Repository: keunwoochoi/torchaudio-contrib
Branch: master
Commit: bdbbb1800db9
Files: 13
Total size: 51.0 KB
Directory structure:
gitextract_ztnwls02/
├── .flake8
├── .gitignore
├── .travis.yml
├── README.md
├── requirements.txt
├── setup.cfg
├── setup.py
├── tests/
│ ├── test_functional.py
│ └── test_layers.py
└── torchaudio_contrib/
├── __init__.py
├── beta_hpss.py
├── functional.py
└── layers.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .flake8
================================================
[flake8]
max-line-length = 120
ignore = E305,E402,E721,E741,F403,F405,F821,F841,F999,W503,W504
exclude = beta_*.py, .git/
================================================
FILE: .gitignore
================================================
# Intellij Idea
.idea/
*.iml
# python
__pycache__/
*.pyc
## pyenv
.python-version
## python virtual environments
env/
venv/
.env/
.venv
# OSX
.DS_Store
._*
# swap files for vim users
[._]*.swp
[._]swp
# ctags
tags
================================================
FILE: .travis.yml
================================================
language: python
python:
- "3.5"
install:
- pip install -e .[tests]
script:
- python -m pytest
================================================
FILE: README.md
================================================
# SUNSETTING torcnaudio-contrib
We made some progress in this repo and contributed to the original repo [pytorch/audio](https://github.com/pytorch/audio) which satisfied us. We happily stopped working here :) Please visit [pytorch/audio](https://github.com/pytorch/audio) for any issue/request!
.
.
.
.
.
.
.
.
.
.
(We keep the existing content as below ⬇)
# torchaudio-contrib
Goal: To propose audio processing Pytorch codes with nice and easy-to-use APIs and functionality.
:open_hands: This should be seen as a community based proposal and the basis for a discussion we should have inside the pytorch audio user community. Everyone should be welcome to join and discuss.
Our motivation is:
- API design: Clear, readible names for class/functions/arguments, sensible default values, and shapes.
- Reference: [librosa](http://librosa.github.io/librosa/) (audio and MIR on Numpy), [kapre](https://github.com/keunwoochoi/kapre) (audio on Keras), [pytorch/audio](https://github.com/pytorch/audio) (audio on Pytorch)
- Fast processing on GPU
- Methodology: Both layer and functional
- Layers (`nn.Module`) for reusability and easier use
- and identical implementation with `Functionals`
- Simple installation
- Multi-channel support
## Contribution
Making things quicker and open! We're `-contrib` repo, hence it's *easy to enter but hard to graduate*.
1. Make a new [Issue](https://github.com/keunwoochoi/torchaudio-contrib/issues) for a potential PR
2. Until it's in a good shape,
1. Make a PR with following the current conventions and unittest
2. Review-merge.
3. Based on it, make a PR to [torch/audio](https://github.com/pytorch/audio)
Discussion on how to contribute - https://github.com/keunwoochoi/torchaudio-contrib/issues/37
## Current issues/future work
- Better module/sub-module hierarchy
- Complex number support
- More time-frequency representations
- Signal processing modules, e.g., vocoder
- Augmentation
# API suggestions
## Notes
* Audio signals can be multi-channel
* `STFT`: short-time Fourier transform, outputing a complex-numbered representation
* `Spectrogram`: magnitudes of STFT
* `Melspectrogram`: mel-filterbank applied to `spectrogram`
## Shapes
* audio signals: `(batch, channel, time)`
* E.g., `STFT` input shape
* Based on `torch.stft` input shape
* 2D representations: `(batch, channel, freq, time)`
* E.g., `STFT` output shape
* Channel-first, following torch convention.
* Then, `(freq, time)`, following `torch.stft`
## Overview
### `STFT`
```python
class STFT(fft_len=2048, hop_len=None, frame_len=None, window=None, pad=0, pad_mode="reflect", **kwargs)
def stft(signal, fft_len, hop_len, window, pad=0, pad_mode="reflect", **kwargs)
```
### `MelFilterbank`
```python
class MelFilterbank(num_bands=128, sample_rate=16000, min_freq=0.0, max_freq=None, num_bins=1025, htk=False)
def create_mel_filter(num_bands, sample_rate, min_freq, max_freq, num_bins, to_hertz, from_hertz)
```
### `Spectrogram`
```python
def Spectrogram(fft_len=2048, hop_len=None, frame_len=None, window=None, pad=0, pad_mode="reflect", power=1., **kwargs)
```
Creates an `nn.Sequential`:
```
>>> Sequential(
>>> (0): STFT(fft_len=2048, hop_len=512, frame_len=2048)
>>> (1): ComplexNorm(power=1.0)
)
```
### `Melspectrogram`
```python
def Melspectrogram(num_bands=128, sample_rate=16000, min_freq=0.0, max_freq=None, num_bins=None, htk=False, mel_filterbank=None, **kwargs)
```
Creates an `nn.Sequential`:
```
>>> Sequential(
>>> (0): STFT(fft_len=2048, hop_len=512, frame_len=2048)
>>> (1): ComplexNorm(power=2.0)
>>> (2): ApplyFilterbank()
)
```
### `AmplitudeToDb`/`amplitude_to_db`
```python
class AmplitudeToDb(ref=1.0, amin=1e-7)
def amplitude_to_db(x, ref=1.0, amin=1e-7)
```
Arguments names and the default value of `ref` follow librosa. The default value of `amin` however follows Keras's float32 Epsilon, which seems making sense.
### `DbToAmplitude`/`db_to_amplitude`
```python
class DbToAmplitude(ref=1.0)
def db_to_amplitude(x, ref=1.0)
```
### `MuLawEncoding`/`mu_law_encoding`
```python
class MuLawEncoding(n_quantize=256)
def mu_law_encoding(x, n_quantize=256)
```
### `MuLawDecoding`/`mu_law_decoding`
```python
class MuLawDecoding(n_quantize=256)
def mu_law_decoding(x_mu, n_quantize=256)
```
----------
# A Big Issue - Remove SoX Dependency
We propose to remove the SoX dependency because:
* Many audio ML tasks don’t require the functionality included in Sox (filtering, cutting, effects)
* Many issues in torchaudio are related to the installation with respect to Sox. While this could be simplified by a [conda build or a wheel](https://github.com/pytorch/builder/issues/279), it will continue being difficult to maintain the repo.
* SOX doesn’t support MP4 containers, which makes it unusable for multi-stream audio
* Loading speed is good with torchaudio but e.g. for __wav__, its not faster than other libraries (including cast to torch tensor) -- as in the graph below. See more detailed benchmarks [here](https://github.com/faroit/python_audio_loading_benchmark).
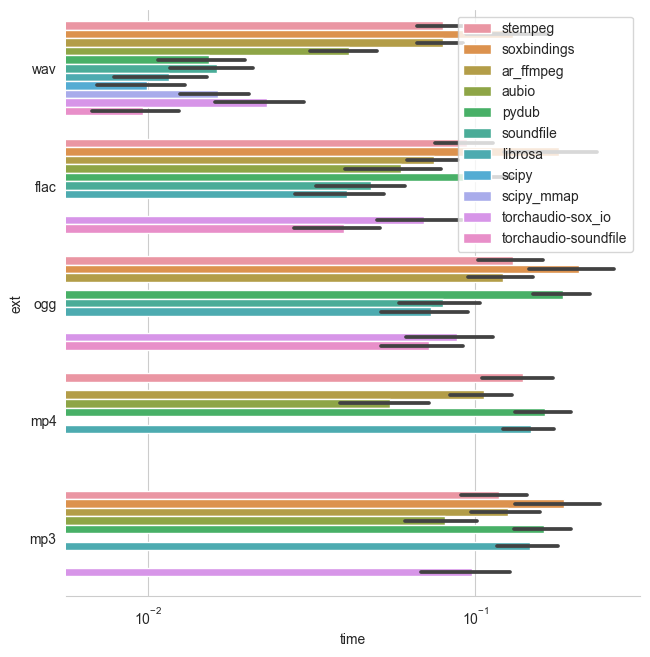
## Proposal
Introduce I/O backends and move the functions that depend on `_torch_sox` to a `backend_sox.py`, which is *not* required to install. Additionally, we could then introduce more backends like scipy.io or pysoundfile. Each backend then imports the (optional) lib within the backend file and each backend includes a minimum spec such as:
```python
import _torch_sox
def load(...)
# returns audio, rate
def save(...)
# write file
def info(...)
# returns metadata without reading the full file
```
### Backend proposals
* `scipy.io` or `soundfile` as default for __wav__ files
* `aubio` or `audioread` for __mp3__ and __mp4__
### Installation
```bash
pip install -e .
```
### Importing
import torchaudio_contrib
## Authors
Keunwoo Choi, Faro Stöter, Kiran Sanjeevan, Jan Schlüter
================================================
FILE: requirements.txt
================================================
torch
================================================
FILE: setup.cfg
================================================
[tool:pytest]
xfail_strict = true
================================================
FILE: setup.py
================================================
from setuptools import setup
setup(name='torchaudio_contrib',
version='0.1',
description='To propose audio processing Pytorch codes with nice and easy-to-use APIs and functionality',
url='https://github.com/keunwoochoi/torchaudio-contrib',
author='Keunwoo Choi, Faro Stöter, Kiran Sanjeevan, Jan Schlüter',
author_email='gnuchoi@gmail.com',
license='MIT',
install_requires=['torch'],
extras_require={'tests': ['pytest', 'librosa']},
packages=['torchaudio_contrib'],
zip_safe=False)
================================================
FILE: tests/test_functional.py
================================================
import pytest
import librosa
import numpy as np
import torch
from torchaudio_contrib.functional import (stft, phase_vocoder, magphase, amplitude_to_db, db_to_amplitude,
complex_norm, mu_law_encoding, mu_law_decoding, apply_filterbank
)
xfail = pytest.mark.xfail
def _num_stft_bins(signal_len, fft_len, hop_length, pad):
return (signal_len + 2 * pad - fft_len + hop_length) // hop_length
def _approx_all_equal(x, y, atol=1e-7):
return torch.all(torch.lt(torch.abs(torch.add(x, -y)), atol))
def _all_equal(x, y):
return torch.all(torch.eq(x, y))
@pytest.mark.parametrize('fft_length', [512])
@pytest.mark.parametrize('hop_length', [256])
@pytest.mark.parametrize('waveform', [
(torch.randn(1, 100000)),
(torch.randn(1, 2, 100000)),
pytest.param(torch.randn(1, 100), marks=xfail(raises=RuntimeError)),
])
@pytest.mark.parametrize('pad_mode', [
# 'constant',
'reflect',
])
def test_stft(waveform, fft_length, hop_length, pad_mode):
"""
Test STFT for multi-channel signals.
Padding: Value in having padding outside of torch.stft?
"""
pad = fft_length // 2
window = torch.hann_window(fft_length)
complex_spec = stft(waveform, fft_length=fft_length, hop_length=hop_length, window=window, pad_mode=pad_mode)
mag_spec, phase_spec = magphase(complex_spec)
# == Test shape
expected_size = list(waveform.size()[:-1])
expected_size += [fft_length // 2 + 1, _num_stft_bins(
waveform.size(-1), fft_length, hop_length, pad), 2]
assert complex_spec.dim() == waveform.dim() + 2
assert complex_spec.size() == torch.Size(expected_size)
# == Test values
fft_config = dict(n_fft=fft_length, hop_length=hop_length, pad_mode=pad_mode)
# note that librosa *automatically* pad with fft_length // 2.
expected_complex_spec = np.apply_along_axis(librosa.stft, -1,
waveform.numpy(), **fft_config)
expected_mag_spec, _ = librosa.magphase(expected_complex_spec)
# Convert torch to np.complex
complex_spec = complex_spec.numpy()
complex_spec = complex_spec[..., 0] + 1j * complex_spec[..., 1]
assert np.allclose(complex_spec, expected_complex_spec, atol=1e-5)
assert np.allclose(mag_spec.numpy(), expected_mag_spec, atol=1e-5)
@pytest.mark.parametrize('rate', [0.5, 1.01, 1.3])
@pytest.mark.parametrize('complex_specgrams', [
torch.randn(1, 2, 1025, 400, 2),
torch.randn(1, 1025, 400, 2)
])
@pytest.mark.parametrize('hop_length', [256])
def test_phase_vocoder(complex_specgrams, rate, hop_length):
class use_double_precision:
def __enter__(self):
self.default_dtype = torch.get_default_dtype()
torch.set_default_dtype(torch.float64)
def __exit__(self, type, value, traceback):
torch.set_default_dtype(self.default_dtype)
# Due to cummulative sum, numerical error in using torch.float32 will
# result in bottom right values of the stretched sectrogram to not
# match with librosa
with use_double_precision():
complex_specgrams = complex_specgrams.type(torch.get_default_dtype())
phase_advance = torch.linspace(0, np.pi * hop_length, complex_specgrams.shape[-3])[..., None]
complex_specgrams_stretch = phase_vocoder(complex_specgrams, rate=rate, phase_advance=phase_advance)
# == Test shape
expected_size = list(complex_specgrams.size())
expected_size[-2] = int(np.ceil(expected_size[-2] / rate))
assert complex_specgrams.dim() == complex_specgrams_stretch.dim()
assert complex_specgrams_stretch.size() == torch.Size(expected_size)
# == Test values
index = [0] * (complex_specgrams.dim() - 3) + [slice(None)] * 3
mono_complex_specgram = complex_specgrams[index].numpy()
mono_complex_specgram = mono_complex_specgram[..., 0] + \
mono_complex_specgram[..., 1] * 1j
expected_complex_stretch = librosa.phase_vocoder(
mono_complex_specgram,
rate=rate,
hop_length=hop_length)
complex_stretch = complex_specgrams_stretch[index].numpy()
complex_stretch = complex_stretch[..., 0] + \
1j * complex_stretch[..., 1]
assert np.allclose(complex_stretch,
expected_complex_stretch, atol=1e-5)
@pytest.mark.parametrize('complex_tensor', [
torch.randn(1, 2, 1025, 400, 2),
torch.randn(1025, 400, 2)
])
@pytest.mark.parametrize('power', [1, 2, 0.7])
def test_complex_norm(complex_tensor, power):
expected_norm_tensor = complex_tensor.pow(2).sum(-1).pow(power / 2)
norm_tensor = complex_norm(complex_tensor, power)
assert _approx_all_equal(expected_norm_tensor, norm_tensor, atol=1e-5)
@pytest.mark.parametrize('new_len', [120, 36])
@pytest.mark.parametrize('mag_spec', [
torch.randn(1, 257, 391),
torch.randn(1, 2, 257, 391),
])
def test_apply_filterbank(mag_spec, new_len):
filterbank = torch.randn(mag_spec.size(-2), new_len)
mag_spec_filterbanked = apply_filterbank(mag_spec, filterbank)
assert mag_spec.size(-1) == mag_spec_filterbanked.size(-1)
assert mag_spec_filterbanked.size(-2) == new_len
assert mag_spec.dim() == mag_spec_filterbanked.dim()
@pytest.mark.parametrize('amplitude,db', [
(torch.Tensor([0.000001, 0.0001, 0.1, 1.0, 10.0, 1000000.0]),
torch.Tensor([-60.0, -40.0, -10.0, 0.0, 10.0, 60.0]))
])
def test_amplitude_db(amplitude, db):
"""Test amplitude_to_db and db_to_amplitude."""
amplitude = np.sqrt(amplitude)
assert _approx_all_equal(db, amplitude_to_db(amplitude, ref=1.0))
assert _approx_all_equal(amplitude, db_to_amplitude(db, ref=1.0))
# both ways
assert _approx_all_equal(db_to_amplitude(amplitude_to_db(amplitude, ref=1.0), ref=1.0),
amplitude)
assert _approx_all_equal(amplitude_to_db(db_to_amplitude(db, ref=1.0), ref=1.0),
db,
atol=1e-5)
@pytest.mark.parametrize('waveform', [
torch.randn(1, 100000),
(torch.randn(1, 2, 100000)),
])
@pytest.mark.parametrize('n_quantize', [256])
def test_mu_law(waveform, n_quantize):
"""test mu-law encoding and decoding"""
def _test_mu_encoding(waveform, n_quantize):
waveform = 2 * (waveform - 0.5)
# manual computation
mu = torch.tensor(n_quantize - 1, dtype=waveform.dtype)
waveform_mu = waveform.sign() * torch.log1p(mu * waveform.abs()) / torch.log1p(mu)
waveform_mu = ((waveform_mu + 1) / 2 * mu + 0.5).long()
assert _all_equal(mu_law_encoding(waveform, n_quantize),
waveform_mu)
def _test_mu_decoding(waveform, n_quantize):
waveform_mu = torch.randint(low=0, high=n_quantize - 1,
size=(1, 1024))
# manual computation
waveform_mu = waveform_mu.float()
mu = torch.tensor(n_quantize - 1, dtype=waveform_mu.dtype) # confused about dtype here..
waveform = (waveform_mu / mu) * 2 - 1.
waveform = waveform.sign() * (torch.exp(waveform.abs() * torch.log1p(mu)) - 1.) / mu
assert _all_equal(mu_law_decoding(waveform_mu, n_quantize),
waveform)
def _test_both_ways(waveform, n_quantize):
waveform_mu = torch.randint(low=0, high=n_quantize - 1,
size=(1, 1024))
assert _all_equal(waveform_mu,
mu_law_encoding(mu_law_decoding(waveform_mu, n_quantize), n_quantize))
_test_mu_encoding(waveform, n_quantize)
_test_mu_decoding(waveform, n_quantize)
_test_both_ways(waveform, n_quantize)
================================================
FILE: tests/test_layers.py
================================================
"""
Test the layers. Currently only on cpu since travis doesn't have GPU.
"""
import unittest
import pytest
import librosa
import numpy as np
import torch
import torch.nn as nn
from torchaudio_contrib.layers import (STFT, Spectrogram, MelFilterbank, AmplitudeToDb, TimeStretch,
ComplexNorm, ApplyFilterbank)
from test_functional import _num_stft_bins
xfail = pytest.mark.xfail
@pytest.mark.parametrize('fft_len', [512])
@pytest.mark.parametrize('hop_length', [256])
@pytest.mark.parametrize('waveform', [
torch.randn(1, 100000)
])
@pytest.mark.parametrize('pad_mode', [
# 'constant',
'reflect',
])
def test_STFT(waveform, fft_len, hop_length, pad_mode):
"""
Test STFT for multi-channel signals.
Padding: Value in having padding outside of torch.stft?
"""
pad = fft_len // 2
layer = STFT(fft_length=fft_len, hop_length=hop_length, pad_mode=pad_mode)
assert torch.is_tensor(layer.window)
assert not layer.window.requires_grad
assert layer.window.size(0) <= layer.fft_length
@pytest.mark.parametrize('rate', [0.7])
@pytest.mark.parametrize('complex_specgrams', [
torch.randn(1, 2, 1025, 400, 2),
torch.randn(1, 1025, 400, 2)
])
@pytest.mark.parametrize('hop_length', [256])
def test_TimeStretch(complex_specgrams, rate, hop_length):
layer = TimeStretch(hop_length=hop_length, num_freqs=complex_specgrams.shape[-3])
assert torch.is_tensor(layer.phase_advance)
assert not layer.phase_advance.requires_grad
@pytest.mark.parametrize('fft_length', [512])
@pytest.mark.parametrize('hop_length', [256])
@pytest.mark.parametrize('waveform', [
torch.randn(1, 100000),
torch.randn(1, 2, 100000)
])
@pytest.mark.parametrize('pad_mode', [
# 'constant',
'reflect',
])
def test_SpectrogramDb(waveform, fft_length, hop_length, pad_mode):
ref, amin = 1.0, 1e-7
window = torch.hann_window(fft_length)
model = torch.nn.Sequential(*Spectrogram(fft_length, hop_length=hop_length, window=window, pad_mode=pad_mode),
AmplitudeToDb(ref=ref, amin=amin))
db_spec = model(waveform).numpy()
fft_config = dict(n_fft=fft_length, hop_length=hop_length, pad_mode=pad_mode)
expected_db_spec = np.abs(np.apply_along_axis(librosa.stft, -1,
waveform.numpy(), **fft_config))
db_config = dict(ref=ref, amin=amin, top_db=None)
expected_db_spec = np.apply_along_axis(librosa.power_to_db,
-1,
expected_db_spec**2,
**db_config)
assert np.allclose(db_spec, expected_db_spec, atol=1e-2), np.abs(expected_db_spec - db_spec).max()
@pytest.mark.parametrize('fft_length', [512])
@pytest.mark.parametrize('num_mels', [128])
@pytest.mark.parametrize('hop_length', [256])
@pytest.mark.parametrize('waveform', [
torch.randn(1, 2, 100000),
torch.randn(4, 100000)
])
@pytest.mark.parametrize('rate', [0.7])
def test_MelspectrogramStretch(waveform, fft_length, num_mels, hop_length, rate):
num_freqs = fft_length // 2 + 1
fb = MelFilterbank(num_freqs=num_freqs, num_mels=num_mels, max_freq=1.0).get_filterbank()
model = nn.Sequential(STFT(fft_length, hop_length=hop_length),
TimeStretch(hop_length=hop_length, num_freqs=num_freqs, fixed_rate=rate),
ComplexNorm(power=2.0),
ApplyFilterbank(fb))
mel_spec = model(waveform)
num_bins = _num_stft_bins(waveform.size(-1), fft_length, hop_length, fft_length // 2)
assert mel_spec.size(-2) == num_mels
assert mel_spec.size(-1) == np.ceil(num_bins / rate)
if __name__ == '__main__':
unittest.main()
================================================
FILE: torchaudio_contrib/__init__.py
================================================
from .functional import * # noqa: F401
from .layers import * # noqa: F401
================================================
FILE: torchaudio_contrib/beta_hpss.py
================================================
"""This is a beta-version of harmonic-percussive source separation.
Currently it only returns the separated magnitude spectrograms. Once we have inverse-STFT,
we can extend it to get waveform results.
TODO: add test
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class HPSS(nn.Module):
"""
Wrap hpss.
Args and Returns --> see `hpss`.
"""
def __init__(self, kernel_size=31, power=2.0, hard=False, mask_only=False):
super(HPSS, self).__init__()
self.kernel_size = kernel_size
self.power = power
self.hard = hard
self.mask_only = mask_only
def forward(self, mag_specgrams):
return hpss(mag_specgrams, self.kernel_size, self.power, self.hard, self.mask_only)
def __repr__(self):
return self.__class__.__name__ + \
'(kernel_size={}, power={}, hard={}, mask_only={})'.format(
self.kernel_size, self.power, self.hard, self.mask_only)
def hpss(mag_specgrams, kernel_size=31, power=2.0, hard=False, mask_only=False):
"""
A function that performs harmonic-percussive source separation.
Original method is by Derry Fitzgerald
(https://www.researchgate.net/publication/254583990_HarmonicPercussive_Separation_using_Median_Filtering).
Args:
mag_specgrams (Tensor): any magnitude spectrograms in batch, (not in a decibel scale!)
in a shape of (batch, ch, freq, time)
kernel_size (int or (int, int)): odd-numbered
if tuple,
1st: width of percussive-enhancing filter (one along freq axis)
2nd: width of harmonic-enhancing filter (one along time axis)
if int,
it's applied for both perc/harm filters
power (float): to which the enhanced spectrograms are used in computing soft masks.
hard (bool): whether the mask will be binarized (True) or not
mask_only (bool): if true, returns the masks only.
Returns:
ret (Tuple): A tuple of four
ret[0]: magnitude spectrograms - harmonic parts (Tensor, in same size with `mag_specgrams`)
ret[1]: magnitude spectrograms - percussive parts (Tensor, in same size with `mag_specgrams`)
ret[2]: harmonic mask (Tensor, in same size with `mag_specgrams`)
ret[3]: percussive mask (Tensor, in same size with `mag_specgrams`)
"""
def _enhance_either_hpss(mag_specgrams_padded, out, kernel_size, power, which, offset):
"""
A helper function for HPSS
Args:
mag_specgrams_padded (Tensor): one that median filtering can be directly applied
out (Tensor): The tensor to store the result
kernel_size (int): The kernel size of median filter
power (float): to which the enhanced spectrograms are used in computing soft masks.
which (str): either 'harm' or 'perc'
offset (int): the padded length
"""
if which == 'harm':
for t in range(out.shape[3]):
out[:, :, :, t] = torch.median(mag_specgrams_padded[:, :, offset:-offset, t:t + kernel_size], dim=3)[0]
elif which == 'perc':
for f in range(out.shape[2]):
out[:, :, f, :] = torch.median(mag_specgrams_padded[:, :, f:f + kernel_size, offset:-offset], dim=2)[0]
else:
raise NotImplementedError('it should be either but you passed which={}'.format(which))
if power != 1.0:
out.pow_(power)
# end of the helper function
eps = 1e-6
if not (isinstance(kernel_size, tuple) or isinstance(kernel_size, int)):
raise TypeError('kernel_size is expected to be either tuple of input, but it is: %s' % type(kernel_size))
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
pad = (kernel_size[0] // 2, kernel_size[0] // 2,
kernel_size[1] // 2, kernel_size[1] // 2,)
harm, perc, ret = torch.empty_like(mag_specgrams), torch.empty_like(mag_specgrams), torch.empty_like(mag_specgrams)
mag_specgrams_padded = F.pad(mag_specgrams, pad=pad, mode='reflect')
_enhance_either_hpss(mag_specgrams_padded, out=perc, kernel_size=kernel_size[0], power=power, which='perc',
offset=kernel_size[1] // 2)
_enhance_either_hpss(mag_specgrams_padded, out=harm, kernel_size=kernel_size[1], power=power, which='harm',
offset=kernel_size[0] // 2)
if hard:
mask_harm = harm > perc
mask_perc = harm < perc
else:
mask_harm = (harm + eps) / (harm + perc + eps)
mask_perc = (perc + eps) / (harm + perc + eps)
if mask_only:
return None, None, mask_harm, mask_perc
return mag_specgrams * mask_harm, mag_specgrams * mask_perc, mask_harm, mask_perc
# def pss_src(x, kernel_size=31, power=2.0, hard=False):
# """perform percusive source separation using `hpss()`.
# x: (batch, time)"""
# n_fft = 1024
# hop_length = 256
# x_stft = torch.stft(x, n_fft=n_fft, hop_length=hop_length)
# x_mag = x_stft.pow(2).sum(-1).unsqueeze(1) # add channel dim
# _, _, _, mask_perc = hpss(x_mag, kernel_size, power, hard, mask_only=True)
# mask_perc.squeeze_(1).unsqueeze_(3) # remove channel, add last dim for complex
# x_perc = time_freq.istft(x_stft * mask_perc, hop_length=hop_length, length=x.shape[1])
# return x_perc
================================================
FILE: torchaudio_contrib/functional.py
================================================
import torch
import math
def _mel_to_hertz(mel, htk):
"""
Converting mel values into frequency
"""
mel = torch.as_tensor(mel).type(torch.get_default_dtype())
if htk:
return 700. * (10 ** (mel / 2595.) - 1.)
f_min = 0.0
f_sp = 200.0 / 3
hz = f_min + f_sp * mel
min_log_hz = 1000.0
min_log_mel = (min_log_hz - f_min) / f_sp
logstep = math.log(6.4) / 27.0
return torch.where(mel >= min_log_mel, min_log_hz *
torch.exp(logstep * (mel - min_log_mel)), hz)
def _hertz_to_mel(hz, htk):
"""
Converting frequency into mel values
"""
hz = torch.as_tensor(hz).type(torch.get_default_dtype())
if htk:
return 2595. * torch.log10(torch.tensor(1., dtype=torch.get_default_dtype()) + (hz / 700.))
f_min = 0.0
f_sp = 200.0 / 3
mel = (hz - f_min) / f_sp
min_log_hz = 1000.0
min_log_mel = (min_log_hz - f_min) / f_sp
logstep = math.log(6.4) / 27.0
return torch.where(hz >= min_log_hz, min_log_mel +
torch.log(hz / min_log_hz) / logstep, mel)
def stft(waveforms, fft_length, hop_length=None, win_length=None, window=None,
center=True, pad_mode='reflect', normalized=False, onesided=True):
"""Compute a short-time Fourier transform of the input waveform(s).
It wraps `torch.stft` but after reshaping the input audio
to allow for `waveforms` that `.dim()` >= 3.
It follows most of the `torch.stft` default value, but for `window`,
if it's not specified (`None`), it uses hann window.
Args:
waveforms (Tensor): Tensor of audio signal
of size `(*, channel, time)`
fft_length (int): FFT size [sample]
hop_length (int): Hop size [sample] between STFT frames.
Defaults to `fft_length // 4` (75%-overlapping windows)
by `torch.stft`.
win_length (int): Size of STFT window.
Defaults to `fft_length` by `torch.stft`.
window (Tensor): 1-D Tensor.
Defaults to Hann Window of size `win_length`
*unlike* `torch.stft`.
center (bool): Whether to pad `waveforms` on both sides so that the
`t`-th frame is centered at time `t * hop_length`.
Defaults to `True` by `torch.stft`.
pad_mode (str): padding method (see `torch.nn.functional.pad`).
Defaults to `'reflect'` by `torch.stft`.
normalized (bool): Whether the results are normalized.
Defaults to `False` by `torch.stft`.
onesided (bool): Whether the half + 1 frequency bins
are returned to removethe symmetric part of STFT
of real-valued signal. Defaults to `True`
by `torch.stft`.
Returns:
complex_specgrams (Tensor): `(*, channel, num_freqs, time, complex=2)`
Example:
>>> waveforms = torch.randn(16, 2, 10000) # (batch, channel, time)
>>> x = stft(waveforms, 2048, 512)
>>> x.shape
torch.Size([16, 2, 1025, 20])
"""
leading_dims = waveforms.shape[:-1]
waveforms = waveforms.reshape(-1, waveforms.size(-1))
if window is None:
if win_length is None:
window = torch.hann_window(fft_length)
else:
window = torch.hann_window(win_length)
complex_specgrams = torch.stft(waveforms,
n_fft=fft_length,
hop_length=hop_length,
win_length=win_length,
window=window,
center=center,
pad_mode=pad_mode,
normalized=normalized,
onesided=onesided)
complex_specgrams = complex_specgrams.reshape(
leading_dims +
complex_specgrams.shape[1:])
return complex_specgrams
def complex_norm(complex_tensor, power=1.0):
"""Compute the norm of complex tensor input
Args:
complex_tensor (Tensor): Tensor shape of `(*, complex=2)`
power (float): Power of the norm. Defaults to `1.0`.
Returns:
Tensor: power of the normed input tensor, shape of `(*, )`
"""
if power == 1.0:
return torch.norm(complex_tensor, 2, -1)
return torch.norm(complex_tensor, 2, -1).pow(power)
def create_mel_filter(num_freqs, num_mels, min_freq, max_freq, htk):
"""
Creates filter matrix to transform fft frequency bins
into mel frequency bins.
Equivalent to librosa.filters.mel(sample_rate,
fft_len,
htk=True,
norm=None).
Args:
num_freqs (int): number of filter banks from stft.
num_mels (int): number of mel bins.
min_freq (float): minimum frequency.
max_freq (float): maximum frequency.
htk (bool): whether following htk-mel scale or not
Returns:
mel_filterbank (Tensor): (num_freqs, num_mels)
"""
# Convert to find mel lower/upper bounds
m_min = _hertz_to_mel(min_freq, htk)
m_max = _hertz_to_mel(max_freq, htk)
# Compute stft frequency values
stft_freqs = torch.linspace(min_freq, max_freq, num_freqs)
# Find mel values, and convert them to frequency units
m_pts = torch.linspace(m_min, m_max, num_mels + 2)
f_pts = _mel_to_hertz(m_pts, htk)
f_diff = f_pts[1:] - f_pts[:-1] # (num_mels + 1)
# (num_freqs, num_mels + 2)
slopes = f_pts.unsqueeze(0) - stft_freqs.unsqueeze(1)
down_slopes = (-1. * slopes[:, :-2]) / f_diff[:-1] # (num_freqs, num_mels)
up_slopes = slopes[:, 2:] / f_diff[1:] # (num_freqs, num_mels)
mel_filterbank = torch.clamp(torch.min(down_slopes, up_slopes), min=0.)
return mel_filterbank
def apply_filterbank(mag_specgrams, filterbank):
"""
Transform spectrogram given a filterbank matrix.
Args:
mag_specgrams (Tensor): (batch, channel, num_freqs, time)
filterbank (Tensor): (num_freqs, num_bands)
Returns:
(Tensor): (batch, channel, num_bands, time)
"""
return torch.matmul(mag_specgrams.transpose(-2, -1),
filterbank).transpose(-2, -1)
def angle(complex_tensor):
"""
Return angle of a complex tensor with shape (*, 2).
"""
return torch.atan2(complex_tensor[..., 1], complex_tensor[..., 0])
def magphase(complex_tensor, power=1.):
"""
Separate a complex-valued spectrogram with shape (*,2)
into its magnitude and phase.
"""
mag = complex_norm(complex_tensor, power)
phase = angle(complex_tensor)
return mag, phase
def phase_vocoder(complex_specgrams, rate, phase_advance):
"""
Phase vocoder. Given a STFT tensor, speed up in time
without modifying pitch by a factor of `rate`.
Args:
complex_specgrams (Tensor):
(*, channel, num_freqs, time, complex=2)
rate (float): Speed-up factor.
phase_advance (Tensor): Expected phase advance in
each bin. (num_freqs, 1).
Returns:
complex_specgrams_stretch (Tensor):
(*, channel, num_freqs, ceil(time/rate), complex=2).
Example:
>>> num_freqs, hop_length = 1025, 512
>>> # (batch, channel, num_freqs, time, complex=2)
>>> complex_specgrams = torch.randn(16, 1, num_freqs, 300, 2)
>>> rate = 1.3 # Slow down by 30%
>>> phase_advance = torch.linspace(
>>> 0, math.pi * hop_length, num_freqs)[..., None]
>>> x = phase_vocoder(complex_specgrams, rate, phase_advance)
>>> x.shape # with 231 == ceil(300 / 1.3)
torch.Size([16, 1, 1025, 231, 2])
"""
ndim = complex_specgrams.dim()
time_slice = [slice(None)] * (ndim - 2)
time_steps = torch.arange(0, complex_specgrams.size(
-2), rate, device=complex_specgrams.device)
alphas = torch.remainder(time_steps,
torch.tensor(1., device=complex_specgrams.device))
phase_0 = angle(complex_specgrams[time_slice + [slice(1)]])
# Time Padding
complex_specgrams = torch.nn.functional.pad(
complex_specgrams, [0, 0, 0, 2])
complex_specgrams_0 = complex_specgrams[time_slice +
[time_steps.long()]]
# (new_bins, num_freqs, 2)
complex_specgrams_1 = complex_specgrams[time_slice +
[(time_steps + 1).long()]]
angle_0 = angle(complex_specgrams_0)
angle_1 = angle(complex_specgrams_1)
norm_0 = torch.norm(complex_specgrams_0, dim=-1)
norm_1 = torch.norm(complex_specgrams_1, dim=-1)
phase = angle_1 - angle_0 - phase_advance
phase = phase - 2 * math.pi * torch.round(phase / (2 * math.pi))
# Compute Phase Accum
phase = phase + phase_advance
phase = torch.cat([phase_0, phase[time_slice + [slice(-1)]]], dim=-1)
phase_acc = torch.cumsum(phase, -1)
mag = alphas * norm_1 + (1 - alphas) * norm_0
real_stretch = mag * torch.cos(phase_acc)
imag_stretch = mag * torch.sin(phase_acc)
complex_specgrams_stretch = torch.stack(
[real_stretch, imag_stretch],
dim=-1)
return complex_specgrams_stretch
def amplitude_to_db(x, ref=1.0, amin=1e-7):
"""
Amplitude-to-decibel conversion (logarithmic mapping with base=10)
By using `amin=1e-7`, it assumes 32-bit floating point input. If the
data precision differs, use approproate `amin` accordingly.
Args:
x (Tensor): Input amplitude
ref (float): Amplitude value that is equivalent to 0 decibel
amin (float): Minimum amplitude. Any input that is smaller than `amin` is
clamped to `amin`.
Returns:
(Tensor): same size of x, after conversion
"""
x = x.pow(2.)
x = torch.clamp(x, min=amin)
return 10.0 * (torch.log10(x) - torch.log10(torch.tensor(ref,
device=x.device,
requires_grad=False,
dtype=x.dtype)))
def db_to_amplitude(x, ref=1.0):
"""
Decibel-to-amplitude conversion (exponential mapping with base=10)
Args:
x (Tensor): Input in decibel to be converted
ref (float): Amplitude value that is equivalent to 0 decibel
Returns:
(Tensor): same size of x, after conversion
"""
power_spec = torch.pow(10.0, x / 10.0 + torch.log10(torch.tensor(ref,
device=x.device,
requires_grad=False,
dtype=x.dtype)))
return power_spec.pow(0.5)
def mu_law_encoding(x, n_quantize=256):
"""Apply mu-law encoding to the input tensor.
Usually applied to waveforms
Args:
x (Tensor): input value
n_quantize (int): quantization level. For 8-bit encoding, set 256 (2 ** 8).
Returns:
(Tensor): same size of x, after encoding
"""
if not x.dtype.is_floating_point:
x = x.to(torch.float)
mu = torch.tensor(n_quantize - 1, dtype=x.dtype, requires_grad=False) # confused about dtype here..
x_mu = x.sign() * torch.log1p(mu * x.abs()) / torch.log1p(mu)
x_mu = ((x_mu + 1) / 2 * mu + 0.5).long()
return x_mu
def mu_law_decoding(x_mu, n_quantize=256, dtype=torch.get_default_dtype()):
"""Apply mu-law decoding (expansion) to the input tensor.
Args:
x_mu (Tensor): mu-law encoded input
n_quantize (int): quantization level. For 8-bit decoding, set 256 (2 ** 8).
dtype: specifies `dtype` for the decoded value. Default: `torch.get_default_dtype()`
Returns:
(Tensor): mu-law decoded tensor
"""
if not x_mu.dtype.is_floating_point:
x_mu = x_mu.to(dtype)
mu = torch.tensor(n_quantize - 1, dtype=x_mu.dtype, requires_grad=False) # confused about dtype here..
x = (x_mu / mu) * 2 - 1.
x = x.sign() * (torch.exp(x.abs() * torch.log1p(mu)) - 1.) / mu
return x
================================================
FILE: torchaudio_contrib/layers.py
================================================
import torch
import math
import torch.nn as nn
from .functional import stft, complex_norm, \
create_mel_filter, phase_vocoder, apply_filterbank, \
amplitude_to_db, db_to_amplitude, \
mu_law_encoding, mu_law_decoding
class _ModuleNoStateBuffers(nn.Module):
"""
Extension of nn.Module that removes buffers
from state_dict.
"""
def state_dict(self, destination=None, prefix='', keep_vars=False):
ret = super(_ModuleNoStateBuffers, self).state_dict(
destination, prefix, keep_vars)
for k in self._buffers:
del ret[prefix + k]
return ret
def _load_from_state_dict(self, state_dict, prefix, *args, **kwargs):
# temporarily hide the buffers; we do not want to restore them
buffers = self._buffers
self._buffers = {}
result = super(_ModuleNoStateBuffers, self)._load_from_state_dict(
state_dict, prefix, *args, **kwargs)
self._buffers = buffers
return result
class STFT(_ModuleNoStateBuffers):
"""Compute a short-time Fourier transform of the input waveform(s).
It essentially wraps `torch.stft` but after reshaping the input audio
to allow for `waveforms` that `.dim()` >= 3.
It follows most of the `torch.stft` default value, but for `window`,
if it's not specified (`None`), it uses hann window.
Args:
fft_length (int): FFT size [sample]
hop_length (int): Hop size [sample] between STFT frames.
Defaults to `fft_length // 4` (75%-overlapping windows) by `torch.stft`.
win_length (int): Size of STFT window.
Defaults to `fft_length` by `torch.stft`.
window (Tensor): 1-D Tensor.
Defaults to Hann Window of size `win_length` *unlike* `torch.stft`.
center (bool): Whether to pad `waveforms` on both sides so that the
`t`-th frame is centered at time `t * hop_length`.
Defaults to `True` by `torch.stft`.
pad_mode (str): padding method (see `torch.nn.functional.pad`).
Defaults to `'reflect'` by `torch.stft`.
normalized (bool): Whether the results are normalized.
Defaults to `False` by `torch.stft`.
onesided (bool): Whether the half + 1 frequency bins are returned to remove
the symmetric part of STFT of real-valued signal.
Defaults to `True` by `torch.stft`.
"""
def __init__(self, fft_length, hop_length=None, win_length=None,
window=None, center=True, pad_mode='reflect',
normalized=False, onesided=True):
super(STFT, self).__init__()
self.fft_length = fft_length
self.hop_length = hop_length
self.win_length = win_length
self.center = center
self.pad_mode = pad_mode
self.normalized = normalized
self.onesided = onesided
if window is None:
if win_length is None:
window = torch.hann_window(fft_length)
else:
window = torch.hann_window(win_length)
self.register_buffer('window', window)
def forward(self, waveforms):
"""
Args:
waveforms (Tensor): Tensor of audio signal of size `(*, channel, time)`
Returns:
complex_specgrams (Tensor): `(*, channel, num_freqs, time, complex=2)`
"""
complex_specgrams = stft(waveforms, self.fft_length,
hop_length=self.hop_length,
win_length=self.win_length,
window=self.window,
center=self.center,
pad_mode=self.pad_mode,
normalized=self.normalized,
onesided=self.onesided)
return complex_specgrams
def __repr__(self):
param_str1 = '(fft_length={}, hop_length={}, win_length={})'.format(
self.fft_length, self.hop_length, self.win_length)
param_str2 = '(center={}, pad_mode={}, normalized={}, onesided={})'.format(
self.center, self.pad_mode, self.normalized, self.onesided)
return self.__class__.__name__ + param_str1 + param_str2
class ComplexNorm(nn.Module):
"""Compute the norm of complex tensor input
Args:
power (float): Power of the norm. Defaults to `1.0`.
"""
def __init__(self, power=1.0):
super(ComplexNorm, self).__init__()
self.power = power
def forward(self, complex_tensor):
"""
Args:
complex_tensor (Tensor): Tensor shape of `(*, complex=2)`
Returns:
Tensor: norm of the input tensor, shape of `(*, )`
"""
return complex_norm(complex_tensor, self.power)
def __repr__(self):
return self.__class__.__name__ + '(power={})'.format(self.power)
class ApplyFilterbank(_ModuleNoStateBuffers):
"""
Applies a filterbank transform.
"""
def __init__(self, filterbank):
super(ApplyFilterbank, self).__init__()
self.register_buffer('filterbank', filterbank)
def forward(self, mag_specgrams):
"""
Args:
mag_specgrams (Tensor): (channel, time, freq) or (batch, channel, time, freq).
Returns:
(Tensor): freq -> filterbank.size(0)
"""
return apply_filterbank(mag_specgrams, self.filterbank)
class Filterbank(object):
"""
Base class for providing a filterbank matrix.
"""
def __init__(self):
super(Filterbank, self).__init__()
def get_filterbank(self):
raise NotImplementedError
class MelFilterbank(Filterbank):
"""
Provides a filterbank matrix to convert a spectrogram into a mel frequency spectrogram.
Args:
num_freqs (int, optional): number of filter banks from stft.
Defaults to 2048//2 + 1.
num_mels (int): number of mel bins. Defaults to 128.
min_freq (float): minimum frequency. Defaults to 0.
max_freq (float, optional): maximum frequency. Defaults to sample_rate // 2.
sample_rate (int): sample rate of audio signal. Defaults to None.
htk (bool, optional): use HTK formula instead of Slaney. Defaults to False.
"""
def __init__(self, num_freqs=1025, num_mels=128,
min_freq=0.0, max_freq=None, sample_rate=None, htk=False):
super(MelFilterbank, self).__init__()
if sample_rate is None and max_freq is None:
raise ValueError('Either max_freq or sample_rate should be specified.'
', but both are None.')
self.num_freqs = num_freqs
self.num_mels = num_mels
self.min_freq = min_freq
self.max_freq = max_freq if max_freq else sample_rate // 2
self.htk = htk
def get_filterbank(self):
return create_mel_filter(
num_freqs=self.num_freqs,
num_mels=self.num_mels,
min_freq=self.min_freq,
max_freq=self.max_freq,
htk=self.htk)
def __repr__(self):
param_str1 = '(num_freqs={}, snum_mels={}'.format(
self.num_freqs, self.num_mels)
param_str2 = ', min_freq={}, max_freq={})'.format(
self.min_freq, self.max_freq)
param_str3 = ', htk={}'.format(
self.htk)
return self.__class__.__name__ + param_str1 + param_str2 + param_str3
class TimeStretch(_ModuleNoStateBuffers):
"""
Stretch stft in time without modifying pitch for a given rate.
Args:
hop_length (int): Number audio of frames between STFT columns.
num_freqs (int, optional): number of filter banks from stft.
fixed_rate (float): rate to speed up or slow down by.
Defaults to None (in which case a rate must be
passed to the forward method per batch).
"""
def __init__(self, hop_length, num_freqs, fixed_rate=None):
super(TimeStretch, self).__init__()
self.fixed_rate = fixed_rate
phase_advance = torch.linspace(
0, math.pi * hop_length, num_freqs)[..., None]
self.register_buffer('phase_advance', phase_advance)
def forward(self, complex_specgrams, overriding_rate=None):
"""
Args:
complex_specgrams (Tensor): complex spectrogram
(*, channel, freq, time, complex=2)
overriding_rate (float or None): speed up to apply to this batch.
If no rate is passed, use self.fixed_rate.
Returns:
(Tensor): (*, channel, num_freqs, ceil(time/rate), complex=2)
"""
if overriding_rate is None:
rate = self.fixed_rate
if rate is None:
raise ValueError("If no fixed_rate is specified"
", must pass a valid rate to the forward method.")
else:
rate = overriding_rate
if rate == 1.0:
return complex_specgrams
return phase_vocoder(complex_specgrams, rate, self.phase_advance)
def __repr__(self):
param_str = '(fixed_rate={})'.format(self.fixed_rate)
return self.__class__.__name__ + param_str
def Spectrogram(fft_length, hop_length=None, win_length=None,
window=None, center=True, pad_mode='reflect',
normalized=False, onesided=True, power=1.):
"""Get spectrogram module, which is a Sequential module of
`[STFT(), ComplexNorm()]`.
Args:
fft_length (int): FFT size [sample]
hop_length (int): Hop size [sample] between STFT frames.
Defaults to `fft_length // 4` (75%-overlapping windows) by `torch.stft`.
win_length (int): Size of STFT window.
Defaults to `fft_length` by `torch.stft`.
window (Tensor): 1-D Tensor.
Defaults to Hann Window of size `win_length` *unlike* `torch.stft`.
center (bool): Whether to pad `waveforms` on both sides so that the
`t`-th frame is centered at time `t * hop_length`.
Defaults to `True` by `torch.stft`.
pad_mode (str): padding method (see `torch.nn.functional.pad`).
Defaults to `'reflect'` by `torch.stft`.
normalized (bool): Whether the results are normalized.
Defaults to `False` by `torch.stft`.
onesided (bool): Whether the half + 1 frequency bins are returned to remove
the symmetric part of STFT of real-valued signal.
Defaults to `True` by `torch.stft`.
power (float): Exponent of the magnitude. Defaults to `1.0`.
"""
return nn.Sequential(
STFT(
fft_length,
hop_length,
win_length,
window,
center,
pad_mode,
normalized,
onesided),
ComplexNorm(power))
def Melspectrogram(
num_mels=128,
sample_rate=22050,
min_freq=0.0,
max_freq=None,
num_freqs=None,
htk=False,
mel_filterbank=None,
**kwargs):
"""
Get melspectrogram module.
Args:
num_mels (int): number of mel bins. Defaults to 128.
sample_rate (int): sample rate of audio signal. Defaults to 22050.
min_freq (float): minimum frequency. Defaults to 0.
max_freq (float, optional): maximum frequency. Defaults to sample_rate // 2.
num_freqs (int, optional): number of filter banks from stft.
Defaults to fft_len//2 + 1 if 'fft_len' in kwargs else 1025.
htk (bool, optional): use HTK formula instead of Slaney. Defaults to False.
mel_filterbank (class, optional): MelFilterbank class to build filterbank matrix
**kwargs: torchaudio_contrib.Spectrogram parameters.
"""
fft_length = kwargs.get('fft_length', None)
num_freqs = fft_length // 2 + 1 if fft_length else 1025
# keunwoo: Why is num_freqs specified like this and not by the passed argument?
# Check if custom MelFilterbank is passed
if mel_filterbank is None:
mel_filterbank = MelFilterbank
mel_fb_matrix = mel_filterbank(
num_mels=num_mels,
sample_rate=sample_rate,
min_freq=min_freq,
max_freq=max_freq,
num_freqs=num_freqs,
htk=htk).get_filterbank()
return nn.Sequential(*Spectrogram(power=2., **kwargs),
ApplyFilterbank(mel_fb_matrix))
class AmplitudeToDb(_ModuleNoStateBuffers):
"""
Amplitude-to-decibel conversion (logarithmic mapping with base=10)
By using `amin=1e-7`, it assumes 32-bit floating point input. If the
data precision differs, use approproate `amin` accordingly.
Args:
ref (float): Amplitude value that is equivalent to 0 decibel
amin (float): Minimum amplitude. Any input that is smaller than `amin` is
clamped to `amin`.
"""
def __init__(self, ref=1.0, amin=1e-7):
super(AmplitudeToDb, self).__init__()
self.ref = ref
self.amin = amin
assert ref > amin, "Reference value is expected to be bigger than amin, but I have" \
"ref:{} and amin:{}".format(ref, amin)
def forward(self, x):
"""
Args:
x (Tensor): Input amplitude
Returns:
(Tensor): same size of x, after conversion
"""
return amplitude_to_db(x, ref=self.ref, amin=self.amin)
def __repr__(self):
param_str = '(ref={}, amin={})'.format(self.ref, self.amin)
return self.__class__.__name__ + param_str
class DbToAmplitude(_ModuleNoStateBuffers):
"""
Decibel-to-amplitude conversion (exponential mapping with base=10)
Args:
x (Tensor): Input in decibel to be converted
ref (float): Amplitude value that is equivalent to 0 decibel
Returns:
(Tensor): same size of x, after conversion
"""
def __init__(self, ref=1.0):
super(DbToAmplitude, self).__init__()
self.ref = ref
def forward(self, x):
"""
Args:
x (Tensor): Input in decibel to be converted
Returns:
(Tensor): same size of x, after conversion
"""
return db_to_amplitude(x, ref=self.ref)
def __repr__(self):
param_str = '(ref={})'.format(self.ref)
return self.__class__.__name__ + param_str
class MuLawEncoding(_ModuleNoStateBuffers):
"""Apply mu-law encoding to the input tensor.
Usually applied to waveforms
Args:
n_quantize (int): quantization level. For 8-bit encoding, set 256 (2 ** 8).
"""
def __init__(self, n_quantize=256):
super(MuLawEncoding, self).__init__()
self.n_quantize = n_quantize
def forward(self, x):
"""
Args:
x (Tensor): input value
Returns:
(Tensor): same size of x, after encoding
"""
return mu_law_encoding(x, self.n_quantize)
def __repr__(self):
param_str = '(n_quantize={})'.format(self.n_quantize)
return self.__class__.__name__ + param_str
class MuLawDecoding(_ModuleNoStateBuffers):
"""Apply mu-law decoding (expansion) to the input tensor.
Usually applied to waveforms
Args:
n_quantize (int): quantization level. For 8-bit decoding, set 256 (2 ** 8).
"""
def __init__(self, n_quantize=256):
super(MuLawDecoding, self).__init__()
self.n_quantize = n_quantize
def forward(self, x_mu):
"""
Args:
x_mu (Tensor): mu-law encoded input
Returns:
(Tensor): mu-law decoded tensor
"""
return mu_law_decoding(x_mu, self.n_quantize)
def __repr__(self):
param_str = '(n_quantize={})'.format(self.n_quantize)
return self.__class__.__name__ + param_str
gitextract_ztnwls02/
├── .flake8
├── .gitignore
├── .travis.yml
├── README.md
├── requirements.txt
├── setup.cfg
├── setup.py
├── tests/
│ ├── test_functional.py
│ └── test_layers.py
└── torchaudio_contrib/
├── __init__.py
├── beta_hpss.py
├── functional.py
└── layers.py
SYMBOL INDEX (74 symbols across 5 files)
FILE: tests/test_functional.py
function _num_stft_bins (line 14) | def _num_stft_bins(signal_len, fft_len, hop_length, pad):
function _approx_all_equal (line 18) | def _approx_all_equal(x, y, atol=1e-7):
function _all_equal (line 22) | def _all_equal(x, y):
function test_stft (line 37) | def test_stft(waveform, fft_length, hop_length, pad_mode):
function test_phase_vocoder (line 75) | def test_phase_vocoder(complex_specgrams, rate, hop_length):
function test_complex_norm (line 124) | def test_complex_norm(complex_tensor, power):
function test_apply_filterbank (line 136) | def test_apply_filterbank(mag_spec, new_len):
function test_amplitude_db (line 148) | def test_amplitude_db(amplitude, db):
function test_mu_law (line 166) | def test_mu_law(waveform, n_quantize):
FILE: tests/test_layers.py
function test_STFT (line 27) | def test_STFT(waveform, fft_len, hop_length, pad_mode):
function test_TimeStretch (line 47) | def test_TimeStretch(complex_specgrams, rate, hop_length):
function test_SpectrogramDb (line 65) | def test_SpectrogramDb(waveform, fft_length, hop_length, pad_mode):
function test_MelspectrogramStretch (line 94) | def test_MelspectrogramStretch(waveform, fft_length, num_mels, hop_lengt...
FILE: torchaudio_contrib/beta_hpss.py
class HPSS (line 12) | class HPSS(nn.Module):
method __init__ (line 19) | def __init__(self, kernel_size=31, power=2.0, hard=False, mask_only=Fa...
method forward (line 26) | def forward(self, mag_specgrams):
method __repr__ (line 29) | def __repr__(self):
function hpss (line 35) | def hpss(mag_specgrams, kernel_size=31, power=2.0, hard=False, mask_only...
FILE: torchaudio_contrib/functional.py
function _mel_to_hertz (line 5) | def _mel_to_hertz(mel, htk):
function _hertz_to_mel (line 26) | def _hertz_to_mel(hz, htk):
function stft (line 48) | def stft(waveforms, fft_length, hop_length=None, win_length=None, window...
function complex_norm (line 116) | def complex_norm(complex_tensor, power=1.0):
function create_mel_filter (line 131) | def create_mel_filter(num_freqs, num_mels, min_freq, max_freq, htk):
function apply_filterbank (line 172) | def apply_filterbank(mag_specgrams, filterbank):
function angle (line 187) | def angle(complex_tensor):
function magphase (line 194) | def magphase(complex_tensor, power=1.):
function phase_vocoder (line 204) | def phase_vocoder(complex_specgrams, rate, phase_advance):
function amplitude_to_db (line 277) | def amplitude_to_db(x, ref=1.0, amin=1e-7):
function db_to_amplitude (line 299) | def db_to_amplitude(x, ref=1.0):
function mu_law_encoding (line 317) | def mu_law_encoding(x, n_quantize=256):
function mu_law_decoding (line 338) | def mu_law_decoding(x_mu, n_quantize=256, dtype=torch.get_default_dtype()):
FILE: torchaudio_contrib/layers.py
class _ModuleNoStateBuffers (line 11) | class _ModuleNoStateBuffers(nn.Module):
method state_dict (line 17) | def state_dict(self, destination=None, prefix='', keep_vars=False):
method _load_from_state_dict (line 24) | def _load_from_state_dict(self, state_dict, prefix, *args, **kwargs):
class STFT (line 35) | class STFT(_ModuleNoStateBuffers):
method __init__ (line 62) | def __init__(self, fft_length, hop_length=None, win_length=None,
method forward (line 84) | def forward(self, waveforms):
method __repr__ (line 104) | def __repr__(self):
class ComplexNorm (line 112) | class ComplexNorm(nn.Module):
method __init__ (line 120) | def __init__(self, power=1.0):
method forward (line 124) | def forward(self, complex_tensor):
method __repr__ (line 134) | def __repr__(self):
class ApplyFilterbank (line 138) | class ApplyFilterbank(_ModuleNoStateBuffers):
method __init__ (line 143) | def __init__(self, filterbank):
method forward (line 147) | def forward(self, mag_specgrams):
class Filterbank (line 158) | class Filterbank(object):
method __init__ (line 163) | def __init__(self):
method get_filterbank (line 166) | def get_filterbank(self):
class MelFilterbank (line 170) | class MelFilterbank(Filterbank):
method __init__ (line 184) | def __init__(self, num_freqs=1025, num_mels=128,
method get_filterbank (line 197) | def get_filterbank(self):
method __repr__ (line 205) | def __repr__(self):
class TimeStretch (line 215) | class TimeStretch(_ModuleNoStateBuffers):
method __init__ (line 228) | def __init__(self, hop_length, num_freqs, fixed_rate=None):
method forward (line 237) | def forward(self, complex_specgrams, overriding_rate=None):
method __repr__ (line 262) | def __repr__(self):
function Spectrogram (line 267) | def Spectrogram(fft_length, hop_length=None, win_length=None,
function Melspectrogram (line 307) | def Melspectrogram(
class AmplitudeToDb (line 350) | class AmplitudeToDb(_ModuleNoStateBuffers):
method __init__ (line 362) | def __init__(self, ref=1.0, amin=1e-7):
method forward (line 369) | def forward(self, x):
method __repr__ (line 379) | def __repr__(self):
class DbToAmplitude (line 384) | class DbToAmplitude(_ModuleNoStateBuffers):
method __init__ (line 396) | def __init__(self, ref=1.0):
method forward (line 400) | def forward(self, x):
method __repr__ (line 410) | def __repr__(self):
class MuLawEncoding (line 415) | class MuLawEncoding(_ModuleNoStateBuffers):
method __init__ (line 424) | def __init__(self, n_quantize=256):
method forward (line 428) | def forward(self, x):
method __repr__ (line 438) | def __repr__(self):
class MuLawDecoding (line 443) | class MuLawDecoding(_ModuleNoStateBuffers):
method __init__ (line 451) | def __init__(self, n_quantize=256):
method forward (line 455) | def forward(self, x_mu):
method __repr__ (line 465) | def __repr__(self):
Condensed preview — 13 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (55K chars).
[
{
"path": ".flake8",
"chars": 122,
"preview": "[flake8]\nmax-line-length = 120\nignore = E305,E402,E721,E741,F403,F405,F821,F841,F999,W503,W504\nexclude = beta_*.py, .git"
},
{
"path": ".gitignore",
"chars": 218,
"preview": "# Intellij Idea\n.idea/\n*.iml\n\n# python\n__pycache__/\n*.pyc\n## pyenv\n.python-version\n## python virtual environments\nenv/\nv"
},
{
"path": ".travis.yml",
"chars": 101,
"preview": "language: python\npython:\n - \"3.5\"\ninstall:\n - pip install -e .[tests]\nscript:\n - python -m pytest\n"
},
{
"path": "README.md",
"chars": 6054,
"preview": "# SUNSETTING torcnaudio-contrib\n\nWe made some progress in this repo and contributed to the original repo [pytorch/audio]"
},
{
"path": "requirements.txt",
"chars": 5,
"preview": "torch"
},
{
"path": "setup.cfg",
"chars": 34,
"preview": "[tool:pytest]\nxfail_strict = true\n"
},
{
"path": "setup.py",
"chars": 543,
"preview": "from setuptools import setup\n\nsetup(name='torchaudio_contrib',\n version='0.1',\n description='To propose audio "
},
{
"path": "tests/test_functional.py",
"chars": 7774,
"preview": "import pytest\nimport librosa\nimport numpy as np\nimport torch\n\nfrom torchaudio_contrib.functional import (stft, phase_voc"
},
{
"path": "tests/test_layers.py",
"chars": 3772,
"preview": "\"\"\"\nTest the layers. Currently only on cpu since travis doesn't have GPU.\n\"\"\"\nimport unittest\nimport pytest\nimport libro"
},
{
"path": "torchaudio_contrib/__init__.py",
"chars": 76,
"preview": "from .functional import * # noqa: F401\nfrom .layers import * # noqa: F401\n"
},
{
"path": "torchaudio_contrib/beta_hpss.py",
"chars": 5450,
"preview": "\"\"\"This is a beta-version of harmonic-percussive source separation.\nCurrently it only returns the separated magnitude sp"
},
{
"path": "torchaudio_contrib/functional.py",
"chars": 12183,
"preview": "import torch\nimport math\n\n\ndef _mel_to_hertz(mel, htk):\n \"\"\"\n Converting mel values into frequency\n \"\"\"\n mel"
},
{
"path": "torchaudio_contrib/layers.py",
"chars": 15861,
"preview": "import torch\nimport math\nimport torch.nn as nn\n\nfrom .functional import stft, complex_norm, \\\n create_mel_filter, pha"
}
]
About this extraction
This page contains the full source code of the keunwoochoi/torchaudio-contrib GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 13 files (51.0 KB), approximately 13.6k tokens, and a symbol index with 74 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.