Repository: lmnt-com/haste
Branch: master
Commit: ceba32ecd373
Files: 102
Total size: 762.7 KB
Directory structure:
gitextract_l70fejx2/
├── .gitignore
├── CHANGELOG.md
├── LICENSE
├── Makefile
├── README.md
├── benchmarks/
│ ├── benchmark_gru.cc
│ ├── benchmark_lstm.cc
│ ├── cudnn_wrappers.h
│ └── report.py
├── build/
│ ├── MANIFEST.in
│ ├── common.py
│ ├── setup.pytorch.py
│ └── setup.tf.py
├── docs/
│ ├── pytorch/
│ │ ├── haste_pytorch/
│ │ │ ├── GRU.md
│ │ │ ├── IndRNN.md
│ │ │ ├── LSTM.md
│ │ │ ├── LayerNormGRU.md
│ │ │ └── LayerNormLSTM.md
│ │ └── haste_pytorch.md
│ └── tf/
│ ├── haste_tf/
│ │ ├── GRU.md
│ │ ├── GRUCell.md
│ │ ├── IndRNN.md
│ │ ├── LSTM.md
│ │ ├── LayerNorm.md
│ │ ├── LayerNormGRU.md
│ │ ├── LayerNormGRUCell.md
│ │ ├── LayerNormLSTM.md
│ │ ├── LayerNormLSTMCell.md
│ │ └── ZoneoutWrapper.md
│ └── haste_tf.md
├── examples/
│ ├── device_ptr.h
│ ├── gru.cc
│ └── lstm.cc
├── frameworks/
│ ├── pytorch/
│ │ ├── __init__.py
│ │ ├── base_rnn.py
│ │ ├── gru.cc
│ │ ├── gru.py
│ │ ├── indrnn.cc
│ │ ├── indrnn.py
│ │ ├── layer_norm_gru.cc
│ │ ├── layer_norm_gru.py
│ │ ├── layer_norm_indrnn.cc
│ │ ├── layer_norm_indrnn.py
│ │ ├── layer_norm_lstm.cc
│ │ ├── layer_norm_lstm.py
│ │ ├── lstm.cc
│ │ ├── lstm.py
│ │ ├── support.cc
│ │ └── support.h
│ └── tf/
│ ├── __init__.py
│ ├── arena.h
│ ├── base_rnn.py
│ ├── gru.cc
│ ├── gru.py
│ ├── gru_cell.py
│ ├── indrnn.cc
│ ├── indrnn.py
│ ├── layer_norm.cc
│ ├── layer_norm.py
│ ├── layer_norm_gru.cc
│ ├── layer_norm_gru.py
│ ├── layer_norm_gru_cell.py
│ ├── layer_norm_indrnn.cc
│ ├── layer_norm_indrnn.py
│ ├── layer_norm_lstm.cc
│ ├── layer_norm_lstm.py
│ ├── layer_norm_lstm_cell.py
│ ├── lstm.cc
│ ├── lstm.py
│ ├── support.cc
│ ├── support.h
│ ├── weight_config.py
│ └── zoneout_wrapper.py
├── lib/
│ ├── blas.h
│ ├── device_assert.h
│ ├── gru_backward_gpu.cu.cc
│ ├── gru_forward_gpu.cu.cc
│ ├── haste/
│ │ ├── gru.h
│ │ ├── indrnn.h
│ │ ├── layer_norm.h
│ │ ├── layer_norm_gru.h
│ │ ├── layer_norm_indrnn.h
│ │ ├── layer_norm_lstm.h
│ │ └── lstm.h
│ ├── haste.h
│ ├── indrnn_backward_gpu.cu.cc
│ ├── indrnn_forward_gpu.cu.cc
│ ├── inline_ops.h
│ ├── layer_norm_backward_gpu.cu.cc
│ ├── layer_norm_forward_gpu.cu.cc
│ ├── layer_norm_gru_backward_gpu.cu.cc
│ ├── layer_norm_gru_forward_gpu.cu.cc
│ ├── layer_norm_indrnn_backward_gpu.cu.cc
│ ├── layer_norm_indrnn_forward_gpu.cu.cc
│ ├── layer_norm_lstm_backward_gpu.cu.cc
│ ├── layer_norm_lstm_forward_gpu.cu.cc
│ ├── lstm_backward_gpu.cu.cc
│ └── lstm_forward_gpu.cu.cc
└── validation/
├── pytorch.py
├── pytorch_speed.py
├── tf.py
└── tf_pytorch.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
*.a
*.o
*.so
*.whl
benchmark_lstm
benchmark_gru
haste_lstm
haste_gru
================================================
FILE: CHANGELOG.md
================================================
# ChangeLog
## 0.4.0 (2020-04-13)
### Added
- New layer normalized GRU layer (`LayerNormGRU`).
- New IndRNN layer.
- CPU support for all PyTorch layers.
- Support for building PyTorch API on Windows.
- Added `state` argument to PyTorch layers to specify initial state.
- Added weight transforms to TensorFlow API (see docs for details).
- Added `get_weights` method to extract weights from RNN layers (TensorFlow).
- Added `to_native_weights` and `from_native_weights` to PyTorch API for `LSTM` and `GRU` layers.
- Validation tests to check for correctness.
### Changed
- Performance improvements to GRU layer.
- BREAKING CHANGE: PyTorch layers default to CPU instead of GPU.
- BREAKING CHANGE: `h` must not be transposed before passing it to `gru::BackwardPass::Iterate`.
### Fixed
- Multi-GPU training with TensorFlow caused by invalid sharing of `cublasHandle_t`.
## 0.3.0 (2020-03-09)
### Added
- PyTorch support.
- New layer normalized LSTM layer (`LayerNormLSTM`).
- New fused layer normalization layer.
### Fixed
- Occasional uninitialized memory use in TensorFlow LSTM implementation.
## 0.2.0 (2020-02-12)
### Added
- New time-fused API for LSTM (`lstm::ForwardPass::Run`, `lstm::BackwardPass::Run`).
- Benchmarking code to evaluate the performance of an implementation.
### Changed
- Performance improvements to existing iterative LSTM API.
- BREAKING CHANGE: `h` must not be transposed before passing it to `lstm::BackwardPass::Iterate`.
- BREAKING CHANGE: `dv` does not need to be allocated and `v` must be passed instead to `lstm::BackwardPass::Iterate`.
## 0.1.0 (2020-01-29)
### Added
- Initial release of Haste.
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2020 LMNT, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: Makefile
================================================
AR ?= ar
CXX ?= g++
NVCC ?= nvcc -ccbin $(CXX)
PYTHON ?= python
ifeq ($(OS),Windows_NT)
LIBHASTE := haste.lib
CUDA_HOME ?= $(CUDA_PATH)
AR := lib
AR_FLAGS := /nologo /out:$(LIBHASTE)
NVCC_FLAGS := -x cu -Xcompiler "/MD"
else
LIBHASTE := libhaste.a
CUDA_HOME ?= /usr/local/cuda
AR ?= ar
AR_FLAGS := -crv $(LIBHASTE)
NVCC_FLAGS := -std=c++11 -x cu -Xcompiler -fPIC
endif
LOCAL_CFLAGS := -I/usr/include/eigen3 -I$(CUDA_HOME)/include -Ilib -O3
LOCAL_LDFLAGS := -L$(CUDA_HOME)/lib64 -L. -lcudart -lcublas
GPU_ARCH_FLAGS := -gencode arch=compute_37,code=compute_37 -gencode arch=compute_60,code=compute_60 -gencode arch=compute_70,code=compute_70
# Small enough project that we can just recompile all the time.
.PHONY: all haste haste_tf haste_pytorch libhaste_tf examples benchmarks clean
all: haste haste_tf haste_pytorch examples benchmarks
haste:
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/lstm_forward_gpu.cu.cc -o lib/lstm_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/lstm_backward_gpu.cu.cc -o lib/lstm_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/gru_forward_gpu.cu.cc -o lib/gru_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/gru_backward_gpu.cu.cc -o lib/gru_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_forward_gpu.cu.cc -o lib/layer_norm_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_backward_gpu.cu.cc -o lib/layer_norm_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_lstm_forward_gpu.cu.cc -o lib/layer_norm_lstm_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_lstm_backward_gpu.cu.cc -o lib/layer_norm_lstm_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_gru_forward_gpu.cu.cc -o lib/layer_norm_gru_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_gru_backward_gpu.cu.cc -o lib/layer_norm_gru_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/indrnn_backward_gpu.cu.cc -o lib/indrnn_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/indrnn_forward_gpu.cu.cc -o lib/indrnn_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_indrnn_forward_gpu.cu.cc -o lib/layer_norm_indrnn_forward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(NVCC) $(GPU_ARCH_FLAGS) -c lib/layer_norm_indrnn_backward_gpu.cu.cc -o lib/layer_norm_indrnn_backward_gpu.o $(NVCC_FLAGS) $(LOCAL_CFLAGS)
$(AR) $(AR_FLAGS) lib/*.o
libhaste_tf: haste
$(eval TF_CFLAGS := $(shell $(PYTHON) -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags()))'))
$(eval TF_LDFLAGS := $(shell $(PYTHON) -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags()))'))
$(CXX) -std=c++11 -c frameworks/tf/lstm.cc -o frameworks/tf/lstm.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/gru.cc -o frameworks/tf/gru.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/layer_norm.cc -o frameworks/tf/layer_norm.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/layer_norm_gru.cc -o frameworks/tf/layer_norm_gru.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/layer_norm_indrnn.cc -o frameworks/tf/layer_norm_indrnn.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/layer_norm_lstm.cc -o frameworks/tf/layer_norm_lstm.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/indrnn.cc -o frameworks/tf/indrnn.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -std=c++11 -c frameworks/tf/support.cc -o frameworks/tf/support.o $(LOCAL_CFLAGS) $(TF_CFLAGS) -fPIC
$(CXX) -shared frameworks/tf/*.o libhaste.a -o frameworks/tf/libhaste_tf.so $(LOCAL_LDFLAGS) $(TF_LDFLAGS) -fPIC
# Dependencies handled by setup.py
haste_tf:
@$(eval TMP := $(shell mktemp -d))
@cp -r . $(TMP)
@cat build/common.py build/setup.tf.py > $(TMP)/setup.py
@(cd $(TMP); $(PYTHON) setup.py -q bdist_wheel)
@cp $(TMP)/dist/*.whl .
@rm -rf $(TMP)
# Dependencies handled by setup.py
haste_pytorch:
@$(eval TMP := $(shell mktemp -d))
@cp -r . $(TMP)
@cat build/common.py build/setup.pytorch.py > $(TMP)/setup.py
@(cd $(TMP); $(PYTHON) setup.py -q bdist_wheel)
@cp $(TMP)/dist/*.whl .
@rm -rf $(TMP)
dist:
@$(eval TMP := $(shell mktemp -d))
@cp -r . $(TMP)
@cp build/MANIFEST.in $(TMP)
@cat build/common.py build/setup.tf.py > $(TMP)/setup.py
@(cd $(TMP); $(PYTHON) setup.py -q sdist)
@cp $(TMP)/dist/*.tar.gz .
@rm -rf $(TMP)
@$(eval TMP := $(shell mktemp -d))
@cp -r . $(TMP)
@cp build/MANIFEST.in $(TMP)
@cat build/common.py build/setup.pytorch.py > $(TMP)/setup.py
@(cd $(TMP); $(PYTHON) setup.py -q sdist)
@cp $(TMP)/dist/*.tar.gz .
@rm -rf $(TMP)
examples: haste
$(CXX) -std=c++11 examples/lstm.cc $(LIBHASTE) $(LOCAL_CFLAGS) $(LOCAL_LDFLAGS) -o haste_lstm -Wno-ignored-attributes
$(CXX) -std=c++11 examples/gru.cc $(LIBHASTE) $(LOCAL_CFLAGS) $(LOCAL_LDFLAGS) -o haste_gru -Wno-ignored-attributes
benchmarks: haste
$(CXX) -std=c++11 benchmarks/benchmark_lstm.cc $(LIBHASTE) $(LOCAL_CFLAGS) $(LOCAL_LDFLAGS) -o benchmark_lstm -Wno-ignored-attributes -lcudnn
$(CXX) -std=c++11 benchmarks/benchmark_gru.cc $(LIBHASTE) $(LOCAL_CFLAGS) $(LOCAL_LDFLAGS) -o benchmark_gru -Wno-ignored-attributes -lcudnn
clean:
rm -fr benchmark_lstm benchmark_gru haste_lstm haste_gru haste_*.whl haste_*.tar.gz
find . \( -iname '*.o' -o -iname '*.so' -o -iname '*.a' -o -iname '*.lib' \) -delete
================================================
FILE: README.md
================================================

--------------------------------------------------------------------------------
[](https://github.com/lmnt-com/haste/releases) [](https://colab.research.google.com/drive/1hzYhcyvbXYMAUwa3515BszSkhx1UUFSt) [](LICENSE)
**We're hiring!**
If you like what we're building here, [come join us at LMNT](https://explore.lmnt.com).
Haste is a CUDA implementation of fused RNN layers with built-in [DropConnect](http://proceedings.mlr.press/v28/wan13.html) and [Zoneout](https://arxiv.org/abs/1606.01305) regularization. These layers are exposed through C++ and Python APIs for easy integration into your own projects or machine learning frameworks.
Which RNN types are supported?
- [GRU](https://en.wikipedia.org/wiki/Gated_recurrent_unit)
- [IndRNN](http://arxiv.org/abs/1803.04831)
- [LSTM](https://en.wikipedia.org/wiki/Long_short-term_memory)
- [Layer Normalized GRU](https://arxiv.org/abs/1607.06450)
- [Layer Normalized LSTM](https://arxiv.org/abs/1607.06450)
What's included in this project?
- a standalone C++ API (`libhaste`)
- a TensorFlow Python API (`haste_tf`)
- a PyTorch API (`haste_pytorch`)
- examples for writing your own custom C++ inference / training code using `libhaste`
- benchmarking programs to evaluate the performance of RNN implementations
For questions or feedback about Haste, please open an issue on GitHub or send us an email at [haste@lmnt.com](mailto:haste@lmnt.com).
## Install
Here's what you'll need to get started:
- a [CUDA Compute Capability](https://developer.nvidia.com/cuda-gpus) 3.7+ GPU (required)
- [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit) 10.0+ (required)
- [TensorFlow GPU](https://www.tensorflow.org/install/gpu) 1.14+ or 2.0+ for TensorFlow integration (optional)
- [PyTorch](https://pytorch.org) 1.3+ for PyTorch integration (optional)
- [Eigen 3](http://eigen.tuxfamily.org/) to build the C++ examples (optional)
- [cuDNN Developer Library](https://developer.nvidia.com/rdp/cudnn-archive) to build benchmarking programs (optional)
Once you have the prerequisites, you can install with pip or by building the source code.
### Using pip
```
pip install haste_pytorch
pip install haste_tf
```
### Building from source
```
make # Build everything
make haste # ;) Build C++ API
make haste_tf # Build TensorFlow API
make haste_pytorch # Build PyTorch API
make examples
make benchmarks
```
If you built the TensorFlow or PyTorch API, install it with `pip`:
```
pip install haste_tf-*.whl
pip install haste_pytorch-*.whl
```
If the CUDA Toolkit that you're building against is not in `/usr/local/cuda`, you must specify the
`$CUDA_HOME` environment variable before running make:
```
CUDA_HOME=/usr/local/cuda-10.2 make
```
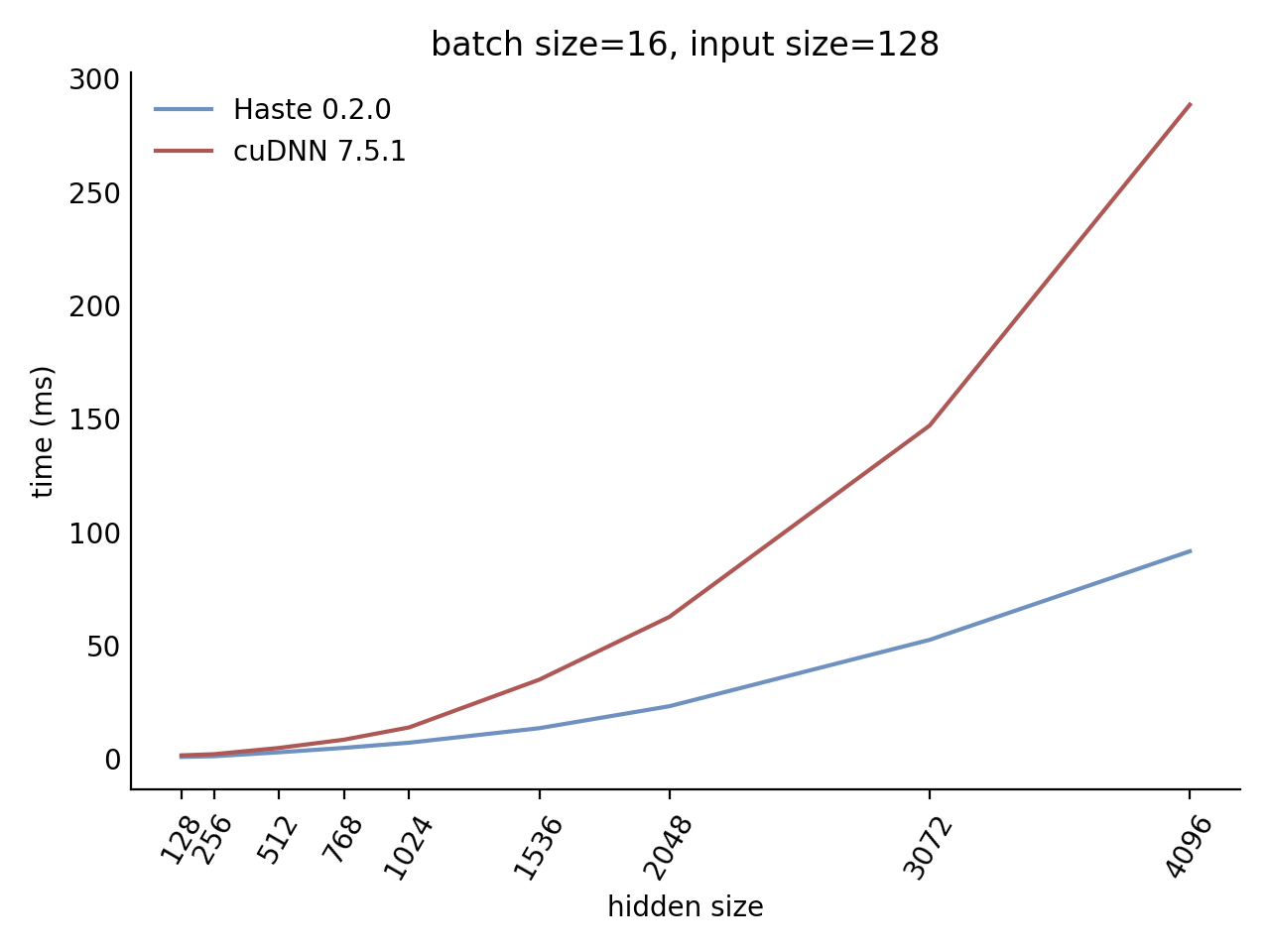
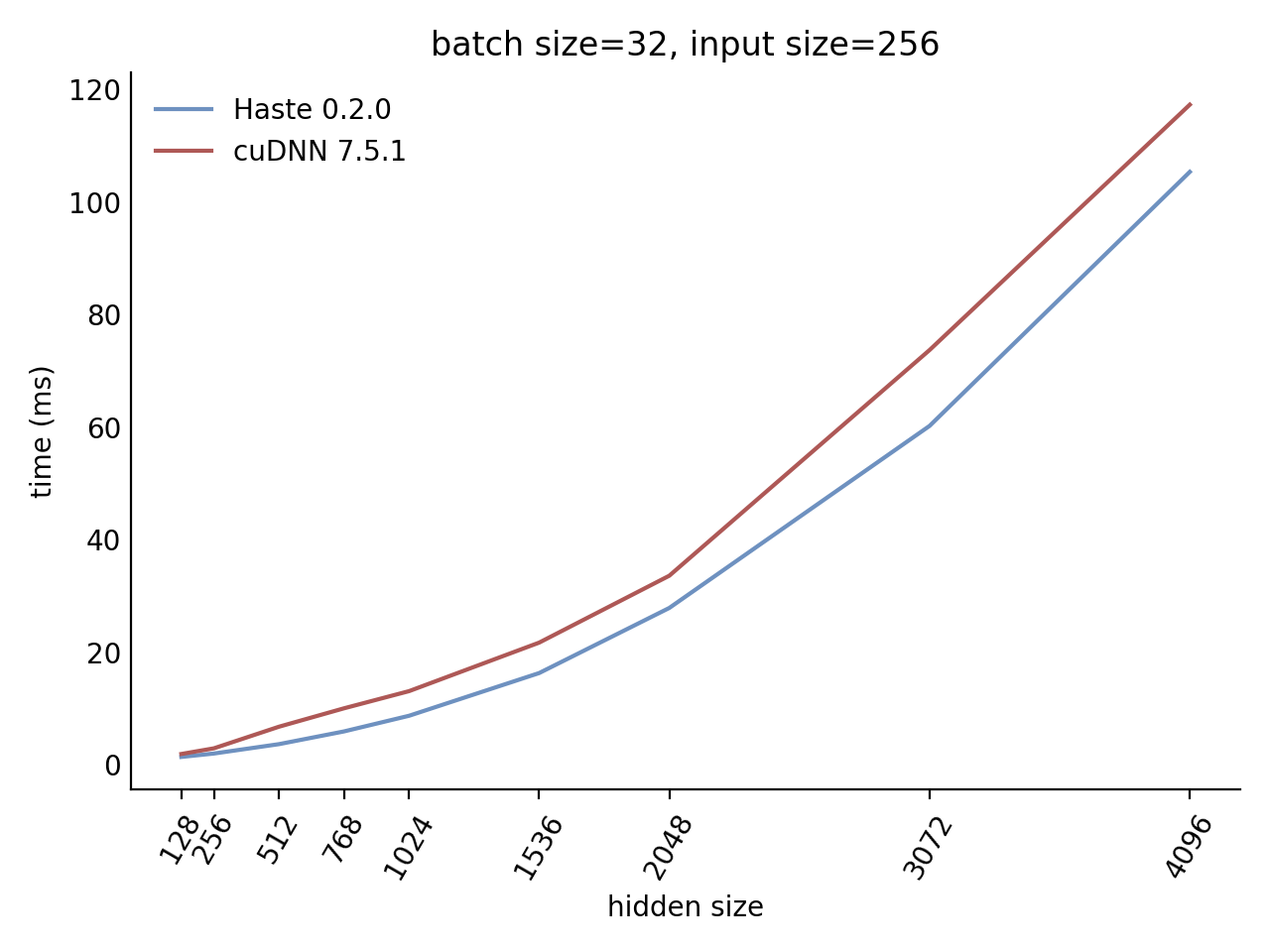
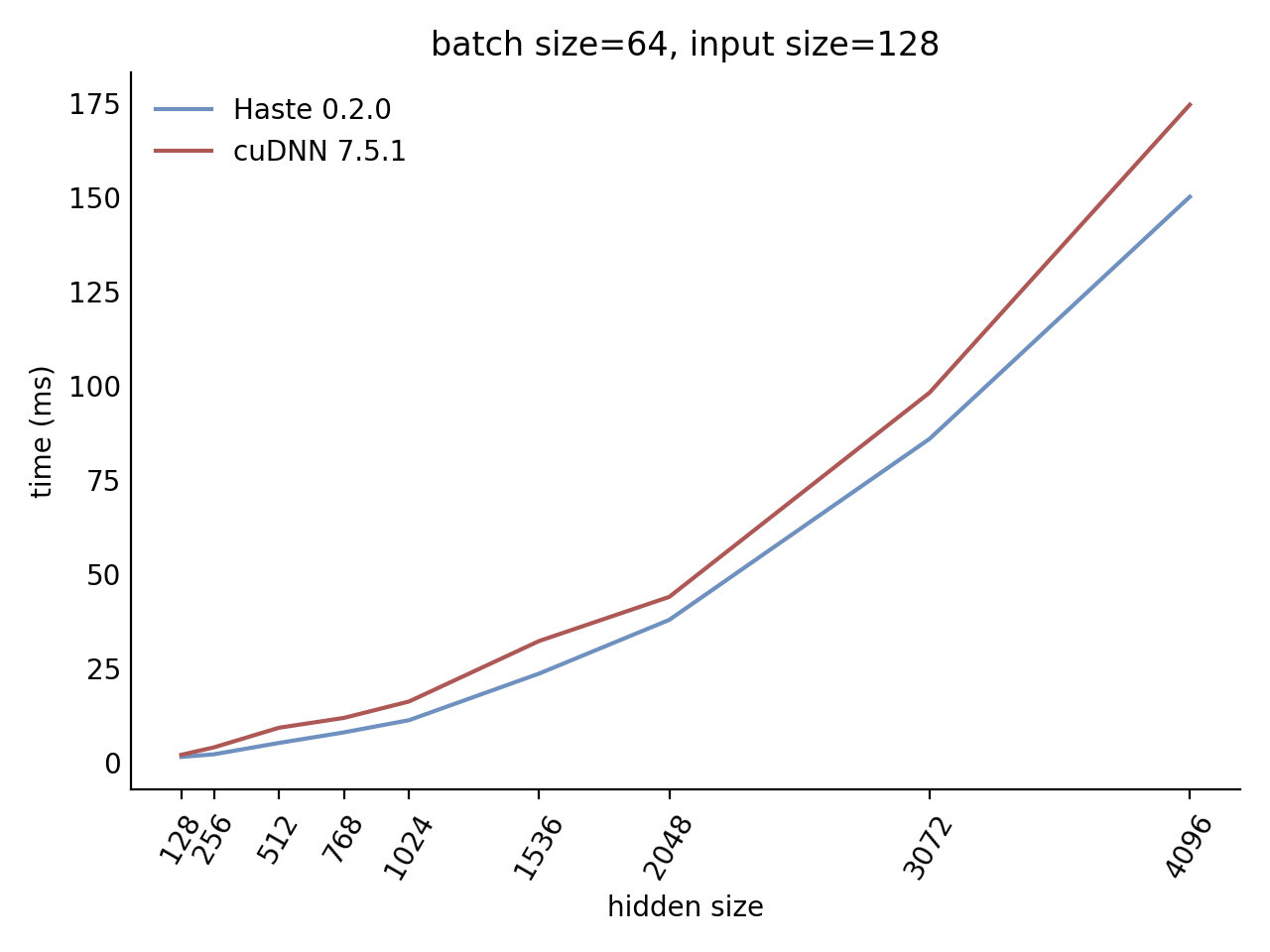
## Performance
Our LSTM and GRU benchmarks indicate that Haste has the fastest publicly available implementation for nearly all problem sizes. The following charts show our LSTM results, but the GRU results are qualitatively similar.
Here is our complete LSTM benchmark result grid:
[`N=1 C=64`](https://lmnt.com/assets/haste/benchmark/report_n=1_c=64.png)
[`N=1 C=128`](https://lmnt.com/assets/haste/benchmark/report_n=1_c=128.png)
[`N=1 C=256`](https://lmnt.com/assets/haste/benchmark/report_n=1_c=256.png)
[`N=1 C=512`](https://lmnt.com/assets/haste/benchmark/report_n=1_c=512.png)
[`N=32 C=64`](https://lmnt.com/assets/haste/benchmark/report_n=32_c=64.png)
[`N=32 C=128`](https://lmnt.com/assets/haste/benchmark/report_n=32_c=128.png)
[`N=32 C=256`](https://lmnt.com/assets/haste/benchmark/report_n=32_c=256.png)
[`N=32 C=512`](https://lmnt.com/assets/haste/benchmark/report_n=32_c=512.png)
[`N=64 C=64`](https://lmnt.com/assets/haste/benchmark/report_n=64_c=64.png)
[`N=64 C=128`](https://lmnt.com/assets/haste/benchmark/report_n=64_c=128.png)
[`N=64 C=256`](https://lmnt.com/assets/haste/benchmark/report_n=64_c=256.png)
[`N=64 C=512`](https://lmnt.com/assets/haste/benchmark/report_n=64_c=512.png)
[`N=128 C=64`](https://lmnt.com/assets/haste/benchmark/report_n=128_c=64.png)
[`N=128 C=128`](https://lmnt.com/assets/haste/benchmark/report_n=128_c=128.png)
[`N=128 C=256`](https://lmnt.com/assets/haste/benchmark/report_n=128_c=256.png)
[`N=128 C=512`](https://lmnt.com/assets/haste/benchmark/report_n=128_c=512.png)
## Documentation
### TensorFlow API
```python
import haste_tf as haste
gru_layer = haste.GRU(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
indrnn_layer = haste.IndRNN(num_units=256, direction='bidirectional', zoneout=0.1)
lstm_layer = haste.LSTM(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
norm_gru_layer = haste.LayerNormGRU(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
norm_lstm_layer = haste.LayerNormLSTM(num_units=256, direction='bidirectional', zoneout=0.1, dropout=0.05)
# `x` is a tensor with shape [N,T,C]
x = tf.random.normal([5, 25, 128])
y, state = gru_layer(x, training=True)
y, state = indrnn_layer(x, training=True)
y, state = lstm_layer(x, training=True)
y, state = norm_gru_layer(x, training=True)
y, state = norm_lstm_layer(x, training=True)
```
The TensorFlow Python API is documented in [`docs/tf/haste_tf.md`](docs/tf/haste_tf.md).
### PyTorch API
```python
import torch
import haste_pytorch as haste
gru_layer = haste.GRU(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
indrnn_layer = haste.IndRNN(input_size=128, hidden_size=256, zoneout=0.1)
lstm_layer = haste.LSTM(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
norm_gru_layer = haste.LayerNormGRU(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
norm_lstm_layer = haste.LayerNormLSTM(input_size=128, hidden_size=256, zoneout=0.1, dropout=0.05)
gru_layer.cuda()
indrnn_layer.cuda()
lstm_layer.cuda()
norm_gru_layer.cuda()
norm_lstm_layer.cuda()
# `x` is a CUDA tensor with shape [T,N,C]
x = torch.rand([25, 5, 128]).cuda()
y, state = gru_layer(x)
y, state = indrnn_layer(x)
y, state = lstm_layer(x)
y, state = norm_gru_layer(x)
y, state = norm_lstm_layer(x)
```
The PyTorch API is documented in [`docs/pytorch/haste_pytorch.md`](docs/pytorch/haste_pytorch.md).
### C++ API
The C++ API is documented in [`lib/haste/*.h`](lib/haste/) and there are code samples in [`examples/`](examples/).
## Code layout
- [`benchmarks/`](benchmarks): programs to evaluate performance of RNN implementations
- [`docs/tf/`](docs/tf): API reference documentation for `haste_tf`
- [`docs/pytorch/`](docs/pytorch): API reference documentation for `haste_pytorch`
- [`examples/`](examples): examples for writing your own C++ inference / training code using `libhaste`
- [`frameworks/tf/`](frameworks/tf): TensorFlow Python API and custom op code
- [`frameworks/pytorch/`](frameworks/pytorch): PyTorch API and custom op code
- [`lib/`](lib): CUDA kernels and C++ API
- [`validation/`](validation): scripts to validate output and gradients of RNN layers
## Implementation notes
- the GRU implementation is based on `1406.1078v1` (same as cuDNN) rather than `1406.1078v3`
- Zoneout on LSTM cells is applied to the hidden state only, and not the cell state
- the layer normalized LSTM implementation uses [these equations](https://github.com/lmnt-com/haste/issues/1)
## References
1. Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. _Neural Computation_, _9_(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
1. Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. _arXiv:1406.1078 [cs, stat]_. http://arxiv.org/abs/1406.1078.
1. Wan, L., Zeiler, M., Zhang, S., Cun, Y. L., & Fergus, R. (2013). Regularization of Neural Networks using DropConnect. In _International Conference on Machine Learning_ (pp. 1058–1066). Presented at the International Conference on Machine Learning. http://proceedings.mlr.press/v28/wan13.html.
1. Krueger, D., Maharaj, T., Kramár, J., Pezeshki, M., Ballas, N., Ke, N. R., et al. (2017). Zoneout: Regularizing RNNs by Randomly Preserving Hidden Activations. _arXiv:1606.01305 [cs]_. http://arxiv.org/abs/1606.01305.
1. Ba, J., Kiros, J.R., & Hinton, G.E. (2016). Layer Normalization. _arXiv:1607.06450 [cs, stat]_. https://arxiv.org/abs/1607.06450.
1. Li, S., Li, W., Cook, C., Zhu, C., & Gao, Y. (2018). Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. _arXiv:1803.04831 [cs]_. http://arxiv.org/abs/1803.04831.
## Citing this work
To cite this work, please use the following BibTeX entry:
```
@misc{haste2020,
title = {Haste: a fast, simple, and open RNN library},
author = {Sharvil Nanavati},
year = 2020,
month = "Jan",
howpublished = {\url{https://github.com/lmnt-com/haste/}},
}
```
## License
[Apache 2.0](LICENSE)
================================================
FILE: benchmarks/benchmark_gru.cc
================================================
// Copyright 2020 LMNT, Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// ==============================================================================
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "../examples/device_ptr.h"
#include "cudnn_wrappers.h"
#include "haste.h"
using haste::v0::gru::BackwardPass;
using haste::v0::gru::ForwardPass;
using std::string;
using Tensor1 = Eigen::Tensor;
using Tensor2 = Eigen::Tensor;
using Tensor3 = Eigen::Tensor;
static constexpr int DEFAULT_SAMPLE_SIZE = 10;
static constexpr int DEFAULT_TIME_STEPS = 50;
static cudnnHandle_t g_cudnn_handle;
static cublasHandle_t g_blas_handle;
float TimeLoop(std::function fn, int iterations) {
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
for (int i = 0; i < iterations; ++i)
fn();
float elapsed_ms;
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsed_ms / iterations;
}
float CudnnInference(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& bx,
const Tensor1& br,
const Tensor3& x) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
device_ptr x_dev(x);
device_ptr h_dev(batch_size * hidden_size);
device_ptr c_dev(batch_size * hidden_size);
device_ptr y_dev(time_steps * batch_size * hidden_size);
device_ptr h_out_dev(batch_size * hidden_size);
device_ptr c_out_dev(batch_size * hidden_size);
h_dev.zero();
c_dev.zero();
// Descriptors all the way down. Nice.
RnnDescriptor rnn_descriptor(g_cudnn_handle, hidden_size, CUDNN_GRU);
TensorDescriptorArray x_descriptors(time_steps, { batch_size, input_size, 1 });
TensorDescriptorArray y_descriptors(time_steps, { batch_size, hidden_size, 1 });
auto h_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto c_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto h_out_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto c_out_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
size_t workspace_size;
cudnnGetRNNWorkspaceSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&x_descriptors,
&workspace_size);
auto workspace_dev = device_ptr::NewByteSized(workspace_size);
size_t w_count;
cudnnGetRNNParamsSize(
g_cudnn_handle,
*rnn_descriptor,
*&x_descriptors,
&w_count,
CUDNN_DATA_FLOAT);
auto w_dev = device_ptr::NewByteSized(w_count);
FilterDescriptor w_descriptor(w_dev.Size());
float ms = TimeLoop([&]() {
cudnnRNNForwardInference(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&x_descriptors,
x_dev.data,
*h_descriptor,
h_dev.data,
*c_descriptor,
c_dev.data,
*w_descriptor,
w_dev.data,
&y_descriptors,
y_dev.data,
*h_out_descriptor,
h_out_dev.data,
*c_out_descriptor,
c_out_dev.data,
workspace_dev.data,
workspace_size);
}, sample_size);
return ms;
}
float CudnnTrain(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& bx,
const Tensor1& br,
const Tensor3& x,
const Tensor3& dh) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
device_ptr y_dev(time_steps * batch_size * hidden_size);
device_ptr dy_dev(time_steps * batch_size * hidden_size);
device_ptr dhy_dev(batch_size * hidden_size);
device_ptr dcy_dev(batch_size * hidden_size);
device_ptr hx_dev(batch_size * hidden_size);
device_ptr cx_dev(batch_size * hidden_size);
device_ptr dx_dev(time_steps * batch_size * input_size);
device_ptr dhx_dev(batch_size * hidden_size);
device_ptr dcx_dev(batch_size * hidden_size);
RnnDescriptor rnn_descriptor(g_cudnn_handle, hidden_size, CUDNN_GRU);
TensorDescriptorArray y_descriptors(time_steps, { batch_size, hidden_size, 1 });
TensorDescriptorArray dy_descriptors(time_steps, { batch_size, hidden_size, 1 });
TensorDescriptorArray dx_descriptors(time_steps, { batch_size, input_size, 1 });
TensorDescriptor dhy_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dcy_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor hx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor cx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dhx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dcx_descriptor({ 1, batch_size, hidden_size });
size_t workspace_size = 0;
cudnnGetRNNWorkspaceSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
&workspace_size);
auto workspace_dev = device_ptr::NewByteSized(workspace_size);
size_t w_count = 0;
cudnnGetRNNParamsSize(
g_cudnn_handle,
*rnn_descriptor,
*&dx_descriptors,
&w_count,
CUDNN_DATA_FLOAT);
auto w_dev = device_ptr::NewByteSized(w_count);
FilterDescriptor w_descriptor(w_dev.Size());
size_t reserve_size = 0;
cudnnGetRNNTrainingReserveSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
&reserve_size);
auto reserve_dev = device_ptr::NewByteSized(reserve_size);
float ms = TimeLoop([&]() {
cudnnRNNForwardTraining(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
dx_dev.data,
*hx_descriptor,
hx_dev.data,
*cx_descriptor,
cx_dev.data,
*w_descriptor,
w_dev.data,
&y_descriptors,
y_dev.data,
*dhy_descriptor,
dhy_dev.data,
*dcy_descriptor,
dcy_dev.data,
workspace_dev.data,
workspace_size,
reserve_dev.data,
reserve_size);
cudnnRNNBackwardData(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&y_descriptors,
y_dev.data,
&dy_descriptors,
dy_dev.data,
*dhy_descriptor,
dhy_dev.data,
*dcy_descriptor,
dcy_dev.data,
*w_descriptor,
w_dev.data,
*hx_descriptor,
hx_dev.data,
*cx_descriptor,
cx_dev.data,
&dx_descriptors,
dx_dev.data,
*dhx_descriptor,
dhx_dev.data,
*dcx_descriptor,
dcx_dev.data,
workspace_dev.data,
workspace_size,
reserve_dev.data,
reserve_size);
cudnnRNNBackwardWeights(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
dx_dev.data,
*hx_descriptor,
hx_dev.data,
&y_descriptors,
y_dev.data,
workspace_dev.data,
workspace_size,
*w_descriptor,
w_dev.data,
reserve_dev.data,
reserve_size);
}, sample_size);
return ms;
}
float HasteInference(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& bx,
const Tensor1& br,
const Tensor3& x) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
// Copy weights over to GPU.
device_ptr W_dev(W);
device_ptr R_dev(R);
device_ptr bx_dev(bx);
device_ptr br_dev(br);
device_ptr x_dev(x);
device_ptr h_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr tmp_Wx_dev(time_steps * batch_size * hidden_size * 3);
device_ptr tmp_Rh_dev(batch_size * hidden_size * 3);
h_dev.zero();
// Settle down the GPU and off we go!
cudaDeviceSynchronize();
float ms = TimeLoop([&]() {
ForwardPass forward(
false,
batch_size,
input_size,
hidden_size,
g_blas_handle);
forward.Run(
time_steps,
W_dev.data,
R_dev.data,
bx_dev.data,
br_dev.data,
x_dev.data,
h_dev.data,
nullptr,
tmp_Wx_dev.data,
tmp_Rh_dev.data,
0.0f,
nullptr);
}, sample_size);
return ms;
}
float HasteTrain(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& bx,
const Tensor1& br,
const Tensor3& x,
const Tensor3& dh) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
device_ptr W_dev(W);
device_ptr R_dev(R);
device_ptr x_dev(x);
device_ptr h_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr v_dev(time_steps * batch_size * hidden_size * 4);
device_ptr tmp_Wx_dev(time_steps * batch_size * hidden_size * 3);
device_ptr tmp_Rh_dev(batch_size * hidden_size * 3);
device_ptr W_t_dev(W);
device_ptr R_t_dev(R);
device_ptr bx_dev(bx);
device_ptr br_dev(br);
device_ptr x_t_dev(x);
// These gradients should actually come "from above" but we're just allocating
// a bunch of uninitialized memory and passing it in.
device_ptr dh_new_dev(dh);
device_ptr dx_dev(time_steps * batch_size * input_size);
device_ptr dW_dev(input_size * hidden_size * 3);
device_ptr dR_dev(hidden_size * hidden_size * 3);
device_ptr dbx_dev(hidden_size * 3);
device_ptr dbr_dev(hidden_size * 3);
device_ptr dh_dev(batch_size * hidden_size);
device_ptr dp_dev(time_steps * batch_size * hidden_size * 3);
device_ptr dq_dev(time_steps * batch_size * hidden_size * 3);
ForwardPass forward(
true,
batch_size,
input_size,
hidden_size,
g_blas_handle);
BackwardPass backward(
batch_size,
input_size,
hidden_size,
g_blas_handle);
static const float alpha = 1.0f;
static const float beta = 0.0f;
cudaDeviceSynchronize();
float ms = TimeLoop([&]() {
forward.Run(
time_steps,
W_dev.data,
R_dev.data,
bx_dev.data,
br_dev.data,
x_dev.data,
h_dev.data,
v_dev.data,
tmp_Wx_dev.data,
tmp_Rh_dev.data,
0.0f,
nullptr);
// Haste needs `x`, `W`, and `R` to be transposed between the forward
// pass and backward pass. Add these transposes in here to get a fair
// measurement of the overall time it takes to run an entire training
// loop.
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
batch_size * time_steps, input_size,
&alpha,
x_dev.data, input_size,
&beta,
x_dev.data, batch_size * time_steps,
x_t_dev.data, batch_size * time_steps);
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
input_size, hidden_size * 3,
&alpha,
W_dev.data, hidden_size * 3,
&beta,
W_dev.data, input_size,
W_t_dev.data, input_size);
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
hidden_size, hidden_size * 3,
&alpha,
R_dev.data, hidden_size * 3,
&beta,
R_dev.data, hidden_size,
R_t_dev.data, hidden_size);
backward.Run(
time_steps,
W_t_dev.data,
R_t_dev.data,
bx_dev.data,
br_dev.data,
x_t_dev.data,
h_dev.data,
v_dev.data,
dh_new_dev.data,
dx_dev.data,
dW_dev.data,
dR_dev.data,
dbx_dev.data,
dbr_dev.data,
dh_dev.data,
dp_dev.data,
dq_dev.data,
nullptr);
}, sample_size);
return ms;
}
void usage(const char* name) {
printf("Usage: %s [OPTION]...\n", name);
printf(" -h, --help\n");
printf(" -i, --implementation IMPL (default: haste)\n");
printf(" -m, --mode MODE (default: training)\n");
printf(" -s, --sample_size NUM number of runs to average over (default: %d)\n",
DEFAULT_SAMPLE_SIZE);
printf(" -t, --time_steps NUM number of time steps in RNN (default: %d)\n",
DEFAULT_TIME_STEPS);
}
int main(int argc, char* const* argv) {
srand(time(0));
cudnnCreate(&g_cudnn_handle);
cublasCreate(&g_blas_handle);
static struct option long_options[] = {
{ "help", no_argument, 0, 'h' },
{ "implementation", required_argument, 0, 'i' },
{ "mode", required_argument, 0, 'm' },
{ "sample_size", required_argument, 0, 's' },
{ "time_steps", required_argument, 0, 't' },
{ 0, 0, 0, 0 }
};
int c;
int opt_index;
bool inference_flag = false;
bool haste_flag = true;
int sample_size = DEFAULT_SAMPLE_SIZE;
int time_steps = DEFAULT_TIME_STEPS;
while ((c = getopt_long(argc, argv, "hi:m:s:t:", long_options, &opt_index)) != -1)
switch (c) {
case 'h':
usage(argv[0]);
return 0;
case 'i':
if (optarg[0] == 'c' || optarg[0] == 'C')
haste_flag = false;
break;
case 'm':
if (optarg[0] == 'i' || optarg[0] == 'I')
inference_flag = true;
break;
case 's':
sscanf(optarg, "%d", &sample_size);
break;
case 't':
sscanf(optarg, "%d", &time_steps);
break;
}
printf("# Benchmark configuration:\n");
printf("# Mode: %s\n", inference_flag ? "inference" : "training");
printf("# Implementation: %s\n", haste_flag ? "Haste" : "cuDNN");
printf("# Sample size: %d\n", sample_size);
printf("# Time steps: %d\n", time_steps);
printf("#\n");
printf("# batch_size,hidden_size,input_size,time_ms\n");
for (const int N : { 1, 16, 32, 64, 128 }) {
for (const int H : { 128, 256, 512, 768, 1024, 1536, 2048, 3072, 4096 }) {
for (const int C : { 64, 128, 256, 512 }) {
Tensor2 W(H * 3, C);
Tensor2 R(H * 3, H);
Tensor1 bx(H * 3);
Tensor1 br(H * 3);
Tensor3 x(C, N, time_steps);
Tensor3 dh(H, N, time_steps + 1);
float ms;
if (inference_flag) {
if (haste_flag)
ms = HasteInference(sample_size, W, R, bx, br, x);
else
ms = CudnnInference(sample_size, W, R, bx, br, x);
} else {
if (haste_flag)
ms = HasteTrain(sample_size, W, R, bx, br, x, dh);
else
ms = CudnnTrain(sample_size, W, R, bx, br, x, dh);
}
printf("%d,%d,%d,%f\n", N, H, C, ms);
}
}
}
cublasDestroy(g_blas_handle);
cudnnDestroy(g_cudnn_handle);
return 0;
}
================================================
FILE: benchmarks/benchmark_lstm.cc
================================================
// Copyright 2020 LMNT, Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// ==============================================================================
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "../examples/device_ptr.h"
#include "cudnn_wrappers.h"
#include "haste.h"
using haste::v0::lstm::BackwardPass;
using haste::v0::lstm::ForwardPass;
using std::string;
using Tensor1 = Eigen::Tensor;
using Tensor2 = Eigen::Tensor;
using Tensor3 = Eigen::Tensor;
static constexpr int DEFAULT_SAMPLE_SIZE = 10;
static constexpr int DEFAULT_TIME_STEPS = 50;
static cudnnHandle_t g_cudnn_handle;
static cublasHandle_t g_blas_handle;
float TimeLoop(std::function fn, int iterations) {
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
for (int i = 0; i < iterations; ++i)
fn();
float elapsed_ms;
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsed_ms / iterations;
}
float CudnnInference(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& b,
const Tensor3& x) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
device_ptr x_dev(x);
device_ptr h_dev(batch_size * hidden_size);
device_ptr c_dev(batch_size * hidden_size);
device_ptr y_dev(time_steps * batch_size * hidden_size);
device_ptr h_out_dev(batch_size * hidden_size);
device_ptr c_out_dev(batch_size * hidden_size);
h_dev.zero();
c_dev.zero();
// Descriptors all the way down. Nice.
RnnDescriptor rnn_descriptor(g_cudnn_handle, hidden_size, CUDNN_LSTM);
TensorDescriptorArray x_descriptors(time_steps, { batch_size, input_size, 1 });
TensorDescriptorArray y_descriptors(time_steps, { batch_size, hidden_size, 1 });
auto h_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto c_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto h_out_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
auto c_out_descriptor = TensorDescriptor({ 1, batch_size, hidden_size });
size_t workspace_size;
cudnnGetRNNWorkspaceSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&x_descriptors,
&workspace_size);
auto workspace_dev = device_ptr::NewByteSized(workspace_size);
size_t w_count;
cudnnGetRNNParamsSize(
g_cudnn_handle,
*rnn_descriptor,
*&x_descriptors,
&w_count,
CUDNN_DATA_FLOAT);
auto w_dev = device_ptr::NewByteSized(w_count);
FilterDescriptor w_descriptor(w_dev.Size());
float ms = TimeLoop([&]() {
cudnnRNNForwardInference(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&x_descriptors,
x_dev.data,
*h_descriptor,
h_dev.data,
*c_descriptor,
c_dev.data,
*w_descriptor,
w_dev.data,
&y_descriptors,
y_dev.data,
*h_out_descriptor,
h_out_dev.data,
*c_out_descriptor,
c_out_dev.data,
workspace_dev.data,
workspace_size);
}, sample_size);
return ms;
}
float CudnnTrain(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& b,
const Tensor3& x,
const Tensor3& dh,
const Tensor3& dc) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
device_ptr y_dev(time_steps * batch_size * hidden_size);
device_ptr dy_dev(time_steps * batch_size * hidden_size);
device_ptr dhy_dev(batch_size * hidden_size);
device_ptr dcy_dev(batch_size * hidden_size);
device_ptr hx_dev(batch_size * hidden_size);
device_ptr cx_dev(batch_size * hidden_size);
device_ptr dx_dev(time_steps * batch_size * input_size);
device_ptr dhx_dev(batch_size * hidden_size);
device_ptr dcx_dev(batch_size * hidden_size);
RnnDescriptor rnn_descriptor(g_cudnn_handle, hidden_size, CUDNN_LSTM);
TensorDescriptorArray y_descriptors(time_steps, { batch_size, hidden_size, 1 });
TensorDescriptorArray dy_descriptors(time_steps, { batch_size, hidden_size, 1 });
TensorDescriptorArray dx_descriptors(time_steps, { batch_size, input_size, 1 });
TensorDescriptor dhy_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dcy_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor hx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor cx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dhx_descriptor({ 1, batch_size, hidden_size });
TensorDescriptor dcx_descriptor({ 1, batch_size, hidden_size });
size_t workspace_size = 0;
cudnnGetRNNWorkspaceSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
&workspace_size);
auto workspace_dev = device_ptr::NewByteSized(workspace_size);
size_t w_count = 0;
cudnnGetRNNParamsSize(
g_cudnn_handle,
*rnn_descriptor,
*&dx_descriptors,
&w_count,
CUDNN_DATA_FLOAT);
auto w_dev = device_ptr::NewByteSized(w_count);
FilterDescriptor w_descriptor(w_dev.Size());
size_t reserve_size = 0;
cudnnGetRNNTrainingReserveSize(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
&reserve_size);
auto reserve_dev = device_ptr::NewByteSized(reserve_size);
float ms = TimeLoop([&]() {
cudnnRNNForwardTraining(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
dx_dev.data,
*hx_descriptor,
hx_dev.data,
*cx_descriptor,
cx_dev.data,
*w_descriptor,
w_dev.data,
&y_descriptors,
y_dev.data,
*dhy_descriptor,
dhy_dev.data,
*dcy_descriptor,
dcy_dev.data,
workspace_dev.data,
workspace_size,
reserve_dev.data,
reserve_size);
cudnnRNNBackwardData(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&y_descriptors,
y_dev.data,
&dy_descriptors,
dy_dev.data,
*dhy_descriptor,
dhy_dev.data,
*dcy_descriptor,
dcy_dev.data,
*w_descriptor,
w_dev.data,
*hx_descriptor,
hx_dev.data,
*cx_descriptor,
cx_dev.data,
&dx_descriptors,
dx_dev.data,
*dhx_descriptor,
dhx_dev.data,
*dcx_descriptor,
dcx_dev.data,
workspace_dev.data,
workspace_size,
reserve_dev.data,
reserve_size);
cudnnRNNBackwardWeights(
g_cudnn_handle,
*rnn_descriptor,
time_steps,
&dx_descriptors,
dx_dev.data,
*hx_descriptor,
hx_dev.data,
&y_descriptors,
y_dev.data,
workspace_dev.data,
workspace_size,
*w_descriptor,
w_dev.data,
reserve_dev.data,
reserve_size);
}, sample_size);
return ms;
}
float HasteInference(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& b,
const Tensor3& x) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
// Copy weights over to GPU.
device_ptr W_dev(W);
device_ptr R_dev(R);
device_ptr b_dev(b);
device_ptr x_dev(x);
device_ptr h_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr c_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr v_dev(time_steps * batch_size * hidden_size * 4);
device_ptr tmp_Rh_dev(batch_size * hidden_size * 4);
h_dev.zero();
c_dev.zero();
// Settle down the GPU and off we go!
cudaDeviceSynchronize();
float ms = TimeLoop([&]() {
ForwardPass forward(
false,
batch_size,
input_size,
hidden_size,
g_blas_handle);
forward.Run(
time_steps,
W_dev.data,
R_dev.data,
b_dev.data,
x_dev.data,
h_dev.data,
c_dev.data,
v_dev.data,
tmp_Rh_dev.data,
0.0f,
nullptr);
}, sample_size);
return ms;
}
float HasteTrain(
int sample_size,
const Tensor2& W,
const Tensor2& R,
const Tensor1& b,
const Tensor3& x,
const Tensor3& dh,
const Tensor3& dc) {
const int time_steps = x.dimension(2);
const int batch_size = x.dimension(1);
const int input_size = x.dimension(0);
const int hidden_size = R.dimension(1);
Eigen::array transpose_x({ 1, 2, 0 });
Tensor3 x_t = x.shuffle(transpose_x);
Eigen::array transpose({ 1, 0 });
Tensor2 W_t = W.shuffle(transpose);
Tensor2 R_t = R.shuffle(transpose);
device_ptr W_dev(W);
device_ptr R_dev(R);
device_ptr x_dev(x);
device_ptr h_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr c_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr v_dev(time_steps * batch_size * hidden_size * 4);
device_ptr tmp_Rh_dev(batch_size * hidden_size * 4);
device_ptr W_t_dev(W_t);
device_ptr R_t_dev(R_t);
device_ptr b_dev(b);
device_ptr x_t_dev(x_t);
// These gradients should actually come "from above" but we're just allocating
// a bunch of uninitialized memory and passing it in.
device_ptr dh_new_dev(dh);
device_ptr dc_new_dev(dc);
device_ptr dx_dev(time_steps * batch_size * input_size);
device_ptr dW_dev(input_size * hidden_size * 4);
device_ptr dR_dev(hidden_size * hidden_size * 4);
device_ptr db_dev(hidden_size * 4);
device_ptr dh_dev((time_steps + 1) * batch_size * hidden_size);
device_ptr dc_dev((time_steps + 1) * batch_size * hidden_size);
dW_dev.zero();
dR_dev.zero();
db_dev.zero();
dh_dev.zero();
dc_dev.zero();
ForwardPass forward(
true,
batch_size,
input_size,
hidden_size,
g_blas_handle);
BackwardPass backward(
batch_size,
input_size,
hidden_size,
g_blas_handle);
static const float alpha = 1.0f;
static const float beta = 0.0f;
cudaDeviceSynchronize();
float ms = TimeLoop([&]() {
forward.Run(
time_steps,
W_dev.data,
R_dev.data,
b_dev.data,
x_dev.data,
h_dev.data,
c_dev.data,
v_dev.data,
tmp_Rh_dev.data,
0.0f,
nullptr);
// Haste needs `x`, `W`, and `R` to be transposed between the forward
// pass and backward pass. Add these transposes in here to get a fair
// measurement of the overall time it takes to run an entire training
// loop.
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
batch_size * time_steps, input_size,
&alpha,
x_dev.data, input_size,
&beta,
x_dev.data, batch_size * time_steps,
x_t_dev.data, batch_size * time_steps);
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
input_size, hidden_size * 4,
&alpha,
W_dev.data, hidden_size * 4,
&beta,
W_dev.data, input_size,
W_t_dev.data, input_size);
cublasSgeam(
g_blas_handle,
CUBLAS_OP_T, CUBLAS_OP_N,
hidden_size, hidden_size * 4,
&alpha,
R_dev.data, hidden_size * 4,
&beta,
R_dev.data, hidden_size,
R_t_dev.data, hidden_size);
backward.Run(
time_steps,
W_t_dev.data,
R_t_dev.data,
b_dev.data,
x_t_dev.data,
h_dev.data,
c_dev.data,
dh_new_dev.data,
dc_new_dev.data,
dx_dev.data,
dW_dev.data,
dR_dev.data,
db_dev.data,
dh_dev.data,
dc_dev.data,
v_dev.data,
nullptr);
}, sample_size);
return ms;
}
void usage(const char* name) {
printf("Usage: %s [OPTION]...\n", name);
printf(" -h, --help\n");
printf(" -i, --implementation IMPL (default: haste)\n");
printf(" -m, --mode MODE (default: training)\n");
printf(" -s, --sample_size NUM number of runs to average over (default: %d)\n",
DEFAULT_SAMPLE_SIZE);
printf(" -t, --time_steps NUM number of time steps in RNN (default: %d)\n",
DEFAULT_TIME_STEPS);
}
int main(int argc, char* const* argv) {
srand(time(0));
cudnnCreate(&g_cudnn_handle);
cublasCreate(&g_blas_handle);
static struct option long_options[] = {
{ "help", no_argument, 0, 'h' },
{ "implementation", required_argument, 0, 'i' },
{ "mode", required_argument, 0, 'm' },
{ "sample_size", required_argument, 0, 's' },
{ "time_steps", required_argument, 0, 't' },
{ 0, 0, 0, 0 }
};
int c;
int opt_index;
bool inference_flag = false;
bool haste_flag = true;
int sample_size = DEFAULT_SAMPLE_SIZE;
int time_steps = DEFAULT_TIME_STEPS;
while ((c = getopt_long(argc, argv, "hi:m:s:t:", long_options, &opt_index)) != -1)
switch (c) {
case 'h':
usage(argv[0]);
return 0;
case 'i':
if (optarg[0] == 'c' || optarg[0] == 'C')
haste_flag = false;
break;
case 'm':
if (optarg[0] == 'i' || optarg[0] == 'I')
inference_flag = true;
break;
case 's':
sscanf(optarg, "%d", &sample_size);
break;
case 't':
sscanf(optarg, "%d", &time_steps);
break;
}
printf("# Benchmark configuration:\n");
printf("# Mode: %s\n", inference_flag ? "inference" : "training");
printf("# Implementation: %s\n", haste_flag ? "Haste" : "cuDNN");
printf("# Sample size: %d\n", sample_size);
printf("# Time steps: %d\n", time_steps);
printf("#\n");
printf("# batch_size,hidden_size,input_size,time_ms\n");
for (const int N : { 1, 16, 32, 64, 128 }) {
for (const int H : { 128, 256, 512, 768, 1024, 1536, 2048, 3072, 4096 }) {
for (const int C : { 64, 128, 256, 512 }) {
Tensor2 W(H * 4, C);
Tensor2 R(H * 4, H);
Tensor1 b(H * 4);
Tensor3 x(C, N, time_steps);
Tensor3 dh(H, N, time_steps + 1);
Tensor3 dc(H, N, time_steps + 1);
float ms;
if (inference_flag) {
if (haste_flag)
ms = HasteInference(sample_size, W, R, b, x);
else
ms = CudnnInference(sample_size, W, R, b, x);
} else {
if (haste_flag)
ms = HasteTrain(sample_size, W, R, b, x, dh, dc);
else
ms = CudnnTrain(sample_size, W, R, b, x, dh, dc);
}
printf("%d,%d,%d,%f\n", N, H, C, ms);
}
}
}
cublasDestroy(g_blas_handle);
cudnnDestroy(g_cudnn_handle);
return 0;
}
================================================
FILE: benchmarks/cudnn_wrappers.h
================================================
// Copyright 2020 LMNT, Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// ==============================================================================
#pragma once
#include
#include
#include
template
struct CudnnDataType {};
template<>
struct CudnnDataType {
static constexpr auto value = CUDNN_DATA_FLOAT;
};
template<>
struct CudnnDataType {
static constexpr auto value = CUDNN_DATA_DOUBLE;
};
template
class TensorDescriptor {
public:
TensorDescriptor(const std::vector& dims) {
std::vector strides;
int stride = 1;
for (int i = dims.size() - 1; i >= 0; --i) {
strides.insert(strides.begin(), stride);
stride *= dims[i];
}
cudnnCreateTensorDescriptor(&descriptor_);
cudnnSetTensorNdDescriptor(descriptor_, CudnnDataType::value, dims.size(), &dims[0], &strides[0]);
}
~TensorDescriptor() {
cudnnDestroyTensorDescriptor(descriptor_);
}
cudnnTensorDescriptor_t& operator*() {
return descriptor_;
}
private:
cudnnTensorDescriptor_t descriptor_;
};
template
class TensorDescriptorArray {
public:
TensorDescriptorArray(int count, const std::vector& dims) {
std::vector strides;
int stride = 1;
for (int i = dims.size() - 1; i >= 0; --i) {
strides.insert(strides.begin(), stride);
stride *= dims[i];
}
for (int i = 0; i < count; ++i) {
cudnnTensorDescriptor_t descriptor;
cudnnCreateTensorDescriptor(&descriptor);
cudnnSetTensorNdDescriptor(descriptor, CudnnDataType::value, dims.size(), &dims[0], &strides[0]);
descriptors_.push_back(descriptor);
}
}
~TensorDescriptorArray() {
for (auto& desc : descriptors_)
cudnnDestroyTensorDescriptor(desc);
}
cudnnTensorDescriptor_t* operator&() {
return &descriptors_[0];
}
private:
std::vector descriptors_;
};
class DropoutDescriptor {
public:
DropoutDescriptor(const cudnnHandle_t& handle) {
cudnnCreateDropoutDescriptor(&descriptor_);
cudnnSetDropoutDescriptor(descriptor_, handle, 0.0f, nullptr, 0, 0LL);
}
~DropoutDescriptor() {
cudnnDestroyDropoutDescriptor(descriptor_);
}
cudnnDropoutDescriptor_t& operator*() {
return descriptor_;
}
private:
cudnnDropoutDescriptor_t descriptor_;
};
template
class RnnDescriptor {
public:
RnnDescriptor(const cudnnHandle_t& handle, int size, cudnnRNNMode_t algorithm) : dropout_(handle) {
cudnnCreateRNNDescriptor(&descriptor_);
cudnnSetRNNDescriptor(
handle,
descriptor_,
size,
1,
*dropout_,
CUDNN_LINEAR_INPUT,
CUDNN_UNIDIRECTIONAL,
algorithm,
CUDNN_RNN_ALGO_STANDARD,
CudnnDataType::value);
}
~RnnDescriptor() {
cudnnDestroyRNNDescriptor(descriptor_);
}
cudnnRNNDescriptor_t& operator*() {
return descriptor_;
}
private:
cudnnRNNDescriptor_t descriptor_;
DropoutDescriptor dropout_;
};
template
class FilterDescriptor {
public:
FilterDescriptor(const size_t size) {
int filter_dim[] = { (int)size, 1, 1 };
cudnnCreateFilterDescriptor(&descriptor_);
cudnnSetFilterNdDescriptor(descriptor_, CudnnDataType::value, CUDNN_TENSOR_NCHW, 3, filter_dim);
}
~FilterDescriptor() {
cudnnDestroyFilterDescriptor(descriptor_);
}
cudnnFilterDescriptor_t& operator*() {
return descriptor_;
}
private:
cudnnFilterDescriptor_t descriptor_;
};
================================================
FILE: benchmarks/report.py
================================================
# Copyright 2020 LMNT, Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import argparse
import matplotlib.pyplot as plt
import numpy as np
import os
def extract(x, predicate):
return np.array(list(filter(predicate, x)))
def main(args):
np.set_printoptions(suppress=True)
A = np.loadtxt(args.A, delimiter=',')
B = np.loadtxt(args.B, delimiter=',')
faster = 1.0 - A[:,-1] / B[:,-1]
print(f'A is faster than B by:')
print(f' mean: {np.mean(faster)*100:7.4}%')
print(f' std: {np.std(faster)*100:7.4}%')
print(f' median: {np.median(faster)*100:7.4}%')
print(f' min: {np.min(faster)*100:7.4}%')
print(f' max: {np.max(faster)*100:7.4}%')
for batch_size in np.unique(A[:,0]):
for input_size in np.unique(A[:,2]):
a = extract(A, lambda x: x[0] == batch_size and x[2] == input_size)
b = extract(B, lambda x: x[0] == batch_size and x[2] == input_size)
fig, ax = plt.subplots(dpi=200)
ax.set_xticks(a[:,1])
ax.set_xticklabels(a[:,1].astype(np.int32), rotation=60)
ax.tick_params(axis='y', which='both', length=0)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.title(f'batch size={int(batch_size)}, input size={int(input_size)}')
plt.plot(a[:,1], a[:,-1], color=args.color[0])
plt.plot(a[:,1], b[:,-1], color=args.color[1])
plt.xlabel('hidden size')
plt.ylabel('time (ms)')
plt.legend(args.name, frameon=False)
plt.tight_layout()
if args.save:
os.makedirs(args.save[0], exist_ok=True)
plt.savefig(f'{args.save[0]}/report_n={int(batch_size)}_c={int(input_size)}.png', dpi=200)
else:
plt.show()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--name', nargs=2, default=['A', 'B'])
parser.add_argument('--color', nargs=2, default=['#1f77b4', '#2ca02c'])
parser.add_argument('--save', nargs=1, default=None)
parser.add_argument('A')
parser.add_argument('B')
main(parser.parse_args())
================================================
FILE: build/MANIFEST.in
================================================
include Makefile
include frameworks/tf/*.h
include frameworks/tf/*.cc
include frameworks/pytorch/*.h
include frameworks/pytorch/*.cc
include lib/*.cc
include lib/*.h
include lib/haste/*.h
================================================
FILE: build/common.py
================================================
# Copyright 2020 LMNT, Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
VERSION = '0.5.0-rc0'
DESCRIPTION = 'Haste: a fast, simple, and open RNN library.'
AUTHOR = 'LMNT, Inc.'
AUTHOR_EMAIL = 'haste@lmnt.com'
URL = 'https://haste.lmnt.com'
LICENSE = 'Apache 2.0'
CLASSIFIERS = [
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Intended Audience :: Education',
'Intended Audience :: Science/Research',
'License :: OSI Approved :: Apache Software License',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
'Topic :: Scientific/Engineering :: Mathematics',
'Topic :: Software Development :: Libraries :: Python Modules',
'Topic :: Software Development :: Libraries',
]
================================================
FILE: build/setup.pytorch.py
================================================
# Copyright 2020 LMNT, Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import os
import sys
from glob import glob
from platform import platform
from torch.utils import cpp_extension
from setuptools import setup
from setuptools.dist import Distribution
class BuildHaste(cpp_extension.BuildExtension):
def run(self):
os.system('make haste')
super().run()
base_path = os.path.dirname(os.path.realpath(__file__))
if 'Windows' in platform():
CUDA_HOME = os.environ.get('CUDA_HOME', os.environ.get('CUDA_PATH'))
extra_args = []
else:
CUDA_HOME = os.environ.get('CUDA_HOME', '/usr/local/cuda')
extra_args = ['-Wno-sign-compare']
with open(f'frameworks/pytorch/_version.py', 'wt') as f:
f.write(f'__version__ = "{VERSION}"')
extension = cpp_extension.CUDAExtension(
'haste_pytorch_lib',
sources = glob('frameworks/pytorch/*.cc'),
extra_compile_args = extra_args,
include_dirs = [os.path.join(base_path, 'lib'), os.path.join(CUDA_HOME, 'include')],
libraries = ['haste'],
library_dirs = ['.'])
setup(name = 'haste_pytorch',
version = VERSION,
description = DESCRIPTION,
long_description = open('README.md', 'r',encoding='utf-8').read(),
long_description_content_type = 'text/markdown',
author = AUTHOR,
author_email = AUTHOR_EMAIL,
url = URL,
license = LICENSE,
keywords = 'pytorch machine learning rnn lstm gru custom op',
packages = ['haste_pytorch'],
package_dir = { 'haste_pytorch': 'frameworks/pytorch' },
install_requires = [],
ext_modules = [extension],
cmdclass = { 'build_ext': BuildHaste },
classifiers = CLASSIFIERS)
================================================
FILE: build/setup.tf.py
================================================
# Copyright 2020 LMNT, Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import os
import sys
from setuptools import setup
from setuptools.dist import Distribution
from distutils.command.build import build as _build
class BinaryDistribution(Distribution):
"""This class is needed in order to create OS specific wheels."""
def has_ext_modules(self):
return True
class BuildHaste(_build):
def run(self):
os.system('make libhaste_tf')
super().run()
with open(f'frameworks/tf/_version.py', 'wt') as f:
f.write(f'__version__ = "{VERSION}"')
setup(name = 'haste_tf',
version = VERSION,
description = DESCRIPTION,
long_description = open('README.md', 'r').read(),
long_description_content_type = 'text/markdown',
author = AUTHOR,
author_email = AUTHOR_EMAIL,
url = URL,
license = LICENSE,
keywords = 'tensorflow machine learning rnn lstm gru custom op',
packages = ['haste_tf'],
package_dir = { 'haste_tf': 'frameworks/tf' },
package_data = { 'haste_tf': ['*.so'] },
install_requires = [],
zip_safe = False,
distclass = BinaryDistribution,
cmdclass = { 'build': BuildHaste },
classifiers = CLASSIFIERS)
================================================
FILE: docs/pytorch/haste_pytorch/GRU.md
================================================
# haste_pytorch.GRU
## Class `GRU`
Gated Recurrent Unit layer.
This GRU layer offers a fused, GPU-accelerated PyTorch op for inference
and training. There are two commonly-used variants of GRU cells. This one
implements 1406.1078v1 which applies the reset gate to the hidden state
after matrix multiplication. cuDNN also implements this variant. The other
variant, 1406.1078v3, applies the reset gate before matrix multiplication
and is currently unsupported.
This layer has built-in support for DropConnect and Zoneout, which are
both techniques used to regularize RNNs.
See [\_\_init\_\_](#__init__) and [forward](#forward) for usage.
See [from_native_weights](#from_native_weights) and
[to_native_weights](#to_native_weights) for compatibility with PyTorch GRUs.
``` python
__init__(
input_size,
hidden_size,
batch_first=False,
dropout=0.0,
zoneout=0.0
)
```
Initialize the parameters of the GRU layer.
#### Arguments:
* `input_size`: int, the feature dimension of the input.
* `hidden_size`: int, the feature dimension of the output.
* `batch_first`: (optional) bool, if `True`, then the input and output
tensors are provided as `(batch, seq, feature)`.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization.
#### Variables:
* `kernel`: the input projection weight matrix. Dimensions
(input_size, hidden_size * 3) with `z,r,h` gate layout. Initialized
with Xavier uniform initialization.
* `recurrent_kernel`: the recurrent projection weight matrix. Dimensions
(hidden_size, hidden_size * 3) with `z,r,h` gate layout. Initialized
with orthogonal initialization.
* `bias`: the input projection bias vector. Dimensions (hidden_size * 3) with
`z,r,h` gate layout. Initialized to zeros.
* `recurrent_bias`: the recurrent projection bias vector. Dimensions
(hidden_size * 3) with `z,r,h` gate layout. Initialized to zeros.
## Methods
``` python
__call__(
*input,
**kwargs
)
```
Call self as a function.
``` python
add_module(
name,
module
)
```
Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
#### Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
``` python
apply(fn)
```
Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`nn-init-doc`).
#### Args:
fn (:class:`Module` -> None): function to be applied to each submodule
#### Returns:
* `Module`: self
Example::
```
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
```
``` python
buffers(recurse=True)
```
Returns an iterator over module buffers.
#### Args:
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `torch.Tensor`: module buffer
Example::
```
>>> for buf in model.buffers():
>>> print(type(buf.data), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
children()
```
Returns an iterator over immediate children modules.
#### Yields:
* `Module`: a child module
``` python
cpu()
```
Moves all model parameters and buffers to the CPU.
#### Returns:
* `Module`: self
``` python
cuda(device=None)
```
Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
#### Arguments:
device (int, optional): if specified, all parameters will be
copied to that device
#### Returns:
* `Module`: self
``` python
double()
```
Casts all floating point parameters and buffers to ``double`` datatype.
#### Returns:
* `Module`: self
``` python
eval()
```
Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
#### Returns:
* `Module`: self
``` python
extra_repr()
```
Set the extra representation of the module
To print customized extra information, you should reimplement
this method in your own modules. Both single-line and multi-line
strings are acceptable.
``` python
float()
```
Casts all floating point parameters and buffers to float datatype.
#### Returns:
* `Module`: self
``` python
forward(
input,
state=None,
lengths=None
)
```
Runs a forward pass of the GRU layer.
#### Arguments:
* `input`: Tensor, a batch of input sequences to pass through the GRU.
Dimensions (seq_len, batch_size, input_size) if `batch_first` is
`False`, otherwise (batch_size, seq_len, input_size).
* `lengths`: (optional) Tensor, list of sequence lengths for each batch
element. Dimension (batch_size). This argument may be omitted if
all batch elements are unpadded and have the same sequence length.
#### Returns:
* `output`: Tensor, the output of the GRU layer. Dimensions
(seq_len, batch_size, hidden_size) if `batch_first` is `False` (default)
or (batch_size, seq_len, hidden_size) if `batch_first` is `True`. Note
that if `lengths` was specified, the `output` tensor will not be
masked. It's the caller's responsibility to either not use the invalid
entries or to mask them out before using them.
* `h_n`: the hidden state for the last sequence item. Dimensions
(1, batch_size, hidden_size).
``` python
from_native_weights(
weight_ih_l0,
weight_hh_l0,
bias_ih_l0,
bias_hh_l0
)
```
Copies and converts the provided PyTorch GRU weights into this layer.
#### Arguments:
* `weight_ih_l0`: Parameter, the input-hidden weights of the PyTorch GRU layer.
* `weight_hh_l0`: Parameter, the hidden-hidden weights of the PyTorch GRU layer.
* `bias_ih_l0`: Parameter, the input-hidden bias of the PyTorch GRU layer.
* `bias_hh_l0`: Parameter, the hidden-hidden bias of the PyTorch GRU layer.
``` python
half()
```
Casts all floating point parameters and buffers to ``half`` datatype.
#### Returns:
* `Module`: self
``` python
load_state_dict(
state_dict,
strict=True
)
```
Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~torch.nn.Module.state_dict` function.
#### Arguments:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~torch.nn.Module.state_dict` function. Default: ``True``
#### Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
``` python
modules()
```
Returns an iterator over all modules in the network.
#### Yields:
* `Module`: a module in the network
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
print(idx, '->', m)
```
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
``` python
named_buffers(
prefix='',
recurse=True
)
```
Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
#### Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `(string, torch.Tensor)`: Tuple containing the name and buffer
Example::
```
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
```
``` python
named_children()
```
Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple containing a name and child module
Example::
```
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
```
``` python
named_modules(
memo=None,
prefix=''
)
```
Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple of name and module
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
print(idx, '->', m)
```
0 -> ('', Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
``` python
named_parameters(
prefix='',
recurse=True
)
```
Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
#### Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `(string, Parameter)`: Tuple containing the name and parameter
Example::
```
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
```
``` python
parameters(recurse=True)
```
Returns an iterator over module parameters.
This is typically passed to an optimizer.
#### Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `Parameter`: module parameter
Example::
```
>>> for param in model.parameters():
>>> print(type(param.data), param.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
register_backward_hook(hook)
```
Registers a backward hook on the module.
The hook will be called every time the gradients with respect to module
inputs are computed. The hook should have the following signature::
hook(module, grad_input, grad_output) -> Tensor or None
The :attr:`grad_input` and :attr:`grad_output` may be tuples if the
module has multiple inputs or outputs. The hook should not modify its
arguments, but it can optionally return a new gradient with respect to
input that will be used in place of :attr:`grad_input` in subsequent
computations.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
.. warning ::
The current implementation will not have the presented behavior
for complex :class:`Module` that perform many operations.
In some failure cases, :attr:`grad_input` and :attr:`grad_output` will only
contain the gradients for a subset of the inputs and outputs.
For such :class:`Module`, you should use :func:`torch.Tensor.register_hook`
directly on a specific input or output to get the required gradients.
``` python
register_buffer(
name,
tensor
)
```
Adds a persistent buffer to the module.
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the persistent state.
Buffers can be accessed as attributes using given names.
#### Args:
name (string): name of the buffer. The buffer can be accessed
from this module using the given name
tensor (Tensor): buffer to be registered.
Example::
```
>>> self.register_buffer('running_mean', torch.zeros(num_features))
```
``` python
register_forward_hook(hook)
```
Registers a forward hook on the module.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None or modified output
The hook can modify the output. It can modify the input inplace but
it will not have effect on forward since this is called after
:func:`forward` is called.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_forward_pre_hook(hook)
```
Registers a forward pre-hook on the module.
The hook will be called every time before :func:`forward` is invoked.
It should have the following signature::
hook(module, input) -> None or modified input
The hook can modify the input. User can either return a tuple or a
single modified value in the hook. We will wrap the value into a tuple
if a single value is returned(unless that value is already a tuple).
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_parameter(
name,
param
)
```
Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
#### Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
``` python
requires_grad_(requires_grad=True)
```
Change if autograd should record operations on parameters in this
module.
This method sets the parameters' :attr:`requires_grad` attributes
in-place.
This method is helpful for freezing part of the module for finetuning
or training parts of a model individually (e.g., GAN training).
#### Args:
requires_grad (bool): whether autograd should record operations on
parameters in this module. Default: ``True``.
#### Returns:
* `Module`: self
``` python
reset_parameters()
```
Resets this layer's parameters to their initial values.
``` python
share_memory()
```
``` python
state_dict(
destination=None,
prefix='',
keep_vars=False
)
```
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
#### Returns:
* `dict`: a dictionary containing a whole state of the module
Example::
```
>>> module.state_dict().keys()
['bias', 'weight']
```
``` python
to(
*args,
**kwargs
)
```
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point desired :attr:`dtype` s. In addition, this method will
only cast the floating point parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
#### Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
#### Returns:
* `Module`: self
Example::
```
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
```
``` python
to_native_weights()
```
Converts Haste GRU weights to native PyTorch GRU weights.
#### Returns:
* `weight_ih_l0`: Parameter, the input-hidden weights of the GRU layer.
* `weight_hh_l0`: Parameter, the hidden-hidden weights of the GRU layer.
* `bias_ih_l0`: Parameter, the input-hidden bias of the GRU layer.
* `bias_hh_l0`: Parameter, the hidden-hidden bias of the GRU layer.
``` python
train(mode=True)
```
Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
#### Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
#### Returns:
* `Module`: self
``` python
type(dst_type)
```
Casts all parameters and buffers to :attr:`dst_type`.
#### Arguments:
dst_type (type or string): the desired type
#### Returns:
* `Module`: self
``` python
zero_grad()
```
Sets gradients of all model parameters to zero.
================================================
FILE: docs/pytorch/haste_pytorch/IndRNN.md
================================================
# haste_pytorch.IndRNN
## Class `IndRNN`
Independently Recurrent Neural Network layer.
This layer offers a fused, GPU-accelerated PyTorch op for inference and
training. It also supports Zoneout regularization.
See [\_\_init\_\_](#__init__) and [forward](#forward) for usage.
``` python
__init__(
input_size,
hidden_size,
batch_first=False,
zoneout=0.0
)
```
Initialize the parameters of the IndRNN layer.
#### Arguments:
* `input_size`: int, the feature dimension of the input.
* `hidden_size`: int, the feature dimension of the output.
* `batch_first`: (optional) bool, if `True`, then the input and output
tensors are provided as `(batch, seq, feature)`.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization.
#### Variables:
* `kernel`: the input projection weight matrix. Dimensions
(input_size, hidden_size). Initialized with Xavier uniform
initialization.
* `recurrent_scale`: the recurrent scale weight vector. Dimensions
(hidden_size). Initialized uniformly in [-0.5, 0.5]. Note that this
initialization scheme is different than in the original authors'
implementation. See https://github.com/lmnt-com/haste/issues/7 for
details.
* `bias`: the RNN bias vector. Dimensions (hidden_size). Initialized to zeros.
## Methods
``` python
__call__(
*input,
**kwargs
)
```
Call self as a function.
``` python
add_module(
name,
module
)
```
Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
#### Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
``` python
apply(fn)
```
Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`nn-init-doc`).
#### Args:
fn (:class:`Module` -> None): function to be applied to each submodule
#### Returns:
* `Module`: self
Example::
```
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
```
``` python
buffers(recurse=True)
```
Returns an iterator over module buffers.
#### Args:
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `torch.Tensor`: module buffer
Example::
```
>>> for buf in model.buffers():
>>> print(type(buf.data), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
children()
```
Returns an iterator over immediate children modules.
#### Yields:
* `Module`: a child module
``` python
cpu()
```
Moves all model parameters and buffers to the CPU.
#### Returns:
* `Module`: self
``` python
cuda(device=None)
```
Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
#### Arguments:
device (int, optional): if specified, all parameters will be
copied to that device
#### Returns:
* `Module`: self
``` python
double()
```
Casts all floating point parameters and buffers to ``double`` datatype.
#### Returns:
* `Module`: self
``` python
eval()
```
Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
#### Returns:
* `Module`: self
``` python
extra_repr()
```
Set the extra representation of the module
To print customized extra information, you should reimplement
this method in your own modules. Both single-line and multi-line
strings are acceptable.
``` python
float()
```
Casts all floating point parameters and buffers to float datatype.
#### Returns:
* `Module`: self
``` python
forward(
input,
state=None,
lengths=None
)
```
Runs a forward pass of the IndRNN layer.
#### Arguments:
* `input`: Tensor, a batch of input sequences to pass through the GRU.
Dimensions (seq_len, batch_size, input_size) if `batch_first` is
`False`, otherwise (batch_size, seq_len, input_size).
* `state`: (optional) Tensor, the initial state for each batch element in
`input`. Dimensions (1, batch_size, hidden_size). Defaults to zeros.
* `lengths`: (optional) Tensor, list of sequence lengths for each batch
element. Dimension (batch_size). This argument may be omitted if
all batch elements are unpadded and have the same sequence length.
#### Returns:
* `output`: Tensor, the output of the GRU layer. Dimensions
(seq_len, batch_size, hidden_size) if `batch_first` is `False` (default)
or (batch_size, seq_len, hidden_size) if `batch_first` is `True`. Note
that if `lengths` was specified, the `output` tensor will not be
masked. It's the caller's responsibility to either not use the invalid
entries or to mask them out before using them.
* `state`: the hidden state for the last sequence item. Dimensions
(1, batch_size, hidden_size).
``` python
half()
```
Casts all floating point parameters and buffers to ``half`` datatype.
#### Returns:
* `Module`: self
``` python
load_state_dict(
state_dict,
strict=True
)
```
Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~torch.nn.Module.state_dict` function.
#### Arguments:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~torch.nn.Module.state_dict` function. Default: ``True``
#### Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
``` python
modules()
```
Returns an iterator over all modules in the network.
#### Yields:
* `Module`: a module in the network
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
print(idx, '->', m)
```
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
``` python
named_buffers(
prefix='',
recurse=True
)
```
Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
#### Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `(string, torch.Tensor)`: Tuple containing the name and buffer
Example::
```
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
```
``` python
named_children()
```
Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple containing a name and child module
Example::
```
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
```
``` python
named_modules(
memo=None,
prefix=''
)
```
Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple of name and module
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
print(idx, '->', m)
```
0 -> ('', Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
``` python
named_parameters(
prefix='',
recurse=True
)
```
Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
#### Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `(string, Parameter)`: Tuple containing the name and parameter
Example::
```
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
```
``` python
parameters(recurse=True)
```
Returns an iterator over module parameters.
This is typically passed to an optimizer.
#### Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `Parameter`: module parameter
Example::
```
>>> for param in model.parameters():
>>> print(type(param.data), param.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
register_backward_hook(hook)
```
Registers a backward hook on the module.
The hook will be called every time the gradients with respect to module
inputs are computed. The hook should have the following signature::
hook(module, grad_input, grad_output) -> Tensor or None
The :attr:`grad_input` and :attr:`grad_output` may be tuples if the
module has multiple inputs or outputs. The hook should not modify its
arguments, but it can optionally return a new gradient with respect to
input that will be used in place of :attr:`grad_input` in subsequent
computations.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
.. warning ::
The current implementation will not have the presented behavior
for complex :class:`Module` that perform many operations.
In some failure cases, :attr:`grad_input` and :attr:`grad_output` will only
contain the gradients for a subset of the inputs and outputs.
For such :class:`Module`, you should use :func:`torch.Tensor.register_hook`
directly on a specific input or output to get the required gradients.
``` python
register_buffer(
name,
tensor
)
```
Adds a persistent buffer to the module.
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the persistent state.
Buffers can be accessed as attributes using given names.
#### Args:
name (string): name of the buffer. The buffer can be accessed
from this module using the given name
tensor (Tensor): buffer to be registered.
Example::
```
>>> self.register_buffer('running_mean', torch.zeros(num_features))
```
``` python
register_forward_hook(hook)
```
Registers a forward hook on the module.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None or modified output
The hook can modify the output. It can modify the input inplace but
it will not have effect on forward since this is called after
:func:`forward` is called.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_forward_pre_hook(hook)
```
Registers a forward pre-hook on the module.
The hook will be called every time before :func:`forward` is invoked.
It should have the following signature::
hook(module, input) -> None or modified input
The hook can modify the input. User can either return a tuple or a
single modified value in the hook. We will wrap the value into a tuple
if a single value is returned(unless that value is already a tuple).
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_parameter(
name,
param
)
```
Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
#### Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
``` python
requires_grad_(requires_grad=True)
```
Change if autograd should record operations on parameters in this
module.
This method sets the parameters' :attr:`requires_grad` attributes
in-place.
This method is helpful for freezing part of the module for finetuning
or training parts of a model individually (e.g., GAN training).
#### Args:
requires_grad (bool): whether autograd should record operations on
parameters in this module. Default: ``True``.
#### Returns:
* `Module`: self
``` python
reset_parameters()
```
``` python
share_memory()
```
``` python
state_dict(
destination=None,
prefix='',
keep_vars=False
)
```
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
#### Returns:
* `dict`: a dictionary containing a whole state of the module
Example::
```
>>> module.state_dict().keys()
['bias', 'weight']
```
``` python
to(
*args,
**kwargs
)
```
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point desired :attr:`dtype` s. In addition, this method will
only cast the floating point parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
#### Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
#### Returns:
* `Module`: self
Example::
```
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
```
``` python
train(mode=True)
```
Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
#### Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
#### Returns:
* `Module`: self
``` python
type(dst_type)
```
Casts all parameters and buffers to :attr:`dst_type`.
#### Arguments:
dst_type (type or string): the desired type
#### Returns:
* `Module`: self
``` python
zero_grad()
```
Sets gradients of all model parameters to zero.
================================================
FILE: docs/pytorch/haste_pytorch/LSTM.md
================================================
# haste_pytorch.LSTM
## Class `LSTM`
Long Short-Term Memory layer.
This LSTM layer offers a fused, GPU-accelerated PyTorch op for inference
and training. Although this implementation is comparable in performance to
cuDNN's LSTM, it offers additional options not typically found in other
high-performance implementations. DropConnect and Zoneout regularization are
built-in, and this layer allows setting a non-zero initial forget gate bias.
See [\_\_init\_\_](#__init__) and [forward](#forward) for general usage.
See [from_native_weights](#from_native_weights) and
[to_native_weights](#to_native_weights) for compatibility with PyTorch LSTMs.
``` python
__init__(
input_size,
hidden_size,
batch_first=False,
forget_bias=1.0,
dropout=0.0,
zoneout=0.0
)
```
Initialize the parameters of the LSTM layer.
#### Arguments:
* `input_size`: int, the feature dimension of the input.
* `hidden_size`: int, the feature dimension of the output.
* `batch_first`: (optional) bool, if `True`, then the input and output
tensors are provided as `(batch, seq, feature)`.
* `forget_bias`: (optional) float, sets the initial bias of the forget gate
for this LSTM cell.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization.
#### Variables:
* `kernel`: the input projection weight matrix. Dimensions
(input_size, hidden_size * 4) with `i,g,f,o` gate layout. Initialized
with Xavier uniform initialization.
* `recurrent_kernel`: the recurrent projection weight matrix. Dimensions
(hidden_size, hidden_size * 4) with `i,g,f,o` gate layout. Initialized
with orthogonal initialization.
* `bias`: the projection bias vector. Dimensions (hidden_size * 4) with
`i,g,f,o` gate layout. The forget gate biases are initialized to
`forget_bias` and the rest are zeros.
## Methods
``` python
__call__(
*input,
**kwargs
)
```
Call self as a function.
``` python
add_module(
name,
module
)
```
Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
#### Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
``` python
apply(fn)
```
Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`nn-init-doc`).
#### Args:
fn (:class:`Module` -> None): function to be applied to each submodule
#### Returns:
* `Module`: self
Example::
```
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
```
``` python
buffers(recurse=True)
```
Returns an iterator over module buffers.
#### Args:
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `torch.Tensor`: module buffer
Example::
```
>>> for buf in model.buffers():
>>> print(type(buf.data), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
children()
```
Returns an iterator over immediate children modules.
#### Yields:
* `Module`: a child module
``` python
cpu()
```
Moves all model parameters and buffers to the CPU.
#### Returns:
* `Module`: self
``` python
cuda(device=None)
```
Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
#### Arguments:
device (int, optional): if specified, all parameters will be
copied to that device
#### Returns:
* `Module`: self
``` python
double()
```
Casts all floating point parameters and buffers to ``double`` datatype.
#### Returns:
* `Module`: self
``` python
eval()
```
Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
#### Returns:
* `Module`: self
``` python
extra_repr()
```
Set the extra representation of the module
To print customized extra information, you should reimplement
this method in your own modules. Both single-line and multi-line
strings are acceptable.
``` python
float()
```
Casts all floating point parameters and buffers to float datatype.
#### Returns:
* `Module`: self
``` python
forward(
input,
state=None,
lengths=None
)
```
Runs a forward pass of the LSTM layer.
#### Arguments:
* `input`: Tensor, a batch of input sequences to pass through the LSTM.
Dimensions (seq_len, batch_size, input_size) if `batch_first` is
`False`, otherwise (batch_size, seq_len, input_size).
* `lengths`: (optional) Tensor, list of sequence lengths for each batch
element. Dimension (batch_size). This argument may be omitted if
all batch elements are unpadded and have the same sequence length.
#### Returns:
* `output`: Tensor, the output of the LSTM layer. Dimensions
(seq_len, batch_size, hidden_size) if `batch_first` is `False` (default)
or (batch_size, seq_len, hidden_size) if `batch_first` is `True`. Note
that if `lengths` was specified, the `output` tensor will not be
masked. It's the caller's responsibility to either not use the invalid
entries or to mask them out before using them.
* `(h_n, c_n)`: the hidden and cell states, respectively, for the last
sequence item. Dimensions (1, batch_size, hidden_size).
``` python
from_native_weights(
weight_ih_l0,
weight_hh_l0,
bias_ih_l0,
bias_hh_l0
)
```
Copies and converts the provided PyTorch LSTM weights into this layer.
#### Arguments:
* `weight_ih_l0`: Parameter, the input-hidden weights of the PyTorch LSTM layer.
* `weight_hh_l0`: Parameter, the hidden-hidden weights of the PyTorch LSTM layer.
* `bias_ih_l0`: Parameter, the input-hidden bias of the PyTorch LSTM layer.
* `bias_hh_l0`: Parameter, the hidden-hidden bias of the PyTorch LSTM layer.
``` python
half()
```
Casts all floating point parameters and buffers to ``half`` datatype.
#### Returns:
* `Module`: self
``` python
load_state_dict(
state_dict,
strict=True
)
```
Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~torch.nn.Module.state_dict` function.
#### Arguments:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~torch.nn.Module.state_dict` function. Default: ``True``
#### Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
``` python
modules()
```
Returns an iterator over all modules in the network.
#### Yields:
* `Module`: a module in the network
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
print(idx, '->', m)
```
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
``` python
named_buffers(
prefix='',
recurse=True
)
```
Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
#### Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `(string, torch.Tensor)`: Tuple containing the name and buffer
Example::
```
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
```
``` python
named_children()
```
Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple containing a name and child module
Example::
```
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
```
``` python
named_modules(
memo=None,
prefix=''
)
```
Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple of name and module
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
print(idx, '->', m)
```
0 -> ('', Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
``` python
named_parameters(
prefix='',
recurse=True
)
```
Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
#### Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `(string, Parameter)`: Tuple containing the name and parameter
Example::
```
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
```
``` python
parameters(recurse=True)
```
Returns an iterator over module parameters.
This is typically passed to an optimizer.
#### Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `Parameter`: module parameter
Example::
```
>>> for param in model.parameters():
>>> print(type(param.data), param.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
register_backward_hook(hook)
```
Registers a backward hook on the module.
The hook will be called every time the gradients with respect to module
inputs are computed. The hook should have the following signature::
hook(module, grad_input, grad_output) -> Tensor or None
The :attr:`grad_input` and :attr:`grad_output` may be tuples if the
module has multiple inputs or outputs. The hook should not modify its
arguments, but it can optionally return a new gradient with respect to
input that will be used in place of :attr:`grad_input` in subsequent
computations.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
.. warning ::
The current implementation will not have the presented behavior
for complex :class:`Module` that perform many operations.
In some failure cases, :attr:`grad_input` and :attr:`grad_output` will only
contain the gradients for a subset of the inputs and outputs.
For such :class:`Module`, you should use :func:`torch.Tensor.register_hook`
directly on a specific input or output to get the required gradients.
``` python
register_buffer(
name,
tensor
)
```
Adds a persistent buffer to the module.
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the persistent state.
Buffers can be accessed as attributes using given names.
#### Args:
name (string): name of the buffer. The buffer can be accessed
from this module using the given name
tensor (Tensor): buffer to be registered.
Example::
```
>>> self.register_buffer('running_mean', torch.zeros(num_features))
```
``` python
register_forward_hook(hook)
```
Registers a forward hook on the module.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None or modified output
The hook can modify the output. It can modify the input inplace but
it will not have effect on forward since this is called after
:func:`forward` is called.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_forward_pre_hook(hook)
```
Registers a forward pre-hook on the module.
The hook will be called every time before :func:`forward` is invoked.
It should have the following signature::
hook(module, input) -> None or modified input
The hook can modify the input. User can either return a tuple or a
single modified value in the hook. We will wrap the value into a tuple
if a single value is returned(unless that value is already a tuple).
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_parameter(
name,
param
)
```
Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
#### Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
``` python
requires_grad_(requires_grad=True)
```
Change if autograd should record operations on parameters in this
module.
This method sets the parameters' :attr:`requires_grad` attributes
in-place.
This method is helpful for freezing part of the module for finetuning
or training parts of a model individually (e.g., GAN training).
#### Args:
requires_grad (bool): whether autograd should record operations on
parameters in this module. Default: ``True``.
#### Returns:
* `Module`: self
``` python
reset_parameters()
```
Resets this layer's parameters to their initial values.
``` python
share_memory()
```
``` python
state_dict(
destination=None,
prefix='',
keep_vars=False
)
```
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
#### Returns:
* `dict`: a dictionary containing a whole state of the module
Example::
```
>>> module.state_dict().keys()
['bias', 'weight']
```
``` python
to(
*args,
**kwargs
)
```
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point desired :attr:`dtype` s. In addition, this method will
only cast the floating point parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
#### Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
#### Returns:
* `Module`: self
Example::
```
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
```
``` python
to_native_weights()
```
Converts Haste LSTM weights to native PyTorch LSTM weights.
#### Returns:
* `weight_ih_l0`: Parameter, the input-hidden weights of the LSTM layer.
* `weight_hh_l0`: Parameter, the hidden-hidden weights of the LSTM layer.
* `bias_ih_l0`: Parameter, the input-hidden bias of the LSTM layer.
* `bias_hh_l0`: Parameter, the hidden-hidden bias of the LSTM layer.
``` python
train(mode=True)
```
Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
#### Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
#### Returns:
* `Module`: self
``` python
type(dst_type)
```
Casts all parameters and buffers to :attr:`dst_type`.
#### Arguments:
dst_type (type or string): the desired type
#### Returns:
* `Module`: self
``` python
zero_grad()
```
Sets gradients of all model parameters to zero.
================================================
FILE: docs/pytorch/haste_pytorch/LayerNormGRU.md
================================================
# haste_pytorch.LayerNormGRU
## Class `LayerNormGRU`
Layer Normalized Gated Recurrent Unit layer.
This GRU layer applies layer normalization to the input and recurrent output
activations of a standard GRU. The implementation is fused and
GPU-accelerated. There are two commonly-used variants of GRU cells. This one
implements 1406.1078v1 which applies the reset gate to the hidden state
after matrix multiplication. The other variant, 1406.1078v3, applies the
reset gate before matrix multiplication and is currently unsupported.
This layer has built-in support for DropConnect and Zoneout, which are
both techniques used to regularize RNNs.
See [\_\_init\_\_](#__init__) and [forward](#forward) for usage.
``` python
__init__(
input_size,
hidden_size,
batch_first=False,
dropout=0.0,
zoneout=0.0
)
```
Initialize the parameters of the GRU layer.
#### Arguments:
* `input_size`: int, the feature dimension of the input.
* `hidden_size`: int, the feature dimension of the output.
* `batch_first`: (optional) bool, if `True`, then the input and output
tensors are provided as `(batch, seq, feature)`.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization.
#### Variables:
* `kernel`: the input projection weight matrix. Dimensions
(input_size, hidden_size * 3) with `z,r,h` gate layout. Initialized
with Xavier uniform initialization.
* `recurrent_kernel`: the recurrent projection weight matrix. Dimensions
(hidden_size, hidden_size * 3) with `z,r,h` gate layout. Initialized
with orthogonal initialization.
* `bias`: the input projection bias vector. Dimensions (hidden_size * 3) with
`z,r,h` gate layout. Initialized to zeros.
* `recurrent_bias`: the recurrent projection bias vector. Dimensions
(hidden_size * 3) with `z,r,h` gate layout. Initialized to zeros.
* `gamma`: the input and recurrent normalization gain. Dimensions
(2, hidden_size * 4) with `gamma[0]` specifying the input gain and
`gamma[1]` specifying the recurrent gain. Initialized to ones.
## Methods
``` python
__call__(
*input,
**kwargs
)
```
Call self as a function.
``` python
add_module(
name,
module
)
```
Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
#### Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
``` python
apply(fn)
```
Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`nn-init-doc`).
#### Args:
fn (:class:`Module` -> None): function to be applied to each submodule
#### Returns:
* `Module`: self
Example::
```
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
```
``` python
buffers(recurse=True)
```
Returns an iterator over module buffers.
#### Args:
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `torch.Tensor`: module buffer
Example::
```
>>> for buf in model.buffers():
>>> print(type(buf.data), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
children()
```
Returns an iterator over immediate children modules.
#### Yields:
* `Module`: a child module
``` python
cpu()
```
Moves all model parameters and buffers to the CPU.
#### Returns:
* `Module`: self
``` python
cuda(device=None)
```
Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
#### Arguments:
device (int, optional): if specified, all parameters will be
copied to that device
#### Returns:
* `Module`: self
``` python
double()
```
Casts all floating point parameters and buffers to ``double`` datatype.
#### Returns:
* `Module`: self
``` python
eval()
```
Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
#### Returns:
* `Module`: self
``` python
extra_repr()
```
Set the extra representation of the module
To print customized extra information, you should reimplement
this method in your own modules. Both single-line and multi-line
strings are acceptable.
``` python
float()
```
Casts all floating point parameters and buffers to float datatype.
#### Returns:
* `Module`: self
``` python
forward(
input,
state=None,
lengths=None
)
```
Runs a forward pass of the GRU layer.
#### Arguments:
* `input`: Tensor, a batch of input sequences to pass through the GRU.
Dimensions (seq_len, batch_size, input_size) if `batch_first` is
`False`, otherwise (batch_size, seq_len, input_size).
* `state`: (optional) Tensor, the intial state for each batch element in
`input`. Dimensions (1, batch_size, hidden_size). Defaults to zeros.
* `lengths`: (optional) Tensor, list of sequence lengths for each batch
element. Dimension (batch_size). This argument may be omitted if
all batch elements are unpadded and have the same sequence length.
#### Returns:
* `output`: Tensor, the output of the GRU layer. Dimensions
(seq_len, batch_size, hidden_size) if `batch_first` is `False` (default)
or (batch_size, seq_len, hidden_size) if `batch_first` is `True`. Note
that if `lengths` was specified, the `output` tensor will not be
masked. It's the caller's responsibility to either not use the invalid
entries or to mask them out before using them.
* `h_n`: the hidden state for the last sequence item. Dimensions
(1, batch_size, hidden_size).
``` python
half()
```
Casts all floating point parameters and buffers to ``half`` datatype.
#### Returns:
* `Module`: self
``` python
load_state_dict(
state_dict,
strict=True
)
```
Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~torch.nn.Module.state_dict` function.
#### Arguments:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~torch.nn.Module.state_dict` function. Default: ``True``
#### Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
``` python
modules()
```
Returns an iterator over all modules in the network.
#### Yields:
* `Module`: a module in the network
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
print(idx, '->', m)
```
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
``` python
named_buffers(
prefix='',
recurse=True
)
```
Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
#### Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `(string, torch.Tensor)`: Tuple containing the name and buffer
Example::
```
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
```
``` python
named_children()
```
Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple containing a name and child module
Example::
```
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
```
``` python
named_modules(
memo=None,
prefix=''
)
```
Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple of name and module
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
print(idx, '->', m)
```
0 -> ('', Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
``` python
named_parameters(
prefix='',
recurse=True
)
```
Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
#### Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `(string, Parameter)`: Tuple containing the name and parameter
Example::
```
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
```
``` python
parameters(recurse=True)
```
Returns an iterator over module parameters.
This is typically passed to an optimizer.
#### Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `Parameter`: module parameter
Example::
```
>>> for param in model.parameters():
>>> print(type(param.data), param.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
register_backward_hook(hook)
```
Registers a backward hook on the module.
The hook will be called every time the gradients with respect to module
inputs are computed. The hook should have the following signature::
hook(module, grad_input, grad_output) -> Tensor or None
The :attr:`grad_input` and :attr:`grad_output` may be tuples if the
module has multiple inputs or outputs. The hook should not modify its
arguments, but it can optionally return a new gradient with respect to
input that will be used in place of :attr:`grad_input` in subsequent
computations.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
.. warning ::
The current implementation will not have the presented behavior
for complex :class:`Module` that perform many operations.
In some failure cases, :attr:`grad_input` and :attr:`grad_output` will only
contain the gradients for a subset of the inputs and outputs.
For such :class:`Module`, you should use :func:`torch.Tensor.register_hook`
directly on a specific input or output to get the required gradients.
``` python
register_buffer(
name,
tensor
)
```
Adds a persistent buffer to the module.
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the persistent state.
Buffers can be accessed as attributes using given names.
#### Args:
name (string): name of the buffer. The buffer can be accessed
from this module using the given name
tensor (Tensor): buffer to be registered.
Example::
```
>>> self.register_buffer('running_mean', torch.zeros(num_features))
```
``` python
register_forward_hook(hook)
```
Registers a forward hook on the module.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None or modified output
The hook can modify the output. It can modify the input inplace but
it will not have effect on forward since this is called after
:func:`forward` is called.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_forward_pre_hook(hook)
```
Registers a forward pre-hook on the module.
The hook will be called every time before :func:`forward` is invoked.
It should have the following signature::
hook(module, input) -> None or modified input
The hook can modify the input. User can either return a tuple or a
single modified value in the hook. We will wrap the value into a tuple
if a single value is returned(unless that value is already a tuple).
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_parameter(
name,
param
)
```
Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
#### Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
``` python
requires_grad_(requires_grad=True)
```
Change if autograd should record operations on parameters in this
module.
This method sets the parameters' :attr:`requires_grad` attributes
in-place.
This method is helpful for freezing part of the module for finetuning
or training parts of a model individually (e.g., GAN training).
#### Args:
requires_grad (bool): whether autograd should record operations on
parameters in this module. Default: ``True``.
#### Returns:
* `Module`: self
``` python
reset_parameters()
```
Resets this layer's parameters to their initial values.
``` python
share_memory()
```
``` python
state_dict(
destination=None,
prefix='',
keep_vars=False
)
```
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
#### Returns:
* `dict`: a dictionary containing a whole state of the module
Example::
```
>>> module.state_dict().keys()
['bias', 'weight']
```
``` python
to(
*args,
**kwargs
)
```
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point desired :attr:`dtype` s. In addition, this method will
only cast the floating point parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
#### Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
#### Returns:
* `Module`: self
Example::
```
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
```
``` python
train(mode=True)
```
Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
#### Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
#### Returns:
* `Module`: self
``` python
type(dst_type)
```
Casts all parameters and buffers to :attr:`dst_type`.
#### Arguments:
dst_type (type or string): the desired type
#### Returns:
* `Module`: self
``` python
zero_grad()
```
Sets gradients of all model parameters to zero.
================================================
FILE: docs/pytorch/haste_pytorch/LayerNormLSTM.md
================================================
# haste_pytorch.LayerNormLSTM
## Class `LayerNormLSTM`
Layer Normalized Long Short-Term Memory layer.
This LSTM layer applies layer normalization to the input, recurrent, and
output activations of a standard LSTM. The implementation is fused and
GPU-accelerated. DropConnect and Zoneout regularization are built-in, and
this layer allows setting a non-zero initial forget gate bias.
Details about the exact function this layer implements can be found at
https://github.com/lmnt-com/haste/issues/1.
See [\_\_init\_\_](#__init__) and [forward](#forward) for usage.
``` python
__init__(
input_size,
hidden_size,
batch_first=False,
forget_bias=1.0,
dropout=0.0,
zoneout=0.0
)
```
Initialize the parameters of the LSTM layer.
#### Arguments:
* `input_size`: int, the feature dimension of the input.
* `hidden_size`: int, the feature dimension of the output.
* `batch_first`: (optional) bool, if `True`, then the input and output
tensors are provided as `(batch, seq, feature)`.
* `forget_bias`: (optional) float, sets the initial bias of the forget gate
for this LSTM cell.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization.
#### Variables:
* `kernel`: the input projection weight matrix. Dimensions
(input_size, hidden_size * 4) with `i,g,f,o` gate layout. Initialized
with Xavier uniform initialization.
* `recurrent_kernel`: the recurrent projection weight matrix. Dimensions
(hidden_size, hidden_size * 4) with `i,g,f,o` gate layout. Initialized
with orthogonal initialization.
* `bias`: the projection bias vector. Dimensions (hidden_size * 4) with
`i,g,f,o` gate layout. The forget gate biases are initialized to
`forget_bias` and the rest are zeros.
* `gamma`: the input and recurrent normalization gain. Dimensions
(2, hidden_size * 4) with `gamma[0]` specifying the input gain and
`gamma[1]` specifying the recurrent gain. Initialized to ones.
* `gamma_h`: the output normalization gain. Dimensions (hidden_size).
Initialized to ones.
* `beta_h`: the output normalization bias. Dimensions (hidden_size).
Initialized to zeros.
## Methods
``` python
__call__(
*input,
**kwargs
)
```
Call self as a function.
``` python
add_module(
name,
module
)
```
Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
#### Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
``` python
apply(fn)
```
Applies ``fn`` recursively to every submodule (as returned by ``.children()``)
as well as self. Typical use includes initializing the parameters of a model
(see also :ref:`nn-init-doc`).
#### Args:
fn (:class:`Module` -> None): function to be applied to each submodule
#### Returns:
* `Module`: self
Example::
```
>>> def init_weights(m):
>>> print(m)
>>> if type(m) == nn.Linear:
>>> m.weight.data.fill_(1.0)
>>> print(m.weight)
>>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
>>> net.apply(init_weights)
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Linear(in_features=2, out_features=2, bias=True)
Parameter containing:
tensor([[ 1., 1.],
[ 1., 1.]])
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
```
``` python
buffers(recurse=True)
```
Returns an iterator over module buffers.
#### Args:
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `torch.Tensor`: module buffer
Example::
```
>>> for buf in model.buffers():
>>> print(type(buf.data), buf.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
children()
```
Returns an iterator over immediate children modules.
#### Yields:
* `Module`: a child module
``` python
cpu()
```
Moves all model parameters and buffers to the CPU.
#### Returns:
* `Module`: self
``` python
cuda(device=None)
```
Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
#### Arguments:
device (int, optional): if specified, all parameters will be
copied to that device
#### Returns:
* `Module`: self
``` python
double()
```
Casts all floating point parameters and buffers to ``double`` datatype.
#### Returns:
* `Module`: self
``` python
eval()
```
Sets the module in evaluation mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
This is equivalent with :meth:`self.train(False) `.
#### Returns:
* `Module`: self
``` python
extra_repr()
```
Set the extra representation of the module
To print customized extra information, you should reimplement
this method in your own modules. Both single-line and multi-line
strings are acceptable.
``` python
float()
```
Casts all floating point parameters and buffers to float datatype.
#### Returns:
* `Module`: self
``` python
forward(
input,
state=None,
lengths=None
)
```
Runs a forward pass of the LSTM layer.
#### Arguments:
* `input`: Tensor, a batch of input sequences to pass through the LSTM.
Dimensions (seq_len, batch_size, input_size) if `batch_first` is
`False`, otherwise (batch_size, seq_len, input_size).
* `lengths`: (optional) Tensor, list of sequence lengths for each batch
element. Dimension (batch_size). This argument may be omitted if
all batch elements are unpadded and have the same sequence length.
#### Returns:
* `output`: Tensor, the output of the LSTM layer. Dimensions
(seq_len, batch_size, hidden_size) if `batch_first` is `False` (default)
or (batch_size, seq_len, hidden_size) if `batch_first` is `True`. Note
that if `lengths` was specified, the `output` tensor will not be
masked. It's the caller's responsibility to either not use the invalid
entries or to mask them out before using them.
* `(h_n, c_n)`: the hidden and cell states, respectively, for the last
sequence item. Dimensions (1, batch_size, hidden_size).
``` python
half()
```
Casts all floating point parameters and buffers to ``half`` datatype.
#### Returns:
* `Module`: self
``` python
load_state_dict(
state_dict,
strict=True
)
```
Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~torch.nn.Module.state_dict` function.
#### Arguments:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~torch.nn.Module.state_dict` function. Default: ``True``
#### Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
``` python
modules()
```
Returns an iterator over all modules in the network.
#### Yields:
* `Module`: a module in the network
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.modules()):
print(idx, '->', m)
```
0 -> Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
1 -> Linear(in_features=2, out_features=2, bias=True)
``` python
named_buffers(
prefix='',
recurse=True
)
```
Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
#### Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module.
#### Yields:
* `(string, torch.Tensor)`: Tuple containing the name and buffer
Example::
```
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
```
``` python
named_children()
```
Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple containing a name and child module
Example::
```
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
```
``` python
named_modules(
memo=None,
prefix=''
)
```
Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
#### Yields:
* `(string, Module)`: Tuple of name and module
#### Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
Example::
```
>>> l = nn.Linear(2, 2)
>>> net = nn.Sequential(l, l)
>>> for idx, m in enumerate(net.named_modules()):
print(idx, '->', m)
```
0 -> ('', Sequential(
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
))
1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
``` python
named_parameters(
prefix='',
recurse=True
)
```
Returns an iterator over module parameters, yielding both the
name of the parameter as well as the parameter itself.
#### Args:
prefix (str): prefix to prepend to all parameter names.
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `(string, Parameter)`: Tuple containing the name and parameter
Example::
```
>>> for name, param in self.named_parameters():
>>> if name in ['bias']:
>>> print(param.size())
```
``` python
parameters(recurse=True)
```
Returns an iterator over module parameters.
This is typically passed to an optimizer.
#### Args:
recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that
are direct members of this module.
#### Yields:
* `Parameter`: module parameter
Example::
```
>>> for param in model.parameters():
>>> print(type(param.data), param.size())
(20L,)
(20L, 1L, 5L, 5L)
```
``` python
register_backward_hook(hook)
```
Registers a backward hook on the module.
The hook will be called every time the gradients with respect to module
inputs are computed. The hook should have the following signature::
hook(module, grad_input, grad_output) -> Tensor or None
The :attr:`grad_input` and :attr:`grad_output` may be tuples if the
module has multiple inputs or outputs. The hook should not modify its
arguments, but it can optionally return a new gradient with respect to
input that will be used in place of :attr:`grad_input` in subsequent
computations.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
.. warning ::
The current implementation will not have the presented behavior
for complex :class:`Module` that perform many operations.
In some failure cases, :attr:`grad_input` and :attr:`grad_output` will only
contain the gradients for a subset of the inputs and outputs.
For such :class:`Module`, you should use :func:`torch.Tensor.register_hook`
directly on a specific input or output to get the required gradients.
``` python
register_buffer(
name,
tensor
)
```
Adds a persistent buffer to the module.
This is typically used to register a buffer that should not to be
considered a model parameter. For example, BatchNorm's ``running_mean``
is not a parameter, but is part of the persistent state.
Buffers can be accessed as attributes using given names.
#### Args:
name (string): name of the buffer. The buffer can be accessed
from this module using the given name
tensor (Tensor): buffer to be registered.
Example::
```
>>> self.register_buffer('running_mean', torch.zeros(num_features))
```
``` python
register_forward_hook(hook)
```
Registers a forward hook on the module.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None or modified output
The hook can modify the output. It can modify the input inplace but
it will not have effect on forward since this is called after
:func:`forward` is called.
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_forward_pre_hook(hook)
```
Registers a forward pre-hook on the module.
The hook will be called every time before :func:`forward` is invoked.
It should have the following signature::
hook(module, input) -> None or modified input
The hook can modify the input. User can either return a tuple or a
single modified value in the hook. We will wrap the value into a tuple
if a single value is returned(unless that value is already a tuple).
#### Returns:
:class:`torch.utils.hooks.RemovableHandle`:
a handle that can be used to remove the added hook by calling
``handle.remove()``
``` python
register_parameter(
name,
param
)
```
Adds a parameter to the module.
The parameter can be accessed as an attribute using given name.
#### Args:
name (string): name of the parameter. The parameter can be accessed
from this module using the given name
param (Parameter): parameter to be added to the module.
``` python
requires_grad_(requires_grad=True)
```
Change if autograd should record operations on parameters in this
module.
This method sets the parameters' :attr:`requires_grad` attributes
in-place.
This method is helpful for freezing part of the module for finetuning
or training parts of a model individually (e.g., GAN training).
#### Args:
requires_grad (bool): whether autograd should record operations on
parameters in this module. Default: ``True``.
#### Returns:
* `Module`: self
``` python
reset_parameters()
```
Resets this layer's parameters to their initial values.
``` python
share_memory()
```
``` python
state_dict(
destination=None,
prefix='',
keep_vars=False
)
```
Returns a dictionary containing a whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
#### Returns:
* `dict`: a dictionary containing a whole state of the module
Example::
```
>>> module.state_dict().keys()
['bias', 'weight']
```
``` python
to(
*args,
**kwargs
)
```
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point desired :attr:`dtype` s. In addition, this method will
only cast the floating point parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
#### Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
#### Returns:
* `Module`: self
Example::
```
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
```
``` python
train(mode=True)
```
Sets the module in training mode.
This has any effect only on certain modules. See documentations of
particular modules for details of their behaviors in training/evaluation
mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,
etc.
#### Args:
mode (bool): whether to set training mode (``True``) or evaluation
mode (``False``). Default: ``True``.
#### Returns:
* `Module`: self
``` python
type(dst_type)
```
Casts all parameters and buffers to :attr:`dst_type`.
#### Arguments:
dst_type (type or string): the desired type
#### Returns:
* `Module`: self
``` python
zero_grad()
```
Sets gradients of all model parameters to zero.
================================================
FILE: docs/pytorch/haste_pytorch.md
================================================
# Module: haste_pytorch
Haste: a fast, simple, and open RNN library.
## Classes
[`class GRU`](./haste_pytorch/GRU.md): Gated Recurrent Unit layer.
[`class IndRNN`](./haste_pytorch/IndRNN.md): Independently Recurrent Neural Network layer.
[`class LSTM`](./haste_pytorch/LSTM.md): Long Short-Term Memory layer.
[`class LayerNormGRU`](./haste_pytorch/LayerNormGRU.md): Layer Normalized Gated Recurrent Unit layer.
[`class LayerNormLSTM`](./haste_pytorch/LayerNormLSTM.md): Layer Normalized Long Short-Term Memory layer.
================================================
FILE: docs/tf/haste_tf/GRU.md
================================================
# haste_tf.GRU
## Class `GRU`
Gated Recurrent Unit layer.
This GRU layer offers a fused, GPU-accelerated TensorFlow op for inference
and training. There are two commonly-used variants of GRU cells. This one
implements 1406.1078v1 which applies the reset gate to the hidden state
after matrix multiplication. cuDNN also implements this variant. The other
variant, 1406.1078v3, applies the reset gate before matrix multiplication
and is currently unsupported.
This layer has built-in support for DropConnect and Zoneout, which are
both techniques used to regularize RNNs.
``` python
__init__(
num_units,
direction='unidirectional',
**kwargs
)
```
Initialize the parameters of the GRU layer.
#### Arguments:
* `num_units`: int, the number of units in the LSTM cell.
* `direction`: string, 'unidirectional' or 'bidirectional'.
* `**kwargs`: Dict, keyword arguments (see below).
#### Keyword Arguments:
* `kernel_initializer`: (optional) the initializer to use for the input
matrix weights. Defaults to `glorot_uniform`.
* `recurrent_initializer`: (optional) the initializer to use for the
recurrent matrix weights. Defaults to `orthogonal`.
* `bias_initializer`: (optional) the initializer to use for input bias
vectors. Defaults to `zeros`.
* `recurrent_bias_initializer`: (optional) the initializer to use for
recurrent bias vectors. Defaults to `zeros`.
* `kernel_transform`: (optional) a function with signature
`(kernel: Tensor) -> Tensor` that transforms the kernel before it is
used. Defaults to the identity function.
* `recurrent_transform`: (optional) a function with signature
`(recurrent_kernel: Tensor) -> Tensor` that transforms the recurrent
kernel before it is used. Defaults to the identity function.
* `bias_transform`: (optional) a function with signature
`(bias: Tensor) -> Tensor` that transforms the bias before it is used.
Defaults to the identity function.
* `recurrent_bias_transform`: (optional) a function with signature
`(recurrent_bias: Tensor) -> Tensor` that transforms the recurrent bias
before it is used. Defaults to the identity function.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix. Defaults to 0.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization. Defaults to 0.
* `dtype`: (optional) the data type for this layer. Defaults to `tf.float32`.
* `name`: (optional) string, the name for this layer.
## Properties
bidirectional
`True` if this is a bidirectional RNN, `False` otherwise.
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
output_size
state_size
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(
inputs,
training,
sequence_length=None,
time_major=False
)
```
Runs the RNN layer.
#### Arguments:
* `inputs`: Tensor, a rank 3 input tensor with shape [N,T,C] if `time_major`
is `False`, or with shape [T,N,C] if `time_major` is `True`.
* `training`: bool, `True` if running in training mode, `False` if running
in inference mode.
* `sequence_length`: (optional) Tensor, a rank 1 tensor with shape [N] and
dtype of `tf.int32` or `tf.int64`. This tensor specifies the unpadded
length of each example in the input minibatch.
* `time_major`: (optional) bool, specifies whether `input` has shape [N,T,C]
(`time_major=False`) or shape [T,N,C] (`time_major=True`).
#### Returns:
A pair, `(output, state)` for unidirectional layers, or a pair
`([output_fw, output_bw], [state_fw, state_bw])` for bidirectional
layers.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the RNN class. It is called
internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/GRUCell.md
================================================
# haste_tf.GRUCell
## Class `GRUCell`
A GRU cell that's compatible with the Haste GRU layer.
This cell can be used on hardware other than GPUs and with other TensorFlow
classes that operate on RNN cells (e.g. `dynamic_rnn`, `BasicDecoder`, cell
wrappers, etc.).
``` python
__init__(
num_units,
name=None,
**kwargs
)
```
## Properties
activity_regularizer
Optional regularizer function for the output of this layer.
dtype
dynamic
graph
DEPRECATED FUNCTION
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version.
Instructions for updating:
Stop using this property because tf.layers layers no longer track their graph.
Retrieves the input tensor(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer.
#### Returns:
Input tensor or list of input tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
#### Raises:
* `RuntimeError`: If called in Eager mode.
* `AttributeError`: If no inbound nodes are found.
Retrieves the input mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Input mask tensor (potentially None) or list of input
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
Retrieves the input shape(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer, or if all inputs
have the same shape.
#### Returns:
Input shape, as an integer shape tuple
(or list of shape tuples, one tuple per input tensor).
#### Raises:
* `AttributeError`: if the layer has no defined input_shape.
* `RuntimeError`: if called in Eager mode.
losses
Losses which are associated with this `Layer`.
Variable regularization tensors are created when this property is accessed,
so it is eager safe: accessing `losses` under a `tf.GradientTape` will
propagate gradients back to the corresponding variables.
#### Returns:
A list of tensors.
metrics
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
non_trainable_variables
non_trainable_weights
output
Retrieves the output tensor(s) of a layer.
Only applicable if the layer has exactly one output,
i.e. if it is connected to one incoming layer.
#### Returns:
Output tensor or list of output tensors.
#### Raises:
* `AttributeError`: if the layer is connected to more than one incoming
layers.
* `RuntimeError`: if called in Eager mode.
output_mask
Retrieves the output mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Output mask tensor (potentially None) or list of output
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
output_shape
Retrieves the output shape(s) of a layer.
Only applicable if the layer has one output,
or if all outputs have the same shape.
#### Returns:
Output shape, as an integer shape tuple
(or list of shape tuples, one tuple per output tensor).
#### Raises:
* `AttributeError`: if the layer has no defined output shape.
* `RuntimeError`: if called in Eager mode.
output_size
Integer or TensorShape: size of outputs produced by this cell.
scope_name
state_size
size(s) of state(s) used by this cell.
It can be represented by an Integer, a TensorShape or a tuple of Integers
or TensorShapes.
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
trainable_weights
updates
variables
Returns the list of all layer variables/weights.
Alias of `self.weights`.
#### Returns:
A list of variables.
weights
Returns the list of all layer variables/weights.
#### Returns:
A list of variables.
## Methods
``` python
__call__(
inputs,
state,
scope=None
)
```
Run this RNN cell on inputs, starting from the given state.
#### Args:
* `inputs`: `2-D` tensor with shape `[batch_size, input_size]`.
* `state`: if `self.state_size` is an integer, this should be a `2-D Tensor`
with shape `[batch_size, self.state_size]`. Otherwise, if
`self.state_size` is a tuple of integers, this should be a tuple with
shapes `[batch_size, s] for s in self.state_size`.
* `scope`: VariableScope for the created subgraph; defaults to class name.
#### Returns:
* `A pair containing`:
- Output: A `2-D` tensor with shape `[batch_size, self.output_size]`.
- New state: Either a single `2-D` tensor, or a tuple of tensors matching
the arity and shapes of `state`.
``` python
apply(
inputs,
*args,
**kwargs
)
```
Apply the layer on a input.
This is an alias of `self.__call__`.
#### Arguments:
* `inputs`: Input tensor(s).
* `*args`: additional positional arguments to be passed to `self.call`.
* `**kwargs`: additional keyword arguments to be passed to `self.call`.
#### Returns:
Output tensor(s).
``` python
build(shape)
```
Creates the variables of the layer (optional, for subclass implementers).
This is a method that implementers of subclasses of `Layer` or `Model`
can override if they need a state-creation step in-between
layer instantiation and layer call.
This is typically used to create the weights of `Layer` subclasses.
#### Arguments:
* `input_shape`: Instance of `TensorShape`, or list of instances of
`TensorShape` if the layer expects a list of inputs
(one instance per input).
``` python
compute_mask(
inputs,
mask=None
)
```
Computes an output mask tensor.
#### Arguments:
* `inputs`: Tensor or list of tensors.
* `mask`: Tensor or list of tensors.
#### Returns:
None or a tensor (or list of tensors,
one per output tensor of the layer).
``` python
compute_output_shape(input_shape)
```
Computes the output shape of the layer.
Assumes that the layer will be built
to match that input shape provided.
#### Arguments:
* `input_shape`: Shape tuple (tuple of integers)
or list of shape tuples (one per output tensor of the layer).
Shape tuples can include None for free dimensions,
instead of an integer.
#### Returns:
An input shape tuple.
``` python
count_params()
```
Count the total number of scalars composing the weights.
#### Returns:
An integer count.
#### Raises:
* `ValueError`: if the layer isn't yet built
(in which case its weights aren't yet defined).
``` python
@classmethod
from_config(
cls,
config
)
```
Creates a layer from its config.
This method is the reverse of `get_config`,
capable of instantiating the same layer from the config
dictionary. It does not handle layer connectivity
(handled by Network), nor weights (handled by `set_weights`).
#### Arguments:
* `config`: A Python dictionary, typically the
output of get_config.
#### Returns:
A layer instance.
``` python
get_config()
```
Returns the config of the layer.
A layer config is a Python dictionary (serializable)
containing the configuration of a layer.
The same layer can be reinstantiated later
(without its trained weights) from this configuration.
The config of a layer does not include connectivity
information, nor the layer class name. These are handled
by `Network` (one layer of abstraction above).
#### Returns:
Python dictionary.
``` python
get_initial_state(
inputs=None,
batch_size=None,
dtype=None
)
```
``` python
get_input_at(node_index)
```
Retrieves the input tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_input_mask_at(node_index)
```
Retrieves the input mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple inputs).
``` python
get_input_shape_at(node_index)
```
Retrieves the input shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_losses_for(inputs)
```
Retrieves losses relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of loss tensors of the layer that depend on `inputs`.
``` python
get_output_at(node_index)
```
Retrieves the output tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_output_mask_at(node_index)
```
Retrieves the output mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple outputs).
``` python
get_output_shape_at(node_index)
```
Retrieves the output shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_updates_for(inputs)
```
Retrieves updates relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of update ops of the layer that depend on `inputs`.
``` python
get_weights()
```
Returns the current weights of the layer.
#### Returns:
Weights values as a list of numpy arrays.
``` python
set_weights(weights)
```
Sets the weights of the layer, from Numpy arrays.
#### Arguments:
* `weights`: a list of Numpy arrays. The number
of arrays and their shape must match
number of the dimensions of the weights
of the layer (i.e. it should match the
output of `get_weights`).
#### Raises:
* `ValueError`: If the provided weights list does not match the
layer's specifications.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
``` python
zero_state(
batch_size,
dtype
)
```
Return zero-filled state tensor(s).
#### Args:
* `batch_size`: int, float, or unit Tensor representing the batch size.
* `dtype`: the data type to use for the state.
#### Returns:
If `state_size` is an int or TensorShape, then the return value is a
`N-D` tensor of shape `[batch_size, state_size]` filled with zeros.
If `state_size` is a nested list or tuple, then the return value is
a nested list or tuple (of the same structure) of `2-D` tensors with
the shapes `[batch_size, s]` for each s in `state_size`.
================================================
FILE: docs/tf/haste_tf/IndRNN.md
================================================
# haste_tf.IndRNN
## Class `IndRNN`
Independently Recurrent Neural Network layer.
This layer offers a fused, GPU-accelerated TensorFlow op for inference and
training. It also supports Zoneout regularization.
``` python
__init__(
num_units,
direction='unidirectional',
**kwargs
)
```
Initialize the parameters of the IndRNN layer.
#### Arguments:
* `num_units`: int, the number of units in the IndRNN cell.
* `direction`: string, 'unidirectional' or 'bidirectional'.
* `**kwargs`: Dict, keyword arguments (see below).
#### Keyword Arguments:
* `kernel_initializer`: (optional) the initializer to use for the input
matrix weights. Defaults to `glorot_uniform`.
* `recurrent_initializer`: (optional) the initializer to use for the
recurrent scale weights. Defaults to uniform random in [-0.5, 0.5].
Note that this initialization scheme is different than in the original
authors' implementation. See https://github.com/lmnt-com/haste/issues/7
for details.
* `bias_initializer`: (optional) the initializer to use for the bias vector.
Defaults to `zeros`.
* `kernel_transform`: (optional) a function with signature
`(kernel: Tensor) -> Tensor` that transforms the kernel before it is
used. Defaults to the identity function.
* `recurrent_transform`: (optional) a function with signature
`(recurrent_scale: Tensor) -> Tensor` that transforms the recurrent
scale vector before it is used. Defaults to the identity function.
* `bias_transform`: (optional) a function with signature
`(bias: Tensor) -> Tensor` that transforms the bias before it is used.
Defaults to the identity function.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization. Defaults to 0.
* `dtype`: (optional) the data type for this layer. Defaults to `tf.float32`.
* `name`: (optional) string, the name for this layer.
## Properties
bidirectional
`True` if this is a bidirectional RNN, `False` otherwise.
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
output_size
state_size
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(
inputs,
training,
sequence_length=None,
time_major=False
)
```
Runs the RNN layer.
#### Arguments:
* `inputs`: Tensor, a rank 3 input tensor with shape [N,T,C] if `time_major`
is `False`, or with shape [T,N,C] if `time_major` is `True`.
* `training`: bool, `True` if running in training mode, `False` if running
in inference mode.
* `sequence_length`: (optional) Tensor, a rank 1 tensor with shape [N] and
dtype of `tf.int32` or `tf.int64`. This tensor specifies the unpadded
length of each example in the input minibatch.
* `time_major`: (optional) bool, specifies whether `input` has shape [N,T,C]
(`time_major=False`) or shape [T,N,C] (`time_major=True`).
#### Returns:
A pair, `(output, state)` for unidirectional layers, or a pair
`([output_fw, output_bw], [state_fw, state_bw])` for bidirectional
layers.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the RNN class. It is called
internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/LSTM.md
================================================
# haste_tf.LSTM
## Class `LSTM`
Long Short-Term Memory layer.
This LSTM layer offers a fused, GPU-accelerated TensorFlow op for inference
and training. Its weights and variables are compatible with `BasicLSTMCell`,
`LSTMCell`, and `LSTMBlockCell` by default, and is able to load weights
from `tf.contrib.cudnn_rnn.CudnnLSTM` when `cudnn_compat=True` is specified.
Although this implementation is comparable in performance to cuDNN's LSTM,
it offers additional options not typically found in other high-performance
implementations. DropConnect and Zoneout regularization are built-in, and
this layer allows setting a non-zero initial forget gate bias.
``` python
__init__(
num_units,
direction='unidirectional',
**kwargs
)
```
Initialize the parameters of the LSTM layer.
#### Arguments:
* `num_units`: int, the number of units in the LSTM cell.
* `direction`: string, 'unidirectional' or 'bidirectional'.
* `**kwargs`: Dict, keyword arguments (see below).
#### Keyword Arguments:
* `kernel_initializer`: (optional) the initializer to use for the input
matrix weights. Defaults to `glorot_uniform`.
* `recurrent_initializer`: (optional) the initializer to use for the
recurrent matrix weights. Defaults to `orthogonal`.
* `bias_initializer`: (optional) the initializer to use for both input and
recurrent bias vectors. Defaults to `zeros` unless `forget_bias` is
non-zero (see below).
* `kernel_transform`: (optional) a function with signature
`(kernel: Tensor) -> Tensor` that transforms the kernel before it is
used. Defaults to the identity function.
* `recurrent_transform`: (optional) a function with signature
`(recurrent_kernel: Tensor) -> Tensor` that transforms the recurrent
kernel before it is used. Defaults to the identity function.
* `bias_transform`: (optional) a function with signature
`(bias: Tensor) -> Tensor` that transforms the bias before it is used.
Defaults to the identity function.
* `forget_bias`: (optional) float, sets the initial weights for the forget
gates. Defaults to 1 and overrides the `bias_initializer` unless this
argument is set to 0.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix. Defaults to 0.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization. Defaults to 0.
* `dtype`: (optional) the data type for this layer. Defaults to `tf.float32`.
* `name`: (optional) string, the name for this layer.
* `cudnn_compat`: (optional) bool, if `True`, the variables created by this
layer are compatible with `tf.contrib.cudnn_rnn.CudnnLSTM`. Note that
this should only be set if you're restoring variables from a cuDNN
model. It's currently not possible to train a model with
`cudnn_compat=True` and restore it with CudnnLSTM. Defaults to `False`.
## Properties
bidirectional
`True` if this is a bidirectional RNN, `False` otherwise.
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
output_size
state_size
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(
inputs,
training,
sequence_length=None,
time_major=False
)
```
Runs the RNN layer.
#### Arguments:
* `inputs`: Tensor, a rank 3 input tensor with shape [N,T,C] if `time_major`
is `False`, or with shape [T,N,C] if `time_major` is `True`.
* `training`: bool, `True` if running in training mode, `False` if running
in inference mode.
* `sequence_length`: (optional) Tensor, a rank 1 tensor with shape [N] and
dtype of `tf.int32` or `tf.int64`. This tensor specifies the unpadded
length of each example in the input minibatch.
* `time_major`: (optional) bool, specifies whether `input` has shape [N,T,C]
(`time_major=False`) or shape [T,N,C] (`time_major=True`).
#### Returns:
A pair, `(output, state)` for unidirectional layers, or a pair
`([output_fw, output_bw], [state_fw, state_bw])` for bidirectional
layers.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the RNN class. It is called
internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/LayerNorm.md
================================================
# haste_tf.LayerNorm
## Class `LayerNorm`
Layer normalization layer.
This class exposes a fused and GPU-accelerated implementation of layer
normalization as described by [Ba et al.](https://arxiv.org/abs/1607.06450)
``` python
__init__(name=None)
```
Initialize the parameters of the layer normalization layer.
#### Arguments:
* `name`: (optional) string, the name for this layer.
## Properties
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(x)
```
Runs the layer.
#### Arguments:
* `x`: Tensor, a rank R tensor.
#### Returns:
* `y`: Tensor, a rank R tensor with the last dimension normalized.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the LayerNorm class. It is
called internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/LayerNormGRU.md
================================================
# haste_tf.LayerNormGRU
## Class `LayerNormGRU`
Layer Normalized Gated Recurrent Unit layer.
This GRU layer applies layer normalization to the input and recurrent output
activations of a standard GRU. The implementation is fused and
GPU-accelerated. There are two commonly-used variants of GRU cells. This one
implements 1406.1078v1 which applies the reset gate to the hidden state
after matrix multiplication. The other variant, 1406.1078v3, applies the
reset gate before matrix multiplication and is currently unsupported.
This layer has built-in support for DropConnect and Zoneout, which are
both techniques used to regularize RNNs.
``` python
__init__(
num_units,
direction='unidirectional',
**kwargs
)
```
Initialize the parameters of the GRU layer.
#### Arguments:
* `num_units`: int, the number of units in the LSTM cell.
* `direction`: string, 'unidirectional' or 'bidirectional'.
* `**kwargs`: Dict, keyword arguments (see below).
#### Keyword Arguments:
* `kernel_initializer`: (optional) the initializer to use for the input
matrix weights. Defaults to `glorot_uniform`.
* `recurrent_initializer`: (optional) the initializer to use for the
recurrent matrix weights. Defaults to `orthogonal`.
* `bias_initializer`: (optional) the initializer to use for input bias
vectors. Defaults to `zeros`.
* `recurrent_bias_initializer`: (optional) the initializer to use for
recurrent bias vectors. Defaults to `zeros`.
* `kernel_transform`: (optional) a function with signature
`(kernel: Tensor) -> Tensor` that transforms the kernel before it is
used. Defaults to the identity function.
* `recurrent_transform`: (optional) a function with signature
`(recurrent_kernel: Tensor) -> Tensor` that transforms the recurrent
kernel before it is used. Defaults to the identity function.
* `bias_transform`: (optional) a function with signature
`(bias: Tensor) -> Tensor` that transforms the bias before it is used.
Defaults to the identity function.
* `recurrent_bias_transform`: (optional) a function with signature
`(recurrent_bias: Tensor) -> Tensor` that transforms the recurrent bias
before it is used. Defaults to the identity function.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix. Defaults to 0.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization. Defaults to 0.
* `dtype`: (optional) the data type for this layer. Defaults to `tf.float32`.
* `name`: (optional) string, the name for this layer.
## Properties
bidirectional
`True` if this is a bidirectional RNN, `False` otherwise.
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
output_size
state_size
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(
inputs,
training,
sequence_length=None,
time_major=False
)
```
Runs the RNN layer.
#### Arguments:
* `inputs`: Tensor, a rank 3 input tensor with shape [N,T,C] if `time_major`
is `False`, or with shape [T,N,C] if `time_major` is `True`.
* `training`: bool, `True` if running in training mode, `False` if running
in inference mode.
* `sequence_length`: (optional) Tensor, a rank 1 tensor with shape [N] and
dtype of `tf.int32` or `tf.int64`. This tensor specifies the unpadded
length of each example in the input minibatch.
* `time_major`: (optional) bool, specifies whether `input` has shape [N,T,C]
(`time_major=False`) or shape [T,N,C] (`time_major=True`).
#### Returns:
A pair, `(output, state)` for unidirectional layers, or a pair
`([output_fw, output_bw], [state_fw, state_bw])` for bidirectional
layers.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the RNN class. It is called
internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/LayerNormGRUCell.md
================================================
# haste_tf.LayerNormGRUCell
## Class `LayerNormGRUCell`
A GRU cell that's compatible with the Haste LayerNormGRU layer.
This cell can be used on hardware other than GPUs and with other TensorFlow
classes that operate on RNN cells (e.g. `dynamic_rnn`, `BasicDecoder`, cell
wrappers, etc.).
``` python
__init__(
num_units,
forget_bias=1.0,
dropout=0.0,
dtype=None,
name=None,
**kwargs
)
```
## Properties
activity_regularizer
Optional regularizer function for the output of this layer.
dtype
dynamic
graph
DEPRECATED FUNCTION
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version.
Instructions for updating:
Stop using this property because tf.layers layers no longer track their graph.
Retrieves the input tensor(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer.
#### Returns:
Input tensor or list of input tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
#### Raises:
* `RuntimeError`: If called in Eager mode.
* `AttributeError`: If no inbound nodes are found.
Retrieves the input mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Input mask tensor (potentially None) or list of input
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
Retrieves the input shape(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer, or if all inputs
have the same shape.
#### Returns:
Input shape, as an integer shape tuple
(or list of shape tuples, one tuple per input tensor).
#### Raises:
* `AttributeError`: if the layer has no defined input_shape.
* `RuntimeError`: if called in Eager mode.
losses
Losses which are associated with this `Layer`.
Variable regularization tensors are created when this property is accessed,
so it is eager safe: accessing `losses` under a `tf.GradientTape` will
propagate gradients back to the corresponding variables.
#### Returns:
A list of tensors.
metrics
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
non_trainable_variables
non_trainable_weights
output
Retrieves the output tensor(s) of a layer.
Only applicable if the layer has exactly one output,
i.e. if it is connected to one incoming layer.
#### Returns:
Output tensor or list of output tensors.
#### Raises:
* `AttributeError`: if the layer is connected to more than one incoming
layers.
* `RuntimeError`: if called in Eager mode.
output_mask
Retrieves the output mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Output mask tensor (potentially None) or list of output
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
output_shape
Retrieves the output shape(s) of a layer.
Only applicable if the layer has one output,
or if all outputs have the same shape.
#### Returns:
Output shape, as an integer shape tuple
(or list of shape tuples, one tuple per output tensor).
#### Raises:
* `AttributeError`: if the layer has no defined output shape.
* `RuntimeError`: if called in Eager mode.
output_size
Integer or TensorShape: size of outputs produced by this cell.
scope_name
state_size
size(s) of state(s) used by this cell.
It can be represented by an Integer, a TensorShape or a tuple of Integers
or TensorShapes.
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
trainable_weights
updates
variables
Returns the list of all layer variables/weights.
Alias of `self.weights`.
#### Returns:
A list of variables.
weights
Returns the list of all layer variables/weights.
#### Returns:
A list of variables.
## Methods
``` python
__call__(
inputs,
state,
scope=None
)
```
Run this RNN cell on inputs, starting from the given state.
#### Args:
* `inputs`: `2-D` tensor with shape `[batch_size, input_size]`.
* `state`: if `self.state_size` is an integer, this should be a `2-D Tensor`
with shape `[batch_size, self.state_size]`. Otherwise, if
`self.state_size` is a tuple of integers, this should be a tuple with
shapes `[batch_size, s] for s in self.state_size`.
* `scope`: VariableScope for the created subgraph; defaults to class name.
#### Returns:
* `A pair containing`:
- Output: A `2-D` tensor with shape `[batch_size, self.output_size]`.
- New state: Either a single `2-D` tensor, or a tuple of tensors matching
the arity and shapes of `state`.
``` python
apply(
inputs,
*args,
**kwargs
)
```
Apply the layer on a input.
This is an alias of `self.__call__`.
#### Arguments:
* `inputs`: Input tensor(s).
* `*args`: additional positional arguments to be passed to `self.call`.
* `**kwargs`: additional keyword arguments to be passed to `self.call`.
#### Returns:
Output tensor(s).
``` python
build(shape)
```
Creates the variables of the layer (optional, for subclass implementers).
This is a method that implementers of subclasses of `Layer` or `Model`
can override if they need a state-creation step in-between
layer instantiation and layer call.
This is typically used to create the weights of `Layer` subclasses.
#### Arguments:
* `input_shape`: Instance of `TensorShape`, or list of instances of
`TensorShape` if the layer expects a list of inputs
(one instance per input).
``` python
compute_mask(
inputs,
mask=None
)
```
Computes an output mask tensor.
#### Arguments:
* `inputs`: Tensor or list of tensors.
* `mask`: Tensor or list of tensors.
#### Returns:
None or a tensor (or list of tensors,
one per output tensor of the layer).
``` python
compute_output_shape(input_shape)
```
Computes the output shape of the layer.
Assumes that the layer will be built
to match that input shape provided.
#### Arguments:
* `input_shape`: Shape tuple (tuple of integers)
or list of shape tuples (one per output tensor of the layer).
Shape tuples can include None for free dimensions,
instead of an integer.
#### Returns:
An input shape tuple.
``` python
count_params()
```
Count the total number of scalars composing the weights.
#### Returns:
An integer count.
#### Raises:
* `ValueError`: if the layer isn't yet built
(in which case its weights aren't yet defined).
``` python
@classmethod
from_config(
cls,
config
)
```
Creates a layer from its config.
This method is the reverse of `get_config`,
capable of instantiating the same layer from the config
dictionary. It does not handle layer connectivity
(handled by Network), nor weights (handled by `set_weights`).
#### Arguments:
* `config`: A Python dictionary, typically the
output of get_config.
#### Returns:
A layer instance.
``` python
get_config()
```
Returns the config of the layer.
A layer config is a Python dictionary (serializable)
containing the configuration of a layer.
The same layer can be reinstantiated later
(without its trained weights) from this configuration.
The config of a layer does not include connectivity
information, nor the layer class name. These are handled
by `Network` (one layer of abstraction above).
#### Returns:
Python dictionary.
``` python
get_initial_state(
inputs=None,
batch_size=None,
dtype=None
)
```
``` python
get_input_at(node_index)
```
Retrieves the input tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_input_mask_at(node_index)
```
Retrieves the input mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple inputs).
``` python
get_input_shape_at(node_index)
```
Retrieves the input shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_losses_for(inputs)
```
Retrieves losses relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of loss tensors of the layer that depend on `inputs`.
``` python
get_output_at(node_index)
```
Retrieves the output tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_output_mask_at(node_index)
```
Retrieves the output mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple outputs).
``` python
get_output_shape_at(node_index)
```
Retrieves the output shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_updates_for(inputs)
```
Retrieves updates relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of update ops of the layer that depend on `inputs`.
``` python
get_weights()
```
Returns the current weights of the layer.
#### Returns:
Weights values as a list of numpy arrays.
``` python
set_weights(weights)
```
Sets the weights of the layer, from Numpy arrays.
#### Arguments:
* `weights`: a list of Numpy arrays. The number
of arrays and their shape must match
number of the dimensions of the weights
of the layer (i.e. it should match the
output of `get_weights`).
#### Raises:
* `ValueError`: If the provided weights list does not match the
layer's specifications.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
``` python
zero_state(
batch_size,
dtype
)
```
Return zero-filled state tensor(s).
#### Args:
* `batch_size`: int, float, or unit Tensor representing the batch size.
* `dtype`: the data type to use for the state.
#### Returns:
If `state_size` is an int or TensorShape, then the return value is a
`N-D` tensor of shape `[batch_size, state_size]` filled with zeros.
If `state_size` is a nested list or tuple, then the return value is
a nested list or tuple (of the same structure) of `2-D` tensors with
the shapes `[batch_size, s]` for each s in `state_size`.
================================================
FILE: docs/tf/haste_tf/LayerNormLSTM.md
================================================
# haste_tf.LayerNormLSTM
## Class `LayerNormLSTM`
Layer Normalized Long Short-Term Memory layer.
This LSTM layer applies layer normalization to the input, recurrent, and
output activations of a standard LSTM. The implementation is fused and
GPU-accelerated. DropConnect and Zoneout regularization are built-in, and
this layer allows setting a non-zero initial forget gate bias.
Details about the exact function this layer implements can be found at
https://github.com/lmnt-com/haste/issues/1.
``` python
__init__(
num_units,
direction='unidirectional',
**kwargs
)
```
Initialize the parameters of the LSTM layer.
#### Arguments:
* `num_units`: int, the number of units in the LSTM cell.
* `direction`: string, 'unidirectional' or 'bidirectional'.
* `**kwargs`: Dict, keyword arguments (see below).
#### Keyword Arguments:
* `kernel_initializer`: (optional) the initializer to use for the input
matrix weights. Defaults to `glorot_uniform`.
* `recurrent_initializer`: (optional) the initializer to use for the
recurrent matrix weights. Defaults to `orthogonal`.
* `bias_initializer`: (optional) the initializer to use for both input and
recurrent bias vectors. Defaults to `zeros` unless `forget_bias` is
non-zero (see below).
* `kernel_transform`: (optional) a function with signature
`(kernel: Tensor) -> Tensor` that transforms the kernel before it is
used. Defaults to the identity function.
* `recurrent_transform`: (optional) a function with signature
`(recurrent_kernel: Tensor) -> Tensor` that transforms the recurrent
kernel before it is used. Defaults to the identity function.
* `bias_transform`: (optional) a function with signature
`(bias: Tensor) -> Tensor` that transforms the bias before it is used.
Defaults to the identity function.
* `forget_bias`: (optional) float, sets the initial weights for the forget
gates. Defaults to 1 and overrides the `bias_initializer` unless this
argument is set to 0.
* `dropout`: (optional) float, sets the dropout rate for DropConnect
regularization on the recurrent matrix. Defaults to 0.
* `zoneout`: (optional) float, sets the zoneout rate for Zoneout
regularization. Defaults to 0.
* `dtype`: (optional) the data type for this layer. Defaults to `tf.float32`.
* `name`: (optional) string, the name for this layer.
## Properties
bidirectional
`True` if this is a bidirectional RNN, `False` otherwise.
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
output_size
state_size
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
## Methods
``` python
__call__(
inputs,
training,
sequence_length=None,
time_major=False
)
```
Runs the RNN layer.
#### Arguments:
* `inputs`: Tensor, a rank 3 input tensor with shape [N,T,C] if `time_major`
is `False`, or with shape [T,N,C] if `time_major` is `True`.
* `training`: bool, `True` if running in training mode, `False` if running
in inference mode.
* `sequence_length`: (optional) Tensor, a rank 1 tensor with shape [N] and
dtype of `tf.int32` or `tf.int64`. This tensor specifies the unpadded
length of each example in the input minibatch.
* `time_major`: (optional) bool, specifies whether `input` has shape [N,T,C]
(`time_major=False`) or shape [T,N,C] (`time_major=True`).
#### Returns:
A pair, `(output, state)` for unidirectional layers, or a pair
`([output_fw, output_bw], [state_fw, state_bw])` for bidirectional
layers.
``` python
build(shape)
```
Creates the variables of the layer.
Calling this method is optional for users of the RNN class. It is called
internally with the correct shape when `__call__` is invoked.
#### Arguments:
* `shape`: instance of `TensorShape`.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
================================================
FILE: docs/tf/haste_tf/LayerNormLSTMCell.md
================================================
# haste_tf.LayerNormLSTMCell
## Class `LayerNormLSTMCell`
An LSTM cell that's compatible with the Haste LayerNormLSTM layer.
This cell can be used on hardware other than GPUs and with other TensorFlow
classes that operate on RNN cells (e.g. `dynamic_rnn`, `BasicDecoder`, cell
wrappers, etc.).
``` python
__init__(
num_units,
forget_bias=1.0,
dropout=0.0,
dtype=None,
name=None,
**kwargs
)
```
## Properties
activity_regularizer
Optional regularizer function for the output of this layer.
dtype
dynamic
graph
DEPRECATED FUNCTION
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version.
Instructions for updating:
Stop using this property because tf.layers layers no longer track their graph.
Retrieves the input tensor(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer.
#### Returns:
Input tensor or list of input tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
#### Raises:
* `RuntimeError`: If called in Eager mode.
* `AttributeError`: If no inbound nodes are found.
Retrieves the input mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Input mask tensor (potentially None) or list of input
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
Retrieves the input shape(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer, or if all inputs
have the same shape.
#### Returns:
Input shape, as an integer shape tuple
(or list of shape tuples, one tuple per input tensor).
#### Raises:
* `AttributeError`: if the layer has no defined input_shape.
* `RuntimeError`: if called in Eager mode.
losses
Losses which are associated with this `Layer`.
Variable regularization tensors are created when this property is accessed,
so it is eager safe: accessing `losses` under a `tf.GradientTape` will
propagate gradients back to the corresponding variables.
#### Returns:
A list of tensors.
metrics
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
non_trainable_variables
non_trainable_weights
output
Retrieves the output tensor(s) of a layer.
Only applicable if the layer has exactly one output,
i.e. if it is connected to one incoming layer.
#### Returns:
Output tensor or list of output tensors.
#### Raises:
* `AttributeError`: if the layer is connected to more than one incoming
layers.
* `RuntimeError`: if called in Eager mode.
output_mask
Retrieves the output mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Output mask tensor (potentially None) or list of output
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
output_shape
Retrieves the output shape(s) of a layer.
Only applicable if the layer has one output,
or if all outputs have the same shape.
#### Returns:
Output shape, as an integer shape tuple
(or list of shape tuples, one tuple per output tensor).
#### Raises:
* `AttributeError`: if the layer has no defined output shape.
* `RuntimeError`: if called in Eager mode.
output_size
Integer or TensorShape: size of outputs produced by this cell.
scope_name
state_size
size(s) of state(s) used by this cell.
It can be represented by an Integer, a TensorShape or a tuple of Integers
or TensorShapes.
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
trainable_weights
updates
variables
Returns the list of all layer variables/weights.
Alias of `self.weights`.
#### Returns:
A list of variables.
weights
Returns the list of all layer variables/weights.
#### Returns:
A list of variables.
## Methods
``` python
__call__(
inputs,
state,
scope=None
)
```
Run this RNN cell on inputs, starting from the given state.
#### Args:
* `inputs`: `2-D` tensor with shape `[batch_size, input_size]`.
* `state`: if `self.state_size` is an integer, this should be a `2-D Tensor`
with shape `[batch_size, self.state_size]`. Otherwise, if
`self.state_size` is a tuple of integers, this should be a tuple with
shapes `[batch_size, s] for s in self.state_size`.
* `scope`: VariableScope for the created subgraph; defaults to class name.
#### Returns:
* `A pair containing`:
- Output: A `2-D` tensor with shape `[batch_size, self.output_size]`.
- New state: Either a single `2-D` tensor, or a tuple of tensors matching
the arity and shapes of `state`.
``` python
apply(
inputs,
*args,
**kwargs
)
```
Apply the layer on a input.
This is an alias of `self.__call__`.
#### Arguments:
* `inputs`: Input tensor(s).
* `*args`: additional positional arguments to be passed to `self.call`.
* `**kwargs`: additional keyword arguments to be passed to `self.call`.
#### Returns:
Output tensor(s).
``` python
build(shape)
```
Creates the variables of the layer (optional, for subclass implementers).
This is a method that implementers of subclasses of `Layer` or `Model`
can override if they need a state-creation step in-between
layer instantiation and layer call.
This is typically used to create the weights of `Layer` subclasses.
#### Arguments:
* `input_shape`: Instance of `TensorShape`, or list of instances of
`TensorShape` if the layer expects a list of inputs
(one instance per input).
``` python
compute_mask(
inputs,
mask=None
)
```
Computes an output mask tensor.
#### Arguments:
* `inputs`: Tensor or list of tensors.
* `mask`: Tensor or list of tensors.
#### Returns:
None or a tensor (or list of tensors,
one per output tensor of the layer).
``` python
compute_output_shape(input_shape)
```
Computes the output shape of the layer.
Assumes that the layer will be built
to match that input shape provided.
#### Arguments:
* `input_shape`: Shape tuple (tuple of integers)
or list of shape tuples (one per output tensor of the layer).
Shape tuples can include None for free dimensions,
instead of an integer.
#### Returns:
An input shape tuple.
``` python
count_params()
```
Count the total number of scalars composing the weights.
#### Returns:
An integer count.
#### Raises:
* `ValueError`: if the layer isn't yet built
(in which case its weights aren't yet defined).
``` python
@classmethod
from_config(
cls,
config
)
```
Creates a layer from its config.
This method is the reverse of `get_config`,
capable of instantiating the same layer from the config
dictionary. It does not handle layer connectivity
(handled by Network), nor weights (handled by `set_weights`).
#### Arguments:
* `config`: A Python dictionary, typically the
output of get_config.
#### Returns:
A layer instance.
``` python
get_config()
```
Returns the config of the layer.
A layer config is a Python dictionary (serializable)
containing the configuration of a layer.
The same layer can be reinstantiated later
(without its trained weights) from this configuration.
The config of a layer does not include connectivity
information, nor the layer class name. These are handled
by `Network` (one layer of abstraction above).
#### Returns:
Python dictionary.
``` python
get_initial_state(
inputs=None,
batch_size=None,
dtype=None
)
```
``` python
get_input_at(node_index)
```
Retrieves the input tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_input_mask_at(node_index)
```
Retrieves the input mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple inputs).
``` python
get_input_shape_at(node_index)
```
Retrieves the input shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_losses_for(inputs)
```
Retrieves losses relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of loss tensors of the layer that depend on `inputs`.
``` python
get_output_at(node_index)
```
Retrieves the output tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_output_mask_at(node_index)
```
Retrieves the output mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple outputs).
``` python
get_output_shape_at(node_index)
```
Retrieves the output shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_updates_for(inputs)
```
Retrieves updates relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of update ops of the layer that depend on `inputs`.
``` python
get_weights()
```
Returns the current weights of the layer.
#### Returns:
Weights values as a list of numpy arrays.
``` python
set_weights(weights)
```
Sets the weights of the layer, from Numpy arrays.
#### Arguments:
* `weights`: a list of Numpy arrays. The number
of arrays and their shape must match
number of the dimensions of the weights
of the layer (i.e. it should match the
output of `get_weights`).
#### Raises:
* `ValueError`: If the provided weights list does not match the
layer's specifications.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
``` python
zero_state(
batch_size,
dtype
)
```
Return zero-filled state tensor(s).
#### Args:
* `batch_size`: int, float, or unit Tensor representing the batch size.
* `dtype`: the data type to use for the state.
#### Returns:
If `state_size` is an int or TensorShape, then the return value is a
`N-D` tensor of shape `[batch_size, state_size]` filled with zeros.
If `state_size` is a nested list or tuple, then the return value is
a nested list or tuple (of the same structure) of `2-D` tensors with
the shapes `[batch_size, s]` for each s in `state_size`.
================================================
FILE: docs/tf/haste_tf/ZoneoutWrapper.md
================================================
# haste_tf.ZoneoutWrapper
## Class `ZoneoutWrapper`
An LSTM/GRU cell wrapper that applies zoneout to the inner cell's hidden state.
The zoneout paper applies zoneout to both the cell state and hidden state,
each with its own zoneout rate. This class (and the `LSTM` implementation in Haste)
applies zoneout to the hidden state and not the cell state.
``` python
__init__(
cell,
rate,
training
)
```
Initialize the parameters of the zoneout wrapper.
#### Arguments:
* `cell`: RNNCell, an instance of {`BasicLSTMCell`, `LSTMCell`,
`LSTMBlockCell`, haste_tf.GRUCell} on which to apply zoneout.
* `rate`: float, 0 <= rate <= 1, the percent of hidden units to zone out per
time step.
* `training`: bool, `True` if used during training, `False` if used during
inference.
## Properties
activity_regularizer
Optional regularizer function for the output of this layer.
dtype
dynamic
graph
DEPRECATED FUNCTION
Warning: THIS FUNCTION IS DEPRECATED. It will be removed in a future version.
Instructions for updating:
Stop using this property because tf.layers layers no longer track their graph.
Retrieves the input tensor(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer.
#### Returns:
Input tensor or list of input tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
#### Raises:
* `RuntimeError`: If called in Eager mode.
* `AttributeError`: If no inbound nodes are found.
Retrieves the input mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Input mask tensor (potentially None) or list of input
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
Retrieves the input shape(s) of a layer.
Only applicable if the layer has exactly one input,
i.e. if it is connected to one incoming layer, or if all inputs
have the same shape.
#### Returns:
Input shape, as an integer shape tuple
(or list of shape tuples, one tuple per input tensor).
#### Raises:
* `AttributeError`: if the layer has no defined input_shape.
* `RuntimeError`: if called in Eager mode.
losses
Losses which are associated with this `Layer`.
Variable regularization tensors are created when this property is accessed,
so it is eager safe: accessing `losses` under a `tf.GradientTape` will
propagate gradients back to the corresponding variables.
#### Returns:
A list of tensors.
metrics
name
Returns the name of this module as passed or determined in the ctor.
NOTE: This is not the same as the `self.name_scope.name` which includes
parent module names.
name_scope
Returns a `tf.name_scope` instance for this class.
non_trainable_variables
non_trainable_weights
output
Retrieves the output tensor(s) of a layer.
Only applicable if the layer has exactly one output,
i.e. if it is connected to one incoming layer.
#### Returns:
Output tensor or list of output tensors.
#### Raises:
* `AttributeError`: if the layer is connected to more than one incoming
layers.
* `RuntimeError`: if called in Eager mode.
output_mask
Retrieves the output mask tensor(s) of a layer.
Only applicable if the layer has exactly one inbound node,
i.e. if it is connected to one incoming layer.
#### Returns:
Output mask tensor (potentially None) or list of output
mask tensors.
#### Raises:
* `AttributeError`: if the layer is connected to
more than one incoming layers.
output_shape
Retrieves the output shape(s) of a layer.
Only applicable if the layer has one output,
or if all outputs have the same shape.
#### Returns:
Output shape, as an integer shape tuple
(or list of shape tuples, one tuple per output tensor).
#### Raises:
* `AttributeError`: if the layer has no defined output shape.
* `RuntimeError`: if called in Eager mode.
output_size
Integer or TensorShape: size of outputs produced by this cell.
scope_name
state_size
size(s) of state(s) used by this cell.
It can be represented by an Integer, a TensorShape or a tuple of Integers
or TensorShapes.
submodules
Sequence of all sub-modules.
Submodules are modules which are properties of this module, or found as
properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
assert list(a.submodules) == [b, c]
assert list(b.submodules) == [c]
assert list(c.submodules) == []
```
#### Returns:
A sequence of all submodules.
trainable
trainable_variables
Sequence of variables owned by this module and it's submodules.
Note: this method uses reflection to find variables on the current instance
and submodules. For performance reasons you may wish to cache the result
of calling this method if you don't expect the return value to change.
#### Returns:
A sequence of variables for the current module (sorted by attribute
name) followed by variables from all submodules recursively (breadth
first).
trainable_weights
updates
variables
Returns the list of all layer variables/weights.
Alias of `self.weights`.
#### Returns:
A list of variables.
weights
Returns the list of all layer variables/weights.
#### Returns:
A list of variables.
## Methods
``` python
__call__(
inputs,
state,
scope=None
)
```
Runs one step of the RNN cell with zoneout applied.
#### Arguments:
see documentation for the inner cell.
``` python
apply(
inputs,
*args,
**kwargs
)
```
Apply the layer on a input.
This is an alias of `self.__call__`.
#### Arguments:
* `inputs`: Input tensor(s).
* `*args`: additional positional arguments to be passed to `self.call`.
* `**kwargs`: additional keyword arguments to be passed to `self.call`.
#### Returns:
Output tensor(s).
``` python
build(_)
```
Creates the variables of the layer (optional, for subclass implementers).
This is a method that implementers of subclasses of `Layer` or `Model`
can override if they need a state-creation step in-between
layer instantiation and layer call.
This is typically used to create the weights of `Layer` subclasses.
#### Arguments:
* `input_shape`: Instance of `TensorShape`, or list of instances of
`TensorShape` if the layer expects a list of inputs
(one instance per input).
``` python
compute_mask(
inputs,
mask=None
)
```
Computes an output mask tensor.
#### Arguments:
* `inputs`: Tensor or list of tensors.
* `mask`: Tensor or list of tensors.
#### Returns:
None or a tensor (or list of tensors,
one per output tensor of the layer).
``` python
compute_output_shape(input_shape)
```
Computes the output shape of the layer.
Assumes that the layer will be built
to match that input shape provided.
#### Arguments:
* `input_shape`: Shape tuple (tuple of integers)
or list of shape tuples (one per output tensor of the layer).
Shape tuples can include None for free dimensions,
instead of an integer.
#### Returns:
An input shape tuple.
``` python
count_params()
```
Count the total number of scalars composing the weights.
#### Returns:
An integer count.
#### Raises:
* `ValueError`: if the layer isn't yet built
(in which case its weights aren't yet defined).
``` python
@classmethod
from_config(
cls,
config
)
```
Creates a layer from its config.
This method is the reverse of `get_config`,
capable of instantiating the same layer from the config
dictionary. It does not handle layer connectivity
(handled by Network), nor weights (handled by `set_weights`).
#### Arguments:
* `config`: A Python dictionary, typically the
output of get_config.
#### Returns:
A layer instance.
``` python
get_config()
```
Returns the config of the layer.
A layer config is a Python dictionary (serializable)
containing the configuration of a layer.
The same layer can be reinstantiated later
(without its trained weights) from this configuration.
The config of a layer does not include connectivity
information, nor the layer class name. These are handled
by `Network` (one layer of abstraction above).
#### Returns:
Python dictionary.
``` python
get_initial_state(
inputs=None,
batch_size=None,
dtype=None
)
```
``` python
get_input_at(node_index)
```
Retrieves the input tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_input_mask_at(node_index)
```
Retrieves the input mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple inputs).
``` python
get_input_shape_at(node_index)
```
Retrieves the input shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple inputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_losses_for(inputs)
```
Retrieves losses relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of loss tensors of the layer that depend on `inputs`.
``` python
get_output_at(node_index)
```
Retrieves the output tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A tensor (or list of tensors if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_output_mask_at(node_index)
```
Retrieves the output mask tensor(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A mask tensor
(or list of tensors if the layer has multiple outputs).
``` python
get_output_shape_at(node_index)
```
Retrieves the output shape(s) of a layer at a given node.
#### Arguments:
* `node_index`: Integer, index of the node
from which to retrieve the attribute.
E.g. `node_index=0` will correspond to the
first time the layer was called.
#### Returns:
A shape tuple
(or list of shape tuples if the layer has multiple outputs).
#### Raises:
* `RuntimeError`: If called in Eager mode.
``` python
get_updates_for(inputs)
```
Retrieves updates relevant to a specific set of inputs.
#### Arguments:
* `inputs`: Input tensor or list/tuple of input tensors.
#### Returns:
List of update ops of the layer that depend on `inputs`.
``` python
get_weights()
```
Returns the current weights of the layer.
#### Returns:
Weights values as a list of numpy arrays.
``` python
set_weights(weights)
```
Sets the weights of the layer, from Numpy arrays.
#### Arguments:
* `weights`: a list of Numpy arrays. The number
of arrays and their shape must match
number of the dimensions of the weights
of the layer (i.e. it should match the
output of `get_weights`).
#### Raises:
* `ValueError`: If the provided weights list does not match the
layer's specifications.
``` python
@classmethod
with_name_scope(
cls,
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 64]))
return tf.matmul(x, self.w)
```
Using the above module would produce `tf.Variable`s and `tf.Tensor`s whose
names included the module name:
```
mod = MyModule()
mod(tf.ones([8, 32]))
# ==>
mod.w
# ==>
```
#### Args:
* `method`: The method to wrap.
#### Returns:
The original method wrapped such that it enters the module's name scope.
``` python
zero_state(
batch_size,
dtype
)
```
Return zero-filled state tensor(s).
#### Args:
* `batch_size`: int, float, or unit Tensor representing the batch size.
* `dtype`: the data type to use for the state.
#### Returns:
If `state_size` is an int or TensorShape, then the return value is a
`N-D` tensor of shape `[batch_size, state_size]` filled with zeros.
If `state_size` is a nested list or tuple, then the return value is
a nested list or tuple (of the same structure) of `2-D` tensors with
the shapes `[batch_size, s]` for each s in `state_size`.
================================================
FILE: docs/tf/haste_tf.md
================================================
# Module: haste_tf
Haste: a fast, simple, and open RNN library.
## Classes
[`class GRU`](./haste_tf/GRU.md): Gated Recurrent Unit layer.
[`class GRUCell`](./haste_tf/GRUCell.md): A GRU cell that's compatible with the Haste GRU layer.
[`class IndRNN`](./haste_tf/IndRNN.md): Independently Recurrent Neural Network layer.
[`class LSTM`](./haste_tf/LSTM.md): Long Short-Term Memory layer.
[`class LayerNorm`](./haste_tf/LayerNorm.md): Layer normalization layer.
[`class LayerNormGRU`](./haste_tf/LayerNormGRU.md): Layer Normalized Gated Recurrent Unit layer.
[`class LayerNormGRUCell`](./haste_tf/LayerNormGRUCell.md): A GRU cell that's compatible with the Haste LayerNormGRU layer.
[`class LayerNormLSTM`](./haste_tf/LayerNormLSTM.md): Layer Normalized Long Short-Term Memory layer.
[`class LayerNormLSTMCell`](./haste_tf/LayerNormLSTMCell.md): An LSTM cell that's compatible with the Haste LayerNormLSTM layer.
[`class ZoneoutWrapper`](./haste_tf/ZoneoutWrapper.md): An LSTM/GRU cell wrapper that applies zoneout to the inner cell's hidden state.
================================================
FILE: examples/device_ptr.h
================================================
// Copyright 2020 LMNT, Inc. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// ==============================================================================
#pragma once
#include
#include
#include
template
struct device_ptr {
static constexpr size_t ElemSize = sizeof(typename T::Scalar);
static device_ptr NewByteSized(size_t bytes) {
return device_ptr((bytes + ElemSize - 1) / ElemSize);
}
explicit device_ptr(size_t size_)
: data(nullptr), size(size_) {
void* tmp;
cudaMalloc(&tmp, size * ElemSize);
data = static_cast(tmp);
}
explicit device_ptr(const T& elem)
: data(nullptr), size(elem.size()) {
void* tmp;
cudaMalloc(&tmp, size * ElemSize);
data = static_cast