j5qnvr) and put the data (mat files) into the `data` folder.
Run `demo_office_caltech_surf.m`.
## Results
MEDA achieved **state-of-the-art** performances compared to a lot of traditional and deep methods as of 2018. The testing datasets are most popular domain adaptation and transfer learning datasets: Office+Caltech10, Office-31, USPS+MNIST, ImageNet+VOC2007.
The following results are from the original paper and its [supplementary file](https://www.jianguoyun.com/p/DRuWOFkQjKnsBRjkr2E).
## Office-31 dataset
Using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). It seems **MEDA** is the only traditional method that can challenge these heavy deep adversarial methods.
[Download Office-31 ResNet-50 features](https://pan.baidu.com/s/1UoyJSqoCKCda-NcP-zraVg)
| | Method | A - W | D - W | W-D | A - D | D - A | W-A | AVG |
|---------|-----------|-------|-------|--------|-------|-------|-------|-------|
| cvpr16 | ResNet-50 | 68.4 | 96.7 | 99.3 | 68.9 | 62.5 | 60.7 | 76.1 |
| icml15 | DAN | 80.5 | 97.1 | 99.6 | 78.6 | 63.6 | 62.8 | 80.4 |
| nips16 | RTN | 84.5 | 96.8 | 99.4 | 77.5 | 66.2 | 64.8 | 81.6 |
| icml15 | DANN | 82.0 | 96.9 | 99.1 | 79.7 | 68.2 | 67.4 | 82.2 |
| cvpr17 | ADDA | 86.2 | 96.2 | 98.4 | 77.8 | 69.5 | 68.9 | 82.9 |
| icml17 | JAN | 85.4 | 97.4 | 99.8 | 84.7 | 68.6 | 70.0 | 84.3 |
| cvpr17 | GTA | 89.5 | 97.9 | 99.8 | 87.7 | 72.8 | 71.4 | 86.5 |
| nips18 | CDAN-RM | 93.0 | 98.4 | 100.0 | 89.2 | 70.2 | 67.4 | 86.4 |
| nips18 | CDAN-M | 93.1 | 98.6 | 100.0 | 92.9 | 71.0 | 69.3 | 87.5 |
| cvpr18 | CAN | 81.5 | 63.4 | 85.5 | 65.9 | 99.7 | 98.2 | 82.4 |
| aaai19 | JDDA | 82.6 | 95.2 | 99.7 | 79.8 | 57.4 | 66.7 | 80.2 |
| aaai18 | MADA | 90.1 | 97.4 | 99.6 | 87.8 | 70.3 | 66.4 | 85.2 |
| ACMMM18 | MEDA | 86.2 | 97.2 | 99.4 | 85.3 | 72.4 | 74.0 | 85.7 |
## Office-Home
Using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). Again, it seems that **MEDA** achieves the best performance.
[Download Office-Home ResNet-50 pretrained features](https://pan.baidu.com/s/1qvcWJCXVG8JkZnoM4BVoGg)
| | Method | Ar-Cl | Ar-Pr | Ar-Rw | Cl-Ar | Cl-Pr | Cl-Rw | Pr-Ar | Pr-Cl | Pr-Rw | Rw-Ar | Rw-Cl | Rw-Pr | Avg |
|---------|-----------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|
| | AlexNet | 26.4 | 32.6 | 41.3 | 22.1 | 41.7 | 42.1 | 20.5 | 20.3 | 51.1 | 31.0 | 27.9 | 54.9 | 34.3 |
| icml15 | DAN | 31.7 | 43.2 | 55.1 | 33.8 | 48.6 | 50.8 | 30.1 | 35.1 | 57.7 | 44.6 | 39.3 | 63.7 | 44.5 |
| icml15 | DANN | 36.4 | 45.2 | 54.7 | 35.2 | 51.8 | 55.1 | 31.6 | 39.7 | 59.3 | 45.7 | 46.4 | 65.9 | 47.3 |
| icml17 | JAN | 35.5 | 46.1 | 57.7 | 36.4 | 53.3 | 54.5 | 33.4 | 40.3 | 60.1 | 45.9 | 47.4 | 67.9 | 48.2 |
| nips18 | CDAN-RM | 36.2 | 47.3 | 58.6 | 37.3 | 54.4 | 58.3 | 33.2 | 43.9 | 62.1 | 48.2 | 48.1 | 70.7 | 49.9 |
| nips18 | CDAN-M | 38.1 | 50.3 | 60.3 | 39.7 | 56.4 | 57.8 | 35.5 | 43.1 | 63.2 | 48.4 | 48.5 | 71.1 | 51.0 |
| cvpr16 | ResNet-50 | 34.9 | 50.0 | 58.0 | 37.4 | 41.9 | 46.2 | 38.5 | 31.2 | 60.4 | 53.9 | 41.2 | 59.9 | 46.1 |
| icml15 | DAN | 43.6 | 57.0 | 67.9 | 45.8 | 56.5 | 60.4 | 44.0 | 43.6 | 67.7 | 63.1 | 51.5 | 74.3 | 56.3 |
| icml15 | DANN | 45.6 | 59.3 | 70.1 | 47.0 | 58.5 | 60.9 | 46.1 | 43.7 | 68.5 | 63.2 | 51.8 | 76.8 | 57.6 |
| icml17 | JAN | 45.9 | 61.2 | 68.9 | 50.4 | 59.7 | 61.0 | 45.8 | 43.4 | 70.3 | 63.9 | 52.4 | 76.8 | 58.3 |
| nips18 | CDAN-RM | 49.2 | 64.8 | 72.9 | 53.8 | 62.4 | 62.9 | 49.8 | 48.8 | 71.5 | 65.8 | 56.4 | 79.2 | 61.5 |
| nips18 | CDAN-M | 50.6 | 65.9 | 73.4 | 55.7 | 62.7 | 64.2 | 51.8 | 49.1 | 74.5 | 68.2 | 56.9 | 80.7 | 62.8 |
| ACMMM18 | MEDA | **54.6** | **75.2** | **77.0** | **56.5** | **72.8** | **72.3** | **59.0** | **51.9** | **78.2** | 67.7 | **57.2** | **81.8** | **67.0** |
## Image-CLEF DA
using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). Again, it seems that **MEDA** achieves the best performance.
[Download Image-CLEF ResNet-50 pretrained features](https://pan.baidu.com/s/16wBgDJI6drA0oYq537h4FQ)
| Method | I-P | P-I | I-C | C-I | C-P | P-C | Avg |
|-----------|-------|-------|-------|-------|-------|-------|-------|
| AlexNet | 66.2 | 70.0 | 84.3 | 71.3 | 59.3 | 84.5 | 73.9 |
| DAN | 67.3 | 80.5 | 87.7 | 76.0 | 61.6 | 88.4 | 76.9 |
| DANN | 66.5 | 81.8 | 89.0 | 79.8 | 63.5 | 88.7 | 78.2 |
| JAN | 67.2 | 82.8 | 91.3 | 80.0 | 63.5 | 91.0 | 79.3 |
| CDAN-RM | 67.0 | 84.8 | 92.4 | 81.3 | 64.7 | 91.6 | 80.3 |
| CDAN-M | 67.7 | 83.3 | 91.8 | 81.5 | 63.0 | 91.5 | 79.8 |
| ResNet-50 | 74.8 | 83.9 | 91.5 | 78.0 | 65.5 | 91.2 | 80.7 |
| DAN | 74.5 | 82.2 | 92.8 | 86.3 | 69.2 | 89.8 | 82.5 |
| DANN | 75.0 | 86.0 | 96.2 | 87.0 | 74.3 | 91.5 | 85.0 |
| RTN | 75.6 | 86.8 | 95.3 | 86.9 | 72.7 | 92.2 | 84.9 |
| JAN | 76.8 | 88.0 | 94.7 | 89.5 | 74.2 | 91.7 | 85.8 |
| MADA | 75.0 | 87.9 | 96.0 | 88.8 | 75.2 | 92.2 | 85.8 |
| CDAN-RM | 77.2 | 88.3 | **98.3** | 90.7 | 76.7 | 94.0 | 87.5 |
| CDAN-M | 78.3 | 91.2 | 96.7 | 91.2 | 77.2 | 93.7 | 88.1 |
| CAN | 78.2 | 87.5 | 94.2 | 89.5 | 75.8 | 89.2 | 85.7 |
| iCAN | 79.5 | 89.7 | 94.7 | 89.9 | 78.5 | 92.0 | 87.4 |
| MEDA | **79.7** | **92.5** | 95.7 | **92.2** | **78.5** | **95.5** | **89.0** |
- Office-31 dataset using DECAF features (compare with deep methods with AlexNet):
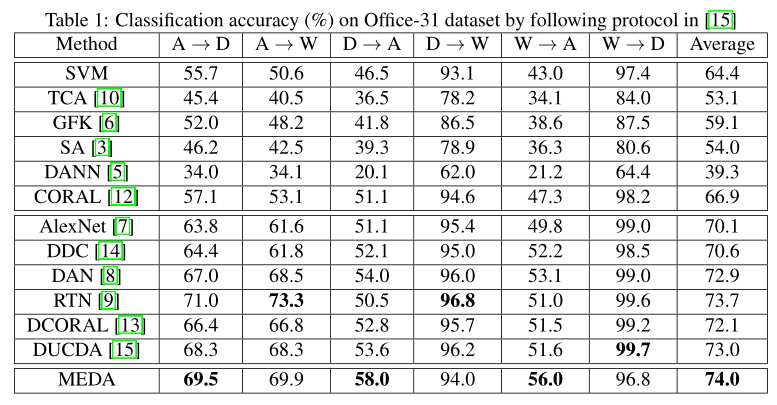
- Office+Caltech 10 datasets and MNIST+USPS and ImageNet+VOC:
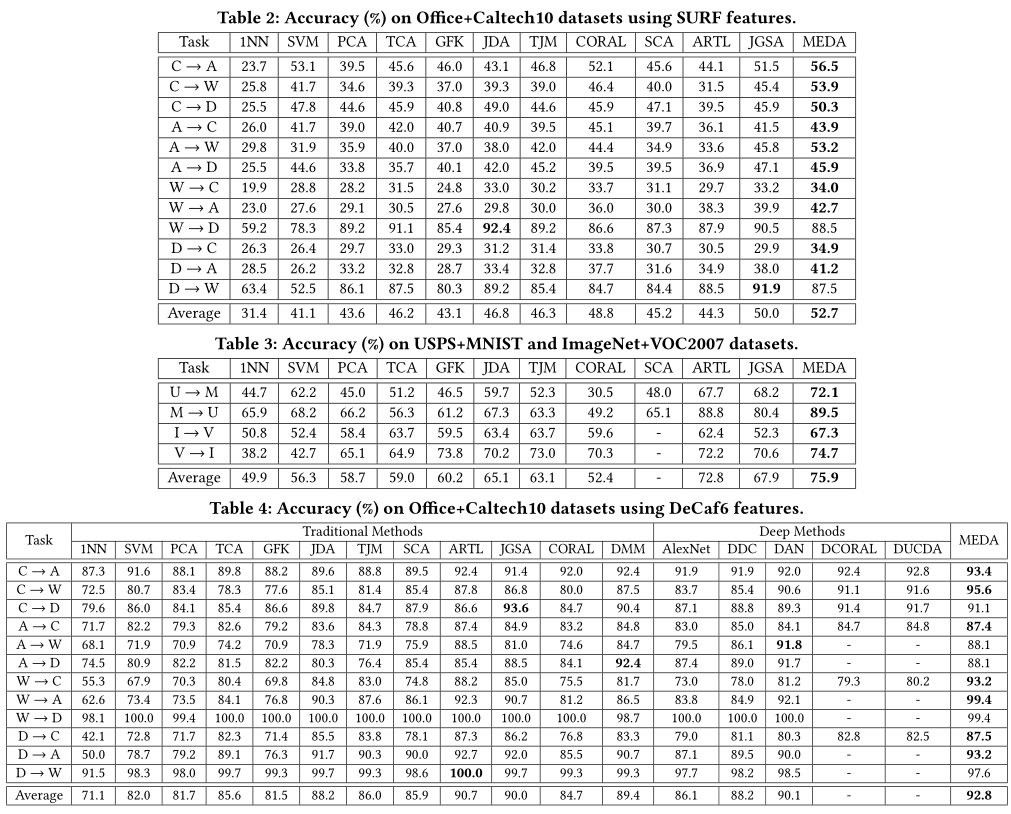
## Reference
If you use this code, please cite it as:
`
Jindong Wang, Wenjie Feng, Yiqiang Chen, Han Yu, Meiyu Huang, Philip S. Yu. Visual Domain Adaptation with Manifold Embedded Distribution Alignment. ACM Multimedia conference 2018.
Wang J, Chen Y, Feng W, et al. Transfer learning with dynamic distribution adaptation[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2020, 11(1): 1-25.
`
Or in bibtex style:
```
@inproceedings{wang2018visual,
title={Visual Domain Adaptation with Manifold Embedded Distribution Alignment},
author={Wang, Jindong and Feng, Wenjie and Chen, Yiqiang and Yu, Han and Huang, Meiyu and Yu, Philip S},
booktitle={ACM Multimedia Conference (ACM MM)},
year={2018}
}
```
```
@article{wang2020transfer,
title={Transfer learning with dynamic distribution adaptation},
author={Wang, Jindong and Chen, Yiqiang and Feng, Wenjie and Yu, Han and Huang, Meiyu and Yang, Qiang},
journal={ACM Transactions on Intelligent Systems and Technology (TIST)},
volume={11},
number={1},
pages={1--25},
year={2020},
publisher={ACM New York, NY, USA}
}
```
================================================
FILE: code/traditional/MyTJM.m
================================================
function [acc,acc_list,A] = MyTJM(X_src,Y_src,X_tar,Y_tar,options)
% This is the implementation of Transfer Joint Matching.
% Reference: Mingsheng Long. Transfer Joing Matching for visual domain adaptation. CVPR 2014.
% Inputs:
%%% X_src : source feature matrix, ns * n_feature
%%% Y_src : source label vector, ns * 1
%%% X_tar : target feature matrix, nt * n_feature
%%% Y_tar : target label vector, nt * 1
%%% options : option struct
%%%%% lambda : regularization parameter
%%%%% dim : dimension after adaptation, dim <= n_feature
%%%%% kernel_tpye : kernel name, choose from 'primal' | 'linear' | 'rbf'
%%%%% gamma : bandwidth for rbf kernel, can be missed for other kernels
%%%%% T : n_iterations, T >= 1. T <= 10 is suffice
% Outputs:
%%% acc : final accuracy using knn, float
%%% acc_list : list of all accuracies during iterations
%%% A : final adaptation matrix, (ns + nt) * (ns + nt)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% Set options
lambda = options.lambda; %% lambda for the regularization
dim = options.dim; %% dim is the dimension after adaptation, dim <= m
kernel_type = options.kernel_type; %% kernel_type is the kernel name, primal|linear|rbf
gamma = options.gamma; %% gamma is the bandwidth of rbf kernel
T = options.T; %% iteration number
fprintf('TJM: dim=%d lambda=%f\n',dim,lambda);
% Set predefined variables
X = [X_src',X_tar'];
X = X*diag(sparse(1./sqrt(sum(X.^2))));
ns = size(X_src,1);
nt = size(X_tar,1);
n = ns+nt;
% Construct kernel matrix
K = kernel_tjm(kernel_type,X,[],gamma);
% Construct centering matrix
H = eye(n)-1/(n)*ones(n,n);
% Construct MMD matrix
e = [1/ns*ones(ns,1);-1/nt*ones(nt,1)];
C = length(unique(Y_src));
M = e*e' * C;
Cls = [];
% Transfer Joint Matching: JTM
G = speye(n);
acc_list = [];
for t = 1:T
%%% Mc [If want to add conditional distribution]
N = 0;
if ~isempty(Cls) && length(Cls)==nt
for c = reshape(unique(Y_src),1,C)
e = zeros(n,1);
e(Y_src==c) = 1 / length(find(Y_src==c));
e(ns+find(Cls==c)) = -1 / length(find(Cls==c));
e(isinf(e)) = 0;
N = N + e*e';
end
end
M = M + N;
M = M/norm(M,'fro');
[A,~] = eigs(K*M*K'+lambda*G,K*H*K',dim,'SM');
% [A,~] = eigs(X*M*X'+lambda*G,X*H*X',k,'SM');
G(1:ns,1:ns) = diag(sparse(1./(sqrt(sum(A(1:ns,:).^2,2)+eps))));
Z = A'*K;
Z = Z*diag(sparse(1./sqrt(sum(Z.^2))));
Zs = Z(:,1:ns)';
Zt = Z(:,ns+1:n)';
knn_model = fitcknn(Zs,Y_src,'NumNeighbors',1);
Cls = knn_model.predict(Zt);
acc = sum(Cls==Y_tar)/nt;
acc_list = [acc_list;acc(1)];
fprintf('[%d] acc=%f\n',t,full(acc(1)));
end
fprintf('Algorithm JTM terminated!!!\n\n');
end
% With Fast Computation of the RBF kernel matrix
% To speed up the computation, we exploit a decomposition of the Euclidean distance (norm)
%
% Inputs:
% ker: 'linear','rbf','sam'
% X: data matrix (features * samples)
% gamma: bandwidth of the RBF/SAM kernel
% Output:
% K: kernel matrix
function K = kernel_tjm(ker,X,X2,gamma)
switch ker
case 'linear'
if isempty(X2)
K = X'*X;
else
K = X'*X2;
end
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
if isempty(X2)
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
else
n2sq = sum(X2.^2,1);
n2 = size(X2,2);
D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
end
K = exp(-gamma*D);
case 'sam'
if isempty(X2)
D = X'*X;
else
D = X'*X2;
end
K = exp(-gamma*acos(D).^2);
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/traditional/SA_SVM.m
================================================
%% Subspace Alignment ICCV-13
% Inputs
% Source_Data : normalized source data. Use NormalizeData function to
% normalize the data before
%
% Target_Data :normalized target data. Use NormalizeData function to
% normalize the data before
%
% Xs : source eigenvectors obtained from normalized source data (e.g. PCA)
% Xt : target eigenvectors obtained from normalized source data (e.g. PCA)
%
% Source_label : source class label
% Target_label : target class label
%
%
function [acc,y_pred,time_pass] = SA_SVM(Source_Data,Source_label,Target_Data,Target_label,Xs,Xt)
% Subspace alignment and projections
% NN_Neighbours = 1; % neares neighbour classifier
% predicted_Label = cvKnn(Target_Projected_Data', Target_Aligned_Source_Data', Source_label, NN_Neighbours);
% r=find(predicted_Label==Target_label);
% accuracy_sa_nn = length(r)/length(Target_label)*100;
%
% NN_Neighbours = 1; % neares neighbour classifier
% predicted_Label = cvKnn(Target_Data', Source_Data', Source_label, NN_Neighbours);
% r=find(predicted_Label==Target_label);
% accuracy_na_nn = length(r)/length(Target_label)*100;
time_start = clock();
A = (Xs*Xs')*(Xt*Xt');
Sim = Source_Data * A * Target_Data';
[acc,y_pred] = SVM_Accuracy (Source_Data, A,Target_label,Sim,Source_label);
time_end = clock();
% accuracy_na_svm = LinAccuracy(Source_Data,Target_Data,Source_label,Target_label) ;
time_pass = etime(time_end,time_start);
end
function Data = NormalizeData(Data)
Data = Data ./ repmat(sum(Data,2),1,size(Data,2));
Data = zscore(Data,1);
end
function [res,predicted_label] = SVM_Accuracy (trainset, M,testlabelsref,Sim,trainlabels)
Sim_Trn = trainset * M * trainset';
index = [1:1:size(Sim,1)]';
Sim = [[1:1:size(Sim,2)]' Sim'];
Sim_Trn = [index Sim_Trn ];
C = [0.001 0.01 0.1 1.0 10 100 1000 10000];
parfor i = 1 :size(C,2)
model(i) = libsvmtrain(trainlabels, Sim_Trn, sprintf('-t 4 -c %d -v 2 -q',C(i)));
end
[val indx]=max(model);
CVal = C(indx);
model = libsvmtrain(trainlabels, Sim_Trn, sprintf('-t 4 -c %d -q',CVal));
[predicted_label, accuracy, decision_values] = svmpredict(testlabelsref, Sim, model);
res = accuracy(1,1);
end
function acc = LinAccuracy(trainset,testset,trainlbl,testlbl)
model = trainSVM_Model(trainset,trainlbl);
[predicted_label, accuracy, decision_values] = svmpredict(testlbl, testset, model);
acc = accuracy(1,1);
end
function svmmodel = trainSVM_Model(trainset,trainlbl)
C = [0.001 0.01 0.1 1.0 10 100 ];
parfor i = 1 :size(C,2)
model(i) = libsvmtrain(double(trainlbl), sparse(double((trainset))),sprintf('-c %d -q -v 2',C(i) ));
end
[val indx]=max(model);
CVal = C(indx);
svmmodel = libsvmtrain(double(trainlbl), sparse(double((trainset))),sprintf('-c %d -q',CVal));
end
================================================
FILE: code/traditional/SCL.py
================================================
import numpy as np
import scipy as sp
import sklearn
from sklearn import linear_model
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
class SCL(object):
'''
class of structural correspondence learning
'''
def __init__(self, l2=1.0, num_pivots=10, base_classifer=LinearSVC()):
self.l2 = l2
self.num_pivots = num_pivots
self.W = 0
self.base_classifer = base_classifer
# self.train_data_dim = None
def fit(self, Xs, Xt):
'''
find pivot features and transfer the Xs and Xt
Param Xs: source data
Param Xt: target data
output Xs_new: new source data features
output Xt_new: new target data features
output W: transform matrix
'''
_, ds = Xs.shape
_, dt = Xt.shape
assert ds == dt
X = np.concatenate((Xs, Xt), axis=0)
ix = np.argsort(np.sum(X, axis=0))
ix = ix[::-1][:self.num_pivots]
pivots = (X[:, ix]>0).astype('float')
p = np.zeros((ds, self.num_pivots))
# train for the classifers
for i in range(self.num_pivots):
clf = linear_model.SGDClassifier(loss="modified_huber", alpha=self.l2)
clf.fit(X, pivots[:, i])
p[:, i] = clf.coef_
_, W = np.linalg.eig(np.cov(p))
W = W[:, :self.num_pivots].astype('float')
self.W = W
Xs_new = np.concatenate((np.dot(Xs, W), Xs), axis=1)
Xt_new = np.concatenate((np.dot(Xt, W), Xt), axis=1)
return Xs_new, Xt_new, W
def transform(self, X):
'''
transform the origianl data by add new features
Param X: original data
output x_new: X with new features
'''
X_new = np.concatenate((np.dot(X, self.W),X), axis=1)
return X_new
def fit_predict(self, Xs, Xt, X_test, Ys, Y_test):
self.fit(Xs, Xt)
Xs = self.transform(Xs)
self.base_classifer.fit(Xs, Ys)
X_test = self.transform(X_test)
y_pred = self.base_classifer.predict(X_test)
acc = accuracy_score(Y_test, y_pred)
return acc
================================================
FILE: code/traditional/SFA.py
================================================
import sys
import math
import numpy as np
import scipy.io as sio
import scipy.sparse as sp
from scipy.sparse.linalg import svds as SVD
from sklearn import svm
from sklearn.metrics import accuracy_score
class SFA:
'''
spectrual feature alignment
'''
def __init__(self, l=500, K=100, base_classifer=svm.SVC()):
self.l = l
self.K = K
self.m = 0
self.ut = None
self.phi = 1
self.base_classifer = base_classifer
self.ix = None
self._ix = None
return
def fit(self, Xs, Xt):
ix_s = np.argsort(np.sum(Xs, axis=0))
ix_t = np.argsort(np.sum(Xt, axis=0))
ix_s = ix_s[::-1][:self.l]
ix_t = ix_t[::-1][:self.l]
ix = np.intersect1d(ix_s, ix_t)
_ix = np.setdiff1d(range(Xs.shape[1]), ix)
self.ix = ix
self._ix = _ix
self.m = len(_ix)
self.l = len(ix)
X = np.concatenate((Xs, Xt), axis=0)
DI = (X[:, ix] > 0).astype('float')
DS = (X[:, _ix] > 0).astype('float')
# construct co-occurrence matrix DSxDI
M = np.zeros((self.m, self.l))
for i in range(X.shape[0]):
tem1 = np.reshape(DS[i], (1, self.m))
tem2 = np.reshape(DI[i], (1, self.l))
M += np.matmul(tem1.T, tem2)
M = M/np.linalg.norm(M, 'fro')
# #construct A matrix
# tem_1 = np.zeros((self.m, self.m))
# tem_2 = np.zeros((self.l, self.l))
# A1 = np.concatenate((tem_1, M.T), axis=0)
# A2 = np.concatenate((M, tem_2), axis=0)
# A = np.concatenate((A1, A2), axis=1)
# # compute laplace
# D = np.zeros((A.shape[0], A.shape[1]))
# for i in range(self.l+self.m):
# D[i,i] = 1.0/np.sqrt(np.sum(A[i,:]))
# L = (D.dot(A)).dot(D)
# ut, _, _ = np.linalg.svd(L)
M = sp.lil_matrix(M)
D1 = sp.lil_matrix((self.m, self.m))
D2 = sp.lil_matrix((self.l, self.l))
for i in range(self.m):
D1[i, i] = 1.0/np.sqrt(np.sum(M[1, :]).data[0])
for i in range(self.l):
D2[i, i] = 1.0/np.sqrt(np.sum(M[:, i]).T.data[0])
B = (D1.tocsr().dot(M.tocsr())).dot(D2.tocsr())
# print("Done.")
# print("Computing SVD...")
ut, s, vt = SVD(B.tocsc(), k=self.K)
self.ut = ut
return ut
def transform(self, X):
return np.concatenate((X, X[:, self._ix].dot(self.ut)), axis=1)
def fit_predict(self, Xs, Xt, X_test, Ys, Y_test):
ut = self.fit(Xs, Xt)
Xs = self.transform(Xs)
self.base_classifer.fit(Xs, Ys)
X_test = self.transform(X_test)
y_pred = self.base_classifer.predict(X_test)
acc = accuracy_score(Y_test, y_pred)
return acc
================================================
FILE: code/traditional/SVM.m
================================================
function [acc,y_pred,time_pass] = SVM(Xs,Ys,Xt,Yt)
Xs = double(Xs);
Xt = double(Yt);
time_start = clock();
[acc,y_pred] = LinAccuracy(Xs,Xt,Ys,Yt);
time_end = clock();
time_pass = etime(time_end,time_start);
end
function [acc,predicted_label] = LinAccuracy(trainset,testset,trainlbl,testlbl)
model = trainSVM_Model(trainset,trainlbl);
[predicted_label, accuracy, decision_values] = svmpredict(testlbl, testset, model);
acc = accuracy(1,1);
end
function svmmodel = trainSVM_Model(trainset,trainlbl)
C = [0.001 0.01 0.1 1.0 10 100 ];
parfor i = 1 :size(C,2)
model(i) = libsvmtrain(double(trainlbl), sparse(double((trainset))),sprintf('-c %d -q -v 2',C(i) ));
end
[val indx]=max(model);
CVal = C(indx);
svmmodel = libsvmtrain(double(trainlbl), sparse(double((trainset))),sprintf('-c %d -q',CVal));
end
================================================
FILE: code/traditional/TCA/TCA.m
================================================
function [X_src_new,X_tar_new,A] = TCA(X_src,X_tar,options)
% The is the implementation of Transfer Component Analysis.
% Reference: Sinno Pan et al. Domain Adaptation via Transfer Component Analysis. TNN 2011.
% Inputs:
%%% X_src : source feature matrix, ns * n_feature
%%% X_tar : target feature matrix, nt * n_feature
%%% options : option struct
%%%%% lambda : regularization parameter
%%%%% dim : dimensionality after adaptation (dim <= n_feature)
%%%%% kernel_tpye : kernel name, choose from 'primal' | 'linear' | 'rbf'
%%%%% gamma : bandwidth for rbf kernel, can be missed for other kernels
% Outputs:
%%% X_src_new : transformed source feature matrix, ns * dim
%%% X_tar_new : transformed target feature matrix, nt * dim
%%% A : adaptation matrix, (ns + nt) * (ns + nt)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% Set options
lambda = options.lambda;
dim = options.dim;
kernel_type = options.kernel_type;
gamma = options.gamma;
%% Calculate
X = [X_src',X_tar'];
X = X*diag(sparse(1./sqrt(sum(X.^2))));
[m,n] = size(X);
ns = size(X_src,1);
nt = size(X_tar,1);
e = [1/ns*ones(ns,1);-1/nt*ones(nt,1)];
M = e * e';
M = M / norm(M,'fro');
H = eye(n)-1/(n)*ones(n,n);
if strcmp(kernel_type,'primal')
[A,~] = eigs(X*M*X'+lambda*eye(m),X*H*X',dim,'SM');
Z = A' * X;
Z = Z * diag(sparse(1./sqrt(sum(Z.^2))));
X_src_new = Z(:,1:ns)';
X_tar_new = Z(:,ns+1:end)';
else
K = TCA_kernel(kernel_type,X,[],gamma);
[A,~] = eigs(K*M*K'+lambda*eye(n),K*H*K',dim,'SM');
Z = A' * K;
Z = Z*diag(sparse(1./sqrt(sum(Z.^2))));
X_src_new = Z(:,1:ns)';
X_tar_new = Z(:,ns+1:end)';
end
end
% With Fast Computation of the RBF kernel matrix
% To speed up the computation, we exploit a decomposition of the Euclidean distance (norm)
%
% Inputs:
% ker: 'linear','rbf','sam'
% X: data matrix (features * samples)
% gamma: bandwidth of the RBF/SAM kernel
% Output:
% K: kernel matrix
%
% Gustavo Camps-Valls
% 2006(c)
% Jordi (jordi@uv.es), 2007
% 2007-11: if/then -> switch, and fixed RBF kernel
% Modified by Mingsheng Long
% 2013(c)
% Mingsheng Long (longmingsheng@gmail.com), 2013
function K = TCA_kernel(ker,X,X2,gamma)
switch ker
case 'linear'
if isempty(X2)
K = X'*X;
else
K = X'*X2;
end
case 'rbf'
n1sq = sum(X.^2,1);
n1 = size(X,2);
if isempty(X2)
D = (ones(n1,1)*n1sq)' + ones(n1,1)*n1sq -2*X'*X;
else
n2sq = sum(X2.^2,1);
n2 = size(X2,2);
D = (ones(n2,1)*n1sq)' + ones(n1,1)*n2sq -2*X'*X2;
end
K = exp(-gamma*D);
case 'sam'
if isempty(X2)
D = X'*X;
else
D = X'*X2;
end
K = exp(-gamma*acos(D).^2);
otherwise
error(['Unsupported kernel ' ker])
end
end
================================================
FILE: code/traditional/TCA/TCA.py
================================================
# encoding=utf-8
"""
Created on 21:29 2018/11/12
@author: Jindong Wang
"""
import numpy as np
import scipy.io
import scipy.linalg
import sklearn.metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
def kernel(ker, X1, X2, gamma):
K = None
if not ker or ker == 'primal':
K = X1
elif ker == 'linear':
if X2 is not None:
K = sklearn.metrics.pairwise.linear_kernel(
np.asarray(X1).T, np.asarray(X2).T)
else:
K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T)
elif ker == 'rbf':
if X2 is not None:
K = sklearn.metrics.pairwise.rbf_kernel(
np.asarray(X1).T, np.asarray(X2).T, gamma)
else:
K = sklearn.metrics.pairwise.rbf_kernel(
np.asarray(X1).T, None, gamma)
return K
class TCA:
def __init__(self, kernel_type='primal', dim=30, lamb=1, gamma=1):
'''
Init func
:param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'
:param dim: dimension after transfer
:param lamb: lambda value in equation
:param gamma: kernel bandwidth for rbf kernel
'''
self.kernel_type = kernel_type
self.dim = dim
self.lamb = lamb
self.gamma = gamma
def fit(self, Xs, Xt):
'''
Transform Xs and Xt
:param Xs: ns * n_feature, source feature
:param Xt: nt * n_feature, target feature
:return: Xs_new and Xt_new after TCA
'''
X = np.hstack((Xs.T, Xt.T))
X /= np.linalg.norm(X, axis=0)
m, n = X.shape
ns, nt = len(Xs), len(Xt)
e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))
M = e * e.T
M = M / np.linalg.norm(M, 'fro')
H = np.eye(n) - 1 / n * np.ones((n, n))
K = kernel(self.kernel_type, X, None, gamma=self.gamma)
n_eye = m if self.kernel_type == 'primal' else n
a, b = K @ M @ K.T + self.lamb * np.eye(n_eye), K @ H @ K.T
w, V = scipy.linalg.eig(a, b)
ind = np.argsort(w)
A = V[:, ind[:self.dim]]
Z = A.T @ K
Z /= np.linalg.norm(Z, axis=0)
Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T
return Xs_new, Xt_new
def fit_predict(self, Xs, Ys, Xt, Yt):
'''
Transform Xs and Xt, then make predictions on target using 1NN
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt: nt * n_feature, target feature
:param Yt: nt * 1, target label
:return: Accuracy and predicted_labels on the target domain
'''
Xs_new, Xt_new = self.fit(Xs, Xt)
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
y_pred = clf.predict(Xt_new)
acc = sklearn.metrics.accuracy_score(Yt, y_pred)
return acc, y_pred
# TCA code is done here. You can ignore fit_new and fit_predict_new.
def fit_new(self, Xs, Xt, Xt2):
'''
Map Xt2 to the latent space created from Xt and Xs
:param Xs : ns * n_feature, source feature
:param Xt : nt * n_feature, target feature
:param Xt2: n_s, n_feature, target feature to be mapped
:return: Xt2_new, mapped Xt2 with projection created by Xs and Xt
'''
# Computing projection matrix A from Xs an Xt
X = np.hstack((Xs.T, Xt.T))
X /= np.linalg.norm(X, axis=0)
m, n = X.shape
ns, nt = len(Xs), len(Xt)
e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))
M = e * e.T
M = M / np.linalg.norm(M, 'fro')
H = np.eye(n) - 1 / n * np.ones((n, n))
K = kernel(self.kernel_type, X, None, gamma=self.gamma)
n_eye = m if self.kernel_type == 'primal' else n
a, b = np.linalg.multi_dot(
[K, M, K.T]) + self.lamb * np.eye(n_eye), np.linalg.multi_dot([K, H, K.T])
w, V = scipy.linalg.eig(a, b)
ind = np.argsort(w)
A = V[:, ind[:self.dim]]
# Compute kernel with Xt2 as target and X as source
Xt2 = Xt2.T
K = kernel(self.kernel_type, X1=Xt2, X2=X, gamma=self.gamma)
# New target features
Xt2_new = K @ A
return Xt2_new
def fit_predict_new(self, Xt, Xs, Ys, Xt2, Yt2):
'''
Transfrom Xt and Xs, get Xs_new
Transform Xt2 with projection matrix created by Xs and Xt, get Xt2_new
Make predictions on Xt2_new using classifier trained on Xs_new
:param Xt: ns * n_feature, target feature
:param Xs: ns * n_feature, source feature
:param Ys: ns * 1, source label
:param Xt2: nt * n_feature, new target feature
:param Yt2: nt * 1, new target label
:return: Accuracy and predicted_labels on the target domain
'''
Xs_new, _ = self.fit(Xs, Xt)
Xt2_new = self.fit_new(Xs, Xt, Xt2)
clf = KNeighborsClassifier(n_neighbors=1)
clf.fit(Xs_new, Ys.ravel())
y_pred = clf.predict(Xt2_new)
acc = sklearn.metrics.accuracy_score(Yt2, y_pred)
return acc, y_pred
def train_valid():
# If you want to perform train-valid-test, you can use this function
domains = ['caltech.mat', 'amazon.mat', 'webcam.mat', 'dslr.mat']
for i in [1]:
for j in [2]:
if i != j:
src, tar = 'data/' + domains[i], 'data/' + domains[j]
src_domain, tar_domain = scipy.io.loadmat(
src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
# Split target data
Xt1, Xt2, Yt1, Yt2 = train_test_split(
Xt, Yt, train_size=50, stratify=Yt, random_state=42)
# Create latent space and evaluate using Xs and Xt1
tca = TCA(kernel_type='linear', dim=30, lamb=1, gamma=1)
acc1, ypre1 = tca.fit_predict(Xs, Ys, Xt1, Yt1)
# Project and evaluate Xt2 existing projection matrix and classifier
acc2, ypre2 = tca.fit_predict_new(Xt1, Xs, Ys, Xt2, Yt2)
print(f'Accuracy of mapped source and target1 data : {acc1:.3f}') # 0.800
print(f'Accuracy of mapped target2 data : {acc2:.3f}') # 0.706
if __name__ == '__main__':
# Note: if the .mat file names are not the same, you can change them.
# Note: to reproduce the results of my transfer learning book, use the dataset here: https://www.jianguoyun.com/p/DWJ_7qgQmN7PCBj29KsD (Password: cnfjmc)
domains = ['caltech_surf_10.mat', 'amazon_surf_10.mat',
'webcam_surf_10.mat', 'dslr_surf_10.mat']
for i in [0]:
for j in [1]:
if i != j:
src, tar = domains[i], domains[j]
src_domain, tar_domain = scipy.io.loadmat(
src), scipy.io.loadmat(tar)
Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']
tca = TCA(kernel_type='linear', dim=30, lamb=1, gamma=1)
acc, ypred = tca.fit_predict(Xs, Ys, Xt, Yt)
print(f'Accuracy: {acc:.3f}')
================================================
FILE: code/traditional/TCA/readme.md
================================================
# Transfer Component Analysis
This is the implementation of Transfer Component Analysis (TCA) in Python and Matlab.
Remark: The core of TCA is a generalized eigendecompsition problem. In Matlab, it can be solved by calling `eigs()` function. In Python, the implementation `scipy.linalg.eig()` function can do the same thing. However, they are a bit different. So the results may be different.
The test dataset can be downloaded [HERE](https://github.com/jindongwang/transferlearning/tree/master/data).
The python file can be used directly, while the matlab code just contains the core function of TCA. To use the matlab code, you need to learn from the code of [BDA](https://github.com/jindongwang/transferlearning/tree/master/code/BDA) and set out the parameters.
**Reference**
Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis[J]. IEEE Transactions on Neural Networks, 2011, 22(2): 199-210.
================================================
FILE: code/traditional/TrAdaBoost.py
================================================
import numpy as np
from sklearn import tree
class TrAdaBoost:
def __init__(self, iters=10):
'''
Implement TrAdaBoost
To read more about the TrAdaBoost, check the following paper:
Dai, Wenyuan, et al. "Boosting for transfer learning." Proceedings of the 24th international conference on Machine learning. ACM, 2007.
The code is modified according to https://github.com/chenchiwei/tradaboost/blob/master/TrAdaboost.py
'''
self.iters = iters
def fit_predict(self, trans_S, trans_A, label_S, label_A, test):
N = self.iters
trans_data = np.concatenate((trans_A, trans_S), axis=0)
trans_label = np.concatenate((label_A, label_S), axis=0)
row_A = trans_A.shape[0]
row_S = trans_S.shape[0]
row_T = test.shape[0]
test_data = np.concatenate((trans_data, test), axis=0)
# 初始化权重
weights_A = np.ones([row_A, 1]) / row_A
weights_S = np.ones([row_S, 1]) / row_S
weights = np.concatenate((weights_A, weights_S), axis=0)
bata = 1 / (1 + np.sqrt(2 * np.log(row_A / N)))
# 存储每次迭代的标签和bata值?
bata_T = np.zeros([1, N])
result_label = np.ones([row_A + row_S + row_T, N])
predict = np.zeros([row_T])
# print ('params initial finished.')
trans_data = np.asarray(trans_data, order='C')
trans_label = np.asarray(trans_label, order='C')
test_data = np.asarray(test_data, order='C')
for i in range(N):
P = self.calculate_P(weights, trans_label)
result_label[:, i] = self.train_classify(trans_data, trans_label,
test_data, P)
# print ('result,', result_label[:, i], row_A, row_S, i, result_label.shape)
error_rate = self.calculate_error_rate(label_S, result_label[row_A:row_A + row_S, i],
weights[row_A:row_A + row_S, :])
print ('Error rate:', error_rate)
if error_rate > 0.5:
error_rate = 0.5
if error_rate == 0:
N = i
break # 防止过拟合
# error_rate = 0.001
bata_T[0, i] = error_rate / (1 - error_rate)
# 调整源域样本权重
for j in range(row_S):
weights[row_A + j] = weights[row_A + j] * np.power(bata_T[0, i],
(-np.abs(result_label[row_A + j, i] - label_S[j])))
# 调整辅域样本权重
for j in range(row_A):
weights[j] = weights[j] * np.power(bata, np.abs(result_label[j, i] - label_A[j]))
# print bata_T
for i in range(row_T):
# 跳过训练数据的标签
left = np.sum(
result_label[row_A + row_S + i, int(np.ceil(N / 2)):N] * np.log(1 / bata_T[0, int(np.ceil(N / 2)):N]))
right = 0.5 * np.sum(np.log(1 / bata_T[0, int(np.ceil(N / 2)):N]))
if left >= right:
predict[i] = 1
else:
predict[i] = 0
# print left, right, predict[i]
return predict
def calculate_P(self, weights, label):
total = np.sum(weights)
return np.asarray(weights / total, order='C')
def train_classify(self, trans_data, trans_label, test_data, P):
clf = tree.DecisionTreeClassifier(criterion="gini", max_features="log2", splitter="random")
clf.fit(trans_data, trans_label, sample_weight=P[:, 0])
return clf.predict(test_data)
def calculate_error_rate(self, label_R, label_H, weight):
total = np.sum(weight)
# print(weight[:, 0] / total)
# print(np.abs(label_R - label_H))
return np.sum(weight[:, 0] / total * np.abs(label_R - label_H))
================================================
FILE: code/traditional/pyEasyTL/.gitignore
================================================
data/
*.pyc
*.mps
*.sol
================================================
FILE: code/traditional/pyEasyTL/EasyTL.py
================================================
import numpy as np
from intra_alignment import CORAL_map, GFK_map, PCA_map
# from label_prop import label_prop
from label_prop_v2 import label_prop
def get_cosine_dist(A, B):
B = np.reshape(B, (1, -1))
if A.shape[1] == 1:
A = np.hstack((A, np.zeros((A.shape[0], 1))))
B = np.hstack((B, np.zeros((B.shape[0], 1))))
aa = np.sum(np.multiply(A, A), axis=1).reshape(-1, 1)
bb = np.sum(np.multiply(B, B), axis=1).reshape(-1, 1)
ab = A @ B.T
# to avoid NaN for zero norm
aa[aa==0] = 1
bb[bb==0] = 1
D = np.real(np.ones((A.shape[0], B.shape[0])) - np.multiply((1/np.sqrt(np.kron(aa, bb.T))), ab))
return D
def get_ma_dist(A, B):
Y = A.copy()
X = B.copy()
S = np.cov(X.T)
try:
SI = np.linalg.inv(S)
except:
print("Singular Matrix: using np.linalg.pinv")
SI = np.linalg.pinv(S)
mu = np.mean(X, axis=0)
diff = Y - mu
Dct_c = np.diag(diff @ SI @ diff.T)
return Dct_c
def get_class_center(Xs,Ys,Xt,dist):
source_class_center = np.array([])
Dct = np.array([])
for i in np.unique(Ys):
sel_mask = Ys == i
X_i = Xs[sel_mask.flatten()]
mean_i = np.mean(X_i, axis=0)
if len(source_class_center) == 0:
source_class_center = mean_i.reshape(-1, 1)
else:
source_class_center = np.hstack((source_class_center, mean_i.reshape(-1, 1)))
if dist == "ma":
Dct_c = get_ma_dist(Xt, X_i)
elif dist == "euclidean":
Dct_c = np.sqrt(np.nansum((mean_i - Xt)**2, axis=1))
elif dist == "sqeuc":
Dct_c = np.nansum((mean_i - Xt)**2, axis=1)
elif dist == "cosine":
Dct_c = get_cosine_dist(Xt, mean_i)
elif dist == "rbf":
Dct_c = np.nansum((mean_i - Xt)**2, axis=1)
Dct_c = np.exp(- Dct_c / 1);
if len(Dct) == 0:
Dct = Dct_c.reshape(-1, 1)
else:
Dct = np.hstack((Dct, Dct_c.reshape(-1, 1)))
return source_class_center, Dct
def EasyTL(Xs,Ys,Xt,Yt,intra_align="coral",dist="euclidean",lp="linear"):
# Inputs:
# Xs : source data, ns * m
# Ys : source label, ns * 1
# Xt : target data, nt * m
# Yt : target label, nt * 1
# The following inputs are not necessary
# intra_align : intra-domain alignment: coral(default)|gfk|pca|raw
# dist : distance: Euclidean(default)|ma(Mahalanobis)|cosine|rbf
# lp : linear(default)|binary
# Outputs:
# acc : final accuracy
# y_pred : predictions for target domain
# Reference:
# Jindong Wang, Yiqiang Chen, Han Yu, Meiyu Huang, Qiang Yang.
# Easy Transfer Learning By Exploiting Intra-domain Structures.
# IEEE International Conference on Multimedia & Expo (ICME) 2019.
C = len(np.unique(Ys))
if C > np.max(Ys):
Ys += 1
Yt += 1
m = len(Yt)
if intra_align == "raw":
print('EasyTL using raw feature...')
elif intra_align == "pca":
print('EasyTL using PCA...')
print('Not implemented yet, using raw feature')
#Xs, Xt = PCA_map(Xs, Xt)
elif intra_align == "gfk":
print('EasyTL using GFK...')
print('Not implemented yet, using raw feature')
#Xs, Xt = GFK_map(Xs, Xt)
elif intra_align == "coral":
print('EasyTL using CORAL...')
Xs = CORAL_map(Xs, Xt)
_, Dct = get_class_center(Xs,Ys,Xt,dist)
print('Start intra-domain programming...')
Mcj = label_prop(C,m,Dct,lp)
y_pred = np.argmax(Mcj, axis=1) + 1
acc = np.mean(y_pred == Yt.flatten());
return acc, y_pred
================================================
FILE: code/traditional/pyEasyTL/demo_amazon_review.py
================================================
import scipy.io
import scipy.stats
import numpy as np
from EasyTL import EasyTL
import time
if __name__ == "__main__":
datadir = r"D:\Datasets\EasyTL\amazon_review"
str_domain = ["books", "dvd", "elec", "kitchen"]
list_acc = []
for i in range(len(str_domain)):
for j in range(len(str_domain)):
if i == j:
continue
print("{} - {}".format(str_domain[i], str_domain[j]))
mat1 = scipy.io.loadmat(datadir + "/{}_400.mat".format(str_domain[i]))
Xs = mat1["fts"]
Ys = mat1["labels"]
mat2 = scipy.io.loadmat(datadir + "/{}_400.mat".format(str_domain[j]))
Xt = mat2["fts"]
Yt = mat2["labels"]
Ys += 1
Yt += 1
Xs = Xs / np.tile(np.sum(Xs,axis=1).reshape(-1,1), [1, Xs.shape[1]])
Xs = scipy.stats.mstats.zscore(Xs);
Xt = Xt / np.tile(np.sum(Xt,axis=1).reshape(-1,1), [1, Xt.shape[1]])
Xt = scipy.stats.mstats.zscore(Xt);
Xs[np.isnan(Xs)] = 0
Xt[np.isnan(Xt)] = 0
t0 = time.time()
Acc1, _ = EasyTL(Xs,Ys,Xt,Yt,"raw")
t1 = time.time()
print("Time Elapsed: {:.2f} sec".format(t1 - t0))
Acc2, _ = EasyTL(Xs,Ys,Xt,Yt)
t2 = time.time()
print("Time Elapsed: {:.2f} sec".format(t2 - t1))
print('EasyTL(c) Acc: {:.1f} % || EasyTL Acc: {:.1f} %'.format(Acc1*100, Acc2*100))
list_acc.append([Acc1,Acc2])
acc = np.array(list_acc)
avg = np.mean(acc, axis=0)
print('EasyTL(c) AVG Acc: {:.1f} %'.format(avg[0]*100))
print('EasyTL AVG Acc: {:.1f} %'.format(avg[1]*100))
================================================
FILE: code/traditional/pyEasyTL/demo_image.py
================================================
# -*- coding: utf-8 -*-
import os
import time
import scipy.stats
import numpy as np
from EasyTL import EasyTL
import pandas as pd
if __name__ == "__main__":
img_dataset = 'image-clef' # 'image-clef' or 'office-home'
if img_dataset == 'image-clef':
str_domains = ['c', 'i', 'p']
datadir = r"D:\Datasets\EasyTL\imageCLEF_resnet50"
elif img_dataset == 'office-home':
str_domains = ['Art', 'Clipart', 'Product', 'RealWorld']
datadir = r"D:\Datasets\EasyTL\officehome_resnet50"
list_acc = []
for i in range(len(str_domains)):
for j in range(len(str_domains)):
if i == j:
continue
print("{} - {}".format(str_domains[i], str_domains[j]))
src = str_domains[i]
tar = str_domains[j]
x1file = "{}_{}.csv".format(src, src)
x2file = "{}_{}.csv".format(src, tar)
df1 = pd.read_csv(os.path.join(datadir, x1file), header=None)
Xs = df1.values[:, :-1]
Ys = df1.values[:, -1] + 1
df2 = pd.read_csv(os.path.join(datadir, x2file), header=None)
Xt = df2.values[:, :-1]
Yt = df2.values[:, -1] + 1
Xs = Xs / np.tile(np.sum(Xs,axis=1).reshape(-1,1), [1, Xs.shape[1]])
Xs = scipy.stats.mstats.zscore(Xs)
Xt = Xt / np.tile(np.sum(Xt,axis=1).reshape(-1,1), [1, Xt.shape[1]])
Xt = scipy.stats.mstats.zscore(Xt)
t0 = time.time()
Acc1, _ = EasyTL(Xs,Ys,Xt,Yt,'raw')
t1 = time.time()
print("Time Elapsed: {:.2f} sec".format(t1 - t0))
Acc2, _ = EasyTL(Xs,Ys,Xt,Yt)
t2 = time.time()
print("Time Elapsed: {:.2f} sec".format(t2 - t1))
print('EasyTL(c) Acc: {:.1f} % || EasyTL Acc: {:.1f} %'.format(Acc1*100, Acc2*100))
list_acc.append([Acc1,Acc2])
acc = np.array(list_acc)
avg = np.mean(acc, axis=0)
print('EasyTL(c) AVG Acc: {:.1f} %'.format(avg[0]*100))
print('EasyTL AVG Acc: {:.1f} %'.format(avg[1]*100))
================================================
FILE: code/traditional/pyEasyTL/demo_office_caltech.py
================================================
# -*- coding: utf-8 -*-
import scipy.io
import scipy.stats
import numpy as np
from EasyTL import EasyTL
if __name__ == "__main__":
datadir = r"D:\Datasets\EasyTL\surf"
str_domain = [ 'Caltech10', 'amazon', 'webcam', 'dslr' ]
list_acc = []
for i in range(len(str_domain)):
for j in range(len(str_domain)):
if i == j:
continue
print("{} - {}".format(str_domain[i], str_domain[j]))
mat1 = scipy.io.loadmat(datadir + "/{}_SURF_L10.mat".format(str_domain[i]))
Xs = mat1["fts"]
Ys = mat1["labels"]
mat2 = scipy.io.loadmat(datadir + "/{}_SURF_L10.mat".format(str_domain[j]))
Xt = mat2["fts"]
Yt = mat2["labels"]
Xs = Xs / np.tile(np.sum(Xs,axis=1).reshape(-1,1), [1, Xs.shape[1]])
Xs = scipy.stats.mstats.zscore(Xs);
Xt = Xt / np.tile(np.sum(Xt,axis=1).reshape(-1,1), [1, Xt.shape[1]])
Xt = scipy.stats.mstats.zscore(Xt);
Xs[np.isnan(Xs)] = 0
Xt[np.isnan(Xt)] = 0
Acc1, _ = EasyTL(Xs,Ys,Xt,Yt,'raw')
Acc2, _ = EasyTL(Xs,Ys,Xt,Yt)
print('EasyTL(c) Acc: {:.1f} % || EasyTL Acc: {:.1f} %'.format(Acc1*100, Acc2*100))
list_acc.append([Acc1,Acc2])
acc = np.array(list_acc)
avg = np.mean(acc, axis=0)
print('EasyTL(c) AVG Acc: {:.1f} %'.format(avg[0]*100))
print('EasyTL AVG Acc: {:.1f} %'.format(avg[1]*100))
================================================
FILE: code/traditional/pyEasyTL/intra_alignment.py
================================================
import numpy as np
import scipy
from sklearn.decomposition import PCA
import math
def GFK_map(Xs, Xt):
pass
def gsvd(A, B):
pass
def getAngle(Ps, Pt, DD):
Q = np.hstack((Ps, scipy.linalg.null_space(Ps.T)))
dim = Pt.shape[1]
QPt = Q.T @ Pt
A, B = QPt[:dim, :], QPt[dim:, :]
U,V,X,C,S = gsvd(A, B)
alpha = np.zeros([1, DD])
for i in range(DD):
alpha[0][i] = math.sin(np.real(math.acos(C[i][i]*math.pi/180)))
return alpha
def getGFKDim(Xs, Xt):
Pss = PCA().fit(Xs).components_.T
Pts = PCA().fit(Xt).components_.T
Psstt = PCA().fit(np.vstack((Xs, Xt))).components_.T
DIM = round(Xs.shape[1]*0.5)
res = -1
for d in range(1, DIM+1):
Ps = Pss[:, :d]
Pt = Pts[:, :d]
Pst = Psstt[:, :d]
alpha1 = getAngle(Ps, Pst, d)
alpha2 = getAngle(Pt, Pst, d)
D = (alpha1 + alpha2) * 0.5
check = [round(D[1, dd]*100) == 100 for dd in range(d)]
if True in check:
res = list(map(lambda i: i == True, check)).index(True)
return res
def PCA_map(Xs, Xt):
dim = getGFKDim(Xs, Xt)
X = np.vstack((Xs, Xt))
X_new = PCA().fit_transform(X)[:, :dim]
Xs_new = X_new[:Xs.shape[0], :]
Xt_new = X_new[Xs.shape[0]:, :]
return Xs_new, Xt_new
def CORAL_map(Xs,Xt):
Ds = Xs.copy()
Dt = Xt.copy()
cov_src = np.ma.cov(Ds.T) + np.eye(Ds.shape[1])
cov_tar = np.ma.cov(Dt.T) + np.eye(Dt.shape[1])
Cs = scipy.linalg.sqrtm(np.linalg.inv(np.array(cov_src)))
Ct = scipy.linalg.sqrtm(np.array(cov_tar))
Xs_new = np.linalg.multi_dot([Ds, Cs, Ct])
return Xs_new
================================================
FILE: code/traditional/pyEasyTL/label_prop.py
================================================
import numpy as np
from scipy.optimize import linprog
import pulp
def label_prop(C, nt, Dct, lp="linear"):
#Inputs:
# C : Number of share classes between src and tar
# nt : Number of target domain samples
# Dct : All d_ct in matrix form, nt * C
# lp : Type of linear programming: linear (default) | binary
#Outputs:
# Mcj : all M_ct in matrix form, m * C
intcon = C * nt
Aeq = np.zeros([nt, intcon])
Beq = np.ones([nt, 1])
for i in range(nt):
Aeq[i, i*C:(i+1)*C] = 1;
D_vec = np.reshape(Dct, (1, intcon))
CC = np.asarray(D_vec, dtype=np.double)
A = np.array([])
B = -1 * np.ones([C, 1])
for i in range(C):
all_zeros = np.zeros([1, intcon])
for j in range(i, C * nt, C):
all_zeros[0][j] = -1
if i == 0:
A = all_zeros
else:
A = np.vstack((A, all_zeros))
if lp == "binary":
print("not implemented yet!")
else:
res = linprog(CC,A,B,Aeq,Beq, bounds=tuple((0, 1) for _ in range(intcon)))
Mct_vec = res.get("x")[0:C*nt]
Mcj = Mct_vec.reshape((C,nt), order="F").T
return Mcj
================================================
FILE: code/traditional/pyEasyTL/label_prop_v2.py
================================================
import numpy as np
import pulp
def label_prop(C, nt, Dct, lp="linear"):
#Inputs:
# C : Number of share classes between src and tar
# nt : Number of target domain samples
# Dct : All d_ct in matrix form, nt * C
# lp : Type of linear programming: linear (default) | binary
#Outputs:
# Mcj : all M_ct in matrix form, m * C
Dct = abs(Dct)
model = pulp.LpProblem("Cost minimising problem", pulp.LpMinimize)
Mcj = pulp.LpVariable.dicts("Probability",
((i, j) for i in range(C) for j in range(nt)),
lowBound=0,
upBound=1,
cat='Continuous')
# Objective Function
model += (
pulp.lpSum([Dct[j, i]*Mcj[(i, j)] for i in range(C) for j in range(nt)])
)
# Constraints
for j in range(nt):
model += pulp.lpSum([Mcj[(i, j)] for i in range(C)]) == 1
for i in range(C):
model += pulp.lpSum([Mcj[(i, j)] for j in range(nt)]) >= 1
# Solve our problem
model.solve()
pulp.LpStatus[model.status]
Output = [[Mcj[i, j].varValue for i in range(C)] for j in range(nt)]
return np.array(Output)
================================================
FILE: code/traditional/pyEasyTL/license
================================================
Copyright (C) 2020 KodeWorker
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
================================================
FILE: code/traditional/pyEasyTL/readme.md
================================================
# pyEasyTL
## Introduction
This [project](https://github.com/KodeWorker/pyEasyTL) is the implementation of EasyTL in Python.
The EasyTL paper on the [website](http://transferlearning.xyz/code/traditional/EasyTL/) show this domain adaptation method is intuitive and parametric-free.
The MATLAB source code is on this [Repo](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/EasyTL).
- scipy.optimize.linprog is slower than PuLP
- M^(-1/2) = (M^(-1))^(1/2) = scipy.linalg.sqrtm(np.linalg.inv(np.array(cov_src)))
- scipy.linalg.sqrtm will introduce complex number [#3549](https://github.com/scipy/scipy/issues/3549) and cause our Dct parameter to be a complex array.
## To Do
- PCA_map in intra_alignment.py
- GFK_map in intra_alignment.py
## Dev Log
- **2020/02/25** PuLP type conversion problems (can't convert complex to float) is fixed
- **2020/02/24** write label_prop_v2.py using PuLP
- **2020/02/05** implement get_ma_dist and get_cosine_dist in EasyTL.py (fixed)
- **2020/02/03** more distance measurement in get_class_center
- **2020/01/31** CORAL_map still has some issue. (fixed)
- **2020/01/31** The primitive results of Amazon dataset show that we'v successfully implemented the EasyTL(c).
# Reference:
1. Easy Transfer Learning By Exploiting Intra-domain Structures
2. Geodesic Flow Kernel for Unsupervised Domain Adaptation
================================================
FILE: code/traditional/pyEasyTL/requirement.txt
================================================
numpy
scipy
pandas
pulp
================================================
FILE: code/traditional/pyEasyTL/results.txt
================================================
[amazon]
books - dvd
C:\Users\Kelvin_Wu\AppData\Roaming\Python\Python36\site-packages\scipy\stats\stats.py:2419: RuntimeWarning: invalid value encountered in true_divide
return (a - mns) / sstd
EasyTL using raw feature...
Start intra-domain programming...
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Anaconda3_64\envs\pyEasyTL\lib\site-packages\pulp\pulp.py:1138: UserWarning: Spaces are not permitted in the name. Converted to '_'
warnings.warn("Spaces are not permitted in the name. Converted to '_'")
Time Elapsed: 1.04 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.94 sec
EasyTL(c) Acc: 78.4 % || EasyTL Acc: 79.8 %
books - elec
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.73 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 2.03 sec
EasyTL(c) Acc: 77.5 % || EasyTL Acc: 79.7 %
books - kitchen
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.79 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 2.02 sec
EasyTL(c) Acc: 79.2 % || EasyTL Acc: 80.9 %
dvd - books
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.87 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.90 sec
EasyTL(c) Acc: 79.5 % || EasyTL Acc: 79.9 %
dvd - elec
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.76 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.97 sec
EasyTL(c) Acc: 77.4 % || EasyTL Acc: 80.8 %
dvd - kitchen
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.76 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.99 sec
EasyTL(c) Acc: 80.4 % || EasyTL Acc: 82.0 %
elec - books
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.75 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.99 sec
EasyTL(c) Acc: 73.0 % || EasyTL Acc: 75.0 %
elec - dvd
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.72 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.88 sec
EasyTL(c) Acc: 73.1 % || EasyTL Acc: 75.3 %
elec - kitchen
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.74 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.87 sec
EasyTL(c) Acc: 84.6 % || EasyTL Acc: 84.9 %
kitchen - books
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.71 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.93 sec
EasyTL(c) Acc: 75.1 % || EasyTL Acc: 76.5 %
kitchen - dvd
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.72 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.90 sec
EasyTL(c) Acc: 73.8 % || EasyTL Acc: 76.3 %
kitchen - elec
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 0.82 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 1.91 sec
EasyTL(c) Acc: 82.0 % || EasyTL Acc: 82.5 %
EasyTL(c) AVG Acc: 77.8 %
EasyTL AVG Acc: 79.5 %
[office caltech]
Caltech10 - amazon
EasyTL using raw feature...
Start intra-domain programming...
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Anaconda3_64\envs\pyEasyTL\lib\site-packages\pulp\pulp.py:1138: UserWarning: Spaces are not permitted in the name. Converted to '_'
warnings.warn("Spaces are not permitted in the name. Converted to '_'")
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 50.1 % || EasyTL Acc: 52.6 %
Caltech10 - webcam
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 49.5 % || EasyTL Acc: 53.9 %
Caltech10 - dslr
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 48.4 % || EasyTL Acc: 51.6 %
amazon - Caltech10
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 43.0 % || EasyTL Acc: 42.3 %
amazon - webcam
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 40.7 % || EasyTL Acc: 43.1 %
amazon - dslr
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 38.9 % || EasyTL Acc: 48.4 %
webcam - Caltech10
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 29.7 % || EasyTL Acc: 35.4 %
webcam - amazon
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 35.2 % || EasyTL Acc: 38.2 %
webcam - dslr
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 77.1 % || EasyTL Acc: 79.6 %
dslr - Caltech10
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 31.2 % || EasyTL Acc: 36.1 %
dslr - amazon
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 31.9 % || EasyTL Acc: 38.3 %
dslr - webcam
EasyTL using raw feature...
Start intra-domain programming...
EasyTL using CORAL...
Start intra-domain programming...
EasyTL(c) Acc: 69.5 % || EasyTL Acc: 86.1 %
EasyTL(c) AVG Acc: 45.4 %
EasyTL AVG Acc: 50.5 %
[image CLEF]
c - i
EasyTL using raw feature...
Start intra-domain programming...
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Anaconda3_64\envs\pyEasyTL\lib\site-packages\pulp\pulp.py:1138: UserWarning: Spaces are not permitted in the name. Converted to '_'
warnings.warn("Spaces are not permitted in the name. Converted to '_'")
Time Elapsed: 1.61 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 28.79 sec
EasyTL(c) Acc: 85.5 % || EasyTL Acc: 91.5 %
c - p
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 3.54 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 25.90 sec
EasyTL(c) Acc: 72.0 % || EasyTL Acc: 77.7 %
i - c
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 5.46 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 27.18 sec
EasyTL(c) Acc: 93.3 % || EasyTL Acc: 96.0 %
i - p
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 1.38 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 24.51 sec
EasyTL(c) Acc: 78.5 % || EasyTL Acc: 78.7 %
p - c
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 1.37 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 25.13 sec
EasyTL(c) Acc: 91.0 % || EasyTL Acc: 95.0 %
p - i
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 1.32 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 24.98 sec
EasyTL(c) Acc: 89.5 % || EasyTL Acc: 90.3 %
EasyTL(c) AVG Acc: 85.0 %
EasyTL AVG Acc: 88.2 %
[image office home]
Art - Clipart
EasyTL using raw feature...
Start intra-domain programming...
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Anaconda3_64\envs\pyEasyTL\lib\site-packages\pulp\pulp.py:1138: UserWarning: Spaces are not permitted in the name. Converted to '_'
warnings.warn("Spaces are not permitted in the name. Converted to '_'")
Time Elapsed: 56.79 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 91.04 sec
EasyTL(c) Acc: 51.5 % || EasyTL Acc: 52.8 %
Art - Product
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 46.09 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 79.61 sec
EasyTL(c) Acc: 68.1 % || EasyTL Acc: 72.1 %
Art - RealWorld
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 41.90 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 78.72 sec
EasyTL(c) Acc: 74.2 % || EasyTL Acc: 75.9 %
Clipart - Art
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 23.47 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 63.94 sec
EasyTL(c) Acc: 53.1 % || EasyTL Acc: 55.0 %
Clipart - Product
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 48.85 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 85.14 sec
EasyTL(c) Acc: 62.9 % || EasyTL Acc: 65.9 %
Clipart - RealWorld
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 41.73 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 95.50 sec
EasyTL(c) Acc: 65.3 % || EasyTL Acc: 67.6 %
Product - Art
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 27.09 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 65.90 sec
EasyTL(c) Acc: 52.8 % || EasyTL Acc: 54.4 %
Product - Clipart
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 43.16 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 85.76 sec
EasyTL(c) Acc: 45.8 % || EasyTL Acc: 46.9 %
Product - RealWorld
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 43.31 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 87.33 sec
EasyTL(c) Acc: 73.5 % || EasyTL Acc: 74.7 %
RealWorld - Art
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 22.91 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 63.16 sec
EasyTL(c) Acc: 62.2 % || EasyTL Acc: 63.8 %
RealWorld - Clipart
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 42.27 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 86.62 sec
EasyTL(c) Acc: 50.1 % || EasyTL Acc: 52.3 %
RealWorld - Product
EasyTL using raw feature...
Start intra-domain programming...
Time Elapsed: 49.03 sec
EasyTL using CORAL...
Start intra-domain programming...
Time Elapsed: 86.44 sec
EasyTL(c) Acc: 76.0 % || EasyTL Acc: 77.9 %
EasyTL(c) AVG Acc: 61.3 %
EasyTL AVG Acc: 63.3 %
================================================
FILE: code/traditional/readme.md
================================================
# Traditional transfer learning
Here we implement several popular traditional transfer learning methods.
Most of the datasets are based on Office-Caltech10 Surf features, which can be downloaded here: https://www.jianguoyun.com/p/DaKoCGIQmN7PCBju9KsD, with password `PRSZD9`.
We also provide a notebook for you to directly run two algorithms using **Jupyter notebook**.
You can easily download the notebook from [here](https://github.com/jindongwang/transferlearning/tree/master/notebooks/traditional_transfer_learning.ipynb).
We also put it on [Google Colab](https://colab.research.google.com/drive/1w4WkCrZeCKaornJo66P4hxC7kzm4l70U?usp=sharing).
Try and experiment on them!
================================================
FILE: code/traditional/sot/SOT.py
================================================
#coding utf-8
from numpy.lib.function_base import rot90
from scipy.spatial.distance import cdist
from sklearn.neighbors import KNeighborsClassifier
from sklearn import mixture
from collections import Counter
import json
import random
import numpy as np
from sklearn.metrics import euclidean_distances
import ot
import os
import joblib
from ot.optim import line_search_armijo
def norm_max(x):
for i in range(x.shape[1]):
tmax=x[:,i].max()
x[:,i]=x[:,i]/tmax
return x
def load_from_file(root_dir,filename,ss,ts):
f1=root_dir+filename
with open(f1,'r') as f:
s=f.read()
data=json.loads(s)
xs,ys,xt,yt = np.array(data[ss]['x']), np.array(data[ss]['y']), np.array(data[ts]['x']),np.array(data[ts]['y'])
xs=norm_max(xs)
xt=norm_max(xt)
ys=np.squeeze(ys)
yt=np.squeeze(yt)
ttty=min(Counter(ys).keys())
ys=ys-ttty
yt=yt-ttty
return xs,ys,xt,yt
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
def gmm_target(X,w,c,rootdir,filepath,modelpath,targetname,covtype='diag'):
if not os.path.exists(rootdir+'data/'):
os.mkdir(rootdir+'data/')
if not os.path.exists(rootdir+'model/'):
os.mkdir(rot90+'model/')
if os.path.exists(filepath):
pass
else:
gmm = mixture.GaussianMixture(n_components=c,covariance_type=covtype)
gmm.fit(X)
x1=[]
x2=[]
xmu=[]
for i in range(len(gmm.weights_)):
xmu.append(gmm.weights_[i]*w)
x1.append(gmm.means_[i])
x2.append(np.sqrt(gmm.covariances_[i]))
data={'xntmu':np.array(xmu),'xnt1':np.array(x1),'xnt2':np.array(x2)}
record={}
record[targetname]=data
with open(filepath,'w') as f:
json.dump(record,f,cls=MyEncoder)
joblib.dump(gmm,modelpath)
def gmm_source_class(X,w,slist,covtype='diag'):
bicr=10000000000
c=0
gmm = mixture.GaussianMixture(n_components=slist[c],covariance_type=covtype)
gmm.fit(X)
while (c np.min((np.sum(a), np.sum(b))):
m=np.min((np.sum(a),np.sum(b)))
K = np.empty(M.shape, dtype=M.dtype)
np.divide(M, -reg, out=K)
np.exp(K, out=K)
np.multiply(K, m / np.sum(K), out=K)
K2 = np.dot(K, np.diag(b / np.sum(K, axis=0)))
return K2
class SOT:
def __init__(self,taskname='ACT',root_dir='./clustertemp/',d=200,
reg_e=0.1, reg_cl=0.1, reg_ce=0.1,rule='median'):
self.taskname=taskname
self.root_dir=root_dir
self.d=d
self.reg_e=reg_e
self.reg_cl=reg_cl
self.reg_ce=reg_ce
self.rule=rule
def get_target(self,filepath,modelpath,targetname):
with open(filepath, 'r') as f:
s = f.read()
record = json.loads(s)
self.diag_t = record[targetname]
self.diag_g = joblib.load(modelpath)
def get_source(self,filepath,sourcename):
with open(filepath,'r') as f:
s=f.read()
record1=json.loads(s)
self.diag_s=record1[sourcename]
def partot_DA(self,Sx,Sy,Tx,b,xt1,ttt=1):
a1 = np.ones(len(Sx))
M = cdist(Sx, Tx, metric='sqeuclidean')
M = M / np.median(M)
b=np.ones(len(Tx))/len(Tx)
T = entropic_partial_wasserstein(a1, b, M, self.reg_ce,m=1)
if np.sum(T)<0.5:
a=np.ones(len(Sx))/len(Sx)
T=np.outer(a,b)
gmm=self.diag_g
index=gmm.predict(xt1)
a=T.dot(np.ones(len(Tx)))
b=(T.T).dot(np.ones(len(Sx)))
G=ot.da.sinkhorn_lpl1_mm(a,Sy,b,M,self.reg_e,self.reg_cl)
if np.sum(G)<0.5:
a=np.ones(len(Sx))/len(Sx)
G=np.outer(a,b)
transp_Xs_lpl1 = np.diag(1 / G.dot(np.ones(len(Tx)))) @ G.dot(Tx)
knn_clf = KNeighborsClassifier(n_neighbors=1)
knn_clf.fit(transp_Xs_lpl1, Sy)
Cls2 = knn_clf.predict(Tx)
return Cls2[index]
def fit_predict(self, Sx, Sy, Tx, Ty,sfilepath,sourcename,tfilepath,tmodelpath,targetname):
gmm_source(Sx,Sy,sfilepath,sourcename)
self.get_source(sfilepath,sourcename)
gmm_target(Tx,1,self.d,self.root_dir,tfilepath,tmodelpath,targetname)
self.get_target(tfilepath,tmodelpath,targetname)
ss1 = self.diag_s
tt1 = self.diag_t
xns,yns=ss1['xn1'],ss1['yns']
xntmu,xnt=tt1['xntmu'],tt1['xnt1']
pred= self.partot_DA(xns,yns,xnt,xntmu,Tx,ttt=2)
acc= np.mean(Ty==pred)
return pred,acc
================================================
FILE: code/traditional/sot/main.py
================================================
#coding=utf-8
from SOT import SOT,load_from_file
import numpy as np
if __name__=='__main__':
tsot=SOT('ACT','./clustertemp/',19,0.5,1,3)
Sx,Sy,Tx,Ty=load_from_file('./data/','MDA_JCPOT_ACT.json','D','H')
spath='./data/test_MDA_JCPOT_ACT_diag_SG.json'
tpath='./clustertemp/data/test_MDA_JCPOT_ACT_19_diag_TG.json'
tmodelpath='./clustertemp/model/test_MDA_JCPOT_ACT_19_diag_H'
pred,acc=tsot.fit_predict(Sx,Sy,Tx,Ty,spath,'D',tpath,tmodelpath,'H')
print(acc)
================================================
FILE: code/traditional/sot/readme.md
================================================
## SOT (Substructural Optimal Transport)
This is the implementation of SOT in Python. Please refer to the paper [Cross-domain Activity Recognition via Substructural Optimal Transport](https://arxiv.org/abs/2102.03353) for more detail.
### Requirements
The codes only need common machine learning packages and ```ot```. To install ot, just run the following command,
```pip install pot```
To get more information on POT, please refer to [pot](https://pythonot.github.io/).
### Usage
4 hyper-paramters need to be carefully set:
- `d` means the cluster numbers of the target data
- `reg_e` corresponds to λ
- `reg_cl` corresponds to η
- `reg_ce` corresponds to λ1 in the origin paper.
### Demo
We offer a basic demo to run on the datasets used in the paper. Download the test data [HERE](https://pan.baidu.com/s/1m-lkCklSWSreuEeBfp9GPQ). Extraction code is ```1zk9```. Run
```python main.py```
### Results
SOT achieved **state-of-the-art** performances compared to a lot of traditional methods. The following results are from the original paper.
| | Method | D - H | D - U | D - P | H - D | H - U | H-P | U - D | U - H | U - P | P - D | P - H | P-U | AVG |
|---------|-----------|-------|-------|--------|-------|-------|-------|-------|-------|--------|-------|-------|-------|-------|
| | 1NN | 62.70 | 56.40 | 66.03 | 65.16 | 55.03 | 60.81 | 71.30 | 61.38 | 60.37 | 60.99 | 55.26 | 51.63 | 60.59 |
| | LMNN | 55.24|65.74|48.38|64.27|56.55|65.00|64.58|65.46|67.13|59.53|39.11|41.21|57.68 |
| | TCA | 60.79|51.98|65.66|62.50|41.87|52.06|69.06|53.43|60.88|57.81|46.38|51.45|56.16 |
| ICCV 2013 | SA | 63.61|57.36|65.44|66.35|55.60|60.88|70.62|59.64|61.18|62.60|55.45|50.58|60.78 |
| AAAI 2016| CORAL | 64.23|52.25|64.85|64.48|53.03|64.41|68.75|61.93|60.15|60.21|56.20|54.46|60.41 |
| Percom 2018 | STL | 62.83|70.93|65.66|66.15|65.89|67.43|74.69|68.76|65.00|68.96|56.75|55.27|65.69 |
| | OT | 62.13|65.86|65.66|68.91|58.58|67.50|69.90|59.49|63.75|66.77|51.71|57.59|63.15|
| TPAMI 2016 | OTDA | 59.36|54.97|65.52|68.91|59.45|67.50|70.26|62.25|63.09|67.19|53.41|59.09|62.58 |
| IJCAL 2020 | MLOT |62.53|53.33|64.85|68.12|58.10|62.13|69.53|59.68|61.25|65.99|63.30|49.24|61.51 |
| | SOT | **67.74**|**79.74**|**73.31**|**73.39**|**70.87**|**73.23**|**80.99**|**78.04**|**74.41**|**76.46**|**72.82**|**76.51**|**74.79** |
### Reference
If you use this code, please cite it as:
`
Lu W, Chen Y, Wang J, et al. Cross-domain Activity Recognition via Substructural Optimal Transport[J]. Neurocomputing, 2021.
`
Or in bibtex style:
```
@article{lu2021cross,
title={Cross-domain Activity Recognition via Substructural Optimal Transport},
author={Lu, Wang and Chen, Yiqiang and Wang, Jindong and Qin, Xin},
journal={Neurocomputing},
year={2021}
}
```
================================================
FILE: code/utils/feature_vis.py
================================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
class FeatureVisualize(object):
'''
Visualize features by TSNE
'''
def __init__(self, features, labels):
'''
features: (m,n)
labels: (m,)
'''
self.features = features
self.labels = labels
def plot_tsne(self, save_eps=False):
''' Plot TSNE figure. Set save_eps=True if you want to save a .eps file.
'''
tsne = TSNE(n_components=2, init='pca', random_state=0)
features = tsne.fit_transform(self.features)
x_min, x_max = np.min(features, 0), np.max(features, 0)
data = (features - x_min) / (x_max - x_min)
del features
for i in range(data.shape[0]):
plt.text(data[i, 0], data[i, 1], str(self.labels[i]),
color=plt.cm.Set1(self.labels[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.title('T-SNE')
if save_eps:
plt.savefig('tsne.eps', dpi=600, format='eps')
plt.show()
if __name__ == '__main__':
digits = datasets.load_digits(n_class=5)
features, labels = digits.data, digits.target
print(features.shape)
print(labels.shape)
vis = FeatureVisualize(features, labels)
vis.plot_tsne(save_eps=True)
================================================
FILE: code/utils/grl.py
================================================
'''
Gradient reversal layer. Reference:
Ganin et al. Unsupervised domain adaptation by backpropagation. ICML 2015.
'''
import torch
import numpy as np
# For pytorch version > 1.0
# Usage:
# b = GradReverse.apply(a, 1) # 1 is the lambda value, you are free to set it
class GradReverse(torch.autograd.Function):
@staticmethod
def forward(ctx, x, lambd, **kwargs: None):
ctx.lambd = lambd
return x.view_as(x)
@staticmethod
def backward(ctx, *grad_output):
return grad_output * -ctx.lambd, None
# For pytorch version 1.0
# Usage:
# grl = GradientReverseLayer(1) # 1 is the lambda value, you are free to set it
# b = GradReverse(a)
class GradientReverseLayer(torch.autograd.Function):
def __init__(self, lambd=1):
self.lambd = lambd
def forward(self, input):
output = input * 1.0
return output
def backward(self, grad_output):
return -self.lambd * grad_output
================================================
FILE: data/benchmark.md
================================================
# Benchmark
This file contains some benchmark results of popular transfer learning (domain adaptation) methods gathered from published papers. Right now there are only results of the most popular Office+Caltech10 datasets. You're welcome to add more results.
The full list of datasets can be found in [datasets](https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md).
Here, we provide benchmark results for the following datasets:
- [Benchmark](#benchmark)
- [Domain adaptation](#domain-adaptation)
- [Adaptiope dataset](#adaptiope-dataset)
- [Office-31 dataset](#office-31-dataset)
- [Office-Home](#office-home)
- [Image-CLEF DA](#image-clef-da)
- [Office+Caltech](#officecaltech)
- [SURF](#surf)
- [Decaf6](#decaf6)
- [MNIST+USPS](#mnistusps)
- [Domain generalization](#domain-generalization)
- [PACS (Resnet-18)](#pacs-resnet-18)
- [Office-Home (Resnet-18)](#office-home-resnet-18)
- [References](#references)
**Update at 2022-11:** You may want to check the *zero-shot* results by CLIP in [HERE](https://github.com/jindongwang/transferlearning/tree/master/code/clip#results), which I believe will blow your mind:)
## Domain adaptation
### Adaptiope dataset
Using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone).
| Cite | Method | P-R | P-S | R-P | R-S | S-P | S-R | AVG |
|---------|-----------|-------|-------|--------|-------|-------|-------|-------|
| | Source Only | 63.6 | 26.7 | 85.3 | 27.6 | 7.6 | 2.0 | 35.5 |
| icml15[19] | RSDA-DANN | **78.6** | 48.5 | 90.0 | 43.9 | 63.2 | 37.0 | 60.2 |
| icml18[30] | RSDA-MSTN | 73.8 | 59.2 | 87.5 | 50.3 | **69.5** | 44.6 | 64.2 |
| TNNLS20[29] | DSAN | 77.8 | **60.1** | **91.9** | **55.7** | 68.8 | **47.8** | **67.0** |
### Office-31 dataset
Using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). It seems **MEDA** is the only traditional method that can challenge these heavy deep adversarial methods.
Finetuned ResNet-50 models For Office-31 dataset: [BaiduYun](https://pan.baidu.com/s/1mRVDYOpeLz3siIId3tni6Q) | [Mega](https://mega.nz/file/dSpjyCwR#9ctB4q1RIE65a4NoJy0ox3gngh15cJqKq1XpOILJt9s)
**Results reported in original papers:**
| Cite | Method | A-W | D-W | W-D | A-D | D-A | W-A | AVG |
|---------|-----------|-------|-------|--------|-------|-------|-------|-------|
| cvpr16 | ResNet-50 | 68.4 | 96.7 | 99.3 | 68.9 | 62.5 | 60.7 | 76.1 |
| icml15[17] | DAN | 80.5 | 97.1 | 99.6 | 78.6 | 63.6 | 62.8 | 80.4 |
| icml15[19] | DANN | 82.0 | 96.9 | 99.1 | 79.7 | 68.2 | 67.4 | 82.2 |
| cvpr17[20] | ADDA | 86.2 | 96.2 | 98.4 | 77.8 | 69.5 | 68.9 | 82.9 |
| icml17[21] | JAN | 85.4 | 97.4 | 99.8 | 84.7 | 68.6 | 70.0 | 84.3 |
| cvpr17[22] | GTA | 89.5 | 97.9 | 99.8 | 87.7 | 72.8 | 71.4 | 86.5 |
| cvpr18[24] | CAN | 81.5 | 98.2 | 99.7 | 85.5 | 65.9 | 63.4 | 82.4 |
| aaai19[25] | JDDA | 82.6 | 95.2 | 99.7 | 79.8 | 57.4 | 66.7 | 80.2 |
| acmmm18[27] | MEDA | 86.2 | 97.2 | 99.4 | 85.3 | 72.4 | 74.0 | 85.8 |
| neural network19[28] | MRAN | 91.4 | 96.9 | 99.8 | 86.4 | 68.3 | 70.9 | 85.6 |
| TNNLS20[29] | DSAN | **93.6** | **98.4** | **100.0** | **90.2** | **73.5** | **74.8** | **88.4** |
**Results using our unified and fair [codes](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA):**
| Method | D - A | D - W | A - W | W - A | A - D | W - D | Average |
|-------------|-------|-------|-------|-------|--------|--------|---------|
| Source-only | 66.17 | 97.61 | 80.63 | 65.07 | 82.73 | 100.00 | 82.03 |
| DAN [1] | 68.16 | 97.48 | 85.79 | 66.56 | 84.34 | 100.00 | 83.72 |
| DeepCoral [2] | 66.06 | 97.36 | 80.25 | 65.32 | 82.53 | 100.00 | 81.92 |
| DANN [3] | 67.06 | 97.86 | 84.65 | 71.03 | 82.73 | 100.00 | 83.89 |
| DSAN [4] | 76.04 | 98.49 | 94.34 | 72.91 | 89.96 | 100.00 | 88.62 |
### Office-Home
Using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). Again, it seems that **MEDA** achieves the best performance.
Finetuned ResNet-50 models For Office-Home dataset: [BaiduYun](https://pan.baidu.com/s/1i_g-QC2HZ0ZUhTnnySFIWw) | [Mega](https://mega.nz/#F!pGIkjIxC!MDD3ps6RzTXWobMfHh0Slw)
**Results reported in original papers:**
| Cite | Method | Ar-Cl | Ar-Pr | Ar-Rw | Cl-Ar | Cl-Pr | Cl-Rw | Pr-Ar | Pr-Cl | Pr-Rw | Rw-Ar | Rw-Cl | Rw-Pr | Avg |
|---------|-----------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|
| nips12 | AlexNet | 26.4 | 32.6 | 41.3 | 22.1 | 41.7 | 42.1 | 20.5 | 20.3 | 51.1 | 31.0 | 27.9 | 54.9 | 34.3 |
| icml15[17] | DAN | 31.7 | 43.2 | 55.1 | 33.8 | 48.6 | 50.8 | 30.1 | 35.1 | 57.7 | 44.6 | 39.3 | 63.7 | 44.5 |
| icml15[19] | DANN | 36.4 | 45.2 | 54.7 | 35.2 | 51.8 | 55.1 | 31.6 | 39.7 | 59.3 | 45.7 | 46.4 | 65.9 | 47.3 |
| icml17[21] | JAN | 35.5 | 46.1 | 57.7 | 36.4 | 53.3 | 54.5 | 33.4 | 40.3 | 60.1 | 45.9 | 47.4 | 67.9 | 48.2 |
| cvpr16 | ResNet-50 | 34.9 | 50.0 | 58.0 | 37.4 | 41.9 | 46.2 | 38.5 | 31.2 | 60.4 | 53.9 | 41.2 | 59.9 | 46.1 |
| icml15[17] | DAN | 43.6 | 57.0 | 67.9 | 45.8 | 56.5 | 60.4 | 44.0 | 43.6 | 67.7 | 63.1 | 51.5 | 74.3 | 56.3 |
| icml15[19] | DANN | 45.6 | 59.3 | 70.1 | 47.0 | 58.5 | 60.9 | 46.1 | 43.7 | 68.5 | 63.2 | 51.8 | 76.8 | 57.6 |
| icml17[21] | JAN | 45.9 | 61.2 | 68.9 | 50.4 | 59.7 | 61.0 | 45.8 | 43.4 | 70.3 | 63.9 | 52.4 | 76.8 | 58.3 |
| acmmm18[27] | MEDA | **55.2** | **76.2** | **77.3** | 58.0 | **73.7** | **71.9** | 59.3 | 52.4 | 77.9 | 68.2 | 57.5 | 81.8 | **67.5** |
| neural network19[28] | MRAN | 53.8 | 68.6 | 75.0 | 57.3 | 68.5 | 68.3 | 58.5 | 54.6 | 77.5 | 70.4 | 60.0 | 82.2 | 66.2 |
| TNNLS20[29] | DSAN | 54.4 | 70.8 | 75.4 | **60.4** | 67.8 | 68.0 | **62.6** | **55.9** | **78.5** | **73.8** | **60.6** | **83.1** | **67.6** |
**Results using our unified and fair [codes](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA):**
| Method | A - C | A - P | A - R | C - A | C - P | C - R | P - A | P - C | P - R | R - A | R - C | R - P | Average |
|-------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|---------|
| Source-only | 51.04 | 68.21 | 74.85 | 54.22 | 63.64 | 66.84 | 53.65 | 45.41 | 74.57 | 65.68 | 53.56 | 79.34 | 62.58 |
| DAN [1] | 52.51 | 68.48 | 74.82 | 57.48 | 65.71 | 67.82 | 55.42 | 47.51 | 75.28 | 66.54 | 54.36 | 79.91 | 63.82 |
| DeepCoral [2] | 52.26 | 67.72 | 74.91 | 56.20 | 64.70 | 67.48 | 55.79 | 47.17 | 74.89 | 66.13 | 54.34 | 79.05 | 63.39 |
| DANN [3] | 51.48 | 67.27 | 74.18 | 53.23 | 65.10 | 65.41 | 53.15 | 50.22 | 75.05 | 65.35 | 57.48 | 79.45 | 63.12 |
| DSAN [4] | 54.48 | 71.12 | 75.37 | 60.53 | 70.92 | 68.53 | 62.71 | 56.04 | 78.29 | 74.37 | 60.34 | 82.99 | 67.97 |
### Image-CLEF DA
using ResNet-50 features (compare with the latest deep methods with ResNet-50 as backbone). Again, it seems that **MEDA** achieves the best performance.
Finetuned ResNet-50 models For ImageCLEF dataset: [BaiduYun](https://pan.baidu.com/s/1y9tqyzBL7LZTd7Td380fxA) | [Mega](https://mega.nz/#F!QPJCzShS!b6qQUXWnCCGBMVs0m6MdQw)
| Cite | Method | I-P | P-I | I-C | C-I | C-P | P-C | Avg |
|---------|-----------|-------|-------|-------|-------|-------|-------|-------|
| nips12 | AlexNet | 66.2 | 70.0 | 84.3 | 71.3 | 59.3 | 84.5 | 73.9 |
| icml15[17] | DAN | 67.3 | 80.5 | 87.7 | 76.0 | 61.6 | 88.4 | 76.9 |
| icml15[19] | DANN | 66.5 | 81.8 | 89.0 | 79.8 | 63.5 | 88.7 | 78.2 |
| icml17[21] | JAN | 67.2 | 82.8 | 91.3 | 80.0 | 63.5 | 91.0 | 79.3 |
| nips18[23]| CDAN-RM | 67.0 | 84.8 | 92.4 | 81.3 | 64.7 | 91.6 | 80.3 |
| nips18[23] | CDAN-M | 67.7 | 83.3 | 91.8 | 81.5 | 63.0 | 91.5 | 79.8 |
| cvpr16 | ResNet-50 | 74.8 | 83.9 | 91.5 | 78.0 | 65.5 | 91.2 | 80.7 |
| icml15[17] | DAN | 74.5 | 82.2 | 92.8 | 86.3 | 69.2 | 89.8 | 82.5 |
| icml15[19] | DANN | 75.0 | 86.0 | 96.2 | 87.0 | 74.3 | 91.5 | 85.0 |
| icml17[19] | JAN | 76.8 | 88.0 | 94.7 | 89.5 | 74.2 | 91.7 | 85.8 |
| cvpr18[24] | CAN | 78.2 | 87.5 | 94.2 | 89.5 | 75.8 | 89.2 | 85.7 |
| cvpr18[24] | iCAN | 79.5 | 89.7 | 94.7 | 89.9 | 78.5 | 92.0 | 87.4 |
| acmmm18[27] | MEDA | **80.2** | 91.5 | 96.2 | 92.7 | 79.1 | 95.8 | 89.3 |
| neural network19[28] | MRAN | 78.8 | 91.7 | 95.0 | 93.5 | 77.7 | 93.1 | 88.3 |
| TNNLS20[29] | DSAN | **80.2** | **93.3** | **97.2** | **93.8** | **80.8** |**95.9** | **90.2** |
### Office+Caltech
We provide results on SURF and DeCaf features.
#### SURF
| Task | C - A | C - W | C - D | A - C | A - W | A - D | W - C | W - A | W - D | D - C | D - A | D - W | Average |
|-----------------|-------------|-------------|-------------|-------------|-------------|-------------|-----------|-------------|-------------|-------------|-------------|-------------|-------------|
| 1NN | 23.7 | 25.8 | 25.5 | 26 | 29.8 | 25.5 | 19.9 | 23 | 59.2 | 26.3 | 28.5 | 63.4 | 31.4 |
| SVM | 53.1 | 41.7 | 47.8 | 41.7 | 31.9 | 44.6 | 28.8 | 27.6 | 78.3 | 26.4 | 26.2 | 52.5 | 41.1 |
| PCA | 39.5 | 34.6 | 44.6 | 39 | 35.9 | 33.8 | 28.2 | 29.1 | 89.2 | 29.7 | 33.2 | 86.1 | 43.6 |
| TCA | 45.6 | 39.3 | 45.9 | 42 | 40 | 35.7 | 31.5 | 30.5 | 91.1 | 33 | 32.8 | 87.5 | 46.2 |
| GFK | 46 | 37 | 40.8 | 40.7 | 37 | 40.1 | 24.8 | 27.6 | 85.4 | 29.3 | 28.7 | 80.3 | 43.1 |
| JDA | 43.1 | 39.3 | 49 | 40.9 | 38 | 42 | 33 | 29.8 | 92.4 | 31.2 | 33.4 | 89.2 | 46.8 |
| CORAL | 52.1 | 46.4 | 45.9 | 45.1 | 44.4 | 39.5 | 33.7 | 36 | 86.6 | 33.8 | 37.7 | 84.7 | 48.8 |
| SCA | 45.6 | 40 | 47.1 | 39.7 | 34.9 | 39.5 | 31.1 | 30 | 87.3 | 30.7 | 31.6 | 84.4 | 45.2 |
| JGSA | 51.5 | 45.4 | 45.9 | 41.5 | 45.8 | 47.1 | 33.2 | 39.9 | 90.5 | 29.9 | 38 | 91.9 | 50 |
| MEDA[27] | **56.5** | **53.9** | **50.3** | **43.9** | **53.2** | **45.9** | **34.0** | **42.7** | **88.5** | **34.9** | **41.2** | **87.5** | **52.7** |
- - -
#### Decaf6
| Method | C - A | C - W | C - D | A - C | A - W | A - D | W - C | W - A | W - D | D - C | D - A | D - W | Average |
|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| 1NN | 87.3 | 72.5 | 79.6 | 71.7 | 68.1 | 74.5 | 55.3 | 62.6 | 98.1 | 42.1 | 50 | 91.5 | 71.1 |
| SVM | 91.6 | 80.7 | 86 | 82.2 | 71.9 | 80.9 | 67.9 | 73.4 | 100 | 72.8 | 78.7 | 98.3 | 82 |
| PCA | 88.1 | 83.4 | 84.1 | 79.3 | 70.9 | 82.2 | 70.3 | 73.5 | 99.4 | 71.7 | 79.2 | 98 | 81.7 |
| TCA | 89.8 | 78.3 | 85.4 | 82.6 | 74.2 | 81.5 | 80.4 | 84.1 | 100 | 82.3 | 89.1 | 99.7 | 85.6 |
| GFK | 88.2 | 77.6 | 86.6 | 79.2 | 70.9 | 82.2 | 69.8 | 76.8 | 100 | 71.4 | 76.3 | 99.3 | 81.5 |
| JDA | 89.6 | 85.1 | 89.8 | 83.6 | 78.3 | 80.3 | 84.8 | 90.3 | 100 | 85.5 | 91.7 | 99.7 | 88.2 |
| SCA | 89.5 | 85.4 | 87.9 | 78.8 | 75.9 | 85.4 | 74.8 | 86.1 | 100 | 78.1 | 90 | 98.6 | 85.9 |
| JGSA | 91.4 | 86.8 | **93.6** | 84.9 | 81 | 88.5 | 85 | 90.7 | 100 | 86.2 | 92 | 99.7 | 90 |
| CORAL | 92 | 80 | 84.7 | 83.2 | 74.6 | 84.1 | 75.5 | 81.2 | 100 | 76.8 | 85.5 | 99.3 | 84.7 |
| AlexNet | 91.9 | 83.7 | 87.1 | 83 | 79.5 | 87.4 | 73 | 83.8 | 100 | 79 | 87.1 | 97.7 | 86.1 |
| DDC | 91.9 | 85.4 | 88.8 | 85 | 86.1 | 89 | 78 | 84.9 | 100 | 81.1 | 89.5 | 98.2 | 88.2 |
| DAN | 92 | 90.6 | 89.3 | 84.1 | 91.8 | 91.7 | 81.2 | 92.1 | 100 | 80.3 | 90 | 98.5 | 90.1 |
| DCORAL | 92.4 | 91.1 | 91.4 | 84.7 | - | - | 79.3 | - | - | 82.8 | - | - | - |
| MEDA[27] | **93.4** | **95.6** | 91.1 | **87.4** | 88.1 | 88.1 | **93.2** | **99.4** | 99.4 | **87.5** | **93.2** | 97.6 | **92.8** |
- - -
### MNIST+USPS
There are plenty of different configurations in MNIST+USPS datasets. Here we only show some the recent results with the same network (based on LeNet) and training/test split.
| Method | MNIST-USPS |
|:-------:|:----------:|
| DDC | 79.1 |
| DANN | 77.1 |
| CoGAN | 91.2 |
| ADDA | 89.4 |
| MSTN | 92.9 |
| MEDA | 94.3 |
| CyCADA | 95.6 |
| PixelDA | 95.9 |
| UNIT | 95.9 |
| DSAN | 96.9 |
## Domain generalization
We get the results on PACS and Office-Home using our [codebase](https://github.com/jindongwang/transferlearning/blob/master/code/DeepDG).
### PACS (Resnet-18)
| Method | A | C | P | S | AVG |
|----------|----------|----------|----------|----------|----------|
| ERM | 76.90 | 76.41 | 93.83 | 65.26 | 78.10 |
| DANN | 79.30 | 77.13 | 92.93 | 77.20 | 81.64 |
| Mixup | 76.32 | 71.93 | 92.28 | 70.50 | 77.76 |
| RSC | 75.68 | 75.60 | 94.43 | 70.81 | 79.13 |
| CORAL | 73.34 | 76.62 | 87.96 | 73.86 | 77.94 |
| GroupDRO | 71.92 | 77.13 | 87.13 | 75.01 | 77.80 |
### Office-Home (Resnet-18)
| Method | A | C | P | R | AVG |
|----------|----------|----------|----------|----------|----------|
| ERM | 51.38 | 37.69 | 64.83 | 67.62 | 55.38 |
| DANN | 51.59 | 38.01 | 64.56 | 67.41 | 55.39 |
| Mixup | 50.97 | 37.64 | 62.81 | 66.28 | 54.43 |
| RSC | 52.45 | 39.15 | 65.24 | 67.96 | 56.20 |
| CORAL | 51.71 | 38.53 | 63.84 | 67.00 | 55.27 |
| MMD | 51.83 | 38.05 | 63.82 | 67.00 | 55.17 |
| MLDG | 45.65 | 32.28 | 58.62 | 60.64 | 49.30 |
## References
[1] Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 2066-2073.
[2] Russell B C, Torralba A, Murphy K P, et al. LabelMe: a database and web-based tool for image annotation[J]. International journal of computer vision, 2008, 77(1): 157-173.
[3] Griffin G, Holub A, Perona P. Caltech-256 object category dataset[J]. 2007.
[4] Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 2200-2207.
[5] http://attributes.kyb.tuebingen.mpg.de/
[6] http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie/Multi-Pie/Home.html
[7] http://www.cs.dartmouth.edu/~chenfang/proj_page/FXR_iccv13/
[8] M. Everingham, L. Van-Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (VOC) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, 2010.
[9] M. J. Choi, J. J. Lim, A. Torralba, and A. S. Willsky, “Exploiting hierarchical context on a large database of object categories,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogit., 2010, pp. 129–136
[10] http://www.uow.edu.au/~jz960/
[11] Zhang J, Li W, Ogunbona P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation[C]. CVPR 2017.
[12] Tahmoresnezhad J, Hashemi S. Visual domain adaptation via transfer feature learning[J]. Knowledge and Information Systems, 2017, 50(2): 585-605.
[13] Long M, Wang J, Sun J, et al. Domain invariant transfer kernel learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(6): 1519-1532.
[14] Venkateswara H, Eusebio J, Chakraborty S, et al. Deep hashing network for unsupervised domain adaptation[C]. CVPR 2017.
[15] Daumé III H. Frustratingly easy domain adaptation[J]. arXiv preprint arXiv:0907.1815, 2009.
[16] Luo L, Chen L, Hu S. Discriminative Label Consistent Domain Adaptation[J]. arXiv preprint arXiv:1802.08077, 2018.
[17] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In ICML, pages 97–105, 2015.
[19] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, pages 1180–1189, 2015.
[20] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Computer Vision and Pattern Recognition (CVPR), volume 1, page 4, 2017.
[21] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Deep transfer learning with joint adaptation networks. In International Conference on Machine Learning, pages 2208–2217, 2017.
[22] Swami Sankaranarayanan, Yogesh Balaji, Carlos D Castillo, and Rama Chellappa. Generate to adapt: Aligning domains using generative adversarial networks. In CVPR, 2018.
[24] Weichen Zhang, Wanli Ouyang, Wen Li, and Dong Xu. Collaborative and adversarial network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3801–3809, 2018.
[25] Chao Chen, Zhihong Chen, Boyuan Jiang, and Xinyu Jin. Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation. In AAAI, 2019.
[27] Wang, Jindong, et al. "Visual Domain Adaptation with Manifold Embedded Distribution Alignment." 2018 ACM Multimedia Conference on Multimedia Conference. ACM, 2018.
[28] Yongchun Zhu, Fuzhen Zhuang, Jindong Wang, et al. "Multi-representation adaptation network for cross-domain image classification." Neural Network 2019, 119.
[29] Yongchun Zhu, Fuzhen Zhuang, Jindong Wang, et al. "Deep Subdomain Adaptation Network for Image Classification." IEEE Transactions on Neural Networks and Learning Systems 2020.
[30] Xie S, Zheng Z, Chen L, et al. Learning semantic representations for unsupervised domain adaptation. International conference on machine learning. PMLR, 2018: 5423-5432.
================================================
FILE: data/dataset.md
================================================
## Datasets for domain adaptation and transfer learning
- *How many times have you been* **struggling to find** the useful datasets?
- *How much time have you been wasting to* **preprocess datasets**?
- *How burdersome is it to compare with other methods*? Will you re-run their code? or there is **No** code?
**Datasets are critical to machine learning**, but *You should focus on* **YOUR** work! So we want to save your time by:
**JUST GIVE THEM TO YOU** so you can **DIRECTLY** use them!
- - -
**If you are tired of repeating the experiments of other methods, you can directly use the [benchmark](https://github.com/jindongwang/transferlearning/blob/master/data/benchmark.md).**
Most datasets are image datasets:
| Dataset | Area | #Sample | #Feature | #Class | Subdomain | Reference |
|:--------------:|:------------------:|:-------:|:-------------------:|:------:|:------------:|:--------:|
| [Office+Caltech](#office+caltech) | Object recognition | 2533 | SURF:800 DeCAF:4096 | 10 | C, A, W, D | [1] |
| [Office-31](#office-31) | Object recognition | 4110 | SURF:800 DeCAF:4096 | 31 | A, W, D | [1] |
| [Modern Office-31](#modern-office-31) | Image Classification | 6712 | — | 31 | A, S, W | [20] |
| [MNIST+USPS](#mnist+usps) | Digit recognition | 3800 | 256 | 10 | USPS, MNIST | [4] |
| [COIL20](#coil20) | Object recognition | 1440 | 1024 | 20 | COIL1, COIL2 | [4] |
| [PIE](#pie) | Face recognition | 11554 | 1024 | 68 | PIE1~PIE5 | [6] |
| [VOC2007](#vlsc) | Object recognition | 3376 | DeCAF:4096 | 5 | V | [8] |
| [LabelMe](#vlsc) | Object recognition | 2656 | DeCAF:4096 | 5 | L | [2] |
| [SUN09](#vlsc) | Object recognition | 3282 | DeCAF:4096 | 5 | S | [9] |
| [Caltech101](#vlsc) | Object recognition | 1415 | DeCAF:4096 | 5 | C | [3] |
| [IMAGENET](#imagenet) | Object recognition | 7341 | DeCAF:4096 | 5 | I | [7] |
| [AWA](#animals-with-attributes) | Animal recognition | 30475 | DeCAF:4096 SIFT/SURF:2000 | 50 | I | [5] |
| [Office-Home](#office-home) | Object recognition | 30475 | Original Images | 65 | 4 domains | [10] |
| [Cross-dataset Testbed](#testbed) | Image Classification | * | Decaf7 | 40 | 3 domains | [15] |
| [ImageCLEF](#imageclef) | Image Classification | * | raw | 12 | 3 domains | [17] |
| [VisDA](#VisDA) | Image Classification / segmentation | 280157 | raw | 12 | 3 domains/3 domain | [18] |
| [LSDAC](#LSDAC) | Image Classification | 569010 | raw | 345 | 6 domains | [19] |
| [Adaptiope](#adaptiope) | Image Classification | 36900 | — | 123 | P, S, R | [20] |
**NEW** A even larger dataset called [DomainNet](http://ai.bu.edu/M3SDA/#refs) is released by BU, with half a million images, 6 domains, and 345 classes!
**NEW** A new dataset released by Stanford and UC Berkeley: [Syn2Real: A New Benchmark forSynthetic-to-Real Visual Domain Adaptation](https://arxiv.org/abs/1806.09755)
## Text datasets:
Amazon review for sentiment classification
You can download the datasets [here](https://pan.baidu.com/s/1F69rBEF9_DwrVcEjHXk96w) with code `a82t`.
- - -
### Office+Caltech
#### Area
Visual object recognition
#### Introduction
Perhaps it is the **most popular** dataset for domain adaptation. Four domains are included: C(Caltech), A(Amazon), W(Webcam) and D(DSLR). In fact, this dataset is constructed from two datasets: Office-31 (which contains 31 classes of A, W and D) and Caltech-256 (which contains 256 classes of C). There are just 10 common classes in both, so the Office+Caltech dataset is formed.
Even for the same category, the data distribution of different domains is exactly different. The following picture [1] indicates this fact by the monitor images from 4 domains.

#### Features
There are ususlly two kinds of features: SURF and DeCAF6. They are with the same number of samples per domain, resulting 2533 samples in total:
- C: 1123
- A: 958
- W: 295
- D: 157
And the dimension of features is:
- For SURF: 800
- For DeCAF6: 4096
#### Copyright
This dataset was first introduced by Gong et al. [1]. I got the SURF features from the website of [1], while DeCAF features from [10].
See benchmark results of many popular methods [here(SURF)](https://github.com/jindongwang/transferlearning/blob/master/doc/benchmark.md#officecaltech-surf) and [here(DeCaf)](https://github.com/jindongwang/transferlearning/blob/master/doc/benchmark.md#officecaltech10-decaf6).
#### Download
Download Office+Caltech original images [[Baiduyun](https://pan.baidu.com/s/14JEGQ56LJX7LMbd6GLtxCw)]
Download Office+Caltech SURF dataset [[MEGA](https://mega.nz/#F!AaJTGIzD!XHM2XMsSd9V-ljVi0EtvFg)|[Baiduyun](https://pan.baidu.com/s/1bp4g7Av)]
Download Office+Caltech DeCAF dataset [[MEGA](https://mega.nz/#F!QDxBBC4J!LizxWbE1_JEwPSrA2mrrrw)|[Baiduyun](https://pan.baidu.com/s/1nvn7eUd)]
- - -
### Office-31
This is the full Office dataset, which contains 31 categories from Amazon, webcam and DSLR.
See benchmarks on Office-31 datasets [here](https://github.com/jindongwang/transferlearning/blob/master/doc/benchmark.md#office-31).
#### Download
Download Office-31 raw images:
- [Jianguoyun](https://www.jianguoyun.com/p/Dblj5GcQmN7PCBiA9asD) (Password: FcaDrw)
- [MEGA](https://mega.nz/file/dSpjyCwR#9ctB4q1RIE65a4NoJy0ox3gngh15cJqKq1XpOILJt9s)
- [Azure (supports wget)](https://wjdcloud.blob.core.windows.net/dataset/OFFICE31.zip)
Download Office-31 DeCAF6 and DeCAF7 features:
- [Jianguoyun](https://www.jianguoyun.com/p/DcNAUg0QmN7PCBiF9asD) (Password: qqLA7D)
Download Office-31 Resnet-50 features:
- [Jianguoyun](https://www.jianguoyun.com/p/DSO1BC0QmN7PCBicraIE) (Password: eS5fMT)
- [MEGA](https://mega.nz/#F!laI2lKoJ!nSmVQXrpu1Ov794sy2wFKg)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/office31_resnet50.zip)
- - -
### MNIST+USPS
**Area** Handwritten digit recognition
It is also popular. It contains randomly selected samples from MNIST and USPS. Then the source and target domains are constructed using each other.
Download MNIST+USPS SURF dataset [[MEGA](https://mega.nz/#F!oHJ2UCoK!r62nRoZ0gH8NXIcgmyWReA)|[Baiduyun](https://pan.baidu.com/s/1c8mwdo)]
- - -
### COIL20
**Area** Object recognition
It contains 20 classes. There are two datasets extracted: COIL1 and COIL2.
Download COIL20 SURF dataset [[MEGA](https://mega.nz/#F!xWxyTDaZ!MWamSH17Uu065XbDNYymkQ)|[Baiduyun](https://pan.baidu.com/s/1pKM1VCn)]
- - -
### PIE
**Area** Facial recognition
It is a relatively large dataset with many classes.
Download PIE SURF dataset [[MEGA](https://mega.nz/#F!lPgmkZQB!z2QuBEmCzj2XR5AAQaIj7Q)|[Baiduyun](https://pan.baidu.com/s/1o8KFgtO)]
- - -
### VLSC
**Area** Image classification
It contains four domains: V(VOC2007), L(LabelMe), S(SUN09) and C(Caltech). There are 5 classes: 'bird', 'car', 'chair', 'dog', 'person'.
Download the VLSC DeCAF dataset [[MEGA](https://mega.nz/#F!gTJxGTJK!w9UJjZVq3ClqGj4mBDmT4A)|[Baiduyun](https://pan.baidu.com/s/1nuNiJ0l)]
- - -
### IMAGENET
It is selected from imagenet challange.
Download the IMAGENET DeCAF dataset [[MEGA](https://mega.nz/#F!gTJxGTJK!w9UJjZVq3ClqGj4mBDmT4A)|[Baiduyun](https://pan.baidu.com/s/1nuNiJ0l)]
- - -
### Animals-with-Attributes
Download the SURF/SIFT/DeCAF features [[MEGA](https://mega.nz/#F!Na5jyLiC!LT29_gyoPsd_eEoym3CgMg)|[Baiduyun](https://pan.baidu.com/s/1mi7RYQW)]
- - -
### Office-Home
This is a **new** dataset released at CVPR 2017. It contains 65 kinds of objects crawled from the web. The main research goal is for domain adatpation algorithms benchmark.
The project home page is: http://hemanthdv.org/OfficeHome-Dataset/.
Download original images:
- [Jianguoyun](https://www.jianguoyun.com/p/DSCLvuoQmN7PCBiWraIE) (Password: 726GYD)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/OfficeHome.zip)
Download ResNet-50 pre-trained features:
- [Baiduyun](https://pan.baidu.com/s/1qvcWJCXVG8JkZnoM4BVoGg)
- [MEGA](https://mega.nz/#F!pGIkjIxC!MDD3ps6RzTXWobMfHh0Slw)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/officehome_resnet50.zip)
- - -
### Cross-dataset Testbed
This is a Decaf7 based cross-dataset image classification dataset. It contains 40 categories of images from 3 domains: 3,847 images in Caltech256(C), 4,000 images in ImageNet(I), and 2,626 images for SUN(S).
[Download the Cross-dataset testbed](https://pan.baidu.com/s/1o8MeVUi)
- - -
### ImageCLEF
This is a dataset from ImageCLEF 2014 challenge.
Download original images:
- [Jianguoyun](https://www.jianguoyun.com/p/DW5Gc_sQmN7PCBjwrKIE) (Password: e5v8GG)
- [MEGA](https://mega.nz/#!AKYhEYaY!mSwEK3_9SLVSqXXNzUxNWpQymlH10vcEhuC8fbOIAwk)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/image_CLEF.zip)
Download ResNet-50 pre-trained features:
- [Baiduyun](https://pan.baidu.com/s/16wBgDJI6drA0oYq537h4FQ)
- [MEGA](https://mega.nz/#F!QPJCzShS!b6qQUXWnCCGBMVs0m6MdQw)
- - -
### VisDA
This is a dataset from VisDA 2017 challenge. It contains two subdatasets, one for image classification tasks and the other for image segmentation tasks.
[Download the VisDA-classification dataset](http://csr.bu.edu/ftp/visda17/clf/)
[Download the VisDA-segmentation dataset](http://csr.bu.edu/ftp/visda17/seg/)
[Download VisDA classification dataset features by ResNet-50](https://pan.baidu.com/s/1sbuDqWWzwLyB1fFIpo5BdQ) | [Download from MEGA](https://mega.nz/#F!ZDY2jShR!r_M2sR7MBi_9JPsRUXXy0g)
- - -
### LSDAC
This is probably the **largest and latest** domain adaptation datasets ever! It is collected by Boston U, which contains 6 domains from 345 categories, leading to 600K images. Dataset download link will be available soon once the authors release their datasets. You can refer to [19] for more information.
- - -
### Amazon review
Downlaod Amazon review dataset:
- [Mega](https://mega.nz/#F!RS43DADD!4pWwFA0CBJP1oLhAR23bTA)
- [Jianguoyun](https://www.jianguoyun.com/p/DfOeHxIQmN7PCBiT9asD) (Password: AXMDi5)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/amazon_review.zip)
- - -
### Adaptiope
Adaptiope is probably one of the most versatile domain adaptation datasets with **synthetic images** (3D renderings). Overall, Adaptiope contains images of 123 categories in the 3 domains product, real life and synthetic for a total of 36,900 images. Please refer to the [project website](https://gitlab.com/tringwald/adaptiope) for more information.
[Download Adaptiope](https://drive.google.com/file/d/1FmdsvetC0oVyrFJ9ER7fcN-cXPOWx2gq/view?usp=sharing)
- - -
### Modern-Office-31
Modern Office-31 is a modernized version of the popular [Office-31](#office-31) dataset. This version fixes many of the annotation errors in the original dataset and also adds a challenging synthetic domain. Overall, Modern Office-31 contains 6,712 images in the 3 domains Amazon, synthetic and webcam.
Please refer to the [project website](https://gitlab.com/tringwald/adaptiope) for more information.
[Download Modern Office-31](https://drive.google.com/file/d/1p7ecv9kP3YbmdiY49vSjTaG0Aw51n26x/view?usp=sharing)
- - -
### References
[1] Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 2066-2073.
[2] Russell B C, Torralba A, Murphy K P, et al. LabelMe: a database and web-based tool for image annotation[J]. International journal of computer vision, 2008, 77(1): 157-173.
[3] Griffin G, Holub A, Perona P. Caltech-256 object category dataset[J]. 2007.
[4] Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 2200-2207.
[5] http://attributes.kyb.tuebingen.mpg.de/
[6] http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie/Multi-Pie/Home.html
[7] http://www.cs.dartmouth.edu/~chenfang/proj_page/FXR_iccv13/
[8] M. Everingham, L. Van-Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (VOC) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, 2010.
[9] M. J. Choi, J. J. Lim, A. Torralba, and A. S. Willsky, “Exploiting hierarchical context on a large database of object categories,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogit., 2010, pp. 129–136
[10] http://www.uow.edu.au/~jz960/
[11] Zhang J, Li W, Ogunbona P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation[C]. CVPR 2017.
[12] Tahmoresnezhad J, Hashemi S. Visual domain adaptation via transfer feature learning[J]. Knowledge and Information Systems, 2017, 50(2): 585-605.
[13] Long M, Wang J, Sun J, et al. Domain invariant transfer kernel learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(6): 1519-1532.
[14] Venkateswara H, Eusebio J, Chakraborty S, et al. Deep hashing network for unsupervised domain adaptation[C]. CVPR 2017.
[15] Daumé III H. Frustratingly easy domain adaptation[J]. arXiv preprint arXiv:0907.1815, 2009.
[16] Luo L, Chen L, Hu S. Discriminative Label Consistent Domain Adaptation[J]. arXiv preprint arXiv:1802.08077, 2018.
[17] http://imageclef.org/2014/adaptation
[18] Peng X. VisDA: The Visual Domain Adaptation Challenge. arXiv preprint arXiv:1710.06924.
[19] Xingchao Peng, et al. Moment Matching for Multi-Source Domain Adaptation. arXiv 1812.01754.
[20] T. Ringwald, et al. "Adaptiope: A Modern Benchmark for Unsupervised Domain Adaptation", Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021
================================================
FILE: data/readme.md
================================================
# Transfer Learning Datasets and Benchmark
Please refer to `dataset.md` for datasets description and download, and `benchmark.md` for benchmark results of popular methods.
## Data download
- [Transfer Learning Datasets and Benchmark](#transfer-learning-datasets-and-benchmark)
- [Data download](#data-download)
- [Office-Caltech10](#office-caltech10)
- [Office-31](#office-31)
- [Office-Home](#office-home)
- [ImageCLEF](#imageclef)
- [USPS+MNIST](#uspsmnist)
- [VisDA-17](#visda-17)
- [Amazon review](#amazon-review)
- [Cross-dataset Testbed](#cross-dataset-testbed)
- [COIL20](#coil20)
- [CMU-PIE](#cmu-pie)
- [VLSC](#vlsc)
- [Animals-with-Attributes](#animals-with-attributes)
### Office-Caltech10
Download Office+Caltech original images:
- [Baiduyun](https://pan.baidu.com/s/14JEGQ56LJX7LMbd6GLtxCw)
Download Office+Caltech SURF dataset:
- [Jianguoyun](https://www.jianguoyun.com/p/DaKoCGIQmN7PCBju9KsD) (Password: PRSZD9)
- [MEGA](https://mega.nz/#F!AaJTGIzD!XHM2XMsSd9V-ljVi0EtvFg)
Download Office+Caltech DeCAF dataset:
- [Jianguoyun](https://www.jianguoyun.com/p/DWJ_7qgQmN7PCBj29KsD) (Password: cnfjmc)
- [MEGA](https://mega.nz/#F!QDxBBC4J!LizxWbE1_JEwPSrA2mrrrw)
### Office-31
Download Office-31 raw images:
- [Jianguoyun](https://www.jianguoyun.com/p/Dblj5GcQmN7PCBiA9asD) (Password: FcaDrw)
- [MEGA](https://mega.nz/file/dSpjyCwR#9ctB4q1RIE65a4NoJy0ox3gngh15cJqKq1XpOILJt9s)
- [Azure (supports wget)](https://wjdcloud.blob.core.windows.net/dataset/OFFICE31.zip)
Download Office-31 Resnet-50 features:
- [Jianguoyun](https://www.jianguoyun.com/p/DSO1BC0QmN7PCBicraIE) (Password: eS5fMT)
- [MEGA](https://mega.nz/#F!laI2lKoJ!nSmVQXrpu1Ov794sy2wFKg)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/office31_resnet50.zip)
Download Office-31 DeCAF6 and DeCAF7 features:
- [Jianguoyun](https://www.jianguoyun.com/p/DcNAUg0QmN7PCBiF9asD) (Password: qqLA7D)
### Office-Home
Download original images:
- [Jianguoyun](https://www.jianguoyun.com/p/DSCLvuoQmN7PCBiWraIE) (Password: 726GYD)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/OfficeHome.zip)
Download ResNet-50 pre-trained features:
- [Baiduyun](https://pan.baidu.com/s/1qvcWJCXVG8JkZnoM4BVoGg)
- [MEGA](https://mega.nz/#F!pGIkjIxC!MDD3ps6RzTXWobMfHh0Slw)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/officehome_resnet50.zip)
### ImageCLEF
Download original images:
- [Jianguoyun](https://www.jianguoyun.com/p/DW5Gc_sQmN7PCBjwrKIE) (Password: e5v8GG)
- [MEGA](https://mega.nz/#!AKYhEYaY!mSwEK3_9SLVSqXXNzUxNWpQymlH10vcEhuC8fbOIAwk)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/image_CLEF.zip)
Download ResNet-50 pre-trained features:
- [Baiduyun](https://pan.baidu.com/s/16wBgDJI6drA0oYq537h4FQ)
- [MEGA](https://mega.nz/#F!QPJCzShS!b6qQUXWnCCGBMVs0m6MdQw)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/imageCLEF_resnet50.zip)
### USPS+MNIST
Download MNIST+USPS SURF dataset:
- [MEGA](https://mega.nz/#F!oHJ2UCoK!r62nRoZ0gH8NXIcgmyWReA)
- [Jianguoyun](https://www.jianguoyun.com/p/DeCNnNkQmN7PCBjd9KsD) (Password: kQujmV)
### VisDA-17
[Download the VisDA-classification dataset](http://csr.bu.edu/ftp/visda17/clf/)
[Download the VisDA-segmentation dataset](http://csr.bu.edu/ftp/visda17/seg/)
[Download VisDA classification dataset features by ResNet-50](https://pan.baidu.com/s/1sbuDqWWzwLyB1fFIpo5BdQ) | [Download from MEGA](https://mega.nz/#F!ZDY2jShR!r_M2sR7MBi_9JPsRUXXy0g)
### Amazon review
Downlaod Amazon review dataset:
- [Mega](https://mega.nz/#F!RS43DADD!4pWwFA0CBJP1oLhAR23bTA)
- [Jianguoyun](https://www.jianguoyun.com/p/DfOeHxIQmN7PCBiT9asD) (Password: AXMDi5)
- [Azure (Supports wget)](https://wjdcloud.blob.core.windows.net/dataset/amazon_review.zip)
### Cross-dataset Testbed
[Download the Cross-dataset testbed](https://pan.baidu.com/s/1o8MeVUi)
### COIL20
Download COIL20 SURF dataset [[MEGA](https://mega.nz/#F!xWxyTDaZ!MWamSH17Uu065XbDNYymkQ)|[Baiduyun](https://pan.baidu.com/s/1pKM1VCn)]
### CMU-PIE
Download PIE SURF dataset:
- [MEGA](https://mega.nz/#F!lPgmkZQB!z2QuBEmCzj2XR5AAQaIj7Q)
- [Jianguoyun](https://www.jianguoyun.com/p/Da9HTXUQmN7PCBiO9asD) (Password: gWDSkq)
### VLSC
Download the VLSC DeCAF dataset:
- [MEGA](https://mega.nz/#F!gTJxGTJK!w9UJjZVq3ClqGj4mBDmT4A)
- [Jianguoyun](https://www.jianguoyun.com/p/DegKxO8QmN7PCBiI9asD) (Password: FxQLfH)
### Animals-with-Attributes
Download the SURF/SIFT/DeCAF features [[MEGA](https://mega.nz/#F!Na5jyLiC!LT29_gyoPsd_eEoym3CgMg)|[Baiduyun](https://pan.baidu.com/s/1mi7RYQW)]
================================================
FILE: doc/awesome_paper.md
================================================
# Awesome Transfer Learning Papers
Let's read some awesome transfer learning / domain adaptation papers.
Here, we list some papers by topic. For list by date, please refer to [papers by date](awesome_paper.md).
这里收录了迁移学习各个研究领域的最新文章。
- [Awesome Transfer Learning Papers](#awesome-transfer-learning-papers)
- [Survey](#survey)
- [Large models](#large-models)
- [Theory](#theory)
- [Per-training/Finetuning](#per-trainingfinetuning)
- [Knowledge distillation](#knowledge-distillation)
- [Traditional domain adaptation](#traditional-domain-adaptation)
- [Deep domain adaptation](#deep-domain-adaptation)
- [Domain generalization](#domain-generalization)
- [Survey \& tutorial](#survey--tutorial)
- [Papers](#papers)
- [Source-free domain adaptation](#source-free-domain-adaptation)
- [Multi-source domain adaptation](#multi-source-domain-adaptation)
- [Heterogeneous transfer learning](#heterogeneous-transfer-learning)
- [Online transfer learning](#online-transfer-learning)
- [Zero-shot / few-shot learning](#zero-shot--few-shot-learning)
- [Multi-task learning](#multi-task-learning)
- [Transfer reinforcement learning](#transfer-reinforcement-learning)
- [Transfer metric learning](#transfer-metric-learning)
- [Federated transfer learning](#federated-transfer-learning)
- [Lifelong transfer learning](#lifelong-transfer-learning)
- [Safe transfer learning](#safe-transfer-learning)
- [Transfer learning applications](#transfer-learning-applications)
## Survey
- Transfer Learning Applied to Computer Vision Problems: Survey on Current Progress, Limitations, and Opportunities [[arxiv](https://arxiv.org/abs/2409.07736)]
- Transfer learning for computer vision survey
- A Survey of Heterogeneous Transfer Learning [[arxiv](https://arxiv.org/abs/2310.08459v2)]
- A recent survey of heterogeneous transfer learning 一篇最近的关于异构迁移学习的综述
- Review of Large Vision Models and Visual Prompt Engineering [[arxiv](https://arxiv.org/abs/2307.00855)]
- A survey of large vision model and prompt tuning 一个关于大视觉模型的prompt tuning的综述
- IEEE TNNLS-22 [Towards Personalized Federated Learning](http://arxiv.org/abs/2103.00710)
- A survey on personalized federated learning 一个关于个性化联邦学习的综述
- 2022 [Transfer Learning for Future Wireless Networks: A Comprehensive Survey](https://arxiv.org/abs/2102.07572)
- 2022 [A Review of Deep Transfer Learning and Recent Advancements](https://arxiv.org/abs/2201.09679)
- 2022 [Transferability in Deep Learning: A Survey](https://paperswithcode.com/paper/transferability-in-deep-learning-a-survey)
- 2021 Domain generalization: IJCAI-21 [Generalizing to Unseen Domains: A Survey on Domain Generalization](https://arxiv.org/abs/2103.03097) | [知乎文章](https://zhuanlan.zhihu.com/p/354740610) | [微信公众号](https://mp.weixin.qq.com/s/DsoVDYqLB1N7gj9X5UnYqw)
- First survey on domain generalization
- 第一篇对Domain generalization (领域泛化)的综述
- 2021 Vision-based activity recognition: [A Survey of Vision-Based Transfer Learning in Human Activity Recognition](https://www.mdpi.com/2079-9292/10/19/2412)
- 2021 ICSAI [A State-of-the-Art Survey of Transfer Learning in Structural Health Monitoring](https://ieeexplore.ieee.org/abstract/document/9664171)
- 2020 [Transfer learning: survey and classification](https://link.springer.com/chapter/10.1007/978-981-15-5345-5_13), Advances in Intelligent Systems and Computing.
- 2020 迁移学习最新survey,来自中科院计算所庄福振团队,发表在Proceedings of the IEEE: [A Comprehensive Survey on Transfer Learning](https://arxiv.org/abs/1911.02685)
- 2020 负迁移的综述:[Overcoming Negative Transfer: A Survey](https://arxiv.org/abs/2009.00909)
- 2020 知识蒸馏的综述: [Knowledge Distillation: A Survey](https://arxiv.org/abs/2006.05525)
- 用transfer learning进行sentiment classification的综述:[A Survey of Sentiment Analysis Based on Transfer Learning](https://ieeexplore.ieee.org/abstract/document/8746210)
- 2019 一篇新survey:[Transfer Adaptation Learning: A Decade Survey](https://arxiv.org/abs/1903.04687)
- 2018 一篇迁移度量学习的综述: [Transfer Metric Learning: Algorithms, Applications and Outlooks](https://arxiv.org/abs/1810.03944)
- 2018 一篇最近的非对称情况下的异构迁移学习综述:[Asymmetric Heterogeneous Transfer Learning: A Survey](https://arxiv.org/abs/1804.10834)
- 2018 Neural style transfer的一个survey:[Neural Style Transfer: A Review](https://arxiv.org/abs/1705.04058)
- 2018 深度domain adaptation的一个综述:[Deep Visual Domain Adaptation: A Survey](https://www.sciencedirect.com/science/article/pii/S0925231218306684)
- 2017 多任务学习的综述,来自香港科技大学杨强团队:[A survey on multi-task learning](https://arxiv.org/abs/1707.08114)
- 2017 异构迁移学习的综述:[A survey on heterogeneous transfer learning](https://link.springer.com/article/10.1186/s40537-017-0089-0)
- 2017 跨领域数据识别的综述:[Cross-dataset recognition: a survey](https://arxiv.org/abs/1705.04396)
- 2016 [A survey of transfer learning](https://pan.baidu.com/s/1gfgXLXT)。其中交代了一些比较经典的如同构、异构等学习方法代表性文章。
- 2015 中文综述:[迁移学习研究进展](https://pan.baidu.com/s/1bpautob)
- 2010 [A survey on transfer learning](http://ieeexplore.ieee.org/abstract/document/5288526/)
- Survey on applications - 应用导向的综述:
- 视觉domain adaptation综述:[Visual Domain Adaptation: A Survey of Recent Advances](https://pan.baidu.com/s/1o8BR7Vc)
- 迁移学习应用于行为识别综述:[Transfer Learning for Activity Recognition: A Survey](https://pan.baidu.com/s/1kVABOYr)
- 迁移学习与增强学习:[Transfer Learning for Reinforcement Learning Domains: A Survey](https://pan.baidu.com/s/1slfr0w1)
- 多个源域进行迁移的综述:[A Survey of Multi-source Domain Adaptation](https://pan.baidu.com/s/1eSGREF4)。
- [Data-Free Knowledge Transfer: A Survey](https://arxiv.org/abs/2112.15278)
- A survey on data-free distillation and source-free DA
- 一篇关于data-free蒸馏和source-free DA的综述
## Large models
- TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent Collaboration [[arxiv](http://arxiv.org/abs/2410.12183)]
- Transfer vision-language models for collaboration
- Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities [[arxiv](http://arxiv.org/abs/2409.03444)]
- Fine-tuning LLMs for domain adaptation
- ICLR'24-spotlight Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks [[arxiv](https://arxiv.org/abs/2309.17002)]
- Noisy model learning: fine-tuning to supress the bad effect of noisy pretraining data 通过使用轻量级finetune减少噪音预训练数据对下游任务的影响
- ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning [[arxiv](https://arxiv.org/abs/2310.05143)]
- Black-box foundation models for personalized federated learning 黑盒的blackbox模型进行个性化迁移学习
- IJCV'23 Exploring Vision-Language Models for Imbalanced Learning [[arxiv](https://arxiv.org/abs/2304.01457)] [[code](https://github.com/Imbalance-VLM/Imbalance-VLM)]
- Explore vision-language models for imbalanced learning 探索视觉大模型在不平衡问题上的表现
- ICCV'23 Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning [[arxiv](https://arxiv.org/abs/2308.02533)] [[code](https://github.com/microsoft/robustlearn)]
- 达到对抗鲁棒性和泛化能力的trade off
- Towards Realistic Unsupervised Fine-tuning with CLIP [[arxiv](http://arxiv.org/abs/2308.12919)]
- Unsupervised fine-tuning of CLIP
## Theory
- [Improved OOD Generalization via Conditional Invariant Regularizer](https://arxiv.org/abs/2207.06687)
- Improved OOD generalization via conditional invariant regularizer 通过条件不变正则进行OOD泛化
- [An Information-Theoretic Analysis for Transfer Learning: Error Bounds and Applications](https://arxiv.org/abs/2207.05377)
- Information-theoretic analysis for transfer learning 用信息理论解释迁移学习
- [PAC-Bayesian Domain Adaptation Bounds for Multiclass Learners](https://arxiv.org/abs/2207.05685)
- PAC-Bayesian domain adaptation 基于PAC-Bayesian的domain adaptation
- [Optimal Representations for Covariate Shift](https://arxiv.org/abs/2201.00057)
- Learning optimal representations for covariate shift
- 为covariate shift学习最优的表达
- NeurIPS-21 [On Learning Domain-Invariant Representations for Transfer Learning with Multiple Sources](https://arxiv.org/abs/2111.13822)
- Theory and algorithm of domain-invariant learning for transfer learning
- 对invariant representation的理论和算法
- 20210625 ICML-21 [f-Domain-Adversarial Learning: Theory and Algorithms](http://arxiv.org/abs/2106.11344)
- New theory based on f-divergence
- 基于f-divergence给出新的DA理论和算法
- 20210521 [When is invariance useful in an Out-of-Distribution Generalization problem ?](http://arxiv.org/abs/2008.01883)
- When is invariant useful in OOD?
- 理论上分析了在OOD问题中invariance什么时候有用
- 20200220 [Butterfly: One-step Approach towards Wildly Unsupervised Domain Adaptation](http://arxiv.org/abs/1905.07720)
- Noisy domain adaptation
- 用于噪声环境中的domain adaptation的方法
- 20210127 [A Unified Joint Maximum Mean Discrepancy for Domain Adaptation](http://arxiv.org/abs/2101.09979)
- 一个理论上更一般化的MMD差异用于领域自适应
- A more general MMD for domain adaptation
- 20200615 [Double Double Descent: On Generalization Errors in Transfer Learning between Linear Regression Tasks](https://arxiv.org/abs/2006.07002)
- 20200813 [A Boundary Based Out-of-Distribution Classifier for Generalized Zero-Shot Learning](https://arxiv.org/abs/2008.04872)
- OOD classifier for generalized zero-shot learning
- 20200813 ICML-20 [On Learning Language-Invariant Representations for Universal Machine Translation](https://arxiv.org/abs/2008.04510)
- Theory for universal machine translation
- 对统一机器翻译模型进行了理论论证
- 20200702 ICML-20 [Few-shot domain adaptation by causal mechanism transfer](https://arxiv.org/pdf/2002.03497.pdf)
- The first work on causal transfer learning
- 日本理论组大佬Sugiyama的工作,causal transfer learning
- 20191008 CVPR-19 [Characterizing and Avoiding Negative Transfer](https://arxiv.org/abs/1811.09751)
- Characterizing and avoid negative transfer
- 形式化并提出如何避免负迁移
- 20190301 ALT-19 [A Generalized Neyman-Pearson Criterion for Optimal Domain Adaptation](https://arxiv.org/abs/1810.01545)
- A new criterion for domain adaptation
- 提出一种新的可以强化domain adaptation表现的度量
- 20181219 arXiv [PAC Learning Guarantees Under Covariate Shift](https://arxiv.org/abs/1812.06393)
- PAC learning theory for covariate shift
- Covariate shift问题的PAC学习理论
- 20181206 arXiv [Transferring Knowledge across Learning Processes](https://arxiv.org/abs/1812.01054)
- Transfer learning across learning processes
- 学习过程中的知识迁移
- 20181128 arXiv [Theoretical Guarantees of Transfer Learning](https://arxiv.org/abs/1810.05986)
- Some theoretical analysis of transfer learning
- 一些关于迁移学习的理论分析
- 20181117 arXiv [Theoretical Perspective of Deep Domain Adaptation](https://arxiv.org/abs/1811.06199)
- Providing some theory analysis on deep domain adaptation
- 对deep domain adaptaiton做出了一些理论上的分析
- 20181106 workshop [GENERALIZATION BOUNDS FOR DOMAIN ADAPTATION VIA DOMAIN TRANSFORMATIONS](https://ieeexplore.ieee.org/abstract/document/8517092)
- Analyze some generalization bound for domain adaptation
- 对domain adaptation进行了一些理论上的分析
- 20180724 arXiv [Generalization Bounds for Unsupervised Cross-Domain Mapping with WGANs](https://arxiv.org/abs/1807.08501)
- Provide a generalization bound for unsupervised WGAN in transfer learning
- 对迁移学习中无监督的WGAN进行了一些理论上的分析
## Per-training/Finetuning
- Transfer Learning of CATE with Kernel Ridge Regression [[arxiv](https://arxiv.org/abs/2502.11331)]
- Transfer learning with kernel ridge regression
- Privacy in Fine-tuning Large Language Models: Attacks, Defenses, and Future Directions [[arxiv](http://arxiv.org/abs/2412.16504)]
- Privacy in LLM fine-tuning
- Transfer Learning on Multi-Dimensional Data: A Novel Approach to Neural Network-Based Surrogate Modeling [[arxiv](http://arxiv.org/abs/2410.12241)]
- Transfer learning on multi-dimensioal data
- Safety-Aware Fine-Tuning of Large Language Models [[arxiv](https://arxiv.org/abs/2410.10014)]
- Fine-tuning with safety in LLMs
- - Deep Transfer Learning: Model Framework and Error Analysis [[arxiv](https://arxiv.org/abs/2410.09383)]
- Deep transfer learning framework
- Cross-Domain Distribution Alignment for Segmentation of Private Unannotated 3D Medical Images [[arxiv](https://arxiv.org/abs/2410.09210)]
- Cross-domain adaptation of private unannotated 3D medical images
- Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs [[arxiv](https://arxiv.org/abs/2410.08020)]
- Active fine-tuning of LLMs
- LLM Embeddings Improve Test-time Adaptation to Tabular Y|X shifts [[arxiv](https://arxiv.org/abs/2410.07395)]
- Test-time adaptation via LLMs
- Can Your Generative Model Detect Out-of-Distribution Covariate Shift? [[arxiv](http://arxiv.org/abs/2409.03043)]
- Can your generative models detect OOD covariate shift?
- Rethinking Knowledge Transfer in Learning Using Privileged Information [[arxiv](https://arxiv.org/abs/2408.14319)]
- Using privileged information for knowledge transfer
- Adapting Vision-Language Models to Open Classes via Test-Time Prompt Tuning [[arxiv](https://arxiv.org/abs/2408.16486)]
- Test-time prompt tuning for open classes
- SAFT: Towards Out-of-Distribution Generalization in Fine-Tuning [[arxiv](https://arxiv.org/abs/2407.03036)]
- OOD fine-tuning for foundation models 大模型的OOD微调
- Transfer Learning for CSI-based Positioning with Multi-environment Meta-learning [[arxiv](https://arxiv.org/abs/2405.11816)]
- Transfer learning for CSI-based positioning 用迁移学习进行基于CSI的定位
- CVPR'24 Exploring the Transferability of Visual Prompting for Multimodal Large Language Models [[arxiv](https://arxiv.org/abs/2404.11207)]
- Explore the transferability of visual prompting for multimodal LLM 探索多模态大模型visual prompt tuning的可迁移性
- MedMerge: Merging Models for Effective Transfer Learning to Medical Imaging Tasks [[arxiv](https://arxiv.org/abs/2403.11646)]
- Model merge for medical transfer learning 通过模型合并进行医学迁移学习
- ICLR'24 扩展版 Learning with Noisy Foundation Models [[arxiv](https://arxiv.org/abs/2403.06869)]
- Fine-tune a noisy foundation model 基础模型有noisy的时候如何finetune
- Learning with Noisy Foundation Models [[arxiv](https://arxiv.org/abs/2403.06869)]
- Learning with noisy foundation models
- Attention Prompt Tuning: Parameter-efficient Adaptation of Pre-trained Models for Spatiotemporal Modeling [[arxiv](https://arxiv.org/abs/2403.06978)]
- Parameter-efficient adaptation for spatiotemporal modeling
- Facing the Elephant in the Room: Visual Prompt Tuning or Full Finetuning? [[arxiv](https://arxiv.org/abs/2401.12902)]
- A comparison between visual prompt tuning and full finetuning 比较prompt tuning和全finetune
- ICLR'24 spotlight Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks [[arxiv](https://arxiv.org/abs/2309.17002)]
- A new research direction of transfer learning in the era of foundation models 大模型时代一个新研究方向:研究预训练数据的噪声对下游任务影响
- NeurIPS'23 Geodesic Multi-Modal Mixup for Robust Fine-Tuning [[paper](https://openreview.net/forum?id=iAAXq60Bw1)]
- Geodesic mixup for robust fine-tuning
- NeurIPS'23 Parameter and Computation Efficient Transfer Learning for Vision-Language Pre-trained Models [[paper](https://openreview.net/forum?id=TPeAmxwPK2)]
- Parameter and computation efficient transfer learning by reinforcement learning
- Equivariant Adaptation of Large Pre-Trained Models [[arxiv](http://arxiv.org/abs/2310.01647)]
- Equivariant adaptation of large pre-trained models 对大模型进行等边自适应
- Effective and Parameter-Efficient Reusing Fine-Tuned Models [[arxiv](http://arxiv.org/abs/2310.01886)]
- Effective and parameter-efficient reusing fine-tuned models 高效使用预训练模型
- Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks [[arxiv](https://arxiv.org/abs/2309.17002)]
- Noisy model learning: fine-tuning to supress the bad effect of noisy pretraining data 通过使用轻量级finetune减少噪音预训练数据对下游任务的影响
- DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning [[arxiv](http://arxiv.org/abs/2309.05173)]
- Decomposed prompt tuning for parameter-efficient fine-tuning 基于分解prompt tuning的参数高效微调
- Towards Realistic Unsupervised Fine-tuning with CLIP [[arxiv](http://arxiv.org/abs/2308.12919)]
- Unsupervised fine-tuning of CLIP
- Fine-tuning can cripple your foundation model; preserving features may be the solution [[arxiv](http://arxiv.org/abs/2308.13320)]
- Fine-tuning will cripple foundation model
- Unified Transfer Learning Models for High-Dimensional Linear Regression [[arxiv](https://arxiv.org/abs/2307.00238)]
- Transfer learning for high-dimensional linar regression 迁移学习用于高维线性回归
- Review of Large Vision Models and Visual Prompt Engineering [[arxiv](https://arxiv.org/abs/2307.00855)]
- A survey of large vision model and prompt tuning 一个关于大视觉模型的prompt tuning的综述
- Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning [[arxiv](http://arxiv.org/abs/2303.15647)]
- A guide for parameter-efficient fine-tuning 一个对parameter efficient fine-tuning的全面介绍
- ICML'23 A Kernel-Based View of Language Model Fine-Tuning [[arxiv](http://arxiv.org/abs/2210.05643)]
- A kernel-based view of language model fine-tuning 一种以kernel的视角来看待fine-tuning的方法
- ICML'23 Improving Visual Prompt Tuning for Self-supervised Vision Transformers [[arxiv](http://arxiv.org/abs/2306.05067)]
- Improving visual prompt tuning for self-supervision 为自监督模型提高其 prompt tuning 表现
- Adapting Pre-trained Language Models to Vision-Language Tasks via Dynamic Visual Prompting [[arxiv](http://arxiv.org/abs/2306.00409)]
- Using dynamic visual prompting for model adaptation 用动态视觉prompt进行模型适配
- ACL'23 Parameter-Efficient Fine-Tuning without Introducing New Latency [[arxiv](http://arxiv.org/abs/2305.16742)]
- Parameter-efficient finetuning 参数高效的finetune
- Ahead-of-Time P-Tuning [[arxiv](http://arxiv.org/abs/2305.10835)]
- Ahead-ot-time P-tuning for language models
- Parameter-Efficient Tuning Makes a Good Classification Head [[arxiv](http://arxiv.org/abs/2210.16771)]
- Parameter-efficient tuning makes a good classification head 参数高效的迁移学习成就一个好的分类头
- CVPR'23 Trainable Projected Gradient Method for Robust Fine-tuning [[arxiv](http://arxiv.org/abs/2303.10720)]
- Trainable PGD for robust fine-tuning 可训练的pgd用于鲁棒的微调技术
- ICLR'23 Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning [[arxiv](http://arxiv.org/abs/2303.11866)]
- Contrastive alignment for vision language models using transfer learning 使用参数高效迁移进行视觉语言模型的对比对齐
- ICLR'23 workshop SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models [[arxiv](http://arxiv.org/abs/2303.10464)]
- Sparse pre-training and dense fine-tuning
- A Unified Continual Learning Framework with General Parameter-Efficient Tuning [[arxiv](http://arxiv.org/abs/2303.10070)]
- A continual learning framework for parameter-efficient tuning 一个对于参数高效迁移的连续学习框架
- Transfer Learning for Real-time Deployment of a Screening Tool for Depression Detection Using Actigraphy [[arxiv](https://arxiv.org/abs/2303.07847)]
- Transfer learning for Depression detection 迁移学习用于脉动计焦虑检测
- ICLR'23 AutoTransfer: AutoML with Knowledge Transfer -- An Application to Graph Neural Networks [[arxiv](https://arxiv.org/abs/2303.07669)]
- GNN with autoML transfer learning 用于GNN的自动迁移学习
- Revisit Parameter-Efficient Transfer Learning: A Two-Stage Paradigm [[arxiv](https://arxiv.org/abs/2303.07910)]
- Parameter-efficient transfer learning: a two-stage approach 一种两阶段的参数高效迁移学习
- To Stay or Not to Stay in the Pre-train Basin: Insights on Ensembling in Transfer Learning [[arxiv](https://arxiv.org/abs/2303.03374)]
- Ensembling in transfer learning 调研迁移学习中的集成
- CVPR'13 Masked Images Are Counterfactual Samples for Robust Fine-tuning [[arxiv](https://arxiv.org/abs/2303.03052)]
- Masked images for robust fine-tuning 调研masked image对于fine-tuning的影响
- Finetune like you pretrain: Improved finetuning of zero-shot vision models [[arxiv]](http://arxiv.org/abs/2212.00638)]
- Improved fine-tuning of zero-shot models 针对zero-shot model提高fine-tuneing
- CVPR'22 Does Robustness on ImageNet Transfer to Downstream Tasks? [[arxiv](https://openaccess.thecvf.com/content/CVPR2022/papers/Yamada_Does_Robustness_on_ImageNet_Transfer_to_Downstream_Tasks_CVPR_2022_paper.pdf)]
- Does robustness on imagenet transfer lto downstream tasks?
- NeurIPS'22 Improved Fine-Tuning by Better Leveraging Pre-Training Data [[openreview](https://openreview.net/forum?id=YTXIIc7cAQ)]
- Using pre-training data for fine-tuning 用预训练数据来做微调
- On Fine-Tuned Deep Features for Unsupervised Domain Adaptation [[arxiv](http://arxiv.org/abs/2210.14083)]
- Fine-tuned features for domain adaptation 微调的特征用于域自适应
- Transfer of Machine Learning Fairness across Domains [[arxiv](http://arxiv.org/abs/1906.09688)]
- Fairness transfer in transfer learning 迁移学习中的公平性迁移
- CVPR-20 Regularizing CNN Transfer Learning With Randomised Regression [[arxiv](https://openaccess.thecvf.com/content_CVPR_2020/html/Zhong_Regularizing_CNN_Transfer_Learning_With_Randomised_Regression_CVPR_2020_paper.html)]
- Using randomized regression to regularize CNN 用随机回归约束CNN迁移学习
- AAAI-21 TransTailor: Pruning the Pre-trained Model for Improved Transfer Learning [[arxiv](https://ojs.aaai.org/index.php/AAAI/article/view/17046)]
- Pruning pre-trained model for transfer learning 通过对预训练模型进行剪枝来进行迁移学习
- Test-Time Training with Masked Autoencoders [[arxiv](https://arxiv.org/abs/2209.07522)]
- Test-time training with MAE MAE的测试时训练
- Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models [[arxiv](https://arxiv.org/abs/2209.07511)]
- Test-time prompt tuning 测试时的prompt tuning
- TeST: test-time self-training under distribution shift [[arxiv](https://assets.amazon.science/02/1c/b469914c4732a9c29ac765f948f9/test-test-time-self-training-under-distribution-shift.pdf)]
- Test-time self-training 测试时的self-training
- [Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets](https://arxiv.org/pdf/2208.07463.pdf)
- Parameter efficient CNN adapter for transfer learning 参数高效的CNN adapter用于迁移学习
- [Hyper-Representations for Pre-Training and Transfer Learning](https://arxiv.org/abs/2207.10951)
- Hyper-representation for pre-training and fine-tuning 对于预训练和微调的超表示
- [Zero-Shot AutoML with Pretrained Models](https://arxiv.org/abs/2206.08476)
- 用预训练模型进行零样本的自动机器学习
- [How robust are pre-trained models to distribution shift?](https://arxiv.org/abs/2206.08871)
- How robust are pre-trained models to distribution shift 评估预训练模型对于distribution shift的鲁棒性
- [Wav2vec-S: Semi-Supervised Pre-Training for Speech Recognition](https://arxiv.org/abs/2110.04484)
- Pretraining for speech recognition 用预训练模型进行语音识别
- [ScholarBERT: Bigger is Not Always Better](https://arxiv.org/abs/2205.11342)
- Empirical study on fine-tuning experiments 提出ScholarBERT进行大规模finetuning实验
- [A Domain-adaptive Pre-training Approach for Language Bias Detection in News](https://arxiv.org/abs/2205.10773)
- Domain-adaptive pre-training for language bias detection 领域适配预训练用于新闻语言偏见检测
- IJCAI-22 [Parameter-Efficient Sparsity for Large Language Models Fine-Tuning](https://arxiv.org/abs/2205.11005)
- Parameter-efficient sparsity for language model fine-tuning 参数高效的稀疏学习用于语言模型微调
- NAACL-22 [Efficient Few-Shot Fine-Tuning for Opinion Summarization](https://arxiv.org/abs/2205.02170)
- Few-shot fine-tuning for opinion summarization 小样本微调技术用于评论总结
- ACL-22 [Probing Simile Knowledge from Pre-trained Language Models](https://arxiv.org/abs/2204.12807)
- Probe simile knowledge from pre-trained model 从预训练模型中找出明喻知识
- [Transfer Learning with Pre-trained Conditional Generative Models](https://arxiv.org/abs/2204.12833)
- Transfer learning with pre-trained conditional generative models 条件生成模型用于迁移学习
- ICLR-22 [Towards a Unified View of Parameter-Efficient Transfer Learning](https://openreview.net/forum?id=0RDcd5Axok)
- Unified view of parameter-efficient transfer learning 一个统一视角看待参数高效的迁移学习
- ICLR-22 [Exploring the Limits of Large Scale Pre-training](https://openreview.net/forum?id=V3C8p78sDa)
- Many experiments to explore pre-training 许多实验来探索预训练
- [Just Fine-tune Twice: Selective Differential Privacy for Large Language Models](https://arxiv.org/abs/2204.07667)
- Differential privacy by just fine-tune twice 通过微调两次进行差分隐私
- [On Effectively Learning of Knowledge in Continual Pre-training](https://arxiv.org/abs/2204.07994)
- Continual per-training 持续的预训练
- NAACL-22 [GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering](https://arxiv.org/abs/2204.04179)
- Fast fine-tuning for content-based collaborative filtering
- 快速的适用于协同过滤的微调
- AAAI-22 [Powering Finetuning in Few-shot Learning: Domain-Agnostic Feature Adaptation with Rectified Class Prototypes](https://arxiv.org/abs/2204.03749)
- Finetuning in few-shot learning
- 小样本学习中的微调
- CVPR-22 [Does Robustness on ImageNet Transfer to Downstream Tasks?](https://arxiv.org/abs/2204.03934)
- Transfer learning robustness
- 迁移学习鲁棒性
- [Blockchain as an Enabler for Transfer Learning in Smart Environments](https://arxiv.org/abs/2204.03959)
- Blockchain transfer learning
- 用区块链进行迁移学习
- ICLR-22 [Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution](https://openreview.net/forum?id=UYneFzXSJWh)
- Fin-tuning and linear probing for ood generalization
- 先linear probing最后一层再finetune对OOD任务最好
- [A Broad Study of Pre-training for Domain Generalization and Adaptation](https://arxiv.org/abs/2203.11819)
- A broad study of pre-training models for DA and DG
- 大量的实验进行DA和DG
- ACL-22 [Language-Agnostic Meta-Learning for Low-Resource Text-to-Speech with Articulatory Features](https://arxiv.org/abs/2203.03191)
- Language-agnostic meta-learning for TTS
- 语言无关的元学习用于TTS
- [Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models](https://arxiv.org/abs/2203.03131)
- Adapt unfamiliar inputs to frozen pretrained models
- 让固定的预训练模型适配不熟悉的输入
- [Pre-trained Token-replaced Detection Model as Few-shot Learner](https://arxiv.org/abs/2203.03235)
- Pre-trained token-replaced detection model as few-shot learner
- 预训练的替换token的检测模型
- ICLR-22 spotlight [Towards a Unified View of Parameter-Efficient Transfer Learning](https://openreview.net/pdf?id=0RDcd5Axok)
- Detailed analysis of parameter-efficient transfer learning
- 对参数高效的迁移学习进行分析
- ICLR-22 [BEiT: BERT Pre-Training of Image Transformers](https://openreview.net/forum?id=p-BhZSz59o4)
- BERT pre-training of image transformers
- 用BERT的方式pre-train transformer
- [Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice](http://arxiv.org/abs/2111.12292)
- Using pre-training data to improve fine-tuning
- 使用预训练数据来帮助finetune
- [An Ensemble of Pre-trained Transformer Models For Imbalanced Multiclass Malware Classification](https://arxiv.org/abs/2112.13236)
- An ensemble of pre-trained transformer for malware classification
- 预训练的transformer通过集成进行恶意软件检测
- [SLIP: Self-supervision meets Language-Image Pre-training](https://arxiv.org/abs/2112.12750)
- Self-supervised learning + language image pretraining
- 用自监督学习用于语言到图像的预训练
- [VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks](http://arxiv.org/abs/2112.06825)
- Vision-language efficient transfer learning
- 参数高校的vision-language任务迁移
- [Revisiting the Transferability of Supervised Pretraining: an MLP Perspective](https://arxiv.org/abs/2112.00496)
- Revisit the transferability of supervised pretraining
- 重新思考有监督预训练的可迁移性
- NeurIPS-21 workshop [Maximum Mean Discrepancy for Generalization in the Presence of Distribution and Missingness Shift](https://arxiv.org/abs/2111.10344)
- MMD for covariate shift
- 用MMD来解决covariate shift问题
- [Combined Scaling for Zero-shot Transfer Learning](https://arxiv.org/abs/2111.10050)
- Scaling up for zero-shot transfer learning
- 增大训练规模用于zero-shot迁移学习
- [Improved Regularization and Robustness for Fine-tuning in Neural Networks](https://arxiv.org/abs/2111.04578)
- Improve regularization and robustness for finetuning
- 针对finetune提高其正则和鲁棒性
- NeurIPS-21 [Modular Gaussian Processes for Transfer Learning](https://arxiv.org/abs/2110.13515)
- Modular Gaussian process for transfer learning
- 在迁移学习中使用modular Gaussian过程
- [Rethinking supervised pre-training for better downstream transferring](https://arxiv.org/abs/2110.06014)
- Rethink better finetune
- 重新思考预训练以便更好finetune
- EMNLP-21 [Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning](https://arxiv.org/abs/2109.06349)
- Few-shot intent detection using pretrain and finetune
- 用迁移学习进行少样本意图检测
- [KroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation](https://arxiv.org/abs/2109.06243)
- Using Kronecker decomposition and knowledge distillation for pre-trained language models compression
- 用Kronecker分解和知识蒸馏来进行语言模型的压缩
- [How Does Adversarial Fine-Tuning Benefit BERT?](https://arxiv.org/abs/2108.13602)
- Examine how does adversarial fine-tuning help BERT
- 探索对抗性finetune如何帮助BERT
- [A Data Augmented Approach to Transfer Learning for Covid-19 Detection](https://arxiv.org/abs/2108.02870)
- Data augmentation to transfer learning for COVID
- 迁移学习使用数据增强,用于COVID-19
- [Finetuning Pretrained Transformers into Variational Autoencoders](https://arxiv.org/abs/2108.02446)
- Finetune transformer to VAE
- 把transformer迁移到VAE
- [Pre-trained Models for Sonar Images](http://arxiv.org/abs/2108.01111)
- Pre-trained models for sonar images
- 针对声纳图像的预训练模型
- [Domain Adaptor Networks for Hyperspectral Image Recognition](http://arxiv.org/abs/2108.01555)
- Finetune for hyperspectral image recognition
- 针对高光谱图像识别的迁移学习
- CVPR-21 [Efficient Conditional GAN Transfer With Knowledge Propagation Across Classes](https://openaccess.thecvf.com/content/CVPR2021/html/Shahbazi_Efficient_Conditional_GAN_Transfer_With_Knowledge_Propagation_Across_Classes_CVPR_2021_paper.html)
- Transfer conditional GANs to unseen classes
- 通过知识传递,迁移预训练的conditional GAN到新类别
- 20191011 arXiv [Estimating Transfer Entropy via Copula Entropy](https://arxiv.org/abs/1910.04375)
- Evaluate the transfer entopy via copula entropy
- 评估迁移熵
- 20180925 arXiv [DT-LET: Deep Transfer Learning by Exploring where to Transfer](https://arxiv.org/pdf/1809.08541.pdf)
- Explore the suitable layers to transfer
- 探索深度网络中效果表现好的对应的迁移层
- 20200629 [Transfer learning via L1 regulaziation](https://arxiv.org/abs/2006.14845)
- Using L1 regularizationg for transfer learning
- 20201016 [Deep Ensembles for Low-Data Transfer Learning](https://arxiv.org/abs/2010.06866)
- Deep ensemble models for transfer learning
- 20210511 ACL-21 [Are Pre-trained Convolutions Better than Pre-trained Transformers?](https://arxiv.org/abs/2105.03322)
- Empirically investigate pre-trained convolutions and Transformers
- 设计实验探索预训练的卷积和Transformer的对比
- 20190111 arXiv [Transfer Representation Learning with TSK Fuzzy System](https://arxiv.org/abs/1901.02703)
- Transfer learning with fuzzy system
- 基于模糊系统的迁移学习
- 20201203 [Pre-Trained Image Processing Transformer](https://arxiv.org/abs/2012.00364)
- 用transformer做low-level的图像任务
- 20200821 [Self-Supervised Learning Across Domains](https://arxiv.org/abs/2007.12368)
- 跨领域自监督学习
- 20180403 arXiv 选择最优的子类生成方便迁移的特征:[Class Subset Selection for Transfer Learning using Submodularity](https://arxiv.org/abs/1804.00060)
- 20180326 ICMLA-17 在类别不平衡情况下比较了一些迁移学习和传统方法的性能,并做出一些结论:[Comparing Transfer Learning and Traditional Learning Under Domain Class Imbalance](http://ieeexplore.ieee.org/abstract/document/8260654/)
- 20190626 arXiv [Transfer of Machine Learning Fairness across Domains](https://arxiv.org/abs/1906.09688)
- Transfer of machine learning fairness across domains
- 机器学习的公平性的迁移
- 20200615 [Rethinking Pre-training and Self-training](https://arxiv.org/abs/2006.06882)
- 20200210 WACVW-20 [Impact of ImageNet Model Selection on Domain Adaptation](https://arxiv.org/abs/2002.02559)
- A good experiment paper to indicate the power of representations
- 一篇很好的实验paper,揭示了深度特征+传统方法的有效性
- 20191015 arXiv [The Visual Task Adaptation Benchmark](https://arxiv.org/abs/1910.04867)
- A new large benchmark for visual adaptation tasks by Google
- Google提出的一个巨大的视觉迁移任务数据集
- 20190305 arXiv [Let's Transfer Transformations of Shared Semantic Representations](https://arxiv.org/abs/1903.00793)
- Transfer transformations from shared semantic representations
- 从共享的语义表示中进行特征迁移
- 20190409 arXiv [Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning](https://arxiv.org/abs/1904.03949)
- Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning
- 通过可选择的CNN滤波器进行图像分类的fine-tuning
- 20190111 arXiv [Low-Cost Transfer Learning of Face Tasks](https://arxiv.org/abs/1901.02675)
- Infer what task transfers better and how to transfer
- 探索对于一个预训练好的网络来说哪个任务适合迁移、如何迁移
- 20191119 ICDM-19 [Towards Making Deep Transfer Learning Never Hurt](https://arxiv.org/abs/1911.07489)
- Towards making deep transfer learning never hurt
- 通过正则避免负迁移
- 20181123 arXiv [SpotTune: Transfer Learning through Adaptive Fine-tuning](https://arxiv.org/abs/1811.08737)
- Very interesting work: how exactly determine the finetune process?
- 很有意思的工作:如何决定finetune的策略?
- 20180425 arXiv 探索各个层对于迁移任务的作用,方便以后的迁移。比较有意思:[CactusNets: Layer Applicability as a Metric for Transfer Learning](https://arxiv.org/abs/1804.07846)
- 传递迁移学习的第一篇文章,来自杨强团队,发表在KDD-15上:[Transitive Transfer Learning](http://dl.acm.org/citation.cfm?id=2783295)
- AAAI-17 杨强团队最新的传递迁移学习:[Distant Domain Transfer Learning](http://www3.ntu.edu.sg/home/sinnopan/publications/[AAAI17]Distant%20Domain%20Transfer%20Learning.pdf)
- 20180819 LNCS-2018 [Distant Domain Adaptation for Text Classification](https://link.springer.com/chapter/10.1007/978-3-319-99365-2_5)
- Propose a selected algorithm for distant domain text classification
- 提出一个用于远域的文本分类方法
- 20190220 arXiv [Fully-Featured Attribute Transfer](https://arxiv.org/abs/1902.06258)
- Fully-featured image attribute transfer
- 图像特征迁移
- 20190926 arXiv [Transfer Learning across Languages from Someone Else's NMT Model](https://arxiv.org/abs/1909.10955)
- Transfer learning across languages from NMT pretrained model
- 利用预训练好的NMT模型进行迁移学习
- 20190929 NeurIPS-19 [Deep Model Transferability from Attribution Maps](https://arxiv.org/abs/1909.11902)
- Using attribution map for network similarity
- 与cvpr18的taskmony类似,这次用了属性图的方式探索网络的相似性
- 20181121 arXiv [An Efficient Transfer Learning Technique by Using Final Fully-Connected Layer Output Features of Deep Networks](https://arxiv.org/abs/1811.07459)
- Using final fc layer to perform transfer learning
- 使用最后一层全连接层进行迁移学习
- ICML-14 著名的DeCAF特征:[DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition](https://arxiv.org/abs/1310.1531.pdf)
- [Simultaneous Deep Transfer Across Domains and Tasks](https://www.cv-foundation.org/openaccess/content_iccv_2015/html/Tzeng_Simultaneous_Deep_Transfer_ICCV_2015_paper.html)
- 发表在ICCV-15上,在传统深度迁移方法上又加了新东西
- [我的解读](https://zhuanlan.zhihu.com/p/30621691)
## Knowledge distillation
- NeurIPS'22 Respecting Transfer Gap in Knowledge Distillation [[arxiv](http://arxiv.org/abs/2210.12787)]
- Transfer gap in distillation 知识蒸馏中的迁移gap
- [Cross-Architecture Knowledge Distillation](https://arxiv.org/abs/2207.05273)
- Cross-architecture knowledge distillation 跨架构的知识蒸馏
- ECCV-22 [Knowledge Condensation Distillation](https://arxiv.org/abs/2207.05409)
- Knowledge condensation distillation 知识压缩蒸馏
- [FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning](https://arxiv.org/abs/2205.07246)
- Self-adaptive thresholding for semi-supervised learning 新的自适应阈值半监督方法
- TIP-22 [Spot-adaptive Knowledge Distillation](https://arxiv.org/abs/2205.02399)
- Spot-adaptive knowledge distillation 层次自适应的知识蒸馏
- CVPR-22 [Decoupled Knowledge Distillation](https://arxiv.org/abs/2203.08679)
- Decoupled knowledge distillation
- 解耦的知识蒸馏
- [On Representation Knowledge Distillation for Graph Neural Networks](https://arxiv.org/abs/2111.04964)
- Knowledge distillation for GNN
- 适用于GNN的知识蒸馏
- [Estimating and Maximizing Mutual Information for Knowledge Distillation](https://arxiv.org/abs/2110.15946)
- Global and local mutual information maximation for knowledge distillation
- 局部和全局互信息最大化用于蒸馏
- 20210426 [Distill on the Go: Online knowledge distillation in self-supervised learning](http://arxiv.org/abs/2104.09866)
- Online knowledge distillation in self-supervised learning
- 自监督学习中的在线知识蒸馏
- 20210202 ICLR-21 [Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective](https://arxiv.org/abs/2102.00650)
- Rethink soft labels for KD in a bias-variance tradeoff perspective
- 从偏差-方差的角度重新思考蒸馏中的软标签
- 20200706 [Interactive Knowledge Distillation](https://arxiv.org/abs/2007.01476)
- 20200412 ICML-19 [Towards understanding knowledge distillation](http://proceedings.mlr.press/v97/phuong19a.html)
- Some theoretical and empirical understanding to knowledge distllation
- 对知识蒸馏的一些理论和实验的分析
- 20191202 AAAI-20 [Towards Oracle Knowledge Distillation with Neural Architecture Search](https://arxiv.org/abs/1911.13019)
- Using NAS for knowledge Distillation
- 用NAS帮助知识蒸馏
- 20190401 arXiv [Distilling Task-Specific Knowledge from BERT into Simple Neural Networks](https://arxiv.org/abs/1903.12136)
- Distill knowledge from BERT to simple neural networks
- 从BERT模型中迁移知识到简单网络中
- 20181207 arXiv [Feature Matters: A Stage-by-Stage Approach for Knowledge Transfer](https://arxiv.org/abs/1812.01819)
- Feature transfer in student-teacher networks
- 在学生-教师网络中进行特征迁移
- 20191204 AAAI-20 [Online Knowledge Distillation with Diverse Peers](https://arxiv.org/abs/1912.00350)
- Online Knowledge Distillation with Diverse Peers
- 20191222 AAAI-20 [Improved Knowledge Distillation via Teacher Assistant](https://arxiv.org/abs/1902.03393)
- Teacher assistant helps knowledge distillation
- - -
## Traditional domain adaptation
- [On Label Shift in Domain Adaptation via Wasserstein Distance](https://arxiv.org/abs/2110.15520)
- Using Wasserstein distance to solve label shift in domain adaptation
- 在DA领域中用Wasserstein distance去解决label shift问题
- 20210319 [Cross-domain Activity Recognition via Substructural Optimal Transport](https://arxiv.org/abs/2102.03353) | [知乎文章](https://zhuanlan.zhihu.com/p/356904023) | [微信公众号](https://mp.weixin.qq.com/s/QuVrqnPruHgfolYltI1Peg)
- Using sub-structures for domain adaptation
- 采用子结构进行domain adaptation,比传统方法快5倍
- 20210607 ICML-21 [Sequential Domain Adaptation by Synthesizing Distributionally Robust Experts](http://arxiv.org/abs/2106.00322)
- Sequential DA using distributionally robust experts
- 用鲁棒专家模型进行连续式领域自适应
- 20200615 [Deep Transfer Learning with Ridge Regression](https://arxiv.org/abs/2006.06791)
- 20200324 [Domain Adaptation by Class Centroid Matching and Local Manifold Self-Learning](https://arxiv.org/abs/2003.09391)
- Domain adaptation by class centroid matching and local manifold self-learning
- 集合了聚类、中心匹配,及自学习的DA
- 20191204 arXiv [Transferability versus Discriminability: Joint Probability Distribution Adaptation (JPDA)](https://arxiv.org/abs/1912.00320)
- Joint adaptation with different weights
- 不同权重的联合概率适配
- 20191125 AAAI-20 [Unsupervised Domain Adaptation via Structured Prediction Based Selective Pseudo-Labeling](https://arxiv.org/abs/1911.07982)
- DA with selective pseudo label
- 结构化和选择性的伪标签用于DA
- 20190703 arXiv [Domain Adaptation via Low-Rank Basis Approximation](https://arxiv.org/abs/1907.01343)
- Domain adaptation with low-rank basis approximation
- 低秩分解进行domain adaptation
- 20190508 IJCNN-19 [Unsupervised Domain Adaptation using Graph Transduction Games](https://arxiv.org/abs/1905.02036)
- Domain adaptation using graph transduction games
- 用图转换博弈进行domain adaptation
- 20190403 ICME-19 [Easy Transfer Learning By Exploiting Intra-domain Structures](https://arxiv.org/abs/1904.01376) [Code](http://transferlearning.xyz/code/traditional/EasyTL)
- An easy transfer learning approach with good performance
- 一个非常简单但效果很好的迁移方法
- 20180724 ACMMM-18 [Visual Domain Adaptation with Manifold Embedded Distribution Alignment](https://arxiv.org/abs/1807.07258)
- The state-of-the-art results of domain adaptation, better than most traditional and deep methods
- 目前效果最好的非深度迁移学习方法,领先绝大多数最近的方法
- Code: [MEDA](https://github.com/jindongwang/transferlearning/tree/master/code/traditional/MEDA)
- 20180912 arXiv [Unsupervised Domain Adaptation Based on Source-guided Discrepancy](https://arxiv.org/abs/1809.03839)
- Using source domain information to help domain adaptation
- 使用源领域数据辅助目标领域进行domain adaptation
- 20181219 arXiv [Domain Adaptation on Graphs by Learning Graph Topologies: Theoretical Analysis and an Algorithm](https://arxiv.org/abs/1812.06944)
- Domain adaptation on graphs
- 在图上的领域自适应
- 20181121 arXiv [Deep Discriminative Learning for Unsupervised Domain Adaptation](https://arxiv.org/abs/1811.07134)
- Deep discriminative learning for domain adaptation
- 同时进行源域和目标域上的分类判别
- 20181114 arXiv [Multiple Subspace Alignment Improves Domain Adaptation](https://arxiv.org/abs/1811.04491)
- Project domains into multiple subsapce to do domain adaptation
- 将domain映射到多个subsapce上然后进行adaptation
- 20180912 ICIP-18 [Structural Domain Adaptation with Latent Graph Alignment](https://ieeexplore.ieee.org/abstract/document/8451245/)
- Using graph alignment for domain adaptation
- 使用图对齐方式进行domain adaptation
- 20180912 IEEE Access [Unsupervised Domain Adaptation by Mapped Correlation Alignment](https://ieeexplore.ieee.org/abstract/document/8434290/)
- Mapped correlation alignment for domain adaptation
- 用映射的关联对齐进行domain adaptation
- 20180912 ICALIP-18 [Domain Adaptation for Gaussian Process Classification](https://ieeexplore.ieee.org/abstract/document/8455721/)
- Domain Adaptation for Gaussian Process Classification
- 在高斯过程分类中进行domain adaptation
- 20180701 arXiv 对domain adaptation问题,基于optimal transport提出一种新的特征选择方法:[Feature Selection for Unsupervised Domain Adaptation using Optimal Transport](https://arxiv.org/abs/1806.10861)
- 20180510 IEEE Trans. Cybernetics 提出一个通用的迁移学习框架,对不同的domain进行不同的特征变换:[Transfer Independently Together: A Generalized Framework for Domain Adaptation](https://ieeexplore-ieee-org.lib.ezproxy.ust.hk/abstract/document/8337102/)
- 20180403 TIP-18 一篇传统方法做domain adaptation的文章,比很多深度方法结果都好:[An Embarrassingly Simple Approach to Visual Domain Adaptation](http://ieeexplore.ieee.org/abstract/document/8325317/)
- 20180326 ICMLA-17 利用subsapce alignment进行迁移学习:[Transfer Learning for Large Scale Data Using Subspace Alignment](http://ieeexplore.ieee.org/abstract/document/8260772)
- 20180228 arXiv 一篇通过标签一致性和MMD准则进行domain adaptation的文章: [Discriminative Label Consistent Domain Adaptation](https://arxiv.org/abs/1802.08077)
- 20180110 arXiv 一篇比较新的传统方法做domain adaptation的文章 [Close Yet Discriminative Domain Adaptation](https://arxiv.org/abs/1704.04235)
- 20180105 arXiv 最优的贝叶斯迁移学习 [Optimal Bayesian Transfer Learning](https://arxiv.org/abs/1801.00857)
- 20171201 ICCV-17 [When Unsupervised Domain Adaptation Meets Tensor Representations](http://openaccess.thecvf.com/content_iccv_2017/html/Lu_When_Unsupervised_Domain_ICCV_2017_paper.html)
- 第一篇将Tensor与domain adaptation结合的文章。[代码](https://github.com/poppinace/TAISL)
- [我的解读](https://zhuanlan.zhihu.com/p/31834244)
- 201711 ICCV-17 [Open set domain adaptation](http://openaccess.thecvf.com/content_iccv_2017/html/Busto_Open_Set_Domain_ICCV_2017_paper.html)。
- 当source和target只共享某一些类别时,怎么处理?这个文章获得了ICCV 2017的Marr Prize Honorable Mention,值得好好研究。
- [我的解读](https://zhuanlan.zhihu.com/p/31230331)
- 201710 [Domain Adaptation in Computer Vision Applications](https://books.google.com.hk/books?id=7181DwAAQBAJ&pg=PA95&lpg=PA95&dq=Learning+Domain+Invariant+Embeddings+by+Matching%E2%80%A6&source=bl&ots=fSc1yvZxU3&sig=XxmGZkrfbJ2zSsJcsHhdfRpjaqk&hl=zh-CN&sa=X&ved=0ahUKEwjzvODqkI3XAhUCE5QKHYStBywQ6AEIRDAE#v=onepage&q=Learning%20Domain%20Invariant%20Embeddings%20by%20Matching%E2%80%A6&f=false) 里面收录了若干篇domain adaptation的文章,可以大概看看。
- [学习迁移](https://arxiv.org/abs/1708.05629)(Learning to Transfer, L2T)
- 迁移学习领域的新方向:与在线、增量学习结合
- [我的解读](https://zhuanlan.zhihu.com/p/28888554)
- 201707 [Mutual Alignment Transfer Learning](https://arxiv.org/abs/1707.07907)
- 201708 [Learning Invariant Riemannian Geometric Representations Using Deep Nets](https://arxiv.org/abs/1708.09485)
- 20170812 ICML-18 [Learning To Transfer](https://arxiv.org/abs/1708.05629),将迁移学习和增量学习的思想结合起来,为迁移学习的发展开辟了一个崭新的研究方向。[我的解读](https://zhuanlan.zhihu.com/p/28888554)
- NIPS-17 [JDOT: Joint distribution optimal transportation for domain adaptation](https://arxiv.org/pdf/1705.08848.pdf)
- AAAI-16 [Return of Frustratingly Easy Domain Adaptation](https://arxiv.org/abs/1511.05547)
- JMLR-16 [Distribution-Matching Embedding for Visual Domain Adaptation](http://www.jmlr.org/papers/volume17/15-207/15-207.pdf)
- CoRR abs/1610.04420 (2016) [Theoretical Analysis of Domain Adaptation with Optimal Transport](https://arxiv.org/pdf/1610.04420.pdf)
- CVPR-14 [Transfer Joint Matching for Unsupervised Domain Adaptation](http://ise.thss.tsinghua.edu.cn/~mlong/doc/transfer-joint-matching-cvpr14.pdf)
- ICCV-13 [Transfer Feature Learning with Joint Distribution Adaptation](http://ise.thss.tsinghua.edu.cn/~mlong/doc/joint-distribution-adaptation-iccv13.pdf)
- 迁移成分分析方法(Transfer component analysis, TCA)
- [Domain adaptation via tranfer component analysis](https://mega.nz/#!JTwElLrL!j5-TanhHCMESsGBNvY6I_hX6uspsrTxyopw8bPQ2azU)
- 发表在IEEE Trans. Neural Network期刊上(现改名为IEEE trans. Neural Network and Learning System),前作会议文章发在AAAI-09上
- [我的解读](https://zhuanlan.zhihu.com/p/26764147?group_id=844611188275965952)
- 联合分布适配方法(joint distribution adaptation,JDA)
- [Transfer Feature Learning with Joint Distribution Adaptation](http://ise.thss.tsinghua.edu.cn/~mlong/doc/joint-distribution-adaptation-iccv13.pdf)
- 发表在2013年的ICCV上
- [我的解读](https://zhuanlan.zhihu.com/p/27336930)
- 测地线流式核方法(Geodesic flow kernel, GFK)
- [Geodesic flow kernel for unsupervised domain adaptation](https://mega.nz/#!tDY1lCSD!flMSgl-0uIswpSFL3sdZgKi6fOyFVLtcO8P6SE0OUPU)
- 发表在CVPR-12上
- [我的解读](https://zhuanlan.zhihu.com/p/27782708)
- 领域不变性迁移核学习(Transfer Kernel Learning, TKL)
- [Domain invariant transfer kernel learning](https://mega.nz/#!tOoCCRhB!YyoorOUcp6XIPPd6A0s7qglYnaSiRJFEQBphtZ2c58Q)
- 发表在IEEE Trans. Knowledge and Data Engineering期刊上
## Deep domain adaptation
- Simulations of Common Unsupervised Domain Adaptation Algorithms for Image Classification [[arxiv](https://arxiv.org/abs/2502.10694)]
- Unsupervised domain adaptaiton for image classification
- Semantics-aware Test-time Adaptation for 3D Human Pose Estimation [[arxiv](https://arxiv.org/abs/2502.10724)]
- Test-time adaptation for3D human pose estimation
- Beyond Batch Learning: Global Awareness Enhanced Domain Adaptation [[arxiv](https://arxiv.org/abs/2502.06272)]
- Global awareness for enhanced domain adaptation
- Stratified Domain Adaptation: A Progressive Self-Training Approach for Scene Text Recognition [[arxiv](https://arxiv.org/abs/2410.09913)]
- Stratified domain adaptation
- Spatial Adaptation Layer: Interpretable Domain Adaptation For Biosignal Sensor Array Applications [[arxiv](https://arxiv.org/abs/2409.08058)]
- Interpretable domain adaptation
- Unsupervised Domain Adaptation Via Data Pruning [[arxiv](https://arxiv.org/abs/2409.12076)]
- Using pruning for domain adaptation
- LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models [[arxiv](https://arxiv.org/abs/2409.11919)]
- Black-box adaptation of vision language models
- Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection [[arxiv](https://arxiv.org/abs/2408.15637)]
- Transfer learning from simulated to real scens for monocular 3D
- Multi-source Domain Adaptation for Panoramic Semantic Segmentation [[arxiv](https://arxiv.org/abs/2408.16469)]
- Multi-source domain adaptation for panoramic semantic segmentation
- A More Unified Theory of Transfer Learning [[arxiv](https://arxiv.org/abs/2408.16189)]
- More unified theory of transfer learning
- Low Saturation Confidence Distribution-based Test-Time Adaptation for Cross-Domain Remote Sensing Image Classification [[arxiv](https://arxiv.org/abs/2408.16265)]
- Test-time adaptation for remote sensing image classification
- COD: Learning Conditional Invariant Representation for Domain Adaptation Regression [[arxiv](https://arxiv.org/abs/2408.06638)]
- Conditional invariant representation for domain adaptation regression
- Unsupervised Domain Adaption Harnessing Vision-Language Pre-training [[arxiv](https://arxiv.org/abs/2408.02192)]
- Domain adaptation using vision-language pre-training
- Can Modifying Data Address Graph Domain Adaptation? [[arxiv](https://arxiv.org/abs/2407.19311)]
- Alignment and rescaling for graph DA
- Improving Domain Adaptation Through Class Aware Frequency Transformation [[arxiv](https://arxiv.org/abs/2407.19551)]
- Class aware frequency transformation for domain adaptation
- Rethinking Domain Adaptation and Generalization in the Era of CLIP [[arxiv](http://arxiv.org/abs/2407.15173)]
- Rethinking domain adaptation in CLIP era
- Training-Free Model Merging for Multi-target Domain Adaptation [[arxiv](http://arxiv.org/abs/2407.13771)]
- Model merging for multi-target domain adaptation
- Multi-Task Domain Adaptation for Language Grounding with 3D Objects [[arxiv](https://arxiv.org/abs/2407.02846)]
- Multi-task domain adaptation for language grounding
- Versatile Teacher: A Class-aware Teacher-student Framework for Cross-domain Adaptation [[arxiv](https://arxiv.org/abs/2405.11754)]
- Teacher-student framework for cross-domain adaptation 教师-学生框架进行跨领域适配
- MICCAI'24 MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection [[arxiv](https://arxiv.org/abs/2405.11315)]
- Adapting clip for few-shot medical image anomaly detection 对CLIP模型进行适配,以用于少样本图片异常检测
- MDDD: Manifold-based Domain Adaptation with Dynamic Distribution for Non-Deep Transfer Learning in Cross-subject and Cross-session EEG-based Emotion Recognition [[arxiv](https://arxiv.org/abs/2404.15615)]
- Manifold-based domain adaptation for EEG-based emotion recognition 基于流形的DA用于EEG情绪识别
- Domain Adaptation for Learned Image Compression with Supervised Adapters [[arxiv](https://arxiv.org/abs/2404.15591)]
- Domain adaptation for learned image compression DA用于图片压缩
- Test-Time Training on Graphs with Large Language Models (LLMs) [[arxiv](https://arxiv.org/abs/2404.13571)]
- Test-time training on graphs with LLMs 使用大语言模型在图上进行测试时训练
- DACAD: Domain Adaptation Contrastive Learning for Anomaly Detection in Multivariate Time Series [[arxiv](https://arxiv.org/abs/2404.11269)]
- Domain adaptation for anomaly detection 使用域自适应进行时间序列异常检测
- CVPR'24 Unified Language-driven Zero-shot Domain Adaptation [[arxiv](https://arxiv.org/abs/2404.07155)]
- Language-driven zero-shot domain adaptation 语言驱动的零样本 DA
- CoDA: Instructive Chain-of-Domain Adaptation with Severity-Aware Visual Prompt Tuning [[arxiv](http://arxiv.org/abs/2403.17369)]
- Chain-of-domain adaptation with visual prompt tuning 领域链adaptation
- Deep Domain Adaptation: A Sim2Real Neural Approach for Improving Eye-Tracking Systems [[arxiv](https://arxiv.org/abs/2403.15947)]
- Domain adaptation for eye-tracking systems 用DA进行眼球追踪
- SPA: A Graph Spectral Alignment Perspective for Domain Adaptation [[NeurIPS 2023]](https://arxiv.org/abs/2310.17594) [[Pytorch]](https://github.com/CrownX/SPA)
- Graph spectral alignment and neighbor-aware propagation for domain adaptation
- Neurocomputing'24 Uncertainty-Aware Pseudo-Label Filtering for Source-Free Unsupervised Domain Adaptation [[arxiv](https://arxiv.org/abs/2403.11256)]
- Unvertainty-aware source-free domain adaptation 基于不确定性伪标签的domain adaptation
- Efficient Domain Adaptation for Endoscopic Visual Odometry [[arxiv](https://arxiv.org/abs/2403.10860)]
- Efficient domain adaptation for visual odometry 高效DA用于odometry
- Potential of Domain Adaptation in Machine Learning in Ecology and Hydrology to Improve Model Extrapolability [[arxiv](https://arxiv.org/abs/2403.11331)]
- Domain adaptation in ecology and hydrology 研究生态学和水文学中的DA
- ICLR'24 SF(DA)2: Source-free Domain Adaptation Through the Lens of Data Augmentation [[arxiv](https://arxiv.org/abs/2403.10834)]
- Source-free DA by data augmentation 通过数据增强来进行source-free DA
- CVPR'24 Universal Semi-Supervised Domain Adaptation by Mitigating Common-Class Bias [[arxiv](https://arxiv.org/abs/2403.11234)]
- Unviersal semi-supervised DA 通过公共类bias进行半监督DA
- Domain Adaptation Using Pseudo Labels for COVID-19 Detection [[arxiv](https://arxiv.org/abs/2403.11498)]
- Domain adaptation for COVID-19 detection 用DA进行covid-19检查
- Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans [[arxiv](https://arxiv.org/abs/2403.11338)]
- Covid-19 test using domain adaptation 使用集成和测试增强用于DA covid-19
- Addressing Source Scale Bias via Image Warping for Domain Adaptation [[arxiv](https://arxiv.org/abs/2403.12712)]
- Address the source scale bias for domain adaptation 解决源域的scale bias
- Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation [[arxiv](https://arxiv.org/abs/2403.10001)]
- Foundation models help domain adaptation 基础模型帮助领域自适应
- Unsupervised Domain Adaptation within Deep Foundation Latent Spaces [[arxiv](https://arxiv.org/abs/2402.14976)]
- Domain adaptation using foundation models
- LanDA: Language-Guided Multi-Source Domain Adaptation [[arxiv](https://arxiv.org/abs/2401.14148)]
- Language guided multi-source DA 在多源域自适应中使用语言指导
- AdaEmbed: Semi-supervised Domain Adaptation in the Embedding Space [[arxiv](https://arxiv.org/abs/2401.12421)]
- Semi-spuervised domain adaptation in the embedding space 在嵌入空间中进行半监督域自适应
- Inter-Domain Mixup for Semi-Supervised Domain Adaptation [[arxiv](https://arxiv.org/abs/2401.11453)]
- Inter-domain mixup for semi-supervised domain adaptation 跨领域mixup用于半监督域自适应
- Source-Free and Image-Only Unsupervised Domain Adaptation for Category Level Object Pose Estimation [[arxiv](https://arxiv.org/abs/2401.10848)]
- Source-free and image-only unsupervised domain adaptation
- Multi-Source Domain Adaptation with Transformer-based Feature Generation for Subject-Independent EEG-based Emotion Recognition [[arxiv](https://arxiv.org/abs/2401.02344)]
- Multi-source DA with Transformer-based feature generation
- Multi-Modal Domain Adaptation Across Video Scenes for Temporal Video Grounding [[arxiv](https://arxiv.org/abs/2312.13633)]
- Multi-modal domain adaptation 多模态领域自适应
- Domain Adaptive Graph Classification [[arxiv](https://arxiv.org/abs/2312.13536)]
- Domain adaptive graph classification 域适应的图分类
- Understanding and Estimating Domain Complexity Across Domains [[arxiv](https://arxiv.org/abs/2312.13487)]
- Understanding and estimating domain complexity 解释领域复杂性
- Prompt-based Domain Discrimination for Multi-source Time Series Domain Adaptation [[arxiv](https://arxiv.org/abs/2312.12276v1)]
- Prompt-based domain discrimination for time series domain adaptation 基于prompt的时间序列域自适应
- NeurIPS'23 SwapPrompt: Test-Time Prompt Adaptation for Vision-Language Models [[arxiv](https://openreview.net/forum?id=EhdNQiOWgQ)]
- Test-time prompt adaptation for vision language models 对视觉-语言大模型的测试时prompt自适应
- DARNet: Bridging Domain Gaps in Cross-Domain Few-Shot Segmentation with Dynamic Adaptation [[arxiv](http://arxiv.org/abs/2312.04813)]
- Dynamic adaptation for cross-domain few-shot segmentation 动态适配用于跨领域小样本分割
- A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting [[arxiv](http://arxiv.org/abs/2312.05024)]
- Instance weighting for domain adaptation 样本加权用于领域自适应
- Target-agnostic Source-free Domain Adaptation for Regression Tasks [[arxiv](http://arxiv.org/abs/2312.00540)]
- Target-agnostic source-free DA for regression 用于回归任务的source-free DA
- Proposal-Level Unsupervised Domain Adaptation for Open World Unbiased Detector [[arxiv](https://arxiv.org/abs/2311.02342)]
- Proposal-level unsupervised domain adaptation
- Better Practices for Domain Adaptation [[arxiv](http://arxiv.org/abs/2309.03879)]
- Better practice for domain adaptation
- Domain Adaptation for Efficiently Fine-tuning Vision Transformer with Encrypted Images [[arxiv](http://arxiv.org/abs/2309.02556)]
- Domain adaptation for efficient ViT
- Robust Activity Recognition for Adaptive Worker-Robot Interaction using Transfer Learning [[arxiv](http://arxiv.org/abs/2308.14843)]
- Activity recognition using domain adaptation
- Unsupervised Domain Adaptation via Domain-Adaptive Diffusion [[arxiv](http://arxiv.org/abs/2308.13893)]
- Domain-adaptive diffusion for domain adaptation 领域自适应的diffusion
- SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation [[arxiv](https://arxiv.org/abs/2307.01024)]
- Using SAM for domain adaptation 使用segment anything进行domain adaptation
- Cross-Database and Cross-Channel ECG Arrhythmia Heartbeat Classification Based on Unsupervised Domain Adaptation [[arxiv](http://arxiv.org/abs/2306.04433)]
- EEG using unsupervised domain adaptation 用无监督DA来进行EEG心跳分类
- Real-Time Online Unsupervised Domain Adaptation for Real-World Person Re-identification [[arxiv](http://arxiv.org/abs/2306.03993)]
- Real-time online unsupervised domain adaptation for REID 无监督DA用于REID
- Can We Evaluate Domain Adaptation Models Without Target-Domain Labels? A Metric for Unsupervised Evaluation of Domain Adaptation [[arxiv](http://arxiv.org/abs/2305.18712)]
- Evaluate domain adaptation models 评测domain adaptation的模型
- Universal Test-time Adaptation through Weight Ensembling, Diversity Weighting, and Prior Correction [[arxiv](http://arxiv.org/abs/2306.00650)]
- Universal test-time adaptation
- Universal Domain Adaptation from Foundation Models [[arxiv](http://arxiv.org/abs/2305.11092)]
- Using foundation models for universal domain adaptation
- Multi-Source to Multi-Target Decentralized Federated Domain Adaptation [[arxiv](http://arxiv.org/abs/2304.12422)]
- Decentralized federated domain adaptation
- Multi-Source to Multi-Target Decentralized Federated Domain Adaptation [[arxiv](https://arxiv.org/abs/2304.12422)]
- Multi-source to multi-target federated domain adaptation 多源多目标的联邦域自适应
- ICML'23 AdaNPC: Exploring Non-Parametric Classifier for Test-Time Adaptation [[arxiv](https://arxiv.org/abs/2304.12566)]
- Adaptive test-time adaptation 非参数化分类器进行测试时adaptation
- CVPR'23 Zero-shot Generative Model Adaptation via Image-specific Prompt Learning [[arxiv](http://arxiv.org/abs/2304.03119)]
- Zero-shot generative model adaptation via image-specific prompt learning 零样本的生成模型adaptation
- Source-free Domain Adaptation Requires Penalized Diversity [[arxiv](http://arxiv.org/abs/2304.02798)]
- Source-free DA requires penalized diversity
- Complementary Domain Adaptation and Generalization for Unsupervised Continual Domain Shift Learning [[arxiv](http://arxiv.org/abs/2303.15833)]
- Continual domain shift learning using adaptation and generalization 使用 adaptation和DG进行持续分布变化的学习
- CVPR'23 Feature Alignment and Uniformity for Test Time Adaptation [[arxiv](http://arxiv.org/abs/2303.10902)]
- Feature alignment for test-time adaptation 使用特征对齐进行测试时adaptation
- TempT: Temporal consistency for Test-time adaptation [[arxiv](http://arxiv.org/abs/2303.10536)]
- Temporeal consistency for test-time adaptation 时间一致性用于test-time adaptation
- CVPR'23 A New Benchmark: On the Utility of Synthetic Data with Blender for Bare Supervised Learning and Downstream Domain Adaptation [[arxiv](http://arxiv.org/abs/2303.09165)]
- A new benchmark for domain adaptation 一个对于domain adaptation最新的benchmark
- Unsupervised domain adaptation by learning using privileged information [[arxiv](http://arxiv.org/abs/2303.09350)]
- Domain adaptation by privileged information 使用高级信息进行domain adaptation
- Probabilistic Domain Adaptation for Biomedical Image Segmentation [[arxiv](http://arxiv.org/abs/2303.11790)]
- Probabilistic domain adaptation for biomedical image segmentation 概率的domain adaptation用于生物医疗图像分割
- Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow [[arxiv](https://arxiv.org/abs/2303.07564)]
- Domain adaptation for foggy scene optical flow 领域自适应用于雾场景的光流
- Domain Adaptation for Time Series Under Feature and Label Shifts [[arxiv](https://arxiv.org/abs/2302.03133)]
- Domain adaptation for time series 用于时间序列的domain adaptation
- TPAMI'23 Source-Free Unsupervised Domain Adaptation: A Survey [[arxiv](http://arxiv.org/abs/2301.00265)]
- A survey on source-free domain adaptation 关于source-free DA的一个最新综述
- Discriminative Radial Domain Adaptation [[arxiv](http://arxiv.org/abs/2301.00383)]
- Discriminative radial domain adaptation 判别性的放射式domain adaptation
- WACV'23 Cross-Domain Video Anomaly Detection without Target Domain Adaptation [[arxiv](https://arxiv.org/abs/2212.07010)]
- Cross-domain video anomaly detection without target domain adaptation 跨域视频异常检测
- Co-Learning with Pre-Trained Networks Improves Source-Free Domain Adaptation [[arxiv](https://arxiv.org/abs/2212.07585)]
- Pre-trained models for source-free domain adaptation 用预训练模型进行source-free DA
- CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars [[arxiv](https://arxiv.org/abs/2212.00621)]
- Continual DA for self-driving cars 连续的domain adaptation用于自动驾驶
- Robust Mean Teacher for Continual and Gradual Test-Time Adaptation [[arxiv](https://arxiv.org/abs/2211.13081)]
- Mean teacher for test-time adaptation 在测试时用mean teacher进行适配
- ECCV-22 DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation [[arXiv](https://arxiv.org/pdf/2207.09988.pdf)] [[Code](https://github.com/dvlab-research/DecoupleNet)]
- Domain adaptation in semantic segmentation 语义分割域适应
- NeurIPS'22 Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning [[openreview](https://openreview.net/forum?id=NjImFaBEHl)]
- Adaptive contrastive learning for source-free DA 自适应的对比学习用于source-free DA
- NeurIPS'22 MetaTeacher: Coordinating Multi-Model Domain Adaptation for Medical Image Classification [[openreview](https://openreview.net/forum?id=AQd4ugzALQ1)]
- Multi-model domain adaptation mor medical image classification 多模型DA用于医疗数据
- NeurIPS'22 Domain Adaptation under Open Set Label Shift [[openreview](https://openreview.net/forum?id=OMZG4vsKmm7)]
- Domain adaptation under open set label shift 在开放集的label shift中的DA
- NeurIPS'22 Test Time Adaptation via Conjugate Pseudo-labels [[openreview](https://openreview.net/forum?id=2yvUYc-YNUH)]
- Test-time adaptation with conjugate pseudo-labels 用伪标签进行测试时adaptation
- On Fine-Tuned Deep Features for Unsupervised Domain Adaptation [[arxiv](http://arxiv.org/abs/2210.14083)]
- Fine-tuned features for domain adaptation 微调的特征用于域自适应
- WACV-23 ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing [[arxiv](https://arxiv.org/abs/2210.11539)]
- Domain adaptation for object detection using confidence mixing 用置信度mix做domain adaptation
- Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup [[arxiv](https://arxiv.org/abs/2210.03250)]
- Domain adaptation for COVID-19 用DA进行COVID-19预测
- ICONIP'22 IDPL: Intra-subdomain adaptation adversarial learning segmentation method based on Dynamic Pseudo Labels [[arxiv](https://arxiv.org/abs/2210.03435)]
- Intra-domain adaptation for segmentation 子领域对抗Adaptation
- NeurIPS'22 Polyhistor: Parameter-Efficient Multi-Task Adaptation for Dense Vision Tasks [[arxiv](https://arxiv.org/abs/2210.03265)]
- Parameter-efficient multi-task adaptation 参数高效的多任务adaptation
- Deep Domain Adaptation for Detecting Bomb Craters in Aerial Images [[arxiv](https://arxiv.org/abs/2209.11299)]
- Bomb craters detection using domain adaptation 用DA检测遥感图像中的炮弹弹坑
- WACV-23 TeST: Test-time Self-Training under Distribution Shift [[arxiv](https://arxiv.org/abs/2209.11459)]
- Test-time self-training 测试时训练
- Robust Domain Adaptation for Machine Reading Comprehension [[arxiv](https://arxiv.org/abs/2209.11615)]
- Domain adaptation for machine reading comprehension 机器阅读理解的domain adaptation
- IEEE-TMM'22 Uncertainty Modeling for Robust Domain Adaptation Under Noisy Environments [[IEEE](https://ieeexplore.ieee.org/abstract/document/9882310)]
- Uncertainty modeling for domain adaptation 噪声环境下的domain adaptation
- MM-22 [Making the Best of Both Worlds: A Domain-Oriented Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2208.01195)
- Transformer for domain adaptation 用transformer进行DA
- NeurIPS-21 [The balancing principle for parameter choice in distance-regularized domain adaptation](https://papers.nips.cc/paper/2021/hash/ae0909a324fb2530e205e52d40266418-Abstract.html)
- Hyperparameter selection for domain adaptation 对adaptation中的正则项系数进行选择
- ECCV-22 [Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation](https://arxiv.org/abs/2207.10856)
- Prototype continual domain adaptation 基于原型的类增量domain adaptation
- [Transferability-Guided Cross-Domain Cross-Task Transfer Learning](https://arxiv.org/abs/2207.05510)
- Cross-domain cross-task transfer learning 用迁移性指标指导跨领域跨任务迁移
- [A Data-Based Perspective on Transfer Learning](https://arxiv.org/abs/2207.05739)
- Analyze the data numbers in transfer learning 分析迁移学习中数据的重要性
- [Few-Max: Few-Shot Domain Adaptation for Unsupervised Contrastive Representation Learning](https://arxiv.org/abs/2206.10137)
- Few-shot DA for unsupervised constrastive learning 小样本DA用于无监督对比学习
- ICPR-22 [OTAdapt: Optimal Transport-based Approach For Unsupervised Domain Adaptation](https://arxiv.org/abs/2205.10738)
- Optimal transport-based domain adaptation 利用最优传输进行领域自适应
- CVPR-22 [Safe Self-Refinement for Transformer-based Domain Adaptation](https://arxiv.org/abs/2204.07683)
- Transformer-based domain adaptation 基于transformer的domain adaptation
- ISPASS-22 [Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices](https://arxiv.org/abs/2203.11295)
- Benchmarking test-time adaptation for edge devices
- 在端设备上评测test-time adaptation算法
- [Multi-Source Domain Adaptation Based on Federated Knowledge Alignment](https://arxiv.org/abs/2203.11635)
- Multi-source domain adaptation
- 多源域自适应
- [A Broad Study of Pre-training for Domain Generalization and Adaptation](https://arxiv.org/abs/2203.11819)
- A broad study of pre-training models for DA and DG
- 大量的实验进行DA和DG
- [Open Set Domain Adaptation By Novel Class Discovery](https://arxiv.org/abs/2203.03329)
- Open set DA by novel class discovery
- 基于新类发现的open set da
- ICML-21 workshop [Domain Adaptation with Factorizable Joint Shift](https://arxiv.org/abs/2203.02902)
- Domain adaptation with factorizable joint shift
- 基于可分解的联合漂移的领域自适应
- [Causal Domain Adaptation with Copula Entropy based Conditional Independence Test](https://arxiv.org/abs/2202.13482)
- Use copula entropy based conditional independence test for csusal domain adaptation
- 使用基于copula entopy的条件独立测试进行causal domain adaptation
- ICLR-22 [Graph-Relational Domain Adaptation](https://arxiv.org/abs/2202.03628)
- Graph-relational domain adapttion using topological structures
- 图级别的domain adaptation,使用拓扑结构
- [UMAD: Universal Model Adaptation under Domain and Category Shift](https://arxiv.org/abs/2112.08553)
- Model adaptation under domain and category shift
- 在domain和class都有shift的前提下进行模型适配
- [A Survey of Unsupervised Domain Adaptation for Visual Recognition](http://arxiv.org/abs/2112.06745)
- A new survey article of domain adaptation
- 对UDA的一个综述文章,来自作者博士论文
- [Unsupervised Domain Adaptation: A Reality Check](https://arxiv.org/abs/2111.15672)
- Doing experiments to show the progress of DA methods over the years
- 用大量的实验来验证近几年来DA方法的进展
- [Hierarchical Optimal Transport for Unsupervised Domain Adaptation](https://arxiv.org/abs/2112.02073)
- hierarchical optimal transport for UDA
- 层次性的最优传输用于domain adaptation
- [Boosting Unsupervised Domain Adaptation with Soft Pseudo-label and Curriculum Learning](https://arxiv.org/abs/2112.01948)
- Using soft pseudo-label and curriculum learning to boost UDA
- 用软的伪标签和课程学习增强UDA方法
- WACV-22 [Semi-supervised Domain Adaptation via Sample-to-Sample Self-Distillation](https://arxiv.org/abs/2111.14353)
- Sample-level self-distillation for semi-supervised DA
- 样本层次的自蒸馏用于半监督DA
- [C-MADA: Unsupervised Cross-Modality Adversarial Domain Adaptation framework for medical Image Segmentation](https://arxiv.org/abs/2110.15823)
- Cross-modality domain adaptation for medical image segmentation
- 跨模态的DA用于医学图像分割
- [Domain Adaptation for Rare Classes Augmented with Synthetic Samples](https://arxiv.org/abs/2110.12216)
- Domain adaptation for rare class
- 稀疏类的domain adaptation
- BMVC-21 [Dynamic Feature Alignment for Semi-supervised Domain Adaptation](https://arxiv.org/abs/2110.09641)
- Dynamic feature alignment for semi-supervised DA
- 动态特征对齐用于半监督DA
- IEEE TIP-21 [Joint Clustering and Discriminative Feature Alignment for Unsupervised Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/9535218)
- Clustering and discriminative alignment for DA
- 聚类与判定式对齐用于DA
- IEEE TNNLS-21 [Entropy Minimization Versus Diversity Maximization for Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/9537640)
- Entropy minimization versus diversity max for DA
- 熵最小化与diversity最大化
- [Cross-Region Domain Adaptation for Class-level Alignment](https://arxiv.org/abs/2109.06422)
- Cross-region domain adaptation for class-level alignment
- 跨区域的领域自适应用于类级别的对齐
- EMNLP-21 [Non-Parametric Unsupervised Domain Adaptation for Neural Machine Translation](https://arxiv.org/abs/2109.06604)
- UDA for machine translation
- 用领域自适应进行机器翻译
- [Unsupervised domain adaptation for cross-modality liver segmentation via joint adversarial learning and self-learning](https://arxiv.org/abs/2109.05664)
- Domain adaptation for cross-modality liver segmentation
- 使用domain adaptation进行肝脏的跨模态分割
- [CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2109.06165)
- Cross-domain transformer for domain adaptation
- 基于transformer进行domain adaptation
- [Robust Ensembling Network for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.09473)
- Ensembling network for domain adaptation
- 集成嵌入网络用于domain adaptation
- [TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.05988)
- Vision transformer for domain adaptation
- 用视觉transformer进行DA
- [Learning Transferable Parameters for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.06129)
- Learning partial transfer parameters for DA
- 学习适用于迁移部分的参数做UDA任务
- ICCV-21 [BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation](https://arxiv.org/abs/2108.03267)
- Bijective MMD for domain adaptation
- 双射MMD用于语义分割
- MM-21 [Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding](https://arxiv.org/abs/2108.02953)
- Few-shot DA with image-to-class sparse similarity encoding
- 小样本的领域自适应
- [Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning](https://arxiv.org/abs/2108.02959)
- Prototype transfer and structure regularization
- 原型的迁移学习
- CVPR-21 [Conditional Bures Metric for Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Luo_Conditional_Bures_Metric_for_Domain_Adaptation_CVPR_2021_paper.html)
- A new metric for domain adaptation
- 提出一个新的metric用于domain adaptation
- CVPR-21 [Generalized Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Mitsuzumi_Generalized_Domain_Adaptation_CVPR_2021_paper.html)
- A general definition for domain adaptation
- 一个更抽象更一般的domain adaptation定义
- CVPR-21 [Reducing Domain Gap by Reducing Style Bias](https://openaccess.thecvf.com/content/CVPR2021/html/Nam_Reducing_Domain_Gap_by_Reducing_Style_Bias_CVPR_2021_paper.html)
- Syle-invariant training for adaptation and generalization
- 通过训练图像对style无法辨别来进行DA和DG
- 20210706 CVPR-21 [Instance Level Affinity-Based Transfer for Unsupervised Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Sharma_Instance_Level_Affinity-Based_Transfer_for_Unsupervised_Domain_Adaptation_CVPR_2021_paper.html)
- Instance affinity learning for domain adaptation
- 样本间相似度学习,用于DA
- 20210716 BMCV-extend [Exploring Dropout Discriminator for Domain Adaptation](https://arxiv.org/abs/2107.04231)
- Using multiple discriminators for domain adaptation
- 用分布估计代替点估计来做domain adaptation
- 20201208 TIP [Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation](http://arxiv.org/abs/2012.02621)
- 用label propagation做半监督domain adaptation
- 20201203 [Unpaired Image-to-Image Translation via Latent Energy Transport](https://arxiv.org/abs/2012.00649)
- 用能量模型做图像翻译
- 20200927 [Privacy-preserving Transfer Learning via Secure Maximum Mean Discrepancy](https://arxiv.org/abs/2009.11680)
- 加密情况下的MMD用于迁移学习
- 20200914 [A First Step Towards Distribution Invariant Regression Metrics](https://arxiv.org/abs/2009.05176)
- 分布无关的回归评价
- 20200813 ECCV-20 [Learning to Cluster under Domain Shift](https://arxiv.org/abs/2008.04646)
- Learning to cluster under domain shift
- 在domain shift的情况下进行聚类
- 20200706 [Learn Faster and Forget Slower via Fast and Stable Task Adaptation](https://arxiv.org/abs/2007.01388)
- 20200629 [ICML-20] [Graph Optimal Transport for Cross-Domain Alignment](https://arxiv.org/abs/2006.14744)
- Graph OT for cross-domain alignment
- 20191202 AAAI-20 [Stable Learning via Sample Reweighting](https://arxiv.org/abs/1911.12580)
- Theoretical sample reweigting
- 理论和方法,用于sample reweight
- 20191202 arXiv [Domain-invariant Stereo Matching Networks](https://arxiv.org/abs/1911.13287)
- Domain-invariant stereo matching networks
- 领域不变的匹配网络
- 20191202 arXiv [Learning Generalizable Representations via Diverse Supervision](https://arxiv.org/abs/1911.12911)
- Diverse supervision helps to learn generalizable representations
- 20191202 arXiv [Domain-Aware Dynamic Networks](https://arxiv.org/abs/1911.13237)
- Edge devices adaptative computing
- 边缘计算上的自适应计算
- 20191029 [Reducing Domain Gap via Style-Agnostic Networks](https://arxiv.org/abs/1910.11645)
- Use style-agnostic networks to avoid domain gap
- 通过风格无关的网络来避免领域的gap
- 20191008 arXiv [DIVA: Domain Invariant Variational Autoencoders](https://arxiv.org/abs/1905.10427)
- Domain invariant variational autoencoders
- 领域不变的变分自编码器
- 20190821 arXiv [Transfer Learning-Based Label Proportions Method with Data of Uncertainty](https://arxiv.org/abs/1908.06603)
- Transfer learning with source and target having uncertainty
- 当source和target都有不确定label时进行迁移
- 20190703 arXiv [Inferred successor maps for better transfer learning](https://arxiv.org/abs/1906.07663)
- Inferred successor maps for better transfer learning
- 20190531 IJCAI-19 [Adversarial Imitation Learning from Incomplete Demonstrations](https://arxiv.org/abs/1905.12310)
- Adversarial imitation learning from imcomplete demonstrations
- 基于不完整实例的对抗模仿学习
- 20190517 arXiv [Budget-Aware Adapters for Multi-Domain Learning](https://arxiv.org/abs/1905.06242)
- Budget-Aware Adapters for Multi-Domain Learning
- 20190301 SysML-19 [FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning](https://arxiv.org/abs/1902.11128)
- An efficient hardware for mobile computer vision applications using transfer learning
- 提出一个高效的用于移动计算机视觉应用的硬件
- 20190118 arXiv [Domain Adaptation for Structured Output via Discriminative Patch Representations](https://arxiv.org/abs/1901.05427)
- Domain adaptation for structured output
- Domain adaptation用于结构化输出
- 20181217 arXiv [When Semi-Supervised Learning Meets Transfer Learning: Training Strategies, Models and Datasets](https://arxiv.org/abs/1812.05313)
- Combining semi-supervised learning and transfer learning
- 将半监督方法应用于迁移学习
- 20181127 arXiv [Privacy-preserving Transfer Learning for Knowledge Sharing](https://arxiv.org/abs/1811.09491)
- First work on privacy preserving in transfer learning
- 探讨迁移学习中隐私保护的文章
- 20181121 arXiv [Not just a matter of semantics: the relationship between visual similarity and semantic similarity](https://arxiv.org/abs/1811.07120)
- Interpreting relationships between visual similarity and semantic similarity
- 解释了视觉相似性和语义相似性的不同
- 20181008 arXiv [Unsupervised Learning via Meta-Learning](https://arxiv.org/abs/1810.02334)
- Meta-learning for unsupervised learning
- 用于无监督学习的元学习
- 20180919 JMLR [Invariant Models for Causal Transfer Learning](http://jmlr.csail.mit.edu/papers/volume19/16-432/16-432.pdf)
- Invariant models for causal transfer learning
- 针对causal transfer learning提出不变模型
- 20180912 arXiv [Transfer Learning with Neural AutoML](https://arxiv.org/abs/1803.02780)
- Applying transfer learning into autoML search
- 将迁移学习思想应用于automl
- 20190904 arXiv [On the Minimal Supervision for Training Any Binary Classifier from Only Unlabeled Data](https://arxiv.org/abs/1808.10585)
- Train binary classifiers from only unlabeled data
- 仅从无标记数据训练二分类器
- 20180904 arXiv [Learning Data-adaptive Nonparametric Kernels](https://arxiv.org/abs/1808.10724)
- Learn a kernel that can do adaptation
- 学习一个可以自适应的kernel
- 20180901 arXiv [Distance Based Source Domain Selection for Sentiment Classification](https://arxiv.org/abs/1808.09271)
- Propose a new domain selection method by combining existing distance functions
- 提出一种混合已有多种距离公式的源领域选择方法
- 20180901 KBS [Transfer subspace learning via low-rank and discriminative reconstruction matrix](https://www.sciencedirect.com/science/article/pii/S0950705118304222)
- Transfer subspace learning via low-rank and discriminative reconstruction matrix
- 通过低秩和重构进行迁移学习
- 20180825 arXiv [Transfer Learning for Estimating Causal Effects using Neural Networks](https://arxiv.org/abs/1808.07804)
- Using transfer learning for casual effect learning
- 用迁移学习进行因果推理
- 20180724 ICPKR-18 [Knowledge-based Transfer Learning Explanation](https://arxiv.org/abs/1807.08372)
- Explain transfer learning things with some knowledge-based theory
- 用一些基于knowledge的方法解释迁移学习
- 20180628 arXiv 提出Office数据集的实验室又放出一个数据集用于close set、open set、以及object detection的迁移学习:[Syn2Real: A New Benchmark forSynthetic-to-Real Visual Domain Adaptation](https://arxiv.org/abs/1806.09755)
- 20180604 arXiv 在Open set domain adaptation中,用共享和私有部分重建进行问题的解决:[Learning Factorized Representations for Open-set Domain Adaptation](https://arxiv.org/abs/1805.12277)
- 20210706 CVPR-21 [Multi-Target Domain Adaptation With Collaborative Consistency Learning](https://openaccess.thecvf.com/content/CVPR2021/html/Isobe_Multi-Target_Domain_Adaptation_With_Collaborative_Consistency_Learning_CVPR_2021_paper.html)
- Using collaborative consistency training for multi-target DA
- 用多个模型做集成一致性训练进行多目标DA
- 20210625 CVPR-21 [Generalized Domain Adaptation](http://arxiv.org/abs/2106.01656)
- Generalized domain adaptation
- 更通用更一般的domain adaptation
- 20210625 CVPR-21 [A Fourier-based Framework for Domain Generalization](http://arxiv.org/abs/2105.11120)
- Fourier based domain generalization
- 基于傅里叶特征的DG
- 20210329 ICLR-21 [Tent: Fully Test-Time Adaptation by Entropy Minimization](https://openreview.net/forum?id=uXl3bZLkr3c)
- Test time adaptation by entropy minimization
- 测试时通过熵最小化进行adaptation
- 20210329 [Adversarial Branch Architecture Search for Unsupervised Domain Adaptation](https://arxiv.org/abs/2102.06679v2)
- NAS for domain adaptation
- 用神经网络结构搜索做领域自适应
- 20210312 [Discrepancy-Based Active Learning for Domain Adaptation](https://arxiv.org/abs/2103.03757v1)
- Discrepancy and active learning for DA
- 基于主动学习的DA
- 20210312 [Unbalanced minibatch Optimal Transport; applications to Domain Adaptation](https://arxiv.org/abs/2103.03606v1)
- Unbalanced minibatch OT for DA
- 非均衡的OT用于DA问题
- 20210127 [Hierarchical Domain Invariant Variational Auto-Encoding with weak domain supervision](http://arxiv.org/abs/2101.09436)
- 利用VAE和解耦去做domain generalization
- Using VAE and disentanglement for domain generalization
- 20201214 WWW-20 [Domain Adaptation with Category Attention Network for Deep Sentiment Analysis](https://dl.acm.org/doi/abs/10.1145/3366423.3380088?casa_token=W6UxRKT4pDQAAAAA%3ACTbuFKp72M88OdbcURQSSua5XaM0GI2Y90795GGFv6ZiEx584ZGj8HT3x8nBSAUhvr2-DhQbnmVY1YM)
- Unify pivots and non-pivots, and provide interpretability for domain adaptation in sentiment analysis
- 统一pivots和non-pivots,并提供可解释性进行DA情感分析
- 20201208 NIPS-20 [Heuristic Domain Adaptation](https://proceedings.neurips.cc/paper/2020/file/555d6702c950ecb729a966504af0a635-Paper.pdf)
- 启发式domain adaptation
- 20200804 ECCV-20 spotlight [Side-Tuning: A Baseline for Network Adaptation via Additive Side Networks](https://arxiv.org/abs/1912.13503)
- 将现有的finetune机制进行扩展
- Extending finetune mechanism
- 20200804 ACMMM-20 [Adversarial Bipartite Graph Learning for Video Domain Adaptation](https://arxiv.org/abs/2007.15829)
- Video domain adaptation
- 视频的领域自适应
- 20200804 MICCAI-20 [Whole MILC: generalizing learned dynamics across tasks, datasets, and populations](https://arxiv.org/abs/2007.16041)
- Generalizing across tasks, datasets, populations
- 在任务、数据集、人群之间做泛化
- 20200724 [Learning to Match Distributions for Domain Adaptation](https://arxiv.org/abs/2007.10791)
- 自动深度迁移学习
- Automatic domain adaptation
- 20200529 TNNLS [Deep Subdomain Adaptation Network for Image Classification](https://github.com/easezyc/deep-transfer-learning/tree/master/UDA/pytorch1.0/DSAN)
- A fine-grained adaptation method with LMMD, which is very simple and effective
- 一种细粒度自适应的方法,使用LMMD进行对齐,该方法非常简单有效
- 20200420 arXiv [One-vs-Rest Network-based Deep Probability Model for Open Set Recognition](https://arxiv.org/abs/2004.08067)
- One-vs-rest deep model for open set recognition
- 用于开放集的识别的深度网络
- 20200414 ICLR-20 [Gradient as features for deep representation learning](https://openreview.net/pdf?id=BkeoaeHKDS)
- Gradients as features for deep representation learning on pretrained models
- 在预训练模型基础上,将梯度作为额外的feature,提高学习表现
- 20200414 ICLR-20 [Domain adaptive multi-branch networks](https://openreview.net/forum?id=rJxycxHKDS)
- A domain adaptation framework using a multi-branch cascade structure
- 一个用了多层级联、多分支结构的DA框架
- 20200405 CVPR-20 [Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations](https://arxiv.org/abs/2003.12237)
- A simple regularization-based adaptation method
- 一个非常简单的基于能量最小化的adaptation方法
- 20200210 AAAI-20 [Bi-Directional Generation for Unsupervised Domain Adaptation](https://arxiv.org/abs/2002.04869)
- Bidirectional GANs for domain adaptation
- 双向的GAN用来做DA
- 20191202 PR-19 [Correlation-aware Adversarial Domain Adaptation and Generalization](https://arxiv.org/abs/1911.12983)
- CORAL and adversarial for adaptation and generalization
- 基于CORAL和对抗网络的DA和DG
- 20191201 BMVC-19 [Domain Adaptation for Object Detection via Style Consistency](https://arxiv.org/abs/1911.10033)
- Use style consistency for domain adaptation
- 通过结构一致性来进行domain adaptation
- 20191124 AAAI-20 [Knowledge Graph Transfer Network for Few-Shot Recognition](https://arxiv.org/abs/1911.09579)
- GNN for semantic transfer for few-shot learning
- 用GNN进行类别的语义迁移用于few-shot learning
- 20191124 arXiv [Improving Unsupervised Domain Adaptation with Variational Information Bottleneck](https://arxiv.org/abs/1911.09310)
- Information bottleneck for unsupervised da
- 用了信息瓶颈来进行DA
- 20191124 AAAI-20 (AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning)(https://arxiv.org/abs/1911.09659)
- Adaptively determine which layer to transfer or finetune
- 自适应地决定迁移哪个层或微调哪个层
- 20191113 arXiv [Knowledge Distillation for Incremental Learning in Semantic Segmentation](https://arxiv.org/abs/1911.03462)
- Knowledge distillation for incremental learning in semantic segmentation
- 在语义分割问题中针对增量学习进行知识蒸馏
- 20191111 NIPS-19 [PointDAN: A Multi-Scale 3D Domain Adaption Network for Point Cloud Representation](https://arxiv.org/abs/1911.02744)
- Multi-scale 3D DA network for point cloud representation
- 20191111 CCIA-19 [Feature discriminativity estimation in CNNs for transfer learning](https://arxiv.org/abs/1911.03332)
- Feature discriminativity estimation in CNN for TL
- 20191012 ICCV-19 [Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation](https://arxiv.org/abs/1910.05562)
- Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation
- 直接適應:學習非監督域自適應的判別功能
- 20191015 arXiv [Deep Kernel Transfer in Gaussian Processes for Few-shot Learning](https://arxiv.org/abs/1910.05199)
- Deep kernel transfer learing in Gaussian process
- 高斯过程中的深度迁移学习
- 20191008 EMNLP-19 workshop [Domain Differential Adaptation for Neural Machine Translation](https://arxiv.org/abs/1910.02555)
- Embrace the difference between domains for adaptation
- 拥抱domain的不同,并利用这些不同帮助adaptation
- 20191008 BMVC-19 [Multi-Weight Partial Domain Adaptation](https://bmvc2019.org/wp-content/uploads/papers/0406-paper.pdf)
- Class and sample weight contribution for partial domain adaptation
- 同时考虑类别和样本比重用于部分迁移学习
- 20190813 ICCV-19 oral [UM-Adapt: Unsupervised Multi-Task Adaptation Using Adversarial Cross-Task Distillation](https://arxiv.org/abs/1908.03884)
- A unified framework for domain adaptation
- 一个统一的用于domain adaptation的框架
- 20190809 arXiv [Multi-Purposing Domain Adaptation Discriminators for Pseudo Labeling Confidence](https://arxiv.org/abs/1907.07802)
- Improve pseudo label confidence using multi-purposing DA
- 用多目标DA提高伪标签准确率
- 20190809 arXiv [Semi-supervised representation learning via dual autoencoders for domain adaptation](https://arxiv.org/abs/1908.01342)
- Semi-supervised learning via autoencoders
- 半监督autoencoder用于DA
- 20190809 arXiv [Mind2Mind : transfer learning for GANs](https://arxiv.org/abs/1906.11613)
- Transfer learning using GANs
- 用GAN进行迁移学习
- 20190809 arXiv [Self-supervised Domain Adaptation for Computer Vision Tasks](https://arxiv.org/abs/1907.10915)
- Self-supervised DA
- 自监督DA
- 20190809 arXiv [Hidden Covariate Shift: A Minimal Assumption For Domain Adaptation](https://arxiv.org/abs/1907.12299)
- Hidden covariate shift
- 一种新的DA假设
- 20190809 PR-19 [Cross-domain Network Representations](https://arxiv.org/abs/1908.00205)
- Cross-domain network representation learning
- 跨领域网络表达学习
- 20190809 ICCV-19 [Larger Norm More Transferable: An Adaptive Feature Norm Approach for Unsupervised Domain Adaptation](https://arxiv.org/abs/1811.07456)
- Adaptive Feature Norm Approach for Unsupervised Domain Adaptation
- 自适应的特征归一化用于DA
- 20190731 MICCAI-19 Unsupervised Domain Adaptation via Disentangled Representations: Application to Cross-Modality Liver Segmentation
- Disentangled representations for unsupervised domain adaptation
- 基于解耦表征的无监督领域自适应
- 20190719 arXiv [Agile Domain Adaptation](https://arxiv.org/abs/1907.04978)
- Domain adaptation by considering the difficulty in classification
- 通过考虑不同样本分离的难度进行domain adaptation
- 20190718 arXiv [Measuring the Transferability of Adversarial Examples](https://arxiv.org/abs/1907.06291)
- Measure the transferability of adversarial examples
- 度量对抗样本的可迁移性
- 20190604 IJCAI-19 [DANE: Domain Adaptive Network Embedding](https://arxiv.org/abs/1906.00684)
- Transfered network embeddings for different networks
- 不同网络表达的迁移
- 20190604 arXiv [Learning to Transfer: Unsupervised Meta Domain Translation](https://arxiv.org/abs/1906.00181)
- Unsupervised meta domain translation
- 无监督领域翻译
- 20190530 arXiv [Learning Bregman Divergences](https://arxiv.org/abs/1905.11545)
- Learning Bregman divergence
- 学习Bregman差异
- 20190530 arXiv [Adversarial Domain Adaptation Being Aware of Class Relationships](https://arxiv.org/abs/1905.11931)
- Using class relationship for adversarial domain adaptation
- 利用类别关系进行对抗的domain adaptaition
- 20190530 arXiv [Cross-Domain Transferability of Adversarial Perturbations](https://arxiv.org/abs/1905.11736)
- Cross-Domain Transferability of Adversarial Perturbations
- 20190525 PAMI-19 [Learning More Universal Representations for Transfer-Learning](https://ieeexplore.ieee.org/abstract/document/8703078)
- Learning more universal representations for transfer learning
- 对迁移学习设计2种方式学到更通用的表达
- 20190517 ICML-19 [Learning What and Where to Transfer](https://arxiv.org/abs/1905.05901)
- Learning what and where to transfer in deep networks
- 学习深度网络从何处迁移
- 20190517 ICML-19 [Zero-Shot Voice Style Transfer with Only Autoencoder Loss](https://arxiv.org/abs/1905.05879)
- Zero-shot voice style transfer with only autoencoder loss
- 零次声音迁移
- 20190515 CVPR-19 [Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection](https://arxiv.org/abs/1905.05396)
- Domain adaptation for object detection
- 领域自适应用于物体检测
- 20190507 NAACL-HLT 19 [Transfer of Adversarial Robustness Between Perturbation Types](https://arxiv.org/abs/1905.01034)
- Transfer of Adversarial Robustness Between Perturbation Types
- 20190416 arXiv [ACE: Adapting to Changing Environments for Semantic Segmentation](https://arxiv.org/abs/1904.06268)
- Propose a new method that can adapt to new environments
- 提出一种可以适配不同环境的方法
- 20190416 arXiv [Incremental multi-domain learning with network latent tensor factorization](https://arxiv.org/abs/1904.06345)
- Incremental multi-domain learning with network latent tensor factorization
- 网络隐性tensor分解应用于多领域增量学习
- 20190415 PAKDD-19 [Parameter Transfer Unit for Deep Neural Networks](https://link.springer.com/chapter/10.1007/978-3-030-16145-3_7)
- Propose a parameter transfer unit for DNN
- 对深度网络提出参数迁移单元
- 20190412 PAMI-19 [Beyond Sharing Weights for Deep Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/8310033)
- Domain adaptation by not sharing weights
- 通过不共享权重来进行domain adaptation
- 20190405 IJCNN-19 [Accelerating Deep Unsupervised Domain Adaptation with Transfer Channel Pruning](https://arxiv.org/abs/1904.02654)
- The first work to accelerate transfer learning
- 第一个加速迁移学习的工作
- 20190102 WSDM-19 [Learning to Selectively Transfer: Reinforced Transfer Learning for Deep Text Matching](https://arxiv.org/abs/1812.11561)
- Reinforced transfer learning for deep text matching
- 迁移学习进行深度文本匹配
- 20190102 arXiv [DART: Domain-Adversarial Residual-Transfer Networks for Unsupervised Cross-Domain Image Classification](https://arxiv.org/abs/1812.11478)
- Adversarial + residual for domain adaptation
- 对抗+残差进行domain adaptation
- 20181220 arXiv [TWINs: Two Weighted Inconsistency-reduced Networks for Partial Domain Adaptation](https://arxiv.org/abs/1812.07405)
- Two weighted inconsistency-reduced networks for partial domain adaptation
- 两个权重网络用于部分domain adaptation
- 20181127 arXiv [Learning Grouped Convolution for Efficient Domain Adaptation](https://arxiv.org/abs/1811.09341)
- Group convolution for domain adaptation
- 群体卷积进行domain adaptation
- 20181121 arXiv [Unsupervised Domain Adaptation: An Adaptive Feature Norm Approach](https://arxiv.org/abs/1811.07456)
- A nonparametric method for domain adaptation
- 一种无参数的domain adaptation方法
- 20181121 arXiv [Domain Adaptive Transfer Learning with Specialist Models](https://arxiv.org/abs/1811.07056)
- Sample reweighting methods for domain adaptative
- 样本权重更新法进行domain adaptation
- 20180926 ICLR-18 [Self-ensembling for visual domain adaptation](https://arxiv.org/abs/1706.05208)
- Self-ensembling for domain adaptation
- 将self-ensembling应用于da
- 20180620 CVPR-18 用迁移学习进行fine tune:[Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning](https://arxiv.org/abs/1806.06193)
- 20180321 CVPR-18 构建了一个迁移学习算法,用于解决跨数据集之间的person-reidenfication: [Unsupervised Cross-dataset Person Re-identification by Transfer Learning of Spatial-Temporal Patterns](https://arxiv.org/abs/1803.07293)
- 20180315 ICLR-17 一篇综合进行two-sample stest的文章:[Revisiting Classifier Two-Sample Tests](https://arxiv.org/abs/1610.06545)
- 20171214 arXiv [Investigating the Impact of Data Volume and Domain Similarity on Transfer Learning Applications](https://arxiv.org/abs/1712.04008)
- 在实验中探索了数据量多少,和相似度这两个因素对迁移学习效果的影响
- NIPS-17 [Learning Multiple Tasks with Multilinear Relationship Networks](http://papers.nips.cc/paper/6757-learning-multiple-tasks-with-deep-relationship-networks)
- 20210420 arXiv [On Universal Black-Box Domain Adaptation](https://arxiv.org/abs/2104.04665)
- Universal black-box domain adaptation
- 黑盒情况下的universal domain adaptation
- 20210319 [Learning Invariant Representations across Domains and Tasks](https://arxiv.org/abs/2103.05114)
- Automatically learn to match distributions
- 自动适配分布的任务适配网络
- 20191222 arXiv [Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion](https://arxiv.org/abs/1912.08795)
- Generate data without priors for transfer learning based on deep dream
- 只用网络架构不用原来数据,生成新数据用于迁移
- 20191201 arXiv [A Unified Framework for Lifelong Learning in Deep Neural Networks](https://arxiv.org/abs/1911.09704)
- A unified framework for life-long learing in DNN
- 20191201 arXiv [ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring](https://arxiv.org/abs/1911.09785)
- Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
- 20191119 NIPS-19 workshop [Collaborative Unsupervised Domain Adaptation for Medical Image Diagnosis](https://arxiv.org/abs/1911.07293)
- Ensemble DA using noise labels
- 在ensemble中出现noise label时如何处理
- 20191029 KBS [Semi-supervised representation learning via dual autoencoders for domain adaptation](https://arxiv.org/abs/1908.01342)
- Semi-supervised domain adaptation with autoencoders
- 用自动编码器进行半监督的DA
- 20190926 arXiv [Learning a Domain-Invariant Embedding for Unsupervised Domain Adaptation Using Class-Conditioned Distribution Alignment](https://arxiv.org/abs/1907.02271)
- Use class-conditional DA for domain adaptation
- 使用类条件对齐进行domain adaptation
- 20190926 arXiv [A Deep Learning-Based Approach for Measuring the Domain Similarity of Persian Texts](https://arxiv.org/abs/1909.09690)
- Deep learning based domain similarity learning
- 利用深度学习进行领域相似度的学习
- 20190926 arXiv [FEED: Feature-level Ensemble for Knowledge Distillation](https://arxiv.org/abs/1909.10754)
- Feature-level knowledge distillation
- 特征层面的知识蒸馏
- 20190926 ICCV-19 [Self-similarity Grouping: A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-identification](https://arxiv.org/abs/1811.10144)
- A simple approach for domain adaptation
- 一个很简单的DA方法
- 20190910 BMVC-19 [Curriculum based Dropout Discriminator for Domain Adaptation](https://arxiv.org/abs/1907.10628)
- Curriculum dropout for domain adaptation
- 基于课程学习的dropout用于DA
- 20190909 PAMI [Inferring Latent Domains for Unsupervised Deep Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/8792192)
- Inferring latent domains for unsupervised deep domain
- 在深度迁移学习中推断隐含领域
- 20190729 ICCV workshop [Multi-level Domain Adaptive learning for Cross-Domain Detection](https://arxiv.org/abs/1907.11484)
- Multi-level domain adaptation for cross-domain Detection
- 多层次的domain adaptation
- 20190626 IJCAI-19 [Bayesian Uncertainty Matching for Unsupervised Domain Adaptation](https://arxiv.org/abs/1906.09693)
- Bayesian uncertainty matching for da
- 贝叶斯网络用于da
- 20190419 CVPR-19 [DDLSTM: Dual-Domain LSTM for Cross-Dataset Action Recognition](https://arxiv.org/abs/1904.08634)
- Dual-Domain LSTM for Cross-Dataset Action Recognition
- 跨数据集的动作识别
- 20190109 InfSc [Robust Unsupervised Domain Adaptation for Neural Networks via Moment Alignment](https://doi.org/10.1016/j.ins.2019.01.025)
- Extension of Central Moment Discrepancy (ICLR-17) approach
- 20181212 ICONIP-18 [Domain Adaptation via Identical Distribution Across Models and Tasks](https://link.springer.com/chapter/10.1007/978-3-030-04167-0_21)
- Transfer from large net to small net
- 从大网络迁移到小网络
- 20181212 AIKP [Deep Domain Adaptation](https://link.springer.com/chapter/10.1007/978-3-030-00734-8_9)
- Low-rank + deep nn for domain adaptation
- Low-rank用于深度迁移
- 20181211 arXiv [Deep Variational Transfer: Transfer Learning through Semi-supervised Deep Generative Models](https://arxiv.org/abs/1812.03123)
- Transfer learning with deep generative model
- 通过深度生成模型进行迁移学习
- 20181121 arXiv [Integrating domain knowledge: using hierarchies to improve deep classifiers](https://arxiv.org/abs/1811.07125)
- Using hierarchies to help deep learning
- 借助于层次关系来帮助深度网络进行学习
- 20181117 arXiv [AdapterNet - learning input transformation for domain adaptation](https://arxiv.org/abs/1805.11601)
- Learning input transformation for domain adaptation
- 对domain adaptation任务学习输入的自适应
- 20181115 AAAI-19 [Exploiting Local Feature Patterns for Unsupervised Domain Adaptation](https://arxiv.org/abs/1811.05042)
- Local domain alignment for domain adaptation
- 局部领域自适应
- 20181115 NIPS-18 [Co-regularized Alignment for Unsupervised Domain Adaptation](https://arxiv.org/abs/1811.05443)
- The idea is the same with the above one...
- 20181113 NIPS-18 [Generalized Zero-Shot Learning with Deep Calibration Network](http://ise.thss.tsinghua.edu.cn/~mlong/doc/deep-calibration-network-nips18.pdf)
- Deep calibration network for zero-shot learning
- 提出deep calibration network进行zero-shot learning
- 20181110 AAAI-19 [Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons](https://arxiv.org/abs/1811.03233)
- Transfer learning for bounding neuron activation boundaries
- 使用迁移学习进行神经元激活边界判定
- 20181108 arXiv [Deep feature transfer between localization and segmentation tasks](https://arxiv.org/abs/1811.02539)
- Feature transfer between localization and segmentation
- 在定位与分割任务间进行迁移
- 20181107 BigData-18 [Transfer learning for time series classification](https://arxiv.org/abs/1811.01533)
- First work on deep transfer learning for time series classification
- 第一个将深度迁移学习用于时间序列分类
- 20181106 PRCV-18 [Deep Local Descriptors with Domain Adaptation](https://link.springer.com/chapter/10.1007/978-3-030-03335-4_30)
- Adding MMD layers to conv and fc layers
- 在卷积和全连接层都加入MMD
- 20181106 LNCS-18 [LSTN: Latent Subspace Transfer Network for Unsupervised Domain Adaptation](https://link.springer.com/chapter/10.1007/978-3-030-03335-4_24)
- Combine subspace learning and neural network for DA
- 将子空间表示和深度网络结合起来用于DA
- 20181105 SIGGRAPI-18 [Unsupervised representation learning using convolutional and stacked auto-encoders: a domain and cross-domain feature space analysis](https://arxiv.org/abs/1811.00473)
- Representation learning for cross-domains
- 跨领域的特征学习
- 20181105 arXiv [Progressive Memory Banks for Incremental Domain Adaptation](https://arxiv.org/abs/1811.00239)
- Progressive memory bank in RNN for incremental DA
- 针对增量的domain adaptation,进行记忆单元的RNN学习
- 20180901 arXiv [Joint Domain Alignment and Discriminative Feature Learning for Unsupervised Deep Domain Adaptation](https://arxiv.org/abs/1808.09347)
- deep domain adaptation + intra-class / inter-class distance
- 深度domain adaptation再加上类内类间距离学习
- 20180819 arXiv [Conceptual Domain Adaptation Using Deep Learning](https://arxiv.org/abs/1808.05355)
- A search framework for deep transfer learning
- 提出一个可以搜索的framework进行迁移学习
- 20180731 ECCV-18 [DeepJDOT: Deep Joint Distribution Optimal Transport for Unsupervised Domain Adaptation](https://arxiv.org/abs/1803.10081)
- Deep + Joint distribution adaptation + optimal transport
- 深度 + 联合分布适配 + optimal transport
- 20180731 ICLR-18 [Few Shot Learning with Simplex](https://arxiv.org/abs/1807.10726)
- Represent deep learning using the simplex
- 用单纯性表征深度学习
- 20180724 AIAI-18 [Improving Deep Models of Person Re-identification for Cross-Dataset Usage](https://arxiv.org/abs/1807.08526)
- apply deep models to cross-dataset RE-ID
- 将深度迁移学习应用于跨数据集的Re-ID
- 20180724 ECCV-18 [Zero-Shot Deep Domain Adaptation](https://arxiv.org/abs/1707.01922)
- Perform zero-shot domain adaptation when there is no target domain data available
- 当目标领域的数据不可用时如何进行domain adaptation :
- 20180724 ICCSE-18 [Deep Transfer Learning for Cross-domain Activity Recognition](https://arxiv.org/abs/1807.07963)
- Provide source domain selection and activity recognition for cross-domain activity recognition
- 提出了跨领域行为识别中的深度方法模型,以及相关的领域选择方法
- 20180530 arXiv 用于深度网络的鲁棒性domain adaptation方法:[Robust Unsupervised Domain Adaptation for Neural Networks via Moment Alignment](https://arxiv.org/abs/1711.06114)
- 20180522 arXiv 用CNN进行跨领域的属性学习:[Cross-domain attribute representation based on convolutional neural network](https://arxiv.org/abs/1805.07295)
- 20180428 CVPR-18 相互协同学习:[Deep Mutual Learning](https://github.com/YingZhangDUT/Deep-Mutual-Learning)
- 20180428 ICLR-18 自集成学习用于domain adaptation:[Self-ensembling for visual domain adaptation](https://github.com/Britefury/self-ensemble-visual-domain-adapt)
- 20180428 IJCAI-18 将knowledge distilation用于transfer learning,然后进行视频分类:[Better and Faster: Knowledge Transfer from Multiple Self-supervised Learning Tasks via Graph Distillation for Video Classification](https://arxiv.org/abs/1804.10069)
- 20180426 arXiv 深度学习中的参数如何进行迁移?(杨强团队):[Parameter Transfer Unit for Deep Neural Networks](https://arxiv.org/abs/1804.08613)
- 20180425 CVPR-18(oral) 对不同的视觉任务进行建模,从而可以进行深层次的transfer:[Taskonomy: Disentangling Task Transfer Learning](https://arxiv.org/abs/1804.08328)
- 20180410 ICLR-17 第一篇用可变RNN进行多维时间序列迁移的文章:[Variational Recurrent Adversarial Deep Domain Adaptation](https://openreview.net/forum?id=rk9eAFcxg¬eId=SJN7BGyPl)
- 20180403 arXiv 本地和云端CNN迁移融合的图片分类:[Hierarchical Transfer Convolutional Neural Networks for Image Classification](https://arxiv.org/abs/1804.00021)
- 20180402 CVPR-18 渐进式domain adaptation:[Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation](https://arxiv.org/abs/1803.11365)
- 20180329 arXiv 基于attention机制的多任务学习:[End-to-End Multi-Task Learning with Attention](https://arxiv.org/abs/1803.10704)
- 20180326 arXiv 将迁移学习用于Faster R-CNN对象识别中:[Domain Adaptive Faster R-CNN for Object Detection in the Wild](https://arxiv.org/abs/1803.03243)
- 20180326 Pattern Recognition-17 多标签迁移学习方法应用于脸部属性分类:[Multi-label Learning Based Deep Transfer Neural Network for Facial Attribute Classification](https://www.sciencedirect.com/science/article/pii/S0031320318301080)
- 20180326 类似于ResNet的思想,在传统layer的ReLU之前加一个additive layer进行domain adaptation,思想简洁,效果非常好:[Layer-wise domain correction for unsupervised domain adaptation](https://link.springer.com/article/10.1631/FITEE.1700774)
- 20180326 Pattern Recognition-17 基于Batch normalization提出了AdaBN,很简单:[Adaptive Batch Normalization for practical domain adaptation](http://ieeexplore.ieee.org/abstract/document/8168121/)
- 20180309 arXiv 利用已有网络的先验知识来加速目标网络的训练:[Transfer Automatic Machine Learning](https://arxiv.org/abs/1803.02780)
- 2018 ICLR-18 最小熵领域对齐方法 [Minimal-Entropy Correlation Alignment for Unsupervised Deep Domain Adaptation](https://openreview.net/forum?id=rJWechg0Z) [code](https://github.com/pmorerio/minimal-entropy-correlation-alignment/tree/master/svhn2mnist)
- ICLR-17 [Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning](https://openreview.net/pdf?id=SkB-_mcel)
- ICCV-17 [AutoDIAL: Automatic DomaIn Alignment Layers](https://arxiv.org/pdf/1704.08082.pdf)
- ICCV-17 [CCSA: Unified Deep Supervised Domain Adaptation and Generalization](http://vision.csee.wvu.edu/~motiian/papers/CCSA.pdf)
- ICML-17 [JAN: Deep Transfer Learning with Joint Adaptation Networks](http://ise.thss.tsinghua.edu.cn/~mlong/doc/joint-adaptation-networks-icml17.pdf)
- 2017 Google: [Learning Transferable Architectures for Scalable Image Recognition](https://arxiv.org/abs/1707.07012)
- NIPS-16 [RTN: Unsupervised Domain Adaptation with Residual Transfer Networks](http://ise.thss.tsinghua.edu.cn/~mlong/doc/residual-transfer-network-nips16.pdf)
- CoRR abs/1603.04779 (2016) [AdaBN: Revisiting batch normalization for practical domain adaptation](https://arxiv.org/pdf/1603.04779.pdf)
- JMLR-16 [DANN: Domain-adversarial training of neural networks](http://www.jmlr.org/papers/volume17/15-239/15-239.pdf)
- 20171226 NIPS 2016 把传统工作搬到深度网络中的范例:不是只学习domain之间的共同feature,还学习每个domain specific的feature。这篇文章写得非常清楚,通俗易懂! [Domain Separation Networks](http://papers.nips.cc/paper/6254-domain-separation-networks) | [代码](https://github.com/tensorflow/models/tree/master/research/domain_adaptation)
- 20171222 ICCV 2017 对于target中只有很少量的标记数据,用深度网络结合孪生网络的思想进行泛化:[Unified Deep Supervised Domain Adaptation and Generalization](http://openaccess.thecvf.com/content_ICCV_2017/papers/Motiian_Unified_Deep_Supervised_ICCV_2017_paper.pdf) | [代码和数据](https://github.com/samotiian/CCSA)
- 20171126 NIPS-17 [Label Efficient Learning of Transferable Representations acrosss Domains and Tasks](http://papers.nips.cc/paper/6621-label-efficient-learning-of-transferable-representations-acrosss-domains-and-tasks)
- 李飞飞小组发在NIPS 2017的文章。针对不同的domain、不同的feature、不同的label space,统一学习一个深度网络进行表征。
- 201711 一个很好的深度学习+迁移学习的实践教程,有代码有数据,可以直接上手:[基于深度学习和迁移学习的识花实践](https://cosx.org/2017/10/transfer-learning/)
- ECCV-16 [Deep CORAL: Correlation Alignment for Deep Domain Adaptation](https://arxiv.org/abs/1607.01719.pdf)
- ECCV-16 [DRCN: Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation](https://arxiv.org/abs/1607.03516.pdf)
- ICML-15 [DAN: Learning Transferable Features with Deep Adaptation Networks](http://ise.thss.tsinghua.edu.cn/~mlong/doc/deep-adaptation-networks-icml15.pdf)
- ICML-15 [GRL: Unsupervised Domain Adaptation by Backpropagation](http://sites.skoltech.ru/compvision/projects/grl/files/paper.pdf)
- ICCV-15 [Simultaneous Deep Transfer Across Domains and Tasks](https://people.eecs.berkeley.edu/~jhoffman/papers/Tzeng_ICCV2015.pdf)
- NIPS-14 [How transferable are features in deep neural networks?](http://yosinski.com/media/papers/Yosinski__2014__NIPS__How_Transferable_with_Supp.pdf)
- CoRR abs/1412.3474 (2014) [Deep Domain Confusion(DDC): Maximizing for Domain Invariance](http://www.arxiv.org/pdf/1412.3474.pdf)
- [深度联合适配网络](http://proceedings.mlr.press/v70/long17a.html)(Joint Adaptation Network, JAN)
- Deep Transfer Learning with Joint Adaptation Networks
- 延续了之前的DAN工作,这次考虑联合适配
- 20191214 arXiv [Learning Domain Adaptive Features with Unlabeled Domain Bridges](https://arxiv.org/abs/1912.05004)
- Learning domain adaptive features with unlabeled CycleGAN
- 20191214 AAAI-20 [Adversarial Domain Adaptation with Domain Mixup](https://arxiv.org/abs/1912.01805)
- Domain adaptation with data mixup
- 20190916 arXiv [Compound Domain Adaptation in an Open World](https://arxiv.org/abs/1909.03403)
- Domain adaptation using the target domain knowledge
- 使用目标域的知识来进行domain adaptation
- 20101008 ICCV-19 [Enhancing Adversarial Example Transferability with an Intermediate Level Attack](https://arxiv.org/abs/1907.10823)
- Enhancing adversarial examples transerability
- 增强对抗样本的可迁移性
- 20190408 arXiv [DeceptionNet: Network-Driven Domain Randomization](https://arxiv.org/abs/1904.02750)
- Using only source data for domain randomization
- 仅利用源域数据进行domain randomization
- 20190220 arXiv [Unsupervised Domain Adaptation using Deep Networks with Cross-Grafted Stacks](https://arxiv.org/abs/1902.06328)
- Domain adaptation using deep learning with cross-grafted stacks
- 用跨领域嫁接栈进行domain adaptation
- 20181217 arXiv [DLOW: Domain Flow for Adaptation and Generalization](https://arxiv.org/abs/1812.05418)
- Domain flow for adaptation and generalization
- 域流方法应用于领域自适应和扩展
- 20181212 arXiv [Learning Transferable Adversarial Examples via Ghost Networks](https://arxiv.org/abs/1812.03413)
- Use ghost networks to learn transferrable adversarial examples
- 使用ghost网络来学习可迁移的对抗样本
- 20181205 arXiv [Unsupervised Domain Adaptation using Generative Models and Self-ensembling](https://arxiv.org/abs/1812.00479)
- UDA using CycleGAN
- 基于CycleGAN的domain adaptation
- 20181205 arXiv [VADRA: Visual Adversarial Domain Randomization and Augmentation](https://arxiv.org/abs/1812.00491)
- Domain randomization and augmentation
- Domain randomization和增强
- 20181128 arXiv [Geometry-Consistent Generative Adversarial Networks for One-Sided Unsupervised Domain Mapping](https://arxiv.org/abs/1809.05852)
- CycleGAN for domain adaptation
- 20181127 arXiv [Distorting Neural Representations to Generate Highly Transferable Adversarial Examples](https://arxiv.org/abs/1811.09020)
- Generate transferrable examples to fool networks
- 生成一些可迁移的对抗样本来迷惑神经网络,在各个网络上都表现好
- 20181123 arXiv [Progressive Feature Alignment for Unsupervised Domain Adaptation](https://arxiv.org/abs/1811.08585)
- Progressively selecting confident pseudo labeled samples for transfer
- 渐进式选择置信度高的伪标记进行迁移
- 20181113 NIPS-18 [Conditional Adversarial Domain Adaptation](http://ise.thss.tsinghua.edu.cn/~mlong/doc/conditional-adversarial-domain-adaptation-nips18.pdf)
- Using conditional GAN for domain adaptation
- 用conditional GAN进行domain adaptation
- 20181107 NIPS-18 [Invariant Representations without Adversarial Training](https://arxiv.org/abs/1805.09458)
- Get invariant representations without adversarial training
- 不进行对抗训练获得不变特征表达
- 20181105 arXiv [Efficient Multi-Domain Dictionary Learning with GANs](https://arxiv.org/abs/1811.00274)
- Dictionary learning for multi-domains using GAN
- 用GAN进行多个domain的字典学习
- 20181012 arXiv [Domain Confusion with Self Ensembling for Unsupervised Adaptation](https://arxiv.org/abs/1810.04472)
- Domain confusion and self-ensembling for DA
- 用于Domain adaptation的confusion和self-ensembling方法
- 20180912 arXiv [Improving Adversarial Discriminative Domain Adaptation](https://arxiv.org/abs/1809.03625)
- Improve ADDA using source domain labels
- 提高ADDA方法的精度,使用source domain的label
- 20180731 ECCV-18 [Dist-GAN: An Improved GAN using Distance Constraints](https://arxiv.org/abs/1803.08887)
- Embed an autoencoder in GAN to improve its stability in training and propose two distances
- 将autoencoder集成到GAN中,提出相应的两种距离进行度量,提高了GAN的稳定性
- 20180724 ECCV-18 [Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks](https://arxiv.org/abs/1807.08536)
- Using stacked CycleGAN to perform image-to-image translation
- 用stacked cycleGAN进行image-to-image的翻译
- 20180628 ICML-18 Pixel-level和feature-level的domain adaptation:[CyCADA: Cycle-Consistent Adversarial Domain Adaptation](https://arxiv.org/abs/1711.03213)
- 20180619 CVPR-18 将optimal transport加入adversarial中进行domain adaptation:[Re-weighted Adversarial Adaptation Network for Unsupervised Domain Adaptation](http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/1224.pdf)
- 20180616 CVPR-18 用GAN进行domain adaptation:[Generate To Adapt: Aligning Domains using Generative Adversarial Networks](https://arxiv.org/abs/1704.01705)
- 20180612 ICML-18 利用多个数据集辅助,从而提高目标领域的学习能力:[RadialGAN: Leveraging multiple datasets to improve target-specific predictive models using Generative Adversarial Networks](https://arxiv.org/abs/1802.06403)
- 20180612 ICML-18 利用GAN进行多个domain的联合分布优化:[JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets](https://arxiv.org/abs/1806.02978)
- 20180605 arXiv [NAM: Non-Adversarial Unsupervised Domain Mapping](https://arxiv.org/abs/1806.00804)
- 20180508 arXiv 利用GAN,从有限数据中生成另一个domain的数据:[Transferring GANs: generating images from limited data](https://arxiv.org/abs/1805.01677)
- 20180501 arXiv Open set domain adaptation的对抗网络版本:[Open Set Domain Adaptation by Backpropagation](https://arxiv.org/abs/1804.10427)
- 20180427 arXiv 提出了adversarial residual的概念,进行深度对抗迁移:[Unsupervised Domain Adaptation with Adversarial Residual Transform Networks](https://arxiv.org/abs/1804.09578)
- 20180424 CVPR-18 用GAN和迁移学习进行图像增强:[Adversarial Feature Augmentation for Unsupervised Domain Adaptation](https://arxiv.org/pdf/1711.08561.pdf)
- 20180413 arXiv 一种思想非常简单的深度迁移方法,仅考虑进行domain之间的类别概率矫正就能取得非常好的效果:[Simple Domain Adaptation with Class Prediction Uncertainty Alignment](https://arxiv.org/abs/1804.04448)
- 20180413 arXiv Mingming Gong提出的用因果生成网络进行深度迁移:[Causal Generative Domain Adaptation Networks](https://arxiv.org/abs/1804.04333)
- 20180410 CVPR-18(oral) 用两个分类器进行对抗迁移:[Maximum Classifier Discrepancy for Unsupervised Domain Adaptation](https://arxiv.org/abs/1712.02560) [代码](https://github.com/mil-tokyo/MCD_DA)
- 20180403 CVPR-18 将样本权重应用于对抗partial transfer中:[Importance Weighted Adversarial Nets for Partial Domain Adaptation](https://arxiv.org/abs/1803.09210
- 20180326 MLSP-17 把domain separation network和对抗结合起来,提出了一个对抗网络进行迁移学习:[Adversarial domain separation and adaptation](http://ieeexplore.ieee.org/abstract/document/8168121/)
- 20180326 ICIP-17 类似于domain separation network,加入了对抗判别训练,同时优化分类、判别、相似度三个loss:[Semi-supervised domain adaptation via convolutional neural network](http://ieeexplore.ieee.org/abstract/document/8296801/)
- 20180116 ICLR-18 用对偶的形式替代对抗训练中原始问题的表达,从而进行分布对齐 [Stable Distribution Alignment using the Dual of the Adversarial Distance](https://arxiv.org/abs/1707.04046)
- 20180111 arXiv 在GAN中用原始问题的对偶问题替换max问题,使得梯度更好收敛 [Stable Distribution Alignment Using the Dual of the Adversarial Distance](https://arxiv.org/abs/1707.04046)
- 20180110 AAAI-18 将Wasserstein GAN用到domain adaptaiton中 [Wasserstein Distance Guided Representation Learning for Domain Adaptation](https://arxiv.org/abs/1707.01217)
- 201707 CVPR-17 [Adversarial Representation Learning For Domain Adaptation](https://arxiv.org/abs/1707.01217)
- AAAI-18 [Multi-Adversarial Domain Adaptation](http://ise.thss.tsinghua.edu.cn/~mlong/doc/multi-adversarial-domain-adaptation-aaai18.pdf)
- ICCV-17 [CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/pdf/1703.10593.pdf)
- ICCV-17 [DualGAN: DualGAN: Unsupervised Dual Learning for Image-to-Image Translation](https://arxiv.org/pdf/1704.02510.pdf)
- CVPR-17 [Asymmetric Tri-training for Unsupervised Domain Adaptation](https://arxiv.org/abs/1702.08400.pdf)
- ICML-17 [DiscoGAN: Learning to Discover Cross-Domain Relations with Generative Adversarial Networks](https://arxiv.org/abs/1703.05192)
- - -
## Domain generalization
### Survey & tutorial
- TKDE-22 [Generalizing to Unseen Domains: A Survey on Domain Generalization](https://arxiv.org/abs/2103.03097) | [知乎文章](https://zhuanlan.zhihu.com/p/354740610) | [微信公众号](https://mp.weixin.qq.com/s/DsoVDYqLB1N7gj9X5UnYqw) | [Code](https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG)
- First survey on domain generalization
- 第一篇对Domain generalization (领域泛化)的综述
- Federated Domain Generalization: A Survey [[arxiv](http://arxiv.org/abs/2306.01334)]
- A survey on federated domain generalization 一篇关于联邦域泛化的综述
- KDD 2023 tutorial: trustworthy machine learning: robustness, generalization, and interpretability [[link](https://mltrust.github.io/)]
- WSDM-23 and IJCAI-22 A tutorial on domain generalization [[link](https://dl.acm.org/doi/10.1145/3539597.3572722)] | [[website](https://dgresearch.github.io/)]
- A tutorial on domain generalization
### Papers
- Why Domain Generalization Fail? A View of Necessity and Sufficiency [[arxiv](https://arxiv.org/abs/2502.10716)]
- Analyze why domain generalization fail from the view of necessity and sufficiency
- Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers [[arxiv](http://arxiv.org/abs/2412.16901)]
- Generate gradients for TTA
- Is Large-Scale Pretraining the Secret to Good Domain Generalization? [[arxiv](https://arxiv.org/abs/2412.02856)]
- Large-scale pre-training vs domain generalization
- Generating Out-Of-Distribution Scenarios Using Language Models [[arxiv](https://arxiv.org/abs/2411.16554)]
- Generating OOD settings using language models
- Unified Domain Generalization and Adaptation for Multi-View 3D Object Detection [[arxiv](https://arxiv.org/abs/2410.22461)]
- Unified domain generalization and adaptation for multi-view 3D object detection
- Test-time adaptation for image compression with distribution regularization [[arxiv](http://arxiv.org/abs/2410.12191)]
- Test-time adaptation for image compression with distribution regularization
- WeatherDG: LLM-assisted Procedural Weather Generation for Domain-Generalized Semantic Segmentation [[arxiv](http://arxiv.org/abs/2410.12075)]
- Weather domain generalization
- Can In-context Learning Really Generalize to Out-of-distribution Tasks? [[arxiv](https://arxiv.org/abs/2410.09695)]
- Can in-context learning generalize to OOD tasks?
- Domain-Conditioned Transformer for Fully Test-time Adaptation [[arxiv](https://arxiv.org/abs/2410.10442)]
- Fully test-tim adaptation with domain-conditioned transformer
- AHA: Human-Assisted Out-of-Distribution Generalization and Detection [[arxiv](https://arxiv.org/abs/2410.08000)]
- Human-assisted OOD generalization and detection
- DICS: Find Domain-Invariant and Class-Specific Features for Out-of-Distribution Generalization [[arxiv](https://arxiv.org/abs/2409.08557)]
- Domain-invariant and class-specific features for OOD generalization
- Dual-Path Adversarial Lifting for Domain Shift Correction in Online Test-time Adaptation [[arxiv](https://arxiv.org/abs/2408.13983)]
- Online test-time adaptation using dual-path adversarial lifting
- Domain penalisation for improved Out-of-Distribution Generalisation [[arxiv](https://arxiv.org/abs/2408.01746)]
- OOD using domain penalization
- Weighted Risk Invariance: Domain Generalization under Invariant Feature Shift [[arxiv](http://arxiv.org/abs/2407.18428)]
- Domain generalization under invariant feature shift
- Reducing Spurious Correlation for Federated Domain Generalization [[arxiv](https://arxiv.org/abs/2407.19174)]
- Federated domain generalization by reducing spurious correlation
- DGMamba: Domain Generalization via Generalized State Space Model [[arXiv](https://arxiv.org/abs/2404.07794)]
- Domain generalization using mamba 用Mamba结构进行DG
- ICASSP'24 Learning Inference-Time Drift Sensor-Actuator for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447537?casa_token=6xrw2hE7cVEAAAAA:9i_ITqbfyLTzQYjdp4Oi16ziD8uheMMZJHRn4gHmzl9nN_j2c5u8MBxUtYYdzlj1Vn4l8F5OJnrw3BY)]
- Inference-time drift actuator for OOD generalization
- ICASSP'24 SBM: Smoothness-Based Minimization for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446613?casa_token=kO10uC18NMQAAAAA:6WJvMr57dSMyORMAnBgFGXi01aE_AmIAA6CQINztT7pHG2u8RmojDxMdV09UO6O9IfFsVEJDrYl1uiU)]
- Smoothness-based minimization for OOD generalization
- ICASSP'24 G2G: Generalized Learning by Cross-Domain Knowledge Transfer for Federated Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447043?casa_token=ihJ_LaxqnfUAAAAA:8Petax0UdQ9bvJLrRbFrujWcVjDzIckhYLDvIk-rUZxo-S7pa6xgbGBxkLWjs8c8H1jR4E8Rop8e7cc)]
- Federated domain generalization
- ICASSP'24 Single-Source Domain Generalization in Fundus Image Segmentation Via Moderating and Interpolating Input Space Augmentation [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447741?casa_token=t0FGpPfYxeoAAAAA:yyZ1zKhXstoaxNOtP6zKBj1ArLF8JZ7gGQOtR-k6DAHCO9SWTIOwLG5TF71BrcenWvO002MYku-wtQI)]
- Single-source DG in fundus image segmentation
- ICASSP'24 Style Factorization: Explore Diverse Style Variation for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447540?casa_token=inLqNDEGEjQAAAAA:7jNUOViyS9PIn-BwIV0LJ-5oCzmM7BXpMLfyLosedaxmxZ-_c_2sA615GlCgrlwaspjdVKa4eogm6Z4)]
- Style variation for domain generalization
- ICASSP'24 SPDG-Net: Semantics Preserving Domain Augmentation through Style Interpolation for Multi-Source Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447210?casa_token=NSBeXUg0AdUAAAAA:4rrMR38UcDN2YRzD9Fvm42gT3dyEX5lO0arFkmVIu3VwQLT9UFLAmU3a5ZOfxtr812_Fic1SCcw9mr0)]
- Domain augmentation for multi-source DG
- ICASSP'24 Domaindiff: Boost out-of-Distribution Generalization with Synthetic Data [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446788?casa_token=Rh3MGM6szOQAAAAA:0GRegU3dIidLVvIYtJb97m2ZDCl0wwKVTmTZH7XTE0fzEBmRuwJHSn_T1U6NgwSYHFPKlWHox_BO4Eg)]
- Using synthetic data for OOD generalization
- ICASSP'24 Multi-Level Augmentation Consistency Learning and Sample Selection for Semi-Supervised Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446462?casa_token=vfAJ1GINr0AAAAAA:YS4NVt-kR8-sJqhfo6H7d04ZmckxUUpsIYuy2agnB4IpgCnR7xOzyrNv59MZ2lcbVhNvsN6Cl4p_7YI)]
- Multi-level augmentation for semi-supervised domain generalization
- ICASSP'24 MMS: Morphology-Mixup Stylized Data Generation for Single Domain Generalization in Medical Image Segmentation [[IEEE](https://ieeexplore.ieee.org/abstract/document/10448305?casa_token=14-2Vm39RD4AAAAA:Zmzm9KTl3INP2I83T2MLwQXtHUZKwXYfhDOPU9F0Eu9SrznInqGpSBrMYH0ek3eemDKdyL4bBU6EVaY)]
- Morphology-mixup for domain generalization
- On the Benefits of Over-parameterization for Out-of-Distribution Generalization [[arxiv](http://arxiv.org/abs/2403.17592)]
- Over-parameterazation for OOD generalizaiton 分析了过参数化对OOD的影响
- EAGLE: A Domain Generalization Framework for AI-generated Text Detection [[arxiv](https://arxiv.org/abs/2403.15690)]
- Domain generalization for AI content detection 用DG进行AI生成内容检测
- DPStyler: Dynamic PromptStyler for Source-Free Domain Generalization [[arxiv](https://arxiv.org/abs/2403.16697)]
- Dynamic propmtstyler for source-free DG 动态prompt分格化用于source-free DG
- V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions [[arxiv](https://arxiv.org/abs/2403.11371)]
- DG for multi-agent perception 领域泛化用于极端天气
- Bidirectional Multi-Step Domain Generalization for Visible-Infrared Person Re-Identification [[arxiv](https://arxiv.org/abs/2403.10782)]
- Bidirectional multi-step DG for REID 双向领域泛化用于REID
- ICASSP'24 Test-time Distribution Learning Adapter for Cross-modal Visual Reasoning [[arxiv](https://arxiv.org/abs/2403.06059)]
- Test-time distribution learning adapter
- A Study on Domain Generalization for Failure Detection through Human Reactions in HRI [[arxiv](https://arxiv.org/abs/2403.06315)]
- Domain generalization for failure detection through human reactions in HRI
- ICLR'24 Towards Robust Out-of-Distribution Generalization Bounds via Sharpness [[arxiv](https://arxiv.org/abs/2403.06392)]
- Robust OOD generalization bounds
- Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy [[arxiv](https://arxiv.org/abs/2401.12129)]
- OOD detection for ablated learned temperature energy
- ICLR'24 Supervised Knowledge Makes Large Language Models Better In-context Learners [[arxiv](https://arxiv.org/abs/2312.15918)]
- Small models help large language models for better OOD 用小模型帮助大模型进行更好的OOD
- NeurIPS'23 Test-Time Distribution Normalization for Contrastively Learned Visual-language Models [[paper](https://openreview.net/forum?id=VKbEO2eh5w)]
- Test-time distribution normalization for contrastively learned VLM
- NeurIPS'23 A Closer Look at the Robustness of Contrastive Language-Image Pre-Training (CLIP) [[paper](https://openreview.net/forum?id=wMNpMe0vp3)]
- A fine-gained analysis of CLIP robustness
- NeurIPS'23 CODA: Generalizing to Open and Unseen Domains with Compaction and Disambiguation [[arxiv](https://openreview.net/forum?id=Jw0KRTjsGA)]
- Open set domain generalization using extra classes
- CPAL'24 FIXED: Frustratingly Easy Domain Generalization with Mixup [[arxiv](https://arxiv.org/abs/2211.05228)]
- Easy domain generalization with mixup
- SDM'24 Towards Optimization and Model Selection for Domain Generalization: A Mixup-guided Solution [[arxiv](https://arxiv.org/abs/2209.00652)]
- Optimization and model selection for domain generalization
- Leveraging SAM for Single-Source Domain Generalization in Medical Image Segmentation [[arxiv](https://arxiv.org/abs/2401.02076)]
- SAM for single-source domain generalization
- Open Domain Generalization with a Single Network by Regularization Exploiting Pre-trained Features [[arxiv](http://arxiv.org/abs/2312.05141)]
- Open domain generalization with a single network 用单一网络结构进行开放式domain generalizaition
- Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation [[arxiv](http://arxiv.org/abs/2312.04265)]
- Using vision foundation models for domain genealized semantic segmentation 用视觉基础模型进行域泛化语义分割
- On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals [[arxiv](http://arxiv.org/abs/2312.00502)]
- OOD robustness for self-supervised learning for phonocardiogram 心音图信号自监督的OOD鲁棒性
- A2XP: Towards Private Domain Generalization [[arxiv](https://arxiv.org/abs/2311.10339)]
- Private domain generalization 隐私保护的domain generalization
- Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation [[arxiv](http://arxiv.org/abs/2311.05858)]
- Auto-weighting for test-time adaptation 自动权重的TTA
- Domain Generalization by Learning from Privileged Medical Imaging Information [[arxiv](http://arxiv.org/abs/2311.05861)]
- Domain generalizaiton by learning from privileged medical imageing inforamtion
- SSL-DG: Rethinking and Fusing Semi-supervised Learning and Domain Generalization in Medical Image Segmentation [[arxiv](https://arxiv.org/abs/2311.02583)]
- Semi-supervised learning + domain generalization 把半监督和领域泛化结合在一起
- WACV'24 Learning Class and Domain Augmentations for Single-Source Open-Domain Generalization [[arxiv](https://arxiv.org/abs/2311.02599)]
- Class and domain augmentation for single-source open-domain DG 结合类和domain增强做单源DG
- Robust Fine-Tuning of Vision-Language Models for Domain Generalization [[arxiv](https://arxiv.org/abs/2311.02236)]
- Robust fine-tuning for domain generalization 用于领域泛化的鲁棒微调
- NeurIPS 2023 Distilling Out-of-Distribution Robustness from Vision-Language Foundation Models [[arxiv](https://arxiv.org/abs/2311.01441)]
- Distill OOD robustness from vision-language foundational models 从VLM模型中蒸馏出OOD鲁棒性
- UbiComp 2024 Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition [[arxiv](https://arxiv.org/abs/2310.18562)]
- Test-time adaptation for activity recognition 测试时adaptation用于行为识别
- Prompting-based Efficient Temporal Domain Generalization [[arxiv](http://arxiv.org/abs/2310.02473)]
- Prompt based temporal domain generalization 基于prompt的时间域domain generalization
- Domain Generalization with Fourier Transform and Soft Thresholding [[arxiv](http://arxiv.org/abs/2309.09866)]
- Domain generalization with Fourier transform 基于傅里叶变换和软阈值进行domain generalization
- Multi-Scale and Multi-Layer Contrastive Learning for Domain Generalization [[arxiv](http://arxiv.org/abs/2308.14418)]
- Multi-scale and multi-layer contrastive learning for DG 多尺度和多层对比学习用于DG
- Exploring the Transfer Learning Capabilities of CLIP in Domain Generalization for Diabetic Retinopathy [[arxiv](http://arxiv.org/abs/2308.14212)]
- Domain generalization for diabetic retinopathy 用领域泛化进行糖尿病视网膜病
- NormAUG: Normalization-guided Augmentation for Domain Generalization [[arxiv](http://arxiv.org/abs/2307.13492)]
- Normalization augmentation for domain generalization
- Benchmarking Algorithms for Federated Domain Generalization [[arxiv](http://arxiv.org/abs/2307.04942)]
- Benchmark algorthms for federated domain generalization 对联邦域泛化算法进行的benchmark
- DISPEL: Domain Generalization via Domain-Specific Liberating [[arxiv](http://arxiv.org/abs/2307.07181)]
- Domain generalization via domain-specific liberating
- Intra- & Extra-Source Exemplar-Based Style Synthesis for Improved Domain Generalization [[arxiv](https://arxiv.org/abs/2307.00648)]
- Exemplar-based style synthesis for domain generalization 样例格式合成用于DG
- Pruning for Better Domain Generalizability [[arxiv](http://arxiv.org/abs/2306.13237)]
- Using pruning for better domain generalization 使用剪枝操作进行domain generalization
- TMLR'23 Generalizability of Adversarial Robustness Under Distribution Shifts [[openreview](https://openreview.net/forum?id=XNFo3dQiCJ)]
- Evaluate the OOD perormance of adversarial training 评测对抗训练模型的OOD鲁棒性
- Domain Generalization for Domain-Linked Classes [[arxiv](http://arxiv.org/abs/2306.00879)]
- Domain generalization for domain-linked classes
- Selective Mixup Helps with Distribution Shifts, But Not (Only) because of Mixup [[arxiv](https://arxiv.org/abs/2305.16817)]
- Why mixup works for domain generalization? 系统性研究为啥mixup对OOD很work
- Improved Test-Time Adaptation for Domain Generalization [[arxiv](http://arxiv.org/abs/2304.04494)]
- Improved test-time adaptation for domain generalization
- Reweighted Mixup for Subpopulation Shift [[arxiv](http://arxiv.org/abs/2304.04148)]
- Reweighted mixup for subpopulation shift
- Domain Generalization with Adversarial Intensity Attack for Medical Image Segmentation [[arxiv](http://arxiv.org/abs/2304.02720)]
- Domain generalization for medical segmentation 用domain generalization进行医学分割
- CVPR'23 Meta-causal Learning for Single Domain Generalization [[arxiv](http://arxiv.org/abs/2304.03709)]
- Meta-causal learning for domain generalization
- Domain Generalization In Robust Invariant Representation [[arxiv](http://arxiv.org/abs/2304.03431)]
- Domain generalization in robust invariant representation
- Beyond Empirical Risk Minimization: Local Structure Preserving Regularization for Improving Adversarial Robustness [[arxiv](http://arxiv.org/abs/2303.16861)]
- Local structure preserving for adversarial robustness 通过保留局部结构来进行对抗鲁棒性
- TFS-ViT: Token-Level Feature Stylization for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.15698)]
- Token-level feature stylization for domain generalization 用token-level特征变换进行domain generalization
- Are Data-driven Explanations Robust against Out-of-distribution Data? [[arxiv](http://arxiv.org/abs/2303.16390)]
- Data-driven explanations robust? 探索数据驱动的解释是否是OOD鲁棒的
- ERM++: An Improved Baseline for Domain Generalization [[arxiv](http://arxiv.org/abs/2304.01973)]
- Improved ERM for domain generalization 提高的ERM用于domain generalization
- Complementary Domain Adaptation and Generalization for Unsupervised Continual Domain Shift Learning [[arxiv](http://arxiv.org/abs/2303.15833)]
- Continual domain shift learning using adaptation and generalization 使用 adaptation和DG进行持续分布变化的学习
- CVPR'23 TWINS: A Fine-Tuning Framework for Improved Transferability of Adversarial Robustness and Generalization [[arxiv](http://arxiv.org/abs/2303.11135)]
- Improve generalization and adversarial robustness 同时提高鲁棒性和泛化性
- Finding Competence Regions in Domain Generalization [[arxiv](http://arxiv.org/abs/2303.09989)]
- Finding competence regions in domain generalization 在DG中发现能力区域
- CVPR'23 ALOFT: A Lightweight MLP-like Architecture with Dynamic Low-frequency Transform for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.11674)]
- A lightweight module for domain generalization 一个用于DG的轻量级模块
- CVPR'23 Sharpness-Aware Gradient Matching for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.10353)]
- Sharpness-aware gradient matching for DG 利用梯度匹配进行domain generalization
- Domain Generalization via Nuclear Norm Regularization [[arxiv](https://arxiv.org/abs/2303.07527)]
- Domain generalization via nuclear norm regularization 使用核归一化进行domain generalization
- Imbalanced Domain Generalization for Robust Single Cell Classification in Hematological Cytomorphology [[arxiv](https://arxiv.org/abs/2303.07771)]
- Imbalanced domain generalization for single cell classification 不平衡的DG用于单细胞分类
- FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning [[arxiv](https://arxiv.org/abs/2302.13485v1)]
- Fast generalization for federated CLIP 在联邦中进行快速的CLIP训练
- Robust Representation Learning with Self-Distillation for Domain Generalization [[arxiv](http://arxiv.org/abs/2302.06874)]
- Robust representation learning with self-distillation
- ICLR-23 Temporal Coherent Test-Time Optimization for Robust Video Classification [[arxiv](http://arxiv.org/abs/2302.14309)]
- Temporal distribution shift in video classification
- On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective [[arxiv](https://arxiv.org/abs/2302.12095)] | [[code](https://github.com/microsoft/robustlearn)]
- Adversarial and OOD evaluation of ChatGPT 对ChatGPT鲁棒性的评测
- How Reliable is Your Regression Model's Uncertainty Under Real-World Distribution Shifts? [[arxiv](https://arxiv.org/abs/2302.03679)]
- Regression models uncertainty for distribution shift 回归模型对于分布漂移的不确定性
- ICLR'23 SoftMatch: Addressing the Quantity-Quality Tradeoff in Semi-supervised Learning [[arxiv](https://arxiv.org/abs/2301.10921)]
- Semi-supervised learning algorithm 解决标签质量问题的半监督学习方法
- Empirical Study on Optimizer Selection for Out-of-Distribution Generalization [[arxiv](http://arxiv.org/abs/2211.08583)]
- Opimizer selection for OOD generalization OOD泛化中的学习器选择
- ICML'22 Understanding the failure modes of out-of-distribution generalization [[arxiv](https://openreview.net/forum?id=fSTD6NFIW_b)]
- Understand the failure modes of OOD generalization 探索OOD泛化中的失败现象
- ICLR'23 Out-of-distribution Representation Learning for Time Series Classification [[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 时间序列分类的OOD算法
- CLIP the Gap: A Single Domain Generalization Approach for Object Detection [[arxiv](https://arxiv.org/abs/2301.05499)]
- Using CLIP for domain generalization object detection 使用CLIP进行域泛化的目标检测
- TMLR'22 A Unified Survey on Anomaly, Novelty, Open-Set, and Out of-Distribution Detection: Solutions and Future Challenges [[openreview](https://openreview.net/forum?id=aRtjVZvbpK)]
- A recent survey on OOD/anomaly detection 一篇最新的关于OOD/anomaly detection的综述
- NeurIPS'18 A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks [[paper](https://proceedings.neurips.cc/paper/2018/hash/abdeb6f575ac5c6676b747bca8d09cc2-Abstract.html)]
- Using class-conditional distribution for OOD detection 使用类条件概率进行OOD检测
- ICLR'22 Discrete Representations Strengthen Vision Transformer Robustness [[arxiv](http://arxiv.org/abs/2111.10493)]
- Embed discrete representation for OOD generalization 在ViT中加入离散表征增强OOD性能
- Learning to Learn Domain-invariant Parameters for Domain Generalization [[arxiv](Learning to Learn Domain-invariant Parameters for Domain Generalization)]
- Learning to learn domain-invariant parameters for DG 元学习进行domain generalization
- HMOE: Hypernetwork-based Mixture of Experts for Domain Generalization [[arxiv](https://arxiv.org/abs/2211.08253)]
- Hypernetwork-based ensembling for domain generalization 超网络构成的集成学习用于domain generalization
- The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning [[arxiv](https://arxiv.org/abs/2106.15831)]
- OOD using fine-tuning 系统总结了基于fine-tuning进行OOD的一些结果
- GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective [[arxiv](https://arxiv.org/abs/2211.08073)]
- OOD for natural language processing evaluation 提出GLUE-X用于OOD在NLP数据上的评估
- CVPR'22 Delving Deep Into the Generalization of Vision Transformers Under Distribution Shifts [[arxiv](https://openaccess.thecvf.com/content/CVPR2022/html/Zhang_Delving_Deep_Into_the_Generalization_of_Vision_Transformers_Under_Distribution_CVPR_2022_paper.html)]
- Vision transformers generalization under distribution shifts 评估ViT的分布漂移
- NeurIPS'22 Models Out of Line: A Fourier Lens on Distribution Shift Robustness [[arxiv](https://openreview.net/forum?id=YZ-N-sejjwO)]
- A fourier lens on distribution shift robustness 通过傅里叶视角来看分布漂移的鲁棒性
- Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts [[arxiv](https://arxiv.org/abs/2211.04393)]
- Normalization perturbation for domain generalization 通过归一化扰动来进行domain generalization
- FIXED: Frustraitingly easy domain generalization using Mixup [[arxiv](https://arxiv.org/pdf/2211.05228.pdf)]
- 使用Mixup进行domain generalization
- Learning to Learn Domain-invariant Parameters for Domain Generalization [[arxiv](https://arxiv.org/abs/2211.04582)]
- Learning to learn domain-invariant parameters for domain generalization
- NeurIPS'22 LOG: Active Model Adaptation for Label-Efficient OOD Generalization [[openreview](https://openreview.net/forum?id=VdQWVdT_8v)]
- Model adaptation for label-efficient OOD generalization
- NeurIPS'22 Domain Generalization without Excess Empirical Risk [[openreview](https://openreview.net/forum?id=pluyPFTiTeJ)]
- Domain generalization without excess empirical risk
- NeurIPS'22 FedSR: A Simple and Effective Domain Generalization Method for Federated Learning [[openreview](https://openreview.net/forum?id=mrt90D00aQX)]
- FedSR for federated learning domain generalization 用于联邦学习的domain generalization
- NeurIPS'22 Probable Domain Generalization via Quantile Risk Minimization [[openreview](https://openreview.net/forum?id=6FkSHynJr1)]
- Domain generalization with quantile risk minimization 用quantile风险最小化的domain generalization
- NeurIPS'22 Your Out-of-Distribution Detection Method is Not Robust! [[openreview](https://openreview.net/forum?id=YUEP3ZmkL1)]
- OOD models are not robust 分布外泛化模型不够鲁棒
- PhDthesis Generalizing in the Real World with Representation Learning [[arxiv](http://arxiv.org/abs/2210.09925)]
- A phd thesis about generalization in real world 一篇关于现实世界如何做Generalization的博士论文
- The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning [[arxiv](https://openreview.net/forum?id=Qs3EfpieOh)]
- Evolution of OOD robustness by fine-tuning
- Out-of-Distribution Generalization in Algorithmic Reasoning Through Curriculum Learning [[arxiv](https://arxiv.org/abs/2210.03275)]
- OOD in algorithmic reasoning 算法reasoning过程中的OOD
- Towards Out-of-Distribution Adversarial Robustness [[arxiv](https://arxiv.org/abs/2210.03150)]
- OOD adversarial robustness OOD对抗鲁棒性
- TripleE: Easy Domain Generalization via Episodic Replay [[arxiv](https://arxiv.org/pdf/2210.01807.pdf)]
- Easy domain generalization by episodic replay
- Deep Spatial Domain Generalization [[arxiv](https://web7.arxiv.org/pdf/2210.00729.pdf)]
- Deep spatial domain generalization
- Assaying Out-Of-Distribution Generalization in Transfer Learning [[arXiv](http://arxiv.org/abs/2207.09239)]
- A lot of experiments to show OOD performance
- ICML-21 Accuracy on the Line: on the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization [[arxiv](https://proceedings.mlr.press/v139/miller21b.html)]
- Strong correlation between ID and OOD
- Generalized representations learning for time series classification[[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 域泛化用于时间序列分类
- Language-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification [[arxiv](https://arxiv.org/pdf/2209.02700.pdf)]
- Domain generalization for cross-scene hyperspectral image classification 域泛化用于高光谱图像分类
- Improving Robustness to Out-of-Distribution Data by Frequency-based Augmentation [arxiv](https://arxiv.org/abs/2209.02369)
- OOD by frequency-based augmentation 通过基于频率的数据增强进行OOD
- Domain Generalization for Prostate Segmentation in Transrectal Ultrasound Images: A Multi-center Study [arxiv](https://arxiv.org/abs/2209.02126)
- Domain generalizationfor prostate segmentation 领域泛化用于前列腺分割
- Domain Adaptation from Scratch [arxiv](https://arxiv.org/abs/2209.00830)
- Domain adaptation from scratch
- Towards Optimization and Model Selection for Domain Generalization: A Mixup-guided Solution [arxiv](https://arxiv.org/abs/2209.00652)
- Model selection for domain generalization 域泛化中的模型选择问题
- [Equivariant Disentangled Transformation for Domain Generalization under Combination Shift](https://arxiv.org/abs/2208.02011)
- Equivariant disentangled transformation for domain generalization 新的建模domain generalization的思路
- ECCV-22 workshop [Domain-Specific Risk Minimization](https://arxiv.org/abs/2208.08661)
- Domain-specific risk minization for OOD 领域特异性风险最小化用于域泛化
- IJCAI-22 [Domain Generalization through the Lens of Angular Invariance](https://www.ijcai.org/proceedings/2022/0139.pdf)
- Using angular invariance for domain generalization 使用角度不变性进行domain generalization
- [Adaptive Domain Generalization via Online Disagreement Minimization](https://arxiv.org/abs/2208.01996)
- Online domain generalization via disagreement minimization 在线DG
- [Self-Distilled Vision Transformer for Domain Generalization](http://arxiv.org/abs/2207.12392)
- Vision transformer for domain generalization 用ViT做domain generalization
- TMLR-22 [Domain-invariant Feature Exploration for Domain Generalization](https://arxiv.org/abs/2207.12020)
- Exploring domain-invariant feature for domain generalization 探索领域不变特征在领域泛化中的应用
- TIST-22 [Domain Generalization for Activity Recognition via Adaptive Feature Fusion](https://arxiv.org/abs/2207.11221)
- Domain generalization for activity recognition 领域泛化用于行为识别
- [The Importance of Background Information for Out of Distribution Generalization](https://arxiv.org/abs/2206.08794)
- Background information for OOD generalization 背景信息对于OOD泛化的重要性
- [Causal Balancing for Domain Generalization](https://arxiv.org/abs/2206.05263)
- Causal balancing for domain generalization 因果平衡用于领域泛化
- [Temporal Domain Generalization with Drift-Aware Dynamic Neural Network](https://arxiv.org/abs/2205.10664)
- Temporal domain generalization with drift-aware dynamic neural network 时序域泛化
- [Multiple Domain Causal Networks](https://arxiv.org/abs/2205.06791)
- Mlutiple domain causal networks 多领域的因果网络
- IJCAI-21 [Test-time Fourier Style Calibration for Domain Generalization](https://arxiv.org/abs/2205.06427)
- Test-time calibration for domain generalization 用傅立叶变化进行域泛化的测试时矫正
- [Out-Of-Distribution Detection In Unsupervised Continual Learning](https://arxiv.org/abs/2204.05462)
- OOD detection in unsupervised continual learning 无监督持续学习中进行OOD检测
- ICLR-22 [Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution](https://openreview.net/forum?id=UYneFzXSJWh)
- Fin-tuning and linear probing for ood generalization
- 先linear probing最后一层再finetune对OOD任务最好
- ICLR-22 [Asymmetry Learning for Counterfactually-invariant Classification in OOD Tasks](https://openreview.net/forum?id=avgclFZ221l)
- Asymmetry learning for OOD tasks
- 非对称学习用于OOD任务
- [Improving Generalization in Federated Learning by Seeking Flat Minima](https://arxiv.org/abs/2203.11834)
- Seeking flat minima for domain generalization in federated learning
- 通过寻找平坦值进行联邦学习领域泛化
- [Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection](https://arxiv.org/abs/2203.11432)
- Channel masking for domain generalization object detection
- 通过一个gate控制channel masking进行object detection DG
- [A Broad Study of Pre-training for Domain Generalization and Adaptation](https://arxiv.org/abs/2203.11819)
- A broad study of pre-training models for DA and DG
- 大量的实验进行DA和DG
- [Learning Semantic Segmentation from Multiple Datasets with Label Shifts](https://arxiv.org/abs/2202.14030)
- Learning semantic segmentation from many datasets with label shifts
- 在有标签漂移的情况下从多个数据集中学习语义分割
- PAKDD-22 [Layer Adaptive Deep Neural Networks for Out-of-distribution Detection](https://arxiv.org/abs/2203.00192)
- Layer adaptive network for OOD detection
- 层自适应的网络进行OOD检测
- ICLR-22 oral [A Fine-Grained Analysis on Distribution Shift](https://openreview.net/forum?id=Dl4LetuLdyK)
- Extensive experiments on distribution shift for OOD
- 大量的实验进行OOD验证
- ICLR-22 oral [Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution](https://openreview.net/forum?id=UYneFzXSJWh)
- Fine-tuning with linear probing for OOD
- 微调加上linear probing用于OOD
- ICLR-22 [Uncertainty Modeling for Out-of-Distribution Generalization](https://arxiv.org/abs/2202.03958)
- Uncertainty modeling for OOD generalization
- 用于分布外泛化的不确定性建模
- TKDE-22 [Adaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection](https://arxiv.org/abs/2201.00464)
- Adaptiev memory network for anomaly detection
- 自适应的记忆网络用于异常检测
- ICIP-22 [Meta-Learned Feature Critics for Domain Generalized Semantic Segmentation](https://arxiv.org/abs/2112.13538)
- Meta-learning for domain generalization
- 元学习用于domain generalization
- ICIP-22 [Few-Shot Classification in Unseen Domains by Episodic Meta-Learning Across Visual Domains](https://arxiv.org/abs/2112.13539)
- Few-shot generalization using meta-learning
- 用元学习进行小样本的泛化
- [More is Better: A Novel Multi-view Framework for Domain Generalization](https://arxiv.org/abs/2112.12329)
- Multi-view learning for domain generalization
- 使用多视图学习来进行domain generalization
- [Unsupervised Domain Generalization by Learning a Bridge Across Domains](https://arxiv.org/abs/2112.02300)
- Unsupervised domain generalization
- 无监督的domain generalization
- [ROBIN : A Benchmark for Robustness to Individual Nuisancesin Real-World Out-of-Distribution Shifts](https://arxiv.org/abs/2111.14341)
- A benchmark for robustness to individual OOD
- 一个OOD的benchmark
- ICML-21 workshop [Towards Principled Disentanglement for Domain Generalization](https://arxiv.org/abs/2111.13839)
- Principled disentanglement for domain generalization
- Principled解耦用于domain generalization
- [Federated Learning with Domain Generalization](https://arxiv.org/abs/2111.10487)
- Federated domain generalization
- 联邦学习+domain generalization
- [Semi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline](https://arxiv.org/abs/2111.10221)
- Semi-supervised domain generalization
- 半监督+domain generalization
- MICCAI-21 [Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning](https://arxiv.org/abs/2111.10827)
- Domain generalization for mammography detection
- 领域泛化用于乳房X射线检查
- WACV-21 [Domain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition](https://arxiv.org/abs/2110.10101)
- Domain generalization by audio-visual alignment
- 通过音频-视频对齐进行domain generalization
- [Dynamically Decoding Source Domain Knowledge For Unseen Domain Generalization](http://arxiv.org/abs/2110.03027)
- Ensemble learning for domain generalization
- 用集成学习进行domain generalization
- [Scale Invariant Domain Generalization Image Recapture Detection](http://arxiv.org/abs/2110.03496)
- Scale invariant domain generalizaiton
- 尺度不变的domain generalization
- ICCV-21 [Shape-Biased Domain Generalization via Shock Graph Embeddings](https://arxiv.org/abs/2109.05671)
- Domain generalization based on shape information
- 基于形状进行domain generalization
- [Domain and Content Adaptive Convolution for Domain Generalization in Medical Image Segmentation](https://arxiv.org/abs/2109.05676)
- Domain generalization for medical image segmentation
- 领域泛化用于医学图像分割
- [Fishr: Invariant Gradient Variances for Out-of-distribution Generalization](https://arxiv.org/abs/2109.02934)
- Invariant gradient variances for OOD generalization
- 不变梯度方差,用于OOD
- [Class-conditioned Domain Generalization via Wasserstein Distributional Robust Optimization](https://arxiv.org/abs/2109.03676)
- Domain generalization with wasserstein DRO
- 使用Wasserstein DRO进行domain generalization
- CIKM-21 [AdaRNN: Adaptive Learning and Forecasting of Time Series](https://arxiv.org/abs/2108.04443) [Code](https://github.com/jindongwang/transferlearning/tree/master/code/deep/adarnn) [知乎文章](https://zhuanlan.zhihu.com/p/398036372) [Video](https://www.bilibili.com/video/BV1Gh411B7rj/)
- A new perspective to using transfer learning for time series analysis
- 一种新的建模时间序列的迁移学习视角
- 20190531 arXiv [Image Alignment in Unseen Domains via Domain Deep Generalization](https://arxiv.org/abs/1905.12028)
- Deep domain generalization for image alignment
- 深度领域泛化用于图像对齐
- 20200821 ECCV-20 [Towards Recognizing Unseen Categories in Unseen Domains](https://arxiv.org/abs/2007.12256)
- Recognizing unseen classes in unseen domains
- 对未知领域识别未知类
- 20200706 ICLR-21 [In Search of Lost Domain Generalization](https://arxiv.org/abs/2007.01434)
- 20201016 [Energy-based Out-of-distribution Detection](https://arxiv.org/abs/2010.03759)
- Energy-based OOD
- 20201222 AAAI-21 [DecAug: Out-of-Distribution Generalization via Decomposed Feature Representation and Semantic Augmentation](http://arxiv.org/abs/2012.09382)
- OOD generalization
- 用特征分解和语义增强做OOD泛化
- 20210106 [Style Normalization and Restitution for Domain Generalization and Adaptation](http://arxiv.org/abs/2101.00588)
- Style normalization and restitution for DA and DG
- 风格归一化用于DA和DG任务
- CVPR-21 [Uncertainty-Guided Model Generalization to Unseen Domains](https://openaccess.thecvf.com/content/CVPR2021/html/Qiao_Uncertainty-Guided_Model_Generalization_to_Unseen_Domains_CVPR_2021_paper.html)
- Uncertainty-guided generalization
- 基于不确定性的domain generalization
- CVPR-21 [Adaptive Methods for Real-World Domain Generalization](https://openaccess.thecvf.com/content/CVPR2021/html/Dubey_Adaptive_Methods_for_Real-World_Domain_Generalization_CVPR_2021_paper.html)
- Adaptive methods for domain generalization
- 动态算法,用于domain generalization
- 20180701 arXiv 做迁移时,只用source数据,不用target数据训练:[Generalizing to Unseen Domains via Adversarial Data Augmentation](https://arxiv.org/abs/1805.12018)
- 201711 ICLR-18 [GENERALIZING ACROSS DOMAINS VIA CROSS-GRADIENT TRAINING](https://openreview.net/pdf?id=r1Dx7fbCW)
- 不同于以往的工作,本文运用贝叶斯网络建模label和domain的依赖关系,抓住training、inference 两个过程,有效引入domain perturbation来实现domain adaptation。
- ICLR-18 [generalizing across domains via cross-gradient training](https://openreview.net/pdf?id=r1Dx7fbCW)
- 20181106 PRCV-18 [Domain Attention Model for Domain Generalization in Object Detection](https://link.springer.com/chapter/10.1007/978-3-030-03341-5_3)
- Adding attention for domain generalization
- 在domain generalization中加入了attention机制
- 20181225 WACV-19 [Multi-component Image Translation for Deep Domain Generalization](https://arxiv.org/abs/1812.08974)
- Using GAN generated images for domain generalization
- 用GAN生成的图像进行domain generalization
- 20180724 arXiv [Domain Generalization via Conditional Invariant Representation](https://arxiv.org/abs/1807.08479)
- Using Conditional Invariant Representation for domain generalization
- 生成条件不变的特征表达,用于domain generalization问题
- 20181212 arXiv [Beyond Domain Adaptation: Unseen Domain Encapsulation via Universal Non-volume Preserving Models](https://arxiv.org/abs/1812.03407)
- Domain generalization method
- 一种针对于unseen domain的学习方法
- 20171210 AAAI-18 [Learning to Generalize: Meta-Learning for Domain Generalization](https://arxiv.org/pdf/1710.03463.pdf)
- 将Meta-Learning与domain generalization结合的文章,可以联系到近期较为流行的few-shot learning进行下一步思考。
- - -
## Source-free domain adaptation
- NeurIPS'23 When Visual Prompt Tuning Meets Source-Free Domain Adaptive Semantic Segmentation [[paper](https://openreview.net/forum?id=ChGGbmTNgE)]
- Source-free domain adaptation using visual prompt tuning
- PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization [[arxiv](https://arxiv.org/abs/2307.15199)]
- Prompt-driven style generation for source-free domain generalization
- Source-Free Collaborative Domain Adaptation via Multi-Perspective Feature Enrichment for Functional MRI Analysis [[arxiv](http://arxiv.org/abs/2308.12495)]
- Source-free domain adaptation for MRI analysis
- ICCV'23 Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation [[arxiv](https://arxiv.org/abs/2308.14023)]
- Domain-specificity for source-free DA 用领域特异性驱动的source-free DA
- Visual Prompt Tuning for Test-time Domain Adaptation [[arxiv](http://arxiv.org/abs/2210.04831)]
- VPT for test-time adaptation 用prompt tuning进行test-time DA
- [Active Source Free Domain Adaptation](https://arxiv.org/abs/2205.10711)
- Active source-free DA 主动学习-无源域DA
- NeurIPS-21 [Model Adaptation: Historical Contrastive Learning for Unsupervised Domain Adaptation without Source Data](http://arxiv.org/abs/2110.03374)
- Source-free domain adaptation using constrastive learning
- 无源域数据的DA,利用对比学习
- 20200706 [Domain Adaptation without Source Data](https://arxiv.org/abs/2007.01524)
- 20200629 ICML-20 [Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2002.08546)
- Source-free adaptation
- 在adaptation过程中不访问source data
- - -
## Multi-source domain adaptation
- [Open-Set Crowdsourcing using Multiple-Source Transfer Learning](https://arxiv.org/abs/2111.04073)
- Open-set crowdsourcing using multiple-source transfer learning
- 使用多源迁移进行开放集的crowdsourcing
- BMVC-21 [Domain Attention Consistency for Multi-Source Domain Adaptation](https://arxiv.org/abs/2111.03911)
- Multi-source domain adaptation using attention consistency
- 用attention一致性进行多源的domain adaptation
- CVPR-21 [Wasserstein Barycenter for Multi-Source Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Montesuma_Wasserstein_Barycenter_for_Multi-Source_Domain_Adaptation_CVPR_2021_paper.html)
- Use Wasserstein Barycenter for multi-source domain adaptation
- 利用Wasserstein Barycenter进行DA
- 20210430 [Graphical Modeling for Multi-Source Domain Adaptation](http://arxiv.org/abs/2104.13057)
- Graphical models for multi-source DA
- 用概率图模型进行多源领域自适应
- 20210430 [Unsupervised Multi-Source Domain Adaptation for Person Re-Identification](http://arxiv.org/abs/2104.12961)
- ReID using multi-source DA
- 用多源领域自适应进行ReID任务
- 20200427 [TriGAN: Image-to-Image Translation for Multi-Source Domain Adaptation](https://arxiv.org/abs/2004.08769)
- A cycle-gan style multi-source DA
- 类似于cyclegan的多源领域适应
- 20190902 AAAI-19 [Aligning Domain-Specific Distribution and Classifier for Cross-Domain Classification from Multiple Sources](https://www.aaai.org/ojs/index.php/AAAI/article/download/4551/4429)
- Multi-source domain adaptation using both features and classifier adaptation
- 利用特征和分类器同时适配进行多源迁移,效果很好
- 20181212 AIKP [Multi-source Transfer Learning](https://link.springer.com/chapter/10.1007/978-3-030-00734-8_8)
- Multi-source transfer
- 20181207 arXiv [Moment Matching for Multi-Source Domain Adaptation](https://arxiv.org/abs/1812.01754)
- Moment matching and propose a new large dataset for domain adaptation
- 提出一种moment matching的网络,并且提出一种新的domain adaptation数据集,很大
- CoRR abs/1711.09020 (2017) [StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation](https://arxiv.org/pdf/1707.01217.pdf)
- 20180524 arXiv 探索了Multi-source迁移学习的一些理论:[Algorithms and Theory for Multiple-Source Adaptation](https://arxiv.org/abs/1805.08727)
- 20181117 AAAI-19 [Robust Optimization over Multiple Domains](https://arxiv.org/abs/1805.07588)
- Optimization on multi domains
- 针对多个domain建模并优化
- 20180912 arXiv [Multi-target Unsupervised Domain Adaptation without Exactly Shared Categories](https://arxiv.org/abs/1809.00852)
- Multi-target domain adaptation
- 多目标的domain adaptation
- 20180316 arXiv 用optimal transport解决domain adaptation中类别不平衡的问题:[Optimal Transport for Multi-source Domain Adaptation under Target Shift](https://arxiv.org/abs/1803.04899)
- - -
## Heterogeneous transfer learning
- 20190717 AAAI [Heterogeneous Transfer Learning via Deep Matrix Completion with Adversarial Kernel Embedding](https://144.208.67.177/ojs/index.php/AAAI/article/view/4880)
- Transfer Learning via Deep Matrix Completion with Adversarial Kernel Embedding
- 异构迁移学习中用对抗核嵌入的深度矩阵
- 20190829 ACMMM-19 [Heterogeneous Domain Adaptation via Soft Transfer Network](https://arxiv.org/abs/1908.10552)
- Soft-mmd loss in heterogeneous domain adaptation
- 异构迁移学习中用soft-mmd loss
- 20181113 ACML-18 [Unsupervised Heterogeneous Domain Adaptation with Sparse Feature Transformation](http://proceedings.mlr.press/v95/shen18b/shen18b.pdf)
- Heterogeneous domain adaptation
- 异构domain adaptation
- 20180901 TKDE [A General Domain Specific Feature Transfer Framework for Hybrid Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/8432087/)
- Hybrid DA: special case in Heterogeneous DA
- 提出一种新的混合DA问题和方法
- 20180606 arXiv 一篇最近的对非对称情况下的异构迁移学习综述:[Asymmetric Heterogeneous Transfer Learning: A Survey](https://arxiv.org/abs/1804.10834)
- 20180403 Neural Processing Letters-18 异构迁移学习:[Label Space Embedding of Manifold Alignment for Domain Adaption](https://link.springer.com/article/10.1007/s11063-018-9822-8)
- 20180105 arXiv 异构迁移学习 [Heterogeneous transfer learning](https://arxiv.org/abs/1701.02511)
- - -
## Online transfer learning
- CVPR-22 workshop [Online Unsupervised Domain Adaptation for Person Re-identification](https://arxiv.org/abs/2205.04383)
- Online domain adaptation for REID 在线adaptation
- [Mixture of basis for interpretable continual learning with distribution shifts](https://arxiv.org/abs/2201.01853)
- Incremental learning with mixture of basis
- 用mixture of domains进行增量学习
- 20180326 考虑主动获取label的budget情况下的在线迁移学习:[Online domain adaptation by exploiting labeled features and pro-active learning](https://dl.acm.org/citation.cfm?id=3152507)
- 20180128 **第一篇**在线迁移学习的文章,发表在ICML-10上,系统性地定义了在线迁移学习的任务,给出了进行在线同构和异构迁移学习的两种学习模式。[Online Transfer Learning](https://dl.acm.org/citation.cfm?id=3104478)
- 扩充的期刊文章发在2014年的AIJ上:[Online Transfer Learning](https://www.sciencedirect.com/science/article/pii/S0004370214000800)
- [我的解读](https://zhuanlan.zhihu.com/p/33557802?group_id=943152232741535744)
- 文章代码:[OTL](http://stevenhoi.org/otl)
- 20180126 两篇在线迁移学习:
- [Online transfer learning by leveraging multiple source domains](https://link.springer.com/article/10.1007/s10115-016-1021-1)
- [Online Heterogeneous Transfer by Hedge Ensemble of Offline and Online Decisions](http://ieeexplore.ieee.org/document/8064213/)
- 20180126 TKDE-17 同时有多个同构和异构源域时的在线迁移学习:[Online Transfer Learning with Multiple Homogeneous or Heterogeneous Sources](http://ieeexplore.ieee.org/abstract/document/7883886/)
- KIS-17 Online transfer learning by leveraging multiple source domains 提出一种综合衡量多个源域进行在线迁移学习的方法。文章的related work是很不错的survey。
- CIKM-13 OMS-TL: A Framework of Online Multiple Source Transfer Learning 第一次在mulitple source上做online transfer,也是用的分类器集成。
- ICLR-17 ONLINE BAYESIAN TRANSFER LEARNING FOR SEQUENTIAL DATA MODELING 用贝叶斯的方法学习在线的HMM迁移学习模型,并应用于行为识别、睡眠监测,以及未来流量分析。
- KDD-14 Scalable Hands-Free Transfer Learning for Online Advertising 提出一种无参数的SGD方法,预测广告量
- TNNLS-17 Online Feature Transformation Learning for Cross-Domain Object Category Recognition 在线feature transformation方法
- ICPR-12 Online Transfer Boosting for Object Tracking 在线transfer 样本
- TKDE-14 Online Feature Selection and Its Applications 在线特征选择
- AAAI-15 Online Transfer Learning in Reinforcement Learning Domains 应用于强化学习的在线迁移学习
- AAAI-15 Online Boosting Algorithms for Anytime Transfer and Multitask Learning 一种通用的在线迁移学习方法,可以适配在现有方法的后面
- IJSR-13 Knowledge Transfer Using Cost Sensitive Online Learning Classification 探索在线迁移方法,用样本cost
- - -
## Zero-shot / few-shot learning
- [Few-Max: Few-Shot Domain Adaptation for Unsupervised Contrastive Representation Learning](https://arxiv.org/abs/2206.10137)
- Few-shot DA for unsupervised constrastive learning 小样本DA用于无监督对比学习
- [Interpretable Concept-based Prototypical Networks for Few-Shot Learning](https://arxiv.org/abs/2202.13474)
- Concept-based prototypical network for few-shot learning
- 基于概念的原型网络用于小样本学习
- [How Well Do Self-Supervised Methods Perform in Cross-Domain Few-Shot Learning?](https://arxiv.org/abs/2202.09014)
- Self-supervised learning for cross-domain few-shot
- 自监督用于跨领域小样本
- 20181128 arXiv [One Shot Domain Adaptation for Person Re-Identification](https://arxiv.org/abs/1811.10144)
- One shot learning for REID
- One shot for再识别
- 20210426 [Few-shot Continual Learning: a Brain-inspired Approach](http://arxiv.org/abs/2104.09034)
- Few-shot continual learning
- 小样本持续学习
- 20201203 [How to fine-tune deep neural networks in few-shot learning?](https://arxiv.org/abs/2012.00204)
- 对few-shot任务如何fine-tune深度网络?
- 20201116 [Filter Pre-Pruning for Improved Fine-tuning of Quantized Deep Neural Networks](https://arxiv.org/abs/2011.06751)
- 量子神经网络中的finetune
- 20200608 ICML-20 [Few-Shot Learning as Domain Adaptation: Algorithm and Analysis](https://arxiv.org/abs/2002.02050)
- Using domain adaptation to solve the few-shot learning
- 20200408 ICLR-20 [A Baseline for Few-Shot Image Classification](https://openreview.net/forum?id=rylXBkrYDS)
- A simple finetune+entropy minimization approach with strong baseline
- 一个微调+最小化熵的小样本学习方法,结果很强
- 20200405 ICCV-19 [Variational few-shot learning](http://openaccess.thecvf.com/content_ICCV_2019/html/Zhang_Variational_Few-Shot_Learning_ICCV_2019_paper.html)
- Variational few-shot learning
- 变分小样本学习
- 20200405 ICLR-20 [A baseline for few-shot image classification](https://openreview.net/forum?id=rylXBkrYDS¬eId=rylXBkrYDS)
- A simple but powerful baseline for few-shot image classification
- 一个简单但是很有效的few-shot baseline
- 20200324 IEEE TNNLS [Few-Shot Learning with Geometric Constraints](https://arxiv.org/abs/2003.09151)
- Few-shot learning with geometric constraints
- 用了一些几何约束进行小样本学习
- 20190813 arXiv [Domain-Specific Embedding Network for Zero-Shot Recognition](https://arxiv.org/abs/1908.04174)
- Domain-specific embedding network for zero-shot learning
- 领域自适应的zero-shot learning
- 20190401 TIp-19 [Few-Shot Deep Adversarial Learning for Video-based Person Re-identification](https://arxiv.org/abs/1903.12395)
- Few-shot deep adversarial learning
- Few-shot对抗学习
- 20190305 arXiv [Zero-Shot Task Transfer](https://arxiv.org/abs/1903.01092)
- Zero-shot task transfer
- Zero-shot任务迁移学习
- 20190221 arXiv [Adaptive Cross-Modal Few-Shot Learning](https://arxiv.org/abs/1902.07104)
- Adaptive cross-modal few-shot learning
- 跨模态的few-shot
- 20180612 CVPR-18 泛化的Zero-shot learning:[Generalized Zero-Shot Learning via Synthesized Examples](https://arxiv.org/abs/1712.03878)
- 20181106 arXiv [Zero-Shot Transfer VQA Dataset](https://arxiv.org/abs/1811.00692)
- English: A dataset for zero-shot VQA transfer
- 中文:一个针对zero-shot VQA的迁移学习数据集
- 20171222 NIPS 2017 用adversarial网络,当target中有很少量的label时如何进行domain adaptation:[Few-Shot Adversarial Domain Adaptation](http://papers.nips.cc/paper/7244-few-shot-adversarial-domain-adaptation)
- 20181225 arXiv [Learning Compositional Representations for Few-Shot Recognition](https://arxiv.org/abs/1812.09213)
- Few-shot recognition
- 20181127 WACV-19 [Self Paced Adversarial Training for Multimodal Few-shot Learning](https://arxiv.org/abs/1811.09192)
- Multimodal training for single modal testing
- 用多模态数据针对单一模态进行迁移
- 20180728 arXiv [Meta-learning autoencoders for few-shot prediction](https://arxiv.org/abs/1807.09912)
- Using meta-learning for few-shot transfer learning
- 用元学习进行迁移学习
- 20171216 arXiv [Zero-Shot Deep Domain Adaptation](https://arxiv.org/abs/1707.01922)
- 当target domain的数据不可用时,如何用相关domain的数据进行辅助学习?
- 20191204 arXiv [MetAdapt: Meta-Learned Task-Adaptive Architecture for Few-Shot Classification](https://arxiv.org/abs/1912.00412)
- Task adaptive structure for few-shot learning
- 目标自适应的结构用于小样本学习
- 20190409 ICLR-19 [A Closer Look at Few-shot Classification](https://arxiv.org/abs/1904.04232)
- Give some important conclusions on few-shot classification
- 在few-shot上给了一些有用的结论
- 20190401 IJCNN-19 [Zero-shot Image Recognition Using Relational Matching, Adaptation and Calibration](https://arxiv.org/abs/1903.11701)
- Zero-shot image recognition
- 零次学习的图像识别
- 20171022 ICCVW-17 [Zero-shot learning posed as a missing data problem](http://openaccess.thecvf.com/content_ICCV_2017_workshops/papers/w38/Zhao_Zero-Shot_Learning_Posed_ICCV_2017_paper.pdf)
- 算法首先学习 semantic embeddings 的结构性知识,利用学习到的知识和已知类的 image features 合成未知类的 image features。再利用无标记的未知类数据对合成数据进行修正。 算法假设未知类数据呈混合高斯分布,用 GMM-EM 算法进行无监督修正。
- 20180516 arXiv-18 [A Large-scale Attribute Dataset for Zero-shot Learning](https://arxiv.org/pdf/1804.04314v2.pdf)
- 传统 ZSL 数据集(如 AwA, CUB)存在规模小,属性标注不丰富等问题。本文提出一个新的属性数据集 LAD 用于测试零样本学习算法。新数据集包含 230 类, 78,017 张图片,标注了 359 种属性。基于此数据集举办了 AI Challenger 零样本学习竞赛。 110+ 支来自海内外的参赛队伍提交了成绩。
- 20180710 ICML-18 [MSplit LBI: Realizing Feature Selection and Dense Estimation Simultaneously in Few-shot and Zero-shot Learning](https://arxiv.org/pdf/1806.04360.pdf)
- 针对 L1 (欠拟合) 和 L2 (无特征选择、有偏) 正则项存在的问题,提出 MSplit LBI 用于同时实现特征选择和密集估计。在 Few-shot Learning 和 Zero-shot Learning 两个问题上进行了实验。实验表明 MSplit LBI 由优于 L1 和 L2。针对 ZSL 进行了特征可视化实验。
- 20190108 WACV-19 [Zero-shot Learning via Recurrent Knowledge Transfer](https://drive.google.com/open?id=1cUsQWX80zeCxTyVSCcYlqEWZP-Hq0KzR)
- 基于样本合成的零样本学习算法通常将 semantic embeddings 的知识迁移到 image features 以实现 ZSL。然而,这种 training 和 testing space 的不一致,会导致这种迁移失效。因此,本文提出 Space Shift Problem,并针对此问题,提出一种(在 image feature space 和 semantic embedding space 之间)递归传递知识的解决方案。
- - -
## Multi-task learning
- [Gap Minimization for Knowledge Sharing and Transfer](https://arxiv.org/abs/2201.11231)
- Multitask learning with gap minimization
- 用于多任务学习的gap minimization方法
- 20190806 KDD-19 [Relation Extraction via Domain-aware Transfer Learning](https://dl.acm.org/citation.cfm?id=3330890)
- Relation extraction using transfer learning for knowledge base construction
- 利用迁移学习进行关系抽取
- 20190531 arXiv [Multi-task Learning in Deep Gaussian Processes with Multi-kernel Layers](https://arxiv.org/abs/1905.12407)
- Multi-task learning in deep Gaussian process
- 深度高斯过程中的多任务学习
- 20200927 [Knowledge Distillation for Multi-task Learning](https://arxiv.org/abs/2007.06889)
- 针对多任务学习的知识蒸馏
- 20200914 ECML-PKDD-20 [Towards Interpretable Multi-Task Learning Using Bilevel Programming](https://arxiv.org/abs/2009.05483)
- 用bilevel programming解释多任务学习
- 20191202 arXiv [AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://arxiv.org/abs/1911.12423)
- Learning what to share for multi-task learning
- 对多任务学习如何share
- 20191125 AAAI-20 [Adaptive Activation Network and Functional Regularization for Efficient and Flexible Deep Multi-Task Learning](https://arxiv.org/abs/1911.08065)
- Adaptive activation network for deep multi-task learning
- 自适应的激活网络用于深度多任务学习
- 20191015 arXiv [Gumbel-Matrix Routing for Flexible Multi-task Learning](https://arxiv.org/abs/1910.04915)
- Effective method for flexible multi-task learning
- 一种很有效的方法用于多任务学习
- 20190718 arXiv [Task Selection Policies for Multitask Learning](https://arxiv.org/abs/1907.06214)
- Task selection in multitask learning
- 在多任务学习中的任务选择机制
- 20190509 FG-19 [Multi-task human analysis in still images: 2D/3D pose, depth map, and multi-part segmentation](https://arxiv.org/abs/1905.03003)
- Multi-task human analysis in still images
- 多任务人体静止图像分析
- 20190409 NAACL-19 [AutoSeM: Automatic Task Selection and Mixing in Multi-Task Learning](https://arxiv.org/abs/1904.04153)
- Automatic Task Selection and Mixing in Multi-Task Learning
- 多任务学习中自动任务选择和混淆
- 20190409 TNNLS-19 [Heterogeneous Multi-task Metric Learning across Multiple Domains](https://arxiv.org/abs/1904.04081)
- Heterogeneous Multi-task Metric Learning across Multiple Domains
- 在多个领域之间进行异构多任务度量学习
- 20190409 NeurIPS-18 [Synthesized Policies for Transfer and Adaptation across Tasks and Environments](https://arxiv.org/abs/1904.03276)
- Transfer across tasks and environments
- 通过任务和环境之间进行迁移
- 20190408 ICMR-19 [Learning Task Relatedness in Multi-Task Learning for Images in Context](https://arxiv.org/abs/1904.03011)
- Using task relatedness in multi-task learning
- 在多任务学习中学习任务之间的相关性
- 20190408 CVPR-19 [End-to-End Multi-Task Learning with Attention](https://arxiv.org/abs/1803.10704)
- End-to-End Multi-Task Learning with Attention
- 基于attention的端到端的多任务学习
- 20190401 arXiv [Many Task Learning with Task Routing](https://arxiv.org/abs/1903.12117)
- From multi-task leanring to many-task learning
- 许多任务同时学习
- 20190324 arXiv [A Principled Approach for Learning Task Similarity in Multitask Learning](https://arxiv.org/abs/1903.09109)
- Provide some theoretical analysis of the similarity learning in multi-task learning
- 为多任务学习中的相似度学习提供了一些理论分析
- 20181128 arXiv [A Framework of Transfer Learning in Object Detection for Embedded Systems](https://arxiv.org/abs/1811.04863)
- A Framework of Transfer Learning in Object Detection for Embedded Systems
- 一个用于嵌入式系统的迁移学习框架
- 20181012 NIPS-18 [Multi-Task Learning as Multi-Objective Optimization](https://arxiv.org/abs/1810.04650)
- Solve the multi-task learning as a multi-objective optimization problem
- 将多任务问题看成一个多目标优化问题进行求解
- 20181008 PSB-19 [The Effectiveness of Multitask Learning for Phenotyping with Electronic Health Records Data](https://arxiv.org/abs/1808.03331)
- Evaluate the effectiveness of multitask learning for phenotyping
- 评估多任务学习对于表型的作用
- 20180828 arXiv [Self-Paced Multi-Task Clustering](https://arxiv.org/abs/1808.08068)
- Multi-task clustering
- 多任务聚类
- 20180622 arXiv 探索了多任务迁移学习中的不确定性:[Uncertainty in Multitask Transfer Learning](https://arxiv.org/abs/1806.07528)
- 20180524 arXiv 杨强团队、与之前的learning to learning类似,这里提供了一个从经验中学习的learning to multitask框架:[Learning to Multitask](https://arxiv.org/abs/1805.07541)
- - -
## Transfer reinforcement learning
- [Multi-Agent Transfer Learning in Reinforcement Learning-Based Ride-Sharing Systems](https://arxiv.org/abs/2112.00424)
- Multi-agent transfer in RL
- 在RL中的多智能体迁移
- NeurIPS-21 workshop [Component Transfer Learning for Deep RL Based on Abstract Representations](https://arxiv.org/abs/2111.11525)
- Deep transfer learning for RL
- 深度迁移学习用于强化学习
- [Xi-Learning: Successor Feature Transfer Learning for General Reward Functions](https://arxiv.org/abs/2110.15701)
- General reward function transfer learning in RL
- 在强化学习中general reward function的迁移学习
- NeurIPS-21 [Unsupervised Domain Adaptation with Dynamics-Aware Rewards in Reinforcement Learning](https://arxiv.org/abs/2110.12997)
- Domain adaptation in reinforcement learning
- 在强化学习中应用domain adaptation
- [Understanding Domain Randomization for Sim-to-real Transfer](http://arxiv.org/abs/2110.03239)
- Understanding domain randomizationfor sim-to-real transfer
- 对强化学习中的sim-to-real transfer进行理论上的分析
- 20191214 arXiv [Does Knowledge Transfer Always Help to Learn a Better Policy?](https://arxiv.org/abs/1912.02986)
- Transfer learning in reinforcement learning
- 20191212 AAAI-20 [Transfer value iteration networks](https://arxiv.org/abs/1911.05701)
- Transferred value iteration networks
- 20190821 arXiv [Transfer in Deep Reinforcement Learning using Knowledge Graphs](https://arxiv.org/abs/1908.06556)
- Use knowledge graph to transfer in reinforcement learning
- 用知识图谱进行强化迁移
- 20190320 arXiv [Learning to Augment Synthetic Images for Sim2Real Policy Transfer](https://arxiv.org/abs/1903.07740)
- Augment synthetic images for sim to real policy transfer
- 学习对于策略迁移如何合成图像
- 20190305 arXiv [Sim-to-Real Transfer for Biped Locomotion]
- Transfer learning for robot locomotion
- 用迁移学习进行机器人定位
- 20190220 arXiv [DIViS: Domain Invariant Visual Servoing for Collision-Free Goal Reaching](https://arxiv.org/abs/1902.05947)
- Transfer learning for robot reinforcement learning
- 迁移学习用于机器人的强化学习目标搜寻
- 20181212 NeurIPS-18 workshop [Efficient transfer learning and online adaptation with latent variable models for continuous control](https://arxiv.org/abs/1812.03399)
- Reinforcement transfer learning with latent models
- 隐变量模型用于迁移强化学习的控制
- 20181128 arXiv [Hardware Conditioned Policies for Multi-Robot Transfer Learning](https://arxiv.org/abs/1811.09864)
- Hardware Conditioned Policies for Multi-Robot Transfer Learning
- 多个机器人之间的迁移学习
- 20180926 arXiv [Target Transfer Q-Learning and Its Convergence Analysis](https://arxiv.org/abs/1809.08923)
- Analyze the risk of transfer q-learning
- 提供了在�Q learning的任务迁移中一些理论分析
- 20180926 arXiv [Domain Adaptation in Robot Fault Diagnostic Systems](https://arxiv.org/abs/1809.08626)
- Apply domain adaptation in robot fault diagnostic system
- 将domain adaptation应用于机器人故障检测系统
- 20180912 arXiv [VPE: Variational Policy Embedding for Transfer Reinforcement Learning](https://arxiv.org/abs/1809.03548)
- Policy transfer in reinforcement learning
- 增强学习中的策略迁移
- 20180909 arXiv [Transferring Deep Reinforcement Learning with Adversarial Objective and Augmentation](https://arxiv.org/abs/1809.00770)
- deep + adversarial + reinforcement learning transfer
- 深度对抗迁移学习用于强化学习
- 20180530 ICML-18 强化迁移学习:[Importance Weighted Transfer of Samples in Reinforcement Learning](https://arxiv.org/abs/1805.10886)
- 20180524 arXiv 用深度强化学习的方法学习domain adaptation中的采样策略:[Learning Sampling Policies for Domain Adaptation](https://arxiv.org/abs/1805.07641)
- 20180516 arXiv 探索了强化学习中的任务迁移:[Adversarial Task Transfer from Preference](https://arxiv.org/abs/1805.04686)
- 20180413 NIPS-17 基于后继特征迁移的强化学习:[Successor Features for Transfer in Reinforcement Learning](https://arxiv.org/abs/1606.05312)
- 20180404 IEEE TETCI-18 用迁移学习来玩星际争霸游戏:[StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning](https://arxiv.org/abs/1804.00810)
- - -
## Transfer metric learning
- 20190515 TNNLS-19 [A Distributed Approach towards Discriminative Distance Metric Learning](https://arxiv.org/abs/1905.05177)
- Discriminative distance metric learning
- 分布式度量学习
- 20190409 TNNLS-19 [Heterogeneous Multi-task Metric Learning across Multiple Domains](https://arxiv.org/abs/1904.04081)
- Heterogeneous Multi-task Metric Learning across Multiple Domains
- 在多个领域之间进行异构多任务度量学习
- 20190409 PAMI-19 [Transferring Knowledge Fragments for Learning Distance Metric from A Heterogeneous Domain](https://arxiv.org/abs/1904.04061)
- Heterogeneous transfer metric learning by transferring fragments
- 通过迁移知识片段来进行异构迁移度量学习
- 20190409 arXiv [Decomposition-Based Transfer Distance Metric Learning for Image Classification](https://arxiv.org/abs/1904.03846)
- Transfer metric learning based on decomposition
- 基于特征向量分解的迁移度量学习
- 20181012 arXiv [Transfer Metric Learning: Algorithms, Applications and Outlooks](https://arxiv.org/abs/1810.03944)
- A survey on transfer metric learning
- 一篇迁移度量学习的综述
- 20180622 arXiv 基于深度迁移学习的度量学习:[DEFRAG: Deep Euclidean Feature Representations through Adaptation on the Grassmann Manifold](https://arxiv.org/abs/1806.07688)
- 20181117 arXiv [Distance Measure Machines](https://arxiv.org/abs/1803.00250)
- Machines that measures distances
- 衡量距离的算法
- 20180605 KDD-10 迁移度量学习:[Transfer metric learning by learning task relationships](https://dl.acm.org/citation.cfm?id=1835954)
- 20180606 arXiv 将流形和统计信息联合起来构成一个domain adaptation框架:[A Unified Framework for Domain Adaptation using Metric Learning on Manifolds](https://arxiv.org/abs/1804.10834)
- 20180605 CVPR-15 深度度量迁移学习:[Deep metric transfer learning](https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Hu_Deep_Transfer_Metric_2015_CVPR_paper.pdf)
- - -
## Federated transfer learning
- ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning [[arxiv](https://arxiv.org/abs/2310.05143)]
- Black-box foundation models for personalized federated learning 黑盒的blackbox模型进行个性化迁移学习
- Benchmarking Algorithms for Federated Domain Generalization [[arxiv](http://arxiv.org/abs/2307.04942)]
- Benchmark algorthms for federated domain generalization 对联邦域泛化算法进行的benchmark
- IEEE'23 FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning [[arxiv](https://arxiv.org/abs/2302.13485v1)]
- Fast generalization for federated CLIP 在联邦中进行快速的CLIP训练
- [Federated Semi-Supervised Domain Adaptation via Knowledge Transfer](https://arxiv.org/abs/2207.10727)
- Federated semi-supervised DA 联邦半监督DA
- FL-IJCAI-22 [MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare](https://arxiv.org/abs/2206.08516)
- MetaFed: a new form of federated learning
- 联邦之联邦学习、新范式
- Interspeech-22 [Decoupled Federated Learning for ASR with Non-IID Data](https://jd92.wang/assets/files/DecoupleFL-IS22.pdf)
- Decoupled federated learning for non IID
- 解耦的联邦架构用于Non-IID语音识别
- [Test-Time Robust Personalization for Federated Learning](https://arxiv.org/abs/2205.10920)
- Test-time robust personalization for FL
- 测试时鲁棒联邦学习
- IEEE TNNLS-22 [Towards Personalized Federated Learning](http://arxiv.org/abs/2103.00710)
- A survey on personalized federated learning
- 一个关于个性化联邦学习的综述
- [Improving Generalization in Federated Learning by Seeking Flat Minima](https://arxiv.org/abs/2203.11834)
- Seeking flat minima for domain generalization in federated learning
- 通过寻找平坦值进行联邦学习领域泛化
- [SemiPFL: Personalized Semi-Supervised Federated Learning Framework for Edge Intelligence](https://arxiv.org/abs/2203.08176)
- Personalized federated learning
- 个性化联邦学习
- NeurIPS-21 [Parameterized Knowledge Transfer for Personalized Federated Learning](https://proceedings.neurips.cc/paper/2021/hash/5383c7318a3158b9bc261d0b6996f7c2-Abstract.html)
- personalized group knowledge transfer training
- 个性化群体知识迁移
- ICML-21 [Federated Continual Learning with Weighted Inter-client Transfer](https://proceedings.mlr.press/v139/yoon21b.html)
- Federated Weighted Inter-client Transfer (FedWeIT) for Federated Continual Learning
- 联邦加权客户端间传输方法,用于联邦持续学习
- SIGIR-21 [FedCT: Federated Collaborative Transfer for Recommendation](https://doi.org/10.1145/3404835.3462825)
- Federated learning for cross-domain recommendation
- 使用联邦迁移学习执行跨域推荐任务
- KDD-21 [Federated Adversarial Debiasing for Fair and Transferable Representations](https://doi.org/10.1145/3447548.3467281)
- Federated Adversarial DEbiasing (FADE)
- 通过对抗性学习对联邦学习过程去除偏见
- [Federated Learning with Adaptive Batchnorm for Personalized Healthcare](https://arxiv.org/abs/2112.00734)
- Federated learning with adaptive batchnorm
- 用自适应BN进行个性化联邦学习
- [FedZKT: Zero-Shot Knowledge Transfer towards Heterogeneous On-Device Models in Federated Learning](https://arxiv.org/abs/2109.03775)
- Zero-shot transfer in heterogeneous federated learning
- 零次迁移用于联邦学习
- [Federated Multi-Task Learning under a Mixture of Distributions](https://arxiv.org/abs/2108.10252)
- Federated multi-task learning
- 联邦多任务学习
- NeurIPS-20 [Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge](https://proceedings.neurips.cc/paper/2020/hash/a1d4c20b182ad7137ab3606f0e3fc8a4-Abstract.html)
- Group knowledge transfer training
- 群体知识迁移
- [Fine-tuning is Fine in Federated Learning](http://arxiv.org/abs/2108.07313)
- Finetuning in federated learning
- 在联邦学习中进行finetune
- [Federated Multi-Target Domain Adaptation](http://arxiv.org/abs/2108.07792)
- Federated multi-target DA
- 联邦学习场景下的多目标DA
- 20190909 IJCAI-FML-19 [FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare](http://jd92.wang/assets/files/a15_ijcai19.pdf)
- The first work on federated transfer learning for wearable healthcare
- 第一个将联邦迁移学习用于可穿戴健康监护的工作
- 20180605 arXiv 解决federated learning中的数据不同分布的问题:[Federated Learning with Non-IID Data](https://arxiv.org/abs/1806.00582)
- 20190301 NeurIPS-18 workshp [One-Shot Federated Learning](https://arxiv.org/abs/1902.11175)
- One-shot federated learning
- - -
## Lifelong transfer learning
- Complementary Domain Adaptation and Generalization for Unsupervised Continual Domain Shift Learning [[arxiv](http://arxiv.org/abs/2303.15833)]
- Continual domain shift learning using adaptation and generalization 使用 adaptation和DG进行持续分布变化的学习
- TMLR'23 Learn, Unlearn and Relearn: An Online Learning Paradigm for Deep Neural Networks [[arxiv](http://arxiv.org/abs/2303.10455)]
- A framework for online learning 一个在线学习的框架
- NeurIPS'22 Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer [[arxiv](http://arxiv.org/abs/2211.00789)]
- Continual learning with backward knowledge transfer 反向知识迁移的持续学习
- [Mixture of basis for interpretable continual learning with distribution shifts](https://arxiv.org/abs/2201.01853)
- Incremental learning with mixture of basis
- 用mixture of domains进行增量学习
- 20101008 arXiv [Concept-drifting Data Streams are Time Series; The Case for Continuous Adaptation](https://arxiv.org/abs/1810.02266)
- Continuous adaptation for time series data
- 对时间序列进行连续adaptation
- 20191011 arXiv [Learning to Remember from a Multi-Task Teacher](https://arxiv.org/abs/1910.04650)
- Dealing with the catastrophic forgetting during sequential learning
- 在序列学习时处理灾难遗忘
- 20191029 [Adversarial Feature Alignment: Avoid Catastrophic Forgetting in Incremental Task Lifelong Learning](https://arxiv.org/abs/1910.10986)
- Avoid catastrophic forgeeting in incremental task lifelong learning
- 在终身学习中避免灾难遗忘
- 20200706 [ICML-20] [Continuously Indexed Domain Adaptation](https://arxiv.org/abs/2007.01807)
- 20210716 TPAMI-21 [Lifelong Teacher-Student Network Learning](https://arxiv.org/abs/2107.04689)
- Lifelong distillation
- 持续的知识蒸馏
- 20210716 ICML-21 [Continual Learning in the Teacher-Student Setup: Impact of Task Similarity](https://arxiv.org/abs/2107.04384)
- Investigating task similarity in teacher-student learning
- 调研在continual learning下teacher-student learning问题的任务相似度
- 20190912 NeurIPS-19 [Meta-Learning with Implicit Gradients](https://arxiv.org/abs/1909.04630)
- Meta-learning with implicit gradients
- 隐式梯度的元学习
- 20180323 arXiv 终身迁移学习与增量学习结合:[Incremental Learning-to-Learn with Statistical Guarantees](https://arxiv.org/abs/1803.08089)
- 20180111 arXiv 一种新的终身学习框架,与L2T的思路有一些类似 [Lifelong Learning for Sentiment Classification](https://arxiv.org/abs/1801.02808)
- - -
## Safe transfer learning
- ICSE-22 [ReMoS: Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing](https://link.zhihu.com/?target=https%3A//jd92.wang/assets/files/icse22-remos.pdf) | [Code](https://github.com/ziqi-zhang/ReMoS_artifact) | [Blog](https://zhuanlan.zhihu.com/p/446453487) | [Video](https://www.bilibili.com/video/BV1mi4y1C7bP)
- Safe transfer learning by reducing defect inheritance
- 安全迁移学习的最新工作
- CVPR workshop-21 [Renofeation: A Simple Transfer Learning Method for Improved Adversarial Robustness](https://openaccess.thecvf.com/content/CVPR2021W/TCV/html/Chin_Renofeation_A_Simple_Transfer_Learning_Method_for_Improved_Adversarial_Robustness_CVPRW_2021_paper.html)
- Improve adversarial robustness of transfer learning models
- 提高迁移学习对于adversarial robustness的鲁棒性
- ICLR-20 [A Target-Agnostic Attack on Deep Models: Exploiting Security Vulnerabilities of Transfer Learning](https://openreview.net/forum?id=BylVcTNtDS)
- Softmax layer is easy to get attacked
- 设计实验来攻击迁移学习的softmax layer
- RAID'18 [Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks](https://link.springer.com/chapter/10.1007/978-3-030-00470-5_13)
- Finetune and prune the weights against backdoor attack
- 在finetune过程中剪枝来预防后门攻击
- ACM CCS-18 [Model-Reuse Attacks on Deep Learning Systems](https://dl.acm.org/doi/10.1145/3243734.3243757)
- Model-resuse attack on transfer learning models
- 设计实验来攻击迁移学习的预训练模型
- USENIX Security-18 [With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning](https://www.usenix.org/system/files/conference/usenixsecurity18/sec18-wang.pdf)
- First work to design experiments to attack pretrained models
- 第一个设计实验来攻击预训练模型的工作
- - -
## Transfer learning applications
See [HERE](https://github.com/jindongwang/transferlearning/blob/master/doc/transfer_learning_application.md) for a full list of transfer learning applications.
================================================
FILE: doc/awesome_paper_date.md
================================================
# Awesome papers by date
Here, we list some papers related to transfer learning by date (starting from 2021-07). For papers older than 2021-07, please refer to the [papers by topic](awesome_paper.md), which contains more papers.
- [Awesome papers by date](#awesome-papers-by-date)
- [2024-12](#2024-12)
- [2024-11](#2024-11)
- [2024-10](#2024-10)
- [2024-09](#2024-09)
- [2024-08](#2024-08)
- [2024-07](#2024-07)
- [2024-05](#2024-05)
- [2024-04](#2024-04)
- [2024-03](#2024-03)
- [2024-02](#2024-02)
- [2024-01](#2024-01)
- [2023-12](#2023-12)
- [2023-11](#2023-11)
- [2023-10](#2023-10)
- [2023-09](#2023-09)
- [2023-08](#2023-08)
- [2023-07](#2023-07)
- [2023-06](#2023-06)
- [2023-05](#2023-05)
- [2023-04](#2023-04)
- [2023-03](#2023-03)
- [2023-02](#2023-02)
- [2023-01](#2023-01)
- [2022-12](#2022-12)
- [2022-11](#2022-11)
- [2022-10](#2022-10)
- [2022-09](#2022-09)
- [2022-08](#2022-08)
- [2022-07](#2022-07)
- [2022-06](#2022-06)
- [2022-05](#2022-05)
- [2022-04](#2022-04)
- [2022-03](#2022-03)
- [2022-02](#2022-02)
- [2022-01](#2022-01)
- [2021-12](#2021-12)
- [2021-11](#2021-11)
- [2021-10](#2021-10)
- [2021-09](#2021-09)
- [2021-08](#2021-08)
- [2021-07](#2021-07)
## 2024-12
- Privacy in Fine-tuning Large Language Models: Attacks, Defenses, and Future Directions [[arxiv](http://arxiv.org/abs/2412.16504)]
- Privacy in LLM fine-tuning
- Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers [[arxiv](http://arxiv.org/abs/2412.16901)]
- Generate gradients for TTA
- Is Large-Scale Pretraining the Secret to Good Domain Generalization? [[arxiv](https://arxiv.org/abs/2412.02856)]
- Large-scale pre-training vs domain generalization
## 2024-11
- Generating Out-Of-Distribution Scenarios Using Language Models [[arxiv](https://arxiv.org/abs/2411.16554)]
- Generating OOD settings using language models
- Unified Domain Generalization and Adaptation for Multi-View 3D Object Detection [[arxiv](https://arxiv.org/abs/2410.22461)]
- Unified domain generalization and adaptation for multi-view 3D object detection
## 2024-10
- Transfer Learning on Multi-Dimensional Data: A Novel Approach to Neural Network-Based Surrogate Modeling [[arxiv](http://arxiv.org/abs/2410.12241)]
- Transfer learning on multi-dimensioal data
- TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent Collaboration [[arxiv](http://arxiv.org/abs/2410.12183)]
- Transfer vision-language models for collaboration
- Test-time adaptation for image compression with distribution regularization [[arxiv](http://arxiv.org/abs/2410.12191)]
- Test-time adaptation for image compression with distribution regularization
- WeatherDG: LLM-assisted Procedural Weather Generation for Domain-Generalized Semantic Segmentation [[arxiv](http://arxiv.org/abs/2410.12075)]
- Weather domain generalization
- Can In-context Learning Really Generalize to Out-of-distribution Tasks? [[arxiv](https://arxiv.org/abs/2410.09695)]
- Can in-context learning generalize to OOD tasks?
- Domain-Conditioned Transformer for Fully Test-time Adaptation [[arxiv](https://arxiv.org/abs/2410.10442)]
- Fully test-tim adaptation with domain-conditioned transformer
- Safety-Aware Fine-Tuning of Large Language Models [[arxiv](https://arxiv.org/abs/2410.10014)]
- Fine-tuning with safety in LLMs
- - Deep Transfer Learning: Model Framework and Error Analysis [[arxiv](https://arxiv.org/abs/2410.09383)]
- Deep transfer learning framework
- Cross-Domain Distribution Alignment for Segmentation of Private Unannotated 3D Medical Images [[arxiv](https://arxiv.org/abs/2410.09210)]
- Cross-domain adaptation of private unannotated 3D medical images
- Stratified Domain Adaptation: A Progressive Self-Training Approach for Scene Text Recognition [[arxiv](https://arxiv.org/abs/2410.09913)]
- Stratified domain adaptation
- Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs [[arxiv](https://arxiv.org/abs/2410.08020)]
- Active fine-tuning of LLMs
- LLM Embeddings Improve Test-time Adaptation to Tabular Y|X shifts [[arxiv](https://arxiv.org/abs/2410.07395)]
- Test-time adaptation via LLMs
- AHA: Human-Assisted Out-of-Distribution Generalization and Detection [[arxiv](https://arxiv.org/abs/2410.08000)]
- Human-assisted OOD generalization and detection
## 2024-09
- Transfer Learning Applied to Computer Vision Problems: Survey on Current Progress, Limitations, and Opportunities [[arxiv](https://arxiv.org/abs/2409.07736)]
- Transfer learning for computer vision survey
- Spatial Adaptation Layer: Interpretable Domain Adaptation For Biosignal Sensor Array Applications [[arxiv](https://arxiv.org/abs/2409.08058)]
- Interpretable domain adaptation
- DICS: Find Domain-Invariant and Class-Specific Features for Out-of-Distribution Generalization [[arxiv](https://arxiv.org/abs/2409.08557)]
- Domain-invariant and class-specific features for OOD generalization
- Unsupervised Domain Adaptation Via Data Pruning [[arxiv](https://arxiv.org/abs/2409.12076)]
- Using pruning for domain adaptation
- LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models [[arxiv](https://arxiv.org/abs/2409.11919)]
- Black-box adaptation of vision language models
- Can Your Generative Model Detect Out-of-Distribution Covariate Shift? [[arxiv](http://arxiv.org/abs/2409.03043)]
- Can your generative models detect OOD covariate shift?
- Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities [[arxiv](http://arxiv.org/abs/2409.03444)]
- Fine-tuning LLMs for domain adaptation
- Dual-Path Adversarial Lifting for Domain Shift Correction in Online Test-time Adaptation [[arxiv](https://arxiv.org/abs/2408.13983)]
- Online test-time adaptation using dual-path adversarial lifting
- Rethinking Knowledge Transfer in Learning Using Privileged Information [[arxiv](https://arxiv.org/abs/2408.14319)]
- Using privileged information for knowledge transfer
- Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection [[arxiv](https://arxiv.org/abs/2408.15637)]
- Transfer learning from simulated to real scens for monocular 3D
- Multi-source Domain Adaptation for Panoramic Semantic Segmentation [[arxiv](https://arxiv.org/abs/2408.16469)]
- Multi-source domain adaptation for panoramic semantic segmentation
- Adapting Vision-Language Models to Open Classes via Test-Time Prompt Tuning [[arxiv](https://arxiv.org/abs/2408.16486)]
- Test-time prompt tuning for open classes
- A More Unified Theory of Transfer Learning [[arxiv](https://arxiv.org/abs/2408.16189)]
- More unified theory of transfer learning
- Low Saturation Confidence Distribution-based Test-Time Adaptation for Cross-Domain Remote Sensing Image Classification [[arxiv](https://arxiv.org/abs/2408.16265)]
- Test-time adaptation for remote sensing image classification
## 2024-08
- Unsupervised Domain Adaption Harnessing Vision-Language Pre-training [[arxiv](https://arxiv.org/abs/2408.02192)]
- Domain adaptation using vision-language pre-training
- Domain penalisation for improved Out-of-Distribution Generalisation [[arxiv](https://arxiv.org/abs/2408.01746)]
- OOD using domain penalization
- Weighted Risk Invariance: Domain Generalization under Invariant Feature Shift [[arxiv](http://arxiv.org/abs/2407.18428)]
- Domain generalization under invariant feature shift
## 2024-07
- Reducing Spurious Correlation for Federated Domain Generalization [[arxiv](https://arxiv.org/abs/2407.19174)]
- Federated domain generalization by reducing spurious correlation
- Can Modifying Data Address Graph Domain Adaptation? [[arxiv](https://arxiv.org/abs/2407.19311)]
- Alignment and rescaling for graph DA
- Improving Domain Adaptation Through Class Aware Frequency Transformation [[arxiv](https://arxiv.org/abs/2407.19551)]
- Class aware frequency transformation for domain adaptation
- Rethinking Domain Adaptation and Generalization in the Era of CLIP [[arxiv](http://arxiv.org/abs/2407.15173)]
- Rethinking domain adaptation in CLIP era
- Training-Free Model Merging for Multi-target Domain Adaptation [[arxiv](http://arxiv.org/abs/2407.13771)]
- Model merging for multi-target domain adaptation
- SAFT: Towards Out-of-Distribution Generalization in Fine-Tuning [[arxiv](https://arxiv.org/abs/2407.03036)]
- OOD fine-tuning for foundation models 大模型的OOD微调
- Multi-Task Domain Adaptation for Language Grounding with 3D Objects [[arxiv](https://arxiv.org/abs/2407.02846)]
- Multi-task domain adaptation for language grounding
## 2024-05
- Transfer Learning for CSI-based Positioning with Multi-environment Meta-learning [[arxiv](https://arxiv.org/abs/2405.11816)]
- Transfer learning for CSI-based positioning 用迁移学习进行基于CSI的定位
- Versatile Teacher: A Class-aware Teacher-student Framework for Cross-domain Adaptation [[arxiv](https://arxiv.org/abs/2405.11754)]
- Teacher-student framework for cross-domain adaptation 教师-学生框架进行跨领域适配
- MICCAI'24 MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection [[arxiv](https://arxiv.org/abs/2405.11315)]
- Adapting clip for few-shot medical image anomaly detection 对CLIP模型进行适配,以用于少样本图片异常检测
## 2024-04
- MDDD: Manifold-based Domain Adaptation with Dynamic Distribution for Non-Deep Transfer Learning in Cross-subject and Cross-session EEG-based Emotion Recognition [[arxiv](https://arxiv.org/abs/2404.15615)]
- Manifold-based domain adaptation for EEG-based emotion recognition 基于流形的DA用于EEG情绪识别
- Domain Adaptation for Learned Image Compression with Supervised Adapters [[arxiv](https://arxiv.org/abs/2404.15591)]
- Domain adaptation for learned image compression DA用于图片压缩
- Test-Time Training on Graphs with Large Language Models (LLMs) [[arxiv](https://arxiv.org/abs/2404.13571)]
- Test-time training on graphs with LLMs 使用大语言模型在图上进行测试时训练
- DACAD: Domain Adaptation Contrastive Learning for Anomaly Detection in Multivariate Time Series [[arxiv](https://arxiv.org/abs/2404.11269)]
- Domain adaptation for anomaly detection 使用域自适应进行时间序列异常检测
- CVPR'24 Exploring the Transferability of Visual Prompting for Multimodal Large Language Models [[arxiv](https://arxiv.org/abs/2404.11207)]
- Explore the transferability of visual prompting for multimodal LLM 探索多模态大模型visual prompt tuning的可迁移性
- DGMamba: Domain Generalization via Generalized State Space Model [[arXiv](https://arxiv.org/abs/2404.07794)]
- Domain generalization using mamba 用Mamba结构进行DG
- CVPR'24 Unified Language-driven Zero-shot Domain Adaptation [[arxiv](https://arxiv.org/abs/2404.07155)]
- Language-driven zero-shot domain adaptation 语言驱动的零样本 DA
- ICASSP'24 Learning Inference-Time Drift Sensor-Actuator for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447537?casa_token=6xrw2hE7cVEAAAAA:9i_ITqbfyLTzQYjdp4Oi16ziD8uheMMZJHRn4gHmzl9nN_j2c5u8MBxUtYYdzlj1Vn4l8F5OJnrw3BY)]
- Inference-time drift actuator for OOD generalization
- ICASSP'24 SBM: Smoothness-Based Minimization for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446613?casa_token=kO10uC18NMQAAAAA:6WJvMr57dSMyORMAnBgFGXi01aE_AmIAA6CQINztT7pHG2u8RmojDxMdV09UO6O9IfFsVEJDrYl1uiU)]
- Smoothness-based minimization for OOD generalization
- ICASSP'24 G2G: Generalized Learning by Cross-Domain Knowledge Transfer for Federated Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447043?casa_token=ihJ_LaxqnfUAAAAA:8Petax0UdQ9bvJLrRbFrujWcVjDzIckhYLDvIk-rUZxo-S7pa6xgbGBxkLWjs8c8H1jR4E8Rop8e7cc)]
- Federated domain generalization
- ICASSP'24 Single-Source Domain Generalization in Fundus Image Segmentation Via Moderating and Interpolating Input Space Augmentation [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447741?casa_token=t0FGpPfYxeoAAAAA:yyZ1zKhXstoaxNOtP6zKBj1ArLF8JZ7gGQOtR-k6DAHCO9SWTIOwLG5TF71BrcenWvO002MYku-wtQI)]
- Single-source DG in fundus image segmentation
- ICASSP'24 Style Factorization: Explore Diverse Style Variation for Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447540?casa_token=inLqNDEGEjQAAAAA:7jNUOViyS9PIn-BwIV0LJ-5oCzmM7BXpMLfyLosedaxmxZ-_c_2sA615GlCgrlwaspjdVKa4eogm6Z4)]
- Style variation for domain generalization
- ICASSP'24 SPDG-Net: Semantics Preserving Domain Augmentation through Style Interpolation for Multi-Source Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447210?casa_token=NSBeXUg0AdUAAAAA:4rrMR38UcDN2YRzD9Fvm42gT3dyEX5lO0arFkmVIu3VwQLT9UFLAmU3a5ZOfxtr812_Fic1SCcw9mr0)]
- Domain augmentation for multi-source DG
- ICASSP'24 Domaindiff: Boost out-of-Distribution Generalization with Synthetic Data [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446788?casa_token=Rh3MGM6szOQAAAAA:0GRegU3dIidLVvIYtJb97m2ZDCl0wwKVTmTZH7XTE0fzEBmRuwJHSn_T1U6NgwSYHFPKlWHox_BO4Eg)]
- Using synthetic data for OOD generalization
- ICASSP'24 Multi-Level Augmentation Consistency Learning and Sample Selection for Semi-Supervised Domain Generalization [[IEEE](https://ieeexplore.ieee.org/abstract/document/10446462?casa_token=vfAJ1GINr0AAAAAA:YS4NVt-kR8-sJqhfo6H7d04ZmckxUUpsIYuy2agnB4IpgCnR7xOzyrNv59MZ2lcbVhNvsN6Cl4p_7YI)]
- Multi-level augmentation for semi-supervised domain generalization
- ICASSP'24 MMS: Morphology-Mixup Stylized Data Generation for Single Domain Generalization in Medical Image Segmentation [[IEEE](https://ieeexplore.ieee.org/abstract/document/10448305?casa_token=14-2Vm39RD4AAAAA:Zmzm9KTl3INP2I83T2MLwQXtHUZKwXYfhDOPU9F0Eu9SrznInqGpSBrMYH0ek3eemDKdyL4bBU6EVaY)]
- Morphology-mixup for domain generalization
## 2024-03
- On the Benefits of Over-parameterization for Out-of-Distribution Generalization [[arxiv](http://arxiv.org/abs/2403.17592)]
- Over-parameterazation for OOD generalizaiton 分析了过参数化对OOD的影响
- CoDA: Instructive Chain-of-Domain Adaptation with Severity-Aware Visual Prompt Tuning [[arxiv](http://arxiv.org/abs/2403.17369)]
- Chain-of-domain adaptation with visual prompt tuning 领域链adaptation
- Deep Domain Adaptation: A Sim2Real Neural Approach for Improving Eye-Tracking Systems [[arxiv](https://arxiv.org/abs/2403.15947)]
- Domain adaptation for eye-tracking systems 用DA进行眼球追踪
- EAGLE: A Domain Generalization Framework for AI-generated Text Detection [[arxiv](https://arxiv.org/abs/2403.15690)]
- Domain generalization for AI content detection 用DG进行AI生成内容检测
- DPStyler: Dynamic PromptStyler for Source-Free Domain Generalization [[arxiv](https://arxiv.org/abs/2403.16697)]
- Dynamic propmtstyler for source-free DG 动态prompt分格化用于source-free DG
- Neurocomputing'24 Uncertainty-Aware Pseudo-Label Filtering for Source-Free Unsupervised Domain Adaptation [[arxiv](https://arxiv.org/abs/2403.11256)]
- Unvertainty-aware source-free domain adaptation 基于不确定性伪标签的domain adaptation
- Efficient Domain Adaptation for Endoscopic Visual Odometry [[arxiv](https://arxiv.org/abs/2403.10860)]
- Efficient domain adaptation for visual odometry 高效DA用于odometry
- Potential of Domain Adaptation in Machine Learning in Ecology and Hydrology to Improve Model Extrapolability [[arxiv](https://arxiv.org/abs/2403.11331)]
- Domain adaptation in ecology and hydrology 研究生态学和水文学中的DA
- ICLR'24 SF(DA)2: Source-free Domain Adaptation Through the Lens of Data Augmentation [[arxiv](https://arxiv.org/abs/2403.10834)]
- Source-free DA by data augmentation 通过数据增强来进行source-free DA
- CVPR'24 Universal Semi-Supervised Domain Adaptation by Mitigating Common-Class Bias [[arxiv](https://arxiv.org/abs/2403.11234)]
- Unviersal semi-supervised DA 通过公共类bias进行半监督DA
- Domain Adaptation Using Pseudo Labels for COVID-19 Detection [[arxiv](https://arxiv.org/abs/2403.11498)]
- Domain adaptation for COVID-19 detection 用DA进行covid-19检查
- Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans [[arxiv](https://arxiv.org/abs/2403.11338)]
- Covid-19 test using domain adaptation 使用集成和测试增强用于DA covid-19
- V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions [[arxiv](https://arxiv.org/abs/2403.11371)]
- DG for multi-agent perception 领域泛化用于极端天气
- Bidirectional Multi-Step Domain Generalization for Visible-Infrared Person Re-Identification [[arxiv](https://arxiv.org/abs/2403.10782)]
- Bidirectional multi-step DG for REID 双向领域泛化用于REID
- MedMerge: Merging Models for Effective Transfer Learning to Medical Imaging Tasks [[arxiv](https://arxiv.org/abs/2403.11646)]
- Model merge for medical transfer learning 通过模型合并进行医学迁移学习
- SPA: A Graph Spectral Alignment Perspective for Domain Adaptation [[NeurIPS 2023]](https://arxiv.org/abs/2310.17594) [[Pytorch]](https://github.com/CrownX/SPA)
- Graph spectral alignment and neighbor-aware propagation for domain adaptation
- Addressing Source Scale Bias via Image Warping for Domain Adaptation [[arxiv](https://arxiv.org/abs/2403.12712)]
- Address the source scale bias for domain adaptation 解决源域的scale bias
- ICLR'24 扩展版 Learning with Noisy Foundation Models [[arxiv](https://arxiv.org/abs/2403.06869)]
- Fine-tune a noisy foundation model 基础模型有noisy的时候如何finetune
- Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation [[arxiv](https://arxiv.org/abs/2403.10001)]
- Foundation models help domain adaptation 基础模型帮助领域自适应
- Attention Prompt Tuning: Parameter-efficient Adaptation of Pre-trained Models for Spatiotemporal Modeling [[arxiv](https://arxiv.org/abs/2403.06978)]
- Parameter-efficient adaptation for spatiotemporal modeling
- ICASSP'24 Test-time Distribution Learning Adapter for Cross-modal Visual Reasoning [[arxiv](https://arxiv.org/abs/2403.06059)]
- Test-time distribution learning adapter
- A Study on Domain Generalization for Failure Detection through Human Reactions in HRI [[arxiv](https://arxiv.org/abs/2403.06315)]
- Domain generalization for failure detection through human reactions in HRI
- ICLR'24 Towards Robust Out-of-Distribution Generalization Bounds via Sharpness [[arxiv](https://arxiv.org/abs/2403.06392)]
- Robust OOD generalization bounds
- Learning with Noisy Foundation Models [[arxiv](https://arxiv.org/abs/2403.06869)]
- Learning with noisy foundation models
## 2024-02
- Unsupervised Domain Adaptation within Deep Foundation Latent Spaces [[arxiv](https://arxiv.org/abs/2402.14976)]
- Domain adaptation using foundation models
## 2024-01
- Facing the Elephant in the Room: Visual Prompt Tuning or Full Finetuning? [[arxiv](https://arxiv.org/abs/2401.12902)]
- A comparison between visual prompt tuning and full finetuning 比较prompt tuning和全finetune
- Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy [[arxiv](https://arxiv.org/abs/2401.12129)]
- OOD detection for ablated learned temperature energy
- LanDA: Language-Guided Multi-Source Domain Adaptation [[arxiv](https://arxiv.org/abs/2401.14148)]
- Language guided multi-source DA 在多源域自适应中使用语言指导
- AdaEmbed: Semi-supervised Domain Adaptation in the Embedding Space [[arxiv](https://arxiv.org/abs/2401.12421)]
- Semi-spuervised domain adaptation in the embedding space 在嵌入空间中进行半监督域自适应
- Inter-Domain Mixup for Semi-Supervised Domain Adaptation [[arxiv](https://arxiv.org/abs/2401.11453)]
- Inter-domain mixup for semi-supervised domain adaptation 跨领域mixup用于半监督域自适应
- Source-Free and Image-Only Unsupervised Domain Adaptation for Category Level Object Pose Estimation [[arxiv](https://arxiv.org/abs/2401.10848)]
- Source-free and image-only unsupervised domain adaptation
- ICLR'24 spotlight Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks [[arxiv](https://arxiv.org/abs/2309.17002)]
- A new research direction of transfer learning in the era of foundation models 大模型时代一个新研究方向:研究预训练数据的噪声对下游任务影响
- ICLR'24 Supervised Knowledge Makes Large Language Models Better In-context Learners [[arxiv](https://arxiv.org/abs/2312.15918)]
- Small models help large language models for better OOD 用小模型帮助大模型进行更好的OOD
- NeurIPS'23 Geodesic Multi-Modal Mixup for Robust Fine-Tuning [[paper](https://openreview.net/forum?id=iAAXq60Bw1)]
- Geodesic mixup for robust fine-tuning
- NeurIPS'23 Parameter and Computation Efficient Transfer Learning for Vision-Language Pre-trained Models [[paper](https://openreview.net/forum?id=TPeAmxwPK2)]
- Parameter and computation efficient transfer learning by reinforcement learning
- NeurIPS'23 Test-Time Distribution Normalization for Contrastively Learned Visual-language Models [[paper](https://openreview.net/forum?id=VKbEO2eh5w)]
- Test-time distribution normalization for contrastively learned VLM
- NeurIPS'23 A Closer Look at the Robustness of Contrastive Language-Image Pre-Training (CLIP) [[paper](https://openreview.net/forum?id=wMNpMe0vp3)]
- A fine-gained analysis of CLIP robustness
- NeurIPS'23 When Visual Prompt Tuning Meets Source-Free Domain Adaptive Semantic Segmentation [[paper](https://openreview.net/forum?id=ChGGbmTNgE)]
- Source-free domain adaptation using visual prompt tuning
- NeurIPS'23 CODA: Generalizing to Open and Unseen Domains with Compaction and Disambiguation [[arxiv](https://openreview.net/forum?id=Jw0KRTjsGA)]
- Open set domain generalization using extra classes
- CPAL'24 FIXED: Frustratingly Easy Domain Generalization with Mixup [[arxiv](https://arxiv.org/abs/2211.05228)]
- Easy domain generalization with mixup
- SDM'24 Towards Optimization and Model Selection for Domain Generalization: A Mixup-guided Solution [[arxiv](https://arxiv.org/abs/2209.00652)]
- Optimization and model selection for domain generalization
- Leveraging SAM for Single-Source Domain Generalization in Medical Image Segmentation [[arxiv](https://arxiv.org/abs/2401.02076)]
- SAM for single-source domain generalization
- Multi-Source Domain Adaptation with Transformer-based Feature Generation for Subject-Independent EEG-based Emotion Recognition [[arxiv](https://arxiv.org/abs/2401.02344)]
- Multi-source DA with Transformer-based feature generation
## 2023-12
- Multi-Modal Domain Adaptation Across Video Scenes for Temporal Video Grounding [[arxiv](https://arxiv.org/abs/2312.13633)]
- Multi-modal domain adaptation 多模态领域自适应
- Domain Adaptive Graph Classification [[arxiv](https://arxiv.org/abs/2312.13536)]
- Domain adaptive graph classification 域适应的图分类
- Understanding and Estimating Domain Complexity Across Domains [[arxiv](https://arxiv.org/abs/2312.13487)]
- Understanding and estimating domain complexity 解释领域复杂性
- Prompt-based Domain Discrimination for Multi-source Time Series Domain Adaptation [[arxiv](https://arxiv.org/abs/2312.12276v1)]
- Prompt-based domain discrimination for time series domain adaptation 基于prompt的时间序列域自适应
- NeurIPS'23 SwapPrompt: Test-Time Prompt Adaptation for Vision-Language Models [[arxiv](https://openreview.net/forum?id=EhdNQiOWgQ)]
- Test-time prompt adaptation for vision language models 对视觉-语言大模型的测试时prompt自适应
- AAAI24 Relax Image-Specific Prompt Requirement in SAM: A Single Generic Prompt for Segmenting Camouflaged Objects [[arxiv](https://arxiv.org/abs/2312.07374)][[code](https://github.com/jyLin8100/GenSAM)]
- A training-free test-time adaptation approach to relax the instance-specific prompts requirment in SAM.
- Open Domain Generalization with a Single Network by Regularization Exploiting Pre-trained Features [[arxiv](http://arxiv.org/abs/2312.05141)]
- Open domain generalization with a single network 用单一网络结构进行开放式domain generalizaition
- Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation [[arxiv](http://arxiv.org/abs/2312.04265)]
- Using vision foundation models for domain genealized semantic segmentation 用视觉基础模型进行域泛化语义分割
- DARNet: Bridging Domain Gaps in Cross-Domain Few-Shot Segmentation with Dynamic Adaptation [[arxiv](http://arxiv.org/abs/2312.04813)]
- Dynamic adaptation for cross-domain few-shot segmentation 动态适配用于跨领域小样本分割
- A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting [[arxiv](http://arxiv.org/abs/2312.05024)]
- Instance weighting for domain adaptation 样本加权用于领域自适应
- Target-agnostic Source-free Domain Adaptation for Regression Tasks [[arxiv](http://arxiv.org/abs/2312.00540)]
- Target-agnostic source-free DA for regression 用于回归任务的source-free DA
- On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals [[arxiv](http://arxiv.org/abs/2312.00502)]
- OOD robustness for self-supervised learning for phonocardiogram 心音图信号自监督的OOD鲁棒性
- Student Activity Recognition in Classroom Environments using Transfer Learning [[arxiv](http://arxiv.org/abs/2312.00348)]
- Using transfer learning to recognize student activities 用迁移学习来识别学生课堂行为
## 2023-11
- A2XP: Towards Private Domain Generalization [[arxiv](https://arxiv.org/abs/2311.10339)]
- Private domain generalization 隐私保护的domain generalization
- Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation [[arxiv](http://arxiv.org/abs/2311.05858)]
- Auto-weighting for test-time adaptation 自动权重的TTA
- Domain Generalization by Learning from Privileged Medical Imaging Information [[arxiv](http://arxiv.org/abs/2311.05861)]
- Domain generalizaiton by learning from privileged medical imageing inforamtion
- SSL-DG: Rethinking and Fusing Semi-supervised Learning and Domain Generalization in Medical Image Segmentation [[arxiv](https://arxiv.org/abs/2311.02583)]
- Semi-supervised learning + domain generalization 把半监督和领域泛化结合在一起
- WACV'24 Learning Class and Domain Augmentations for Single-Source Open-Domain Generalization [[arxiv](https://arxiv.org/abs/2311.02599)]
- Class and domain augmentation for single-source open-domain DG 结合类和domain增强做单源DG
- Proposal-Level Unsupervised Domain Adaptation for Open World Unbiased Detector [[arxiv](https://arxiv.org/abs/2311.02342)]
- Proposal-level unsupervised domain adaptation
- Robust Fine-Tuning of Vision-Language Models for Domain Generalization [[arxiv](https://arxiv.org/abs/2311.02236)]
- Robust fine-tuning for domain generalization 用于领域泛化的鲁棒微调
- NeurIPS 2023 Distilling Out-of-Distribution Robustness from Vision-Language Foundation Models [[arxiv](https://arxiv.org/abs/2311.01441)]
- Distill OOD robustness from vision-language foundational models 从VLM模型中蒸馏出OOD鲁棒性
- UbiComp 2024 Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition [[arxiv](https://arxiv.org/abs/2310.18562)]
- Test-time adaptation for activity recognition 测试时adaptation用于行为识别
## 2023-10
- PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization [[arxiv](https://arxiv.org/abs/2307.15199)]
- Prompt-driven style generation for source-free domain generalization
- A Survey of Heterogeneous Transfer Learning [[arxiv](https://arxiv.org/abs/2310.08459v2)]
- A recent survey of heterogeneous transfer learning 一篇最近的关于异构迁移学习的综述
- Equivariant Adaptation of Large Pre-Trained Models [[arxiv](http://arxiv.org/abs/2310.01647)]
- Equivariant adaptation of large pre-trained models 对大模型进行等边自适应
- Effective and Parameter-Efficient Reusing Fine-Tuned Models [[arxiv](http://arxiv.org/abs/2310.01886)]
- Effective and parameter-efficient reusing fine-tuned models 高效使用预训练模型
- Prompting-based Efficient Temporal Domain Generalization [[arxiv](http://arxiv.org/abs/2310.02473)]
- Prompt based temporal domain generalization 基于prompt的时间域domain generalization
- Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks [[arxiv](https://arxiv.org/abs/2309.17002)]
- Noisy model learning: fine-tuning to supress the bad effect of noisy pretraining data 通过使用轻量级finetune减少噪音预训练数据对下游任务的影响
- ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning [[arxiv](https://arxiv.org/abs/2310.05143)]
- Black-box foundation models for personalized federated learning 黑盒的blackbox模型进行个性化迁移学习
## 2023-09
- Domain Generalization with Fourier Transform and Soft Thresholding [[arxiv](http://arxiv.org/abs/2309.09866)]
- Domain generalization with Fourier transform 基于傅里叶变换和软阈值进行domain generalization
- DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning [[arxiv](http://arxiv.org/abs/2309.05173)]
- Decomposed prompt tuning for parameter-efficient fine-tuning 基于分解prompt tuning的参数高效微调
- Better Practices for Domain Adaptation [[arxiv](http://arxiv.org/abs/2309.03879)]
- Better practice for domain adaptation
- Domain Adaptation for Efficiently Fine-tuning Vision Transformer with Encrypted Images [[arxiv](http://arxiv.org/abs/2309.02556)]
- Domain adaptation for efficient ViT
- Robust Activity Recognition for Adaptive Worker-Robot Interaction using Transfer Learning [[arxiv](http://arxiv.org/abs/2308.14843)]
- Activity recognition using domain adaptation
## 2023-08
- IJCV'23 Exploring Vision-Language Models for Imbalanced Learning [[arxiv](https://arxiv.org/abs/2304.01457)] [[code](https://github.com/Imbalance-VLM/Imbalance-VLM)]
- Explore vision-language models for imbalanced learning 探索视觉大模型在不平衡问题上的表现
- ICCV'23 Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning [[arxiv](https://arxiv.org/abs/2308.02533)] [[code](https://github.com/microsoft/robustlearn)]
- 达到对抗鲁棒性和泛化能力的trade off
- ICCV'23 Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation [[arxiv](https://arxiv.org/abs/2308.14023)]
- Domain-specificity for source-free DA 用领域特异性驱动的source-free DA
- Unsupervised Domain Adaptation via Domain-Adaptive Diffusion [[arxiv](http://arxiv.org/abs/2308.13893)]
- Domain-adaptive diffusion for domain adaptation 领域自适应的diffusion
- Multi-Scale and Multi-Layer Contrastive Learning for Domain Generalization [[arxiv](http://arxiv.org/abs/2308.14418)]
- Multi-scale and multi-layer contrastive learning for DG 多尺度和多层对比学习用于DG
- Exploring the Transfer Learning Capabilities of CLIP in Domain Generalization for Diabetic Retinopathy [[arxiv](http://arxiv.org/abs/2308.14212)]
- Domain generalization for diabetic retinopathy 用领域泛化进行糖尿病视网膜病
- Federated Fine-tuning of Billion-Sized Language Models across Mobile Devices [[arxiv](http://arxiv.org/abs/2308.13894)]
- Federated fine-tuning for large models 大模型联邦微调
- Source-Free Collaborative Domain Adaptation via Multi-Perspective Feature Enrichment for Functional MRI Analysis [[arxiv](http://arxiv.org/abs/2308.12495)]
- Source-free domain adaptation for MRI analysis
- Towards Realistic Unsupervised Fine-tuning with CLIP [[arxiv](http://arxiv.org/abs/2308.12919)]
- Unsupervised fine-tuning of CLIP
- Fine-tuning can cripple your foundation model; preserving features may be the solution [[arxiv](http://arxiv.org/abs/2308.13320)]
- Fine-tuning will cripple foundation model
- Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models [[arxiv](http://arxiv.org/abs/2308.07706)]
- Transfer learning for medical image segmentation
- Transfer Learning for Portfolio Optimization [[arxiv](http://arxiv.org/abs/2307.13546)]
- Transfer learning for portfolio optimization
- NormAUG: Normalization-guided Augmentation for Domain Generalization [[arxiv](http://arxiv.org/abs/2307.13492)]
- Normalization augmentation for domain generalization
## 2023-07
- Benchmarking Algorithms for Federated Domain Generalization [[arxiv](http://arxiv.org/abs/2307.04942)]
- Benchmark algorthms for federated domain generalization 对联邦域泛化算法进行的benchmark
- DISPEL: Domain Generalization via Domain-Specific Liberating [[arxiv](http://arxiv.org/abs/2307.07181)]
- Domain generalization via domain-specific liberating
- Review of Large Vision Models and Visual Prompt Engineering [[arxiv](https://arxiv.org/abs/2307.00855)]
- A survey of large vision model and prompt tuning 一个关于大视觉模型的prompt tuning的综述
- Intra- & Extra-Source Exemplar-Based Style Synthesis for Improved Domain Generalization [[arxiv](https://arxiv.org/abs/2307.00648)]
- Exemplar-based style synthesis for domain generalization 样例格式合成用于DG
- SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation [[arxiv](https://arxiv.org/abs/2307.01024)]
- Using SAM for domain adaptation 使用segment anything进行domain adaptation
- Unified Transfer Learning Models for High-Dimensional Linear Regression [[arxiv](https://arxiv.org/abs/2307.00238)]
- Transfer learning for high-dimensional linar regression 迁移学习用于高维线性回归
## 2023-06
- Pruning for Better Domain Generalizability [[arxiv](http://arxiv.org/abs/2306.13237)]
- Using pruning for better domain generalization 使用剪枝操作进行domain generalization
- TMLR'23 Generalizability of Adversarial Robustness Under Distribution Shifts [[openreview](https://openreview.net/forum?id=XNFo3dQiCJ)]
- Evaluate the OOD perormance of adversarial training 评测对抗训练模型的OOD鲁棒性
- Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning [[arxiv](http://arxiv.org/abs/2303.15647)]
- A guide for parameter-efficient fine-tuning 一个对parameter efficient fine-tuning的全面介绍
- ICML'23 A Kernel-Based View of Language Model Fine-Tuning [[arxiv](http://arxiv.org/abs/2210.05643)]
- A kernel-based view of language model fine-tuning 一种以kernel的视角来看待fine-tuning的方法
- ICML'23 Improving Visual Prompt Tuning for Self-supervised Vision Transformers [[arxiv](http://arxiv.org/abs/2306.05067)]
- Improving visual prompt tuning for self-supervision 为自监督模型提高其 prompt tuning 表现
- Cross-Database and Cross-Channel ECG Arrhythmia Heartbeat Classification Based on Unsupervised Domain Adaptation [[arxiv](http://arxiv.org/abs/2306.04433)]
- EEG using unsupervised domain adaptation 用无监督DA来进行EEG心跳分类
- Real-Time Online Unsupervised Domain Adaptation for Real-World Person Re-identification [[arxiv](http://arxiv.org/abs/2306.03993)]
- Real-time online unsupervised domain adaptation for REID 无监督DA用于REID
- Federated Domain Generalization: A Survey [[arxiv](http://arxiv.org/abs/2306.01334)]
- A survey on federated domain generalization 一篇关于联邦域泛化的综述
- Domain Generalization for Domain-Linked Classes [[arxiv](http://arxiv.org/abs/2306.00879)]
- Domain generalization for domain-linked classes
- Can We Evaluate Domain Adaptation Models Without Target-Domain Labels? A Metric for Unsupervised Evaluation of Domain Adaptation [[arxiv](http://arxiv.org/abs/2305.18712)]
- Evaluate domain adaptation models 评测domain adaptation的模型
- Universal Test-time Adaptation through Weight Ensembling, Diversity Weighting, and Prior Correction [[arxiv](http://arxiv.org/abs/2306.00650)]
- Universal test-time adaptation
- Adapting Pre-trained Language Models to Vision-Language Tasks via Dynamic Visual Prompting [[arxiv](http://arxiv.org/abs/2306.00409)]
- Using dynamic visual prompting for model adaptation 用动态视觉prompt进行模型适配
## 2023-05
- Selective Mixup Helps with Distribution Shifts, But Not (Only) because of Mixup [[arxiv](https://arxiv.org/abs/2305.16817)]
- Why mixup works for domain generalization? 系统性研究为啥mixup对OOD很work
- ACL'23 Parameter-Efficient Fine-Tuning without Introducing New Latency [[arxiv](http://arxiv.org/abs/2305.16742)]
- Parameter-efficient finetuning 参数高效的finetune
- Universal Domain Adaptation from Foundation Models [[arxiv](http://arxiv.org/abs/2305.11092)]
- Using foundation models for universal domain adaptation
- Ahead-of-Time P-Tuning [[arxiv](http://arxiv.org/abs/2305.10835)]
- Ahead-ot-time P-tuning for language models
- Multi-Source to Multi-Target Decentralized Federated Domain Adaptation [[arxiv](http://arxiv.org/abs/2304.12422)]
- Decentralized federated domain adaptation
- Benchmarking Low-Shot Robustness to Natural Distribution Shifts [[arxiv](http://arxiv.org/abs/2304.11263)]
- Low-shot robustness to distribution shifts
## 2023-04
- Multi-Source to Multi-Target Decentralized Federated Domain Adaptation [[arxiv](https://arxiv.org/abs/2304.12422)]
- Multi-source to multi-target federated domain adaptation 多源多目标的联邦域自适应
- ICML'23 AdaNPC: Exploring Non-Parametric Classifier for Test-Time Adaptation [[arxiv](https://arxiv.org/abs/2304.12566)]
- Adaptive test-time adaptation 非参数化分类器进行测试时adaptation
- Improved Test-Time Adaptation for Domain Generalization [[arxiv](http://arxiv.org/abs/2304.04494)]
- Improved test-time adaptation for domain generalization
- Reweighted Mixup for Subpopulation Shift [[arxiv](http://arxiv.org/abs/2304.04148)]
- Reweighted mixup for subpopulation shift
- CVPR'23 Zero-shot Generative Model Adaptation via Image-specific Prompt Learning [[arxiv](http://arxiv.org/abs/2304.03119)]
- Zero-shot generative model adaptation via image-specific prompt learning 零样本的生成模型adaptation
- Source-free Domain Adaptation Requires Penalized Diversity [[arxiv](http://arxiv.org/abs/2304.02798)]
- Source-free DA requires penalized diversity
- Domain Generalization with Adversarial Intensity Attack for Medical Image Segmentation [[arxiv](http://arxiv.org/abs/2304.02720)]
- Domain generalization for medical segmentation 用domain generalization进行医学分割
- CVPR'23 Meta-causal Learning for Single Domain Generalization [[arxiv](http://arxiv.org/abs/2304.03709)]
- Meta-causal learning for domain generalization
- Domain Generalization In Robust Invariant Representation [[arxiv](http://arxiv.org/abs/2304.03431)]
- Domain generalization in robust invariant representation
- Beyond Empirical Risk Minimization: Local Structure Preserving Regularization for Improving Adversarial Robustness [[arxiv](http://arxiv.org/abs/2303.16861)]
- Local structure preserving for adversarial robustness 通过保留局部结构来进行对抗鲁棒性
- TFS-ViT: Token-Level Feature Stylization for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.15698)]
- Token-level feature stylization for domain generalization 用token-level特征变换进行domain generalization
- Are Data-driven Explanations Robust against Out-of-distribution Data? [[arxiv](http://arxiv.org/abs/2303.16390)]
- Data-driven explanations robust? 探索数据驱动的解释是否是OOD鲁棒的
- ERM++: An Improved Baseline for Domain Generalization [[arxiv](http://arxiv.org/abs/2304.01973)]
- Improved ERM for domain generalization 提高的ERM用于domain generalization
- CVPR'23 Feature Alignment and Uniformity for Test Time Adaptation [[arxiv](http://arxiv.org/abs/2303.10902)]
- Feature alignment for test-time adaptation 使用特征对齐进行测试时adaptation
- Finding Competence Regions in Domain Generalization [[arxiv](http://arxiv.org/abs/2303.09989)]
- Finding competence regions in domain generalization 在DG中发现能力区域
- CVPR'23 TWINS: A Fine-Tuning Framework for Improved Transferability of Adversarial Robustness and Generalization [[arxiv](http://arxiv.org/abs/2303.11135)]
- Improve generalization and adversarial robustness 同时提高鲁棒性和泛化性
- CVPR'23 Trainable Projected Gradient Method for Robust Fine-tuning [[arxiv](http://arxiv.org/abs/2303.10720)]
- Trainable PGD for robust fine-tuning 可训练的pgd用于鲁棒的微调技术
- Parameter-Efficient Tuning Makes a Good Classification Head [[arxiv](http://arxiv.org/abs/2210.16771)]
- Parameter-efficient tuning makes a good classification head 参数高效的迁移学习成就一个好的分类头
- Complementary Domain Adaptation and Generalization for Unsupervised Continual Domain Shift Learning [[arxiv](http://arxiv.org/abs/2303.15833)]
- Continual domain shift learning using adaptation and generalization 使用 adaptation和DG进行持续分布变化的学习
## 2023-03
- CVPR'23 A New Benchmark: On the Utility of Synthetic Data with Blender for Bare Supervised Learning and Downstream Domain Adaptation [[arxiv](http://arxiv.org/abs/2303.09165)]
- A new benchmark for domain adaptation 一个对于domain adaptation最新的benchmark
- Unsupervised domain adaptation by learning using privileged information [[arxiv](http://arxiv.org/abs/2303.09350)]
- Domain adaptation by privileged information 使用高级信息进行domain adaptation
- A Unified Continual Learning Framework with General Parameter-Efficient Tuning [[arxiv](http://arxiv.org/abs/2303.10070)]
- A continual learning framework for parameter-efficient tuning 一个对于参数高效迁移的连续学习框架
- CVPR'23 Sharpness-Aware Gradient Matching for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.10353)]
- Sharpness-aware gradient matching for DG 利用梯度匹配进行domain generalization
- TempT: Temporal consistency for Test-time adaptation [[arxiv](http://arxiv.org/abs/2303.10536)]
- Temporeal consistency for test-time adaptation 时间一致性用于test-time adaptation
- TMLR'23 Learn, Unlearn and Relearn: An Online Learning Paradigm for Deep Neural Networks [[arxiv](http://arxiv.org/abs/2303.10455)]
- A framework for online learning 一个在线学习的框架
- ICLR'23 workshop SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models [[arxiv](http://arxiv.org/abs/2303.10464)]
- Sparse pre-training and dense fine-tuning
- CVPR'23 ALOFT: A Lightweight MLP-like Architecture with Dynamic Low-frequency Transform for Domain Generalization [[arxiv](http://arxiv.org/abs/2303.11674)]
- A lightweight module for domain generalization 一个用于DG的轻量级模块
- ICLR'23 Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning [[arxiv](http://arxiv.org/abs/2303.11866)]
- Contrastive alignment for vision language models using transfer learning 使用参数高效迁移进行视觉语言模型的对比对齐
- Probabilistic Domain Adaptation for Biomedical Image Segmentation [[arxiv](http://arxiv.org/abs/2303.11790)]
- Probabilistic domain adaptation for biomedical image segmentation 概率的domain adaptation用于生物医疗图像分割
- Imbalanced Domain Generalization for Robust Single Cell Classification in Hematological Cytomorphology [[arxiv](https://arxiv.org/abs/2303.07771)]
- Imbalanced domain generalization for single cell classification 不平衡的DG用于单细胞分类
- Revisit Parameter-Efficient Transfer Learning: A Two-Stage Paradigm [[arxiv](https://arxiv.org/abs/2303.07910)]
- Parameter-efficient transfer learning: a two-stage approach 一种两阶段的参数高效迁移学习
- Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow [[arxiv](https://arxiv.org/abs/2303.07564)]
- Domain adaptation for foggy scene optical flow 领域自适应用于雾场景的光流
- ICLR'23 AutoTransfer: AutoML with Knowledge Transfer -- An Application to Graph Neural Networks [[arxiv](https://arxiv.org/abs/2303.07669)]
- GNN with autoML transfer learning 用于GNN的自动迁移学习
- Transfer Learning for Real-time Deployment of a Screening Tool for Depression Detection Using Actigraphy [[arxiv](https://arxiv.org/abs/2303.07847)]
- Transfer learning for Depression detection 迁移学习用于脉动计焦虑检测
- Domain Generalization via Nuclear Norm Regularization [[arxiv](https://arxiv.org/abs/2303.07527)]
- Domain generalization via nuclear norm regularization 使用核归一化进行domain generalization
- To Stay or Not to Stay in the Pre-train Basin: Insights on Ensembling in Transfer Learning [[arxiv](https://arxiv.org/abs/2303.03374)]
- Ensembling in transfer learning 调研迁移学习中的集成
- CVPR'13 Masked Images Are Counterfactual Samples for Robust Fine-tuning [[arxiv](https://arxiv.org/abs/2303.03052)]
- Masked images for robust fine-tuning 调研masked image对于fine-tuning的影响
- FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning [[arxiv](https://arxiv.org/abs/2302.13485v1)]
- Fast generalization for federated CLIP 在联邦中进行快速的CLIP训练
- Robust Representation Learning with Self-Distillation for Domain Generalization [[arxiv](http://arxiv.org/abs/2302.06874)]
- Robust representation learning with self-distillation
- ICLR-23 Temporal Coherent Test-Time Optimization for Robust Video Classification [[arxiv](http://arxiv.org/abs/2302.14309)]
- Temporal distribution shift in video classification
- WSDM-23 A tutorial on domain generalization [[link](https://dl.acm.org/doi/10.1145/3539597.3572722)] | [[website](https://dgresearch.github.io/)]
- A tutorial on domain generalization
## 2023-02
- On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective [[arxiv](https://arxiv.org/abs/2302.12095)] | [[code](https://github.com/microsoft/robustlearn)]
- Adversarial and OOD evaluation of ChatGPT 对ChatGPT鲁棒性的评测
- Transfer learning for process design with reinforcement learning [[arxiv](https://arxiv.org/abs/2302.03375)]
- Transfer learning for process design with reinforcement learning 使用强化迁移学习进行过程设计
- Domain Adaptation for Time Series Under Feature and Label Shifts [[arxiv](https://arxiv.org/abs/2302.03133)]
- Domain adaptation for time series 用于时间序列的domain adaptation
- How Reliable is Your Regression Model's Uncertainty Under Real-World Distribution Shifts? [[arxiv](https://arxiv.org/abs/2302.03679)]
- Regression models uncertainty for distribution shift 回归模型对于分布漂移的不确定性
- ICLR'23 SoftMatch: Addressing the Quantity-Quality Tradeoff in Semi-supervised Learning [[arxiv](https://arxiv.org/abs/2301.10921)]
- Semi-supervised learning algorithm 解决标签质量问题的半监督学习方法
- Empirical Study on Optimizer Selection for Out-of-Distribution Generalization [[arxiv](http://arxiv.org/abs/2211.08583)]
- Opimizer selection for OOD generalization OOD泛化中的学习器选择
- ICML'22 Understanding the failure modes of out-of-distribution generalization [[arxiv](https://openreview.net/forum?id=fSTD6NFIW_b)]
- Understand the failure modes of OOD generalization 探索OOD泛化中的失败现象
- ICLR'23 Out-of-distribution Representation Learning for Time Series Classification [[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 时间序列分类的OOD算法
## 2023-01
- ICLR'23 FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning [[arxiv](https://arxiv.org/abs/2205.07246)]
- New baseline for semi-supervised learning 半监督学习新算法
- CLIP the Gap: A Single Domain Generalization Approach for Object Detection [[arxiv](https://arxiv.org/abs/2301.05499)]
- Using CLIP for domain generalization object detection 使用CLIP进行域泛化的目标检测
- Language-Informed Transfer Learning for Embodied Household Activities [[arxiv](https://arxiv.org/abs/2301.05318)]
- Transfer learning for robust control in household 在家居机器人上使用强化迁移学习
- Does progress on ImageNet transfer to real-world datasets? [[arxiv](https://arxiv.org/abs/2301.04644)]
- ImageNet accuracy does not transfer to down-stream tasks
- TPAMI'23 Source-Free Unsupervised Domain Adaptation: A Survey [[arxiv](http://arxiv.org/abs/2301.00265)]
- A survey on source-free domain adaptation 关于source-free DA的一个最新综述
- Discriminative Radial Domain Adaptation [[arxiv](http://arxiv.org/abs/2301.00383)]
- Discriminative radial domain adaptation 判别性的放射式domain adaptation
## 2022-12
- WACV'23 Cross-Domain Video Anomaly Detection without Target Domain Adaptation [[arxiv](https://arxiv.org/abs/2212.07010)]
- Cross-domain video anomaly detection without target domain adaptation 跨域视频异常检测
- Co-Learning with Pre-Trained Networks Improves Source-Free Domain Adaptation [[arxiv](https://arxiv.org/abs/2212.07585)]
- Pre-trained models for source-free domain adaptation 用预训练模型进行source-free DA
- TMLR'22 A Unified Survey on Anomaly, Novelty, Open-Set, and Out of-Distribution Detection: Solutions and Future Challenges [[openreview](https://openreview.net/forum?id=aRtjVZvbpK)]
- A recent survey on OOD/anomaly detection 一篇最新的关于OOD/anomaly detection的综述
- NeurIPS'18 A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks [[paper](https://proceedings.neurips.cc/paper/2018/hash/abdeb6f575ac5c6676b747bca8d09cc2-Abstract.html)]
- Using class-conditional distribution for OOD detection 使用类条件概率进行OOD检测
- ICLR'22 Discrete Representations Strengthen Vision Transformer Robustness [[arxiv](http://arxiv.org/abs/2111.10493)]
- Embed discrete representation for OOD generalization 在ViT中加入离散表征增强OOD性能
- CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars [[arxiv](https://arxiv.org/abs/2212.00621)]
- Continual DA for self-driving cars 连续的domain adaptation用于自动驾驶
- Finetune like you pretrain: Improved finetuning of zero-shot vision models [[arxiv]](http://arxiv.org/abs/2212.00638)]
- Improved fine-tuning of zero-shot models 针对zero-shot model提高fine-tuneing
## 2022-11
- ECCV-22 DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation [[arXiv](https://arxiv.org/pdf/2207.09988.pdf)] [[Code](https://github.com/dvlab-research/DecoupleNet)]
- Domain adaptation in semantic segmentation 语义分割域适应
- Robust Mean Teacher for Continual and Gradual Test-Time Adaptation [[arxiv](https://arxiv.org/abs/2211.13081)]
- Mean teacher for test-time adaptation 在测试时用mean teacher进行适配
- Learning to Learn Domain-invariant Parameters for Domain Generalization [[arxiv](Learning to Learn Domain-invariant Parameters for Domain Generalization)]
- Learning to learn domain-invariant parameters for DG 元学习进行domain generalization
- HMOE: Hypernetwork-based Mixture of Experts for Domain Generalization [[arxiv](https://arxiv.org/abs/2211.08253)]
- Hypernetwork-based ensembling for domain generalization 超网络构成的集成学习用于domain generalization
- The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning [[arxiv](https://arxiv.org/abs/2106.15831)]
- OOD using fine-tuning 系统总结了基于fine-tuning进行OOD的一些结果
- GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective [[arxiv](https://arxiv.org/abs/2211.08073)]
- OOD for natural language processing evaluation 提出GLUE-X用于OOD在NLP数据上的评估
- CVPR'22 Delving Deep Into the Generalization of Vision Transformers Under Distribution Shifts [[arxiv](https://openaccess.thecvf.com/content/CVPR2022/html/Zhang_Delving_Deep_Into_the_Generalization_of_Vision_Transformers_Under_Distribution_CVPR_2022_paper.html)]
- Vision transformers generalization under distribution shifts 评估ViT的分布漂移
- NeurIPS'22 Models Out of Line: A Fourier Lens on Distribution Shift Robustness [[arxiv](https://openreview.net/forum?id=YZ-N-sejjwO)]
- A fourier lens on distribution shift robustness 通过傅里叶视角来看分布漂移的鲁棒性
- CVPR'22 Does Robustness on ImageNet Transfer to Downstream Tasks? [[arxiv](https://openaccess.thecvf.com/content/CVPR2022/papers/Yamada_Does_Robustness_on_ImageNet_Transfer_to_Downstream_Tasks_CVPR_2022_paper.pdf)]
- Does robustness on imagenet transfer lto downstream tasks?
- Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts [[arxiv](https://arxiv.org/abs/2211.04393)]
- Normalization perturbation for domain generalization 通过归一化扰动来进行domain generalization
- FIXED: Frustraitingly easy domain generalization using Mixup [[arxiv](https://arxiv.org/pdf/2211.05228.pdf)]
- 使用Mixup进行domain generalization
- Learning to Learn Domain-invariant Parameters for Domain Generalization [[arxiv](https://arxiv.org/abs/2211.04582)]
- Learning to learn domain-invariant parameters for domain generalization
- NeurIPS'22 Improved Fine-Tuning by Better Leveraging Pre-Training Data [[openreview](https://openreview.net/forum?id=YTXIIc7cAQ)]
- Using pre-training data for fine-tuning 用预训练数据来做微调
- NeurIPS'22 Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning [[openreview](https://openreview.net/forum?id=NjImFaBEHl)]
- Adaptive contrastive learning for source-free DA 自适应的对比学习用于source-free DA
- NeurIPS'22 LOG: Active Model Adaptation for Label-Efficient OOD Generalization [[openreview](https://openreview.net/forum?id=VdQWVdT_8v)]
- Model adaptation for label-efficient OOD generalization
- NeurIPS'22 MetaTeacher: Coordinating Multi-Model Domain Adaptation for Medical Image Classification [[openreview](https://openreview.net/forum?id=AQd4ugzALQ1)]
- Multi-model domain adaptation mor medical image classification 多模型DA用于医疗数据
- NeurIPS'22 Domain Adaptation under Open Set Label Shift [[openreview](https://openreview.net/forum?id=OMZG4vsKmm7)]
- Domain adaptation under open set label shift 在开放集的label shift中的DA
- NeurIPS'22 Domain Generalization without Excess Empirical Risk [[openreview](https://openreview.net/forum?id=pluyPFTiTeJ)]
- Domain generalization without excess empirical risk
- NeurIPS'22 FedSR: A Simple and Effective Domain Generalization Method for Federated Learning [[openreview](https://openreview.net/forum?id=mrt90D00aQX)]
- FedSR for federated learning domain generalization 用于联邦学习的domain generalization
- NeurIPS'22 Probable Domain Generalization via Quantile Risk Minimization [[openreview](https://openreview.net/forum?id=6FkSHynJr1)]
- Domain generalization with quantile risk minimization 用quantile风险最小化的domain generalization
- NeurIPS'22 Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer [[arxiv](http://arxiv.org/abs/2211.00789)]
- Continual learning with backward knowledge transfer 反向知识迁移的持续学习
- NeurIPS'22 Test Time Adaptation via Conjugate Pseudo-labels [[openreview](https://openreview.net/forum?id=2yvUYc-YNUH)]
- Test-time adaptation with conjugate pseudo-labels 用伪标签进行测试时adaptation
- NeurIPS'22 Your Out-of-Distribution Detection Method is Not Robust! [[openreview](https://openreview.net/forum?id=YUEP3ZmkL1)]
- OOD models are not robust 分布外泛化模型不够鲁棒
## 2022-10
- NeurIPS'22 Respecting Transfer Gap in Knowledge Distillation [[arxiv](http://arxiv.org/abs/2210.12787)]
- Transfer gap in distillation 知识蒸馏中的迁移gap
- Transfer of Machine Learning Fairness across Domains [[arxiv](http://arxiv.org/abs/1906.09688)]
- Fairness transfer in transfer learning 迁移学习中的公平性迁移
- On Fine-Tuned Deep Features for Unsupervised Domain Adaptation [[arxiv](http://arxiv.org/abs/2210.14083)]
- Fine-tuned features for domain adaptation 微调的特征用于域自适应
- WACV-23 ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing [[arxiv](https://arxiv.org/abs/2210.11539)]
- Domain adaptation for object detection using confidence mixing 用置信度mix做domain adaptation
- CVPR-20 Regularizing CNN Transfer Learning With Randomised Regression [[arxiv](https://openaccess.thecvf.com/content_CVPR_2020/html/Zhong_Regularizing_CNN_Transfer_Learning_With_Randomised_Regression_CVPR_2020_paper.html)]
- Using randomized regression to regularize CNN 用随机回归约束CNN迁移学习
- AAAI-21 TransTailor: Pruning the Pre-trained Model for Improved Transfer Learning [[arxiv](https://ojs.aaai.org/index.php/AAAI/article/view/17046)]
- Pruning pre-trained model for transfer learning 通过对预训练模型进行剪枝来进行迁移学习
- PhDthesis Generalizing in the Real World with Representation Learning [[arxiv](http://arxiv.org/abs/2210.09925)]
- A phd thesis about generalization in real world 一篇关于现实世界如何做Generalization的博士论文
- The Evolution of Out-of-Distribution Robustness Throughout Fine-Tuning [[arxiv](https://openreview.net/forum?id=Qs3EfpieOh)]
- Evolution of OOD robustness by fine-tuning
- Visual Prompt Tuning for Test-time Domain Adaptation [[arxiv](http://arxiv.org/abs/2210.04831)]
- VPT for test-time adaptation 用prompt tuning进行test-time DA
- Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup [[arxiv](https://arxiv.org/abs/2210.03250)]
- Domain adaptation for COVID-19 用DA进行COVID-19预测
- ICONIP'22 IDPL: Intra-subdomain adaptation adversarial learning segmentation method based on Dynamic Pseudo Labels [[arxiv](https://arxiv.org/abs/2210.03435)]
- Intra-domain adaptation for segmentation 子领域对抗Adaptation
- NeurIPS'22 Polyhistor: Parameter-Efficient Multi-Task Adaptation for Dense Vision Tasks [[arxiv](https://arxiv.org/abs/2210.03265)]
- Parameter-efficient multi-task adaptation 参数高效的多任务adaptation
- Out-of-Distribution Generalization in Algorithmic Reasoning Through Curriculum Learning [[arxiv](https://arxiv.org/abs/2210.03275)]
- OOD in algorithmic reasoning 算法reasoning过程中的OOD
- Towards Out-of-Distribution Adversarial Robustness [[arxiv](https://arxiv.org/abs/2210.03150)]
- OOD adversarial robustness OOD对抗鲁棒性
- TripleE: Easy Domain Generalization via Episodic Replay [[arxiv](https://arxiv.org/pdf/2210.01807.pdf)]
- Easy domain generalization by episodic replay
- Deep Spatial Domain Generalization [[arxiv](https://web7.arxiv.org/pdf/2210.00729.pdf)]
- Deep spatial domain generalization
## 2022-09
- Assaying Out-Of-Distribution Generalization in Transfer Learning [[arXiv](http://arxiv.org/abs/2207.09239)]
- A lot of experiments to show OOD performance
- ICML-21 Accuracy on the Line: on the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization [[arxiv](https://proceedings.mlr.press/v139/miller21b.html)]
- Strong correlation between ID and OOD
- Deep Domain Adaptation for Detecting Bomb Craters in Aerial Images [[arxiv](https://arxiv.org/abs/2209.11299)]
- Bomb craters detection using domain adaptation 用DA检测遥感图像中的炮弹弹坑
- WACV-23 TeST: Test-time Self-Training under Distribution Shift [[arxiv](https://arxiv.org/abs/2209.11459)]
- Test-time self-training 测试时训练
- StyleTime: Style Transfer for Synthetic Time Series Generation [[arxiv](https://arxiv.org/abs/2209.11306)]
- Style transfer for time series generation 时间序列生成的风格迁移
- Robust Domain Adaptation for Machine Reading Comprehension [[arxiv](https://arxiv.org/abs/2209.11615)]
- Domain adaptation for machine reading comprehension 机器阅读理解的domain adaptation
- Generalized representations learning for time series classification [[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 域泛化用于时间序列分类
- USB: A Unified Semi-supervised Learning Benchmark [[arxiv](https://arxiv.org/abs/2208.07204)] [[code](https://github.com/microsoft/Semi-supervised-learning)]
- Unified semi-supervised learning codebase 半监督学习统一代码库
- Test-Time Training with Masked Autoencoders [[arxiv](https://arxiv.org/abs/2209.07522)]
- Test-time training with MAE MAE的测试时训练
- Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models [[arxiv](https://arxiv.org/abs/2209.07511)]
- Test-time prompt tuning 测试时的prompt tuning
- TeST: test-time self-training under distribution shift [[arxiv](https://assets.amazon.science/02/1c/b469914c4732a9c29ac765f948f9/test-test-time-self-training-under-distribution-shift.pdf)]
- Test-time self-training 测试时的self-training
- Language-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification [[arxiv](https://arxiv.org/pdf/2209.02700.pdf)]
- Domain generalization for cross-scene hyperspectral image classification 域泛化用于高光谱图像分类
- IEEE-TMM'22 Uncertainty Modeling for Robust Domain Adaptation Under Noisy Environments [[IEEE](https://ieeexplore.ieee.org/abstract/document/9882310)]
- Uncertainty modeling for domain adaptation 噪声环境下的domain adaptation
- Improving Robustness to Out-of-Distribution Data by Frequency-based Augmentation [arxiv](https://arxiv.org/abs/2209.02369)
- OOD by frequency-based augmentation 通过基于频率的数据增强进行OOD
- Domain Generalization for Prostate Segmentation in Transrectal Ultrasound Images: A Multi-center Study [arxiv](https://arxiv.org/abs/2209.02126)
- Domain generalizationfor prostate segmentation 领域泛化用于前列腺分割
- Domain Adaptation from Scratch [arxiv](https://arxiv.org/abs/2209.00830)
- Domain adaptation from scratch
- Towards Optimization and Model Selection for Domain Generalization: A Mixup-guided Solution [arxiv](https://arxiv.org/abs/2209.00652)
- Model selection for domain generalization 域泛化中的模型选择问题
- [Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets](https://arxiv.org/pdf/2208.07463.pdf)
- Parameter efficient CNN adapter for transfer learning 参数高效的CNN adapter用于迁移学习
- [Equivariant Disentangled Transformation for Domain Generalization under Combination Shift](https://arxiv.org/abs/2208.02011)
- Equivariant disentangled transformation for domain generalization 新的建模domain generalization的思路
## 2022-08
- ECCV-22 workshop [Domain-Specific Risk Minimization](https://arxiv.org/abs/2208.08661)
- Domain-specific risk minization for OOD 领域特异性风险最小化用于域泛化
- TPAMI [Semi-Supervised and Unsupervised Deep Visual Learning: A Survey](https://arxiv.org/abs/2208.11296)
- Survey on semi and unsupervsed learning 半监督和无监督综述
- [Improving video retrieval using multilingual knowledge transfer](https://arxiv.org/abs/2208.11553)
- Video retrieval using multilingual knowledge transfer 多语言知识迁移用于视频检索
- [Transfer Learning-based State of Health Estimation for Lithium-ion Battery with Cycle Synchronization](https://arxiv.org/abs/2208.11204)
- Battery health estimation using transfer learning 用迁移学习进行电池健康估计
- IJCAI-22 [Domain Generalization through the Lens of Angular Invariance](https://www.ijcai.org/proceedings/2022/0139.pdf)
- Using angular invariance for domain generalization 使用角度不变性进行domain generalization
- MM-22 [Making the Best of Both Worlds: A Domain-Oriented Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2208.01195)
- Transformer for domain adaptation 用transformer进行DA
- [Adaptive Domain Generalization via Online Disagreement Minimization](https://arxiv.org/abs/2208.01996)
- Online domain generalization via disagreement minimization 在线DG
- [Self-Distilled Vision Transformer for Domain Generalization](http://arxiv.org/abs/2207.12392)
- Vision transformer for domain generalization 用ViT做domain generalization
- NeurIPS-21 [The balancing principle for parameter choice in distance-regularized domain adaptation](https://papers.nips.cc/paper/2021/hash/ae0909a324fb2530e205e52d40266418-Abstract.html)
- Hyperparameter selection for domain adaptation 对adaptation中的正则项系数进行选择
- [Transfer Learning for Segmentation Problems: Choose the Right Encoder and Skip the Decoder](https://arxiv.org/abs/2207.14508)
- Transfer learning for segmentation problems 统一表示迁移学习于分割问题的思路
## 2022-07
- TMLR-22 [Domain-invariant Feature Exploration for Domain Generalization](https://arxiv.org/abs/2207.12020)
- Exploring domain-invariant feature for domain generalization 探索领域不变特征在领域泛化中的应用
- TIST-22 [Domain Generalization for Activity Recognition via Adaptive Feature Fusion](https://arxiv.org/abs/2207.11221)
- Domain generalization for activity recognition 领域泛化用于行为识别
- ECCV-22 [Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation](https://arxiv.org/abs/2207.10856)
- Prototype continual domain adaptation 基于原型的类增量domain adaptation
- [Federated Semi-Supervised Domain Adaptation via Knowledge Transfer](https://arxiv.org/abs/2207.10727)
- Federated semi-supervised DA 联邦半监督DA
- [Hyper-Representations for Pre-Training and Transfer Learning](https://arxiv.org/abs/2207.10951)
- Hyper-representation for pre-training and fine-tuning 对于预训练和微调的超表示
- MM-22 [Source-Free Domain Adaptation for Real-world Image Dehazing](https://arxiv.org/abs/2207.06644)
- Source-free DA for image dehazing 无需源域的迁移用于图像去雾
- [Improved OOD Generalization via Conditional Invariant Regularizer](https://arxiv.org/abs/2207.06687)
- Improved OOD generalization via conditional invariant regularizer 通过条件不变正则进行OOD泛化
- CVPR-22 [Segmenting Across Places: The Need for Fair Transfer Learning With Satellite Imagery](https://openaccess.thecvf.com/content/CVPR2022W/FaDE-TCV/html/Zhang_Segmenting_Across_Places_The_Need_for_Fair_Transfer_Learning_With_CVPRW_2022_paper.html)
- Fair transfer learning with satellite imagery 公平迁移学习
- [Transferability-Guided Cross-Domain Cross-Task Transfer Learning](https://arxiv.org/abs/2207.05510)
- Cross-domain cross-task transfer learning 用迁移性指标指导跨领域跨任务迁移
- [Cross-Architecture Knowledge Distillation](https://arxiv.org/abs/2207.05273)
- Cross-architecture knowledge distillation 跨架构的知识蒸馏
- ECCV-22 [Knowledge Condensation Distillation](https://arxiv.org/abs/2207.05409)
- Knowledge condensation distillation 知识压缩蒸馏
- [An Information-Theoretic Analysis for Transfer Learning: Error Bounds and Applications](https://arxiv.org/abs/2207.05377)
- Information-theoretic analysis for transfer learning 用信息理论解释迁移学习
- [A Data-Based Perspective on Transfer Learning](https://arxiv.org/abs/2207.05739)
- Analyze the data numbers in transfer learning 分析迁移学习中数据的重要性
- [PAC-Bayesian Domain Adaptation Bounds for Multiclass Learners](https://arxiv.org/abs/2207.05685)
- PAC-Bayesian domain adaptation 基于PAC-Bayesian的domain adaptation
## 2022-06
- NeurIPS-21 [Parameterized Knowledge Transfer for Personalized Federated Learning](https://proceedings.neurips.cc/paper/2021/hash/5383c7318a3158b9bc261d0b6996f7c2-Abstract.html)
- personalized group knowledge transfer training
- 个性化群体知识迁移
- ICML-21 [Federated Continual Learning with Weighted Inter-client Transfer](https://proceedings.mlr.press/v139/yoon21b.html)
- Federated Weighted Inter-client Transfer (FedWeIT) for Federated Continual Learning
- 联邦加权客户端间传输方法,用于联邦持续学习
- SIGIR-21 [FedCT: Federated Collaborative Transfer for Recommendation](https://doi.org/10.1145/3404835.3462825)
- Federated learning for cross-domain recommendation
- 使用联邦迁移学习执行跨域推荐任务
- KDD-21 [Federated Adversarial Debiasing for Fair and Transferable Representations](https://doi.org/10.1145/3447548.3467281)
- Federated Adversarial DEbiasing (FADE)
- 通过对抗性学习对联邦学习过程去除偏见
- NeurIPS-20 [Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge](https://proceedings.neurips.cc/paper/2020/hash/a1d4c20b182ad7137ab3606f0e3fc8a4-Abstract.html)
- Group knowledge transfer training
- 群体知识迁移
- FL-IJCAI-22 [MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare](https://arxiv.org/abs/2206.08516)
- MetaFed: a new form of federated learning 联邦之联邦学习、新范式
- Interspeech-22 [Decoupled Federated Learning for ASR with Non-IID Data](https://jd92.wang/assets/files/DecoupleFL-IS22.pdf)
- Decoupled federated learning for non IID 解耦的联邦架构用于Non-IID语音识别
- [Few-Max: Few-Shot Domain Adaptation for Unsupervised Contrastive Representation Learning](https://arxiv.org/abs/2206.10137)
- Few-shot DA for unsupervised constrastive learning 小样本DA用于无监督对比学习
- [The Importance of Background Information for Out of Distribution Generalization](https://arxiv.org/abs/2206.08794)
- Background information for OOD generalization 背景信息对于OOD泛化的重要性
- [Zero-Shot AutoML with Pretrained Models](https://arxiv.org/abs/2206.08476)
- 用预训练模型进行零样本的自动机器学习
- [How robust are pre-trained models to distribution shift?](https://arxiv.org/abs/2206.08871)
- How robust are pre-trained models to distribution shift 评估预训练模型对于distribution shift的鲁棒性
- [FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification](https://arxiv.org/abs/2206.08671)
- Few-shot transfer learning for image classification 小样本迁移学习用于图像分类
- [COVID-19 Detection using Transfer Learning with Convolutional Neural Network](https://arxiv.org/abs/2206.08557)
- COVID-19 using transfer learning 用迁移学习进行COVID-19检测
- [Wav2vec-S: Semi-Supervised Pre-Training for Speech Recognition](https://arxiv.org/abs/2110.04484)
- Pretraining for speech recognition 用预训练模型进行语音识别
- [Causal Balancing for Domain Generalization](https://arxiv.org/abs/2206.05263)
- Causal balancing for domain generalization 因果平衡用于领域泛化
- NAACL-22 [Modularized Transfer Learning with Multiple Knowledge Graphs for Zero-shot Commonsense Reasoning](https://arxiv.org/abs/2206.03715)
- Transfer learning for zero-shot reasoning 迁移学习用于零次常识推理
- [ConFUDA: Contrastive Fewshot Unsupervised Domain Adaptation for Medical Image Segmentation](https://arxiv.org/abs/2206.03888)
- Fewshot UDA for medical image segmentation 小样本域自适应用于医疗图像分割
- [One Ring to Bring Them All: Towards Open-Set Recognition under Domain Shift](https://arxiv.org/abs/2206.03600)
- Open set recognition with domain shift 开放集+domain shift
- [Toward Certified Robustness Against Real-World Distribution Shifts](https://arxiv.org/abs/2206.03669)
- Certified robustness against real-world distribution shifts 真实世界中的distribution shift
- [On Transfer Learning in Functional Linear Regression](https://arxiv.org/abs/2206.04277)
- Transfer learning in functional linear regression 迁移学习用于函数式线性回归
## 2022-05
- IJCAI-22 [Parameter-Efficient Sparsity for Large Language Models Fine-Tuning](https://arxiv.org/abs/2205.11005)
- Parameter-efficient sparsity for language model fine-tuning 参数高效的稀疏学习用于语言模型微调
- [A Domain-adaptive Pre-training Approach for Language Bias Detection in News](https://arxiv.org/abs/2205.10773)
- Domain-adaptive pre-training for language bias detection 领域适配预训练用于新闻语言偏见检测
- [ScholarBERT: Bigger is Not Always Better](https://arxiv.org/abs/2205.11342)
- Empirical study on fine-tuning experiments 提出ScholarBERT进行大规模finetuning实验
- ICPR-22 [OTAdapt: Optimal Transport-based Approach For Unsupervised Domain Adaptation](https://arxiv.org/abs/2205.10738)
- Optimal transport-based domain adaptation 利用最优传输进行领域自适应
- [Temporal Domain Generalization with Drift-Aware Dynamic Neural Network](https://arxiv.org/abs/2205.10664)
- Temporal domain generalization with drift-aware dynamic neural network 时序域泛化
- [Active Source Free Domain Adaptation](https://arxiv.org/abs/2205.10711)
- Active source-free DA 主动学习-无源域DA
- [Test-Time Robust Personalization for Federated Learning](https://arxiv.org/abs/2205.10920)
- Test-time robust personalization for FL 测试时鲁棒联邦学习
- [FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning](https://arxiv.org/abs/2205.07246)
- Self-adaptive thresholding for semi-supervised learning 新的自适应阈值半监督方法
- IJCAI-22 [Test-time Fourier Style Calibration for Domain Generalization](https://arxiv.org/abs/2205.06427)
- Test-time calibration for domain generalization 用傅立叶变化进行域泛化的测试时矫正
- [Multiple Domain Causal Networks](https://arxiv.org/abs/2205.06791)
- Mlutiple domain causal networks 多领域的因果网络
- ICLR-22 [Enhancing Cross-lingual Transfer by Manifold Mixup](https://arxiv.org/abs/2205.04182)
- Cross-lingual transfer using manifold mixup 用Mixup进行cross-lingual transfer
- CVPR-22 workshop [Online Unsupervised Domain Adaptation for Person Re-identification](https://arxiv.org/abs/2205.04383)
- Online domain adaptation for REID 在线adaptation
- [Time-Series Domain Adaptation via Sparse Associative Structure Alignment: Learning Invariance and Variance](https://arxiv.org/abs/2205.03554)
- Time series domain adaptation 时间序列domain adaptation
- TIP-22 [Spot-adaptive Knowledge Distillation](https://arxiv.org/abs/2205.02399)
- Spot-adaptive knowledge distillation 层次自适应的知识蒸馏
- NAACL-22 [Efficient Few-Shot Fine-Tuning for Opinion Summarization](https://arxiv.org/abs/2205.02170)
- Few-shot fine-tuning for opinion summarization 小样本微调技术用于评论总结
- ICME-22 [Unsupervised Domain Adaptation Learning for Hierarchical Infant Pose Recognition with Synthetic Data](https://arxiv.org/abs/2205.01892)
- Unsupervised domain adaptation for infant pose recognition 用领域自适应进行婴儿姿势识别
## 2022-04
*Updated at 2022-04-29:*
- ACL-22 [Probing Simile Knowledge from Pre-trained Language Models](https://arxiv.org/abs/2204.12807)
- Probe simile knowledge from pre-trained model 从预训练模型中找出明喻知识
- [Parkinson's disease diagnostics using AI and natural language knowledge transfer](https://arxiv.org/abs/2204.12559)
- Transfer learning for Parkinson's disease diagnostics 迁移学习用于帕金森诊断
- CVPR-22 [MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation](https://arxiv.org/abs/2204.12667)
- Multi-modal test-time adaptation for 3D semantic segmentation 多模态测试时adaptation用于3D语义分割
- [Transfer Learning with Pre-trained Conditional Generative Models](https://arxiv.org/abs/2204.12833)
- Transfer learning with pre-trained conditional generative models 条件生成模型用于迁移学习
- ICLR-22 [Towards a Unified View of Parameter-Efficient Transfer Learning](https://openreview.net/forum?id=0RDcd5Axok)
- Unified view of parameter-efficient transfer learning 一个统一视角看待参数高效的迁移学习
- ICLR-22 [Exploring the Limits of Large Scale Pre-training](https://openreview.net/forum?id=V3C8p78sDa)
- Many experiments to explore pre-training 许多实验来探索预训练
- IEEE TNNLS-22 [Towards Personalized Federated Learning](http://arxiv.org/abs/2103.00710)
- A survey on personalized federated learning 一个关于个性化联邦学习的综述
- [On Effectively Learning of Knowledge in Continual Pre-training](https://arxiv.org/abs/2204.07994)
- Continual per-training 持续的预训练
- [Just Fine-tune Twice: Selective Differential Privacy for Large Language Models](https://arxiv.org/abs/2204.07667)
- Differential privacy by just fine-tune twice 通过微调两次进行差分隐私
- CVPR-22 [Safe Self-Refinement for Transformer-based Domain Adaptation](https://arxiv.org/abs/2204.07683)
- Transformer-based domain adaptation 基于transformer的domain adaptation
- [Undoing the Damage of Label Shift for Cross-domain Semantic Segmentation](https://arxiv.org/abs/2204.05546)
- Handle the label shift in cross-domain semantic segmentation 在跨域语义分割时考虑label shift
- CVPR-22 workshop [Out-Of-Distribution Detection In Unsupervised Continual Learning](https://arxiv.org/abs/2204.05462)
- OOD detection in unsupervised continual learning 无监督持续学习中进行OOD检测
- [Transfer Learning for Autonomous Chatter Detection in Machining](https://arxiv.org/abs/2204.05400)
- Transfer learning for autonomous chatter detection
- NAACL-22 [GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering](https://arxiv.org/abs/2204.04179)
- Fast fine-tuning for content-based collaborative filtering
- 快速的适用于协同过滤的微调
- AAAI-22 [Powering Finetuning in Few-shot Learning: Domain-Agnostic Feature Adaptation with Rectified Class Prototypes](https://arxiv.org/abs/2204.03749)
- Finetuning in few-shot learning
- 小样本学习中的微调
- CVPR-22 [Does Robustness on ImageNet Transfer to Downstream Tasks?](https://arxiv.org/abs/2204.03934)
- Transfer learning robustness
- 迁移学习鲁棒性
- [Blockchain as an Enabler for Transfer Learning in Smart Environments](https://arxiv.org/abs/2204.03959)
- Blockchain transfer learning
- 用区块链进行迁移学习
- ICLR-22 [Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution](https://openreview.net/forum?id=UYneFzXSJWh)
- Fin-tuning and linear probing for ood generalization
- 先linear probing最后一层再finetune对OOD任务最好
- ICLR-22 [Asymmetry Learning for Counterfactually-invariant Classification in OOD Tasks](https://openreview.net/forum?id=avgclFZ221l)
- Asymmetry learning for OOD tasks
- 非对称学习用于OOD任务
## 2022-03
- [Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection](https://arxiv.org/abs/2203.11432)
- Channel masking for domain generalization object detection
- 通过一个gate控制channel masking进行object detection DG
- [A Broad Study of Pre-training for Domain Generalization and Adaptation](https://arxiv.org/abs/2203.11819)
- A broad study of pre-training models for DA and DG
- 大量的实验进行DA和DG
- ISPASS-22 [Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices](https://arxiv.org/abs/2203.11295)
- Benchmarking test-time adaptation for edge devices
- 在端设备上评测test-time adaptation算法
- [Multi-Source Domain Adaptation Based on Federated Knowledge Alignment](https://arxiv.org/abs/2203.11635)
- Multi-source domain adaptation
- 多源域自适应
- [Improving Generalization in Federated Learning by Seeking Flat Minima](https://arxiv.org/abs/2203.11834)
- Seeking flat minima for domain generalization in federated learning
- 通过寻找平坦值进行联邦学习领域泛化
- CVPR-22 [Decoupled Knowledge Distillation](https://arxiv.org/abs/2203.08679)
- Decoupled knowledge distillation
- 解耦的知识蒸馏
- [SemiPFL: Personalized Semi-Supervised Federated Learning Framework for Edge Intelligence](https://arxiv.org/abs/2203.08176)
- Personalized federated learning
- 个性化联邦学习
- ICSE-22 [ReMoS: Reducing Defect Inheritance in Transfer Learning via Relevant Model Slicing](https://link.zhihu.com/?target=https%3A//jd92.wang/assets/files/icse22-remos.pdf) | [Code](https://github.com/ziqi-zhang/ReMoS_artifact) | [Blog](https://zhuanlan.zhihu.com/p/446453487) | [Video](https://www.bilibili.com/video/BV1mi4y1C7bP)
- Safe transfer learning by reducing defect inheritance
- 安全迁移学习的最新工作
- ACL-22 [Language-Agnostic Meta-Learning for Low-Resource Text-to-Speech with Articulatory Features](https://arxiv.org/abs/2203.03191)
- Language-agnostic meta-learning for TTS
- 语言无关的元学习用于TTS
- [Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models](https://arxiv.org/abs/2203.03131)
- Adapt unfamiliar inputs to frozen pretrained models
- 让固定的预训练模型适配不熟悉的输入
- [One Model, Multiple Tasks: Pathways for Natural Language Understanding](https://arxiv.org/abs/2203.03312)
- Pathways for natural language understanding
- 使用一个model用于所有NLP任务
- [Pre-trained Token-replaced Detection Model as Few-shot Learner](https://arxiv.org/abs/2203.03235)
- Pre-trained token-replaced detection model as few-shot learner
- 预训练的替换token的检测模型
- [Open Set Domain Adaptation By Novel Class Discovery](https://arxiv.org/abs/2203.03329)
- Open set DA by novel class discovery
- 基于新类发现的open set da
- ICML-21 workshop [Domain Adaptation with Factorizable Joint Shift](https://arxiv.org/abs/2203.02902)
- Domain adaptation with factorizable joint shift
- 基于可分解的联合漂移的领域自适应
- ICC-22 [Knowledge Transfer in Deep Reinforcement Learning for Slice-Aware Mobility Robustness Optimization](https://arxiv.org/abs/2203.03227)
- Knowledge transfer in RL
- 强化迁移学习
- ACL-22 [Investigating Selective Prediction Approaches Across Several Tasks in IID, OOD, and Adversarial Settings](https://arxiv.org/abs/2203.00211)
- Investigate selective prediction approaches in IID, OOD, and ADV settings
- 在独立同分布、分布外、对抗情境中调研选择性预测方法
- PAKDD-22 [Layer Adaptive Deep Neural Networks for Out-of-distribution Detection](https://arxiv.org/abs/2203.00192)
- Layer adaptive network for OOD detection
- 层自适应的网络进行OOD检测
- [Learning Semantic Segmentation from Multiple Datasets with Label Shifts](https://arxiv.org/abs/2202.14030)
- Learning semantic segmentation from many datasets with label shifts
- 在有标签漂移的情况下从多个数据集中学习语义分割
- [Causal Domain Adaptation with Copula Entropy based Conditional Independence Test](https://arxiv.org/abs/2202.13482)
- Use copula entropy based conditional independence test for csusal domain adaptation
- 使用基于copula entopy的条件独立测试进行causal domain adaptation
- [Interpretable Concept-based Prototypical Networks for Few-Shot Learning](https://arxiv.org/abs/2202.13474)
- Concept-based prototypical network for few-shot learning
- 基于概念的原型网络用于小样本学习
## 2022-02
- [How Well Do Self-Supervised Methods Perform in Cross-Domain Few-Shot Learning?](https://arxiv.org/abs/2202.09014)
- Self-supervised learning for cross-domain few-shot
- 自监督用于跨领域小样本
- [Deep Transfer Learning on Satellite Imagery Improves Air Quality Estimates in Developing Nations](https://arxiv.org/abs/2202.08890)
- Deep transfer learning for air quality estimate
- 深度迁移学习用于卫星图到空气质量预测
- ICLR-22 oral [A Fine-Grained Analysis on Distribution Shift](https://openreview.net/forum?id=Dl4LetuLdyK)
- Extensive experiments on distribution shift for OOD
- 大量的实验进行OOD验证
- ICLR-22 oral [Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution](https://openreview.net/forum?id=UYneFzXSJWh)
- Fine-tuning with linear probing for OOD
- 微调加上linear probing用于OOD
- ICLR-22 spotlight [Towards a Unified View of Parameter-Efficient Transfer Learning](https://openreview.net/pdf?id=0RDcd5Axok)
- Detailed analysis of parameter-efficient transfer learning
- 对参数高效的迁移学习进行分析
- ICLR-22 [Graph-Relational Domain Adaptation](https://arxiv.org/abs/2202.03628)
- Graph-relational domain adapttion using topological structures
- 图级别的domain adaptation,使用拓扑结构
- [Domain Adversarial Spatial-Temporal Network: A Transferable Framework for Short-term Traffic Forecasting across Cities](https://arxiv.org/abs/2202.03630)
- Transfer learning for traffic forecasting across cities
- 用迁移学习进行跨城市的交通流量预测
- ICLR-22 [Uncertainty Modeling for Out-of-Distribution Generalization](https://arxiv.org/abs/2202.03958)
- Uncertainty modeling for OOD generalization
- 用于分布外泛化的不确定性建模
- ICLR-22 [BEiT: BERT Pre-Training of Image Transformers](https://openreview.net/forum?id=p-BhZSz59o4)
- BERT pre-training of image transformers
- 用BERT的方式pre-train transformer
- [Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice](http://arxiv.org/abs/2111.12292)
- Using pre-training data to improve fine-tuning
- 使用预训练数据来帮助finetune
## 2022-01
- [IGLUE: A Benchmark for Transfer Learning across Modalities, Tasks, and Languages](https://arxiv.org/abs/2201.11732)
- A benchmark for transfer learning in NLP
- 一个用于NLP跨模态、任务、语言的benchmark
- [Domain generalization in deep learning-based mass detection in mammography: A large-scale multi-center study](https://arxiv.org/abs/2201.11620)
- Domain generalization in mass detection in mammography
- Domain generalization进行胸部射线检测
- [Domain-Invariant Representation Learning from EEG with Private Encoders](https://arxiv.org/abs/2201.11613)
- Domain-invariant learning from EEG
- 用于EEG信号的领域不变特征研究
- [Gap Minimization for Knowledge Sharing and Transfer](https://arxiv.org/abs/2201.11231)
- Multitask learning with gap minimization
- 用于多任务学习的gap minimization方法
- [DROPO: Sim-to-Real Transfer with Offline Domain Randomization](https://arxiv.org/abs/2201.08434)
- Sim-to-real transfer with domain randomization
- 用domain randomization进行sim-to-real transfer
- AAAI-22 [Knowledge Sharing via Domain Adaptation in Customs Fraud Detection](https://arxiv.org/abs/2201.06759)
- Domain adaptation for fraud detection
- 用领域自适应进行欺诈检测
- [Continual Coarse-to-Fine Domain Adaptation in Semantic Segmentation](https://arxiv.org/abs/2201.06974)
- Domain adaptation in semantic segmentation
- 领域自适应在语义分割的应用
- KBS-22 [Intra-domain and cross-domain transfer learning for time series data -- How transferable are the features](https://arxiv.org/abs/2201.04449)
- An overview of transfer learning for time series data
- 一个用迁移学习进行时间序列分析的小综述
- [A Likelihood Ratio based Domain Adaptation Method for E2E Models](2201.03655)
- Domain adaptation for speech recognition
- 用domain adaptation进行语音识别
- [Transfer Learning for Scene Text Recognition in Indian Languages](2201.03180)
- Transfer learning for scene text recognition in Indian languages
- 用迁移学习进行印度语的场景文字识别
- IEEE TMM-22 [Decompose to Adapt: Cross-domain Object Detection via Feature Disentanglement](https://arxiv.org/abs/2201.01929)
- Invariant and shared components for Faster RCNN detection
- 解耦公共和私有表征进行目标检测
- [Mixture of basis for interpretable continual learning with distribution shifts](https://arxiv.org/abs/2201.01853)
- Incremental learning with mixture of basis
- 用mixture of domains进行增量学习
- TKDE-22 [Adaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection](https://arxiv.org/abs/2201.00464)
- Adaptiev memory network for anomaly detection
- 自适应的记忆网络用于异常检测
- ICIP-22 [Meta-Learned Feature Critics for Domain Generalized Semantic Segmentation](https://arxiv.org/abs/2112.13538)
- Meta-learning for domain generalization
- 元学习用于domain generalization
- ICIP-22 [Few-Shot Classification in Unseen Domains by Episodic Meta-Learning Across Visual Domains](https://arxiv.org/abs/2112.13539)
- Few-shot generalization using meta-learning
- 用元学习进行小样本的泛化
- [Data-Free Knowledge Transfer: A Survey](https://arxiv.org/abs/2112.15278)
- A survey on data-free distillation and source-free DA
- 一篇关于data-free蒸馏和source-free DA的综述
- [An Ensemble of Pre-trained Transformer Models For Imbalanced Multiclass Malware Classification](https://arxiv.org/abs/2112.13236)
- An ensemble of pre-trained transformer for malware classification
- 预训练的transformer通过集成进行恶意软件检测
- [Optimal Representations for Covariate Shift](https://arxiv.org/abs/2201.00057)
- Learning optimal representations for covariate shift
- 为covariate shift学习最优的表达
- [Transfer-learning-based Surrogate Model for Thermal Conductivity of Nanofluids](https://arxiv.org/abs/2201.00435)
- Transfer learning for thermal conductivity
- 迁移学习用于热传导
- [Transfer learning of phase transitions in percolation and directed percolation](https://arxiv.org/abs/2112.15516)
- Transfer learning of phase transitions in percolation and directed percolation
- 迁移学习用于precolation
- [Transfer learning for cancer diagnosis in histopathological images](https://arxiv.org/abs/2112.15523)
- Transfer learning for cancer diagnosis
- 迁移学习用于癌症诊断
## 2021-12
- IEEE TASLP-22 [Exploiting Adapters for Cross-lingual Low-resource Speech Recognition](https://arxiv.org/abs/2105.11905) [Zhihu article](https://zhuanlan.zhihu.com/p/448216624)
- Cross-lingual speech recogntion using meta-learning and transfer learning
- 用元学习和迁移学习进行跨语言的低资源语音识别
- [More is Better: A Novel Multi-view Framework for Domain Generalization](https://arxiv.org/abs/2112.12329)
- Multi-view learning for domain generalization
- 使用多视图学习来进行domain generalization
- [SLIP: Self-supervision meets Language-Image Pre-training](https://arxiv.org/abs/2112.12750)
- Self-supervised learning + language image pretraining
- 用自监督学习用于语言到图像的预训练
- [Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems](https://arxiv.org/abs/2112.08718)
- Prompt for domain adaptation in speech recognition
- 用Prompt在语音识别中进行domain adaptation
- [UMAD: Universal Model Adaptation under Domain and Category Shift](https://arxiv.org/abs/2112.08553)
- Model adaptation under domain and category shift
- 在domain和class都有shift的前提下进行模型适配
- [Domain Adaptation on Point Clouds via Geometry-Aware Implicits](https://arxiv.org/abs/2112.09343)
- Domain adaptation for point cloud
- 针对点云的domain adaptation
- [A Survey of Unsupervised Domain Adaptation for Visual Recognition](http://arxiv.org/abs/2112.06745)
- A new survey article of domain adaptation
- 对UDA的一个综述文章,来自作者博士论文
- [VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks](http://arxiv.org/abs/2112.06825)
- Vision-language efficient transfer learning
- 参数高校的vision-language任务迁移
- [Federated Learning with Adaptive Batchnorm for Personalized Healthcare](https://arxiv.org/abs/2112.00734)
- Federated learning with adaptive batchnorm
- 用自适应BN进行个性化联邦学习
- [Unsupervised Domain Adaptation: A Reality Check](https://arxiv.org/abs/2111.15672)
- Doing experiments to show the progress of DA methods over the years
- 用大量的实验来验证近几年来DA方法的进展
- [Hierarchical Optimal Transport for Unsupervised Domain Adaptation](https://arxiv.org/abs/2112.02073)
- hierarchical optimal transport for UDA
- 层次性的最优传输用于domain adaptation
- [Unsupervised Domain Generalization by Learning a Bridge Across Domains](https://arxiv.org/abs/2112.02300)
- Unsupervised domain generalization
- 无监督的domain generalization
- [Boosting Unsupervised Domain Adaptation with Soft Pseudo-label and Curriculum Learning](https://arxiv.org/abs/2112.01948)
- Using soft pseudo-label and curriculum learning to boost UDA
- 用软的伪标签和课程学习增强UDA方法
- [Subtask-dominated Transfer Learning for Long-tail Person Search](https://arxiv.org/abs/2112.00527)
- Subtask-dominated transfer for long-tail person search
- 子任务驱动的长尾人物搜索
- [Revisiting the Transferability of Supervised Pretraining: an MLP Perspective](https://arxiv.org/abs/2112.00496)
- Revisit the transferability of supervised pretraining
- 重新思考有监督预训练的可迁移性
- [Multi-Agent Transfer Learning in Reinforcement Learning-Based Ride-Sharing Systems](https://arxiv.org/abs/2112.00424)
- Multi-agent transfer in RL
- 在RL中的多智能体迁移
- NeurIPS-21 [On Learning Domain-Invariant Representations for Transfer Learning with Multiple Sources](https://arxiv.org/abs/2111.13822)
- Theory and algorithm of domain-invariant learning for transfer learning
- 对invariant representation的理论和算法
- WACV-22 [Semi-supervised Domain Adaptation via Sample-to-Sample Self-Distillation](https://arxiv.org/abs/2111.14353)
- Sample-level self-distillation for semi-supervised DA
- 样本层次的自蒸馏用于半监督DA
- [ROBIN : A Benchmark for Robustness to Individual Nuisancesin Real-World Out-of-Distribution Shifts](https://arxiv.org/abs/2111.14341)
- A benchmark for robustness to individual OOD
- 一个OOD的benchmark
- ICML-21 workshop [Towards Principled Disentanglement for Domain Generalization](https://arxiv.org/abs/2111.13839)
- Principled disentanglement for domain generalization
- Principled解耦用于domain generalization
## 2021-11
- NeurIPS-21 workshop [CytoImageNet: A large-scale pretraining dataset for bioimage transfer learning](https://arxiv.org/abs/2111.11646)
- A large-scale dataset for bioimage transfer learning
- 一个大规模的生物图像数据集用于迁移学习
- NeurIPS-21 workshop [Component Transfer Learning for Deep RL Based on Abstract Representations](https://arxiv.org/abs/2111.11525)
- Deep transfer learning for RL
- 深度迁移学习用于强化学习
- NeurIPS-21 workshop [Maximum Mean Discrepancy for Generalization in the Presence of Distribution and Missingness Shift](https://arxiv.org/abs/2111.10344)
- MMD for covariate shift
- 用MMD来解决covariate shift问题
- [Combined Scaling for Zero-shot Transfer Learning](https://arxiv.org/abs/2111.10050)
- Scaling up for zero-shot transfer learning
- 增大训练规模用于zero-shot迁移学习
- [Federated Learning with Domain Generalization](https://arxiv.org/abs/2111.10487)
- Federated domain generalization
- 联邦学习+domain generalization
- [Semi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline](https://arxiv.org/abs/2111.10221)
- Semi-supervised domain generalization
- 半监督+domain generalization
- MICCAI-21 [Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning](https://arxiv.org/abs/2111.10827)
- Domain generalization for mammography detection
- 领域泛化用于乳房X射线检查
- [On Representation Knowledge Distillation for Graph Neural Networks](https://arxiv.org/abs/2111.04964)
- Knowledge distillation for GNN
- 适用于GNN的知识蒸馏
- BMVC-21 [Domain Attention Consistency for Multi-Source Domain Adaptation](https://arxiv.org/abs/2111.03911)
- Multi-source domain adaptation using attention consistency
- 用attention一致性进行多源的domain adaptation
- [Action Recognition using Transfer Learning and Majority Voting for CSGO](https://arxiv.org/abs/2111.03882)
- Using transfer learning and majority voting for action recognition
- 使用迁移学习和多数投票进行动作识别
- [Open-Set Crowdsourcing using Multiple-Source Transfer Learning](https://arxiv.org/abs/2111.04073)
- Open-set crowdsourcing using multiple-source transfer learning
- 使用多源迁移进行开放集的crowdsourcing
- [Improved Regularization and Robustness for Fine-tuning in Neural Networks](https://arxiv.org/abs/2111.04578)
- Improve regularization and robustness for finetuning
- 针对finetune提高其正则和鲁棒性
- [TimeMatch: Unsupervised Cross-Region Adaptation by Temporal Shift Estimation](https://arxiv.org/abs/2111.02682)
- Temporal domain adaptation
- NeurIPS-21 [Modular Gaussian Processes for Transfer Learning](https://arxiv.org/abs/2110.13515)
- Modular Gaussian process for transfer learning
- 在迁移学习中使用modular Gaussian过程
- [Estimating and Maximizing Mutual Information for Knowledge Distillation](https://arxiv.org/abs/2110.15946)
- Global and local mutual information maximation for knowledge distillation
- 局部和全局互信息最大化用于蒸馏
- [On Label Shift in Domain Adaptation via Wasserstein Distance](https://arxiv.org/abs/2110.15520)
- Using Wasserstein distance to solve label shift in domain adaptation
- 在DA领域中用Wasserstein distance去解决label shift问题
- [Xi-Learning: Successor Feature Transfer Learning for General Reward Functions](https://arxiv.org/abs/2110.15701)
- General reward function transfer learning in RL
- 在强化学习中general reward function的迁移学习
- [C-MADA: Unsupervised Cross-Modality Adversarial Domain Adaptation framework for medical Image Segmentation](https://arxiv.org/abs/2110.15823)
- Cross-modality domain adaptation for medical image segmentation
- 跨模态的DA用于医学图像分割
- [Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation](https://arxiv.org/abs/2110.14509)
- Domain adaptation for multi-source entiry linkage
- 用DA进行多源的实体链接
- [Temporal Knowledge Distillation for On-device Audio Classification](https://arxiv.org/abs/2110.14131)
- Temporal knowledge distillation for on-device ASR
- 时序知识蒸馏用于设备端的语音识别
- [Transferring Domain-Agnostic Knowledge in Video Question Answering](https://arxiv.org/abs/2110.13395)
- Domain-agnostic learning for VQA
- 在VQA任务中进行迁移学习
## 2021-10
- BMVC-21 [SILT: Self-supervised Lighting Transfer Using Implicit Image Decomposition](https://arxiv.org/abs/2110.12914)
- Lighting transfer using implicit image decomposition
- 用隐式图像分解进行光照迁移
- [Domain Adaptation in Multi-View Embedding for Cross-Modal Video Retrieval](https://arxiv.org/abs/2110.12812)
- Domain adaptation for cross-modal video retrieval
- 用领域自适应进行跨模态的视频检索
- [Age and Gender Prediction using Deep CNNs and Transfer Learning](https://arxiv.org/abs/2110.12633)
- Age and gender prediction using transfer learning
- 用迁移学习进行年龄和性别预测
- [Domain Adaptation for Rare Classes Augmented with Synthetic Samples](https://arxiv.org/abs/2110.12216)
- Domain adaptation for rare class
- 稀疏类的domain adaptation
- WACV-22 [AuxAdapt: Stable and Efficient Test-Time Adaptation for Temporally Consistent Video Semantic Segmentation](https://arxiv.org/abs/2110.12369)
- Test-time adaptation for video semantic segmentation
- 测试时adaptation用于视频语义分割
- NeurIPS-21 [Unsupervised Domain Adaptation with Dynamics-Aware Rewards in Reinforcement Learning](https://arxiv.org/abs/2110.12997)
- Domain adaptation in reinforcement learning
- 在强化学习中应用domain adaptation
- WACV-21 [Domain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition](https://arxiv.org/abs/2110.10101)
- Domain generalization by audio-visual alignment
- 通过音频-视频对齐进行domain generalization
- BMVC-21 [Dynamic Feature Alignment for Semi-supervised Domain Adaptation](https://arxiv.org/abs/2110.09641)
- Dynamic feature alignment for semi-supervised DA
- 动态特征对齐用于半监督DA
- NeurIPS-21 [FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling](https://arxiv.org/abs/2110.08263) [知乎解读](https://zhuanlan.zhihu.com/p/422930830) [code](https://github.com/TorchSSL/TorchSSL)
- Curriculum pseudo label with a unified codebase TorchSSL
- 半监督方法FlexMatch和统一算法库TorchSSL
- [Rethinking supervised pre-training for better downstream transferring](https://arxiv.org/abs/2110.06014)
- Rethink better finetune
- 重新思考预训练以便更好finetune
- [Music Sentiment Transfer](https://arxiv.org/abs/2110.05765)
- Music sentiment transfer learning
- 迁移学习用于音乐sentiment
- NeurIPS-21 [Model Adaptation: Historical Contrastive Learning for Unsupervised Domain Adaptation without Source Data](http://arxiv.org/abs/2110.03374)
- Source-free domain adaptation using constrastive learning
- 无源域数据的DA,利用对比学习
- [Understanding Domain Randomization for Sim-to-real Transfer](http://arxiv.org/abs/2110.03239)
- Understanding domain randomizationfor sim-to-real transfer
- 对强化学习中的sim-to-real transfer进行理论上的分析
- [Dynamically Decoding Source Domain Knowledge For Unseen Domain Generalization](http://arxiv.org/abs/2110.03027)
- Ensemble learning for domain generalization
- 用集成学习进行domain generalization
- [Scale Invariant Domain Generalization Image Recapture Detection](http://arxiv.org/abs/2110.03496)
- Scale invariant domain generalizaiton
- 尺度不变的domain generalization
## 2021-09
- IEEE TIP-21 [Joint Clustering and Discriminative Feature Alignment for Unsupervised Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/9535218)
- Clustering and discriminative alignment for DA
- 聚类与判定式对齐用于DA
- IEEE TNNLS-21 [Entropy Minimization Versus Diversity Maximization for Domain Adaptation](https://ieeexplore.ieee.org/abstract/document/9537640)
- Entropy minimization versus diversity max for DA
- 熵最小化与diversity最大化
- [Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation](https://arxiv.org/abs/2109.11798)
- Adversarial domain adaptation for bronchoscopic depth estimation
- 用对抗领域自适应进行支气管镜的深度估计
- EMNLP-21 [Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning](https://arxiv.org/abs/2109.06349)
- Few-shot intent detection using pretrain and finetune
- 用迁移学习进行少样本意图检测
- EMNLP-21 [Non-Parametric Unsupervised Domain Adaptation for Neural Machine Translation](https://arxiv.org/abs/2109.06604)
- UDA for machine translation
- 用领域自适应进行机器翻译
- [KroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation](https://arxiv.org/abs/2109.06243)
- Using Kronecker decomposition and knowledge distillation for pre-trained language models compression
- 用Kronecker分解和知识蒸馏来进行语言模型的压缩
- [Cross-Region Domain Adaptation for Class-level Alignment](https://arxiv.org/abs/2109.06422)
- Cross-region domain adaptation for class-level alignment
- 跨区域的领域自适应用于类级别的对齐
- [Unsupervised domain adaptation for cross-modality liver segmentation via joint adversarial learning and self-learning](https://arxiv.org/abs/2109.05664)
- Domain adaptation for cross-modality liver segmentation
- 使用domain adaptation进行肝脏的跨模态分割
- [CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2109.06165)
- Cross-domain transformer for domain adaptation
- 基于transformer进行domain adaptation
- ICCV-21 [Shape-Biased Domain Generalization via Shock Graph Embeddings](https://arxiv.org/abs/2109.05671)
- Domain generalization based on shape information
- 基于形状进行domain generalization
- [Domain and Content Adaptive Convolution for Domain Generalization in Medical Image Segmentation](https://arxiv.org/abs/2109.05676)
- Domain generalization for medical image segmentation
- 领域泛化用于医学图像分割
- [Class-conditioned Domain Generalization via Wasserstein Distributional Robust Optimization](https://arxiv.org/abs/2109.03676)
- Domain generalization with wasserstein DRO
- 使用Wasserstein DRO进行domain generalization
- [FedZKT: Zero-Shot Knowledge Transfer towards Heterogeneous On-Device Models in Federated Learning](https://arxiv.org/abs/2109.03775)
- Zero-shot transfer in heterogeneous federated learning
- 零次迁移用于联邦学习
- [Fishr: Invariant Gradient Variances for Out-of-distribution Generalization](https://arxiv.org/abs/2109.02934)
- Invariant gradient variances for OOD generalization
- 不变梯度方差,用于OOD
- [How Does Adversarial Fine-Tuning Benefit BERT?](https://arxiv.org/abs/2108.13602)
- Examine how does adversarial fine-tuning help BERT
- 探索对抗性finetune如何帮助BERT
- [Contrastive Domain Adaptation for Question Answering using Limited Text Corpora](https://arxiv.org/abs/2108.13854)
- Contrastive domain adaptation for QA
- QA任务中应用对比domain adaptation
## 2021-08
- [Robust Ensembling Network for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.09473)
- Ensembling network for domain adaptation
- 集成嵌入网络用于domain adaptation
- [Federated Multi-Task Learning under a Mixture of Distributions](https://arxiv.org/abs/2108.10252)
- Federated multi-task learning
- 联邦多任务学习
- [Fine-tuning is Fine in Federated Learning](http://arxiv.org/abs/2108.07313)
- Finetuning in federated learning
- 在联邦学习中进行finetune
- [Federated Multi-Target Domain Adaptation](http://arxiv.org/abs/2108.07792)
- Federated multi-target DA
- 联邦学习场景下的多目标DA
- [Learning Transferable Parameters for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.06129)
- Learning partial transfer parameters for DA
- 学习适用于迁移部分的参数做UDA任务
- MICCAI-21 [A Systematic Benchmarking Analysis of Transfer Learning for Medical Image Analysis](https://arxiv.org/abs/2108.05930)
- A benchmark of transfer learning for medical image
- 一个详细的迁移学习用于医学图像的benchmark
- [TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation](https://arxiv.org/abs/2108.05988)
- Vision transformer for domain adaptation
- 用视觉transformer进行DA
- CIKM-21 [AdaRNN: Adaptive Learning and Forecasting of Time Series](https://arxiv.org/abs/2108.04443) [Code](https://github.com/jindongwang/transferlearning/tree/master/code/deep/adarnn) [知乎文章](https://zhuanlan.zhihu.com/p/398036372) [Video](https://www.bilibili.com/video/BV1Gh411B7rj/)
- A new perspective to using transfer learning for time series analysis
- 一种新的建模时间序列的迁移学习视角
- TKDE-21 [Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals](https://arxiv.org/abs/2107.12626)
- Anomaly detection using semi-supervised and transfer learning
- 半监督学习用于无监督异常检测
- SemDIAL-21 [Generating Personalized Dialogue via Multi-Task Meta-Learning](https://arxiv.org/abs/2108.03377)
- Generate personalized dialogue using multi-task meta-learning
- 用多任务元学习生成个性化的对话
- ICCV-21 [BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation](https://arxiv.org/abs/2108.03267)
- Bijective MMD for domain adaptation
- 双射MMD用于语义分割
- [A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions](https://arxiv.org/abs/2108.03357)
- A survey on cross-domain recommendation
- 跨领域的推荐的综述
- [A Data Augmented Approach to Transfer Learning for Covid-19 Detection](https://arxiv.org/abs/2108.02870)
- Data augmentation to transfer learning for COVID
- 迁移学习使用数据增强,用于COVID-19
- MM-21 [Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding](https://arxiv.org/abs/2108.02953)
- Few-shot DA with image-to-class sparse similarity encoding
- 小样本的领域自适应
- [Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning](https://arxiv.org/abs/2108.02959)
- Prototype transfer and structure regularization
- 原型的迁移学习
- [Finetuning Pretrained Transformers into Variational Autoencoders](https://arxiv.org/abs/2108.02446)
- Finetune transformer to VAE
- 把transformer迁移到VAE
- [Pre-trained Models for Sonar Images](http://arxiv.org/abs/2108.01111)
- Pre-trained models for sonar images
- 针对声纳图像的预训练模型
- [Domain Adaptor Networks for Hyperspectral Image Recognition](http://arxiv.org/abs/2108.01555)
- Finetune for hyperspectral image recognition
- 针对高光谱图像识别的迁移学习
## 2021-07
- CVPR-21 [Efficient Conditional GAN Transfer With Knowledge Propagation Across Classes](https://openaccess.thecvf.com/content/CVPR2021/html/Shahbazi_Efficient_Conditional_GAN_Transfer_With_Knowledge_Propagation_Across_Classes_CVPR_2021_paper.html)
- Transfer conditional GANs to unseen classes
- 通过知识传递,迁移预训练的conditional GAN到新类别
- CVPR-21 [Ego-Exo: Transferring Visual Representations From Third-Person to First-Person Videos](https://openaccess.thecvf.com/content/CVPR2021/html/Li_Ego-Exo_Transferring_Visual_Representations_From_Third-Person_to_First-Person_Videos_CVPR_2021_paper.html)
- Transfer learning from third-person to first-person video
- 从第三人称视频迁移到第一人称
- [Toward Co-creative Dungeon Generation via Transfer Learning](http://arxiv.org/abs/2107.12533)
- Game scene generation with transfer learning
- 用迁移学习生成游戏场景
- [Transfer Learning in Electronic Health Records through Clinical Concept Embedding](https://arxiv.org/abs/2107.12919)
- Transfer learning in electronic health record
- 迁移学习用于医疗记录管理
- CVPR-21 [Conditional Bures Metric for Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Luo_Conditional_Bures_Metric_for_Domain_Adaptation_CVPR_2021_paper.html)
- A new metric for domain adaptation
- 提出一个新的metric用于domain adaptation
- CVPR-21 [Wasserstein Barycenter for Multi-Source Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Montesuma_Wasserstein_Barycenter_for_Multi-Source_Domain_Adaptation_CVPR_2021_paper.html)
- Use Wasserstein Barycenter for multi-source domain adaptation
- 利用Wasserstein Barycenter进行DA
- CVPR-21 [Generalized Domain Adaptation](https://openaccess.thecvf.com/content/CVPR2021/html/Mitsuzumi_Generalized_Domain_Adaptation_CVPR_2021_paper.html)
- A general definition for domain adaptation
- 一个更抽象更一般的domain adaptation定义
- CVPR-21 [Reducing Domain Gap by Reducing Style Bias](https://openaccess.thecvf.com/content/CVPR2021/html/Nam_Reducing_Domain_Gap_by_Reducing_Style_Bias_CVPR_2021_paper.html)
- Syle-invariant training for adaptation and generalization
- 通过训练图像对style无法辨别来进行DA和DG
- CVPR-21 [Uncertainty-Guided Model Generalization to Unseen Domains](https://openaccess.thecvf.com/content/CVPR2021/html/Qiao_Uncertainty-Guided_Model_Generalization_to_Unseen_Domains_CVPR_2021_paper.html)
- Uncertainty-guided generalization
- 基于不确定性的domain generalization
- CVPR-21 [Adaptive Methods for Real-World Domain Generalization](https://openaccess.thecvf.com/content/CVPR2021/html/Dubey_Adaptive_Methods_for_Real-World_Domain_Generalization_CVPR_2021_paper.html)
- Adaptive methods for domain generalization
- 动态算法,用于domain generalization
- 20210716 ICML-21 [Continual Learning in the Teacher-Student Setup: Impact of Task Similarity](https://arxiv.org/abs/2107.04384)
- Investigating task similarity in teacher-student learning
- 调研在continual learning下teacher-student learning问题的任务相似度
- 20210716 BMCV-extend [Exploring Dropout Discriminator for Domain Adaptation](https://arxiv.org/abs/2107.04231)
- Using multiple discriminators for domain adaptation
- 用分布估计代替点估计来做domain adaptation
- 20210716 TPAMI-21 [Lifelong Teacher-Student Network Learning](https://arxiv.org/abs/2107.04689)
- Lifelong distillation
- 持续的知识蒸馏
- 20210716 MICCAI-21 [Few-Shot Domain Adaptation with Polymorphic Transformers](https://arxiv.org/abs/2107.04805)
- Few-shot domain adaptation with polymorphic transformer
- 用多模态transformer做少样本的domain adaptation
- 20210716 InterSpeech-21 [Speech2Video: Cross-Modal Distillation for Speech to Video Generation](https://arxiv.org/abs/2107.04806)
- Cross-model distillation for video generation
- 跨模态蒸馏用于语音到video的生成
- 20210716 ICML-21 workshop [Leveraging Domain Adaptation for Low-Resource Geospatial Machine Learning](https://arxiv.org/abs/2107.04983)
- Using domain adaptation for geospatial ML
- 用domain adaptation进行地理空间的机器学习
================================================
FILE: doc/domain_adaptation.md
================================================
### Domain adaptation介绍及代表性文章梳理
Domain adaptation,DA,中文可翻译为域适配、域匹配、域适应,是迁移学习中的一类非常重要的问题,也是一个持续的研究热点。Domain adaptation可用于计算机视觉、物体识别、文本分类、声音识别等常见应用中。这个问题的基本定义是,假设源域和目标域的类别空间一样,特征空间也一样,但是数据的分布不一样,如何利用有标定的源域数据,来学习目标域数据的标定?
事实上,根据目标域中是否有少量的标定可用,可以将domain adaptation大致分为无监督(目标域中完全无label)和半监督(目标域中有少量label)两大类。我们这里偏重介绍无监督。
[视觉domain adaptation综述](https://mega.nz/#!hWQ3HLhJ!GTCIUTVDcmnn3f7-Ulhjs_MxGv6xnFyp1nayemt9Nis)
关于迁移学习的理论方面,有三篇连贯式的理论分析文章连续发表在NIPS和Machine Learning上:[理论分析](https://mega.nz/#F!ULoGFYDK!O3TQRZwrNeqTncNMIfXNTg)
- - -
#### 形式化
给定:有标定的,以及无标定的
求:的标定 (在实验环境中,是有标定的,仅用来测试算法精度)
条件:
- ,即源域和目标域的特征空间相同(都是维)
- ,即源域和目标域的类别空间相同
- ) ),即源域和目标域的数据分布不同
- - -
#### 例子
比如说,同样都是一台电脑,在不同角度,不同光照,以及不同背景下拍照,图像的数据具有不同的分布,但是从根本上来说,都是一台电脑的图像。Domain adaptation要做的就是,如何根据这些不同分布的数据,很好地学习缺失的标定。

代表方法和文章请见这里:https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md#deep-domain-adaptation
================================================
FILE: doc/scholar_TL.md
================================================
# 迁移学习相关学者、机构信息总结
这里列出了一些迁移学习领域代表性学者以及他们的最具代表性的工作。一般这些工作都是由他们一作,或者是由自己的学生做出来的。当然,这里所列的文章比起这些大牛发过的文章会少得多,仅仅是他们最知名的工作。欢迎补充!
## 应用研究
### 1. [Qiang Yang](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwj2kqCb3p_XAhUDJ5QKHVbmCZcQFggoMAA&url=http%3A%2F%2Fwww.cs.ust.hk%2F~qyang%2F&usg=AOvVaw3KdNXmoIZgeYil--7c4w3P) @ HKUST
迁移学习领域权威大牛。他所在的课题组基本都做迁移学习方面的研究。迁移学习综述《A survey on transfer learning》就出自杨强老师课题组。他的学生们:
#### 1). Sinno J. Pan
现为老师,详细介绍见第二条。
#### 2). Ben Tan
主要研究传递迁移学习(transitive transfer learning)。代表文章:
- Transitive Transfer Learning. KDD 2015.
- Distant Domain Transfer Learning. AAAI 2017.
#### 3). [Derek Hao Hu](https://scholar.google.com/citations?user=Ks81aO0AAAAJ&hl=zh-CN&oi=ao)
主要研究迁移学习与行为识别结合,目前在Snap公司。代表文章:
- Transfer Learning for Activity Recognition via Sensor Mapping. IJCAI 2011.
- Cross-domain activity recognition via transfer learning. PMC 2011.
- Bridging domains using world wide knowledge for transfer learning. TKDE 2010.
#### 4). [Vencent Wencheng Zheng](https://sites.google.com/site/vincentwzheng/)
也做行为识别与迁移学习的结合,目前在新加坡一个研究所当研究科学家。
代表文章:
- User-dependent Aspect Model for Collaborative Activity Recognition. IJCAI 2011.
- Transfer Learning by Reusing Structured Knowledge. AI Magazine.
- Transferring Multi-device Localization Models using Latent Multi-task Learning. AAAI 2008.
- Transferring Localization Models Over Time. AAAI 2008.
- Cross-Domain Activity Recognition. Ubicomp 2009.
- Collaborative Location and Activity Recommendations with GPS History Data. WWW 2010.
#### 5). Ying Wei
做迁移学习与数据挖掘相关的研究。代表工作:
- Instilling Social to Physical: Co-Regularized Heterogeneous Transfer Learning. AAAI 2016.
- Transfer Knowledge between Cities. KDD 2016
#### 其他还有很多学生都做迁移学习方面的研究,更多请参考杨强老师主页。
### 2. [Sinno J. Pan](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwiSk5-k3p_XAhWBRJQKHcXjDtcQFgglMAA&url=http%3A%2F%2Fwww.ntu.edu.sg%2Fhome%2Fsinnopan%2F&usg=AOvVaw1d-1_GwPc2LwOzzFgxziRp) @ NTU
杨强老师学生,比较著名的工作是TCA方法。现在在NTU当老师,一直都在做迁移学习研究。代表工作:
- A Survey On Transfer Learning. TKDE 2010.
- Domain Adaptation via Transfer Component Analysis. TNNLS 2011. [著名的TCA方法]
- Cross-domain sentiment classification via spectral feature alignment. WWW 2010. [著名的SFA方法]
- Transferring Localization Models across Space. AAAI 2008.
### 3. [Lixin Duan](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&cad=rja&uact=8&ved=0ahUKEwjxoeCv3p_XAhWMipQKHapLDoIQFgguMAE&url=http%3A%2F%2Fwww.lxduan.info%2F&usg=AOvVaw0yeoDaeBK9SqTcEgbElQX5) @ UESTC
毕业于NTU,现在在UESTC当老师。代表工作:
- Domain Transfer Multiple Kernel Learning. PAMI 2012.
- Visual Event Recognition in Videos by Learning from Web Data. PAMI 2012.
### 4. [Mingsheng Long](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwi06qa73p_XAhVDi5QKHaCdDlsQFggpMAA&url=http%3A%2F%2Fise.thss.tsinghua.edu.cn%2F~mlong%2F&usg=AOvVaw2A62X80qNKbrwCVzr2pteE) @ THU
毕业于清华大学,现在在清华大学当老师,一直在做迁移学习方面的工作。代表工作:
- Dual Transfer Learning. SDM 2012.
- Transfer Feature Learning with Joint Distribution Adaptation. ICCV 2013.
- Transfer Joint Matching for Unsupervised Domain Adaptation. CVPR 2014.
- Learning transferable features with deep adaptation networks. ICML 2015. [著名的DAN方法]
- Deep Transfer Learning with Joint Adaptation Networks. ICML 2017.
### 5. [Judy Hoffman](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwjH__nD3p_XAhVFopQKHQI1COIQFgglMAA&url=https%3A%2F%2Fpeople.eecs.berkeley.edu%2F~jhoffman%2F&usg=AOvVaw22Ho00Ej2cYKBYqyDIgMnz) @ UC Berkeley & Stanford
Feifei Li的博士后,现在当老师。她有个学生叫做Eric Tzeng,做深度迁移学习。代表工作:
- Simultaneous Deep Transfer Across Domains and Tasks. ICCV 2015.
- Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014.
- Adversarial Discriminative Domain Adaptation. arXiv 2017.
### 6. [Fuzhen Zhuang](http://www.intsci.ac.cn/users/zhuangfuzhen/) @ ICT, CAS
中科院计算所当老师,主要做迁移学习与文本结合的研究。代表工作:
- Transfer Learning from Multiple Source Domains via Consensus Regularization. CIKM 2008.
### 7. [Kilian Q. Weinberger](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwjprr3f3p_XAhXLnJQKHfXbDWwQFgglMAA&url=https%3A%2F%2Fwww.cs.cornell.edu%2F~kilian%2F&usg=AOvVaw08HXYXl1c5tietksaCvieY) @ Cornell U.
现在康奈尔大学当老师。Minmin Chen是他的学生。代表工作:
- Distance metric learning for large margin nearest neighbor classification. JMLR 2009.
- Feature hashing for large scale multitask learning. ICML 2009.
- An introduction to nonlinear dimensionality reduction by maximum variance unfolding. AAAI 2006. [著名的MVU方法]
- Co-training for domain adaptation. NIPS 2011. [著名的Co-training方法]
### 8. [Fei Sha](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&cad=rja&uact=8&ved=0ahUKEwj_vuvp3p_XAhWDQpQKHVReDkQQFgg2MAE&url=http%3A%2F%2Fwww-bcf.usc.edu%2F~feisha%2Fresearch.html&usg=AOvVaw0gE-A0SerdcE5VmaXmxqI_) @ USC
USC教授。学生Boqing Gong提出了著名的GFK方法。代表工作:
- Connecting the Dots with Landmarks: Discriminatively Learning Domain-Invariant Features for Unsupervised Domain Adaptation. ICML 2013.
- Geodesic flow kernel for unsupervised domain adaptation. CVPR 2012. [著名的GFK方法]
### 9. Mahsa Baktashmotlagh @ U. Quessland
现在当老师。主要做流形学习与domain adaptation结合。代表工作:
- Unsupervised Domain Adaptation by Domain Invariant Projection. ICCV 2013.
- Domain Adaptation on the Statistical Manifold. CVPR 2014.
- Distribution-Matching Embedding for Visual Domain Adaptation. JMLR 2016.
### 10. Baochen Sun @ Microsoft
现在在微软。著名的CoRAL系列方法的作者。代表工作:
- Return of Frustratingly Easy Domain Adaptation. AAAI 2016.
- Deep coral: Correlation alignment for deep domain adaptation. ECCV 2016.
### 11. Wenyuan Dai
著名的第四范式创始人,虽然不做研究了,但是当年求学时几篇迁移学习文章至今都很高引。代表工作:
- Boosting for transfer learning. ICML 2007. [著名的TrAdaboost方法]
- Self-taught clustering. ICML 2008.
## 理论研究
### 1. [Arthur Gretton](http://www.gatsby.ucl.ac.uk/~gretton/) @ UCL
主要做two-sample test。代表工作:
- A Kernel Two-Sample Test. JMLR 2013.
- Optimal kernel choice for large-scale two-sample tests. NIPS 2012. [著名的MK-MMD]
### 2. Shai Ben-David @ U.Waterloo
很多迁移学习的理论工作由他给出。代表工作:
- Analysis of representations for domain adaptation. NIPS 2007.
- A theory of learning from different domains. Machine Learning 2010.
### 3. [Alex Smola](https://alex.smola.org/index.html) @ CMU
也是做一些机器学习的理论工作,和上面两位合作比较多。代表工作非常多,不列了。
### 4. [John Blitzer](http://john.blitzer.com/) @ Google
著名的SCL方法提出者,现在也在做机器学习。代表工作:
- Domain adaptation with structural correspondence learning. ECML 2007. [著名的SCL方法]
### 5. [Yoshua Bengio](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwjYqbz83p_XAhXBk5QKHa6UB_UQFgglMAA&url=http%3A%2F%2Fwww.iro.umontreal.ca%2F~bengioy%2Fyoshua_en%2F&usg=AOvVaw09I6hAJANiRHoLSXH2TtCV) @ U.Montreal
深度学习领军人物,主要做深度迁移学习的一些理论工作。代表工作:
- Deep Learning of Representations for Unsupervised and Transfer Learning. ICML 2012.
- How transferable are features in deep neural networks? NIPS 2014.
- Unsupervised and Transfer Learning Challenge: a Deep Learning Approach. ICML 2012.
### 6. [Geoffrey Hinton](https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwi4tZrI35_XAhUEkZQKHVqICfcQFgglMAA&url=http%3A%2F%2Fwww.cs.toronto.edu%2F~hinton%2F&usg=AOvVaw2XmUOIPVI9N62UYhcFk43i) @ U.Toronto
深度学习领军人物,也做深度迁移学习的理论工作。
- Distilling the knowledge in a neural network. NIPS 2014.
================================================
FILE: doc/transfer_learning_application.md
================================================
# Transfer learning applications
By reverse chronological order.
迁移学习的应用,按照时间顺序倒序排列。
- [Transfer learning applications](#transfer-learning-applications)
- [Computer vision](#computer-vision)
- [Medical and healthcare](#medical-and-healthcare)
- [Natural language processing](#natural-language-processing)
- [Time series](#time-series)
- [Speech](#speech)
- [Multimedia](#multimedia)
- [Recommendation](#recommendation)
- [Human activity recognition](#human-activity-recognition)
- [Autonomous driving](#autonomous-driving)
- [Others](#others)
## Computer vision
- WeatherDG: LLM-assisted Procedural Weather Generation for Domain-Generalized Semantic Segmentation [[arxiv](http://arxiv.org/abs/2410.12075)]
- Weather domain generalization
- Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models [[arxiv](http://arxiv.org/abs/2308.07706)]
- Transfer learning for medical image segmentation
- Transfer Learning for Portfolio Optimization [[arxiv](http://arxiv.org/abs/2307.13546)]
- Transfer learning for portfolio optimization
- Imbalanced Domain Generalization for Robust Single Cell Classification in Hematological Cytomorphology [[arxiv](https://arxiv.org/abs/2303.07771)]
- Imbalanced domain generalization for single cell classification 不平衡的DG用于单细胞分类
- Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow [[arxiv](https://arxiv.org/abs/2303.07564)]
- Domain adaptation for foggy scene optical flow 领域自适应用于雾场景的光流
- CLIP the Gap: A Single Domain Generalization Approach for Object Detection [[arxiv](https://arxiv.org/abs/2301.05499)]
- Using CLIP for domain generalization object detection 使用CLIP进行域泛化的目标检测
- ECCV-22 DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation [[arXiv](https://arxiv.org/pdf/2207.09988.pdf)] [[Code](https://github.com/dvlab-research/DecoupleNet)]
- Domain adaptation in semantic segmentation 语义分割域适应
- Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup [[arxiv](https://arxiv.org/abs/2210.03250)]
- Domain adaptation for COVID-19 用DA进行COVID-19预测
- Deep Domain Adaptation for Detecting Bomb Craters in Aerial Images [[arxiv](https://arxiv.org/abs/2209.11299)]
- Bomb craters detection using domain adaptation 用DA检测遥感图像中的炮弹弹坑
- Language-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification [[arxiv](https://arxiv.org/pdf/2209.02700.pdf)]
- Domain generalization for cross-scene hyperspectral image classification 域泛化用于高光谱图像分类
- MM-22 [Source-Free Domain Adaptation for Real-world Image Dehazing](https://arxiv.org/abs/2207.06644)
- Source-free DA for image dehazing 无需源域的迁移用于图像去雾
- CVPR-22 [Segmenting Across Places: The Need for Fair Transfer Learning With Satellite Imagery](https://openaccess.thecvf.com/content/CVPR2022W/FaDE-TCV/html/Zhang_Segmenting_Across_Places_The_Need_for_Fair_Transfer_Learning_With_CVPRW_2022_paper.html)
- Fair transfer learning with satellite imagery 公平迁移学习
- [FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification](https://arxiv.org/abs/2206.08671)
- Few-shot transfer learning for image classification 小样本迁移学习用于图像分类
- [COVID-19 Detection using Transfer Learning with Convolutional Neural Network](https://arxiv.org/abs/2206.08557)
- COVID-19 using transfer learning 用迁移学习进行COVID-19检测
- [Toward Certified Robustness Against Real-World Distribution Shifts](https://arxiv.org/abs/2206.03669)
- Certified robustness against real-world distribution shifts 真实世界中的distribution shift
- [One Ring to Bring Them All: Towards Open-Set Recognition under Domain Shift](https://arxiv.org/abs/2206.03600)
- Open set recognition with domain shift 开放集+domain shift
- [ConFUDA: Contrastive Fewshot Unsupervised Domain Adaptation for Medical Image Segmentation](https://arxiv.org/abs/2206.03888)
- Fewshot UDA for medical image segmentation 小样本域自适应用于医疗图像分割
- ICME-22 [Unsupervised Domain Adaptation Learning for Hierarchical Infant Pose Recognition with Synthetic Data](https://arxiv.org/abs/2205.01892)
- Unsupervised domain adaptation for infant pose recognition 用领域自适应进行婴儿姿势识别
- CVPR-22 [MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation](https://arxiv.org/abs/2204.12667)
- Multi-modal test-time adaptation for 3D semantic segmentation 多模态测试时adaptation用于3D语义分割
- [Undoing the Damage of Label Shift for Cross-domain Semantic Segmentation](https://arxiv.org/abs/2204.05546)
- Handle the label shift in cross-domain semantic segmentation 在跨域语义分割时考虑label shift
- [Gated Domain-Invariant Feature Disentanglement for Domain Generalizable Object Detection](https://arxiv.org/abs/2203.11432)
- Channel masking for domain generalization object detection
- 通过一个gate控制channel masking进行object detection DG
- [Domain generalization in deep learning-based mass detection in mammography: A large-scale multi-center study](https://arxiv.org/abs/2201.11620)
- Domain generalization in mass detection in mammography
- Domain generalization进行胸部射线检测
- [Continual Coarse-to-Fine Domain Adaptation in Semantic Segmentation](https://arxiv.org/abs/2201.06974)
- Domain adaptation in semantic segmentation
- 领域自适应在语义分割的应用
- [Transfer Learning for Scene Text Recognition in Indian Languages](2201.03180)
- Transfer learning for scene text recognition in Indian languages
- 用迁移学习进行印度语的场景文字识别
- IEEE TMM-22 [Decompose to Adapt: Cross-domain Object Detection via Feature Disentanglement](https://arxiv.org/abs/2201.01929)
- Invariant and shared components for Faster RCNN detection
- 解耦公共和私有表征进行目标检测
- [Transfer learning of phase transitions in percolation and directed percolation](https://arxiv.org/abs/2112.15516)
- Transfer learning of phase transitions in percolation and directed percolation
- 迁移学习用于precolation
- [Transfer learning for cancer diagnosis in histopathological images](https://arxiv.org/abs/2112.15523)
- Transfer learning for cancer diagnosis
- 迁移学习用于癌症诊断
- [Subtask-dominated Transfer Learning for Long-tail Person Search](https://arxiv.org/abs/2112.00527)
- Subtask-dominated transfer for long-tail person search
- 子任务驱动的长尾人物搜索
- NeurIPS-21 workshop [CytoImageNet: A large-scale pretraining dataset for bioimage transfer learning](https://arxiv.org/abs/2111.11646)
- A large-scale dataset for bioimage transfer learning
- 一个大规模的生物图像数据集用于迁移学习
- MICCAI-21 [Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning](https://arxiv.org/abs/2111.10827)
- Domain generalization for mammography detection
- 领域泛化用于乳房X射线检查
- [Action Recognition using Transfer Learning and Majority Voting for CSGO](https://arxiv.org/abs/2111.03882)
- Using transfer learning and majority voting for action recognition
- 使用迁移学习和多数投票进行动作识别
- [C-MADA: Unsupervised Cross-Modality Adversarial Domain Adaptation framework for medical Image Segmentation](https://arxiv.org/abs/2110.15823)
- Cross-modality domain adaptation for medical image segmentation
- 跨模态的DA用于医学图像分割
- BMVC-21 [SILT: Self-supervised Lighting Transfer Using Implicit Image Decomposition](https://arxiv.org/abs/2110.12914)
- Lighting transfer using implicit image decomposition
- 用隐式图像分解进行光照迁移
- [Domain Adaptation in Multi-View Embedding for Cross-Modal Video Retrieval](https://arxiv.org/abs/2110.12812)
- Domain adaptation for cross-modal video retrieval
- 用领域自适应进行跨模态的视频检索
- [Age and Gender Prediction using Deep CNNs and Transfer Learning](https://arxiv.org/abs/2110.12633)
- Age and gender prediction using transfer learning
- 用迁移学习进行年龄和性别预测
- WACV-22 [AuxAdapt: Stable and Efficient Test-Time Adaptation for Temporally Consistent Video Semantic Segmentation](https://arxiv.org/abs/2110.12369)
- Test-time adaptation for video semantic segmentation
- 测试时adaptation用于视频语义分割
- NeurIPS-21 [FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling](https://arxiv.org/abs/2110.08263) [知乎解读](https://zhuanlan.zhihu.com/p/422930830) [code](https://github.com/TorchSSL/TorchSSL)
- Curriculum pseudo label with a unified codebase TorchSSL
- 半监督方法FlexMatch和统一算法库TorchSSL
- ICCV-21 [BiMaL: Bijective Maximum Likelihood Approach to Domain Adaptation in Semantic Scene Segmentation](https://arxiv.org/abs/2108.03267)
- Bijective MMD for domain adaptation
- 双射MMD用于语义分割
- CVPR-21 [Ego-Exo: Transferring Visual Representations From Third-Person to First-Person Videos](https://openaccess.thecvf.com/content/CVPR2021/html/Li_Ego-Exo_Transferring_Visual_Representations_From_Third-Person_to_First-Person_Videos_CVPR_2021_paper.html)
- Transfer learning from third-person to first-person video
- 从第三人称视频迁移到第一人称
- 20210511 [Adaptive Domain-Specific Normalization for Generalizable Person Re-Identification](https://arxiv.org/abs/2105.03042)
- Adaptive domain-specific normalization for generalizable ReID
- 自适应的领域特异归一化用于ReID
- 20210220 [DRIV100: In-The-Wild Multi-Domain Dataset and Evaluation for Real-World Domain Adaptation of Semantic Segmentation](http://arxiv.org/abs/2102.00150)
- A new dataset for domain adaptation on semantic segmentation
- 一个用于domain adaptation做语义分割的新数据集
- 20210127 [Transferable Interactiveness Knowledge for Human-Object Interaction Detection](http://arxiv.org/abs/2101.10292)
- A transferable HOI model
- 一个可迁移的人-物交互检测模型
- 20201208 [Domain Adaptation of Aerial Semantic Segmentation](http://arxiv.org/abs/2012.02264)
- 用domain adaptation做航空图像分割
- 20200420 AAAI-20 [Generative Adversarial Networks for Video-to-Video Domain Adaptation](https://arxiv.org/abs/2004.08058)
- Using GAN for video domain adaptation
- GAN用于视频到视频的adaptation
- 20191029 WACV-20 [Progressive Domain Adaptation for Object Detection](https://arxiv.org/abs/1910.11319)
- Progressive domain adaptation for object recognition
- 渐进式的DA用于物体检测
- 20191011 ICIP-19 [Cross-modal knowledge distillation for action recognition](https://arxiv.org/abs/1910.04641)
- Cross-modal knowledge distillation for action recognition
- 跨模态的知识蒸馏并用于动作识别
- 20191008 arXiv, ICCV-19 demo [Cross-Domain Complementary Learning with Synthetic Data for Multi-Person Part Segmentation](https://arxiv.org/abs/1907.05193)
- Learning human body part segmentation without human labeling
- 基於合成數據的跨域互補學習人體部位分割
- 20191008 ICONIP-19 [Semi-Supervised Domain Adaptation with Representation Learning for Semantic Segmentation across Time](https://arxiv.org/abs/1805.04141)
- Semi-supervised domain adaptation with representation learning for semantic segmentation
- 半监督DA用于语义分割
- 20190926 arXiv [Restyling Data: Application to Unsupervised Domain Adaptation](https://arxiv.org/abs/1909.10900)
- Restyle data using domain adaptation
- 使用domain adaptation进行风格迁移
- 20180828 ICCV-19 workshop [Unsupervised Deep Feature Transfer for Low Resolution Image Classification](https://arxiv.org/abs/1908.10012)
- Deep feature transfer for low resolution image classification
- 深度特征迁移用于低分辨率图像分类
- 20190809 IJCAI-19 [Progressive Transfer Learning for Person Re-identification](https://arxiv.org/abs/1908.02492)
- Progressive transfer learning for RE_ID
- 渐进式迁移学习用于RE_ID
- 20190703 arXiv [Disentangled Makeup Transfer with Generative Adversarial Network](https://arxiv.org/abs/1907.01144)
- Makeup transfer with GAN
- 用GAN进行化妆的迁移
- 20190509 arXiv [Unsupervised Domain Adaptation using Generative Adversarial Networks for Semantic Segmentation of Aerial Images](https://arxiv.org/abs/1905.03198)
- Domain adaptation for semantic segmentation in aerial images
- DA应用于鸟瞰图像语义分割
- 20190415 PAKDD-19 [Adaptively Transfer Category-Classifier for Handwritten Chinese Character Recognition](https://link.springer.com/chapter/10.1007/978-3-030-16148-4_9)
- Transfer learning for handwritten Chinese character recognition
- 用迁移学习进行中文手写体识别
- 20190409 arXiv [Unsupervised Domain Adaptation for Multispectral Pedestrian Detection](https://arxiv.org/abs/1904.03692)
- Domain adaptation for pedestrian detection
- 无监督领域自适应用于多模态行人检测
- 20190305 arXiv [Unsupervised Domain Adaptation Learning Algorithm for RGB-D Staircase Recognition](https://arxiv.org/abs/1903.01212)
- Domain adaptation for RGB-D staircase recognition
- Domain adaptation进行深度和RGB楼梯识别
- 20190123 arXiv [Adapting Convolutional Neural Networks for Geographical Domain Shift](https://arxiv.org/abs/1901.06345)
- Convolutional neural network for geographical domain shift
- 将卷积网络用于地理学上的domain shift问题
- 20190115 IJAERS [Weightless Neural Network with Transfer Learning to Detect Distress in Asphalt](https://arxiv.org/abs/1901.03660)
- Transfer learning to detect distress in asphalt
- 用迁移学习检测路面情况
- 20190102 arXiv [High Quality Monocular Depth Estimation via Transfer Learning](https://arxiv.org/abs/1812.11941)
- Monocular depth estimation using transfer learning
- 用迁移学习进行单眼深度估计
- 20181213 arXiv [Multichannel Semantic Segmentation with Unsupervised Domain Adaptation](https://arxiv.org/abs/1812.04351)
- Robot vision semantic segmentation with domain adaptation
- 用于机器视觉中语义分割的domain adaptation
- 20181212 arXiv [3D Scene Parsing via Class-Wise Adaptation](https://arxiv.org/abs/1812.03622)
- Class-wise adaptation for 3D scene parsing
- 类别的适配用于3D场景分析
- 20181130 arXiv [Identity Preserving Generative Adversarial Network for Cross-Domain Person Re-identification](https://arxiv.org/abs/1811.11510)
- Cross-domain reID
- 跨领域的行人再识别
- 20181128 arXiv [Cross-domain Deep Feature Combination for Bird Species Classification with Audio-visual Data](https://arxiv.org/abs/1811.10199)
- Cross-domain deep feature combination for bird species classification
- 跨领域的鸟分类
- 20181128 WACV-19 [CNN based dense underwater 3D scene reconstruction by transfer learning using bubble database](https://arxiv.org/abs/1811.09675)
- Transfer learning for underwater 3D scene reconstruction
- 用迁移学习进行水下3D场景重建
- 20181128 arXiv [Low-resolution Face Recognition in the Wild via Selective Knowledge Distillation](https://arxiv.org/abs/1811.09998)
- Knowledge distilation for low-resolution face recognition
- 将知识蒸馏应用于低分辨率的人脸识别
- 20181121 arXiv [Distribution Discrepancy Maximization for Image Privacy Preserving](https://arxiv.org/abs/1811.07335)
- Distribution Discrepancy Maximization for Image Privacy Preserving
- 通过最大化分布差异来进行图片隐私保护
- 20181114 arXiv [A Framework of Transfer Learning in Object Detection for Embedded Systems](https://arxiv.org/abs/1811.04863)
- Transfer learning in embedded system for object detection
- 在嵌入式系统中进行针对目标检测的迁移学习
- 20181012 arXiv [Bird Species Classification using Transfer Learning with Multistage Training](https://arxiv.org/abs/1810.04250)
- Using transfer learning for bird species classification
- 用迁移学习进行鸟类分类
- 20180912 ICIP-18 [Adversarial Domain Adaptation with a Domain Similarity Discriminator for Semantic Segmentation of Urban Areas](https://ieeexplore.ieee.org/abstract/document/8451010/)
- Semantic segmentation using transfer learning
- 用迁移学习进行语义分割
- 20180912 arXiv [Tensor Alignment Based Domain Adaptation for Hyperspectral Image Classification](https://arxiv.org/abs/1808.09769)
- Hyperspectral image classification using domain adaptation
- 用domain adaptation进行图像分类
- 20180904 ICPR-18 [Document Image Classification with Intra-Domain Transfer Learning and Stacked Generalization of Deep Convolutional Neural Networks](https://arxiv.org/abs/1801.09321)
- Document image classification using transfer learning
- 使用迁移学习进行文档图像的分类
- 20180826 ISPRS journal [Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images](https://arxiv.org/abs/1808.07675)
- a multi-task learning network for remote sensing
- 提出一个多任务的深度网络用于遥感图像检测
- 20180819 arXiv [Transfer Learning and Organic Computing for Autonomous Vehicles](https://arxiv.org/abs/1808.05443)
- Propose different transfer learning methods to adapt the situation of autonomous driving
- 提出一些不同的迁移学习方法应用于自动驾驶的环境适配
- 20180801 ECCV-18 [DOCK: Detecting Objects by transferring Common-sense Knowledge](https://arxiv.org/abs/1804.01077)
- A method called DOCK for object detection using transfer learning
- 提出一个叫做DOCK的方法进行基于迁移学习的目标检测
- 20180801 ECCV-18 [A Zero-Shot Framework for Sketch-based Image Retrieval](https://arxiv.org/abs/1807.11724)
- A Zero-Shot Framework for Sketch-based Image Retrieval
- 一个针对于简笔画图像检索的zero-shot框架
- 20180731 ICANN-18 [Metric Embedding Autoencoders for Unsupervised Cross-Dataset Transfer Learning](https://arxiv.org/abs/1807.10591)
- Deep transfer learning for Re-ID
- 将深度迁移学习用于Re-ID
- 20180627 arXiv 生成模型用于姿态迁移:[Generative Models for Pose Transfer](https://arxiv.org/abs/1806.09070)
- 20180622 arXiv 跨领域的人脸识别用于银行认证系统:[Cross-Domain Deep Face Matching for Real Banking Security Systems](https://arxiv.org/abs/1806.07644)
- 20180614 arXiv 跨数据集的person reid:[Cross-dataset Person Re-Identification Using Similarity Preserved Generative Adversarial Networks](https://arxiv.org/abs/1806.04533)
- 20180610 CEIG-17 将迁移学习用于插图分类:[Transfer Learning for Illustration Classification](https://arxiv.org/abs/1806.02682)
- 20180519 arXiv 用迁移学习进行物体检测,200帧/秒:[Object detection at 200 Frames Per Second](https://arxiv.org/abs/1804.04775)
- 20180519 arXiv 用迁移学习进行肢体语言识别:[Optimization of Transfer Learning for Sign Language Recognition Targeting Mobile Platform](https://arxiv.org/abs/1805.06618)
- 20180427 CVPR-18(workshop) 将深度迁移学习用于Person-reidentification: [Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification](https://arxiv.org/abs/1804.09347)
- 20180410 arXiv 用迁移学习进行犯罪现场的图像匹配:[Cross-Domain Image Matching with Deep Feature Maps](https://arxiv.org/abs/1804.02367)
- 20180408 arXiv 小数据集上的迁移学习手写体识别:[Boosting Handwriting Text Recognition in Small Databases with Transfer Learning](https://arxiv.org/abs/1804.01527)
- 20180404 arXiv 用迁移学习进行物体检测:[Transferring Common-Sense Knowledge for Object Detection](https://arxiv.org/abs/1804.01077)
## Medical and healthcare
- ICASSP'24 Single-Source Domain Generalization in Fundus Image Segmentation Via Moderating and Interpolating Input Space Augmentation [[IEEE](https://ieeexplore.ieee.org/abstract/document/10447741?casa_token=t0FGpPfYxeoAAAAA:yyZ1zKhXstoaxNOtP6zKBj1ArLF8JZ7gGQOtR-k6DAHCO9SWTIOwLG5TF71BrcenWvO002MYku-wtQI)]
- Single-source DG in fundus image segmentation
- Efficient Domain Adaptation for Endoscopic Visual Odometry [[arxiv](https://arxiv.org/abs/2403.10860)]
- Efficient domain adaptation for visual odometry 高效DA用于odometry
- MedMerge: Merging Models for Effective Transfer Learning to Medical Imaging Tasks [[arxiv](https://arxiv.org/abs/2403.11646)]
- Model merge for medical transfer learning 通过模型合并进行医学迁移学习
- Domain Adaptation Using Pseudo Labels for COVID-19 Detection [[arxiv](https://arxiv.org/abs/2403.11498)]
- Domain adaptation for COVID-19 detection 用DA进行covid-19检查
- Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans [[arxiv](https://arxiv.org/abs/2403.11338)]
- Covid-19 test using domain adaptation 使用集成和测试增强用于DA covid-19
- On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals [[arxiv](http://arxiv.org/abs/2312.00502)]
- OOD robustness for self-supervised learning for phonocardiogram 心音图信号自监督的OOD鲁棒性
- Domain Generalization with Adversarial Intensity Attack for Medical Image Segmentation [[arxiv](http://arxiv.org/abs/2304.02720)]
- Domain generalization for medical segmentation 用domain generalization进行医学分割
- Probabilistic Domain Adaptation for Biomedical Image Segmentation [[arxiv](http://arxiv.org/abs/2303.11790)]
- Probabilistic domain adaptation for biomedical image segmentation 概率的domain adaptation用于生物医疗图像分割
- Transfer Learning for Real-time Deployment of a Screening Tool for Depression Detection Using Actigraphy [[arxiv](https://arxiv.org/abs/2303.07847)]
- Transfer learning for Depression detection 迁移学习用于脉动计焦虑检测
- Imbalanced Domain Generalization for Robust Single Cell Classification in Hematological Cytomorphology [[arxiv](https://arxiv.org/abs/2303.07771)]
- Imbalanced domain generalization for single cell classification 不平衡的DG用于单细胞分类
- Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup [[arxiv](https://arxiv.org/abs/2210.03250)]
- Domain adaptation for COVID-19 用DA进行COVID-19预测
- FL-IJCAI-22 [MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare](https://arxiv.org/abs/2206.08516)
- MetaFed: a new form of federated learning 联邦之联邦学习、新范式
- [Parkinson's disease diagnostics using AI and natural language knowledge transfer](https://arxiv.org/abs/2204.12559)
- Transfer learning for Parkinson's disease diagnostics 迁移学习用于帕金森诊断
- [Federated Learning with Adaptive Batchnorm for Personalized Healthcare](https://arxiv.org/abs/2112.00734)
- Federated learning with adaptive batchnorm
- 用自适应BN进行个性化联邦学习
- [Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation](https://arxiv.org/abs/2109.11798)
- Adversarial domain adaptation for bronchoscopic depth estimation
- 用对抗领域自适应进行支气管镜的深度估计
- [Domain and Content Adaptive Convolution for Domain Generalization in Medical Image Segmentation](https://arxiv.org/abs/2109.05676)
- Domain generalization for medical image segmentation
- 领域泛化用于医学图像分割
- [Unsupervised domain adaptation for cross-modality liver segmentation via joint adversarial learning and self-learning](https://arxiv.org/abs/2109.05664)
- Domain adaptation for cross-modality liver segmentation
- 使用domain adaptation进行肝脏的跨模态分割
- MICCAI-21 [A Systematic Benchmarking Analysis of Transfer Learning for Medical Image Analysis](https://arxiv.org/abs/2108.05930)
- A benchmark of transfer learning for medical image
- 一个详细的迁移学习用于医学图像的benchmark
- [A Data Augmented Approach to Transfer Learning for Covid-19 Detection](https://arxiv.org/abs/2108.02870)
- Data augmentation to transfer learning for COVID
- 迁移学习使用数据增强,用于COVID-19
- [Transfer Learning in Electronic Health Records through Clinical Concept Embedding](https://arxiv.org/abs/2107.12919)
- Transfer learning in electronic health record
- 迁移学习用于医疗记录管理
- 20210607 [FedHealth 2: Weighted Federated Transfer Learning via Batch Normalization for Personalized Healthcare](https://arxiv.org/abs/2106.01009)
- Federated transfer learning framework 2
- FedHealth联邦迁移学习框架第二代
- 20201222 [Transfer Learning Through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images](http://arxiv.org/abs/2012.09250)
- Transfer learning for vessel segmentation from retinal images
- 迁移学习用于视网膜血管分割
- 20201215 [Distant Domain Transfer Learning for Medical Imaging](https://arxiv.org/abs/2012.06346)
- Distant domain transfer learning for medical imaging
- 用于COVID检测的远领域迁移学习
- 20201215 AAAI-21 [Transfer Graph Neural Networks for Pandemic Forecasting](https://arxiv.org/abs/2009.08388)
- GNN and transfer learning for pandemic forecasting
- 用基于GNN的迁移学习进行流行病预测
- 20201116 [A Study of Domain Generalization on Ultrasound-based Multi-Class Segmentation of Arteries, Veins, Ligaments, and Nerves Using Transfer Learning](https://arxiv.org/abs/2011.07019)
- Domain generalization用于医学分类
- 20200927 [Transfer Learning by Cascaded Network to identify and classify lung nodules for cancer detection](https://arxiv.org/abs/2009.11587)
- 迁移学习用于肺癌检测
- 20200813 [Transfer Learning for Protein Structure Classification and Function Inference at Low Resolution](https://arxiv.org/abs/2008.04757)
- 迁移学习用于低分辨率下的蛋白质结构分类
- 20191111 NIPS-19 workshop [Transfer Learning in 4D for Breast Cancer Diagnosis using Dynamic Contrast-Enhanced Magnetic Resonance Imaging](https://arxiv.org/abs/1911.03022)
- Transfer learning in 4D for breast cancer diagnosis
- 20191029 arXiv [NER Models Using Pre-training and Transfer Learning for Healthcare](https://arxiv.org/abs/1910.11241)
- Pretraining NER models for healthcare
- 预训练的NER模型用于健康监护
- 20191008 arXiv [Transfer Brain MRI Tumor Segmentation Models Across Modalities with Adversarial Networks](https://arxiv.org/abs/1910.02717)
- Transfer learning for multi-modal brain MRI tumor segmentation
- 用迁移学习进行多模态的MRI肿瘤分割
- 20191008 arXiv [Noise as Domain Shift: Denoising Medical Images by Unpaired Image Translation](https://arxiv.org/abs/1910.02702)
- Noise as domain shift for medical images
- 医学图像中的噪声进行adaptation
- 20190912 MICCAI workshop [Multi-Domain Adaptation in Brain MRI through Paired Consistency and Adversarial Learning](https://arxiv.org/abs/1908.05959)
- Multi-domain adaptation for brain MRI
- 多领域的adaptation用于大脑MRI识别
- 20190909 IJCAI-FML-19 [FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare](http://jd92.wang/assets/files/a15_ijcai19.pdf)
- The first work on federated transfer learning for wearable healthcare
- 第一个将联邦迁移学习用于可穿戴健康监护的工作
- 20190828 MICCAI-19 workshop [Cross-modality Knowledge Transfer for Prostate Segmentation from CT Scans](https://arxiv.org/abs/1908.10208)
- Cross-modality transfer for prostate segmentation
- 跨模态的迁移用于前列腺分割
- 20190802 arXiv [Towards More Accurate Automatic Sleep Staging via Deep Transfer Learning](https://arxiv.org/abs/1907.13177)
- Accurate Sleep Staging with deep transfer learning
- 用深度迁移学习进行精准的睡眠阶段估计
- 20190729 MICCAI-19 [Annotation-Free Cardiac Vessel Segmentation via Knowledge Transfer from Retinal Images](https://arxiv.org/abs/1907.11483)
- Cardiac vessel segmentation using transfer learning from Retinal Images
- 用视网膜图片进行迁移学习用于心脏血管分割
- 20190703 arXiv [Applying Transfer Learning To Deep Learned Models For EEG Analysis](https://arxiv.org/abs/1907.01332)
- Apply transfer learning to EEG
- 用深度迁移学习进行EEG分析
- 20190626 arXiv [A Novel Deep Transfer Learning Method for Detection of Myocardial Infarction](https://arxiv.org/abs/1906.09358)
- A deep transfer learning method for detecting myocardial infarction
- 一种用于监测心肌梗塞的深度迁移方法
- 20190416 arXiv [Deep Transfer Learning for Single-Channel Automatic Sleep Staging with Channel Mismatch](https://arxiv.org/abs/1904.05945)
- Using deep transfer learning for sleep stage recognition
- 用深度迁移学习进行睡眠阶段的检测
- 20190403 arXiv [Transfer Learning for Clinical Time Series Analysis using Deep Neural Networks](https://arxiv.org/abs/1904.00655)
- Using transfer learning for multivariate clinical data
- 使用迁移学习进行多元医疗数据迁移
- 20190403 arXiv [Med3D: Transfer Learning for 3D Medical Image Analysis](https://arxiv.org/abs/1904.00625)
- Transfer learning for 3D medical image analysis
- 迁移学习用于3D医疗图像分析
- 20190221 arXiv [Transfusion: Understanding Transfer Learning with Applications to Medical Imaging](https://arxiv.org/abs/1902.07208)
- Analyzing the influence of transfer learning in medical imaging
- 在医疗图像中分析迁移学习作用
- 20190117 NeurIPS-18 workshop [Transfer Learning for Prosthetics Using Imitation Learning](https://arxiv.org/abs/1901.04772)
- Using transfer learning for prosthetics
- 用迁移学习进行义肢的模仿学习
- 20190115 arXiv [Disease Knowledge Transfer across Neurodegenerative Diseases](https://arxiv.org/abs/1901.03517)
- Transfer learning for neurodegenerative disease
- 迁移学习用于神经退行性疾病
- 20181225 arXiv [An Integrated Transfer Learning and Multitask Learning Approach for Pharmacokinetic Parameter Prediction](https://arxiv.org/abs/1812.09073)
- Using transfer learning for Pharmacokinetic Parameter Prediction
- 用迁移学习进行药代动力学参数估计
- 20181221 arXiv [PnP-AdaNet: Plug-and-Play Adversarial Domain Adaptation Network with a Benchmark at Cross-modality Cardiac Segmentation](https://arxiv.org/abs/1812.07907)
- Adversarial transfer learning for medical images
- 对抗迁移学习用于医学图像分割
- 20181214 BioCAS-19 [ECG Arrhythmia Classification Using Transfer Learning from 2-Dimensional Deep CNN Features](https://arxiv.org/abs/1812.04693)
- Deep transfer learning for EEG Arrhythmia Classification
- 深度迁移学习用于心率不齐分类
- 20181206 NeurIPS-18 workshop [Towards Continuous Domain adaptation for Healthcare](https://arxiv.org/abs/1812.01281)
- Continuous domain adaptation for healthcare
- 连续的domain adaptation用于健康监护
- 20181206 NeurIPS-18 workshop [A Hybrid Instance-based Transfer Learning Method](https://arxiv.org/abs/1812.01063)
- Instance-based transfer learning for healthcare
- 基于样本的迁移学习用于健康监护
- 20181205 arXiv [Learning from a tiny dataset of manual annotations: a teacher/student approach for surgical phase recognition](https://arxiv.org/abs/1812.00033)
- Transfer learning for surgical phase recognition
- 迁移学习用于外科手术阶段识别
- 20181128 NeurIPS-18 workshop [Multi-Task Generative Adversarial Network for Handling Imbalanced Clinical Data](https://arxiv.org/abs/1811.10419)
- Multi-task learning for imbalanced clinical data
- 多任务学习用于不平衡的就诊数据
- 20181127 NeurIPS-18 workshop [Predicting Diabetes Disease Evolution Using Financial Records and Recurrent Neural Networks](https://arxiv.org/abs/1811.09350)
- Predicting diabetes using financial records
- 用财务记录预测糖尿病
- 20181123 NIPS-18 workshop [Population-aware Hierarchical Bayesian Domain Adaptation](https://arxiv.org/abs/1811.08579)
- Applying domain adaptation to health
- 将domain adaptation应用于健康
- 20181121 arXiv [Transferrable End-to-End Learning for Protein Interface Prediction](https://arxiv.org/abs/1807.01297)
- Transfer learning for protein interface prediction
- 用迁移学习进行蛋白质接口预测
- 20181117 arXiv [Unsupervised domain adaptation for medical imaging segmentation with self-ensembling](https://arxiv.org/abs/1811.06042)
- Medical imaging using transfer learning
- 使用迁移学习进行医学图像分割
- 20181117 AAAI-19 [GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition](https://arxiv.org/abs/1811.06186)
- Cross-view gait recognition
- 跨视图的步态识别
- 20181012 arXiv [Survival prediction using ensemble tumor segmentation and transfer learning](https://arxiv.org/abs/1810.04274)
- Predicting the survival of the tumor patient using transfer learning
- 用迁移学习估计肿瘤病人存活时间
- 20180904 EMBC-18 [Multi-Cell Multi-Task Convolutional Neural Networks for Diabetic Retinopathy Grading Kang](https://arxiv.org/abs/1808.10564)
- Use multi-task CNN for Diabetic Retinopathy Grading Kang
- 用多任务的CNN进行糖尿病的视网膜粒度检查
- 20180823 ICPR-18 [Multi-task multiple kernel machines for personalized pain recognition from functional near-infrared spectroscopy brain signals](https://arxiv.org/abs/1808.06774)
- A multi-task method to recognize pains
- 提出一个multi-task框架来检测pain
- 20180801 MICCAI-18 [Leveraging Unlabeled Whole-Slide-Images for Mitosis Detection](https://arxiv.org/abs/1807.11677)
- Use unlabeled images for mitosis detection
- 用未标记的图片进行细胞有丝分裂的检测
- 20180627 arXiv 用迁移学习进行感染预测:[Domain Adaptation for Infection Prediction from Symptoms Based on Data from Different Study Designs and Contexts](https://arxiv.org/abs/1806.08835)
- 20180621 arXiv 迁移学习用于角膜组织的分类:[Transfer Learning with Human Corneal Tissues: An Analysis of Optimal Cut-Off Layer](https://arxiv.org/abs/1806.07073)
- 20180612 KDD-18 多任务学习用于ICU病人数据挖掘:[Learning Tasks for Multitask Learning: Heterogenous Patient Populations in the ICU](https://arxiv.org/abs/1806.02878)
- 20180610 BioNLP-18 将迁移学习用于病人实体分类:[Embedding Transfer for Low-Resource Medical Named Entity Recognition: A Case Study on Patient Mobility](https://arxiv.org/abs/1806.02814)
- 20180610 MICCAI-18 将迁移学习用于前列腺图分类:[Adversarial Domain Adaptation for Classification of Prostate Histopathology Whole-Slide Images](https://arxiv.org/abs/1806.01357)
- 20180605 arXiv 迁移学习应用于胸X光片分割:[Semantic-Aware Generative Adversarial Nets for Unsupervised Domain Adaptation in Chest X-ray Segmentation](https://arxiv.org/abs/1806.00600)
- 20180604 arXiv 用CNN迁移学习进行硬化症检测:[One-shot domain adaptation in multiple sclerosis lesion segmentation using convolutional neural networks](https://arxiv.org/abs/1805.12415)
- 20180504 arXiv 用迁移学习进行心脏病检测分类:[ECG Heartbeat Classification: A Deep Transferable Representation](https://arxiv.org/abs/1805.00794)
- 20180426 arXiv 迁移学习用于医学名字实体检测;[Label-aware Double Transfer Learning for Cross-Specialty Medical Named Entity Recognition](https://arxiv.org/abs/1804.09021)
- 20180402 arXiv 将迁移学习用于癌症检测:[Improve the performance of transfer learning without fine-tuning using dissimilarity-based multi-view learning for breast cancer histology images](https://arxiv.org/abs/1803.11241)
## Natural language processing
- On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective [[arxiv](https://arxiv.org/abs/2302.12095)] | [[code](https://github.com/microsoft/robustlearn)]
- Adversarial and OOD evaluation of ChatGPT 对ChatGPT鲁棒性的评测
- GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-distribution Generalization Perspective [[arxiv](https://arxiv.org/abs/2211.08073)]
- OOD for natural language processing evaluation 提出GLUE-X用于OOD在NLP数据上的评估
- Robust Domain Adaptation for Machine Reading Comprehension [[arxiv](https://arxiv.org/abs/2209.11615)]
- Domain adaptation for machine reading comprehension 机器阅读理解的domain adaptation
- NAACL-22 [Modularized Transfer Learning with Multiple Knowledge Graphs for Zero-shot Commonsense Reasoning](https://arxiv.org/abs/2206.03715)
- Transfer learning for zero-shot reasoning 迁移学习用于零次常识推理
- ICLR-22 [Enhancing Cross-lingual Transfer by Manifold Mixup](https://arxiv.org/abs/2205.04182)
- Cross-lingual transfer using manifold mixup 用Mixup进行cross-lingual transfer
- NAACL-22 [Efficient Few-Shot Fine-Tuning for Opinion Summarization](https://arxiv.org/abs/2205.02170)
- Few-shot fine-tuning for opinion summarization 小样本微调技术用于评论总结
- NAACL-22 [GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering](https://arxiv.org/abs/2204.04179)
- Fast fine-tuning for content-based collaborative filtering
- 快速的适用于协同过滤的微调
- [One Model, Multiple Tasks: Pathways for Natural Language Understanding](https://arxiv.org/abs/2203.03312)
- Pathways for natural language understanding
- 使用一个model用于所有NLP任务
- ACL-22 [Investigating Selective Prediction Approaches Across Several Tasks in IID, OOD, and Adversarial Settings](https://arxiv.org/abs/2203.00211)
- Investigate selective prediction approaches in IID, OOD, and ADV settings
- 在独立同分布、分布外、对抗情境中调研选择性预测方法
- [IGLUE: A Benchmark for Transfer Learning across Modalities, Tasks, and Languages](https://arxiv.org/abs/2201.11732)
- A benchmark for transfer learning in NLP
- 一个用于NLP跨模态、任务、语言的benchmark
- [Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation](https://arxiv.org/abs/2110.14509)
- Domain adaptation for multi-source entiry linkage
- 用DA进行多源的实体链接
- EMNLP-21 [Non-Parametric Unsupervised Domain Adaptation for Neural Machine Translation](https://arxiv.org/abs/2109.06604)
- UDA for machine translation
- 用领域自适应进行机器翻译
- EMNLP-21 [Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning](https://arxiv.org/abs/2109.06349)
- Few-shot intent detection using pretrain and finetune
- 用迁移学习进行少样本意图检测
- [Contrastive Domain Adaptation for Question Answering using Limited Text Corpora](https://arxiv.org/abs/2108.13854)
- Contrastive domain adaptation for QA
- QA任务中应用对比domain adaptation
- SemDIAL-21 [Generating Personalized Dialogue via Multi-Task Meta-Learning](https://arxiv.org/abs/2108.03377)
- Generate personalized dialogue using multi-task meta-learning
- 用多任务元学习生成个性化的对话
- 20210607 [Bilingual Alignment Pre-training for Zero-shot Cross-lingual Transfer](http://arxiv.org/abs/2106.01732)
- Zero-shot cross-lingual transfer using bilingual alignment pretraining
- 通过双语言进行对齐预训练进行零资源的跨语言迁移
- 20210607 [Pre-training Universal Language Representation](http://arxiv.org/abs/2105.14478)
- Pretraining for universal language representation
- 用统一的预训练进行语言表征建模
- 20210516 [A cost-benefit analysis of cross-lingual transfer methods](https://arxiv.org/abs/2105.06813)
- Analysis of the running time of cross-lingual transfer
- 分析了跨语言迁移方法的时间
- 20210420 arXiv [Domain Adaptation and Multi-Domain Adaptation for Neural Machine Translation: A Survey](https://arxiv.org/abs/2104.06951)
- A survey on domain adaptation for machine translation
- 关于用领域自适应进行神经机器翻译的综述
- 20210202 [Transfer Learning Approach for Detecting Psychological Distress in Brexit Tweets](https://arxiv.org/abs/2102.00912)
- 检测英国脱欧twitter中的心理压力
- 20210106 [Decoding Time Lexical Domain Adaptation for Neural Machine Translation](http://arxiv.org/abs/2101.00421)
- DA for NMT
- DA用于机器翻译任务上
- 20210104 [A Closer Look at Few-Shot Crosslingual Transfer: Variance, Benchmarks and Baselines](http://arxiv.org/abs/2012.15682)
- A closer look at few-shot crosslingual transfer
- 20201215 AAAI-21 [Multilingual Transfer Learning for QA Using Translation as Data Augmentation](https://arxiv.org/abs/2012.05958)
- Multilingual transfer learning for QA
- 用于QA任务的多语言迁移学习
- 20201208 [Fine-tuning BERT for Low-Resource Natural Language Understanding via Active Learning](http://arxiv.org/abs/2012.02462)
- 用BERT结合主动学习进行低资源的NLP任务
- 20200927 EMNLP-20 [Feature Adaptation of Pre-Trained Language Models across Languages and Domains for Text Classification](https://arxiv.org/abs/2009.11538)
- 跨语言和领域的预训练模型用于文本分类
- 20200420 ACL-20 [Geometry-aware Domain Adaptation for Unsupervised Alignment of Word Embeddings](https://arxiv.org/abs/2004.08243)
- DA for unsupervised word embeddings alignment
- 领域自适应用于word embedding对齐
- 20191214 arXiv [Unsupervised Transfer Learning via BERT Neuron Selection](https://arxiv.org/abs/1912.05308)
- Unsupervised transfer learning via BERT neuron selection
- 20191201 arXiv [A Transfer Learning Method for Goal Recognition Exploiting Cross-Domain Spatial Features](https://arxiv.org/abs/1911.10134)
- A transfer learning method for goal recognition
- 用迁移学习分析语言中的目标
- 20191201 AAAI-20 [Zero-Resource Cross-Lingual Named Entity Recognition](https://arxiv.org/abs/1911.09812)
- Zero-resource cross-lingual NER
- 零资源的跨语言NER
- 20191115 arXiv [Instance-based Transfer Learning for Multilingual Deep Retrieval](https://arxiv.org/abs/1911.06111)
- Instance based transfer learning for multilingual deep retrieval
- 基于实例的迁移学习用于多语言的retrieval
- 20191115 arXiv [Unsupervised Pre-training for Natural Language Generation: A Literature Review](https://arxiv.org/abs/1911.06171)
- Unsupervised pre-training for natural language generation survey
- 一篇无监督预训练用于自然语言生成的综述
- 20191115 AAAI-20 [Unsupervised Domain Adaptation on Reading Comprehension](https://arxiv.org/abs/1911.06137)
- 无监督DA用于阅读理解
- Unsupervised DA for reading comprehension
- 20191113 arXiv [Open-Ended Visual Question Answering by Multi-Modal Domain Adaptation](https://arxiv.org/abs/1911.04058)
- Supervised multi-modal domain adaptation in VQA
- 有监督的多模态DA用于VQA任务
- 20191113 AAAI-20 [TANDA: Transfer and Adapt Pre-Trained Transformer Models for Answer Sentence Selection](https://arxiv.org/abs/1911.04118)
- Finetune twice for answer sentence selection
- 两次finetune用于answer sentence selection
- 20191113 arXiv [NegBERT: A Transfer Learning Approach for Negation Detection and Scope Resolution](https://arxiv.org/abs/1911.04211)
- Transfer learning for negation detection and scope resolution
- 迁移学习用于否定检测
- 20191111 arXiv [Unsupervised Domain Adaptation of Contextual Embeddings for Low-Resource Duplicate Question Detection](https://arxiv.org/abs/1911.02645)
- Unsupervised DA for low-resource duplicate question detection
- 20191111 arXiv [SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization](https://arxiv.org/abs/1911.03437)
- Fine-tuning for pre-trained language model
- 20191111 arXiv [Towards Domain Adaptation from Limited Data for Question Answering Using Deep Neural Networks](https://arxiv.org/abs/1911.02655)
- DA for question answering using DNN
- 20191101 arXiv [Transferable End-to-End Aspect-based Sentiment Analysis with Selective Adversarial Learning](https://arxiv.org/abs/1910.14192)
- Adversarial transfer learning for aspect-based sentement analysis
- 对抗迁移用于aspect层级的情感分析
- 20191101 [Transfer Learning from Transformers to Fake News Challenge Stance Detection (FNC-1) Task](https://arxiv.org/abs/1910.14353)
- A fake news challenges based on transformers
- 一个基于transformer的假新闻检测挑战
- 20191029 WSDM-20 [Meta-Learning with Dynamic-Memory-Based Prototypical Network for Few-Shot Event Detection](https://arxiv.org/abs/1910.11621)
- Meta learning with dynamic memory based prototypical network for few-shot event detection
- 20191017 arXiv [Evolution of transfer learning in natural language processing](https://arxiv.org/abs/1910.07370)
- Survey transfer learning works in NLP
- 综述了最近迁移学习在NLP的一些进展
- 20191015 arXiv [Emotion Recognition in Conversations with Transfer Learning from Generative Conversation Modeling](https://arxiv.org/abs/1910.04980)
- Emotion recognition in conversations with transfer learning
- 用迁移学习进行对话中的情绪识别
- 20191011 NeurIPS-19 [Unified Language Model Pre-training for Natural Language Understanding and Generation](https://arxiv.org/abs/1905.03197)
- Unified language model pre-training for understanding and generation
- 统一的语言模型预训练用于自然语言理解和生成
- 20191011 NeurIPS-19 workshop [Language Transfer for Early Warning of Epidemics from Social Media](https://arxiv.org/abs/1910.04519)
- Language transfer to predict epidemics from social media
- 通过社交网络数据预测传染病并进行语言模型的迁移
- 20190829 EMNLP-19 [Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks](https://arxiv.org/abs/1908.10423)
- Investigating MAML for low-resource NMT
- 调查了MAML方法用于低资源的NMT问题的表现
- 20190829 EMNLP-19 [Unsupervised Domain Adaptation for Neural Machine Translation with Domain-Aware Feature Embeddings](https://arxiv.org/abs/1908.10430)
- Domain adaptation for NMT
- 20190821 arXiv [Shallow Domain Adaptive Embeddings for Sentiment Analysis](https://arxiv.org/abs/1908.06082)
- Domain adaptative embedding for sentiment analysis
- 迁移学习用于情感分类
- 20190809 ICCASP-19 [Cross-lingual Text-independent Speaker Verification using Unsupervised Adversarial Discriminative Domain Adaptation](https://arxiv.org/abs/1908.01447)
- Text independent speaker verification using adversarial DA
- 文本无关的speaker verification用DA
- 20190809 NeurIPS-18 [MacNet: Transferring Knowledge from Machine Comprehension to Sequence-to-Sequence Models](https://arxiv.org/abs/1908.01816)
- Transfer learning from machine comprehension to sequence to senquence Models
- 从机器理解到序列模型迁移
- 20190515 ACL-19 [Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies](https://arxiv.org/abs/1905.05475)
- Cross-lingual transfer of NMT
- 跨语言的NMT模型迁移
- 20190508 arXiv [On Transfer Learning For Chatter Detection in Turning Using Wavelet Packet Transform and Empirical Mode Decomposition](https://arxiv.org/abs/1905.01982)
- Transfer learning for chatter detection
- 用迁移学习进行叽叽喳喳聊天识别
- 20190415 PAKDD-19 [Multi-task Learning for Target-Dependent Sentiment Classification](https://link.springer.com/chapter/10.1007/978-3-030-16148-4_15)
- Multi-task learning for sentiment classification
- 用多任务学习进行任务依赖的情感分析
- 20190408 arXiv [Unsupervised Domain Adaptation of Contextualized Embeddings: A Case Study in Early Modern English](https://arxiv.org/abs/1904.02817)
- Domain adaptation in early modern english
- Case study: 在英文中的domain adaptation
- 20190111 ICMLA-18 [Supervised Transfer Learning for Product Information Question Answering](https://arxiv.org/abs/1901.02539)
- Transfer learning for product information question answering
- 利用迁移学习进行产品信息的对话
- 20181221 arXiv [Deep Transfer Learning for Static Malware Classification](https://arxiv.org/abs/1812.07606)
- Deep Transfer Learning for Static Malware Classification
- 用深度迁移学习进行恶意软件分类
- 20181204 arXiv [From Known to the Unknown: Transferring Knowledge to Answer Questions about Novel Visual and Semantic Concepts](https://arxiv.org/abs/1811.12772)
- Transfer learning for VQA
- 用迁移学习进行VQA任务
- 20181129 AAAI-19 [Exploiting Coarse-to-Fine Task Transfer for Aspect-level Sentiment Classification](https://arxiv.org/abs/1811.10999)
- Aspect-level sentiment classification
- 迁移学习用于情感分类
- 20181115 AAAI-19 [Unsupervised Transfer Learning for Spoken Language Understanding in Intelligent Agents](https://arxiv.org/abs/1811.05232)
- Transfer learning for spoken language understanding
- 无监督迁移学习用于语言理解
- 20181107 ICONIP-18 [Transductive Learning with String Kernels for Cross-Domain Text Classification](https://arxiv.org/abs/1811.01734)
- String kernel for cross-domain text classification using transfer learning
- 用string kernel进行迁移学习跨领域文本分类
- 20180613 CVPR-18 跨数据集的VQA:[Cross-Dataset Adaptation for Visual Question Answering](https://arxiv.org/abs/1806.03726)
- 20180612 ICASSP-18 迁移学习用于资源少的情感分类:[Semi-supervised and Transfer learning approaches for low resource sentiment classification](https://arxiv.org/abs/1806.02863)
- 20180516 ACL-18 将对抗迁移学习用于危机状态下的舆情分析:[Domain Adaptation with Adversarial Training and Graph Embeddings](https://arxiv.org/abs/1805.05151)
- 20180425 arXiv 迁移学习应用于自然语言任务:[Dropping Networks for Transfer Learning](https://arxiv.org/abs/1804.08501)
- 20191214 NIPS-19 workshop [Cross-Language Aphasia Detection using Optimal Transport Domain Adaptation](https://arxiv.org/abs/1912.04370)
- Optimal transport domain adaptation
## Time series
- ICLR'23 Out-of-distribution Representation Learning for Time Series Classification [[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 时间序列分类的OOD算法
- Domain Adaptation for Time Series Under Feature and Label Shifts [[arxiv](https://arxiv.org/abs/2302.03133)]
- Domain adaptation for time series 用于时间序列的domain adaptation
- StyleTime: Style Transfer for Synthetic Time Series Generation [[arxiv](https://arxiv.org/abs/2209.11306)]
- Style transfer for time series generation 时间序列生成的风格迁移
- Generalized representations learning for time series classification [[arxiv](https://arxiv.org/abs/2209.07027)]
- OOD for time series classification 域泛化用于时间序列分类
- [Time-Series Domain Adaptation via Sparse Associative Structure Alignment: Learning Invariance and Variance](https://arxiv.org/abs/2205.03554)
- Time series domain adaptation 时间序列domain adaptation
- [Domain Adversarial Spatial-Temporal Network: A Transferable Framework for Short-term Traffic Forecasting across Cities](https://arxiv.org/abs/2202.03630)
- Transfer learning for traffic forecasting across cities
- 用迁移学习进行跨城市的交通流量预测
- [Domain-Invariant Representation Learning from EEG with Private Encoders](https://arxiv.org/abs/2201.11613)
- Domain-invariant learning from EEG
- 用于EEG信号的领域不变特征研究
- KBS-22 [Intra-domain and cross-domain transfer learning for time series data -- How transferable are the features](https://arxiv.org/abs/2201.04449)
- An overview of transfer learning for time series data
- 一个用迁移学习进行时间序列分析的小综述
- CIKM-21 [AdaRNN: Adaptive Learning and Forecasting of Time Series](https://arxiv.org/abs/2108.04443) [Code](https://github.com/jindongwang/transferlearning/tree/master/code/deep/adarnn) [知乎文章](https://zhuanlan.zhihu.com/p/398036372) [Video](https://www.bilibili.com/video/BV1Gh411B7rj/)
- A new perspective to using transfer learning for time series analysis
- 一种新的建模时间序列的迁移学习视角
- TKDE-21 [Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals](https://arxiv.org/abs/2107.12626)
- Anomaly detection using semi-supervised and transfer learning
- 半监督学习用于无监督异常检测
- 20190703 arXiv [Applying Transfer Learning To Deep Learned Models For EEG Analysis](https://arxiv.org/abs/1907.01332)
- Apply transfer learning to EEG
- 用深度迁移学习进行EEG分析
## Speech
- Interspeech-22 [Decoupled Federated Learning for ASR with Non-IID Data](https://jd92.wang/assets/files/DecoupleFL-IS22.pdf)
- Decoupled federated learning for non IID 解耦的联邦架构用于Non-IID语音识别
- [A Likelihood Ratio based Domain Adaptation Method for E2E Models](2201.03655)
- Domain adaptation for speech recognition
- 用domain adaptation进行语音识别
- [Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems](https://arxiv.org/abs/2112.08718)
- Prompt for domain adaptation in speech recognition
- 用Prompt在语音识别中进行domain adaptation
- IEEE TASLP-22 [Exploiting Adapters for Cross-lingual Low-resource Speech Recognition](https://arxiv.org/abs/2105.11905)
- Cross-lingual speech recogntion using meta-learning and transfer learning
- 用元学习和迁移学习进行跨语言的低资源语音识别
- [Temporal Knowledge Distillation for On-device Audio Classification](https://arxiv.org/abs/2110.14131)
- Temporal knowledge distillation for on-device ASR
- 时序知识蒸馏用于设备端的语音识别
- [Music Sentiment Transfer](https://arxiv.org/abs/2110.05765)
- Music sentiment transfer learning
- 迁移学习用于音乐sentiment
- 20210716 InterSpeech-21 [Speech2Video: Cross-Modal Distillation for Speech to Video Generation](https://arxiv.org/abs/2107.04806)
- Cross-model distillation for video generation
- 跨模态蒸馏用于语音到video的生成
- 20210607 Interspeech-21 [Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching](https://arxiv.org/abs/2104.07491)
- Domain adaptation for speech recognition
- 用domain adaptation进行跨领域的语音识别
- 20201116 [Arabic Dialect Identification Using BERT-Based Domain Adaptation](https://arxiv.org/abs/2011.06977)
- 用基于BERT的domain adaptation进行阿拉伯方言识别
- 20191124 [Cantonese Automatic Speech Recognition Using Transfer Learning from Mandarin](https://arxiv.org/abs/1911.09271)
- Cantonese speech recognition using transfer learning from mandarin
- 普通话语音识别迁移到广东话识别
- 20191111 arXiv [Teacher-Student Training for Robust Tacotron-based TTS](https://arxiv.org/abs/1911.02839)
- Teacher-student network for robust TTS
- 20191111 arXiv [Change your singer: a transfer learning generative adversarial framework for song to song conversion](https://arxiv.org/abs/1911.02933)
- Adversarial transfer learning for song-to-song conversion
- 20190828 arXiv [VAE-based Domain Adaptation for Speaker Verification](https://arxiv.org/abs/1908.10092)
- Speaker verification using VAE domain adaptation
- 基于VAE的speaker verification
- 20181230 arXiv [The CORAL+ Algorithm for Unsupervised Domain Adaptation of PLDA](https://arxiv.org/abs/1812.10260)
- Use CORAL for speaker recognition
- 用CORAL改进版进行speaker识别
- 20180821 arXiv [Unsupervised adversarial domain adaptation for acoustic scene classification](https://arxiv.org/abs/1808.05777)
- Using transfer learning for acoustic classification
- 迁移学习用于声音场景分类
- 20180615 Interspeech-18 很全面地探索了很多类方法在语音识别上的应用:[A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition](https://arxiv.org/abs/1806.04841)
- 20180615 Interspeech-18 对话中的语音识别:[Unsupervised Adaptation with Interpretable Disentangled Representations for Distant Conversational Speech Recognition](https://arxiv.org/abs/1806.04872)
- 20180614 arXiv 将迁移学习应用于多个speaker的文字到语音:[Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis](https://arxiv.org/abs/1806.04558)
- 20180408 ASRU-18 用迁移学习中的domain separation network进行speech recognition:[Unsupervised Adaptation with Domain Separation Networks for Robust Speech Recognition](https://arxiv.org/abs/1711.08010)
## Multimedia
- [SLIP: Self-supervision meets Language-Image Pre-training](https://arxiv.org/abs/2112.12750)
- Self-supervised learning + language image pretraining
- 用自监督学习用于语言到图像的预训练
- [Domain Adaptation on Point Clouds via Geometry-Aware Implicits](https://arxiv.org/abs/2112.09343)
- Domain adaptation for point cloud
- 针对点云的domain adaptation
- [VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks](http://arxiv.org/abs/2112.06825)
- Vision-language efficient transfer learning
- 参数高校的vision-language任务迁移
- [TimeMatch: Unsupervised Cross-Region Adaptation by Temporal Shift Estimation](https://arxiv.org/abs/2111.02682)
- Temporal domain adaptation
- [Transferring Domain-Agnostic Knowledge in Video Question Answering](https://arxiv.org/abs/2110.13395)
- Domain-agnostic learning for VQA
- 在VQA任务中进行迁移学习
- WACV-21 [Domain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition](https://arxiv.org/abs/2110.10101)
- Domain generalization by audio-visual alignment
- 通过音频-视频对齐进行domain generalization
- 20210716 MICCAI-21 [Few-Shot Domain Adaptation with Polymorphic Transformers](https://arxiv.org/abs/2107.04805)
- Few-shot domain adaptation with polymorphic transformer
- 用多模态transformer做少样本的domain adaptation
- 20210716 InterSpeech-21 [Speech2Video: Cross-Modal Distillation for Speech to Video Generation](https://arxiv.org/abs/2107.04806)
- Cross-model distillation for video generation
- 跨模态蒸馏用于语音到video的生成
- 20190409 arXiv [Unsupervised Domain Adaptation for Multispectral Pedestrian Detection](https://arxiv.org/abs/1904.03692)
- Domain adaptation for pedestrian detection
- 无监督领域自适应用于多模态行人检测
- 20181117 arXiv [Performance Estimation of Synthesis Flows cross Technologies using LSTMs and Transfer Learning](https://arxiv.org/abs/1811.06017)
- Performance Estimation of Synthesis Flows cross Technologies using LSTMs and Transfer Learning
- 利用迁移学习进行合成flow评价
- 20180801 arXiv [Multimodal Deep Domain Adaptation](https://arxiv.org/abs/1807.11697)
- Use multi-modal DA in robotic vision
- 在机器人视觉中使用多模态的domain adaptation
- 20180413 arXiv 跨模态检索:[Cross-Modal Retrieval with Implicit Concept Association](https://arxiv.org/abs/1804.04318)
## Recommendation
- WSDM-22 [Personalized Transfer of User Preferences for Cross-domain Recommendation](https://arxiv.org/pdf/2110.11154.pdf) [code](https://github.com/easezyc/WSDM2022-PTUPCDR)
- Personalized Transfer of User Preferences by meta learner for cross-domain recommendation.
- 使用元学习器个性化迁移用户兴趣偏好,用于跨领域推荐
- SIGIR-21 [Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users](https://arxiv.org/abs/2105.04785)
- A Transfer-Meta Training Framework for cross-domain recommendation
- 一种新的迁移-元学习训练框架用于跨领域推荐
- [A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions](https://arxiv.org/abs/2108.03357)
- A survey on cross-domain recommendation
- 跨领域的推荐的综述
- 20191017 arXiv [Unsupervised Domain Adaptation Meets Offline Recommender Learning](https://arxiv.org/abs/1910.07295)
- Unsupervised DA meets offline recommender learning
- 无监督DA用于离线推荐系统
- 20191017 [Transfer Learning for Algorithm Recommendation](https://arxiv.org/abs/1910.07012)
- Transfer learning for algorithm recommendation
- 迁移学习用于算法推荐
- 20191015 WSDM-20 [DDTCDR: Deep Dual Transfer Cross Domain Recommendation](https://arxiv.org/abs/1910.05189)
- Cross-modal recommendation using dual transfer learning
- 用对偶迁移进行跨模态推荐
- 20190123 arXiv [Cold-start Playlist Recommendation with Multitask Learning](https://arxiv.org/abs/1901.06125)
- Cold-start playlist recommendation with multitask learning
- 用多任务学习进行冷启动状态下的播放列表推荐
- 20180801 arXiv [Rank and Rate: Multi-task Learning for Recommender Systems](https://arxiv.org/abs/1807.11698)
- A multi-task system for recommendation
- 一个针对于推荐系统的多任务学习
- 20180613 SIGIR-18 多任务学习用于推荐系统:[Explainable Recommendation via Multi-Task Learning in Opinionated Text Data](https://arxiv.org/abs/1806.03568)
- 20180419 arXiv 跨领域的推荐系统:[CoNet: Collaborative Cross Networks for Cross-Domain Recommendation](https://arxiv.org/abs/1804.06769)
## Human activity recognition
- TKDE-22 [Adaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection](https://arxiv.org/abs/2201.00464)
- Adaptiev memory network for anomaly detection
- 自适应的记忆网络用于异常检测
- [迁移学习用于行为识别 Transfer learning for activity recognition](https://github.com/jindongwang/activityrecognition/tree/master/notes)
- 20200405 arXiv [Joint Deep Cross-Domain Transfer Learning for Emotion Recognition](https://arxiv.org/abs/2003.11136)
- Transfer learning for emotion recognition
- 迁移学习用于情绪识别
- 20190916 ISWC-19 [Cross-dataset deep transfer learning for activity recognition](https://dl.acm.org/citation.cfm?id=3344865)
- Cross-dataset transfer learning for activity recognition
- 跨数据集的深度迁移学习用于行为识别
- 20190401 arXiv [Cross-Subject Transfer Learning in Human Activity Recognition Systems using Generative Adversarial Networks](https://arxiv.org/abs/1903.12489)
- Cross-subject transfer learning using GAN
- 用对抗网络进行跨用户的行为识别
- 20181225 arXiv [A Multi-task Neural Approach for Emotion Attribution, Classification and Summarization](https://arxiv.org/abs/1812.09041)
- A multi-task approach for emotion attribution, classification, and summarization
- 一个多任务方法同时用于情绪归属、分类和总结
- 20181220 arXiv [Deep UL2DL: Channel Knowledge Transfer from Uplink to Downlink](https://arxiv.org/abs/1812.07518)
- Channel knowledge transfer in CSI
- Wifi定位中的知识迁移
- 20180912 PervasiveHealth-18 [Transfer Learning and Data Fusion Approach to Recognize Activities of Daily Life](https://dl.acm.org/citation.cfm?id=3240949)
- Transfer learning to perform activity recognition using multi-model sensors
- 用多模态传感器进行迁移学习,用于行为识别
- 20180819 arXiv [Transfer Learning for Brain-Computer Interfaces: An Euclidean Space Data Alignment Approach](https://arxiv.org/abs/1808.05464)
- Propose to align the different distributions of EEG signals using transfer learning
- 针对EEG信号不同人分布不一样的问题提出迁移学习和数据增强的方式加以解决
- 20180529 arXiv 迁移学习用于表情识别:[Meta Transfer Learning for Facial Emotion Recognition](https://arxiv.org/abs/1805.09946)
## Autonomous driving
- CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars [[arxiv](https://arxiv.org/abs/2212.00621)]
- Continual DA for self-driving cars 连续的domain adaptation用于自动驾驶
- 20180909 arXiv [Driving Experience Transfer Method for End-to-End Control of Self-Driving Cars](https://arxiv.org/abs/1809.01822)
- Driving experience transfer on self-driving cars
- 自动驾驶车上的驾驶经验迁移
- 20180705 arXiv 将迁移学习应用于自动驾驶中的不同天气适配:[Modular Vehicle Control for Transferring Semantic Information to Unseen Weather Conditions using GANs](https://arxiv.org/abs/1807.01001)
- 20181219 ICCPS-19 [Simulation to scaled city: zero-shot policy transfer for traffic control via autonomous vehicles](https://arxiv.org/abs/1812.06120)
- Transfer learning in autonomous vehicles
- 迁移学习用于自动驾驶车辆的策略迁移
## Others
- V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions [[arxiv](https://arxiv.org/abs/2403.11371)]
- DG for multi-agent perception 领域泛化用于极端天气
- Potential of Domain Adaptation in Machine Learning in Ecology and Hydrology to Improve Model Extrapolability [[arxiv](https://arxiv.org/abs/2403.11331)]
- Domain adaptation in ecology and hydrology 研究生态学和水文学中的DA
- Student Activity Recognition in Classroom Environments using Transfer Learning [[arxiv](http://arxiv.org/abs/2312.00348)]
- Using transfer learning to recognize student activities 用迁移学习来识别学生课堂行为
- Transfer learning for process design with reinforcement learning [[arxiv](https://arxiv.org/abs/2302.03375)]
- Transfer learning for process design with reinforcement learning 使用强化迁移学习进行过程设计
- Language-Informed Transfer Learning for Embodied Household Activities [[arxiv](https://arxiv.org/abs/2301.05318)]
- Transfer learning for robust control in household 在家居机器人上使用强化迁移学习
- FL-IJCAI-22 [MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare](https://arxiv.org/abs/2206.08516)
- MetaFed: a new form of federated learning 联邦之联邦学习、新范式
- [On Transfer Learning in Functional Linear Regression](https://arxiv.org/abs/2206.04277)
- Transfer learning in functional linear regression 迁移学习用于函数式线性回归
- [Transfer Learning for Autonomous Chatter Detection in Machining](https://arxiv.org/abs/2204.05400)
- Transfer learning for autonomous chatter detection
- ISPASS-22 [Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices](https://arxiv.org/abs/2203.11295)
- Benchmarking test-time adaptation for edge devices
- 在端设备上评测test-time adaptation算法
- ICC-22 [Knowledge Transfer in Deep Reinforcement Learning for Slice-Aware Mobility Robustness Optimization](https://arxiv.org/abs/2203.03227)
- Knowledge transfer in RL
- 强化迁移学习
- [Deep Transfer Learning on Satellite Imagery Improves Air Quality Estimates in Developing Nations](https://arxiv.org/abs/2202.08890)
- Deep transfer learning for air quality estimate
- 深度迁移学习用于卫星图到空气质量预测
- [DROPO: Sim-to-Real Transfer with Offline Domain Randomization](https://arxiv.org/abs/2201.08434)
- Sim-to-real transfer with domain randomization
- 用domain randomization进行sim-to-real transfer
- AAAI-22 [Knowledge Sharing via Domain Adaptation in Customs Fraud Detection](https://arxiv.org/abs/2201.06759)
- Domain adaptation for fraud detection
- 用领域自适应进行欺诈检测
- [Transfer-learning-based Surrogate Model for Thermal Conductivity of Nanofluids](https://arxiv.org/abs/2201.00435)
- Transfer learning for thermal conductivity
- 迁移学习用于热传导
- [Toward Co-creative Dungeon Generation via Transfer Learning](http://arxiv.org/abs/2107.12533)
- Game scene generation with transfer learning
- 用迁移学习生成游戏场景
- 20210716 ICML-21 workshop [Leveraging Domain Adaptation for Low-Resource Geospatial Machine Learning](https://arxiv.org/abs/2107.04983)
- Using domain adaptation for geospatial ML
- 用domain adaptation进行地理空间的机器学习
- 20210202 [Admix: Enhancing the Transferability of Adversarial Attacks](https://arxiv.org/abs/2102.00436)
- Enhancing the transferability of adversarial attacks
- 增强对抗攻击的可迁移性
- 20201116 [Cross-Domain Learning for Classifying Propaganda in Online Contents](https://arxiv.org/abs/2011.06844)
- 跨领域学习用于检测在线推广
- 20201116 [Filter Pre-Pruning for Improved Fine-tuning of Quantized Deep Neural Networks](https://arxiv.org/abs/2011.06751)
- 量子神经网络中的finetune
- 20200914 [Transfer Learning of Graph Neural Networks with Ego-graph Information Maximization](https://arxiv.org/abs/2009.05204)
- 迁移学习用于GNN
- 20200529 WWW-20 [Modeling Users’ Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection](https://dl.acm.org/doi/abs/10.1145/3366423.3380172)
- Transfer learning for cross-domain fraud detection
- 迁移学习用于跨领域欺诈检测
- 20200420 arXiv [Transfer Learning with Graph Neural Networks for Short-Term Highway Traffic Forecasting](https://arxiv.org/abs/2004.08038)
- Transfer learning with GNN for highway traffic forecasting
- 迁移学习+GNN用于交通流量预测
- 20191222 NIPS-19 workshop [Sim-to-Real Domain Adaptation For High Energy Physics](https://arxiv.org/abs/1912.08001)
- Transfer learning for high energy physics
- 迁移学习用于高能物理
- 20191222 arXiv [Transfer learning in hybrid classical-quantum neural networks](https://arxiv.org/abs/1912.08278)
- Transfer learning for quantum neural networks
- 20191214 arXiv [Transfer Learning-Based Outdoor Position Recovery with Telco Data](https://arxiv.org/abs/1912.04521)
- Outdoor position recorvey with Telco data using transfer learning
- 20191111 BigData-19 [Deep Transfer Learning for Thermal Dynamics Modeling in Smart Buildings](https://arxiv.org/abs/1911.03318)
- Transfer learning for thermal dynamics modeling
- 20191111 arXiv [Transfer Learning in Spatial-Temporal Forecasting of the Solar Magnetic Field](https://arxiv.org/abs/1911.03193)
- Transfer learning for solar magnetic field
- 20191111 arXiv [Deep geometric knowledge distillation with graphs](https://arxiv.org/abs/1911.03080)
- Deep geometric knowledge distillation with graphs
- 20190813 IJAIT [Transferring knowledge from monitored to unmonitored areas for forecasting parking spaces](https://arxiv.org/abs/1908.03629)
- Transfer learning for forecasting parking spaces
- 用迁移学习预测停车空间
- 20190517 PHM-19 [Domain Adaptive Transfer Learning for Fault Diagnosis](https://arxiv.org/abs/1905.06004)
- Domain adaptation for fault diagnosis
- 领域自适应用于错误检测
- 20190508 arXiv [Text2Node: a Cross-Domain System for Mapping Arbitrary Phrases to a Taxonomy](https://arxiv.org/abs/1905.01958)
- Cross-domain system for mapping arbitrary phrases to a taxonomy
- 20190415 PAKDD-19 [Targeted Knowledge Transfer for Learning Traffic Signal Plans](https://link.springer.com/chapter/10.1007/978-3-030-16145-3_14)
- Targeted knowledge transfer for traffic control
- 目标知识迁移应用于交通红绿灯
- 20190415 PAKDD-19 [Knowledge Graph Rule Mining via Transfer Learning](https://link.springer.com/chapter/10.1007/978-3-030-16142-2_38)
- Knowledge Graph Rule Mining via Transfer Learning
- 迁移学习应用于知识图谱
- 20190415 PAKDD-19 [Spatial-Temporal Multi-Task Learning for Within-Field Cotton Yield Prediction](https://link.springer.com/chapter/10.1007/978-3-030-16148-4_27)
- Spatial-Temporal multi-task learning for cotton yield prediction
- 时空依赖的多任务学习用于棉花收入预测
- 20190415 PAKDD-19 [Passenger Demand Forecasting with Multi-Task Convolutional Recurrent Neural Networks](https://link.springer.com/chapter/10.1007/978-3-030-16145-3_3)
- Passenger demand forecasting with multi-task CRNN
- 用多任务CRNN模型进行顾客需求估计
- 20190123 arXiv [Transfer Learning and Meta Classification Based Deep Churn Prediction System for Telecom Industry](https://arxiv.org/abs/1901.06091)
- Transfer learning in telcom industry
- 迁移学习用于电信行业
- 20181225 arXiv [A General Approach to Domain Adaptation with Applications in Astronomy](https://arxiv.org/abs/1812.08839)
- Adopting active learning to transfer model
- 用主动学习来进行模型迁移并应用到天文学上
- 20181220 arXiv [Domain Adaptation for Reinforcement Learning on the Atari](https://arxiv.org/abs/1812.07452)
- Reinforcement domain adaptation on Atari games
- 迁移强化学习用于Atari游戏
- 20181219 NER-19 [Transfer Learning in Brain-Computer Interfaces with Adversarial Variational Autoencoders](https://arxiv.org/abs/1812.06857)
- Transfer learning in brain-computer interfaces
- 迁移学习在脑机交互中的应用
- 20181218 arXiv [Transfer learning to model inertial confinement fusion experiments](https://arxiv.org/abs/1812.06055)
- Using transfer learning for inertial confinement fusion
- 用迁移学习进行惯性约束聚变
- 20181214 arXiv [Bridging the Generalization Gap: Training Robust Models on Confounded Biological Data](https://arxiv.org/abs/1812.04778)
- Transfer learning for generalizing on biological data
- 用迁移学习增强生物数据的泛化能力
- 20181214 LAK-19 [Transfer Learning using Representation Learning in Massive Online Open Courses](https://arxiv.org/abs/1812.05043)
- Transfer learning in MOOCs
- 迁移学习用于大规模在线网络课程
- 20181214 DVPBA-19 [Considering Race a Problem of Transfer Learning](https://arxiv.org/abs/1812.04751)
- Consider race in transfer learning
- 在迁移学习问题中考虑种族问题(跨种族迁移)
- 20181121 NSFREU-18 [Transfer Learning with Deep CNNs for Gender Recognition and Age Estimation](https://arxiv.org/abs/1811.07344)
- Deep transfer learning for Gender Recognition and Age Estimation
- 用深度迁移学习进行性别识别和年龄估计
- 20181120 arXiv [Spatial-temporal Multi-Task Learning for Within-field Cotton Yield Prediction](https://arxiv.org/abs/1811.06665)
- Multi-task learning for cotton yield prediction
- 多任务学习用于棉花产量预测
- 20181012 ICMLA-18 [Virtual Battery Parameter Identification using Transfer Learning based Stacked Autoencoder](https://arxiv.org/abs/1810.04642)
- Using transfer learning for calculating the virtual battery in a thermostatics load
- 用迁移学习进行恒温器的电量估计
- 20180909 arXiv [Deep Learning for Domain Adaption: Engagement Recognition](https://arxiv.org/abs/1808.02324)
- deep transfer learning for engagement recognition
- 用深度迁移学习进行人机交互中的engagement识别
- 20180621 arXiv 迁移学习用于强化学习中的图像翻译:[Transfer Learning for Related Reinforcement Learning Tasks via Image-to-Image Translation](https://arxiv.org/abs/1806.07377)
- 20180610 arXiv 迁移学习用于Coffee crop分类:[A Comparative Study on Unsupervised Domain Adaptation Approaches for Coffee Crop Mapping](https://arxiv.org/abs/1806.02400)
- 20180530 MNRAS 用迁移学习检测银河星系兼并:[Using transfer learning to detect galaxy mergers](https://arxiv.org/abs/1805.10289)
- 20180524 KDD-18 用迁移学习方法进行人们的ID迁移:[Learning and Transferring IDs Representation in E-commerce](https://arxiv.org/abs/1712.08289)
- 20180421 arXiv 采用联合分布适配的深度迁移网络用于工业生产中的错误诊断:[Deep Transfer Network with Joint Distribution Adaptation: A New Intelligent Fault Diagnosis Framework for Industry Application](https://arxiv.org/abs/1804.07265)
================================================
FILE: doc/venues.md
================================================
# Journals and Conferences for transfer learning papers
We only list several popular or top conferences and journals for your reference.
Statement:
1. Of course this is not complete since I'm not an expert in all areas. You are welcome to add more.
2. A paper can be interdisplinary that may submit to different venues.
## Machine learning and AI
### Journals
1. JMLR: Journal of Machine Learning Research
2. AIJ: Artificial Intelligence Journal
3. MLJ: Machine Learning
4. Pattern Recognition
5. IEEE TNNLS: IEEE Transactions on Neural Networks and Learning Systems
### Conferences
| Venue | Full name | submission deadline | Notification date |
| ------- | ----------- | --------------------- | ------------------- |
|ICML | International Conference on Machine Learning | Late Jan. or early Feb. | May |
| NeurIPS | Neural Information Processing Systems | Late May or Early Jun. | Late Sep. |
| ICLR | International Conference on Learning Representations | Late Sep. or Early Oct. | Late Jan. |
| IJCAI | International Joint Conference on Artificial Intelligence | Late Jan. | Late Apr. |
| AAAI | AAAI conference on Artificial Intelligence | Early Sep. | Nov. |
## Computer vision and multimedia
### Journals
1. IEEE TPAMI: IEEE Transactions on Pattern Recognition and Machine Intelligence
2. IEEE TIP: IEEE Transactions on Image Processing
3. IJCV: International Journal of Computer Vision
4. IEEE TMM: IEEE Transactions on Multimedia
### Conferences
| Venue | Full name | submission deadline | Notification date |
| ------- | ----------- | --------------------- | ------------------- |
|CVPR | IEEE/CVF Conference on Computer Vision and Pattern Recognition | Nov. | Feb. |
| ICCV | International Conference on Computer Vision | Mar. | Late Jul. |
| ACMMM | ACM International Conference on Multimedia | Apr. | Jul. |
| ECCV | European Conference on Computer Vision | Mar. | Jul. |
| ICME | IEEE International Conference on Multimedia and Expo | Dec. | Mar. |
## Natural language processing and speech
### Journals
1. TASLP: IEEE/ACM Transactions on Audio, Speech and Language Processing
### Conferences
| Venue | Full name | submission deadline | Notification date |
| ------- | ----------- | --------------------- | ------------------- |
|ACL | Annual Meeting of the Association for Computational Linguistics | Jan. | Apr. |
| EMNLP | Conference on Empirical Methods in Natural Language Processing | May | Aug. |
| ICASSP | IEEE International Conference on Acoustics, Speech and Signal Processing | Oct. | Late Jan. |
| InterSpeech | Interspeech | Apr. | Jun. |
## Ubiquitous computing
### Journals
1. TOCHI: ACM Transactions on Computer-Human Interaction
2. IJHCS: International Journal of Human Computer Studies
3. PMC: Pervasive and Mobile Computing
4. PUC: Personal and Ubiquitous Computing
### Conferences
| Venue | Full name | submission deadline | Notification date |
| ------- | ----------- | --------------------- | ------------------- |
|UbiComp | ACM International Conference on Ubiquitous Computing | 2, 5, 8, 11 months | ~2 months later |
| CHI | ACM Conference on Human Factors in Computing Systems | Sep. | Jan. |
| PerCom | IEEE International Conference on Pervasive Computing and Communications | Sep. | Dec. |
## Data mining
### Journals
1. IEEE TKDE: IEEE Transactions on Knowledge and Data Engineering
2. ACM TKDD: ACM Transactions on Knowledge Discovery from Data
3. ACM TIST: ACM Transactions on Intelligent Systems and Technology
### Conferences
| Venue | Full name | submission deadline | Notification date |
| ------- | ----------- | --------------------- | ------------------- |
|KDD | ACM Knowledge Discovery and Data Mining | Early Feb. | May |
|ICDE | IEEE International Conference on Data Engineering | Oct. | Jan. |
| ICDM | International Conference on Data Mining | Jun. | Aug. |
| WWW | International World Wide Web Conferences | Oct. | Jan. |
| CIKM | ACM International Conference on Information and Knowledge Management | May | Aug. |
================================================
FILE: doc/迁移学习简介.md
================================================
### 迁移学习简介
迁移学习(transfer learning)通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋;已经会编写Java程序,就可以类比着来学习C#;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
图1不同位置、不同传感器的迁移标定。已知一个房间中A点的WiFi信号与相应的人体行为,如何标定另一个房间中C点的蓝牙信号?
具体地,在迁移学习中,我们已有的知识叫做源域(source domain),要学习的新知识叫目标域(target domain)。迁移学习研究如何把源域的知识迁移到目标域上。特别地,在机器学习领域中,迁移学习研究如何将已有模型应用到新的不同的、但是有一定关联的领域中。传统机器学习在应对数据的分布、维度,以及模型的输出变化等任务时,模型不够灵活、结果不够好,而迁移学习放松了这些假设。在数据分布、特征维度以及模型输出变化条件下,有机地利用源域中的知识来对目标域更好地建模。另外,在有标定数据缺乏的情况下,迁移学习可以很好地利用相关领域有标定的数据完成数据的标定。
图2 迁移学习与传统机器学习的不同。(a)传统机器学习对不同的学习任务建立不同的模型,(b)迁移学习利用源域中的数据将知识迁移到目标域,完成模型建立。插图来自:Sinno Jialin Pan and Qiang Yang, A survey on transfer learning. IEEE TKDE 2010.
迁移学习按照学习方式可以分为基于样本的迁移,基于特征的迁移,基于模型的迁移,以及基于关系的迁移。基于样本的迁移通过对源域中有标定样本的加权利用完成知识迁移;基于特征的迁移通过将源域和目标域映射到相同的空间(或者将其中之一映射到另一个的空间中)并最小化源域和目标域的距离来完成知识迁移;基于模型的迁移将源域和目标域的模型与样本结合起来调整模型的参数;基于关系的迁移则通过在源域中学习概念之间的关系,然后将其类比到目标域中,完成知识的迁移。
理论上,任何领域之间都可以做迁移学习。但是,如果源域和目标域之间相似度不够,迁移结果并不会理想,出现所谓的负迁移情况。比如,一个人会骑自行车,就可以类比学电动车;但是如果类比着学开汽车,那就有点天方夜谭了。如何找到相似度尽可能高的源域和目标域,是整个迁移过程最重要的前提。
迁移学习方面,代表人物有香港科技大学的Qiang Yang教授,南洋理工大学的Sinno Jialin Pan,以及第四范式的CEO戴文渊等。代表文献是Sinno Jialin Pan和Qiang Yang的A survey on transfer learning。
作者网站:http://jd92.wang.
[参考资料]
[1] Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on knowledge and data engineering, 2010, 22(10): 1345-1359.
[2] Introduction to Transfer Learning: http://jd92.wang/assets/files/l03_transferlearning.pdf。
[3] Qiang Yang: http://www.cse.ust.hk/~qyang/.
[4] Sinno Jialin Pan: http://www.ntu.edu.sg/home/sinnopan/.
[5] Wenyuan Dai: https://scholar.google.com/citations?user=AGR9pP0AAAAJ&hl=zh-CN.
================================================
FILE: docs/CNAME
================================================
transferlearning.xyz
================================================
FILE: docs/_config.yml
================================================
remote_theme: just-the-docs/just-the-docs
title: Transfer Learning
# description: Dates to be announced.
search_enabled: false
heading_anchors: true
================================================
FILE: docs/index.md
================================================

Everything about Transfer Learning. 有关迁移学习的一切资料.
View on Github
Papers •
Tutorials •
Research areas •
Theory •
Survey •
Code •
Dataset & benchmark
Thesis •
Scholars •
Contests •
Journal/conference •
Applications •
Others •
Contributing
**Widely used by top conferences and journals:**
- Conferences: [[CVPR'22](https://openaccess.thecvf.com/content/CVPR2022W/FaDE-TCV/html/Zhang_Segmenting_Across_Places_The_Need_for_Fair_Transfer_Learning_With_CVPRW_2022_paper.html)] [[NeurIPS'21](https://proceedings.neurips.cc/paper/2021/file/731b03008e834f92a03085ef47061c4a-Paper.pdf)] [[IJCAI'21](https://arxiv.org/abs/2103.03097)] [[ESEC/FSE'20](https://dl.acm.org/doi/abs/10.1145/3368089.3409696)] [[IJCNN'20](https://ieeexplore.ieee.org/abstract/document/9207556)] [[ACMMM'18](https://dl.acm.org/doi/abs/10.1145/3240508.3240512)] [[ICME'19](https://ieeexplore.ieee.org/abstract/document/8784776/)]
- Journals: [[IEEE TKDE](https://ieeexplore.ieee.org/abstract/document/9782500/)] [[ACM TIST](https://dl.acm.org/doi/abs/10.1145/3360309)] [[Information sciences](https://www.sciencedirect.com/science/article/pii/S0020025520308458)] [[Neurocomputing](https://www.sciencedirect.com/science/article/pii/S0925231221007025)] [[IEEE Transactions on Cognitive and Developmental Systems](https://ieeexplore.ieee.org/abstract/document/9659817)]
```
@Misc{transferlearning.xyz,
howpublished = {\url{http://transferlearning.xyz}},
title = {Everything about Transfer Learning and Domain Adapation},
author = {Wang, Jindong and others}
}
```
[](https://awesome.re) [](https://opensource.org/licenses/MIT) [](https://github.com/996icu/996.ICU/blob/master/LICENSE) [](https://996.icu)
Related repos:
- Large language model evaluation: [[llm-eval](https://llm-eval.github.io/)]
- Large language model enhancement: [[llm-enhance](https://llm-enhance.github.io/)]
- Robust machine learning: [[robustlearn: robust machine learning](https://github.com/microsoft/robustlearn)]
- Semi-supervised learning:
- [[USB: unified semi-supervised learning benchmark](https://github.com/microsoft/Semi-supervised-learning)]
- [[TorchSSL: a unified SSL library](https://github.com/TorchSSL/TorchSSL)]
- LLM benchmark: [[PromptBench: adverarial robustness of prompts of LLMs](https://github.com/microsoft/promptbench)]
- Federated learning: [[PersonalizedFL: library for personalized federated learning](https://github.com/microsoft/PersonalizedFL)]
- Activity recognition and machine learning:
- [[Activity recognition](https://github.com/jindongwang/activityrecognition)]
- [[Machine learning](https://github.com/jindongwang/MachineLearning)]
================================================
FILE: notebooks/deep_transfer_tutorial.ipynb
================================================
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "deep_transfer_tutorial.ipynb",
"provenance": [],
"collapsed_sections": []
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "BOlo4Ctmtm4p"
},
"source": [
"# Deep transfer learning tutorial\n",
"This notebook contains two popular paradigms of transfer learning: **Finetune** and **Domain adaptation**.\n",
"Since most of the codes are shared by them, we show how they work in just one single notebook.\n",
"I think that transfer learning and domain adaptation are both easy, and there's no need to create some library or packages for this simple purpose, which only makes things difficult. \n",
"The purpose of this note book is we **don't even need to install a library or package** to train a domain adaptation or finetune model."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9P9av5SNtm4r"
},
"source": [
"## Preparation"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Mcjr5uA7tm4r"
},
"source": [
"First of all, install `pytorch` and `torchvision`. \n",
"Skip this step if you already installed."
]
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "f3rx2L6hSvGY",
"outputId": "9ea41815-ee01-4bdb-de6b-042696efbbd0"
},
"source": [
"!pip install torch torchvision"
],
"execution_count": null,
"outputs": [
{
"output_type": "stream",
"text": [
"Requirement already satisfied: torch in /home/jindwang/miniconda3/lib/python3.8/site-packages (1.7.1)\r\n",
"Requirement already satisfied: torchvision in /home/jindwang/miniconda3/lib/python3.8/site-packages (0.8.2)\r\n",
"Requirement already satisfied: typing-extensions in /home/jindwang/miniconda3/lib/python3.8/site-packages (from torch) (3.7.4.3)\r\n",
"Requirement already satisfied: numpy in /home/jindwang/miniconda3/lib/python3.8/site-packages (from torch) (1.19.5)\r\n",
"Requirement already satisfied: pillow>=4.1.1 in /home/jindwang/miniconda3/lib/python3.8/site-packages (from torchvision) (8.1.0)\r\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qWlAlAeRtm4s"
},
"source": [
"Then, prepare the dataset you need. Here, we wil use the classical **Office-31** dataset.\n",
"We just need to download it, and then extract it.\n",
"Skip this step if you already have the data on your disk."
]
},
{
"cell_type": "code",
"metadata": {
"id": "4UCJrNkMtm4s"
},
"source": [
"!wget https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/office31.zip\n",
"!unzip office31.zip"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "xKVY0mi6tm4t"
},
"source": [
"To verify the dataset, we show its structures."
]
},
{
"cell_type": "code",
"metadata": {
"id": "bpqUe9URtm4t"
},
"source": [
"!apt install tree\n",
"!tree office31 -d 1"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "yyP-9VnQtm4t"
},
"source": [
"## Some imports."
]
},
{
"cell_type": "code",
"metadata": {
"id": "6R098oQTS_TC"
},
"source": [
"import os\n",
"import torch\n",
"import torchvision\n",
"from torchvision import transforms, datasets\n",
"import torch.nn as nn\n",
"import time\n",
"from torchvision import models\n",
"torch.cuda.set_device(1)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "K9Ut17hwUDq-"
},
"source": [
"Set the dataset folder, batch size, number of classes, and domain name."
]
},
{
"cell_type": "code",
"metadata": {
"id": "j4e--IIRU68M"
},
"source": [
"data_folder = 'office31'\n",
"batch_size = 32\n",
"n_class = 31\n",
"domain_src, domain_tar = 'amazon', 'webcam'"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "XA6e2YaPtm4u"
},
"source": [
"## Data load\n",
"Now, define a data loader function."
]
},
{
"cell_type": "code",
"metadata": {
"id": "6JtN_bK9VFcM"
},
"source": [
"def load_data(root_path, domain, batch_size, phase):\n",
" transform_dict = {\n",
" 'src': transforms.Compose(\n",
" [transforms.RandomResizedCrop(224),\n",
" transforms.RandomHorizontalFlip(),\n",
" transforms.ToTensor(),\n",
" transforms.Normalize(mean=[0.485, 0.456, 0.406],\n",
" std=[0.229, 0.224, 0.225]),\n",
" ]),\n",
" 'tar': transforms.Compose(\n",
" [transforms.Resize(224),\n",
" transforms.ToTensor(),\n",
" transforms.Normalize(mean=[0.485, 0.456, 0.406],\n",
" std=[0.229, 0.224, 0.225]),\n",
" ])}\n",
" data = datasets.ImageFolder(root=os.path.join(root_path, domain), transform=transform_dict[phase])\n",
" data_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=phase=='src', drop_last=phase=='tar', num_workers=4)\n",
" return data_loader"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "PHy09lD9tm4v"
},
"source": [
"Load the data using the above function to test it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "Jf_Gw2HRVJM_"
},
"source": [
"src_loader = load_data(data_folder, domain_src, batch_size, phase='src')\n",
"tar_loader = load_data(data_folder, domain_tar, batch_size, phase='tar')\n",
"print(f'Source data number: {len(src_loader.dataset)}')\n",
"print(f'Target data number: {len(tar_loader.dataset)}')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "caKMn438tm4v"
},
"source": [
"## Define the finetune model\n",
"The model for finetune is based on ResNet-50 for its popularity. Of course you can use other base networks.\n",
"The main logic of this class is to get the pretrained ResNet-50, use all of its layers but the last one, which we will replace by a new FC layer for classification. Since the original ResNet-50 is for 1000 classes classification, we only need it to classify 31."
]
},
{
"cell_type": "code",
"metadata": {
"id": "OXAjmY7pVK8t"
},
"source": [
"class TransferModel(nn.Module):\n",
" def __init__(self,\n",
" base_model : str = 'resnet50',\n",
" pretrain : bool = True,\n",
" n_class : int = 31):\n",
" super(TransferModel, self).__init__()\n",
" self.base_model = base_model\n",
" self.pretrain = pretrain\n",
" self.n_class = n_class\n",
" if self.base_model == 'resnet50':\n",
" self.model = torchvision.models.resnet50(pretrained=True)\n",
" n_features = self.model.fc.in_features\n",
" fc = torch.nn.Linear(n_features, n_class)\n",
" self.model.fc = fc\n",
" else:\n",
" # Use other models you like, such as vgg or alexnet\n",
" pass\n",
" self.model.fc.weight.data.normal_(0, 0.005)\n",
" self.model.fc.bias.data.fill_(0.1)\n",
"\n",
" def forward(self, x):\n",
" return self.model(x)\n",
" \n",
" def predict(self, x):\n",
" return self.forward(x)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "UAqT-0jRtm4w"
},
"source": [
"Now, we define a model and test it using a random tensor."
]
},
{
"cell_type": "code",
"metadata": {
"id": "LewRmYIvXEIo"
},
"source": [
"model = TransferModel().cuda()\n",
"RAND_TENSOR = torch.randn(1, 3, 224, 224).cuda()\n",
"output = model(RAND_TENSOR)\n",
"print(output)\n",
"print(output.shape)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "UpX-fuiXtm4w"
},
"source": [
"## Finetune ResNet-50\n",
"Define some variables. Note that Office-31 doesn't have a validation set, so we use its target domain as the validation set."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0uNeAiPatm4w"
},
"source": [
"Now the most important part: write the finetune function.\n",
"This function is pretty easy: it is basically a standard classification function. We train it on the 'src' domain, valid it on the 'val' domain, and then test it on the 'tar' domain.\n",
"The only difference is that Office-31 dataset has no validation set, so we will use the target domain as the validation set. For your own data, you should use its standard validation set.\n",
"We also set an early_stop variable."
]
},
{
"cell_type": "code",
"metadata": {
"id": "h74gKIVqtm4w"
},
"source": [
"dataloaders = {'src': src_loader,\n",
" 'val': tar_loader,\n",
" 'tar': tar_loader}\n",
"n_epoch = 100\n",
"criterion = nn.CrossEntropyLoss()\n",
"early_stop = 20"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "-fz_FlAIXsTF"
},
"source": [
"def finetune(model, dataloaders, optimizer):\n",
" since = time.time()\n",
" best_acc = 0\n",
" stop = 0\n",
" for epoch in range(0, n_epoch):\n",
" stop += 1\n",
" # You can uncomment this line for scheduling learning rate\n",
" # lr_schedule(optimizer, epoch)\n",
" for phase in ['src', 'val', 'tar']:\n",
" if phase == 'src':\n",
" model.train()\n",
" else:\n",
" model.eval()\n",
" total_loss, correct = 0, 0\n",
" for inputs, labels in dataloaders[phase]:\n",
" inputs, labels = inputs.cuda(), labels.cuda()\n",
" optimizer.zero_grad()\n",
" with torch.set_grad_enabled(phase == 'src'):\n",
" outputs = model(inputs)\n",
" loss = criterion(outputs, labels)\n",
" preds = torch.max(outputs, 1)[1]\n",
" if phase == 'src':\n",
" loss.backward()\n",
" optimizer.step()\n",
" total_loss += loss.item() * inputs.size(0)\n",
" correct += torch.sum(preds == labels.data)\n",
" epoch_loss = total_loss / len(dataloaders[phase].dataset)\n",
" epoch_acc = correct.double() / len(dataloaders[phase].dataset)\n",
" print(f'Epoch: [{epoch:02d}/{n_epoch:02d}]---{phase}, loss: {epoch_loss:.6f}, acc: {epoch_acc:.4f}')\n",
" if phase == 'val' and epoch_acc > best_acc:\n",
" stop = 0\n",
" best_acc = epoch_acc\n",
" torch.save(model.state_dict(), 'model.pkl')\n",
" if stop >= early_stop:\n",
" break\n",
" print()\n",
" \n",
" time_pass = time.time() - since\n",
" print(f'Training complete in {time_pass // 60:.0f}m {time_pass % 60:.0f}s')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "rGUZGrm7tm4x"
},
"source": [
"Now, define some train parameters and the optimizer. For simplicity, we use SGD, and the learning rate for the FC layer is 10 times of other layers, which is a common trick."
]
},
{
"cell_type": "code",
"metadata": {
"id": "HGVIu0JXZaGT"
},
"source": [
"param_group = []\n",
"learning_rate = 0.0001\n",
"momentum = 5e-4\n",
"for k, v in model.named_parameters():\n",
" if not k.__contains__('fc'):\n",
" param_group += [{'params': v, 'lr': learning_rate}]\n",
" else:\n",
" param_group += [{'params': v, 'lr': learning_rate * 10}]\n",
"optimizer = torch.optim.SGD(param_group, momentum=momentum)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "F7zGR_PFtm4y"
},
"source": [
"## Train and test\n",
"Now we can train and test it."
]
},
{
"cell_type": "code",
"metadata": {
"id": "uKKrah-AZsHt"
},
"source": [
"finetune(model, dataloaders, optimizer)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "GR5Y1x4btm4y"
},
"source": [
"def test(model, target_test_loader):\n",
" model.eval()\n",
" correct = 0\n",
" len_target_dataset = len(target_test_loader.dataset)\n",
" with torch.no_grad():\n",
" for data, target in target_test_loader:\n",
" data, target = data.cuda(), target.cuda()\n",
" s_output = model.predict(data)\n",
" pred = torch.max(s_output, 1)[1]\n",
" correct += torch.sum(pred == target)\n",
" acc = correct.double() / len(target_test_loader.dataset)\n",
" return acc"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "1O2CBxmxtm4y"
},
"source": [
"model.load_state_dict(torch.load('model.pkl'))\n",
"acc_test = test(model, dataloaders['tar'])\n",
"print(f'Test accuracy: {acc_test}')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "I7Iuk_Mitm4z"
},
"source": [
"It's over for finetune. Of course, you should use some learning rate decay trick in real training. But that is not our goal.\n",
"Next, we will continue to use the same dataloader for domain adaptation."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bO4c_QcGtm4z"
},
"source": [
"## Domain adaptation\n",
"Now we are in domain adaptation."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "VJwcwLQftm40"
},
"source": [
"## Logic for domain adaptation\n",
"The logic for domain adaptation is mostly similar to finetune, except that we must add a loss to the finetune model to **regularize the distribution discrepancy** between two domains.\n",
"Therefore, the most different parts are:\n",
"- Define some **loss function** to compute the distance (which is the main contribution of most existing DA papers)\n",
"- Define a new model class to use that loss function for **forward** pass.\n",
"- Write a slightly different script to train, since we have to take both **source data, source label, and target data**."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Jy_1xwdJtm40"
},
"source": [
"### Loss function\n",
"The most popular loss function for DA is **MMD (Maximum Mean Discrepancy)**. For comaprison, we also use another popular loss **CORAL (CORrelation ALignment)**. They are defined as follows."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "z3-wKorUtm40"
},
"source": [
"#### MMD loss"
]
},
{
"cell_type": "code",
"metadata": {
"id": "MpQH6VFwtm41"
},
"source": [
"class MMD_loss(nn.Module):\n",
" def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5):\n",
" super(MMD_loss, self).__init__()\n",
" self.kernel_num = kernel_num\n",
" self.kernel_mul = kernel_mul\n",
" self.fix_sigma = None\n",
" self.kernel_type = kernel_type\n",
"\n",
" def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):\n",
" n_samples = int(source.size()[0]) + int(target.size()[0])\n",
" total = torch.cat([source, target], dim=0)\n",
" total0 = total.unsqueeze(0).expand(\n",
" int(total.size(0)), int(total.size(0)), int(total.size(1)))\n",
" total1 = total.unsqueeze(1).expand(\n",
" int(total.size(0)), int(total.size(0)), int(total.size(1)))\n",
" L2_distance = ((total0-total1)**2).sum(2)\n",
" if fix_sigma:\n",
" bandwidth = fix_sigma\n",
" else:\n",
" bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)\n",
" bandwidth /= kernel_mul ** (kernel_num // 2)\n",
" bandwidth_list = [bandwidth * (kernel_mul**i)\n",
" for i in range(kernel_num)]\n",
" kernel_val = [torch.exp(-L2_distance / bandwidth_temp)\n",
" for bandwidth_temp in bandwidth_list]\n",
" return sum(kernel_val)\n",
"\n",
" def linear_mmd2(self, f_of_X, f_of_Y):\n",
" loss = 0.0\n",
" delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)\n",
" loss = delta.dot(delta.T)\n",
" return loss\n",
"\n",
" def forward(self, source, target):\n",
" if self.kernel_type == 'linear':\n",
" return self.linear_mmd2(source, target)\n",
" elif self.kernel_type == 'rbf':\n",
" batch_size = int(source.size()[0])\n",
" kernels = self.guassian_kernel(\n",
" source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)\n",
" XX = torch.mean(kernels[:batch_size, :batch_size])\n",
" YY = torch.mean(kernels[batch_size:, batch_size:])\n",
" XY = torch.mean(kernels[:batch_size, batch_size:])\n",
" YX = torch.mean(kernels[batch_size:, :batch_size])\n",
" loss = torch.mean(XX + YY - XY - YX)\n",
" return loss\n"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "NcfUy_2Dtm41"
},
"source": [
"#### CORAL loss"
]
},
{
"cell_type": "code",
"metadata": {
"id": "uZhKJq15tm41"
},
"source": [
"def CORAL(source, target):\n",
" d = source.size(1)\n",
" ns, nt = source.size(0), target.size(0)\n",
"\n",
" # source covariance\n",
" tmp_s = torch.ones((1, ns)).cuda() @ source\n",
" cs = (source.t() @ source - (tmp_s.t() @ tmp_s) / ns) / (ns - 1)\n",
"\n",
" # target covariance\n",
" tmp_t = torch.ones((1, nt)).cuda() @ target\n",
" ct = (target.t() @ target - (tmp_t.t() @ tmp_t) / nt) / (nt - 1)\n",
"\n",
" # frobenius norm\n",
" loss = (cs - ct).pow(2).sum().sqrt()\n",
" loss = loss / (4 * d * d)\n",
"\n",
" return loss"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "VB2cDp8Gtm41"
},
"source": [
"### Model\n",
"Now we use ResNet-50 again just like finetune. The difference is that we rewrite the ResNet-50 class to drop its last layer."
]
},
{
"cell_type": "code",
"metadata": {
"id": "UOLx_OSxtm41"
},
"source": [
"from torchvision import models\n",
"class ResNet50Fc(nn.Module):\n",
" def __init__(self):\n",
" super(ResNet50Fc, self).__init__()\n",
" model_resnet50 = models.resnet50(pretrained=True)\n",
" self.conv1 = model_resnet50.conv1\n",
" self.bn1 = model_resnet50.bn1\n",
" self.relu = model_resnet50.relu\n",
" self.maxpool = model_resnet50.maxpool\n",
" self.layer1 = model_resnet50.layer1\n",
" self.layer2 = model_resnet50.layer2\n",
" self.layer3 = model_resnet50.layer3\n",
" self.layer4 = model_resnet50.layer4\n",
" self.avgpool = model_resnet50.avgpool\n",
" self.__in_features = model_resnet50.fc.in_features\n",
"\n",
" def forward(self, x):\n",
" x = self.conv1(x)\n",
" x = self.bn1(x)\n",
" x = self.relu(x)\n",
" x = self.maxpool(x)\n",
" x = self.layer1(x)\n",
" x = self.layer2(x)\n",
" x = self.layer3(x)\n",
" x = self.layer4(x)\n",
" x = self.avgpool(x)\n",
" x = x.view(x.size(0), -1)\n",
" return x\n",
"\n",
" def output_num(self):\n",
" return self.__in_features"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "IRgdNM3Wtm42"
},
"source": [
"Now the main class for DA. We take ResNet-50 as its backbone, add a bottleneck layer and our own FC layer for classification.\n",
"Note the `adapt_loss` function. It is just using our predefined MMD or CORAL loss. Of course you can use your own loss."
]
},
{
"cell_type": "code",
"metadata": {
"id": "oC5NKJpJtm42"
},
"source": [
"class TransferNet(nn.Module):\n",
" def __init__(self,\n",
" num_class, \n",
" base_net='resnet50', \n",
" transfer_loss='mmd', \n",
" use_bottleneck=True, \n",
" bottleneck_width=256, \n",
" width=1024):\n",
" super(TransferNet, self).__init__()\n",
" if base_net == 'resnet50':\n",
" self.base_network = ResNet50Fc()\n",
" else:\n",
" # Your own basenet\n",
" return\n",
" self.use_bottleneck = use_bottleneck\n",
" self.transfer_loss = transfer_loss\n",
" bottleneck_list = [nn.Linear(self.base_network.output_num(\n",
" ), bottleneck_width), nn.BatchNorm1d(bottleneck_width), nn.ReLU(), nn.Dropout(0.5)]\n",
" self.bottleneck_layer = nn.Sequential(*bottleneck_list)\n",
" classifier_layer_list = [nn.Linear(self.base_network.output_num(), width), nn.ReLU(), nn.Dropout(0.5),\n",
" nn.Linear(width, num_class)]\n",
" self.classifier_layer = nn.Sequential(*classifier_layer_list)\n",
"\n",
" self.bottleneck_layer[0].weight.data.normal_(0, 0.005)\n",
" self.bottleneck_layer[0].bias.data.fill_(0.1)\n",
" for i in range(2):\n",
" self.classifier_layer[i * 3].weight.data.normal_(0, 0.01)\n",
" self.classifier_layer[i * 3].bias.data.fill_(0.0)\n",
"\n",
" def forward(self, source, target):\n",
" source = self.base_network(source)\n",
" target = self.base_network(target)\n",
" source_clf = self.classifier_layer(source)\n",
" if self.use_bottleneck:\n",
" source = self.bottleneck_layer(source)\n",
" target = self.bottleneck_layer(target)\n",
" transfer_loss = self.adapt_loss(source, target, self.transfer_loss)\n",
" return source_clf, transfer_loss\n",
"\n",
" def predict(self, x):\n",
" features = self.base_network(x)\n",
" clf = self.classifier_layer(features)\n",
" return clf\n",
"\n",
" def adapt_loss(self, X, Y, adapt_loss):\n",
" \"\"\"Compute adaptation loss, currently we support mmd and coral\n",
"\n",
" Arguments:\n",
" X {tensor} -- source matrix\n",
" Y {tensor} -- target matrix\n",
" adapt_loss {string} -- loss type, 'mmd' or 'coral'. You can add your own loss\n",
"\n",
" Returns:\n",
" [tensor] -- adaptation loss tensor\n",
" \"\"\"\n",
" if adapt_loss == 'mmd':\n",
" mmd_loss = MMD_loss()\n",
" loss = mmd_loss(X, Y)\n",
" elif adapt_loss == 'coral':\n",
" loss = CORAL(X, Y)\n",
" else:\n",
" # Your own loss\n",
" loss = 0\n",
" return loss"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "hAdPs27btm42"
},
"source": [
"### Train\n",
"Now the train part."
]
},
{
"cell_type": "code",
"metadata": {
"id": "OK6P8uMDtm42"
},
"source": [
"transfer_loss = 'mmd'\n",
"learning_rate = 0.0001\n",
"transfer_model = TransferNet(n_class, transfer_loss=transfer_loss, base_net='resnet50').cuda()\n",
"optimizer = torch.optim.SGD([\n",
" {'params': transfer_model.base_network.parameters()},\n",
" {'params': transfer_model.bottleneck_layer.parameters(), 'lr': 10 * learning_rate},\n",
" {'params': transfer_model.classifier_layer.parameters(), 'lr': 10 * learning_rate},\n",
"], lr=learning_rate, momentum=0.9, weight_decay=5e-4)\n",
"lamb = 10 # weight for transfer loss, it is a hyperparameter that needs to be tuned"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "4WpUfcHItm42"
},
"source": [
"The main train function. Since we have to enumerate all source and target samples, we have to use `zip` operation to enumerate each pair of these two domains. It is common that two domains have different sizes, but we think by randomly sampling them in many epochs, we may sample each one of them."
]
},
{
"cell_type": "code",
"metadata": {
"id": "AGlVNI2ktm42"
},
"source": [
"def train(dataloaders, model, optimizer):\n",
" source_loader, target_train_loader, target_test_loader = dataloaders['src'], dataloaders['val'], dataloaders['tar']\n",
" len_source_loader = len(source_loader)\n",
" len_target_loader = len(target_train_loader)\n",
" best_acc = 0\n",
" stop = 0\n",
" n_batch = min(len_source_loader, len_target_loader)\n",
" for e in range(n_epoch):\n",
" stop += 1\n",
" train_loss_clf, train_loss_transfer, train_loss_total = 0, 0, 0\n",
" model.train()\n",
" for (src, tar) in zip(source_loader, target_train_loader):\n",
" data_source, label_source = src\n",
" data_target, _ = tar\n",
" data_source, label_source = data_source.cuda(), label_source.cuda()\n",
" data_target = data_target.cuda()\n",
"\n",
" optimizer.zero_grad()\n",
" label_source_pred, transfer_loss = model(data_source, data_target)\n",
" clf_loss = criterion(label_source_pred, label_source)\n",
" loss = clf_loss + lamb * transfer_loss\n",
" loss.backward()\n",
" optimizer.step()\n",
" train_loss_clf = clf_loss.detach().item() + train_loss_clf\n",
" train_loss_transfer = transfer_loss.detach().item() + train_loss_transfer\n",
" train_loss_total = loss.detach().item() + train_loss_total\n",
" acc = test(model, target_test_loader)\n",
" print(f'Epoch: [{e:2d}/{n_epoch}], cls_loss: {train_loss_clf/n_batch:.4f}, transfer_loss: {train_loss_transfer/n_batch:.4f}, total_Loss: {train_loss_total/n_batch:.4f}, acc: {acc:.4f}')\n",
" if best_acc < acc:\n",
" best_acc = acc\n",
" torch.save(model.state_dict(), 'trans_model.pkl')\n",
" stop = 0\n",
" if stop >= early_stop:\n",
" break"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"scrolled": true,
"id": "nqSCG6-Xtm43"
},
"source": [
"train(dataloaders, transfer_model, optimizer)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "yWvYODRDtm43"
},
"source": [
"transfer_model.load_state_dict(torch.load('trans_model.pkl'))\n",
"acc_test = test(transfer_model, dataloaders['tar'])\n",
"print(f'Test accuracy: {acc_test}')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "jbw6KndNtm43"
},
"source": [
"Now we are done."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JQX2ak-jtm43"
},
"source": [
"You see, we don't even need to install a library or package to train a domain adaptation or finetune model.\n",
"In your own work, you can also use this notebook to test your own algorithms."
]
}
]
}
================================================
FILE: notebooks/traditional_transfer_learning.ipynb
================================================
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "Traditional_transfer_learning.ipynb",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3",
"language": "python"
},
"language_info": {
"name": "python",
"version": "3.7.6-final"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "icVPttAPFurS"
},
"source": [
"# Traditional transfer learning tutorial\n",
"This is a tutorial notebook for traditional transfer learning (i.e., non-deep learning).\n",
"\n",
"We'll implement two algorithms:\n",
"- **TCA** (Transfer Component Analysis) [1]\n",
"- **BDA** (Balanced Distribution Adaptation) [2]\n",
"\n",
"Then, we test the algorithms using **Office-Caltech10** SURF dataset. This dataset will be downloaded automatically in this tutorial.\n",
"\n",
"References:\n",
"\n",
"[1] Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis[J]. IEEE Transactions on Neural Networks, 2010, 22(2): 199-210.\n",
"\n",
"[2] Wang J, Chen Y, Hao S, et al. Balanced distribution adaptation for transfer learning[C]//2017 IEEE international conference on data mining (ICDM). IEEE, 2017: 1129-1134."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Fs_zONUnFurW"
},
"source": [
"## Download and unzip dataset\n",
"You can also download the dataset from here: https://github.com/jindongwang/transferlearning/tree/master/data#office-caltech10"
]
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "UItzY-rN-C6Z",
"outputId": "fe3bb35e-292f-48bb-db11-385fc1e53191"
},
"source": [
"!wget https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/office-caltech-surf.zip\n",
"!unzip office-caltech-surf.zip"
],
"execution_count": 9,
"outputs": [
{
"output_type": "stream",
"text": [
"--2021-03-30 12:27:06-- https://transferlearningdrive.blob.core.windows.net/teamdrive/dataset/office-caltech-surf.zip\n",
"Resolving transferlearningdrive.blob.core.windows.net (transferlearningdrive.blob.core.windows.net)... 20.150.17.228\n",
"Connecting to transferlearningdrive.blob.core.windows.net (transferlearningdrive.blob.core.windows.net)|20.150.17.228|:443... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 2487903 (2.4M) [application/x-zip-compressed]\n",
"Saving to: ‘office-caltech-surf.zip.1’\n",
"\n",
"office-caltech-surf 100%[===================>] 2.37M 1.13MB/s in 2.1s \n",
"\n",
"2021-03-30 12:27:09 (1.13 MB/s) - ‘office-caltech-surf.zip.1’ saved [2487903/2487903]\n",
"\n",
"Archive: office-caltech-surf.zip\n",
" inflating: amazon_surf_10.mat \n",
" inflating: caltech_surf_10.mat \n",
" inflating: dslr_surf_10.mat \n",
" inflating: webcam_surf_10.mat \n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4wSXVFUZFurX"
},
"source": [
"## Import libraries"
]
},
{
"cell_type": "code",
"metadata": {
"id": "fRoy6hvY-zKM"
},
"source": [
"import numpy as np\n",
"import scipy.io\n",
"import scipy.linalg\n",
"import sklearn.metrics\n",
"from sklearn.neighbors import KNeighborsClassifier"
],
"execution_count": 2,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "Z3fuq1sqFurY"
},
"source": [
"## Define a kernel function"
]
},
{
"cell_type": "code",
"metadata": {
"id": "FAmo6hc_-5Pu"
},
"source": [
"def kernel(ker, X1, X2, gamma):\n",
" K = None\n",
" if not ker or ker == 'primal':\n",
" K = X1\n",
" elif ker == 'linear':\n",
" if X2 is not None:\n",
" K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T, np.asarray(X2).T)\n",
" else:\n",
" K = sklearn.metrics.pairwise.linear_kernel(np.asarray(X1).T)\n",
" elif ker == 'rbf':\n",
" if X2 is not None:\n",
" K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, np.asarray(X2).T, gamma)\n",
" else:\n",
" K = sklearn.metrics.pairwise.rbf_kernel(np.asarray(X1).T, None, gamma)\n",
" return K"
],
"execution_count": 3,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "GhngbY7DFurY"
},
"source": [
"# Implement TCA"
]
},
{
"cell_type": "code",
"metadata": {
"id": "yjaBHq7P-8qB"
},
"source": [
"class TCA:\n",
" def __init__(self, kernel_type='primal', dim=30, lamb=1, gamma=1):\n",
" '''\n",
" Init func\n",
" :param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'\n",
" :param dim: dimension after transfer\n",
" :param lamb: lambda value in equation\n",
" :param gamma: kernel bandwidth for rbf kernel\n",
" '''\n",
" self.kernel_type = kernel_type\n",
" self.dim = dim\n",
" self.lamb = lamb\n",
" self.gamma = gamma\n",
"\n",
" def fit(self, Xs, Xt):\n",
" '''\n",
" Transform Xs and Xt\n",
" :param Xs: ns * n_feature, source feature\n",
" :param Xt: nt * n_feature, target feature\n",
" :return: Xs_new and Xt_new after TCA\n",
" '''\n",
" X = np.hstack((Xs.T, Xt.T))\n",
" X /= np.linalg.norm(X, axis=0)\n",
" m, n = X.shape\n",
" ns, nt = len(Xs), len(Xt)\n",
" e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))\n",
" M = e * e.T\n",
" M = M / np.linalg.norm(M, 'fro')\n",
" H = np.eye(n) - 1 / n * np.ones((n, n))\n",
" K = kernel(self.kernel_type, X, None, gamma=self.gamma)\n",
" n_eye = m if self.kernel_type == 'primal' else n\n",
" a, b = np.linalg.multi_dot([K, M, K.T]) + self.lamb * np.eye(n_eye), np.linalg.multi_dot([K, H, K.T])\n",
" w, V = scipy.linalg.eig(a, b)\n",
" ind = np.argsort(w)\n",
" A = V[:, ind[:self.dim]]\n",
" Z = np.dot(A.T, K)\n",
" Z /= np.linalg.norm(Z, axis=0)\n",
" Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T\n",
" return Xs_new, Xt_new\n",
"\n",
" def fit_predict(self, Xs, Ys, Xt, Yt):\n",
" '''\n",
" Transform Xs and Xt, then make predictions on target using 1NN\n",
" :param Xs: ns * n_feature, source feature\n",
" :param Ys: ns * 1, source label\n",
" :param Xt: nt * n_feature, target feature\n",
" :param Yt: nt * 1, target label\n",
" :return: Accuracy and predicted_labels on the target domain\n",
" '''\n",
" Xs_new, Xt_new = self.fit(Xs, Xt)\n",
" clf = KNeighborsClassifier(n_neighbors=1)\n",
" clf.fit(Xs_new, Ys.ravel())\n",
" y_pred = clf.predict(Xt_new)\n",
" acc = sklearn.metrics.accuracy_score(Yt, y_pred)\n",
" return acc, y_pred"
],
"execution_count": 4,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "yuKeKRCUFurZ"
},
"source": [
"## Implement BDA"
]
},
{
"cell_type": "code",
"metadata": {
"id": "wVb8DLYA_U03"
},
"source": [
"class BDA:\n",
" def __init__(self, kernel_type='primal', dim=30, lamb=1, mu=0.5, gamma=1, T=10, mode='BDA', estimate_mu=False):\n",
" '''\n",
" Init func\n",
" :param kernel_type: kernel, values: 'primal' | 'linear' | 'rbf'\n",
" :param dim: dimension after transfer\n",
" :param lamb: lambda value in equation\n",
" :param mu: mu. Default is -1, if not specificied, it calculates using A-distance\n",
" :param gamma: kernel bandwidth for rbf kernel\n",
" :param T: iteration number\n",
" :param mode: 'BDA' | 'WBDA'\n",
" :param estimate_mu: True | False, if you want to automatically estimate mu instead of manally set it\n",
" '''\n",
" self.kernel_type = kernel_type\n",
" self.dim = dim\n",
" self.lamb = lamb\n",
" self.mu = mu\n",
" self.gamma = gamma\n",
" self.T = T\n",
" self.mode = mode\n",
" self.estimate_mu = estimate_mu\n",
"\n",
" def fit_predict(self, Xs, Ys, Xt, Yt):\n",
" '''\n",
" Transform and Predict using 1NN as JDA paper did\n",
" :param Xs: ns * n_feature, source feature\n",
" :param Ys: ns * 1, source label\n",
" :param Xt: nt * n_feature, target feature\n",
" :param Yt: nt * 1, target label\n",
" :return: acc, y_pred, list_acc\n",
" '''\n",
" list_acc = []\n",
" X = np.hstack((Xs.T, Xt.T))\n",
" X /= np.linalg.norm(X, axis=0)\n",
" m, n = X.shape\n",
" ns, nt = len(Xs), len(Xt)\n",
" e = np.vstack((1 / ns * np.ones((ns, 1)), -1 / nt * np.ones((nt, 1))))\n",
" C = len(np.unique(Ys))\n",
" H = np.eye(n) - 1 / n * np.ones((n, n))\n",
" mu = self.mu\n",
" M = 0\n",
" Y_tar_pseudo = None\n",
" Xs_new = None\n",
" for t in range(self.T):\n",
" N = 0\n",
" M0 = e * e.T * C\n",
" if Y_tar_pseudo is not None and len(Y_tar_pseudo) == nt:\n",
" for c in range(1, C + 1):\n",
" e = np.zeros((n, 1))\n",
" Ns = len(Ys[np.where(Ys == c)])\n",
" Nt = len(Y_tar_pseudo[np.where(Y_tar_pseudo == c)])\n",
"\n",
" if self.mode == 'WBDA':\n",
" Ps = Ns / len(Ys)\n",
" Pt = Nt / len(Y_tar_pseudo)\n",
" alpha = Pt / Ps\n",
" mu = 1\n",
" else:\n",
" alpha = 1\n",
"\n",
" tt = Ys == c\n",
" e[np.where(tt == True)] = 1 / Ns\n",
" yy = Y_tar_pseudo == c\n",
" ind = np.where(yy == True)\n",
" inds = [item + ns for item in ind]\n",
" e[tuple(inds)] = -alpha / Nt\n",
" e[np.isinf(e)] = 0\n",
" N = N + np.dot(e, e.T)\n",
"\n",
" # In BDA, mu can be set or automatically estimated using A-distance\n",
" # In WBDA, we find that setting mu=1 is enough\n",
" if self.estimate_mu and self.mode == 'BDA':\n",
" if Xs_new is not None:\n",
" mu = estimate_mu(Xs_new, Ys, Xt_new, Y_tar_pseudo)\n",
" else:\n",
" mu = 0\n",
" M = (1 - mu) * M0 + mu * N\n",
" M /= np.linalg.norm(M, 'fro')\n",
" K = kernel(self.kernel_type, X, None, gamma=self.gamma)\n",
" n_eye = m if self.kernel_type == 'primal' else n\n",
" a, b = np.linalg.multi_dot(\n",
" [K, M, K.T]) + self.lamb * np.eye(n_eye), np.linalg.multi_dot([K, H, K.T])\n",
" w, V = scipy.linalg.eig(a, b)\n",
" ind = np.argsort(w)\n",
" A = V[:, ind[:self.dim]]\n",
" Z = np.dot(A.T, K)\n",
" Z /= np.linalg.norm(Z, axis=0)\n",
" Xs_new, Xt_new = Z[:, :ns].T, Z[:, ns:].T\n",
"\n",
" clf = sklearn.neighbors.KNeighborsClassifier(n_neighbors=1)\n",
" clf.fit(Xs_new, Ys.ravel())\n",
" Y_tar_pseudo = clf.predict(Xt_new)\n",
" acc = sklearn.metrics.accuracy_score(Yt, Y_tar_pseudo)\n",
" list_acc.append(acc)\n",
" print('{} iteration [{}/{}]: Acc: {:.4f}'.format(self.mode, t + 1, self.T, acc))\n",
" return acc, Y_tar_pseudo, list_acc\n"
],
"execution_count": 5,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "5IuuTWGlFurc"
},
"source": [
"## Load data\n",
"We'll load data. For demonstration, we use *Caltech* as the source and *amazon* as the target domain."
]
},
{
"cell_type": "code",
"metadata": {
"id": "aRBJ87xg-_H7"
},
"source": [
"src, tar = 'caltech_surf_10.mat', 'amazon_surf_10.mat'\n",
"src_domain, tar_domain = scipy.io.loadmat(src), scipy.io.loadmat(tar)\n",
"Xs, Ys, Xt, Yt = src_domain['feas'], src_domain['label'], tar_domain['feas'], tar_domain['label']"
],
"execution_count": 10,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "p1qkzPZxFure"
},
"source": [
"## Test TCA"
]
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "7U6Ez1B2Furf",
"outputId": "47398327-4c65-41e9-fee0-1783fe562325"
},
"source": [
"tca = TCA(kernel_type='linear', dim=30, lamb=1, gamma=1)\n",
"acc, ypre = tca.fit_predict(Xs, Ys, Xt, Yt)\n",
"print(f'The accuracy of TCA is: {acc:.4f}')"
],
"execution_count": 11,
"outputs": [
{
"output_type": "stream",
"text": [
"The accuracy of TCA is: 0.4562\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "68GhdRh4Furf"
},
"source": [
"## Test BDA"
]
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "5m609OVBFurf",
"outputId": "8165ebd1-4ebb-49f2-f893-f1e9b24afe10"
},
"source": [
"bda = BDA(kernel_type='primal', dim=30, lamb=1, mu=0.5, mode='BDA', gamma=1, estimate_mu=False)\n",
"acc, ypre, list_acc = bda.fit_predict(Xs, Ys, Xt, Yt)\n",
"print(f'The accuracy of BDA is: {acc:.4f}')"
],
"execution_count": 12,
"outputs": [
{
"output_type": "stream",
"text": [
"BDA iteration [1/10]: Acc: 0.4666\n",
"BDA iteration [2/10]: Acc: 0.4593\n",
"BDA iteration [3/10]: Acc: 0.4656\n",
"BDA iteration [4/10]: Acc: 0.4624\n",
"BDA iteration [5/10]: Acc: 0.4666\n",
"BDA iteration [6/10]: Acc: 0.4666\n",
"BDA iteration [7/10]: Acc: 0.4656\n",
"BDA iteration [8/10]: Acc: 0.4656\n",
"BDA iteration [9/10]: Acc: 0.4656\n",
"BDA iteration [10/10]: Acc: 0.4656\n",
"The accuracy of BDA is: 0.4656\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sp2axlhhILUF"
},
"source": [
"## Test WBDA"
]
},
{
"cell_type": "code",
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "somL-0WnFurf",
"outputId": "a5ba906f-ee1b-416f-9e7f-b2fbbb4de3de"
},
"source": [
"wbda = BDA(kernel_type='primal', dim=30, lamb=1, mode='WBDA', gamma=1, estimate_mu=False)\n",
"acc, ypre, list_acc = wbda.fit_predict(Xs, Ys, Xt, Yt)\n",
"print(f'The accuracy of WBDA is: {acc:.4f}')"
],
"execution_count": 15,
"outputs": [
{
"output_type": "stream",
"text": [
"WBDA iteration [1/10]: Acc: 0.4666\n",
"WBDA iteration [2/10]: Acc: 0.4635\n",
"WBDA iteration [3/10]: Acc: 0.4520\n",
"WBDA iteration [4/10]: Acc: 0.4635\n",
"WBDA iteration [5/10]: Acc: 0.4603\n",
"WBDA iteration [6/10]: Acc: 0.4624\n",
"WBDA iteration [7/10]: Acc: 0.4572\n",
"WBDA iteration [8/10]: Acc: 0.4624\n",
"WBDA iteration [9/10]: Acc: 0.4614\n",
"WBDA iteration [10/10]: Acc: 0.4593\n",
"The accuracy of WBDA is: 0.4593\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "h5B5VO8yKBQC"
},
"source": [
""
],
"execution_count": null,
"outputs": []
}
]
}