


![]()
![]()
![]()
![]()

``` Reading package lists... Done Building dependency tree Reading state information... Done build-essential is already the newest version (12.8ubuntu1.1). 0 upgraded, 0 newly installed, 0 to remove and 94 not upgraded. Reading package lists... Done Building dependency tree Reading state information... Done libboost-program-options-dev is already the newest version (1.71.0.0ubuntu2). 0 upgraded, 0 newly installed, 0 to remove and 94 not upgraded. Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: cmake-data libarchive13 libicu66 libjsoncpp1 librhash0 libuv1 libxml2 tzdata Suggested packages: cmake-doc ninja-build lrzip The following NEW packages will be installed: cmake cmake-data libarchive13 libicu66 libjsoncpp1 librhash0 libuv1 libxml2 tzdata 0 upgraded, 9 newly installed, 0 to remove and 94 not upgraded. Need to get 15.3 MB of archives. ... Setting up libuv1:amd64 (1.34.2-1ubuntu1.3) ... Setting up librhash0:amd64 (1.3.9-1) ... Setting up cmake-data (3.16.3-1ubuntu1.20.04.1) ... Setting up libjsoncpp1:amd64 (1.7.4-3.1ubuntu2) ... Setting up libicu66:amd64 (66.1-2ubuntu2.1) ... Setting up libxml2:amd64 (2.9.10+dfsg-5ubuntu0.20.04.6) ... Setting up libarchive13:amd64 (3.4.0-2ubuntu1.2) ... Setting up cmake (3.16.3-1ubuntu1.20.04.1) ... Processing triggers for libc-bin (2.31-0ubuntu9.9) ... -- The CUDA compiler identification is NVIDIA 11.8.89 -- The CXX compiler identification is GNU 9.4.0 -- Detecting CUDA compiler ABI info -- Detecting CUDA compiler ABI info - done -- Check for working CUDA compiler: /usr/local/cuda/bin/nvcc - skipped -- Detecting CUDA compile features -- Detecting CUDA compile features - done -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Check for working CXX compiler: /usr/bin/c++ - skipped -- Detecting CXX compile features -- Detecting CXX compile features - done -- Found Boost: /usr/lib/x86_64-linux-gnu/cmake/Boost-1.71.0/BoostConfig.cmake (found version "1.71.0") found components: program_options -- Configuring done -- Generating done -- Build files have been written to: /root/nvbandwidth [ 14%] Building CXX object CMakeFiles/nvbandwidth.dir/testcase.cpp.o [ 28%] Building CXX object CMakeFiles/nvbandwidth.dir/testcases_ce.cpp.o [ 42%] Building CXX object CMakeFiles/nvbandwidth.dir/testcases_sm.cpp.o [ 57%] Building CUDA object CMakeFiles/nvbandwidth.dir/kernels.cu.o [ 71%] Building CXX object CMakeFiles/nvbandwidth.dir/memcpy.cpp.o [ 85%] Building CXX object CMakeFiles/nvbandwidth.dir/nvbandwidth.cpp.o [100%] Linking CXX executable nvbandwidth [100%] Built target nvbandwidth ```
``` nvbandwidth Version: v0.2 Built from Git version: 42e94d2 nvbandwidth CLI: -h [ --help ] Produce help message --bufferSize arg (=64) Memcpy buffer size in MiB --loopCount arg (=16) Iterations of memcpy to be performed -l [ --list ] List available testcases -t [ --testcase ] arg Testcase(s) to run (by name or index) -v [ --verbose ] Verbose output(详细输出) -d [ --disableAffinity ] Disable automatic CPU affinity control ```
```python class BertEncoder(nn.Module): def __init__(self, config): super().__init__() self.config = config self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)]) self.gradient_checkpointing = False def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.FloatTensor] = None, head_mask: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.FloatTensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = False, output_hidden_states: Optional[bool] = False, return_dict: Optional[bool] = True, ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]: all_hidden_states = () if output_hidden_states else None all_self_attentions = () if output_attentions else None all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None if self.gradient_checkpointing and self.training: if use_cache: logger.warning_once( "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..." ) use_cache = False next_decoder_cache = () if use_cache else None for i, layer_module in enumerate(self.layer): if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) layer_head_mask = head_mask[i] if head_mask is not None else None past_key_value = past_key_values[i] if past_key_values is not None else None if self.gradient_checkpointing and self.training: def create_custom_forward(module): def custom_forward(*inputs): return module(*inputs, past_key_value, output_attentions) return custom_forward layer_outputs = torch.utils.checkpoint.checkpoint( create_custom_forward(layer_module), hidden_states, attention_mask, layer_head_mask, encoder_hidden_states, encoder_attention_mask, ) else: layer_outputs = layer_module( hidden_states, attention_mask, layer_head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions, ) hidden_states = layer_outputs[0] if use_cache: next_decoder_cache += (layer_outputs[-1],) if output_attentions: all_self_attentions = all_self_attentions + (layer_outputs[1],) if self.config.add_cross_attention: all_cross_attentions = all_cross_attentions + (layer_outputs[2],) if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) if not return_dict: return tuple( v for v in [ hidden_states, next_decoder_cache, all_hidden_states, all_self_attentions, all_cross_attentions, ] if v is not None ) return BaseModelOutputWithPastAndCrossAttentions( last_hidden_state=hidden_states, past_key_values=next_decoder_cache, hidden_states=all_hidden_states, attentions=all_self_attentions, cross_attentions=all_cross_attentions, ) ```
```python class BertModel(BertPreTrainedModel): """ The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of cross-attention is added between the self-attention layers, following the architecture described in [Attention is all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and `add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass. """ def __init__(self, config, add_pooling_layer=True): super().__init__(config) self.config = config self.embeddings = BertEmbeddings(config) self.encoder = BertEncoder(config) self.pooler = BertPooler(config) if add_pooling_layer else None # Initialize weights and apply final processing self.post_init() def get_input_embeddings(self): return self.embeddings.word_embeddings def set_input_embeddings(self, value): self.embeddings.word_embeddings = value def _prune_heads(self, heads_to_prune): """ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base class PreTrainedModel """ for layer, heads in heads_to_prune.items(): self.encoder.layer[layer].attention.prune_heads(heads) @add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length")) @add_code_sample_docstrings( checkpoint=_CHECKPOINT_FOR_DOC, output_type=BaseModelOutputWithPoolingAndCrossAttentions, config_class=_CONFIG_FOR_DOC, ) def forward( self, input_ids: Optional[torch.Tensor] = None, attention_mask: Optional[torch.Tensor] = None, token_type_ids: Optional[torch.Tensor] = None, position_ids: Optional[torch.Tensor] = None, head_mask: Optional[torch.Tensor] = None, inputs_embeds: Optional[torch.Tensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.Tensor] = None, past_key_values: Optional[List[torch.FloatTensor]] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]: r""" encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if the model is configured as a decoder. encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*): Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`: - 1 for tokens that are **not masked**, - 0 for tokens that are **masked**. past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`): Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding. If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`. use_cache (`bool`, *optional*): If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see `past_key_values`). """ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions output_hidden_states = ( output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states ) return_dict = return_dict if return_dict is not None else self.config.use_return_dict if self.config.is_decoder: use_cache = use_cache if use_cache is not None else self.config.use_cache else: use_cache = False if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") elif input_ids is not None: self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask) input_shape = input_ids.size() elif inputs_embeds is not None: input_shape = inputs_embeds.size()[:-1] else: raise ValueError("You have to specify either input_ids or inputs_embeds") batch_size, seq_length = input_shape device = input_ids.device if input_ids is not None else inputs_embeds.device # past_key_values_length past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0 if attention_mask is None: attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device) if token_type_ids is None: if hasattr(self.embeddings, "token_type_ids"): buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length] buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length) token_type_ids = buffered_token_type_ids_expanded else: token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device) # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length] # ourselves in which case we just need to make it broadcastable to all heads. extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape) # If a 2D or 3D attention mask is provided for the cross-attention # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length] if self.config.is_decoder and encoder_hidden_states is not None: encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size() encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length) if encoder_attention_mask is None: encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device) encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask) else: encoder_extended_attention_mask = None # Prepare head mask if needed # 1.0 in head_mask indicate we keep the head # attention_probs has shape bsz x n_heads x N x N # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads] # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length] head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers) embedding_output = self.embeddings( input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds, past_key_values_length=past_key_values_length, ) encoder_outputs = self.encoder( embedding_output, attention_mask=extended_attention_mask, head_mask=head_mask, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_extended_attention_mask, past_key_values=past_key_values, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) sequence_output = encoder_outputs[0] pooled_output = self.pooler(sequence_output) if self.pooler is not None else None if not return_dict: return (sequence_output, pooled_output) + encoder_outputs[1:] return BaseModelOutputWithPoolingAndCrossAttentions( last_hidden_state=sequence_output, pooler_output=pooled_output, past_key_values=encoder_outputs.past_key_values, hidden_states=encoder_outputs.hidden_states, attentions=encoder_outputs.attentions, cross_attentions=encoder_outputs.cross_attentions, ) ```
```python class GLMBlock(torch.nn.Module): def __init__( self, hidden_size, num_attention_heads, layernorm_epsilon, layer_id, inner_hidden_size=None, hidden_size_per_attention_head=None, layernorm=LayerNorm, use_bias=True, params_dtype=torch.float, num_layers=28, position_encoding_2d=True, empty_init=True ): super(GLMBlock, self).__init__() # Set output layer initialization if not provided. self.layer_id = layer_id # Transformer 层 ID # Layernorm on the input data. self.input_layernorm = layernorm(hidden_size, eps=layernorm_epsilon) self.position_encoding_2d = position_encoding_2d # Self attention. self.attention = SelfAttention( hidden_size, num_attention_heads, layer_id, hidden_size_per_attention_head=hidden_size_per_attention_head, bias=use_bias, params_dtype=params_dtype, position_encoding_2d=self.position_encoding_2d, empty_init=empty_init ) # Layernorm on the input data. self.post_attention_layernorm = layernorm(hidden_size, eps=layernorm_epsilon) self.num_layers = num_layers # GLU self.mlp = GLU( hidden_size, inner_hidden_size=inner_hidden_size, bias=use_bias, layer_id=layer_id, params_dtype=params_dtype, empty_init=empty_init ) def forward( self, hidden_states: torch.Tensor, position_ids, attention_mask: torch.Tensor, layer_id, layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, use_cache: bool = False, output_attentions: bool = False, ): """ hidden_states: [seq_len, batch, hidden_size] attention_mask: [(1, 1), seq_len, seq_len] """ # Layer norm at the begining of the transformer layer. # [seq_len, batch, hidden_size] attention_input = self.input_layernorm(hidden_states) # Self attention. attention_outputs = self.attention( attention_input, position_ids, attention_mask=attention_mask, layer_id=layer_id, layer_past=layer_past, use_cache=use_cache, output_attentions=output_attentions ) attention_output = attention_outputs[0] outputs = attention_outputs[1:] # Residual connection. alpha = (2 * self.num_layers) ** 0.5 hidden_states = attention_input * alpha + attention_output mlp_input = self.post_attention_layernorm(hidden_states) # MLP. mlp_output = self.mlp(mlp_input) # Second residual connection. output = mlp_input * alpha + mlp_output if use_cache: outputs = (output,) + outputs else: outputs = (output,) + outputs[1:] return outputs # hidden_states, present, attentions ```

EvalScope 整体架构图.
| 语言 | 知识 | 推理 | 考试 |
字词释义- WiC - SummEdits成语习语- CHID语义相似度- AFQMC - BUSTM指代消解- CLUEWSC - WSC - WinoGrande翻译- Flores - IWSLT2017多语种问答- TyDi-QA - XCOPA多语种总结- XLSum |
知识问答- BoolQ - CommonSenseQA - NaturalQuestions - TriviaQA |
文本蕴含- CMNLI - OCNLI - OCNLI_FC - AX-b - AX-g - CB - RTE - ANLI常识推理- StoryCloze - COPA - ReCoRD - HellaSwag - PIQA - SIQA数学推理- MATH - GSM8K定理应用- TheoremQA - StrategyQA - SciBench综合推理- BBH |
初中/高中/大学/职业考试- C-Eval - AGIEval - MMLU - GAOKAO-Bench - CMMLU - ARC - Xiezhi医学考试- CMB |
| 理解 | 长文本 | 安全 | 代码 |
阅读理解- C3 - CMRC - DRCD - MultiRC - RACE - DROP - OpenBookQA - SQuAD2.0内容总结- CSL - LCSTS - XSum - SummScreen内容分析- EPRSTMT - LAMBADA - TNEWS |
长文本理解- LEval - LongBench - GovReports - NarrativeQA - Qasper |
安全- CivilComments - CrowsPairs - CValues - JigsawMultilingual - TruthfulQA健壮性- AdvGLUE |
代码- HumanEval - HumanEvalX - MBPP - APPs - DS1000 |
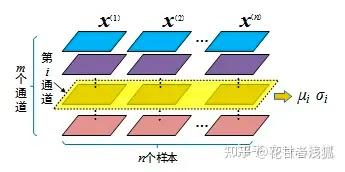 i.transformer为什么要用三个不一样的QKV?
前面提到过,是为了增强网络的容量和表达能力。更极端点,如果完全不要project_q/k/v,就是输入x本身来做,当然可以,但是表征能力太弱了(x的参数更新得至少会很拧巴)
j.为什么要多头?
举例说明多头相比单头注意力的优势和上一问一样,进一步增强网络的容量和表达能力。你可以类比CV中的不同的channel(不同卷积核)会关注不同的信息,事实上不同的头也会关注不同的信息。
================================================
FILE: llm-interview/comprehensive.md
================================================
- 解决显存不足的方法有哪些?
训练:
推理:
-
================================================
FILE: llm-interview/llm-algo.md
================================================
> Transformers 结构中 Encoder-only,Decoder-only,Encoder-Decoder 划分的具体标准是什么?典型代表模型有哪些?
> BatchNorm与LayerNorm的异同
https://zhuanlan.zhihu.com/p/428620330
代码:
https://zhuanlan.zhihu.com/p/656647661
https://www.zhihu.com/question/395811291/answer/1251829041
选择什么样的归一化方式,取决于你关注数据的哪部分信息。如果某个维度信息的差异性很重要,需要被拟合,那就别在那个维度进行归一化。
关联性 --- 差异性
CV 里面 不同样本的同一channel有关联性, 同一样本的不同channel是有差异性的(没有关联性)
CV 里面 不同样本的同一特性没有关联性(有差异性),同一样本的不同特征有关联性
https://zhuanlan.zhihu.com/p/643560888
> 为什么像 baichuan2 和 llama 使用 RMSNorm 归一化?
RMS是LayerNorm的平替,发表在“Root Mean Square Layer Normalization ”,其提出的动机是LayerNorm运算量比较大,所提出的RMSNorm性能和LayerNorm相当,但是可以节省7%到64%的运算。RMSNorm和LayerNorm的主要区别在于RMSNorm不需要同时计算均值和方差两个统计量,而只需要计算均方根Root Mean Square这一个统计量。
- https://zhuanlan.zhihu.com/p/694909672
> Post-Norm vs. Pre-Norm
同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。Pre Norm更容易训练好理解,因为它的恒等路径更突出.
post-norm和pre-norm其实各有优势,post-norm在残差之后做归一化,对参数正则化的效果更强,进而模型的鲁棒性也会更好;
pre-norm相对于post-norm,因为有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失,因此,这里笔者可以得出的一个结论是如果层数少post-norm的效果其实要好一些,如果要把层数加大,为了保证模型的训练,pre-norm显然更好一些。
================================================
FILE: llm-interview/llm-app.md
================================================
================================================
FILE: llm-interview/llm-compress.md
================================================
## 量化
### 常见的大模型量化方法有哪些?
## 剪枝
## 蒸馏
================================================
FILE: llm-interview/llm-eval.md
================================================
> 如何评测生成,改写等开放性任务?
指导思想,开放性任务的写作能力这类任务本身就很主观,我们不太方便用Rouge或者BLEU这样的评价指标,因为它本身就不能体现模型的核心能力,而且与人类基准就是不对齐的(偏离实际需求)。
从更贴近实际需求的角度来说,Elo的方式还是最合理的;
或者如果你的模型的核心业务就是生成/改写/总结,那你本身就应该有一套业务逻辑的评价指标来评测你的模型——以你的业务需求为导向。
================================================
FILE: llm-interview/llm-ft.md
================================================
## 微调
> 介绍下 LoRA、AdaLoRA、QLoRA 这几种高效微调方法及其特点
> 在LoRA中,A和B低秩矩阵的初始化方法,对A采用高斯初始化,对B采用零矩阵初始化,目的是让训练刚开始时BA的值为0,这样不会给模型带来额外的噪声。那么,对A做零矩阵初始化,对B做高斯初始化行不行呢?反正看起来只要让初始化为0就行?
当前作者还没有发现转换初始化方式产生的显著区别,只要这两者中任意一者为0,另一者不为0即可。
参考:https://github.com/microsoft/LoRA/issues/98
> 介绍下 Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2 这四种高效微调方法的区别与联系?
1. Prompt Tuning和P-Tuning都是只在Embbedding层加入虚拟Token。而 Prefix Tuning、P-Tuning v2 会在每一层都加入虚拟Token,从而引入了更多的可训练参数;通过加入到更深层结构中的Prompt,能给模型预测带来更直接的影响。
2. P-Tuning通过 LSTM + MLP 去编码这些virtual token,再输入到模型,可以让模型收敛更快。
3. Prefix Tuning 为了防止直接更新 Prefix 的参数(virtual token)导致训练不稳定和性能下降的情况,在Prefix层前面加了MLP结构,训练完成后,只保留Prefix的参数。
================================================
FILE: llm-interview/llm-inference.md
================================================
常见LLM推理服务性能评估指标
https://zhuanlan.zhihu.com/p/704649189
- 首Token生成时间(Time To First Token,简称TTFT):即用户输入提示后,模型生成第一个输出词元(Token)所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。此指标受处理提示信息并生成首个输出词元所需的时间所驱动。通常,不仅对平均TTFT感兴趣,还包括其分布,如P50、P90、P95和P99等。
- 单个输出Token的生成时间(Time Per Output Token,简称TPOT):即为每个用户的查询生成一个输出词元所需的时间。这一指标与每个用户对模型“速度”的感知相关。例如,TPOT为100毫秒/词元表示每个用户每秒可处理10个词元,或者每分钟处理约450个词元,那么这一速度远超普通人的阅读速度。
- 端到端时延:模型为用户生成完整响应所需的总时间。整体响应时延可使用前两个指标计算得出:时延 = (TTFT)+ (TPOT)*(待生成的词元数)。
- 每分钟完成的请求数:通常情况下,我们都希望系统能够处理并发请求。可能是因为你正在处理来自多个用户的输入或者可能有一个批量推理任务。
单个请求的成本:API 提供商通常会权衡其他指标(如:时延)以换取成本。例如,可以通过在更多GPU上运行相同的模型或使用更高端的GPU来降低时延。
- 最大利用率下每百万Token的成本:比较不同配置的成本(例如,可以在1个A800-80G GPU、1个H800-80G GPU或1个A100-40GB GPU上提供Llama 2-7B模型等),估算给定输出的部署总成本也十分重要。
- 预加载时间:预加载时间只能通过对输入提示的首次oken的生成来间接估算。一些研究发现在250个输入词元和800个输入词元之间,输入词元与TTFT之间似乎并不存在明显的关系,且由于其他原因,它被TTFT中的随机噪声掩盖。通常情况下,输入词元对端到端时延的影响约为输出词元的1%。
- 生成Token吞吐量:推理服务在所有用户请求中每秒可生成的输出词元(Token)数。考虑到无法测量预加载时间,并且总推理时延所花时间更多地取决于生成的Token数量,而不是输入的Token数量,因此,将注意力集中在输出Token上通常是正确的抉择。
- 总吞吐量:包括输入的Token和生成的Token。
对于一些场景,需要考虑端到端推理延迟作为目标,需要注意如下几点:
- 输出Token长度决定总体响应延迟:对于总体平均时延,您通常只需将预期最大输出token长度乘以模型每个输出token的总体平均时延即可。
- 输入长度对端到端推理性能并不重要,但对硬件要求很重要:一些研究表明在 MPT 模型中, 512 个输入token增加的延迟小于生成 8 个额外输出Token的延迟。但支持长输入的需求可能会使模型更难以服务。通常建议使用 A100-80GB(或更新版本)来服务 MPT-7B,其最大上下文长度为 2048 个Token。我在 MindIE Service 上,使用羊驼中文数据集,针对百川和千问大模型做了一个简单测试,发现100Token以内,随着输入Token长度的增加,并没有显著增加首Token的时延,如下图所示。
- 端到端推理延迟与模型大小呈次线性关系:在相同的硬件上,较大的模型推理速度较慢,但推理速度比不一定与模型参数量比匹配。例如:MPT-30B 延迟约为 MPT-7B 延迟的 2.5 倍。Llama2-70B 延迟约为 Llama2-13B 延迟的 2 倍。
================================================
FILE: llm-interview/llm-rlhf.md
================================================
## RLHF
> RLHF 完整训练过程是什么?RL建模过程中涉及到几个模型?
> RLHF 过程中RM随着训练过程的进行,得分越来越高,效果就一定好吗?
>
================================================
FILE: llm-interview/llm-train.md
================================================
> 模型训练通常关注的性能指标有哪些?
在模型训练过程中,通常关注的性能指标如下:
| 指标名称 | 单位 | 指标含义 |
| :---- | :----------------- | ----- |
| 吞吐率 | samples/s、tokens/s | 单位时间(例如1s)内处理的Token数/训练样本数 |
| 单步时间 | s | 执行一个step所花费的时间 |
| 线性度、加速比 | values | 单卡训练扩展到多卡,单机拓展到集群的效率度量指标 |
| 内存占用 | 百分比 | - |
| 带宽占比 | 百分比 | - |
| 训练效率 | tokens/day | - |
| 浮点运算 | TFLOPS | 每秒浮点运算次数,是计算设备的计算性能指标 |
| 模型算力利用率(Model FLOPs Utilization, MFU)| 百分比 | 模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
| 硬件算力利用率(Hardware FLOPs Utilization, HFU)| 百分比 | 考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
在计算性能指标时,通常的优先级排序为:**吞吐率 > 单步迭代时间 > 线性度 > 内存占用 > 带宽占用 > 训练效率 > 浮点计算次数每秒 > 算力利用率**。
> 混合精度训练使用半精度训练的优缺点
半精度训练优点:跑得快+省显存
半精度训练缺点:精度(下溢+舍入误差)的问题。
使用了半精度训练,一般会采用一些捆绑的技术来弥补半精度的缺点。
- FP32 权重备份:对权重备份一份float32版本的版本,在梯度更新的时候避免float16精度不够而发生舍入误差导致的无效梯度更新,但是这样会占用额外的权重的内存,不过这些显存在一些情况下并不致命也就是了。
- loss scale:由于下溢的问题,也就是训练后期,梯度会很小,float16 容易产生 underflow,所以可以对loss做scale操作,毕竟loss的scale也会作用在梯度上(链式法则),这样一个大的scale比每个梯度都scale下要划算很多。
layer norm的层可能会完全使用float32,因为需要计算一组值的均值和方差,而这需要进行加法和除法运算,所以float16可能会出岔子。
> 使用bf16和fp16进行半精度训练的优缺点
## DeepSpeed
> DeepSpeed的特点是什么?各个 ZeRO Stage 都有什么用?
> 流水线并行能与DeepSpeed ZeRO 2/3一起训练吗?
https://www.zhihu.com/question/652836990/answer/3468210626
PP + ZeRO 2/3 不推荐一起训练。 PP需要累积梯度(accumulate gradients),但 ZeRO2 需要对梯度进行分块(chunk)。 即使能够实现,也没有真正的性能提升。
将两者结合使用来提高效率并不容易,PP + ZeRO 2 实际上比 ZeRO2(无 PP)更慢且内存效率低。如果用户内存不足,用户可以使用 ZeRO3 代替 ZeRO2 + PP。而正因为如此,在 DeepSpeed 中, PP + ZeRO 2/3 之间不兼容。使用将 PP + ZeRO 1 进行组合使用。
即使该方法效率不高,但是 ColossalAI 为了支持更多的并行训练方法。ColossalAI 还是提供了 ZeRO 3 + PP + TP 一起组合的方案。
参考:
- https://github.com/microsoft/DeepSpeed/issues/1110
- https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/runtime/pipe/engine.py#L71
- https://github.com/hpcaitech/ColossalAI/issues/682
- https://github.com/hpcaitech/ColossalAI/pull/477
---
## PyTorch
================================================
FILE: llm-localization/README.md
================================================
# 大模型国产化适配
## 昇腾
- [大模型国产化适配-华为昇腾AI全栈软硬件平台总结](https://github.com/liguodongiot/llm-action/blob/main/docs/llm_localization/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%9B%BD%E4%BA%A7%E5%8C%96%E9%80%82%E9%85%8D-%E5%8D%8E%E4%B8%BA%E6%98%87%E8%85%BEAI%E5%85%A8%E6%A0%88%E8%BD%AF%E7%A1%AC%E4%BB%B6%E5%B9%B3%E5%8F%B0%E6%80%BB%E7%BB%93.md)
- https://gitee.com/ascend/ModelLink
- 昇腾Ascend处理器相关介绍:https://huahuaboy.blog.csdn.net/article/details/127171363
- AI芯片:华为Ascend(昇腾)910结构分析:https://blog.csdn.net/evolone/article/details/100061616
## 海光
## 寒武纪
================================================
FILE: llm-localization/ascend/FAQ.md
================================================
docker: Error response from daemon: failed to create shim task: OCI runtime create failed: unable to retrieve OCI runtime error (open /var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/579418211a825ef5c7fcf5becdbe90804f0ed7862d9c59663995f9dd463937b4/log.json: no such file or directory): /usr/local/Ascend/Ascend-Docker-Runtime/ascend-docker-runtime did not terminate successfully: exit status 1: 2024/07/24 09:59:29 owner not right /usr/bin/runc 1000
错误信息表明/usr/bin/runc这个文件的所有权不正确,即它不是由root用户拥有或者它的所属用户不是1000。Docker在创建并运行容器时需要runc这个二进制文件,如果权限设置不当,Docker将无法正确执行。
解决办法:
查看权限
ls -lah /usr/bin/runc
修改权限
sudo chown root:root /usr/bin/runc
================================================
FILE: llm-localization/ascend/README.md
================================================
## 镜像地址
https://quay.io/repository/ascend/cann?tab=tags
## pytorch
- https://gitee.com/ascend/pytorch
- https://gitee.com/ascend/transformers#fqa
- https://gitee.com/ascend/AscendSpeed
- https://gitee.com/ascend/AscendSpeed2
- https://gitee.com/ascend/DeepSpeed
- https://gitee.com/ascend/Megatron-LM
## mindspore
https://gitee.com/mindspore/mindspore
https://gitee.com/mindspore/mindformers
https://www.mindspore.cn/versions#2.2.10
```
cd /tmp
curl -O https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py37_4.10.3-Linux-$(arch).sh
bash Miniconda3-py37_4.10.3-Linux-$(arch).sh -b
cd -
. ~/miniconda3/etc/profile.d/conda.sh
conda init bash
```
```
conda create -n mindspore_py37 python=3.7.5 -y
conda activate mindspore_py37
```
```
CentOS 7可以使用以下命令安装。
sudo yum install centos-release-scl
sudo yum install devtoolset-7
安装完成后,需要使用如下命令切换到GCC 7。
scl enable devtoolset-7 bash
```
### 推理
https://www.mindspore.cn/lite/docs/zh-CN/r2.2/quick_start/one_hour_introduction_cloud.html
export LITE_HOME=$some_path/mindpsore-lite-2.0.0-linux-x64
export LD_LIBRARY_PATH=$LITE_HOME/runtime/lib:$LITE_HOME/runtime/third_party/dnnl:$LITE_HOME/tools/converter/lib:$LD_LIBRARY_PATH
export PATH=$LITE_HOME/tools/converter/converter:$LITE_HOME/tools/benchmark:$PATH
## MindIE 日志
https://www.hiascend.com/document/detail/zh/mindie/21RC2/ref/logreference/mindie_log_0210.html
================================================
FILE: llm-localization/ascend/ascend-c/README.md
================================================
算子API:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha001/quickstart/quickstart/quickstart_18_0001.html
---
192.168.137.101
255.255.255.0
连接开发板:
- ssh root@192.168.137.100
- Mind@123
---
cd /home/HwHiAiUser/samples/samples/operator/AddCustomSample/FrameworkLaunch/AddCustom
bash build.sh
cd build_out
./custom_opp_ubuntu_aarch64.run
cd /home/HwHiAiUser/samples/samples/operator/AddCustomSample/FrameworkLaunch/AclNNInvocation
bash run.sh
================================================
FILE: llm-localization/ascend/ascend-infra/HCCL.md
================================================
- https://www.hiascend.com/document/detail/zh/canncommercial/80RC1/apiref/hcclapiref/hcclapi_07_0001.html
HCCL提供了Python与C++两种语言的接口,其中Python语言的接口用于实现TensorFlow网络在昇腾AI处理器执行分布式优化;C++语言接口用于实现OPBase模式下的框架适配,实现分布式能力,例如HCCL单算子API嵌入到PyTorch后端代码中,PyTorch用户直接使用PyTorch原生集合通信API,即可实现分布式能力。
================================================
FILE: llm-localization/ascend/ascend-infra/MacOS环境.md
================================================
```
conda create -n mindspore-venv python=3.8 -y
conda activate mindspore-venv
pip install torch transformers
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.14/MindSpore/cpu/aarch64/mindspore-2.2.14-cp38-cp38-macosx_11_0_arm64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-dmi.md
================================================
# Ascend-DMI
主要为Atlas产品的标卡、板卡及模组类产品提供带宽测试、算力测试、功耗测试等功能。
本系统通过调用底层DCMI(设备控制管理接口)/DSMI(设备系统管理接口)以及ACL(Ascend Computing Language,昇腾计算语言)相关接口完成相关检测功能,对于系统级别的信息查询通过调用系统提供的通用库来实现,用户使用工具时通过配置参数来实现不同的测试功能。
参考:https://www.hiascend.com/document/detail/zh/canncommercial/321/othertools/ascenddmi/ascenddmi_000002.html
## 带宽测试
## 算力测试
## 功耗测试
## 设备实时状态查询
## 故障诊断
## 软硬件版本兼容性测试
## 设备拓扑检测
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-docker-runtime.md
================================================
昇腾docker runtime仓库,在docker容器场景下,使用昇腾NPU,提供更简单的设备和依赖路径挂载方法。
https://gitee.com/ascend/ascend-docker-runtime
安装:https://www.hiascend.com/document/detail/zh/mindx-dl/300/dluserguide/clusterscheduling/dlug_installation_02_000025.html
Ascend Docker Runtime组件参考信息说明:
https://www.hiascend.com/document/detail/zh/mindx-dl/300/dluserguide/clusterscheduling/dlug_installation_02_000036.html
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-docker.md
================================================
```
docker login -u 15708484031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.RC2-centos7
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-llm下载.md
================================================
```
https://hf-mirror.com/
yum install python3-pip
virtualenv -p python3 venv-py3
source /home/aicc/venv-py3/bin/activate
pip3 install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --token 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 --resume-download Baichuan2-7B-Base --local-dir Baichuan2-7B-Base
huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-7B-Chat --local-dir Baichuan2-7B-Chat --local-dir-use-symlinks False
nohup huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-7B-Chat --local-dir Baichuan2-7B-Chat --local-dir-use-symlinks False > Baichuan2.log 2>&1 &
nohup huggingface-cli download --token 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 --resume-download THUDM/chatglm3-6b --local-dir chatglm3-6b-chat --local-dir-use-symlinks False > chatglm3.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen-72B-Chat --local-dir Qwen-72B-Chat --local-dir-use-symlinks False > qwen-72b.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen-72B-Chat --local-dir Qwen-72B-Chat --local-dir-use-symlinks False > qwen-72b.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-14B-Chat --local-dir Qwen1.5-14B-Chat --local-dir-use-symlinks False > Qwen1.5-14B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-7B-Chat --local-dir Qwen1.5-7B-Chat --local-dir-use-symlinks False > Qwen1.5-7B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-72B-Chat --local-dir Qwen1.5-72B-Chat --local-dir-use-symlinks False > Qwen1.5-72B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-13B-Chat --local-dir Baichuan2-13B-Chat --local-dir-use-symlinks False > Baichuan2-13B-Chat.log 2>&1 &
```
```
cd /home/aicc
mkdir -p ./model_from_hf/Baichuan2-7B-Chat/
cd ./model_from_hf/Baichuan2-7B-Chat/
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/configuration_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/generation_utils.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/modeling_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00001-of-00002.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00002-of-00002.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model.bin.index.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/quantizer.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/special_tokens_map.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenization_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer.model
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer_config.json
cd ../../
```
```
cd /home/aicc
mkdir -p ./model_from_hf/Baichuan2-7B-Chat/
cd ./model_from_hf/Baichuan2-7B-Chat/
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/configuration_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/generation_config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/generation_utils.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/modeling_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/pytorch_model.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/quantizer.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/special_tokens_map.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenization_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenizer.model
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenizer_config.json
cd ../../
```
## 拷贝模型
```
rsync -P --rsh=ssh -r root@192.xxx.16.210:/home/model_from_hf/Qwen1.5-72B/ ./
scp -r root@192.xxx.16.210:/home/model_from_hf/Qwen1.5-72B/ ./
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-npu-smi.md
================================================
- https://support.huawei.com/enterprise/zh/doc/EDOC1100288566/e39bbfe6
```
npu-smi info -t device-share -i 1
```
## GPU/Memory 使用率
```
npu-smi info -t common -i 1
NPU ID : 1
Chip Count : 1
Chip ID : 0
Memory Usage Rate(%) : 0
HBM Usage Rate(%) : 91
Aicore Usage Rate(%) : 6
Aicore Freq(MHZ) : 1800
Aicore curFreq(MHZ) : 1800
Aicore Count : 20
Temperature(C) : 46
NPU Real-time Power(W) : 130.4
Chip Name : mcu
Temperature(C) : 40
npu-smi info -t common -i 7
NPU ID : 7
Chip Count : 1
Chip ID : 0
Memory Usage Rate(%) : 0
HBM Usage Rate(%) : 82
Aicore Usage Rate(%) : 70
Aicore Freq(MHZ) : 1800
Aicore curFreq(MHZ) : 1800
Aicore Count : 20
Temperature(C) : 66
NPU Real-time Power(W) : 331.1
Chip Name : mcu
Temperature(C) : 58
```
## 查询设备1所有芯片的统计信息
```
npu-smi info -t usages -i 1
NPU ID : 1
Chip Count : 1
DDR Capacity(MB) : 15079
DDR Usage Rate(%) : 14
DDR Hugepages Total(page) : 0
DDR Hugepages Usage Rate(%) : 0
HBM Capacity(MB) : 32768
HBM Usage Rate(%) : 0
Aicore Usage Rate(%) : 0
Aicpu Usage Rate(%) : 0
Ctrlcpu Usage Rate(%) : 0
DDR Bandwidth Usage Rate(%) : 0
HBM Bandwidth Usage Rate(%) : 0
Chip ID : 0
```
## 查看和修改网卡配置
```
hccn_tool -i 3 -status -g
Netdev status:Settings for eth3:
Supported ports: [ FIBRE ]
Supported link modes: 40000baseCR4/Full
40000baseSR4/Full
40000baseLR4/Full
25000baseCR/Full
25000baseSR/Full
50000baseCR2/Full
100000baseSR4/Full
100000baseCR4/Full
100000baseLR4_ER4/Full
50000baseSR2/Full
1000baseX/Full
10000baseCR/Full
10000baseSR/Full
10000baseLR/Full
50000baseLR_ER_FR/Full
200000baseSR4/Full
200000baseLR4_ER4_FR4/Full
200000baseCR4/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: No
Supported FEC modes: None RS
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: None RS
Speed: 200000Mb/s
Duplex: Full
Auto-negotiation: off
Port: Direct Attach Copper
PHYAD: 0
Transceiver: internal
Current message level: 0x00000036 (54)
probe link ifdown ifup
Link detected: yes
```
## 查看网卡的 IP 地址和路由
```
> hccn_tool -i 3 -ip -g
ipaddr:10.20.11.24
netmask:255.255.255.0
> hccn_tool -i 3 -route -g
Routing table:
Destination Gateway Genmask Flags Metric Ref Use Iface
10.20.11.0 * 255.255.255.0 U 0 0 0 eth3
127.0.0.1 * 255.255.255.255 UH 0 0 0 lo
192.168.1.0 * 255.255.255.0 U 0 0 0 end3v0
192.168.2.0 * 255.255.255.0 U 0 0 0 end3v0
```
RDMA 网卡的启动配置其实在配置文件
```
> cat /etc/hccn.conf # RDMA 网卡 0-7 的配置
address_0=10.20.11.11
netmask_0=255.255.255.0
address_1=10.20.11.12
netmask_1=255.255.255.0
address_2=10.20.11.13
netmask_2=255.255.255.0
address_3=10.20.11.14
netmask_3=255.255.255.0
address_4=10.20.11.15
netmask_4=255.255.255.0
address_5=10.20.11.16
netmask_5=255.255.255.0
address_6=10.20.11.17
netmask_6=255.255.255.0
address_7=10.20.11.18
netmask_7=255.255.255.0
```
## 查询所有芯片闪存信息
```
npu-smi info -t flash -i 0
NPU ID : 0
Chip Count : 1
Flash Count : 1
Flash ID : 1730504
Manufacturer ID : 0xC8
Capacity(MB) : 64
Chip ID : 0
```
## 查询设备1的所有芯片的内存信息。
```
npu-smi info -t memory -i 1
NPU ID : 1
Chip Count : 1
DDR Capacity(MB) : 0
DDR Clock Speed(MHz) : 0
HBM Capacity(MB) : 32768
HBM Clock Speed(MHz) : 1600
HBM Temperature(C) : 35
HBM Manufacturer ID : 0x57
Chip ID : 0
```
## RDMA ping
```
> hccn_tool -i 3 -ping -g address 10.20.11.16
device 3 PING 10.20.11.16
recv seq=0,time=0.137000ms
recv seq=1,time=0.046000ms
recv seq=2,time=0.058000ms
3 packets transmitted, 3 received, 0.00% packet loss
```
================================================
FILE: llm-localization/ascend/ascend-infra/docker环境升级cann.md
================================================
```
docker login -u 157xxx4031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A2-ubuntu18.04
```
```
https://www.hiascend.com/zh/software/cann/community-history
wget -c https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C18B800TP015/Ascend-cann-kernels-910b_8.0.RC2.alpha001_linux.run
wget -c https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C18B800TP015/Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run
```
```
docker stop pytorch_ubuntu_dev
docker rm -f pytorch_ubuntu_upgrade
docker run -it -u root \
--name pytorch_ubuntu_upgrade \
--network host \
--shm-size 4G \
-e ASCEND_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
-v /etc/localtime:/etc/localtime \
-v /var/log/npu/:/usr/slog \
-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \
-v /data/containerd/workspace/:/workspace \
ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A2-ubuntu18.04 \
/bin/bash
docker start pytorch_ubuntu_upgrade
docker exec -it pytorch_ubuntu_upgrade bash
```
```
cd /usr/local/Ascend/ascend-toolkit/7.0.0/aarch64-linux/script/
./uninstall.sh
chmod +x Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run
./Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run --check
./Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run --install
. /usr/local/Ascend/ascend-toolkit/set_env.sh
```
```
./Ascend-cann-kernels-910b_8.0.RC2.alpha001_linux.run --install --feature=aclnn_ops_train
```
```
. /usr/local/Ascend/ascend-toolkit/set_env.sh
```
```
bash Miniconda3-py39_24.4.0-0-Linux-aarch64.sh -p /workspace/installs/conda-upgrade
conda init
source ~/.bashrc
export PATH=/root/miniconda3/bin:$PATH
conda list
conda create -n llm-dev python=3.9
conda activate llm-dev
```
```
pip3 install torch==2.1.0
pip3 install pyyaml setuptools
pip3 install torch-npu==2.1.0.post3
pip3 install numpy attrs decorator psutil absl-py cloudpickle psutil scipy synr tornado
. /usr/local/Ascend/ascend-toolkit/set_env.sh
import torch
import torch_npu
x = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
z = x.mm(y)
print(z)
```
```
pip install --no-cache-dir -r requirements-npu.txt && rm -rf ~/.cache/pip/* && conda clean -all
```
```
docker start pytorch_ubuntu_upgrade
docker exec -it pytorch_ubuntu_upgrade bash
. /usr/local/Ascend/ascend-toolkit/set_env.sh
conda activate llm-dev
```
docker tag harbor.llm.io/base/llm-train-unify:v1-20240603 harbor.llm.io/base/llm-train-unify:v1-20240603
================================================
FILE: llm-localization/ascend/ascend-infra/network.md
================================================
## 集群网络
Atlas 900 AI集群采用“HCCS、 PCIe 4.0、100G以太”三类高速互联方式,百TB全互联无阻塞专属参数同步网络,降低网络时延,梯度同步时延缩短10~70%。
在AI服务器内部,昇腾910 AI处理器之间通过HCCS高速总线互联;昇腾910 AI处理器和CPU之间以最新的PCIe 4.0(速率16Gbps)技术互联,其速率是业界主流采用的PCIe 3.0(8.0Gbps)技术的两倍,使得数据传输更加快速和高效。在集群层面,采用面向数据中心的CloudEngine 8800系列交换机,提供单端口100Gbps的交换速率,将集群内的所有AI服务器接入高速交换网络。
独创iLossless 智能无损交换算法,对集群内的网络流量进行实时的学习训练,实现网络0丢包与E2E μs级时延。
## 系统级调优
Atlas 900 AI集群通过华为集合通信库和作业调度平台,整合HCCS、 PCIe 4.0 和100G RoCE三种高速接口,充分释放昇腾910 AI处理器的强大性能。
华为集合通信库提供训练网络所需的分布式并行库,通信库+网络拓扑+训练算法进行系统级调优,实现集群线性度>80%,极大提升了作业调度效率。
================================================
FILE: llm-localization/ascend/ascend-infra/npu监控.md
================================================
- AI模型运维——GPU性能监控NVML和DCGM
- https://www.cnblogs.com/maxgongzuo/p/12582286.html
dcgm exporter 监控GPU
NPU-Exporter 监控NPU
================================================
FILE: llm-localization/ascend/ascend-infra/操作系统.md
================================================
# Kylin
```
> cat /etc/os-release
NAME="Kylin Linux Advanced Server"
VERSION="V10 (Tercel)"
ID="kylin"
VERSION_ID="V10"
PRETTY_NAME="Kylin Linux Advanced Server V10 (Tercel)"
ANSI_COLOR="0;31"
```
```
> yum install dmidecode
> dmidecode -t system
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.
# SMBIOS implementations newer than version 3.2.0 are not
# fully supported by this version of dmidecode.
Handle 0x0001, DMI type 1, 27 bytes
System Information
Manufacturer: Huawei
Product Name: A800I A2
Version: To be filled by O.E.M.
Serial Number: 2102314VFG10Q1100025
UUID: a6202cac-b04f-8889-ee11-4ab078e0b272
Wake-up Type: Power Switch
SKU Number: To be filled by O.E.M.
Family: To be filled by O.E.M.
Handle 0x0005, DMI type 32, 11 bytes
System Boot Information
Status: No errors detected
```
# OpenEuler
- https://repo.openeuler.org/openEuler-24.03-LTS/OS/aarch64/Packages/
# Ubuntu
更换源
- https://blog.csdn.net/zwcslj/article/details/134322879
```
先备份旧的源
设置新的镜像源
vim /etc/apt/sources.list
更新软件包列表并升级已安装的软件包
apt-get update
apt-get upgrade
```
```
docker pull ubuntu:20.04
docker pull ubuntu:22.04
```
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾卡-soc版本.md
================================================
```
SOC版本:设备类型
100: "910PremiumA", 101: "910ProA", 102: "910A", 103: "910ProB", 104: "910B",
200: "310P1", 201: "310P2", 202: "310P3", 203: "310P4",
220: "910B1", 221: "910B2", 222: "910B3", 223: "910B4",
240: "310B1", 241: "310B2", 242: "310B3",
250: "910C1", 251: "910C2", 252: "910C3", 253: "910C4"
```
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾卡注意事项.md
================================================
--privileged 特权模型下,昇腾或者英伟达的 docker runtime 中会默认分配本机所有卡。
- ASCEND_VISIBLE_DEVICES 容器级控制卡
- ASCEND_RT_VISIBLE_DEVICES 进程级控制卡 类似于 CUDA_VISIBLE_DEVICES
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾镜像.md
================================================
## 镜像仓库
- https://ascendhub.huawei.com/#/index
- https://www.hiascend.com/developer/ascendhub/
- http://mirrors.cn-central-221.ovaijisuan.com/mirrors.html
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/dxy/pytorch2_1_0_kernels:PyTorch2.1.0-cann7.0.0.alpha003_py_3.9-euler_2.8.3-64GB
```
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/mindformers/mindformers1.3_mindspore2.4:20241114
```
## ascend-mindspore
A1支持A300T-9000、A800-9000、A800-9010和Atlas 300T Pro,A2支持Atlas 900 A2 PoD、Atlas 800T A2、Atlas 200T A2 Box16和Atlas 300T A2
```
# 910A
docker login -u 157xxxx4031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A1-centos7
docker pull --platform=arm64 ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A1-ubuntu18.04
```
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/mindformers/mindformers1.3_mindspore2.4:20241114
```
================================================
FILE: llm-localization/ascend/ascend-infra/服务器配置.md
================================================
最低配置:
```
Atlas 800 9000 A2
CPU:4 * 鲲鹏920 48核@2.6GHZ
GPU:8 * Ascend 910B4
内存:512G
硬盘:2 * 480G SSD,2 * 1.92 T PCIe SSD
```
推荐配置:
```
Atlas 800 9000 A2
CPU:4*鲲鹏920 48核@2.6GHZ
GPU:8 * Ascend 910B3
内存:1T
硬盘:2 * 960G SSD,2 * 3.84T PCIe SSD
```
================================================
FILE: llm-localization/ascend/ascend-infra/环境安装.md
================================================
## 安装Python-3.9.2
```
wget https://www.python.org/ftp/python/3.9.2/Python-3.9.2.tgz
tar -zxvf Python-3.9.2.tgz
cd Python-3.9.2
./configure --prefix=/usr/local/python3.9.2 --with-ssl-default-suites=openssl --enable-shared CFLAGS=-fPIC
make
sudo make install
#用于设置python3.9.2库文件路径
export LD_LIBRARY_PATH=/usr/local/python3.9.2/lib:$LD_LIBRARY_PATH
#如果用户环境存在多个python3版本,则指定使用python3.9.2版本
export PATH=/usr/local/python3.9.2/bin:$PATH
python3 --version
pip3 --version
```
##
================================================
FILE: llm-localization/ascend/ascend-infra/达芬奇架构.md
================================================
- 基本概念: https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha001/devguide/opdevg/ascendcopdevg/atlas_ascendc_10_0009.html
================================================
FILE: llm-localization/ascend/ascend910-env-install.md
================================================
## 查看操作系统
```
>cat /etc/os-release
PRETTY_NAME="Ubuntu 22.04.3 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.3 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy
> uname -a
Linux nodo-1 5.15.0-78-generic #85-Ubuntu SMP Fri Jul 7 15:29:30 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
```
## 查看服务器的型号信息
```
# yum install dmidecode
> apt-get install dmidecode
> dmidecode -t system
# dmidecode 3.3
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.
Handle 0x0001, DMI type 1, 27 bytes
System Information
Manufacturer: Huawei
Product Name: A800 9000 A2
Version: To be filled by O.E.M.
Serial Number: 2102314RHT10P81000xx
UUID: a61414fb-b04f-b618-ee11-c0441xx24b6d
Wake-up Type: Power Switch
SKU Number: To be filled by O.E.M.
Family: To be filled by O.E.M.
Handle 0x0005, DMI type 32, 11 bytes
System Boot Information
Status: No errors detected
- Atlas 900 RCK A2 Compute Node
- A800 9000 A2
```
以下操作如无特别说明,都是针对EulerOS系统。
## 安装驱动与固件
先安装驱动,再安装固件。
```
chmod +x Ascend-hdk-910-npu-driver_23.0.rc1_linux-aarch64.run
./Ascend-hdk-910-npu-driver_23.0.rc1_linux-aarch64.run --full --install-path=/usr/local/Ascend
```
i.transformer为什么要用三个不一样的QKV?
前面提到过,是为了增强网络的容量和表达能力。更极端点,如果完全不要project_q/k/v,就是输入x本身来做,当然可以,但是表征能力太弱了(x的参数更新得至少会很拧巴)
j.为什么要多头?
举例说明多头相比单头注意力的优势和上一问一样,进一步增强网络的容量和表达能力。你可以类比CV中的不同的channel(不同卷积核)会关注不同的信息,事实上不同的头也会关注不同的信息。
================================================
FILE: llm-interview/comprehensive.md
================================================
- 解决显存不足的方法有哪些?
训练:
推理:
-
================================================
FILE: llm-interview/llm-algo.md
================================================
> Transformers 结构中 Encoder-only,Decoder-only,Encoder-Decoder 划分的具体标准是什么?典型代表模型有哪些?
> BatchNorm与LayerNorm的异同
https://zhuanlan.zhihu.com/p/428620330
代码:
https://zhuanlan.zhihu.com/p/656647661
https://www.zhihu.com/question/395811291/answer/1251829041
选择什么样的归一化方式,取决于你关注数据的哪部分信息。如果某个维度信息的差异性很重要,需要被拟合,那就别在那个维度进行归一化。
关联性 --- 差异性
CV 里面 不同样本的同一channel有关联性, 同一样本的不同channel是有差异性的(没有关联性)
CV 里面 不同样本的同一特性没有关联性(有差异性),同一样本的不同特征有关联性
https://zhuanlan.zhihu.com/p/643560888
> 为什么像 baichuan2 和 llama 使用 RMSNorm 归一化?
RMS是LayerNorm的平替,发表在“Root Mean Square Layer Normalization ”,其提出的动机是LayerNorm运算量比较大,所提出的RMSNorm性能和LayerNorm相当,但是可以节省7%到64%的运算。RMSNorm和LayerNorm的主要区别在于RMSNorm不需要同时计算均值和方差两个统计量,而只需要计算均方根Root Mean Square这一个统计量。
- https://zhuanlan.zhihu.com/p/694909672
> Post-Norm vs. Pre-Norm
同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。Pre Norm更容易训练好理解,因为它的恒等路径更突出.
post-norm和pre-norm其实各有优势,post-norm在残差之后做归一化,对参数正则化的效果更强,进而模型的鲁棒性也会更好;
pre-norm相对于post-norm,因为有一部分参数直接加在了后面,不需要对这部分参数进行正则化,正好可以防止模型的梯度爆炸或者梯度消失,因此,这里笔者可以得出的一个结论是如果层数少post-norm的效果其实要好一些,如果要把层数加大,为了保证模型的训练,pre-norm显然更好一些。
================================================
FILE: llm-interview/llm-app.md
================================================
================================================
FILE: llm-interview/llm-compress.md
================================================
## 量化
### 常见的大模型量化方法有哪些?
## 剪枝
## 蒸馏
================================================
FILE: llm-interview/llm-eval.md
================================================
> 如何评测生成,改写等开放性任务?
指导思想,开放性任务的写作能力这类任务本身就很主观,我们不太方便用Rouge或者BLEU这样的评价指标,因为它本身就不能体现模型的核心能力,而且与人类基准就是不对齐的(偏离实际需求)。
从更贴近实际需求的角度来说,Elo的方式还是最合理的;
或者如果你的模型的核心业务就是生成/改写/总结,那你本身就应该有一套业务逻辑的评价指标来评测你的模型——以你的业务需求为导向。
================================================
FILE: llm-interview/llm-ft.md
================================================
## 微调
> 介绍下 LoRA、AdaLoRA、QLoRA 这几种高效微调方法及其特点
> 在LoRA中,A和B低秩矩阵的初始化方法,对A采用高斯初始化,对B采用零矩阵初始化,目的是让训练刚开始时BA的值为0,这样不会给模型带来额外的噪声。那么,对A做零矩阵初始化,对B做高斯初始化行不行呢?反正看起来只要让初始化为0就行?
当前作者还没有发现转换初始化方式产生的显著区别,只要这两者中任意一者为0,另一者不为0即可。
参考:https://github.com/microsoft/LoRA/issues/98
> 介绍下 Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2 这四种高效微调方法的区别与联系?
1. Prompt Tuning和P-Tuning都是只在Embbedding层加入虚拟Token。而 Prefix Tuning、P-Tuning v2 会在每一层都加入虚拟Token,从而引入了更多的可训练参数;通过加入到更深层结构中的Prompt,能给模型预测带来更直接的影响。
2. P-Tuning通过 LSTM + MLP 去编码这些virtual token,再输入到模型,可以让模型收敛更快。
3. Prefix Tuning 为了防止直接更新 Prefix 的参数(virtual token)导致训练不稳定和性能下降的情况,在Prefix层前面加了MLP结构,训练完成后,只保留Prefix的参数。
================================================
FILE: llm-interview/llm-inference.md
================================================
常见LLM推理服务性能评估指标
https://zhuanlan.zhihu.com/p/704649189
- 首Token生成时间(Time To First Token,简称TTFT):即用户输入提示后,模型生成第一个输出词元(Token)所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。此指标受处理提示信息并生成首个输出词元所需的时间所驱动。通常,不仅对平均TTFT感兴趣,还包括其分布,如P50、P90、P95和P99等。
- 单个输出Token的生成时间(Time Per Output Token,简称TPOT):即为每个用户的查询生成一个输出词元所需的时间。这一指标与每个用户对模型“速度”的感知相关。例如,TPOT为100毫秒/词元表示每个用户每秒可处理10个词元,或者每分钟处理约450个词元,那么这一速度远超普通人的阅读速度。
- 端到端时延:模型为用户生成完整响应所需的总时间。整体响应时延可使用前两个指标计算得出:时延 = (TTFT)+ (TPOT)*(待生成的词元数)。
- 每分钟完成的请求数:通常情况下,我们都希望系统能够处理并发请求。可能是因为你正在处理来自多个用户的输入或者可能有一个批量推理任务。
单个请求的成本:API 提供商通常会权衡其他指标(如:时延)以换取成本。例如,可以通过在更多GPU上运行相同的模型或使用更高端的GPU来降低时延。
- 最大利用率下每百万Token的成本:比较不同配置的成本(例如,可以在1个A800-80G GPU、1个H800-80G GPU或1个A100-40GB GPU上提供Llama 2-7B模型等),估算给定输出的部署总成本也十分重要。
- 预加载时间:预加载时间只能通过对输入提示的首次oken的生成来间接估算。一些研究发现在250个输入词元和800个输入词元之间,输入词元与TTFT之间似乎并不存在明显的关系,且由于其他原因,它被TTFT中的随机噪声掩盖。通常情况下,输入词元对端到端时延的影响约为输出词元的1%。
- 生成Token吞吐量:推理服务在所有用户请求中每秒可生成的输出词元(Token)数。考虑到无法测量预加载时间,并且总推理时延所花时间更多地取决于生成的Token数量,而不是输入的Token数量,因此,将注意力集中在输出Token上通常是正确的抉择。
- 总吞吐量:包括输入的Token和生成的Token。
对于一些场景,需要考虑端到端推理延迟作为目标,需要注意如下几点:
- 输出Token长度决定总体响应延迟:对于总体平均时延,您通常只需将预期最大输出token长度乘以模型每个输出token的总体平均时延即可。
- 输入长度对端到端推理性能并不重要,但对硬件要求很重要:一些研究表明在 MPT 模型中, 512 个输入token增加的延迟小于生成 8 个额外输出Token的延迟。但支持长输入的需求可能会使模型更难以服务。通常建议使用 A100-80GB(或更新版本)来服务 MPT-7B,其最大上下文长度为 2048 个Token。我在 MindIE Service 上,使用羊驼中文数据集,针对百川和千问大模型做了一个简单测试,发现100Token以内,随着输入Token长度的增加,并没有显著增加首Token的时延,如下图所示。
- 端到端推理延迟与模型大小呈次线性关系:在相同的硬件上,较大的模型推理速度较慢,但推理速度比不一定与模型参数量比匹配。例如:MPT-30B 延迟约为 MPT-7B 延迟的 2.5 倍。Llama2-70B 延迟约为 Llama2-13B 延迟的 2 倍。
================================================
FILE: llm-interview/llm-rlhf.md
================================================
## RLHF
> RLHF 完整训练过程是什么?RL建模过程中涉及到几个模型?
> RLHF 过程中RM随着训练过程的进行,得分越来越高,效果就一定好吗?
>
================================================
FILE: llm-interview/llm-train.md
================================================
> 模型训练通常关注的性能指标有哪些?
在模型训练过程中,通常关注的性能指标如下:
| 指标名称 | 单位 | 指标含义 |
| :---- | :----------------- | ----- |
| 吞吐率 | samples/s、tokens/s | 单位时间(例如1s)内处理的Token数/训练样本数 |
| 单步时间 | s | 执行一个step所花费的时间 |
| 线性度、加速比 | values | 单卡训练扩展到多卡,单机拓展到集群的效率度量指标 |
| 内存占用 | 百分比 | - |
| 带宽占比 | 百分比 | - |
| 训练效率 | tokens/day | - |
| 浮点运算 | TFLOPS | 每秒浮点运算次数,是计算设备的计算性能指标 |
| 模型算力利用率(Model FLOPs Utilization, MFU)| 百分比 | 模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
| 硬件算力利用率(Hardware FLOPs Utilization, HFU)| 百分比 | 考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值 |
在计算性能指标时,通常的优先级排序为:**吞吐率 > 单步迭代时间 > 线性度 > 内存占用 > 带宽占用 > 训练效率 > 浮点计算次数每秒 > 算力利用率**。
> 混合精度训练使用半精度训练的优缺点
半精度训练优点:跑得快+省显存
半精度训练缺点:精度(下溢+舍入误差)的问题。
使用了半精度训练,一般会采用一些捆绑的技术来弥补半精度的缺点。
- FP32 权重备份:对权重备份一份float32版本的版本,在梯度更新的时候避免float16精度不够而发生舍入误差导致的无效梯度更新,但是这样会占用额外的权重的内存,不过这些显存在一些情况下并不致命也就是了。
- loss scale:由于下溢的问题,也就是训练后期,梯度会很小,float16 容易产生 underflow,所以可以对loss做scale操作,毕竟loss的scale也会作用在梯度上(链式法则),这样一个大的scale比每个梯度都scale下要划算很多。
layer norm的层可能会完全使用float32,因为需要计算一组值的均值和方差,而这需要进行加法和除法运算,所以float16可能会出岔子。
> 使用bf16和fp16进行半精度训练的优缺点
## DeepSpeed
> DeepSpeed的特点是什么?各个 ZeRO Stage 都有什么用?
> 流水线并行能与DeepSpeed ZeRO 2/3一起训练吗?
https://www.zhihu.com/question/652836990/answer/3468210626
PP + ZeRO 2/3 不推荐一起训练。 PP需要累积梯度(accumulate gradients),但 ZeRO2 需要对梯度进行分块(chunk)。 即使能够实现,也没有真正的性能提升。
将两者结合使用来提高效率并不容易,PP + ZeRO 2 实际上比 ZeRO2(无 PP)更慢且内存效率低。如果用户内存不足,用户可以使用 ZeRO3 代替 ZeRO2 + PP。而正因为如此,在 DeepSpeed 中, PP + ZeRO 2/3 之间不兼容。使用将 PP + ZeRO 1 进行组合使用。
即使该方法效率不高,但是 ColossalAI 为了支持更多的并行训练方法。ColossalAI 还是提供了 ZeRO 3 + PP + TP 一起组合的方案。
参考:
- https://github.com/microsoft/DeepSpeed/issues/1110
- https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/runtime/pipe/engine.py#L71
- https://github.com/hpcaitech/ColossalAI/issues/682
- https://github.com/hpcaitech/ColossalAI/pull/477
---
## PyTorch
================================================
FILE: llm-localization/README.md
================================================
# 大模型国产化适配
## 昇腾
- [大模型国产化适配-华为昇腾AI全栈软硬件平台总结](https://github.com/liguodongiot/llm-action/blob/main/docs/llm_localization/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%9B%BD%E4%BA%A7%E5%8C%96%E9%80%82%E9%85%8D-%E5%8D%8E%E4%B8%BA%E6%98%87%E8%85%BEAI%E5%85%A8%E6%A0%88%E8%BD%AF%E7%A1%AC%E4%BB%B6%E5%B9%B3%E5%8F%B0%E6%80%BB%E7%BB%93.md)
- https://gitee.com/ascend/ModelLink
- 昇腾Ascend处理器相关介绍:https://huahuaboy.blog.csdn.net/article/details/127171363
- AI芯片:华为Ascend(昇腾)910结构分析:https://blog.csdn.net/evolone/article/details/100061616
## 海光
## 寒武纪
================================================
FILE: llm-localization/ascend/FAQ.md
================================================
docker: Error response from daemon: failed to create shim task: OCI runtime create failed: unable to retrieve OCI runtime error (open /var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/579418211a825ef5c7fcf5becdbe90804f0ed7862d9c59663995f9dd463937b4/log.json: no such file or directory): /usr/local/Ascend/Ascend-Docker-Runtime/ascend-docker-runtime did not terminate successfully: exit status 1: 2024/07/24 09:59:29 owner not right /usr/bin/runc 1000
错误信息表明/usr/bin/runc这个文件的所有权不正确,即它不是由root用户拥有或者它的所属用户不是1000。Docker在创建并运行容器时需要runc这个二进制文件,如果权限设置不当,Docker将无法正确执行。
解决办法:
查看权限
ls -lah /usr/bin/runc
修改权限
sudo chown root:root /usr/bin/runc
================================================
FILE: llm-localization/ascend/README.md
================================================
## 镜像地址
https://quay.io/repository/ascend/cann?tab=tags
## pytorch
- https://gitee.com/ascend/pytorch
- https://gitee.com/ascend/transformers#fqa
- https://gitee.com/ascend/AscendSpeed
- https://gitee.com/ascend/AscendSpeed2
- https://gitee.com/ascend/DeepSpeed
- https://gitee.com/ascend/Megatron-LM
## mindspore
https://gitee.com/mindspore/mindspore
https://gitee.com/mindspore/mindformers
https://www.mindspore.cn/versions#2.2.10
```
cd /tmp
curl -O https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py37_4.10.3-Linux-$(arch).sh
bash Miniconda3-py37_4.10.3-Linux-$(arch).sh -b
cd -
. ~/miniconda3/etc/profile.d/conda.sh
conda init bash
```
```
conda create -n mindspore_py37 python=3.7.5 -y
conda activate mindspore_py37
```
```
CentOS 7可以使用以下命令安装。
sudo yum install centos-release-scl
sudo yum install devtoolset-7
安装完成后,需要使用如下命令切换到GCC 7。
scl enable devtoolset-7 bash
```
### 推理
https://www.mindspore.cn/lite/docs/zh-CN/r2.2/quick_start/one_hour_introduction_cloud.html
export LITE_HOME=$some_path/mindpsore-lite-2.0.0-linux-x64
export LD_LIBRARY_PATH=$LITE_HOME/runtime/lib:$LITE_HOME/runtime/third_party/dnnl:$LITE_HOME/tools/converter/lib:$LD_LIBRARY_PATH
export PATH=$LITE_HOME/tools/converter/converter:$LITE_HOME/tools/benchmark:$PATH
## MindIE 日志
https://www.hiascend.com/document/detail/zh/mindie/21RC2/ref/logreference/mindie_log_0210.html
================================================
FILE: llm-localization/ascend/ascend-c/README.md
================================================
算子API:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha001/quickstart/quickstart/quickstart_18_0001.html
---
192.168.137.101
255.255.255.0
连接开发板:
- ssh root@192.168.137.100
- Mind@123
---
cd /home/HwHiAiUser/samples/samples/operator/AddCustomSample/FrameworkLaunch/AddCustom
bash build.sh
cd build_out
./custom_opp_ubuntu_aarch64.run
cd /home/HwHiAiUser/samples/samples/operator/AddCustomSample/FrameworkLaunch/AclNNInvocation
bash run.sh
================================================
FILE: llm-localization/ascend/ascend-infra/HCCL.md
================================================
- https://www.hiascend.com/document/detail/zh/canncommercial/80RC1/apiref/hcclapiref/hcclapi_07_0001.html
HCCL提供了Python与C++两种语言的接口,其中Python语言的接口用于实现TensorFlow网络在昇腾AI处理器执行分布式优化;C++语言接口用于实现OPBase模式下的框架适配,实现分布式能力,例如HCCL单算子API嵌入到PyTorch后端代码中,PyTorch用户直接使用PyTorch原生集合通信API,即可实现分布式能力。
================================================
FILE: llm-localization/ascend/ascend-infra/MacOS环境.md
================================================
```
conda create -n mindspore-venv python=3.8 -y
conda activate mindspore-venv
pip install torch transformers
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.14/MindSpore/cpu/aarch64/mindspore-2.2.14-cp38-cp38-macosx_11_0_arm64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-dmi.md
================================================
# Ascend-DMI
主要为Atlas产品的标卡、板卡及模组类产品提供带宽测试、算力测试、功耗测试等功能。
本系统通过调用底层DCMI(设备控制管理接口)/DSMI(设备系统管理接口)以及ACL(Ascend Computing Language,昇腾计算语言)相关接口完成相关检测功能,对于系统级别的信息查询通过调用系统提供的通用库来实现,用户使用工具时通过配置参数来实现不同的测试功能。
参考:https://www.hiascend.com/document/detail/zh/canncommercial/321/othertools/ascenddmi/ascenddmi_000002.html
## 带宽测试
## 算力测试
## 功耗测试
## 设备实时状态查询
## 故障诊断
## 软硬件版本兼容性测试
## 设备拓扑检测
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-docker-runtime.md
================================================
昇腾docker runtime仓库,在docker容器场景下,使用昇腾NPU,提供更简单的设备和依赖路径挂载方法。
https://gitee.com/ascend/ascend-docker-runtime
安装:https://www.hiascend.com/document/detail/zh/mindx-dl/300/dluserguide/clusterscheduling/dlug_installation_02_000025.html
Ascend Docker Runtime组件参考信息说明:
https://www.hiascend.com/document/detail/zh/mindx-dl/300/dluserguide/clusterscheduling/dlug_installation_02_000036.html
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-docker.md
================================================
```
docker login -u 15708484031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.RC2-centos7
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-llm下载.md
================================================
```
https://hf-mirror.com/
yum install python3-pip
virtualenv -p python3 venv-py3
source /home/aicc/venv-py3/bin/activate
pip3 install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --token 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 --resume-download Baichuan2-7B-Base --local-dir Baichuan2-7B-Base
huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-7B-Chat --local-dir Baichuan2-7B-Chat --local-dir-use-symlinks False
nohup huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-7B-Chat --local-dir Baichuan2-7B-Chat --local-dir-use-symlinks False > Baichuan2.log 2>&1 &
nohup huggingface-cli download --token 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 --resume-download THUDM/chatglm3-6b --local-dir chatglm3-6b-chat --local-dir-use-symlinks False > chatglm3.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen-72B-Chat --local-dir Qwen-72B-Chat --local-dir-use-symlinks False > qwen-72b.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen-72B-Chat --local-dir Qwen-72B-Chat --local-dir-use-symlinks False > qwen-72b.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-14B-Chat --local-dir Qwen1.5-14B-Chat --local-dir-use-symlinks False > Qwen1.5-14B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-7B-Chat --local-dir Qwen1.5-7B-Chat --local-dir-use-symlinks False > Qwen1.5-7B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download Qwen/Qwen1.5-72B-Chat --local-dir Qwen1.5-72B-Chat --local-dir-use-symlinks False > Qwen1.5-72B-Chat.log 2>&1 &
export HF_ENDPOINT=https://hf-mirror.com
nohup huggingface-cli download --token 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 --resume-download baichuan-inc/Baichuan2-13B-Chat --local-dir Baichuan2-13B-Chat --local-dir-use-symlinks False > Baichuan2-13B-Chat.log 2>&1 &
```
```
cd /home/aicc
mkdir -p ./model_from_hf/Baichuan2-7B-Chat/
cd ./model_from_hf/Baichuan2-7B-Chat/
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/configuration_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/generation_utils.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/modeling_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00001-of-00002.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00002-of-00002.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model.bin.index.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/quantizer.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/special_tokens_map.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenization_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer.model
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer_config.json
cd ../../
```
```
cd /home/aicc
mkdir -p ./model_from_hf/Baichuan2-7B-Chat/
cd ./model_from_hf/Baichuan2-7B-Chat/
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/configuration_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/generation_config.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/generation_utils.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/modeling_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/pytorch_model.bin
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/quantizer.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/special_tokens_map.json
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenization_baichuan.py
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenizer.model
wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenizer_config.json
cd ../../
```
## 拷贝模型
```
rsync -P --rsh=ssh -r root@192.xxx.16.210:/home/model_from_hf/Qwen1.5-72B/ ./
scp -r root@192.xxx.16.210:/home/model_from_hf/Qwen1.5-72B/ ./
```
================================================
FILE: llm-localization/ascend/ascend-infra/ascend-npu-smi.md
================================================
- https://support.huawei.com/enterprise/zh/doc/EDOC1100288566/e39bbfe6
```
npu-smi info -t device-share -i 1
```
## GPU/Memory 使用率
```
npu-smi info -t common -i 1
NPU ID : 1
Chip Count : 1
Chip ID : 0
Memory Usage Rate(%) : 0
HBM Usage Rate(%) : 91
Aicore Usage Rate(%) : 6
Aicore Freq(MHZ) : 1800
Aicore curFreq(MHZ) : 1800
Aicore Count : 20
Temperature(C) : 46
NPU Real-time Power(W) : 130.4
Chip Name : mcu
Temperature(C) : 40
npu-smi info -t common -i 7
NPU ID : 7
Chip Count : 1
Chip ID : 0
Memory Usage Rate(%) : 0
HBM Usage Rate(%) : 82
Aicore Usage Rate(%) : 70
Aicore Freq(MHZ) : 1800
Aicore curFreq(MHZ) : 1800
Aicore Count : 20
Temperature(C) : 66
NPU Real-time Power(W) : 331.1
Chip Name : mcu
Temperature(C) : 58
```
## 查询设备1所有芯片的统计信息
```
npu-smi info -t usages -i 1
NPU ID : 1
Chip Count : 1
DDR Capacity(MB) : 15079
DDR Usage Rate(%) : 14
DDR Hugepages Total(page) : 0
DDR Hugepages Usage Rate(%) : 0
HBM Capacity(MB) : 32768
HBM Usage Rate(%) : 0
Aicore Usage Rate(%) : 0
Aicpu Usage Rate(%) : 0
Ctrlcpu Usage Rate(%) : 0
DDR Bandwidth Usage Rate(%) : 0
HBM Bandwidth Usage Rate(%) : 0
Chip ID : 0
```
## 查看和修改网卡配置
```
hccn_tool -i 3 -status -g
Netdev status:Settings for eth3:
Supported ports: [ FIBRE ]
Supported link modes: 40000baseCR4/Full
40000baseSR4/Full
40000baseLR4/Full
25000baseCR/Full
25000baseSR/Full
50000baseCR2/Full
100000baseSR4/Full
100000baseCR4/Full
100000baseLR4_ER4/Full
50000baseSR2/Full
1000baseX/Full
10000baseCR/Full
10000baseSR/Full
10000baseLR/Full
50000baseLR_ER_FR/Full
200000baseSR4/Full
200000baseLR4_ER4_FR4/Full
200000baseCR4/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: No
Supported FEC modes: None RS
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: None RS
Speed: 200000Mb/s
Duplex: Full
Auto-negotiation: off
Port: Direct Attach Copper
PHYAD: 0
Transceiver: internal
Current message level: 0x00000036 (54)
probe link ifdown ifup
Link detected: yes
```
## 查看网卡的 IP 地址和路由
```
> hccn_tool -i 3 -ip -g
ipaddr:10.20.11.24
netmask:255.255.255.0
> hccn_tool -i 3 -route -g
Routing table:
Destination Gateway Genmask Flags Metric Ref Use Iface
10.20.11.0 * 255.255.255.0 U 0 0 0 eth3
127.0.0.1 * 255.255.255.255 UH 0 0 0 lo
192.168.1.0 * 255.255.255.0 U 0 0 0 end3v0
192.168.2.0 * 255.255.255.0 U 0 0 0 end3v0
```
RDMA 网卡的启动配置其实在配置文件
```
> cat /etc/hccn.conf # RDMA 网卡 0-7 的配置
address_0=10.20.11.11
netmask_0=255.255.255.0
address_1=10.20.11.12
netmask_1=255.255.255.0
address_2=10.20.11.13
netmask_2=255.255.255.0
address_3=10.20.11.14
netmask_3=255.255.255.0
address_4=10.20.11.15
netmask_4=255.255.255.0
address_5=10.20.11.16
netmask_5=255.255.255.0
address_6=10.20.11.17
netmask_6=255.255.255.0
address_7=10.20.11.18
netmask_7=255.255.255.0
```
## 查询所有芯片闪存信息
```
npu-smi info -t flash -i 0
NPU ID : 0
Chip Count : 1
Flash Count : 1
Flash ID : 1730504
Manufacturer ID : 0xC8
Capacity(MB) : 64
Chip ID : 0
```
## 查询设备1的所有芯片的内存信息。
```
npu-smi info -t memory -i 1
NPU ID : 1
Chip Count : 1
DDR Capacity(MB) : 0
DDR Clock Speed(MHz) : 0
HBM Capacity(MB) : 32768
HBM Clock Speed(MHz) : 1600
HBM Temperature(C) : 35
HBM Manufacturer ID : 0x57
Chip ID : 0
```
## RDMA ping
```
> hccn_tool -i 3 -ping -g address 10.20.11.16
device 3 PING 10.20.11.16
recv seq=0,time=0.137000ms
recv seq=1,time=0.046000ms
recv seq=2,time=0.058000ms
3 packets transmitted, 3 received, 0.00% packet loss
```
================================================
FILE: llm-localization/ascend/ascend-infra/docker环境升级cann.md
================================================
```
docker login -u 157xxx4031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A2-ubuntu18.04
```
```
https://www.hiascend.com/zh/software/cann/community-history
wget -c https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C18B800TP015/Ascend-cann-kernels-910b_8.0.RC2.alpha001_linux.run
wget -c https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C18B800TP015/Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run
```
```
docker stop pytorch_ubuntu_dev
docker rm -f pytorch_ubuntu_upgrade
docker run -it -u root \
--name pytorch_ubuntu_upgrade \
--network host \
--shm-size 4G \
-e ASCEND_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
-v /etc/localtime:/etc/localtime \
-v /var/log/npu/:/usr/slog \
-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \
-v /data/containerd/workspace/:/workspace \
ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A2-ubuntu18.04 \
/bin/bash
docker start pytorch_ubuntu_upgrade
docker exec -it pytorch_ubuntu_upgrade bash
```
```
cd /usr/local/Ascend/ascend-toolkit/7.0.0/aarch64-linux/script/
./uninstall.sh
chmod +x Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run
./Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run --check
./Ascend-cann-toolkit_8.0.RC2.alpha001_linux-aarch64.run --install
. /usr/local/Ascend/ascend-toolkit/set_env.sh
```
```
./Ascend-cann-kernels-910b_8.0.RC2.alpha001_linux.run --install --feature=aclnn_ops_train
```
```
. /usr/local/Ascend/ascend-toolkit/set_env.sh
```
```
bash Miniconda3-py39_24.4.0-0-Linux-aarch64.sh -p /workspace/installs/conda-upgrade
conda init
source ~/.bashrc
export PATH=/root/miniconda3/bin:$PATH
conda list
conda create -n llm-dev python=3.9
conda activate llm-dev
```
```
pip3 install torch==2.1.0
pip3 install pyyaml setuptools
pip3 install torch-npu==2.1.0.post3
pip3 install numpy attrs decorator psutil absl-py cloudpickle psutil scipy synr tornado
. /usr/local/Ascend/ascend-toolkit/set_env.sh
import torch
import torch_npu
x = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
z = x.mm(y)
print(z)
```
```
pip install --no-cache-dir -r requirements-npu.txt && rm -rf ~/.cache/pip/* && conda clean -all
```
```
docker start pytorch_ubuntu_upgrade
docker exec -it pytorch_ubuntu_upgrade bash
. /usr/local/Ascend/ascend-toolkit/set_env.sh
conda activate llm-dev
```
docker tag harbor.llm.io/base/llm-train-unify:v1-20240603 harbor.llm.io/base/llm-train-unify:v1-20240603
================================================
FILE: llm-localization/ascend/ascend-infra/network.md
================================================
## 集群网络
Atlas 900 AI集群采用“HCCS、 PCIe 4.0、100G以太”三类高速互联方式,百TB全互联无阻塞专属参数同步网络,降低网络时延,梯度同步时延缩短10~70%。
在AI服务器内部,昇腾910 AI处理器之间通过HCCS高速总线互联;昇腾910 AI处理器和CPU之间以最新的PCIe 4.0(速率16Gbps)技术互联,其速率是业界主流采用的PCIe 3.0(8.0Gbps)技术的两倍,使得数据传输更加快速和高效。在集群层面,采用面向数据中心的CloudEngine 8800系列交换机,提供单端口100Gbps的交换速率,将集群内的所有AI服务器接入高速交换网络。
独创iLossless 智能无损交换算法,对集群内的网络流量进行实时的学习训练,实现网络0丢包与E2E μs级时延。
## 系统级调优
Atlas 900 AI集群通过华为集合通信库和作业调度平台,整合HCCS、 PCIe 4.0 和100G RoCE三种高速接口,充分释放昇腾910 AI处理器的强大性能。
华为集合通信库提供训练网络所需的分布式并行库,通信库+网络拓扑+训练算法进行系统级调优,实现集群线性度>80%,极大提升了作业调度效率。
================================================
FILE: llm-localization/ascend/ascend-infra/npu监控.md
================================================
- AI模型运维——GPU性能监控NVML和DCGM
- https://www.cnblogs.com/maxgongzuo/p/12582286.html
dcgm exporter 监控GPU
NPU-Exporter 监控NPU
================================================
FILE: llm-localization/ascend/ascend-infra/操作系统.md
================================================
# Kylin
```
> cat /etc/os-release
NAME="Kylin Linux Advanced Server"
VERSION="V10 (Tercel)"
ID="kylin"
VERSION_ID="V10"
PRETTY_NAME="Kylin Linux Advanced Server V10 (Tercel)"
ANSI_COLOR="0;31"
```
```
> yum install dmidecode
> dmidecode -t system
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.
# SMBIOS implementations newer than version 3.2.0 are not
# fully supported by this version of dmidecode.
Handle 0x0001, DMI type 1, 27 bytes
System Information
Manufacturer: Huawei
Product Name: A800I A2
Version: To be filled by O.E.M.
Serial Number: 2102314VFG10Q1100025
UUID: a6202cac-b04f-8889-ee11-4ab078e0b272
Wake-up Type: Power Switch
SKU Number: To be filled by O.E.M.
Family: To be filled by O.E.M.
Handle 0x0005, DMI type 32, 11 bytes
System Boot Information
Status: No errors detected
```
# OpenEuler
- https://repo.openeuler.org/openEuler-24.03-LTS/OS/aarch64/Packages/
# Ubuntu
更换源
- https://blog.csdn.net/zwcslj/article/details/134322879
```
先备份旧的源
设置新的镜像源
vim /etc/apt/sources.list
更新软件包列表并升级已安装的软件包
apt-get update
apt-get upgrade
```
```
docker pull ubuntu:20.04
docker pull ubuntu:22.04
```
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾卡-soc版本.md
================================================
```
SOC版本:设备类型
100: "910PremiumA", 101: "910ProA", 102: "910A", 103: "910ProB", 104: "910B",
200: "310P1", 201: "310P2", 202: "310P3", 203: "310P4",
220: "910B1", 221: "910B2", 222: "910B3", 223: "910B4",
240: "310B1", 241: "310B2", 242: "310B3",
250: "910C1", 251: "910C2", 252: "910C3", 253: "910C4"
```
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾卡注意事项.md
================================================
--privileged 特权模型下,昇腾或者英伟达的 docker runtime 中会默认分配本机所有卡。
- ASCEND_VISIBLE_DEVICES 容器级控制卡
- ASCEND_RT_VISIBLE_DEVICES 进程级控制卡 类似于 CUDA_VISIBLE_DEVICES
================================================
FILE: llm-localization/ascend/ascend-infra/昇腾镜像.md
================================================
## 镜像仓库
- https://ascendhub.huawei.com/#/index
- https://www.hiascend.com/developer/ascendhub/
- http://mirrors.cn-central-221.ovaijisuan.com/mirrors.html
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/dxy/pytorch2_1_0_kernels:PyTorch2.1.0-cann7.0.0.alpha003_py_3.9-euler_2.8.3-64GB
```
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/mindformers/mindformers1.3_mindspore2.4:20241114
```
## ascend-mindspore
A1支持A300T-9000、A800-9000、A800-9010和Atlas 300T Pro,A2支持Atlas 900 A2 PoD、Atlas 800T A2、Atlas 200T A2 Box16和Atlas 300T A2
```
# 910A
docker login -u 157xxxx4031 ascendhub.huawei.com
docker pull ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A1-centos7
docker pull --platform=arm64 ascendhub.huawei.com/public-ascendhub/ascend-mindspore:23.0.0-A1-ubuntu18.04
```
```
docker pull --platform=arm64 swr.cn-central-221.ovaijisuan.com/mindformers/mindformers1.3_mindspore2.4:20241114
```
================================================
FILE: llm-localization/ascend/ascend-infra/服务器配置.md
================================================
最低配置:
```
Atlas 800 9000 A2
CPU:4 * 鲲鹏920 48核@2.6GHZ
GPU:8 * Ascend 910B4
内存:512G
硬盘:2 * 480G SSD,2 * 1.92 T PCIe SSD
```
推荐配置:
```
Atlas 800 9000 A2
CPU:4*鲲鹏920 48核@2.6GHZ
GPU:8 * Ascend 910B3
内存:1T
硬盘:2 * 960G SSD,2 * 3.84T PCIe SSD
```
================================================
FILE: llm-localization/ascend/ascend-infra/环境安装.md
================================================
## 安装Python-3.9.2
```
wget https://www.python.org/ftp/python/3.9.2/Python-3.9.2.tgz
tar -zxvf Python-3.9.2.tgz
cd Python-3.9.2
./configure --prefix=/usr/local/python3.9.2 --with-ssl-default-suites=openssl --enable-shared CFLAGS=-fPIC
make
sudo make install
#用于设置python3.9.2库文件路径
export LD_LIBRARY_PATH=/usr/local/python3.9.2/lib:$LD_LIBRARY_PATH
#如果用户环境存在多个python3版本,则指定使用python3.9.2版本
export PATH=/usr/local/python3.9.2/bin:$PATH
python3 --version
pip3 --version
```
##
================================================
FILE: llm-localization/ascend/ascend-infra/达芬奇架构.md
================================================
- 基本概念: https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha001/devguide/opdevg/ascendcopdevg/atlas_ascendc_10_0009.html
================================================
FILE: llm-localization/ascend/ascend910-env-install.md
================================================
## 查看操作系统
```
>cat /etc/os-release
PRETTY_NAME="Ubuntu 22.04.3 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.3 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy
> uname -a
Linux nodo-1 5.15.0-78-generic #85-Ubuntu SMP Fri Jul 7 15:29:30 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
```
## 查看服务器的型号信息
```
# yum install dmidecode
> apt-get install dmidecode
> dmidecode -t system
# dmidecode 3.3
Getting SMBIOS data from sysfs.
SMBIOS 3.3.0 present.
Handle 0x0001, DMI type 1, 27 bytes
System Information
Manufacturer: Huawei
Product Name: A800 9000 A2
Version: To be filled by O.E.M.
Serial Number: 2102314RHT10P81000xx
UUID: a61414fb-b04f-b618-ee11-c0441xx24b6d
Wake-up Type: Power Switch
SKU Number: To be filled by O.E.M.
Family: To be filled by O.E.M.
Handle 0x0005, DMI type 32, 11 bytes
System Boot Information
Status: No errors detected
- Atlas 900 RCK A2 Compute Node
- A800 9000 A2
```
以下操作如无特别说明,都是针对EulerOS系统。
## 安装驱动与固件
先安装驱动,再安装固件。
```
chmod +x Ascend-hdk-910-npu-driver_23.0.rc1_linux-aarch64.run
./Ascend-hdk-910-npu-driver_23.0.rc1_linux-aarch64.run --full --install-path=/usr/local/Ascend
```
``` Verifying archive integrity... 100% SHA256 checksums are OK. All good. Uncompressing ASCEND DRIVER RUN PACKAGE 100% [Driver] [2023-07-10 22:24:33] [INFO]Start time: 2023-07-10 22:24:33 [Driver] [2023-07-10 22:24:33] [INFO]LogFile: /var/log/ascend_seclog/ascend_install.log [Driver] [2023-07-10 22:24:33] [INFO]OperationLogFile: /var/log/ascend_seclog/operation.log [Driver] [2023-07-10 22:24:33] [WARNING]Do not power off or restart the system during the installation/upgrade [Driver] [2023-07-10 22:24:33] [INFO]set username and usergroup, HwHiAiUser:HwHiAiUser [Driver] [2023-07-10 22:24:34] [INFO]driver install type: Direct [Driver] [2023-07-10 22:24:34] [INFO]upgradePercentage:10% [Driver] [2023-07-10 22:24:38] [INFO]upgradePercentage:30% [Driver] [2023-07-10 22:24:38] [INFO]upgradePercentage:40% [Driver] [2023-07-10 22:24:40] [INFO]upgradePercentage:90% [Driver] [2023-07-10 22:24:40] [INFO]Waiting for device startup... [Driver] [2023-07-10 22:24:42] [INFO]Device startup success [Driver] [2023-07-10 22:24:53] [INFO]upgradePercentage:100% [Driver] [2023-07-10 22:25:04] [INFO]Driver package installed successfully! The new version takes effect immediately. [Driver] [2023-07-10 22:25:04] [INFO]End time: 2023-07-10 22:25:04 ```
``` Verifying archive integrity... 100% SHA256 checksums are OK. All good. Uncompressing ASCEND-HDK-910-NPU FIRMWARE RUN PACKAGE 100% [Firmware] [2023-07-10 22:27:29] [INFO]Start time: 2023-07-10 22:27:29 [Firmware] [2023-07-10 22:27:29] [INFO]LogFile: /var/log/ascend_seclog/ascend_install.log [Firmware] [2023-07-10 22:27:29] [INFO]OperationLogFile: /var/log/ascend_seclog/operation.log [Firmware] [2023-07-10 22:27:29] [WARNING]Do not power off or restart the system during the installation/upgrade [Firmware] [2023-07-10 22:27:34] [INFO]upgradePercentage: 0% [Firmware] [2023-07-10 22:27:42] [INFO]upgradePercentage: 0% [Firmware] [2023-07-10 22:27:51] [INFO]upgradePercentage: 0% [Firmware] [2023-07-10 22:27:57] [INFO]upgradePercentage: 100% [Firmware] [2023-07-10 22:27:57] [INFO]The firmware of [8] chips are successfully upgraded. [Firmware] [2023-07-10 22:27:57] [INFO]Firmware package installed successfully! Reboot now or after driver installation for the installation/upgrade to take effect. [Firmware] [2023-07-10 22:27:57] [INFO]End time: 2023-07-10 22:27:57 ```
``` Verifying archive integrity... 100% SHA256 checksums are OK. All good. Uncompressing ASCEND_RUN_PACKAGE 100% [Toolkit] [20230710-22:44:15] [INFO] LogFile:/var/log/ascend_seclog/ascend_toolkit_install.log [Toolkit] [20230710-22:44:15] [INFO] install start [Toolkit] [20230710-22:44:15] [INFO] The installation path is /usr/local/Ascend. [Toolkit] [20230710-22:44:15] [INFO] install package CANN-runtime-6.3.0.1.241-linux.aarch64.run start [Toolkit] [20230710-22:44:21] [INFO] CANN-runtime-6.3.0.1.241-linux.aarch64.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:44:21] [INFO] install package CANN-compiler-6.3.0.1.241-linux.aarch64.run start WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv [Toolkit] [20230710-22:44:56] [INFO] CANN-compiler-6.3.0.1.241-linux.aarch64.run --full --pylocal --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:44:56] [INFO] install package CANN-opp-6.3.0.1.241-linux.aarch64.run start [Toolkit] [20230710-22:45:39] [INFO] CANN-opp-6.3.0.1.241-linux.aarch64.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:45:39] [INFO] install package CANN-toolkit-6.3.0.1.241-linux.aarch64.run start [Toolkit] [20230710-22:46:20] [INFO] CANN-toolkit-6.3.0.1.241-linux.aarch64.run --full --pylocal --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:46:20] [INFO] install package CANN-aoe-6.3.0.1.241-linux.aarch64.run start [Toolkit] [20230710-22:46:23] [INFO] CANN-aoe-6.3.0.1.241-linux.aarch64.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:46:23] [INFO] install package Ascend-mindstudio-toolkit_6.0.RC1_linux-aarch64.run start [Toolkit] [20230710-22:46:30] [INFO] Ascend-mindstudio-toolkit_6.0.RC1_linux-aarch64.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:46:30] [INFO] install package Ascend-test-ops_6.3.RC1_linux.run start [Toolkit] [20230710-22:46:30] [INFO] Ascend-test-ops_6.3.RC1_linux.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:46:30] [INFO] install package Ascend-pyACL_6.3.RC1_linux-aarch64.run start [Toolkit] [20230710-22:46:30] [INFO] Ascend-pyACL_6.3.RC1_linux-aarch64.run --full --quiet --nox11 --install-for-all install success [Toolkit] [20230710-22:46:30] [INFO] install package CANN-ncs-6.3.0.1.241-linux.aarch64.run start [Toolkit] [20230710-22:46:33] [INFO] CANN-ncs-6.3.0.1.241-linux.aarch64.run --full --quiet --nox11 --install-for-all install success =========== = Summary = =========== Driver: Installed in /usr/local/Ascend/driver. Toolkit: Ascend-cann-toolkit_6.3.RC1_linux-aarch64 install success, installed in /usr/local/Ascend. Please make sure that the environment variables have been configured. - To take effect for all users, you can add "source /usr/local/Ascend/ascend-toolkit/set_env.sh" to /etc/profile. - To take effect for current user, you can exec command below: source /usr/local/Ascend/ascend-toolkit/set_env.sh or add "source /usr/local/Ascend/ascend-toolkit/set_env.sh" to ~/.bashrc. ```
```
python run_mindformer.py \
> --config ./configs/glm/run_glm_6b_infer.yaml \
> --run_mode eval \
> --load_checkpoint /root/workspace/output/fullft_merge_checkpoint/filtered_transformed.ckpt \
> --eval_dataset_dir /root/workspace/data/AdvertiseGen-ms/eval_0711_256.mindrecord \
> --device_id 7
2023-07-11 16:52:59,073 - mindformers - INFO - full_batch will be forced to False when the parallel mode is stand_alone or data_parallel
2023-07-11 16:52:59,075 - mindformers - INFO - .........Build context config..........
2023-07-11 16:52:59,075 - mindformers - INFO - initial moe_config from dict: {'expert_num': 1, 'capacity_factor': 1.05, 'aux_loss_factor': 0.05, 'num_experts_chosen': 1}
2023-07-11 16:52:59,075 - mindformers - INFO - initial recompute_config from dict: {'recompute': False, 'parallel_optimizer_comm_recompute': False, 'mp_comm_recompute': True, 'recompute_slice_activation': False}
2023-07-11 16:52:59,075 - mindformers - INFO - initial parallel_config from dict: {'data_parallel': 1, 'model_parallel': 1, 'pipeline_stage': 1, 'expert_parallel': 1, 'optimizer_shard': False, 'micro_batch_num': 1, 'vocab_emb_dp': True, 'gradient_aggregation_group': 4}
2023-07-11 16:52:59,075 - mindformers - INFO - context config is: [ParallelConfig]
_recompute:[ParallelConfig]
_recompute:False
_parallel_optimizer_comm_recompute:False
_mp_comm_recompute:True
_recompute_slice_activation:False
_optimizer_shard:False
_gradient_aggregation_group:4
_embed_dp_mp_config:[ParallelConfig]
_dp_mp_config:[ParallelConfig]
_data_parallel:1
_model_parallel:1
_vocab_emb_dp:True
_pp_config:[ParallelConfig]
_pipeline_stage:1
_micro_batch_num:1
_moe_config:[ParallelConfig]
_dpmp:[ParallelConfig]
_data_parallel:1
_model_parallel:1
_expert_parallel:1
2023-07-11 16:52:59,076 - mindformers - INFO - moe config is: