Copy disabled (too large)
Download .txt
Showing preview only (13,057K chars total). Download the full file to get everything.
Repository: kvcache-ai/ktransformers
Branch: main
Commit: 8561a71dd11e
Files: 1146
Total size: 12.2 MB
Directory structure:
gitextract_0e22n38f/
├── .github/
│ ├── CODE_OF_CONDUCT.md
│ ├── CONTRIBUTING.md
│ ├── ISSUE_TEMPLATE/
│ │ ├── -bug-.yaml
│ │ ├── -feature-.yaml
│ │ └── config.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ ├── SECURITY.md
│ └── workflows/
│ ├── book-ci.yml
│ ├── deploy.yml
│ ├── docker-image.yml
│ ├── kt-kernel-tests.yml
│ ├── release-fake-tag.yml
│ ├── release-pypi.yml
│ ├── release-sglang-kt.yml
│ └── sync-sglang-submodule.yml
├── .gitignore
├── .gitmodules
├── LICENSE
├── MAINTAINERS.md
├── README.md
├── README_ZH.md
├── archive/
│ ├── .devcontainer/
│ │ ├── Dockerfile
│ │ └── devcontainer.json
│ ├── .flake8
│ ├── .gitmodules
│ ├── .pylintrc
│ ├── Dockerfile
│ ├── Dockerfile.xpu
│ ├── LICENSE
│ ├── MANIFEST.in
│ ├── Makefile
│ ├── README.md
│ ├── README_LEGACY.md
│ ├── README_ZH.md
│ ├── README_ZH_LEGACY.md
│ ├── SECURITY.md
│ ├── book.toml
│ ├── config.json
│ ├── csrc/
│ │ ├── balance_serve/
│ │ │ └── CMakeLists.txt
│ │ ├── custom_marlin/
│ │ │ ├── __init__.py
│ │ │ ├── binding.cpp
│ │ │ ├── gptq_marlin/
│ │ │ │ ├── gptq_marlin.cu
│ │ │ │ ├── gptq_marlin.cuh
│ │ │ │ ├── gptq_marlin_dtypes.cuh
│ │ │ │ ├── gptq_marlin_repack.cu
│ │ │ │ └── ops.h
│ │ │ ├── setup.py
│ │ │ ├── test_cuda_graph.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── format24.py
│ │ │ ├── marlin_24_perms.py
│ │ │ ├── marlin_perms.py
│ │ │ ├── marlin_utils.py
│ │ │ └── quant_utils.py
│ │ └── ktransformers_ext/
│ │ ├── CMakeLists.txt
│ │ ├── bench/
│ │ │ ├── bench_attention.py
│ │ │ ├── bench_attention_torch.py
│ │ │ ├── bench_linear.py
│ │ │ ├── bench_linear_torch.py
│ │ │ ├── bench_mlp.py
│ │ │ ├── bench_mlp_torch.py
│ │ │ ├── bench_moe.py
│ │ │ ├── bench_moe_amx.py
│ │ │ └── bench_moe_torch.py
│ │ ├── cmake/
│ │ │ └── FindSIMD.cmake
│ │ ├── cpu_backend/
│ │ │ ├── backend.cpp
│ │ │ ├── backend.h
│ │ │ ├── cpuinfer.h
│ │ │ ├── shared_mem_buffer.cpp
│ │ │ ├── shared_mem_buffer.h
│ │ │ ├── task_queue.cpp
│ │ │ ├── task_queue.h
│ │ │ └── vendors/
│ │ │ ├── README.md
│ │ │ ├── cuda.h
│ │ │ ├── hip.h
│ │ │ ├── musa.h
│ │ │ └── vendor.h
│ │ ├── cuda/
│ │ │ ├── binding.cpp
│ │ │ ├── custom_gguf/
│ │ │ │ ├── dequant.cu
│ │ │ │ └── ops.h
│ │ │ ├── gptq_marlin/
│ │ │ │ ├── gptq_marlin.cu
│ │ │ │ ├── gptq_marlin.cuh
│ │ │ │ ├── gptq_marlin_dtypes.cuh
│ │ │ │ └── ops.h
│ │ │ ├── setup.py
│ │ │ └── test_dequant.py
│ │ ├── examples/
│ │ │ ├── test_attention.py
│ │ │ ├── test_linear.py
│ │ │ ├── test_mlp.py
│ │ │ └── test_moe.py
│ │ ├── ext_bindings.cpp
│ │ ├── operators/
│ │ │ ├── amx/
│ │ │ │ ├── la/
│ │ │ │ │ ├── amx.hpp
│ │ │ │ │ └── utils.hpp
│ │ │ │ └── moe.hpp
│ │ │ ├── kvcache/
│ │ │ │ ├── kvcache.h
│ │ │ │ ├── kvcache_attn.cpp
│ │ │ │ ├── kvcache_load_dump.cpp
│ │ │ │ ├── kvcache_read_write.cpp
│ │ │ │ └── kvcache_utils.cpp
│ │ │ └── llamafile/
│ │ │ ├── conversion.h
│ │ │ ├── linear.cpp
│ │ │ ├── linear.h
│ │ │ ├── mlp.cpp
│ │ │ ├── mlp.h
│ │ │ ├── moe.cpp
│ │ │ └── moe.h
│ │ └── vendors/
│ │ ├── cuda.h
│ │ ├── hip.h
│ │ ├── musa.h
│ │ └── vendor.h
│ ├── install-with-cache.sh
│ ├── install.bat
│ ├── install.sh
│ ├── ktransformers/
│ │ ├── __init__.py
│ │ ├── configs/
│ │ │ ├── config.yaml
│ │ │ └── log_config.ini
│ │ ├── ktransformers_ext/
│ │ │ ├── operators/
│ │ │ │ └── custom_marlin/
│ │ │ │ └── quantize/
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── format_24.py
│ │ │ │ ├── marlin_24_perms.py
│ │ │ │ ├── marlin_perms.py
│ │ │ │ ├── marlin_utils.py
│ │ │ │ └── quant_utils.py
│ │ │ └── triton/
│ │ │ └── fp8gemm.py
│ │ ├── local_chat.py
│ │ ├── local_chat_test.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── ascend/
│ │ │ │ ├── custom_ascend_modeling_deepseek_v3.py
│ │ │ │ └── custom_ascend_modeling_qwen3.py
│ │ │ ├── configuration_deepseek.py
│ │ │ ├── configuration_deepseek_v3.py
│ │ │ ├── configuration_glm4_moe.py
│ │ │ ├── configuration_llama.py
│ │ │ ├── configuration_qwen2_moe.py
│ │ │ ├── configuration_qwen3_moe.py
│ │ │ ├── configuration_qwen3_next.py
│ │ │ ├── configuration_smallthinker.py
│ │ │ ├── custom_cache.py
│ │ │ ├── custom_modeling_deepseek_v2.py
│ │ │ ├── custom_modeling_deepseek_v3.py
│ │ │ ├── custom_modeling_glm4_moe.py
│ │ │ ├── custom_modeling_qwen2_moe.py
│ │ │ ├── custom_modeling_qwen3_moe.py
│ │ │ ├── custom_modeling_qwen3_next.py
│ │ │ ├── custom_modeling_smallthinker.py
│ │ │ ├── modeling_deepseek.py
│ │ │ ├── modeling_deepseek_v3.py
│ │ │ ├── modeling_glm4_moe.py
│ │ │ ├── modeling_llama.py
│ │ │ ├── modeling_mixtral.py
│ │ │ ├── modeling_qwen2_moe.py
│ │ │ ├── modeling_qwen3_moe.py
│ │ │ ├── modeling_qwen3_next.py
│ │ │ └── modeling_smallthinker.py
│ │ ├── operators/
│ │ │ ├── RoPE.py
│ │ │ ├── __init__.py
│ │ │ ├── ascend/
│ │ │ │ ├── ascend_attention.py
│ │ │ │ ├── ascend_experts.py
│ │ │ │ ├── ascend_gate.py
│ │ │ │ ├── ascend_layernorm.py
│ │ │ │ ├── ascend_linear.py
│ │ │ │ └── ascend_mlp.py
│ │ │ ├── attention.py
│ │ │ ├── balance_serve_attention.py
│ │ │ ├── base_operator.py
│ │ │ ├── cpuinfer.py
│ │ │ ├── dynamic_attention.py
│ │ │ ├── experts.py
│ │ │ ├── flashinfer_batch_prefill_wrapper.py
│ │ │ ├── flashinfer_wrapper.py
│ │ │ ├── gate.py
│ │ │ ├── layernorm.py
│ │ │ ├── linear.py
│ │ │ ├── mlp.py
│ │ │ ├── models.py
│ │ │ ├── triton_attention.py
│ │ │ └── triton_attention_prefill.py
│ │ ├── optimize/
│ │ │ ├── optimize.py
│ │ │ └── optimize_rules/
│ │ │ ├── DeepSeek-V2-Chat-multi-gpu-4.yaml
│ │ │ ├── DeepSeek-V2-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V2-Chat.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-gpu-cpu.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat.yaml
│ │ │ ├── DeepSeek-V3-Chat-amx.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve-amx.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-4.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-8.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-fp8-linear-ggml-experts.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-marlin.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V3-Chat-npu.yaml
│ │ │ ├── DeepSeek-V3-Chat-serve.yaml
│ │ │ ├── DeepSeek-V3-Chat.yaml
│ │ │ ├── Glm4Moe-serve.yaml
│ │ │ ├── Internlm2_5-7b-Chat-1m.yaml
│ │ │ ├── Mixtral.yaml
│ │ │ ├── Moonlight-16B-A3B-serve.yaml
│ │ │ ├── Moonlight-16B-A3B.yaml
│ │ │ ├── Qwen2-57B-A14B-Instruct-multi-gpu.yaml
│ │ │ ├── Qwen2-57B-A14B-Instruct.yaml
│ │ │ ├── Qwen2-serve-amx.yaml
│ │ │ ├── Qwen2-serve.yaml
│ │ │ ├── Qwen3Moe-serve-amx.yaml
│ │ │ ├── Qwen3Moe-serve.yaml
│ │ │ ├── Qwen3Next-serve.yaml
│ │ │ ├── Smallthinker-serve.yaml
│ │ │ ├── npu/
│ │ │ │ ├── DeepSeek-V3-Chat-300IA2-npu-serve.yaml
│ │ │ │ ├── DeepSeek-V3-Chat-300IA2-npu.yaml
│ │ │ │ └── Qwen3-Chat-300IA2-npu-serve.yaml
│ │ │ ├── rocm/
│ │ │ │ └── DeepSeek-V3-Chat.yaml
│ │ │ └── xpu/
│ │ │ ├── DeepSeek-V2-Chat.yaml
│ │ │ ├── DeepSeek-V3-Chat.yaml
│ │ │ └── Qwen3Moe-Chat.yaml
│ │ ├── server/
│ │ │ ├── __init__.py
│ │ │ ├── api/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── ollama/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── completions.py
│ │ │ │ ├── openai/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── assistants/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── assistants.py
│ │ │ │ │ │ ├── messages.py
│ │ │ │ │ │ ├── runs.py
│ │ │ │ │ │ └── threads.py
│ │ │ │ │ ├── endpoints/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ └── chat.py
│ │ │ │ │ └── legacy/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── completions.py
│ │ │ │ └── web/
│ │ │ │ ├── __init__.py
│ │ │ │ └── system.py
│ │ │ ├── args.py
│ │ │ ├── backend/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── base.py
│ │ │ │ ├── context_manager.py
│ │ │ │ └── interfaces/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── balance_serve.py
│ │ │ │ ├── exllamav2.py
│ │ │ │ ├── ktransformers.py
│ │ │ │ └── transformers.py
│ │ │ ├── balance_serve/
│ │ │ │ ├── inference/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── config.py
│ │ │ │ │ ├── distributed/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── communication_op.py
│ │ │ │ │ │ ├── cuda_wrapper.py
│ │ │ │ │ │ ├── custom_all_reduce.py
│ │ │ │ │ │ ├── custom_all_reduce_utils.py
│ │ │ │ │ │ ├── parallel_state.py
│ │ │ │ │ │ ├── pynccl.py
│ │ │ │ │ │ ├── pynccl_wrapper.py
│ │ │ │ │ │ └── utils.py
│ │ │ │ │ ├── forward_batch.py
│ │ │ │ │ ├── model_runner.py
│ │ │ │ │ ├── query_manager.py
│ │ │ │ │ └── sampling/
│ │ │ │ │ ├── penaltylib/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── orchestrator.py
│ │ │ │ │ │ └── penalizers/
│ │ │ │ │ │ ├── frequency_penalty.py
│ │ │ │ │ │ ├── min_new_tokens.py
│ │ │ │ │ │ ├── presence_penalty.py
│ │ │ │ │ │ └── repetition_penalty.py
│ │ │ │ │ └── sampler.py
│ │ │ │ ├── sched_rpc.py
│ │ │ │ └── settings.py
│ │ │ ├── config/
│ │ │ │ ├── config.py
│ │ │ │ ├── log.py
│ │ │ │ └── singleton.py
│ │ │ ├── crud/
│ │ │ │ ├── __init__.py
│ │ │ │ └── assistants/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants.py
│ │ │ │ ├── messages.py
│ │ │ │ ├── runs.py
│ │ │ │ └── threads.py
│ │ │ ├── exceptions.py
│ │ │ ├── main.py
│ │ │ ├── models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── assistants/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants.py
│ │ │ │ ├── messages.py
│ │ │ │ ├── run_steps.py
│ │ │ │ ├── runs.py
│ │ │ │ └── threads.py
│ │ │ ├── requirements.txt
│ │ │ ├── schemas/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── assistants.py
│ │ │ │ │ ├── messages.py
│ │ │ │ │ ├── runs.py
│ │ │ │ │ ├── streaming.py
│ │ │ │ │ ├── threads.py
│ │ │ │ │ └── tool.py
│ │ │ │ ├── base.py
│ │ │ │ ├── conversation.py
│ │ │ │ ├── endpoints/
│ │ │ │ │ └── chat.py
│ │ │ │ └── legacy/
│ │ │ │ ├── __init__.py
│ │ │ │ └── completions.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── create_interface.py
│ │ │ ├── multi_timer.py
│ │ │ ├── serve_profiling.py
│ │ │ └── sql_utils.py
│ │ ├── tests/
│ │ │ ├── .gitignore
│ │ │ ├── AIME_2024/
│ │ │ │ ├── eval_api.py
│ │ │ │ ├── evaluation.py
│ │ │ │ └── prompts.py
│ │ │ ├── UT/
│ │ │ │ ├── test_kdeepseek_attention_w8a8a2serve_npu.py
│ │ │ │ └── test_kdeepseek_ln_npu.py
│ │ │ ├── dequant_gpu.py
│ │ │ ├── dequant_gpu_t.py
│ │ │ ├── function_call_test.py
│ │ │ ├── humaneval/
│ │ │ │ ├── eval_api.py
│ │ │ │ ├── evaluation.py
│ │ │ │ └── prompts.py
│ │ │ ├── mmlu_pro_test.py
│ │ │ ├── mmlu_test.py
│ │ │ ├── mmlu_test_multi.py
│ │ │ ├── parse_cover_info.py
│ │ │ ├── score.py
│ │ │ ├── test_client.py
│ │ │ ├── test_prefix.py
│ │ │ ├── test_pytorch_q8.py
│ │ │ ├── test_speed.py
│ │ │ └── triton_fp8gemm_test.py
│ │ ├── util/
│ │ │ ├── ascend/
│ │ │ │ └── ascend_utils.py
│ │ │ ├── cuda_graph_runner.py
│ │ │ ├── custom_gguf.py
│ │ │ ├── custom_loader.py
│ │ │ ├── modeling_rope_utils.py
│ │ │ ├── npu_graph_runner.py
│ │ │ ├── textstream.py
│ │ │ ├── utils.py
│ │ │ ├── vendors.py
│ │ │ └── weight_loader.py
│ │ └── website/
│ │ ├── .browserslistrc
│ │ ├── .eslintrc.js
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── config.d.ts
│ │ ├── jest.config.js
│ │ ├── package.json
│ │ ├── public/
│ │ │ ├── config.js
│ │ │ ├── css/
│ │ │ │ └── reset.css
│ │ │ └── index.html
│ │ ├── src/
│ │ │ ├── App.vue
│ │ │ ├── api/
│ │ │ │ ├── api-client.ts
│ │ │ │ ├── assistant.ts
│ │ │ │ ├── message.ts
│ │ │ │ ├── run.ts
│ │ │ │ └── thread.ts
│ │ │ ├── assets/
│ │ │ │ ├── css/
│ │ │ │ │ └── mixins.styl
│ │ │ │ └── iconfont/
│ │ │ │ ├── demo.css
│ │ │ │ ├── demo_index.html
│ │ │ │ ├── iconfont.css
│ │ │ │ ├── iconfont.js
│ │ │ │ └── iconfont.json
│ │ │ ├── components/
│ │ │ │ └── chat/
│ │ │ │ └── index.vue
│ │ │ ├── conf/
│ │ │ │ └── config.ts
│ │ │ ├── locals/
│ │ │ │ ├── en.js
│ │ │ │ ├── index.js
│ │ │ │ └── zh.js
│ │ │ ├── main.ts
│ │ │ ├── router/
│ │ │ │ └── index.ts
│ │ │ ├── shims-vue.d.ts
│ │ │ ├── store/
│ │ │ │ └── index.ts
│ │ │ ├── utils/
│ │ │ │ ├── copy.ts
│ │ │ │ └── types.ts
│ │ │ └── views/
│ │ │ └── home.vue
│ │ ├── tests/
│ │ │ └── unit/
│ │ │ └── example.spec.ts
│ │ ├── tsconfig.json
│ │ └── vue.config.js
│ ├── merge_tensors/
│ │ ├── merge_safetensor_gguf.py
│ │ └── merge_safetensor_gguf_for_qwen3.py
│ ├── pyproject.toml
│ ├── requirements-local_chat.txt
│ ├── setup.py
│ └── third_party/
│ ├── llamafile/
│ │ ├── README.md
│ │ ├── bench.h
│ │ ├── flags.cpp
│ │ ├── flags.h
│ │ ├── iqk_mul_mat.inc
│ │ ├── iqk_mul_mat_amd_avx2.cpp
│ │ ├── iqk_mul_mat_amd_zen4.cpp
│ │ ├── iqk_mul_mat_arm.inc
│ │ ├── iqk_mul_mat_arm82.cpp
│ │ ├── iqk_mul_mat_x86.inc
│ │ ├── macros.h
│ │ ├── micros.h
│ │ ├── numba.h
│ │ ├── sgemm.cpp
│ │ ├── sgemm.h
│ │ ├── sgemm_arm.cpp
│ │ ├── sgemm_x86.cpp
│ │ ├── tinyblas_cpu.h
│ │ ├── tinyblas_cpu_mixmul.inc
│ │ ├── tinyblas_cpu_mixmul_amd_avx.cpp
│ │ ├── tinyblas_cpu_mixmul_amd_avx2.cpp
│ │ ├── tinyblas_cpu_mixmul_amd_avx512f.cpp
│ │ ├── tinyblas_cpu_mixmul_amd_avxvnni.cpp
│ │ ├── tinyblas_cpu_mixmul_amd_fma.cpp
│ │ ├── tinyblas_cpu_mixmul_amd_zen4.cpp
│ │ ├── tinyblas_cpu_mixmul_arm80.cpp
│ │ ├── tinyblas_cpu_mixmul_arm82.cpp
│ │ ├── tinyblas_cpu_sgemm.inc
│ │ ├── tinyblas_cpu_sgemm_amd_avx.cpp
│ │ ├── tinyblas_cpu_sgemm_amd_avx2.cpp
│ │ ├── tinyblas_cpu_sgemm_amd_avx512f.cpp
│ │ ├── tinyblas_cpu_sgemm_amd_avxvnni.cpp
│ │ ├── tinyblas_cpu_sgemm_amd_fma.cpp
│ │ ├── tinyblas_cpu_sgemm_amd_zen4.cpp
│ │ ├── tinyblas_cpu_sgemm_arm.inc
│ │ ├── tinyblas_cpu_sgemm_arm80.cpp
│ │ ├── tinyblas_cpu_sgemm_arm82.cpp
│ │ ├── tinyblas_cpu_sgemm_x86.inc
│ │ └── tinyblas_cpu_unsupported.cpp
│ └── nlohmann/
│ ├── json.hpp
│ └── json_fwd.hpp
├── book.toml
├── doc/
│ ├── SUMMARY.md
│ ├── basic/
│ │ ├── note1.md
│ │ └── note2.md
│ ├── en/
│ │ ├── AMX.md
│ │ ├── DeepseekR1_V3_tutorial.md
│ │ ├── Docker.md
│ │ ├── Docker_xpu.md
│ │ ├── FAQ.md
│ │ ├── Kimi-K2-Thinking.md
│ │ ├── Kimi-K2.5.md
│ │ ├── Kimi-K2.md
│ │ ├── Kllama_tutorial_DeepSeekV2Lite.ipynb
│ │ ├── MiniMax-M2.5.md
│ │ ├── Qwen3-Next.md
│ │ ├── Qwen3.5.md
│ │ ├── ROCm.md
│ │ ├── SFT/
│ │ │ ├── DPO_tutorial.md
│ │ │ ├── KTransformers-Fine-Tuning_Developer-Technical-Notes.md
│ │ │ ├── KTransformers-Fine-Tuning_User-Guide.md
│ │ │ ├── README.md
│ │ │ └── injection_tutorial.md
│ │ ├── SFT_Installation_Guide_KimiK2.5.md
│ │ ├── SFT_Installation_Guide_KimiK2.md
│ │ ├── SmallThinker_and_Glm4moe.md
│ │ ├── V3-success.md
│ │ ├── api/
│ │ │ └── server/
│ │ │ ├── api.md
│ │ │ ├── server.md
│ │ │ ├── tabby.md
│ │ │ └── website.md
│ │ ├── balance-serve.md
│ │ ├── benchmark.md
│ │ ├── deepseek-v2-injection.md
│ │ ├── fp8_kernel.md
│ │ ├── install.md
│ │ ├── kt-kernel/
│ │ │ ├── GLM-5-Tutorial.md
│ │ │ ├── Kimi-K2-Thinking-Native.md
│ │ │ ├── MiniMax-M2.1-Tutorial.md
│ │ │ ├── Native-Precision-Tutorial.md
│ │ │ ├── Qwen3-Coder-Next-Tutorial.md
│ │ │ ├── README.md
│ │ │ ├── amd_blis.md
│ │ │ ├── deepseek-v3.2-sglang-tutorial.md
│ │ │ ├── experts-sched-Tutorial.md
│ │ │ └── kt-cli.md
│ │ ├── llama4.md
│ │ ├── long_context_introduction.md
│ │ ├── long_context_tutorial.md
│ │ ├── makefile_usage.md
│ │ ├── multi-gpu-tutorial.md
│ │ ├── operators/
│ │ │ └── llamafile.md
│ │ ├── prefix_cache.md
│ │ └── xpu.md
│ └── zh/
│ ├── DeepseekR1_V3_tutorial_zh.md
│ ├── DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md
│ ├── KTransformers-Fine-Tuning_Developer-Technical-Notes_zh.md
│ ├── KTransformers-Fine-Tuning_User-Guide_zh.md
│ ├── Qwen3-MoE_tutorial_zh_for_Ascend_NPU.md
│ ├── api/
│ │ └── server/
│ │ ├── api.md
│ │ ├── server.md
│ │ ├── tabby.md
│ │ └── website.md
│ └── clawdbot_integration_guide.md
├── docker/
│ ├── Dockerfile
│ ├── README-packaging.md
│ ├── docker-utils.sh
│ └── push-to-dockerhub.sh
├── install.sh
├── kt-kernel/
│ ├── .clang-format
│ ├── .githooks/
│ │ ├── commit-msg
│ │ └── pre-commit
│ ├── .gitignore
│ ├── .gitmodules
│ ├── CMakeLists.txt
│ ├── CMakePresets.json
│ ├── MANIFEST.in
│ ├── README.md
│ ├── README_zh.md
│ ├── bench/
│ │ ├── .gitignore
│ │ ├── Makefile
│ │ ├── bench_attention.py
│ │ ├── bench_attention_torch.py
│ │ ├── bench_bf16_moe.py
│ │ ├── bench_fp8_moe.py
│ │ ├── bench_fp8_perchannel_moe.py
│ │ ├── bench_k2_moe_amx.py
│ │ ├── bench_k2_write_buffer.py
│ │ ├── bench_linear.py
│ │ ├── bench_linear_torch.py
│ │ ├── bench_mla.py
│ │ ├── bench_mlp.py
│ │ ├── bench_mlp_torch.py
│ │ ├── bench_moe.py
│ │ ├── bench_moe_amx.py
│ │ ├── bench_moe_amx_k.py
│ │ ├── bench_moe_kernel.py
│ │ ├── bench_moe_kernel_tiling.py
│ │ ├── bench_moe_kml.py
│ │ ├── bench_moe_torch.py
│ │ ├── bench_write_buffer.py
│ │ ├── compare_moe_performance.py
│ │ ├── multi_bench_moe.py
│ │ └── upload-bench-json.py
│ ├── cmake/
│ │ ├── DetectCPU.cmake
│ │ └── FindSIMD.cmake
│ ├── cpu_backend/
│ │ ├── cpuinfer.h
│ │ ├── shared_mem_buffer.cpp
│ │ ├── shared_mem_buffer.h
│ │ ├── task_queue.cpp
│ │ ├── task_queue.h
│ │ ├── vendors/
│ │ │ ├── README.md
│ │ │ ├── cuda.h
│ │ │ ├── hip.h
│ │ │ ├── musa.h
│ │ │ └── vendor.h
│ │ ├── worker_pool.cpp
│ │ └── worker_pool.h
│ ├── cuda/
│ │ ├── binding.cpp
│ │ ├── custom_gguf/
│ │ │ ├── dequant.cu
│ │ │ └── ops.h
│ │ ├── gptq_marlin/
│ │ │ ├── gptq_marlin.cu
│ │ │ ├── gptq_marlin.cuh
│ │ │ ├── gptq_marlin_dtypes.cuh
│ │ │ └── ops.h
│ │ ├── moe/
│ │ │ ├── moe_topk_softmax_kernels.cu
│ │ │ ├── ops.h
│ │ │ └── utils.h
│ │ ├── setup.py
│ │ └── test_dequant.py
│ ├── demo/
│ │ ├── .gitignore
│ │ ├── Makefile
│ │ ├── bench_reorder_bandwidth.cpp
│ │ ├── bf16-test.cpp
│ │ ├── fp16-test.cpp
│ │ ├── plot.py
│ │ ├── simple_test.cpp
│ │ ├── simple_test_aocl.cpp
│ │ └── tflops.py
│ ├── examples/
│ │ ├── .gitignore
│ │ ├── bench_moe_amx_int8.py
│ │ ├── configuration_deepseek_v3.py
│ │ ├── modeling_deepseek_v3.py
│ │ ├── repro_llamafile_re.py
│ │ ├── test-debug.py
│ │ ├── test_apply_rope.py
│ │ ├── test_attention.py
│ │ ├── test_awq_moe_amx.py
│ │ ├── test_bf16_moe.py
│ │ ├── test_deepseekv3.py
│ │ ├── test_deepseekv3_prefill.py
│ │ ├── test_deepseekv3_prefill_speed.py
│ │ ├── test_fp8_moe.py
│ │ ├── test_fp8_perchannel_moe.py
│ │ ├── test_gate.py
│ │ ├── test_k2_moe_amx.py
│ │ ├── test_k2_write_buffer.py
│ │ ├── test_linear.py
│ │ ├── test_mla.py
│ │ ├── test_mla_qlen.py
│ │ ├── test_mla_quant.py
│ │ ├── test_mla_simple.py
│ │ ├── test_mla_torch.py
│ │ ├── test_mlp.py
│ │ ├── test_moe.py
│ │ ├── test_moe_amx.py
│ │ ├── test_moe_kernel.py
│ │ ├── test_moe_kml.py
│ │ ├── test_rope.cpp
│ │ ├── test_rope.py
│ │ ├── test_softmax.py
│ │ ├── test_write_buffer.py
│ │ └── torch_attention.py
│ ├── ext_bindings.cpp
│ ├── install.sh
│ ├── operators/
│ │ ├── amx/
│ │ │ ├── awq-moe.hpp
│ │ │ ├── bf16-moe.hpp
│ │ │ ├── fp8-moe.hpp
│ │ │ ├── fp8-perchannel-moe.hpp
│ │ │ ├── k2-moe.hpp
│ │ │ ├── la/
│ │ │ │ ├── amx-example.cpp
│ │ │ │ ├── amx.hpp
│ │ │ │ ├── amx_buffers.hpp
│ │ │ │ ├── amx_config.hpp
│ │ │ │ ├── amx_kernels.hpp
│ │ │ │ ├── amx_quantization.hpp
│ │ │ │ ├── amx_raw_buffers.hpp
│ │ │ │ ├── amx_raw_kernels.hpp
│ │ │ │ ├── amx_utils.hpp
│ │ │ │ ├── pack.hpp
│ │ │ │ └── utils.hpp
│ │ │ ├── moe.hpp
│ │ │ ├── moe_base.hpp
│ │ │ └── test/
│ │ │ ├── amx-bkgroup-test.cpp
│ │ │ ├── amx-c-reduce-test.cpp
│ │ │ ├── amx-kgroup-test.cpp
│ │ │ ├── amx-test.cpp
│ │ │ ├── analyze-error.cpp
│ │ │ ├── avx-test.cpp
│ │ │ ├── debug-kgroup-details.cpp
│ │ │ ├── debug-kgroup.cpp
│ │ │ ├── debug-specific-dims.cpp
│ │ │ ├── mat-test.hpp
│ │ │ ├── mmq-test.cpp
│ │ │ ├── mmq.cpp
│ │ │ ├── mmq.h
│ │ │ ├── test-kgroup-128.cpp
│ │ │ ├── test-kgroup-kernel.cpp
│ │ │ ├── test-specific-dims.cpp
│ │ │ ├── thread_test.sh
│ │ │ ├── timer.hh
│ │ │ └── verify-kgroup.cpp
│ │ ├── common.hpp
│ │ ├── kvcache/
│ │ │ ├── kvcache.h
│ │ │ ├── kvcache_attn.cpp
│ │ │ ├── kvcache_load_dump.cpp
│ │ │ ├── kvcache_read_write.cpp
│ │ │ └── kvcache_utils.cpp
│ │ ├── llamafile/
│ │ │ ├── conversion.h
│ │ │ ├── linear.cpp
│ │ │ ├── linear.h
│ │ │ ├── mla.hpp
│ │ │ ├── mlp.cpp
│ │ │ ├── mlp.h
│ │ │ └── moe.hpp
│ │ ├── mla-tp.hpp
│ │ ├── moe-tp.hpp
│ │ ├── moe_kernel/
│ │ │ ├── api/
│ │ │ │ ├── common.h
│ │ │ │ └── mat_kernel.h
│ │ │ ├── la/
│ │ │ │ ├── kernel.hpp
│ │ │ │ ├── mat_kernel.cpp
│ │ │ │ └── utils.hpp
│ │ │ ├── mat_kernel/
│ │ │ │ ├── aocl_kernel/
│ │ │ │ │ └── kernel.cpp
│ │ │ │ └── batch_gemm_api.hpp
│ │ │ ├── moe.hpp
│ │ │ └── test/
│ │ │ ├── convert-test.cpp
│ │ │ ├── debug.hpp
│ │ │ ├── int4_mul-test.cpp
│ │ │ ├── mat_test.cpp
│ │ │ └── utils_test.cpp
│ │ ├── reduce.hpp
│ │ ├── rms-norm.hpp
│ │ ├── rope.hpp
│ │ ├── softmax.hpp
│ │ └── tp.hpp
│ ├── pyproject.toml
│ ├── pytest.ini
│ ├── python/
│ │ ├── __init__.py
│ │ ├── _cpu_detect.py
│ │ ├── cli/
│ │ │ ├── __init__.py
│ │ │ ├── commands/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bench.py
│ │ │ │ ├── chat.py
│ │ │ │ ├── config.py
│ │ │ │ ├── doctor.py
│ │ │ │ ├── model.py
│ │ │ │ ├── quant.py
│ │ │ │ ├── run.py
│ │ │ │ ├── sft.py
│ │ │ │ └── version.py
│ │ │ ├── completions/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _kt
│ │ │ │ ├── kt-completion.bash
│ │ │ │ └── kt.fish
│ │ │ ├── config/
│ │ │ │ ├── __init__.py
│ │ │ │ └── settings.py
│ │ │ ├── i18n.py
│ │ │ ├── main.py
│ │ │ ├── requirements/
│ │ │ │ ├── inference.txt
│ │ │ │ └── sft.txt
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── analyze_moe_model.py
│ │ │ ├── console.py
│ │ │ ├── debug_configs.py
│ │ │ ├── download_helper.py
│ │ │ ├── environment.py
│ │ │ ├── input_validators.py
│ │ │ ├── kv_cache_calculator.py
│ │ │ ├── model_discovery.py
│ │ │ ├── model_registry.py
│ │ │ ├── model_scanner.py
│ │ │ ├── model_table_builder.py
│ │ │ ├── model_verifier.py
│ │ │ ├── port_checker.py
│ │ │ ├── quant_interactive.py
│ │ │ ├── repo_detector.py
│ │ │ ├── run_configs.py
│ │ │ ├── run_interactive.py
│ │ │ ├── sglang_checker.py
│ │ │ ├── tuna_engine.py
│ │ │ └── user_model_registry.py
│ │ ├── experts.py
│ │ ├── experts_base.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── amx.py
│ │ ├── llamafile.py
│ │ ├── loader.py
│ │ └── moe_kernel.py
│ ├── requirements.txt
│ ├── scripts/
│ │ ├── README.md
│ │ ├── check.py
│ │ ├── check_cpu_features.py
│ │ ├── compare_weights.py
│ │ ├── convert_cpu_weights.py
│ │ ├── convert_gpu_weights.py
│ │ ├── convert_kimi_k2_fp8_to_bf16_cpu.py
│ │ ├── convert_moe_to_bf16.py
│ │ └── install-git-hooks.sh
│ ├── setup.py
│ └── test/
│ ├── __init__.py
│ ├── ci/
│ │ ├── __init__.py
│ │ ├── ci_register.py
│ │ └── ci_utils.py
│ ├── per_commit/
│ │ ├── __init__.py
│ │ ├── test_amd_placeholder.py
│ │ ├── test_basic_cpu.py
│ │ ├── test_cuda_placeholder.py
│ │ ├── test_moe_amx_accuracy_int4.py
│ │ ├── test_moe_amx_accuracy_int4_1.py
│ │ ├── test_moe_amx_accuracy_int4_1k.py
│ │ ├── test_moe_amx_accuracy_int8.py
│ │ ├── test_moe_amx_bench_int4.py
│ │ ├── test_moe_amx_bench_int4_1.py
│ │ ├── test_moe_amx_bench_int4_1k.py
│ │ └── test_moe_amx_bench_int8.py
│ ├── run_suite.py
│ └── test_generate_gpu_experts_masks.py
├── kt-sft/
│ ├── .flake8
│ ├── .gitignore
│ ├── .gitmodules
│ ├── .pylintrc
│ ├── Dockerfile
│ ├── Dockerfile.xpu
│ ├── LICENSE
│ ├── MANIFEST.in
│ ├── Makefile
│ ├── README.md
│ ├── SECURITY.md
│ ├── autosetup.sh
│ ├── book.toml
│ ├── csrc/
│ │ ├── custom_marlin/
│ │ │ ├── __init__.py
│ │ │ ├── binding.cpp
│ │ │ ├── gptq_marlin/
│ │ │ │ ├── gptq_marlin.cu
│ │ │ │ ├── gptq_marlin.cuh
│ │ │ │ ├── gptq_marlin_dtypes.cuh
│ │ │ │ ├── gptq_marlin_repack.cu
│ │ │ │ └── ops.h
│ │ │ ├── setup.py
│ │ │ ├── test_cuda_graph.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── format24.py
│ │ │ ├── marlin_24_perms.py
│ │ │ ├── marlin_perms.py
│ │ │ ├── marlin_utils.py
│ │ │ └── quant_utils.py
│ │ └── ktransformers_ext/
│ │ ├── CMakeLists.txt
│ │ ├── bench/
│ │ │ ├── bench_attention.py
│ │ │ ├── bench_attention_torch.py
│ │ │ ├── bench_linear.py
│ │ │ ├── bench_linear_torch.py
│ │ │ ├── bench_mlp.py
│ │ │ ├── bench_mlp_torch.py
│ │ │ ├── bench_moe.py
│ │ │ ├── bench_moe_amx.py
│ │ │ └── bench_moe_torch.py
│ │ ├── cmake/
│ │ │ └── FindSIMD.cmake
│ │ ├── cpu_backend/
│ │ │ ├── backend.cpp
│ │ │ ├── backend.h
│ │ │ ├── cpuinfer.h
│ │ │ ├── shared_mem_buffer.cpp
│ │ │ ├── shared_mem_buffer.h
│ │ │ ├── task_queue.cpp
│ │ │ ├── task_queue.h
│ │ │ └── vendors/
│ │ │ ├── README.md
│ │ │ ├── cuda.h
│ │ │ ├── hip.h
│ │ │ ├── musa.h
│ │ │ └── vendor.h
│ │ ├── cuda/
│ │ │ ├── binding.cpp
│ │ │ ├── custom_gguf/
│ │ │ │ ├── dequant.cu
│ │ │ │ └── ops.h
│ │ │ ├── gptq_marlin/
│ │ │ │ ├── gptq_marlin.cu
│ │ │ │ ├── gptq_marlin.cuh
│ │ │ │ ├── gptq_marlin_dtypes.cuh
│ │ │ │ └── ops.h
│ │ │ ├── setup.py
│ │ │ └── test_dequant.py
│ │ ├── examples/
│ │ │ ├── test_attention.py
│ │ │ ├── test_linear.py
│ │ │ ├── test_mlp.py
│ │ │ ├── test_moe.py
│ │ │ ├── test_sft_amx_moe.py
│ │ │ └── test_sft_moe.py
│ │ ├── ext_bindings.cpp
│ │ ├── operators/
│ │ │ ├── amx/
│ │ │ │ ├── debug_sft_moe.hpp
│ │ │ │ ├── debug_tools_sft_moe.hpp
│ │ │ │ ├── la/
│ │ │ │ │ ├── amx.hpp
│ │ │ │ │ └── utils.hpp
│ │ │ │ ├── moe.hpp
│ │ │ │ └── sft_moe.hpp
│ │ │ ├── kvcache/
│ │ │ │ ├── kvcache.h
│ │ │ │ ├── kvcache_attn.cpp
│ │ │ │ ├── kvcache_load_dump.cpp
│ │ │ │ ├── kvcache_read_write.cpp
│ │ │ │ └── kvcache_utils.cpp
│ │ │ └── llamafile/
│ │ │ ├── conversion.h
│ │ │ ├── linear.cpp
│ │ │ ├── linear.h
│ │ │ ├── mlp.cpp
│ │ │ ├── mlp.h
│ │ │ ├── moe.cpp
│ │ │ ├── moe.h
│ │ │ ├── sft_moe.cpp
│ │ │ ├── sft_moe.h
│ │ │ └── sft_moe_forward_cache.h
│ │ └── vendors/
│ │ ├── cuda.h
│ │ ├── hip.h
│ │ ├── musa.h
│ │ └── vendor.h
│ ├── install-with-cache.sh
│ ├── install.bat
│ ├── install.sh
│ ├── ktransformers/
│ │ ├── __init__.py
│ │ ├── configs/
│ │ │ ├── config.yaml
│ │ │ ├── log_config.ini
│ │ │ └── model_config/
│ │ │ ├── config.json
│ │ │ └── configuration_deepseek.py
│ │ ├── ktransformers_ext/
│ │ │ ├── operators/
│ │ │ │ └── custom_marlin/
│ │ │ │ └── quantize/
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── format_24.py
│ │ │ │ ├── marlin_24_perms.py
│ │ │ │ ├── marlin_perms.py
│ │ │ │ ├── marlin_utils.py
│ │ │ │ └── quant_utils.py
│ │ │ └── triton/
│ │ │ └── fp8gemm.py
│ │ ├── local_chat.py
│ │ ├── local_chat.sh
│ │ ├── lora_test_module.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── configuration_deepseek.py
│ │ │ ├── configuration_deepseek_v3.py
│ │ │ ├── configuration_llama.py
│ │ │ ├── configuration_qwen2_moe.py
│ │ │ ├── configuration_qwen3_moe.py
│ │ │ ├── custom_cache.py
│ │ │ ├── custom_modeling_deepseek_v2.py
│ │ │ ├── custom_modeling_deepseek_v3.py
│ │ │ ├── custom_modeling_qwen2_moe.py
│ │ │ ├── custom_modeling_qwen3_moe.py
│ │ │ ├── modeling_deepseek.py
│ │ │ ├── modeling_deepseek_v3.py
│ │ │ ├── modeling_llama.py
│ │ │ ├── modeling_mixtral.py
│ │ │ ├── modeling_qwen2_moe.py
│ │ │ └── modeling_qwen3_moe.py
│ │ ├── moe_test_module.py
│ │ ├── moe_test_module_old.py
│ │ ├── operators/
│ │ │ ├── RoPE.py
│ │ │ ├── __init__.py
│ │ │ ├── attention.py
│ │ │ ├── balance_serve_attention.py
│ │ │ ├── base_operator.py
│ │ │ ├── cpuinfer.py
│ │ │ ├── dynamic_attention.py
│ │ │ ├── experts.py
│ │ │ ├── flashinfer_batch_prefill_wrapper.py
│ │ │ ├── flashinfer_wrapper.py
│ │ │ ├── gate.py
│ │ │ ├── layernorm.py
│ │ │ ├── linear.py
│ │ │ ├── mlp.py
│ │ │ ├── models.py
│ │ │ ├── triton_attention.py
│ │ │ └── triton_attention_prefill.py
│ │ ├── optimize/
│ │ │ ├── optimize.py
│ │ │ └── optimize_rules/
│ │ │ ├── DeepSeek-V2-Chat-multi-gpu-4.yaml
│ │ │ ├── DeepSeek-V2-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V2-Chat-sft-amx.yaml
│ │ │ ├── DeepSeek-V2-Chat.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-sft-amx-multi-gpu.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-sft-amx.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-sft.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat-use-adapter.yaml
│ │ │ ├── DeepSeek-V2-Lite-Chat.yaml
│ │ │ ├── DeepSeek-V3-Chat-amx.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve-amx.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve.yaml
│ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-4.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-8.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-fp8-linear-ggml-experts.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu-marlin.yaml
│ │ │ ├── DeepSeek-V3-Chat-multi-gpu.yaml
│ │ │ ├── DeepSeek-V3-Chat-serve.yaml
│ │ │ ├── DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml
│ │ │ ├── DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml
│ │ │ ├── DeepSeek-V3-Chat-sft-amx.yaml
│ │ │ ├── DeepSeek-V3-Chat.yaml
│ │ │ ├── Internlm2_5-7b-Chat-1m.yaml
│ │ │ ├── Mixtral.yaml
│ │ │ ├── Moonlight-16B-A3B-serve.yaml
│ │ │ ├── Moonlight-16B-A3B.yaml
│ │ │ ├── Qwen2-57B-A14B-Instruct-multi-gpu.yaml
│ │ │ ├── Qwen2-57B-A14B-Instruct.yaml
│ │ │ ├── Qwen2-serve-amx.yaml
│ │ │ ├── Qwen2-serve.yaml
│ │ │ ├── Qwen3Moe-serve-amx.yaml
│ │ │ ├── Qwen3Moe-serve.yaml
│ │ │ ├── Qwen3Moe-sft-amx.yaml
│ │ │ ├── rocm/
│ │ │ │ └── DeepSeek-V3-Chat.yaml
│ │ │ └── xpu/
│ │ │ ├── DeepSeek-V2-Chat.yaml
│ │ │ ├── DeepSeek-V3-Chat.yaml
│ │ │ └── Qwen3Moe-Chat.yaml
│ │ ├── server/
│ │ │ ├── __init__.py
│ │ │ ├── api/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── ollama/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── completions.py
│ │ │ │ ├── openai/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── assistants/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── assistants.py
│ │ │ │ │ │ ├── messages.py
│ │ │ │ │ │ ├── runs.py
│ │ │ │ │ │ └── threads.py
│ │ │ │ │ ├── endpoints/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ └── chat.py
│ │ │ │ │ └── legacy/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── completions.py
│ │ │ │ └── web/
│ │ │ │ ├── __init__.py
│ │ │ │ └── system.py
│ │ │ ├── args.py
│ │ │ ├── backend/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── base.py
│ │ │ │ ├── context_manager.py
│ │ │ │ └── interfaces/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── balance_serve.py
│ │ │ │ ├── exllamav2.py
│ │ │ │ ├── ktransformers.py
│ │ │ │ └── transformers.py
│ │ │ ├── balance_serve/
│ │ │ │ ├── inference/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── config.py
│ │ │ │ │ ├── distributed/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── communication_op.py
│ │ │ │ │ │ ├── cuda_wrapper.py
│ │ │ │ │ │ ├── custom_all_reduce.py
│ │ │ │ │ │ ├── custom_all_reduce_utils.py
│ │ │ │ │ │ ├── parallel_state.py
│ │ │ │ │ │ ├── pynccl.py
│ │ │ │ │ │ ├── pynccl_wrapper.py
│ │ │ │ │ │ └── utils.py
│ │ │ │ │ ├── forward_batch.py
│ │ │ │ │ ├── model_runner.py
│ │ │ │ │ ├── query_manager.py
│ │ │ │ │ └── sampling/
│ │ │ │ │ ├── penaltylib/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── orchestrator.py
│ │ │ │ │ │ └── penalizers/
│ │ │ │ │ │ ├── frequency_penalty.py
│ │ │ │ │ │ ├── min_new_tokens.py
│ │ │ │ │ │ ├── presence_penalty.py
│ │ │ │ │ │ └── repetition_penalty.py
│ │ │ │ │ └── sampler.py
│ │ │ │ ├── sched_rpc.py
│ │ │ │ └── settings.py
│ │ │ ├── config/
│ │ │ │ ├── config.py
│ │ │ │ ├── log.py
│ │ │ │ └── singleton.py
│ │ │ ├── crud/
│ │ │ │ ├── __init__.py
│ │ │ │ └── assistants/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants.py
│ │ │ │ ├── messages.py
│ │ │ │ ├── runs.py
│ │ │ │ └── threads.py
│ │ │ ├── exceptions.py
│ │ │ ├── main.py
│ │ │ ├── models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── assistants/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants.py
│ │ │ │ ├── messages.py
│ │ │ │ ├── run_steps.py
│ │ │ │ ├── runs.py
│ │ │ │ └── threads.py
│ │ │ ├── schemas/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assistants/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── assistants.py
│ │ │ │ │ ├── messages.py
│ │ │ │ │ ├── runs.py
│ │ │ │ │ ├── streaming.py
│ │ │ │ │ ├── threads.py
│ │ │ │ │ └── tool.py
│ │ │ │ ├── base.py
│ │ │ │ ├── conversation.py
│ │ │ │ ├── endpoints/
│ │ │ │ │ └── chat.py
│ │ │ │ └── legacy/
│ │ │ │ ├── __init__.py
│ │ │ │ └── completions.py
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── create_interface.py
│ │ │ ├── multi_timer.py
│ │ │ └── sql_utils.py
│ │ ├── sft/
│ │ │ ├── __init__.py
│ │ │ ├── flops_utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── custom_profile.py
│ │ │ │ └── lora_test_utils.py
│ │ │ ├── lora.py
│ │ │ ├── metrics.py
│ │ │ ├── metrics_utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── constants.py
│ │ │ │ ├── env.py
│ │ │ │ ├── logging.py
│ │ │ │ ├── misc.py
│ │ │ │ ├── packages.py
│ │ │ │ └── ploting.py
│ │ │ ├── monkey_patch_torch_module.py
│ │ │ ├── peft_utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── lora_layer.py
│ │ │ │ ├── lora_model.py
│ │ │ │ ├── mapping.py
│ │ │ │ └── peft_model.py
│ │ │ └── torchviz_test.py
│ │ ├── tests/
│ │ │ ├── .gitignore
│ │ │ ├── AIME_2024/
│ │ │ │ ├── eval_api.py
│ │ │ │ ├── evaluation.py
│ │ │ │ └── prompts.py
│ │ │ ├── dequant_gpu.py
│ │ │ ├── dequant_gpu_t.py
│ │ │ ├── function_call_test.py
│ │ │ ├── humaneval/
│ │ │ │ ├── eval_api.py
│ │ │ │ ├── evaluation.py
│ │ │ │ └── prompts.py
│ │ │ ├── mmlu_pro_test.py
│ │ │ ├── mmlu_test.py
│ │ │ ├── mmlu_test_multi.py
│ │ │ ├── score.py
│ │ │ ├── test_client.py
│ │ │ ├── test_pytorch_q8.py
│ │ │ ├── test_speed.py
│ │ │ └── triton_fp8gemm_test.py
│ │ ├── util/
│ │ │ ├── cuda_graph_runner.py
│ │ │ ├── custom_gguf.py
│ │ │ ├── custom_loader.py
│ │ │ ├── globals.py
│ │ │ ├── grad_wrapper.py
│ │ │ ├── inference_state.py
│ │ │ ├── modeling_rope_utils.py
│ │ │ ├── textstream.py
│ │ │ ├── utils.py
│ │ │ ├── vendors.py
│ │ │ └── weight_loader.py
│ │ └── website/
│ │ ├── .browserslistrc
│ │ ├── .eslintrc.js
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── config.d.ts
│ │ ├── jest.config.js
│ │ ├── package.json
│ │ ├── public/
│ │ │ ├── config.js
│ │ │ ├── css/
│ │ │ │ └── reset.css
│ │ │ └── index.html
│ │ ├── src/
│ │ │ ├── App.vue
│ │ │ ├── api/
│ │ │ │ ├── api-client.ts
│ │ │ │ ├── assistant.ts
│ │ │ │ ├── message.ts
│ │ │ │ ├── run.ts
│ │ │ │ └── thread.ts
│ │ │ ├── assets/
│ │ │ │ ├── css/
│ │ │ │ │ └── mixins.styl
│ │ │ │ └── iconfont/
│ │ │ │ ├── demo.css
│ │ │ │ ├── demo_index.html
│ │ │ │ ├── iconfont.css
│ │ │ │ ├── iconfont.js
│ │ │ │ └── iconfont.json
│ │ │ ├── components/
│ │ │ │ └── chat/
│ │ │ │ └── index.vue
│ │ │ ├── conf/
│ │ │ │ └── config.ts
│ │ │ ├── locals/
│ │ │ │ ├── en.js
│ │ │ │ ├── index.js
│ │ │ │ └── zh.js
│ │ │ ├── main.ts
│ │ │ ├── router/
│ │ │ │ └── index.ts
│ │ │ ├── shims-vue.d.ts
│ │ │ ├── store/
│ │ │ │ └── index.ts
│ │ │ ├── utils/
│ │ │ │ ├── copy.ts
│ │ │ │ └── types.ts
│ │ │ └── views/
│ │ │ └── home.vue
│ │ ├── tests/
│ │ │ └── unit/
│ │ │ └── example.spec.ts
│ │ ├── tsconfig.json
│ │ └── vue.config.js
│ ├── merge_tensors/
│ │ └── merge_safetensor_gguf.py
│ ├── pyproject.toml
│ ├── requirements-sft.txt
│ ├── setup.py
│ ├── test_adapter/
│ │ ├── data_transfer.py
│ │ ├── infer_with_adapter.py
│ │ ├── inspect_adapter.py
│ │ ├── pred2metrics.py
│ │ ├── test_grad.py
│ │ └── time_test_lora_train.py
│ └── withoutKT_PEFT.py
├── pyproject.toml
├── setup.py
├── third_party/
│ └── llamafile/
│ ├── README.md
│ ├── bench.h
│ ├── flags.cpp
│ ├── flags.h
│ ├── iqk_mul_mat.inc
│ ├── iqk_mul_mat_amd_avx2.cpp
│ ├── iqk_mul_mat_amd_zen4.cpp
│ ├── iqk_mul_mat_arm.inc
│ ├── iqk_mul_mat_arm82.cpp
│ ├── macros.h
│ ├── micros.h
│ ├── numba.h
│ ├── sgemm.cpp
│ ├── sgemm.h
│ ├── tinyblas_cpu.h
│ ├── tinyblas_cpu_mixmul.inc
│ ├── tinyblas_cpu_mixmul_amd_avx.cpp
│ ├── tinyblas_cpu_mixmul_amd_avx2.cpp
│ ├── tinyblas_cpu_mixmul_amd_avx512f.cpp
│ ├── tinyblas_cpu_mixmul_amd_avxvnni.cpp
│ ├── tinyblas_cpu_mixmul_amd_fma.cpp
│ ├── tinyblas_cpu_mixmul_amd_zen4.cpp
│ ├── tinyblas_cpu_mixmul_arm80.cpp
│ ├── tinyblas_cpu_mixmul_arm82.cpp
│ ├── tinyblas_cpu_sgemm.inc
│ ├── tinyblas_cpu_sgemm_amd_avx.cpp
│ ├── tinyblas_cpu_sgemm_amd_avx2.cpp
│ ├── tinyblas_cpu_sgemm_amd_avx512f.cpp
│ ├── tinyblas_cpu_sgemm_amd_avxvnni.cpp
│ ├── tinyblas_cpu_sgemm_amd_fma.cpp
│ ├── tinyblas_cpu_sgemm_amd_zen4.cpp
│ ├── tinyblas_cpu_sgemm_arm80.cpp
│ ├── tinyblas_cpu_sgemm_arm82.cpp
│ └── tinyblas_cpu_unsupported.cpp
└── version.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our community a harassment-free experience for everyone, regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes, and learning from the experience
* Focusing on what is best not just for us as individuals, but for the overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of acceptable behavior and will take appropriate and fair corrective action in response to any behavior that they deem inappropriate, threatening, offensive, or harmful.
Community leaders have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, and will communicate reasons for moderation decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when an individual is officially representing the community in public spaces. Examples of representing our community include using an official e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported to the community leaders responsible for enforcement at [INSERT CONTACT METHOD]. All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing clarity around the nature of the violation and an explanation of why the behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series of actions.
**Consequence**: A warning with consequences for continued behavior. No interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, for a specified period of time. This includes avoiding interactions in community spaces as well as external channels like social media. Violating these terms may lead to a temporary or permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public communication with the community for a specified period of time. No public or private interaction with the people involved, including unsolicited interaction with those enforcing the Code of Conduct, is allowed during this period. Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community standards, including sustained inappropriate behavior, harassment of an individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at [https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at [https://www.contributor-covenant.org/faq][FAQ]. Translations are available at [https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
================================================
FILE: .github/CONTRIBUTING.md
================================================
## Before Commit!
Your commit message must follow Conventional Commits (https://www.conventionalcommits.org/) and your code should be formatted. The Git hooks will do most of the work automatically:
### Tool Requirements
You need a recent `clang-format` (>= 18). In a conda environment you can install:
```shell
conda install -c conda-forge clang-format=18
```
If you previously configured with an older version, remove the build directory and reconfigure:
```shell
rm -rf kt-kernel/build
```
Install `black` for Python formatting:
```shell
conda install black
```
### Install hook:
```shell
bash kt-kernel/scripts/install-git-hooks.sh
#or just cmake the kt-kernel
cmake -S kt-kernel -B kt-kernel/build
```
There are manual commands if you need format.
```shell
cmake -S kt-kernel -B kt-kernel/build
cmake --build kt-kernel/build --target format
```
## Developer Note
Formatting and commit message rules are enforced by Git hooks. After installing `clang-format` and `black`, just commit normally—the hooks will run formatting for you.
> [!NOTE]
> If formatting modifies files, the commit is aborted after staging those changes. Review them and run `git commit` again. Repeat until no further formatting changes appear.
---
### Conventional Commit Regex (Reference)
The commit-msg hook enforces this pattern:
```text
regex='^\[(feat|fix|docs|style|refactor|perf|test|build|ci|chore|revert|wip)\](\([^\)]+\))?(!)?: .+'
```
Meaning (English):
* `[type]` required — one of feat|fix|docs|style|refactor|perf|test|build|ci|chore|revert|wip
* Optional scope: `(scope)` — any chars except `)`
* Optional breaking change marker: `!` right after type or scope
* Separator: `: ` (colon + space)
* Subject: free text (at least one character)
Examples:
```text
[feat]: add adaptive batching
[fix(parser)]: handle empty token list
[docs]!: update API section for breaking rename
```
You can bypass locally (not recommended) with:
```shell
git commit --no-verify
```
## 提交前提醒
提交信息必须满足 Conventional Commits 规范 (https://www.conventionalcommits.org/),代码需要符合格式要求。Git 钩子已经集成了大部分工作:
### 软件要求
需要较新的 `clang-format` (>= 18),在 conda 环境中安装:
```shell
conda install -c conda-forge clang-format=18
```
如果之前用老版本配置过,请删除构建目录重新配置:
```shell
rm -rf kt-kernel/build
```
安装 `black` 以进行 Python 文件格式化:
```shell
conda install black
```
### 安装钩子
```shell
bash kt-kernel/scripts/install-git-hooks.sh
#or just cmake the kt-kernel
cmake -S kt-kernel -B kt-kernel/build
```
如果你需要手动格式化:
```shell
cmake -S kt-kernel -B kt-kernel/build
cmake --build kt-kernel/build --target format
```
## 开发者说明
本仓库通过 Git hooks 自动执行代码格式化与提交信息规范检查。只需安装好 `clang-format` 与 `black` 后正常执行提交即可,钩子会自动格式化。
> [!NOTE]
> 如果格式化修改了文件,钩子会终止提交并已暂存这些改动。请查看修改后再次执行 `git commit`,重复直到没有新的格式化变更。
### 提交信息正则(参考)
钩子使用如下正则检查提交信息:
```text
regex='^\[(feat|fix|docs|style|refactor|perf|test|build|ci|chore|revert|wip)\](\([^\)]+\))?(!)?: .+'
```
含义:
* `[type]` 必填:feat|fix|docs|style|refactor|perf|test|build|ci|chore|revert|wip
* 作用域可选:`(scope)`,不能包含右括号
* 可选的破坏性标记:`!`
* 分隔符:冒号+空格 `: `
* 描述:至少一个字符
示例:
```text
[feat]: 增加自适应 batch 功能
[fix(tokenizer)]: 修复空 token 列表处理
[docs]!: 更新接口文档(存在破坏性修改)
```
跳过钩子(不推荐,仅紧急时):
```shell
git commit --no-verify
```
================================================
FILE: .github/ISSUE_TEMPLATE/-bug-.yaml
================================================
name: "\U0001F41B Bug / Help"
description: Create a report to help us improve the ktransformers project
labels: ["pending"]
body:
- type: markdown
attributes:
value: |
Issues included in **[FAQs](https://github.com/kvcache-ai/ktransformers/issues/1608)** or those with **insufficient** information may be closed without a response.
已经包含在 **[常见问题](https://github.com/kvcache-ai/ktransformers/issues/1608)** 内或提供信息**不完整**的 issues 可能不会被回复。
- type: checkboxes
id: reminder
attributes:
label: Reminder
description: |
Please ensure you have read the above rules carefully and searched the existing issues (including FAQs).
请确保您已经认真阅读了上述规则并且搜索过现有的 issues(包括常见问题)。
options:
- label: I have read the above rules and searched the existing issues.
required: true
- type: textarea
id: system-info
validations:
required: true
attributes:
label: System Info
description: |
Please share your system info with us. You can run the command **lscpu**, ** nvidia-smi ** etc. and copy-paste its output below.
请提供您的系统信息。您可以在命令行运行 **lscpu**, **nvidia-smi** 等命令,并将其输出复制到该文本框中。
placeholder: ktransformers version,sglang version, platform, python version, cpu info, GPU/NPU info ...
- type: textarea
id: reproduction
validations:
required: true
attributes:
label: Reproduction
description: |
Please provide entry arguments, error messages and stack traces that reproduces the problem.
请提供入口参数,错误日志以及异常堆栈以便于我们复现问题。
value: |
```text
Put your message here.
```
- type: textarea
id: others
validations:
required: false
attributes:
label: Others
================================================
FILE: .github/ISSUE_TEMPLATE/-feature-.yaml
================================================
name: "\U0001F680 Feature request"
description: Submit a request for a new feature
labels: ["enhancement", "pending"]
body:
- type: markdown
attributes:
value: |
Please do not create issues that are not related to new features under this category.
请勿在此分类下创建和新特性无关的 issues。
- type: checkboxes
id: reminder
attributes:
label: Reminder
description: |
Please ensure you have read the above rules carefully and searched the existing issues.
请确保您已经认真阅读了上述规则并且搜索过现有的 issues。
options:
- label: I have read the above rules and searched the existing issues.
required: true
- type: textarea
id: description
validations:
required: true
attributes:
label: Description
description: |
A clear and concise description of the feature proposal.
请详细描述您希望加入的新功能特性。
- type: textarea
id: contribution
validations:
required: false
attributes:
label: Pull Request
description: |
Have you already created the relevant PR and submitted the code?
您是否已经创建了相关 PR 并提交了代码?
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
blank_issues_enabled: false
contact_links:
- name: 📚 FAQs | 常见问题
url: https://github.com/kvcache-ai/ktransformers/issues/1608
about: Reading in advance is recommended | 建议提前阅读
================================================
FILE: .github/PULL_REQUEST_TEMPLATE.md
================================================
# What does this PR do?
Fixes # (issue)
## Before submitting
- [ ] Did you read the [contributor guideline](https://github.com/kvcache-ai/ktransformers/blob/main/.github/CONTRIBUTING.md)?
- [ ] Did you write any new necessary tests?
================================================
FILE: .github/SECURITY.md
================================================
# Reporting Security Issues
To report a security issue, please use the GitHub Security Advisory ["Report a Vulnerability"](https://github.com/kvcache-ai/ktransformers/security/advisories/new) tab.
We will send a response indicating the next steps in handling your report. After the initial reply to your report, the security team will keep you informed of the progress towards a fix and full announcement, and may ask for additional information or guidance.
Report security bugs in third-party modules to the person or team maintaining the module.
================================================
FILE: .github/workflows/book-ci.yml
================================================
name: Book-CI
on:
push:
branches:
- main
# - server_support
pull_request:
branches:
- main
# - server_support
jobs:
test:
name: test
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
steps:
- uses: actions/checkout@v4
- name: Install Rust
run: |
rustup set profile minimal
rustup toolchain install stable
rustup default stable
- name: Setup mdBook
uses: peaceiris/actions-mdbook@v2
with:
mdbook-version: "latest"
# - name: Run tests
# run: mdbook test
================================================
FILE: .github/workflows/deploy.yml
================================================
name: Deploy
on:
push:
branches:
- main
# - server_support
pull_request:
branches:
- main
# - server_support
defaults:
run:
shell: bash
permissions:
contents: write
jobs:
deploy:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
steps:
- uses: actions/checkout@v4
- name: Install Rust
run: |
rustup set profile minimal
rustup toolchain install stable
rustup default stable
- name: Setup mdBook
uses: peaceiris/actions-mdbook@v2
with:
mdbook-version: "latest"
- run: mdbook build
# - name: Copy Assets
# run: |
# chmod +x ci/copy-assets.sh
# ci/copy-assets.sh ${{ matrix.os }}
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
# or || github.ref == 'refs/heads/server_support'
if: ${{ github.ref == 'refs/heads/main' }}
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./book
================================================
FILE: .github/workflows/docker-image.yml
================================================
name: DockerHub CI
on:
release:
types: [published]
workflow_dispatch:
inputs:
push_to_dockerhub:
description: 'Push image to DockerHub? (true/false)'
required: true
default: 'false'
type: boolean
cuda_version:
description: 'CUDA version (e.g., 12.8.1)'
required: false
default: '12.8.1'
type: string
push_simplified_tag:
description: 'Also push simplified tag? (true/false)'
required: false
default: 'true'
type: boolean
ubuntu_mirror:
description: 'Use Tsinghua Ubuntu mirror? (0/1)'
required: false
default: '0'
type: string
# push:
# branches:
# - main
env:
DOCKERHUB_REPO: ${{ secrets.DOCKERHUB_USERNAME }}/ktransformers
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run tests
run: |
if [ -f docker-compose.test.yml ]; then
docker-compose --file docker-compose.test.yml build
docker-compose --file docker-compose.test.yml run sut
else
docker build . --file docker/Dockerfile
fi
build-and-push:
needs: test
name: Build and Push Multi-Variant Docker Image
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Move Docker data directory
run: |
sudo systemctl stop docker
sudo mkdir -p /mnt/docker
sudo rsync -avz /var/lib/docker/ /mnt/docker
sudo rm -rf /var/lib/docker
sudo ln -s /mnt/docker /var/lib/docker
sudo systemctl start docker
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Docker Hub
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Determine build parameters
id: params
run: |
# Determine if we should push
if [ "${{ github.event_name }}" = "release" ]; then
echo "should_push=true" >> $GITHUB_OUTPUT
echo "push_simplified=true" >> $GITHUB_OUTPUT
elif [ "${{ github.event_name }}" = "workflow_dispatch" ]; then
echo "should_push=${{ inputs.push_to_dockerhub }}" >> $GITHUB_OUTPUT
echo "push_simplified=${{ inputs.push_simplified_tag }}" >> $GITHUB_OUTPUT
else
echo "should_push=false" >> $GITHUB_OUTPUT
echo "push_simplified=false" >> $GITHUB_OUTPUT
fi
# Determine CUDA version
if [ "${{ github.event_name }}" = "workflow_dispatch" ] && [ -n "${{ inputs.cuda_version }}" ]; then
echo "cuda_version=${{ inputs.cuda_version }}" >> $GITHUB_OUTPUT
else
echo "cuda_version=12.8.1" >> $GITHUB_OUTPUT
fi
# Determine Ubuntu mirror setting
if [ "${{ github.event_name }}" = "workflow_dispatch" ] && [ -n "${{ inputs.ubuntu_mirror }}" ]; then
echo "ubuntu_mirror=${{ inputs.ubuntu_mirror }}" >> $GITHUB_OUTPUT
else
echo "ubuntu_mirror=0" >> $GITHUB_OUTPUT
fi
- name: Build and push Docker image
run: |
cd docker
# Build command arguments
BUILD_ARGS=(
--cuda-version "${{ steps.params.outputs.cuda_version }}"
--ubuntu-mirror "${{ steps.params.outputs.ubuntu_mirror }}"
--repository "${{ env.DOCKERHUB_REPO }}"
)
# Add simplified tag option if enabled
if [ "${{ steps.params.outputs.push_simplified }}" = "true" ]; then
BUILD_ARGS+=(--also-push-simplified)
fi
# Add HTTP proxy if available
if [ -n "${{ secrets.HTTP_PROXY }}" ]; then
BUILD_ARGS+=(--http-proxy "${{ secrets.HTTP_PROXY }}")
fi
# Add HTTPS proxy if available
if [ -n "${{ secrets.HTTPS_PROXY }}" ]; then
BUILD_ARGS+=(--https-proxy "${{ secrets.HTTPS_PROXY }}")
fi
# Dry run if not pushing
if [ "${{ steps.params.outputs.should_push }}" != "true" ]; then
BUILD_ARGS+=(--dry-run)
fi
# Execute build script
./push-to-dockerhub.sh "${BUILD_ARGS[@]}"
- name: Display image information
if: steps.params.outputs.should_push == 'true'
run: |
echo "::notice title=Docker Image::Image pushed successfully to ${{ env.DOCKERHUB_REPO }}"
echo "Pull command: docker pull ${{ env.DOCKERHUB_REPO }}:v\$(VERSION)-cu\$(CUDA_SHORT)"
================================================
FILE: .github/workflows/kt-kernel-tests.yml
================================================
name: PR KT-Kernel Test
on:
pull_request:
branches:
- main
- develop
types: [synchronize, labeled]
workflow_dispatch:
concurrency:
group: pr-kt-kernel-test-${{ github.ref }}
cancel-in-progress: true
jobs:
# =============================================== check changes ====================================================
check-changes:
runs-on: ubuntu-latest
outputs:
kt_kernel: ${{ steps.filter.outputs.kt_kernel }}
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Fail if the PR does not have the 'run-ci' label
if: github.event_name == 'pull_request' && !contains(github.event.pull_request.labels.*.name, 'run-ci')
run: |
echo "This pull request does not have the 'run-ci' label. Failing the workflow."
exit 1
- name: Fail if the PR is a draft
if: github.event_name == 'pull_request' && github.event.pull_request.draft == true
run: |
echo "This pull request is a draft. Failing the workflow."
exit 1
- name: Detect file changes
id: filter
uses: dorny/paths-filter@v3
with:
filters: |
kt_kernel:
- "kt-kernel/**"
- ".github/workflows/kt-kernel-tests.yml"
# =============================================== KT-Kernel tests ====================================================
per-commit-kt-kernel-cpu:
needs: [check-changes]
if: always() && !failure() && !cancelled() &&
(needs.check-changes.outputs.kt_kernel == 'true' || github.event_name == 'workflow_dispatch')
runs-on: kt-cpu
continue-on-error: false
steps:
- name: Cleanup
run: |
sudo rm -rf $GITHUB_WORKSPACE/* || true
- name: Checkout code
uses: actions/checkout@v4
with:
submodules: recursive
- name: Install KT-Kernel
run: |
cd kt-kernel
bash install.sh build
- name: Run KT-Kernel CPU tests
timeout-minutes: 60
run: |
cd kt-kernel/test
python3 run_suite.py --hw cpu --suite default
# =============================================== finish ====================================================
pr-test-kt-kernel-finish:
needs: [check-changes, per-commit-kt-kernel-cpu]
if: always()
runs-on: ubuntu-latest
steps:
- name: Check all dependent job statuses
run: |
# Convert the 'needs' context to a JSON string
json_needs='${{ toJson(needs) }}'
# Get a list of all job names from the JSON keys
job_names=$(echo "$json_needs" | jq -r 'keys_unsorted[]')
for job in $job_names; do
# For each job, extract its result
result=$(echo "$json_needs" | jq -r --arg j "$job" '.[$j].result')
# Print the job name and its result
echo "$job: $result"
# Check for failure or cancellation and exit if found
if [[ "$result" == "failure" || "$result" == "cancelled" ]]; then
echo "The above jobs failed."
exit 1
fi
done
# If the loop completes, all jobs were successful
echo "All jobs completed successfully"
exit 0
================================================
FILE: .github/workflows/release-fake-tag.yml
================================================
name: Release Fake Tag
on:
push:
branches:
- main
paths:
- "version.py"
workflow_dispatch:
permissions:
contents: write
jobs:
publish:
if: github.repository == 'kvcache-ai/ktransformers'
runs-on: ubuntu-latest
environment: 'prod'
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
token: ${{ secrets.GITHUB_TOKEN }}
- name: Get version
id: get_version
run: |
version=$(cat version.py | grep '__version__' | cut -d'"' -f2)
echo "TAG=v$version" >> $GITHUB_OUTPUT
- name: Create and push tag
run: |
git config user.name "ktransformers-bot"
git config user.email "ktransformers-bot@users.noreply.github.com"
git tag ${{ steps.get_version.outputs.TAG }}
git push origin ${{ steps.get_version.outputs.TAG }}
================================================
FILE: .github/workflows/release-pypi.yml
================================================
name: Release to PyPI
on:
push:
branches:
- main
paths:
- "version.py"
workflow_dispatch:
inputs:
test_pypi:
description: 'Publish to TestPyPI instead of PyPI (for testing)'
required: false
default: 'false'
type: choice
options:
- 'true'
- 'false'
permissions:
contents: read
jobs:
# ── sglang-kt (must be on PyPI before users can pip install kt-kernel) ──
build-and-publish-sglang-kt:
name: Build & publish sglang-kt
runs-on: [self-hosted, linux, x64]
if: github.repository == 'kvcache-ai/ktransformers' && github.ref == 'refs/heads/main'
environment: prod
permissions:
id-token: write
contents: read
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: recursive
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.12'
- name: Install build tools
run: |
python -m pip install --upgrade pip
pip install build wheel setuptools twine
- name: Build sglang-kt wheel
working-directory: third_party/sglang/python
run: |
KT_VERSION=$(python3 -c "exec(open('${{ github.workspace }}/version.py').read()); print(__version__)")
export SGLANG_KT_VERSION="$KT_VERSION"
echo "Building sglang-kt v${KT_VERSION} wheel..."
python -m build --wheel -v
ls dist/ | grep -q "sglang_kt" || (echo "ERROR: Wheel name does not contain sglang_kt" && exit 1)
- name: Publish sglang-kt to PyPI
if: github.event.inputs.test_pypi != 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
run: |
python -m twine upload --skip-existing --verbose third_party/sglang/python/dist/*.whl
- name: Publish sglang-kt to TestPyPI (if requested)
if: github.event.inputs.test_pypi == 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_API_TOKEN }}
run: |
python -m twine upload --repository testpypi --skip-existing --verbose third_party/sglang/python/dist/*.whl
# ── kt-kernel ──
build-kt-kernel:
name: Build kt-kernel (Python ${{ matrix.python-version }})
runs-on: [self-hosted, linux, x64, gpu]
strategy:
fail-fast: false
matrix:
python-version: ['3.11', '3.12']
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: recursive
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
- name: Verify CUDA availability
run: |
nvidia-smi || (echo "ERROR: GPU not available" && exit 1)
nvcc --version || (echo "ERROR: CUDA toolkit not found" && exit 1)
- name: Install dependencies
run: |
apt-get update && apt-get install -y cmake libhwloc-dev pkg-config libnuma-dev
python -m pip install --upgrade pip
pip install build wheel setuptools torch --index-url https://download.pytorch.org/whl/cu118
- name: Build kt-kernel wheel
working-directory: kt-kernel
env:
CPUINFER_BUILD_ALL_VARIANTS: '1'
CPUINFER_USE_CUDA: '1'
CPUINFER_CUDA_ARCHS: '80;86;89;90'
CPUINFER_CUDA_STATIC_RUNTIME: '1'
CPUINFER_BUILD_TYPE: 'Release'
CPUINFER_PARALLEL: '4'
CPUINFER_FORCE_REBUILD: '1'
CUDA_HOME: '/usr/local/cuda-11.8'
run: |
echo "Building kt-kernel with:"
echo " - CUDA support (SM 80, 86, 89, 90)"
echo " - CPU multi-variant (AMX, AVX512, AVX2)"
python -m build --wheel -v
- name: Verify wheel
working-directory: kt-kernel
run: |
echo "Generated wheel:"
ls -lh dist/
# Install and test
pip install dist/*.whl
python -c "import kt_kernel; print(f'✓ Version: {kt_kernel.__version__}')"
python -c "import kt_kernel; print(f'✓ CPU variant: {kt_kernel.__cpu_variant__}')"
# Verify CUDA support
python -c "
from kt_kernel import kt_kernel_ext
cpu_infer = kt_kernel_ext.CPUInfer(4)
methods = dir(cpu_infer)
has_cuda = 'submit_with_cuda_stream' in methods
print(f'✓ CUDA support: {has_cuda}')
"
# Verify CPU multi-variant support
echo "Checking CPU variants in wheel..."
python -m zipfile -l dist/*.whl | grep "_kt_kernel_ext_" || echo "Warning: No variant .so files found"
python -m zipfile -l dist/*.whl | grep "_kt_kernel_ext_amx.cpython" && echo "✓ AMX variant found" || echo "Note: AMX variant missing"
python -m zipfile -l dist/*.whl | grep "_kt_kernel_ext_avx512" && echo "✓ AVX512 variants found" || echo "Note: AVX512 variants missing"
python -m zipfile -l dist/*.whl | grep "_kt_kernel_ext_avx2.cpython" && echo "✓ AVX2 variant found" || echo "Note: AVX2 variant missing"
# Verify static linking (should NOT depend on libcudart.so)
rm -rf /tmp/check
unzip -q dist/*.whl -d /tmp/check
if ldd /tmp/check/kt_kernel/*.so 2>/dev/null | grep -q "libcudart.so"; then
echo "ERROR: Dynamic cudart found, should be statically linked"
exit 1
else
echo "✓ CUDA runtime statically linked"
fi
- name: Repair wheel for manylinux
working-directory: kt-kernel
run: |
pip install auditwheel patchelf
mkdir -p wheelhouse
for wheel in dist/*.whl; do
auditwheel repair "$wheel" --plat manylinux_2_17_x86_64 --exclude libcuda.so.1 -w wheelhouse/ || \
cp "$wheel" wheelhouse/$(basename "$wheel" | sed 's/linux_x86_64/manylinux_2_17_x86_64/')
done
rm -f dist/*.whl && cp wheelhouse/*.whl dist/
- name: Upload artifact
uses: actions/upload-artifact@v4
with:
name: kt-kernel-wheels-py${{ matrix.python-version }}
path: kt-kernel/dist/*.whl
retention-days: 7
publish-pypi:
name: Publish kt-kernel to PyPI
needs: [build-and-publish-sglang-kt, build-kt-kernel]
runs-on: [self-hosted, linux, x64]
if: github.repository == 'kvcache-ai/ktransformers' && github.ref == 'refs/heads/main'
environment: prod
permissions:
id-token: write # For trusted publishing (OIDC)
contents: read
steps:
- name: Download all wheel artifacts
uses: actions/download-artifact@v4
with:
path: artifacts/
- name: Organize wheels into dist/
run: |
mkdir -p dist/
find artifacts/ -name "*.whl" -exec cp {} dist/ \;
echo "Wheels to publish:"
ls -lh dist/
- name: Get version from wheel
id: get_version
run: |
# Extract version from first wheel filename
wheel_name=$(ls dist/*.whl | head -1 | xargs basename)
# Extract version (format: kt_kernel-X.Y.Z-...)
version=$(echo "$wheel_name" | sed 's/kt_kernel-\([0-9.]*\)-.*/\1/')
echo "VERSION=$version" >> $GITHUB_OUTPUT
echo "Publishing version: $version"
- name: Install twine
run: |
python -m pip install --upgrade pip
pip install twine
- name: Publish to TestPyPI (if requested)
if: github.event.inputs.test_pypi == 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_API_TOKEN }}
run: |
python -m twine upload \
--repository testpypi \
--skip-existing \
--verbose \
dist/*.whl
- name: Publish to PyPI
if: github.event.inputs.test_pypi != 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
run: |
python -m twine upload \
--skip-existing \
--verbose \
dist/*.whl
- name: Create release summary
run: |
echo "## 🎉 kt-kernel v${{ steps.get_version.outputs.VERSION }} Published to PyPI" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "### Installation" >> $GITHUB_STEP_SUMMARY
echo '```bash' >> $GITHUB_STEP_SUMMARY
echo "pip install kt-kernel==${{ steps.get_version.outputs.VERSION }}" >> $GITHUB_STEP_SUMMARY
echo '```' >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "### Published Wheels" >> $GITHUB_STEP_SUMMARY
echo "Total: $(ls -1 dist/*.whl | wc -l) wheels (Python 3.10, 3.11, 3.12)" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "### Features" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "**CPU Multi-Variant Support:**" >> $GITHUB_STEP_SUMMARY
echo "- ✅ AMX (Intel Sapphire Rapids+, 2023)" >> $GITHUB_STEP_SUMMARY
echo "- ✅ AVX512 Base/VNNI/VBMI/BF16 (Intel Skylake-X/Ice Lake/Cascade Lake, 2017+)" >> $GITHUB_STEP_SUMMARY
echo "- ✅ AVX2 (Maximum compatibility, 2013+)" >> $GITHUB_STEP_SUMMARY
echo "- 🔧 Runtime CPU detection: Automatically selects optimal variant" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "**CUDA Support:**" >> $GITHUB_STEP_SUMMARY
echo "- ✅ SM 80 (Ampere: A100, RTX 3000 series)" >> $GITHUB_STEP_SUMMARY
echo "- ✅ SM 86 (Ampere: RTX 3060-3090)" >> $GITHUB_STEP_SUMMARY
echo "- ✅ SM 89 (Ada Lovelace: RTX 4000 series)" >> $GITHUB_STEP_SUMMARY
echo "- ✅ SM 90 (Hopper: H100)" >> $GITHUB_STEP_SUMMARY
echo "- 🔧 Static CUDA runtime: Compatible with CUDA 11.8+ and 12.x drivers" >> $GITHUB_STEP_SUMMARY
echo "- 🔧 Works on CPU-only systems (CUDA features disabled gracefully)" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "**Requirements:**" >> $GITHUB_STEP_SUMMARY
echo "- Python 3.10, 3.11, or 3.12" >> $GITHUB_STEP_SUMMARY
echo "- Linux x86-64 (manylinux_2_17 compatible)" >> $GITHUB_STEP_SUMMARY
echo "- For CUDA features: NVIDIA driver with CUDA 11.8+ or 12.x support" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "PyPI link: https://pypi.org/project/kt-kernel/${{ steps.get_version.outputs.VERSION }}/" >> $GITHUB_STEP_SUMMARY
================================================
FILE: .github/workflows/release-sglang-kt.yml
================================================
name: Release sglang-kt to PyPI
on:
push:
branches:
- main
paths:
- "third_party/sglang"
- "version.py"
workflow_dispatch:
inputs:
test_pypi:
description: 'Publish to TestPyPI instead of PyPI (for testing)'
required: false
default: 'false'
type: choice
options:
- 'true'
- 'false'
permissions:
contents: read
jobs:
build-sglang-kt:
name: Build sglang-kt wheel
runs-on: [self-hosted, linux, x64]
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: recursive
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.12'
- name: Install build tools
run: |
python -m pip install --upgrade pip
pip install build wheel setuptools
- name: Build sglang-kt wheel
working-directory: third_party/sglang/python
run: |
# Read version from ktransformers version.py
KT_VERSION=$(python3 -c "exec(open('${{ github.workspace }}/version.py').read()); print(__version__)")
export SGLANG_KT_VERSION="$KT_VERSION"
echo "Building sglang-kt v${KT_VERSION} wheel..."
python -m build --wheel -v
- name: Verify wheel
working-directory: third_party/sglang/python
run: |
echo "Generated wheel:"
ls -lh dist/
# Verify the wheel has the correct package name
ls dist/ | grep -q "sglang_kt" || (echo "ERROR: Wheel name does not contain sglang_kt" && exit 1)
echo "Wheel name verified."
- name: Upload artifact
uses: actions/upload-artifact@v4
with:
name: sglang-kt-wheel
path: third_party/sglang/python/dist/*.whl
retention-days: 7
publish-pypi:
name: Publish sglang-kt to PyPI
needs: [build-sglang-kt]
runs-on: [self-hosted, linux, x64]
if: github.repository == 'kvcache-ai/ktransformers' && github.ref == 'refs/heads/main'
environment: prod
permissions:
id-token: write
contents: read
steps:
- name: Download wheel artifact
uses: actions/download-artifact@v4
with:
name: sglang-kt-wheel
path: dist/
- name: Display wheels
run: |
echo "Wheels to publish:"
ls -lh dist/
- name: Install twine
run: |
python -m pip install --upgrade pip
pip install twine
- name: Publish to TestPyPI (if requested)
if: github.event.inputs.test_pypi == 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_API_TOKEN }}
run: |
python -m twine upload \
--repository testpypi \
--skip-existing \
--verbose \
dist/*.whl
- name: Publish to PyPI
if: github.event.inputs.test_pypi != 'true'
env:
TWINE_USERNAME: __token__
TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
run: |
python -m twine upload \
--skip-existing \
--verbose \
dist/*.whl
- name: Create release summary
run: |
echo "## sglang-kt Published to PyPI" >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "### Installation" >> $GITHUB_STEP_SUMMARY
echo '```bash' >> $GITHUB_STEP_SUMMARY
echo "pip install sglang-kt" >> $GITHUB_STEP_SUMMARY
echo '```' >> $GITHUB_STEP_SUMMARY
echo "" >> $GITHUB_STEP_SUMMARY
echo "This is the kvcache-ai fork of SGLang with kt-kernel support." >> $GITHUB_STEP_SUMMARY
echo "PyPI link: https://pypi.org/project/sglang-kt/" >> $GITHUB_STEP_SUMMARY
================================================
FILE: .github/workflows/sync-sglang-submodule.yml
================================================
name: Sync sglang submodule
on:
schedule:
# Run daily at 08:00 UTC
- cron: "0 8 * * *"
workflow_dispatch:
permissions:
contents: write
pull-requests: write
jobs:
sync:
name: Check for sglang-kt updates
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: true
fetch-depth: 0
token: ${{ secrets.GITHUB_TOKEN }}
- name: Update sglang submodule to latest main
id: update
run: |
OLD_SHA=$(git -C third_party/sglang rev-parse HEAD)
git submodule update --remote third_party/sglang
NEW_SHA=$(git -C third_party/sglang rev-parse HEAD)
echo "old_sha=$OLD_SHA" >> "$GITHUB_OUTPUT"
echo "new_sha=$NEW_SHA" >> "$GITHUB_OUTPUT"
if [ "$OLD_SHA" = "$NEW_SHA" ]; then
echo "changed=false" >> "$GITHUB_OUTPUT"
echo "sglang submodule is already up to date ($OLD_SHA)"
else
echo "changed=true" >> "$GITHUB_OUTPUT"
# Collect commit log between old and new
COMMITS=$(git -C third_party/sglang log --oneline "$OLD_SHA..$NEW_SHA" | head -20)
echo "commits<<EOF" >> "$GITHUB_OUTPUT"
echo "$COMMITS" >> "$GITHUB_OUTPUT"
echo "EOF" >> "$GITHUB_OUTPUT"
# sglang-kt version = ktransformers version (from version.py)
VERSION=$(python3 -c "exec(open('version.py').read()); print(__version__)" 2>/dev/null || echo "unknown")
echo "version=$VERSION" >> "$GITHUB_OUTPUT"
echo "sglang submodule updated: $OLD_SHA -> $NEW_SHA (v$VERSION)"
fi
- name: Create pull request
if: steps.update.outputs.changed == 'true'
uses: peter-evans/create-pull-request@v6
with:
token: ${{ secrets.GITHUB_TOKEN }}
commit-message: |
[build]: sync sglang submodule to ${{ steps.update.outputs.new_sha }}
branch: auto/sync-sglang
delete-branch: true
title: "[build] Sync sglang-kt submodule (v${{ steps.update.outputs.version }})"
body: |
Automated sync of `third_party/sglang` submodule to latest `main`.
**Old ref:** `${{ steps.update.outputs.old_sha }}`
**New ref:** `${{ steps.update.outputs.new_sha }}`
**sglang-kt version:** `${{ steps.update.outputs.version }}`
### Commits included
```
${{ steps.update.outputs.commits }}
```
---
*This PR was created automatically by the [sync-sglang-submodule](${{ github.server_url }}/${{ github.repository }}/actions/workflows/sync-sglang-submodule.yml) workflow.*
labels: |
dependencies
automated
================================================
FILE: .gitignore
================================================
__pycache__
build
.vscode
*.so
*.cache
server.db
logs
node_modules
*.nsys-rep
.vs/
*pycache*
*build/
.DS_Store
compile_commands.json
*.egg-info*
*dist/
ktransformers/server/local_store/
ktransformers/server_test1.db
*.patch
img/
tmp*.txt
test.txt
book
ktransformers/tests/chat_txt.txt
mmlu_result*
ktransformers/ktransformers_ext/cuda_musa/
test_prompt.txt
csrc/demo
build*
CMakeFiles/
kvc2/
sched/
*.png
================================================
FILE: .gitmodules
================================================
[submodule "third_party/llama.cpp"]
path = third_party/llama.cpp
url = https://github.com/ggerganov/llama.cpp.git
[submodule "third_party/pybind11"]
path = third_party/pybind11
url = https://github.com/pybind/pybind11.git
[submodule "third_party/custom_flashinfer"]
path = third_party/custom_flashinfer
url = https://github.com/kvcache-ai/custom_flashinfer.git
branch = fix-precision-mla-merge-main
[submodule "third_party/sglang"]
path = third_party/sglang
url = https://github.com/kvcache-ai/sglang.git
branch = main
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MAINTAINERS.md
================================================
# Maintainers
This document lists the current maintainers and outlines their responsibilities.
## Current Maintainers
| Name | GitHub | Role | Affiliation | Email |
|------|--------|------|-------------|-------|
| Weiyu Xie | [@ErvinXie](https://github.com/ErvinXie) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | xwy21@mails.tsinghua.edu.cn |
| Hongtao Chen | [@chenht2022](https://github.com/chenht2022) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | cht22@mails.tsinghua.edu.cn |
| Jianwei Dong | [@ovowei](https://github.com/ovowei) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | dongjw24@mails.tsinghua.edu.cn |
| Ziwei Yuan | [@KMSorSMS](https://github.com/KMSorSMS) | Maintainer | [Approaching.AI](http://approaching.ai/) | 2022090910005@std.uestc.edu.cn |
| Qingliang Ou | [@ouqingliang](https://github.com/ouqingliang) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | oql@bupt.edu.cn |
| Jiaqi Liao | [@SkqLiao](https://github.com/SkqLiao) | Maintainer | [Approaching.AI](http://approaching.ai/) | jiaqi.liao@bit.edu.cn |
| Peilin Li | [@JimmyPeilinLi](https://github.com/JimmyPeilinLi) | Maintainer | [Approaching.AI](http://approaching.ai/) | lipeilin@mail.nwpu.edu.cn |
| Xingxing Hao | [@mrhaoxx](https://github.com/mrhaoxx) | Maintainer | [Approaching.AI](http://approaching.ai/) | mr.haoxx@gmail.com |
| Boxin Zhang | [@Atream](https://github.com/Atream) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | zhangbx24@mails.tsinghua.edu.cn |
| Jingqi Tang | [@Azure-Tang](https://github.com/Azure-Tang) | Maintainer | [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University | tangjq25@mails.tsinghua.edu.cn |
| Jiahao Wang | [@qiyuxinlin](https://github.com/qiyuxinlin) | Maintainer | [Approaching.AI](http://approaching.ai/) | 202241050020@hdu.edu.cn |
## Responsibilities
Maintainers steward the project and keep it healthy for users and contributors.
- Review and approve pull requests; ensure changes meet quality, testing, and documentation standards.
- Triage issues, keep labels organized, and respond to questions in a timely manner.
- Uphold the project’s code of conduct and report violations when needed.
- Maintain CI reliability and address regressions promptly.
- Oversee releases and keep compatibility with supported dependency versions.
- Protect project security and follow the security disclosure process.
## Becoming a Maintainer
We welcome contributors who show sustained, high-quality contributions and collaborative behavior. If you are interested, please contact an existing maintainer and share your recent contributions and areas of focus.
================================================
FILE: README.md
================================================
<div align="center">
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>A Flexible Framework for Experiencing Cutting-edge LLM Inference/Fine-tune Optimizations</h3>
<strong><a href="#-overview">🎯 Overview</a> | <a href="#-kt-kernel---high-performance-inference-kernels">🚀 kt-kernel</a> | <a href="#-kt-sft---fine-tuning-framework">🎓 kt-sft</a> | <a href="#-citation">🔥 Citation</a> | <a href="https://github.com/kvcache-ai/ktransformers/issues/1582">🚀 Roadmap(2025Q4)</a> </strong>
</div>
## 🎯 Overview
KTransformers is a research project focused on efficient inference and fine-tuning of large language models through CPU-GPU heterogeneous computing. The project has evolved into **two core modules**: [kt-kernel](https://github.com/kvcache-ai/ktransformers/tree/main/kt-kernel/) and [kt-sft](https://github.com/kvcache-ai/ktransformers/tree/main/kt-sft).
## 🔥 Updates
* **Feb 13, 2026**: MiniMax-M2.5 Day0 Support! ([Tutorial](./doc/en/MiniMax-M2.5.md))
* **Feb 12, 2026**: GLM-5 Day0 Support! ([Tutorial](./doc/en/kt-kernel/GLM-5-Tutorial.md))
* **Jan 27, 2026**: Kimi-K2.5 Day0 Support! ([Tutorial](./doc/en/Kimi-K2.5.md)) ([SFT Tutorial](./doc/en/SFT_Installation_Guide_KimiK2.5.md))
* **Jan 22, 2026**: Support [CPU-GPU Expert Scheduling](./doc/en/kt-kernel/experts-sched-Tutorial.md), [Native BF16 and FP8 per channel Precision](./doc/en/kt-kernel/Native-Precision-Tutorial.md) and [AutoDL unified fine-tuning and inference](./doc/zh/【云端低价训推】%20KTransformers%2BAutoDL%2BLlamaFactory:随用随租的低成本超大模型「微调%2B推理」一体化流程.pdf)
* **Dec 24, 2025**: Support Native MiniMax-M2.1 inference. ([Tutorial](./doc/en/kt-kernel/MiniMax-M2.1-Tutorial.md))
* **Dec 22, 2025**: Support RL-DPO fine-tuning with LLaMA-Factory. ([Tutorial](./doc/en/SFT/DPO_tutorial.md))
* **Dec 5, 2025**: Support Native Kimi-K2-Thinking inference ([Tutorial](./doc/en/kt-kernel/Kimi-K2-Thinking-Native.md))
* **Nov 6, 2025**: Support Kimi-K2-Thinking inference ([Tutorial](./doc/en/Kimi-K2-Thinking.md)) and fine-tune ([Tutorial](./doc/en/SFT_Installation_Guide_KimiK2.md))
* **Nov 4, 2025**: KTransformers Fine-Tuning × LLaMA-Factory Integration. ([Tutorial](./doc/en/KTransformers-Fine-Tuning_User-Guide.md))
* **Oct 27, 2025**: Support Ascend NPU. ([Tutorial](./doc/zh/DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md))
* **Oct 10, 2025**: Integrating into SGLang. ([Roadmap](https://github.com/sgl-project/sglang/issues/11425), [Blog](https://lmsys.org/blog/2025-10-22-KTransformers/))
* **Sept 11, 2025**: Support Qwen3-Next. ([Tutorial](./doc/en/Qwen3-Next.md))
* **Sept 05, 2025**: Support Kimi-K2-0905. ([Tutorial](./doc/en/Kimi-K2.md))
* **July 26, 2025**: Support SmallThinker and GLM4-MoE. ([Tutorial](./doc/en/SmallThinker_and_Glm4moe.md))
* **July 11, 2025**: Support Kimi-K2. ([Tutorial](./doc/en/Kimi-K2.md))
* **June 30, 2025**: Support 3-layer (GPU-CPU-Disk) [prefix cache](./doc/en/prefix_cache.md) reuse.
* **May 14, 2025**: Support Intel Arc GPU ([Tutorial](./doc/en/xpu.md)).
* **Apr 29, 2025**: Support AMX-Int8、 AMX-BF16 and Qwen3MoE ([Tutorial](./doc/en/AMX.md))
* **Apr 9, 2025**: Experimental support for LLaMA 4 models ([Tutorial](./doc/en/llama4.md)).
* **Apr 2, 2025**: Support Multi-concurrency. ([Tutorial](./doc/en/balance-serve.md)).
* **Mar 15, 2025**: Support ROCm on AMD GPU ([Tutorial](./doc/en/ROCm.md)).
* **Mar 5, 2025**: Support unsloth 1.58/2.51 bits weights and [IQ1_S/FP8 hybrid](./doc/en/fp8_kernel.md) weights. Support 139K [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022--v023-longer-context--fp8-kernel) for DeepSeek-V3 and R1 in 24GB VRAM.
* **Feb 25, 2025**: Support [FP8 GPU kernel](./doc/en/fp8_kernel.md) for DeepSeek-V3 and R1; [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022-longer-context).
* **Feb 15, 2025**: Longer Context (from 4K to 8K for 24GB VRAM) & Slightly Faster Speed (+15%, up to 16 Tokens/s), update [docs](./doc/en/DeepseekR1_V3_tutorial.md) and [online books](https://kvcache-ai.github.io/ktransformers/).
* **Feb 10, 2025**: Support Deepseek-R1 and V3 on single (24GB VRAM)/multi gpu and 382G DRAM, up to 3~28x speedup. For detailed show case and reproduction tutorial, see [here](./doc/en/DeepseekR1_V3_tutorial.md).
* **Aug 28, 2024**: Decrease DeepseekV2's required VRAM from 21G to 11G.
* **Aug 15, 2024**: Update detailed [tutorial](doc/en/injection_tutorial.md) for injection and multi-GPU.
* **Aug 14, 2024**: Support llamfile as linear backend.
* **Aug 12, 2024**: Support multiple GPU; Support new model: mixtral 8\*7B and 8\*22B; Support q2k, q3k, q5k dequant on gpu.
* **Aug 9, 2024**: Support windows native.
---
## 📦 Core Modules
### 🚀 [kt-kernel](./kt-kernel/) - High-Performance Inference Kernels
CPU-optimized kernel operations for heterogeneous LLM inference.
<img width="1049" height="593" alt="image" src="https://github.com/user-attachments/assets/68f423da-3f55-4025-bdc9-9ceaa554f00b" />
**Key Features:**
- **AMX/AVX Acceleration**: Intel AMX and AVX512/AVX2 optimized kernels for INT4/INT8 quantized inference
- **MoE Optimization**: Efficient Mixture-of-Experts inference with NUMA-aware memory management
- **Quantization Support**: CPU-side INT4/INT8 quantized weights, GPU-side GPTQ support
- **Easy Integration**: Clean Python API for SGLang and other frameworks
**Quick Start:**
```bash
cd kt-kernel
pip install .
```
**Use Cases:**
- CPU-GPU hybrid inference for large MoE models
- Integration with SGLang for production serving
- Heterogeneous expert placement (hot experts on GPU, cold experts on CPU)
**Performance Examples:**
| Model | Hardware Configuration | Total Throughput | Output Throughput |
|-------|------------------------|------------------|-------------------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8-way concurrency) |
👉 **[Full Documentation →](./kt-kernel/README.md)**
---
### 🎓 [kt-sft](./kt-sft/) - Fine-Tuning Framework
KTransformers × LLaMA-Factory integration for ultra-large MoE model fine-tuning.
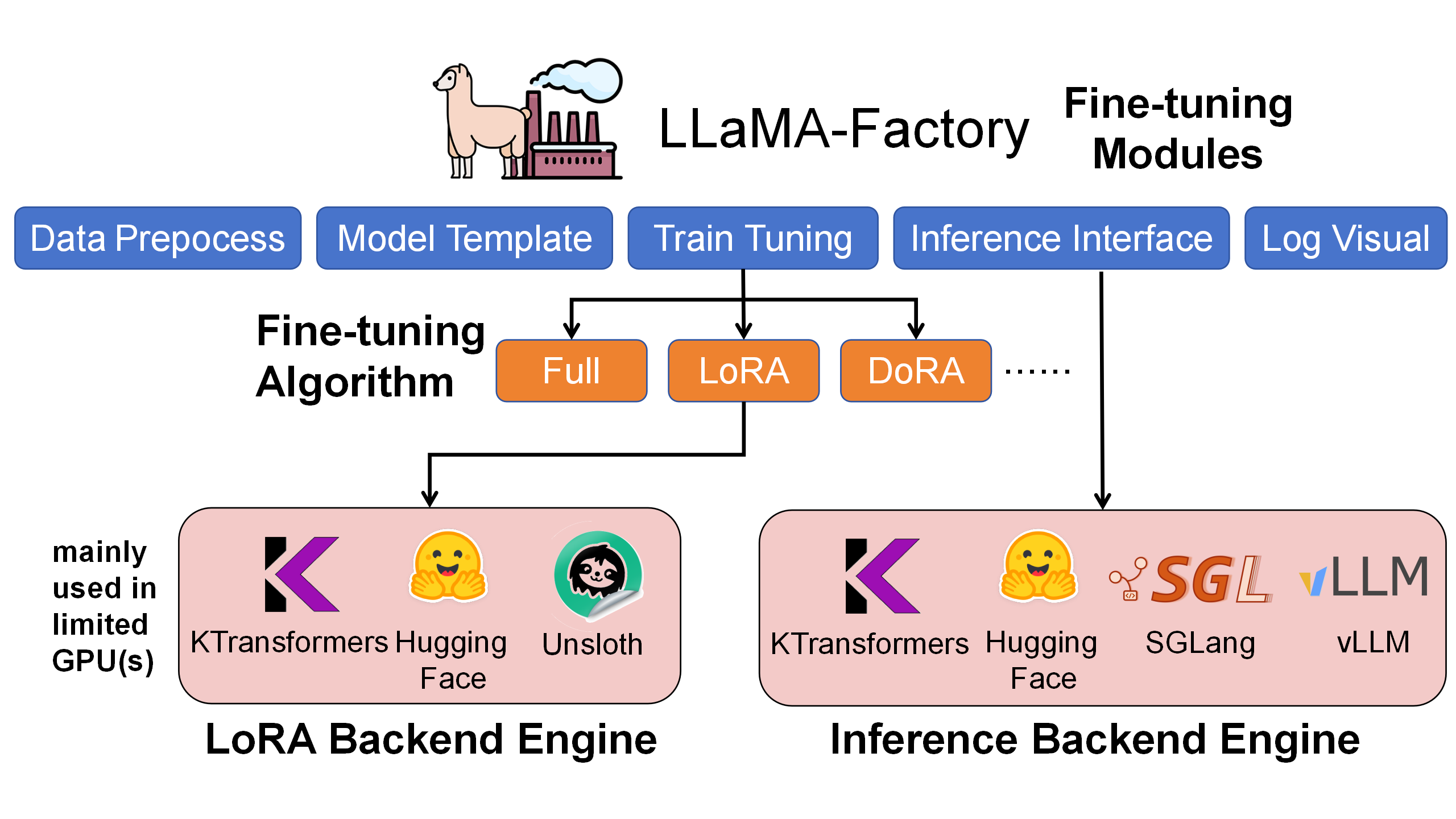
**Key Features:**
- **Resource Efficient**: Fine-tune 671B DeepSeek-V3 with just **70GB GPU memory** + 1.3TB RAM
- **LoRA Support**: Full LoRA fine-tuning with heterogeneous acceleration
- **LLaMA-Factory Integration**: Seamless integration with popular fine-tuning framework
- **Production Ready**: Chat, batch inference, and metrics evaluation
**Performance Examples:**
| Model | Configuration | Throughput | GPU Memory |
|-------|--------------|------------|------------|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (multi-GPU) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
**Quick Start:**
```bash
cd kt-sft
# Install environment following kt-sft/README.md
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
```
👉 **[Full Documentation →](./kt-sft/README.md)**
---
## 🔥 Citation
If you use KTransformers in your research, please cite our paper:
```bibtex
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
## 👥 Contributors & Team
Developed and maintained by:
- [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University
- [Approaching.AI](http://approaching.ai/)
- [9#AISoft](https://github.com/aisoft9)
- Community contributors
We welcome contributions! Please feel free to submit issues and pull requests.
## 💬 Community & Support
- **GitHub Issues**: [Report bugs or request features](https://github.com/kvcache-ai/ktransformers/issues)
- **WeChat Group**: See [archive/WeChatGroup.png](./archive/WeChatGroup.png)
## 📦 KT original Code
The original integrated KTransformers framework has been archived to the [`archive/`](./archive/) directory for reference. The project now focuses on the two core modules above for better modularity and maintainability.
For the original documentation with full quick-start guides and examples, see:
- [archive/README.md](./archive/README.md) (English)
- [archive/README_ZH.md](./archive/README_ZH.md) (中文)
================================================
FILE: README_ZH.md
================================================
<div align="center">
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>一个用于体验尖端 LLM 推理/微调优化的灵活框架</h3>
<strong><a href="#-概览">🎯 概览</a> | <a href="#-kt-kernel---高性能推理内核">🚀 kt-kernel</a> | <a href="#-kt-sft---微调框架">🎓 kt-sft</a> | <a href="#-引用">🔥 引用</a> </strong>
</div>
## 🎯 概览
KTransformers 是一个专注于通过 CPU-GPU 异构计算实现大语言模型高效推理和微调的研究项目。该项目已发展为**两个核心模块**:[kt-kernel](./kt-kernel/) 和 [kt-sft](./kt-sft/)。
## 🔥 更新
* **2025 年 12 月 5 日**:支持原生 Kimi-K2-Thinking 推理([教程](./doc/en/Kimi-K2-Thinking-Native.md))
* **2025 年 11 月 6 日**:支持 Kimi-K2-Thinking 推理([教程](./doc/en/Kimi-K2-Thinking.md))和微调([教程](./doc/en/SFT_Installation_Guide_KimiK2.md))
* **2025 年 11 月 4 日**:KTransformers 微调 × LLaMA-Factory 集成([教程](./doc/en/KTransformers-Fine-Tuning_User-Guide.md))
* **2025 年 10 月 27 日**:支持昇腾 NPU([教程](./doc/zh/DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md))
* **2025 年 10 月 10 日**:集成到 SGLang([路线图](https://github.com/sgl-project/sglang/issues/11425),[博客](https://lmsys.org/blog/2025-10-22-KTransformers/))
* **2025 年 9 月 11 日**:支持 Qwen3-Next([教程](./doc/en/Qwen3-Next.md))
* **2025 年 9 月 5 日**:支持 Kimi-K2-0905([教程](./doc/en/Kimi-K2.md))
* **2025 年 7 月 26 日**:支持 SmallThinker 和 GLM4-MoE([教程](./doc/en/SmallThinker_and_Glm4moe.md))
* **2025 年 7 月 11 日**:支持 Kimi-K2([教程](./doc/en/Kimi-K2.md))
* **2025 年 6 月 30 日**:支持 3 层(GPU-CPU-磁盘)[前缀缓存](./doc/en/prefix_cache.md)复用
* **2025 年 5 月 14 日**:支持 Intel Arc GPU([教程](./doc/en/xpu.md))
* **2025 年 4 月 29 日**:支持 AMX-Int8、AMX-BF16 和 Qwen3MoE([教程](./doc/en/AMX.md))
* **2025 年 4 月 9 日**:实验性支持 LLaMA 4 模型([教程](./doc/en/llama4.md))
* **2025 年 4 月 2 日**:支持多并发([教程](./doc/en/balance-serve.md))
* **2025 年 3 月 15 日**:支持 AMD GPU 上的 ROCm([教程](./doc/en/ROCm.md))
* **2025 年 3 月 5 日**:支持 unsloth 1.58/2.51 位权重和 [IQ1_S/FP8 混合](./doc/en/fp8_kernel.md)权重。在 24GB VRAM 中支持 DeepSeek-V3 和 R1 的 139K [更长上下文](./doc/en/DeepseekR1_V3_tutorial.md#v022--v023-longer-context--fp8-kernel)
* **2025 年 2 月 25 日**:为 DeepSeek-V3 和 R1 支持 [FP8 GPU 内核](./doc/en/fp8_kernel.md);[更长上下文](./doc/en/DeepseekR1_V3_tutorial.md#v022-longer-context)
* **2025 年 2 月 15 日**:更长上下文(24GB VRAM 从 4K 到 8K)& 速度稍快(+15%,最高 16 Tokens/s),更新[文档](./doc/en/DeepseekR1_V3_tutorial.md)和[在线手册](https://kvcache-ai.github.io/ktransformers/)
* **2025 年 2 月 10 日**:支持 Deepseek-R1 和 V3 在单 GPU(24GB VRAM)/多 GPU 和 382GB DRAM 上运行,速度提升高达 3~28 倍。详细案例展示和复现教程请参见[这里](./doc/en/DeepseekR1_V3_tutorial.md)
* **2024 年 8 月 28 日**:将 DeepseekV2 所需的 VRAM 从 21GB 降低到 11GB
* **2024 年 8 月 15 日**:更新了关于注入和多 GPU 的详细[教程](doc/en/injection_tutorial.md)
* **2024 年 8 月 14 日**:支持 llamfile 作为线性后端
* **2024 年 8 月 12 日**:支持多 GPU;支持新模型:mixtral 8\*7B 和 8\*22B;支持 GPU 上的 q2k、q3k、q5k 去量化
* **2024 年 8 月 9 日**:支持 Windows 原生环境
---
## 📦 核心模块
### 🚀 [kt-kernel](./kt-kernel/) - 高性能推理内核
用于异构 LLM 推理的 CPU 优化内核操作。

**主要特性:**
- **AMX/AVX 加速**:Intel AMX 和 AVX512/AVX2 优化的内核,用于 INT4/INT8 量化推理
- **MoE 优化**:高效的专家混合推理,具有 NUMA 感知内存管理
- **量化支持**:CPU 端 INT4/INT8 量化权重,GPU 端 GPTQ 支持
- **易于集成**:为 SGLang 和其他框架提供简洁的 Python API
**快速开始:**
```bash
cd kt-kernel
pip install .
```
**使用场景:**
- 大型 MoE 模型的 CPU-GPU 混合推理
- 与 SGLang 集成用于生产服务
- 异构专家放置(热专家在 GPU 上,冷专家在 CPU 上)
**性能示例:**
| 模型 | 硬件配置 | 总吞吐量 | 输出吞吐量 |
|-------|------------------------|------------------|-------------------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s(8 路并发)|
👉 **[完整文档 →](./kt-kernel/README.md)**
---
### 🎓 [kt-sft](./kt-sft/) - 微调框架
KTransformers × LLaMA-Factory 集成,用于超大型 MoE 模型微调。

**主要特性:**
- **资源高效**:仅需 **70GB GPU 显存** + 1.3TB 内存即可微调 671B DeepSeek-V3
- **LoRA 支持**:完整的 LoRA 微调,带有异构加速
- **LLaMA-Factory 集成**:与流行的微调框架无缝集成
- **生产就绪**:聊天、批量推理和指标评估
**性能示例:**
| 模型 | 配置 | 吞吐量 | GPU 显存 |
|-------|--------------|------------|--------------|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB(多 GPU)|
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
**快速开始:**
```bash
cd kt-sft
# 按照 kt-sft/README.md 安装环境
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
```
👉 **[完整文档 →](./kt-sft/README.md)**
---
## 🔥 引用
如果您在研究中使用了 KTransformers,请引用我们的论文:
```bibtex
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
## 👥 贡献者与团队
由以下团队开发和维护:
- 清华大学 [MADSys 实验室](https://madsys.cs.tsinghua.edu.cn/)
- [Approaching.AI](http://approaching.ai/)
- 社区贡献者
我们欢迎贡献!请随时提交问题和拉取请求。
## 💬 社区与支持
- **GitHub Issues**:[报告问题或请求功能](https://github.com/kvcache-ai/ktransformers/issues)
- **微信群**:请参见 [archive/WeChatGroup.png](./archive/WeChatGroup.png)
## 📦 KT原仓库
原始的集成 KTransformers 框架已归档到 [`archive/`](./archive/) 目录以供参考。该项目现在专注于上述两个核心模块,以获得更好的模块化和可维护性。
有关原始文档以及完整的快速入门指南和示例,请参见:
- [archive/README.md](./archive/README.md)(英文)
- [archive/README_ZH.md](./archive/README_ZH.md)(中文)
================================================
FILE: archive/.devcontainer/Dockerfile
================================================
FROM pytorch/pytorch:2.5.1-cuda12.1-cudnn9-devel as compile_server
WORKDIR /workspace
ENV CUDA_HOME /usr/local/cuda
RUN <<EOF
apt update -y && apt install -y --no-install-recommends \
git \
wget \
vim \
gcc \
g++ \
cmake &&
rm -rf /var/lib/apt/lists/* &&
pip install --upgrade pip &&
pip install ninja pyproject numpy cpufeature &&
pip install flash-attn &&
cp /usr/lib/x86_64-linux-gnu/libstdc++.so.6 /opt/conda/lib/
EOF
# Set the default shell to bash
CMD ["/bin/bash"]
================================================
FILE: archive/.devcontainer/devcontainer.json
================================================
{
"name": "Ktrans Dev Container",
"privileged": true,
"build": {
"dockerfile": "Dockerfile",
"context": "..",
"args": {
"http_proxy": "${env:http_proxy}",
"https_proxy": "${env:https_proxy}",
}
},
"runArgs": [
"--network=host",
"--gpus",
"all"
// "--gpu all"
],
"workspaceFolder": "/workspace",
"workspaceMount": "source=${localWorkspaceFolder},target=/workspace,type=bind,consistency=cached",
"mounts": [
"source=/mnt/data,target=/mnt/incontainer,type=bind,consistency=cached"
],
"customizations": {
"vscode": {
"extensions": [
],
"settings": {
"terminal.integrated.shell.linux": "/bin/bash",
"cmake.configureOnOpen": true,
"cmake.generator": "Ninja"
}
}
}
}
================================================
FILE: archive/.flake8
================================================
[flake8]
max-line-length = 120
extend-select = B950
extend-ignore = E203,E501,E701, B001,B006,B007,B008,B009,B010,B011,B016,B028,B031,B950,E265,E266,E401,E402,E711,E712,E713,E721,E722,E731,F401,F403,F405,F541,F811,F821,F841,W391
================================================
FILE: archive/.gitmodules
================================================
[submodule "third_party/llama.cpp"]
path = archive/third_party/llama.cpp
url = https://github.com/ggerganov/llama.cpp.git
[submodule "third_party/pybind11"]
path = archive/third_party/pybind11
url = https://github.com/pybind/pybind11.git
[submodule "third_party/spdlog"]
path = archive/third_party/spdlog
url = https://github.com/gabime/spdlog.git
[submodule "third_party/custom_flashinfer"]
path = archive/third_party/custom_flashinfer
url = https://github.com/kvcache-ai/custom_flashinfer.git
branch = fix-precision-mla-merge-main
[submodule "third_party/xxHash"]
path = archive/third_party/xxHash
url = https://github.com/Cyan4973/xxHash.git
[submodule "third_party/prometheus-cpp"]
path = archive/third_party/prometheus-cpp
url = https://github.com/jupp0r/prometheus-cpp
[submodule "third_party/PhotonLibOS"]
path = archive/third_party/PhotonLibOS
url = https://github.com/alibaba/PhotonLibOS.git
[submodule "kt-kernel/third_party/llama.cpp"]
path = kt-kernel/third_party/llama.cpp
url = https://github.com/ggerganov/llama.cpp.git
[submodule "kt-kernel/third_party/pybind11"]
path = kt-kernel/third_party/pybind11
url = https://github.com/pybind/pybind11.git
================================================
FILE: archive/.pylintrc
================================================
[MASTER]
extension-pkg-whitelist=pydantic
max-line-length=120
[MESSAGES CONTROL]
disable=missing-function-docstring
================================================
FILE: archive/Dockerfile
================================================
FROM pytorch/pytorch:2.5.1-cuda12.1-cudnn9-devel as compile_server
ARG CPU_INSTRUCT=NATIVE
# 设置工作目录和 CUDA 路径
WORKDIR /workspace
ENV CUDA_HOME=/usr/local/cuda
# 安装依赖
RUN apt update -y
RUN apt install -y --no-install-recommends \
libtbb-dev \
libssl-dev \
libcurl4-openssl-dev \
libaio1 \
libaio-dev \
libfmt-dev \
libgflags-dev \
zlib1g-dev \
patchelf \
git \
wget \
vim \
gcc \
g++ \
cmake
# 拷贝代码
RUN git clone https://github.com/kvcache-ai/ktransformers.git
# 清理 apt 缓存
RUN rm -rf /var/lib/apt/lists/*
# 进入项目目录
WORKDIR /workspace/ktransformers
# 初始化子模块
RUN git submodule update --init --recursive
# 升级 pip
RUN pip install --upgrade pip
# 安装构建依赖
RUN pip install ninja pyproject numpy cpufeature aiohttp zmq openai
# 安装 flash-attn(提前装可以避免后续某些编译依赖出错)
RUN pip install flash-attn
# 安装 ktransformers 本体(含编译)
RUN CPU_INSTRUCT=${CPU_INSTRUCT} \
USE_BALANCE_SERVE=1 \
KTRANSFORMERS_FORCE_BUILD=TRUE \
TORCH_CUDA_ARCH_LIST="8.0;8.6;8.7;8.9;9.0+PTX" \
pip install . --no-build-isolation --verbose
RUN pip install third_party/custom_flashinfer/
# 清理 pip 缓存
RUN pip cache purge
# 拷贝 C++ 运行时库
RUN cp /usr/lib/x86_64-linux-gnu/libstdc++.so.6 /opt/conda/lib/
# 保持容器运行(调试用)
ENTRYPOINT ["tail", "-f", "/dev/null"]
================================================
FILE: archive/Dockerfile.xpu
================================================
# Base image
FROM intel/oneapi-basekit:2025.0.1-0-devel-ubuntu22.04
ARG http_proxy
ARG https_proxy
ENV DEBIAN_FRONTEND=noninteractive
ENV CONDA_DIR=/opt/conda
# Install dependencies
RUN apt-get update && apt-get install -y \
wget \
curl \
bash \
git \
vim \
ca-certificates \
binutils \
cmake \
g++ \
&& rm -rf /var/lib/apt/lists/*
# Install Miniforge
RUN wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh -O /tmp/miniforge.sh && \
bash /tmp/miniforge.sh -b -p $CONDA_DIR && \
rm /tmp/miniforge.sh && \
$CONDA_DIR/bin/conda clean -afy
# Add conda to PATH
ENV PATH=$CONDA_DIR/bin:$PATH
RUN bash -c "\
source /opt/conda/etc/profile.d/conda.sh && \
conda create --name ktransformers python=3.11 -y && \
conda activate ktransformers && \
conda env list && \
conda install -c conda-forge libstdcxx-ng -y && \
strings \$(find /opt/conda/envs/ktransformers/lib -name 'libstdc++.so.6') | grep GLIBCXX | grep 3.4.32 \
"
RUN bash -c "\
source /opt/conda/etc/profile.d/conda.sh && \
conda activate ktransformers && \
pip install ipex-llm[xpu_2.6]==2.3.0b20250518 --extra-index-url https://download.pytorch.org/whl/xpu && \
pip uninstall -y torch torchvision torchaudio && \
pip install torch==2.7+xpu torchvision torchaudio --index-url https://download.pytorch.org/whl/test/xpu && \
pip uninstall -y intel-opencl-rt dpcpp-cpp-rt && \
pip list \
"
# Clone and set up ktransformers repo
RUN bash -c "\
source $CONDA_DIR/etc/profile.d/conda.sh && \
conda activate ktransformers && \
git clone https://github.com/kvcache-ai/ktransformers.git && \
cd ktransformers && \
git submodule update --init && \
sed -i 's/torch\.xpu\.is_available()/True/g' setup.py && \
bash install.sh --dev xpu \
"
# Init conda and prepare bashrc
RUN conda init bash && \
echo "source $CONDA_DIR/etc/profile.d/conda.sh" >> ~/.bashrc && \
echo "conda activate ktransformers" >> ~/.bashrc
WORKDIR /ktransformers/
CMD ["bash"]
================================================
FILE: archive/LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: archive/MANIFEST.in
================================================
graft third_party
graft ktransformers
graft local_chat.py
graft csrc
include LICENSE README.md
prune ktransformers/website
prune ktransformers/logs
prune ktransformers.egg-info
prune third_party/llama.cpp/models
graft ktransformers/website/dist
global-exclude __pycache__
include KTransformersOps.*.so
include cpuinfer_ext.*.so
================================================
FILE: archive/Makefile
================================================
flake_find:
cd ktransformers && flake8 | grep -Eo '[A-Z][0-9]{3}' | sort | uniq| paste -sd ',' -
format:
@cd ktransformers && black .
@black setup.py
dev_install:
# clear build dirs
rm -rf build
rm -rf *.egg-info
rm -rf ktransformers/ktransformers_ext/build
rm -rf ktransformers/ktransformers_ext/cuda/build
rm -rf ktransformers/ktransformers_ext/cuda/dist
rm -rf ktransformers/ktransformers_ext/cuda/*.egg-info
# install ktransformers
echo "Installing python dependencies from requirements.txt"
pip install -r requirements-local_chat.txt
echo "Installing ktransformers"
KTRANSFORMERS_FORCE_BUILD=TRUE pip install -e . -v --no-build-isolation
echo "Installation completed successfully"
clean:
rm -rf build
rm -rf *.egg-info
rm -rf ktransformers/ktransformers_ext/build
rm -rf ktransformers/ktransformers_ext/cuda/build
rm -rf ktransformers/ktransformers_ext/cuda/dist
rm -rf ktransformers/ktransformers_ext/cuda/*.egg-info
install_numa:
USE_NUMA=1 make dev_install
install_no_numa:
env -u USE_NUMA make dev_install
================================================
FILE: archive/README.md
================================================
<div align="center">
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>High-Performance CPU-GPU Hybrid Inference for Large Language Models</h3>
</div>
## 🎯 Overview
KTransformers is a research project focused on efficient inference and fine-tuning of large language models through CPU-GPU heterogeneous computing. The project has evolved into **two core modules**: [kt-kernel](./kt-kernel/) and [kt-sft](./kt-sft/).
## 🔥 Updates
* **Nov 6, 2025**: Support Kimi-K2-Thinking inference and fine-tune
* **Nov 4, 2025**: KTransformers Fine-Tuning × LLaMA-Factory Integration
* **Oct 27, 2025**: Support Ascend NPU
* **Oct 10, 2025**: Integrating into SGLang ([Roadmap](https://github.com/sgl-project/sglang/issues/11425), [Blog](https://lmsys.org/blog/2025-10-22-KTransformers/))
* **Sept 11, 2025**: Support Qwen3-Next
* **Sept 05, 2025**: Support Kimi-K2-0905
* **July 26, 2025**: Support SmallThinker and GLM4-MoE
* **June 30, 2025**: Support 3-layer (GPU-CPU-Disk) prefix cache reuse
* **May 14, 2025**: Support Intel Arc GPU
* **Apr 29, 2025**: Support AMX-Int8、AMX-BF16 and Qwen3MoE
* **Apr 9, 2025**: Experimental support for LLaMA 4 models
* **Apr 2, 2025**: Support Multi-concurrency
* **Mar 15, 2025**: Support ROCm on AMD GPU
* **Mar 5, 2025**: Support unsloth 1.58/2.51 bits weights and IQ1_S/FP8 hybrid weights; 139K longer context for DeepSeek-V3/R1
* **Feb 25, 2025**: Support FP8 GPU kernel for DeepSeek-V3 and R1
* **Feb 10, 2025**: Support Deepseek-R1 and V3, up to 3~28x speedup
---
## 📦 Core Modules
### 🚀 [kt-kernel](./kt-kernel/) - High-Performance Inference Kernels
CPU-optimized kernel operations for heterogeneous LLM inference.

**Key Features:**
- **AMX/AVX Acceleration**: Intel AMX and AVX512/AVX2 optimized kernels for INT4/INT8 quantized inference
- **MoE Optimization**: Efficient Mixture-of-Experts inference with NUMA-aware memory management
- **Quantization Support**: CPU-side INT4/INT8 quantized weights, GPU-side GPTQ support
- **Easy Integration**: Clean Python API for SGLang and other frameworks
**Quick Start:**
```bash
cd kt-kernel
pip install .
```
**Use Cases:**
- CPU-GPU hybrid inference for large MoE models
- Integration with SGLang for production serving
- Heterogeneous expert placement (hot experts on GPU, cold experts on CPU)
**Performance Examples:**
| Model | Hardware Configuration | Total Throughput | Output Throughput |
|-------|------------------------|------------------|-------------------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s (8-way concurrency) |
👉 **[Full Documentation →](./kt-kernel/README.md)**
---
### 🎓 [kt-sft](./kt-sft/) - Fine-Tuning Framework
KTransformers × LLaMA-Factory integration for ultra-large MoE model fine-tuning.

**Key Features:**
- **Resource Efficient**: Fine-tune 671B DeepSeek-V3 with just **70GB GPU memory** + 1.3TB RAM
- **LoRA Support**: Full LoRA fine-tuning with heterogeneous acceleration
- **LLaMA-Factory Integration**: Seamless integration with popular fine-tuning framework
- **Production Ready**: Chat, batch inference, and metrics evaluation
**Performance Examples:**
| Model | Configuration | Throughput | GPU Memory |
|-------|--------------|------------|------------|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (multi-GPU) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
**Quick Start:**
```bash
cd kt-sft
# Install environment following kt-sft/README.md
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
```
👉 **[Full Documentation →](./kt-sft/README.md)**
---
## 🔥 Citation
If you use KTransformers in your research, please cite our paper:
```bibtex
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
## 👥 Contributors & Team
Developed and maintained by:
- [MADSys Lab](https://madsys.cs.tsinghua.edu.cn/) @ Tsinghua University
- [Approaching.AI](http://approaching.ai/)
- Community contributors
We welcome contributions! Please feel free to submit issues and pull requests.
## 💬 Community & Support
- **GitHub Issues**: [Report bugs or request features](https://github.com/kvcache-ai/ktransformers/issues)
- **GitHub Discussions**: [Ask questions and share ideas](https://github.com/kvcache-ai/ktransformers/discussions)
- **WeChat Group**: See [archive/WeChatGroup.png](./archive/WeChatGroup.png)
## 📦 Legacy Code
The original integrated KTransformers framework has been archived to the [`archive/`](./archive/) directory for reference. The project now focuses on the two core modules above for better modularity and maintainability.
For the original documentation with full quick-start guides and examples, see:
- [archive/README_LEGACY.md](./archive/README_LEGACY.md) (English)
- [archive/README_ZH_LEGACY.md](./archive/README_ZH_LEGACY.md) (中文)
================================================
FILE: archive/README_LEGACY.md
================================================
<div align="center">
<!-- <h1>KTransformers</h1> -->
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations</h3>
<strong><a href="#show-cases">🌟 Show Cases</a> | <a href="#quick-start">🚀 Quick Start</a> | <a href="#tutorial">📃 Tutorial</a> | <a href="#Citation">🔥 Citation </a> | <a href="https://github.com/kvcache-ai/ktransformers/discussions">💬 Discussion </a>|<a href="#FAQ"> 🙋 FAQ</a> </strong>
</div>
<h2 id="intro">🎉 Introduction</h2>
KTransformers, pronounced as Quick Transformers, is designed to enhance your 🤗 <a href="https://github.com/huggingface/transformers">Transformers</a> experience with advanced kernel optimizations and placement/parallelism strategies.
<br/><br/>
KTransformers is a flexible, Python-centric framework designed with extensibility at its core.
By implementing and injecting an optimized module with a single line of code, users gain access to a Transformers-compatible
interface, RESTful APIs compliant with OpenAI and Ollama, and even a simplified ChatGPT-like web UI.
<br/><br/>
Our vision for KTransformers is to serve as a flexible platform for experimenting with innovative LLM inference optimizations. Please let us know if you need any other features.
<h2 id="Updates">🔥 Updates</h2>
* **Nov 6, 2025**: Support Kimi-K2-Thinking inference ([Tutorial](./doc/en/Kimi-K2-Thinking.md)) and fine-tune ([Tutorial](./doc/en/SFT_Installation_Guide_KimiK2.md))
* **Nov 4, 2025**: KTransformers Fine-Tuning × LLaMA-Factory Integration. ([Tutorial](./doc/en/KTransformers-Fine-Tuning_User-Guide.md))
* **Oct 27, 2025**: Support Ascend NPU. ([Tutorial](./doc/zh/DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md))
* **Oct 10, 2025**: Integrating into SGLang. ([Roadmap](https://github.com/sgl-project/sglang/issues/11425))
* **Sept 11, 2025**: Support Qwen3-Next. ([Tutorial](./doc/en/Qwen3-Next.md))
* **Sept 05, 2025**: Support Kimi-K2-0905. ([Tutorial](./doc/en/Kimi-K2.md))
* **July 26, 2025**: Support SmallThinker and GLM4-MoE. ([Tutorial](./doc/en/SmallThinker_and_Glm4moe.md))
* **July 11, 2025**: Support Kimi-K2. ([Tutorial](./doc/en/Kimi-K2.md))
* **June 30, 2025**: Support 3-layer (GPU-CPU-Disk) [prefix cache](./doc/en/prefix_cache.md) reuse.
* **May 14, 2025**: Support Intel Arc GPU ([Tutorial](./doc/en/xpu.md)).
* **Apr 29, 2025**: Support AMX-Int8、 AMX-BF16 and Qwen3MoE ([Tutorial](./doc/en/AMX.md))
https://github.com/user-attachments/assets/fafe8aec-4e22-49a8-8553-59fb5c6b00a2
* **Apr 9, 2025**: Experimental support for LLaMA 4 models ([Tutorial](./doc/en/llama4.md)).
* **Apr 2, 2025**: Support Multi-concurrency. ([Tutorial](./doc/en/balance-serve.md)).
https://github.com/user-attachments/assets/faa3bda2-928b-45a7-b44f-21e12ec84b8a
* **Mar 15, 2025**: Support ROCm on AMD GPU ([Tutorial](./doc/en/ROCm.md)).
* **Mar 5, 2025**: Support unsloth 1.58/2.51 bits weights and [IQ1_S/FP8 hybrid](./doc/en/fp8_kernel.md) weights. Support 139K [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022--v023-longer-context--fp8-kernel) for DeepSeek-V3 and R1 in 24GB VRAM.
* **Feb 25, 2025**: Support [FP8 GPU kernel](./doc/en/fp8_kernel.md) for DeepSeek-V3 and R1; [Longer Context](./doc/en/DeepseekR1_V3_tutorial.md#v022-longer-context).
* **Feb 15, 2025**: Longer Context (from 4K to 8K for 24GB VRAM) & Slightly Faster Speed (+15%, up to 16 Tokens/s), update [docs](./doc/en/DeepseekR1_V3_tutorial.md) and [online books](https://kvcache-ai.github.io/ktransformers/).
* **Feb 10, 2025**: Support Deepseek-R1 and V3 on single (24GB VRAM)/multi gpu and 382G DRAM, up to 3~28x speedup. For detailed show case and reproduction tutorial, see [here](./doc/en/DeepseekR1_V3_tutorial.md).
* **Aug 28, 2024**: Decrease DeepseekV2's required VRAM from 21G to 11G.
* **Aug 15, 2024**: Update detailed [tutorial](doc/en/injection_tutorial.md) for injection and multi-GPU.
* **Aug 14, 2024**: Support llamfile as linear backend.
* **Aug 12, 2024**: Support multiple GPU; Support new model: mixtral 8\*7B and 8\*22B; Support q2k, q3k, q5k dequant on gpu.
* **Aug 9, 2024**: Support windows native.
<!-- * **Aug 28, 2024**: Support 1M context under the InternLM2.5-7B-Chat-1M model, utilizing 24GB of VRAM and 150GB of DRAM. The detailed tutorial is [here](./doc/en/long_context_tutorial.md). -->
<h2 id="show-cases">🌟 Show Cases</h2>
<div>
<h3>GPT-4/o1-level Local VSCode Copilot on a Desktop with only 24GB VRAM</h3>
</div>
https://github.com/user-attachments/assets/ebd70bfa-b2c1-4abb-ae3b-296ed38aa285
</p>
- **[NEW!!!] Local 671B DeepSeek-Coder-V3/R1:** Running its Q4_K_M version using only 14GB VRAM and 382GB DRAM([Tutorial](./doc/en/DeepseekR1_V3_tutorial.md)).
- Prefill Speed (tokens/s):
- KTransformers: 54.21 (32 cores) → 74.362 (dual-socket, 2×32 cores) → 255.26 (optimized AMX-based MoE kernel, V0.3 only) → 286.55 (selectively using 6 experts, V0.3 only)
- Compared to 10.31 tokens/s in llama.cpp with 2×32 cores, achieving up to **27.79× speedup**.
- Decode Speed (tokens/s):
- KTransformers: 8.73 (32 cores) → 11.26 (dual-socket, 2×32 cores) → 13.69 (selectively using 6 experts, V0.3 only)
- Compared to 4.51 tokens/s in llama.cpp with 2×32 cores, achieving up to **3.03× speedup**.
- Upcoming Open Source Release:
- AMX optimizations and selective expert activation will be open-sourced in V0.3.
- Currently available only in preview binary distribution, which can be downloaded [here](./doc/en/DeepseekR1_V3_tutorial.md).
- **Local 236B DeepSeek-Coder-V2:** Running its Q4_K_M version using only 21GB VRAM and 136GB DRAM, attainable on a local desktop machine, which scores even better than GPT4-0613 in [BigCodeBench](https://huggingface.co/blog/leaderboard-bigcodebench).
<p align="center">
<picture>
<img alt="DeepSeek-Coder-V2 Score" src="https://github.com/user-attachments/assets/d052924e-8631-44de-aad2-97c54b965693" width=100%>
</picture>
</p>
- **Faster Speed:** Achieving 126 tokens/s for 2K prompt prefill and 13.6 tokens/s for generation through MoE offloading and injecting advanced kernels from [Llamafile](https://github.com/Mozilla-Ocho/llamafile/tree/main) and [Marlin](https://github.com/IST-DASLab/marlin).
- **VSCode Integration:** Wrapped into an OpenAI and Ollama compatible API for seamless integration as a backend for [Tabby](https://github.com/TabbyML/tabby) and various other frontends.
<p align="center">
https://github.com/user-attachments/assets/4c6a8a38-05aa-497d-8eb1-3a5b3918429c
</p>
<!-- <h3>1M Context Local Inference on a Desktop with Only 24GB VRAM</h3>
<p align="center">
https://github.com/user-attachments/assets/a865e5e4-bca3-401e-94b8-af3c080e6c12
* **1M Context InternLM 2.5 7B**: Operates at full bf16 precision, utilizing 24GB VRAM and 150GB DRAM, which is feasible on a local desktop setup. It achieves a 92.88% success rate on the 1M "Needle In a Haystack" test and 100% on the 128K NIAH test.
<p align="center">
<picture>
<img alt="Single Needle Retrieval 128K" src="./doc/assets/needle_128K.png" width=100%>
</picture>
</p>
<p align="center">
<picture>
<img alt="Single Needle Retrieval 1000K" src="./doc/assets/needle_1M.png" width=100%>
</picture>
</p>
* **Enhanced Speed**: Reaches 16.91 tokens/s for generation with a 1M context using sparse attention, powered by llamafile kernels. This method is over 10 times faster than full attention approach of llama.cpp.
* **Flexible Sparse Attention Framework**: Offers a flexible block sparse attention framework for CPU offloaded decoding. Compatible with SnapKV, Quest, and InfLLm. Further information is available [here](./doc/en/long_context_introduction.md).
-->
<strong>More advanced features will coming soon, so stay tuned!</strong>
<h2 id="quick-start">🚀 Quick Start</h2>
Getting started with KTransformers is simple! Follow the steps below to set up and start using it.
we have already supported vendors:
- Metax
- Sanechips (ZhuFeng V1.0)
- Intel
- Ascend
- Kunpeng
- AMD
### 📥 Installation
To install KTransformers, follow the official [Installation Guide](https://kvcache-ai.github.io/ktransformers/en/install.html).
<h2 id="tutorial">📃 Brief Injection Tutorial</h2>
At the heart of KTransformers is a user-friendly, template-based injection framework.
This allows researchers to easily replace original torch modules with optimized variants. It also simplifies the process of combining multiple optimizations, allowing the exploration of their synergistic effects.
</br>
<p align="center">
<picture>
<img alt="Inject-Struction" src="https://github.com/user-attachments/assets/6b4c1e54-9f6d-45c5-a3fc-8fa45e7d257e" width=65%>
</picture>
</p>
Given that vLLM already serves as a great framework for large-scale deployment optimizations, KTransformers is particularly focused on local deployments that are constrained by limited resources. We pay special attention to heterogeneous computing opportunities, such as GPU/CPU offloading of quantized models. For example, we support the efficient <a herf="https://github.com/Mozilla-Ocho/llamafile/tree/main">Llamafile</a> and <a herf="https://github.com/IST-DASLab/marlin">Marlin</a> kernels for CPU and GPU, respectively. More details can be found <a herf="doc/en/operators/llamafile.md">here</a>.
<h3>Example Usage</h3>
To utilize the provided kernels, users only need to create a YAML-based injection template and add the call to `optimize_and_load_gguf` before using the Transformers model.
```python
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_config_path, gguf_path, config)
...
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)
```
In this example, the AutoModel is first initialized on the meta device to avoid occupying any memory resources. Then, `optimize_and_load_gguf` iterates through all sub-modules of the model, matches rules specified in your YAML rule file, and replaces them with advanced modules as specified.
After injection, the original `generate` interface is available, but we also provide a compatible `prefill_and_generate` method, which enables further optimizations like CUDAGraph to improve generation speed.
<h3>How to custom your model</h3>
A detailed tutorial of the injection and multi-GPU using DeepSeek-V2 as an example is given [here](doc/en/injection_tutorial.md).
Below is an example of a YAML template for replacing all original Linear modules with Marlin, an advanced 4-bit quantization kernel.
```yaml
- match:
name: "^model\\.layers\\..*$" # regular expression
class: torch.nn.Linear # only match modules matching name and class simultaneously
replace:
class: ktransformers.operators.linear.KTransformerLinear # optimized Kernel on quantized data types
device: "cpu" # which devices to load this module when initializing
kwargs:
generate_device: "cuda"
generate_linear_type: "QuantizedLinearMarlin"
```
Each rule in the YAML file has two parts: `match` and `replace`. The `match` part specifies which module should be replaced, and the `replace` part specifies the module to be injected into the model along with the initialization keywords.
You can find example rule templates for optimizing DeepSeek-V2 and Qwen2-57B-A14, two SOTA MoE models, in the [ktransformers/optimize/optimize_rules](ktransformers/optimize/optimize_rules) directory. These templates are used to power the `local_chat.py` demo.
If you are interested in our design principles and the implementation of the injection framework, please refer to the [design document](doc/en/deepseek-v2-injection.md).
<h2 id="Citation">🔥 Citation</h2>
If you use KTransformers for your research, please cite our [paper](https://madsys.cs.tsinghua.edu.cn/publication/ktransformers-unleashing-the-full-potential-of-cpu/gpu-hybrid-inference-for-moe-models/):
```
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
<h2 id="ack">Acknowledgment and Contributors</h2>
The development of KTransformers is based on the flexible and versatile framework provided by Transformers. We also benefit from advanced kernels such as GGUF/GGML, Llamafile, Marlin, sglang and flashinfer. We are planning to contribute back to the community by upstreaming our modifications.
KTransformers is actively maintained and developed by contributors from the <a href="https://madsys.cs.tsinghua.edu.cn/">MADSys group</a> at Tsinghua University and members from <a href="http://approaching.ai/">Approaching.AI</a>. We welcome new contributors to join us in making KTransformers faster and easier to use.
<h2 id="ack">Discussion</h2>
If you have any questions, feel free to open an issue. Alternatively, you can join our WeChat group for further discussion. QR Code: [WeChat Group](WeChatGroup.png)
<h2 id="FAQ">🙋 FAQ</h2>
Some common questions are answered in the [FAQ](doc/en/FAQ.md).
================================================
FILE: archive/README_ZH.md
================================================
<div align="center">
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>高性能 CPU-GPU 异构大语言模型推理</h3>
</div>
## 🎯 项目概述
KTransformers 是一个专注于大语言模型高效推理和微调的研究项目,通过 CPU-GPU 异构计算实现资源受限环境下的模型部署。项目已演进为**两个核心模块**:[kt-kernel](./kt-kernel/) 和 [kt-sft](./kt-sft/)。
## 🔥 更新
* **2025年11月6日**:支持 Kimi-K2-Thinking 推理和微调
* **2025年11月4日**:KTransformers 微调 × LLaMA-Factory 集成
* **2025年10月27日**:支持 Ascend NPU
* **2025年10月10日**:集成到 SGLang ([路线图](https://github.com/sgl-project/sglang/issues/11425), [博客](https://lmsys.org/blog/2025-10-22-KTransformers/))
* **2025年9月11日**:支持 Qwen3-Next
* **2025年9月5日**:支持 Kimi-K2-0905
* **2025年7月26日**:支持 SmallThinker 和 GLM4-MoE
* **2025年6月30日**:支持 3层(GPU-CPU-磁盘)前缀缓存复用
* **2025年5月14日**:支持 Intel Arc GPU
* **2025年4月29日**:支持 AMX-Int8、AMX-BF16 和 Qwen3MoE
* **2025年4月9日**:实验性支持 LLaMA 4 模型
* **2025年4月2日**:支持多并发
* **2025年3月15日**:支持 AMD GPU 的 ROCm
* **2025年3月5日**:支持 unsloth 1.58/2.51 bits 权重和 IQ1_S/FP8 混合权重;DeepSeek-V3/R1 支持 139K 长上下文
* **2025年2月25日**:支持 DeepSeek-V3 和 R1 的 FP8 GPU 内核
* **2025年2月10日**:支持 Deepseek-R1 和 V3,速度提升最高达 3~28 倍
---
## 📦 核心模块
### 🚀 [kt-kernel](./kt-kernel/) - 高性能推理内核
面向异构 LLM 推理的 CPU 优化内核操作库。

**核心特性:**
- **AMX/AVX 加速**:Intel AMX 和 AVX512/AVX2 优化内核,支持 INT4/INT8 量化推理
- **MoE 优化**:高效的专家混合推理,支持 NUMA 感知内存管理
- **量化支持**:CPU 端 INT4/INT8 量化权重,GPU 端 GPTQ 支持
- **易于集成**:简洁的 Python API,可集成到 SGLang 等框架
**快速开始:**
```bash
cd kt-kernel
pip install .
```
**应用场景:**
- 大型 MoE 模型的 CPU-GPU 混合推理
- 与 SGLang 集成用于生产服务
- 异构专家放置(热门专家在 GPU,冷门专家在 CPU)
**性能示例:**
| 模型 | 硬件配置 | 总吞吐量 | 输出吞吐量 |
|------|---------|---------|-----------|
| DeepSeek-R1-0528 (FP8) | 8×L20 GPU + Xeon Gold 6454S | 227.85 tokens/s | 87.58 tokens/s(8路并发)|
👉 **[完整文档 →](./kt-kernel/README.md)**
---
### 🎓 [kt-sft](./kt-sft/) - 微调框架
KTransformers × LLaMA-Factory 集成,支持超大 MoE 模型微调。

**核心特性:**
- **资源高效**:仅需 **70GB 显存** + 1.3TB 内存即可微调 671B DeepSeek-V3
- **LoRA 支持**:完整的 LoRA 微调与异构加速
- **LLaMA-Factory 集成**:与流行微调框架无缝集成
- **生产就绪**:支持对话、批量推理和指标评估
**性能示例:**
| 模型 | 配置 | 吞吐量 | GPU 显存 |
|------|------|--------|----------|
| DeepSeek-V3 (671B) | LoRA + AMX | ~40 tokens/s | 70GB (多卡) |
| DeepSeek-V2-Lite (14B) | LoRA + AMX | ~530 tokens/s | 6GB |
**快速开始:**
```bash
cd kt-sft
# 按照 kt-sft/README.md 安装环境
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml
```
👉 **[完整文档 →](./kt-sft/README.md)**
---
## 🔥 引用
如果您在研究中使用了 KTransformers,请引用我们的论文:
```bibtex
@inproceedings{10.1145/3731569.3764843,
title = {KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models},
author = {Chen, Hongtao and Xie, Weiyu and Zhang, Boxin and Tang, Jingqi and Wang, Jiahao and Dong, Jianwei and Chen, Shaoyuan and Yuan, Ziwei and Lin, Chen and Qiu, Chengyu and Zhu, Yuening and Ou, Qingliang and Liao, Jiaqi and Chen, Xianglin and Ai, Zhiyuan and Wu, Yongwei and Zhang, Mingxing},
booktitle = {Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles},
year = {2025}
}
```
## 👥 贡献者与团队
由以下团队开发和维护:
- 清华大学 [MADSys 实验室](https://madsys.cs.tsinghua.edu.cn/)
- [Approaching.AI](http://approaching.ai/)
- 社区贡献者
我们欢迎贡献!请随时提交 issues 和 pull requests。
## 💬 社区与支持
- **GitHub Issues**:[报告 bug 或请求功能](https://github.com/kvcache-ai/ktransformers/issues)
- **GitHub Discussions**:[提问和分享想法](https://github.com/kvcache-ai/ktransformers/discussions)
- **微信群**:查看 [archive/WeChatGroup.png](./archive/WeChatGroup.png)
## 📦 历史代码
原完整的 KTransformers 框架代码已归档至 [`archive/`](./archive/) 目录供参考。项目现专注于上述两个核心模块,以实现更好的模块化和可维护性。
关于原始完整文档(包含快速入门指南和示例),请查看:
- [archive/README_LEGACY.md](./archive/README_LEGACY.md) (English)
- [archive/README_ZH_LEGACY.md](./archive/README_ZH_LEGACY.md) (中文)
================================================
FILE: archive/README_ZH_LEGACY.md
================================================
<div align="center">
<!-- <h1>KTransformers</h1> -->
<p align="center">
<picture>
<img alt="KTransformers" src="https://github.com/user-attachments/assets/d5a2492f-a415-4456-af99-4ab102f13f8b" width=50%>
</picture>
</p>
<h3>一个用于体验尖端 LLM 推理优化的灵活框架</h3>
<strong><a href="#show-cases">🌟 案例展示</a> | <a href="#quick-start">🚀 快速入门</a> | <a href="#tutorial">📃 教程</a> | <a href="https://github.com/kvcache-ai/ktransformers/discussions">💬 讨论</a> | <a href="#FAQ">🙋 常见问题</a> </strong>
</div>
<h2 id="intro">🎉 介绍</h2>
KTransformers(发音为 Quick Transformers)旨在通过先进的内核优化和放置/并行策略来增强您对 🤗 [Transformers](https://github.com/huggingface/transformers) 的体验。
<br/><br/>
KTransformers 是一个以 Python 为中心的灵活框架,其核心是可扩展性。通过用一行代码实现并注入优化模块,用户可以获得与 Transformers 兼容的接口、符合 OpenAI 和 Ollama 的 RESTful API,甚至是一个简化的类似 ChatGPT 的 Web 界面。
<br/><br/>
我们对 KTransformers 的愿景是成为一个用于实验创新 LLM 推理优化的灵活平台。如果您需要任何其他功能,请告诉我们。
<h2 id="Updates">🔥 更新</h2>
* **2025 年 2 月 15 日**:为DeepSeek-V3/R1支持[FP8 GPU内核](./doc/en/fp8_kernel.md); 支持更长的上下文([教程](./doc/en/DeepseekR1_V3_tutorial.md#v022-longer-context)).
* **2025 年 2 月 15 日**:长上下文(从4K到8K,24GB VRAM) & 稍快的速度(+15%)(最快 16 Tokens/s),文档请参见 [这里](./doc/en/DeepseekR1_V3_tutorial.md) 和 [在线指南](https://kvcache-ai.github.io/ktransformers/) 。
* **2025 年 2 月 10 日**:支持 Deepseek-R1 和 V3 在单个(24GB VRAM)/多 GPU 和 382G DRAM 上运行,速度提升高达 3~28 倍。详细教程请参见 [这里](./doc/en/DeepseekR1_V3_tutorial.md)。
* **2024 年 8 月 28 日**:支持 InternLM2.5-7B-Chat-1M 模型下的 1M 上下文,使用 24GB 的 VRAM 和 150GB 的 DRAM。详细教程请参见 [这里](./doc/en/long_context_tutorial.md)。
* **2024 年 8 月 28 日**:将 DeepseekV2 所需的 VRAM 从 21G 降低到 11G。
* **2024 年 8 月 15 日**:更新了详细的 [教程](doc/en/injection_tutorial.md),介绍注入和多 GPU 的使用。
* **2024 年 8 月 14 日**:支持 llamfile 作为线性后端。
* **2024 年 8 月 12 日**:支持多 GPU;支持新模型:mixtral 8\*7B 和 8\*22B;支持 q2k、q3k、q5k 在 GPU 上的去量化。
* **2024 年 8 月 9 日**:支持 Windows。
<h2 id="show-cases">🌟 案例展示</h2>
<div>
<h3>在仅 24GB VRAM 的桌面上运行 GPT-4/o1 级别的本地 VSCode Copilot</h3>
</div>
https://github.com/user-attachments/assets/ebd70bfa-b2c1-4abb-ae3b-296ed38aa285
</p>
- **[NEW!!!] 本地 671B DeepSeek-Coder-V3/R1**:使用其 Q4_K_M 版本,仅需 14GB VRAM 和 382GB DRAM 即可运行(教程请参见 [这里](./doc/en/DeepseekR1_V3_tutorial.md))。
- 预填充速度(tokens/s):
- KTransformers:54.21(32 核)→ 74.362(双插槽,2×32 核)→ 255.26(优化的 AMX 基 MoE 内核,仅 V0.3)→ 286.55(选择性使用 6 个专家,仅 V0.3)
- 与 llama.cpp 在 2×32 核下相比,达到 **27.79× 速度提升**。
- 解码速度(tokens/s):
- KTransformers:8.73(32 核)→ 11.26(双插槽,2×32 核)→ 13.69(选择性使用 6 个专家,仅 V0.3)
- 与 llama.cpp 在 2×32 核下相比,达到 **3.03× 速度提升**。
- 即将开源发布:
- AMX 优化和选择性专家激活将在 V0.3 中开源。
- 目前仅在预览二进制分发中可用,可从 [这里](./doc/en/DeepseekR1_V3_tutorial.md) 下载。
- **本地 236B DeepSeek-Coder-V2**:使用其 Q4_K_M 版本,仅需 21GB VRAM 和 136GB DRAM 即可运行,甚至在 [BigCodeBench](https://huggingface.co/blog/leaderboard-bigcodebench) 中得分超过 GPT4-0613。
<p align="center">
<picture>
<img alt="DeepSeek-Coder-V2 Score" src="https://github.com/user-attachments/assets/d052924e-8631-44de-aad2-97c54b965693" width=100%>
</picture>
</p>
- **更快的速度**:通过 MoE 卸载和注入来自 [Llamafile](https://github.com/Mozilla-Ocho/llamafile/tree/main) 和 [Marlin](https://github.com/IST-DASLab/marlin) 的高级内核,实现了 2K 提示预填充 126 tokens/s 和生成 13.6 tokens/s 的速度。
- **VSCode 集成**:封装成符合 OpenAI 和 Ollama 的 API,可无缝集成到 [Tabby](https://github.com/TabbyML/tabby) 和其他前端的后端。
<p align="center">
https://github.com/user-attachments/assets/4c6a8a38-05aa-497d-8eb1-3a5b3918429c
</p>
<!-- <h3>在仅 24GB VRAM 的桌面上进行 1M 上下文本地推理</h3>
<p align="center"> -->
<!-- https://github.com/user-attachments/assets/a865e5e4-bca3-401e-94b8-af3c080e6c12 -->
<!--
* **1M 上下文 InternLM 2.5 7B**:以全 bf16 精度运行,使用 24GB VRAM 和 150GB DRAM,可在本地桌面设置中实现。在 1M "针在干草堆中" 测试中达到 92.88% 的成功率,在 128K NIAH 测试中达到 100%。
<p align="center">
<picture>
<img alt="Single Needle Retrieval 128K" src="./doc/assets/needle_128K.png" width=100%>
</picture>
</p>
<p align="center">
<picture>
<img alt="Single Needle Retrieval 1000K" src="./doc/assets/needle_1M.png" width=100%>
</picture>
</p>
* **增强的速度**:使用稀疏注意力,通过 llamafile 内核实现 1M 上下文生成 16.91 tokens/s 的速度。这种方法比 llama.cpp 的全注意力方法快 10 倍以上。
* **灵活的稀疏注意力框架**:提供了一个灵活的块稀疏注意力框架,用于 CPU 卸载解码。与 SnapKV、Quest 和 InfLLm 兼容。更多信息请参见 [这里](./doc/en/long_context_introduction.md)。 -->
<strong>更多高级功能即将推出,敬请期待!</strong>
<h2 id="quick-start">🚀 快速入门</h2>
KTransformers 的入门非常简单!请参考我们的[安装指南]((https://kvcache-ai.github.io/ktransformers/))进行安装。
<h2 id="tutorial">📃 简要注入教程</h2>
KTransformers 的核心是一个用户友好的、基于模板的注入框架。这使得研究人员可以轻松地将原始 torch 模块替换为优化的变体。它还简化了多种优化的组合过程,允许探索它们的协同效应。
</br>
<p align="center">
<picture>
<img alt="Inject-Struction" src="https://github.com/user-attachments/assets/6b4c1e54-9f6d-45c5-a3fc-8fa45e7d257e" width=65%>
</picture>
</p>
鉴于 vLLM 已经是一个用于大规模部署优化的优秀框架,KTransformers 特别关注受资源限制的本地部署。我们特别关注异构计算时机,例如量化模型的 GPU/CPU 卸载。例如,我们支持高效的 <a herf="https://github.com/Mozilla-Ocho/llamafile/tree/main">Llamafile</a> 和<a herf="https://github.com/IST-DASLab/marlin">Marlin</a> 内核,分别用于 CPU 和 GPU。 更多详细信息可以在 <a herf="doc/en/operators/llamafile.md">这里</a>找到。
<h3>示例用法</h3>
要使用提供的内核,用户只需创建一个基于 YAML 的注入模板,并在使用 Transformers 模型之前添加对 `optimize_and_load_gguf` 的调用。
```python
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_config_path, gguf_path, config)
...
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)
```
在这个示例中,首先在 meta 设备上初始化 AutoModel,以避免占用任何内存资源。然后,`optimize_and_load_gguf` 遍历模型的所有子模块,匹配您的 YAML 规则文件中指定的规则,并将它们替换为指定的高级模块。
注入后,原始的 `generate` 接口仍然可用,但我们还提供了一个兼容的 `prefill_and_generate` 方法,这使得可以进一步优化,例如使用 CUDAGraph 提高生成速度。
<h3>如何自定义您的模型</h3>
一个详细的使用 DeepSeek-V2 作为示例的注入和 multi-GPU 教程在 [这里](doc/en/injection_tutorial.md)。
以下是一个将所有原始 Linear 模块替换为 Marlin 的 YAML 模板示例,Marlin 是一个高级的 4 位量化内核。
```yaml
- match:
name: "^model\\.layers\\..*$" # 正则表达式
class: torch.nn.Linear # 仅匹配同时符合名称和类的模块
replace:
class: ktransformers.operators.linear.KTransformerLinear # 量化数据类型的优化内核
device: "cpu" # 初始化时加载该模块的 device
kwargs:
generate_device: "cuda"
generate_linear_type: "QuantizedLinearMarlin"
```
YAML 文件中的每个规则都有两部分:`match` 和 `replace`。`match` 部分指定应替换的模块,`replace` 部分指定要注入到模型中的模块以及初始化关键字。
您可以在 [ktransformers/optimize/optimize_rules](ktransformers/optimize/optimize_rules) 目录中找到用于优化 DeepSeek-V2 和 Qwen2-57B-A14 的示例规则模板。这些模板用于为 `local_chat.py` 示例提供支持。
如果您对我们的设计原则和注入框架的实现感兴趣,请参考 [设计文档](doc/en/deepseek-v2-injection.md)。
<h2 id="ack">致谢和贡献者</h2>
KTransformers 的开发基于 Transformers 提供的灵活和多功能框架。我们还受益于 GGUF/GGML、Llamafile 、 Marlin、sglang和flashinfer 等高级内核。我们计划通过向上游贡献我们的修改来回馈社区。
KTransformers 由清华大学 <a href="https://madsys.cs.tsinghua.edu.cn/">MADSys group</a> 小组的成员以及 <a href="http://approaching.ai/">Approaching.AI</a> 的成员积极维护和开发。我们欢迎新的贡献者加入我们,使 KTransformers 更快、更易于使用。
<h2 id="ack">讨论</h2>
如果您有任何问题,欢迎随时提出 issue。或者,您可以加入我们的微信群进行进一步讨论。二维码: [微信群](WeChatGroup.png)
<h2 id="FAQ">🙋 常见问题</h2>
一些常见问题的答案可以在 [FAQ](doc/en/FAQ.md) 中找到。
================================================
FILE: archive/SECURITY.md
================================================
# Security Policy
## Supported Versions
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
## Reporting a Vulnerability
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
================================================
FILE: archive/book.toml
================================================
[book]
authors = ["kvcache-ai"]
language = "zh-CN"
title = "Ktransformers"
src = "doc"
[output.html]
git-repository-url = "https://github.com/kvcache-ai/ktransformers"
edit-url-template = "https://github.com/kvcache-ai/ktransformers/edit/main/{path}"
[output.html.playground]
editable = true
copy-js = true
# line-numbers = true
[output.html.fold]
enable = true
level = 0
================================================
FILE: archive/config.json
================================================
================================================
FILE: archive/csrc/balance_serve/CMakeLists.txt
================================================
option(KTRANSFORMERS_USE_NPU "ktransformers: use NPU" OFF)
if(KTRANSFORMERS_USE_NPU)
add_definitions(-DKTRANSFORMERS_USE_NPU=1)
endif()
if(KTRANSFORMERS_USE_NPU)
set(ASCEND_HOME_PATH "$ENV{ASCEND_HOME_PATH}")
message(STATUS "ASCEND_HOME_PATH is ${ASCEND_HOME_PATH}")
include_directories(${ASCEND_HOME_PATH}/include)
link_directories(${TORCH_INSTALL_PREFIX}/../torch.libs)
# find torch_npu
execute_process(
COMMAND python -c "import torch; import torch_npu; print(torch_npu.__path__[0])"
OUTPUT_VARIABLE TORCH_NPU_PATH
OUTPUT_STRIP_TRAILING_WHITESPACE
)
message(STATUS "Found PTA at: ${TORCH_NPU_PATH}")
find_library(PTA_LIBRARY torch_npu PATH "${TORCH_NPU_PATH}/lib")
endif()
cmake_minimum_required(VERSION 3.21)
find_program(GCC_COMPILER NAMES g++-13 g++-12 g++-11 g++ REQUIRED)
set(CMAKE_CXX_COMPILER ${GCC_COMPILER})
# 显示选定的编译器
message(STATUS "Using compiler: ${CMAKE_CXX_COMPILER}")
project(balance_serve VERSION 0.1.0)
set(CMAKE_CXX_STANDARD 20)
set(CMAKE_CXX_FLAGS "-Og -march=native -Wall -Wextra -g -fPIC")
set(CMAKE_BUILD_TYPE "Debug")
# set(CMAKE_CXX_FLAGS "-O3 -march=native -Wall -Wextra -fPIC")
# set(CMAKE_BUILD_TYPE "Release")
if(NOT DEFINED _GLIBCXX_USE_CXX11_ABI)
find_package(Python3 REQUIRED COMPONENTS Interpreter)
execute_process(
COMMAND ${Python3_EXECUTABLE} -c
"import torch; print('1' if torch.compiled_with_cxx11_abi() else '0')"
OUTPUT_VARIABLE ABI_FLAG
OUTPUT_STRIP_TRAILING_WHITESPACE
)
set(_GLIBCXX_USE_CXX11_ABI ${ABI_FLAG} CACHE STRING "C++11 ABI setting from PyTorch" FORCE)
endif()
# 无论是否是自动检测,都传给编译器
add_compile_definitions(_GLIBCXX_USE_CXX11_ABI=${_GLIBCXX_USE_CXX11_ABI})
message(STATUS "_GLIBCXX_USE_CXX11_ABI=${_GLIBCXX_USE_CXX11_ABI}")
file(GLOB_RECURSE FMT_SOURCES "${CMAKE_CURRENT_SOURCE_DIR}/*.cpp" "${CMAKE_CURRENT_SOURCE_DIR}/*.hpp" "${CMAKE_CURRENT_SOURCE_DIR}/*.h")
add_custom_target(
format
COMMAND clang-format
-i
-style=file
${FMT_SOURCES}
COMMENT "Running clang-format on all source files"
)
set(BUILD_SHARED_LIBS ON)
set(ENABLE_PUSH OFF)
set(ENABLE_COMPRESSION OFF)
# set(CMAKE_BUILD_TYPE "Release")
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
set(THIRD_PARTY_DIR ${CMAKE_CURRENT_SOURCE_DIR}/../../third_party)
set(THIRD_PARTY_BUILD_DIR ${CMAKE_CURRENT_BINARY_DIR}/third_party)
add_subdirectory(${THIRD_PARTY_DIR}/prometheus-cpp ${THIRD_PARTY_BUILD_DIR}/prometheus-cpp EXCLUDE_FROM_ALL)
add_subdirectory(${THIRD_PARTY_DIR}/xxHash/cmake_unofficial ${THIRD_PARTY_BUILD_DIR}/xxHash EXCLUDE_FROM_ALL)
set_target_properties(xxhash PROPERTIES POSITION_INDEPENDENT_CODE ON)
# add_subdirectory(${CMAKE_CURRENT_SOURCE_DIR}/third_party/prometheus-cpp ${CMAKE_CURRENT_BINARY_DIR}/third_party/prometheus-cpp)
set(SPDLOG_DIR ${THIRD_PARTY_DIR}/spdlog)
set(FMT_DIR ${THIRD_PARTY_DIR}/fmt)
set(KVC2_INCLUDE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/kvc2/src)
include_directories(${THIRD_PARTY_DIR})
add_subdirectory(${THIRD_PARTY_DIR}/pybind11 ${THIRD_PARTY_BUILD_DIR}/pybind11)
execute_process(
COMMAND python3 -c "import torch; print(torch.__path__[0])"
OUTPUT_VARIABLE TORCH_INSTALL_PREFIX
OUTPUT_STRIP_TRAILING_WHITESPACE
)
message(STATUS "Found PyTorch at: ${TORCH_INSTALL_PREFIX}")
# set(TORCH_INSTALL_PREFIX "/home/xwy/.conda/envs/kvc/lib/python3.12/site-packages/torch")
find_library(TORCH_PYTHON_LIBRARY torch_python PATH "${TORCH_INSTALL_PREFIX}/lib")
find_package(Torch REQUIRED PATHS "${TORCH_INSTALL_PREFIX}/share/cmake/Torch" NO_DEFAULT_PATH)
add_subdirectory(kvc2)
add_subdirectory(sched)
# add_subdirectory(test)
================================================
FILE: archive/csrc/custom_marlin/__init__.py
================================================
================================================
FILE: archive/csrc/custom_marlin/binding.cpp
================================================
/**
* @Description :
* @Author : Azure-Tang
* @Date : 2024-07-25 13:38:30
* @Version : 1.0.0
* @LastEditors : kkk1nak0
* @LastEditTime : 2024-08-12 03:05:04
* @Copyright (c) 2024 by KVCache.AI, All Rights Reserved.
**/
#include "gptq_marlin/ops.h"
// Python bindings
#include <pybind11/pybind11.h>
#include <pybind11/stl.h>
#include <torch/extension.h>
#include <torch/library.h>
#include <torch/torch.h>
// namespace py = pybind11;
PYBIND11_MODULE(vLLMMarlin, m) {
/*m.def("dequantize_q8_0", &dequantize_q8_0, "Function to dequantize q8_0
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_q6_k", &dequantize_q6_k, "Function to dequantize q6_k
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_q5_k", &dequantize_q5_k, "Function to dequantize q5_k
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_q4_k", &dequantize_q4_k, "Function to dequantize q4_k
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_q3_k", &dequantize_q3_k, "Function to dequantize q3_k
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_q2_k", &dequantize_q2_k, "Function to dequantize q2_k
data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));
m.def("dequantize_iq4_xs", &dequantize_iq4_xs, "Function to dequantize
iq4_xs data.", py::arg("data"), py::arg("blk_size"), py::arg("device"));*/
m.def("gptq_marlin_gemm", &gptq_marlin_gemm,
"Function to perform GEMM using Marlin quantization.", py::arg("a"),
py::arg("b_q_weight"), py::arg("b_scales"), py::arg("g_idx"),
py::arg("perm"), py::arg("workspace"), py::arg("num_bits"), py::arg("size_m_tensor"),
py::arg("size_m"), py::arg("size_n"), py::arg("size_k"),
py::arg("sms"), py::arg("is_k_full"));
m.def("gptq_marlin_repack", &gptq_marlin_repack,
"gptq_marlin repack from GPTQ");
}
================================================
FILE: archive/csrc/custom_marlin/gptq_marlin/gptq_marlin.cu
================================================
/*
* Modified by Neural Magic
* Copyright (C) Marlin.2024 Elias Frantar
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
/*
* Adapted from https://github.com/IST-DASLab/marlin
*/
/*
* Adapted from
* https://github.com/vllm-project/vllm/tree/main/csrc/quantization/gptq_marlin
*/
#include "gptq_marlin.cuh"
#include "gptq_marlin_dtypes.cuh"
#include <c10/cuda/CUDAGuard.h>
#define STATIC_ASSERT_SCALAR_TYPE_VALID(scalar_t) \
static_assert(std::is_same<scalar_t, half>::value || \
std::is_same<scalar_t, nv_bfloat16>::value, \
"only float16 and bfloat16 is supported");
template <typename T> inline std::string str(T x) { return std::to_string(x); }
namespace gptq_marlin {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ < 800
__global__ void permute_cols_kernel(int4 const* __restrict__ a_int4_ptr,
int const* __restrict__ perm_int_ptr,
int4* __restrict__ out_int4_ptr, int size_m,
int size_k, int block_rows) {}
template <typename scalar_t, // compute dtype, half or nv_float16
const int num_bits, // number of bits used for weights
const int threads, // number of threads in a threadblock
const int thread_m_blocks, // number of 16x16 blocks in the m
// dimension (batchsize) of the
// threadblock
const int thread_n_blocks, // same for n dimension (output)
const int thread_k_blocks, // same for k dimension (reduction)
const int stages, // number of stages for the async global->shared
// fetch pipeline
const bool has_act_order, // whether act_order is enabled
const int group_blocks = -1 // number of consecutive 16x16 blocks
// with a separate quantization scale
>
__global__ void
Marlin(const int4* __restrict__ A, // fp16 input matrix of shape mxk
const int4* __restrict__ B, // 4bit quantized weight matrix of shape kxn
int4* __restrict__ C, // fp16 output buffer of shape mxn
const int4* __restrict__ scales_ptr, // fp16 quantization scales of shape
// (k/groupsize)xn
const int* __restrict__ g_idx, // int32 group indices of shape k
int num_groups, // number of scale groups per output channel
int prob_m, // batch dimension m
int prob_n, // output dimension n
int prob_k, // reduction dimension k
int* locks // extra global storage for barrier synchronization
) {}
} // namespace gptq_marlin
torch::Tensor gptq_marlin_gemm(torch::Tensor& a, torch::Tensor& b_q_weight,
torch::Tensor& b_scales, torch::Tensor& g_idx,
torch::Tensor& perm, torch::Tensor& workspace,
int64_t num_bits, int64_t size_m, int64_t size_n,
int64_t size_k, bool is_k_full) {
TORCH_CHECK_NOT_IMPLEMENTED(false,
"marlin_gemm(..) requires CUDA_ARCH >= 8.0");
return torch::empty({ 1, 1 });
}
#else
// m16n8k16 tensor core mma instruction with fp16 inputs and fp32
// output/accumulation.
template <typename scalar_t>
__device__ inline void mma(const typename ScalarType<scalar_t>::FragA& a_frag,
const typename ScalarType<scalar_t>::FragB& frag_b,
typename ScalarType<scalar_t>::FragC& frag_c) {
const uint32_t* a = reinterpret_cast<const uint32_t*>(&a_frag);
const uint32_t* b = reinterpret_cast<const uint32_t*>(&frag_b);
float* c = reinterpret_cast<float*>(&frag_c);
if constexpr (std::is_same<scalar_t, half>::value) {
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0,%1,%2,%3}, {%4,%5,%6,%7}, {%8,%9}, {%10,%11,%12,%13};\n"
: "=f"(c[0]), "=f"(c[1]), "=f"(c[2]), "=f"(c[3])
: "r"(a[0]), "r"(a[1]), "r"(a[2]), "r"(a[3]), "r"(b[0]), "r"(b[1]),
"f"(c[0]), "f"(c[1]), "f"(c[2]), "f"(c[3]));
}
else if constexpr (std::is_same<scalar_t, nv_bfloat16>::value) {
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 "
"{%0,%1,%2,%3}, {%4,%5,%6,%7}, {%8,%9}, {%10,%11,%12,%13};\n"
: "=f"(c[0]), "=f"(c[1]), "=f"(c[2]), "=f"(c[3])
: "r"(a[0]), "r"(a[1]), "r"(a[2]), "r"(a[3]), "r"(b[0]), "r"(b[1]),
"f"(c[0]), "f"(c[1]), "f"(c[2]), "f"(c[3]));
}
else {
STATIC_ASSERT_SCALAR_TYPE_VALID(scalar_t);
}
}
// Instruction for loading a full 16x16 matrix fragment of operand A from shared
// memory, directly in tensor core layout.
template <typename scalar_t>
__device__ inline void ldsm4(typename ScalarType<scalar_t>::FragA& frag_a,
const void* smem_ptr) {
uint32_t* a = reinterpret_cast<uint32_t*>(&frag_a);
uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 {%0,%1,%2,%3}, [%4];\n"
: "=r"(a[0]), "=r"(a[1]), "=r"(a[2]), "=r"(a[3])
: "r"(smem));
}
// Lookup-table based 3-input logical operation; explicitly used for
// dequantization as the compiler does not seem to automatically recognize it in
// all cases.
template <int lut> __device__ inline int lop3(int a, int b, int c) {
int res;
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(res)
: "r"(a), "r"(b), "r"(c), "n"(lut));
return res;
}
// Constructs destination register by taking bytes from 2 sources (based on
// mask)
template <int start_byte, int mask>
__device__ inline uint32_t prmt(uint32_t a) {
uint32_t res;
asm volatile("prmt.b32 %0, %1, %2, %3;\n"
: "=r"(res)
: "r"(a), "n"(start_byte), "n"(mask));
return res;
}
// Efficiently dequantize an int32 value into a full B-fragment of 4 fp16
// values. We mostly follow the strategy in the link below, with some small
// changes:
// - FP16:
// https://github.com/NVIDIA/FasterTransformer/blob/release/v5.3_tag/src/fastertransformer/cutlass_extensions/include/cutlass_extensions/interleaved_numeric_conversion.h#L215-L287
// - BF16:
// https://github.com/NVIDIA/FasterTransformer/blob/release/v5.3_tag/src/fastertransformer/cutlass_extensions/include/cutlass_extensions/interleaved_numeric_conversion.h#L327-L385
template <typename scalar_t>
__device__ inline typename ScalarType<scalar_t>::FragB dequant_4bit(int q) {
STATIC_ASSERT_SCALAR_TYPE_VALID(scalar_t);
}
template <>
__device__ inline typename ScalarType<half>::FragB dequant_4bit<half>(int q) {
const int LO = 0x000f000f;
const int HI = 0x00f000f0;
const int EX = 0x64006400;
// Guarantee that the `(a & b) | c` operations are LOP3s.
int lo = lop3<(0xf0 & 0xcc) | 0xaa>(q, LO, EX);
int hi = lop3<(0xf0 & 0xcc) | 0xaa>(q, HI, EX);
// We want signed int4 outputs, hence we fuse the `-8` symmetric zero point
// directly into `SUB` and `ADD`.
const int SUB = 0x64086408;
const int MUL = 0x2c002c00;
const int ADD = 0xd480d480;
typename ScalarType<half>::FragB frag_b;
frag_b[0] = __hsub2(*reinterpret_cast<half2*>(&lo),
*reinterpret_cast<const half2*>(&SUB));
frag_b[1] = __hfma2(*reinterpret_cast<half2*>(&hi),
*reinterpret_cast<const half2*>(&MUL),
*reinterpret_cast<const half2*>(&ADD));
return frag_b;
}
template <>
__device__ inline typename ScalarType<nv_bfloat16>::FragB
dequant_4bit<nv_bfloat16>(int q) {
static constexpr uint32_t MASK = 0x000f000f;
static constexpr uint32_t EX = 0x43004300;
// Guarantee that the `(a & b) | c` operations are LOP3s.
int lo = lop3<(0xf0 & 0xcc) | 0xaa>(q, MASK, EX);
q >>= 4;
int hi = lop3<(0xf0 & 0xcc) | 0xaa>(q, MASK, EX);
typename ScalarType<nv_bfloat16>::FragB frag_b;
static constexpr uint32_t MUL = 0x3F803F80;
static constexpr uint32_t ADD = 0xC308C308;
frag_b[0] = __hfma2(*reinterpret_cast<nv_bfloat162*>(&lo),
*reinterpret_cast<const nv_bfloat162*>(&MUL),
*reinterpret_cast<const nv_bfloat162*>(&ADD));
frag_b[1] = __hfma2(*reinterpret_cast<nv_bfloat162*>(&hi),
*reinterpret_cast<const nv_bfloat162*>(&MUL),
*reinterpret_cast<const nv_bfloat162*>(&ADD));
return frag_b;
}
// Fast Int8ToFp16/Int8ToBf16: Efficiently dequantize 8bit int values to fp16 or
// bf16 Reference:
// - FP16:
// https://github.com/NVIDIA/FasterTransformer/blob/release/v5.3_tag/src/fastertransformer/cutlass_extensions/include/cutlass_extensions/interleaved_numeric_conversion.h#L53-L85
// - BF16:
// https://github.com/NVIDIA/FasterTransformer/blob/release/v5.3_tag/src/fastertransformer/cutlass_extensions/include/cutlass_extensions/interleaved_numeric_conversion.h#L125-L175
template <typename scalar_t>
__device__ inline typename ScalarType<scalar_t>::FragB dequant_8bit(int q) {
STATIC_ASSERT_SCALAR_TYPE_VALID(scalar_t);
}
template <>
__device__ inline typename ScalarType<half>::FragB dequant_8bit<half>(int q) {
static constexpr uint32_t mask_for_elt_01 = 0x5250;
static constexpr uint32_t mask_for_elt_23 = 0x5351;
static constexpr uint32_t start_byte_for_fp16 = 0x64646464;
uint32_t lo = prmt<start_byte_for_fp16, mask_for_elt_01>(q);
uint32_t hi = prmt<start_byte_for_fp16, mask_for_elt_23>(q);
static constexpr uint32_t I8s_TO_F16s_MAGIC_NUM = 0x64806480;
typename ScalarType<half>::FragB frag_b;
frag_b[0] =
__hsub2(*reinterpret_cast<half2*>(&lo),
*reinterpret_cast<const half2*>(&I8s_TO_F16s_MAGIC_NUM));
frag_b[1] =
__hsub2(*reinterpret_cast<half2*>(&hi),
*reinterpret_cast<const half2*>(&I8s_TO_F16s_MAGIC_NUM));
return frag_b;
}
template <>
__device__ inline typename ScalarType<nv_bfloat16>::FragB
dequant_8bit<nv_bfloat16>(int q) {
typename ScalarType<nv_bfloat16>::FragB frag_b;
float fp32_intermediates[4];
uint32_t* fp32_intermediates_casted =
reinterpret_cast<uint32_t*>(fp32_intermediates);
static constexpr uint32_t fp32_base = 0x4B000000;
fp32_intermediates_casted[0] = __byte_perm(q, fp32_base, 0x7650);
fp32_intermediates_casted[1] = __byte_perm(q, fp32_base, 0x7652);
fp32_intermediates_casted[2] = __byte_perm(q, fp32_base, 0x7651);
fp32_intermediates_casted[3] = __byte_perm(q, fp32_base, 0x7653);
fp32_intermediates[0] -= 8388736.f;
fp32_intermediates[1] -= 8388736.f;
fp32_intermediates[2] -= 8388736.f;
fp32_intermediates[3] -= 8388736.f;
uint32_t* bf16_result_ptr = reinterpret_cast<uint32_t*>(&frag_b);
bf16_result_ptr[0] = __byte_perm(fp32_intermediates_casted[0],
fp32_intermediates_casted[1], 0x7632);
bf16_result_ptr[1] = __byte_perm(fp32_intermediates_casted[2],
fp32_intermediates_casted[3], 0x7632);
return frag_b;
}
// Multiply dequantized values by the corresponding quantization scale; used
// only for grouped quantization.
template <typename scalar_t>
__device__ inline void scale(typename ScalarType<scalar_t>::FragB& frag_b,
typename ScalarType<scalar_t>::FragS& frag_s,
int i) {
using scalar_t2 = typename ScalarType<scalar_t>::scalar_t2;
scalar_t2 s = ScalarType<scalar_t>::num2num2(
reinterpret_cast<scalar_t*>(&frag_s)[i]);
frag_b[0] = __hmul2(frag_b[0], s);
frag_b[1] = __hmul2(frag_b[1], s);
}
// Same as above, but for act_order (each K is multiplied individually)
template <typename scalar_t>
__device__ inline void scale4(typename ScalarType<scalar_t>::FragB& frag_b,
typename ScalarType<scalar_t>::FragS& frag_s_1,
typename ScalarType<scalar_t>::FragS& frag_s_2,
typename ScalarType<scalar_t>::FragS& frag_s_3,
typename ScalarType<scalar_t>::FragS& frag_s_4,
int i) {
using scalar_t2 = typename ScalarType<scalar_t>::scalar_t2;
scalar_t2 s_val_1_2;
s_val_1_2.x = reinterpret_cast<scalar_t*>(&frag_s_1)[i];
s_val_1_2.y = reinterpret_cast<scalar_t*>(&frag_s_2)[i];
scalar_t2 s_val_3_4;
s_val_3_4.x = reinterpret_cast<scalar_t*>(&frag_s_3)[i];
s_val_3_4.y = reinterpret_cast<scalar_t*>(&frag_s_4)[i];
frag_b[0] = __hmul2(frag_b[0], s_val_1_2);
frag_b[1] = __hmul2(frag_b[1], s_val_3_4);
}
// Given 2 floats multiply by 2 scales (halves)
template <typename scalar_t>
__device__ inline void scale_float(float* c,
typename ScalarType<scalar_t>::FragS& s) {
scalar_t* s_ptr = reinterpret_cast<scalar_t*>(&s);
c[0] = __fmul_rn(c[0], ScalarType<scalar_t>::num2float(s_ptr[0]));
c[1] = __fmul_rn(c[1], ScalarType<scalar_t>::num2float(s_ptr[1]));
}
// Wait until barrier reaches `count`, then lock for current threadblock.
__device__ inline void barrier_acquire(int* lock, int count) {
if (threadIdx.x == 0) {
int state = -1;
do
// Guarantee that subsequent writes by this threadblock will be
// visible globally.
asm volatile("ld.global.acquire.gpu.b32 %0, [%1];\n"
: "=r"(state)
: "l"(lock));
while (state != count);
}
__syncthreads();
}
// Release barrier and increment visitation count.
__device__ inline void barrier_release(int* lock, bool reset = false) {
__syncthreads();
if (threadIdx.x == 0) {
if (reset) {
lock[0] = 0;
return;
}
int val = 1;
// Make sure that all writes since acquiring this barrier are visible
// globally, while releasing the barrier.
asm volatile("fence.acq_rel.gpu;\n");
asm volatile("red.relaxed.gpu.global.add.s32 [%0], %1;\n"
:
: "l"(lock), "r"(val));
}
}
// For a given "a" of size [M,K] performs a permutation of the K columns based
// on the given "perm" indices.
__global__ void permute_cols_kernel(int4 const* __restrict__ a_int4_ptr,
int const* __restrict__ perm_int_ptr,
int4* __restrict__ out_int4_ptr, int size_m,
int size_k, int block_rows) {
int start_row = block_rows * blockIdx.x;
int finish_row = start_row + block_rows;
if (finish_row > size_m) {
finish_row = size_m;
}
int cur_block_rows = finish_row - start_row;
int row_stride = size_k * sizeof(half) / 16;
auto permute_row = [&](int row) {
int iters = size_k / default_threads;
int rest = size_k % default_threads;
int offset = row * row_stride;
half const* a_row_half =
reinterpret_cast<half const*>(a_int4_ptr + offset);
half* out_half = reinterpret_cast<half*>(out_int4_ptr + offset);
int base_k = 0;
for (int i = 0; i < iters; i++) {
int cur_k = base_k + threadIdx.x;
int src_pos = perm_int_ptr[cur_k];
out_half[cur_k] = a_row_half[src_pos];
base_k += default_threads;
}
if (rest) {
if (threadIdx.x < rest) {
int cur_k = base_k + threadIdx.x;
int src_pos = perm_int_ptr[cur_k];
out_half[cur_k] = a_row_half[src_pos];
}
}
};
for (int i = 0; i < cur_block_rows; i++) {
int cur_row = start_row + i;
if (cur_row < size_m) {
permute_row(cur_row);
}
}
}
template <typename scalar_t, // compute dtype, half or nv_float16
const int num_bits, // number of bits used for weights
const int threads, // number of threads in a threadblock
const int thread_m_blocks, // number of 16x16 blocks in the m
// dimension (batchsize) of the
// threadblock
const int thread_n_blocks, // same for n dimension (output)
const int thread_k_blocks, // same for k dimension (reduction)
const int stages, // number of stages for the async global->shared
// fetch pipeline
const bool has_act_order, // whether act_order is enabled
const int group_blocks = -1 // number of consecutive 16x16 blocks
// with a separate quantization scale
>
__device__ void
Marlin(const int4* __restrict__ A, // fp16 input matrix of shape mxk
const int4* __restrict__ B, // 4bit quantized weight matrix of shape kxn
int4* __restrict__ C, // fp16 output buffer of shape mxn
const int4* __restrict__ scales_ptr, // fp16 quantization scales of shape
// (k/groupsize)xn
const int* __restrict__ g_idx, // int32 group indices of shape k
int num_groups, // number of scale groups per output channel
int prob_m, // batch dimension m, should be divisible by (16 * thread_m_blocks) if bigger than that
int prob_n, // output dimension n
int prob_k, // reduction dimension k
int* locks // extra global storage for barrier synchronization
) {
// Each threadblock processes one "stripe" of the B matrix with (roughly) the
// same size, which might involve multiple column "slices" (of width 16 *
// `thread_n_blocks`). Stripes are defined as shown in the 3x3 matrix 5 SM
// example:
// 0 1 3
// 0 2 3
// 1 2 4
// While this kind of partitioning makes things somewhat more complicated, it
// ensures good utilization of all SMs for many kinds of shape and GPU
// configurations, while requiring as few slow global cross-threadblock
// reductions as possible.
using Dtype = ScalarType<scalar_t>;
using scalar_t2 = typename ScalarType<scalar_t>::scalar_t2;
using FragA = typename ScalarType<scalar_t>::FragA;
using FragB = typename ScalarType<scalar_t>::FragB;
using FragC = typename ScalarType<scalar_t>::FragC;
using FragS = typename ScalarType<scalar_t>::FragS;
constexpr int pack_factor = 32 / num_bits;
// int prob_m = *prob_m_ptr;
// const int thread_m_blocks = min(div_ceil(prob_m, 16), template_thread_m_blocks);
// constexpr int thread_m_blocks = template_thread_m_blocks;
// For larger GEMMs we run multiple batchsize 64 versions in parallel for a
// better partitioning with less reductions
int parallel = 1;
if (prob_m > 16 * thread_m_blocks) {
parallel = prob_m / (16 * thread_m_blocks);
prob_m = 16 * thread_m_blocks;
}
int k_tiles = prob_k / 16 / thread_k_blocks;
int n_tiles = prob_n / 16 / thread_n_blocks;
int iters = div_ceil(k_tiles * n_tiles * parallel, gridDim.x);
if constexpr (!has_act_order && group_blocks != -1) {
if (group_blocks >= thread_k_blocks) {
// Ensure that the number of tiles in each stripe is a multiple of the
// groupsize; this avoids an annoying special case where a stripe starts
// in the middle of group.
iters = (group_blocks / thread_k_blocks) *
div_ceil(iters, (group_blocks / thread_k_blocks));
}
}
int slice_row = (iters * blockIdx.x) % k_tiles;
int slice_col_par = (iters * blockIdx.x) / k_tiles;
int slice_col = slice_col_par;
int slice_iters; // number of threadblock tiles in the current slice
int slice_count =
0; // total number of active threadblocks in the current slice
int slice_idx; // index of threadblock in current slice; numbered bottom to
// top
// We can easily implement parallel problem execution by just remapping
// indices and advancing global pointers
if (slice_col_par >= n_tiles) {
A += (slice_col_par / n_tiles) * 16 * thread_m_blocks * prob_k / 8;
C += (slice_col_par / n_tiles) * 16 * thread_m_blocks * prob_n / 8;
locks += (slice_col_par / n_tiles) * n_tiles;
slice_col = slice_col_par % n_tiles;
}
// Compute all information about the current slice which is required for
// synchronization.
auto init_slice = [&]() {
slice_iters =
iters * (blockIdx.x + 1) - (k_tiles * slice_col_par + slice_row);
if (slice_iters < 0 || slice_col_par >= n_tiles * parallel) slice_iters = 0;
if (slice_iters == 0) return;
if (slice_row + slice_iters > k_tiles) slice_iters = k_tiles - slice_row;
slice_count = 1;
slice_idx = 0;
int col_first = iters * div_ceil(k_tiles * slice_col_par, iters);
if (col_first <= k_tiles * (slice_col_par + 1)) {
int col_off = col_first - k_tiles * slice_col_par;
slice_count = div_ceil(k_tiles - col_off, iters);
if (col_off > 0) slice_count++;
int delta_first = iters * blockIdx.x - col_first;
if (delta_first < 0 || (col_off == 0 && delta_first == 0))
slice_idx = slice_count - 1;
else {
slice_idx = slice_count - 1 - delta_first / iters;
if (col_off > 0) slice_idx--;
}
}
if (slice_col == n_tiles) {
A += 16 * thread_m_blocks * prob_k / 8;
C += 16 * thread_m_blocks * prob_n / 8;
locks += n_tiles;
slice_col = 0;
}
};
init_slice();
// A sizes/strides
// stride of the A matrix in global memory
int a_gl_stride = prob_k / 8;
// stride of an A matrix tile in shared memory
constexpr int a_sh_stride = 16 * thread_k_blocks / 8;
// delta between subsequent A tiles in global memory
constexpr int a_gl_rd_delta_o = 16 * thread_k_blocks / 8;
// between subsequent accesses within a tile
int a_gl_rd_delta_i = a_gl_stride * (threads / a_gl_rd_delta_o);
// between shared memory writes
constexpr int a_sh_wr_delta = a_sh_stride * (threads / a_gl_rd_delta_o);
// between shared memory tile reads
constexpr int a_sh_rd_delta_o = 2 * ((threads / 32) / (thread_n_blocks / 4));
// within a shared memory tile
constexpr int a_sh_rd_delta_i = a_sh_stride * 16;
// overall size of a tile
constexpr int a_sh_stage = a_sh_stride * (16 * thread_m_blocks);
// number of shared write iterations for a tile
constexpr int a_sh_wr_iters = div_ceil(a_sh_stage, a_sh_wr_delta);
// B sizes/strides
int b_gl_stride = 16 * prob_n / (pack_factor * 4);
constexpr int b_sh_stride = ((thread_n_blocks * 16) * 16 / pack_factor) / 4;
constexpr int b_thread_vecs = num_bits == 4 ? 1 : 2;
constexpr int b_sh_stride_threads = b_sh_stride / b_thread_vecs;
int b_gl_rd_delta_o = b_gl_stride * thread_k_blocks;
int b_gl_rd_delta_i = b_gl_stride * (threads / b_sh_stride_threads);
constexpr int b_sh_wr_delta = threads * b_thread_vecs;
constexpr int b_sh_rd_delta = threads * b_thread_vecs;
constexpr int b_sh_stage = b_sh_stride * thread_k_blocks;
constexpr int b_sh_wr_iters = b_sh_stage / b_sh_wr_delta;
// Scale sizes/strides without act_order
int s_gl_stride = prob_n / 8;
constexpr int s_sh_stride = 16 * thread_n_blocks / 8;
constexpr int s_tb_groups =
!has_act_order && group_blocks != -1 && group_blocks < thread_k_blocks
? thread_k_blocks / group_blocks
: 1;
constexpr int s_sh_stage = s_tb_groups * s_sh_stride;
int s_gl_rd_delta = s_gl_stride;
// Scale size/strides with act_order
constexpr int tb_k = 16 * thread_k_blocks;
constexpr int g_idx_stage = has_act_order ? (tb_k * sizeof(int)) / 16 : 0;
// constexpr int act_s_row_stride = 1;
// int act_s_col_stride = act_s_row_stride * num_groups;
int act_s_col_stride = 1;
int act_s_col_warp_stride = act_s_col_stride * 8;
int tb_n_warps = thread_n_blocks / 4;
int act_s_col_tb_stride = act_s_col_warp_stride * tb_n_warps;
// Global A read index of current thread.
int a_gl_rd = a_gl_stride * (threadIdx.x / a_gl_rd_delta_o) +
(threadIdx.x % a_gl_rd_delta_o);
a_gl_rd += a_gl_rd_delta_o * slice_row;
// Shared write index of current thread.
int a_sh_wr = a_sh_stride * (threadIdx.x / a_gl_rd_delta_o) +
(threadIdx.x % a_gl_rd_delta_o);
// Shared read index.
int a_sh_rd =
a_sh_stride * ((threadIdx.x % 32) % 16) + (threadIdx.x % 32) / 16;
a_sh_rd += 2 * ((threadIdx.x / 32) / (thread_n_blocks / 4));
int b_gl_rd = b_gl_stride * (threadIdx.x / b_sh_stride_threads) +
(threadIdx.x % b_sh_stride_threads) * b_thread_vecs;
b_gl_rd += b_sh_stride * slice_col;
b_gl_rd += b_gl_rd_delta_o * slice_row;
int b_sh_wr = threadIdx.x * b_thread_vecs;
int b_sh_rd = threadIdx.x * b_thread_vecs;
// For act_order
constexpr int k_iter_size = tb_k / b_sh_wr_iters;
int slice_k_start = tb_k * slice_row;
int slice_k_finish = slice_k_start + tb_k * slice_iters;
int slice_k_start_shared_fetch = slice_k_start;
int slice_n_offset = act_s_col_tb_stride * slice_col;
// No act_order
int s_gl_rd;
if constexpr (!has_act_order) {
if constexpr (group_blocks == -1) {
s_gl_rd = s_sh_stride * slice_col + threadIdx.x;
}
else {
s_gl_rd = s_gl_stride * ((thread_k_blocks * slice_row) / group_blocks) +
s_sh_stride * slice_col + threadIdx.x;
}
}
int s_sh_wr = threadIdx.x;
bool s_sh_wr_pred = threadIdx.x < s_sh_stride;
// We use a different scale layout for grouped and column-wise quantization as
// we scale a `half2` tile in column-major layout in the former and in
// row-major in the latter case.
int s_sh_rd;
if constexpr (group_blocks != -1)
s_sh_rd = 8 * ((threadIdx.x / 32) % (thread_n_blocks / 4)) +
(threadIdx.x % 32) / 4;
else
s_sh_rd = 8 * ((threadIdx.x / 32) % (thread_n_blocks / 4)) +
(threadIdx.x % 32) % 4;
// Precompute which thread should not read memory in which iterations; this is
// needed if there are more threads than required for a certain tilesize or
// when the batchsize is not a multiple of 16.
bool a_sh_wr_pred[a_sh_wr_iters];
#pragma unroll
for (int i = 0; i < a_sh_wr_iters; i++) {
a_sh_wr_pred[i] = a_sh_wr_delta * i + a_sh_wr < a_sh_stride * prob_m;
}
// To ensure that writing and reading A tiles to/from shared memory, the
// latter in fragment format, is fully bank conflict free, we need to use a
// rather fancy XOR-based layout. The key here is that neither reads nor
// writes of the 16-byte `int4` blocks of 8 consecutive threads involve the
// same shared memory banks. Further, it seems (based on NSight-Compute) that
// each warp must also write a consecutive memory segment?
auto transform_a = [&](int i) {
int row = i / a_gl_rd_delta_o;
return a_gl_rd_delta_o * row + (i % a_gl_rd_delta_o) ^ row;
};
// Since the computation of this remapping is non-trivial and, due to our main
// loop unrolls, all shared memory accesses are static, we simply precompute
// both transformed reads and writes.
int a_sh_wr_trans[a_sh_wr_iters];
#pragma unroll
for (int i = 0; i < a_sh_wr_iters; i++) {
a_sh_wr_trans[i] = transform_a(a_sh_wr_delta * i + a_sh_wr);
}
int a_sh_rd_trans[b_sh_wr_iters][thread_m_blocks];
#pragma unroll
for (int i = 0; i < b_sh_wr_iters; i++) {
#pragma unroll
for (int j = 0; j < thread_m_blocks; j++)
{
a_sh_rd_trans[i][j] =
transform_a(a_sh_rd_delta_o * i + a_sh_rd_delta_i * j + a_sh_rd);
}
}
// Since B-accesses have non-constant stride they have to be computed at
// runtime; we break dependencies between subsequent accesses with a tile by
// maintining multiple pointers (we have enough registers), a tiny
// optimization.
const int4* B_ptr[b_sh_wr_iters];
#pragma unroll
for (int i = 0; i < b_sh_wr_iters; i++)
B_ptr[i] = B + b_gl_rd_delta_i * i + b_gl_rd;
extern __shared__ int4 sh[];
// Shared memory storage for global fetch pipelines.
int4* sh_a = sh;
int4* sh_b = sh_a + (stages * a_sh_stage);
int4* sh_g_idx = sh_b + (stages * b_sh_stage);
int4* sh_s = sh_g_idx + (stages * g_idx_stage);
// Register storage for double buffer of shared memory reads.
FragA frag_a[2][thread_m_blocks];
I4 frag_b_quant[2][b_thread_vecs];
FragC frag_c[thread_m_blocks][4][2];
FragS frag_s[2][4]; // No act-order
FragS act_frag_s[2][4][4]; // For act-order
// Zero accumulators.
auto zero_accums = [&]() {
#pragma unroll
for (int i = 0; i < thread_m_blocks * 4 * 2 * 4; i++)
{
reinterpret_cast<float*>(frag_c)[i] = 0;
}
};
int sh_first_group_id = -1;
int sh_num_groups = -1;
constexpr int sh_max_num_groups = 32;
auto fetch_scales_to_shared = [&](bool is_async, int first_group_id,
int last_group_id) {
sh_first_group_id = first_group_id;
sh_num_groups = last_group_id - first_group_id + 1;
if (sh_num_groups < sh_max_num_groups) {
sh_num_groups = sh_max_num_groups;
}
if (sh_first_group_id + sh_num_groups > num_groups) {
sh_num_groups = num_groups - sh_first_group_id;
}
int row_offset = first_group_id * s_gl_stride;
if (is_async) {
for (int i = 0; i < sh_num_groups; i++) {
if (threadIdx.x < s_sh_stride) {
cp_async4_pred(&sh_s[(i * s_sh_stride) + threadIdx.x],
&scales_ptr[row_offset + (i * s_gl_stride) +
slice_n_offset + threadIdx.x]);
}
}
}
else {
for (int i = 0; i < sh_num_groups; i++) {
if (threadIdx.x < s_sh_stride) {
sh_s[(i * s_sh_stride) + threadIdx.x] =
scales_ptr[row_offset + (i * s_gl_stride) + slice_n_offset +
threadIdx.x];
}
}
}
};
// Asynchronously fetch the next A, B and s tile from global to the next
// shared memory pipeline location.
auto fetch_to_shared = [&](int pipe, int a_off, bool pred = true) {
if (pred) {
int4* sh_a_stage = sh_a + a_sh_stage * pipe;
#pragma unroll
for (int i = 0; i < a_sh_wr_iters; i++) {
cp_async4_pred(
&sh_a_stage[a_sh_wr_trans[i]],
&A[a_gl_rd_delta_i * i + a_gl_rd + a_gl_rd_delta_o * a_off],
a_sh_wr_pred[i]);
}
int4* sh_b_stage = sh_b + b_sh_stage * pipe;
#pragma unroll
for (int i = 0; i < b_sh_wr_iters; i++) {
#pragma unroll
for (int j = 0; j < b_thread_vecs; j++) {
cp_async4(&sh_b_stage[b_sh_wr_delta * i + b_sh_wr + j], B_ptr[i] + j);
}
B_ptr[i] += b_gl_rd_delta_o;
}
if constexpr (has_act_order) {
// Fetch g_idx thread-block portion
int full_pipe = a_off;
int cur_k = slice_k_start_shared_fetch + tb_k * full_pipe;
if (cur_k < prob_k && cur_k < slice_k_finish) {
int4* sh_g_idx_stage = sh_g_idx + g_idx_stage * pipe;
int4 const* cur_g_idx_stage_ptr =
reinterpret_cast<int4 const*>(&g_idx[cur_k]);
if (threadIdx.x < g_idx_stage) {
cp_async4_pred(&sh_g_idx_stage[threadIdx.x],
&cur_g_idx_stage_ptr[threadIdx.x]);
}
}
}
else {
if constexpr (group_blocks != -1) {
int4* sh_s_stage = sh_s + s_sh_stage * pipe;
if constexpr (group_blocks >= thread_k_blocks) {
// Only fetch scales if this tile starts a new group
if (pipe % (group_blocks / thread_k_blocks) == 0) {
if (s_sh_wr_pred) {
cp_async4(&sh_s_stage[s_sh_wr], &scales_ptr[s_gl_rd]);
}
s_gl_rd += s_gl_rd_delta;
}
}
else {
for (int i = 0; i < s_tb_groups; i++) {
if (s_sh_wr_pred) {
cp_async4(&sh_s_stage[i * s_sh_stride + s_sh_wr],
&scales_ptr[s_gl_rd]);
}
s_gl_rd += s_gl_rd_delta;
}
}
}
}
}
// Insert a fence even when we are winding down the pipeline to ensure that
// waiting is also correct at this point.
cp_async_fence();
};
// Wait until the next thread tile has been loaded to shared memory.
auto wait_for_stage = [&]() {
// We only have `stages - 2` active fetches since we are double buffering
// and can only issue the next fetch when it is guaranteed that the previous
// shared memory load is fully complete (as it may otherwise be
// overwritten).
cp_async_wait<stages - 2>();
__syncthreads();
};
// Load the next sub-tile from the current location in the shared memory pipe
// into the current register buffer.
auto fetch_to_registers = [&](int k, int pipe) {
int4* sh_a_stage = sh_a + a_sh_stage * pipe;
#pragma unroll
for (int i = 0; i < thread_m_blocks; i++)
{
ldsm4<scalar_t>(frag_a[k % 2][i],
&sh_a_stage[a_sh_rd_trans[k % b_sh_wr_iters][i]]);
}
int4* sh_b_stage = sh_b + b_sh_stage * pipe;
#pragma unroll
for (int i = 0; i < b_thread_vecs; i++) {
frag_b_quant[k % 2][i] = *reinterpret_cast<I4*>(
&sh_b_stage[b_sh_rd_delta * (k % b_sh_wr_iters) + b_sh_rd + i]);
}
};
bool is_same_group[stages];
int same_group_id[stages];
auto init_same_group = [&](int pipe) {
if constexpr (!has_act_order) {
is_same_group[pipe] = false;
same_group_id[pipe] = 0;
return;
}
int4* sh_g_idx_stage = sh_g_idx + g_idx_stage * pipe;
int* sh_g_idx_int_ptr = reinterpret_cast<int*>(sh_g_idx_stage);
int group_id_1 = sh_g_idx_int_ptr[0];
int group_id_2 = sh_g_idx_int_ptr[tb_k - 1];
is_same_group[pipe] = group_id_1 == group_id_2;
same_group_id[pipe] = group_id_1;
};
auto fetch_scales_to_registers = [&](int k, int full_pipe) {
int pipe = full_pipe % stages;
if constexpr (!has_act_order) {
// No act-order case
if constexpr (group_blocks != -1) {
if constexpr (group_blocks >= thread_k_blocks) {
int4* sh_s_stage =
sh_s + s_sh_stage * ((group_blocks / thread_k_blocks) *
(pipe / (group_blocks / thread_k_blocks)));
reinterpret_cast<int4*>(&frag_s[k % 2])[0] = sh_s_stage[s_sh_rd];
}
else {
int warp_id = threadIdx.x / 32;
int n_warps = thread_n_blocks / 4;
int warp_row = warp_id / n_warps;
int cur_k = warp_row * 16;
cur_k += k_iter_size * (k % b_sh_wr_iters);
int k_blocks = cur_k / 16;
int cur_group_id = k_blocks / group_blocks;
int4* sh_s_stage = sh_s + s_sh_stage * pipe;
reinterpret_cast<int4*>(&frag_s[k % 2])[0] =
sh_s_stage[s_sh_rd + cur_group_id * s_sh_stride];
}
}
return;
}
// Act-order case
// Determine K of the "current" thread-block
int cur_k = slice_k_start + tb_k * full_pipe;
if (cur_k >= prob_k || cur_k >= slice_k_finish) {
return;
}
// Reset (to current thread-block) since we read g_idx portion from the
// shared memory
cur_k = 0;
// Progress to current iteration
cur_k += k_iter_size * (k % b_sh_wr_iters);
// Determine "position" inside the thread-block (based on warp and
// thread-id)
int warp_id = threadIdx.x / 32;
int n_warps =
thread_n_blocks / 4; // Each warp processes 4 16-size tiles over N
int warp_row = warp_id / n_warps;
int warp_col = warp_id % n_warps;
cur_k += warp_row * 16;
int th_id = threadIdx.x % 32;
cur_k += (th_id % 4) * 2; // Due to tensor-core layout for fp16 B matrix
int s_col_shift =
/*slice_n_offset +*/ (act_s_col_warp_stride * warp_col) +
(th_id / 4) * act_s_col_stride;
if (is_same_group[pipe]) {
if (k % 2 == 0) {
*(reinterpret_cast<int4*>(&(act_frag_s[k % 2][0][0]))) =
sh_s[(same_group_id[pipe] - sh_first_group_id) * s_sh_stride +
s_col_shift];
}
else {
*(reinterpret_cast<int4*>(&(act_frag_s[k % 2][0][0]))) =
*(reinterpret_cast<int4*>(&(act_frag_s[(k - 1) % 2][0][0])));
}
for (int i = 1; i < 4; i++) {
*(reinterpret_cast<int4*>(&(act_frag_s[k % 2][i][0]))) =
*(reinterpret_cast<int4*>(&(act_frag_s[k % 2][0][0])));
}
return;
}
int4* sh_g_idx_stage = sh_g_idx + g_idx_stage * pipe;
int* sh_g_idx_int_ptr = reinterpret_cast<int*>(sh_g_idx_stage);
constexpr int k_frag_offsets[4] = { 0, 1, 8,
9 }; // Tensor core offsets per thread
#pragma unroll
for (int i = 0; i < 4; i++) {
int actual_k = cur_k + k_frag_offsets[i];
int group_id = sh_g_idx_int_ptr[actual_k];
int rel_group_id = group_id - sh_first_group_id;
*(reinterpret_cast<int4*>(&(act_frag_s[k % 2][i][0]))) =
sh_s[rel_group_id * s_sh_stride + s_col_shift];
}
};
// Execute the actual tensor core matmul of a sub-tile.
auto matmul = [&](int k) {
// We have the m dimension as the inner loop in order to encourage overlapping
// dequantization and matmul operations.
#pragma unroll
for (int j = 0; j < 4; j++) {
FragB frag_b0;
FragB frag_b1;
if constexpr (num_bits == 4) {
int b_quant = frag_b_quant[k % 2][0][j];
int b_quant_shift = b_quant >> 8;
frag_b0 = dequant_4bit<scalar_t>(b_quant);
frag_b1 = dequant_4bit<scalar_t>(b_quant_shift);
}
else {
int* frag_b_quant_ptr = reinterpret_cast<int*>(frag_b_quant[k % 2]);
int b_quant_0 = frag_b_quant_ptr[j * 2 + 0];
int b_quant_1 = frag_b_quant_ptr[j * 2 + 1];
frag_b0 = dequant_8bit<scalar_t>(b_quant_0);
frag_b1 = dequant_8bit<scalar_t>(b_quant_1);
}
// Apply scale to frag_b0
if constexpr (has_act_order) {
scale4<scalar_t>(frag_b0, act_frag_s[k % 2][0][j],
act_frag_s[k % 2][1][j], act_frag_s[k % 2][2][j],
act_frag_s[k % 2][3][j], 0);
}
else {
if constexpr (group_blocks != -1) {
scale<scalar_t>(frag_b0, frag_s[k % 2][j], 0);
}
}
// Apply scale to frag_b1
if constexpr (has_act_order) {
scale4<scalar_t>(frag_b1, act_frag_s[k % 2][0][j],
act_frag_s[k % 2][1][j], act_frag_s[k % 2][2][j],
act_frag_s[k % 2][3][j], 1);
}
else {
if constexpr (group_blocks != -1) {
scale<scalar_t>(frag_b1, frag_s[k % 2][j], 1);
}
}
#pragma unroll
for (int i = 0; i < thread_m_blocks; i++) {
mma<scalar_t>(frag_a[k % 2][i], frag_b0, frag_c[i][j][0]);
mma<scalar_t>(frag_a[k % 2][i], frag_b1, frag_c[i][j][1]);
}
}
};
// Since we slice across the k dimension of a tile in order to increase the
// number of warps while keeping the n dimension of a tile reasonable, we have
// multiple warps that accumulate their partial sums of the same output
// location; which we have to reduce over in the end. We do in shared memory.
auto thread_block_reduce = [&]() {
constexpr int red_off = threads / b_sh_stride_threads / 2;
if (red_off >= 1) {
int red_idx = threadIdx.x / b_sh_stride_threads;
constexpr int red_sh_stride = b_sh_stride_threads * 4 * 2;
constexpr int red_sh_delta = b_sh_stride_threads;
int red_sh_rd = red_sh_stride * (threadIdx.x / b_sh_stride_threads) +
(threadIdx.x % b_sh_stride_threads);
// Parallel logarithmic shared memory reduction. We make sure to avoid any
// unnecessary read or write iterations, e.g., for two warps we write only
// once by warp 1 and read only once by warp 0.
#pragma unroll
for (int m_block = 0; m_block < thread_m_blocks; m_block++) {
#pragma unroll
for (int i = red_off; i > 0; i /= 2) {
if (i <= red_idx && red_idx < 2 * i) {
#pragma unroll
for (int j = 0; j < 4 * 2; j++) {
int red_sh_wr =
red_sh_delta * j + (red_sh_rd - red_sh_stride * i);
if (i < red_off) {
float* c_rd =
reinterpret_cast<float*>(&sh[red_sh_delta * j + red_sh_rd]);
float* c_wr = reinterpret_cast<float*>(&sh[red_sh_wr]);
#pragma unroll
for (int k = 0; k < 4; k++)
reinterpret_cast<FragC*>(frag_c)[4 * 2 * m_block + j][k] +=
c_rd[k] + c_wr[k];
}
sh[red_sh_wr] =
reinterpret_cast<int4*>(&frag_c)[4 * 2 * m_block + j];
}
}
__syncthreads();
}
if (red_idx == 0) {
#pragma unroll
for (int i = 0; i < 4 * 2; i++) {
float* c_rd =
reinterpret_cast<float*>(&sh[red_sh_delta * i + red_sh_rd]);
#pragma unroll
for (int j = 0; j < 4; j++)
reinterpret_cast<FragC*>(frag_c)[4 * 2 * m_block + i][j] +=
c_rd[j];
}
}
__syncthreads();
}
}
};
// Since multiple threadblocks may process parts of the same column slice, we
// finally have to globally reduce over the results. As the striped
// partitioning minimizes the number of such reductions and our outputs are
// usually rather small, we perform this reduction serially in L2 cache.
auto global_reduce = [&](bool first = false, bool last = false) {
// We are very careful here to reduce directly in the output buffer to
// maximize L2 cache utilization in this step. To do this, we write out
// results in FP16 (but still reduce with FP32 compute).
constexpr int active_threads = 32 * thread_n_blocks / 4;
if (threadIdx.x < active_threads) {
int c_gl_stride = prob_n / 8;
int c_gl_wr_delta_o = 8 * c_gl_stride;
int c_gl_wr_delta_i = 4 * (active_threads / 32);
int c_gl_wr = c_gl_stride * ((threadIdx.x % 32) / 4) +
4 * (threadIdx.x / 32) + threadIdx.x % 4;
c_gl_wr += (2 * thread_n_blocks) * slice_col;
constexpr int c_sh_wr_delta = active_threads;
int c_sh_wr = threadIdx.x;
int row = (threadIdx.x % 32) / 4;
if (!first) {
// Interestingly, doing direct global accesses here really seems to mess up
// the compiler and lead to slowdowns, hence we also use async-copies even
// though these fetches are not actually asynchronous.
#pragma unroll
for (int i = 0; i < thread_m_blocks * 4; i++) {
cp_async4_pred(
&sh[c_sh_wr + c_sh_wr_delta * i],
&C[c_gl_wr + c_gl_wr_delta_o * (i / 2) +
c_gl_wr_delta_i * (i % 2)],
i < (thread_m_blocks - 1) * 4 || 8 * (i / 2) + row < prob_m);
}
cp_async_fence();
cp_async_wait<0>();
}
#pragma unroll
for (int i = 0; i < thread_m_blocks * 4; i++) {
if (i < (thread_m_blocks - 1) * 4 || 8 * (i / 2) + row < prob_m) {
if (!first) {
int4 c_red = sh[c_sh_wr + i * c_sh_wr_delta];
#pragma unroll
for (int j = 0; j < 2 * 4; j++) {
reinterpret_cast<float*>(
&frag_c)[4 * 2 * 4 * (i / 4) + 4 * j + (i % 4)] +=
Dtype::num2float(reinterpret_cast<scalar_t*>(&c_red)[j]);
}
}
if (!last) {
int4 c;
#pragma unroll
for (int j = 0; j < 2 * 4; j++) {
reinterpret_cast<scalar_t*>(&c)[j] =
Dtype::float2num(reinterpret_cast<float*>(
&frag_c)[4 * 2 * 4 * (i / 4) + 4 * j + (i % 4)]);
}
C[c_gl_wr + c_gl_wr_delta_o * (i / 2) + c_gl_wr_delta_i * (i % 2)] =
c;
}
}
}
}
};
// Write out the reduce final result in the correct layout. We only actually
// reshuffle matrix fragments in this step, the reduction above is performed
// in fragment layout.
auto write_result = [&]() {
int c_gl_stride = prob_n / 8;
constexpr int c_sh_stride = 2 * thread_n_blocks + 1;
int c_gl_wr_delta = c_gl_stride * (threads / (2 * thread_n_blocks));
constexpr int c_sh_rd_delta =
c_sh_stride * (threads / (2 * thread_n_blocks));
int c_gl_wr = c_gl_stride * (threadIdx.x / (2 * thread_n_blocks)) +
(threadIdx.x % (2 * thread_n_blocks));
c_gl_wr += (2 * thread_n_blocks) * slice_col;
int c_sh_wr =
(4 * c_sh_stride) * ((threadIdx.x % 32) / 4) + (threadIdx.x % 32) % 4;
c_sh_wr += 32 * (threadIdx.x / 32);
int c_sh_rd = c_sh_stride * (threadIdx.x / (2 * thread_n_blocks)) +
(threadIdx.x % (2 * thread_n_blocks));
int c_gl_wr_end = c_gl_stride * prob_m;
// We first reorder in shared memory to guarantee the most efficient final
// global write patterns
auto write = [&](int idx, float c0, float c1, FragS& s) {
scalar_t2 res =
Dtype::nums2num2(Dtype::float2num(c0), Dtype::float2num(c1));
// For per-column quantization we finally apply the scale here (only for
// 4-bit)
if constexpr (!has_act_order && group_blocks == -1 && num_bits == 4) {
res = __hmul2(res, s[0]);
}
((scalar_t2*)sh)[idx] = res;
};
if (threadIdx.x / 32 < thread_n_blocks / 4) {
#pragma unroll
for (int i = 0; i < thread_m_blocks; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
int wr = c_sh_wr + 8 * j;
write(wr + (4 * c_sh_stride) * 0 + 0, frag_c[i][j][0][0],
frag_c[i][j][0][1], frag_s[j / 2][2 * (j % 2) + 0]);
write(wr + (4 * c_sh_stride) * 8 + 0, frag_c[i][j][0][2],
frag_c[i][j][0][3], frag_s[j / 2][2 * (j % 2) + 0]);
write(wr + (4 * c_sh_stride) * 0 + 4, frag_c[i][j][1][0],
frag_c[i][j][1][1], frag_s[j / 2][2 * (j % 2) + 1]);
write(wr + (4 * c_sh_stride) * 8 + 4, frag_c[i][j][1][2],
frag_c[i][j][1][3], frag_s[j / 2][2 * (j % 2) + 1]);
}
c_sh_wr += 16 * (4 * c_sh_stride);
}
}
__syncthreads();
#pragma unroll
for (int i = 0;
i < div_ceil(16 * thread_m_blocks, threads / (2 * thread_n_blocks));
i++) {
if (c_gl_wr < c_gl_wr_end) {
C[c_gl_wr] = sh[c_sh_rd];
c_gl_wr += c_gl_wr_delta;
c_sh_rd += c_sh_rd_delta;
}
}
};
// Start global fetch and register load pipelines.
auto start_pipes = [&]() {
#pragma unroll
for (int i = 0; i < stages - 1; i++) {
if (has_act_order && i == 0) {
int last_g_idx = slice_k_start + stages * tb_k * 2;
if (last_g_idx >= prob_k) {
last_g_idx = prob_k - 1;
}
fetch_scales_to_shared(true, g_idx[slice_k_start], g_idx[last_g_idx]);
}
fetch_to_shared(i, i, i < slice_iters);
}
zero_accums();
wait_for_stage();
init_same_group(0);
fetch_to_registers(0, 0);
fetch_scales_to_registers(0, 0);
a_gl_rd += a_gl_rd_delta_o * (stages - 1);
slice_k_start_shared_fetch += tb_k * (stages - 1);
};
if (slice_iters) {
start_pipes();
}
// Main loop.
while (slice_iters) {
// We unroll over both the global fetch and the register load pipeline to
// ensure all shared memory accesses are static. Note that both pipelines
// have even length meaning that the next iteration will always start at
// index 0.
#pragma unroll
for (int pipe = 0; pipe < stages;) {
#pragma unroll
for (int k = 0; k < b_sh_wr_iters; k++) {
fetch_to_registers(k + 1, pipe % stages);
fetch_scales_to_registers(k + 1, pipe);
if (k == b_sh_wr_iters - 2) {
fetch_to_shared((pipe + stages - 1) % stages, pipe,
slice_iters >= stages);
pipe++;
wait_for_stage();
init_same_group(pipe % stages);
}
matmul(k);
}
slice_iters--;
if (slice_iters == 0) {
break;
}
}
a_gl_rd += a_gl_rd_delta_o * stages;
slice_k_start += tb_k * stages;
slice_k_start_shared_fetch += tb_k * stages;
if constexpr (has_act_order) {
int first_group_id = g_idx[slice_k_start];
int last_g_idx = slice_k_start + stages * tb_k * 2;
if (last_g_idx >= prob_k) {
last_g_idx = prob_k - 1;
}
int last_group_id = g_idx[last_g_idx];
if (last_group_id >= sh_first_group_id + sh_num_groups) {
fetch_scales_to_shared(false, first_group_id, last_group_id);
__syncthreads();
}
}
// Process results and, if necessary, proceed to the next column slice.
// While this pattern may not be the most readable, other ways of writing
// the loop seemed to noticeably worse performance after compilation.
if (slice_iters == 0) {
cp_async_wait<0>();
bool last = slice_idx == slice_count - 1;
// For per-column scales, we only fetch them here in the final step before
// write-out
if constexpr (!has_act_order && group_blocks == -1) {
if constexpr (num_bits == 8) {
if (s_sh_wr_pred) {
cp_async4(&sh_s[s_sh_wr], &scales_ptr[s_gl_rd]);
}
cp_async_fence();
}
else {
if (last) {
if (s_sh_wr_pred) {
cp_async4(&sh_s[s_sh_wr], &scales_ptr[s_gl_rd]);
}
cp_async_fence();
}
}
}
thread_block_reduce();
if constexpr (!has_act_order && group_blocks == -1) {
if constexpr (num_bits == 8) {
cp_async_wait<0>();
__syncthreads();
if (threadIdx.x / 32 < thread_n_blocks / 4) {
reinterpret_cast<int4*>(&frag_s)[0] = sh_s[s_sh_rd + 0];
reinterpret_cast<int4*>(&frag_s)[1] = sh_s[s_sh_rd + 4];
}
}
else {
if (last) {
cp_async_wait<0>();
__syncthreads();
if (threadIdx.x / 32 < thread_n_blocks / 4) {
reinterpret_cast<int4*>(&frag_s)[0] = sh_s[s_sh_rd + 0];
reinterpret_cast<int4*>(&frag_s)[1] = sh_s[s_sh_rd + 4];
}
}
}
}
// For 8-bit channelwise, we apply the scale before the global reduction
// that converts the fp32 results to fp16 (so that we avoid possible
// overflow in fp16)
if constexpr (!has_act_order && group_blocks == -1 && num_bits == 8) {
if (threadIdx.x / 32 < thread_n_blocks / 4) {
#pragma unroll
for (int i = 0; i < thread_m_blocks; i++) {
#pragma unroll
for (int j = 0; j < 4; j++) {
scale_float<scalar_t>(
reinterpret_cast<float*>(&frag_c[i][j][0][0]),
frag_s[j / 2][2 * (j % 2) + 0]);
scale_float<scalar_t>(
reinterpret_cast<float*>(&frag_c[i][j][0][2]),
frag_s[j / 2][2 * (j % 2) + 0]);
scale_float<scalar_t>(
reinterpret_cast<float*>(&frag_c[i][j][1][0]),
frag_s[j / 2][2 * (j % 2) + 1]);
scale_float<scalar_t>(
reinterpret_cast<float*>(&frag_c[i][j][1][2]),
frag_s[j / 2][2 * (j % 2) + 1]);
}
}
}
}
if (slice_count > 1) { // only globally reduce if there is more than one
// block in a slice
barrier_acquire(&locks[slice_col], slice_idx);
global_reduce(slice_idx == 0, last);
barrier_release(&locks[slice_col], last);
}
if (last) // only the last block in a slice actually writes the result
write_result();
slice_row = 0;
slice_col_par++;
slice_col++;
init_slice();
if (slice_iters) {
a_gl_rd = a_gl_stride * (threadIdx.x / a_gl_rd_delta_o) +
(threadIdx.x % a_gl_rd_delta_o);
#pragma unroll
for (int i = 0; i < b_sh_wr_iters; i++)
B_ptr[i] += b_sh_stride - b_gl_rd_delta_o * k_tiles;
if (slice_col == 0) {
#pragma unroll
for (int i = 0; i < b_sh_wr_iters; i++) B_ptr[i] -= b_gl_stride;
}
// Update slice k/n for scales loading
if constexpr (has_act_order) {
slice_k_start = tb_k * slice_row;
slice_k_finish = slice_k_start + tb_k * slice_iters;
slice_k_start_shared_fetch = slice_k_start;
slice_n_offset = act_s_col_tb_stride * slice_col;
}
else {
s_gl_rd = s_sh_stride * slice_col + threadIdx.x;
}
start_pipes();
}
}
}
}
template <typename scalar_t, // compute dtype, half or nv_float16
const int num_bits, // number of bits used for weights
const int threads, // number of threads in a threadblock
const int template_thread_m_blocks, // number of 16x16 blocks in the m
// dimension (batchsize) of the
// threadblock
const int thread_n_blocks, // same for n dimension (output)
const int thread_k_blocks, // same for k dimension (reduction)
const int stages, // number of stages for the async global->shared
// fetch pipeline
const bool has_act_order, // whether act_order is enabled
const int group_blocks = -1 // number of consecutive 16x16 blocks
// with a separate quantization scale
>
__global__ void
Marlin_wrapper(const int4* __restrict__ A, // fp16 input matrix of shape mxk
const int4* __restrict__ B, // 4bit quantized weight matrix of shape kxn
int4* __restrict__ C, // fp16 output buffer of shape mxn
const int4* __restrict__ scales_ptr, // fp16 quantization scales of shape
// (k/groupsize)xn
const int* __restrict__ g_idx, // int32 group indices of shape k
int num_groups, // number of scale groups per output channel
const int* __restrict__ prob_m_ptr, // batch dimension m
int prob_n, // output dimension n
int prob_k, // reduction dimension k
int* locks // extra global storage for barrier synchronization
) {
int prob_m = *prob_m_ptr;
prob_m = min(prob_m, 1024);
const int thread_m_blocks = min(div_ceil(prob_m, 16), template_thread_m_blocks);
if(prob_m > 16 * thread_m_blocks)
prob_m = (16 * thread_m_blocks) * div_ceil(prob_m, (16 * thread_m_blocks));
/*if (blockIdx.x == 0 && threadIdx.x == 0)
printf("marlin prob_m %d\n", prob_m);*/
if (thread_m_blocks == 1) {
Marlin<scalar_t, num_bits, threads, 1,
thread_n_blocks, thread_k_blocks, stages, has_act_order,
group_blocks>(
A, B, C, scales_ptr, g_idx, num_groups, prob_m, prob_n,
prob_k, locks);
}
else if (thread_m_blocks == 2) {
Marlin<scalar_t, num_bits, threads, 2,
thread_n_blocks, thread_k_blocks, stages, has_act_order,
group_blocks>(
A, B, C, scales_ptr, g_idx, num_groups, prob_m, prob_n,
prob_k, locks);
}
else if (thread_m_blocks == 3) {
Marlin<scalar_t, num_bits, threads, 3,
thread_n_blocks, thread_k_blocks, stages, has_act_order,
group_blocks>(
A, B, C, scales_ptr, g_idx, num_groups, prob_m, prob_n,
prob_k, locks);
}
else if (thread_m_blocks == 4) {
Marlin<scalar_t, num_bits, threads, 4,
thread_n_blocks, thread_k_blocks, stages, has_act_order,
group_blocks>(
A, B, C, scales_ptr, g_idx, num_groups, prob_m, prob_n,
prob_k, locks);
}
}
#define __CALL_IF(NUM_BITS, THREAD_M_BLOCKS, THREAD_N_BLOCKS, THREAD_K_BLOCKS, \
HAS_ACT_ORDER, GROUP_BLOCKS, NUM_THREADS) \
else if (num_bits == NUM_BITS && thread_m_blocks == THREAD_M_BLOCKS && \
thread_n_blocks == THREAD_N_BLOCKS && \
thread_k_blocks == THREAD_K_BLOCKS && \
has_act_order == HAS_ACT_ORDER && group_blocks == GROUP_BLOCKS && \
num_threads == NUM_THREADS) { \
cudaFuncSetAttribute( \
Marlin_wrapper<scalar_t, NUM_BITS, NUM_THREADS, THREAD_M_BLOCKS, \
THREAD_N_BLOCKS, THREAD_K_BLOCKS, pipe_stages, \
HAS_ACT_ORDER, GROUP_BLOCKS>, \
cudaFuncAttributeMaxDynamicSharedMemorySize, max_shared_mem); \
Marlin_wrapper<scalar_t, NUM_BITS, NUM_THREADS, THREAD_M_BLOCKS, \
THREAD_N_BLOCKS, THREAD_K_BLOCKS, pipe_stages, HAS_ACT_ORDER, \
GROUP_BLOCKS><<<blocks, NUM_THREADS, max_shared_mem, stream>>>( \
A_ptr, B_ptr, C_ptr, s_ptr, g_idx_ptr, num_groups, prob_m_ptr, prob_n, \
prob_k, locks); \
}
typedef struct {
int thread_k;
int thread_n;
int num_threads;
} thread_config_t;
typedef struct {
int max_m_blocks;
thread_config_t tb_cfg;
} exec_config_t;
thread_config_t small_batch_thread_configs[] = {
// Ordered by priority
// thread_k, thread_n, num_threads
{128, 128, 256},
{64, 128, 128},
{128, 64, 128},
};
thread_config_t large_batch_thread_configs[] = {
// Ordered by priority
// thread_k, thread_n, num_threads
{64, 256, 256},
// {128, 128, 256},
{64, 128, 128},
{128, 64, 128},
};
int get_scales_cache_size(thread_config_t const& th_config, int prob_m,
int prob_n, int prob_k, int num_bits, int group_size,
bool has_act_order, bool is_k_full) {
bool cache_scales_chunk = has_act_order && !is_k_full;
int tb_n = th_config.thread_n;
int tb_k = th_config.thread_k;
// Get max scale groups per thread-block
int tb_groups;
if (group_size == -1) {
tb_groups = 1;
}
else if (group_size == 0) {
tb_groups = div_ceil(tb_k, 32); // Worst case is 32 group size
}
else {
tb_groups = div_ceil(tb_k, group_size);
}
if (cache_scales_chunk) {
int load_groups =
tb_groups * pipe_stages * 2; // Chunk size is 2x pipeline over dim K
load_groups = max(load_groups, 32); // We load at least 32 scale groups
return load_groups * tb_n * 2;
}
else {
int tb_scales = tb_groups * tb_n * 2;
return tb_scales * pipe_stages;
}
}
bool is_valid_cache_size(thread_config_t const& th_config, int max_m_blocks,
int prob_m, int prob_n, int prob_k, int num_bits,
int scales_cache_size, int max_shared_mem) {
int pack_factor = 32 / num_bits;
// Get B size
int tb_k = th_config.thread_k;
int tb_n = th_config.thread_n;
int b_size = (tb_k * tb_n / pack_factor) * 4;
// Get A size
int m_blocks = div_ceil(prob_m, 16);
int tb_max_m = 16;
// zbx: too ugly
// origin
/*while (true) {
if (m_blocks >= max_m_blocks) {
tb_max_m *= max_m_blocks;
break;
}
max_m_blocks--;
if (max_m_blocks == 0) {
TORCH_CHECK(false, "Unexpected m_blocks = ", m_blocks);
}
}*/
// refactor
tb_max_m *= std::min(m_blocks, max_m_blocks);
int a_size = (tb_max_m * tb_k) * 2;
float pipe_size = (a_size + b_size) * pipe_
gitextract_0e22n38f/ ├── .github/ │ ├── CODE_OF_CONDUCT.md │ ├── CONTRIBUTING.md │ ├── ISSUE_TEMPLATE/ │ │ ├── -bug-.yaml │ │ ├── -feature-.yaml │ │ └── config.yml │ ├── PULL_REQUEST_TEMPLATE.md │ ├── SECURITY.md │ └── workflows/ │ ├── book-ci.yml │ ├── deploy.yml │ ├── docker-image.yml │ ├── kt-kernel-tests.yml │ ├── release-fake-tag.yml │ ├── release-pypi.yml │ ├── release-sglang-kt.yml │ └── sync-sglang-submodule.yml ├── .gitignore ├── .gitmodules ├── LICENSE ├── MAINTAINERS.md ├── README.md ├── README_ZH.md ├── archive/ │ ├── .devcontainer/ │ │ ├── Dockerfile │ │ └── devcontainer.json │ ├── .flake8 │ ├── .gitmodules │ ├── .pylintrc │ ├── Dockerfile │ ├── Dockerfile.xpu │ ├── LICENSE │ ├── MANIFEST.in │ ├── Makefile │ ├── README.md │ ├── README_LEGACY.md │ ├── README_ZH.md │ ├── README_ZH_LEGACY.md │ ├── SECURITY.md │ ├── book.toml │ ├── config.json │ ├── csrc/ │ │ ├── balance_serve/ │ │ │ └── CMakeLists.txt │ │ ├── custom_marlin/ │ │ │ ├── __init__.py │ │ │ ├── binding.cpp │ │ │ ├── gptq_marlin/ │ │ │ │ ├── gptq_marlin.cu │ │ │ │ ├── gptq_marlin.cuh │ │ │ │ ├── gptq_marlin_dtypes.cuh │ │ │ │ ├── gptq_marlin_repack.cu │ │ │ │ └── ops.h │ │ │ ├── setup.py │ │ │ ├── test_cuda_graph.py │ │ │ └── utils/ │ │ │ ├── __init__.py │ │ │ ├── format24.py │ │ │ ├── marlin_24_perms.py │ │ │ ├── marlin_perms.py │ │ │ ├── marlin_utils.py │ │ │ └── quant_utils.py │ │ └── ktransformers_ext/ │ │ ├── CMakeLists.txt │ │ ├── bench/ │ │ │ ├── bench_attention.py │ │ │ ├── bench_attention_torch.py │ │ │ ├── bench_linear.py │ │ │ ├── bench_linear_torch.py │ │ │ ├── bench_mlp.py │ │ │ ├── bench_mlp_torch.py │ │ │ ├── bench_moe.py │ │ │ ├── bench_moe_amx.py │ │ │ └── bench_moe_torch.py │ │ ├── cmake/ │ │ │ └── FindSIMD.cmake │ │ ├── cpu_backend/ │ │ │ ├── backend.cpp │ │ │ ├── backend.h │ │ │ ├── cpuinfer.h │ │ │ ├── shared_mem_buffer.cpp │ │ │ ├── shared_mem_buffer.h │ │ │ ├── task_queue.cpp │ │ │ ├── task_queue.h │ │ │ └── vendors/ │ │ │ ├── README.md │ │ │ ├── cuda.h │ │ │ ├── hip.h │ │ │ ├── musa.h │ │ │ └── vendor.h │ │ ├── cuda/ │ │ │ ├── binding.cpp │ │ │ ├── custom_gguf/ │ │ │ │ ├── dequant.cu │ │ │ │ └── ops.h │ │ │ ├── gptq_marlin/ │ │ │ │ ├── gptq_marlin.cu │ │ │ │ ├── gptq_marlin.cuh │ │ │ │ ├── gptq_marlin_dtypes.cuh │ │ │ │ └── ops.h │ │ │ ├── setup.py │ │ │ └── test_dequant.py │ │ ├── examples/ │ │ │ ├── test_attention.py │ │ │ ├── test_linear.py │ │ │ ├── test_mlp.py │ │ │ └── test_moe.py │ │ ├── ext_bindings.cpp │ │ ├── operators/ │ │ │ ├── amx/ │ │ │ │ ├── la/ │ │ │ │ │ ├── amx.hpp │ │ │ │ │ └── utils.hpp │ │ │ │ └── moe.hpp │ │ │ ├── kvcache/ │ │ │ │ ├── kvcache.h │ │ │ │ ├── kvcache_attn.cpp │ │ │ │ ├── kvcache_load_dump.cpp │ │ │ │ ├── kvcache_read_write.cpp │ │ │ │ └── kvcache_utils.cpp │ │ │ └── llamafile/ │ │ │ ├── conversion.h │ │ │ ├── linear.cpp │ │ │ ├── linear.h │ │ │ ├── mlp.cpp │ │ │ ├── mlp.h │ │ │ ├── moe.cpp │ │ │ └── moe.h │ │ └── vendors/ │ │ ├── cuda.h │ │ ├── hip.h │ │ ├── musa.h │ │ └── vendor.h │ ├── install-with-cache.sh │ ├── install.bat │ ├── install.sh │ ├── ktransformers/ │ │ ├── __init__.py │ │ ├── configs/ │ │ │ ├── config.yaml │ │ │ └── log_config.ini │ │ ├── ktransformers_ext/ │ │ │ ├── operators/ │ │ │ │ └── custom_marlin/ │ │ │ │ └── quantize/ │ │ │ │ └── utils/ │ │ │ │ ├── __init__.py │ │ │ │ ├── format_24.py │ │ │ │ ├── marlin_24_perms.py │ │ │ │ ├── marlin_perms.py │ │ │ │ ├── marlin_utils.py │ │ │ │ └── quant_utils.py │ │ │ └── triton/ │ │ │ └── fp8gemm.py │ │ ├── local_chat.py │ │ ├── local_chat_test.py │ │ ├── models/ │ │ │ ├── __init__.py │ │ │ ├── ascend/ │ │ │ │ ├── custom_ascend_modeling_deepseek_v3.py │ │ │ │ └── custom_ascend_modeling_qwen3.py │ │ │ ├── configuration_deepseek.py │ │ │ ├── configuration_deepseek_v3.py │ │ │ ├── configuration_glm4_moe.py │ │ │ ├── configuration_llama.py │ │ │ ├── configuration_qwen2_moe.py │ │ │ ├── configuration_qwen3_moe.py │ │ │ ├── configuration_qwen3_next.py │ │ │ ├── configuration_smallthinker.py │ │ │ ├── custom_cache.py │ │ │ ├── custom_modeling_deepseek_v2.py │ │ │ ├── custom_modeling_deepseek_v3.py │ │ │ ├── custom_modeling_glm4_moe.py │ │ │ ├── custom_modeling_qwen2_moe.py │ │ │ ├── custom_modeling_qwen3_moe.py │ │ │ ├── custom_modeling_qwen3_next.py │ │ │ ├── custom_modeling_smallthinker.py │ │ │ ├── modeling_deepseek.py │ │ │ ├── modeling_deepseek_v3.py │ │ │ ├── modeling_glm4_moe.py │ │ │ ├── modeling_llama.py │ │ │ ├── modeling_mixtral.py │ │ │ ├── modeling_qwen2_moe.py │ │ │ ├── modeling_qwen3_moe.py │ │ │ ├── modeling_qwen3_next.py │ │ │ └── modeling_smallthinker.py │ │ ├── operators/ │ │ │ ├── RoPE.py │ │ │ ├── __init__.py │ │ │ ├── ascend/ │ │ │ │ ├── ascend_attention.py │ │ │ │ ├── ascend_experts.py │ │ │ │ ├── ascend_gate.py │ │ │ │ ├── ascend_layernorm.py │ │ │ │ ├── ascend_linear.py │ │ │ │ └── ascend_mlp.py │ │ │ ├── attention.py │ │ │ ├── balance_serve_attention.py │ │ │ ├── base_operator.py │ │ │ ├── cpuinfer.py │ │ │ ├── dynamic_attention.py │ │ │ ├── experts.py │ │ │ ├── flashinfer_batch_prefill_wrapper.py │ │ │ ├── flashinfer_wrapper.py │ │ │ ├── gate.py │ │ │ ├── layernorm.py │ │ │ ├── linear.py │ │ │ ├── mlp.py │ │ │ ├── models.py │ │ │ ├── triton_attention.py │ │ │ └── triton_attention_prefill.py │ │ ├── optimize/ │ │ │ ├── optimize.py │ │ │ └── optimize_rules/ │ │ │ ├── DeepSeek-V2-Chat-multi-gpu-4.yaml │ │ │ ├── DeepSeek-V2-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V2-Chat.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-gpu-cpu.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat.yaml │ │ │ ├── DeepSeek-V3-Chat-amx.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve-amx.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-4.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-8.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-fp8-linear-ggml-experts.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-marlin.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V3-Chat-npu.yaml │ │ │ ├── DeepSeek-V3-Chat-serve.yaml │ │ │ ├── DeepSeek-V3-Chat.yaml │ │ │ ├── Glm4Moe-serve.yaml │ │ │ ├── Internlm2_5-7b-Chat-1m.yaml │ │ │ ├── Mixtral.yaml │ │ │ ├── Moonlight-16B-A3B-serve.yaml │ │ │ ├── Moonlight-16B-A3B.yaml │ │ │ ├── Qwen2-57B-A14B-Instruct-multi-gpu.yaml │ │ │ ├── Qwen2-57B-A14B-Instruct.yaml │ │ │ ├── Qwen2-serve-amx.yaml │ │ │ ├── Qwen2-serve.yaml │ │ │ ├── Qwen3Moe-serve-amx.yaml │ │ │ ├── Qwen3Moe-serve.yaml │ │ │ ├── Qwen3Next-serve.yaml │ │ │ ├── Smallthinker-serve.yaml │ │ │ ├── npu/ │ │ │ │ ├── DeepSeek-V3-Chat-300IA2-npu-serve.yaml │ │ │ │ ├── DeepSeek-V3-Chat-300IA2-npu.yaml │ │ │ │ └── Qwen3-Chat-300IA2-npu-serve.yaml │ │ │ ├── rocm/ │ │ │ │ └── DeepSeek-V3-Chat.yaml │ │ │ └── xpu/ │ │ │ ├── DeepSeek-V2-Chat.yaml │ │ │ ├── DeepSeek-V3-Chat.yaml │ │ │ └── Qwen3Moe-Chat.yaml │ │ ├── server/ │ │ │ ├── __init__.py │ │ │ ├── api/ │ │ │ │ ├── __init__.py │ │ │ │ ├── ollama/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ └── completions.py │ │ │ │ ├── openai/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── assistants/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── assistants.py │ │ │ │ │ │ ├── messages.py │ │ │ │ │ │ ├── runs.py │ │ │ │ │ │ └── threads.py │ │ │ │ │ ├── endpoints/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ └── chat.py │ │ │ │ │ └── legacy/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ └── completions.py │ │ │ │ └── web/ │ │ │ │ ├── __init__.py │ │ │ │ └── system.py │ │ │ ├── args.py │ │ │ ├── backend/ │ │ │ │ ├── __init__.py │ │ │ │ ├── args.py │ │ │ │ ├── base.py │ │ │ │ ├── context_manager.py │ │ │ │ └── interfaces/ │ │ │ │ ├── __init__.py │ │ │ │ ├── balance_serve.py │ │ │ │ ├── exllamav2.py │ │ │ │ ├── ktransformers.py │ │ │ │ └── transformers.py │ │ │ ├── balance_serve/ │ │ │ │ ├── inference/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── config.py │ │ │ │ │ ├── distributed/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── communication_op.py │ │ │ │ │ │ ├── cuda_wrapper.py │ │ │ │ │ │ ├── custom_all_reduce.py │ │ │ │ │ │ ├── custom_all_reduce_utils.py │ │ │ │ │ │ ├── parallel_state.py │ │ │ │ │ │ ├── pynccl.py │ │ │ │ │ │ ├── pynccl_wrapper.py │ │ │ │ │ │ └── utils.py │ │ │ │ │ ├── forward_batch.py │ │ │ │ │ ├── model_runner.py │ │ │ │ │ ├── query_manager.py │ │ │ │ │ └── sampling/ │ │ │ │ │ ├── penaltylib/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── orchestrator.py │ │ │ │ │ │ └── penalizers/ │ │ │ │ │ │ ├── frequency_penalty.py │ │ │ │ │ │ ├── min_new_tokens.py │ │ │ │ │ │ ├── presence_penalty.py │ │ │ │ │ │ └── repetition_penalty.py │ │ │ │ │ └── sampler.py │ │ │ │ ├── sched_rpc.py │ │ │ │ └── settings.py │ │ │ ├── config/ │ │ │ │ ├── config.py │ │ │ │ ├── log.py │ │ │ │ └── singleton.py │ │ │ ├── crud/ │ │ │ │ ├── __init__.py │ │ │ │ └── assistants/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants.py │ │ │ │ ├── messages.py │ │ │ │ ├── runs.py │ │ │ │ └── threads.py │ │ │ ├── exceptions.py │ │ │ ├── main.py │ │ │ ├── models/ │ │ │ │ ├── __init__.py │ │ │ │ └── assistants/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants.py │ │ │ │ ├── messages.py │ │ │ │ ├── run_steps.py │ │ │ │ ├── runs.py │ │ │ │ └── threads.py │ │ │ ├── requirements.txt │ │ │ ├── schemas/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── assistants.py │ │ │ │ │ ├── messages.py │ │ │ │ │ ├── runs.py │ │ │ │ │ ├── streaming.py │ │ │ │ │ ├── threads.py │ │ │ │ │ └── tool.py │ │ │ │ ├── base.py │ │ │ │ ├── conversation.py │ │ │ │ ├── endpoints/ │ │ │ │ │ └── chat.py │ │ │ │ └── legacy/ │ │ │ │ ├── __init__.py │ │ │ │ └── completions.py │ │ │ └── utils/ │ │ │ ├── __init__.py │ │ │ ├── create_interface.py │ │ │ ├── multi_timer.py │ │ │ ├── serve_profiling.py │ │ │ └── sql_utils.py │ │ ├── tests/ │ │ │ ├── .gitignore │ │ │ ├── AIME_2024/ │ │ │ │ ├── eval_api.py │ │ │ │ ├── evaluation.py │ │ │ │ └── prompts.py │ │ │ ├── UT/ │ │ │ │ ├── test_kdeepseek_attention_w8a8a2serve_npu.py │ │ │ │ └── test_kdeepseek_ln_npu.py │ │ │ ├── dequant_gpu.py │ │ │ ├── dequant_gpu_t.py │ │ │ ├── function_call_test.py │ │ │ ├── humaneval/ │ │ │ │ ├── eval_api.py │ │ │ │ ├── evaluation.py │ │ │ │ └── prompts.py │ │ │ ├── mmlu_pro_test.py │ │ │ ├── mmlu_test.py │ │ │ ├── mmlu_test_multi.py │ │ │ ├── parse_cover_info.py │ │ │ ├── score.py │ │ │ ├── test_client.py │ │ │ ├── test_prefix.py │ │ │ ├── test_pytorch_q8.py │ │ │ ├── test_speed.py │ │ │ └── triton_fp8gemm_test.py │ │ ├── util/ │ │ │ ├── ascend/ │ │ │ │ └── ascend_utils.py │ │ │ ├── cuda_graph_runner.py │ │ │ ├── custom_gguf.py │ │ │ ├── custom_loader.py │ │ │ ├── modeling_rope_utils.py │ │ │ ├── npu_graph_runner.py │ │ │ ├── textstream.py │ │ │ ├── utils.py │ │ │ ├── vendors.py │ │ │ └── weight_loader.py │ │ └── website/ │ │ ├── .browserslistrc │ │ ├── .eslintrc.js │ │ ├── .gitignore │ │ ├── README.md │ │ ├── config.d.ts │ │ ├── jest.config.js │ │ ├── package.json │ │ ├── public/ │ │ │ ├── config.js │ │ │ ├── css/ │ │ │ │ └── reset.css │ │ │ └── index.html │ │ ├── src/ │ │ │ ├── App.vue │ │ │ ├── api/ │ │ │ │ ├── api-client.ts │ │ │ │ ├── assistant.ts │ │ │ │ ├── message.ts │ │ │ │ ├── run.ts │ │ │ │ └── thread.ts │ │ │ ├── assets/ │ │ │ │ ├── css/ │ │ │ │ │ └── mixins.styl │ │ │ │ └── iconfont/ │ │ │ │ ├── demo.css │ │ │ │ ├── demo_index.html │ │ │ │ ├── iconfont.css │ │ │ │ ├── iconfont.js │ │ │ │ └── iconfont.json │ │ │ ├── components/ │ │ │ │ └── chat/ │ │ │ │ └── index.vue │ │ │ ├── conf/ │ │ │ │ └── config.ts │ │ │ ├── locals/ │ │ │ │ ├── en.js │ │ │ │ ├── index.js │ │ │ │ └── zh.js │ │ │ ├── main.ts │ │ │ ├── router/ │ │ │ │ └── index.ts │ │ │ ├── shims-vue.d.ts │ │ │ ├── store/ │ │ │ │ └── index.ts │ │ │ ├── utils/ │ │ │ │ ├── copy.ts │ │ │ │ └── types.ts │ │ │ └── views/ │ │ │ └── home.vue │ │ ├── tests/ │ │ │ └── unit/ │ │ │ └── example.spec.ts │ │ ├── tsconfig.json │ │ └── vue.config.js │ ├── merge_tensors/ │ │ ├── merge_safetensor_gguf.py │ │ └── merge_safetensor_gguf_for_qwen3.py │ ├── pyproject.toml │ ├── requirements-local_chat.txt │ ├── setup.py │ └── third_party/ │ ├── llamafile/ │ │ ├── README.md │ │ ├── bench.h │ │ ├── flags.cpp │ │ ├── flags.h │ │ ├── iqk_mul_mat.inc │ │ ├── iqk_mul_mat_amd_avx2.cpp │ │ ├── iqk_mul_mat_amd_zen4.cpp │ │ ├── iqk_mul_mat_arm.inc │ │ ├── iqk_mul_mat_arm82.cpp │ │ ├── iqk_mul_mat_x86.inc │ │ ├── macros.h │ │ ├── micros.h │ │ ├── numba.h │ │ ├── sgemm.cpp │ │ ├── sgemm.h │ │ ├── sgemm_arm.cpp │ │ ├── sgemm_x86.cpp │ │ ├── tinyblas_cpu.h │ │ ├── tinyblas_cpu_mixmul.inc │ │ ├── tinyblas_cpu_mixmul_amd_avx.cpp │ │ ├── tinyblas_cpu_mixmul_amd_avx2.cpp │ │ ├── tinyblas_cpu_mixmul_amd_avx512f.cpp │ │ ├── tinyblas_cpu_mixmul_amd_avxvnni.cpp │ │ ├── tinyblas_cpu_mixmul_amd_fma.cpp │ │ ├── tinyblas_cpu_mixmul_amd_zen4.cpp │ │ ├── tinyblas_cpu_mixmul_arm80.cpp │ │ ├── tinyblas_cpu_mixmul_arm82.cpp │ │ ├── tinyblas_cpu_sgemm.inc │ │ ├── tinyblas_cpu_sgemm_amd_avx.cpp │ │ ├── tinyblas_cpu_sgemm_amd_avx2.cpp │ │ ├── tinyblas_cpu_sgemm_amd_avx512f.cpp │ │ ├── tinyblas_cpu_sgemm_amd_avxvnni.cpp │ │ ├── tinyblas_cpu_sgemm_amd_fma.cpp │ │ ├── tinyblas_cpu_sgemm_amd_zen4.cpp │ │ ├── tinyblas_cpu_sgemm_arm.inc │ │ ├── tinyblas_cpu_sgemm_arm80.cpp │ │ ├── tinyblas_cpu_sgemm_arm82.cpp │ │ ├── tinyblas_cpu_sgemm_x86.inc │ │ └── tinyblas_cpu_unsupported.cpp │ └── nlohmann/ │ ├── json.hpp │ └── json_fwd.hpp ├── book.toml ├── doc/ │ ├── SUMMARY.md │ ├── basic/ │ │ ├── note1.md │ │ └── note2.md │ ├── en/ │ │ ├── AMX.md │ │ ├── DeepseekR1_V3_tutorial.md │ │ ├── Docker.md │ │ ├── Docker_xpu.md │ │ ├── FAQ.md │ │ ├── Kimi-K2-Thinking.md │ │ ├── Kimi-K2.5.md │ │ ├── Kimi-K2.md │ │ ├── Kllama_tutorial_DeepSeekV2Lite.ipynb │ │ ├── MiniMax-M2.5.md │ │ ├── Qwen3-Next.md │ │ ├── Qwen3.5.md │ │ ├── ROCm.md │ │ ├── SFT/ │ │ │ ├── DPO_tutorial.md │ │ │ ├── KTransformers-Fine-Tuning_Developer-Technical-Notes.md │ │ │ ├── KTransformers-Fine-Tuning_User-Guide.md │ │ │ ├── README.md │ │ │ └── injection_tutorial.md │ │ ├── SFT_Installation_Guide_KimiK2.5.md │ │ ├── SFT_Installation_Guide_KimiK2.md │ │ ├── SmallThinker_and_Glm4moe.md │ │ ├── V3-success.md │ │ ├── api/ │ │ │ └── server/ │ │ │ ├── api.md │ │ │ ├── server.md │ │ │ ├── tabby.md │ │ │ └── website.md │ │ ├── balance-serve.md │ │ ├── benchmark.md │ │ ├── deepseek-v2-injection.md │ │ ├── fp8_kernel.md │ │ ├── install.md │ │ ├── kt-kernel/ │ │ │ ├── GLM-5-Tutorial.md │ │ │ ├── Kimi-K2-Thinking-Native.md │ │ │ ├── MiniMax-M2.1-Tutorial.md │ │ │ ├── Native-Precision-Tutorial.md │ │ │ ├── Qwen3-Coder-Next-Tutorial.md │ │ │ ├── README.md │ │ │ ├── amd_blis.md │ │ │ ├── deepseek-v3.2-sglang-tutorial.md │ │ │ ├── experts-sched-Tutorial.md │ │ │ └── kt-cli.md │ │ ├── llama4.md │ │ ├── long_context_introduction.md │ │ ├── long_context_tutorial.md │ │ ├── makefile_usage.md │ │ ├── multi-gpu-tutorial.md │ │ ├── operators/ │ │ │ └── llamafile.md │ │ ├── prefix_cache.md │ │ └── xpu.md │ └── zh/ │ ├── DeepseekR1_V3_tutorial_zh.md │ ├── DeepseekR1_V3_tutorial_zh_for_Ascend_NPU.md │ ├── KTransformers-Fine-Tuning_Developer-Technical-Notes_zh.md │ ├── KTransformers-Fine-Tuning_User-Guide_zh.md │ ├── Qwen3-MoE_tutorial_zh_for_Ascend_NPU.md │ ├── api/ │ │ └── server/ │ │ ├── api.md │ │ ├── server.md │ │ ├── tabby.md │ │ └── website.md │ └── clawdbot_integration_guide.md ├── docker/ │ ├── Dockerfile │ ├── README-packaging.md │ ├── docker-utils.sh │ └── push-to-dockerhub.sh ├── install.sh ├── kt-kernel/ │ ├── .clang-format │ ├── .githooks/ │ │ ├── commit-msg │ │ └── pre-commit │ ├── .gitignore │ ├── .gitmodules │ ├── CMakeLists.txt │ ├── CMakePresets.json │ ├── MANIFEST.in │ ├── README.md │ ├── README_zh.md │ ├── bench/ │ │ ├── .gitignore │ │ ├── Makefile │ │ ├── bench_attention.py │ │ ├── bench_attention_torch.py │ │ ├── bench_bf16_moe.py │ │ ├── bench_fp8_moe.py │ │ ├── bench_fp8_perchannel_moe.py │ │ ├── bench_k2_moe_amx.py │ │ ├── bench_k2_write_buffer.py │ │ ├── bench_linear.py │ │ ├── bench_linear_torch.py │ │ ├── bench_mla.py │ │ ├── bench_mlp.py │ │ ├── bench_mlp_torch.py │ │ ├── bench_moe.py │ │ ├── bench_moe_amx.py │ │ ├── bench_moe_amx_k.py │ │ ├── bench_moe_kernel.py │ │ ├── bench_moe_kernel_tiling.py │ │ ├── bench_moe_kml.py │ │ ├── bench_moe_torch.py │ │ ├── bench_write_buffer.py │ │ ├── compare_moe_performance.py │ │ ├── multi_bench_moe.py │ │ └── upload-bench-json.py │ ├── cmake/ │ │ ├── DetectCPU.cmake │ │ └── FindSIMD.cmake │ ├── cpu_backend/ │ │ ├── cpuinfer.h │ │ ├── shared_mem_buffer.cpp │ │ ├── shared_mem_buffer.h │ │ ├── task_queue.cpp │ │ ├── task_queue.h │ │ ├── vendors/ │ │ │ ├── README.md │ │ │ ├── cuda.h │ │ │ ├── hip.h │ │ │ ├── musa.h │ │ │ └── vendor.h │ │ ├── worker_pool.cpp │ │ └── worker_pool.h │ ├── cuda/ │ │ ├── binding.cpp │ │ ├── custom_gguf/ │ │ │ ├── dequant.cu │ │ │ └── ops.h │ │ ├── gptq_marlin/ │ │ │ ├── gptq_marlin.cu │ │ │ ├── gptq_marlin.cuh │ │ │ ├── gptq_marlin_dtypes.cuh │ │ │ └── ops.h │ │ ├── moe/ │ │ │ ├── moe_topk_softmax_kernels.cu │ │ │ ├── ops.h │ │ │ └── utils.h │ │ ├── setup.py │ │ └── test_dequant.py │ ├── demo/ │ │ ├── .gitignore │ │ ├── Makefile │ │ ├── bench_reorder_bandwidth.cpp │ │ ├── bf16-test.cpp │ │ ├── fp16-test.cpp │ │ ├── plot.py │ │ ├── simple_test.cpp │ │ ├── simple_test_aocl.cpp │ │ └── tflops.py │ ├── examples/ │ │ ├── .gitignore │ │ ├── bench_moe_amx_int8.py │ │ ├── configuration_deepseek_v3.py │ │ ├── modeling_deepseek_v3.py │ │ ├── repro_llamafile_re.py │ │ ├── test-debug.py │ │ ├── test_apply_rope.py │ │ ├── test_attention.py │ │ ├── test_awq_moe_amx.py │ │ ├── test_bf16_moe.py │ │ ├── test_deepseekv3.py │ │ ├── test_deepseekv3_prefill.py │ │ ├── test_deepseekv3_prefill_speed.py │ │ ├── test_fp8_moe.py │ │ ├── test_fp8_perchannel_moe.py │ │ ├── test_gate.py │ │ ├── test_k2_moe_amx.py │ │ ├── test_k2_write_buffer.py │ │ ├── test_linear.py │ │ ├── test_mla.py │ │ ├── test_mla_qlen.py │ │ ├── test_mla_quant.py │ │ ├── test_mla_simple.py │ │ ├── test_mla_torch.py │ │ ├── test_mlp.py │ │ ├── test_moe.py │ │ ├── test_moe_amx.py │ │ ├── test_moe_kernel.py │ │ ├── test_moe_kml.py │ │ ├── test_rope.cpp │ │ ├── test_rope.py │ │ ├── test_softmax.py │ │ ├── test_write_buffer.py │ │ └── torch_attention.py │ ├── ext_bindings.cpp │ ├── install.sh │ ├── operators/ │ │ ├── amx/ │ │ │ ├── awq-moe.hpp │ │ │ ├── bf16-moe.hpp │ │ │ ├── fp8-moe.hpp │ │ │ ├── fp8-perchannel-moe.hpp │ │ │ ├── k2-moe.hpp │ │ │ ├── la/ │ │ │ │ ├── amx-example.cpp │ │ │ │ ├── amx.hpp │ │ │ │ ├── amx_buffers.hpp │ │ │ │ ├── amx_config.hpp │ │ │ │ ├── amx_kernels.hpp │ │ │ │ ├── amx_quantization.hpp │ │ │ │ ├── amx_raw_buffers.hpp │ │ │ │ ├── amx_raw_kernels.hpp │ │ │ │ ├── amx_utils.hpp │ │ │ │ ├── pack.hpp │ │ │ │ └── utils.hpp │ │ │ ├── moe.hpp │ │ │ ├── moe_base.hpp │ │ │ └── test/ │ │ │ ├── amx-bkgroup-test.cpp │ │ │ ├── amx-c-reduce-test.cpp │ │ │ ├── amx-kgroup-test.cpp │ │ │ ├── amx-test.cpp │ │ │ ├── analyze-error.cpp │ │ │ ├── avx-test.cpp │ │ │ ├── debug-kgroup-details.cpp │ │ │ ├── debug-kgroup.cpp │ │ │ ├── debug-specific-dims.cpp │ │ │ ├── mat-test.hpp │ │ │ ├── mmq-test.cpp │ │ │ ├── mmq.cpp │ │ │ ├── mmq.h │ │ │ ├── test-kgroup-128.cpp │ │ │ ├── test-kgroup-kernel.cpp │ │ │ ├── test-specific-dims.cpp │ │ │ ├── thread_test.sh │ │ │ ├── timer.hh │ │ │ └── verify-kgroup.cpp │ │ ├── common.hpp │ │ ├── kvcache/ │ │ │ ├── kvcache.h │ │ │ ├── kvcache_attn.cpp │ │ │ ├── kvcache_load_dump.cpp │ │ │ ├── kvcache_read_write.cpp │ │ │ └── kvcache_utils.cpp │ │ ├── llamafile/ │ │ │ ├── conversion.h │ │ │ ├── linear.cpp │ │ │ ├── linear.h │ │ │ ├── mla.hpp │ │ │ ├── mlp.cpp │ │ │ ├── mlp.h │ │ │ └── moe.hpp │ │ ├── mla-tp.hpp │ │ ├── moe-tp.hpp │ │ ├── moe_kernel/ │ │ │ ├── api/ │ │ │ │ ├── common.h │ │ │ │ └── mat_kernel.h │ │ │ ├── la/ │ │ │ │ ├── kernel.hpp │ │ │ │ ├── mat_kernel.cpp │ │ │ │ └── utils.hpp │ │ │ ├── mat_kernel/ │ │ │ │ ├── aocl_kernel/ │ │ │ │ │ └── kernel.cpp │ │ │ │ └── batch_gemm_api.hpp │ │ │ ├── moe.hpp │ │ │ └── test/ │ │ │ ├── convert-test.cpp │ │ │ ├── debug.hpp │ │ │ ├── int4_mul-test.cpp │ │ │ ├── mat_test.cpp │ │ │ └── utils_test.cpp │ │ ├── reduce.hpp │ │ ├── rms-norm.hpp │ │ ├── rope.hpp │ │ ├── softmax.hpp │ │ └── tp.hpp │ ├── pyproject.toml │ ├── pytest.ini │ ├── python/ │ │ ├── __init__.py │ │ ├── _cpu_detect.py │ │ ├── cli/ │ │ │ ├── __init__.py │ │ │ ├── commands/ │ │ │ │ ├── __init__.py │ │ │ │ ├── bench.py │ │ │ │ ├── chat.py │ │ │ │ ├── config.py │ │ │ │ ├── doctor.py │ │ │ │ ├── model.py │ │ │ │ ├── quant.py │ │ │ │ ├── run.py │ │ │ │ ├── sft.py │ │ │ │ └── version.py │ │ │ ├── completions/ │ │ │ │ ├── __init__.py │ │ │ │ ├── _kt │ │ │ │ ├── kt-completion.bash │ │ │ │ └── kt.fish │ │ │ ├── config/ │ │ │ │ ├── __init__.py │ │ │ │ └── settings.py │ │ │ ├── i18n.py │ │ │ ├── main.py │ │ │ ├── requirements/ │ │ │ │ ├── inference.txt │ │ │ │ └── sft.txt │ │ │ └── utils/ │ │ │ ├── __init__.py │ │ │ ├── analyze_moe_model.py │ │ │ ├── console.py │ │ │ ├── debug_configs.py │ │ │ ├── download_helper.py │ │ │ ├── environment.py │ │ │ ├── input_validators.py │ │ │ ├── kv_cache_calculator.py │ │ │ ├── model_discovery.py │ │ │ ├── model_registry.py │ │ │ ├── model_scanner.py │ │ │ ├── model_table_builder.py │ │ │ ├── model_verifier.py │ │ │ ├── port_checker.py │ │ │ ├── quant_interactive.py │ │ │ ├── repo_detector.py │ │ │ ├── run_configs.py │ │ │ ├── run_interactive.py │ │ │ ├── sglang_checker.py │ │ │ ├── tuna_engine.py │ │ │ └── user_model_registry.py │ │ ├── experts.py │ │ ├── experts_base.py │ │ └── utils/ │ │ ├── __init__.py │ │ ├── amx.py │ │ ├── llamafile.py │ │ ├── loader.py │ │ └── moe_kernel.py │ ├── requirements.txt │ ├── scripts/ │ │ ├── README.md │ │ ├── check.py │ │ ├── check_cpu_features.py │ │ ├── compare_weights.py │ │ ├── convert_cpu_weights.py │ │ ├── convert_gpu_weights.py │ │ ├── convert_kimi_k2_fp8_to_bf16_cpu.py │ │ ├── convert_moe_to_bf16.py │ │ └── install-git-hooks.sh │ ├── setup.py │ └── test/ │ ├── __init__.py │ ├── ci/ │ │ ├── __init__.py │ │ ├── ci_register.py │ │ └── ci_utils.py │ ├── per_commit/ │ │ ├── __init__.py │ │ ├── test_amd_placeholder.py │ │ ├── test_basic_cpu.py │ │ ├── test_cuda_placeholder.py │ │ ├── test_moe_amx_accuracy_int4.py │ │ ├── test_moe_amx_accuracy_int4_1.py │ │ ├── test_moe_amx_accuracy_int4_1k.py │ │ ├── test_moe_amx_accuracy_int8.py │ │ ├── test_moe_amx_bench_int4.py │ │ ├── test_moe_amx_bench_int4_1.py │ │ ├── test_moe_amx_bench_int4_1k.py │ │ └── test_moe_amx_bench_int8.py │ ├── run_suite.py │ └── test_generate_gpu_experts_masks.py ├── kt-sft/ │ ├── .flake8 │ ├── .gitignore │ ├── .gitmodules │ ├── .pylintrc │ ├── Dockerfile │ ├── Dockerfile.xpu │ ├── LICENSE │ ├── MANIFEST.in │ ├── Makefile │ ├── README.md │ ├── SECURITY.md │ ├── autosetup.sh │ ├── book.toml │ ├── csrc/ │ │ ├── custom_marlin/ │ │ │ ├── __init__.py │ │ │ ├── binding.cpp │ │ │ ├── gptq_marlin/ │ │ │ │ ├── gptq_marlin.cu │ │ │ │ ├── gptq_marlin.cuh │ │ │ │ ├── gptq_marlin_dtypes.cuh │ │ │ │ ├── gptq_marlin_repack.cu │ │ │ │ └── ops.h │ │ │ ├── setup.py │ │ │ ├── test_cuda_graph.py │ │ │ └── utils/ │ │ │ ├── __init__.py │ │ │ ├── format24.py │ │ │ ├── marlin_24_perms.py │ │ │ ├── marlin_perms.py │ │ │ ├── marlin_utils.py │ │ │ └── quant_utils.py │ │ └── ktransformers_ext/ │ │ ├── CMakeLists.txt │ │ ├── bench/ │ │ │ ├── bench_attention.py │ │ │ ├── bench_attention_torch.py │ │ │ ├── bench_linear.py │ │ │ ├── bench_linear_torch.py │ │ │ ├── bench_mlp.py │ │ │ ├── bench_mlp_torch.py │ │ │ ├── bench_moe.py │ │ │ ├── bench_moe_amx.py │ │ │ └── bench_moe_torch.py │ │ ├── cmake/ │ │ │ └── FindSIMD.cmake │ │ ├── cpu_backend/ │ │ │ ├── backend.cpp │ │ │ ├── backend.h │ │ │ ├── cpuinfer.h │ │ │ ├── shared_mem_buffer.cpp │ │ │ ├── shared_mem_buffer.h │ │ │ ├── task_queue.cpp │ │ │ ├── task_queue.h │ │ │ └── vendors/ │ │ │ ├── README.md │ │ │ ├── cuda.h │ │ │ ├── hip.h │ │ │ ├── musa.h │ │ │ └── vendor.h │ │ ├── cuda/ │ │ │ ├── binding.cpp │ │ │ ├── custom_gguf/ │ │ │ │ ├── dequant.cu │ │ │ │ └── ops.h │ │ │ ├── gptq_marlin/ │ │ │ │ ├── gptq_marlin.cu │ │ │ │ ├── gptq_marlin.cuh │ │ │ │ ├── gptq_marlin_dtypes.cuh │ │ │ │ └── ops.h │ │ │ ├── setup.py │ │ │ └── test_dequant.py │ │ ├── examples/ │ │ │ ├── test_attention.py │ │ │ ├── test_linear.py │ │ │ ├── test_mlp.py │ │ │ ├── test_moe.py │ │ │ ├── test_sft_amx_moe.py │ │ │ └── test_sft_moe.py │ │ ├── ext_bindings.cpp │ │ ├── operators/ │ │ │ ├── amx/ │ │ │ │ ├── debug_sft_moe.hpp │ │ │ │ ├── debug_tools_sft_moe.hpp │ │ │ │ ├── la/ │ │ │ │ │ ├── amx.hpp │ │ │ │ │ └── utils.hpp │ │ │ │ ├── moe.hpp │ │ │ │ └── sft_moe.hpp │ │ │ ├── kvcache/ │ │ │ │ ├── kvcache.h │ │ │ │ ├── kvcache_attn.cpp │ │ │ │ ├── kvcache_load_dump.cpp │ │ │ │ ├── kvcache_read_write.cpp │ │ │ │ └── kvcache_utils.cpp │ │ │ └── llamafile/ │ │ │ ├── conversion.h │ │ │ ├── linear.cpp │ │ │ ├── linear.h │ │ │ ├── mlp.cpp │ │ │ ├── mlp.h │ │ │ ├── moe.cpp │ │ │ ├── moe.h │ │ │ ├── sft_moe.cpp │ │ │ ├── sft_moe.h │ │ │ └── sft_moe_forward_cache.h │ │ └── vendors/ │ │ ├── cuda.h │ │ ├── hip.h │ │ ├── musa.h │ │ └── vendor.h │ ├── install-with-cache.sh │ ├── install.bat │ ├── install.sh │ ├── ktransformers/ │ │ ├── __init__.py │ │ ├── configs/ │ │ │ ├── config.yaml │ │ │ ├── log_config.ini │ │ │ └── model_config/ │ │ │ ├── config.json │ │ │ └── configuration_deepseek.py │ │ ├── ktransformers_ext/ │ │ │ ├── operators/ │ │ │ │ └── custom_marlin/ │ │ │ │ └── quantize/ │ │ │ │ └── utils/ │ │ │ │ ├── __init__.py │ │ │ │ ├── format_24.py │ │ │ │ ├── marlin_24_perms.py │ │ │ │ ├── marlin_perms.py │ │ │ │ ├── marlin_utils.py │ │ │ │ └── quant_utils.py │ │ │ └── triton/ │ │ │ └── fp8gemm.py │ │ ├── local_chat.py │ │ ├── local_chat.sh │ │ ├── lora_test_module.py │ │ ├── models/ │ │ │ ├── __init__.py │ │ │ ├── configuration_deepseek.py │ │ │ ├── configuration_deepseek_v3.py │ │ │ ├── configuration_llama.py │ │ │ ├── configuration_qwen2_moe.py │ │ │ ├── configuration_qwen3_moe.py │ │ │ ├── custom_cache.py │ │ │ ├── custom_modeling_deepseek_v2.py │ │ │ ├── custom_modeling_deepseek_v3.py │ │ │ ├── custom_modeling_qwen2_moe.py │ │ │ ├── custom_modeling_qwen3_moe.py │ │ │ ├── modeling_deepseek.py │ │ │ ├── modeling_deepseek_v3.py │ │ │ ├── modeling_llama.py │ │ │ ├── modeling_mixtral.py │ │ │ ├── modeling_qwen2_moe.py │ │ │ └── modeling_qwen3_moe.py │ │ ├── moe_test_module.py │ │ ├── moe_test_module_old.py │ │ ├── operators/ │ │ │ ├── RoPE.py │ │ │ ├── __init__.py │ │ │ ├── attention.py │ │ │ ├── balance_serve_attention.py │ │ │ ├── base_operator.py │ │ │ ├── cpuinfer.py │ │ │ ├── dynamic_attention.py │ │ │ ├── experts.py │ │ │ ├── flashinfer_batch_prefill_wrapper.py │ │ │ ├── flashinfer_wrapper.py │ │ │ ├── gate.py │ │ │ ├── layernorm.py │ │ │ ├── linear.py │ │ │ ├── mlp.py │ │ │ ├── models.py │ │ │ ├── triton_attention.py │ │ │ └── triton_attention_prefill.py │ │ ├── optimize/ │ │ │ ├── optimize.py │ │ │ └── optimize_rules/ │ │ │ ├── DeepSeek-V2-Chat-multi-gpu-4.yaml │ │ │ ├── DeepSeek-V2-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V2-Chat-sft-amx.yaml │ │ │ ├── DeepSeek-V2-Chat.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-sft-amx-multi-gpu.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-sft-amx.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-sft.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat-use-adapter.yaml │ │ │ ├── DeepSeek-V2-Lite-Chat.yaml │ │ │ ├── DeepSeek-V3-Chat-amx.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve-amx.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve.yaml │ │ │ ├── DeepSeek-V3-Chat-fp8-linear-ggml-experts.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-4.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-8.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-fp8-linear-ggml-experts.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu-marlin.yaml │ │ │ ├── DeepSeek-V3-Chat-multi-gpu.yaml │ │ │ ├── DeepSeek-V3-Chat-serve.yaml │ │ │ ├── DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml │ │ │ ├── DeepSeek-V3-Chat-sft-amx-multi-gpu.yaml │ │ │ ├── DeepSeek-V3-Chat-sft-amx.yaml │ │ │ ├── DeepSeek-V3-Chat.yaml │ │ │ ├── Internlm2_5-7b-Chat-1m.yaml │ │ │ ├── Mixtral.yaml │ │ │ ├── Moonlight-16B-A3B-serve.yaml │ │ │ ├── Moonlight-16B-A3B.yaml │ │ │ ├── Qwen2-57B-A14B-Instruct-multi-gpu.yaml │ │ │ ├── Qwen2-57B-A14B-Instruct.yaml │ │ │ ├── Qwen2-serve-amx.yaml │ │ │ ├── Qwen2-serve.yaml │ │ │ ├── Qwen3Moe-serve-amx.yaml │ │ │ ├── Qwen3Moe-serve.yaml │ │ │ ├── Qwen3Moe-sft-amx.yaml │ │ │ ├── rocm/ │ │ │ │ └── DeepSeek-V3-Chat.yaml │ │ │ └── xpu/ │ │ │ ├── DeepSeek-V2-Chat.yaml │ │ │ ├── DeepSeek-V3-Chat.yaml │ │ │ └── Qwen3Moe-Chat.yaml │ │ ├── server/ │ │ │ ├── __init__.py │ │ │ ├── api/ │ │ │ │ ├── __init__.py │ │ │ │ ├── ollama/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ └── completions.py │ │ │ │ ├── openai/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── assistants/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── assistants.py │ │ │ │ │ │ ├── messages.py │ │ │ │ │ │ ├── runs.py │ │ │ │ │ │ └── threads.py │ │ │ │ │ ├── endpoints/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ └── chat.py │ │ │ │ │ └── legacy/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ └── completions.py │ │ │ │ └── web/ │ │ │ │ ├── __init__.py │ │ │ │ └── system.py │ │ │ ├── args.py │ │ │ ├── backend/ │ │ │ │ ├── __init__.py │ │ │ │ ├── args.py │ │ │ │ ├── base.py │ │ │ │ ├── context_manager.py │ │ │ │ └── interfaces/ │ │ │ │ ├── __init__.py │ │ │ │ ├── balance_serve.py │ │ │ │ ├── exllamav2.py │ │ │ │ ├── ktransformers.py │ │ │ │ └── transformers.py │ │ │ ├── balance_serve/ │ │ │ │ ├── inference/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── config.py │ │ │ │ │ ├── distributed/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── communication_op.py │ │ │ │ │ │ ├── cuda_wrapper.py │ │ │ │ │ │ ├── custom_all_reduce.py │ │ │ │ │ │ ├── custom_all_reduce_utils.py │ │ │ │ │ │ ├── parallel_state.py │ │ │ │ │ │ ├── pynccl.py │ │ │ │ │ │ ├── pynccl_wrapper.py │ │ │ │ │ │ └── utils.py │ │ │ │ │ ├── forward_batch.py │ │ │ │ │ ├── model_runner.py │ │ │ │ │ ├── query_manager.py │ │ │ │ │ └── sampling/ │ │ │ │ │ ├── penaltylib/ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ ├── orchestrator.py │ │ │ │ │ │ └── penalizers/ │ │ │ │ │ │ ├── frequency_penalty.py │ │ │ │ │ │ ├── min_new_tokens.py │ │ │ │ │ │ ├── presence_penalty.py │ │ │ │ │ │ └── repetition_penalty.py │ │ │ │ │ └── sampler.py │ │ │ │ ├── sched_rpc.py │ │ │ │ └── settings.py │ │ │ ├── config/ │ │ │ │ ├── config.py │ │ │ │ ├── log.py │ │ │ │ └── singleton.py │ │ │ ├── crud/ │ │ │ │ ├── __init__.py │ │ │ │ └── assistants/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants.py │ │ │ │ ├── messages.py │ │ │ │ ├── runs.py │ │ │ │ └── threads.py │ │ │ ├── exceptions.py │ │ │ ├── main.py │ │ │ ├── models/ │ │ │ │ ├── __init__.py │ │ │ │ └── assistants/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants.py │ │ │ │ ├── messages.py │ │ │ │ ├── run_steps.py │ │ │ │ ├── runs.py │ │ │ │ └── threads.py │ │ │ ├── schemas/ │ │ │ │ ├── __init__.py │ │ │ │ ├── assistants/ │ │ │ │ │ ├── __init__.py │ │ │ │ │ ├── assistants.py │ │ │ │ │ ├── messages.py │ │ │ │ │ ├── runs.py │ │ │ │ │ ├── streaming.py │ │ │ │ │ ├── threads.py │ │ │ │ │ └── tool.py │ │ │ │ ├── base.py │ │ │ │ ├── conversation.py │ │ │ │ ├── endpoints/ │ │ │ │ │ └── chat.py │ │ │ │ └── legacy/ │ │ │ │ ├── __init__.py │ │ │ │ └── completions.py │ │ │ └── utils/ │ │ │ ├── __init__.py │ │ │ ├── create_interface.py │ │ │ ├── multi_timer.py │ │ │ └── sql_utils.py │ │ ├── sft/ │ │ │ ├── __init__.py │ │ │ ├── flops_utils/ │ │ │ │ ├── __init__.py │ │ │ │ ├── custom_profile.py │ │ │ │ └── lora_test_utils.py │ │ │ ├── lora.py │ │ │ ├── metrics.py │ │ │ ├── metrics_utils/ │ │ │ │ ├── __init__.py │ │ │ │ ├── constants.py │ │ │ │ ├── env.py │ │ │ │ ├── logging.py │ │ │ │ ├── misc.py │ │ │ │ ├── packages.py │ │ │ │ └── ploting.py │ │ │ ├── monkey_patch_torch_module.py │ │ │ ├── peft_utils/ │ │ │ │ ├── __init__.py │ │ │ │ ├── lora_layer.py │ │ │ │ ├── lora_model.py │ │ │ │ ├── mapping.py │ │ │ │ └── peft_model.py │ │ │ └── torchviz_test.py │ │ ├── tests/ │ │ │ ├── .gitignore │ │ │ ├── AIME_2024/ │ │ │ │ ├── eval_api.py │ │ │ │ ├── evaluation.py │ │ │ │ └── prompts.py │ │ │ ├── dequant_gpu.py │ │ │ ├── dequant_gpu_t.py │ │ │ ├── function_call_test.py │ │ │ ├── humaneval/ │ │ │ │ ├── eval_api.py │ │ │ │ ├── evaluation.py │ │ │ │ └── prompts.py │ │ │ ├── mmlu_pro_test.py │ │ │ ├── mmlu_test.py │ │ │ ├── mmlu_test_multi.py │ │ │ ├── score.py │ │ │ ├── test_client.py │ │ │ ├── test_pytorch_q8.py │ │ │ ├── test_speed.py │ │ │ └── triton_fp8gemm_test.py │ │ ├── util/ │ │ │ ├── cuda_graph_runner.py │ │ │ ├── custom_gguf.py │ │ │ ├── custom_loader.py │ │ │ ├── globals.py │ │ │ ├── grad_wrapper.py │ │ │ ├── inference_state.py │ │ │ ├── modeling_rope_utils.py │ │ │ ├── textstream.py │ │ │ ├── utils.py │ │ │ ├── vendors.py │ │ │ └── weight_loader.py │ │ └── website/ │ │ ├── .browserslistrc │ │ ├── .eslintrc.js │ │ ├── .gitignore │ │ ├── README.md │ │ ├── config.d.ts │ │ ├── jest.config.js │ │ ├── package.json │ │ ├── public/ │ │ │ ├── config.js │ │ │ ├── css/ │ │ │ │ └── reset.css │ │ │ └── index.html │ │ ├── src/ │ │ │ ├── App.vue │ │ │ ├── api/ │ │ │ │ ├── api-client.ts │ │ │ │ ├── assistant.ts │ │ │ │ ├── message.ts │ │ │ │ ├── run.ts │ │ │ │ └── thread.ts │ │ │ ├── assets/ │ │ │ │ ├── css/ │ │ │ │ │ └── mixins.styl │ │ │ │ └── iconfont/ │ │ │ │ ├── demo.css │ │ │ │ ├── demo_index.html │ │ │ │ ├── iconfont.css │ │ │ │ ├── iconfont.js │ │ │ │ └── iconfont.json │ │ │ ├── components/ │ │ │ │ └── chat/ │ │ │ │ └── index.vue │ │ │ ├── conf/ │ │ │ │ └── config.ts │ │ │ ├── locals/ │ │ │ │ ├── en.js │ │ │ │ ├── index.js │ │ │ │ └── zh.js │ │ │ ├── main.ts │ │ │ ├── router/ │ │ │ │ └── index.ts │ │ │ ├── shims-vue.d.ts │ │ │ ├── store/ │ │ │ │ └── index.ts │ │ │ ├── utils/ │ │ │ │ ├── copy.ts │ │ │ │ └── types.ts │ │ │ └── views/ │ │ │ └── home.vue │ │ ├── tests/ │ │ │ └── unit/ │ │ │ └── example.spec.ts │ │ ├── tsconfig.json │ │ └── vue.config.js │ ├── merge_tensors/ │ │ └── merge_safetensor_gguf.py │ ├── pyproject.toml │ ├── requirements-sft.txt │ ├── setup.py │ ├── test_adapter/ │ │ ├── data_transfer.py │ │ ├── infer_with_adapter.py │ │ ├── inspect_adapter.py │ │ ├── pred2metrics.py │ │ ├── test_grad.py │ │ └── time_test_lora_train.py │ └── withoutKT_PEFT.py ├── pyproject.toml ├── setup.py ├── third_party/ │ └── llamafile/ │ ├── README.md │ ├── bench.h │ ├── flags.cpp │ ├── flags.h │ ├── iqk_mul_mat.inc │ ├── iqk_mul_mat_amd_avx2.cpp │ ├── iqk_mul_mat_amd_zen4.cpp │ ├── iqk_mul_mat_arm.inc │ ├── iqk_mul_mat_arm82.cpp │ ├── macros.h │ ├── micros.h │ ├── numba.h │ ├── sgemm.cpp │ ├── sgemm.h │ ├── tinyblas_cpu.h │ ├── tinyblas_cpu_mixmul.inc │ ├── tinyblas_cpu_mixmul_amd_avx.cpp │ ├── tinyblas_cpu_mixmul_amd_avx2.cpp │ ├── tinyblas_cpu_mixmul_amd_avx512f.cpp │ ├── tinyblas_cpu_mixmul_amd_avxvnni.cpp │ ├── tinyblas_cpu_mixmul_amd_fma.cpp │ ├── tinyblas_cpu_mixmul_amd_zen4.cpp │ ├── tinyblas_cpu_mixmul_arm80.cpp │ ├── tinyblas_cpu_mixmul_arm82.cpp │ ├── tinyblas_cpu_sgemm.inc │ ├── tinyblas_cpu_sgemm_amd_avx.cpp │ ├── tinyblas_cpu_sgemm_amd_avx2.cpp │ ├── tinyblas_cpu_sgemm_amd_avx512f.cpp │ ├── tinyblas_cpu_sgemm_amd_avxvnni.cpp │ ├── tinyblas_cpu_sgemm_amd_fma.cpp │ ├── tinyblas_cpu_sgemm_amd_zen4.cpp │ ├── tinyblas_cpu_sgemm_arm80.cpp │ ├── tinyblas_cpu_sgemm_arm82.cpp │ └── tinyblas_cpu_unsupported.cpp └── version.py
Showing preview only (649K chars total). Download the full file or copy to clipboard to get everything.
SYMBOL INDEX (7608 symbols across 621 files)
FILE: archive/csrc/custom_marlin/binding.cpp
function PYBIND11_MODULE (line 20) | PYBIND11_MODULE(vLLMMarlin, m) {
FILE: archive/csrc/custom_marlin/test_cuda_graph.py
function setup_seed (line 14) | def setup_seed(seed):
function get_usable_mem (line 33) | def get_usable_mem():
function exp_range (line 42) | def exp_range(start, stop, step = 2):
function timing (line 48) | def timing(func, iters, epochs=100):
class LinearMarlin (line 88) | class LinearMarlin(nn.Linear):
method __init__ (line 94) | def __init__(
method forward (line 168) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor) -> torch....
function benchLinearMarlin (line 208) | def benchLinearMarlin(input_dim, output_dim):#, out_file
function printMinMax (line 314) | def printMinMax(tensor):
FILE: archive/csrc/custom_marlin/utils/format24.py
function _calculate_meta_reordering_scatter_offsets (line 21) | def _calculate_meta_reordering_scatter_offsets(m, meta_ncols, meta_dtype,
function sparse_semi_structured_from_dense_cutlass (line 52) | def sparse_semi_structured_from_dense_cutlass(dense):
function sparse_semi_structured_to_dense_cutlass (line 184) | def sparse_semi_structured_to_dense_cutlass(sparse, meta_reordered):
function mask_creator (line 279) | def mask_creator(tensor):
FILE: archive/csrc/custom_marlin/utils/marlin_24_perms.py
function get_perms_24 (line 21) | def get_perms_24(num_bits: int):
FILE: archive/csrc/custom_marlin/utils/marlin_perms.py
function get_perms (line 21) | def get_perms(num_bits: int):
FILE: archive/csrc/custom_marlin/utils/marlin_utils.py
function is_marlin_supported (line 31) | def is_marlin_supported():
function marlin_permute_weights (line 35) | def marlin_permute_weights(q_w, size_k, size_n, perm, tile=MARLIN_TILE):
function marlin_weights (line 50) | def marlin_weights(q_w, size_k, size_n, num_bits, perm):
function marlin_permute_scales (line 70) | def marlin_permute_scales(s, size_k, size_n, group_size, scale_perm,
function marlin_quantize (line 81) | def marlin_quantize(
function inject_24 (line 119) | def inject_24(w, size_k, size_n):
function check_24 (line 127) | def check_24(w, num_rows_to_sample=50, _verbose=False):
function compress_quantized_24_weight (line 154) | def compress_quantized_24_weight(q_24, size_k, size_n, num_bits):
function marlin_24_quantize (line 177) | def marlin_24_quantize(
function compute_max_diff (line 218) | def compute_max_diff(output, output_ref):
class MarlinWorkspace (line 223) | class MarlinWorkspace:
method __init__ (line 225) | def __init__(self, out_features, min_thread_n, max_parallel, device):
FILE: archive/csrc/custom_marlin/utils/quant_utils.py
function get_pack_factor (line 9) | def get_pack_factor(num_bits):
function permute_rows (line 14) | def permute_rows(q_w: torch.Tensor, w_ref: torch.Tensor, group_size: int):
function dequantize_weights (line 40) | def dequantize_weights(qweight, qzeros, scales, g_idx, bits=4, group_siz...
function quantize_weights (line 67) | def quantize_weights(w: torch.Tensor, num_bits: int, group_size: int,
function sort_weights (line 137) | def sort_weights(q_w: torch.Tensor, g_idx: torch.Tensor):
function gptq_pack (line 153) | def gptq_pack(
function gptq_unpack (line 176) | def gptq_unpack(
FILE: archive/csrc/ktransformers_ext/bench/bench_attention.py
function bench_linear (line 41) | def bench_linear(cache_seqlen: int):
FILE: archive/csrc/ktransformers_ext/bench/bench_attention_torch.py
function bench_linear (line 29) | def bench_linear(cache_seqlen: int, device):
FILE: archive/csrc/ktransformers_ext/bench/bench_linear.py
function bench_linear (line 28) | def bench_linear(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_linear_torch.py
function bench_linear (line 26) | def bench_linear(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_mlp.py
function bench_mlp (line 28) | def bench_mlp(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_mlp_torch.py
function act_fn (line 26) | def act_fn(x):
function mlp_torch (line 29) | def mlp_torch(input, gate_proj, up_proj, down_proj):
function bench_mlp (line 47) | def bench_mlp(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_moe.py
function bench_moe (line 31) | def bench_moe(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_moe_amx.py
function bench_moe (line 29) | def bench_moe(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/bench/bench_moe_torch.py
function act_fn (line 28) | def act_fn(x):
function mlp_torch (line 31) | def mlp_torch(input, gate_proj, up_proj, down_proj):
function moe_torch (line 49) | def moe_torch(input, expert_ids, weights, gate_proj, up_proj, down_proj):
function bench_moe (line 80) | def bench_moe(quant_mode: str):
FILE: archive/csrc/ktransformers_ext/cpu_backend/backend.cpp
type bitmask (line 93) | struct bitmask
FILE: archive/csrc/ktransformers_ext/cpu_backend/backend.h
type ThreadStatus (line 21) | enum ThreadStatus {
type ThreadState (line 27) | struct ThreadState {
function class (line 33) | class Backend {
FILE: archive/csrc/ktransformers_ext/cpu_backend/cpuinfer.h
function class (line 36) | class CPUInfer {
function submit (line 58) | void submit(std::pair<intptr_t, intptr_t> params) {
function sync (line 65) | void sync() {
function submit_with_cuda_stream (line 69) | void submit_with_cuda_stream(intptr_t user_cuda_stream, std::pair<intptr...
function sync_ (line 80) | static void sync_(void* cpu_infer_ptr) {
function sync_with_cuda_stream (line 85) | void sync_with_cuda_stream(intptr_t user_cuda_stream) {
FILE: archive/csrc/ktransformers_ext/cpu_backend/shared_mem_buffer.h
function class (line 19) | class SharedMemBuffer {
FILE: archive/csrc/ktransformers_ext/cpu_backend/task_queue.h
function class (line 24) | class custom_mutex {
function class (line 74) | class custom_condition_variable {
function class (line 119) | class TaskQueue {
FILE: archive/csrc/ktransformers_ext/cpu_backend/vendors/hip.h
type hip_bfloat16 (line 172) | typedef hip_bfloat16 nv_bfloat16;
FILE: archive/csrc/ktransformers_ext/cpu_backend/vendors/musa.h
type mt_bfloat16 (line 137) | typedef mt_bfloat16 nv_bfloat16;
FILE: archive/csrc/ktransformers_ext/cuda/binding.cpp
function PYBIND11_MODULE (line 21) | PYBIND11_MODULE(KTransformersOps, m) {
FILE: archive/csrc/ktransformers_ext/examples/test_mlp.py
function act_fn (line 31) | def act_fn(x):
function mlp_torch (line 34) | def mlp_torch(input, gate_proj, up_proj, down_proj):
FILE: archive/csrc/ktransformers_ext/examples/test_moe.py
function act_fn (line 34) | def act_fn(x):
function mlp_torch (line 37) | def mlp_torch(input, gate_proj, up_proj, down_proj):
function moe_torch (line 44) | def moe_torch(input, expert_ids, weights, gate_proj, up_proj, down_proj):
FILE: archive/csrc/ktransformers_ext/ext_bindings.cpp
class KVCacheBindings (line 37) | class KVCacheBindings {
class AttnBindings (line 39) | class AttnBindings {
type Args (line 41) | struct Args {
method inner (line 58) | static void inner(void *args) {
method cpuinfer_interface (line 67) | static std::pair<intptr_t, intptr_t>
class GetAllKVCacheOneLayerBindings (line 93) | class GetAllKVCacheOneLayerBindings {
type Args (line 95) | struct Args {
method inner (line 102) | static void inner(void *args) {
method cpuinfer_interface (line 108) | static std::pair<intptr_t, intptr_t>
class GetAndUpdateKVCacheFp16Bindings (line 117) | class GetAndUpdateKVCacheFp16Bindings {
type Args (line 119) | struct Args {
method inner (line 131) | static void inner(void *args) {
method cpuinfer_interface (line 139) | static std::pair<intptr_t, intptr_t>
class GetKVCacheFp16Bindings (line 157) | class GetKVCacheFp16Bindings {
type Args (line 159) | struct Args {
method inner (line 170) | static void inner(void *args) {
method cpuinfer_interface (line 177) | static std::pair<intptr_t, intptr_t>
class UpdateKVCacheFp16Bindings (line 194) | class UpdateKVCacheFp16Bindings {
type Args (line 196) | struct Args {
method inner (line 208) | static void inner(void *args) {
method cpuinfer_interface (line 216) | static std::pair<intptr_t, intptr_t>
class UpdateImportanceBindings (line 235) | class UpdateImportanceBindings {
type Args (line 237) | struct Args {
method inner (line 248) | static void inner(void *args) {
method cpuinfer_interface (line 255) | static std::pair<intptr_t, intptr_t>
class AttnWithKVCacheBindings (line 272) | class AttnWithKVCacheBindings {
type Args (line 274) | struct Args {
method inner (line 292) | static void inner(void *args) {
method cpuinfer_interface (line 301) | static std::pair<intptr_t, intptr_t>
class ClearImportanceAllLayersBindings (line 328) | class ClearImportanceAllLayersBindings {
type Args (line 330) | struct Args {
method inner (line 338) | static void inner(void *args) {
method cpuinfer_interface (line 345) | static std::pair<intptr_t, intptr_t>
class CalcAnchorAllLayersBindinds (line 359) | class CalcAnchorAllLayersBindinds {
type Args (line 361) | struct Args {
method inner (line 369) | static void inner(void *args) {
method cpuinfer_interface (line 376) | static std::pair<intptr_t, intptr_t>
class LoadKVCacheBindings (line 390) | class LoadKVCacheBindings {
type Args (line 392) | struct Args {
method inner (line 397) | static void inner(void *args) {
method cpuinfer_interface (line 402) | static std::pair<intptr_t, intptr_t>
class DumpKVCacheBindings (line 409) | class DumpKVCacheBindings {
type Args (line 411) | struct Args {
method inner (line 418) | static void inner(void *args) {
method cpuinfer_interface (line 424) | static std::pair<intptr_t, intptr_t>
class LinearBindings (line 435) | class LinearBindings {
class WarmUpBindinds (line 437) | class WarmUpBindinds {
type Args (line 439) | struct Args {
method inner (line 443) | static void inner(void *args) {
method cpuinfer_interface (line 447) | static std::pair<intptr_t, intptr_t>
class ForwardBindings (line 453) | class ForwardBindings {
type Args (line 455) | struct Args {
method inner (line 462) | static void inner(void *args) {
method cpuinfer_interface (line 467) | static std::pair<intptr_t, intptr_t>
class MLPBindings (line 477) | class MLPBindings {
class WarmUpBindinds (line 479) | class WarmUpBindinds {
type Args (line 481) | struct Args {
method inner (line 485) | static void inner(void *args) {
method cpuinfer_interface (line 489) | static std::pair<intptr_t, intptr_t> cpuinfer_interface(MLP &mlp) {
class ForwardBindings (line 494) | class ForwardBindings {
type Args (line 496) | struct Args {
method inner (line 503) | static void inner(void *args) {
method cpuinfer_interface (line 508) | static std::pair<intptr_t, intptr_t>
class MOEBindings (line 518) | class MOEBindings {
class WarmUpBindinds (line 520) | class WarmUpBindinds {
type Args (line 522) | struct Args {
method inner (line 526) | static void inner(void *args) {
method cpuinfer_interface (line 530) | static std::pair<intptr_t, intptr_t> cpuinfer_interface(MOE &moe) {
class ForwardBindings (line 535) | class ForwardBindings {
type Args (line 537) | struct Args {
method inner (line 548) | static void inner(void *args) {
method cpuinfer_interface (line 554) | static std::pair<intptr_t, intptr_t>
class AMX_MOEBindings (line 574) | class AMX_MOEBindings {
class WarmUpBindings (line 576) | class WarmUpBindings {
type Args (line 578) | struct Args {
method inner (line 582) | static void inner(void *args) {
method cpuinfer_interface (line 586) | static std::pair<intptr_t, intptr_t> cpuinfer_interface(AMX_MOE<T> &...
class LoadWeightsBindings (line 591) | class LoadWeightsBindings {
type Args (line 593) | struct Args {
method inner (line 597) | static void inner(void *args) {
method cpuinfer_interface (line 601) | static std::pair<intptr_t, intptr_t> cpuinfer_interface(AMX_MOE<T> &...
class ForwardBindings (line 606) | class ForwardBindings {
type Args (line 608) | struct Args {
method inner (line 619) | static void inner(void *args) {
method cpuinfer_interface (line 625) | static std::pair<intptr_t, intptr_t>
function PYBIND11_MODULE (line 643) | PYBIND11_MODULE(cpuinfer_ext, m) {
FILE: archive/csrc/ktransformers_ext/operators/amx/la/amx.hpp
type amx (line 41) | namespace amx {
function enable_amx (line 63) | inline bool enable_amx() {
type TileConfig (line 80) | struct alignas(64) TileConfig {
method TileConfig (line 89) | TileConfig() {
method set_row_col (line 97) | void set_row_col(int i, uint8_t row, uint16_t col) {
method set_config (line 102) | void set_config() { _tile_loadconfig(this); }
method load_data (line 104) | static void load_data(int to, void *from, size_t stride) {
method store_data (line 135) | static void store_data(int from, void *to, size_t stride) {
function debug_tile (line 169) | inline void debug_tile(int t) {
function debug_tiles (line 182) | inline void debug_tiles(int to = 8) {
function debug_m512 (line 188) | inline void debug_m512(__m512 x) {
function transpose_16x16_32bit (line 198) | inline void transpose_16x16_32bit(__m512i *v) {
function transpose_16x16_32bit (line 273) | inline void transpose_16x16_32bit(__m512i *v, size_t stride) {
type GemmKernel224BF (line 348) | struct GemmKernel224BF {
method recommended_nth (line 363) | static int recommended_nth(int n) { return (n + N_BLOCK - 1) / N_BLO...
method split_range_n (line 365) | static std::pair<int, int> split_range_n(int n, int ith, int nth) {
method config (line 371) | static void config() {
method load_a (line 390) | static void load_a(dt *a, size_t lda) {
method load_b (line 395) | static void load_b(dt *b, size_t ldb) {
method clean_c (line 400) | static void clean_c() {
method load_c (line 407) | static void load_c(output_t *c, size_t ldc) {
method store_c (line 414) | static void store_c(output_t *c, size_t ldc) {
method run_tile (line 421) | static void run_tile() {
type BufferA (line 428) | struct BufferA {
method required_size (line 432) | static size_t required_size(int max_m, int k) { return max_m * k *...
method BufferA (line 434) | BufferA(int max_m, int k, void *ptr) : max_m(max_m), k(k) {
method from_mat (line 441) | void from_mat(int m, ggml_bf16_t *src, int ith, int nth) {
method ggml_bf16_t (line 460) | ggml_bf16_t *get_submat(int m, int k, int m_begin, int k_begin) {
type BufferB (line 469) | struct BufferB {
method required_size (line 473) | static size_t required_size(int n, int k) { return n * k * sizeof(...
method BufferB (line 475) | BufferB(int n, int k, void *ptr) : n(n), k(k) {
method from_mat (line 482) | void from_mat(ggml_bf16_t *src, int ith, int nth) {
method ggml_bf16_t (line 505) | ggml_bf16_t *get_submat(int n, int k, int n_begin, int k_begin) {
type BufferC (line 516) | struct BufferC {
method required_size (line 520) | static size_t required_size(int max_m, int n) { return max_m * n *...
method BufferC (line 522) | BufferC(int max_m, int n, void *ptr) : max_m(max_m), n(n) {
method to_mat (line 529) | void to_mat(int m, ggml_bf16_t *dst, int ith, int nth) {
type GemmKernel224Int8 (line 558) | struct GemmKernel224Int8 {
method recommended_nth (line 573) | static int recommended_nth(int n) { return (n + N_BLOCK - 1) / N_BLO...
method split_range_n (line 575) | static std::pair<int, int> split_range_n(int n, int ith, int nth) {
method config (line 581) | static void config() {
method load_a (line 600) | static void load_a(dt *a, size_t lda) {
method load_b (line 605) | static void load_b(dt *b, size_t ldb) {
method clean_c (line 610) | static void clean_c() {
method load_c (line 617) | static void load_c(output_t *c, size_t ldc) {
method store_c (line 624) | static void store_c(output_t *c, size_t ldc) {
method run_tile (line 631) | static void run_tile() {
type BufferA (line 638) | struct BufferA {
method required_size (line 643) | static size_t required_size(int max_m, int k) { return max_m * k *...
method BufferA (line 645) | BufferA(int max_m, int k, void *ptr) : max_m(max_m), k(k) {
method from_mat (line 653) | void from_mat(int m, ggml_bf16_t *src, int ith, int nth) {
type BufferB (line 708) | struct BufferB {
method required_size (line 713) | static size_t required_size(int n, int k) { return n * k * sizeof(...
method BufferB (line 715) | BufferB(int n, int k, void *ptr) : n(n), k(k) {
method from_mat (line 723) | void from_mat(ggml_bf16_t *src, int ith, int nth) {
type BufferC (line 787) | struct BufferC {
method required_size (line 791) | static size_t required_size(int max_m, int n) { return max_m * n *...
method BufferC (line 793) | BufferC(int max_m, int n, void *ptr) : max_m(max_m), n(n) {
method to_mat (line 800) | void to_mat(int m, ggml_bf16_t *dst, int ith, int nth) {
function mat_mul (line 829) | inline void mat_mul(int m, int n, int k, std::shared_ptr<GemmKernel224...
function __m512i (line 883) | inline __m512i _mm512_dpbssd_epi32(__m512i src, __m512i a, __m512i b) {
function mat_mul (line 900) | inline void mat_mul(int m, int n, int k, std::shared_ptr<GemmKernel224...
FILE: archive/csrc/ktransformers_ext/operators/amx/la/utils.hpp
function T (line 16) | T* offset_pointer(T* ptr, std::size_t byte_offset) {
function T (line 21) | const T* offset_pointer(const T* ptr, std::size_t byte_offset) {
function T (line 26) | T* offset_pointer_row_major(T* t, int row, int col, std::size_t ld) {
function T (line 31) | T* offset_pointer_col_major(T* t, int row, int col, std::size_t ld) {
function avx512_copy_32xbf16 (line 35) | static inline void avx512_copy_32xbf16(__m512i* src, __m512i* dst) {
function avx512_32xfp32_to_32xbf16 (line 39) | static inline void avx512_32xfp32_to_32xbf16(__m512* src0, __m512* src1,...
function avx512_32xbf16_to_32xfp32 (line 43) | static inline void avx512_32xbf16_to_32xfp32(__m512i* src, __m512* dst0,...
FILE: archive/csrc/ktransformers_ext/operators/amx/moe.hpp
function __m512 (line 38) | static inline __m512 exp_avx512(__m512 x) {
function __m512 (line 63) | static inline __m512 act_fn(__m512 gate_val, __m512 up_val) {
function __m512 (line 72) | static inline __m512 relu_act_fn(__m512 gate_val, __m512 up_val) {
type AMX_MOEConfig (line 78) | struct AMX_MOEConfig {
method AMX_MOEConfig (line 89) | AMX_MOEConfig() {}
method AMX_MOEConfig (line 91) | AMX_MOEConfig(int expert_num, int routed_expert_num, int hidden_size, ...
class AMX_MOE (line 98) | class AMX_MOE {
method AMX_MOE (line 135) | AMX_MOE(AMX_MOEConfig config) {
method load_weights (line 230) | void load_weights(Backend *backend) {
method warm_up (line 278) | void warm_up(Backend *backend) {}
method forward (line 280) | void forward(int qlen, int k, const uint64_t *expert_ids, const float ...
FILE: archive/csrc/ktransformers_ext/operators/kvcache/kvcache.h
type AnchorType (line 63) | enum AnchorType {
type RetrievalType (line 94) | enum RetrievalType {
type KVCacheConfig (line 122) | struct KVCacheConfig {
function class (line 193) | class KVCache {
FILE: archive/csrc/ktransformers_ext/operators/kvcache/kvcache_utils.cpp
function ggml_type_to_string (line 15) | std::string ggml_type_to_string(ggml_type type) {
function AnchorTypeToString (line 28) | std::string AnchorTypeToString(AnchorType type) {
function RetrievalTypeToString (line 43) | std::string RetrievalTypeToString(RetrievalType type) {
function ggml_vec_scale_f32 (line 1130) | void ggml_vec_scale_f32(const int n, float *y, const float v) {
FILE: archive/csrc/ktransformers_ext/operators/llamafile/conversion.h
function to_float (line 16) | inline void to_float(const void* input, float* output, int size, ggml_ty...
function from_float (line 24) | inline void from_float(const float* input, void* output, int size, ggml_...
FILE: archive/csrc/ktransformers_ext/operators/llamafile/linear.h
type LinearConfig (line 27) | struct LinearConfig {
FILE: archive/csrc/ktransformers_ext/operators/llamafile/mlp.cpp
function act_fn (line 49) | static float act_fn(float x) { return x / (1.0f + expf(-x)); }
FILE: archive/csrc/ktransformers_ext/operators/llamafile/mlp.h
type MLPConfig (line 27) | struct MLPConfig {
FILE: archive/csrc/ktransformers_ext/operators/llamafile/moe.cpp
function act_fn (line 134) | static float act_fn(float x) {
function act_fn_relu (line 138) | static float act_fn_relu(float x) {
FILE: archive/csrc/ktransformers_ext/operators/llamafile/moe.h
type MOEConfig (line 27) | struct MOEConfig {
FILE: archive/csrc/ktransformers_ext/vendors/hip.h
type hip_bfloat16 (line 172) | typedef hip_bfloat16 nv_bfloat16;
FILE: archive/csrc/ktransformers_ext/vendors/musa.h
type mt_bfloat16 (line 137) | typedef mt_bfloat16 nv_bfloat16;
FILE: archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/format_24.py
function _calculate_meta_reordering_scatter_offsets (line 21) | def _calculate_meta_reordering_scatter_offsets(m, meta_ncols, meta_dtype,
function sparse_semi_structured_from_dense_cutlass (line 52) | def sparse_semi_structured_from_dense_cutlass(dense):
function sparse_semi_structured_to_dense_cutlass (line 184) | def sparse_semi_structured_to_dense_cutlass(sparse, meta_reordered):
function mask_creator (line 279) | def mask_creator(tensor):
FILE: archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_24_perms.py
function get_perms_24 (line 16) | def get_perms_24(num_bits: int):
FILE: archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_perms.py
function get_perms (line 16) | def get_perms(num_bits: int):
FILE: archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_utils.py
function is_marlin_supported (line 29) | def is_marlin_supported():
function marlin_permute_weights (line 33) | def marlin_permute_weights(q_w, size_k, size_n, perm, tile=MARLIN_TILE):
function marlin_weights (line 48) | def marlin_weights(q_w, size_k, size_n, num_bits, perm):
function marlin_permute_scales (line 68) | def marlin_permute_scales(s, size_k, size_n, group_size, scale_perm,
function marlin_quantize (line 79) | def marlin_quantize(
function vllm_marlin_quantize (line 117) | def vllm_marlin_quantize(
function inject_24 (line 155) | def inject_24(w, size_k, size_n):
function check_24 (line 163) | def check_24(w, num_rows_to_sample=50, _verbose=False):
function compress_quantized_24_weight (line 190) | def compress_quantized_24_weight(q_24, size_k, size_n, num_bits):
function marlin_24_quantize (line 213) | def marlin_24_quantize(
function compute_max_diff (line 254) | def compute_max_diff(output, output_ref):
class MarlinWorkspace (line 259) | class MarlinWorkspace:
method __init__ (line 261) | def __init__(self, out_features, min_thread_n, max_parallel, device):
FILE: archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/quant_utils.py
function get_pack_factor (line 9) | def get_pack_factor(num_bits):
function permute_rows (line 14) | def permute_rows(q_w: torch.Tensor, group_size: int):
function quantize_weights (line 36) | def quantize_weights(w: torch.Tensor, num_bits: int, group_size: int,
function sort_weights (line 101) | def sort_weights(q_w: torch.Tensor, g_idx: torch.Tensor):
function gptq_pack (line 117) | def gptq_pack(
FILE: archive/ktransformers/ktransformers_ext/triton/fp8gemm.py
function act_quant_kernel (line 11) | def act_quant_kernel(x_ptr, y_ptr, s_ptr, BLOCK_SIZE: tl.constexpr):
function act_quant (line 34) | def act_quant(x: torch.Tensor, block_size: int = 128) -> Tuple[torch.Ten...
function weight_dequant_kernel (line 57) | def weight_dequant_kernel(x_ptr, s_ptr, y_ptr, M, N, BLOCK_SIZE: tl.cons...
function weight_dequant (line 85) | def weight_dequant(x: torch.Tensor, s: torch.Tensor, block_size: int = 1...
function fp8_gemm_kernel (line 117) | def fp8_gemm_kernel(a_ptr, b_ptr, c_ptr,
function fp8_gemm (line 172) | def fp8_gemm(a: torch.Tensor, a_s: torch.Tensor, b: torch.Tensor, b_s: t...
FILE: archive/ktransformers/local_chat.py
function local_chat (line 76) | def local_chat(
FILE: archive/ktransformers/local_chat_test.py
function local_chat (line 55) | def local_chat(
FILE: archive/ktransformers/models/ascend/custom_ascend_modeling_deepseek_v3.py
class KNPUDeepseekV3ForCausalLM (line 31) | class KNPUDeepseekV3ForCausalLM(DeepseekV3PreTrainedModel):
method __init__ (line 36) | def __init__(
method init_wrapper (line 54) | def init_wrapper(self, use_cuda_graph, device, max_batch_size, max_pag...
method batch_embeddings (line 57) | def batch_embeddings(self, batch: ForwardBatchInput, device="npu:0", i...
method print_callback (line 111) | def print_callback(self, param):
method forward (line 118) | def forward(
method flash_infer_attn_plan (line 215) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/ascend/custom_ascend_modeling_qwen3.py
class KNPUQwen3MoeForCausalLM (line 39) | class KNPUQwen3MoeForCausalLM(Qwen3MoePreTrainedModel):
method __init__ (line 44) | def __init__(
method init_wrapper (line 84) | def init_wrapper(self):
method batch_embeddings (line 90) | def batch_embeddings(
method forward (line 158) | def forward(
method flash_infer_attn_plan (line 275) | def flash_infer_attn_plan(
FILE: archive/ktransformers/models/configuration_deepseek.py
class DeepseekV2Config (line 11) | class DeepseekV2Config(PretrainedConfig):
method __init__ (line 113) | def __init__(
FILE: archive/ktransformers/models/configuration_deepseek_v3.py
class DeepseekV3Config (line 7) | class DeepseekV3Config(PretrainedConfig):
method __init__ (line 106) | def __init__(
FILE: archive/ktransformers/models/configuration_glm4_moe.py
class Glm4MoeConfig (line 26) | class Glm4MoeConfig(PretrainedConfig):
method __init__ (line 170) | def __init__(
FILE: archive/ktransformers/models/configuration_llama.py
class LlamaConfig (line 26) | class LlamaConfig(PretrainedConfig):
method __init__ (line 143) | def __init__(
FILE: archive/ktransformers/models/configuration_qwen2_moe.py
class Qwen2MoeConfig (line 24) | class Qwen2MoeConfig(PretrainedConfig):
method __init__ (line 115) | def __init__(
FILE: archive/ktransformers/models/configuration_qwen3_moe.py
class Qwen3MoeConfig (line 25) | class Qwen3MoeConfig(PretrainedConfig):
method __init__ (line 161) | def __init__(
FILE: archive/ktransformers/models/configuration_qwen3_next.py
class Qwen3NextConfig (line 25) | class Qwen3NextConfig(PretrainedConfig):
method __init__ (line 180) | def __init__(
FILE: archive/ktransformers/models/configuration_smallthinker.py
class SmallthinkerConfig (line 4) | class SmallthinkerConfig(PretrainedConfig):
method __init__ (line 65) | def __init__(self,
FILE: archive/ktransformers/models/custom_cache.py
class StaticCache (line 27) | class StaticCache(transformers.StaticCache):
method __init__ (line 45) | def __init__(self, config: PretrainedConfig, max_batch_size: int, max_...
method max_batch_size (line 140) | def max_batch_size(self):
method max_cache_len (line 144) | def max_cache_len(self):
method update (line 147) | def update(
method get_seq_length (line 204) | def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
method change_seq_length (line 211) | def change_seq_length(self, bias: Optional[int] = 0) -> int:
method get_max_length (line 219) | def get_max_length(self) -> Optional[int]:
method get_usable_length (line 223) | def get_usable_length(self, kv_seq_len, layer_idx: Optional[int] = 0) ...
method reset (line 226) | def reset(self):
method remove_suffix (line 238) | def remove_suffix(self, start_pos):
method get_max_cache_shape (line 249) | def get_max_cache_shape(self) -> Tuple[int, int, int, int]:
class KVC2StaticCache (line 253) | class KVC2StaticCache:
method __init__ (line 258) | def __init__(self, config: PretrainedConfig, max_batch_size, page_size...
method load (line 275) | def load(self, inference_context):
method update (line 289) | def update(
method get_seq_length (line 328) | def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
method get_usable_length (line 332) | def get_usable_length(self, kv_seq_len, layer_idx: Optional[int] = 0) ...
method change_seq_length (line 335) | def change_seq_length(self, bias: Optional[int] = 0) -> int:
method get_max_length (line 339) | def get_max_length(self) -> Optional[int]:
method reset (line 343) | def reset(self, inference_context):
method get_page_table (line 354) | def get_page_table(self, mini_batch, bsz_tensors: torch.tensor = None,...
class KDeepSeekV3Cache (line 387) | class KDeepSeekV3Cache(nn.Module):
method __init__ (line 388) | def __init__(
method load (line 406) | def load(self, inference_context: "sched_ext.InferenceContext"):
method update (line 414) | def update(
method get_page_table (line 450) | def get_page_table(self, cache_position: torch.Tensor, q_indptr: torch...
class KGQACache (line 468) | class KGQACache(nn.Module):
method __init__ (line 469) | def __init__(
method load (line 486) | def load(self, inference_context: "sched_ext.InferenceContext"):
method get_page_table (line 501) | def get_page_table(self, cache_position: torch.Tensor, q_indptr: torch...
method get_k_cache (line 519) | def get_k_cache(self, layer_idx):
method get_v_cache (line 522) | def get_v_cache(self, layer_idx):
class KVC2Qwen3Cache (line 526) | class KVC2Qwen3Cache(nn.Module):
method __init__ (line 528) | def __init__(self, config, max_batch_size, page_size=256,
method load (line 547) | def load(self, inference_context):
method update (line 575) | def update(
method get_k_cache (line 635) | def get_k_cache(self, layer_idx):
method get_v_cache (line 638) | def get_v_cache(self, layer_idx):
method get_page_table (line 642) | def get_page_table(
FILE: archive/ktransformers/models/custom_modeling_deepseek_v2.py
class KDeepseekV2ForCausalLM (line 21) | class KDeepseekV2ForCausalLM(DeepseekV2PreTrainedModel):
method __init__ (line 25) | def __init__(
method init_wrapper (line 40) | def init_wrapper(self, use_cuda_graph, device, max_batch_size, max_pag...
method batch_embeddings (line 57) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 71) | def forward(
method flash_infer_attn_plan (line 140) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_deepseek_v3.py
class KDeepseekV3ForCausalLM (line 27) | class KDeepseekV3ForCausalLM(DeepseekV3PreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 43) | def init_wrapper(self, use_cuda_graph, device, max_batch_size, max_pag...
method batch_embeddings (line 61) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 75) | def forward(
method flash_infer_attn_plan (line 136) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_glm4_moe.py
class KGlm4MoeForCausalLM (line 27) | class KGlm4MoeForCausalLM(Glm4MoePreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 45) | def init_wrapper(self, use_cuda_graph, device, max_batch_token, max_ba...
method batch_embeddings (line 49) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 63) | def forward(
method flash_infer_attn_plan (line 111) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_qwen2_moe.py
class KQwen2MoeForCausalLM (line 27) | class KQwen2MoeForCausalLM(Qwen2MoePreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 44) | def init_wrapper(self, use_cuda_graph, device, max_batch_token, max_ba...
method batch_embeddings (line 48) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 62) | def forward(
method flash_infer_attn_plan (line 120) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_qwen3_moe.py
class KQwen3MoeForCausalLM (line 27) | class KQwen3MoeForCausalLM(Qwen3MoePreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 44) | def init_wrapper(self, use_cuda_graph, device, max_batch_token, max_ba...
method batch_embeddings (line 48) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 62) | def forward(
method flash_infer_attn_plan (line 120) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_qwen3_next.py
class KQwen3NextForCausalLM (line 27) | class KQwen3NextForCausalLM(Qwen3NextPreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 46) | def init_wrapper(self, use_cuda_graph, device, max_batch_token, max_ba...
method batch_embeddings (line 50) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method reset_conv_states (line 63) | def reset_conv_states(self):
method forward (line 69) | def forward(
method flash_infer_attn_plan (line 127) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/custom_modeling_smallthinker.py
class KSmallThinkerForCausalLM (line 27) | class KSmallThinkerForCausalLM(SmallthinkerPreTrainedModel):
method __init__ (line 31) | def __init__(
method init_wrapper (line 45) | def init_wrapper(self, use_cuda_graph, device, max_batch_token, max_ba...
method batch_embeddings (line 49) | def batch_embeddings(self, batch: ForwardBatchInput, device="cuda:0"):
method forward (line 63) | def forward(
method flash_infer_attn_plan (line 110) | def flash_infer_attn_plan(self, batch: ForwardBatchInput, bsz_tensors,...
FILE: archive/ktransformers/models/modeling_deepseek.py
function _get_unpad_data (line 88) | def _get_unpad_data(attention_mask):
class DeepseekV2RMSNorm (line 102) | class DeepseekV2RMSNorm(nn.Module):
method __init__ (line 103) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 112) | def forward(self, hidden_states):
class DeepseekV2RotaryEmbedding (line 123) | class DeepseekV2RotaryEmbedding(nn.Module):
method __init__ (line 124) | def __init__(self, dim, max_position_embeddings=2048, base=10000, devi...
method forward (line 136) | def forward(self, x, position_ids):
class DeepseekV2LinearScalingRotaryEmbedding (line 152) | class DeepseekV2LinearScalingRotaryEmbedding(DeepseekV2RotaryEmbedding):
method __init__ (line 155) | def __init__(
method _set_cos_sin_cache (line 167) | def _set_cos_sin_cache(self, seq_len, device, dtype):
class DeepseekV2DynamicNTKScalingRotaryEmbedding (line 182) | class DeepseekV2DynamicNTKScalingRotaryEmbedding(DeepseekV2RotaryEmbeddi...
method __init__ (line 185) | def __init__(
method _set_cos_sin_cache (line 197) | def _set_cos_sin_cache(self, seq_len, device, dtype):
function yarn_find_correction_dim (line 222) | def yarn_find_correction_dim(
function yarn_find_correction_range (line 231) | def yarn_find_correction_range(
function yarn_get_mscale (line 243) | def yarn_get_mscale(scale=1, mscale=1):
function yarn_linear_ramp_mask (line 249) | def yarn_linear_ramp_mask(min, max, dim):
class DeepseekV2YarnRotaryEmbedding (line 257) | class DeepseekV2YarnRotaryEmbedding(DeepseekV2RotaryEmbedding):
method __init__ (line 258) | def __init__(
method forward (line 313) | def forward(self, x, position_ids):
function rotate_half (line 329) | def rotate_half(x):
function apply_rotary_pos_emb (line 337) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
class DeepseekV2MLP (line 367) | class DeepseekV2MLP(nn.Module):
method __init__ (line 368) | def __init__(self, config, hidden_size=None, intermediate_size=None):
method forward (line 381) | def forward(self, x):
class MoEGate (line 386) | class MoEGate(nn.Module):
method __init__ (line 387) | def __init__(self, config):
method reset_parameters (line 408) | def reset_parameters(self) -> None:
method forward (line 413) | def forward(self, hidden_states):
class AddAuxiliaryLoss (line 493) | class AddAuxiliaryLoss(torch.autograd.Function):
method forward (line 500) | def forward(ctx, x, loss):
method backward (line 507) | def backward(ctx, grad_output):
class DeepseekV2MoE (line 513) | class DeepseekV2MoE(nn.Module):
method __init__ (line 518) | def __init__(self, config):
method forward (line 558) | def forward(self, hidden_states):
method moe_infer (line 581) | def moe_infer(self, x, topk_ids, topk_weight):
function repeat_kv (line 657) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
class DeepseekV2Attention (line 671) | class DeepseekV2Attention(nn.Module):
method __init__ (line 674) | def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] ...
method _init_rope (line 741) | def _init_rope(self):
method _shape (line 787) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 794) | def forward(
class DeepseekV2FlashAttention2 (line 893) | class DeepseekV2FlashAttention2(DeepseekV2Attention):
method __init__ (line 900) | def __init__(self, *args, **kwargs):
method forward (line 908) | def forward(
method _flash_attention_forward (line 1038) | def _flash_attention_forward(
method _upad_input (line 1129) | def _upad_input(
class DeepseekV2DecoderLayer (line 1180) | class DeepseekV2DecoderLayer(nn.Module):
method __init__ (line 1181) | def __init__(self, config: DeepseekV2Config, layer_idx: int):
method forward (line 1205) | def forward(
class DeepseekV2PreTrainedModel (line 1291) | class DeepseekV2PreTrainedModel(PreTrainedModel):
method _init_weights (line 1301) | def _init_weights(self, module):
class DeepseekV2Model (line 1387) | class DeepseekV2Model(DeepseekV2PreTrainedModel):
method __init__ (line 1395) | def __init__(self, config: DeepseekV2Config):
method get_input_embeddings (line 1416) | def get_input_embeddings(self):
method set_input_embeddings (line 1419) | def set_input_embeddings(self, value):
method forward (line 1423) | def forward(
method _update_causal_mask (line 1563) | def _update_causal_mask(
class DeepseekV2ForCausalLM (line 1644) | class DeepseekV2ForCausalLM(DeepseekV2PreTrainedModel):
method __init__ (line 1647) | def __init__(self, config):
method get_input_embeddings (line 1656) | def get_input_embeddings(self):
method set_input_embeddings (line 1659) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1662) | def get_output_embeddings(self):
method set_output_embeddings (line 1665) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1668) | def set_decoder(self, decoder):
method get_decoder (line 1671) | def get_decoder(self):
method forward (line 1678) | def forward(
method prepare_inputs_for_generation (line 1773) | def prepare_inputs_for_generation(
method _reorder_cache (line 1851) | def _reorder_cache(past_key_values, beam_idx):
class DeepseekV2ForSequenceClassification (line 1878) | class DeepseekV2ForSequenceClassification(DeepseekV2PreTrainedModel):
method __init__ (line 1879) | def __init__(self, config):
method get_input_embeddings (line 1888) | def get_input_embeddings(self):
method set_input_embeddings (line 1891) | def set_input_embeddings(self, value):
method forward (line 1895) | def forward(
FILE: archive/ktransformers/models/modeling_deepseek_v3.py
function _get_unpad_data (line 87) | def _get_unpad_data(attention_mask):
class DeepseekV3RMSNorm (line 101) | class DeepseekV3RMSNorm(nn.Module):
method __init__ (line 102) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 111) | def forward(self, hidden_states):
class DeepseekV3RotaryEmbedding (line 122) | class DeepseekV3RotaryEmbedding(nn.Module):
method __init__ (line 123) | def __init__(self, dim, max_position_embeddings=2048, base=10000, devi...
method _set_cos_sin_cache (line 142) | def _set_cos_sin_cache(self, seq_len, device, dtype):
method forward (line 154) | def forward(self, x, seq_len=None):
class DeepseekV3LinearScalingRotaryEmbedding (line 166) | class DeepseekV3LinearScalingRotaryEmbedding(DeepseekV3RotaryEmbedding):
method __init__ (line 169) | def __init__(
method _set_cos_sin_cache (line 180) | def _set_cos_sin_cache(self, seq_len, device, dtype):
class DeepseekV3DynamicNTKScalingRotaryEmbedding (line 195) | class DeepseekV3DynamicNTKScalingRotaryEmbedding(DeepseekV3RotaryEmbeddi...
method __init__ (line 198) | def __init__(
method _set_cos_sin_cache (line 209) | def _set_cos_sin_cache(self, seq_len, device, dtype):
function yarn_find_correction_dim (line 234) | def yarn_find_correction_dim(
function yarn_find_correction_range (line 243) | def yarn_find_correction_range(
function yarn_get_mscale (line 255) | def yarn_get_mscale(scale=1, mscale=1):
function yarn_linear_ramp_mask (line 261) | def yarn_linear_ramp_mask(min, max, dim):
class DeepseekV3YarnRotaryEmbedding (line 270) | class DeepseekV3YarnRotaryEmbedding(DeepseekV3RotaryEmbedding):
method __init__ (line 272) | def __init__(
method _set_cos_sin_cache (line 293) | def _set_cos_sin_cache(self, seq_len, device, dtype):
function rotate_half (line 339) | def rotate_half(x):
function apply_rotary_pos_emb (line 347) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
class DeepseekV3MLP (line 382) | class DeepseekV3MLP(nn.Module):
method __init__ (line 383) | def __init__(self, config, hidden_size=None, intermediate_size=None):
method forward (line 396) | def forward(self, x):
class MoEGate (line 401) | class MoEGate(nn.Module):
method __init__ (line 402) | def __init__(self, config):
method reset_parameters (line 425) | def reset_parameters(self) -> None:
method forward (line 430) | def forward(self, hidden_states):
class DeepseekV3MoE (line 483) | class DeepseekV3MoE(nn.Module):
method __init__ (line 488) | def __init__(self, config):
method forward (line 530) | def forward(self, hidden_states):
method moe_infer (line 543) | def moe_infer(self, x, topk_ids, topk_weight):
function repeat_kv (line 620) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
class DeepseekV3Attention (line 635) | class DeepseekV3Attention(nn.Module):
method __init__ (line 638) | def __init__(self, config: DeepseekV3Config, layer_idx: Optional[int] ...
method _init_rope (line 705) | def _init_rope(self):
method _shape (line 751) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 758) | def forward(
class DeepseekV3FlashAttention2 (line 869) | class DeepseekV3FlashAttention2(DeepseekV3Attention):
method __init__ (line 876) | def __init__(self, *args, **kwargs):
method forward (line 884) | def forward(
method _flash_attention_forward (line 1020) | def _flash_attention_forward(
method _upad_input (line 1100) | def _upad_input(
class DeepseekV3DecoderLayer (line 1152) | class DeepseekV3DecoderLayer(nn.Module):
method __init__ (line 1153) | def __init__(self, config: DeepseekV3Config, layer_idx: int):
method forward (line 1177) | def forward(
class DeepseekV3PreTrainedModel (line 1265) | class DeepseekV3PreTrainedModel(PreTrainedModel):
method _init_weights (line 1274) | def _init_weights(self, module):
class DeepseekV3Model (line 1360) | class DeepseekV3Model(DeepseekV3PreTrainedModel):
method __init__ (line 1368) | def __init__(self, config: DeepseekV3Config):
method get_input_embeddings (line 1389) | def get_input_embeddings(self):
method set_input_embeddings (line 1392) | def set_input_embeddings(self, value):
method forward (line 1396) | def forward(
method _update_causal_mask (line 1530) | def _update_causal_mask(
class DeepseekV3ForCausalLM (line 1610) | class DeepseekV3ForCausalLM(DeepseekV3PreTrainedModel, GenerationMixin):
method __init__ (line 1613) | def __init__(self, config):
method get_input_embeddings (line 1622) | def get_input_embeddings(self):
method set_input_embeddings (line 1625) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1628) | def get_output_embeddings(self):
method set_output_embeddings (line 1631) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1634) | def set_decoder(self, decoder):
method get_decoder (line 1637) | def get_decoder(self):
method forward (line 1644) | def forward(
method prepare_inputs_for_generation (line 1749) | def prepare_inputs_for_generation(
method _reorder_cache (line 1814) | def _reorder_cache(past_key_values, beam_idx):
class DeepseekV3ForSequenceClassification (line 1841) | class DeepseekV3ForSequenceClassification(DeepseekV3PreTrainedModel):
method __init__ (line 1842) | def __init__(self, config):
method get_input_embeddings (line 1851) | def get_input_embeddings(self):
method set_input_embeddings (line 1854) | def set_input_embeddings(self, value):
method forward (line 1858) | def forward(
FILE: archive/ktransformers/models/modeling_glm4_moe.py
function repeat_kv (line 45) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
function eager_attention_forward (line 57) | def eager_attention_forward(
function rotate_half (line 83) | def rotate_half(x):
function apply_rotary_pos_emb (line 90) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
class Glm4MoeAttention (line 128) | class Glm4MoeAttention(nn.Module):
method __init__ (line 131) | def __init__(self, config: Glm4MoeConfig, layer_idx: Optional[int] = N...
method forward (line 156) | def forward(
class Glm4MoeMLP (line 208) | class Glm4MoeMLP(nn.Module):
method __init__ (line 209) | def __init__(self, config, hidden_size=None, intermediate_size=None):
method forward (line 220) | def forward(self, x):
class Glm4MoeTopkRouter (line 225) | class Glm4MoeTopkRouter(nn.Module):
method __init__ (line 226) | def __init__(self, config: Glm4MoeConfig):
method get_topk_indices (line 240) | def get_topk_indices(self, scores):
method forward (line 259) | def forward(self, hidden_states):
class Glm4MoeRMSNorm (line 273) | class Glm4MoeRMSNorm(nn.Module):
method __init__ (line 274) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 283) | def forward(self, hidden_states):
method extra_repr (line 290) | def extra_repr(self):
class Glm4MoeMoE (line 294) | class Glm4MoeMoE(nn.Module):
method __init__ (line 299) | def __init__(self, config):
method moe (line 313) | def moe(self, hidden_states: torch.Tensor, topk_indices: torch.Tensor,...
method forward (line 339) | def forward(self, hidden_states):
class Glm4MoeDecoderLayer (line 349) | class Glm4MoeDecoderLayer(GradientCheckpointingLayer):
method __init__ (line 350) | def __init__(self, config: Glm4MoeConfig, layer_idx: int):
method forward (line 364) | def forward(
class Glm4MoePreTrainedModel (line 398) | class Glm4MoePreTrainedModel(PreTrainedModel):
method _init_weights (line 414) | def _init_weights(self, module):
class Glm4MoeRotaryEmbedding (line 430) | class Glm4MoeRotaryEmbedding(nn.Module):
method __init__ (line 431) | def __init__(self, config: Glm4MoeConfig, device=None):
method forward (line 450) | def forward(self, x, position_ids):
class Glm4MoeModel (line 465) | class Glm4MoeModel(Glm4MoePreTrainedModel):
method __init__ (line 468) | def __init__(self, config: Glm4MoeConfig):
method get_input_embeddings (line 484) | def get_input_embeddings(self):
method set_input_embeddings (line 487) | def set_input_embeddings(self, value):
method forward (line 492) | def forward(
class Glm4MoeForCausalLM (line 551) | class Glm4MoeForCausalLM(Glm4MoePreTrainedModel, GenerationMixin):
method __init__ (line 556) | def __init__(self, config):
method get_input_embeddings (line 565) | def get_input_embeddings(self):
method set_input_embeddings (line 568) | def set_input_embeddings(self, value):
method get_output_embeddings (line 571) | def get_output_embeddings(self):
method set_output_embeddings (line 574) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 577) | def set_decoder(self, decoder):
method get_decoder (line 580) | def get_decoder(self):
method forward (line 585) | def forward(
FILE: archive/ktransformers/models/modeling_llama.py
class LlamaRMSNorm (line 58) | class LlamaRMSNorm(nn.Module):
method __init__ (line 59) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 67) | def forward(self, hidden_states):
class LlamaRotaryEmbedding (line 78) | class LlamaRotaryEmbedding(nn.Module):
method __init__ (line 79) | def __init__(
method _dynamic_frequency_update (line 134) | def _dynamic_frequency_update(self, position_ids, device):
method forward (line 159) | def forward(self, x, position_ids):
class LlamaLinearScalingRotaryEmbedding (line 190) | class LlamaLinearScalingRotaryEmbedding(LlamaRotaryEmbedding):
method __init__ (line 193) | def __init__(self, *args, **kwargs):
class LlamaDynamicNTKScalingRotaryEmbedding (line 202) | class LlamaDynamicNTKScalingRotaryEmbedding(LlamaRotaryEmbedding):
method __init__ (line 205) | def __init__(self, *args, **kwargs):
function rotate_half (line 215) | def rotate_half(x):
function apply_rotary_pos_emb (line 222) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
class LlamaMLP (line 249) | class LlamaMLP(nn.Module):
method __init__ (line 250) | def __init__(self, config):
method forward (line 266) | def forward(self, x):
function repeat_kv (line 300) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
class LlamaAttention (line 314) | class LlamaAttention(nn.Module):
method __init__ (line 317) | def __init__(self, config: LlamaConfig, layer_idx: Optional[int] = None):
method forward (line 364) | def forward(
class LlamaFlashAttention2 (line 496) | class LlamaFlashAttention2(LlamaAttention):
method __init__ (line 503) | def __init__(self, *args, **kwargs):
method forward (line 511) | def forward(
class LlamaSdpaAttention (line 627) | class LlamaSdpaAttention(LlamaAttention):
method forward (line 635) | def forward(
class LlamaDecoderLayer (line 745) | class LlamaDecoderLayer(nn.Module):
method __init__ (line 746) | def __init__(self, config: LlamaConfig, layer_idx: int):
method forward (line 760) | def forward(
class LlamaPreTrainedModel (line 854) | class LlamaPreTrainedModel(PreTrainedModel):
method _init_weights (line 866) | def _init_weights(self, module):
class LlamaModel (line 956) | class LlamaModel(LlamaPreTrainedModel):
method __init__ (line 964) | def __init__(self, config: LlamaConfig):
method get_input_embeddings (line 985) | def get_input_embeddings(self):
method set_input_embeddings (line 988) | def set_input_embeddings(self, value):
method forward (line 992) | def forward(
method _update_causal_mask (line 1133) | def _update_causal_mask(
class LlamaForCausalLM (line 1236) | class LlamaForCausalLM(LlamaPreTrainedModel):
method __init__ (line 1239) | def __init__(self, config):
method get_input_embeddings (line 1248) | def get_input_embeddings(self):
method set_input_embeddings (line 1251) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1254) | def get_output_embeddings(self):
method set_output_embeddings (line 1257) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1260) | def set_decoder(self, decoder):
method get_decoder (line 1263) | def get_decoder(self):
method forward (line 1270) | def forward(
method prepare_inputs_for_generation (line 1376) | def prepare_inputs_for_generation(
class LlamaForSequenceClassification (line 1440) | class LlamaForSequenceClassification(LlamaPreTrainedModel):
method __init__ (line 1441) | def __init__(self, config):
method get_input_embeddings (line 1450) | def get_input_embeddings(self):
method set_input_embeddings (line 1453) | def set_input_embeddings(self, value):
method forward (line 1457) | def forward(
class LlamaForQuestionAnswering (line 1567) | class LlamaForQuestionAnswering(LlamaPreTrainedModel):
method __init__ (line 1571) | def __init__(self, config):
method get_input_embeddings (line 1579) | def get_input_embeddings(self):
method set_input_embeddings (line 1582) | def set_input_embeddings(self, value):
method forward (line 1586) | def forward(
class LlamaForTokenClassification (line 1668) | class LlamaForTokenClassification(LlamaPreTrainedModel):
method __init__ (line 1669) | def __init__(self, config):
method get_input_embeddings (line 1685) | def get_input_embeddings(self):
method set_input_embeddings (line 1688) | def set_input_embeddings(self, value):
method forward (line 1692) | def forward(
FILE: archive/ktransformers/models/modeling_mixtral.py
function load_balancing_loss_func (line 89) | def load_balancing_loss_func(
function _get_unpad_data (line 166) | def _get_unpad_data(attention_mask):
class MixtralRMSNorm (line 179) | class MixtralRMSNorm(nn.Module):
method __init__ (line 180) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 188) | def forward(self, hidden_states):
method extra_repr (line 195) | def extra_repr(self):
class MixtralRotaryEmbedding (line 201) | class MixtralRotaryEmbedding(nn.Module):
method __init__ (line 202) | def __init__(self, dim, max_position_embeddings=2048, base=10000, devi...
method forward (line 215) | def forward(self, x, position_ids):
function rotate_half (line 231) | def rotate_half(x):
function apply_rotary_pos_emb (line 240) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
function repeat_kv (line 270) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
class MixtralAttention (line 284) | class MixtralAttention(nn.Module):
method __init__ (line 290) | def __init__(self, config: MixtralConfig, layer_idx: Optional[int] = N...
method _shape (line 327) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 330) | def forward(
class MixtralFlashAttention2 (line 406) | class MixtralFlashAttention2(MixtralAttention):
method forward (line 413) | def forward(
method _flash_attention_forward (line 549) | def _flash_attention_forward(
method _upad_input (line 660) | def _upad_input(self, query_layer, key_layer, value_layer, attention_m...
class MixtralSdpaAttention (line 706) | class MixtralSdpaAttention(MixtralAttention):
method forward (line 714) | def forward(
class MixtralBlockSparseTop2MLP (line 803) | class MixtralBlockSparseTop2MLP(nn.Module):
method __init__ (line 804) | def __init__(self, config: MixtralConfig):
method forward (line 815) | def forward(self, hidden_states):
class MixtralSparseMoeBlock (line 821) | class MixtralSparseMoeBlock(nn.Module):
method __init__ (line 833) | def __init__(self, config):
method forward (line 848) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class MixtralDecoderLayer (line 889) | class MixtralDecoderLayer(nn.Module):
method __init__ (line 890) | def __init__(self, config: MixtralConfig, layer_idx: int):
method forward (line 900) | def forward(
class MixtralPreTrainedModel (line 992) | class MixtralPreTrainedModel(PreTrainedModel):
method _init_weights (line 1002) | def _init_weights(self, module):
class MixtralModel (line 1091) | class MixtralModel(MixtralPreTrainedModel):
method __init__ (line 1099) | def __init__(self, config: MixtralConfig):
method get_input_embeddings (line 1115) | def get_input_embeddings(self):
method set_input_embeddings (line 1118) | def set_input_embeddings(self, value):
method forward (line 1123) | def forward(
method _update_causal_mask (line 1256) | def _update_causal_mask(
class MixtralForCausalLM (line 1337) | class MixtralForCausalLM(MixtralPreTrainedModel):
method __init__ (line 1340) | def __init__(self, config):
method get_input_embeddings (line 1351) | def get_input_embeddings(self):
method set_input_embeddings (line 1354) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1357) | def get_output_embeddings(self):
method set_output_embeddings (line 1360) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1363) | def set_decoder(self, decoder):
method get_decoder (line 1366) | def get_decoder(self):
method forward (line 1372) | def forward(
method prepare_inputs_for_generation (line 1482) | def prepare_inputs_for_generation(
class MixtralForSequenceClassification (line 1545) | class MixtralForSequenceClassification(MixtralPreTrainedModel):
method __init__ (line 1546) | def __init__(self, config):
method get_input_embeddings (line 1555) | def get_input_embeddings(self):
method set_input_embeddings (line 1558) | def set_input_embeddings(self, value):
method forward (line 1562) | def forward(
class MixtralForTokenClassification (line 1661) | class MixtralForTokenClassification(MixtralPreTrainedModel):
method __init__ (line 1662) | def __init__(self, config):
method get_input_embeddings (line 1678) | def get_input_embeddings(self):
method set_input_embeddings (line 1681) | def set_input_embeddings(self, value):
method forward (line 1685) | def forward(
FILE: archive/ktransformers/models/modeling_qwen2_moe.py
function load_balancing_loss_func (line 76) | def load_balancing_loss_func(
function _get_unpad_data (line 153) | def _get_unpad_data(attention_mask):
class Qwen2MoeRMSNorm (line 166) | class Qwen2MoeRMSNorm(nn.Module):
method __init__ (line 167) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 175) | def forward(self, hidden_states):
class Qwen2MoeRotaryEmbedding (line 183) | class Qwen2MoeRotaryEmbedding(nn.Module):
method __init__ (line 184) | def __init__(self, dim, max_position_embeddings=2048, base=10000, devi...
method forward (line 196) | def forward(self, x, position_ids):
function rotate_half (line 213) | def rotate_half(x):
function apply_rotary_pos_emb (line 221) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
class Qwen2MoeMLP (line 249) | class Qwen2MoeMLP(nn.Module):
method __init__ (line 250) | def __init__(self, config, intermediate_size=None):
method forward (line 260) | def forward(self, x):
function repeat_kv (line 265) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
class Qwen2MoeAttention (line 278) | class Qwen2MoeAttention(nn.Module):
method __init__ (line 284) | def __init__(self, config: Qwen2MoeConfig, layer_idx: Optional[int] = ...
method forward (line 321) | def forward(
class Qwen2MoeFlashAttention2 (line 396) | class Qwen2MoeFlashAttention2(Qwen2MoeAttention):
method __init__ (line 406) | def __init__(self, *args, **kwargs):
method forward (line 414) | def forward(
method _flash_attention_forward (line 546) | def _flash_attention_forward(
method _upad_input (line 663) | def _upad_input(self, query_layer, key_layer, value_layer, attention_m...
class Qwen2MoeSdpaAttention (line 707) | class Qwen2MoeSdpaAttention(Qwen2MoeAttention):
method forward (line 715) | def forward(
class Qwen2MoeSparseMoeBlock (line 803) | class Qwen2MoeSparseMoeBlock(nn.Module):
method __init__ (line 804) | def __init__(self, config):
method forward (line 819) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class Qwen2MoeDecoderLayer (line 865) | class Qwen2MoeDecoderLayer(nn.Module):
method __init__ (line 866) | def __init__(self, config: Qwen2MoeConfig, layer_idx: int):
method forward (line 882) | def forward(
class Qwen2MoePreTrainedModel (line 979) | class Qwen2MoePreTrainedModel(PreTrainedModel):
method _init_weights (line 990) | def _init_weights(self, module):
class Qwen2MoeModel (line 1083) | class Qwen2MoeModel(Qwen2MoePreTrainedModel):
method __init__ (line 1091) | def __init__(self, config: Qwen2MoeConfig):
method get_input_embeddings (line 1107) | def get_input_embeddings(self):
method set_input_embeddings (line 1110) | def set_input_embeddings(self, value):
method forward (line 1114) | def forward(
method _update_causal_mask (line 1247) | def _update_causal_mask(
class Qwen2MoeForCausalLM (line 1328) | class Qwen2MoeForCausalLM(Qwen2MoePreTrainedModel):
method __init__ (line 1331) | def __init__(self, config):
method get_input_embeddings (line 1343) | def get_input_embeddings(self):
method set_input_embeddings (line 1346) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1349) | def get_output_embeddings(self):
method set_output_embeddings (line 1352) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1355) | def set_decoder(self, decoder):
method get_decoder (line 1358) | def get_decoder(self):
method forward (line 1363) | def forward(
method prepare_inputs_for_generation (line 1472) | def prepare_inputs_for_generation(
method _reorder_cache (line 1550) | def _reorder_cache(past_key_values, beam_idx):
class Qwen2MoeForSequenceClassification (line 1575) | class Qwen2MoeForSequenceClassification(Qwen2MoePreTrainedModel):
method __init__ (line 1576) | def __init__(self, config):
method get_input_embeddings (line 1585) | def get_input_embeddings(self):
method set_input_embeddings (line 1588) | def set_input_embeddings(self, value):
method forward (line 1592) | def forward(
class Qwen2MoeForTokenClassification (line 1691) | class Qwen2MoeForTokenClassification(Qwen2MoePreTrainedModel):
method __init__ (line 1692) | def __init__(self, config):
method get_input_embeddings (line 1708) | def get_input_embeddings(self):
method set_input_embeddings (line 1711) | def set_input_embeddings(self, value):
method forward (line 1715) | def forward(
FILE: archive/ktransformers/models/modeling_qwen3_moe.py
function rotate_half (line 65) | def rotate_half(x):
function apply_rotary_pos_emb (line 72) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
function repeat_kv (line 99) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
function eager_attention_forward (line 111) | def eager_attention_forward(
class Qwen3MoeAttention (line 137) | class Qwen3MoeAttention(nn.Module):
method __init__ (line 140) | def __init__(self, config: Qwen3MoeConfig, layer_idx: int):
method forward (line 183) | def forward(
class Qwen3MoeMLP (line 234) | class Qwen3MoeMLP(nn.Module):
method __init__ (line 235) | def __init__(self, config, intermediate_size=None):
method forward (line 245) | def forward(self, x):
class Qwen3MoeSparseMoeBlock (line 250) | class Qwen3MoeSparseMoeBlock(nn.Module):
method __init__ (line 251) | def __init__(self, config):
method forward (line 263) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class Qwen3MoeRMSNorm (line 303) | class Qwen3MoeRMSNorm(nn.Module):
method __init__ (line 304) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 313) | def forward(self, hidden_states):
method extra_repr (line 320) | def extra_repr(self):
class Qwen3MoeDecoderLayer (line 324) | class Qwen3MoeDecoderLayer(nn.Module):
method __init__ (line 325) | def __init__(self, config: Qwen3MoeConfig, layer_idx: int):
method forward (line 344) | def forward(
function _compute_default_rope_parameters (line 421) | def _compute_default_rope_parameters(
class Qwen3MoeRotaryEmbedding (line 461) | class Qwen3MoeRotaryEmbedding(nn.Module):
method __init__ (line 462) | def __init__(self, config: Qwen3MoeConfig, device=None):
method _dynamic_frequency_update (line 485) | def _dynamic_frequency_update(self, position_ids, device):
method forward (line 505) | def forward(self, x, position_ids):
class Qwen3MoePreTrainedModel (line 550) | class Qwen3MoePreTrainedModel(PreTrainedModel):
method _init_weights (line 564) | def _init_weights(self, module):
class Qwen3MoeModel (line 647) | class Qwen3MoeModel(Qwen3MoePreTrainedModel):
method __init__ (line 655) | def __init__(self, config: Qwen3MoeConfig):
method get_input_embeddings (line 671) | def get_input_embeddings(self):
method set_input_embeddings (line 674) | def set_input_embeddings(self, value):
method forward (line 678) | def forward(
method _update_causal_mask (line 796) | def _update_causal_mask(
method _prepare_4d_causal_attention_mask_with_cache_position (line 880) | def _prepare_4d_causal_attention_mask_with_cache_position(
class KwargsForCausalLM (line 950) | class KwargsForCausalLM(): ...
function load_balancing_loss_func (line 953) | def load_balancing_loss_func(
class Qwen3MoeForCausalLM (line 1035) | class Qwen3MoeForCausalLM(Qwen3MoePreTrainedModel, GenerationMixin):
method __init__ (line 1040) | def __init__(self, config):
method get_input_embeddings (line 1052) | def get_input_embeddings(self):
method set_input_embeddings (line 1055) | def set_input_embeddings(self, value):
method get_output_embeddings (line 1058) | def get_output_embeddings(self):
method set_output_embeddings (line 1061) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 1064) | def set_decoder(self, decoder):
method get_decoder (line 1067) | def get_decoder(self):
method forward (line 1073) | def forward(
class Qwen3MoeForSequenceClassification (line 1199) | class Qwen3MoeForSequenceClassification(Qwen3MoePreTrainedModel):
method __init__ (line 1200) | def __init__(self, config):
method get_input_embeddings (line 1209) | def get_input_embeddings(self):
method set_input_embeddings (line 1212) | def set_input_embeddings(self, value):
method forward (line 1216) | def forward(
class Qwen3MoeForTokenClassification (line 1298) | class Qwen3MoeForTokenClassification(Qwen3MoePreTrainedModel):
method __init__ (line 1299) | def __init__(self, config):
method get_input_embeddings (line 1315) | def get_input_embeddings(self):
method set_input_embeddings (line 1318) | def set_input_embeddings(self, value):
method forward (line 1327) | def forward(
class Qwen3MoeForQuestionAnswering (line 1386) | class Qwen3MoeForQuestionAnswering(Qwen3MoePreTrainedModel):
method __init__ (line 1389) | def __init__(self, config):
method get_input_embeddings (line 1397) | def get_input_embeddings(self):
method set_input_embeddings (line 1400) | def set_input_embeddings(self, value):
method forward (line 1404) | def forward(
FILE: archive/ktransformers/models/modeling_qwen3_next.py
class Qwen3NextRMSNormGated (line 82) | class Qwen3NextRMSNormGated(nn.Module):
method __init__ (line 83) | def __init__(self, hidden_size, eps=1e-6, **kwargs):
method forward (line 88) | def forward(self, hidden_states, gate=None):
class Qwen3NextDynamicCache (line 100) | class Qwen3NextDynamicCache:
method __init__ (line 116) | def __init__(self, config: Qwen3NextConfig):
method __len__ (line 130) | def __len__(self):
method __getitem__ (line 133) | def __getitem__(self, layer_idx: int) -> tuple[torch.Tensor, torch.Ten...
method update (line 136) | def update(
method reorder_cache (line 152) | def reorder_cache(self, beam_idx: torch.LongTensor):
method get_seq_length (line 167) | def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
method get_mask_sizes (line 175) | def get_mask_sizes(self, cache_position: torch.Tensor, layer_idx: int)...
method has_previous_state (line 188) | def has_previous_state(self):
class Qwen3NextRotaryEmbedding (line 193) | class Qwen3NextRotaryEmbedding(nn.Module):
method __init__ (line 196) | def __init__(self, config: Qwen3NextConfig, device=None):
method forward (line 215) | def forward(self, x, position_ids):
class Qwen3NextRMSNorm (line 229) | class Qwen3NextRMSNorm(nn.Module):
method __init__ (line 230) | def __init__(self, dim: int, eps: float = 1e-6):
method _norm (line 237) | def _norm(self, x):
method forward (line 240) | def forward(self, x):
method extra_repr (line 247) | def extra_repr(self):
function rotate_half (line 251) | def rotate_half(x):
function apply_rotary_pos_emb (line 259) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
function repeat_kv (line 299) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
function eager_attention_forward (line 311) | def eager_attention_forward(
class Qwen3NextAttention (line 337) | class Qwen3NextAttention(nn.Module):
method __init__ (line 340) | def __init__(self, config: Qwen3NextConfig, layer_idx: int):
method forward (line 369) | def forward(
function apply_mask_to_padding_states (line 420) | def apply_mask_to_padding_states(hidden_states, attention_mask):
function torch_causal_conv1d_update (line 436) | def torch_causal_conv1d_update(
function torch_chunk_gated_delta_rule (line 454) | def torch_chunk_gated_delta_rule(
function torch_recurrent_gated_delta_rule (line 534) | def torch_recurrent_gated_delta_rule(
class Qwen3NextGatedDeltaNet (line 576) | class Qwen3NextGatedDeltaNet(nn.Module):
method __init__ (line 577) | def __init__(self, config: Qwen3NextConfig, layer_idx: int):
method fix_query_key_value_ordering (line 645) | def fix_query_key_value_ordering(self, mixed_qkvz, mixed_ba):
method forward (line 674) | def forward(
class Qwen3NextMLP (line 792) | class Qwen3NextMLP(nn.Module):
method __init__ (line 793) | def __init__(self, config, intermediate_size=None):
method forward (line 803) | def forward(self, x):
class Qwen3NextSparseMoeBlock (line 808) | class Qwen3NextSparseMoeBlock(nn.Module):
method __init__ (line 809) | def __init__(self, config):
method forward (line 824) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
class Qwen3NextDecoderLayer (line 871) | class Qwen3NextDecoderLayer(GradientCheckpointingLayer):
method __init__ (line 872) | def __init__(self, config: Qwen3NextConfig, layer_idx: int):
method forward (line 894) | def forward(
class Qwen3NextPreTrainedModel (line 966) | class Qwen3NextPreTrainedModel(PreTrainedModel):
method _init_weights (line 982) | def _init_weights(self, module):
class Qwen3NextModel (line 989) | class Qwen3NextModel(Qwen3NextPreTrainedModel):
method __init__ (line 990) | def __init__(self, config: Qwen3NextConfig):
method forward (line 1004) | def forward(
method _update_linear_attn_mask (line 1068) | def _update_linear_attn_mask(self, attention_mask, cache_position):
function load_balancing_loss_func (line 1081) | def load_balancing_loss_func(
class Qwen3NextForCausalLM (line 1164) | class Qwen3NextForCausalLM(Qwen3NextPreTrainedModel, GenerationMixin):
method __init__ (line 1169) | def __init__(self, config):
method forward (line 1183) | def forward(
class Qwen3NextForSequenceClassification (line 1268) | class Qwen3NextForSequenceClassification(GenericForSequenceClassificatio...
class Qwen3NextForTokenClassification (line 1272) | class Qwen3NextForTokenClassification(GenericForTokenClassification, Qwe...
class Qwen3NextForQuestionAnswering (line 1276) | class Qwen3NextForQuestionAnswering(GenericForQuestionAnswering, Qwen3Ne...
FILE: archive/ktransformers/models/modeling_smallthinker.py
class SmallthinkerHierarchicalMLP (line 33) | class SmallthinkerHierarchicalMLP(nn.Module):
method __init__ (line 34) | def __init__(self, config: SmallthinkerConfig):
method forward (line 49) | def forward(self, secondary_gate_input: torch.Tensor, hidden_states: t...
class SmallthinkerMoeBlock (line 70) | class SmallthinkerMoeBlock(nn.Module):
method __init__ (line 71) | def __init__(self, config: SmallthinkerConfig):
method forward (line 81) | def forward(self, router_input: torch.Tensor, hidden_states: torch.Ten...
class SmallthinkerDenseMlpBlock (line 130) | class SmallthinkerDenseMlpBlock(nn.Module):
method __init__ (line 131) | def __init__(self, config: SmallthinkerConfig):
method forward (line 140) | def forward(self, router_input: torch.Tensor, hidden_states: torch.Ten...
class SmallthinkerRMSNorm (line 146) | class SmallthinkerRMSNorm(nn.Module):
method __init__ (line 147) | def __init__(self, hidden_size, eps=1e-6):
method forward (line 156) | def forward(self, hidden_states):
method extra_repr (line 163) | def extra_repr(self):
function rotate_half (line 167) | def rotate_half(x):
function apply_rotary_pos_emb (line 174) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_di...
function repeat_kv (line 201) | def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
function eager_attention_forward (line 213) | def eager_attention_forward(
class SmallthinkerAttention (line 239) | class SmallthinkerAttention(nn.Module):
method __init__ (line 240) | def __init__(self, config: SmallthinkerConfig, layer_idx: int):
method forward (line 257) | def forward(
class SmallthinkerDecoderLayer (line 317) | class SmallthinkerDecoderLayer(nn.Module):
method __init__ (line 318) | def __init__(self, config: SmallthinkerConfig, layer_idx: int):
method forward (line 327) | def forward(
class SmallthinkerRotaryEmbedding (line 396) | class SmallthinkerRotaryEmbedding(nn.Module):
method __init__ (line 397) | def __init__(self, config: SmallthinkerConfig, device=None):
method forward (line 416) | def forward(self, x, position_ids):
class SmallthinkerPreTrainedModel (line 430) | class SmallthinkerPreTrainedModel(PreTrainedModel):
method _init_weights (line 444) | def _init_weights(self, module):
class SmallthinkerModel (line 459) | class SmallthinkerModel(SmallthinkerPreTrainedModel):
method __init__ (line 460) | def __init__(self, config: SmallthinkerConfig):
method get_input_embeddings (line 477) | def get_input_embeddings(self):
method set_input_embeddings (line 480) | def set_input_embeddings(self, value):
method forward (line 485) | def forward(
method _update_causal_mask (line 601) | def _update_causal_mask(
method _prepare_4d_causal_attention_mask_with_cache_position (line 688) | def _prepare_4d_causal_attention_mask_with_cache_position(
class KwargsForCausalLM (line 756) | class KwargsForCausalLM(FlashAttentionKwargs): ...
function load_balancing_loss_func (line 759) | def load_balancing_loss_func(
class SmallThinkerForCausalLM (line 842) | class SmallThinkerForCausalLM(SmallthinkerPreTrainedModel, GenerationMix...
method __init__ (line 844) | def __init__(self, config):
method get_input_embeddings (line 855) | def get_input_embeddings(self):
method set_input_embeddings (line 858) | def set_input_embeddings(self, value):
method get_output_embeddings (line 861) | def get_output_embeddings(self):
method set_output_embeddings (line 864) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 867) | def set_decoder(self, decoder):
method get_decoder (line 870) | def get_decoder(self):
method forward (line 875) | def forward(
FILE: archive/ktransformers/operators/RoPE.py
class RotaryEmbedding (line 34) | class RotaryEmbedding(BaseInjectedModule, DeepseekV2RotaryEmbedding):
method __init__ (line 35) | def __init__(
method load (line 55) | def load(self):
class RotaryEmbeddingV3 (line 64) | class RotaryEmbeddingV3(BaseInjectedModule):
method __init__ (line 65) | def __init__(
method forward (line 83) | def forward(self, x, position_ids):
method load (line 98) | def load(self):
method _init (line 105) | def _init(self, dim, max_position_embeddings, base, device, scaling_fa...
class RotaryEmbeddingV2 (line 115) | class RotaryEmbeddingV2(BaseInjectedModule, LlamaRotaryEmbedding):
method __init__ (line 116) | def __init__(
method load (line 141) | def load(self):
class YarnRotaryEmbedding (line 152) | class YarnRotaryEmbedding(BaseInjectedModule, DeepseekV2YarnRotaryEmbedd...
method __init__ (line 153) | def __init__(
method load (line 182) | def load(self):
class YarnRotaryEmbeddingV3 (line 222) | class YarnRotaryEmbeddingV3(BaseInjectedModule):
method __init__ (line 223) | def __init__(
method load (line 240) | def load(self):
method forward (line 262) | def forward(self, x, position_ids):
method _init (line 277) | def _init(
class DynamicNTKScalingRotaryEmbedding (line 328) | class DynamicNTKScalingRotaryEmbedding(
method __init__ (line 331) | def __init__(
method load (line 354) | def load(self):
class RotaryEmbeddingV4 (line 367) | class RotaryEmbeddingV4(BaseInjectedModule):
method __init__ (line 368) | def __init__(
method forward (line 386) | def forward(self, x, position_ids):
method load (line 401) | def load(self):
method _init (line 408) | def _init(self, dim, max_position_embeddings, base, device, scaling_fa...
class KQwen3MoeRotaryEmbedding (line 418) | class KQwen3MoeRotaryEmbedding(BaseInjectedModule, DeepseekV2RotaryEmbed...
method __init__ (line 419) | def __init__(
method load (line 439) | def load(self):
class KSmallthinkerRotaryEmbedding (line 445) | class KSmallthinkerRotaryEmbedding(BaseInjectedModule, SmallthinkerRotar...
method __init__ (line 446) | def __init__(
method load (line 466) | def load(self):
method forward (line 473) | def forward(self, x, position_ids):
class KGlm4MoeRotaryEmbedding (line 486) | class KGlm4MoeRotaryEmbedding(BaseInjectedModule, Glm4MoeRotaryEmbedding):
method __init__ (line 487) | def __init__(
method load (line 507) | def load(self):
method forward (line 514) | def forward(self, x, position_ids):
FILE: archive/ktransformers/operators/ascend/ascend_attention.py
function apply_rotary_pos_emb_fusion (line 39) | def apply_rotary_pos_emb_fusion(q, k, cos, sin, unsqueeze_dim=1):
class MatMulOps (line 51) | class MatMulOps(object):
method execute (line 52) | def execute(self, x_input):
class DynamicQuantOps (line 64) | class DynamicQuantOps(object):
method execute (line 69) | def execute(self, x_input):
class KDeepseekV2AttentionW8A8A2 (line 74) | class KDeepseekV2AttentionW8A8A2(BaseInjectedModule, DeepseekV2Attention):
class PageKVWrapper (line 78) | class PageKVWrapper(object):
method __init__ (line 83) | def __init__(self, past_key_value: StaticCache):
method update (line 91) | def update(self, compressed_kv, k_pe, layer_idx, cache_kwargs):
method get_usable_length (line 94) | def get_usable_length(self, kv_seq_len, layer_idx):
method get_seq_length (line 97) | def get_seq_length(self, layer_idx):
method get_block_table (line 100) | def get_block_table(self, layer_idx):
method init_page_kv_wrapper (line 103) | def init_page_kv_wrapper(self, past_key_value: StaticCache):
method __init__ (line 106) | def __init__(self,
method forward_chunck (line 140) | def forward_chunck(
method forward_paged (line 329) | def forward_paged(
method forward_windows (line 416) | def forward_windows(
method forward (line 486) | def forward(
class KDeepseekV2AttentionW8A8A2Serve (line 512) | class KDeepseekV2AttentionW8A8A2Serve(BaseInjectedModule, DeepseekV2Atte...
method __init__ (line 516) | def __init__(self,
method print_callback (line 541) | def print_callback(self, param):
method forward (line 554) | def forward(
method forward_paged (line 757) | def forward_paged(
function rotate_half (line 851) | def rotate_half(x):
function apply_rotary_pos_emb (line 856) | def apply_rotary_pos_emb(q, k, cos, sin, unsqueeze_dim=1):
class KQwen3MoeAttentionW8A8A2Serve (line 864) | class KQwen3MoeAttentionW8A8A2Serve(BaseInjectedModule, Qwen3MoeAttention):
method __init__ (line 868) | def __init__(self,
method _linear_w8a8a2 (line 903) | def _linear_w8a8a2(self, x: torch.Tensor, proj: nn.Module, name: str) ...
method forward (line 923) | def forward(self,
method _forward_prefill (line 997) | def _forward_prefill(
method forward_paged (line 1155) | def forward_paged(
FILE: archive/ktransformers/operators/ascend/ascend_experts.py
class KExpertsCPUW8A8 (line 38) | class KExpertsCPUW8A8(KExpertsCPU):
method forward (line 40) | def forward(self, input_tensor, expert_ids, weights, bsz_tensor=None, ...
class KTransformersExpertsW8A8 (line 70) | class KTransformersExpertsW8A8(KTransformersExperts):
method forward (line 71) | def forward(self, input_tensor, expert_ids, weights, cuda_graph_idx=No...
class KDeepseekV3MoEW8A8 (line 82) | class KDeepseekV3MoEW8A8(KDeepseekV3MoE):
method forward (line 83) | def forward(self, hidden_states, stream=None, para_stream=None):
method cpu_moe_kexperts (line 176) | def cpu_moe_kexperts(self, moe_kexperts_param) -> torch.Tensor:
method moe_kexperts (line 181) | def moe_kexperts(self, x: torch.Tensor, topk_ids: torch.Tensor, topk_w...
class KQwen3MoeSparseMoeBlockW8A8 (line 185) | class KQwen3MoeSparseMoeBlockW8A8(BaseInjectedModule):
method __init__ (line 186) | def __init__(
method set_inference_mode (line 226) | def set_inference_mode(self, mode: InferenceState):
method cpu_moe_kexperts (line 231) | def cpu_moe_kexperts(self, moe_kexperts_param):
method moe_kexperts (line 242) | def moe_kexperts(
method forward (line 260) | def forward(
FILE: archive/ktransformers/operators/ascend/ascend_gate.py
class KDeepseekV3GateA2 (line 8) | class KDeepseekV3GateA2(KMoEGate):
method load (line 9) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method forward (line 25) | def forward(self, hidden_states) -> torch.Tensor:
FILE: archive/ktransformers/operators/ascend/ascend_layernorm.py
class KDeepseekV3RMSNormW8A8 (line 32) | class KDeepseekV3RMSNormW8A8(BaseInjectedModule):
method __init__ (line 33) | def __init__(self,
method forward (line 46) | def forward(self, hidden_states):
method load (line 51) | def load(self):
method unload (line 55) | def unload(self):
class KQwen3MoeRMSNormW8A8 (line 61) | class KQwen3MoeRMSNormW8A8(BaseInjectedModule):
method __init__ (line 62) | def __init__(self,
method forward (line 78) | def forward(self, x: torch.Tensor):
method load (line 91) | def load(self):
method unload (line 104) | def unload(self):
class KQwen3FinalRMSNormNPU (line 108) | class KQwen3FinalRMSNormNPU(nn.Module):
method __init__ (line 109) | def __init__(self, orig_module: nn.Module):
method forward (line 123) | def forward(self, x: torch.Tensor):
FILE: archive/ktransformers/operators/ascend/ascend_linear.py
class KLinearW8A8 (line 34) | class KLinearW8A8(KLinearBase):
method __init__ (line 35) | def __init__(
method load_weight (line 46) | def load_weight(self, override_key: str | None = None, device: str | N...
method load (line 102) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 106) | def unload(self):
class KLinearTorchW8A8A2 (line 110) | class KLinearTorchW8A8A2(KLinearW8A8):
method __init__ (line 111) | def __init__(
method forward (line 131) | def forward(self, x: torch.Tensor, bsz_tensor) -> torch.Tensor:
method load (line 136) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 184) | def unload(self):
class KTransformersLinearW8A8A2 (line 200) | class KTransformersLinearW8A8A2(BaseInjectedModule, KLinearW8A8):
method __init__ (line 201) | def __init__(
method forward (line 229) | def forward(self, x, bsz_tensor=None):
method load (line 238) | def load(self, w: dict | nn.Parameter | tuple | None = None, mode: Inf...
method unload (line 272) | def unload(self):
method set_inference_mode (line 279) | def set_inference_mode(self, mode: InferenceState):
FILE: archive/ktransformers/operators/ascend/ascend_mlp.py
class KDeepseekV3MLPW8A8A2V1 (line 26) | class KDeepseekV3MLPW8A8A2V1(BaseInjectedModule, DeepseekV3MLP):
method forward (line 28) | def forward(self, x, is_prefill=None, use_cuda_graph=False):
class KDeepseekV3MLPW8A8A2V2 (line 63) | class KDeepseekV3MLPW8A8A2V2(BaseInjectedModule, DeepseekV3MLP):
method forward (line 65) | def forward(self, x, is_prefill=None, use_cuda_graph=False):
class KQwen3MoeMLPW8A8A2 (line 92) | class KQwen3MoeMLPW8A8A2(BaseInjectedModule, Qwen3MoeMLP):
method forward (line 94) | def forward(self, x, is_prefill=None, use_cuda_graph=False):
FILE: archive/ktransformers/operators/attention.py
function rotate_half (line 41) | def rotate_half(x):
class KDeepseekV2Attention (line 48) | class KDeepseekV2Attention(BaseInjectedModule, DeepseekV2Attention):
method __init__ (line 52) | def __init__(self,
method get_absorbed (line 69) | def get_absorbed(self) -> Tuple[torch.Tensor, torch.Tensor]:
method forward_chunck (line 77) | def forward_chunck(
method forward_linux_triton (line 196) | def forward_linux_triton(
method forward_linux_flashinfer (line 349) | def forward_linux_flashinfer(
method forward_windows (line 525) | def forward_windows(
method forward_xpu (line 591) | def forward_xpu(
method forward (line 685) | def forward(
class KLlamaAttention (line 746) | class KLlamaAttention(BaseInjectedModule):
method __init__ (line 749) | def __init__(self,
method apply_rotary_pos_emb (line 760) | def apply_rotary_pos_emb(self, q, k, cos, sin, position_ids=None, unsq...
method forward (line 785) | def forward(
class KQwen3MoeAttentionIPEXLLM (line 876) | class KQwen3MoeAttentionIPEXLLM(BaseInjectedModule, Qwen3MoeAttention):
method __init__ (line 877) | def __init__(self,
method forward (line 893) | def forward(
FILE: archive/ktransformers/operators/balance_serve_attention.py
function rotate_half (line 26) | def rotate_half(x):
class flashinfer_attn (line 32) | class flashinfer_attn(BaseInjectedModule, DeepseekV2Attention):
method __init__ (line 33) | def __init__(self,
method get_absorbed (line 48) | def get_absorbed(self) -> Tuple[torch.Tensor, torch.Tensor]:
method forward (line 65) | def forward(self,
class KQwen2MoeAttention (line 120) | class KQwen2MoeAttention(BaseInjectedModule, Qwen2MoeAttention):
method __init__ (line 121) | def __init__(self,
method apply_rotary_pos_emb (line 137) | def apply_rotary_pos_emb(self, q, k, cos, sin, position_ids=None, unsq...
method forward (line 164) | def forward(self,
class KQwen3MoeAttention (line 206) | class KQwen3MoeAttention(BaseInjectedModule, Qwen3MoeAttention):
method __init__ (line 207) | def __init__(self,
method apply_rotary_pos_emb (line 223) | def apply_rotary_pos_emb(self, q, k, cos, sin, position_ids=None, unsq...
method forward (line 250) | def forward(self,
class deepseek_torch_attn (line 296) | class deepseek_torch_attn(BaseInjectedModule, DeepseekV2Attention):
method __init__ (line 297) | def __init__(self,
method get_absorbed (line 312) | def get_absorbed(self) -> Tuple[torch.Tensor, torch.Tensor]:
method forward (line 330) | def forward(self,
class KSmallthinkerAttention (line 462) | class KSmallthinkerAttention(BaseInjectedModule, SmallthinkerAttention):
method __init__ (line 463) | def __init__(self,
method apply_rotary_pos_emb (line 477) | def apply_rotary_pos_emb(self, q, k, cos, sin, position_ids=None, unsq...
method forward (line 503) | def forward(self,
class KGlm4MoeAttention (line 555) | class KGlm4MoeAttention(BaseInjectedModule, Glm4MoeAttention):
method __init__ (line 556) | def __init__(self,
method apply_rotary_pos_emb (line 570) | def apply_rotary_pos_emb(
method forward (line 598) | def forward(self,
class KQwen3NextAttention (line 654) | class KQwen3NextAttention(BaseInjectedModule, Qwen3NextAttention):
method __init__ (line 655) | def __init__(self,
method apply_rotary_pos_emb (line 670) | def apply_rotary_pos_emb(self, q, k, cos, sin, position_ids=None, unsq...
method forward (line 709) | def forward(self,
class KQwen3NextGatedDeltaNet (line 763) | class KQwen3NextGatedDeltaNet(BaseInjectedModule, Qwen3NextGatedDeltaNet):
method __init__ (line 764) | def __init__(self,
method fix_query_key_value_ordering (line 778) | def fix_query_key_value_ordering(self, mixed_qkvz, mixed_ba):
method forward (line 807) | def forward(
FILE: archive/ktransformers/operators/base_operator.py
class BaseInjectedModule (line 12) | class BaseInjectedModule(nn.Module):
method __init__ (line 14) | def __init__(self,
method __getattr__ (line 31) | def __getattr__(self, name: str) -> Any:
method __setattr__ (line 51) | def __setattr__(self, name: str, value: Tensor | nn.Module) -> None:
method forward (line 58) | def forward(self, *args, **kwargs):
method load (line 61) | def load(self):
FILE: archive/ktransformers/operators/cpuinfer.py
class CPUInferKVCache (line 29) | class CPUInferKVCache:
method __init__ (line 30) | def __init__(
method load_kvcache (line 100) | def load_kvcache(self, tensor_file_path: str):
method dump_kvcache (line 105) | def dump_kvcache(
method update_cache_total_len (line 135) | def update_cache_total_len(self, cache_total_len: int):
method attn (line 143) | def attn(
method update_kvcache_one_block_fp16 (line 256) | def update_kvcache_one_block_fp16(
method get_kvcache_one_block_fp16 (line 292) | def get_kvcache_one_block_fp16(
method update_importance_one_block (line 328) | def update_importance_one_block(
method get_importance_one_block (line 354) | def get_importance_one_block(
method get_anchor_one_block (line 380) | def get_anchor_one_block(self, anchor: torch.Tensor, layer_id: int, bl...
method update_anchor_one_block (line 406) | def update_anchor_one_block(
method calc_anchor_all_layers (line 434) | def calc_anchor_all_layers(
method clear_importance_all_layers (line 473) | def clear_importance_all_layers(
method get_cache_total_len (line 512) | def get_cache_total_len(self):
method update_kvcache_q4 (line 515) | def update_kvcache_q4(
method update_kvcache_fp16 (line 528) | def update_kvcache_fp16(
method get_kvcache_q4 (line 550) | def get_kvcache_q4(
method get_kvcache_fp16 (line 563) | def get_kvcache_fp16(
method get_and_update_kvcache_fp16 (line 584) | def get_and_update_kvcache_fp16(
method update_importance (line 606) | def update_importance(
method get_attn_sparsity (line 627) | def get_attn_sparsity(
method attn_with_kvcache (line 665) | def attn_with_kvcache(
method get_all_kvcache_one_layer (line 704) | def get_all_kvcache_one_layer(
method get_importance (line 713) | def get_importance(
method get_anchor (line 720) | def get_anchor(
class CPUInfer (line 728) | class CPUInfer:
method __init__ (line 732) | def __init__(self, thread_num):
method submit (line 738) | def submit(self, task):
method submit_with_cuda_stream (line 741) | def submit_with_cuda_stream(self, current_cuda_stream, task):
method sync (line 744) | def sync(self):
method sync_with_cuda_stream (line 747) | def sync_with_cuda_stream(self, current_cuda_stream):
FILE: archive/ktransformers/operators/dynamic_attention.py
class DynamicScaledDotProductAttention (line 30) | class DynamicScaledDotProductAttention:
method __init__ (line 34) | def __init__(
method get_attn_score_one_block (line 233) | def get_attn_score_one_block(
method get_preselect_block_table_and_attn_score (line 271) | def get_preselect_block_table_and_attn_score(
method get_attn_score (line 374) | def get_attn_score(
method swap_in_and_swap_out (line 467) | def swap_in_and_swap_out(self, layer_idx, past_len, q_len, key, value):
method calc_anchor (line 518) | def calc_anchor(self, cache_seqlens: int):
method clear_importance (line 533) | def clear_importance(self, cache_seqlens: int):
method clear_kvcache (line 549) | def clear_kvcache(self, cache_seqlens: int):
method get_attn_sparsity (line 564) | def get_attn_sparsity(
method apply (line 605) | def apply(
method save (line 762) | def save(self, path: str, length: int):
method load (line 775) | def load(self, path: str, length: int):
FILE: archive/ktransformers/operators/experts.py
function deduplicate_and_sort (line 48) | def deduplicate_and_sort(lst):
function generate_cuda_graphs (line 50) | def generate_cuda_graphs(chunk_size: int) -> list:
class KExpertsBase (line 68) | class KExpertsBase(ABC):
method __init__ (line 69) | def __init__(self, key: str, gguf_loader: GGUFLoader, config: Pretrain...
method forward (line 77) | def forward(self, input_tensor, expert_ids, weights):
method load (line 81) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 85) | def unload():
method load_weights (line 88) | def load_weights(self, override_key: str | None = None, device: str = ...
method load_multi (line 136) | def load_multi(self, key: str, keys: list[str], device: str = "cpu"):
class KExpertsCPU (line 143) | class KExpertsCPU(KExpertsBase):
method __init__ (line 152) | def __init__(
method load (line 169) | def load(self, w: dict | nn.Parameter | tuple | None = None, device:st...
method submit_for_one_decode (line 293) | def submit_for_one_decode(self, input_tensor, expert_ids, weights, bsz...
method sync_for_one_decode (line 310) | def sync_for_one_decode(self, cuda_graph_idx=0):
method forward (line 320) | def forward(self, input_tensor, expert_ids, weights, bsz_tensor=None, ...
method unload (line 364) | def unload(self):
method load_weights (line 367) | def load_weights(self, override_key: str | None = None, device: str = ...
class KExpertsMarlin (line 437) | class KExpertsMarlin(KExpertsBase):
method __init__ (line 440) | def __init__(
method load (line 466) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 499) | def unload(self):
method load_weights (line 506) | def load_weights(self, override_key: str | None = None):
method forward (line 525) | def forward(self, hidden_states_cpu: torch.Tensor, selected_experts_cp...
class KExpertsTorch (line 562) | class KExpertsTorch(KExpertsBase):
method __init__ (line 568) | def __init__(
method load (line 589) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 617) | def unload(self):
method load_weights (line 623) | def load_weights(self, override_key: str | None = None):
method forward (line 642) | def forward(self, hidden_states_cpu: torch.Tensor, selected_experts_cp...
class KTransformersExperts (line 686) | class KTransformersExperts(BaseInjectedModule, KExpertsBase):
method __init__ (line 687) | def __init__(self,
method load (line 712) | def load(self, w: dict = None, mode: InferenceState = None, warmup: b...
method unload (line 732) | def unload(self):
method forward (line 739) | def forward(self, input_tensor, expert_ids, weights):
method set_inference_mode (line 749) | def set_inference_mode(self, mode: InferenceState):
class KQwen2MoeSparseMoeBlock (line 770) | class KQwen2MoeSparseMoeBlock(BaseInjectedModule, Qwen2MoeSparseMoeBlock):
method forward (line 771) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
method moe_kexperts (line 825) | def moe_kexperts(self, x: torch.Tensor, topk_ids: torch.Tensor, topk_w...
method moe_infer_simple (line 831) | def moe_infer_simple(self, hidden_states_cpu: torch.Tensor, selected_e...
method moe_infer (line 845) | def moe_infer(self, hidden_states_cpu: torch.Tensor, selected_experts_...
class KDeepseekV2MoE (line 874) | class KDeepseekV2MoE(BaseInjectedModule, DeepseekV2MoE):
method forward (line 875) | def forward(self, hidden_states):
method moe_kexperts (line 915) | def moe_kexperts(self, x: torch.Tensor, topk_ids: torch.Tensor, topk_w...
method moe_infer_simple (line 921) | def moe_infer_simple(
method moe_infer (line 939) | def moe_infer(self, x, topk_ids, topk_weight):
class KDeepseekV3MoE (line 972) | class KDeepseekV3MoE(BaseInjectedModule, DeepseekV3MoE):
method forward (line 974) | def forward(self, hidden_states):
method moe_kexperts (line 1017) | def moe_kexperts(self, x: torch.Tensor, topk_ids: torch.Tensor, topk_w...
method moe_infer_simple (line 1023) | def moe_infer_simple(
method moe_infer (line 1041) | def moe_infer(self, x, topk_ids, topk_weight):
class KMistralSparseMoEBlock (line 1074) | class KMistralSparseMoEBlock(BaseInjectedModule, MixtralSparseMoeBlock):
method forward (line 1076) | def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
method moe_kexperts (line 1123) | def moe_kexperts(self, x: torch.Tensor, topk_ids: torch.Tensor, topk_w...
method moe_infer_simple (line 1129) | def moe_infer_simple(self, hidden_states_cpu: torch.Tensor, selected_e...
method moe_infer (line 1143) | def moe_infer(self, hidden_states_cpu: torch.Tensor, selected_experts_...
class KDeepseekV3MoEV2 (line 1172) | class KDeepseekV3MoEV2(BaseInjectedModule, DeepseekV3MoE):
method forward (line 1173) | def forward(self, hidden_states, bsz_tensor, cuda_graph_idx=0):
method moe_on_cpuinfer (line 1215) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 1222) | def moe_infer_simple(
method moe_infer (line 1240) | def moe_infer(self, x, topk_ids, topk_weight):
class KTransformersExpertsV2 (line 1273) | class KTransformersExpertsV2(BaseInjectedModule, KExpertsBase):
method __init__ (line 1274) | def __init__(self,
method load (line 1305) | def load(self, w: dict = None, mode: InferenceState = None, warmup: b...
method unload (line 1325) | def unload(self):
method forward (line 1332) | def forward(self, input_tensor, expert_ids, weights, bsz_tensor, cuda_...
method set_inference_mode (line 1342) | def set_inference_mode(self, mode: InferenceState):
class KSmallthinkerExperts (line 1353) | class KSmallthinkerExperts(BaseInjectedModule, KExpertsBase):
method __init__ (line 1354) | def __init__(self,
method load (line 1378) | def load(self, w: dict = None, mode: InferenceState = None, warmup: b...
method unload (line 1398) | def unload(self):
method forward (line 1405) | def forward(self, input_tensor, expert_ids, weights, bsz_tensor, cuda_...
method set_inference_mode (line 1415) | def set_inference_mode(self, mode: InferenceState):
class KGlm4Experts (line 1425) | class KGlm4Experts(BaseInjectedModule, KExpertsBase):
method __init__ (line 1426) | def __init__(self,
method load (line 1450) | def load(self, w: dict = None, mode: InferenceState = None, warmup: b...
method unload (line 1470) | def unload(self):
method forward (line 1477) | def forward(self, input_tensor, expert_ids, weights, bsz_tensor, cuda_...
method set_inference_mode (line 1487) | def set_inference_mode(self, mode: InferenceState):
class KQwen2MoeSparseMoeBlockV2 (line 1498) | class KQwen2MoeSparseMoeBlockV2(BaseInjectedModule, Qwen2MoeSparseMoeBlo...
method forward (line 1499) | def forward(self, hidden_states, bsz_tensor, cuda_graph_idx=0):
method moe_on_cpuinfer (line 1553) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 1560) | def moe_infer_simple(
method moe_infer (line 1578) | def moe_infer(self, x, topk_ids, topk_weight):
class KQwen3MoeSparseMoeBlockV2 (line 1611) | class KQwen3MoeSparseMoeBlockV2(BaseInjectedModule, Qwen3MoeSparseMoeBlo...
method forward (line 1612) | def forward(self, hidden_states, bsz_tensor=None, cuda_graph_idx=0):
method moe_on_cpuinfer (line 1675) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 1682) | def moe_infer_simple(
method moe_infer (line 1700) | def moe_infer(self, x, topk_ids, topk_weight):
class KSmallthinkerMoeBlock (line 1734) | class KSmallthinkerMoeBlock(BaseInjectedModule, SmallthinkerMoeBlock):
method forward (line 1735) | def forward(self, router_input: torch.Tensor, hidden_states: torch.Ten...
method moe_on_cpuinfer (line 1809) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 1816) | def moe_infer_simple(
method moe_infer (line 1834) | def moe_infer(self, x, topk_ids, topk_weight):
class KGlm4MoeMoE (line 1868) | class KGlm4MoeMoE(BaseInjectedModule, Glm4MoeMoE):
method forward (line 1869) | def forward(self, hidden_states, bsz_tensor=None, cuda_graph_idx=0):
method moe_on_cpuinfer (line 1915) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 1922) | def moe_infer_simple(
method moe_infer (line 1940) | def moe_infer(self, x, topk_ids, topk_weight):
class KQwen3NextSparseMoeBlockV2 (line 1974) | class KQwen3NextSparseMoeBlockV2(BaseInjectedModule, Qwen3NextSparseMoeB...
method forward (line 1975) | def forward(self, hidden_states, bsz_tensor=None, cuda_graph_idx=0):
method moe_on_cpuinfer (line 2041) | def moe_on_cpuinfer(self, x: torch.Tensor, topk_ids: torch.Tensor, top...
method moe_infer_simple (line 2048) | def moe_infer_simple(
method moe_infer (line 2066) | def moe_infer(self, x, topk_ids, topk_weight):
FILE: archive/ktransformers/operators/flashinfer_batch_prefill_wrapper.py
function setup_seed (line 13) | def setup_seed(seed):
class flashInferAttn (line 34) | class flashInferAttn():
method __init__ (line 37) | def __init__(self,
method plan (line 72) | def plan(self,
method calc_batch_indices (line 106) | def calc_batch_indices(self, ragged_size = None):
method forward (line 114) | def forward(self, q, k_cache, v_cache, k, v):
function testCudaGraph (line 123) | def testCudaGraph():
function testAttentionFlashInfer (line 267) | def testAttentionFlashInfer(
FILE: archive/ktransformers/operators/flashinfer_wrapper.py
function attention_ref_torch (line 30) | def attention_ref_torch(
class MLAWrapper (line 78) | class MLAWrapper():
method __init__ (line 79) | def __init__(self,
method plan (line 117) | def plan(self,
method run (line 160) | def run(self, q_nope, q_pe, ckv, k_pe, return_lse = False):
class MLAWrapperSingleton (line 163) | class MLAWrapperSingleton():
method get_instance (line 167) | def get_instance(cls, device, *args, **kwargs)->MLAWrapper:
method make_instance (line 173) | def make_instance(cls, device, *args, **kwargs):
method plan_all (line 177) | def plan_all(cls, qo_indptr,
method need_plan_all (line 206) | def need_plan_all(cls):
method reset_buffer (line 211) | def reset_buffer(cls):
method update_buffer (line 216) | def update_buffer(cls, max_pages):
function checksame (line 222) | def checksame():
FILE: archive/ktransformers/operators/gate.py
class KMoEGateBase (line 15) | class KMoEGateBase(ABC):
method __init__ (line 16) | def __init__(self,
method forward (line 32) | def forward(self, input_tensor, expert_ids, weights):
method load (line 36) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 40) | def unload():
method load_weights (line 43) | def load_weights(self, override_key: str | None = None, device: str = ...
method load_multi (line 84) | def load_multi(self, key: str, keys: list[str], device: str = "cpu"):
class KMoEGate (line 91) | class KMoEGate(BaseInjectedModule, KMoEGateBase):
method __init__ (line 92) | def __init__(
method forward (line 107) | def forward(self, hidden_states) -> torch.Tensor:
method load (line 110) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 122) | def unload(self):
class KMoEGateQwen2Moe (line 129) | class KMoEGateQwen2Moe(BaseInjectedModule, KMoEGateBase):
method __init__ (line 130) | def __init__(
method forward (line 159) | def forward(self, hidden_states) -> torch.Tensor:
method load (line 177) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 191) | def unload(self):
class KMoEGateIPEXLLM (line 198) | class KMoEGateIPEXLLM(KMoEGate):
method __init__ (line 199) | def __init__(
method forward (line 214) | def forward(self, hidden_states) -> torch.Tensor:
FILE: archive/ktransformers/operators/layernorm.py
class RMSNorm (line 46) | class RMSNorm(DeepseekV3RMSNorm, BaseInjectedModule):
method __init__ (line 47) | def __init__(self,
method forward (line 59) | def forward(
method forward_native (line 77) | def forward_native(
class KQwen2MoeRMSNorm (line 87) | class KQwen2MoeRMSNorm(Qwen2MoeRMSNorm, BaseInjectedModule):
method __init__ (line 88) | def __init__(self,
method forward (line 100) | def forward(
method forward_native (line 118) | def forward_native(
class KQwen3MoeRMSNorm (line 128) | class KQwen3MoeRMSNorm(Qwen3MoeRMSNorm, BaseInjectedModule):
method __init__ (line 129) | def __init__(self,
method forward (line 141) | def forward(
method forward_native (line 162) | def forward_native(
class KQwen3NextRMSNorm (line 171) | class KQwen3NextRMSNorm(Qwen3NextRMSNorm, BaseInjectedModule):
method __init__ (line 172) | def __init__(self,
method _norm (line 184) | def _norm(self, x):
method forward (line 187) | def forward(self, x, num_tokens_tensors, residual = None):
method extra_repr (line 201) | def extra_repr(self):
class KSmallthinkerRMSNorm (line 205) | class KSmallthinkerRMSNorm(SmallthinkerRMSNorm, BaseInjectedModule):
method __init__ (line 206) | def __init__(self,
method forward (line 218) | def forward(
method forward_native (line 239) | def forward_native(
class KGlm4MoeRMSNorm (line 248) | class KGlm4MoeRMSNorm(Glm4MoeRMSNorm, BaseInjectedModule):
method __init__ (line 249) | def __init__(self,
method forward (line 261) | def forward(
method forward_native (line 282) | def forward_native(
class DeepseekV3RMSNormTorch (line 293) | class DeepseekV3RMSNormTorch(DeepseekV3RMSNorm, BaseInjectedModule):
method __init__ (line 294) | def __init__(self,
method forward (line 306) | def forward(
class KDeepseekRMSNormIPEXLLM (line 325) | class KDeepseekRMSNormIPEXLLM(DeepseekV3RMSNorm, BaseInjectedModule):
method __init__ (line 326) | def __init__(self,
method forward (line 339) | def forward(self, x: torch.Tensor) -> torch.Tensor:
method load (line 347) | def load(self):
FILE: archive/ktransformers/operators/linear.py
class KLinearBase (line 57) | class KLinearBase(ABC):
method __init__ (line 58) | def __init__(
method forward (line 89) | def forward(self, x: torch.Tensor) -> torch.Tensor:
method load_weight (line 92) | def load_weight(self, override_key: str | None = None, device: str | N...
method load_multi (line 143) | def load_multi(self, key: str, keys: list[str], device: str = "cpu"):
method load (line 150) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 154) | def unload(self):
class KLinearTorch (line 158) | class KLinearTorch(KLinearBase):
method __init__ (line 159) | def __init__(
method forward (line 174) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor=None, **kw...
method load (line 185) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 212) | def unload(self):
class KLinearQ8 (line 218) | class KLinearQ8(KLinearBase):
method __init__ (line 219) | def __init__(
method forward (line 237) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor=None) -> t...
method _dequantize_weight (line 254) | def _dequantize_weight(self, q_matrix, scales, bits=8):
method _quantize_weight (line 290) | def _quantize_weight(self, matrix, bits=8):
method load (line 345) | def load(self, w: Union[Dict, nn.Parameter, Tuple, None] = None, devic...
method unload (line 376) | def unload(self):
class KLinearFP8 (line 388) | class KLinearFP8(KLinearBase):
method __init__ (line 394) | def __init__(
method forward (line 409) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor) -> torch....
method load (line 416) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 431) | def unload(self):
class VLinearMarlin (line 439) | class VLinearMarlin(KLinearBase):
method __init__ (line 445) | def __init__(
method load (line 477) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method forward (line 525) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor = None) ->...
method unload (line 564) | def unload(self):
method _pad_input (line 574) | def _pad_input(self, x):
class KLinearMarlin (line 595) | class KLinearMarlin(KLinearBase):
method __init__ (line 601) | def __init__(
method load (line 633) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method forward (line 679) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor=None, **kw...
method unload (line 713) | def unload(self):
class KLinearCPUInfer (line 723) | class KLinearCPUInfer(KLinearBase):
method __init__ (line 725) | def __init__(
method forward (line 748) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor = None) ->...
method load (line 787) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method load_weights (line 808) | def load_weights(self, w: dict | nn.Parameter | tuple | None = None, d...
method unload (line 821) | def unload(self):
class KLinearIPEXLLM (line 827) | class KLinearIPEXLLM(KLinearBase):
method __init__ (line 828) | def __init__(
method forward (line 846) | def forward(self, x: torch.Tensor, bsz_tensor: torch.Tensor = None) ->...
method load (line 857) | def load(self, w: dict | nn.Parameter | tuple | None = None, device: s...
method unload (line 890) | def unload(self):
class KTransformersLinear (line 906) | class KTransformersLinear(BaseInjectedModule, KLinearBase):
method __init__ (line 907) | def __init__(
method forward (line 935) | def forward(self, x, bsz_tensor=None):
method load (line 944) | def load(self, w: dict | nn.Parameter | tuple | None = None, mode: Inf...
method unload (line 966) | def unload(self):
method set_inference_mode (line 973) | def set_inference_mode(self, mode: InferenceState):
FILE: archive/ktransformers/operators/mlp.py
class kDeepseekV3MLP (line 10) | class kDeepseekV3MLP(DeepseekV3MLP, BaseInjectedModule):
method __init__ (line 11) | def __init__(self,
method forward (line 22) | def forward(self, x, bsz_tensor):
class KQwen2MoeMLP (line 25) | class KQwen2MoeMLP(Qwen2MoeMLP, BaseInjectedModule):
method __init__ (line 26) | def __init__(self,
method forward (line 37) | def forward(self, x, bsz_tensor):
class KSmallthinkerDenseMlpBlock (line 42) | class KSmallthinkerDenseMlpBlock(SmallthinkerDenseMlpBlock, BaseInjected...
method __init__ (line 43) | def __init__(self,
method forward (line 53) | def forward(self, x, bsz_tensor):
class KGlm4MoeMLP (line 57) | class KGlm4MoeMLP(Glm4MoeMLP, BaseInjectedModule):
method __init__ (line 58) | def __init__(self,
method forward (line 68) | def forward(self, x, bsz_tensor):
FILE: archive/ktransformers/operators/models.py
class KQwen2MoeModel (line 185) | class KQwen2MoeModel(BaseInjectedModule):
method __init__ (line 193) | def __init__(
method forward (line 212) | def forward(
method load_layer_to (line 443) | def load_layer_to(self, layer: Qwen2MoeDecoderLayer, target: Inference...
class KDeepseekV2Model (line 547) | class KDeepseekV2Model(BaseInjectedModule):
method __init__ (line 555) | def __init__(
method forward (line 574) | def forward(
method load_layer_to (line 843) | def load_layer_to(self, layer: DeepseekV2DecoderLayer, target: Inferen...
class LlamaPreTrainedModel (line 969) | class LlamaPreTrainedModel(PreTrainedModel):
method _init_weights (line 981) | def _init_weights(self, module):
class KLlamaModel (line 993) | class KLlamaModel(BaseInjectedModule):
method __init__ (line 1003) | def __init__(
method get_input_embeddings (line 1050) | def get_input_embeddings(self):
method set_input_embeddings (line 1053) | def set_input_embeddings(self, value):
method forward (line 1057) | def forward(
method forward_chunk (line 1194) | def forward_chunk(
method _update_causal_mask (line 1295) | def _update_causal_mask(
FILE: archive/ktransformers/operators/triton_attention.py
function tanh (line 11) | def tanh(x):
function _fwd_grouped_kernel_stage1 (line 16) | def _fwd_grouped_kernel_stage1(
function _decode_grouped_att_m_fwd (line 165) | def _decode_grouped_att_m_fwd(
function _fwd_kernel_stage2 (line 258) | def _fwd_kernel_stage2(
function _decode_softmax_reducev_fwd (line 313) | def _decode_softmax_reducev_fwd(
function decode_attention_fwd_grouped (line 358) | def decode_attention_fwd_grouped(
FILE: archive/ktransformers/operators/triton_attention_prefill.py
function _fwd_kernel (line 24) | def _fwd_kernel(
function context_attention_fwd (line 159) | def context_attention_fwd(
FILE: archive/ktransformers/optimize/optimize.py
function inject (line 28) | def inject(module, local_optimization_dict, model_config:AutoConfig ,ggu...
function del_meta (line 56) | def del_meta(module:nn.Module):
function gen_optimize_config (line 67) | def gen_optimize_config(module: nn.Module, out_data: Mapping, rule_list:...
function translate_model_config (line 121) | def translate_model_config(model_config: PretrainedConfig):
function optimize_and_load_gguf (line 129) | def optimize_and_load_gguf(module: nn.Module, rule_file: str, gguf_path:...
FILE: archive/ktransformers/server/api/ollama/completions.py
class OllamaGenerateCompletionRequest (line 21) | class OllamaGenerateCompletionRequest(BaseModel):
class OllamaGenerationStreamResponse (line 45) | class OllamaGenerationStreamResponse(BaseModel):
class OllamaGenerationResponse (line 51) | class OllamaGenerationResponse(BaseModel):
function generate (line 58) | async def generate(request: Request, input: OllamaGenerateCompletionRequ...
class OllamaChatCompletionMessage (line 103) | class OllamaChatCompletionMessage(BaseModel):
class OllamaChatCompletionRequest (line 107) | class OllamaChatCompletionRequest(BaseModel):
class OllamaChatCompletionStreamResponse (line 113) | class OllamaChatCompletionStreamResponse(BaseModel):
class OllamaChatCompletionResponse (line 126) | class OllamaChatCompletionResponse(BaseModel):
function chat (line 140) | async def chat(request: Request, input: OllamaChatCompletionRequest):
class OllamaModel (line 227) | class OllamaModel(BaseModel):
function tags (line 235) | async def tags():
class OllamaModelInfo (line 240) | class OllamaModelInfo(BaseModel):
class OllamaShowRequest (line 244) | class OllamaShowRequest(BaseModel):
class OllamaShowDetial (line 249) | class OllamaShowDetial(BaseModel):
class OllamaShowResponse (line 257) | class OllamaShowResponse(BaseModel):
class Config (line 264) | class Config:
function show (line 268) | async def show(request: Request, input: OllamaShowRequest):
FILE: archive/ktransformers/server/api/openai/__init__.py
function post_db_creation_operations (line 14) | def post_db_creation_operations():
FILE: archive/ktransformers/server/api/openai/assistants/assistants.py
function create_assistant (line 19) | async def create_assistant(
function list_assistants (line 26) | async def list_assistants(
function list_assistants_with_status (line 38) | async def list_assistants_with_status(
function retrieve_assistant (line 48) | async def retrieve_assistant(
function modify_assistant (line 55) | async def modify_assistant(
function delete_assistant (line 63) | async def delete_assistant(assistant_id: str):
function get_related_thread (line 69) | async def get_related_thread(assistant_id: ObjectID):
function create_default_assistant (line 74) | def create_default_assistant():
function test_create_assistant (line 90) | def test_create_assistant():
FILE: archive/ktransformers/server/api/openai/assistants/messages.py
function create_message (line 16) | async def create_message(thread_id: str, msg: MessageCreate):
function list_messages (line 26) | async def list_messages(
function retrieve_message (line 38) | async def retrieve_message(thread_id: ObjectID, message_id: ObjectID):
function modify_message (line 43) | async def modify_message(thread_id: ObjectID, message_id: ObjectID, msg:...
function delete_message (line 49) | async def delete_message(thread_id: ObjectID, message_id: ObjectID):
FILE: archive/ktransformers/server/api/openai/assistants/runs.py
function create_run (line 20) | async def create_run(request: Request, thread_id: str, run_create: RunCr...
function create_thread_and_run (line 40) | async def create_thread_and_run(run_thread: RunThreadCreate):
function list_runs (line 45) | async def list_runs(
function retrieve_run (line 56) | async def retrieve_run(
function modify_run (line 67) | async def modify_run(
function submit_tool_outputs_to_run (line 76) | async def submit_tool_outputs_to_run(thread_id: str, run_id: str, submit...
function cancel_run (line 81) | async def cancel_run(thread_id: str, run_id: str):
FILE: archive/ktransformers/server/api/openai/assistants/threads.py
function create_thread (line 14) | async def create_thread(thread: ThreadCreate):
function list_threads (line 19) | async def list_threads(limit: Optional[int] = 20, order: Order = Order.D...
function retrieve_thread (line 24) | async def retrieve_thread(thread_id: ObjectID):
function modify_thread (line 29) | async def modify_thread(thread_id: ObjectID, thread: ThreadModify):
function delete_thread (line 34) | async def delete_thread(thread_id: ObjectID):
FILE: archive/ktransformers/server/api/openai/endpoints/chat.py
class Choice (line 22) | class Choice(BaseModel):
class ChatCompletion (line 30) | class ChatCompletion(BaseModel):
class ChatCompletionMessageToolCallFunction (line 41) | class ChatCompletionMessageToolCallFunction(BaseModel):
class ChatCompletionMessageToolCall (line 45) | class ChatCompletionMessageToolCall(BaseModel):
class ChatCompletionMessage (line 50) | class ChatCompletionMessage(BaseModel):
function list_models (line 58) | async def list_models():
function getTools (line 61) | def getTools(buffer):
function get_tool_instructions (line 117) | def get_tool_instructions():
function chat_completion (line 136) | async def chat_completion(request: Request, create: ChatCompletionCreate):
FILE: archive/ktransformers/server/api/openai/legacy/completions.py
function create_completion (line 15) | async def create_completion(request:Request, create:CompletionCreate):
FILE: archive/ktransformers/server/api/web/system.py
function system_info (line 8) | def system_info():
FILE: archive/ktransformers/server/args.py
class ArgumentParser (line 10) | class ArgumentParser:
method __init__ (line 11) | def __init__(self, cfg):
method parse_args (line 14) | def parse_args(self):
FILE: archive/ktransformers/server/backend/args.py
class ConfigArgs (line 6) | class ConfigArgs(BaseModel):
class Config (line 15) | class Config:
FILE: archive/ktransformers/server/backend/base.py
class BackendInterfaceBase (line 27) | class BackendInterfaceBase:
method __init__ (line 36) | def __init__(self, args:ConfigArgs = default_args):
method inference (line 40) | async def inference(self,local_messages,request_unique_id:Optional[str...
method report_last_time_performance (line 57) | def report_last_time_performance(self):
class ThreadContext (line 70) | class ThreadContext:
method __init__ (line 89) | def __init__(self, run: RunObject,interface:BackendInterfaceBase, args...
method get_local_messages (line 102) | def get_local_messages(self):
method update_by_run (line 109) | def update_by_run(self,run:RunObject,args:ConfigArgs = default_args):
method put_user_message (line 113) | def put_user_message(self, message: MessageObject):
method delete_user_message (line 119) | def delete_user_message(self,message_id: ObjectID):
method work (line 122) | async def work(self)->AsyncIterator:
FILE: archive/ktransformers/server/backend/context_manager.py
class ThreadContextManager (line 17) | class ThreadContextManager:
method __init__ (line 22) | def __init__(self,interface) -> None:
method get_context_by_run_object (line 29) | async def get_context_by_run_object(self, run: RunObject) -> ThreadCon...
method get_context_by_thread_id (line 57) | async def get_context_by_thread_id(self, thread_id: ObjectID) -> Optio...
FILE: archive/ktransformers/server/backend/interfaces/balance_serve.py
function chat_stream (line 102) | async def chat_stream(queue: asyncio.Queue, tokenizer: AutoTokenizer):
function fill_generated_tokens (line 122) | def fill_generated_tokens(query_updates: list[sched_ext.QueryUpdate], ge...
function report_last_time_performance (line 132) | def report_last_time_performance(profiler: Profiler):
class Engine (line 144) | class Engine:
method __init__ (line 152) | def __init__(self, args: ConfigArgs = default_args, generated_token_qu...
method sampling (line 300) | def sampling(self, forward_output: ForwardBatchOutput):
method loop (line 323) | def loop(self):
class BalanceServeThreadContext (line 383) | class BalanceServeThreadContext(ThreadContext):
method get_local_messages (line 384) | def get_local_messages(self):
function init_distributed (line 392) | def init_distributed(rank: int,
function run_engine (line 408) | def run_engine(args, token_queue, broadcast_endpoint, event, kvcache_eve...
class BalanceServeInterface (line 427) | class BalanceServeInterface(BackendInterfaceBase):
method __init__ (line 443) | def __init__(self, args: ConfigArgs = default_args, input_args=None):
method get_params (line 529) | def get_params(self, temperature: Optional[float] = None, top_p: Optio...
method run_queue_proxy (line 550) | def run_queue_proxy(self):
method lifespan (line 556) | async def lifespan(self, app: FastAPI):
method queue_proxy (line 560) | async def queue_proxy(self):
method tokenize_prompt (line 577) | def tokenize_prompt(self, prompt: str):
method format_and_tokenize_input_ids (line 581) | def format_and_tokenize_input_ids(self, thread_id: ObjectID, messages:...
method inference (line 601) | async def inference(self, local_messages, thread_id: str, temperature:...
FILE: archive/ktransformers/server/backend/interfaces/exllamav2.py
class ExllamaThreadContext (line 14) | class ExllamaThreadContext(ThreadContext):
method __init__ (line 15) | def __init__(self, run: RunObject, args: ConfigArgs = default_args) ->...
method get_interface (line 18) | def get_interface(self):
method get_local_messages (line 21) | def get_local_messages(self):
class ExllamaInterface (line 27) | class ExllamaInterface(BackendInterfaceBase):
method __init__ (line 29) | def __init__(self, args: ConfigArgs = ...):
method tokenize_prompt (line 32) | def tokenize_prompt(self, prompt: str) -> torch.Tensor:
method inference (line 35) | async def inference(self,local_messages,request_unique_id:Optional[str...
FILE: archive/ktransformers/server/backend/interfaces/ktransformers.py
class KTransformersThreadContext (line 52) | class KTransformersThreadContext(TransformersThreadContext):
class KTransformersInterface (line 56) | class KTransformersInterface(TransformersInterface):
method __init__ (line 57) | def __init__(self, args: ConfigArgs = default_args, input_args=None):
method decode_one_tokens (line 130) | def decode_one_tokens(self):
method prefill (line 206) | def prefill(self, input_ids: torch.Tensor, is_new: bool, temperature: ...
method active_cache_position (line 353) | def active_cache_position(self):
method sampling (line 357) | def sampling(self, logits, do_sample):
method verify_by_tokenid (line 377) | def verify_by_tokenid(self, main_token: int, draft_token: int):
method verify_speculative_decoding (line 380) | def verify_speculative_decoding(self, main_prob: torch.Tensor, draft_p...
method logits_to_token (line 397) | def logits_to_token(self, logits: torch.Tensor):
method inference (line 410) | async def inference(self, local_messages, thread_id: str, temperature:...
method sync_inference (line 424) | def sync_inference(self, local_messages, thread_id: str, temperature: ...
FILE: archive/ktransformers/server/backend/interfaces/transformers.py
class TextStreamer (line 47) | class TextStreamer:
method __init__ (line 49) | def __init__(self, tokenizer: "AutoTokenizer", skip_prompt: bool = Fal...
method reset (line 59) | def reset(self):
method put (line 63) | def put(self, value) -> Optional[str]:
method end (line 93) | def end(self) -> Optional[str]:
method _is_chinese_char (line 106) | def _is_chinese_char(self, cp):
class TransformersThreadContext (line 131) | class TransformersThreadContext(ThreadContext):
method get_local_messages (line 132) | def get_local_messages(self):
class TransformersInterface (line 140) | class TransformersInterface(BackendInterfaceBase):
method __init__ (line 156) | def __init__(self, args: ConfigArgs = default_args):
method current_ids (line 175) | def current_ids(self):
method active_cache_position (line 179) | def active_cache_position(self):
method tokenize_prompt (line 182) | def tokenize_prompt(self, prompt: str):
method format_and_tokenize_input_ids (line 186) | def format_and_tokenize_input_ids(self, thread_id: ObjectID, messages:...
method append_new_tokens (line 224) | def append_new_tokens(self, new_tokens: int) -> Optional[str]:
method tf_logits_warper (line 231) | def tf_logits_warper(generation_config):
method prepare_logits_wrapper (line 282) | def prepare_logits_wrapper(self, inputs, device, temperature: Optional...
method logits_to_token (line 301) | def logits_to_token(self, logits: torch.Tensor):
method decode_one_tokens (line 316) | def decode_one_tokens(self):
method prefill (line 332) | def prefill(self, input_ids: torch.Tensor, is_new: bool, temperature: ...
method generate (line 409) | def generate(self):
method check_is_new (line 445) | def check_is_new(self, thread_id: str):
method inference (line 458) | async def inference(self, local_messages, thread_id: str, temperature:...
FILE: archive/ktransformers/server/balance_serve/inference/config.py
class ModelConfig (line 21) | class ModelConfig:
method __init__ (line 58) | def __init__(self, config):
method load_config (line 72) | def load_config(self):
class ParallelConfig (line 90) | class ParallelConfig:
method __init__ (line 91) | def __init__(
class AttnConfig (line 100) | class AttnConfig:
method __init__ (line 106) | def __init__(self, config):
class SamplerConfig (line 113) | class SamplerConfig():
method __init__ (line 118) | def __init__(self, config):
function load_yaml_config (line 123) | def load_yaml_config(file_path):
class LLMConfig (line 130) | class LLMConfig:
method __init__ (line 137) | def __init__(self, config_file):
FILE: archive/ktransformers/server/balance_serve/inference/distributed/communication_op.py
function tensor_model_parallel_all_reduce (line 15) | def tensor_model_parallel_all_reduce(input_: torch.Tensor, bsz_tensor: t...
function tensor_model_parallel_all_gather (line 20) | def tensor_model_parallel_all_gather(
function tensor_model_parallel_gather (line 27) | def tensor_model_parallel_gather(
function broadcast_tensor_dict (line 34) | def broadcast_tensor_dict(
FILE: archive/ktransformers/server/balance_serve/inference/distributed/cuda_wrapper.py
class cudaIpcMemHandle_t (line 21) | class cudaIpcMemHandle_t(ctypes.Structure):
class Function (line 26) | class Function:
function find_loaded_library (line 32) | def find_loaded_library(lib_name) -> Optional[str]:
class CudaRTLibrary (line 58) | class CudaRTLibrary:
method __init__ (line 100) | def __init__(self, so_file: Optional[str] = None):
method CUDART_CHECK (line 120) | def CUDART_CHECK(self, result: cudaError_t) -> None:
method cudaGetErrorString (line 125) | def cudaGetErrorString(self, error: cudaError_t) -> str:
method cudaSetDevice (line 128) | def cudaSetDevice(self, device: int) -> None:
method cudaDeviceSynchronize (line 131) | def cudaDeviceSynchronize(self) -> None:
method cudaDeviceReset (line 134) | def cudaDeviceReset(self) -> None:
method cudaMalloc (line 137) | def cudaMalloc(self, size: int) -> ctypes.c_void_p:
method cudaFree (line 142) | def cudaFree(self, devPtr: ctypes.c_void_p) -> None:
method cudaMemset (line 145) | def cudaMemset(self, devPtr: ctypes.c_void_p, value: int,
method cudaMemcpy (line 149) | def cudaMemcpy(self, dst: ctypes.c_void_p, src: ctypes.c_void_p,
method cudaIpcGetMemHandle (line 155) | def cudaIpcGetMemHandle(self,
method cudaIpcOpenMemHandle (line 162) | def cudaIpcOpenMemHandle(self,
FILE: archive/ktransformers/server/balance_serve/inference/distributed/custom_all_reduce.py
function _can_p2p (line 25) | def _can_p2p(rank: int, world_size: int) -> bool:
function is_weak_contiguous (line 37) | def is_weak_contiguous(inp: torch.Tensor):
class CustomAllreduce (line 44) | class CustomAllreduce:
method __init__ (line 49) | def __init__(
method create_shared_buffer (line 179) | def create_shared_buffer(
method free_shared_buffer (line 204) | def free_shared_buffer(
method capture (line 212) | def capture(self):
method register_graph_buffers (line 226) | def register_graph_buffers(self):
method should_custom_ar (line 244) | def should_custom_ar(self, inp: torch.Tensor):
method all_reduce (line 259) | def all_reduce(
method custom_all_reduce (line 284) | def custom_all_reduce(self, input: torch.Tensor, bsz_tensor: torch.Ten...
method close (line 302) | def close(self):
method __del__ (line 309) | def __del__(self):
FILE: archive/ktransformers/server/balance_serve/inference/distributed/custom_all_reduce_utils.py
function producer (line 19) | def producer(
function consumer (line 53) | def consumer(
function can_actually_p2p (line 94) | def can_actually_p2p(
function gpu_p2p_access_check (line 194) | def gpu_p2p_access_check(src: int, tgt: int) -> bool:
FILE: archive/ktransformers/server/balance_serve/inference/distributed/parallel_state.py
class GraphCaptureContext (line 43) | class GraphCaptureContext:
function _split_tensor_dict (line 50) | def _split_tensor_dict(
function _get_unique_name (line 79) | def _get_unique_name(name: str) -> str:
function _register_group (line 95) | def _register_group(group: "GroupCoordinator") -> None:
function inplace_all_reduce (line 101) | def inplace_all_reduce(tensor: torch.Tensor, group_name: str) -> None:
function inplace_all_reduce_fake (line 108) | def inplace_all_reduce_fake(tensor: torch.Tensor, group_name: str) -> None:
function outplace_all_reduce (line 118) | def outplace_all_reduce(tensor: torch.Tensor, group_name: str, bsz_tenso...
function outplace_all_reduce_fake (line 125) | def outplace_all_reduce_fake(tensor: torch.Tensor, group_name: str, bsz_...
class GroupCoordinator (line 136) | class GroupCoordinator:
method __init__ (line 169) | def __init__(
method first_rank (line 271) | def first_rank(self):
method last_rank (line 276) | def last_rank(self):
method is_first_rank (line 281) | def is_first_rank(self):
method is_last_rank (line 286) | def is_last_rank(self):
method next_rank (line 291) | def next_rank(self):
method prev_rank (line 298) | def prev_rank(self):
method graph_capture (line 305) | def graph_capture(
method all_reduce (line 352) | def all_reduce(self, input_: torch.Tensor, bsz_tensor: torch.Tensor, i...
method _all_reduce_out_place (line 406) | def _all_reduce_out_place(self, input_: torch.Tensor, bsz_tensor: torc...
method _all_reduce_in_place (line 414) | def _all_reduce_in_place(self, input_: torch.Tensor) -> None:
method all_gather (line 421) | def all_gather(self, input_: torch.Tensor, dim: int = -1) -> torch.Ten...
method gather (line 464) | def gather(
method broadcast (line 499) | def broadcast(self, input_: torch.Tensor, src: int = 0):
method broadcast_object (line 514) | def broadcast_object(self, obj: Optional[Any] = None, src: int = 0):
method broadcast_object_list (line 538) | def broadcast_object_list(
method send_object (line 555) | def send_object(self, obj: Any, dst: int) -> None:
method recv_object (line 582) | def recv_object(self, src: int) -> Any:
method broadcast_tensor_dict (line 618) | def broadcast_tensor_dict(
method send_tensor_dict (line 700) | def send_tensor_dict(
method recv_tensor_dict (line 753) | def recv_tensor_dict(
method barrier (line 815) | def barrier(self):
method send (line 824) | def send(self, tensor: torch.Tensor, dst: Optional[int] = None) -> None:
method recv (line 836) | def recv(
method destroy (line 852) | def destroy(self):
function get_world_group (line 870) | def get_world_group() -> GroupCoordinator:
function init_world_group (line 875) | def init_world_group(
function init_model_parallel_group (line 891) | def init_model_parallel_group(
function get_tp_group (line 918) | def get_tp_group() -> GroupCoordinator:
function get_pp_group (line 929) | def get_pp_group() -> GroupCoordinator:
function graph_capture (line 939) | def graph_capture():
function set_custom_all_reduce (line 962) | def set_custom_all_reduce(enable: bool):
function init_distributed_environment (line 967) | def init_distributed_environment(
function initialize_model_parallel (line 1014) | def initialize_model_parallel(
function ensure_model_parallel_initialized (line 1091) | def ensure_model_parallel_initialized(
function model_parallel_is_initialized (line 1120) | def model_parallel_is_initialized():
function patch_tensor_parallel_group (line 1129) | def patch_tensor_parallel_group(tp_group: GroupCoordinator):
function get_tensor_model_parallel_world_size (line 1153) | def get_tensor_model_parallel_world_size():
function get_tensor_model_parallel_rank (line 1158) | def get_tensor_model_parallel_rank():
function destroy_model_parallel (line 1163) | def destroy_model_parallel():
function destroy_distributed_environment (line 1176) | def destroy_distributed_environment():
function cleanup_dist_env_and_memory (line 1185) | def cleanup_dist_env_and_memory(shutdown_ray: bool = False):
function in_the_same_node_as (line 1199) | def in_the_same_node_as(pg: ProcessGroup, source_rank: int = 0) -> List[...
FILE: archive/ktransformers/server/balance_serve/inference/distributed/pynccl.py
class PyNcclCommunicator (line 21) | class PyNcclCommunicator:
method __init__ (line 23) | def __init__(
method all_reduce (line 119) | def all_reduce(
method send (line 143) | def send(self, tensor: torch.Tensor, dst: int, stream=None):
method recv (line 161) | def recv(self, tensor: torch.Tensor, src: int, stream=None):
method change_state (line 180) | def change_state(
FILE: archive/ktransformers/server/balance_serve/inference/distributed/pynccl_wrapper.py
class ncclUniqueId (line 41) | class ncclUniqueId(ctypes.Structure):
class ncclDataTypeEnum (line 51) | class ncclDataTypeEnum:
method from_torch (line 70) | def from_torch(cls, dtype: torch.dtype) -> int:
class ncclRedOpTypeEnum (line 93) | class ncclRedOpTypeEnum:
method from_torch (line 102) | def from_torch(cls, op: ReduceOp) -> int:
class Function (line 117) | class Function:
class NCCLLibrary (line 123) | class NCCLLibrary:
method __init__ (line 184) | def __init__(self, so_file: Optional[str] = None):
method ncclGetErrorString (line 215) | def ncclGetErrorString(self, result: ncclResult_t) -> str:
method NCCL_CHECK (line 218) | def NCCL_CHECK(self, result: ncclResult_t) -> None:
method ncclGetVersion (line 223) | def ncclGetVersion(self) -> str:
method ncclGetUniqueId (line 233) | def ncclGetUniqueId(self) -> ncclUniqueId:
method ncclCommInitRank (line 239) | def ncclCommInitRank(self, world_size: int, unique_id: ncclUniqueId,
method ncclAllReduce (line 247) | def ncclAllReduce(self, sendbuff: buffer_type, recvbuff: buffer_type,
method ncclSend (line 259) | def ncclSend(self, sendbuff: buffer_type, count: int, datatype: int,
method ncclRecv (line 264) | def ncclRecv(self, recvbuff: buffer_type, count: int, datatype: int,
method ncclCommDestroy (line 269) | def ncclCommDestroy(self, comm: ncclComm_t) -> None:
FILE: archive/ktransformers/server/balance_serve/inference/distributed/utils.py
function ensure_divisibility (line 17) | def ensure_divisibility(numerator, denominator):
function divide (line 24) | def divide(numerator, denominator):
function split_tensor_along_last_dim (line 31) | def split_tensor_along_last_dim(
function get_pp_indices (line 59) | def get_pp_indices(
class StatelessProcessGroup (line 92) | class StatelessProcessGroup:
method __post_init__ (line 113) | def __post_init__(self):
method send_obj (line 119) | def send_obj(self, obj: Any, dst: int):
method expire_data (line 127) | def expire_data(self):
method recv_obj (line 138) | def recv_obj(self, src: int) -> Any:
method broadcast_obj (line 146) | def broadcast_obj(self, obj: Optional[Any], src: int) -> Any:
method all_gather_obj (line 164) | def all_gather_obj(self, obj: Any) -> list[Any]:
method barrier (line 176) | def barrier(self):
method create (line 185) | def create(
FILE: archive/ktransformers/server/balance_serve/inference/forward_batch.py
class ForwardMiniBatchCombine (line 18) | class ForwardMiniBatchCombine:
method __init__ (line 36) | def __init__(self, prefill_querys_info: list[QueryInfo], decode_querys...
method fill (line 99) | def fill(self, prefill_querys_info: list[QueryInfo], decode_querys_inf...
method __str__ (line 168) | def __str__(self):
class ForwardMiniBatchSplit (line 177) | class ForwardMiniBatchSplit:
method __init__ (line 202) | def __init__(
method fill (line 466) | def fill(
method __str__ (line 719) | def __str__(self):
class ForwardBatchInput (line 732) | class ForwardBatchInput:
method __init__ (line 739) | def __init__(self, batch : sched_ext.BatchQueryTodo = None, query_mana...
method gen_max_forward_batch (line 769) | def gen_max_forward_batch(
method fill (line 821) | def fill(self, batch : sched_ext.BatchQueryTodo = None, query_manager:...
class ForwardBatchOutput (line 845) | class ForwardBatchOutput:
method __init__ (line 856) | def __init__(self):
method merge (line 867) | def merge(self, new_output):
method __str__ (line 877) | def __str__(self):
FILE: archive/ktransformers/server/balance_serve/inference/model_runner.py
function pad_num_tokens (line 53) | def pad_num_tokens(num_tokens):
function deduplicate_and_sort (line 56) | def deduplicate_and_sort(lst):
function generate_cuda_graphs (line 58) | def generate_cuda_graphs(chunk_size: int) -> list:
class ModelRunner (line 69) | class ModelRunner:
method __init__ (line 80) | def __init__(self, model = None, cache = None, device = None, use_cuda...
method model_attn_plan (line 135) | def model_attn_plan(self, batch, cuda_graph_idx=0):
method warmup (line 151) | def warmup(self):
method warmup_npu (line 206) | def warmup_npu(self):
method run (line 267) | def run(self, batch: sched_ext.BatchQueryTodo = None, query_manager: Q...
method run_split (line 349) | def run_split(self, batch: sched_ext.BatchQueryTodo = None, query_mana...
method replay (line 465) | def replay(self, cuda_graph_idx=-1):
method sync (line 478) | def sync(self, calc_time = True):
function get_or_create_model_runner (line 484) | def get_or_create_model_runner(model=None, cache=None, device=None, use_...
FILE: archive/ktransformers/server/balance_serve/inference/query_manager.py
class QueryInfo (line 13) | class QueryInfo:
method __init__ (line 32) | def __init__(self, id, query_length: int, max_length: int, page_size: ...
method check_stop (line 58) | def check_stop(self):
method print (line 93) | def print(self):
class QueryManager (line 101) | class QueryManager:
method __init__ (line 108) | def __init__(self, max_length = 65536, page_size = 256, device = torch...
method print (line 114) | def print(self, hint: str = ""):
method add_query (line 122) | def add_query(self, batch: sched_ext.BatchQueryTodo):
method update (line 148) | def update(self, batch: sched_ext.BatchQueryTodo) -> list[sched_ext.Qu...
FILE: archive/ktransformers/server/balance_serve/inference/sampling/penaltylib/orchestrator.py
class _ReqLike (line 9) | class _ReqLike:
class _BatchLike (line 14) | class _BatchLike:
method batch_size (line 17) | def batch_size(self):
class BatchedPenalizerOrchestrator (line 21) | class BatchedPenalizerOrchestrator:
method __init__ (line 27) | def __init__(
method reqs (line 51) | def reqs(self):
method batch_size (line 54) | def batch_size(self):
method cumulate_input_tokens (line 57) | def cumulate_input_tokens(
method cumulate_output_tokens (line 74) | def cumulate_output_tokens(
method apply (line 94) | def apply(self, logits: torch.Tensor) -> torch.Tensor:
method filter (line 113) | def filter(
method merge (line 149) | def merge(self, their: "BatchedPenalizerOrchestrator"):
class _TokenIDs (line 171) | class _TokenIDs:
method __init__ (line 185) | def __init__(
method occurrence_count (line 204) | def occurrence_count(self) -> torch.Tensor:
class _BatchedPenalizer (line 244) | class _BatchedPenalizer(abc.ABC):
method __init__ (line 252) | def __init__(self, orchestrator: BatchedPenalizerOrchestrator):
method is_prepared (line 255) | def is_prepared(self) -> bool:
method is_required (line 258) | def is_required(self) -> bool:
method prepare (line 261) | def prepare(self):
method prepare_if_required (line 266) | def prepare_if_required(self):
method teardown (line 273) | def teardown(self):
method cumulate_input_tokens (line 278) | def cumulate_input_tokens(self, input_ids: _TokenIDs):
method cumulate_output_tokens (line 284) | def cumulate_output_tokens(self, output_ids: _TokenIDs):
method apply (line 290) | def apply(self, logits: torch.Tensor) -> torch.Tensor:
method filter (line 296) | def filter(
method merge (line 307) | def merge(self, their: "_BatchedPenalizer"):
method _is_required (line 316) | def _is_required(self) -> bool:
method _prepare (line 323) | def _prepare(self):
method _teardown (line 331) | def _teardown(self):
method _cumulate_input_tokens (line 339) | def _cumulate_input_tokens(self, input_ids: _TokenIDs):
method _cumulate_output_tokens (line 347) | def _cumulate_output_tokens(self, output_ids: _TokenIDs):
method _apply (line 355) | def _apply(self, logits: torch.Tensor) -> torch.Tensor:
method _filter (line 363) | def _filter(
method _merge (line 372) | def _merge(self, their: "_BatchedPenalizer"):
FILE: archive/ktransformers/server/balance_serve/inference/sampling/penaltylib/penalizers/frequency_penalty.py
class BatchedFrequencyPenalizer (line 8) | class BatchedFrequencyPenalizer(_BatchedPenalizer):
method _is_required (line 16) | def _is_required(self) -> bool:
method _prepare (line 22) | def _prepare(self):
method _teardown (line 46) | def _teardown(self):
method _cumulate_input_tokens (line 53) | def _cumulate_input_tokens(self, input_ids: _TokenIDs):
method _cumulate_output_tokens (line 56) | def _cumulate_output_tokens(self, output_ids: _TokenIDs):
method _apply (line 61) | def _apply(self, logits: torch.Tensor) -> torch.Tensor:
method _filter (line 65) | def _filter(
method _merge (line 73) | def _merge(self, their: "BatchedFrequencyPenalizer"):
FILE: archive/ktransformers/server/balance_serve/inference/sampling/penaltylib/penalizers/min_new_tokens.py
class BatchedMinNewTokensPenalizer (line 8) | class BatchedMinNewTokensPenalizer(_BatchedPenalizer):
method _is_required (line 17) | def _is_required(self) -> bool:
method _prepare (line 22) | def _prepare(self):
method _teardown (line 72) | def _teardown(self):
method _cumulate_input_tokens (line 81) | def _cumulate_input_tokens(self, input_ids: _TokenIDs):
method _cumulate_output_tokens (line 84) | def _cumulate_output_tokens(self, output_ids: _TokenIDs):
method _apply (line 87) | def _apply(self, logits: torch.Tensor) -> torch.Tensor:
method _filter (line 92) | def _filter(
method _merge (line 99) | def _merge(self, their: "BatchedMinNewTokensPenalizer"):
FILE: archive/ktransformers/server/balance_serve/inference/sampling/penaltylib/penalizers/presence_penalty.py
class BatchedPresencePenalizer (line 8) | class BatchedPresencePenalizer(_BatchedPenalizer):
method _is_required (line 16) | def _is_required(self) -> bool:
method _prepare (line 22) | def _prepare(self):
method _teardown (line 46) | def _teardown(self):
method _cumulate_input_tokens (line 53) | def _cumulate_input_tokens(self, input_ids: _TokenIDs):
method _cumulate_output_tokens (line 56) | def _cumulate_output_tokens(self, output_ids: _TokenIDs):
method _apply (line 60) | def _apply(self, logits: torch.Tensor) -> torch.Tensor:
method _filter (line 64) | def _filter(
method _merge (line 72) | def _merge(self, their: "BatchedPresencePenalizer"):
FILE: archive/ktransformers/server/balance_serve/inference/sampling/penaltylib/penalizers/repetition_penalty.py
class BatchedRepetitionPenalizer (line 8) | class BatchedRepetitionPenalizer(_BatchedPenalizer):
method _is_required (line 16) | def _is_required(self) -> bool:
method _prepare (line 22) | def _prepare(self):
method _teardown (line 46) | def _teardown(self):
method _cumulate_input_tokens (line 53) | def _cumulate_input_tokens(self, input_ids: _TokenIDs):
method _cumulate_output_tokens (line 57) | def _cumulate_output_tokens(self, output_ids: _TokenIDs):
method _apply (line 61) | def _apply(self, logits: torch.Tensor) -> torch.Tensor:
method _filter (line 68) | def _filter(
method _merge (line 76) | def _merge(self, their: "BatchedRepetitionPenalizer"):
FILE: archive/ktransformers/server/balance_serve/inference/sampling/sampler.py
class SamplingOptions (line 25) | class SamplingOptions():
method __init__ (line 38) | def __init__(self, bsz = 1, device = torch.device('cuda'), pretrained_...
class Sampler (line 59) | class Sampler(nn.Module):
method __init__ (line 60) | def __init__(self):
method forward (line 63) | def forward(
FILE: archive/ktransformers/server/balance_serve/sched_rpc.py
class SchedulerServer (line 31) | class SchedulerServer:
method __init__ (line 32) | def __init__(self, settings, main_args):
method run_scheduler (line 50) | def run_scheduler(self):
method stop_scheduler (line 54) | def stop_scheduler(self):
method start_proxy (line 58) | def start_proxy(self):
method worker_routine (line 63) | def worker_routine(self):
method start_rpc_service (line 129) | def start_rpc_service(self):
method stop_rpc_service (line 148) | def stop_rpc_service(self):
function start_server (line 154) | def start_server(settings, main_args):
class SchedulerClient (line 160) | class SchedulerClient:
method __init__ (line 161) | def __init__(self, sched_port):
method __del__ (line 169) | def __del__(self):
method send_request (line 173) | def send_request(self, method, params=None):
method add_query (line 190) | def add_query(self, query):
method cancel_query (line 194) | def cancel_query(self, query_id):
method update_last_batch (line 197) | def update_last_batch(self, updates):
method rebuild_inferece_context (line 202) | def rebuild_inferece_context(self,response):
method get_inference_context_raw (line 210) | def get_inference_context_raw(self):
FILE: archive/ktransformers/server/balance_serve/settings.py
function create_sched_settings (line 19) | def create_sched_settings(args):
function create_sched_settings_qwen2moe (line 71) | def create_sched_settings_qwen2moe(args):
function create_sched_settings_qwen3moe (line 125) | def create_sched_settings_qwen3moe(args):
function create_sched_settings_glm4moe (line 177) | def create_sched_settings_glm4moe(args):
function create_sched_settings_smallthinker (line 229) | def create_sched_settings_smallthinker(args):
function create_sched_settings_qwen3next (line 281) | def create_sched_settings_qwen3next(args):
FILE: archive/ktransformers/server/config/config.py
class Config (line 20) | class Config(metaclass=Singleton):
method load (line 26) | def load() -> dict:
method to_path (line 53) | def to_path(path: str) -> str:
method __init__ (line 61) | def __init__(self):
FILE: archive/ktransformers/server/config/log.py
class DailyRotatingFileHandler (line 25) | class DailyRotatingFileHandler(BaseRotatingHandler):
method __init__ (line 32) | def __init__(self, filename, backupCount=0, encoding=None, delay=False...
method shouldRollover (line 46) | def shouldRollover(self, record):
method doRollover (line 59) | def doRollover(self):
method _compute_fn (line 78) | def _compute_fn(self):
method _open (line 84) | def _open(self):
method delete_expired_files (line 106) | def delete_expired_files(self):
class Logger (line 132) | class Logger(object):
method __init__ (line 144) | def __init__(self, level: str = 'info'):
FILE: archive/ktransformers/server/config/singleton.py
class Singleton (line 13) | class Singleton(abc.ABCMeta, type):
method __call__ (line 24) | def __call__(cls, *args, **kwds):
class AbstractSingleton (line 29) | class AbstractSingleton(abc.ABC, metaclass=Singleton):
FILE: archive/ktransformers/server/crud/assistants/assistants.py
class AssistantDatabaseManager (line 12) | class AssistantDatabaseManager:
method __init__ (line 13) | def __init__(self) -> None:
method create_assistant_object (line 16) | def create_assistant_object(self, assistant: AssistantCreate) -> Assis...
method db_count_assistants (line 25) | def db_count_assistants(self) -> int:
method db_create_assistant (line 29) | def db_create_assistant(self, assistant: AssistantCreate):
method db_list_assistants (line 34) | def db_list_assistants(self, limit: Optional[int], order: Order) -> Li...
method db_get_assistant_by_id (line 44) | def db_get_assistant_by_id(self, assistant_id: str) -> Optional[Assist...
method db_update_assistant_by_id (line 53) | def db_update_assistant_by_id(self, assistant_id: str, assistant: Assi...
method db_delete_assistant_by_id (line 60) | def db_delete_assistant_by_id(self, assistant_id: str):
FILE: archive/ktransformers/server/crud/assistants/messages.py
class MessageDatabaseManager (line 10) | class MessageDatabaseManager:
method __init__ (line 11) | def __init__(self) -> None:
method create_db_message_by_core (line 15) | def create_db_message_by_core(message: MessageCore):
method create_db_message (line 19) | def create_db_message(self, message: MessageCreate):
method db_add_message (line 22) | def db_add_message(self, message: Message):
method db_create_message (line 27) | def db_create_message(self, thread_id: str, message: MessageCreate, st...
method create_message_object (line 35) | def create_message_object(thread_id: ObjectID, run_id: ObjectID, messa...
method db_sync_message (line 47) | def db_sync_message(self, message: MessageObject):
method db_list_messages_of_thread (line 54) | def db_list_messages_of_thread(
method db_get_message_by_id (line 72) | def db_get_message_by_id(self, thread_id: ObjectID, message_id: Object...
method db_delete_message_by_id (line 80) | def db_delete_message_by_id(self, thread_id: ObjectID, message_id: Obj...
FILE: archive/ktransformers/server/crud/assistants/runs.py
class RunsDatabaseManager (line 10) | class RunsDatabaseManager:
method __init__ (line 11) | def __init__(self) -> None:
method create_run_object (line 14) | def create_run_object(self, thread_id: ObjectID, run: RunCreate) -> Ru...
method db_create_run (line 26) | def db_create_run(self, thread_id: str, run: RunCreate):
method db_sync_run (line 40) | def db_sync_run(self, run: RunObject) -> None:
method db_get_run (line 47) | def db_get_run(self, run_id: ObjectID) -> RunObject:
FILE: archive/ktransformers/server/crud/assistants/threads.py
class ThreadsDatabaseManager (line 15) | class ThreadsDatabaseManager:
method __init__ (line 16) | def __init__(self) -> None:
method db_create_thread (line 21) | def db_create_thread(self, thread: ThreadCreate):
method db_get_thread_by_id (line 54) | def db_get_thread_by_id(self, thread_id: ObjectID):
method db_list_threads (line 59) | def db_list_threads(self, limit: Optional[int], order: Order) -> List[...
method db_list_threads_preview (line 71) | def db_list_threads_preview(self, limit: Optional[int], order: Order) ...
method db_delete_thread_by_id (line 88) | def db_delete_thread_by_id(self, thread_id: ObjectID):
FILE: archive/ktransformers/server/exceptions.py
function db_exception (line 4) | def db_exception():
function not_implemented (line 11) | def not_implemented(what):
function internal_server_error (line 18) | def internal_server_error(what):
function request_error (line 22) | def request_error(what):
FILE: archive/ktransformers/server/main.py
function mount_app_routes (line 29) | def mount_app_routes(mount_app: FastAPI):
function create_app (line 37) | def create_app():
function update_web_port (line 57) | def update_web_port(config_file: str):
function mount_index_routes (line 69) | def mount_index_routes(app: FastAPI):
function run_api (line 83) | def run_api(app, host, port, **kwargs):
function custom_openapi (line 96) | def custom_openapi(app):
function verify_arg (line 111) | def verify_arg(args):
function main (line 127) | def main():
FILE: archive/ktransformers/server/models/assistants/assistants.py
class Assistant (line 7) | class Assistant(Base):
FILE: archive/ktransformers/server/models/assistants/messages.py
class Message (line 7) | class Message(Base):
FILE: archive/ktransformers/server/models/assistants/run_steps.py
class RunStep (line 7) | class RunStep(Base):
FILE: archive/ktransformers/server/models/assistants/runs.py
class Run (line 7) | class Run(Base):
FILE: archive/ktransformers/server/models/assistants/threads.py
class Thread (line 7) | class Thread(Base):
FILE: archive/ktransformers/server/schemas/assistants/assistants.py
class AssistantBase (line 21) | class AssistantBase(BaseModel):
method validate_tools (line 28) | def validate_tools(cls, value):
method validate_tool_resources (line 51) | def validate_tool_resources(cls, value):
method convert_meta_data (line 70) | def convert_meta_data(cls, values):
class AssistantCreate (line 79) | class AssistantCreate(AssistantBase):
class AssistantBuildStatus (line 83) | class AssistantBuildStatus(BaseModel):
class Status (line 84) | class Status(Enum):
method to_stream_reply (line 112) | def to_stream_reply(self) -> str:
class AssistantObject (line 116) | class AssistantObject(AssistantBase, ObjectWithCreatedTime):
method as_api_response (line 123) | def as_api_response(self):
method get_related_threads_ids (line 126) | def get_related_threads_ids(self) -> List[ObjectID]:
method get_related_threads_objects (line 133) | def get_related_threads_objects(self) -> List:
method append_related_threads (line 145) | def append_related_threads(self, thread_ids: List[ObjectID]):
method update_build_status (line 156) | async def update_build_status(self, events: AsyncIterable) -> AsyncIte...
method get_build_status (line 178) | def get_build_status(self) -> AssistantBuildStatus:
method sync_db (line 182) | def sync_db(self)->None:
method get_encoded_instruction (line 191) | def get_encoded_instruction(self,encode_fn:Callable)->torch.Tensor:
class AssistantModify (line 198) | class AssistantModify(AssistantBase):
FILE: archive/ktransformers/server/schemas/assistants/messages.py
class IncompleteDetails (line 15) | class IncompleteDetails(BaseModel):
class ContentType (line 19) | class ContentType(Enum):
class ContentObject (line 25) | class ContentObject(BaseModel):
class ImageFile (line 29) | class ImageFile(BaseModel):
class ImageFileObject (line 34) | class ImageFileObject(ContentObject):
class ImageUrl (line 38) | class ImageUrl(BaseModel):
class ImageUrlObject (line 43) | class ImageUrlObject(ContentObject):
class Annotation (line 47) | class Annotation(BaseModel):
class Text (line 51) | class Text(BaseModel):
class TextObject (line 56) | class TextObject(ContentObject):
method filter_append (line 62) | def filter_append(self,text:str):
class Attachment (line 72) | class Attachment(BaseModel):
class Role (line 77) | class Role(Enum):
method is_user (line 81) | def is_user(self)->bool:
class MessageCore (line 85) | class MessageCore(BaseModel):
method convert_meta_data (line 92) | def convert_meta_data(cls,values):
class MessageBase (line 98) | class MessageBase(MessageCore):
class Status (line 99) | class Status(Enum):
class MessageObject (line 116) | class MessageObject(MessageBase, ObjectWithCreatedTime):
method get_text_content (line 120) | def get_text_content(self) -> str:
method get_encoded_content (line 129) | async def get_encoded_content(self,encode_fn:Callable):
method get_attached_files (line 142) | def get_attached_files(self):
method append_message_delta (line 147) | def append_message_delta(self,text:str):
method sync_db (line 150) | def sync_db(self):
method stream_response_with_event (line 160) | def stream_response_with_event(self, event: MessageBase.Status) -> Mes...
class MessageStreamResponse (line 169) | class MessageStreamResponse(BaseModel):
method to_stream_reply (line 173) | def to_stream_reply(self):
class MessageCreate (line 177) | class MessageCreate(BaseModel):
method convert_meta_data (line 184) | def convert_meta_data(cls,values):
method to_core (line 189) | def to_core(self) -> MessageCore:
class MessageModify (line 206) | class MessageModify(BaseModel):
method convert_meta_data (line 210) | def convert_meta_data(cls,values):
FILE: archive/ktransformers/server/schemas/assistants/runs.py
class ToolCall (line 13) | class ToolCall(BaseModel):
class SubmitToolOutputs (line 19) | class SubmitToolOutputs(BaseModel):
class RequiredAction (line 23) | class RequiredAction(BaseModel):
class LastError (line 28) | class LastError(BaseModel):
class IncompleteDetails (line 33) | class IncompleteDetails(BaseModel):
class Usage (line 37) | class Usage(BaseModel):
class TruncationStrategy (line 43) | class TruncationStrategy(BaseModel):
class ToolChoiceType (line 48) | class ToolChoiceType(Enum):
class RunBase (line 54) | class RunBase(BaseModel):
class Status (line 55) | class Status(Enum):
method convert_meta_data (line 84) | def convert_meta_data(cls,values):
method set_compute_save (line 89) | def set_compute_save(self,save:int):
class RunObject (line 104) | class RunObject(RunBase, ObjectWithCreatedTime):
method stream_response_with_event (line 105) | def stream_response_with_event(self,event:RunBase.Status)->RunStreamRe...
method sync_db (line 114) | def sync_db(self):
method create_message_creation_step (line 123) | def create_message_creation_step(self):
class RunStreamResponse (line 127) | class RunStreamResponse(BaseModel):
method to_stream_reply (line 130) | def to_stream_reply(self):
class RunCreate (line 133) | class RunCreate(BaseModel):
method convert_meta_data (line 144) | def convert_meta_data(cls,values):
class RunThreadCreate (line 159) | class RunThreadCreate(BaseModel):
method convert_meta_data (line 169) | def convert_meta_data(cls,values):
class RunModify (line 184) | class RunModify(BaseModel):
method convert_meta_data (line 188) | def convert_meta_data(cls,values):
class ToolOutput (line 194) | class ToolOutput(BaseModel):
class RunSubmit (line 199) | class RunSubmit(BaseModel):
FILE: archive/ktransformers/server/schemas/assistants/streaming.py
class TextObjectWithIndex (line 15) | class TextObjectWithIndex(TextObject):
class ImageFileObjectWithIndex (line 19) | class ImageFileObjectWithIndex(ImageFileObject):
class ImageUrlObjectWithIndex (line 23) | class ImageUrlObjectWithIndex(ImageUrlObject):
class MessageDeltaImpl (line 31) | class MessageDeltaImpl(BaseModel):
class MessageDelta (line 36) | class MessageDelta(Object):
method to_stream_reply (line 39) | def to_stream_reply(self):
function text_delta (line 43) | def text_delta(index: int, text: str):
function append_message_delta (line 47) | def append_message_delta(self: MessageObject, text: str):
class RunStepDeltaImpl (line 63) | class RunStepDeltaImpl(BaseModel):
class RunStepDelta (line 67) | class RunStepDelta(Object):
method to_stream_reply (line 70) | def to_stream_reply(self):
class Done (line 74) | class Done():
method to_stream_reply (line 75) | def to_stream_reply(self):
function check_client_link (line 79) | async def check_client_link(request: Request, async_events: AsyncIterable):
function add_done (line 86) | async def add_done(async_events: AsyncIterable):
function to_stream_reply (line 92) | async def to_stream_reply(async_events: AsyncIterable):
function filter_api_event (line 100) | async def filter_api_event(async_events: AsyncIterable):
function filter_chat_chunk (line 106) | async def filter_chat_chunk(async_events: AsyncIterable):
function filter_by_types (line 112) | async def filter_by_types(async_events: AsyncIterable, types: List):
function api_stream_response (line 120) | def api_stream_response(request: Request, async_events: AsyncIterable):
function chat_stream_response (line 124) | def chat_stream_response(request: Request, async_events: AsyncIterable):
function stream_response (line 128) | def stream_response(request: Request, async_events: AsyncIterable):
function check_link_response (line 132) | def check_link_response(request: Request, async_events: AsyncIterable):
function wrap_async_generator_into_queue (line 136) | def wrap_async_generator_into_queue(async_events: AsyncIterable) -> asyn...
function unwrap_async_queue (line 151) | async def unwrap_async_queue(queue: asyncio.Queue) -> AsyncIterable:
function unwrap_async_queue_slow (line 163) | async def unwrap_async_queue_slow(queue: asyncio.Queue) -> AsyncIterable:
FILE: archive/ktransformers/server/schemas/assistants/threads.py
class ThreadBase (line 12) | class ThreadBase(BaseModel):
method convert_meta_data (line 16) | def convert_meta_data(cls,values):
class ThreadObject (line 24) | class ThreadObject(ThreadBase, ObjectWithCreatedTime):
method check_is_related_threads (line 28) | def check_is_related_threads(self)->Self:
class StreamEvent (line 34) | class StreamEvent(Enum):
method to_stream_reply (line 37) | def to_stream_reply(self,event:StreamEvent):
class ThreadCreate (line 41) | class ThreadCreate(ThreadBase):
class ThreadModify (line 45) | class ThreadModify(ThreadBase):
FILE: archive/ktransformers/server/schemas/assistants/tool.py
class ToolType (line 9) | class ToolType(str, Enum):
class ToolBase (line 16) | class ToolBase(BaseModel):
class CodeInterpreter (line 20) | class CodeInterpreter(ToolBase):
class FileSearch (line 24) | class FileSearch(ToolBase):
class RelatedThreads (line 28) | class RelatedThreads(ToolBase):
class FuntionTool (line 32) | class FuntionTool(ToolBase):
class CodeInterpreterResource (line 41) | class CodeInterpreterResource(BaseModel):
class FileSearchResource (line 45) | class FileSearchResource(BaseModel):
class RelatedThreadsResource (line 50) | class RelatedThreadsResource(BaseModel):
FILE: archive/ktransformers/server/schemas/base.py
class Object (line 12) | class Object(BaseModel):
class ObjectWithCreatedTime (line 20) | class ObjectWithCreatedTime(Object):
class Order (line 25) | class Order(str, Enum):
method to_sqlalchemy_order (line 29) | def to_sqlalchemy_order(self):
class DeleteResponse (line 41) | class DeleteResponse(Object):
class OperationResponse (line 44) | class OperationResponse(BaseModel):
FILE: archive/ktransformers/server/schemas/conversation.py
class ThreadPreview (line 9) | class ThreadPreview(BaseModel):
FILE: archive/ktransformers/server/schemas/endpoints/chat.py
class CompletionUsage (line 13) | class CompletionUsage(BaseModel):
class Role (line 22) | class Role(Enum):
class Message (line 29) | class Message(BaseModel):
method to_tokenizer_message (line 36) | def to_tokenizer_message(self):
class FunctionParameters (line 48) | class FunctionParameters(BaseModel):
class FunctionDefinition (line 53) | class FunctionDefinition(BaseModel):
class ToolFunction (line 58) | class ToolFunction(BaseModel):
class Tool (line 61) | class Tool(BaseModel):
class ChatCompletionCreate (line 65) | class ChatCompletionCreate(BaseModel):
method get_tokenizer_messages (line 79) | def get_tokenizer_messages(self):
class ChatCompletionChunk (line 82) | class ChatCompletionChunk(BaseModel):
method to_stream_reply (line 92) | def to_stream_reply(self):
class RawUsage (line 95) | class RawUsage(BaseModel):
FILE: archive/ktransformers/server/schemas/legacy/completions.py
class CompletionCreate (line 7) | class CompletionCreate(BaseModel):
method get_tokenizer_messages (line 16) | def get_tokenizer_messages(self):
class FinishReason (line 22) | class FinishReason(Enum):
class Choice (line 26) | class Choice(BaseModel):
class CompletionObject (line 33) | class CompletionObject(Object):
method set_token (line 40) | def set_token(self,token:str):
method append_token (line 45) | def append_token(self,token:str):
method to_stream_reply (line 50) | def to_stream_reply(self):
FILE: archive/ktransformers/server/utils/create_interface.py
function create_interface (line 19) | def create_interface(config: Config, default_args: ConfigArgs, input_arg...
class GlobalContextManager (line 38) | class GlobalContextManager:
class GlobalInterface (line 40) | class GlobalInterface:
function get_thread_context_manager (line 43) | def get_thread_context_manager() -> GlobalContextManager:
function get_interface (line 45) | def get_interface() -> GlobalInterface:
FILE: archive/ktransformers/server/utils/multi_timer.py
function format_time (line 4) | def format_time(seconds):
class Profiler (line 20) | class Profiler:
method __init__ (line 21) | def __init__(self):
method create_timer (line 25) | def create_timer(self, name):
method start_timer (line 32) | def start_timer(self, name):
method pause_timer (line 40) | def pause_timer(self, name):
method get_timer_sec (line 48) | def get_timer_sec(self, name):
method get_all_timers (line 57) | def get_all_timers(self):
method report_timer_string (line 63) | def report_timer_string(self, name):
method create_and_start_timer (line 66) | def create_and_start_timer(self, name):
method inc (line 72) | def inc(self,key:str,delta:int=1):
method set_counter (line 75) | def set_counter(self,key:str,to=0):
method get_counter (line 78) | def get_counter(self,key:str):
FILE: archive/ktransformers/server/utils/serve_profiling.py
class ProfStatKey (line 8) | class ProfStatKey(StrEnum):
class ProfTimeStat (line 15) | class ProfTimeStat:
method __init__ (line 16) | def __init__(self):
method record_start_time (line 30) | def record_start_time(self):
method add_time_stat (line 34) | def add_time_stat(self, key: ProfStatKey, time_ns, is_prefill):
method print_all (line 45) | def print_all(self):
method reset_all (line 58) | def reset_all(self):
class ProfStatItem (line 65) | class ProfStatItem:
method __init__ (line 66) | def __init__(self):
method add_item (line 75) | def add_item(self, cost_time_ns):
method reset (line 88) | def reset(self):
method get_stat (line 94) | def get_stat(self):
FILE: archive/ktransformers/server/utils/sql_utils.py
class SQLUtil (line 27) | class SQLUtil(metaclass=Singleton):
method __init__ (line 34) | def __init__(self) -> None:
method get_db (line 40) | def get_db(self):
method init_engine (line 53) | def init_engine(cfg: Config):
method create_sqllite_url (line 70) | def create_sqllite_url(cfg):
method db_add_commit_refresh (line 89) | def db_add_commit_refresh(self, session: Session, what):
method db_merge_commit (line 104) | def db_merge_commit(self, session: Session, what):
method db_update_commit_refresh (line 115) | def db_update_commit_refresh(self, session: Session, existing, what):
FILE: archive/ktransformers/tests/AIME_2024/eval_api.py
function generate_text (line 16) | def generate_text(api_url,question , model_name, stream=False, auth_toke...
function load_data (line 40) | def load_data(file_path):
function get_score (line 54) | def get_score(pred, answer):
function run_eval_api (line 74) | def run_eval_api(
function main (line 120) | def main(output_path, api_url, model_name, auth_token, format_tabs,probl...
FILE: archive/ktransformers/tests/AIME_2024/evaluation.py
function filter_answer (line 2) | def filter_answer(completion: str) -> str:
FILE: archive/ktransformers/tests/AIME_2024/prompts.py
function instruct_prompt (line 1) | def instruct_prompt(prompt: str) -> str:
FILE: archive/ktransformers/tests/UT/test_kdeepseek_attention_w8a8a2serve_npu.py
class DummyConfig (line 15) | class DummyConfig:
method __init__ (line 16) | def __init__(self, hidden_size=4, num_attention_heads=1):
class DummyOrigAttn (line 21) | class DummyOrigAttn(nn.Module):
method __init__ (line 22) | def __init__(self, config=None, layer_idx=0):
class DummyDynamicQuantOps (line 35) | class DummyDynamicQuantOps:
method execute (line 36) | def execute(self, inputs):
class DummyMatMulOps (line 41) | class DummyMatMulOps:
method execute (line 42) | def execute(self, inputs):
class DummyQuantProj (line 47) | class DummyQuantProj(nn.Module):
method __init__ (line 48) | def __init__(self, dim):
class DummyStaticCache (line 57) | class DummyStaticCache:
method __init__ (line 58) | def __init__(self, page_size=16):
method get_usable_length (line 61) | def get_usable_length(self, kv_seq_len, layer_idx):
method update (line 64) | def update(self, combined, layer_idx, cache_kwargs):
class DummyNpuFusedAttention (line 68) | class DummyNpuFusedAttention:
method __call__ (line 69) | def __call__(self, q, k, v, **kwargs):
method out (line 77) | def out(self, q, k, v, workspace=None,
class DummyOpsNpu (line 92) | class DummyOpsNpu:
method npu_fused_infer_attention_score (line 93) | def npu_fused_infer_attention_score(self, q, k, v, **kwargs):
function fake_apply_rotary_pos_emb_fusion (line 101) | def fake_apply_rotary_pos_emb_fusion(q_pe, k_pe, cos, sin):
function build_attention_module (line 104) | def build_attention_module(q_lora_rank=None):
function _patch_env (line 175) | def _patch_env(monkeypatch):
function test_print_callback_smoke (line 225) | def test_print_callback_smoke():
function _common_inputs_prefill (line 241) | def _common_inputs_prefill():
function test_forward_prefill_with_mask (line 261) | def test_forward_prefill_with_mask():
function test_forward_prefill_without_mask_and_q_lora (line 298) | def test_forward_prefill_without_mask_and_q_lora():
function test_forward_decode_paged_path (line 335) | def test_forward_decode_paged_path():
function test_forward_prefill_layer_idx_none_raises (line 378) | def test_forward_prefill_layer_idx_none_raises():
function test_forward_prefill_attn_output_shape_mismatch_raises (line 408) | def test_forward_prefill_attn_output_shape_mismatch_raises(monkeypatch):
function test_forward_paged_use_npu_graph (line 452) | def test_forward_paged_use_npu_graph(monkeypatch):
FILE: archive/ktransformers/tests/UT/test_kdeepseek_ln_npu.py
class DummyOrigModule (line 16) | class DummyOrigModule(nn.Module):
method __init__ (line 17) | def __init__(self, hidden_size=4, variance_epsilon=1e-5):
class DummySafeTensorLoader (line 23) | class DummySafeTensorLoader:
method __init__ (line 24) | def __init__(self):
method load_tensor (line 28) | def load_tensor(self, name: str):
class DummyGGUFLoader (line 33) | class DummyGGUFLoader:
method __init__ (line 34) | def __init__(self, safetensor_loader: DummySafeTensorLoader):
class DummyConfig (line 38) | class DummyConfig:
class FakeRMSNorm (line 42) | class FakeRMSNorm:
method __init__ (line 43) | def __init__(self):
method __call__ (line 46) | def __call__(self, hidden_states, weight, eps):
function build_rms_module (line 53) | def build_rms_module(hidden_size=4, eps=1e-5, safetensor_loader=None):
function patch_utils_and_npu (line 70) | def patch_utils_and_npu(monkeypatch):
function get_fake_rms (line 81) | def get_fake_rms():
function test_forward_preserves_shape_and_dtype (line 85) | def test_forward_preserves_shape_and_dtype():
function test_forward_with_bfloat16_dtype (line 103) | def test_forward_with_bfloat16_dtype():
function test_forward_uses_bias (line 114) | def test_forward_uses_bias():
function test_load_from_safetensor_loader (line 132) | def test_load_from_safetensor_loader():
function test_unload_sets_weight_and_bias_to_none_idempotent (line 150) | def test_unload_sets_weight_and_bias_to_none_idempotent():
FILE: archive/ktransformers/tests/function_call_test.py
function send_messages (line 3) | def send_messages(messages):
FILE: archive/ktransformers/tests/humaneval/eval_api.py
function generate_text (line 11) | def generate_text(api_url,question , model_name, stream=False, auth_toke...
function run_eval_api (line 35) | def run_eval_api(
function main (line 81) | def main(output_path, api_url, model_name, auth_token, format_tabs,probl...
FILE: archive/ktransformers/tests/humaneval/evaluation.py
function filter_code (line 2) | def filter_code(completion: str) -> str:
function fix_indents (line 14) | def fix_indents(text: str) -> str:
FILE: archive/ktransformers/tests/humaneval/prompts.py
function instruct_prompt (line 1) | def instruct_prompt(prompt: str) -> str:
function standard_prompt (line 5) | def standard_prompt(prompt: str) -> str:
function write_prompt (line 9) | def write_prompt(prompt: str) -> str:
function replit_glaive_prompt (line 13) | def replit_glaive_prompt(prompt: str) -> str:
FILE: archive/ktransformers/tests/mmlu_pro_test.py
class DataEvaluator (line 16) | class DataEvaluator:
method __init__ (line 17) | def __init__(self):
method load_data (line 21) | def load_data(self, file_path):
method get_prompt (line 45) | def get_prompt(self, record):
method post_processing (line 56) | def post_processing(self, text):
method score (line 65) | def score(self, pred, answers):
function generate_text (line 80) | def generate_text(api_url, question, model_name, stream=False):
function main (line 105) | def main(concurrent_requests, data_evaluator: DataEvaluator, result_file...
FILE: archive/ktransformers/tests/mmlu_test.py
class DataEvaluator (line 16) | class DataEvaluator:
method __init__ (line 17) | def __init__(self):
method load_data (line 21) | def load_data(self, file_path):
method get_prompt (line 36) | def get_prompt(self, record):
method post_processing (line 47) | def post_processing(self, text):
method score (line 56) | def score(self, pred, answers):
function generate_text (line 71) | def generate_text(api_url, question, model_name, stream=False):
function main (line 96) | def main(concurrent_requests, data_evaluator: DataEvaluator, result_file...
FILE: archive/ktransformers/tests/mmlu_test_multi.py
function extract_final_answer (line 19) | def extract_final_answer(text):
class DataEvaluator (line 62) | class DataEvaluator:
method __init__ (line 63) | def __init__(self):
method load_data (line 66) | def load_data(self, file_path):
method get_prompt (line 77) | def get_prompt(self, record):
method post_processing (line 85) | def post_processing(self, text):
method score (line 92) | def score(self, pred, answer):
function generate_text (line 100) | def generate_text(api_url, question, model_name, stream=False):
function main (line 120) | def main(concurrent_requests, data_evaluator: DataEvaluator, result_file...
FILE: archive/ktransformers/tests/parse_cover_info.py
function main (line 7) | def main():
FILE: archive/ktransformers/tests/score.py
function wait_for_server (line 7) | def wait_for_server(base_url: str, timeout: int = None) -> None:
function enqueue_output (line 63) | def enqueue_output(out, queue):
FILE: archive/ktransformers/tests/test_client.py
function fetch_event_stream (line 15) | async def fetch_event_stream(session, payload, request_id, stream):
function main (line 77) | async def main(prompt_id, model, stream, max_tokens, temperature, top_p):
FILE: archive/ktransformers/tests/test_prefix.py
function fetch_message_once (line 18) | async def fetch_message_once(session, request_id, messages, max_tokens, ...
function multi_turn_conversation (line 79) | async def multi_turn_conversation(session, request_id, rounds, max_token...
function main (line 104) | async def main(concurrent_requests, rounds, max_tokens, model):
FILE: archive/ktransformers/tests/test_pytorch_q8.py
class LinearModel (line 4) | class LinearModel(torch.nn.Module):
method __init__ (line 5) | def __init__(self, in_features, out_features):
method forward (line 9) | def forward(self, x):
FILE: archive/ktransformers/tests/test_speed.py
function fetch_event_stream (line 48) | async def fetch_event_stream(session, request_id, prompt, max_tokens, mo...
function main (line 137) | async def main(concurrent_requests , prompt, max_tokens, model):
FILE: archive/ktransformers/tests/triton_fp8gemm_test.py
function test_fp8_gemm_vs_torch_matmul (line 21) | def test_fp8_gemm_vs_torch_matmul():
function test_fp8_gemm_vs_torch_matmul_load (line 48) | def test_fp8_gemm_vs_torch_matmul_load():
function test_fp8_gemm_tplops (line 71) | def test_fp8_gemm_tplops():
FILE: archive/ktransformers/util/ascend/ascend_utils.py
function setup_model_parallel (line 33) | def setup_model_parallel(distributed_timeout_minutes: int = 30, tp: int ...
function get_tensor_parallel_size (line 90) | def get_tensor_parallel_size():
function get_tensor_parallel_group (line 95) | def get_tensor_parallel_group():
function get_tensor_parallel_rank (line 100) | def get_tensor_parallel_rank():
function get_data_parallel_size (line 105) | def get_data_parallel_size():
function get_data_parallel_gloo (line 110) | def get_data_parallel_gloo():
function get_data_parallel_group (line 115) | def get_data_parallel_group():
function get_data_parallel_rank (line 120) | def get_data_parallel_rank():
function get_nccl_options (line 126) | def get_nccl_options(pg_name, nccl_comm_cfgs):
function get_safetensors_cut_weight (line 137) | def get_safetensors_cut_weight(name: str, weights: torch.Tensor):
function get_absort_weight (line 166) | def get_absort_weight(model, config):
function allredeuce_warpper (line 198) | def allredeuce_warpper(func):
FILE: archive/ktransformers/util/cuda_graph_runner.py
class CUDAGraphRunner (line 10) | class CUDAGraphRunner:
method __init__ (line 12) | def __init__(self):
method capture (line 17) | def capture(
method forward (line 63) | def forward(
method __call__ (line 83) | def __call__(self, *args, **kwargs):
FILE: archive/ktransformers/util/custom_gguf.py
class GGMLQuantizationType (line 40) | class GGMLQuantizationType(IntEnum):
function quant_shape_to_byte_shape (line 105) | def quant_shape_to_byte_shape(shape: Sequence[int], quant_type: GGMLQuan...
function read_value (line 177) | def read_value(f, data_type):
function dequantize_q2_k (line 225) | def dequantize_q2_k(data):
function dequantize_q2_k_gpu (line 262) | def dequantize_q2_k_gpu(data, device:str ="cuda", target_dtype = torch.g...
function dequantize_q3_k (line 272) | def dequantize_q3_k(data):
function dequantize_q3_k_gpu (line 314) | def dequantize_q3_k_gpu(data, device:str ="cuda", target_dtype = torch.g...
function dequantize_q4_k (line 324) | def dequantize_q4_k(data):
function dequantize_q4_k_gpu (line 346) | def dequantize_q4_k_gpu(data, device:str ="cuda", target_dtype = torch.g...
function dequantize_q5_k (line 356) | def dequantize_q5_k(data):
function dequantize_q5_k_gpu (line 412) | def dequantize_q5_k_gpu(data, device:str ="cuda", target_dtype = torch.g...
function dequantize_q6_k (line 422) | def dequantize_q6_k(data):
function dequantize_q6_k_gpu (line 471) | def dequantize_q6_k_gpu(data: np.ndarray, device:str = "cuda", target_dt...
function dequantize_iq4_xs (line 482) | def dequantize_iq4_xs(data):
function dequantize_iq4_xs_gpu (line 512) | def dequantize_iq4_xs_gpu(data: np.ndarray, device:str = "cuda", target_...
function dequantize_q4_0 (line 521) | def dequantize_q4_0(data):
function dequantize_q4_0_gpu (line 536) | def dequantize_q4_0_gpu(data, device:str = "cuda", target_dtype = torch....
function dequantize_q5_0 (line 539) | def dequantize_q5_0(data):
function dequantize_q5_0_gpu (line 560) | def dequantize_q5_0_gpu(data, device:str = "cuda", target_dtype = torch....
function dequantize_q8_0 (line 563) | def dequantize_q8_0(data):
function dequantize_q8_0_gpu (line 572) | def dequantize_q8_0_gpu(data, device:str = "cuda", target_dtype = torch....
function dequantize_f32 (line 584) | def dequantize_f32(data):
function dequantize_f32_gpu (line 587) | def dequantize_f32_gpu(data, device, target_dtype = torch.get_default_dt...
function dequantize_f16 (line 594) | def dequantize_f16(data):
function dequantize_f16_gpu (line 597) | def dequantize_f16_gpu(data, device, target_dtype = torch.get_default_dt...
function dequantize_bf16_gpu (line 604) | def dequantize_bf16_gpu(data, device, target_dtype = torch.get_default_d...
function translate_name_to_gguf_mixtral (line 642) | def translate_name_to_gguf_mixtral(name):
function translate_name_to_gguf (line 665) | def translate_name_to_gguf(name):
FILE: archive/ktransformers/util/custom_loader.py
class ModelLoader (line 28) | class ModelLoader(ABC):
method has_tensor (line 35) | def has_tensor(cls, name: str):
class SafeTensorLoader (line 47) | class SafeTensorLoader(ModelLoader):
method __init__ (line 53) | def __init__(self, file_path: str):
method __load_tensor_file_map (line 56) | def __load_tensor_file_map(self, file_path: str):
method load_tensor (line 96) | def load_tensor(self, key: str, device: str = "cpu"):
method load_experts (line 114) | def load_experts(self, key: str, device: str="cpu"):
method load_gate (line 225) | def load_gate(self, key: str, device: str="cpu"):
method close_all_handles (line 252) | def close_all_handles(self):
method load_dequantized_tensor (line 257) | def load_dequantized_tensor(self, key: str, device: str = "cpu"):
method has_tensor (line 275) | def has_tensor(self, name: str):
class GGUFLoader (line 278) | class GGUFLoader(ModelLoader):
method __init__ (line 284) | def __init__(self, gguf_path: str, quantize: str = None):
method load_gguf (line 323) | def load_gguf(self, f):
method get_mmap_tensor (line 405) | def get_mmap_tensor(self, name):
method get_undequanted_tensor_and_ggml_type (line 416) | def get_undequanted_tensor_and_ggml_type(self, name):
method load_expert_tensor (line 424) | def load_expert_tensor(self, name, data, expert_id, elements_per_exper...
method load_gguf_tensor (line 453) | def load_gguf_tensor(self, name: str, device:str = "cpu", target_dtype...
method has_tensor (line 518) | def has_tensor(self, name: str):
method get_ggml_type (line 522) | def get_ggml_type(self, name: str):
class ModelLoaderFactory (line 528) | class ModelLoaderFactory:
method create_loader (line 535) | def create_loader(path: str):
class W8A8SafeTensorLoader (line 600) | class W8A8SafeTensorLoader(SafeTensorLoader):
method load_tensor (line 601) | def load_tensor(self, key: str, device: str = "cpu"):
method load_dequantized_tensor (line 625) | def load_dequantized_tensor(self, key: str, device: str = "cpu"):
FILE: archive/ktransformers/util/modeling_rope_utils.py
function _compute_default_rope_parameters (line 29) | def _compute_default_rope_parameters(
function _compute_linear_scaling_rope_parameters (line 71) | def _compute_linear_scaling_rope_parameters(
function _compute_dynamic_ntk_parameters (line 112) | def _compute_dynamic_ntk_parameters(
function _compute_yarn_parameters (line 163) | def _compute_yarn_parameters(
function _compute_longrope_parameters (line 259) | def _compute_longrope_parameters(
function _compute_llama3_parameters (line 322) | def _compute_llama3_parameters(
function _check_received_keys (line 378) | def _check_received_keys(
function _validate_default_rope_parameters (line 407) | def _validate_default_rope_parameters(config: PretrainedConfig, ignore_k...
function _validate_linear_scaling_rope_parameters (line 415) | def _validate_linear_scaling_rope_parameters(config: PretrainedConfig, i...
function _validate_dynamic_scaling_rope_parameters (line 427) | def _validate_dynamic_scaling_rope_parameters(config: PretrainedConfig, ...
function _validate_yarn_parameters (line 441) | def _validate_yarn_parameters(config: PretrainedConfig, ignore_keys: Opt...
function _validate_longrope_parameters (line 479) | def _validate_longrope_parameters(config: PretrainedConfig, ignore_keys:...
function _validate_llama3_parameters (line 529) | def _validate_llama3_parameters(config: PretrainedConfig, ignore_keys: O...
function rope_config_validation (line 576) | def rope_config_validation(config: PretrainedConfig, ignore_keys: Option...
FILE: archive/ktransformers/util/npu_graph_runner.py
class NPUGraphRunner (line 14) | class NPUGraphRunner:
method __init__ (line 16) | def __init__(self, deviceId):
method init (line 23) | def init(self, batch_size, seq_length):
method destroy (line 32) | def destroy(self):
method capture (line 37) | def capture(
method forward (line 65) | def forward(
method launch_callback (line 86) | def launch_callback(self, func, data, block, stream):
method __call__ (line 89) | def __call__(self, *args, **kwargs):
function check_runner (line 94) | def check_runner(deviceId: int):
function destory_runner (line 101) | def destory_runner(deviceId: int):
function get_or_create_runner (line 107) | def get_or_create_runner(deviceId: int):
FILE: archive/ktransformers/util/textstream.py
class TextStreamer (line 2) | class TextStreamer:
method __init__ (line 4) | def __init__(self, tokenizer: "AutoTokenizer", skip_prompt: bool = Fal...
method reset (line 14) | def reset(self):
method put (line 18) | def put(self, value)->Optional[str]:
method end (line 49) | def end(self)->Optional[str]:
method _is_chinese_char (line 62) | def _is_chinese_char(self, cp):
FILE: archive/ktransformers/util/utils.py
function get_use_npu_graph (line 56) | def get_use_npu_graph():
class StatKey (line 62) | class StatKey(StrEnum):
class TimeStat (line 74) | class TimeStat:
method __init__ (line 75) | def __init__(self):
method record_start_time (line 89) | def record_start_time(self):
method add_time_stat (line 93) | def add_time_stat(self, key: StatKey, time_ns, is_prefill):
method print_all (line 104) | def print_all(self):
method reset_all (line 117) | def reset_all(self):
class StatItem (line 124) | class StatItem:
method __init__ (line 125) | def __init__(self):
method add_item (line 131) | def add_item(self, cost_time_ns):
method reset (line 137) | def reset(self):
method get_stat (line 143) | def get_stat(self):
function get_free_ports (line 157) | def get_free_ports(n: int, continue_prot: list):
function get_current_device (line 173) | def get_current_device():
function get_compute_capability (line 179) | def get_compute_capability(device:torch.device = None):
function set_module (line 193) | def set_module(model, submodule_key, module):
function set_param (line 207) | def set_param(module: nn.Module, name: str, weights: torch.Tensor):
function get_device (line 214) | def get_device(gguf_module_key:str, device_map:dict):
function get_all_used_cuda_device (line 220) | def get_all_used_cuda_device(device_map:dict):
function load_cur_state_dict_npu (line 232) | def load_cur_state_dict_npu(module: nn.Module, gguf_loader: ModelLoader,...
function load_cur_state_dict (line 263) | def load_cur_state_dict(module: nn.Module, gguf_loader: ModelLoader, pre...
function sync_all_device (line 310) | def sync_all_device(all_device_list):
function xpu_fp16_model (line 323) | def xpu_fp16_model(config):
function load_weights (line 335) | def load_weights(module:nn.Module, gguf_loader:ModelLoader, prefix='', d...
function tf_logits_warper (line 344) | def tf_logits_warper(generation_config):
function prefill_and_generate (line 394) | def prefill_and_generate(model, tokenizer, inputs, max_new_tokens=10000,...
class InferenceState (line 809) | class InferenceState(enum.Enum):
FILE: archive/ktransformers/util/vendors.py
class GPUVendor (line 7) | class GPUVendor(IntEnum):
class DeviceManager (line 15) | class DeviceManager:
method __init__ (line 19) | def __init__(self):
method _detect_gpu_vendor (line 23) | def _detect_gpu_vendor(self) -> GPUVendor:
method _get_available_devices (line 60) | def _get_available_devices(self) -> List[int]:
method get_device_str (line 75) | def get_device_str(self, device_id: Union[int, str]) -> str:
method to_torch_device (line 102) | def to_torch_device(self, device_id: Union[int, str] = 0) -> torch.dev...
method move_tensor_to_device (line 126) | def move_tensor_to_device(self, tensor: torch.Tensor, device_id: Union...
method is_available (line 140) | def is_available(self, index: int = 0) -> bool:
method get_all_devices (line 155) | def get_all_devices(self) -> List[int]:
function get_device (line 168) | def get_device(device_id: Union[int, str] = 0) -> torch.device:
function to_device (line 180) | def to_device(tensor: torch.Tensor, device_id: Union[int, str] = 0) -> t...
FILE: archive/ktransformers/util/weight_loader.py
class ModelLoader (line 8) | class ModelLoader(ABC):
method load_tensor (line 15) | def load_tensor(self, name: str, device: str = "cpu") -> torch.Tensor:
method supports_format (line 30) | def supports_format(cls, path: str) -> bool:
class SafeTensorLoader (line 43) | class SafeTensorLoader(ModelLoader):
method __init__ (line 48) | def __init__(self, path: str):
method _load_tensor_file_map (line 59) | def _load_tensor_file_map(self, path: str) -> None:
method load_tensor (line 102) | def load_tensor(self, name: str, device: str = "cpu") -> torch.Tensor:
method load_dequantized_tensor (line 122) | def load_dequantized_tensor(self, name: str, device: str = "cpu") -> t...
method close_all_handles (line 148) | def close_all_handles(self) -> None:
method supports_format (line 157) | def supports_format(cls, path: str) -> bool:
class GGUFLoader (line 185) | class GGUFLoader(ModelLoader):
method __init__ (line 190) | def __init__(self, path: str):
method _load_gguf (line 228) | def _load_gguf(self, f) -> None:
method _read_value (line 287) | def _read_value(self, f, data_type) -> Any:
method load_tensor (line 310) | def load_tensor(self, name: str, device: str = "cpu") -> torch.Tensor:
method load_gguf_tensor (line 324) | def load_gguf_tensor(self, name: str, device: str = "cpu", target_dtyp...
method supports_format (line 346) | def supports_format(cls, path: str) -> bool:
FILE: archive/ktransformers/website/src/api/assistant.ts
function filterAndConvert (line 3) | function filterAndConvert(
type IAssistantData (line 12) | interface IAssistantData {
FILE: archive/ktransformers/website/src/api/run.ts
type IRunData (line 4) | interface IRunData {
function cancelRun (line 87) | async function cancelRun(threadId: string, runId: string){
FILE: archive/ktransformers/website/src/assets/iconfont/iconfont.js
function s (line 1) | function s(){h||(h=!0,e())}
function d (line 1) | function d(){try{a.documentElement.doScroll("left")}catch(t){return void...
FILE: archive/ktransformers/website/src/conf/config.ts
type Window (line 2) | interface Window {
FILE: archive/ktransformers/website/src/utils/copy.ts
function showCopySuccessMessage (line 75) | function showCopySuccessMessage() {
function showCopyErrorMessage (line 93) | function showCopyErrorMessage() {
FILE: archive/ktransformers/website/src/utils/types.ts
type IAssistant (line 1) | interface IAssistant {
type IAssistantWithStatus (line 17) | interface IAssistantWithStatus {
type IMessage (line 34) | interface IMessage {
type IThread (line 51) | interface IThread {
type IRun (line 59) | interface IRun {
type IFile (line 88) | interface IFile {
type IMessageData (line 97) | interface IMessageData {
type IThreadAndMessageAndAssistant (line 104) | interface IThreadAndMessageAndAssistant {
type IDeleteResult (line 110) | interface IDeleteResult {
type IBuildData (line 115) | interface IBuildData {
FILE: archive/merge_tensors/merge_safetensor_gguf.py
function read_safetensor_keys_from_folder (line 15) | def read_safetensor_keys_from_folder(folder_path)->dict:
function translate_name (line 58) | def translate_name(name:str)->str:
function combine_tensor_sources (line 71) | def combine_tensor_sources(safetensor_path:str, gguf_path:str):
function write_combined_tensor (line 97) | def write_combined_tensor(target_tensor_map: dict, output_path: str, ggu...
function main (line 190) | def main():
FILE: archive/merge_tensors/merge_safetensor_gguf_for_qwen3.py
function read_safetensor_keys_from_folder (line 27) | def read_safetensor_keys_from_folder(folder_path) -> dict:
function translate_name (line 60) | def translate_name(name: str) -> str:
function combine_tensor_sources (line 69) | def combine_tensor_sources(safetensor_path: str, gguf_path: str):
function write_combined_tensor (line 103) | def write_combined_tensor(target_tensor_map: dict, output_path: str, ggu...
function main (line 198) | def main():
FILE: archive/setup.py
class CpuInstructInfo (line 62) | class CpuInstructInfo:
class VersionInfo (line 72) | class VersionInfo:
method get_musa_bare_metal_version (line 80) | def get_musa_bare_metal_version(self, musa_dir):
method get_rocm_bare_metal_version (line 90) | def get_rocm_bare_metal_version(self, rocm_dir):
method get_cuda_bare_metal_version (line 154) | def get_cuda_bare_metal_version(self, cuda_dir):
method get_cuda_version_of_torch (line 163) | def get_cuda_version_of_torch(self):
method get_platform (line 170) | def get_platform(self,):
method get_cpu_instruct (line 181) | def get_cpu_instruct(self,):
method get_torch_version (line 224) | def get_torch_version(self,):
method get_flash_version (line 229) | def get_flash_version(self,):
method get_package_version (line 238) | def get_package_version(self, full_version=False):
class BuildWheelsCommand (line 263) | class BuildWheelsCommand(_bdist_wheel):
method get_wheel_name (line 264) | def get_wheel_name(self,):
method run (line 274) | def run(self):
function colored (line 304) | def colored(text, color=None, bold=False):
function split_line (line 316) | def split_line(text: str) -> List[str]:
function colored (line 337) | def colored(text, color=None, bold=False):
function split_line (line 349) | def split_line(text: str) -> List[str]:
function run_command_with_live_tail (line 365) | def run_command_with_live_tail(ext: str, command: List[str], output_line...
class CMakeExtension (line 475) | class CMakeExtension(Extension):
method __init__ (line 476) | def __init__(self, name: str, sour
Copy disabled (too large)
Download .json
Condensed preview — 1146 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (13,352K chars).
[
{
"path": ".github/CODE_OF_CONDUCT.md",
"chars": 5466,
"preview": "\n# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make particip"
},
{
"path": ".github/CONTRIBUTING.md",
"chars": 3194,
"preview": "## Before Commit!\n\nYour commit message must follow Conventional Commits (https://www.conventionalcommits.org/) and your "
},
{
"path": ".github/ISSUE_TEMPLATE/-bug-.yaml",
"chars": 1769,
"preview": "name: \"\\U0001F41B Bug / Help\"\ndescription: Create a report to help us improve the ktransformers project\nlabels: [\"pendin"
},
{
"path": ".github/ISSUE_TEMPLATE/-feature-.yaml",
"chars": 1131,
"preview": "name: \"\\U0001F680 Feature request\"\ndescription: Submit a request for a new feature\nlabels: [\"enhancement\", \"pending\"]\nbo"
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 185,
"preview": "blank_issues_enabled: false\ncontact_links:\n - name: 📚 FAQs | 常见问题\n url: https://github.com/kvcache-ai/ktransformers/"
},
{
"path": ".github/PULL_REQUEST_TEMPLATE.md",
"chars": 235,
"preview": "# What does this PR do?\n\nFixes # (issue)\n\n## Before submitting\n\n- [ ] Did you read the [contributor guideline](https://g"
},
{
"path": ".github/SECURITY.md",
"chars": 550,
"preview": "# Reporting Security Issues\n\nTo report a security issue, please use the GitHub Security Advisory [\"Report a Vulnerabilit"
},
{
"path": ".github/workflows/book-ci.yml",
"chars": 661,
"preview": "name: Book-CI\n\non:\n push:\n branches:\n - main\n # - server_support\n\n pull_request:\n branches:\n - ma"
},
{
"path": ".github/workflows/deploy.yml",
"chars": 1088,
"preview": "name: Deploy\n\non:\n push:\n branches:\n - main\n # - server_support\n\n pull_request:\n branches:\n - mai"
},
{
"path": ".github/workflows/docker-image.yml",
"chars": 4711,
"preview": "name: DockerHub CI\n\non:\n release:\n types: [published]\n workflow_dispatch:\n inputs:\n push_to_dockerhub:\n "
},
{
"path": ".github/workflows/kt-kernel-tests.yml",
"chars": 3310,
"preview": "name: PR KT-Kernel Test\n\non:\n pull_request:\n branches:\n - main\n - develop\n types: [synchronize, labeled"
},
{
"path": ".github/workflows/release-fake-tag.yml",
"chars": 895,
"preview": "name: Release Fake Tag\n\non:\n push:\n branches:\n - main\n paths:\n - \"version.py\"\n workflow_dispatch:\n\nper"
},
{
"path": ".github/workflows/release-pypi.yml",
"chars": 10702,
"preview": "name: Release to PyPI\n\non:\n push:\n branches:\n - main\n paths:\n - \"version.py\"\n workflow_dispatch:\n i"
},
{
"path": ".github/workflows/release-sglang-kt.yml",
"chars": 3848,
"preview": "name: Release sglang-kt to PyPI\n\non:\n push:\n branches:\n - main\n paths:\n - \"third_party/sglang\"\n - "
},
{
"path": ".github/workflows/sync-sglang-submodule.yml",
"chars": 2834,
"preview": "name: Sync sglang submodule\n\non:\n schedule:\n # Run daily at 08:00 UTC\n - cron: \"0 8 * * *\"\n workflow_dispatch:\n\n"
},
{
"path": ".gitignore",
"chars": 404,
"preview": "__pycache__\nbuild\n.vscode\n*.so\n*.cache\nserver.db\nlogs\nnode_modules\n*.nsys-rep\n.vs/\n*pycache*\n*build/\n.DS_Store\ncompile_c"
},
{
"path": ".gitmodules",
"chars": 529,
"preview": "[submodule \"third_party/llama.cpp\"]\n\tpath = third_party/llama.cpp\n\turl = https://github.com/ggerganov/llama.cpp.git\n[sub"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "MAINTAINERS.md",
"chars": 2801,
"preview": "# Maintainers\n\nThis document lists the current maintainers and outlines their responsibilities.\n\n## Current Maintainers\n"
},
{
"path": "README.md",
"chars": 8687,
"preview": "<div align=\"center\">\n <p align=\"center\">\n\n<picture>\n <img alt=\"KTransformers\" src=\"https://github.com/user-attachmen"
},
{
"path": "README_ZH.md",
"chars": 5418,
"preview": "<div align=\"center\">\n <p align=\"center\">\n\n<picture>\n <img alt=\"KTransformers\" src=\"https://github.com/user-attachmen"
},
{
"path": "archive/.devcontainer/Dockerfile",
"chars": 499,
"preview": "FROM pytorch/pytorch:2.5.1-cuda12.1-cudnn9-devel as compile_server\nWORKDIR /workspace\nENV CUDA_HOME /usr/local/cuda\nRUN "
},
{
"path": "archive/.devcontainer/devcontainer.json",
"chars": 915,
"preview": "{\n \"name\": \"Ktrans Dev Container\",\n \"privileged\": true,\n \"build\": {\n \"dockerfile\": \"Dockerfile\",\n "
},
{
"path": "archive/.flake8",
"chars": 228,
"preview": "[flake8]\nmax-line-length = 120\nextend-select = B950\nextend-ignore = E203,E501,E701, B001,B006,B007,B008,B009,B010,B011,B"
},
{
"path": "archive/.gitmodules",
"chars": 1182,
"preview": "[submodule \"third_party/llama.cpp\"]\n\tpath = archive/third_party/llama.cpp\n\turl = https://github.com/ggerganov/llama.cpp."
},
{
"path": "archive/.pylintrc",
"chars": 116,
"preview": "[MASTER]\nextension-pkg-whitelist=pydantic\nmax-line-length=120\n\n[MESSAGES CONTROL]\ndisable=missing-function-docstring"
},
{
"path": "archive/Dockerfile",
"chars": 1287,
"preview": "FROM pytorch/pytorch:2.5.1-cuda12.1-cudnn9-devel as compile_server\n\n\nARG CPU_INSTRUCT=NATIVE\n\n# 设置工作目录和 CUDA 路径\nWORKDIR "
},
{
"path": "archive/Dockerfile.xpu",
"chars": 2083,
"preview": "# Base image\nFROM intel/oneapi-basekit:2025.0.1-0-devel-ubuntu22.04\n\nARG http_proxy\nARG https_proxy\n\nENV DEBIAN_FRONTEND"
},
{
"path": "archive/LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "archive/MANIFEST.in",
"chars": 328,
"preview": "graft third_party\ngraft ktransformers\ngraft local_chat.py\ngraft csrc\ninclude LICENSE README.md\nprune ktransformers/websi"
},
{
"path": "archive/Makefile",
"chars": 1040,
"preview": "flake_find:\n\tcd ktransformers && flake8 | grep -Eo '[A-Z][0-9]{3}' | sort | uniq| paste -sd ',' - \nformat:\n\t@cd ktransfo"
},
{
"path": "archive/README.md",
"chars": 5587,
"preview": "<div align=\"center\">\n <p align=\"center\">\n <picture>\n <img alt=\"KTransformers\" src=\"https://github.com/user-atta"
},
{
"path": "archive/README_LEGACY.md",
"chars": 13581,
"preview": "<div align=\"center\">\n <!-- <h1>KTransformers</h1> -->\n <p align=\"center\">\n\n<picture>\n <img alt=\"KTransformers\" src="
},
{
"path": "archive/README_ZH.md",
"chars": 3903,
"preview": "<div align=\"center\">\n <p align=\"center\">\n <picture>\n <img alt=\"KTransformers\" src=\"https://github.com/user-atta"
},
{
"path": "archive/README_ZH_LEGACY.md",
"chars": 6904,
"preview": "<div align=\"center\">\n <!-- <h1>KTransformers</h1> -->\n <p align=\"center\">\n\n<picture>\n <img alt=\"KTransformers\" src="
},
{
"path": "archive/SECURITY.md",
"chars": 619,
"preview": "# Security Policy\n\n## Supported Versions\n\nUse this section to tell people about which versions of your project are\ncurre"
},
{
"path": "archive/book.toml",
"chars": 374,
"preview": "[book]\nauthors = [\"kvcache-ai\"]\nlanguage = \"zh-CN\"\ntitle = \"Ktransformers\"\nsrc = \"doc\"\n\n[output.html]\ngit-repository-url"
},
{
"path": "archive/config.json",
"chars": 0,
"preview": ""
},
{
"path": "archive/csrc/balance_serve/CMakeLists.txt",
"chars": 3683,
"preview": "option(KTRANSFORMERS_USE_NPU \"ktransformers: use NPU\" OFF)\nif(KTRANSFORMERS_US"
},
{
"path": "archive/csrc/custom_marlin/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "archive/csrc/custom_marlin/binding.cpp",
"chars": 2045,
"preview": "/**\n * @Description :\n * @Author : Azure-Tang\n * @Date : 2024-07-25 13:38:30\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/custom_marlin/gptq_marlin/gptq_marlin.cu",
"chars": 87409,
"preview": "/*\n * Modified by Neural Magic\n * Copyright (C) Marlin.2024 Elias Frantar\n *\n * Licensed under the Apache License, Versi"
},
{
"path": "archive/csrc/custom_marlin/gptq_marlin/gptq_marlin.cuh",
"chars": 2330,
"preview": "// Adapted from\n// https://github.com/vllm-project/vllm/tree/main/csrc/quantization/gptq_marlin\n// Copyrigth 2024 The vL"
},
{
"path": "archive/csrc/custom_marlin/gptq_marlin/gptq_marlin_dtypes.cuh",
"chars": 2216,
"preview": "// Adapted from\n// https://github.com/vllm-project/vllm/tree/main/csrc/quantization/gptq_marlin\n// Copyrigth 2024 The vL"
},
{
"path": "archive/csrc/custom_marlin/gptq_marlin/gptq_marlin_repack.cu",
"chars": 11605,
"preview": "#include \"gptq_marlin.cuh\"\n\nnamespace gptq_marlin {\n\nstatic constexpr int repack_stages = 8;\n\nstatic constexpr int repac"
},
{
"path": "archive/csrc/custom_marlin/gptq_marlin/ops.h",
"chars": 948,
"preview": "/**\n * @Description :\n * @Author : Azure\n * @Date : 2024-07-22 09:27:55\n * @Version : 1.0.0\n * @Last"
},
{
"path": "archive/csrc/custom_marlin/setup.py",
"chars": 727,
"preview": "from setuptools import setup, Extension\nfrom torch.utils import cpp_extension\nfrom torch.utils.cpp_extension import Buil"
},
{
"path": "archive/csrc/custom_marlin/test_cuda_graph.py",
"chars": 10677,
"preview": "import csv\r\nimport torch\r\nimport torch.nn as nn\r\nimport vLLMMarlin\r\ntorch.set_grad_enabled(False)\r\nfrom utils.marlin_uti"
},
{
"path": "archive/csrc/custom_marlin/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "archive/csrc/custom_marlin/utils/format24.py",
"chars": 12766,
"preview": "#\n# Modified by Roberto Lopez Castro (roberto.lopez.castro@udc.es).\n#\n\nimport torch\n\n\n# This is PyTorch implementation o"
},
{
"path": "archive/csrc/custom_marlin/utils/marlin_24_perms.py",
"chars": 2475,
"preview": "'''\nDate: 2024-11-08 02:46:07\nLastEditors: djw\nLastEditTime: 2024-11-08 02:46:41\n'''\n\"\"\"This file is used for /tests and"
},
{
"path": "archive/csrc/custom_marlin/utils/marlin_perms.py",
"chars": 2354,
"preview": "'''\nDate: 2024-11-08 02:46:47\nLastEditors: djw\nLastEditTime: 2024-11-08 02:46:55\n'''\n\"\"\"This file is used for /tests and"
},
{
"path": "archive/csrc/custom_marlin/utils/marlin_utils.py",
"chars": 7325,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nimport random\n\nimport numpy\nimport torch\n\nfrom .format24 import (\n "
},
{
"path": "archive/csrc/custom_marlin/utils/quant_utils.py",
"chars": 5870,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nimport numpy\nimport torch\n\nSUPPORTED_NUM_BITS = [4, 8]\nSUPPORTED_GROU"
},
{
"path": "archive/csrc/ktransformers_ext/CMakeLists.txt",
"chars": 16551,
"preview": "cmake_minimum_required(VERSION 3.16)\nproject(cpuinfer_ext VERSION 0.1.0)\n\n\nset(CMAKE_CXX_STANDARD 17)\n\n\nset(CMAKE_CXX_FL"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_attention.py",
"chars": 4974,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : \nAuthor : Jianwei Dong\nDate : 2024-08-28 10:32:05"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_attention_torch.py",
"chars": 2520,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : \nAuthor : Jianwei Dong\nDate : 2024-08-28 10:32:05"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_linear.py",
"chars": 4214,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:31:59\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_linear_torch.py",
"chars": 3103,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:31:59\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_mlp.py",
"chars": 5846,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-16 10:43:18\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_mlp_torch.py",
"chars": 4590,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-16 10:43:18\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_moe.py",
"chars": 6638,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:32:05\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_moe_amx.py",
"chars": 4420,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2025-04-25 18:28:12\nV"
},
{
"path": "archive/csrc/ktransformers_ext/bench/bench_moe_torch.py",
"chars": 6591,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:32:05\nV"
},
{
"path": "archive/csrc/ktransformers_ext/cmake/FindSIMD.cmake",
"chars": 2657,
"preview": "include(CheckCSourceRuns)\n\nset(AVX_CODE \"\n #include <immintrin.h>\n int main()\n {\n __m256 a;\n a = "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/backend.cpp",
"chars": 5219,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-22 02:03:05\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/backend.h",
"chars": 1374,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-22 02:03:05\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/cpuinfer.h",
"chars": 2890,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-16 10:43:18\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/shared_mem_buffer.cpp",
"chars": 1388,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-08-05 04:49:08\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/shared_mem_buffer.h",
"chars": 884,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-08-05 04:49:08\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/task_queue.cpp",
"chars": 1653,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-17 12:25:51\n * @Version : 1.0.0\n * @LastEditor"
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/task_queue.h",
"chars": 2472,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-16 10:43:18\n * @Version : 1.0.0\n * @LastEditor"
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/vendors/README.md",
"chars": 81,
"preview": "## TODO\n\nThis directory can be removed after updating the version of `llama.cpp`."
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/vendors/cuda.h",
"chars": 485,
"preview": "#pragma once\n\n#include <cuda_runtime.h>\n#include <cuda.h>\n#include <cublas_v2.h>\n#include <cuda_bf16.h>\n#include <cuda_f"
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/vendors/hip.h",
"chars": 7690,
"preview": "#pragma once\n\n#define HIP_ENABLE_WARP_SYNC_BUILTINS 1\n#include <hip/hip_runtime.h>\n#include <hipblas/hipblas.h>\n#include"
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/vendors/musa.h",
"chars": 6158,
"preview": "#pragma once\n\n#include <musa_runtime.h>\n#include <musa.h>\n#include <mublas.h>\n#include <musa_bf16.h>\n#include <musa_fp16"
},
{
"path": "archive/csrc/ktransformers_ext/cpu_backend/vendors/vendor.h",
"chars": 237,
"preview": "#ifndef CPUINFER_VENDOR_VENDOR_H\n#define CPUINFER_VENDOR_VENDOR_H\n\n#ifdef USE_CUDA\n#include \"cuda.h\"\n#elif USE_HIP\n#defi"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/binding.cpp",
"chars": 4557,
"preview": "/**\n * @Description :\n * @Author : Azure-Tang, Boxin Zhang\n * @Date : 2024-07-25 13:38:30\n * @Version "
},
{
"path": "archive/csrc/ktransformers_ext/cuda/custom_gguf/dequant.cu",
"chars": 42251,
"preview": "/*\n * @Description : \n * @Author : Azure-Tang, Boxin Zhang\n * @Date : 2024-07-25 13:38:30\n * @Version "
},
{
"path": "archive/csrc/ktransformers_ext/cuda/custom_gguf/ops.h",
"chars": 1576,
"preview": "/**\n * @Description :\n * @Author : Azure-Tang\n * @Date : 2024-07-22 09:27:55\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/cuda/gptq_marlin/gptq_marlin.cu",
"chars": 72899,
"preview": "/*\n * Modified by Neural Magic\n * Copyright (C) Marlin.2024 Elias Frantar\n *\n * Licensed under the Apache License, Versi"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/gptq_marlin/gptq_marlin.cuh",
"chars": 2275,
"preview": "// Adapted from\n// https://github.com/vllm-project/vllm/tree/main/csrc/quantization/gptq_marlin\n// Copyrigth 2024 The vL"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/gptq_marlin/gptq_marlin_dtypes.cuh",
"chars": 2230,
"preview": "// Adapted from\n// https://github.com/vllm-project/vllm/tree/main/csrc/quantization/gptq_marlin\n// Copyrigth 2024 The vL"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/gptq_marlin/ops.h",
"chars": 923,
"preview": "/**\n * @Description : \n * @Author : Azure\n * @Date : 2024-07-22 09:27:55\n * @Version : 1.0.0\n * @La"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/setup.py",
"chars": 729,
"preview": "\nfrom setuptools import setup, Extension\nfrom torch.utils import cpp_extension\nfrom torch.utils.cpp_extension import Bui"
},
{
"path": "archive/csrc/ktransformers_ext/cuda/test_dequant.py",
"chars": 549,
"preview": "import os\nimport sys\nsys.path.insert(0,\"/home/zbx/ktransformers\")\nfrom ktransformers.util.custom_loader import GGUFLoade"
},
{
"path": "archive/csrc/ktransformers_ext/examples/test_attention.py",
"chars": 3979,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : \nAuthor : Jianwei Dong\nDate : 2024-08-28 10:32:05"
},
{
"path": "archive/csrc/ktransformers_ext/examples/test_linear.py",
"chars": 1882,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:32:05\nV"
},
{
"path": "archive/csrc/ktransformers_ext/examples/test_mlp.py",
"chars": 2817,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:32:05\nV"
},
{
"path": "archive/csrc/ktransformers_ext/examples/test_moe.py",
"chars": 4368,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : chenht2022\nDate : 2024-07-25 10:32:05\nV"
},
{
"path": "archive/csrc/ktransformers_ext/ext_bindings.cpp",
"chars": 32983,
"preview": "/**\n * @Description :\n * @Author : chenht2022, Jianwei Dong\n * @Date : 2024-07-22 02:03:22\n * @Version "
},
{
"path": "archive/csrc/ktransformers_ext/operators/amx/la/amx.hpp",
"chars": 36720,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2025-04-25 18:28:12\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/amx/la/utils.hpp",
"chars": 1550,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2025-04-25 18:28:12\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/amx/moe.hpp",
"chars": 20200,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2025-04-25 18:28:12\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/kvcache/kvcache.h",
"chars": 31567,
"preview": "/**\n * @Description :\n * @Author : Jianwei Dong\n * @Date : 2024-08-26 22:47:06\n * @Version : 1.0.0\n "
},
{
"path": "archive/csrc/ktransformers_ext/operators/kvcache/kvcache_attn.cpp",
"chars": 130379,
"preview": "/**\n * @Description :\n * @Author : Jianwei Dong\n * @Date : 2024-08-26 22:47:06\n * @Version : 1.0.0\n "
},
{
"path": "archive/csrc/ktransformers_ext/operators/kvcache/kvcache_load_dump.cpp",
"chars": 5677,
"preview": "/**\n * @Description :\n * @Author : Jianwei Dong\n * @Date : 2024-08-26 22:47:06\n * @Version : 1.0.0\n "
},
{
"path": "archive/csrc/ktransformers_ext/operators/kvcache/kvcache_read_write.cpp",
"chars": 51884,
"preview": "/**\n * @Description :\n * @Author : Jianwei Dong\n * @Date : 2024-08-26 22:47:06\n * @Version : 1.0.0\n "
},
{
"path": "archive/csrc/ktransformers_ext/operators/kvcache/kvcache_utils.cpp",
"chars": 62397,
"preview": "/**\n * @Description :\n * @Author : Jianwei Dong\n * @Date : 2024-08-26 22:47:06\n * @Version : 1.0.0\n "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/conversion.h",
"chars": 925,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-12 10:07:58\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/linear.cpp",
"chars": 4376,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-12 10:07:58\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/linear.h",
"chars": 1861,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-12 10:07:58\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/mlp.cpp",
"chars": 9393,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-16 10:43:18\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/mlp.h",
"chars": 2941,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-12 10:07:58\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/moe.cpp",
"chars": 28365,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-22 02:03:22\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/operators/llamafile/moe.h",
"chars": 6446,
"preview": "/**\n * @Description :\n * @Author : chenht2022\n * @Date : 2024-07-22 02:03:22\n * @Version : 1.0.0\n * "
},
{
"path": "archive/csrc/ktransformers_ext/vendors/cuda.h",
"chars": 485,
"preview": "#pragma once\n\n#include <cuda_runtime.h>\n#include <cuda.h>\n#include <cublas_v2.h>\n#include <cuda_bf16.h>\n#include <cuda_f"
},
{
"path": "archive/csrc/ktransformers_ext/vendors/hip.h",
"chars": 7690,
"preview": "#pragma once\n\n#define HIP_ENABLE_WARP_SYNC_BUILTINS 1\n#include <hip/hip_runtime.h>\n#include <hipblas/hipblas.h>\n#include"
},
{
"path": "archive/csrc/ktransformers_ext/vendors/musa.h",
"chars": 6158,
"preview": "#pragma once\n\n#include <musa_runtime.h>\n#include <musa.h>\n#include <mublas.h>\n#include <musa_bf16.h>\n#include <musa_fp16"
},
{
"path": "archive/csrc/ktransformers_ext/vendors/vendor.h",
"chars": 237,
"preview": "#ifndef CPUINFER_VENDOR_VENDOR_H\n#define CPUINFER_VENDOR_VENDOR_H\n\n#ifdef USE_CUDA\n#include \"cuda.h\"\n#elif USE_HIP\n#defi"
},
{
"path": "archive/install-with-cache.sh",
"chars": 959,
"preview": "#!/bin/bash\nset -e \n\n# clear build dirs\n# rm -rf build\n# rm -rf *.egg-info\n# rm -rf csrc/build\n# rm -rf csrc/ktransform"
},
{
"path": "archive/install.bat",
"chars": 540,
"preview": "@echo off\n\nREM clear build dirs\nrmdir /S /Q ktransformers\\ktransformers_ext\\build\nrmdir /S /Q ktransformers\\ktransformer"
},
{
"path": "archive/install.sh",
"chars": 1302,
"preview": "#!/bin/bash\nset -e \n\n# default backend\nDEV=\"cuda\"\n\n# parse --dev argument\nwhile [[ \"$#\" -gt 0 ]]; do\n case $1 in\n "
},
{
"path": "archive/ktransformers/__init__.py",
"chars": 221,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : kkk1nak0\nDate : 2024-08-15 07:34:46\nVers"
},
{
"path": "archive/ktransformers/configs/config.yaml",
"chars": 1330,
"preview": "log:\n dir: \"logs\"\n file: \"lexllama.log\"\n #log level: debug, info, warn, error, crit\n level: \"debug\"\n backup_count: "
},
{
"path": "archive/ktransformers/configs/log_config.ini",
"chars": 861,
"preview": "[loggers]\nkeys=root,uvicorn,uvicornError,uvicornAccess\n\n[handlers]\nkeys=consoleHandler,fileHandler\n\n[formatters]\nkeys=de"
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/format_24.py",
"chars": 12767,
"preview": "#\n# Modified by Roberto Lopez Castro (roberto.lopez.castro@udc.es).\n#\n\nimport torch\n\n\n# This is PyTorch implementation o"
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_24_perms.py",
"chars": 2391,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nfrom typing import Dict, List\n\nimport numpy\nimport torch\n\n\n# Precompu"
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_perms.py",
"chars": 2270,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nfrom typing import Dict, List\n\nimport numpy\nimport torch\n\n\n# Precompu"
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/marlin_utils.py",
"chars": 8812,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nimport random\n\nimport numpy\nimport torch\n\nfrom ktransformers.ktransfo"
},
{
"path": "archive/ktransformers/ktransformers_ext/operators/custom_marlin/quantize/utils/quant_utils.py",
"chars": 3688,
"preview": "\"\"\"This file is used for /tests and /benchmarks\"\"\"\nimport numpy\nimport torch\n\nSUPPORTED_NUM_BITS = [4, 8]\nSUPPORTED_GROU"
},
{
"path": "archive/ktransformers/ktransformers_ext/triton/fp8gemm.py",
"chars": 8217,
"preview": "# Adopted from https://huggingface.co/deepseek-ai/DeepSeek-V3/blob/main/inference/kernel.py\nfrom typing import Tuple\n\nim"
},
{
"path": "archive/ktransformers/local_chat.py",
"chars": 11068,
"preview": "\"\"\"\nDescription : \nAuthor : Boxin Zhang, Azure-Tang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All R"
},
{
"path": "archive/ktransformers/local_chat_test.py",
"chars": 6984,
"preview": "\"\"\"\nDescription : \nAuthor : Boxin Zhang, Azure-Tang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All R"
},
{
"path": "archive/ktransformers/models/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "archive/ktransformers/models/ascend/custom_ascend_modeling_deepseek_v3.py",
"chars": 9945,
"preview": "\"\"\"\r\nDate: 2024-11-06 10:05:11\r\nLastEditors: djw\r\nLastEditTime: 2024-11-13 07:50:51\r\n\"\"\"\r\n\r\nimport math\r\nfrom dataclasse"
},
{
"path": "archive/ktransformers/models/ascend/custom_ascend_modeling_qwen3.py",
"chars": 10883,
"preview": "# coding=utf-8\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\n# Copyright 2025 The ZhipuAI Inc"
},
{
"path": "archive/ktransformers/models/configuration_deepseek.py",
"chars": 10641,
"preview": "# Adapted from\n# https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat-0628/blob/main/configuration_deepseek.py\n# Copyrigh"
},
{
"path": "archive/ktransformers/models/configuration_deepseek_v3.py",
"chars": 9891,
"preview": "from transformers.configuration_utils import PretrainedConfig\nfrom transformers.utils import logging\n\nlogger = logging.g"
},
{
"path": "archive/ktransformers/models/configuration_glm4_moe.py",
"chars": 13153,
"preview": "# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨\n# This file was automatically generated from"
},
{
"path": "archive/ktransformers/models/configuration_llama.py",
"chars": 11057,
"preview": "# coding=utf-8\n# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.\n#\n# This code is based on"
},
{
"path": "archive/ktransformers/models/configuration_qwen2_moe.py",
"chars": 8900,
"preview": "# coding=utf-8\n# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.\n#\n# Lic"
},
{
"path": "archive/ktransformers/models/configuration_qwen3_moe.py",
"chars": 12997,
"preview": "# coding=utf-8\n# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.\n#\n# Lic"
},
{
"path": "archive/ktransformers/models/configuration_qwen3_next.py",
"chars": 14416,
"preview": "# coding=utf-8\n# Copyright 2025 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.\n#\n# Lic"
},
{
"path": "archive/ktransformers/models/configuration_smallthinker.py",
"chars": 7543,
"preview": "# coding=utf-8\nfrom transformers.configuration_utils import PretrainedConfig\n\nclass SmallthinkerConfig(PretrainedConfig)"
},
{
"path": "archive/ktransformers/models/custom_cache.py",
"chars": 29901,
"preview": "'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\n'''\n# Adapted from\n# https://github.com/huggingface"
},
{
"path": "archive/ktransformers/models/custom_modeling_deepseek_v2.py",
"chars": 6952,
"preview": "import math\nfrom dataclasses import dataclass\nimport torch\nimport torch.nn as nn\nfrom torch.nn import functional as F\nim"
},
{
"path": "archive/ktransformers/models/custom_modeling_deepseek_v3.py",
"chars": 6601,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/custom_modeling_glm4_moe.py",
"chars": 4998,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/custom_modeling_qwen2_moe.py",
"chars": 5835,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/custom_modeling_qwen3_moe.py",
"chars": 5843,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/custom_modeling_qwen3_next.py",
"chars": 5830,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/custom_modeling_smallthinker.py",
"chars": 5156,
"preview": "\"\"\"\nDate: 2024-11-06 10:05:11\nLastEditors: djw\nLastEditTime: 2024-11-13 07:50:51\n\"\"\"\n\nimport math\nfrom dataclasses impor"
},
{
"path": "archive/ktransformers/models/modeling_deepseek.py",
"chars": 84594,
"preview": "# coding=utf-8\n'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\n'''\n# Adapted from\n# https://hugging"
},
{
"path": "archive/ktransformers/models/modeling_deepseek_v3.py",
"chars": 81389,
"preview": "# coding=utf-8\n# Copyright 2023 DeepSeek-AI and The HuggingFace Inc. team. All rights reserved.\n#\n# This code is based o"
},
{
"path": "archive/ktransformers/models/modeling_glm4_moe.py",
"chars": 28012,
"preview": "# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨\n# This file was automatically generated from"
},
{
"path": "archive/ktransformers/models/modeling_llama.py",
"chars": 75112,
"preview": "# coding=utf-8\n# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.\n#\n# This code is based on"
},
{
"path": "archive/ktransformers/models/modeling_mixtral.py",
"chars": 79557,
"preview": "# coding=utf-8\n'''\nDescription : \nAuthor : kkk1nak0\nDate : 2024-07-29 02:58:57\nVersion : 1.0.0\nLastE"
},
{
"path": "archive/ktransformers/models/modeling_qwen2_moe.py",
"chars": 82072,
"preview": "# coding=utf-8\n'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\n''' \n# Adapted from\n# https://github"
},
{
"path": "archive/ktransformers/models/modeling_qwen3_moe.py",
"chars": 67397,
"preview": "# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨\n# This file was automatically generated from"
},
{
"path": "archive/ktransformers/models/modeling_qwen3_next.py",
"chars": 56217,
"preview": "# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨\n# This file was automatically generated from"
},
{
"path": "archive/ktransformers/models/modeling_smallthinker.py",
"chars": 56478,
"preview": "# coding=utf-8\nfrom functools import partial\nfrom typing import Callable, List, Optional, Tuple, Union\n\nimport torch\nimp"
},
{
"path": "archive/ktransformers/operators/RoPE.py",
"chars": 19320,
"preview": "\"\"\"\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All Rights Reserv"
},
{
"path": "archive/ktransformers/operators/__init__.py",
"chars": 1,
"preview": "\n"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_attention.py",
"chars": 58872,
"preview": "# coding=utf-8\r\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\r\n# Copyright 2025 The ZhipuAI I"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_experts.py",
"chars": 18696,
"preview": "# coding=utf-8\r\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\r\n# Copyright 2025 The ZhipuAI I"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_gate.py",
"chars": 1777,
"preview": "import torch\r\nimport torch_npu\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\nfrom ktransformers.operators.gat"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_layernorm.py",
"chars": 4876,
"preview": "# coding=utf-8\r\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\r\n# Copyright 2025 The ZhipuAI I"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_linear.py",
"chars": 14011,
"preview": "# coding=utf-8\r\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\r\n# Copyright 2025 The ZhipuAI I"
},
{
"path": "archive/ktransformers/operators/ascend/ascend_mlp.py",
"chars": 5400,
"preview": "# coding=utf-8\r\n# Copyright (c) 2025. Huawei Technologies Co., Ltd. All rights reserved.\r\n# Copyright 2025 The ZhipuAI I"
},
{
"path": "archive/ktransformers/operators/attention.py",
"chars": 46094,
"preview": "'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All Rights Reserv"
},
{
"path": "archive/ktransformers/operators/balance_serve_attention.py",
"chars": 45055,
"preview": "'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.2.5\nCopyright (c) 2024 by KVCache.AI, All Rights Reserv"
},
{
"path": "archive/ktransformers/operators/base_operator.py",
"chars": 2949,
"preview": "'''\nDescription : \nAuthor : Boxin Zhang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All Rights Reserv"
},
{
"path": "archive/ktransformers/operators/cpuinfer.py",
"chars": 26097,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : This script defines the `CPUInferKVCache` and `CPUInfer` classes"
},
{
"path": "archive/ktransformers/operators/dynamic_attention.py",
"chars": 29612,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : \nAuthor : Jianwei Dong\nDate : 2024-08-26 23:25:24"
},
{
"path": "archive/ktransformers/operators/experts.py",
"chars": 100079,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : Azure-Tang, Boxin Zhang, chenht2022\nDate "
},
{
"path": "archive/ktransformers/operators/flashinfer_batch_prefill_wrapper.py",
"chars": 12705,
"preview": "import torch\nimport flashinfer\nimport gc\ntry:\n from flash_attn import flash_attn_with_kvcache\n print(\"found flash_"
},
{
"path": "archive/ktransformers/operators/flashinfer_wrapper.py",
"chars": 16969,
"preview": "'''\nDescription : flashinfer MLA wrapper\nAuthor : Boxin Zhang\nVersion : 0.2.3\n'''\nimport torch\nimport os\n\nfl"
},
{
"path": "archive/ktransformers/operators/gate.py",
"chars": 9661,
"preview": "from typing import Optional\nfrom torch import nn\nimport torch\nimport torch.nn.functional as F\nimport os\nfrom ktransforme"
},
{
"path": "archive/ktransformers/operators/layernorm.py",
"chars": 15024,
"preview": "'''\nDate: 2024-11-13 15:05:52\nLastEditors: Xie Weiyu ervinxie@qq.com\nLastEditTime: 2024-11-25 08:59:19\n'''\n\"\"\"\nCopyright"
},
{
"path": "archive/ktransformers/operators/linear.py",
"chars": 38317,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n'''\nDescription : \nAuthor : Azure-Tang, Boxin Zhang\nDate : 2024-07-"
},
{
"path": "archive/ktransformers/operators/mlp.py",
"chars": 3448,
"preview": "\nfrom ktransformers.operators.base_operator import BaseInjectedModule\nfrom ktransformers.util.custom_loader import GGUFL"
},
{
"path": "archive/ktransformers/operators/models.py",
"chars": 60812,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\"\"\"\nDescription : \nAuthor : Azure-Tang\nDate : 2024-07-25 11:25:24\nV"
},
{
"path": "archive/ktransformers/operators/triton_attention.py",
"chars": 11898,
"preview": "# Adapted from\r\n# https://github.com/sgl-project/sglang/blob/9f635ea50de920aa507f486daafba26a5b837574/python/sglang/srt/"
},
{
"path": "archive/ktransformers/operators/triton_attention_prefill.py",
"chars": 5914,
"preview": "\n# Adapted from\n# https://github.com/sgl-project/sglang/blob/9f635ea50de920aa507f486daafba26a5b837574/python/sglang/srt/"
},
{
"path": "archive/ktransformers/optimize/optimize.py",
"chars": 8081,
"preview": "'''\nDescription : \nAuthor : Boxin Zhang, Azure-Tang\nVersion : 0.1.0\nCopyright (c) 2024 by KVCache.AI, All R"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Chat-multi-gpu-4.yaml",
"chars": 8428,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Chat-multi-gpu.yaml",
"chars": 4495,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Chat.yaml",
"chars": 2217,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek.DeepseekV2YarnRotaryEmbedding\n replace:\n class: ktransfor"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Lite-Chat-gpu-cpu.yaml",
"chars": 5539,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Lite-Chat-multi-gpu.yaml",
"chars": 4405,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V2-Lite-Chat.yaml",
"chars": 2217,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek.DeepseekV2YarnRotaryEmbedding\n replace:\n class: ktransfor"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-amx.yaml",
"chars": 2718,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve-amx.yaml",
"chars": 3021,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-fp8-linear-ggml-experts-serve.yaml",
"chars": 2994,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-fp8-linear-ggml-experts.yaml",
"chars": 2152,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu-4.yaml",
"chars": 10862,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu-8.yaml",
"chars": 20382,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu-fp8-linear-ggml-experts.yaml",
"chars": 5172,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu-marlin.yaml",
"chars": 5686,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu.yaml",
"chars": 5088,
"preview": "- match:\n name: \"^model.embed_tokens\"\n replace:\n class: \"default\"\n kwargs:\n generate_device: \"cpu\"\n "
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-npu.yaml",
"chars": 2637,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-serve.yaml",
"chars": 3096,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat.yaml",
"chars": 2653,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/Glm4Moe-serve.yaml",
"chars": 2952,
"preview": "- match:\n class: ktransformers.models.modeling_glm4_moe.Glm4MoeRotaryEmbedding\n replace:\n class: ktransformers.op"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/Internlm2_5-7b-Chat-1m.yaml",
"chars": 771,
"preview": "- match:\n class: ktransformers.models.modeling_llama.LlamaRotaryEmbedding\n replace:\n class: ktransformers.operato"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/Mixtral.yaml",
"chars": 1764,
"preview": "- match:\n class: ktransformers.models.modeling_mixtral.MixtralRotaryEmbedding\n replace:\n class: ktransformers.ope"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/Moonlight-16B-A3B-serve.yaml",
"chars": 3094,
"preview": "\n\n- match:\n name: \"^lm_head$\" # regular expression \n class: torch.nn.Linear # only match modules matching name a"
},
{
"path": "archive/ktransformers/optimize/optimize_rules/Moonlight-16B-A3B.yaml",
"chars": 3071,
"preview": "- match:\n class: ktransformers.models.modeling_deepseek_v3.DeepseekV3RotaryEmbedding\n replace:\n class: ktransform"
}
]
// ... and 946 more files (download for full content)
About this extraction
This page contains the full source code of the kvcache-ai/ktransformers GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 1146 files (12.2 MB), approximately 3.3M tokens, and a symbol index with 7608 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.