Showing preview only (2,711K chars total). Download the full file or copy to clipboard to get everything.
Repository: labuladong/fucking-algorithm
Branch: english
Commit: a3a28d05b60e
Files: 71
Total size: 2.6 MB
Directory structure:
gitextract_jc1mrgvh/
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── 01-algo-website-bug.md
│ │ ├── 02-algo-visualize-bug.md
│ │ ├── 03-chrome-extension-bug.md
│ │ ├── 04-vscode-extension-bug.md
│ │ ├── 05-jetbrain-plugin-bug.md
│ │ └── 06-suggestion.md
│ └── PULL_REQUEST_TEMPLATE.md
├── README.md
├── algorithmic-thinking/
│ ├── README.md
│ ├── backtracking.md
│ ├── bfs-framework.md
│ ├── binary-search.md
│ ├── bit-manipulation.md
│ ├── difference-array.md
│ ├── matrix-traversal.md
│ ├── pancake-sorting.md
│ ├── prefix-sum.md
│ ├── probability-problems.md
│ ├── set-partition.md
│ ├── sliding-window.md
│ ├── string-multiplication.md
│ ├── two-pointers.md
│ └── union-find.md
├── data-structures/
│ ├── README.md
│ ├── binary-tree-practice1.md
│ ├── binary-tree-practice2.md
│ ├── binary-tree-summary.md
│ ├── bst-part1.md
│ ├── bst-part2.md
│ ├── calculator.md
│ ├── dijkstra.md
│ ├── monotonic-queue.md
│ ├── monotonic-stack.md
│ ├── queue-stack.md
│ ├── reverse-linked-list.md
│ └── topological-sort.md
├── dynamic-programming/
│ ├── README.md
│ ├── dp-framework.md
│ ├── edit-distance.md
│ ├── egg-drop.md
│ ├── game-theory.md
│ ├── house-robber.md
│ ├── interval-scheduling.md
│ ├── knapsack.md
│ ├── longest-common-subsequence.md
│ ├── magic-tower.md
│ ├── optimal-substructure.md
│ ├── regular-expression.md
│ ├── state-compression.md
│ ├── stock-problems.md
│ ├── subsequence-problems.md
│ └── word-break.md
├── interview/
│ ├── README.md
│ ├── binary-search-in-action.md
│ ├── celebrity-problem.md
│ ├── count-primes.md
│ ├── island-problems.md
│ ├── lru-cache.md
│ ├── meeting-rooms.md
│ ├── missing-duplicate-element.md
│ ├── palindrome-linked-list.md
│ ├── random-weight.md
│ ├── subset-permutation-combination.md
│ └── trapping-rain-water.md
├── multi-language-solutions/
│ ├── contribution-guide.md
│ └── solution_code.md
└── technical/
├── cryptography.md
├── linux-process.md
├── linux-shell.md
├── problem-solving-tips.md
└── session-and-cookie.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/ISSUE_TEMPLATE/01-algo-website-bug.md
================================================
---
name: Website bug
about: Report bug on website `labuladong.online`
title: ''
labels: algo-websie-bug
assignees: labuladong
---
**Version:**
What's the extension version are you using?
**Describe the bug**
A clear and concise description of what the bug is.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Platform**
Mobile phone or PC?
What kind of web browser? (chrome/edge/...)
================================================
FILE: .github/ISSUE_TEMPLATE/02-algo-visualize-bug.md
================================================
---
name: Algo-visualize bug
about: Report bug for algo-visualize tool in website/plugins
title: ''
labels: algo-visualize-bug
assignees: labuladong
---
================================================
FILE: .github/ISSUE_TEMPLATE/03-chrome-extension-bug.md
================================================
---
name: Chrome extension bug
about: Report bug on Chrome extension
title: ''
labels: algo-website, chrome-extension-bug
assignees: labuladong
---
**Describe the bug**
A clear and concise description of what the bug is.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Platform**
What kind of web browser are you using? (chrome/edge/...)
================================================
FILE: .github/ISSUE_TEMPLATE/04-vscode-extension-bug.md
================================================
---
name: VSCode extension bug
about: Report bug on vscode extension
title: ''
labels: vscode-extension-bug
assignees: labuladong
---
**Version:**
What's the extension version are you using?
**Describe the bug**
A clear and concise description of what the bug is.
**Screenshots**
If applicable, add screenshots to help explain your problem.
================================================
FILE: .github/ISSUE_TEMPLATE/05-jetbrain-plugin-bug.md
================================================
---
name: JetBrain plugin bug
about: Report bug on JetBrain plugin
title: ''
labels: jb-plugin-bug
assignees: labuladong
---
**Version:**
What's the plugin version are you using?
**Describe the bug**
A clear and concise description of what the bug is.
**Screenshots**
If applicable, add screenshots to help explain your problem.
================================================
FILE: .github/ISSUE_TEMPLATE/06-suggestion.md
================================================
---
name: Suggestion
about: Suggest an idea/improvement for this project
title: ''
labels: feature-request
assignees: labuladong
---
Do you have any suggestions?
Is there anything that you feel inconvenient to use?
================================================
FILE: .github/PULL_REQUEST_TEMPLATE.md
================================================
================================================
FILE: README.md
================================================
[](https://star-history.com/#labuladong/fucking-algorithm&Date)
# labuladong Algo Notes
This repository contains 60+ original articles based on LeetCode problems, covering all problem types and techniques. The goal is to help you **think algorithmically** — not just memorize solutions.
When it comes to LeetCode, what matters is not the answer itself, but the **thought process** behind it. A repository full of raw code without explanation isn't very useful. The real value lies in understanding the frameworks and patterns that let you solve new problems on your own.
Most people grind LeetCode to land a job, not to compete in programming contests. So the focus here is on **clarity and practical understanding** — building reusable mental frameworks that make algorithm problems approachable and solvable.
## Before You Start
**1. Give this repo a star** if you find it helpful — it keeps me motivated to write more.
**2. I recommend studying on my website, where each article links to the corresponding LeetCode problems so you can read and practice side by side. The site covers 500+ problems with step-by-step guidance:**
https://labuladong.online/en/algo/

## Table of Contents
* [Introduction](https://labuladong.online/en/algo/home/)
* [Study Plans for Beginners and Quick Mastery](https://labuladong.online/en/algo/menu/plan/)
* [Fast-Track Learning Plan](https://labuladong.online/en/algo/intro/quick-learning-plan/)
* [Complete Learning Plan](https://labuladong.online/en/algo/intro/beginner-learning-plan/)
* [How to Learn Algorithms Efficiently](https://labuladong.online/en/algo/intro/how-to-learn-algorithms/)
* [How to Practice](https://labuladong.online/en/algo/intro/how-to-practice/)
* [Tools and Algorithm Visualization](https://labuladong.online/en/algo/menu/tools/)
* [AI Assistant for Questions](https://labuladong.online/en/algo/intro/ai-assistant/)
* [Algorithm Visualization Introduction](https://labuladong.online/en/algo/intro/visualize/)
* [Algorithm Game Introduction](https://labuladong.online/en/algo/intro/game/)
* [Chrome Extension for LeetCode](https://labuladong.online/en/algo/intro/chrome/)
* [vscode/cursor Plugin for LeetCode](https://labuladong.online/en/algo/intro/vscode/)
* [JetBrains Plugin for LeetCode](https://labuladong.online/en/algo/intro/jetbrains/)
* [Subscribe to Pro](https://labuladong.online/en/algo/intro/site-vip/)
* [Programming Language Basics](https://labuladong.online/en/algo/menu/)
* [Chapter Introduction](https://labuladong.online/en/algo/intro/programming-language-basic/)
* [C++ Basics](https://labuladong.online/en/algo/programming-language-basic/cpp/)
* [Java Basics](https://labuladong.online/en/algo/programming-language-basic/java/)
* [Golang Basics](https://labuladong.online/en/algo/programming-language-basic/golang/)
* [Python Basics](https://labuladong.online/en/algo/programming-language-basic/python/)
* [JavaScript Basics](https://labuladong.online/en/algo/intro/js/)
* [LeetCode Guide](https://labuladong.online/en/algo/intro/leetcode/)
* [Let's Have Fun with LeetCode](https://labuladong.online/en/algo/programming-language-basic/lc-practice/)
* [ACM Mode Code Template](https://labuladong.online/en/algo/intro/acm-mode/)
* [Getting Started: Data Structures and Sorting](https://labuladong.online/en/algo/menu/quick-start/)
* [Chapter Introduction](https://labuladong.online/en/algo/intro/data-structure-basic/)
* [Basic Time Complexity](https://labuladong.online/en/algo/intro/complexity-basic/)
* [Implement Dynamic Arrays](https://labuladong.online/en/algo/menu/dynamic-array/)
* [Array (Sequential Storage)](https://labuladong.online/en/algo/data-structure-basic/array-basic/)
* [Dynamic Array Code Implementation](https://labuladong.online/en/algo/data-structure-basic/array-implement/)
* [Implement Single/Double Linked List](https://labuladong.online/en/algo/menu/linked-list/)
* [Linked List (Chain Storage)](https://labuladong.online/en/algo/data-structure-basic/linkedlist-basic/)
* [Linked List Code Implementation](https://labuladong.online/en/algo/data-structure-basic/linkedlist-implement/)
* [Implement Snake Game](https://labuladong.online/en/algo/game/snake/)
* [Array and LinkedList Variations](https://labuladong.online/en/algo/menu/arr-linked/)
* [Circular Array Technique and Implementation](https://labuladong.online/en/algo/data-structure-basic/cycle-array/)
* [Skip List Basics](https://labuladong.online/en/algo/data-structure-basic/skip-list-basic/)
* [BitMap Principles and Implementation](https://labuladong.online/en/algo/data-structure-basic/bitmap/)
* [Implement Queue and Stack](https://labuladong.online/en/algo/menu/queue-stack/)
* [Queue/Stack Basic](https://labuladong.online/en/algo/data-structure-basic/queue-stack-basic/)
* [Implement Queue/Stack with Linked List](https://labuladong.online/en/algo/data-structure-basic/linked-queue-stack/)
* [Implement Queue/Stack with Array](https://labuladong.online/en/algo/data-structure-basic/array-queue-stack/)
* [Deque Implementation](https://labuladong.online/en/algo/data-structure-basic/deque-implement/)
* [Implement HashMap](https://labuladong.online/en/algo/menu/hash-table/)
* [Basic Concept of HashMap](https://labuladong.online/en/algo/data-structure-basic/hashmap-basic/)
* [Implement HashMap with Separate Chaining](https://labuladong.online/en/algo/data-structure-basic/hashtable-chaining/)
* [Key Points to Implement Linear Probing](https://labuladong.online/en/algo/data-structure-basic/linear-probing-key-point/)
* [Two Implementations of Linear Probing](https://labuladong.online/en/algo/data-structure-basic/linear-probing-code/)
* [Hash Set Basic and Implementation](https://labuladong.online/en/algo/data-structure-basic/hash-set/)
* [Hash Table Variations](https://labuladong.online/en/algo/menu/hash-table-variation/)
* [Use Linked List to Enhance Hash Table (LinkedHashMap)](https://labuladong.online/en/algo/data-structure-basic/hashtable-with-linked-list/)
* [Use Array to Enhance Hash Table (ArrayHashMap)](https://labuladong.online/en/algo/data-structure-basic/hashtable-with-array/)
* [Bloom Filter Implementation](https://labuladong.online/en/algo/data-structure-basic/bloom-filter/)
* [Binary Tree Structure and Traversal](https://labuladong.online/en/algo/menu/binary-tree/)
* [Binary Tree Basic and Common Types](https://labuladong.online/en/algo/data-structure-basic/binary-tree-basic/)
* [Binary Tree Recursive/Level Traversal](https://labuladong.online/en/algo/data-structure-basic/binary-tree-traverse-basic/)
* [Use cases of DFS and BFS](https://labuladong.online/en/algo/data-structure-basic/use-case-of-dfs-bfs/)
* [N-ary Tree Recursive/Level Traversal](https://labuladong.online/en/algo/data-structure-basic/n-ary-tree-traverse-basic/)
* [Binary Tree Variations](https://labuladong.online/en/algo/menu/binary-tree/)
* [TreeMap Structure and Visualization](https://labuladong.online/en/algo/data-structure-basic/tree-map-basic/)
* [Red-Black Trees Basics and Visualization](https://labuladong.online/en/algo/data-structure-basic/rbtree-basic/)
* [Trie, Digital Tree, Prefix Tree Basics and Visualization](https://labuladong.online/en/algo/data-structure-basic/trie-map-basic/)
* [Basic Concept of Binary Heap](https://labuladong.online/en/algo/data-structure-basic/binary-heap-basic/)
* [Binary Heap/Priority Queue Code Implementation](https://labuladong.online/en/algo/data-structure-basic/binary-heap-implement/)
* [Segment Tree Basics and Visualization](https://labuladong.online/en/algo/data-structure-basic/segment-tree-basic/)
* [Data Compression and Huffman Tree](https://labuladong.online/en/algo/data-structure-basic/huffman-tree/)
* [Updating](https://labuladong.online/en/algo/intro/updating/)
* [Graph Structure and Algorithm Overview](https://labuladong.online/en/algo/menu/graph-theory/)
* [Basic Terminology in Graph Theory](https://labuladong.online/en/algo/data-structure-basic/graph-terminology/)
* [Graph Structure Code Implementation](https://labuladong.online/en/algo/data-structure-basic/graph-basic/)
* [Graph Structure DFS/BFS Traversal](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/)
* [Eulerian Graph and One-Stroke Game](https://labuladong.online/en/algo/data-structure-basic/eulerian-graph/)
* [Graph Shortest Path Algorithms Overview](https://labuladong.online/en/algo/data-structure-basic/graph-shortest-path/)
* [Minimum Spanning Tree Algorithms Overview](https://labuladong.online/en/algo/data-structure-basic/graph-minimum-spanning-tree/)
* [Basic Concept of Union Find Algorithm](https://labuladong.online/en/algo/data-structure-basic/union-find-basic/)
* [Updating](https://labuladong.online/en/algo/intro/updating/)
* [Implement and Visualize 10 Sorting Algorithms](https://labuladong.online/en/algo/menu/sorting/)
* [Chapter Introduction](https://labuladong.online/en/algo/intro/sorting/)
* [Key Metrics of Sorting Algorithms](https://labuladong.online/en/algo/data-structure-basic/sort-basic/)
* [Explore Selection Sort in Depth](https://labuladong.online/en/algo/data-structure-basic/select-sort/)
* [Bubble Sort with Stability](https://labuladong.online/en/algo/data-structure-basic/bubble-sort/)
* [Insertion Sort with Reverse Thinking](https://labuladong.online/en/algo/data-structure-basic/insertion-sort/)
* [Shell Sort - Better than O(N^2)](https://labuladong.online/en/algo/data-structure-basic/shell-sort/)
* [Quick Sort and Binary Tree Preorder](https://labuladong.online/en/algo/data-structure-basic/quick-sort/)
* [Merge Sort and Binary Tree Postorder](https://labuladong.online/en/algo/data-structure-basic/merge-sort/)
* [Heap Sort and Binary Heap](https://labuladong.online/en/algo/data-structure-basic/heap-sort/)
* [Counting Sort: A New Pespective on Sorting](https://labuladong.online/en/algo/data-structure-basic/counting-sort/)
* [Bucket Sort](https://labuladong.online/en/algo/data-structure-basic/bucket-sort/)
* [Radix Sort](https://labuladong.online/en/algo/data-structure-basic/radix-sort/)
* [Updating](https://labuladong.online/en/algo/intro/updating/)
* [Chapter 0. Classic Problem Solving Templates](https://labuladong.online/en/algo/menu/core/)
* [Chapter Introduction](https://labuladong.online/en/algo/intro/core-intro/)
* [How to Think About Data Structure and Algorithm](https://labuladong.online/en/algo/essential-technique/algorithm-summary/)
* [Two Pointer Techniques for Linked List Problems](https://labuladong.online/en/algo/essential-technique/linked-list-skills-summary/)
* [Two Pointer Techniques for Array Problems](https://labuladong.online/en/algo/essential-technique/array-two-pointers-summary/)
* [Sliding Window Algorithm Code Template](https://labuladong.online/en/algo/essential-technique/sliding-window-framework/)
* [Thinking Recursion Algorithms from Binary Tree Perspective](https://labuladong.online/en/algo/essential-technique/binary-tree-summary/)
* [One Perspective + Two Thinking Patterns to Master Recursion](https://labuladong.online/en/algo/essential-technique/understand-recursion/)
* [Dynamic Programming Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/dynamic-programming-framework/)
* [Backtracking Algorithm Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/backtrack-framework/)
* [BFS Algorithm Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/bfs-framework/)
* [Backtracking Algorithm to Solve All Permutation/Combination/Subset Problems](https://labuladong.online/en/algo/essential-technique/permutation-combination-subset-all-in-one/)
* [Greedy Algorithms Principles and Techniques](https://labuladong.online/en/algo/essential-technique/greedy/)
* [Divide and Conquer Principles and Techniques](https://labuladong.online/en/algo/essential-technique/divide-and-conquer/)
* [Time and Space Complexity Analysis Practical Guide](https://labuladong.online/en/algo/essential-technique/complexity-analysis/)
* [Chapter 1. Data Structure Algorithms](https://labuladong.online/en/algo/menu/ds/)
* [Linked List Algorithm](https://labuladong.online/en/algo/menu/linked-list/)
* [Two Pointer Techniques for Linked List Problems](https://labuladong.online/en/algo/essential-technique/linked-list-skills-summary/)
* [Exercise: Two Pointer Techniques for Linked List](https://labuladong.online/en/algo/problem-set/linkedlist-two-pointers/)
* [Tricks to Reverse a Linked List Recursively](https://labuladong.online/en/algo/data-structure/reverse-linked-list-recursion/)
* [How to Determine a Palindrome Linked List](https://labuladong.online/en/algo/data-structure/palindrome-linked-list/)
* [Array Algorithm](https://labuladong.online/en/algo/menu/array/)
* [Two Pointer Techniques for Array Problems](https://labuladong.online/en/algo/essential-technique/array-two-pointers-summary/)
* [Match Three Game](https://labuladong.online/en/algo/game/match-three/)
* [Tricks to Traverse a 2D Array](https://labuladong.online/en/algo/practice-in-action/2d-array-traversal-summary/)
* [Exercise: Two Pointer Techniques for Array](https://labuladong.online/en/algo/problem-set/array-two-pointers/)
* [Game of Life](https://labuladong.online/en/algo/game/life-game/)
* [One Trick to Solve All N-Sum Problems](https://labuladong.online/en/algo/practice-in-action/nsum/)
* [Prefix Sum Array Technique](https://labuladong.online/en/algo/data-structure/prefix-sum/)
* [Exercise: Prefix Sum Techniques](https://labuladong.online/en/algo/problem-set/perfix-sum/)
* [Difference Array Technique](https://labuladong.online/en/algo/data-structure/diff-array/)
* [Sliding Window Algorithm Code Template](https://labuladong.online/en/algo/essential-technique/sliding-window-framework/)
* [Exercise: Sliding Window In Action](https://labuladong.online/en/algo/problem-set/sliding-window/)
* [Sliding Window: Rabin Karp Algorithm](https://labuladong.online/en/algo/practice-in-action/rabinkarp/)
* [Binary Search Algorithm Code Template](https://labuladong.online/en/algo/essential-technique/binary-search-framework/)
* [Binary Search Follow-up](https://labuladong.online/en/algo/essential-technique/binary-search-left-open/)
* [Binary Search in Action](https://labuladong.online/en/algo/frequency-interview/binary-search-in-action/)
* [Exercise: Binary Search Algorithm](https://labuladong.online/en/algo/problem-set/binary-search/)
* [Weighted Random Selection Algorithm](https://labuladong.online/en/algo/frequency-interview/random-pick-with-weight/)
* [Advantage Shuffle Algorithm](https://labuladong.online/en/algo/practice-in-action/advantage-shuffle/)
* [Stack/Queue Algorithm](https://labuladong.online/en/algo/menu/queue-stack/)
* [Implement Stack with Queue, Implement Queue with Stack](https://labuladong.online/en/algo/data-structure/stack-queue/)
* [Exercise: Stack Problems on LeetCode](https://labuladong.online/en/algo/problem-set/stack/)
* [Exercise: Bracket Problems on LeetCode](https://labuladong.online/en/algo/problem-set/parentheses/)
* [Exercise: Queue Problems on LeetCode](https://labuladong.online/en/algo/problem-set/queue/)
* [Monotonic Stack Code Template](https://labuladong.online/en/algo/data-structure/monotonic-stack/)
* [Exercise: Monotonic Stack Problems on LeetCode](https://labuladong.online/en/algo/problem-set/monotonic-stack/)
* [Monotonic Queue to Solve Sliding Window Problems](https://labuladong.online/en/algo/data-structure/monotonic-queue/)
* [Exercise: Monotonic Queue Implementation and Leetcode Problems](https://labuladong.online/en/algo/problem-set/monotonic-queue/)
* [Binary Tree Algorithm](https://labuladong.online/en/algo/menu/binary-tree/)
* [Thinking Recursion Algorithms from Binary Tree Perspective](https://labuladong.online/en/algo/essential-technique/binary-tree-summary/)
* [Binary Tree in Action (Traversal)](https://labuladong.online/en/algo/data-structure/binary-tree-part1/)
* [Binary Tree in Action (Construction)](https://labuladong.online/en/algo/data-structure/binary-tree-part2/)
* [Binary Tree in Action (Post-order)](https://labuladong.online/en/algo/data-structure/binary-tree-part3/)
* [Binary Tree in Action (Serialization)](https://labuladong.online/en/algo/data-structure/serialize-and-deserialize-binary-tree/)
* [Binary Search Tree in Action (In-order)](https://labuladong.online/en/algo/data-structure/bst-part1/)
* [Binary Search Tree in Action (Basic Operations)](https://labuladong.online/en/algo/data-structure/bst-part2/)
* [Binary Search Tree in Action (Construction)](https://labuladong.online/en/algo/data-structure/bst-part3/)
* [Binary Search Tree in Action (Post-order)](https://labuladong.online/en/algo/data-structure/bst-part4/)
* [Master Binary Tree Problems](https://labuladong.online/en/algo/menu/100-bt/)
* [Chapter Introduction](https://labuladong.online/en/algo/intro/binary-tree-practice/)
* [Exercise: Binary Tree Traversal I](https://labuladong.online/en/algo/problem-set/binary-tree-traverse-i/)
* [Exercise: Binary Tree Traversal II](https://labuladong.online/en/algo/problem-set/binary-tree-traverse-ii/)
* [Exercise: Binary Tree Traversal III](https://labuladong.online/en/algo/problem-set/binary-tree-traverse-iii/)
* [Exercise: Binary Tree Divide and Conquer I](https://labuladong.online/en/algo/problem-set/binary-tree-divide-i/)
* [Exercise: Binary Tree Divide and Conquer II](https://labuladong.online/en/algo/problem-set/binary-tree-divide-ii/)
* [Exercise: Binary Tree Combine Two Views](https://labuladong.online/en/algo/problem-set/binary-tree-combine-two-view/)
* [Exercise: Binary Tree Post-order I](https://labuladong.online/en/algo/problem-set/binary-tree-post-order-i/)
* [Exercise: Binary Tree Post-order II](https://labuladong.online/en/algo/problem-set/binary-tree-post-order-ii/)
* [Exercise: Binary Tree Post-order III](https://labuladong.online/en/algo/problem-set/binary-tree-post-order-iii/)
* [Exercise: Binary Tree Level I](https://labuladong.online/en/algo/problem-set/binary-tree-level-i/)
* [Exercise: Binary Tree Level II](https://labuladong.online/en/algo/problem-set/binary-tree-level-ii/)
* [Exercise: Binary Search Tree I](https://labuladong.online/en/algo/problem-set/bst1/)
* [Exercise: Binary Search Tree II](https://labuladong.online/en/algo/problem-set/bst2/)
* [Binary Tree Follow-up](https://labuladong.online/en/algo/menu/more-bt/)
* [Lowest Common Ancestor All in One](https://labuladong.online/en/algo/practice-in-action/lowest-common-ancestor-summary/)
* [Trick: How to Count Nodes in a Complete Binary Tree](https://labuladong.online/en/algo/data-structure/count-complete-tree-nodes/)
* [Trick: Lazy Expansion of a Multiway Tree](https://labuladong.online/en/algo/data-structure/flatten-nested-list-iterator/)
* [Follow-up: Merge Sort Implementation and Applications](https://labuladong.online/en/algo/practice-in-action/merge-sort/)
* [Follow-up: Quick Sort Implementation and Applications](https://labuladong.online/en/algo/practice-in-action/quick-sort/)
* [Trick: Traverse Binary Tree with Stack](https://labuladong.online/en/algo/data-structure/iterative-traversal-binary-tree/)
* [Design Data Structures](https://labuladong.online/en/algo/menu/design/)
* [Implementing LRU Cache like Building a Lego](https://labuladong.online/en/algo/data-structure/lru-cache/)
* [Implementing LFU Cache like Building a Lego](https://labuladong.online/en/algo/frequency-interview/lfu/)
* [How to Deleting Array Element in O(1) Time](https://labuladong.online/en/algo/data-structure/random-set/)
* [Exercise: Hash Table Problems on LeetCode](https://labuladong.online/en/algo/problem-set/hash-table/)
* [Exercise: Priority Queue Problems on LeetCode](https://labuladong.online/en/algo/problem-set/binary-heap/)
* [Implementing TreeMap/TreeSet](https://labuladong.online/en/algo/data-structure-basic/tree-map-implement/)
* [Basic Segment Tree Implementation](https://labuladong.online/en/algo/data-structure/segment-tree-implement/)
* [Dynamic Segment Tree Implementation](https://labuladong.online/en/algo/data-structure/segment-tree-dynamic/)
* [Lazy Update Segment Tree Implementation](https://labuladong.online/en/algo/data-structure/segment-tree-lazy-update/)
* [Exercise: Segment Tree Problems](https://labuladong.online/en/algo/problem-set/segment-tree/)
* [Implementing Trie Tree](https://labuladong.online/en/algo/data-structure/trie-implement/)
* [Exercise: Trie Problems on LeetCode](https://labuladong.online/en/algo/problem-set/trie/)
* [Designing an Exam Room Algorithm](https://labuladong.online/en/algo/frequency-interview/exam-room/)
* [Exercise: Classic Design Problems on LeetCode](https://labuladong.online/en/algo/problem-set/ds-design/)
* [Implement Huffman Coding Compression](https://labuladong.online/en/algo/data-structure/huffman-tree-implementation/)
* [Implement Consistent Hashing Algorithm](https://labuladong.online/en/algo/data-structure/consistent-hashing/)
* [How to Implement a Calculator](https://labuladong.online/en/algo/data-structure/implement-calculator/)
* [Implementing Median Algorithm with Two Binary Heaps](https://labuladong.online/en/algo/practice-in-action/find-median-from-data-stream/)
* [Removing Duplicates from an Array (Hard Version)](https://labuladong.online/en/algo/frequency-interview/remove-duplicate-letters/)
* [Graph Algorithm](https://labuladong.online/en/algo/menu/graph/)
* [How to Determine a Bipartite Graph](https://labuladong.online/en/algo/data-structure/bipartite-graph/)
* [Hierholzer Algorithm to Find Eulerian Path](https://labuladong.online/en/algo/data-structure/eulerian-graph-hierholzer/)
* [Exercise: Eulerian Path](https://labuladong.online/en/algo/problem-set/eulerian-path/)
* [Cycle Detection Algorithm](https://labuladong.online/en/algo/data-structure/cycle-detection/)
* [Topological Sort Algorithm](https://labuladong.online/en/algo/data-structure/topological-sort/)
* [Union-Find Algorithm](https://labuladong.online/en/algo/data-structure/union-find/)
* [Exercise: Union-Find Problems on LeetCode](https://labuladong.online/en/algo/problem-set/union-find/)
* [Dijkstra Algorithm](https://labuladong.online/en/algo/data-structure/dijkstra/)
* [Dijkstra Algorithm with Restrictions](https://labuladong.online/en/algo/data-structure/dijkstra-follow-up/)
* [Exercise: Dijkstra Problems](https://labuladong.online/en/algo/problem-set/dijkstra/)
* [A* Algorithm](https://labuladong.online/en/algo/data-structure/a-star/)
* [Kruskal Minimum Spanning Tree Algorithm](https://labuladong.online/en/algo/data-structure/kruskal/)
* [Prim Minimum Spanning Tree Algorithm](https://labuladong.online/en/algo/data-structure/prim/)
* [Chapter 2. Brute Force Search](https://labuladong.online/en/algo/menu/braute-force-search/)
* [DFS and Backtracking Algorithm](https://labuladong.online/en/algo/menu/dfs/)
* [Backtracking Algorithm Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/backtrack-framework/)
* [Backtracking in Action: Sudoku and N-Queens](https://labuladong.online/en/algo/practice-in-action/sudoku-nqueue/)
* [Implement Sudoku Cheat](https://labuladong.online/en/algo/game/sudoku/)
* [Backtracking Algorithm to Solve All Permutation/Combination/Subset Problems](https://labuladong.online/en/algo/essential-technique/permutation-combination-subset-all-in-one/)
* [Some Questions About Backtracking and DFS Algorithms](https://labuladong.online/en/algo/essential-technique/backtrack-vs-dfs/)
* [Solve All Island Problems with DFS](https://labuladong.online/en/algo/frequency-interview/island-dfs-summary/)
* [Minesweeper Game II](https://labuladong.online/en/algo/game/minesweeper-ii/)
* [Ball and Box: Two Perspectives of Backtracking Enumeration](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/)
* [Backtracking Algorithm Practice: Generating Valid Parentheses](https://labuladong.online/en/algo/practice-in-action/generate-parentheses/)
* [Backtracking Algorithm Practice: Partitioning k Subsets](https://labuladong.online/en/algo/practice-in-action/partition-to-k-equal-sum-subsets/)
* [Exercise: Backtracking Problems on LeetCode I](https://labuladong.online/en/algo/problem-set/backtrack-i/)
* [Exercise: Backtracking Problems on LeetCode II](https://labuladong.online/en/algo/problem-set/backtrack-ii/)
* [Exercise: Backtracking Problems on LeetCode III](https://labuladong.online/en/algo/problem-set/backtrack-iii/)
* [BFS Algorithm](https://labuladong.online/en/algo/menu/bfs/)
* [BFS Algorithm Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/bfs-framework/)
* [Solve Maze Game](https://labuladong.online/en/algo/game/maze/)
* [Huarong Road Game](https://labuladong.online/en/algo/game/huarong-road/)
* [Connect Two Game](https://labuladong.online/en/algo/game/connect-two/)
* [Exercise: BFS Problems on LeetCode I](https://labuladong.online/en/algo/problem-set/bfs/)
* [Exercise: BFS Problems on LeetCode II](https://labuladong.online/en/algo/problem-set/bfs-ii/)
* [Chapter 3. Dynamic Programming Algorithms](https://labuladong.online/en/algo/menu/dp/)
* [Basic DP Techniques](https://labuladong.online/en/algo/menu/dp-basic/)
* [Dynamic Programming Common Patterns and Code Template](https://labuladong.online/en/algo/essential-technique/dynamic-programming-framework/)
* [How to Design Transition Equations](https://labuladong.online/en/algo/dynamic-programming/longest-increasing-subsequence/)
* [How to Determine the Base Case and Initial Values for Memoization?](https://labuladong.online/en/algo/dynamic-programming/memo-fundamental/)
* [Two Perspectives of Dynamic Programming Enumeration](https://labuladong.online/en/algo/dynamic-programming/two-views-of-dp/)
* [How to Convert Backtracking to Dynamic Programming](https://labuladong.online/en/algo/dynamic-programming/word-break/)
* [Optimize Space Complexity for Dynamic Programming](https://labuladong.online/en/algo/dynamic-programming/space-optimization/)
* [Clarifying Some Questions About Dynamic Programming](https://labuladong.online/en/algo/dynamic-programming/faq-summary/)
* [Subsequence Problems](https://labuladong.online/en/algo/menu/subsequence/)
* [Classic DP: Edit Distance](https://labuladong.online/en/algo/dynamic-programming/edit-distance/)
* [DP Design: Maximum Subarray](https://labuladong.online/en/algo/dynamic-programming/maximum-subarray/)
* [Classic DP: Longest Common Subsequence](https://labuladong.online/en/algo/dynamic-programming/longest-common-subsequence/)
* [Subsequence Problem Patterns for DP](https://labuladong.online/en/algo/dynamic-programming/subsequence-problem/)
* [Knapsack Problems](https://labuladong.online/en/algo/menu/knapsack/)
* [Classic DP: 0-1 Knapsack Problem](https://labuladong.online/en/algo/dynamic-programming/knapsack1/)
* [Classic DP: Subset Knapsack Problem](https://labuladong.online/en/algo/dynamic-programming/knapsack2/)
* [Classic DP: Unbounded Knapsack Problem](https://labuladong.online/en/algo/dynamic-programming/knapsack3/)
* [A Variant of the Knapsack Problem: Target Sum](https://labuladong.online/en/algo/dynamic-programming/target-sum/)
* [Dynamic Programming Game](https://labuladong.online/en/algo/menu/dp-game/)
* [Classic DP: Minimum Path Sum](https://labuladong.online/en/algo/dynamic-programming/minimum-path-sum/)
* [Play Dungeon Game with DP](https://labuladong.online/en/algo/dynamic-programming/magic-tower/)
* [Play Freedom Trail with DP](https://labuladong.online/en/algo/dynamic-programming/freedom-trail/)
* [Save Money on Your Trip: Weighted Shortest Path](https://labuladong.online/en/algo/dynamic-programming/cheap-travel/)
* [Multi-source shortest path: Floyd algorithm](https://labuladong.online/en/algo/data-structure/floyd/)
* [Classic DP: Regular Expression Matching](https://labuladong.online/en/algo/dynamic-programming/regular-expression-matching/)
* [Classic DP: Egg Drop](https://labuladong.online/en/algo/dynamic-programming/egg-drop/)
* [Classic DP: Burst Balloons](https://labuladong.online/en/algo/dynamic-programming/burst-balloons/)
* [Classic DP: Game Theory](https://labuladong.online/en/algo/dynamic-programming/game-theory/)
* [One Method to Solve All House Robber Problems on LeetCode](https://labuladong.online/en/algo/dynamic-programming/house-robber/)
* [One Method to Solve all Stock Problems on LeetCode](https://labuladong.online/en/algo/dynamic-programming/stock-problem-summary/)
* [Dynamic Programming ProblemSet](https://labuladong.online/en/algo/menu/dp-basic/)
* [Exercise: Rob House Pattern](https://labuladong.online/en/algo/problem-set/rob-house/)
* [Exercise: Knapsack Problems](https://labuladong.online/en/algo/problem-set/knapsack/)
* [Exercise: Dynamic Programming Problems I](https://labuladong.online/en/algo/problem-set/dynamic-programming-i/)
* [Exercise: Dynamic Programming Problems II](https://labuladong.online/en/algo/problem-set/dynamic-programming-ii/)
* [Greedy](https://labuladong.online/en/algo/menu/greedy/)
* [Greedy Algorithms Principles and Techniques](https://labuladong.online/en/algo/essential-technique/greedy/)
* [Two Approaches for Gas Station Problem](https://labuladong.online/en/algo/frequency-interview/gas-station-greedy/)
* [Greedy Algorithm for Interval Scheduling Problem](https://labuladong.online/en/algo/frequency-interview/interval-scheduling/)
* [Scan Line Technique: Scheduling Meeting Rooms](https://labuladong.online/en/algo/frequency-interview/scan-line-technique/)
* [Cut Video with a Greedy Algorithm](https://labuladong.online/en/algo/frequency-interview/cut-video/)
* [Chapter 4. Other Common Techniques](https://labuladong.online/en/algo/menu/other/)
* [Mathematical Techniques](https://labuladong.online/en/algo/menu/math/)
* [LeetCode Problems with One Line Solution](https://labuladong.online/en/algo/frequency-interview/one-line-solutions/)
* [Common Bit Manipulation Techniques](https://labuladong.online/en/algo/frequency-interview/bitwise-operation/)
* [Essential Math Techniques](https://labuladong.online/en/algo/essential-technique/math-techniques-summary/)
* [Minesweeper Game I](https://labuladong.online/en/algo/game/minesweeper/)
* [Random Algorithms in Games](https://labuladong.online/en/algo/frequency-interview/random-algorithm/)
* [Two Classic Factorial Problems on LeetCode](https://labuladong.online/en/algo/frequency-interview/factorial-problems/)
* [How to Efficiently Count Prime Numbers](https://labuladong.online/en/algo/frequency-interview/print-prime-number/)
* [How to Find Missing and Duplicate Elements](https://labuladong.online/en/algo/frequency-interview/mismatch-set/)
* [Interesting Probability Problems](https://labuladong.online/en/algo/frequency-interview/probability-problem/)
* [Exercise: Math Tricks](https://labuladong.online/en/algo/problem-set/math-tricks/)
* [Classic Interview Problems](https://labuladong.online/en/algo/menu/interview/)
* [How to Efficiently Solve the Trapping Rain Water Problem](https://labuladong.online/en/algo/frequency-interview/trapping-rain-water/)
* [One Article to Solve All Ugly Number Problems on LeetCode](https://labuladong.online/en/algo/frequency-interview/ugly-number-summary/)
* [One Method to Solve Three Interval Problems on LeetCode](https://labuladong.online/en/algo/practice-in-action/interval-problem-summary/)
* [Split Array into Consecutive Subsequences](https://labuladong.online/en/algo/practice-in-action/split-array-into-consecutive-subsequences/)
* [Pancake Sorting Algorithm](https://labuladong.online/en/algo/frequency-interview/pancake-sorting/)
* [String Multiplication Calculation](https://labuladong.online/en/algo/practice-in-action/multiply-strings/)
* [How to Determine if a Rectangle is Perfect](https://labuladong.online/en/algo/frequency-interview/perfect-rectangle/)
* [More Topics](https://labuladong.online/en/algo/menu/appendix/)
* [Computer Science](https://labuladong.online/en/algo/menu/computer-basics/)
* [Frontend Development Introduction for AI Era](https://labuladong.online/en/algo/computer-science/frontend-introduction/)
* [Introduction to Modern Encryption](https://labuladong.online/en/algo/computer-science/encryption-intro/)
* [Understand Session and Cookie](https://labuladong.online/en/algo/other-skills/session-and-cookie/)
* [Understanding JSON Web Token (JWT)](https://labuladong.online/en/algo/computer-science/how-jwt-works/)
* [Authentication vs. Authorization](https://labuladong.online/en/algo/computer-science/authentication-vs-authorization/)
* [Understanding OAuth 2.0 Authorization Framework](https://labuladong.online/en/algo/computer-science/oauth2-explained/)
* [OAuth 2.0 and OIDC Authentication](https://labuladong.online/en/algo/computer-science/oidc/)
* [OAuth 2.0 and PKCE](https://labuladong.online/en/algo/computer-science/pkce/)
* [Understanding Single Sign-On (SSO)](https://labuladong.online/en/algo/computer-science/sso/)
* [Certificate and CA](https://labuladong.online/en/algo/computer-science/certificate-and-ca/)
* [TLS Key Exchange](https://labuladong.online/en/algo/computer-science/tls-key-exchange/)
* [Mutual TLS Authentication](https://labuladong.online/en/algo/computer-science/mtls/)
* [Introduction to Linux File System](https://labuladong.online/en/algo/other-skills/linux-file-system/)
* [Linux Processes, Threads and File Descriptors](https://labuladong.online/en/algo/other-skills/linux-process/)
* [Pitfalls of Linux Pipeline](https://labuladong.online/en/algo/other-skills/linux-pipeline/)
* [Linux Shell Tips](https://labuladong.online/en/algo/other-skills/linux-shell/)
* [LSM Tree in Storage System](https://labuladong.online/en/algo/other-skills/lsm-tree/)
* [Updating](https://labuladong.online/en/algo/intro/updating/)
* [Design Pattern](https://labuladong.online/en/algo/menu/design-pattern/)
* [Design Pattern: Singleton](https://labuladong.online/en/algo/design-pattern/singleton/)
* [Design Pattern: Factory Method](https://labuladong.online/en/algo/design-pattern/factory-method/)
* [Design Pattern: Abstract Factory](https://labuladong.online/en/algo/design-pattern/abstract-factory/)
* [Design Pattern: Builder](https://labuladong.online/en/algo/design-pattern/builder/)
* [Design Pattern: Prototype](https://labuladong.online/en/algo/design-pattern/prototype/)
* [Design Pattern: Adapter](https://labuladong.online/en/algo/design-pattern/adapter/)
* [Design Pattern: Composite](https://labuladong.online/en/algo/design-pattern/composite/)
* [Design Pattern: Decorator](https://labuladong.online/en/algo/design-pattern/decorator/)
* [Design Pattern: Bridge](https://labuladong.online/en/algo/design-pattern/bridge/)
* [Design Pattern: Observer](https://labuladong.online/en/algo/design-pattern/observer/)
* [Design Pattern: Strategy](https://labuladong.online/en/algo/design-pattern/strategy/)
* [Updating](https://labuladong.online/en/algo/intro/updating/)
================================================
FILE: algorithmic-thinking/README.md
================================================
# 算法思维系列
本章包含一些常用的算法技巧,比如前缀和、回溯思想、位操作、双指针、如何正确书写二分查找等等。
欢迎关注我的公众号 labuladong,查看全部文章:


================================================
FILE: algorithmic-thinking/backtracking.md
================================================
::: info Prerequisites
Before reading this article, you should first learn:
- [Binary Tree Basics](https://labuladong.online/en/algo/data-structure-basic/binary-tree-basic/)
- [Binary Tree Traversal Framework](https://labuladong.online/en/algo/data-structure-basic/binary-tree-traverse-basic/)
- [N-ary Tree Structure and Traversal Framework](https://labuladong.online/en/algo/data-structure-basic/n-ary-tree-traverse-basic/)
:::
This article answers several questions:
What is backtracking? What techniques help with backtracking problems? How should you study backtracking? Is there a pattern to backtracking code?
Backtracking and DFS are essentially the same algorithm. I explain the subtle differences in [FAQ on DFS and Backtracking](https://labuladong.online/en/algo/essential-technique/backtrack-vs-dfs/). This article focuses on backtracking and won't dive into that distinction.
**At a high level, solving a backtracking problem is really just traversing a decision tree. Each leaf node holds a valid answer. Traverse the entire tree, collect all the answers at the leaf nodes, and you've got every valid solution.**
Standing at any node on the backtracking tree, you only need to think about 3 things:
1. **Path**: the choices you've already made.
2. **Choice list**: the choices you can currently make.
3. **Termination condition**: the point where you've reached the bottom of the decision tree and can't make any more choices.
Don't worry if these don't fully click yet—we'll use the classic "permutations" problem to make everything concrete. Just keep them in mind for now.
On the code side, here's the backtracking framework:
```python
result = []
def backtrack(path, choice_list):
if termination_condition_met:
result.add(path)
return
for choice in choice_list:
make_choice
backtrack(path, choice_list)
undo_choice
```
**The core idea is the recursion inside the for loop: "make a choice" before the recursive call, and "undo the choice" after it.** Dead simple.
But what does "make a choice" and "undo a choice" really mean? What's the underlying principle behind this framework? Let's use the "permutations" problem to clear things up!
## Permutations Problem Breakdown
LeetCode problem 46, "[Permutations](https://leetcode.cn/problems/permutations/)," gives you an array `nums` and asks you to return all possible permutations of those numbers.
::: info Note
**The permutations problem we're discussing here doesn't involve duplicate numbers. I cover the extension with duplicates in [Backtracking: 9 Types of Permutation/Combination/Subset Problems](https://labuladong.online/en/algo/essential-technique/permutation-combination-subset-all-in-one/).**
Also, some of you may have seen permutation code that uses `swap` to exchange elements, which is different from my approach here. These are two different enumeration strategies for backtracking, and I'll explain both in [Ball-in-Box Model: Two Perspectives on Backtracking Enumeration](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/). It's not the right time to introduce that approach yet—just follow along with my method for now.
:::
You probably did permutation and combination problems back in high school math. You know that `n` distinct numbers have `n!` total permutations. But how did you actually enumerate them back then?
Say you're given `[1,2,3]`. You wouldn't just randomly guess permutations—you'd do something like this:
Fix the first position as 1, then the second can be 2, which forces the third to be 3. Then change the second to 3, forcing the third to be 2. Then change the first position to 2, and enumerate the remaining two positions...
That's backtracking! You already knew how to do it intuitively in high school. Some of you might even draw out the backtracking tree like this:

Just traverse this tree from the root and record the numbers along each path—those are all the permutations. **Let's call this the "decision tree" of the backtracking algorithm.**
**Why "decision tree"? Because at every node, you're making a decision.** For example, say you're standing at the red node below:

You're choosing right now—you can go down the branch for 1 or the branch for 3. Why only 1 and 3? Because the branch for 2 is behind you; you already made that choice, and permutations don't allow reusing numbers.
**Now we can clarify those terms from earlier: `[2]` is the "path"—the record of choices you've already made. `[1,3]` is the "choice list"—the choices currently available to you. The "termination condition" is when you reach a leaf node at the bottom of the tree, which here means the choice list is empty.**
Once you understand these terms, you can think of "path" and "choice list" as attributes of each node in the decision tree. The diagram below shows the attributes for a few blue nodes:

**The `backtrack` function we define is essentially a pointer walking through this tree, maintaining each node's attributes correctly. Whenever it reaches a leaf node, the "path" at that point is a complete permutation.**
Going one step further: how do you traverse a tree? That shouldn't be too hard. Recall what we discussed in [A Framework for Learning Data Structures](https://labuladong.online/en/algo/essential-technique/algorithm-summary/)—all kinds of search problems are really tree traversal problems. The N-ary tree traversal framework looks like this:
```java
void traverse(TreeNode root) {
for (TreeNode child : root.childern) {
// operations needed at the preorder position
traverse(child);
// operations needed at the postorder position
}
}
```
::: info Info
Sharp readers might wonder: shouldn't the pre-order and post-order positions in the N-ary tree DFS traversal framework be outside the for loop, not inside it? Why did they move inside the for loop in backtracking?
Good catch. The pre-order and post-order positions in DFS should indeed be outside the for loop. However, backtracking is slightly different from standard DFS. I'll explain this in detail in [FAQ on Backtracking/DFS](https://labuladong.online/en/algo/essential-technique/backtrack-vs-dfs/). For now, you can set this question aside.
:::
As for pre-order and post-order traversal, they're just two useful points in time. Let me draw a picture to make it clear:

**Pre-order code executes at the moment just before entering a node; post-order code executes at the moment just after leaving a node.**
Remember what we said: "path" and "choices" are attributes of each node, and the function needs to handle these attributes correctly as it walks the tree. That means we need to take action at these two special time points:

Now, does this core backtracking framework make sense?
```python
for choice in choice_list:
# make a choice
remove choice from choice_list
path.add(choice)
backtrack(path, choice_list)
# undo the choice
path.remove(choice)
add choice back to choice_list
```
**Just make a choice before the recursion and undo it after the recursion**, and you'll correctly maintain each node's choice list and path.
Now let's look at the actual permutations code:
```java
class Solution {
List<List<Integer>> res = new LinkedList<>();
// Main function, input a set of unique numbers, return their permutations
List<List<Integer>> permute(int[] nums) {
// Record "path"
LinkedList<Integer> track = new LinkedList<>();
// Elements in the "path" will be marked as true to avoid reuse
boolean[] used = new boolean[nums.length];
backtrack(nums, track, used);
return res;
}
// Path: recorded in track
// Selection list: elements in nums that are not in track (used[i] is false)
// Termination condition: all elements in nums appear in track
void backtrack(int[] nums, LinkedList<Integer> track, boolean[] used) {
// Trigger termination condition
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// Exclude invalid choices
if (used[i]) {
/**<extend up -200>

*/
// nums[i] is already in track, skip
continue;
}
// Make a choice
track.add(nums[i]);
used[i] = true;
// Enter the next level of the decision tree
backtrack(nums, track, used);
// Cancel the choice
track.removeLast();
used[i] = false;
}
}
}
```
<visual slug='permutations' />
We made a small tweak here: instead of explicitly tracking a "choice list," we use a `used` array to exclude elements already in `track`, effectively deriving the current choice list:

And that's how we've used the permutations problem to explain the underlying mechanics of backtracking. Of course, this isn't the most efficient way to solve permutations—you may have seen solutions that don't even use a `used` array and instead swap elements directly. That approach is a bit harder to understand, so I'll cover it in [Ball-in-Box Model: Two Perspectives on Backtracking Enumeration](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/).
One thing to be clear about: no matter how you optimize, it still fits the backtracking framework, and the time complexity can't go below O(N!). Enumerating the entire decision tree is unavoidable—you ultimately need to produce all N! permutations.
**This is a key characteristic of backtracking: unlike dynamic programming where overlapping subproblems allow optimization, backtracking is pure brute-force enumeration, so the complexity is generally high.**
## Final Summary
Backtracking is essentially an N-ary tree traversal problem. The key is to perform operations at the pre-order and post-order traversal positions. Here's the framework:
```python
def backtrack(...):
for choice in choice_list:
make_choice
backtrack(...)
undo_choice
```
**When writing the `backtrack` function, you need to maintain the "path" (choices made so far) and the current "choice list." When the "termination condition" is triggered, add the "path" to your result set.**
Here's something interesting to think about: doesn't backtracking look a lot like dynamic programming? We've emphasized many times in the dynamic programming series that DP requires three things: "state," "choices," and "base case." Don't those map directly to "path," "choice list," and "termination condition"?
Both dynamic programming and backtracking abstract the problem into a tree structure, but the two algorithms take completely different approaches. You'll see the deeper distinctions and connections between them in [Binary Tree Essentials (Overview)](https://labuladong.online/en/algo/essential-technique/binary-tree-summary/).
================================================
FILE: algorithmic-thinking/bfs-framework.md
================================================
::: info Prerequisites
Before reading this article, you need to learn:
- [Binary Tree Recursive/Level Order Traversal](https://labuladong.online/en/algo/data-structure-basic/binary-tree-traverse-basic/)
- [N-ary Tree Recursive/Level Order Traversal](https://labuladong.online/en/algo/data-structure-basic/n-ary-tree-traverse-basic/)
- [DFS/BFS Traversal of Graphs](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/)
:::
I have said many times, algorithms like DFS, backtracking, and BFS are actually about turning a problem into a tree structure and then traversing that tree with brute-force search. So, the code for these brute-force algorithms is really just tree traversal code.
Let’s sort out the logic here:
The core of DFS and backtracking is to recursively traverse an "exhaustive tree" (an N-ary tree). And recursive traversal of an N-ary tree comes from recursive traversal of a binary tree. That’s why I say DFS and backtracking are really recursive traversal of binary trees.
The core of BFS is traversing a graph. As you will see soon, the BFS framework is just like the [DFS/BFS traversal of graphs](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/).
Graph traversal is basically N-ary tree traversal, but with a `visited` array to avoid infinite loops. And N-ary tree traversal comes from binary tree traversal. So I say, at its core, BFS is really level order traversal of a binary tree.
Why is BFS often used to solve shortest path problems? In [When to Use DFS and BFS](https://labuladong.online/en/algo/data-structure-basic/use-case-of-dfs-bfs/), I explained this in detail with the example of binary tree minimum depth.
In fact, all shortest path problems are similar to the minimum depth problem of a binary tree (finding the closest leaf node to the root). Recursive traversal must visit all nodes to find the target, but level order traversal can find the answer without visiting every node. That’s why level order traversal is good for shortest path problems.
Is this clear enough now?
**So before reading this article, make sure you have learned [Binary Tree Recursive/Level Order Traversal](https://labuladong.online/en/algo/data-structure-basic/binary-tree-traverse-basic/), [N-ary Tree Recursive/Level Order Traversal](https://labuladong.online/en/algo/data-structure-basic/n-ary-tree-traverse-basic/), and [DFS/BFS Traversal of Graphs](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/). Once you understand how to traverse these basic data structures, other algorithms will be much easier to learn.**
The main point of this article is to teach you how to turn real algorithm problems into abstract models, then use the BFS framework to solve them.
In real coding interviews, you won’t be directly asked to traverse a tree or graph. Instead, you’ll get a real-world problem, and you have to turn it into a standard graph or tree, then use BFS to find the answer.
For example, you are given a maze game and asked to find the minimum number of steps to reach the exit. If the maze has teleporters that instantly move you to another spot, what is the minimum number of steps then?
Or, given two words, you can change one into another by replacing, deleting, or inserting one character each time. What is the smallest number of operations needed?
Or, in a tile-matching game, two tiles can only be matched if the shortest line connecting them has at most two turns. When you click two tiles, how does the game check how many turns the line between them has?
At first, these problems don’t seem related to trees or graphs. But with a bit of abstraction, they are really just tree or graph traversal problems. They just look simple and boring.
Let’s use a few examples to show how to use the BFS framework, so you won’t find these problems hard anymore.
## Algorithm Framework
The BFS framework is actually the same as the [DFS/BFS Traversal of Graphs](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/) article. There are three ways to write BFS.
For real BFS problems, the first way is simple but not often used because it’s limited. The second way is the most common—most medium-level BFS problems can be solved this way. The third way is a bit more complex but more flexible. For harder problems, you may need the third way. In the next chapter, [BFS Problems](https://labuladong.online/en/algo/problem-set/bfs/), you’ll see some hard questions that use the third way. You can try them yourself later.
The examples in this article are all medium difficulty, so the solutions are based on the second way:
```java
// BFS traversal of the graph starting from s, and record the steps
// When the target node is reached, return the number of steps
int bfs(int s, int target) {
boolean[] visited = new boolean[graph.size()];
Queue<Integer> q = new LinkedList<>();
q.offer(s);
visited[s] = true;
// record the number of steps taken from s to the current node
int step = 0;
while (!q.isEmpty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
int cur = q.poll();
System.out.println("visit " + cur + " at step " + step);
// determine if the target point is reached
if (cur == target) {
return step;
}
// add the neighbors to the queue to search around
for (int to : neighborsOf(cur)) {
if (!visited[to]) {
q.offer(to);
visited[to] = true;
}
}
}
step++;
}
// If we reach here, it means the target node was not found in the graph
return -1;
}
```
The code framework above is almost copied from [DFS/BFS Traversal of Graphs](https://labuladong.online/en/algo/data-structure-basic/graph-traverse-basic/). It just adds a `target` parameter, so when you reach the target for the first time, you stop and return the number of steps.
Next, let’s use a few examples to see how to use this framework.
## Sliding Puzzle
LeetCode Problem 773 "[Sliding Puzzle](https://leetcode.com/problems/sliding-puzzle/)" is a problem that can be solved using the BFS framework. The problem is described as follows:
You are given a 2x3 sliding puzzle, represented as a 2x3 array `board`. The board contains numbers 0 to 5. The number 0 represents the empty slot. You can move the numbers. When `board` becomes `[[1,2,3],[4,5,0]]`, you win the game.
Write an algorithm to find the minimum number of moves to win the game. If it is impossible to win, return -1.
For example, if the input is `board = [[4,1,2],[5,0,3]]`, the algorithm should return 5:

If the input is `board = [[1,2,3],[5,4,0]]`, the algorithm should return -1 because there is no way to win from this situation.
This puzzle is quite interesting. I played similar games when I was young, such as the "Huarong Dao":

You need to move the blocks and try to move Cao Cao from the starting position to the exit at the bottom.
"Huarong Dao" is harder than this problem because the blocks have different sizes, while in this problem, each block has the same size.
Back to this problem, how do we change it into a tree or graph structure so we can use the BFS algorithm?
The initial state of the board is the starting point:
```
[[2,4,1],
[5,0,3]]
```
Our goal is to turn the board into this:
```
[[1,2,3],
[4,5,0]]
```
This is the target.
Now, this problem becomes a graph problem. The question is actually asking for the shortest path from the start to the target.
Who are the neighbors of the start? You can swap the 0 with the numbers above, below, left, or right. These are the neighbors of the start (since the board is 2x3, the actual neighbors are less than four if on the edge):

In the same way, each neighbor has its own neighbors. This makes a graph.
So, we can use BFS from the start. The first time we reach the target, the number of steps is the answer.
Here is the pseudocode:
```java
int bfs(int[][] board, int[][] target) {
Queue<int[][]> q = new LinkedList<>();
HashSet visited = new HashSet<>();
// add the start point to the queue
q.offer(board);
visited.add(board);
int step = 0;
while (!q.isEmpty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
int[][] cur = q.poll();
// determine if the end point is reached
if (cur == target) {
return step;
}
// add the neighbors of the current node to the queue
for (int[][] neighbor : getNeighbors(cur)) {
if (!visited.contains(neighbor)) {
q.offer(neighbor);
visited.add(neighbor);
}
}
}
step++;
}
return -1;
}
List<int[][]> getNeighbors(int[][] board) {
// swap the number 0 with the numbers above, below, left, and right, to get 4 neighbors
}
```
For this problem, the graph we build could have cycles, so we need a `visited` array to record the nodes we have already visited, to avoid falling into an infinite loop.
For example, if we start from the node `[[2,4,1],[5,0,3]]`, moving 0 to the right gives us a new node `[[2,4,1],[5,3,0]]`. But from this new node, 0 can also move to the left to return to `[[2,4,1],[5,0,3]]`. This creates a cycle. So we need a `visited` hash set to keep track of the nodes we have visited and avoid infinite loops caused by cycles.
There is another point: in this problem, `board` is a 2D array. In our article [Basics of Hash Table/Set](https://labuladong.online/en/algo/data-structure-basic/hashmap-basic/), we mentioned that a 2D array is a mutable structure and cannot be directly stored in a hash set.
So we need to use a small trick: convert the 2D array into an immutable type before storing it in the hash set. A common way is to serialize the 2D array into a string, so we can save it in the hash set.
**The tricky part is: since the 2D array has “up, down, left, right” movements, how can we swap 0 with its neighbors after converting the board to a 1D string?**
In this problem, the input board is always size 2 x 3, so we can write out this mapping by hand:
```java
// Record the adjacent indices of one-dimensional strings
int[][] neighbor = new int[][]{
{1, 3},
{0, 4, 2},
{1, 5},
{0, 4},
{3, 1, 5},
{4, 2}
};
```
**This mapping means: in the 1D string, the neighbor indexes of index `i` in the 2D board are `neighbor[i]`**.
For example, we know that the neighbors of `neighbor[4]` are `neighbor[3], neighbor[1], neighbor[5]`:

:::: details What if it is an `m x n` 2D array?
For an `m x n` 2D array, it is not realistic to write the 1D mapping by hand. We need code to generate the neighbor index mapping.
Looking at the image above, you can see: if an element `e` in the 2D array has index `i` in the 1D array, then its left and right neighbor indexes are `i - 1` and `i + 1`, and its up and down neighbors are `i - n` and `i + n`, where `n` is the number of columns.
So for an `m x n` 2D array, we can write a function to generate its `neighbor` index mapping:
```java
int[][] generateNeighborMapping(int m, int n) {
int[][] neighbor = new int[m * n][];
for (int i = 0; i < m * n; i++) {
List<Integer> neighbors = new ArrayList<>();
// if it is not the first column, it has a left neighbor
if (i % n != 0) neighbors.add(i - 1);
// if it is not the last column, it has a right neighbor
if (i % n != n - 1) neighbors.add(i + 1);
// if it is not the first row, it has an upper neighbor
if (i - n >= 0) neighbors.add(i - n);
// if it is not the last row, it has a lower neighbor
if (i + n < m * n) neighbors.add(i + n);
// Java language feature, convert List type to int[] array
neighbor[i] = neighbors.stream().mapToInt(Integer::intValue).toArray();
}
return neighbor;
}
```
::::
With this mapping, no matter where the 0 is, we can find its neighbors by these indexes and swap them. Here is the complete code:
```java
class Solution {
public int slidingPuzzle(int[][] board) {
int m = 2, n = 3;
StringBuilder sb = new StringBuilder();
String target = "123450";
// convert the 2x3 array into a string as the starting point for bfs
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
sb.append(board[i][j]);
}
}
String start = sb.toString();
// record the adjacent indices of the 1d string
int[][] neighbor = new int[][]{
{1, 3},
{0, 4, 2},
{1, 5},
{0, 4},
{3, 1, 5},
{4, 2}
};
// ****** Start of BFS algorithm framework ******
Queue<String> q = new LinkedList<>();
HashSet<String> visited = new HashSet<>();
// start bfs search from the starting point
q.offer(start);
visited.add(start);
int step = 0;
while (!q.isEmpty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
String cur = q.poll();
// check if the target state is reached
if (target.equals(cur)) {
return step;
}
// find the index of the number 0
int idx = 0;
for (; cur.charAt(idx) != '0'; idx++) ;
// swap the number 0 with adjacent numbers
for (int adj : neighbor[idx]) {
String new_board = swap(cur.toCharArray(), adj, idx);
// prevent revisiting the same state
if (!visited.contains(new_board)) {
q.offer(new_board);
visited.add(new_board);
}
}
}
step++;
}
// ****** End of BFS algorithm framework ******
return -1;
}
private String swap(char[] chars, int i, int j) {
char temp = chars[i];
chars[i] = chars[j];
chars[j] = temp;
return new String(chars);
}
}
```
<visual slug='sliding-puzzle'/>
This problem is solved. You can see that writing BFS algorithm is always the same pattern. The hard part is turning the problem into a BFS brute-force model and finding a good way to turn a multi-dimensional array into a string, so that we can use a hash set to record visited nodes.
Now, let’s look at another real problem.
## Minimum Turns to Unlock the Lock
Let's look at LeetCode problem 752 "[Open the Lock](https://leetcode.com/problems/open-the-lock/)". It's an interesting problem:
**LeetCode 752. Open the Lock** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: `'0', '1', '2', '3', '4', '5', '6', '7', '8', '9'`. The wheels can rotate freely and wrap around: for example we can turn `'9'` to be `'0'`, or `'0'` to be `'9'`. Each move consists of turning one wheel one slot.
The lock initially starts at `'0000'`, a string representing the state of the 4 wheels.
You are given a list of `deadends` dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.
Given a `target` representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.
Example 1:**
```
**Input:** deadends = ["0201","0101","0102","1212","2002"], target = "0202"
**Output:** 6
**Explanation:**
A sequence of valid moves would be "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202".
Note that a sequence like "0000" -> "0001" -> "0002" -> "0102" -> "0202" would be invalid,
because the wheels of the lock become stuck after the display becomes the dead end "0102".
```
Example 2:**
```
**Input:** deadends = ["8888"], target = "0009"
**Output:** 1
**Explanation:** We can turn the last wheel in reverse to move from "0000" -> "0009".
```
Example 3:**
```
**Input:** deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888"
**Output:** -1
**Explanation:** We cannot reach the target without getting stuck.
```
**Constraints:**
- `1 <= deadends.length <= 500`
- `deadends[i].length == 4`
- `target.length == 4`
- target **will not be** in the list `deadends`.
- `target` and `deadends[i]` consist of digits only.
Here is the function signature:
```java
class Solution {
public int openLock(String[] deadends, String target) {
// ...
}
}
```
The problem describes a password lock that we often see in daily life. If there are no restrictions, it's easy to count the minimum number of turns. For example, if you want to reach `"1234"`, you just turn each digit. The minimum turns will be `1 + 2 + 3 + 4 = 10`.
But the difficulty is that you cannot go through any `deadends` while turning the lock. How do you handle `deadends` to make the total number of turns as few as possible?
Don't worry about the details or try to consider every specific case. Remember, the heart of algorithms is brute-force. We can simply try every possible turn from `"0000"`. If we try all possible combinations, won't we definitely find the minimum turns?
**First, ignore all restrictions like `deadends` and `target`. Think about this: if you need to write an algorithm to try all possible combinations, how would you do it?**
Start from `"0000"`. How many possibilities are there if you turn the lock once? There are 4 positions, and each can turn up or down. That is, you can get `"1000", "9000", "0100", "0900"...`, a total of 8 combinations.
Then, for each of these 8 combinations, you can turn again and get 8 more combinations for each, and so on...
Can you see the recursion tree? It is an 8-way tree, and each node has 8 children.
This pseudocode below describes this idea, using level-order traversal of an 8-way tree:
```java
// increment s[j] by one
String plusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '9')
ch[j] = '0';
else
ch[j] += 1;
return new String(ch);
}
// decrement s[j] by one
String minusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '0')
ch[j] = '9';
else
ch[j] -= 1;
return new String(ch);
}
// BFS framework to find the minimum number of moves
void BFS(String target) {
Queue<String> q = new LinkedList<>();
q.offer("0000");
int step = 0;
while (!q.isEmpty()) {
int sz = q.size();
// spread all nodes in the current queue to their neighbors
for (int i = 0; i < sz; i++) {
String cur = q.poll();
// determine if the end point is reached
if (cur.equals(target)) {
return step;
}
// a password can derive 8 neighboring passwords
for (String neighbor : getNeighbors(cur)) {
q.offer(neighbor);
}
}
// increase the step count here
step++;
}
}
// increment or decrement each digit of s by one, return 8 neighboring passwords
List<String> getNeighbors(String s) {
List<String> neighbors = new ArrayList<>();
for (int i = 0; i < 4; i++) {
neighbors.add(plusOne(s, i));
neighbors.add(minusOne(s, i));
}
return neighbors;
}
```
This code can already try all possible combinations, but there are still some problems to solve.
1. There will be repeated paths. For example, you can go from `"0000"` to `"1000"`, but when you take `"1000"` from the queue, you can turn it back to `"0000"`. This will create an infinite loop.
This is easy to fix. Actually, it is a cycle in the graph. We can use a `visited` set to record all passwords we have already tried. If you see the same password again, just don't add it to the queue.
2. We haven't handled `deadends`. We should avoid these "dead passwords".
This can also be fixed easily. Use a `deadends` set to record these passwords. Whenever you meet one, do not add it to the queue.
Or even simpler, just add all `deadends` to the `visited` set at the beginning. This works too.
Here is the complete code:
```java
class Solution {
public int openLock(String[] deadends, String target) {
// record the deadends that need to be skipped
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
if (deads.contains("0000")) return -1;
// record the passwords that have been exhausted to prevent backtracking
Set<String> visited = new HashSet<>();
Queue<String> q = new LinkedList<>();
// start breadth-first search from the starting point
int step = 0;
q.offer("0000");
visited.add("0000");
while (!q.isEmpty()) {
int sz = q.size();
// spread all nodes in the current queue to their surroundings
for (int i = 0; i < sz; i++) {
String cur = q.poll();
// determine if the end is reached
if (cur.equals(target))
return step;
// add the valid adjacent nodes of a node to the queue
for (String neighbor : getNeighbors(cur)) {
if (!visited.contains(neighbor) && !deads.contains(neighbor)) {
q.offer(neighbor);
visited.add(neighbor);
}
}
}
// increment the step count here
step++;
}
// if the target password is not found after exhaustion, then it is not found
return -1;
}
// turn s[j] up once
String plusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '9')
ch[j] = '0';
else
ch[j] += 1;
return new String(ch);
}
// turn s[i] down once
String minusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '0')
ch[j] = '9';
else
ch[j] -= 1;
return new String(ch);
}
// increment or decrement each digit of s by one, return 8 neighboring passwords
List<String> getNeighbors(String s) {
List<String> neighbors = new ArrayList<>();
for (int i = 0; i < 4; i++) {
neighbors.add(plusOne(s, i));
neighbors.add(minusOne(s, i));
}
return neighbors;
}
}
```
## Bidirectional BFS Optimization
Now let's talk about an optimization for BFS called **Bidirectional BFS**. This method can make BFS faster.
Think of this technique as extra reading. In most interviews and tests, normal BFS is enough. Only consider bidirectional BFS when your solution is too slow or if the interviewer asks for more optimization.
Bidirectional BFS is an advanced version of standard BFS:
**In normal BFS, you start from the starting point and search outwards until you find the target. In bidirectional BFS, you start searching from both the start and the end at the same time. When the two searches meet, you stop.**
Why is this faster?
It's like person A is looking for person B. In normal BFS, A goes to find B while B stays in place. In bidirectional BFS, both A and B walk toward each other. Of course, they will meet faster this way.


In the picture above, if the target is at the bottom of the tree, normal BFS will search the whole tree before finding the target. But bidirectional BFS only searches half the tree before the two searches meet, so it is faster.
From the Big O notation, both methods are $O(N)$ in the worst case, since both might search all nodes. But in real practice, bidirectional BFS is often much faster.
::: info Limitations of Bidirectional BFS
**You must know where the target is to use bidirectional BFS.**
For BFS, you always know the start point. But sometimes you do not know the target node at the beginning.
For example, in the lock problem or the sliding puzzle problem above, the target is given, so you can use bidirectional BFS.
But in the [Binary Tree DFS/BFS traversal](https://labuladong.online/en/algo/data-structure-basic/binary-tree-traverse-basic/), the start is the root, but the target is the nearest leaf, which you do not know at the start. So you can't use bidirectional BFS there.
:::
Let's use the lock problem as an example to see how to upgrade BFS to bidirectional BFS. Here is the code:
```java
class Solution {
public int openLock(String[] deadends, String target) {
Set<String> deads = new HashSet<>();
for (String s : deadends) deads.add(s);
// base case
if (deads.contains("0000")) return -1;
if (target.equals("0000")) return 0;
// Use a set instead of a queue to quickly determine if an element exists
Set<String> q1 = new HashSet<>();
Set<String> q2 = new HashSet<>();
Set<String> visited = new HashSet<>();
int step = 0;
q1.add("0000");
visited.add("0000");
q2.add(target);
visited.add(target);
while (!q1.isEmpty() && !q2.isEmpty()) {
/**<extend down -200>

*/
// Increment the step count here
step++;
// The hash set cannot be modified during traversal, so use newQ1 to store the neighbor nodes
Set<String> newQ1 = new HashSet<>();
// Get the neighbors of all nodes in q1
for (String cur : q1) {
// Add an unvisited neighboring node of a node to the set
for (String neighbor : getNeighbors(cur)) {
// Determine if the end point is reached
if (q2.contains(neighbor)) {
return step;
}
if (!visited.contains(neighbor) && !deads.contains(neighbor)) {
newQ1.add(neighbor);
visited.add(neighbor);
}
}
}
// newQ1 stores the neighbors of q1
q1 = newQ1;
// Because each BFS spreads q1, the set with fewer elements is used as q1
if (q1.size() > q2.size()) {
Set<String> temp = q1;
q1 = q2;
q2 = temp;
}
}
return -1;
}
// Turn s[j] up once
String plusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '9')
ch[j] = '0';
else
ch[j] += 1;
return new String(ch);
}
// Turn s[i] down once
String minusOne(String s, int j) {
char[] ch = s.toCharArray();
if (ch[j] == '0')
ch[j] = '9';
else
ch[j] -= 1;
return new String(ch);
}
List<String> getNeighbors(String s) {
List<String> neighbors = new ArrayList<>();
for (int i = 0; i < 4; i++) {
neighbors.add(plusOne(s, i));
neighbors.add(minusOne(s, i));
}
return neighbors;
}
}
```
Bidirectional BFS still follows the BFS framework, but there are a few differences:
1. Instead of using a queue, use a [hash set](https://labuladong.online/en/algo/data-structure-basic/hash-set/) to store elements. This makes it easier and faster to check if two sets have any common elements.
2. The place to return `step` is changed. In bidirectional BFS, you do not just check if you reached the end. Instead, you check if the two sets have common elements as soon as you find neighbors.
3. Another tip is to always make `q1` the smaller set each time you search. This helps reduce the search size.
In BFS, the more elements in your queue (or set), the more neighbors you will add in the next round. In bidirectional BFS, if you always expand the smaller set, the total number of nodes searched grows more slowly and makes the algorithm faster.
Again, **no matter if you use normal BFS or bidirectional BFS, and no matter if you optimize or not, the Big O time complexity is the same**. Bidirectional BFS is just an advanced trick to speed up code in practice. It's not required.
The most important thing is to remember the general BFS framework and practice using it. Later, there is a [BFS Exercise Section](https://labuladong.online/en/algo/problem-set/bfs/). Try to use the tips from this article to solve those problems.
================================================
FILE: algorithmic-thinking/binary-search.md
================================================
::: info Prerequisite
Before reading this article, you should first learn:
- [Array Basics](https://labuladong.online/en/algo/data-structure-basic/array-basic/)
:::
First, a small joke:
One day, A-Dong borrowed `N` books from the library. When he was leaving, the alarm went off. The security guard stopped him to check which book was not registered. A-Dong was about to scan each book through the gate one by one to find the problem book, but the guard looked at him with disdain: "You don't even know binary search?"
So the guard split the books into two piles. He let the first pile pass the gate. The alarm sounded, which meant the problem book was in this pile. Then he split this pile into two piles again and let the first pile pass the gate. The alarm sounded again, and he kept splitting into two piles...
After `logN` checks, the guard finally found the book that triggered the alarm. He looked proud and mocking. Then A-Dong walked away with all the remaining books.
From then on, the library lost `N - 1` books.
Binary search is not simple. Knuth (the one who invented the KMP algorithm) said about binary search: **the idea is simple, the devil is in the details**. Many people like to talk about the integer overflow bug, but the real traps in binary search are not that small detail. The real questions are: should you add one or subtract one from `mid`? Should the while condition be `<=` or `<`?
If you do not really understand these details, writing binary search will feel like magic. You will rely on luck to avoid bugs, and only the writer knows how unreliable it is.
This article will explore the three most common binary search cases: find a number, find the left boundary, and find the right boundary. These three cases use one unified framework: the while condition is always `<=`, and the boundary updates always use `mid ± 1`, which is easy to remember.
## Binary Search Framework
There are two main styles of binary search:
- both ends closed, `[left, right]`
- left closed, right open, `[left, right)`
**This article uses the “both ends closed” style** because it is easier to remember and unify. The left-closed-right-open style is explained in another article: [Binary Search: Left-Closed-Right-Open Style](https://labuladong.online/en/algo/essential-technique/binary-search-left-open/).
No matter which style you use, the code follows this general framework:
```java
int binarySearch(int[] nums, int target) {
int left = 0, right = ...;
while(...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
return ...;
}
```
The parts marked with `...` are where details can go wrong. When you read any binary search code, first look at these places. Later we will see how they change in different cases.
One trick to write correct binary search is: do not use plain `else`. Instead, write all branches as `else if`, so every case is clear. After you fully understand all the details, you can simplify the code yourself.
**Another point: when computing `mid`, you must avoid overflow.** In the code, `left + (right - left) / 2` is the same as `(left + right) / 2` in result, but it prevents overflow when `left` and `right` are very large.
## The Idea of Search Interval
To really understand binary search, you must understand the idea of the “search interval” — what `left` and `right` mean.
For example, if we set `right = nums.length - 1`, the index of the last element, then the search interval is a closed interval `[left, right]`. This is exactly the range we search each time.
If we set `right = nums.length`, which is last index + 1, then the search interval is left-closed-right-open `[left, right)`.
**The essence of binary search is to use a `while` loop to move `left` and `right`, shrinking the search interval again and again, until we lock onto the index of the target value.**
Different open/closed choices give different code. For a correct binary search, we must make sure:
- When the search interval is empty, the search must stop. Otherwise, the algorithm will run forever.
- During the search, we must not skip any element. Otherwise, the answer can be wrong.
Keep these two rules in mind. Next, we will use the **both-ends-closed** style to handle three cases: find a number, find the left boundary, and find the right boundary.
## Find a Number
This is the simplest case: search for a number. If it exists, return its index; otherwise, return -1.
```java
class Solution {
// standard binary search framework, search for the index of the target element, return -1 if it does not exist
public int search(int[] nums, int target) {
int left = 0;
// note
int right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
// note
left = mid + 1;
} else if (nums[mid] > target) {
// note
right = mid - 1;
}
}
return -1;
}
}
```
<visual slug='binary-search'/>
This code solves LeetCode 704 “[Binary Search](https://leetcode.com/problems/binary-search/)”. Let’s look at the details.
### Why is the while condition `<=` and not `<`?
For a closed search interval, `<=` will not miss elements.
The loop `while (left <= right)` stops when `left == right + 1`. The search interval is then `[right + 1, right]`. There is no index that is both `>= right + 1` and `<= right`, so the interval is empty. Stopping here is correct.
If we use `while (left < right)`, the loop stops when `left == right`. The interval is `[left, left]`, which still has **one element**, but the while loop has stopped. That element is skipped. If the target is that element, the algorithm will wrongly think the target does not exist.
This shows why binary search is hard to write perfectly: bugs are not always visible. Most test cases might pass, and only some special cases will fail.
You must really understand the search interval to write fully correct code.
### Why `left = mid + 1` and `right = mid - 1`?
Because `mid` has already been checked, so we must remove it from the search interval.
Our interval is closed: `[left, right]`. When we find that index `mid` is not the target, the next search interval must be either `[left, mid - 1]` or `[mid + 1, right]`.
### What limitation does this algorithm have?
For example, in a sorted array `nums = [1,2,2,2,3]`, with `target = 2`, this algorithm returns index 2. That is fine. But what if we want the **left boundary** (index 1), or the **right boundary** (index 3)? This algorithm cannot do that.
You might say: once we find one `target`, we can linearly scan left or right. That works, but then we lose the logarithmic time advantage of binary search.
The next algorithms will handle these two “boundary search” cases, which are very common in real problems.
## Find the Left Boundary
First, look at the code for finding the left boundary:
```java
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
// the search range is [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// the search range becomes [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// the search range becomes [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// shrink the right boundary
right = mid - 1;
}
}
return left;
}
```
<visual slug='binary-search-left-bound'/>
### Why does this algorithm find the left boundary?
The key is how we handle `nums[mid] == target`:
```java
if (nums[mid] == target) {
// shrink the right boundary
right = mid - 1;
}
```
We do not return as soon as we find `target`. Instead, we shrink the right boundary with `right = mid - 1` and keep searching in `[left, mid - 1]`. This keeps moving the interval to the left, so we can lock onto the leftmost position of `target`.
### What if `target` does not exist?
If `target` does not exist, `left_bound` returns the index of the **smallest element that is greater than `target`**.
You do not need to memorize this. Just see an example: `nums = [2,3,5,7], target = 4`. The return value is 2, because the element 5 is the smallest element greater than 4.
If you want to return -1 when `target` does not exist, you can check `nums[left]` at the end:
```java
// if index is out of bounds, target definitely does not exist
if (left < 0 || left >= nums.length) {
return -1;
}
// if nums[left] is not target, then target does not exist
if (nums[left] != target) {
return -1;
}
// nums[left] == target, so left is the target index
return left;
```
## Find the Right Boundary
Now look at the code for finding the right boundary:
```java
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// here change to shrink the left boundary
left = mid + 1;
}
}
// finally change to return right
return right;
}
```
<visual slug='binary-search-right-bound'/>
### Why does this algorithm find the right boundary?
Again, the key is how we handle `nums[mid] == target`:
```java
if (nums[mid] == target) {
// shrink the left boundary
left = mid + 1;
}
```
We do not return as soon as we find `target`. Instead, we shrink the left boundary with `left = mid + 1` and keep searching in `[mid + 1, right]`. This keeps moving the interval to the right, so we can lock onto the rightmost position of `target`.
### What if `target` does not exist?
If `target` does not exist, `right_bound` returns the index of the **largest element that is less than `target`**.
For example, `nums = [2,3,5,7], target = 4`. The return value is 1, because the element 3 is the largest element smaller than 4.
If you want to return -1 when `target` does not exist, you can check `nums[right]` at the end:
```java
// if index is out of bounds, target does not exist
if (right < 0 || right >= nums.length) {
return -1;
}
// if nums[right] is not target, then target does not exist
if (nums[right] != target) {
return -1;
}
// nums[right] == target, so right is the target index
return right;
```
## Unified Template
All three cases use the same closed search interval `[left, right]`. The only difference is what we do when `nums[mid] == target`:
```java
int binary_search(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if(nums[mid] == target) {
// return directly
return mid;
}
}
// return directly
return -1;
}
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// do not return, lock the left boundary
right = mid - 1;
}
}
// determine if target exists in nums
if (left < 0 || left >= nums.length) {
return -1;
}
// check if nums[left] is the target
return nums[left] == target ? left : -1;
}
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// do not return, lock the right boundary
left = mid + 1;
}
}
// since the while loop ends with right == left - 1 and we are now looking for the right boundary
// it's easier to remember to use right instead of left - 1
if (right < 0 || right >= nums.length) {
return -1;
}
return nums[right] == target ? right : -1;
}
```
From this article, you learned:
1. When you read or write binary search code, avoid plain `else`. Use only `if` and `else if` so that all cases are clear.
2. Always think about the “search interval” and the stopping condition of the while loop. Stop when the search interval is empty.
3. Use the same closed-interval style for all three cases, and only change the `nums[mid] == target` branch and the return logic.
In the end, this binary search framework is the “technique” level. On the “idea” level, **the core of binary search thinking is: use the known information to shrink (halve) the search space as much as possible**, so brute-force search becomes much faster.
If you understand this article, you can write correct binary search code. The closed-interval style here is my recommended style: one unified framework for all three cases, easy to remember.
You may also see another style on the internet: left-closed-right-open `[left, right)`, using `while (left < right)` and `right = mid`. That style is also common. If you want to deeply understand it, see [Binary Search: Left-Closed-Right-Open Style](https://labuladong.online/en/algo/essential-technique/binary-search-left-open/).
In real problems you are rarely asked to just “write binary search code”. I will further explain how to use binary search thinking to improve brute-force solutions in [Applications of Binary Search](https://labuladong.online/en/algo/frequency-interview/binary-search-in-action/) and [More Binary Search Exercises](https://labuladong.online/en/algo/problem-set/binary-search/).
================================================
FILE: algorithmic-thinking/bit-manipulation.md
================================================
Bit manipulation has many tricks. There is a website called “Bit Twiddling Hacks” that collects almost all bit tricks:
http://graphics.stanford.edu/~seander/bithacks.html
But most of these tricks are too hard to read. I think you can use that site like a dictionary, no need to study every line. What we really need to learn are the bit tricks that are interesting and useful.
So in this article, we will start from the basics, explain some simple ideas of bit operations, then summarize some common bit tricks used in algorithm problems and real-world development.
## Basics of Bit Operations
### Binary representation
In a computer, all data is finally stored in binary form. Binary has only two digits: 0 and 1. Each digit is called a bit.
For example, the decimal number 13 is `1101` in binary:
```
1101 = 1×2³ + 1×2² + 0×2¹ + 1×2⁰ = 8 + 4 + 0 + 1 = 13
```
In Java and some other languages, we can use the `0b` prefix to write binary numbers:
```java
int a = 0b1101; // same as decimal 13
int b = 0b1010; // same as decimal 10
```
### Shift operations
**Left shift `<<`**: move the bits to the left, and fill 0s on the right. Shifting left by n bits is the same as multiplying by 2^n.
```java
int a = 5; // binary: 0b0101
int b = a << 1; // binary: 0b1010, decimal: 10
int c = a << 2; // binary: 0b10100, decimal: 20
// Left shift n bits is like multiply by 2^n
// 5 << 1 = 5 * 2¹ = 10
// 5 << 2 = 5 * 2² = 20
```
**Right shift `>>`**: move the bits to the right, and fill the left side with the sign bit. Shifting right by n bits is like dividing by 2^n and taking the floor.
```java
int a = 20; // binary: 0b10100
int b = a >> 1; // binary: 0b1010, decimal: 10
int c = a >> 2; // binary: 0b101, decimal: 5
// Right shift n bits is like divide by 2^n
// 20 >> 1 = 20 / 2¹ = 10
// 20 >> 2 = 20 / 2² = 5
```
### AND operation
**AND `&`**: the result bit is 1 only when both bits are 1, otherwise it is 0.
```java
int a = 12; // binary: 0b1100
int b = 10; // binary: 0b1010
int c = a & b; // binary: 0b1000, decimal: 8
// bit by bit:
// 1100
// 1010
// ----
// 1000
```
**Common uses**:
- Check odd or even: `n & 1`, result 1 means odd, 0 means even
- Get a specific bit: `n & (1 << k)` can get the k-th bit of n
```java
int n = 13; // binary: 0b1101
boolean isOdd = (n & 1) == 1; // true, 13 is odd
// get bit 2 (count from right, starting at 0)
int bit2 = (n & (1 << 2)) != 0 ? 1 : 0; // result is 1
```
### OR operation
**OR `|`**: the result bit is 1 if at least one of the bits is 1.
```java
int a = 12; // binary: 0b1100
int b = 10; // binary: 0b1010
int c = a | b; // binary: 0b1110, decimal: 14
// bit by bit:
// 1100
// 1010
// ----
// 1110
```
**Common uses**:
- Set a specific bit to 1: `n | (1 << k)` sets the k-th bit of n to 1
```java
int n = 12; // binary: 0b1100
n = n | (1 << 0); // set bit 0 to 1, result: 0b1101, decimal: 13
```
### XOR operation
**XOR `^`**: the result bit is 1 only when the two bits are different; if they are the same, the result is 0.
```java
int a = 12; // binary: 0b1100
int b = 10; // binary: 0b1010
int c = a ^ b; // binary: 0b0110, decimal: 6
// bit by bit:
// 1100
// 1010
// ----
// 0110
```
**Important properties of XOR**:
1. `a ^ a = 0`: any number XOR itself is 0
2. `a ^ 0 = a`: any number XOR 0 is itself
3. XOR is commutative and associative: `a ^ b ^ c = a ^ (b ^ c) = (a ^ b) ^ c`
```java
int a = 5;
int result1 = a ^ a; // result is 0
int result2 = a ^ 0; // result is 5
// commutative and associative
int x = 3, y = 5, z = 7;
int r1 = x ^ y ^ z; // result is 1
int r2 = x ^ (y ^ z); // result is 1
int r3 = (x ^ y) ^ z; // result is 1
```
**Common uses**:
- Flip a specific bit: `n ^ (1 << k)` flips the k-th bit of n (0 -> 1, 1 -> 0)
- Swap two numbers (will be explained later)
```java
int n = 12; // binary: 0b1100
n = n ^ (1 << 0); // flip bit 0, result: 0b1101, decimal: 13
n = n ^ (1 << 0); // flip bit 0 again, result: 0b1100, decimal: 12
```
Once we understand these basic bit operations, we can move on to some interesting bit tricks.
## Some Interesting Bit Operations
```java
// 1. Use OR `|` with space to convert English letters to lowercase
('a' | ' ') = 'a'
('A' | ' ') = 'a'
// 2. Use AND `&` with underscore to convert English letters to uppercase
('b' & '_') = 'B'
('B' & '_') = 'B'
// 3. Use XOR `^` with space to flip letter case
('d' ^ ' ') = 'D'
('D' ^ ' ') = 'd'
// These work because of ASCII codes.
// Characters are actually numbers, and the codes for space and underscore
// can flip case through bit operations.
// If you are interested, you can check the ASCII table and do the math yourself.
// 4. Swap two numbers without a temp variable
int a = 1, b = 2;
a ^= b;
b ^= a;
a ^= b;
// now a = 2, b = 1
// 5. Add one
int n = 1;
n = -~n;
// now n = 2
// 6. Subtract one
int n = 2;
n = ~-n;
// now n = 1
// 7. Check if two numbers have different signs
int x = -1, y = 2;
boolean f = ((x ^ y) < 0); // true
int x = 3, y = 2;
boolean f = ((x ^ y) < 0); // false
```
The first 6 tricks are not very useful in real code. But the 7th trick is quite practical. It uses the sign bit in **two’s complement**.
In integer encoding, the highest bit is the sign bit. For negative numbers, the sign bit is 1. For non-negative numbers, the sign bit is 0. With XOR, you can know whether two numbers have different signs.
If you do not use bit operations, you must use if-else to check the sign, which is more trouble. You may think of using the product to check the sign, but that can easily cause integer overflow and give wrong results.
## Modulo with Power of 2
For modulus (remainder), we usually use the `%` operator. But in some code (for example, in the source code of HashMap), you may see `&` instead. This is an optimization.
**When the modulus `m` is a power of 2, `x % m` is the same as `x & (m - 1)`.**
The bit operation `&` is much faster than `%`, so this trick is very useful where performance matters.
A common use is in a circular array. The normal way is to use `%` so that the index loops in `[0, arr.length - 1]`:
```java
int[] arr = {1,2,3,4};
int index = 0;
while (true) {
// looping in a circular array
print(arr[index % arr.length]);
index++;
}
// output: 1,2,3,4,1,2,3,4,1,2,3,4...
```
If the array length is a power of 2, we can use `&` to speed up the modulus:
```java
int[] arr = {1,2,3,4};
int index = 0;
while (true) {
// loop in the circular array
print(arr[index & (arr.length - 1)]);
index++;
}
// output: 1,2,3,4,1,2,3,4,1,2,3,4...
```
::: important Important
This trick only works when the array length is a power of 2, like 2, 4, 8, 16, 32, and so on. There are clever bit hacks that can round a number up to a power of 2. You can check https://graphics.stanford.edu/~seander/bithacks.html#RoundUpPowerOf2
:::
Simply put, `& (arr.length - 1)` can replace `% arr.length` and gives better performance.
Now another question: we keep doing `index++`, and this gives us a circular effect. But if we keep doing `index--`, can we still get a circular array?
If you use `%` for modulus, once `index` becomes negative, the result of `%` can also be negative, and you must handle this case specially. But with `&`, `index` will not become negative and everything still works:
```java
int[] arr = {1,2,3,4};
int index = 0;
while (true) {
// looping in a circular array
print(arr[index & (arr.length - 1)]);
index--;
}
// output: 1,4,3,2,1,4,3,2,1,4,3,2,1...
```
You may not use this trick often in your own code, but you will see it a lot when reading other code bases. Just keep it in mind so you are not confused when you see it.
## The Usage of `n & (n-1)`
The operation **`n & (n-1)` is common in algorithms, and its effect is to remove the last 1 in the binary form of `n`**.
Look at the picture and it becomes clear:

The key idea: `n - 1` will remove the last 1 in `n`, and turn all the bits after it into 1. Then `n & (n - 1)` will clear only that last 1 to 0.
### Hamming Weight
This is LeetCode 191: “[Number of 1 Bits](https://leetcode.com/problems/number-of-1-bits/)”:
**LeetCode 191. Number of 1 Bits** <span class="inline-block w-2 h-2 rounded-full bg-green-500"></span>
Write a function that takes the binary representation of a positive integer and returns the number of set bits it has (also known as the [Hamming weight](http://en.wikipedia.org/wiki/Hamming_weight)).
Example 1:**
**Input:** n = 11
**Output:** 3
**Explanation:**
The input binary string **1011** has a total of three set bits.
Example 2:**
**Input:** n = 128
**Output:** 1
**Explanation:**
The input binary string **10000000** has a total of one set bit.
Example 3:**
**Input:** n = 2147483645
**Output:** 30
**Explanation:**
The input binary string **1111111111111111111111111111101** has a total of thirty set bits.
**Constraints:**
- `1 <= n <= 2^(31) - 1`
**Follow up:** If this function is called many times, how would you optimize it?
You need to return how many 1s are in the binary form of `n`. Since `n & (n - 1)` can remove the last 1, we can keep doing this in a loop and count, until `n` becomes 0.
```java
public class Solution {
// you need to treat n as an unsigned value
public int hammingWeight(int n) {
int res = 0;
while (n != 0) {
n = n & (n - 1);
res++;
}
return res;
}
}
```
### Check If a Number Is a Power of 2
This is LeetCode 231: “[Power of Two](https://leetcode.com/problems/power-of-two/)”.
If a number is a power of 2, its binary form has exactly one 1:
```java
2^0 = 1 = 0b0001
2^1 = 2 = 0b0010
2^2 = 4 = 0b0100
```
Using the trick `n & (n - 1)` makes it easy (note operator precedence, you cannot remove the parentheses):
```java
class Solution {
public boolean isPowerOfTwo(int n) {
if (n <= 0) return false;
return (n & (n - 1)) == 0;
}
}
```
## The Usage of `a ^ a = 0`
We must remember these properties of XOR:
A number XOR itself is 0, that is `a ^ a = 0`.
A number XOR 0 is the number itself, that is `a ^ 0 = a`.
### Find the Element That Appears Only Once
This is LeetCode 136: “[Single Number](https://leetcode.com/problems/single-number/)”:
**LeetCode 136. Single Number** <span class="inline-block w-2 h-2 rounded-full bg-green-500"></span>
Given a **non-empty** array of integers `nums`, every element appears *twice* except for one. Find that single one.
You must implement a solution with a linear runtime complexity and use only constant extra space.
Example 1:**
```
**Input:** nums = [2,2,1]
**Output:** 1
```
Example 2:**
```
**Input:** nums = [4,1,2,1,2]
**Output:** 4
```
Example 3:**
```
**Input:** nums = [1]
**Output:** 1
```
**Constraints:**
- `1 <= nums.length <= 3 * 10^(4)`
- `-3 * 10^(4) <= nums[i] <= 3 * 10^(4)`
- Each element in the array appears twice except for one element which appears only once.
For this problem, we just XOR all numbers together. Pairs of equal numbers will become 0. The single number XOR 0 is still itself, so the final XOR result is the element that appears only once:
```java
class Solution {
public int singleNumber(int[] nums) {
int res = 0;
for (int n : nums) {
res ^= n;
}
return res;
}
}
```
### Find the Missing Number
This is LeetCode Problem 268: [Missing Number](https://leetcode.com/problems/missing-number/):
**LeetCode 268. Missing Number** <span class="inline-block w-2 h-2 rounded-full bg-green-500"></span>
Given an array `nums` containing `n` distinct numbers in the range `[0, n]`, return *the only number in the range that is missing from the array.*
Example 1:**
```
**Input:** nums = [3,0,1]
**Output:** 2
**Explanation:** n = 3 since there are 3 numbers, so all numbers are in the range [0,3]. 2 is the missing number in the range since it does not appear in nums.
```
Example 2:**
```
**Input:** nums = [0,1]
**Output:** 2
**Explanation:** n = 2 since there are 2 numbers, so all numbers are in the range [0,2]. 2 is the missing number in the range since it does not appear in nums.
```
Example 3:**
```
**Input:** nums = [9,6,4,2,3,5,7,0,1]
**Output:** 8
**Explanation:** n = 9 since there are 9 numbers, so all numbers are in the range [0,9]. 8 is the missing number in the range since it does not appear in nums.
```
**Constraints:**
- `n == nums.length`
- `1 <= n <= 10^(4)`
- `0 <= nums[i] <= n`
- All the numbers of `nums` are **unique**.
**Follow up:** Could you implement a solution using only `O(1)` extra space complexity and `O(n)` runtime complexity?
You are given an array of length `n`. The valid indices are `[0, n)`, but now you want to put `n + 1` numbers `[0, n]` into it. So one number must be missing. Please find this missing number.
This problem is not hard. We can easily think of sorting the array first, then scan it once to find the missing number.
Or we can use a data structure: put all numbers from the array into a HashSet, then iterate through the numbers in `[0, n]` and check which one is not in the HashSet.
The sorting solution has time complexity O(NlogN). The HashSet solution has time complexity O(N), but it also needs O(N) extra space to store the HashSet.
There is a very simple solution for this problem: the sum formula of an arithmetic sequence.
We can understand the problem like this: we have an arithmetic sequence `0, 1, 2, ..., n`, and one number is missing. We need to find it. Then the answer is:
`sum(0, 1, ..., n) - sum(nums)`.
```java
int missingNumber(int[] nums) {
int n = nums.length;
// Although the data range given by the problem is not large, we should use long type to prevent integer overflow for the sake of rigor
// Sum formula: (first term + last term) * number of terms / 2
long expect = (0 + n) * (n + 1) / 2;
long sum = 0;
for (int x : nums) {
sum += x;
}
return (int)(expect - sum);
}
```
But the main topic of this article is bit operations. So we will see how to use bit tricks to solve this problem.
Recall the properties of XOR:
- A number XOR itself is 0.
- A number XOR 0 is still the number itself.
XOR also has commutative and associative laws. That is:
```java
2 ^ 3 ^ 2 = 3 ^ (2 ^ 2) = 3 ^ 0 = 3
```
We can use these properties to find the missing number. For example, `nums = [0, 3, 1, 4]`:

To make it easier to understand, we first imagine extending the index by one, then match each element with the index that has the same value:

After doing this, except for the missing number, every index and element form a pair. If we can find the lonely index 2, we find the missing number.
How do we find this lonely number? **Just XOR all the indices and all the elements together. All paired numbers will cancel out to 0, and only the lonely one will remain.** That is our answer:
```java
class Solution {
public int missingNumber(int[] nums) {
int n = nums.length;
int res = 0;
// first XOR with the new added index
res ^= n;
// XOR with other elements and indices
for (int i = 0; i < n; i++)
res ^= i ^ nums[i];
return res;
}
}
```

Because XOR is commutative and associative, we can always cancel all pairs and keep only the missing number.
Up to here, we have covered most common bit operations. These tricks are easy once you get them, and you do not need to memorize them. Just keep a rough idea in mind, and that is enough.
================================================
FILE: algorithmic-thinking/difference-array.md
================================================
::: info Prerequisite Knowledge
Before reading this article, you should first learn:
- [Array Basics](https://labuladong.online/en/algo/data-structure-basic/array-basic/)
- [Prefix Sum Technique](https://labuladong.online/en/algo/data-structure/prefix-sum/)
:::
The [Prefix Sum Technique](https://labuladong.online/en/algo/data-structure/prefix-sum/) is mainly used when the original array does not change, and you need to quickly find the sum of any interval. The key code is below:
```java
class PrefixSum {
// prefix sum array
private int[] preSum;
// input an array to construct the prefix sum
public PrefixSum(int[] nums) {
// preSum[0] = 0, convenient for calculating cumulative sum
preSum = new int[nums.length + 1];
// calculate the cumulative sum of nums
for (int i = 1; i < preSum.length; i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
// query the cumulative sum of the closed interval [left, right]
public int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
}
```

`preSum[i]` means the sum of all elements from `nums[0]` to `nums[i-1]`. If you want to find the sum from `nums[i]` to `nums[j]`, just calculate `preSum[j+1] - preSum[i]`. You don't need to loop through the whole interval.
In this article, we talk about another technique similar to prefix sum: the **Difference Array**. The main use of the difference array is when you need to frequently increase or decrease the values in a range of the original array.
For example, suppose you have an array `nums`, and you need to:
- add 1 to all elements from `nums[2]` to `nums[6]`
- subtract 3 from all elements from `nums[3]` to `nums[9]`
- add 2 to all elements from `nums[0]` to `nums[4]`
- and so on...
After many such operations, what is the final value of the `nums` array?
The usual way is simple. If you want to add `val` to all elements from `nums[i]` to `nums[j]`, just use a for loop and add `val` to each element. But this takes $O(N)$ time for each operation. If there are many operations, this will be slow.
Here is where the difference array helps. Just like the prefix sum uses a `preSum` array, we can build a `diff` array for `nums`. **`diff[i]` is the difference between `nums[i]` and `nums[i-1]`**:
```java
int[] diff = new int[nums.length];
// construct the difference array
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
```

Using this `diff` array, you can get back the original `nums` array. The code is like this:
```java
int[] res = new int[diff.length];
// construct the result array based on the difference array
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
```
**With the difference array `diff`, you can quickly increase or decrease a range of elements.** If you want to add 3 to all elements from `nums[i]` to `nums[j]`, just do `diff[i] += 3` and `diff[j+1] -= 3`:

**The idea is simple. When you set `diff[i] += 3`, it means you add 3 to all elements from `nums[i]` and after. Then `diff[j+1] -= 3` means you subtract 3 from all elements from `nums[j+1]` and after. In total, only the elements from `nums[i]` to `nums[j]` get increased by 3.**
You only need O(1) time to change the `diff` array, which is like updating an entire interval in the original `nums` array. Do all your changes to `diff`, then build the final `nums` from `diff`.
Now, let's make the difference array into a class with `increment` and `result` methods:
```java
// Difference Array Utility Class
class Difference {
// difference array
private int[] diff;
// input an initial array, range operations will be performed on this array
public Difference(int[] nums) {
diff = new int[nums.length];
// construct the difference array based on the initial array
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
// increment the closed interval [i, j] by val (can be negative)
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
// return the result array
public int[] result() {
int[] res = new int[diff.length];
// construct the result array based on the difference array
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
}
```
Notice the `if` statement in the `increment` method:
```java
void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
```
When `j+1 >= diff.length`, it means you are changing all elements from `nums[i]` to the end, so you don't need to subtract `val` from `diff` anymore.
<visual slug="diff-array-example" >
You can open the panel below. Click the line <code type="click">diff[i] = nums[i] - nums[i - 1]</code> several times to see how the `diff` array is built. Then click <code type="click">df.increment</code> a few times to see how the `diff` array changes:
</visual>
## Practical Examples
LeetCode problem 370 "[Range Addition](https://leetcode.com/problems/range-addition/)" directly tests the difference array technique. You're given an array `nums` of length `n` initialized to all zeros, asked to perform increment/decrement operations on ranges, and finally return the resulting `nums` array.
Just copy over the `Difference` class we implemented and you're done:
```java
class Solution {
public int[] getModifiedArray(int length, int[][] updates) {
// nums initialized to all 0s
int[] nums = new int[length];
// construct difference method
Difference df = new Difference(nums);
for (int[] update : updates) {
int i = update[0];
int j = update[1];
int val = update[2];
df.increment(i, j, val);
}
return df.result();
}
class Difference {
// difference array
private int[] diff;
public Difference(int[] nums) {
diff = new int[nums.length];
// construct difference array
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
// increment closed interval [i, j] by val (can be negative)
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
public int[] result() {
int[] res = new int[diff.length];
// construct result array based on difference array
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
}
}
```
Of course, in real problems you'll need to recognize and abstract the pattern—they won't be this obvious about using difference arrays. Let's look at LeetCode problem 1109 "[Corporate Flight Bookings](https://leetcode.com/problems/corporate-flight-bookings/)":
**LeetCode 1109. Corporate Flight Bookings** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
There are `n` flights that are labeled from `1` to `n`.
You are given an array of flight bookings `bookings`, where `bookings[i] = [firsti, lasti, seatsi]` represents a booking for flights `firsti` through `lasti` (**inclusive**) with `seatsi` seats reserved for **each flight** in the range.
Return *an array *`answer`* of length *`n`*, where *`answer[i]`* is the total number of seats reserved for flight *`i`.
Example 1:**
```
**Input:** bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
**Output:** [10,55,45,25,25]
**Explanation:**
Flight labels: 1 2 3 4 5
Booking 1 reserved: 10 10
Booking 2 reserved: 20 20
Booking 3 reserved: 25 25 25 25
Total seats: 10 55 45 25 25
Hence, answer = [10,55,45,25,25]
```
Example 2:**
```
**Input:** bookings = [[1,2,10],[2,2,15]], n = 2
**Output:** [10,25]
**Explanation:**
Flight labels: 1 2
Booking 1 reserved: 10 10
Booking 2 reserved: 15
Total seats: 10 25
Hence, answer = [10,25]
```
**Constraints:**
- `1 <= n <= 2 * 10^(4)`
- `1 <= bookings.length <= 2 * 10^(4)`
- `bookings[i].length == 3`
- `1 <= firsti <= lasti <= n`
- `1 <= seatsi <= 10^(4)`
The function signature is:
```java
int[] corpFlightBookings(int[][] bookings, int n)
```
This problem wraps things in confusing language, but it's really just a difference array problem. Let me translate it for you:
You're given an array `nums` of length `n` where all elements are 0. You're also given `bookings`, which contains several triplets `(i, j, k)`. Each triplet means you need to add `k` to all elements in the closed interval `[i-1, j-1]` of `nums`. Return the final `nums` array.
::: note Note
Since the problem counts `n` starting from 1, but array indices start from 0, the triplet `(i, j, k)` corresponds to the array interval `[i-1, j-1]`.
:::
Now it's clear—this is a standard difference array problem! We can directly reuse the class we wrote:
```java
class Solution {
public int[] corpFlightBookings(int[][] bookings, int n) {
// initialize nums as all 0
int[] nums = new int[n];
// construct the difference array
Difference df = new Difference(nums);
for (int[] booking : bookings) {
// note that converting to array index needs to subtract one
int i = booking[0] - 1;
int j = booking[1] - 1;
int val = booking[2];
// increment the range nums[i..j] by val
df.increment(i, j, val);
}
// return the final result array
return df.result();
}
class Difference {
// difference array
private int[] diff;
public Difference(int[] nums) {
diff = new int[nums.length];
// construct the difference array
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
// increment the closed interval [i, j] by val (can be negative)
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
public int[] result() {
int[] res = new int[diff.length];
// construct the result array based on the difference array
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
}
}
```
Problem solved.
Here's another similar problem—LeetCode problem 1094 "[Car Pooling](https://leetcode.com/problems/car-pooling/)":
**LeetCode 1094. Car Pooling** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
There is a car with `capacity` empty seats. The vehicle only drives east (i.e., it cannot turn around and drive west).
You are given the integer `capacity` and an array `trips` where `trips[i] = [numPassengersi, fromi, toi]` indicates that the `i^(th)` trip has `numPassengersi` passengers and the locations to pick them up and drop them off are `fromi` and `toi` respectively. The locations are given as the number of kilometers due east from the car's initial location.
Return `true`* if it is possible to pick up and drop off all passengers for all the given trips, or *`false`* otherwise*.
Example 1:**
```
**Input:** trips = [[2,1,5],[3,3,7]], capacity = 4
**Output:** false
```
Example 2:**
```
**Input:** trips = [[2,1,5],[3,3,7]], capacity = 5
**Output:** true
```
**Constraints:**
- `1 <= trips.length <= 1000`
- `trips[i].length == 3`
- `1 <= numPassengersi <= 100`
- `0 <= fromi < toi <= 1000`
- `1 <= capacity <= 10^(5)`
The function signature is:
```java
boolean carPooling(int[][] trips, int capacity);
```
For example, given:
```
trips = [[2,1,5],[3,3,7]], capacity = 4
```
This trip can't be completed in one go because `trips[1]` can only pick up 2 more passengers at most, otherwise the car would be overloaded.
You've probably already connected this to difference arrays: **each `trips[i]` represents a range operation—passengers boarding and alighting correspond to incrementing and decrementing ranges. If every element in the result array is less than `capacity`, all passengers can be transported without overloading.**
But what should the length of the difference array (number of stops) be? The problem doesn't tell us directly, but gives us the data range:
```java
0 <= trips[i][1] < trips[i][2] <= 1000
```
Stop numbers range from 0 to at most 1000, meaning there are at most 1001 stops. So we can set our difference array length to 1001, which covers all possible stop numbers:
```java
class Solution {
public boolean carPooling(int[][] trips, int capacity) {
// at most there are 1000 stops
int[] nums = new int[1001];
// construct the difference array method
Difference df = new Difference(nums);
for (int[] trip : trips) {
// number of passengers
int val = trip[0];
// passengers get on at stop trip[1]
int i = trip[1];
// passengers get off at stop trip[2],
// meaning the interval passengers are on the car is [trip[1], trip[2] - 1]
int j = trip[2] - 1;
// perform interval operation
df.increment(i, j, val);
}
int[] res = df.result();
// the car should never exceed its capacity
for (int i = 0; i < res.length; i++) {
if (capacity < res[i]) {
return false;
}
}
return true;
}
// difference array utility class
class Difference {
// difference array
private int[] diff;
// input an initial array, interval operations will be performed on this array
public Difference(int[] nums) {
diff = new int[nums.length];
// construct the difference array based on the initial array
diff[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
diff[i] = nums[i] - nums[i - 1];
}
}
// increment the closed interval [i, j] by val (can be negative)
public void increment(int i, int j, int val) {
diff[i] += val;
if (j + 1 < diff.length) {
diff[j + 1] -= val;
}
}
// return the result array
public int[] result() {
int[] res = new int[diff.length];
// construct the result array based on the difference array
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
return res;
}
}
}
```
And that solves this problem too.
Both difference arrays and prefix sum arrays are common and clever techniques. They suit different scenarios, and once you understand them, they're straightforward—but tricky if you don't.
## Further Reading
First question: to use the difference array technique, you need to create a `diff` array with the same length as your interval. What if you have a huge interval like `[0, 10^9]`? Do you really need to create an array of length `10^9` just to start doing range operations?
Second question: prefix sums enable fast range queries, while difference arrays enable fast range updates. Can we combine them to get both fast range updates AND fast range queries?
These are common questions when dealing with range problems. The ultimate answer is the [Segment Tree](https://labuladong.online/en/algo/data-structure-basic/segment-tree-basic/) data structure, which can perform both range updates and range queries on intervals of any length in $O(\log N)$ time.
================================================
FILE: algorithmic-thinking/matrix-traversal.md
================================================
::: info Prerequisites
Before reading this article, you should learn:
- [Array Basics](https://labuladong.online/en/algo/data-structure-basic/array-basic/)
:::
Some readers say that after reading many articles on this site, they learned “framework thinking” and can solve most problems that follow a fixed pattern.
But framework thinking is not magic. Some special tricks are like this: if you know them, they are easy; if you don’t, they feel very hard. You can only learn them by doing more problems and summarizing.
In this article, I will share some smart operations on 2D arrays. Just remember the idea. Next time you see a similar problem, you won’t get stuck.
## Rotate a Matrix Clockwise / Counterclockwise
Rotating a 2D array is a common interview test question. LeetCode 48, “[Rotate Image](https://leetcode.com/problems/rotate-image/)”, is a classic one:
**LeetCode 48. Rotate Image** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
You are given an `n x n` 2D `matrix` representing an image, rotate the image by **90** degrees (clockwise).
You have to rotate the image [**in-place**](https://en.wikipedia.org/wiki/In-place_algorithm), which means you have to modify the input 2D matrix directly. **DO NOT** allocate another 2D matrix and do the rotation.
Example 1:**
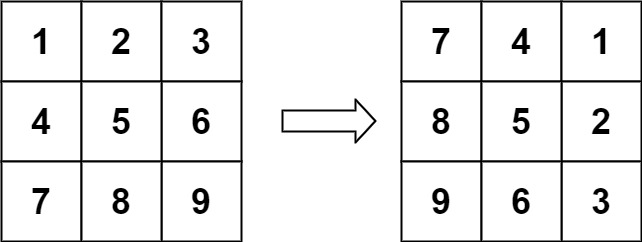
```
**Input:** matrix = [[1,2,3],[4,5,6],[7,8,9]]
**Output:** [[7,4,1],[8,5,2],[9,6,3]]
```
Example 2:**
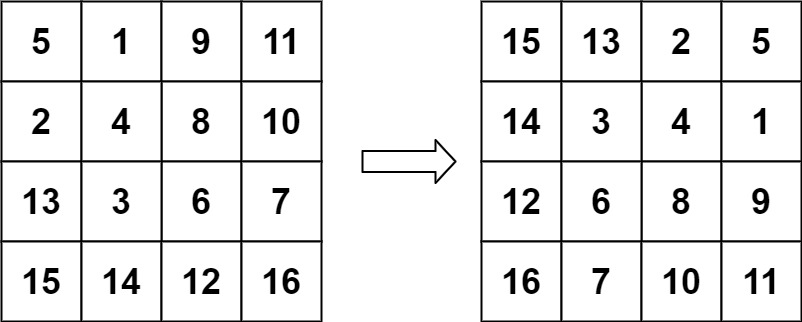
```
**Input:** matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
**Output:** [[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
```
**Constraints:**
- `n == matrix.length == matrix[i].length`
- `1 <= n <= 20`
- `-1000 <= matrix[i][j] <= 1000`
The problem is easy to understand: rotate a 2D matrix 90 degrees clockwise. The hard part is: **you must modify it in-place**. The function signature is:
```java
void rotate(int[][] matrix)
```
How do we rotate a 2D matrix in-place? If you think a bit, it feels complicated. You may think you need to rotate it “layer by layer”:

**But for this problem, you need a different idea.** Before we talk about the smart solution, let’s warm up with another problem that Google once asked:
You are given a string `s` with words and spaces. Write an algorithm to reverse the order of words **in-place**.
For example:
```shell
s = "hello world labuladong"
```
You need to make it:
```shell
s = "labuladong world hello"
```
A common way is: split by spaces, reverse the word list, then join. But that uses extra space, so it is not “in-place”.
**The correct trick is: first reverse the whole string `s`:**
```shell
s = "gnodalubal dlrow olleh"
```
**Then reverse each word by itself:**
```shell
s = "labuladong world hello"
```
Now you reversed the word order in-place. LeetCode 151, “[Reverse Words in a String](https://leetcode.com/problems/reverse-words-in-a-string/)”, is a similar problem.
This trick can be used in other problems too. For example, LeetCode 61, “[Rotate List](https://leetcode.com/problems/rotate-list/)”: given a singly linked list, rotate it so every node moves right by `k` positions.
Example: `1 -> 2 -> 3 -> 4 -> 5`, `k = 2`. The result is `4 -> 5 -> 1 -> 2 -> 3`.
For this problem, don’t move nodes one by one. Let me translate it: it really means “move the last `k` nodes to the head”, right?
Still not clear? Moving the last `k` nodes to the head means you split the list into the first `n - k` nodes and the last `k` nodes, then reverse them in-place, right?
This is the same idea as reversing words in-place. You first reverse the whole list, then reverse the first `n - k` nodes and the last `k` nodes.
There are some details. For example, `k` can be larger than the list length. So you should compute the length `n` first, then do `k = k % n`. Then `k` will be valid and the result will be correct.
If you have time, try this problem yourself. It is not hard, so I won’t show the code here.
Why did I talk about these two problems?
**The point is: our “natural” idea is not always the best for a computer; and the computer’s clean idea is not always natural for us.** That may be the fun part of algorithms.
<!-- hide -->
Back to rotating an `n x n` matrix clockwise. The common idea is to find a mapping from old coordinates to new coordinates. But we can try a jump in thinking: do reverse or mirror operations. That can give a new way.
**First, mirror the `n x n` matrix `matrix` across the main diagonal (top-left to bottom-right):**

**Then reverse each row:**

**You will get the matrix rotated 90 degrees clockwise:**

Turn this idea into code and you can solve the problem:
```java
class Solution {
public void rotate(int[][] matrix) {
int n = matrix.length;
// first, reverse the 2D matrix along the diagonal
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
// swap(matrix[i][j], matrix[j][i]);
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
// then, reverse each row of the 2D matrix
for (int[] row : matrix) {
reverse(row);
}
}
// reverse a 1D array
void reverse(int[] arr) {
int i = 0, j = arr.length - 1;
while (j > i) {
// swap(arr[i], arr[j]);
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++;
j--;
}
}
}
```
<visual slug='rotate-image'>
You can open the panel below. Click the line <code type="click">let temp = matrix[i][j]</code> many times to see the diagonal mirror step. Then click <code type="click">reverse(row)</code> many times to see each row reversed and get the final answer:
</visual>
Some readers may ask: if I never did this problem before, how could I think of this?
Yes, if you never saw this type of problem, it’s hard to think of. But now you have seen it. If you know it, it’s easy; if you don’t, it’s hard. You will probably never forget it.
**Now let’s extend it: how do we rotate the matrix 90 degrees counterclockwise?**
The idea is similar: mirror the matrix across the other diagonal, then reverse each row. That gives the counterclockwise result:

The code is:
```java
class Solution {
// rotate the two-dimensional matrix 90 degrees counterclockwise in place
public void rotate2(int[][] matrix) {
int n = matrix.length;
// mirror the two-dimensional matrix along the diagonal from bottom left to top right
for (int i = 0; i < n; i++) {
for (int j = 0; j < n - i; j++) {
// swap(matrix[i][j], matrix[n-j-1][n-i-1])
int temp = matrix[i][j];
matrix[i][j] = matrix[n - j - 1][n - i - 1];
matrix[n - j - 1][n - i - 1] = temp;
}
}
// then reverse each row of the two-dimensional matrix
for (int[] row : matrix) {
reverse(row);
}
}
void reverse(int[] arr) {
// see above
}
}
```
Now the rotation problem is solved.
## Spiral Traversal of a Matrix
Next, let’s look at LeetCode 54, “[Spiral Matrix](https://leetcode.com/problems/spiral-matrix/)”, and see a common way to traverse a 2D matrix:
**LeetCode 54. Spiral Matrix** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
Given an `m x n` `matrix`, return *all elements of the* `matrix` *in spiral order*.
Example 1:**

```
**Input:** matrix = [[1,2,3],[4,5,6],[7,8,9]]
**Output:** [1,2,3,6,9,8,7,4,5]
```
Example 2:**

```
**Input:** matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
**Output:** [1,2,3,4,8,12,11,10,9,5,6,7]
```
**Constraints:**
- `m == matrix.length`
- `n == matrix[i].length`
- `1 <= m, n <= 10`
- `-100 <= matrix[i][j] <= 100`
```java
// The function signature is as follows
List<Integer> spiralOrder(int[][] matrix)
```
**The key idea is to traverse in the order: right, down, left, up, and use four variables to mark the borders of the unvisited area:**

As we traverse in a spiral, the borders shrink, until we finish the whole matrix:

With this idea, writing the code is easy:
```java
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
int upper_bound = 0, lower_bound = m - 1;
int left_bound = 0, right_bound = n - 1;
List<Integer> res = new LinkedList<>();
// if res.size() == m * n, the entire array has been traversed
while (res.size() < m * n) {
if (upper_bound <= lower_bound) {
// traverse from left to right at the top
for (int j = left_bound; j <= right_bound; j++) {
res.add(matrix[upper_bound][j]);
}
// move the upper boundary down
upper_bound++;
}
if (left_bound <= right_bound) {
// traverse from top to bottom on the right
for (int i = upper_bound; i <= lower_bound; i++) {
res.add(matrix[i][right_bound]);
}
// move the right boundary left
right_bound--;
}
if (upper_bound <= lower_bound) {
// traverse from right to left at the bottom
for (int j = right_bound; j >= left_bound; j--) {
res.add(matrix[lower_bound][j]);
}
// move the lower boundary up
lower_bound--;
}
if (left_bound <= right_bound) {
// traverse from bottom to top on the left
for (int i = lower_bound; i >= upper_bound; i--) {
res.add(matrix[i][left_bound]);
}
// move the left boundary right
left_bound++;
}
}
return res;
}
}
```
<visual slug='spiral-matrix' >
You can open the panel below. Click the line <code type="click">while (res.length < m * n)</code> many times to see the spiral traversal from outside to inside:
</visual>
LeetCode 59, “[Spiral Matrix II](https://leetcode.com/problems/spiral-matrix-ii/)”, is very similar, but reversed: it asks you to generate a matrix in spiral order:
**LeetCode 59. Spiral Matrix II** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
Given a positive integer `n`, generate an `n x n` `matrix` filled with elements from `1` to `n^(2)` in spiral order.
Example 1:**
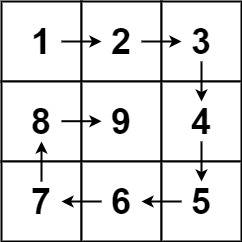
```
**Input:** n = 3
**Output:** [[1,2,3],[8,9,4],[7,6,5]]
```
Example 2:**
```
**Input:** n = 1
**Output:** [[1]]
```
**Constraints:**
- `1 <= n <= 20`
```java
// The function signature is as follows
int[][] generateMatrix(int n)
```
With the setup above, you can finish it with small code changes:
```java
class Solution {
public int[][] generateMatrix(int n) {
int[][] matrix = new int[n][n];
int upper_bound = 0, lower_bound = n - 1;
int left_bound = 0, right_bound = n - 1;
// the number to be filled into the matrix
int num = 1;
while (num <= n * n) {
if (upper_bound <= lower_bound) {
// traverse from left to right at the top
for (int j = left_bound; j <= right_bound; j++) {
matrix[upper_bound][j] = num++;
}
// move the upper bound down
upper_bound++;
}
if (left_bound <= right_bound) {
// traverse from top to bottom on the right
for (int i = upper_bound; i <= lower_bound; i++) {
matrix[i][right_bound] = num++;
}
// move the right bound left
right_bound--;
}
if (upper_bound <= lower_bound) {
// traverse from right to left at the bottom
for (int j = right_bound; j >= left_bound; j--) {
matrix[lower_bound][j] = num++;
}
// move the lower bound up
lower_bound--;
}
if (left_bound <= right_bound) {
// traverse from bottom to top on the left
for (int i = lower_bound; i >= upper_bound; i--) {
matrix[i][left_bound] = num++;
}
// move the left bound right
left_bound++;
}
}
return matrix;
}
}
```
<visual slug='spiral-matrix-ii' >
You can open the panel below. Click the line <code type="click">while (num <= n * n)</code> many times to see the spiral matrix being generated:
</visual>
Now both spiral matrix problems are solved.
These are some useful 2D array traversal tricks. For other array tricks, see: [Prefix Sum Array](https://labuladong.online/en/algo/data-structure/prefix-sum/), [Difference Array](https://labuladong.online/en/algo/data-structure/diff-array/), [Two-Pointer Tricks for Arrays](https://labuladong.online/en/algo/essential-technique/array-two-pointers-summary/). For linked list tricks, see: [Six Key Tricks for Singly Linked Lists](https://labuladong.online/en/algo/essential-technique/linked-list-skills-summary/).
================================================
FILE: algorithmic-thinking/pancake-sorting.md
================================================
LeetCode Problem 969 ["Pancake Sorting"](https://leetcode.com/problems/pancake-sorting/) is an interesting real-world problem: Imagine you have `n` pancakes of different sizes on a plate. Using a spatula, how can you flip the pancakes a few times to sort them by size (smallest on top, largest on bottom)?

Think of flipping a stack of pancakes with a spatula. There is a rule: each time, you can only flip the top few pancakes.

Our task is: **How can we use an algorithm to find a sequence of flips to make the pancake stack sorted?**
First, we need to model the problem. We use an array to represent the pancake stack:
**LeetCode 969. Pancake Sorting** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
Given an array of integers `arr`, sort the array by performing a series of **pancake flips**.
In one pancake flip we do the following steps:
- Choose an integer `k` where `1 <= k <= arr.length`.
- Reverse the sub-array `arr[0...k-1]` (**0-indexed**).
For example, if `arr = [3,2,1,4]` and we performed a pancake flip choosing `k = 3`, we reverse the sub-array `[3,2,1]`, so `arr = [1,2,3,4]` after the pancake flip at `k = 3`.
Return *an array of the *`k`*-values corresponding to a sequence of pancake flips that sort *`arr`. Any valid answer that sorts the array within `10 * arr.length` flips will be judged as correct.
Example 1:**
```
**Input:** arr = [3,2,4,1]
**Output:** [4,2,4,3]
**Explanation: **
We perform 4 pancake flips, with k values 4, 2, 4, and 3.
Starting state: arr = [3, 2, 4, 1]
After 1st flip (k = 4): arr = [1, 4, 2, 3]
After 2nd flip (k = 2): arr = [4, 1, 2, 3]
After 3rd flip (k = 4): arr = [3, 2, 1, 4]
After 4th flip (k = 3): arr = [1, 2, 3, 4], which is sorted.
```
Example 2:**
```
**Input:** arr = [1,2,3]
**Output:** []
**Explanation: **The input is already sorted, so there is no need to flip anything.
Note that other answers, such as [3, 3], would also be accepted.
```
**Constraints:**
- `1 <= arr.length <= 100`
- `1 <= arr[i] <= arr.length`
- All integers in `arr` are unique (i.e. `arr` is a permutation of the integers from `1` to `arr.length`).
How do we solve this problem? Like in the article [Recursively Reverse Part of a Linked List](https://labuladong.online/en/algo/data-structure/reverse-linked-list-recursion/), we need to use recursion.
### 1. Idea Analysis
Why does this problem have the property of recursion? For example, we can make a function like this:
```java
// cakes is a pile of pancakes, the function will sort the first n pancakes
void sort(int[] cakes, int n);
```
If we find the largest pancake among the first `n` pancakes, and flip it to the bottom:

Now the problem size is smaller, so we can recursively call `pancakeSort(A, n-1)`:

Next, for these `n - 1` pancakes, how to sort them? Again, find the largest, put it at the bottom, and call `pancakeSort(A, n-1-1)`...
You see, this is recursion. To summarize:
1. Find the largest pancake among the `n` pancakes.
2. Move this largest pancake to the bottom.
3. Recursively call `pancakeSort(A, n - 1)`.
Base case: When `n == 1`, there is only one pancake, so no flips are needed.
Now, one last question: **How do we move a certain pancake to the bottom?**
It's simple. For example, if the 3rd pancake is the largest and you want to move it to the bottom (the `n`th position):
1. Use the spatula to flip the top 3 pancakes. Now the largest is at the top.
2. Flip the top `n` pancakes. Now the largest is at the bottom.
With these two steps, you can write the solution. The problem also asks us to return the flip operation sequence. We just need to record each flip.
### 2. Code Implementation
Just write the above idea in code. Note: array index starts from 0, but the answer should use 1-based indices.
```java
class Solution {
// record the sequence of flip operations
LinkedList<Integer> res = new LinkedList<>();
public List<Integer> pancakeSort(int[] cakes) {
sort(cakes, cakes.length);
return res;
}
void sort(int[] cakes, int n) {
// base case
if (n == 1) return;
// find the index of the largest pancake
int maxCake = 0;
int maxCakeIndex = 0;
for (int i = 0; i < n; i++)
if (cakes[i] > maxCake) {
maxCakeIndex = i;
maxCake = cakes[i];
}
// first flip, move the largest pancake to the top
reverse(cakes, 0, maxCakeIndex);
res.add(maxCakeIndex + 1);
// second flip, move the largest pancake to the bottom
reverse(cakes, 0, n - 1);
res.add(n);
/**<extend up -150>

*/
// recursive call
sort(cakes, n - 1);
/**<extend up -150>

*/
}
void reverse(int[] arr, int i, int j) {
while (i < j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++;
j--;
}
}
}
```
<visual slug='pancake-sorting'/>
With the explanation above, the code should be clear.
The time complexity is easy to calculate. There are `n` recursive calls, and each call has a for loop of O(n), so total time complexity is O(n^2).
**Finally, let's think about a question:** In this solution, the length of the flip sequence is `2(n - 1)`, because each recursion does 2 flips, and there are `n` layers of recursion. But the base case does not flip, so the total number is `2(n - 1)`.
Clearly, this is not the optimal (shortest) sequence. For example, with pancakes `[3,2,4,1]`, our algorithm gives flips `[3,4,2,3,1,2]`. But the shortest flip sequence is `[2,3,4]`:
```
Start: [3,2,4,1]
Flip top 2: [2,3,4,1]
Flip top 3: [4,3,2,1]
Flip top 4: [1,2,3,4]
```
If you are asked to find the **shortest** flip sequence to sort the pancakes, how would you solve it? What is the core idea to find the optimal solution? What algorithm should you use? Feel free to share your thoughts.
================================================
FILE: algorithmic-thinking/prefix-sum.md
================================================
::: info Prerequisite
Before reading this article, you should first learn:
- [Array Basics](https://labuladong.online/en/algo/data-structure-basic/array-basic/)
:::
The prefix sum technique is used to quickly and repeatedly calculate the sum of elements in a range of indices.
## Prefix Sum in a 1D Array
Let’s look at an example: LeetCode 303 “[Range Sum Query - Immutable](https://leetcode.com/problems/range-sum-query-immutable/)”. You need to calculate the sum of elements in a subarray. This is a standard prefix sum problem:
**LeetCode 303. Range Sum Query - Immutable** <span class="inline-block w-2 h-2 rounded-full bg-green-500"></span>
Given an integer array `nums`, handle multiple queries of the following type:
- Calculate the **sum** of the elements of `nums` between indices `left` and `right` **inclusive** where `left <= right`.
Implement the `NumArray` class:
- `NumArray(int[] nums)` Initializes the object with the integer array `nums`.
- `int sumRange(int left, int right)` Returns the **sum** of the elements of `nums` between indices `left` and `right` **inclusive** (i.e. `nums[left] + nums[left + 1] + ... + nums[right]`).
Example 1:**
```
**Input**
["NumArray", "sumRange", "sumRange", "sumRange"]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
**Output**
[null, 1, -1, -3]
**Explanation**
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return (-2) + 0 + 3 = 1
numArray.sumRange(2, 5); // return 3 + (-5) + 2 + (-1) = -1
numArray.sumRange(0, 5); // return (-2) + 0 + 3 + (-5) + 2 + (-1) = -3
```
**Constraints:**
- `1 <= nums.length <= 10^(4)`
- `-10^(5) <= nums[i] <= 10^(5)`
- `0 <= left <= right < nums.length`
- At most `10^(4)` calls will be made to `sumRange`.
```java
// The problem requires you to implement such a class
class NumArray {
public NumArray(int[] nums) {}
// Query the cumulative sum of the closed interval [left, right]
public int sumRange(int left, int right) {}
}
```
The `sumRange` function needs to return the sum of elements in a given index range. Without prefix sum, people may write code like this:
```java
class NumArray {
private int[] nums;
public NumArray(int[] nums) {
this.nums = nums;
}
public int sumRange(int left, int right) {
// use a for loop to compute the sum
int sum = 0;
for (int i = left; i <= right; i++) {
sum += nums[i];
}
return sum;
}
}
```
This solution runs a for loop every time `sumRange` is called. The time complexity is $O(N)$. Since `sumRange` may be called very often, this is not efficient.
The correct way is to use prefix sum to optimize it, so the time complexity of `sumRange` becomes $O(1)$:
```java
class NumArray {
// prefix sum array
private int[] preSum;
// input an array to construct the prefix sum
public NumArray(int[] nums) {
// preSum[0] = 0, to facilitate the calculation of accumulated sums
preSum = new int[nums.length + 1];
// calculate the accumulated sums of nums
for (int i = 1; i < preSum.length; i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
// query the sum of the closed interval [left, right]
public int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
}
```
The key idea is to create a new array `preSum`, where `preSum[i]` stores the sum of `nums[0..i-1]`. See the picture, where $10 = 3 + 5 + 2$:

With this `preSum` array, if we want the sum of the elements in the index range `[1, 4]`, we can compute `preSum[5] - preSum[1]`.
In this way, `sumRange` only needs one subtraction, no loop, so the worst-case time complexity is constant $O(1)$.
<visual slug='range-sum-query-immutable' >
Open the visualization below and click the line <code type="click">preSum[i] = preSum[i - 1] + nums[i - 1]</code> to see how the `preSum` array is built. Click the line <code type="click">console.log</code> multiple times to see calls to `sumRange`:
</visual>
This technique also appears in real life. For example, your class has several students, each with a final exam score (full score is 100). You need to design an API: given a score range, return how many students have scores in this range.
You can first use counting sort to count how many students got each score, then use prefix sum to build the score-range query API:
```java
// scores of all students
int[] scores = new int[]{...};
// full score is 100
int[] count = new int[100 + 1];
// count how many students got each score
for (int score : scores) {
count[score]++;
}
// build the prefix sum array
for (int i = 1; i < count.length; i++) {
count[i] = count[i] + count[i-1];
}
// use the prefix sum array `count` to do range queries
// query how many students scored in [80, 90]
int result = count[90] - count[79];
```
Next, we will see how the prefix sum idea works in 2D arrays.
## Prefix Sum in 2D Matrix
This is LeetCode 304: [Range Sum Query 2D – Immutable](https://leetcode.com/problems/range-sum-query-2d-immutable/). It is very similar to the previous problem. The previous one asked you to compute the sum of a subarray. This one asks you to compute the sum of a submatrix in a 2D matrix:
**LeetCode 304. Range Sum Query 2D - Immutable** <span class="inline-block w-2 h-2 rounded-full bg-yellow-500"></span>
Given a 2D matrix `matrix`, handle multiple queries of the following type:
- Calculate the **sum** of the elements of `matrix` inside the rectangle defined by its **upper left corner** `(row1, col1)` and **lower right corner** `(row2, col2)`.
Implement the `NumMatrix` class:
- `NumMatrix(int[][] matrix)` Initializes the object with the integer matrix `matrix`.
- `int sumRegion(int row1, int col1, int row2, int col2)` Returns the **sum** of the elements of `matrix` inside the rectangle defined by its **upper left corner** `(row1, col1)` and **lower right corner** `(row2, col2)`.
You must design an algorithm where `sumRegion` works on `O(1)` time complexity.
Example 1:**
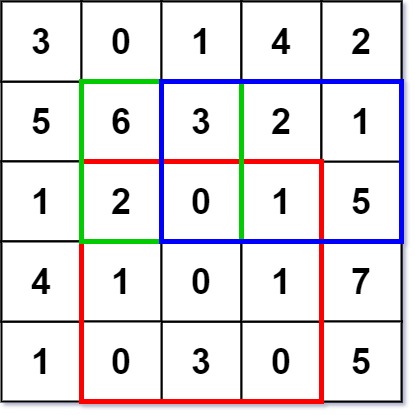
```
**Input**
["NumMatrix", "sumRegion", "sumRegion", "sumRegion"]
[[[[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]], [2, 1, 4, 3], [1, 1, 2, 2], [1, 2, 2, 4]]
**Output**
[null, 8, 11, 12]
**Explanation**
NumMatrix numMatrix = new NumMatrix([[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]);
numMatrix.sumRegion(2, 1, 4, 3); // return 8 (i.e sum of the red rectangle)
numMatrix.sumRegion(1, 1, 2, 2); // return 11 (i.e sum of the green rectangle)
numMatrix.sumRegion(1, 2, 2, 4); // return 12 (i.e sum of the blue rectangle)
```
**Constraints:**
- `m == matrix.length`
- `n == matrix[i].length`
- `1 <= m, n <= 200`
- `-10^(4) <= matrix[i][j] <= 10^(4)`
- `0 <= row1 <= row2 < m`
- `0 <= col1 <= col2 < n`
- At most `10^(4)` calls will be made to `sumRegion`.
Of course, you can use nested for loops to scan the matrix. But then the time complexity of the `sumRegion` function will be high, and your algorithm will look naive.
Notice that the sum of any submatrix can be turned into a combination of sums of several larger rectangles:

These four large rectangles share a key feature: their top-left corner is always the origin `(0, 0)`.
So the better idea for this problem is very similar to prefix sum in a 1D array. We can keep a 2D `preSum` array. `preSum[i][j]` records the sum of all elements in the matrix with top-left at the origin and bottom-right at `(i, j)`. Then we can use a few additions and subtractions to get the sum of any submatrix:
```java
class NumMatrix {
// preSum[i][j] records the sum of elements in the matrix [0, 0, i-1, j-1]
private int[][] preSum;
public NumMatrix(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
if (m == 0 || n == 0) return;
// construct the prefix sum matrix
preSum = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// calculate the sum of elements for each matrix [0, 0, i, j]
preSum[i][j] = preSum[i-1][j] + preSum[i][j-1] + matrix[i - 1][j - 1] - preSum[i-1][j-1];
}
}
}
// calculate the sum of elements in the submatrix [x1, y1, x2, y2]
public int sumRegion(int x1, int y1, int x2, int y2) {
// the sum of the target matrix is obtained by operations on four adjacent matrices
return preSum[x2+1][y2+1] - preSum[x1][y2+1] - preSum[x2+1][y1] + preSum[x1][y1];
}
}
```
In this way, the time complexity of the `sumRegion` function is optimized to $O(1)$ with the prefix sum trick. This is a classic “space-for-time” method.
<visual slug='range-sum-query-2d-immutable' >
You can open the visualization below. Click the line <code type="click">preSum[i][j] = ...</code> many times to see how the <code type="click">preSum</code> array is computed. Click the <code type="click">console.log</code> line many times to see how the <code type="click">sumRegion</code> function is called:
</visual>
This is all for the prefix sum technique. You can say this skill is easy once you get it, but hard if you do not. In real problems, you should train your flexibility in thinking, so you can quickly see that a problem is a prefix sum problem.
## Further Expansion
The prefix sum technique explained in this article uses a precomputed `preSum` array to quickly calculate the sum of elements within a given index range. However, it is not limited to summation; it can also be used for quickly computing products and other scenarios.
Moreover, prefix sum arrays are often combined with other data structures or algorithmic techniques. I will explain these combinations in [High-Frequency Prefix Sum Exercises](https://labuladong.online/en/algo/problem-set/perfix-sum/) along with relevant exercises.
However, the prefix sum technique has several limitations.
**First Limitation: The prerequisite for using the prefix sum technique is that the original array `nums` does not change.**
If an element in the original array changes, the values in the `preSum` array after that element become invalid, requiring $O(n)$ time to recalculate the `preSum` array, which is similar to the brute-force method.
**Second Limitation: The prefix sum technique is only applicable in scenarios with inverse operations.**
For example, in summation scenarios, if you know $x + 6 = 10$, you can deduce $x = 10 - 6 = 4$. Similarly, in product scenarios, if you know $x * 6 = 12$, you can deduce $x = 12 / 6 = 2$. This is known as having an inverse operation, which allows the use of the prefix sum technique.
However, some scenarios do not have inverse operations. For example, in maximum value scenarios, if you know $max(x, 8) = 8$, you cannot deduce the value of $x$.
To address both issues simultaneously, more advanced data structures are required. The most general solution is the [Segment Tree](https://labuladong.online/en/algo/data-structure-basic/segment-tree-basic/), which will be explained in detail in the data structure design chapter.
================================================
FILE: algorithmic-thinking/probability-problems.md
================================================
In the previous article [Discussing Random Algorithms in Games](https://labuladong.online/en/algo/frequency-interview/random-algorithm/), we talked about the Monte Carlo method for verifying probability algorithms. Today, let's dive into some lighter content: a few interesting problems related to probability.
There are two simplest principles for calculating probability:
**Principle One:** To calculate probability, you must have a reference frame called the "sample space," which includes all possible outcomes of a random event. The probability of event A occurring = Number of sample points in A / Total number of sample points in the sample space.
**Principle Two:** When calculating probability, it's crucial to understand that probability is a continuous whole. You cannot split continuous probability, which is known as conditional probability.
We learned these two principles in high school, but we still easily make mistakes. Interestingly, the process of making these mistakes often follows a similar pattern:
First, we overlook Principle Two and incorrectly calculate the sample space. Then, using Principle One, we arrive at the wrong answer.
Next, let's explore a few simple yet deceptive problems: the Boy or Girl problem, the Birthday Paradox, and the Monty Hall problem. Of course, the Monty Hall problem is probably the most familiar to everyone, so we'll delve into some interesting thoughts about it.
### I. The Boy-Girl Problem
Imagine a family with two children. You are told that one of the children is a boy. What is the probability that the other child is also a boy?
Many people, including myself, might instinctively answer: 1/2, because the other child could either be a boy or a girl, with equal probability. However, the correct answer is actually 1/3.
Why is the initial thought wrong? It's because the sample space was not correctly calculated, leading to a mistake in the principle of probability calculation. With two children, the sample space consists of 4 possibilities: older brother and younger sister, older brother and younger brother, older sister and younger sister, and older sister and younger brother. Knowing that one child is a boy eliminates the older sister and younger sister scenario, reducing the sample space to 3. Only one of these scenarios involves both children being boys (older brother and younger brother), so the probability is 1/3.
Why does the calculation of the sample space often go wrong? It's because we overlook conditional probability, confusing the following two questions:
1. If a family has only one child, what is the probability that the child is a boy?
2. If a family has two children, and one of them is a boy, what is the probability that the other child is also a boy?
According to the second principle, probability problems are continuous, and these two questions should not be confused. The second question requires the use of conditional probability, which is the probability of one child being a boy given that the other child is a boy. Applying the formula for conditional probability makes this calculation straightforward.
Through this problem, readers should understand the relationship between the two principles of probability calculation. The most misleading aspect is the neglect of conditional probability. To avoid being misled, the simplest method is to enumerate all possible outcomes.
Finally, I've encountered a rather odd objection to this problem: What if the two children are twins and there is no age difference between them?
I must admit, there seems to be a hint of logic in this! However, we use age difference to represent the independence of the two children. Even if the children are of the same gender, there are still two distinct possibilities. So, let's not use twins as a counterargument.
### II. Birthday Paradox
The birthday paradox arises from the question: How many people need to be in a room for there to be at least a 50% chance that two of them share the same birthday?
The answer is 23 people, meaning that if there are 23 people in a room, there's a 50% chance that two of them will have the same birthday. This conclusion seems counterintuitive, hence it is called a paradox. Intuitively, you might think you need at least 183 people to reach a 50% probability, since there are 365 days in a year. However, this isn't the case, and the disbelief stems from two common misconceptions:
**The first misconception is misunderstanding the meaning of "exist."**
Readers might assume that if there's a 50% chance of a shared birthday among 23 people, it implies:
Suppose there are 22 people in a room, and I join them, there's a 50% chance that one of them shares my birthday. But how can that be possible?
It's not. This thinking is self-centered, whereas the problem's probability describes the group as a whole. "Exist" means any two of the 23 people, involving combinations, largely unrelated to you.
If you want to calculate the probability of someone having the same birthday as you, you can do it like this:
1 - P(22 people have different birthdays from mine) = 1 - (364/365)^22 = 0.06
Doesn't this result seem more reasonable? The birthday paradox doesn't focus on a single individual but rather on the group, including all possible combinations, making the total probability much larger.
**The second misconception is thinking that probability changes linearly.**
Readers might think that if 23 people give a 50% probability of a shared birthday, then 46 people should give a 100% probability.
This is incorrect. Like a game with a 50% win rate, playing twice doesn't guarantee a 100% win rate. Clearly, playing twice gives a 75% win rate:
`P(winning in two tries) = P(winning the first time) + P(not winning the first time but winning the second time) = 1/2 + 1/2*1/2 = 75%`
The same logic applies to the birthday paradox. Probability isn't simply additive; it involves a continuous process. Thus, the conclusion isn't unreasonable.
Why is it that with just 23 people, the probability of sharing a birthday exceeds 50%? First, calculate the probability that all 23 have unique (non-repeating) birthdays. With 1 person, the probability is `365/365`; with 2 people, it's `365/365 × 364/365`, and so on. For 23 people, the probability is:

This calculation yields approximately 0.493, so the probability of at least two people sharing a birthday is 0.507, roughly 50%. In fact, following this method, when the number of people reaches 70, the probability of a shared birthday rises to 99.9%, almost certain. Thus, probabilistically, it's not surprising to find people with the same birthday in a small group of a few dozen people.
### 3. The Monty Hall Problem
This classic game involves a participant facing three doors. Behind two doors are goats, and behind one door is a car. The participant picks a door, and whatever is behind it becomes theirs (the car is obviously more valuable). The host decides to assist: after the participant chooses a door, the host opens one of the remaining doors to reveal a goat (the host knows what is behind each door). The participant is then given a chance to switch doors. Should they switch or stick with their original choice?
To avoid confusion for those encountering this problem for the first time, let's describe it in more detail:
You are the participant in the game. There are doors 1, 2, and 3. Suppose you randomly choose door 1. The host then opens door 3 and shows you a goat. Should you stick with your initial choice of door 1, or switch to door 2?

The answer is to switch doors. If you switch, the probability of winning the car is 2/3, whereas if you don't switch, it is 1/3. This counterintuitive result might suggest that the probability should be 1/2 since there are two remaining doors, one with a goat and one with a car. However, this is not the case.
Like the boy-girl paradox mentioned earlier, the simplest and safest method is to enumerate all possible outcomes:

It is clear that the probability of winning by switching doors is 2/3, while not switching gives a probability of 1/3.
There is an even simpler explanation for this problem: the host's action effectively "condenses" the probability. Initially, the chance of choosing the car is 1/3, leaving a probability of 2/3 for the car being behind one of the other two doors. When the host reveals a goat behind one door, the 2/3 probability is transferred to the remaining door. Thus, would you hold onto the 1/3 probability door, or switch to the "condensed" 2/3 probability door?
To make it more intuitive, suppose you have 1 door selected and 2 remaining, and 98 additional doors with goats are added, making 100 doors in total. If asked whether to switch, you would likely refuse, as the probability seems diluted, suggesting the original door is most likely to contain the car. Now, consider starting with 100 doors. You choose one, and the host eliminates 98 goat doors from the remaining 99. Should you switch? Absolutely, because your selected door has a 1% chance, while the other has 99%. Alternatively, not switching is like choosing 1 door, while switching is like choosing 99 doors, making the outcome obvious.
Some readers might have thought about this concept. Consider this: If Xiao Ming, unaware of previous events, barges in to help you decide, knowing only that there are two doors, one with a car and one with a goat, what is his probability of choosing the car?
For Xiao Ming, the probability is 1/2, and this misinterpretation is the root cause of many errors in solving the Monty Hall problem. Similar to the birthday paradox, people often calculate based on their own perspective, which leads to mistakes.
Imagine there are two boxes: Box 1 contains 4 black balls and 2 red balls, while Box 2 contains 2 black balls and 4 red balls. Choosing a box at random, and picking a ball, what is the probability of drawing a red ball?
For Xiao Ming, who is uninformed, he randomly picks a box and a ball, leading to a probability of: 1/2 × 2/6 + 1/2 × 4/6 = 1/2
For you, who is informed and knows the higher probability of drawing from Box 2, the probability is: 0 × 2/6 + 1 × 4/6 = 2/3
================================================
FILE: algorithmic-thinking/set-partition.md
================================================
::: info Prerequisite Knowledge
Before reading this article, you should first learn:
- [N-ary Tree Structure and Traversal Framework](https://labuladong.online/en/algo/data-structure-basic/n-ary-tree-traverse-basic/)
- [Binary Tree Algorithms (Overview)](https://labuladong.online/en/algo/essential-technique/binary-tree-summary/)
- [Backtracking Algorithm Framework](https://labuladong.online/en/algo/essential-technique/backtrack-framework/)
- [Ball-and-Box Model: Two Brute-Force Views of Backtracking](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/)
:::
I said before that backtracking is the most useful algorithm in written tests. When you have no idea, just use backtracking to do a brute-force search. Even if you cannot pass all test cases, you can still pass some of them. The basic skill of backtracking is not hard: you brute-force a decision tree, and for each step, you "make a choice" before recursion and "undo the choice" after recursion.
**However, even for brute-force search, some ideas are better than others.** In this article, we look at a classic backtracking problem: LeetCode 698, “[Partition to K Equal Sum Subsets](https://leetcode.com/problems/partition-to-k-equal-sum-subsets/)”. This problem can help you understand the backtracking mindset more deeply and write backtracking functions more easily.
The problem is very simple:
You are given an array `nums` and a positive integer `k`. Please check whether `nums` can be divided into `k` subsets such that the sum of elements in each subset is the same.
The function signature is:
```java
boolean canPartitionKSubsets(int[] nums, int k);
```
::: info Thinking Question
Earlier, in [Subset Partition as a Knapsack Problem](https://labuladong.online/en/algo/dynamic-programming/knapsack2/), we solved a subset partition problem. But that problem only asked us to split the set into two equal subsets, and we could turn it into a knapsack problem and solve it with dynamic programming.
Why can partitioning into two equal subsets be transformed into a knapsack problem and solved with dynamic programming, but partitioning into `k` equal subsets cannot be transformed this way and must be solved by brute-force backtracking? Please think about this yourself first.
:::
::: details Answer to the Thinking Question
Why can partitioning into two equal subsets be transformed into a knapsack problem?
In the setting of [Subset Partition as a Knapsack Problem](https://labuladong.online/en/algo/dynamic-programming/knapsack2/), we have one knapsack and several items. Each item has **two choices**: "put it into the knapsack" or "do not put it into the knapsack".
When we split the original set `S` into two equal subsets `S_1` and `S_2`, each element in `S` also has **two choices**: "put it into `S_1`" or "do not put it into `S_1` (put it into `S_2`)". The brute-force idea here is actually the same as in the knapsack problem.
But if you want to split `S` into `k` equal subsets, then each element in `S` has **`k` choices**. This is essentially different from the standard knapsack setting, so you cannot directly use the knapsack DP approach. You have to use backtracking and brute-force search.
:::
<!-- hide -->
## Problem Idea
Now back to this problem. We need to partition the array into subsets. Subset problems are different from permutation and combination problems, but we can still use the “balls and boxes model” to think about it from two different views.
We want to split an array `nums` with `n` numbers into `k` subsets with the same sum. You can imagine putting `n` numbers into `k` “buckets”, and at the end, the sum of numbers in each of the `k` buckets must be the same.
In the earlier article [Understanding Backtracking with the Balls and Boxes Model](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/), we said the key of backtracking is:
You must know how to “make choices”, then you can use recursion to do brute-force search.
If we imitate the way we derive the permutation formula, and assign `n` numbers into `k` buckets, we can also have two views:
**First view: from the `n` numbers’ perspective, each number must choose one of the `k` buckets to go into.**

**Second view: from the `k` buckets’ perspective, for each bucket, you go through all `n` numbers in `nums`, and decide whether to put the current number into this bucket.**

You may ask, what is the difference between these two views?
Just like in the permutation and subset problems, using different views to do brute-force search gives the same result, but the code logic is different. The concrete implementation is different, and the time and space complexity may also be different. We want to choose the solution with lower complexity.
## Number-based view
Everyone knows how to iterate through the `nums` array with a for loop:
```java
for (int index = 0; index < nums.length; index++) {
print(nums[index]);
}
```
Can you traverse the array with recursion? It is also simple:
```java
void traverse(int[] nums, int index) {
if (index == nums.length) {
return;
}
print(nums[index]);
traverse(nums, index + 1);
}
```
If you call `traverse(nums, 0)`, it has the same effect as the for loop.
Now back to this problem. From the numbers’ view, each number chooses one of `k` buckets. The for-loop version looks like this:
```java
// k buckets (collections), record the sum of numbers in each bucket
int[] bucket = new int[k];
// enumerate each number in nums
for (int index = 0; index < nums.length; index++) {
// enumerate each bucket
for (int i = 0; i < k; i++) {
// decide whether nums[index] should go into the i-th bucket
// ...
}
}
```
If we change it to a recursive version, the logic becomes:
```java
// k buckets (collections), record the sum of numbers in each bucket
int[] bucket = new int[k];
// enumerate each number in nums
void backtrack(int[] nums, int index) {
// base case
if (index == nums.length) {
return;
}
// enumerate each bucket
for (int i = 0; i < bucket.length; i++) {
// choose to put it into the i-th bucket
bucket[i] += nums[index];
// recursively enumerate the next number's choice
backtrack(nums, index + 1);
// undo the choice
bucket[i] -= nums[index];
}
}
```
The above code is only the brute-force structure, it cannot solve the problem yet. But we can fix it with some small changes:
```java
class Solution {
public boolean canPartitionKSubsets(int[] nums, int k) {
// exclude some base cases
if (k > nums.length) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) return false;
// k buckets (sets), record the sum of numbers in each bucket
int[] bucket = new int[k];
// the theoretical sum of numbers in each bucket
int target = sum / k;
// try all possibilities, to see if nums can be divided into k subsets with sum of target
return backtrack(nums, 0, bucket, target);
}
// recursively try each number in nums
boolean backtrack(
int[] nums, int index, int[] bucket, int target) {
if (index == nums.length) {
// check if the sum of numbers in all buckets is target
for (int i = 0; i < bucket.length; i++) {
if (bucket[i] != target) {
return false;
}
}
// successfully divide nums into k subsets
return true;
}
// try all possible buckets for nums[index]
for (int i = 0; i < bucket.length; i++) {
// pruning, the bucket is full
if (bucket[i] + nums[index] > target) {
continue;
}
// put nums[index] into bucket[i]
bucket[i] += nums[index];
/**<extend down -200>

*/
// recursively try the next number's choices
if (backtrack(nums, index + 1, bucket, target)) {
return true;
}
// undo the choice
bucket[i] -= nums[index];
}
// nums[index] cannot be put into any bucket
return false;
}
}
```
With the earlier explanation, this code should be easy to understand. In fact, we can still do one more optimization.
Look at the recursive part of the `backtrack` function:
```java
for (int i = 0; i < bucket.length; i++) {
// pruning
if (bucket[i] + nums[index] > target) {
continue;
}
if (backtrack(nums, index + 1, bucket, target)) {
return true;
}
}
```
**If we can make more cases hit that pruning `if` branch, we can reduce the number of recursive calls, and thus reduce the time complexity to some extent.**
How can we make more cases hit this `if` branch? Note that our `index` parameter increases from 0, which means we go through the `nums` array from 0 in the recursion.
If we sort the `nums` array in advance and put larger numbers in front, then larger numbers will be put into the `bucket` first. After that, for the remaining numbers, `bucket[i] + nums[index]` will be larger, so the pruning `if` condition is easier to trigger.
So we can add some code to the previous solution:
```java
boolean canPartitionKSubsets(int[] nums, int k) {
// other code remains unchanged
// ...
// sort the nums array in descending order
Arrays.sort(nums);
// reverse the array to get the descending order array
for (i = 0, j = nums.length - 1; i < j; i++, j--) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
// *****************
return backtrack(nums, 0, bucket, target);
}
```
This solution is correct, but it is still slow and cannot pass all test cases. Next we will look at the solution from the other view.
## The Bucket Perspective
At the beginning of the article, we said: **from the bucket perspective, we use brute-force. For each bucket, we scan all numbers in `nums` and decide whether to put the current number into this bucket. After one bucket is full, we continue to fill the next bucket, until all buckets are full**.
We can express this idea with the following code:
```java
// fill all the buckets until
while (k > 0) {
// record the sum of numbers in the current bucket
int bucket = 0;
for (int i = 0; i < nums.length; i++) {
// decide whether to put nums[i] into the current bucket
if (canAdd(bucket, num[i])) {
bucket += nums[i];
}
if (bucket == target) {
// filled one bucket, move on to the next one
k--;
break;
}
}
}
```
We can also rewrite this `while` loop as a recursive function. It is a bit more complex than before. First, we write a `backtrack` function:
```java
boolean backtrack(int k, int bucket, int[] nums, int start, boolean[] used, int target);
```
Do not be scared by so many parameters. I will explain them one by one. If you fully understood the earlier article [Understanding Backtracking with the Ball-and-Box Model](https://labuladong.online/en/algo/practice-in-action/two-views-of-backtrack/), you can also write such a backtracking function easily.
The parameters of this `backtrack` function can be understood like this:
Now bucket `k` is deciding whether it should take the element `nums[start]`. The current sum of numbers already in bucket `k` is `bucket`. `used` marks whether an element has already been put into some bucket. `target` is the required sum for each bucket.
With this function definition, we can call `backtrack` like this:
```java
class Solution {
public boolean canPartitionKSubsets(int[] nums, int k) {
// exclude some base cases
if (k > nums.length) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) return false;
boolean[] used = new boolean[nums.length];
int target = sum / k;
// the k-th bucket is initially empty, start making choices from nums[0]
return backtrack(k, 0, nums, 0, used, target);
}
}
```
Before we implement the logic of `backtrack`, repeat the bucket perspective again:
1. We must scan all numbers in `nums` and decide which numbers should be put into the current bucket.
2. If the current bucket is full (the sum in this bucket reaches `target`), we move on to the next bucket and repeat step 1.
The code below implements this logic:
```java
class Solution {
public boolean canPartitionKSubsets(int[] nums, int k) {
// see the above text
}
boolean backtrack(int k, int bucket,
int[] nums, int start, boolean[] used, int target) {
// base case
if (k == 0) {
// all buckets are full, and nums must all be used up
// because target == sum / k
return true;
}
if (bucket == target) {
/**<extend down -200>

*/
// the current bucket is full, recursively enumerate the choices for the next bucket
// let the next bucket start selecting numbers from nums[0]
return backtrack(k - 1, 0 ,nums, 0, used, target);
}
// start from start to look back for valid nums[i] to put into the current bucket
for (int i = start; i < nums.length; i++) {
// pruning
if (used[i]) {
// nums[i] has already been placed in another bucket
continue;
}
if (nums[i] + bucket > target) {
// the current bucket cannot hold nums[i]
continue;
}
// make a choice, put nums[i] into the current bucket
used[i] = true;
bucket += nums[i];
// recursively enumerate whether the next number should be placed in the current bucket
if (backtrack(k, bucket, nums, i + 1, used, target)) {
return true;
}
// cancel the choice
used[i] = false;
bucket -= nums[i];
}
// having exhausted all numbers, none can fill the current bucket
return false;
}
}
```
**This code can produce the correct answer, but it is very slow. We should think about how to optimize it.**
First, in this solution each bucket is actually identical, but our backtracking algorithm treats them as different. This causes repeated work.
What does this mean? Our backtracking algorithm is, in the end, brute-forcing all possible combinations, and checking whether we can form `k` buckets (subsets) each with sum `target`.
For example, in the case below, `target = 5`. The algorithm may first fill the first bucket with `1, 4`:

Now the first bucket is full, so we fill the second bucket. The algorithm may put `2, 3` in it:

Then it continues with the later elements, using brute-force to try to build more buckets with sum 5.
But if, in the end, we cannot form `k` subsets with sum `target`, what will the algorithm do?
Backtracking will go back to the first bucket and try again. Now it knows `{1, 4}` in the first bucket does not work, so it will try `{2, 3}` in the first bucket:

Now the first bucket is full again. Then it starts to fill the second bucket with `{1, 4}`:

Here you should see the problem. This situation is actually the same as the previous one. That means we already know there is no solution. We do not need to brute-force again.
But our algorithm will still keep searching, because it thinks: “The first and second buckets hold different elements now, so these are two different cases.”
How can we make the algorithm smarter, so it can recognize this and avoid redundant work?
Notice that the `used` array must be the same in these two situations. So we can treat the `used` array as the “state” of the backtracking process.
**So we can use a `memo` map. When we fill one bucket, we record the current `used` state. If the same `used` state appears again later, we know we have already tried this situation, so we can stop and prune the search.**
You may ask: `used` is a boolean array, how can we use it as a key? This is easy. We can convert the array to a string and then use the string as the key in a hash map.
Look at the code. We only need to slightly change the `backtrack` function:
```java
class Solution {
// Memoization, storing the state of the used array
HashMap<String, Boolean> memo = new HashMap<>();
public boolean canPartitionKSubsets(int[] nums, int k) {
// See above
}
boolean backtrack(int k, int bucket, int[] nums, int start, boolean[] used, int target) {
// base case
if (k == 0) {
return true;
}
// Convert the state of used into a string like [true, false, ...]
// for easy storage in the HashMap
String state = Arrays.toString(used);
if (bucket == target) {
// The current bucket is filled, recursively enumerate the choices for the next bucket
boolean res = backtrack(k - 1, 0, nums, 0, used, target);
// Store the current state and result in the memoization
memo.put(state, res);
return res;
}
if (memo.containsKey(state)) {
// If the current state has been calculated before, return directly without further recursion
return memo.get(state);
}
// Other logic remains unchanged...
}
}
```
If we submit this version, we will still find it slow. This time, the problem is not the algorithm logic, but the implementation.
**Because in each recursion we convert the `used` array to a string, which is costly for the language runtime. So we can optimize further.**
Notice the constraint: `nums.length <= 16`. That means `used` will never have more than 16 elements. So we can use a bit-mask trick: use one integer variable `used` instead of a boolean array.
More precisely, we can use the `i`-th bit of integer `used` (`(used >> i) & 1`) to represent `used[i]` being true or false.
With this, we both save space and can use the integer `used` directly as the key in a HashMap, without converting arrays to strings.
Here is the final solution:
```java
class Solution {
public boolean canPartitionKSubsets(int[] nums, int k) {
// exclude some basic cases
if (k > nums.length) return false;
int sum = 0;
for (int v : nums) sum += v;
if (sum % k != 0) return false;
// use bit manipulation technique
int used = 0;
int target = sum / k;
// the k-th bucket initially has nothing, start choosing from nums[0]
return backtrack(k, 0, nums, 0, used, target);
}
HashMap<Integer, Boolean> memo = new HashMap<>();
boolean backtrack(int k, int bucket,
int[] nums, int start, int used, int target) {
// base case
if (k == 0) {
// all buckets are filled, and all nums must have been used
return true;
}
if (bucket == target) {
// current bucket is filled, recursively enumerate the choices for the next bucket
// let the next bucket start choosing from nums[0]
boolean res = backtrack(k - 1, 0, nums, 0, used, target);
// cache the result
memo.put(used, res);
return res;
}
if (memo.containsKey(used)) {
// avoid redundant calculations
return memo.get(used);
}
for (int i = start; i < nums.length; i++) {
// pruning
// check if the i-th bit is 1
if (((used >> i) & 1) == 1) {
// nums[i] has already been used in another bucket
continue;
}
if (nums[i] + bucket > target) {
continue;
}
// make a choice
// set the i-th bit to 1
used |= 1 << i;
bucket += nums[i];
// recursively enumerate whether the next number goes into the current bucket
if (backtrack(k, bucket, nums, i + 1, used, target)) {
return true;
}
// undo the choice
// use XOR operation to reset the i-th bit to 0
used ^= 1 << i;
bucket -= nums[i];
}
return false;
}
}
```
<visual slug='partition-to-k-equal-sum-subsets'/>
Now the second idea for this problem is done.
## Final Summary
Both ideas in this article can produce the correct answer. But even with sorting optimization, the first solution is clearly slower than the second one. Why?
Let’s analyze the time complexity. Assume `n` is the number of elements in `nums`.
For the first solution (the number perspective): for each of the `n` numbers, we have `k` choices (which bucket to put it in). So the number of combinations is `k^n`, and the time complexity is $O(k^n)$.
For the second solution (the bucket perspective): each bucket scans `n` numbers, and for each number we have two choices: “put in” or “not put in”. So there are `2^n` combinations per bucket. We have `k` buckets, so the time complexity is $O(k * 2^n)$.
**Of course, these are rough upper bounds for the worst case. In practice the complexity is much better thanks to all our pruning. But from the upper bounds we can already see that the first idea is much slower.**
So, who says backtracking has no technique? Backtracking is brute-force, but brute-force can be smart or stupid. The key is: from which “perspective” do you brute-force?
In simple words, we should try to “do more small steps” instead of “one huge step”. That is, it is better to have more choices with small branching (multiplicative growth), instead of having a huge branching factor (exponential growth). Doing `n` times of “k choices once” giving $O(k^n)$ is often worse than doing `n` times of “2 choices” repeated `k` times giving $O(k * 2^n)$.
In this problem, we tried brute-force from two perspectives. The code looks long, but the core logic is similar. After reading this article, you should have a deeper understanding of backtracking.
================================================
FILE: algorithmic-thinking/sliding-window.md
================================================
<txplayer slug='sliding-window' open />
In the previous article [Double Pointer Techniques](https://labuladong.online/en/algo/essential-technique/array-two-pointers-summary/), we talked about some simple double pointer tricks for arrays. In this article, we will discuss a slightly more complex technique: the sliding window.
The sliding window can be seen as a fast and slow double pointer. One pointer moves fast, the other slow, and the part between them is the window. **The sliding window algorithm is mainly used to solve subarray problems, such as finding the longest or shortest subarray that meets certain conditions.**
<visual slug='minimum-window-substring' >
You can open the visualization panel below. Click the line <code type="click">while (right < s.length)</code> multiple times to see how the window moves step by step:
</visual>
This article will give you a template that helps you write correct solutions easily. Each problem also has a visualization panel to help you better understand how the window slides.
## Sliding Window Framework Overview
If you use brute-force, you need nested for-loops to go through all subarrays. The time complexity is $O(N^2)$:
```java
for (int i = 0; i < nums.length; i++) {
for (int j = i; j < nums.length; j++) {
// nums[i, j] is a subarray
}
}
```
The sliding window idea is simple: keep a window, move it step by step, and update the answer. The general logic is:
```java
// The range [left, right) is the window
int left = 0, right = 0;
while (right < nums.size()) {
// Expand the window
window.addLast(nums[right]);
right++;
while (window needs shrink) {
// Shrink the window
window.removeFirst(nums[left]);
left++;
}
}
```
If you use this sliding window framework, the time complexity is $O(N)$, which is much faster than the brute-force solution.
::: info Why is it $O(N)$?
Some of you may ask, "Isn't there a nested while loop? Why is the complexity $O(N)$?"
Simply put, the pointers `left` and `right` never move backward. They only move forward. So, each element in the string/array is added to the window once, and removed once. No element is added or removed more than once, so the time complexity is proportional to the length of the string/array.
But in the nested for-loop brute-force solution, `j` moves backward, so some elements are counted many times. That's why its time complexity is $O(N^2)$.
If you want to learn more about time and space complexity, check my article [Guide to Analyzing Algorithm Complexity](https://labuladong.online/en/algo/essential-technique/complexity-analysis/).
:::
::: info Can sliding window really list all subarrays in $O(N)$ time?
Actually, this is a mistake. **Sliding window cannot list all substrings.** If you want to go through all substrings, you have to use the nested for-loops.
But for some problems, you don't need to check all substrings to find the answer. In these cases, the sliding window is a good template to make the solution faster and avoid extra calculations.
That's why in [The Essence of Algorithms](https://labuladong.online/en/algo/essential-technique/algorithm-summary/), I put sliding window in the category of "smart enumeration".
:::
What really confuses people are the details. For example, how to add new elements to the window, when to shrink the window, and when to update the result. Even if you know these, the code may still have bugs, and it's not easy to debug.
**So today I will give you a sliding window code template. I will even add print debug statements for you. Next time you see a related problem, just recall this template and change three places. This will help you avoid bugs.**
Since most examples in this article are substring problems, and a string is just an array, the input will be a string. When you solve problems, adapt as needed:
```java
// Pseudocode framework of sliding window algorithm
void slidingWindow(String s) {
// Use an appropriate data structure to record the data in the window, which can vary according to the specific scenario
// For example, if I want to record the frequency of elements in the window, I would use a map
// If I want to record the sum of elements in the window, I could just use an int
Object window = ...
int left = 0, right = 0;
while (right < s.length()) {
// c is the character that will be added to the window
char c = s[right];
window.add(c)
// Expand the window
right++;
// Perform a series of updates to the data within the window
...
// *** Position of debug output ***
// Note that in the final solution code, do not use print
// Because IO operations are time-consuming and may cause timeouts
printf("window: [%d, %d)
", left, right);
// ***********************
// Determine whether the left side of the window needs to shrink
while (left < right && window needs shrink) {
// d is the character that will be removed from the window
char d = s[left];
window.remove(d)
// Shrink the window
left++;
// Perform a series of updates to the data within the window
...
}
}
}
```
**There are two places in the template marked with `...`. These are where you update the data for the window. In a real problem, just fill in your logic here. These two places are for expanding and shrinking the window, and you will see that their logic is almost the same, just opposite.**
With this template, if you get a substring or subarray problem, just answer these three questions:
1. When should you move `right` to expand the window? What data should you update when adding a character to the window?
2. When should you stop expanding and start moving `left` to shrink the window? What data should you update when removing a character from the window?
3. When should you update the result?
If you can answer these questions, you can use the sliding window technique for the problem.
Next, we'll use this template to solve four LeetCode problems. For the first problem, I will explain the ideas in detail. For the others, just use the template and solve them quickly.
## 1. Minimum Window Substring
Let's look at LeetCode problem 76: ["Minimum Window Substring"](https://leetcode.com/problems/minimum-window-substring/) (Hard):
**LeetCode 76. Minimum Window Substring** <span class="inline-block w-2 h-2 rounded-full bg-red-500"></span>
Given two strings `s` and `t` of lengths `m` and `n` respectively, return *the **minimum window*** ***substring**** of *`s`* such that every character in *`t`* (**including duplicates**) is included in the window*. If there is no such substring, return *the empty string *`""`.
The testcases will be generated such that the answer is **unique**.
Example 1:**
```
**Input:** s = "ADOBECODEBANC", t = "ABC"
**Output:** "BANC"
**Explanation:** The minimum window substring "BANC" includes 'A', 'B', and 'C' from string t.
```
Example 2:**
```
**Input:** s = "a", t = "a"
**Output:** "a"
**Explanation:** The entire string s is the minimum window.
```
Example 3:**
```
**Input:** s = "a", t = "aa"
**Output:** ""
**Explanation:** Both 'a's from t must be included in the window.
Since the largest window of s only has one 'a', return empty string.
```
**Constraints:**
- `m == s.length`
- `n == t.length`
- `1 <= m, n <= 10^(5)`
- `s` and `t` consist of uppercase and lowercase English letters.
**Follow up:** Could you find an algorithm that runs in `O(m + n)` time?
You need to find a substring in `S` (source) that co
gitextract_jc1mrgvh/
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── 01-algo-website-bug.md
│ │ ├── 02-algo-visualize-bug.md
│ │ ├── 03-chrome-extension-bug.md
│ │ ├── 04-vscode-extension-bug.md
│ │ ├── 05-jetbrain-plugin-bug.md
│ │ └── 06-suggestion.md
│ └── PULL_REQUEST_TEMPLATE.md
├── README.md
├── algorithmic-thinking/
│ ├── README.md
│ ├── backtracking.md
│ ├── bfs-framework.md
│ ├── binary-search.md
│ ├── bit-manipulation.md
│ ├── difference-array.md
│ ├── matrix-traversal.md
│ ├── pancake-sorting.md
│ ├── prefix-sum.md
│ ├── probability-problems.md
│ ├── set-partition.md
│ ├── sliding-window.md
│ ├── string-multiplication.md
│ ├── two-pointers.md
│ └── union-find.md
├── data-structures/
│ ├── README.md
│ ├── binary-tree-practice1.md
│ ├── binary-tree-practice2.md
│ ├── binary-tree-summary.md
│ ├── bst-part1.md
│ ├── bst-part2.md
│ ├── calculator.md
│ ├── dijkstra.md
│ ├── monotonic-queue.md
│ ├── monotonic-stack.md
│ ├── queue-stack.md
│ ├── reverse-linked-list.md
│ └── topological-sort.md
├── dynamic-programming/
│ ├── README.md
│ ├── dp-framework.md
│ ├── edit-distance.md
│ ├── egg-drop.md
│ ├── game-theory.md
│ ├── house-robber.md
│ ├── interval-scheduling.md
│ ├── knapsack.md
│ ├── longest-common-subsequence.md
│ ├── magic-tower.md
│ ├── optimal-substructure.md
│ ├── regular-expression.md
│ ├── state-compression.md
│ ├── stock-problems.md
│ ├── subsequence-problems.md
│ └── word-break.md
├── interview/
│ ├── README.md
│ ├── binary-search-in-action.md
│ ├── celebrity-problem.md
│ ├── count-primes.md
│ ├── island-problems.md
│ ├── lru-cache.md
│ ├── meeting-rooms.md
│ ├── missing-duplicate-element.md
│ ├── palindrome-linked-list.md
│ ├── random-weight.md
│ ├── subset-permutation-combination.md
│ └── trapping-rain-water.md
├── multi-language-solutions/
│ ├── contribution-guide.md
│ └── solution_code.md
└── technical/
├── cryptography.md
├── linux-process.md
├── linux-shell.md
├── problem-solving-tips.md
└── session-and-cookie.md
Condensed preview — 71 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,802K chars).
[
{
"path": ".github/ISSUE_TEMPLATE/01-algo-website-bug.md",
"chars": 420,
"preview": "---\nname: Website bug\nabout: Report bug on website `labuladong.online`\ntitle: ''\nlabels: algo-websie-bug\nassignees: labu"
},
{
"path": ".github/ISSUE_TEMPLATE/02-algo-visualize-bug.md",
"chars": 156,
"preview": "---\nname: Algo-visualize bug\nabout: Report bug for algo-visualize tool in website/plugins\ntitle: ''\nlabels: algo-visuali"
},
{
"path": ".github/ISSUE_TEMPLATE/03-chrome-extension-bug.md",
"chars": 373,
"preview": "---\nname: Chrome extension bug\nabout: Report bug on Chrome extension\ntitle: ''\nlabels: algo-website, chrome-extension-bu"
},
{
"path": ".github/ISSUE_TEMPLATE/04-vscode-extension-bug.md",
"chars": 345,
"preview": "---\nname: VSCode extension bug\nabout: Report bug on vscode extension\ntitle: ''\nlabels: vscode-extension-bug\nassignees: l"
},
{
"path": ".github/ISSUE_TEMPLATE/05-jetbrain-plugin-bug.md",
"chars": 333,
"preview": "---\nname: JetBrain plugin bug\nabout: Report bug on JetBrain plugin\ntitle: ''\nlabels: jb-plugin-bug\nassignees: labuladong"
},
{
"path": ".github/ISSUE_TEMPLATE/06-suggestion.md",
"chars": 218,
"preview": "---\nname: Suggestion\nabout: Suggest an idea/improvement for this project\ntitle: ''\nlabels: feature-request\nassignees: la"
},
{
"path": ".github/PULL_REQUEST_TEMPLATE.md",
"chars": 0,
"preview": ""
},
{
"path": "README.md",
"chars": 36060,
"preview": "[](https://star-hist"
},
{
"path": "algorithmic-thinking/README.md",
"chars": 172,
"preview": "# 算法思维系列\n\n本章包含一些常用的算法技巧,比如前缀和、回溯思想、位操作、双指针、如何正确书写二分查找等等。\n\n欢迎关注我的公众号 labuladong,查看全部文章:\n\n is an interesting real-world pr"
},
{
"path": "algorithmic-thinking/prefix-sum.md",
"chars": 11260,
"preview": "::: info Prerequisite\n\nBefore reading this article, you should first learn:\n\n- [Array Basics](https://labuladong.online/"
},
{
"path": "algorithmic-thinking/probability-problems.md",
"chars": 10311,
"preview": "In the previous article [Discussing Random Algorithms in Games](https://labuladong.online/en/algo/frequency-interview/ra"
},
{
"path": "algorithmic-thinking/set-partition.md",
"chars": 22668,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [N-ary Tree Structure and Trave"
},
{
"path": "algorithmic-thinking/sliding-window.md",
"chars": 26563,
"preview": "<txplayer slug='sliding-window' open />\n\nIn the previous article [Double Pointer Techniques](https://labuladong.online/e"
},
{
"path": "algorithmic-thinking/string-multiplication.md",
"chars": 5034,
"preview": "For small numbers, you can use the operators provided by your programming language to do calculations. But if the number"
},
{
"path": "algorithmic-thinking/two-pointers.md",
"chars": 22586,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Array Basics](https://labuladong.online"
},
{
"path": "algorithmic-thinking/union-find.md",
"chars": 17369,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first study:\n\n- [Basics and Traversal of N-ary "
},
{
"path": "data-structures/README.md",
"chars": 164,
"preview": "# 数据结构系列\n\n这一章主要是一些特殊的数据结构设计,比如单调栈解决 Next Greater Number,单调队列解决滑动窗口问题;还有常用数据结构的操作,比如链表、树、二叉堆。\n\n欢迎关注我的公众号 labuladong,查看全部文"
},
{
"path": "data-structures/binary-tree-practice1.md",
"chars": 16026,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first study:\n\n- [Basics of Binary Tree Structure](https:"
},
{
"path": "data-structures/binary-tree-practice2.md",
"chars": 26083,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Basics of Binary Tree Structur"
},
{
"path": "data-structures/binary-tree-summary.md",
"chars": 44549,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Binary Tree Structure Basics](https://l"
},
{
"path": "data-structures/bst-part1.md",
"chars": 11709,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to study:\n\n- [Binary Tree Basics](https://labuladong.onlin"
},
{
"path": "data-structures/bst-part2.md",
"chars": 16180,
"preview": "::: info Prerequisite\n\nBefore reading this article, you should first learn:\n\n- [Basics of Binary Tree Structure](https:/"
},
{
"path": "data-structures/calculator.md",
"chars": 14386,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [Principles of Queue/Stack](https://labuladon"
},
{
"path": "data-structures/dijkstra.md",
"chars": 15388,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Graph Basics and General Imple"
},
{
"path": "data-structures/monotonic-queue.md",
"chars": 14368,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Basic Array](https://labuladon"
},
{
"path": "data-structures/monotonic-stack.md",
"chars": 12851,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Array Basics](https://labuladong.online"
},
{
"path": "data-structures/queue-stack.md",
"chars": 8460,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Array Basics](https://labuladong.online"
},
{
"path": "data-structures/reverse-linked-list.md",
"chars": 19846,
"preview": "Reversing a singly linked list with iteration is not hard, but the recursive solution is a bit tricky. If we add more di"
},
{
"path": "data-structures/topological-sort.md",
"chars": 12866,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [DFS/BFS Traversal of Graph Structures](https"
},
{
"path": "dynamic-programming/README.md",
"chars": 373,
"preview": "# 动态规划系列\n\n我们公众号最火的就是动态规划系列的文章,也许是动态规划问题有难度而且有意思,也许因为它是面试常考题型。不管你之前是否害怕动态规划系列的问题,相信这一章的内容足以帮助你消除对动态规划算法的恐惧。\n\n具体来说,动态规划的一般"
},
{
"path": "dynamic-programming/dp-framework.md",
"chars": 32333,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Binary Tree Traversal Framewor"
},
{
"path": "dynamic-programming/edit-distance.md",
"chars": 19439,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Binary Tree Algorithms (Overview)](http"
},
{
"path": "dynamic-programming/egg-drop.md",
"chars": 21979,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Dynamic Programming Core Framework](htt"
},
{
"path": "dynamic-programming/game-theory.md",
"chars": 14218,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Core Framework of Dynamic Prog"
},
{
"path": "dynamic-programming/house-robber.md",
"chars": 12128,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Binary Tree Algorithms (Overview)](http"
},
{
"path": "dynamic-programming/interval-scheduling.md",
"chars": 8015,
"preview": "What is a greedy algorithm? You can think of a greedy algorithm as a special case of dynamic programming. Compared to dy"
},
{
"path": "dynamic-programming/knapsack.md",
"chars": 7221,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first study:\n\n- [Core Framework of Dynamic Prog"
},
{
"path": "dynamic-programming/longest-common-subsequence.md",
"chars": 16540,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you need to learn:\n\n- [Dynamic Programming Core Framework]"
},
{
"path": "dynamic-programming/magic-tower.md",
"chars": 13403,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you need to learn:\n\n- [Core Framework of Dynamic Programmi"
},
{
"path": "dynamic-programming/optimal-substructure.md",
"chars": 16566,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [Dynamic Programming Core Framework](https://"
},
{
"path": "dynamic-programming/regular-expression.md",
"chars": 11329,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you need to study:\n\n- [Core Framework of Dynamic Programmi"
},
{
"path": "dynamic-programming/state-compression.md",
"chars": 12238,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first study:\n\n- [Dynamic Programming Core Framework](htt"
},
{
"path": "dynamic-programming/stock-problems.md",
"chars": 39666,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [Dynamic Programming Core Framework](https://"
},
{
"path": "dynamic-programming/subsequence-problems.md",
"chars": 11190,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [Dynamic Programming Core Framework](https://"
},
{
"path": "dynamic-programming/word-break.md",
"chars": 26981,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to study:\n\n- [Binary Tree Algorithms Series (Overview)](ht"
},
{
"path": "interview/README.md",
"chars": 117,
"preview": "# 高频面试系列\n\n8 说了,本章都是高频面试题,配合前面的动态规划系列,祝各位马到成功!\n\n欢迎关注我的公众号 labuladong,查看全部文章:\n\n"
},
{
"path": "interview/binary-search-in-action.md",
"chars": 25872,
"preview": "::: info Required Knowledge\n\nBefore reading this article, you need to learn:\n\n- [Binary Search Framework in Detail](http"
},
{
"path": "interview/celebrity-problem.md",
"chars": 10153,
"preview": "::: info Prerequisite\n\nBefore reading this article, you should first learn:\n\n- [Graph Basics and Common Implementations]"
},
{
"path": "interview/count-primes.md",
"chars": 5766,
"preview": "The definition of a prime number looks very simple: if a number can only be divided by 1 and itself, then this number is"
},
{
"path": "interview/island-problems.md",
"chars": 21484,
"preview": "::: info Prerequisite Knowledge\n\nBefore reading this article, you should first learn:\n\n- [Binary Tree Algorithms (Overvi"
},
{
"path": "interview/lru-cache.md",
"chars": 19048,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should first learn:\n\n- [Linked List Basics](https://labuladong."
},
{
"path": "interview/meeting-rooms.md",
"chars": 10686,
"preview": "In a previous interview, I was asked a very classic and practical algorithm problem: the meeting room scheduling problem"
},
{
"path": "interview/missing-duplicate-element.md",
"chars": 5747,
"preview": "Today, let's discuss a seemingly simple yet ingenious problem: finding the missing and duplicate elements. A similar pro"
},
{
"path": "interview/palindrome-linked-list.md",
"chars": 9713,
"preview": "::: info Prerequisites\n\nBefore reading this article, you need to learn:\n\n- [Linked List Basics](https://labuladong.onlin"
},
{
"path": "interview/random-weight.md",
"chars": 11633,
"preview": "::: info Prerequisites\n\nBefore reading this article, you should be familiar with:\n\n- [Prefix Sum Techniques](https://lab"
},
{
"path": "interview/subset-permutation-combination.md",
"chars": 35363,
"preview": "::: info Prerequisite\n\nBefore reading this article, you need to learn:\n\n- [Binary Tree Algorithms (Overview)](https://la"
},
{
"path": "interview/trapping-rain-water.md",
"chars": 12723,
"preview": "::: info Prerequisite\n\nBefore reading this article, you need to learn:\n\n- [Two Pointers Techniques for Arrays](https://l"
},
{
"path": "multi-language-solutions/contribution-guide.md",
"chars": 2878,
"preview": "# 修正 labuladong 刷题插件中的错误\n\n## 背景\n\n为了帮助大家更好地学习算法,我之前写了很多算法教程,并开发了一系列刷题插件,统称为《labuladong 的刷题全家桶》,详情见 [这里](https://labuladon"
},
{
"path": "multi-language-solutions/solution_code.md",
"chars": 1731772,
"preview": "https://leetcode.cn/problems/01-matrix 的多语言解法👇\n\n```cpp\n// by chatGPT (cpp)\nclass Solution {\npublic:\n vector<vector<in"
},
{
"path": "technical/cryptography.md",
"chars": 16357,
"preview": "When we talk about passwords, the first thing we think of is the login password for our account. But from the view of cr"
},
{
"path": "technical/linux-process.md",
"chars": 7858,
"preview": "When it comes to processes, the most common interview question is the relationship between processes and threads. Here i"
},
{
"path": "technical/linux-shell.md",
"chars": 11702,
"preview": "I personally like using Linux systems. Although Windows has a better graphical interface, its support for scripts is poo"
},
{
"path": "technical/problem-solving-tips.md",
"chars": 14005,
"preview": "First, let's address a question: Is it better to practice LeetCode problems directly on the website or on a local IDE?\n\n"
},
{
"path": "technical/session-and-cookie.md",
"chars": 8203,
"preview": "Most people are familiar with cookies. For example, after logging into a website for a while, you will be asked to log i"
}
]
About this extraction
This page contains the full source code of the labuladong/fucking-algorithm GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 71 files (2.6 MB), approximately 678.0k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.