Repository: kevwan/mapreduce
Branch: main
Commit: a6e43ced8658
Files: 13
Total size: 41.8 KB
Directory structure:
gitextract_on_ozn84/
├── .github/
│ └── workflows/
│ ├── codeql-analysis.yml
│ ├── go.yml
│ └── reviewdog.yml
├── .gitignore
├── LICENSE
├── examples/
│ └── sum.go
├── go.mod
├── go.sum
├── mapreduce.go
├── mapreduce_fuzz_test.go
├── mapreduce_test.go
├── readme-cn.md
└── readme.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/codeql-analysis.yml
================================================
# For most projects, this workflow file will not need changing; you simply need
# to commit it to your repository.
#
# You may wish to alter this file to override the set of languages analyzed,
# or to provide custom queries or build logic.
#
# ******** NOTE ********
# We have attempted to detect the languages in your repository. Please check
# the `language` matrix defined below to confirm you have the correct set of
# supported CodeQL languages.
#
name: "CodeQL"
on:
push:
branches: [ main ]
pull_request:
# The branches below must be a subset of the branches above
branches: [ main ]
schedule:
- cron: '18 19 * * 6'
jobs:
analyze:
name: Analyze
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
language: [ 'go' ]
# CodeQL supports [ 'cpp', 'csharp', 'go', 'java', 'javascript', 'python' ]
# Learn more:
# https://docs.github.com/en/free-pro-team@latest/github/finding-security-vulnerabilities-and-errors-in-your-code/configuring-code-scanning#changing-the-languages-that-are-analyzed
steps:
- name: Checkout repository
uses: actions/checkout@v2
# Initializes the CodeQL tools for scanning.
- name: Initialize CodeQL
uses: github/codeql-action/init@v1
with:
languages: ${{ matrix.language }}
# If you wish to specify custom queries, you can do so here or in a config file.
# By default, queries listed here will override any specified in a config file.
# Prefix the list here with "+" to use these queries and those in the config file.
# queries: ./path/to/local/query, your-org/your-repo/queries@main
# Autobuild attempts to build any compiled languages (C/C++, C#, or Java).
# If this step fails, then you should remove it and run the build manually (see below)
- name: Autobuild
uses: github/codeql-action/autobuild@v1
# ℹ️ Command-line programs to run using the OS shell.
# 📚 https://git.io/JvXDl
# ✏️ If the Autobuild fails above, remove it and uncomment the following three lines
# and modify them (or add more) to build your code if your project
# uses a compiled language
#- run: |
# make bootstrap
# make release
- name: Perform CodeQL Analysis
uses: github/codeql-action/analyze@v1
================================================
FILE: .github/workflows/go.yml
================================================
name: Go
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
name: Build
runs-on: ubuntu-latest
steps:
- name: Set up Go 1.x
uses: actions/setup-go@v2
with:
go-version: ^1.18
id: go
- name: Check out code into the Go module directory
uses: actions/checkout@v2
- name: Get dependencies
run: |
go get -v -t -d ./...
- name: Lint
run: |
go vet -stdmethods=false $(go list ./...)
go install mvdan.cc/gofumpt@latest
test -z "$(gofumpt -s -l -extra .)" || echo "Please run 'gofumpt -l -w -extra .'"
- name: Test
run: go test -race -coverprofile=coverage.txt -covermode=atomic ./...
- name: Codecov
uses: codecov/codecov-action@v2
================================================
FILE: .github/workflows/reviewdog.yml
================================================
name: reviewdog
on: [pull_request]
jobs:
staticcheck:
name: runner / staticcheck
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-go@v3
with:
go-version: "1.18"
- uses: reviewdog/action-staticcheck@v1
with:
github_token: ${{ secrets.github_token }}
# Change reviewdog reporter if you need [github-pr-check,github-check,github-pr-review].
reporter: github-pr-review
# Report all results.
filter_mode: nofilter
# Exit with 1 when it find at least one finding.
fail_on_error: true
# Set staticcheck flags
staticcheck_flags: -checks=inherit,-SA1019,-SA1029,-SA5008
================================================
FILE: .gitignore
================================================
# Binaries for programs and plugins
*.exe
*.exe~
*.dll
*.so
*.dylib
# dev files
.idea
# For test
**/testdata
*.test
# Output of the go coverage tool, specifically when used with LiteIDE
*.out
# Dependency directories (remove the comment below to include it)
# vendor/
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 Kevin Wan
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: examples/sum.go
================================================
package main
import (
"fmt"
"log"
"github.com/kevwan/mapreduce/v2"
)
func main() {
val, err := mapreduce.MapReduce(func(source chan<- int) {
for i := 0; i < 10; i++ {
source <- i
}
}, func(item int, writer mapreduce.Writer[int], cancel func(error)) {
writer.Write(item * item)
}, func(pipe <-chan int, writer mapreduce.Writer[int], cancel func(error)) {
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
================================================
FILE: go.mod
================================================
module github.com/kevwan/mapreduce/v2
go 1.18
require (
github.com/stretchr/testify v1.7.0
go.uber.org/goleak v1.1.12
)
require (
github.com/davecgh/go-spew v1.1.1 // indirect
github.com/kr/pretty v0.2.1 // indirect
github.com/pmezard/go-difflib v1.0.0 // indirect
gopkg.in/yaml.v3 v3.0.0-20210107192922-496545a6307b // indirect
)
================================================
FILE: go.sum
================================================
github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
github.com/davecgh/go-spew v1.1.1 h1:vj9j/u1bqnvCEfJOwUhtlOARqs3+rkHYY13jYWTU97c=
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
github.com/kevwan/mapreduce/v2 v2.0.1 h1:i+elkbdsdj1IK85dY+hVtYNdWVMx+O/q0TRr55r+mRI=
github.com/kevwan/mapreduce/v2 v2.0.1/go.mod h1:CRVNCu3oR6NcBIXGxzLjhYjMtNXlEwI5jASt5JZaBLk=
github.com/kr/pretty v0.1.0/go.mod h1:dAy3ld7l9f0ibDNOQOHHMYYIIbhfbHSm3C4ZsoJORNo=
github.com/kr/pretty v0.2.1 h1:Fmg33tUaq4/8ym9TJN1x7sLJnHVwhP33CNkpYV/7rwI=
github.com/kr/pretty v0.2.1/go.mod h1:ipq/a2n7PKx3OHsz4KJII5eveXtPO4qwEXGdVfWzfnI=
github.com/kr/pty v1.1.1/go.mod h1:pFQYn66WHrOpPYNljwOMqo10TkYh1fy3cYio2l3bCsQ=
github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
github.com/kr/text v0.2.0 h1:5Nx0Ya0ZqY2ygV366QzturHI13Jq95ApcVaJBhpS+AY=
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
github.com/stretchr/testify v1.7.0 h1:nwc3DEeHmmLAfoZucVR881uASk0Mfjw8xYJ99tb5CcY=
github.com/stretchr/testify v1.7.0/go.mod h1:6Fq8oRcR53rry900zMqJjRRixrwX3KX962/h/Wwjteg=
github.com/yuin/goldmark v1.3.5/go.mod h1:mwnBkeHKe2W/ZEtQ+71ViKU8L12m81fl3OWwC1Zlc8k=
go.uber.org/goleak v1.1.12 h1:gZAh5/EyT/HQwlpkCy6wTpqfH9H8Lz8zbm3dZh+OyzA=
go.uber.org/goleak v1.1.12/go.mod h1:cwTWslyiVhfpKIDGSZEM2HlOvcqm+tG4zioyIeLoqMQ=
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
golang.org/x/crypto v0.0.0-20191011191535-87dc89f01550/go.mod h1:yigFU9vqHzYiE8UmvKecakEJjdnWj3jj499lnFckfCI=
golang.org/x/lint v0.0.0-20190930215403-16217165b5de h1:5hukYrvBGR8/eNkX5mdUezrA6JiaEZDtJb9Ei+1LlBs=
golang.org/x/lint v0.0.0-20190930215403-16217165b5de/go.mod h1:6SW0HCj/g11FgYtHlgUYUwCkIfeOF89ocIRzGO/8vkc=
golang.org/x/mod v0.4.2/go.mod h1:s0Qsj1ACt9ePp/hMypM3fl4fZqREWJwdYDEqhRiZZUA=
golang.org/x/net v0.0.0-20190311183353-d8887717615a/go.mod h1:t9HGtf8HONx5eT2rtn7q6eTqICYqUVnKs3thJo3Qplg=
golang.org/x/net v0.0.0-20190404232315-eb5bcb51f2a3/go.mod h1:t9HGtf8HONx5eT2rtn7q6eTqICYqUVnKs3thJo3Qplg=
golang.org/x/net v0.0.0-20190620200207-3b0461eec859/go.mod h1:z5CRVTTTmAJ677TzLLGU+0bjPO0LkuOLi4/5GtJWs/s=
golang.org/x/net v0.0.0-20210405180319-a5a99cb37ef4/go.mod h1:p54w0d4576C0XHj96bSt6lcn1PtDYWL6XObtHCRCNQM=
golang.org/x/sync v0.0.0-20190423024810-112230192c58/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
golang.org/x/sys v0.0.0-20190412213103-97732733099d/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
golang.org/x/sys v0.0.0-20210330210617-4fbd30eecc44/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
golang.org/x/sys v0.0.0-20210510120138-977fb7262007/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
golang.org/x/tools v0.0.0-20190311212946-11955173bddd/go.mod h1:LCzVGOaR6xXOjkQ3onu1FJEFr0SW1gC7cKk1uF8kGRs=
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
golang.org/x/tools v0.1.5 h1:ouewzE6p+/VEB31YYnTbEJdi8pFqKp4P4n85vwo3DHA=
golang.org/x/tools v0.1.5/go.mod h1:o0xws9oXOQQZyjljx8fwUC0k7L1pTE6eaCbjGeHmOkk=
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
golang.org/x/xerrors v0.0.0-20191011141410-1b5146add898/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
golang.org/x/xerrors v0.0.0-20200804184101-5ec99f83aff1/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c h1:Hei/4ADfdWqJk1ZMxUNpqntNwaWcugrBjAiHlqqRiVk=
gopkg.in/yaml.v3 v3.0.0-20200313102051-9f266ea9e77c/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
gopkg.in/yaml.v3 v3.0.0-20210107192922-496545a6307b h1:h8qDotaEPuJATrMmW04NCwg7v22aHH28wwpauUhK9Oo=
gopkg.in/yaml.v3 v3.0.0-20210107192922-496545a6307b/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
================================================
FILE: mapreduce.go
================================================
package mapreduce
import (
"context"
"errors"
"sync"
"sync/atomic"
)
const (
defaultWorkers = 16
minWorkers = 1
)
var (
// ErrCancelWithNil is an error that mapreduce was cancelled with nil.
ErrCancelWithNil = errors.New("mapreduce cancelled with nil")
// ErrReduceNoOutput is an error that reduce did not output a value.
ErrReduceNoOutput = errors.New("reduce not writing value")
)
type (
// ForEachFunc is used to do element processing, but no output.
ForEachFunc[T any] func(item T)
// GenerateFunc is used to let callers send elements into source.
GenerateFunc[T any] func(source chan<- T)
// MapFunc is used to do element processing and write the output to writer.
MapFunc[T, U any] func(item T, writer Writer[U])
// MapperFunc is used to do element processing and write the output to writer,
// use cancel func to cancel the processing.
MapperFunc[T, U any] func(item T, writer Writer[U], cancel func(error))
// ReducerFunc is used to reduce all the mapping output and write to writer,
// use cancel func to cancel the processing.
ReducerFunc[U, V any] func(pipe <-chan U, writer Writer[V], cancel func(error))
// VoidReducerFunc is used to reduce all the mapping output, but no output.
// Use cancel func to cancel the processing.
VoidReducerFunc[U any] func(pipe <-chan U, cancel func(error))
// Option defines the method to customize the mapreduce.
Option func(opts *mapReduceOptions)
mapperContext[T, U any] struct {
ctx context.Context
mapper MapFunc[T, U]
source <-chan T
panicChan *onceChan
collector chan<- U
doneChan <-chan struct{}
workers int
}
mapReduceOptions struct {
ctx context.Context
workers int
}
// Writer interface wraps Write method.
Writer[T any] interface {
Write(v T)
}
)
// Finish runs fns parallelly, cancelled on any error.
func Finish(fns ...func() error) error {
if len(fns) == 0 {
return nil
}
return MapReduceVoid(func(source chan<- func() error) {
for _, fn := range fns {
source <- fn
}
}, func(fn func() error, writer Writer[any], cancel func(error)) {
if err := fn(); err != nil {
cancel(err)
}
}, func(pipe <-chan any, cancel func(error)) {
}, WithWorkers(len(fns)))
}
// FinishVoid runs fns parallelly.
func FinishVoid(fns ...func()) {
if len(fns) == 0 {
return
}
ForEach(func(source chan<- func()) {
for _, fn := range fns {
source <- fn
}
}, func(fn func()) {
fn()
}, WithWorkers(len(fns)))
}
// ForEach maps all elements from given generate but no output.
func ForEach[T any](generate GenerateFunc[T], mapper ForEachFunc[T], opts ...Option) {
options := buildOptions(opts...)
panicChan := &onceChan{channel: make(chan any)}
source := buildSource(generate, panicChan)
collector := make(chan any)
done := make(chan struct{})
go executeMappers(mapperContext[T, any]{
ctx: options.ctx,
mapper: func(item T, _ Writer[any]) {
mapper(item)
},
source: source,
panicChan: panicChan,
collector: collector,
doneChan: done,
workers: options.workers,
})
for {
select {
case v := <-panicChan.channel:
panic(v)
case _, ok := <-collector:
if !ok {
return
}
}
}
}
// MapReduce maps all elements generated from given generate func,
// and reduces the output elements with given reducer.
func MapReduce[T, U, V any](generate GenerateFunc[T], mapper MapperFunc[T, U], reducer ReducerFunc[U, V],
opts ...Option) (V, error) {
panicChan := &onceChan{channel: make(chan any)}
source := buildSource(generate, panicChan)
return mapReduceWithPanicChan(source, panicChan, mapper, reducer, opts...)
}
// MapReduceChan maps all elements from source, and reduce the output elements with given reducer.
func MapReduceChan[T, U, V any](source <-chan T, mapper MapperFunc[T, U], reducer ReducerFunc[U, V],
opts ...Option) (V, error) {
panicChan := &onceChan{channel: make(chan any)}
return mapReduceWithPanicChan(source, panicChan, mapper, reducer, opts...)
}
// mapReduceWithPanicChan maps all elements from source, and reduce the output elements with given reducer.
func mapReduceWithPanicChan[T, U, V any](source <-chan T, panicChan *onceChan, mapper MapperFunc[T, U],
reducer ReducerFunc[U, V], opts ...Option) (val V, err error) {
options := buildOptions(opts...)
// output is used to write the final result
output := make(chan V)
defer func() {
// reducer can only write once, if more, panic
for range output {
panic("more than one element written in reducer")
}
}()
// collector is used to collect data from mapper, and consume in reducer
collector := make(chan U, options.workers)
// if done is closed, all mappers and reducer should stop processing
done := make(chan struct{})
writer := newGuardedWriter(options.ctx, output, done)
var closeOnce sync.Once
// use atomic.Value to avoid data race
var retErr atomic.Value
finish := func() {
closeOnce.Do(func() {
close(done)
close(output)
})
}
cancel := once(func(err error) {
if err != nil {
retErr.Store(err)
} else {
retErr.Store(ErrCancelWithNil)
}
drain(source)
finish()
})
go func() {
defer func() {
drain(collector)
if r := recover(); r != nil {
panicChan.write(r)
}
finish()
}()
reducer(collector, writer, cancel)
}()
go executeMappers(mapperContext[T, U]{
ctx: options.ctx,
mapper: func(item T, w Writer[U]) {
mapper(item, w, cancel)
},
source: source,
panicChan: panicChan,
collector: collector,
doneChan: done,
workers: options.workers,
})
select {
case <-options.ctx.Done():
cancel(context.DeadlineExceeded)
err = context.DeadlineExceeded
case v := <-panicChan.channel:
// drain output here, otherwise for loop panic in defer
drain(output)
panic(v)
case v, ok := <-output:
if e := retErr.Load(); e != nil {
err = e.(error)
} else if ok {
val = v
} else {
err = ErrReduceNoOutput
}
}
return
}
// MapReduceVoid maps all elements generated from given generate,
// and reduce the output elements with given reducer.
func MapReduceVoid[T, U any](generate GenerateFunc[T], mapper MapperFunc[T, U],
reducer VoidReducerFunc[U], opts ...Option) error {
_, err := MapReduce(generate, mapper, func(input <-chan U, writer Writer[any], cancel func(error)) {
reducer(input, cancel)
}, opts...)
if errors.Is(err, ErrReduceNoOutput) {
return nil
}
return err
}
// WithContext customizes a mapreduce processing accepts a given ctx.
func WithContext(ctx context.Context) Option {
return func(opts *mapReduceOptions) {
opts.ctx = ctx
}
}
// WithWorkers customizes a mapreduce processing with given workers.
func WithWorkers(workers int) Option {
return func(opts *mapReduceOptions) {
if workers < minWorkers {
opts.workers = minWorkers
} else {
opts.workers = workers
}
}
}
func buildOptions(opts ...Option) *mapReduceOptions {
options := newOptions()
for _, opt := range opts {
opt(options)
}
return options
}
func buildSource[T any](generate GenerateFunc[T], panicChan *onceChan) chan T {
source := make(chan T)
go func() {
defer func() {
if r := recover(); r != nil {
panicChan.write(r)
}
close(source)
}()
generate(source)
}()
return source
}
// drain drains the channel.
func drain[T any](channel <-chan T) {
// drain the channel
for range channel {
}
}
func executeMappers[T, U any](mCtx mapperContext[T, U]) {
var wg sync.WaitGroup
defer func() {
wg.Wait()
close(mCtx.collector)
drain(mCtx.source)
}()
var failed int32
pool := make(chan struct{}, mCtx.workers)
writer := newGuardedWriter(mCtx.ctx, mCtx.collector, mCtx.doneChan)
for atomic.LoadInt32(&failed) == 0 {
select {
case <-mCtx.ctx.Done():
return
case <-mCtx.doneChan:
return
case pool <- struct{}{}:
item, ok := <-mCtx.source
if !ok {
<-pool
return
}
wg.Add(1)
go func() {
defer func() {
if r := recover(); r != nil {
atomic.AddInt32(&failed, 1)
mCtx.panicChan.write(r)
}
wg.Done()
<-pool
}()
mCtx.mapper(item, writer)
}()
}
}
}
func newOptions() *mapReduceOptions {
return &mapReduceOptions{
ctx: context.Background(),
workers: defaultWorkers,
}
}
func once(fn func(error)) func(error) {
once := new(sync.Once)
return func(err error) {
once.Do(func() {
fn(err)
})
}
}
type guardedWriter[T any] struct {
ctx context.Context
channel chan<- T
done <-chan struct{}
}
func newGuardedWriter[T any](ctx context.Context, channel chan<- T, done <-chan struct{}) guardedWriter[T] {
return guardedWriter[T]{
ctx: ctx,
channel: channel,
done: done,
}
}
func (gw guardedWriter[T]) Write(v T) {
select {
case <-gw.ctx.Done():
return
case <-gw.done:
return
default:
gw.channel <- v
}
}
type onceChan struct {
channel chan any
wrote int32
}
func (oc *onceChan) write(val any) {
if atomic.CompareAndSwapInt32(&oc.wrote, 0, 1) {
oc.channel <- val
}
}
================================================
FILE: mapreduce_fuzz_test.go
================================================
//go:build go1.18
// +build go1.18
package mapreduce
import (
"fmt"
"math/rand"
"runtime"
"strings"
"testing"
"time"
"github.com/stretchr/testify/assert"
"go.uber.org/goleak"
)
func FuzzMapReduce(f *testing.F) {
rand.Seed(time.Now().UnixNano())
f.Add(int64(10), runtime.NumCPU())
f.Fuzz(func(t *testing.T, n int64, workers int) {
n = n%5000 + 5000
genPanic := rand.Intn(100) == 0
mapperPanic := rand.Intn(100) == 0
reducerPanic := rand.Intn(100) == 0
genIdx := rand.Int63n(n)
mapperIdx := rand.Int63n(n)
reducerIdx := rand.Int63n(n)
squareSum := (n - 1) * n * (2*n - 1) / 6
fn := func() (int64, error) {
defer goleak.VerifyNone(t, goleak.IgnoreCurrent())
return MapReduce(func(source chan<- int64) {
for i := int64(0); i < n; i++ {
source <- i
if genPanic && i == genIdx {
panic("foo")
}
}
}, func(v int64, writer Writer[int64], cancel func(error)) {
if mapperPanic && v == mapperIdx {
panic("bar")
}
writer.Write(v * v)
}, func(pipe <-chan int64, writer Writer[int64], cancel func(error)) {
var idx int64
var total int64
for v := range pipe {
if reducerPanic && idx == reducerIdx {
panic("baz")
}
total += v
idx++
}
writer.Write(total)
}, WithWorkers(workers%50+runtime.NumCPU()))
}
if genPanic || mapperPanic || reducerPanic {
var buf strings.Builder
buf.WriteString(fmt.Sprintf("n: %d", n))
buf.WriteString(fmt.Sprintf(", genPanic: %t", genPanic))
buf.WriteString(fmt.Sprintf(", mapperPanic: %t", mapperPanic))
buf.WriteString(fmt.Sprintf(", reducerPanic: %t", reducerPanic))
buf.WriteString(fmt.Sprintf(", genIdx: %d", genIdx))
buf.WriteString(fmt.Sprintf(", mapperIdx: %d", mapperIdx))
buf.WriteString(fmt.Sprintf(", reducerIdx: %d", reducerIdx))
assert.Panicsf(t, func() { fn() }, buf.String())
} else {
val, err := fn()
assert.Nil(t, err)
assert.Equal(t, squareSum, val)
}
})
}
================================================
FILE: mapreduce_test.go
================================================
package mapreduce
import (
"context"
"errors"
"io/ioutil"
"log"
"runtime"
"sync/atomic"
"testing"
"time"
"github.com/stretchr/testify/assert"
"go.uber.org/goleak"
)
var errDummy = errors.New("dummy")
func init() {
log.SetOutput(ioutil.Discard)
}
func TestFinish(t *testing.T) {
defer goleak.VerifyNone(t)
var total uint32
err := Finish(func() error {
atomic.AddUint32(&total, 2)
return nil
}, func() error {
atomic.AddUint32(&total, 3)
return nil
}, func() error {
atomic.AddUint32(&total, 5)
return nil
})
assert.Equal(t, uint32(10), atomic.LoadUint32(&total))
assert.Nil(t, err)
}
func TestFinishNone(t *testing.T) {
defer goleak.VerifyNone(t)
assert.Nil(t, Finish())
}
func TestFinishVoidNone(t *testing.T) {
defer goleak.VerifyNone(t)
FinishVoid()
}
func TestFinishErr(t *testing.T) {
defer goleak.VerifyNone(t)
var total uint32
err := Finish(func() error {
atomic.AddUint32(&total, 2)
return nil
}, func() error {
atomic.AddUint32(&total, 3)
return errDummy
}, func() error {
atomic.AddUint32(&total, 5)
return nil
})
assert.Equal(t, errDummy, err)
}
func TestFinishVoid(t *testing.T) {
defer goleak.VerifyNone(t)
var total uint32
FinishVoid(func() {
atomic.AddUint32(&total, 2)
}, func() {
atomic.AddUint32(&total, 3)
}, func() {
atomic.AddUint32(&total, 5)
})
assert.Equal(t, uint32(10), atomic.LoadUint32(&total))
}
func TestForEach(t *testing.T) {
const tasks = 1000
t.Run("all", func(t *testing.T) {
defer goleak.VerifyNone(t)
var count uint32
ForEach(func(source chan<- int) {
for i := 0; i < tasks; i++ {
source <- i
}
}, func(item int) {
atomic.AddUint32(&count, 1)
}, WithWorkers(-1))
assert.Equal(t, tasks, int(count))
})
t.Run("odd", func(t *testing.T) {
defer goleak.VerifyNone(t)
var count uint32
ForEach(func(source chan<- int) {
for i := 0; i < tasks; i++ {
source <- i
}
}, func(item int) {
if item%2 == 0 {
atomic.AddUint32(&count, 1)
}
})
assert.Equal(t, tasks/2, int(count))
})
t.Run("all", func(t *testing.T) {
defer goleak.VerifyNone(t)
assert.PanicsWithValue(t, "foo", func() {
ForEach(func(source chan<- int) {
for i := 0; i < tasks; i++ {
source <- i
}
}, func(item int) {
panic("foo")
})
})
})
}
func TestGeneratePanic(t *testing.T) {
defer goleak.VerifyNone(t)
t.Run("all", func(t *testing.T) {
assert.PanicsWithValue(t, "foo", func() {
ForEach(func(source chan<- int) {
panic("foo")
}, func(item int) {
})
})
})
}
func TestMapperPanic(t *testing.T) {
defer goleak.VerifyNone(t)
const tasks = 1000
var run int32
t.Run("all", func(t *testing.T) {
assert.PanicsWithValue(t, "foo", func() {
_, _ = MapReduce(func(source chan<- int) {
for i := 0; i < tasks; i++ {
source <- i
}
}, func(item int, writer Writer[int], cancel func(error)) {
atomic.AddInt32(&run, 1)
panic("foo")
}, func(pipe <-chan int, writer Writer[int], cancel func(error)) {
})
})
assert.True(t, atomic.LoadInt32(&run) < tasks/2)
})
}
func TestMapReduce(t *testing.T) {
defer goleak.VerifyNone(t)
tests := []struct {
name string
mapper MapperFunc[int, int]
reducer ReducerFunc[int, int]
expectErr error
expectValue int
}{
{
name: "simple",
expectErr: nil,
expectValue: 30,
},
{
name: "cancel with error",
mapper: func(v int, writer Writer[int], cancel func(error)) {
if v%3 == 0 {
cancel(errDummy)
}
writer.Write(v * v)
},
expectErr: errDummy,
},
{
name: "cancel with nil",
mapper: func(v int, writer Writer[int], cancel func(error)) {
if v%3 == 0 {
cancel(nil)
}
writer.Write(v * v)
},
expectErr: ErrCancelWithNil,
},
{
name: "cancel with more",
reducer: func(pipe <-chan int, writer Writer[int], cancel func(error)) {
var result int
for item := range pipe {
result += item
if result > 10 {
cancel(errDummy)
}
}
writer.Write(result)
},
expectErr: errDummy,
},
}
t.Run("MapReduce", func(t *testing.T) {
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if test.mapper == nil {
test.mapper = func(v int, writer Writer[int], cancel func(error)) {
writer.Write(v * v)
}
}
if test.reducer == nil {
test.reducer = func(pipe <-chan int, writer Writer[int], cancel func(error)) {
var result int
for item := range pipe {
result += item
}
writer.Write(result)
}
}
value, err := MapReduce(func(source chan<- int) {
for i := 1; i < 5; i++ {
source <- i
}
}, test.mapper, test.reducer, WithWorkers(runtime.NumCPU()))
assert.Equal(t, test.expectErr, err)
assert.Equal(t, test.expectValue, value)
})
}
})
t.Run("MapReduce", func(t *testing.T) {
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if test.mapper == nil {
test.mapper = func(v int, writer Writer[int], cancel func(error)) {
writer.Write(v * v)
}
}
if test.reducer == nil {
test.reducer = func(pipe <-chan int, writer Writer[int], cancel func(error)) {
var result int
for item := range pipe {
result += item
}
writer.Write(result)
}
}
source := make(chan int)
go func() {
for i := 1; i < 5; i++ {
source <- i
}
close(source)
}()
value, err := MapReduceChan(source, test.mapper, test.reducer, WithWorkers(-1))
assert.Equal(t, test.expectErr, err)
assert.Equal(t, test.expectValue, value)
})
}
})
}
func TestMapReduceWithReduerWriteMoreThanOnce(t *testing.T) {
defer goleak.VerifyNone(t)
assert.Panics(t, func() {
MapReduce(func(source chan<- int) {
for i := 0; i < 10; i++ {
source <- i
}
}, func(item int, writer Writer[int], cancel func(error)) {
writer.Write(item)
}, func(pipe <-chan int, writer Writer[string], cancel func(error)) {
drain(pipe)
writer.Write("one")
writer.Write("two")
})
})
}
func TestMapReduceVoid(t *testing.T) {
defer goleak.VerifyNone(t)
var value uint32
tests := []struct {
name string
mapper MapperFunc[int, int]
reducer VoidReducerFunc[int]
expectValue uint32
expectErr error
}{
{
name: "simple",
expectValue: 30,
expectErr: nil,
},
{
name: "cancel with error",
mapper: func(v int, writer Writer[int], cancel func(error)) {
if v%3 == 0 {
cancel(errDummy)
}
writer.Write(v * v)
},
expectErr: errDummy,
},
{
name: "cancel with nil",
mapper: func(v int, writer Writer[int], cancel func(error)) {
if v%3 == 0 {
cancel(nil)
}
writer.Write(v * v)
},
expectErr: ErrCancelWithNil,
},
{
name: "cancel with more",
reducer: func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
result := atomic.AddUint32(&value, uint32(item))
if result > 10 {
cancel(errDummy)
}
}
},
expectErr: errDummy,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
atomic.StoreUint32(&value, 0)
if test.mapper == nil {
test.mapper = func(v int, writer Writer[int], cancel func(error)) {
writer.Write(v * v)
}
}
if test.reducer == nil {
test.reducer = func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
atomic.AddUint32(&value, uint32(item))
}
}
}
err := MapReduceVoid(func(source chan<- int) {
for i := 1; i < 5; i++ {
source <- i
}
}, test.mapper, test.reducer)
assert.Equal(t, test.expectErr, err)
if err == nil {
assert.Equal(t, test.expectValue, atomic.LoadUint32(&value))
}
})
}
}
func TestMapReduceVoidWithDelay(t *testing.T) {
defer goleak.VerifyNone(t)
var result []int
err := MapReduceVoid(func(source chan<- int) {
source <- 0
source <- 1
}, func(i int, writer Writer[int], cancel func(error)) {
if i == 0 {
time.Sleep(time.Millisecond * 50)
}
writer.Write(i)
}, func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
i := item
result = append(result, i)
}
})
assert.Nil(t, err)
assert.Equal(t, 2, len(result))
assert.Equal(t, 1, result[0])
assert.Equal(t, 0, result[1])
}
func TestMapReducePanic(t *testing.T) {
defer goleak.VerifyNone(t)
assert.Panics(t, func() {
_, _ = MapReduce(func(source chan<- int) {
source <- 0
source <- 1
}, func(i int, writer Writer[int], cancel func(error)) {
writer.Write(i)
}, func(pipe <-chan int, writer Writer[int], cancel func(error)) {
for range pipe {
panic("panic")
}
})
})
}
func TestMapReducePanicOnce(t *testing.T) {
defer goleak.VerifyNone(t)
assert.Panics(t, func() {
_, _ = MapReduce(func(source chan<- int) {
for i := 0; i < 100; i++ {
source <- i
}
}, func(i int, writer Writer[int], cancel func(error)) {
if i == 0 {
panic("foo")
}
writer.Write(i)
}, func(pipe <-chan int, writer Writer[int], cancel func(error)) {
for range pipe {
panic("bar")
}
})
})
}
func TestMapReducePanicBothMapperAndReducer(t *testing.T) {
defer goleak.VerifyNone(t)
assert.Panics(t, func() {
_, _ = MapReduce(func(source chan<- int) {
source <- 0
source <- 1
}, func(item int, writer Writer[int], cancel func(error)) {
panic("foo")
}, func(pipe <-chan int, writer Writer[int], cancel func(error)) {
panic("bar")
})
})
}
func TestMapReduceVoidCancel(t *testing.T) {
defer goleak.VerifyNone(t)
var result []int
err := MapReduceVoid(func(source chan<- int) {
source <- 0
source <- 1
}, func(i int, writer Writer[int], cancel func(error)) {
if i == 1 {
cancel(errors.New("anything"))
}
writer.Write(i)
}, func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
i := item
result = append(result, i)
}
})
assert.NotNil(t, err)
assert.Equal(t, "anything", err.Error())
}
func TestMapReduceVoidCancelWithRemains(t *testing.T) {
defer goleak.VerifyNone(t)
var done int32
var result []int
err := MapReduceVoid(func(source chan<- int) {
for i := 0; i < defaultWorkers*2; i++ {
source <- i
}
atomic.AddInt32(&done, 1)
}, func(i int, writer Writer[int], cancel func(error)) {
if i == defaultWorkers/2 {
cancel(errors.New("anything"))
}
writer.Write(i)
}, func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
result = append(result, item)
}
})
assert.NotNil(t, err)
assert.Equal(t, "anything", err.Error())
assert.Equal(t, int32(1), done)
}
func TestMapReduceWithoutReducerWrite(t *testing.T) {
defer goleak.VerifyNone(t)
uids := []int{1, 2, 3}
res, err := MapReduce(func(source chan<- int) {
for _, uid := range uids {
source <- uid
}
}, func(item int, writer Writer[int], cancel func(error)) {
writer.Write(item)
}, func(pipe <-chan int, writer Writer[int], cancel func(error)) {
drain(pipe)
// not calling writer.Write(...), should not panic
})
assert.Equal(t, ErrReduceNoOutput, err)
assert.Equal(t, 0, res)
}
func TestMapReduceVoidPanicInReducer(t *testing.T) {
defer goleak.VerifyNone(t)
const message = "foo"
assert.Panics(t, func() {
var done int32
_ = MapReduceVoid(func(source chan<- int) {
for i := 0; i < defaultWorkers*2; i++ {
source <- i
}
atomic.AddInt32(&done, 1)
}, func(i int, writer Writer[int], cancel func(error)) {
writer.Write(i)
}, func(pipe <-chan int, cancel func(error)) {
panic(message)
}, WithWorkers(1))
})
}
func TestForEachWithContext(t *testing.T) {
defer goleak.VerifyNone(t)
var done int32
ctx, cancel := context.WithCancel(context.Background())
ForEach(func(source chan<- int) {
for i := 0; i < defaultWorkers*2; i++ {
source <- i
}
atomic.AddInt32(&done, 1)
}, func(i int) {
if i == defaultWorkers/2 {
cancel()
}
}, WithContext(ctx))
}
func TestMapReduceWithContext(t *testing.T) {
defer goleak.VerifyNone(t)
var done int32
var result []int
ctx, cancel := context.WithCancel(context.Background())
err := MapReduceVoid(func(source chan<- int) {
for i := 0; i < defaultWorkers*2; i++ {
source <- i
}
atomic.AddInt32(&done, 1)
}, func(i int, writer Writer[int], c func(error)) {
if i == defaultWorkers/2 {
cancel()
}
writer.Write(i)
}, func(pipe <-chan int, cancel func(error)) {
for item := range pipe {
i := item
result = append(result, i)
}
}, WithContext(ctx))
assert.NotNil(t, err)
assert.Equal(t, context.DeadlineExceeded, err)
}
func BenchmarkMapReduce(b *testing.B) {
b.ReportAllocs()
mapper := func(v int64, writer Writer[int64], cancel func(error)) {
writer.Write(v * v)
}
reducer := func(input <-chan int64, writer Writer[int64], cancel func(error)) {
var result int64
for v := range input {
result += v
}
writer.Write(result)
}
for i := 0; i < b.N; i++ {
MapReduce(func(input chan<- int64) {
for j := 0; j < 2; j++ {
input <- int64(j)
}
}, mapper, reducer)
}
}
================================================
FILE: readme-cn.md
================================================
# mapreduce
[English](readme.md) | 简体中文
[](https://github.com/kevwan/mapreduce/actions)
[](https://codecov.io/gh/kevwan/mapreduce)
[](https://goreportcard.com/report/github.com/kevwan/mapreduce)
[](https://github.com/kevwan/mapreduce)
[](https://opensource.org/licenses/MIT)
## 为什么会有这个项目
`mapreduce` 其实是 [go-zero](https://github.com/zeromicro/go-zero) 的一部分,但是一些用户问我是不是可以单独使用 `mapreduce` 而不用引入 `go-zero` 的依赖,所以我考虑再三,还是单独提供一个吧。但是,我强烈推荐你使用 `go-zero`,因为 `go-zero` 真的提供了很多很好的功能。
## 为什么需要 MapReduce
在实际的业务场景中我们常常需要从不同的 rpc 服务中获取相应属性来组装成复杂对象。
比如要查询商品详情:
1. 商品服务-查询商品属性
2. 库存服务-查询库存属性
3. 价格服务-查询价格属性
4. 营销服务-查询营销属性
如果是串行调用的话响应时间会随着 rpc 调用次数呈线性增长,所以我们要优化性能一般会将串行改并行。
简单的场景下使用 waitGroup 也能够满足需求,但是如果我们需要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总呢?继续使用 waitGroup 就有点力不从心了,go 的官方库中并没有这种工具(java 中提供了 CompleteFuture),go-zero 作者依据 mapReduce 架构思想实现了进程内的数据批处理 mapReduce 并发工具类。
## 设计思路
我们尝试梳理一下并发工具可能的示例业务场景:
1. 查询商品详情:支持并发调用多个服务来组合产品属性,支持调用错误可以立即结束。
2. 商品详情页自动推荐用户卡券:支持并发校验卡券,校验失败自动剔除,返回全部卡券。
以上实际都是在进行对输入数据进行处理最后输出清洗后的数据,针对数据处理有个非常经典的异步模式:生产者消费者模式。于是我们可以抽象一下数据批处理的生命周期,大致可以分为三个阶段:
 1. 数据生产 generate
2. 数据加工 mapper
3. 数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。
再来思考一下不同阶段之间数据应该如何流转,既然不同阶段的数据处理都是由不同 goroutine 执行的,那么很自然的可以考虑采用 channel 来实现 goroutine 之间的通信。
1. 数据生产 generate
2. 数据加工 mapper
3. 数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。
再来思考一下不同阶段之间数据应该如何流转,既然不同阶段的数据处理都是由不同 goroutine 执行的,那么很自然的可以考虑采用 channel 来实现 goroutine 之间的通信。
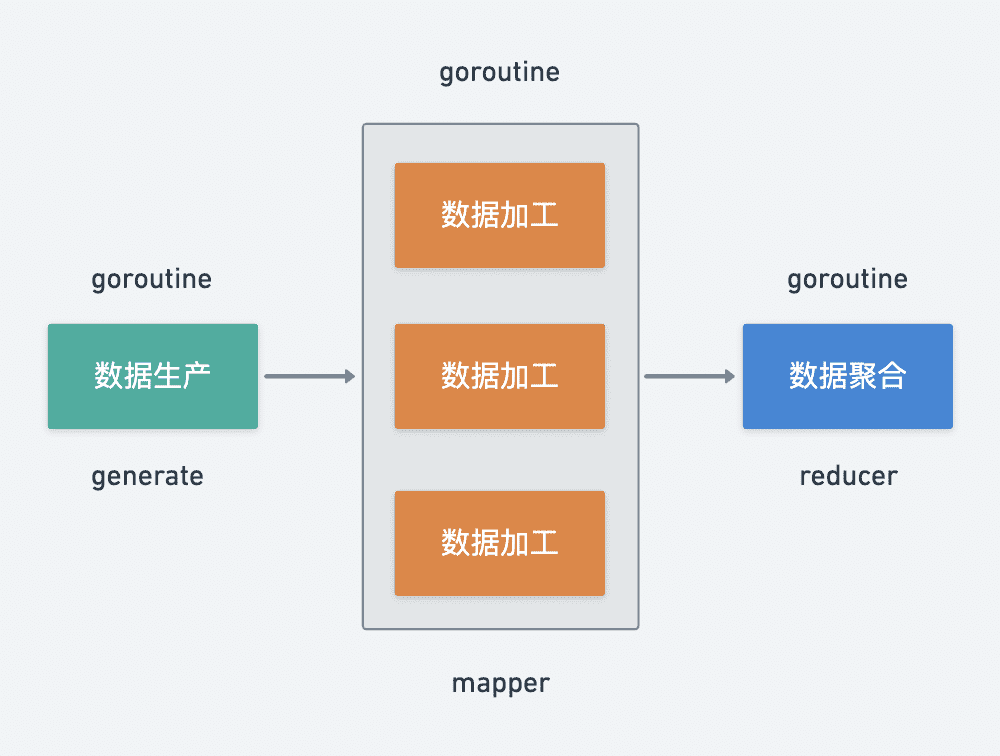 如何实现随时终止流程呢?
`goroutine` 中监听一个全局的结束 `channel` 和调用方提供的 `ctx` 就行。
## 版本选择
- `v1`(默认)- 非泛型版本
- `v2`(泛型版)- 泛型版本,需要 Go 版本 >= 1.18
## 简单示例
并行求平方和(不要嫌弃示例简单,只是模拟并发)
```go
package main
import (
"fmt"
"log"
"github.com/kevwan/mapreduce/v2"
)
func main() {
val, err := mapreduce.MapReduce(func(source chan<- int) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(i int, writer mapreduce.Writer[int], cancel func(error)) {
// mapper
writer.Write(i * i)
}, func(pipe <-chan int, writer mapreduce.Writer[int], cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
更多示例:[https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## 强烈推荐!
go-zero: [https://github.com/zeromicro/go-zero](https://github.com/zeromicro/go-zero)
## 欢迎 star!⭐
如果你正在使用或者觉得这个项目对你有帮助,请 **star** 支持,感谢!
================================================
FILE: readme.md
================================================
如何实现随时终止流程呢?
`goroutine` 中监听一个全局的结束 `channel` 和调用方提供的 `ctx` 就行。
## 版本选择
- `v1`(默认)- 非泛型版本
- `v2`(泛型版)- 泛型版本,需要 Go 版本 >= 1.18
## 简单示例
并行求平方和(不要嫌弃示例简单,只是模拟并发)
```go
package main
import (
"fmt"
"log"
"github.com/kevwan/mapreduce/v2"
)
func main() {
val, err := mapreduce.MapReduce(func(source chan<- int) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(i int, writer mapreduce.Writer[int], cancel func(error)) {
// mapper
writer.Write(i * i)
}, func(pipe <-chan int, writer mapreduce.Writer[int], cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
更多示例:[https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## 强烈推荐!
go-zero: [https://github.com/zeromicro/go-zero](https://github.com/zeromicro/go-zero)
## 欢迎 star!⭐
如果你正在使用或者觉得这个项目对你有帮助,请 **star** 支持,感谢!
================================================
FILE: readme.md
================================================
 # mapreduce
English | [简体中文](readme-cn.md)
[](https://github.com/kevwan/mapreduce/actions)
[](https://codecov.io/gh/kevwan/mapreduce)
[](https://goreportcard.com/report/github.com/kevwan/mapreduce)
[](https://github.com/kevwan/mapreduce)
[](https://opensource.org/licenses/MIT)
## Why we have this repo
`mapreduce` is part of [go-zero](https://github.com/zeromicro/go-zero), but a few people asked if mapreduce can be used separately. But I recommend you to use `go-zero` for many more features.
## Why MapReduce is needed
In practical business scenarios we often need to get the corresponding properties from different rpc services to assemble complex objects.
For example, to query product details.
1. product service - query product attributes
2. inventory service - query inventory properties
3. price service - query price attributes
4. marketing service - query marketing properties
If it is a serial call, the response time will increase linearly with the number of rpc calls, so we will generally change serial to parallel to optimize response time.
Simple scenarios using `WaitGroup` can also meet the needs, but what if we need to check the data returned by the rpc call, data processing, data aggregation? The official go library does not have such a tool (CompleteFuture is provided in java), so we implemented an in-process data batching MapReduce concurrent tool based on the MapReduce architecture.
## Design ideas
Let's sort out the possible business scenarios for the concurrency tool:
1. querying product details: supporting concurrent calls to multiple services to combine product attributes, and supporting call errors that can be ended immediately.
2. automatic recommendation of user card coupons on product details page: support concurrently verifying card coupons, automatically rejecting them if they fail, and returning all of them.
The above is actually processing the input data and finally outputting the cleaned data. There is a very classic asynchronous pattern for data processing: the producer-consumer pattern. So we can abstract the life cycle of data batch processing, which can be roughly divided into three phases.
# mapreduce
English | [简体中文](readme-cn.md)
[](https://github.com/kevwan/mapreduce/actions)
[](https://codecov.io/gh/kevwan/mapreduce)
[](https://goreportcard.com/report/github.com/kevwan/mapreduce)
[](https://github.com/kevwan/mapreduce)
[](https://opensource.org/licenses/MIT)
## Why we have this repo
`mapreduce` is part of [go-zero](https://github.com/zeromicro/go-zero), but a few people asked if mapreduce can be used separately. But I recommend you to use `go-zero` for many more features.
## Why MapReduce is needed
In practical business scenarios we often need to get the corresponding properties from different rpc services to assemble complex objects.
For example, to query product details.
1. product service - query product attributes
2. inventory service - query inventory properties
3. price service - query price attributes
4. marketing service - query marketing properties
If it is a serial call, the response time will increase linearly with the number of rpc calls, so we will generally change serial to parallel to optimize response time.
Simple scenarios using `WaitGroup` can also meet the needs, but what if we need to check the data returned by the rpc call, data processing, data aggregation? The official go library does not have such a tool (CompleteFuture is provided in java), so we implemented an in-process data batching MapReduce concurrent tool based on the MapReduce architecture.
## Design ideas
Let's sort out the possible business scenarios for the concurrency tool:
1. querying product details: supporting concurrent calls to multiple services to combine product attributes, and supporting call errors that can be ended immediately.
2. automatic recommendation of user card coupons on product details page: support concurrently verifying card coupons, automatically rejecting them if they fail, and returning all of them.
The above is actually processing the input data and finally outputting the cleaned data. There is a very classic asynchronous pattern for data processing: the producer-consumer pattern. So we can abstract the life cycle of data batch processing, which can be roughly divided into three phases.
 1. data production generate
2. data processing mapper
3. data aggregation reducer
Data producing is an indispensable stage, data processing and data aggregation are optional stages, data producing and processing support concurrent calls, data aggregation is basically a pure memory operation, so a single concurrent process can do it.
Since different stages of data processing are performed by different goroutines, it is natural to consider the use of channel to achieve communication between goroutines.
1. data production generate
2. data processing mapper
3. data aggregation reducer
Data producing is an indispensable stage, data processing and data aggregation are optional stages, data producing and processing support concurrent calls, data aggregation is basically a pure memory operation, so a single concurrent process can do it.
Since different stages of data processing are performed by different goroutines, it is natural to consider the use of channel to achieve communication between goroutines.
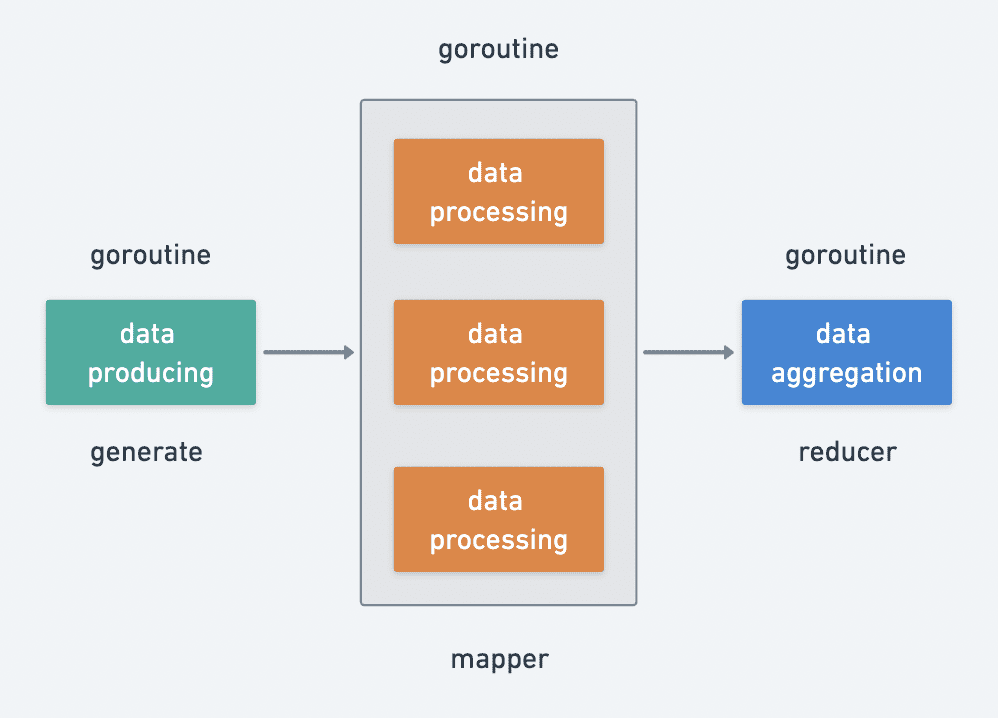 How can I terminate the process at any time?
It's simple, just receive from a channel or the given context in the goroutine.
## Choose the right version
- `v1` (default) - non-generic version
- `v2` (generics) - generic version, needs Go version >= 1.18
## A simple example
Calculate the sum of squares, simulating the concurrency.
```go
package main
import (
"fmt"
"log"
"github.com/kevwan/mapreduce/v2"
)
func main() {
val, err := mapreduce.MapReduce(func(source chan<- int) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(i int, writer mapreduce.Writer[int], cancel func(error)) {
// mapper
writer.Write(i * i)
}, func(pipe <-chan int, writer mapreduce.Writer[int], cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
More examples: [https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## References
go-zero: [https://github.com/zeromicro/go-zero](https://github.com/zeromicro/go-zero)
## Give a Star! ⭐
If you like or are using this project to learn or start your solution, please give it a star. Thanks!
How can I terminate the process at any time?
It's simple, just receive from a channel or the given context in the goroutine.
## Choose the right version
- `v1` (default) - non-generic version
- `v2` (generics) - generic version, needs Go version >= 1.18
## A simple example
Calculate the sum of squares, simulating the concurrency.
```go
package main
import (
"fmt"
"log"
"github.com/kevwan/mapreduce/v2"
)
func main() {
val, err := mapreduce.MapReduce(func(source chan<- int) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(i int, writer mapreduce.Writer[int], cancel func(error)) {
// mapper
writer.Write(i * i)
}, func(pipe <-chan int, writer mapreduce.Writer[int], cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
More examples: [https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## References
go-zero: [https://github.com/zeromicro/go-zero](https://github.com/zeromicro/go-zero)
## Give a Star! ⭐
If you like or are using this project to learn or start your solution, please give it a star. Thanks!