Repository: lllyasviel/IC-Light
Branch: main
Commit: bcf3f29ca85b
Files: 9
Total size: 75.4 KB
Directory structure:
gitextract_sw4pv86u/
├── .gitignore
├── LICENSE
├── README.md
├── briarmbg.py
├── db_examples.py
├── gradio_demo.py
├── gradio_demo_bg.py
├── models/
│ └── model_download_here
└── requirements.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
*.safetensors
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
.idea/
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
# IC-Light
IC-Light is a project to manipulate the illumination of images.
The name "IC-Light" stands for **"Imposing Consistent Light"** (we will briefly describe this at the end of this page).
Currently, we release two types of models: text-conditioned relighting model and background-conditioned model. Both types take foreground images as inputs.
**Note that "iclightai dot com" is a scam website. They have no relationship with us. Do not give scam websites money! This GitHub repo is the only official IC-Light.**
# News
[Alternative model](https://github.com/lllyasviel/IC-Light/discussions/109) for stronger illumination modifications.
Some news about flux is [here](https://github.com/lllyasviel/IC-Light/discussions/98). (A fix [update](https://github.com/lllyasviel/IC-Light/discussions/98#discussioncomment-11370266) is added at Nov 25, more demos will be uploaded soon.)
# Get Started
Below script will run the text-conditioned relighting model:
git clone https://github.com/lllyasviel/IC-Light.git
cd IC-Light
conda create -n iclight python=3.10
conda activate iclight
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
python gradio_demo.py
Or, to use background-conditioned demo:
python gradio_demo_bg.py
Model downloading is automatic.
Note that the "gradio_demo.py" has an official [huggingFace Space here](https://huggingface.co/spaces/lllyasviel/IC-Light).
# Screenshot
### Text-Conditioned Model
(Note that the "Lighting Preference" are just initial latents - eg., if the Lighting Preference is "Left" then initial latent is left white right black.)
---
**Prompt: beautiful woman, detailed face, warm atmosphere, at home, bedroom**
Lighting Preference: Left

---
**Prompt: beautiful woman, detailed face, sunshine from window**
Lighting Preference: Left

---
**beautiful woman, detailed face, neon, Wong Kar-wai, warm**
Lighting Preference: Left

---
**Prompt: beautiful woman, detailed face, sunshine, outdoor, warm atmosphere**
Lighting Preference: Right

---
**Prompt: beautiful woman, detailed face, sunshine, outdoor, warm atmosphere**
Lighting Preference: Left

---
**Prompt: beautiful woman, detailed face, sunshine from window**
Lighting Preference: Right

---
**Prompt: beautiful woman, detailed face, shadow from window**
Lighting Preference: Left

---
**Prompt: beautiful woman, detailed face, sunset over sea**
Lighting Preference: Right

---
**Prompt: handsome boy, detailed face, neon light, city**
Lighting Preference: Left

---
**Prompt: beautiful woman, detailed face, light and shadow**
Lighting Preference: Left

(beautiful woman, detailed face, soft studio lighting)

---
**Prompt: Buddha, detailed face, sci-fi RGB glowing, cyberpunk**
Lighting Preference: Left

---
**Prompt: Buddha, detailed face, natural lighting**
Lighting Preference: Left

---
**Prompt: toy, detailed face, shadow from window**
Lighting Preference: Bottom
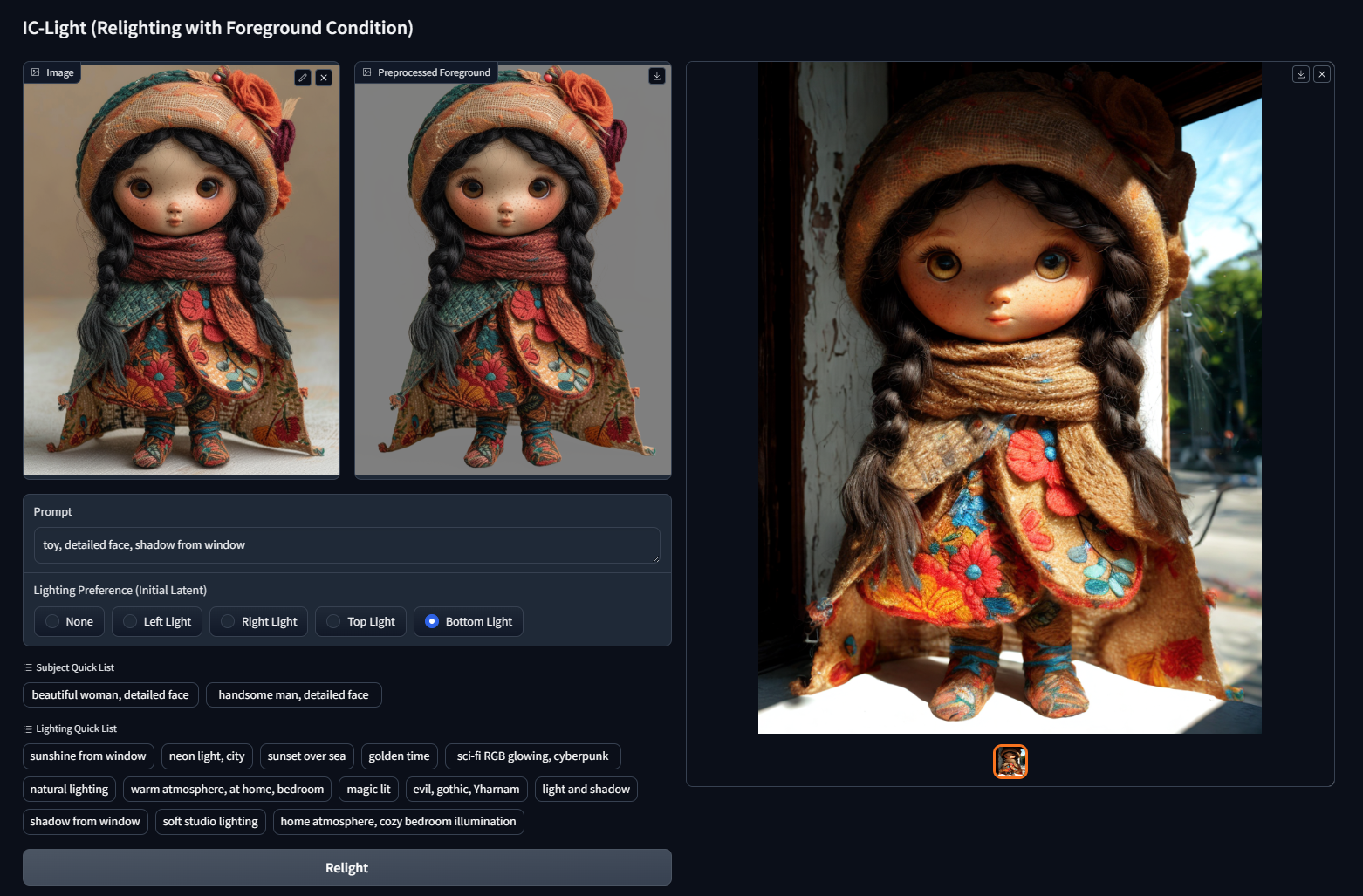
---
**Prompt: toy, detailed face, sunset over sea**
Lighting Preference: Right

---
**Prompt: dog, magic lit, sci-fi RGB glowing, studio lighting**
Lighting Preference: Bottom

---
**Prompt: mysteriou human, warm atmosphere, warm atmosphere, at home, bedroom**
Lighting Preference: Right

---
### Background-Conditioned Model
The background conditioned model does not require careful prompting. One can just use simple prompts like "handsome man, cinematic lighting".
---




---
A more structured visualization:

# Imposing Consistent Light
In HDR space, illumination has a property that all light transports are independent.
As a result, the blending of appearances of different light sources is equivalent to the appearance with mixed light sources:

Using the above [light stage](https://www.pauldebevec.com/Research/LS/) as an example, the two images from the "appearance mixture" and "light source mixture" are consistent (mathematically equivalent in HDR space, ideally).
We imposed such consistency (using MLPs in latent space) when training the relighting models.
As a result, the model is able to produce highly consistent relight - **so** consistent that different relightings can even be merged as normal maps! Despite the fact that the models are latent diffusion.

From left to right are inputs, model outputs relighting, devided shadow image, and merged normal maps. Note that the model is not trained with any normal map data. This normal estimation comes from the consistency of relighting.
You can reproduce this experiment using this button (it is 4x slower because it relight image 4 times)


Below are bigger images (feel free to try yourself to get more results!)


For reference, [geowizard](https://fuxiao0719.github.io/projects/geowizard/) (geowizard is a really great work!):

And, [switchlight](https://arxiv.org/pdf/2402.18848) (switchlight is another great work!):

# Model Notes
* **iclight_sd15_fc.safetensors** - The default relighting model, conditioned on text and foreground. You can use initial latent to influence the relighting.
* **iclight_sd15_fcon.safetensors** - Same as "iclight_sd15_fc.safetensors" but trained with offset noise. Note that the default "iclight_sd15_fc.safetensors" outperform this model slightly in a user study. And this is the reason why the default model is the model without offset noise.
* **iclight_sd15_fbc.safetensors** - Relighting model conditioned with text, foreground, and background.
Also, note that the original [BRIA RMBG 1.4](https://huggingface.co/briaai/RMBG-1.4) is for non-commercial use. If you use IC-Light in commercial projects, replace it with other background replacer like [BiRefNet](https://github.com/ZhengPeng7/BiRefNet).
# Cite
@inproceedings{
zhang2025scaling,
title={Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport},
author={Lvmin Zhang and Anyi Rao and Maneesh Agrawala},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=u1cQYxRI1H}
}
# Related Work
Also read ...
[Total Relighting: Learning to Relight Portraits for Background Replacement](https://augmentedperception.github.io/total_relighting/)
[Relightful Harmonization: Lighting-aware Portrait Background Replacement](https://arxiv.org/abs/2312.06886)
[SwitchLight: Co-design of Physics-driven Architecture and Pre-training Framework for Human Portrait Relighting](https://arxiv.org/pdf/2402.18848)
================================================
FILE: briarmbg.py
================================================
# RMBG1.4 (diffusers implementation)
# Found on huggingface space of several projects
# Not sure which project is the source of this file
import torch
import torch.nn as nn
import torch.nn.functional as F
from huggingface_hub import PyTorchModelHubMixin
class REBNCONV(nn.Module):
def __init__(self, in_ch=3, out_ch=3, dirate=1, stride=1):
super(REBNCONV, self).__init__()
self.conv_s1 = nn.Conv2d(
in_ch, out_ch, 3, padding=1 * dirate, dilation=1 * dirate, stride=stride
)
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self, x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
def _upsample_like(src, tar):
src = F.interpolate(src, size=tar.shape[2:], mode="bilinear")
return src
### RSU-7 ###
class RSU7(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3, img_size=512):
super(RSU7, self).__init__()
self.in_ch = in_ch
self.mid_ch = mid_ch
self.out_ch = out_ch
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) ## 1 -> 1/2
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv7 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv6d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
b, c, h, w = x.shape
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx = self.pool5(hx5)
hx6 = self.rebnconv6(hx)
hx7 = self.rebnconv7(hx6)
hx6d = self.rebnconv6d(torch.cat((hx7, hx6), 1))
hx6dup = _upsample_like(hx6d, hx5)
hx5d = self.rebnconv5d(torch.cat((hx6dup, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-6 ###
class RSU6(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU6, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx6 = self.rebnconv6(hx5)
hx5d = self.rebnconv5d(torch.cat((hx6, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-5 ###
class RSU5(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU5, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx5 = self.rebnconv5(hx4)
hx4d = self.rebnconv4d(torch.cat((hx5, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-4 ###
class RSU4(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
return hx1d + hxin
### RSU-4F ###
class RSU4F(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU4F, self).__init__()
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=2)
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=4)
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=8)
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=4)
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=2)
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
def forward(self, x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx2 = self.rebnconv2(hx1)
hx3 = self.rebnconv3(hx2)
hx4 = self.rebnconv4(hx3)
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
hx2d = self.rebnconv2d(torch.cat((hx3d, hx2), 1))
hx1d = self.rebnconv1d(torch.cat((hx2d, hx1), 1))
return hx1d + hxin
class myrebnconv(nn.Module):
def __init__(
self,
in_ch=3,
out_ch=1,
kernel_size=3,
stride=1,
padding=1,
dilation=1,
groups=1,
):
super(myrebnconv, self).__init__()
self.conv = nn.Conv2d(
in_ch,
out_ch,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
)
self.bn = nn.BatchNorm2d(out_ch)
self.rl = nn.ReLU(inplace=True)
def forward(self, x):
return self.rl(self.bn(self.conv(x)))
class BriaRMBG(nn.Module, PyTorchModelHubMixin):
def __init__(self, config: dict = {"in_ch": 3, "out_ch": 1}):
super(BriaRMBG, self).__init__()
in_ch = config["in_ch"]
out_ch = config["out_ch"]
self.conv_in = nn.Conv2d(in_ch, 64, 3, stride=2, padding=1)
self.pool_in = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage1 = RSU7(64, 32, 64)
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage2 = RSU6(64, 32, 128)
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage3 = RSU5(128, 64, 256)
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage4 = RSU4(256, 128, 512)
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage5 = RSU4F(512, 256, 512)
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.stage6 = RSU4F(512, 256, 512)
# decoder
self.stage5d = RSU4F(1024, 256, 512)
self.stage4d = RSU4(1024, 128, 256)
self.stage3d = RSU5(512, 64, 128)
self.stage2d = RSU6(256, 32, 64)
self.stage1d = RSU7(128, 16, 64)
self.side1 = nn.Conv2d(64, out_ch, 3, padding=1)
self.side2 = nn.Conv2d(64, out_ch, 3, padding=1)
self.side3 = nn.Conv2d(128, out_ch, 3, padding=1)
self.side4 = nn.Conv2d(256, out_ch, 3, padding=1)
self.side5 = nn.Conv2d(512, out_ch, 3, padding=1)
self.side6 = nn.Conv2d(512, out_ch, 3, padding=1)
# self.outconv = nn.Conv2d(6*out_ch,out_ch,1)
def forward(self, x):
hx = x
hxin = self.conv_in(hx)
# hx = self.pool_in(hxin)
# stage 1
hx1 = self.stage1(hxin)
hx = self.pool12(hx1)
# stage 2
hx2 = self.stage2(hx)
hx = self.pool23(hx2)
# stage 3
hx3 = self.stage3(hx)
hx = self.pool34(hx3)
# stage 4
hx4 = self.stage4(hx)
hx = self.pool45(hx4)
# stage 5
hx5 = self.stage5(hx)
hx = self.pool56(hx5)
# stage 6
hx6 = self.stage6(hx)
hx6up = _upsample_like(hx6, hx5)
# -------------------- decoder --------------------
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
hx5dup = _upsample_like(hx5d, hx4)
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
hx4dup = _upsample_like(hx4d, hx3)
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
hx3dup = _upsample_like(hx3d, hx2)
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
hx2dup = _upsample_like(hx2d, hx1)
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
# side output
d1 = self.side1(hx1d)
d1 = _upsample_like(d1, x)
d2 = self.side2(hx2d)
d2 = _upsample_like(d2, x)
d3 = self.side3(hx3d)
d3 = _upsample_like(d3, x)
d4 = self.side4(hx4d)
d4 = _upsample_like(d4, x)
d5 = self.side5(hx5d)
d5 = _upsample_like(d5, x)
d6 = self.side6(hx6)
d6 = _upsample_like(d6, x)
return [
F.sigmoid(d1),
F.sigmoid(d2),
F.sigmoid(d3),
F.sigmoid(d4),
F.sigmoid(d5),
F.sigmoid(d6),
], [hx1d, hx2d, hx3d, hx4d, hx5d, hx6]
================================================
FILE: db_examples.py
================================================
foreground_conditioned_examples = [
[
"imgs/i1.webp",
"beautiful woman, detailed face, sunshine, outdoor, warm atmosphere",
"Right Light",
512,
960,
12345,
"imgs/o1.png",
],
[
"imgs/i1.webp",
"beautiful woman, detailed face, sunshine, outdoor, warm atmosphere",
"Left Light",
512,
960,
50,
"imgs/o2.png",
],
[
"imgs/i3.png",
"beautiful woman, detailed face, neon, Wong Kar-wai, warm",
"Left Light",
512,
768,
12345,
"imgs/o3.png",
],
[
"imgs/i3.png",
"beautiful woman, detailed face, sunshine from window",
"Left Light",
512,
768,
12345,
"imgs/o4.png",
],
[
"imgs/i5.png",
"beautiful woman, detailed face, warm atmosphere, at home, bedroom",
"Left Light",
512,
768,
123,
"imgs/o5.png",
],
[
"imgs/i6.jpg",
"beautiful woman, detailed face, sunshine from window",
"Right Light",
512,
768,
42,
"imgs/o6.png",
],
[
"imgs/i7.jpg",
"beautiful woman, detailed face, shadow from window",
"Left Light",
512,
768,
8888,
"imgs/o7.png",
],
[
"imgs/i8.webp",
"beautiful woman, detailed face, sunset over sea",
"Right Light",
512,
640,
42,
"imgs/o8.png",
],
[
"imgs/i9.png",
"handsome boy, detailed face, neon light, city",
"Left Light",
512,
640,
12345,
"imgs/o9.png",
],
[
"imgs/i10.png",
"beautiful woman, detailed face, light and shadow",
"Left Light",
512,
960,
8888,
"imgs/o10.png",
],
[
"imgs/i11.png",
"Buddha, detailed face, sci-fi RGB glowing, cyberpunk",
"Left Light",
512,
768,
8888,
"imgs/o11.png",
],
[
"imgs/i11.png",
"Buddha, detailed face, natural lighting",
"Left Light",
512,
768,
12345,
"imgs/o12.png",
],
[
"imgs/i13.png",
"toy, detailed face, shadow from window",
"Bottom Light",
512,
704,
12345,
"imgs/o13.png",
],
[
"imgs/i14.png",
"toy, detailed face, sunset over sea",
"Right Light",
512,
704,
100,
"imgs/o14.png",
],
[
"imgs/i15.png",
"dog, magic lit, sci-fi RGB glowing, studio lighting",
"Bottom Light",
512,
768,
12345,
"imgs/o15.png",
],
[
"imgs/i16.png",
"mysteriou human, warm atmosphere, warm atmosphere, at home, bedroom",
"Right Light",
512,
768,
100,
"imgs/o16.png",
],
]
bg_samples = [
'imgs/bgs/1.webp',
'imgs/bgs/2.webp',
'imgs/bgs/3.webp',
'imgs/bgs/4.webp',
'imgs/bgs/5.webp',
'imgs/bgs/6.webp',
'imgs/bgs/7.webp',
'imgs/bgs/8.webp',
'imgs/bgs/9.webp',
'imgs/bgs/10.webp',
'imgs/bgs/11.png',
'imgs/bgs/12.png',
'imgs/bgs/13.png',
'imgs/bgs/14.png',
'imgs/bgs/15.png',
]
background_conditioned_examples = [
[
"imgs/alter/i3.png",
"imgs/bgs/7.webp",
"beautiful woman, cinematic lighting",
"Use Background Image",
512,
768,
12345,
"imgs/alter/o1.png",
],
[
"imgs/alter/i2.png",
"imgs/bgs/11.png",
"statue of an angel, natural lighting",
"Use Flipped Background Image",
512,
768,
12345,
"imgs/alter/o2.png",
],
[
"imgs/alter/i1.jpeg",
"imgs/bgs/2.webp",
"beautiful woman, cinematic lighting",
"Use Background Image",
512,
768,
12345,
"imgs/alter/o3.png",
],
[
"imgs/alter/i1.jpeg",
"imgs/bgs/3.webp",
"beautiful woman, cinematic lighting",
"Use Background Image",
512,
768,
12345,
"imgs/alter/o4.png",
],
[
"imgs/alter/i6.webp",
"imgs/bgs/15.png",
"handsome man, cinematic lighting",
"Use Background Image",
512,
768,
12345,
"imgs/alter/o5.png",
],
]
================================================
FILE: gradio_demo.py
================================================
import os
import math
import gradio as gr
import numpy as np
import torch
import safetensors.torch as sf
import db_examples
from PIL import Image
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
from diffusers import AutoencoderKL, UNet2DConditionModel, DDIMScheduler, EulerAncestralDiscreteScheduler, DPMSolverMultistepScheduler
from diffusers.models.attention_processor import AttnProcessor2_0
from transformers import CLIPTextModel, CLIPTokenizer
from briarmbg import BriaRMBG
from enum import Enum
from torch.hub import download_url_to_file
# 'stablediffusionapi/realistic-vision-v51'
# 'runwayml/stable-diffusion-v1-5'
sd15_name = 'stablediffusionapi/realistic-vision-v51'
tokenizer = CLIPTokenizer.from_pretrained(sd15_name, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(sd15_name, subfolder="text_encoder")
vae = AutoencoderKL.from_pretrained(sd15_name, subfolder="vae")
unet = UNet2DConditionModel.from_pretrained(sd15_name, subfolder="unet")
rmbg = BriaRMBG.from_pretrained("briaai/RMBG-1.4")
# Change UNet
with torch.no_grad():
new_conv_in = torch.nn.Conv2d(8, unet.conv_in.out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
new_conv_in.bias = unet.conv_in.bias
unet.conv_in = new_conv_in
unet_original_forward = unet.forward
def hooked_unet_forward(sample, timestep, encoder_hidden_states, **kwargs):
c_concat = kwargs['cross_attention_kwargs']['concat_conds'].to(sample)
c_concat = torch.cat([c_concat] * (sample.shape[0] // c_concat.shape[0]), dim=0)
new_sample = torch.cat([sample, c_concat], dim=1)
kwargs['cross_attention_kwargs'] = {}
return unet_original_forward(new_sample, timestep, encoder_hidden_states, **kwargs)
unet.forward = hooked_unet_forward
# Load
model_path = './models/iclight_sd15_fc.safetensors'
if not os.path.exists(model_path):
download_url_to_file(url='https://huggingface.co/lllyasviel/ic-light/resolve/main/iclight_sd15_fc.safetensors', dst=model_path)
sd_offset = sf.load_file(model_path)
sd_origin = unet.state_dict()
keys = sd_origin.keys()
sd_merged = {k: sd_origin[k] + sd_offset[k] for k in sd_origin.keys()}
unet.load_state_dict(sd_merged, strict=True)
del sd_offset, sd_origin, sd_merged, keys
# Device
device = torch.device('cuda')
text_encoder = text_encoder.to(device=device, dtype=torch.float16)
vae = vae.to(device=device, dtype=torch.bfloat16)
unet = unet.to(device=device, dtype=torch.float16)
rmbg = rmbg.to(device=device, dtype=torch.float32)
# SDP
unet.set_attn_processor(AttnProcessor2_0())
vae.set_attn_processor(AttnProcessor2_0())
# Samplers
ddim_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
euler_a_scheduler = EulerAncestralDiscreteScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
steps_offset=1
)
dpmpp_2m_sde_karras_scheduler = DPMSolverMultistepScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
algorithm_type="sde-dpmsolver++",
use_karras_sigmas=True,
steps_offset=1
)
# Pipelines
t2i_pipe = StableDiffusionPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=dpmpp_2m_sde_karras_scheduler,
safety_checker=None,
requires_safety_checker=False,
feature_extractor=None,
image_encoder=None
)
i2i_pipe = StableDiffusionImg2ImgPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=dpmpp_2m_sde_karras_scheduler,
safety_checker=None,
requires_safety_checker=False,
feature_extractor=None,
image_encoder=None
)
@torch.inference_mode()
def encode_prompt_inner(txt: str):
max_length = tokenizer.model_max_length
chunk_length = tokenizer.model_max_length - 2
id_start = tokenizer.bos_token_id
id_end = tokenizer.eos_token_id
id_pad = id_end
def pad(x, p, i):
return x[:i] if len(x) >= i else x + [p] * (i - len(x))
tokens = tokenizer(txt, truncation=False, add_special_tokens=False)["input_ids"]
chunks = [[id_start] + tokens[i: i + chunk_length] + [id_end] for i in range(0, len(tokens), chunk_length)]
chunks = [pad(ck, id_pad, max_length) for ck in chunks]
token_ids = torch.tensor(chunks).to(device=device, dtype=torch.int64)
conds = text_encoder(token_ids).last_hidden_state
return conds
@torch.inference_mode()
def encode_prompt_pair(positive_prompt, negative_prompt):
c = encode_prompt_inner(positive_prompt)
uc = encode_prompt_inner(negative_prompt)
c_len = float(len(c))
uc_len = float(len(uc))
max_count = max(c_len, uc_len)
c_repeat = int(math.ceil(max_count / c_len))
uc_repeat = int(math.ceil(max_count / uc_len))
max_chunk = max(len(c), len(uc))
c = torch.cat([c] * c_repeat, dim=0)[:max_chunk]
uc = torch.cat([uc] * uc_repeat, dim=0)[:max_chunk]
c = torch.cat([p[None, ...] for p in c], dim=1)
uc = torch.cat([p[None, ...] for p in uc], dim=1)
return c, uc
@torch.inference_mode()
def pytorch2numpy(imgs, quant=True):
results = []
for x in imgs:
y = x.movedim(0, -1)
if quant:
y = y * 127.5 + 127.5
y = y.detach().float().cpu().numpy().clip(0, 255).astype(np.uint8)
else:
y = y * 0.5 + 0.5
y = y.detach().float().cpu().numpy().clip(0, 1).astype(np.float32)
results.append(y)
return results
@torch.inference_mode()
def numpy2pytorch(imgs):
h = torch.from_numpy(np.stack(imgs, axis=0)).float() / 127.0 - 1.0 # so that 127 must be strictly 0.0
h = h.movedim(-1, 1)
return h
def resize_and_center_crop(image, target_width, target_height):
pil_image = Image.fromarray(image)
original_width, original_height = pil_image.size
scale_factor = max(target_width / original_width, target_height / original_height)
resized_width = int(round(original_width * scale_factor))
resized_height = int(round(original_height * scale_factor))
resized_image = pil_image.resize((resized_width, resized_height), Image.LANCZOS)
left = (resized_width - target_width) / 2
top = (resized_height - target_height) / 2
right = (resized_width + target_width) / 2
bottom = (resized_height + target_height) / 2
cropped_image = resized_image.crop((left, top, right, bottom))
return np.array(cropped_image)
def resize_without_crop(image, target_width, target_height):
pil_image = Image.fromarray(image)
resized_image = pil_image.resize((target_width, target_height), Image.LANCZOS)
return np.array(resized_image)
@torch.inference_mode()
def run_rmbg(img, sigma=0.0):
H, W, C = img.shape
assert C == 3
k = (256.0 / float(H * W)) ** 0.5
feed = resize_without_crop(img, int(64 * round(W * k)), int(64 * round(H * k)))
feed = numpy2pytorch([feed]).to(device=device, dtype=torch.float32)
alpha = rmbg(feed)[0][0]
alpha = torch.nn.functional.interpolate(alpha, size=(H, W), mode="bilinear")
alpha = alpha.movedim(1, -1)[0]
alpha = alpha.detach().float().cpu().numpy().clip(0, 1)
result = 127 + (img.astype(np.float32) - 127 + sigma) * alpha
return result.clip(0, 255).astype(np.uint8), alpha
@torch.inference_mode()
def process(input_fg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, lowres_denoise, bg_source):
bg_source = BGSource(bg_source)
input_bg = None
if bg_source == BGSource.NONE:
pass
elif bg_source == BGSource.LEFT:
gradient = np.linspace(255, 0, image_width)
image = np.tile(gradient, (image_height, 1))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.RIGHT:
gradient = np.linspace(0, 255, image_width)
image = np.tile(gradient, (image_height, 1))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.TOP:
gradient = np.linspace(255, 0, image_height)[:, None]
image = np.tile(gradient, (1, image_width))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.BOTTOM:
gradient = np.linspace(0, 255, image_height)[:, None]
image = np.tile(gradient, (1, image_width))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
else:
raise 'Wrong initial latent!'
rng = torch.Generator(device=device).manual_seed(int(seed))
fg = resize_and_center_crop(input_fg, image_width, image_height)
concat_conds = numpy2pytorch([fg]).to(device=vae.device, dtype=vae.dtype)
concat_conds = vae.encode(concat_conds).latent_dist.mode() * vae.config.scaling_factor
conds, unconds = encode_prompt_pair(positive_prompt=prompt + ', ' + a_prompt, negative_prompt=n_prompt)
if input_bg is None:
latents = t2i_pipe(
prompt_embeds=conds,
negative_prompt_embeds=unconds,
width=image_width,
height=image_height,
num_inference_steps=steps,
num_images_per_prompt=num_samples,
generator=rng,
output_type='latent',
guidance_scale=cfg,
cross_attention_kwargs={'concat_conds': concat_conds},
).images.to(vae.dtype) / vae.config.scaling_factor
else:
bg = resize_and_center_crop(input_bg, image_width, image_height)
bg_latent = numpy2pytorch([bg]).to(device=vae.device, dtype=vae.dtype)
bg_latent = vae.encode(bg_latent).latent_dist.mode() * vae.config.scaling_factor
latents = i2i_pipe(
image=bg_latent,
strength=lowres_denoise,
prompt_embeds=conds,
negative_prompt_embeds=unconds,
width=image_width,
height=image_height,
num_inference_steps=int(round(steps / lowres_denoise)),
num_images_per_prompt=num_samples,
generator=rng,
output_type='latent',
guidance_scale=cfg,
cross_attention_kwargs={'concat_conds': concat_conds},
).images.to(vae.dtype) / vae.config.scaling_factor
pixels = vae.decode(latents).sample
pixels = pytorch2numpy(pixels)
pixels = [resize_without_crop(
image=p,
target_width=int(round(image_width * highres_scale / 64.0) * 64),
target_height=int(round(image_height * highres_scale / 64.0) * 64))
for p in pixels]
pixels = numpy2pytorch(pixels).to(device=vae.device, dtype=vae.dtype)
latents = vae.encode(pixels).latent_dist.mode() * vae.config.scaling_factor
latents = latents.to(device=unet.device, dtype=unet.dtype)
image_height, image_width = latents.shape[2] * 8, latents.shape[3] * 8
fg = resize_and_center_crop(input_fg, image_width, image_height)
concat_conds = numpy2pytorch([fg]).to(device=vae.device, dtype=vae.dtype)
concat_conds = vae.encode(concat_conds).latent_dist.mode() * vae.config.scaling_factor
latents = i2i_pipe(
image=latents,
strength=highres_denoise,
prompt_embeds=conds,
negative_prompt_embeds=unconds,
width=image_width,
height=image_height,
num_inference_steps=int(round(steps / highres_denoise)),
num_images_per_prompt=num_samples,
generator=rng,
output_type='latent',
guidance_scale=cfg,
cross_attention_kwargs={'concat_conds': concat_conds},
).images.to(vae.dtype) / vae.config.scaling_factor
pixels = vae.decode(latents).sample
return pytorch2numpy(pixels)
@torch.inference_mode()
def process_relight(input_fg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, lowres_denoise, bg_source):
input_fg, matting = run_rmbg(input_fg)
results = process(input_fg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, lowres_denoise, bg_source)
return input_fg, results
quick_prompts = [
'sunshine from window',
'neon light, city',
'sunset over sea',
'golden time',
'sci-fi RGB glowing, cyberpunk',
'natural lighting',
'warm atmosphere, at home, bedroom',
'magic lit',
'evil, gothic, Yharnam',
'light and shadow',
'shadow from window',
'soft studio lighting',
'home atmosphere, cozy bedroom illumination',
'neon, Wong Kar-wai, warm'
]
quick_prompts = [[x] for x in quick_prompts]
quick_subjects = [
'beautiful woman, detailed face',
'handsome man, detailed face',
]
quick_subjects = [[x] for x in quick_subjects]
class BGSource(Enum):
NONE = "None"
LEFT = "Left Light"
RIGHT = "Right Light"
TOP = "Top Light"
BOTTOM = "Bottom Light"
block = gr.Blocks().queue()
with block:
with gr.Row():
gr.Markdown("## IC-Light (Relighting with Foreground Condition)")
with gr.Row():
with gr.Column():
with gr.Row():
input_fg = gr.Image(source='upload', type="numpy", label="Image", height=480)
output_bg = gr.Image(type="numpy", label="Preprocessed Foreground", height=480)
prompt = gr.Textbox(label="Prompt")
bg_source = gr.Radio(choices=[e.value for e in BGSource],
value=BGSource.NONE.value,
label="Lighting Preference (Initial Latent)", type='value')
example_quick_subjects = gr.Dataset(samples=quick_subjects, label='Subject Quick List', samples_per_page=1000, components=[prompt])
example_quick_prompts = gr.Dataset(samples=quick_prompts, label='Lighting Quick List', samples_per_page=1000, components=[prompt])
relight_button = gr.Button(value="Relight")
with gr.Group():
with gr.Row():
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
seed = gr.Number(label="Seed", value=12345, precision=0)
with gr.Row():
image_width = gr.Slider(label="Image Width", minimum=256, maximum=1024, value=512, step=64)
image_height = gr.Slider(label="Image Height", minimum=256, maximum=1024, value=640, step=64)
with gr.Accordion("Advanced options", open=False):
steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=25, step=1)
cfg = gr.Slider(label="CFG Scale", minimum=1.0, maximum=32.0, value=2, step=0.01)
lowres_denoise = gr.Slider(label="Lowres Denoise (for initial latent)", minimum=0.1, maximum=1.0, value=0.9, step=0.01)
highres_scale = gr.Slider(label="Highres Scale", minimum=1.0, maximum=3.0, value=1.5, step=0.01)
highres_denoise = gr.Slider(label="Highres Denoise", minimum=0.1, maximum=1.0, value=0.5, step=0.01)
a_prompt = gr.Textbox(label="Added Prompt", value='best quality')
n_prompt = gr.Textbox(label="Negative Prompt", value='lowres, bad anatomy, bad hands, cropped, worst quality')
with gr.Column():
result_gallery = gr.Gallery(height=832, object_fit='contain', label='Outputs')
with gr.Row():
dummy_image_for_outputs = gr.Image(visible=False, label='Result')
gr.Examples(
fn=lambda *args: ([args[-1]], None),
examples=db_examples.foreground_conditioned_examples,
inputs=[
input_fg, prompt, bg_source, image_width, image_height, seed, dummy_image_for_outputs
],
outputs=[result_gallery, output_bg],
run_on_click=True, examples_per_page=1024
)
ips = [input_fg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, lowres_denoise, bg_source]
relight_button.click(fn=process_relight, inputs=ips, outputs=[output_bg, result_gallery])
example_quick_prompts.click(lambda x, y: ', '.join(y.split(', ')[:2] + [x[0]]), inputs=[example_quick_prompts, prompt], outputs=prompt, show_progress=False, queue=False)
example_quick_subjects.click(lambda x: x[0], inputs=example_quick_subjects, outputs=prompt, show_progress=False, queue=False)
block.launch(server_name='0.0.0.0')
================================================
FILE: gradio_demo_bg.py
================================================
import os
import math
import gradio as gr
import numpy as np
import torch
import safetensors.torch as sf
import db_examples
from PIL import Image
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
from diffusers import AutoencoderKL, UNet2DConditionModel, DDIMScheduler, EulerAncestralDiscreteScheduler, DPMSolverMultistepScheduler
from diffusers.models.attention_processor import AttnProcessor2_0
from transformers import CLIPTextModel, CLIPTokenizer
from briarmbg import BriaRMBG
from enum import Enum
from torch.hub import download_url_to_file
# 'stablediffusionapi/realistic-vision-v51'
# 'runwayml/stable-diffusion-v1-5'
sd15_name = 'stablediffusionapi/realistic-vision-v51'
tokenizer = CLIPTokenizer.from_pretrained(sd15_name, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(sd15_name, subfolder="text_encoder")
vae = AutoencoderKL.from_pretrained(sd15_name, subfolder="vae")
unet = UNet2DConditionModel.from_pretrained(sd15_name, subfolder="unet")
rmbg = BriaRMBG.from_pretrained("briaai/RMBG-1.4")
# Change UNet
with torch.no_grad():
new_conv_in = torch.nn.Conv2d(12, unet.conv_in.out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
new_conv_in.bias = unet.conv_in.bias
unet.conv_in = new_conv_in
unet_original_forward = unet.forward
def hooked_unet_forward(sample, timestep, encoder_hidden_states, **kwargs):
c_concat = kwargs['cross_attention_kwargs']['concat_conds'].to(sample)
c_concat = torch.cat([c_concat] * (sample.shape[0] // c_concat.shape[0]), dim=0)
new_sample = torch.cat([sample, c_concat], dim=1)
kwargs['cross_attention_kwargs'] = {}
return unet_original_forward(new_sample, timestep, encoder_hidden_states, **kwargs)
unet.forward = hooked_unet_forward
# Load
model_path = './models/iclight_sd15_fbc.safetensors'
if not os.path.exists(model_path):
download_url_to_file(url='https://huggingface.co/lllyasviel/ic-light/resolve/main/iclight_sd15_fbc.safetensors', dst=model_path)
sd_offset = sf.load_file(model_path)
sd_origin = unet.state_dict()
keys = sd_origin.keys()
sd_merged = {k: sd_origin[k] + sd_offset[k] for k in sd_origin.keys()}
unet.load_state_dict(sd_merged, strict=True)
del sd_offset, sd_origin, sd_merged, keys
# Device
device = torch.device('cuda')
text_encoder = text_encoder.to(device=device, dtype=torch.float16)
vae = vae.to(device=device, dtype=torch.bfloat16)
unet = unet.to(device=device, dtype=torch.float16)
rmbg = rmbg.to(device=device, dtype=torch.float32)
# SDP
unet.set_attn_processor(AttnProcessor2_0())
vae.set_attn_processor(AttnProcessor2_0())
# Samplers
ddim_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
euler_a_scheduler = EulerAncestralDiscreteScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
steps_offset=1
)
dpmpp_2m_sde_karras_scheduler = DPMSolverMultistepScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
algorithm_type="sde-dpmsolver++",
use_karras_sigmas=True,
steps_offset=1
)
# Pipelines
t2i_pipe = StableDiffusionPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=dpmpp_2m_sde_karras_scheduler,
safety_checker=None,
requires_safety_checker=False,
feature_extractor=None,
image_encoder=None
)
i2i_pipe = StableDiffusionImg2ImgPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=dpmpp_2m_sde_karras_scheduler,
safety_checker=None,
requires_safety_checker=False,
feature_extractor=None,
image_encoder=None
)
@torch.inference_mode()
def encode_prompt_inner(txt: str):
max_length = tokenizer.model_max_length
chunk_length = tokenizer.model_max_length - 2
id_start = tokenizer.bos_token_id
id_end = tokenizer.eos_token_id
id_pad = id_end
def pad(x, p, i):
return x[:i] if len(x) >= i else x + [p] * (i - len(x))
tokens = tokenizer(txt, truncation=False, add_special_tokens=False)["input_ids"]
chunks = [[id_start] + tokens[i: i + chunk_length] + [id_end] for i in range(0, len(tokens), chunk_length)]
chunks = [pad(ck, id_pad, max_length) for ck in chunks]
token_ids = torch.tensor(chunks).to(device=device, dtype=torch.int64)
conds = text_encoder(token_ids).last_hidden_state
return conds
@torch.inference_mode()
def encode_prompt_pair(positive_prompt, negative_prompt):
c = encode_prompt_inner(positive_prompt)
uc = encode_prompt_inner(negative_prompt)
c_len = float(len(c))
uc_len = float(len(uc))
max_count = max(c_len, uc_len)
c_repeat = int(math.ceil(max_count / c_len))
uc_repeat = int(math.ceil(max_count / uc_len))
max_chunk = max(len(c), len(uc))
c = torch.cat([c] * c_repeat, dim=0)[:max_chunk]
uc = torch.cat([uc] * uc_repeat, dim=0)[:max_chunk]
c = torch.cat([p[None, ...] for p in c], dim=1)
uc = torch.cat([p[None, ...] for p in uc], dim=1)
return c, uc
@torch.inference_mode()
def pytorch2numpy(imgs, quant=True):
results = []
for x in imgs:
y = x.movedim(0, -1)
if quant:
y = y * 127.5 + 127.5
y = y.detach().float().cpu().numpy().clip(0, 255).astype(np.uint8)
else:
y = y * 0.5 + 0.5
y = y.detach().float().cpu().numpy().clip(0, 1).astype(np.float32)
results.append(y)
return results
@torch.inference_mode()
def numpy2pytorch(imgs):
h = torch.from_numpy(np.stack(imgs, axis=0)).float() / 127.0 - 1.0 # so that 127 must be strictly 0.0
h = h.movedim(-1, 1)
return h
def resize_and_center_crop(image, target_width, target_height):
pil_image = Image.fromarray(image)
original_width, original_height = pil_image.size
scale_factor = max(target_width / original_width, target_height / original_height)
resized_width = int(round(original_width * scale_factor))
resized_height = int(round(original_height * scale_factor))
resized_image = pil_image.resize((resized_width, resized_height), Image.LANCZOS)
left = (resized_width - target_width) / 2
top = (resized_height - target_height) / 2
right = (resized_width + target_width) / 2
bottom = (resized_height + target_height) / 2
cropped_image = resized_image.crop((left, top, right, bottom))
return np.array(cropped_image)
def resize_without_crop(image, target_width, target_height):
pil_image = Image.fromarray(image)
resized_image = pil_image.resize((target_width, target_height), Image.LANCZOS)
return np.array(resized_image)
@torch.inference_mode()
def run_rmbg(img, sigma=0.0):
H, W, C = img.shape
assert C == 3
k = (256.0 / float(H * W)) ** 0.5
feed = resize_without_crop(img, int(64 * round(W * k)), int(64 * round(H * k)))
feed = numpy2pytorch([feed]).to(device=device, dtype=torch.float32)
alpha = rmbg(feed)[0][0]
alpha = torch.nn.functional.interpolate(alpha, size=(H, W), mode="bilinear")
alpha = alpha.movedim(1, -1)[0]
alpha = alpha.detach().float().cpu().numpy().clip(0, 1)
result = 127 + (img.astype(np.float32) - 127 + sigma) * alpha
return result.clip(0, 255).astype(np.uint8), alpha
@torch.inference_mode()
def process(input_fg, input_bg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, bg_source):
bg_source = BGSource(bg_source)
if bg_source == BGSource.UPLOAD:
pass
elif bg_source == BGSource.UPLOAD_FLIP:
input_bg = np.fliplr(input_bg)
elif bg_source == BGSource.GREY:
input_bg = np.zeros(shape=(image_height, image_width, 3), dtype=np.uint8) + 64
elif bg_source == BGSource.LEFT:
gradient = np.linspace(224, 32, image_width)
image = np.tile(gradient, (image_height, 1))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.RIGHT:
gradient = np.linspace(32, 224, image_width)
image = np.tile(gradient, (image_height, 1))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.TOP:
gradient = np.linspace(224, 32, image_height)[:, None]
image = np.tile(gradient, (1, image_width))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
elif bg_source == BGSource.BOTTOM:
gradient = np.linspace(32, 224, image_height)[:, None]
image = np.tile(gradient, (1, image_width))
input_bg = np.stack((image,) * 3, axis=-1).astype(np.uint8)
else:
raise 'Wrong background source!'
rng = torch.Generator(device=device).manual_seed(seed)
fg = resize_and_center_crop(input_fg, image_width, image_height)
bg = resize_and_center_crop(input_bg, image_width, image_height)
concat_conds = numpy2pytorch([fg, bg]).to(device=vae.device, dtype=vae.dtype)
concat_conds = vae.encode(concat_conds).latent_dist.mode() * vae.config.scaling_factor
concat_conds = torch.cat([c[None, ...] for c in concat_conds], dim=1)
conds, unconds = encode_prompt_pair(positive_prompt=prompt + ', ' + a_prompt, negative_prompt=n_prompt)
latents = t2i_pipe(
prompt_embeds=conds,
negative_prompt_embeds=unconds,
width=image_width,
height=image_height,
num_inference_steps=steps,
num_images_per_prompt=num_samples,
generator=rng,
output_type='latent',
guidance_scale=cfg,
cross_attention_kwargs={'concat_conds': concat_conds},
).images.to(vae.dtype) / vae.config.scaling_factor
pixels = vae.decode(latents).sample
pixels = pytorch2numpy(pixels)
pixels = [resize_without_crop(
image=p,
target_width=int(round(image_width * highres_scale / 64.0) * 64),
target_height=int(round(image_height * highres_scale / 64.0) * 64))
for p in pixels]
pixels = numpy2pytorch(pixels).to(device=vae.device, dtype=vae.dtype)
latents = vae.encode(pixels).latent_dist.mode() * vae.config.scaling_factor
latents = latents.to(device=unet.device, dtype=unet.dtype)
image_height, image_width = latents.shape[2] * 8, latents.shape[3] * 8
fg = resize_and_center_crop(input_fg, image_width, image_height)
bg = resize_and_center_crop(input_bg, image_width, image_height)
concat_conds = numpy2pytorch([fg, bg]).to(device=vae.device, dtype=vae.dtype)
concat_conds = vae.encode(concat_conds).latent_dist.mode() * vae.config.scaling_factor
concat_conds = torch.cat([c[None, ...] for c in concat_conds], dim=1)
latents = i2i_pipe(
image=latents,
strength=highres_denoise,
prompt_embeds=conds,
negative_prompt_embeds=unconds,
width=image_width,
height=image_height,
num_inference_steps=int(round(steps / highres_denoise)),
num_images_per_prompt=num_samples,
generator=rng,
output_type='latent',
guidance_scale=cfg,
cross_attention_kwargs={'concat_conds': concat_conds},
).images.to(vae.dtype) / vae.config.scaling_factor
pixels = vae.decode(latents).sample
pixels = pytorch2numpy(pixels, quant=False)
return pixels, [fg, bg]
@torch.inference_mode()
def process_relight(input_fg, input_bg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, bg_source):
input_fg, matting = run_rmbg(input_fg)
results, extra_images = process(input_fg, input_bg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, bg_source)
results = [(x * 255.0).clip(0, 255).astype(np.uint8) for x in results]
return results + extra_images
@torch.inference_mode()
def process_normal(input_fg, input_bg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, bg_source):
input_fg, matting = run_rmbg(input_fg, sigma=16)
print('left ...')
left = process(input_fg, input_bg, prompt, image_width, image_height, 1, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, BGSource.LEFT.value)[0][0]
print('right ...')
right = process(input_fg, input_bg, prompt, image_width, image_height, 1, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, BGSource.RIGHT.value)[0][0]
print('bottom ...')
bottom = process(input_fg, input_bg, prompt, image_width, image_height, 1, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, BGSource.BOTTOM.value)[0][0]
print('top ...')
top = process(input_fg, input_bg, prompt, image_width, image_height, 1, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, BGSource.TOP.value)[0][0]
inner_results = [left * 2.0 - 1.0, right * 2.0 - 1.0, bottom * 2.0 - 1.0, top * 2.0 - 1.0]
ambient = (left + right + bottom + top) / 4.0
h, w, _ = ambient.shape
matting = resize_and_center_crop((matting[..., 0] * 255.0).clip(0, 255).astype(np.uint8), w, h).astype(np.float32)[..., None] / 255.0
def safa_divide(a, b):
e = 1e-5
return ((a + e) / (b + e)) - 1.0
left = safa_divide(left, ambient)
right = safa_divide(right, ambient)
bottom = safa_divide(bottom, ambient)
top = safa_divide(top, ambient)
u = (right - left) * 0.5
v = (top - bottom) * 0.5
sigma = 10.0
u = np.mean(u, axis=2)
v = np.mean(v, axis=2)
h = (1.0 - u ** 2.0 - v ** 2.0).clip(0, 1e5) ** (0.5 * sigma)
z = np.zeros_like(h)
normal = np.stack([u, v, h], axis=2)
normal /= np.sum(normal ** 2.0, axis=2, keepdims=True) ** 0.5
normal = normal * matting + np.stack([z, z, 1 - z], axis=2) * (1 - matting)
results = [normal, left, right, bottom, top] + inner_results
results = [(x * 127.5 + 127.5).clip(0, 255).astype(np.uint8) for x in results]
return results
quick_prompts = [
'beautiful woman',
'handsome man',
'beautiful woman, cinematic lighting',
'handsome man, cinematic lighting',
'beautiful woman, natural lighting',
'handsome man, natural lighting',
'beautiful woman, neo punk lighting, cyberpunk',
'handsome man, neo punk lighting, cyberpunk',
]
quick_prompts = [[x] for x in quick_prompts]
class BGSource(Enum):
UPLOAD = "Use Background Image"
UPLOAD_FLIP = "Use Flipped Background Image"
LEFT = "Left Light"
RIGHT = "Right Light"
TOP = "Top Light"
BOTTOM = "Bottom Light"
GREY = "Ambient"
block = gr.Blocks().queue()
with block:
with gr.Row():
gr.Markdown("## IC-Light (Relighting with Foreground and Background Condition)")
with gr.Row():
with gr.Column():
with gr.Row():
input_fg = gr.Image(source='upload', type="numpy", label="Foreground", height=480)
input_bg = gr.Image(source='upload', type="numpy", label="Background", height=480)
prompt = gr.Textbox(label="Prompt")
bg_source = gr.Radio(choices=[e.value for e in BGSource],
value=BGSource.UPLOAD.value,
label="Background Source", type='value')
example_prompts = gr.Dataset(samples=quick_prompts, label='Prompt Quick List', components=[prompt])
bg_gallery = gr.Gallery(height=450, object_fit='contain', label='Background Quick List', value=db_examples.bg_samples, columns=5, allow_preview=False)
relight_button = gr.Button(value="Relight")
with gr.Group():
with gr.Row():
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
seed = gr.Number(label="Seed", value=12345, precision=0)
with gr.Row():
image_width = gr.Slider(label="Image Width", minimum=256, maximum=1024, value=512, step=64)
image_height = gr.Slider(label="Image Height", minimum=256, maximum=1024, value=640, step=64)
with gr.Accordion("Advanced options", open=False):
steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
cfg = gr.Slider(label="CFG Scale", minimum=1.0, maximum=32.0, value=7.0, step=0.01)
highres_scale = gr.Slider(label="Highres Scale", minimum=1.0, maximum=3.0, value=1.5, step=0.01)
highres_denoise = gr.Slider(label="Highres Denoise", minimum=0.1, maximum=0.9, value=0.5, step=0.01)
a_prompt = gr.Textbox(label="Added Prompt", value='best quality')
n_prompt = gr.Textbox(label="Negative Prompt",
value='lowres, bad anatomy, bad hands, cropped, worst quality')
normal_button = gr.Button(value="Compute Normal (4x Slower)")
with gr.Column():
result_gallery = gr.Gallery(height=832, object_fit='contain', label='Outputs')
with gr.Row():
dummy_image_for_outputs = gr.Image(visible=False, label='Result')
gr.Examples(
fn=lambda *args: [args[-1]],
examples=db_examples.background_conditioned_examples,
inputs=[
input_fg, input_bg, prompt, bg_source, image_width, image_height, seed, dummy_image_for_outputs
],
outputs=[result_gallery],
run_on_click=True, examples_per_page=1024
)
ips = [input_fg, input_bg, prompt, image_width, image_height, num_samples, seed, steps, a_prompt, n_prompt, cfg, highres_scale, highres_denoise, bg_source]
relight_button.click(fn=process_relight, inputs=ips, outputs=[result_gallery])
normal_button.click(fn=process_normal, inputs=ips, outputs=[result_gallery])
example_prompts.click(lambda x: x[0], inputs=example_prompts, outputs=prompt, show_progress=False, queue=False)
def bg_gallery_selected(gal, evt: gr.SelectData):
return gal[evt.index]['name']
bg_gallery.select(bg_gallery_selected, inputs=bg_gallery, outputs=input_bg)
block.launch(server_name='0.0.0.0')
================================================
FILE: models/model_download_here
================================================
model download here
================================================
FILE: requirements.txt
================================================
diffusers==0.27.2
transformers==4.36.2
opencv-python
safetensors
pillow==10.2.0
einops
torch
peft
gradio==3.41.2
protobuf==3.20
gitextract_sw4pv86u/ ├── .gitignore ├── LICENSE ├── README.md ├── briarmbg.py ├── db_examples.py ├── gradio_demo.py ├── gradio_demo_bg.py ├── models/ │ └── model_download_here └── requirements.txt
SYMBOL INDEX (49 symbols across 3 files)
FILE: briarmbg.py
class REBNCONV (line 11) | class REBNCONV(nn.Module):
method __init__ (line 12) | def __init__(self, in_ch=3, out_ch=3, dirate=1, stride=1):
method forward (line 21) | def forward(self, x):
function _upsample_like (line 28) | def _upsample_like(src, tar):
class RSU7 (line 34) | class RSU7(nn.Module):
method __init__ (line 35) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3, img_size=512):
method forward (line 70) | def forward(self, x):
class RSU6 (line 116) | class RSU6(nn.Module):
method __init__ (line 117) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 144) | def forward(self, x):
class RSU5 (line 183) | class RSU5(nn.Module):
method __init__ (line 184) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 207) | def forward(self, x):
class RSU4 (line 240) | class RSU4(nn.Module):
method __init__ (line 241) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 260) | def forward(self, x):
class RSU4F (line 287) | class RSU4F(nn.Module):
method __init__ (line 288) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 303) | def forward(self, x):
class myrebnconv (line 321) | class myrebnconv(nn.Module):
method __init__ (line 322) | def __init__(
method forward (line 346) | def forward(self, x):
class BriaRMBG (line 350) | class BriaRMBG(nn.Module, PyTorchModelHubMixin):
method __init__ (line 351) | def __init__(self, config: dict = {"in_ch": 3, "out_ch": 1}):
method forward (line 391) | def forward(self, x):
FILE: gradio_demo.py
function hooked_unet_forward (line 40) | def hooked_unet_forward(sample, timestep, encoder_hidden_states, **kwargs):
function encode_prompt_inner (line 133) | def encode_prompt_inner(txt: str):
function encode_prompt_pair (line 154) | def encode_prompt_pair(positive_prompt, negative_prompt):
function pytorch2numpy (line 175) | def pytorch2numpy(imgs, quant=True):
function numpy2pytorch (line 192) | def numpy2pytorch(imgs):
function resize_and_center_crop (line 198) | def resize_and_center_crop(image, target_width, target_height):
function resize_without_crop (line 213) | def resize_without_crop(image, target_width, target_height):
function run_rmbg (line 220) | def run_rmbg(img, sigma=0.0):
function process (line 235) | def process(input_fg, prompt, image_width, image_height, num_samples, se...
function process_relight (line 340) | def process_relight(input_fg, prompt, image_width, image_height, num_sam...
class BGSource (line 372) | class BGSource(Enum):
FILE: gradio_demo_bg.py
function hooked_unet_forward (line 40) | def hooked_unet_forward(sample, timestep, encoder_hidden_states, **kwargs):
function encode_prompt_inner (line 133) | def encode_prompt_inner(txt: str):
function encode_prompt_pair (line 154) | def encode_prompt_pair(positive_prompt, negative_prompt):
function pytorch2numpy (line 175) | def pytorch2numpy(imgs, quant=True):
function numpy2pytorch (line 192) | def numpy2pytorch(imgs):
function resize_and_center_crop (line 198) | def resize_and_center_crop(image, target_width, target_height):
function resize_without_crop (line 213) | def resize_without_crop(image, target_width, target_height):
function run_rmbg (line 220) | def run_rmbg(img, sigma=0.0):
function process (line 235) | def process(input_fg, input_bg, prompt, image_width, image_height, num_s...
function process_relight (line 327) | def process_relight(input_fg, input_bg, prompt, image_width, image_heigh...
function process_normal (line 335) | def process_normal(input_fg, input_bg, prompt, image_width, image_height...
class BGSource (line 396) | class BGSource(Enum):
function bg_gallery_selected (line 459) | def bg_gallery_selected(gal, evt: gr.SelectData):
Condensed preview — 9 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (80K chars).
[
{
"path": ".gitignore",
"chars": 3092,
"preview": "*.safetensors\n\n# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distrib"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "README.md",
"chars": 9682,
"preview": "# IC-Light\n\nIC-Light is a project to manipulate the illumination of images.\n\nThe name \"IC-Light\" stands for **\"Imposing "
},
{
"path": "briarmbg.py",
"chars": 13432,
"preview": "# RMBG1.4 (diffusers implementation)\n# Found on huggingface space of several projects\n# Not sure which project is the so"
},
{
"path": "db_examples.py",
"chars": 4521,
"preview": "foreground_conditioned_examples = [\n [\n \"imgs/i1.webp\",\n \"beautiful woman, detailed face, sunshine, out"
},
{
"path": "gradio_demo.py",
"chars": 16591,
"preview": "import os\nimport math\nimport gradio as gr\nimport numpy as np\nimport torch\nimport safetensors.torch as sf\nimport db_examp"
},
{
"path": "gradio_demo_bg.py",
"chars": 18348,
"preview": "import os\nimport math\nimport gradio as gr\nimport numpy as np\nimport torch\nimport safetensors.torch as sf\nimport db_examp"
},
{
"path": "models/model_download_here",
"chars": 20,
"preview": "model download here\n"
},
{
"path": "requirements.txt",
"chars": 128,
"preview": "diffusers==0.27.2\ntransformers==4.36.2\nopencv-python\nsafetensors\npillow==10.2.0\neinops\ntorch\npeft\ngradio==3.41.2\nprotobu"
}
]
About this extraction
This page contains the full source code of the lllyasviel/IC-Light GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 9 files (75.4 KB), approximately 21.6k tokens, and a symbol index with 49 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.