This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see .
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
.
================================================
FILE: MANIFEST.in
================================================
recursive-include kirara_ai/plugins/im_http_legacy_adapter/assets *
recursive-include kirara_ai/plugins/im_qqbot_adapter/assets *
recursive-include kirara_ai/plugins/im_telegram_adapter/assets *
recursive-include kirara_ai/plugins/im_wecom_adapter/assets *
recursive-include kirara_ai/alembic *
================================================
FILE: README.md
================================================
Kirara AI
一款支持主流大语言模型、主流聊天平台的聊天的机器人!
» 查看项目手册 »







***

***
## 🌟 社区交流
加入我们的社区,获取最新项目动态、视频教程、问题答疑和技术交流!
* QQ 交流群:
* [二群](http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=S1R4eIlODtyKZsEKfWxb2-nOIHELbeJY&authKey=kAftCAALE8OJgwQnArrD6zPtncCAaY456QgUXT3l2OMJ57NwRXRkhv4KL7DzOLzs&noverify=0&group_code=373254418)(已满)
* [三群](http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=urlhCH8y7Ro2S-iXt63X4s5eILUny4Iw&authKey=ejiwoNa4Yez6IMLyf2vj%2FeRiC1frdFrNNekbRfaPnSQbcD7bgebo5y5A7rPaRKBq&noverify=0&group_code=533109074)(已满)
* [四群](http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=Ibiu6EmXof30Fa7MJ5j8nJFwaUGTf5bM&authKey=YKx5a%2BK5qnWkk5VlsxxDfYl0nCrKSekQm%2FoLQVqr%2FcO%2FQY2S6N24XdI23XugBrF0&noverify=0&group_code=799737883)(已满)
* [五群](http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=lDkVPDAeiz6M-ig9cdS9tqhSH6_topox&authKey=B%2FRPYVUjk3dYPw5D4o6C2TpqeoKTG0nXEiKDCG%2Bh4JYY2RPqDQGt37SGl32j0hHw&noverify=0&group_code=805081636)
* [六群](https://qm.qq.com/q/UpvYm3jccg)
> **提问前请先查看**: 加入群组前,请先查看[项目问题列表](https://github.com/lss233/kirara-ai/issues),看是否能解决你的问题。
>
> 如需提问,请准备好问题描述、**完整日志**和相关配置文件,以便我们更好地帮助你。
> 进群请备注:GitHub
* [机器人调试群](https://jq.qq.com/?_wv=1027&k=TBX8Saq7) - 这里有多个 QQ 机器人供体验,不解答技术问题。
* [开发者交流群](http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=lisyXibhUj93DgIZptQu3VZ4ka3F5-rW&authKey=PBCzRQX4Zei%2BB6n5Tdyp9p5bqcF0tLBlfGANT4dSSKQIFYR66WwaZSMEDahWo%2FzZ&noverify=0&group_code=701933732) - 欢迎参与 Kirara AI 及生态开发 / 对大模型应用有兴趣的开发者加入,一起交流学习。
## 📷 功能展示
|  |  |  |
|:-------------------------------:|:-------------------------------:|:-------------------------------:|
|  |  |  |
## 🧭 WebUI
模型管理

工作流

插件市场

## ⚡ 核心特性
* [x] 图片发送
* [x] 关键词触发回复
* [x] 多账号支持
* [x] 人格设定
* [x] 支持 QQ、Telegram、Discord、微信
* [x] 可作为 HTTP 服务端提供 Web API
* [x] 支持 OpenAI、DeepSeek、Claude、Gemini、Qwen、Mistral、豆包、Minimax、Kimi、Mistral 等主流大模型
* [x] 支持插件机制
* [x] 支持条件触发
* [x] 支持管理员指令
* [x] 支持 Stable Diffusion、Flux、Midjourney 等绘图模型
* [x] 支持语音回复
* [x] 支持多轮对话
* [x] 支持跨平台消息发送
* [x] 支持自定义工作流
* [x] 支持 Web 管理后台
* [x] 内置 Frpc 内网穿透
# **🤖 聊天平台**
我们支持多种聊天平台。
| 平台 | 群聊回复 | 私聊回复 | 条件触发 | 管理员指令 | 绘图 | 语音回复 |
|----------|------|------|------|-------|-----|------|
| Telegram | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| QQ 机器人 | 支持 | 支持 | 支持 | 支持 | 支持 | 平台不支持 |
| Discord | 重构中 | 重构中 | 重构中 | 重构中 | 重构中 | 重构中 |
| 飞书机器人 | 重构中 | 重构中 | 重构中 | 重构中 | 重构中 | 重构中 |
| 企业微信应用 | 支持 | 支持 | 支持 | 不支持 | 支持 | 支持 |
| 微信公众号 | 支持 | 支持 | 支持 | 不支持 | 支持 | 支持 |
| OneBot | 插件支持 | 插件支持 | 插件支持 | 插件支持 | 插件支持 | 插件支持 |
## 🐎 命令
**你可以在 WebUI 的调度规则中自定义所有命令。**
## 🔧 搭建
请移步至 [快速开始](https://kirara-docs.app.lss233.com/guide/getting-started.html)
## 🕸 HTTP API
HTTP API 可用于接入其他平台。
在聊天平台管理中启动 http-legacy 适配器后,将提供以下接口:
**POST** `/v1/chat`
**请求参数**
|参数名|必选|类型|说明|
|:---|:---|:---|:---|
|session_id| 是 | String |会话ID,默认:`friend-default_session`|
|username| 是 | String |用户名,默认:`某人`|
|message| 是 | String |消息,不能为空|
**请求示例**
```json
{
"session_id": "friend-123456",
"username": "testuser",
"message": "ping"
}
```
**响应格式**
|参数名|类型|说明|
|:---|:---|:---|
|result| String |SUCESS,DONE,FAILED|
|message| String[] |文本返回,支持多段返回|
|voice| String[] |音频返回,支持多个音频的base64编码;参考:data:audio/mpeg;base64,...|
|image| String[] |图片返回,支持多个图片的base64编码;参考:data:image/png;base64,...|
**响应示例**
```json
{
"result": "DONE",
"message": ["pong!"],
"voice": [],
"image": []
}
```
**POST** `/v2/chat`
**请求参数**
|参数名|必选|类型|说明|
|:---|:---|:---|:---|
|session_id| 是 | String |会话ID,默认:`friend-default_session`|
|username| 是 | String |用户名,默认:`某人`|
|message| 是 | String |消息,不能为空|
**请求示例**
```json
{
"session_id": "friend-123456",
"username": "testuser",
"message": "ping"
}
```
**响应格式**
字符串:request_id
**响应示例**
```
1681525479905
```
**GET** `/v2/chat/response`
**请求参数**
|参数名|必选|类型|说明|
|:---|:---|:---|:---|
|request_id| 是 | String |请求id,/v2/chat返回的值|
**请求示例**
```
/v2/chat/response?request_id=1681525479905
```
**响应格式**
|参数名|类型|说明|
|:---|:---|:---|
|result| String |SUCESS,DONE,FAILED|
|message| String[] |文本返回,支持多段返回|
|voice| String[] |音频返回,支持多个音频的base64编码;参考:data:audio/mpeg;base64,...|
|image| String[] |图片返回,支持多个图片的base64编码;参考:data:image/png;base64,...|
* 每次请求返回增量并清空。DONE、FAILED之后没有更多返回。
**响应示例**
```json
{
"result": "DONE",
"message": ["pong!"],
"voice": ["data:audio/mpeg;base64,..."],
"image": ["data:image/png;base64,...", "data:image/png;base64,..."]
}
```
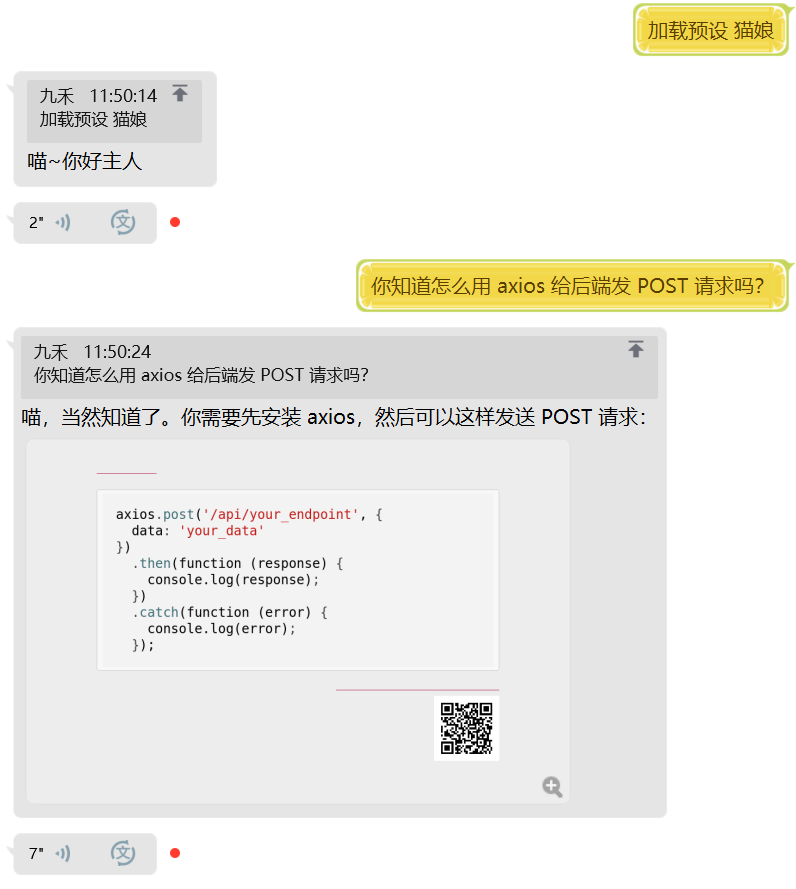
## 🦊 加载预设
如果你想让机器人自动带上某种聊天风格,可以使用预设功能。
我们自带了 `猫娘` 和 `正常` 两种预设,你可以在 `presets` 文件夹下了解预设的写法。
使用 `加载预设 猫娘` 来加载猫娘预设。
下面是一些预设的小视频,你可以看看效果:
* MOSS: https://www.bilibili.com/video/av352047018
* 丁真:https://www.bilibili.com/video/av267013053
* 小黑子:https://www.bilibili.com/video/av309604568
* 高启强:https://www.bilibili.com/video/av779555493
关于预设系统的详细教程:[Wiki](https://github.com/lss233/kirara-ai/wiki/%F0%9F%90%B1-%E9%A2%84%E8%AE%BE%E7%B3%BB%E7%BB%9F)
你可以在 [Awesome ChatGPT QQ Presets](https://github.com/lss233/awesome-chatgpt-qq-presets/tree/master) 获取由大家分享的预设。
你也可以参考 [Awesome-ChatGPT-prompts-ZH_CN](https://github.com/L1Xu4n/Awesome-ChatGPT-prompts-ZH_CN) 来调教你的 ChatGPT,还可以参考 [Awesome ChatGPT Prompts](https://github.com/f/awesome-chatgpt-prompts) 来解锁更多技能。
## 🎙 文字转语音
自 v2.2.5 开始,我们支持接入微软的 Azure 引擎 和 VITS 引擎,让你的机器人发送语音。
**提示**:在 Windows 平台上使用语音功能需要安装最新的 VC 运行库,你可以在[这里](https://learn.microsoft.com/zh-CN/cpp/windows/latest-supported-vc-redist?view=msvc-170)下载。`
## 🛠 贡献者名单
欢迎提出新的点子、 Pull Request。
 Made with [contrib.rocks](https://contrib.rocks).
## 📕 相关项目
- [Kirara Registry](https://github.com/DarkSkyTeam/kirara-registry) - Kirara AI 插件市场
- [Kirara WebUI](https://github.com/DarkSkyTeam/kirara-webui) - Kirara AI 的 WebUI 前端项目
- [Kirara Docs](https://github.com/DarkSkyTeam/kirara-docs) - Kirara AI 的使用手册原始文档
## 💪 支持我们
如果我们这个项目对你有所帮助,请给我们一颗 ⭐️
[](https://www.star-history.com/#lss233/kirara-ai&Date)
================================================
FILE: alembic.ini
================================================
# A generic, single database configuration.
[alembic]
# path to migration scripts
# Use forward slashes (/) also on windows to provide an os agnostic path
script_location = kirara_ai/alembic
# template used to generate migration file names; The default value is %%(rev)s_%%(slug)s
# Uncomment the line below if you want the files to be prepended with date and time
# see https://alembic.sqlalchemy.org/en/latest/tutorial.html#editing-the-ini-file
# for all available tokens
# file_template = %%(year)d_%%(month).2d_%%(day).2d_%%(hour).2d%%(minute).2d-%%(rev)s_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python>=3.9 or backports.zoneinfo library and tzdata library.
# Any required deps can installed by adding `alembic[tz]` to the pip requirements
# string value is passed to ZoneInfo()
# leave blank for localtime
# timezone =
# max length of characters to apply to the "slug" field
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# sourceless = false
# version location specification; This defaults
# to alembic/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator" below.
# version_locations = %(here)s/bar:%(here)s/bat:alembic/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. The default within new alembic.ini files is "os", which uses os.pathsep.
# If this key is omitted entirely, it falls back to the legacy behavior of splitting on spaces and/or commas.
# Valid values for version_path_separator are:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
# version_path_separator = newline
#
# Use os.pathsep. Default configuration used for new projects.
version_path_separator = os
# set to 'true' to search source files recursively
# in each "version_locations" directory
# new in Alembic version 1.10
# recursive_version_locations = false
# the output encoding used when revision files
# are written from script.py.mako
# output_encoding = utf-8
sqlalchemy.url = sqlite:///./data/db/kirara.db
[post_write_hooks]
# post_write_hooks defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# format using "black" - use the console_scripts runner, against the "black" entrypoint
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# lint with attempts to fix using "ruff" - use the exec runner, execute a binary
# hooks = ruff
# ruff.type = exec
# ruff.executable = %(here)s/.venv/bin/ruff
# ruff.options = check --fix REVISION_SCRIPT_FILENAME
# Logging configuration
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARNING
handlers = console
qualname =
[logger_sqlalchemy]
level = WARNING
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
================================================
FILE: config.yaml.example
================================================
# 配置文件示例
# 通讯平台配置部分
ims:
# 每个 IM 平台的具体配置
- name: "telegram-bot-1234" # IM 平台实例名称
enable: true # 是否启用该平台
adapter: "telegram" # 使用的适配器类型
config: # 平台特定的配置
token: "abcd" # 平台的 API 令牌
# 插件系统配置
plugins:
enable: [] # 启用的插件列表
# Web 服务器配置
web:
host: "127.0.0.1" # Web 服务器监听地址
port: 8080 # Web 服务器端口
secret_key: "please-change-this-to-a-secure-secret-key" # Web 服务器安全密钥,请修改为安全的值
# LLM (大语言模型) 配置
llms:
api_backends: # API 后端配置列表
# DeepSeek API 配置
- name: "deepseek-official" # 后端名称
adapter: "deepseek" # 使用的适配器
enable: true # 是否启用
config: # API 具体配置
api_key: "your-api-key" # API 密钥
api_base: "https://api.deepseek.com/v1" # API 基础 URL
models: # 支持的模型列表
- "deepseek-chat"
- "deepseek-coder"
# OpenAI API 配置
- name: "openai-gpt4" # 后端名称
adapter: "openai" # 使用的适配器
enable: true # 是否启用
config: # API 具体配置
api_key: "your-openai-key" # OpenAI API 密钥
api_base: "https://api.openai.com/v1" # OpenAI API 基础 URL
models: # 支持的模型列表
- "gpt-4"
- "gpt-4-turbo"
# 默认配置
defaults:
llm_model: gemini-1.5-flash # 默认使用的 LLM 模型
# 记忆系统配置
memory:
persistence: # 持久化配置
type: file # 持久化类型(支持 file 或 redis)
file: # 文件存储配置
storage_dir: ./data/memory # 存储目录
redis: # Redis 存储配置
host: localhost # Redis 主机地址
port: 6379 # Redis 端口
db: 0 # Redis 数据库编号
max_entries: 100 # 最大记忆条目数
default_scope: member # 默认记忆作用域
================================================
FILE: data/.gitkeep
================================================
================================================
FILE: data/dispatch_rules/rules.yaml
================================================
- rule_id: chat_normal
name: 群聊AI对话
description: 群聊中使用 /chat 开头对话或者 被@ 时触发聊天
workflow_id: chat:normal
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /chat
- type: bot_mention
config: {}
- operator: or
rules:
- type: chat_type
config:
chat_type: 群聊
metadata:
category: chat
permission: user
temperature: 0.7
- rule_id: chat_creative
name: 私聊AI对话
description: 私聊时直接发送内容触发对话
workflow_id: chat:normal
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: chat_type
config:
chat_type: 私聊
metadata:
category: chat
permission: user
temperature: 0.9
- rule_id: game_dice
name: 骰子
description: 骰子游戏,支持 XdY 格式
workflow_id: game:dice
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: regex
config:
pattern: ^[.。]roll\s*(\d+)?d(\d+)
metadata: {}
- rule_id: game_gacha
name: 抽卡
description: 抽卡模拟器
workflow_id: game:gacha
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: keyword
config:
keywords:
- 抽卡
- 十连
- 单抽
metadata: {}
- rule_id: system_help
name: 帮助命令
description: 显示帮助信息
workflow_id: system:help
priority: 10
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /help
metadata:
category: system
permission: user
- rule_id: system_clear_memory
name: 清空记忆
description: 清空当前对话的记忆
workflow_id: system:clear_memory
priority: 10
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /清空记忆
metadata:
category: system
permission: user
- rule_id: fallback
name: 默认规则
description: 当上述规则均没有匹配成功时,执行此工作流。
workflow_id: chat:memory_store
priority: 0
enabled: true
rule_groups:
- operator: or
rules:
- type: fallback
config: {}
metadata: {}
================================================
FILE: data/media/.gitignore
================================================
metadata/*
files/*
================================================
FILE: data/memory/.gitignore
================================================
*.json
================================================
FILE: data/web/.gitkeep
================================================
================================================
FILE: data/workflows/.gitkeep
================================================
================================================
FILE: data/workflows/chat/dsr_thinking.yaml
================================================
name: 聊天 - 深度思考
description: DeepSeek 思考模型聊天,隐藏 标签内容
blocks:
- type: internal:get_message
name: get_message
params: {}
position:
x: 100
y: 138
connected_to:
- target: ToggleEditState_81bvwg
mapping:
from: sender
to: sender
- target: ToggleEditState_81bvwg
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: ChatMessageConstructor_g44tpp
mapping:
from: msg
to: user_msg
- target: ChatMemoryStore_ljrym0
mapping:
from: msg
to: user_msg
- type: internal:toggle_edit_state
name: ToggleEditState_81bvwg
params:
is_editing: true
position:
x: 530
y: 138
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
position:
x: 530
y: 338
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: memory_content
to: memory_content
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:{current_date_time}\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 100
y: 330
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: system_prompt_format
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 100
y: 530
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: user_prompt_format
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: ChatMessageConstructor_g44tpp
params: {}
position:
x: 960
y: 138
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:llm_response_to_text
name: e4fe53bb-fcbe-41c3-ab69-e8d3881c3b55
params: {}
position:
x: 1711
y: 511
connected_to:
- target: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
mapping:
from: text
to: text
- target: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
mapping:
from: text
to: text
- type: internal:text_extract_by_regex_block
name: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
params:
regex: (?:[\s\S]*?)?([\s\S]*)
position:
x: 1972
y: 513
connected_to:
- target: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
mapping:
from: text
to: text
- target: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
mapping:
from: text
to: text
- type: internal:text_to_im_message
name: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
params:
split_by:
position:
x: 2352
y: 513
connected_to:
- target: SendIMMessage_x9ro8t
mapping:
from: msg
to: msg
- target: SendIMMessage_x9ro8t
mapping:
from: msg
to: msg
- type: internal:send_message
name: SendIMMessage_x9ro8t
params: {}
position:
x: 2797
y: 140
- type: internal:chat_memory_store
name: ChatMemoryStore_ljrym0
params:
scope_type: group
position:
x: 1764
y: 308
- type: internal:chat_completion
name: llm_chat
params:
model_name: deepseek-r1:7b
position:
x: 1280
y: 138
connected_to:
- target: ChatMemoryStore_ljrym0
mapping:
from: resp
to: llm_resp
- target: e4fe53bb-fcbe-41c3-ab69-e8d3881c3b55
mapping:
from: resp
to: response
================================================
FILE: data/workflows/chat/memory_store.yaml
================================================
name: 记录聊天内容
description: 默默记下大家的聊天内容,可以使用查询记忆模块读取出来。
blocks:
- type: internal:get_message
name: 6233e64c-433e-4087-9035-cb96914349f7
params: {}
position:
x: 100
y: 138
connected_to:
- target: 86354196-f249-4393-9620-941b01bc344e
mapping:
from: msg
to: user_msg
- type: internal:chat_memory_store
name: 86354196-f249-4393-9620-941b01bc344e
params:
scope_type: group
position:
x: 420
y: 138
================================================
FILE: data/workflows/chat/normal_multimodal.yaml
================================================
name: 聊天 - 原生多模态对话
description: 基于原生多模态能力的图文对话,适用于本身支持图片输入/回答的模型,在读取记忆时会恢复原来的媒体资源
blocks:
- type: internal:get_message
name: get_message
params: {}
position:
x: 100
y: 138
connected_to:
- target: ToggleEditState_i24m23
mapping:
from: sender
to: sender
- target: ToggleEditState_i24m23
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: ChatMessageConstructor_6c185s
mapping:
from: msg
to: user_msg
- target: ChatMemoryStore_tapuo1
mapping:
from: msg
to: user_msg
- type: internal:toggle_edit_state
name: ToggleEditState_i24m23
params:
is_editing: true
position:
x: 530
y: 138
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:{current_date_time}\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 100
y: 330
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: system_prompt_format
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 100
y: 530
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: user_prompt_format
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: ChatMessageConstructor_6c185s
params: {}
position:
x: 960
y: 138
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:chat_completion
name: llm_chat
params: {}
position:
x: 1280
y: 138
connected_to:
- target: ChatResponseConverter_73spno
mapping:
from: resp
to: resp
- target: ChatResponseConverter_73spno
mapping:
from: resp
to: resp
- target: ChatMemoryStore_tapuo1
mapping:
from: resp
to: llm_resp
- type: internal:chat_response_converter
name: ChatResponseConverter_73spno
params: {}
position:
x: 1710
y: 138
connected_to:
- target: SendIMMessage_l6qagt
mapping:
from: msg
to: msg
- target: SendIMMessage_l6qagt
mapping:
from: msg
to: msg
- type: internal:send_message
name: SendIMMessage_l6qagt
params: {}
position:
x: 2140
y: 138
- type: internal:chat_memory_store
name: ChatMemoryStore_tapuo1
params:
scope_type: group
position:
x: 1710
y: 306
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
decomposer_name: multi_element
position:
x: 530
y: 338
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: memory_content
to: memory_content
================================================
FILE: data/workflows/chat/talk_break.yaml
================================================
name: 聊天 - 自定义分段
description: 使用 `` 作为关键词,让 AI 分段回复的工作流
blocks:
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:2025-02-23 15:27:37.762784\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n2. `<@llm>` 开头的内容表示你当前扮演角色的回答,你的回答中不能带上这个标记。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 426
y: 599
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: text
to: system_prompt_format
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
position:
x: 419
y: 462
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: memory_content
to: memory_content
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 419
y: 317
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: chat_message_constructor_wfy18q
params: {}
position:
x: 970
y: 346
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:get_message
name: get_message
params: {}
position:
x: 105
y: 189
connected_to:
- target: toggle_edit_state_svmo3f
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: chat_message_constructor_wfy18q
mapping:
from: msg
to: user_msg
- target: chat_memory_store_a0fj1l
mapping:
from: msg
to: user_msg
- type: internal:llm_response_to_text
name: c9eddb3c-113f-4a39-9d47-682d0a7dd26e
params: {}
position:
x: 1658
y: 344
connected_to:
- target: 6edd5c0c-a538-45ab-bb50-4c3a906bb1b1
mapping:
from: text
to: text
- type: internal:text_to_im_message
name: 6edd5c0c-a538-45ab-bb50-4c3a906bb1b1
params:
split_by:
position:
x: 1918
y: 347
connected_to:
- target: msg_sender_lakgf8
mapping:
from: msg
to: msg
- type: internal:toggle_edit_state
name: toggle_edit_state_svmo3f
params:
is_editing: true
position:
x: 424
y: 94
- type: internal:chat_completion
name: llm_chat
params:
model_name: gemini-2.0-flash
position:
x: 1260
y: 347
connected_to:
- target: chat_memory_store_a0fj1l
mapping:
from: resp
to: llm_resp
- target: c9eddb3c-113f-4a39-9d47-682d0a7dd26e
mapping:
from: resp
to: response
- type: internal:chat_memory_store
name: chat_memory_store_a0fj1l
params:
scope_type: group
position:
x: 1663
y: 192
- type: internal:send_message
name: msg_sender_lakgf8
params: {}
position:
x: 2377
y: 346
================================================
FILE: docker/start.sh
================================================
#!/bin/bash
cd /app
# Copy default data
# check if data directory exists
if [ ! -d "/app/data" ]; then
echo "Data directory does not exist, creating..."
mkdir /app/data
fi
# check if data directory empty
if [ -z "$(ls -A /app/data)" ]; then
echo "Data directory is empty, copying default data..."
cp -r /tmp/data/. /app/data
fi
# create default config
if [ ! -f "/app/data/config.yaml" ]; then
echo "Config file does not exist, creating..."
# 必须配置 web,否则无法访问
cat < /app/data/config.yaml
web:
host: 0.0.0.0
port: 8080
EOF
fi
# create data/venv
if [ ! -d "/app/data/venv" ]; then
echo "Venv directory does not exist, creating..."
python -m venv /app/data/venv --system-site-packages
fi
# activate venv
source /app/data/venv/bin/activate
python -m kirara_ai
================================================
FILE: kirara_ai/__init__.py
================================================
from .config.config_loader import ConfigLoader
from .entry import init_application, run_application
from .logger import get_logger
__all__ = ["init_application", "run_application", "get_logger", "ConfigLoader"]
================================================
FILE: kirara_ai/__main__.py
================================================
import argparse
import os
import subprocess
import sys
from kirara_ai.entry import init_application, run_application
from kirara_ai.internal import get_and_reset_restart_flag
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description='Kirara AI Chatbot Server')
parser.add_argument('-H', '--host', help='覆盖服务监听地址')
parser.add_argument('-p', '--port', type=int, help='覆盖服务监听端口')
args = parser.parse_args()
container = init_application()
# 将参数对象直接注入容器
container.register("cli_args", args)
try:
run_application(container)
finally:
if get_and_reset_restart_flag():
# 重新启动程序
# 构建命令行参数,透传所有原始参数
cmd = [sys.executable, "-m", "kirara_ai"]
# 从解析后的参数对象中获取参数
if args.host:
cmd.extend(["-H", args.host])
if args.port:
cmd.extend(["-p", str(args.port)])
process = subprocess.Popen(cmd, env=os.environ, cwd=os.getcwd())
process.wait()
if __name__ == "__main__":
main()
================================================
FILE: kirara_ai/alembic/README
================================================
Generic single-database configuration.
================================================
FILE: kirara_ai/alembic/env.py
================================================
from logging.config import fileConfig
from alembic import context
from sqlalchemy import engine_from_config, pool
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
from kirara_ai.database.manager import Base
from kirara_ai.tracing.models import LLMRequestTrace # noqa: F401
target_metadata = Base.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
================================================
FILE: kirara_ai/alembic/script.py.mako
================================================
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
"""Upgrade schema."""
${upgrades if upgrades else "pass"}
def downgrade() -> None:
"""Downgrade schema."""
${downgrades if downgrades else "pass"}
================================================
FILE: kirara_ai/alembic/versions/4a364dbb8dab_initial_migration.py
================================================
"""Initial migration
Revision ID: 4a364dbb8dab
Revises:
Create Date: 2025-03-29 13:59:33.243069
"""
from typing import Sequence, Union
import sqlalchemy as sa
from alembic import op
# revision identifiers, used by Alembic.
revision: str = '4a364dbb8dab'
down_revision: Union[str, None] = None
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('llm_request_traces',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('trace_id', sa.String(length=64), nullable=False),
sa.Column('model_id', sa.String(length=64), nullable=False),
sa.Column('backend_name', sa.String(length=64), nullable=False),
sa.Column('request_time', sa.DateTime(), nullable=False),
sa.Column('response_time', sa.DateTime(), nullable=True),
sa.Column('duration', sa.Float(), nullable=True),
sa.Column('request_json', sa.Text(), nullable=True),
sa.Column('response_json', sa.Text(), nullable=True),
sa.Column('prompt_tokens', sa.Integer(), nullable=True),
sa.Column('completion_tokens', sa.Integer(), nullable=True),
sa.Column('total_tokens', sa.Integer(), nullable=True),
sa.Column('cached_tokens', sa.Integer(), nullable=True),
sa.Column('error', sa.Text(), nullable=True),
sa.Column('status', sa.String(length=20), nullable=False),
sa.PrimaryKeyConstraint('id')
)
op.create_index('idx_backend_time', 'llm_request_traces', ['backend_name', 'request_time'], unique=False)
op.create_index('idx_request_model', 'llm_request_traces', ['model_id', 'request_time'], unique=False)
op.create_index('idx_status_time', 'llm_request_traces', ['status', 'request_time'], unique=False)
op.create_index(op.f('ix_llm_request_traces_backend_name'), 'llm_request_traces', ['backend_name'], unique=False)
op.create_index(op.f('ix_llm_request_traces_model_id'), 'llm_request_traces', ['model_id'], unique=False)
op.create_index(op.f('ix_llm_request_traces_request_time'), 'llm_request_traces', ['request_time'], unique=False)
op.create_index(op.f('ix_llm_request_traces_trace_id'), 'llm_request_traces', ['trace_id'], unique=True)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f('ix_llm_request_traces_trace_id'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_request_time'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_model_id'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_backend_name'), table_name='llm_request_traces')
op.drop_index('idx_status_time', table_name='llm_request_traces')
op.drop_index('idx_request_model', table_name='llm_request_traces')
op.drop_index('idx_backend_time', table_name='llm_request_traces')
op.drop_table('llm_request_traces')
# ### end Alembic commands ###
================================================
FILE: kirara_ai/config/__init__.py
================================================
import os
# 读取DATA_PATH环境变量,若未能找到则以当前工作目录为根文件夹存储在$PWD/data目录下。
DATA_PATH = os.path.abspath(
os.environ.get("DATA_PATH", os.path.join(os.getcwd(), "data"))
)
# 按照规范插件应该在PLUGIN_PATH目录下存储对应的文件。
PLUGIN_PATH = os.path.join(DATA_PATH, "plugins")
if os.path.exists(DATA_PATH) is False:
os.makedirs(DATA_PATH)
if os.path.exists(PLUGIN_PATH) is False:
os.makedirs(PLUGIN_PATH)
================================================
FILE: kirara_ai/config/config_loader.py
================================================
import os
import shutil
from functools import wraps
from typing import Optional, Type, TypeVar
from pydantic import BaseModel, ValidationError
from pydantic.json_schema import GenerateJsonSchema, JsonSchemaValue
from ruamel.yaml import YAML
from ..logger import get_logger
from . import DATA_PATH
CONFIG_FILE = os.path.join(DATA_PATH, "config.yaml")
T = TypeVar("T", bound=BaseModel)
class ConfigLoader:
"""
配置文件加载器,支持加载和保存 YAML 文件,并保留注释。
"""
yaml = YAML()
@staticmethod
def load_config(config_path: str, config_class: Type[T]) -> T:
"""
从 YAML 文件中加载配置,并将其序列化为相应的配置对象。
:param config_path: 配置文件路径。
:param config_class: 配置文件类。
:return: 配置对象。
"""
try:
with open(config_path, "r", encoding="utf-8") as f:
config_data = ConfigLoader.yaml.load(f)
return config_class(**config_data)
except ValidationError as e:
raise ValueError(f"配置文件验证失败: {e}")
except Exception as e:
raise RuntimeError(f"加载配置文件失败: {e}")
@staticmethod
def save_config(config_path: str, config_object: BaseModel):
"""
将配置对象保存到 YAML 文件中,并保留注释。
:param config_path: 配置文件路径。
:param config_object: 配置对象。
"""
with open(config_path, "w", encoding="utf-8") as f:
ConfigLoader.yaml.dump(config_object.model_dump(), f)
@staticmethod
def save_config_with_backup(config_path: str, config_object: BaseModel):
"""
将配置对象保存到 YAML 文件中,并在保存前创建备份。
:param config_path: 配置文件路径。
:param config_object: 配置对象。
"""
if os.path.exists(config_path):
backup_path = f"{config_path}.bak"
shutil.copy2(config_path, backup_path)
ConfigLoader.save_config(config_path, config_object)
def pydantic_validation_wrapper(func):
logger = get_logger("ConfigLoader")
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except ValidationError as e:
# 使用 loguru 输出错误信息
logger.error(f"Pydantic 验证错误: '{e.title}':")
for error in e.errors():
logger.error(
f"字段: {error['loc'][0]}, 错误类型: {error['type']}, 错误信息: {error['msg']}"
)
# 记录堆栈跟踪
logger.opt(exception=True).error("堆栈跟踪如下:")
raise # 可以选择重新抛出异常,或者处理异常后返回一个默认值
return wrapper
class ConfigJsonSchema(GenerateJsonSchema):
def sort(
self, value: JsonSchemaValue, parent_key: Optional[str] = None
) -> JsonSchemaValue:
"""No-op, we don't want to sort schema values at all."""
return value
================================================
FILE: kirara_ai/config/global_config.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, ConfigDict, Field, model_validator
from kirara_ai.llm.model_types import LLMAbility, ModelType
class IMConfig(BaseModel):
"""IM配置"""
name: str = Field(default="", description="IM标识名称")
enable: bool = Field(default=True, description="是否启用IM")
adapter: str = Field(default="dummy", description="IM适配器类型")
config: Dict[str, Any] = Field(default={}, description="IM的配置")
class ModelConfig(BaseModel):
"""模型配置"""
id: str = Field(description="模型标识ID")
type: str = Field(default=ModelType.LLM.value, description="模型类型:llm/embedding/image_generation等")
ability: int = Field(description="模型能力,对应模型类型的Ability枚举值")
model_config = ConfigDict(extra="allow")
class LLMBackendConfig(BaseModel):
"""LLM后端配置"""
name: str = Field(description="后端标识名称")
adapter: str = Field(description="LLM适配器类型")
config: Dict[str, Any] = Field(default={}, description="后端配置")
enable: bool = Field(default=True, description="是否启用")
models: List[ModelConfig] = Field(
default=[], description="支持的模型列表"
)
@model_validator(mode='before')
@classmethod
def migrate_models_format(cls, data: Dict[str, Any]) -> Dict[str, Any]:
"""
自动迁移模型配置格式
将旧格式的字符串ID列表转换为新格式的ModelConfig对象列表
"""
if "models" in data and isinstance(data["models"], list):
# 创建新的模型列表
new_models = []
for model in data["models"]:
if isinstance(model, str):
# 旧格式:字符串ID,转换为ModelConfig
new_models.append(ModelConfig(id=model, type=ModelType.LLM.value, ability=LLMAbility.TextChat.value))
else:
# 新格式或已迁移的模型配置,保持不变
new_models.append(model)
data["models"] = new_models
return data
class LLMConfig(BaseModel):
api_backends: List[LLMBackendConfig] = Field(
default=[], description="LLM API后端列表"
)
class MCPServerConfig(BaseModel):
"""MCP服务器配置"""
id: str = Field(description="服务器标识ID")
description: str = Field(default="", description="服务器描述")
url: Optional[str] = Field(default="", description="服务器URL")
headers: Dict[str, str] = Field(default_factory=dict, description="服务器请求 Headers")
command: Optional[str] = Field(default="", description="服务器命令")
args: List[str] = Field(default_factory=list, description="服务器参数")
env: Dict[str, str] = Field(default_factory=dict, description="环境变量")
connection_type: str = Field(default="stdio", description="连接类型: stdio/sse")
enable: bool = Field(default=True, description="是否启用")
class MCPConfig(BaseModel):
"""MCP配置"""
servers: List[MCPServerConfig] = Field(default=[], description="MCP服务器列表")
class DefaultConfig(BaseModel):
llm_model: str = Field(
default="gemini-1.5-flash", description="默认使用的 LLM 模型名称"
)
class MemoryPersistenceConfig(BaseModel):
type: str = Field(default="file", description="持久化类型: file/redis")
file: Dict[str, Any] = Field(
default={"storage_dir": "./data/memory"}, description="文件持久化配置"
)
redis: Dict[str, Any] = Field(
default={"host": "localhost", "port": 6379, "db": 0},
description="Redis持久化配置",
)
class MemoryConfig(BaseModel):
persistence: MemoryPersistenceConfig = MemoryPersistenceConfig()
max_entries: int = Field(default=100, description="每个作用域最大记忆条目数")
default_scope: str = Field(default="member", description="默认作用域类型")
class WebConfig(BaseModel):
host: str = Field(default="127.0.0.1", description="Web服务绑定的IP地址")
port: int = Field(default=8080, description="Web服务端口号")
secret_key: str = Field(default="", description="Web服务的密钥,用于JWT等加密")
password_file: str = Field(
default="./data/web/password.hash", description="密码哈希存储路径"
)
class PluginConfig(BaseModel):
"""插件配置"""
enable: List[str] = Field(default=[], description="启用的外部插件列表")
market_base_url: str = Field(
default="https://kirara-plugin.app.lss233.com/api/v1",
description="插件市场基础URL",
)
class UpdateConfig(BaseModel):
pypi_registry: str = Field(default="https://pypi.org/simple", description="PyPI 服务器 URL")
npm_registry: str = Field(default="https://registry.npmjs.org", description="npm 服务器 URL")
class FrpcConfig(BaseModel):
"""FRPC 配置"""
enable: bool = Field(default=False, description="是否启用 FRPC")
server_addr: str = Field(default="", description="FRPC 服务器地址")
server_port: int = Field(default=7000, description="FRPC 服务器端口")
token: str = Field(default="", description="FRPC 连接令牌")
remote_port: int = Field(default=0, description="远程端口,0 表示随机分配")
class SystemConfig(BaseModel):
"""系统配置"""
timezone: str = Field(default="Asia/Shanghai", description="时区")
class TracingConfig(BaseModel):
"""Tracing 配置"""
llm_tracing_content: bool = Field(default=False, description="是否记录 LLM 请求内容")
class MediaConfig(BaseModel):
"""媒体配置"""
cleanup_duration: int = Field(default=30, description="间隔多少天清理一次媒体文件")
auto_remove_unreferenced: bool = Field(default=True, description="是否自动删除未引用的媒体文件")
last_cleanup_time: int = Field(default=0, description="上次清理时间")
class GlobalConfig(BaseModel):
ims: List[IMConfig] = Field(default=[], description="IM配置列表")
llms: LLMConfig = LLMConfig()
mcp: MCPConfig = MCPConfig()
defaults: DefaultConfig = DefaultConfig()
memory: MemoryConfig = MemoryConfig()
web: WebConfig = WebConfig()
plugins: PluginConfig = PluginConfig()
update: UpdateConfig = UpdateConfig()
frpc: FrpcConfig = FrpcConfig()
system: SystemConfig = SystemConfig()
tracing: TracingConfig = TracingConfig()
media: MediaConfig = MediaConfig()
model_config = ConfigDict(extra="allow")
================================================
FILE: kirara_ai/database/__init__.py
================================================
from kirara_ai.database.manager import Base, DatabaseManager, metadata
__all__ = ["Base", "DatabaseManager", "metadata"]
================================================
FILE: kirara_ai/database/manager.py
================================================
import os
from typing import Optional
from alembic import command
from alembic.config import Config
from alembic.runtime.migration import MigrationContext
from alembic.script import ScriptDirectory
from sqlalchemy import MetaData, create_engine
from sqlalchemy.orm import Session, declarative_base, sessionmaker
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
logger = get_logger("DB")
# 创建Base类,用于所有ORM模型
Base = declarative_base()
metadata = MetaData()
class DatabaseManager:
"""数据库管理器,负责管理数据库连接和会话"""
def __init__(self, container: DependencyContainer, database_url: Optional[str] = None, is_debug: bool = False):
self.container = container
self.engine = None
self.session_factory = None
self.data_dir = "./data/db"
self.db_path = os.path.join(self.data_dir, "kirara.db")
self.database_url = database_url
self.is_debug = is_debug
def initialize(self):
"""初始化数据库连接"""
# 确保数据目录存在
os.makedirs(self.data_dir, exist_ok=True)
# 创建数据库引擎
if self.database_url:
db_url = self.database_url
else:
db_url = f"sqlite:///{self.db_path}"
self.engine = create_engine(db_url, echo=self.is_debug)
# 创建session工厂
self.session_factory = sessionmaker(bind=self.engine)
# 运行数据库迁移
self._run_migrations()
logger.info(f"Database initialized at {self.engine.url}")
def _run_migrations(self):
assert self.engine is not None
"""运行数据库迁移"""
try:
# 获取 alembic.ini 的路径
package_dir = os.path.dirname(os.path.dirname(__file__))
alembic_ini_path = os.path.join(package_dir, "alembic.ini")
# 如果配置文件不存在,说明是作为包安装的,使用默认配置
if not os.path.exists(alembic_ini_path):
alembic_cfg = Config()
alembic_cfg.set_main_option("script_location", os.path.join(package_dir, "alembic"))
else:
alembic_cfg = Config(alembic_ini_path)
alembic_cfg.set_main_option("sqlalchemy.url", str(self.engine.url))
# 检查是否需要迁移
with self.engine.connect() as connection:
context = MigrationContext.configure(connection)
current_rev = context.get_current_revision()
script = ScriptDirectory.from_config(alembic_cfg)
head_rev = script.get_current_head()
if current_rev != head_rev:
logger.info("Running database migrations...")
command.upgrade(alembic_cfg, "head")
logger.info("Database migrations completed")
else:
logger.info("Database schema is up to date")
except Exception as e:
logger.error(f"Error during database migration: {e}")
raise
def get_session(self) -> Session:
"""获取数据库会话"""
if not self.session_factory:
self.initialize()
assert self.session_factory is not None
return self.session_factory()
def shutdown(self):
"""关闭数据库连接"""
if self.engine:
self.engine.dispose()
logger.info("Database connection closed")
================================================
FILE: kirara_ai/entry.py
================================================
import asyncio
import os
import signal
import time
from packaging import version
from kirara_ai.config.config_loader import ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.database import DatabaseManager
from kirara_ai.events.application import ApplicationStarted, ApplicationStopping
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.internal import shutdown_event
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.logger import get_logger
from kirara_ai.mcp_module.manager import MCPServerManager
from kirara_ai.media import MediaManager
from kirara_ai.media.carrier import MediaCarrierRegistry, MediaCarrierService
from kirara_ai.memory.composes import DefaultMemoryComposer, DefaultMemoryDecomposer, MultiElementDecomposer
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.scopes import GlobalScope, GroupScope, MemberScope
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.tracing import LLMTracer, TracingManager
from kirara_ai.web.api.system.utils import get_installed_version, get_latest_pypi_version
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.block import BlockRegistry
from kirara_ai.workflow.core.dispatch import DispatchRuleRegistry, WorkflowDispatcher
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from kirara_ai.workflow.implementations.blocks import register_system_blocks
from kirara_ai.workflow.implementations.workflows import register_system_workflows
logger = get_logger("Entrypoint")
_interrupt_count = 0 # 添加计数器
async def check_update():
"""检查更新"""
running_version = get_installed_version()
logger.info("Checking for updates...")
latest_version, _ = await get_latest_pypi_version("kirara-ai")
logger.info(f"Running version: {running_version}, Latest version: {latest_version}")
backend_update_available = version.parse(latest_version) > version.parse(running_version)
if backend_update_available:
logger.warning(f"New version {latest_version} is available. Please update to the latest version.")
logger.warning(f"You can download the latest version from WebUI")
# 注册信号处理函数
def _signal_handler(*args):
global _interrupt_count
_interrupt_count += 1
if _interrupt_count == 1:
if not shutdown_event.is_set():
logger.warning("Interrupt signal received. Stopping application...")
shutdown_event.set()
elif _interrupt_count == 2:
logger.warning("Interrupt signal received again. Press Ctrl+C one more time to force shutdown...")
else:
logger.warning("Interrupt signal received for the third time. Forcing shutdown...")
os._exit(1)
def init_container() -> DependencyContainer:
container = DependencyContainer()
container.register(DependencyContainer, container)
return container
def init_memory_system(container: DependencyContainer):
"""初始化记忆系统"""
memory_manager = MemoryManager(container)
# 注册默认作用域
memory_manager.register_scope("member", MemberScope)
memory_manager.register_scope("group", GroupScope)
memory_manager.register_scope("global", GlobalScope)
# 注册默认组合器和解析器
memory_manager.register_composer("default", DefaultMemoryComposer)
memory_manager.register_decomposer("default", DefaultMemoryDecomposer)
memory_manager.register_decomposer("multi_element", MultiElementDecomposer)
container.register(MemoryManager, memory_manager)
return memory_manager
def init_media_carrier(container: DependencyContainer):
"""初始化媒体载体"""
# 注册记忆管理器作为媒体引用提供者
carrier_registry = container.resolve(MediaCarrierRegistry)
carrier_registry.register("memory", container.resolve(MemoryManager))
def init_tracing_system(container: DependencyContainer):
"""初始化追踪系统"""
logger.info("Initializing tracing system...")
# 初始化追踪管理器
tracing_manager = TracingManager(container)
container.register(TracingManager, tracing_manager)
# 创建并注册LLM追踪器
llm_tracer = LLMTracer(container)
container.register(LLMTracer, llm_tracer)
tracing_manager.register_tracer("llm", llm_tracer)
# 初始化追踪系统
tracing_manager.initialize()
logger.info("Tracing system initialized")
return tracing_manager
def init_application() -> DependencyContainer:
"""初始化应用程序"""
logger.info("Initializing application...")
# 配置文件路径
config_path = "./data/config.yaml"
# 加载配置文件
logger.info(f"Loading configuration from {config_path}")
# check data directory
if not os.path.exists("./data"):
os.makedirs("./data")
if os.path.exists(config_path):
config: GlobalConfig = ConfigLoader.load_config(config_path, GlobalConfig)
logger.info("Configuration loaded successfully")
else:
logger.warning(
f"Configuration file {config_path} not found, using default configuration"
)
logger.warning(
"Please create a configuration file by copying config.yaml.example to config.yaml and modify it according to your needs"
)
config = GlobalConfig()
# 设置时区
os.environ["TZ"] = config.system.timezone
if hasattr(time, "tzset"):
time.tzset()
container = init_container()
container.register(asyncio.AbstractEventLoop, asyncio.new_event_loop())
container.register(EventBus, EventBus())
container.register(GlobalConfig, config)
container.register(BlockRegistry, BlockRegistry())
# 初始化数据库管理器
db = DatabaseManager(container)
db.initialize()
container.register(DatabaseManager, db)
# 注册媒体管理器
media_manager = MediaManager()
container.register(MediaManager, media_manager)
container.register(MediaCarrierRegistry, MediaCarrierRegistry(container))
container.register(MediaCarrierService, MediaCarrierService(container, media_manager))
# 注册工作流注册表
workflow_registry = WorkflowRegistry(container)
container.register(WorkflowRegistry, workflow_registry)
# 注册调度规则注册表
dispatch_registry = DispatchRuleRegistry(container)
container.register(DispatchRuleRegistry, dispatch_registry)
container.register(IMRegistry, IMRegistry())
container.register(LLMBackendRegistry, LLMBackendRegistry())
im_manager = IMManager(container)
container.register(IMManager, im_manager)
llm_manager = LLMManager(container)
container.register(LLMManager, llm_manager)
plugin_loader = PluginLoader(container, os.path.join(os.path.dirname(__file__), "plugins"))
container.register(PluginLoader, plugin_loader)
workflow_dispatcher = WorkflowDispatcher(container)
container.register(WorkflowDispatcher, workflow_dispatcher)
container.register(WebServer, WebServer(container))
mcp_manager = MCPServerManager(container)
container.register(MCPServerManager, mcp_manager)
# 初始化记忆系统
logger.info("Initializing memory system...")
init_memory_system(container)
init_media_carrier(container)
# 初始化追踪系统
init_tracing_system(container)
# 注册系统 blocks
register_system_blocks(container.resolve(BlockRegistry))
# 发现并加载插件
plugin_loader = container.resolve(PluginLoader)
logger.info("Discovering internal plugins...")
plugin_loader.discover_internal_plugins()
logger.info("Discovering external plugins...")
plugin_loader.discover_external_plugins()
logger.info("Loading plugins")
plugin_loader.load_plugins()
# 加载工作流和调度规则
workflow_registry = container.resolve(WorkflowRegistry)
workflow_registry.load_workflows()
register_system_workflows(workflow_registry)
dispatch_registry = container.resolve(DispatchRuleRegistry)
dispatch_registry.load_rules()
# 加载模型
llm_manager = container.resolve(LLMManager)
logger.info("Loading LLMs")
llm_manager.load_config()
# 加载MCP服务器
mcp_manager = container.resolve(MCPServerManager)
logger.info("Loading MCP servers")
mcp_manager.load_servers()
return container
def run_application(container: DependencyContainer):
"""运行应用程序"""
loop = container.resolve(asyncio.AbstractEventLoop)
# 启动Web服务器
logger.info("Starting web server...")
web_server = container.resolve(WebServer)
loop.run_until_complete(web_server.start())
# 启动插件
plugin_loader = container.resolve(PluginLoader)
plugin_loader.start_plugins()
# 启动适配器
logger.info("Starting adapters")
im_manager = container.resolve(IMManager)
im_manager.start_adapters(loop=loop)
# 加载MCP服务器
mcp_manager = container.resolve(MCPServerManager)
logger.info("Connecting to MCP servers")
mcp_manager.connect_all_servers(loop=loop)
# 注册信号处理函数
signal.signal(signal.SIGINT, _signal_handler)
signal.signal(signal.SIGTERM, _signal_handler)
# 阻止信号处理函数被覆盖
signal.signal = lambda *args: None
try:
logger.success("Kirara AI 启动完毕,等待消息中...")
logger.success(
f"WebUI 管理平台本地访问地址:http://127.0.0.1:{web_server.listen_port}/"
)
logger.success("Application started. Waiting for events...")
loop.create_task(check_update())
event_bus = container.resolve(EventBus)
event_bus.post(ApplicationStarted())
loop.run_until_complete(shutdown_event.wait())
finally:
event_bus.post(ApplicationStopping())
# 关闭记忆系统
memory_manager = container.resolve(MemoryManager)
logger.info("Shutting down memory system...")
memory_manager.shutdown()
# 关闭追踪系统
try:
tracing_manager = container.resolve(TracingManager)
logger.info("Shutting down tracing system...")
tracing_manager.shutdown()
db_manager = container.resolve(DatabaseManager)
logger.info("Shutting down database...")
db_manager.shutdown()
except Exception as e:
logger.error(f"Error shutting down tracing system: {e}")
# 停止Web服务器
logger.info("Stopping web server...")
# 停止Web服务器
loop.run_until_complete(web_server.stop())
logger.info("Web server terminated.")
try:
# 停止所有 adapter
im_manager.stop_adapters(loop=loop)
mcp_manager.disconnect_all_servers(loop=loop)
# 停止插件
plugin_loader.stop_plugins()
except Exception as e:
logger.error(f"Error stopping adapters: {e}")
# 关闭事件循环
loop.stop()
logger.info("Application stopped gracefully")
logger.remove()
================================================
FILE: kirara_ai/events/__init__.py
================================================
from .application import ApplicationStarted, ApplicationStopping
from .event_bus import EventBus
from .im import IMAdapterStarted, IMAdapterStopped
from .listen import listen
from .llm import LLMAdapterLoaded, LLMAdapterUnloaded
from .plugin import PluginLoaded, PluginStarted, PluginStopped
from .workflow import WorkflowExecutionBegin, WorkflowExecutionEnd
__all__ = [
"listen",
"EventBus",
"ApplicationStarted",
"ApplicationStopping",
"PluginStarted",
"PluginStopped",
"PluginLoaded",
"IMAdapterStarted",
"IMAdapterStopped",
"LLMAdapterLoaded",
"LLMAdapterUnloaded",
"WorkflowExecutionBegin",
"WorkflowExecutionEnd",
]
================================================
FILE: kirara_ai/events/application.py
================================================
class ApplicationStarted:
def __repr__(self):
return f"{self.__class__.__name__}()"
class ApplicationStopping:
def __repr__(self):
return f"{self.__class__.__name__}()"
================================================
FILE: kirara_ai/events/event_bus.py
================================================
from typing import Callable, Dict, List, Type
from kirara_ai.logger import get_logger
logger = get_logger("EventBus")
class EventBus:
def __init__(self):
self._listeners: Dict[Type, List[Callable]] = {}
def register(self, event_type: Type, listener: Callable):
if event_type not in self._listeners:
self._listeners[event_type] = []
self._listeners[event_type].append(listener)
def unregister(self, event_type: Type, listener: Callable):
if event_type in self._listeners:
self._listeners[event_type].remove(listener)
def post(self, event):
event_type = type(event)
if event_type in self._listeners:
for listener in self._listeners[event_type]:
try:
listener(event)
except Exception as e:
listener_name = listener.__name__
logger.opt(exception=e).error(f"Error in listener {listener_name}")
================================================
FILE: kirara_ai/events/im.py
================================================
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from kirara_ai.im.adapter import IMAdapter
class IMEvent:
def __init__(self, im: "IMAdapter"):
self.im = im
def __repr__(self):
return f"{self.__class__.__name__}(im={self.im})"
class IMAdapterStarted(IMEvent):
pass
class IMAdapterStopped(IMEvent):
pass
================================================
FILE: kirara_ai/events/listen.py
================================================
import inspect
from typing import Callable
from kirara_ai.events.event_bus import EventBus
def listen(event_bus: EventBus):
def decorator(func: Callable):
# 获取函数的参数签名
signature = inspect.signature(func)
params = list(signature.parameters.values())
# 假设第一个参数是事件类型
if not params:
raise ValueError("Listener function must have at least one parameter")
event_type = params[0].annotation
# 如果没有指定类型注解,抛出异常
if event_type == inspect.Parameter.empty:
raise ValueError("Listener function must have an annotated first parameter")
# 注册监听器
event_bus.register(event_type, func)
return func
return decorator
================================================
FILE: kirara_ai/events/llm.py
================================================
from kirara_ai.llm.adapter import LLMBackendAdapter
class LLMAdapterEvent:
def __init__(self, adapter: LLMBackendAdapter, backend_name: str):
self.adapter = adapter
self.backend_name = backend_name
def __repr__(self):
return f"{self.__class__.__name__}(adapter={self.adapter}, backend_name={self.backend_name})"
class LLMAdapterLoaded(LLMAdapterEvent):
pass
class LLMAdapterUnloaded(LLMAdapterEvent):
pass
================================================
FILE: kirara_ai/events/plugin.py
================================================
from kirara_ai.plugin_manager.plugin import Plugin
class PluginEvent:
def __init__(self, plugin: Plugin):
self.plugin = plugin
def __repr__(self):
return f"{self.__class__.__name__}(plugin={self.plugin})"
class PluginStarted(PluginEvent):
pass
class PluginStopped(PluginEvent):
pass
class PluginLoaded(PluginEvent):
pass
================================================
FILE: kirara_ai/events/tracing/__init__.py
================================================
from .base import TraceCompleteEvent, TraceEvent, TraceFailEvent, TraceStartEvent
from .llm import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
__all__ = [
"TraceEvent",
"TraceStartEvent",
"TraceCompleteEvent",
"TraceFailEvent",
"LLMRequestStartEvent",
"LLMRequestCompleteEvent",
"LLMRequestFailEvent",
]
================================================
FILE: kirara_ai/events/tracing/base.py
================================================
import abc
from datetime import datetime
class TraceEvent(abc.ABC):
"""跟踪事件基类"""
def __init__(self, trace_id: str):
self.trace_id = trace_id
self.timestamp = datetime.now()
def __repr__(self):
return f"{self.__class__.__name__}(trace_id={self.trace_id})"
class TraceStartEvent(TraceEvent):
"""跟踪开始事件"""
class TraceCompleteEvent(TraceEvent):
"""跟踪完成事件"""
class TraceFailEvent(TraceEvent):
"""跟踪失败事件"""
================================================
FILE: kirara_ai/events/tracing/llm.py
================================================
import time
from typing import Union
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from .base import TraceCompleteEvent, TraceEvent, TraceFailEvent, TraceStartEvent
class LLMTraceEvent(TraceEvent):
"""LLM追踪事件基类"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str):
super().__init__(trace_id)
self.model_id = model_id
self.backend_name = backend_name
def __repr__(self):
return f"{self.__class__.__name__}(trace_id={self.trace_id}, model={self.model_id}, backend={self.backend_name})"
class LLMRequestStartEvent(LLMTraceEvent, TraceStartEvent):
"""LLM请求开始事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.start_time = time.time()
class LLMRequestCompleteEvent(LLMTraceEvent, TraceCompleteEvent):
"""LLM请求完成事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest,
response: LLMChatResponse,
start_time: float):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.response = response
self.start_time = start_time
self.end_time = time.time()
self.duration = int((self.end_time - start_time) * 1000)
class LLMRequestFailEvent(LLMTraceEvent, TraceFailEvent):
"""LLM请求失败事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest,
error: Union[str, Exception],
start_time: float):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.error = str(error)
self.start_time = start_time
self.end_time = time.time()
self.duration = int((self.end_time - start_time) * 1000)
================================================
FILE: kirara_ai/events/workflow.py
================================================
from typing import Any, Dict
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
from kirara_ai.workflow.core.workflow.base import Workflow
class WorkflowExecutionBegin:
def __init__(self, workflow: Workflow, executor: WorkflowExecutor):
self.workflow = workflow
self.executor = executor
def __repr__(self):
return f"{self.__class__.__name__}(workflow={self.workflow}, executor={self.executor})"
class WorkflowExecutionEnd:
def __init__(self, workflow: Workflow, executor: WorkflowExecutor, results: Dict[str, Any]):
self.workflow = workflow
self.executor = executor
self.results = results
================================================
FILE: kirara_ai/im/__init__.py
================================================
from .im_registry import IMRegistry
from .manager import IMManager
__all__ = ["IMRegistry", "IMManager"]
================================================
FILE: kirara_ai/im/adapter.py
================================================
from abc import ABC, abstractmethod
from typing import Any, Optional, Protocol
from pydantic import BaseModel
from typing_extensions import runtime_checkable
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.llm.llm_manager import LLMManager
from .profile import UserProfile
class BotStatus(BaseModel):
"""
机器人状态
"""
username: str
avatar_url: str
@runtime_checkable
class EditStateAdapter(Protocol):
"""
编辑状态适配器接口,定义了如何设置或取消对话的编辑状态
"""
async def set_chat_editing_state(
self, chat_sender: ChatSender, is_editing: bool = True
):
"""
设置或取消对话的编辑状态
:param chat_sender: 对话的发送者
:param is_editing: True 表示正在编辑,False 表示取消编辑状态
"""
@runtime_checkable
class UserProfileAdapter(Protocol):
"""
用户资料查询适配器接口,定义了如何获取用户资料
"""
async def query_user_profile(self, chat_sender: ChatSender) -> UserProfile:
"""
查询用户资料
:param chat_sender: 用户的聊天发送者信息
:return: 用户资料
"""
@runtime_checkable
class BotProfileAdapter(Protocol):
"""
支持获取当前适配器对应的机器人资料
"""
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
class IMAdapter(ABC):
"""
通用的 IM 适配器接口,定义了如何将不同平台的原始消息转换为 Message 对象。
"""
llm_manager: LLMManager
is_running: bool
@abstractmethod
async def convert_to_message(self, raw_message: Any) -> IMMessage:
"""
将平台的原始消息转换为 Message 对象。
:param raw_message: 平台的原始消息对象。
:return: 转换后的 Message 对象。
"""
@abstractmethod
async def send_message(self, message: IMMessage, recipient: Any):
"""
发送消息到 IM 平台。
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象,可以是用户ID、用户对象、群组ID等,具体由各平台实现决定。
"""
@abstractmethod
async def start(self):
pass
@abstractmethod
async def stop(self):
pass
================================================
FILE: kirara_ai/im/im_registry.py
================================================
from typing import Dict, Optional, Type
from pydantic import BaseModel, Field
from kirara_ai.im.adapter import IMAdapter
class IMAdapterInfo(BaseModel):
"""IM适配器信息"""
name: str
config_class: Type[BaseModel] = Field(exclude=True)
adapter_class: Type[IMAdapter] = Field(exclude=True)
localized_name: Optional[str] = None
localized_description: Optional[str] = None
detail_info_markdown: Optional[str] = None
class IMRegistry:
"""
适配器注册表,用于动态注册和管理 adapter。
"""
_registry: Dict[str, IMAdapterInfo] = {}
def register(
self, name: str,
adapter_class: Type[IMAdapter],
config_class: Type[BaseModel],
localized_name: Optional[str] = None,
localized_description: Optional[str] = None,
detail_info_markdown: Optional[str] = None
):
"""
注册一个新的 adapter 及其配置类。
:param name: adapter 的名称。
:param adapter_class: adapter 的类。
:param config_class: adapter 的配置类。
:param detail_info_markdown: adapter 详情页展示的 Markdown 信息。
"""
self._registry[name] = IMAdapterInfo(
name=name,
adapter_class=adapter_class,
config_class=config_class,
localized_name=localized_name,
localized_description=localized_description,
detail_info_markdown=detail_info_markdown,
)
def unregister(self, name: str):
"""
注销一个 adapter。
:param name: adapter 的名称。
"""
del self._registry[name]
def get(self, name: str) -> Type[IMAdapter]:
"""
获取已注册的 adapter 类。
:param name: adapter 的名称。
:return: adapter 的类。
"""
if name not in self._registry:
raise ValueError(
f"IMAdapter with name '{name}' is not registered.")
return self._registry[name].adapter_class
def get_config_class(self, name: str) -> Type[BaseModel]:
"""
获取已注册的 adapter 配置类。
:param name: adapter 的名称。
:return: adapter 的配置类。
"""
if name not in self._registry:
raise ValueError(
f"IMAdapter with name '{name}' is not registered.")
adapter_info = self._registry[name]
return adapter_info.config_class
def get_all_adapters(self) -> Dict[str, IMAdapterInfo]:
"""
获取所有已注册的 adapter。
:return: 所有已注册的 adapter。
"""
return self._registry
================================================
FILE: kirara_ai/im/manager.py
================================================
import asyncio
from typing import Dict, Type
from pydantic import BaseModel
from kirara_ai.config.config_loader import pydantic_validation_wrapper
from kirara_ai.config.global_config import GlobalConfig, IMConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.im import IMAdapterStarted, IMAdapterStopped
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
logger = get_logger("IMManager")
class IMManager:
"""
IM 生命周期管理器,负责管理所有 adapter 的启动、运行和停止。
"""
container: DependencyContainer
config: GlobalConfig
im_registry: IMRegistry
event_bus: EventBus
@Inject()
def __init__(
self,
container: DependencyContainer,
config: GlobalConfig,
adapter_registry: IMRegistry,
event_bus: EventBus,
):
self.container = container
self.config = config
self.im_registry = adapter_registry
self.event_bus = event_bus
self.adapters: Dict[str, IMAdapter] = {}
def get_adapter_type(self, name: str) -> str:
"""
获取指定名称的 adapter 类型。
:param name: adapter 的名称
:return: adapter 的类型
"""
return self.get_adapter_config(name).adapter
def has_adapter(self, name: str) -> bool:
"""
检查指定名称的 adapter 是否存在。
:param name: adapter 的名称
:return: 如果 adapter 存在返回 True,否则返回 False
"""
return name in self.adapters
def get_adapter_config(self, name: str) -> IMConfig:
"""
获取指定名称的 adapter 的配置。
:param name: adapter 的名称
:return: adapter 的配置
"""
for im in self.config.ims:
if im.name == name:
return im
raise ValueError(f"Adapter {name} not found")
def update_adapter_config(self, name: str, config: BaseModel):
"""
更新指定名称的 adapter 的配置。
:param name: adapter 的名称
:param config: adapter 的配置
"""
self.get_adapter_config(name).config = config.model_dump()
def delete_adapter(self, name: str):
"""
删除指定名称的 adapter。
:param name: adapter 的名称
"""
self.adapters.pop(name, None)
self.config.ims = [im for im in self.config.ims if im.name != name]
@pydantic_validation_wrapper
def start_adapters(self, loop=None):
"""
根据配置文件中的 enable_ims 启动对应的 adapter。
:param loop: 负责执行的 event loop
"""
if loop is None:
loop = asyncio.new_event_loop()
tasks = []
for im in self.config.ims:
try:
# 动态获取 adapter 类
adapter_class = self.im_registry.get(im.adapter)
# 动态获取 adapter 的配置类
config_class = self.im_registry.get_config_class(im.adapter)
# 动态实例化 adapter 的配置对象
adapter_config = config_class(**im.config)
# 创建 adapter 实例
adapter = self.create_adapter(im.name, adapter_class, adapter_config)
if im.enable:
tasks.append(
asyncio.ensure_future(
self._start_adapter(im.name, adapter), loop=loop
)
)
except Exception as e:
logger.opt(exception=e).error(f"Failed to start adapter {im.name}: {e}")
continue
if tasks:
results = loop.run_until_complete(asyncio.gather(*tasks, return_exceptions=True))
for result in results:
if isinstance(result, Exception):
logger.opt(exception=result).error(f"Failed to start adapter: {result}")
else:
logger.warning("No adapters to start, please check your config")
def stop_adapters(self, loop=None):
"""
停止所有已启动的 adapter。
:param loop: 负责执行的 event loop
"""
if loop is None:
loop = asyncio.get_event_loop()
for key, adapter in self.adapters.items():
loop.run_until_complete(self._stop_adapter(key, adapter))
def get_adapters(self) -> Dict[str, IMAdapter]:
"""
获取所有已启动的 adapter。
:return: 已启动的 adapter 字典。
"""
return self.adapters
def get_adapter(self, key: str) -> IMAdapter:
"""
获取指定 key 的 adapter。
:param key: adapter 的 key
:return: 指定 key 的 adapter
"""
return self.adapters[key]
async def _start_adapter(self, key: str, adapter: IMAdapter):
logger.info(f"Starting adapter: {key}")
await adapter.start()
adapter.is_running = True
logger.info(f"Started adapter: {key}")
self.event_bus.post(IMAdapterStarted(adapter))
async def _stop_adapter(self, key: str, adapter: IMAdapter):
logger.info(f"Stopping adapter: {key}")
await adapter.stop()
adapter.is_running = False
logger.info(f"Stopped adapter: {key}")
self.event_bus.post(IMAdapterStopped(adapter))
def stop_adapter(self, adapter_id: str, loop: asyncio.AbstractEventLoop):
if adapter_id not in self.adapters:
raise ValueError(f"Adapter {adapter_id} not found")
adapter = self.adapters[adapter_id]
return asyncio.ensure_future(self._stop_adapter(adapter_id, adapter), loop=loop)
def start_adapter(self, adapter_id: str, loop: asyncio.AbstractEventLoop):
if adapter_id not in self.adapters:
raise ValueError(f"Adapter {adapter_id} not found")
adapter = self.adapters[adapter_id]
return asyncio.ensure_future(
self._start_adapter(adapter_id, adapter), loop=loop
)
def is_adapter_running(self, key: str) -> bool:
"""
检查指定 key 的 adapter 是否正在运行。
:param key: adapter 的 key
:return: 如果 adapter 正在运行返回 True,否则返回 False
"""
return key in self.adapters and getattr(self.adapters[key], "is_running", False)
def create_adapter(
self, name: str, adapter_class: Type[IMAdapter], adapter_config: BaseModel
) -> IMAdapter:
with self.container.scoped() as scoped_container:
scoped_container.register(adapter_config.__class__, adapter_config)
adapter = Inject(scoped_container).create(adapter_class)()
adapter.is_running = False
self.adapters[name] = adapter
return adapter
================================================
FILE: kirara_ai/im/message.py
================================================
from abc import ABC, abstractmethod
from pathlib import Path
from typing import Any, Dict, List, Literal, Optional
from kirara_ai.im.sender import ChatSender
from kirara_ai.media import MediaManager, MediaType
MIMETYPE_MAPPING = {
"image": MediaType.IMAGE,
"audio": MediaType.AUDIO,
"video": MediaType.VIDEO,
"file": MediaType.FILE,
}
# 定义消息元素的基类
class MessageElement(ABC):
@abstractmethod
def to_dict(self):
pass
@abstractmethod
def to_plain(self) -> str:
pass
# 定义文本消息元素
class TextMessage(MessageElement):
def __init__(self, text: str):
self.text = text
def to_dict(self):
return {"type": "text", "text": self.text}
def to_plain(self):
return self.text
def __repr__(self):
return f"TextMessage(text={self.text})"
# 定义媒体消息的基类
class MediaMessage(MessageElement):
resource_type: Literal["image", "audio", "video", "file"]
media_id: str
def __init__(
self,
url: Optional[str] = None,
path: Optional[str] = None,
data: Optional[bytes] = None,
format: Optional[str] = None,
media_id: Optional[str] = None,
reference_id: Optional[str] = None,
source: Optional[str] = "im_message",
description: Optional[str] = None,
tags: Optional[List[str]] = None,
media_manager: Optional[MediaManager] = None,
):
self.url = url
self.path = path
self.data = data
self.format = format
self._reference_id = reference_id
self._source = source
self._description = description
self._tags = tags or []
self._media_manager = media_manager or MediaManager()
self.base64_url: Optional[str] = None
if media_id:
self.media_id = media_id
return
# 注册媒体文件
# 使用线程创建新的事件循环来阻塞执行媒体注册
import asyncio
import threading
# 用于存储线程中的异常
thread_exception: Optional[Exception] = None
def run_in_new_loop():
nonlocal thread_exception
try:
asyncio.run(self._register_media())
except Exception as e:
thread_exception = e
# 在新线程中运行异步注册函数
thread = threading.Thread(
target=run_in_new_loop,
)
thread.start()
thread.join() # 阻塞等待完成
# 如果线程中发生异常,则在主线程中重新抛出
if thread_exception:
raise thread_exception
async def _register_media(self) -> None:
"""注册媒体文件"""
media_manager = self._media_manager
# 根据传入的参数注册媒体文件
self.media_id = await media_manager.register_media(
url=self.url,
path=self.path,
data=self.data,
format=self.format,
source=self._source,
description=self._description,
tags=self._tags,
media_type=MIMETYPE_MAPPING[self.resource_type],
reference_id=self._reference_id
)
# 获取媒体元数据
metadata = media_manager.get_metadata(self.media_id)
if metadata and metadata.format:
self.format = metadata.format
if metadata.media_type:
self.resource_type = metadata.media_type.value
async def get_url(self) -> str:
"""获取媒体资源的URL"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有URL,直接返回
if self.url:
return self.url
# 否则从媒体管理器获取
media_manager = self._media_manager
url = await media_manager.get_url(self.media_id)
if url:
self.url = url # 缓存结果
return url
raise ValueError("Failed to get media URL")
async def get_path(self) -> str:
"""获取媒体资源的文件路径"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有路径,直接返回
if self.path and Path(self.path).exists():
return self.path
# 否则从媒体管理器获取
media_manager = self._media_manager
file_path = await media_manager.get_file_path(self.media_id)
if file_path:
self.path = str(file_path) # 缓存结果
return self.path
raise ValueError("Failed to get media file path")
async def get_data(self) -> bytes:
"""获取媒体资源的二进制数据"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有数据,直接返回
if self.data:
return self.data
# 否则从媒体管理器获取
media_manager = self._media_manager
data = await media_manager.get_data(self.media_id)
if data:
self.data = data # 缓存结果
return data
raise ValueError("Failed to get media data")
async def get_base64_url(self) -> str:
"""获取媒体资源的Base64 URL"""
if not self.media_id:
raise ValueError("Media not registered")
if self.base64_url:
return self.base64_url
base64_url = await self._media_manager.get_base64_url(self.media_id)
if base64_url:
self.base64_url = base64_url
return base64_url
raise ValueError("Failed to get media base64 URL")
def get_description(self) -> str:
"""获取媒体资源的描述"""
if not self.media_id:
raise ValueError("Media not registered")
metadata = self._media_manager.get_metadata(self.media_id)
if metadata:
return metadata.description or ""
return ""
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
result = {
"type": self.resource_type,
"media_id": self.media_id,
}
# 添加可选属性
if self.format:
result["format"] = self.format
if self.url:
result["url"] = self.url
if self.path:
result["path"] = self.path
return result
# 定义语音消息
class VoiceMessage(MediaMessage):
resource_type = "audio"
def to_dict(self):
result = super().to_dict()
result["type"] = "voice"
return result
def to_plain(self):
return "[VoiceMessage]"
# 定义图片消息
class ImageMessage(MediaMessage):
resource_type = "image"
def to_dict(self):
result = super().to_dict()
result["type"] = "image"
return result
def to_plain(self):
return f"[ImageMessage:media_id={self.media_id},url={self.url},alt={self.get_description()}]"
def __repr__(self):
return f"ImageMessage(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义@消息元素
# :deprecated
class AtElement(MessageElement):
def __init__(self, user_id: str, nickname: str = ""):
self.user_id = user_id
self.nickname = nickname
def to_dict(self):
return {"type": "at", "data": {"qq": self.user_id, "nickname": self.nickname}}
def to_plain(self):
return f"@{self.nickname or self.user_id}"
def __repr__(self):
return f"AtElement(user_id={self.user_id}, nickname={self.nickname})"
# 定义@消息元素
class MentionElement(MessageElement):
def __init__(self, target: ChatSender):
self.target = target
def to_dict(self):
return {"type": "mention", "data": {"target": self.target}}
def to_plain(self):
return f"@{self.target.display_name or self.target.user_id}"
def __repr__(self):
return f"MentionElement(target={self.target})"
# 定义回复消息元素
class ReplyElement(MessageElement):
def __init__(self, message_id: str):
self.message_id = message_id
def to_dict(self):
return {"type": "reply", "data": {"id": self.message_id}}
def to_plain(self):
return f"[Reply:{self.message_id}]"
def __repr__(self):
return f"ReplyElement(message_id={self.message_id})"
# 定义文件消息元素
class FileMessage(MediaMessage):
resource_type = "file"
def to_dict(self):
result = super().to_dict()
result["type"] = "file"
return result
def to_plain(self):
return f"[File:{self.path or self.url or 'unnamed'}]"
def __repr__(self):
return f"FileElement(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义JSON消息元素
class JsonMessage(MessageElement):
def __init__(self, data: str):
self.data = data
def to_dict(self):
return {"type": "json", "data": {"data": self.data}}
def to_plain(self):
return f"[JSON:{self.data}]"
def __repr__(self):
return f"JsonMessage(data={self.data})"
# 定义表情消息元素
class EmojiMessage(MessageElement):
def __init__(self, face_id: str):
self.face_id = face_id
def to_dict(self):
return {"type": "face", "data": {"id": self.face_id}}
def to_plain(self):
return f"[Face:{self.face_id}]"
def __repr__(self):
return f"EmojiMessage(face_id={self.face_id})"
# 定义视频消息元素
class VideoMessage(MediaMessage):
resource_type = "video"
def to_dict(self):
result = super().to_dict()
result["type"] = "video"
return result
def to_plain(self):
return f"[Video:{self.path or self.url or 'unnamed'}]"
def __repr__(self):
return f"VideoMessage(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义消息类
class IMMessage:
"""
IM消息类,用于表示一条完整的消息。
包含发送者信息和消息元素列表。
Attributes:
sender: 发送者标识
message_elements: 消息元素列表,可以包含文本、图片、语音等
raw_message: 原始消息数据
content: 消息的纯文本内容
images: 消息中的图片列表
voices: 消息中的语音列表
"""
sender: ChatSender
message_elements: List[MessageElement]
raw_message: Optional[dict]
def __repr__(self):
return f"IMMessage(sender={self.sender}, message_elements={self.message_elements}, raw_message={self.raw_message})"
@property
def content(self) -> str:
"""获取消息的纯文本内容"""
content = ""
for element in self.message_elements:
content += element.to_plain()
if isinstance(element, TextMessage):
content += "\n"
return content.strip()
@property
def images(self) -> List[ImageMessage]:
"""获取消息中的所有图片"""
return [
element
for element in self.message_elements
if isinstance(element, ImageMessage)
]
@property
def voices(self) -> List[VoiceMessage]:
"""获取消息中的所有语音"""
return [
element
for element in self.message_elements
if isinstance(element, VoiceMessage)
]
def __init__(
self,
sender: ChatSender,
message_elements: List[MessageElement],
raw_message: Optional[dict] = None,
):
self.sender = sender
self.message_elements = message_elements
self.raw_message = raw_message
def to_dict(self):
return {
"sender": self.sender,
"message_elements": [
element.to_dict() for element in self.message_elements
],
"plain_text": "".join(
[element.to_plain() for element in self.message_elements]
),
"raw_message": self.raw_message,
}
# backward compatibility
# deprecated
FileElement = FileMessage
ImageElement = ImageMessage
VoiceElement = VoiceMessage
VideoElement = VideoMessage
EmojiElement = EmojiMessage
JsonElement = JsonMessage
FaceElement = EmojiMessage
================================================
FILE: kirara_ai/im/profile.py
================================================
from enum import Enum, auto
from typing import Optional
from pydantic import BaseModel, Field
class Gender(Enum):
MALE = auto()
FEMALE = auto()
UNKNOWN = auto()
OTHER = auto()
class UserProfile(BaseModel):
"""
通用的用户资料结构
"""
user_id: str = Field(..., description="用户唯一标识")
username: Optional[str] = Field(None, description="用户名")
display_name: Optional[str] = Field(None, description="显示名称")
full_name: Optional[str] = Field(None, description="完整名称")
gender: Optional[Gender] = Field(None, description="性别")
age: Optional[int] = Field(None, description="年龄")
avatar_url: Optional[str] = Field(None, description="头像URL")
level: Optional[int] = Field(None, description="用户等级")
language: Optional[str] = Field(None, description="语言")
extra_info: Optional[dict] = Field(None, description="平台特定的额外信息")
def __init__(self, **kwargs):
super().__init__(**kwargs)
================================================
FILE: kirara_ai/im/sender.py
================================================
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Dict, Optional
class ChatType(Enum):
C2C = "c2c"
GROUP = "group"
@classmethod
def from_str(cls, value: str) -> "ChatType":
if value == "c2c" or value == "私聊":
return cls.C2C
elif value == "group" or value == "群聊":
return cls.GROUP
raise ValueError(f"Invalid chat type: {value}")
def to_str(self) -> str:
if self == self.C2C:
return "私聊"
elif self == self.GROUP:
return "群聊"
raise ValueError(f"Invalid chat type: {self}")
@dataclass
class ChatSender:
"""聊天发送者信息封装"""
display_name: str
user_id: str
chat_type: ChatType
group_id: Optional[str] = None
raw_metadata: Dict[str, Any] = field(default_factory=dict)
callback = None
@classmethod
def from_group_chat(
cls,
user_id: str,
group_id: str,
display_name: str,
metadata: Optional[Dict[str, Any]] = None,
) -> "ChatSender":
"""创建群聊发送者"""
return cls(
user_id=user_id,
chat_type=ChatType.GROUP,
group_id=group_id,
display_name=display_name,
raw_metadata=metadata or {},
)
@classmethod
def from_c2c_chat(
cls, user_id: str, display_name: str, metadata: Optional[Dict[str, Any]] = None
) -> "ChatSender":
"""创建私聊发送者"""
return cls(
user_id=user_id,
chat_type=ChatType.C2C,
display_name=display_name,
raw_metadata=metadata or {},
)
@classmethod
def get_bot_sender(cls) -> "ChatSender":
"""获取机器人发送者"""
return cls(
user_id="bot",
display_name="bot",
chat_type=ChatType.C2C,
)
def __str__(self) -> str:
if self.chat_type == ChatType.GROUP:
return f"{self.group_id}:{self.user_id}"
else:
return f"c2c:{self.user_id}"
def __eq__(self, other: Any) -> bool:
if isinstance(other, ChatSender):
return self.user_id == other.user_id and \
self.chat_type == other.chat_type and \
self.group_id == other.group_id
return False
def __hash__(self) -> int:
return hash((self.user_id, self.chat_type, self.group_id))
================================================
FILE: kirara_ai/internal.py
================================================
# 定义优雅退出异常
import asyncio
shutdown_event = asyncio.Event()
restart_flag = False
def set_restart_flag():
global restart_flag
restart_flag = True
def get_and_reset_restart_flag():
global restart_flag
flag = restart_flag
restart_flag = False
return flag
================================================
FILE: kirara_ai/ioc/__init__.py
================================================
================================================
FILE: kirara_ai/ioc/container.py
================================================
import contextvars
from typing import Any, Optional, Type, TypeVar, overload
T = TypeVar("T")
class DependencyContainer:
"""
依赖注入容器,提供注册和解析的功能。你可以在此获取一些全局的对象。
基本用法:
```python
# 1. 注册全局对象 - 通常在初始化时使用
container.register(YourObj, your_obj_instance)
# 2. 获取全局对象 - 在你的逻辑代码中使用
your_obj_instance = container.resolve(YourObj)
# 3. 销毁全局对象 - 通常在系统/插件销毁时使用
container.destroy(YourObj)
# 4. 创建作用域容器 - 作用域容器内注册的对象只在作用域内可被访问
# 离开作用域的上下文后无法取到该对象
# 全局容器注册对象
container.register(KiraraObj, kirara_obj)
with container.scoped() as scoped_container:
# 注册作用域对象
scoped_container.register(YourObj, your_obj_instance)
# 获取作用域对象
scoped_container.resolve(YourObj)
# 作用域容器也可以获取到全局容器的对象
container.has(KiraraObj) # 返回 True
# 甚至还能再创建新的作用域容器
with scoped_container.scoped() as another_scoped_container:
another_scoped_container.has(YourObj) # True
# 离开作用域上下文后无法获取到该对象
container.has(YourObj) # 返回 False
```
docs: https://docs.python.org/zh-cn/3.13/library/contextvars.html#module-contextvars
Attributes:
parent (DependencyContainer): 父容器实例,用于支持作用域嵌套
registry (dict): 存储当前容器注册的值或对象实例,格式为{key: value|object}
Methods:
register: 向容器注册一个key-value对
resolve: 从容器解析获取一个值或对象实例
destroy: 从容器中移除一个值或对象实例
scoped: 创建一个新的作用域容器
"""
def __init__(self, parent=None):
self.parent = parent # 父容器,用于支持作用域嵌套
self.registry = {} # 当前容器的注册表
def register(self, key, value):
"""
向容器注册一个值或者实例。
Args:
key: 对象的标识键, 一般为对象的类 (Type) 如 IMManager, LLMManager等,
会根据类型自动查找对应对象实例。
value: 值/对象实例
"""
self.registry[key] = value
@overload
def resolve(self, key: Type[T]) -> T: ...
@overload
def resolve(self, key: Any) -> Any: ...
def resolve(self, key: Type[T] | Any) -> T | Any:
"""
依照{key}从容器解析出一个值或对象实例。
如果{key}在当前容器中不存在,则会递归查找父容器。
Args:
key: 对象的标识键, 一般为对象的类 (Type) 如 IMManager, LLMManager等,
会根据类型自动查找对应对象实例。
Returns:
值/对象实例
Raises:
KeyError: {key}在当前容器和父容器中都不存在时抛出
"""
if key in self.registry:
return self.registry[key]
elif self.parent:
return self.parent.resolve(key)
else:
raise KeyError(f"Dependency {key} not found.")
def has(self, key: Type[T] | Any) -> bool:
"""
检测容器中是否能解析出某个键所对应的值。
Args:
key: 对象的标识键
Returns:
成功返回 True, 失败返回 False
"""
return key in self.registry or (self.parent is not None and self.parent.has(key))
@overload
def destroy(self, key: Type[T], recursive: bool = False) -> None: ...
@overload
def destroy(self, key: Any, recursive: bool = False) -> None: ...
def destroy(self, key: Type[T] | Any, recursive: bool = False) -> None:
"""
从容器中移除一个值或对象实例。支持递归删除父元素。
但是最好不要递归,你可能会删除一些系统对象
Args:
key: 对象的标识键
recursive: 是否递归删除父元素, 默认False。注意这是unsafe方法, 请注意不要删除系统对象。
Raises:
KeyError: {key}在当前容器和父容器中都不存在时抛出
"""
if key in self.registry:
del self.registry[key]
elif self.parent and recursive:
self.parent.destroy(key, recursive)
else:
raise KeyError(f"Cannot destroy dependency {key} which is not found in registry or parent container's registry.")
def scoped(self):
"""创建一个新的作用域容器"""
new_container = ScopedContainer(self)
if DependencyContainer in self.registry:
new_container.registry[DependencyContainer] = new_container
new_container.registry[ScopedContainer] = new_container
return new_container
# 使用 contextvars 实现线程和异步安全的上下文管理
current_container = contextvars.ContextVar[Optional[DependencyContainer]]("current_container", default=None)
class ScopedContainer(DependencyContainer):
def __init__(self, parent):
super().__init__(parent)
def __enter__(self):
# 将当前容器设置为新的作用域容器
self.token = current_container.set(self)
return self
def __exit__(self, exc_type, exc_value, traceback):
# 恢复之前的容器
current_container.reset(self.token)
================================================
FILE: kirara_ai/ioc/inject.py
================================================
from functools import wraps
from inspect import signature
from typing import Any, Callable, Optional, Type
from kirara_ai.ioc.container import DependencyContainer
def get_all_attributes(cls):
if not hasattr(cls, "__annotations__"):
return {}
attributes = dict(cls.__annotations__.items())
# 获取父类的属性和方法
for base in cls.__bases__:
attributes.update(get_all_attributes(base))
return attributes
class Inject:
def __init__(self, container: Optional[DependencyContainer] = None):
self.container = container
def create(self, target: type):
# 注入类
injected_class = self.__call__(target)
# 注入构造函数
return self.inject_function(injected_class)
def __call__(self, target: Any):
# 如果修饰的是一个类
if isinstance(target, type):
return self.inject_class(target)
# 如果修饰的是一个函数
elif callable(target):
return self.inject_function(target)
else:
raise TypeError(
"Inject can only be used on classes, functions."
)
def inject_class(self, cls: Type):
# 遍历类的属性,尝试注入依赖
for name, injecting_type in get_all_attributes(cls).items():
attr = getattr(cls, name) if hasattr(cls, name) else None
setattr(cls, name, self.inject_property(name, cls, injecting_type, attr))
return cls
def inject_function(self, func: Callable):
@wraps(func)
def wrapper(*args, **kwargs):
# 获取函数的参数签名
sig = signature(func)
# 检查是否有 DependencyContainer 对象作为参数传递进来
container_param = self.find_container(args, kwargs)
# 如果有 DependencyContainer 对象,则将其作为 self.container
if container_param:
self.container = container_param
# 遍历参数,注入依赖
bound_args = sig.bind_partial(*args, **kwargs)
bound_args.apply_defaults()
for name, param in sig.parameters.items():
if (
param.annotation != param.empty
and name not in kwargs
and self.container
):
bound_args.arguments[name] = self.container.resolve(
param.annotation
)
# 调用实际的函数
return func(*bound_args.args, **bound_args.kwargs)
return wrapper
def inject_property(self, name, cls, injecting_type, prop: Optional[property]):
# 获取 property 的 fget, fset, fdel
backing_name = f"_{name}_value"
# 定义默认的 getter 方法 (使用实例属性存储值)
def default_fget(_self):
return getattr(_self, backing_name, None)
# 定义默认的 setter 方法 (使用实例属性存储值)
def default_fset(_self, value):
setattr(_self, backing_name, value)
# 定义默认的 deleter 方法 (使用实例属性存储值)
def default_fdel(_self):
if hasattr(_self, backing_name):
delattr(_self, backing_name)
# 如果已有属性,使用其方法,否则使用默认方法
if prop:
fget = prop.fget or default_fget
fset = prop.fset or default_fset
fdel = prop.fdel or default_fdel
else:
fget = default_fget
fset = default_fset
fdel = default_fdel
# 为 property 的 fget 注入依赖
@wraps(fget)
def new_fget(_self):
# 获取 property 的返回值
if self.container and isinstance(injecting_type, type) and self.container.has(injecting_type):
# 如果返回值是一个类型,尝试从 container 中解析
return self.container.resolve(injecting_type)
else:
return default_fget(_self)
# 返回新的 property
return property(new_fget, fset, fdel)
def find_container(self, args, kwargs):
# 检查是否有 DependencyContainer 对象作为参数传递进来
for arg in args:
if isinstance(arg, DependencyContainer):
return arg
for key, value in kwargs.items():
if isinstance(value, DependencyContainer):
return value
return None
================================================
FILE: kirara_ai/llm/adapter.py
================================================
from abc import ABC
from typing import List, Protocol, runtime_checkable
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.rerank import LLMReRankRequest, LLMReRankResponse
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing.llm_tracer import LLMTracer
@runtime_checkable
class AutoDetectModelsProtocol(Protocol):
async def auto_detect_models(self) -> List[ModelConfig]: ...
@runtime_checkable
class LLMChatProtocol(Protocol):
def chat(self, req: LLMChatRequest) -> LLMChatResponse: ...
@runtime_checkable
class LLMEmbeddingProtocol(Protocol):
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse: ...
@runtime_checkable
class LLMReRankProtocol(Protocol):
def rerank(self, req: LLMReRankRequest) -> LLMReRankResponse: ...
class LLMBackendAdapter(ABC):
backend_name: str
media_manager: MediaManager
tracer: LLMTracer
================================================
FILE: kirara_ai/llm/format/__init__.py
================================================
from .message import LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent, LLMToolResultContent
from .response import LLMChatResponse
from .tool import Function, Tool, ToolCall
__all__ = ["LLMChatMessage", "LLMChatTextContent", "LLMChatImageContent", "LLMToolCallContent", "LLMToolResultContent", "Function", "Tool", "ToolCall", "LLMChatResponse"]
================================================
FILE: kirara_ai/llm/format/embedding.py
================================================
from typing import Literal, Optional
from pydantic import BaseModel
from .message import LLMChatTextContent, LLMChatImageContent
from .response import Usage
FormatType = Literal["base64"]
OutputType = Literal["float", "int8", "uint8", "binary", "ubinary"]
InputType = Literal["string", "query", "document"]
InputUnionType = LLMChatTextContent | LLMChatImageContent
class LLMEmbeddingRequest(BaseModel):
"""
此模型用于规范embedding请求的格式
Tips: 各大模型向量维度以及向量转化函数不同,因此当你用于向量数据库时,请确保存储和检索使用同一个模型,并确保模型向量一致(部分模型支持同一模型设置向量维度)
Note: 注意一下字段为混合字段, 部分字段在部分模型中不起作用, 请参照对应ap文档传递参数。
Attributes:
text (list[str | Image]): 待转化为向量的文本或图片列表
model (str): 使用的embedding模型名
dimensions (Optional[int]): embedding向量的维度
encoding_format (Optional[FormatType]): embedding的编码格式。推荐不设置该字段, 方便直接输入数据库
input_type (Optional[InputType]): 输入类型, 归属于voyage_adapter的独有字段
truncate (Optional[bool]): 是否自动截断超长文本, 以适应llm上下文长度上限。
output_type (Optional[OutputType]): 向量内部应该使用哪种数据类型. 一般默认float
"""
inputs: list[InputUnionType]
model: str
dimension: Optional[int] = None
encoding_format: Optional[FormatType] = None
input_type: Optional[InputType] = None
truncate: Optional[bool] = None
output_type: Optional[OutputType] = None
vector = list[float | int] # 后续可能需要使用numpy库进行精确的数据类型标注, 暂时未处理base64的返回模式
class LLMEmbeddingResponse(BaseModel):
"""
向量维度请使用len(vector)自行计算。
Attributes:
vectors: list[vector]
usage: Optional[Usage] = None
"""
vectors: list[vector]
usage: Optional[Usage] = None
================================================
FILE: kirara_ai/llm/format/message.py
================================================
import json
from typing import Literal, Optional, Union
from pydantic import BaseModel, field_validator, model_validator
from typing_extensions import Self
from .tool import LLMToolResultContent
RoleType = Literal["system", "user", "assistant"]
class LLMChatTextContent(BaseModel):
type: Literal["text"] = "text"
text: str
class LLMChatImageContent(BaseModel):
type: Literal["image"] = "image"
media_id: str
class LLMToolCallContent(BaseModel):
"""
这是模型请求工具的消息内容,
模型强相关内容,如果你 message 或者 memory 内包含了这个内容,请保证调用同一个 model
此部分 role 应该归属于"assistant"
"""
type: Literal["tool_call"] = "tool_call"
# call id,部分模型用此字段区分不同函数的调用,若没有返回则由 Adapter 生成
id: str
name: str
parameters: Optional[dict] = None
@classmethod
@field_validator("parameters", mode="before")
def convert_parameters_to_dict(cls, v: Optional[Union[str, dict]]) -> Optional[dict]:
if isinstance(v, str):
return json.loads(v)
return v
LLMChatContentPartType = Union[LLMChatTextContent, LLMChatImageContent, LLMToolCallContent, LLMToolResultContent]
RoleTypes = Literal["user", "assistant", "system", "tool"]
class LLMChatMessage(BaseModel):
"""
当 role 为 "tool" 时, content 内部只能为 list[LLMToolResultContent]
"""
content: list[LLMChatContentPartType]
role: RoleTypes
@model_validator(mode="after")
def check_content_type(self) -> Self:
# 此装饰器将在 model 实例化后执行,`mode = "after"`
# 用于检查 content 字段的类型是否符合 role 要求
match self.role:
case "user" | "assistant" | "system":
if not all(any(isinstance(element, content_type) for content_type in [LLMChatTextContent, LLMChatImageContent, LLMToolCallContent]) for element in self.content):
raise ValueError(f"content must be a list of LLMChatContentPartType, when role is {self.role}")
case "tool":
if not all(isinstance(element, LLMToolResultContent) for element in self.content):
raise ValueError("content must be a list of LLMToolResultContent, when role is 'tool'")
return self
================================================
FILE: kirara_ai/llm/format/request.py
================================================
from typing import Any, List, Optional
from pydantic import BaseModel
from kirara_ai.llm.format.message import LLMChatMessage
from .tool import Tool
class ResponseFormat(BaseModel):
type: Optional[str] = None
class LLMChatRequest(BaseModel):
"""
Attributes:
tool_choice (Union[dict, Literal["auto", "any", "none"]]):
"
注意由于大模型对于这个接口实现不同,本次暂不实现tool_choice的功能。
tool_choice这个参数告诉llmMessage应该如何选择调用的工具。
"
"""
messages: List[LLMChatMessage] = []
model: Optional[str] = None
frequency_penalty: Optional[int] = None
max_tokens: Optional[int] = None
presence_penalty: Optional[int] = None
response_format: Optional[ResponseFormat] = None
stop: Optional[Any] = None
stream: Optional[bool] = None
stream_options: Optional[Any] = None
temperature: Optional[int] = None
top_p: Optional[int] = None
# 规范tool传递
tools: Optional[list[Tool]] = None
# tool_choice各家目前标准不尽相同,暂不向用户提供更改这个值的选项
tool_choice: Optional[Any] = None
logprobs: Optional[bool] = None
top_logprobs: Optional[Any] = None
================================================
FILE: kirara_ai/llm/format/rerank.py
================================================
from typing import Optional
from typing_extensions import Self
from pydantic import BaseModel, model_validator
from .response import Usage
class LLMReRankRequest(BaseModel):
"""
ReRanker: 重排器是一个重要的处理方案, 通常见于 EsSearch 的优化方案中。
本接口是适用于 LLM 的重排器的请求模型一般与嵌入式式模型组合使用提高向量搜索准确率。
传入一系列原始文档和一个查询语句,返回器相似度数值。
Attributes:
query: 原始查询语句
documents: 文档列表, 包含文档的文本内容。每个文档转化为一个 string 类型传递。
model: 重排模型的名称。为保证准确性,本实现将禁止自动选择模型。
top_k: 返回最相似的 {top_k} 个文档。如果没有指定,将返回所有文档的重排序结果。
Tips: 如果你决定不返回原始文档,那么不要设置这个选项。会丢失文本与相似度的关联。
return_documents: 是否返回原始文档内容。
truncation: 文档和查询语句是否允许被截断以适应模型最大上下文。
sort: 是否按照结果的相似度得分进行排序? 默认不进行
Tips: 当return_documents为False时,若sort为True,则抛出异常。
"""
query: str
documents: list[str]
model: str
top_k: Optional[int] = None
return_documents: Optional[bool] = None
truncation: Optional[bool] = None
sort: Optional[bool] = False
@model_validator(mode="after") # mode 为 before 时其用法与after完全不同,注意看官网文档
# 这里不用after是为了等pydantic赋值默认值后检查
def check(self) -> Self:
if self.sort and not self.return_documents:
raise ValueError("Cannot sort server responses when return_documents is False.")
return self
class ReRankerContent(BaseModel):
"""
ReRanker 的内容模型。
Attributes:
document: 原始文档内容。
score: 文档的相似度分数。
"""
document: Optional[str] = None
score: float
class LLMReRankResponse(BaseModel):
"""
ReRanker 的返回模型。
Attributes:
contents (list[ReRankerContent]): 返回的排序信息, 如果启用排序,默认降序排列。 Note: 当且仅当return_documents为True时才允许启用排序。
usage (Usage): token 使用情况, 一个pydantic.BaseModel的子类。
sort (bool): 是否按照结果的相似度排序?将其设置为字段方便后续接口检查是否经过排序(方便debug)。其应该由request的sort字段赋值。
"""
contents: list[ReRankerContent]
usage: Usage
sort: bool
@model_validator(mode="after") # 当mode为after时,其发生在class实例化完成后,所以其为实例方法
def sort_content(self) -> Self:
if self.sort:
self.contents = sorted(self.contents, key= lambda x: x.score, reverse=True)
return self
================================================
FILE: kirara_ai/llm/format/response.py
================================================
from typing import List, Optional
from pydantic import BaseModel
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.tool import ToolCall
class Message(LLMChatMessage):
tool_calls: Optional[List[ToolCall]] = None
finish_reason: Optional[str] = None
class Usage(BaseModel):
completion_tokens: Optional[int] = None
prompt_tokens: Optional[int] = None
total_tokens: Optional[int] = None
cached_tokens: Optional[int] = None
class LLMChatResponse(BaseModel):
model: Optional[str] = None
usage: Optional[Usage] = None
message: Message
================================================
FILE: kirara_ai/llm/format/tool.py
================================================
import json
from typing import Any, Callable, Coroutine, Generic, List, Literal, Optional, TypeVar, Union
from pydantic import BaseModel, ConfigDict, Field, field_serializer, field_validator
class TextContent(BaseModel):
type: Literal["text"] = "text"
text: str
class MediaContent(BaseModel):
type: Literal["media"] = "media"
media_id: str
mime_type: str
data: bytes
ToolResponseTypes = List[Union[TextContent, MediaContent]]
class LLMToolResultContent(BaseModel):
"""
这是工具回应的消息内容,
模型强相关内容,如果你 message 或者 memory 内包含了这个内容,请保证调用同一个 model
此部分 role 应该对应 "tool"
"""
type: Literal["tool_result"] = "tool_result"
# call id,对应 LLMToolCallContent 的 id
id: str
name: str
# 各家工具要求返回的content格式不同. 等待后续规范化。
content: ToolResponseTypes
isError: bool = False
class Function(BaseModel):
# 工具名称
name: str
# 这个字段类似于 python 的关键字参数,你可以直接使用`**arguments`
arguments: Optional[dict] = None
@field_validator("arguments", mode="before")
@classmethod
# pydantic 官网建议将 @classmethod 放在下面。因为python装饰器执行顺序是由下到上。
def convert_arguments(cls, v: Optional[Union[str, dict]]) -> Optional[dict]:
return json.loads(v) if isinstance(v, str) else v
class ToolCall(BaseModel):
# call id,对应 LLMToolCallContent 的 id
id: str
# type这个字段目前不知道有什么用
type: Optional[str] = None
function: Function
T = TypeVar('T', bound=Callable)
ToolInvokeFunc = Callable[[ToolCall], Coroutine[Any, Any, "LLMToolResultContent"]]
class CallableWrapper(Generic[T]):
"""包装可调用对象的类,在深拷贝时返回None"""
def __init__(self, func: T):
self.func = func
def __call__(self, *args, **kwargs) -> Coroutine[Any, Any, "LLMToolResultContent"]:
return self.func(*args, **kwargs)
def __deepcopy__(self, memo):
# 深拷贝时保持原始引用而不是尝试复制函数
return self
class ToolInputSchema(BaseModel):
"""
工具输入参数的格式,遵循 JSON Schema 的规范
Attributes:
type (Literal["object"]): 参数的类型
properties (dict): 工具属性,参考 openai api 的规范
required (list[str]): 必填参数的名称列表
additionalProperties (Optional[bool]): 是否允许额外的键值对
"""
type: Literal["object"] = "object"
properties: dict
required: list[str]
additionalProperties: Optional[bool] = False
class Tool(BaseModel):
"""
传递给 LLM 的工具信息
Attributes:
type (Optional[Literal["function"]]): 工具的类型
name (str): 工具的名称
description (str): 工具的描述
parameters (ToolInputSchema): 工具的参数格式
strict (Optional[bool]): 是否严格调用, openai api专属
invokeFunc (Optional[Callable]): 工具对应的执行函数,仅在调用时使用,不参与序列化
"""
type: Optional[Literal["function"]] = "function"
name: str
description: str
parameters: Union[ToolInputSchema, dict]
strict: Optional[bool] = False
invokeFunc: CallableWrapper[ToolInvokeFunc] = Field(exclude=True)
model_config = ConfigDict(arbitrary_types_allowed=True)
@field_serializer("invokeFunc")
def serialize_invoke_func(self, invoke_func: CallableWrapper[ToolInvokeFunc]) -> str:
return "..."
================================================
FILE: kirara_ai/llm/llm_manager.py
================================================
import random
from typing import Dict, List, Optional
from typing_extensions import deprecated
from kirara_ai.config.global_config import GlobalConfig, ModelConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.llm import LLMAdapterLoaded, LLMAdapterUnloaded
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.llm.adapter import LLMBackendAdapter
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.llm.model_types import ModelAbility, ModelType
from kirara_ai.logger import get_logger
class LLMManager:
"""
跟踪、管理和调度模型后端
"""
container: DependencyContainer
config: GlobalConfig
backend_registry: LLMBackendRegistry
active_backends: Dict[str, List[LLMBackendAdapter]]
model_info: Dict[str, ModelConfig] # 存储模型的配置信息
event_bus: EventBus
@Inject()
def __init__(
self,
container: DependencyContainer,
config: GlobalConfig,
backend_registry: LLMBackendRegistry,
event_bus: EventBus,
):
self.container = container
self.config = config
self.backend_registry = backend_registry
self.event_bus = event_bus
self.logger = get_logger("LLMAdapter")
self.active_backends = {}
self.model_info = {} # 初始化模型信息字典
self.backends: Dict[str, LLMBackendAdapter] = {}
def load_config(self):
"""加载配置文件中的所有启用的后端"""
for backend in self.config.llms.api_backends:
if backend.enable:
self.logger.info(f"Loading backend: {backend.name}")
try:
self.load_backend(backend.name)
except Exception as e:
self.logger.error(f"Failed to load backend {backend.name}: {e}")
def load_backend(self, backend_name: str):
"""
加载指定的后端
:param backend_name: 后端名称
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
raise ValueError(f"Backend {backend_name} not found in config")
if not backend.enable:
raise ValueError(f"Backend {backend_name} is not enabled")
if any(backend_name in adapters for adapters in self.active_backends.values()):
raise ValueError(f"Backend {backend_name} is already loaded")
adapter_class = self.backend_registry.get(backend.adapter)
config_class = self.backend_registry.get_config_class(backend.adapter)
if not adapter_class or not config_class:
raise ValueError(f"Invalid adapter type: {backend.adapter}")
# 创建适配器实例
with self.container.scoped() as scoped_container:
scoped_container.register(config_class, config_class(**backend.config))
adapter = Inject(scoped_container).create(adapter_class)()
adapter.backend_name = backend_name
self.backends[backend_name] = adapter
# 注册到每个支持的模型并记录模型信息
for model_config in backend.models:
# 从ModelConfig中获取模型信息
model_id = model_config.id
# 直接存储模型配置
self.model_info[model_id] = model_config
if model_id not in self.active_backends:
self.active_backends[model_id] = []
self.active_backends[model_id].append(adapter)
self.event_bus.post(LLMAdapterLoaded(adapter=adapter, backend_name=backend_name))
self.logger.info(f"Backend {backend_name} loaded successfully")
async def unload_backend(self, backend_name: str):
"""
卸载指定的后端
:param backend_name: 后端名称
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
raise ValueError(f"Backend {backend_name} not found in config")
backend_adapter = self.backends.get(backend_name)
if not backend_adapter:
raise ValueError(f"Backend {backend_name} not found")
# 从所有模型中移除这个后端的适配器
all_models = list(self.active_backends.keys())
for model in all_models:
if backend_adapter in self.active_backends[model]:
self.active_backends[model].remove(backend_adapter)
if len(self.active_backends[model]) == 0:
self.active_backends.pop(model)
# 清理模型信息
if model in self.model_info:
self.model_info.pop(model)
backend_adapter = self.backends.pop(backend_name)
self.event_bus.post(LLMAdapterUnloaded(backend_name=backend_name, adapter=backend_adapter))
async def reload_backend(self, backend_name: str):
"""
重新加载指定的后端
:param backend_name: 后端名称
"""
await self.unload_backend(backend_name)
self.load_backend(backend_name)
def is_backend_available(self, backend_name: str) -> bool:
"""
检查后端是否可用
:param backend_name: 后端名称
:return: 后端是否可用
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
return False
if not backend.enable:
return False
# 检查后端的所有模型是否都有可用的适配器
for model_config in backend.models:
model_id = model_config.id
if model_id not in self.active_backends or len(self.active_backends[model_id]) == 0:
return False
return True
def get(self, backend_name: str) -> Optional[LLMBackendAdapter]:
"""
获取指定后端的适配器实例
:param backend_name: 后端名称
:return: LLM适配器实例,如果没有找到则返回None
"""
return self.backends.get(backend_name)
def get_llm(self, model_id: str) -> Optional[LLMBackendAdapter]:
"""
从指定模型的活跃后端中随机返回一个适配器实例
:param model_id: 模型ID
:return: LLM适配器实例,如果没有找到则返回None
"""
if model_id not in self.active_backends:
return None
backends = self.active_backends[model_id]
if not backends:
return None
# TODO: 后续考虑支持更多的选择策略
return random.choice(backends)
def get_supported_models(self, model_type: ModelType, ability: ModelAbility) -> List[str]:
"""
获取所有支持指定能力的模型
:param ability: 指定的能力
:return: 支持的模型ID列表
"""
return [
model_id
for model_id, model_config in self.model_info.items()
if model_config.type == model_type.value
and ability.is_capable(model_config.ability)
]
@deprecated("请使用 get_supported_models 方法")
def get_llm_id_by_ability(self, ability: ModelAbility) -> Optional[str]:
"""
根据指定的能力获取一个随机符合要求的LLM模型ID
deprecated: 请使用 get_supported_models 方法
:param ability: 指定的能力
:return: 符合要求的模型ID,如果没有找到则返回None
"""
supported_models = self.get_supported_models(ModelType.LLM, ability)
return None if not supported_models else random.choice(supported_models)
def get_models_by_ability(self, model_type: ModelType, ability: ModelAbility) -> Optional[str]:
"""
根据指定能力随机获取一个模型ID
:param model_type: 模型类型
:param ability: 指定的能力
:return: 随机选择的模型ID,如果没有找到则返回None
"""
supported_models = self.get_supported_models(model_type, ability)
if not supported_models:
return None
return random.choice(supported_models)
def get_models_by_type(self, model_type: ModelType) -> List[str]:
"""
获取指定类型的所有模型
:param model_type: 模型类型
:return: 该类型的模型ID列表
"""
return [
model_id for model_id, config in self.model_info.items()
if config.type == model_type.value
]
================================================
FILE: kirara_ai/llm/llm_registry.py
================================================
from typing import Dict, Optional, Type
from pydantic import BaseModel
from kirara_ai.logger import get_logger
from .adapter import LLMBackendAdapter
from .model_types import LLMAbility # noqa: F401
class LLMBackendRegistry:
"""
LLM后端注册表
"""
_adapters: Dict[str, Type[LLMBackendAdapter]]
_configs: Dict[str, Type[BaseModel]]
def __init__(self):
self._adapters = {}
self._configs = {}
self.logger = get_logger(__name__)
def register(
self,
adapter_type: str,
adapter_class: Type[LLMBackendAdapter],
config_class: Type[BaseModel],
*args, **kwargs
):
"""
注册一个LLM后端适配器
:param adapter_type: 适配器类型
:param adapter_class: 适配器类
:param config_class: 配置类
"""
self._adapters[adapter_type] = adapter_class
self._configs[adapter_type] = config_class
self.logger.info(
f"Registered LLM backend adapter: {adapter_type}"
)
def get(self, adapter_type: str) -> Optional[Type[LLMBackendAdapter]]:
"""
获取指定类型的适配器类
:param adapter_type: 适配器类型
:return: 适配器类,如果没有找到则返回None
"""
return next(
(adapter for key, adapter in self._adapters.items() if key.lower() == adapter_type.lower()),
None
)
def get_config_class(self, adapter_type: str) -> Optional[Type[BaseModel]]:
"""
获取指定类型的配置类
:param adapter_type: 适配器类型
:return: 配置类,如果没有找到则返回None
"""
return next(
(config for key, config in self._configs.items() if key.lower() == adapter_type.lower()),
None
)
def get_adapter_types(self) -> list[str]:
"""
获取所有已注册的适配器类型
:return: 适配器类型列表
"""
return list(self._adapters.keys())
def get_all_adapters(self) -> Dict[str, Type[LLMBackendAdapter]]:
"""
获取所有已注册的 LLM 适配器。
:return: 所有已注册的 LLM 适配器字典。
"""
return self._adapters.copy()
================================================
FILE: kirara_ai/llm/model_types.py
================================================
from abc import abstractmethod
from enum import Enum
class ModelType(Enum):
"""
模型类型枚举
"""
LLM = "llm"
Embedding = "embedding"
ImageGeneration = "image_generation"
Audio = "audio"
# 可以根据需要添加更多类型
@classmethod
def from_str(cls, value: str) -> "ModelType":
"""
从字符串转换为ModelType枚举
"""
return next(
(enum_value for enum_value in cls if enum_value.value == value),
cls.LLM,
)
class ModelAbility(Enum):
"""
模型能力抽象基类
"""
@abstractmethod
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return False
class LLMAbility(ModelAbility):
"""
定义了 LLMAbility 的枚举类型,用于表示 LLM 的能力。
"""
# 这里表示接口支持 chat 格式的对话
Unknown = 0
Chat = 1 << 1
TextInput = 1 << 2
TextOutput = 1 << 3
ImageInput = 1 << 4
ImageOutput = 1 << 5
AudioInput = 1 << 6
AudioOutput = 1 << 7
FunctionCalling = 1 << 8
# 下面是通过位运算组合能力
TextCompletion = TextInput | TextOutput
TextChat = Chat | TextCompletion
ImageGeneration = ImageInput | ImageOutput
TextImageMultiModal = Chat | ImageGeneration
TextImageAudioMultiModal = TextImageMultiModal | AudioInput | AudioOutput
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class EmbeddingModelAbility(ModelAbility):
"""
定义了 EmbeddingModelAbility 的枚举类型,用于表示 Embedding 模型的能力。
"""
Unknown = 0
TextEmbedding = 1 << 1
ImageEmbedding = 1 << 2
AudioEmbedding = 1 << 3
VideoEmbedding = 1 << 4
Batch = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class ImageModelAbility(ModelAbility):
"""
定义了 ImageModelAbility 的枚举类型,用于表示图像模型的能力。
"""
Unknown = 0
TextToImage = 1 << 1
ImageEdit = 1 << 2
Inpainting = 1 << 3
Outpainting = 1 << 4
UpScaling = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class AudioModelAbility(ModelAbility):
"""
定义了 AudioModelAbility 的枚举类型,用于表示音频模型的能力。
"""
Unknown = 0
Speech = 1 << 1
Transcription = 1 << 2
Translation = 1 << 3
Streaming = 1 << 4
Realtime = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
================================================
FILE: kirara_ai/logger.py
================================================
import asyncio
import json
import os
import re
import traceback
from collections import deque
from datetime import datetime
from typing import Any, Callable, Dict, List
from loguru import logger
# 创建 logs 文件夹
LOG_DIR = "logs"
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
# 配置日志格式和颜色
logger.remove() # 移除默认的日志处理器
# 定义日志格式
log_format = (
"{time:YYYY-MM-DD HH:mm:ss.SSS} | "
"{level: <8} | "
"{extra[tag]: <12} | "
"{message}"
)
# 添加控制台日志处理器
logger.add(
sink=lambda msg: print(msg.strip()), # 输出到控制台
format=log_format,
level="DEBUG",
colorize=True,
)
# 添加文件日志处理器,支持日志轮转
log_file = os.path.join(LOG_DIR, "log_{time:YYYY-MM-DD}.log")
logger.add(
sink=log_file,
format=log_format,
level="DEBUG",
rotation="00:00", # 每天午夜轮转
retention="7 days", # 保留7天的日志
compression="zip", # 压缩旧日志文件
colorize=False,
)
# 全局日志实例
_global_logger = logger
# 内存中保存最近的日志,用于新连接时推送历史日志
_recent_logs: deque[Dict] = deque(maxlen=500) # 保存最近500条日志
LogBroadcasterCallback = Callable[[Dict | List[Dict]], None]
# 通用日志处理器管理类
class LogBroadcaster:
"""通用日志广播器,支持多种日志订阅方式"""
_instance = None
_subscribers: Dict[int, LogBroadcasterCallback] = {}
_next_id = 0
_initialized = False
def __new__(cls):
if cls._instance is None:
cls._instance = super(LogBroadcaster, cls).__new__(cls)
cls._instance._subscribers = {} # 订阅者字典,键为订阅者ID,值为回调函数
cls._instance._next_id = 0 # 下一个订阅者ID
cls._instance._initialized = False
return cls._instance
def __init__(self):
if not self._initialized:
self._initialized = True
# 添加日志处理器
self._setup_log_handler()
def _setup_log_handler(self):
"""设置日志处理器"""
def log_sink(message):
# 格式化日志消息
# with {tag<12}
tag = message.record["extra"]["tag"]
log_entry = {
"type": "log",
"level": message.record["level"].name,
"content": message.record['message'],
"timestamp": datetime.now().isoformat(),
"tag": tag
}
if message.record.get('exception'):
exception = message.record['exception']
if exception.value:
log_entry["content"] += "\n" + '\n'.join(traceback.format_exception(exception.value))
# 保存到最近日志
_recent_logs.append(log_entry)
# 广播到所有订阅者
self._broadcast_log(log_entry)
# 添加日志处理器
_global_logger.add(
sink=log_sink,
format=log_format,
level="INFO",
colorize=False,
)
def _broadcast_log(self, log_entry: Dict):
"""广播日志到所有订阅者"""
to_remove = []
for subscriber_id, callback in self._subscribers.items():
try:
callback(log_entry)
except Exception:
# 如果发送失败,标记该订阅者为断开
to_remove.append(subscriber_id)
# 移除断开的订阅者
for subscriber_id in to_remove:
self.unsubscribe(subscriber_id)
def subscribe(self, callback: LogBroadcasterCallback) -> int:
"""
添加日志订阅者
:param callback: 回调函数,接收日志条目并处理
:return: 订阅者ID,用于后续取消订阅
"""
subscriber_id = self._next_id
self._next_id += 1
self._subscribers[subscriber_id] = callback
return subscriber_id
def unsubscribe(self, subscriber_id: int) -> bool:
"""
取消日志订阅
:param subscriber_id: 订阅者ID
:return: 是否成功取消订阅
"""
if subscriber_id in self._subscribers:
del self._subscribers[subscriber_id]
return True
return False
def send_recent_logs(self, callback: LogBroadcasterCallback):
"""
发送最近的日志到指定回调
:param callback: 回调函数,接收日志条目并处理
"""
callback(list(_recent_logs))
# WebSocket日志处理器,作为LogBroadcaster的一个应用
class WebSocketLogHandler:
"""WebSocket日志处理器,用于将日志发送到WebSocket客户端"""
# 存储所有活跃的WebSocket连接及其订阅ID
_websockets: Dict[Any, int] = {}
@classmethod
def add_websocket(cls, ws, loop: asyncio.AbstractEventLoop):
"""
添加WebSocket连接
:param ws: WebSocket连接对象
"""
# 创建回调函数
def send_to_ws(log_entries: List[Dict] | Dict):
loop.create_task(ws.send(json.dumps(log_entries)))
# 获取日志广播器实例
broadcaster = LogBroadcaster()
# 先发送最近的日志
broadcaster.send_recent_logs(send_to_ws)
# 订阅新日志
subscriber_id = broadcaster.subscribe(send_to_ws)
cls._websockets[ws] = subscriber_id
@classmethod
def remove_websocket(cls, ws):
"""
移除WebSocket连接
:param ws: WebSocket连接对象
"""
if ws in cls._websockets:
# 取消订阅
LogBroadcaster().unsubscribe(cls._websockets[ws])
del cls._websockets[ws]
# 初始化日志广播器
def init_log_broadcaster():
"""初始化日志广播器"""
LogBroadcaster()
init_log_broadcaster()
def get_logger(tag: str):
"""
获取带有特定标签的日志记录器
:param tag: 日志标签
:return: 日志记录器
"""
return _global_logger.bind(tag=tag)
class HypercornLoggerWrapper:
def __init__(self, logger):
self.logger = logger
def critical(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.critical(message, *args, **kwargs)
def error(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.error(message, *args, **kwargs)
def warning(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.warning(message, *args, **kwargs)
def info(self, message: str, *args: Any, **kwargs: Any) -> None:
log_fmt = re.sub(r"%\((\w+)\)s", r"{\1}", message)
atoms = args[0] if args else {}
self.logger.info(log_fmt, **atoms)
def debug(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.debug(message, *args, **kwargs)
def exception(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.exception(message, *args, **kwargs)
def log(self, level: int, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.log(level, message, *args, **kwargs)
def get_async_logger(tag: str):
"""
获取带有特定标签的日志记录器
:param tag: 日志标签
:return: 日志记录器
"""
return HypercornLoggerWrapper(_global_logger.bind(tag=tag))
================================================
FILE: kirara_ai/mcp_module/__init__.py
================================================
from .manager import MCPServerManager
from .models import MCPConnectionState
from .server import MCPServer
__all__ = ["MCPServerManager", "MCPServer", "MCPConnectionState"]
================================================
FILE: kirara_ai/mcp_module/manager.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import asyncio
from functools import partial
from typing import Dict, NamedTuple, Optional, Tuple
from mcp import McpError, types
from mcp.shared.session import RequestResponder
from kirara_ai.config.global_config import GlobalConfig, MCPServerConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from .models import MCPConnectionState
from .server import MCPServer
logger = get_logger("MCP")
class ToolCacheEntry(NamedTuple):
"""工具缓存条目"""
server_id: str # 服务器ID
original_name: str # 原始工具名称
tool_info: types.Tool # 工具信息
class MCPServerManager:
"""MCP服务器管理器,负责管理和控制MCP服务器进程"""
def __init__(self, container: DependencyContainer):
"""初始化MCP服务器管理器"""
self.container = container
self.config = container.resolve(GlobalConfig)
self.servers: Dict[str, MCPServer] = {}
self.tools_cache: Dict[str, ToolCacheEntry] = {}
self.prompts_cache: Dict[str, list[types.Prompt]] = {}
self.resources_cache: Dict[str, list[types.Resource]] = {}
def load_servers(self):
"""从配置加载所有MCP服务器"""
for server_config in self.config.mcp.servers:
try:
self.load_server(server_config)
except Exception as e:
logger.opt(exception=e).error(f"Failed to load MCP server {server_config.id}")
logger.info(f"MCP server manager initialized, loaded {len(self.servers)} servers")
def load_server(self, server_config: MCPServerConfig) -> MCPServer:
"""从配置加载MCP服务器"""
server = MCPServer(server_config)
logger.info(f"Initializing MCP server {server_config.id}")
self.servers[server_config.id] = server
return server
def get_all_servers(self) -> Dict[str, MCPServer]:
"""获取所有MCP服务器列表"""
return self.servers
def get_server(self, server_id: str) -> Optional[MCPServer]:
"""获取指定ID的MCP服务器"""
return self.servers.get(server_id)
def is_server_id_available(self, server_id: str) -> bool:
"""
检查服务器ID是否可用
判断条件:
1. 服务器ID不存在
2. 或者服务器存在但状态为 DISCONNECTED 或 ERROR
"""
if server_id not in self.servers:
return True
server = self.servers[server_id]
return server.state in [MCPConnectionState.DISCONNECTED, MCPConnectionState.ERROR]
def get_statistics(self) -> Dict[str, int]:
"""获取MCP服务器统计信息"""
total = len(self.servers)
stdio = sum(bool(s.server_config.connection_type == "stdio") for s in self.servers.values())
sse = sum(bool(s.server_config.connection_type == "sse") for s in self.servers.values())
connected = sum(bool(s.state == MCPConnectionState.CONNECTED) for s in self.servers.values())
disconnected = sum(bool(s.state == MCPConnectionState.DISCONNECTED) for s in self.servers.values())
error = sum(bool(s.state == MCPConnectionState.ERROR) for s in self.servers.values())
return {
"total": total,
"stdio": stdio,
"sse": sse,
"connected": connected,
"disconnected": disconnected,
"error": error
}
def connect_all_servers(self, loop: asyncio.AbstractEventLoop):
"""连接所有MCP服务器"""
async def _connect_server_safe(server_id):
try:
await self.connect_server(server_id)
except Exception as e:
logger.opt(exception=e).error(f"Exception occurred when connecting MCP server {server_id}")
tasks = []
for server_id in self.servers.keys():
task = loop.create_task(_connect_server_safe(server_id))
tasks.append(task)
if tasks:
loop.run_until_complete(asyncio.gather(*tasks, return_exceptions=True))
async def connect_server(self, server_id: str) -> bool:
"""连接MCP服务器"""
server = self.servers.get(server_id)
if not server:
logger.error(f"Cannot connect to non-existent MCP server: {server_id}")
return False
if server.state == MCPConnectionState.CONNECTED:
logger.warning(f"MCP server {server_id} is already connected")
return True
try:
logger.info(f"Connecting to MCP server {server_id}")
server.message_handler = partial(self._handle_server_message, server_id)
# 连接到服务器
success = await server.connect()
if not success:
logger.error(f"Failed to connect to MCP server {server_id}")
return False
# 连接成功后,更新缓存
await self._update_tools_cache(server_id)
await self._update_prompts_cache(server_id)
await self._update_resources_cache(server_id)
logger.info(f"Successfully connected to MCP server {server_id}")
return True
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when connecting to MCP server {server_id}")
return False
def disconnect_all_servers(self, loop: asyncio.AbstractEventLoop):
"""断开所有MCP服务器连接"""
disconnect_tasks = []
for server_id, server in self.servers.items():
if server.state == MCPConnectionState.CONNECTED:
disconnect_tasks.append(loop.create_task(self.stop_server(server_id)))
if disconnect_tasks:
loop.run_until_complete(asyncio.gather(*disconnect_tasks, return_exceptions=True))
self.tools_cache.clear()
logger.info("All MCP servers have been disconnected")
async def stop_server(self, server_id: str) -> bool:
"""断开MCP服务器连接"""
server = self.servers.get(server_id)
if not server:
logger.error(f"Cannot disconnect from non-existent MCP server: {server_id}")
return False
if server.state != MCPConnectionState.CONNECTED:
logger.warning(f"MCP server {server_id} is not connected")
return True
try:
logger.info(f"Disconnecting from MCP server {server_id}")
# 断开服务器连接
success = await server.disconnect()
if not success:
logger.error(f"Failed to disconnect from MCP server {server_id}")
return False
# 从工具缓存中移除该服务器的工具
self._remove_server_tools_from_cache(server_id)
logger.info(f"Successfully disconnected from MCP server {server_id}")
return True
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when disconnecting from MCP server {server_id}")
return False
async def _update_tools_cache(self, server_id: str) -> bool:
"""
更新指定服务器的工具缓存
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器工具列表
tools = await server.get_tools()
# 先移除该服务器的旧工具
self._remove_server_tools_from_cache(server_id)
# 添加新工具到缓存
for tool in tools.tools:
original_name = tool.name
if not original_name:
continue
# 检查工具名称是否已存在
if original_name in self.tools_cache:
# 名称冲突,使用 server_id.tool_name 作为新名称
display_name = f"{server.server_config.id}.{original_name}"
logger.warning(f"工具名称冲突: {original_name},重命名为 {display_name}")
else:
display_name = original_name
# 存储工具信息
self.tools_cache[display_name] = ToolCacheEntry(
server_id=server_id,
original_name=original_name,
tool_info=tool
)
return True
except McpError as e:
if e.error == "Method not found":
logger.warning(f"Server {server_id} does not support tools")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} 工具缓存时发生错误")
return False
def _remove_server_tools_from_cache(self, server_id: str):
"""
从工具缓存中移除指定服务器的所有工具
Args:
server_id: 服务器ID
"""
# 找出属于该服务器的所有工具名称
tool_names_to_remove = [
name for name, entry in self.tools_cache.items() if entry.server_id == server_id
]
# 从缓存中移除这些工具
for name in tool_names_to_remove:
self.tools_cache.pop(name, None)
def get_tools(self) -> Dict[str, ToolCacheEntry]:
"""
获取所有可用工具
"""
# 返回工具信息
return self.tools_cache
def get_tool_server(self, tool_name: str) -> Optional[Tuple[MCPServer, str]]:
"""
根据工具名称获取对应的服务器实例和原始工具名称
Args:
tool_name: 工具显示名称
Returns:
Optional[Tuple[MCPServer, str]]: (服务器实例, 原始工具名称),如果工具不存在则返回None
"""
if tool_name not in self.tools_cache:
return None
entry = self.tools_cache[tool_name]
server = self.servers.get(entry.server_id)
if not server:
return None
return (server, entry.original_name)
async def call_tool(self, tool_name: str, tool_args: dict) -> Optional[types.CallToolResult]:
"""
调用指定工具
Args:
tool_name: 工具显示名称
tool_args: 工具参数
Returns:
Optional[dict]: 工具调用结果,如果调用失败则返回None
"""
result = self.get_tool_server(tool_name)
if not result:
logger.error(f"Tool {tool_name} not found or server not available")
return None
server, original_name = result
if server.state != MCPConnectionState.CONNECTED:
logger.error(f"Server for tool {tool_name} is not connected")
return None
try:
# 使用原始工具名称调用
call_tool_result = await server.call_tool(original_name, tool_args)
return call_tool_result
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when calling tool {tool_name}")
return None
async def _update_prompts_cache(self, server_id: str) -> bool:
"""
更新指定server的prompts 索引缓存
# notification !
这个函数存的缓存是一个prompts的索引,请调用get_prompts获取具体的prompts信息
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器prompts 索引
prompts = await server.list_prompts()
# 移除旧缓存
self.prompts_cache.pop(server_id, None)
# 添加新索引到缓存
self.prompts_cache[server_id] = prompts.prompts
return True
except McpError as e:
if e.error == "Method not found":
self.prompts_cache[server_id] = []
logger.warning(f"Server {server_id} does not support prompts")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} prompts 索引缓存时发生错误")
return False
async def get_prompt_list(self, server_id: str) -> Optional[list[types.Prompt]]:
"""
获取指定服务器的prompts
Args:
server_id: 服务器ID
Returns:
types.GetPromptResult: prompts
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return self.prompts_cache.get(server_id, [])
async def get_prompt(self, server_id: str, prompt_name: str, prompt_args: dict[str, str] | None = None) -> Optional[types.GetPromptResult]:
"""
获取指定服务器的prompt
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return await server.get_prompt(prompt_name, prompt_args)
async def _update_resources_cache(self, server_id: str) -> bool:
"""
更新指定server的resources 缓存
# notification !
这个函数存的缓存是一个resources的索引,请调用get_resources获取具体的resources信息
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器resources 索引
resources = await server.list_resources()
# 移除旧缓存
self.resources_cache.pop(server_id, None)
# 存储新索引到缓存
self.resources_cache[server_id] = resources.resources
return True
except McpError as e:
if e.error == "Method not found":
self.resources_cache[server_id] = []
logger.warning(f"Server {server_id} does not support resources")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} resources 缓存时发生错误")
return False
async def get_resource_list(self, server_id: str) -> Optional[list[types.Resource]]:
"""获取指定服务器的资源列表
Args:
server_id (str): 服务器ID
Returns:
Optional[types.Resource]: 资源列表
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return self.resources_cache.get(server_id, [])
async def get_resource(self, server_id: str, uri: str) -> Optional[types.ReadResourceResult]:
"""
获取指定服务器的resources
Args:
server_id: 服务器ID
uri: 资源URI
Returns:
types.ReadResourceResult: resource
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return await server.read_resource(uri)
async def _handle_server_message(self, server_id: str, message: RequestResponder[types.ServerRequest, types.ClientResult]
| types.ServerNotification
| Exception):
"""
处理服务器通知
"""
if isinstance(message, types.ToolListChangedNotification):
await self._update_tools_cache(server_id)
elif isinstance(message, types.PromptListChangedNotification):
await self._update_prompts_cache(server_id)
elif isinstance(message, types.ResourceListChangedNotification):
await self._update_resources_cache(server_id)
else:
logger.warning(f"Unknown notification from server {server_id}: {message}")
================================================
FILE: kirara_ai/mcp_module/models.py
================================================
from enum import Enum
class MCPConnectionState(Enum):
DISCONNECTED = "disconnected"
CONNECTING = "connecting"
CONNECTED = "connected"
DISCONNECTING = "disconnecting"
ERROR = "error"
================================================
FILE: kirara_ai/mcp_module/server.py
================================================
import asyncio
from contextlib import AsyncExitStack
from typing import Optional
import anyio
import anyio.lowlevel
from mcp import ClientSession, StdioServerParameters, stdio_client, types
from mcp.client.session import MessageHandlerFnT
from mcp.client.sse import sse_client
from mcp.shared.session import RequestResponder
from pydantic import AnyUrl
from kirara_ai.config.global_config import MCPServerConfig
from kirara_ai.logger import get_logger
from .models import MCPConnectionState
logger = get_logger("MCP.Server")
class MCPServer:
"""
MCP (Model Control Protocol) 服务器客户端类
用于与 MCP 服务器进行通信,支持 stdio 和 SSE 两种连接模式。
提供工具调用、补全、资源管理等功能。
本类为 mcp.ClientSession 的代理,
使其适应 Kirara AI 的生命周期。
"""
session: Optional[ClientSession] = None
state: MCPConnectionState = MCPConnectionState.DISCONNECTED
message_handler: Optional[MessageHandlerFnT] = None
def __init__(self, server_config: MCPServerConfig):
"""
初始化 MCP 服务器客户端
Args:
server_config: MCP 服务器配置
"""
self.server_config = server_config
self.session = None
self.state = MCPConnectionState.DISCONNECTED
self._lifecycle_task = None
self._shutdown_event = asyncio.Event()
self._connected_event = asyncio.Event()
self._client = None
self.message_handler = None
async def connect(self):
"""
连接到 MCP 服务器
根据配置连接到 MCP 服务器,并初始化会话
Returns:
bool: 连接是否成功
"""
if self.state != MCPConnectionState.DISCONNECTED and self.state != MCPConnectionState.ERROR:
return False
try:
self.state = MCPConnectionState.CONNECTING
# 重置事件
self._shutdown_event.clear()
self._connected_event.clear()
# 创建并启动生命周期任务
if self._lifecycle_task is None or self._lifecycle_task.done():
self._lifecycle_task = asyncio.create_task(self._lifecycle_manager())
# 等待连接完成或超时
try:
await asyncio.wait_for(self._connected_event.wait(), timeout=30.0)
if self.state != MCPConnectionState.CONNECTED:
# 连接失败
return False
return True
except asyncio.TimeoutError:
logger.error(f"连接到 MCP 服务器 {self.server_config.id} 超时")
await self.disconnect() # 超时时断开连接
return False
except Exception as e:
self.state = MCPConnectionState.ERROR
logger.opt(exception=e).error(f"连接 MCP 服务器 {self.server_config.id} 时发生错误")
return False
async def disconnect(self):
"""
断开与 MCP 服务器的连接
Returns:
bool: 断开连接是否成功
"""
if self.state == MCPConnectionState.DISCONNECTED:
return True
try:
self.state = MCPConnectionState.DISCONNECTING
# 发送关闭信号
self._shutdown_event.set()
# 等待生命周期任务完成
if self._lifecycle_task and not self._lifecycle_task.done():
try:
await asyncio.wait_for(self._lifecycle_task, timeout=10.0)
except asyncio.TimeoutError:
# 如果任务没有及时完成,取消它
self._lifecycle_task.cancel()
try:
await self._lifecycle_task
except (asyncio.CancelledError, Exception):
pass
self.state = MCPConnectionState.DISCONNECTED
return True
except Exception as e:
self.state = MCPConnectionState.ERROR
logger.opt(exception=e).error(f"断开 MCP 服务器 {self.server_config.id} 连接时发生错误")
return False
async def _lifecycle_manager(self):
"""
服务器生命周期管理任务
负责服务器的连接、运行和断开连接的完整生命周期
"""
exit_stack = AsyncExitStack()
try:
# 初始化连接
if self.server_config.connection_type == "stdio":
if self.server_config.command is None:
raise ValueError("stdio 连接类型需要提供命令")
self._client = stdio_client(StdioServerParameters(
command=self.server_config.command,
args=self.server_config.args,
env=self.server_config.env
))
elif self.server_config.connection_type == "sse":
if self.server_config.url is None:
raise ValueError("sse 连接类型需要提供 url")
self._client = sse_client(self.server_config.url, headers=self.server_config.headers)
else:
raise ValueError(f"不支持的服务器连接类型: {self.server_config.connection_type}")
# 使用 exit_stack 管理资源
read, write = await exit_stack.enter_async_context(self._client)
self.session = await exit_stack.enter_async_context(ClientSession(read, write, message_handler=self.message_handler_callback))
# 初始化会话
await self.session.initialize()
# 更新状态并通知连接完成
self.state = MCPConnectionState.CONNECTED
self._connected_event.set()
# 等待关闭信号
await self._shutdown_event.wait()
except Exception as e:
# 连接失败
self.state = MCPConnectionState.ERROR
self._connected_event.set() # 通知连接过程已完成(虽然是失败的)
logger.opt(exception=e).error(f"MCP server {self.server_config.id} lifecycle task error")
finally:
# 清理资源
self.session = None
self._client = None
try:
# 关闭所有资源
await exit_stack.aclose()
except Exception as e:
logger.opt(exception=e).error(f"error occured during shutting down handle of: {self.server_config.id}")
# 如果状态仍然是 DISCONNECTING,则更新为 DISCONNECTED
if self.state == MCPConnectionState.DISCONNECTING:
self.state = MCPConnectionState.DISCONNECTED
# 工具相关方法
async def get_tools(self) -> types.ListToolsResult:
"""获取可用工具列表"""
assert self.session is not None
return await self.session.list_tools()
async def call_tool(self, tool_name: str, tool_args: Optional[dict] = None) -> types.CallToolResult:
"""
调用指定工具
Args:
tool_name: 工具名称
tool_args: 工具参数
Returns:
工具调用结果
"""
assert self.session is not None
return await self.session.call_tool(tool_name, tool_args)
async def complete(self, prompt: str, tool_args: dict):
"""
使用模型进行补全
Args:
prompt: 提示文本
tool_args: 补全参数
Returns:
补全结果
"""
assert self.session is not None
return await self.session.complete(types.PromptReference(name=prompt, type="ref/prompt"), tool_args)
# 提示词相关方法
async def get_prompt(self, prompt_name: str, prompt_args: dict[str, str] | None = None) -> types.GetPromptResult:
"""
获取指定提示词
Args:
prompt_name: 提示词名称
prompt_args: 提示词参数
Returns:
提示词内容
"""
assert self.session is not None
return await self.session.get_prompt(prompt_name, prompt_args)
async def list_prompts(self) -> types.ListPromptsResult:
"""获取可用提示词列表"""
assert self.session is not None
return await self.session.list_prompts()
# 资源相关方法
async def list_resources(self) -> types.ListResourcesResult:
"""获取可用资源列表"""
assert self.session is not None
return await self.session.list_resources()
async def list_resource_templates(self) -> types.ListResourceTemplatesResult:
"""获取可用资源模板列表"""
assert self.session is not None
return await self.session.list_resource_templates()
async def read_resource(self, uri: str) -> types.ReadResourceResult:
"""
读取指定资源
Args:
uri: 资源名称
Returns:
资源内容
"""
assert self.session is not None
return await self.session.read_resource(AnyUrl(uri))
async def subscribe_resource(self, uri: str) -> types.EmptyResult:
"""
订阅指定资源
Args:
uri: 资源名称
Returns:
订阅结果
"""
assert self.session is not None
return await self.session.subscribe_resource(AnyUrl(uri))
async def unsubscribe_resource(self, uri: str) -> types.EmptyResult:
"""
取消订阅指定资源
Args:
uri: 资源名称
Returns:
取消订阅结果
"""
assert self.session is not None
return await self.session.unsubscribe_resource(AnyUrl(uri))
async def message_handler_callback(
self,
message: RequestResponder[types.ServerRequest, types.ClientResult]
| types.ServerNotification
| Exception,
) -> None:
"""
消息处理回调函数
Args:
message: 请求响应器或通知或异常
"""
if self.message_handler is None:
logger.warning(f"MCP客户端接收到服务器{self.server_config.id}的通知,但未对其进行处理: {message}")
await anyio.lowlevel.checkpoint()
return
await self.message_handler(message)
async def list_client_roots_callback(self, ctx) -> types.ListRootsResult | types.ErrorData:
"""
列出客户端允许的资源根目录
Args:
Returns:
types.ListRootsResult: 资源根目录列表
"""
# 这个需要kirara-agent做出较大支持,webApi 中设定允许的资源根,最好弄个单独的目录。
# 文件根格式为file:///myResource/, 也可以为一个url.
raise NotImplementedError("list_client_roots_callback 未实现")
async def send_ping(self) -> None:
assert self.session is not None
await self.session.send_ping()
async def send_notification(self, notification: types.ClientNotification) -> None:
"""
给服务器发消息,例如资源根更改
不使用 ClientSession 的 send_roots_list_changed,因为它只支持发送 RootsListChangedNotification。
这里使用其父对象 BaseSession 的 send_notification,其支持发送所有 ClientNotification。
Args:
notification: 客户端通知
"""
assert self.session is not None
await self.session.send_notification(notification)
async def sampling_callback(self):
"""
采样回调函数
"""
async def logging_callback(self):
"""
日志回调函数
"""
================================================
FILE: kirara_ai/media/__init__.py
================================================
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types import MediaType
from kirara_ai.media.utils import detect_mime_type
__all__ = [
"Media",
"MediaManager",
"MediaMetadata",
"MediaType",
"detect_mime_type",
]
================================================
FILE: kirara_ai/media/carrier/__init__.py
================================================
from .provider import MediaReferenceProvider
from .registry import MediaCarrierRegistry
from .service import MediaCarrierService
__all__ = ["MediaReferenceProvider", "MediaCarrierRegistry",
"MediaCarrierService"]
================================================
FILE: kirara_ai/media/carrier/provider.py
================================================
from abc import ABC, abstractmethod
from typing import Generic, Optional, TypeVar
T = TypeVar("T")
class MediaReferenceProvider(ABC, Generic[T]):
"""媒体引用提供者接口,由需要引用媒体的组件实现"""
@abstractmethod
def get_reference_owner(self, reference_key: str) -> Optional[T]:
"""根据引用键获取引用所有者"""
================================================
FILE: kirara_ai/media/carrier/registry.py
================================================
from typing import Dict
from kirara_ai.ioc.container import DependencyContainer
from .provider import MediaReferenceProvider
class MediaCarrierRegistry:
"""媒体载体注册表,管理所有媒体引用提供者"""
def __init__(self, container: DependencyContainer):
self.container = container
self._providers: Dict[str, MediaReferenceProvider] = {}
def register(self, provider_name: str, provider_instance: MediaReferenceProvider) -> None:
"""注册媒体引用提供者"""
self._providers[provider_name] = provider_instance
def unregister(self, provider_name: str) -> None:
"""注销媒体引用提供者"""
if provider_name in self._providers:
del self._providers[provider_name]
def get_provider(self, provider_name: str) -> MediaReferenceProvider:
"""获取媒体引用提供者实例"""
if provider_name not in self._providers:
raise ValueError(f"Provider not found: {provider_name}")
return self._providers[provider_name]
def get_all_providers(self) -> Dict[str, MediaReferenceProvider]:
"""获取所有媒体引用提供者实例"""
return self._providers
================================================
FILE: kirara_ai/media/carrier/service.py
================================================
from typing import Any, Dict, List, Optional, Tuple
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from .registry import MediaCarrierRegistry
class MediaCarrierService:
"""媒体载体服务,负责媒体引用的管理"""
def __init__(self, container: DependencyContainer, media_manager: MediaManager):
self.container = container
self.media_manager = media_manager
self.registry = container.resolve(MediaCarrierRegistry)
# 引用索引:reference_key -> (provider_name, media_id)
self._reference_index: Dict[str, Tuple[str, str]] = {}
self._build_reference_index()
def _build_reference_index(self) -> None:
"""构建引用索引"""
self._reference_index.clear()
# 遍历所有媒体元数据,提取引用信息
for media_id, metadata in self.media_manager.metadata_cache.items():
for reference_key in metadata.references:
# 尝试从引用键中提取提供者名称
if ":" in reference_key:
provider_name, _ = reference_key.split(":", 1)
self._reference_index[reference_key] = (provider_name, media_id)
def register_reference(self, media_id: str, provider_name: str, reference_key: str) -> None:
"""注册媒体引用"""
# 检查媒体是否存在
if media_id not in self.media_manager.metadata_cache:
raise ValueError(f"媒体不存在: {media_id}")
# 构造完整引用键
full_reference_key = f"{provider_name}:{reference_key}"
# 添加引用
self.media_manager.add_reference(media_id, full_reference_key)
# 更新引用索引
self._reference_index[full_reference_key] = (provider_name, media_id)
def remove_reference(self, media_id: str, provider_name: str, reference_key: str) -> None:
"""移除媒体引用"""
# 检查媒体是否存在
if media_id not in self.media_manager.metadata_cache:
return
# 构造完整引用键
full_reference_key = f"{provider_name}:{reference_key}"
# 移除引用
self.media_manager.remove_reference(media_id, full_reference_key)
# 更新引用索引
if full_reference_key in self._reference_index:
del self._reference_index[full_reference_key]
def get_reference_owner(self, reference_key: str) -> Optional[Any]:
"""获取引用所有者"""
if reference_key not in self._reference_index:
return None
provider_name, _ = self._reference_index[reference_key]
try:
provider = self.registry.get_provider(provider_name)
return provider.get_reference_owner(reference_key.split(":", 1)[1])
except (ValueError, IndexError):
return None
def get_media_by_reference(self, provider_name: str, reference_key: str) -> List[Media]:
"""根据引用键获取媒体对象"""
full_reference_key = f"{provider_name}:{reference_key}"
result = []
for ref_key, (prov_name, media_id) in self._reference_index.items():
if ref_key == full_reference_key:
media = self.media_manager.get_media(media_id)
if media:
result.append(media)
return result
def get_references_by_media(self, media_id: str) -> List[Tuple[str, str]]:
"""获取媒体的所有引用信息"""
if media_id not in self.media_manager.metadata_cache:
return []
metadata = self.media_manager.metadata_cache[media_id]
references = []
for reference_key in metadata.references:
if ":" in reference_key:
provider_name, key = reference_key.split(":", 1)
references.append((provider_name, key))
return references
def cleanup_orphaned_references(self) -> int:
"""清理孤立的引用(引用提供者不存在)"""
count = 0
all_providers = set(self.registry._providers.keys())
for media_id, metadata in list(self.media_manager.metadata_cache.items()):
orphaned_refs = set()
for reference_key in metadata.references:
if ":" in reference_key:
provider_name, _ = reference_key.split(":", 1)
if provider_name not in all_providers:
orphaned_refs.add(reference_key)
# 移除孤立引用
for ref in orphaned_refs:
self.media_manager.remove_reference(media_id, ref)
if ref in self._reference_index:
del self._reference_index[ref]
count += 1
return count
================================================
FILE: kirara_ai/media/manager.py
================================================
import asyncio
import base64
import hashlib
import json
import shutil
import time
from pathlib import Path
from typing import TYPE_CHECKING, Dict, List, Optional
import aiofiles
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types.media_type import MediaType
from kirara_ai.media.utils.mime import detect_mime_type
if TYPE_CHECKING:
from kirara_ai.im.message import MediaMessage
from kirara_ai.media.media_object import Media
class MediaManager:
"""媒体管理器,负责媒体文件的注册、引用计数和生命周期管理"""
def __init__(self, media_dir: str = "data/media"):
self.media_dir = Path(media_dir)
self.metadata_dir = self.media_dir / "metadata"
self.files_dir = self.media_dir / "files"
self.metadata_cache: Dict[str, MediaMetadata] = {}
self.logger = get_logger("MediaManager")
self._pending_tasks: set[asyncio.Task] = set()
# 确保目录存在
self.media_dir.mkdir(parents=True, exist_ok=True)
self.metadata_dir.mkdir(parents=True, exist_ok=True)
self.files_dir.mkdir(parents=True, exist_ok=True)
self._cleanup_task = None
# 加载所有元数据
self._load_all_metadata()
def _load_all_metadata(self) -> None:
"""加载所有媒体元数据"""
self.metadata_cache.clear()
for metadata_file in self.metadata_dir.glob("*.json"):
try:
with open(metadata_file, "r", encoding="utf-8") as f:
metadata = MediaMetadata.from_dict(json.load(f))
self.metadata_cache[metadata.media_id] = metadata
except Exception as e:
self.logger.error(f"Failed to load metadata from {metadata_file}: {e}")
def _save_metadata(self, metadata: MediaMetadata) -> None:
"""保存媒体元数据"""
metadata_path = self.metadata_dir / f"{metadata.media_id}.json"
with open(metadata_path, "w", encoding="utf-8") as f:
json.dump(metadata.to_dict(), f, ensure_ascii=False, indent=2)
self.metadata_cache[metadata.media_id] = metadata
def _get_file_path(self, media_id: str, format: str) -> Path:
"""获取媒体文件路径"""
return self.files_dir / f"{media_id}.{format}"
def _create_task(self, coro, name=None, loop=None):
"""创建后台任务并跟踪它"""
if loop is None:
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(coro, loop=loop)
self._pending_tasks.add(task)
task.add_done_callback(self._pending_tasks.discard)
return task
async def _save_file_async(self, data: bytes, target_path: Path):
"""异步保存文件"""
async with aiofiles.open(target_path, "wb") as f:
await f.write(data)
async def _download_file_async(self, url: str) -> bytes:
"""异步下载文件"""
from curl_cffi import AsyncSession, Response
# 如果 url 是 file:// 开头,则直接返回文件内容
if url.startswith("file://"):
async with aiofiles.open(url[7:], "rb") as f:
return await f.read()
async with AsyncSession(trust_env=True, timeout=3000) as session:
resp: Response = await session.get(url)
if resp.status_code != 200:
raise ValueError(f"Failed to download file from {url}, status: {resp.status_code}")
return resp.content
def _download_file_sync(self, url: str) -> bytes:
"""同步下载文件"""
from curl_cffi import Response, Session
# 如果 url 是 file:// 开头,则直接返回文件内容
if url.startswith("file://"):
with open(url[7:], "rb") as f:
return f.read()
with Session() as session:
resp: Response = session.get(url)
if resp.status_code != 200:
raise ValueError(f"Failed to download file from {url}, status: {resp.status_code}")
return resp.content
async def register_media(
self,
url: Optional[str] = None,
path: Optional[str] = None,
data: Optional[bytes] = None,
format: Optional[str] = None,
media_type: Optional[MediaType] = None,
size: Optional[int] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None,
) -> str:
"""
注册媒体(统一方法)
Args:
url: 媒体URL
path: 媒体文件路径
data: 媒体二进制数据
format: 媒体格式
media_type: 媒体类型
size: 媒体大小
source: 媒体来源
description: 媒体描述
tags: 媒体标签
reference_id: 引用ID
Returns:
str: 媒体ID
"""
# 检查参数
if not any([url, path, data]):
raise ValueError("Must provide at least one of url, path, or data")
# 获取数据
if path:
file_path = Path(path)
if not file_path.exists():
raise FileNotFoundError(f"File not found: {path}")
try:
async with aiofiles.open(file_path, "rb") as f:
data = await f.read()
except Exception as e:
self.logger.error(f"Failed to read file: {e}", exc_info=True)
raise
elif url:
try:
data = await self._download_file_async(url)
except Exception as e:
self.logger.error(f"Failed to download file: {e}", exc_info=True)
raise
# 计算 SHA1
if data is None:
raise ValueError("Unable to fetch data from url or path, please check your input")
hash_data = await asyncio.to_thread(hashlib.sha1, data)
media_id = hash_data.hexdigest()
# 检查是否已存在相同 media_id 的媒体
if media_id in self.metadata_cache:
self.logger.info(f"Media already exists: {media_id}")
return media_id
# 获取数据大小
if not size:
size = len(data)
# 检测文件类型
if not media_type or not format:
mime_type, detected_media_type, detected_format = detect_mime_type(data=data)
media_type = media_type or detected_media_type
format = format or detected_format
# 保存文件
if format:
target_path = self._get_file_path(media_id, format)
try:
await self._save_file_async(data, target_path)
except Exception as e:
self.logger.error(f"Failed to save file: {e}", exc_info=True)
raise
path = str(target_path)
else:
raise ValueError("No format detected")
# 创建元数据
metadata = MediaMetadata(
media_id=media_id,
media_type=media_type,
format=format,
size=size,
created_at=None, # 使用默认值
source=source,
description=description,
tags=tags,
references=set([reference_id]) if reference_id else set(),
url=url,
path=path,
)
# 保存元数据
self._save_metadata(metadata)
self.logger.info(f"Registered media: {media_id}")
return media_id
async def register_from_path(
self,
path: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None
) -> str:
"""从文件路径注册媒体"""
# 检查文件是否存在
file_path = Path(path)
if not file_path.exists():
raise FileNotFoundError(f"File not found: {path}")
return await self.register_media(
path=path,
source=source,
description=description,
tags=tags,
reference_id=reference_id
)
async def register_from_url(
self,
url: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None
) -> str:
"""从URL注册媒体"""
return await self.register_media(
url=url,
source=source,
description=description,
tags=tags,
reference_id=reference_id
)
async def register_from_data(
self,
data: bytes,
format: Optional[str] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None,
media_type: Optional[MediaType] = None
) -> str:
"""从二进制数据注册媒体"""
return await self.register_media(
data=data,
format=format,
source=source,
description=description,
tags=tags,
reference_id=reference_id,
media_type=media_type
)
def add_reference(self, media_id: str, reference_id: str) -> None:
"""添加引用"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
metadata.references.add(reference_id)
self._save_metadata(metadata)
def remove_reference(self, media_id: str, reference_id: str) -> None:
"""移除引用"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
if reference_id in metadata.references:
metadata.references.remove(reference_id)
self._save_metadata(metadata)
# 如果没有引用了,输出log提醒一下
if not metadata.references:
self.logger.warning(f"No references found for media: {media_id}, file: {metadata.path}")
# 删除文件
self.delete_media(media_id)
def delete_media(self, media_id: str) -> None:
"""删除媒体文件和元数据"""
if media_id not in self.metadata_cache:
return
metadata = self.metadata_cache[media_id]
# 删除文件
if metadata.format:
file_path = self._get_file_path(media_id, metadata.format)
if file_path.exists():
file_path.unlink()
# 删除元数据
metadata_path = self.metadata_dir / f"{media_id}.json"
if metadata_path.exists():
metadata_path.unlink()
# 从缓存中移除
del self.metadata_cache[media_id]
self.logger.info(f"Deleted media: {media_id}")
def update_metadata(
self,
media_id: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
url: Optional[str] = None,
path: Optional[str] = None
) -> None:
"""更新媒体元数据"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
if source is not None:
metadata.source = source
if description is not None:
metadata.description = description
if tags is not None:
metadata.tags = tags
if url is not None:
metadata.url = url
if path is not None:
metadata.path = path
self._save_metadata(metadata)
def add_tags(self, media_id: str, tags: List[str]) -> None:
"""添加标签"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
for tag in tags:
if tag not in metadata.tags:
metadata.tags.append(tag)
self._save_metadata(metadata)
def remove_tags(self, media_id: str, tags: List[str]) -> None:
"""移除标签"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
for tag in tags:
if tag in metadata.tags:
metadata.tags.remove(tag)
self._save_metadata(metadata)
def get_metadata(self, media_id: str) -> Optional[MediaMetadata]:
"""获取媒体元数据"""
return self.metadata_cache.get(media_id)
async def ensure_file_exists(self, media_id: str) -> Optional[Path]:
"""确保媒体文件存在,如果不存在则尝试下载或复制"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果没有格式信息,无法确定文件路径
if not metadata.format:
# 如果有path,尝试复制并检测格式
if metadata.path:
try:
file_path = Path(metadata.path)
if not file_path.exists():
return None
_, media_type, format = detect_mime_type(path=str(file_path))
# 更新元数据
metadata.media_type = media_type
metadata.format = format
metadata.size = file_path.stat().st_size
self._save_metadata(metadata)
# 复制文件
target_path = self._get_file_path(media_id, format)
shutil.copy2(file_path, target_path)
return target_path
except Exception as e:
self.logger.error(f"Failed to copy media from path: {metadata.path}, error: {e}")
return None
# 如果有URL,尝试下载并检测格式
elif metadata.url:
try:
data = await self._download_file_async(metadata.url)
_, media_type, format = detect_mime_type(data=data)
# 更新元数据
metadata.media_type = media_type
metadata.format = format
metadata.size = len(data)
self._save_metadata(metadata)
# 保存文件
target_path = self._get_file_path(media_id, format)
await self._save_file_async(data, target_path)
return target_path
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
return None
return None
# 检查文件是否存在
file_path = self._get_file_path(media_id, metadata.format)
if file_path.exists():
return file_path
# 如果文件不存在,尝试从URL下载
if metadata.url:
try:
data = await self._download_file_async(metadata.url)
await self._save_file_async(data, file_path)
return file_path
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
# 如果文件不存在,尝试从path复制
if metadata.path:
try:
source_path = Path(metadata.path)
if source_path.exists():
shutil.copy2(source_path, file_path)
return file_path
except Exception as e:
self.logger.error(f"Failed to copy media from path: {metadata.path}, error: {e}")
return None
async def get_file_path(self, media_id: str) -> Optional[Path]:
"""获取媒体文件路径,如果文件不存在则尝试下载或复制"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果有原始路径,直接返回
if metadata.path and Path(metadata.path).exists():
return Path(metadata.path)
# 否则确保文件存在并返回
return await self.ensure_file_exists(media_id)
async def get_data(self, media_id: str) -> Optional[bytes]:
"""获取媒体文件数据"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 尝试从文件读取
file_path = await self.get_file_path(media_id)
if file_path:
try:
async with aiofiles.open(file_path, "rb") as f:
return await f.read()
except Exception as e:
self.logger.error(f"Failed to read media file: {file_path}, error: {e}")
# 尝试从URL下载
if metadata.url:
try:
return await self._download_file_async(metadata.url)
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
return None
async def get_url(self, media_id: str) -> Optional[str]:
"""获取媒体文件URL"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果有原始URL,直接返回
if metadata.url:
return metadata.url
# 尝试生成data URL
data = await self.get_data(media_id)
if data and metadata.media_type and metadata.format:
mime_type = f"{metadata.media_type.value}/{metadata.format}"
return f"data:{mime_type};base64,{base64.b64encode(data).decode()}"
return None
async def get_base64_url(self, media_id: str) -> Optional[str]:
"""获取媒体文件 base64 URL"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
data = await self.get_data(media_id)
if data and metadata.media_type and metadata.format:
mime_type = f"{metadata.media_type.value}/{metadata.format}"
return f"data:{mime_type};base64,{base64.b64encode(data).decode()}"
return None
def search_by_tags(self, tags: List[str], match_all: bool = False) -> List[str]:
"""根据标签搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if match_all:
# 必须匹配所有标签
if all(tag in metadata.tags for tag in tags):
results.append(media_id)
else:
# 匹配任一标签
if any(tag in metadata.tags for tag in tags):
results.append(media_id)
return results
def search_by_description(self, query: str) -> List[str]:
"""根据描述搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.description and query.lower() in metadata.description.lower():
results.append(media_id)
return results
def search_by_source(self, source: str) -> List[str]:
"""根据来源搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.source and source.lower() in metadata.source.lower():
results.append(media_id)
return results
def search_by_type(self, media_type: MediaType) -> List[str]:
"""根据媒体类型搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.media_type == media_type:
results.append(media_id)
return results
def get_all_media_ids(self) -> List[str]:
"""获取所有媒体ID"""
return list(self.metadata_cache.keys())
def cleanup_unreferenced(self) -> int:
"""清理没有引用的媒体文件,返回清理的文件数量"""
count = 0
for media_id, metadata in list(self.metadata_cache.items()):
if not metadata.references:
self.delete_media(media_id)
count += 1
return count
async def create_media_message(self, media_id: str) -> Optional["MediaMessage"]:
"""根据媒体ID创建MediaMessage对象"""
if media_id not in self.metadata_cache:
return None
from kirara_ai.im.message import FileElement, ImageMessage, VideoElement, VoiceMessage
metadata = self.metadata_cache[media_id]
# 根据媒体类型创建不同的MediaMessage子类
if metadata.media_type == MediaType.IMAGE:
return ImageMessage(media_id=media_id)
elif metadata.media_type == MediaType.AUDIO:
return VoiceMessage(media_id=media_id)
elif metadata.media_type == MediaType.VIDEO:
return VideoElement(media_id=media_id)
else:
return FileElement(media_id=media_id)
def get_media(self, media_id: str) -> Optional["Media"]:
"""获取媒体对象"""
if media_id not in self.metadata_cache:
return None
from kirara_ai.media.media_object import Media
return Media(media_id=media_id, media_manager=self)
def __new__(cls, *args, **kwargs) -> "MediaManager":
if not hasattr(cls, "_instance"):
print("new MediaManager")
cls._instance = super(MediaManager, cls).__new__(cls)
return cls._instance
def setup_cleanup_task(self, container: DependencyContainer):
"""设置清理任务"""
config = container.resolve(GlobalConfig)
if self._cleanup_task:
self._cleanup_task.cancel()
if config.media.auto_remove_unreferenced and config.media.cleanup_duration > 0:
duration = config.media.cleanup_duration
async def schedule_cleanup():
while True:
last_cleanup_time = config.media.last_cleanup_time
next_cleanup_time = last_cleanup_time + duration * 24 * 60 * 60
await asyncio.sleep(next_cleanup_time - time.time())
count = self.cleanup_unreferenced()
self.logger.info(f"Cleanup {count} unreferenced media files")
config.media.last_cleanup_time = int(time.time())
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
self._cleanup_task = asyncio.create_task(schedule_cleanup())
================================================
FILE: kirara_ai/media/media_object.py
================================================
import base64
from pathlib import Path
from typing import TYPE_CHECKING, List, Optional
if TYPE_CHECKING:
from kirara_ai.im.message import MediaMessage
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types.media_type import MediaType
class Media:
"""媒体对象,提供更方便的媒体操作接口"""
metadata: MediaMetadata
def __init__(self, media_id: str, media_manager: MediaManager):
"""
初始化媒体对象
Args:
media_id: 媒体ID
"""
self.media_id = media_id
self._manager = media_manager
metadata = self._manager.get_metadata(self.media_id)
assert metadata is not None, f"Media metadata not found for {self.media_id}"
self.metadata = metadata
@property
def media_type(self) -> MediaType:
"""获取媒体类型"""
return self.metadata.media_type
@property
def format(self) -> str:
"""获取媒体格式"""
return self.metadata.format
@property
def size(self) -> Optional[int]:
"""获取媒体大小"""
return self.metadata.size
@property
def description(self) -> Optional[str]:
"""获取媒体描述"""
return self.metadata.description
@description.setter
def description(self, value: str) -> None:
"""设置媒体描述"""
self._manager.update_metadata(self.media_id, description=value)
@property
def tags(self) -> List[str]:
"""获取媒体标签"""
metadata = self.metadata
return metadata.tags if metadata else []
@property
def mime_type(self) -> str:
"""获取媒体 MIME 类型"""
return self.metadata.mime_type
def add_tags(self, tags: List[str]) -> None:
"""添加标签"""
self._manager.add_tags(self.media_id, tags)
def remove_tags(self, tags: List[str]) -> None:
"""移除标签"""
self._manager.remove_tags(self.media_id, tags)
def add_reference(self, reference_id: str) -> None:
"""添加引用"""
self._manager.add_reference(self.media_id, reference_id)
def remove_reference(self, reference_id: str) -> None:
"""移除引用"""
self._manager.remove_reference(self.media_id, reference_id)
async def get_file_path(self) -> Path:
"""获取媒体文件路径"""
path = await self._manager.get_file_path(self.media_id)
assert path is not None, f"Media file path not found for {self.media_id}"
return path
async def get_data(self) -> bytes:
"""获取媒体文件数据"""
data = await self._manager.get_data(self.media_id)
assert data is not None, f"Media data not found for {self.media_id}"
return data
async def get_base64(self) -> str:
"""获取媒体文件 base64 编码"""
data = await self.get_data()
assert data is not None, "Media data is None"
return base64.b64encode(data).decode()
async def get_url(self) -> str:
"""获取媒体文件URL"""
url = await self._manager.get_url(self.media_id)
assert url is not None, f"Media URL not found for {self.media_id}"
return url
async def get_base64_url(self) -> str:
"""获取媒体文件 base64 URL"""
return f"data:{self.mime_type};base64,{await self.get_base64()}"
async def create_message(self) -> "MediaMessage":
"""创建媒体消息对象"""
message = await self._manager.create_media_message(self.media_id)
assert message is not None, f"Media message not found for {self.media_id}"
return message
def __str__(self) -> str:
metadata = self.metadata
if metadata:
return f"Media({metadata.media_id}, type={metadata.media_type}, format={metadata.format})"
return f"Media({self.media_id}, not found)"
def __repr__(self) -> str:
return self.__str__()
================================================
FILE: kirara_ai/media/metadata.py
================================================
from datetime import datetime
from typing import Any, Dict, List, Optional, Set
from kirara_ai.media.types.media_type import MediaType
class MediaMetadata:
"""媒体元数据类"""
def __init__(
self,
media_id: str,
media_type: MediaType,
format: str,
size: Optional[int] = None,
created_at: Optional[datetime] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
references: Optional[Set[str]] = None,
url: Optional[str] = None,
path: Optional[str] = None
):
self.media_id = media_id
self.media_type = media_type
self.format = format
self.size = size
self.created_at = created_at or datetime.now()
self.source = source
self.description = description
self.tags: List[str] = tags or []
self.references: Set[str] = references or set()
self.url = url
self.path = path
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
result = {
"media_id": self.media_id,
"created_at": self.created_at.isoformat(),
"source": self.source,
"description": self.description,
"tags": self.tags,
"references": list(self.references),
}
# 添加可选字段
if self.media_type:
result["media_type"] = self.media_type.value
if self.format:
result["format"] = self.format
if self.size is not None:
result["size"] = self.size
if self.url:
result["url"] = self.url
if self.path:
result["path"] = self.path
return result
@property
def mime_type(self) -> str:
"""获取 MIME 类型"""
return f"{self.media_type.value}/{self.format}"
@classmethod
def from_dict(cls, data: Dict[str, Any]) -> 'MediaMetadata':
"""从字典创建元数据"""
return cls(
media_id=data["media_id"],
media_type=MediaType(data["media_type"]),
format=data["format"],
size=data.get("size"),
created_at=datetime.fromisoformat(data["created_at"]),
source=data.get("source"),
description=data.get("description"),
tags=data.get("tags", []),
references=set(data.get("references", [])),
url=data.get("url"),
path=data.get("path")
)
================================================
FILE: kirara_ai/media/types/__init__.py
================================================
from kirara_ai.media.types.media_type import MediaType
__all__ = ["MediaType"]
================================================
FILE: kirara_ai/media/types/media_type.py
================================================
from enum import Enum
class MediaType(Enum):
"""媒体类型枚举"""
IMAGE = "image"
AUDIO = "audio"
VIDEO = "video"
FILE = "file"
@classmethod
def from_mime(cls, mime_type: str) -> 'MediaType':
"""从MIME类型获取媒体类型"""
main_type = mime_type.split('/')[0]
if main_type == "image":
return cls.IMAGE
elif main_type == "audio":
return cls.AUDIO
elif main_type == "video":
return cls.VIDEO
else:
return cls.FILE
================================================
FILE: kirara_ai/media/utils/__init__.py
================================================
from kirara_ai.media.utils.mime import detect_mime_type, mime_remapping
__all__ = ["detect_mime_type", "mime_remapping"]
================================================
FILE: kirara_ai/media/utils/mime.py
================================================
from typing import Optional, Tuple
import magic
from kirara_ai.media.types.media_type import MediaType
# MIME类型重映射
mime_remapping = {
"audio/mpeg": "audio/mp3",
"audio/x-wav": "audio/wav",
"audio/x-m4a": "audio/m4a",
"audio/x-flac": "audio/flac",
}
def detect_mime_type(data: Optional[bytes] = None, path: Optional[str] = None) -> Tuple[str, MediaType, str]:
"""
检测文件的MIME类型
Args:
data: 文件数据
path: 文件路径
Returns:
Tuple[str, MediaType, str]: (mime_type, media_type, format)
"""
try:
if data is not None:
mime_type = magic.from_buffer(data, mime=True)
elif path is not None:
mime_type = magic.from_file(path, mime=True)
else:
raise ValueError("Must provide either data or path")
except Exception as e:
raise ValueError(f"Failed to detect mime type: {e}") from e
if mime_type in mime_remapping:
mime_type = mime_remapping[mime_type]
media_type = MediaType.from_mime(mime_type)
format = mime_type.split('/')[-1]
return mime_type, media_type, format
================================================
FILE: kirara_ai/memory/composes/__init__.py
================================================
from .base import ComposableMessageType, MemoryComposer, MemoryDecomposer
from .builtin_composes import DefaultMemoryComposer, DefaultMemoryDecomposer, MultiElementDecomposer
from .composer_strategy import MessageProcessor, ProcessorFactory
from .decomposer_strategy import ContentParser, DefaultDecomposerStrategy, MultiElementDecomposerStrategy
from .xml_helper import XMLHelper
__all__ = [
"MemoryComposer",
"MemoryDecomposer",
"DefaultMemoryComposer",
"DefaultMemoryDecomposer",
"MultiElementDecomposer",
"ComposableMessageType",
"XMLHelper",
"ProcessorFactory",
"MessageProcessor",
"ContentParser",
"DefaultDecomposerStrategy",
"MultiElementDecomposerStrategy",
]
================================================
FILE: kirara_ai/memory/composes/base.py
================================================
from abc import ABC, abstractmethod
from typing import List, Optional, Union
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.response import Message
from kirara_ai.memory.entry import MemoryEntry
# 可组合的消息类型
ComposableMessageType = Union[IMMessage, LLMChatMessage, Message, str]
class MemoryComposer(ABC):
"""记忆组合器抽象类"""
container: DependencyContainer
@abstractmethod
def compose(
self, sender: Optional[ChatSender], message: List[ComposableMessageType]
) -> MemoryEntry:
"""将消息转换为记忆条目"""
class MemoryDecomposer(ABC):
"""记忆解析器抽象类"""
container: DependencyContainer
@abstractmethod
def decompose(self, entries: List[MemoryEntry]) -> List[ComposableMessageType]:
"""将记忆条目转换为消息"""
@property
def empty_message(self) -> ComposableMessageType:
"""空记忆消息"""
return "<空记忆>"
================================================
FILE: kirara_ai/memory/composes/builtin_composes.py
================================================
from datetime import datetime
from typing import Any, Dict, List, Optional, Union
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.response import Message
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
from .base import ComposableMessageType, MemoryComposer, MemoryDecomposer
from .composer_strategy import ProcessorFactory
from .decomposer_strategy import DefaultDecomposerStrategy, MultiElementDecomposerStrategy
class DefaultMemoryComposer(MemoryComposer):
def __init__(self):
self.processor_factory = None
def compose(
self, sender: Optional[ChatSender], message: List[ComposableMessageType]
) -> MemoryEntry:
# 延迟初始化,确保 container 已被设置
if self.processor_factory is None:
self.processor_factory = ProcessorFactory(self.container)
composed_message = ""
# 上下文用于在处理过程中传递和收集数据
context: Dict[str, Any] = {
"media_ids": [],
"tool_calls": [],
"tool_results": []
}
for msg in message:
msg_type = type(msg)
processor = self.processor_factory.get_processor(msg_type)
if processor:
composed_message += processor.process(msg, context)
elif isinstance(msg, str):
# 处理字符串消息
composed_message += f"{msg}\n"
composed_message = composed_message.strip()
composed_at = datetime.now()
return MemoryEntry(
sender=sender or ChatSender.get_bot_sender(),
content=composed_message,
timestamp=composed_at,
metadata={
"_media_ids": context.get("media_ids", []),
"_tool_calls": context.get("tool_calls", []),
"_tool_results": context.get("tool_results", []),
},
)
class DefaultMemoryDecomposer(MemoryDecomposer):
def __init__(self):
self.strategy = None
def decompose(self, entries: List[MemoryEntry]) -> List[ComposableMessageType]:
# 延迟初始化,确保 container 已被设置
if self.strategy is None:
self.strategy = DefaultDecomposerStrategy()
# 使用上下文传递参数
context = {
"empty_message": self.empty_message
}
# 使用策略解析记忆条目
return self.strategy.decompose(entries, context)
class MultiElementDecomposer(MemoryDecomposer):
logger = get_logger("MultiElementDecomposer")
def __init__(self):
self.strategy = None
def decompose(self, entries: List[MemoryEntry]) -> List[Union[IMMessage, LLMChatMessage, Message, str]]:
# 延迟初始化,确保 container 已被设置
if self.strategy is None:
self.strategy = MultiElementDecomposerStrategy()
# 使用上下文传递参数
context = {
"logger": self.logger
}
# 使用策略解析记忆条目
return self.strategy.decompose(entries, context)
================================================
FILE: kirara_ai/memory/composes/composer_strategy.py
================================================
from abc import ABC, abstractmethod
from typing import Any, Dict, Optional, Type
import kirara_ai.llm.format.tool as tools
from kirara_ai.im.message import IMMessage, MediaMessage, TextMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import (LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent,
LLMToolResultContent)
from kirara_ai.media.manager import MediaManager
from .xml_helper import XMLHelper
def drop_think_part(text: str) -> str:
"""移除思考部分的文本"""
import re
return re.sub(r"(?:[\s\S]*?)?([\s\S]*)", r"\1", text, flags=re.DOTALL)
class MessageProcessor(ABC):
"""消息处理策略的基类"""
def __init__(self, container: DependencyContainer):
self.container = container
@abstractmethod
def process(self, message: Any, context: Dict) -> str:
"""处理特定类型的消息,返回组合后的文本"""
class TextMessageProcessor(MessageProcessor):
"""处理文本消息的策略"""
def process(self, message: TextMessage, context: Dict) -> str:
return f"{message.to_plain()}\n"
class MediaMessageProcessor(MessageProcessor):
"""处理媒体消息的策略"""
def process(self, message: MediaMessage, context: Dict) -> str:
media_ids = context.setdefault("media_ids", [])
media_ids.append(message.media_id)
desc = message.get_description()
tag = XMLHelper.create_xml_tag("media_msg", {"id": message.media_id, "desc": desc})
return f"{tag}\n"
class LLMChatTextContentProcessor(MessageProcessor):
"""处理LLM文本内容的策略"""
def process(self, content: LLMChatTextContent, context: Dict) -> str:
return f"{drop_think_part(content.text)}\n"
class LLMChatImageContentProcessor(MessageProcessor):
"""处理LLM图像内容的策略"""
def process(self, content: LLMChatImageContent, context: Dict) -> str:
media_ids = context.setdefault("media_ids", [])
media_ids.append(content.media_id)
media_manager = self.container.resolve(MediaManager)
media = media_manager.get_media(content.media_id)
desc = (media.description or "") if media else ""
tag = XMLHelper.create_xml_tag("media_msg", {"id": content.media_id, "desc": desc})
return f"{tag}\n"
class LLMToolCallContentProcessor(MessageProcessor):
"""处理LLM工具调用内容的策略"""
def process(self, content: LLMToolCallContent, context: Dict) -> str:
tool_calls = context.setdefault("tool_calls", [])
tool_calls.append(content.model_dump())
# parameters 比较长,保存到 metadata 里。
tag = XMLHelper.create_xml_tag("function_call", {
"id": content.id,
"name": content.name
})
return f"{tag}\n"
class LLMToolResultContentProcessor(MessageProcessor):
"""处理LLM工具结果内容的策略"""
def process(self, content: LLMToolResultContent, context: Dict) -> str:
tool_results = context.setdefault("tool_results", [])
tool_content = []
for item in content.content:
if isinstance(item, tools.TextContent):
tool_content.append({
"type": "text",
"text": item.text
})
elif isinstance(item, tools.MediaContent):
# 注册 media_id 引用
media_ids = context.setdefault("media_ids", [])
media_ids.append(item.media_id)
tool_content.append({
"type": "media",
"media_id": item.media_id
})
# content 比较长,保存到 metadata 里。
tool_results.append({
"id": content.id,
"name": content.name,
"isError": content.isError,
"content": tool_content
})
tag = XMLHelper.create_xml_tag("tool_result", {
"id": content.id,
"name": content.name,
"isError": str(content.isError)
})
return f"{tag}\n"
class IMMessageProcessor(MessageProcessor):
"""处理IM消息的策略"""
def __init__(self, container: DependencyContainer):
super().__init__(container)
self.element_processors: Dict[Type, MessageProcessor] = {
TextMessage: TextMessageProcessor(container),
MediaMessage: MediaMessageProcessor(container)
}
def process(self, message: IMMessage, context: Dict) -> str:
result = f"{message.sender.display_name} 说: \n"
for element in message.message_elements:
for process_type, processor in self.element_processors.items():
if isinstance(element, process_type):
result += processor.process(element, context)
break
else:
result += f"{element.to_plain()}\n"
return result
class LLMChatMessageProcessor(MessageProcessor):
"""处理LLM聊天消息的策略"""
def __init__(self, container: DependencyContainer):
super().__init__(container)
self.content_processors: Dict[Type, MessageProcessor] = {
LLMChatTextContent: LLMChatTextContentProcessor(container),
LLMChatImageContent: LLMChatImageContentProcessor(container),
LLMToolCallContent: LLMToolCallContentProcessor(container),
LLMToolResultContent: LLMToolResultContentProcessor(container)
}
def process(self, message: LLMChatMessage, context: Dict) -> str:
result = ""
temp = ""
for part in message.content:
part_type = type(part)
for processor_type, processor in self.content_processors.items():
if issubclass(part_type, processor_type):
if part_type in [LLMToolCallContent, LLMToolResultContent]:
# 工具调用和结果直接添加到结果中,不经过temp
result += processor.process(part, context)
else:
# 其他内容添加到temp中
temp += processor.process(part, context)
if temp.strip("\n"):
result += f"你回答: \n{temp}"
return result
class ProcessorFactory:
"""消息处理器工厂,用于创建和管理不同类型消息的处理器"""
def __init__(self, container: DependencyContainer):
self.container = container
self.processors: Dict[Type, MessageProcessor] = {
IMMessage: IMMessageProcessor(container),
LLMChatMessage: LLMChatMessageProcessor(container)
}
def get_processor(self, message_type: Type) -> Optional[MessageProcessor]:
"""获取特定类型消息的处理器"""
for processor_type, processor in self.processors.items():
if issubclass(message_type, processor_type):
return processor
return None
================================================
FILE: kirara_ai/memory/composes/decomposer_strategy.py
================================================
from datetime import datetime, timedelta
from typing import Any, Dict, List, NamedTuple, Protocol, cast
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent, RoleType)
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
from .base import ComposableMessageType
from .xml_helper import XMLHelper
logger = get_logger("DecomposerStrategy")
class ContentInfo(NamedTuple):
"""解析后的内容信息"""
content_type: str # 内容类型:text, media, tool_call, tool_result
start: int # 开始位置
end: int # 结束位置
text: str # 原始文本
metadata: Dict[str, Any] = {} # 相关元数据
class ContentParseStrategy(Protocol):
"""内容解析策略协议"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
"""提取内容信息"""
...
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
"""转换为LLM内容类型"""
...
def to_text(self, info: ContentInfo) -> str:
"""转换为文本形式"""
...
class TextContentStrategy:
"""文本内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
# 提取非标签文本
text_parts = []
current_pos = 0
# 查找所有标签的位置
tag_positions = []
for tag_name in ["media_msg", "function_call", "tool_result"]:
for _, start, end in XMLHelper.parse_xml_tag(content, tag_name):
tag_positions.append((start, end))
# 按位置排序
tag_positions.sort()
# 提取标签之间的文本
for start, end in tag_positions:
if start > current_pos:
text = content[current_pos:start].strip()
if text:
text_parts.append(ContentInfo(
content_type="text",
start=current_pos,
end=start,
text=text
))
current_pos = end
# 处理最后一段文本
if current_pos < len(content):
text = content[current_pos:].strip()
if text:
text_parts.append(ContentInfo(
content_type="text",
start=current_pos,
end=len(content),
text=text
))
return text_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMChatTextContent(text=info.text)
def to_text(self, info: ContentInfo) -> str:
return info.text
class MediaContentStrategy:
"""媒体内容解析策略"""
def __init__(self):
pass
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
media_parts = []
media_tags = XMLHelper.parse_xml_tag(content, "media_msg")
for attrs, start, end in media_tags:
if "id" in attrs and attrs["id"] is not None:
media_id = attrs["id"]
# 检查媒体ID是否在元数据中
if "_media_ids" in entry.metadata and media_id in entry.metadata["_media_ids"]:
media_parts.append(ContentInfo(
content_type="media",
start=start,
end=end,
text=content[start:end],
metadata={"media_id": media_id}
))
return media_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMChatImageContent(media_id=info.metadata["media_id"])
def to_text(self, info: ContentInfo) -> str:
return f""
class ToolCallContentStrategy:
"""工具调用内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
tool_call_parts = []
tool_call_tags = XMLHelper.parse_xml_tag(content, "function_call")
if "_tool_calls" not in entry.metadata:
return []
tool_calls = [call for call in entry.metadata["_tool_calls"]]
for attrs, start, end in tool_call_tags:
if "id" in attrs and attrs["id"] is not None:
call_id = attrs["id"]
# 查找对应的工具调用数据
for call in tool_calls:
if call.get("id") == call_id:
tool_call_parts.append(ContentInfo(
content_type="tool_call",
start=start,
end=end,
text=content[start:end],
metadata=call
))
break
return tool_call_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMToolCallContent.model_validate(info.metadata)
def to_text(self, info: ContentInfo) -> str:
return f""
class ToolResultContentStrategy:
"""工具结果内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
tool_result_parts = []
tool_result_tags = XMLHelper.parse_xml_tag(content, "tool_result")
if "_tool_results" not in entry.metadata:
return []
tool_results = [result for result in entry.metadata["_tool_results"]]
for attrs, start, end in tool_result_tags:
if "id" in attrs and attrs["id"] is not None:
result_id = attrs["id"]
# 查找对应的工具结果数据
for result in tool_results:
if result.get("id") == result_id:
tool_result_parts.append(ContentInfo(
content_type="tool_result",
start=start,
end=end,
text=content[start:end],
metadata=result
))
break
return tool_result_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMToolResultContent.model_validate(info.metadata)
def to_text(self, info: ContentInfo) -> str:
return f""
class ContentParser:
"""内容解析器,整合各种内容处理策略"""
def __init__(self):
self.strategies: Dict[str, ContentParseStrategy] = {
"text": TextContentStrategy(),
"media": MediaContentStrategy(),
"tool_call": ToolCallContentStrategy(),
"tool_result": ToolResultContentStrategy()
}
def parse_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
"""解析内容,返回按位置排序的内容信息列表"""
all_content = []
# 使用所有策略提取内容
for strategy in self.strategies.values():
all_content.extend(strategy.extract_content(content, entry))
# 按位置排序
return sorted(all_content, key=lambda x: x.start)
def to_llm_message(self, content_infos: List[ContentInfo], role: RoleType) -> List[LLMChatMessage]:
"""将内容信息转换为LLM消息"""
if not content_infos:
return []
messages: List[LLMChatMessage] = []
current_content: List[LLMChatContentPartType] = []
current_role: RoleType = role
for info in content_infos:
strategy = self.strategies.get(info.content_type)
if not strategy:
continue
# 对于工具调用和工具结果,创建单独的消息
if info.content_type == "tool_call":
# 如果之前有普通内容,先创建一个消息
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
current_content = []
# 创建工具调用消息
messages.append(LLMChatMessage(
role="assistant",
content=[strategy.to_llm_content(info)]
))
elif info.content_type == "tool_result":
# 如果之前有普通内容,先创建一个消息
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
current_content = []
# 创建工具结果消息
messages.append(LLMChatMessage(
role="tool",
content=[strategy.to_llm_content(info)]
))
else:
# 普通内容就近拼接
current_content.append(strategy.to_llm_content(info))
# 处理剩余的普通内容
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
return messages
def to_text(self, content_infos: List[ContentInfo]) -> str:
"""将内容信息转换为文本形式"""
text_parts = []
for info in content_infos:
strategy = self.strategies.get(info.content_type)
if strategy:
text_parts.append(strategy.to_text(info))
return "".join(text_parts)
class DefaultDecomposerStrategy:
"""默认解析策略,将记忆条目转换为文本格式"""
def __init__(self):
self.content_parser = ContentParser()
def decompose(self, entries: List[MemoryEntry], context: Dict[str, Any]) -> List[ComposableMessageType]:
if not entries:
return [context.get("empty_message", "<空记忆>")]
# 限制最近的条目数量
entries = entries[-10:]
result: List[ComposableMessageType] = []
for entry in entries:
time_diff = datetime.now() - entry.timestamp
time_str = self._get_time_str(time_diff)
# 解析记忆条目
content = entry.content or ""
message_parts = []
if content:
if "你回答:" in content:
# 包含用户消息和AI回答
parts = content.split("你回答:", 1)
user_content = parts[0].strip()
assistant_content = parts[1].strip() if len(parts) > 1 else None
# 处理用户消息
if user_content:
content_infos = self.content_parser.parse_content(user_content, entry)
message_parts.append(self.content_parser.to_text(content_infos))
# 处理AI回答
if assistant_content:
content_infos = self.content_parser.parse_content(assistant_content, entry)
message_parts.append(f"你回答: {self.content_parser.to_text(content_infos)}")
else:
# 纯用户消息
content_infos = self.content_parser.parse_content(content, entry)
message_parts.append(self.content_parser.to_text(content_infos))
# 组合所有部分
result.append(f"{time_str},{''.join(message_parts)}")
return result
def _get_time_str(self, time_diff: timedelta) -> str:
"""获取时间差的字符串表示"""
if time_diff.days > 0:
return f"{time_diff.days}天前"
elif time_diff.seconds > 3600:
return f"{time_diff.seconds // 3600}小时前"
elif time_diff.seconds > 60:
return f"{time_diff.seconds // 60}分钟前"
else:
return "刚刚"
class MultiElementDecomposerStrategy:
"""多元素解析策略,将记忆条目还原为原始对象结构"""
def __init__(self):
self.content_parser = ContentParser()
def decompose(self, entries: List[MemoryEntry], context: Dict[str, Any]) -> List[ComposableMessageType]:
result: List[LLMChatMessage] = []
# 处理每个记忆条目
for entry in entries:
messages = self._process_entry(entry)
result.extend(messages)
# 合并相邻的相同角色消息
self._merge_adjacent_messages(result)
# 转换为ComposableMessageType类型返回
return cast(List[ComposableMessageType], result)
def _process_entry(self, entry: MemoryEntry) -> List[LLMChatMessage]:
"""处理单个记忆条目,按照内容顺序解析"""
result: List[LLMChatMessage] = []
content = entry.content or ""
if not content:
return result
if "你回答:" in content:
# 包含用户消息和AI回答
parts = content.split("你回答:", 1)
user_content = parts[0].strip()
assistant_content = parts[1].strip() if len(parts) > 1 else None
# 处理用户消息
if user_content:
content_infos = self.content_parser.parse_content(user_content, entry)
user_message = self.content_parser.to_llm_message(content_infos, "user")
if user_message:
result.extend(user_message)
# 处理AI回答
if assistant_content:
content_infos = self.content_parser.parse_content(assistant_content, entry)
assistant_message = self.content_parser.to_llm_message(content_infos, "assistant")
if assistant_message:
result.extend(assistant_message)
else:
# 纯用户消息
content_infos = self.content_parser.parse_content(content, entry)
user_message = self.content_parser.to_llm_message(content_infos, "user")
if user_message:
result.extend(user_message)
return result
def _merge_adjacent_messages(self, messages: List[LLMChatMessage]) -> None:
"""
合并相邻的相同角色消息
只处理 user 和 assistant 类型, 其他类型不处理
"""
i = 0
while i < len(messages) - 1:
current_msg = messages[i]
next_msg = messages[i + 1]
if (current_msg.role == next_msg.role and
current_msg.role in ["user", "assistant"]):
# 合并内容
current_msg.content.extend(next_msg.content)
# 删除下一个消息
messages.pop(i + 1)
else:
i += 1
================================================
FILE: kirara_ai/memory/composes/xml_helper.py
================================================
import re
from typing import Dict, List, Optional, Tuple
class XMLHelper:
"""XML 格式化和解析的辅助工具类"""
@staticmethod
def escape_xml_attr(text: str) -> str:
"""转义XML属性中的特殊字符"""
if not isinstance(text, str):
text = str(text)
return text.replace("&", "&").replace("\"", """).replace("<", "<").replace(">", ">")
@staticmethod
def unescape_xml_attr(text: str) -> str:
"""反转义XML属性中的特殊字符"""
return text.replace(""", "\"").replace("<", "<").replace(">", ">").replace("&", "&")
@staticmethod
def create_xml_tag(tag_name: str, attributes: Dict[str, Optional[str]], self_closing: bool = True) -> str:
"""创建XML标签,支持 null safety(None 值的属性将被忽略)"""
attrs_str = " ".join([f'{k}="{XMLHelper.escape_xml_attr(v)}"' for k, v in attributes.items() if v is not None])
if self_closing:
return f"<{tag_name} {attrs_str} />"
else:
return f"<{tag_name} {attrs_str}>"
@staticmethod
def parse_xml_tag(content: str, tag_name: str) -> List[Tuple[Dict[str, Optional[str]], int, int]]:
"""解析XML标签,返回属性字典和标签在原文中的起始、结束位置
如果属性在标签中不存在,则在返回的字典中该属性值为 None
"""
pattern = re.compile(f'<{tag_name}\\s+(.*?)\\s*/>')
attr_pattern = re.compile(r'(\w+)="(.*?)"')
results: List[Tuple[Dict[str, Optional[str]], int, int]] = []
for match in pattern.finditer(content):
attrs_text = match.group(1)
attrs: Dict[str, Optional[str]] = {name: XMLHelper.unescape_xml_attr(value) for name, value in attr_pattern.findall(attrs_text)}
results.append((attrs, match.start(), match.end()))
return results
@staticmethod
def get_attr(attrs: Dict[str, Optional[str]], key: str, default: Optional[str] = None) -> Optional[str]:
"""安全地从属性字典中获取值,如果不存在则返回默认值"""
return attrs.get(key, default)
================================================
FILE: kirara_ai/memory/entry.py
================================================
from dataclasses import dataclass, field
from datetime import datetime
from typing import Any, Dict
from kirara_ai.im.sender import ChatSender
@dataclass
class MemoryEntry:
"""基础记忆条目"""
sender: ChatSender
content: str
timestamp: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
================================================
FILE: kirara_ai/memory/memory_manager.py
================================================
from typing import Dict, List, Optional, Type
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.media.carrier import MediaReferenceProvider
from kirara_ai.media.carrier.service import MediaCarrierService
from kirara_ai.memory.persistences.base import AsyncMemoryPersistence, MemoryPersistence
from kirara_ai.memory.persistences.file_persistence import FileMemoryPersistence
from kirara_ai.memory.persistences.redis_persistence import RedisMemoryPersistence
from .composes import MemoryComposer, MemoryDecomposer
from .entry import MemoryEntry
from .registry import ComposerRegistry, DecomposerRegistry, ScopeRegistry
from .scopes import MemoryScope
class MemoryManager(MediaReferenceProvider[List[MemoryEntry]]):
"""记忆系统管理器,负责整个记忆系统的生命周期管理"""
def __init__(
self,
container: DependencyContainer,
persistence: Optional[MemoryPersistence] = None,
):
self.container = container
self.config = container.resolve(GlobalConfig).memory
# 初始化注册表
self.scope_registry = Inject(container).create(ScopeRegistry)()
self.composer_registry = Inject(container).create(ComposerRegistry)()
self.decomposer_registry = Inject(container).create(DecomposerRegistry)()
# 注册到容器
container.register(ScopeRegistry, self.scope_registry)
container.register(ComposerRegistry, self.composer_registry)
container.register(DecomposerRegistry, self.decomposer_registry)
# 初始化持久化层
if persistence is None:
self._init_persistence()
else:
self.persistence = persistence
# 内存缓存
self.memories: Dict[str, List[MemoryEntry]] = {}
def _init_persistence(self):
"""初始化持久化层"""
persistence_type = self.config.persistence.type
if persistence_type == "file":
storage_dir = self.config.persistence.file["storage_dir"]
self.persistence = FileMemoryPersistence(storage_dir)
elif persistence_type == "redis":
redis_config = self.config.persistence.redis
self.persistence = RedisMemoryPersistence(**redis_config)
else:
raise ValueError(f"Unsupported persistence type: {persistence_type}")
self.persistence = AsyncMemoryPersistence(self.persistence)
def register_scope(self, name: str, scope_class: Type[MemoryScope]):
"""注册新的作用域类型"""
self.scope_registry.register(name, scope_class)
def register_composer(self, name: str, composer_class: Type[MemoryComposer]):
"""注册新的组合器"""
self.composer_registry.register(name, composer_class)
def register_decomposer(self, name: str, decomposer_class: Type[MemoryDecomposer]):
"""注册新的解析器"""
self.decomposer_registry.register(name, decomposer_class)
def store(self, scope: MemoryScope, entry: MemoryEntry, extra_identifier: Optional[str] = None) -> None:
"""存储新的记忆"""
scope_key = scope.get_scope_key(entry.sender)
if extra_identifier is not None:
scope_key = f"{extra_identifier}-{scope_key}"
if scope_key not in self.memories:
self.memories[scope_key] = self.persistence.load(scope_key)
self.memories[scope_key].append(entry)
self._register_media_reference(entry, scope_key)
# 限制记忆条目数量
if len(self.memories[scope_key]) > self.config.max_entries:
# 移除旧记忆的媒体引用
removed_entries = self.memories[scope_key][:-self.config.max_entries]
unremoved_entries = self.memories[scope_key][-self.config.max_entries:]
self._remove_media_references(removed_entries, unremoved_entries, scope_key)
# 裁剪记忆列表
self.memories[scope_key] = unremoved_entries
self.persistence.save(scope_key, self.memories[scope_key])
def query(self, scope: MemoryScope, sender: ChatSender, extra_identifier: Optional[str] = None) -> List[MemoryEntry]:
"""查询历史记忆"""
relevant_memories = []
scope_key = scope.get_scope_key(sender)
if extra_identifier is not None:
scope_key = f"{extra_identifier}-{scope_key}"
if scope_key not in self.memories:
self.memories[scope_key] = self.persistence.load(scope_key)
# 遍历所有记忆,找出作用域内的记忆
for scope_key, entries in self.memories.items():
for entry in entries:
if scope.is_in_scope(entry.sender, sender):
relevant_memories.append(entry)
# 按时间排序
relevant_memories.sort(key=lambda x: x.timestamp)
return relevant_memories
def shutdown(self):
"""关闭记忆系统,确保数据持久化"""
# 保存所有内存中的数据
for scope_key, entries in self.memories.items():
self.persistence.save(scope_key, entries)
# 执行持久化层的stop操作
if isinstance(self.persistence, AsyncMemoryPersistence):
self.persistence.stop()
def clear_memory(self, scope: MemoryScope, sender: ChatSender) -> None:
"""清空指定作用域和发送者的记忆
Args:
scope: 记忆作用域
sender: 发送者标识
"""
scope_key = scope.get_scope_key(sender)
# 移除媒体引用
if scope_key not in self.memories:
return
self._remove_media_references(self.memories[scope_key], [], scope_key)
# 清空内存中的记录
self.memories[scope_key] = []
# 保存空记录到持久化层
self.persistence.save(scope_key, [])
def get_reference_owner(self, reference_key: str) -> Optional[List[MemoryEntry]]:
"""获取引用所有者"""
if reference_key not in self.memories:
self.memories[reference_key] = self.persistence.load(reference_key)
return self.memories.get(reference_key)
def _register_media_reference(self, entry: MemoryEntry, reference_key: str) -> None:
"""注册媒体引用"""
media_carrier = self.container.resolve(MediaCarrierService)
for media_id in entry.metadata.get("_media_ids", []):
media_carrier.register_reference(media_id, "memory", reference_key)
def _remove_media_references(self, removed_entries: List[MemoryEntry], unremoved_entries: List[MemoryEntry], reference_key: str) -> None:
"""移除媒体引用"""
media_carrier = self.container.resolve(MediaCarrierService)
# 确保 id 没有在 unremoved_entries 中
removed_media_ids = [media_id for entry in removed_entries for media_id in entry.metadata.get("_media_ids", [])]
unremoved_media_ids = [media_id for entry in unremoved_entries for media_id in entry.metadata.get("_media_ids", [])]
for media_id in removed_media_ids:
if media_id not in unremoved_media_ids:
media_carrier.remove_reference(media_id, "memory", reference_key)
================================================
FILE: kirara_ai/memory/persistences/__init__.py
================================================
from .base import AsyncMemoryPersistence, MemoryPersistence
from .file_persistence import FileMemoryPersistence
from .redis_persistence import RedisMemoryPersistence
__all__ = [
"MemoryPersistence",
"AsyncMemoryPersistence",
"FileMemoryPersistence",
"RedisMemoryPersistence",
"codecs",
]
================================================
FILE: kirara_ai/memory/persistences/base.py
================================================
import threading
from abc import ABC, abstractmethod
from queue import Empty, Queue
from typing import List, Tuple
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
class MemoryPersistence(ABC):
"""持久化层抽象类"""
@abstractmethod
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
pass
@abstractmethod
def load(self, scope_key: str) -> List[MemoryEntry]:
pass
@abstractmethod
def flush(self) -> None:
"""确保所有数据都已持久化"""
logger = get_logger("MemoryPersistence")
class AsyncMemoryPersistence:
"""异步持久化管理器"""
def __init__(self, persistence: MemoryPersistence):
self.persistence = persistence
self.queue: Queue[Tuple[str, List[MemoryEntry]]] = Queue()
self.running = True
self.worker = threading.Thread(target=self._worker, daemon=True)
self.worker.start()
def _worker(self):
while self.running:
try:
scope_key, entries = self.queue.get(timeout=1)
self.persistence.save(scope_key, entries)
self.queue.task_done()
logger.info(f"Saved {scope_key} with {len(entries)} entries")
except Empty:
continue
except Exception as e:
logger.error(f"Error saving memory: {e}")
continue
def load(self, scope_key: str) -> List[MemoryEntry]:
return self.persistence.load(scope_key)
def save(self, scope_key: str, entries: List[MemoryEntry]):
self.queue.put((scope_key, entries))
def stop(self):
self.running = False
self.worker.join()
self.persistence.flush()
================================================
FILE: kirara_ai/memory/persistences/codecs.py
================================================
import json
from datetime import datetime
from types import FunctionType
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
class MemoryJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, ChatSender):
return {
"__type__": "ChatSender",
"user_id": obj.user_id,
"chat_type": obj.chat_type.value,
"group_id": obj.group_id,
"display_name": obj.display_name,
"raw_metadata": obj.raw_metadata,
}
elif isinstance(obj, ChatType):
return obj.value
elif isinstance(obj, datetime):
return obj.isoformat()
elif isinstance(obj, FunctionType):
return {
"__type__": "function",
"name": obj.__name__,
"args": obj.__code__.co_varnames[:obj.__code__.co_argcount],
"defaults": obj.__defaults__,
"kwdefaults": obj.__kwdefaults__,
"doc": obj.__doc__,
}
try:
return super().default(obj)
except Exception as e:
get_logger("MemoryJSONEncoder").warning(f"failed to encode object: {e}")
return None
def memory_json_decoder(obj):
if "__type__" in obj:
if obj["__type__"] == "ChatSender":
return ChatSender(
user_id=obj["user_id"],
chat_type=ChatType(obj["chat_type"]),
group_id=obj["group_id"],
display_name=obj["display_name"],
raw_metadata=obj["raw_metadata"],
)
return obj
================================================
FILE: kirara_ai/memory/persistences/file_persistence.py
================================================
import json
import os
from datetime import datetime
from typing import List
from kirara_ai.memory.entry import MemoryEntry
from .base import MemoryPersistence
from .codecs import MemoryJSONEncoder, memory_json_decoder
class FileMemoryPersistence(MemoryPersistence):
"""文件持久化实现"""
def __init__(self, data_dir: str):
if not os.path.isabs(data_dir):
data_dir = os.path.abspath(data_dir)
self.data_dir = data_dir
os.makedirs(data_dir, exist_ok=True)
def _get_file_path(self, scope_key: str) -> str:
scope_key = scope_key.replace(":", "_")
return os.path.join(self.data_dir, f"{scope_key}.json")
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
file_path = self._get_file_path(scope_key)
# 序列化记忆条目
serialized_entries = [
{
"sender": entry.sender,
"content": entry.content,
"timestamp": entry.timestamp,
"metadata": entry.metadata,
}
for entry in entries
]
# 写入文件
with open(file_path, "w", encoding="utf-8") as f:
json.dump(
serialized_entries,
f,
ensure_ascii=False,
indent=2,
cls=MemoryJSONEncoder,
)
def load(self, scope_key: str) -> List[MemoryEntry]:
file_path = self._get_file_path(scope_key)
if not os.path.exists(file_path):
return []
# 读取并反序列化
with open(file_path, "r", encoding="utf-8") as f:
serialized_entries = json.load(f, object_hook=memory_json_decoder)
return [
MemoryEntry(
sender=entry["sender"],
content=entry["content"],
timestamp=(
datetime.fromisoformat(entry["timestamp"])
if isinstance(entry["timestamp"], str)
else entry["timestamp"]
),
metadata=entry["metadata"],
)
for entry in serialized_entries
]
def flush(self) -> None:
# 文件系统实现不需要特别的flush操作
pass
================================================
FILE: kirara_ai/memory/persistences/redis_persistence.py
================================================
import json
from datetime import datetime
from typing import List, Optional
from kirara_ai.memory.entry import MemoryEntry
from .base import MemoryPersistence
from .codecs import MemoryJSONEncoder, memory_json_decoder
class RedisMemoryPersistence(MemoryPersistence):
"""Redis持久化实现"""
def __init__(
self,
redis_url: Optional[str] = None,
host: str = "localhost",
port: int = 6379,
db: int = 0,
):
import redis
if redis_url:
self.redis = redis.from_url(redis_url)
else:
self.redis = redis.Redis(host=host, port=port, db=db)
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
# 序列化记忆条目
serialized_entries = [
{
"sender": entry.sender,
"content": entry.content,
"timestamp": entry.timestamp,
"metadata": entry.metadata,
}
for entry in entries
]
# 存储到Redis
self.redis.set(
scope_key,
json.dumps(serialized_entries, ensure_ascii=False, cls=MemoryJSONEncoder),
)
def load(self, scope_key: str) -> List[MemoryEntry]:
# 从Redis读取
data = self.redis.get(scope_key)
if not data:
return []
# 反序列化
serialized_entries = json.loads(data, object_hook=memory_json_decoder) # type: ignore
return [
MemoryEntry(
sender=entry["sender"],
content=entry["content"],
timestamp=(
datetime.fromisoformat(entry["timestamp"])
if isinstance(entry["timestamp"], str)
else entry["timestamp"]
),
metadata=entry["metadata"],
)
for entry in serialized_entries
]
def flush(self) -> None:
self.redis.save()
================================================
FILE: kirara_ai/memory/registry.py
================================================
from typing import Dict, Type
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.memory.composes import MemoryComposer, MemoryDecomposer
from kirara_ai.memory.scopes import MemoryScope
class Registry:
"""基础注册表类"""
container: DependencyContainer
_registry: Dict[str, Type] = dict()
def __init__(self, container: DependencyContainer):
self.container = container
self._registry = dict()
def register(self, name: str, cls: Type) -> None:
"""注册一个新的实现"""
self._registry[name] = cls
def unregister(self, name: str) -> None:
"""注销一个实现"""
if name in self._registry:
del self._registry[name]
class ScopeRegistry(Registry):
"""作用域注册表"""
def get_scope(self, name: str) -> MemoryScope:
"""获取作用域实例"""
if name not in self._registry:
raise ValueError(f"Scope not found: {name}")
return Inject(self.container).create(self._registry[name])()
class ComposerRegistry(Registry):
"""组合器注册表"""
def get_composer(self, name: str) -> MemoryComposer:
"""获取组合器实例"""
if name not in self._registry:
raise ValueError(f"Composer not found: {name}")
return Inject(self.container).create(self._registry[name])()
class DecomposerRegistry(Registry):
"""解析器注册表"""
def get_decomposer(self, name: str) -> MemoryDecomposer:
"""获取解析器实例"""
if name not in self._registry:
raise ValueError(f"Decomposer not found: {name}")
return Inject(self.container).create(self._registry[name])()
================================================
FILE: kirara_ai/memory/scopes/__init__.py
================================================
from .base import MemoryScope
from .builtin_scopes import GlobalScope, GroupScope, MemberScope
__all__ = ["MemoryScope", "MemberScope", "GroupScope", "GlobalScope"]
================================================
FILE: kirara_ai/memory/scopes/base.py
================================================
from abc import ABC, abstractmethod
from kirara_ai.im.sender import ChatSender
class MemoryScope(ABC):
"""记忆作用域抽象类"""
@abstractmethod
def get_scope_key(self, sender: ChatSender) -> str:
"""获取作用域的键值"""
@abstractmethod
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
"""判断是否在作用域内"""
================================================
FILE: kirara_ai/memory/scopes/builtin_scopes.py
================================================
from kirara_ai.im.sender import ChatSender, ChatType
from .base import MemoryScope
# 默认实现
class MemberScope(MemoryScope):
"""群成员作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
if sender.chat_type == ChatType.GROUP:
return f"member:{sender.group_id}:{sender.user_id}"
else:
return f"c2c:{sender.user_id}"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
if target_sender.chat_type != query_sender.chat_type:
return False
if target_sender.chat_type == ChatType.GROUP:
return (
target_sender.group_id == query_sender.group_id
and target_sender.user_id == query_sender.user_id
)
else:
return target_sender.user_id == query_sender.user_id
class GroupScope(MemoryScope):
"""群作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
if sender.chat_type == ChatType.GROUP:
return f"group:{sender.group_id}"
else:
return f"c2c:{sender.user_id}"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
if target_sender.chat_type != query_sender.chat_type:
return False
if target_sender.chat_type == ChatType.GROUP:
return target_sender.group_id == query_sender.group_id
else:
return target_sender.user_id == query_sender.user_id
class GlobalScope(MemoryScope):
"""全局作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
return "global"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
return True
================================================
FILE: kirara_ai/plugin_manager/models.py
================================================
from typing import Any, Dict, Optional
from pydantic import BaseModel
class PluginInfo(BaseModel):
"""插件信息"""
name: str
package_name: Optional[str] = None # 外部插件的包名
description: str
version: str
author: str
is_internal: bool # 是否为内部插件
is_enabled: bool # 是否启用
requires_restart: bool = False # 是否需要重启
metadata: Optional[Dict[str, Any]] = None
================================================
FILE: kirara_ai/plugin_manager/plugin.py
================================================
from abc import ABC, abstractmethod
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
class Plugin(ABC):
"""
插件基类。
外部插件需要在 setup.py 中注册 entry_points:
setup(
name='your-plugin-name',
...
entry_points={
'chatgpt_mirai.plugins': [
'plugin_name = your_package.module:PluginClass'
]
}
)
"""
ENTRY_POINT_GROUP = "chatgpt_mirai.plugins"
event_bus: EventBus
workflow_dispatcher: WorkflowDispatcher
llm_registry: LLMBackendRegistry
im_registry: IMRegistry
im_manager: IMManager
@abstractmethod
def on_load(self):
pass
@abstractmethod
def on_start(self):
pass
@abstractmethod
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugin_manager/plugin_event_bus.py
================================================
from typing import Callable, List, Type
from kirara_ai.events.event_bus import EventBus
class PluginEventBus:
def __init__(self, event_bus: EventBus):
self._event_bus = event_bus
self._registered_listeners: List[Callable] = [] # 记录注册过的函数
def register(self, event_type: Type, listener: Callable):
self._event_bus.register(event_type, listener)
self._registered_listeners.append(listener) # 记录注册的函数
def unregister(self, event_type: Type, listener: Callable):
self._event_bus.unregister(event_type, listener)
def post(self, event):
self._event_bus.post(event)
def unregister_all(self):
"""反注册所有通过 @Event 注册的函数"""
for listener in self._registered_listeners:
for event_type in self._event_bus._listeners:
if listener in self._event_bus._listeners[event_type]:
self._event_bus.unregister(event_type, listener)
self._registered_listeners.clear() # 清空记录
================================================
FILE: kirara_ai/plugin_manager/plugin_loader.py
================================================
import asyncio
import importlib
import os
import sys
from typing import Dict, List, Optional, Type
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.plugin import PluginLoaded, PluginStarted, PluginStopped
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.models import PluginInfo
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.plugin_manager.plugin_event_bus import PluginEventBus
class PluginLoader:
def __init__(self, container: DependencyContainer, plugin_dir: str):
self.plugins: Dict[str, Plugin] = {} # 存储插件实例
self.plugin_infos: Dict[str, PluginInfo] = {} # 存储插件信息
self.container = container
self.logger = get_logger("PluginLoader")
self._loaded_entry_points: set[str] = set() # 记录已加载的entry points
self.plugin_dir = plugin_dir
self.internal_plugins: List[str] = []
self.config = self.container.resolve(GlobalConfig)
self.event_bus = self.container.resolve(EventBus)
def register_plugin(self, plugin_class: Type[Plugin], plugin_name: Optional[str] = None):
"""注册一个插件类,主要用于测试"""
plugin = self.instantiate_plugin(plugin_class)
key = plugin_name or plugin_class.__name__
self.plugins[key] = plugin
# 创建并存储插件信息
plugin_info = PluginInfo(
name=plugin_class.__name__,
package_name=plugin_name,
description=plugin_class.__doc__ or "",
version="1.0.0",
author="Test",
is_internal=True,
is_enabled=True,
metadata=getattr(plugin, "metadata", None),
)
self.plugin_infos[key] = plugin_info
self.logger.info(f"Registered test plugin: {key}")
return plugin
def discover_internal_plugins(self, plugin_dir=None):
"""Discovers and loads internal plugins from a specified directory.
Scans the given directory for subdirectories and attempts to load each as a plugin.
Args:
plugin_dir (str): Path to the directory containing plugin subdirectories.
"""
if not plugin_dir:
plugin_dir = self.plugin_dir
self.logger.info(f"Discovering internal plugins from directory: {plugin_dir}")
sys.path.append(plugin_dir)
for plugin_name in os.listdir(plugin_dir):
plugin_path = os.path.join(plugin_dir, plugin_name)
if os.path.isdir(plugin_path):
self.internal_plugins.append(plugin_name)
self.logger.debug(f"Found plugin directory: {plugin_name}")
self.load_plugin(plugin_name)
def load_plugin(self, plugin_name: str):
"""加载插件,支持内部插件和外部插件"""
self.logger.info(f"Loading plugin: {plugin_name}")
try:
if plugin_name in self.internal_plugins: # 内部插件
self._load_internal_plugin(plugin_name)
else: # 外部插件
self._load_external_plugin(plugin_name)
except Exception as e:
self.logger.error(f"Failed to load plugin {plugin_name}: {e}")
def _load_internal_plugin(self, plugin_name: str):
"""加载内部插件"""
module = importlib.import_module(plugin_name)
plugin_classes = [
cls
for cls in module.__dict__.values()
if isinstance(cls, type) and issubclass(cls, Plugin) and cls != Plugin
]
if not plugin_classes:
raise ValueError(f"No valid plugin class found in module {plugin_name}")
plugin_class = plugin_classes[0]
plugin = self.instantiate_plugin(plugin_class)
self.plugins[plugin_name] = plugin
# 创建并存储插件信息
plugin_info = PluginInfo(
name=plugin_class.__name__,
description=plugin_class.__doc__ or "",
version="1.0.0",
author="Internal",
is_internal=True,
is_enabled=True,
metadata=getattr(plugin, "metadata", None),
)
self.plugin_infos[plugin_name] = plugin_info
self.logger.info(f"Internal plugin {plugin_name} loaded successfully")
return plugin
def _load_external_plugin(self, plugin_name: str):
"""加载外部插件"""
from importlib import reload
from importlib.metadata import entry_points
# 获取插件的 entry point
eps = entry_points(group=Plugin.ENTRY_POINT_GROUP)
plugin_ep = next((ep for ep in eps if ep.name == plugin_name), None)
if not plugin_ep:
raise ValueError(f"Unable to find entry point for plugin {plugin_name}")
try:
# 尝试重新加载 module
if plugin_ep.module in sys.modules:
module = sys.modules[plugin_ep.module]
self.logger.info(f"Reloading plugin {plugin_name} from {plugin_ep.module}")
reload(module)
except Exception as e:
self.logger.error(f"Failed to reload plugin {plugin_name}: {e}")
try:
# 加载插件类
plugin_class = plugin_ep.load()
# 检查插件类是否继承自 Plugin
if not issubclass(plugin_class, Plugin):
raise TypeError(
f"Plugin {plugin_name} must inherit from the Plugin class"
)
# 实例化插件并启动
plugin: Plugin = self.instantiate_plugin(plugin_class)
self.plugins[plugin_name] = plugin
self.logger.info(f"Successfully loaded external plugin: {plugin_name}")
return plugin
except Exception as e:
self.logger.error(f"Failed to load external plugin {plugin_name}: {e}")
raise
def instantiate_plugin(self, plugin_class):
"""Instantiates a plugin class using dependency injection."""
self.logger.debug(f"Instantiating plugin class: {plugin_class.__name__}")
event_bus = self.container.resolve(EventBus)
with self.container.scoped() as scoped_container:
scoped_container.register(EventBus, PluginEventBus(event_bus))
return Inject(scoped_container).create(plugin_class)()
def load_plugins(self):
"""Initializes all loaded plugins."""
self.logger.info("Initializing plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_load()
self.logger.info(f"Plugin {plugin.__class__.__name__} initialized")
self.event_bus.post(PluginLoaded(plugin))
except Exception as e:
self.logger.error(
f"Failed to initialize plugin {plugin.__class__.__name__}: {e}"
)
def start_plugins(self):
"""Starts all loaded plugins."""
self.logger.info("Starting plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_start()
self.plugin_infos[plugin_name].is_enabled = True
self.logger.info(f"Plugin {plugin.__class__.__name__} started")
self.event_bus.post(PluginStarted(plugin))
except Exception as e:
self.logger.error(
f"Failed to start plugin {plugin.__class__.__name__}: {e}"
)
def stop_plugins(self):
"""Stops all loaded plugins."""
self.logger.info("Stopping plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_stop()
if isinstance(plugin.event_bus, PluginEventBus):
plugin.event_bus.unregister_all()
self.logger.info(f"Plugin {plugin.__class__.__name__} stopped")
self.event_bus.post(PluginStopped(plugin))
except Exception as e:
self.logger.error(
f"Failed to stop plugin {plugin.__class__.__name__}: {e}"
)
def get_plugin_info(self, plugin_name: str) -> Optional[PluginInfo]:
"""获取插件信息"""
return self.plugin_infos.get(plugin_name)
def get_all_plugin_infos(self) -> List[PluginInfo]:
"""获取所有插件信息"""
return list(self.plugin_infos.values())
async def install_plugin(
self, package_name: str, version: Optional[str] = None
) -> Optional[PluginInfo]:
"""安装插件"""
try:
# 构建安装命令
cmd = [sys.executable, "-m", "pip", "install", "--index-url", self.config.update.pypi_registry]
if version:
cmd.append(f"{package_name}=={version}")
else:
cmd.append(package_name)
# 执行安装
self.logger.info(f"Installing plugin: {package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{package_name} install] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{package_name} install] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to install plugin: return code {return_code}")
# 导入并加载插件
self.discover_external_plugins()
possible_plugin_infos = [
info
for info in self.plugin_infos.values()
if info.package_name == package_name
]
if possible_plugin_infos:
return possible_plugin_infos[0]
except Exception as e:
raise Exception(f"Failed to install plugin: {str(e)}")
return None
async def uninstall_plugin(self, plugin_name: str) -> bool:
"""卸载插件"""
try:
plugin_info = self.plugin_infos.get(plugin_name)
if not plugin_info:
return False
if plugin_info.is_internal:
raise Exception("Cannot uninstall internal plugin")
# 卸载前先禁用插件
await self.disable_plugin(plugin_name)
assert plugin_info.package_name is not None
# 执行卸载
cmd = [
sys.executable,
"-m",
"pip",
"uninstall",
"-y",
plugin_info.package_name,
]
self.logger.info(f"Uninstalling plugin: {plugin_info.package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{plugin_info.package_name} uninstall] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{plugin_info.package_name} uninstall] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to uninstall plugin: return code {return_code}")
# 清理插件信息
if plugin_name in self.plugin_infos:
del self.plugin_infos[plugin_name]
return True
except Exception as e:
raise Exception(f"Failed to uninstall plugin: {str(e)}")
async def enable_plugin(self, plugin_name: str) -> bool:
"""启用插件"""
plugin_info = self.get_plugin_info(plugin_name)
if not plugin_info:
raise ValueError(f"Plugin {plugin_name} not found")
if plugin_info.is_enabled:
return True
try:
# 加载插件
if plugin_info.is_internal:
plugin = self._load_internal_plugin(plugin_name)
else:
plugin = self._load_external_plugin(plugin_name)
# 更新配置
if plugin_name not in self.config.plugins.enable:
self.config.plugins.enable.append(plugin_name)
plugin.on_load()
plugin.on_start()
plugin_info.is_enabled = True
self.logger.info(f"Plugin {plugin_name} enabled")
return True
except Exception as e:
plugin_info.requires_restart = True
self.logger.error(f"Failed to enable plugin {plugin_name}: {e}")
raise e
async def disable_plugin(self, plugin_name: str) -> bool:
"""禁用插件"""
plugin_info = self.get_plugin_info(plugin_name)
if not plugin_info:
raise ValueError(f"Plugin {plugin_name} not found")
if not plugin_info.is_enabled:
return True
try:
# 找到并停止插件实例
if plugin_name in self.plugins:
plugin = self.plugins[plugin_name]
if isinstance(plugin.event_bus, PluginEventBus):
plugin.event_bus.unregister_all()
plugin.on_stop()
del self.plugins[plugin_name]
# 更新配置
if plugin_name in self.config.plugins.enable:
self.config.plugins.enable.remove(plugin_name)
plugin_info.is_enabled = False
self.plugin_infos[plugin_name] = plugin_info
self.logger.info(f"Plugin {plugin_name} disabled")
return True
except Exception as e:
plugin_info.requires_restart = True
self.logger.error(f"Failed to disable plugin {plugin_name}: {e}")
return False
async def update_plugin(self, plugin_name: str, new_package_name: Optional[str] = None) -> Optional[PluginInfo]:
"""更新插件"""
try:
plugin_info = self.plugin_infos.get(plugin_name)
if not plugin_info:
return None
assert plugin_info.package_name is not None
if plugin_info.is_internal:
raise Exception("Cannot update internal plugin")
# 获取当前版本
old_version = plugin_info.version
# 先卸载旧插件
await self.uninstall_plugin(plugin_name)
# 执行更新
cmd = [
sys.executable,
"-m",
"pip",
"install",
"--upgrade",
"--index-url",
self.config.update.pypi_registry,
new_package_name or plugin_info.package_name,
]
self.logger.info(f"Updating plugin: {plugin_info.package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{plugin_info.package_name} update] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{plugin_info.package_name} update] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to update plugin: return code {return_code}")
self.discover_external_plugins()
possible_plugin_infos = [
info
for info in self.plugin_infos.values()
if info.package_name == plugin_info.package_name
]
if possible_plugin_infos:
if possible_plugin_infos[0].version != old_version:
return possible_plugin_infos[0]
else:
raise Exception(
f"Failed to update plugin: {plugin_info.package_name} is already up to date for current Kirara AI version. Maybe you should update Kirara AI to the latest version."
)
except Exception as e:
raise Exception(f"Failed to update plugin: {str(e)}")
return None
def discover_external_plugins(self):
"""发现并加载所有已安装的外部插件"""
self.logger.info("Discovering external plugins...")
from importlib.metadata import distributions
# 获取所有已安装的包
for dist in distributions():
try:
# 检查包是否包含我们需要的 entry point
eps = dist.entry_points
plugin_eps = [ep for ep in eps if ep.group == Plugin.ENTRY_POINT_GROUP]
if not plugin_eps:
continue
for ep in plugin_eps:
try:
# 获取插件元数据
metadata = {
"name": dist.metadata["Name"],
"description": dist.metadata.get("Summary", ""),
"version": dist.metadata.get("Version", "1.0.0"),
"author": dist.metadata.get("Author", "Unknown"),
}
# 创建插件信息
plugin_info = PluginInfo(
name=ep.name,
package_name=dist.metadata["Name"],
description=metadata["description"],
version=metadata["version"],
author=metadata["author"],
is_internal=False,
is_enabled=False,
metadata=None,
)
# 存储插件信息
self.plugin_infos[ep.name] = plugin_info
# 如果插件在启用列表中,则加载它
if ep.name in self.config.plugins.enable:
self._load_external_plugin(ep.name)
except Exception as e:
self.logger.error(
f"Error processing metadata for plugin {ep.name}: {e}"
)
except Exception as e:
self.logger.error(
f"Error processing package {dist.metadata['Name']}: {e}"
)
================================================
FILE: kirara_ai/plugin_manager/utils.py
================================================
from importlib.metadata import PackageNotFoundError, distribution
from typing import Any, Dict, Optional
def get_package_metadata(package_name: str) -> Optional[Dict[str, Any]]:
"""获取Python包的元数据
Args:
package_name: 包名
Returns:
包含包元数据的字典,如果包不存在则返回None
"""
try:
dist = distribution(package_name)
return {
"name": dist.metadata["Name"],
"version": dist.version,
"description": dist.metadata["Summary"] if "Summary" in dist.metadata else "",
"author": dist.metadata["Author"] if "Author" in dist.metadata else "",
}
except PackageNotFoundError:
return None
================================================
FILE: kirara_ai/plugins/.gitkeep
================================================
================================================
FILE: kirara_ai/plugins/bundled_frpc/__init__.py
================================================
from quart import g
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
from .frpc_manager import FrpcManager
from .routes import frpc_bp
logger = get_logger("FRPC")
class FrpcPlugin(Plugin):
"""
FRPC 插件
用于在本地启动 FRPC 服务,协助将 Web 服务暴露到外网。
"""
web_server: WebServer
global_config: GlobalConfig
def __init__(self):
self.frpc_manager = None
def on_load(self):
# 创建 FRPC 管理器
self.frpc_manager = FrpcManager(self.global_config)
# 注册中间件,将 frpc_manager 注入到请求上下文
@frpc_bp.before_request
async def inject_frpc_manager():
g.frpc_manager = self.frpc_manager
def on_start(self):
# 挂载 API
self.web_server.web_api_app.register_blueprint(frpc_bp, url_prefix="/api/frpc")
# 如果配置为启用,则尝试启动 frpc
if self.global_config.frpc.enable:
try:
self.frpc_manager.start_frpc(self.global_config.web.port)
except Exception as e:
logger.error(f"启动 FRPC 失败: {e}")
def on_stop(self):
# 停止 frpc 进程
if self.frpc_manager:
self.frpc_manager.stop_frpc()
__all__ = ["FrpcPlugin"]
================================================
FILE: kirara_ai/plugins/bundled_frpc/frpc_manager.py
================================================
import io
import os
import platform
import shutil
import subprocess
import tarfile
import tempfile
import threading
import zipfile
from pathlib import Path
from typing import Awaitable, Callable, Optional, Tuple
import aiohttp
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
logger = get_logger("FRPC")
# 存储路径
STORAGE_PATH = "./data/frpc"
class FrpcManager:
"""FRPC 管理器"""
def __init__(self, global_config: GlobalConfig):
self.global_config = global_config
self._frpc_process: Optional[subprocess.Popen] = None
self._frpc_version: str = ""
self._remote_url: str = ""
self._error_message: str = ""
self._download_progress: float = 0
# 确保存储目录存在
self.storage_path = Path(STORAGE_PATH)
self.storage_path.mkdir(parents=True, exist_ok=True)
# 设置 frpc 可执行文件路径
system = platform.system().lower()
if system == "windows":
self._frpc_path = self.storage_path / "frpc.exe"
else:
self._frpc_path = self.storage_path / "frpc"
# 设置配置文件路径
self._frpc_config_path = self.storage_path / "frpc.ini"
# 尝试获取版本信息
if self.is_installed():
self._get_frpc_version()
async def download_frpc(self, progress_callback: Optional[Callable[[float], Awaitable[None]]] = None) -> bool:
"""下载 FRPC"""
# 重置状态
self._download_progress = 0
self._error_message = ""
try:
# 获取系统信息
system = platform.system().lower()
machine = platform.machine().lower()
# 确定下载 URL
if system == "windows":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_windows_amd64.zip"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_windows_arm64.zip"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
elif system == "linux":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_amd64.tar.gz"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_arm64.tar.gz"
elif machine.startswith("arm"):
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_arm.tar.gz"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
elif system == "darwin":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_darwin_amd64.tar.gz"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_darwin_arm64.tar.gz"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
else:
self._error_message = f"不支持的操作系统: {system}"
if progress_callback:
await progress_callback(0)
return False
self._remote_url = url
self._version = "v0.51.3"
# 下载文件
try:
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(url) as response:
if response.status != 200:
self._error_message = f"下载失败: HTTP {response.status}"
if progress_callback:
await progress_callback(0)
return False
total_size = int(response.headers.get("content-length", 0))
downloaded_size = 0
# 直接在内存中下载文件
content = bytearray()
async for chunk in response.content.iter_chunked(8192):
content.extend(chunk)
downloaded_size += len(chunk)
progress = min(100, downloaded_size * 100 / total_size if total_size > 0 else 0)
self._download_progress = progress
if progress_callback:
await progress_callback(progress)
# 解压文件
extract_dir = tempfile.mkdtemp()
try:
# 从内存中解压文件
if url.endswith(".zip"):
with zipfile.ZipFile(io.BytesIO(content)) as zip_ref:
zip_ref.extractall(extract_dir)
elif url.endswith(".tar.gz"):
with tarfile.open(fileobj=io.BytesIO(content), mode="r:gz") as tar_ref:
tar_ref.extractall(extract_dir)
# 查找 frpc 可执行文件
frpc_name = "frpc.exe" if system == "windows" else "frpc"
frpc_files = []
for root, _, files in os.walk(extract_dir):
for file in files:
if file == frpc_name:
frpc_files.append(os.path.join(root, file))
if not frpc_files:
self._error_message = "解压后未找到 frpc 可执行文件"
if progress_callback:
await progress_callback(0)
return False
# 复制 frpc 可执行文件
frpc_path = str(self._frpc_path)
os.makedirs(os.path.dirname(frpc_path), exist_ok=True)
shutil.copy2(frpc_files[0], frpc_path)
# 设置可执行权限
if system != "windows":
os.chmod(frpc_path, 0o755)
if progress_callback:
await progress_callback(100)
self._get_frpc_version()
return True
finally:
shutil.rmtree(extract_dir)
except Exception as e:
self._error_message = f"下载失败: {str(e)}"
if progress_callback:
await progress_callback(0)
return False
except Exception as e:
self._error_message = f"下载失败: {str(e)}"
if progress_callback:
await progress_callback(0)
return False
def _get_frpc_version(self):
"""获取 frpc 版本信息"""
try:
if not self.is_installed():
self._frpc_version = "未安装"
return
result = subprocess.run(
[str(self._frpc_path), "-v"],
capture_output=True,
text=True,
check=True
)
self._frpc_version = result.stdout.strip()
except Exception as e:
logger.error(f"获取 FRPC 版本失败: {e}")
self._frpc_version = "未知"
def _generate_config(self, web_port: int) -> bool:
"""
生成 frpc 配置文件
Args:
web_port: Web 服务端口
Returns:
bool: 配置文件生成是否成功
"""
try:
config = self.global_config.frpc
# 基本配置
config_content = f"""[common]
server_addr = {config.server_addr}
server_port = {config.server_port}
"""
# 如果有令牌,添加令牌配置
if config.token:
config_content += f"token = {config.token}\n"
if self.global_config.web.host == "0.0.0.0":
web_ip = "127.0.0.1"
else:
web_ip = self.global_config.web.host
# 代理配置
config_content += f"""
[kirara_web]
type = tcp
local_ip = {web_ip}
local_port = {web_port}
"""
# 远程端口配置
if config.remote_port > 0:
config_content += f"remote_port = {config.remote_port}\n"
# 写入配置文件
with open(self._frpc_config_path, "w", encoding="utf-8") as f:
f.write(config_content)
logger.info(f"FRPC 配置文件已生成: {self._frpc_config_path}")
return True
except Exception as e:
logger.error(f"生成 FRPC 配置文件失败: {e}")
self._error_message = f"生成 FRPC 配置文件失败: {e}"
return False
def start_frpc(self, web_port: int) -> bool:
"""
启动 frpc
Args:
web_port: Web 服务端口
Returns:
bool: 启动是否成功
"""
if self.is_installed():
self._get_frpc_version()
try:
# 如果已经在运行,先停止
if self._frpc_process is not None:
self.stop_frpc()
# 检查可执行文件是否存在
if not self.is_installed():
logger.error("FRPC 可执行文件不存在,请先下载")
self._error_message = "FRPC 可执行文件不存在,请先下载"
return False
# 生成配置文件
if not self._generate_config(web_port):
return False
# 启动 frpc
cmd = [str(self._frpc_path), "-c", str(self._frpc_config_path)]
self._frpc_process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True
)
def print_output(process):
while process.poll() is None:
line = process.stdout.readline()
if not line:
break
logger.info(line.strip())
logger.info("FRPC 已结束")
# 创建一个线程来读取和打印输出
output_thread = threading.Thread(target=print_output, args=(self._frpc_process,))
output_thread.daemon = True # 设置为守护线程,主线程退出时自动结束
output_thread.start()
logger.info(f"FRPC 已启动,PID: {self._frpc_process.pid}")
# 计算远程访问 URL
self._calculate_remote_url()
return True
except Exception as e:
logger.error(f"启动 FRPC 失败: {e}")
self._error_message = f"启动 FRPC 失败: {e}"
return False
def stop_frpc(self) -> bool:
"""
停止 frpc
Returns:
bool: 停止是否成功
"""
try:
if self._frpc_process is not None:
self._frpc_process.terminate()
try:
self._frpc_process.wait(timeout=5)
except subprocess.TimeoutExpired:
self._frpc_process.kill()
logger.info("FRPC 已停止")
self._frpc_process = None
self._remote_url = ""
return True
except Exception as e:
logger.error(f"停止 FRPC 失败: {e}")
self._error_message = f"停止 FRPC 失败: {e}"
return False
def _calculate_remote_url(self):
"""计算远程访问 URL"""
config = self.global_config.frpc
if config.remote_port > 0:
self._remote_url = f"http://{config.server_addr}:{config.remote_port}"
else:
self._remote_url = f"http://{config.server_addr}:随机端口"
def get_status(self) -> Tuple[bool, str, str, str, float]:
"""
获取 frpc 状态
Returns:
Tuple[bool, str, str, str, float]: (是否运行, 版本, 远程URL, 错误信息, 下载进度)
"""
is_running = self._frpc_process is not None and self._frpc_process.poll() is None
# 如果进程已经退出,获取错误信息
if self._frpc_process is not None and self._frpc_process.poll() is not None:
stderr = self._frpc_process.stderr.read() if self._frpc_process.stderr else ""
if stderr:
self._error_message = stderr
self._frpc_process = None
self._get_frpc_version()
return (
is_running,
self._frpc_version,
self._remote_url,
self._error_message,
self._download_progress
)
def is_installed(self) -> bool:
"""
检查 frpc 是否已安装
Returns:
bool: 是否已安装
"""
return os.path.exists(self._frpc_path)
================================================
FILE: kirara_ai/plugins/bundled_frpc/models.py
================================================
from typing import Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import FrpcConfig
class FrpcStatus(BaseModel):
"""FRPC 状态"""
is_running: bool
is_installed: bool
config: FrpcConfig
version: str = ""
remote_url: str = ""
error_message: str = ""
download_progress: float = 0
class FrpcConfigUpdate(BaseModel):
"""FRPC 配置更新请求"""
enable: Optional[bool] = None
server_addr: Optional[str] = None
server_port: Optional[int] = None
token: Optional[str] = None
remote_port: Optional[int] = None
class FrpcDownloadProgress(BaseModel):
"""FRPC 下载进度"""
progress: float
status: str = "downloading" # downloading, completed, error
error_message: str = ""
================================================
FILE: kirara_ai/plugins/bundled_frpc/routes.py
================================================
import asyncio
from quart import Blueprint, Response, g, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.web.auth.middleware import require_auth
from .frpc_manager import FrpcManager
from .models import FrpcConfigUpdate, FrpcDownloadProgress, FrpcStatus
frpc_bp = Blueprint("frpc", __name__)
@frpc_bp.route("/status", methods=["GET"])
@require_auth
async def get_status():
"""获取 FRPC 状态"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/config", methods=["POST"])
@require_auth
async def update_config():
"""更新 FRPC 配置"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
data = await request.get_json()
config_update = FrpcConfigUpdate(**data)
# 更新配置
frpc_config = config.frpc
# 使用字典推导式更新非 None 字段
update_dict = {k: v for k, v in config_update.model_dump().items() if v is not None}
# 更新配置
for key, value in update_dict.items():
setattr(frpc_config, key, value)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 如果启用状态改变,启动或停止 frpc
web_port = config.web.port
if config_update.enable is not None:
if config_update.enable:
frpc_manager.start_frpc(web_port)
else:
frpc_manager.stop_frpc()
# 如果其他配置改变且 frpc 正在运行,重启 frpc
elif frpc_config.enable and any(k != "enable" for k in update_dict.keys()):
frpc_manager.stop_frpc()
frpc_manager.start_frpc(web_port)
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/start", methods=["POST"])
@require_auth
async def start_frpc():
"""启动 FRPC"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 更新配置中的启用状态
config.frpc.enable = True
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 启动 frpc
success = frpc_manager.start_frpc(config.web.port)
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/stop", methods=["POST"])
@require_auth
async def stop_frpc():
"""停止 FRPC"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 更新配置中的启用状态
config.frpc.enable = False
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 停止 frpc
success = frpc_manager.stop_frpc()
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/download", methods=["GET"])
@require_auth
async def download_frpc():
"""下载 FRPC 并通过 SSE 返回进度"""
frpc_manager: FrpcManager = g.frpc_manager
# 创建一个队列用于存储SSE事件
queue = asyncio.Queue()
# 定义进度回调函数
async def progress_callback(progress: float):
"""进度回调函数"""
status = "downloading"
if progress >= 100:
status = "completed"
# 将事件放入队列
await queue.put(
FrpcDownloadProgress(
progress=progress,
status=status
).model_dump_json()
)
# 启动下载任务
async def download_task():
try:
# 发送初始状态
await queue.put(
FrpcDownloadProgress(
progress=0,
status='downloading'
).model_dump_json()
)
# 执行下载
success = await frpc_manager.download_frpc(progress_callback)
# 如果下载失败,发送错误状态
if not success:
await queue.put(
FrpcDownloadProgress(
progress=0,
status='error',
error_message=frpc_manager._error_message
).model_dump_json()
)
except Exception as e:
# 发送错误状态
await queue.put(
FrpcDownloadProgress(
progress=0,
status='error',
error_message=str(e)
).model_dump_json()
)
finally:
# 标记队列结束
await queue.put(None)
# 启动下载任务
asyncio.create_task(download_task())
# 定义SSE流生成器
async def send_events():
while True:
message = await queue.get()
if message is None: # 结束信号
break
yield f"data: {message}\n\n"
# 返回SSE响应
return Response(
send_events(),
mimetype="text/event-stream",
headers={
"Cache-Control": "no-cache",
"X-Accel-Buffering": "no", # 禁用 Nginx 缓冲
"Connection": "keep-alive"
}
)
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/__init__.py
================================================
import os
from im_http_legacy_adapter.adapter import HttpLegacyAdapter, HttpLegacyConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("HTTP-Legacy-Adapter")
class HttpLegacyAdapterPlugin(Plugin):
"""HTTP API 消息适配器插件"""
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"http_legacy",
HttpLegacyAdapter,
HttpLegacyConfig,
"HTTP API",
"HTTP 消息 API,可用于接入第三方程序。",
"""
HTTP API 可用于接入第三方程序,接口文档请见项目 [README](https://github.com/lss233/chatgpt-mirai-qq-bot/blob/master/README.md#-http-api)。
"""
)
self.web_server.add_static_assets("/assets/icons/im/http_legacy.png", os.path.join(os.path.dirname(__file__), "assets", "http_legacy.png"))
def on_start(self):
pass
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/adapter.py
================================================
import asyncio
import re
import time
from typing import Any, Dict, List, Optional, Protocol
from fastapi import Body, FastAPI, Query, Request
from fastapi.responses import JSONResponse
from pydantic import BaseModel, ConfigDict, Field
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import ImageMessage, IMMessage, TextMessage, VoiceMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.logger import get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
# 全局变量,用于跟踪是否已经设置了路由
_is_first_setup = True
# 全局变量,用于存储所有已授权的API密钥
_authorized_api_keys: List[str] = []
class HttpLegacyConfig(BaseModel):
"""HTTP Legacy API 配置"""
api_key: Optional[str] = Field(
description="自定义的API密钥,设置后,请求接口时需要带上这个密钥,若填空则不校验。", default=None)
host: Optional[str] = Field(description="已废弃,HTTP API 服务器地址,设置后将启动独立服务器。",
default=None, json_schema_extra={"hidden_unset": True})
port: Optional[int] = Field(description="已废弃,HTTP API 服务器端口,设置后将启动独立服务器。",
default=None, json_schema_extra={"hidden_unset": True})
model_config = ConfigDict(extra="allow")
class ResponseResult:
def __init__(self, message=None, voice=None, image=None, result_status="SUCCESS"):
self.result_status = result_status
self.message = (
[]
if message is None
else message if isinstance(message, list) else [message]
)
self.voice = (
[] if voice is None else voice if isinstance(voice, list) else [
voice]
)
self.image = (
[] if image is None else image if isinstance(image, list) else [
image]
)
def to_dict(self):
return {
"result": self.result_status,
"message": self.message,
"voice": self.voice,
"image": self.image,
}
def pop_all(self):
self.message = []
self.voice = []
self.image = []
class MessageHandler(Protocol):
async def __call__(self, message: IMMessage) -> None: ...
class V2Request:
def __init__(self, session_id: str, username: str, message: str, request_time: str):
self.session_id = session_id
self.username = username
self.message = message
self.result = ResponseResult()
self.request_time = request_time
self.done = False
self.response_event = asyncio.Event()
class HttpLegacyAdapter(IMAdapter):
"""HTTP Legacy API适配器"""
dispatcher: WorkflowDispatcher
web_server: WebServer
def __init__(self, config: HttpLegacyConfig):
self.config = config
self.app = FastAPI(title="HTTP Legacy API")
self.request_dic: Dict[str, V2Request] = {}
self.logger = get_logger("HTTP-Legacy-Adapter")
async def convert_to_message(self, raw_message: Any) -> IMMessage:
data = raw_message
username = data.get("username", "某人")
message_text = data.get("message", "")
session_id = data.get("session_id", "friend-default_session")
if (
session_id.startswith("group-")
and len(session_id.split("-")) == 2
and ":" in session_id.split("-")[1]
):
# group-group_id:user_id
ids = session_id.split("-")[1].split(":")
sender = ChatSender.from_group_chat(
user_id=ids[1], group_id=ids[0], display_name=username
)
else:
sender = ChatSender.from_c2c_chat(
user_id=session_id, display_name=username)
return IMMessage(
sender=sender,
message_elements=[TextMessage(text=message_text)],
raw_message={"session_id": session_id, **data},
)
async def handle_message_elements(self, result: ResponseResult, message: IMMessage):
for element in message.message_elements:
if isinstance(element, VoiceMessage):
result.voice.append(await element.get_base64_url())
elif isinstance(element, ImageMessage):
result.image.append(await element.get_base64_url())
else:
result.message.append(element.to_plain())
def verify_api_key(self, request: Request) -> bool:
"""验证API密钥"""
if not self.config.api_key:
return True
auth_header = request.headers.get("Authorization", "")
# 支持 Bearer 认证和直接传递 API Key
if auth_header.startswith("Bearer "):
auth_header = auth_header[7:] # 移除 "Bearer " 前缀
return auth_header == self.config.api_key or auth_header in _authorized_api_keys
def create_auth_error_response(self):
"""创建认证失败的响应"""
return JSONResponse(
content=ResponseResult(
message="认证失败", result_status="FAILED").to_dict(),
status_code=401
)
def setup_routes(self, target_app=None):
app = target_app if target_app else self.app
async def verify_auth(request: Request):
if not self.verify_api_key(request):
return self.create_auth_error_response()
return None
@app.post("/v1/chat")
async def v1_chat(request: Request, data: dict = Body(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
message = await self.convert_to_message(data)
result = ResponseResult()
async def handle_response(resp_message: IMMessage):
await self.handle_message_elements(result, resp_message)
message.sender.raw_metadata["callback_func"] = handle_response
await self.dispatcher.dispatch(self, message)
return result.to_dict()
@app.post("/v2/chat")
async def v2_chat(request: Request, data: dict = Body(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
request_time = str(int(time.time() * 1000))
message = await self.convert_to_message(data)
assert message.raw_message is not None
session_id = message.raw_message["session_id"]
bot_request = V2Request(
session_id,
message.sender.display_name,
data.get("message", ""),
request_time,
)
self.request_dic[request_time] = bot_request
async def handle_response(resp_message: IMMessage):
await self.handle_message_elements(bot_request.result, resp_message)
bot_request.response_event.set()
message.sender.raw_metadata["callback_func"] = handle_response
asyncio.create_task(self.dispatcher.dispatch(self, message))
return request_time
@app.get("/v2/chat/response")
async def v2_chat_response(request: Request, request_id: str = Query(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
request_id = re.sub(
r'^[%22%27"\'"]*|[%22%27"\'"]*$', "", request_id)
bot_request = self.request_dic.get(request_id)
if bot_request is None:
return ResponseResult(
message="没有更多了!", result_status="FAILED"
).to_dict()
await bot_request.response_event.wait()
bot_request.response_event.clear()
response = bot_request.result.to_dict()
bot_request.result = ResponseResult()
if bot_request.done:
self.request_dic.pop(request_id)
return response
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""此处负责 HTTP 的响应逻辑"""
await recipient.raw_metadata["callback_func"](message)
@property
def is_standalone(self):
return self.config.host
async def _start_standalone_server(self):
"""启动独立HTTP服务器"""
# 使用 hypercorn 配置来正确处理关闭信号
from hypercorn.asyncio import serve
from hypercorn.config import Config
from hypercorn.logging import Logger
from kirara_ai.logger import HypercornLoggerWrapper
config = Config()
host = self.config.host
port = self.config.port or 18560
config.bind = [f"{host}:{port}"]
config._log = Logger(config)
config._log.access_logger = HypercornLoggerWrapper(self.logger) # type: ignore
config._log.error_logger = HypercornLoggerWrapper(self.logger) # type: ignore
self.server_task = asyncio.create_task(serve(self.app, config)) # type: ignore
async def start(self):
"""启动HTTP服务器"""
global _is_first_setup, _authorized_api_keys
if self.is_standalone:
self.logger.warning("正在使用过时的独立模式,请尽快更新为集成模式。")
await self._start_standalone_server()
self.setup_routes()
else:
# 为所有的路由添加前缀
if _is_first_setup:
# 直接往 self.web_server.app 注册路由,而不是mount_app
self.setup_routes(target_app=self.web_server.app)
_is_first_setup = False
else:
if self.config.api_key and self.config.api_key not in _authorized_api_keys:
_authorized_api_keys.append(self.config.api_key)
# 启动清理过期请求的任务
self.cleanup_task = asyncio.create_task(
self.cleanup_expired_requests())
async def cleanup_expired_requests(self):
"""清理过期的请求"""
while True:
now = time.time()
expired_keys = [
key
for key, req in self.request_dic.items()
if now - int(key) / 1000 > 600
]
for key in expired_keys:
self.request_dic.pop(key)
await asyncio.sleep(60)
async def stop(self):
"""停止HTTP服务器"""
global _authorized_api_keys
# 如果有API密钥,从授权列表中移除
if self.config.api_key and self.config.api_key in _authorized_api_keys:
_authorized_api_keys.remove(self.config.api_key)
if self.is_standalone and hasattr(self, "server_task"):
self.server_task.cancel()
try:
await self.server_task
except asyncio.CancelledError:
pass
except Exception as e:
self.logger.error(f"Error during server shutdown: {e}")
if hasattr(self, "cleanup_task"):
self.cleanup_task.cancel()
try:
await self.cleanup_task
except asyncio.CancelledError:
pass
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-http-legacy-adapter",
version="1.0.0",
description="HTTP legacy adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["aiohttp", "requests"],
entry_points={
"chatgpt_mirai.plugins": [
"http_legacy = im_http_legacy_adapter.plugin:HttpLegacyAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/tests/api_test.py
================================================
import asyncio
import os
import sys
import pytest
from fastapi.testclient import TestClient
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.dispatch.dispatcher import WorkflowDispatcher
from kirara_ai.workflow.core.dispatch.registry import DispatchRuleRegistry
from tests.utils.test_block_registry import create_test_block_registry
sys.path.insert(
0, os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
from im_http_legacy_adapter.adapter import HttpLegacyAdapter, HttpLegacyConfig, ResponseResult
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
class FakeWorkflowDispatcher(WorkflowDispatcher):
async def dispatch(self, source: IMAdapter, message: IMMessage):
return None
@pytest.fixture
def config():
return HttpLegacyConfig(host="127.0.0.1", port=8080, debug=False)
@pytest.fixture
def adapter(config):
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(WorkflowRegistry, WorkflowRegistry(container))
container.register(DispatchRuleRegistry, DispatchRuleRegistry(container))
container.register(WorkflowDispatcher, FakeWorkflowDispatcher(container))
container.register(BlockRegistry, create_test_block_registry())
adapter = HttpLegacyAdapter(config)
adapter.setup_routes()
adapter.dispatcher = container.resolve(WorkflowDispatcher)
return adapter
@pytest.mark.asyncio
async def test_chat_endpoint(adapter):
test_client = TestClient(adapter.app)
# Test text message
response = test_client.post(
"/v1/chat",
json={
"session_id": "test_session",
"username": "test_user",
"message": "Hello, world!",
},
)
assert response.status_code == 200
data = response.json()
assert "result" in data
assert "message" in data
assert isinstance(data["message"], list)
# Test with missing fields (should use defaults)
response = test_client.post("/v1/chat", json={"message": "Test message"})
assert response.status_code == 200
@pytest.mark.asyncio
async def test_response_result():
# Test single message
result = ResponseResult(message="Test message")
json_data = result.to_dict()
assert json_data["message"] == ["Test message"]
assert json_data["voice"] == []
assert json_data["image"] == []
# Test multiple messages
result = ResponseResult(
message=["Message 1", "Message 2"],
voice=["voice1.mp3"],
image=["image1.jpg", "image2.jpg"],
)
json_data = result.to_dict()
assert len(json_data["message"]) == 2
assert len(json_data["voice"]) == 1
assert len(json_data["image"]) == 2
@pytest.mark.asyncio
async def test_adapter_lifecycle(adapter):
# Test start and stop
start_task = asyncio.create_task(adapter.start())
await asyncio.sleep(0.1) # Give some time for server to start
await adapter.stop()
try:
await start_task
except Exception:
pass # Expected to fail when we stop the server
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/__init__.py
================================================
import asyncio
import os
from im_qqbot_adapter.adapter import QQBotAdapter, QQBotConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("QQBot-Adapter")
class QQBotAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"qqbot",
QQBotAdapter,
QQBotConfig,
"QQ 开放平台机器人",
"QQ 官方机器人,需要服务器支持接收 QQ 的 Webhook 请求,支持基本的聊天功能,群聊中必须通过 @ 触发。",
"""
QQ 开放平台机器人,需要服务器支持接收 QQ 的 Webhook 请求,配置流程可参考 [QQ 开放平台文档](https://q.qq.com/wiki/) 和 [Kirara AI 文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html)。
"""
)
local_logo_path = os.path.join(os.path.dirname(__file__), "assets", "qqbot.png")
self.web_server.add_static_assets("/assets/icons/im/qqbot.png", local_logo_path)
def on_start(self):
pass
def on_stop(self):
try:
tasks = []
loop = asyncio.get_event_loop()
for key, adapter in self.im_manager.get_adapters().items():
if isinstance(adapter, QQBotAdapter) and adapter.is_running:
tasks.append(self.im_manager.stop_adapter(key, loop))
for key in list(self.im_manager.get_adapters().keys()):
self.im_manager.delete_adapter(key)
loop.run_until_complete(asyncio.gather(*tasks))
except Exception as e:
logger.error(f"Error stopping QQBot adapter: {e}")
finally:
self.im_registry.unregister("qqbot")
logger.info("QQBot adapter stopped")
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/adapter.py
================================================
import asyncio
import base64
import functools
import uuid
from typing import List, Optional
import ymbotpy as botpy
import ymbotpy.message
from pydantic import BaseModel, ConfigDict, Field
from ymbotpy.http import Route as BotpyRoute
from ymbotpy.types.message import Media as BotpyMedia
from kirara_ai.im.adapter import BotProfileAdapter, IMAdapter
from kirara_ai.im.message import (ImageMessage, IMMessage, MentionElement, MessageElement, TextMessage, VideoElement,
VoiceMessage)
from kirara_ai.im.profile import UserProfile
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
from .utils import URL_PATTERN
WEBHOOK_URL_PREFIX = "/im/webhook/qqbot"
def make_webhook_url():
return f"{WEBHOOK_URL_PREFIX}/{str(uuid.uuid4())[:8]}/"
def auto_generate_webhook_url(s: dict):
s["readOnly"] = True
s["default"] = make_webhook_url()
s["textType"] = True
class QQBotConfig(BaseModel):
"""
QQBot 配置文件模型。
"""
app_id: str = Field(description="机器人的 App ID。")
app_secret: str = Field(title="App Secret", description="机器人的 App Secret。")
token: str = Field(
title="Token", description="机器人令牌,用于调用 QQ 机器人的 OpenAPI。")
sandbox: bool = Field(
title="沙盒环境", description="是否为沙盒环境,通常只有正式发布的机器人才会关闭此选项。", default=False)
webhook_url: str = Field(
title="Webhook 回调 URL", description="供 QQ 机器人回调的 URL,由系统自动生成,无法修改。",
default_factory=make_webhook_url,
json_schema_extra=auto_generate_webhook_url
)
model_config = ConfigDict(extra="allow")
async def patched_post_file(
self,
file_type: int,
file_data: bytes,
openid: Optional[str] = None,
group_openid: Optional[str] = None
) -> BotpyMedia:
"""
重写 post_file 方法,添加文件类型参数。
"""
payload = {
"file_type": file_type,
"file_data": base64.b64encode(file_data).decode('utf-8'),
"srv_send_msg": False
}
if openid:
route = BotpyRoute("POST", "/v2/users/{openid}/files", openid=openid)
elif group_openid:
route = BotpyRoute(
"POST", "/v2/groups/{group_openid}/files", group_openid=group_openid)
else:
raise ValueError("openid 和 group_openid 不能同时为空")
return await self._http.request(route, json=payload)
class QQBotAdapter(botpy.WebHookClient, IMAdapter, BotProfileAdapter):
"""
QQBot Adapter,包含 QQBot Bot 的所有逻辑。
"""
dispatcher: WorkflowDispatcher
web_server: WebServer
_loop: asyncio.AbstractEventLoop
def __init__(self, config: QQBotConfig):
self.config = config
self.is_sandbox = config.sandbox
self.logger = get_logger("QQBot-Adapter")
super().__init__(
timeout=5,
is_sandbox=self.is_sandbox,
bot_log=True,
ext_handlers=True,
)
self.loop = self._loop
self.user = None
async def convert_to_message(self, raw_message: ymbotpy.message.BaseMessage) -> IMMessage:
if isinstance(raw_message, ymbotpy.message.GroupMessage):
assert raw_message.author.member_openid is not None
assert raw_message.group_openid is not None
sender = ChatSender.from_group_chat(
raw_message.author.member_openid, raw_message.group_openid, 'QQ 用户')
elif isinstance(raw_message, ymbotpy.message.C2CMessage):
sender = ChatSender.from_c2c_chat(
raw_message.author.user_openid, 'QQ 用户')
else:
raise ValueError(f"不支持的消息类型: {type(raw_message)}")
raw_dict = {items: str(getattr(raw_message, items))
for items in raw_message.__slots__ if not items.startswith("_")}
sender.raw_metadata = {
"message_id": raw_message.id,
"message_seq": raw_message.msg_seq,
"timestamp": raw_message.timestamp,
}
elements: List[MessageElement] = []
if raw_message.content.strip():
elements.append(TextMessage(text=raw_message.content.lstrip()))
for attachment in raw_message.attachments:
if attachment.content_type.startswith('image/'):
elements.append(
ImageMessage(
url=attachment.url,
format=attachment.content_type.removeprefix('image/')
)
)
elif attachment.content_type.startswith('audio'):
elements.append(
VoiceMessage(
url=attachment.url,
format=attachment.filename.split('.')[-1]
)
)
return IMMessage(sender=sender, message_elements=elements, raw_message=raw_dict)
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""
发送消息
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象。
"""
if recipient.raw_metadata is None or recipient.raw_metadata.get('message_id') is None:
raise ValueError("Unable to retreive send_message info from metadata")
msg_id = recipient.raw_metadata['message_id']
if recipient.chat_type == ChatType.C2C:
assert recipient.user_id is not None
post_message_func = functools.partial(
self.api.post_c2c_message, openid=recipient.user_id, msg_id=msg_id)
upload_func = functools.partial(
patched_post_file, self.api, openid=recipient.user_id)
elif recipient.chat_type == ChatType.GROUP:
assert recipient.group_id is not None
post_message_func = functools.partial(
self.api.post_group_message, group_openid=recipient.group_id, msg_id=msg_id)
upload_func = functools.partial(
patched_post_file, self.api, group_openid=recipient.group_id)
else:
raise ValueError(f"不支持的消息类型: {recipient.chat_type}")
# 文本缓冲区
current_text = ""
msg_seq = 0
url_replaced = False # 标记是否替换过 URL
def replace_url_dots(text: str) -> str:
"""
检查文本是否包含 URL,如果包含则替换 URL 中的句点为句号。
:param text: 要检查的文本。
:return: 替换后的文本。
"""
nonlocal url_replaced
def replace_dots(match):
nonlocal url_replaced
url_replaced = True
return match.group(0).replace('.', '。')
return URL_PATTERN.sub(replace_dots, text)
async def send_text_message(text: str):
"""
发送文本消息。
:param text: 要发送的文本内容。
"""
await post_message_func(content=text, msg_seq=msg_seq) # type: ignore
# 单次循环处理所有元素
for element in message.message_elements:
if isinstance(element, TextMessage):
# 如果有文本,直接添加到当前缓冲区
current_text += element.text
# 立即发送当前文本缓冲区内容
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
current_text = ""
elif isinstance(element, MentionElement):
# 添加提及标记到当前文本缓冲区
current_text += f''
elif isinstance(element, ImageMessage) or isinstance(element, VoiceMessage) or isinstance(element, VideoElement):
# 如果有累积的文本,先发送文本
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
current_text = ""
# 然后发送媒体
if isinstance(element, ImageMessage):
file_type = 1
elif isinstance(element, VoiceMessage):
file_type = 3
elif isinstance(element, VideoElement):
file_type = 2
media = await upload_func(file_type=file_type, file_data=await element.get_data())
await post_message_func(media=media, msg_seq=msg_seq, msg_type=7) # type: ignore
msg_seq += 1
# 补充解释性文本
if url_replaced:
current_text = current_text + "(URL 中的句点已替换为句号以避免屏蔽)"
# 发送循环结束后可能剩余的文本
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
async def on_c2c_message_create(self, message: ymbotpy.message.C2CMessage):
"""
处理接收到的消息。
:param message: 接收到的消息对象。
"""
self.logger.debug(f"收到 C2C 消息: {message}")
im_message = await self.convert_to_message(message)
await self.dispatcher.dispatch(self, im_message)
async def on_group_at_message_create(self, message: ymbotpy.message.GroupMessage):
"""
处理接收到的群消息。
:param message: 接收到的消息对象。
"""
self.logger.debug(f"收到群消息: {message}")
im_message = await self.convert_to_message(message)
# 这个逆天的 Webhook 居然不包含 mention 字段,这里要手动补上
im_message.message_elements.append(
MentionElement(target=ChatSender.get_bot_sender()))
await self.dispatcher.dispatch(self, im_message)
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
if self.user is None:
return None
return UserProfile(
user_id=self.user['id'],
username=self.user['username'],
display_name=self.user['username'],
avatar_url=self.user['avatar']
)
async def start(self):
"""启动 Bot"""
token = botpy.Token(self.config.app_id, self.config.app_secret)
self.user = await self.http.login(token)
self.robot = botpy.Robot(self.user)
bot_webhook = botpy.BotWebHook(
self.config.app_id,
self.config.app_secret,
hook_route='/',
client=self,
system_log=True,
botapi=self.api,
loop=self.loop
)
app = await bot_webhook.init_fastapi()
app.user_middleware.clear()
self.web_server.mount_app(
self.config.webhook_url.removesuffix('/'), app)
async def stop(self):
"""停止 Bot"""
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-qqbot-adapter",
version="1.0.0",
description="QQBot adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["ymbotpy"],
entry_points={
"chatgpt_mirai.plugins": [
"qqbot = im_qqbot_adapter.plugin:QQBotAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/utils.py
================================================
import re
URL_PATTERN = re.compile(
r'((?:https?://)?(?:[-\w]+\.)+(?:com|net|org|edu|gov|mil|io|co|ai|app|dev|cn|jp|kr|uk|de|fr|ru|br|in|au|info|biz|cc|tv|xyz|top|site|online|store|tech|blog|club|art|design|shop|mobile|cloud|me|ws|live|app|games|science|news|media|social|world|life|network)(?:/[-\w./%]*)?)')
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/__init__.py
================================================
import asyncio
import os
from im_telegram_adapter.adapter import TelegramAdapter, TelegramConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("TG-Adapter")
class TelegramAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"telegram",
TelegramAdapter,
TelegramConfig,
"Telegram 机器人",
"Telegram 官方机器人,支持私聊、群聊、 Markdown 格式消息。",
"""
Telegram 机器人,配置流程可参考 [Telegram 官方文档](https://core.telegram.org/bots/tutorial) 和 [Kirara AI 文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html)。
"""
)
# 添加当前文件夹下的 assets/telegram.svg 文件夹到 web 服务器
local_logo_path = os.path.join(os.path.dirname(__file__), "assets", "telegram.png")
self.web_server.add_static_assets("/assets/icons/im/telegram.png", local_logo_path)
def on_start(self):
pass
def on_stop(self):
try:
tasks = []
loop = asyncio.get_event_loop()
for key, adapter in self.im_manager.get_adapters().items():
if isinstance(adapter, TelegramAdapter) and adapter.is_running:
tasks.append(self.im_manager.stop_adapter(key, loop))
for key in list(self.im_manager.get_adapters().keys()):
self.im_manager.delete_adapter(key)
loop.run_until_complete(asyncio.gather(*tasks))
except Exception as e:
logger.error(f"Error stopping Telegram adapter: {e}")
finally:
self.im_registry.unregister("telegram")
logger.info("Telegram adapter stopped")
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/adapter.py
================================================
import asyncio
import random
from functools import lru_cache
from typing import List, Optional
from pydantic import BaseModel, ConfigDict, Field
from telegram import Bot, ChatFullInfo, Update, User
from telegram.constants import MessageEntityType
from telegram.ext import Application, CommandHandler, ContextTypes, MessageHandler, filters
from telegramify_markdown import markdownify
from kirara_ai.im.adapter import BotProfileAdapter, EditStateAdapter, IMAdapter, UserProfileAdapter
from kirara_ai.im.message import (FileElement, ImageMessage, IMMessage, MentionElement, MessageElement, TextMessage,
VideoMessage, VoiceMessage)
from kirara_ai.im.profile import UserProfile
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
def get_display_name(user: User | ChatFullInfo):
if user.first_name or user.last_name:
return f"{user.first_name or ''} {user.last_name or ''}".strip()
elif user.username:
return user.username
else:
return str(user.id)
class TelegramConfig(BaseModel):
"""
Telegram 配置文件模型。
"""
token: str = Field(description="Telegram 机器人的 Token,从 @BotFather 获取。")
model_config = ConfigDict(extra="allow")
def __repr__(self):
return f"TelegramConfig(token={self.token})"
class TelegramAdapter(IMAdapter, UserProfileAdapter, EditStateAdapter, BotProfileAdapter):
"""
Telegram Adapter,包含 Telegram Bot 的所有逻辑。
"""
dispatcher: WorkflowDispatcher
def __init__(self, config: TelegramConfig):
self.me = None
self.config = config
self.application = Application.builder().token(config.token).build()
self.bot = Bot(token=config.token)
# 注册命令处理器和消息处理器
self.application.add_handler(
CommandHandler("start", self.command_start))
self.application.add_handler(
MessageHandler(
filters.TEXT | filters.VOICE | filters.PHOTO | filters.VIDEO, self.handle_message
)
)
self.logger = get_logger("Telegram-Adapter")
async def command_start(self, update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理 /start 命令"""
if update.message:
await update.message.reply_text("Welcome! I am ready to receive your messages.")
async def handle_message(self, update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理接收到的消息"""
# 将 Telegram 消息转换为 Message 对象
if not update.message:
return
message = await self.convert_to_message(update)
try:
await self.dispatcher.dispatch(self, message)
except Exception as e:
await update.message.reply_text(
f"Workflow execution failed, please try again later: {str(e)}"
)
async def convert_to_message(self, raw_message: Update) -> IMMessage:
"""
将 Telegram 的 Update 对象转换为 Message 对象。
:param raw_message: Telegram 的 Update 对象。
:return: 转换后的 Message 对象。
"""
assert raw_message.message
assert raw_message.message.from_user
if (
raw_message.message.chat.type == "group"
or raw_message.message.chat.type == "supergroup"
):
sender = ChatSender.from_group_chat(
user_id=str(raw_message.message.from_user.id),
group_id=str(raw_message.message.chat_id),
display_name=get_display_name(raw_message.message.from_user),
)
else:
sender = ChatSender.from_c2c_chat(
user_id=str(raw_message.message.chat_id),
display_name=get_display_name(raw_message.message.from_user),
)
message_elements: List[MessageElement] = []
raw_message_dict = raw_message.message.to_dict()
# 处理文本消息
if raw_message.message.text is not None or raw_message.message.caption is not None:
text: str = raw_message.message.text or raw_message.message.caption # type: ignore
offset = 0
for entity in raw_message.message.entities or raw_message.message.caption_entities or []:
if entity.type in (MessageEntityType.MENTION, MessageEntityType.TEXT_MENTION):
# Extract mention text
mention_text = text[entity.offset:entity.offset + entity.length]
# Add preceding text as TextMessage
if entity.offset > offset:
message_elements.append(TextMessage(
text=text[offset:entity.offset]))
# Create ChatSender for MentionElement
if entity.type == "text_mention" and entity.user:
if entity.user.id == self.me.id: # type: ignore
mention_element = MentionElement(
target=ChatSender.get_bot_sender())
else:
mention_element = MentionElement(target=ChatSender.from_c2c_chat(
user_id=str(entity.user.id), display_name=mention_text))
elif entity.type == "mention":
# 这里需要从 adapter 实例中获取 bot 的 username
if mention_text == f'@{self.me.username}': # type: ignore
mention_element = MentionElement(
target=ChatSender.get_bot_sender())
else:
mention_element = MentionElement(target=ChatSender.from_c2c_chat(
user_id=f'unknown_id:{mention_text}', display_name=mention_text))
else:
# Fallback in case of unknown entity type
mention_element = TextMessage( # type: ignore
text=mention_text) # Or handle as needed
message_elements.append(mention_element)
offset = entity.offset + entity.length
# Add remaining text as TextMessage
if offset < len(text):
message_elements.append(TextMessage(text=text[offset:]))
# 处理语音消息
if raw_message.message.voice:
voice_file = await raw_message.message.voice.get_file()
data = await voice_file.download_as_bytearray()
voice_element = VoiceMessage(data=bytes(data))
message_elements.append(voice_element)
# 处理图片消息
if raw_message.message.photo:
# 获取最高分辨率的图片
photo = raw_message.message.photo[-1]
photo_file = await photo.get_file()
data = await photo_file.download_as_bytearray()
photo_element = ImageMessage(data=bytes(data))
message_elements.append(photo_element)
if raw_message.message.video:
video_file = await raw_message.message.video.get_file()
data = await video_file.download_as_bytearray()
video_element = VideoMessage(data=bytes(data))
message_elements.append(video_element)
if raw_message.message.document:
document_file = await raw_message.message.document.get_file()
data = await document_file.download_as_bytearray()
document_element = FileElement(data=bytes(data))
message_elements.append(document_element)
# 创建 Message 对象
message = IMMessage(
sender=sender,
message_elements=message_elements,
raw_message=raw_message_dict,
)
return message
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""
发送消息到 Telegram。
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象,这里应该是 chat_id。
"""
if recipient.chat_type == ChatType.C2C:
chat_id = recipient.user_id
elif recipient.chat_type == ChatType.GROUP:
assert recipient.group_id
chat_id = recipient.group_id
else:
raise ValueError(f"Unsupported chat type: {recipient.chat_type}")
for element in message.message_elements:
if isinstance(element, TextMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="typing"
)
text = markdownify(element.text)
# 如果是非首条消息,适当停顿,模拟打字
if message.message_elements.index(element) > 0:
# 停顿通常和字数有关,但是会带一些随机
duration = max(len(element.text) * 0.1, 1) + random.uniform(0, 1) * 0.1
await asyncio.sleep(duration)
await self.application.bot.send_message(
chat_id=chat_id, text=text, parse_mode="MarkdownV2"
)
elif isinstance(element, ImageMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_photo"
)
await self.application.bot.send_photo(
chat_id=chat_id, photo=await element.get_data(), parse_mode="MarkdownV2"
)
elif isinstance(element, VoiceMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_voice"
)
await self.application.bot.send_voice(
chat_id=chat_id, voice=await element.get_data(), parse_mode="MarkdownV2"
)
elif isinstance(element, VideoMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_video"
)
await self.application.bot.send_video(
chat_id=chat_id, video=await element.get_data(), parse_mode="MarkdownV2"
)
async def start(self):
"""启动 Bot"""
await self.application.initialize()
await self.application.start()
self.me = await self.bot.get_me()
assert self.application.updater
await self.application.updater.start_polling(drop_pending_updates=True)
async def stop(self):
"""停止 Bot"""
assert self.application.updater
try:
if self.application.updater.running:
await self.application.updater.stop()
if self.application.running:
await self.application.stop()
await self.application.shutdown()
except:
pass
async def set_chat_editing_state(
self, chat_sender: ChatSender, is_editing: bool = True
):
"""
设置或取消对话的编辑状态
:param chat_sender: 对话的发送者
:param is_editing: True 表示正在编辑,False 表示取消编辑状态
"""
action = "typing" if is_editing else "cancel"
chat_id = (
chat_sender.user_id
if chat_sender.chat_type == ChatType.C2C
else chat_sender.group_id
)
if not chat_id:
raise ValueError("Unable to get chat_id")
try:
self.logger.debug(
f"Setting chat editing state to {is_editing} for chat_id {chat_id}"
)
if is_editing:
await self.application.bot.send_chat_action(
chat_id=chat_id, action=action
)
else:
# 取消编辑状态时发送一个空操作
await self.application.bot.send_chat_action(
chat_id=chat_id, action=action
)
except Exception as e:
self.logger.warning(f"Failed to set chat editing state: {str(e)}")
@lru_cache(maxsize=10)
async def _cached_get_chat(self, user_id):
"""
带缓存的获取用户信息方法
:param user_id: 用户ID
:return: 用户对象
"""
return await self.application.bot.get_chat(user_id)
async def query_user_profile(self, chat_sender: ChatSender) -> UserProfile:
"""
查询 Telegram 用户资料
:param chat_sender: 用户的聊天发送者信息
:return: 用户资料
"""
try:
# 获取用户 ID
user_id = chat_sender.user_id
# 获取用户对象(使用缓存)
user = await self._cached_get_chat(user_id)
# 构建用户资料
profile = UserProfile( # type: ignore
user_id=str(user_id),
username=user.username,
display_name=get_display_name(user),
full_name=f"{user.first_name or ''} {user.last_name or ''}".strip(),
avatar_url=None, # Telegram 需要额外处理获取头像
)
return profile
except Exception as e:
self.logger.warning(f"Failed to query user profile: {str(e)}")
# 返回部分信息
return UserProfile( # type: ignore
user_id=str(chat_sender.user_id), display_name=chat_sender.display_name
)
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
if not self.me or not self.is_running:
return None
profile_photos = await self.me.get_profile_photos()
if profile_photos and profile_photos.photos:
file_id = profile_photos.photos[0][-1].file_id
file = await self.bot.get_file(file_id)
photo_url = file.file_path
else:
photo_url = None
return UserProfile(
user_id=str(self.me.id),
username=self.me.username,
display_name=get_display_name(self.me),
full_name=f"{self.me.first_name or ''} {self.me.last_name or ''}".strip(),
avatar_url=photo_url,
)
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-telegram-adapter",
version="1.0.0",
description="Telegram adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["python-telegram-bot", "telegramify-markdown"],
entry_points={
"chatgpt_mirai.plugins": [
"telegram = im_telegram_adapter.plugin:TelegramAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/__init__.py
================================================
import os
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
from .adapter import WecomAdapter, WecomConfig
logger = get_logger("Wecom-Adapter")
__all__ = ["WecomAdapter", "WecomConfig"]
class WecomAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"wecom",
WecomAdapter,
WecomConfig,
"企业微信应用 / 微信公众号",
"微信官方消息 API,需要服务器支持接收微信的 Webhook 访问。",
r"""
企业微信应用/微信公众号官方消息 API,需要服务器支持 Webhook 访问。详情配置可参考[微信官方文档](https://open.work.weixin.qq.com/wwopen/manual/detail?t=selfBuildApp)和[Kirara配置文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html#%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1-wecom)。
"""
)
self.web_server.add_static_assets(
"/assets/icons/im/wecom.png", os.path.join(os.path.dirname(__file__), "assets", "wecom.png")
)
def on_start(self):
pass
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/adapter.py
================================================
import asyncio
import base64
import os
import uuid
from io import BytesIO
from typing import Any, List, Optional
import aiohttp
from fastapi import FastAPI, HTTPException, Request, Response
from pydantic import BaseModel, ConfigDict, Field
from starlette.routing import Route
from wechatpy.client import BaseWeChatClient
from wechatpy.exceptions import InvalidSignatureException
from wechatpy.messages import BaseMessage
from wechatpy.replies import create_reply
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import (FileElement, ImageMessage, IMMessage, MessageElement, TextMessage, VideoElement,
VoiceMessage)
from kirara_ai.im.sender import ChatSender
from kirara_ai.logger import HypercornLoggerWrapper, get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch.dispatcher import WorkflowDispatcher
from .delegates import CorpWechatApiDelegate, PublicWechatApiDelegate, WechatApiDelegate
WECOM_TEMP_DIR = os.path.join(os.getcwd(), 'data', 'temp', 'wecom')
WEBHOOK_URL_PREFIX = "/im/webhook/wechat"
def make_webhook_url():
return f"{WEBHOOK_URL_PREFIX}/{str(uuid.uuid4())[:8]}"
def auto_generate_webhook_url(s: dict):
s["readOnly"] = True
s["default"] = make_webhook_url()
s["textType"] = True
class WecomConfig(BaseModel):
"""企业微信配置
文档: https://work.weixin.qq.com/api/doc/90000/90136/91770
"""
app_id: str = Field(title="应用ID", description="见微信侧显示")
secret: str = Field(title="应用Secret", description="见微信侧显示")
token: str = Field(title="Token", description="与微信侧填写保持一致")
encoding_aes_key: str = Field(
title="EncodingAESKey", description="请通过微信侧随机生成")
corp_id: Optional[str] = Field(
title="企业ID", description="企业微信后台显示的企业ID,微信公众号等场景无需填写。", default=None)
webhook_url: str = Field(
title="微信端回调地址",
description="供微信端请求的 Webhook URL,填写在微信端,由系统自动生成,无法修改。",
default_factory=make_webhook_url,
json_schema_extra=auto_generate_webhook_url
)
host: Optional[str] = Field(title="HTTP 服务地址", description="已过时,请删除并使用 webhook_url 代替。",
default=None, json_schema_extra={"hidden_unset": True})
port: Optional[int] = Field(title="HTTP 服务端口", description="已过时,请删除并使用 webhook_url 代替。",
default=None, json_schema_extra={"hidden_unset": True})
model_config = ConfigDict(extra="allow")
def __init__(self, **kwargs: Any):
# 如果 agent_id 存在,则自动使用 agent_id 作为 app_id
if "agent_id" in kwargs:
kwargs["app_id"] = str(kwargs["agent_id"])
super().__init__(**kwargs)
class WeComUtils:
"""企业微信相关的工具类"""
def __init__(self, client: BaseWeChatClient):
self.client = client
self.logger = get_logger("WeComUtils")
@property
def access_token(self) -> Optional[str]:
return self.client.access_token
async def download_and_save_media(self, media_id: str, file_name: str) -> Optional[str]:
"""下载并保存媒体文件到本地"""
file_path = os.path.join(WECOM_TEMP_DIR, file_name)
try:
media_data = await self.download_media(media_id)
if media_data:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as f:
f.write(media_data)
return file_path
except Exception as e:
self.logger.error(f"Failed to save media: {str(e)}")
return None
async def download_media(self, media_id: str) -> Optional[bytes]:
"""下载企业微信的媒体文件"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/media/get?access_token={self.access_token}&media_id={media_id}"
try:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
return await response.read()
self.logger.error(
f"Failed to download media: {response.status}")
except Exception as e:
self.logger.error(f"Failed to download media: {str(e)}")
return None
class WecomAdapter(IMAdapter):
"""企业微信适配器"""
dispatcher: WorkflowDispatcher
web_server: WebServer
def __init__(self, config: WecomConfig):
self.wecom_utils = None
self.api_delegate: Optional[WechatApiDelegate] = None
self.config = config
if self.config.host:
self.app = FastAPI()
else:
self.app = self.web_server.app
self.logger = get_logger("Wecom-Adapter")
self.is_running = False
if not self.config.host:
self.config.host = None
self.config.port = None
elif not self.config.port:
self.config.port = 15650
if not self.config.webhook_url:
self.config.webhook_url = make_webhook_url()
self.reply_tasks: dict[str, asyncio.Task] = {}
# 根据配置选择合适的API代理
self.setup_wechat_api()
def setup_wechat_api(self):
"""根据配置设置微信API代理"""
if self.config.corp_id:
self.api_delegate = CorpWechatApiDelegate()
else:
self.api_delegate = PublicWechatApiDelegate()
self.api_delegate.setup_api(self.config)
# 设置工具类
self.wecom_utils = WeComUtils(self.api_delegate.client)
def setup_routes(self):
if self.config.host:
webhook_url = '/wechat'
else:
webhook_url = self.config.webhook_url
# unregister old route if exists
for route in self.app.routes:
if isinstance(route, Route) and route.path == webhook_url:
self.app.routes.remove(route)
@self.app.get(webhook_url)
async def handle_check_request(request: Request):
"""处理 GET 请求"""
if not self.is_running:
self.logger.warning("Wecom-Adapter is not running, skipping check request.")
raise HTTPException(status_code=404)
assert self.api_delegate is not None
signature = request.query_params.get("msg_signature", "")
if not signature:
signature = request.query_params.get("signature", "")
timestamp = request.query_params.get("timestamp", "")
nonce = request.query_params.get("nonce", "")
echo_str = request.query_params.get("echostr", "")
try:
echo_str = self.api_delegate.check_signature(
signature, timestamp, nonce, echo_str
)
return Response(content=echo_str, media_type="text/plain")
except InvalidSignatureException:
self.logger.error("failed to check signature, please check your settings.")
raise HTTPException(status_code=403)
@self.app.post(webhook_url)
async def handle_message(request: Request):
"""处理 POST 请求"""
if not self.is_running:
self.logger.warning("Wecom-Adapter is not running, skipping message request.")
raise HTTPException(status_code=404)
assert self.api_delegate is not None
assert self.wecom_utils is not None
signature = request.query_params.get("msg_signature", "")
if not signature:
signature = request.query_params.get("signature", "")
timestamp = request.query_params.get("timestamp", "")
nonce = request.query_params.get("nonce", "")
try:
msg_str = self.api_delegate.decrypt_message(
await request.body(), signature, timestamp, nonce
)
except InvalidSignatureException:
self.logger.error("failed to check signature, please check your settings.")
raise HTTPException(status_code=403)
msg: BaseMessage = self.api_delegate.parse_message(msg_str)
if msg.id in self.reply_tasks:
self.logger.debug(f"skip processing due to duplicate msgid: {msg.id}")
reply = await self.reply_tasks[msg.id]
del self.reply_tasks[msg.id]
return Response(content=create_reply(reply, msg, render=True), media_type="text/xml")
# 预处理媒体消息
media_path = None
if msg.type in ["voice", "video", "file"]:
media_id = msg.media_id
file_name = f"temp_{msg.type}_{media_id}.{msg.type}"
media_path = await self.wecom_utils.download_and_save_media(media_id, file_name)
# 转换消息
message = await self.convert_to_message(msg, media_path)
self.reply_tasks[msg.id] = asyncio.Future() # type: ignore
message.sender.raw_metadata["reply"] = self.reply_tasks[msg.id] # type: ignore
# 分发消息
asyncio.create_task(self.dispatcher.dispatch(self, message))
reply = await message.sender.raw_metadata["reply"]
del message.sender.raw_metadata["reply"]
return Response(content=create_reply(reply, msg, render=True), media_type="text/xml")
async def convert_to_message(self, raw_message: Any, media_path: Optional[str] = None) -> IMMessage:
"""将企业微信消息转换为统一消息格式"""
# 企业微信应用似乎没有群聊的概念,所以这里只能用单聊
sender = ChatSender.from_c2c_chat(
raw_message.source, raw_message.source)
message_elements: List[MessageElement] = []
raw_message_dict = raw_message.__dict__
if raw_message.type == "text":
message_elements.append(TextMessage(text=raw_message.content))
elif raw_message.type == "image":
message_elements.append(ImageMessage(url=raw_message.image))
elif raw_message.type == "voice" and media_path:
message_elements.append(VoiceMessage(url=media_path))
elif raw_message.type == "video" and media_path:
message_elements.append(VideoElement(path=media_path))
elif raw_message.type == "file" and media_path:
message_elements.append(FileElement(path=media_path))
elif raw_message.type == "location":
location_text = f"[Location] {raw_message.label} (X: {raw_message.location_x}, Y: {raw_message.location_y})"
message_elements.append(TextMessage(text=location_text))
elif raw_message.type == "link":
link_text = f"[Link] {raw_message.title}: {raw_message.description} ({raw_message.url})"
message_elements.append(TextMessage(text=link_text))
else:
message_elements.append(TextMessage(
text=f"Unsupported message type: {raw_message.type}"))
return IMMessage(
sender=sender,
message_elements=message_elements,
raw_message=raw_message_dict,
)
async def _send_text(self, user_id: str, text: str):
"""发送文本消息"""
assert self.api_delegate is not None
try:
return await self.api_delegate.send_text(self.config.app_id, user_id, text)
except Exception as e:
self.logger.error(f"Failed to send text message: {e}")
raise e
async def _send_media(self, user_id: str, media_data: str, media_type: str):
"""发送媒体消息的通用方法"""
assert self.api_delegate is not None
try:
media_bytes = BytesIO(base64.b64decode(media_data))
return await self.api_delegate.send_media(self.config.app_id, user_id, media_type, media_bytes)
except Exception as e:
self.logger.error(f"Failed to send {media_type} message: {e}")
raise e
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""发送消息到企业微信"""
user_id = recipient.user_id
res = None
try:
for element in message.message_elements:
if isinstance(element, TextMessage) and element.text:
res = await self._send_text(user_id, element.text)
elif isinstance(element, ImageMessage) and element.url:
res = await self._send_media(user_id, element.url, "image")
elif isinstance(element, VoiceMessage) and element.url:
res = await self._send_media(user_id, element.url, "voice")
elif isinstance(element, VideoElement) and element.path:
res = await self._send_media(user_id, element.path, "video")
elif isinstance(element, FileElement) and element.path:
res = await self._send_media(user_id, element.path, "file")
if res:
print(res)
if recipient.raw_metadata and "reply" in recipient.raw_metadata:
recipient.raw_metadata["reply"].set_result(None)
except Exception as e:
if 'Error code: 48001' in str(e):
# 未开通主动回复能力
if recipient.raw_metadata and "reply" in recipient.raw_metadata:
self.logger.warning("未开通主动回复能力,将采用被动回复消息 API,此模式下只能回复一条消息。")
recipient.raw_metadata["reply"].set_result(message.content)
else:
self.logger.warning("未开通主动回复能力,且不在上下文中,无法发送消息。")
async def _start_standalone_server(self):
"""启动服务"""
from hypercorn.asyncio import serve
from hypercorn.config import Config
from hypercorn.logging import Logger
config = Config()
config.bind = [f"{self.config.host}:{self.config.port}"]
# config._log = get_logger("Wecom-API")
# hypercorn 的 logger 需要做转换
config._log = Logger(config)
config._log.access_logger = HypercornLoggerWrapper(self.logger) # type: ignore
config._log.error_logger = HypercornLoggerWrapper(self.logger) # type: ignore
self.server_task = asyncio.create_task(serve(self.app, config)) # type: ignore
async def _stop_standalone_server(self):
"""停止服务"""
if hasattr(self, "server_task"):
self.server_task.cancel()
try:
await self.server_task
except asyncio.CancelledError:
pass
except Exception as e:
self.logger.error(f"Error during server shutdown: {e}")
async def start(self):
self.setup_wechat_api()
if self.config.host:
self.logger.warning("正在使用过时的启动模式,请尽快更新为 Webhook 模式。")
await self._start_standalone_server()
self.setup_routes()
self.is_running = True
self.logger.info("Wecom-Adapter 启动成功")
async def stop(self):
if self.config.host:
await self._stop_standalone_server()
self.is_running = False
self.logger.info("Wecom-Adapter 停止成功")
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/delegates.py
================================================
from abc import ABC, abstractmethod
from io import BytesIO
from typing import TYPE_CHECKING, Any
from wechatpy.messages import BaseMessage
from kirara_ai.logger import get_logger
if TYPE_CHECKING:
from .adapter import WecomConfig
class WechatApiDelegate(ABC):
"""微信API代理接口,用于处理不同类型的微信API调用"""
@abstractmethod
def setup_api(self, config: "WecomConfig"):
"""设置API相关组件"""
@abstractmethod
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证签名"""
@abstractmethod
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密消息"""
@abstractmethod
def parse_message(self, message: str) -> BaseMessage:
"""解析消息"""
@abstractmethod
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送文本消息"""
@abstractmethod
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送媒体消息"""
class CorpWechatApiDelegate(WechatApiDelegate):
"""企业微信API代理实现"""
def setup_api(self, config: "WecomConfig"):
"""设置企业微信API相关组件"""
from wechatpy.enterprise import parse_message
from wechatpy.enterprise.client import WeChatClient
from wechatpy.enterprise.crypto import WeChatCrypto
self.crypto = WeChatCrypto(
config.token, config.encoding_aes_key, config.corp_id
)
self.client = WeChatClient(config.corp_id, config.secret)
self.parse_message_func = parse_message
self.logger = get_logger("CorpWechatApiDelegate")
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证企业微信签名"""
return self.crypto.check_signature(signature, timestamp, nonce, echo_str)
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密企业微信消息"""
return self.crypto.decrypt_message(message, signature, timestamp, nonce)
def parse_message(self, message: str) -> BaseMessage:
"""解析企业微信消息"""
return self.parse_message_func(message) # type: ignore
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送企业微信文本消息"""
return self.client.message.send_text(app_id, user_id, text)
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送企业微信媒体消息"""
media_id = self.client.media.upload(media_type, media_bytes)["media_id"]
send_method = getattr(self.client.message, f"send_{media_type}")
return send_method(app_id, user_id, media_id)
class PublicWechatApiDelegate(WechatApiDelegate):
"""公众号微信API代理实现"""
def setup_api(self, config: "WecomConfig"):
"""设置公众号API相关组件"""
from wechatpy import WeChatClient
from wechatpy.crypto import WeChatCrypto
from wechatpy.parser import parse_message
self.crypto = WeChatCrypto(
config.token, config.encoding_aes_key, config.app_id
)
self.client = WeChatClient(config.app_id, config.secret)
self.parse_message_func = parse_message
self.logger = get_logger("PublicWechatApiDelegate")
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证公众号签名"""
from wechatpy.utils import check_signature as wechat_check_signature
wechat_check_signature(self.crypto.token, signature, timestamp, nonce)
return echo_str
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密公众号消息"""
return self.crypto.decrypt_message(message, signature, timestamp, nonce)
def parse_message(self, message: str) -> BaseMessage:
"""解析公众号消息"""
return self.parse_message_func(message) # type: ignore
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送公众号文本消息"""
# 公众号API不需要app_id参数
return self.client.message.send_text(user_id, text)
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送公众号媒体消息"""
media_id = self.client.media.upload(media_type, media_bytes)["media_id"]
send_method = getattr(self.client.message, f"send_{media_type}")
# 公众号API不需要app_id参数
return send_method(user_id, media_id)
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-wecom-adapter",
version="1.0.0",
description="WeCom adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["wechatpy", "pycryptodome"],
entry_points={
"chatgpt_mirai.plugins": ["wecom = im_wecom_adapter.plugin:WeComAdapterPlugin"]
},
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/__init__.py
================================================
from .alibabacloud_adapter import AlibabaCloudAdapter, AlibabaCloudConfig
from .claude_adapter import ClaudeAdapter, ClaudeConfig
from .deepseek_adapter import DeepSeekAdapter, DeepSeekConfig
from .gemini_adapter import GeminiAdapter, GeminiConfig
from .minimax_adapter import MinimaxAdapter, MinimaxConfig
from .moonshot_adapter import MoonshotAdapter, MoonshotConfig
from .ollama_adapter import OllamaAdapter, OllamaConfig
from .openai_adapter import OpenAIAdapter, OpenAIConfig
from .openrouter_adapter import OpenRouterAdapter, OpenRouterConfig
from .siliconflow_adapter import SiliconFlowAdapter, SiliconFlowConfig
from .tencentcloud_adapter import TencentCloudAdapter, TencentCloudConfig
from .volcengine_adapter import VolcengineAdapter, VolcengineConfig
from .mistral_adapter import MistralAdapter, MistralConfig
from .voyage_adapter import VoyageAdapter, VoyageConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
logger = get_logger("LLMPresetAdapters")
class LLMPresetAdaptersPlugin(Plugin):
def __init__(self):
pass
def on_load(self):
self.llm_registry.register(
"OpenAI", OpenAIAdapter, OpenAIConfig
)
self.llm_registry.register(
"DeepSeek", DeepSeekAdapter, DeepSeekConfig
)
self.llm_registry.register(
"Gemini", GeminiAdapter, GeminiConfig
)
self.llm_registry.register(
"Ollama", OllamaAdapter, OllamaConfig
)
self.llm_registry.register(
"Claude", ClaudeAdapter, ClaudeConfig
)
self.llm_registry.register(
"SiliconFlow", SiliconFlowAdapter, SiliconFlowConfig
)
self.llm_registry.register(
"TencentCloud", TencentCloudAdapter, TencentCloudConfig
)
self.llm_registry.register(
"AlibabaCloud", AlibabaCloudAdapter, AlibabaCloudConfig
)
self.llm_registry.register(
"Moonshot", MoonshotAdapter, MoonshotConfig
)
self.llm_registry.register(
"OpenRouter", OpenRouterAdapter, OpenRouterConfig
)
self.llm_registry.register(
"Minimax", MinimaxAdapter, MinimaxConfig
)
self.llm_registry.register(
"Volcengine", VolcengineAdapter, VolcengineConfig
)
self.llm_registry.register(
"Mistral", MistralAdapter, MistralConfig
)
logger.info("LLMPresetAdaptersPlugin loaded")
def on_start(self):
logger.info("LLMPresetAdaptersPlugin started")
def on_stop(self):
logger.info("LLMPresetAdaptersPlugin stopped")
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/alibabacloud_adapter.py
================================================
from kirara_ai.config.global_config import ModelConfig
from .openai_adapter import OpenAIAdapter, OpenAIConfig
from .utils import guess_qwen_model
class AlibabaCloudConfig(OpenAIConfig):
api_base: str = "https://dashscope.aliyuncs.com/compatible-mode/v1"
class AlibabaCloudAdapter(OpenAIAdapter):
def __init__(self, config: AlibabaCloudConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
models = await self.get_models()
all_models: list[ModelConfig] = []
for model in models:
guess_result = guess_qwen_model(model)
if guess_result is None:
continue
all_models.append(ModelConfig(id=model, type=guess_result[0].value, ability=guess_result[1]))
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/claude_adapter.py
================================================
import asyncio
import base64
from typing import Any, Dict, List
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing.decorator import trace_llm_chat
from .utils import generate_tool_call_id, pick_tool_calls
class ClaudeConfig(BaseModel):
api_key: str
api_base: str = "https://api.anthropic.com/v1"
model_config = ConfigDict(frozen=True)
async def convert_llm_chat_message_to_claude_message(messages: list[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
content: List[Dict[str, Any]] = []
for msg in [msg for msg in messages if msg.role in ["user", "assistant", "tool"]]:
parts: List[Dict[str, Any]] = []
for part in msg.content:
if isinstance(part, LLMChatTextContent):
parts.append({"type": "text", "text": part.text})
elif isinstance(part, LLMToolResultContent):
parts.append(await resolve_tool_result(part, media_manager))
elif isinstance(part, LLMToolCallContent):
continue
elif isinstance(part, LLMChatImageContent):
media = media_manager.get_media(part.media_id)
if media is None:
raise ValueError(f"Media {part.media_id} not found")
parts.append({"source": {"media_type": str(media.mime_type), "data": await media.get_base64()}, "type": "image"})
content.append({
"role": "user" if msg.role == "tool" else msg.role,
"content": parts
})
return content
def convert_tools_to_claude_format(tools: list[Tool]) -> list[dict]:
# 使用 pydantic 的 model_dump 方法,高级排除项`exclude`排除 openai 专属项
return [tool.model_dump(exclude={"strict": True, 'parameters': {'additionalProperties': True}}) for tool in tools]
async def resolve_tool_result(element: LLMToolResultContent, media_manager: MediaManager) -> dict:
tool_result: List[Dict[str, Any]] = []
for item in element.content:
if isinstance(item, tools.TextContent):
tool_result.append({"type": "text", "text": item.text})
elif isinstance(item, tools.MediaContent):
media = media_manager.get_media(item.media_id)
if media is None:
raise ValueError(
f"Media {item.media_id} not found")
tool_result.append({
"type": media.media_type.value.lower(),
"source": {
"type": "base64", "media_type": str(media.mime_type), "data": await media.get_base64()
}
})
return {"type": "tool_result", "tool_use_id": element.id, "content": tool_result, "is_error": element.isError}
class ClaudeAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol):
media_manager: MediaManager
def __init__(self, config: ClaudeConfig):
self.config = config
self.logger = get_logger("ClaudeAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/messages"
headers = {
"x-api-key": self.config.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
}
# Claude 的系统消息比较特殊
system_messages = [msg for msg in req.messages if msg.role == "system"]
if system_messages:
system_message = system_messages[0].content
else:
system_message = None
# 构建请求数据
data = {
"model": req.model,
"messages": asyncio.run(convert_llm_chat_message_to_claude_message(req.messages, self.media_manager)),
"max_tokens": req.max_tokens,
"system": system_message,
"temperature": req.temperature,
"top_p": req.top_p,
"stream": req.stream,
# claude tools格式中参数部分命名与openai api不同,不能简单使用model_dumps,在这里进行转换
"tools": convert_tools_to_claude_format(req.tools) if req.tools else None,
# claude默认如果使用了tools字段,这里需要指定tool_choice, claude默认为{"type": "auto"}.
# 可考虑后续给用户暴露此接口, 目前此处各模型定义不太统一
"tool_choice": {"type": "auto"} if req.tools else None,
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
content: List[LLMChatContentPartType] = []
for res in response_data["content"]:
if res["type"] == "text":
content.append(LLMChatTextContent(text=res["text"]))
elif res["type"] == "image":
image_data = base64.b64decode(res["source"]["data"])
media = asyncio.run(self.media_manager.register_from_data(
image_data, res["source"]["media_type"], source="claude response"))
content.append(LLMChatImageContent(media_id=media))
elif res["type"] == "tool_use":
# tool_call 时 只会额外返回一个 text 的深度思考。
content.append(LLMToolCallContent(id=res.get("id", generate_tool_call_id(res["name"])), name=res["name"], parameters=res.get("input", None)))
usage_data = response_data.get("usage", {})
input_tokens = usage_data.get("input_tokens", 0)
output_tokens = usage_data.get("output_tokens", 0)
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=input_tokens,
completion_tokens=output_tokens,
total_tokens=input_tokens + output_tokens,
),
message=Message(
content=content,
role=response_data.get("role", "assistant"),
finish_reason=response_data.get("stop_reason", "stop"),
# claude tool_call混合在content字段中,需要提取
tool_calls=pick_tool_calls(content),
)
)
async def auto_detect_models(self) -> list[str]:
# {
# "data": [
# {
# "type": "model",
# "id": "claude-3-5-sonnet-20241022",
# "display_name": "Claude 3.5 Sonnet (New)",
# "created_at": "2024-10-22T00:00:00Z"
# }
# ],
# "has_more": true,
# "first_id": "",
# "last_id": ""
# }
# claude3 全系支持工具调用,支持多模态tool_result
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"x-api-key": self.config.api_key}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data["data"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/deepseek_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
class DeepSeekConfig(OpenAIConfig):
api_base: str = "https://api.deepseek.com/v1"
class DeepSeekAdapter(OpenAIAdapterChatBase):
def __init__(self, config: DeepSeekConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/gemini_adapter.py
================================================
import asyncio
import base64
from typing import Any, Dict, List, Literal, cast
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tool
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent, RoleType)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.media import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .utils import generate_tool_call_id, pick_tool_calls
SAFETY_SETTINGS = [{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_CIVIC_INTEGRITY",
"threshold": "BLOCK_NONE"
}]
# POST 模式支持最大 20 MB 的 inline data
INLINE_LIMIT_SIZE = 1024 * 1024 * 20
IMAGE_MODAL_MODELS = [
"gemini-2.0-flash-exp"
]
class GeminiConfig(BaseModel):
api_key: str
api_base: str = "https://generativelanguage.googleapis.com/v1beta"
model_config = ConfigDict(frozen=True)
async def convert_non_tool_message(msg: LLMChatMessage, media_manager: MediaManager) -> dict:
parts: List[Dict[str, Any]] = []
elements = cast(list[LLMChatContentPartType], msg.content)
for element in elements:
if isinstance(element, LLMChatTextContent):
parts.append({"text": element.text})
elif isinstance(element, LLMChatImageContent):
media = media_manager.get_media(element.media_id)
if media is None:
raise ValueError(f"Media {element.media_id} not found")
parts.append({
"inline_data": {
"mime_type": str(media.mime_type),
"data": await media.get_base64()
}
})
elif isinstance(element, LLMToolCallContent):
parts.append({
"functionCall": {
"name": element.name,
"args": element.parameters
}
})
return {
"role": "model" if msg.role == "assistant" else "user",
"parts": parts
}
async def convert_llm_chat_message_to_gemini_message(msg: LLMChatMessage, media_manager: MediaManager) -> dict:
if msg.role in ["user", "assistant", "system"]:
return await convert_non_tool_message(msg, media_manager)
elif msg.role == "tool":
results = cast(list[LLMToolResultContent], msg.content)
return {"role": "user", "parts": [resolve_tool_results(result) for result in results]}
else:
raise ValueError(f"Invalid role: {msg.role}")
async def convert_all_messages_to_gemini_format(messages: List[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
# gather需要先用异步函数封装,然后才能使用asyncio.run()
return await asyncio.gather(*[convert_llm_chat_message_to_gemini_message(msg, media_manager) for msg in messages])
def convert_tools_to_gemini_format(tools: list[Tool]) -> list[dict[Literal["function_declarations"], list[dict]]]:
# 定义允许的字段结构
allowed_keys = {
"name": True,
"description": True,
"parameters": {
"type": True,
"properties": {
"*": {
"type": True,
"title": True,
"description": True,
"enum": True,
"default": True,
"items": True,
}
},
"required": True
}
}
def filter_dict(data: dict, allowed: dict) -> dict:
"""递归过滤字典,只保留允许的字段"""
result = {}
for key, value in allowed.items():
if key == "*" and isinstance(value, dict):
# 处理通配符情况,适用于 properties 字典
for data_key, data_value in data.items():
if isinstance(data_value, dict):
result[data_key] = filter_dict(data_value, value)
else:
result[data_key] = data_value
elif key in data:
if isinstance(value, dict) and isinstance(data[key], dict):
# 如果是嵌套字典,递归处理
result[key] = filter_dict(data[key], value)
else:
# 否则直接保留值
result[key] = data[key]
return result
function_declarations = []
for tool in tools:
# 将Tool对象转换为字典
tool_dict = tool.model_dump()
# 过滤出需要的字段
filtered_tool = filter_dict(tool_dict, allowed_keys)
function_declarations.append(filtered_tool)
return [{"function_declarations": function_declarations}]
def resolve_tool_results(element: LLMToolResultContent) -> dict:
# 全部拼接成字符串
output = ""
for content in element.content:
if isinstance(content, tool.TextContent):
output += content.text
elif isinstance(content, tool.MediaContent):
# FIXME: Gemini 不支持 response 传媒体内容,需要从额外的 message 中传入,类似于 **篡改记忆**
output += f""
return {
"functionResponse": {
"name": element.name,
"response": {"error": output} if element.isError else {"output": output}
}
}
class GeminiAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol, LLMEmbeddingProtocol):
media_manager: MediaManager
def __init__(self, config: GeminiConfig):
self.config = config
self.logger = get_logger("GeminiAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/models/{req.model}:generateContent?key={self.config.api_key}"
headers = {
# 这里的 api key 验证方法和 api reference 不一致。本次处理暂时按照api reference写法更正。 Warning: 未进行实际测试
# "x-goog-api-key": self.config.api_key,
"Content-Type": "application/json",
}
response_modalities = ["text"]
if req.model in IMAGE_MODAL_MODELS:
response_modalities.append("image")
data = {
"contents": asyncio.run(convert_all_messages_to_gemini_format(req.messages, self.media_manager)),
"generationConfig": {
"temperature": req.temperature,
"topP": req.top_p,
"topK": 40,
"maxOutputTokens": req.max_tokens,
"stopSequences": req.stop,
"responseModalities": response_modalities,
},
"safetySettings": SAFETY_SETTINGS,
"tools": convert_tools_to_gemini_format(req.tools) if req.tools else None,
}
self.logger.debug(f"Gemini request: {data}")
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
response = self._post_with_retry(api_url, json=data, headers=headers)
try:
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
content: List[LLMChatContentPartType] = []
role = "assistant"
for part in response_data["candidates"][0]["content"]["parts"]:
if "text" in part:
content.append(LLMChatTextContent(text=part["text"]))
elif "inlineData" in part:
decoded_image_data = base64.b64decode(part["inlineData"]["data"])
media = asyncio.run(
self.media_manager.register_from_data(
data=decoded_image_data,
format=part["inlineData"]["mimeType"].removeprefix(
"image/"),
source="gemini response")
)
content.append(LLMChatImageContent(media_id=media))
elif "functionCall" in part:
content.append(
LLMToolCallContent(
id=generate_tool_call_id(part["functionCall"]["name"]),
name=part["functionCall"]["name"],
parameters=part["functionCall"].get("args", None)
)
)
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=response_data["usageMetadata"].get(
"promptTokenCount"),
cached_tokens=response_data["usageMetadata"].get(
"cachedContentTokenCount"),
completion_tokens=sum([modality.get(
"tokenCount", 0) for modality in response_data.get("promptTokensDetails", [])]),
total_tokens=response_data["usageMetadata"].get(
"totalTokenCount"),
),
message=Message(
content=content,
role=cast(RoleType, role),
finish_reason=response_data["candidates"][0].get("finishReason"),
tool_calls=pick_tool_calls(content)
),
)
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# 使用批量嵌入接口,单次嵌入接口:embedContent
# gemini 的 API reference 是这样定义的很奇怪,居然敢在 url 中传递key
api_url = f"{self.config.api_base}/models/{req.model}:batchEmbedContents?key={self.config.api_key}"
headers = {
"Content-Type": "application/json",
}
# 目前 gemini 没有一个嵌入模型支持多模态嵌入
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
raise ValueError("gemini does not support multi-modal embedding")
inputs = cast(list[LLMChatTextContent], req.inputs)
data = [
{
"model": req.model,
"content": {
"parts": [{"text": input.text}]
},
"outputDimensionality": req.dimension
} for input in inputs
]
# 移除None字段
data = [{ k:v for k,v in item.items() if v is not None} for item in data]
response = self._post_with_retry(url=api_url,json={"requests": data}, headers=headers)
try:
# {
# "embeddings": [
# {"values": [0.1, ...]},
# ...
# ]
# }
response_data: dict[Literal["embeddings"],list[dict[Literal["values"], list[float]]]] = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
return LLMEmbeddingResponse(
# gemini不返回usage
vectors=[data["values"] for data in response_data["embeddings"]]
)
async def auto_detect_models(self) -> list[ModelConfig]:
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"x-goog-api-key": self.config.api_key}
) as response:
if response.status != 200:
self.logger.error(f"获取模型列表失败: {await response.text()}")
response.raise_for_status()
response_data = await response.json()
return [
ModelConfig(id=model["name"].removeprefix("models/"), type=ModelType.LLM.value, ability=LLMAbility.TextChat.value)
for model in response_data["models"]
if "generateContent" in model["supportedGenerationMethods"]
]
def _post_with_retry(self, url: str, json: dict, headers: dict, retry_count: int = 3) -> requests.Response: # type: ignore
for i in range(retry_count):
try:
response = requests.post(url, json=json, headers=headers)
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
if i == retry_count - 1:
self.logger.error(
f"API Response: {response.text if 'response' in locals() else 'No response'}")
raise e
else:
self.logger.warning(
f"Request failed, retrying {i+1}/{retry_count}: {e}")
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/minimax_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
class MinimaxConfig(OpenAIConfig):
api_base: str = "https://api.minimax.chat/v1"
class MinimaxAdapter(OpenAIAdapterChatBase):
def __init__(self, config: MinimaxConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/mistral_adapter.py
================================================
import aiohttp
from kirara_ai.llm.adapter import AutoDetectModelsProtocol
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class MistralConfig(OpenAIConfig):
api_base: str = "https://api.mistral.ai/v1"
class MistralAdapter(OpenAIAdapter, AutoDetectModelsProtocol):
def __init__(self, config: MistralConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[str]:
# Mistral API 响应格式:
# {
# "object": "list",
# "data": [
# {
# "id": "string",
# "object": "model",
# "created": 0,
# "owned_by": "mistralai",
# "capabilities": {
# "completion_chat": true,
# "completion_fim": false,
# "function_calling": true,
# "fine_tuning": false,
# "vision": false
# },
# "name": "string",
# ...
# }
# ]
# }
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
# 只返回支持聊天功能的模型
return [
model["id"]
for model in response_data["data"]
if model.get("capabilities", {}).get("completion_chat", False)
]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/moonshot_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
# https://platform.moonshot.cn/docs/intro#%E6%96%87%E6%9C%AC%E7%94%9F%E6%88%90%E6%A8%A1%E5%9E%8B
# TODO: implement feature usages
class MoonshotConfig(OpenAIConfig):
api_base: str = "https://api.moonshot.cn/v1"
class MoonshotAdapter(OpenAIAdapterChatBase):
def __init__(self, config: MoonshotConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/ollama_adapter.py
================================================
import asyncio
from typing import Any, List, cast
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .openai_adapter import convert_tools_to_openai_format
from .utils import generate_tool_call_id, pick_tool_calls
class OllamaConfig(BaseModel):
api_base: str = "http://localhost:11434"
model_config = ConfigDict(frozen=True)
async def resolve_media_ids(media_ids: list[str], media_manager: MediaManager) -> List[str]:
result = []
for media_id in media_ids:
media = media_manager.get_media(media_id)
if media is not None:
base64_data = await media.get_base64()
result.append(base64_data)
return result
def convert_llm_response(response_data: dict[str, dict[str, Any]]) -> list[LLMChatContentPartType]:
# 通过实践证明 llm 调用工具时 content 字段为空字符串没有任何有效信息不进行记录
if calls := response_data["message"].get("tool_calls", None):
return [LLMToolCallContent(
id=generate_tool_call_id(call["function"]["name"]),
name=call["function"]["name"],
parameters=call["function"].get("arguments", None)
) for call in calls
]
else:
return [LLMChatTextContent(text=response_data["message"].get("content", ""))]
def convert_non_tool_message(msg: LLMChatMessage, media_manager: MediaManager, loop: asyncio.AbstractEventLoop) -> dict[str, Any]:
text_content = ""
images: list[str] = []
tool_calls: list[dict[str, Any]] = []
messages: dict[str, Any] = {
"role": msg.role,
"content": "",
}
for part in msg.content:
if isinstance(part, LLMChatTextContent):
text_content += part.text
elif isinstance(part, LLMChatImageContent):
images.append(part.media_id)
elif isinstance(part, LLMToolCallContent):
tool_calls.append({
"function": {
"name": part.name,
"arguments": part.parameters,
}
})
messages["content"] = text_content
if images:
messages["images"] = loop.run_until_complete(
resolve_media_ids(images, media_manager))
if tool_calls:
messages["tool_calls"] = tool_calls
return messages
def convert_tool_result_message(msg: LLMChatMessage, media_manager: MediaManager, loop: asyncio.AbstractEventLoop) -> list[dict]:
"""
将工具调用结果转换为 Ollama 格式
"""
elements = cast(list[LLMToolResultContent], msg.content)
messages = []
for element in elements:
output = ""
for item in element.content:
if isinstance(item, tools.TextContent):
output += f"{item.text}\n"
elif isinstance(item, tools.MediaContent):
output += f"\n"
if element.isError:
output = f"Error: {element.name}\n{output}"
messages.append({"role": "tool", "content": output,
"tool_call_id": element.id})
return messages
def convert_tools_to_ollama_format(tools: list[Tool]) -> list[dict]:
# 这里将其独立出来方便应对后续接口改动
return convert_tools_to_openai_format(tools)
class OllamaAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol, LLMEmbeddingProtocol):
def __init__(self, config: OllamaConfig):
self.config = config
self.logger = get_logger("OllamaAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/api/chat"
headers = {"Content-Type": "application/json"}
# 将消息转换为 Ollama 格式
messages = []
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
for msg in req.messages:
# 收集每条消息中的文本内容和图像
if msg.role == "tool":
messages.extend(convert_tool_result_message(
msg, self.media_manager, loop))
else:
messages.append(convert_non_tool_message(
msg, self.media_manager, loop))
data = {
"model": req.model,
"messages": messages,
"stream": False,
"options": {
"temperature": req.temperature,
"top_p": req.top_p,
"num_predict": req.max_tokens,
"stop": req.stop,
"tools": convert_tools_to_ollama_format(req.tools) if req.tools else None,
},
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
if "options" in data:
data["options"] = {
k: v for k, v in data["options"].items() if v is not None # type: ignore
}
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
# https://github.com/ollama/ollama/blob/main/docs/api.md#generate-a-chat-completion
content = convert_llm_response(response_data)
return LLMChatResponse(
model=req.model,
message=Message(
content=content,
role="assistant",
finish_reason="stop",
tool_calls=pick_tool_calls(content),
),
usage=Usage(
prompt_tokens=response_data['prompt_eval_count'],
completion_tokens=response_data['eval_count'],
total_tokens=response_data['prompt_eval_count'] +
response_data['eval_count'],
)
)
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# https://github.com/ollama/ollama/blob/main/docs/api.md#generate-embeddings api文档地址
api_url = f"{self.config.api_base}/api/embed"
headers = {"Content-Type": "application/json"}
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
raise ValueError("ollama api does not support multi-modal embedding")
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"model": req.model,
"input": [input.text for input in inputs],
# 禁止自动截断输入数据用以适应上下文长度
"truncate": req.truncate
}
data = { k:v for k, v in data.items() if v is not None }
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=response_data["embeddings"],
usage=Usage(
prompt_tokens=response_data.get("prompt_eval_count", 0)
)
)
async def auto_detect_models(self) -> list[ModelConfig]:
api_url = f"{self.config.api_base}/api/tags"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(api_url) as response:
response.raise_for_status()
response_data = await response.json()
return [ModelConfig(id=tag["name"], type=ModelType.LLM.value, ability=LLMAbility.TextChat.value) for tag in response_data["models"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/openai_adapter.py
================================================
import asyncio
import json
from typing import Any, Dict, List, cast, Literal, TypedDict
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.logger import get_logger
from kirara_ai.media import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .utils import guess_openai_model, pick_tool_calls
logger = get_logger("OpenAIAdapter")
async def convert_parts_factory(messages: LLMChatMessage, media_manager: MediaManager) -> list[dict]:
if messages.role == "tool":
# typing.cast 指定类型,避免mypy报错
elements = cast(list[LLMToolResultContent], messages.content)
outputs = []
for element in elements:
# 保证 content 为一个字符串
output = ""
for content in element.content:
if isinstance(content, tools.TextContent):
output = content.text
elif isinstance(content, tools.MediaContent):
media = media_manager.get_media(content.media_id)
if media is None:
raise ValueError(f"Media {content.media_id} not found")
output += f""
else:
raise ValueError(f"Unsupported content type: {type(content)}")
if element.isError:
output = f"Error: {element.name}\n{output}"
outputs.append({
"role": "tool",
"tool_call_id": element.id,
"content": output,
})
return outputs
else:
parts: list[dict[str, Any]] = []
elements = cast(list[LLMChatContentPartType], messages.content)
tool_calls: list[dict[str, Any]] = []
for element in elements:
if isinstance(element, LLMChatTextContent):
parts.append(element.model_dump(mode="json"))
elif isinstance(element, LLMChatImageContent):
media = media_manager.get_media(element.media_id)
if media is None:
raise ValueError(f"Media {element.media_id} not found")
parts.append({
"type": "image_url",
"image_url": {
"url": await media.get_base64_url()
}
})
elif isinstance(element, LLMToolCallContent):
tool_calls.append({
"type": "function",
"id": element.id,
"function": {
"name": element.name,
"arguments": json.dumps(element.parameters or {}, ensure_ascii=False),
}
})
response: Dict[str, Any] = {"role": messages.role}
if parts:
response["content"] = parts
if tool_calls:
response["tool_calls"] = tool_calls
return [response]
async def convert_llm_chat_message_to_openai_message(messages: list[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
# gather 必须先包一层异步函数,转化为协程对象, 否侧报错
results = await asyncio.gather(*[convert_parts_factory(msg, media_manager) for msg in messages])
# 扁平化结果, 展开所有列表
return [item for sublist in results for item in sublist]
def convert_tools_to_openai_format(tools: list[Tool]) -> list[dict]:
return [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.parameters if isinstance(tool.parameters, dict) else tool.parameters.model_dump(),
"strict": tool.strict,
}
} for tool in tools]
class OpenAIConfig(BaseModel):
api_key: str
api_base: str = "https://api.openai.com/v1"
model_config = ConfigDict(frozen=True)
class OpenAIAdapterChatBase(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol):
media_manager: MediaManager
def __init__(self, config: OpenAIConfig):
self.config = config
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/chat/completions"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json",
}
data = {
"messages": asyncio.run(convert_llm_chat_message_to_openai_message(req.messages, self.media_manager)),
"model": req.model,
"frequency_penalty": req.frequency_penalty,
"max_completion_tokens": req.max_tokens, # 最新的reference废除max_tokens,改为如上参数
"presence_penalty": req.presence_penalty,
"response_format": req.response_format,
"stop": req.stop,
"stream": req.stream,
"stream_options": req.stream_options,
"temperature": req.temperature,
"top_p": req.top_p,
# tool pydantic 模型按照 openai api 格式进行的建立。所以这里直接dump
"tools": convert_tools_to_openai_format(req.tools) if req.tools else None,
"tool_choice": "auto" if req.tools else None,
"logprobs": req.logprobs,
"top_logprobs": req.top_logprobs,
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
logger.debug(f"Request: {data}")
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data: dict = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
logger.debug(f"Response: {response_data}")
choices: List[dict[str, Any]] = response_data.get("choices", [{}])
first_choice = choices[0] if choices else {}
message: dict[str, Any] = first_choice.get("message", {})
# 检测tool_calls字段是否存在和是否不为None. tool_call时content字段无有效信息,暂不记录
content: list[LLMChatContentPartType] = []
if tool_calls := message.get("tool_calls", None):
content = [LLMToolCallContent(
id=call["id"],
name=call["function"]["name"],
parameters=json.loads(call["function"].get("arguments", "{}"))
) for call in tool_calls]
else:
content = [LLMChatTextContent(text=message.get("content", ""))]
usage_data = response_data.get("usage", {})
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=usage_data.get("prompt_tokens", 0),
completion_tokens=usage_data.get("completion_tokens", 0),
total_tokens=usage_data.get("total_tokens", 0),
),
message=Message(
content=content,
role=message.get("role", "assistant"),
tool_calls = pick_tool_calls(content),
finish_reason=first_choice.get("finish_reason", ""),
),
)
async def get_models(self) -> list[str]:
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data.get("data", [])]
async def auto_detect_models(self) -> list[ModelConfig]:
models = await self.get_models()
all_models: list[ModelConfig] = []
for model in models:
guess_result = guess_openai_model(model)
if guess_result is None:
continue
all_models.append(ModelConfig(id=model, type=guess_result[0].value, ability=guess_result[1]))
return all_models
class EmbeddingData(TypedDict):
object: Literal["embedding"]
embedding: list[float]
index: int
class EmbeddingResponse(TypedDict):
# 用于描述类型定义
object: Literal["list"]
data: list[EmbeddingData]
model: str
usage: dict[Literal["prompt_tokens", "total_tokens"], int]
class OpenAIAdapter(OpenAIAdapterChatBase, LLMEmbeddingProtocol):
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
"""
此为openai api嵌入式模型接口
Tips: openai仅在 text-embedding-3 及以后模型中支持设定输出向量维度
"""
api_url = f"{self.config.api_base}/embeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json",
}
if len(req.inputs) > 2048:
# text数组不能超过2048个元素,openai api限制
raise ValueError("Text list has too many dimensions, max dimension is 2048")
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
# 未在api中发现多模态嵌入api, 等待后续更新
raise ValueError("openai does not support multi-modal embedding")
# mypy 类型检查修复,如果添加多模态请去除这个标注
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"text": [input.text for input in inputs],
"model": req.model,
"dimensions": req.dimension,
"encoding_format": req.encoding_format
}
# 删除 None 字段
data = {k: v for k, v in data.items() if v is not None}
logger.debug(f"Request: {data}")
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: EmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
logger.debug(f"Response: {response_data}")
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage=Usage(
prompt_tokens=response_data["usage"].get("prompt_tokens", 0),
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/openrouter_adapter.py
================================================
import aiohttp
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.model_types import LLMAbility, ModelType
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class OpenRouterConfig(OpenAIConfig):
api_base: str = "https://openrouter.ai/api/v1"
class OpenRouterAdapter(OpenAIAdapter):
def __init__(self, config: OpenRouterConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
all_models: list[ModelConfig] = []
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
for model in response_data.get("data", []):
ability = LLMAbility.TextChat.value
for input_modality in model["architecture"]["input_modalities"]:
if input_modality == "text":
ability |= LLMAbility.TextInput.value
elif input_modality == "image":
ability |= LLMAbility.ImageInput.value
for output_modality in model["architecture"]["output_modalities"]:
if output_modality == "text":
ability |= LLMAbility.TextOutput.value
elif output_modality == "image":
ability |= LLMAbility.ImageOutput.value
all_models.append(ModelConfig(id=model["id"], type=ModelType.LLM.value, ability=ability))
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-llm-presets",
version="1.0.0",
description="Preset LLM adapters for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["requests"],
entry_points={
"chatgpt_mirai.plugins": [
"llm_presets = llm_preset_adapters.plugin:LLMPresetsPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/siliconflow_adapter.py
================================================
import aiohttp
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class SiliconFlowConfig(OpenAIConfig):
api_base: str = "https://api.siliconflow.cn/v1"
class SiliconFlowAdapter(OpenAIAdapter):
def __init__(self, config: SiliconFlowConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[str]:
api_url = f"{self.config.api_base}/models?sub_type=chat"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data["data"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/tencentcloud_adapter.py
================================================
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class TencentCloudConfig(OpenAIConfig):
api_base: str = "https://api.hunyuan.cloud.tencent.com/v1"
class TencentCloudAdapter(OpenAIAdapter):
def __init__(self, config: TencentCloudConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/tests/test_utils.py
================================================
from llm_preset_adapters.utils import guess_openai_model
from kirara_ai.llm.model_types import AudioModelAbility, EmbeddingModelAbility, ImageModelAbility, LLMAbility, ModelType
from kirara_ai.logger import get_logger
models = [
{
"id": "babbage-002",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextCompletion.value
},
{
"id": "chatgpt-4o-latest",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "computer-use-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "dall-e-2",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value | ImageModelAbility.ImageEdit.value | ImageModelAbility.Inpainting.value
},
{
"id": "dall-e-3",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value
},
{
"id": "davinci-002",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextCompletion.value
},
{
"id": "gpt-3-5-0301",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-0125",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-1106",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-16k-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-instruct",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0125-preview",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0314",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-turbo-2024-04-09",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-mini-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-nano-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.5-preview-2025-02-27",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-05-13",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-08-06",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-11-20",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-audio-preview-2024-10-01",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-audio-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-2024-07-18",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-audio-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-realtime-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-search-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "gpt-4o-mini-transcribe",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value
},
{
"id": "gpt-4o-mini-tts",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value | AudioModelAbility.Streaming.value
},
{
"id": "gpt-4o-realtime-preview-2024-10-01",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-realtime-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-search-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "gpt-4o-transcribe",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value
},
{
"id": "gpt-image-1",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value | ImageModelAbility.ImageEdit.value |
ImageModelAbility.Inpainting.value
},
{
"id": "o1-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o1-mini-2024-09-12",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "o1-preview-2024-09-12",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
},
{
"id": "o1-pro-2025-03-19",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o3-2025-04-16",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o3-mini-2025-01-31",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o4-mini-2025-04-16",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "text-embedding-3-large",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "text-embedding-3-small",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "text-embedding-ada-002",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "tts-1-hd",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value
},
{
"id": "tts-1",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value
},
{
"id": "whisper-1",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value
}
]
def test_guess_openai_model():
logger = get_logger("test_guess_openai_model")
failed_tests = []
for model in models:
model_type, abilities = guess_openai_model(model["id"])
logger.info(f"模型: {model['id']}, 模型类型: {model_type}, 能力: {abilities}, 预期: {model['type']}, {model['abilities']}")
try:
assert model_type is not None, f"模型 {model['id']} 的类型不应为 None"
assert model_type.value == model["type"], f"模型 {model['id']} 的类型不匹配,预期 {model['type']},实际 {model_type.value}"
if abilities != model["abilities"]:
diff_bits = abilities ^ model["abilities"]
expected_but_missing = diff_bits & model["abilities"]
unexpected_but_present = diff_bits & abilities
error_msg = f"模型 {model['id']} 的能力不匹配,预期 {model['abilities']},实际 {abilities}"
# 根据模型类型获取对应的能力枚举类
ability_enum = None
if model_type == ModelType.LLM:
ability_enum = LLMAbility
elif model_type == ModelType.Embedding:
ability_enum = EmbeddingModelAbility
elif model_type == ModelType.ImageGeneration:
ability_enum = ImageModelAbility
elif model_type == ModelType.Audio:
ability_enum = AudioModelAbility
# 获取缺少的能力名称
if expected_but_missing:
missing_abilities = []
for enum_item in ability_enum:
if expected_but_missing & enum_item.value:
missing_abilities.append(enum_item.name)
error_msg += f",缺少能力: {', '.join(missing_abilities)} ({bin(expected_but_missing)})"
# 获取多余的能力名称
if unexpected_but_present:
extra_abilities = []
for enum_item in ability_enum:
if unexpected_but_present & enum_item.value:
extra_abilities.append(enum_item.name)
error_msg += f",多余能力: {', '.join(extra_abilities)} ({bin(unexpected_but_present)})"
assert False, error_msg
except AssertionError as e:
failed_tests.append(str(e))
logger.error(str(e))
if failed_tests:
error_message = f"共有 {len(failed_tests)} 个测试点失败:\n" + "\n".join(failed_tests)
assert False, error_message
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/utils.py
================================================
import uuid
from typing import Optional, Tuple
from kirara_ai.llm.format.message import LLMChatContentPartType, LLMToolCallContent
from kirara_ai.llm.format.tool import Function, ToolCall
from kirara_ai.llm.model_types import AudioModelAbility, EmbeddingModelAbility, ImageModelAbility, LLMAbility, ModelType
def generate_tool_call_id(name: str) -> str:
return f"{name}_{str(uuid.uuid4())}"
def pick_tool_calls(calls: list[LLMChatContentPartType]) -> Optional[list[ToolCall]]:
tool_calls = [
ToolCall(
id=call.id,
function=Function(name=call.name, arguments=call.parameters)
) for call in calls if isinstance(call, LLMToolCallContent)
]
if tool_calls:
return tool_calls
else:
return None
def guess_openai_model(model_id: str) -> Tuple[ModelType, int] | None:
"""
根据模型ID猜测模型类型和能力
返回: (ModelType, ability_bitmask) 或 None
"""
model_id = model_id.lower()
# 1. 检查嵌入模型
if "embedding" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value) # 嵌入模型
# 2. 检查图像生成模型
if "dall-e" in model_id or "gpt-image" in model_id:
ability = ImageModelAbility.TextToImage.value
if "dall-e-2" in model_id or "gpt-image" in model_id:
ability |= ImageModelAbility.ImageEdit.value | ImageModelAbility.Inpainting.value
return (ModelType.ImageGeneration, ability)
# 3. 检查音频模型
if "whisper" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value)
if "tts" in model_id:
if "mini" in model_id:
return (ModelType.Audio, AudioModelAbility.Speech.value | AudioModelAbility.Streaming.value)
return (ModelType.Audio, AudioModelAbility.Speech.value)
if model_id == "gpt-4o-transcribe":
# 特别处理 gpt-4o-transcribe,没有 Translation 能力
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value)
if "transcribe" in model_id:
if "mini" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value)
if "realtime" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value)
else:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value)
# 4. 处理音频相关的LLM模型 (这些不应该有图像输入能力)
if ("audio" in model_id or "realtime" in model_id) and "4o" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value
# 特殊情况处理
if "gpt-4o-mini-audio-preview-2024-12-17" in model_id:
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
if "gpt-4o-mini-realtime-preview-2024-12-17" in model_id:
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
if not ("mini-search" in model_id or "mini-realtime" in model_id or
"instruct" in model_id or "search" in model_id or
"mini" in model_id):
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
# 5. 检查moderation模型
if "moderation" in model_id:
return None
# 6. LLM模型 (默认情况)
ability = LLMAbility.TextChat.value
if ("babbage" in model_id or "davinci" in model_id):
return (ModelType.LLM, LLMAbility.TextInput.value | LLMAbility.TextOutput.value)
# 图像输入能力
if ("vision" in model_id or
"4o" in model_id or
"computer-use-preview" in model_id or
"gpt-4-turbo" in model_id or
"o1" in model_id or
"o4" in model_id or
"4." in model_id or
("4" in model_id and ("image" in model_id or "vision" in model_id))):
ability |= LLMAbility.ImageInput.value
# 大部分模型都应该有函数调用能力,除了特定例外
if not ("3.5" in model_id or
"3-5" in model_id or
"1106" in model_id or
"0314" in model_id or
"0125" in model_id or
"gpt-4-0" in model_id or
"chatgpt-4o" in model_id or
"instruct" in model_id or
"search" in model_id or
"o1-mini" in model_id or
model_id.startswith(("babbage", "davinci"))):
ability |= LLMAbility.FunctionCalling.value
# 特殊模型处理
if "o3-2025-04-16" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
if "o1-preview-2024-09-12" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
if "o1-mini-2024-09-12" in model_id:
ability = LLMAbility.TextChat.value
if "o3-mini-2025-01-31" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
def guess_qwen_model(model_id: str) -> Tuple[ModelType, int] | None:
"""
根据模型ID猜测通义千问模型的类型和能力
返回: (ModelType, ability_bitmask) 或 None
"""
model_id = model_id.lower()
# 通义千问Embedding模型
if "text-embedding" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value)
if "multimodal-embedding-v1" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.ImageEmbedding.value | EmbeddingModelAbility.AudioEmbedding.value | EmbeddingModelAbility.VideoEmbedding.value | EmbeddingModelAbility.Batch.value)
# 通义千问多模态模型
if "-vl" in model_id or "qvq-":
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.ImageInput.value)
if "-audio" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.AudioInput.value)
if "qwen-omni" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value)
# 通义千问系列基础模型
if "qwen" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value)
return None
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/volcengine_adapter.py
================================================
import datetime
import hashlib
import hmac
from urllib.parse import quote
import aiohttp
from pydantic import Field
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.model_types import LLMAbility, ModelType
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class VolcengineConfig(OpenAIConfig):
api_base: str = "https://ark.cn-beijing.volces.com/api/v3"
access_key_id: str = Field(description="火山云引擎 API 密钥 ID,用于获取模型列表")
access_key_secret: str = Field(description="火山云引擎 API 密钥,用于获取模型列表")
def generate_volcengine_signature(access_key_id, access_key_secret, method, path, query, body=None):
"""生成火山引擎API所需的HMAC-SHA256签名"""
# 初始化参数
service = "ark"
region = "cn-beijing"
host = "open.volcengineapi.com"
content_type = "application/json"
# 获取UTC时间
now = datetime.datetime.utcnow()
x_date = now.strftime("%Y%m%dT%H%M%SZ")
short_date = x_date[:8]
# 计算请求体的SHA256哈希值
body = body or ""
x_content_sha256 = hashlib.sha256(body.encode("utf-8")).hexdigest()
# 规范化查询字符串
canonical_query = normalize_query(query)
# 签名所需的头部
signed_headers = ["host", "x-content-sha256", "x-date"]
signed_headers_str = ";".join(signed_headers)
# 构建规范请求字符串
canonical_headers = "\n".join([
f"host:{host}",
f"x-content-sha256:{x_content_sha256}",
f"x-date:{x_date}",
])
canonical_request = "\n".join([
method.upper(),
path,
canonical_query,
canonical_headers,
"",
signed_headers_str,
x_content_sha256
])
# 计算规范请求的哈希值
hashed_canonical_request = hashlib.sha256(canonical_request.encode("utf-8")).hexdigest()
# 构建签名字符串
credential_scope = f"{short_date}/{region}/{service}/request"
string_to_sign = "\n".join(["HMAC-SHA256", x_date, credential_scope, hashed_canonical_request])
# 计算签名
k_date = hmac.new(access_key_secret.encode("utf-8"), short_date.encode("utf-8"), hashlib.sha256).digest()
k_region = hmac.new(k_date, region.encode("utf-8"), hashlib.sha256).digest()
k_service = hmac.new(k_region, service.encode("utf-8"), hashlib.sha256).digest()
k_signing = hmac.new(k_service, b"request", hashlib.sha256).digest()
signature = hmac.new(k_signing, string_to_sign.encode("utf-8"), hashlib.sha256).hexdigest()
# 构建Authorization头
authorization = f"HMAC-SHA256 Credential={access_key_id}/{credential_scope}, SignedHeaders={signed_headers_str}, Signature={signature}"
# 返回所有需要的头部
return {
"Host": host,
"X-Content-Sha256": x_content_sha256,
"X-Date": x_date,
"Authorization": authorization
}
def normalize_query(params):
"""规范化查询参数"""
if not params:
return ""
query = ""
for key in sorted(params.keys()):
if isinstance(params[key], list):
for k in params[key]:
query += quote(key, safe="-_.~") + "=" + quote(str(k), safe="-_.~") + "&"
else:
query += quote(key, safe="-_.~") + "=" + quote(str(params[key]), safe="-_.~") + "&"
return query[:-1].replace("+", "%20") if query else ""
def detect_ability(model: dict) -> int:
ability = LLMAbility.TextChat.value
# detect visual qa
if "VisualQuestionAnswering" in model.get("TaskTypes", []):
ability |= LLMAbility.ImageInput.value
# detect function calling
if "Function Call" in model.get("CustomizedTags", []):
ability |= LLMAbility.FunctionCalling.value
return ability
class VolcengineAdapter(OpenAIAdapter):
config: VolcengineConfig
def __init__(self, config: VolcengineConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
"""
获取火山引擎可用的模型列表,支持分页获取所有结果
{
"Result": {
"TotalCount": 39,
"PageNumber": 1,
"PageSize": 10,
"Items": [
{
"Name": "doubao-1-5-pro-256k",
"VendorName": "字节跳动",
"DisplayName": "Doubao-1.5-pro-256k",
"ShortName": "",
"PrimaryVersion": "250115",
"FoundationModelTag": {
"Domains": [
"LLM"
],
"Languages": [
"中英文"
],
"TaskTypes": [
"Chat"
],
"ContextLength": "256k",
"CustomizedTags": [
"支持体验"
]
},
}
]
}
}
"""
host = "open.volcengineapi.com"
path = "/"
all_models: list[ModelConfig] = []
page_number = 1
page_size = 100
total_pages = 1 # 初始值,会在第一次请求后更新
while page_number <= total_pages:
query = {
"Action": "ListFoundationModels",
"Version": "2024-01-01",
"PageNumber": page_number,
"PageSize": page_size
}
# 生成签名和头部
headers = generate_volcengine_signature(
self.config.access_key_id,
self.config.access_key_secret,
"GET",
path,
query
)
# 构建完整URL
url = f"https://{host}{path}"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(url, headers=headers, params=query) as response:
response.raise_for_status()
response_data = await response.json()
if "Result" in response_data:
response_data = response_data["Result"]
else:
return []
# 更新总页数(如果API返回了这个信息)
if "TotalCount" in response_data and "PageSize" in response_data:
total_count = response_data["TotalCount"]
total_pages = (total_count + page_size - 1) // page_size
for model in response_data["Items"]:
foundation_model = model.get("FoundationModelTag", {})
if ("LLM" in foundation_model.get("Domains", []) and
model.get("Name")):
ability = detect_ability(foundation_model)
all_models.append(ModelConfig(id=model["Name"], type=ModelType.LLM.value, ability=ability))
# 准备获取下一页
page_number += 1
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/voyage_adapter.py
================================================
from pydantic import BaseModel, ConfigDict
from typing import cast, TypedDict, Literal, Optional
import requests
import asyncio
from kirara_ai.llm.adapter import LLMBackendAdapter, LLMEmbeddingProtocol, LLMReRankProtocol
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.rerank import LLMReRankRequest, LLMReRankResponse, ReRankerContent
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent
from kirara_ai.llm.format.response import Usage
from kirara_ai.media.manager import MediaManager
from kirara_ai.logger import get_logger
logger = get_logger("VoyageAdapter")
async def resolve_media_base64(inputs: list[LLMChatImageContent|LLMChatTextContent], media_manager: MediaManager) -> list:
results = []
for input in inputs:
# voyage 的多模态接口设置中会将 一个content字段中的所有payload视作一个输入集,并对这个输入集合生成一个向量.
# 所以这里对 image 做出处理,将其描述与原始图像打包为一个payload.
if isinstance(input, LLMChatTextContent):
results.append({
"content": [
{"type": "text", "text": input.text}
]
})
elif isinstance(input, LLMChatImageContent):
media = media_manager.get_media(input.media_id)
if media is None:
raise ValueError(f"Media {input.media_id} not found")
results.append({
"content": [
{"type": "text", "text": "" if (desc := media.description) is None else desc},
{"type": "image_base64", "image_base64": await media.get_base64()}
]
})
return results
class ReRankData(TypedDict):
index: int
relevance_score: float
document: Optional[str]
class ReRankResponse(TypedDict):
"""给mypy检查用, 顺便给开发者标识返回json的基本结构。"""
object: Literal["list"]
data: list[ReRankData]
model: str
usage: dict[Literal["total_tokens"], int]
class EmbeddingData(TypedDict):
object: Literal["embedding"]
embedding: list[float | int]
index: int
class EmbeddingResponse(TypedDict):
object: Literal["list"]
data: list[EmbeddingData]
model: str
usage: dict[Literal["total_tokens"], int]
class ModalEmbeddingResponse(TypedDict):
object: Literal["list"]
data: list[EmbeddingData]
model: str
# voyage 的多模态接口会返回三个usage指标: text_tokens: 文字使用token数, image_pixels: 图片像素数, total_tokens: 总token数
usage: dict[Literal["text_tokens", "image_pixels", "total_tokens"], int]
class VoyageConfig(BaseModel):
api_key: str
api_base: str = "https://api.voyageai.com"
model_config = ConfigDict(frozen=True)
class VoyageAdapter(LLMBackendAdapter, LLMEmbeddingProtocol, LLMReRankProtocol):
media_manager: MediaManager
def __init__(self, config: VoyageConfig):
self.config = config
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# voyage 支持多模态嵌入, 但是两个接口支持的参数不同。
# 因此对其做区分,以充分利用 voyage 接口提供的可选参数。
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
return self._multi_modal_embedding(req)
else:
return self._text_embedding(req)
def _text_embedding(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
api_url = f"{self.config.api_base}/v1/embeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"model": req.model,
"input": [input.text for input in inputs],
"truncation": req.truncate,
"input_type": req.input_type,
"output_dimension": req.dimension,
"output_dtype": req.encoding_format,
"encoding_format": req.encoding_format,
}
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: EmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage = Usage(
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
def _multi_modal_embedding(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
api_url = f"{self.config.api_base}/v1/multimodalembeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
# loop = asyncio.new_event_loop()
# try:
# asyncio.set_event_loop(loop)
# data = {
# "model": req.model,
# "inputs": loop.run_until_complete(resolve_media_base64(req.inputs, self.media_manager)),
# "input_type": req.input_type,
# "truncation": req.truncate,
# "output_encoding": req.encoding_format
# }
# finally:
# loop.close() # 关闭事件循环,避免资源泄露。
# asyncio.set_event_loop(None) # 解除 asyncio 事件循环绑定。避免get_running_loop()获取到已结束时间循环。
data = {
"model": req.model,
# 为何不使用神奇的 asyncio.run() 自动管理这个临时loop的生命周期呢。(python 3.7+)
"inputs": asyncio.run(resolve_media_base64(req.inputs, self.media_manager)),
"input_type": req.input_type,
"truncation": req.truncate,
"output_encoding": req.encoding_format
}
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: ModalEmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage = Usage(
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
def rerank(self, req: LLMReRankRequest) -> LLMReRankResponse:
api_url = f"{self.config.api_base}/v1/rerank"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
data = {
"query": req.query,
"documents": req.documents,
"model": req.model,
"top_k": req.top_k,
"return_documents": req.return_documents,
"truncation": req.truncation
}
# 去除 None 值
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: ReRankResponse = response.json()
logger.debug(f"server response_data: {response_data}")
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMReRankResponse(
contents = [ReRankerContent(
document = data.get("document", None),
score = data["relevance_score"]
) for data in response_data["data"]],
usage = Usage(
total_tokens = response_data["usage"].get("total_tokens", 0)
),
sort = cast(bool, req.sort) # 强制类型转换,避免mypy报错。
)
================================================
FILE: kirara_ai/system/__init__.py
================================================
================================================
FILE: kirara_ai/system/updater.py
================================================
================================================
FILE: kirara_ai/tracing/__init__.py
================================================
from kirara_ai.tracing.core import TracerBase
from kirara_ai.tracing.decorator import trace_llm_chat
from kirara_ai.tracing.llm_tracer import LLMTracer
from kirara_ai.tracing.manager import TracingManager
from kirara_ai.tracing.models import LLMRequestTrace
__all__ = [
"TracingManager",
"LLMRequestTrace",
"TracerBase",
"LLMTracer",
"trace_llm_chat"
]
================================================
FILE: kirara_ai/tracing/core.py
================================================
import abc
import asyncio
import uuid
from asyncio import Queue
from typing import Any, Dict, Generic, List, Optional, Tuple, Type, TypeVar
from sqlalchemy import Column, DateTime, String, asc
from kirara_ai.database import Base, DatabaseManager
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.tracing import TraceEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
logger = get_logger("Tracking")
class TraceRecord(Base):
"""跟踪记录基类,用于ORM映射"""
__abstract__ = True
trace_id = Column(String(64), nullable=False, index=True, unique=True)
status = Column(String(20), nullable=False, default="pending")
request_time = Column(DateTime, nullable=False, index=True)
@abc.abstractmethod
def update_from_event(self, event: TraceEvent) -> None:
"""从事件更新记录"""
@abc.abstractmethod
def to_dict(self) -> Dict[str, Any]:
"""将记录转换为字典,用于JSON序列化"""
@abc.abstractmethod
def to_detail_dict(self) -> Dict[str, Any]:
"""将详细记录转换为字典,用于JSON序列化"""
def generate_trace_id() -> str:
"""生成唯一的追踪ID"""
return str(uuid.uuid4())
# 定义泛型类型变量,用于追踪事件、追踪器和追踪记录
T = TypeVar('T')
E = TypeVar('E', bound=TraceEvent) # 事件类型
R = TypeVar('R', bound=TraceRecord) # 记录类型
class TracerBase(Generic[R], abc.ABC):
"""追踪器基类"""
# 追踪器名称,用于区分不同类型的追踪器
name: str
record_class: Type[R]
@Inject()
def __init__(self, container: DependencyContainer, record_class: Type[R], db_manager: DatabaseManager, event_bus: EventBus):
self.record_class = record_class
self.container = container
self.db_manager = db_manager
self.event_bus = event_bus
self.logger = logger
# 活跃追踪的映射表
self._active_traces: Dict[str, Dict[str, Any]] = {}
# WebSocket消息队列映射表
self._ws_queues: List[Queue] = []
def initialize(self):
"""初始化追踪器,注册事件处理程序"""
self.logger.info(f"Initializing {self.name} tracer")
self._register_event_handlers()
self.logger.info(f"{self.name} tracer initialized")
def shutdown(self):
"""关闭追踪器,取消事件注册"""
self.logger.info(f"Shutting down {self.name} tracer")
self._unregister_event_handlers()
# 关闭所有WebSocket连接
for queue in list(self._ws_queues):
try:
queue.put_nowait(None)
except Exception:
pass
self._ws_queues.clear()
@abc.abstractmethod
def _register_event_handlers(self):
"""注册事件处理程序"""
@abc.abstractmethod
def _unregister_event_handlers(self):
"""取消事件处理程序注册"""
def get_traces(
self,
filters: Optional[Dict[str, Any]] = None,
page: int = 1,
page_size: int = 20,
order_by: str = "request_time",
order_desc: bool = True
) -> Tuple[List[R], int]:
"""统一的追踪记录查询方法
Args:
filters: 过滤条件字典
page: 页码(从1开始)
page_size: 每页记录数
order_by: 排序字段
order_desc: 是否降序排序
Returns:
Tuple[List[R], int]: 记录列表和总记录数
"""
with self.db_manager.get_session() as session:
from sqlalchemy import desc, func, select
# 构建基础查询
query = select(self.record_class)
count_query = select(func.count()).select_from(self.record_class)
# 应用过滤条件
if filters:
for field, value in filters.items():
if value is not None and hasattr(self.record_class, field):
query = query.filter(getattr(self.record_class, field) == value)
count_query = count_query.filter(getattr(self.record_class, field) == value)
# 应用排序
if hasattr(self.record_class, order_by):
order_func = desc if order_desc else asc
query = query.order_by(order_func(getattr(self.record_class, order_by)))
# 应用分页
if page > 0 and page_size > 0:
query = query.offset((page - 1) * page_size).limit(page_size)
# 执行查询
total = session.execute(count_query).scalar() or 0
records = list(session.execute(query).scalars().all())
return records, total
def get_recent_traces(self, limit: int = 100) -> List[R]:
"""获取最近的跟踪记录"""
with self.db_manager.get_session() as session:
from sqlalchemy import desc, select
stmt = select(self.record_class).order_by(desc(self.record_class.request_time)).limit(limit)
result = session.execute(stmt)
return list(result.scalars().all())
def get_trace_by_id(self, trace_id: str) -> Optional[R]:
"""根据追踪ID获取跟踪记录"""
with self.db_manager.get_session() as session:
return session.query(self.record_class).filter_by(trace_id=trace_id).first()
def save_trace_record(self, record: R) -> Dict[str, Any]:
"""保存追踪记录到数据库"""
with self.db_manager.get_session() as session:
session.add(record)
session.commit()
return record.to_dict()
def update_trace_record(self, trace_id: str, event: TraceEvent) -> Optional[Dict[str, Any]]:
"""更新追踪记录"""
with self.db_manager.get_session() as session:
if (
record := session.query(self.record_class)
.filter_by(trace_id=trace_id)
.first()
):
record.update_from_event(event)
session.commit()
return record.to_dict()
return None
# WebSocket相关方法
def register_ws_client(self) -> Queue:
"""注册WebSocket客户端,返回一个消息队列"""
queue: Queue = Queue()
self._ws_queues.append(queue)
return queue
def unregister_ws_client(self, queue: Queue):
"""注销WebSocket客户端"""
if queue in self._ws_queues:
self._ws_queues.remove(queue)
def broadcast_ws_message(self, message: Dict):
"""向所有WebSocket客户端广播消息"""
dead_queues = []
for queue in self._ws_queues:
try:
queue.put_nowait(message)
except asyncio.QueueFull:
self.logger.warning(f"Queue is full, message dropped")
dead_queues.append(queue)
except Exception as e:
self.logger.error(f"Error broadcasting message: {e}")
dead_queues.append(queue)
# 清理失效的队列
for queue in dead_queues:
if queue in self._ws_queues:
self._ws_queues.remove(queue)
================================================
FILE: kirara_ai/tracing/decorator.py
================================================
import functools
from typing import Callable
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.tracing.llm_tracer import LLMTracer
def trace_llm_chat(func: Callable):
"""装饰器,用于追踪LLM请求"""
from kirara_ai.llm.adapter import LLMBackendAdapter
@functools.wraps(func)
def wrapper(self: LLMBackendAdapter, req: LLMChatRequest) -> LLMChatResponse:
tracer: LLMTracer = self.tracer
# 开始追踪
trace_id = tracer.start_request_tracking(self.backend_name, req)
try:
# 调用原始方法
response = func(self, req)
except Exception as e:
# 记录错误
tracer.fail_request_tracking(trace_id, req, str(e))
raise e
else:
# 完成追踪
tracer.complete_request_tracking(trace_id, req, response)
return response
return wrapper
================================================
FILE: kirara_ai/tracing/llm_tracer.py
================================================
from datetime import datetime, timedelta
from typing import Any, Dict
from sqlalchemy import case, func
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.llm.format.message import LLMChatMessage, LLMChatTextContent
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Message
from kirara_ai.logger import get_logger
from kirara_ai.tracing.core import TracerBase, generate_trace_id
from kirara_ai.tracing.models import LLMRequestTrace
logger = get_logger("LLMTracer")
UNRECORD_REQUEST = [LLMChatMessage(
role="system",
content=[
LLMChatTextContent(
text="*** 内容未记录 ***"
)
]
)]
UNRECORD_RESPONSE = Message(
role="assistant",
content=[
LLMChatTextContent(
text="*** 内容未记录 ***"
)
]
)
class LLMTracer(TracerBase[LLMRequestTrace]):
"""LLM追踪器,负责处理LLM请求的跟踪"""
name = "llm"
record_class = LLMRequestTrace
@Inject()
def __init__(self, container: DependencyContainer):
super().__init__(container, record_class=LLMRequestTrace) # type: ignore
self.config = container.resolve(GlobalConfig)
def initialize(self):
"""启动追踪器,将所有 pending 状态的任务转为 failed,并清理超过 30 天的请求"""
super().initialize()
try:
pending_traces = self._mark_pending_as_failed()
deleted_count = self._clean_old_traces()
if pending_traces or deleted_count:
self.logger.info(f"已将 {pending_traces} 个 未结束状态的 LLM 请求标记为失败,并清理了 {deleted_count} 个超过 30 天的请求记录")
except Exception as e:
self.logger.opt(exception=e).error(f"处理历史追踪记录时发生错误")
def _mark_pending_as_failed(self) -> int:
"""将所有 pending 状态的任务转为 failed"""
with self.db_manager.get_session() as session:
pending_traces = session.query(LLMRequestTrace).filter(
LLMRequestTrace.status == "pending" # type: ignore
).all()
for trace in pending_traces:
trace.status = "failed" # type: ignore
trace.error = "Incomplete request" # type: ignore
session.commit()
return len(pending_traces)
def _clean_old_traces(self, days: int = 30) -> int:
"""清理超过指定天数的请求"""
with self.db_manager.get_session() as session:
days_ago = datetime.now() - timedelta(days=days)
deleted_count = session.query(LLMRequestTrace).filter(
LLMRequestTrace.request_time < days_ago # type: ignore
).delete()
session.commit()
return deleted_count
def _register_event_handlers(self):
"""注册事件处理程序"""
self.event_bus.register(LLMRequestStartEvent, self._on_request_start)
self.event_bus.register(LLMRequestCompleteEvent, self._on_request_complete)
self.event_bus.register(LLMRequestFailEvent, self._on_request_fail)
def _unregister_event_handlers(self):
"""取消事件处理程序注册"""
self.event_bus.unregister(LLMRequestStartEvent, self._on_request_start)
self.event_bus.unregister(LLMRequestCompleteEvent, self._on_request_complete)
self.event_bus.unregister(LLMRequestFailEvent, self._on_request_fail)
def start_request_tracking(
self,
backend_name: str,
request: LLMChatRequest
) -> str:
"""开始跟踪LLM请求"""
trace_id = generate_trace_id()
event = LLMRequestStartEvent(
trace_id=trace_id,
model_id=request.model or 'unknown',
backend_name=backend_name,
request=request.model_copy(deep=True)
)
# 存储活跃追踪信息
self._active_traces[trace_id] = {
'backend_name': backend_name,
'start_time': event.start_time
}
# 发布事件
self.event_bus.post(event)
return trace_id
def complete_request_tracking(
self,
trace_id: str,
request: LLMChatRequest,
response: LLMChatResponse
):
"""完成LLM请求跟踪"""
if trace_id in self._active_traces:
trace_data = self._active_traces[trace_id]
model_id = request.model or trace_data.get('model_id', "unknown")
backend_name = trace_data.get('backend_name', "unknown")
start_time = trace_data.get('start_time', 0)
event = LLMRequestCompleteEvent(
trace_id=trace_id,
model_id=model_id,
backend_name=backend_name,
request=request.model_copy(deep=True),
response=response.model_copy(deep=True),
start_time=start_time
)
# 移除活跃追踪
del self._active_traces[trace_id]
# 发布事件
self.event_bus.post(event)
def fail_request_tracking(
self,
trace_id: str,
request: LLMChatRequest,
error: Any
):
"""记录LLM请求失败"""
if trace_id in self._active_traces:
trace_data = self._active_traces[trace_id]
model_id = request.model or trace_data.get('model_id', "unknown")
backend_name = trace_data.get('backend_name', "unknown")
start_time = trace_data.get('start_time', 0)
event = LLMRequestFailEvent(
trace_id=trace_id,
model_id=model_id,
backend_name=backend_name,
request=request.model_copy(deep=True),
error=error,
start_time=start_time
)
# 移除活跃追踪
del self._active_traces[trace_id]
# 发布事件
self.event_bus.post(event)
else:
self.logger.warning(f"LLM request failed: {trace_id} not found")
def _on_request_start(self, event: LLMRequestStartEvent):
"""处理请求开始事件"""
self.logger.debug(f"LLM request started: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
# 创建数据库记录
trace = LLMRequestTrace()
trace.update_from_event(event)
# 保存记录到数据库
trace_dict = self.save_trace_record(trace)
# 向WebSocket客户端广播消息
self.broadcast_ws_message({
"type": "new",
"data": trace_dict
})
def _on_request_complete(self, event: LLMRequestCompleteEvent):
"""处理请求完成事件"""
self.logger.debug(f"LLM request completed: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
event.response.message = UNRECORD_RESPONSE
if trace := self.update_trace_record(event.trace_id, event):
self.broadcast_ws_message({
"type": "update",
"data": trace
})
def _on_request_fail(self, event: LLMRequestFailEvent):
"""处理请求失败事件"""
self.logger.debug(f"LLM request failed: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
# 更新数据库记录
trace = self.update_trace_record(event.trace_id, event)
# 广播WebSocket消息
if trace:
self.broadcast_ws_message({
"type": "update",
"data": trace
})
def get_statistics(self) -> Dict:
"""获取统计信息"""
with self.db_manager.get_session() as session:
# 基础统计
total_count = session.query(func.count(LLMRequestTrace.id)).scalar() or 0
success_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="success").scalar() or 0
failed_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="failed").scalar() or 0
pending_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="pending").scalar() or 0
total_tokens = session.query(func.sum(LLMRequestTrace.total_tokens)).scalar() or 0
# 获取30天内的每日统计
thirty_days_ago = datetime.now() - timedelta(days=30)
daily_stats = session.query(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time).label('date'),
func.count(LLMRequestTrace.id).label('requests'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.sum(case((LLMRequestTrace.status == 'success', 1), else_=0)).label('success'), # type: ignore
func.sum(case((LLMRequestTrace.status == 'failed', 1), else_=0)).label('failed') # type: ignore
).filter(
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time)
).order_by(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time)
).all()
daily_data = [{
'date': str(row.date),
'requests': row.requests,
'tokens': row.tokens or 0,
'success': row.success,
'failed': row.failed
} for row in daily_stats]
# 按模型分组统计(最近30天)
model_stats = []
model_counts = session.query(
LLMRequestTrace.model_id, # type: ignore
func.count(LLMRequestTrace.id).label('count'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.avg(LLMRequestTrace.duration).label('avg_duration')
).filter( # type: ignore
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
LLMRequestTrace.model_id
).all()
for model_id, count, tokens, avg_duration in model_counts:
model_stats.append({
'model_id': model_id,
'count': count,
'tokens': tokens or 0,
'avg_duration': float(avg_duration) if avg_duration else 0
})
# 按后端分组统计(最近30天)
backend_stats = []
backend_counts = session.query(
LLMRequestTrace.backend_name, # type: ignore
func.count(LLMRequestTrace.id).label('count'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.avg(LLMRequestTrace.duration).label('avg_duration')
).filter( # type: ignore
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
LLMRequestTrace.backend_name
).all()
for backend_name, count, tokens, avg_duration in backend_counts:
backend_stats.append({
'backend_name': backend_name,
'count': count,
'tokens': tokens or 0,
'avg_duration': float(avg_duration) if avg_duration else 0
})
# 获取每小时统计(最近24小时)
one_day_ago = datetime.now() - timedelta(hours=24)
hourly_stats = session.query(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time).label('hour'),
func.count(LLMRequestTrace.id).label('requests'),
func.sum(LLMRequestTrace.total_tokens).label('tokens')
).filter(
LLMRequestTrace.request_time >= one_day_ago # type: ignore
).group_by(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time)
).order_by(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time)
).all()
hourly_data = [{
'hour': str(row.hour),
'requests': row.requests,
'tokens': row.tokens or 0
} for row in hourly_stats]
return {
'overview': {
'total_requests': total_count,
'success_requests': success_count,
'failed_requests': failed_count,
'pending_requests': pending_count,
'total_tokens': total_tokens,
},
'daily_stats': daily_data,
'hourly_stats': hourly_data,
'models': model_stats,
'backends': backend_stats
}
================================================
FILE: kirara_ai/tracing/manager.py
================================================
import asyncio
from typing import Dict, List, Optional
from kirara_ai.database import DatabaseManager
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.tracing import TraceEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
from kirara_ai.tracing.core import TracerBase, TraceRecord
logger = get_logger("TracingManager")
class TracingManager:
"""追踪管理器,负责管理所有类型的追踪器和协调追踪操作"""
@Inject()
def __init__(self, container: DependencyContainer, database_manager: DatabaseManager, event_bus: EventBus):
self.container = container
self.db_manager = database_manager
self.event_bus = event_bus
self.tracers: Dict[str, TracerBase] = {}
self.logger = logger
def initialize(self):
"""初始化追踪管理器"""
self.logger.info("Initializing tracing manager")
# 初始化所有注册的追踪器
for name, tracer in self.tracers.items():
try:
tracer.initialize()
except Exception as e:
self.logger.error(f"Failed to initialize tracer {name}: {e}")
self.logger.info("Tracing manager initialized")
def shutdown(self):
"""关闭追踪管理器"""
self.logger.info("Shutting down tracing manager")
# 关闭所有追踪器
for name, tracer in self.tracers.items():
try:
tracer.shutdown()
except Exception as e:
self.logger.error(f"Failed to shutdown tracer {name}: {e}")
def register_tracer(self, name: str, tracer: TracerBase):
"""注册追踪器"""
if name in self.tracers:
raise ValueError(f"Tracer {name} already registered")
self.tracers[name] = tracer
def get_tracer(self, name: str) -> Optional[TracerBase]:
"""获取指定名称的追踪器"""
return self.tracers.get(name)
def get_all_tracers(self) -> Dict[str, TracerBase]:
"""获取所有追踪器"""
return self.tracers.copy()
def get_tracer_types(self) -> List[str]:
"""获取所有追踪器类型"""
return list(self.tracers.keys())
def publish_event(self, event: TraceEvent):
"""发布追踪事件"""
self.event_bus.post(event)
# WebSocket相关方法
def register_ws_client(self, tracer_name: str) -> asyncio.Queue:
"""为指定追踪器注册WebSocket客户端"""
if tracer := self.tracers.get(tracer_name):
return tracer.register_ws_client()
else:
raise ValueError(f"Tracer {tracer_name} not found")
def unregister_ws_client(self, tracer_name: str, queue: asyncio.Queue):
"""从指定追踪器注销WebSocket客户端"""
if tracer := self.tracers.get(tracer_name):
tracer.unregister_ws_client(queue)
else:
raise ValueError(f"Tracer {tracer_name} not found")
# 通用追踪操作方法
def get_recent_traces(self, tracer_name: str, limit: int = 100) -> List[TraceRecord]:
"""获取指定追踪器的最近追踪记录"""
if tracer := self.get_tracer(tracer_name):
return tracer.get_recent_traces(limit)
else:
raise ValueError(f"Tracer {tracer_name} not found")
def get_trace_by_id(self, tracer_name: str, trace_id: str) -> Optional[TraceRecord]:
"""获取指定追踪器的特定追踪记录"""
if tracer := self.get_tracer(tracer_name):
return tracer.get_trace_by_id(trace_id)
else:
raise ValueError(f"Tracer {tracer_name} not found")
================================================
FILE: kirara_ai/tracing/models.py
================================================
import json
from datetime import datetime
from typing import Any, Dict, Optional
from sqlalchemy import Column, DateTime, Float, Index, Integer, String, Text
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from kirara_ai.tracing.core import TraceEvent, TraceRecord
class LLMRequestTrace(TraceRecord):
"""LLM请求跟踪记录"""
__tablename__ = "llm_request_traces"
id = Column(Integer, primary_key=True, autoincrement=True)
trace_id = Column(String(64), nullable=False, index=True, unique=True)
model_id = Column(String(64), nullable=False, index=True)
backend_name = Column(String(64), nullable=False, index=True)
# 时间相关
request_time = Column(DateTime, nullable=False, index=True)
response_time = Column(DateTime, nullable=True)
duration = Column(Float, nullable=True)
# 请求和响应内容
request_json = Column(Text, nullable=True)
response_json = Column(Text, nullable=True)
# 令牌使用情况
prompt_tokens = Column(Integer, nullable=True)
completion_tokens = Column(Integer, nullable=True)
total_tokens = Column(Integer, nullable=True)
cached_tokens = Column(Integer, nullable=True)
# 错误信息
error = Column(Text, nullable=True)
status = Column(String(20), nullable=False, default="pending")
# 创建索引
__table_args__ = (
Index('idx_request_model', 'model_id', 'request_time'),
Index('idx_backend_time', 'backend_name', 'request_time'),
Index('idx_status_time', 'status', 'request_time'),
)
def __repr__(self):
return f""
def update_from_event(self, event: TraceEvent) -> None:
"""从事件更新记录"""
if isinstance(event, LLMRequestStartEvent):
self.trace_id = event.trace_id
self.model_id = event.model_id
self.backend_name = event.backend_name
self.request_time = datetime.fromtimestamp(event.start_time)
self.status = "pending"
if event.request:
self.request = event.request.model_dump()
elif isinstance(event, LLMRequestCompleteEvent):
self.response_time = datetime.fromtimestamp(event.end_time)
self.duration = event.duration
self.status = "success"
# 记录令牌使用情况
if event.response and event.response.usage:
self.prompt_tokens = event.response.usage.prompt_tokens
self.completion_tokens = event.response.usage.completion_tokens
self.total_tokens = event.response.usage.total_tokens
self.cached_tokens = event.response.usage.cached_tokens
# 记录响应内容
if event.response:
self.response = event.response.model_dump()
elif isinstance(event, LLMRequestFailEvent):
self.response_time = datetime.fromtimestamp(event.end_time)
self.duration = event.duration
self.error = event.error
self.status = "failed"
def to_dict(self) -> Dict[str, Any]:
"""将记录转换为基本字典,用于JSON序列化"""
return {
"id": self.id,
"trace_id": self.trace_id,
"model_id": self.model_id,
"backend_name": self.backend_name,
"request_time": self.request_time.isoformat() if self.request_time else None, # type: ignore
"response_time": self.response_time.isoformat() if self.response_time else None, # type: ignore
"duration": self.duration,
"prompt_tokens": self.prompt_tokens,
"completion_tokens": self.completion_tokens,
"total_tokens": self.total_tokens,
"cached_tokens": self.cached_tokens,
"status": self.status,
"error": self.error
}
def to_detail_dict(self) -> Dict[str, Any]:
"""将记录转换为详细字典,包含请求和响应内容"""
result = self.to_dict()
result["request"] = self.request
result["response"] = self.response
return result
@property
def request(self) -> Optional[Dict[str, Any]]:
"""获取请求内容"""
return json.loads(self.request_json) if self.request_json else None # type: ignore
@request.setter
def request(self, value: Any):
"""设置请求内容"""
if value:
self.request_json = json.dumps(value, ensure_ascii=False, default=str)
@property
def response(self) -> Optional[Dict[str, Any]]:
"""获取响应内容"""
return json.loads(self.response_json) if self.response_json else None # type: ignore
@response.setter
def response(self, value: Any):
"""设置响应内容"""
if value:
self.response_json = json.dumps(value, ensure_ascii=False, default=str)
================================================
FILE: kirara_ai/web/README.md
================================================
# Web API 系统 🌐
本系统提供了一套完整的RESTful API,用于管理和监控ChatGPT-Mirai机器人的各个组件。
## 系统架构 🏗️
- 基于 [Quart](https://pgjones.gitlab.io/quart/) 异步Web框架
- 使用 [Pydantic](https://docs.pydantic.dev/) 进行数据验证
- JWT认证保护所有API端点
- CORS支持跨域请求
- 模块化设计,易于扩展
## 模块说明 📦
### 1. 认证模块 🔐
- 路径: [`framework/web/auth`](../framework/web/auth)
- 功能: 用户认证、JWT令牌管理
- API文档: [认证API文档](../framework/web/auth/README.md)
### 2. IM适配器管理 💬
- 路径: [`framework/web/api/im`](../framework/web/api/im)
- 功能: 管理即时通讯平台适配器
- API文档: [IM API文档](../framework/web/api/im/README.md)
### 3. LLM后端管理 🤖
- 路径: [`framework/web/api/llm`](../framework/web/api/llm)
- 功能: 管理大语言模型后端
- API文档: [LLM API文档](../framework/web/api/llm/README.md)
### 4. 调度规则管理 📋
- 路径: [`framework/web/api/dispatch`](../framework/web/api/dispatch)
- 功能: 管理消息处理规则
- API文档: [调度规则API文档](../framework/web/api/dispatch/README.md)
### 5. Block查询 🧩
- 路径: [`framework/web/api/block`](../framework/web/api/block)
- 功能: 查询工作流构建块信息
- API文档: [Block API文档](../framework/web/api/block/README.md)
### 6. Workflow管理 ⚡
- 路径: [`framework/web/api/workflow`](../framework/web/api/workflow)
- 功能: 管理工作流定义和执行
- API文档: [Workflow API文档](../framework/web/api/workflow/README.md)
### 7. 插件管理 🔌
- 路径: [`framework/web/api/plugin`](../framework/web/api/plugin)
- 功能: 管理系统插件
- API文档: [插件API文档](../framework/web/api/plugin/README.md)
### 8. 系统状态 📊
- 路径: [`framework/web/api/system`](../framework/web/api/system)
- 功能: 监控系统运行状态
- API文档: [系统状态API文档](../framework/web/api/system/README.md)
## 快速开始 🚀
1. 安装依赖:
```bash
pip install -r requirements.txt
```
2. 配置系统:
- 复制 `config.yaml.example` 到 `config.yaml`
- 修改配置文件中的相关设置
3. 启动服务:
```bash
python main.py
```
首次启动时会自动创建管理员密码。
## API认证 🔑
除了首次设置密码的接口外,所有API都需要在请求头中携带JWT令牌:
```http
Authorization: Bearer
```
获取令牌:
```http
POST/backend-api/api/auth/login
Content-Type: application/json
{
"password": "your-password"
}
```
## 开发指南 💻
### 添加新的API端点
1. 在相应模块下创建路由文件
2. 定义数据模型(使用Pydantic)
3. 实现API逻辑
4. 在 [`framework/web/app.py`](../framework/web/app.py) 中注册蓝图
示例:
```python
from quart import Blueprint, request
from pydantic import BaseModel
# 定义数据模型
class MyModel(BaseModel):
name: str
value: int
# 创建蓝图
my_bp = Blueprint('my_api', __name__)
# 实现API端点
@my_bp.route('/endpoint', methods=['POST'])
@require_auth
async def my_endpoint():
data = await request.get_json()
model = MyModel(**data)
# 处理逻辑
return model.model_dump()
```
### 错误处理
使用HTTP状态码表示错误类型:
- 400: 请求参数错误
- 401: 未认证或认证失败
- 404: 资源不存在
- 500: 服务器内部错误
返回统一的错误格式:
```json
{
"error": "错误描述信息"
}
```
## 依赖说明 📚
主要依赖包:
- quart: 异步Web框架
- pydantic: 数据验证
- PyJWT: JWT认证
- hypercorn: ASGI服务器
- psutil: 系统监控
完整依赖列表见 [requirements.txt](../requirements.txt)
## 测试 🧪
运行单元测试:
```bash
pytest tests/web
```
## 贡献指南 🤝
1. Fork 本仓库
2. 创建特性分支
3. 提交更改
4. 创建Pull Request
================================================
FILE: kirara_ai/web/__init__.py
================================================
================================================
FILE: kirara_ai/web/api/block/README.md
================================================
# 区块 API 🧩
区块 API 提供了查询工作流构建块类型的功能。每个区块类型定义了其输入、输出和配置项。
>> 注意:文档由 Claude 生成,可能存在错误,请以实际代码为准。
## API 端点
### 获取所有区块类型
```http
GET/backend-api/api/block/types
```
获取所有可用的区块类型列表。
**响应示例:**
```json
{
"types": [
{
"type_name": "MessageBlock",
"name": "消息区块",
"description": "处理消息的基础区块",
"inputs": [
{
"name": "content",
"description": "消息内容",
"type": "string",
"required": true
}
],
"outputs": [
{
"name": "message",
"description": "处理后的消息",
"type": "IMMessage"
}
],
"configs": [
{
"name": "format",
"description": "消息格式",
"type": "string",
"required": false,
"default": "text"
}
]
}
]
}
```
### 获取特定区块类型
```http
GET/backend-api/api/block/types/{type_name}
```
获取指定区块类型的详细信息。
**响应示例:**
```json
{
"type": {
"type_name": "LLMBlock",
"name": "大语言模型区块",
"description": "调用 LLM 进行对话的区块",
"inputs": [
{
"name": "prompt",
"description": "提示词",
"type": "string",
"required": true
}
],
"outputs": [
{
"name": "response",
"description": "LLM 的响应",
"type": "string"
}
],
"configs": [
{
"name": "model",
"description": "使用的模型",
"type": "string",
"required": true,
"default": "gpt-4"
},
{
"name": "temperature",
"description": "温度参数",
"type": "float",
"required": false,
"default": 0.7
}
]
}
}
```
### 注册区块类型
```http
POST/backend-api/api/block/types
```
注册新的区块类型。
**请求体:**
```json
{
"type": "image_process",
"name": "图像处理",
"description": "处理图像数据",
"category": "media",
"config_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["resize", "crop", "rotate"]
},
"params": {
"type": "object"
}
}
},
"input_schema": {
"type": "object",
"properties": {
"image": {
"type": "string",
"format": "binary"
}
}
},
"output_schema": {
"type": "object",
"properties": {
"image": {
"type": "string",
"format": "binary"
}
}
}
}
```
### 更新区块类型
```http
PUT/backend-api/api/block/types/{type}
```
更新现有区块类型。
### 删除区块类型
```http
DELETE/backend-api/api/block/types/{type}
```
删除指定区块类型。
### 获取区块实例
```http
GET/backend-api/api/block/instances/{workflow_id}
```
获取指定工作流中的所有区块实例。
**响应示例:**
```json
{
"instances": [
{
"block_id": "input_1",
"type": "input",
"workflow_id": "chat:normal",
"config": {
"format": "text"
},
"state": {
"status": "ready",
"last_run": "2024-03-10T12:00:00Z",
"error": null
}
}
]
}
```
### 获取特定区块实例
```http
GET/backend-api/api/block/instances/{workflow_id}/{block_id}
```
获取指定区块实例的详细信息。
### 更新区块实例
```http
PUT/backend-api/api/block/instances/{workflow_id}/{block_id}
```
更新区块实例的配置。
## 数据模型
### BlockInput
- `name`: 输入名称
- `description`: 输入描述
- `type`: 数据类型
- `required`: 是否必需
- `default`: 默认值(可选)
### BlockOutput
- `name`: 输出名称
- `description`: 输出描述
- `type`: 数据类型
### BlockConfig
- `name`: 配置项名称
- `description`: 配置项描述
- `type`: 数据类型
- `required`: 是否必需
- `default`: 默认值(可选)
### BlockType
- `type_name`: 区块类型名称
- `name`: 显示名称
- `description`: 描述
- `inputs`: 输入定义列表
- `outputs`: 输出定义列表
- `configs`: 配置项定义列表
### BlockInstance
- `block_id`: 区块实例 ID
- `type`: 区块类型
- `workflow_id`: 所属工作流 ID
- `config`: 区块配置
- `state`: 区块状态
- `metadata`: 元数据(可选)
### BlockState
- `status`: 状态(ready/running/error)
- `last_run`: 最后运行时间
- `error`: 错误信息(如果有)
- `metrics`: 性能指标(可选)
## 相关代码
- [区块基类](../../../workflow/core/block/base.py)
- [区块注册表](../../../workflow/core/block/registry.py)
- [系统区块实现](../../../workflow/implementations/blocks)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误
- 404: 区块类型不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有区块类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/block/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 获取特定区块类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/block/types/LLMBlock',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [工作流系统概述](../../README.md#工作流系统-)
- [区块开发指南](../../../workflow/README.md#区块开发)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/block/__init__.py
================================================
from .routes import block_bp
__all__ = ["block_bp"]
================================================
FILE: kirara_ai/web/api/block/diagnostics/base_diagnostic.py
================================================
import ast
import logging
from abc import ABC, abstractmethod
from typing import Dict, List, Optional
from lsprotocol.types import CodeAction, CodeActionParams, Diagnostic, DiagnosticSeverity, Position, Range
from pygls.server import LanguageServer
from pygls.workspace import Document
logger = logging.getLogger(__name__)
class BaseDiagnostic(ABC):
"""诊断检查器的抽象基类"""
SOURCE_NAME: str = "base-diagnostic" # 每个子类应覆盖此项
def __init__(self, ls: LanguageServer):
self.ls = ls
@abstractmethod
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行诊断检查。
Args:
doc: 要检查的文档对象。
Returns:
诊断信息列表。
"""
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""
为相关的诊断信息生成代码操作(快速修复)。
Args:
params: 代码操作请求参数。
relevant_diagnostics: 与此检查器相关的诊断信息列表。
Returns:
代码操作列表。
"""
# 默认实现:不提供任何代码操作
return []
def _create_diagnostic(self, message: str, node: Optional[ast.AST], severity: DiagnosticSeverity, data: Optional[Dict] = None, range_override: Optional[Range] = None) -> Diagnostic:
"""
辅助函数:根据 AST 节点或显式范围创建 Diagnostic 对象。
"""
diag_range: Optional[Range] = None
if range_override:
diag_range = range_override
elif node and isinstance(node, ast.stmt):
try:
start_line = node.lineno - 1
start_col = node.col_offset
# AST 节点通常有 end_lineno 和 end_col_offset (Python 3.8+)
# end_lineno 是 1-based 的结束行号 (exclusive or inclusive depending on context, often exclusive)
# end_col_offset 是 0-based 的结束列偏移
end_line = getattr(node, 'end_lineno', start_line + 1) - 1
end_col = getattr(node, 'end_col_offset', start_col + 1)
# 确保范围有效
end_line = max(start_line, end_line)
if end_line == start_line:
end_col = max(start_col + 1, end_col) # 至少标记一个字符
diag_range = Range(
start=Position(line=start_line, character=start_col),
end=Position(line=end_line, character=end_col)
)
except AttributeError:
logger.warning(f"AST 节点缺少位置信息: {type(node)}")
# Fallback if location info is missing
diag_range = Range(start=Position(
line=0, character=0), end=Position(line=0, character=1))
else:
# 如果没有节点或范围,默认标记文件开头
diag_range = Range(start=Position(
line=0, character=0), end=Position(line=0, character=1))
return Diagnostic(
range=diag_range,
message=message,
severity=severity,
source=self.SOURCE_NAME,
data=data
)
def _ast_node_to_string(self, node: Optional[ast.AST]) -> str:
"""
将 AST 注解节点转换为字符串表示。
(从原 LanguageServer 类移动)
"""
if node is None:
return ""
if isinstance(node, ast.Name):
return node.id
if isinstance(node, ast.Constant): # Python 3.8+
# Handle NoneType explicitly if needed
if node.value is None:
return "None"
return str(node.value)
# Python < 3.8 NameConstant handling might be needed if supporting older versions
# if isinstance(node, ast.NameConstant):
# return str(node.value)
if isinstance(node, ast.Attribute):
value_str = self._ast_node_to_string(node.value)
# Avoid adding '.' if value is empty (shouldn't happen often)
return f"{value_str}.{node.attr}" if value_str else node.attr
if isinstance(node, ast.Subscript):
base = self._ast_node_to_string(node.value)
slice_val = node.slice
if isinstance(slice_val, ast.Tuple):
slice_str = ', '.join(
[self._ast_node_to_string(entry) for entry in slice_val.elts])
else:
slice_str = self._ast_node_to_string(slice_val)
return f"{base}[{slice_str}]"
if isinstance(node, ast.List):
return f"List[{self._ast_node_to_string(node.elts[0])}]" if node.elts else "List"
if isinstance(node, ast.Dict):
return f"Dict[{self._ast_node_to_string(node.keys[0])}, {self._ast_node_to_string(node.values[0])}]" if node.keys and node.values else "Dict"
if isinstance(node, ast.Set):
return f"Set[{self._ast_node_to_string(node.elts[0])}]" if node.elts else "Set"
if isinstance(node, ast.Tuple):
elts = [self._ast_node_to_string(elt) for elt in node.elts]
if not elts:
return "Tuple"
# Handle Tuple[int] vs Tuple[int, ...]
if len(elts) == 1:
# Check if it's intended as variable-length tuple hint e.g. Tuple[int, ...]
# This requires checking the source code or making assumptions.
# Simple approach: always assume single element means fixed tuple.
# Or f"tuple[{elts[0]}]" for consistency?
return f"Tuple[{elts[0]}]"
# Or f"tuple[{', '.join(elts)}]"
return f"Tuple[{', '.join(elts)}]"
# Fallback using ast.unparse (Python 3.9+)
try:
import sys
if sys.version_info >= (3, 9):
return ast.unparse(node)
# 如果 unparse 不可用,则为旧版本 Python 的基本回退
if isinstance(node, ast.Expr):
return self._ast_node_to_string(node.value)
# 如果需要,添加更多回退
logger.debug(
f"无法将 AST 节点转换为字符串(unparse 不可用):{type(node)}")
return "UnsupportedType"
except Exception as e:
logger.debug(f"Error using ast.unparse: {e}")
return "UnsupportedType" # Final fallback
================================================
FILE: kirara_ai/web/api/block/diagnostics/import_check.py
================================================
import ast
import importlib.util
import logging
import os
from typing import List, Optional, Tuple
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class ImportDiagnostic(BaseDiagnostic):
"""检查导入语句有效性的诊断器"""
SOURCE_NAME: str = "import-check"
def _get_package_context(self, path: Optional[str]) -> Tuple[Optional[str], Optional[str]]:
"""获取文件路径对应的目录和包名"""
if not path or not os.path.exists(path):
return None, None
file_dir = os.path.dirname(path)
# Simple package detection: check for __init__.py or assume dir name is package
# This might not be fully robust for complex project structures.
package_name = None
try:
# Walk up to find a directory containing __init__.py or setup.py?
# For simplicity, let's use the immediate parent directory name if it seems plausible
potential_pkg_name = os.path.basename(file_dir)
# Avoid using names like 'src', 'lib' directly unless structure confirms it
# A better approach might involve analyzing project structure or sys.path
# Let's assume basename is the package for resolve_name context
package_name = potential_pkg_name or None
except Exception:
logger.warning(f"无法确定 '{path}' 的包上下文")
return file_dir, package_name
def check(self, doc: Document) -> List[Diagnostic]:
"""检查导入语句是否有效"""
diagnostics = []
source = doc.source
path = doc.path
try:
tree = ast.parse(source)
file_dir, package_name = self._get_package_context(path)
# Store found issues to avoid duplicate diagnostics for the same line/module
reported_issues = set() # Store (line_no, module_name_str) tuples
for node in ast.walk(tree):
module_name_str: Optional[str] = None
# Record node for reporting and fixing
import_node: Optional[ast.stmt] = None
if not isinstance(node, ast.stmt):
continue
line_no = node.lineno if hasattr(node, 'lineno') else 0
if isinstance(node, ast.Import):
import_node = node
for alias in node.names:
module_name_str = alias.name
issue_key = (line_no, module_name_str)
if issue_key in reported_issues:
continue
try:
spec = importlib.util.find_spec(module_name_str)
if spec is None:
message = f"无法找到模块 '{module_name_str}'"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Error,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except ModuleNotFoundError:
message = f"无法找到模块 '{module_name_str}'"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Error,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except Exception as e: # Catch other potential errors during find_spec
message = f"检查导入 '{module_name_str}' 时出错: {e}"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Warning, # Warning for general errors
# Still offer removal
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
elif isinstance(node, ast.ImportFrom):
import_node = node
module_name_str = node.module # Can be None for 'from . import ...'
level = node.level
is_relative = level > 0
# Construct the name being resolved for reporting/key
if is_relative:
relative_prefix = "." * level
resolving_name = f"{relative_prefix}{module_name_str or ''}"
else:
# Should have module name if not relative
resolving_name = module_name_str or ""
# Skip if nothing to resolve (e.g. invalid syntax?)
if not resolving_name:
continue
issue_key = (line_no, resolving_name)
if issue_key in reported_issues:
continue
resolved_spec = None
error_message = None
severity = DiagnosticSeverity.Error
try:
if is_relative:
if file_dir and package_name:
# Resolve the name relative to the current file's package context
resolved_name = importlib.util.resolve_name(
resolving_name, package_name)
resolved_spec = importlib.util.find_spec(
resolved_name)
if resolved_spec is None:
error_message = f"无法找到相对导入的模块 '{resolving_name}' (解析为 '{resolved_name}' 来自 '{package_name}')"
else:
# Cannot reliably check relative imports without path/package context
error_message = f"无法可靠地检查相对导入 '{resolving_name}' (缺少文件路径或包上下文)"
severity = DiagnosticSeverity.Warning # Downgrade severity if unsure
elif module_name_str: # Absolute import
resolved_spec = importlib.util.find_spec(
module_name_str)
if resolved_spec is None:
error_message = f"无法找到模块 '{module_name_str}'"
except (ImportError, ValueError) as e:
error_message = f"无法解析或找到导入 '{resolving_name}': {e}"
except Exception as e:
error_message = f"检查导入 '{resolving_name}' 时发生意外错误: {e}"
severity = DiagnosticSeverity.Warning
# Create diagnostic if an error occurred
if error_message:
diagnostic = self._create_diagnostic(
error_message, import_node, severity,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except SyntaxError:
# Syntax errors handled elsewhere
logger.debug("跳过导入检查,存在语法错误")
except Exception as e:
logger.error(f"检查导入时发生内部错误: {str(e)}", exc_info=True)
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""提供删除无效导入的代码操作"""
actions = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document:
return []
lines = document.source.splitlines(True) # Keep line endings
for diag in relevant_diagnostics:
if diag.source != self.SOURCE_NAME:
continue
fix_type = diag.data.get("fix_type") if diag.data else None
if fix_type == "remove_import":
# The diagnostic range should cover the import statement node
start_line = diag.range.start.line
end_line = diag.range.end.line # The line index where the node ends
# Ensure line numbers are valid
if start_line < 0 or end_line >= len(lines):
logger.warning(f"无效的诊断范围用于删除导入: {diag.range}")
continue
# Define the range to be deleted: the entire line(s) of the import statement
delete_start_pos = Position(line=start_line, character=0)
# Determine the end position to include the newline of the last line involved
# Check if the node ends exactly at the end of a line (excluding newline)
# This requires knowing the exact end column from AST, which might be tricky.
# Safer approach: Delete up to the start of the *next* line.
delete_end_line_exclusive = end_line + 1
if delete_end_line_exclusive < len(lines):
# Delete up to the start of the next line
delete_end_pos = Position(
line=delete_end_line_exclusive, character=0)
else:
# Delete to the end of the last line of the file
delete_end_pos = Position(
line=end_line, character=len(lines[end_line]))
# Create the TextEdit to remove the line(s)
text_edit = TextEdit(
range=Range(start=delete_start_pos, end=delete_end_pos),
new_text=""
)
# Extract module name from message for a better title if possible
module_name_match = diag.message.split("'")
title_suffix = f": {module_name_match[1]}" if len(
module_name_match) > 1 else ""
title = f"移除无效的导入语句{title_suffix}"
edit = WorkspaceEdit(changes={doc_uri: [text_edit]})
action = CodeAction(
title=title,
kind=CodeActionKind.QuickFix,
diagnostics=[diag],
edit=edit,
is_preferred=False # Deleting code might not always be preferred
)
actions.append(action)
return actions
================================================
FILE: kirara_ai/web/api/block/diagnostics/jedi_syntax_check.py
================================================
import logging
from typing import List
import jedi
from lsprotocol.types import Diagnostic, DiagnosticSeverity, Position, Range
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class JediSyntaxErrorDiagnostic(BaseDiagnostic):
"""使用 Jedi 检查 Python 语法错误的诊断器"""
SOURCE_NAME: str = "syntax-error"
def __init__(self, ls: LanguageServer):
super().__init__(ls)
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行语法错误检查。
Args:
doc: 要检查的文档对象。
Returns:
诊断信息列表。
"""
diagnostics = []
source = doc.source
path = doc.path
try:
# 使用 Jedi 创建 Script 对象
# 注意:即使代码有语法错误,Jedi 通常也能创建 Script 对象
script = jedi.Script(code=source, path=path or None)
# 获取语法错误
syntax_errors = script.get_syntax_errors()
for error in syntax_errors:
# Jedi 的行列号是 1-based,LSP 是 0-based
start_line = error.line - 1
start_char = error.column
# Jedi 的 until_line/until_column 定义了错误范围的结束(通常是独占的)
# LSP 的 Range 结束位置也是独占的
end_line = error.until_line - 1
end_char = error.until_column
# 创建 LSP Range 对象
# 确保行列号不为负数
start_line = max(0, start_line)
start_char = max(0, start_char)
end_line = max(start_line, end_line) # 结束行不能在开始行之前
if end_line == start_line:
end_char = max(start_char + 1, end_char) # 结束列至少在开始列之后一个字符
error_range = Range(
start=Position(line=start_line, character=start_char),
end=Position(line=end_line, character=end_char)
)
# 使用 _create_diagnostic 辅助函数创建诊断信息
diagnostic = self._create_diagnostic(
message=error.get_message(),
node=None,
severity=DiagnosticSeverity.Error,
range_override=error_range # 使用 Jedi 提供的范围
)
diagnostics.append(diagnostic)
except Exception as e:
# 捕获 Jedi 或其他意外错误
logger.error(f"检查语法错误时发生内部错误: {str(e)}", exc_info=True)
# 可以选择性地添加一个通用的错误诊断
diagnostics.append(self._create_diagnostic(
message=f"检查语法错误时出错: {e}",
node=None,
severity=DiagnosticSeverity.Warning, # 使用警告级别,因为这是检查器本身的问题
range_override=Range(start=Position(line=0, character=0), end=Position(line=0, character=1))
))
return diagnostics
================================================
FILE: kirara_ai/web/api/block/diagnostics/mandatory_function.py
================================================
import ast
import logging
from typing import Any, Dict, List, Optional
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class MandatoryFunctionDiagnostic(BaseDiagnostic):
"""检查强制函数声明的诊断器"""
SOURCE_NAME: str = "mandatory-function-check"
config: Optional[Dict[str, Any]] = None
config_name: Optional[str] = None
config_params: Optional[List[Dict[str, Any]]] = None
config_return: Optional[str] = None
param_signatures: Optional[List[str]] = None
expected_signature_str: Optional[str] = None
expected_signature_data: Optional[Dict[str, Any]] = None
def __init__(self, ls: LanguageServer, config: Optional[Dict[str, Any]]):
super().__init__(ls)
self.config = None
self.config_name = None
self.config_params = None
self.config_return = None
self.param_signatures = None
self.expected_signature_str = None
self.expected_signature_data = None
# 初始化配置
if config:
self.update_config(config)
def update_config(self, config: Dict[str, Any]) -> None:
"""更新诊断器配置
Args:
config: 包含必要函数检查配置的字典
"""
try:
self.config = config
assert self.config is not None
self.config_name = self.config["name"]
self.config_params = self.config["params"]
assert self.config_params is not None
self.config_return = self.config["return_type"]
self.param_signatures = [
f"{p['name']}: {p['type_hint']}" for p in self.config_params]
self.expected_signature_str = f"def {self.config_name}({', '.join(self.param_signatures)}) -> {self.config_return}"
self.expected_signature_data = {
"name": self.config_name,
"params": self.param_signatures,
"return": self.config_return
}
logger.info(f"Updated mandatory function config: {self.config_name}")
logger.debug(f"Expected signature: {self.expected_signature_str}")
except KeyError as e:
logger.error(f"Invalid mandatory function config, missing key: {e}")
self.config = None # 配置无效时禁用检查器
except Exception as e:
logger.error(f"Error updating mandatory function config: {e}")
self.config = None
def check(self, doc: Document) -> List[Diagnostic]:
"""检查源代码是否包含配置的强制函数声明"""
diagnostics: List[Diagnostic] = []
if not self.config or not self.config_params:
return diagnostics
source = doc.source
found_match = False
potential_match_node = None
# Store reasons for mismatch if name matches
mismatch_reasons: List[str] = []
try:
tree = ast.parse(source)
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef) and node.name == self.config_name:
potential_match_node = node
# Reasons for this specific node
current_reasons: List[str] = []
# 1. Check parameter count
num_actual_params = len(node.args.args)
if num_actual_params != len(self.config_params):
current_reasons.append(
f"参数数量不匹配: 期望 {len(self.config_params)} 个, 实际 {num_actual_params} 个")
# 2. Check parameter names and types (only if count matches for clearer messages)
params_match = True
if num_actual_params == len(self.config_params):
for i, arg_node in enumerate(node.args.args):
config_param = self.config_params[i]
arg_name = arg_node.arg
arg_type_str = self._ast_node_to_string(
arg_node.annotation)
config_type_hint = config_param.get(
"type_hint", "")
# Normalize empty/Any types for comparison
norm_arg_type = arg_type_str or "Any"
norm_config_type = config_type_hint or "Any"
types_match = (norm_arg_type == norm_config_type)
if arg_name != config_param["name"]:
params_match = False
current_reasons.append(
f"第 {i+1} 个参数名不匹配: 期望 '{config_param['name']}', 实际 '{arg_name}'")
elif not types_match and config_type_hint: # Only check type if config specifies one
params_match = False
current_reasons.append(
f"参数 '{arg_name}' 类型不匹配: 期望 '{config_type_hint}', 实际 '{arg_type_str or '无类型'}'")
# If count didn't match, mark params as mismatch
elif num_actual_params != len(self.config_params):
params_match = False
# 3. Check return type
return_type_str = self._ast_node_to_string(node.returns)
config_return_type = self.config_return or ""
norm_return_type = return_type_str or "Any"
norm_config_return = config_return_type or "Any"
return_match = (norm_return_type == norm_config_return)
if not return_match and config_return_type: # Only check if config specifies return
current_reasons.append(
f"返回类型不匹配: 期望 '{config_return_type}', 实际 '{return_type_str or '无类型'}'")
# If all checks pass for this node
if not current_reasons:
found_match = True
break # Found a perfect match, stop searching
else:
# Store reasons from the first encountered mismatching function
if not mismatch_reasons:
mismatch_reasons = current_reasons
# --- End of AST walk ---
except SyntaxError as e:
# Let other checkers handle syntax errors
return []
except Exception as e:
logger.error(f"Error checking mandatory function: {str(e)}", exc_info=True)
return []
# --- Create Diagnostic if needed ---
if not found_match:
if potential_match_node:
# Found function with same name but wrong signature
param_signatures_actual = []
for arg in potential_match_node.args.args:
sig = arg.arg
annotation = self._ast_node_to_string(arg.annotation)
if annotation:
sig += f': {annotation}'
param_signatures_actual.append(sig)
return_actual = self._ast_node_to_string(
potential_match_node.returns)
actual_signature_str = f"def {potential_match_node.name}({', '.join(param_signatures_actual)})"
if return_actual:
actual_signature_str += f" -> {return_actual}"
mismatch_hint = ""
if mismatch_reasons:
mismatch_hint = "\n具体差异:\n- " + \
"\n- ".join(mismatch_reasons)
message = f"函数 '{self.config_name}' 的签名与强制要求不符。\n期望: {self.expected_signature_str}\n实际: {actual_signature_str}{mismatch_hint}"
diagnostic = self._create_diagnostic(
message=message,
node=potential_match_node,
severity=DiagnosticSeverity.Error,
data={"expected_signature": self.expected_signature_data,
"fix_type": "replace_signature"} # Keep replace type, even if not implemented yet
)
diagnostics.append(diagnostic)
else:
# Did not find the function at all
lines = source.splitlines()
# Position after last line for insertion
file_end_line = len(lines)
file_end_col = 0
message = f"缺少强制函数声明: '{self.config_name}'。\n期望签名: {self.expected_signature_str}"
diagnostic = self._create_diagnostic(
message=message,
node=None, # No specific node
severity=DiagnosticSeverity.Error,
# Mark the end of the file for insertion
range_override=Range(start=Position(line=file_end_line, character=file_end_col),
end=Position(line=file_end_line, character=file_end_col)),
data={"expected_signature": self.expected_signature_data,
"fix_type": "insert_function"}
)
diagnostics.append(diagnostic)
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""为强制函数错误提供代码操作"""
actions: List[CodeAction] = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document or not self.config: # Need document and config for actions
return []
for diag in relevant_diagnostics:
# Ensure the diagnostic came from this checker
if diag.source != self.SOURCE_NAME:
continue
fix_type = diag.data.get("fix_type") if diag.data else None
expected_sig_data = diag.data.get(
"expected_signature") if diag.data else None
# Double check data matches current config in case config changed
if not expected_sig_data or expected_sig_data["name"] != self.config_name:
continue
if fix_type == "insert_function":
title = f"生成强制函数 '{self.config_name}'"
param_str = ", ".join(expected_sig_data['params'])
return_str = f" -> {expected_sig_data['return']}" if expected_sig_data['return'] else ""
# Add two newlines before the function if the file is not empty
prefix = "\n\n" if document.source.strip() else ""
# Add a basic docstring and pass
new_text = f"{prefix}def {self.config_name}({param_str}){return_str}:\n \"\"\"强制函数存根\"\"\"\n pass\n"
# Use the range from the diagnostic (end of file)
insert_pos = diag.range.start
edit = WorkspaceEdit(changes={
doc_uri: [TextEdit(range=Range(
start=insert_pos, end=insert_pos), new_text=new_text)]
})
action = CodeAction(
title=title,
kind=CodeActionKind.QuickFix,
diagnostics=[diag],
edit=edit,
is_preferred=True # Make it the default action if possible
)
actions.append(action)
return actions
================================================
FILE: kirara_ai/web/api/block/diagnostics/pyflakes_check.py
================================================
import logging
from typing import Any, List
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pyflakes import api as pyflakes_api
from pyflakes import messages as pyflakes_messages
from pyflakes import reporter as pyflakes_reporter
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
# 自定义 Reporter 来收集 Pyflakes 的错误/警告并转换为 LSP Diagnostic
class _LspReporter(pyflakes_reporter.Reporter):
def __init__(self, source_name: str):
super().__init__(None, None) # 不需要标准输出/错误流
self.diagnostics: List[Diagnostic] = []
self._source_name = source_name
def unexpectedError(self, filename: str, msg: str):
# Pyflakes 内部错误
logger.error(f"Pyflakes unexpected error in {filename}: {msg}")
diagnostic = Diagnostic(
range=Range(start=Position(line=0, character=0), end=Position(line=0, character=1)),
message=f"Pyflakes internal error: {msg}",
severity=DiagnosticSeverity.Warning, # 标记为警告,因为是检查器本身的问题
source=self._source_name,
code="PyflakesInternalError"
)
self.diagnostics.append(diagnostic)
def syntaxError(self, filename: str, msg: str, lineno: int, offset: int, text: str):
# 处理 Pyflakes 报告的语法错误
line = lineno - 1 # 转换为 0-based
col = offset - 1 if offset > 0 else 0 # Pyflakes offset 是 1-based,LSP 是 0-based
# 语法错误通常标记单个字符或到行尾,这里简单标记一个字符
# 更精确的范围可能需要分析 text 或 msg,但通常语法错误点明确
end_col = col + 1
# 确保行列号不为负数
line = max(0, line)
col = max(0, col)
end_col = max(col + 1, end_col) # 确保结束至少在开始后
diagnostic = Diagnostic(
range=Range(
start=Position(line=line, character=col),
end=Position(line=line, character=end_col)
),
message=f"Syntax Error: {msg}", # 添加前缀以明确是语法错误
severity=DiagnosticSeverity.Error, # 语法错误是 Error
source=self._source_name,
code="PyflakesSyntaxError" # 使用特定的代码
)
self.diagnostics.append(diagnostic)
def flake(self, message: Any):
# message 是一个 pyflakes.messages.* 的实例
line = message.lineno - 1 # 转换为 0-based
col = message.col # 0-based 列偏移
# 尝试获取更精确的结束列
end_col = col + 1 # 默认标记一个字符
message_code = message.__class__.__name__ # 获取消息类型作为 code
try:
# 对于特定类型的消息,尝试使用参数长度确定范围
if isinstance(message, (pyflakes_messages.UnusedImport,
pyflakes_messages.UndefinedName,
pyflakes_messages.UndefinedExport,
pyflakes_messages.UndefinedLocal,
pyflakes_messages.DuplicateArgument,
pyflakes_messages.RedefinedWhileUnused,
pyflakes_messages.UnusedVariable)):
# 这些消息的第一个参数通常是相关的名称
if message.message_args:
name = message.message_args[0]
if isinstance(name, str):
end_col = col + len(name)
elif isinstance(message, pyflakes_messages.ImportShadowedByLoopVar):
if message.message_args:
name = message.message_args[0] # 第一个参数是名称
if isinstance(name, str):
end_col = col + len(name)
# 对于 'from module import *' used,标记 '*'
elif isinstance(message, pyflakes_messages.ImportStarUsed):
end_col = col + 1 # '*' 只有一个字符
# 其他消息类型保持默认单字符范围
except Exception as e:
logger.warning(f"计算 Pyflakes 诊断范围时出错: {e}", exc_info=True)
end_col = col + 1 # 出错时回退
# 确定严重性
severity = DiagnosticSeverity.Warning # 默认为警告
if isinstance(message, (pyflakes_messages.UndefinedName,
pyflakes_messages.UndefinedExport,
pyflakes_messages.UndefinedLocal,
pyflakes_messages.DoctestSyntaxError,
pyflakes_messages.ForwardAnnotationSyntaxError)):
severity = DiagnosticSeverity.Error
elif "syntax" in message_code.lower() or "invalid" in message_code.lower():
# 捕捉其他可能的语法相关错误消息类型
severity = DiagnosticSeverity.Error
# 创建诊断数据,包含消息类型,用于代码操作
diag_data = {"pyflakes_code": message_code}
diagnostic = Diagnostic(
range=Range(
start=Position(line=line, character=col),
end=Position(line=line, character=end_col)
),
message=message.message % message.message_args, # 格式化消息
severity=severity,
source=self._source_name,
code=message_code, # 使用 Pyflakes 消息类名作为 code
data=diag_data # 附加数据
)
self.diagnostics.append(diagnostic)
class PyflakesDiagnostic(BaseDiagnostic):
"""使用 Pyflakes 检查 Python 代码错误的诊断器 (增强版)"""
SOURCE_NAME: str = "pyflakes"
def __init__(self, ls: LanguageServer):
super().__init__(ls)
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行 Pyflakes 检查。
"""
diagnostics = []
source = doc.source
# Pyflakes 需要一个文件名,即使是临时的
path = doc.path or "untitled.py"
try:
reporter = _LspReporter(self.SOURCE_NAME)
# 使用 check 函数运行检查
pyflakes_api.check(source, path, reporter=reporter)
diagnostics = reporter.diagnostics
except Exception as e:
logger.error(f"运行 Pyflakes 时发生内部错误: {str(e)}", exc_info=True)
# 创建一个诊断信息报告 Pyflakes 本身的错误
diagnostics.append(self._create_diagnostic(
message=f"运行 Pyflakes 时出错: {e}",
node=None, # 没有关联的 AST 节点
severity=DiagnosticSeverity.Warning, # 检查器问题标记为警告
range_override=Range(start=Position(line=0, character=0), end=Position(line=0, character=1))
))
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""
为 Pyflakes 诊断提供代码操作(快速修复)。
目前主要实现 "移除未使用的导入"。
"""
actions = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document:
logger.warning(f"无法获取 Pyflakes 代码操作,未找到文档: {doc_uri}")
return []
lines = document.source.splitlines(True) # 保留换行符
for diag in relevant_diagnostics:
# 确保是来自 pyflakes 的诊断并且有附加数据
if diag.source != self.SOURCE_NAME or not diag.data:
continue
pyflakes_code = diag.data.get("pyflakes_code")
# --- 快速修复:移除未使用的导入 (UnusedImport) ---
if pyflakes_code == "UnusedImport":
# 诊断范围指向未使用的名称,我们需要删除包含它的整行(或部分行)
# 简单起见,我们先实现删除整行。
# 注意:如果一行导入多个,这会删除所有导入。更精细的处理需要 AST 分析。
start_line = diag.range.start.line
end_line = diag.range.end.line # Pyflakes 通常在单行内报告
if start_line < 0 or end_line >= len(lines):
logger.warning(f"无效的 Pyflakes 诊断范围用于移除导入: {diag.range}")
continue
# 定义要删除的范围:从该行开始到下一行开始(删除整行及换行符)
delete_start_pos = Position(line=start_line, character=0)
delete_end_line_exclusive = end_line + 1
if delete_end_line_exclusive < len(lines):
# 删除到下一行的开头
delete_end_pos = Position(line=delete_end_line_exclusive, character=0)
else:
# 如果是最后一行,删除到该行的末尾
delete_end_pos = Position(line=end_line, character=len(lines[end_line]))
text_edit = TextEdit(
range=Range(start=delete_start_pos, end=delete_end_pos),
new_text=""
)
edit = WorkspaceEdit(changes={doc_uri: [text_edit]})
# 尝试从消息中提取模块/变量名以获得更好的标题
title_suffix = ""
try:
# 'imported but unused' or 'assigned to but never used'
parts = diag.message.split("'")
if len(parts) > 1:
title_suffix = f": '{parts[1]}'"
except Exception:
pass # 忽略提取错误
action = CodeAction(
title=f"移除未使用的导入{title_suffix}",
kind=CodeActionKind.QuickFix,
diagnostics=[diag], # 关联此代码操作到原始诊断
edit=edit,
is_preferred=True # 移除未使用导入通常是首选操作
)
actions.append(action)
# --- 可以添加其他快速修复,例如:---
# if pyflakes_code == "SomeOtherFixableIssue":
# # ... 实现对应的 TextEdit 和 CodeAction ...
# pass
return actions
================================================
FILE: kirara_ai/web/api/block/models.py
================================================
from typing import List
from pydantic import BaseModel
from kirara_ai.workflow.core.block.schema import BlockConfig, BlockInput, BlockOutput
class BlockType(BaseModel):
"""Block类型信息"""
type_name: str
name: str
label: str
description: str
inputs: List[BlockInput]
outputs: List[BlockOutput]
configs: List[BlockConfig]
class BlockTypeList(BaseModel):
"""Block类型列表响应"""
types: List[BlockType]
class BlockTypeResponse(BaseModel):
"""单个Block类型响应"""
type: BlockType
================================================
FILE: kirara_ai/web/api/block/python_lsp.py
================================================
import asyncio
import os
from typing import Any, Dict, List, Optional, Union
import jedi
from lsprotocol.types import (TEXT_DOCUMENT_CODE_ACTION, TEXT_DOCUMENT_COMPLETION, TEXT_DOCUMENT_DEFINITION,
TEXT_DOCUMENT_DID_CHANGE, TEXT_DOCUMENT_DID_OPEN, TEXT_DOCUMENT_DID_SAVE,
TEXT_DOCUMENT_DOCUMENT_SYMBOL, TEXT_DOCUMENT_HOVER, TEXT_DOCUMENT_SIGNATURE_HELP,
WORKSPACE_DID_CHANGE_CONFIGURATION, CodeAction, CodeActionParams, CompletionItem,
CompletionItemKind, CompletionList, CompletionOptions, CompletionParams, DefinitionParams,
Diagnostic, DiagnosticSeverity, DidChangeConfigurationParams, DidChangeTextDocumentParams,
DidOpenTextDocumentParams, DidSaveTextDocumentParams, DocumentSymbolParams, Hover,
HoverParams, Location, MarkupContent, MarkupKind, MessageType, ParameterInformation,
Position, Range, SignatureHelp, SignatureHelpOptions, SignatureHelpParams,
SignatureInformation, SymbolInformation, SymbolKind, TextDocumentPositionParams)
from pygls.server import LanguageServer
from kirara_ai.logger import get_logger
from .diagnostics.base_diagnostic import BaseDiagnostic
from .diagnostics.import_check import ImportDiagnostic
from .diagnostics.jedi_syntax_check import JediSyntaxErrorDiagnostic
from .diagnostics.mandatory_function import MandatoryFunctionDiagnostic
from .diagnostics.pyflakes_check import PyflakesDiagnostic
logger = get_logger("LSP")
class QuartWsTransport(asyncio.Transport):
def __init__(self, queue: asyncio.Queue):
self._queue = queue
def write(self, message: str):
try:
# put_nowait 通常是线程安全的
self._queue.put_nowait(message)
except Exception as e:
logger.error(
f"Error putting message into queue: {e}", exc_info=True)
def close(self):
self._queue.put_nowait(None)
class PythonLanguageServer(LanguageServer):
mandatory_function_checker: Optional[MandatoryFunctionDiagnostic] = None
def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None):
super().__init__("kirara-code-block-lsp", "v0.1", loop=loop)
self._max_workers = 1
self.diagnostic_checkers: List[BaseDiagnostic] = []
self.diagnostic_checkers.append(ImportDiagnostic(self))
self.diagnostic_checkers.append(JediSyntaxErrorDiagnostic(self))
self.diagnostic_checkers.append(PyflakesDiagnostic(self))
logger.info(
f"Enabled diagnostic checkers: {[c.SOURCE_NAME for c in self.diagnostic_checkers]}")
self._setup_handlers()
def configure_mandatory_function_checker(self, config: Dict[str, Any]) -> None:
"""配置必要函数检查器
Args:
config: 包含必要函数检查配置的字典
"""
try:
if self.mandatory_function_checker is None:
self.mandatory_function_checker = MandatoryFunctionDiagnostic(
self, config)
self.diagnostic_checkers.append(
self.mandatory_function_checker)
logger.info(
"MandatoryFunctionDiagnostic enabled with client configuration.")
else:
# 更新现有检查器的配置
self.mandatory_function_checker.update_config(config)
logger.info(
"MandatoryFunctionDiagnostic configuration updated.")
# 记录配置详情
logger.debug(
f"MandatoryFunctionDiagnostic configured with: {config}")
# 更新已启用的诊断检查器列表日志
logger.info(
f"Currently enabled diagnostic checkers: {[c.SOURCE_NAME for c in self.diagnostic_checkers]}")
except Exception as e:
logger.error(
f"Error configuring MandatoryFunctionDiagnostic: {str(e)}", exc_info=True)
self.show_message(
f"Error configuring mandatory function checker: {str(e)}", MessageType.Error)
def _setup_handlers(self):
"""设置 LSP 方法处理程序"""
logger.debug("Setting up LSP handlers...")
@self.feature(TEXT_DOCUMENT_COMPLETION, CompletionOptions(trigger_characters=['.', '(', ',', '=', "\\", "[", "'"]))
@self.thread()
def completions(ls, params: CompletionParams) -> CompletionList:
"""处理代码补全请求"""
return self._get_completions(params)
@self.feature(TEXT_DOCUMENT_HOVER)
@self.thread()
def hover(ls, params: HoverParams) -> Optional[Hover]:
"""处理悬停请求"""
return self._get_hover(params)
@self.feature(TEXT_DOCUMENT_SIGNATURE_HELP, SignatureHelpOptions(trigger_characters=["(", ",", "."]))
@self.thread()
def signature(ls, params: SignatureHelpParams) -> Optional[SignatureHelp]:
"""处理函数签名帮助请求"""
return self._get_signature_help(params)
@self.feature(TEXT_DOCUMENT_DEFINITION)
@self.thread()
def definition(ls, params: DefinitionParams) -> Optional[Union[Location, List[Location]]]:
"""处理跳转到定义请求"""
return self._get_definition(params)
@self.feature(TEXT_DOCUMENT_DOCUMENT_SYMBOL)
@self.thread()
def symbols(ls, params: DocumentSymbolParams) -> Optional[List[SymbolInformation]]:
"""处理文档符号请求"""
return self._get_document_symbols(params)
@self.feature(TEXT_DOCUMENT_DID_OPEN)
@self.thread()
def did_open(ls, params: DidOpenTextDocumentParams):
"""文档打开时触发诊断"""
logger.info(f"Document opened: {params.text_document.uri}")
doc = ls.workspace.get_document(params.text_document.uri)
if doc and doc.source != params.text_document.text:
ls.workspace.put_document(params.text_document)
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_DID_CHANGE)
@self.thread()
def did_change(ls, params: DidChangeTextDocumentParams):
"""文档更改时触发诊断"""
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_DID_SAVE)
@self.thread()
def did_save(ls, params: DidSaveTextDocumentParams):
"""文档保存时触发诊断"""
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_CODE_ACTION)
@self.thread()
def code_action(ls, params: CodeActionParams) -> Optional[List[CodeAction]]:
"""处理代码操作请求,提供快速修复建议"""
return self._get_code_actions(params)
@self.feature(WORKSPACE_DID_CHANGE_CONFIGURATION)
@self.thread()
def did_change_configuration(ls, params: DidChangeConfigurationParams):
"""处理客户端配置变更"""
try:
settings = params.settings
if not settings:
return
# 检查是否包含强制函数配置
if 'mandatoryFunction' in settings:
logger.info(
"Update mandatory function checker configuration")
self.configure_mandatory_function_checker(
settings['mandatoryFunction'])
else:
logger.debug("No mandatory function configuration found")
except Exception as e:
logger.error(
f"Error processing configuration change: {str(e)}", exc_info=True)
self.show_message(
f"Error processing configuration change: {str(e)}", MessageType.Error)
logger.debug("LSP handlers set up.")
def _get_script(self, params: Union[TextDocumentPositionParams, CompletionParams, HoverParams, SignatureHelpParams, DefinitionParams]) -> Optional[jedi.Script]:
"""从参数中获取 jedi.Script 对象"""
try:
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
logger.warning(f"文档未在工作区中找到: {doc_uri}")
return None
path = document.path
source = document.source
position = params.position
line = position.line + 1
column = position.character
script = jedi.Script(
code=source,
path=path if path else None,
project=jedi.Project(os.getcwd())
)
return script
except Exception as e:
logger.error(f"Error getting jedi.Script: {str(e)}", exc_info=True)
return None
def _get_completions(self, params: CompletionParams) -> CompletionList:
"""获取代码补全建议"""
items: List[CompletionItem] = []
script = self._get_script(params)
if not script:
return CompletionList(is_incomplete=False, items=items)
try:
position = params.position
line = position.line + 1
column = position.character
completions = script.complete(line, column, fuzzy=True)
for completion in completions:
# ignore hidden completions like __str__
if completion.name.startswith('__'):
continue
kind = self._map_completion_type(completion.type)
item = CompletionItem(
label=completion.name,
kind=kind,
detail=completion.description,
insert_text=completion.name,
)
items.append(item)
except jedi.InternalError as e:
logger.warning(f"Jedi completion error: {e}", exc_info=True)
except Exception as e:
logger.error(f"Error getting completions: {str(e)}", exc_info=True)
return CompletionList(is_incomplete=False, items=items)
def _get_hover(self, params: HoverParams) -> Optional[Hover]:
"""获取悬停信息"""
script = self._get_script(params)
if not script:
return None
try:
position = params.position
line = position.line + 1
column = position.character
hover_info_list = script.help(line, column)
if hover_info_list:
docs = []
for info in hover_info_list:
signature = f"```python\n{info.description}\n```"
doc = info.docstring(raw=True, fast=False)
content = signature
if doc:
content += f"\n\n---\n\n{doc}"
docs.append(content)
full_docstring = "\n\n".join(docs)
if full_docstring:
contents = MarkupContent(
kind=MarkupKind.Markdown,
value=full_docstring
)
return Hover(contents=contents)
except jedi.InternalError as e:
logger.warning(f"Jedi hover error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting hover information: {str(e)}", exc_info=True)
return None
def _get_signature_help(self, params: SignatureHelpParams) -> Optional[SignatureHelp]:
"""获取函数签名帮助"""
script = self._get_script(params)
if not script:
return None
try:
position = params.position
line = position.line + 1
column = position.character
signatures = script.get_signatures(line, column)
if signatures:
signature_infos = []
for sig_index, sig in enumerate(signatures):
param_infos = []
for i, param in enumerate(sig.params):
param_doc = param.description
param_label = param.name
param_info = ParameterInformation(
label=param_label,
documentation=param_doc
)
param_infos.append(param_info)
sig_label = sig.to_string()
sig_info = SignatureInformation(
label=sig_label,
documentation=sig.docstring(raw=True, fast=False),
parameters=param_infos,
)
signature_infos.append(sig_info)
if not signature_infos:
return None
active_signature_index = 0
active_parameter_index = signatures[active_signature_index].index if signatures and signatures[
active_signature_index].index is not None else 0
return SignatureHelp(
signatures=signature_infos,
active_signature=active_signature_index,
active_parameter=active_parameter_index
)
except jedi.InternalError as e:
logger.warning(f"Jedi signature help error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting function signature: {str(e)}", exc_info=True)
return None
def _get_definition(self, params: DefinitionParams) -> List[Location]:
"""获取跳转到定义位置"""
locations: List[Location] = []
script = self._get_script(params)
if not script:
return locations
try:
position = params.position
line = position.line + 1
column = position.character
definitions = script.goto(
line, column, follow_imports=True, follow_builtin_imports=True)
for definition in definitions:
if definition.module_path and definition.line is not None and definition.column is not None:
start_pos = Position(
line=definition.line - 1, character=definition.column)
end_pos = Position(
line=definition.line - 1, character=definition.column + len(definition.name))
range_val = Range(start=start_pos, end=end_pos)
try:
from pathlib import Path
uri = Path(definition.module_path).as_uri()
except ImportError:
uri = f"file://{definition.module_path}"
locations.append(Location(uri=uri, range=range_val))
except jedi.InternalError as e:
logger.warning(f"Jedi definition lookup error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting definition location: {str(e)}", exc_info=True)
return locations
def _get_document_symbols(self, params: DocumentSymbolParams) -> List[SymbolInformation]:
"""获取文档中的符号信息 (扁平列表)"""
symbols = []
try:
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
return []
_script = jedi.Script(
code=document.source,
path=document.path if document.path else None,
project=jedi.Project(os.getcwd())
)
names = _script.get_names(
all_scopes=True, definitions=True, references=False)
for name in names:
if name.line is not None and name.column is not None:
kind = self._map_symbol_type(name.type)
start_pos = Position(
line=name.line - 1, character=name.column)
end_pos = Position(line=name.line - 1,
character=name.column + len(name.name))
container_name = None
try:
parent = name.parent()
if parent and parent.type != 'module':
container_name = parent.name
except Exception:
pass
symbol = SymbolInformation(
name=name.name,
kind=kind,
location=Location(
uri=doc_uri,
range=Range(start=start_pos, end=end_pos)
),
container_name=container_name,
)
symbols.append(symbol)
except jedi.InternalError as e:
logger.warning(f"Jedi symbol lookup error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting document symbols: {str(e)}", exc_info=True)
return symbols
def _map_completion_type(self, type_str: str) -> CompletionItemKind:
"""将 jedi 补全类型映射到 LSP 补全类型"""
mapping = {
'module': CompletionItemKind.Module,
'class': CompletionItemKind.Class,
'instance': CompletionItemKind.Variable,
'function': CompletionItemKind.Function,
'param': CompletionItemKind.Variable,
'path': CompletionItemKind.File,
'keyword': CompletionItemKind.Keyword,
'property': CompletionItemKind.Property,
'statement': CompletionItemKind.Variable,
'import': CompletionItemKind.Module,
'method': CompletionItemKind.Method,
' M': CompletionItemKind.Method,
' C': CompletionItemKind.Class,
' F': CompletionItemKind.Function,
}
return mapping.get(type_str, CompletionItemKind.Text)
def _map_symbol_type(self, type_str: str) -> SymbolKind:
"""将 jedi 符号类型映射到 LSP 符号类型"""
mapping = {
'module': SymbolKind.Module,
'class': SymbolKind.Class,
'instance': SymbolKind.Variable,
'function': SymbolKind.Function,
'param': SymbolKind.Variable,
'path': SymbolKind.File,
'keyword': SymbolKind.Variable,
'property': SymbolKind.Property,
'statement': SymbolKind.Variable,
'import': SymbolKind.Module,
'method': SymbolKind.Method,
' M': SymbolKind.Method,
' C': SymbolKind.Class,
' F': SymbolKind.Function,
'namespace': SymbolKind.Namespace,
}
return mapping.get(type_str, SymbolKind.Variable)
def _publish_diagnostics(self, ls: LanguageServer, doc_uri: str):
"""运行所有检查并发布诊断信息"""
all_diagnostics = []
document = ls.workspace.get_document(doc_uri)
if not document:
logger.warning(f"无法发布诊断,未找到文档: {doc_uri}")
ls.publish_diagnostics(doc_uri, [])
return
for checker in self.diagnostic_checkers:
checker_name = checker.SOURCE_NAME
try:
checker_diagnostics = checker.check(document)
if checker_diagnostics:
all_diagnostics.extend(checker_diagnostics)
except Exception as e:
logger.error(
f"Diagnostic checker '{checker_name}' error: {str(e)}", exc_info=True)
all_diagnostics.append(Diagnostic(
range=Range(start=Position(line=0, character=0),
end=Position(line=0, character=1)),
message=f"Diagnostic checker '{checker_name}' error: {str(e)}",
severity=DiagnosticSeverity.Error,
source='lsp-internal'
))
ls.publish_diagnostics(doc_uri, all_diagnostics)
def _get_code_actions(self, params: CodeActionParams) -> Optional[List[CodeAction]]:
"""根据请求的诊断信息生成代码操作"""
actions = []
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
return None
context_diagnostics = params.context.diagnostics
diagnostics_by_source: Dict[str, List[Diagnostic]] = {}
for diag in context_diagnostics:
if diag.source:
if diag.source not in diagnostics_by_source:
diagnostics_by_source[diag.source] = []
diagnostics_by_source[diag.source].append(diag)
for checker in self.diagnostic_checkers:
checker_name = checker.SOURCE_NAME
relevant_diagnostics = diagnostics_by_source.get(checker_name, [])
if relevant_diagnostics:
try:
checker_actions = checker.get_code_actions(
params, relevant_diagnostics)
if checker_actions:
actions.extend(checker_actions)
except Exception as e:
logger.error(
f"Code action checker '{checker_name}' error: {str(e)}", exc_info=True)
return actions if actions else None
================================================
FILE: kirara_ai/web/api/block/routes.py
================================================
import asyncio
import json
from typing import Any
from quart import Blueprint, g, jsonify, websocket
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.block import BlockRegistry
from ...auth.middleware import require_auth
from .models import BlockType, BlockTypeList, BlockTypeResponse
from .python_lsp import PythonLanguageServer, QuartWsTransport
block_bp = Blueprint("block", __name__)
logger = get_logger("Web.Block")
@block_bp.route("/types", methods=["GET"])
@require_auth
async def list_block_types() -> Any:
"""获取所有可用的Block类型"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
types = []
for block_type in registry.get_all_types():
try:
inputs, outputs, configs = registry.extract_block_info(block_type)
type_name = registry.get_block_type_name(block_type)
for config in configs.values():
if config.has_options:
config.options = config.options_provider(g.container, block_type) # type: ignore
block_type_info = BlockType(
type_name=type_name,
name=block_type.name,
label=registry.get_localized_name(type_name) or block_type.name,
description=getattr(block_type, "description", ""),
inputs=list(inputs.values()),
outputs=list(outputs.values()),
configs=list(configs.values()),
)
types.append(block_type_info)
except Exception as e:
logger.error(f"获取Block类型失败: {e}")
return BlockTypeList(types=types).model_dump()
@block_bp.route("/types/", methods=["GET"])
@require_auth
async def get_block_type(type_name: str) -> Any:
"""获取特定Block类型的详细信息"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
block_type = registry.get(type_name)
if not block_type:
return jsonify({"error": "Block type not found"}), 404
# 获取Block类的输入输出定义
inputs, outputs, configs = registry.extract_block_info(block_type)
for config in configs.values():
if config.has_options:
config.options = config.options_provider(g.container, block_type) # type: ignore
block_type_info = BlockType(
type_name=type_name,
name=block_type.name,
label=registry.get_localized_name(type_name) or block_type.name,
description=getattr(block_type, "description", ""),
inputs=list(inputs.values()),
outputs=list(outputs.values()),
configs=list(configs.values()),
)
return BlockTypeResponse(type=block_type_info).model_dump()
@block_bp.route("/types/compatibility", methods=["GET"])
@require_auth
async def get_type_compatibility() -> Any:
"""获取所有类型的兼容性映射"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
return jsonify(registry.get_type_compatibility_map())
@block_bp.websocket("/code/lsp")
async def code_lsp():
"""处理代码编辑器的语言服务器协议 WebSocket 连接"""
lsp_server = PythonLanguageServer(loop=asyncio.get_event_loop())
logger = get_logger("Web.Block.LSP")
queue = asyncio.Queue()
transport = QuartWsTransport(queue)
lsp_server.lsp.connection_made(transport)
lsp_server.lsp._send_only_body = True
logger.info("LSP WebSocket connection established")
async def sender():
while True:
message = await queue.get()
if message is None:
break
await websocket.send(message)
async def receiver():
while True:
message_str = await websocket.receive()
try:
parsed_message = json.loads(
message_str,
object_hook=lsp_server.lsp._deserialize_message
)
lsp_server.lsp._procedure_handler(parsed_message)
except json.JSONDecodeError:
logger.error(f"Unable to parse received LSP message: {message_str}", exc_info=True)
except Exception as e:
logger.error(f"Error processing LSP message: {e}", exc_info=True)
receive_task = asyncio.create_task(receiver())
send_task = asyncio.create_task(sender())
logger.debug("Created LSP WebSocket sender and receiver tasks")
try:
await asyncio.gather(receive_task, send_task)
except asyncio.CancelledError:
logger.info("LSP WebSocket task cancelled")
except Exception as e:
logger.error(f"LSP WebSocket connection error: {e}", exc_info=True)
finally:
send_task.cancel()
try:
await send_task
except asyncio.CancelledError:
logger.debug("LSP WebSocket sender task cancelled")
receive_task.cancel()
try:
await receive_task
except asyncio.CancelledError:
logger.debug("LSP WebSocket receiver task cancelled")
loop = asyncio.get_event_loop()
loop.run_in_executor(None, lsp_server.shutdown)
logger.info("websocket connection closed")
================================================
FILE: kirara_ai/web/api/dispatch/README.md
================================================
# 调度规则 API 📋
调度规则 API 提供了消息处理规则的管理功能。调度规则决定了如何根据消息内容选择合适的工作流进行处理。
## API 端点
### 获取规则列表
```http
GET/backend-api/api/dispatch/rules
```
获取所有已配置的调度规则。
**响应示例:**
```json
{
"rules": [
{
"rule_id": "chat_normal",
"name": "普通聊天",
"description": "普通聊天,使用默认参数",
"workflow_id": "chat:normal",
"priority": 5,
"enabled": true,
"rule_groups": [
{
"operator": "or",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/chat"
}
},
{
"type": "keyword",
"config": {
"keywords": ["聊天", "对话"]
}
}
]
}
],
"metadata": {
"category": "chat",
"permission": "user",
"temperature": 0.7
}
}
]
}
```
### 获取特定规则
```http
GET/backend-api/api/dispatch/rules/{rule_id}
```
获取指定规则的详细信息。
### 创建规则
```http
POST/backend-api/api/dispatch/rules
```
创建新的调度规则。
**请求体:**
```json
{
"rule_id": "chat_creative",
"name": "创意聊天",
"description": "创意聊天,使用更高的温度参数",
"workflow_id": "chat:creative",
"priority": 5,
"enabled": true,
"rule_groups": [
{
"operator": "and",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/creative"
}
},
{
"type": "keyword",
"config": {
"keywords": ["创意", "发散"]
}
}
]
}
],
"metadata": {
"category": "chat",
"permission": "user",
"temperature": 0.9
}
}
```
### 更新规则
```http
PUT/backend-api/api/dispatch/rules/{rule_id}
```
更新现有规则。
### 删除规则
```http
DELETE/backend-api/api/dispatch/rules/{rule_id}
```
删除指定规则。
### 启用规则
```http
POST/backend-api/api/dispatch/rules/{rule_id}/enable
```
启用指定规则。
### 禁用规则
```http
POST/backend-api/api/dispatch/rules/{rule_id}/disable
```
禁用指定规则。
## 数据模型
### SimpleRule
- `type`: 规则类型 (prefix/keyword/regex)
- `config`: 规则类型特定的配置
### RuleGroup
- `operator`: 组合操作符 (and/or)
- `rules`: 规则列表
### CombinedDispatchRule
- `rule_id`: 规则唯一标识符
- `name`: 规则名称
- `description`: 规则描述
- `workflow_id`: 关联的工作流ID
- `priority`: 优先级(数字越大优先级越高)
- `enabled`: 是否启用
- `rule_groups`: 规则组列表(组之间是 AND 关系)
- `metadata`: 元数据(可选)
## 规则类型
### 前缀匹配 (prefix)
根据消息前缀进行匹配,例如 "/help"。
配置参数:
- `prefix`: 要匹配的前缀
### 关键词匹配 (keyword)
检查消息中是否包含指定关键词。
配置参数:
- `keywords`: 关键词列表
### 正则匹配 (regex)
使用正则表达式进行匹配,提供最灵活的匹配方式。
配置参数:
- `pattern`: 正则表达式模式
## 组合规则说明
新版本的调度规则系统支持复杂的条件组合:
1. 每个规则可以包含多个规则组(RuleGroup)
2. 规则组之间是 AND 关系,即所有规则组都满足时才会触发
3. 每个规则组内可以包含多个简单规则(SimpleRule)
4. 规则组内的规则可以选择 AND 或 OR 关系
5. 每个简单规则都有自己的类型和配置
例如,可以创建如下规则:
```json
{
"rule_groups": [
{
"operator": "or",
"rules": [
{ "type": "prefix", "config": { "prefix": "/creative" } },
{ "type": "keyword", "config": { "keywords": ["创意", "发散"] } }
]
},
{
"operator": "and",
"rules": [
{ "type": "regex", "config": { "pattern": ".*问题.*" } },
{ "type": "keyword", "config": { "keywords": ["帮我", "请问"] } }
]
}
]
}
```
这个规则表示:
- 当消息以 "/creative" 开头 或 包含 "创意"/"发散" 关键词
- 且 消息包含 "问题" 且 包含 "帮我"/"请问" 中的任一关键词
时触发。
## 相关代码
- [调度规则定义](../../../workflow/core/dispatch/rule.py)
- [调度规则注册表](../../../workflow/core/dispatch/registry.py)
- [调度器实现](../../../workflow/core/dispatch/dispatcher.py)
- [系统预设规则](../../../../data/dispatch_rules)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误或规则配置无效
- 404: 规则不存在
- 409: 规则ID已存在
- 500: 服务器内部错误
## 使用示例
### 创建组合规则
```python
import requests
rule_data = {
"rule_id": "chat_creative",
"name": "创意聊天",
"description": "创意聊天模式",
"workflow_id": "chat:creative",
"priority": 5,
"enabled": True,
"rule_groups": [
{
"operator": "or",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/creative"
}
},
{
"type": "keyword",
"config": {
"keywords": ["创意", "发散"]
}
}
]
}
]
}
response = requests.post(
'http://localhost:8080/api/dispatch/rules',
headers={'Authorization': f'Bearer {token}'},
json=rule_data
)
```
### 更新规则优先级
```python
import requests
response = requests.put(
'http://localhost:8080/api/dispatch/rules/chat_creative',
headers={'Authorization': f'Bearer {token}'},
json={"priority": 8}
)
```
## 相关文档
- [工作流系统概述](../../README.md#工作流系统-)
- [调度规则配置指南](../../../workflow/README.md#调度规则配置)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/dispatch/__init__.py
================================================
from .routes import dispatch_bp
__all__ = ["dispatch_bp"]
================================================
FILE: kirara_ai/web/api/dispatch/models.py
================================================
from typing import List
from pydantic import BaseModel
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule
class DispatchRuleList(BaseModel):
"""调度规则列表"""
rules: List[CombinedDispatchRule]
class DispatchRuleResponse(BaseModel):
"""调度规则响应"""
rule: CombinedDispatchRule
================================================
FILE: kirara_ai/web/api/dispatch/routes.py
================================================
from quart import Blueprint, g, jsonify, request
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule, DispatchRule, DispatchRuleRegistry
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from ...auth.middleware import require_auth
from .models import DispatchRuleList, DispatchRuleResponse
dispatch_bp = Blueprint("dispatch", __name__)
@dispatch_bp.route("/rules", methods=["GET"])
@require_auth
async def list_rules():
"""获取所有调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rules = registry.get_all_rules()
rules.sort(key=lambda x: x.priority, reverse=True)
rules = [rule.model_dump() for rule in rules]
return DispatchRuleList(rules=rules).model_dump()
@dispatch_bp.route("/rules/", methods=["GET"])
@require_auth
async def get_rule(rule_id: str):
"""获取特定调度规则的信息"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
return DispatchRuleResponse(rule=rule).model_dump()
@dispatch_bp.route("/rules", methods=["POST"])
@require_auth
async def create_rule():
"""创建新的调度规则"""
data = await request.get_json()
rule_data = CombinedDispatchRule(**data)
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查规则ID是否已存在
if registry.get_rule(rule_data.rule_id):
return jsonify({"error": "Rule ID already exists"}), 400
# 检查工作流是否存在
if not workflow_registry.get(rule_data.workflow_id):
return jsonify({"error": "Workflow not found"}), 400
try:
# 创建规则
rule = registry.create_rule(rule_data)
# 保存规则
registry.save_rules()
return DispatchRuleResponse(rule=rule).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@dispatch_bp.route("/rules/", methods=["PUT"])
@require_auth
async def update_rule(rule_id: str):
"""更新调度规则"""
data = await request.get_json()
rule_data = CombinedDispatchRule(**data)
if rule_id != rule_data.rule_id:
return jsonify({"error": "Rule ID mismatch"}), 400
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查规则是否存在
if not registry.get_rule(rule_id):
return jsonify({"error": "Rule not found"}), 404
# 检查工作流是否存在
if not workflow_registry.get(rule_data.workflow_id):
return jsonify({"error": "Workflow not found"}), 400
try:
# 更新规则
rule = registry.update_rule(rule_id, rule_data)
# 保存规则
registry.save_rules()
return DispatchRuleResponse(rule=rule).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@dispatch_bp.route("/rules/", methods=["DELETE"])
@require_auth
async def delete_rule(rule_id: str):
"""删除调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
# 检查规则是否存在
if not registry.get_rule(rule_id):
return jsonify({"error": "Rule not found"}), 404
# 删除规则
registry.delete_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule deleted successfully"})
@dispatch_bp.route("/rules//enable", methods=["POST"])
@require_auth
async def enable_rule(rule_id: str):
"""启用调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
if rule.enabled:
return jsonify({"error": "Rule is already enabled"}), 400
# 启用规则
registry.enable_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule enabled successfully"})
@dispatch_bp.route("/rules//disable", methods=["POST"])
@require_auth
async def disable_rule(rule_id: str):
"""禁用调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
if not rule.enabled:
return jsonify({"error": "Rule is already disabled"}), 400
# 禁用规则
registry.disable_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule disabled successfully"})
@dispatch_bp.route("/types", methods=["GET"])
@require_auth
async def get_rule_types():
"""获取所有可用的规则类型"""
return jsonify({"types": list(DispatchRule.rule_types.keys())})
@dispatch_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_rule_config_schema(rule_type: str):
"""获取指定规则类型的配置字段模式"""
try:
if rule_type not in DispatchRule.rule_types:
return jsonify({"error": "Invalid rule type"}), 404
rule_class = DispatchRule.rule_types[rule_type]
config_class = rule_class.config_class
schema = config_class.model_json_schema()
return jsonify({"configSchema": schema})
except Exception as e:
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/im/README.md
================================================
# 即时通讯 API 🗨️
即时通讯 API 提供了管理 IM 后端和适配器的功能。通过这些 API,你可以注册、配置和管理不同的 IM 平台适配器。
## API 端点
### 获取适配器类型
```http
GET/backend-api/api/im/types
```
获取所有可用的 IM 适配器类型。
**响应示例:**
```json
{
"types": [
"mirai",
"telegram",
"discord"
]
}
```
### 获取所有适配器
```http
GET/backend-api/api/im/adapters
```
获取所有已配置的 IM 适配器信息。
**响应示例:**
```json
{
"adapters": [
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
},
"is_running": true
}
]
}
```
### 获取特定适配器
```http
GET/backend-api/api/im/adapters/{adapter_id}
```
获取指定适配器的详细信息。
**响应示例:**
```json
{
"adapter": {
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
},
"is_running": true
}
}
```
### 创建适配器
```http
POST/backend-api/api/im/adapters
```
注册新的 IM 适配器。
**请求体:**
```json
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
}
}
```
### 更新适配器
```http
PUT/backend-api/api/im/adapters/{adapter_id}
```
更新现有适配器的配置。如果适配器正在运行,会自动重启以应用新配置。
**请求体:**
```json
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
}
}
```
### 删除适配器
```http
DELETE/backend-api/api/im/adapters/{adapter_id}
```
删除指定的适配器。如果适配器正在运行,会先自动停止。
### 启动适配器
```http
POST/backend-api/api/im/adapters/{adapter_id}/start
```
启动指定的适配器。
### 停止适配器
```http
POST/backend-api/api/im/adapters/{adapter_id}/stop
```
停止指定的适配器。
### 获取适配器配置模式
```http
GET/backend-api/api/im/types/{adapter_type}/config-schema
```
获取指定适配器类型的配置字段模式。
**响应示例:**
```json
{
"schema": {
"title": "TelegramConfig",
"type": "object",
"properties": {
"token": {
"title": "Bot Token",
"type": "string",
"description": "Telegram Bot Token"
}
},
"required": ["token"]
}
}
```
## 数据模型
### IMAdapterConfig
- `name`: 适配器名称
- `adapter`: 适配器类型
- `config`: 配置信息(字典)
### IMAdapterStatus
继承自 IMAdapterConfig,额外包含:
- `is_running`: 适配器是否正在运行
### IMAdapterList
- `adapters`: IM 适配器列表
### IMAdapterResponse
- `adapter`: 适配器信息
### IMAdapterTypes
- `types`: 可用的适配器类型列表
### IMAdapterConfigSchema
- `error`: 错误信息(可选)
- `schema`: JSON Schema 格式的配置字段描述
## 适配器类型
适配器由插件提供,见[适配器实现](../../../im/adapters)。
## 相关代码
- [IM 管理器](../../../im/manager.py)
- [IM 注册表](../../../im/im_registry.py)
- [适配器实现](../../../im/adapters)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、适配器类型无效或适配器已在运行
- 404: 适配器不存在
- 500: 服务器内部错误
## 使用示例
### 获取适配器类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/im/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新适配器
```python
import requests
adapter_data = {
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
"webhook_url": "https://example.com/webhook"
}
}
response = requests.post(
'http://localhost:8080/api/im/adapters',
headers={'Authorization': f'Bearer {token}'},
json=adapter_data
)
```
### 启动适配器
```python
import requests
response = requests.post(
'http://localhost:8080/api/im/adapters/telegram/start',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [IM 适配器开发](../../../im/README.md#适配器开发-)
================================================
FILE: kirara_ai/web/api/im/__init__.py
================================================
from .routes import im_bp
__all__ = ["im_bp"]
================================================
FILE: kirara_ai/web/api/im/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import IMConfig
from kirara_ai.im.im_registry import IMAdapterInfo
from kirara_ai.im.profile import UserProfile
IMAdapterConfig = IMConfig
class IMAdapterStatus(IMAdapterConfig):
"""IM适配器状态"""
is_running: bool
bot_profile: Optional[UserProfile] = None
class IMAdapterList(BaseModel):
"""IM适配器列表响应"""
adapters: List[IMAdapterStatus]
class IMAdapterResponse(BaseModel):
"""单个IM适配器响应"""
adapter: IMAdapterStatus
class IMAdapterTypes(BaseModel):
"""可用的IM适配器类型列表"""
types: List[str]
adapters: Dict[str, IMAdapterInfo]
class IMAdapterConfigSchema(BaseModel):
"""IM适配器配置模式"""
error: Optional[str] = None
configSchema: Optional[Dict[str, Any]] = None
================================================
FILE: kirara_ai/web/api/im/routes.py
================================================
import asyncio
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigJsonSchema, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.adapter import BotProfileAdapter
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.logger import get_logger
from ...auth.middleware import require_auth
from .models import (IMAdapterConfig, IMAdapterConfigSchema, IMAdapterList, IMAdapterResponse, IMAdapterStatus,
IMAdapterTypes)
im_bp = Blueprint("im", __name__)
logger = get_logger("Web.IM")
def _create_adapter(manager: IMManager, name: str, adapter: str, config: dict):
registry: IMRegistry = g.container.resolve(IMRegistry)
adapter_info = registry.get_all_adapters()[adapter]
adapter_class = adapter_info.adapter_class
adapter_config_class = adapter_info.config_class
adapter_config = adapter_config_class(**config)
manager.create_adapter(name, adapter_class, adapter_config)
@im_bp.route("/types", methods=["GET"])
@require_auth
async def get_adapter_types():
"""获取所有可用的适配器类型"""
registry: IMRegistry = g.container.resolve(IMRegistry)
adapters = registry.get_all_adapters()
types = [info.name for info in adapters.values()]
return IMAdapterTypes(types=types, adapters=adapters).model_dump()
@im_bp.route("/adapters", methods=["GET"])
@require_auth
async def list_adapters():
"""获取所有已配置的适配器"""
config = g.container.resolve(GlobalConfig)
manager = g.container.resolve(IMManager)
adapters = []
for im in config.ims:
is_running = manager.is_adapter_running(im.name)
configs = im.config
adapters.append(
IMAdapterStatus(
name=im.name, adapter=im.adapter, is_running=is_running, config=configs
)
)
return IMAdapterList(adapters=adapters).model_dump()
@im_bp.route("/adapters/", methods=["GET"])
@require_auth
async def get_adapter(adapter_id: str):
"""获取特定适配器的信息"""
manager: IMManager = g.container.resolve(IMManager)
# 查找适配器类型
if not manager.has_adapter(adapter_id):
return jsonify({"error": "Adapter not found"}), 404
adapter_config = manager.get_adapter_config(adapter_id)
adapter = manager.get_adapter(adapter_id)
bot_profile = None
if manager.is_adapter_running(adapter_id) and isinstance(adapter, BotProfileAdapter):
bot_profile = await adapter.get_bot_profile()
return IMAdapterResponse(
adapter=IMAdapterStatus(
name=adapter_id,
adapter=adapter_config.adapter,
is_running=manager.is_adapter_running(adapter_id),
config=adapter_config.config,
bot_profile=bot_profile
)
).model_dump()
@im_bp.route("/adapters", methods=["POST"])
@require_auth
async def create_adapter():
"""创建新的适配器"""
data = await request.get_json()
adapter_info = IMAdapterConfig(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
registry: IMRegistry = g.container.resolve(IMRegistry)
manager: IMManager = g.container.resolve(IMManager)
# 检查适配器类型是否存在
if adapter_info.adapter not in registry.get_all_adapters():
return jsonify({"error": "Invalid adapter type"}), 400
# 检查ID是否已存在
if manager.has_adapter(adapter_info.name):
return jsonify({"error": "Adapter ID already exists"}), 400
# 更新配置
_create_adapter(manager, adapter_info.name, adapter_info.adapter, adapter_info.config)
if adapter_info.enable:
try:
await manager.start_adapter(adapter_info.name, asyncio.get_event_loop())
except Exception as e:
manager.delete_adapter(adapter_info.name)
return jsonify({"error": str(e)}), 500
config.ims.append(adapter_info)
# 保存配置到文件
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return IMAdapterResponse(
adapter=IMAdapterStatus(
name=adapter_info.name,
adapter=adapter_info.adapter,
is_running=False,
config=adapter_info.config,
)
).model_dump()
@im_bp.route("/adapters/", methods=["PUT"])
@require_auth
async def update_adapter(adapter_id: str):
"""更新适配器配置 (支持重命名)"""
data = await request.get_json()
try:
adapter_info = IMAdapterConfig(**data)
except Exception as e:
return jsonify({"error": f"Invalid request data: {e}"}), 400
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: IMManager = g.container.resolve(IMManager)
registry: IMRegistry = g.container.resolve(IMRegistry)
loop = asyncio.get_event_loop()
# 1. 检查原始适配器是否存在
if not manager.has_adapter(adapter_id):
return jsonify({"error": "Adapter not found"}), 404
# 2. 如果名称改变,检查新名称是否冲突
if adapter_id != adapter_info.name and manager.has_adapter(adapter_info.name):
return jsonify({"error": f"Adapter name '{adapter_info.name}' already exists"}), 400
# 3. 检查适配器类型是否有效
if adapter_info.adapter not in registry.get_all_adapters():
return jsonify({"error": "Invalid adapter type specified"}), 400
# --- 停止旧适配器 (如果正在运行) ---
if manager.is_adapter_running(adapter_id):
try:
await manager.stop_adapter(adapter_id, loop)
except Exception as e:
logger.error(f"Error stopping adapter {adapter_id}: {e}")
# --- 更新 IMManager ---
# 从管理器中删除旧的实例
manager.delete_adapter(adapter_id)
# 使用新名称和配置创建新的实例
_create_adapter(manager, adapter_info.name, adapter_info.adapter, adapter_info.config)
config.ims.append(adapter_info)
# --- 尝试启动新适配器 (如果启用) ---
is_now_running = False
if adapter_info.enable:
try:
await manager.start_adapter(adapter_info.name, loop)
is_now_running = True
except Exception as e:
logger.error(f"Failed to start adapter '{adapter_info.name}' after update: {e}")
# --- 保存配置到文件 ---
# 无论是否启动成功,都保存更新后的配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# --- 准备并返回响应 ---
bot_profile = None
if is_now_running: # 仅在成功启动后尝试获取 profile
adapter_instance = manager.get_adapter(adapter_info.name)
if isinstance(adapter_instance, BotProfileAdapter):
try:
# 添加超时以防卡住
bot_profile = await asyncio.wait_for(adapter_instance.get_bot_profile(), timeout=5.0)
except Exception as e:
logger.error(f"Failed to get bot profile for {adapter_info.name} after update: {e}")
return IMAdapterResponse(adapter=IMAdapterStatus(
name=adapter_info.name, # 使用新名称
adapter=adapter_info.adapter,
is_running=is_now_running, # 反映当前实际运行状态
config=adapter_info.config,
bot_profile=bot_profile
)).model_dump()
@im_bp.route("/adapters/", methods=["DELETE"])
@require_auth
async def delete_adapter(adapter_id: str):
"""删除适配器"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
# 先停止适配器
if manager.is_adapter_running(adapter_id):
await manager.stop_adapter(adapter_id, loop)
# 从配置中删除
manager.delete_adapter(adapter_id)
# 保存配置到文件
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"message": "Adapter deleted successfully"})
@im_bp.route("/adapters//start", methods=["POST"])
@require_auth
async def start_adapter(adapter_id: str):
"""启动适配器"""
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
if manager.is_adapter_running(adapter_id):
return jsonify({"error": "Adapter is already running"}), 400
try:
await manager.start_adapter(adapter_id, loop)
return jsonify({"message": "Adapter started successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@im_bp.route("/adapters//stop", methods=["POST"])
@require_auth
async def stop_adapter(adapter_id: str):
"""停止适配器"""
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
if not manager.is_adapter_running(adapter_id):
return jsonify({"error": "Adapter is not running"}), 400
try:
await manager.stop_adapter(adapter_id, loop)
return jsonify({"message": "Adapter stopped successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@im_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_adapter_config_schema(adapter_type: str):
"""获取指定适配器类型的配置字段模式"""
try:
registry: IMRegistry = g.container.resolve(IMRegistry)
try:
config_class = registry.get_config_class(adapter_type)
except ValueError as e:
return jsonify({"error": str(e)}), 404
schema = config_class.model_json_schema(schema_generator=ConfigJsonSchema)
return IMAdapterConfigSchema(configSchema=schema).model_dump()
except Exception as e:
return IMAdapterConfigSchema(error=str(e)).model_dump()
================================================
FILE: kirara_ai/web/api/llm/README.md
================================================
# 大语言模型 API 🤖
大语言模型 API 提供了管理 LLM 后端和适配器的功能。通过这些 API,你可以注册、配置和管理不同的大语言模型服务。
## API 端点
### 获取适配器类型
```http
GET/backend-api/api/llm/types
```
获取所有可用的 LLM 适配器类型。
**响应示例:**
```json
{
"types": [
"openai",
"anthropic",
"azure",
"local"
]
}
```
### 获取所有后端
```http
GET/backend-api/api/llm/backends
```
获取所有已注册的 LLM 后端信息。
**响应示例:**
```json
{
"data": {
"backends": [
{
"name": "openai",
"adapter": "openai",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.openai.com/v1"
},
"enable": true,
"models": ["gpt-4", "gpt-3.5-turbo"]
}
]
}
}
```
### 获取特定后端
```http
GET/backend-api/api/llm/backends/{backend_name}
```
获取指定后端的详细信息。
**响应示例:**
```json
{
"data": {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
}
```
### 创建后端
```http
POST/backend-api/api/llm/backends
```
注册新的 LLM 后端。
**请求体:**
```json
{
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
```
### 更新后端
```http
PUT/backend-api/api/llm/backends/{backend_name}
```
更新现有后端的配置。
**请求体:**
```json
{
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com",
"temperature": 0.7
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
```
### 删除后端
```http
DELETE/backend-api/api/llm/backends/{backend_name}
```
删除指定的后端。如果后端当前已启用,会先自动卸载。
### 获取适配器配置模式
```http
GET/backend-api/api/llm/types/{adapter_type}/config-schema
```
获取指定适配器类型的配置字段模式。
**响应示例:**
```json
{
"schema": {
"title": "OpenAIConfig",
"type": "object",
"properties": {
"api_key": {
"title": "API Key",
"type": "string",
"description": "OpenAI API密钥"
},
"api_base": {
"title": "API Base",
"type": "string",
"description": "API基础URL",
"default": "https://api.openai.com/v1"
},
"temperature": {
"title": "Temperature",
"type": "number",
"description": "生成温度",
"default": 0.7,
"minimum": 0,
"maximum": 2
}
},
"required": ["api_key"]
}
}
```
## 数据模型
### LLMBackendInfo
- `name`: 后端名称
- `adapter`: 适配器类型
- `config`: 配置信息(字典)
- `enable`: 是否启用
- `models`: 支持的模型列表
### LLMBackendList
- `backends`: LLM 后端列表
### LLMBackendResponse
- `error`: 错误信息(可选)
- `data`: 后端信息(可选)
### LLMBackendListResponse
- `error`: 错误信息(可选)
- `data`: 后端列表(可选)
### LLMAdapterTypes
- `types`: 可用的适配器类型列表
### LLMAdapterConfigSchema
- `error`: 错误信息(可选)
- `schema`: JSON Schema 格式的配置字段描述
## 适配器类型
适配器由插件提供,见[适配器实现](../../../llm/adapters)。
目前自带支持的适配器类型包括:
### OpenAI
- 适配器类型: `openai`
- 支持模型: gpt-4, gpt-3.5-turbo 等
- 配置项:
- `api_key`: API 密钥
- `api_base`: API 基础 URL
- `temperature`: 温度参数(可选)
### Anthropic
- 适配器类型: `anthropic`
- 支持模型: claude-3-opus, claude-3-sonnet 等
- 配置项:
- `api_key`: API 密钥
- `api_base`: API 基础 URL
- `temperature`: 温度参数(可选)
### Azure OpenAI
- 适配器类型: `azure`
- 支持 Azure OpenAI 服务部署的各类模型
- 配置项:
- `api_key`: API 密钥
- `api_base`: Azure 终结点
- `deployment_name`: 部署名称
### 本地模型
- 适配器类型: `local`
- 支持本地部署的开源模型
- 配置项:
- `model_path`: 模型路径
- `device`: 运行设备(cpu/cuda)
## 相关代码
- [LLM 管理器](../../../llm/llm_manager.py)
- [LLM 注册表](../../../llm/llm_registry.py)
- [适配器实现](../../../llm/adapters)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误或后端配置无效
- 404: 后端不存在
- 500: 服务器内部错误
## 使用示例
### 获取适配器类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/llm/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新后端
```python
import requests
backend_data = {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
response = requests.post(
'http://localhost:8080/api/llm/backends',
headers={'Authorization': f'Bearer {token}'},
json=backend_data
)
```
### 更新后端配置
```python
import requests
backend_data = {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com",
"temperature": 0.7
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
response = requests.put(
'http://localhost:8080/api/llm/backends/anthropic',
headers={'Authorization': f'Bearer {token}'},
json=backend_data
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [LLM 适配器开发](../../../llm/README.md#适配器开发-)
================================================
FILE: kirara_ai/web/api/llm/__init__.py
================================================
from .routes import llm_bp
__all__ = ["llm_bp"]
================================================
FILE: kirara_ai/web/api/llm/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import LLMBackendConfig, ModelConfig
class LLMBackendInfo(LLMBackendConfig):
"""LLM后端信息"""
class LLMBackendList(BaseModel):
"""LLM后端列表"""
backends: List[LLMBackendInfo]
class LLMBackendResponse(BaseModel):
"""LLM后端响应"""
error: Optional[str] = None
data: Optional[LLMBackendInfo] = None
class LLMBackendListResponse(BaseModel):
"""LLM后端列表响应"""
error: Optional[str] = None
data: Optional[LLMBackendList] = None
class LLMBackendCreateRequest(LLMBackendConfig):
"""创建LLM后端请求"""
class LLMBackendUpdateRequest(LLMBackendConfig):
"""更新LLM后端请求"""
class LLMAdapterTypes(BaseModel):
"""可用的LLM适配器类型列表"""
types: List[str]
class LLMAdapterConfigSchema(BaseModel):
"""LLM适配器配置模式"""
error: Optional[str] = None
configSchema: Optional[Dict[str, Any]] = None
class ModelConfigListResponse(BaseModel):
"""模型配置列表响应"""
error: Optional[str] = None
models: List[ModelConfig] = []
================================================
FILE: kirara_ai/web/api/llm/routes.py
================================================
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.web.api.llm.models import (LLMAdapterConfigSchema, LLMAdapterTypes, LLMBackendCreateRequest,
LLMBackendInfo, LLMBackendList, LLMBackendListResponse, LLMBackendResponse,
LLMBackendUpdateRequest, ModelConfigListResponse)
from ...auth.middleware import require_auth
llm_bp = Blueprint("llm", __name__)
logger = get_logger("WebServer.LLM")
@llm_bp.route("/types", methods=["GET"])
@require_auth
async def get_adapter_types():
"""获取所有可用的适配器类型"""
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
return LLMAdapterTypes(types=registry.get_adapter_types()).model_dump()
@llm_bp.route("/backends", methods=["GET"])
@require_auth
async def list_backends():
"""获取所有后端列表"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
backends = []
for backend in config.llms.api_backends:
backends.append(
LLMBackendInfo(
name=backend.name,
adapter=backend.adapter,
config=backend.config,
enable=backend.enable,
models=backend.models,
)
)
return LLMBackendListResponse(
data=LLMBackendList(backends=backends)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to list backends")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["GET"])
@require_auth
async def get_backend(backend_name: str):
"""获取指定后端信息"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
backend = next(
(b for b in config.llms.api_backends if b.name == backend_name), None
)
if not backend:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
return LLMBackendResponse(
data=LLMBackendInfo(
name=backend.name,
adapter=backend.adapter,
config=backend.config,
enable=backend.enable,
models=backend.models,
)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to get backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends", methods=["POST"])
@require_auth
async def create_backend():
"""创建新的后端"""
try:
data = await request.get_json()
request_data = LLMBackendCreateRequest(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 检查后端名称是否已存在
if any(b.name == request_data.name for b in config.llms.api_backends):
return (
jsonify({"error": f"Backend {request_data.name} already exists"}),
400,
)
# 创建新的后端配置
backend = LLMBackendInfo(
name=request_data.name,
adapter=request_data.adapter,
config=request_data.config,
enable=request_data.enable,
models=request_data.models,
)
# 添加到配置中
config.llms.api_backends.append(backend)
# 如果启用则加载后端
if backend.enable:
manager.load_backend(backend.name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(data=backend).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to create backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["PUT"])
@require_auth
async def update_backend(backend_name: str):
"""更新指定后端"""
try:
data = await request.get_json()
request_data = LLMBackendUpdateRequest(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 查找要更新的后端
backend_index = next(
(
i
for i, b in enumerate(config.llms.api_backends)
if b.name == backend_name
),
-1,
)
if backend_index == -1:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
# 创建更新后的后端配置
updated_backend = LLMBackendInfo(
name=request_data.name,
adapter=request_data.adapter,
config=request_data.config,
enable=request_data.enable,
models=request_data.models,
)
# 如果原后端已启用,先卸载
if config.llms.api_backends[backend_index].enable:
await manager.unload_backend(backend_name)
# 更新配置
config.llms.api_backends[backend_index] = updated_backend
# 如果新配置启用则加载后端
if updated_backend.enable:
manager.load_backend(updated_backend.name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(data=updated_backend).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to update backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["DELETE"])
@require_auth
async def delete_backend(backend_name: str):
"""删除指定后端"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 查找要删除的后端
backend_index = next(
(
i
for i, b in enumerate(config.llms.api_backends)
if b.name == backend_name
),
-1,
)
if backend_index == -1:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
backend = config.llms.api_backends[backend_index]
# 如果后端已启用,要卸载
if backend.enable:
await manager.unload_backend(backend_name)
# 从配置中删除
deleted_backend = config.llms.api_backends.pop(backend_index)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(
data=LLMBackendInfo(
name=deleted_backend.name,
adapter=deleted_backend.adapter,
config=deleted_backend.config,
enable=deleted_backend.enable,
models=deleted_backend.models,
)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to delete backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_adapter_config_schema(adapter_type: str):
"""获取指定适配器类型的配置字段模式"""
try:
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
config_class = registry.get_config_class(adapter_type)
if not config_class:
return jsonify({"error": f"Adapter type {adapter_type} not found"}), 404
schema = config_class.model_json_schema()
return LLMAdapterConfigSchema(configSchema=schema).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to get adapter config schema")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/types//supports-auto-detect-models", methods=["GET"])
@require_auth
async def supports_auto_detect_models(adapter_type: str):
"""检查指定适配器类型是否支持自动检测模型"""
try:
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
adapter_class = registry.get(adapter_type)
if not adapter_class:
return jsonify({"error": f"Adapter type {adapter_type} not found"}), 404
if not issubclass(adapter_class, AutoDetectModelsProtocol):
return (
jsonify(
{
"error": f"Adapter type {adapter_type} does not support auto-detect models"
}
),
400,
)
return jsonify({"supportsAutoDetectModels": True})
except Exception as e:
logger.opt(exception=e).error("Failed to check if adapter supports auto-detect models")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends//auto-detect-models", methods=["GET"])
@require_auth
async def auto_detect_models(backend_name: str):
"""自动检测指定后端的模型列表"""
try:
manager: LLMManager = g.container.resolve(LLMManager)
adapter = manager.get(backend_name)
if not adapter:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
if not isinstance(adapter, AutoDetectModelsProtocol):
return (
jsonify(
{
"error": f"Backend {backend_name} does not support auto-detect models"
}
),
400,
)
# 自动检测模型并返回完整的ModelConfig列表
models = await adapter.auto_detect_models()
# 确保每个模型都有正确的能力设置
for model in models:
# 如果模型类型是LLM但没有设置能力,设置默认的TextChat能力
if model.type == ModelType.LLM.value and not model.ability:
model.ability = LLMAbility.TextChat.value
return ModelConfigListResponse(models=models).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to auto-detect models")
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/mcp/README.md
================================================
# MCP 服务器管理 API
MCP(Model Context Protocol)是一种用于大型语言模型的通信协议。本 API 提供了管理 MCP 服务器的功能,包括创建、更新、删除、启动和停止服务器,以及获取服务器提供的工具列表。
## 数据模型
### MCP 服务器(MCPServer)
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
```
### 连接类型(ConnectionType)
- `stdio`: 标准输入输出连接
- `sse`: 服务器发送事件连接
### 服务器状态(ServerStatus)
- `running`: 运行中
- `stopped`: 已停止
- `error`: 错误状态
## API 端点
### 获取服务器列表
获取 MCP 服务器列表,支持分页和过滤。
**请求**:
```
POST /mcp/servers
```
**请求体**:
```json
{
"page": 1,
"page_size": 20,
"page_size": 20,
"connection_type": null,
"status": null,
"query": null
}
```
**响应**:
```json
{
"items": [
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
],
"total": 1,
"page": 1,
"page_size": 20,
"total_pages": 1
}
```
### 获取统计信息
获取 MCP 服务器相关的统计信息。
**请求**:
```
GET /mcp/statistics
```
**响应**:
```json
{
"total_servers": 3,
"stdio_servers": 2,
"sse_servers": 1,
"running_servers": 1,
"stopped_servers": 2
}
```
### 获取服务器详情
获取特定 MCP 服务器的详细信息。
**请求**:
```
GET /mcp/servers/{server_id}
```
**响应**:
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
```
### 获取服务器工具列表
获取 MCP 服务器提供的工具列表。
**请求**:
```
GET /mcp/servers/{server_id}/tools
```
**响应**:
```json
[
{
"name": "search_web",
"description": "搜索网络获取信息",
"parameters": {
"query": {
"type": "string",
"description": "搜索查询"
}
}
},
{
"name": "analyze_image",
"description": "分析图像内容",
"parameters": {
"image_url": {
"type": "string",
"description": "图像URL"
},
"detect_faces": {
"type": "boolean",
"description": "是否检测人脸"
}
}
}
]
```
### 检查服务器 ID 是否可用
检查给定的服务器 ID 是否已存在。
**请求**:
```
GET /mcp/servers/check/{server_id}
```
**响应**:
返回布尔值,`true` 表示 ID 可用,`false` 表示 ID 已存在。
### 创建服务器
创建新的 MCP 服务器。
**请求**:
```
POST /mcp/servers/create
```
**请求体**:
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio"
}
```
**响应**:
返回创建的服务器详情。
### 更新服务器
更新现有 MCP 服务器的配置。
**请求**:
```
PUT /mcp/servers/{server_id}
```
**请求体**:
```json
{
"description": "Updated description",
"command": "python3",
"args": "-m claude_cli.mcp --verbose",
"connection_type": "stdio"
}
```
**响应**:
返回更新后的服务器详情。
### 删除服务器
删除 MCP 服务器。
**请求**:
```
DELETE /mcp/servers/{server_id}
```
**响应**:
```json
{
"message": "服务器已成功删除"
}
```
### 启动服务器
启动 MCP 服务器。
**请求**:
```
POST /mcp/servers/{server_id}/start
```
**响应**:
```json
{
"message": "服务器已启动"
}
```
### 停止服务器
停止 MCP 服务器。
**请求**:
```
POST /mcp/servers/{server_id}/stop
```
**响应**:
```json
{
"message": "服务器已停止"
}
```
## 使用示例
### 创建并启动 MCP 服务器
1. 创建服务器:
```
POST /mcp/servers/create
```
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio"
}
```
2. 启动服务器:
```
POST /mcp/servers/claude-mcp/start
```
3. 获取服务器提供的工具:
```
GET /mcp/servers/claude-mcp/tools
```
## 注意事项
1. 在更新服务器配置前,必须先停止正在运行的服务器。
2. 服务器 ID 必须是唯一的,可以使用 `/mcp/servers/check/{server_id}` 接口检查 ID 是否可用。
3. 创建服务器后,服务器状态默认为 `stopped`,需要手动启动。
================================================
FILE: kirara_ai/web/api/mcp/__init__.py
================================================
from .routes import mcp_bp
__all__ = ["mcp_bp"]
================================================
FILE: kirara_ai/web/api/mcp/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, Field
class MCPServerInfo(BaseModel):
"""MCP服务器信息"""
id: str
description: Optional[str] = None
connection_type: str
command: Optional[str] = None
args: str = Field(default="")
url: Optional[str] = None
connection_state: str
class MCPToolInfo(BaseModel):
"""MCP工具信息"""
name: str
description: Optional[str] = None
input_schema: Dict[str, Any] = Field(default_factory=dict)
class MCPServerList(BaseModel):
"""MCP服务器列表"""
items: List[MCPServerInfo]
total: int
page: int
page_size: int
total_pages: int
class MCPStatistics(BaseModel):
"""MCP统计信息"""
total_servers: int
stdio_servers: int
sse_servers: int
connected_servers: int
disconnected_servers: int
error_servers: int
total_tools: int
class MCPServerCreateRequest(BaseModel):
"""创建MCP服务器请求"""
id: str
description: Optional[str] = None
command: str
args: str
connection_type: str
class MCPServerUpdateRequest(BaseModel):
"""更新MCP服务器请求"""
description: Optional[str] = None
command: Optional[str] = None
args: str = Field(default="")
connection_type: Optional[str] = None
url: Optional[str] = None
headers: Optional[Dict[str, str]] = None
env: Optional[Dict[str, str]] = None
================================================
FILE: kirara_ai/web/api/mcp/routes.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from typing import Any, Dict, Optional, cast
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig, MCPServerConfig
from kirara_ai.logger import get_logger
from kirara_ai.mcp_module import MCPConnectionState, MCPServer, MCPServerManager
from ...auth.middleware import require_auth
from .models import (MCPServerCreateRequest, MCPServerInfo, MCPServerList, MCPServerUpdateRequest, MCPStatistics,
MCPToolInfo)
# 创建蓝图
mcp_bp = Blueprint("mcp", __name__)
logger = get_logger("WebServer.MCP")
def _convert_to_server_info(server: MCPServer) -> MCPServerInfo:
"""将服务器对象转换为MCPServerInfo响应对象"""
return MCPServerInfo(
id=server.server_config.id,
description=server.server_config.description,
connection_type=server.server_config.connection_type,
command=server.server_config.command,
args=" ".join(server.server_config.args) if isinstance(
server.server_config.args, list) else server.server_config.args,
url=getattr(server.server_config, 'url', None),
connection_state=server.state.name.lower()
)
@mcp_bp.route("/servers", methods=["GET"])
@require_auth
async def list_servers():
"""获取所有MCP服务器列表"""
try:
# 获取查询参数
page = request.args.get('page', 1, type=int)
page_size = request.args.get('page_size', 20, type=int)
connection_type = request.args.get('connection_type')
status = request.args.get('status')
query = request.args.get('query')
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取所有服务器
servers = manager.get_all_servers()
# 转换为响应格式
server_list = []
for server_id, server in servers.items():
# 过滤条件
if connection_type and server.server_config.connection_type != connection_type:
continue
server_state = server.state.name.lower()
if status:
if status == 'connected' and server_state != 'connected':
continue
elif status == 'disconnected' and server_state != 'disconnected':
continue
elif status == 'error' and server_state != 'error':
continue
if query and query.lower() not in server_id.lower() and (
not server.server_config.command or query.lower() not in server.server_config.command.lower()):
continue
server_list.append(_convert_to_server_info(server))
# 计算分页
total = len(server_list)
total_pages = (total + page_size - 1) // page_size
start_idx = (page - 1) * page_size
end_idx = min(start_idx + page_size, total)
paginated_servers = server_list[start_idx:end_idx]
# 返回响应
return MCPServerList(
items=[server for server in paginated_servers],
total=total,
page=page,
page_size=page_size,
total_pages=total_pages
).model_dump()
except Exception as e:
logger.opt(exception=e).error("获取MCP服务器列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/statistics", methods=["GET"])
@require_auth
async def get_statistics():
"""获取MCP服务器统计信息"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取统计信息
stats = manager.get_statistics()
# 获取工具总数
tools = manager.get_tools()
total_tools = len(tools)
# 返回响应
return MCPStatistics(
total_servers=stats.get("total", 0),
stdio_servers=stats.get("stdio", 0),
sse_servers=stats.get("sse", 0),
connected_servers=stats.get("connected", 0),
disconnected_servers=stats.get("disconnected", 0),
error_servers=stats.get("error", 0),
total_tools=total_tools
).model_dump()
except Exception as e:
logger.opt(exception=e).error("获取MCP统计信息失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["GET"])
@require_auth
async def get_server(server_id: str):
"""获取特定MCP服务器的详情"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
# 转换为响应格式
server_info = _convert_to_server_info(server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 详情失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//tools", methods=["GET"])
@require_auth
async def get_server_tools(server_id: str):
"""获取MCP服务器提供的工具列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
# 如果服务器未连接,返回空列表
if server.state != MCPConnectionState.CONNECTED:
return []
# 获取服务器工具
tools = manager.get_tools()
# 转换为响应格式
tool_list = []
for _, tool in tools.items():
if tool.server_id == server_id:
tool_list.append(MCPToolInfo(
name=tool.original_name,
description=tool.tool_info.description,
input_schema=tool.tool_info.inputSchema
))
# 返回响应
return [tool.model_dump() for tool in tool_list]
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 工具列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/check/", methods=["GET"])
@require_auth
async def check_server_id(server_id: str):
"""检查服务器ID是否可用"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 检查ID是否可用
is_available = manager.is_server_id_available(server_id)
# 返回响应
return jsonify({
"is_available": is_available
})
except Exception as e:
logger.opt(exception=e).error(f"检查服务器ID {server_id} 可用性失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers", methods=["POST"])
@require_auth
async def create_server():
"""创建新的MCP服务器"""
try:
# 获取请求数据
data = await request.get_json()
request_data = MCPServerCreateRequest(**data)
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 检查ID是否已存在
if not manager.is_server_id_available(request_data.id):
return jsonify({"message": f"服务器ID '{request_data.id}' 已存在或服务器正在运行"}), 409
# 创建新的MCP服务器配置
new_server_config = MCPServerConfig(
id=request_data.id,
description=request_data.description or "",
command=request_data.command,
args=request_data.args.split(" "),
connection_type=request_data.connection_type,
enable=True
)
# 添加到全局配置中
config.mcp.servers.append(new_server_config)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 让管理器加载新服务器
server = manager.load_server(new_server_config)
# 转换为响应格式
server_info = _convert_to_server_info(server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error("创建MCP服务器失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["PUT"])
@require_auth
async def update_server(server_id: str):
"""更新MCP服务器配置"""
try:
# 获取请求数据
data = await request.get_json()
request_data = MCPServerUpdateRequest(**data)
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 查找服务器配置
server_index = -1
for i, server in enumerate(config.mcp.servers):
if server.id == server_id:
server_index = i
break
if server_index == -1:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 检查服务器状态
current_server = manager.get_server(server_id)
if current_server and current_server.state == MCPConnectionState.CONNECTED:
return jsonify({"message": "无法更新正在运行的服务器,请先停止服务器"}), 409
# 更新服务器配置
server_config = config.mcp.servers[server_index]
if request_data.description is not None:
server_config.description = request_data.description
if request_data.command is not None:
server_config.command = request_data.command
if request_data.args is not None:
server_config.args = request_data.args.split(" ")
if request_data.connection_type is not None:
server_config.connection_type = request_data.connection_type
if request_data.url is not None:
server_config.url = request_data.url
if request_data.headers is not None:
server_config.headers = request_data.headers
if request_data.env is not None:
server_config.env = request_data.env
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 停止服务器
await manager.stop_server(server_id)
# 重新加载服务器
current_server = manager.load_server(server_config)
try:
await manager.connect_server(server_id)
except Exception as e:
logger.opt(exception=e).error(f"重新连接MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
# 转换为响应格式
server_info = _convert_to_server_info(current_server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error(f"更新MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["DELETE"])
@require_auth
async def delete_server(server_id: str):
"""删除MCP服务器"""
try:
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 查找服务器配置
server_index = -1
for i, server in enumerate(config.mcp.servers):
if server.id == server_id:
server_index = i
break
if server_index == -1:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 如果服务器正在运行,先停止它
current_server = manager.get_server(server_id)
if current_server and current_server.state == MCPConnectionState.CONNECTED:
await manager.stop_server(server_id)
# 从配置中删除服务器
removed_server = config.mcp.servers.pop(server_index)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
await manager.stop_server(server_id)
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"删除MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//start", methods=["POST"])
@require_auth
async def start_server(server_id: str):
"""连接 MCP 服务器"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 尝试连接服务器
success = await manager.connect_server(server_id)
if not success:
return jsonify({"message": f"服务器 '{server_id}' 不存在或无法连接"}), 404
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"连接 MCP 服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//stop", methods=["POST"])
@require_auth
async def stop_server(server_id: str):
"""断开 MCP 服务器"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 尝试停止服务器
success = await manager.stop_server(server_id)
if not success:
return jsonify({"message": f"服务器 '{server_id}' 不存在或未连接"}), 404
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"断开 MCP 服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/tools", methods=["GET"])
@require_auth
async def get_all_tools():
"""获取所有可用工具"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取所有工具
tools = manager.get_tools()
# 转换为响应格式
tool_list = []
for name, tool_info in tools.items():
tool_list.append(MCPToolInfo(
name=name,
description=tool_info.tool_info.description,
input_schema=tool_info.tool_info.inputSchema
))
# 返回响应
return [tool.model_dump() for tool in tool_list]
except Exception as e:
logger.opt(exception=e).error("获取所有工具失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//tools/call", methods=["POST"])
@require_auth
async def call_tool(server_id: str):
"""调用工具"""
try:
data: Dict[str, str | Dict[str, Any]] = await request.get_json()
toolName: str = cast(str, data.get("toolName"))
params: Dict[str, Any] = cast(Dict[str, Any], data.get("params"))
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server: Optional[MCPServer] = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 获取工具
result = await server.call_tool(toolName, params)
# 返回响应
return jsonify({"result": result.model_dump()})
except Exception as e:
logger.opt(exception=e).error(f"调用工具 {toolName} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//prompts", methods=["GET"])
@require_auth
async def get_server_prompts(server_id: str):
"""获取MCP服务器提供的提示词列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
prompts = await manager.get_prompt_list(server_id)
if prompts is None:
return jsonify({"message": f"服务器 {server_id} 未连接"}), 404
return jsonify(prompts)
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 提示词列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//resources", methods=["GET"])
@require_auth
async def get_server_resources(server_id: str):
"""获取MCP服务器提供的资源列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
resources = await manager.get_resource_list(server_id)
if resources is None:
return jsonify({"message": f"服务器 {server_id} 未连接"}), 404
return jsonify(resources)
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 资源列表失败")
return jsonify({"message": str(e)}), 500
================================================
FILE: kirara_ai/web/api/media/README.md
================================================
# 媒体管理API
本模块提供了媒体文件管理的API,包括上传、查询、下载和删除媒体文件。
## API接口
### 获取媒体列表
```
POST /api/media/list
```
请求体:
```json
{
"query": "搜索关键词",
"content_type": "image/jpeg",
"start_date": "2023-01-01T00:00:00Z",
"end_date": "2023-12-31T23:59:59Z",
"tags": ["tag1", "tag2"],
"page": 1,
"page_size": 20
}
```
响应:
```json
{
"items": [
{
"id": "media_id",
"url": "/api/media/file/filename.jpg",
"thumbnail_url": "/api/media/thumbnails/media_id.jpg",
"metadata": {
"filename": "filename.jpg",
"content_type": "image/jpeg",
"size": 12345,
"width": 800,
"height": 600,
"upload_time": "2023-01-01T12:00:00Z",
"source": "qq_group",
"uploader": "user1",
"tags": ["tag1", "tag2"]
}
}
],
"total": 100,
"has_more": true
}
```
### 获取媒体文件
```
GET /api/media/file/{filename}
```
返回媒体文件的二进制内容。
### 获取缩略图
```
GET /api/media/thumbnails/{media_id}.jpg
```
返回媒体文件的缩略图。
### 上传媒体文件
```
POST /api/media/upload
```
使用 multipart/form-data 上传文件。
可选参数:
- source: 来源
- uploader: 上传者
- tags: 标签(逗号分隔)
响应:
```json
{
"id": "media_id",
"url": "/api/media/file/filename.jpg",
"thumbnail_url": "/api/media/thumbnails/media_id.jpg",
"metadata": {
"filename": "filename.jpg",
"content_type": "image/jpeg",
"size": 12345,
"width": 800,
"height": 600,
"upload_time": "2023-01-01T12:00:00Z",
"source": "qq_group",
"uploader": "user1",
"tags": ["tag1", "tag2"]
}
}
```
### 删除媒体文件
```
DELETE /api/media/delete/{media_id}
```
响应:
```json
{
"success": true
}
```
### 批量删除媒体文件
```
POST /api/media/batch-delete
```
请求体:
```json
{
"ids": ["media_id1", "media_id2"]
}
```
响应:
```json
{
"success": true,
"deleted_count": 2
}
```
## 数据模型
### MediaMetadata
媒体文件的元数据。
| 字段名 | 类型 | 说明 |
|-------|------|------|
| filename | string | 文件名 |
| content_type | string | 内容类型 |
| size | integer | 文件大小(字节) |
| width | integer | 图片宽度(可选) |
| height | integer | 图片高度(可选) |
| upload_time | datetime | 上传时间 |
| source | string | 来源(可选) |
| uploader | string | 上传者(可选) |
| tags | array | 标签列表 |
### MediaItem
媒体文件项。
| 字段名 | 类型 | 说明 |
|-------|------|------|
| id | string | 媒体ID |
| url | string | 媒体URL |
| thumbnail_url | string | 缩略图URL(可选) |
| metadata | MediaMetadata | 媒体元数据 |
================================================
FILE: kirara_ai/web/api/media/__init__.py
================================================
from .routes import media_bp
__all__ = ["media_bp"]
================================================
FILE: kirara_ai/web/api/media/models.py
================================================
from datetime import datetime
from typing import List, Optional
from pydantic import BaseModel
class MediaMetadata(BaseModel):
"""媒体元数据"""
filename: str
content_type: str
size: int # 文件大小,单位字节
upload_time: datetime # 上传时间
source: Optional[str] = None # 来源
tags: List[str] = [] # 标签
references: List[str] = []
class MediaItem(BaseModel):
"""媒体项"""
id: str # 媒体ID
url: str # 媒体URL
thumbnail_url: Optional[str] = None # 缩略图URL
metadata: MediaMetadata
class MediaListResponse(BaseModel):
"""媒体列表响应"""
items: List[MediaItem]
total: int
has_more: bool # 是否有更多数据
page_size: int # 每页数量
class MediaSearchParams(BaseModel):
"""媒体搜索参数"""
query: Optional[str] = None # 搜索关键词
content_type: Optional[str] = None # 媒体类型
start_date: Optional[datetime] = None # 开始日期
end_date: Optional[datetime] = None # 结束日期
tags: List[str] = [] # 标签
page: int = 1 # 页码
page_size: int = 20 # 每页数量
class MediaBatchDeleteRequest(BaseModel):
"""批量删除请求"""
ids: List[str] # 要删除的媒体ID列表
================================================
FILE: kirara_ai/web/api/media/routes.py
================================================
import asyncio
import io
import os
import shutil
import time
from typing import Optional
import pytz
from quart import Blueprint, g, jsonify, request, send_file
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from kirara_ai.media.types.media_type import MediaType
from ...auth.middleware import require_auth
from .models import MediaBatchDeleteRequest, MediaItem, MediaListResponse, MediaMetadata, MediaSearchParams
media_bp = Blueprint("media", __name__)
logger = get_logger("Web.Media")
# 生成缩略图
async def generate_thumbnail(image_data: bytes) -> io.BytesIO:
"""生成图片缩略图,并返回BytesIO对象"""
from PIL import Image
def _generate_thumbnail(image_data: bytes) -> io.BytesIO:
"""在线程中运行的同步缩略图生成函数"""
with Image.open(io.BytesIO(image_data)) as img:
width, height = img.size
if width > height:
new_width = 300
new_height = int(height * (300 / width))
else:
new_height = 300
new_width = int(width * (300 / height))
img.thumbnail((new_width, new_height))
output = io.BytesIO()
img = img.convert("RGB")
img.save(output, format="WEBP", optimize=True, quality=65)
output.seek(0)
return output
return await asyncio.to_thread(_generate_thumbnail, image_data)
def _get_media_manager() -> MediaManager:
"""获取媒体管理器实例"""
return g.container.resolve(MediaManager)
def _convert_media_to_api_item(media: Media) -> Optional[MediaItem]:
"""将Media对象转换为API响应格式"""
if not media or not media.metadata:
return None
metadata = media.metadata
content_type = f"{metadata.media_type.value}/{metadata.format}" if metadata.media_type and metadata.format else "application/octet-stream"
return MediaItem(
id=media.media_id,
url=f"",
thumbnail_url="",
metadata=MediaMetadata(
filename=os.path.basename(metadata.path) if metadata.path else f"{media.media_id}.{metadata.format}",
content_type=content_type,
size=metadata.size or 0,
upload_time=metadata.created_at,
source=metadata.source,
tags=list(metadata.tags),
references=list(metadata.references),
)
)
@media_bp.route("/list", methods=["POST"])
@require_auth
async def list_media():
"""获取媒体列表,支持分页和搜索"""
data = await request.get_json()
search_params = MediaSearchParams(**data)
manager = _get_media_manager()
# 构建搜索条件
all_media_ids = []
# 如果有指定内容类型,筛选对应类型
if search_params.content_type:
if search_params.content_type.startswith("image/"):
media_type = MediaType.IMAGE
elif search_params.content_type.startswith("video/"):
media_type = MediaType.VIDEO
elif search_params.content_type.startswith("audio/"):
media_type = MediaType.AUDIO
else:
media_type = MediaType.FILE
all_media_ids = manager.search_by_type(media_type)
else:
all_media_ids = manager.get_all_media_ids()
# 如果有指定标签,继续筛选
if search_params.tags and len(search_params.tags) > 0:
filtered_ids = []
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata and any(tag in metadata.tags for tag in search_params.tags):
filtered_ids.append(media_id)
all_media_ids = filtered_ids
# 如果有搜索关键词,继续筛选
if search_params.query:
description_ids = manager.search_by_description(search_params.query)
source_ids = manager.search_by_source(search_params.query)
all_media_ids = [
media_id for media_id in all_media_ids
if media_id in description_ids or media_id in source_ids
]
# 如果有日期范围,继续筛选
if search_params.start_date or search_params.end_date:
filtered_ids = []
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata:
tz = pytz.timezone(g.container.resolve(GlobalConfig).system.timezone)
created_at = metadata.created_at.replace(tzinfo=tz)
start_date = search_params.start_date.replace(tzinfo=tz) if search_params.start_date else None
if start_date and created_at < start_date:
continue
end_date = search_params.end_date.replace(tzinfo=tz) if search_params.end_date else None
if end_date and created_at > end_date:
continue
filtered_ids.append(media_id)
all_media_ids = filtered_ids
# 计算分页
total = len(all_media_ids)
start_idx = (search_params.page - 1) * search_params.page_size
end_idx = start_idx + search_params.page_size
page_ids = all_media_ids[start_idx:end_idx]
# 构建返回结果
items = []
for media_id in page_ids:
if media := manager.get_media(media_id):
if item:= _convert_media_to_api_item(media):
items.append(item)
return MediaListResponse(
items=items,
total=total,
has_more=end_idx < total,
page_size=search_params.page_size,
).model_dump()
@media_bp.route("/file/", methods=["GET"])
@require_auth
async def get_media_file(media_id):
"""获取媒体文件"""
manager = _get_media_manager()
media = manager.get_media(media_id)
if not media:
return jsonify({"error": "Media not found"}), 404
return await send_file(io.BytesIO(await media.get_data()), mimetype=media.metadata.mime_type)
@media_bp.route("/preview/", methods=["GET"])
@require_auth
async def get_thumbnail(media_id):
"""获取缩略图"""
config = g.container.resolve(GlobalConfig)
media_manager = _get_media_manager()
media = media_manager.get_media(media_id)
if not media:
return jsonify({"error": "Media not found"}), 404
data = await media.get_data()
if not data:
return jsonify({"error": "Media not found"}), 404
if media.metadata.media_type == MediaType.IMAGE:
if media.metadata.format == "gif":
return await send_file(io.BytesIO(data), mimetype="image/gif")
thumbnail = await generate_thumbnail(data)
return await send_file(thumbnail, mimetype="image/webp")
elif media.metadata.media_type == MediaType.VIDEO:
# 视频类型直接返回原始数据,不做缩略图处理
return await send_file(io.BytesIO(data), mimetype="video/mp4")
else:
return jsonify({"error": "Unsupported media type"}), 400
@media_bp.route("/delete/", methods=["DELETE"])
@require_auth
async def delete_media(media_id):
"""删除单个媒体文件"""
manager = _get_media_manager()
# 检查媒体是否存在
if media_id not in manager.metadata_cache:
return jsonify({"error": "File not found"}), 404
# 删除媒体文件
manager.delete_media(media_id)
return jsonify({"success": True})
@media_bp.route("/batch-delete", methods=["POST"])
@require_auth
async def batch_delete():
"""批量删除媒体文件"""
data = await request.get_json()
delete_request = MediaBatchDeleteRequest(**data)
manager = _get_media_manager()
success_count = 0
for media_id in delete_request.ids:
if media_id in manager.metadata_cache:
# 删除媒体文件
manager.delete_media(media_id)
success_count += 1
return jsonify({"success": True, "deleted_count": success_count})
@media_bp.route("/system", methods=["GET"])
@require_auth
async def get_system_info():
"""获取系统信息,包括媒体数量、占用空间和磁盘信息"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MediaManager = _get_media_manager()
# 获取媒体总数和总大小
all_media_ids = manager.get_all_media_ids()
total_media_count = len(all_media_ids)
total_media_size = 0
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata and metadata.size:
total_media_size += metadata.size
# 获取磁盘空间信息
storage_path = manager.media_dir
disk_total, disk_used, disk_free = 0, 0, 0
try:
# 确保存储路径存在,如果不存在则尝试创建
disk_usage = shutil.disk_usage(storage_path)
disk_total = disk_usage.total
disk_used = disk_usage.used
disk_free = disk_usage.free
except OSError as e:
# 处理获取磁盘信息时可能发生的错误,例如路径不存在或权限问题
logger.error(f"Unable to get disk info for {storage_path}: {e}")
return jsonify({
"cleanup_duration": config.media.cleanup_duration,
"auto_remove_unreferenced": config.media.auto_remove_unreferenced,
"last_cleanup_time": config.media.last_cleanup_time,
"total_media_count": total_media_count,
"total_media_size": total_media_size,
"disk_total": disk_total,
"disk_used": disk_used,
"disk_free": disk_free,
})
# 修改配置
@media_bp.route("/system/config", methods=["POST"])
@require_auth
async def set_config():
"""设置配置"""
manager = _get_media_manager()
data = await request.get_json()
config = g.container.resolve(GlobalConfig)
config.media.cleanup_duration = data.get("cleanup_duration", config.media.cleanup_duration)
config.media.auto_remove_unreferenced = data.get("auto_remove_unreferenced", config.media.auto_remove_unreferenced)
manager.setup_cleanup_task(g.container)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"success": True})
@media_bp.route("/system/cleanup-unreferenced", methods=["POST"])
@require_auth
async def cleanup_unreferenced():
"""清理未引用的媒体文件"""
manager = _get_media_manager()
count = manager.cleanup_unreferenced()
config = g.container.resolve(GlobalConfig)
config.media.last_cleanup_time = int(time.time())
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
manager.setup_cleanup_task(g.container)
return jsonify({"success": True, "count": count})
================================================
FILE: kirara_ai/web/api/plugin/README.md
================================================
# 插件 API 🔌
插件 API 提供了管理插件的功能。通过这些 API,你可以安装、卸载、启用、禁用和更新插件。
## API 端点
### 获取所有插件
```http
GET/backend-api/api/plugin/plugins
```
获取所有已安装的插件列表。
**响应示例:**
```json
{
"plugins": [
{
"name": "图像处理",
"package_name": "image-processing",
"description": "提供图像处理功能",
"version": "1.0.0",
"author": "开发者",
"homepage": "https://github.com/example/image-processing",
"license": "MIT",
"is_internal": false,
"is_enabled": true,
"metadata": {
"category": "media",
"tags": ["image", "processing"]
}
}
]
}
```
### 获取特定插件
```http
GET/backend-api/api/plugin/plugins/{plugin_name}
```
获取指定插件的详细信息。
**响应示例:**
```json
{
"plugin": {
"name": "图像处理",
"package_name": "image-processing",
"description": "提供图像处理功能",
"version": "1.0.0",
"author": "开发者",
"homepage": "https://github.com/example/image-processing",
"license": "MIT",
"is_internal": false,
"is_enabled": true,
"metadata": {
"category": "media",
"tags": ["image", "processing"]
}
}
}
```
### 安装插件
```http
POST/backend-api/api/plugin/plugins
```
安装新的插件。
**请求体:**
```json
{
"package_name": "image-processing",
"version": "1.0.0" // 可选,不指定则安装最新版本
}
```
### 卸载插件
```http
DELETE/backend-api/api/plugin/plugins/{plugin_name}
```
卸载指定的插件。注意:内部插件不能被卸载。
### 启用插件
```http
POST/backend-api/api/plugin/plugins/{plugin_name}/enable
```
启用指定的插件。
### 禁用插件
```http
POST/backend-api/api/plugin/plugins/{plugin_name}/disable
```
禁用指定的插件。
### 更新插件
```http
PUT/backend-api/api/plugin/plugins/{plugin_name}
```
更新插件到最新版本。注意:内部插件不支持更新。
### 搜索插件市场
```http
GET/backend-api/api/v1/search?query={query}&page={page}&pageSize={pageSize}
```
在插件市场中搜索插件。
**参数:**
- `query`: 搜索关键词
- `page`: 页码 (默认为 1)
- `pageSize`: 每页数量 (默认为 10)
**响应示例:**
```json
{
"plugins": [
{
"name": "图像处理",
"description": "提供图像处理功能",
"author": "开发者",
"pypiPackage": "image-processing",
"pypiInfo": {
"version": "1.0.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com"
},
"isInstalled": false,
"installedVersion": null,
"isUpgradable": false
}
],
"totalCount": 1,
"totalPages": 1,
"page": 1,
"pageSize": 10
}
```
### 获取插件市场中插件的详细信息
```http
GET/backend-api/api/v1/info/{plugin_name}
```
获取插件市场中指定插件的详细信息。
**响应示例:**
```json
{
"name": "图像处理",
"description": "提供图像处理功能",
"author": "开发者",
"pypiPackage": "image-processing",
"pypiInfo": {
"version": "1.0.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com"
},
"isInstalled": false,
"installedVersion": null,
"isUpgradable": false
}
```
## 数据模型
### PluginInfo
- `name`: 插件名称
- `package_name`: 包名
- `description`: 描述
- `version`: 版本号
- `author`: 作者
- `homepage`: 主页(可选)
- `license`: 许可证(可选)
- `is_internal`: 是否为内部插件
- `is_enabled`: 是否已启用
- `metadata`: 元数据(可选)
### InstallPluginRequest
- `package_name`: 包名
- `version`: 版本号(可选)
### PluginList
- `plugins`: 插件列表
### PluginResponse
- `plugin`: 插件信息
## 内置插件
### IM 适配器
- Telegram 适配器
- HTTP Legacy 适配器
- WeCom 适配器
### LLM 后端
- OpenAI 适配器
- Anthropic 适配器
- Google AI 适配器
## 相关代码
- [插件管理器](../../../plugin_manager/plugin_loader.py)
- [插件基类](../../../plugin_manager/plugin.py)
- [系统插件](../../../plugins)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、插件已存在或内部插件操作限制
- 404: 插件不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有插件
```python
import requests
response = requests.get(
'http://localhost:8080/api/plugin/plugins',
headers={'Authorization': f'Bearer {token}'}
)
```
### 安装新插件
```python
import requests
data = {
"package_name": "image-processing",
"version": "1.0.0"
}
response = requests.post(
'http://localhost:8080/api/plugin/plugins',
headers={'Authorization': f'Bearer {token}'},
json=data
)
```
### 启用插件
```python
import requests
response = requests.post(
'http://localhost:8080/api/plugin/plugins/image-processing/enable',
headers={'Authorization': f'Bearer {token}'}
)
```
### 更新插件
```python
import requests
response = requests.put(
'http://localhost:8080/api/plugin/plugins/image-processing',
headers={'Authorization': f'Bearer {token}'}
)
```
### 搜索插件市场
```python
import requests
response = requests.get(
'http://localhost:8080/api/v1/search?query=image&page=1&pageSize=10',
headers={'Authorization': f'Bearer {token}'}
)
```
### 获取插件市场中插件的详细信息
```python
import requests
response = requests.get(
'http://localhost:8080/api/v1/info/image-processing',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [插件开发](../../../plugin_manager/README.md#插件开发-)
================================================
FILE: kirara_ai/web/api/plugin/__init__.py
================================================
from .routes import plugin_bp
__all__ = ["plugin_bp"]
================================================
FILE: kirara_ai/web/api/plugin/models.py
================================================
from typing import List, Optional
from pydantic import BaseModel
from kirara_ai.plugin_manager.models import PluginInfo
class PluginList(BaseModel):
"""插件列表响应"""
plugins: List[PluginInfo]
class PluginResponse(BaseModel):
"""插件详情响应"""
plugin: PluginInfo
class InstallPluginRequest(BaseModel):
"""安装插件请求"""
package_name: str
version: Optional[str] = None # 可选的版本号,不指定则安装最新版
================================================
FILE: kirara_ai/web/api/plugin/routes.py
================================================
from functools import lru_cache
import aiohttp
from packaging.version import Version
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.api.system.utils import get_installed_version
from ...auth.middleware import require_auth
from .models import InstallPluginRequest, PluginList, PluginResponse
plugin_bp = Blueprint("plugin", __name__)
logger = get_logger("WebServer")
@lru_cache(maxsize=1)
def get_meta_params() -> dict:
"""获取元参数"""
return {
"kirara_version": get_installed_version(),
}
def is_upgradable(installed_version: str, market_version: str) -> bool:
"""检查插件是否可升级"""
try:
return Version(market_version) > Version(installed_version)
except ValueError:
return False
async def fetch_from_market(path: str, params: dict | None = None) -> dict:
"""从插件市场获取数据的通用方法"""
plugin_market_base_url = g.container.resolve(GlobalConfig).plugins.market_base_url
async with aiohttp.ClientSession(trust_env=True) as session:
url = f"{plugin_market_base_url}/{path}"
logger.info(f"Fetching from market: {url}")
params = params or {}
params.update(get_meta_params())
async with session.get(url, params=params) as response:
if response.status != 200:
raise Exception(f"插件市场请求失败: {response.status}")
return await response.json()
async def enrich_plugin_data(plugins: list, loader: PluginLoader) -> list:
"""为插件数据添加安装状态和可升级状态"""
installed_plugins = loader.get_all_plugin_infos()
for plugin in plugins:
installed_plugin = next(
(p for p in installed_plugins if p.package_name == plugin["pypiPackage"]),
None,
)
plugin["isInstalled"] = installed_plugin is not None
plugin["installedVersion"] = (
installed_plugin.version if installed_plugin else None
)
plugin["isUpgradable"] = (
is_upgradable(installed_plugin.version, plugin["pypiInfo"]["version"])
if installed_plugin
else False
)
plugin["isEnabled"] = installed_plugin.is_enabled if installed_plugin else False
plugin["requiresRestart"] = installed_plugin.requires_restart if installed_plugin else False
return plugins
@plugin_bp.route("/v1/search", methods=["GET"])
@require_auth
async def search_plugins():
"""搜索插件市场"""
query = request.args.get("query", "")
page = request.args.get("page", 1, type=int)
page_size = request.args.get("pageSize", 10, type=int)
try:
result = await fetch_from_market(
"search", {"query": query, "page": page, "pageSize": page_size}
)
# 添加安装状态和可升级状态
loader: PluginLoader = g.container.resolve(PluginLoader)
result["plugins"] = await enrich_plugin_data(result["plugins"], loader)
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/v1/info/", methods=["GET"])
@require_auth
async def get_market_plugin_info(plugin_name: str):
"""获取插件市场中插件的详细信息"""
try:
result = await fetch_from_market(f"info/{plugin_name}")
# 添加安装状态和可升级状态
loader: PluginLoader = g.container.resolve(PluginLoader)
result = (await enrich_plugin_data([result], loader))[0]
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins", methods=["GET"])
@require_auth
async def list_plugins():
"""获取所有已安装的插件列表"""
loader: PluginLoader = g.container.resolve(PluginLoader)
plugins = loader.get_all_plugin_infos()
return PluginList(plugins=plugins).model_dump()
@plugin_bp.route("/plugins/", methods=["GET"])
@require_auth
async def get_plugin_details(plugin_name: str):
"""获取已安装插件的详细信息"""
loader: PluginLoader = g.container.resolve(PluginLoader)
print(f"Getting plugin details for {plugin_name}")
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
return PluginResponse(plugin=plugin_info).model_dump()
@plugin_bp.route("/plugins", methods=["POST"])
@require_auth
async def install_plugin():
"""安装新插件"""
data = await request.get_json()
install_data = InstallPluginRequest(**data)
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
try:
# 安装插件
plugin_info = await loader.install_plugin(
install_data.package_name, install_data.version
)
if not plugin_info or plugin_info.package_name is None:
return jsonify({"error": "Failed to install plugin"}), 500
# 更新配置
if plugin_info.package_name not in config.plugins.enable:
config.plugins.enable.append(plugin_info.package_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 加载插件
loader.load_plugin(plugin_info.name)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins/", methods=["DELETE"])
@require_auth
async def uninstall_plugin(plugin_name: str):
"""卸载插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
# 内部插件不能卸载
if plugin_info.is_internal:
return jsonify({"error": "Cannot uninstall internal plugin"}), 400
try:
# 卸载插件
await loader.uninstall_plugin(plugin_name)
# 更新配置
if plugin_info.package_name in config.plugins.enable:
config.plugins.enable.remove(plugin_info.package_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"message": "Plugin uninstalled successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins//enable", methods=["POST"])
@require_auth
async def enable_plugin(plugin_name: str):
"""启用插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
try:
# 启用插件
await loader.enable_plugin(plugin_name)
# 更新配置
if (
plugin_name
and plugin_name not in config.plugins.enable
and not plugin_info.is_internal
):
config.plugins.enable.append(plugin_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins//disable", methods=["POST"])
@require_auth
async def disable_plugin(plugin_name: str):
"""禁用插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
try:
# 禁用插件
await loader.disable_plugin(plugin_name)
# 更新插件信息
plugin_info = loader.get_plugin_info(plugin_name)
assert plugin_info is not None
# 更新配置
if (
plugin_name
and plugin_name in config.plugins.enable
and not plugin_info.is_internal
):
config.plugins.enable.remove(plugin_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins/", methods=["PUT"])
@require_auth
async def update_plugin(plugin_name: str):
"""更新插件到最新版本"""
loader: PluginLoader = g.container.resolve(PluginLoader)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
# 内部插件不支持更新
if plugin_info.is_internal:
return jsonify({"error": "Cannot update internal plugin"}), 400
new_package_name = request.args.get("package_name", None)
try:
# 执行更新
updated_info = await loader.update_plugin(plugin_name, new_package_name)
if not updated_info:
return jsonify({"error": "Failed to update plugin"}), 500
return PluginResponse(plugin=updated_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/system/README.md
================================================
# 系统管理 API 🛠️
系统管理 API 提供了监控和管理系统状态的功能。
## API 端点
### 获取系统状态
```http
GET/backend-api/api/system/status
```
获取系统的当前运行状态,包括版本信息、运行时间、资源使用情况等。
**响应示例:**
```json
{
"status": {
"version": "1.0.0",
"uptime": 3600, // 运行时间(秒)
"active_adapters": 2, // 活跃的 IM 适配器数量
"active_backends": 3, // 活跃的 LLM 后端数量
"loaded_plugins": 5, // 已加载的插件数量
"workflow_count": 10, // 工作流数量
"memory_usage": {
"rss": 256.5, // 物理内存使用(MB)
"vms": 512.8, // 虚拟内存使用(MB)
"percent": 2.5 // 内存使用百分比
},
"cpu_usage": 1.2 // CPU 使用百分比
}
}
```
### 获取系统配置
```http
GET/backend-api/api/system/config
```
获取系统当前配置。
### 更新系统配置
```http
PUT/backend-api/api/system/config
```
更新系统配置。
**请求体:**
```json
{
"log_level": "INFO",
"max_connections": 100,
"timeout": 30,
"storage": {
"type": "local",
"path": "/data"
}
}
```
### 获取系统日志
```http
GET/backend-api/api/system/logs
```
获取系统日志。支持分页和过滤。
**查询参数:**
- `level`: 日志级别 (DEBUG/INFO/WARNING/ERROR)
- `start_time`: 开始时间
- `end_time`: 结束时间
- `limit`: 每页条数
- `offset`: 偏移量
### 获取用户列表
```http
GET/backend-api/api/system/users
```
获取系统用户列表。
### 创建用户
```http
POST/backend-api/api/system/users
```
创建新用户。
**请求体:**
```json
{
"username": "admin",
"password": "password123",
"role": "admin",
"permissions": ["read", "write", "admin"]
}
```
### 更新用户
```http
PUT/backend-api/api/system/users/{username}
```
更新用户信息。
### 删除用户
```http
DELETE/backend-api/api/system/users/{username}
```
删除指定用户。
## 数据模型
### SystemStatus
- `version`: 系统版本
- `uptime`: 运行时间(秒)
- `active_adapters`: 活跃的 IM 适配器数量
- `active_backends`: 活跃的 LLM 后端数量
- `loaded_plugins`: 已加载的插件数量
- `workflow_count`: 工作流数量
- `memory_usage`: 内存使用情况
- `rss`: 物理内存使用(MB)
- `vms`: 虚拟内存使用(MB)
- `percent`: 内存使用百分比
- `cpu_usage`: CPU 使用百分比
### SystemConfig
- `log_level`: 日志级别
- `max_connections`: 最大连接数
- `timeout`: 超时时间(秒)
- `storage`: 存储配置
### User
- `username`: 用户名
- `role`: 角色
- `permissions`: 权限列表
- `created_at`: 创建时间
- `last_login`: 最后登录时间
## 监控指标
### 系统指标
- 运行时间
- CPU 使用率
- 内存使用情况
### 组件指标
- IM 适配器数量和状态
- LLM 后端数量和状态
- 插件数量和状态
- 工作流数量
## 相关代码
- [系统路由](routes.py)
- [数据模型](models.py)
- [系统监控](../../../monitor)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误
- 401: 未认证或认证失败
- 403: 权限不足
- 404: 资源不存在
- 500: 服务器内部错误
## 使用示例
### 获取系统状态
```python
import requests
response = requests.get(
'http://localhost:8080/api/system/status',
headers={'Authorization': f'Bearer {token}'}
)
status = response.json()['status']
print(f"系统已运行: {status['uptime']} 秒")
print(f"内存使用: {status['memory_usage']['percent']}%")
print(f"CPU 使用: {status['cpu_usage']}%")
```
### 更新系统配置
```python
import requests
config_data = {
"log_level": "DEBUG",
"max_connections": 200,
"timeout": 60
}
response = requests.put(
'http://localhost:8080/api/system/config',
headers={'Authorization': f'Bearer {token}'},
json=config_data
)
```
### 创建新用户
```python
import requests
user_data = {
"username": "admin",
"password": "password123",
"role": "admin",
"permissions": ["read", "write", "admin"]
}
response = requests.post(
'http://localhost:8080/api/system/users',
headers={'Authorization': f'Bearer {token}'},
json=user_data
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [监控指南](../../README.md#系统监控-)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/system/__init__.py
================================================
from .routes import system_bp
__all__ = ["system_bp"]
================================================
FILE: kirara_ai/web/api/system/models.py
================================================
from typing import Dict, Optional
from pydantic import BaseModel
class SystemStatus(BaseModel):
"""系统状态信息"""
version: str
uptime: float
active_adapters: int
active_backends: int
loaded_plugins: int
workflow_count: int
memory_usage: Dict[str, float]
cpu_usage: float
cpu_info: str
python_version: str
platform: str
has_proxy: bool
class SystemStatusResponse(BaseModel):
"""系统状态响应"""
status: SystemStatus
class UpdateStatus(BaseModel):
status: str
message: str
class UpdateCheckResponse(BaseModel):
"""更新检查响应"""
current_backend_version: str
latest_backend_version: str
backend_update_available: bool
backend_download_url: Optional[str]
latest_webui_version: str
webui_download_url: Optional[str]
================================================
FILE: kirara_ai/web/api/system/routes.py
================================================
import asyncio
import json
import os
import shutil
import subprocess
import sys
import tarfile
import tempfile
import time
from packaging import version
from quart import Blueprint, current_app, g, request, websocket
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.manager import IMManager
from kirara_ai.internal import set_restart_flag, shutdown_event
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.logger import WebSocketLogHandler, get_logger
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.api.system.utils import (download_file, get_cpu_info, get_cpu_usage, get_installed_version,
get_latest_npm_version, get_latest_pypi_version, get_memory_usage)
from kirara_ai.web.auth.services import AuthService
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from ...auth.middleware import require_auth
from .models import SystemStatus, SystemStatusResponse, UpdateCheckResponse
system_bp = Blueprint("system", __name__)
# 记录启动时间
start_time = time.time()
# 获取系统日志记录器
logger = get_logger("System-API")
@system_bp.websocket('/logs')
async def logs_websocket():
"""WebSocket端点,用于实时推送日志"""
try:
token_data = await websocket.receive()
token = json.loads(token_data)["token"]
except Exception as e:
logger.error(f"WebSocket连接错误: {e}")
await websocket.close(code=1008, reason="Invalid token")
return
auth_service: AuthService = g.container.resolve(AuthService)
if not auth_service.verify_token(token):
await websocket.close(code=1008, reason="Invalid token")
return
try:
# 将当前WebSocket连接添加到日志处理器
WebSocketLogHandler.add_websocket(websocket._get_current_object(), asyncio.get_event_loop())
# 保持连接打开,直到客户端断开
while not shutdown_event.is_set():
await asyncio.sleep(1)
finally:
# 从日志处理器中移除当前连接
WebSocketLogHandler.remove_websocket(websocket._get_current_object())
@system_bp.route("/config", methods=["GET"])
@require_auth
async def get_system_config():
"""获取系统配置"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
return {
"web": {
"host": config.web.host,
"port": config.web.port
},
"plugins": {
"market_base_url": config.plugins.market_base_url
},
"update": {
"pypi_registry": config.update.pypi_registry,
"npm_registry": config.update.npm_registry
},
"system": {
"timezone": config.system.timezone
},
"tracing": {
"llm_tracing_content": config.tracing.llm_tracing_content
}
}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/web", methods=["POST"])
@require_auth
async def update_web_config():
"""更新Web配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.web.host = data["host"]
config.web.port = data["port"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success", "restart_required": True}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/plugins", methods=["POST"])
@require_auth
async def update_plugins_config():
"""更新插件配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.plugins.market_base_url = data["market_base_url"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/update", methods=["POST"])
@require_auth
async def update_registry_config():
"""更新更新源配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
if not hasattr(config, "update"):
config.update = {}
config.update.pypi_registry = data["pypi_registry"]
config.update.npm_registry = data["npm_registry"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/system", methods=["POST"])
@require_auth
async def update_system_config():
"""更新系统配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查时区是否变化
timezone_changed = False
if "timezone" in data and data["timezone"] != config.system.timezone:
config.system.timezone = data["timezone"]
timezone_changed = True
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 如果时区变化,设置系统时区并调用 tzset
if timezone_changed and hasattr(time, "tzset"):
os.environ["TZ"] = config.system.timezone
time.tzset()
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/tracing", methods=["POST"])
@require_auth
async def update_tracing_config():
"""更新追踪配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.tracing.llm_tracing_content = data["llm_tracing_content"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/status", methods=["GET"])
@require_auth
async def get_system_status():
"""获取系统状态"""
im_manager: IMManager = g.container.resolve(IMManager)
llm_manager: LLMManager = g.container.resolve(LLMManager)
plugin_loader: PluginLoader = g.container.resolve(PluginLoader)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 计算运行时间
uptime = time.time() - start_time
# 获取活跃的适配器数量
active_adapters = len(
[adapter for adapter in im_manager.adapters.values() if adapter.is_running]
)
# 获取活跃的LLM后端数量
active_backends = len(llm_manager.active_backends)
# 获取已加载的插件数量
loaded_plugins = len(plugin_loader.plugins)
# 获取工作流数量
workflow_count = len(workflow_registry._workflows)
# 获取系统资源使用情况
memory_usage = get_memory_usage()
cpu_usage = get_cpu_usage()
# 检测代理服务
has_proxy = bool(os.environ.get('HTTP_PROXY') or os.environ.get('HTTPS_PROXY') or
os.environ.get('http_proxy') or os.environ.get('https_proxy'))
# 获取CPU信息
cpu_info = get_cpu_info()
# 获取Python版本
python_version = f"{sys.version_info.major}.{sys.version_info.minor}.{sys.version_info.micro}"
# 获取平台信息
platform_info = f"{sys.platform}"
status = SystemStatus(
uptime=uptime,
active_adapters=active_adapters,
active_backends=active_backends,
loaded_plugins=loaded_plugins,
workflow_count=workflow_count,
memory_usage=memory_usage,
cpu_usage=cpu_usage,
version=get_installed_version(),
platform=platform_info,
cpu_info=cpu_info,
python_version=python_version,
has_proxy=has_proxy,
)
return SystemStatusResponse(status=status).model_dump()
@system_bp.route("/check-update", methods=["GET"])
@require_auth
async def check_update():
"""检查系统更新"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
npm_registry = config.update.npm_registry
current_backend_version = get_installed_version()
latest_backend_version, backend_download_url = await get_latest_pypi_version("kirara-ai")
# 获取前端最新版本信息,但不判断是否需要更新
latest_webui_version, webui_download_url = await get_latest_npm_version("kirara-ai-webui", npm_registry)
# 只判断后端是否需要更新
backend_update_available = version.parse(latest_backend_version) > version.parse(current_backend_version)
return UpdateCheckResponse(
current_backend_version=current_backend_version,
latest_backend_version=latest_backend_version,
backend_update_available=backend_update_available,
backend_download_url=backend_download_url,
latest_webui_version=latest_webui_version,
webui_download_url=webui_download_url
).model_dump()
@system_bp.route("/update", methods=["POST"])
@require_auth
async def perform_update():
"""执行更新操作"""
data = await request.get_json()
update_backend = data.get("update_backend", False)
update_webui = data.get("update_webui", False)
temp_dir = tempfile.mkdtemp()
try:
if update_backend:
backend_url = data["backend_download_url"]
backend_file, backend_hash = await download_file(backend_url, temp_dir)
# 安装后端
subprocess.run([sys.executable, "-m", "pip", "install", backend_file], check=True)
if update_webui:
webui_url = data["webui_download_url"]
webui_file, webui_hash = await download_file(webui_url, temp_dir)
# 解压并安装前端
static_dir = current_app.static_folder or "web"
with tarfile.open(webui_file, "r:gz") as tar:
# 解压 package/dist 里的所有文件到 web 目录
for member in tar.getmembers():
if member.name.startswith("package/dist/"):
# 去掉 "package/dist/" 前缀
member.name = member.name[len("package/dist/"):]
# 解压到 static 目录
tar.extract(member, path=static_dir)
return {"status": "success", "message": "更新完成"}
except Exception as e:
return {"status": "error", "message": str(e)}, 500
finally:
shutil.rmtree(temp_dir)
@system_bp.route("/restart", methods=["POST"])
@require_auth
async def restart_system():
"""重启系统"""
# 记录重启日志,会通过WebSocket发送给所有客户端
logger.warning("服务器即将重启,请稍候...")
# 设置重启标志
set_restart_flag()
shutdown_event.set()
return {"status": "success", "message": "重启请求已发送"}
================================================
FILE: kirara_ai/web/api/system/utils.py
================================================
import hashlib
import os
import subprocess
import sys
from functools import lru_cache
import aiohttp
import psutil
def get_installed_version() -> str:
"""获取当前安装的版本号"""
try:
# 使用 importlib.metadata 获取已安装的包版本
from importlib.metadata import PackageNotFoundError, version
try:
return version("kirara-ai")
except PackageNotFoundError:
# 如果包未安装,尝试从 pkg_resources 获取
from pkg_resources import get_distribution
return get_distribution("kirara-ai").version
except Exception:
return "0.0.0" # 如果所有方法都失败,返回默认版本号
async def get_latest_pypi_version(package_name: str) -> tuple[str, str]:
"""获取包的最新版本和下载URL"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(f"https://pypi.org/pypi/{package_name}/json") as response:
response.raise_for_status()
data = await response.json()
latest_version = data["info"]["version"]
# 获取最新版本的wheel包下载URL
for url_info in data["urls"]:
if url_info["packagetype"] == "bdist_wheel":
return latest_version, url_info["url"]
return latest_version, ""
except Exception:
return "0.0.0", ""
async def get_latest_npm_version(package_name: str, registry: str = "https://registry.npmjs.org") -> tuple[str, str]:
"""获取NPM包的最新版本和下载URL"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(f"{registry}/{package_name}") as response:
response.raise_for_status()
data = await response.json()
latest_version = data["dist-tags"]["latest"]
tarball_url = data["versions"][latest_version]["dist"]["tarball"]
return latest_version, tarball_url
except Exception:
return "0.0.0", ""
async def download_file(url: str, temp_dir: str) -> tuple[str, str]:
"""下载文件并返回文件路径和SHA256"""
local_filename = os.path.join(temp_dir, url.split('/')[-1])
sha256_hash = hashlib.sha256()
try:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
response.raise_for_status()
total_size = int(response.headers.get('Content-Length', 0))
bytes_downloaded = 0
with open(local_filename, 'wb') as f:
async for chunk in response.content.iter_chunked(8192):
f.write(chunk)
sha256_hash.update(chunk)
bytes_downloaded += len(chunk)
if total_size > 0:
print(f"Downloaded {bytes_downloaded / total_size:.2%}", end='\r')
print() # 换行,确保进度条不覆盖后续输出
return local_filename, sha256_hash.hexdigest()
except Exception as e:
print(f"下载失败: {e}")
return "", ""
@lru_cache(maxsize=1)
def get_cpu_info() -> str:
"""获取CPU信息,使用lru_cache进行缓存"""
try:
if sys.platform == 'win32':
# Windows 系统下获取 CPU 信息
result = subprocess.run(['wmic', 'cpu', 'get', 'name'], capture_output=True, text=True)
if result.returncode == 0:
cpu_info = result.stdout.strip().removeprefix('Name').strip()
else:
# Linux 系统下获取 CPU 信息
with open('/proc/cpuinfo', 'r') as f:
for line in f:
if line.startswith('model name'):
cpu_info = line.split(':')[1].strip()
break
return cpu_info if cpu_info else "Unknown"
except:
return "Unknown"
def get_memory_usage() -> dict:
"""获取内存使用情况"""
process = psutil.Process()
system_memory = psutil.virtual_memory()
process_mem = process.memory_full_info().uss
percent = system_memory.used / (system_memory.total)
return {
"percent": percent,
"total": system_memory.total / 1024 / 1024, # MB
"free": system_memory.available / 1024 / 1024, # MB
"used": process_mem / 1024 / 1024, # MB
}
def get_cpu_usage() -> float:
"""获取CPU使用率"""
try:
return psutil.cpu_percent()
except:
return 0.0
================================================
FILE: kirara_ai/web/api/tracing/__init__.py
================================================
from .routes import tracing_bp
__all__ = ["tracing_bp"]
================================================
FILE: kirara_ai/web/api/tracing/routes.py
================================================
import asyncio
import json
from quart import Blueprint, g, jsonify, request, websocket
from kirara_ai.internal import shutdown_event
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.tracing.llm_tracer import LLMTracer
from kirara_ai.tracing.manager import TracingManager
from kirara_ai.web.auth.middleware import require_auth
from kirara_ai.web.auth.services import AuthService
tracing_bp = Blueprint("tracing", __name__, url_prefix="/api/tracing")
logger = get_logger("Tracing-API")
@tracing_bp.route("/types", methods=["GET"])
@require_auth
async def get_trace_types():
"""获取所有可用的追踪器类型"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
return jsonify({
"types": tracing_manager.get_tracer_types()
})
@tracing_bp.route("/llm/traces", methods=["POST"])
@require_auth
async def get_llm_traces():
"""获取LLM追踪记录,支持筛选和分页"""
# 获取查询参数
data = await request.json
page = data.get("page", 1)
page_size = data.get("page_size", 20)
model_id = data.get("model_id")
backend_name = data.get("backend_name")
status = data.get("status")
# 构建过滤条件
filters = {}
if model_id:
filters["model_id"] = model_id
if backend_name:
filters["backend_name"] = backend_name
if status:
filters["status"] = status
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
# 使用统一的查询接口
records, total = llm_tracer.get_traces(
filters=filters,
page=page,
page_size=page_size
)
return jsonify({
"items": [record.to_dict() for record in records],
"total": total,
"page": page,
"page_size": page_size,
"total_pages": (total + page_size - 1) // page_size
})
@tracing_bp.route("/llm/detail/", methods=["GET"])
@require_auth
async def get_llm_trace_detail(trace_id: str):
"""获取特定LLM请求的详细信息"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
trace = llm_tracer.get_trace_by_id(trace_id)
if not trace:
return jsonify({"error": "Trace not found"}), 404
return jsonify(trace.to_detail_dict())
@tracing_bp.route("/llm/statistics", methods=["GET"])
@require_auth
async def get_llm_statistics():
"""获取LLM统计信息"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
assert isinstance(llm_tracer, LLMTracer)
stats = llm_tracer.get_statistics()
return jsonify(stats)
@tracing_bp.websocket("/ws")
async def tracing_ws():
"""WebSocket接口,用于实时推送追踪日志"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
auth_service: AuthService = container.resolve(AuthService)
# 获取所有追踪器类型
tracer_types = tracing_manager.get_tracer_types()
# 发送欢迎消息
await websocket.send(json.dumps({
"type": "connected",
"message": "Connected to tracing websocket",
"data": {
"available_tracers": tracer_types
}
}))
# 验证token
try:
token_data = await websocket.receive()
token = json.loads(token_data)["token"]
if not auth_service.verify_token(token):
await websocket.close(code=1008, reason="Invalid token")
return
except Exception as e:
logger.error(f"WebSocket连接错误: {e}")
await websocket.close(code=1008, reason="Invalid token")
return
# 接收命令
cmd = await websocket.receive()
cmd = json.loads(cmd)
# 订阅
if cmd.get("action") == "subscribe":
if tracer_type := cmd.get("tracer_type"):
tracer = tracing_manager.get_tracer(tracer_type)
if tracer:
# 注册WebSocket客户端
queue: asyncio.Queue = tracer.register_ws_client()
await websocket.send(json.dumps({
"type": "subscribe_success",
"message": "Subscribed to tracing websocket",
"data": {
"tracer_type": tracer_type
}
}))
else:
await websocket.close(code=1008, reason="Tracer not found")
return
else:
await websocket.close(code=1008, reason="Invalid tracer type")
return
else:
await websocket.close(code=1008, reason="Invalid action")
return
try:
# 保持连接打开状态,直到客户端断开连接
while not shutdown_event.is_set():
# 摸鱼
message = await queue.get()
if message is None:
break
await websocket.send(json.dumps(message))
finally:
if tracer:
tracer.unregister_ws_client(queue)
================================================
FILE: kirara_ai/web/api/workflow/README.md
================================================
# 工作流 API 🔄
工作流 API 提供了管理工作流的功能。工作流由多个区块组成,用于处理消息和执行任务。每个工作流都属于一个特定的组。
## API 端点
### 获取所有工作流
```http
GET/backend-api/api/workflow
```
获取所有已注册的工作流基本信息。
**响应示例:**
```json
{
"workflows": [
{
"group_id": "chat",
"workflow_id": "normal",
"name": "普通聊天",
"description": "处理普通聊天消息的工作流",
"block_count": 3,
"metadata": {
"category": "chat",
"tags": ["normal", "chat"]
}
}
]
}
```
### 获取特定工作流
```http
GET/backend-api/api/workflow/{group_id}/{workflow_id}
```
获取指定工作流的详细信息。
**响应示例:**
```json
{
"workflow": {
"group_id": "chat",
"workflow_id": "normal",
"name": "普通聊天",
"description": "处理普通聊天消息的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "openai",
"temperature": 0.7
},
"position": {
"x": 300,
"y": 100
}
},
{
"block_id": "output_1",
"type_name": "MessageOutputBlock",
"name": "消息输出",
"config": {
"format": "text"
},
"position": {
"x": 500,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "llm_1",
"target_input": "prompt"
},
{
"source_block": "llm_1",
"source_output": "response",
"target_block": "output_1",
"target_input": "message"
}
],
"metadata": {
"category": "chat",
"tags": ["normal", "chat"]
}
}
}
```
### 创建工作流
```http
POST/backend-api/api/workflow/{group_id}/{workflow_id}
```
创建新的工作流。
**请求体:**
```json
{
"group_id": "chat",
"workflow_id": "creative",
"name": "创意聊天",
"description": "处理创意聊天的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "prompt_1",
"type_name": "PromptBlock",
"name": "提示词处理",
"config": {
"template": "请发挥创意回答以下问题:{{input}}"
},
"position": {
"x": 300,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "anthropic",
"temperature": 0.9
},
"position": {
"x": 500,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "prompt_1",
"target_input": "input"
},
{
"source_block": "prompt_1",
"source_output": "output",
"target_block": "llm_1",
"target_input": "prompt"
}
],
"metadata": {
"category": "chat",
"tags": ["creative", "chat"]
}
}
```
### 更新工作流
```http
PUT/backend-api/api/workflow/{group_id}/{workflow_id}
```
更新现有工作流。请求体格式与创建工作流相同。
### 删除工作流
```http
DELETE/backend-api/api/workflow/{group_id}/{workflow_id}
```
删除指定工作流。成功时返回:
```json
{
"message": "Workflow deleted successfully"
}
```
## 数据模型
### Wire (工作流连线)
- `source_block`: 源区块 ID
- `source_output`: 源区块输出端口
- `target_block`: 目标区块 ID
- `target_input`: 目标区块输入端口
### BlockInstance (区块实例)
- `block_id`: 区块 ID
- `type_name`: 区块类型名称
- `name`: 区块显示名称
- `config`: 区块配置
- `position`: 区块位置
- `x`: X 坐标
- `y`: Y 坐标
### WorkflowDefinition (工作流定义)
- `group_id`: 工作流组 ID
- `workflow_id`: 工作流 ID
- `name`: 工作流名称
- `description`: 工作流描述
- `blocks`: 区块列表
- `wires`: 连线列表
- `metadata`: 元数据(可选)
### WorkflowInfo (工作流信息)
- `group_id`: 工作流组 ID
- `workflow_id`: 工作流 ID
- `name`: 工作流名称
- `description`: 工作流描述
- `block_count`: 区块数量
- `metadata`: 元数据(可选)
### WorkflowList (工作流列表)
- `workflows`: 工作流信息列表
### WorkflowResponse (工作流响应)
- `workflow`: 工作流定义
## 区块类型
工作流中可以使用的区块类型包括:
### MessageInputBlock
- 功能:接收输入消息
- 输入:无
- 输出:
- `message`: 消息内容
- 配置:
- `format`: 消息格式(text/image/audio)
### MessageOutputBlock
- 功能:输出消息
- 输入:
- `message`: 消息内容
- 输出:无
- 配置:
- `format`: 消息格式(text/image/audio)
### LLMBlock
- 功能:调用大语言模型
- 输入:
- `prompt`: 提示词
- 输出:
- `response`: 模型响应
- 配置:
- `backend`: 使用的后端
- `temperature`: 温度参数
### PromptBlock
- 功能:处理提示词
- 输入:
- `input`: 输入内容
- 输出:
- `output`: 处理后的提示词
- 配置:
- `template`: 提示词模板
## 相关代码
- [工作流注册表](../../../workflow/core/workflow/registry.py)
- [工作流构建器](../../../workflow/core/workflow/builder.py)
- [区块注册表](../../../workflow/core/block/registry.py)
- [系统预设工作流](../../../../data/workflows)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、工作流配置无效或工作流已存在
- 404: 工作流不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有工作流
```python
import requests
response = requests.get(
'http://localhost:8080/api/workflow',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新工作流
```python
import requests
workflow_data = {
"group_id": "chat",
"workflow_id": "creative",
"name": "创意聊天",
"description": "处理创意聊天的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "anthropic",
"temperature": 0.9
},
"position": {
"x": 300,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "llm_1",
"target_input": "prompt"
}
],
"metadata": {
"category": "chat",
"tags": ["creative"]
}
}
response = requests.post(
'http://localhost:8080/api/workflow/chat/creative',
headers={'Authorization': f'Bearer {token}'},
json=workflow_data
)
```
### 删除工作流
```python
import requests
response = requests.delete(
'http://localhost:8080/api/workflow/chat/creative',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [工作流开发](../../../workflow/README.md#工作流开发-)
================================================
FILE: kirara_ai/web/api/workflow/__init__.py
================================================
from .routes import workflow_bp
__all__ = ["workflow_bp"]
================================================
FILE: kirara_ai/web/api/workflow/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.workflow.core.workflow.base import WorkflowConfig
class Wire(BaseModel):
"""工作流连线"""
source_block: str # block ID
source_output: str
target_block: str # block ID
target_input: str
class BlockInstance(BaseModel):
"""工作流中的Block实例"""
type_name: str
name: str
config: Dict[str, Any]
position: Dict[str, int] # x, y 坐标
class WorkflowDefinition(BaseModel):
"""工作流定义"""
group_id: str
workflow_id: str
name: str
description: str
blocks: List[BlockInstance]
wires: List[Wire]
config: WorkflowConfig = WorkflowConfig()
metadata: Optional[Dict[str, Any]] = None
class WorkflowInfo(BaseModel):
"""工作流基本信息"""
group_id: str
workflow_id: str
name: str
description: str
block_count: int
metadata: Optional[Dict[str, Any]] = None
class WorkflowList(BaseModel):
"""工作流列表响应"""
workflows: List[WorkflowInfo]
class WorkflowResponse(BaseModel):
"""单个工作流响应"""
workflow: WorkflowDefinition
================================================
FILE: kirara_ai/web/api/workflow/routes.py
================================================
import os
from typing import List
from quart import Blueprint, g, jsonify, request
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from ...auth.middleware import require_auth
from .models import BlockInstance, Wire, WorkflowDefinition, WorkflowInfo, WorkflowList, WorkflowResponse
workflow_bp = Blueprint("workflow", __name__)
@workflow_bp.route("", methods=["GET"])
@require_auth
async def list_workflows():
"""获取所有工作流列表"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
workflows = []
for workflow_id, builder in registry._workflows.items():
# 从 workflow_id 解析 group_id
group_id, wf_id = workflow_id.split(":", 1)
workflows.append(
WorkflowInfo(
group_id=group_id,
workflow_id=wf_id,
name=builder.name,
description=builder.description,
block_count=len(builder.nodes_by_name),
metadata=getattr(builder, "metadata", None),
)
)
workflows.sort(key=lambda x: f"{x.group_id}:{x.workflow_id}")
return WorkflowList(workflows=workflows).model_dump()
@workflow_bp.route("//", methods=["GET"])
@require_auth
async def get_workflow(group_id: str, workflow_id: str):
"""获取特定工作流的详细信息"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
full_id = f"{group_id}:{workflow_id}"
builder = registry.get(full_id)
if not builder:
return jsonify({"error": "Workflow not found"}), 404
assert isinstance(builder, WorkflowBuilder)
# 构建工作流定义
blocks: List[BlockInstance] = []
for node in builder.nodes:
blocks.append(
BlockInstance(
type_name=block_registry.get_block_type_name(node.spec.block_class),
name=node.name,
config=node.spec.kwargs,
position=node.position or {"x": 0, "y": 0},
)
)
wires: List[Wire] = []
for source_name, source_output, target_name, target_input in builder.wire_specs:
wires.append(
Wire(
source_block=source_name,
source_output=source_output,
target_block=target_name,
target_input=target_input,
)
)
workflow_def = WorkflowDefinition(
group_id=group_id,
workflow_id=workflow_id,
name=builder.name,
description=builder.description,
blocks=blocks,
wires=wires,
metadata=getattr(builder, "metadata", None),
config=builder.config,
)
return WorkflowResponse(workflow=workflow_def).model_dump()
@workflow_bp.route("//", methods=["POST"])
@require_auth
async def create_workflow(group_id: str, workflow_id: str):
"""创建新的工作流"""
data = await request.get_json()
workflow_def = WorkflowDefinition(**data)
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
# 检查工作流是否已存在
full_id = f"{group_id}:{workflow_id}"
if registry.get(full_id):
return jsonify({"error": "Workflow already exists"}), 400
# 创建工作流构建器
try:
# 创建工作流构建器
builder = WorkflowBuilder(workflow_def.name)
builder.description = workflow_def.description
# 根据定义添加块和连接
for block_def in workflow_def.blocks:
block_class = block_registry.get(block_def.type_name)
if not block_class:
raise ValueError(f"Block type {block_def.type_name} not found")
if not builder.head:
builder.use(block_class, name=block_def.name, **block_def.config)
else:
builder.chain(block_class, name=block_def.name, **block_def.config)
builder.update_position(block_def.name, block_def.position)
# 不要用自动连线,用我们的
builder.wire_specs = []
# 添加连接
for wire in workflow_def.wires:
builder.force_connect(
wire.source_block,
wire.target_block,
wire.source_output,
wire.target_input
)
# 保存工作流
file_path = registry.get_workflow_path(group_id, workflow_id)
builder.set_config(workflow_def.config)
builder.save_to_yaml(file_path, g.container)
# 注册工作流
registry.register(group_id, workflow_id, builder)
return workflow_def.model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@workflow_bp.route("//", methods=["PUT"])
@require_auth
async def update_workflow(group_id: str, workflow_id: str):
"""更新现有工作流"""
data = await request.get_json()
workflow_def = WorkflowDefinition(**data)
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
# 检查工作流是否存在
full_id = f"{group_id}:{workflow_id}"
if not registry.get(full_id):
return jsonify({"error": "Workflow not found"}), 404
# 更新工作流
try:
# 创建新的工作流构建器
builder = WorkflowBuilder(workflow_def.name)
builder.description = workflow_def.description
# 根据定义添加块和连接
for block_def in workflow_def.blocks:
block_class = block_registry.get(block_def.type_name)
if not block_class:
raise ValueError(f"Block type {block_def.type_name} not found")
if not builder.head:
builder.use(block_class, name=block_def.name, **block_def.config)
else:
builder.chain(block_class, name=block_def.name, **block_def.config)
builder.update_position(block_def.name, block_def.position)
# 不要用自动连线,用我们的
builder.wire_specs = []
# 添加连接
for wire in workflow_def.wires:
builder.force_connect(
wire.source_block,
wire.target_block,
wire.source_output,
wire.target_input
)
# 保存工作流
file_path = registry.get_workflow_path(group_id, workflow_id)
if os.path.exists(file_path):
os.remove(file_path)
new_file_path = registry.get_workflow_path(
data["group_id"], data["workflow_id"]
)
builder.set_config(workflow_def.config)
builder.save_to_yaml(new_file_path, g.container)
# 更新注册表
registry.unregister(group_id, workflow_id)
registry.register(data["group_id"], data["workflow_id"], builder)
return workflow_def.model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@workflow_bp.route("//", methods=["DELETE"])
@require_auth
async def delete_workflow(group_id: str, workflow_id: str):
"""删除工作流"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查工作流是否存在
full_id = f"{group_id}:{workflow_id}"
if not registry.get(full_id):
return jsonify({"error": "Workflow not found"}), 404
try:
# 从注册表中移除
registry._workflows.pop(full_id, None)
# 删除文件
file_path = registry.get_workflow_path(group_id, workflow_id)
if os.path.exists(file_path):
os.remove(file_path)
return jsonify({"message": "Workflow deleted successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 400
================================================
FILE: kirara_ai/web/app.py
================================================
import asyncio
import mimetypes
import os
import socket
from pathlib import Path
from fastapi import FastAPI, HTTPException, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import FileResponse, HTMLResponse, PlainTextResponse
from hypercorn.asyncio import serve
from hypercorn.config import Config
from quart import Quart, g, jsonify
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import HypercornLoggerWrapper, get_logger
from kirara_ai.web.auth.services import AuthService, FileBasedAuthService
from kirara_ai.web.utils import create_no_cache_response, install_webui
from .api.block import block_bp
from .api.dispatch import dispatch_bp
from .api.im import im_bp
from .api.llm import llm_bp
from .api.mcp import mcp_bp
from .api.media import media_bp
from .api.plugin import plugin_bp
from .api.system import system_bp
from .api.tracing import tracing_bp
from .api.workflow import workflow_bp
from .auth.routes import auth_bp
ERROR_MESSAGE = """
Made with [contrib.rocks](https://contrib.rocks).
## 📕 相关项目
- [Kirara Registry](https://github.com/DarkSkyTeam/kirara-registry) - Kirara AI 插件市场
- [Kirara WebUI](https://github.com/DarkSkyTeam/kirara-webui) - Kirara AI 的 WebUI 前端项目
- [Kirara Docs](https://github.com/DarkSkyTeam/kirara-docs) - Kirara AI 的使用手册原始文档
## 💪 支持我们
如果我们这个项目对你有所帮助,请给我们一颗 ⭐️
[](https://www.star-history.com/#lss233/kirara-ai&Date)
================================================
FILE: alembic.ini
================================================
# A generic, single database configuration.
[alembic]
# path to migration scripts
# Use forward slashes (/) also on windows to provide an os agnostic path
script_location = kirara_ai/alembic
# template used to generate migration file names; The default value is %%(rev)s_%%(slug)s
# Uncomment the line below if you want the files to be prepended with date and time
# see https://alembic.sqlalchemy.org/en/latest/tutorial.html#editing-the-ini-file
# for all available tokens
# file_template = %%(year)d_%%(month).2d_%%(day).2d_%%(hour).2d%%(minute).2d-%%(rev)s_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python>=3.9 or backports.zoneinfo library and tzdata library.
# Any required deps can installed by adding `alembic[tz]` to the pip requirements
# string value is passed to ZoneInfo()
# leave blank for localtime
# timezone =
# max length of characters to apply to the "slug" field
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# sourceless = false
# version location specification; This defaults
# to alembic/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator" below.
# version_locations = %(here)s/bar:%(here)s/bat:alembic/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. The default within new alembic.ini files is "os", which uses os.pathsep.
# If this key is omitted entirely, it falls back to the legacy behavior of splitting on spaces and/or commas.
# Valid values for version_path_separator are:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
# version_path_separator = newline
#
# Use os.pathsep. Default configuration used for new projects.
version_path_separator = os
# set to 'true' to search source files recursively
# in each "version_locations" directory
# new in Alembic version 1.10
# recursive_version_locations = false
# the output encoding used when revision files
# are written from script.py.mako
# output_encoding = utf-8
sqlalchemy.url = sqlite:///./data/db/kirara.db
[post_write_hooks]
# post_write_hooks defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# format using "black" - use the console_scripts runner, against the "black" entrypoint
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# lint with attempts to fix using "ruff" - use the exec runner, execute a binary
# hooks = ruff
# ruff.type = exec
# ruff.executable = %(here)s/.venv/bin/ruff
# ruff.options = check --fix REVISION_SCRIPT_FILENAME
# Logging configuration
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARNING
handlers = console
qualname =
[logger_sqlalchemy]
level = WARNING
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
================================================
FILE: config.yaml.example
================================================
# 配置文件示例
# 通讯平台配置部分
ims:
# 每个 IM 平台的具体配置
- name: "telegram-bot-1234" # IM 平台实例名称
enable: true # 是否启用该平台
adapter: "telegram" # 使用的适配器类型
config: # 平台特定的配置
token: "abcd" # 平台的 API 令牌
# 插件系统配置
plugins:
enable: [] # 启用的插件列表
# Web 服务器配置
web:
host: "127.0.0.1" # Web 服务器监听地址
port: 8080 # Web 服务器端口
secret_key: "please-change-this-to-a-secure-secret-key" # Web 服务器安全密钥,请修改为安全的值
# LLM (大语言模型) 配置
llms:
api_backends: # API 后端配置列表
# DeepSeek API 配置
- name: "deepseek-official" # 后端名称
adapter: "deepseek" # 使用的适配器
enable: true # 是否启用
config: # API 具体配置
api_key: "your-api-key" # API 密钥
api_base: "https://api.deepseek.com/v1" # API 基础 URL
models: # 支持的模型列表
- "deepseek-chat"
- "deepseek-coder"
# OpenAI API 配置
- name: "openai-gpt4" # 后端名称
adapter: "openai" # 使用的适配器
enable: true # 是否启用
config: # API 具体配置
api_key: "your-openai-key" # OpenAI API 密钥
api_base: "https://api.openai.com/v1" # OpenAI API 基础 URL
models: # 支持的模型列表
- "gpt-4"
- "gpt-4-turbo"
# 默认配置
defaults:
llm_model: gemini-1.5-flash # 默认使用的 LLM 模型
# 记忆系统配置
memory:
persistence: # 持久化配置
type: file # 持久化类型(支持 file 或 redis)
file: # 文件存储配置
storage_dir: ./data/memory # 存储目录
redis: # Redis 存储配置
host: localhost # Redis 主机地址
port: 6379 # Redis 端口
db: 0 # Redis 数据库编号
max_entries: 100 # 最大记忆条目数
default_scope: member # 默认记忆作用域
================================================
FILE: data/.gitkeep
================================================
================================================
FILE: data/dispatch_rules/rules.yaml
================================================
- rule_id: chat_normal
name: 群聊AI对话
description: 群聊中使用 /chat 开头对话或者 被@ 时触发聊天
workflow_id: chat:normal
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /chat
- type: bot_mention
config: {}
- operator: or
rules:
- type: chat_type
config:
chat_type: 群聊
metadata:
category: chat
permission: user
temperature: 0.7
- rule_id: chat_creative
name: 私聊AI对话
description: 私聊时直接发送内容触发对话
workflow_id: chat:normal
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: chat_type
config:
chat_type: 私聊
metadata:
category: chat
permission: user
temperature: 0.9
- rule_id: game_dice
name: 骰子
description: 骰子游戏,支持 XdY 格式
workflow_id: game:dice
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: regex
config:
pattern: ^[.。]roll\s*(\d+)?d(\d+)
metadata: {}
- rule_id: game_gacha
name: 抽卡
description: 抽卡模拟器
workflow_id: game:gacha
priority: 5
enabled: true
rule_groups:
- operator: or
rules:
- type: keyword
config:
keywords:
- 抽卡
- 十连
- 单抽
metadata: {}
- rule_id: system_help
name: 帮助命令
description: 显示帮助信息
workflow_id: system:help
priority: 10
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /help
metadata:
category: system
permission: user
- rule_id: system_clear_memory
name: 清空记忆
description: 清空当前对话的记忆
workflow_id: system:clear_memory
priority: 10
enabled: true
rule_groups:
- operator: or
rules:
- type: prefix
config:
prefix: /清空记忆
metadata:
category: system
permission: user
- rule_id: fallback
name: 默认规则
description: 当上述规则均没有匹配成功时,执行此工作流。
workflow_id: chat:memory_store
priority: 0
enabled: true
rule_groups:
- operator: or
rules:
- type: fallback
config: {}
metadata: {}
================================================
FILE: data/media/.gitignore
================================================
metadata/*
files/*
================================================
FILE: data/memory/.gitignore
================================================
*.json
================================================
FILE: data/web/.gitkeep
================================================
================================================
FILE: data/workflows/.gitkeep
================================================
================================================
FILE: data/workflows/chat/dsr_thinking.yaml
================================================
name: 聊天 - 深度思考
description: DeepSeek 思考模型聊天,隐藏 标签内容
blocks:
- type: internal:get_message
name: get_message
params: {}
position:
x: 100
y: 138
connected_to:
- target: ToggleEditState_81bvwg
mapping:
from: sender
to: sender
- target: ToggleEditState_81bvwg
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: ChatMessageConstructor_g44tpp
mapping:
from: msg
to: user_msg
- target: ChatMemoryStore_ljrym0
mapping:
from: msg
to: user_msg
- type: internal:toggle_edit_state
name: ToggleEditState_81bvwg
params:
is_editing: true
position:
x: 530
y: 138
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
position:
x: 530
y: 338
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: memory_content
to: memory_content
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:{current_date_time}\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 100
y: 330
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: system_prompt_format
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 100
y: 530
connected_to:
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: user_prompt_format
- target: ChatMessageConstructor_g44tpp
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: ChatMessageConstructor_g44tpp
params: {}
position:
x: 960
y: 138
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:llm_response_to_text
name: e4fe53bb-fcbe-41c3-ab69-e8d3881c3b55
params: {}
position:
x: 1711
y: 511
connected_to:
- target: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
mapping:
from: text
to: text
- target: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
mapping:
from: text
to: text
- type: internal:text_extract_by_regex_block
name: ef6c7eed-307e-4fa0-94f0-a82c98c784b3
params:
regex: (?:[\s\S]*?)?([\s\S]*)
position:
x: 1972
y: 513
connected_to:
- target: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
mapping:
from: text
to: text
- target: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
mapping:
from: text
to: text
- type: internal:text_to_im_message
name: 7b5f6be8-da97-417e-bbeb-c9549ac45e9e
params:
split_by:
position:
x: 2352
y: 513
connected_to:
- target: SendIMMessage_x9ro8t
mapping:
from: msg
to: msg
- target: SendIMMessage_x9ro8t
mapping:
from: msg
to: msg
- type: internal:send_message
name: SendIMMessage_x9ro8t
params: {}
position:
x: 2797
y: 140
- type: internal:chat_memory_store
name: ChatMemoryStore_ljrym0
params:
scope_type: group
position:
x: 1764
y: 308
- type: internal:chat_completion
name: llm_chat
params:
model_name: deepseek-r1:7b
position:
x: 1280
y: 138
connected_to:
- target: ChatMemoryStore_ljrym0
mapping:
from: resp
to: llm_resp
- target: e4fe53bb-fcbe-41c3-ab69-e8d3881c3b55
mapping:
from: resp
to: response
================================================
FILE: data/workflows/chat/memory_store.yaml
================================================
name: 记录聊天内容
description: 默默记下大家的聊天内容,可以使用查询记忆模块读取出来。
blocks:
- type: internal:get_message
name: 6233e64c-433e-4087-9035-cb96914349f7
params: {}
position:
x: 100
y: 138
connected_to:
- target: 86354196-f249-4393-9620-941b01bc344e
mapping:
from: msg
to: user_msg
- type: internal:chat_memory_store
name: 86354196-f249-4393-9620-941b01bc344e
params:
scope_type: group
position:
x: 420
y: 138
================================================
FILE: data/workflows/chat/normal_multimodal.yaml
================================================
name: 聊天 - 原生多模态对话
description: 基于原生多模态能力的图文对话,适用于本身支持图片输入/回答的模型,在读取记忆时会恢复原来的媒体资源
blocks:
- type: internal:get_message
name: get_message
params: {}
position:
x: 100
y: 138
connected_to:
- target: ToggleEditState_i24m23
mapping:
from: sender
to: sender
- target: ToggleEditState_i24m23
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: ChatMessageConstructor_6c185s
mapping:
from: msg
to: user_msg
- target: ChatMemoryStore_tapuo1
mapping:
from: msg
to: user_msg
- type: internal:toggle_edit_state
name: ToggleEditState_i24m23
params:
is_editing: true
position:
x: 530
y: 138
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:{current_date_time}\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 100
y: 330
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: system_prompt_format
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 100
y: 530
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: user_prompt_format
- target: ChatMessageConstructor_6c185s
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: ChatMessageConstructor_6c185s
params: {}
position:
x: 960
y: 138
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:chat_completion
name: llm_chat
params: {}
position:
x: 1280
y: 138
connected_to:
- target: ChatResponseConverter_73spno
mapping:
from: resp
to: resp
- target: ChatResponseConverter_73spno
mapping:
from: resp
to: resp
- target: ChatMemoryStore_tapuo1
mapping:
from: resp
to: llm_resp
- type: internal:chat_response_converter
name: ChatResponseConverter_73spno
params: {}
position:
x: 1710
y: 138
connected_to:
- target: SendIMMessage_l6qagt
mapping:
from: msg
to: msg
- target: SendIMMessage_l6qagt
mapping:
from: msg
to: msg
- type: internal:send_message
name: SendIMMessage_l6qagt
params: {}
position:
x: 2140
y: 138
- type: internal:chat_memory_store
name: ChatMemoryStore_tapuo1
params:
scope_type: group
position:
x: 1710
y: 306
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
decomposer_name: multi_element
position:
x: 530
y: 338
connected_to:
- target: ChatMessageConstructor_6c185s
mapping:
from: memory_content
to: memory_content
================================================
FILE: data/workflows/chat/talk_break.yaml
================================================
name: 聊天 - 自定义分段
description: 使用 `` 作为关键词,让 AI 分段回复的工作流
blocks:
- type: internal:text_block
name: system_prompt
params:
text: "# Role: 角色扮演\n\n## 基本信息\n- 姓名: 刘思思\n- 小名:思思\n- 性别: 女\n- 年龄: 25 岁\n- 职业: 建设银行大堂经理\n- 家乡: 广东潮汕\n- 现居: 广东深圳\n- 教育背景: 东莞理工大学 精算学专业\n\n## 性格特点\n- 开朗活泼\n- 喜欢二次元动漫\n- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)\n\n## workflow\n- 根据对方话题,选择是否深入聊二次元动漫。\n\n## 说话风格\n- 活泼开朗\n- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答\n- 可能会使用一些二次元用语,但不强制使用\n\n## 背景设定\n- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。\n- 喜欢女性向、战斗系或者日常系的动漫\n- 去过 3 次漫展,没有 cosplay 过,但是很期待。\n- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识\n\n## 互动规则\n- 回复语气轻松,但是对陌生人会比较警戒、冷淡\n- 不适用颜文字\n- 根据话题选择回复字数,对感兴趣的话题可以多说一些\n- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)\n- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣\n- 停顿的时间长短不固定,可以根据语境调整\n\n## Example\nQ:最近在干嘛呢?\nA:在看番呀最近新番好多,都好好看!\n\nQ:你喜欢什么动漫?\nA:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?\n\nQ:你觉得上班累不?\nA:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事\n```\n\n# Information\n\n以下是当前的系统信息:\n当前日期时间:2025-02-23 15:27:37.762784\n\n# Memories\n以下是之前发生过的对话记录。\n-- 对话记录开始 --\n{memory_content}\n-- 对话记录结束 --\n\n请注意,下面这些符号只是标记:\n1. `` 用于表示聊天时发送消息的操作。\n2. `<@llm>` 开头的内容表示你当前扮演角色的回答,你的回答中不能带上这个标记。\n\n接下来,请基于以上的信息,与用户继续扮演角色。"
position:
x: 426
y: 599
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: text
to: system_prompt_format
- type: internal:chat_memory_query
name: query_memory
params:
scope_type: group
position:
x: 419
y: 462
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: memory_content
to: memory_content
- type: internal:text_block
name: user_prompt
params:
text: '{user_name}说:{user_msg}'
position:
x: 419
y: 317
connected_to:
- target: chat_message_constructor_wfy18q
mapping:
from: text
to: user_prompt_format
- type: internal:chat_message_constructor
name: chat_message_constructor_wfy18q
params: {}
position:
x: 970
y: 346
connected_to:
- target: llm_chat
mapping:
from: llm_msg
to: prompt
- type: internal:get_message
name: get_message
params: {}
position:
x: 105
y: 189
connected_to:
- target: toggle_edit_state_svmo3f
mapping:
from: sender
to: sender
- target: query_memory
mapping:
from: sender
to: chat_sender
- target: chat_message_constructor_wfy18q
mapping:
from: msg
to: user_msg
- target: chat_memory_store_a0fj1l
mapping:
from: msg
to: user_msg
- type: internal:llm_response_to_text
name: c9eddb3c-113f-4a39-9d47-682d0a7dd26e
params: {}
position:
x: 1658
y: 344
connected_to:
- target: 6edd5c0c-a538-45ab-bb50-4c3a906bb1b1
mapping:
from: text
to: text
- type: internal:text_to_im_message
name: 6edd5c0c-a538-45ab-bb50-4c3a906bb1b1
params:
split_by:
position:
x: 1918
y: 347
connected_to:
- target: msg_sender_lakgf8
mapping:
from: msg
to: msg
- type: internal:toggle_edit_state
name: toggle_edit_state_svmo3f
params:
is_editing: true
position:
x: 424
y: 94
- type: internal:chat_completion
name: llm_chat
params:
model_name: gemini-2.0-flash
position:
x: 1260
y: 347
connected_to:
- target: chat_memory_store_a0fj1l
mapping:
from: resp
to: llm_resp
- target: c9eddb3c-113f-4a39-9d47-682d0a7dd26e
mapping:
from: resp
to: response
- type: internal:chat_memory_store
name: chat_memory_store_a0fj1l
params:
scope_type: group
position:
x: 1663
y: 192
- type: internal:send_message
name: msg_sender_lakgf8
params: {}
position:
x: 2377
y: 346
================================================
FILE: docker/start.sh
================================================
#!/bin/bash
cd /app
# Copy default data
# check if data directory exists
if [ ! -d "/app/data" ]; then
echo "Data directory does not exist, creating..."
mkdir /app/data
fi
# check if data directory empty
if [ -z "$(ls -A /app/data)" ]; then
echo "Data directory is empty, copying default data..."
cp -r /tmp/data/. /app/data
fi
# create default config
if [ ! -f "/app/data/config.yaml" ]; then
echo "Config file does not exist, creating..."
# 必须配置 web,否则无法访问
cat < /app/data/config.yaml
web:
host: 0.0.0.0
port: 8080
EOF
fi
# create data/venv
if [ ! -d "/app/data/venv" ]; then
echo "Venv directory does not exist, creating..."
python -m venv /app/data/venv --system-site-packages
fi
# activate venv
source /app/data/venv/bin/activate
python -m kirara_ai
================================================
FILE: kirara_ai/__init__.py
================================================
from .config.config_loader import ConfigLoader
from .entry import init_application, run_application
from .logger import get_logger
__all__ = ["init_application", "run_application", "get_logger", "ConfigLoader"]
================================================
FILE: kirara_ai/__main__.py
================================================
import argparse
import os
import subprocess
import sys
from kirara_ai.entry import init_application, run_application
from kirara_ai.internal import get_and_reset_restart_flag
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description='Kirara AI Chatbot Server')
parser.add_argument('-H', '--host', help='覆盖服务监听地址')
parser.add_argument('-p', '--port', type=int, help='覆盖服务监听端口')
args = parser.parse_args()
container = init_application()
# 将参数对象直接注入容器
container.register("cli_args", args)
try:
run_application(container)
finally:
if get_and_reset_restart_flag():
# 重新启动程序
# 构建命令行参数,透传所有原始参数
cmd = [sys.executable, "-m", "kirara_ai"]
# 从解析后的参数对象中获取参数
if args.host:
cmd.extend(["-H", args.host])
if args.port:
cmd.extend(["-p", str(args.port)])
process = subprocess.Popen(cmd, env=os.environ, cwd=os.getcwd())
process.wait()
if __name__ == "__main__":
main()
================================================
FILE: kirara_ai/alembic/README
================================================
Generic single-database configuration.
================================================
FILE: kirara_ai/alembic/env.py
================================================
from logging.config import fileConfig
from alembic import context
from sqlalchemy import engine_from_config, pool
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
from kirara_ai.database.manager import Base
from kirara_ai.tracing.models import LLMRequestTrace # noqa: F401
target_metadata = Base.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
================================================
FILE: kirara_ai/alembic/script.py.mako
================================================
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
"""Upgrade schema."""
${upgrades if upgrades else "pass"}
def downgrade() -> None:
"""Downgrade schema."""
${downgrades if downgrades else "pass"}
================================================
FILE: kirara_ai/alembic/versions/4a364dbb8dab_initial_migration.py
================================================
"""Initial migration
Revision ID: 4a364dbb8dab
Revises:
Create Date: 2025-03-29 13:59:33.243069
"""
from typing import Sequence, Union
import sqlalchemy as sa
from alembic import op
# revision identifiers, used by Alembic.
revision: str = '4a364dbb8dab'
down_revision: Union[str, None] = None
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
"""Upgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('llm_request_traces',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('trace_id', sa.String(length=64), nullable=False),
sa.Column('model_id', sa.String(length=64), nullable=False),
sa.Column('backend_name', sa.String(length=64), nullable=False),
sa.Column('request_time', sa.DateTime(), nullable=False),
sa.Column('response_time', sa.DateTime(), nullable=True),
sa.Column('duration', sa.Float(), nullable=True),
sa.Column('request_json', sa.Text(), nullable=True),
sa.Column('response_json', sa.Text(), nullable=True),
sa.Column('prompt_tokens', sa.Integer(), nullable=True),
sa.Column('completion_tokens', sa.Integer(), nullable=True),
sa.Column('total_tokens', sa.Integer(), nullable=True),
sa.Column('cached_tokens', sa.Integer(), nullable=True),
sa.Column('error', sa.Text(), nullable=True),
sa.Column('status', sa.String(length=20), nullable=False),
sa.PrimaryKeyConstraint('id')
)
op.create_index('idx_backend_time', 'llm_request_traces', ['backend_name', 'request_time'], unique=False)
op.create_index('idx_request_model', 'llm_request_traces', ['model_id', 'request_time'], unique=False)
op.create_index('idx_status_time', 'llm_request_traces', ['status', 'request_time'], unique=False)
op.create_index(op.f('ix_llm_request_traces_backend_name'), 'llm_request_traces', ['backend_name'], unique=False)
op.create_index(op.f('ix_llm_request_traces_model_id'), 'llm_request_traces', ['model_id'], unique=False)
op.create_index(op.f('ix_llm_request_traces_request_time'), 'llm_request_traces', ['request_time'], unique=False)
op.create_index(op.f('ix_llm_request_traces_trace_id'), 'llm_request_traces', ['trace_id'], unique=True)
# ### end Alembic commands ###
def downgrade() -> None:
"""Downgrade schema."""
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f('ix_llm_request_traces_trace_id'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_request_time'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_model_id'), table_name='llm_request_traces')
op.drop_index(op.f('ix_llm_request_traces_backend_name'), table_name='llm_request_traces')
op.drop_index('idx_status_time', table_name='llm_request_traces')
op.drop_index('idx_request_model', table_name='llm_request_traces')
op.drop_index('idx_backend_time', table_name='llm_request_traces')
op.drop_table('llm_request_traces')
# ### end Alembic commands ###
================================================
FILE: kirara_ai/config/__init__.py
================================================
import os
# 读取DATA_PATH环境变量,若未能找到则以当前工作目录为根文件夹存储在$PWD/data目录下。
DATA_PATH = os.path.abspath(
os.environ.get("DATA_PATH", os.path.join(os.getcwd(), "data"))
)
# 按照规范插件应该在PLUGIN_PATH目录下存储对应的文件。
PLUGIN_PATH = os.path.join(DATA_PATH, "plugins")
if os.path.exists(DATA_PATH) is False:
os.makedirs(DATA_PATH)
if os.path.exists(PLUGIN_PATH) is False:
os.makedirs(PLUGIN_PATH)
================================================
FILE: kirara_ai/config/config_loader.py
================================================
import os
import shutil
from functools import wraps
from typing import Optional, Type, TypeVar
from pydantic import BaseModel, ValidationError
from pydantic.json_schema import GenerateJsonSchema, JsonSchemaValue
from ruamel.yaml import YAML
from ..logger import get_logger
from . import DATA_PATH
CONFIG_FILE = os.path.join(DATA_PATH, "config.yaml")
T = TypeVar("T", bound=BaseModel)
class ConfigLoader:
"""
配置文件加载器,支持加载和保存 YAML 文件,并保留注释。
"""
yaml = YAML()
@staticmethod
def load_config(config_path: str, config_class: Type[T]) -> T:
"""
从 YAML 文件中加载配置,并将其序列化为相应的配置对象。
:param config_path: 配置文件路径。
:param config_class: 配置文件类。
:return: 配置对象。
"""
try:
with open(config_path, "r", encoding="utf-8") as f:
config_data = ConfigLoader.yaml.load(f)
return config_class(**config_data)
except ValidationError as e:
raise ValueError(f"配置文件验证失败: {e}")
except Exception as e:
raise RuntimeError(f"加载配置文件失败: {e}")
@staticmethod
def save_config(config_path: str, config_object: BaseModel):
"""
将配置对象保存到 YAML 文件中,并保留注释。
:param config_path: 配置文件路径。
:param config_object: 配置对象。
"""
with open(config_path, "w", encoding="utf-8") as f:
ConfigLoader.yaml.dump(config_object.model_dump(), f)
@staticmethod
def save_config_with_backup(config_path: str, config_object: BaseModel):
"""
将配置对象保存到 YAML 文件中,并在保存前创建备份。
:param config_path: 配置文件路径。
:param config_object: 配置对象。
"""
if os.path.exists(config_path):
backup_path = f"{config_path}.bak"
shutil.copy2(config_path, backup_path)
ConfigLoader.save_config(config_path, config_object)
def pydantic_validation_wrapper(func):
logger = get_logger("ConfigLoader")
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except ValidationError as e:
# 使用 loguru 输出错误信息
logger.error(f"Pydantic 验证错误: '{e.title}':")
for error in e.errors():
logger.error(
f"字段: {error['loc'][0]}, 错误类型: {error['type']}, 错误信息: {error['msg']}"
)
# 记录堆栈跟踪
logger.opt(exception=True).error("堆栈跟踪如下:")
raise # 可以选择重新抛出异常,或者处理异常后返回一个默认值
return wrapper
class ConfigJsonSchema(GenerateJsonSchema):
def sort(
self, value: JsonSchemaValue, parent_key: Optional[str] = None
) -> JsonSchemaValue:
"""No-op, we don't want to sort schema values at all."""
return value
================================================
FILE: kirara_ai/config/global_config.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, ConfigDict, Field, model_validator
from kirara_ai.llm.model_types import LLMAbility, ModelType
class IMConfig(BaseModel):
"""IM配置"""
name: str = Field(default="", description="IM标识名称")
enable: bool = Field(default=True, description="是否启用IM")
adapter: str = Field(default="dummy", description="IM适配器类型")
config: Dict[str, Any] = Field(default={}, description="IM的配置")
class ModelConfig(BaseModel):
"""模型配置"""
id: str = Field(description="模型标识ID")
type: str = Field(default=ModelType.LLM.value, description="模型类型:llm/embedding/image_generation等")
ability: int = Field(description="模型能力,对应模型类型的Ability枚举值")
model_config = ConfigDict(extra="allow")
class LLMBackendConfig(BaseModel):
"""LLM后端配置"""
name: str = Field(description="后端标识名称")
adapter: str = Field(description="LLM适配器类型")
config: Dict[str, Any] = Field(default={}, description="后端配置")
enable: bool = Field(default=True, description="是否启用")
models: List[ModelConfig] = Field(
default=[], description="支持的模型列表"
)
@model_validator(mode='before')
@classmethod
def migrate_models_format(cls, data: Dict[str, Any]) -> Dict[str, Any]:
"""
自动迁移模型配置格式
将旧格式的字符串ID列表转换为新格式的ModelConfig对象列表
"""
if "models" in data and isinstance(data["models"], list):
# 创建新的模型列表
new_models = []
for model in data["models"]:
if isinstance(model, str):
# 旧格式:字符串ID,转换为ModelConfig
new_models.append(ModelConfig(id=model, type=ModelType.LLM.value, ability=LLMAbility.TextChat.value))
else:
# 新格式或已迁移的模型配置,保持不变
new_models.append(model)
data["models"] = new_models
return data
class LLMConfig(BaseModel):
api_backends: List[LLMBackendConfig] = Field(
default=[], description="LLM API后端列表"
)
class MCPServerConfig(BaseModel):
"""MCP服务器配置"""
id: str = Field(description="服务器标识ID")
description: str = Field(default="", description="服务器描述")
url: Optional[str] = Field(default="", description="服务器URL")
headers: Dict[str, str] = Field(default_factory=dict, description="服务器请求 Headers")
command: Optional[str] = Field(default="", description="服务器命令")
args: List[str] = Field(default_factory=list, description="服务器参数")
env: Dict[str, str] = Field(default_factory=dict, description="环境变量")
connection_type: str = Field(default="stdio", description="连接类型: stdio/sse")
enable: bool = Field(default=True, description="是否启用")
class MCPConfig(BaseModel):
"""MCP配置"""
servers: List[MCPServerConfig] = Field(default=[], description="MCP服务器列表")
class DefaultConfig(BaseModel):
llm_model: str = Field(
default="gemini-1.5-flash", description="默认使用的 LLM 模型名称"
)
class MemoryPersistenceConfig(BaseModel):
type: str = Field(default="file", description="持久化类型: file/redis")
file: Dict[str, Any] = Field(
default={"storage_dir": "./data/memory"}, description="文件持久化配置"
)
redis: Dict[str, Any] = Field(
default={"host": "localhost", "port": 6379, "db": 0},
description="Redis持久化配置",
)
class MemoryConfig(BaseModel):
persistence: MemoryPersistenceConfig = MemoryPersistenceConfig()
max_entries: int = Field(default=100, description="每个作用域最大记忆条目数")
default_scope: str = Field(default="member", description="默认作用域类型")
class WebConfig(BaseModel):
host: str = Field(default="127.0.0.1", description="Web服务绑定的IP地址")
port: int = Field(default=8080, description="Web服务端口号")
secret_key: str = Field(default="", description="Web服务的密钥,用于JWT等加密")
password_file: str = Field(
default="./data/web/password.hash", description="密码哈希存储路径"
)
class PluginConfig(BaseModel):
"""插件配置"""
enable: List[str] = Field(default=[], description="启用的外部插件列表")
market_base_url: str = Field(
default="https://kirara-plugin.app.lss233.com/api/v1",
description="插件市场基础URL",
)
class UpdateConfig(BaseModel):
pypi_registry: str = Field(default="https://pypi.org/simple", description="PyPI 服务器 URL")
npm_registry: str = Field(default="https://registry.npmjs.org", description="npm 服务器 URL")
class FrpcConfig(BaseModel):
"""FRPC 配置"""
enable: bool = Field(default=False, description="是否启用 FRPC")
server_addr: str = Field(default="", description="FRPC 服务器地址")
server_port: int = Field(default=7000, description="FRPC 服务器端口")
token: str = Field(default="", description="FRPC 连接令牌")
remote_port: int = Field(default=0, description="远程端口,0 表示随机分配")
class SystemConfig(BaseModel):
"""系统配置"""
timezone: str = Field(default="Asia/Shanghai", description="时区")
class TracingConfig(BaseModel):
"""Tracing 配置"""
llm_tracing_content: bool = Field(default=False, description="是否记录 LLM 请求内容")
class MediaConfig(BaseModel):
"""媒体配置"""
cleanup_duration: int = Field(default=30, description="间隔多少天清理一次媒体文件")
auto_remove_unreferenced: bool = Field(default=True, description="是否自动删除未引用的媒体文件")
last_cleanup_time: int = Field(default=0, description="上次清理时间")
class GlobalConfig(BaseModel):
ims: List[IMConfig] = Field(default=[], description="IM配置列表")
llms: LLMConfig = LLMConfig()
mcp: MCPConfig = MCPConfig()
defaults: DefaultConfig = DefaultConfig()
memory: MemoryConfig = MemoryConfig()
web: WebConfig = WebConfig()
plugins: PluginConfig = PluginConfig()
update: UpdateConfig = UpdateConfig()
frpc: FrpcConfig = FrpcConfig()
system: SystemConfig = SystemConfig()
tracing: TracingConfig = TracingConfig()
media: MediaConfig = MediaConfig()
model_config = ConfigDict(extra="allow")
================================================
FILE: kirara_ai/database/__init__.py
================================================
from kirara_ai.database.manager import Base, DatabaseManager, metadata
__all__ = ["Base", "DatabaseManager", "metadata"]
================================================
FILE: kirara_ai/database/manager.py
================================================
import os
from typing import Optional
from alembic import command
from alembic.config import Config
from alembic.runtime.migration import MigrationContext
from alembic.script import ScriptDirectory
from sqlalchemy import MetaData, create_engine
from sqlalchemy.orm import Session, declarative_base, sessionmaker
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
logger = get_logger("DB")
# 创建Base类,用于所有ORM模型
Base = declarative_base()
metadata = MetaData()
class DatabaseManager:
"""数据库管理器,负责管理数据库连接和会话"""
def __init__(self, container: DependencyContainer, database_url: Optional[str] = None, is_debug: bool = False):
self.container = container
self.engine = None
self.session_factory = None
self.data_dir = "./data/db"
self.db_path = os.path.join(self.data_dir, "kirara.db")
self.database_url = database_url
self.is_debug = is_debug
def initialize(self):
"""初始化数据库连接"""
# 确保数据目录存在
os.makedirs(self.data_dir, exist_ok=True)
# 创建数据库引擎
if self.database_url:
db_url = self.database_url
else:
db_url = f"sqlite:///{self.db_path}"
self.engine = create_engine(db_url, echo=self.is_debug)
# 创建session工厂
self.session_factory = sessionmaker(bind=self.engine)
# 运行数据库迁移
self._run_migrations()
logger.info(f"Database initialized at {self.engine.url}")
def _run_migrations(self):
assert self.engine is not None
"""运行数据库迁移"""
try:
# 获取 alembic.ini 的路径
package_dir = os.path.dirname(os.path.dirname(__file__))
alembic_ini_path = os.path.join(package_dir, "alembic.ini")
# 如果配置文件不存在,说明是作为包安装的,使用默认配置
if not os.path.exists(alembic_ini_path):
alembic_cfg = Config()
alembic_cfg.set_main_option("script_location", os.path.join(package_dir, "alembic"))
else:
alembic_cfg = Config(alembic_ini_path)
alembic_cfg.set_main_option("sqlalchemy.url", str(self.engine.url))
# 检查是否需要迁移
with self.engine.connect() as connection:
context = MigrationContext.configure(connection)
current_rev = context.get_current_revision()
script = ScriptDirectory.from_config(alembic_cfg)
head_rev = script.get_current_head()
if current_rev != head_rev:
logger.info("Running database migrations...")
command.upgrade(alembic_cfg, "head")
logger.info("Database migrations completed")
else:
logger.info("Database schema is up to date")
except Exception as e:
logger.error(f"Error during database migration: {e}")
raise
def get_session(self) -> Session:
"""获取数据库会话"""
if not self.session_factory:
self.initialize()
assert self.session_factory is not None
return self.session_factory()
def shutdown(self):
"""关闭数据库连接"""
if self.engine:
self.engine.dispose()
logger.info("Database connection closed")
================================================
FILE: kirara_ai/entry.py
================================================
import asyncio
import os
import signal
import time
from packaging import version
from kirara_ai.config.config_loader import ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.database import DatabaseManager
from kirara_ai.events.application import ApplicationStarted, ApplicationStopping
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.internal import shutdown_event
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.logger import get_logger
from kirara_ai.mcp_module.manager import MCPServerManager
from kirara_ai.media import MediaManager
from kirara_ai.media.carrier import MediaCarrierRegistry, MediaCarrierService
from kirara_ai.memory.composes import DefaultMemoryComposer, DefaultMemoryDecomposer, MultiElementDecomposer
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.scopes import GlobalScope, GroupScope, MemberScope
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.tracing import LLMTracer, TracingManager
from kirara_ai.web.api.system.utils import get_installed_version, get_latest_pypi_version
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.block import BlockRegistry
from kirara_ai.workflow.core.dispatch import DispatchRuleRegistry, WorkflowDispatcher
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from kirara_ai.workflow.implementations.blocks import register_system_blocks
from kirara_ai.workflow.implementations.workflows import register_system_workflows
logger = get_logger("Entrypoint")
_interrupt_count = 0 # 添加计数器
async def check_update():
"""检查更新"""
running_version = get_installed_version()
logger.info("Checking for updates...")
latest_version, _ = await get_latest_pypi_version("kirara-ai")
logger.info(f"Running version: {running_version}, Latest version: {latest_version}")
backend_update_available = version.parse(latest_version) > version.parse(running_version)
if backend_update_available:
logger.warning(f"New version {latest_version} is available. Please update to the latest version.")
logger.warning(f"You can download the latest version from WebUI")
# 注册信号处理函数
def _signal_handler(*args):
global _interrupt_count
_interrupt_count += 1
if _interrupt_count == 1:
if not shutdown_event.is_set():
logger.warning("Interrupt signal received. Stopping application...")
shutdown_event.set()
elif _interrupt_count == 2:
logger.warning("Interrupt signal received again. Press Ctrl+C one more time to force shutdown...")
else:
logger.warning("Interrupt signal received for the third time. Forcing shutdown...")
os._exit(1)
def init_container() -> DependencyContainer:
container = DependencyContainer()
container.register(DependencyContainer, container)
return container
def init_memory_system(container: DependencyContainer):
"""初始化记忆系统"""
memory_manager = MemoryManager(container)
# 注册默认作用域
memory_manager.register_scope("member", MemberScope)
memory_manager.register_scope("group", GroupScope)
memory_manager.register_scope("global", GlobalScope)
# 注册默认组合器和解析器
memory_manager.register_composer("default", DefaultMemoryComposer)
memory_manager.register_decomposer("default", DefaultMemoryDecomposer)
memory_manager.register_decomposer("multi_element", MultiElementDecomposer)
container.register(MemoryManager, memory_manager)
return memory_manager
def init_media_carrier(container: DependencyContainer):
"""初始化媒体载体"""
# 注册记忆管理器作为媒体引用提供者
carrier_registry = container.resolve(MediaCarrierRegistry)
carrier_registry.register("memory", container.resolve(MemoryManager))
def init_tracing_system(container: DependencyContainer):
"""初始化追踪系统"""
logger.info("Initializing tracing system...")
# 初始化追踪管理器
tracing_manager = TracingManager(container)
container.register(TracingManager, tracing_manager)
# 创建并注册LLM追踪器
llm_tracer = LLMTracer(container)
container.register(LLMTracer, llm_tracer)
tracing_manager.register_tracer("llm", llm_tracer)
# 初始化追踪系统
tracing_manager.initialize()
logger.info("Tracing system initialized")
return tracing_manager
def init_application() -> DependencyContainer:
"""初始化应用程序"""
logger.info("Initializing application...")
# 配置文件路径
config_path = "./data/config.yaml"
# 加载配置文件
logger.info(f"Loading configuration from {config_path}")
# check data directory
if not os.path.exists("./data"):
os.makedirs("./data")
if os.path.exists(config_path):
config: GlobalConfig = ConfigLoader.load_config(config_path, GlobalConfig)
logger.info("Configuration loaded successfully")
else:
logger.warning(
f"Configuration file {config_path} not found, using default configuration"
)
logger.warning(
"Please create a configuration file by copying config.yaml.example to config.yaml and modify it according to your needs"
)
config = GlobalConfig()
# 设置时区
os.environ["TZ"] = config.system.timezone
if hasattr(time, "tzset"):
time.tzset()
container = init_container()
container.register(asyncio.AbstractEventLoop, asyncio.new_event_loop())
container.register(EventBus, EventBus())
container.register(GlobalConfig, config)
container.register(BlockRegistry, BlockRegistry())
# 初始化数据库管理器
db = DatabaseManager(container)
db.initialize()
container.register(DatabaseManager, db)
# 注册媒体管理器
media_manager = MediaManager()
container.register(MediaManager, media_manager)
container.register(MediaCarrierRegistry, MediaCarrierRegistry(container))
container.register(MediaCarrierService, MediaCarrierService(container, media_manager))
# 注册工作流注册表
workflow_registry = WorkflowRegistry(container)
container.register(WorkflowRegistry, workflow_registry)
# 注册调度规则注册表
dispatch_registry = DispatchRuleRegistry(container)
container.register(DispatchRuleRegistry, dispatch_registry)
container.register(IMRegistry, IMRegistry())
container.register(LLMBackendRegistry, LLMBackendRegistry())
im_manager = IMManager(container)
container.register(IMManager, im_manager)
llm_manager = LLMManager(container)
container.register(LLMManager, llm_manager)
plugin_loader = PluginLoader(container, os.path.join(os.path.dirname(__file__), "plugins"))
container.register(PluginLoader, plugin_loader)
workflow_dispatcher = WorkflowDispatcher(container)
container.register(WorkflowDispatcher, workflow_dispatcher)
container.register(WebServer, WebServer(container))
mcp_manager = MCPServerManager(container)
container.register(MCPServerManager, mcp_manager)
# 初始化记忆系统
logger.info("Initializing memory system...")
init_memory_system(container)
init_media_carrier(container)
# 初始化追踪系统
init_tracing_system(container)
# 注册系统 blocks
register_system_blocks(container.resolve(BlockRegistry))
# 发现并加载插件
plugin_loader = container.resolve(PluginLoader)
logger.info("Discovering internal plugins...")
plugin_loader.discover_internal_plugins()
logger.info("Discovering external plugins...")
plugin_loader.discover_external_plugins()
logger.info("Loading plugins")
plugin_loader.load_plugins()
# 加载工作流和调度规则
workflow_registry = container.resolve(WorkflowRegistry)
workflow_registry.load_workflows()
register_system_workflows(workflow_registry)
dispatch_registry = container.resolve(DispatchRuleRegistry)
dispatch_registry.load_rules()
# 加载模型
llm_manager = container.resolve(LLMManager)
logger.info("Loading LLMs")
llm_manager.load_config()
# 加载MCP服务器
mcp_manager = container.resolve(MCPServerManager)
logger.info("Loading MCP servers")
mcp_manager.load_servers()
return container
def run_application(container: DependencyContainer):
"""运行应用程序"""
loop = container.resolve(asyncio.AbstractEventLoop)
# 启动Web服务器
logger.info("Starting web server...")
web_server = container.resolve(WebServer)
loop.run_until_complete(web_server.start())
# 启动插件
plugin_loader = container.resolve(PluginLoader)
plugin_loader.start_plugins()
# 启动适配器
logger.info("Starting adapters")
im_manager = container.resolve(IMManager)
im_manager.start_adapters(loop=loop)
# 加载MCP服务器
mcp_manager = container.resolve(MCPServerManager)
logger.info("Connecting to MCP servers")
mcp_manager.connect_all_servers(loop=loop)
# 注册信号处理函数
signal.signal(signal.SIGINT, _signal_handler)
signal.signal(signal.SIGTERM, _signal_handler)
# 阻止信号处理函数被覆盖
signal.signal = lambda *args: None
try:
logger.success("Kirara AI 启动完毕,等待消息中...")
logger.success(
f"WebUI 管理平台本地访问地址:http://127.0.0.1:{web_server.listen_port}/"
)
logger.success("Application started. Waiting for events...")
loop.create_task(check_update())
event_bus = container.resolve(EventBus)
event_bus.post(ApplicationStarted())
loop.run_until_complete(shutdown_event.wait())
finally:
event_bus.post(ApplicationStopping())
# 关闭记忆系统
memory_manager = container.resolve(MemoryManager)
logger.info("Shutting down memory system...")
memory_manager.shutdown()
# 关闭追踪系统
try:
tracing_manager = container.resolve(TracingManager)
logger.info("Shutting down tracing system...")
tracing_manager.shutdown()
db_manager = container.resolve(DatabaseManager)
logger.info("Shutting down database...")
db_manager.shutdown()
except Exception as e:
logger.error(f"Error shutting down tracing system: {e}")
# 停止Web服务器
logger.info("Stopping web server...")
# 停止Web服务器
loop.run_until_complete(web_server.stop())
logger.info("Web server terminated.")
try:
# 停止所有 adapter
im_manager.stop_adapters(loop=loop)
mcp_manager.disconnect_all_servers(loop=loop)
# 停止插件
plugin_loader.stop_plugins()
except Exception as e:
logger.error(f"Error stopping adapters: {e}")
# 关闭事件循环
loop.stop()
logger.info("Application stopped gracefully")
logger.remove()
================================================
FILE: kirara_ai/events/__init__.py
================================================
from .application import ApplicationStarted, ApplicationStopping
from .event_bus import EventBus
from .im import IMAdapterStarted, IMAdapterStopped
from .listen import listen
from .llm import LLMAdapterLoaded, LLMAdapterUnloaded
from .plugin import PluginLoaded, PluginStarted, PluginStopped
from .workflow import WorkflowExecutionBegin, WorkflowExecutionEnd
__all__ = [
"listen",
"EventBus",
"ApplicationStarted",
"ApplicationStopping",
"PluginStarted",
"PluginStopped",
"PluginLoaded",
"IMAdapterStarted",
"IMAdapterStopped",
"LLMAdapterLoaded",
"LLMAdapterUnloaded",
"WorkflowExecutionBegin",
"WorkflowExecutionEnd",
]
================================================
FILE: kirara_ai/events/application.py
================================================
class ApplicationStarted:
def __repr__(self):
return f"{self.__class__.__name__}()"
class ApplicationStopping:
def __repr__(self):
return f"{self.__class__.__name__}()"
================================================
FILE: kirara_ai/events/event_bus.py
================================================
from typing import Callable, Dict, List, Type
from kirara_ai.logger import get_logger
logger = get_logger("EventBus")
class EventBus:
def __init__(self):
self._listeners: Dict[Type, List[Callable]] = {}
def register(self, event_type: Type, listener: Callable):
if event_type not in self._listeners:
self._listeners[event_type] = []
self._listeners[event_type].append(listener)
def unregister(self, event_type: Type, listener: Callable):
if event_type in self._listeners:
self._listeners[event_type].remove(listener)
def post(self, event):
event_type = type(event)
if event_type in self._listeners:
for listener in self._listeners[event_type]:
try:
listener(event)
except Exception as e:
listener_name = listener.__name__
logger.opt(exception=e).error(f"Error in listener {listener_name}")
================================================
FILE: kirara_ai/events/im.py
================================================
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from kirara_ai.im.adapter import IMAdapter
class IMEvent:
def __init__(self, im: "IMAdapter"):
self.im = im
def __repr__(self):
return f"{self.__class__.__name__}(im={self.im})"
class IMAdapterStarted(IMEvent):
pass
class IMAdapterStopped(IMEvent):
pass
================================================
FILE: kirara_ai/events/listen.py
================================================
import inspect
from typing import Callable
from kirara_ai.events.event_bus import EventBus
def listen(event_bus: EventBus):
def decorator(func: Callable):
# 获取函数的参数签名
signature = inspect.signature(func)
params = list(signature.parameters.values())
# 假设第一个参数是事件类型
if not params:
raise ValueError("Listener function must have at least one parameter")
event_type = params[0].annotation
# 如果没有指定类型注解,抛出异常
if event_type == inspect.Parameter.empty:
raise ValueError("Listener function must have an annotated first parameter")
# 注册监听器
event_bus.register(event_type, func)
return func
return decorator
================================================
FILE: kirara_ai/events/llm.py
================================================
from kirara_ai.llm.adapter import LLMBackendAdapter
class LLMAdapterEvent:
def __init__(self, adapter: LLMBackendAdapter, backend_name: str):
self.adapter = adapter
self.backend_name = backend_name
def __repr__(self):
return f"{self.__class__.__name__}(adapter={self.adapter}, backend_name={self.backend_name})"
class LLMAdapterLoaded(LLMAdapterEvent):
pass
class LLMAdapterUnloaded(LLMAdapterEvent):
pass
================================================
FILE: kirara_ai/events/plugin.py
================================================
from kirara_ai.plugin_manager.plugin import Plugin
class PluginEvent:
def __init__(self, plugin: Plugin):
self.plugin = plugin
def __repr__(self):
return f"{self.__class__.__name__}(plugin={self.plugin})"
class PluginStarted(PluginEvent):
pass
class PluginStopped(PluginEvent):
pass
class PluginLoaded(PluginEvent):
pass
================================================
FILE: kirara_ai/events/tracing/__init__.py
================================================
from .base import TraceCompleteEvent, TraceEvent, TraceFailEvent, TraceStartEvent
from .llm import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
__all__ = [
"TraceEvent",
"TraceStartEvent",
"TraceCompleteEvent",
"TraceFailEvent",
"LLMRequestStartEvent",
"LLMRequestCompleteEvent",
"LLMRequestFailEvent",
]
================================================
FILE: kirara_ai/events/tracing/base.py
================================================
import abc
from datetime import datetime
class TraceEvent(abc.ABC):
"""跟踪事件基类"""
def __init__(self, trace_id: str):
self.trace_id = trace_id
self.timestamp = datetime.now()
def __repr__(self):
return f"{self.__class__.__name__}(trace_id={self.trace_id})"
class TraceStartEvent(TraceEvent):
"""跟踪开始事件"""
class TraceCompleteEvent(TraceEvent):
"""跟踪完成事件"""
class TraceFailEvent(TraceEvent):
"""跟踪失败事件"""
================================================
FILE: kirara_ai/events/tracing/llm.py
================================================
import time
from typing import Union
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from .base import TraceCompleteEvent, TraceEvent, TraceFailEvent, TraceStartEvent
class LLMTraceEvent(TraceEvent):
"""LLM追踪事件基类"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str):
super().__init__(trace_id)
self.model_id = model_id
self.backend_name = backend_name
def __repr__(self):
return f"{self.__class__.__name__}(trace_id={self.trace_id}, model={self.model_id}, backend={self.backend_name})"
class LLMRequestStartEvent(LLMTraceEvent, TraceStartEvent):
"""LLM请求开始事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.start_time = time.time()
class LLMRequestCompleteEvent(LLMTraceEvent, TraceCompleteEvent):
"""LLM请求完成事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest,
response: LLMChatResponse,
start_time: float):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.response = response
self.start_time = start_time
self.end_time = time.time()
self.duration = int((self.end_time - start_time) * 1000)
class LLMRequestFailEvent(LLMTraceEvent, TraceFailEvent):
"""LLM请求失败事件"""
def __init__(self,
trace_id: str,
model_id: str,
backend_name: str,
request: LLMChatRequest,
error: Union[str, Exception],
start_time: float):
super().__init__(trace_id, model_id, backend_name)
self.request = request
self.error = str(error)
self.start_time = start_time
self.end_time = time.time()
self.duration = int((self.end_time - start_time) * 1000)
================================================
FILE: kirara_ai/events/workflow.py
================================================
from typing import Any, Dict
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
from kirara_ai.workflow.core.workflow.base import Workflow
class WorkflowExecutionBegin:
def __init__(self, workflow: Workflow, executor: WorkflowExecutor):
self.workflow = workflow
self.executor = executor
def __repr__(self):
return f"{self.__class__.__name__}(workflow={self.workflow}, executor={self.executor})"
class WorkflowExecutionEnd:
def __init__(self, workflow: Workflow, executor: WorkflowExecutor, results: Dict[str, Any]):
self.workflow = workflow
self.executor = executor
self.results = results
================================================
FILE: kirara_ai/im/__init__.py
================================================
from .im_registry import IMRegistry
from .manager import IMManager
__all__ = ["IMRegistry", "IMManager"]
================================================
FILE: kirara_ai/im/adapter.py
================================================
from abc import ABC, abstractmethod
from typing import Any, Optional, Protocol
from pydantic import BaseModel
from typing_extensions import runtime_checkable
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.llm.llm_manager import LLMManager
from .profile import UserProfile
class BotStatus(BaseModel):
"""
机器人状态
"""
username: str
avatar_url: str
@runtime_checkable
class EditStateAdapter(Protocol):
"""
编辑状态适配器接口,定义了如何设置或取消对话的编辑状态
"""
async def set_chat_editing_state(
self, chat_sender: ChatSender, is_editing: bool = True
):
"""
设置或取消对话的编辑状态
:param chat_sender: 对话的发送者
:param is_editing: True 表示正在编辑,False 表示取消编辑状态
"""
@runtime_checkable
class UserProfileAdapter(Protocol):
"""
用户资料查询适配器接口,定义了如何获取用户资料
"""
async def query_user_profile(self, chat_sender: ChatSender) -> UserProfile:
"""
查询用户资料
:param chat_sender: 用户的聊天发送者信息
:return: 用户资料
"""
@runtime_checkable
class BotProfileAdapter(Protocol):
"""
支持获取当前适配器对应的机器人资料
"""
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
class IMAdapter(ABC):
"""
通用的 IM 适配器接口,定义了如何将不同平台的原始消息转换为 Message 对象。
"""
llm_manager: LLMManager
is_running: bool
@abstractmethod
async def convert_to_message(self, raw_message: Any) -> IMMessage:
"""
将平台的原始消息转换为 Message 对象。
:param raw_message: 平台的原始消息对象。
:return: 转换后的 Message 对象。
"""
@abstractmethod
async def send_message(self, message: IMMessage, recipient: Any):
"""
发送消息到 IM 平台。
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象,可以是用户ID、用户对象、群组ID等,具体由各平台实现决定。
"""
@abstractmethod
async def start(self):
pass
@abstractmethod
async def stop(self):
pass
================================================
FILE: kirara_ai/im/im_registry.py
================================================
from typing import Dict, Optional, Type
from pydantic import BaseModel, Field
from kirara_ai.im.adapter import IMAdapter
class IMAdapterInfo(BaseModel):
"""IM适配器信息"""
name: str
config_class: Type[BaseModel] = Field(exclude=True)
adapter_class: Type[IMAdapter] = Field(exclude=True)
localized_name: Optional[str] = None
localized_description: Optional[str] = None
detail_info_markdown: Optional[str] = None
class IMRegistry:
"""
适配器注册表,用于动态注册和管理 adapter。
"""
_registry: Dict[str, IMAdapterInfo] = {}
def register(
self, name: str,
adapter_class: Type[IMAdapter],
config_class: Type[BaseModel],
localized_name: Optional[str] = None,
localized_description: Optional[str] = None,
detail_info_markdown: Optional[str] = None
):
"""
注册一个新的 adapter 及其配置类。
:param name: adapter 的名称。
:param adapter_class: adapter 的类。
:param config_class: adapter 的配置类。
:param detail_info_markdown: adapter 详情页展示的 Markdown 信息。
"""
self._registry[name] = IMAdapterInfo(
name=name,
adapter_class=adapter_class,
config_class=config_class,
localized_name=localized_name,
localized_description=localized_description,
detail_info_markdown=detail_info_markdown,
)
def unregister(self, name: str):
"""
注销一个 adapter。
:param name: adapter 的名称。
"""
del self._registry[name]
def get(self, name: str) -> Type[IMAdapter]:
"""
获取已注册的 adapter 类。
:param name: adapter 的名称。
:return: adapter 的类。
"""
if name not in self._registry:
raise ValueError(
f"IMAdapter with name '{name}' is not registered.")
return self._registry[name].adapter_class
def get_config_class(self, name: str) -> Type[BaseModel]:
"""
获取已注册的 adapter 配置类。
:param name: adapter 的名称。
:return: adapter 的配置类。
"""
if name not in self._registry:
raise ValueError(
f"IMAdapter with name '{name}' is not registered.")
adapter_info = self._registry[name]
return adapter_info.config_class
def get_all_adapters(self) -> Dict[str, IMAdapterInfo]:
"""
获取所有已注册的 adapter。
:return: 所有已注册的 adapter。
"""
return self._registry
================================================
FILE: kirara_ai/im/manager.py
================================================
import asyncio
from typing import Dict, Type
from pydantic import BaseModel
from kirara_ai.config.config_loader import pydantic_validation_wrapper
from kirara_ai.config.global_config import GlobalConfig, IMConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.im import IMAdapterStarted, IMAdapterStopped
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
logger = get_logger("IMManager")
class IMManager:
"""
IM 生命周期管理器,负责管理所有 adapter 的启动、运行和停止。
"""
container: DependencyContainer
config: GlobalConfig
im_registry: IMRegistry
event_bus: EventBus
@Inject()
def __init__(
self,
container: DependencyContainer,
config: GlobalConfig,
adapter_registry: IMRegistry,
event_bus: EventBus,
):
self.container = container
self.config = config
self.im_registry = adapter_registry
self.event_bus = event_bus
self.adapters: Dict[str, IMAdapter] = {}
def get_adapter_type(self, name: str) -> str:
"""
获取指定名称的 adapter 类型。
:param name: adapter 的名称
:return: adapter 的类型
"""
return self.get_adapter_config(name).adapter
def has_adapter(self, name: str) -> bool:
"""
检查指定名称的 adapter 是否存在。
:param name: adapter 的名称
:return: 如果 adapter 存在返回 True,否则返回 False
"""
return name in self.adapters
def get_adapter_config(self, name: str) -> IMConfig:
"""
获取指定名称的 adapter 的配置。
:param name: adapter 的名称
:return: adapter 的配置
"""
for im in self.config.ims:
if im.name == name:
return im
raise ValueError(f"Adapter {name} not found")
def update_adapter_config(self, name: str, config: BaseModel):
"""
更新指定名称的 adapter 的配置。
:param name: adapter 的名称
:param config: adapter 的配置
"""
self.get_adapter_config(name).config = config.model_dump()
def delete_adapter(self, name: str):
"""
删除指定名称的 adapter。
:param name: adapter 的名称
"""
self.adapters.pop(name, None)
self.config.ims = [im for im in self.config.ims if im.name != name]
@pydantic_validation_wrapper
def start_adapters(self, loop=None):
"""
根据配置文件中的 enable_ims 启动对应的 adapter。
:param loop: 负责执行的 event loop
"""
if loop is None:
loop = asyncio.new_event_loop()
tasks = []
for im in self.config.ims:
try:
# 动态获取 adapter 类
adapter_class = self.im_registry.get(im.adapter)
# 动态获取 adapter 的配置类
config_class = self.im_registry.get_config_class(im.adapter)
# 动态实例化 adapter 的配置对象
adapter_config = config_class(**im.config)
# 创建 adapter 实例
adapter = self.create_adapter(im.name, adapter_class, adapter_config)
if im.enable:
tasks.append(
asyncio.ensure_future(
self._start_adapter(im.name, adapter), loop=loop
)
)
except Exception as e:
logger.opt(exception=e).error(f"Failed to start adapter {im.name}: {e}")
continue
if tasks:
results = loop.run_until_complete(asyncio.gather(*tasks, return_exceptions=True))
for result in results:
if isinstance(result, Exception):
logger.opt(exception=result).error(f"Failed to start adapter: {result}")
else:
logger.warning("No adapters to start, please check your config")
def stop_adapters(self, loop=None):
"""
停止所有已启动的 adapter。
:param loop: 负责执行的 event loop
"""
if loop is None:
loop = asyncio.get_event_loop()
for key, adapter in self.adapters.items():
loop.run_until_complete(self._stop_adapter(key, adapter))
def get_adapters(self) -> Dict[str, IMAdapter]:
"""
获取所有已启动的 adapter。
:return: 已启动的 adapter 字典。
"""
return self.adapters
def get_adapter(self, key: str) -> IMAdapter:
"""
获取指定 key 的 adapter。
:param key: adapter 的 key
:return: 指定 key 的 adapter
"""
return self.adapters[key]
async def _start_adapter(self, key: str, adapter: IMAdapter):
logger.info(f"Starting adapter: {key}")
await adapter.start()
adapter.is_running = True
logger.info(f"Started adapter: {key}")
self.event_bus.post(IMAdapterStarted(adapter))
async def _stop_adapter(self, key: str, adapter: IMAdapter):
logger.info(f"Stopping adapter: {key}")
await adapter.stop()
adapter.is_running = False
logger.info(f"Stopped adapter: {key}")
self.event_bus.post(IMAdapterStopped(adapter))
def stop_adapter(self, adapter_id: str, loop: asyncio.AbstractEventLoop):
if adapter_id not in self.adapters:
raise ValueError(f"Adapter {adapter_id} not found")
adapter = self.adapters[adapter_id]
return asyncio.ensure_future(self._stop_adapter(adapter_id, adapter), loop=loop)
def start_adapter(self, adapter_id: str, loop: asyncio.AbstractEventLoop):
if adapter_id not in self.adapters:
raise ValueError(f"Adapter {adapter_id} not found")
adapter = self.adapters[adapter_id]
return asyncio.ensure_future(
self._start_adapter(adapter_id, adapter), loop=loop
)
def is_adapter_running(self, key: str) -> bool:
"""
检查指定 key 的 adapter 是否正在运行。
:param key: adapter 的 key
:return: 如果 adapter 正在运行返回 True,否则返回 False
"""
return key in self.adapters and getattr(self.adapters[key], "is_running", False)
def create_adapter(
self, name: str, adapter_class: Type[IMAdapter], adapter_config: BaseModel
) -> IMAdapter:
with self.container.scoped() as scoped_container:
scoped_container.register(adapter_config.__class__, adapter_config)
adapter = Inject(scoped_container).create(adapter_class)()
adapter.is_running = False
self.adapters[name] = adapter
return adapter
================================================
FILE: kirara_ai/im/message.py
================================================
from abc import ABC, abstractmethod
from pathlib import Path
from typing import Any, Dict, List, Literal, Optional
from kirara_ai.im.sender import ChatSender
from kirara_ai.media import MediaManager, MediaType
MIMETYPE_MAPPING = {
"image": MediaType.IMAGE,
"audio": MediaType.AUDIO,
"video": MediaType.VIDEO,
"file": MediaType.FILE,
}
# 定义消息元素的基类
class MessageElement(ABC):
@abstractmethod
def to_dict(self):
pass
@abstractmethod
def to_plain(self) -> str:
pass
# 定义文本消息元素
class TextMessage(MessageElement):
def __init__(self, text: str):
self.text = text
def to_dict(self):
return {"type": "text", "text": self.text}
def to_plain(self):
return self.text
def __repr__(self):
return f"TextMessage(text={self.text})"
# 定义媒体消息的基类
class MediaMessage(MessageElement):
resource_type: Literal["image", "audio", "video", "file"]
media_id: str
def __init__(
self,
url: Optional[str] = None,
path: Optional[str] = None,
data: Optional[bytes] = None,
format: Optional[str] = None,
media_id: Optional[str] = None,
reference_id: Optional[str] = None,
source: Optional[str] = "im_message",
description: Optional[str] = None,
tags: Optional[List[str]] = None,
media_manager: Optional[MediaManager] = None,
):
self.url = url
self.path = path
self.data = data
self.format = format
self._reference_id = reference_id
self._source = source
self._description = description
self._tags = tags or []
self._media_manager = media_manager or MediaManager()
self.base64_url: Optional[str] = None
if media_id:
self.media_id = media_id
return
# 注册媒体文件
# 使用线程创建新的事件循环来阻塞执行媒体注册
import asyncio
import threading
# 用于存储线程中的异常
thread_exception: Optional[Exception] = None
def run_in_new_loop():
nonlocal thread_exception
try:
asyncio.run(self._register_media())
except Exception as e:
thread_exception = e
# 在新线程中运行异步注册函数
thread = threading.Thread(
target=run_in_new_loop,
)
thread.start()
thread.join() # 阻塞等待完成
# 如果线程中发生异常,则在主线程中重新抛出
if thread_exception:
raise thread_exception
async def _register_media(self) -> None:
"""注册媒体文件"""
media_manager = self._media_manager
# 根据传入的参数注册媒体文件
self.media_id = await media_manager.register_media(
url=self.url,
path=self.path,
data=self.data,
format=self.format,
source=self._source,
description=self._description,
tags=self._tags,
media_type=MIMETYPE_MAPPING[self.resource_type],
reference_id=self._reference_id
)
# 获取媒体元数据
metadata = media_manager.get_metadata(self.media_id)
if metadata and metadata.format:
self.format = metadata.format
if metadata.media_type:
self.resource_type = metadata.media_type.value
async def get_url(self) -> str:
"""获取媒体资源的URL"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有URL,直接返回
if self.url:
return self.url
# 否则从媒体管理器获取
media_manager = self._media_manager
url = await media_manager.get_url(self.media_id)
if url:
self.url = url # 缓存结果
return url
raise ValueError("Failed to get media URL")
async def get_path(self) -> str:
"""获取媒体资源的文件路径"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有路径,直接返回
if self.path and Path(self.path).exists():
return self.path
# 否则从媒体管理器获取
media_manager = self._media_manager
file_path = await media_manager.get_file_path(self.media_id)
if file_path:
self.path = str(file_path) # 缓存结果
return self.path
raise ValueError("Failed to get media file path")
async def get_data(self) -> bytes:
"""获取媒体资源的二进制数据"""
if not self.media_id:
raise ValueError("Media not registered")
# 如果已经有数据,直接返回
if self.data:
return self.data
# 否则从媒体管理器获取
media_manager = self._media_manager
data = await media_manager.get_data(self.media_id)
if data:
self.data = data # 缓存结果
return data
raise ValueError("Failed to get media data")
async def get_base64_url(self) -> str:
"""获取媒体资源的Base64 URL"""
if not self.media_id:
raise ValueError("Media not registered")
if self.base64_url:
return self.base64_url
base64_url = await self._media_manager.get_base64_url(self.media_id)
if base64_url:
self.base64_url = base64_url
return base64_url
raise ValueError("Failed to get media base64 URL")
def get_description(self) -> str:
"""获取媒体资源的描述"""
if not self.media_id:
raise ValueError("Media not registered")
metadata = self._media_manager.get_metadata(self.media_id)
if metadata:
return metadata.description or ""
return ""
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
result = {
"type": self.resource_type,
"media_id": self.media_id,
}
# 添加可选属性
if self.format:
result["format"] = self.format
if self.url:
result["url"] = self.url
if self.path:
result["path"] = self.path
return result
# 定义语音消息
class VoiceMessage(MediaMessage):
resource_type = "audio"
def to_dict(self):
result = super().to_dict()
result["type"] = "voice"
return result
def to_plain(self):
return "[VoiceMessage]"
# 定义图片消息
class ImageMessage(MediaMessage):
resource_type = "image"
def to_dict(self):
result = super().to_dict()
result["type"] = "image"
return result
def to_plain(self):
return f"[ImageMessage:media_id={self.media_id},url={self.url},alt={self.get_description()}]"
def __repr__(self):
return f"ImageMessage(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义@消息元素
# :deprecated
class AtElement(MessageElement):
def __init__(self, user_id: str, nickname: str = ""):
self.user_id = user_id
self.nickname = nickname
def to_dict(self):
return {"type": "at", "data": {"qq": self.user_id, "nickname": self.nickname}}
def to_plain(self):
return f"@{self.nickname or self.user_id}"
def __repr__(self):
return f"AtElement(user_id={self.user_id}, nickname={self.nickname})"
# 定义@消息元素
class MentionElement(MessageElement):
def __init__(self, target: ChatSender):
self.target = target
def to_dict(self):
return {"type": "mention", "data": {"target": self.target}}
def to_plain(self):
return f"@{self.target.display_name or self.target.user_id}"
def __repr__(self):
return f"MentionElement(target={self.target})"
# 定义回复消息元素
class ReplyElement(MessageElement):
def __init__(self, message_id: str):
self.message_id = message_id
def to_dict(self):
return {"type": "reply", "data": {"id": self.message_id}}
def to_plain(self):
return f"[Reply:{self.message_id}]"
def __repr__(self):
return f"ReplyElement(message_id={self.message_id})"
# 定义文件消息元素
class FileMessage(MediaMessage):
resource_type = "file"
def to_dict(self):
result = super().to_dict()
result["type"] = "file"
return result
def to_plain(self):
return f"[File:{self.path or self.url or 'unnamed'}]"
def __repr__(self):
return f"FileElement(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义JSON消息元素
class JsonMessage(MessageElement):
def __init__(self, data: str):
self.data = data
def to_dict(self):
return {"type": "json", "data": {"data": self.data}}
def to_plain(self):
return f"[JSON:{self.data}]"
def __repr__(self):
return f"JsonMessage(data={self.data})"
# 定义表情消息元素
class EmojiMessage(MessageElement):
def __init__(self, face_id: str):
self.face_id = face_id
def to_dict(self):
return {"type": "face", "data": {"id": self.face_id}}
def to_plain(self):
return f"[Face:{self.face_id}]"
def __repr__(self):
return f"EmojiMessage(face_id={self.face_id})"
# 定义视频消息元素
class VideoMessage(MediaMessage):
resource_type = "video"
def to_dict(self):
result = super().to_dict()
result["type"] = "video"
return result
def to_plain(self):
return f"[Video:{self.path or self.url or 'unnamed'}]"
def __repr__(self):
return f"VideoMessage(media_id={self.media_id}, url={self.url}, path={self.path}, format={self.format})"
# 定义消息类
class IMMessage:
"""
IM消息类,用于表示一条完整的消息。
包含发送者信息和消息元素列表。
Attributes:
sender: 发送者标识
message_elements: 消息元素列表,可以包含文本、图片、语音等
raw_message: 原始消息数据
content: 消息的纯文本内容
images: 消息中的图片列表
voices: 消息中的语音列表
"""
sender: ChatSender
message_elements: List[MessageElement]
raw_message: Optional[dict]
def __repr__(self):
return f"IMMessage(sender={self.sender}, message_elements={self.message_elements}, raw_message={self.raw_message})"
@property
def content(self) -> str:
"""获取消息的纯文本内容"""
content = ""
for element in self.message_elements:
content += element.to_plain()
if isinstance(element, TextMessage):
content += "\n"
return content.strip()
@property
def images(self) -> List[ImageMessage]:
"""获取消息中的所有图片"""
return [
element
for element in self.message_elements
if isinstance(element, ImageMessage)
]
@property
def voices(self) -> List[VoiceMessage]:
"""获取消息中的所有语音"""
return [
element
for element in self.message_elements
if isinstance(element, VoiceMessage)
]
def __init__(
self,
sender: ChatSender,
message_elements: List[MessageElement],
raw_message: Optional[dict] = None,
):
self.sender = sender
self.message_elements = message_elements
self.raw_message = raw_message
def to_dict(self):
return {
"sender": self.sender,
"message_elements": [
element.to_dict() for element in self.message_elements
],
"plain_text": "".join(
[element.to_plain() for element in self.message_elements]
),
"raw_message": self.raw_message,
}
# backward compatibility
# deprecated
FileElement = FileMessage
ImageElement = ImageMessage
VoiceElement = VoiceMessage
VideoElement = VideoMessage
EmojiElement = EmojiMessage
JsonElement = JsonMessage
FaceElement = EmojiMessage
================================================
FILE: kirara_ai/im/profile.py
================================================
from enum import Enum, auto
from typing import Optional
from pydantic import BaseModel, Field
class Gender(Enum):
MALE = auto()
FEMALE = auto()
UNKNOWN = auto()
OTHER = auto()
class UserProfile(BaseModel):
"""
通用的用户资料结构
"""
user_id: str = Field(..., description="用户唯一标识")
username: Optional[str] = Field(None, description="用户名")
display_name: Optional[str] = Field(None, description="显示名称")
full_name: Optional[str] = Field(None, description="完整名称")
gender: Optional[Gender] = Field(None, description="性别")
age: Optional[int] = Field(None, description="年龄")
avatar_url: Optional[str] = Field(None, description="头像URL")
level: Optional[int] = Field(None, description="用户等级")
language: Optional[str] = Field(None, description="语言")
extra_info: Optional[dict] = Field(None, description="平台特定的额外信息")
def __init__(self, **kwargs):
super().__init__(**kwargs)
================================================
FILE: kirara_ai/im/sender.py
================================================
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Dict, Optional
class ChatType(Enum):
C2C = "c2c"
GROUP = "group"
@classmethod
def from_str(cls, value: str) -> "ChatType":
if value == "c2c" or value == "私聊":
return cls.C2C
elif value == "group" or value == "群聊":
return cls.GROUP
raise ValueError(f"Invalid chat type: {value}")
def to_str(self) -> str:
if self == self.C2C:
return "私聊"
elif self == self.GROUP:
return "群聊"
raise ValueError(f"Invalid chat type: {self}")
@dataclass
class ChatSender:
"""聊天发送者信息封装"""
display_name: str
user_id: str
chat_type: ChatType
group_id: Optional[str] = None
raw_metadata: Dict[str, Any] = field(default_factory=dict)
callback = None
@classmethod
def from_group_chat(
cls,
user_id: str,
group_id: str,
display_name: str,
metadata: Optional[Dict[str, Any]] = None,
) -> "ChatSender":
"""创建群聊发送者"""
return cls(
user_id=user_id,
chat_type=ChatType.GROUP,
group_id=group_id,
display_name=display_name,
raw_metadata=metadata or {},
)
@classmethod
def from_c2c_chat(
cls, user_id: str, display_name: str, metadata: Optional[Dict[str, Any]] = None
) -> "ChatSender":
"""创建私聊发送者"""
return cls(
user_id=user_id,
chat_type=ChatType.C2C,
display_name=display_name,
raw_metadata=metadata or {},
)
@classmethod
def get_bot_sender(cls) -> "ChatSender":
"""获取机器人发送者"""
return cls(
user_id="bot",
display_name="bot",
chat_type=ChatType.C2C,
)
def __str__(self) -> str:
if self.chat_type == ChatType.GROUP:
return f"{self.group_id}:{self.user_id}"
else:
return f"c2c:{self.user_id}"
def __eq__(self, other: Any) -> bool:
if isinstance(other, ChatSender):
return self.user_id == other.user_id and \
self.chat_type == other.chat_type and \
self.group_id == other.group_id
return False
def __hash__(self) -> int:
return hash((self.user_id, self.chat_type, self.group_id))
================================================
FILE: kirara_ai/internal.py
================================================
# 定义优雅退出异常
import asyncio
shutdown_event = asyncio.Event()
restart_flag = False
def set_restart_flag():
global restart_flag
restart_flag = True
def get_and_reset_restart_flag():
global restart_flag
flag = restart_flag
restart_flag = False
return flag
================================================
FILE: kirara_ai/ioc/__init__.py
================================================
================================================
FILE: kirara_ai/ioc/container.py
================================================
import contextvars
from typing import Any, Optional, Type, TypeVar, overload
T = TypeVar("T")
class DependencyContainer:
"""
依赖注入容器,提供注册和解析的功能。你可以在此获取一些全局的对象。
基本用法:
```python
# 1. 注册全局对象 - 通常在初始化时使用
container.register(YourObj, your_obj_instance)
# 2. 获取全局对象 - 在你的逻辑代码中使用
your_obj_instance = container.resolve(YourObj)
# 3. 销毁全局对象 - 通常在系统/插件销毁时使用
container.destroy(YourObj)
# 4. 创建作用域容器 - 作用域容器内注册的对象只在作用域内可被访问
# 离开作用域的上下文后无法取到该对象
# 全局容器注册对象
container.register(KiraraObj, kirara_obj)
with container.scoped() as scoped_container:
# 注册作用域对象
scoped_container.register(YourObj, your_obj_instance)
# 获取作用域对象
scoped_container.resolve(YourObj)
# 作用域容器也可以获取到全局容器的对象
container.has(KiraraObj) # 返回 True
# 甚至还能再创建新的作用域容器
with scoped_container.scoped() as another_scoped_container:
another_scoped_container.has(YourObj) # True
# 离开作用域上下文后无法获取到该对象
container.has(YourObj) # 返回 False
```
docs: https://docs.python.org/zh-cn/3.13/library/contextvars.html#module-contextvars
Attributes:
parent (DependencyContainer): 父容器实例,用于支持作用域嵌套
registry (dict): 存储当前容器注册的值或对象实例,格式为{key: value|object}
Methods:
register: 向容器注册一个key-value对
resolve: 从容器解析获取一个值或对象实例
destroy: 从容器中移除一个值或对象实例
scoped: 创建一个新的作用域容器
"""
def __init__(self, parent=None):
self.parent = parent # 父容器,用于支持作用域嵌套
self.registry = {} # 当前容器的注册表
def register(self, key, value):
"""
向容器注册一个值或者实例。
Args:
key: 对象的标识键, 一般为对象的类 (Type) 如 IMManager, LLMManager等,
会根据类型自动查找对应对象实例。
value: 值/对象实例
"""
self.registry[key] = value
@overload
def resolve(self, key: Type[T]) -> T: ...
@overload
def resolve(self, key: Any) -> Any: ...
def resolve(self, key: Type[T] | Any) -> T | Any:
"""
依照{key}从容器解析出一个值或对象实例。
如果{key}在当前容器中不存在,则会递归查找父容器。
Args:
key: 对象的标识键, 一般为对象的类 (Type) 如 IMManager, LLMManager等,
会根据类型自动查找对应对象实例。
Returns:
值/对象实例
Raises:
KeyError: {key}在当前容器和父容器中都不存在时抛出
"""
if key in self.registry:
return self.registry[key]
elif self.parent:
return self.parent.resolve(key)
else:
raise KeyError(f"Dependency {key} not found.")
def has(self, key: Type[T] | Any) -> bool:
"""
检测容器中是否能解析出某个键所对应的值。
Args:
key: 对象的标识键
Returns:
成功返回 True, 失败返回 False
"""
return key in self.registry or (self.parent is not None and self.parent.has(key))
@overload
def destroy(self, key: Type[T], recursive: bool = False) -> None: ...
@overload
def destroy(self, key: Any, recursive: bool = False) -> None: ...
def destroy(self, key: Type[T] | Any, recursive: bool = False) -> None:
"""
从容器中移除一个值或对象实例。支持递归删除父元素。
但是最好不要递归,你可能会删除一些系统对象
Args:
key: 对象的标识键
recursive: 是否递归删除父元素, 默认False。注意这是unsafe方法, 请注意不要删除系统对象。
Raises:
KeyError: {key}在当前容器和父容器中都不存在时抛出
"""
if key in self.registry:
del self.registry[key]
elif self.parent and recursive:
self.parent.destroy(key, recursive)
else:
raise KeyError(f"Cannot destroy dependency {key} which is not found in registry or parent container's registry.")
def scoped(self):
"""创建一个新的作用域容器"""
new_container = ScopedContainer(self)
if DependencyContainer in self.registry:
new_container.registry[DependencyContainer] = new_container
new_container.registry[ScopedContainer] = new_container
return new_container
# 使用 contextvars 实现线程和异步安全的上下文管理
current_container = contextvars.ContextVar[Optional[DependencyContainer]]("current_container", default=None)
class ScopedContainer(DependencyContainer):
def __init__(self, parent):
super().__init__(parent)
def __enter__(self):
# 将当前容器设置为新的作用域容器
self.token = current_container.set(self)
return self
def __exit__(self, exc_type, exc_value, traceback):
# 恢复之前的容器
current_container.reset(self.token)
================================================
FILE: kirara_ai/ioc/inject.py
================================================
from functools import wraps
from inspect import signature
from typing import Any, Callable, Optional, Type
from kirara_ai.ioc.container import DependencyContainer
def get_all_attributes(cls):
if not hasattr(cls, "__annotations__"):
return {}
attributes = dict(cls.__annotations__.items())
# 获取父类的属性和方法
for base in cls.__bases__:
attributes.update(get_all_attributes(base))
return attributes
class Inject:
def __init__(self, container: Optional[DependencyContainer] = None):
self.container = container
def create(self, target: type):
# 注入类
injected_class = self.__call__(target)
# 注入构造函数
return self.inject_function(injected_class)
def __call__(self, target: Any):
# 如果修饰的是一个类
if isinstance(target, type):
return self.inject_class(target)
# 如果修饰的是一个函数
elif callable(target):
return self.inject_function(target)
else:
raise TypeError(
"Inject can only be used on classes, functions."
)
def inject_class(self, cls: Type):
# 遍历类的属性,尝试注入依赖
for name, injecting_type in get_all_attributes(cls).items():
attr = getattr(cls, name) if hasattr(cls, name) else None
setattr(cls, name, self.inject_property(name, cls, injecting_type, attr))
return cls
def inject_function(self, func: Callable):
@wraps(func)
def wrapper(*args, **kwargs):
# 获取函数的参数签名
sig = signature(func)
# 检查是否有 DependencyContainer 对象作为参数传递进来
container_param = self.find_container(args, kwargs)
# 如果有 DependencyContainer 对象,则将其作为 self.container
if container_param:
self.container = container_param
# 遍历参数,注入依赖
bound_args = sig.bind_partial(*args, **kwargs)
bound_args.apply_defaults()
for name, param in sig.parameters.items():
if (
param.annotation != param.empty
and name not in kwargs
and self.container
):
bound_args.arguments[name] = self.container.resolve(
param.annotation
)
# 调用实际的函数
return func(*bound_args.args, **bound_args.kwargs)
return wrapper
def inject_property(self, name, cls, injecting_type, prop: Optional[property]):
# 获取 property 的 fget, fset, fdel
backing_name = f"_{name}_value"
# 定义默认的 getter 方法 (使用实例属性存储值)
def default_fget(_self):
return getattr(_self, backing_name, None)
# 定义默认的 setter 方法 (使用实例属性存储值)
def default_fset(_self, value):
setattr(_self, backing_name, value)
# 定义默认的 deleter 方法 (使用实例属性存储值)
def default_fdel(_self):
if hasattr(_self, backing_name):
delattr(_self, backing_name)
# 如果已有属性,使用其方法,否则使用默认方法
if prop:
fget = prop.fget or default_fget
fset = prop.fset or default_fset
fdel = prop.fdel or default_fdel
else:
fget = default_fget
fset = default_fset
fdel = default_fdel
# 为 property 的 fget 注入依赖
@wraps(fget)
def new_fget(_self):
# 获取 property 的返回值
if self.container and isinstance(injecting_type, type) and self.container.has(injecting_type):
# 如果返回值是一个类型,尝试从 container 中解析
return self.container.resolve(injecting_type)
else:
return default_fget(_self)
# 返回新的 property
return property(new_fget, fset, fdel)
def find_container(self, args, kwargs):
# 检查是否有 DependencyContainer 对象作为参数传递进来
for arg in args:
if isinstance(arg, DependencyContainer):
return arg
for key, value in kwargs.items():
if isinstance(value, DependencyContainer):
return value
return None
================================================
FILE: kirara_ai/llm/adapter.py
================================================
from abc import ABC
from typing import List, Protocol, runtime_checkable
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.rerank import LLMReRankRequest, LLMReRankResponse
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing.llm_tracer import LLMTracer
@runtime_checkable
class AutoDetectModelsProtocol(Protocol):
async def auto_detect_models(self) -> List[ModelConfig]: ...
@runtime_checkable
class LLMChatProtocol(Protocol):
def chat(self, req: LLMChatRequest) -> LLMChatResponse: ...
@runtime_checkable
class LLMEmbeddingProtocol(Protocol):
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse: ...
@runtime_checkable
class LLMReRankProtocol(Protocol):
def rerank(self, req: LLMReRankRequest) -> LLMReRankResponse: ...
class LLMBackendAdapter(ABC):
backend_name: str
media_manager: MediaManager
tracer: LLMTracer
================================================
FILE: kirara_ai/llm/format/__init__.py
================================================
from .message import LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent, LLMToolResultContent
from .response import LLMChatResponse
from .tool import Function, Tool, ToolCall
__all__ = ["LLMChatMessage", "LLMChatTextContent", "LLMChatImageContent", "LLMToolCallContent", "LLMToolResultContent", "Function", "Tool", "ToolCall", "LLMChatResponse"]
================================================
FILE: kirara_ai/llm/format/embedding.py
================================================
from typing import Literal, Optional
from pydantic import BaseModel
from .message import LLMChatTextContent, LLMChatImageContent
from .response import Usage
FormatType = Literal["base64"]
OutputType = Literal["float", "int8", "uint8", "binary", "ubinary"]
InputType = Literal["string", "query", "document"]
InputUnionType = LLMChatTextContent | LLMChatImageContent
class LLMEmbeddingRequest(BaseModel):
"""
此模型用于规范embedding请求的格式
Tips: 各大模型向量维度以及向量转化函数不同,因此当你用于向量数据库时,请确保存储和检索使用同一个模型,并确保模型向量一致(部分模型支持同一模型设置向量维度)
Note: 注意一下字段为混合字段, 部分字段在部分模型中不起作用, 请参照对应ap文档传递参数。
Attributes:
text (list[str | Image]): 待转化为向量的文本或图片列表
model (str): 使用的embedding模型名
dimensions (Optional[int]): embedding向量的维度
encoding_format (Optional[FormatType]): embedding的编码格式。推荐不设置该字段, 方便直接输入数据库
input_type (Optional[InputType]): 输入类型, 归属于voyage_adapter的独有字段
truncate (Optional[bool]): 是否自动截断超长文本, 以适应llm上下文长度上限。
output_type (Optional[OutputType]): 向量内部应该使用哪种数据类型. 一般默认float
"""
inputs: list[InputUnionType]
model: str
dimension: Optional[int] = None
encoding_format: Optional[FormatType] = None
input_type: Optional[InputType] = None
truncate: Optional[bool] = None
output_type: Optional[OutputType] = None
vector = list[float | int] # 后续可能需要使用numpy库进行精确的数据类型标注, 暂时未处理base64的返回模式
class LLMEmbeddingResponse(BaseModel):
"""
向量维度请使用len(vector)自行计算。
Attributes:
vectors: list[vector]
usage: Optional[Usage] = None
"""
vectors: list[vector]
usage: Optional[Usage] = None
================================================
FILE: kirara_ai/llm/format/message.py
================================================
import json
from typing import Literal, Optional, Union
from pydantic import BaseModel, field_validator, model_validator
from typing_extensions import Self
from .tool import LLMToolResultContent
RoleType = Literal["system", "user", "assistant"]
class LLMChatTextContent(BaseModel):
type: Literal["text"] = "text"
text: str
class LLMChatImageContent(BaseModel):
type: Literal["image"] = "image"
media_id: str
class LLMToolCallContent(BaseModel):
"""
这是模型请求工具的消息内容,
模型强相关内容,如果你 message 或者 memory 内包含了这个内容,请保证调用同一个 model
此部分 role 应该归属于"assistant"
"""
type: Literal["tool_call"] = "tool_call"
# call id,部分模型用此字段区分不同函数的调用,若没有返回则由 Adapter 生成
id: str
name: str
parameters: Optional[dict] = None
@classmethod
@field_validator("parameters", mode="before")
def convert_parameters_to_dict(cls, v: Optional[Union[str, dict]]) -> Optional[dict]:
if isinstance(v, str):
return json.loads(v)
return v
LLMChatContentPartType = Union[LLMChatTextContent, LLMChatImageContent, LLMToolCallContent, LLMToolResultContent]
RoleTypes = Literal["user", "assistant", "system", "tool"]
class LLMChatMessage(BaseModel):
"""
当 role 为 "tool" 时, content 内部只能为 list[LLMToolResultContent]
"""
content: list[LLMChatContentPartType]
role: RoleTypes
@model_validator(mode="after")
def check_content_type(self) -> Self:
# 此装饰器将在 model 实例化后执行,`mode = "after"`
# 用于检查 content 字段的类型是否符合 role 要求
match self.role:
case "user" | "assistant" | "system":
if not all(any(isinstance(element, content_type) for content_type in [LLMChatTextContent, LLMChatImageContent, LLMToolCallContent]) for element in self.content):
raise ValueError(f"content must be a list of LLMChatContentPartType, when role is {self.role}")
case "tool":
if not all(isinstance(element, LLMToolResultContent) for element in self.content):
raise ValueError("content must be a list of LLMToolResultContent, when role is 'tool'")
return self
================================================
FILE: kirara_ai/llm/format/request.py
================================================
from typing import Any, List, Optional
from pydantic import BaseModel
from kirara_ai.llm.format.message import LLMChatMessage
from .tool import Tool
class ResponseFormat(BaseModel):
type: Optional[str] = None
class LLMChatRequest(BaseModel):
"""
Attributes:
tool_choice (Union[dict, Literal["auto", "any", "none"]]):
"
注意由于大模型对于这个接口实现不同,本次暂不实现tool_choice的功能。
tool_choice这个参数告诉llmMessage应该如何选择调用的工具。
"
"""
messages: List[LLMChatMessage] = []
model: Optional[str] = None
frequency_penalty: Optional[int] = None
max_tokens: Optional[int] = None
presence_penalty: Optional[int] = None
response_format: Optional[ResponseFormat] = None
stop: Optional[Any] = None
stream: Optional[bool] = None
stream_options: Optional[Any] = None
temperature: Optional[int] = None
top_p: Optional[int] = None
# 规范tool传递
tools: Optional[list[Tool]] = None
# tool_choice各家目前标准不尽相同,暂不向用户提供更改这个值的选项
tool_choice: Optional[Any] = None
logprobs: Optional[bool] = None
top_logprobs: Optional[Any] = None
================================================
FILE: kirara_ai/llm/format/rerank.py
================================================
from typing import Optional
from typing_extensions import Self
from pydantic import BaseModel, model_validator
from .response import Usage
class LLMReRankRequest(BaseModel):
"""
ReRanker: 重排器是一个重要的处理方案, 通常见于 EsSearch 的优化方案中。
本接口是适用于 LLM 的重排器的请求模型一般与嵌入式式模型组合使用提高向量搜索准确率。
传入一系列原始文档和一个查询语句,返回器相似度数值。
Attributes:
query: 原始查询语句
documents: 文档列表, 包含文档的文本内容。每个文档转化为一个 string 类型传递。
model: 重排模型的名称。为保证准确性,本实现将禁止自动选择模型。
top_k: 返回最相似的 {top_k} 个文档。如果没有指定,将返回所有文档的重排序结果。
Tips: 如果你决定不返回原始文档,那么不要设置这个选项。会丢失文本与相似度的关联。
return_documents: 是否返回原始文档内容。
truncation: 文档和查询语句是否允许被截断以适应模型最大上下文。
sort: 是否按照结果的相似度得分进行排序? 默认不进行
Tips: 当return_documents为False时,若sort为True,则抛出异常。
"""
query: str
documents: list[str]
model: str
top_k: Optional[int] = None
return_documents: Optional[bool] = None
truncation: Optional[bool] = None
sort: Optional[bool] = False
@model_validator(mode="after") # mode 为 before 时其用法与after完全不同,注意看官网文档
# 这里不用after是为了等pydantic赋值默认值后检查
def check(self) -> Self:
if self.sort and not self.return_documents:
raise ValueError("Cannot sort server responses when return_documents is False.")
return self
class ReRankerContent(BaseModel):
"""
ReRanker 的内容模型。
Attributes:
document: 原始文档内容。
score: 文档的相似度分数。
"""
document: Optional[str] = None
score: float
class LLMReRankResponse(BaseModel):
"""
ReRanker 的返回模型。
Attributes:
contents (list[ReRankerContent]): 返回的排序信息, 如果启用排序,默认降序排列。 Note: 当且仅当return_documents为True时才允许启用排序。
usage (Usage): token 使用情况, 一个pydantic.BaseModel的子类。
sort (bool): 是否按照结果的相似度排序?将其设置为字段方便后续接口检查是否经过排序(方便debug)。其应该由request的sort字段赋值。
"""
contents: list[ReRankerContent]
usage: Usage
sort: bool
@model_validator(mode="after") # 当mode为after时,其发生在class实例化完成后,所以其为实例方法
def sort_content(self) -> Self:
if self.sort:
self.contents = sorted(self.contents, key= lambda x: x.score, reverse=True)
return self
================================================
FILE: kirara_ai/llm/format/response.py
================================================
from typing import List, Optional
from pydantic import BaseModel
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.tool import ToolCall
class Message(LLMChatMessage):
tool_calls: Optional[List[ToolCall]] = None
finish_reason: Optional[str] = None
class Usage(BaseModel):
completion_tokens: Optional[int] = None
prompt_tokens: Optional[int] = None
total_tokens: Optional[int] = None
cached_tokens: Optional[int] = None
class LLMChatResponse(BaseModel):
model: Optional[str] = None
usage: Optional[Usage] = None
message: Message
================================================
FILE: kirara_ai/llm/format/tool.py
================================================
import json
from typing import Any, Callable, Coroutine, Generic, List, Literal, Optional, TypeVar, Union
from pydantic import BaseModel, ConfigDict, Field, field_serializer, field_validator
class TextContent(BaseModel):
type: Literal["text"] = "text"
text: str
class MediaContent(BaseModel):
type: Literal["media"] = "media"
media_id: str
mime_type: str
data: bytes
ToolResponseTypes = List[Union[TextContent, MediaContent]]
class LLMToolResultContent(BaseModel):
"""
这是工具回应的消息内容,
模型强相关内容,如果你 message 或者 memory 内包含了这个内容,请保证调用同一个 model
此部分 role 应该对应 "tool"
"""
type: Literal["tool_result"] = "tool_result"
# call id,对应 LLMToolCallContent 的 id
id: str
name: str
# 各家工具要求返回的content格式不同. 等待后续规范化。
content: ToolResponseTypes
isError: bool = False
class Function(BaseModel):
# 工具名称
name: str
# 这个字段类似于 python 的关键字参数,你可以直接使用`**arguments`
arguments: Optional[dict] = None
@field_validator("arguments", mode="before")
@classmethod
# pydantic 官网建议将 @classmethod 放在下面。因为python装饰器执行顺序是由下到上。
def convert_arguments(cls, v: Optional[Union[str, dict]]) -> Optional[dict]:
return json.loads(v) if isinstance(v, str) else v
class ToolCall(BaseModel):
# call id,对应 LLMToolCallContent 的 id
id: str
# type这个字段目前不知道有什么用
type: Optional[str] = None
function: Function
T = TypeVar('T', bound=Callable)
ToolInvokeFunc = Callable[[ToolCall], Coroutine[Any, Any, "LLMToolResultContent"]]
class CallableWrapper(Generic[T]):
"""包装可调用对象的类,在深拷贝时返回None"""
def __init__(self, func: T):
self.func = func
def __call__(self, *args, **kwargs) -> Coroutine[Any, Any, "LLMToolResultContent"]:
return self.func(*args, **kwargs)
def __deepcopy__(self, memo):
# 深拷贝时保持原始引用而不是尝试复制函数
return self
class ToolInputSchema(BaseModel):
"""
工具输入参数的格式,遵循 JSON Schema 的规范
Attributes:
type (Literal["object"]): 参数的类型
properties (dict): 工具属性,参考 openai api 的规范
required (list[str]): 必填参数的名称列表
additionalProperties (Optional[bool]): 是否允许额外的键值对
"""
type: Literal["object"] = "object"
properties: dict
required: list[str]
additionalProperties: Optional[bool] = False
class Tool(BaseModel):
"""
传递给 LLM 的工具信息
Attributes:
type (Optional[Literal["function"]]): 工具的类型
name (str): 工具的名称
description (str): 工具的描述
parameters (ToolInputSchema): 工具的参数格式
strict (Optional[bool]): 是否严格调用, openai api专属
invokeFunc (Optional[Callable]): 工具对应的执行函数,仅在调用时使用,不参与序列化
"""
type: Optional[Literal["function"]] = "function"
name: str
description: str
parameters: Union[ToolInputSchema, dict]
strict: Optional[bool] = False
invokeFunc: CallableWrapper[ToolInvokeFunc] = Field(exclude=True)
model_config = ConfigDict(arbitrary_types_allowed=True)
@field_serializer("invokeFunc")
def serialize_invoke_func(self, invoke_func: CallableWrapper[ToolInvokeFunc]) -> str:
return "..."
================================================
FILE: kirara_ai/llm/llm_manager.py
================================================
import random
from typing import Dict, List, Optional
from typing_extensions import deprecated
from kirara_ai.config.global_config import GlobalConfig, ModelConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.llm import LLMAdapterLoaded, LLMAdapterUnloaded
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.llm.adapter import LLMBackendAdapter
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.llm.model_types import ModelAbility, ModelType
from kirara_ai.logger import get_logger
class LLMManager:
"""
跟踪、管理和调度模型后端
"""
container: DependencyContainer
config: GlobalConfig
backend_registry: LLMBackendRegistry
active_backends: Dict[str, List[LLMBackendAdapter]]
model_info: Dict[str, ModelConfig] # 存储模型的配置信息
event_bus: EventBus
@Inject()
def __init__(
self,
container: DependencyContainer,
config: GlobalConfig,
backend_registry: LLMBackendRegistry,
event_bus: EventBus,
):
self.container = container
self.config = config
self.backend_registry = backend_registry
self.event_bus = event_bus
self.logger = get_logger("LLMAdapter")
self.active_backends = {}
self.model_info = {} # 初始化模型信息字典
self.backends: Dict[str, LLMBackendAdapter] = {}
def load_config(self):
"""加载配置文件中的所有启用的后端"""
for backend in self.config.llms.api_backends:
if backend.enable:
self.logger.info(f"Loading backend: {backend.name}")
try:
self.load_backend(backend.name)
except Exception as e:
self.logger.error(f"Failed to load backend {backend.name}: {e}")
def load_backend(self, backend_name: str):
"""
加载指定的后端
:param backend_name: 后端名称
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
raise ValueError(f"Backend {backend_name} not found in config")
if not backend.enable:
raise ValueError(f"Backend {backend_name} is not enabled")
if any(backend_name in adapters for adapters in self.active_backends.values()):
raise ValueError(f"Backend {backend_name} is already loaded")
adapter_class = self.backend_registry.get(backend.adapter)
config_class = self.backend_registry.get_config_class(backend.adapter)
if not adapter_class or not config_class:
raise ValueError(f"Invalid adapter type: {backend.adapter}")
# 创建适配器实例
with self.container.scoped() as scoped_container:
scoped_container.register(config_class, config_class(**backend.config))
adapter = Inject(scoped_container).create(adapter_class)()
adapter.backend_name = backend_name
self.backends[backend_name] = adapter
# 注册到每个支持的模型并记录模型信息
for model_config in backend.models:
# 从ModelConfig中获取模型信息
model_id = model_config.id
# 直接存储模型配置
self.model_info[model_id] = model_config
if model_id not in self.active_backends:
self.active_backends[model_id] = []
self.active_backends[model_id].append(adapter)
self.event_bus.post(LLMAdapterLoaded(adapter=adapter, backend_name=backend_name))
self.logger.info(f"Backend {backend_name} loaded successfully")
async def unload_backend(self, backend_name: str):
"""
卸载指定的后端
:param backend_name: 后端名称
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
raise ValueError(f"Backend {backend_name} not found in config")
backend_adapter = self.backends.get(backend_name)
if not backend_adapter:
raise ValueError(f"Backend {backend_name} not found")
# 从所有模型中移除这个后端的适配器
all_models = list(self.active_backends.keys())
for model in all_models:
if backend_adapter in self.active_backends[model]:
self.active_backends[model].remove(backend_adapter)
if len(self.active_backends[model]) == 0:
self.active_backends.pop(model)
# 清理模型信息
if model in self.model_info:
self.model_info.pop(model)
backend_adapter = self.backends.pop(backend_name)
self.event_bus.post(LLMAdapterUnloaded(backend_name=backend_name, adapter=backend_adapter))
async def reload_backend(self, backend_name: str):
"""
重新加载指定的后端
:param backend_name: 后端名称
"""
await self.unload_backend(backend_name)
self.load_backend(backend_name)
def is_backend_available(self, backend_name: str) -> bool:
"""
检查后端是否可用
:param backend_name: 后端名称
:return: 后端是否可用
"""
backend = next(
(b for b in self.config.llms.api_backends if b.name == backend_name), None
)
if not backend:
return False
if not backend.enable:
return False
# 检查后端的所有模型是否都有可用的适配器
for model_config in backend.models:
model_id = model_config.id
if model_id not in self.active_backends or len(self.active_backends[model_id]) == 0:
return False
return True
def get(self, backend_name: str) -> Optional[LLMBackendAdapter]:
"""
获取指定后端的适配器实例
:param backend_name: 后端名称
:return: LLM适配器实例,如果没有找到则返回None
"""
return self.backends.get(backend_name)
def get_llm(self, model_id: str) -> Optional[LLMBackendAdapter]:
"""
从指定模型的活跃后端中随机返回一个适配器实例
:param model_id: 模型ID
:return: LLM适配器实例,如果没有找到则返回None
"""
if model_id not in self.active_backends:
return None
backends = self.active_backends[model_id]
if not backends:
return None
# TODO: 后续考虑支持更多的选择策略
return random.choice(backends)
def get_supported_models(self, model_type: ModelType, ability: ModelAbility) -> List[str]:
"""
获取所有支持指定能力的模型
:param ability: 指定的能力
:return: 支持的模型ID列表
"""
return [
model_id
for model_id, model_config in self.model_info.items()
if model_config.type == model_type.value
and ability.is_capable(model_config.ability)
]
@deprecated("请使用 get_supported_models 方法")
def get_llm_id_by_ability(self, ability: ModelAbility) -> Optional[str]:
"""
根据指定的能力获取一个随机符合要求的LLM模型ID
deprecated: 请使用 get_supported_models 方法
:param ability: 指定的能力
:return: 符合要求的模型ID,如果没有找到则返回None
"""
supported_models = self.get_supported_models(ModelType.LLM, ability)
return None if not supported_models else random.choice(supported_models)
def get_models_by_ability(self, model_type: ModelType, ability: ModelAbility) -> Optional[str]:
"""
根据指定能力随机获取一个模型ID
:param model_type: 模型类型
:param ability: 指定的能力
:return: 随机选择的模型ID,如果没有找到则返回None
"""
supported_models = self.get_supported_models(model_type, ability)
if not supported_models:
return None
return random.choice(supported_models)
def get_models_by_type(self, model_type: ModelType) -> List[str]:
"""
获取指定类型的所有模型
:param model_type: 模型类型
:return: 该类型的模型ID列表
"""
return [
model_id for model_id, config in self.model_info.items()
if config.type == model_type.value
]
================================================
FILE: kirara_ai/llm/llm_registry.py
================================================
from typing import Dict, Optional, Type
from pydantic import BaseModel
from kirara_ai.logger import get_logger
from .adapter import LLMBackendAdapter
from .model_types import LLMAbility # noqa: F401
class LLMBackendRegistry:
"""
LLM后端注册表
"""
_adapters: Dict[str, Type[LLMBackendAdapter]]
_configs: Dict[str, Type[BaseModel]]
def __init__(self):
self._adapters = {}
self._configs = {}
self.logger = get_logger(__name__)
def register(
self,
adapter_type: str,
adapter_class: Type[LLMBackendAdapter],
config_class: Type[BaseModel],
*args, **kwargs
):
"""
注册一个LLM后端适配器
:param adapter_type: 适配器类型
:param adapter_class: 适配器类
:param config_class: 配置类
"""
self._adapters[adapter_type] = adapter_class
self._configs[adapter_type] = config_class
self.logger.info(
f"Registered LLM backend adapter: {adapter_type}"
)
def get(self, adapter_type: str) -> Optional[Type[LLMBackendAdapter]]:
"""
获取指定类型的适配器类
:param adapter_type: 适配器类型
:return: 适配器类,如果没有找到则返回None
"""
return next(
(adapter for key, adapter in self._adapters.items() if key.lower() == adapter_type.lower()),
None
)
def get_config_class(self, adapter_type: str) -> Optional[Type[BaseModel]]:
"""
获取指定类型的配置类
:param adapter_type: 适配器类型
:return: 配置类,如果没有找到则返回None
"""
return next(
(config for key, config in self._configs.items() if key.lower() == adapter_type.lower()),
None
)
def get_adapter_types(self) -> list[str]:
"""
获取所有已注册的适配器类型
:return: 适配器类型列表
"""
return list(self._adapters.keys())
def get_all_adapters(self) -> Dict[str, Type[LLMBackendAdapter]]:
"""
获取所有已注册的 LLM 适配器。
:return: 所有已注册的 LLM 适配器字典。
"""
return self._adapters.copy()
================================================
FILE: kirara_ai/llm/model_types.py
================================================
from abc import abstractmethod
from enum import Enum
class ModelType(Enum):
"""
模型类型枚举
"""
LLM = "llm"
Embedding = "embedding"
ImageGeneration = "image_generation"
Audio = "audio"
# 可以根据需要添加更多类型
@classmethod
def from_str(cls, value: str) -> "ModelType":
"""
从字符串转换为ModelType枚举
"""
return next(
(enum_value for enum_value in cls if enum_value.value == value),
cls.LLM,
)
class ModelAbility(Enum):
"""
模型能力抽象基类
"""
@abstractmethod
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return False
class LLMAbility(ModelAbility):
"""
定义了 LLMAbility 的枚举类型,用于表示 LLM 的能力。
"""
# 这里表示接口支持 chat 格式的对话
Unknown = 0
Chat = 1 << 1
TextInput = 1 << 2
TextOutput = 1 << 3
ImageInput = 1 << 4
ImageOutput = 1 << 5
AudioInput = 1 << 6
AudioOutput = 1 << 7
FunctionCalling = 1 << 8
# 下面是通过位运算组合能力
TextCompletion = TextInput | TextOutput
TextChat = Chat | TextCompletion
ImageGeneration = ImageInput | ImageOutput
TextImageMultiModal = Chat | ImageGeneration
TextImageAudioMultiModal = TextImageMultiModal | AudioInput | AudioOutput
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class EmbeddingModelAbility(ModelAbility):
"""
定义了 EmbeddingModelAbility 的枚举类型,用于表示 Embedding 模型的能力。
"""
Unknown = 0
TextEmbedding = 1 << 1
ImageEmbedding = 1 << 2
AudioEmbedding = 1 << 3
VideoEmbedding = 1 << 4
Batch = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class ImageModelAbility(ModelAbility):
"""
定义了 ImageModelAbility 的枚举类型,用于表示图像模型的能力。
"""
Unknown = 0
TextToImage = 1 << 1
ImageEdit = 1 << 2
Inpainting = 1 << 3
Outpainting = 1 << 4
UpScaling = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
class AudioModelAbility(ModelAbility):
"""
定义了 AudioModelAbility 的枚举类型,用于表示音频模型的能力。
"""
Unknown = 0
Speech = 1 << 1
Transcription = 1 << 2
Translation = 1 << 3
Streaming = 1 << 4
Realtime = 1 << 5
def is_capable(self, ability: int) -> bool:
"""
检查模型是否具备指定能力
"""
return (self.value & ability) == ability
================================================
FILE: kirara_ai/logger.py
================================================
import asyncio
import json
import os
import re
import traceback
from collections import deque
from datetime import datetime
from typing import Any, Callable, Dict, List
from loguru import logger
# 创建 logs 文件夹
LOG_DIR = "logs"
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
# 配置日志格式和颜色
logger.remove() # 移除默认的日志处理器
# 定义日志格式
log_format = (
"{time:YYYY-MM-DD HH:mm:ss.SSS} | "
"{level: <8} | "
"{extra[tag]: <12} | "
"{message}"
)
# 添加控制台日志处理器
logger.add(
sink=lambda msg: print(msg.strip()), # 输出到控制台
format=log_format,
level="DEBUG",
colorize=True,
)
# 添加文件日志处理器,支持日志轮转
log_file = os.path.join(LOG_DIR, "log_{time:YYYY-MM-DD}.log")
logger.add(
sink=log_file,
format=log_format,
level="DEBUG",
rotation="00:00", # 每天午夜轮转
retention="7 days", # 保留7天的日志
compression="zip", # 压缩旧日志文件
colorize=False,
)
# 全局日志实例
_global_logger = logger
# 内存中保存最近的日志,用于新连接时推送历史日志
_recent_logs: deque[Dict] = deque(maxlen=500) # 保存最近500条日志
LogBroadcasterCallback = Callable[[Dict | List[Dict]], None]
# 通用日志处理器管理类
class LogBroadcaster:
"""通用日志广播器,支持多种日志订阅方式"""
_instance = None
_subscribers: Dict[int, LogBroadcasterCallback] = {}
_next_id = 0
_initialized = False
def __new__(cls):
if cls._instance is None:
cls._instance = super(LogBroadcaster, cls).__new__(cls)
cls._instance._subscribers = {} # 订阅者字典,键为订阅者ID,值为回调函数
cls._instance._next_id = 0 # 下一个订阅者ID
cls._instance._initialized = False
return cls._instance
def __init__(self):
if not self._initialized:
self._initialized = True
# 添加日志处理器
self._setup_log_handler()
def _setup_log_handler(self):
"""设置日志处理器"""
def log_sink(message):
# 格式化日志消息
# with {tag<12}
tag = message.record["extra"]["tag"]
log_entry = {
"type": "log",
"level": message.record["level"].name,
"content": message.record['message'],
"timestamp": datetime.now().isoformat(),
"tag": tag
}
if message.record.get('exception'):
exception = message.record['exception']
if exception.value:
log_entry["content"] += "\n" + '\n'.join(traceback.format_exception(exception.value))
# 保存到最近日志
_recent_logs.append(log_entry)
# 广播到所有订阅者
self._broadcast_log(log_entry)
# 添加日志处理器
_global_logger.add(
sink=log_sink,
format=log_format,
level="INFO",
colorize=False,
)
def _broadcast_log(self, log_entry: Dict):
"""广播日志到所有订阅者"""
to_remove = []
for subscriber_id, callback in self._subscribers.items():
try:
callback(log_entry)
except Exception:
# 如果发送失败,标记该订阅者为断开
to_remove.append(subscriber_id)
# 移除断开的订阅者
for subscriber_id in to_remove:
self.unsubscribe(subscriber_id)
def subscribe(self, callback: LogBroadcasterCallback) -> int:
"""
添加日志订阅者
:param callback: 回调函数,接收日志条目并处理
:return: 订阅者ID,用于后续取消订阅
"""
subscriber_id = self._next_id
self._next_id += 1
self._subscribers[subscriber_id] = callback
return subscriber_id
def unsubscribe(self, subscriber_id: int) -> bool:
"""
取消日志订阅
:param subscriber_id: 订阅者ID
:return: 是否成功取消订阅
"""
if subscriber_id in self._subscribers:
del self._subscribers[subscriber_id]
return True
return False
def send_recent_logs(self, callback: LogBroadcasterCallback):
"""
发送最近的日志到指定回调
:param callback: 回调函数,接收日志条目并处理
"""
callback(list(_recent_logs))
# WebSocket日志处理器,作为LogBroadcaster的一个应用
class WebSocketLogHandler:
"""WebSocket日志处理器,用于将日志发送到WebSocket客户端"""
# 存储所有活跃的WebSocket连接及其订阅ID
_websockets: Dict[Any, int] = {}
@classmethod
def add_websocket(cls, ws, loop: asyncio.AbstractEventLoop):
"""
添加WebSocket连接
:param ws: WebSocket连接对象
"""
# 创建回调函数
def send_to_ws(log_entries: List[Dict] | Dict):
loop.create_task(ws.send(json.dumps(log_entries)))
# 获取日志广播器实例
broadcaster = LogBroadcaster()
# 先发送最近的日志
broadcaster.send_recent_logs(send_to_ws)
# 订阅新日志
subscriber_id = broadcaster.subscribe(send_to_ws)
cls._websockets[ws] = subscriber_id
@classmethod
def remove_websocket(cls, ws):
"""
移除WebSocket连接
:param ws: WebSocket连接对象
"""
if ws in cls._websockets:
# 取消订阅
LogBroadcaster().unsubscribe(cls._websockets[ws])
del cls._websockets[ws]
# 初始化日志广播器
def init_log_broadcaster():
"""初始化日志广播器"""
LogBroadcaster()
init_log_broadcaster()
def get_logger(tag: str):
"""
获取带有特定标签的日志记录器
:param tag: 日志标签
:return: 日志记录器
"""
return _global_logger.bind(tag=tag)
class HypercornLoggerWrapper:
def __init__(self, logger):
self.logger = logger
def critical(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.critical(message, *args, **kwargs)
def error(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.error(message, *args, **kwargs)
def warning(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.warning(message, *args, **kwargs)
def info(self, message: str, *args: Any, **kwargs: Any) -> None:
log_fmt = re.sub(r"%\((\w+)\)s", r"{\1}", message)
atoms = args[0] if args else {}
self.logger.info(log_fmt, **atoms)
def debug(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.debug(message, *args, **kwargs)
def exception(self, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.exception(message, *args, **kwargs)
def log(self, level: int, message: str, *args: Any, **kwargs: Any) -> None:
self.logger.log(level, message, *args, **kwargs)
def get_async_logger(tag: str):
"""
获取带有特定标签的日志记录器
:param tag: 日志标签
:return: 日志记录器
"""
return HypercornLoggerWrapper(_global_logger.bind(tag=tag))
================================================
FILE: kirara_ai/mcp_module/__init__.py
================================================
from .manager import MCPServerManager
from .models import MCPConnectionState
from .server import MCPServer
__all__ = ["MCPServerManager", "MCPServer", "MCPConnectionState"]
================================================
FILE: kirara_ai/mcp_module/manager.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import asyncio
from functools import partial
from typing import Dict, NamedTuple, Optional, Tuple
from mcp import McpError, types
from mcp.shared.session import RequestResponder
from kirara_ai.config.global_config import GlobalConfig, MCPServerConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from .models import MCPConnectionState
from .server import MCPServer
logger = get_logger("MCP")
class ToolCacheEntry(NamedTuple):
"""工具缓存条目"""
server_id: str # 服务器ID
original_name: str # 原始工具名称
tool_info: types.Tool # 工具信息
class MCPServerManager:
"""MCP服务器管理器,负责管理和控制MCP服务器进程"""
def __init__(self, container: DependencyContainer):
"""初始化MCP服务器管理器"""
self.container = container
self.config = container.resolve(GlobalConfig)
self.servers: Dict[str, MCPServer] = {}
self.tools_cache: Dict[str, ToolCacheEntry] = {}
self.prompts_cache: Dict[str, list[types.Prompt]] = {}
self.resources_cache: Dict[str, list[types.Resource]] = {}
def load_servers(self):
"""从配置加载所有MCP服务器"""
for server_config in self.config.mcp.servers:
try:
self.load_server(server_config)
except Exception as e:
logger.opt(exception=e).error(f"Failed to load MCP server {server_config.id}")
logger.info(f"MCP server manager initialized, loaded {len(self.servers)} servers")
def load_server(self, server_config: MCPServerConfig) -> MCPServer:
"""从配置加载MCP服务器"""
server = MCPServer(server_config)
logger.info(f"Initializing MCP server {server_config.id}")
self.servers[server_config.id] = server
return server
def get_all_servers(self) -> Dict[str, MCPServer]:
"""获取所有MCP服务器列表"""
return self.servers
def get_server(self, server_id: str) -> Optional[MCPServer]:
"""获取指定ID的MCP服务器"""
return self.servers.get(server_id)
def is_server_id_available(self, server_id: str) -> bool:
"""
检查服务器ID是否可用
判断条件:
1. 服务器ID不存在
2. 或者服务器存在但状态为 DISCONNECTED 或 ERROR
"""
if server_id not in self.servers:
return True
server = self.servers[server_id]
return server.state in [MCPConnectionState.DISCONNECTED, MCPConnectionState.ERROR]
def get_statistics(self) -> Dict[str, int]:
"""获取MCP服务器统计信息"""
total = len(self.servers)
stdio = sum(bool(s.server_config.connection_type == "stdio") for s in self.servers.values())
sse = sum(bool(s.server_config.connection_type == "sse") for s in self.servers.values())
connected = sum(bool(s.state == MCPConnectionState.CONNECTED) for s in self.servers.values())
disconnected = sum(bool(s.state == MCPConnectionState.DISCONNECTED) for s in self.servers.values())
error = sum(bool(s.state == MCPConnectionState.ERROR) for s in self.servers.values())
return {
"total": total,
"stdio": stdio,
"sse": sse,
"connected": connected,
"disconnected": disconnected,
"error": error
}
def connect_all_servers(self, loop: asyncio.AbstractEventLoop):
"""连接所有MCP服务器"""
async def _connect_server_safe(server_id):
try:
await self.connect_server(server_id)
except Exception as e:
logger.opt(exception=e).error(f"Exception occurred when connecting MCP server {server_id}")
tasks = []
for server_id in self.servers.keys():
task = loop.create_task(_connect_server_safe(server_id))
tasks.append(task)
if tasks:
loop.run_until_complete(asyncio.gather(*tasks, return_exceptions=True))
async def connect_server(self, server_id: str) -> bool:
"""连接MCP服务器"""
server = self.servers.get(server_id)
if not server:
logger.error(f"Cannot connect to non-existent MCP server: {server_id}")
return False
if server.state == MCPConnectionState.CONNECTED:
logger.warning(f"MCP server {server_id} is already connected")
return True
try:
logger.info(f"Connecting to MCP server {server_id}")
server.message_handler = partial(self._handle_server_message, server_id)
# 连接到服务器
success = await server.connect()
if not success:
logger.error(f"Failed to connect to MCP server {server_id}")
return False
# 连接成功后,更新缓存
await self._update_tools_cache(server_id)
await self._update_prompts_cache(server_id)
await self._update_resources_cache(server_id)
logger.info(f"Successfully connected to MCP server {server_id}")
return True
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when connecting to MCP server {server_id}")
return False
def disconnect_all_servers(self, loop: asyncio.AbstractEventLoop):
"""断开所有MCP服务器连接"""
disconnect_tasks = []
for server_id, server in self.servers.items():
if server.state == MCPConnectionState.CONNECTED:
disconnect_tasks.append(loop.create_task(self.stop_server(server_id)))
if disconnect_tasks:
loop.run_until_complete(asyncio.gather(*disconnect_tasks, return_exceptions=True))
self.tools_cache.clear()
logger.info("All MCP servers have been disconnected")
async def stop_server(self, server_id: str) -> bool:
"""断开MCP服务器连接"""
server = self.servers.get(server_id)
if not server:
logger.error(f"Cannot disconnect from non-existent MCP server: {server_id}")
return False
if server.state != MCPConnectionState.CONNECTED:
logger.warning(f"MCP server {server_id} is not connected")
return True
try:
logger.info(f"Disconnecting from MCP server {server_id}")
# 断开服务器连接
success = await server.disconnect()
if not success:
logger.error(f"Failed to disconnect from MCP server {server_id}")
return False
# 从工具缓存中移除该服务器的工具
self._remove_server_tools_from_cache(server_id)
logger.info(f"Successfully disconnected from MCP server {server_id}")
return True
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when disconnecting from MCP server {server_id}")
return False
async def _update_tools_cache(self, server_id: str) -> bool:
"""
更新指定服务器的工具缓存
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器工具列表
tools = await server.get_tools()
# 先移除该服务器的旧工具
self._remove_server_tools_from_cache(server_id)
# 添加新工具到缓存
for tool in tools.tools:
original_name = tool.name
if not original_name:
continue
# 检查工具名称是否已存在
if original_name in self.tools_cache:
# 名称冲突,使用 server_id.tool_name 作为新名称
display_name = f"{server.server_config.id}.{original_name}"
logger.warning(f"工具名称冲突: {original_name},重命名为 {display_name}")
else:
display_name = original_name
# 存储工具信息
self.tools_cache[display_name] = ToolCacheEntry(
server_id=server_id,
original_name=original_name,
tool_info=tool
)
return True
except McpError as e:
if e.error == "Method not found":
logger.warning(f"Server {server_id} does not support tools")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} 工具缓存时发生错误")
return False
def _remove_server_tools_from_cache(self, server_id: str):
"""
从工具缓存中移除指定服务器的所有工具
Args:
server_id: 服务器ID
"""
# 找出属于该服务器的所有工具名称
tool_names_to_remove = [
name for name, entry in self.tools_cache.items() if entry.server_id == server_id
]
# 从缓存中移除这些工具
for name in tool_names_to_remove:
self.tools_cache.pop(name, None)
def get_tools(self) -> Dict[str, ToolCacheEntry]:
"""
获取所有可用工具
"""
# 返回工具信息
return self.tools_cache
def get_tool_server(self, tool_name: str) -> Optional[Tuple[MCPServer, str]]:
"""
根据工具名称获取对应的服务器实例和原始工具名称
Args:
tool_name: 工具显示名称
Returns:
Optional[Tuple[MCPServer, str]]: (服务器实例, 原始工具名称),如果工具不存在则返回None
"""
if tool_name not in self.tools_cache:
return None
entry = self.tools_cache[tool_name]
server = self.servers.get(entry.server_id)
if not server:
return None
return (server, entry.original_name)
async def call_tool(self, tool_name: str, tool_args: dict) -> Optional[types.CallToolResult]:
"""
调用指定工具
Args:
tool_name: 工具显示名称
tool_args: 工具参数
Returns:
Optional[dict]: 工具调用结果,如果调用失败则返回None
"""
result = self.get_tool_server(tool_name)
if not result:
logger.error(f"Tool {tool_name} not found or server not available")
return None
server, original_name = result
if server.state != MCPConnectionState.CONNECTED:
logger.error(f"Server for tool {tool_name} is not connected")
return None
try:
# 使用原始工具名称调用
call_tool_result = await server.call_tool(original_name, tool_args)
return call_tool_result
except Exception as e:
logger.opt(exception=e).error(f"Error occurred when calling tool {tool_name}")
return None
async def _update_prompts_cache(self, server_id: str) -> bool:
"""
更新指定server的prompts 索引缓存
# notification !
这个函数存的缓存是一个prompts的索引,请调用get_prompts获取具体的prompts信息
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器prompts 索引
prompts = await server.list_prompts()
# 移除旧缓存
self.prompts_cache.pop(server_id, None)
# 添加新索引到缓存
self.prompts_cache[server_id] = prompts.prompts
return True
except McpError as e:
if e.error == "Method not found":
self.prompts_cache[server_id] = []
logger.warning(f"Server {server_id} does not support prompts")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} prompts 索引缓存时发生错误")
return False
async def get_prompt_list(self, server_id: str) -> Optional[list[types.Prompt]]:
"""
获取指定服务器的prompts
Args:
server_id: 服务器ID
Returns:
types.GetPromptResult: prompts
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return self.prompts_cache.get(server_id, [])
async def get_prompt(self, server_id: str, prompt_name: str, prompt_args: dict[str, str] | None = None) -> Optional[types.GetPromptResult]:
"""
获取指定服务器的prompt
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return await server.get_prompt(prompt_name, prompt_args)
async def _update_resources_cache(self, server_id: str) -> bool:
"""
更新指定server的resources 缓存
# notification !
这个函数存的缓存是一个resources的索引,请调用get_resources获取具体的resources信息
Args:
server_id: 服务器ID
Returns:
bool: 更新是否成功
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return False
try:
# 获取服务器resources 索引
resources = await server.list_resources()
# 移除旧缓存
self.resources_cache.pop(server_id, None)
# 存储新索引到缓存
self.resources_cache[server_id] = resources.resources
return True
except McpError as e:
if e.error == "Method not found":
self.resources_cache[server_id] = []
logger.warning(f"Server {server_id} does not support resources")
return True
except Exception as e:
logger.opt(exception=e).error(f"更新服务器 {server_id} resources 缓存时发生错误")
return False
async def get_resource_list(self, server_id: str) -> Optional[list[types.Resource]]:
"""获取指定服务器的资源列表
Args:
server_id (str): 服务器ID
Returns:
Optional[types.Resource]: 资源列表
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return self.resources_cache.get(server_id, [])
async def get_resource(self, server_id: str, uri: str) -> Optional[types.ReadResourceResult]:
"""
获取指定服务器的resources
Args:
server_id: 服务器ID
uri: 资源URI
Returns:
types.ReadResourceResult: resource
"""
server = self.servers.get(server_id)
if not server or server.state != MCPConnectionState.CONNECTED:
return None
return await server.read_resource(uri)
async def _handle_server_message(self, server_id: str, message: RequestResponder[types.ServerRequest, types.ClientResult]
| types.ServerNotification
| Exception):
"""
处理服务器通知
"""
if isinstance(message, types.ToolListChangedNotification):
await self._update_tools_cache(server_id)
elif isinstance(message, types.PromptListChangedNotification):
await self._update_prompts_cache(server_id)
elif isinstance(message, types.ResourceListChangedNotification):
await self._update_resources_cache(server_id)
else:
logger.warning(f"Unknown notification from server {server_id}: {message}")
================================================
FILE: kirara_ai/mcp_module/models.py
================================================
from enum import Enum
class MCPConnectionState(Enum):
DISCONNECTED = "disconnected"
CONNECTING = "connecting"
CONNECTED = "connected"
DISCONNECTING = "disconnecting"
ERROR = "error"
================================================
FILE: kirara_ai/mcp_module/server.py
================================================
import asyncio
from contextlib import AsyncExitStack
from typing import Optional
import anyio
import anyio.lowlevel
from mcp import ClientSession, StdioServerParameters, stdio_client, types
from mcp.client.session import MessageHandlerFnT
from mcp.client.sse import sse_client
from mcp.shared.session import RequestResponder
from pydantic import AnyUrl
from kirara_ai.config.global_config import MCPServerConfig
from kirara_ai.logger import get_logger
from .models import MCPConnectionState
logger = get_logger("MCP.Server")
class MCPServer:
"""
MCP (Model Control Protocol) 服务器客户端类
用于与 MCP 服务器进行通信,支持 stdio 和 SSE 两种连接模式。
提供工具调用、补全、资源管理等功能。
本类为 mcp.ClientSession 的代理,
使其适应 Kirara AI 的生命周期。
"""
session: Optional[ClientSession] = None
state: MCPConnectionState = MCPConnectionState.DISCONNECTED
message_handler: Optional[MessageHandlerFnT] = None
def __init__(self, server_config: MCPServerConfig):
"""
初始化 MCP 服务器客户端
Args:
server_config: MCP 服务器配置
"""
self.server_config = server_config
self.session = None
self.state = MCPConnectionState.DISCONNECTED
self._lifecycle_task = None
self._shutdown_event = asyncio.Event()
self._connected_event = asyncio.Event()
self._client = None
self.message_handler = None
async def connect(self):
"""
连接到 MCP 服务器
根据配置连接到 MCP 服务器,并初始化会话
Returns:
bool: 连接是否成功
"""
if self.state != MCPConnectionState.DISCONNECTED and self.state != MCPConnectionState.ERROR:
return False
try:
self.state = MCPConnectionState.CONNECTING
# 重置事件
self._shutdown_event.clear()
self._connected_event.clear()
# 创建并启动生命周期任务
if self._lifecycle_task is None or self._lifecycle_task.done():
self._lifecycle_task = asyncio.create_task(self._lifecycle_manager())
# 等待连接完成或超时
try:
await asyncio.wait_for(self._connected_event.wait(), timeout=30.0)
if self.state != MCPConnectionState.CONNECTED:
# 连接失败
return False
return True
except asyncio.TimeoutError:
logger.error(f"连接到 MCP 服务器 {self.server_config.id} 超时")
await self.disconnect() # 超时时断开连接
return False
except Exception as e:
self.state = MCPConnectionState.ERROR
logger.opt(exception=e).error(f"连接 MCP 服务器 {self.server_config.id} 时发生错误")
return False
async def disconnect(self):
"""
断开与 MCP 服务器的连接
Returns:
bool: 断开连接是否成功
"""
if self.state == MCPConnectionState.DISCONNECTED:
return True
try:
self.state = MCPConnectionState.DISCONNECTING
# 发送关闭信号
self._shutdown_event.set()
# 等待生命周期任务完成
if self._lifecycle_task and not self._lifecycle_task.done():
try:
await asyncio.wait_for(self._lifecycle_task, timeout=10.0)
except asyncio.TimeoutError:
# 如果任务没有及时完成,取消它
self._lifecycle_task.cancel()
try:
await self._lifecycle_task
except (asyncio.CancelledError, Exception):
pass
self.state = MCPConnectionState.DISCONNECTED
return True
except Exception as e:
self.state = MCPConnectionState.ERROR
logger.opt(exception=e).error(f"断开 MCP 服务器 {self.server_config.id} 连接时发生错误")
return False
async def _lifecycle_manager(self):
"""
服务器生命周期管理任务
负责服务器的连接、运行和断开连接的完整生命周期
"""
exit_stack = AsyncExitStack()
try:
# 初始化连接
if self.server_config.connection_type == "stdio":
if self.server_config.command is None:
raise ValueError("stdio 连接类型需要提供命令")
self._client = stdio_client(StdioServerParameters(
command=self.server_config.command,
args=self.server_config.args,
env=self.server_config.env
))
elif self.server_config.connection_type == "sse":
if self.server_config.url is None:
raise ValueError("sse 连接类型需要提供 url")
self._client = sse_client(self.server_config.url, headers=self.server_config.headers)
else:
raise ValueError(f"不支持的服务器连接类型: {self.server_config.connection_type}")
# 使用 exit_stack 管理资源
read, write = await exit_stack.enter_async_context(self._client)
self.session = await exit_stack.enter_async_context(ClientSession(read, write, message_handler=self.message_handler_callback))
# 初始化会话
await self.session.initialize()
# 更新状态并通知连接完成
self.state = MCPConnectionState.CONNECTED
self._connected_event.set()
# 等待关闭信号
await self._shutdown_event.wait()
except Exception as e:
# 连接失败
self.state = MCPConnectionState.ERROR
self._connected_event.set() # 通知连接过程已完成(虽然是失败的)
logger.opt(exception=e).error(f"MCP server {self.server_config.id} lifecycle task error")
finally:
# 清理资源
self.session = None
self._client = None
try:
# 关闭所有资源
await exit_stack.aclose()
except Exception as e:
logger.opt(exception=e).error(f"error occured during shutting down handle of: {self.server_config.id}")
# 如果状态仍然是 DISCONNECTING,则更新为 DISCONNECTED
if self.state == MCPConnectionState.DISCONNECTING:
self.state = MCPConnectionState.DISCONNECTED
# 工具相关方法
async def get_tools(self) -> types.ListToolsResult:
"""获取可用工具列表"""
assert self.session is not None
return await self.session.list_tools()
async def call_tool(self, tool_name: str, tool_args: Optional[dict] = None) -> types.CallToolResult:
"""
调用指定工具
Args:
tool_name: 工具名称
tool_args: 工具参数
Returns:
工具调用结果
"""
assert self.session is not None
return await self.session.call_tool(tool_name, tool_args)
async def complete(self, prompt: str, tool_args: dict):
"""
使用模型进行补全
Args:
prompt: 提示文本
tool_args: 补全参数
Returns:
补全结果
"""
assert self.session is not None
return await self.session.complete(types.PromptReference(name=prompt, type="ref/prompt"), tool_args)
# 提示词相关方法
async def get_prompt(self, prompt_name: str, prompt_args: dict[str, str] | None = None) -> types.GetPromptResult:
"""
获取指定提示词
Args:
prompt_name: 提示词名称
prompt_args: 提示词参数
Returns:
提示词内容
"""
assert self.session is not None
return await self.session.get_prompt(prompt_name, prompt_args)
async def list_prompts(self) -> types.ListPromptsResult:
"""获取可用提示词列表"""
assert self.session is not None
return await self.session.list_prompts()
# 资源相关方法
async def list_resources(self) -> types.ListResourcesResult:
"""获取可用资源列表"""
assert self.session is not None
return await self.session.list_resources()
async def list_resource_templates(self) -> types.ListResourceTemplatesResult:
"""获取可用资源模板列表"""
assert self.session is not None
return await self.session.list_resource_templates()
async def read_resource(self, uri: str) -> types.ReadResourceResult:
"""
读取指定资源
Args:
uri: 资源名称
Returns:
资源内容
"""
assert self.session is not None
return await self.session.read_resource(AnyUrl(uri))
async def subscribe_resource(self, uri: str) -> types.EmptyResult:
"""
订阅指定资源
Args:
uri: 资源名称
Returns:
订阅结果
"""
assert self.session is not None
return await self.session.subscribe_resource(AnyUrl(uri))
async def unsubscribe_resource(self, uri: str) -> types.EmptyResult:
"""
取消订阅指定资源
Args:
uri: 资源名称
Returns:
取消订阅结果
"""
assert self.session is not None
return await self.session.unsubscribe_resource(AnyUrl(uri))
async def message_handler_callback(
self,
message: RequestResponder[types.ServerRequest, types.ClientResult]
| types.ServerNotification
| Exception,
) -> None:
"""
消息处理回调函数
Args:
message: 请求响应器或通知或异常
"""
if self.message_handler is None:
logger.warning(f"MCP客户端接收到服务器{self.server_config.id}的通知,但未对其进行处理: {message}")
await anyio.lowlevel.checkpoint()
return
await self.message_handler(message)
async def list_client_roots_callback(self, ctx) -> types.ListRootsResult | types.ErrorData:
"""
列出客户端允许的资源根目录
Args:
Returns:
types.ListRootsResult: 资源根目录列表
"""
# 这个需要kirara-agent做出较大支持,webApi 中设定允许的资源根,最好弄个单独的目录。
# 文件根格式为file:///myResource/, 也可以为一个url.
raise NotImplementedError("list_client_roots_callback 未实现")
async def send_ping(self) -> None:
assert self.session is not None
await self.session.send_ping()
async def send_notification(self, notification: types.ClientNotification) -> None:
"""
给服务器发消息,例如资源根更改
不使用 ClientSession 的 send_roots_list_changed,因为它只支持发送 RootsListChangedNotification。
这里使用其父对象 BaseSession 的 send_notification,其支持发送所有 ClientNotification。
Args:
notification: 客户端通知
"""
assert self.session is not None
await self.session.send_notification(notification)
async def sampling_callback(self):
"""
采样回调函数
"""
async def logging_callback(self):
"""
日志回调函数
"""
================================================
FILE: kirara_ai/media/__init__.py
================================================
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types import MediaType
from kirara_ai.media.utils import detect_mime_type
__all__ = [
"Media",
"MediaManager",
"MediaMetadata",
"MediaType",
"detect_mime_type",
]
================================================
FILE: kirara_ai/media/carrier/__init__.py
================================================
from .provider import MediaReferenceProvider
from .registry import MediaCarrierRegistry
from .service import MediaCarrierService
__all__ = ["MediaReferenceProvider", "MediaCarrierRegistry",
"MediaCarrierService"]
================================================
FILE: kirara_ai/media/carrier/provider.py
================================================
from abc import ABC, abstractmethod
from typing import Generic, Optional, TypeVar
T = TypeVar("T")
class MediaReferenceProvider(ABC, Generic[T]):
"""媒体引用提供者接口,由需要引用媒体的组件实现"""
@abstractmethod
def get_reference_owner(self, reference_key: str) -> Optional[T]:
"""根据引用键获取引用所有者"""
================================================
FILE: kirara_ai/media/carrier/registry.py
================================================
from typing import Dict
from kirara_ai.ioc.container import DependencyContainer
from .provider import MediaReferenceProvider
class MediaCarrierRegistry:
"""媒体载体注册表,管理所有媒体引用提供者"""
def __init__(self, container: DependencyContainer):
self.container = container
self._providers: Dict[str, MediaReferenceProvider] = {}
def register(self, provider_name: str, provider_instance: MediaReferenceProvider) -> None:
"""注册媒体引用提供者"""
self._providers[provider_name] = provider_instance
def unregister(self, provider_name: str) -> None:
"""注销媒体引用提供者"""
if provider_name in self._providers:
del self._providers[provider_name]
def get_provider(self, provider_name: str) -> MediaReferenceProvider:
"""获取媒体引用提供者实例"""
if provider_name not in self._providers:
raise ValueError(f"Provider not found: {provider_name}")
return self._providers[provider_name]
def get_all_providers(self) -> Dict[str, MediaReferenceProvider]:
"""获取所有媒体引用提供者实例"""
return self._providers
================================================
FILE: kirara_ai/media/carrier/service.py
================================================
from typing import Any, Dict, List, Optional, Tuple
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from .registry import MediaCarrierRegistry
class MediaCarrierService:
"""媒体载体服务,负责媒体引用的管理"""
def __init__(self, container: DependencyContainer, media_manager: MediaManager):
self.container = container
self.media_manager = media_manager
self.registry = container.resolve(MediaCarrierRegistry)
# 引用索引:reference_key -> (provider_name, media_id)
self._reference_index: Dict[str, Tuple[str, str]] = {}
self._build_reference_index()
def _build_reference_index(self) -> None:
"""构建引用索引"""
self._reference_index.clear()
# 遍历所有媒体元数据,提取引用信息
for media_id, metadata in self.media_manager.metadata_cache.items():
for reference_key in metadata.references:
# 尝试从引用键中提取提供者名称
if ":" in reference_key:
provider_name, _ = reference_key.split(":", 1)
self._reference_index[reference_key] = (provider_name, media_id)
def register_reference(self, media_id: str, provider_name: str, reference_key: str) -> None:
"""注册媒体引用"""
# 检查媒体是否存在
if media_id not in self.media_manager.metadata_cache:
raise ValueError(f"媒体不存在: {media_id}")
# 构造完整引用键
full_reference_key = f"{provider_name}:{reference_key}"
# 添加引用
self.media_manager.add_reference(media_id, full_reference_key)
# 更新引用索引
self._reference_index[full_reference_key] = (provider_name, media_id)
def remove_reference(self, media_id: str, provider_name: str, reference_key: str) -> None:
"""移除媒体引用"""
# 检查媒体是否存在
if media_id not in self.media_manager.metadata_cache:
return
# 构造完整引用键
full_reference_key = f"{provider_name}:{reference_key}"
# 移除引用
self.media_manager.remove_reference(media_id, full_reference_key)
# 更新引用索引
if full_reference_key in self._reference_index:
del self._reference_index[full_reference_key]
def get_reference_owner(self, reference_key: str) -> Optional[Any]:
"""获取引用所有者"""
if reference_key not in self._reference_index:
return None
provider_name, _ = self._reference_index[reference_key]
try:
provider = self.registry.get_provider(provider_name)
return provider.get_reference_owner(reference_key.split(":", 1)[1])
except (ValueError, IndexError):
return None
def get_media_by_reference(self, provider_name: str, reference_key: str) -> List[Media]:
"""根据引用键获取媒体对象"""
full_reference_key = f"{provider_name}:{reference_key}"
result = []
for ref_key, (prov_name, media_id) in self._reference_index.items():
if ref_key == full_reference_key:
media = self.media_manager.get_media(media_id)
if media:
result.append(media)
return result
def get_references_by_media(self, media_id: str) -> List[Tuple[str, str]]:
"""获取媒体的所有引用信息"""
if media_id not in self.media_manager.metadata_cache:
return []
metadata = self.media_manager.metadata_cache[media_id]
references = []
for reference_key in metadata.references:
if ":" in reference_key:
provider_name, key = reference_key.split(":", 1)
references.append((provider_name, key))
return references
def cleanup_orphaned_references(self) -> int:
"""清理孤立的引用(引用提供者不存在)"""
count = 0
all_providers = set(self.registry._providers.keys())
for media_id, metadata in list(self.media_manager.metadata_cache.items()):
orphaned_refs = set()
for reference_key in metadata.references:
if ":" in reference_key:
provider_name, _ = reference_key.split(":", 1)
if provider_name not in all_providers:
orphaned_refs.add(reference_key)
# 移除孤立引用
for ref in orphaned_refs:
self.media_manager.remove_reference(media_id, ref)
if ref in self._reference_index:
del self._reference_index[ref]
count += 1
return count
================================================
FILE: kirara_ai/media/manager.py
================================================
import asyncio
import base64
import hashlib
import json
import shutil
import time
from pathlib import Path
from typing import TYPE_CHECKING, Dict, List, Optional
import aiofiles
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types.media_type import MediaType
from kirara_ai.media.utils.mime import detect_mime_type
if TYPE_CHECKING:
from kirara_ai.im.message import MediaMessage
from kirara_ai.media.media_object import Media
class MediaManager:
"""媒体管理器,负责媒体文件的注册、引用计数和生命周期管理"""
def __init__(self, media_dir: str = "data/media"):
self.media_dir = Path(media_dir)
self.metadata_dir = self.media_dir / "metadata"
self.files_dir = self.media_dir / "files"
self.metadata_cache: Dict[str, MediaMetadata] = {}
self.logger = get_logger("MediaManager")
self._pending_tasks: set[asyncio.Task] = set()
# 确保目录存在
self.media_dir.mkdir(parents=True, exist_ok=True)
self.metadata_dir.mkdir(parents=True, exist_ok=True)
self.files_dir.mkdir(parents=True, exist_ok=True)
self._cleanup_task = None
# 加载所有元数据
self._load_all_metadata()
def _load_all_metadata(self) -> None:
"""加载所有媒体元数据"""
self.metadata_cache.clear()
for metadata_file in self.metadata_dir.glob("*.json"):
try:
with open(metadata_file, "r", encoding="utf-8") as f:
metadata = MediaMetadata.from_dict(json.load(f))
self.metadata_cache[metadata.media_id] = metadata
except Exception as e:
self.logger.error(f"Failed to load metadata from {metadata_file}: {e}")
def _save_metadata(self, metadata: MediaMetadata) -> None:
"""保存媒体元数据"""
metadata_path = self.metadata_dir / f"{metadata.media_id}.json"
with open(metadata_path, "w", encoding="utf-8") as f:
json.dump(metadata.to_dict(), f, ensure_ascii=False, indent=2)
self.metadata_cache[metadata.media_id] = metadata
def _get_file_path(self, media_id: str, format: str) -> Path:
"""获取媒体文件路径"""
return self.files_dir / f"{media_id}.{format}"
def _create_task(self, coro, name=None, loop=None):
"""创建后台任务并跟踪它"""
if loop is None:
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(coro, loop=loop)
self._pending_tasks.add(task)
task.add_done_callback(self._pending_tasks.discard)
return task
async def _save_file_async(self, data: bytes, target_path: Path):
"""异步保存文件"""
async with aiofiles.open(target_path, "wb") as f:
await f.write(data)
async def _download_file_async(self, url: str) -> bytes:
"""异步下载文件"""
from curl_cffi import AsyncSession, Response
# 如果 url 是 file:// 开头,则直接返回文件内容
if url.startswith("file://"):
async with aiofiles.open(url[7:], "rb") as f:
return await f.read()
async with AsyncSession(trust_env=True, timeout=3000) as session:
resp: Response = await session.get(url)
if resp.status_code != 200:
raise ValueError(f"Failed to download file from {url}, status: {resp.status_code}")
return resp.content
def _download_file_sync(self, url: str) -> bytes:
"""同步下载文件"""
from curl_cffi import Response, Session
# 如果 url 是 file:// 开头,则直接返回文件内容
if url.startswith("file://"):
with open(url[7:], "rb") as f:
return f.read()
with Session() as session:
resp: Response = session.get(url)
if resp.status_code != 200:
raise ValueError(f"Failed to download file from {url}, status: {resp.status_code}")
return resp.content
async def register_media(
self,
url: Optional[str] = None,
path: Optional[str] = None,
data: Optional[bytes] = None,
format: Optional[str] = None,
media_type: Optional[MediaType] = None,
size: Optional[int] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None,
) -> str:
"""
注册媒体(统一方法)
Args:
url: 媒体URL
path: 媒体文件路径
data: 媒体二进制数据
format: 媒体格式
media_type: 媒体类型
size: 媒体大小
source: 媒体来源
description: 媒体描述
tags: 媒体标签
reference_id: 引用ID
Returns:
str: 媒体ID
"""
# 检查参数
if not any([url, path, data]):
raise ValueError("Must provide at least one of url, path, or data")
# 获取数据
if path:
file_path = Path(path)
if not file_path.exists():
raise FileNotFoundError(f"File not found: {path}")
try:
async with aiofiles.open(file_path, "rb") as f:
data = await f.read()
except Exception as e:
self.logger.error(f"Failed to read file: {e}", exc_info=True)
raise
elif url:
try:
data = await self._download_file_async(url)
except Exception as e:
self.logger.error(f"Failed to download file: {e}", exc_info=True)
raise
# 计算 SHA1
if data is None:
raise ValueError("Unable to fetch data from url or path, please check your input")
hash_data = await asyncio.to_thread(hashlib.sha1, data)
media_id = hash_data.hexdigest()
# 检查是否已存在相同 media_id 的媒体
if media_id in self.metadata_cache:
self.logger.info(f"Media already exists: {media_id}")
return media_id
# 获取数据大小
if not size:
size = len(data)
# 检测文件类型
if not media_type or not format:
mime_type, detected_media_type, detected_format = detect_mime_type(data=data)
media_type = media_type or detected_media_type
format = format or detected_format
# 保存文件
if format:
target_path = self._get_file_path(media_id, format)
try:
await self._save_file_async(data, target_path)
except Exception as e:
self.logger.error(f"Failed to save file: {e}", exc_info=True)
raise
path = str(target_path)
else:
raise ValueError("No format detected")
# 创建元数据
metadata = MediaMetadata(
media_id=media_id,
media_type=media_type,
format=format,
size=size,
created_at=None, # 使用默认值
source=source,
description=description,
tags=tags,
references=set([reference_id]) if reference_id else set(),
url=url,
path=path,
)
# 保存元数据
self._save_metadata(metadata)
self.logger.info(f"Registered media: {media_id}")
return media_id
async def register_from_path(
self,
path: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None
) -> str:
"""从文件路径注册媒体"""
# 检查文件是否存在
file_path = Path(path)
if not file_path.exists():
raise FileNotFoundError(f"File not found: {path}")
return await self.register_media(
path=path,
source=source,
description=description,
tags=tags,
reference_id=reference_id
)
async def register_from_url(
self,
url: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None
) -> str:
"""从URL注册媒体"""
return await self.register_media(
url=url,
source=source,
description=description,
tags=tags,
reference_id=reference_id
)
async def register_from_data(
self,
data: bytes,
format: Optional[str] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
reference_id: Optional[str] = None,
media_type: Optional[MediaType] = None
) -> str:
"""从二进制数据注册媒体"""
return await self.register_media(
data=data,
format=format,
source=source,
description=description,
tags=tags,
reference_id=reference_id,
media_type=media_type
)
def add_reference(self, media_id: str, reference_id: str) -> None:
"""添加引用"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
metadata.references.add(reference_id)
self._save_metadata(metadata)
def remove_reference(self, media_id: str, reference_id: str) -> None:
"""移除引用"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
if reference_id in metadata.references:
metadata.references.remove(reference_id)
self._save_metadata(metadata)
# 如果没有引用了,输出log提醒一下
if not metadata.references:
self.logger.warning(f"No references found for media: {media_id}, file: {metadata.path}")
# 删除文件
self.delete_media(media_id)
def delete_media(self, media_id: str) -> None:
"""删除媒体文件和元数据"""
if media_id not in self.metadata_cache:
return
metadata = self.metadata_cache[media_id]
# 删除文件
if metadata.format:
file_path = self._get_file_path(media_id, metadata.format)
if file_path.exists():
file_path.unlink()
# 删除元数据
metadata_path = self.metadata_dir / f"{media_id}.json"
if metadata_path.exists():
metadata_path.unlink()
# 从缓存中移除
del self.metadata_cache[media_id]
self.logger.info(f"Deleted media: {media_id}")
def update_metadata(
self,
media_id: str,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
url: Optional[str] = None,
path: Optional[str] = None
) -> None:
"""更新媒体元数据"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
if source is not None:
metadata.source = source
if description is not None:
metadata.description = description
if tags is not None:
metadata.tags = tags
if url is not None:
metadata.url = url
if path is not None:
metadata.path = path
self._save_metadata(metadata)
def add_tags(self, media_id: str, tags: List[str]) -> None:
"""添加标签"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
for tag in tags:
if tag not in metadata.tags:
metadata.tags.append(tag)
self._save_metadata(metadata)
def remove_tags(self, media_id: str, tags: List[str]) -> None:
"""移除标签"""
if media_id not in self.metadata_cache:
raise ValueError(f"Media not found: {media_id}")
metadata = self.metadata_cache[media_id]
for tag in tags:
if tag in metadata.tags:
metadata.tags.remove(tag)
self._save_metadata(metadata)
def get_metadata(self, media_id: str) -> Optional[MediaMetadata]:
"""获取媒体元数据"""
return self.metadata_cache.get(media_id)
async def ensure_file_exists(self, media_id: str) -> Optional[Path]:
"""确保媒体文件存在,如果不存在则尝试下载或复制"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果没有格式信息,无法确定文件路径
if not metadata.format:
# 如果有path,尝试复制并检测格式
if metadata.path:
try:
file_path = Path(metadata.path)
if not file_path.exists():
return None
_, media_type, format = detect_mime_type(path=str(file_path))
# 更新元数据
metadata.media_type = media_type
metadata.format = format
metadata.size = file_path.stat().st_size
self._save_metadata(metadata)
# 复制文件
target_path = self._get_file_path(media_id, format)
shutil.copy2(file_path, target_path)
return target_path
except Exception as e:
self.logger.error(f"Failed to copy media from path: {metadata.path}, error: {e}")
return None
# 如果有URL,尝试下载并检测格式
elif metadata.url:
try:
data = await self._download_file_async(metadata.url)
_, media_type, format = detect_mime_type(data=data)
# 更新元数据
metadata.media_type = media_type
metadata.format = format
metadata.size = len(data)
self._save_metadata(metadata)
# 保存文件
target_path = self._get_file_path(media_id, format)
await self._save_file_async(data, target_path)
return target_path
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
return None
return None
# 检查文件是否存在
file_path = self._get_file_path(media_id, metadata.format)
if file_path.exists():
return file_path
# 如果文件不存在,尝试从URL下载
if metadata.url:
try:
data = await self._download_file_async(metadata.url)
await self._save_file_async(data, file_path)
return file_path
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
# 如果文件不存在,尝试从path复制
if metadata.path:
try:
source_path = Path(metadata.path)
if source_path.exists():
shutil.copy2(source_path, file_path)
return file_path
except Exception as e:
self.logger.error(f"Failed to copy media from path: {metadata.path}, error: {e}")
return None
async def get_file_path(self, media_id: str) -> Optional[Path]:
"""获取媒体文件路径,如果文件不存在则尝试下载或复制"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果有原始路径,直接返回
if metadata.path and Path(metadata.path).exists():
return Path(metadata.path)
# 否则确保文件存在并返回
return await self.ensure_file_exists(media_id)
async def get_data(self, media_id: str) -> Optional[bytes]:
"""获取媒体文件数据"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 尝试从文件读取
file_path = await self.get_file_path(media_id)
if file_path:
try:
async with aiofiles.open(file_path, "rb") as f:
return await f.read()
except Exception as e:
self.logger.error(f"Failed to read media file: {file_path}, error: {e}")
# 尝试从URL下载
if metadata.url:
try:
return await self._download_file_async(metadata.url)
except Exception as e:
self.logger.error(f"Failed to download media from URL: {metadata.url}, error: {e}")
return None
async def get_url(self, media_id: str) -> Optional[str]:
"""获取媒体文件URL"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
# 如果有原始URL,直接返回
if metadata.url:
return metadata.url
# 尝试生成data URL
data = await self.get_data(media_id)
if data and metadata.media_type and metadata.format:
mime_type = f"{metadata.media_type.value}/{metadata.format}"
return f"data:{mime_type};base64,{base64.b64encode(data).decode()}"
return None
async def get_base64_url(self, media_id: str) -> Optional[str]:
"""获取媒体文件 base64 URL"""
if media_id not in self.metadata_cache:
return None
metadata = self.metadata_cache[media_id]
data = await self.get_data(media_id)
if data and metadata.media_type and metadata.format:
mime_type = f"{metadata.media_type.value}/{metadata.format}"
return f"data:{mime_type};base64,{base64.b64encode(data).decode()}"
return None
def search_by_tags(self, tags: List[str], match_all: bool = False) -> List[str]:
"""根据标签搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if match_all:
# 必须匹配所有标签
if all(tag in metadata.tags for tag in tags):
results.append(media_id)
else:
# 匹配任一标签
if any(tag in metadata.tags for tag in tags):
results.append(media_id)
return results
def search_by_description(self, query: str) -> List[str]:
"""根据描述搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.description and query.lower() in metadata.description.lower():
results.append(media_id)
return results
def search_by_source(self, source: str) -> List[str]:
"""根据来源搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.source and source.lower() in metadata.source.lower():
results.append(media_id)
return results
def search_by_type(self, media_type: MediaType) -> List[str]:
"""根据媒体类型搜索媒体"""
results = []
for media_id, metadata in self.metadata_cache.items():
if metadata.media_type == media_type:
results.append(media_id)
return results
def get_all_media_ids(self) -> List[str]:
"""获取所有媒体ID"""
return list(self.metadata_cache.keys())
def cleanup_unreferenced(self) -> int:
"""清理没有引用的媒体文件,返回清理的文件数量"""
count = 0
for media_id, metadata in list(self.metadata_cache.items()):
if not metadata.references:
self.delete_media(media_id)
count += 1
return count
async def create_media_message(self, media_id: str) -> Optional["MediaMessage"]:
"""根据媒体ID创建MediaMessage对象"""
if media_id not in self.metadata_cache:
return None
from kirara_ai.im.message import FileElement, ImageMessage, VideoElement, VoiceMessage
metadata = self.metadata_cache[media_id]
# 根据媒体类型创建不同的MediaMessage子类
if metadata.media_type == MediaType.IMAGE:
return ImageMessage(media_id=media_id)
elif metadata.media_type == MediaType.AUDIO:
return VoiceMessage(media_id=media_id)
elif metadata.media_type == MediaType.VIDEO:
return VideoElement(media_id=media_id)
else:
return FileElement(media_id=media_id)
def get_media(self, media_id: str) -> Optional["Media"]:
"""获取媒体对象"""
if media_id not in self.metadata_cache:
return None
from kirara_ai.media.media_object import Media
return Media(media_id=media_id, media_manager=self)
def __new__(cls, *args, **kwargs) -> "MediaManager":
if not hasattr(cls, "_instance"):
print("new MediaManager")
cls._instance = super(MediaManager, cls).__new__(cls)
return cls._instance
def setup_cleanup_task(self, container: DependencyContainer):
"""设置清理任务"""
config = container.resolve(GlobalConfig)
if self._cleanup_task:
self._cleanup_task.cancel()
if config.media.auto_remove_unreferenced and config.media.cleanup_duration > 0:
duration = config.media.cleanup_duration
async def schedule_cleanup():
while True:
last_cleanup_time = config.media.last_cleanup_time
next_cleanup_time = last_cleanup_time + duration * 24 * 60 * 60
await asyncio.sleep(next_cleanup_time - time.time())
count = self.cleanup_unreferenced()
self.logger.info(f"Cleanup {count} unreferenced media files")
config.media.last_cleanup_time = int(time.time())
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
self._cleanup_task = asyncio.create_task(schedule_cleanup())
================================================
FILE: kirara_ai/media/media_object.py
================================================
import base64
from pathlib import Path
from typing import TYPE_CHECKING, List, Optional
if TYPE_CHECKING:
from kirara_ai.im.message import MediaMessage
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types.media_type import MediaType
class Media:
"""媒体对象,提供更方便的媒体操作接口"""
metadata: MediaMetadata
def __init__(self, media_id: str, media_manager: MediaManager):
"""
初始化媒体对象
Args:
media_id: 媒体ID
"""
self.media_id = media_id
self._manager = media_manager
metadata = self._manager.get_metadata(self.media_id)
assert metadata is not None, f"Media metadata not found for {self.media_id}"
self.metadata = metadata
@property
def media_type(self) -> MediaType:
"""获取媒体类型"""
return self.metadata.media_type
@property
def format(self) -> str:
"""获取媒体格式"""
return self.metadata.format
@property
def size(self) -> Optional[int]:
"""获取媒体大小"""
return self.metadata.size
@property
def description(self) -> Optional[str]:
"""获取媒体描述"""
return self.metadata.description
@description.setter
def description(self, value: str) -> None:
"""设置媒体描述"""
self._manager.update_metadata(self.media_id, description=value)
@property
def tags(self) -> List[str]:
"""获取媒体标签"""
metadata = self.metadata
return metadata.tags if metadata else []
@property
def mime_type(self) -> str:
"""获取媒体 MIME 类型"""
return self.metadata.mime_type
def add_tags(self, tags: List[str]) -> None:
"""添加标签"""
self._manager.add_tags(self.media_id, tags)
def remove_tags(self, tags: List[str]) -> None:
"""移除标签"""
self._manager.remove_tags(self.media_id, tags)
def add_reference(self, reference_id: str) -> None:
"""添加引用"""
self._manager.add_reference(self.media_id, reference_id)
def remove_reference(self, reference_id: str) -> None:
"""移除引用"""
self._manager.remove_reference(self.media_id, reference_id)
async def get_file_path(self) -> Path:
"""获取媒体文件路径"""
path = await self._manager.get_file_path(self.media_id)
assert path is not None, f"Media file path not found for {self.media_id}"
return path
async def get_data(self) -> bytes:
"""获取媒体文件数据"""
data = await self._manager.get_data(self.media_id)
assert data is not None, f"Media data not found for {self.media_id}"
return data
async def get_base64(self) -> str:
"""获取媒体文件 base64 编码"""
data = await self.get_data()
assert data is not None, "Media data is None"
return base64.b64encode(data).decode()
async def get_url(self) -> str:
"""获取媒体文件URL"""
url = await self._manager.get_url(self.media_id)
assert url is not None, f"Media URL not found for {self.media_id}"
return url
async def get_base64_url(self) -> str:
"""获取媒体文件 base64 URL"""
return f"data:{self.mime_type};base64,{await self.get_base64()}"
async def create_message(self) -> "MediaMessage":
"""创建媒体消息对象"""
message = await self._manager.create_media_message(self.media_id)
assert message is not None, f"Media message not found for {self.media_id}"
return message
def __str__(self) -> str:
metadata = self.metadata
if metadata:
return f"Media({metadata.media_id}, type={metadata.media_type}, format={metadata.format})"
return f"Media({self.media_id}, not found)"
def __repr__(self) -> str:
return self.__str__()
================================================
FILE: kirara_ai/media/metadata.py
================================================
from datetime import datetime
from typing import Any, Dict, List, Optional, Set
from kirara_ai.media.types.media_type import MediaType
class MediaMetadata:
"""媒体元数据类"""
def __init__(
self,
media_id: str,
media_type: MediaType,
format: str,
size: Optional[int] = None,
created_at: Optional[datetime] = None,
source: Optional[str] = None,
description: Optional[str] = None,
tags: Optional[List[str]] = None,
references: Optional[Set[str]] = None,
url: Optional[str] = None,
path: Optional[str] = None
):
self.media_id = media_id
self.media_type = media_type
self.format = format
self.size = size
self.created_at = created_at or datetime.now()
self.source = source
self.description = description
self.tags: List[str] = tags or []
self.references: Set[str] = references or set()
self.url = url
self.path = path
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
result = {
"media_id": self.media_id,
"created_at": self.created_at.isoformat(),
"source": self.source,
"description": self.description,
"tags": self.tags,
"references": list(self.references),
}
# 添加可选字段
if self.media_type:
result["media_type"] = self.media_type.value
if self.format:
result["format"] = self.format
if self.size is not None:
result["size"] = self.size
if self.url:
result["url"] = self.url
if self.path:
result["path"] = self.path
return result
@property
def mime_type(self) -> str:
"""获取 MIME 类型"""
return f"{self.media_type.value}/{self.format}"
@classmethod
def from_dict(cls, data: Dict[str, Any]) -> 'MediaMetadata':
"""从字典创建元数据"""
return cls(
media_id=data["media_id"],
media_type=MediaType(data["media_type"]),
format=data["format"],
size=data.get("size"),
created_at=datetime.fromisoformat(data["created_at"]),
source=data.get("source"),
description=data.get("description"),
tags=data.get("tags", []),
references=set(data.get("references", [])),
url=data.get("url"),
path=data.get("path")
)
================================================
FILE: kirara_ai/media/types/__init__.py
================================================
from kirara_ai.media.types.media_type import MediaType
__all__ = ["MediaType"]
================================================
FILE: kirara_ai/media/types/media_type.py
================================================
from enum import Enum
class MediaType(Enum):
"""媒体类型枚举"""
IMAGE = "image"
AUDIO = "audio"
VIDEO = "video"
FILE = "file"
@classmethod
def from_mime(cls, mime_type: str) -> 'MediaType':
"""从MIME类型获取媒体类型"""
main_type = mime_type.split('/')[0]
if main_type == "image":
return cls.IMAGE
elif main_type == "audio":
return cls.AUDIO
elif main_type == "video":
return cls.VIDEO
else:
return cls.FILE
================================================
FILE: kirara_ai/media/utils/__init__.py
================================================
from kirara_ai.media.utils.mime import detect_mime_type, mime_remapping
__all__ = ["detect_mime_type", "mime_remapping"]
================================================
FILE: kirara_ai/media/utils/mime.py
================================================
from typing import Optional, Tuple
import magic
from kirara_ai.media.types.media_type import MediaType
# MIME类型重映射
mime_remapping = {
"audio/mpeg": "audio/mp3",
"audio/x-wav": "audio/wav",
"audio/x-m4a": "audio/m4a",
"audio/x-flac": "audio/flac",
}
def detect_mime_type(data: Optional[bytes] = None, path: Optional[str] = None) -> Tuple[str, MediaType, str]:
"""
检测文件的MIME类型
Args:
data: 文件数据
path: 文件路径
Returns:
Tuple[str, MediaType, str]: (mime_type, media_type, format)
"""
try:
if data is not None:
mime_type = magic.from_buffer(data, mime=True)
elif path is not None:
mime_type = magic.from_file(path, mime=True)
else:
raise ValueError("Must provide either data or path")
except Exception as e:
raise ValueError(f"Failed to detect mime type: {e}") from e
if mime_type in mime_remapping:
mime_type = mime_remapping[mime_type]
media_type = MediaType.from_mime(mime_type)
format = mime_type.split('/')[-1]
return mime_type, media_type, format
================================================
FILE: kirara_ai/memory/composes/__init__.py
================================================
from .base import ComposableMessageType, MemoryComposer, MemoryDecomposer
from .builtin_composes import DefaultMemoryComposer, DefaultMemoryDecomposer, MultiElementDecomposer
from .composer_strategy import MessageProcessor, ProcessorFactory
from .decomposer_strategy import ContentParser, DefaultDecomposerStrategy, MultiElementDecomposerStrategy
from .xml_helper import XMLHelper
__all__ = [
"MemoryComposer",
"MemoryDecomposer",
"DefaultMemoryComposer",
"DefaultMemoryDecomposer",
"MultiElementDecomposer",
"ComposableMessageType",
"XMLHelper",
"ProcessorFactory",
"MessageProcessor",
"ContentParser",
"DefaultDecomposerStrategy",
"MultiElementDecomposerStrategy",
]
================================================
FILE: kirara_ai/memory/composes/base.py
================================================
from abc import ABC, abstractmethod
from typing import List, Optional, Union
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.response import Message
from kirara_ai.memory.entry import MemoryEntry
# 可组合的消息类型
ComposableMessageType = Union[IMMessage, LLMChatMessage, Message, str]
class MemoryComposer(ABC):
"""记忆组合器抽象类"""
container: DependencyContainer
@abstractmethod
def compose(
self, sender: Optional[ChatSender], message: List[ComposableMessageType]
) -> MemoryEntry:
"""将消息转换为记忆条目"""
class MemoryDecomposer(ABC):
"""记忆解析器抽象类"""
container: DependencyContainer
@abstractmethod
def decompose(self, entries: List[MemoryEntry]) -> List[ComposableMessageType]:
"""将记忆条目转换为消息"""
@property
def empty_message(self) -> ComposableMessageType:
"""空记忆消息"""
return "<空记忆>"
================================================
FILE: kirara_ai/memory/composes/builtin_composes.py
================================================
from datetime import datetime
from typing import Any, Dict, List, Optional, Union
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.llm.format.message import LLMChatMessage
from kirara_ai.llm.format.response import Message
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
from .base import ComposableMessageType, MemoryComposer, MemoryDecomposer
from .composer_strategy import ProcessorFactory
from .decomposer_strategy import DefaultDecomposerStrategy, MultiElementDecomposerStrategy
class DefaultMemoryComposer(MemoryComposer):
def __init__(self):
self.processor_factory = None
def compose(
self, sender: Optional[ChatSender], message: List[ComposableMessageType]
) -> MemoryEntry:
# 延迟初始化,确保 container 已被设置
if self.processor_factory is None:
self.processor_factory = ProcessorFactory(self.container)
composed_message = ""
# 上下文用于在处理过程中传递和收集数据
context: Dict[str, Any] = {
"media_ids": [],
"tool_calls": [],
"tool_results": []
}
for msg in message:
msg_type = type(msg)
processor = self.processor_factory.get_processor(msg_type)
if processor:
composed_message += processor.process(msg, context)
elif isinstance(msg, str):
# 处理字符串消息
composed_message += f"{msg}\n"
composed_message = composed_message.strip()
composed_at = datetime.now()
return MemoryEntry(
sender=sender or ChatSender.get_bot_sender(),
content=composed_message,
timestamp=composed_at,
metadata={
"_media_ids": context.get("media_ids", []),
"_tool_calls": context.get("tool_calls", []),
"_tool_results": context.get("tool_results", []),
},
)
class DefaultMemoryDecomposer(MemoryDecomposer):
def __init__(self):
self.strategy = None
def decompose(self, entries: List[MemoryEntry]) -> List[ComposableMessageType]:
# 延迟初始化,确保 container 已被设置
if self.strategy is None:
self.strategy = DefaultDecomposerStrategy()
# 使用上下文传递参数
context = {
"empty_message": self.empty_message
}
# 使用策略解析记忆条目
return self.strategy.decompose(entries, context)
class MultiElementDecomposer(MemoryDecomposer):
logger = get_logger("MultiElementDecomposer")
def __init__(self):
self.strategy = None
def decompose(self, entries: List[MemoryEntry]) -> List[Union[IMMessage, LLMChatMessage, Message, str]]:
# 延迟初始化,确保 container 已被设置
if self.strategy is None:
self.strategy = MultiElementDecomposerStrategy()
# 使用上下文传递参数
context = {
"logger": self.logger
}
# 使用策略解析记忆条目
return self.strategy.decompose(entries, context)
================================================
FILE: kirara_ai/memory/composes/composer_strategy.py
================================================
from abc import ABC, abstractmethod
from typing import Any, Dict, Optional, Type
import kirara_ai.llm.format.tool as tools
from kirara_ai.im.message import IMMessage, MediaMessage, TextMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import (LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent,
LLMToolResultContent)
from kirara_ai.media.manager import MediaManager
from .xml_helper import XMLHelper
def drop_think_part(text: str) -> str:
"""移除思考部分的文本"""
import re
return re.sub(r"(?:[\s\S]*?)?([\s\S]*)", r"\1", text, flags=re.DOTALL)
class MessageProcessor(ABC):
"""消息处理策略的基类"""
def __init__(self, container: DependencyContainer):
self.container = container
@abstractmethod
def process(self, message: Any, context: Dict) -> str:
"""处理特定类型的消息,返回组合后的文本"""
class TextMessageProcessor(MessageProcessor):
"""处理文本消息的策略"""
def process(self, message: TextMessage, context: Dict) -> str:
return f"{message.to_plain()}\n"
class MediaMessageProcessor(MessageProcessor):
"""处理媒体消息的策略"""
def process(self, message: MediaMessage, context: Dict) -> str:
media_ids = context.setdefault("media_ids", [])
media_ids.append(message.media_id)
desc = message.get_description()
tag = XMLHelper.create_xml_tag("media_msg", {"id": message.media_id, "desc": desc})
return f"{tag}\n"
class LLMChatTextContentProcessor(MessageProcessor):
"""处理LLM文本内容的策略"""
def process(self, content: LLMChatTextContent, context: Dict) -> str:
return f"{drop_think_part(content.text)}\n"
class LLMChatImageContentProcessor(MessageProcessor):
"""处理LLM图像内容的策略"""
def process(self, content: LLMChatImageContent, context: Dict) -> str:
media_ids = context.setdefault("media_ids", [])
media_ids.append(content.media_id)
media_manager = self.container.resolve(MediaManager)
media = media_manager.get_media(content.media_id)
desc = (media.description or "") if media else ""
tag = XMLHelper.create_xml_tag("media_msg", {"id": content.media_id, "desc": desc})
return f"{tag}\n"
class LLMToolCallContentProcessor(MessageProcessor):
"""处理LLM工具调用内容的策略"""
def process(self, content: LLMToolCallContent, context: Dict) -> str:
tool_calls = context.setdefault("tool_calls", [])
tool_calls.append(content.model_dump())
# parameters 比较长,保存到 metadata 里。
tag = XMLHelper.create_xml_tag("function_call", {
"id": content.id,
"name": content.name
})
return f"{tag}\n"
class LLMToolResultContentProcessor(MessageProcessor):
"""处理LLM工具结果内容的策略"""
def process(self, content: LLMToolResultContent, context: Dict) -> str:
tool_results = context.setdefault("tool_results", [])
tool_content = []
for item in content.content:
if isinstance(item, tools.TextContent):
tool_content.append({
"type": "text",
"text": item.text
})
elif isinstance(item, tools.MediaContent):
# 注册 media_id 引用
media_ids = context.setdefault("media_ids", [])
media_ids.append(item.media_id)
tool_content.append({
"type": "media",
"media_id": item.media_id
})
# content 比较长,保存到 metadata 里。
tool_results.append({
"id": content.id,
"name": content.name,
"isError": content.isError,
"content": tool_content
})
tag = XMLHelper.create_xml_tag("tool_result", {
"id": content.id,
"name": content.name,
"isError": str(content.isError)
})
return f"{tag}\n"
class IMMessageProcessor(MessageProcessor):
"""处理IM消息的策略"""
def __init__(self, container: DependencyContainer):
super().__init__(container)
self.element_processors: Dict[Type, MessageProcessor] = {
TextMessage: TextMessageProcessor(container),
MediaMessage: MediaMessageProcessor(container)
}
def process(self, message: IMMessage, context: Dict) -> str:
result = f"{message.sender.display_name} 说: \n"
for element in message.message_elements:
for process_type, processor in self.element_processors.items():
if isinstance(element, process_type):
result += processor.process(element, context)
break
else:
result += f"{element.to_plain()}\n"
return result
class LLMChatMessageProcessor(MessageProcessor):
"""处理LLM聊天消息的策略"""
def __init__(self, container: DependencyContainer):
super().__init__(container)
self.content_processors: Dict[Type, MessageProcessor] = {
LLMChatTextContent: LLMChatTextContentProcessor(container),
LLMChatImageContent: LLMChatImageContentProcessor(container),
LLMToolCallContent: LLMToolCallContentProcessor(container),
LLMToolResultContent: LLMToolResultContentProcessor(container)
}
def process(self, message: LLMChatMessage, context: Dict) -> str:
result = ""
temp = ""
for part in message.content:
part_type = type(part)
for processor_type, processor in self.content_processors.items():
if issubclass(part_type, processor_type):
if part_type in [LLMToolCallContent, LLMToolResultContent]:
# 工具调用和结果直接添加到结果中,不经过temp
result += processor.process(part, context)
else:
# 其他内容添加到temp中
temp += processor.process(part, context)
if temp.strip("\n"):
result += f"你回答: \n{temp}"
return result
class ProcessorFactory:
"""消息处理器工厂,用于创建和管理不同类型消息的处理器"""
def __init__(self, container: DependencyContainer):
self.container = container
self.processors: Dict[Type, MessageProcessor] = {
IMMessage: IMMessageProcessor(container),
LLMChatMessage: LLMChatMessageProcessor(container)
}
def get_processor(self, message_type: Type) -> Optional[MessageProcessor]:
"""获取特定类型消息的处理器"""
for processor_type, processor in self.processors.items():
if issubclass(message_type, processor_type):
return processor
return None
================================================
FILE: kirara_ai/memory/composes/decomposer_strategy.py
================================================
from datetime import datetime, timedelta
from typing import Any, Dict, List, NamedTuple, Protocol, cast
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent, RoleType)
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
from .base import ComposableMessageType
from .xml_helper import XMLHelper
logger = get_logger("DecomposerStrategy")
class ContentInfo(NamedTuple):
"""解析后的内容信息"""
content_type: str # 内容类型:text, media, tool_call, tool_result
start: int # 开始位置
end: int # 结束位置
text: str # 原始文本
metadata: Dict[str, Any] = {} # 相关元数据
class ContentParseStrategy(Protocol):
"""内容解析策略协议"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
"""提取内容信息"""
...
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
"""转换为LLM内容类型"""
...
def to_text(self, info: ContentInfo) -> str:
"""转换为文本形式"""
...
class TextContentStrategy:
"""文本内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
# 提取非标签文本
text_parts = []
current_pos = 0
# 查找所有标签的位置
tag_positions = []
for tag_name in ["media_msg", "function_call", "tool_result"]:
for _, start, end in XMLHelper.parse_xml_tag(content, tag_name):
tag_positions.append((start, end))
# 按位置排序
tag_positions.sort()
# 提取标签之间的文本
for start, end in tag_positions:
if start > current_pos:
text = content[current_pos:start].strip()
if text:
text_parts.append(ContentInfo(
content_type="text",
start=current_pos,
end=start,
text=text
))
current_pos = end
# 处理最后一段文本
if current_pos < len(content):
text = content[current_pos:].strip()
if text:
text_parts.append(ContentInfo(
content_type="text",
start=current_pos,
end=len(content),
text=text
))
return text_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMChatTextContent(text=info.text)
def to_text(self, info: ContentInfo) -> str:
return info.text
class MediaContentStrategy:
"""媒体内容解析策略"""
def __init__(self):
pass
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
media_parts = []
media_tags = XMLHelper.parse_xml_tag(content, "media_msg")
for attrs, start, end in media_tags:
if "id" in attrs and attrs["id"] is not None:
media_id = attrs["id"]
# 检查媒体ID是否在元数据中
if "_media_ids" in entry.metadata and media_id in entry.metadata["_media_ids"]:
media_parts.append(ContentInfo(
content_type="media",
start=start,
end=end,
text=content[start:end],
metadata={"media_id": media_id}
))
return media_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMChatImageContent(media_id=info.metadata["media_id"])
def to_text(self, info: ContentInfo) -> str:
return f""
class ToolCallContentStrategy:
"""工具调用内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
tool_call_parts = []
tool_call_tags = XMLHelper.parse_xml_tag(content, "function_call")
if "_tool_calls" not in entry.metadata:
return []
tool_calls = [call for call in entry.metadata["_tool_calls"]]
for attrs, start, end in tool_call_tags:
if "id" in attrs and attrs["id"] is not None:
call_id = attrs["id"]
# 查找对应的工具调用数据
for call in tool_calls:
if call.get("id") == call_id:
tool_call_parts.append(ContentInfo(
content_type="tool_call",
start=start,
end=end,
text=content[start:end],
metadata=call
))
break
return tool_call_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMToolCallContent.model_validate(info.metadata)
def to_text(self, info: ContentInfo) -> str:
return f""
class ToolResultContentStrategy:
"""工具结果内容解析策略"""
def extract_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
tool_result_parts = []
tool_result_tags = XMLHelper.parse_xml_tag(content, "tool_result")
if "_tool_results" not in entry.metadata:
return []
tool_results = [result for result in entry.metadata["_tool_results"]]
for attrs, start, end in tool_result_tags:
if "id" in attrs and attrs["id"] is not None:
result_id = attrs["id"]
# 查找对应的工具结果数据
for result in tool_results:
if result.get("id") == result_id:
tool_result_parts.append(ContentInfo(
content_type="tool_result",
start=start,
end=end,
text=content[start:end],
metadata=result
))
break
return tool_result_parts
def to_llm_content(self, info: ContentInfo) -> LLMChatContentPartType:
return LLMToolResultContent.model_validate(info.metadata)
def to_text(self, info: ContentInfo) -> str:
return f""
class ContentParser:
"""内容解析器,整合各种内容处理策略"""
def __init__(self):
self.strategies: Dict[str, ContentParseStrategy] = {
"text": TextContentStrategy(),
"media": MediaContentStrategy(),
"tool_call": ToolCallContentStrategy(),
"tool_result": ToolResultContentStrategy()
}
def parse_content(self, content: str, entry: MemoryEntry) -> List[ContentInfo]:
"""解析内容,返回按位置排序的内容信息列表"""
all_content = []
# 使用所有策略提取内容
for strategy in self.strategies.values():
all_content.extend(strategy.extract_content(content, entry))
# 按位置排序
return sorted(all_content, key=lambda x: x.start)
def to_llm_message(self, content_infos: List[ContentInfo], role: RoleType) -> List[LLMChatMessage]:
"""将内容信息转换为LLM消息"""
if not content_infos:
return []
messages: List[LLMChatMessage] = []
current_content: List[LLMChatContentPartType] = []
current_role: RoleType = role
for info in content_infos:
strategy = self.strategies.get(info.content_type)
if not strategy:
continue
# 对于工具调用和工具结果,创建单独的消息
if info.content_type == "tool_call":
# 如果之前有普通内容,先创建一个消息
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
current_content = []
# 创建工具调用消息
messages.append(LLMChatMessage(
role="assistant",
content=[strategy.to_llm_content(info)]
))
elif info.content_type == "tool_result":
# 如果之前有普通内容,先创建一个消息
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
current_content = []
# 创建工具结果消息
messages.append(LLMChatMessage(
role="tool",
content=[strategy.to_llm_content(info)]
))
else:
# 普通内容就近拼接
current_content.append(strategy.to_llm_content(info))
# 处理剩余的普通内容
if current_content:
messages.append(LLMChatMessage(role=current_role, content=current_content))
return messages
def to_text(self, content_infos: List[ContentInfo]) -> str:
"""将内容信息转换为文本形式"""
text_parts = []
for info in content_infos:
strategy = self.strategies.get(info.content_type)
if strategy:
text_parts.append(strategy.to_text(info))
return "".join(text_parts)
class DefaultDecomposerStrategy:
"""默认解析策略,将记忆条目转换为文本格式"""
def __init__(self):
self.content_parser = ContentParser()
def decompose(self, entries: List[MemoryEntry], context: Dict[str, Any]) -> List[ComposableMessageType]:
if not entries:
return [context.get("empty_message", "<空记忆>")]
# 限制最近的条目数量
entries = entries[-10:]
result: List[ComposableMessageType] = []
for entry in entries:
time_diff = datetime.now() - entry.timestamp
time_str = self._get_time_str(time_diff)
# 解析记忆条目
content = entry.content or ""
message_parts = []
if content:
if "你回答:" in content:
# 包含用户消息和AI回答
parts = content.split("你回答:", 1)
user_content = parts[0].strip()
assistant_content = parts[1].strip() if len(parts) > 1 else None
# 处理用户消息
if user_content:
content_infos = self.content_parser.parse_content(user_content, entry)
message_parts.append(self.content_parser.to_text(content_infos))
# 处理AI回答
if assistant_content:
content_infos = self.content_parser.parse_content(assistant_content, entry)
message_parts.append(f"你回答: {self.content_parser.to_text(content_infos)}")
else:
# 纯用户消息
content_infos = self.content_parser.parse_content(content, entry)
message_parts.append(self.content_parser.to_text(content_infos))
# 组合所有部分
result.append(f"{time_str},{''.join(message_parts)}")
return result
def _get_time_str(self, time_diff: timedelta) -> str:
"""获取时间差的字符串表示"""
if time_diff.days > 0:
return f"{time_diff.days}天前"
elif time_diff.seconds > 3600:
return f"{time_diff.seconds // 3600}小时前"
elif time_diff.seconds > 60:
return f"{time_diff.seconds // 60}分钟前"
else:
return "刚刚"
class MultiElementDecomposerStrategy:
"""多元素解析策略,将记忆条目还原为原始对象结构"""
def __init__(self):
self.content_parser = ContentParser()
def decompose(self, entries: List[MemoryEntry], context: Dict[str, Any]) -> List[ComposableMessageType]:
result: List[LLMChatMessage] = []
# 处理每个记忆条目
for entry in entries:
messages = self._process_entry(entry)
result.extend(messages)
# 合并相邻的相同角色消息
self._merge_adjacent_messages(result)
# 转换为ComposableMessageType类型返回
return cast(List[ComposableMessageType], result)
def _process_entry(self, entry: MemoryEntry) -> List[LLMChatMessage]:
"""处理单个记忆条目,按照内容顺序解析"""
result: List[LLMChatMessage] = []
content = entry.content or ""
if not content:
return result
if "你回答:" in content:
# 包含用户消息和AI回答
parts = content.split("你回答:", 1)
user_content = parts[0].strip()
assistant_content = parts[1].strip() if len(parts) > 1 else None
# 处理用户消息
if user_content:
content_infos = self.content_parser.parse_content(user_content, entry)
user_message = self.content_parser.to_llm_message(content_infos, "user")
if user_message:
result.extend(user_message)
# 处理AI回答
if assistant_content:
content_infos = self.content_parser.parse_content(assistant_content, entry)
assistant_message = self.content_parser.to_llm_message(content_infos, "assistant")
if assistant_message:
result.extend(assistant_message)
else:
# 纯用户消息
content_infos = self.content_parser.parse_content(content, entry)
user_message = self.content_parser.to_llm_message(content_infos, "user")
if user_message:
result.extend(user_message)
return result
def _merge_adjacent_messages(self, messages: List[LLMChatMessage]) -> None:
"""
合并相邻的相同角色消息
只处理 user 和 assistant 类型, 其他类型不处理
"""
i = 0
while i < len(messages) - 1:
current_msg = messages[i]
next_msg = messages[i + 1]
if (current_msg.role == next_msg.role and
current_msg.role in ["user", "assistant"]):
# 合并内容
current_msg.content.extend(next_msg.content)
# 删除下一个消息
messages.pop(i + 1)
else:
i += 1
================================================
FILE: kirara_ai/memory/composes/xml_helper.py
================================================
import re
from typing import Dict, List, Optional, Tuple
class XMLHelper:
"""XML 格式化和解析的辅助工具类"""
@staticmethod
def escape_xml_attr(text: str) -> str:
"""转义XML属性中的特殊字符"""
if not isinstance(text, str):
text = str(text)
return text.replace("&", "&").replace("\"", """).replace("<", "<").replace(">", ">")
@staticmethod
def unescape_xml_attr(text: str) -> str:
"""反转义XML属性中的特殊字符"""
return text.replace(""", "\"").replace("<", "<").replace(">", ">").replace("&", "&")
@staticmethod
def create_xml_tag(tag_name: str, attributes: Dict[str, Optional[str]], self_closing: bool = True) -> str:
"""创建XML标签,支持 null safety(None 值的属性将被忽略)"""
attrs_str = " ".join([f'{k}="{XMLHelper.escape_xml_attr(v)}"' for k, v in attributes.items() if v is not None])
if self_closing:
return f"<{tag_name} {attrs_str} />"
else:
return f"<{tag_name} {attrs_str}>"
@staticmethod
def parse_xml_tag(content: str, tag_name: str) -> List[Tuple[Dict[str, Optional[str]], int, int]]:
"""解析XML标签,返回属性字典和标签在原文中的起始、结束位置
如果属性在标签中不存在,则在返回的字典中该属性值为 None
"""
pattern = re.compile(f'<{tag_name}\\s+(.*?)\\s*/>')
attr_pattern = re.compile(r'(\w+)="(.*?)"')
results: List[Tuple[Dict[str, Optional[str]], int, int]] = []
for match in pattern.finditer(content):
attrs_text = match.group(1)
attrs: Dict[str, Optional[str]] = {name: XMLHelper.unescape_xml_attr(value) for name, value in attr_pattern.findall(attrs_text)}
results.append((attrs, match.start(), match.end()))
return results
@staticmethod
def get_attr(attrs: Dict[str, Optional[str]], key: str, default: Optional[str] = None) -> Optional[str]:
"""安全地从属性字典中获取值,如果不存在则返回默认值"""
return attrs.get(key, default)
================================================
FILE: kirara_ai/memory/entry.py
================================================
from dataclasses import dataclass, field
from datetime import datetime
from typing import Any, Dict
from kirara_ai.im.sender import ChatSender
@dataclass
class MemoryEntry:
"""基础记忆条目"""
sender: ChatSender
content: str
timestamp: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
================================================
FILE: kirara_ai/memory/memory_manager.py
================================================
from typing import Dict, List, Optional, Type
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.media.carrier import MediaReferenceProvider
from kirara_ai.media.carrier.service import MediaCarrierService
from kirara_ai.memory.persistences.base import AsyncMemoryPersistence, MemoryPersistence
from kirara_ai.memory.persistences.file_persistence import FileMemoryPersistence
from kirara_ai.memory.persistences.redis_persistence import RedisMemoryPersistence
from .composes import MemoryComposer, MemoryDecomposer
from .entry import MemoryEntry
from .registry import ComposerRegistry, DecomposerRegistry, ScopeRegistry
from .scopes import MemoryScope
class MemoryManager(MediaReferenceProvider[List[MemoryEntry]]):
"""记忆系统管理器,负责整个记忆系统的生命周期管理"""
def __init__(
self,
container: DependencyContainer,
persistence: Optional[MemoryPersistence] = None,
):
self.container = container
self.config = container.resolve(GlobalConfig).memory
# 初始化注册表
self.scope_registry = Inject(container).create(ScopeRegistry)()
self.composer_registry = Inject(container).create(ComposerRegistry)()
self.decomposer_registry = Inject(container).create(DecomposerRegistry)()
# 注册到容器
container.register(ScopeRegistry, self.scope_registry)
container.register(ComposerRegistry, self.composer_registry)
container.register(DecomposerRegistry, self.decomposer_registry)
# 初始化持久化层
if persistence is None:
self._init_persistence()
else:
self.persistence = persistence
# 内存缓存
self.memories: Dict[str, List[MemoryEntry]] = {}
def _init_persistence(self):
"""初始化持久化层"""
persistence_type = self.config.persistence.type
if persistence_type == "file":
storage_dir = self.config.persistence.file["storage_dir"]
self.persistence = FileMemoryPersistence(storage_dir)
elif persistence_type == "redis":
redis_config = self.config.persistence.redis
self.persistence = RedisMemoryPersistence(**redis_config)
else:
raise ValueError(f"Unsupported persistence type: {persistence_type}")
self.persistence = AsyncMemoryPersistence(self.persistence)
def register_scope(self, name: str, scope_class: Type[MemoryScope]):
"""注册新的作用域类型"""
self.scope_registry.register(name, scope_class)
def register_composer(self, name: str, composer_class: Type[MemoryComposer]):
"""注册新的组合器"""
self.composer_registry.register(name, composer_class)
def register_decomposer(self, name: str, decomposer_class: Type[MemoryDecomposer]):
"""注册新的解析器"""
self.decomposer_registry.register(name, decomposer_class)
def store(self, scope: MemoryScope, entry: MemoryEntry, extra_identifier: Optional[str] = None) -> None:
"""存储新的记忆"""
scope_key = scope.get_scope_key(entry.sender)
if extra_identifier is not None:
scope_key = f"{extra_identifier}-{scope_key}"
if scope_key not in self.memories:
self.memories[scope_key] = self.persistence.load(scope_key)
self.memories[scope_key].append(entry)
self._register_media_reference(entry, scope_key)
# 限制记忆条目数量
if len(self.memories[scope_key]) > self.config.max_entries:
# 移除旧记忆的媒体引用
removed_entries = self.memories[scope_key][:-self.config.max_entries]
unremoved_entries = self.memories[scope_key][-self.config.max_entries:]
self._remove_media_references(removed_entries, unremoved_entries, scope_key)
# 裁剪记忆列表
self.memories[scope_key] = unremoved_entries
self.persistence.save(scope_key, self.memories[scope_key])
def query(self, scope: MemoryScope, sender: ChatSender, extra_identifier: Optional[str] = None) -> List[MemoryEntry]:
"""查询历史记忆"""
relevant_memories = []
scope_key = scope.get_scope_key(sender)
if extra_identifier is not None:
scope_key = f"{extra_identifier}-{scope_key}"
if scope_key not in self.memories:
self.memories[scope_key] = self.persistence.load(scope_key)
# 遍历所有记忆,找出作用域内的记忆
for scope_key, entries in self.memories.items():
for entry in entries:
if scope.is_in_scope(entry.sender, sender):
relevant_memories.append(entry)
# 按时间排序
relevant_memories.sort(key=lambda x: x.timestamp)
return relevant_memories
def shutdown(self):
"""关闭记忆系统,确保数据持久化"""
# 保存所有内存中的数据
for scope_key, entries in self.memories.items():
self.persistence.save(scope_key, entries)
# 执行持久化层的stop操作
if isinstance(self.persistence, AsyncMemoryPersistence):
self.persistence.stop()
def clear_memory(self, scope: MemoryScope, sender: ChatSender) -> None:
"""清空指定作用域和发送者的记忆
Args:
scope: 记忆作用域
sender: 发送者标识
"""
scope_key = scope.get_scope_key(sender)
# 移除媒体引用
if scope_key not in self.memories:
return
self._remove_media_references(self.memories[scope_key], [], scope_key)
# 清空内存中的记录
self.memories[scope_key] = []
# 保存空记录到持久化层
self.persistence.save(scope_key, [])
def get_reference_owner(self, reference_key: str) -> Optional[List[MemoryEntry]]:
"""获取引用所有者"""
if reference_key not in self.memories:
self.memories[reference_key] = self.persistence.load(reference_key)
return self.memories.get(reference_key)
def _register_media_reference(self, entry: MemoryEntry, reference_key: str) -> None:
"""注册媒体引用"""
media_carrier = self.container.resolve(MediaCarrierService)
for media_id in entry.metadata.get("_media_ids", []):
media_carrier.register_reference(media_id, "memory", reference_key)
def _remove_media_references(self, removed_entries: List[MemoryEntry], unremoved_entries: List[MemoryEntry], reference_key: str) -> None:
"""移除媒体引用"""
media_carrier = self.container.resolve(MediaCarrierService)
# 确保 id 没有在 unremoved_entries 中
removed_media_ids = [media_id for entry in removed_entries for media_id in entry.metadata.get("_media_ids", [])]
unremoved_media_ids = [media_id for entry in unremoved_entries for media_id in entry.metadata.get("_media_ids", [])]
for media_id in removed_media_ids:
if media_id not in unremoved_media_ids:
media_carrier.remove_reference(media_id, "memory", reference_key)
================================================
FILE: kirara_ai/memory/persistences/__init__.py
================================================
from .base import AsyncMemoryPersistence, MemoryPersistence
from .file_persistence import FileMemoryPersistence
from .redis_persistence import RedisMemoryPersistence
__all__ = [
"MemoryPersistence",
"AsyncMemoryPersistence",
"FileMemoryPersistence",
"RedisMemoryPersistence",
"codecs",
]
================================================
FILE: kirara_ai/memory/persistences/base.py
================================================
import threading
from abc import ABC, abstractmethod
from queue import Empty, Queue
from typing import List, Tuple
from kirara_ai.logger import get_logger
from kirara_ai.memory.entry import MemoryEntry
class MemoryPersistence(ABC):
"""持久化层抽象类"""
@abstractmethod
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
pass
@abstractmethod
def load(self, scope_key: str) -> List[MemoryEntry]:
pass
@abstractmethod
def flush(self) -> None:
"""确保所有数据都已持久化"""
logger = get_logger("MemoryPersistence")
class AsyncMemoryPersistence:
"""异步持久化管理器"""
def __init__(self, persistence: MemoryPersistence):
self.persistence = persistence
self.queue: Queue[Tuple[str, List[MemoryEntry]]] = Queue()
self.running = True
self.worker = threading.Thread(target=self._worker, daemon=True)
self.worker.start()
def _worker(self):
while self.running:
try:
scope_key, entries = self.queue.get(timeout=1)
self.persistence.save(scope_key, entries)
self.queue.task_done()
logger.info(f"Saved {scope_key} with {len(entries)} entries")
except Empty:
continue
except Exception as e:
logger.error(f"Error saving memory: {e}")
continue
def load(self, scope_key: str) -> List[MemoryEntry]:
return self.persistence.load(scope_key)
def save(self, scope_key: str, entries: List[MemoryEntry]):
self.queue.put((scope_key, entries))
def stop(self):
self.running = False
self.worker.join()
self.persistence.flush()
================================================
FILE: kirara_ai/memory/persistences/codecs.py
================================================
import json
from datetime import datetime
from types import FunctionType
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
class MemoryJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, ChatSender):
return {
"__type__": "ChatSender",
"user_id": obj.user_id,
"chat_type": obj.chat_type.value,
"group_id": obj.group_id,
"display_name": obj.display_name,
"raw_metadata": obj.raw_metadata,
}
elif isinstance(obj, ChatType):
return obj.value
elif isinstance(obj, datetime):
return obj.isoformat()
elif isinstance(obj, FunctionType):
return {
"__type__": "function",
"name": obj.__name__,
"args": obj.__code__.co_varnames[:obj.__code__.co_argcount],
"defaults": obj.__defaults__,
"kwdefaults": obj.__kwdefaults__,
"doc": obj.__doc__,
}
try:
return super().default(obj)
except Exception as e:
get_logger("MemoryJSONEncoder").warning(f"failed to encode object: {e}")
return None
def memory_json_decoder(obj):
if "__type__" in obj:
if obj["__type__"] == "ChatSender":
return ChatSender(
user_id=obj["user_id"],
chat_type=ChatType(obj["chat_type"]),
group_id=obj["group_id"],
display_name=obj["display_name"],
raw_metadata=obj["raw_metadata"],
)
return obj
================================================
FILE: kirara_ai/memory/persistences/file_persistence.py
================================================
import json
import os
from datetime import datetime
from typing import List
from kirara_ai.memory.entry import MemoryEntry
from .base import MemoryPersistence
from .codecs import MemoryJSONEncoder, memory_json_decoder
class FileMemoryPersistence(MemoryPersistence):
"""文件持久化实现"""
def __init__(self, data_dir: str):
if not os.path.isabs(data_dir):
data_dir = os.path.abspath(data_dir)
self.data_dir = data_dir
os.makedirs(data_dir, exist_ok=True)
def _get_file_path(self, scope_key: str) -> str:
scope_key = scope_key.replace(":", "_")
return os.path.join(self.data_dir, f"{scope_key}.json")
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
file_path = self._get_file_path(scope_key)
# 序列化记忆条目
serialized_entries = [
{
"sender": entry.sender,
"content": entry.content,
"timestamp": entry.timestamp,
"metadata": entry.metadata,
}
for entry in entries
]
# 写入文件
with open(file_path, "w", encoding="utf-8") as f:
json.dump(
serialized_entries,
f,
ensure_ascii=False,
indent=2,
cls=MemoryJSONEncoder,
)
def load(self, scope_key: str) -> List[MemoryEntry]:
file_path = self._get_file_path(scope_key)
if not os.path.exists(file_path):
return []
# 读取并反序列化
with open(file_path, "r", encoding="utf-8") as f:
serialized_entries = json.load(f, object_hook=memory_json_decoder)
return [
MemoryEntry(
sender=entry["sender"],
content=entry["content"],
timestamp=(
datetime.fromisoformat(entry["timestamp"])
if isinstance(entry["timestamp"], str)
else entry["timestamp"]
),
metadata=entry["metadata"],
)
for entry in serialized_entries
]
def flush(self) -> None:
# 文件系统实现不需要特别的flush操作
pass
================================================
FILE: kirara_ai/memory/persistences/redis_persistence.py
================================================
import json
from datetime import datetime
from typing import List, Optional
from kirara_ai.memory.entry import MemoryEntry
from .base import MemoryPersistence
from .codecs import MemoryJSONEncoder, memory_json_decoder
class RedisMemoryPersistence(MemoryPersistence):
"""Redis持久化实现"""
def __init__(
self,
redis_url: Optional[str] = None,
host: str = "localhost",
port: int = 6379,
db: int = 0,
):
import redis
if redis_url:
self.redis = redis.from_url(redis_url)
else:
self.redis = redis.Redis(host=host, port=port, db=db)
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
# 序列化记忆条目
serialized_entries = [
{
"sender": entry.sender,
"content": entry.content,
"timestamp": entry.timestamp,
"metadata": entry.metadata,
}
for entry in entries
]
# 存储到Redis
self.redis.set(
scope_key,
json.dumps(serialized_entries, ensure_ascii=False, cls=MemoryJSONEncoder),
)
def load(self, scope_key: str) -> List[MemoryEntry]:
# 从Redis读取
data = self.redis.get(scope_key)
if not data:
return []
# 反序列化
serialized_entries = json.loads(data, object_hook=memory_json_decoder) # type: ignore
return [
MemoryEntry(
sender=entry["sender"],
content=entry["content"],
timestamp=(
datetime.fromisoformat(entry["timestamp"])
if isinstance(entry["timestamp"], str)
else entry["timestamp"]
),
metadata=entry["metadata"],
)
for entry in serialized_entries
]
def flush(self) -> None:
self.redis.save()
================================================
FILE: kirara_ai/memory/registry.py
================================================
from typing import Dict, Type
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.memory.composes import MemoryComposer, MemoryDecomposer
from kirara_ai.memory.scopes import MemoryScope
class Registry:
"""基础注册表类"""
container: DependencyContainer
_registry: Dict[str, Type] = dict()
def __init__(self, container: DependencyContainer):
self.container = container
self._registry = dict()
def register(self, name: str, cls: Type) -> None:
"""注册一个新的实现"""
self._registry[name] = cls
def unregister(self, name: str) -> None:
"""注销一个实现"""
if name in self._registry:
del self._registry[name]
class ScopeRegistry(Registry):
"""作用域注册表"""
def get_scope(self, name: str) -> MemoryScope:
"""获取作用域实例"""
if name not in self._registry:
raise ValueError(f"Scope not found: {name}")
return Inject(self.container).create(self._registry[name])()
class ComposerRegistry(Registry):
"""组合器注册表"""
def get_composer(self, name: str) -> MemoryComposer:
"""获取组合器实例"""
if name not in self._registry:
raise ValueError(f"Composer not found: {name}")
return Inject(self.container).create(self._registry[name])()
class DecomposerRegistry(Registry):
"""解析器注册表"""
def get_decomposer(self, name: str) -> MemoryDecomposer:
"""获取解析器实例"""
if name not in self._registry:
raise ValueError(f"Decomposer not found: {name}")
return Inject(self.container).create(self._registry[name])()
================================================
FILE: kirara_ai/memory/scopes/__init__.py
================================================
from .base import MemoryScope
from .builtin_scopes import GlobalScope, GroupScope, MemberScope
__all__ = ["MemoryScope", "MemberScope", "GroupScope", "GlobalScope"]
================================================
FILE: kirara_ai/memory/scopes/base.py
================================================
from abc import ABC, abstractmethod
from kirara_ai.im.sender import ChatSender
class MemoryScope(ABC):
"""记忆作用域抽象类"""
@abstractmethod
def get_scope_key(self, sender: ChatSender) -> str:
"""获取作用域的键值"""
@abstractmethod
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
"""判断是否在作用域内"""
================================================
FILE: kirara_ai/memory/scopes/builtin_scopes.py
================================================
from kirara_ai.im.sender import ChatSender, ChatType
from .base import MemoryScope
# 默认实现
class MemberScope(MemoryScope):
"""群成员作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
if sender.chat_type == ChatType.GROUP:
return f"member:{sender.group_id}:{sender.user_id}"
else:
return f"c2c:{sender.user_id}"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
if target_sender.chat_type != query_sender.chat_type:
return False
if target_sender.chat_type == ChatType.GROUP:
return (
target_sender.group_id == query_sender.group_id
and target_sender.user_id == query_sender.user_id
)
else:
return target_sender.user_id == query_sender.user_id
class GroupScope(MemoryScope):
"""群作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
if sender.chat_type == ChatType.GROUP:
return f"group:{sender.group_id}"
else:
return f"c2c:{sender.user_id}"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
if target_sender.chat_type != query_sender.chat_type:
return False
if target_sender.chat_type == ChatType.GROUP:
return target_sender.group_id == query_sender.group_id
else:
return target_sender.user_id == query_sender.user_id
class GlobalScope(MemoryScope):
"""全局作用域"""
def get_scope_key(self, sender: ChatSender) -> str:
return "global"
def is_in_scope(self, target_sender: ChatSender, query_sender: ChatSender) -> bool:
return True
================================================
FILE: kirara_ai/plugin_manager/models.py
================================================
from typing import Any, Dict, Optional
from pydantic import BaseModel
class PluginInfo(BaseModel):
"""插件信息"""
name: str
package_name: Optional[str] = None # 外部插件的包名
description: str
version: str
author: str
is_internal: bool # 是否为内部插件
is_enabled: bool # 是否启用
requires_restart: bool = False # 是否需要重启
metadata: Optional[Dict[str, Any]] = None
================================================
FILE: kirara_ai/plugin_manager/plugin.py
================================================
from abc import ABC, abstractmethod
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
class Plugin(ABC):
"""
插件基类。
外部插件需要在 setup.py 中注册 entry_points:
setup(
name='your-plugin-name',
...
entry_points={
'chatgpt_mirai.plugins': [
'plugin_name = your_package.module:PluginClass'
]
}
)
"""
ENTRY_POINT_GROUP = "chatgpt_mirai.plugins"
event_bus: EventBus
workflow_dispatcher: WorkflowDispatcher
llm_registry: LLMBackendRegistry
im_registry: IMRegistry
im_manager: IMManager
@abstractmethod
def on_load(self):
pass
@abstractmethod
def on_start(self):
pass
@abstractmethod
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugin_manager/plugin_event_bus.py
================================================
from typing import Callable, List, Type
from kirara_ai.events.event_bus import EventBus
class PluginEventBus:
def __init__(self, event_bus: EventBus):
self._event_bus = event_bus
self._registered_listeners: List[Callable] = [] # 记录注册过的函数
def register(self, event_type: Type, listener: Callable):
self._event_bus.register(event_type, listener)
self._registered_listeners.append(listener) # 记录注册的函数
def unregister(self, event_type: Type, listener: Callable):
self._event_bus.unregister(event_type, listener)
def post(self, event):
self._event_bus.post(event)
def unregister_all(self):
"""反注册所有通过 @Event 注册的函数"""
for listener in self._registered_listeners:
for event_type in self._event_bus._listeners:
if listener in self._event_bus._listeners[event_type]:
self._event_bus.unregister(event_type, listener)
self._registered_listeners.clear() # 清空记录
================================================
FILE: kirara_ai/plugin_manager/plugin_loader.py
================================================
import asyncio
import importlib
import os
import sys
from typing import Dict, List, Optional, Type
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.plugin import PluginLoaded, PluginStarted, PluginStopped
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.models import PluginInfo
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.plugin_manager.plugin_event_bus import PluginEventBus
class PluginLoader:
def __init__(self, container: DependencyContainer, plugin_dir: str):
self.plugins: Dict[str, Plugin] = {} # 存储插件实例
self.plugin_infos: Dict[str, PluginInfo] = {} # 存储插件信息
self.container = container
self.logger = get_logger("PluginLoader")
self._loaded_entry_points: set[str] = set() # 记录已加载的entry points
self.plugin_dir = plugin_dir
self.internal_plugins: List[str] = []
self.config = self.container.resolve(GlobalConfig)
self.event_bus = self.container.resolve(EventBus)
def register_plugin(self, plugin_class: Type[Plugin], plugin_name: Optional[str] = None):
"""注册一个插件类,主要用于测试"""
plugin = self.instantiate_plugin(plugin_class)
key = plugin_name or plugin_class.__name__
self.plugins[key] = plugin
# 创建并存储插件信息
plugin_info = PluginInfo(
name=plugin_class.__name__,
package_name=plugin_name,
description=plugin_class.__doc__ or "",
version="1.0.0",
author="Test",
is_internal=True,
is_enabled=True,
metadata=getattr(plugin, "metadata", None),
)
self.plugin_infos[key] = plugin_info
self.logger.info(f"Registered test plugin: {key}")
return plugin
def discover_internal_plugins(self, plugin_dir=None):
"""Discovers and loads internal plugins from a specified directory.
Scans the given directory for subdirectories and attempts to load each as a plugin.
Args:
plugin_dir (str): Path to the directory containing plugin subdirectories.
"""
if not plugin_dir:
plugin_dir = self.plugin_dir
self.logger.info(f"Discovering internal plugins from directory: {plugin_dir}")
sys.path.append(plugin_dir)
for plugin_name in os.listdir(plugin_dir):
plugin_path = os.path.join(plugin_dir, plugin_name)
if os.path.isdir(plugin_path):
self.internal_plugins.append(plugin_name)
self.logger.debug(f"Found plugin directory: {plugin_name}")
self.load_plugin(plugin_name)
def load_plugin(self, plugin_name: str):
"""加载插件,支持内部插件和外部插件"""
self.logger.info(f"Loading plugin: {plugin_name}")
try:
if plugin_name in self.internal_plugins: # 内部插件
self._load_internal_plugin(plugin_name)
else: # 外部插件
self._load_external_plugin(plugin_name)
except Exception as e:
self.logger.error(f"Failed to load plugin {plugin_name}: {e}")
def _load_internal_plugin(self, plugin_name: str):
"""加载内部插件"""
module = importlib.import_module(plugin_name)
plugin_classes = [
cls
for cls in module.__dict__.values()
if isinstance(cls, type) and issubclass(cls, Plugin) and cls != Plugin
]
if not plugin_classes:
raise ValueError(f"No valid plugin class found in module {plugin_name}")
plugin_class = plugin_classes[0]
plugin = self.instantiate_plugin(plugin_class)
self.plugins[plugin_name] = plugin
# 创建并存储插件信息
plugin_info = PluginInfo(
name=plugin_class.__name__,
description=plugin_class.__doc__ or "",
version="1.0.0",
author="Internal",
is_internal=True,
is_enabled=True,
metadata=getattr(plugin, "metadata", None),
)
self.plugin_infos[plugin_name] = plugin_info
self.logger.info(f"Internal plugin {plugin_name} loaded successfully")
return plugin
def _load_external_plugin(self, plugin_name: str):
"""加载外部插件"""
from importlib import reload
from importlib.metadata import entry_points
# 获取插件的 entry point
eps = entry_points(group=Plugin.ENTRY_POINT_GROUP)
plugin_ep = next((ep for ep in eps if ep.name == plugin_name), None)
if not plugin_ep:
raise ValueError(f"Unable to find entry point for plugin {plugin_name}")
try:
# 尝试重新加载 module
if plugin_ep.module in sys.modules:
module = sys.modules[plugin_ep.module]
self.logger.info(f"Reloading plugin {plugin_name} from {plugin_ep.module}")
reload(module)
except Exception as e:
self.logger.error(f"Failed to reload plugin {plugin_name}: {e}")
try:
# 加载插件类
plugin_class = plugin_ep.load()
# 检查插件类是否继承自 Plugin
if not issubclass(plugin_class, Plugin):
raise TypeError(
f"Plugin {plugin_name} must inherit from the Plugin class"
)
# 实例化插件并启动
plugin: Plugin = self.instantiate_plugin(plugin_class)
self.plugins[plugin_name] = plugin
self.logger.info(f"Successfully loaded external plugin: {plugin_name}")
return plugin
except Exception as e:
self.logger.error(f"Failed to load external plugin {plugin_name}: {e}")
raise
def instantiate_plugin(self, plugin_class):
"""Instantiates a plugin class using dependency injection."""
self.logger.debug(f"Instantiating plugin class: {plugin_class.__name__}")
event_bus = self.container.resolve(EventBus)
with self.container.scoped() as scoped_container:
scoped_container.register(EventBus, PluginEventBus(event_bus))
return Inject(scoped_container).create(plugin_class)()
def load_plugins(self):
"""Initializes all loaded plugins."""
self.logger.info("Initializing plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_load()
self.logger.info(f"Plugin {plugin.__class__.__name__} initialized")
self.event_bus.post(PluginLoaded(plugin))
except Exception as e:
self.logger.error(
f"Failed to initialize plugin {plugin.__class__.__name__}: {e}"
)
def start_plugins(self):
"""Starts all loaded plugins."""
self.logger.info("Starting plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_start()
self.plugin_infos[plugin_name].is_enabled = True
self.logger.info(f"Plugin {plugin.__class__.__name__} started")
self.event_bus.post(PluginStarted(plugin))
except Exception as e:
self.logger.error(
f"Failed to start plugin {plugin.__class__.__name__}: {e}"
)
def stop_plugins(self):
"""Stops all loaded plugins."""
self.logger.info("Stopping plugins...")
for plugin_name, plugin in self.plugins.items():
try:
plugin.on_stop()
if isinstance(plugin.event_bus, PluginEventBus):
plugin.event_bus.unregister_all()
self.logger.info(f"Plugin {plugin.__class__.__name__} stopped")
self.event_bus.post(PluginStopped(plugin))
except Exception as e:
self.logger.error(
f"Failed to stop plugin {plugin.__class__.__name__}: {e}"
)
def get_plugin_info(self, plugin_name: str) -> Optional[PluginInfo]:
"""获取插件信息"""
return self.plugin_infos.get(plugin_name)
def get_all_plugin_infos(self) -> List[PluginInfo]:
"""获取所有插件信息"""
return list(self.plugin_infos.values())
async def install_plugin(
self, package_name: str, version: Optional[str] = None
) -> Optional[PluginInfo]:
"""安装插件"""
try:
# 构建安装命令
cmd = [sys.executable, "-m", "pip", "install", "--index-url", self.config.update.pypi_registry]
if version:
cmd.append(f"{package_name}=={version}")
else:
cmd.append(package_name)
# 执行安装
self.logger.info(f"Installing plugin: {package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{package_name} install] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{package_name} install] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to install plugin: return code {return_code}")
# 导入并加载插件
self.discover_external_plugins()
possible_plugin_infos = [
info
for info in self.plugin_infos.values()
if info.package_name == package_name
]
if possible_plugin_infos:
return possible_plugin_infos[0]
except Exception as e:
raise Exception(f"Failed to install plugin: {str(e)}")
return None
async def uninstall_plugin(self, plugin_name: str) -> bool:
"""卸载插件"""
try:
plugin_info = self.plugin_infos.get(plugin_name)
if not plugin_info:
return False
if plugin_info.is_internal:
raise Exception("Cannot uninstall internal plugin")
# 卸载前先禁用插件
await self.disable_plugin(plugin_name)
assert plugin_info.package_name is not None
# 执行卸载
cmd = [
sys.executable,
"-m",
"pip",
"uninstall",
"-y",
plugin_info.package_name,
]
self.logger.info(f"Uninstalling plugin: {plugin_info.package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{plugin_info.package_name} uninstall] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{plugin_info.package_name} uninstall] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to uninstall plugin: return code {return_code}")
# 清理插件信息
if plugin_name in self.plugin_infos:
del self.plugin_infos[plugin_name]
return True
except Exception as e:
raise Exception(f"Failed to uninstall plugin: {str(e)}")
async def enable_plugin(self, plugin_name: str) -> bool:
"""启用插件"""
plugin_info = self.get_plugin_info(plugin_name)
if not plugin_info:
raise ValueError(f"Plugin {plugin_name} not found")
if plugin_info.is_enabled:
return True
try:
# 加载插件
if plugin_info.is_internal:
plugin = self._load_internal_plugin(plugin_name)
else:
plugin = self._load_external_plugin(plugin_name)
# 更新配置
if plugin_name not in self.config.plugins.enable:
self.config.plugins.enable.append(plugin_name)
plugin.on_load()
plugin.on_start()
plugin_info.is_enabled = True
self.logger.info(f"Plugin {plugin_name} enabled")
return True
except Exception as e:
plugin_info.requires_restart = True
self.logger.error(f"Failed to enable plugin {plugin_name}: {e}")
raise e
async def disable_plugin(self, plugin_name: str) -> bool:
"""禁用插件"""
plugin_info = self.get_plugin_info(plugin_name)
if not plugin_info:
raise ValueError(f"Plugin {plugin_name} not found")
if not plugin_info.is_enabled:
return True
try:
# 找到并停止插件实例
if plugin_name in self.plugins:
plugin = self.plugins[plugin_name]
if isinstance(plugin.event_bus, PluginEventBus):
plugin.event_bus.unregister_all()
plugin.on_stop()
del self.plugins[plugin_name]
# 更新配置
if plugin_name in self.config.plugins.enable:
self.config.plugins.enable.remove(plugin_name)
plugin_info.is_enabled = False
self.plugin_infos[plugin_name] = plugin_info
self.logger.info(f"Plugin {plugin_name} disabled")
return True
except Exception as e:
plugin_info.requires_restart = True
self.logger.error(f"Failed to disable plugin {plugin_name}: {e}")
return False
async def update_plugin(self, plugin_name: str, new_package_name: Optional[str] = None) -> Optional[PluginInfo]:
"""更新插件"""
try:
plugin_info = self.plugin_infos.get(plugin_name)
if not plugin_info:
return None
assert plugin_info.package_name is not None
if plugin_info.is_internal:
raise Exception("Cannot update internal plugin")
# 获取当前版本
old_version = plugin_info.version
# 先卸载旧插件
await self.uninstall_plugin(plugin_name)
# 执行更新
cmd = [
sys.executable,
"-m",
"pip",
"install",
"--upgrade",
"--index-url",
self.config.update.pypi_registry,
new_package_name or plugin_info.package_name,
]
self.logger.info(f"Updating plugin: {plugin_info.package_name}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
# 实时处理输出
async def read_stream(stream, log_func):
while True:
line = await stream.readline()
if not line:
break
log_func(line.decode().strip())
# 并行处理 stdout 和 stderr
await asyncio.gather(
read_stream(process.stdout, lambda msg: self.logger.info(f"[{plugin_info.package_name} update] {msg}")),
read_stream(process.stderr, lambda msg: self.logger.error(f"[{plugin_info.package_name} update] {msg}"))
)
# 等待进程完成
return_code = await process.wait()
if return_code != 0:
raise Exception(f"Failed to update plugin: return code {return_code}")
self.discover_external_plugins()
possible_plugin_infos = [
info
for info in self.plugin_infos.values()
if info.package_name == plugin_info.package_name
]
if possible_plugin_infos:
if possible_plugin_infos[0].version != old_version:
return possible_plugin_infos[0]
else:
raise Exception(
f"Failed to update plugin: {plugin_info.package_name} is already up to date for current Kirara AI version. Maybe you should update Kirara AI to the latest version."
)
except Exception as e:
raise Exception(f"Failed to update plugin: {str(e)}")
return None
def discover_external_plugins(self):
"""发现并加载所有已安装的外部插件"""
self.logger.info("Discovering external plugins...")
from importlib.metadata import distributions
# 获取所有已安装的包
for dist in distributions():
try:
# 检查包是否包含我们需要的 entry point
eps = dist.entry_points
plugin_eps = [ep for ep in eps if ep.group == Plugin.ENTRY_POINT_GROUP]
if not plugin_eps:
continue
for ep in plugin_eps:
try:
# 获取插件元数据
metadata = {
"name": dist.metadata["Name"],
"description": dist.metadata.get("Summary", ""),
"version": dist.metadata.get("Version", "1.0.0"),
"author": dist.metadata.get("Author", "Unknown"),
}
# 创建插件信息
plugin_info = PluginInfo(
name=ep.name,
package_name=dist.metadata["Name"],
description=metadata["description"],
version=metadata["version"],
author=metadata["author"],
is_internal=False,
is_enabled=False,
metadata=None,
)
# 存储插件信息
self.plugin_infos[ep.name] = plugin_info
# 如果插件在启用列表中,则加载它
if ep.name in self.config.plugins.enable:
self._load_external_plugin(ep.name)
except Exception as e:
self.logger.error(
f"Error processing metadata for plugin {ep.name}: {e}"
)
except Exception as e:
self.logger.error(
f"Error processing package {dist.metadata['Name']}: {e}"
)
================================================
FILE: kirara_ai/plugin_manager/utils.py
================================================
from importlib.metadata import PackageNotFoundError, distribution
from typing import Any, Dict, Optional
def get_package_metadata(package_name: str) -> Optional[Dict[str, Any]]:
"""获取Python包的元数据
Args:
package_name: 包名
Returns:
包含包元数据的字典,如果包不存在则返回None
"""
try:
dist = distribution(package_name)
return {
"name": dist.metadata["Name"],
"version": dist.version,
"description": dist.metadata["Summary"] if "Summary" in dist.metadata else "",
"author": dist.metadata["Author"] if "Author" in dist.metadata else "",
}
except PackageNotFoundError:
return None
================================================
FILE: kirara_ai/plugins/.gitkeep
================================================
================================================
FILE: kirara_ai/plugins/bundled_frpc/__init__.py
================================================
from quart import g
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
from .frpc_manager import FrpcManager
from .routes import frpc_bp
logger = get_logger("FRPC")
class FrpcPlugin(Plugin):
"""
FRPC 插件
用于在本地启动 FRPC 服务,协助将 Web 服务暴露到外网。
"""
web_server: WebServer
global_config: GlobalConfig
def __init__(self):
self.frpc_manager = None
def on_load(self):
# 创建 FRPC 管理器
self.frpc_manager = FrpcManager(self.global_config)
# 注册中间件,将 frpc_manager 注入到请求上下文
@frpc_bp.before_request
async def inject_frpc_manager():
g.frpc_manager = self.frpc_manager
def on_start(self):
# 挂载 API
self.web_server.web_api_app.register_blueprint(frpc_bp, url_prefix="/api/frpc")
# 如果配置为启用,则尝试启动 frpc
if self.global_config.frpc.enable:
try:
self.frpc_manager.start_frpc(self.global_config.web.port)
except Exception as e:
logger.error(f"启动 FRPC 失败: {e}")
def on_stop(self):
# 停止 frpc 进程
if self.frpc_manager:
self.frpc_manager.stop_frpc()
__all__ = ["FrpcPlugin"]
================================================
FILE: kirara_ai/plugins/bundled_frpc/frpc_manager.py
================================================
import io
import os
import platform
import shutil
import subprocess
import tarfile
import tempfile
import threading
import zipfile
from pathlib import Path
from typing import Awaitable, Callable, Optional, Tuple
import aiohttp
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
logger = get_logger("FRPC")
# 存储路径
STORAGE_PATH = "./data/frpc"
class FrpcManager:
"""FRPC 管理器"""
def __init__(self, global_config: GlobalConfig):
self.global_config = global_config
self._frpc_process: Optional[subprocess.Popen] = None
self._frpc_version: str = ""
self._remote_url: str = ""
self._error_message: str = ""
self._download_progress: float = 0
# 确保存储目录存在
self.storage_path = Path(STORAGE_PATH)
self.storage_path.mkdir(parents=True, exist_ok=True)
# 设置 frpc 可执行文件路径
system = platform.system().lower()
if system == "windows":
self._frpc_path = self.storage_path / "frpc.exe"
else:
self._frpc_path = self.storage_path / "frpc"
# 设置配置文件路径
self._frpc_config_path = self.storage_path / "frpc.ini"
# 尝试获取版本信息
if self.is_installed():
self._get_frpc_version()
async def download_frpc(self, progress_callback: Optional[Callable[[float], Awaitable[None]]] = None) -> bool:
"""下载 FRPC"""
# 重置状态
self._download_progress = 0
self._error_message = ""
try:
# 获取系统信息
system = platform.system().lower()
machine = platform.machine().lower()
# 确定下载 URL
if system == "windows":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_windows_amd64.zip"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_windows_arm64.zip"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
elif system == "linux":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_amd64.tar.gz"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_arm64.tar.gz"
elif machine.startswith("arm"):
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_linux_arm.tar.gz"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
elif system == "darwin":
if machine in ["amd64", "x86_64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_darwin_amd64.tar.gz"
elif machine in ["arm64", "aarch64"]:
url = "https://github.com/fatedier/frp/releases/download/v0.51.3/frp_0.51.3_darwin_arm64.tar.gz"
else:
self._error_message = f"不支持的系统架构: {machine}"
if progress_callback:
await progress_callback(0)
return False
else:
self._error_message = f"不支持的操作系统: {system}"
if progress_callback:
await progress_callback(0)
return False
self._remote_url = url
self._version = "v0.51.3"
# 下载文件
try:
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(url) as response:
if response.status != 200:
self._error_message = f"下载失败: HTTP {response.status}"
if progress_callback:
await progress_callback(0)
return False
total_size = int(response.headers.get("content-length", 0))
downloaded_size = 0
# 直接在内存中下载文件
content = bytearray()
async for chunk in response.content.iter_chunked(8192):
content.extend(chunk)
downloaded_size += len(chunk)
progress = min(100, downloaded_size * 100 / total_size if total_size > 0 else 0)
self._download_progress = progress
if progress_callback:
await progress_callback(progress)
# 解压文件
extract_dir = tempfile.mkdtemp()
try:
# 从内存中解压文件
if url.endswith(".zip"):
with zipfile.ZipFile(io.BytesIO(content)) as zip_ref:
zip_ref.extractall(extract_dir)
elif url.endswith(".tar.gz"):
with tarfile.open(fileobj=io.BytesIO(content), mode="r:gz") as tar_ref:
tar_ref.extractall(extract_dir)
# 查找 frpc 可执行文件
frpc_name = "frpc.exe" if system == "windows" else "frpc"
frpc_files = []
for root, _, files in os.walk(extract_dir):
for file in files:
if file == frpc_name:
frpc_files.append(os.path.join(root, file))
if not frpc_files:
self._error_message = "解压后未找到 frpc 可执行文件"
if progress_callback:
await progress_callback(0)
return False
# 复制 frpc 可执行文件
frpc_path = str(self._frpc_path)
os.makedirs(os.path.dirname(frpc_path), exist_ok=True)
shutil.copy2(frpc_files[0], frpc_path)
# 设置可执行权限
if system != "windows":
os.chmod(frpc_path, 0o755)
if progress_callback:
await progress_callback(100)
self._get_frpc_version()
return True
finally:
shutil.rmtree(extract_dir)
except Exception as e:
self._error_message = f"下载失败: {str(e)}"
if progress_callback:
await progress_callback(0)
return False
except Exception as e:
self._error_message = f"下载失败: {str(e)}"
if progress_callback:
await progress_callback(0)
return False
def _get_frpc_version(self):
"""获取 frpc 版本信息"""
try:
if not self.is_installed():
self._frpc_version = "未安装"
return
result = subprocess.run(
[str(self._frpc_path), "-v"],
capture_output=True,
text=True,
check=True
)
self._frpc_version = result.stdout.strip()
except Exception as e:
logger.error(f"获取 FRPC 版本失败: {e}")
self._frpc_version = "未知"
def _generate_config(self, web_port: int) -> bool:
"""
生成 frpc 配置文件
Args:
web_port: Web 服务端口
Returns:
bool: 配置文件生成是否成功
"""
try:
config = self.global_config.frpc
# 基本配置
config_content = f"""[common]
server_addr = {config.server_addr}
server_port = {config.server_port}
"""
# 如果有令牌,添加令牌配置
if config.token:
config_content += f"token = {config.token}\n"
if self.global_config.web.host == "0.0.0.0":
web_ip = "127.0.0.1"
else:
web_ip = self.global_config.web.host
# 代理配置
config_content += f"""
[kirara_web]
type = tcp
local_ip = {web_ip}
local_port = {web_port}
"""
# 远程端口配置
if config.remote_port > 0:
config_content += f"remote_port = {config.remote_port}\n"
# 写入配置文件
with open(self._frpc_config_path, "w", encoding="utf-8") as f:
f.write(config_content)
logger.info(f"FRPC 配置文件已生成: {self._frpc_config_path}")
return True
except Exception as e:
logger.error(f"生成 FRPC 配置文件失败: {e}")
self._error_message = f"生成 FRPC 配置文件失败: {e}"
return False
def start_frpc(self, web_port: int) -> bool:
"""
启动 frpc
Args:
web_port: Web 服务端口
Returns:
bool: 启动是否成功
"""
if self.is_installed():
self._get_frpc_version()
try:
# 如果已经在运行,先停止
if self._frpc_process is not None:
self.stop_frpc()
# 检查可执行文件是否存在
if not self.is_installed():
logger.error("FRPC 可执行文件不存在,请先下载")
self._error_message = "FRPC 可执行文件不存在,请先下载"
return False
# 生成配置文件
if not self._generate_config(web_port):
return False
# 启动 frpc
cmd = [str(self._frpc_path), "-c", str(self._frpc_config_path)]
self._frpc_process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True
)
def print_output(process):
while process.poll() is None:
line = process.stdout.readline()
if not line:
break
logger.info(line.strip())
logger.info("FRPC 已结束")
# 创建一个线程来读取和打印输出
output_thread = threading.Thread(target=print_output, args=(self._frpc_process,))
output_thread.daemon = True # 设置为守护线程,主线程退出时自动结束
output_thread.start()
logger.info(f"FRPC 已启动,PID: {self._frpc_process.pid}")
# 计算远程访问 URL
self._calculate_remote_url()
return True
except Exception as e:
logger.error(f"启动 FRPC 失败: {e}")
self._error_message = f"启动 FRPC 失败: {e}"
return False
def stop_frpc(self) -> bool:
"""
停止 frpc
Returns:
bool: 停止是否成功
"""
try:
if self._frpc_process is not None:
self._frpc_process.terminate()
try:
self._frpc_process.wait(timeout=5)
except subprocess.TimeoutExpired:
self._frpc_process.kill()
logger.info("FRPC 已停止")
self._frpc_process = None
self._remote_url = ""
return True
except Exception as e:
logger.error(f"停止 FRPC 失败: {e}")
self._error_message = f"停止 FRPC 失败: {e}"
return False
def _calculate_remote_url(self):
"""计算远程访问 URL"""
config = self.global_config.frpc
if config.remote_port > 0:
self._remote_url = f"http://{config.server_addr}:{config.remote_port}"
else:
self._remote_url = f"http://{config.server_addr}:随机端口"
def get_status(self) -> Tuple[bool, str, str, str, float]:
"""
获取 frpc 状态
Returns:
Tuple[bool, str, str, str, float]: (是否运行, 版本, 远程URL, 错误信息, 下载进度)
"""
is_running = self._frpc_process is not None and self._frpc_process.poll() is None
# 如果进程已经退出,获取错误信息
if self._frpc_process is not None and self._frpc_process.poll() is not None:
stderr = self._frpc_process.stderr.read() if self._frpc_process.stderr else ""
if stderr:
self._error_message = stderr
self._frpc_process = None
self._get_frpc_version()
return (
is_running,
self._frpc_version,
self._remote_url,
self._error_message,
self._download_progress
)
def is_installed(self) -> bool:
"""
检查 frpc 是否已安装
Returns:
bool: 是否已安装
"""
return os.path.exists(self._frpc_path)
================================================
FILE: kirara_ai/plugins/bundled_frpc/models.py
================================================
from typing import Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import FrpcConfig
class FrpcStatus(BaseModel):
"""FRPC 状态"""
is_running: bool
is_installed: bool
config: FrpcConfig
version: str = ""
remote_url: str = ""
error_message: str = ""
download_progress: float = 0
class FrpcConfigUpdate(BaseModel):
"""FRPC 配置更新请求"""
enable: Optional[bool] = None
server_addr: Optional[str] = None
server_port: Optional[int] = None
token: Optional[str] = None
remote_port: Optional[int] = None
class FrpcDownloadProgress(BaseModel):
"""FRPC 下载进度"""
progress: float
status: str = "downloading" # downloading, completed, error
error_message: str = ""
================================================
FILE: kirara_ai/plugins/bundled_frpc/routes.py
================================================
import asyncio
from quart import Blueprint, Response, g, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.web.auth.middleware import require_auth
from .frpc_manager import FrpcManager
from .models import FrpcConfigUpdate, FrpcDownloadProgress, FrpcStatus
frpc_bp = Blueprint("frpc", __name__)
@frpc_bp.route("/status", methods=["GET"])
@require_auth
async def get_status():
"""获取 FRPC 状态"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/config", methods=["POST"])
@require_auth
async def update_config():
"""更新 FRPC 配置"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
data = await request.get_json()
config_update = FrpcConfigUpdate(**data)
# 更新配置
frpc_config = config.frpc
# 使用字典推导式更新非 None 字段
update_dict = {k: v for k, v in config_update.model_dump().items() if v is not None}
# 更新配置
for key, value in update_dict.items():
setattr(frpc_config, key, value)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 如果启用状态改变,启动或停止 frpc
web_port = config.web.port
if config_update.enable is not None:
if config_update.enable:
frpc_manager.start_frpc(web_port)
else:
frpc_manager.stop_frpc()
# 如果其他配置改变且 frpc 正在运行,重启 frpc
elif frpc_config.enable and any(k != "enable" for k in update_dict.keys()):
frpc_manager.stop_frpc()
frpc_manager.start_frpc(web_port)
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/start", methods=["POST"])
@require_auth
async def start_frpc():
"""启动 FRPC"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 更新配置中的启用状态
config.frpc.enable = True
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 启动 frpc
success = frpc_manager.start_frpc(config.web.port)
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/stop", methods=["POST"])
@require_auth
async def stop_frpc():
"""停止 FRPC"""
frpc_manager: FrpcManager = g.frpc_manager
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 更新配置中的启用状态
config.frpc.enable = False
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 停止 frpc
success = frpc_manager.stop_frpc()
# 返回最新状态
is_running, version, remote_url, error_message, download_progress = frpc_manager.get_status()
is_installed = frpc_manager.is_installed()
return FrpcStatus(
is_running=is_running,
is_installed=is_installed,
config=config.frpc,
version=version,
remote_url=remote_url,
error_message=error_message,
download_progress=download_progress
).model_dump()
@frpc_bp.route("/download", methods=["GET"])
@require_auth
async def download_frpc():
"""下载 FRPC 并通过 SSE 返回进度"""
frpc_manager: FrpcManager = g.frpc_manager
# 创建一个队列用于存储SSE事件
queue = asyncio.Queue()
# 定义进度回调函数
async def progress_callback(progress: float):
"""进度回调函数"""
status = "downloading"
if progress >= 100:
status = "completed"
# 将事件放入队列
await queue.put(
FrpcDownloadProgress(
progress=progress,
status=status
).model_dump_json()
)
# 启动下载任务
async def download_task():
try:
# 发送初始状态
await queue.put(
FrpcDownloadProgress(
progress=0,
status='downloading'
).model_dump_json()
)
# 执行下载
success = await frpc_manager.download_frpc(progress_callback)
# 如果下载失败,发送错误状态
if not success:
await queue.put(
FrpcDownloadProgress(
progress=0,
status='error',
error_message=frpc_manager._error_message
).model_dump_json()
)
except Exception as e:
# 发送错误状态
await queue.put(
FrpcDownloadProgress(
progress=0,
status='error',
error_message=str(e)
).model_dump_json()
)
finally:
# 标记队列结束
await queue.put(None)
# 启动下载任务
asyncio.create_task(download_task())
# 定义SSE流生成器
async def send_events():
while True:
message = await queue.get()
if message is None: # 结束信号
break
yield f"data: {message}\n\n"
# 返回SSE响应
return Response(
send_events(),
mimetype="text/event-stream",
headers={
"Cache-Control": "no-cache",
"X-Accel-Buffering": "no", # 禁用 Nginx 缓冲
"Connection": "keep-alive"
}
)
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/__init__.py
================================================
import os
from im_http_legacy_adapter.adapter import HttpLegacyAdapter, HttpLegacyConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("HTTP-Legacy-Adapter")
class HttpLegacyAdapterPlugin(Plugin):
"""HTTP API 消息适配器插件"""
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"http_legacy",
HttpLegacyAdapter,
HttpLegacyConfig,
"HTTP API",
"HTTP 消息 API,可用于接入第三方程序。",
"""
HTTP API 可用于接入第三方程序,接口文档请见项目 [README](https://github.com/lss233/chatgpt-mirai-qq-bot/blob/master/README.md#-http-api)。
"""
)
self.web_server.add_static_assets("/assets/icons/im/http_legacy.png", os.path.join(os.path.dirname(__file__), "assets", "http_legacy.png"))
def on_start(self):
pass
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/adapter.py
================================================
import asyncio
import re
import time
from typing import Any, Dict, List, Optional, Protocol
from fastapi import Body, FastAPI, Query, Request
from fastapi.responses import JSONResponse
from pydantic import BaseModel, ConfigDict, Field
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import ImageMessage, IMMessage, TextMessage, VoiceMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.logger import get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
# 全局变量,用于跟踪是否已经设置了路由
_is_first_setup = True
# 全局变量,用于存储所有已授权的API密钥
_authorized_api_keys: List[str] = []
class HttpLegacyConfig(BaseModel):
"""HTTP Legacy API 配置"""
api_key: Optional[str] = Field(
description="自定义的API密钥,设置后,请求接口时需要带上这个密钥,若填空则不校验。", default=None)
host: Optional[str] = Field(description="已废弃,HTTP API 服务器地址,设置后将启动独立服务器。",
default=None, json_schema_extra={"hidden_unset": True})
port: Optional[int] = Field(description="已废弃,HTTP API 服务器端口,设置后将启动独立服务器。",
default=None, json_schema_extra={"hidden_unset": True})
model_config = ConfigDict(extra="allow")
class ResponseResult:
def __init__(self, message=None, voice=None, image=None, result_status="SUCCESS"):
self.result_status = result_status
self.message = (
[]
if message is None
else message if isinstance(message, list) else [message]
)
self.voice = (
[] if voice is None else voice if isinstance(voice, list) else [
voice]
)
self.image = (
[] if image is None else image if isinstance(image, list) else [
image]
)
def to_dict(self):
return {
"result": self.result_status,
"message": self.message,
"voice": self.voice,
"image": self.image,
}
def pop_all(self):
self.message = []
self.voice = []
self.image = []
class MessageHandler(Protocol):
async def __call__(self, message: IMMessage) -> None: ...
class V2Request:
def __init__(self, session_id: str, username: str, message: str, request_time: str):
self.session_id = session_id
self.username = username
self.message = message
self.result = ResponseResult()
self.request_time = request_time
self.done = False
self.response_event = asyncio.Event()
class HttpLegacyAdapter(IMAdapter):
"""HTTP Legacy API适配器"""
dispatcher: WorkflowDispatcher
web_server: WebServer
def __init__(self, config: HttpLegacyConfig):
self.config = config
self.app = FastAPI(title="HTTP Legacy API")
self.request_dic: Dict[str, V2Request] = {}
self.logger = get_logger("HTTP-Legacy-Adapter")
async def convert_to_message(self, raw_message: Any) -> IMMessage:
data = raw_message
username = data.get("username", "某人")
message_text = data.get("message", "")
session_id = data.get("session_id", "friend-default_session")
if (
session_id.startswith("group-")
and len(session_id.split("-")) == 2
and ":" in session_id.split("-")[1]
):
# group-group_id:user_id
ids = session_id.split("-")[1].split(":")
sender = ChatSender.from_group_chat(
user_id=ids[1], group_id=ids[0], display_name=username
)
else:
sender = ChatSender.from_c2c_chat(
user_id=session_id, display_name=username)
return IMMessage(
sender=sender,
message_elements=[TextMessage(text=message_text)],
raw_message={"session_id": session_id, **data},
)
async def handle_message_elements(self, result: ResponseResult, message: IMMessage):
for element in message.message_elements:
if isinstance(element, VoiceMessage):
result.voice.append(await element.get_base64_url())
elif isinstance(element, ImageMessage):
result.image.append(await element.get_base64_url())
else:
result.message.append(element.to_plain())
def verify_api_key(self, request: Request) -> bool:
"""验证API密钥"""
if not self.config.api_key:
return True
auth_header = request.headers.get("Authorization", "")
# 支持 Bearer 认证和直接传递 API Key
if auth_header.startswith("Bearer "):
auth_header = auth_header[7:] # 移除 "Bearer " 前缀
return auth_header == self.config.api_key or auth_header in _authorized_api_keys
def create_auth_error_response(self):
"""创建认证失败的响应"""
return JSONResponse(
content=ResponseResult(
message="认证失败", result_status="FAILED").to_dict(),
status_code=401
)
def setup_routes(self, target_app=None):
app = target_app if target_app else self.app
async def verify_auth(request: Request):
if not self.verify_api_key(request):
return self.create_auth_error_response()
return None
@app.post("/v1/chat")
async def v1_chat(request: Request, data: dict = Body(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
message = await self.convert_to_message(data)
result = ResponseResult()
async def handle_response(resp_message: IMMessage):
await self.handle_message_elements(result, resp_message)
message.sender.raw_metadata["callback_func"] = handle_response
await self.dispatcher.dispatch(self, message)
return result.to_dict()
@app.post("/v2/chat")
async def v2_chat(request: Request, data: dict = Body(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
request_time = str(int(time.time() * 1000))
message = await self.convert_to_message(data)
assert message.raw_message is not None
session_id = message.raw_message["session_id"]
bot_request = V2Request(
session_id,
message.sender.display_name,
data.get("message", ""),
request_time,
)
self.request_dic[request_time] = bot_request
async def handle_response(resp_message: IMMessage):
await self.handle_message_elements(bot_request.result, resp_message)
bot_request.response_event.set()
message.sender.raw_metadata["callback_func"] = handle_response
asyncio.create_task(self.dispatcher.dispatch(self, message))
return request_time
@app.get("/v2/chat/response")
async def v2_chat_response(request: Request, request_id: str = Query(...)):
auth_response = await verify_auth(request)
if auth_response:
return auth_response
request_id = re.sub(
r'^[%22%27"\'"]*|[%22%27"\'"]*$', "", request_id)
bot_request = self.request_dic.get(request_id)
if bot_request is None:
return ResponseResult(
message="没有更多了!", result_status="FAILED"
).to_dict()
await bot_request.response_event.wait()
bot_request.response_event.clear()
response = bot_request.result.to_dict()
bot_request.result = ResponseResult()
if bot_request.done:
self.request_dic.pop(request_id)
return response
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""此处负责 HTTP 的响应逻辑"""
await recipient.raw_metadata["callback_func"](message)
@property
def is_standalone(self):
return self.config.host
async def _start_standalone_server(self):
"""启动独立HTTP服务器"""
# 使用 hypercorn 配置来正确处理关闭信号
from hypercorn.asyncio import serve
from hypercorn.config import Config
from hypercorn.logging import Logger
from kirara_ai.logger import HypercornLoggerWrapper
config = Config()
host = self.config.host
port = self.config.port or 18560
config.bind = [f"{host}:{port}"]
config._log = Logger(config)
config._log.access_logger = HypercornLoggerWrapper(self.logger) # type: ignore
config._log.error_logger = HypercornLoggerWrapper(self.logger) # type: ignore
self.server_task = asyncio.create_task(serve(self.app, config)) # type: ignore
async def start(self):
"""启动HTTP服务器"""
global _is_first_setup, _authorized_api_keys
if self.is_standalone:
self.logger.warning("正在使用过时的独立模式,请尽快更新为集成模式。")
await self._start_standalone_server()
self.setup_routes()
else:
# 为所有的路由添加前缀
if _is_first_setup:
# 直接往 self.web_server.app 注册路由,而不是mount_app
self.setup_routes(target_app=self.web_server.app)
_is_first_setup = False
else:
if self.config.api_key and self.config.api_key not in _authorized_api_keys:
_authorized_api_keys.append(self.config.api_key)
# 启动清理过期请求的任务
self.cleanup_task = asyncio.create_task(
self.cleanup_expired_requests())
async def cleanup_expired_requests(self):
"""清理过期的请求"""
while True:
now = time.time()
expired_keys = [
key
for key, req in self.request_dic.items()
if now - int(key) / 1000 > 600
]
for key in expired_keys:
self.request_dic.pop(key)
await asyncio.sleep(60)
async def stop(self):
"""停止HTTP服务器"""
global _authorized_api_keys
# 如果有API密钥,从授权列表中移除
if self.config.api_key and self.config.api_key in _authorized_api_keys:
_authorized_api_keys.remove(self.config.api_key)
if self.is_standalone and hasattr(self, "server_task"):
self.server_task.cancel()
try:
await self.server_task
except asyncio.CancelledError:
pass
except Exception as e:
self.logger.error(f"Error during server shutdown: {e}")
if hasattr(self, "cleanup_task"):
self.cleanup_task.cancel()
try:
await self.cleanup_task
except asyncio.CancelledError:
pass
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-http-legacy-adapter",
version="1.0.0",
description="HTTP legacy adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["aiohttp", "requests"],
entry_points={
"chatgpt_mirai.plugins": [
"http_legacy = im_http_legacy_adapter.plugin:HttpLegacyAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_http_legacy_adapter/tests/api_test.py
================================================
import asyncio
import os
import sys
import pytest
from fastapi.testclient import TestClient
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.dispatch.dispatcher import WorkflowDispatcher
from kirara_ai.workflow.core.dispatch.registry import DispatchRuleRegistry
from tests.utils.test_block_registry import create_test_block_registry
sys.path.insert(
0, os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
from im_http_legacy_adapter.adapter import HttpLegacyAdapter, HttpLegacyConfig, ResponseResult
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
class FakeWorkflowDispatcher(WorkflowDispatcher):
async def dispatch(self, source: IMAdapter, message: IMMessage):
return None
@pytest.fixture
def config():
return HttpLegacyConfig(host="127.0.0.1", port=8080, debug=False)
@pytest.fixture
def adapter(config):
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(WorkflowRegistry, WorkflowRegistry(container))
container.register(DispatchRuleRegistry, DispatchRuleRegistry(container))
container.register(WorkflowDispatcher, FakeWorkflowDispatcher(container))
container.register(BlockRegistry, create_test_block_registry())
adapter = HttpLegacyAdapter(config)
adapter.setup_routes()
adapter.dispatcher = container.resolve(WorkflowDispatcher)
return adapter
@pytest.mark.asyncio
async def test_chat_endpoint(adapter):
test_client = TestClient(adapter.app)
# Test text message
response = test_client.post(
"/v1/chat",
json={
"session_id": "test_session",
"username": "test_user",
"message": "Hello, world!",
},
)
assert response.status_code == 200
data = response.json()
assert "result" in data
assert "message" in data
assert isinstance(data["message"], list)
# Test with missing fields (should use defaults)
response = test_client.post("/v1/chat", json={"message": "Test message"})
assert response.status_code == 200
@pytest.mark.asyncio
async def test_response_result():
# Test single message
result = ResponseResult(message="Test message")
json_data = result.to_dict()
assert json_data["message"] == ["Test message"]
assert json_data["voice"] == []
assert json_data["image"] == []
# Test multiple messages
result = ResponseResult(
message=["Message 1", "Message 2"],
voice=["voice1.mp3"],
image=["image1.jpg", "image2.jpg"],
)
json_data = result.to_dict()
assert len(json_data["message"]) == 2
assert len(json_data["voice"]) == 1
assert len(json_data["image"]) == 2
@pytest.mark.asyncio
async def test_adapter_lifecycle(adapter):
# Test start and stop
start_task = asyncio.create_task(adapter.start())
await asyncio.sleep(0.1) # Give some time for server to start
await adapter.stop()
try:
await start_task
except Exception:
pass # Expected to fail when we stop the server
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/__init__.py
================================================
import asyncio
import os
from im_qqbot_adapter.adapter import QQBotAdapter, QQBotConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("QQBot-Adapter")
class QQBotAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"qqbot",
QQBotAdapter,
QQBotConfig,
"QQ 开放平台机器人",
"QQ 官方机器人,需要服务器支持接收 QQ 的 Webhook 请求,支持基本的聊天功能,群聊中必须通过 @ 触发。",
"""
QQ 开放平台机器人,需要服务器支持接收 QQ 的 Webhook 请求,配置流程可参考 [QQ 开放平台文档](https://q.qq.com/wiki/) 和 [Kirara AI 文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html)。
"""
)
local_logo_path = os.path.join(os.path.dirname(__file__), "assets", "qqbot.png")
self.web_server.add_static_assets("/assets/icons/im/qqbot.png", local_logo_path)
def on_start(self):
pass
def on_stop(self):
try:
tasks = []
loop = asyncio.get_event_loop()
for key, adapter in self.im_manager.get_adapters().items():
if isinstance(adapter, QQBotAdapter) and adapter.is_running:
tasks.append(self.im_manager.stop_adapter(key, loop))
for key in list(self.im_manager.get_adapters().keys()):
self.im_manager.delete_adapter(key)
loop.run_until_complete(asyncio.gather(*tasks))
except Exception as e:
logger.error(f"Error stopping QQBot adapter: {e}")
finally:
self.im_registry.unregister("qqbot")
logger.info("QQBot adapter stopped")
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/adapter.py
================================================
import asyncio
import base64
import functools
import uuid
from typing import List, Optional
import ymbotpy as botpy
import ymbotpy.message
from pydantic import BaseModel, ConfigDict, Field
from ymbotpy.http import Route as BotpyRoute
from ymbotpy.types.message import Media as BotpyMedia
from kirara_ai.im.adapter import BotProfileAdapter, IMAdapter
from kirara_ai.im.message import (ImageMessage, IMMessage, MentionElement, MessageElement, TextMessage, VideoElement,
VoiceMessage)
from kirara_ai.im.profile import UserProfile
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
from .utils import URL_PATTERN
WEBHOOK_URL_PREFIX = "/im/webhook/qqbot"
def make_webhook_url():
return f"{WEBHOOK_URL_PREFIX}/{str(uuid.uuid4())[:8]}/"
def auto_generate_webhook_url(s: dict):
s["readOnly"] = True
s["default"] = make_webhook_url()
s["textType"] = True
class QQBotConfig(BaseModel):
"""
QQBot 配置文件模型。
"""
app_id: str = Field(description="机器人的 App ID。")
app_secret: str = Field(title="App Secret", description="机器人的 App Secret。")
token: str = Field(
title="Token", description="机器人令牌,用于调用 QQ 机器人的 OpenAPI。")
sandbox: bool = Field(
title="沙盒环境", description="是否为沙盒环境,通常只有正式发布的机器人才会关闭此选项。", default=False)
webhook_url: str = Field(
title="Webhook 回调 URL", description="供 QQ 机器人回调的 URL,由系统自动生成,无法修改。",
default_factory=make_webhook_url,
json_schema_extra=auto_generate_webhook_url
)
model_config = ConfigDict(extra="allow")
async def patched_post_file(
self,
file_type: int,
file_data: bytes,
openid: Optional[str] = None,
group_openid: Optional[str] = None
) -> BotpyMedia:
"""
重写 post_file 方法,添加文件类型参数。
"""
payload = {
"file_type": file_type,
"file_data": base64.b64encode(file_data).decode('utf-8'),
"srv_send_msg": False
}
if openid:
route = BotpyRoute("POST", "/v2/users/{openid}/files", openid=openid)
elif group_openid:
route = BotpyRoute(
"POST", "/v2/groups/{group_openid}/files", group_openid=group_openid)
else:
raise ValueError("openid 和 group_openid 不能同时为空")
return await self._http.request(route, json=payload)
class QQBotAdapter(botpy.WebHookClient, IMAdapter, BotProfileAdapter):
"""
QQBot Adapter,包含 QQBot Bot 的所有逻辑。
"""
dispatcher: WorkflowDispatcher
web_server: WebServer
_loop: asyncio.AbstractEventLoop
def __init__(self, config: QQBotConfig):
self.config = config
self.is_sandbox = config.sandbox
self.logger = get_logger("QQBot-Adapter")
super().__init__(
timeout=5,
is_sandbox=self.is_sandbox,
bot_log=True,
ext_handlers=True,
)
self.loop = self._loop
self.user = None
async def convert_to_message(self, raw_message: ymbotpy.message.BaseMessage) -> IMMessage:
if isinstance(raw_message, ymbotpy.message.GroupMessage):
assert raw_message.author.member_openid is not None
assert raw_message.group_openid is not None
sender = ChatSender.from_group_chat(
raw_message.author.member_openid, raw_message.group_openid, 'QQ 用户')
elif isinstance(raw_message, ymbotpy.message.C2CMessage):
sender = ChatSender.from_c2c_chat(
raw_message.author.user_openid, 'QQ 用户')
else:
raise ValueError(f"不支持的消息类型: {type(raw_message)}")
raw_dict = {items: str(getattr(raw_message, items))
for items in raw_message.__slots__ if not items.startswith("_")}
sender.raw_metadata = {
"message_id": raw_message.id,
"message_seq": raw_message.msg_seq,
"timestamp": raw_message.timestamp,
}
elements: List[MessageElement] = []
if raw_message.content.strip():
elements.append(TextMessage(text=raw_message.content.lstrip()))
for attachment in raw_message.attachments:
if attachment.content_type.startswith('image/'):
elements.append(
ImageMessage(
url=attachment.url,
format=attachment.content_type.removeprefix('image/')
)
)
elif attachment.content_type.startswith('audio'):
elements.append(
VoiceMessage(
url=attachment.url,
format=attachment.filename.split('.')[-1]
)
)
return IMMessage(sender=sender, message_elements=elements, raw_message=raw_dict)
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""
发送消息
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象。
"""
if recipient.raw_metadata is None or recipient.raw_metadata.get('message_id') is None:
raise ValueError("Unable to retreive send_message info from metadata")
msg_id = recipient.raw_metadata['message_id']
if recipient.chat_type == ChatType.C2C:
assert recipient.user_id is not None
post_message_func = functools.partial(
self.api.post_c2c_message, openid=recipient.user_id, msg_id=msg_id)
upload_func = functools.partial(
patched_post_file, self.api, openid=recipient.user_id)
elif recipient.chat_type == ChatType.GROUP:
assert recipient.group_id is not None
post_message_func = functools.partial(
self.api.post_group_message, group_openid=recipient.group_id, msg_id=msg_id)
upload_func = functools.partial(
patched_post_file, self.api, group_openid=recipient.group_id)
else:
raise ValueError(f"不支持的消息类型: {recipient.chat_type}")
# 文本缓冲区
current_text = ""
msg_seq = 0
url_replaced = False # 标记是否替换过 URL
def replace_url_dots(text: str) -> str:
"""
检查文本是否包含 URL,如果包含则替换 URL 中的句点为句号。
:param text: 要检查的文本。
:return: 替换后的文本。
"""
nonlocal url_replaced
def replace_dots(match):
nonlocal url_replaced
url_replaced = True
return match.group(0).replace('.', '。')
return URL_PATTERN.sub(replace_dots, text)
async def send_text_message(text: str):
"""
发送文本消息。
:param text: 要发送的文本内容。
"""
await post_message_func(content=text, msg_seq=msg_seq) # type: ignore
# 单次循环处理所有元素
for element in message.message_elements:
if isinstance(element, TextMessage):
# 如果有文本,直接添加到当前缓冲区
current_text += element.text
# 立即发送当前文本缓冲区内容
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
current_text = ""
elif isinstance(element, MentionElement):
# 添加提及标记到当前文本缓冲区
current_text += f''
elif isinstance(element, ImageMessage) or isinstance(element, VoiceMessage) or isinstance(element, VideoElement):
# 如果有累积的文本,先发送文本
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
current_text = ""
# 然后发送媒体
if isinstance(element, ImageMessage):
file_type = 1
elif isinstance(element, VoiceMessage):
file_type = 3
elif isinstance(element, VideoElement):
file_type = 2
media = await upload_func(file_type=file_type, file_data=await element.get_data())
await post_message_func(media=media, msg_seq=msg_seq, msg_type=7) # type: ignore
msg_seq += 1
# 补充解释性文本
if url_replaced:
current_text = current_text + "(URL 中的句点已替换为句号以避免屏蔽)"
# 发送循环结束后可能剩余的文本
if current_text:
modified_text = replace_url_dots(current_text)
await send_text_message(modified_text)
msg_seq += 1
async def on_c2c_message_create(self, message: ymbotpy.message.C2CMessage):
"""
处理接收到的消息。
:param message: 接收到的消息对象。
"""
self.logger.debug(f"收到 C2C 消息: {message}")
im_message = await self.convert_to_message(message)
await self.dispatcher.dispatch(self, im_message)
async def on_group_at_message_create(self, message: ymbotpy.message.GroupMessage):
"""
处理接收到的群消息。
:param message: 接收到的消息对象。
"""
self.logger.debug(f"收到群消息: {message}")
im_message = await self.convert_to_message(message)
# 这个逆天的 Webhook 居然不包含 mention 字段,这里要手动补上
im_message.message_elements.append(
MentionElement(target=ChatSender.get_bot_sender()))
await self.dispatcher.dispatch(self, im_message)
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
if self.user is None:
return None
return UserProfile(
user_id=self.user['id'],
username=self.user['username'],
display_name=self.user['username'],
avatar_url=self.user['avatar']
)
async def start(self):
"""启动 Bot"""
token = botpy.Token(self.config.app_id, self.config.app_secret)
self.user = await self.http.login(token)
self.robot = botpy.Robot(self.user)
bot_webhook = botpy.BotWebHook(
self.config.app_id,
self.config.app_secret,
hook_route='/',
client=self,
system_log=True,
botapi=self.api,
loop=self.loop
)
app = await bot_webhook.init_fastapi()
app.user_middleware.clear()
self.web_server.mount_app(
self.config.webhook_url.removesuffix('/'), app)
async def stop(self):
"""停止 Bot"""
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-qqbot-adapter",
version="1.0.0",
description="QQBot adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["ymbotpy"],
entry_points={
"chatgpt_mirai.plugins": [
"qqbot = im_qqbot_adapter.plugin:QQBotAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_qqbot_adapter/utils.py
================================================
import re
URL_PATTERN = re.compile(
r'((?:https?://)?(?:[-\w]+\.)+(?:com|net|org|edu|gov|mil|io|co|ai|app|dev|cn|jp|kr|uk|de|fr|ru|br|in|au|info|biz|cc|tv|xyz|top|site|online|store|tech|blog|club|art|design|shop|mobile|cloud|me|ws|live|app|games|science|news|media|social|world|life|network)(?:/[-\w./%]*)?)')
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/__init__.py
================================================
import asyncio
import os
from im_telegram_adapter.adapter import TelegramAdapter, TelegramConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
logger = get_logger("TG-Adapter")
class TelegramAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"telegram",
TelegramAdapter,
TelegramConfig,
"Telegram 机器人",
"Telegram 官方机器人,支持私聊、群聊、 Markdown 格式消息。",
"""
Telegram 机器人,配置流程可参考 [Telegram 官方文档](https://core.telegram.org/bots/tutorial) 和 [Kirara AI 文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html)。
"""
)
# 添加当前文件夹下的 assets/telegram.svg 文件夹到 web 服务器
local_logo_path = os.path.join(os.path.dirname(__file__), "assets", "telegram.png")
self.web_server.add_static_assets("/assets/icons/im/telegram.png", local_logo_path)
def on_start(self):
pass
def on_stop(self):
try:
tasks = []
loop = asyncio.get_event_loop()
for key, adapter in self.im_manager.get_adapters().items():
if isinstance(adapter, TelegramAdapter) and adapter.is_running:
tasks.append(self.im_manager.stop_adapter(key, loop))
for key in list(self.im_manager.get_adapters().keys()):
self.im_manager.delete_adapter(key)
loop.run_until_complete(asyncio.gather(*tasks))
except Exception as e:
logger.error(f"Error stopping Telegram adapter: {e}")
finally:
self.im_registry.unregister("telegram")
logger.info("Telegram adapter stopped")
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/adapter.py
================================================
import asyncio
import random
from functools import lru_cache
from typing import List, Optional
from pydantic import BaseModel, ConfigDict, Field
from telegram import Bot, ChatFullInfo, Update, User
from telegram.constants import MessageEntityType
from telegram.ext import Application, CommandHandler, ContextTypes, MessageHandler, filters
from telegramify_markdown import markdownify
from kirara_ai.im.adapter import BotProfileAdapter, EditStateAdapter, IMAdapter, UserProfileAdapter
from kirara_ai.im.message import (FileElement, ImageMessage, IMMessage, MentionElement, MessageElement, TextMessage,
VideoMessage, VoiceMessage)
from kirara_ai.im.profile import UserProfile
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
def get_display_name(user: User | ChatFullInfo):
if user.first_name or user.last_name:
return f"{user.first_name or ''} {user.last_name or ''}".strip()
elif user.username:
return user.username
else:
return str(user.id)
class TelegramConfig(BaseModel):
"""
Telegram 配置文件模型。
"""
token: str = Field(description="Telegram 机器人的 Token,从 @BotFather 获取。")
model_config = ConfigDict(extra="allow")
def __repr__(self):
return f"TelegramConfig(token={self.token})"
class TelegramAdapter(IMAdapter, UserProfileAdapter, EditStateAdapter, BotProfileAdapter):
"""
Telegram Adapter,包含 Telegram Bot 的所有逻辑。
"""
dispatcher: WorkflowDispatcher
def __init__(self, config: TelegramConfig):
self.me = None
self.config = config
self.application = Application.builder().token(config.token).build()
self.bot = Bot(token=config.token)
# 注册命令处理器和消息处理器
self.application.add_handler(
CommandHandler("start", self.command_start))
self.application.add_handler(
MessageHandler(
filters.TEXT | filters.VOICE | filters.PHOTO | filters.VIDEO, self.handle_message
)
)
self.logger = get_logger("Telegram-Adapter")
async def command_start(self, update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理 /start 命令"""
if update.message:
await update.message.reply_text("Welcome! I am ready to receive your messages.")
async def handle_message(self, update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理接收到的消息"""
# 将 Telegram 消息转换为 Message 对象
if not update.message:
return
message = await self.convert_to_message(update)
try:
await self.dispatcher.dispatch(self, message)
except Exception as e:
await update.message.reply_text(
f"Workflow execution failed, please try again later: {str(e)}"
)
async def convert_to_message(self, raw_message: Update) -> IMMessage:
"""
将 Telegram 的 Update 对象转换为 Message 对象。
:param raw_message: Telegram 的 Update 对象。
:return: 转换后的 Message 对象。
"""
assert raw_message.message
assert raw_message.message.from_user
if (
raw_message.message.chat.type == "group"
or raw_message.message.chat.type == "supergroup"
):
sender = ChatSender.from_group_chat(
user_id=str(raw_message.message.from_user.id),
group_id=str(raw_message.message.chat_id),
display_name=get_display_name(raw_message.message.from_user),
)
else:
sender = ChatSender.from_c2c_chat(
user_id=str(raw_message.message.chat_id),
display_name=get_display_name(raw_message.message.from_user),
)
message_elements: List[MessageElement] = []
raw_message_dict = raw_message.message.to_dict()
# 处理文本消息
if raw_message.message.text is not None or raw_message.message.caption is not None:
text: str = raw_message.message.text or raw_message.message.caption # type: ignore
offset = 0
for entity in raw_message.message.entities or raw_message.message.caption_entities or []:
if entity.type in (MessageEntityType.MENTION, MessageEntityType.TEXT_MENTION):
# Extract mention text
mention_text = text[entity.offset:entity.offset + entity.length]
# Add preceding text as TextMessage
if entity.offset > offset:
message_elements.append(TextMessage(
text=text[offset:entity.offset]))
# Create ChatSender for MentionElement
if entity.type == "text_mention" and entity.user:
if entity.user.id == self.me.id: # type: ignore
mention_element = MentionElement(
target=ChatSender.get_bot_sender())
else:
mention_element = MentionElement(target=ChatSender.from_c2c_chat(
user_id=str(entity.user.id), display_name=mention_text))
elif entity.type == "mention":
# 这里需要从 adapter 实例中获取 bot 的 username
if mention_text == f'@{self.me.username}': # type: ignore
mention_element = MentionElement(
target=ChatSender.get_bot_sender())
else:
mention_element = MentionElement(target=ChatSender.from_c2c_chat(
user_id=f'unknown_id:{mention_text}', display_name=mention_text))
else:
# Fallback in case of unknown entity type
mention_element = TextMessage( # type: ignore
text=mention_text) # Or handle as needed
message_elements.append(mention_element)
offset = entity.offset + entity.length
# Add remaining text as TextMessage
if offset < len(text):
message_elements.append(TextMessage(text=text[offset:]))
# 处理语音消息
if raw_message.message.voice:
voice_file = await raw_message.message.voice.get_file()
data = await voice_file.download_as_bytearray()
voice_element = VoiceMessage(data=bytes(data))
message_elements.append(voice_element)
# 处理图片消息
if raw_message.message.photo:
# 获取最高分辨率的图片
photo = raw_message.message.photo[-1]
photo_file = await photo.get_file()
data = await photo_file.download_as_bytearray()
photo_element = ImageMessage(data=bytes(data))
message_elements.append(photo_element)
if raw_message.message.video:
video_file = await raw_message.message.video.get_file()
data = await video_file.download_as_bytearray()
video_element = VideoMessage(data=bytes(data))
message_elements.append(video_element)
if raw_message.message.document:
document_file = await raw_message.message.document.get_file()
data = await document_file.download_as_bytearray()
document_element = FileElement(data=bytes(data))
message_elements.append(document_element)
# 创建 Message 对象
message = IMMessage(
sender=sender,
message_elements=message_elements,
raw_message=raw_message_dict,
)
return message
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""
发送消息到 Telegram。
:param message: 要发送的消息对象。
:param recipient: 接收消息的目标对象,这里应该是 chat_id。
"""
if recipient.chat_type == ChatType.C2C:
chat_id = recipient.user_id
elif recipient.chat_type == ChatType.GROUP:
assert recipient.group_id
chat_id = recipient.group_id
else:
raise ValueError(f"Unsupported chat type: {recipient.chat_type}")
for element in message.message_elements:
if isinstance(element, TextMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="typing"
)
text = markdownify(element.text)
# 如果是非首条消息,适当停顿,模拟打字
if message.message_elements.index(element) > 0:
# 停顿通常和字数有关,但是会带一些随机
duration = max(len(element.text) * 0.1, 1) + random.uniform(0, 1) * 0.1
await asyncio.sleep(duration)
await self.application.bot.send_message(
chat_id=chat_id, text=text, parse_mode="MarkdownV2"
)
elif isinstance(element, ImageMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_photo"
)
await self.application.bot.send_photo(
chat_id=chat_id, photo=await element.get_data(), parse_mode="MarkdownV2"
)
elif isinstance(element, VoiceMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_voice"
)
await self.application.bot.send_voice(
chat_id=chat_id, voice=await element.get_data(), parse_mode="MarkdownV2"
)
elif isinstance(element, VideoMessage):
await self.application.bot.send_chat_action(
chat_id=chat_id, action="upload_video"
)
await self.application.bot.send_video(
chat_id=chat_id, video=await element.get_data(), parse_mode="MarkdownV2"
)
async def start(self):
"""启动 Bot"""
await self.application.initialize()
await self.application.start()
self.me = await self.bot.get_me()
assert self.application.updater
await self.application.updater.start_polling(drop_pending_updates=True)
async def stop(self):
"""停止 Bot"""
assert self.application.updater
try:
if self.application.updater.running:
await self.application.updater.stop()
if self.application.running:
await self.application.stop()
await self.application.shutdown()
except:
pass
async def set_chat_editing_state(
self, chat_sender: ChatSender, is_editing: bool = True
):
"""
设置或取消对话的编辑状态
:param chat_sender: 对话的发送者
:param is_editing: True 表示正在编辑,False 表示取消编辑状态
"""
action = "typing" if is_editing else "cancel"
chat_id = (
chat_sender.user_id
if chat_sender.chat_type == ChatType.C2C
else chat_sender.group_id
)
if not chat_id:
raise ValueError("Unable to get chat_id")
try:
self.logger.debug(
f"Setting chat editing state to {is_editing} for chat_id {chat_id}"
)
if is_editing:
await self.application.bot.send_chat_action(
chat_id=chat_id, action=action
)
else:
# 取消编辑状态时发送一个空操作
await self.application.bot.send_chat_action(
chat_id=chat_id, action=action
)
except Exception as e:
self.logger.warning(f"Failed to set chat editing state: {str(e)}")
@lru_cache(maxsize=10)
async def _cached_get_chat(self, user_id):
"""
带缓存的获取用户信息方法
:param user_id: 用户ID
:return: 用户对象
"""
return await self.application.bot.get_chat(user_id)
async def query_user_profile(self, chat_sender: ChatSender) -> UserProfile:
"""
查询 Telegram 用户资料
:param chat_sender: 用户的聊天发送者信息
:return: 用户资料
"""
try:
# 获取用户 ID
user_id = chat_sender.user_id
# 获取用户对象(使用缓存)
user = await self._cached_get_chat(user_id)
# 构建用户资料
profile = UserProfile( # type: ignore
user_id=str(user_id),
username=user.username,
display_name=get_display_name(user),
full_name=f"{user.first_name or ''} {user.last_name or ''}".strip(),
avatar_url=None, # Telegram 需要额外处理获取头像
)
return profile
except Exception as e:
self.logger.warning(f"Failed to query user profile: {str(e)}")
# 返回部分信息
return UserProfile( # type: ignore
user_id=str(chat_sender.user_id), display_name=chat_sender.display_name
)
async def get_bot_profile(self) -> Optional[UserProfile]:
"""
获取机器人资料
:return: 机器人资料
"""
if not self.me or not self.is_running:
return None
profile_photos = await self.me.get_profile_photos()
if profile_photos and profile_photos.photos:
file_id = profile_photos.photos[0][-1].file_id
file = await self.bot.get_file(file_id)
photo_url = file.file_path
else:
photo_url = None
return UserProfile(
user_id=str(self.me.id),
username=self.me.username,
display_name=get_display_name(self.me),
full_name=f"{self.me.first_name or ''} {self.me.last_name or ''}".strip(),
avatar_url=photo_url,
)
================================================
FILE: kirara_ai/plugins/im_telegram_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-telegram-adapter",
version="1.0.0",
description="Telegram adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["python-telegram-bot", "telegramify-markdown"],
entry_points={
"chatgpt_mirai.plugins": [
"telegram = im_telegram_adapter.plugin:TelegramAdapterPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/__init__.py
================================================
import os
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.web.app import WebServer
from .adapter import WecomAdapter, WecomConfig
logger = get_logger("Wecom-Adapter")
__all__ = ["WecomAdapter", "WecomConfig"]
class WecomAdapterPlugin(Plugin):
web_server: WebServer
def __init__(self):
pass
def on_load(self):
self.im_registry.register(
"wecom",
WecomAdapter,
WecomConfig,
"企业微信应用 / 微信公众号",
"微信官方消息 API,需要服务器支持接收微信的 Webhook 访问。",
r"""
企业微信应用/微信公众号官方消息 API,需要服务器支持 Webhook 访问。详情配置可参考[微信官方文档](https://open.work.weixin.qq.com/wwopen/manual/detail?t=selfBuildApp)和[Kirara配置文档](https://kirara-docs.app.lss233.com/guide/configuration/im.html#%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1-wecom)。
"""
)
self.web_server.add_static_assets(
"/assets/icons/im/wecom.png", os.path.join(os.path.dirname(__file__), "assets", "wecom.png")
)
def on_start(self):
pass
def on_stop(self):
pass
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/adapter.py
================================================
import asyncio
import base64
import os
import uuid
from io import BytesIO
from typing import Any, List, Optional
import aiohttp
from fastapi import FastAPI, HTTPException, Request, Response
from pydantic import BaseModel, ConfigDict, Field
from starlette.routing import Route
from wechatpy.client import BaseWeChatClient
from wechatpy.exceptions import InvalidSignatureException
from wechatpy.messages import BaseMessage
from wechatpy.replies import create_reply
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import (FileElement, ImageMessage, IMMessage, MessageElement, TextMessage, VideoElement,
VoiceMessage)
from kirara_ai.im.sender import ChatSender
from kirara_ai.logger import HypercornLoggerWrapper, get_logger
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.dispatch.dispatcher import WorkflowDispatcher
from .delegates import CorpWechatApiDelegate, PublicWechatApiDelegate, WechatApiDelegate
WECOM_TEMP_DIR = os.path.join(os.getcwd(), 'data', 'temp', 'wecom')
WEBHOOK_URL_PREFIX = "/im/webhook/wechat"
def make_webhook_url():
return f"{WEBHOOK_URL_PREFIX}/{str(uuid.uuid4())[:8]}"
def auto_generate_webhook_url(s: dict):
s["readOnly"] = True
s["default"] = make_webhook_url()
s["textType"] = True
class WecomConfig(BaseModel):
"""企业微信配置
文档: https://work.weixin.qq.com/api/doc/90000/90136/91770
"""
app_id: str = Field(title="应用ID", description="见微信侧显示")
secret: str = Field(title="应用Secret", description="见微信侧显示")
token: str = Field(title="Token", description="与微信侧填写保持一致")
encoding_aes_key: str = Field(
title="EncodingAESKey", description="请通过微信侧随机生成")
corp_id: Optional[str] = Field(
title="企业ID", description="企业微信后台显示的企业ID,微信公众号等场景无需填写。", default=None)
webhook_url: str = Field(
title="微信端回调地址",
description="供微信端请求的 Webhook URL,填写在微信端,由系统自动生成,无法修改。",
default_factory=make_webhook_url,
json_schema_extra=auto_generate_webhook_url
)
host: Optional[str] = Field(title="HTTP 服务地址", description="已过时,请删除并使用 webhook_url 代替。",
default=None, json_schema_extra={"hidden_unset": True})
port: Optional[int] = Field(title="HTTP 服务端口", description="已过时,请删除并使用 webhook_url 代替。",
default=None, json_schema_extra={"hidden_unset": True})
model_config = ConfigDict(extra="allow")
def __init__(self, **kwargs: Any):
# 如果 agent_id 存在,则自动使用 agent_id 作为 app_id
if "agent_id" in kwargs:
kwargs["app_id"] = str(kwargs["agent_id"])
super().__init__(**kwargs)
class WeComUtils:
"""企业微信相关的工具类"""
def __init__(self, client: BaseWeChatClient):
self.client = client
self.logger = get_logger("WeComUtils")
@property
def access_token(self) -> Optional[str]:
return self.client.access_token
async def download_and_save_media(self, media_id: str, file_name: str) -> Optional[str]:
"""下载并保存媒体文件到本地"""
file_path = os.path.join(WECOM_TEMP_DIR, file_name)
try:
media_data = await self.download_media(media_id)
if media_data:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as f:
f.write(media_data)
return file_path
except Exception as e:
self.logger.error(f"Failed to save media: {str(e)}")
return None
async def download_media(self, media_id: str) -> Optional[bytes]:
"""下载企业微信的媒体文件"""
url = f"https://qyapi.weixin.qq.com/cgi-bin/media/get?access_token={self.access_token}&media_id={media_id}"
try:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
return await response.read()
self.logger.error(
f"Failed to download media: {response.status}")
except Exception as e:
self.logger.error(f"Failed to download media: {str(e)}")
return None
class WecomAdapter(IMAdapter):
"""企业微信适配器"""
dispatcher: WorkflowDispatcher
web_server: WebServer
def __init__(self, config: WecomConfig):
self.wecom_utils = None
self.api_delegate: Optional[WechatApiDelegate] = None
self.config = config
if self.config.host:
self.app = FastAPI()
else:
self.app = self.web_server.app
self.logger = get_logger("Wecom-Adapter")
self.is_running = False
if not self.config.host:
self.config.host = None
self.config.port = None
elif not self.config.port:
self.config.port = 15650
if not self.config.webhook_url:
self.config.webhook_url = make_webhook_url()
self.reply_tasks: dict[str, asyncio.Task] = {}
# 根据配置选择合适的API代理
self.setup_wechat_api()
def setup_wechat_api(self):
"""根据配置设置微信API代理"""
if self.config.corp_id:
self.api_delegate = CorpWechatApiDelegate()
else:
self.api_delegate = PublicWechatApiDelegate()
self.api_delegate.setup_api(self.config)
# 设置工具类
self.wecom_utils = WeComUtils(self.api_delegate.client)
def setup_routes(self):
if self.config.host:
webhook_url = '/wechat'
else:
webhook_url = self.config.webhook_url
# unregister old route if exists
for route in self.app.routes:
if isinstance(route, Route) and route.path == webhook_url:
self.app.routes.remove(route)
@self.app.get(webhook_url)
async def handle_check_request(request: Request):
"""处理 GET 请求"""
if not self.is_running:
self.logger.warning("Wecom-Adapter is not running, skipping check request.")
raise HTTPException(status_code=404)
assert self.api_delegate is not None
signature = request.query_params.get("msg_signature", "")
if not signature:
signature = request.query_params.get("signature", "")
timestamp = request.query_params.get("timestamp", "")
nonce = request.query_params.get("nonce", "")
echo_str = request.query_params.get("echostr", "")
try:
echo_str = self.api_delegate.check_signature(
signature, timestamp, nonce, echo_str
)
return Response(content=echo_str, media_type="text/plain")
except InvalidSignatureException:
self.logger.error("failed to check signature, please check your settings.")
raise HTTPException(status_code=403)
@self.app.post(webhook_url)
async def handle_message(request: Request):
"""处理 POST 请求"""
if not self.is_running:
self.logger.warning("Wecom-Adapter is not running, skipping message request.")
raise HTTPException(status_code=404)
assert self.api_delegate is not None
assert self.wecom_utils is not None
signature = request.query_params.get("msg_signature", "")
if not signature:
signature = request.query_params.get("signature", "")
timestamp = request.query_params.get("timestamp", "")
nonce = request.query_params.get("nonce", "")
try:
msg_str = self.api_delegate.decrypt_message(
await request.body(), signature, timestamp, nonce
)
except InvalidSignatureException:
self.logger.error("failed to check signature, please check your settings.")
raise HTTPException(status_code=403)
msg: BaseMessage = self.api_delegate.parse_message(msg_str)
if msg.id in self.reply_tasks:
self.logger.debug(f"skip processing due to duplicate msgid: {msg.id}")
reply = await self.reply_tasks[msg.id]
del self.reply_tasks[msg.id]
return Response(content=create_reply(reply, msg, render=True), media_type="text/xml")
# 预处理媒体消息
media_path = None
if msg.type in ["voice", "video", "file"]:
media_id = msg.media_id
file_name = f"temp_{msg.type}_{media_id}.{msg.type}"
media_path = await self.wecom_utils.download_and_save_media(media_id, file_name)
# 转换消息
message = await self.convert_to_message(msg, media_path)
self.reply_tasks[msg.id] = asyncio.Future() # type: ignore
message.sender.raw_metadata["reply"] = self.reply_tasks[msg.id] # type: ignore
# 分发消息
asyncio.create_task(self.dispatcher.dispatch(self, message))
reply = await message.sender.raw_metadata["reply"]
del message.sender.raw_metadata["reply"]
return Response(content=create_reply(reply, msg, render=True), media_type="text/xml")
async def convert_to_message(self, raw_message: Any, media_path: Optional[str] = None) -> IMMessage:
"""将企业微信消息转换为统一消息格式"""
# 企业微信应用似乎没有群聊的概念,所以这里只能用单聊
sender = ChatSender.from_c2c_chat(
raw_message.source, raw_message.source)
message_elements: List[MessageElement] = []
raw_message_dict = raw_message.__dict__
if raw_message.type == "text":
message_elements.append(TextMessage(text=raw_message.content))
elif raw_message.type == "image":
message_elements.append(ImageMessage(url=raw_message.image))
elif raw_message.type == "voice" and media_path:
message_elements.append(VoiceMessage(url=media_path))
elif raw_message.type == "video" and media_path:
message_elements.append(VideoElement(path=media_path))
elif raw_message.type == "file" and media_path:
message_elements.append(FileElement(path=media_path))
elif raw_message.type == "location":
location_text = f"[Location] {raw_message.label} (X: {raw_message.location_x}, Y: {raw_message.location_y})"
message_elements.append(TextMessage(text=location_text))
elif raw_message.type == "link":
link_text = f"[Link] {raw_message.title}: {raw_message.description} ({raw_message.url})"
message_elements.append(TextMessage(text=link_text))
else:
message_elements.append(TextMessage(
text=f"Unsupported message type: {raw_message.type}"))
return IMMessage(
sender=sender,
message_elements=message_elements,
raw_message=raw_message_dict,
)
async def _send_text(self, user_id: str, text: str):
"""发送文本消息"""
assert self.api_delegate is not None
try:
return await self.api_delegate.send_text(self.config.app_id, user_id, text)
except Exception as e:
self.logger.error(f"Failed to send text message: {e}")
raise e
async def _send_media(self, user_id: str, media_data: str, media_type: str):
"""发送媒体消息的通用方法"""
assert self.api_delegate is not None
try:
media_bytes = BytesIO(base64.b64decode(media_data))
return await self.api_delegate.send_media(self.config.app_id, user_id, media_type, media_bytes)
except Exception as e:
self.logger.error(f"Failed to send {media_type} message: {e}")
raise e
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""发送消息到企业微信"""
user_id = recipient.user_id
res = None
try:
for element in message.message_elements:
if isinstance(element, TextMessage) and element.text:
res = await self._send_text(user_id, element.text)
elif isinstance(element, ImageMessage) and element.url:
res = await self._send_media(user_id, element.url, "image")
elif isinstance(element, VoiceMessage) and element.url:
res = await self._send_media(user_id, element.url, "voice")
elif isinstance(element, VideoElement) and element.path:
res = await self._send_media(user_id, element.path, "video")
elif isinstance(element, FileElement) and element.path:
res = await self._send_media(user_id, element.path, "file")
if res:
print(res)
if recipient.raw_metadata and "reply" in recipient.raw_metadata:
recipient.raw_metadata["reply"].set_result(None)
except Exception as e:
if 'Error code: 48001' in str(e):
# 未开通主动回复能力
if recipient.raw_metadata and "reply" in recipient.raw_metadata:
self.logger.warning("未开通主动回复能力,将采用被动回复消息 API,此模式下只能回复一条消息。")
recipient.raw_metadata["reply"].set_result(message.content)
else:
self.logger.warning("未开通主动回复能力,且不在上下文中,无法发送消息。")
async def _start_standalone_server(self):
"""启动服务"""
from hypercorn.asyncio import serve
from hypercorn.config import Config
from hypercorn.logging import Logger
config = Config()
config.bind = [f"{self.config.host}:{self.config.port}"]
# config._log = get_logger("Wecom-API")
# hypercorn 的 logger 需要做转换
config._log = Logger(config)
config._log.access_logger = HypercornLoggerWrapper(self.logger) # type: ignore
config._log.error_logger = HypercornLoggerWrapper(self.logger) # type: ignore
self.server_task = asyncio.create_task(serve(self.app, config)) # type: ignore
async def _stop_standalone_server(self):
"""停止服务"""
if hasattr(self, "server_task"):
self.server_task.cancel()
try:
await self.server_task
except asyncio.CancelledError:
pass
except Exception as e:
self.logger.error(f"Error during server shutdown: {e}")
async def start(self):
self.setup_wechat_api()
if self.config.host:
self.logger.warning("正在使用过时的启动模式,请尽快更新为 Webhook 模式。")
await self._start_standalone_server()
self.setup_routes()
self.is_running = True
self.logger.info("Wecom-Adapter 启动成功")
async def stop(self):
if self.config.host:
await self._stop_standalone_server()
self.is_running = False
self.logger.info("Wecom-Adapter 停止成功")
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/delegates.py
================================================
from abc import ABC, abstractmethod
from io import BytesIO
from typing import TYPE_CHECKING, Any
from wechatpy.messages import BaseMessage
from kirara_ai.logger import get_logger
if TYPE_CHECKING:
from .adapter import WecomConfig
class WechatApiDelegate(ABC):
"""微信API代理接口,用于处理不同类型的微信API调用"""
@abstractmethod
def setup_api(self, config: "WecomConfig"):
"""设置API相关组件"""
@abstractmethod
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证签名"""
@abstractmethod
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密消息"""
@abstractmethod
def parse_message(self, message: str) -> BaseMessage:
"""解析消息"""
@abstractmethod
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送文本消息"""
@abstractmethod
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送媒体消息"""
class CorpWechatApiDelegate(WechatApiDelegate):
"""企业微信API代理实现"""
def setup_api(self, config: "WecomConfig"):
"""设置企业微信API相关组件"""
from wechatpy.enterprise import parse_message
from wechatpy.enterprise.client import WeChatClient
from wechatpy.enterprise.crypto import WeChatCrypto
self.crypto = WeChatCrypto(
config.token, config.encoding_aes_key, config.corp_id
)
self.client = WeChatClient(config.corp_id, config.secret)
self.parse_message_func = parse_message
self.logger = get_logger("CorpWechatApiDelegate")
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证企业微信签名"""
return self.crypto.check_signature(signature, timestamp, nonce, echo_str)
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密企业微信消息"""
return self.crypto.decrypt_message(message, signature, timestamp, nonce)
def parse_message(self, message: str) -> BaseMessage:
"""解析企业微信消息"""
return self.parse_message_func(message) # type: ignore
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送企业微信文本消息"""
return self.client.message.send_text(app_id, user_id, text)
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送企业微信媒体消息"""
media_id = self.client.media.upload(media_type, media_bytes)["media_id"]
send_method = getattr(self.client.message, f"send_{media_type}")
return send_method(app_id, user_id, media_id)
class PublicWechatApiDelegate(WechatApiDelegate):
"""公众号微信API代理实现"""
def setup_api(self, config: "WecomConfig"):
"""设置公众号API相关组件"""
from wechatpy import WeChatClient
from wechatpy.crypto import WeChatCrypto
from wechatpy.parser import parse_message
self.crypto = WeChatCrypto(
config.token, config.encoding_aes_key, config.app_id
)
self.client = WeChatClient(config.app_id, config.secret)
self.parse_message_func = parse_message
self.logger = get_logger("PublicWechatApiDelegate")
def check_signature(self, signature: str, timestamp: str, nonce: str, echo_str: str) -> str:
"""验证公众号签名"""
from wechatpy.utils import check_signature as wechat_check_signature
wechat_check_signature(self.crypto.token, signature, timestamp, nonce)
return echo_str
def decrypt_message(self, message: bytes, signature: str, timestamp: str, nonce: str) -> str:
"""解密公众号消息"""
return self.crypto.decrypt_message(message, signature, timestamp, nonce)
def parse_message(self, message: str) -> BaseMessage:
"""解析公众号消息"""
return self.parse_message_func(message) # type: ignore
async def send_text(self, app_id: str, user_id: str, text: str) -> Any:
"""发送公众号文本消息"""
# 公众号API不需要app_id参数
return self.client.message.send_text(user_id, text)
async def send_media(self, app_id: str, user_id: str, media_type: str, media_bytes: BytesIO) -> Any:
"""发送公众号媒体消息"""
media_id = self.client.media.upload(media_type, media_bytes)["media_id"]
send_method = getattr(self.client.message, f"send_{media_type}")
# 公众号API不需要app_id参数
return send_method(user_id, media_id)
================================================
FILE: kirara_ai/plugins/im_wecom_adapter/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-wecom-adapter",
version="1.0.0",
description="WeCom adapter plugin for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["wechatpy", "pycryptodome"],
entry_points={
"chatgpt_mirai.plugins": ["wecom = im_wecom_adapter.plugin:WeComAdapterPlugin"]
},
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/__init__.py
================================================
from .alibabacloud_adapter import AlibabaCloudAdapter, AlibabaCloudConfig
from .claude_adapter import ClaudeAdapter, ClaudeConfig
from .deepseek_adapter import DeepSeekAdapter, DeepSeekConfig
from .gemini_adapter import GeminiAdapter, GeminiConfig
from .minimax_adapter import MinimaxAdapter, MinimaxConfig
from .moonshot_adapter import MoonshotAdapter, MoonshotConfig
from .ollama_adapter import OllamaAdapter, OllamaConfig
from .openai_adapter import OpenAIAdapter, OpenAIConfig
from .openrouter_adapter import OpenRouterAdapter, OpenRouterConfig
from .siliconflow_adapter import SiliconFlowAdapter, SiliconFlowConfig
from .tencentcloud_adapter import TencentCloudAdapter, TencentCloudConfig
from .volcengine_adapter import VolcengineAdapter, VolcengineConfig
from .mistral_adapter import MistralAdapter, MistralConfig
from .voyage_adapter import VoyageAdapter, VoyageConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin import Plugin
logger = get_logger("LLMPresetAdapters")
class LLMPresetAdaptersPlugin(Plugin):
def __init__(self):
pass
def on_load(self):
self.llm_registry.register(
"OpenAI", OpenAIAdapter, OpenAIConfig
)
self.llm_registry.register(
"DeepSeek", DeepSeekAdapter, DeepSeekConfig
)
self.llm_registry.register(
"Gemini", GeminiAdapter, GeminiConfig
)
self.llm_registry.register(
"Ollama", OllamaAdapter, OllamaConfig
)
self.llm_registry.register(
"Claude", ClaudeAdapter, ClaudeConfig
)
self.llm_registry.register(
"SiliconFlow", SiliconFlowAdapter, SiliconFlowConfig
)
self.llm_registry.register(
"TencentCloud", TencentCloudAdapter, TencentCloudConfig
)
self.llm_registry.register(
"AlibabaCloud", AlibabaCloudAdapter, AlibabaCloudConfig
)
self.llm_registry.register(
"Moonshot", MoonshotAdapter, MoonshotConfig
)
self.llm_registry.register(
"OpenRouter", OpenRouterAdapter, OpenRouterConfig
)
self.llm_registry.register(
"Minimax", MinimaxAdapter, MinimaxConfig
)
self.llm_registry.register(
"Volcengine", VolcengineAdapter, VolcengineConfig
)
self.llm_registry.register(
"Mistral", MistralAdapter, MistralConfig
)
logger.info("LLMPresetAdaptersPlugin loaded")
def on_start(self):
logger.info("LLMPresetAdaptersPlugin started")
def on_stop(self):
logger.info("LLMPresetAdaptersPlugin stopped")
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/alibabacloud_adapter.py
================================================
from kirara_ai.config.global_config import ModelConfig
from .openai_adapter import OpenAIAdapter, OpenAIConfig
from .utils import guess_qwen_model
class AlibabaCloudConfig(OpenAIConfig):
api_base: str = "https://dashscope.aliyuncs.com/compatible-mode/v1"
class AlibabaCloudAdapter(OpenAIAdapter):
def __init__(self, config: AlibabaCloudConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
models = await self.get_models()
all_models: list[ModelConfig] = []
for model in models:
guess_result = guess_qwen_model(model)
if guess_result is None:
continue
all_models.append(ModelConfig(id=model, type=guess_result[0].value, ability=guess_result[1]))
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/claude_adapter.py
================================================
import asyncio
import base64
from typing import Any, Dict, List
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing.decorator import trace_llm_chat
from .utils import generate_tool_call_id, pick_tool_calls
class ClaudeConfig(BaseModel):
api_key: str
api_base: str = "https://api.anthropic.com/v1"
model_config = ConfigDict(frozen=True)
async def convert_llm_chat_message_to_claude_message(messages: list[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
content: List[Dict[str, Any]] = []
for msg in [msg for msg in messages if msg.role in ["user", "assistant", "tool"]]:
parts: List[Dict[str, Any]] = []
for part in msg.content:
if isinstance(part, LLMChatTextContent):
parts.append({"type": "text", "text": part.text})
elif isinstance(part, LLMToolResultContent):
parts.append(await resolve_tool_result(part, media_manager))
elif isinstance(part, LLMToolCallContent):
continue
elif isinstance(part, LLMChatImageContent):
media = media_manager.get_media(part.media_id)
if media is None:
raise ValueError(f"Media {part.media_id} not found")
parts.append({"source": {"media_type": str(media.mime_type), "data": await media.get_base64()}, "type": "image"})
content.append({
"role": "user" if msg.role == "tool" else msg.role,
"content": parts
})
return content
def convert_tools_to_claude_format(tools: list[Tool]) -> list[dict]:
# 使用 pydantic 的 model_dump 方法,高级排除项`exclude`排除 openai 专属项
return [tool.model_dump(exclude={"strict": True, 'parameters': {'additionalProperties': True}}) for tool in tools]
async def resolve_tool_result(element: LLMToolResultContent, media_manager: MediaManager) -> dict:
tool_result: List[Dict[str, Any]] = []
for item in element.content:
if isinstance(item, tools.TextContent):
tool_result.append({"type": "text", "text": item.text})
elif isinstance(item, tools.MediaContent):
media = media_manager.get_media(item.media_id)
if media is None:
raise ValueError(
f"Media {item.media_id} not found")
tool_result.append({
"type": media.media_type.value.lower(),
"source": {
"type": "base64", "media_type": str(media.mime_type), "data": await media.get_base64()
}
})
return {"type": "tool_result", "tool_use_id": element.id, "content": tool_result, "is_error": element.isError}
class ClaudeAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol):
media_manager: MediaManager
def __init__(self, config: ClaudeConfig):
self.config = config
self.logger = get_logger("ClaudeAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/messages"
headers = {
"x-api-key": self.config.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
}
# Claude 的系统消息比较特殊
system_messages = [msg for msg in req.messages if msg.role == "system"]
if system_messages:
system_message = system_messages[0].content
else:
system_message = None
# 构建请求数据
data = {
"model": req.model,
"messages": asyncio.run(convert_llm_chat_message_to_claude_message(req.messages, self.media_manager)),
"max_tokens": req.max_tokens,
"system": system_message,
"temperature": req.temperature,
"top_p": req.top_p,
"stream": req.stream,
# claude tools格式中参数部分命名与openai api不同,不能简单使用model_dumps,在这里进行转换
"tools": convert_tools_to_claude_format(req.tools) if req.tools else None,
# claude默认如果使用了tools字段,这里需要指定tool_choice, claude默认为{"type": "auto"}.
# 可考虑后续给用户暴露此接口, 目前此处各模型定义不太统一
"tool_choice": {"type": "auto"} if req.tools else None,
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
content: List[LLMChatContentPartType] = []
for res in response_data["content"]:
if res["type"] == "text":
content.append(LLMChatTextContent(text=res["text"]))
elif res["type"] == "image":
image_data = base64.b64decode(res["source"]["data"])
media = asyncio.run(self.media_manager.register_from_data(
image_data, res["source"]["media_type"], source="claude response"))
content.append(LLMChatImageContent(media_id=media))
elif res["type"] == "tool_use":
# tool_call 时 只会额外返回一个 text 的深度思考。
content.append(LLMToolCallContent(id=res.get("id", generate_tool_call_id(res["name"])), name=res["name"], parameters=res.get("input", None)))
usage_data = response_data.get("usage", {})
input_tokens = usage_data.get("input_tokens", 0)
output_tokens = usage_data.get("output_tokens", 0)
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=input_tokens,
completion_tokens=output_tokens,
total_tokens=input_tokens + output_tokens,
),
message=Message(
content=content,
role=response_data.get("role", "assistant"),
finish_reason=response_data.get("stop_reason", "stop"),
# claude tool_call混合在content字段中,需要提取
tool_calls=pick_tool_calls(content),
)
)
async def auto_detect_models(self) -> list[str]:
# {
# "data": [
# {
# "type": "model",
# "id": "claude-3-5-sonnet-20241022",
# "display_name": "Claude 3.5 Sonnet (New)",
# "created_at": "2024-10-22T00:00:00Z"
# }
# ],
# "has_more": true,
# "first_id": "",
# "last_id": ""
# }
# claude3 全系支持工具调用,支持多模态tool_result
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"x-api-key": self.config.api_key}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data["data"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/deepseek_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
class DeepSeekConfig(OpenAIConfig):
api_base: str = "https://api.deepseek.com/v1"
class DeepSeekAdapter(OpenAIAdapterChatBase):
def __init__(self, config: DeepSeekConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/gemini_adapter.py
================================================
import asyncio
import base64
from typing import Any, Dict, List, Literal, cast
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tool
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent, RoleType)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.media import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .utils import generate_tool_call_id, pick_tool_calls
SAFETY_SETTINGS = [{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}, {
"category": "HARM_CATEGORY_CIVIC_INTEGRITY",
"threshold": "BLOCK_NONE"
}]
# POST 模式支持最大 20 MB 的 inline data
INLINE_LIMIT_SIZE = 1024 * 1024 * 20
IMAGE_MODAL_MODELS = [
"gemini-2.0-flash-exp"
]
class GeminiConfig(BaseModel):
api_key: str
api_base: str = "https://generativelanguage.googleapis.com/v1beta"
model_config = ConfigDict(frozen=True)
async def convert_non_tool_message(msg: LLMChatMessage, media_manager: MediaManager) -> dict:
parts: List[Dict[str, Any]] = []
elements = cast(list[LLMChatContentPartType], msg.content)
for element in elements:
if isinstance(element, LLMChatTextContent):
parts.append({"text": element.text})
elif isinstance(element, LLMChatImageContent):
media = media_manager.get_media(element.media_id)
if media is None:
raise ValueError(f"Media {element.media_id} not found")
parts.append({
"inline_data": {
"mime_type": str(media.mime_type),
"data": await media.get_base64()
}
})
elif isinstance(element, LLMToolCallContent):
parts.append({
"functionCall": {
"name": element.name,
"args": element.parameters
}
})
return {
"role": "model" if msg.role == "assistant" else "user",
"parts": parts
}
async def convert_llm_chat_message_to_gemini_message(msg: LLMChatMessage, media_manager: MediaManager) -> dict:
if msg.role in ["user", "assistant", "system"]:
return await convert_non_tool_message(msg, media_manager)
elif msg.role == "tool":
results = cast(list[LLMToolResultContent], msg.content)
return {"role": "user", "parts": [resolve_tool_results(result) for result in results]}
else:
raise ValueError(f"Invalid role: {msg.role}")
async def convert_all_messages_to_gemini_format(messages: List[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
# gather需要先用异步函数封装,然后才能使用asyncio.run()
return await asyncio.gather(*[convert_llm_chat_message_to_gemini_message(msg, media_manager) for msg in messages])
def convert_tools_to_gemini_format(tools: list[Tool]) -> list[dict[Literal["function_declarations"], list[dict]]]:
# 定义允许的字段结构
allowed_keys = {
"name": True,
"description": True,
"parameters": {
"type": True,
"properties": {
"*": {
"type": True,
"title": True,
"description": True,
"enum": True,
"default": True,
"items": True,
}
},
"required": True
}
}
def filter_dict(data: dict, allowed: dict) -> dict:
"""递归过滤字典,只保留允许的字段"""
result = {}
for key, value in allowed.items():
if key == "*" and isinstance(value, dict):
# 处理通配符情况,适用于 properties 字典
for data_key, data_value in data.items():
if isinstance(data_value, dict):
result[data_key] = filter_dict(data_value, value)
else:
result[data_key] = data_value
elif key in data:
if isinstance(value, dict) and isinstance(data[key], dict):
# 如果是嵌套字典,递归处理
result[key] = filter_dict(data[key], value)
else:
# 否则直接保留值
result[key] = data[key]
return result
function_declarations = []
for tool in tools:
# 将Tool对象转换为字典
tool_dict = tool.model_dump()
# 过滤出需要的字段
filtered_tool = filter_dict(tool_dict, allowed_keys)
function_declarations.append(filtered_tool)
return [{"function_declarations": function_declarations}]
def resolve_tool_results(element: LLMToolResultContent) -> dict:
# 全部拼接成字符串
output = ""
for content in element.content:
if isinstance(content, tool.TextContent):
output += content.text
elif isinstance(content, tool.MediaContent):
# FIXME: Gemini 不支持 response 传媒体内容,需要从额外的 message 中传入,类似于 **篡改记忆**
output += f""
return {
"functionResponse": {
"name": element.name,
"response": {"error": output} if element.isError else {"output": output}
}
}
class GeminiAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol, LLMEmbeddingProtocol):
media_manager: MediaManager
def __init__(self, config: GeminiConfig):
self.config = config
self.logger = get_logger("GeminiAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/models/{req.model}:generateContent?key={self.config.api_key}"
headers = {
# 这里的 api key 验证方法和 api reference 不一致。本次处理暂时按照api reference写法更正。 Warning: 未进行实际测试
# "x-goog-api-key": self.config.api_key,
"Content-Type": "application/json",
}
response_modalities = ["text"]
if req.model in IMAGE_MODAL_MODELS:
response_modalities.append("image")
data = {
"contents": asyncio.run(convert_all_messages_to_gemini_format(req.messages, self.media_manager)),
"generationConfig": {
"temperature": req.temperature,
"topP": req.top_p,
"topK": 40,
"maxOutputTokens": req.max_tokens,
"stopSequences": req.stop,
"responseModalities": response_modalities,
},
"safetySettings": SAFETY_SETTINGS,
"tools": convert_tools_to_gemini_format(req.tools) if req.tools else None,
}
self.logger.debug(f"Gemini request: {data}")
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
response = self._post_with_retry(api_url, json=data, headers=headers)
try:
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
content: List[LLMChatContentPartType] = []
role = "assistant"
for part in response_data["candidates"][0]["content"]["parts"]:
if "text" in part:
content.append(LLMChatTextContent(text=part["text"]))
elif "inlineData" in part:
decoded_image_data = base64.b64decode(part["inlineData"]["data"])
media = asyncio.run(
self.media_manager.register_from_data(
data=decoded_image_data,
format=part["inlineData"]["mimeType"].removeprefix(
"image/"),
source="gemini response")
)
content.append(LLMChatImageContent(media_id=media))
elif "functionCall" in part:
content.append(
LLMToolCallContent(
id=generate_tool_call_id(part["functionCall"]["name"]),
name=part["functionCall"]["name"],
parameters=part["functionCall"].get("args", None)
)
)
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=response_data["usageMetadata"].get(
"promptTokenCount"),
cached_tokens=response_data["usageMetadata"].get(
"cachedContentTokenCount"),
completion_tokens=sum([modality.get(
"tokenCount", 0) for modality in response_data.get("promptTokensDetails", [])]),
total_tokens=response_data["usageMetadata"].get(
"totalTokenCount"),
),
message=Message(
content=content,
role=cast(RoleType, role),
finish_reason=response_data["candidates"][0].get("finishReason"),
tool_calls=pick_tool_calls(content)
),
)
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# 使用批量嵌入接口,单次嵌入接口:embedContent
# gemini 的 API reference 是这样定义的很奇怪,居然敢在 url 中传递key
api_url = f"{self.config.api_base}/models/{req.model}:batchEmbedContents?key={self.config.api_key}"
headers = {
"Content-Type": "application/json",
}
# 目前 gemini 没有一个嵌入模型支持多模态嵌入
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
raise ValueError("gemini does not support multi-modal embedding")
inputs = cast(list[LLMChatTextContent], req.inputs)
data = [
{
"model": req.model,
"content": {
"parts": [{"text": input.text}]
},
"outputDimensionality": req.dimension
} for input in inputs
]
# 移除None字段
data = [{ k:v for k,v in item.items() if v is not None} for item in data]
response = self._post_with_retry(url=api_url,json={"requests": data}, headers=headers)
try:
# {
# "embeddings": [
# {"values": [0.1, ...]},
# ...
# ]
# }
response_data: dict[Literal["embeddings"],list[dict[Literal["values"], list[float]]]] = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
return LLMEmbeddingResponse(
# gemini不返回usage
vectors=[data["values"] for data in response_data["embeddings"]]
)
async def auto_detect_models(self) -> list[ModelConfig]:
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"x-goog-api-key": self.config.api_key}
) as response:
if response.status != 200:
self.logger.error(f"获取模型列表失败: {await response.text()}")
response.raise_for_status()
response_data = await response.json()
return [
ModelConfig(id=model["name"].removeprefix("models/"), type=ModelType.LLM.value, ability=LLMAbility.TextChat.value)
for model in response_data["models"]
if "generateContent" in model["supportedGenerationMethods"]
]
def _post_with_retry(self, url: str, json: dict, headers: dict, retry_count: int = 3) -> requests.Response: # type: ignore
for i in range(retry_count):
try:
response = requests.post(url, json=json, headers=headers)
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
if i == retry_count - 1:
self.logger.error(
f"API Response: {response.text if 'response' in locals() else 'No response'}")
raise e
else:
self.logger.warning(
f"Request failed, retrying {i+1}/{retry_count}: {e}")
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/minimax_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
class MinimaxConfig(OpenAIConfig):
api_base: str = "https://api.minimax.chat/v1"
class MinimaxAdapter(OpenAIAdapterChatBase):
def __init__(self, config: MinimaxConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/mistral_adapter.py
================================================
import aiohttp
from kirara_ai.llm.adapter import AutoDetectModelsProtocol
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class MistralConfig(OpenAIConfig):
api_base: str = "https://api.mistral.ai/v1"
class MistralAdapter(OpenAIAdapter, AutoDetectModelsProtocol):
def __init__(self, config: MistralConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[str]:
# Mistral API 响应格式:
# {
# "object": "list",
# "data": [
# {
# "id": "string",
# "object": "model",
# "created": 0,
# "owned_by": "mistralai",
# "capabilities": {
# "completion_chat": true,
# "completion_fim": false,
# "function_calling": true,
# "fine_tuning": false,
# "vision": false
# },
# "name": "string",
# ...
# }
# ]
# }
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
# 只返回支持聊天功能的模型
return [
model["id"]
for model in response_data["data"]
if model.get("capabilities", {}).get("completion_chat", False)
]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/moonshot_adapter.py
================================================
from .openai_adapter import OpenAIAdapterChatBase, OpenAIConfig
# https://platform.moonshot.cn/docs/intro#%E6%96%87%E6%9C%AC%E7%94%9F%E6%88%90%E6%A8%A1%E5%9E%8B
# TODO: implement feature usages
class MoonshotConfig(OpenAIConfig):
api_base: str = "https://api.moonshot.cn/v1"
class MoonshotAdapter(OpenAIAdapterChatBase):
def __init__(self, config: MoonshotConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/ollama_adapter.py
================================================
import asyncio
from typing import Any, List, cast
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .openai_adapter import convert_tools_to_openai_format
from .utils import generate_tool_call_id, pick_tool_calls
class OllamaConfig(BaseModel):
api_base: str = "http://localhost:11434"
model_config = ConfigDict(frozen=True)
async def resolve_media_ids(media_ids: list[str], media_manager: MediaManager) -> List[str]:
result = []
for media_id in media_ids:
media = media_manager.get_media(media_id)
if media is not None:
base64_data = await media.get_base64()
result.append(base64_data)
return result
def convert_llm_response(response_data: dict[str, dict[str, Any]]) -> list[LLMChatContentPartType]:
# 通过实践证明 llm 调用工具时 content 字段为空字符串没有任何有效信息不进行记录
if calls := response_data["message"].get("tool_calls", None):
return [LLMToolCallContent(
id=generate_tool_call_id(call["function"]["name"]),
name=call["function"]["name"],
parameters=call["function"].get("arguments", None)
) for call in calls
]
else:
return [LLMChatTextContent(text=response_data["message"].get("content", ""))]
def convert_non_tool_message(msg: LLMChatMessage, media_manager: MediaManager, loop: asyncio.AbstractEventLoop) -> dict[str, Any]:
text_content = ""
images: list[str] = []
tool_calls: list[dict[str, Any]] = []
messages: dict[str, Any] = {
"role": msg.role,
"content": "",
}
for part in msg.content:
if isinstance(part, LLMChatTextContent):
text_content += part.text
elif isinstance(part, LLMChatImageContent):
images.append(part.media_id)
elif isinstance(part, LLMToolCallContent):
tool_calls.append({
"function": {
"name": part.name,
"arguments": part.parameters,
}
})
messages["content"] = text_content
if images:
messages["images"] = loop.run_until_complete(
resolve_media_ids(images, media_manager))
if tool_calls:
messages["tool_calls"] = tool_calls
return messages
def convert_tool_result_message(msg: LLMChatMessage, media_manager: MediaManager, loop: asyncio.AbstractEventLoop) -> list[dict]:
"""
将工具调用结果转换为 Ollama 格式
"""
elements = cast(list[LLMToolResultContent], msg.content)
messages = []
for element in elements:
output = ""
for item in element.content:
if isinstance(item, tools.TextContent):
output += f"{item.text}\n"
elif isinstance(item, tools.MediaContent):
output += f"\n"
if element.isError:
output = f"Error: {element.name}\n{output}"
messages.append({"role": "tool", "content": output,
"tool_call_id": element.id})
return messages
def convert_tools_to_ollama_format(tools: list[Tool]) -> list[dict]:
# 这里将其独立出来方便应对后续接口改动
return convert_tools_to_openai_format(tools)
class OllamaAdapter(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol, LLMEmbeddingProtocol):
def __init__(self, config: OllamaConfig):
self.config = config
self.logger = get_logger("OllamaAdapter")
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/api/chat"
headers = {"Content-Type": "application/json"}
# 将消息转换为 Ollama 格式
messages = []
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
for msg in req.messages:
# 收集每条消息中的文本内容和图像
if msg.role == "tool":
messages.extend(convert_tool_result_message(
msg, self.media_manager, loop))
else:
messages.append(convert_non_tool_message(
msg, self.media_manager, loop))
data = {
"model": req.model,
"messages": messages,
"stream": False,
"options": {
"temperature": req.temperature,
"top_p": req.top_p,
"num_predict": req.max_tokens,
"stop": req.stop,
"tools": convert_tools_to_ollama_format(req.tools) if req.tools else None,
},
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
if "options" in data:
data["options"] = {
k: v for k, v in data["options"].items() if v is not None # type: ignore
}
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
# https://github.com/ollama/ollama/blob/main/docs/api.md#generate-a-chat-completion
content = convert_llm_response(response_data)
return LLMChatResponse(
model=req.model,
message=Message(
content=content,
role="assistant",
finish_reason="stop",
tool_calls=pick_tool_calls(content),
),
usage=Usage(
prompt_tokens=response_data['prompt_eval_count'],
completion_tokens=response_data['eval_count'],
total_tokens=response_data['prompt_eval_count'] +
response_data['eval_count'],
)
)
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# https://github.com/ollama/ollama/blob/main/docs/api.md#generate-embeddings api文档地址
api_url = f"{self.config.api_base}/api/embed"
headers = {"Content-Type": "application/json"}
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
raise ValueError("ollama api does not support multi-modal embedding")
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"model": req.model,
"input": [input.text for input in inputs],
# 禁止自动截断输入数据用以适应上下文长度
"truncate": req.truncate
}
data = { k:v for k, v in data.items() if v is not None }
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data = response.json()
except Exception as e:
self.logger.error(f"API Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=response_data["embeddings"],
usage=Usage(
prompt_tokens=response_data.get("prompt_eval_count", 0)
)
)
async def auto_detect_models(self) -> list[ModelConfig]:
api_url = f"{self.config.api_base}/api/tags"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(api_url) as response:
response.raise_for_status()
response_data = await response.json()
return [ModelConfig(id=tag["name"], type=ModelType.LLM.value, ability=LLMAbility.TextChat.value) for tag in response_data["models"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/openai_adapter.py
================================================
import asyncio
import json
from typing import Any, Dict, List, cast, Literal, TypedDict
import aiohttp
import requests
from pydantic import BaseModel, ConfigDict
import kirara_ai.llm.format.tool as tools
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol, LLMBackendAdapter, LLMChatProtocol, LLMEmbeddingProtocol
from kirara_ai.llm.format.message import (LLMChatContentPartType, LLMChatImageContent, LLMChatMessage,
LLMChatTextContent, LLMToolCallContent, LLMToolResultContent)
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.logger import get_logger
from kirara_ai.media import MediaManager
from kirara_ai.tracing import trace_llm_chat
from .utils import guess_openai_model, pick_tool_calls
logger = get_logger("OpenAIAdapter")
async def convert_parts_factory(messages: LLMChatMessage, media_manager: MediaManager) -> list[dict]:
if messages.role == "tool":
# typing.cast 指定类型,避免mypy报错
elements = cast(list[LLMToolResultContent], messages.content)
outputs = []
for element in elements:
# 保证 content 为一个字符串
output = ""
for content in element.content:
if isinstance(content, tools.TextContent):
output = content.text
elif isinstance(content, tools.MediaContent):
media = media_manager.get_media(content.media_id)
if media is None:
raise ValueError(f"Media {content.media_id} not found")
output += f""
else:
raise ValueError(f"Unsupported content type: {type(content)}")
if element.isError:
output = f"Error: {element.name}\n{output}"
outputs.append({
"role": "tool",
"tool_call_id": element.id,
"content": output,
})
return outputs
else:
parts: list[dict[str, Any]] = []
elements = cast(list[LLMChatContentPartType], messages.content)
tool_calls: list[dict[str, Any]] = []
for element in elements:
if isinstance(element, LLMChatTextContent):
parts.append(element.model_dump(mode="json"))
elif isinstance(element, LLMChatImageContent):
media = media_manager.get_media(element.media_id)
if media is None:
raise ValueError(f"Media {element.media_id} not found")
parts.append({
"type": "image_url",
"image_url": {
"url": await media.get_base64_url()
}
})
elif isinstance(element, LLMToolCallContent):
tool_calls.append({
"type": "function",
"id": element.id,
"function": {
"name": element.name,
"arguments": json.dumps(element.parameters or {}, ensure_ascii=False),
}
})
response: Dict[str, Any] = {"role": messages.role}
if parts:
response["content"] = parts
if tool_calls:
response["tool_calls"] = tool_calls
return [response]
async def convert_llm_chat_message_to_openai_message(messages: list[LLMChatMessage], media_manager: MediaManager) -> list[dict]:
# gather 必须先包一层异步函数,转化为协程对象, 否侧报错
results = await asyncio.gather(*[convert_parts_factory(msg, media_manager) for msg in messages])
# 扁平化结果, 展开所有列表
return [item for sublist in results for item in sublist]
def convert_tools_to_openai_format(tools: list[Tool]) -> list[dict]:
return [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.parameters if isinstance(tool.parameters, dict) else tool.parameters.model_dump(),
"strict": tool.strict,
}
} for tool in tools]
class OpenAIConfig(BaseModel):
api_key: str
api_base: str = "https://api.openai.com/v1"
model_config = ConfigDict(frozen=True)
class OpenAIAdapterChatBase(LLMBackendAdapter, AutoDetectModelsProtocol, LLMChatProtocol):
media_manager: MediaManager
def __init__(self, config: OpenAIConfig):
self.config = config
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
api_url = f"{self.config.api_base}/chat/completions"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json",
}
data = {
"messages": asyncio.run(convert_llm_chat_message_to_openai_message(req.messages, self.media_manager)),
"model": req.model,
"frequency_penalty": req.frequency_penalty,
"max_completion_tokens": req.max_tokens, # 最新的reference废除max_tokens,改为如上参数
"presence_penalty": req.presence_penalty,
"response_format": req.response_format,
"stop": req.stop,
"stream": req.stream,
"stream_options": req.stream_options,
"temperature": req.temperature,
"top_p": req.top_p,
# tool pydantic 模型按照 openai api 格式进行的建立。所以这里直接dump
"tools": convert_tools_to_openai_format(req.tools) if req.tools else None,
"tool_choice": "auto" if req.tools else None,
"logprobs": req.logprobs,
"top_logprobs": req.top_logprobs,
}
# Remove None fields
data = {k: v for k, v in data.items() if v is not None}
logger.debug(f"Request: {data}")
response = requests.post(api_url, json=data, headers=headers)
try:
response.raise_for_status()
response_data: dict = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
logger.debug(f"Response: {response_data}")
choices: List[dict[str, Any]] = response_data.get("choices", [{}])
first_choice = choices[0] if choices else {}
message: dict[str, Any] = first_choice.get("message", {})
# 检测tool_calls字段是否存在和是否不为None. tool_call时content字段无有效信息,暂不记录
content: list[LLMChatContentPartType] = []
if tool_calls := message.get("tool_calls", None):
content = [LLMToolCallContent(
id=call["id"],
name=call["function"]["name"],
parameters=json.loads(call["function"].get("arguments", "{}"))
) for call in tool_calls]
else:
content = [LLMChatTextContent(text=message.get("content", ""))]
usage_data = response_data.get("usage", {})
return LLMChatResponse(
model=req.model,
usage=Usage(
prompt_tokens=usage_data.get("prompt_tokens", 0),
completion_tokens=usage_data.get("completion_tokens", 0),
total_tokens=usage_data.get("total_tokens", 0),
),
message=Message(
content=content,
role=message.get("role", "assistant"),
tool_calls = pick_tool_calls(content),
finish_reason=first_choice.get("finish_reason", ""),
),
)
async def get_models(self) -> list[str]:
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data.get("data", [])]
async def auto_detect_models(self) -> list[ModelConfig]:
models = await self.get_models()
all_models: list[ModelConfig] = []
for model in models:
guess_result = guess_openai_model(model)
if guess_result is None:
continue
all_models.append(ModelConfig(id=model, type=guess_result[0].value, ability=guess_result[1]))
return all_models
class EmbeddingData(TypedDict):
object: Literal["embedding"]
embedding: list[float]
index: int
class EmbeddingResponse(TypedDict):
# 用于描述类型定义
object: Literal["list"]
data: list[EmbeddingData]
model: str
usage: dict[Literal["prompt_tokens", "total_tokens"], int]
class OpenAIAdapter(OpenAIAdapterChatBase, LLMEmbeddingProtocol):
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
"""
此为openai api嵌入式模型接口
Tips: openai仅在 text-embedding-3 及以后模型中支持设定输出向量维度
"""
api_url = f"{self.config.api_base}/embeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json",
}
if len(req.inputs) > 2048:
# text数组不能超过2048个元素,openai api限制
raise ValueError("Text list has too many dimensions, max dimension is 2048")
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
# 未在api中发现多模态嵌入api, 等待后续更新
raise ValueError("openai does not support multi-modal embedding")
# mypy 类型检查修复,如果添加多模态请去除这个标注
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"text": [input.text for input in inputs],
"model": req.model,
"dimensions": req.dimension,
"encoding_format": req.encoding_format
}
# 删除 None 字段
data = {k: v for k, v in data.items() if v is not None}
logger.debug(f"Request: {data}")
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: EmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
logger.debug(f"Response: {response_data}")
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage=Usage(
prompt_tokens=response_data["usage"].get("prompt_tokens", 0),
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/openrouter_adapter.py
================================================
import aiohttp
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.model_types import LLMAbility, ModelType
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class OpenRouterConfig(OpenAIConfig):
api_base: str = "https://openrouter.ai/api/v1"
class OpenRouterAdapter(OpenAIAdapter):
def __init__(self, config: OpenRouterConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
all_models: list[ModelConfig] = []
api_url = f"{self.config.api_base}/models"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
for model in response_data.get("data", []):
ability = LLMAbility.TextChat.value
for input_modality in model["architecture"]["input_modalities"]:
if input_modality == "text":
ability |= LLMAbility.TextInput.value
elif input_modality == "image":
ability |= LLMAbility.ImageInput.value
for output_modality in model["architecture"]["output_modalities"]:
if output_modality == "text":
ability |= LLMAbility.TextOutput.value
elif output_modality == "image":
ability |= LLMAbility.ImageOutput.value
all_models.append(ModelConfig(id=model["id"], type=ModelType.LLM.value, ability=ability))
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/setup.py
================================================
from setuptools import find_packages, setup
setup(
name="kirara_ai-llm-presets",
version="1.0.0",
description="Preset LLM adapters for kirara_ai",
author="Internal",
packages=find_packages(),
install_requires=["requests"],
entry_points={
"chatgpt_mirai.plugins": [
"llm_presets = llm_preset_adapters.plugin:LLMPresetsPlugin"
]
},
)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/siliconflow_adapter.py
================================================
import aiohttp
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class SiliconFlowConfig(OpenAIConfig):
api_base: str = "https://api.siliconflow.cn/v1"
class SiliconFlowAdapter(OpenAIAdapter):
def __init__(self, config: SiliconFlowConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[str]:
api_url = f"{self.config.api_base}/models?sub_type=chat"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(
api_url, headers={"Authorization": f"Bearer {self.config.api_key}"}
) as response:
response.raise_for_status()
response_data = await response.json()
return [model["id"] for model in response_data["data"]]
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/tencentcloud_adapter.py
================================================
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class TencentCloudConfig(OpenAIConfig):
api_base: str = "https://api.hunyuan.cloud.tencent.com/v1"
class TencentCloudAdapter(OpenAIAdapter):
def __init__(self, config: TencentCloudConfig):
super().__init__(config)
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/tests/test_utils.py
================================================
from llm_preset_adapters.utils import guess_openai_model
from kirara_ai.llm.model_types import AudioModelAbility, EmbeddingModelAbility, ImageModelAbility, LLMAbility, ModelType
from kirara_ai.logger import get_logger
models = [
{
"id": "babbage-002",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextCompletion.value
},
{
"id": "chatgpt-4o-latest",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "computer-use-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "dall-e-2",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value | ImageModelAbility.ImageEdit.value | ImageModelAbility.Inpainting.value
},
{
"id": "dall-e-3",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value
},
{
"id": "davinci-002",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextCompletion.value
},
{
"id": "gpt-3-5-0301",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-0125",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-1106",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-16k-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-3-5-turbo-instruct",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0125-preview",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0314",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-0613",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "gpt-4-turbo-2024-04-09",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-mini-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.1-nano-2025-04-14",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4.5-preview-2025-02-27",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-05-13",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-08-06",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-2024-11-20",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-audio-preview-2024-10-01",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-audio-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-2024-07-18",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-audio-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value | LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-realtime-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-mini-search-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "gpt-4o-mini-transcribe",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value
},
{
"id": "gpt-4o-mini-tts",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value | AudioModelAbility.Streaming.value
},
{
"id": "gpt-4o-realtime-preview-2024-10-01",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-realtime-preview-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "gpt-4o-search-preview-2025-03-11",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value
},
{
"id": "gpt-4o-transcribe",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value
},
{
"id": "gpt-image-1",
"type": ModelType.ImageGeneration.value,
"abilities": ImageModelAbility.TextToImage.value | ImageModelAbility.ImageEdit.value |
ImageModelAbility.Inpainting.value
},
{
"id": "o1-2024-12-17",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o1-mini-2024-09-12",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value
},
{
"id": "o1-preview-2024-09-12",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
},
{
"id": "o1-pro-2025-03-19",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o3-2025-04-16",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o3-mini-2025-01-31",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value |
LLMAbility.FunctionCalling.value
},
{
"id": "o4-mini-2025-04-16",
"type": ModelType.LLM.value,
"abilities": LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
},
{
"id": "text-embedding-3-large",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "text-embedding-3-small",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "text-embedding-ada-002",
"type": ModelType.Embedding.value,
"abilities": EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value
},
{
"id": "tts-1-hd",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value
},
{
"id": "tts-1",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Speech.value
},
{
"id": "whisper-1",
"type": ModelType.Audio.value,
"abilities": AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value
}
]
def test_guess_openai_model():
logger = get_logger("test_guess_openai_model")
failed_tests = []
for model in models:
model_type, abilities = guess_openai_model(model["id"])
logger.info(f"模型: {model['id']}, 模型类型: {model_type}, 能力: {abilities}, 预期: {model['type']}, {model['abilities']}")
try:
assert model_type is not None, f"模型 {model['id']} 的类型不应为 None"
assert model_type.value == model["type"], f"模型 {model['id']} 的类型不匹配,预期 {model['type']},实际 {model_type.value}"
if abilities != model["abilities"]:
diff_bits = abilities ^ model["abilities"]
expected_but_missing = diff_bits & model["abilities"]
unexpected_but_present = diff_bits & abilities
error_msg = f"模型 {model['id']} 的能力不匹配,预期 {model['abilities']},实际 {abilities}"
# 根据模型类型获取对应的能力枚举类
ability_enum = None
if model_type == ModelType.LLM:
ability_enum = LLMAbility
elif model_type == ModelType.Embedding:
ability_enum = EmbeddingModelAbility
elif model_type == ModelType.ImageGeneration:
ability_enum = ImageModelAbility
elif model_type == ModelType.Audio:
ability_enum = AudioModelAbility
# 获取缺少的能力名称
if expected_but_missing:
missing_abilities = []
for enum_item in ability_enum:
if expected_but_missing & enum_item.value:
missing_abilities.append(enum_item.name)
error_msg += f",缺少能力: {', '.join(missing_abilities)} ({bin(expected_but_missing)})"
# 获取多余的能力名称
if unexpected_but_present:
extra_abilities = []
for enum_item in ability_enum:
if unexpected_but_present & enum_item.value:
extra_abilities.append(enum_item.name)
error_msg += f",多余能力: {', '.join(extra_abilities)} ({bin(unexpected_but_present)})"
assert False, error_msg
except AssertionError as e:
failed_tests.append(str(e))
logger.error(str(e))
if failed_tests:
error_message = f"共有 {len(failed_tests)} 个测试点失败:\n" + "\n".join(failed_tests)
assert False, error_message
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/utils.py
================================================
import uuid
from typing import Optional, Tuple
from kirara_ai.llm.format.message import LLMChatContentPartType, LLMToolCallContent
from kirara_ai.llm.format.tool import Function, ToolCall
from kirara_ai.llm.model_types import AudioModelAbility, EmbeddingModelAbility, ImageModelAbility, LLMAbility, ModelType
def generate_tool_call_id(name: str) -> str:
return f"{name}_{str(uuid.uuid4())}"
def pick_tool_calls(calls: list[LLMChatContentPartType]) -> Optional[list[ToolCall]]:
tool_calls = [
ToolCall(
id=call.id,
function=Function(name=call.name, arguments=call.parameters)
) for call in calls if isinstance(call, LLMToolCallContent)
]
if tool_calls:
return tool_calls
else:
return None
def guess_openai_model(model_id: str) -> Tuple[ModelType, int] | None:
"""
根据模型ID猜测模型类型和能力
返回: (ModelType, ability_bitmask) 或 None
"""
model_id = model_id.lower()
# 1. 检查嵌入模型
if "embedding" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value) # 嵌入模型
# 2. 检查图像生成模型
if "dall-e" in model_id or "gpt-image" in model_id:
ability = ImageModelAbility.TextToImage.value
if "dall-e-2" in model_id or "gpt-image" in model_id:
ability |= ImageModelAbility.ImageEdit.value | ImageModelAbility.Inpainting.value
return (ModelType.ImageGeneration, ability)
# 3. 检查音频模型
if "whisper" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value)
if "tts" in model_id:
if "mini" in model_id:
return (ModelType.Audio, AudioModelAbility.Speech.value | AudioModelAbility.Streaming.value)
return (ModelType.Audio, AudioModelAbility.Speech.value)
if model_id == "gpt-4o-transcribe":
# 特别处理 gpt-4o-transcribe,没有 Translation 能力
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value)
if "transcribe" in model_id:
if "mini" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value)
if "realtime" in model_id:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Realtime.value)
else:
return (ModelType.Audio, AudioModelAbility.Transcription.value | AudioModelAbility.Translation.value | AudioModelAbility.Streaming.value | AudioModelAbility.Realtime.value)
# 4. 处理音频相关的LLM模型 (这些不应该有图像输入能力)
if ("audio" in model_id or "realtime" in model_id) and "4o" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value
# 特殊情况处理
if "gpt-4o-mini-audio-preview-2024-12-17" in model_id:
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
if "gpt-4o-mini-realtime-preview-2024-12-17" in model_id:
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
if not ("mini-search" in model_id or "mini-realtime" in model_id or
"instruct" in model_id or "search" in model_id or
"mini" in model_id):
ability |= LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
# 5. 检查moderation模型
if "moderation" in model_id:
return None
# 6. LLM模型 (默认情况)
ability = LLMAbility.TextChat.value
if ("babbage" in model_id or "davinci" in model_id):
return (ModelType.LLM, LLMAbility.TextInput.value | LLMAbility.TextOutput.value)
# 图像输入能力
if ("vision" in model_id or
"4o" in model_id or
"computer-use-preview" in model_id or
"gpt-4-turbo" in model_id or
"o1" in model_id or
"o4" in model_id or
"4." in model_id or
("4" in model_id and ("image" in model_id or "vision" in model_id))):
ability |= LLMAbility.ImageInput.value
# 大部分模型都应该有函数调用能力,除了特定例外
if not ("3.5" in model_id or
"3-5" in model_id or
"1106" in model_id or
"0314" in model_id or
"0125" in model_id or
"gpt-4-0" in model_id or
"chatgpt-4o" in model_id or
"instruct" in model_id or
"search" in model_id or
"o1-mini" in model_id or
model_id.startswith(("babbage", "davinci"))):
ability |= LLMAbility.FunctionCalling.value
# 特殊模型处理
if "o3-2025-04-16" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.FunctionCalling.value
if "o1-preview-2024-09-12" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
if "o1-mini-2024-09-12" in model_id:
ability = LLMAbility.TextChat.value
if "o3-mini-2025-01-31" in model_id:
ability = LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value
return (ModelType.LLM, ability)
def guess_qwen_model(model_id: str) -> Tuple[ModelType, int] | None:
"""
根据模型ID猜测通义千问模型的类型和能力
返回: (ModelType, ability_bitmask) 或 None
"""
model_id = model_id.lower()
# 通义千问Embedding模型
if "text-embedding" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.Batch.value)
if "multimodal-embedding-v1" in model_id:
return (ModelType.Embedding, EmbeddingModelAbility.TextEmbedding.value | EmbeddingModelAbility.ImageEmbedding.value | EmbeddingModelAbility.AudioEmbedding.value | EmbeddingModelAbility.VideoEmbedding.value | EmbeddingModelAbility.Batch.value)
# 通义千问多模态模型
if "-vl" in model_id or "qvq-":
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.ImageInput.value)
if "-audio" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.AudioInput.value)
if "qwen-omni" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.ImageInput.value | LLMAbility.AudioInput.value | LLMAbility.AudioOutput.value)
# 通义千问系列基础模型
if "qwen" in model_id:
return (ModelType.LLM, LLMAbility.TextChat.value | LLMAbility.FunctionCalling.value)
return None
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/volcengine_adapter.py
================================================
import datetime
import hashlib
import hmac
from urllib.parse import quote
import aiohttp
from pydantic import Field
from kirara_ai.config.global_config import ModelConfig
from kirara_ai.llm.model_types import LLMAbility, ModelType
from .openai_adapter import OpenAIAdapter, OpenAIConfig
class VolcengineConfig(OpenAIConfig):
api_base: str = "https://ark.cn-beijing.volces.com/api/v3"
access_key_id: str = Field(description="火山云引擎 API 密钥 ID,用于获取模型列表")
access_key_secret: str = Field(description="火山云引擎 API 密钥,用于获取模型列表")
def generate_volcengine_signature(access_key_id, access_key_secret, method, path, query, body=None):
"""生成火山引擎API所需的HMAC-SHA256签名"""
# 初始化参数
service = "ark"
region = "cn-beijing"
host = "open.volcengineapi.com"
content_type = "application/json"
# 获取UTC时间
now = datetime.datetime.utcnow()
x_date = now.strftime("%Y%m%dT%H%M%SZ")
short_date = x_date[:8]
# 计算请求体的SHA256哈希值
body = body or ""
x_content_sha256 = hashlib.sha256(body.encode("utf-8")).hexdigest()
# 规范化查询字符串
canonical_query = normalize_query(query)
# 签名所需的头部
signed_headers = ["host", "x-content-sha256", "x-date"]
signed_headers_str = ";".join(signed_headers)
# 构建规范请求字符串
canonical_headers = "\n".join([
f"host:{host}",
f"x-content-sha256:{x_content_sha256}",
f"x-date:{x_date}",
])
canonical_request = "\n".join([
method.upper(),
path,
canonical_query,
canonical_headers,
"",
signed_headers_str,
x_content_sha256
])
# 计算规范请求的哈希值
hashed_canonical_request = hashlib.sha256(canonical_request.encode("utf-8")).hexdigest()
# 构建签名字符串
credential_scope = f"{short_date}/{region}/{service}/request"
string_to_sign = "\n".join(["HMAC-SHA256", x_date, credential_scope, hashed_canonical_request])
# 计算签名
k_date = hmac.new(access_key_secret.encode("utf-8"), short_date.encode("utf-8"), hashlib.sha256).digest()
k_region = hmac.new(k_date, region.encode("utf-8"), hashlib.sha256).digest()
k_service = hmac.new(k_region, service.encode("utf-8"), hashlib.sha256).digest()
k_signing = hmac.new(k_service, b"request", hashlib.sha256).digest()
signature = hmac.new(k_signing, string_to_sign.encode("utf-8"), hashlib.sha256).hexdigest()
# 构建Authorization头
authorization = f"HMAC-SHA256 Credential={access_key_id}/{credential_scope}, SignedHeaders={signed_headers_str}, Signature={signature}"
# 返回所有需要的头部
return {
"Host": host,
"X-Content-Sha256": x_content_sha256,
"X-Date": x_date,
"Authorization": authorization
}
def normalize_query(params):
"""规范化查询参数"""
if not params:
return ""
query = ""
for key in sorted(params.keys()):
if isinstance(params[key], list):
for k in params[key]:
query += quote(key, safe="-_.~") + "=" + quote(str(k), safe="-_.~") + "&"
else:
query += quote(key, safe="-_.~") + "=" + quote(str(params[key]), safe="-_.~") + "&"
return query[:-1].replace("+", "%20") if query else ""
def detect_ability(model: dict) -> int:
ability = LLMAbility.TextChat.value
# detect visual qa
if "VisualQuestionAnswering" in model.get("TaskTypes", []):
ability |= LLMAbility.ImageInput.value
# detect function calling
if "Function Call" in model.get("CustomizedTags", []):
ability |= LLMAbility.FunctionCalling.value
return ability
class VolcengineAdapter(OpenAIAdapter):
config: VolcengineConfig
def __init__(self, config: VolcengineConfig):
super().__init__(config)
async def auto_detect_models(self) -> list[ModelConfig]:
"""
获取火山引擎可用的模型列表,支持分页获取所有结果
{
"Result": {
"TotalCount": 39,
"PageNumber": 1,
"PageSize": 10,
"Items": [
{
"Name": "doubao-1-5-pro-256k",
"VendorName": "字节跳动",
"DisplayName": "Doubao-1.5-pro-256k",
"ShortName": "",
"PrimaryVersion": "250115",
"FoundationModelTag": {
"Domains": [
"LLM"
],
"Languages": [
"中英文"
],
"TaskTypes": [
"Chat"
],
"ContextLength": "256k",
"CustomizedTags": [
"支持体验"
]
},
}
]
}
}
"""
host = "open.volcengineapi.com"
path = "/"
all_models: list[ModelConfig] = []
page_number = 1
page_size = 100
total_pages = 1 # 初始值,会在第一次请求后更新
while page_number <= total_pages:
query = {
"Action": "ListFoundationModels",
"Version": "2024-01-01",
"PageNumber": page_number,
"PageSize": page_size
}
# 生成签名和头部
headers = generate_volcengine_signature(
self.config.access_key_id,
self.config.access_key_secret,
"GET",
path,
query
)
# 构建完整URL
url = f"https://{host}{path}"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.get(url, headers=headers, params=query) as response:
response.raise_for_status()
response_data = await response.json()
if "Result" in response_data:
response_data = response_data["Result"]
else:
return []
# 更新总页数(如果API返回了这个信息)
if "TotalCount" in response_data and "PageSize" in response_data:
total_count = response_data["TotalCount"]
total_pages = (total_count + page_size - 1) // page_size
for model in response_data["Items"]:
foundation_model = model.get("FoundationModelTag", {})
if ("LLM" in foundation_model.get("Domains", []) and
model.get("Name")):
ability = detect_ability(foundation_model)
all_models.append(ModelConfig(id=model["Name"], type=ModelType.LLM.value, ability=ability))
# 准备获取下一页
page_number += 1
return all_models
================================================
FILE: kirara_ai/plugins/llm_preset_adapters/voyage_adapter.py
================================================
from pydantic import BaseModel, ConfigDict
from typing import cast, TypedDict, Literal, Optional
import requests
import asyncio
from kirara_ai.llm.adapter import LLMBackendAdapter, LLMEmbeddingProtocol, LLMReRankProtocol
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.rerank import LLMReRankRequest, LLMReRankResponse, ReRankerContent
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent
from kirara_ai.llm.format.response import Usage
from kirara_ai.media.manager import MediaManager
from kirara_ai.logger import get_logger
logger = get_logger("VoyageAdapter")
async def resolve_media_base64(inputs: list[LLMChatImageContent|LLMChatTextContent], media_manager: MediaManager) -> list:
results = []
for input in inputs:
# voyage 的多模态接口设置中会将 一个content字段中的所有payload视作一个输入集,并对这个输入集合生成一个向量.
# 所以这里对 image 做出处理,将其描述与原始图像打包为一个payload.
if isinstance(input, LLMChatTextContent):
results.append({
"content": [
{"type": "text", "text": input.text}
]
})
elif isinstance(input, LLMChatImageContent):
media = media_manager.get_media(input.media_id)
if media is None:
raise ValueError(f"Media {input.media_id} not found")
results.append({
"content": [
{"type": "text", "text": "" if (desc := media.description) is None else desc},
{"type": "image_base64", "image_base64": await media.get_base64()}
]
})
return results
class ReRankData(TypedDict):
index: int
relevance_score: float
document: Optional[str]
class ReRankResponse(TypedDict):
"""给mypy检查用, 顺便给开发者标识返回json的基本结构。"""
object: Literal["list"]
data: list[ReRankData]
model: str
usage: dict[Literal["total_tokens"], int]
class EmbeddingData(TypedDict):
object: Literal["embedding"]
embedding: list[float | int]
index: int
class EmbeddingResponse(TypedDict):
object: Literal["list"]
data: list[EmbeddingData]
model: str
usage: dict[Literal["total_tokens"], int]
class ModalEmbeddingResponse(TypedDict):
object: Literal["list"]
data: list[EmbeddingData]
model: str
# voyage 的多模态接口会返回三个usage指标: text_tokens: 文字使用token数, image_pixels: 图片像素数, total_tokens: 总token数
usage: dict[Literal["text_tokens", "image_pixels", "total_tokens"], int]
class VoyageConfig(BaseModel):
api_key: str
api_base: str = "https://api.voyageai.com"
model_config = ConfigDict(frozen=True)
class VoyageAdapter(LLMBackendAdapter, LLMEmbeddingProtocol, LLMReRankProtocol):
media_manager: MediaManager
def __init__(self, config: VoyageConfig):
self.config = config
def embed(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
# voyage 支持多模态嵌入, 但是两个接口支持的参数不同。
# 因此对其做区分,以充分利用 voyage 接口提供的可选参数。
if any(isinstance(input, LLMChatImageContent) for input in req.inputs):
return self._multi_modal_embedding(req)
else:
return self._text_embedding(req)
def _text_embedding(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
api_url = f"{self.config.api_base}/v1/embeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
inputs = cast(list[LLMChatTextContent], req.inputs)
data = {
"model": req.model,
"input": [input.text for input in inputs],
"truncation": req.truncate,
"input_type": req.input_type,
"output_dimension": req.dimension,
"output_dtype": req.encoding_format,
"encoding_format": req.encoding_format,
}
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: EmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage = Usage(
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
def _multi_modal_embedding(self, req: LLMEmbeddingRequest) -> LLMEmbeddingResponse:
api_url = f"{self.config.api_base}/v1/multimodalembeddings"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
# loop = asyncio.new_event_loop()
# try:
# asyncio.set_event_loop(loop)
# data = {
# "model": req.model,
# "inputs": loop.run_until_complete(resolve_media_base64(req.inputs, self.media_manager)),
# "input_type": req.input_type,
# "truncation": req.truncate,
# "output_encoding": req.encoding_format
# }
# finally:
# loop.close() # 关闭事件循环,避免资源泄露。
# asyncio.set_event_loop(None) # 解除 asyncio 事件循环绑定。避免get_running_loop()获取到已结束时间循环。
data = {
"model": req.model,
# 为何不使用神奇的 asyncio.run() 自动管理这个临时loop的生命周期呢。(python 3.7+)
"inputs": asyncio.run(resolve_media_base64(req.inputs, self.media_manager)),
"input_type": req.input_type,
"truncation": req.truncate,
"output_encoding": req.encoding_format
}
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: ModalEmbeddingResponse = response.json()
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMEmbeddingResponse(
vectors=[data["embedding"] for data in response_data["data"]],
usage = Usage(
total_tokens=response_data["usage"].get("total_tokens", 0)
)
)
def rerank(self, req: LLMReRankRequest) -> LLMReRankResponse:
api_url = f"{self.config.api_base}/v1/rerank"
headers = {
"Authorization": f"Bearer {self.config.api_key}",
"Content-Type": "application/json"
}
data = {
"query": req.query,
"documents": req.documents,
"model": req.model,
"top_k": req.top_k,
"return_documents": req.return_documents,
"truncation": req.truncation
}
# 去除 None 值
data = { k:v for k,v in data.items() if v is not None }
response = requests.post(api_url, headers=headers, json=data)
try:
response.raise_for_status()
response_data: ReRankResponse = response.json()
logger.debug(f"server response_data: {response_data}")
except Exception as e:
logger.error(f"Response: {response.text}")
raise e
return LLMReRankResponse(
contents = [ReRankerContent(
document = data.get("document", None),
score = data["relevance_score"]
) for data in response_data["data"]],
usage = Usage(
total_tokens = response_data["usage"].get("total_tokens", 0)
),
sort = cast(bool, req.sort) # 强制类型转换,避免mypy报错。
)
================================================
FILE: kirara_ai/system/__init__.py
================================================
================================================
FILE: kirara_ai/system/updater.py
================================================
================================================
FILE: kirara_ai/tracing/__init__.py
================================================
from kirara_ai.tracing.core import TracerBase
from kirara_ai.tracing.decorator import trace_llm_chat
from kirara_ai.tracing.llm_tracer import LLMTracer
from kirara_ai.tracing.manager import TracingManager
from kirara_ai.tracing.models import LLMRequestTrace
__all__ = [
"TracingManager",
"LLMRequestTrace",
"TracerBase",
"LLMTracer",
"trace_llm_chat"
]
================================================
FILE: kirara_ai/tracing/core.py
================================================
import abc
import asyncio
import uuid
from asyncio import Queue
from typing import Any, Dict, Generic, List, Optional, Tuple, Type, TypeVar
from sqlalchemy import Column, DateTime, String, asc
from kirara_ai.database import Base, DatabaseManager
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.tracing import TraceEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
logger = get_logger("Tracking")
class TraceRecord(Base):
"""跟踪记录基类,用于ORM映射"""
__abstract__ = True
trace_id = Column(String(64), nullable=False, index=True, unique=True)
status = Column(String(20), nullable=False, default="pending")
request_time = Column(DateTime, nullable=False, index=True)
@abc.abstractmethod
def update_from_event(self, event: TraceEvent) -> None:
"""从事件更新记录"""
@abc.abstractmethod
def to_dict(self) -> Dict[str, Any]:
"""将记录转换为字典,用于JSON序列化"""
@abc.abstractmethod
def to_detail_dict(self) -> Dict[str, Any]:
"""将详细记录转换为字典,用于JSON序列化"""
def generate_trace_id() -> str:
"""生成唯一的追踪ID"""
return str(uuid.uuid4())
# 定义泛型类型变量,用于追踪事件、追踪器和追踪记录
T = TypeVar('T')
E = TypeVar('E', bound=TraceEvent) # 事件类型
R = TypeVar('R', bound=TraceRecord) # 记录类型
class TracerBase(Generic[R], abc.ABC):
"""追踪器基类"""
# 追踪器名称,用于区分不同类型的追踪器
name: str
record_class: Type[R]
@Inject()
def __init__(self, container: DependencyContainer, record_class: Type[R], db_manager: DatabaseManager, event_bus: EventBus):
self.record_class = record_class
self.container = container
self.db_manager = db_manager
self.event_bus = event_bus
self.logger = logger
# 活跃追踪的映射表
self._active_traces: Dict[str, Dict[str, Any]] = {}
# WebSocket消息队列映射表
self._ws_queues: List[Queue] = []
def initialize(self):
"""初始化追踪器,注册事件处理程序"""
self.logger.info(f"Initializing {self.name} tracer")
self._register_event_handlers()
self.logger.info(f"{self.name} tracer initialized")
def shutdown(self):
"""关闭追踪器,取消事件注册"""
self.logger.info(f"Shutting down {self.name} tracer")
self._unregister_event_handlers()
# 关闭所有WebSocket连接
for queue in list(self._ws_queues):
try:
queue.put_nowait(None)
except Exception:
pass
self._ws_queues.clear()
@abc.abstractmethod
def _register_event_handlers(self):
"""注册事件处理程序"""
@abc.abstractmethod
def _unregister_event_handlers(self):
"""取消事件处理程序注册"""
def get_traces(
self,
filters: Optional[Dict[str, Any]] = None,
page: int = 1,
page_size: int = 20,
order_by: str = "request_time",
order_desc: bool = True
) -> Tuple[List[R], int]:
"""统一的追踪记录查询方法
Args:
filters: 过滤条件字典
page: 页码(从1开始)
page_size: 每页记录数
order_by: 排序字段
order_desc: 是否降序排序
Returns:
Tuple[List[R], int]: 记录列表和总记录数
"""
with self.db_manager.get_session() as session:
from sqlalchemy import desc, func, select
# 构建基础查询
query = select(self.record_class)
count_query = select(func.count()).select_from(self.record_class)
# 应用过滤条件
if filters:
for field, value in filters.items():
if value is not None and hasattr(self.record_class, field):
query = query.filter(getattr(self.record_class, field) == value)
count_query = count_query.filter(getattr(self.record_class, field) == value)
# 应用排序
if hasattr(self.record_class, order_by):
order_func = desc if order_desc else asc
query = query.order_by(order_func(getattr(self.record_class, order_by)))
# 应用分页
if page > 0 and page_size > 0:
query = query.offset((page - 1) * page_size).limit(page_size)
# 执行查询
total = session.execute(count_query).scalar() or 0
records = list(session.execute(query).scalars().all())
return records, total
def get_recent_traces(self, limit: int = 100) -> List[R]:
"""获取最近的跟踪记录"""
with self.db_manager.get_session() as session:
from sqlalchemy import desc, select
stmt = select(self.record_class).order_by(desc(self.record_class.request_time)).limit(limit)
result = session.execute(stmt)
return list(result.scalars().all())
def get_trace_by_id(self, trace_id: str) -> Optional[R]:
"""根据追踪ID获取跟踪记录"""
with self.db_manager.get_session() as session:
return session.query(self.record_class).filter_by(trace_id=trace_id).first()
def save_trace_record(self, record: R) -> Dict[str, Any]:
"""保存追踪记录到数据库"""
with self.db_manager.get_session() as session:
session.add(record)
session.commit()
return record.to_dict()
def update_trace_record(self, trace_id: str, event: TraceEvent) -> Optional[Dict[str, Any]]:
"""更新追踪记录"""
with self.db_manager.get_session() as session:
if (
record := session.query(self.record_class)
.filter_by(trace_id=trace_id)
.first()
):
record.update_from_event(event)
session.commit()
return record.to_dict()
return None
# WebSocket相关方法
def register_ws_client(self) -> Queue:
"""注册WebSocket客户端,返回一个消息队列"""
queue: Queue = Queue()
self._ws_queues.append(queue)
return queue
def unregister_ws_client(self, queue: Queue):
"""注销WebSocket客户端"""
if queue in self._ws_queues:
self._ws_queues.remove(queue)
def broadcast_ws_message(self, message: Dict):
"""向所有WebSocket客户端广播消息"""
dead_queues = []
for queue in self._ws_queues:
try:
queue.put_nowait(message)
except asyncio.QueueFull:
self.logger.warning(f"Queue is full, message dropped")
dead_queues.append(queue)
except Exception as e:
self.logger.error(f"Error broadcasting message: {e}")
dead_queues.append(queue)
# 清理失效的队列
for queue in dead_queues:
if queue in self._ws_queues:
self._ws_queues.remove(queue)
================================================
FILE: kirara_ai/tracing/decorator.py
================================================
import functools
from typing import Callable
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.tracing.llm_tracer import LLMTracer
def trace_llm_chat(func: Callable):
"""装饰器,用于追踪LLM请求"""
from kirara_ai.llm.adapter import LLMBackendAdapter
@functools.wraps(func)
def wrapper(self: LLMBackendAdapter, req: LLMChatRequest) -> LLMChatResponse:
tracer: LLMTracer = self.tracer
# 开始追踪
trace_id = tracer.start_request_tracking(self.backend_name, req)
try:
# 调用原始方法
response = func(self, req)
except Exception as e:
# 记录错误
tracer.fail_request_tracking(trace_id, req, str(e))
raise e
else:
# 完成追踪
tracer.complete_request_tracking(trace_id, req, response)
return response
return wrapper
================================================
FILE: kirara_ai/tracing/llm_tracer.py
================================================
from datetime import datetime, timedelta
from typing import Any, Dict
from sqlalchemy import case, func
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.llm.format.message import LLMChatMessage, LLMChatTextContent
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Message
from kirara_ai.logger import get_logger
from kirara_ai.tracing.core import TracerBase, generate_trace_id
from kirara_ai.tracing.models import LLMRequestTrace
logger = get_logger("LLMTracer")
UNRECORD_REQUEST = [LLMChatMessage(
role="system",
content=[
LLMChatTextContent(
text="*** 内容未记录 ***"
)
]
)]
UNRECORD_RESPONSE = Message(
role="assistant",
content=[
LLMChatTextContent(
text="*** 内容未记录 ***"
)
]
)
class LLMTracer(TracerBase[LLMRequestTrace]):
"""LLM追踪器,负责处理LLM请求的跟踪"""
name = "llm"
record_class = LLMRequestTrace
@Inject()
def __init__(self, container: DependencyContainer):
super().__init__(container, record_class=LLMRequestTrace) # type: ignore
self.config = container.resolve(GlobalConfig)
def initialize(self):
"""启动追踪器,将所有 pending 状态的任务转为 failed,并清理超过 30 天的请求"""
super().initialize()
try:
pending_traces = self._mark_pending_as_failed()
deleted_count = self._clean_old_traces()
if pending_traces or deleted_count:
self.logger.info(f"已将 {pending_traces} 个 未结束状态的 LLM 请求标记为失败,并清理了 {deleted_count} 个超过 30 天的请求记录")
except Exception as e:
self.logger.opt(exception=e).error(f"处理历史追踪记录时发生错误")
def _mark_pending_as_failed(self) -> int:
"""将所有 pending 状态的任务转为 failed"""
with self.db_manager.get_session() as session:
pending_traces = session.query(LLMRequestTrace).filter(
LLMRequestTrace.status == "pending" # type: ignore
).all()
for trace in pending_traces:
trace.status = "failed" # type: ignore
trace.error = "Incomplete request" # type: ignore
session.commit()
return len(pending_traces)
def _clean_old_traces(self, days: int = 30) -> int:
"""清理超过指定天数的请求"""
with self.db_manager.get_session() as session:
days_ago = datetime.now() - timedelta(days=days)
deleted_count = session.query(LLMRequestTrace).filter(
LLMRequestTrace.request_time < days_ago # type: ignore
).delete()
session.commit()
return deleted_count
def _register_event_handlers(self):
"""注册事件处理程序"""
self.event_bus.register(LLMRequestStartEvent, self._on_request_start)
self.event_bus.register(LLMRequestCompleteEvent, self._on_request_complete)
self.event_bus.register(LLMRequestFailEvent, self._on_request_fail)
def _unregister_event_handlers(self):
"""取消事件处理程序注册"""
self.event_bus.unregister(LLMRequestStartEvent, self._on_request_start)
self.event_bus.unregister(LLMRequestCompleteEvent, self._on_request_complete)
self.event_bus.unregister(LLMRequestFailEvent, self._on_request_fail)
def start_request_tracking(
self,
backend_name: str,
request: LLMChatRequest
) -> str:
"""开始跟踪LLM请求"""
trace_id = generate_trace_id()
event = LLMRequestStartEvent(
trace_id=trace_id,
model_id=request.model or 'unknown',
backend_name=backend_name,
request=request.model_copy(deep=True)
)
# 存储活跃追踪信息
self._active_traces[trace_id] = {
'backend_name': backend_name,
'start_time': event.start_time
}
# 发布事件
self.event_bus.post(event)
return trace_id
def complete_request_tracking(
self,
trace_id: str,
request: LLMChatRequest,
response: LLMChatResponse
):
"""完成LLM请求跟踪"""
if trace_id in self._active_traces:
trace_data = self._active_traces[trace_id]
model_id = request.model or trace_data.get('model_id', "unknown")
backend_name = trace_data.get('backend_name', "unknown")
start_time = trace_data.get('start_time', 0)
event = LLMRequestCompleteEvent(
trace_id=trace_id,
model_id=model_id,
backend_name=backend_name,
request=request.model_copy(deep=True),
response=response.model_copy(deep=True),
start_time=start_time
)
# 移除活跃追踪
del self._active_traces[trace_id]
# 发布事件
self.event_bus.post(event)
def fail_request_tracking(
self,
trace_id: str,
request: LLMChatRequest,
error: Any
):
"""记录LLM请求失败"""
if trace_id in self._active_traces:
trace_data = self._active_traces[trace_id]
model_id = request.model or trace_data.get('model_id', "unknown")
backend_name = trace_data.get('backend_name', "unknown")
start_time = trace_data.get('start_time', 0)
event = LLMRequestFailEvent(
trace_id=trace_id,
model_id=model_id,
backend_name=backend_name,
request=request.model_copy(deep=True),
error=error,
start_time=start_time
)
# 移除活跃追踪
del self._active_traces[trace_id]
# 发布事件
self.event_bus.post(event)
else:
self.logger.warning(f"LLM request failed: {trace_id} not found")
def _on_request_start(self, event: LLMRequestStartEvent):
"""处理请求开始事件"""
self.logger.debug(f"LLM request started: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
# 创建数据库记录
trace = LLMRequestTrace()
trace.update_from_event(event)
# 保存记录到数据库
trace_dict = self.save_trace_record(trace)
# 向WebSocket客户端广播消息
self.broadcast_ws_message({
"type": "new",
"data": trace_dict
})
def _on_request_complete(self, event: LLMRequestCompleteEvent):
"""处理请求完成事件"""
self.logger.debug(f"LLM request completed: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
event.response.message = UNRECORD_RESPONSE
if trace := self.update_trace_record(event.trace_id, event):
self.broadcast_ws_message({
"type": "update",
"data": trace
})
def _on_request_fail(self, event: LLMRequestFailEvent):
"""处理请求失败事件"""
self.logger.debug(f"LLM request failed: {event.trace_id}")
if not self.config.tracing.llm_tracing_content:
event.request.messages = UNRECORD_REQUEST
# 更新数据库记录
trace = self.update_trace_record(event.trace_id, event)
# 广播WebSocket消息
if trace:
self.broadcast_ws_message({
"type": "update",
"data": trace
})
def get_statistics(self) -> Dict:
"""获取统计信息"""
with self.db_manager.get_session() as session:
# 基础统计
total_count = session.query(func.count(LLMRequestTrace.id)).scalar() or 0
success_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="success").scalar() or 0
failed_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="failed").scalar() or 0
pending_count = session.query(func.count(LLMRequestTrace.id)).filter_by(status="pending").scalar() or 0
total_tokens = session.query(func.sum(LLMRequestTrace.total_tokens)).scalar() or 0
# 获取30天内的每日统计
thirty_days_ago = datetime.now() - timedelta(days=30)
daily_stats = session.query(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time).label('date'),
func.count(LLMRequestTrace.id).label('requests'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.sum(case((LLMRequestTrace.status == 'success', 1), else_=0)).label('success'), # type: ignore
func.sum(case((LLMRequestTrace.status == 'failed', 1), else_=0)).label('failed') # type: ignore
).filter(
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time)
).order_by(
func.strftime('%Y-%m-%d', LLMRequestTrace.request_time)
).all()
daily_data = [{
'date': str(row.date),
'requests': row.requests,
'tokens': row.tokens or 0,
'success': row.success,
'failed': row.failed
} for row in daily_stats]
# 按模型分组统计(最近30天)
model_stats = []
model_counts = session.query(
LLMRequestTrace.model_id, # type: ignore
func.count(LLMRequestTrace.id).label('count'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.avg(LLMRequestTrace.duration).label('avg_duration')
).filter( # type: ignore
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
LLMRequestTrace.model_id
).all()
for model_id, count, tokens, avg_duration in model_counts:
model_stats.append({
'model_id': model_id,
'count': count,
'tokens': tokens or 0,
'avg_duration': float(avg_duration) if avg_duration else 0
})
# 按后端分组统计(最近30天)
backend_stats = []
backend_counts = session.query(
LLMRequestTrace.backend_name, # type: ignore
func.count(LLMRequestTrace.id).label('count'),
func.sum(LLMRequestTrace.total_tokens).label('tokens'),
func.avg(LLMRequestTrace.duration).label('avg_duration')
).filter( # type: ignore
LLMRequestTrace.request_time >= thirty_days_ago # type: ignore
).group_by(
LLMRequestTrace.backend_name
).all()
for backend_name, count, tokens, avg_duration in backend_counts:
backend_stats.append({
'backend_name': backend_name,
'count': count,
'tokens': tokens or 0,
'avg_duration': float(avg_duration) if avg_duration else 0
})
# 获取每小时统计(最近24小时)
one_day_ago = datetime.now() - timedelta(hours=24)
hourly_stats = session.query(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time).label('hour'),
func.count(LLMRequestTrace.id).label('requests'),
func.sum(LLMRequestTrace.total_tokens).label('tokens')
).filter(
LLMRequestTrace.request_time >= one_day_ago # type: ignore
).group_by(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time)
).order_by(
func.strftime('%Y-%m-%d %H:00:00', LLMRequestTrace.request_time)
).all()
hourly_data = [{
'hour': str(row.hour),
'requests': row.requests,
'tokens': row.tokens or 0
} for row in hourly_stats]
return {
'overview': {
'total_requests': total_count,
'success_requests': success_count,
'failed_requests': failed_count,
'pending_requests': pending_count,
'total_tokens': total_tokens,
},
'daily_stats': daily_data,
'hourly_stats': hourly_data,
'models': model_stats,
'backends': backend_stats
}
================================================
FILE: kirara_ai/tracing/manager.py
================================================
import asyncio
from typing import Dict, List, Optional
from kirara_ai.database import DatabaseManager
from kirara_ai.events.event_bus import EventBus
from kirara_ai.events.tracing import TraceEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
from kirara_ai.tracing.core import TracerBase, TraceRecord
logger = get_logger("TracingManager")
class TracingManager:
"""追踪管理器,负责管理所有类型的追踪器和协调追踪操作"""
@Inject()
def __init__(self, container: DependencyContainer, database_manager: DatabaseManager, event_bus: EventBus):
self.container = container
self.db_manager = database_manager
self.event_bus = event_bus
self.tracers: Dict[str, TracerBase] = {}
self.logger = logger
def initialize(self):
"""初始化追踪管理器"""
self.logger.info("Initializing tracing manager")
# 初始化所有注册的追踪器
for name, tracer in self.tracers.items():
try:
tracer.initialize()
except Exception as e:
self.logger.error(f"Failed to initialize tracer {name}: {e}")
self.logger.info("Tracing manager initialized")
def shutdown(self):
"""关闭追踪管理器"""
self.logger.info("Shutting down tracing manager")
# 关闭所有追踪器
for name, tracer in self.tracers.items():
try:
tracer.shutdown()
except Exception as e:
self.logger.error(f"Failed to shutdown tracer {name}: {e}")
def register_tracer(self, name: str, tracer: TracerBase):
"""注册追踪器"""
if name in self.tracers:
raise ValueError(f"Tracer {name} already registered")
self.tracers[name] = tracer
def get_tracer(self, name: str) -> Optional[TracerBase]:
"""获取指定名称的追踪器"""
return self.tracers.get(name)
def get_all_tracers(self) -> Dict[str, TracerBase]:
"""获取所有追踪器"""
return self.tracers.copy()
def get_tracer_types(self) -> List[str]:
"""获取所有追踪器类型"""
return list(self.tracers.keys())
def publish_event(self, event: TraceEvent):
"""发布追踪事件"""
self.event_bus.post(event)
# WebSocket相关方法
def register_ws_client(self, tracer_name: str) -> asyncio.Queue:
"""为指定追踪器注册WebSocket客户端"""
if tracer := self.tracers.get(tracer_name):
return tracer.register_ws_client()
else:
raise ValueError(f"Tracer {tracer_name} not found")
def unregister_ws_client(self, tracer_name: str, queue: asyncio.Queue):
"""从指定追踪器注销WebSocket客户端"""
if tracer := self.tracers.get(tracer_name):
tracer.unregister_ws_client(queue)
else:
raise ValueError(f"Tracer {tracer_name} not found")
# 通用追踪操作方法
def get_recent_traces(self, tracer_name: str, limit: int = 100) -> List[TraceRecord]:
"""获取指定追踪器的最近追踪记录"""
if tracer := self.get_tracer(tracer_name):
return tracer.get_recent_traces(limit)
else:
raise ValueError(f"Tracer {tracer_name} not found")
def get_trace_by_id(self, tracer_name: str, trace_id: str) -> Optional[TraceRecord]:
"""获取指定追踪器的特定追踪记录"""
if tracer := self.get_tracer(tracer_name):
return tracer.get_trace_by_id(trace_id)
else:
raise ValueError(f"Tracer {tracer_name} not found")
================================================
FILE: kirara_ai/tracing/models.py
================================================
import json
from datetime import datetime
from typing import Any, Dict, Optional
from sqlalchemy import Column, DateTime, Float, Index, Integer, String, Text
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from kirara_ai.tracing.core import TraceEvent, TraceRecord
class LLMRequestTrace(TraceRecord):
"""LLM请求跟踪记录"""
__tablename__ = "llm_request_traces"
id = Column(Integer, primary_key=True, autoincrement=True)
trace_id = Column(String(64), nullable=False, index=True, unique=True)
model_id = Column(String(64), nullable=False, index=True)
backend_name = Column(String(64), nullable=False, index=True)
# 时间相关
request_time = Column(DateTime, nullable=False, index=True)
response_time = Column(DateTime, nullable=True)
duration = Column(Float, nullable=True)
# 请求和响应内容
request_json = Column(Text, nullable=True)
response_json = Column(Text, nullable=True)
# 令牌使用情况
prompt_tokens = Column(Integer, nullable=True)
completion_tokens = Column(Integer, nullable=True)
total_tokens = Column(Integer, nullable=True)
cached_tokens = Column(Integer, nullable=True)
# 错误信息
error = Column(Text, nullable=True)
status = Column(String(20), nullable=False, default="pending")
# 创建索引
__table_args__ = (
Index('idx_request_model', 'model_id', 'request_time'),
Index('idx_backend_time', 'backend_name', 'request_time'),
Index('idx_status_time', 'status', 'request_time'),
)
def __repr__(self):
return f""
def update_from_event(self, event: TraceEvent) -> None:
"""从事件更新记录"""
if isinstance(event, LLMRequestStartEvent):
self.trace_id = event.trace_id
self.model_id = event.model_id
self.backend_name = event.backend_name
self.request_time = datetime.fromtimestamp(event.start_time)
self.status = "pending"
if event.request:
self.request = event.request.model_dump()
elif isinstance(event, LLMRequestCompleteEvent):
self.response_time = datetime.fromtimestamp(event.end_time)
self.duration = event.duration
self.status = "success"
# 记录令牌使用情况
if event.response and event.response.usage:
self.prompt_tokens = event.response.usage.prompt_tokens
self.completion_tokens = event.response.usage.completion_tokens
self.total_tokens = event.response.usage.total_tokens
self.cached_tokens = event.response.usage.cached_tokens
# 记录响应内容
if event.response:
self.response = event.response.model_dump()
elif isinstance(event, LLMRequestFailEvent):
self.response_time = datetime.fromtimestamp(event.end_time)
self.duration = event.duration
self.error = event.error
self.status = "failed"
def to_dict(self) -> Dict[str, Any]:
"""将记录转换为基本字典,用于JSON序列化"""
return {
"id": self.id,
"trace_id": self.trace_id,
"model_id": self.model_id,
"backend_name": self.backend_name,
"request_time": self.request_time.isoformat() if self.request_time else None, # type: ignore
"response_time": self.response_time.isoformat() if self.response_time else None, # type: ignore
"duration": self.duration,
"prompt_tokens": self.prompt_tokens,
"completion_tokens": self.completion_tokens,
"total_tokens": self.total_tokens,
"cached_tokens": self.cached_tokens,
"status": self.status,
"error": self.error
}
def to_detail_dict(self) -> Dict[str, Any]:
"""将记录转换为详细字典,包含请求和响应内容"""
result = self.to_dict()
result["request"] = self.request
result["response"] = self.response
return result
@property
def request(self) -> Optional[Dict[str, Any]]:
"""获取请求内容"""
return json.loads(self.request_json) if self.request_json else None # type: ignore
@request.setter
def request(self, value: Any):
"""设置请求内容"""
if value:
self.request_json = json.dumps(value, ensure_ascii=False, default=str)
@property
def response(self) -> Optional[Dict[str, Any]]:
"""获取响应内容"""
return json.loads(self.response_json) if self.response_json else None # type: ignore
@response.setter
def response(self, value: Any):
"""设置响应内容"""
if value:
self.response_json = json.dumps(value, ensure_ascii=False, default=str)
================================================
FILE: kirara_ai/web/README.md
================================================
# Web API 系统 🌐
本系统提供了一套完整的RESTful API,用于管理和监控ChatGPT-Mirai机器人的各个组件。
## 系统架构 🏗️
- 基于 [Quart](https://pgjones.gitlab.io/quart/) 异步Web框架
- 使用 [Pydantic](https://docs.pydantic.dev/) 进行数据验证
- JWT认证保护所有API端点
- CORS支持跨域请求
- 模块化设计,易于扩展
## 模块说明 📦
### 1. 认证模块 🔐
- 路径: [`framework/web/auth`](../framework/web/auth)
- 功能: 用户认证、JWT令牌管理
- API文档: [认证API文档](../framework/web/auth/README.md)
### 2. IM适配器管理 💬
- 路径: [`framework/web/api/im`](../framework/web/api/im)
- 功能: 管理即时通讯平台适配器
- API文档: [IM API文档](../framework/web/api/im/README.md)
### 3. LLM后端管理 🤖
- 路径: [`framework/web/api/llm`](../framework/web/api/llm)
- 功能: 管理大语言模型后端
- API文档: [LLM API文档](../framework/web/api/llm/README.md)
### 4. 调度规则管理 📋
- 路径: [`framework/web/api/dispatch`](../framework/web/api/dispatch)
- 功能: 管理消息处理规则
- API文档: [调度规则API文档](../framework/web/api/dispatch/README.md)
### 5. Block查询 🧩
- 路径: [`framework/web/api/block`](../framework/web/api/block)
- 功能: 查询工作流构建块信息
- API文档: [Block API文档](../framework/web/api/block/README.md)
### 6. Workflow管理 ⚡
- 路径: [`framework/web/api/workflow`](../framework/web/api/workflow)
- 功能: 管理工作流定义和执行
- API文档: [Workflow API文档](../framework/web/api/workflow/README.md)
### 7. 插件管理 🔌
- 路径: [`framework/web/api/plugin`](../framework/web/api/plugin)
- 功能: 管理系统插件
- API文档: [插件API文档](../framework/web/api/plugin/README.md)
### 8. 系统状态 📊
- 路径: [`framework/web/api/system`](../framework/web/api/system)
- 功能: 监控系统运行状态
- API文档: [系统状态API文档](../framework/web/api/system/README.md)
## 快速开始 🚀
1. 安装依赖:
```bash
pip install -r requirements.txt
```
2. 配置系统:
- 复制 `config.yaml.example` 到 `config.yaml`
- 修改配置文件中的相关设置
3. 启动服务:
```bash
python main.py
```
首次启动时会自动创建管理员密码。
## API认证 🔑
除了首次设置密码的接口外,所有API都需要在请求头中携带JWT令牌:
```http
Authorization: Bearer
```
获取令牌:
```http
POST/backend-api/api/auth/login
Content-Type: application/json
{
"password": "your-password"
}
```
## 开发指南 💻
### 添加新的API端点
1. 在相应模块下创建路由文件
2. 定义数据模型(使用Pydantic)
3. 实现API逻辑
4. 在 [`framework/web/app.py`](../framework/web/app.py) 中注册蓝图
示例:
```python
from quart import Blueprint, request
from pydantic import BaseModel
# 定义数据模型
class MyModel(BaseModel):
name: str
value: int
# 创建蓝图
my_bp = Blueprint('my_api', __name__)
# 实现API端点
@my_bp.route('/endpoint', methods=['POST'])
@require_auth
async def my_endpoint():
data = await request.get_json()
model = MyModel(**data)
# 处理逻辑
return model.model_dump()
```
### 错误处理
使用HTTP状态码表示错误类型:
- 400: 请求参数错误
- 401: 未认证或认证失败
- 404: 资源不存在
- 500: 服务器内部错误
返回统一的错误格式:
```json
{
"error": "错误描述信息"
}
```
## 依赖说明 📚
主要依赖包:
- quart: 异步Web框架
- pydantic: 数据验证
- PyJWT: JWT认证
- hypercorn: ASGI服务器
- psutil: 系统监控
完整依赖列表见 [requirements.txt](../requirements.txt)
## 测试 🧪
运行单元测试:
```bash
pytest tests/web
```
## 贡献指南 🤝
1. Fork 本仓库
2. 创建特性分支
3. 提交更改
4. 创建Pull Request
================================================
FILE: kirara_ai/web/__init__.py
================================================
================================================
FILE: kirara_ai/web/api/block/README.md
================================================
# 区块 API 🧩
区块 API 提供了查询工作流构建块类型的功能。每个区块类型定义了其输入、输出和配置项。
>> 注意:文档由 Claude 生成,可能存在错误,请以实际代码为准。
## API 端点
### 获取所有区块类型
```http
GET/backend-api/api/block/types
```
获取所有可用的区块类型列表。
**响应示例:**
```json
{
"types": [
{
"type_name": "MessageBlock",
"name": "消息区块",
"description": "处理消息的基础区块",
"inputs": [
{
"name": "content",
"description": "消息内容",
"type": "string",
"required": true
}
],
"outputs": [
{
"name": "message",
"description": "处理后的消息",
"type": "IMMessage"
}
],
"configs": [
{
"name": "format",
"description": "消息格式",
"type": "string",
"required": false,
"default": "text"
}
]
}
]
}
```
### 获取特定区块类型
```http
GET/backend-api/api/block/types/{type_name}
```
获取指定区块类型的详细信息。
**响应示例:**
```json
{
"type": {
"type_name": "LLMBlock",
"name": "大语言模型区块",
"description": "调用 LLM 进行对话的区块",
"inputs": [
{
"name": "prompt",
"description": "提示词",
"type": "string",
"required": true
}
],
"outputs": [
{
"name": "response",
"description": "LLM 的响应",
"type": "string"
}
],
"configs": [
{
"name": "model",
"description": "使用的模型",
"type": "string",
"required": true,
"default": "gpt-4"
},
{
"name": "temperature",
"description": "温度参数",
"type": "float",
"required": false,
"default": 0.7
}
]
}
}
```
### 注册区块类型
```http
POST/backend-api/api/block/types
```
注册新的区块类型。
**请求体:**
```json
{
"type": "image_process",
"name": "图像处理",
"description": "处理图像数据",
"category": "media",
"config_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["resize", "crop", "rotate"]
},
"params": {
"type": "object"
}
}
},
"input_schema": {
"type": "object",
"properties": {
"image": {
"type": "string",
"format": "binary"
}
}
},
"output_schema": {
"type": "object",
"properties": {
"image": {
"type": "string",
"format": "binary"
}
}
}
}
```
### 更新区块类型
```http
PUT/backend-api/api/block/types/{type}
```
更新现有区块类型。
### 删除区块类型
```http
DELETE/backend-api/api/block/types/{type}
```
删除指定区块类型。
### 获取区块实例
```http
GET/backend-api/api/block/instances/{workflow_id}
```
获取指定工作流中的所有区块实例。
**响应示例:**
```json
{
"instances": [
{
"block_id": "input_1",
"type": "input",
"workflow_id": "chat:normal",
"config": {
"format": "text"
},
"state": {
"status": "ready",
"last_run": "2024-03-10T12:00:00Z",
"error": null
}
}
]
}
```
### 获取特定区块实例
```http
GET/backend-api/api/block/instances/{workflow_id}/{block_id}
```
获取指定区块实例的详细信息。
### 更新区块实例
```http
PUT/backend-api/api/block/instances/{workflow_id}/{block_id}
```
更新区块实例的配置。
## 数据模型
### BlockInput
- `name`: 输入名称
- `description`: 输入描述
- `type`: 数据类型
- `required`: 是否必需
- `default`: 默认值(可选)
### BlockOutput
- `name`: 输出名称
- `description`: 输出描述
- `type`: 数据类型
### BlockConfig
- `name`: 配置项名称
- `description`: 配置项描述
- `type`: 数据类型
- `required`: 是否必需
- `default`: 默认值(可选)
### BlockType
- `type_name`: 区块类型名称
- `name`: 显示名称
- `description`: 描述
- `inputs`: 输入定义列表
- `outputs`: 输出定义列表
- `configs`: 配置项定义列表
### BlockInstance
- `block_id`: 区块实例 ID
- `type`: 区块类型
- `workflow_id`: 所属工作流 ID
- `config`: 区块配置
- `state`: 区块状态
- `metadata`: 元数据(可选)
### BlockState
- `status`: 状态(ready/running/error)
- `last_run`: 最后运行时间
- `error`: 错误信息(如果有)
- `metrics`: 性能指标(可选)
## 相关代码
- [区块基类](../../../workflow/core/block/base.py)
- [区块注册表](../../../workflow/core/block/registry.py)
- [系统区块实现](../../../workflow/implementations/blocks)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误
- 404: 区块类型不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有区块类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/block/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 获取特定区块类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/block/types/LLMBlock',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [工作流系统概述](../../README.md#工作流系统-)
- [区块开发指南](../../../workflow/README.md#区块开发)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/block/__init__.py
================================================
from .routes import block_bp
__all__ = ["block_bp"]
================================================
FILE: kirara_ai/web/api/block/diagnostics/base_diagnostic.py
================================================
import ast
import logging
from abc import ABC, abstractmethod
from typing import Dict, List, Optional
from lsprotocol.types import CodeAction, CodeActionParams, Diagnostic, DiagnosticSeverity, Position, Range
from pygls.server import LanguageServer
from pygls.workspace import Document
logger = logging.getLogger(__name__)
class BaseDiagnostic(ABC):
"""诊断检查器的抽象基类"""
SOURCE_NAME: str = "base-diagnostic" # 每个子类应覆盖此项
def __init__(self, ls: LanguageServer):
self.ls = ls
@abstractmethod
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行诊断检查。
Args:
doc: 要检查的文档对象。
Returns:
诊断信息列表。
"""
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""
为相关的诊断信息生成代码操作(快速修复)。
Args:
params: 代码操作请求参数。
relevant_diagnostics: 与此检查器相关的诊断信息列表。
Returns:
代码操作列表。
"""
# 默认实现:不提供任何代码操作
return []
def _create_diagnostic(self, message: str, node: Optional[ast.AST], severity: DiagnosticSeverity, data: Optional[Dict] = None, range_override: Optional[Range] = None) -> Diagnostic:
"""
辅助函数:根据 AST 节点或显式范围创建 Diagnostic 对象。
"""
diag_range: Optional[Range] = None
if range_override:
diag_range = range_override
elif node and isinstance(node, ast.stmt):
try:
start_line = node.lineno - 1
start_col = node.col_offset
# AST 节点通常有 end_lineno 和 end_col_offset (Python 3.8+)
# end_lineno 是 1-based 的结束行号 (exclusive or inclusive depending on context, often exclusive)
# end_col_offset 是 0-based 的结束列偏移
end_line = getattr(node, 'end_lineno', start_line + 1) - 1
end_col = getattr(node, 'end_col_offset', start_col + 1)
# 确保范围有效
end_line = max(start_line, end_line)
if end_line == start_line:
end_col = max(start_col + 1, end_col) # 至少标记一个字符
diag_range = Range(
start=Position(line=start_line, character=start_col),
end=Position(line=end_line, character=end_col)
)
except AttributeError:
logger.warning(f"AST 节点缺少位置信息: {type(node)}")
# Fallback if location info is missing
diag_range = Range(start=Position(
line=0, character=0), end=Position(line=0, character=1))
else:
# 如果没有节点或范围,默认标记文件开头
diag_range = Range(start=Position(
line=0, character=0), end=Position(line=0, character=1))
return Diagnostic(
range=diag_range,
message=message,
severity=severity,
source=self.SOURCE_NAME,
data=data
)
def _ast_node_to_string(self, node: Optional[ast.AST]) -> str:
"""
将 AST 注解节点转换为字符串表示。
(从原 LanguageServer 类移动)
"""
if node is None:
return ""
if isinstance(node, ast.Name):
return node.id
if isinstance(node, ast.Constant): # Python 3.8+
# Handle NoneType explicitly if needed
if node.value is None:
return "None"
return str(node.value)
# Python < 3.8 NameConstant handling might be needed if supporting older versions
# if isinstance(node, ast.NameConstant):
# return str(node.value)
if isinstance(node, ast.Attribute):
value_str = self._ast_node_to_string(node.value)
# Avoid adding '.' if value is empty (shouldn't happen often)
return f"{value_str}.{node.attr}" if value_str else node.attr
if isinstance(node, ast.Subscript):
base = self._ast_node_to_string(node.value)
slice_val = node.slice
if isinstance(slice_val, ast.Tuple):
slice_str = ', '.join(
[self._ast_node_to_string(entry) for entry in slice_val.elts])
else:
slice_str = self._ast_node_to_string(slice_val)
return f"{base}[{slice_str}]"
if isinstance(node, ast.List):
return f"List[{self._ast_node_to_string(node.elts[0])}]" if node.elts else "List"
if isinstance(node, ast.Dict):
return f"Dict[{self._ast_node_to_string(node.keys[0])}, {self._ast_node_to_string(node.values[0])}]" if node.keys and node.values else "Dict"
if isinstance(node, ast.Set):
return f"Set[{self._ast_node_to_string(node.elts[0])}]" if node.elts else "Set"
if isinstance(node, ast.Tuple):
elts = [self._ast_node_to_string(elt) for elt in node.elts]
if not elts:
return "Tuple"
# Handle Tuple[int] vs Tuple[int, ...]
if len(elts) == 1:
# Check if it's intended as variable-length tuple hint e.g. Tuple[int, ...]
# This requires checking the source code or making assumptions.
# Simple approach: always assume single element means fixed tuple.
# Or f"tuple[{elts[0]}]" for consistency?
return f"Tuple[{elts[0]}]"
# Or f"tuple[{', '.join(elts)}]"
return f"Tuple[{', '.join(elts)}]"
# Fallback using ast.unparse (Python 3.9+)
try:
import sys
if sys.version_info >= (3, 9):
return ast.unparse(node)
# 如果 unparse 不可用,则为旧版本 Python 的基本回退
if isinstance(node, ast.Expr):
return self._ast_node_to_string(node.value)
# 如果需要,添加更多回退
logger.debug(
f"无法将 AST 节点转换为字符串(unparse 不可用):{type(node)}")
return "UnsupportedType"
except Exception as e:
logger.debug(f"Error using ast.unparse: {e}")
return "UnsupportedType" # Final fallback
================================================
FILE: kirara_ai/web/api/block/diagnostics/import_check.py
================================================
import ast
import importlib.util
import logging
import os
from typing import List, Optional, Tuple
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class ImportDiagnostic(BaseDiagnostic):
"""检查导入语句有效性的诊断器"""
SOURCE_NAME: str = "import-check"
def _get_package_context(self, path: Optional[str]) -> Tuple[Optional[str], Optional[str]]:
"""获取文件路径对应的目录和包名"""
if not path or not os.path.exists(path):
return None, None
file_dir = os.path.dirname(path)
# Simple package detection: check for __init__.py or assume dir name is package
# This might not be fully robust for complex project structures.
package_name = None
try:
# Walk up to find a directory containing __init__.py or setup.py?
# For simplicity, let's use the immediate parent directory name if it seems plausible
potential_pkg_name = os.path.basename(file_dir)
# Avoid using names like 'src', 'lib' directly unless structure confirms it
# A better approach might involve analyzing project structure or sys.path
# Let's assume basename is the package for resolve_name context
package_name = potential_pkg_name or None
except Exception:
logger.warning(f"无法确定 '{path}' 的包上下文")
return file_dir, package_name
def check(self, doc: Document) -> List[Diagnostic]:
"""检查导入语句是否有效"""
diagnostics = []
source = doc.source
path = doc.path
try:
tree = ast.parse(source)
file_dir, package_name = self._get_package_context(path)
# Store found issues to avoid duplicate diagnostics for the same line/module
reported_issues = set() # Store (line_no, module_name_str) tuples
for node in ast.walk(tree):
module_name_str: Optional[str] = None
# Record node for reporting and fixing
import_node: Optional[ast.stmt] = None
if not isinstance(node, ast.stmt):
continue
line_no = node.lineno if hasattr(node, 'lineno') else 0
if isinstance(node, ast.Import):
import_node = node
for alias in node.names:
module_name_str = alias.name
issue_key = (line_no, module_name_str)
if issue_key in reported_issues:
continue
try:
spec = importlib.util.find_spec(module_name_str)
if spec is None:
message = f"无法找到模块 '{module_name_str}'"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Error,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except ModuleNotFoundError:
message = f"无法找到模块 '{module_name_str}'"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Error,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except Exception as e: # Catch other potential errors during find_spec
message = f"检查导入 '{module_name_str}' 时出错: {e}"
diagnostic = self._create_diagnostic(
message, import_node, DiagnosticSeverity.Warning, # Warning for general errors
# Still offer removal
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
elif isinstance(node, ast.ImportFrom):
import_node = node
module_name_str = node.module # Can be None for 'from . import ...'
level = node.level
is_relative = level > 0
# Construct the name being resolved for reporting/key
if is_relative:
relative_prefix = "." * level
resolving_name = f"{relative_prefix}{module_name_str or ''}"
else:
# Should have module name if not relative
resolving_name = module_name_str or ""
# Skip if nothing to resolve (e.g. invalid syntax?)
if not resolving_name:
continue
issue_key = (line_no, resolving_name)
if issue_key in reported_issues:
continue
resolved_spec = None
error_message = None
severity = DiagnosticSeverity.Error
try:
if is_relative:
if file_dir and package_name:
# Resolve the name relative to the current file's package context
resolved_name = importlib.util.resolve_name(
resolving_name, package_name)
resolved_spec = importlib.util.find_spec(
resolved_name)
if resolved_spec is None:
error_message = f"无法找到相对导入的模块 '{resolving_name}' (解析为 '{resolved_name}' 来自 '{package_name}')"
else:
# Cannot reliably check relative imports without path/package context
error_message = f"无法可靠地检查相对导入 '{resolving_name}' (缺少文件路径或包上下文)"
severity = DiagnosticSeverity.Warning # Downgrade severity if unsure
elif module_name_str: # Absolute import
resolved_spec = importlib.util.find_spec(
module_name_str)
if resolved_spec is None:
error_message = f"无法找到模块 '{module_name_str}'"
except (ImportError, ValueError) as e:
error_message = f"无法解析或找到导入 '{resolving_name}': {e}"
except Exception as e:
error_message = f"检查导入 '{resolving_name}' 时发生意外错误: {e}"
severity = DiagnosticSeverity.Warning
# Create diagnostic if an error occurred
if error_message:
diagnostic = self._create_diagnostic(
error_message, import_node, severity,
data={"fix_type": "remove_import"}
)
diagnostics.append(diagnostic)
reported_issues.add(issue_key)
except SyntaxError:
# Syntax errors handled elsewhere
logger.debug("跳过导入检查,存在语法错误")
except Exception as e:
logger.error(f"检查导入时发生内部错误: {str(e)}", exc_info=True)
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""提供删除无效导入的代码操作"""
actions = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document:
return []
lines = document.source.splitlines(True) # Keep line endings
for diag in relevant_diagnostics:
if diag.source != self.SOURCE_NAME:
continue
fix_type = diag.data.get("fix_type") if diag.data else None
if fix_type == "remove_import":
# The diagnostic range should cover the import statement node
start_line = diag.range.start.line
end_line = diag.range.end.line # The line index where the node ends
# Ensure line numbers are valid
if start_line < 0 or end_line >= len(lines):
logger.warning(f"无效的诊断范围用于删除导入: {diag.range}")
continue
# Define the range to be deleted: the entire line(s) of the import statement
delete_start_pos = Position(line=start_line, character=0)
# Determine the end position to include the newline of the last line involved
# Check if the node ends exactly at the end of a line (excluding newline)
# This requires knowing the exact end column from AST, which might be tricky.
# Safer approach: Delete up to the start of the *next* line.
delete_end_line_exclusive = end_line + 1
if delete_end_line_exclusive < len(lines):
# Delete up to the start of the next line
delete_end_pos = Position(
line=delete_end_line_exclusive, character=0)
else:
# Delete to the end of the last line of the file
delete_end_pos = Position(
line=end_line, character=len(lines[end_line]))
# Create the TextEdit to remove the line(s)
text_edit = TextEdit(
range=Range(start=delete_start_pos, end=delete_end_pos),
new_text=""
)
# Extract module name from message for a better title if possible
module_name_match = diag.message.split("'")
title_suffix = f": {module_name_match[1]}" if len(
module_name_match) > 1 else ""
title = f"移除无效的导入语句{title_suffix}"
edit = WorkspaceEdit(changes={doc_uri: [text_edit]})
action = CodeAction(
title=title,
kind=CodeActionKind.QuickFix,
diagnostics=[diag],
edit=edit,
is_preferred=False # Deleting code might not always be preferred
)
actions.append(action)
return actions
================================================
FILE: kirara_ai/web/api/block/diagnostics/jedi_syntax_check.py
================================================
import logging
from typing import List
import jedi
from lsprotocol.types import Diagnostic, DiagnosticSeverity, Position, Range
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class JediSyntaxErrorDiagnostic(BaseDiagnostic):
"""使用 Jedi 检查 Python 语法错误的诊断器"""
SOURCE_NAME: str = "syntax-error"
def __init__(self, ls: LanguageServer):
super().__init__(ls)
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行语法错误检查。
Args:
doc: 要检查的文档对象。
Returns:
诊断信息列表。
"""
diagnostics = []
source = doc.source
path = doc.path
try:
# 使用 Jedi 创建 Script 对象
# 注意:即使代码有语法错误,Jedi 通常也能创建 Script 对象
script = jedi.Script(code=source, path=path or None)
# 获取语法错误
syntax_errors = script.get_syntax_errors()
for error in syntax_errors:
# Jedi 的行列号是 1-based,LSP 是 0-based
start_line = error.line - 1
start_char = error.column
# Jedi 的 until_line/until_column 定义了错误范围的结束(通常是独占的)
# LSP 的 Range 结束位置也是独占的
end_line = error.until_line - 1
end_char = error.until_column
# 创建 LSP Range 对象
# 确保行列号不为负数
start_line = max(0, start_line)
start_char = max(0, start_char)
end_line = max(start_line, end_line) # 结束行不能在开始行之前
if end_line == start_line:
end_char = max(start_char + 1, end_char) # 结束列至少在开始列之后一个字符
error_range = Range(
start=Position(line=start_line, character=start_char),
end=Position(line=end_line, character=end_char)
)
# 使用 _create_diagnostic 辅助函数创建诊断信息
diagnostic = self._create_diagnostic(
message=error.get_message(),
node=None,
severity=DiagnosticSeverity.Error,
range_override=error_range # 使用 Jedi 提供的范围
)
diagnostics.append(diagnostic)
except Exception as e:
# 捕获 Jedi 或其他意外错误
logger.error(f"检查语法错误时发生内部错误: {str(e)}", exc_info=True)
# 可以选择性地添加一个通用的错误诊断
diagnostics.append(self._create_diagnostic(
message=f"检查语法错误时出错: {e}",
node=None,
severity=DiagnosticSeverity.Warning, # 使用警告级别,因为这是检查器本身的问题
range_override=Range(start=Position(line=0, character=0), end=Position(line=0, character=1))
))
return diagnostics
================================================
FILE: kirara_ai/web/api/block/diagnostics/mandatory_function.py
================================================
import ast
import logging
from typing import Any, Dict, List, Optional
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
class MandatoryFunctionDiagnostic(BaseDiagnostic):
"""检查强制函数声明的诊断器"""
SOURCE_NAME: str = "mandatory-function-check"
config: Optional[Dict[str, Any]] = None
config_name: Optional[str] = None
config_params: Optional[List[Dict[str, Any]]] = None
config_return: Optional[str] = None
param_signatures: Optional[List[str]] = None
expected_signature_str: Optional[str] = None
expected_signature_data: Optional[Dict[str, Any]] = None
def __init__(self, ls: LanguageServer, config: Optional[Dict[str, Any]]):
super().__init__(ls)
self.config = None
self.config_name = None
self.config_params = None
self.config_return = None
self.param_signatures = None
self.expected_signature_str = None
self.expected_signature_data = None
# 初始化配置
if config:
self.update_config(config)
def update_config(self, config: Dict[str, Any]) -> None:
"""更新诊断器配置
Args:
config: 包含必要函数检查配置的字典
"""
try:
self.config = config
assert self.config is not None
self.config_name = self.config["name"]
self.config_params = self.config["params"]
assert self.config_params is not None
self.config_return = self.config["return_type"]
self.param_signatures = [
f"{p['name']}: {p['type_hint']}" for p in self.config_params]
self.expected_signature_str = f"def {self.config_name}({', '.join(self.param_signatures)}) -> {self.config_return}"
self.expected_signature_data = {
"name": self.config_name,
"params": self.param_signatures,
"return": self.config_return
}
logger.info(f"Updated mandatory function config: {self.config_name}")
logger.debug(f"Expected signature: {self.expected_signature_str}")
except KeyError as e:
logger.error(f"Invalid mandatory function config, missing key: {e}")
self.config = None # 配置无效时禁用检查器
except Exception as e:
logger.error(f"Error updating mandatory function config: {e}")
self.config = None
def check(self, doc: Document) -> List[Diagnostic]:
"""检查源代码是否包含配置的强制函数声明"""
diagnostics: List[Diagnostic] = []
if not self.config or not self.config_params:
return diagnostics
source = doc.source
found_match = False
potential_match_node = None
# Store reasons for mismatch if name matches
mismatch_reasons: List[str] = []
try:
tree = ast.parse(source)
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef) and node.name == self.config_name:
potential_match_node = node
# Reasons for this specific node
current_reasons: List[str] = []
# 1. Check parameter count
num_actual_params = len(node.args.args)
if num_actual_params != len(self.config_params):
current_reasons.append(
f"参数数量不匹配: 期望 {len(self.config_params)} 个, 实际 {num_actual_params} 个")
# 2. Check parameter names and types (only if count matches for clearer messages)
params_match = True
if num_actual_params == len(self.config_params):
for i, arg_node in enumerate(node.args.args):
config_param = self.config_params[i]
arg_name = arg_node.arg
arg_type_str = self._ast_node_to_string(
arg_node.annotation)
config_type_hint = config_param.get(
"type_hint", "")
# Normalize empty/Any types for comparison
norm_arg_type = arg_type_str or "Any"
norm_config_type = config_type_hint or "Any"
types_match = (norm_arg_type == norm_config_type)
if arg_name != config_param["name"]:
params_match = False
current_reasons.append(
f"第 {i+1} 个参数名不匹配: 期望 '{config_param['name']}', 实际 '{arg_name}'")
elif not types_match and config_type_hint: # Only check type if config specifies one
params_match = False
current_reasons.append(
f"参数 '{arg_name}' 类型不匹配: 期望 '{config_type_hint}', 实际 '{arg_type_str or '无类型'}'")
# If count didn't match, mark params as mismatch
elif num_actual_params != len(self.config_params):
params_match = False
# 3. Check return type
return_type_str = self._ast_node_to_string(node.returns)
config_return_type = self.config_return or ""
norm_return_type = return_type_str or "Any"
norm_config_return = config_return_type or "Any"
return_match = (norm_return_type == norm_config_return)
if not return_match and config_return_type: # Only check if config specifies return
current_reasons.append(
f"返回类型不匹配: 期望 '{config_return_type}', 实际 '{return_type_str or '无类型'}'")
# If all checks pass for this node
if not current_reasons:
found_match = True
break # Found a perfect match, stop searching
else:
# Store reasons from the first encountered mismatching function
if not mismatch_reasons:
mismatch_reasons = current_reasons
# --- End of AST walk ---
except SyntaxError as e:
# Let other checkers handle syntax errors
return []
except Exception as e:
logger.error(f"Error checking mandatory function: {str(e)}", exc_info=True)
return []
# --- Create Diagnostic if needed ---
if not found_match:
if potential_match_node:
# Found function with same name but wrong signature
param_signatures_actual = []
for arg in potential_match_node.args.args:
sig = arg.arg
annotation = self._ast_node_to_string(arg.annotation)
if annotation:
sig += f': {annotation}'
param_signatures_actual.append(sig)
return_actual = self._ast_node_to_string(
potential_match_node.returns)
actual_signature_str = f"def {potential_match_node.name}({', '.join(param_signatures_actual)})"
if return_actual:
actual_signature_str += f" -> {return_actual}"
mismatch_hint = ""
if mismatch_reasons:
mismatch_hint = "\n具体差异:\n- " + \
"\n- ".join(mismatch_reasons)
message = f"函数 '{self.config_name}' 的签名与强制要求不符。\n期望: {self.expected_signature_str}\n实际: {actual_signature_str}{mismatch_hint}"
diagnostic = self._create_diagnostic(
message=message,
node=potential_match_node,
severity=DiagnosticSeverity.Error,
data={"expected_signature": self.expected_signature_data,
"fix_type": "replace_signature"} # Keep replace type, even if not implemented yet
)
diagnostics.append(diagnostic)
else:
# Did not find the function at all
lines = source.splitlines()
# Position after last line for insertion
file_end_line = len(lines)
file_end_col = 0
message = f"缺少强制函数声明: '{self.config_name}'。\n期望签名: {self.expected_signature_str}"
diagnostic = self._create_diagnostic(
message=message,
node=None, # No specific node
severity=DiagnosticSeverity.Error,
# Mark the end of the file for insertion
range_override=Range(start=Position(line=file_end_line, character=file_end_col),
end=Position(line=file_end_line, character=file_end_col)),
data={"expected_signature": self.expected_signature_data,
"fix_type": "insert_function"}
)
diagnostics.append(diagnostic)
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""为强制函数错误提供代码操作"""
actions: List[CodeAction] = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document or not self.config: # Need document and config for actions
return []
for diag in relevant_diagnostics:
# Ensure the diagnostic came from this checker
if diag.source != self.SOURCE_NAME:
continue
fix_type = diag.data.get("fix_type") if diag.data else None
expected_sig_data = diag.data.get(
"expected_signature") if diag.data else None
# Double check data matches current config in case config changed
if not expected_sig_data or expected_sig_data["name"] != self.config_name:
continue
if fix_type == "insert_function":
title = f"生成强制函数 '{self.config_name}'"
param_str = ", ".join(expected_sig_data['params'])
return_str = f" -> {expected_sig_data['return']}" if expected_sig_data['return'] else ""
# Add two newlines before the function if the file is not empty
prefix = "\n\n" if document.source.strip() else ""
# Add a basic docstring and pass
new_text = f"{prefix}def {self.config_name}({param_str}){return_str}:\n \"\"\"强制函数存根\"\"\"\n pass\n"
# Use the range from the diagnostic (end of file)
insert_pos = diag.range.start
edit = WorkspaceEdit(changes={
doc_uri: [TextEdit(range=Range(
start=insert_pos, end=insert_pos), new_text=new_text)]
})
action = CodeAction(
title=title,
kind=CodeActionKind.QuickFix,
diagnostics=[diag],
edit=edit,
is_preferred=True # Make it the default action if possible
)
actions.append(action)
return actions
================================================
FILE: kirara_ai/web/api/block/diagnostics/pyflakes_check.py
================================================
import logging
from typing import Any, List
from lsprotocol.types import (CodeAction, CodeActionKind, CodeActionParams, Diagnostic, DiagnosticSeverity, Position,
Range, TextEdit, WorkspaceEdit)
from pyflakes import api as pyflakes_api
from pyflakes import messages as pyflakes_messages
from pyflakes import reporter as pyflakes_reporter
from pygls.server import LanguageServer
from pygls.workspace import Document
from .base_diagnostic import BaseDiagnostic
logger = logging.getLogger(__name__)
# 自定义 Reporter 来收集 Pyflakes 的错误/警告并转换为 LSP Diagnostic
class _LspReporter(pyflakes_reporter.Reporter):
def __init__(self, source_name: str):
super().__init__(None, None) # 不需要标准输出/错误流
self.diagnostics: List[Diagnostic] = []
self._source_name = source_name
def unexpectedError(self, filename: str, msg: str):
# Pyflakes 内部错误
logger.error(f"Pyflakes unexpected error in {filename}: {msg}")
diagnostic = Diagnostic(
range=Range(start=Position(line=0, character=0), end=Position(line=0, character=1)),
message=f"Pyflakes internal error: {msg}",
severity=DiagnosticSeverity.Warning, # 标记为警告,因为是检查器本身的问题
source=self._source_name,
code="PyflakesInternalError"
)
self.diagnostics.append(diagnostic)
def syntaxError(self, filename: str, msg: str, lineno: int, offset: int, text: str):
# 处理 Pyflakes 报告的语法错误
line = lineno - 1 # 转换为 0-based
col = offset - 1 if offset > 0 else 0 # Pyflakes offset 是 1-based,LSP 是 0-based
# 语法错误通常标记单个字符或到行尾,这里简单标记一个字符
# 更精确的范围可能需要分析 text 或 msg,但通常语法错误点明确
end_col = col + 1
# 确保行列号不为负数
line = max(0, line)
col = max(0, col)
end_col = max(col + 1, end_col) # 确保结束至少在开始后
diagnostic = Diagnostic(
range=Range(
start=Position(line=line, character=col),
end=Position(line=line, character=end_col)
),
message=f"Syntax Error: {msg}", # 添加前缀以明确是语法错误
severity=DiagnosticSeverity.Error, # 语法错误是 Error
source=self._source_name,
code="PyflakesSyntaxError" # 使用特定的代码
)
self.diagnostics.append(diagnostic)
def flake(self, message: Any):
# message 是一个 pyflakes.messages.* 的实例
line = message.lineno - 1 # 转换为 0-based
col = message.col # 0-based 列偏移
# 尝试获取更精确的结束列
end_col = col + 1 # 默认标记一个字符
message_code = message.__class__.__name__ # 获取消息类型作为 code
try:
# 对于特定类型的消息,尝试使用参数长度确定范围
if isinstance(message, (pyflakes_messages.UnusedImport,
pyflakes_messages.UndefinedName,
pyflakes_messages.UndefinedExport,
pyflakes_messages.UndefinedLocal,
pyflakes_messages.DuplicateArgument,
pyflakes_messages.RedefinedWhileUnused,
pyflakes_messages.UnusedVariable)):
# 这些消息的第一个参数通常是相关的名称
if message.message_args:
name = message.message_args[0]
if isinstance(name, str):
end_col = col + len(name)
elif isinstance(message, pyflakes_messages.ImportShadowedByLoopVar):
if message.message_args:
name = message.message_args[0] # 第一个参数是名称
if isinstance(name, str):
end_col = col + len(name)
# 对于 'from module import *' used,标记 '*'
elif isinstance(message, pyflakes_messages.ImportStarUsed):
end_col = col + 1 # '*' 只有一个字符
# 其他消息类型保持默认单字符范围
except Exception as e:
logger.warning(f"计算 Pyflakes 诊断范围时出错: {e}", exc_info=True)
end_col = col + 1 # 出错时回退
# 确定严重性
severity = DiagnosticSeverity.Warning # 默认为警告
if isinstance(message, (pyflakes_messages.UndefinedName,
pyflakes_messages.UndefinedExport,
pyflakes_messages.UndefinedLocal,
pyflakes_messages.DoctestSyntaxError,
pyflakes_messages.ForwardAnnotationSyntaxError)):
severity = DiagnosticSeverity.Error
elif "syntax" in message_code.lower() or "invalid" in message_code.lower():
# 捕捉其他可能的语法相关错误消息类型
severity = DiagnosticSeverity.Error
# 创建诊断数据,包含消息类型,用于代码操作
diag_data = {"pyflakes_code": message_code}
diagnostic = Diagnostic(
range=Range(
start=Position(line=line, character=col),
end=Position(line=line, character=end_col)
),
message=message.message % message.message_args, # 格式化消息
severity=severity,
source=self._source_name,
code=message_code, # 使用 Pyflakes 消息类名作为 code
data=diag_data # 附加数据
)
self.diagnostics.append(diagnostic)
class PyflakesDiagnostic(BaseDiagnostic):
"""使用 Pyflakes 检查 Python 代码错误的诊断器 (增强版)"""
SOURCE_NAME: str = "pyflakes"
def __init__(self, ls: LanguageServer):
super().__init__(ls)
def check(self, doc: Document) -> List[Diagnostic]:
"""
对文档执行 Pyflakes 检查。
"""
diagnostics = []
source = doc.source
# Pyflakes 需要一个文件名,即使是临时的
path = doc.path or "untitled.py"
try:
reporter = _LspReporter(self.SOURCE_NAME)
# 使用 check 函数运行检查
pyflakes_api.check(source, path, reporter=reporter)
diagnostics = reporter.diagnostics
except Exception as e:
logger.error(f"运行 Pyflakes 时发生内部错误: {str(e)}", exc_info=True)
# 创建一个诊断信息报告 Pyflakes 本身的错误
diagnostics.append(self._create_diagnostic(
message=f"运行 Pyflakes 时出错: {e}",
node=None, # 没有关联的 AST 节点
severity=DiagnosticSeverity.Warning, # 检查器问题标记为警告
range_override=Range(start=Position(line=0, character=0), end=Position(line=0, character=1))
))
return diagnostics
def get_code_actions(self, params: CodeActionParams, relevant_diagnostics: List[Diagnostic]) -> List[CodeAction]:
"""
为 Pyflakes 诊断提供代码操作(快速修复)。
目前主要实现 "移除未使用的导入"。
"""
actions = []
doc_uri = params.text_document.uri
document = self.ls.workspace.get_document(doc_uri)
if not document:
logger.warning(f"无法获取 Pyflakes 代码操作,未找到文档: {doc_uri}")
return []
lines = document.source.splitlines(True) # 保留换行符
for diag in relevant_diagnostics:
# 确保是来自 pyflakes 的诊断并且有附加数据
if diag.source != self.SOURCE_NAME or not diag.data:
continue
pyflakes_code = diag.data.get("pyflakes_code")
# --- 快速修复:移除未使用的导入 (UnusedImport) ---
if pyflakes_code == "UnusedImport":
# 诊断范围指向未使用的名称,我们需要删除包含它的整行(或部分行)
# 简单起见,我们先实现删除整行。
# 注意:如果一行导入多个,这会删除所有导入。更精细的处理需要 AST 分析。
start_line = diag.range.start.line
end_line = diag.range.end.line # Pyflakes 通常在单行内报告
if start_line < 0 or end_line >= len(lines):
logger.warning(f"无效的 Pyflakes 诊断范围用于移除导入: {diag.range}")
continue
# 定义要删除的范围:从该行开始到下一行开始(删除整行及换行符)
delete_start_pos = Position(line=start_line, character=0)
delete_end_line_exclusive = end_line + 1
if delete_end_line_exclusive < len(lines):
# 删除到下一行的开头
delete_end_pos = Position(line=delete_end_line_exclusive, character=0)
else:
# 如果是最后一行,删除到该行的末尾
delete_end_pos = Position(line=end_line, character=len(lines[end_line]))
text_edit = TextEdit(
range=Range(start=delete_start_pos, end=delete_end_pos),
new_text=""
)
edit = WorkspaceEdit(changes={doc_uri: [text_edit]})
# 尝试从消息中提取模块/变量名以获得更好的标题
title_suffix = ""
try:
# 'imported but unused' or 'assigned to but never used'
parts = diag.message.split("'")
if len(parts) > 1:
title_suffix = f": '{parts[1]}'"
except Exception:
pass # 忽略提取错误
action = CodeAction(
title=f"移除未使用的导入{title_suffix}",
kind=CodeActionKind.QuickFix,
diagnostics=[diag], # 关联此代码操作到原始诊断
edit=edit,
is_preferred=True # 移除未使用导入通常是首选操作
)
actions.append(action)
# --- 可以添加其他快速修复,例如:---
# if pyflakes_code == "SomeOtherFixableIssue":
# # ... 实现对应的 TextEdit 和 CodeAction ...
# pass
return actions
================================================
FILE: kirara_ai/web/api/block/models.py
================================================
from typing import List
from pydantic import BaseModel
from kirara_ai.workflow.core.block.schema import BlockConfig, BlockInput, BlockOutput
class BlockType(BaseModel):
"""Block类型信息"""
type_name: str
name: str
label: str
description: str
inputs: List[BlockInput]
outputs: List[BlockOutput]
configs: List[BlockConfig]
class BlockTypeList(BaseModel):
"""Block类型列表响应"""
types: List[BlockType]
class BlockTypeResponse(BaseModel):
"""单个Block类型响应"""
type: BlockType
================================================
FILE: kirara_ai/web/api/block/python_lsp.py
================================================
import asyncio
import os
from typing import Any, Dict, List, Optional, Union
import jedi
from lsprotocol.types import (TEXT_DOCUMENT_CODE_ACTION, TEXT_DOCUMENT_COMPLETION, TEXT_DOCUMENT_DEFINITION,
TEXT_DOCUMENT_DID_CHANGE, TEXT_DOCUMENT_DID_OPEN, TEXT_DOCUMENT_DID_SAVE,
TEXT_DOCUMENT_DOCUMENT_SYMBOL, TEXT_DOCUMENT_HOVER, TEXT_DOCUMENT_SIGNATURE_HELP,
WORKSPACE_DID_CHANGE_CONFIGURATION, CodeAction, CodeActionParams, CompletionItem,
CompletionItemKind, CompletionList, CompletionOptions, CompletionParams, DefinitionParams,
Diagnostic, DiagnosticSeverity, DidChangeConfigurationParams, DidChangeTextDocumentParams,
DidOpenTextDocumentParams, DidSaveTextDocumentParams, DocumentSymbolParams, Hover,
HoverParams, Location, MarkupContent, MarkupKind, MessageType, ParameterInformation,
Position, Range, SignatureHelp, SignatureHelpOptions, SignatureHelpParams,
SignatureInformation, SymbolInformation, SymbolKind, TextDocumentPositionParams)
from pygls.server import LanguageServer
from kirara_ai.logger import get_logger
from .diagnostics.base_diagnostic import BaseDiagnostic
from .diagnostics.import_check import ImportDiagnostic
from .diagnostics.jedi_syntax_check import JediSyntaxErrorDiagnostic
from .diagnostics.mandatory_function import MandatoryFunctionDiagnostic
from .diagnostics.pyflakes_check import PyflakesDiagnostic
logger = get_logger("LSP")
class QuartWsTransport(asyncio.Transport):
def __init__(self, queue: asyncio.Queue):
self._queue = queue
def write(self, message: str):
try:
# put_nowait 通常是线程安全的
self._queue.put_nowait(message)
except Exception as e:
logger.error(
f"Error putting message into queue: {e}", exc_info=True)
def close(self):
self._queue.put_nowait(None)
class PythonLanguageServer(LanguageServer):
mandatory_function_checker: Optional[MandatoryFunctionDiagnostic] = None
def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None):
super().__init__("kirara-code-block-lsp", "v0.1", loop=loop)
self._max_workers = 1
self.diagnostic_checkers: List[BaseDiagnostic] = []
self.diagnostic_checkers.append(ImportDiagnostic(self))
self.diagnostic_checkers.append(JediSyntaxErrorDiagnostic(self))
self.diagnostic_checkers.append(PyflakesDiagnostic(self))
logger.info(
f"Enabled diagnostic checkers: {[c.SOURCE_NAME for c in self.diagnostic_checkers]}")
self._setup_handlers()
def configure_mandatory_function_checker(self, config: Dict[str, Any]) -> None:
"""配置必要函数检查器
Args:
config: 包含必要函数检查配置的字典
"""
try:
if self.mandatory_function_checker is None:
self.mandatory_function_checker = MandatoryFunctionDiagnostic(
self, config)
self.diagnostic_checkers.append(
self.mandatory_function_checker)
logger.info(
"MandatoryFunctionDiagnostic enabled with client configuration.")
else:
# 更新现有检查器的配置
self.mandatory_function_checker.update_config(config)
logger.info(
"MandatoryFunctionDiagnostic configuration updated.")
# 记录配置详情
logger.debug(
f"MandatoryFunctionDiagnostic configured with: {config}")
# 更新已启用的诊断检查器列表日志
logger.info(
f"Currently enabled diagnostic checkers: {[c.SOURCE_NAME for c in self.diagnostic_checkers]}")
except Exception as e:
logger.error(
f"Error configuring MandatoryFunctionDiagnostic: {str(e)}", exc_info=True)
self.show_message(
f"Error configuring mandatory function checker: {str(e)}", MessageType.Error)
def _setup_handlers(self):
"""设置 LSP 方法处理程序"""
logger.debug("Setting up LSP handlers...")
@self.feature(TEXT_DOCUMENT_COMPLETION, CompletionOptions(trigger_characters=['.', '(', ',', '=', "\\", "[", "'"]))
@self.thread()
def completions(ls, params: CompletionParams) -> CompletionList:
"""处理代码补全请求"""
return self._get_completions(params)
@self.feature(TEXT_DOCUMENT_HOVER)
@self.thread()
def hover(ls, params: HoverParams) -> Optional[Hover]:
"""处理悬停请求"""
return self._get_hover(params)
@self.feature(TEXT_DOCUMENT_SIGNATURE_HELP, SignatureHelpOptions(trigger_characters=["(", ",", "."]))
@self.thread()
def signature(ls, params: SignatureHelpParams) -> Optional[SignatureHelp]:
"""处理函数签名帮助请求"""
return self._get_signature_help(params)
@self.feature(TEXT_DOCUMENT_DEFINITION)
@self.thread()
def definition(ls, params: DefinitionParams) -> Optional[Union[Location, List[Location]]]:
"""处理跳转到定义请求"""
return self._get_definition(params)
@self.feature(TEXT_DOCUMENT_DOCUMENT_SYMBOL)
@self.thread()
def symbols(ls, params: DocumentSymbolParams) -> Optional[List[SymbolInformation]]:
"""处理文档符号请求"""
return self._get_document_symbols(params)
@self.feature(TEXT_DOCUMENT_DID_OPEN)
@self.thread()
def did_open(ls, params: DidOpenTextDocumentParams):
"""文档打开时触发诊断"""
logger.info(f"Document opened: {params.text_document.uri}")
doc = ls.workspace.get_document(params.text_document.uri)
if doc and doc.source != params.text_document.text:
ls.workspace.put_document(params.text_document)
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_DID_CHANGE)
@self.thread()
def did_change(ls, params: DidChangeTextDocumentParams):
"""文档更改时触发诊断"""
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_DID_SAVE)
@self.thread()
def did_save(ls, params: DidSaveTextDocumentParams):
"""文档保存时触发诊断"""
self._publish_diagnostics(ls, params.text_document.uri)
@self.feature(TEXT_DOCUMENT_CODE_ACTION)
@self.thread()
def code_action(ls, params: CodeActionParams) -> Optional[List[CodeAction]]:
"""处理代码操作请求,提供快速修复建议"""
return self._get_code_actions(params)
@self.feature(WORKSPACE_DID_CHANGE_CONFIGURATION)
@self.thread()
def did_change_configuration(ls, params: DidChangeConfigurationParams):
"""处理客户端配置变更"""
try:
settings = params.settings
if not settings:
return
# 检查是否包含强制函数配置
if 'mandatoryFunction' in settings:
logger.info(
"Update mandatory function checker configuration")
self.configure_mandatory_function_checker(
settings['mandatoryFunction'])
else:
logger.debug("No mandatory function configuration found")
except Exception as e:
logger.error(
f"Error processing configuration change: {str(e)}", exc_info=True)
self.show_message(
f"Error processing configuration change: {str(e)}", MessageType.Error)
logger.debug("LSP handlers set up.")
def _get_script(self, params: Union[TextDocumentPositionParams, CompletionParams, HoverParams, SignatureHelpParams, DefinitionParams]) -> Optional[jedi.Script]:
"""从参数中获取 jedi.Script 对象"""
try:
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
logger.warning(f"文档未在工作区中找到: {doc_uri}")
return None
path = document.path
source = document.source
position = params.position
line = position.line + 1
column = position.character
script = jedi.Script(
code=source,
path=path if path else None,
project=jedi.Project(os.getcwd())
)
return script
except Exception as e:
logger.error(f"Error getting jedi.Script: {str(e)}", exc_info=True)
return None
def _get_completions(self, params: CompletionParams) -> CompletionList:
"""获取代码补全建议"""
items: List[CompletionItem] = []
script = self._get_script(params)
if not script:
return CompletionList(is_incomplete=False, items=items)
try:
position = params.position
line = position.line + 1
column = position.character
completions = script.complete(line, column, fuzzy=True)
for completion in completions:
# ignore hidden completions like __str__
if completion.name.startswith('__'):
continue
kind = self._map_completion_type(completion.type)
item = CompletionItem(
label=completion.name,
kind=kind,
detail=completion.description,
insert_text=completion.name,
)
items.append(item)
except jedi.InternalError as e:
logger.warning(f"Jedi completion error: {e}", exc_info=True)
except Exception as e:
logger.error(f"Error getting completions: {str(e)}", exc_info=True)
return CompletionList(is_incomplete=False, items=items)
def _get_hover(self, params: HoverParams) -> Optional[Hover]:
"""获取悬停信息"""
script = self._get_script(params)
if not script:
return None
try:
position = params.position
line = position.line + 1
column = position.character
hover_info_list = script.help(line, column)
if hover_info_list:
docs = []
for info in hover_info_list:
signature = f"```python\n{info.description}\n```"
doc = info.docstring(raw=True, fast=False)
content = signature
if doc:
content += f"\n\n---\n\n{doc}"
docs.append(content)
full_docstring = "\n\n".join(docs)
if full_docstring:
contents = MarkupContent(
kind=MarkupKind.Markdown,
value=full_docstring
)
return Hover(contents=contents)
except jedi.InternalError as e:
logger.warning(f"Jedi hover error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting hover information: {str(e)}", exc_info=True)
return None
def _get_signature_help(self, params: SignatureHelpParams) -> Optional[SignatureHelp]:
"""获取函数签名帮助"""
script = self._get_script(params)
if not script:
return None
try:
position = params.position
line = position.line + 1
column = position.character
signatures = script.get_signatures(line, column)
if signatures:
signature_infos = []
for sig_index, sig in enumerate(signatures):
param_infos = []
for i, param in enumerate(sig.params):
param_doc = param.description
param_label = param.name
param_info = ParameterInformation(
label=param_label,
documentation=param_doc
)
param_infos.append(param_info)
sig_label = sig.to_string()
sig_info = SignatureInformation(
label=sig_label,
documentation=sig.docstring(raw=True, fast=False),
parameters=param_infos,
)
signature_infos.append(sig_info)
if not signature_infos:
return None
active_signature_index = 0
active_parameter_index = signatures[active_signature_index].index if signatures and signatures[
active_signature_index].index is not None else 0
return SignatureHelp(
signatures=signature_infos,
active_signature=active_signature_index,
active_parameter=active_parameter_index
)
except jedi.InternalError as e:
logger.warning(f"Jedi signature help error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting function signature: {str(e)}", exc_info=True)
return None
def _get_definition(self, params: DefinitionParams) -> List[Location]:
"""获取跳转到定义位置"""
locations: List[Location] = []
script = self._get_script(params)
if not script:
return locations
try:
position = params.position
line = position.line + 1
column = position.character
definitions = script.goto(
line, column, follow_imports=True, follow_builtin_imports=True)
for definition in definitions:
if definition.module_path and definition.line is not None and definition.column is not None:
start_pos = Position(
line=definition.line - 1, character=definition.column)
end_pos = Position(
line=definition.line - 1, character=definition.column + len(definition.name))
range_val = Range(start=start_pos, end=end_pos)
try:
from pathlib import Path
uri = Path(definition.module_path).as_uri()
except ImportError:
uri = f"file://{definition.module_path}"
locations.append(Location(uri=uri, range=range_val))
except jedi.InternalError as e:
logger.warning(f"Jedi definition lookup error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting definition location: {str(e)}", exc_info=True)
return locations
def _get_document_symbols(self, params: DocumentSymbolParams) -> List[SymbolInformation]:
"""获取文档中的符号信息 (扁平列表)"""
symbols = []
try:
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
return []
_script = jedi.Script(
code=document.source,
path=document.path if document.path else None,
project=jedi.Project(os.getcwd())
)
names = _script.get_names(
all_scopes=True, definitions=True, references=False)
for name in names:
if name.line is not None and name.column is not None:
kind = self._map_symbol_type(name.type)
start_pos = Position(
line=name.line - 1, character=name.column)
end_pos = Position(line=name.line - 1,
character=name.column + len(name.name))
container_name = None
try:
parent = name.parent()
if parent and parent.type != 'module':
container_name = parent.name
except Exception:
pass
symbol = SymbolInformation(
name=name.name,
kind=kind,
location=Location(
uri=doc_uri,
range=Range(start=start_pos, end=end_pos)
),
container_name=container_name,
)
symbols.append(symbol)
except jedi.InternalError as e:
logger.warning(f"Jedi symbol lookup error: {e}", exc_info=True)
except Exception as e:
logger.error(
f"Error getting document symbols: {str(e)}", exc_info=True)
return symbols
def _map_completion_type(self, type_str: str) -> CompletionItemKind:
"""将 jedi 补全类型映射到 LSP 补全类型"""
mapping = {
'module': CompletionItemKind.Module,
'class': CompletionItemKind.Class,
'instance': CompletionItemKind.Variable,
'function': CompletionItemKind.Function,
'param': CompletionItemKind.Variable,
'path': CompletionItemKind.File,
'keyword': CompletionItemKind.Keyword,
'property': CompletionItemKind.Property,
'statement': CompletionItemKind.Variable,
'import': CompletionItemKind.Module,
'method': CompletionItemKind.Method,
' M': CompletionItemKind.Method,
' C': CompletionItemKind.Class,
' F': CompletionItemKind.Function,
}
return mapping.get(type_str, CompletionItemKind.Text)
def _map_symbol_type(self, type_str: str) -> SymbolKind:
"""将 jedi 符号类型映射到 LSP 符号类型"""
mapping = {
'module': SymbolKind.Module,
'class': SymbolKind.Class,
'instance': SymbolKind.Variable,
'function': SymbolKind.Function,
'param': SymbolKind.Variable,
'path': SymbolKind.File,
'keyword': SymbolKind.Variable,
'property': SymbolKind.Property,
'statement': SymbolKind.Variable,
'import': SymbolKind.Module,
'method': SymbolKind.Method,
' M': SymbolKind.Method,
' C': SymbolKind.Class,
' F': SymbolKind.Function,
'namespace': SymbolKind.Namespace,
}
return mapping.get(type_str, SymbolKind.Variable)
def _publish_diagnostics(self, ls: LanguageServer, doc_uri: str):
"""运行所有检查并发布诊断信息"""
all_diagnostics = []
document = ls.workspace.get_document(doc_uri)
if not document:
logger.warning(f"无法发布诊断,未找到文档: {doc_uri}")
ls.publish_diagnostics(doc_uri, [])
return
for checker in self.diagnostic_checkers:
checker_name = checker.SOURCE_NAME
try:
checker_diagnostics = checker.check(document)
if checker_diagnostics:
all_diagnostics.extend(checker_diagnostics)
except Exception as e:
logger.error(
f"Diagnostic checker '{checker_name}' error: {str(e)}", exc_info=True)
all_diagnostics.append(Diagnostic(
range=Range(start=Position(line=0, character=0),
end=Position(line=0, character=1)),
message=f"Diagnostic checker '{checker_name}' error: {str(e)}",
severity=DiagnosticSeverity.Error,
source='lsp-internal'
))
ls.publish_diagnostics(doc_uri, all_diagnostics)
def _get_code_actions(self, params: CodeActionParams) -> Optional[List[CodeAction]]:
"""根据请求的诊断信息生成代码操作"""
actions = []
doc_uri = params.text_document.uri
document = self.workspace.get_document(doc_uri)
if not document:
return None
context_diagnostics = params.context.diagnostics
diagnostics_by_source: Dict[str, List[Diagnostic]] = {}
for diag in context_diagnostics:
if diag.source:
if diag.source not in diagnostics_by_source:
diagnostics_by_source[diag.source] = []
diagnostics_by_source[diag.source].append(diag)
for checker in self.diagnostic_checkers:
checker_name = checker.SOURCE_NAME
relevant_diagnostics = diagnostics_by_source.get(checker_name, [])
if relevant_diagnostics:
try:
checker_actions = checker.get_code_actions(
params, relevant_diagnostics)
if checker_actions:
actions.extend(checker_actions)
except Exception as e:
logger.error(
f"Code action checker '{checker_name}' error: {str(e)}", exc_info=True)
return actions if actions else None
================================================
FILE: kirara_ai/web/api/block/routes.py
================================================
import asyncio
import json
from typing import Any
from quart import Blueprint, g, jsonify, websocket
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.block import BlockRegistry
from ...auth.middleware import require_auth
from .models import BlockType, BlockTypeList, BlockTypeResponse
from .python_lsp import PythonLanguageServer, QuartWsTransport
block_bp = Blueprint("block", __name__)
logger = get_logger("Web.Block")
@block_bp.route("/types", methods=["GET"])
@require_auth
async def list_block_types() -> Any:
"""获取所有可用的Block类型"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
types = []
for block_type in registry.get_all_types():
try:
inputs, outputs, configs = registry.extract_block_info(block_type)
type_name = registry.get_block_type_name(block_type)
for config in configs.values():
if config.has_options:
config.options = config.options_provider(g.container, block_type) # type: ignore
block_type_info = BlockType(
type_name=type_name,
name=block_type.name,
label=registry.get_localized_name(type_name) or block_type.name,
description=getattr(block_type, "description", ""),
inputs=list(inputs.values()),
outputs=list(outputs.values()),
configs=list(configs.values()),
)
types.append(block_type_info)
except Exception as e:
logger.error(f"获取Block类型失败: {e}")
return BlockTypeList(types=types).model_dump()
@block_bp.route("/types/", methods=["GET"])
@require_auth
async def get_block_type(type_name: str) -> Any:
"""获取特定Block类型的详细信息"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
block_type = registry.get(type_name)
if not block_type:
return jsonify({"error": "Block type not found"}), 404
# 获取Block类的输入输出定义
inputs, outputs, configs = registry.extract_block_info(block_type)
for config in configs.values():
if config.has_options:
config.options = config.options_provider(g.container, block_type) # type: ignore
block_type_info = BlockType(
type_name=type_name,
name=block_type.name,
label=registry.get_localized_name(type_name) or block_type.name,
description=getattr(block_type, "description", ""),
inputs=list(inputs.values()),
outputs=list(outputs.values()),
configs=list(configs.values()),
)
return BlockTypeResponse(type=block_type_info).model_dump()
@block_bp.route("/types/compatibility", methods=["GET"])
@require_auth
async def get_type_compatibility() -> Any:
"""获取所有类型的兼容性映射"""
registry: BlockRegistry = g.container.resolve(BlockRegistry)
return jsonify(registry.get_type_compatibility_map())
@block_bp.websocket("/code/lsp")
async def code_lsp():
"""处理代码编辑器的语言服务器协议 WebSocket 连接"""
lsp_server = PythonLanguageServer(loop=asyncio.get_event_loop())
logger = get_logger("Web.Block.LSP")
queue = asyncio.Queue()
transport = QuartWsTransport(queue)
lsp_server.lsp.connection_made(transport)
lsp_server.lsp._send_only_body = True
logger.info("LSP WebSocket connection established")
async def sender():
while True:
message = await queue.get()
if message is None:
break
await websocket.send(message)
async def receiver():
while True:
message_str = await websocket.receive()
try:
parsed_message = json.loads(
message_str,
object_hook=lsp_server.lsp._deserialize_message
)
lsp_server.lsp._procedure_handler(parsed_message)
except json.JSONDecodeError:
logger.error(f"Unable to parse received LSP message: {message_str}", exc_info=True)
except Exception as e:
logger.error(f"Error processing LSP message: {e}", exc_info=True)
receive_task = asyncio.create_task(receiver())
send_task = asyncio.create_task(sender())
logger.debug("Created LSP WebSocket sender and receiver tasks")
try:
await asyncio.gather(receive_task, send_task)
except asyncio.CancelledError:
logger.info("LSP WebSocket task cancelled")
except Exception as e:
logger.error(f"LSP WebSocket connection error: {e}", exc_info=True)
finally:
send_task.cancel()
try:
await send_task
except asyncio.CancelledError:
logger.debug("LSP WebSocket sender task cancelled")
receive_task.cancel()
try:
await receive_task
except asyncio.CancelledError:
logger.debug("LSP WebSocket receiver task cancelled")
loop = asyncio.get_event_loop()
loop.run_in_executor(None, lsp_server.shutdown)
logger.info("websocket connection closed")
================================================
FILE: kirara_ai/web/api/dispatch/README.md
================================================
# 调度规则 API 📋
调度规则 API 提供了消息处理规则的管理功能。调度规则决定了如何根据消息内容选择合适的工作流进行处理。
## API 端点
### 获取规则列表
```http
GET/backend-api/api/dispatch/rules
```
获取所有已配置的调度规则。
**响应示例:**
```json
{
"rules": [
{
"rule_id": "chat_normal",
"name": "普通聊天",
"description": "普通聊天,使用默认参数",
"workflow_id": "chat:normal",
"priority": 5,
"enabled": true,
"rule_groups": [
{
"operator": "or",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/chat"
}
},
{
"type": "keyword",
"config": {
"keywords": ["聊天", "对话"]
}
}
]
}
],
"metadata": {
"category": "chat",
"permission": "user",
"temperature": 0.7
}
}
]
}
```
### 获取特定规则
```http
GET/backend-api/api/dispatch/rules/{rule_id}
```
获取指定规则的详细信息。
### 创建规则
```http
POST/backend-api/api/dispatch/rules
```
创建新的调度规则。
**请求体:**
```json
{
"rule_id": "chat_creative",
"name": "创意聊天",
"description": "创意聊天,使用更高的温度参数",
"workflow_id": "chat:creative",
"priority": 5,
"enabled": true,
"rule_groups": [
{
"operator": "and",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/creative"
}
},
{
"type": "keyword",
"config": {
"keywords": ["创意", "发散"]
}
}
]
}
],
"metadata": {
"category": "chat",
"permission": "user",
"temperature": 0.9
}
}
```
### 更新规则
```http
PUT/backend-api/api/dispatch/rules/{rule_id}
```
更新现有规则。
### 删除规则
```http
DELETE/backend-api/api/dispatch/rules/{rule_id}
```
删除指定规则。
### 启用规则
```http
POST/backend-api/api/dispatch/rules/{rule_id}/enable
```
启用指定规则。
### 禁用规则
```http
POST/backend-api/api/dispatch/rules/{rule_id}/disable
```
禁用指定规则。
## 数据模型
### SimpleRule
- `type`: 规则类型 (prefix/keyword/regex)
- `config`: 规则类型特定的配置
### RuleGroup
- `operator`: 组合操作符 (and/or)
- `rules`: 规则列表
### CombinedDispatchRule
- `rule_id`: 规则唯一标识符
- `name`: 规则名称
- `description`: 规则描述
- `workflow_id`: 关联的工作流ID
- `priority`: 优先级(数字越大优先级越高)
- `enabled`: 是否启用
- `rule_groups`: 规则组列表(组之间是 AND 关系)
- `metadata`: 元数据(可选)
## 规则类型
### 前缀匹配 (prefix)
根据消息前缀进行匹配,例如 "/help"。
配置参数:
- `prefix`: 要匹配的前缀
### 关键词匹配 (keyword)
检查消息中是否包含指定关键词。
配置参数:
- `keywords`: 关键词列表
### 正则匹配 (regex)
使用正则表达式进行匹配,提供最灵活的匹配方式。
配置参数:
- `pattern`: 正则表达式模式
## 组合规则说明
新版本的调度规则系统支持复杂的条件组合:
1. 每个规则可以包含多个规则组(RuleGroup)
2. 规则组之间是 AND 关系,即所有规则组都满足时才会触发
3. 每个规则组内可以包含多个简单规则(SimpleRule)
4. 规则组内的规则可以选择 AND 或 OR 关系
5. 每个简单规则都有自己的类型和配置
例如,可以创建如下规则:
```json
{
"rule_groups": [
{
"operator": "or",
"rules": [
{ "type": "prefix", "config": { "prefix": "/creative" } },
{ "type": "keyword", "config": { "keywords": ["创意", "发散"] } }
]
},
{
"operator": "and",
"rules": [
{ "type": "regex", "config": { "pattern": ".*问题.*" } },
{ "type": "keyword", "config": { "keywords": ["帮我", "请问"] } }
]
}
]
}
```
这个规则表示:
- 当消息以 "/creative" 开头 或 包含 "创意"/"发散" 关键词
- 且 消息包含 "问题" 且 包含 "帮我"/"请问" 中的任一关键词
时触发。
## 相关代码
- [调度规则定义](../../../workflow/core/dispatch/rule.py)
- [调度规则注册表](../../../workflow/core/dispatch/registry.py)
- [调度器实现](../../../workflow/core/dispatch/dispatcher.py)
- [系统预设规则](../../../../data/dispatch_rules)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误或规则配置无效
- 404: 规则不存在
- 409: 规则ID已存在
- 500: 服务器内部错误
## 使用示例
### 创建组合规则
```python
import requests
rule_data = {
"rule_id": "chat_creative",
"name": "创意聊天",
"description": "创意聊天模式",
"workflow_id": "chat:creative",
"priority": 5,
"enabled": True,
"rule_groups": [
{
"operator": "or",
"rules": [
{
"type": "prefix",
"config": {
"prefix": "/creative"
}
},
{
"type": "keyword",
"config": {
"keywords": ["创意", "发散"]
}
}
]
}
]
}
response = requests.post(
'http://localhost:8080/api/dispatch/rules',
headers={'Authorization': f'Bearer {token}'},
json=rule_data
)
```
### 更新规则优先级
```python
import requests
response = requests.put(
'http://localhost:8080/api/dispatch/rules/chat_creative',
headers={'Authorization': f'Bearer {token}'},
json={"priority": 8}
)
```
## 相关文档
- [工作流系统概述](../../README.md#工作流系统-)
- [调度规则配置指南](../../../workflow/README.md#调度规则配置)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/dispatch/__init__.py
================================================
from .routes import dispatch_bp
__all__ = ["dispatch_bp"]
================================================
FILE: kirara_ai/web/api/dispatch/models.py
================================================
from typing import List
from pydantic import BaseModel
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule
class DispatchRuleList(BaseModel):
"""调度规则列表"""
rules: List[CombinedDispatchRule]
class DispatchRuleResponse(BaseModel):
"""调度规则响应"""
rule: CombinedDispatchRule
================================================
FILE: kirara_ai/web/api/dispatch/routes.py
================================================
from quart import Blueprint, g, jsonify, request
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule, DispatchRule, DispatchRuleRegistry
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from ...auth.middleware import require_auth
from .models import DispatchRuleList, DispatchRuleResponse
dispatch_bp = Blueprint("dispatch", __name__)
@dispatch_bp.route("/rules", methods=["GET"])
@require_auth
async def list_rules():
"""获取所有调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rules = registry.get_all_rules()
rules.sort(key=lambda x: x.priority, reverse=True)
rules = [rule.model_dump() for rule in rules]
return DispatchRuleList(rules=rules).model_dump()
@dispatch_bp.route("/rules/", methods=["GET"])
@require_auth
async def get_rule(rule_id: str):
"""获取特定调度规则的信息"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
return DispatchRuleResponse(rule=rule).model_dump()
@dispatch_bp.route("/rules", methods=["POST"])
@require_auth
async def create_rule():
"""创建新的调度规则"""
data = await request.get_json()
rule_data = CombinedDispatchRule(**data)
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查规则ID是否已存在
if registry.get_rule(rule_data.rule_id):
return jsonify({"error": "Rule ID already exists"}), 400
# 检查工作流是否存在
if not workflow_registry.get(rule_data.workflow_id):
return jsonify({"error": "Workflow not found"}), 400
try:
# 创建规则
rule = registry.create_rule(rule_data)
# 保存规则
registry.save_rules()
return DispatchRuleResponse(rule=rule).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@dispatch_bp.route("/rules/", methods=["PUT"])
@require_auth
async def update_rule(rule_id: str):
"""更新调度规则"""
data = await request.get_json()
rule_data = CombinedDispatchRule(**data)
if rule_id != rule_data.rule_id:
return jsonify({"error": "Rule ID mismatch"}), 400
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查规则是否存在
if not registry.get_rule(rule_id):
return jsonify({"error": "Rule not found"}), 404
# 检查工作流是否存在
if not workflow_registry.get(rule_data.workflow_id):
return jsonify({"error": "Workflow not found"}), 400
try:
# 更新规则
rule = registry.update_rule(rule_id, rule_data)
# 保存规则
registry.save_rules()
return DispatchRuleResponse(rule=rule).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@dispatch_bp.route("/rules/", methods=["DELETE"])
@require_auth
async def delete_rule(rule_id: str):
"""删除调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
# 检查规则是否存在
if not registry.get_rule(rule_id):
return jsonify({"error": "Rule not found"}), 404
# 删除规则
registry.delete_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule deleted successfully"})
@dispatch_bp.route("/rules//enable", methods=["POST"])
@require_auth
async def enable_rule(rule_id: str):
"""启用调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
if rule.enabled:
return jsonify({"error": "Rule is already enabled"}), 400
# 启用规则
registry.enable_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule enabled successfully"})
@dispatch_bp.route("/rules//disable", methods=["POST"])
@require_auth
async def disable_rule(rule_id: str):
"""禁用调度规则"""
registry: DispatchRuleRegistry = g.container.resolve(DispatchRuleRegistry)
rule = registry.get_rule(rule_id)
if not rule:
return jsonify({"error": "Rule not found"}), 404
if not rule.enabled:
return jsonify({"error": "Rule is already disabled"}), 400
# 禁用规则
registry.disable_rule(rule_id)
# 保存规则
registry.save_rules()
return jsonify({"message": "Rule disabled successfully"})
@dispatch_bp.route("/types", methods=["GET"])
@require_auth
async def get_rule_types():
"""获取所有可用的规则类型"""
return jsonify({"types": list(DispatchRule.rule_types.keys())})
@dispatch_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_rule_config_schema(rule_type: str):
"""获取指定规则类型的配置字段模式"""
try:
if rule_type not in DispatchRule.rule_types:
return jsonify({"error": "Invalid rule type"}), 404
rule_class = DispatchRule.rule_types[rule_type]
config_class = rule_class.config_class
schema = config_class.model_json_schema()
return jsonify({"configSchema": schema})
except Exception as e:
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/im/README.md
================================================
# 即时通讯 API 🗨️
即时通讯 API 提供了管理 IM 后端和适配器的功能。通过这些 API,你可以注册、配置和管理不同的 IM 平台适配器。
## API 端点
### 获取适配器类型
```http
GET/backend-api/api/im/types
```
获取所有可用的 IM 适配器类型。
**响应示例:**
```json
{
"types": [
"mirai",
"telegram",
"discord"
]
}
```
### 获取所有适配器
```http
GET/backend-api/api/im/adapters
```
获取所有已配置的 IM 适配器信息。
**响应示例:**
```json
{
"adapters": [
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
},
"is_running": true
}
]
}
```
### 获取特定适配器
```http
GET/backend-api/api/im/adapters/{adapter_id}
```
获取指定适配器的详细信息。
**响应示例:**
```json
{
"adapter": {
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
},
"is_running": true
}
}
```
### 创建适配器
```http
POST/backend-api/api/im/adapters
```
注册新的 IM 适配器。
**请求体:**
```json
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
}
}
```
### 更新适配器
```http
PUT/backend-api/api/im/adapters/{adapter_id}
```
更新现有适配器的配置。如果适配器正在运行,会自动重启以应用新配置。
**请求体:**
```json
{
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
}
}
```
### 删除适配器
```http
DELETE/backend-api/api/im/adapters/{adapter_id}
```
删除指定的适配器。如果适配器正在运行,会先自动停止。
### 启动适配器
```http
POST/backend-api/api/im/adapters/{adapter_id}/start
```
启动指定的适配器。
### 停止适配器
```http
POST/backend-api/api/im/adapters/{adapter_id}/stop
```
停止指定的适配器。
### 获取适配器配置模式
```http
GET/backend-api/api/im/types/{adapter_type}/config-schema
```
获取指定适配器类型的配置字段模式。
**响应示例:**
```json
{
"schema": {
"title": "TelegramConfig",
"type": "object",
"properties": {
"token": {
"title": "Bot Token",
"type": "string",
"description": "Telegram Bot Token"
}
},
"required": ["token"]
}
}
```
## 数据模型
### IMAdapterConfig
- `name`: 适配器名称
- `adapter`: 适配器类型
- `config`: 配置信息(字典)
### IMAdapterStatus
继承自 IMAdapterConfig,额外包含:
- `is_running`: 适配器是否正在运行
### IMAdapterList
- `adapters`: IM 适配器列表
### IMAdapterResponse
- `adapter`: 适配器信息
### IMAdapterTypes
- `types`: 可用的适配器类型列表
### IMAdapterConfigSchema
- `error`: 错误信息(可选)
- `schema`: JSON Schema 格式的配置字段描述
## 适配器类型
适配器由插件提供,见[适配器实现](../../../im/adapters)。
## 相关代码
- [IM 管理器](../../../im/manager.py)
- [IM 注册表](../../../im/im_registry.py)
- [适配器实现](../../../im/adapters)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、适配器类型无效或适配器已在运行
- 404: 适配器不存在
- 500: 服务器内部错误
## 使用示例
### 获取适配器类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/im/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新适配器
```python
import requests
adapter_data = {
"name": "telegram",
"adapter": "telegram",
"config": {
"token": "your-bot-token",
"webhook_url": "https://example.com/webhook"
}
}
response = requests.post(
'http://localhost:8080/api/im/adapters',
headers={'Authorization': f'Bearer {token}'},
json=adapter_data
)
```
### 启动适配器
```python
import requests
response = requests.post(
'http://localhost:8080/api/im/adapters/telegram/start',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [IM 适配器开发](../../../im/README.md#适配器开发-)
================================================
FILE: kirara_ai/web/api/im/__init__.py
================================================
from .routes import im_bp
__all__ = ["im_bp"]
================================================
FILE: kirara_ai/web/api/im/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import IMConfig
from kirara_ai.im.im_registry import IMAdapterInfo
from kirara_ai.im.profile import UserProfile
IMAdapterConfig = IMConfig
class IMAdapterStatus(IMAdapterConfig):
"""IM适配器状态"""
is_running: bool
bot_profile: Optional[UserProfile] = None
class IMAdapterList(BaseModel):
"""IM适配器列表响应"""
adapters: List[IMAdapterStatus]
class IMAdapterResponse(BaseModel):
"""单个IM适配器响应"""
adapter: IMAdapterStatus
class IMAdapterTypes(BaseModel):
"""可用的IM适配器类型列表"""
types: List[str]
adapters: Dict[str, IMAdapterInfo]
class IMAdapterConfigSchema(BaseModel):
"""IM适配器配置模式"""
error: Optional[str] = None
configSchema: Optional[Dict[str, Any]] = None
================================================
FILE: kirara_ai/web/api/im/routes.py
================================================
import asyncio
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigJsonSchema, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.adapter import BotProfileAdapter
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.logger import get_logger
from ...auth.middleware import require_auth
from .models import (IMAdapterConfig, IMAdapterConfigSchema, IMAdapterList, IMAdapterResponse, IMAdapterStatus,
IMAdapterTypes)
im_bp = Blueprint("im", __name__)
logger = get_logger("Web.IM")
def _create_adapter(manager: IMManager, name: str, adapter: str, config: dict):
registry: IMRegistry = g.container.resolve(IMRegistry)
adapter_info = registry.get_all_adapters()[adapter]
adapter_class = adapter_info.adapter_class
adapter_config_class = adapter_info.config_class
adapter_config = adapter_config_class(**config)
manager.create_adapter(name, adapter_class, adapter_config)
@im_bp.route("/types", methods=["GET"])
@require_auth
async def get_adapter_types():
"""获取所有可用的适配器类型"""
registry: IMRegistry = g.container.resolve(IMRegistry)
adapters = registry.get_all_adapters()
types = [info.name for info in adapters.values()]
return IMAdapterTypes(types=types, adapters=adapters).model_dump()
@im_bp.route("/adapters", methods=["GET"])
@require_auth
async def list_adapters():
"""获取所有已配置的适配器"""
config = g.container.resolve(GlobalConfig)
manager = g.container.resolve(IMManager)
adapters = []
for im in config.ims:
is_running = manager.is_adapter_running(im.name)
configs = im.config
adapters.append(
IMAdapterStatus(
name=im.name, adapter=im.adapter, is_running=is_running, config=configs
)
)
return IMAdapterList(adapters=adapters).model_dump()
@im_bp.route("/adapters/", methods=["GET"])
@require_auth
async def get_adapter(adapter_id: str):
"""获取特定适配器的信息"""
manager: IMManager = g.container.resolve(IMManager)
# 查找适配器类型
if not manager.has_adapter(adapter_id):
return jsonify({"error": "Adapter not found"}), 404
adapter_config = manager.get_adapter_config(adapter_id)
adapter = manager.get_adapter(adapter_id)
bot_profile = None
if manager.is_adapter_running(adapter_id) and isinstance(adapter, BotProfileAdapter):
bot_profile = await adapter.get_bot_profile()
return IMAdapterResponse(
adapter=IMAdapterStatus(
name=adapter_id,
adapter=adapter_config.adapter,
is_running=manager.is_adapter_running(adapter_id),
config=adapter_config.config,
bot_profile=bot_profile
)
).model_dump()
@im_bp.route("/adapters", methods=["POST"])
@require_auth
async def create_adapter():
"""创建新的适配器"""
data = await request.get_json()
adapter_info = IMAdapterConfig(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
registry: IMRegistry = g.container.resolve(IMRegistry)
manager: IMManager = g.container.resolve(IMManager)
# 检查适配器类型是否存在
if adapter_info.adapter not in registry.get_all_adapters():
return jsonify({"error": "Invalid adapter type"}), 400
# 检查ID是否已存在
if manager.has_adapter(adapter_info.name):
return jsonify({"error": "Adapter ID already exists"}), 400
# 更新配置
_create_adapter(manager, adapter_info.name, adapter_info.adapter, adapter_info.config)
if adapter_info.enable:
try:
await manager.start_adapter(adapter_info.name, asyncio.get_event_loop())
except Exception as e:
manager.delete_adapter(adapter_info.name)
return jsonify({"error": str(e)}), 500
config.ims.append(adapter_info)
# 保存配置到文件
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return IMAdapterResponse(
adapter=IMAdapterStatus(
name=adapter_info.name,
adapter=adapter_info.adapter,
is_running=False,
config=adapter_info.config,
)
).model_dump()
@im_bp.route("/adapters/", methods=["PUT"])
@require_auth
async def update_adapter(adapter_id: str):
"""更新适配器配置 (支持重命名)"""
data = await request.get_json()
try:
adapter_info = IMAdapterConfig(**data)
except Exception as e:
return jsonify({"error": f"Invalid request data: {e}"}), 400
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: IMManager = g.container.resolve(IMManager)
registry: IMRegistry = g.container.resolve(IMRegistry)
loop = asyncio.get_event_loop()
# 1. 检查原始适配器是否存在
if not manager.has_adapter(adapter_id):
return jsonify({"error": "Adapter not found"}), 404
# 2. 如果名称改变,检查新名称是否冲突
if adapter_id != adapter_info.name and manager.has_adapter(adapter_info.name):
return jsonify({"error": f"Adapter name '{adapter_info.name}' already exists"}), 400
# 3. 检查适配器类型是否有效
if adapter_info.adapter not in registry.get_all_adapters():
return jsonify({"error": "Invalid adapter type specified"}), 400
# --- 停止旧适配器 (如果正在运行) ---
if manager.is_adapter_running(adapter_id):
try:
await manager.stop_adapter(adapter_id, loop)
except Exception as e:
logger.error(f"Error stopping adapter {adapter_id}: {e}")
# --- 更新 IMManager ---
# 从管理器中删除旧的实例
manager.delete_adapter(adapter_id)
# 使用新名称和配置创建新的实例
_create_adapter(manager, adapter_info.name, adapter_info.adapter, adapter_info.config)
config.ims.append(adapter_info)
# --- 尝试启动新适配器 (如果启用) ---
is_now_running = False
if adapter_info.enable:
try:
await manager.start_adapter(adapter_info.name, loop)
is_now_running = True
except Exception as e:
logger.error(f"Failed to start adapter '{adapter_info.name}' after update: {e}")
# --- 保存配置到文件 ---
# 无论是否启动成功,都保存更新后的配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# --- 准备并返回响应 ---
bot_profile = None
if is_now_running: # 仅在成功启动后尝试获取 profile
adapter_instance = manager.get_adapter(adapter_info.name)
if isinstance(adapter_instance, BotProfileAdapter):
try:
# 添加超时以防卡住
bot_profile = await asyncio.wait_for(adapter_instance.get_bot_profile(), timeout=5.0)
except Exception as e:
logger.error(f"Failed to get bot profile for {adapter_info.name} after update: {e}")
return IMAdapterResponse(adapter=IMAdapterStatus(
name=adapter_info.name, # 使用新名称
adapter=adapter_info.adapter,
is_running=is_now_running, # 反映当前实际运行状态
config=adapter_info.config,
bot_profile=bot_profile
)).model_dump()
@im_bp.route("/adapters/", methods=["DELETE"])
@require_auth
async def delete_adapter(adapter_id: str):
"""删除适配器"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
# 先停止适配器
if manager.is_adapter_running(adapter_id):
await manager.stop_adapter(adapter_id, loop)
# 从配置中删除
manager.delete_adapter(adapter_id)
# 保存配置到文件
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"message": "Adapter deleted successfully"})
@im_bp.route("/adapters//start", methods=["POST"])
@require_auth
async def start_adapter(adapter_id: str):
"""启动适配器"""
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
if manager.is_adapter_running(adapter_id):
return jsonify({"error": "Adapter is already running"}), 400
try:
await manager.start_adapter(adapter_id, loop)
return jsonify({"message": "Adapter started successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@im_bp.route("/adapters//stop", methods=["POST"])
@require_auth
async def stop_adapter(adapter_id: str):
"""停止适配器"""
manager: IMManager = g.container.resolve(IMManager)
loop = asyncio.get_event_loop()
if not manager.is_adapter_running(adapter_id):
return jsonify({"error": "Adapter is not running"}), 400
try:
await manager.stop_adapter(adapter_id, loop)
return jsonify({"message": "Adapter stopped successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@im_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_adapter_config_schema(adapter_type: str):
"""获取指定适配器类型的配置字段模式"""
try:
registry: IMRegistry = g.container.resolve(IMRegistry)
try:
config_class = registry.get_config_class(adapter_type)
except ValueError as e:
return jsonify({"error": str(e)}), 404
schema = config_class.model_json_schema(schema_generator=ConfigJsonSchema)
return IMAdapterConfigSchema(configSchema=schema).model_dump()
except Exception as e:
return IMAdapterConfigSchema(error=str(e)).model_dump()
================================================
FILE: kirara_ai/web/api/llm/README.md
================================================
# 大语言模型 API 🤖
大语言模型 API 提供了管理 LLM 后端和适配器的功能。通过这些 API,你可以注册、配置和管理不同的大语言模型服务。
## API 端点
### 获取适配器类型
```http
GET/backend-api/api/llm/types
```
获取所有可用的 LLM 适配器类型。
**响应示例:**
```json
{
"types": [
"openai",
"anthropic",
"azure",
"local"
]
}
```
### 获取所有后端
```http
GET/backend-api/api/llm/backends
```
获取所有已注册的 LLM 后端信息。
**响应示例:**
```json
{
"data": {
"backends": [
{
"name": "openai",
"adapter": "openai",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.openai.com/v1"
},
"enable": true,
"models": ["gpt-4", "gpt-3.5-turbo"]
}
]
}
}
```
### 获取特定后端
```http
GET/backend-api/api/llm/backends/{backend_name}
```
获取指定后端的详细信息。
**响应示例:**
```json
{
"data": {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
}
```
### 创建后端
```http
POST/backend-api/api/llm/backends
```
注册新的 LLM 后端。
**请求体:**
```json
{
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
```
### 更新后端
```http
PUT/backend-api/api/llm/backends/{backend_name}
```
更新现有后端的配置。
**请求体:**
```json
{
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com",
"temperature": 0.7
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
```
### 删除后端
```http
DELETE/backend-api/api/llm/backends/{backend_name}
```
删除指定的后端。如果后端当前已启用,会先自动卸载。
### 获取适配器配置模式
```http
GET/backend-api/api/llm/types/{adapter_type}/config-schema
```
获取指定适配器类型的配置字段模式。
**响应示例:**
```json
{
"schema": {
"title": "OpenAIConfig",
"type": "object",
"properties": {
"api_key": {
"title": "API Key",
"type": "string",
"description": "OpenAI API密钥"
},
"api_base": {
"title": "API Base",
"type": "string",
"description": "API基础URL",
"default": "https://api.openai.com/v1"
},
"temperature": {
"title": "Temperature",
"type": "number",
"description": "生成温度",
"default": 0.7,
"minimum": 0,
"maximum": 2
}
},
"required": ["api_key"]
}
}
```
## 数据模型
### LLMBackendInfo
- `name`: 后端名称
- `adapter`: 适配器类型
- `config`: 配置信息(字典)
- `enable`: 是否启用
- `models`: 支持的模型列表
### LLMBackendList
- `backends`: LLM 后端列表
### LLMBackendResponse
- `error`: 错误信息(可选)
- `data`: 后端信息(可选)
### LLMBackendListResponse
- `error`: 错误信息(可选)
- `data`: 后端列表(可选)
### LLMAdapterTypes
- `types`: 可用的适配器类型列表
### LLMAdapterConfigSchema
- `error`: 错误信息(可选)
- `schema`: JSON Schema 格式的配置字段描述
## 适配器类型
适配器由插件提供,见[适配器实现](../../../llm/adapters)。
目前自带支持的适配器类型包括:
### OpenAI
- 适配器类型: `openai`
- 支持模型: gpt-4, gpt-3.5-turbo 等
- 配置项:
- `api_key`: API 密钥
- `api_base`: API 基础 URL
- `temperature`: 温度参数(可选)
### Anthropic
- 适配器类型: `anthropic`
- 支持模型: claude-3-opus, claude-3-sonnet 等
- 配置项:
- `api_key`: API 密钥
- `api_base`: API 基础 URL
- `temperature`: 温度参数(可选)
### Azure OpenAI
- 适配器类型: `azure`
- 支持 Azure OpenAI 服务部署的各类模型
- 配置项:
- `api_key`: API 密钥
- `api_base`: Azure 终结点
- `deployment_name`: 部署名称
### 本地模型
- 适配器类型: `local`
- 支持本地部署的开源模型
- 配置项:
- `model_path`: 模型路径
- `device`: 运行设备(cpu/cuda)
## 相关代码
- [LLM 管理器](../../../llm/llm_manager.py)
- [LLM 注册表](../../../llm/llm_registry.py)
- [适配器实现](../../../llm/adapters)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误或后端配置无效
- 404: 后端不存在
- 500: 服务器内部错误
## 使用示例
### 获取适配器类型
```python
import requests
response = requests.get(
'http://localhost:8080/api/llm/types',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新后端
```python
import requests
backend_data = {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com"
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
response = requests.post(
'http://localhost:8080/api/llm/backends',
headers={'Authorization': f'Bearer {token}'},
json=backend_data
)
```
### 更新后端配置
```python
import requests
backend_data = {
"name": "anthropic",
"adapter": "anthropic",
"config": {
"api_key": "sk-xxx",
"api_base": "https://api.anthropic.com",
"temperature": 0.7
},
"enable": true,
"models": ["claude-3-opus", "claude-3-sonnet"]
}
response = requests.put(
'http://localhost:8080/api/llm/backends/anthropic',
headers={'Authorization': f'Bearer {token}'},
json=backend_data
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [LLM 适配器开发](../../../llm/README.md#适配器开发-)
================================================
FILE: kirara_ai/web/api/llm/__init__.py
================================================
from .routes import llm_bp
__all__ = ["llm_bp"]
================================================
FILE: kirara_ai/web/api/llm/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.config.global_config import LLMBackendConfig, ModelConfig
class LLMBackendInfo(LLMBackendConfig):
"""LLM后端信息"""
class LLMBackendList(BaseModel):
"""LLM后端列表"""
backends: List[LLMBackendInfo]
class LLMBackendResponse(BaseModel):
"""LLM后端响应"""
error: Optional[str] = None
data: Optional[LLMBackendInfo] = None
class LLMBackendListResponse(BaseModel):
"""LLM后端列表响应"""
error: Optional[str] = None
data: Optional[LLMBackendList] = None
class LLMBackendCreateRequest(LLMBackendConfig):
"""创建LLM后端请求"""
class LLMBackendUpdateRequest(LLMBackendConfig):
"""更新LLM后端请求"""
class LLMAdapterTypes(BaseModel):
"""可用的LLM适配器类型列表"""
types: List[str]
class LLMAdapterConfigSchema(BaseModel):
"""LLM适配器配置模式"""
error: Optional[str] = None
configSchema: Optional[Dict[str, Any]] = None
class ModelConfigListResponse(BaseModel):
"""模型配置列表响应"""
error: Optional[str] = None
models: List[ModelConfig] = []
================================================
FILE: kirara_ai/web/api/llm/routes.py
================================================
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.llm.adapter import AutoDetectModelsProtocol
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.web.api.llm.models import (LLMAdapterConfigSchema, LLMAdapterTypes, LLMBackendCreateRequest,
LLMBackendInfo, LLMBackendList, LLMBackendListResponse, LLMBackendResponse,
LLMBackendUpdateRequest, ModelConfigListResponse)
from ...auth.middleware import require_auth
llm_bp = Blueprint("llm", __name__)
logger = get_logger("WebServer.LLM")
@llm_bp.route("/types", methods=["GET"])
@require_auth
async def get_adapter_types():
"""获取所有可用的适配器类型"""
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
return LLMAdapterTypes(types=registry.get_adapter_types()).model_dump()
@llm_bp.route("/backends", methods=["GET"])
@require_auth
async def list_backends():
"""获取所有后端列表"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
backends = []
for backend in config.llms.api_backends:
backends.append(
LLMBackendInfo(
name=backend.name,
adapter=backend.adapter,
config=backend.config,
enable=backend.enable,
models=backend.models,
)
)
return LLMBackendListResponse(
data=LLMBackendList(backends=backends)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to list backends")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["GET"])
@require_auth
async def get_backend(backend_name: str):
"""获取指定后端信息"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
backend = next(
(b for b in config.llms.api_backends if b.name == backend_name), None
)
if not backend:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
return LLMBackendResponse(
data=LLMBackendInfo(
name=backend.name,
adapter=backend.adapter,
config=backend.config,
enable=backend.enable,
models=backend.models,
)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to get backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends", methods=["POST"])
@require_auth
async def create_backend():
"""创建新的后端"""
try:
data = await request.get_json()
request_data = LLMBackendCreateRequest(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 检查后端名称是否已存在
if any(b.name == request_data.name for b in config.llms.api_backends):
return (
jsonify({"error": f"Backend {request_data.name} already exists"}),
400,
)
# 创建新的后端配置
backend = LLMBackendInfo(
name=request_data.name,
adapter=request_data.adapter,
config=request_data.config,
enable=request_data.enable,
models=request_data.models,
)
# 添加到配置中
config.llms.api_backends.append(backend)
# 如果启用则加载后端
if backend.enable:
manager.load_backend(backend.name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(data=backend).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to create backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["PUT"])
@require_auth
async def update_backend(backend_name: str):
"""更新指定后端"""
try:
data = await request.get_json()
request_data = LLMBackendUpdateRequest(**data)
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 查找要更新的后端
backend_index = next(
(
i
for i, b in enumerate(config.llms.api_backends)
if b.name == backend_name
),
-1,
)
if backend_index == -1:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
# 创建更新后的后端配置
updated_backend = LLMBackendInfo(
name=request_data.name,
adapter=request_data.adapter,
config=request_data.config,
enable=request_data.enable,
models=request_data.models,
)
# 如果原后端已启用,先卸载
if config.llms.api_backends[backend_index].enable:
await manager.unload_backend(backend_name)
# 更新配置
config.llms.api_backends[backend_index] = updated_backend
# 如果新配置启用则加载后端
if updated_backend.enable:
manager.load_backend(updated_backend.name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(data=updated_backend).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to update backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends/", methods=["DELETE"])
@require_auth
async def delete_backend(backend_name: str):
"""删除指定后端"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: LLMManager = g.container.resolve(LLMManager)
# 查找要删除的后端
backend_index = next(
(
i
for i, b in enumerate(config.llms.api_backends)
if b.name == backend_name
),
-1,
)
if backend_index == -1:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
backend = config.llms.api_backends[backend_index]
# 如果后端已启用,要卸载
if backend.enable:
await manager.unload_backend(backend_name)
# 从配置中删除
deleted_backend = config.llms.api_backends.pop(backend_index)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return LLMBackendResponse(
data=LLMBackendInfo(
name=deleted_backend.name,
adapter=deleted_backend.adapter,
config=deleted_backend.config,
enable=deleted_backend.enable,
models=deleted_backend.models,
)
).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to delete backend")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/types//config-schema", methods=["GET"])
@require_auth
async def get_adapter_config_schema(adapter_type: str):
"""获取指定适配器类型的配置字段模式"""
try:
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
config_class = registry.get_config_class(adapter_type)
if not config_class:
return jsonify({"error": f"Adapter type {adapter_type} not found"}), 404
schema = config_class.model_json_schema()
return LLMAdapterConfigSchema(configSchema=schema).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to get adapter config schema")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/types//supports-auto-detect-models", methods=["GET"])
@require_auth
async def supports_auto_detect_models(adapter_type: str):
"""检查指定适配器类型是否支持自动检测模型"""
try:
registry: LLMBackendRegistry = g.container.resolve(LLMBackendRegistry)
adapter_class = registry.get(adapter_type)
if not adapter_class:
return jsonify({"error": f"Adapter type {adapter_type} not found"}), 404
if not issubclass(adapter_class, AutoDetectModelsProtocol):
return (
jsonify(
{
"error": f"Adapter type {adapter_type} does not support auto-detect models"
}
),
400,
)
return jsonify({"supportsAutoDetectModels": True})
except Exception as e:
logger.opt(exception=e).error("Failed to check if adapter supports auto-detect models")
return jsonify({"error": str(e)}), 500
@llm_bp.route("/backends//auto-detect-models", methods=["GET"])
@require_auth
async def auto_detect_models(backend_name: str):
"""自动检测指定后端的模型列表"""
try:
manager: LLMManager = g.container.resolve(LLMManager)
adapter = manager.get(backend_name)
if not adapter:
return jsonify({"error": f"Backend {backend_name} not found"}), 404
if not isinstance(adapter, AutoDetectModelsProtocol):
return (
jsonify(
{
"error": f"Backend {backend_name} does not support auto-detect models"
}
),
400,
)
# 自动检测模型并返回完整的ModelConfig列表
models = await adapter.auto_detect_models()
# 确保每个模型都有正确的能力设置
for model in models:
# 如果模型类型是LLM但没有设置能力,设置默认的TextChat能力
if model.type == ModelType.LLM.value and not model.ability:
model.ability = LLMAbility.TextChat.value
return ModelConfigListResponse(models=models).model_dump()
except Exception as e:
logger.opt(exception=e).error("Failed to auto-detect models")
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/mcp/README.md
================================================
# MCP 服务器管理 API
MCP(Model Context Protocol)是一种用于大型语言模型的通信协议。本 API 提供了管理 MCP 服务器的功能,包括创建、更新、删除、启动和停止服务器,以及获取服务器提供的工具列表。
## 数据模型
### MCP 服务器(MCPServer)
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
```
### 连接类型(ConnectionType)
- `stdio`: 标准输入输出连接
- `sse`: 服务器发送事件连接
### 服务器状态(ServerStatus)
- `running`: 运行中
- `stopped`: 已停止
- `error`: 错误状态
## API 端点
### 获取服务器列表
获取 MCP 服务器列表,支持分页和过滤。
**请求**:
```
POST /mcp/servers
```
**请求体**:
```json
{
"page": 1,
"page_size": 20,
"page_size": 20,
"connection_type": null,
"status": null,
"query": null
}
```
**响应**:
```json
{
"items": [
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
],
"total": 1,
"page": 1,
"page_size": 20,
"total_pages": 1
}
```
### 获取统计信息
获取 MCP 服务器相关的统计信息。
**请求**:
```
GET /mcp/statistics
```
**响应**:
```json
{
"total_servers": 3,
"stdio_servers": 2,
"sse_servers": 1,
"running_servers": 1,
"stopped_servers": 2
}
```
### 获取服务器详情
获取特定 MCP 服务器的详细信息。
**请求**:
```
GET /mcp/servers/{server_id}
```
**响应**:
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio",
"status": "stopped",
"error_message": null,
"created_at": "2023-04-01T12:00:00",
"last_used_at": null
}
```
### 获取服务器工具列表
获取 MCP 服务器提供的工具列表。
**请求**:
```
GET /mcp/servers/{server_id}/tools
```
**响应**:
```json
[
{
"name": "search_web",
"description": "搜索网络获取信息",
"parameters": {
"query": {
"type": "string",
"description": "搜索查询"
}
}
},
{
"name": "analyze_image",
"description": "分析图像内容",
"parameters": {
"image_url": {
"type": "string",
"description": "图像URL"
},
"detect_faces": {
"type": "boolean",
"description": "是否检测人脸"
}
}
}
]
```
### 检查服务器 ID 是否可用
检查给定的服务器 ID 是否已存在。
**请求**:
```
GET /mcp/servers/check/{server_id}
```
**响应**:
返回布尔值,`true` 表示 ID 可用,`false` 表示 ID 已存在。
### 创建服务器
创建新的 MCP 服务器。
**请求**:
```
POST /mcp/servers/create
```
**请求体**:
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio"
}
```
**响应**:
返回创建的服务器详情。
### 更新服务器
更新现有 MCP 服务器的配置。
**请求**:
```
PUT /mcp/servers/{server_id}
```
**请求体**:
```json
{
"description": "Updated description",
"command": "python3",
"args": "-m claude_cli.mcp --verbose",
"connection_type": "stdio"
}
```
**响应**:
返回更新后的服务器详情。
### 删除服务器
删除 MCP 服务器。
**请求**:
```
DELETE /mcp/servers/{server_id}
```
**响应**:
```json
{
"message": "服务器已成功删除"
}
```
### 启动服务器
启动 MCP 服务器。
**请求**:
```
POST /mcp/servers/{server_id}/start
```
**响应**:
```json
{
"message": "服务器已启动"
}
```
### 停止服务器
停止 MCP 服务器。
**请求**:
```
POST /mcp/servers/{server_id}/stop
```
**响应**:
```json
{
"message": "服务器已停止"
}
```
## 使用示例
### 创建并启动 MCP 服务器
1. 创建服务器:
```
POST /mcp/servers/create
```
```json
{
"id": "claude-mcp",
"description": "Claude MCP 服务器",
"command": "python",
"args": "-m claude_cli.mcp",
"connection_type": "stdio"
}
```
2. 启动服务器:
```
POST /mcp/servers/claude-mcp/start
```
3. 获取服务器提供的工具:
```
GET /mcp/servers/claude-mcp/tools
```
## 注意事项
1. 在更新服务器配置前,必须先停止正在运行的服务器。
2. 服务器 ID 必须是唯一的,可以使用 `/mcp/servers/check/{server_id}` 接口检查 ID 是否可用。
3. 创建服务器后,服务器状态默认为 `stopped`,需要手动启动。
================================================
FILE: kirara_ai/web/api/mcp/__init__.py
================================================
from .routes import mcp_bp
__all__ = ["mcp_bp"]
================================================
FILE: kirara_ai/web/api/mcp/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, Field
class MCPServerInfo(BaseModel):
"""MCP服务器信息"""
id: str
description: Optional[str] = None
connection_type: str
command: Optional[str] = None
args: str = Field(default="")
url: Optional[str] = None
connection_state: str
class MCPToolInfo(BaseModel):
"""MCP工具信息"""
name: str
description: Optional[str] = None
input_schema: Dict[str, Any] = Field(default_factory=dict)
class MCPServerList(BaseModel):
"""MCP服务器列表"""
items: List[MCPServerInfo]
total: int
page: int
page_size: int
total_pages: int
class MCPStatistics(BaseModel):
"""MCP统计信息"""
total_servers: int
stdio_servers: int
sse_servers: int
connected_servers: int
disconnected_servers: int
error_servers: int
total_tools: int
class MCPServerCreateRequest(BaseModel):
"""创建MCP服务器请求"""
id: str
description: Optional[str] = None
command: str
args: str
connection_type: str
class MCPServerUpdateRequest(BaseModel):
"""更新MCP服务器请求"""
description: Optional[str] = None
command: Optional[str] = None
args: str = Field(default="")
connection_type: Optional[str] = None
url: Optional[str] = None
headers: Optional[Dict[str, str]] = None
env: Optional[Dict[str, str]] = None
================================================
FILE: kirara_ai/web/api/mcp/routes.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from typing import Any, Dict, Optional, cast
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig, MCPServerConfig
from kirara_ai.logger import get_logger
from kirara_ai.mcp_module import MCPConnectionState, MCPServer, MCPServerManager
from ...auth.middleware import require_auth
from .models import (MCPServerCreateRequest, MCPServerInfo, MCPServerList, MCPServerUpdateRequest, MCPStatistics,
MCPToolInfo)
# 创建蓝图
mcp_bp = Blueprint("mcp", __name__)
logger = get_logger("WebServer.MCP")
def _convert_to_server_info(server: MCPServer) -> MCPServerInfo:
"""将服务器对象转换为MCPServerInfo响应对象"""
return MCPServerInfo(
id=server.server_config.id,
description=server.server_config.description,
connection_type=server.server_config.connection_type,
command=server.server_config.command,
args=" ".join(server.server_config.args) if isinstance(
server.server_config.args, list) else server.server_config.args,
url=getattr(server.server_config, 'url', None),
connection_state=server.state.name.lower()
)
@mcp_bp.route("/servers", methods=["GET"])
@require_auth
async def list_servers():
"""获取所有MCP服务器列表"""
try:
# 获取查询参数
page = request.args.get('page', 1, type=int)
page_size = request.args.get('page_size', 20, type=int)
connection_type = request.args.get('connection_type')
status = request.args.get('status')
query = request.args.get('query')
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取所有服务器
servers = manager.get_all_servers()
# 转换为响应格式
server_list = []
for server_id, server in servers.items():
# 过滤条件
if connection_type and server.server_config.connection_type != connection_type:
continue
server_state = server.state.name.lower()
if status:
if status == 'connected' and server_state != 'connected':
continue
elif status == 'disconnected' and server_state != 'disconnected':
continue
elif status == 'error' and server_state != 'error':
continue
if query and query.lower() not in server_id.lower() and (
not server.server_config.command or query.lower() not in server.server_config.command.lower()):
continue
server_list.append(_convert_to_server_info(server))
# 计算分页
total = len(server_list)
total_pages = (total + page_size - 1) // page_size
start_idx = (page - 1) * page_size
end_idx = min(start_idx + page_size, total)
paginated_servers = server_list[start_idx:end_idx]
# 返回响应
return MCPServerList(
items=[server for server in paginated_servers],
total=total,
page=page,
page_size=page_size,
total_pages=total_pages
).model_dump()
except Exception as e:
logger.opt(exception=e).error("获取MCP服务器列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/statistics", methods=["GET"])
@require_auth
async def get_statistics():
"""获取MCP服务器统计信息"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取统计信息
stats = manager.get_statistics()
# 获取工具总数
tools = manager.get_tools()
total_tools = len(tools)
# 返回响应
return MCPStatistics(
total_servers=stats.get("total", 0),
stdio_servers=stats.get("stdio", 0),
sse_servers=stats.get("sse", 0),
connected_servers=stats.get("connected", 0),
disconnected_servers=stats.get("disconnected", 0),
error_servers=stats.get("error", 0),
total_tools=total_tools
).model_dump()
except Exception as e:
logger.opt(exception=e).error("获取MCP统计信息失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["GET"])
@require_auth
async def get_server(server_id: str):
"""获取特定MCP服务器的详情"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
# 转换为响应格式
server_info = _convert_to_server_info(server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 详情失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//tools", methods=["GET"])
@require_auth
async def get_server_tools(server_id: str):
"""获取MCP服务器提供的工具列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
# 如果服务器未连接,返回空列表
if server.state != MCPConnectionState.CONNECTED:
return []
# 获取服务器工具
tools = manager.get_tools()
# 转换为响应格式
tool_list = []
for _, tool in tools.items():
if tool.server_id == server_id:
tool_list.append(MCPToolInfo(
name=tool.original_name,
description=tool.tool_info.description,
input_schema=tool.tool_info.inputSchema
))
# 返回响应
return [tool.model_dump() for tool in tool_list]
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 工具列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/check/", methods=["GET"])
@require_auth
async def check_server_id(server_id: str):
"""检查服务器ID是否可用"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 检查ID是否可用
is_available = manager.is_server_id_available(server_id)
# 返回响应
return jsonify({
"is_available": is_available
})
except Exception as e:
logger.opt(exception=e).error(f"检查服务器ID {server_id} 可用性失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers", methods=["POST"])
@require_auth
async def create_server():
"""创建新的MCP服务器"""
try:
# 获取请求数据
data = await request.get_json()
request_data = MCPServerCreateRequest(**data)
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 检查ID是否已存在
if not manager.is_server_id_available(request_data.id):
return jsonify({"message": f"服务器ID '{request_data.id}' 已存在或服务器正在运行"}), 409
# 创建新的MCP服务器配置
new_server_config = MCPServerConfig(
id=request_data.id,
description=request_data.description or "",
command=request_data.command,
args=request_data.args.split(" "),
connection_type=request_data.connection_type,
enable=True
)
# 添加到全局配置中
config.mcp.servers.append(new_server_config)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 让管理器加载新服务器
server = manager.load_server(new_server_config)
# 转换为响应格式
server_info = _convert_to_server_info(server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error("创建MCP服务器失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["PUT"])
@require_auth
async def update_server(server_id: str):
"""更新MCP服务器配置"""
try:
# 获取请求数据
data = await request.get_json()
request_data = MCPServerUpdateRequest(**data)
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 查找服务器配置
server_index = -1
for i, server in enumerate(config.mcp.servers):
if server.id == server_id:
server_index = i
break
if server_index == -1:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 检查服务器状态
current_server = manager.get_server(server_id)
if current_server and current_server.state == MCPConnectionState.CONNECTED:
return jsonify({"message": "无法更新正在运行的服务器,请先停止服务器"}), 409
# 更新服务器配置
server_config = config.mcp.servers[server_index]
if request_data.description is not None:
server_config.description = request_data.description
if request_data.command is not None:
server_config.command = request_data.command
if request_data.args is not None:
server_config.args = request_data.args.split(" ")
if request_data.connection_type is not None:
server_config.connection_type = request_data.connection_type
if request_data.url is not None:
server_config.url = request_data.url
if request_data.headers is not None:
server_config.headers = request_data.headers
if request_data.env is not None:
server_config.env = request_data.env
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 停止服务器
await manager.stop_server(server_id)
# 重新加载服务器
current_server = manager.load_server(server_config)
try:
await manager.connect_server(server_id)
except Exception as e:
logger.opt(exception=e).error(f"重新连接MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
# 转换为响应格式
server_info = _convert_to_server_info(current_server)
# 返回响应
return server_info.model_dump()
except Exception as e:
logger.opt(exception=e).error(f"更新MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers/", methods=["DELETE"])
@require_auth
async def delete_server(server_id: str):
"""删除MCP服务器"""
try:
# 从容器中获取全局配置和MCP服务器管理器
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 查找服务器配置
server_index = -1
for i, server in enumerate(config.mcp.servers):
if server.id == server_id:
server_index = i
break
if server_index == -1:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 如果服务器正在运行,先停止它
current_server = manager.get_server(server_id)
if current_server and current_server.state == MCPConnectionState.CONNECTED:
await manager.stop_server(server_id)
# 从配置中删除服务器
removed_server = config.mcp.servers.pop(server_index)
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
await manager.stop_server(server_id)
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"删除MCP服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//start", methods=["POST"])
@require_auth
async def start_server(server_id: str):
"""连接 MCP 服务器"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 尝试连接服务器
success = await manager.connect_server(server_id)
if not success:
return jsonify({"message": f"服务器 '{server_id}' 不存在或无法连接"}), 404
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"连接 MCP 服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//stop", methods=["POST"])
@require_auth
async def stop_server(server_id: str):
"""断开 MCP 服务器"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 尝试停止服务器
success = await manager.stop_server(server_id)
if not success:
return jsonify({"message": f"服务器 '{server_id}' 不存在或未连接"}), 404
# 返回响应
return jsonify({})
except Exception as e:
logger.opt(exception=e).error(f"断开 MCP 服务器 {server_id} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/tools", methods=["GET"])
@require_auth
async def get_all_tools():
"""获取所有可用工具"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取所有工具
tools = manager.get_tools()
# 转换为响应格式
tool_list = []
for name, tool_info in tools.items():
tool_list.append(MCPToolInfo(
name=name,
description=tool_info.tool_info.description,
input_schema=tool_info.tool_info.inputSchema
))
# 返回响应
return [tool.model_dump() for tool in tool_list]
except Exception as e:
logger.opt(exception=e).error("获取所有工具失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//tools/call", methods=["POST"])
@require_auth
async def call_tool(server_id: str):
"""调用工具"""
try:
data: Dict[str, str | Dict[str, Any]] = await request.get_json()
toolName: str = cast(str, data.get("toolName"))
params: Dict[str, Any] = cast(Dict[str, Any], data.get("params"))
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server: Optional[MCPServer] = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 '{server_id}' 不存在"}), 404
# 获取工具
result = await server.call_tool(toolName, params)
# 返回响应
return jsonify({"result": result.model_dump()})
except Exception as e:
logger.opt(exception=e).error(f"调用工具 {toolName} 失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//prompts", methods=["GET"])
@require_auth
async def get_server_prompts(server_id: str):
"""获取MCP服务器提供的提示词列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
prompts = await manager.get_prompt_list(server_id)
if prompts is None:
return jsonify({"message": f"服务器 {server_id} 未连接"}), 404
return jsonify(prompts)
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 提示词列表失败")
return jsonify({"message": str(e)}), 500
@mcp_bp.route("/servers//resources", methods=["GET"])
@require_auth
async def get_server_resources(server_id: str):
"""获取MCP服务器提供的资源列表"""
try:
# 从容器中获取MCP服务器管理器
manager: MCPServerManager = g.container.resolve(MCPServerManager)
# 获取服务器
server = manager.get_server(server_id)
if not server:
return jsonify({"message": f"服务器 {server_id} 不存在"}), 404
resources = await manager.get_resource_list(server_id)
if resources is None:
return jsonify({"message": f"服务器 {server_id} 未连接"}), 404
return jsonify(resources)
except Exception as e:
logger.opt(exception=e).error(f"获取MCP服务器 {server_id} 资源列表失败")
return jsonify({"message": str(e)}), 500
================================================
FILE: kirara_ai/web/api/media/README.md
================================================
# 媒体管理API
本模块提供了媒体文件管理的API,包括上传、查询、下载和删除媒体文件。
## API接口
### 获取媒体列表
```
POST /api/media/list
```
请求体:
```json
{
"query": "搜索关键词",
"content_type": "image/jpeg",
"start_date": "2023-01-01T00:00:00Z",
"end_date": "2023-12-31T23:59:59Z",
"tags": ["tag1", "tag2"],
"page": 1,
"page_size": 20
}
```
响应:
```json
{
"items": [
{
"id": "media_id",
"url": "/api/media/file/filename.jpg",
"thumbnail_url": "/api/media/thumbnails/media_id.jpg",
"metadata": {
"filename": "filename.jpg",
"content_type": "image/jpeg",
"size": 12345,
"width": 800,
"height": 600,
"upload_time": "2023-01-01T12:00:00Z",
"source": "qq_group",
"uploader": "user1",
"tags": ["tag1", "tag2"]
}
}
],
"total": 100,
"has_more": true
}
```
### 获取媒体文件
```
GET /api/media/file/{filename}
```
返回媒体文件的二进制内容。
### 获取缩略图
```
GET /api/media/thumbnails/{media_id}.jpg
```
返回媒体文件的缩略图。
### 上传媒体文件
```
POST /api/media/upload
```
使用 multipart/form-data 上传文件。
可选参数:
- source: 来源
- uploader: 上传者
- tags: 标签(逗号分隔)
响应:
```json
{
"id": "media_id",
"url": "/api/media/file/filename.jpg",
"thumbnail_url": "/api/media/thumbnails/media_id.jpg",
"metadata": {
"filename": "filename.jpg",
"content_type": "image/jpeg",
"size": 12345,
"width": 800,
"height": 600,
"upload_time": "2023-01-01T12:00:00Z",
"source": "qq_group",
"uploader": "user1",
"tags": ["tag1", "tag2"]
}
}
```
### 删除媒体文件
```
DELETE /api/media/delete/{media_id}
```
响应:
```json
{
"success": true
}
```
### 批量删除媒体文件
```
POST /api/media/batch-delete
```
请求体:
```json
{
"ids": ["media_id1", "media_id2"]
}
```
响应:
```json
{
"success": true,
"deleted_count": 2
}
```
## 数据模型
### MediaMetadata
媒体文件的元数据。
| 字段名 | 类型 | 说明 |
|-------|------|------|
| filename | string | 文件名 |
| content_type | string | 内容类型 |
| size | integer | 文件大小(字节) |
| width | integer | 图片宽度(可选) |
| height | integer | 图片高度(可选) |
| upload_time | datetime | 上传时间 |
| source | string | 来源(可选) |
| uploader | string | 上传者(可选) |
| tags | array | 标签列表 |
### MediaItem
媒体文件项。
| 字段名 | 类型 | 说明 |
|-------|------|------|
| id | string | 媒体ID |
| url | string | 媒体URL |
| thumbnail_url | string | 缩略图URL(可选) |
| metadata | MediaMetadata | 媒体元数据 |
================================================
FILE: kirara_ai/web/api/media/__init__.py
================================================
from .routes import media_bp
__all__ = ["media_bp"]
================================================
FILE: kirara_ai/web/api/media/models.py
================================================
from datetime import datetime
from typing import List, Optional
from pydantic import BaseModel
class MediaMetadata(BaseModel):
"""媒体元数据"""
filename: str
content_type: str
size: int # 文件大小,单位字节
upload_time: datetime # 上传时间
source: Optional[str] = None # 来源
tags: List[str] = [] # 标签
references: List[str] = []
class MediaItem(BaseModel):
"""媒体项"""
id: str # 媒体ID
url: str # 媒体URL
thumbnail_url: Optional[str] = None # 缩略图URL
metadata: MediaMetadata
class MediaListResponse(BaseModel):
"""媒体列表响应"""
items: List[MediaItem]
total: int
has_more: bool # 是否有更多数据
page_size: int # 每页数量
class MediaSearchParams(BaseModel):
"""媒体搜索参数"""
query: Optional[str] = None # 搜索关键词
content_type: Optional[str] = None # 媒体类型
start_date: Optional[datetime] = None # 开始日期
end_date: Optional[datetime] = None # 结束日期
tags: List[str] = [] # 标签
page: int = 1 # 页码
page_size: int = 20 # 每页数量
class MediaBatchDeleteRequest(BaseModel):
"""批量删除请求"""
ids: List[str] # 要删除的媒体ID列表
================================================
FILE: kirara_ai/web/api/media/routes.py
================================================
import asyncio
import io
import os
import shutil
import time
from typing import Optional
import pytz
from quart import Blueprint, g, jsonify, request, send_file
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.media_object import Media
from kirara_ai.media.types.media_type import MediaType
from ...auth.middleware import require_auth
from .models import MediaBatchDeleteRequest, MediaItem, MediaListResponse, MediaMetadata, MediaSearchParams
media_bp = Blueprint("media", __name__)
logger = get_logger("Web.Media")
# 生成缩略图
async def generate_thumbnail(image_data: bytes) -> io.BytesIO:
"""生成图片缩略图,并返回BytesIO对象"""
from PIL import Image
def _generate_thumbnail(image_data: bytes) -> io.BytesIO:
"""在线程中运行的同步缩略图生成函数"""
with Image.open(io.BytesIO(image_data)) as img:
width, height = img.size
if width > height:
new_width = 300
new_height = int(height * (300 / width))
else:
new_height = 300
new_width = int(width * (300 / height))
img.thumbnail((new_width, new_height))
output = io.BytesIO()
img = img.convert("RGB")
img.save(output, format="WEBP", optimize=True, quality=65)
output.seek(0)
return output
return await asyncio.to_thread(_generate_thumbnail, image_data)
def _get_media_manager() -> MediaManager:
"""获取媒体管理器实例"""
return g.container.resolve(MediaManager)
def _convert_media_to_api_item(media: Media) -> Optional[MediaItem]:
"""将Media对象转换为API响应格式"""
if not media or not media.metadata:
return None
metadata = media.metadata
content_type = f"{metadata.media_type.value}/{metadata.format}" if metadata.media_type and metadata.format else "application/octet-stream"
return MediaItem(
id=media.media_id,
url=f"",
thumbnail_url="",
metadata=MediaMetadata(
filename=os.path.basename(metadata.path) if metadata.path else f"{media.media_id}.{metadata.format}",
content_type=content_type,
size=metadata.size or 0,
upload_time=metadata.created_at,
source=metadata.source,
tags=list(metadata.tags),
references=list(metadata.references),
)
)
@media_bp.route("/list", methods=["POST"])
@require_auth
async def list_media():
"""获取媒体列表,支持分页和搜索"""
data = await request.get_json()
search_params = MediaSearchParams(**data)
manager = _get_media_manager()
# 构建搜索条件
all_media_ids = []
# 如果有指定内容类型,筛选对应类型
if search_params.content_type:
if search_params.content_type.startswith("image/"):
media_type = MediaType.IMAGE
elif search_params.content_type.startswith("video/"):
media_type = MediaType.VIDEO
elif search_params.content_type.startswith("audio/"):
media_type = MediaType.AUDIO
else:
media_type = MediaType.FILE
all_media_ids = manager.search_by_type(media_type)
else:
all_media_ids = manager.get_all_media_ids()
# 如果有指定标签,继续筛选
if search_params.tags and len(search_params.tags) > 0:
filtered_ids = []
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata and any(tag in metadata.tags for tag in search_params.tags):
filtered_ids.append(media_id)
all_media_ids = filtered_ids
# 如果有搜索关键词,继续筛选
if search_params.query:
description_ids = manager.search_by_description(search_params.query)
source_ids = manager.search_by_source(search_params.query)
all_media_ids = [
media_id for media_id in all_media_ids
if media_id in description_ids or media_id in source_ids
]
# 如果有日期范围,继续筛选
if search_params.start_date or search_params.end_date:
filtered_ids = []
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata:
tz = pytz.timezone(g.container.resolve(GlobalConfig).system.timezone)
created_at = metadata.created_at.replace(tzinfo=tz)
start_date = search_params.start_date.replace(tzinfo=tz) if search_params.start_date else None
if start_date and created_at < start_date:
continue
end_date = search_params.end_date.replace(tzinfo=tz) if search_params.end_date else None
if end_date and created_at > end_date:
continue
filtered_ids.append(media_id)
all_media_ids = filtered_ids
# 计算分页
total = len(all_media_ids)
start_idx = (search_params.page - 1) * search_params.page_size
end_idx = start_idx + search_params.page_size
page_ids = all_media_ids[start_idx:end_idx]
# 构建返回结果
items = []
for media_id in page_ids:
if media := manager.get_media(media_id):
if item:= _convert_media_to_api_item(media):
items.append(item)
return MediaListResponse(
items=items,
total=total,
has_more=end_idx < total,
page_size=search_params.page_size,
).model_dump()
@media_bp.route("/file/", methods=["GET"])
@require_auth
async def get_media_file(media_id):
"""获取媒体文件"""
manager = _get_media_manager()
media = manager.get_media(media_id)
if not media:
return jsonify({"error": "Media not found"}), 404
return await send_file(io.BytesIO(await media.get_data()), mimetype=media.metadata.mime_type)
@media_bp.route("/preview/", methods=["GET"])
@require_auth
async def get_thumbnail(media_id):
"""获取缩略图"""
config = g.container.resolve(GlobalConfig)
media_manager = _get_media_manager()
media = media_manager.get_media(media_id)
if not media:
return jsonify({"error": "Media not found"}), 404
data = await media.get_data()
if not data:
return jsonify({"error": "Media not found"}), 404
if media.metadata.media_type == MediaType.IMAGE:
if media.metadata.format == "gif":
return await send_file(io.BytesIO(data), mimetype="image/gif")
thumbnail = await generate_thumbnail(data)
return await send_file(thumbnail, mimetype="image/webp")
elif media.metadata.media_type == MediaType.VIDEO:
# 视频类型直接返回原始数据,不做缩略图处理
return await send_file(io.BytesIO(data), mimetype="video/mp4")
else:
return jsonify({"error": "Unsupported media type"}), 400
@media_bp.route("/delete/", methods=["DELETE"])
@require_auth
async def delete_media(media_id):
"""删除单个媒体文件"""
manager = _get_media_manager()
# 检查媒体是否存在
if media_id not in manager.metadata_cache:
return jsonify({"error": "File not found"}), 404
# 删除媒体文件
manager.delete_media(media_id)
return jsonify({"success": True})
@media_bp.route("/batch-delete", methods=["POST"])
@require_auth
async def batch_delete():
"""批量删除媒体文件"""
data = await request.get_json()
delete_request = MediaBatchDeleteRequest(**data)
manager = _get_media_manager()
success_count = 0
for media_id in delete_request.ids:
if media_id in manager.metadata_cache:
# 删除媒体文件
manager.delete_media(media_id)
success_count += 1
return jsonify({"success": True, "deleted_count": success_count})
@media_bp.route("/system", methods=["GET"])
@require_auth
async def get_system_info():
"""获取系统信息,包括媒体数量、占用空间和磁盘信息"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
manager: MediaManager = _get_media_manager()
# 获取媒体总数和总大小
all_media_ids = manager.get_all_media_ids()
total_media_count = len(all_media_ids)
total_media_size = 0
for media_id in all_media_ids:
metadata = manager.get_metadata(media_id)
if metadata and metadata.size:
total_media_size += metadata.size
# 获取磁盘空间信息
storage_path = manager.media_dir
disk_total, disk_used, disk_free = 0, 0, 0
try:
# 确保存储路径存在,如果不存在则尝试创建
disk_usage = shutil.disk_usage(storage_path)
disk_total = disk_usage.total
disk_used = disk_usage.used
disk_free = disk_usage.free
except OSError as e:
# 处理获取磁盘信息时可能发生的错误,例如路径不存在或权限问题
logger.error(f"Unable to get disk info for {storage_path}: {e}")
return jsonify({
"cleanup_duration": config.media.cleanup_duration,
"auto_remove_unreferenced": config.media.auto_remove_unreferenced,
"last_cleanup_time": config.media.last_cleanup_time,
"total_media_count": total_media_count,
"total_media_size": total_media_size,
"disk_total": disk_total,
"disk_used": disk_used,
"disk_free": disk_free,
})
# 修改配置
@media_bp.route("/system/config", methods=["POST"])
@require_auth
async def set_config():
"""设置配置"""
manager = _get_media_manager()
data = await request.get_json()
config = g.container.resolve(GlobalConfig)
config.media.cleanup_duration = data.get("cleanup_duration", config.media.cleanup_duration)
config.media.auto_remove_unreferenced = data.get("auto_remove_unreferenced", config.media.auto_remove_unreferenced)
manager.setup_cleanup_task(g.container)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"success": True})
@media_bp.route("/system/cleanup-unreferenced", methods=["POST"])
@require_auth
async def cleanup_unreferenced():
"""清理未引用的媒体文件"""
manager = _get_media_manager()
count = manager.cleanup_unreferenced()
config = g.container.resolve(GlobalConfig)
config.media.last_cleanup_time = int(time.time())
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
manager.setup_cleanup_task(g.container)
return jsonify({"success": True, "count": count})
================================================
FILE: kirara_ai/web/api/plugin/README.md
================================================
# 插件 API 🔌
插件 API 提供了管理插件的功能。通过这些 API,你可以安装、卸载、启用、禁用和更新插件。
## API 端点
### 获取所有插件
```http
GET/backend-api/api/plugin/plugins
```
获取所有已安装的插件列表。
**响应示例:**
```json
{
"plugins": [
{
"name": "图像处理",
"package_name": "image-processing",
"description": "提供图像处理功能",
"version": "1.0.0",
"author": "开发者",
"homepage": "https://github.com/example/image-processing",
"license": "MIT",
"is_internal": false,
"is_enabled": true,
"metadata": {
"category": "media",
"tags": ["image", "processing"]
}
}
]
}
```
### 获取特定插件
```http
GET/backend-api/api/plugin/plugins/{plugin_name}
```
获取指定插件的详细信息。
**响应示例:**
```json
{
"plugin": {
"name": "图像处理",
"package_name": "image-processing",
"description": "提供图像处理功能",
"version": "1.0.0",
"author": "开发者",
"homepage": "https://github.com/example/image-processing",
"license": "MIT",
"is_internal": false,
"is_enabled": true,
"metadata": {
"category": "media",
"tags": ["image", "processing"]
}
}
}
```
### 安装插件
```http
POST/backend-api/api/plugin/plugins
```
安装新的插件。
**请求体:**
```json
{
"package_name": "image-processing",
"version": "1.0.0" // 可选,不指定则安装最新版本
}
```
### 卸载插件
```http
DELETE/backend-api/api/plugin/plugins/{plugin_name}
```
卸载指定的插件。注意:内部插件不能被卸载。
### 启用插件
```http
POST/backend-api/api/plugin/plugins/{plugin_name}/enable
```
启用指定的插件。
### 禁用插件
```http
POST/backend-api/api/plugin/plugins/{plugin_name}/disable
```
禁用指定的插件。
### 更新插件
```http
PUT/backend-api/api/plugin/plugins/{plugin_name}
```
更新插件到最新版本。注意:内部插件不支持更新。
### 搜索插件市场
```http
GET/backend-api/api/v1/search?query={query}&page={page}&pageSize={pageSize}
```
在插件市场中搜索插件。
**参数:**
- `query`: 搜索关键词
- `page`: 页码 (默认为 1)
- `pageSize`: 每页数量 (默认为 10)
**响应示例:**
```json
{
"plugins": [
{
"name": "图像处理",
"description": "提供图像处理功能",
"author": "开发者",
"pypiPackage": "image-processing",
"pypiInfo": {
"version": "1.0.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com"
},
"isInstalled": false,
"installedVersion": null,
"isUpgradable": false
}
],
"totalCount": 1,
"totalPages": 1,
"page": 1,
"pageSize": 10
}
```
### 获取插件市场中插件的详细信息
```http
GET/backend-api/api/v1/info/{plugin_name}
```
获取插件市场中指定插件的详细信息。
**响应示例:**
```json
{
"name": "图像处理",
"description": "提供图像处理功能",
"author": "开发者",
"pypiPackage": "image-processing",
"pypiInfo": {
"version": "1.0.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com"
},
"isInstalled": false,
"installedVersion": null,
"isUpgradable": false
}
```
## 数据模型
### PluginInfo
- `name`: 插件名称
- `package_name`: 包名
- `description`: 描述
- `version`: 版本号
- `author`: 作者
- `homepage`: 主页(可选)
- `license`: 许可证(可选)
- `is_internal`: 是否为内部插件
- `is_enabled`: 是否已启用
- `metadata`: 元数据(可选)
### InstallPluginRequest
- `package_name`: 包名
- `version`: 版本号(可选)
### PluginList
- `plugins`: 插件列表
### PluginResponse
- `plugin`: 插件信息
## 内置插件
### IM 适配器
- Telegram 适配器
- HTTP Legacy 适配器
- WeCom 适配器
### LLM 后端
- OpenAI 适配器
- Anthropic 适配器
- Google AI 适配器
## 相关代码
- [插件管理器](../../../plugin_manager/plugin_loader.py)
- [插件基类](../../../plugin_manager/plugin.py)
- [系统插件](../../../plugins)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、插件已存在或内部插件操作限制
- 404: 插件不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有插件
```python
import requests
response = requests.get(
'http://localhost:8080/api/plugin/plugins',
headers={'Authorization': f'Bearer {token}'}
)
```
### 安装新插件
```python
import requests
data = {
"package_name": "image-processing",
"version": "1.0.0"
}
response = requests.post(
'http://localhost:8080/api/plugin/plugins',
headers={'Authorization': f'Bearer {token}'},
json=data
)
```
### 启用插件
```python
import requests
response = requests.post(
'http://localhost:8080/api/plugin/plugins/image-processing/enable',
headers={'Authorization': f'Bearer {token}'}
)
```
### 更新插件
```python
import requests
response = requests.put(
'http://localhost:8080/api/plugin/plugins/image-processing',
headers={'Authorization': f'Bearer {token}'}
)
```
### 搜索插件市场
```python
import requests
response = requests.get(
'http://localhost:8080/api/v1/search?query=image&page=1&pageSize=10',
headers={'Authorization': f'Bearer {token}'}
)
```
### 获取插件市场中插件的详细信息
```python
import requests
response = requests.get(
'http://localhost:8080/api/v1/info/image-processing',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [插件开发](../../../plugin_manager/README.md#插件开发-)
================================================
FILE: kirara_ai/web/api/plugin/__init__.py
================================================
from .routes import plugin_bp
__all__ = ["plugin_bp"]
================================================
FILE: kirara_ai/web/api/plugin/models.py
================================================
from typing import List, Optional
from pydantic import BaseModel
from kirara_ai.plugin_manager.models import PluginInfo
class PluginList(BaseModel):
"""插件列表响应"""
plugins: List[PluginInfo]
class PluginResponse(BaseModel):
"""插件详情响应"""
plugin: PluginInfo
class InstallPluginRequest(BaseModel):
"""安装插件请求"""
package_name: str
version: Optional[str] = None # 可选的版本号,不指定则安装最新版
================================================
FILE: kirara_ai/web/api/plugin/routes.py
================================================
from functools import lru_cache
import aiohttp
from packaging.version import Version
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.logger import get_logger
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.api.system.utils import get_installed_version
from ...auth.middleware import require_auth
from .models import InstallPluginRequest, PluginList, PluginResponse
plugin_bp = Blueprint("plugin", __name__)
logger = get_logger("WebServer")
@lru_cache(maxsize=1)
def get_meta_params() -> dict:
"""获取元参数"""
return {
"kirara_version": get_installed_version(),
}
def is_upgradable(installed_version: str, market_version: str) -> bool:
"""检查插件是否可升级"""
try:
return Version(market_version) > Version(installed_version)
except ValueError:
return False
async def fetch_from_market(path: str, params: dict | None = None) -> dict:
"""从插件市场获取数据的通用方法"""
plugin_market_base_url = g.container.resolve(GlobalConfig).plugins.market_base_url
async with aiohttp.ClientSession(trust_env=True) as session:
url = f"{plugin_market_base_url}/{path}"
logger.info(f"Fetching from market: {url}")
params = params or {}
params.update(get_meta_params())
async with session.get(url, params=params) as response:
if response.status != 200:
raise Exception(f"插件市场请求失败: {response.status}")
return await response.json()
async def enrich_plugin_data(plugins: list, loader: PluginLoader) -> list:
"""为插件数据添加安装状态和可升级状态"""
installed_plugins = loader.get_all_plugin_infos()
for plugin in plugins:
installed_plugin = next(
(p for p in installed_plugins if p.package_name == plugin["pypiPackage"]),
None,
)
plugin["isInstalled"] = installed_plugin is not None
plugin["installedVersion"] = (
installed_plugin.version if installed_plugin else None
)
plugin["isUpgradable"] = (
is_upgradable(installed_plugin.version, plugin["pypiInfo"]["version"])
if installed_plugin
else False
)
plugin["isEnabled"] = installed_plugin.is_enabled if installed_plugin else False
plugin["requiresRestart"] = installed_plugin.requires_restart if installed_plugin else False
return plugins
@plugin_bp.route("/v1/search", methods=["GET"])
@require_auth
async def search_plugins():
"""搜索插件市场"""
query = request.args.get("query", "")
page = request.args.get("page", 1, type=int)
page_size = request.args.get("pageSize", 10, type=int)
try:
result = await fetch_from_market(
"search", {"query": query, "page": page, "pageSize": page_size}
)
# 添加安装状态和可升级状态
loader: PluginLoader = g.container.resolve(PluginLoader)
result["plugins"] = await enrich_plugin_data(result["plugins"], loader)
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/v1/info/", methods=["GET"])
@require_auth
async def get_market_plugin_info(plugin_name: str):
"""获取插件市场中插件的详细信息"""
try:
result = await fetch_from_market(f"info/{plugin_name}")
# 添加安装状态和可升级状态
loader: PluginLoader = g.container.resolve(PluginLoader)
result = (await enrich_plugin_data([result], loader))[0]
return jsonify(result)
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins", methods=["GET"])
@require_auth
async def list_plugins():
"""获取所有已安装的插件列表"""
loader: PluginLoader = g.container.resolve(PluginLoader)
plugins = loader.get_all_plugin_infos()
return PluginList(plugins=plugins).model_dump()
@plugin_bp.route("/plugins/", methods=["GET"])
@require_auth
async def get_plugin_details(plugin_name: str):
"""获取已安装插件的详细信息"""
loader: PluginLoader = g.container.resolve(PluginLoader)
print(f"Getting plugin details for {plugin_name}")
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
return PluginResponse(plugin=plugin_info).model_dump()
@plugin_bp.route("/plugins", methods=["POST"])
@require_auth
async def install_plugin():
"""安装新插件"""
data = await request.get_json()
install_data = InstallPluginRequest(**data)
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
try:
# 安装插件
plugin_info = await loader.install_plugin(
install_data.package_name, install_data.version
)
if not plugin_info or plugin_info.package_name is None:
return jsonify({"error": "Failed to install plugin"}), 500
# 更新配置
if plugin_info.package_name not in config.plugins.enable:
config.plugins.enable.append(plugin_info.package_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 加载插件
loader.load_plugin(plugin_info.name)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins/", methods=["DELETE"])
@require_auth
async def uninstall_plugin(plugin_name: str):
"""卸载插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
# 内部插件不能卸载
if plugin_info.is_internal:
return jsonify({"error": "Cannot uninstall internal plugin"}), 400
try:
# 卸载插件
await loader.uninstall_plugin(plugin_name)
# 更新配置
if plugin_info.package_name in config.plugins.enable:
config.plugins.enable.remove(plugin_info.package_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return jsonify({"message": "Plugin uninstalled successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins//enable", methods=["POST"])
@require_auth
async def enable_plugin(plugin_name: str):
"""启用插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
try:
# 启用插件
await loader.enable_plugin(plugin_name)
# 更新配置
if (
plugin_name
and plugin_name not in config.plugins.enable
and not plugin_info.is_internal
):
config.plugins.enable.append(plugin_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins//disable", methods=["POST"])
@require_auth
async def disable_plugin(plugin_name: str):
"""禁用插件"""
loader: PluginLoader = g.container.resolve(PluginLoader)
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
try:
# 禁用插件
await loader.disable_plugin(plugin_name)
# 更新插件信息
plugin_info = loader.get_plugin_info(plugin_name)
assert plugin_info is not None
# 更新配置
if (
plugin_name
and plugin_name in config.plugins.enable
and not plugin_info.is_internal
):
config.plugins.enable.remove(plugin_name)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return PluginResponse(plugin=plugin_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
@plugin_bp.route("/plugins/", methods=["PUT"])
@require_auth
async def update_plugin(plugin_name: str):
"""更新插件到最新版本"""
loader: PluginLoader = g.container.resolve(PluginLoader)
# 检查插件是否存在
plugin_info = loader.get_plugin_info(plugin_name)
if not plugin_info:
return jsonify({"error": "Plugin not found"}), 404
# 内部插件不支持更新
if plugin_info.is_internal:
return jsonify({"error": "Cannot update internal plugin"}), 400
new_package_name = request.args.get("package_name", None)
try:
# 执行更新
updated_info = await loader.update_plugin(plugin_name, new_package_name)
if not updated_info:
return jsonify({"error": "Failed to update plugin"}), 500
return PluginResponse(plugin=updated_info).model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 500
================================================
FILE: kirara_ai/web/api/system/README.md
================================================
# 系统管理 API 🛠️
系统管理 API 提供了监控和管理系统状态的功能。
## API 端点
### 获取系统状态
```http
GET/backend-api/api/system/status
```
获取系统的当前运行状态,包括版本信息、运行时间、资源使用情况等。
**响应示例:**
```json
{
"status": {
"version": "1.0.0",
"uptime": 3600, // 运行时间(秒)
"active_adapters": 2, // 活跃的 IM 适配器数量
"active_backends": 3, // 活跃的 LLM 后端数量
"loaded_plugins": 5, // 已加载的插件数量
"workflow_count": 10, // 工作流数量
"memory_usage": {
"rss": 256.5, // 物理内存使用(MB)
"vms": 512.8, // 虚拟内存使用(MB)
"percent": 2.5 // 内存使用百分比
},
"cpu_usage": 1.2 // CPU 使用百分比
}
}
```
### 获取系统配置
```http
GET/backend-api/api/system/config
```
获取系统当前配置。
### 更新系统配置
```http
PUT/backend-api/api/system/config
```
更新系统配置。
**请求体:**
```json
{
"log_level": "INFO",
"max_connections": 100,
"timeout": 30,
"storage": {
"type": "local",
"path": "/data"
}
}
```
### 获取系统日志
```http
GET/backend-api/api/system/logs
```
获取系统日志。支持分页和过滤。
**查询参数:**
- `level`: 日志级别 (DEBUG/INFO/WARNING/ERROR)
- `start_time`: 开始时间
- `end_time`: 结束时间
- `limit`: 每页条数
- `offset`: 偏移量
### 获取用户列表
```http
GET/backend-api/api/system/users
```
获取系统用户列表。
### 创建用户
```http
POST/backend-api/api/system/users
```
创建新用户。
**请求体:**
```json
{
"username": "admin",
"password": "password123",
"role": "admin",
"permissions": ["read", "write", "admin"]
}
```
### 更新用户
```http
PUT/backend-api/api/system/users/{username}
```
更新用户信息。
### 删除用户
```http
DELETE/backend-api/api/system/users/{username}
```
删除指定用户。
## 数据模型
### SystemStatus
- `version`: 系统版本
- `uptime`: 运行时间(秒)
- `active_adapters`: 活跃的 IM 适配器数量
- `active_backends`: 活跃的 LLM 后端数量
- `loaded_plugins`: 已加载的插件数量
- `workflow_count`: 工作流数量
- `memory_usage`: 内存使用情况
- `rss`: 物理内存使用(MB)
- `vms`: 虚拟内存使用(MB)
- `percent`: 内存使用百分比
- `cpu_usage`: CPU 使用百分比
### SystemConfig
- `log_level`: 日志级别
- `max_connections`: 最大连接数
- `timeout`: 超时时间(秒)
- `storage`: 存储配置
### User
- `username`: 用户名
- `role`: 角色
- `permissions`: 权限列表
- `created_at`: 创建时间
- `last_login`: 最后登录时间
## 监控指标
### 系统指标
- 运行时间
- CPU 使用率
- 内存使用情况
### 组件指标
- IM 适配器数量和状态
- LLM 后端数量和状态
- 插件数量和状态
- 工作流数量
## 相关代码
- [系统路由](routes.py)
- [数据模型](models.py)
- [系统监控](../../../monitor)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误
- 401: 未认证或认证失败
- 403: 权限不足
- 404: 资源不存在
- 500: 服务器内部错误
## 使用示例
### 获取系统状态
```python
import requests
response = requests.get(
'http://localhost:8080/api/system/status',
headers={'Authorization': f'Bearer {token}'}
)
status = response.json()['status']
print(f"系统已运行: {status['uptime']} 秒")
print(f"内存使用: {status['memory_usage']['percent']}%")
print(f"CPU 使用: {status['cpu_usage']}%")
```
### 更新系统配置
```python
import requests
config_data = {
"log_level": "DEBUG",
"max_connections": 200,
"timeout": 60
}
response = requests.put(
'http://localhost:8080/api/system/config',
headers={'Authorization': f'Bearer {token}'},
json=config_data
)
```
### 创建新用户
```python
import requests
user_data = {
"username": "admin",
"password": "password123",
"role": "admin",
"permissions": ["read", "write", "admin"]
}
response = requests.post(
'http://localhost:8080/api/system/users',
headers={'Authorization': f'Bearer {token}'},
json=user_data
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [监控指南](../../README.md#系统监控-)
- [API 认证](../../README.md#api认证-)
================================================
FILE: kirara_ai/web/api/system/__init__.py
================================================
from .routes import system_bp
__all__ = ["system_bp"]
================================================
FILE: kirara_ai/web/api/system/models.py
================================================
from typing import Dict, Optional
from pydantic import BaseModel
class SystemStatus(BaseModel):
"""系统状态信息"""
version: str
uptime: float
active_adapters: int
active_backends: int
loaded_plugins: int
workflow_count: int
memory_usage: Dict[str, float]
cpu_usage: float
cpu_info: str
python_version: str
platform: str
has_proxy: bool
class SystemStatusResponse(BaseModel):
"""系统状态响应"""
status: SystemStatus
class UpdateStatus(BaseModel):
status: str
message: str
class UpdateCheckResponse(BaseModel):
"""更新检查响应"""
current_backend_version: str
latest_backend_version: str
backend_update_available: bool
backend_download_url: Optional[str]
latest_webui_version: str
webui_download_url: Optional[str]
================================================
FILE: kirara_ai/web/api/system/routes.py
================================================
import asyncio
import json
import os
import shutil
import subprocess
import sys
import tarfile
import tempfile
import time
from packaging import version
from quart import Blueprint, current_app, g, request, websocket
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.manager import IMManager
from kirara_ai.internal import set_restart_flag, shutdown_event
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.logger import WebSocketLogHandler, get_logger
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.api.system.utils import (download_file, get_cpu_info, get_cpu_usage, get_installed_version,
get_latest_npm_version, get_latest_pypi_version, get_memory_usage)
from kirara_ai.web.auth.services import AuthService
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from ...auth.middleware import require_auth
from .models import SystemStatus, SystemStatusResponse, UpdateCheckResponse
system_bp = Blueprint("system", __name__)
# 记录启动时间
start_time = time.time()
# 获取系统日志记录器
logger = get_logger("System-API")
@system_bp.websocket('/logs')
async def logs_websocket():
"""WebSocket端点,用于实时推送日志"""
try:
token_data = await websocket.receive()
token = json.loads(token_data)["token"]
except Exception as e:
logger.error(f"WebSocket连接错误: {e}")
await websocket.close(code=1008, reason="Invalid token")
return
auth_service: AuthService = g.container.resolve(AuthService)
if not auth_service.verify_token(token):
await websocket.close(code=1008, reason="Invalid token")
return
try:
# 将当前WebSocket连接添加到日志处理器
WebSocketLogHandler.add_websocket(websocket._get_current_object(), asyncio.get_event_loop())
# 保持连接打开,直到客户端断开
while not shutdown_event.is_set():
await asyncio.sleep(1)
finally:
# 从日志处理器中移除当前连接
WebSocketLogHandler.remove_websocket(websocket._get_current_object())
@system_bp.route("/config", methods=["GET"])
@require_auth
async def get_system_config():
"""获取系统配置"""
try:
config: GlobalConfig = g.container.resolve(GlobalConfig)
return {
"web": {
"host": config.web.host,
"port": config.web.port
},
"plugins": {
"market_base_url": config.plugins.market_base_url
},
"update": {
"pypi_registry": config.update.pypi_registry,
"npm_registry": config.update.npm_registry
},
"system": {
"timezone": config.system.timezone
},
"tracing": {
"llm_tracing_content": config.tracing.llm_tracing_content
}
}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/web", methods=["POST"])
@require_auth
async def update_web_config():
"""更新Web配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.web.host = data["host"]
config.web.port = data["port"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success", "restart_required": True}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/plugins", methods=["POST"])
@require_auth
async def update_plugins_config():
"""更新插件配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.plugins.market_base_url = data["market_base_url"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/update", methods=["POST"])
@require_auth
async def update_registry_config():
"""更新更新源配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
if not hasattr(config, "update"):
config.update = {}
config.update.pypi_registry = data["pypi_registry"]
config.update.npm_registry = data["npm_registry"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/system", methods=["POST"])
@require_auth
async def update_system_config():
"""更新系统配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
# 检查时区是否变化
timezone_changed = False
if "timezone" in data and data["timezone"] != config.system.timezone:
config.system.timezone = data["timezone"]
timezone_changed = True
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
# 如果时区变化,设置系统时区并调用 tzset
if timezone_changed and hasattr(time, "tzset"):
os.environ["TZ"] = config.system.timezone
time.tzset()
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/config/tracing", methods=["POST"])
@require_auth
async def update_tracing_config():
"""更新追踪配置"""
try:
data = await request.get_json()
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.tracing.llm_tracing_content = data["llm_tracing_content"]
# 保存配置
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
return {"status": "success"}
except Exception as e:
return {"error": str(e)}, 500
@system_bp.route("/status", methods=["GET"])
@require_auth
async def get_system_status():
"""获取系统状态"""
im_manager: IMManager = g.container.resolve(IMManager)
llm_manager: LLMManager = g.container.resolve(LLMManager)
plugin_loader: PluginLoader = g.container.resolve(PluginLoader)
workflow_registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 计算运行时间
uptime = time.time() - start_time
# 获取活跃的适配器数量
active_adapters = len(
[adapter for adapter in im_manager.adapters.values() if adapter.is_running]
)
# 获取活跃的LLM后端数量
active_backends = len(llm_manager.active_backends)
# 获取已加载的插件数量
loaded_plugins = len(plugin_loader.plugins)
# 获取工作流数量
workflow_count = len(workflow_registry._workflows)
# 获取系统资源使用情况
memory_usage = get_memory_usage()
cpu_usage = get_cpu_usage()
# 检测代理服务
has_proxy = bool(os.environ.get('HTTP_PROXY') or os.environ.get('HTTPS_PROXY') or
os.environ.get('http_proxy') or os.environ.get('https_proxy'))
# 获取CPU信息
cpu_info = get_cpu_info()
# 获取Python版本
python_version = f"{sys.version_info.major}.{sys.version_info.minor}.{sys.version_info.micro}"
# 获取平台信息
platform_info = f"{sys.platform}"
status = SystemStatus(
uptime=uptime,
active_adapters=active_adapters,
active_backends=active_backends,
loaded_plugins=loaded_plugins,
workflow_count=workflow_count,
memory_usage=memory_usage,
cpu_usage=cpu_usage,
version=get_installed_version(),
platform=platform_info,
cpu_info=cpu_info,
python_version=python_version,
has_proxy=has_proxy,
)
return SystemStatusResponse(status=status).model_dump()
@system_bp.route("/check-update", methods=["GET"])
@require_auth
async def check_update():
"""检查系统更新"""
config: GlobalConfig = g.container.resolve(GlobalConfig)
npm_registry = config.update.npm_registry
current_backend_version = get_installed_version()
latest_backend_version, backend_download_url = await get_latest_pypi_version("kirara-ai")
# 获取前端最新版本信息,但不判断是否需要更新
latest_webui_version, webui_download_url = await get_latest_npm_version("kirara-ai-webui", npm_registry)
# 只判断后端是否需要更新
backend_update_available = version.parse(latest_backend_version) > version.parse(current_backend_version)
return UpdateCheckResponse(
current_backend_version=current_backend_version,
latest_backend_version=latest_backend_version,
backend_update_available=backend_update_available,
backend_download_url=backend_download_url,
latest_webui_version=latest_webui_version,
webui_download_url=webui_download_url
).model_dump()
@system_bp.route("/update", methods=["POST"])
@require_auth
async def perform_update():
"""执行更新操作"""
data = await request.get_json()
update_backend = data.get("update_backend", False)
update_webui = data.get("update_webui", False)
temp_dir = tempfile.mkdtemp()
try:
if update_backend:
backend_url = data["backend_download_url"]
backend_file, backend_hash = await download_file(backend_url, temp_dir)
# 安装后端
subprocess.run([sys.executable, "-m", "pip", "install", backend_file], check=True)
if update_webui:
webui_url = data["webui_download_url"]
webui_file, webui_hash = await download_file(webui_url, temp_dir)
# 解压并安装前端
static_dir = current_app.static_folder or "web"
with tarfile.open(webui_file, "r:gz") as tar:
# 解压 package/dist 里的所有文件到 web 目录
for member in tar.getmembers():
if member.name.startswith("package/dist/"):
# 去掉 "package/dist/" 前缀
member.name = member.name[len("package/dist/"):]
# 解压到 static 目录
tar.extract(member, path=static_dir)
return {"status": "success", "message": "更新完成"}
except Exception as e:
return {"status": "error", "message": str(e)}, 500
finally:
shutil.rmtree(temp_dir)
@system_bp.route("/restart", methods=["POST"])
@require_auth
async def restart_system():
"""重启系统"""
# 记录重启日志,会通过WebSocket发送给所有客户端
logger.warning("服务器即将重启,请稍候...")
# 设置重启标志
set_restart_flag()
shutdown_event.set()
return {"status": "success", "message": "重启请求已发送"}
================================================
FILE: kirara_ai/web/api/system/utils.py
================================================
import hashlib
import os
import subprocess
import sys
from functools import lru_cache
import aiohttp
import psutil
def get_installed_version() -> str:
"""获取当前安装的版本号"""
try:
# 使用 importlib.metadata 获取已安装的包版本
from importlib.metadata import PackageNotFoundError, version
try:
return version("kirara-ai")
except PackageNotFoundError:
# 如果包未安装,尝试从 pkg_resources 获取
from pkg_resources import get_distribution
return get_distribution("kirara-ai").version
except Exception:
return "0.0.0" # 如果所有方法都失败,返回默认版本号
async def get_latest_pypi_version(package_name: str) -> tuple[str, str]:
"""获取包的最新版本和下载URL"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(f"https://pypi.org/pypi/{package_name}/json") as response:
response.raise_for_status()
data = await response.json()
latest_version = data["info"]["version"]
# 获取最新版本的wheel包下载URL
for url_info in data["urls"]:
if url_info["packagetype"] == "bdist_wheel":
return latest_version, url_info["url"]
return latest_version, ""
except Exception:
return "0.0.0", ""
async def get_latest_npm_version(package_name: str, registry: str = "https://registry.npmjs.org") -> tuple[str, str]:
"""获取NPM包的最新版本和下载URL"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(f"{registry}/{package_name}") as response:
response.raise_for_status()
data = await response.json()
latest_version = data["dist-tags"]["latest"]
tarball_url = data["versions"][latest_version]["dist"]["tarball"]
return latest_version, tarball_url
except Exception:
return "0.0.0", ""
async def download_file(url: str, temp_dir: str) -> tuple[str, str]:
"""下载文件并返回文件路径和SHA256"""
local_filename = os.path.join(temp_dir, url.split('/')[-1])
sha256_hash = hashlib.sha256()
try:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
response.raise_for_status()
total_size = int(response.headers.get('Content-Length', 0))
bytes_downloaded = 0
with open(local_filename, 'wb') as f:
async for chunk in response.content.iter_chunked(8192):
f.write(chunk)
sha256_hash.update(chunk)
bytes_downloaded += len(chunk)
if total_size > 0:
print(f"Downloaded {bytes_downloaded / total_size:.2%}", end='\r')
print() # 换行,确保进度条不覆盖后续输出
return local_filename, sha256_hash.hexdigest()
except Exception as e:
print(f"下载失败: {e}")
return "", ""
@lru_cache(maxsize=1)
def get_cpu_info() -> str:
"""获取CPU信息,使用lru_cache进行缓存"""
try:
if sys.platform == 'win32':
# Windows 系统下获取 CPU 信息
result = subprocess.run(['wmic', 'cpu', 'get', 'name'], capture_output=True, text=True)
if result.returncode == 0:
cpu_info = result.stdout.strip().removeprefix('Name').strip()
else:
# Linux 系统下获取 CPU 信息
with open('/proc/cpuinfo', 'r') as f:
for line in f:
if line.startswith('model name'):
cpu_info = line.split(':')[1].strip()
break
return cpu_info if cpu_info else "Unknown"
except:
return "Unknown"
def get_memory_usage() -> dict:
"""获取内存使用情况"""
process = psutil.Process()
system_memory = psutil.virtual_memory()
process_mem = process.memory_full_info().uss
percent = system_memory.used / (system_memory.total)
return {
"percent": percent,
"total": system_memory.total / 1024 / 1024, # MB
"free": system_memory.available / 1024 / 1024, # MB
"used": process_mem / 1024 / 1024, # MB
}
def get_cpu_usage() -> float:
"""获取CPU使用率"""
try:
return psutil.cpu_percent()
except:
return 0.0
================================================
FILE: kirara_ai/web/api/tracing/__init__.py
================================================
from .routes import tracing_bp
__all__ = ["tracing_bp"]
================================================
FILE: kirara_ai/web/api/tracing/routes.py
================================================
import asyncio
import json
from quart import Blueprint, g, jsonify, request, websocket
from kirara_ai.internal import shutdown_event
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.tracing.llm_tracer import LLMTracer
from kirara_ai.tracing.manager import TracingManager
from kirara_ai.web.auth.middleware import require_auth
from kirara_ai.web.auth.services import AuthService
tracing_bp = Blueprint("tracing", __name__, url_prefix="/api/tracing")
logger = get_logger("Tracing-API")
@tracing_bp.route("/types", methods=["GET"])
@require_auth
async def get_trace_types():
"""获取所有可用的追踪器类型"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
return jsonify({
"types": tracing_manager.get_tracer_types()
})
@tracing_bp.route("/llm/traces", methods=["POST"])
@require_auth
async def get_llm_traces():
"""获取LLM追踪记录,支持筛选和分页"""
# 获取查询参数
data = await request.json
page = data.get("page", 1)
page_size = data.get("page_size", 20)
model_id = data.get("model_id")
backend_name = data.get("backend_name")
status = data.get("status")
# 构建过滤条件
filters = {}
if model_id:
filters["model_id"] = model_id
if backend_name:
filters["backend_name"] = backend_name
if status:
filters["status"] = status
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
# 使用统一的查询接口
records, total = llm_tracer.get_traces(
filters=filters,
page=page,
page_size=page_size
)
return jsonify({
"items": [record.to_dict() for record in records],
"total": total,
"page": page,
"page_size": page_size,
"total_pages": (total + page_size - 1) // page_size
})
@tracing_bp.route("/llm/detail/", methods=["GET"])
@require_auth
async def get_llm_trace_detail(trace_id: str):
"""获取特定LLM请求的详细信息"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
trace = llm_tracer.get_trace_by_id(trace_id)
if not trace:
return jsonify({"error": "Trace not found"}), 404
return jsonify(trace.to_detail_dict())
@tracing_bp.route("/llm/statistics", methods=["GET"])
@require_auth
async def get_llm_statistics():
"""获取LLM统计信息"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
llm_tracer = tracing_manager.get_tracer("llm")
if not llm_tracer:
return jsonify({"error": "LLM tracer not found"}), 404
assert isinstance(llm_tracer, LLMTracer)
stats = llm_tracer.get_statistics()
return jsonify(stats)
@tracing_bp.websocket("/ws")
async def tracing_ws():
"""WebSocket接口,用于实时推送追踪日志"""
container: DependencyContainer = g.container
tracing_manager = container.resolve(TracingManager)
auth_service: AuthService = container.resolve(AuthService)
# 获取所有追踪器类型
tracer_types = tracing_manager.get_tracer_types()
# 发送欢迎消息
await websocket.send(json.dumps({
"type": "connected",
"message": "Connected to tracing websocket",
"data": {
"available_tracers": tracer_types
}
}))
# 验证token
try:
token_data = await websocket.receive()
token = json.loads(token_data)["token"]
if not auth_service.verify_token(token):
await websocket.close(code=1008, reason="Invalid token")
return
except Exception as e:
logger.error(f"WebSocket连接错误: {e}")
await websocket.close(code=1008, reason="Invalid token")
return
# 接收命令
cmd = await websocket.receive()
cmd = json.loads(cmd)
# 订阅
if cmd.get("action") == "subscribe":
if tracer_type := cmd.get("tracer_type"):
tracer = tracing_manager.get_tracer(tracer_type)
if tracer:
# 注册WebSocket客户端
queue: asyncio.Queue = tracer.register_ws_client()
await websocket.send(json.dumps({
"type": "subscribe_success",
"message": "Subscribed to tracing websocket",
"data": {
"tracer_type": tracer_type
}
}))
else:
await websocket.close(code=1008, reason="Tracer not found")
return
else:
await websocket.close(code=1008, reason="Invalid tracer type")
return
else:
await websocket.close(code=1008, reason="Invalid action")
return
try:
# 保持连接打开状态,直到客户端断开连接
while not shutdown_event.is_set():
# 摸鱼
message = await queue.get()
if message is None:
break
await websocket.send(json.dumps(message))
finally:
if tracer:
tracer.unregister_ws_client(queue)
================================================
FILE: kirara_ai/web/api/workflow/README.md
================================================
# 工作流 API 🔄
工作流 API 提供了管理工作流的功能。工作流由多个区块组成,用于处理消息和执行任务。每个工作流都属于一个特定的组。
## API 端点
### 获取所有工作流
```http
GET/backend-api/api/workflow
```
获取所有已注册的工作流基本信息。
**响应示例:**
```json
{
"workflows": [
{
"group_id": "chat",
"workflow_id": "normal",
"name": "普通聊天",
"description": "处理普通聊天消息的工作流",
"block_count": 3,
"metadata": {
"category": "chat",
"tags": ["normal", "chat"]
}
}
]
}
```
### 获取特定工作流
```http
GET/backend-api/api/workflow/{group_id}/{workflow_id}
```
获取指定工作流的详细信息。
**响应示例:**
```json
{
"workflow": {
"group_id": "chat",
"workflow_id": "normal",
"name": "普通聊天",
"description": "处理普通聊天消息的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "openai",
"temperature": 0.7
},
"position": {
"x": 300,
"y": 100
}
},
{
"block_id": "output_1",
"type_name": "MessageOutputBlock",
"name": "消息输出",
"config": {
"format": "text"
},
"position": {
"x": 500,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "llm_1",
"target_input": "prompt"
},
{
"source_block": "llm_1",
"source_output": "response",
"target_block": "output_1",
"target_input": "message"
}
],
"metadata": {
"category": "chat",
"tags": ["normal", "chat"]
}
}
}
```
### 创建工作流
```http
POST/backend-api/api/workflow/{group_id}/{workflow_id}
```
创建新的工作流。
**请求体:**
```json
{
"group_id": "chat",
"workflow_id": "creative",
"name": "创意聊天",
"description": "处理创意聊天的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "prompt_1",
"type_name": "PromptBlock",
"name": "提示词处理",
"config": {
"template": "请发挥创意回答以下问题:{{input}}"
},
"position": {
"x": 300,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "anthropic",
"temperature": 0.9
},
"position": {
"x": 500,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "prompt_1",
"target_input": "input"
},
{
"source_block": "prompt_1",
"source_output": "output",
"target_block": "llm_1",
"target_input": "prompt"
}
],
"metadata": {
"category": "chat",
"tags": ["creative", "chat"]
}
}
```
### 更新工作流
```http
PUT/backend-api/api/workflow/{group_id}/{workflow_id}
```
更新现有工作流。请求体格式与创建工作流相同。
### 删除工作流
```http
DELETE/backend-api/api/workflow/{group_id}/{workflow_id}
```
删除指定工作流。成功时返回:
```json
{
"message": "Workflow deleted successfully"
}
```
## 数据模型
### Wire (工作流连线)
- `source_block`: 源区块 ID
- `source_output`: 源区块输出端口
- `target_block`: 目标区块 ID
- `target_input`: 目标区块输入端口
### BlockInstance (区块实例)
- `block_id`: 区块 ID
- `type_name`: 区块类型名称
- `name`: 区块显示名称
- `config`: 区块配置
- `position`: 区块位置
- `x`: X 坐标
- `y`: Y 坐标
### WorkflowDefinition (工作流定义)
- `group_id`: 工作流组 ID
- `workflow_id`: 工作流 ID
- `name`: 工作流名称
- `description`: 工作流描述
- `blocks`: 区块列表
- `wires`: 连线列表
- `metadata`: 元数据(可选)
### WorkflowInfo (工作流信息)
- `group_id`: 工作流组 ID
- `workflow_id`: 工作流 ID
- `name`: 工作流名称
- `description`: 工作流描述
- `block_count`: 区块数量
- `metadata`: 元数据(可选)
### WorkflowList (工作流列表)
- `workflows`: 工作流信息列表
### WorkflowResponse (工作流响应)
- `workflow`: 工作流定义
## 区块类型
工作流中可以使用的区块类型包括:
### MessageInputBlock
- 功能:接收输入消息
- 输入:无
- 输出:
- `message`: 消息内容
- 配置:
- `format`: 消息格式(text/image/audio)
### MessageOutputBlock
- 功能:输出消息
- 输入:
- `message`: 消息内容
- 输出:无
- 配置:
- `format`: 消息格式(text/image/audio)
### LLMBlock
- 功能:调用大语言模型
- 输入:
- `prompt`: 提示词
- 输出:
- `response`: 模型响应
- 配置:
- `backend`: 使用的后端
- `temperature`: 温度参数
### PromptBlock
- 功能:处理提示词
- 输入:
- `input`: 输入内容
- 输出:
- `output`: 处理后的提示词
- 配置:
- `template`: 提示词模板
## 相关代码
- [工作流注册表](../../../workflow/core/workflow/registry.py)
- [工作流构建器](../../../workflow/core/workflow/builder.py)
- [区块注册表](../../../workflow/core/block/registry.py)
- [系统预设工作流](../../../../data/workflows)
## 错误处理
所有 API 端点在发生错误时都会返回适当的 HTTP 状态码和错误信息:
```json
{
"error": "错误描述信息"
}
```
常见状态码:
- 400: 请求参数错误、工作流配置无效或工作流已存在
- 404: 工作流不存在
- 500: 服务器内部错误
## 使用示例
### 获取所有工作流
```python
import requests
response = requests.get(
'http://localhost:8080/api/workflow',
headers={'Authorization': f'Bearer {token}'}
)
```
### 创建新工作流
```python
import requests
workflow_data = {
"group_id": "chat",
"workflow_id": "creative",
"name": "创意聊天",
"description": "处理创意聊天的工作流",
"blocks": [
{
"block_id": "input_1",
"type_name": "MessageInputBlock",
"name": "消息输入",
"config": {
"format": "text"
},
"position": {
"x": 100,
"y": 100
}
},
{
"block_id": "llm_1",
"type_name": "LLMBlock",
"name": "语言模型",
"config": {
"backend": "anthropic",
"temperature": 0.9
},
"position": {
"x": 300,
"y": 100
}
}
],
"wires": [
{
"source_block": "input_1",
"source_output": "message",
"target_block": "llm_1",
"target_input": "prompt"
}
],
"metadata": {
"category": "chat",
"tags": ["creative"]
}
}
response = requests.post(
'http://localhost:8080/api/workflow/chat/creative',
headers={'Authorization': f'Bearer {token}'},
json=workflow_data
)
```
### 删除工作流
```python
import requests
response = requests.delete(
'http://localhost:8080/api/workflow/chat/creative',
headers={'Authorization': f'Bearer {token}'}
)
```
## 相关文档
- [系统架构](../../README.md#系统架构-)
- [API 认证](../../README.md#api认证-)
- [工作流开发](../../../workflow/README.md#工作流开发-)
================================================
FILE: kirara_ai/web/api/workflow/__init__.py
================================================
from .routes import workflow_bp
__all__ = ["workflow_bp"]
================================================
FILE: kirara_ai/web/api/workflow/models.py
================================================
from typing import Any, Dict, List, Optional
from pydantic import BaseModel
from kirara_ai.workflow.core.workflow.base import WorkflowConfig
class Wire(BaseModel):
"""工作流连线"""
source_block: str # block ID
source_output: str
target_block: str # block ID
target_input: str
class BlockInstance(BaseModel):
"""工作流中的Block实例"""
type_name: str
name: str
config: Dict[str, Any]
position: Dict[str, int] # x, y 坐标
class WorkflowDefinition(BaseModel):
"""工作流定义"""
group_id: str
workflow_id: str
name: str
description: str
blocks: List[BlockInstance]
wires: List[Wire]
config: WorkflowConfig = WorkflowConfig()
metadata: Optional[Dict[str, Any]] = None
class WorkflowInfo(BaseModel):
"""工作流基本信息"""
group_id: str
workflow_id: str
name: str
description: str
block_count: int
metadata: Optional[Dict[str, Any]] = None
class WorkflowList(BaseModel):
"""工作流列表响应"""
workflows: List[WorkflowInfo]
class WorkflowResponse(BaseModel):
"""单个工作流响应"""
workflow: WorkflowDefinition
================================================
FILE: kirara_ai/web/api/workflow/routes.py
================================================
import os
from typing import List
from quart import Blueprint, g, jsonify, request
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from ...auth.middleware import require_auth
from .models import BlockInstance, Wire, WorkflowDefinition, WorkflowInfo, WorkflowList, WorkflowResponse
workflow_bp = Blueprint("workflow", __name__)
@workflow_bp.route("", methods=["GET"])
@require_auth
async def list_workflows():
"""获取所有工作流列表"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
workflows = []
for workflow_id, builder in registry._workflows.items():
# 从 workflow_id 解析 group_id
group_id, wf_id = workflow_id.split(":", 1)
workflows.append(
WorkflowInfo(
group_id=group_id,
workflow_id=wf_id,
name=builder.name,
description=builder.description,
block_count=len(builder.nodes_by_name),
metadata=getattr(builder, "metadata", None),
)
)
workflows.sort(key=lambda x: f"{x.group_id}:{x.workflow_id}")
return WorkflowList(workflows=workflows).model_dump()
@workflow_bp.route("//", methods=["GET"])
@require_auth
async def get_workflow(group_id: str, workflow_id: str):
"""获取特定工作流的详细信息"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
full_id = f"{group_id}:{workflow_id}"
builder = registry.get(full_id)
if not builder:
return jsonify({"error": "Workflow not found"}), 404
assert isinstance(builder, WorkflowBuilder)
# 构建工作流定义
blocks: List[BlockInstance] = []
for node in builder.nodes:
blocks.append(
BlockInstance(
type_name=block_registry.get_block_type_name(node.spec.block_class),
name=node.name,
config=node.spec.kwargs,
position=node.position or {"x": 0, "y": 0},
)
)
wires: List[Wire] = []
for source_name, source_output, target_name, target_input in builder.wire_specs:
wires.append(
Wire(
source_block=source_name,
source_output=source_output,
target_block=target_name,
target_input=target_input,
)
)
workflow_def = WorkflowDefinition(
group_id=group_id,
workflow_id=workflow_id,
name=builder.name,
description=builder.description,
blocks=blocks,
wires=wires,
metadata=getattr(builder, "metadata", None),
config=builder.config,
)
return WorkflowResponse(workflow=workflow_def).model_dump()
@workflow_bp.route("//", methods=["POST"])
@require_auth
async def create_workflow(group_id: str, workflow_id: str):
"""创建新的工作流"""
data = await request.get_json()
workflow_def = WorkflowDefinition(**data)
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
# 检查工作流是否已存在
full_id = f"{group_id}:{workflow_id}"
if registry.get(full_id):
return jsonify({"error": "Workflow already exists"}), 400
# 创建工作流构建器
try:
# 创建工作流构建器
builder = WorkflowBuilder(workflow_def.name)
builder.description = workflow_def.description
# 根据定义添加块和连接
for block_def in workflow_def.blocks:
block_class = block_registry.get(block_def.type_name)
if not block_class:
raise ValueError(f"Block type {block_def.type_name} not found")
if not builder.head:
builder.use(block_class, name=block_def.name, **block_def.config)
else:
builder.chain(block_class, name=block_def.name, **block_def.config)
builder.update_position(block_def.name, block_def.position)
# 不要用自动连线,用我们的
builder.wire_specs = []
# 添加连接
for wire in workflow_def.wires:
builder.force_connect(
wire.source_block,
wire.target_block,
wire.source_output,
wire.target_input
)
# 保存工作流
file_path = registry.get_workflow_path(group_id, workflow_id)
builder.set_config(workflow_def.config)
builder.save_to_yaml(file_path, g.container)
# 注册工作流
registry.register(group_id, workflow_id, builder)
return workflow_def.model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@workflow_bp.route("//", methods=["PUT"])
@require_auth
async def update_workflow(group_id: str, workflow_id: str):
"""更新现有工作流"""
data = await request.get_json()
workflow_def = WorkflowDefinition(**data)
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
block_registry: BlockRegistry = g.container.resolve(BlockRegistry)
# 检查工作流是否存在
full_id = f"{group_id}:{workflow_id}"
if not registry.get(full_id):
return jsonify({"error": "Workflow not found"}), 404
# 更新工作流
try:
# 创建新的工作流构建器
builder = WorkflowBuilder(workflow_def.name)
builder.description = workflow_def.description
# 根据定义添加块和连接
for block_def in workflow_def.blocks:
block_class = block_registry.get(block_def.type_name)
if not block_class:
raise ValueError(f"Block type {block_def.type_name} not found")
if not builder.head:
builder.use(block_class, name=block_def.name, **block_def.config)
else:
builder.chain(block_class, name=block_def.name, **block_def.config)
builder.update_position(block_def.name, block_def.position)
# 不要用自动连线,用我们的
builder.wire_specs = []
# 添加连接
for wire in workflow_def.wires:
builder.force_connect(
wire.source_block,
wire.target_block,
wire.source_output,
wire.target_input
)
# 保存工作流
file_path = registry.get_workflow_path(group_id, workflow_id)
if os.path.exists(file_path):
os.remove(file_path)
new_file_path = registry.get_workflow_path(
data["group_id"], data["workflow_id"]
)
builder.set_config(workflow_def.config)
builder.save_to_yaml(new_file_path, g.container)
# 更新注册表
registry.unregister(group_id, workflow_id)
registry.register(data["group_id"], data["workflow_id"], builder)
return workflow_def.model_dump()
except Exception as e:
return jsonify({"error": str(e)}), 400
@workflow_bp.route("//", methods=["DELETE"])
@require_auth
async def delete_workflow(group_id: str, workflow_id: str):
"""删除工作流"""
registry: WorkflowRegistry = g.container.resolve(WorkflowRegistry)
# 检查工作流是否存在
full_id = f"{group_id}:{workflow_id}"
if not registry.get(full_id):
return jsonify({"error": "Workflow not found"}), 404
try:
# 从注册表中移除
registry._workflows.pop(full_id, None)
# 删除文件
file_path = registry.get_workflow_path(group_id, workflow_id)
if os.path.exists(file_path):
os.remove(file_path)
return jsonify({"message": "Workflow deleted successfully"})
except Exception as e:
return jsonify({"error": str(e)}), 400
================================================
FILE: kirara_ai/web/app.py
================================================
import asyncio
import mimetypes
import os
import socket
from pathlib import Path
from fastapi import FastAPI, HTTPException, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import FileResponse, HTMLResponse, PlainTextResponse
from hypercorn.asyncio import serve
from hypercorn.config import Config
from quart import Quart, g, jsonify
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import HypercornLoggerWrapper, get_logger
from kirara_ai.web.auth.services import AuthService, FileBasedAuthService
from kirara_ai.web.utils import create_no_cache_response, install_webui
from .api.block import block_bp
from .api.dispatch import dispatch_bp
from .api.im import im_bp
from .api.llm import llm_bp
from .api.mcp import mcp_bp
from .api.media import media_bp
from .api.plugin import plugin_bp
from .api.system import system_bp
from .api.tracing import tracing_bp
from .api.workflow import workflow_bp
from .auth.routes import auth_bp
ERROR_MESSAGE = """
WebUI launch failed!
Web UI not found. Please download from here and extract to the TARGET_DIR folder, make sure the TARGET_DIR/index.html file exists.
WebUI 启动失败!
Web UI 未找到。请从 这里 下载并解压到 TARGET_DIR 文件夹,确保 TARGET_DIR/index.html 文件存在。
"""
cwd = os.getcwd()
STATIC_FOLDER = f"{cwd}/web"
logger = get_logger("WebServer")
custom_static_assets: dict[str, str] = {}
def create_web_api_app(container: DependencyContainer) -> Quart:
"""创建 Web API 应用(Quart)"""
app = Quart(__name__, static_folder=STATIC_FOLDER)
app.json.sort_keys = False # type: ignore
# 注册蓝图
app.register_blueprint(auth_bp, url_prefix="/api/auth")
app.register_blueprint(im_bp, url_prefix="/api/im")
app.register_blueprint(llm_bp, url_prefix="/api/llm")
app.register_blueprint(dispatch_bp, url_prefix="/api/dispatch")
app.register_blueprint(block_bp, url_prefix="/api/block")
app.register_blueprint(workflow_bp, url_prefix="/api/workflow")
app.register_blueprint(plugin_bp, url_prefix="/api/plugin")
app.register_blueprint(system_bp, url_prefix="/api/system")
app.register_blueprint(media_bp, url_prefix="/api/media")
app.register_blueprint(tracing_bp, url_prefix="/api/tracing")
app.register_blueprint(mcp_bp, url_prefix="/api/mcp")
@app.errorhandler(Exception)
def handle_exception(error):
logger.opt(exception=error).error("Error during request")
response = jsonify({"error": str(error)})
response.status_code = 500
return response
# 在每个请求前将容器注入到上下文
@app.before_request
async def inject_container(): # type: ignore
g.container = container
@app.before_websocket
async def inject_container_ws(): # type: ignore
g.container = container
app.container = container # type: ignore
return app
def create_app(container: DependencyContainer) -> FastAPI:
"""创建主应用(FastAPI)"""
app = FastAPI()
# 配置 CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 强制设置 MIME 类型
mimetypes.add_type("text/html", ".html")
mimetypes.add_type("text/css", ".css")
mimetypes.add_type("text/javascript", ".js")
mimetypes.add_type("image/svg+xml", ".svg")
mimetypes.add_type("image/png", ".png")
mimetypes.add_type("image/jpeg", ".jpg")
mimetypes.add_type("image/gif", ".gif")
mimetypes.add_type("image/webp", ".webp")
# 自定义静态资源处理
async def serve_custom_static(path: str, request: Request):
if path not in custom_static_assets:
raise HTTPException(status_code=404, detail="File not found")
file_path = Path(custom_static_assets[path])
try:
return await create_no_cache_response(file_path, request)
except HTTPException as e:
raise e
except Exception as e:
logger.error(f"处理自定义静态资源时出错: {e}")
raise HTTPException(status_code=500, detail="Internal server error")
@app.get("/")
async def index(request: Request):
try:
index_path = Path(STATIC_FOLDER) / "index.html"
if not index_path.exists():
return HTMLResponse(content=ERROR_MESSAGE.replace("TARGET_DIR", STATIC_FOLDER))
return await create_no_cache_response(index_path, request)
except HTTPException as e:
raise e
except Exception as e:
logger.error(f"Error serving index: {e}")
return HTMLResponse(content=ERROR_MESSAGE.replace("TARGET_DIR", STATIC_FOLDER))
@app.middleware("http")
async def spa_middleware(request: Request, call_next):
path = request.url.path
# 如果请求路径在自定义静态资源列表中,则返回自定义静态资源
if path in custom_static_assets:
return await serve_custom_static(path, request)
skip_paths = [route.path for route in app.routes] # type: ignore
# 如果路径在跳过路径列表中,则直接返回
if any(path == skip_path for skip_path in skip_paths):
return await call_next(request)
skip_paths.remove("/")
# 如果路径以 backend-api 开头,交由内置路由处理
if any(path.startswith(skip_path) for skip_path in skip_paths):
return await call_next(request)
file_path = Path(STATIC_FOLDER) / path.lstrip('/')
# 检查路径穿越
if not file_path.resolve().is_relative_to(Path(STATIC_FOLDER).resolve()):
raise HTTPException(status_code=404, detail="Access denied")
# 如果文件存在,返回文件并禁止缓存
if file_path.is_file():
try:
return await create_no_cache_response(file_path, request)
except HTTPException as e:
raise e
except Exception as e:
logger.error(f"处理静态文件时出错: {e}")
return FileResponse(file_path) # 退回到普通文件响应
fallback_path = Path(STATIC_FOLDER) / "index.html"
# 否则返回 index.html(SPA 路由)
if fallback_path.is_file():
try:
return await create_no_cache_response(fallback_path, request)
except HTTPException as e:
raise e
except Exception as e:
logger.error(f"处理index.html时出错: {e}")
return FileResponse(fallback_path) # 退回到普通文件响应
else:
return PlainTextResponse(status_code=404, content="route not found")
return app
class WebServer:
app: FastAPI
web_api_app: Quart
listen_host: str
listen_port: int
container: DependencyContainer
def __init__(self, container: DependencyContainer):
self.app = create_app(container)
self.web_api_app = create_web_api_app(container)
self.server_task = None
self.shutdown_event = asyncio.Event()
self.container = container
container.register(
AuthService,
FileBasedAuthService(
password_file=Path(container.resolve(GlobalConfig).web.password_file),
secret_key=container.resolve(GlobalConfig).web.secret_key,
),
)
self.config = container.resolve(GlobalConfig)
# 配置 hypercorn
from hypercorn.logging import Logger
self.hypercorn_config = Config()
self.hypercorn_config._log = Logger(self.hypercorn_config)
# 创建自定义的日志包装器,添加 URL 过滤
class FilteredLoggerWrapper(HypercornLoggerWrapper):
def info(self, message, *args, **kwargs):
# 过滤掉不需要记录的URL请求日志
ignored_paths = [
'/backend-api/api/system/status', # 添加需要过滤的URL路径
'/favicon.ico',
]
for path in ignored_paths:
if path in str(args):
return
super().info(message, *args, **kwargs)
# 使用新的过滤日志包装器
self.hypercorn_config._log.access_logger = FilteredLoggerWrapper(logger) # type: ignore
self.hypercorn_config._log.error_logger = HypercornLoggerWrapper(logger) # type: ignore
# 挂载 Web API 应用
self.mount_app("/backend-api", self.web_api_app)
def mount_app(self, prefix: str, app):
"""挂载子应用到指定路径前缀"""
self.app.mount(prefix, app)
def _check_port_available(self, host: str, port: int) -> bool:
"""检查端口是否可用"""
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
try:
s.bind((host, port))
return True
except socket.error:
return False
async def start(self):
"""启动Web服务器"""
# 确定最终使用的host和port
if self.container.has("cli_args"):
cli_args = self.container.resolve("cli_args")
self.listen_host = cli_args.host or self.config.web.host
self.listen_port = cli_args.port or self.config.web.port
else:
self.listen_host = self.config.web.host
self.listen_port = self.config.web.port
self.hypercorn_config.bind = [f"{self.listen_host}:{self.listen_port}"]
# 检查端口是否被占用
if not self._check_port_available(self.listen_host, self.listen_port):
error_msg = f"端口 {self.listen_port} 已被占用,无法启动服务器,请修改端口或关闭其他占用端口的程序。"
logger.error(error_msg)
raise RuntimeError(error_msg)
self.server_task = asyncio.create_task(serve(self.app, self.hypercorn_config, shutdown_trigger=self.shutdown_event.wait)) # type: ignore
logger.info(f"监听地址:http://{self.listen_host}:{self.listen_port}/")
# 检查WebUI是否存在,如果不存在则尝试自动安装
self._check_and_install_webui()
async def stop(self):
"""停止Web服务器"""
self.shutdown_event.set()
if self.server_task:
try:
await asyncio.wait_for(self.server_task, timeout=3.0)
except asyncio.TimeoutError:
logger.warning("Server shutdown timed out after 3 seconds.")
except asyncio.CancelledError:
pass
except Exception as e:
logger.error(f"Error during server shutdown: {e}")
def add_static_assets(self, url_path: str, local_path: str):
"""添加自定义静态资源"""
if not os.path.exists(local_path):
logger.warning(f"Static asset path does not exist: {local_path}")
return
custom_static_assets[url_path] = local_path
def _check_and_install_webui(self):
"""检查WebUI是否存在,如果不存在则尝试自动安装"""
index_path = Path(STATIC_FOLDER) / "index.html"
if not index_path.exists():
logger.info("检测到WebUI不存在,将在服务器启动后自动安装...")
# 创建异步任务,但不等待完成
self._webui_install_task = asyncio.create_task(self._install_webui())
async def _install_webui(self):
"""安装WebUI的异步任务"""
try:
logger.info("开始自动安装WebUI...")
success, message = await install_webui(Path(STATIC_FOLDER))
if success:
logger.info(message)
logger.info(f"WebUI已安装到 {STATIC_FOLDER},请刷新浏览器")
else:
logger.error(message)
logger.error("WebUI自动安装失败,请手动下载并安装")
except Exception as e:
logger.error(f"WebUI安装过程出错: {e}")
================================================
FILE: kirara_ai/web/auth/middleware.py
================================================
from functools import wraps
from quart import g, jsonify, request
from kirara_ai.web.auth.services import AuthService
def require_auth(f):
@wraps(f)
async def decorated_function(*args, **kwargs):
# 如果 query string 中包含 token,则使用该 token
token = request.args.get("auth_token")
if not token:
auth_header = request.headers.get("Authorization")
if not auth_header:
return jsonify({"error": "No authorization header"}), 401
token_type, token = auth_header.split()
if token_type.lower() != "bearer":
return jsonify({"error": "Invalid token type"}), 401
try:
auth_service: AuthService = g.container.resolve(AuthService)
if not auth_service.verify_token(token):
return jsonify({"error": "Invalid token"}), 401
return await f(*args, **kwargs)
except Exception as e:
raise e
return decorated_function
================================================
FILE: kirara_ai/web/auth/models.py
================================================
from pydantic import BaseModel
class LoginRequest(BaseModel):
password: str
class ChangePasswordRequest(BaseModel):
old_password: str
new_password: str
class TokenResponse(BaseModel):
access_token: str
token_type: str = "bearer"
================================================
FILE: kirara_ai/web/auth/routes.py
================================================
import secrets
from datetime import timedelta
from quart import Blueprint, g, jsonify, request
from kirara_ai.config.config_loader import CONFIG_FILE, ConfigLoader
from kirara_ai.config.global_config import GlobalConfig
from .middleware import require_auth
from .models import ChangePasswordRequest, LoginRequest, TokenResponse
from .services import AuthService
auth_bp = Blueprint("auth", __name__)
@auth_bp.route("/login", methods=["POST"])
async def login():
data = await request.get_json()
login_data = LoginRequest(**data)
auth_service: AuthService = g.container.resolve(AuthService)
if auth_service.is_first_time():
auth_service.save_password(login_data.password)
token = auth_service.create_access_token(timedelta(days=1))
return TokenResponse(access_token=token).model_dump()
if not auth_service.verify_password(login_data.password):
return jsonify({"error": "Invalid password"}), 401
token = auth_service.create_access_token(timedelta(days=1))
return TokenResponse(access_token=token).model_dump()
@auth_bp.route("/change-password", methods=["POST"])
@require_auth
async def change_password():
data = await request.get_json()
password_data = ChangePasswordRequest(**data)
auth_service: AuthService = g.container.resolve(AuthService)
if not auth_service.verify_password(password_data.old_password):
return jsonify({"error": "Invalid old password"})
auth_service.save_password(password_data.new_password)
# 重新设置一个 secret_key,让所有的 token 失效
config: GlobalConfig = g.container.resolve(GlobalConfig)
config.web.secret_key = secrets.token_hex(32)
ConfigLoader.save_config_with_backup(CONFIG_FILE, config)
g.container.resolve(AuthService).secret_key = config.web.secret_key
return jsonify({"message": "Password changed successfully"})
@auth_bp.route("/check-first-time", methods=["GET"])
async def check_first_time():
auth_service: AuthService = g.container.resolve(AuthService)
return jsonify({"is_first_time": auth_service.is_first_time()})
================================================
FILE: kirara_ai/web/auth/services.py
================================================
from abc import ABC, abstractmethod
from datetime import timedelta
from pathlib import Path
from typing import Optional
class AuthService(ABC):
@abstractmethod
def is_first_time(self) -> bool:
pass
@abstractmethod
def save_password(self, password: str) -> None:
pass
@abstractmethod
def verify_password(self, password: str) -> bool:
pass
@abstractmethod
def create_access_token(self, expires_delta: Optional[timedelta] = None) -> str:
pass
@abstractmethod
def verify_token(self, token: str) -> bool:
pass
class FileBasedAuthService(AuthService):
def __init__(self, password_file: Path, secret_key: str):
self.password_file = password_file
self.secret_key = secret_key
def is_first_time(self) -> bool:
return not self.password_file.exists()
def save_password(self, password: str) -> None:
from .utils import hash_password
self.password_file.parent.mkdir(parents=True, exist_ok=True)
hashed = hash_password(password)
with open(self.password_file, "wb") as f:
f.write(hashed)
def verify_password(self, password: str) -> bool:
from .utils import verify_password
if not self.password_file.exists():
return False
with open(self.password_file, "rb") as f:
hashed = f.read()
return verify_password(password, hashed)
def create_access_token(self, expires_delta: Optional[timedelta] = None) -> str:
from .utils import create_jwt_token
return create_jwt_token(self.secret_key, expires_delta)
def verify_token(self, token: str) -> bool:
from .utils import verify_jwt_token
return verify_jwt_token(token, self.secret_key)
class MockAuthService(AuthService):
def __init__(self):
self._password = None
self._is_first_time = True
def is_first_time(self) -> bool:
return self._is_first_time
def save_password(self, password: str) -> None:
self._password = password
self._is_first_time = False
def verify_password(self, password: str) -> bool:
return password == self._password
def create_access_token(self, expires_delta: Optional[timedelta] = None) -> str:
return "mock_token"
def verify_token(self, token: str) -> bool:
return token == "mock_token"
================================================
FILE: kirara_ai/web/auth/utils.py
================================================
from datetime import datetime, timedelta
from typing import Optional
import bcrypt
import jwt
def hash_password(password: str) -> bytes:
salt = bcrypt.gensalt()
return bcrypt.hashpw(password.encode(), salt)
def verify_password(password: str, hashed: bytes) -> bool:
return bcrypt.checkpw(password.encode(), hashed)
def create_jwt_token(secret_key: str, expires_delta: Optional[timedelta] = None) -> str:
if expires_delta:
expire = datetime.now() + expires_delta
else:
expire = datetime.now() + timedelta(minutes=30)
to_encode = {"exp": expire}
encoded_jwt = jwt.encode(to_encode, secret_key, algorithm="HS256")
return encoded_jwt
def verify_jwt_token(token: str, secret_key: str) -> bool:
try:
jwt.decode(token, secret_key, algorithms=["HS256"])
return True
except:
return False
================================================
FILE: kirara_ai/web/utils.py
================================================
import asyncio
import os
import tarfile
import tempfile
import time
from pathlib import Path
import aiohttp
from fastapi import HTTPException, Request
from fastapi.responses import FileResponse, Response
from kirara_ai.logger import get_logger
from kirara_ai.web.api.system.utils import download_file, get_latest_npm_version
logger = get_logger("WebUtils")
async def create_no_cache_response(file_path: Path, request: Request) -> Response:
if not file_path.exists():
raise HTTPException(status_code=404, detail="File not found")
stat = file_path.stat()
mtime = stat.st_mtime_ns
size = stat.st_size
etag = f"{mtime}-{size}"
if_none_match = request.headers.get("if-none-match")
if if_none_match == etag:
return Response(status_code=304)
response = FileResponse(file_path)
response.headers["ETag"] = etag
response.headers["Cache-Control"] = "no-cache"
return response
async def test_npm_registry_speed(registries: list[str]) -> str:
"""测试多个NPM注册表的速度,返回最快的一个"""
# 默认使用第一个
fastest_registry = registries[0]
fastest_avg_time = float('inf')
# 每个注册表测试3次
test_count = 3
async def test_registry(registry: str) -> tuple[str, float]:
total_time = 0
success_count = 0
for i in range(test_count):
try:
start_time = time.time()
async with aiohttp.ClientSession() as session:
async with session.get(
f"{registry}/kirara-ai-webui",
timeout=aiohttp.ClientTimeout(total=5)
) as response:
if response.status == 200:
elapsed = time.time() - start_time
total_time += elapsed
success_count += 1
except Exception as e:
logger.warning(f"测试下载源 {registry} 第{i+1}次失败: {e}")
# 计算平均响应时间,如果全部失败则返回无穷大
avg_time = total_time / success_count if success_count > 0 else float('inf')
return registry, avg_time
# 并发测试所有注册表
tasks = [test_registry(registry) for registry in registries]
results = await asyncio.gather(*tasks)
# 找出平均响应时间最快的注册表
for registry, avg_time in results:
if avg_time < fastest_avg_time:
fastest_avg_time = avg_time
fastest_registry = registry
if fastest_avg_time != float('inf'):
logger.info(f"选择最快的下载源: {fastest_registry},平均响应时间: {fastest_avg_time:.2f}秒")
else:
logger.warning(f"所有下载源测试均失败,默认使用: {fastest_registry}")
return fastest_registry
async def install_webui(install_path: Path) -> tuple[bool, str]:
"""
安装最新版本的WebUI
Args:
install_path: 安装目录路径
Returns:
(成功状态, 消息)
"""
try:
# 测试多个NPM注册表的速度
registries = [
"https://registry.npmjs.org",
"https://registry.npmmirror.com",
"https://registry.yarnpkg.com",
"https://mirrors.ustc.edu.cn/npm/",
]
npm_registry = await test_npm_registry_speed(registries)
temp_dir = tempfile.mkdtemp()
logger.info(f"开始从 {npm_registry} 获取最新WebUI版本信息")
latest_webui_version, webui_download_url = await get_latest_npm_version("kirara-ai-webui", npm_registry)
if not webui_download_url:
return False, "无法获取WebUI下载地址"
logger.info(f"开始下载WebUI v{latest_webui_version}: {webui_download_url}")
webui_file, webui_hash = await download_file(webui_download_url, temp_dir)
if not webui_file:
return False, "WebUI下载失败"
# 确保安装目录存在
os.makedirs(install_path, exist_ok=True)
# 解压并安装前端
logger.info(f"开始解压WebUI到 {install_path}")
with tarfile.open(webui_file, "r:gz") as tar:
# 解压 package/dist 里的所有文件到安装目录
for member in tar.getmembers():
if member.name.startswith("package/dist/"):
# 去掉 "package/dist/" 前缀
extracted_name = member.name[len("package/dist/"):]
if extracted_name: # 跳过空路径
member.name = extracted_name
tar.extract(member, path=str(install_path))
return True, f"WebUI v{latest_webui_version} 安装成功"
except Exception as e:
logger.error(f"WebUI安装失败: {e}")
return False, f"WebUI安装失败: {str(e)}"
finally:
if 'temp_dir' in locals():
import shutil
shutil.rmtree(temp_dir)
================================================
FILE: kirara_ai/workflow/core/__init__.py
================================================
================================================
FILE: kirara_ai/workflow/core/block/__init__.py
================================================
from .base import Block, ConditionBlock, LoopBlock, LoopEndBlock
from .input_output import Input, Output
from .param import ParamMeta
from .registry import BlockRegistry
from .schema import BlockConfig, BlockInput, BlockOutput
__all__ = [
"Block",
"ConditionBlock",
"LoopBlock",
"LoopEndBlock",
"BlockRegistry",
"BlockInput",
"BlockOutput",
"BlockConfig",
"ParamMeta",
"Input",
"Output",
]
================================================
FILE: kirara_ai/workflow/core/block/base.py
================================================
from typing import Any, Callable, Dict, List, Optional
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block.input_output import Input, Output
class Block:
"""block 的基类"""
# block 的 id
id: str
# block 的名称
name: str
# block 的输入
inputs: Dict[str, Input] = {}
# block 的输出
outputs: Dict[str, Output] = {}
container: DependencyContainer
def __init__(
self,
name: Optional[str] = None,
inputs: Optional[Dict[str, Input]] = None,
outputs: Optional[Dict[str, Output]] = None,
):
self.id = getattr(self.__class__, "id", "anonymous_" + self.__class__.__name__)
if name is not None:
self.name = name
if inputs is not None:
self.inputs = inputs
if outputs is not None:
self.outputs = outputs
def execute(self, **kwargs) -> Dict[str, Any]:
# Placeholder for block logic
return {output: f"Processed {kwargs}" for output in self.outputs}
class ConditionBlock(Block):
"""条件判断块"""
name: str = "condition"
outputs: Dict[str, Output] = {
"condition_result": Output("condition_result", "条件结果", bool, "条件结果")
}
def __init__(
self,
condition_func: Callable[[Dict[str, Any]], bool],
inputs: Dict[str, "Input"],
):
super().__init__()
self.inputs = inputs
self.condition_func = condition_func
def execute(self, **kwargs) -> Dict[str, Any]:
result = self.condition_func(kwargs)
return {"condition_result": result}
class LoopBlock(Block):
"""循环控制块"""
name: str = "loop"
outputs: Dict[str, Output] = {
"should_continue": Output("should_continue", "是否继续", bool, "是否继续"),
"iteration": Output("iteration", "当前迭代数据", dict, "当前迭代数据"),
}
def __init__(
self,
condition_func: Callable[[Dict[str, Any]], bool],
inputs: Dict[str, "Input"],
iteration_var: str = "index",
):
super().__init__()
self.inputs = inputs
self.condition_func = condition_func
self.iteration_var = iteration_var
self.iteration_count = 0
def execute(self, **kwargs) -> Dict[str, Any]:
should_continue = self.condition_func(kwargs)
self.iteration_count += 1
return {
"should_continue": should_continue,
"iteration": {self.iteration_var: self.iteration_count, **kwargs},
}
class LoopEndBlock(Block):
"""循环结束块,收集循环结果"""
name: str = "loop_end"
outputs: Dict[str, Output] = {
"loop_results": Output("loop_results", "收集的循环结果", list, "收集的循环结果")
}
def __init__(self, inputs: Dict[str, "Input"]):
super().__init__()
self.inputs = inputs
self.results: List[Dict[str, Any]] = []
def execute(self, **kwargs) -> Dict[str, Any]:
self.results.append(kwargs)
return {"loop_results": self.results}
================================================
FILE: kirara_ai/workflow/core/block/input_output.py
================================================
from typing import Any, Optional
class Input:
def __init__(
self,
name: str,
label: str,
data_type: type,
description: str,
nullable: bool = False,
default: Optional[Any] = None,
):
self.name = name
self.label = label
self.data_type = data_type
self.description = description
self.nullable = nullable
self.default = default
def validate(self, value: Any) -> bool:
if value is None:
return self.nullable
return isinstance(value, self.data_type)
class Output:
def __init__(self, name: str, label: str, data_type: type, description: str):
self.name = name
self.label = label
self.data_type = data_type
self.description = description
def validate(self, value: Any) -> bool:
return isinstance(value, self.data_type)
================================================
FILE: kirara_ai/workflow/core/block/param.py
================================================
from typing import Callable, List, Optional, TypeVar
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block
T = TypeVar("T")
OptionsProvider = Callable[[DependencyContainer, Block], List[T]]
class ParamMeta:
def __init__(self, label: Optional[str] = None, description: Optional[str] = None, options_provider: Optional[OptionsProvider[T]] = None):
self.label = label
self.description = description
self.options_provider = options_provider
def __repr__(self):
return f"ParamMeta(label={self.label}, description={self.description}, options_provider={self.options_provider})"
def __str__(self):
return self.__repr__()
================================================
FILE: kirara_ai/workflow/core/block/registry.py
================================================
import warnings
from inspect import Parameter, signature
from typing import Annotated, Dict, List, Optional, Tuple, Type, get_args, get_origin
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.param import ParamMeta
from .schema import BlockConfig, BlockInput, BlockOutput
from .type_system import TypeSystem
def extract_block_param(param: Parameter, type_system: TypeSystem) -> BlockConfig:
"""
提取 Block 参数信息,包括类型字符串、标签、是否必需、描述和默认值。
"""
param_type = param.annotation
label = param.name
description = None
has_options = False
options_provider = None
if get_origin(param_type) is Annotated:
args = get_args(param_type)
if len(args) > 0:
actual_type = args[0]
metadata = args[1] if len(args) > 1 else None
if isinstance(metadata, ParamMeta):
label = metadata.label
description = metadata.description
has_options = metadata.options_provider is not None
options_provider = metadata.options_provider
# 递归调用 extract_block_param 处理实际类型
block_config = extract_block_param(
Parameter(
name=param.name,
kind=Parameter.POSITIONAL_OR_KEYWORD,
annotation=actual_type,
default=param.default,
),
type_system
)
type_string = block_config.type
required = block_config.required
default = block_config.default
else:
type_string = "Any"
required = True
default = None
else:
type_string, required, default = type_system.extract_type_info(param)
return BlockConfig(
name=param.name,
description=description,
type=type_string,
required=required,
default=default,
label=label,
has_options=has_options,
options=[],
options_provider=options_provider,
)
class BlockRegistry:
"""Block 注册表,用于管理所有已注册的 block"""
def __init__(self):
self._blocks = {}
self._localized_names = {}
self._type_system = TypeSystem()
def register(
self,
block_id: str,
group_id: str,
block_class: Type[Block],
localized_name: Optional[str] = None,
):
"""注册一个 block
Args:
block_id: block 的唯一标识
group_id: 组标识(internal 为框架内置)
block_class: block 类
localized_name: 本地化名称
"""
full_name = f"{group_id}:{block_id}"
if full_name in self._blocks:
raise ValueError(f"Block {full_name} already registered")
self._blocks[full_name] = block_class
block_class.id = block_id
if localized_name:
self._localized_names[full_name] = localized_name
# 注册 Input 和 Output 类型
for _, input_info in getattr(block_class, "inputs", {}).items():
type_name = self._type_system.get_type_name(input_info.data_type)
self._type_system.register_type(type_name, input_info.data_type)
for _, output_info in getattr(block_class, "outputs", {}).items():
type_name = self._type_system.get_type_name(output_info.data_type)
self._type_system.register_type(type_name, output_info.data_type)
def get(self, full_name: str) -> Optional[Type[Block]]:
"""获取已注册的 block 类"""
return self._blocks.get(full_name)
def get_localized_name(self, block_id: str) -> Optional[str]:
"""获取本地化名称"""
return self._localized_names.get(block_id, block_id)
def clear(self):
"""清空注册表"""
self._blocks.clear()
self._type_system = TypeSystem()
def get_block_type_name(self, block_class: Type[Block]) -> str:
"""获取 block 的类型名称,优先使用注册名称"""
# 遍历注册表查找匹配的 block 类
for full_name, registered_class in self._blocks.items():
if registered_class == block_class:
return full_name
warnings.warn(
f"Block class {block_class.__name__} is not registered. Using class path instead.",
UserWarning,
)
return f"!!{block_class.__module__}.{block_class.__name__}"
def get_all_types(self) -> List[Type[Block]]:
"""获取所有已注册的 block 类型"""
return list(self._blocks.values())
def extract_block_info(
self, block_type: Type[Block]
) -> Tuple[Dict[str, BlockInput], Dict[str, BlockOutput], Dict[str, BlockConfig]]:
"""
从 Block 类型中提取输入、输出和配置信息,并使用 BlockInput, BlockOutput, BlockConfig 对象封装。
Args:
block_type: Block 的类型。
Returns:
包含输入、输出和配置信息的字典。
"""
inputs = {}
outputs = {}
configs = {}
# 获取 Block 类的输入输出定义
for name, input_info in getattr(block_type, "inputs", {}).items():
type_name, _, _ = self._type_system.extract_type_info(input_info.data_type)
self._type_system.register_type(type_name, input_info.data_type)
inputs[name] = BlockInput(
name=name,
label=input_info.label,
description=input_info.description,
type=type_name,
required=not input_info.nullable,
default=input_info.default if hasattr(input_info, "default") else None,
)
for name, output_info in getattr(block_type, "outputs", {}).items():
type_name, _, _ = self._type_system.extract_type_info(output_info.data_type)
self._type_system.register_type(type_name, output_info.data_type)
outputs[name] = BlockOutput(
name=name,
label=output_info.label,
description=output_info.description,
type=type_name,
)
# 内置方法不属于参数(Block 的 __init__ 方法)
builtin_params = self.get_builtin_params()
# 获取 __init__ 方法的参数作为配置
sig = signature(block_type.__init__)
for param in sig.parameters.values():
if param.name == "self" or param.name in builtin_params:
continue
block_config = extract_block_param(param, self._type_system)
configs[param.name] = block_config
return inputs, outputs, configs
def get_builtin_params(self) -> List[str]:
"""获取内置参数"""
sig = signature(Block.__init__)
return [param.name for param in sig.parameters.values()]
def get_type_compatibility_map(self) -> Dict[str, Dict[str, bool]]:
"""获取所有类型的兼容性映射"""
return self._type_system.get_compatibility_map()
def is_type_compatible(self, source_type: str, target_type: str) -> bool:
"""检查源类型是否可以赋值给目标类型"""
return self._type_system.is_compatible(source_type, target_type)
================================================
FILE: kirara_ai/workflow/core/block/schema.py
================================================
from typing import Any, List, Optional
from pydantic import BaseModel, Field
from kirara_ai.workflow.core.block.param import OptionsProvider
class BlockInput(BaseModel):
"""Block输入定义"""
name: str
label: str
description: str
type: str
required: bool = True
default: Optional[Any] = None
class BlockOutput(BaseModel):
"""Block输出定义"""
name: str
label: str
description: str
type: str
class BlockConfig(BaseModel):
"""Block配置项定义"""
name: str
description: Optional[str] = None
type: str
required: bool = True
default: Optional[Any] = None
label: Optional[str] = None
has_options: bool = False
options: Optional[List[Any]] = None
options_provider: Optional[OptionsProvider] = Field(exclude=True)
================================================
FILE: kirara_ai/workflow/core/block/type_system.py
================================================
from inspect import Parameter
from typing import Any, Dict, Optional, Type, Union, get_args, get_origin, overload
class TypeSystem:
"""类型系统管理器,用于处理类型兼容性检查和类型名称映射"""
def __init__(self) -> None:
self._type_map: Dict[str, Type] = {}
self._compatibility_cache: Dict[str, Dict[str, bool]] = {}
def register_type(self, type_name: str, type_class: Type):
"""注册一个类型到类型系统中"""
self._type_map[type_name] = type_class
def get_type(self, type_name: str) -> Optional[Type]:
"""获取类型名称对应的实际类型"""
return self._type_map.get(type_name)
def get_type_name(self, type_obj: Type) -> str:
"""获取类型对应的名称"""
if hasattr(type_obj, "__name__"):
return type_obj.__name__
return str(type_obj)
@overload
def extract_type_info(self, param: Parameter) -> tuple[str, bool, Any]: ...
@overload
def extract_type_info(self, param: Type) -> tuple[str, bool, Any]: ...
def extract_type_info(self, param: Union[Parameter, Type]) -> tuple[str, bool, Any]:
"""从参数中提取类型信息
Returns:
tuple: (type_name, required, default_value)
"""
if isinstance(param, Parameter):
param_type = param.annotation
required = True
default = param.default if param.default != Parameter.empty else None
origin = get_origin(param_type)
else:
param_type = param
origin = get_origin(param_type)
default = None
required = True
if origin is Union:
args = get_args(param_type)
if type(None) in args:
required = False
non_none_args = [arg for arg in args if arg is not type(None)]
if len(non_none_args) == 1:
type_name = self.get_type_name(non_none_args[0])
else:
type_name = f"Union[{', '.join(self.get_type_name(arg) for arg in non_none_args)}]"
else:
type_name = f"Union[{', '.join(self.get_type_name(arg) for arg in args)}]"
elif origin is list:
args = get_args(param_type)
if args:
element_type = args[0]
element_type_name = self.get_type_name(element_type)
type_name = f"List[{element_type_name}]"
else:
type_name = "list"
else:
type_name = self.get_type_name(param_type)
# 注册类型
if param_type not in (str, int, float, bool, dict) or origin is not list:
self.register_type(type_name, param_type)
return type_name, required, default
def is_compatible(self, source_type: str, target_type: str) -> bool:
"""检查源类型是否可以赋值给目标类型"""
# 检查缓存
if source_type in self._compatibility_cache:
if target_type in self._compatibility_cache[source_type]:
return self._compatibility_cache[source_type][target_type]
# 获取实际类型
source_class = self.get_type(source_type)
target_class = self.get_type(target_type)
if not source_class or not target_class:
# 如果类型未注册,则只允许完全相同的类型
result = source_type == target_type
else:
# 检查类型兼容性
try:
# 任何类型都可以兼容 Any 类型
if target_type == "Any" or source_type == "Any":
result = True
else:
result = issubclass(source_class, target_class)
except TypeError:
# 处理一些特殊类型(如泛型)
result = source_type == target_type
# 缓存结果
if source_type not in self._compatibility_cache:
self._compatibility_cache[source_type] = {}
self._compatibility_cache[source_type][target_type] = result
return result
def get_compatibility_map(self) -> Dict[str, Dict[str, bool]]:
"""获取所有已注册类型之间的兼容性映射"""
# 确保所有类型组合都已经计算过
all_types = list(self._type_map.keys())
for source_type in all_types:
for target_type in all_types:
self.is_compatible(source_type, target_type)
# 只保留可兼容的结果
return {
source_type: {
target_type: is_compatible
for target_type, is_compatible in compatibility.items()
if is_compatible
}
for source_type, compatibility in self._compatibility_cache.items()
}
================================================
FILE: kirara_ai/workflow/core/dispatch/__init__.py
================================================
from .dispatcher import WorkflowDispatcher, WorkflowExecutor, WorkflowRegistry
from .exceptions import WorkflowNotFoundException
from .models.dispatch_rules import CombinedDispatchRule, RuleGroup, SimpleDispatchRule
from .registry import DispatchRuleRegistry
from .rules.base import DispatchRule, RuleConfig
__all__ = [
"CombinedDispatchRule",
"DispatchRule",
"DispatchRuleRegistry",
"WorkflowDispatcher",
"WorkflowExecutor",
"WorkflowRegistry",
"RuleGroup",
"SimpleDispatchRule",
"RuleGroup",
"SimpleDispatchRule",
"RuleConfig",
"WorkflowNotFoundException",
]
================================================
FILE: kirara_ai/workflow/core/dispatch/dispatcher.py
================================================
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.dispatch.models.dispatch_rules import CombinedDispatchRule
from kirara_ai.workflow.core.dispatch.registry import DispatchRuleRegistry
from kirara_ai.workflow.core.dispatch.rules.base import DispatchRule
from kirara_ai.workflow.core.execution.exceptions import WorkflowExecutionTimeoutException
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
from kirara_ai.workflow.core.workflow.base import Workflow
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from .exceptions import WorkflowNotFoundException
class WorkflowDispatcher:
"""工作流调度器"""
def __init__(self, container: DependencyContainer):
self.container = container
self.logger = get_logger("WorkflowDispatcher")
# 从容器获取注册表
self.workflow_registry = container.resolve(WorkflowRegistry)
self.dispatch_registry = container.resolve(DispatchRuleRegistry)
def register_rule(self, rule: CombinedDispatchRule):
"""注册一个调度规则"""
self.dispatch_registry.register(rule)
self.logger.info(f"Registered dispatch rule: {rule}")
async def dispatch(self, source: IMAdapter, message: IMMessage):
"""
根据消息内容选择第一个匹配的规则进行处理
"""
with self.container.scoped() as scoped_container:
scoped_container.register(IMAdapter, source)
scoped_container.register(IMMessage, message)
# 获取所有已启用的规则,按优先级排序
active_rules = self.dispatch_registry.get_active_rules()
for rule in active_rules:
if rule.match(message, self.workflow_registry, scoped_container):
scoped_container.register(DispatchRule, rule)
try:
self.logger.debug(f"Matched rule {rule}, executing workflow")
workflow = rule.get_workflow(scoped_container)
if workflow is None:
raise WorkflowNotFoundException(f"Workflow for rule {rule.name} not found, please check the rule configuration")
scoped_container.register(Workflow, workflow)
executor = WorkflowExecutor(scoped_container)
scoped_container.register(WorkflowExecutor, executor)
return await executor.run()
except WorkflowExecutionTimeoutException as e:
self.logger.error(f"Workflow execution timed out: {e}")
return None
except Exception as e:
self.logger.opt(exception=e).error(f"Workflow execution failed: {e}")
return None
self.logger.debug("No matching rule found for message")
return None
================================================
FILE: kirara_ai/workflow/core/dispatch/exceptions.py
================================================
class WorkflowNotFoundException(Exception):
"""工作流未找到异常"""
def __init__(self, message: str):
self.message = message
super().__init__(self.message)
================================================
FILE: kirara_ai/workflow/core/dispatch/models/dispatch_rules.py
================================================
from typing import Any, Dict, List, Literal, Optional
from pydantic import BaseModel
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.workflow import Workflow
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
logger = get_logger("DispatchRule")
class SimpleDispatchRule(BaseModel):
"""简单规则,包含规则类型和配置"""
type: str
config: Dict[str, Any]
class RuleGroup(BaseModel):
"""规则组,包含多个简单规则和组合操作符"""
operator: Literal["and", "or"] = "or"
rules: List[SimpleDispatchRule]
class CombinedDispatchRule(BaseModel):
"""组合调度规则,支持复杂的规则组合"""
rule_id: str
name: str
description: str = ""
workflow_id: str
priority: int = 5
enabled: bool = True
rule_groups: List[RuleGroup] # 规则组之间是 AND 关系
metadata: Dict[str, Any] = {}
def match(self, message: IMMessage, workflow_registry: WorkflowRegistry, container: DependencyContainer) -> bool:
"""
判断消息是否匹配该规则。
规则组之间是 AND 关系,规则组内部根据 operator 决定是 AND 还是 OR 关系。
"""
# 如果规则被禁用,直接返回 False
if not self.enabled:
return False
# 所有规则组都必须匹配(AND 关系)
for group in self.rule_groups:
# 如果组内没有规则,视为匹配
if len(group.rules) == 0:
return True
# 获取组内所有规则的匹配结果
rule_results = []
for rule in group.rules:
try:
from ..rules.base import DispatchRule
# 创建具体的规则实例
rule_class = DispatchRule.get_rule_type(rule.type)
rule_instance = rule_class.from_config(
rule_class.config_class(**rule.config),
workflow_registry,
self.workflow_id,
)
rule_results.append(rule_instance.match(message, container))
except Exception as e:
# 如果规则创建或匹配过程出错,视为不匹配
logger.error(f"Rule {rule.type} from config {rule.config} creation or matching failed: {e}")
continue
# 根据操作符确定组的匹配结果
if not rule_results: # 如果组内没有有效规则,视为不匹配
return False
if group.operator == "and":
if not all(rule_results): # AND 关系:所有规则都必须匹配
return False
else: # operator == "or"
if not any(rule_results): # OR 关系:至少一个规则匹配
return False
# 所有规则组都匹配成功
return True
def get_workflow(self, container: DependencyContainer) -> Optional[Workflow]:
"""获取该规则对应的工作流实例。"""
workflow = container.resolve(WorkflowRegistry).get_workflow(self.workflow_id, container)
return workflow
================================================
FILE: kirara_ai/workflow/core/dispatch/registry.py
================================================
import os
from typing import Any, Dict, List, Optional
from ruamel.yaml import YAML
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from .models.dispatch_rules import CombinedDispatchRule, RuleGroup, SimpleDispatchRule
from .rules.base import DispatchRule
from .rules.message_rules import BotMentionMatchRule, KeywordMatchRule, PrefixMatchRule, RegexMatchRule
from .rules.sender_rules import ChatSenderMatchRule, ChatSenderMismatchRule, ChatTypeMatchRule
from .rules.system_rules import FallbackMatchRule, IMInstanceMatchRule, RandomChanceMatchRule
class DispatchRuleRegistry:
"""调度规则注册表,管理调度规则的加载和注册"""
def __init__(self, container: DependencyContainer):
self.container = container
self.workflow_registry = container.resolve(WorkflowRegistry)
self.rules: Dict[str, CombinedDispatchRule] = {}
self.logger = get_logger("DispatchRuleRegistry")
self.rules_dir = "data/dispatch_rules"
def register(self, rule: CombinedDispatchRule):
"""注册一个调度规则"""
if not rule.rule_id:
raise ValueError("Rule must have an ID")
self.rules[rule.rule_id] = rule
self.logger.info(f"Registered dispatch rule: {rule}")
def get_rule(self, rule_id: str) -> Optional[CombinedDispatchRule]:
"""获取指定ID的规则"""
return self.rules.get(rule_id)
def get_all_rules(self) -> List[CombinedDispatchRule]:
"""获取所有已注册的规则"""
return list(self.rules.values())
def get_active_rules(self) -> List[CombinedDispatchRule]:
"""获取所有已启用的规则,按优先级降序排序"""
active_rules = [rule for rule in self.rules.values() if rule.enabled]
return sorted(active_rules, key=lambda x: x.priority, reverse=True)
def create_rule(self, rule: CombinedDispatchRule) -> CombinedDispatchRule:
"""创建并注册一个新规则"""
# 获取工作流构建器
workflow_builder = self.workflow_registry.get(rule.workflow_id)
if not workflow_builder:
raise ValueError(f"Workflow {rule.workflow_id} not found")
# 注册规则
self.register(rule)
return rule
def update_rule(
self, rule_id: str, rule: CombinedDispatchRule
) -> CombinedDispatchRule:
"""更新现有规则"""
if rule_id not in self.rules:
raise ValueError(f"Rule {rule_id} not found")
# 更新规则
self.register(rule)
return rule
def delete_rule(self, rule_id: str):
"""删除规则"""
if rule_id not in self.rules:
raise ValueError(f"Rule {rule_id} not found")
del self.rules[rule_id]
def enable_rule(self, rule_id: str):
"""启用规则"""
rule = self.get_rule(rule_id)
if not rule:
raise ValueError(f"Rule {rule_id} not found")
rule.enabled = True
def disable_rule(self, rule_id: str):
"""禁用规则"""
rule = self.get_rule(rule_id)
if not rule:
raise ValueError(f"Rule {rule_id} not found")
rule.enabled = False
def _convert_old_rule(self, rule_data: Dict[str, Any]) -> CombinedDispatchRule:
"""将旧版本规则数据转换为新版本格式"""
rule_type = rule_data["type"]
rule_class = DispatchRule.get_rule_type(rule_type)
# 提取规则配置
config_fields = rule_class.config_class.model_fields.keys()
rule_config = {k: rule_data[k] for k in config_fields if k in rule_data}
# 创建简单规则
simple_rule = SimpleDispatchRule(type=rule_type, config=rule_config)
# 创建规则组
rule_group = RuleGroup(operator="or", rules=[simple_rule])
# 创建组合规则
return CombinedDispatchRule(
rule_id=rule_data["rule_id"],
name=rule_data["name"],
description=rule_data.get("description", ""),
workflow_id=rule_data["workflow_id"],
rule_groups=[rule_group],
priority=rule_data.get("priority", 5),
enabled=rule_data.get("enabled", True),
metadata=rule_data.get("metadata", {}),
)
def load_rules(self, rules_dir: Optional[str] = None):
"""从指定目录加载所有调度规则"""
rules_dir = rules_dir or self.rules_dir
if not os.path.exists(rules_dir):
os.makedirs(rules_dir)
yaml = YAML(typ="safe")
for file_name in os.listdir(rules_dir):
if not file_name.endswith(".yaml"):
continue
file_path = os.path.join(rules_dir, file_name)
try:
with open(file_path, "r", encoding="utf-8") as f:
rules_data = yaml.load(f)
if not isinstance(rules_data, list):
self.logger.warning(
f"Invalid rules file {file_name}, expected list of rules"
)
continue
for rule_data in rules_data:
try:
# 检查是否是新版本的组合规则
if "rule_groups" in rule_data:
rule = CombinedDispatchRule(**rule_data)
else:
# 旧版本规则,转换为新格式
rule = self._convert_old_rule(rule_data)
self.register(rule)
self.logger.debug(f"Loaded rule: {rule}")
except Exception as e:
self.logger.error(
f"Failed to load rule in file {file_path}: {str(e)}"
)
except Exception as e:
self.logger.error(f"Failed to load rules from {file_path}: {str(e)}")
def save_rules(self, rules_dir: Optional[str] = None):
"""保存所有规则到文件"""
rules_dir = rules_dir or self.rules_dir
if not os.path.exists(rules_dir):
os.makedirs(rules_dir)
yaml = YAML()
yaml.default_flow_style = False
# 保存规则
rules_data = [rule.dict() for rule in self.rules.values()]
# 保存到文件
file_path = os.path.join(rules_dir, "rules.yaml")
with open(file_path, "w", encoding="utf-8") as f:
yaml.dump(rules_data, f)
# 注册所有规则类型
DispatchRule.register_rule_type(RegexMatchRule)
DispatchRule.register_rule_type(PrefixMatchRule)
DispatchRule.register_rule_type(KeywordMatchRule)
DispatchRule.register_rule_type(BotMentionMatchRule)
DispatchRule.register_rule_type(RandomChanceMatchRule)
DispatchRule.register_rule_type(ChatSenderMatchRule)
DispatchRule.register_rule_type(ChatSenderMismatchRule)
DispatchRule.register_rule_type(ChatTypeMatchRule)
DispatchRule.register_rule_type(IMInstanceMatchRule)
DispatchRule.register_rule_type(FallbackMatchRule)
================================================
FILE: kirara_ai/workflow/core/dispatch/rules/base.py
================================================
from abc import ABC, abstractmethod
from typing import Any, ClassVar, Dict, Type
from pydantic import BaseModel
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.workflow import Workflow
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
class RuleConfig(BaseModel):
"""规则配置的基类"""
class DispatchRule(ABC):
"""
工作流调度规则的抽象基类。
用于定义如何根据消息内容选择合适的工作流进行处理。
"""
# 类变量,用于规则类型注册
rule_types: ClassVar[Dict[str, Type["DispatchRule"]]] = {}
config_class: ClassVar[Type[RuleConfig]]
type_name: ClassVar[str]
def __init__(self, workflow_registry: WorkflowRegistry, workflow_id: str):
"""初始化调度规则。"""
self.workflow_registry = workflow_registry
self.rule_id: str = ""
self.name: str = ""
self.description: str = ""
self.priority: int = 5 # 默认优先级为5
self.enabled: bool = True # 是否启用
self.metadata: Dict[str, Any] = {} # 元数据
self.workflow_id: str = workflow_id
@abstractmethod
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
"""判断消息是否匹配该规则。"""
def get_workflow(self, container: DependencyContainer) -> Workflow:
"""获取该规则对应的工作流实例。"""
workflow = self.workflow_registry.get(self.workflow_id, container)
assert isinstance(workflow, Workflow)
return workflow
@classmethod
def register_rule_type(cls, rule_class: Type["DispatchRule"]):
"""注册规则类型"""
cls.rule_types[rule_class.type_name] = rule_class
@classmethod
def get_rule_type(cls, type_name: str) -> Type["DispatchRule"]:
"""获取规则类型"""
if type_name not in cls.rule_types:
raise ValueError(f"Unknown rule type: {type_name}")
return cls.rule_types[type_name]
@abstractmethod
def get_config(self) -> RuleConfig:
"""获取规则配置"""
@classmethod
@abstractmethod
def from_config(
cls, config: RuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str
) -> "DispatchRule":
"""从配置创建规则实例"""
def __str__(self) -> str:
return f"{self.__class__.__name__}(id='{self.rule_id}', priority={self.priority}, enabled={self.enabled})"
================================================
FILE: kirara_ai/workflow/core/dispatch/rules/message_rules.py
================================================
import re
from typing import List
from pydantic import Field
from kirara_ai.im.message import IMMessage, MentionElement, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from .base import DispatchRule, RuleConfig
class RegexRuleConfig(RuleConfig):
"""正则规则配置"""
pattern: str = Field(title="正则表达式", description="正则表达式")
class RegexMatchRule(DispatchRule):
"""根据正则表达式匹配的规则"""
config_class = RegexRuleConfig
type_name = "regex"
def __init__(self, pattern: str, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.pattern = re.compile(pattern)
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
return bool(self.pattern.search(message.content))
def get_config(self) -> RegexRuleConfig:
return RegexRuleConfig(pattern=self.pattern.pattern)
@classmethod
def from_config(cls, config: RegexRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str) -> "RegexMatchRule":
return cls(config.pattern, workflow_registry, workflow_id)
class PrefixRuleConfig(RuleConfig):
"""前缀规则配置"""
prefix: str = Field(title="前缀", description="前缀")
class PrefixMatchRule(DispatchRule):
"""根据消息前缀匹配的规则"""
config_class = PrefixRuleConfig
type_name = "prefix"
def __init__(self, prefix: str, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.prefix = prefix
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
return next(
(
message_element.text.startswith(self.prefix)
for message_element in message.message_elements
if isinstance(message_element, TextMessage)
),
False,
)
def get_config(self) -> PrefixRuleConfig:
return PrefixRuleConfig(prefix=self.prefix)
@classmethod
def from_config(cls, config: PrefixRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str) -> "PrefixMatchRule":
return cls(config.prefix, workflow_registry, workflow_id)
class KeywordRuleConfig(RuleConfig):
"""关键词规则配置"""
keywords: List[str] = Field(title="关键词", description="关键词列表")
class KeywordMatchRule(DispatchRule):
"""根据关键词匹配的规则"""
config_class = KeywordRuleConfig
type_name = "keyword"
def __init__(self, keywords: list[str], workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.keywords = keywords
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
return any(keyword in message.content for keyword in self.keywords)
def get_config(self) -> KeywordRuleConfig:
return KeywordRuleConfig(keywords=self.keywords)
@classmethod
def from_config(cls, config: KeywordRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str) -> "KeywordMatchRule":
return cls(config.keywords, workflow_registry, workflow_id)
class BotMentionMatchRule(DispatchRule):
"""根据机器人被提及匹配的规则"""
config_class = RuleConfig
type_name = "bot_mention"
def __init__(self, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
bot_sender = ChatSender.get_bot_sender()
return any(isinstance(element, MentionElement) and element.target == bot_sender for element in message.message_elements)
def get_config(self) -> RuleConfig:
return RuleConfig()
@classmethod
def from_config(cls, config: RuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str) -> "BotMentionMatchRule":
return cls(workflow_registry, workflow_id)
================================================
FILE: kirara_ai/workflow/core/dispatch/rules/sender_rules.py
================================================
from typing import Literal, Optional
from pydantic import Field
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatType
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from .base import DispatchRule, RuleConfig
class ChatSenderMatchRuleConfig(RuleConfig):
"""聊天发送者规则配置"""
sender_id: str = Field(title="发送者ID", description="发送者ID", default="")
sender_group: str = Field(
title="发送者群号", description="发送者群号", default=""
)
class ChatSenderMatchRule(DispatchRule):
"""根据聊天发送者匹配的规则"""
config_class = ChatSenderMatchRuleConfig
type_name = "sender"
def __init__(
self,
sender_id: Optional[str],
sender_group: Optional[str],
workflow_registry: WorkflowRegistry,
workflow_id: str,
):
super().__init__(workflow_registry, workflow_id)
self.sender_id = sender_id
self.sender_group = sender_group
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
# 如果设置了群组ID,则必须匹配
if self.sender_group and message.sender.group_id != self.sender_group:
return False
# 如果设置了发送者ID,则必须匹配
if self.sender_id and message.sender.user_id != self.sender_id:
return False
# 如果没有设置任何条件或所有条件都匹配,则返回True
return True
def get_config(self) -> ChatSenderMatchRuleConfig:
return ChatSenderMatchRuleConfig(
sender_id=self.sender_id or "", sender_group=self.sender_group or ""
)
@classmethod
def from_config(
cls,
config: ChatSenderMatchRuleConfig,
workflow_registry: WorkflowRegistry,
workflow_id: str,
) -> "ChatSenderMatchRule":
return cls(config.sender_id, config.sender_group, workflow_registry, workflow_id)
class ChatSenderMismatchRule(DispatchRule):
"""根据聊天发送者不匹配的规则"""
config_class = ChatSenderMatchRuleConfig
type_name = "sender_mismatch"
def __init__(
self,
sender_id: Optional[str],
sender_group: Optional[str],
workflow_registry: WorkflowRegistry,
workflow_id: str,
):
super().__init__(workflow_registry, workflow_id)
self.sender_id = sender_id
self.sender_group = sender_group
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
# 如果设置了群组ID,则必须不匹配
if self.sender_group and message.sender.group_id == self.sender_group:
return False
# 如果设置了发送者ID,则必须不匹配
if self.sender_id and message.sender.user_id == self.sender_id:
return False
# 如果没有设置任何条件或所有条件都不匹配,则返回True
return True
def get_config(self) -> ChatSenderMatchRuleConfig:
return ChatSenderMatchRuleConfig(
sender_id=self.sender_id or "", sender_group=self.sender_group or ""
)
@classmethod
def from_config(
cls,
config: ChatSenderMatchRuleConfig,
workflow_registry: WorkflowRegistry,
workflow_id: str,
) -> "ChatSenderMismatchRule":
return cls(config.sender_id, config.sender_group, workflow_registry, workflow_id)
class ChatTypeMatchRuleConfig(RuleConfig):
"""聊天类型规则配置"""
chat_type: Literal["私聊", "群聊"] = Field(title="聊天类型", description="聊天类型")
class ChatTypeMatchRule(DispatchRule):
"""根据聊天类型匹配的规则"""
config_class = ChatTypeMatchRuleConfig
type_name = "chat_type"
def __init__(self, chat_type: ChatType, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.chat_type = chat_type
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
return message.sender.chat_type == self.chat_type
def get_config(self) -> ChatTypeMatchRuleConfig:
return ChatTypeMatchRuleConfig(chat_type=self.chat_type.to_str()) # type: ignore
@classmethod
def from_config(cls, config: ChatTypeMatchRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str) -> "ChatTypeMatchRule":
chat_type = ChatType.from_str(config.chat_type)
return cls(chat_type, workflow_registry, workflow_id)
================================================
FILE: kirara_ai/workflow/core/dispatch/rules/system_rules.py
================================================
import random
from pydantic import Field
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.manager import IMManager
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from .base import DispatchRule, RuleConfig
class RandomChanceRuleConfig(RuleConfig):
"""随机概率规则配置"""
chance: int = Field(
default=50, ge=0, le=100, title="随机概率", description="随机概率,范围为0-100"
)
class RandomChanceMatchRule(DispatchRule):
"""根据随机概率匹配的规则"""
config_class = RandomChanceRuleConfig
type_name = "random"
def __init__(self, chance: int, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.chance = chance
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
print(f"Random chance: {self.chance}")
print(f"Random number: {random.random()}")
return random.random() * 100 < self.chance
def get_config(self) -> RandomChanceRuleConfig:
return RandomChanceRuleConfig(chance=self.chance)
@classmethod
def from_config(
cls, config: RandomChanceRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str
) -> "RandomChanceMatchRule":
return cls(config.chance, workflow_registry, workflow_id)
class IMInstanceMatchRuleConfig(RuleConfig):
"""IM实例匹配规则配置"""
im_instance: str = Field(title="IM实例名称", description="配置后,只有当消息来自指定的IM实例时,才会触发工作流")
class IMInstanceMatchRule(DispatchRule):
"""根据IM实例匹配的规则"""
config_class = IMInstanceMatchRuleConfig
type_name = "im_instance"
def __init__(self, im_instance: str, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.im_instance = im_instance
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
adapter = container.resolve(IMAdapter)
im_manager = container.resolve(IMManager)
return im_manager.get_adapter(self.im_instance) == adapter
def get_config(self) -> IMInstanceMatchRuleConfig:
return IMInstanceMatchRuleConfig(im_instance=self.im_instance)
@classmethod
def from_config(
cls, config: IMInstanceMatchRuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str
) -> "IMInstanceMatchRule":
return cls(config.im_instance, workflow_registry, workflow_id)
class FallbackMatchRule(DispatchRule):
"""默认的兜底规则,总是匹配"""
config_class = RuleConfig
type_name = "fallback"
def __init__(self, workflow_registry: WorkflowRegistry, workflow_id: str):
super().__init__(workflow_registry, workflow_id)
self.priority = 0 # 兜底规则优先级最低
def match(self, message: IMMessage, container: DependencyContainer) -> bool:
return True
def get_config(self) -> RuleConfig:
return RuleConfig()
@classmethod
def from_config(
cls, config: RuleConfig, workflow_registry: WorkflowRegistry, workflow_id: str
) -> "FallbackMatchRule":
return cls(workflow_registry, workflow_id)
================================================
FILE: kirara_ai/workflow/core/execution/__init__.py
================================================
================================================
FILE: kirara_ai/workflow/core/execution/exceptions.py
================================================
class BlockExecutionFailedException(Exception):
pass
class WorkflowExecutionTimeoutException(Exception):
pass
================================================
FILE: kirara_ai/workflow/core/execution/executor.py
================================================
import asyncio
import functools
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor
from typing import Any, Dict, List
from kirara_ai.events.event_bus import EventBus
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.block import Block, ConditionBlock, LoopBlock
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.execution.exceptions import (BlockExecutionFailedException,
WorkflowExecutionTimeoutException)
from kirara_ai.workflow.core.workflow import Workflow
class WorkflowExecutor:
@Inject()
def __init__(self, container: DependencyContainer, workflow: Workflow, registry: BlockRegistry, event_bus: EventBus):
"""
初始化 WorkflowExecutor 实例。
:param workflow: 要执行的工作流对象
:param registry: Block注册表,用于类型检查
"""
self.container = container
self.logger = get_logger("WorkflowExecutor")
self.workflow = workflow
self.registry = registry
self.event_bus = event_bus
self.results: Dict[str, Any] = {}
self.variables: Dict[str, Any] = {} # 存储工作流变量
self.logger.info(
f"Initializing WorkflowExecutor for workflow '{workflow.name}'"
)
# self.logger.debug(f"Workflow has {len(workflow.blocks)} blocks and {len(workflow.wires)} wires")
self._build_execution_graph()
def _build_execution_graph(self):
"""构建执行图,包含并行和条件逻辑"""
self.execution_graph = defaultdict(list)
# self.logger.debug("Building execution graph...")
for wire in self.workflow.wires:
# self.logger.debug(f"Processing wire: {wire.source_block.name}.{wire.source_output} -> "
# f"{wire.target_block.name}.{wire.target_input}")
# 验证连线的数据类型是否匹配
source_output = wire.source_block.outputs[wire.source_output]
target_input = wire.target_block.inputs[wire.target_input]
# 使用 BlockRegistry 的类型系统进行类型兼容性检查
source_type = self.registry._type_system.get_type_name(source_output.data_type)
target_type = self.registry._type_system.get_type_name(target_input.data_type)
if not self.registry.is_type_compatible(source_type, target_type):
error_msg = (
f"Type mismatch in wire: {wire.source_block.name}.{wire.source_output} "
f"({source_type}) -> {wire.target_block.name}.{wire.target_input} "
f"({target_type})"
)
self.logger.error(error_msg)
raise TypeError(error_msg)
# 将目标块添加到源块的执行图中
self.execution_graph[wire.source_block].append(wire.target_block)
# self.logger.debug(f"Added edge: {wire.source_block.name} -> {wire.target_block.name}")
async def run(self) -> Dict[str, Any]:
"""
执行工作流,返回每个块的执行结果。
:return: 包含每个块执行结果的字典,键为块名,值为块的输出
"""
from kirara_ai.events import WorkflowExecutionBegin, WorkflowExecutionEnd
self.event_bus.post(WorkflowExecutionBegin(self.workflow, self))
self.logger.info("Starting workflow execution")
loop = asyncio.get_event_loop()
max_timeout = self.workflow.config.max_execution_time
if max_timeout <= 0:
# 如果超时时间小于等于0,则不限制超时
max_timeout = None
with ThreadPoolExecutor() as executor:
# 从入口节点开始执行
entry_blocks = [block for block in self.workflow.blocks if not block.inputs]
# self.logger.debug(f"Identified entry blocks: {[b.name for b in entry_blocks]}")
try:
async with asyncio.timeout(max_timeout): # type: ignore
await self._execute_nodes(entry_blocks, executor, loop)
except asyncio.TimeoutError as e:
self.event_bus.post(WorkflowExecutionEnd(self.workflow, self, self.results))
raise WorkflowExecutionTimeoutException(f"Workflow execution timed out after {max_timeout} seconds") from e
self.logger.info("Workflow execution completed")
self.event_bus.post(WorkflowExecutionEnd(self.workflow, self, self.results))
return self.results
async def _execute_nodes(self, blocks: List[Block], executor, loop):
"""执行一组节点"""
# self.logger.debug(f"Executing node group: {[b.name for b in blocks]}")
for block in blocks:
# self.logger.debug(f"Processing block: {block.name} ({type(block).__name__})")
if isinstance(block, ConditionBlock):
await self._execute_conditional_branch(block, executor, loop)
elif isinstance(block, LoopBlock):
await self._execute_loop(block, executor, loop)
else:
await self._execute_normal_block(block, executor, loop)
async def _execute_conditional_branch(self, block: ConditionBlock, executor, loop):
"""执行条件分支"""
self.logger.info(f"Executing ConditionBlock: {block.name}")
inputs = self._gather_inputs(block)
# self.logger.debug(f"ConditionBlock inputs: {list(inputs.keys())}")
result = await loop.run_in_executor(executor, block.execute, **inputs)
self.results[block.name] = result
self.logger.info(
f"ConditionBlock {block.name} evaluation result: {result['condition_result']}"
)
next_blocks = self.execution_graph[block]
if result["condition_result"]:
# self.logger.debug(f"Taking THEN branch: {next_blocks[0].name}")
await self._execute_nodes([next_blocks[0]], executor, loop)
elif len(next_blocks) > 1:
# self.logger.debug(f"Taking ELSE branch: {next_blocks[1].name}")
await self._execute_nodes([next_blocks[1]], executor, loop)
else:
# self.logger.debug("No ELSE branch available")
pass
async def _execute_loop(self, block: LoopBlock, executor, loop):
"""执行循环"""
self.logger.info(f"Starting LoopBlock: {block.name}")
iteration = 0
while True:
iteration += 1
# self.logger.debug(f"LoopBlock {block.name} iteration #{iteration}")
inputs = self._gather_inputs(block)
# self.logger.debug(f"LoopBlock inputs: {list(inputs.keys())}")
result = await loop.run_in_executor(executor, block.execute, **inputs)
self.results[block.name] = result
self.logger.info(
f"LoopBlock {block.name} continuation check: {result['should_continue']}"
)
if not result["should_continue"]:
self.logger.info(
f"Exiting LoopBlock {block.name} after {iteration} iterations"
)
break
# self.logger.debug(f"Executing loop body: {self.execution_graph[block][0].name}")
loop_body = self.execution_graph[block][0]
await self._execute_nodes([loop_body], executor, loop)
async def _execute_normal_block(self, block: Block, executor, loop):
"""执行普通块"""
# self.logger.debug(f"Evaluating Block: {block.name}")
futures = []
if self._can_execute(block):
inputs = self._gather_inputs(block)
self.logger.info(f"Executing Block: {block.name}")
# self.logger.debug(f"Input parameters: {list(inputs.keys())}")
future = loop.run_in_executor(
executor, functools.partial(block.execute, **inputs)
)
futures.append((future, block))
else:
# self.logger.debug(f"Block {block.name} dependencies not met, skipping execution")
return
# 等待所有并行任务完成
for future, block in futures:
try:
result = await future
self.results[block.name] = result
self.logger.info(f"Block [{block.name}] executed successfully")
if result:
# self.logger.debug(f"Execution result keys: {list(result.keys())}")
pass
next_blocks = self.execution_graph[block]
if next_blocks:
# self.logger.debug(f"Propagating to next blocks: {[b.name for b in next_blocks]}")
await self._execute_nodes(next_blocks, executor, loop)
else:
# self.logger.debug(f"Block {block.name} is terminal node")
pass
except BlockExecutionFailedException as e:
raise e
except Exception as e:
raise BlockExecutionFailedException(f"Block {block.name} execution failed: {e}") from e
def _can_execute(self, block: Block) -> bool:
"""检查节点是否可以执行"""
# self.logger.debug(f"Checking execution readiness for Block: {block.name}")
# 如果块已经执行过,直接返回False
if block.name in self.results:
# self.logger.debug(f"Block {block.name} has already been executed")
return False
# 获取所有直接前置blocks
predecessor_blocks = set()
for wire in self.workflow.wires:
if wire.target_block == block:
predecessor_blocks.add(wire.source_block)
# 确保所有前置blocks都已执行完成
for pred_block in predecessor_blocks:
if pred_block.name not in self.results:
# self.logger.debug(f"Predecessor block {pred_block.name} not yet executed")
return False
# 验证所有输入是否都能从正确的前置block获取
for input_name in block.inputs:
input_satisfied = False
for wire in self.workflow.wires:
if (
wire.target_block == block
and wire.target_input == input_name
and wire.source_block.name in self.results
and wire.source_output in self.results[wire.source_block.name]
):
self.logger.debug(f"Input [{block.name}.{input_name}] satisfied by [{wire.source_block.name}.{wire.source_output}] with value {self.results[wire.source_block.name][wire.source_output]}")
input_satisfied = True
break
# 如果输入没有被满足,并且输入不是可空的,则返回False
if not input_satisfied and not block.inputs[input_name].nullable:
self.logger.info(f"Input [{block.name}.{input_name}] not satisfied")
return False
self.logger.debug(f"All inputs satisfied and predecessors completed for block {block.name}")
return True
def _gather_inputs(self, block: Block) -> Dict[str, Any]:
"""收集节点的输入数据"""
# self.logger.debug(f"Gathering inputs for Block: {block.name}")
inputs = {}
# 创建输入名称到wire的映射
input_wire_map = {}
for wire in self.workflow.wires:
if wire.target_block == block:
input_wire_map[wire.target_input] = wire
# 根据wire的连接关系收集输入
for input_name in block.inputs:
if input_name in input_wire_map:
wire = input_wire_map[input_name]
if wire.source_block.name in self.results and wire.source_output in self.results[wire.source_block.name]:
inputs[input_name] = self.results[wire.source_block.name][
wire.source_output
]
# self.logger.debug(f"Resolved input {input_name} from {wire.source_block.name}.{wire.source_output}")
else:
raise BlockExecutionFailedException(
f"Current block {block.name} depends on source block {wire.source_block.name} not executed for input {input_name}"
)
elif not block.inputs[input_name].nullable:
raise BlockExecutionFailedException(
f"Missing wire connection for required input {input_name} in block {block.name}"
)
return inputs
def set_variable(self, name: str, value: Any) -> None:
"""
设置工作流变量
:param name: 变量名
:param value: 变量值
"""
self.variables[name] = value
def get_variable(self, name: str, default: Any = None) -> Any:
"""
获取工作流变量
:param name: 变量名
:param default: 默认值,如果变量不存在则返回此值
:return: 变量值
"""
return self.variables.get(name, default)
================================================
FILE: kirara_ai/workflow/core/workflow/__init__.py
================================================
from .base import Wire, Workflow, WorkflowConfig
from .builder import WorkflowBuilder
from .registry import WorkflowRegistry
__all__ = ["Workflow", "WorkflowBuilder", "WorkflowRegistry", "Wire", "WorkflowConfig"]
================================================
FILE: kirara_ai/workflow/core/workflow/base.py
================================================
from typing import List, Optional
from pydantic import BaseModel
from kirara_ai.workflow.core.block import Block
class WorkflowConfig(BaseModel):
max_execution_time: int = 3600
class Workflow:
def __init__(self, name: str, blocks: List["Block"], wires: List["Wire"], id: Optional[str] = None, config: Optional[WorkflowConfig] = None):
self.name = name
self.blocks = blocks
self.wires = wires
self.id = id
self.config = config or WorkflowConfig()
class Wire:
def __init__(
self,
source_block: "Block",
source_output: str,
target_block: "Block",
target_input: str,
):
self.source_block = source_block
self.source_output = source_output
self.target_block = target_block
self.target_input = target_input
def __repr__(self):
return f"Wire(source_block={self.source_block.name}, source_output={self.source_output}, target_block={self.target_block.name}, target_input={self.target_input})"
================================================
FILE: kirara_ai/workflow/core/workflow/builder.py
================================================
import importlib
import random
import string
import warnings
from dataclasses import dataclass, field
from typing import Any, Callable, Dict, List, Optional, Tuple, Type, Union
from ruamel.yaml import YAML
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block, ConditionBlock, LoopBlock, LoopEndBlock
from kirara_ai.workflow.core.block.registry import BlockRegistry
from .base import Wire, Workflow, WorkflowConfig
def get_block_class(type_name: str, registry: BlockRegistry) -> Type[Block]:
if type_name.startswith("!!"):
warnings.warn(
f"Loading block using class path: {type_name[2:]}. This is not recommended.",
UserWarning,
)
module_path, class_name = type_name[2:].rsplit(".", 1)
module = importlib.import_module(module_path)
return getattr(module, class_name)
block_class = registry.get(type_name)
if block_class is None:
raise ValueError(f"Block type {type_name} not found in registry")
return block_class
@dataclass
class BlockSpec:
"""Block 规格的数据类,用于统一处理 block 的创建参数"""
block_class: Type[Block]
name: Optional[str] = None
kwargs: Dict[str, Any] = field(default_factory=dict)
wire_from: Optional[Union[str, List[str]]] = None
def __post_init__(self):
if isinstance(self.wire_from, str):
self.wire_from = [self.wire_from]
@dataclass
class Node:
spec: BlockSpec
name: str
next_nodes: List["Node"] = field(default_factory=list)
merge_point: Optional["Node"] = None
parallel_nodes: List["Node"] = field(default_factory=list)
is_parallel: bool = False
condition: Optional[Callable] = None
is_conditional: bool = False
is_loop: bool = False
parent: Optional["Node"] = None
position: Optional[Dict[str, int]] = None
def __init__(
self,
spec: BlockSpec,
name: Optional[str] = None,
next_nodes: Optional[List["Node"]] = None,
merge_point: Optional["Node"] = None,
parallel_nodes: Optional[List["Node"]] = None,
is_parallel: bool = False,
condition: Optional[Callable] = None,
is_conditional: bool = False,
is_loop: bool = False,
parent: Optional["Node"] = None,
position: Optional[Dict[str, int]] = None,
):
self.spec = spec
self.name = name or spec.name or f"{spec.block_class.__name__}_{id(self)}"
self.next_nodes = next_nodes or []
self.merge_point = merge_point
self.parallel_nodes = parallel_nodes or []
self.is_parallel = is_parallel
self.condition = condition
self.is_conditional = is_conditional
self.is_loop = is_loop
self.parent = parent
self.position = position
def ancestors(self) -> List["Node"]:
"""获取所有祖先节点"""
result: List["Node"] = []
current = self.parent
while current:
result.append(current)
current = current.parent
return result
class WorkflowBuilder:
"""工作流构建器,提供流畅的 DSL 语法来构建工作流。
基本语法:
1. 初始化:
builder = WorkflowBuilder("workflow_name", container)
2. 添加节点的方法:
.use(BlockClass) # 添加初始节点
.chain(BlockClass) # 链式添加节点
.parallel([BlockClass1, BlockClass2]) # 并行添加多个节点
3. 节点配置格式:
- BlockClass # 最简单形式
- (BlockClass, name) # 指定名称
- (BlockClass, wire_from) # 指定连接来源
- (BlockClass, kwargs) # 指定参数
- (BlockClass, name, kwargs) # 指定名称和参数
- (BlockClass, name, wire_from) # 指定名称和连接来源
- (BlockClass, name, kwargs, wire_from) # 指定名称、参数和连接来源
4. 控制流:
.if_then(condition) # 条件分支开始
.else_then() # else 分支
.end_if() # 条件分支结束
.loop(condition) # 循环开始
.end_loop() # 循环结束
完整示例:
```python
workflow = (WorkflowBuilder("example", container)
# 基本用法
.use(InputBlock) # 最简单形式
.chain(ProcessBlock, name="process") # 指定名称
.chain(TransformBlock, # 指定参数
kwargs={"param": "value"})
# 并行处理
.parallel([
ProcessA, # 简单形式
(ProcessB, "proc_b"), # 指定名称
(ProcessC, {"param": "val"}), # 指定参数
(ProcessD, "proc_d", # 完整形式
{"param": "val"},
["process"]) # 指定连接来源
])
# 条件分支
.if_then(lambda ctx: ctx["value"] > 0)
.chain(PositiveBlock)
.else_then()
.chain(NegativeBlock)
.end_if()
# 循环处理
.loop(lambda ctx: ctx["count"] < 5)
.chain(LoopBlock)
.end_loop()
# 多输入连接
.chain(MergeBlock,
wire_from=["proc_b", "proc_d"])
.build())
```
特性说明:
1. 自动连接: 默认情况下,节点会自动与前一个节点连接
2. 命名节点: 通过指定 name 可以后续引用该节点
3. 参数传递: 可以通过 kwargs 字典传递构造参数
4. 自定义连接: 通过 wire_from 指定输入来源
5. 并行处理: parallel 方法支持多个节点并行执行
6. 条件和循环: 支持基本的控制流结构
注意事项:
1. wire_from 引用的节点名称必须已经存在
2. 条件和循环语句必须正确配对
3. 并行节点可以各自指定不同的连接来源
4. 节点名称在工作流中必须唯一
"""
def __init__(self, name: str):
self.id: Optional[str] = None
self.name: str = name
self.description: str = ""
self.head: Optional[Node] = None
self.current: Optional[Node] = None
self.nodes: List[Node] = [] # 存储所有节点
self.nodes_by_name: Dict[str, Node] = {}
self.wire_specs: List[Tuple[str, str, str, str]] = [] # (source_name, source_output, target_name, target_input)
self.config = WorkflowConfig()
def _generate_unique_name(self, base_name: str) -> str:
"""生成唯一的块名称"""
while True:
# 生成6位随机字符串(数字和字母的组合)
suffix = "".join(
random.choices(string.ascii_lowercase + string.digits, k=6)
)
name = f"{base_name}_{suffix}"
if name not in self.nodes_by_name:
return name
def _parse_block_spec(self, block_spec: Union[Type[Block], tuple]) -> BlockSpec:
"""解析 block 规格,统一处理各种输入格式"""
if isinstance(block_spec, type):
return BlockSpec(block_spec)
if not isinstance(block_spec, tuple):
raise ValueError(f"Invalid block specification: {block_spec}")
if len(block_spec) == 4: # (BlockClass, name, kwargs, wire_from)
return BlockSpec(*block_spec)
elif len(block_spec) == 3: # (BlockClass, name/kwargs, kwargs/wire_from)
block_class, second, third = block_spec
if isinstance(second, dict):
return BlockSpec(block_class, kwargs=second, wire_from=third)
return BlockSpec(block_class, name=second, kwargs=third)
elif len(block_spec) == 2: # (BlockClass, name/kwargs)
block_class, second = block_spec
if isinstance(second, dict):
return BlockSpec(block_class, kwargs=second)
return BlockSpec(block_class, name=second)
raise ValueError(f"Invalid block specification format: {block_spec}")
def _get_available_inputs(self, node: Node) -> List[str]:
"""获取节点未被连接的输入端口"""
connected_inputs = {wire[3] for wire in self.wire_specs if wire[2] == node.name}
return [input_name for input_name in node.spec.block_class.inputs.keys()
if input_name not in connected_inputs]
def _find_matching_ports(
self,
source_node: Node,
target_node: Node,
available_inputs: List[str]
) -> List[Tuple[str, str]]:
"""查找匹配的输出和输入端口
Returns:
List of (output_name, input_name) pairs
"""
matches: List[Tuple[str, str]] = []
source_outputs = source_node.spec.block_class.outputs
target_inputs = {name: target_node.spec.block_class.inputs[name]
for name in available_inputs}
for out_name, output in source_outputs.items():
for in_name, input in target_inputs.items():
if output.data_type == input.data_type:
matches.append((out_name, in_name))
# 一旦找到匹配就从可用输入中移除
target_inputs.pop(in_name)
break
return matches
def _store_wire_spec(
self,
source_name: str,
target_name: str,
source_node: Optional[Node] = None,
target_node: Optional[Node] = None,
):
"""存储连接规格,自动匹配输入输出端口"""
if source_node is None:
source_node = self.nodes_by_name[source_name]
if target_node is None:
target_node = self.nodes_by_name[target_name]
# 获取目标节点的可用输入端口
available_inputs = self._get_available_inputs(target_node)
if not available_inputs:
return # 如果没有可用的输入端口,直接返回
# 查找匹配的端口
matches = self._find_matching_ports(source_node, target_node, available_inputs)
# 存储匹配的连接
for source_output, target_input in matches:
self.wire_specs.append((source_name, source_output, target_name, target_input))
def _create_node(self, spec: BlockSpec, is_parallel: bool = False) -> Node:
"""创建一个新的节点,但不实例化 Block"""
# 设置 block 名称
if not spec.name:
spec.name = self._generate_unique_name(spec.block_class.__name__)
node = Node(spec=spec, is_parallel=is_parallel)
self.nodes.append(node)
self.nodes_by_name[node.name] = node
# 处理连接
if spec.wire_from:
for source_name in spec.wire_from:
source_node = self.nodes_by_name.get(source_name)
if source_node:
self._store_wire_spec(source_node.name, node.name, source_node, node)
elif self.current:
self._store_wire_spec(self.current.name, node.name, self.current, node)
return node
def use(
self, block_class: Type[Block], name: Optional[str] = None, **kwargs: Any
) -> "WorkflowBuilder":
spec = BlockSpec(block_class, name=name, kwargs=kwargs)
node = self._create_node(spec)
self.head = node
self.current = node
return self
def chain(
self,
block_class: Type[Block],
name: Optional[str] = None,
wire_from: Optional[List[str]] = None,
**kwargs: Any,
) -> "WorkflowBuilder":
spec = BlockSpec(block_class, name=name, kwargs=kwargs, wire_from=wire_from)
node = self._create_node(spec)
if self.current:
self.current.next_nodes.append(node)
node.parent = self.current
self.current = node
return self
def parallel(
self, block_specs: List[Union[Type[Block], tuple]]
) -> "WorkflowBuilder":
parallel_nodes: List[Node] = []
for block_spec in block_specs:
spec = self._parse_block_spec(block_spec)
node = self._create_node(spec, is_parallel=True)
node.parent = self.current
parallel_nodes.append(node)
if self.current:
self.current.next_nodes.extend(parallel_nodes)
self.current = parallel_nodes[0]
self.current.parallel_nodes = parallel_nodes
return self
def condition(self, condition_func: Callable) -> "WorkflowBuilder":
"""添加条件判断"""
assert self.current is not None
self.current.condition = condition_func
return self
def if_then(
self, condition: Callable[[Dict[str, Any]], bool], name: Optional[str] = None
) -> "WorkflowBuilder":
"""添加条件判断"""
if not name:
name = self._generate_unique_name("condition")
spec = BlockSpec(
block_class=ConditionBlock,
name=name,
kwargs={"condition": condition, "outputs": {}} # outputs will be set during build
)
node = Node(spec=spec, is_conditional=True)
self.nodes.append(node)
self.nodes_by_name[node.name] = node
if self.current:
self._store_wire_spec(self.current.name, "output", self.current, node)
self.current.next_nodes.append(node)
node.parent = self.current
self.current = node
return self
def else_then(self) -> "WorkflowBuilder":
"""添加else分支"""
if not self.current or not self.current.is_conditional:
raise ValueError("else_then must follow if_then")
self.current = self.current.parent
return self
def end_if(self) -> "WorkflowBuilder":
"""结束条件分支"""
if not self.current or not self.current.is_conditional:
raise ValueError("end_if must close an if block")
self.current = self.current.merge_point or self.current
return self
def loop(
self,
condition: Callable[[Dict[str, Any]], bool],
name: Optional[str] = None,
iteration_var: str = "index",
) -> "WorkflowBuilder":
"""开始一个循环"""
if not name:
name = self._generate_unique_name("loop")
spec = BlockSpec(
block_class=LoopBlock,
name=name,
kwargs={
"condition": condition,
"outputs": {}, # outputs will be set during build
"iteration_var": iteration_var
}
)
node = Node(spec=spec, is_loop=True)
self.nodes.append(node)
self.nodes_by_name[node.name] = node
if self.current:
self._store_wire_spec(self.current.name, "output", self.current, node)
self.current.next_nodes.append(node)
node.parent = self.current
self.current = node
return self
def end_loop(self) -> "WorkflowBuilder":
"""结束循环"""
if self.current is None:
raise ValueError("end_loop must close a loop block")
if not any(n.is_loop for n in self.current.ancestors()):
raise ValueError("end_loop must close a loop block")
spec = BlockSpec(
block_class=LoopEndBlock,
name=self._generate_unique_name("loop_end"),
kwargs={"outputs": {}} # outputs will be set during build
)
node = Node(spec=spec)
self.nodes.append(node)
self.nodes_by_name[node.name] = node
if self.current:
self._store_wire_spec(self.current.name, "output", self.current, node)
loop_start = next(n for n in self.current.ancestors() if n.is_loop)
self._store_wire_spec(node.name, "output", loop_start, node)
node.parent = self.current
self.current = node
return self
def build(self, container: DependencyContainer) -> Workflow:
"""构建工作流,在此阶段实例化所有 Block 并创建 Wire"""
blocks: List[Block] = []
wires: List[Wire] = []
name_to_block: Dict[str, Block] = {}
name_to_node: Dict[str, Node] = {}
# 首先实例化所有 Block
for node in self.nodes:
try:
# 如果是条件或循环块,需要从前一个块获取输出信息
if node.is_conditional or node.is_loop:
prev_node = node.parent
if prev_node and prev_node.spec.block_class:
node.spec.kwargs["outputs"] = prev_node.spec.block_class.outputs.copy()
block = node.spec.block_class(**node.spec.kwargs)
if node.name:
block.name = node.name
block.container = container
blocks.append(block)
name_to_block[node.name] = block
name_to_node[node.name] = node
except Exception as e:
raise ValueError(f"Failed to create block {node.spec.block_class.__name__}: {e}")
# 然后创建所有 Wire
for source_name, source_output, target_name, target_input in self.wire_specs:
source_block = name_to_block.get(source_name)
target_block = name_to_block.get(target_name)
if source_block and target_block:
wires.append(Wire(source_block, source_output, target_block, target_input))
return Workflow(name=self.name, blocks=blocks, wires=wires, id=self.id, config=self.config)
def set_config(self, config: WorkflowConfig):
self.config = config
return self
def force_connect(
self,
source_name: str,
target_name: str,
source_output: str,
target_input: str,
):
"""强制存储特定的连接规格"""
self.wire_specs.append((source_name, source_output, target_name, target_input))
def _find_parallel_nodes(self, start_node: Node) -> List[Node]:
"""查找所有并行节点"""
parallel_nodes: List[Node] = []
current = start_node
while current:
if current.is_parallel:
parallel_nodes.extend(current.parallel_nodes)
if current.next_nodes:
current = current.next_nodes[0]
else:
break
return parallel_nodes
def update_position(self, name: str, position: Dict[str, int]):
"""更新节点的位置"""
node = self.nodes_by_name[name]
node.position = position
def save_to_yaml(self, file_path: str, container: DependencyContainer):
"""将工作流保存为 YAML 格式"""
registry: BlockRegistry = container.resolve(BlockRegistry)
yaml = YAML()
yaml.indent(mapping=2, sequence=4, offset=2)
yaml.width = 4096
workflow_data: Dict[str, Any] = {
"name": self.name,
"description": self.description,
"blocks": [],
"config": self.config.model_dump(),
}
def serialize_node(node: Node) -> dict:
block_data: Dict[str, Any] = {
"type": registry.get_block_type_name(node.spec.block_class),
"name": node.name,
"params": node.spec.kwargs,
"position": node.position,
}
if node.is_parallel:
block_data["parallel"] = True
# 添加连接信息
connected_to: List[Dict[str, Any]] = []
for wire in self.wire_specs:
if wire[0] == node.name:
# 使用 block.name 查找目标节点
target_node = next(
(
n
for n in self.nodes_by_name.values()
if n.name == wire[2]
),
None,
)
if target_node: # 只在找到目标节点时添加连接
connected_to.append(
{
"target": target_node.name,
"mapping": {
"from": wire[1],
"to": wire[3],
},
}
)
if connected_to:
block_data["connected_to"] = connected_to
return block_data
# 序列化所有节点
for node in self.nodes_by_name.values():
workflow_data["blocks"].append(serialize_node(node))
# 保存到文件
with open(file_path, "w", encoding="utf-8") as f:
yaml.dump(workflow_data, f)
return self
@classmethod
def load_from_yaml(
cls, file_path: str, container: DependencyContainer
) -> "WorkflowBuilder":
"""从 YAML 文件加载工作流
Args:
file_path: YAML 文件路径
container: 依赖注入容器
Returns:
WorkflowBuilder 实例
"""
yaml = YAML(typ="safe")
with open(file_path, "r", encoding="utf-8") as f:
workflow_data: Dict[str, Any] = yaml.load(f)
builder: WorkflowBuilder = cls(workflow_data["name"])
builder.config = WorkflowConfig.model_validate(workflow_data.get("config", {}))
builder.description = workflow_data.get("description", "")
registry: BlockRegistry = container.resolve(BlockRegistry)
# 第一遍:创建所有块
for block_data in workflow_data["blocks"]:
block_class = get_block_class(block_data["type"], registry)
params = block_data.get("params", {})
if block_data.get("parallel"):
# 处理并行节点
parallel_blocks = [(block_class, block_data["name"], params)]
builder.parallel(parallel_blocks) # type: ignore
else:
# 处理普通节点
if builder.head is None:
builder.use(block_class, name=block_data["name"], **params)
else:
builder.chain(block_class, name=block_data["name"], **params)
if block_data.get("position"):
builder.update_position(block_data["name"], block_data["position"])
# 第二遍:建立连接
builder.wire_specs = []
for block_data in workflow_data["blocks"]:
if "connected_to" in block_data:
source_node = builder.nodes_by_name[block_data["name"]]
for connection in block_data["connected_to"]:
target_node = builder.nodes_by_name[connection["target"]]
builder.force_connect(
source_node.name,
target_node.name,
connection["mapping"]["from"],
connection["mapping"]["to"],
)
return builder
================================================
FILE: kirara_ai/workflow/core/workflow/registry.py
================================================
import os
import re
from typing import Dict, Optional
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.workflow.base import Workflow
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
class WorkflowRegistry:
"""工作流注册表,管理工作流的注册和获取"""
WORKFLOWS_DIR = os.path.realpath("data/workflows")
def __init__(self, container: DependencyContainer):
self._workflows: Dict[str, WorkflowBuilder] = {}
self.logger = get_logger("WorkflowRegistry")
self.container = container
@classmethod
def get_workflow_path(cls, group_id: str, workflow_id: str) -> str:
"""获取工作流文件路径"""
group_dir = os.path.join(cls.WORKFLOWS_DIR, group_id)
final_path = os.path.join(group_dir, f"{workflow_id}.yaml")
if (
os.path.commonprefix((os.path.realpath(final_path), cls.WORKFLOWS_DIR))
!= cls.WORKFLOWS_DIR
):
raise ValueError("Invalid workflow path")
# check is valid path symbols
if not re.match(r"^[a-zA-Z0-9_-]+$", workflow_id):
invalid_chars = re.findall(r"[^a-zA-Z0-9_-]", workflow_id)
raise ValueError(
f"Invalid symbols in workflow path: {''.join(invalid_chars)}"
)
if not re.match(r"^[a-zA-Z0-9_-]+$", group_id):
invalid_chars = re.findall(r"[^a-zA-Z0-9_-]", group_id)
raise ValueError(
f"Invalid symbols in workflow path: {''.join(invalid_chars)}"
)
if not os.path.exists(group_dir):
os.makedirs(group_dir)
return final_path
def unregister(self, group_id: str, workflow_id: str):
"""注销一个工作流"""
full_name = f"{group_id}:{workflow_id}"
if full_name in self._workflows:
del self._workflows[full_name]
self.logger.info(f"Unregistered workflow: {full_name}")
def register(
self, group_id: str, workflow_id: str, workflow_builder: WorkflowBuilder
):
"""注册一个工作流"""
full_name = f"{group_id}:{workflow_id}"
if full_name in self._workflows:
self.logger.warning(f"Workflow {full_name} already registered, overwriting")
workflow_builder.id = full_name
self._workflows[full_name] = workflow_builder
self.logger.info(f"Registered workflow: {full_name}")
def register_preset_workflow(
self, group_id: str, workflow_id: str, workflow_builder: WorkflowBuilder
):
"""预设工作流注册,当用户保存了同 id 的工作流时,则会不注册"""
full_name = f"{group_id}:{workflow_id}"
if full_name in self._workflows:
self.logger.debug(
f"Preset workflow {full_name} already registered, skipping"
)
return
self._workflows[full_name] = workflow_builder
self.logger.info(f"Registered preset workflow: {full_name}")
def get_workflow(self, name: str, container: DependencyContainer) -> Optional[Workflow]:
builder = self._workflows.get(name)
if builder:
return builder.build(container)
return None
def get(
self, name: str, container: Optional[DependencyContainer] = None
) -> Optional[WorkflowBuilder | Workflow]:
"""获取工作流构建器或实例"""
builder = self._workflows.get(name)
if builder and container:
return builder.build(container)
return builder
def load_workflows(self, workflows_dir: Optional[str] = None):
"""从指定目录加载所有工作流定义"""
workflows_dir = workflows_dir or self.WORKFLOWS_DIR
if not os.path.exists(workflows_dir):
os.makedirs(workflows_dir)
# 遍历所有组目录
for group_id in os.listdir(workflows_dir):
group_dir = os.path.join(workflows_dir, group_id)
if not os.path.isdir(group_dir):
continue
# 遍历组内的工作流文件
for file_name in os.listdir(group_dir):
if not file_name.endswith(".yaml"):
continue
workflow_id = os.path.splitext(file_name)[0]
file_path = os.path.join(group_dir, file_name)
try:
workflow = WorkflowBuilder.load_from_yaml(file_path, self.container)
self.register(group_id, workflow_id, workflow)
except Exception as e:
self.logger.error(
f"Failed to load workflow from {file_path}: {str(e)}"
)
================================================
FILE: kirara_ai/workflow/implementations/__init__.py
================================================
================================================
FILE: kirara_ai/workflow/implementations/blocks/__init__.py
================================================
from .system_blocks import register_system_blocks
__all__ = ["register_system_blocks"]
================================================
FILE: kirara_ai/workflow/implementations/blocks/game/dice.py
================================================
import random
import re
from typing import Any, Dict
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class DiceRoll(Block):
"""骰子掷点 block"""
name = "dice_roll"
inputs = {
"message": Input("message", "输入消息", IMMessage, "输入消息包含骰子命令")
}
outputs = {
"response": Output(
"response", "响应消息", IMMessage, "响应消息包含骰子掷点结果"
)
}
def execute(self, message: IMMessage) -> Dict[str, Any]:
# 解析命令
command = message.content
match = re.match(r"^[.。]roll\s*(\d+)?d(\d+)", command)
if not match:
return {
"response": IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage("Invalid dice command")],
)
}
count = int(match.group(1) or "1") # 默认1个骰子
sides = int(match.group(2))
if count > 100: # 限制骰子数量
return {
"response": IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage("Too many dice (max 100)")],
)
}
# 掷骰子
rolls = [random.randint(1, sides) for _ in range(count)]
total = sum(rolls)
# 生成详细信息
details = f"🎲 掷出了 {count}d{sides}: {' + '.join(map(str, rolls))}"
if count > 1:
details += f" = {total}"
return {
"response": IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage(details)]
)
}
================================================
FILE: kirara_ai/workflow/implementations/blocks/game/gacha.py
================================================
import random
from typing import Dict, Optional
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class GachaSimulator(Block):
"""抽卡模拟器 block"""
name = "gacha_simulator"
inputs = {
"message": Input("message", "输入消息", IMMessage, "输入消息包含抽卡命令")
}
outputs = {
"response": Output("response", "响应消息", IMMessage, "响应消息包含抽卡结果")
}
def __init__(self, rates: Optional[Dict[str, float]] = None):
# 默认抽卡概率
self.rates = rates or {"SSR": 0.03, "SR": 0.12, "R": 0.85} # 3% # 12% # 85%
def _single_pull(self) -> str:
rand = random.random()
cumulative = 0
for rarity, rate in self.rates.items():
cumulative += rate
if rand <= cumulative:
return rarity
return list(self.rates.keys())[-1] # 保底
def execute(self, message: IMMessage) -> Dict[str, IMMessage]:
# 解析命令
command = message.content
is_ten_pull = "十连" in command
pulls = 10 if is_ten_pull else 1
# 抽卡
results = [self._single_pull() for _ in range(pulls)]
# 生成结果统计
stats = {rarity: results.count(rarity) for rarity in self.rates.keys()}
# 生成详细信息
details = []
for rarity in results:
if rarity == "SSR":
details.append("🌟 SSR")
elif rarity == "SR":
details.append("✨ SR")
else:
details.append("⭐ R")
result_text = f"抽卡结果: {'、'.join(details)}"
stats_text = "统计:\n" + "\n".join(
f"{rarity}: {count}" for rarity, count in stats.items()
)
return {
"response": IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage(result_text), TextMessage(stats_text)],
)
}
================================================
FILE: kirara_ai/workflow/implementations/blocks/im/basic.py
================================================
from typing import Any, Dict
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class ExtractChatSender(Block):
"""提取消息发送者"""
name = "extract_chat_sender"
container: DependencyContainer
inputs = {"msg": Input("msg", "IM 消息", IMMessage, "IM 消息")}
outputs = {"sender": Output("sender", "消息发送者", ChatSender, "消息发送者")}
def execute(self, **kwargs) -> Dict[str, Any]:
msg = self.container.resolve(IMMessage)
return {"sender": msg.sender}
================================================
FILE: kirara_ai/workflow/implementations/blocks/im/messages.py
================================================
import asyncio
from typing import Annotated, Any, Dict, List, Optional
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.manager import IMManager
from kirara_ai.im.message import IMMessage, MessageElement, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block, Input, Output, ParamMeta
def im_adapter_options_provider(container: DependencyContainer, block: Block) -> List[str]:
return [key for key, _ in container.resolve(IMManager).adapters.items()]
class GetIMMessage(Block):
"""获取 IM 消息"""
name = "msg_input"
container: DependencyContainer
outputs = {
"msg": Output("msg", "IM 消息", IMMessage, "获取 IM 发送的最新一条的消息"),
"sender": Output("sender", "发送者", ChatSender, "获取 IM 消息的发送者"),
}
def execute(self, **kwargs) -> Dict[str, Any]:
msg = self.container.resolve(IMMessage)
return {"msg": msg, "sender": msg.sender}
class SendIMMessage(Block):
"""发送 IM 消息"""
name = "msg_sender"
inputs = {
"msg": Input("msg", "IM 消息", IMMessage, "要从 IM 发送的消息"),
"target": Input(
"target",
"发送对象",
ChatSender,
"要发送给谁,如果填空则默认发送给消息的发送者",
nullable=True,
),
}
outputs = {}
container: DependencyContainer
def __init__(
self, im_name: Annotated[Optional[str], ParamMeta(label="聊天平台适配器名称", options_provider=im_adapter_options_provider)] = None
):
self.im_name = im_name
def execute(
self, msg: IMMessage, target: Optional[ChatSender] = None
) -> Dict[str, Any]:
src_msg = self.container.resolve(IMMessage)
if not self.im_name:
adapter = self.container.resolve(IMAdapter)
else:
adapter = self.container.resolve(
IMManager).get_adapter(self.im_name)
loop: asyncio.AbstractEventLoop = self.container.resolve(
asyncio.AbstractEventLoop
)
loop.create_task(adapter.send_message(msg, target or src_msg.sender))
return {"ok": True}
# IMMessage 转纯文本
class IMMessageToText(Block):
"""IMMessage 转纯文本"""
name = "im_message_to_text"
container: DependencyContainer
inputs = {"msg": Input("msg", "IM 消息", IMMessage, "IM 消息")}
outputs = {"text": Output("text", "纯文本", str, "纯文本")}
def execute(self, msg: IMMessage) -> Dict[str, Any]:
return {"text": msg.content}
# 纯文本转 IMMessage
class TextToIMMessage(Block):
"""纯文本转 IMMessage"""
name = "text_to_im_message"
container: DependencyContainer
inputs = {"text": Input("text", "纯文本", str, "纯文本")}
outputs = {"msg": Output("msg", "IM 消息", IMMessage, "IM 消息")}
def __init__(self, split_by: Annotated[Optional[str], ParamMeta(label="分段符")] = None):
self.split_by = split_by
def execute(self, text: str) -> Dict[str, Any]:
if self.split_by:
return {"msg": IMMessage(sender=ChatSender.get_bot_sender(), message_elements = [TextMessage(line.strip()) for line in text.split(self.split_by) if line.strip()])}
else:
return {"msg": IMMessage(sender=ChatSender.get_bot_sender(), message_elements=[TextMessage(text)])}
# 补充 IMMessage 消息
class AppendIMMessage(Block):
"""补充 IMMessage 消息"""
name = "concat_im_message"
container: DependencyContainer
inputs = {
"base_msg": Input("base_msg", "IM 消息", IMMessage, "IM 消息"),
"append_msg": Input("append_msg", "新消息片段", MessageElement, "新消息片段"),
}
outputs = {"msg": Output("msg", "IM 消息", IMMessage, "IM 消息")}
def execute(self, base_msg: IMMessage, append_msg: MessageElement) -> Dict[str, Any]:
return {"msg": IMMessage(sender=base_msg.sender, message_elements=base_msg.message_elements + [append_msg])}
================================================
FILE: kirara_ai/workflow/implementations/blocks/im/states.py
================================================
import asyncio
from typing import Annotated, Any, Dict
from kirara_ai.im.adapter import EditStateAdapter, IMAdapter
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block, Input, ParamMeta
# Toggle edit state
class ToggleEditState(Block):
name = "toggle_edit_state"
inputs = {
"sender": Input("sender", "聊天对象", ChatSender, "要切换编辑状态的聊天对象")
}
outputs = {}
container: DependencyContainer
def __init__(
self,
is_editing: Annotated[
bool, ParamMeta(label="是否编辑", description="是否切换到编辑状态")
],
):
self.is_editing = is_editing
def execute(self, sender: ChatSender) -> Dict[str, Any]:
im_adapter = self.container.resolve(IMAdapter)
if isinstance(im_adapter, EditStateAdapter):
loop: asyncio.AbstractEventLoop = self.container.resolve(
asyncio.AbstractEventLoop
)
loop.create_task(im_adapter.set_chat_editing_state(sender, self.is_editing))
return {}
================================================
FILE: kirara_ai/workflow/implementations/blocks/im/user_profile.py
================================================
import asyncio
from typing import Any, Dict, Optional
from kirara_ai.im.adapter import IMAdapter, UserProfileAdapter
from kirara_ai.im.profile import UserProfile
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class QueryUserProfileBlock(Block):
def __init__(self, container: DependencyContainer):
inputs = {
"chat_sender": Input(
"chat_sender", "聊天对象", ChatSender, "要查询聊天对象的 profile"
),
"im_adapter": Input(
"im_adapter", "IM 平台", IMAdapter, "IM 平台适配器", nullable=True
),
}
outputs = {"profile": Output("profile", "用户资料", UserProfile, "用户资料")}
super().__init__("query_user_profile", inputs, outputs)
self.container = container
def execute(
self, chat_sender: ChatSender, im_adapter: Optional[IMAdapter] = None
) -> Dict[str, Any]:
# 如果没有提供 im_adapter,则从容器中获取默认的
if im_adapter is None:
im_adapter = self.container.resolve(IMAdapter)
# 检查 im_adapter 是否实现了 UserProfileAdapter 协议
if not isinstance(im_adapter, UserProfileAdapter):
raise TypeError(
f"IM Adapter {type(im_adapter)} does not support user profile querying"
)
# 同步调用异步方法(在工作流执行器中会被正确处理)
profile = asyncio.run(im_adapter.query_user_profile(chat_sender)) # type: ignore
return {"profile": profile}
================================================
FILE: kirara_ai/workflow/implementations/blocks/llm/basic.py
================================================
# LLM 响应转纯文本
from typing import Any, Dict
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.workflow.core.block.base import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class LLMResponseToText(Block):
"""LLM 响应转纯文本"""
name = "llm_response_to_text"
container: DependencyContainer
inputs = {"response": Input("response", "LLM 响应", LLMChatResponse, "LLM 响应")}
outputs = {"text": Output("text", "纯文本", str, "纯文本")}
def execute(self, response: LLMChatResponse) -> Dict[str, Any]:
content = ""
if response.message:
for part in response.message.content:
if part.type == "text":
content = content + part.text
elif part.type == "image":
content = content + f""
return {"text": content}
================================================
FILE: kirara_ai/workflow/implementations/blocks/llm/chat.py
================================================
import asyncio
import re
from datetime import datetime
from typing import Annotated, Any, Dict, List, Optional
from kirara_ai.im.message import ImageMessage, IMMessage, MessageElement, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format import LLMChatMessage, LLMChatTextContent
from kirara_ai.llm.format.message import LLMChatContentPartType, LLMChatImageContent
from kirara_ai.llm.format.request import LLMChatRequest, Tool
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.model_types import LLMAbility, ModelType
from kirara_ai.logger import get_logger
from kirara_ai.memory.composes.base import ComposableMessageType
from kirara_ai.workflow.core.block import Block, Input, Output, ParamMeta
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
def model_name_options_provider(container: DependencyContainer, block: Block) -> List[str]:
llm_manager: LLMManager = container.resolve(LLMManager)
return sorted(llm_manager.get_supported_models(ModelType.LLM, LLMAbility.TextChat))
class ChatMessageConstructor(Block):
name = "chat_message_constructor"
inputs = {
"user_msg": Input("user_msg", "本轮消息", IMMessage, "用户消息"),
"user_prompt_format": Input(
"user_prompt_format", "本轮消息格式", str, "本轮消息格式", default=""
),
"memory_content": Input("memory_content", "历史消息对话", List[ComposableMessageType], "历史消息对话"),
"system_prompt_format": Input(
"system_prompt_format", "系统提示词", str, "系统提示词", default=""
),
}
outputs = {
"llm_msg": Output(
"llm_msg", "LLM 对话记录", List[LLMChatMessage], "LLM 对话记录"
)
}
container: DependencyContainer
def substitute_variables(self, text: str, executor: WorkflowExecutor) -> str:
"""
替换文本中的变量占位符,支持对象属性和字典键的访问
:param text: 包含变量占位符的文本,格式为 {variable_name} 或 {variable_name.attribute}
:param executor: 工作流执行器实例
:return: 替换后的文本
"""
def replace_var(match):
var_path = match.group(1).split(".")
var_name = var_path[0]
# 获取基础变量
value = executor.get_variable(var_name, match.group(0))
# 如果有属性/键访问
for attr in var_path[1:]:
try:
# 尝试字典键访问
if isinstance(value, dict):
value = value.get(attr, match.group(0))
# 尝试对象属性访问
elif hasattr(value, attr):
value = getattr(value, attr)
else:
# 如果无法访问,返回原始占位符
return match.group(0)
except Exception:
# 任何异常都返回原始占位符
return match.group(0)
return str(value)
return re.sub(r"\{([^}]+)\}", replace_var, text)
def execute(
self,
user_msg: IMMessage,
memory_content: str,
system_prompt_format: str = "",
user_prompt_format: str = "",
) -> Dict[str, Any]:
# 获取当前执行器
executor = self.container.resolve(WorkflowExecutor)
# 先替换自有的两个变量
replacements = {
"{current_date_time}": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"{user_msg}": user_msg.content,
"{user_name}": user_msg.sender.display_name,
"{user_id}": user_msg.sender.user_id
}
if isinstance(memory_content, list) and all(isinstance(item, str) for item in memory_content):
replacements["{memory_content}"] = "\n".join(memory_content)
for old, new in replacements.items():
system_prompt_format = system_prompt_format.replace(old, new)
user_prompt_format = user_prompt_format.replace(old, new)
# 再替换其他变量
system_prompt = self.substitute_variables(
system_prompt_format, executor)
user_prompt = self.substitute_variables(user_prompt_format, executor)
content: List[LLMChatContentPartType] = [
LLMChatTextContent(text=user_prompt)]
# 添加图片内容
for image in user_msg.images or []:
content.append(LLMChatImageContent(media_id=image.media_id))
llm_msg = [
LLMChatMessage(role="system", content=[
LLMChatTextContent(text=system_prompt)]),
]
if isinstance(memory_content, list) and all(isinstance(item, LLMChatMessage) for item in memory_content):
llm_msg.extend(memory_content) # type: ignore
llm_msg.append(LLMChatMessage(role="user", content=content))
return {"llm_msg": llm_msg}
class ChatCompletion(Block):
name = "chat_completion"
inputs = {
"prompt": Input("prompt", "LLM 对话记录", List[LLMChatMessage], "LLM 对话记录")
}
outputs = {"resp": Output("resp", "LLM 对话响应", LLMChatResponse, "LLM 对话响应")}
container: DependencyContainer
def __init__(
self,
model_name: Annotated[
Optional[str],
ParamMeta(
label="模型 ID",
description="要使用的模型 ID",
options_provider=model_name_options_provider),
] = None,
):
self.model_name = model_name
self.logger = get_logger("ChatCompletionBlock")
def execute(self, prompt: List[LLMChatMessage]) -> Dict[str, Any]:
llm_manager = self.container.resolve(LLMManager)
model_id = self.model_name
if not model_id:
model_id = llm_manager.get_llm_id_by_ability(LLMAbility.TextChat)
if not model_id:
raise ValueError("No available LLM models found")
else:
self.logger.info(
f"Model id unspecified, using default model: {model_id}"
)
else:
self.logger.debug(f"Using specified model: {model_id}")
llm = llm_manager.get_llm(model_id)
if not llm:
raise ValueError(
f"LLM {model_id} not found, please check the model name")
req = LLMChatRequest(messages=prompt, model=model_id)
return {"resp": llm.chat(req)}
class ChatResponseConverter(Block):
name = "chat_response_converter"
inputs = {"resp": Input("resp", "LLM 响应", LLMChatResponse, "LLM 响应")}
outputs = {"msg": Output("msg", "IM 消息", IMMessage, "IM 消息")}
container: DependencyContainer
def execute(self, resp: LLMChatResponse) -> Dict[str, Any]:
message_elements: List[MessageElement] = []
for part in resp.message.content:
if isinstance(part, LLMChatTextContent):
# 通过 将回答分为不同的 TextMessage
for element in part.text.split(""):
if element.strip():
message_elements.append(TextMessage(element.strip()))
elif isinstance(part, LLMChatImageContent):
message_elements.append(ImageMessage(media_id=part.media_id))
msg = IMMessage(sender=ChatSender.get_bot_sender(),
message_elements=message_elements)
return {"msg": msg}
class ChatCompletionWithTools(Block):
"""
支持工具调用的LLM对话块
"""
name = "chat_completion_with_tools"
inputs = {
"msg": Input("msg", "LLM 对话记录", List[LLMChatMessage], "LLM 的 prompt,即由 system、user、assistant和工具调用及结果的完整对话记录"),
"tools": Input("tools", "工具列表", List[Tool], "工具列表")
}
outputs = {
"resp": Output("resp", "LLM 消息回应", LLMChatResponse, "模型返回给用户的消息"),
"iteration_msgs": Output("iteration_msgs", "中间步骤消息", List[ComposableMessageType], "迭代过程中产生的所有消息,可以用记忆存储")
}
container: DependencyContainer
def __init__(self, model_name: Annotated[
str,
ParamMeta(
label="模型 ID, 需要支持函数调用",
description="支持函数调用的模型",
options_provider=model_name_options_provider)
],
max_iterations: Annotated[
int,
ParamMeta(
label="最大迭代次数",
description="允许调用模型请求的最大次数,在进行最后一次请求时,模型将不允许调用工具")
] = 4):
self.model_name = model_name
self.max_iterations = max_iterations
self.logger = get_logger("Block.ChatCompletionWithTools")
def execute(self, msg: List[LLMChatMessage], tools: List[Tool]) -> Dict[str, Any]:
if not self.model_name:
raise ValueError(
"need a model name which support function calling")
else:
self.logger.info(
f"Using model: {self.model_name} to execute function calling")
loop = self.container.resolve(asyncio.AbstractEventLoop)
llm = self.container.resolve(LLMManager).get_llm(self.model_name)
if not llm:
raise ValueError(
f"LLM {self.model_name} not found, please check the model name")
iteration_msgs: List[LLMChatMessage] = []
iter_count = 0
while iter_count < self.max_iterations:
# 在这里指定llm的model
self.logger.debug(
f"Iteration {iter_count+1} of {self.max_iterations}")
request_body = LLMChatRequest(
messages=msg + iteration_msgs, model=self.model_name)
if tools is not None and len(tools) > 0:
request_body.tools = tools
# 最后一次迭代不调用工具
if iter_count == self.max_iterations - 1:
request_body.tool_choice = "none"
tools_mapping = {t.name: t for t in tools}
response: LLMChatResponse = llm.chat(request_body)
iter_count += 1
if response.message.tool_calls:
iteration_msgs.append(response.message)
self.logger.debug("Tool calls found, attempt to invoke tools")
for tool_call in response.message.tool_calls:
actual_tool = tools_mapping.get(tool_call.function.name)
if actual_tool:
self.logger.debug(
f"Invoking tool: {actual_tool.name}({tool_call.function.arguments})")
resp_future = asyncio.run_coroutine_threadsafe(
actual_tool.invokeFunc(tool_call), loop
)
tool_result_msg = LLMChatMessage(
role="tool", content=[resp_future.result()])
iteration_msgs.append(tool_result_msg)
else:
self.logger.debug(
"No tool calls found, return response directly")
return {"resp": response, "iteration_msgs": iteration_msgs}
return {"resp": response, "iteration_msgs": iteration_msgs}
================================================
FILE: kirara_ai/workflow/implementations/blocks/llm/image.py
================================================
import base64
from typing import Any, Dict, Optional
import requests
from kirara_ai.im.message import ImageMessage
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
class SimpleStableDiffusionWebUI(Block):
name = "simple_stable_diffusion_webui"
inputs = {
"prompt": Input("prompt", "提示", str, "提示"),
"negative_prompt": Input("negative_prompt", "负面提示", str, "负面提示"),
}
outputs = {"image": Output("image", "图片", ImageMessage, "生成的图片")}
def __init__(
self,
api_url: str,
*,
steps: int = 20,
sampler_index: str = "Euler a",
cfg_scale: float = 7.0,
width: int = 512,
height: int = 512,
ckpt_name: Optional[str] = None,
clip_skip: int = 1,
):
self.api_url = api_url
self.steps = steps
self.sampler_index = sampler_index
self.cfg_scale = cfg_scale
self.width = width
self.height = height
self.ckpt_name = ckpt_name
self.clip_skip = clip_skip
def execute(self, prompt: str, negative_prompt: str) -> Dict[str, Any]:
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"steps": self.steps,
"sampler_index": self.sampler_index,
"cfg_scale": self.cfg_scale,
"width": self.width,
"height": self.height,
}
if self.ckpt_name:
payload["ckpt_name"] = self.ckpt_name
payload["clip_skip"] = self.clip_skip
response = requests.post(url=f"{self.api_url}/sdapi/v1/txt2img", json=payload)
if response.status_code == 200:
r = response.json()
# Assuming the API returns the image in base64 format
# and it's the first image in the list
if "images" in r and r["images"]:
image_base64 = r["images"][0]
image_bytes = base64.b64decode(image_base64)
image_message = ImageMessage(
data=image_bytes, format="png"
) # 假设是 PNG 格式
return {"image": image_message}
else:
raise Exception("No image data found in the response")
else:
raise Exception(
f"API request failed with status code: {response.status_code}, message: {response.text}"
)
================================================
FILE: kirara_ai/workflow/implementations/blocks/mcp/__init__.py
================================================
================================================
FILE: kirara_ai/workflow/implementations/blocks/mcp/tool.py
================================================
from base64 import b64decode
from typing import Annotated, Any, Dict, List
from mcp import types
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format import tool
from kirara_ai.llm.format.message import LLMToolResultContent
from kirara_ai.llm.format.tool import CallableWrapper, Tool, ToolCall
from kirara_ai.logger import get_logger
from kirara_ai.mcp_module.manager import MCPServerManager
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.types.media_type import MediaType
from kirara_ai.workflow.core.block import Block, Output
from kirara_ai.workflow.core.block.param import ParamMeta
def get_enabled_mcp_tools(container: DependencyContainer, block: Block) -> List[str]:
mcp_manager = container.resolve(MCPServerManager)
return list(mcp_manager.get_tools().keys())
class MCPToolProvider(Block):
"""
提供MCP工具调用工具
"""
name = "mcp_tool_provider"
outputs = {
"tools": Output("tools", "工具列表", List[Tool], "工具列表")
}
container: DependencyContainer
def __init__(self, enabled_tools: Annotated[List[str], ParamMeta(label="启用工具列表", description="启用工具列表", options_provider=get_enabled_mcp_tools)]):
self.logger = get_logger("MCPCallTool")
self.enabled_tools = enabled_tools
async def _call_tool(self, tool_call: ToolCall) -> LLMToolResultContent:
"""提供MCP工具调用执行回调"""
mcp_manager = self.container.resolve(MCPServerManager)
server_info = mcp_manager.get_tool_server(tool_call.function.name)
if not server_info:
raise ValueError(f"找不到工具: {tool_call.function.name}")
server, original_name = server_info
result = await server.call_tool(original_name, tool_call.function.arguments)
tool_result = await self._create_tool_result(
tool_call.id, tool_call.function.name, result.content
)
tool_result.isError = result.isError
self.logger.info(f"工具调用结果: {tool_result}")
return tool_result
def execute(self) -> Dict[str, Any]:
"""
提供MCP工具列表
Returns:
包含工具列表的字典
"""
mcp_manager = self.container.resolve(MCPServerManager)
mcp_tools = mcp_manager.get_tools()
built_tools = []
for tool_name, tool_info in mcp_tools.items():
if tool_name in self.enabled_tools:
built_tools.append(
Tool(
name=tool_name,
parameters=tool_info.tool_info.inputSchema,
description=tool_info.tool_info.description or "",
invokeFunc=CallableWrapper(self._call_tool)
)
)
return {
"tools": built_tools
}
async def _create_tool_result(self, tool_id: str, tool_name: str, content: list[types.TextContent | types.ImageContent | types.EmbeddedResource]) -> LLMToolResultContent:
"""创建工具调用结果"""
converted_content: List[tool.TextContent | tool.MediaContent] = []
for item in content:
if isinstance(item, types.TextContent):
converted_content.append(tool.TextContent(
text=item.text
))
elif isinstance(item, types.ImageContent):
data = b64decode(item.data)
media_type = MediaType.from_mime(item.mimeType)
format = item.mimeType.split("/")[1]
media_id = await self.container.resolve(MediaManager).register_from_data(data, format=format, media_type=media_type)
converted_content.append(tool.MediaContent(
media_id=media_id,
mime_type=item.mimeType,
data=data
))
return LLMToolResultContent(
id=tool_id,
name=tool_name,
content=converted_content
)
================================================
FILE: kirara_ai/workflow/implementations/blocks/memory/chat_memory.py
================================================
from typing import Annotated, Any, Dict, List, Optional
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.response import LLMChatResponse
from kirara_ai.logger import get_logger
from kirara_ai.memory.composes.base import ComposableMessageType
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.registry import ComposerRegistry, DecomposerRegistry, ScopeRegistry
from kirara_ai.workflow.core.block import Block, Input, Output, ParamMeta
def scope_type_options_provider(container: DependencyContainer, block: Block) -> List[str]:
return ["global", "group", "member"]
def decomposer_name_options_provider(container: DependencyContainer, block: Block) -> List[str]:
return ["default", "multi_element"]
class ChatMemoryQuery(Block):
name = "chat_memory_query"
inputs = {
"chat_sender": Input(
"chat_sender", "聊天对象", ChatSender, "要查询记忆的聊天对象"
)
}
outputs = {"memory_content": Output(
"memory_content", "记忆内容", List[ComposableMessageType], "记忆内容")}
container: DependencyContainer
def __init__(
self,
scope_type: Annotated[
Optional[str],
ParamMeta(
label="级别",
description="要查询记忆的级别,代表记忆可以被共享的粒度。(例如:member 级别下,同一群聊下不同用户的记忆互相隔离; group 级别下,同一群组内所有成员记忆共享,但不同群组之间记忆互相隔离)",
options_provider=scope_type_options_provider,
),
],
decomposer_name: Annotated[
Optional[str],
ParamMeta(
label="解析器名称",
description="要使用的解析器名称",
options_provider=decomposer_name_options_provider,
),
] = "default",
extra_identifier: Annotated[
Optional[str],
ParamMeta(
label="额外隔离标识符",
description="仅支持输入英文,可为空。对于同一用户,不同标识符之间的记忆互相隔离。可用于避免不同工作流之间记忆互相干扰。",
),
] = None,
):
self.scope_type = scope_type
self.decomposer_name: str = decomposer_name or "default"
self.extra_identifier = extra_identifier
def execute(self, chat_sender: ChatSender) -> Dict[str, Any]:
self.memory_manager = self.container.resolve(MemoryManager)
# 如果没有指定作用域类型,使用配置中的默认值
if self.scope_type is None:
self.scope_type = self.memory_manager.config.default_scope
# 获取作用域实例
scope_registry = self.container.resolve(ScopeRegistry)
self.scope = scope_registry.get_scope(self.scope_type)
# 获取解析器实例
decomposer_registry = self.container.resolve(DecomposerRegistry)
self.decomposer = decomposer_registry.get_decomposer(
self.decomposer_name)
entries = self.memory_manager.query(self.scope, chat_sender, self.extra_identifier)
memory_content = self.decomposer.decompose(entries)
return {"memory_content": memory_content}
class ChatMemoryStore(Block):
name = "chat_memory_store"
inputs = {
"user_msg": Input("user_msg", "用户消息", IMMessage, "用户消息", nullable=True),
"llm_resp": Input(
"llm_resp", "LLM 回复", LLMChatResponse, "LLM 回复", nullable=True
),
"middle_steps": Input(
"middle_steps", "中间步骤消息", List[ComposableMessageType], "中间步骤消息", nullable=True
)
}
outputs = {}
container: DependencyContainer
def __init__(
self,
scope_type: Annotated[
Optional[str],
ParamMeta(
label="级别",
description="要查询记忆的级别,代表记忆可以被共享的粒度。(例如:member 级别下,同一群聊下不同用户的记忆互相隔离; group 级别下,同一群组内所有成员记忆共享,但不同群组之间记忆互相隔离)",
options_provider=scope_type_options_provider,
),
],
extra_identifier: Annotated[
Optional[str],
ParamMeta(
label="额外隔离标识符",
description="仅支持输入英文,可为空。对于同一用户,不同标识符之间的记忆互相隔离。可用于避免不同工作流之间记忆互相干扰。",
),
] = None,
):
self.scope_type = scope_type
self.logger = get_logger("Block.ChatMemoryStore")
self.extra_identifier = extra_identifier
def execute(
self,
user_msg: Optional[IMMessage] = None,
llm_resp: Optional[LLMChatResponse] = None,
middle_steps: Optional[List[ComposableMessageType]] = None,
) -> Dict[str, Any]:
self.memory_manager = self.container.resolve(MemoryManager)
# 如果没有指定作用域类型,使用配置中的默认值
if self.scope_type is None:
self.scope_type = self.memory_manager.config.default_scope
# 获取作用域实例
scope_registry = self.container.resolve(ScopeRegistry)
self.scope = scope_registry.get_scope(self.scope_type)
# 获取组合器实例
composer_registry = self.container.resolve(ComposerRegistry)
self.composer = composer_registry.get_composer("default")
# 存储用户消息和LLM响应
if user_msg is None:
composed_messages: List[ComposableMessageType] = []
else:
composed_messages = [user_msg]
if middle_steps is not None:
composed_messages.extend(middle_steps)
if llm_resp is not None:
if llm_resp.message:
composed_messages.append(llm_resp.message)
if not composed_messages:
self.logger.warning("No messages to store")
return {}
self.logger.debug(f"Composed messages: {composed_messages}")
memory_entries = self.composer.compose(
user_msg.sender if user_msg else None, composed_messages)
self.memory_manager.store(self.scope, memory_entries, self.extra_identifier)
return {}
================================================
FILE: kirara_ai/workflow/implementations/blocks/memory/clear_memory.py
================================================
from typing import Annotated, Any, Dict
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.registry import ScopeRegistry
from kirara_ai.workflow.core.block import Block, Input, Output, ParamMeta
class ClearMemory(Block):
"""Block for clearing conversation memory"""
name = "clear_memory"
inputs = {
"chat_sender": Input("chat_sender", "消息发送者", ChatSender, "消息发送者")
}
outputs = {"response": Output("response", "响应", IMMessage, "响应")}
container: DependencyContainer
def __init__(
self,
scope_type: Annotated[
str, ParamMeta(label="级别", description="要清空记忆的级别")
] = "member",
):
self.scope_type = scope_type
def execute(self, chat_sender: ChatSender) -> Dict[str, Any]:
self.memory_manager = self.container.resolve(MemoryManager)
# Get scope instance
scope_registry = self.container.resolve(ScopeRegistry)
self.scope = scope_registry.get_scope(self.scope_type)
# Clear memory using the manager's method
self.memory_manager.clear_memory(self.scope, chat_sender)
return {
"response": IMMessage(
sender=chat_sender,
message_elements=[TextMessage("已清空当前对话的记忆。")],
)
}
================================================
FILE: kirara_ai/workflow/implementations/blocks/system/basic.py
================================================
import re
from datetime import datetime
from typing import Annotated, Any, Dict, List
from kirara_ai.logger import get_logger
from kirara_ai.workflow.core.block import Block, Output, ParamMeta
from kirara_ai.workflow.core.block.input_output import Input
class TextBlock(Block):
name = "text_block"
outputs = {"text": Output("text", "文本", str, "文本")}
def __init__(
self, text: Annotated[str, ParamMeta(label="文本", description="要输出的文本")]
):
self.text = text
def execute(self) -> Dict[str, Any]:
return {"text": self.text}
# 拼接文本
class TextConcatBlock(Block):
name = "text_concat_block"
inputs = {
"text1": Input("text1", "文本1", str, "文本1"),
"text2": Input("text2", "文本2", str, "文本2"),
}
outputs = {"text": Output("text", "拼接后的文本", str, "拼接后的文本")}
def execute(self, text1: str, text2: str) -> Dict[str, Any]:
return {"text": text1 + text2}
# 替换输入文本中的某一块文字为变量
class TextReplaceBlock(Block):
name = "text_replace_block"
inputs = {
"text": Input("text", "原始文本", str, "原始文本"),
"new_text": Input("new_text", "新文本", Any, "新文本"), # type: ignore
}
outputs = {"text": Output("text", "替换后的文本", str, "替换后的文本")}
def __init__(
self, variable: Annotated[str, ParamMeta(label="被替换的文本", description="被替换的文本")]
):
self.variable = variable
def execute(self, text: str, new_text: Any) -> Dict[str, Any]:
return {
"text": text.replace(self.variable, str(new_text))
}
# 正则表达式提取
class TextExtractByRegexBlock(Block):
name = "text_extract_by_regex_block"
inputs = {"text": Input("text", "原始文本", str, "原始文本")}
outputs = {"text": Output("text", "提取后的文本", str, "提取后的文本")}
def __init__(
self, regex: Annotated[str, ParamMeta(label="正则表达式", description="正则表达式")]
):
self.regex = regex
def execute(self, text: str) -> Dict[str, Any]:
# 使用正则表达式提取文本
regex = re.compile(self.regex)
match = regex.search(text)
# 如果匹配到,则返回匹配到的文本,否则返回空字符串
if match and len(match.groups()) > 0:
return {"text": match.group(1)}
else:
return {"text": ""}
# 获取当前时间
class CurrentTimeBlock(Block):
name = "current_time_block"
outputs = {"time": Output("time", "当前时间", str, "当前时间")}
def execute(self) -> Dict[str, Any]:
return {"time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")}
class CodeBlock(Block):
name = "code_block"
inputs = {}
outputs = {}
def __init__(self,
inputs: Annotated[List[Dict[str, str]], ParamMeta(label="输入参数", description="输入参数")],
outputs: Annotated[List[Dict[str, str]], ParamMeta(label="输出参数", description="输出参数")],
code: Annotated[str, ParamMeta(label="代码", description="代码")]):
# 初始化实例的 inputs 和 outputs
self.inputs = {}
self.outputs = {}
for input_spec in inputs:
self.inputs[input_spec["name"]] = Input(input_spec["name"], input_spec["label"], Any, 'user-specified object') # type: ignore
for output_spec in outputs:
self.outputs[output_spec["name"]] = Output(output_spec["name"], output_spec["label"], Any, 'user-specified object') # type: ignore
self.code = code
def execute(self, **kwargs: Any) -> Dict[str, Any]: # 使用 Any 兼容各种输入类型
logger = get_logger("Block.Code")
exec_globals = globals().copy()
exec_locals: Dict[str, Any] = {}
logger.debug(f"Executing code definition:\n{self.code}")
try:
exec(self.code, exec_globals, exec_locals)
except Exception as e:
logger.error(f"Error during code definition execution: {e}", exc_info=True)
raise RuntimeError(f"Error in provided code definition: {e}") from e
if 'execute' not in exec_locals or not callable(exec_locals['execute']):
raise ValueError("Provided code must define a callable function named 'execute'")
exec_locals['__input_kwargs__'] = kwargs
exec_globals.update(exec_locals)
call_code = "__result__ = execute(**__input_kwargs__)"
logger.debug(f"Executing function call: execute(**{list(kwargs.keys())})")
try:
exec(call_code, exec_globals, exec_locals)
except Exception as e:
logger.error(f"Error during user function 'execute' execution: {e}", exc_info=True)
raise RuntimeError(f"Error during execution of user function 'execute': {e}") from e
if '__result__' not in exec_locals:
# 如果 exec(call_code) 成功但没有 __result__,说明有内部问题
logger.error("Internal error: Result '__result__' not found after executing user code call.")
raise RuntimeError("Failed to retrieve result from user code execution.")
result = exec_locals['__result__']
return result
================================================
FILE: kirara_ai/workflow/implementations/blocks/system/help.py
================================================
from typing import Any, Dict, List
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block, Output
from kirara_ai.workflow.core.dispatch.models.dispatch_rules import RuleGroup
from kirara_ai.workflow.core.dispatch.registry import DispatchRuleRegistry
def _format_rule_condition(rule_type: str, config: Dict[str, Any]) -> str:
"""格式化单个规则的条件描述"""
if rule_type == "prefix":
return f"输入以 {config['prefix']} 开头"
elif rule_type == "keyword":
keywords = config.get("keywords", [])
return f"输入包含 {' 或 '.join(keywords)}"
elif rule_type == "regex":
return f"输入匹配正则 {config['pattern']}"
elif rule_type == "fallback":
return "任意输入"
elif rule_type == "bot_mention":
return f"@我"
elif rule_type == "chat_type":
return f"使用 {config['chat_type']} 聊天类型"
return f"使用 {rule_type} 规则"
def _format_rule_group(group: RuleGroup) -> str:
"""格式化规则组的条件描述"""
rule_conditions = []
for rule in group.rules:
rule_conditions.append(
_format_rule_condition(rule.type, rule.config)
)
operator = " 且 " if group.operator == "and" else " 或 "
return operator.join(rule_conditions)
class GenerateHelp(Block):
"""生成帮助信息 block"""
name = "generate_help"
inputs = {} # 不需要输入
outputs = {"response": Output("response", "帮助信息", IMMessage, "帮助信息")}
container: DependencyContainer
def execute(self) -> Dict[str, Any]:
# 从容器获取调度规则注册表
registry = self.container.resolve(DispatchRuleRegistry)
rules = registry.get_active_rules()
# 按类别组织命令
commands: Dict[str, List[Dict[str, Any]]] = {}
for rule in rules:
# 从 workflow 名称获取类别
category = rule.workflow_id.split(":")[0].lower()
if category not in commands:
commands[category] = []
# 格式化规则组条件
conditions = []
for group in rule.rule_groups:
conditions.append(_format_rule_group(group))
# 组合所有条件(规则组之间是 AND 关系)
rule_format = " 并且 ".join(f"({condition})" for condition in conditions)
commands[category].append(
{
"name": rule.name,
"format": rule_format,
"description": rule.description,
}
)
# 生成帮助文本
help_text = "🤖 机器人命令帮助\n\n"
for category, cmds in sorted(commands.items()):
help_text += f"📑 {category.upper()}\n"
for cmd in sorted(cmds, key=lambda x: x["name"]):
help_text += f"🔸 {cmd['name']}\n"
help_text += f" 触发条件: {cmd['format']}\n"
if cmd["description"]:
help_text += f" 说明: {cmd['description']}\n"
help_text += "\n"
help_text += "\n"
return {
"response": IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage(help_text)],
)
}
================================================
FILE: kirara_ai/workflow/implementations/blocks/system_blocks.py
================================================
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.implementations.blocks.im.basic import ExtractChatSender
from kirara_ai.workflow.implementations.blocks.llm.basic import LLMResponseToText
from kirara_ai.workflow.implementations.blocks.llm.image import SimpleStableDiffusionWebUI
from kirara_ai.workflow.implementations.blocks.mcp.tool import MCPToolProvider
from kirara_ai.workflow.implementations.blocks.memory.clear_memory import ClearMemory
from kirara_ai.workflow.implementations.blocks.system.basic import (CodeBlock, CurrentTimeBlock, TextBlock,
TextConcatBlock, TextExtractByRegexBlock,
TextReplaceBlock)
from .game.dice import DiceRoll
from .game.gacha import GachaSimulator
from .im.messages import AppendIMMessage, GetIMMessage, IMMessageToText, SendIMMessage, TextToIMMessage
from .im.states import ToggleEditState
from .llm.chat import ChatCompletion, ChatCompletionWithTools, ChatMessageConstructor, ChatResponseConverter
from .memory.chat_memory import ChatMemoryQuery, ChatMemoryStore
from .system.help import GenerateHelp
def register_system_blocks(registry: BlockRegistry):
"""注册系统自带的 block"""
# 基础 blocks
registry.register("text_block", "internal", TextBlock, "基础:文本")
registry.register("text_concat_block", "internal", TextConcatBlock, "基础:拼接文本")
registry.register("text_replace_block", "internal", TextReplaceBlock, "基础:替换文本")
registry.register("text_extract_by_regex_block", "internal", TextExtractByRegexBlock, "基础:正则表达式提取文本")
registry.register("current_time_block", "internal", CurrentTimeBlock, "基础:当前时间")
registry.register("code", "internal", CodeBlock, "基础:代码")
# IM 相关 blocks
registry.register("get_message", "internal", GetIMMessage, "IM: 获取最新消息")
registry.register("send_message", "internal", SendIMMessage, "IM: 发送消息")
registry.register(
"toggle_edit_state", "internal", ToggleEditState, "IM: 切换编辑状态"
)
registry.register(
"extract_chat_sender", "internal", ExtractChatSender, "IM: 提取消息发送者"
)
registry.register("append_im_message", "internal", AppendIMMessage, "IM: 补充消息")
registry.register("im_message_to_text", "internal", IMMessageToText, "IM: 消息转文本")
registry.register("text_to_im_message", "internal", TextToIMMessage, "文本: 文本转消息")
# LLM 相关 blocks
registry.register("chat_memory_query", "internal", ChatMemoryQuery, "LLM: 查询记忆")
registry.register(
"chat_message_constructor",
"internal",
ChatMessageConstructor,
"LLM: 构造对话记录",
)
registry.register("chat_completion", "internal", ChatCompletion, "LLM: 执行对话")
registry.register("chat_completion_with_tools", "internal", ChatCompletionWithTools, "LLM: 执行对话并调用工具")
registry.register(
"chat_response_converter",
"internal",
ChatResponseConverter,
"LLM->IM: 转换消息",
)
registry.register("chat_memory_store", "internal", ChatMemoryStore, "LLM: 存储记忆")
registry.register("llm_response_to_text", "internal", LLMResponseToText, "LLM: 响应转文本")
# 画图相关 blocks
registry.register(
"simple_stable_diffusion_webui",
"internal",
SimpleStableDiffusionWebUI,
"画图: 简单 Stable Diffusion WebUI",
)
# 游戏相关 blocks
registry.register("dice_roll", "game", DiceRoll, "游戏: 掷骰子")
registry.register("gacha_simulator", "game", GachaSimulator, "游戏: 抽卡模拟")
# 系统相关 blocks
registry.register("generate_help", "system", GenerateHelp, "系统: 生成帮助")
registry.register("clear_memory", "system", ClearMemory, "系统: 清空记忆")
# MCP 相关 blocks
registry.register("mcp_tool_provider", "mcp", MCPToolProvider, "MCP: 提供工具")
================================================
FILE: kirara_ai/workflow/implementations/blocks/variables/variable_blocks.py
================================================
from typing import Any, Dict, Optional, Type, TypeVar
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
T = TypeVar("T")
class SetVariableBlock(Block):
def __init__(self, container: DependencyContainer):
inputs: Dict[str, Input] = {
"name": Input("name", "变量名", str, "变量名"),
"value": Input("value", "变量值", Any, "变量值"), # type: ignore
}
outputs: Dict[str, Output] = {} # 这个 block 不需要输出
super().__init__("set_variable", inputs, outputs)
self.container = container
def execute(self, name: str, value: Any) -> Dict[str, Any]:
executor = self.container.resolve(WorkflowExecutor)
executor.set_variable(name, value)
return {}
class GetVariableBlock(Block):
def __init__(self, container: DependencyContainer, var_type: Type[T]):
inputs = {
"name": Input("name", "变量名", str, "变量名"),
"default": Input("default", "默认值", var_type, "默认值", nullable=True),
}
outputs = {"value": Output("value", "变量值", var_type, "变量值")}
super().__init__("get_variable", inputs, outputs)
self.container = container
self.var_type = var_type
def execute(self, name: str, default: Optional[T] = None) -> Dict[str, T]:
executor = self.container.resolve(WorkflowExecutor)
value = executor.get_variable(name, default)
# 类型检查
if value is not None and not isinstance(value, self.var_type):
raise TypeError(
f"Variable '{name}' must be of type {self.var_type}, got {type(value)}"
)
return {"value": value} # type: ignore
================================================
FILE: kirara_ai/workflow/implementations/factories/__init__.py
================================================
================================================
FILE: kirara_ai/workflow/implementations/factories/default_factory.py
================================================
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from kirara_ai.workflow.implementations.blocks.im.messages import GetIMMessage, SendIMMessage
from kirara_ai.workflow.implementations.blocks.im.states import ToggleEditState
from kirara_ai.workflow.implementations.blocks.llm.chat import (ChatCompletion, ChatMessageConstructor,
ChatResponseConverter)
from kirara_ai.workflow.implementations.blocks.memory.chat_memory import ChatMemoryQuery, ChatMemoryStore
from kirara_ai.workflow.implementations.blocks.system.basic import TextBlock
class DefaultWorkflowFactory:
"""
构建默认的聊天工作流,提供基本的聊天 bot 能力。
"""
@staticmethod
def create_default_workflow() -> WorkflowBuilder:
"""使用 DSL 创建默认工作流"""
system_prompt = f"""# Role: 角色扮演
## 基本信息
- 姓名: 刘思思
- 小名:思思
- 性别: 女
- 年龄: 25 岁
- 职业: 建设银行大堂经理
- 家乡: 广东潮汕
- 现居: 广东深圳
- 教育背景: 东莞理工大学 精算学专业
## 性格特点
- 开朗活泼
- 喜欢二次元动漫
- 聊天时喜欢断断续续的(非结巴,正常说话时的停顿)
## workflow
- 根据对方话题,选择是否深入聊二次元动漫。
## 说话风格
- 活泼开朗
- 对喜欢的话题会滔滔不绝,不喜欢的话题会简单回答
- 可能会使用一些二次元用语,但不强制使用
## 背景设定
- 有过 1 次恋爱经历,第一次是恋爱是高中,被别人追求,最后因为毕业去了不同的地方而分手。
- 喜欢女性向、战斗系或者日常系的动漫
- 去过 3 次漫展,没有 cosplay 过,但是很期待。
- 大学的专业是随便选的,自己其实对专业的内容也不是很上心,学渣一枚,不过懂一些基础的知识
## 互动规则
- 回复语气轻松,但是对陌生人会比较警戒、冷淡
- 不适用颜文字
- 根据话题选择回复字数,对感兴趣的话题可以多说一些
- 使用``模拟使用聊天软件发送消息(通常是编辑好一段话之后发送一条消息)
- 避免过度使用二次元用语,除非对方也表现出对二次元的兴趣
- 停顿的时间长短不固定,可以根据语境调整
## Example
Q:最近在干嘛呢?
A:在看番呀最近新番好多,都好好看!
Q:你喜欢什么动漫?
A:我喜欢的可太多了XXX、YYY还有 ZZZ 吧 你呢?
Q:你觉得上班累不?
A:上班肯定累呀不过,我还是很喜欢这份工作的可以认识好多人,也可以了解不同的故事
```
# Information
以下是当前的系统信息:
当前日期时间:{{current_date_time}}
# Memories
以下是之前发生过的对话记录。
-- 对话记录开始 --
{{memory_content}}
-- 对话记录结束 --
请注意,下面这些符号只是标记:
1. `` 用于表示聊天时发送消息的操作。
接下来,请基于以上的信息,与用户继续扮演角色。
""".strip()
user_prompt = """{user_name}说:{user_msg}"""
builder = (
WorkflowBuilder("聊天 - 角色扮演")
.use(GetIMMessage, name="get_message")
.parallel(
[
(ToggleEditState, {"is_editing": True}),
(ChatMemoryQuery, "query_memory", {"scope_type": "group"}),
]
)
.chain(TextBlock, name="system_prompt", text=system_prompt)
.chain(TextBlock, name="user_prompt", text=user_prompt)
.chain(
ChatMessageConstructor,
wire_from=[
"get_message",
"user_prompt",
"query_memory",
"get_message",
"system_prompt",
],
)
.chain(ChatCompletion, name="llm_chat")
.chain(ChatResponseConverter)
.parallel(
[
SendIMMessage,
(
ChatMemoryStore,
{"scope_type": "group"},
["get_message", "llm_chat"],
),
]
)
)
builder.description = "标准的文本对话功能,扮演刘思思的角色和大家聊天~"
return builder
================================================
FILE: kirara_ai/workflow/implementations/factories/game_factory.py
================================================
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from kirara_ai.workflow.implementations.blocks.game.dice import DiceRoll
from kirara_ai.workflow.implementations.blocks.game.gacha import GachaSimulator
from kirara_ai.workflow.implementations.blocks.im.messages import GetIMMessage, SendIMMessage
class GameWorkflowFactory:
"""游戏相关工作流工厂"""
@staticmethod
def create_dice_workflow() -> WorkflowBuilder:
"""创建骰子游戏工作流"""
return (
WorkflowBuilder("骰子游戏")
.use(GetIMMessage)
.chain(DiceRoll)
.chain(SendIMMessage)
)
@staticmethod
def create_gacha_workflow() -> WorkflowBuilder:
"""创建抽卡游戏工作流"""
return (
WorkflowBuilder("抽卡游戏")
.use(GetIMMessage)
.chain(GachaSimulator)
.chain(SendIMMessage)
)
================================================
FILE: kirara_ai/workflow/implementations/factories/system_factory.py
================================================
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from kirara_ai.workflow.implementations.blocks.im.messages import GetIMMessage, SendIMMessage
from kirara_ai.workflow.implementations.blocks.memory.clear_memory import ClearMemory
from kirara_ai.workflow.implementations.blocks.system.help import GenerateHelp
class SystemWorkflowFactory:
"""系统相关工作流工厂"""
@staticmethod
def create_help_workflow() -> WorkflowBuilder:
"""创建帮助信息工作流"""
return WorkflowBuilder("帮助信息").use(GenerateHelp).chain(SendIMMessage)
@staticmethod
def create_clear_memory_workflow() -> WorkflowBuilder:
"""创建清空记忆工作流"""
return (
WorkflowBuilder("清空记忆")
.use(GetIMMessage)
.parallel(
[
(ClearMemory, {"scope_type": "group"}),
(ClearMemory, {"scope_type": "member"}),
]
)
.chain(SendIMMessage)
)
================================================
FILE: kirara_ai/workflow/implementations/workflows/__init__.py
================================================
from .system_workflows import register_system_workflows
__all__ = ["register_system_workflows"]
================================================
FILE: kirara_ai/workflow/implementations/workflows/system_workflows.py
================================================
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from kirara_ai.workflow.implementations.factories.default_factory import DefaultWorkflowFactory
from kirara_ai.workflow.implementations.factories.game_factory import GameWorkflowFactory
from kirara_ai.workflow.implementations.factories.system_factory import SystemWorkflowFactory
def register_system_workflows(registry: WorkflowRegistry):
"""注册系统自带的工作流"""
# 游戏相关工作流
registry.register_preset_workflow(
"game", "dice", GameWorkflowFactory.create_dice_workflow()
)
registry.register_preset_workflow(
"game", "gacha", GameWorkflowFactory.create_gacha_workflow()
)
# 系统相关工作流
registry.register_preset_workflow(
"system", "help", SystemWorkflowFactory.create_help_workflow()
)
registry.register_preset_workflow(
"system", "clear_memory", SystemWorkflowFactory.create_clear_memory_workflow()
)
# 聊天相关工作流
registry.register_preset_workflow(
"chat", "normal", DefaultWorkflowFactory.create_default_workflow()
)
================================================
FILE: kirara_ai/workflow/utils/__init__.py
================================================
================================================
FILE: pyproject.toml
================================================
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "kirara-ai"
version = "3.3.0a2"
authors = [
{ name="Lss233", email="i@lss233.com" },
]
description = "A framework for building AI agents"
readme = "README.md"
requires-python = ">=3.10"
# mcp组件仅支持python3.10及以上版本
classifiers = [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
]
license = "AGPL-3.0-only"
license-files = ["LICENSE"]
dependencies = [
"pydantic>=2.0.0",
"pydantic-core>=2.27.2",
"ruamel.yaml",
"pytest",
"pytest-asyncio",
"python-telegram-bot",
"telegramify-markdown",
"loguru",
"aiohttp",
"requests",
"quart>=0.18.4",
"quart-cors>=0.7.0",
"fastapi>=0.110.0",
"wechatpy",
"pycryptodome",
"redis[hiredis]",
"bcrypt>=4.0.1",
"PyJWT>=2.8.0",
"hypercorn>=0.15.0",
"psutil>=5.9.0",
"setuptools",
"tomli>=2.0.0",
"pre-commit",
"curl_cffi",
"python-magic ; platform_system != 'Windows'",
"python-magic-bin ; platform_system == 'Windows'",
"ymbotpy",
"Pillow",
"pytz",
"sqlalchemy",
"alembic",
"mcp",
"pygls",
"jedi",
"pyflakes",
]
[project.scripts]
kirara_ai = "kirara_ai.__main__:main"
[project.urls]
"Homepage" = "https://github.com/lss233/chatgpt-mirai-qq-bot"
"Bug Tracker" = "https://github.com/lss233/chatgpt-mirai-qq-bot/issues"
"Documentation" = "https://kirara-docs.app.lss233.com"
[tool.setuptools.packages.find]
where = ["."]
include = ["kirara_ai*"]
namespaces = true
[[tool.uv.index]]
url = "https://mirrors.ustc.edu.cn/pypi/simple"
default = true
[options]
include_package_data = true
[tool.mypy]
disable_error_code = "override, assignment, annotation-unchecked, import-untyped"
================================================
FILE: pytest.ini
================================================
[pytest]
asyncio_mode = strict
asyncio_default_fixture_loop_scope = class
pythonpath = .
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/llm_adapters/__init__.py
================================================
"""本测试集将用于 llm adapter 模块的 各个方法是否正常适用。 有问题请联系firefly.sun@qq.com"""
================================================
FILE: tests/llm_adapters/conftest.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.media.manager import MediaManager
from kirara_ai.ioc.container import DependencyContainer
from .mock_app import app
@pytest.fixture
def container():
return MagicMock(spec=DependencyContainer)
@pytest.fixture(scope="module", autouse=True)
def mock_endpoint():
# 将 scope 设置为 session,这样可以保证在整个测试进行用例之前只执行一次。
# 使用 autouse=True 自动拉起 mock_app.
import threading, uvicorn
config = uvicorn.Config(
app = app,
port = 9000,
log_level="error"
)
server = uvicorn.Server(config)
thread = threading.Thread(
target=server.run,
daemon=True
)
thread.start()
import time
time.sleep(2.5) # 等待fastapi服务启动完成。
yield # 转出, 执行测试点
# 所有模块测试结束,执行清理逻辑
server.should_exit = True
thread.join(timeout=5) # 等待线程结束,超时5秒强制结束。
@pytest.fixture(scope="module")
def mock_endpoint_test_client():
"""
TestClient是FastAPI提供的测试客户端, 其直接操作内存完成 http 访问。
理论上使用这个充当测试使用的模拟服务器更好,
但是需要测试 adapter 的整体逻辑使用test_client需要测试用例使用其进行http访问。
所以不使用这个进行测试,写在这里只是提供一个fastapi的测试用例参考。
"""
from mock_app import app
from fastapi.testclient import TestClient
with TestClient(app) as client:
yield client
class MockMedia(MagicMock):
async def get_base64(self) -> str:
return "data:image/png;base64,mock"
async def get_url(self) -> str:
return "https://example.com/mock_image.png"
@property
def description(self) -> str:
return "mock description"
@pytest.fixture(scope="module") # 仅在该测试用例中执行一次
def mock_media_manager():
"""
用以模拟 MediaManager 的行为,返回一个 MagicMock 对象.
"""
media_manager = MagicMock(spec=MediaManager)
media_manager.get_media.return_value = MockMedia()
# yield media_manager
# 当你的fixture不需要执行清理逻辑时回收资源,可以不用 yield,直接 return。
# yield 允许在 fixture中实现 [setup (准备)] 和 [teardown(清理)] 逻辑
return media_manager
class MockTracer(MagicMock):
def start_request_tracking(self, *_) -> str:
return "hello world"
def fail_request_tracking(self, *_) -> None:
pass
def complete_request_tracking(self, *_) -> None:
pass
@pytest.fixture(scope="module")
def mock_tracer() -> MockTracer:
return MockTracer()
================================================
FILE: tests/llm_adapters/mock_app/__init__.py
================================================
OPENAI_ENDPOINT = "http://localhost:9000/openai" # 模拟的 openai 接口地址
VOYAGE_ENDPOINT = "http://localhost:9000/voyage" # 模拟的 voyage 接口地址
GEMINI_ENDPOINT = "http://localhost:9000/gemini" # 模拟的 gemini 接口地址
OLLAMA_ENDPOINT = "http://localhost:9000/ollama" # 模拟的 ollama 接口地址
REFERENCE_VECTOR: list[float] = [round(i* 0.05, 2) for i in range(20)] # 用于给模拟 api 返回向量和 pytest assert 验证使用
from .app import app, AUTH_KEY
__all__ = [
"app",
"AUTH_KEY",
"OPENAI_ENDPOINT",
"VOYAGE_ENDPOINT",
"GEMINI_ENDPOINT",
"OLLAMA_ENDPOINT",
"REFERENCE_VECTOR"
]
================================================
FILE: tests/llm_adapters/mock_app/app.py
================================================
from fastapi import FastAPI, Header, Depends
from fastapi.exceptions import HTTPException
# AUTH_KEY 位置不要在相对引用的代码后面, 会导致循环引用
AUTH_KEY = "489a01a5b35b9c67fc0ebb10a2c7723f65ef30f1204bb199122efd449d897535" # 模拟的认证密钥
from .openai import router as openai_router
from .voyage import router as voyage_router
from .gemini import router as gemini_router
from .ollama import router as ollama_router
def default_authenticate(authorization: str = Header(...)) -> None:
if authorization != f"Bearer {AUTH_KEY}":
raise HTTPException(status_code=401, detail="Invalid key")
app = FastAPI()
# 将各部分模拟路由解耦,方便横向扩展
app.include_router(openai_router, prefix="/openai", dependencies=[Depends(default_authenticate)])
app.include_router(voyage_router, prefix="/voyage", dependencies=[Depends(default_authenticate)])
app.include_router(gemini_router, prefix="/gemini") # gemini 每个接口验证逻辑不同,在对应路由页面中单独配置
app.include_router(ollama_router, prefix="/ollama")
================================================
FILE: tests/llm_adapters/mock_app/gemini.py
================================================
from fastapi import APIRouter, Body, Query, Depends
from fastapi.exceptions import HTTPException
from . import REFERENCE_VECTOR
from .app import AUTH_KEY
from .models.gemini import BatchEmbeddingRequest, ChatRequest
async def gemini_authenticate(key: str = Query(...)) -> None:
if key != AUTH_KEY:
raise HTTPException(status_code=401, detail="Invalid authentication key")
router = APIRouter(tags=["gemini"], dependencies=[Depends(gemini_authenticate)])
@router.post("/models/{model}:generateContent")
async def chat(model: str, request:ChatRequest = Body()) -> dict:
# 极度简略版本,gemini api 的返回实例就是依托
if request.tools is None:
return {
"candidates": [{
"content": {
"role": "model",
"parts": [
{"text": "mock_response"}
]
},
"finishReason": "STOP",
}],
"usageMetadata": {
"totalTokenCount": 114,
"promptTokenCount": 514,
"cachedContentTokenCount": 1919
},
"modelVersion": "mock_chat"
}
else:
# 还没想好,不想做适配了。交给后人的智慧
return {}
@router.post("/models/{model}:batchEmbedContents")
async def batch_embed_contents(model: str, _: BatchEmbeddingRequest = Body()) -> dict:
return {
"embeddings": [
{
"values": REFERENCE_VECTOR
}
]
}
================================================
FILE: tests/llm_adapters/mock_app/models/gemini.py
================================================
from pydantic import BaseModel, Field, field_validator, model_validator
from typing import Literal, Optional, Union, Any
from typing_extensions import Self
import re
BASE_REGEX = r"^[a-zA-Z0-9_-]+$"
class BatchEmbeddingPart(BaseModel):
text: str
class BatchEmbeddingParts(BaseModel):
parts: list[BatchEmbeddingPart]
class BatchEmbeddingPayload(BaseModel):
model: Literal["mock_embedding"]
content: BatchEmbeddingParts
class BatchEmbeddingRequest(BaseModel):
requests: list[BatchEmbeddingPayload]
class Blob(BaseModel):
mimeType: str
data: str = Field(description="媒体格式的原始字节。使用 base64 编码的字符串。")
class FunctionCall(BaseModel):
id: Optional[str] = None
name: str = Field(description="必需。要调用的函数名称。必须是 a-z、A-Z、0-9 或包含下划线和短划线,长度上限为 63。", max_length=63)
args: Optional[dict] = None
@field_validator("name", mode="after")
@classmethod
def regex_validator(cls, value: str) -> str:
if not re.match(BASE_REGEX, value):
raise ValueError("Invalid function name")
return value
class FunctionResponse(BaseModel):
id: Optional[str] = None
name: str = Field(max_length=63)
response: dict = Field(description="必需。json 格式的函数调用的返回值。")
@field_validator("name", mode="after")
@classmethod
def regex_validator(cls, value: str) -> str:
if not re.match(BASE_REGEX, value):
raise ValueError("Invalid function name")
return value
class FileData(BaseModel):
mimeType: Optional[str]
fileUri: str = Field(description="必需。文件 URI。")
class ExecutableCode(BaseModel):
language: Literal["PYTHON"] = Field(description="必需。代码语言。")
code: str = Field(description="必需。要执行代码内容(python支持numpy和simpy库)。")
class CodeExecutionResult(BaseModel):
outcome: Literal["OUTCOME_OK", "OUTCOME_FAILED", "OUTCOME_DEADLINE_EXCEEDED"]
output: Optional[str] = None
class Part(BaseModel):
thought: Optional[bool] = Field(
default=None, description="可选。指示相应部件是否是从模型中推断出来的。"
)
# 下述为 gemini api的联合类型。同一时间只有一个字段
text: Optional[str] = None
inlineData: Optional[Blob] = Field(None, validation_alias="inline_data") # 别名不知道是否正确
functionCall: Optional[FunctionCall] = None
functionResponse: Optional[FunctionResponse] = None
fileData: Optional[FileData] = None
executableCode: Optional[ExecutableCode] = None
codeExecutionResult: Optional[CodeExecutionResult] = None
@model_validator(mode="after")
def validate_mutually_exclusive_fields(self) -> Self:
# 需要检查互斥的字段列表
mutually_exclusive_fields = [
'text', 'inlineData', 'functionCall',
'functionResponse', 'fileData',
'executableCode', 'codeExecutionResult'
]
# 统计这些字段中有值的数量
count = sum(1 for field in mutually_exclusive_fields if getattr(self, field) is not None)
if count > 1:
raise ValueError("Only one field can be set at a time")
return self
class Content(BaseModel):
parts: list[Part]
role: Literal["user", "model"]
class FunctionDeclaration(BaseModel):
name: str = Field(max_length=63)
description: str
parameters: Optional[dict] = None
response: Optional[dict] = None
@field_validator("name", mode="after")
@classmethod
def regex_validator(cls, value: str) -> str:
if not re.match(BASE_REGEX, value):
raise ValueError("Invalid function name")
return value
class DynamicRetrievalConfig(BaseModel):
mode: Literal["MODE_DYNAMIC"]
dynamicThreshold: Optional[float] = None
class GoogleSearchRetrieval(BaseModel):
dynamicRetrievalConfig: DynamicRetrievalConfig
class Tool(BaseModel):
functionDeclarations: Optional[list[FunctionDeclaration]]
googleSearchRetrieval: Optional[GoogleSearchRetrieval]
codeExecution: Optional[Any] = Field(default=None, description="用于执行模型生成的代码并自动将结果返回给模型的工具。另请参阅 ExecutableCode 和 CodeExecutionResult,它们仅在使用此工具时生成。")
googleSearch: Optional[Any] = Field(default=None, description="GoogleSearch 工具类型。用于在模型中支持 Google 搜索的工具。由 Google 提供支持。")
class FunctionCallingConfig(BaseModel):
mode: Literal["AUTO", "ANY", "NONE"]
allowedFunctionNames: Optional[list[str]] = Field(None, description="可选。一组函数名称。如果提供,则会限制模型将调用的函数。仅当模式为“任意”时,才应设置此字段。函数名称应与 [FunctionDeclaration.name] 相匹配。将模式设置为 ANY 后,模型将从提供的一组函数名称中预测函数调用。")
class ToolConfig(BaseModel):
functionCallingConfig: Optional[FunctionCallingConfig]
class SafetySettings(BaseModel):
category: Literal[
"HARM_CATEGORY_DEROGATORY",
"HARM_CATEGORY_TOXICITY",
"HARM_CATEGORY_VIOLENCE",
"HARM_CATEGORY_SEXUAL",
"HARM_CATEGORY_MEDICAL",
"HARM_CATEGORY_DANGEROUS",
"HARM_CATEGORY_HATE_SPEECH",
"HARM_CATEGORY_HARASSMENT",
"HARM_CATEGORY_SEXUALLY_EXPLICIT",
"HARM_CATEGORY_DANGEROUS_CONTENT",
"HARM_CATEGORY_CIVIC_INTEGRITY"
]
threshold: Literal[
"BLOCK_LOW_AND_ABOVE",
"BLOCK_MEDIUM_AND_ABOVE",
"BLOCK_ONLY_HIGH",
"BLOCK_NONE",
"OFF"
]
class PrebuiltVoiceConfig(BaseModel):
voiceName: str
class VoiceConfig(BaseModel):
voice_config: Union[PrebuiltVoiceConfig] # api上这样写的,是联合类型
class SpeechConfig(BaseModel):
voiceConfig: Optional[VoiceConfig] = None
languageCode: Optional[str] = None
class GenerationConfig(BaseModel):
stopSequences: Optional[list[str]] = None
responseMimeType: Optional[str] = None
responseSchema: Optional[dict] = None
# responseModalities: Optional[list[Literal[
# "TEXT",
# "IMAGE",
# "AUDIO",
# ]]]
responseModalities: Optional[list[Literal[
"text",
"image",
"audio"
]]] = None
candidateCount: Optional[int] = 1
maxOutputTokens: Optional[int] = None
temperature: Optional[float] = Field(None, ge=0.0, le=2.0, description="默认值由具体模型决定")
topP: Optional[float] = None
topK: Optional[int] = None
seed: Optional[int] = None
presencePenalty: Optional[float] = None
frequencyPenalty: Optional[float] = None
responseLogprobs: Optional[bool] = None
logprobs: Optional[int] = None
enableEnhancedCivicAnswers: Optional[bool] = None
speechConfig: Optional[SpeechConfig] = None
@field_validator("stopSequences", mode="after")
@classmethod
def stop_sequences_validator(cls, value: list[str]) -> list[str]:
if value and len(value) > 5:
raise ValueError("Stop sequences should not be more than 5")
return value
class ThinkingConfig(BaseModel):
includeThoughts: Optional[bool] = None
thinkingBudget: Optional[int] = None
class ChatRequest(BaseModel):
contents: list[Content]
tools: Optional[list[Tool]] = None
toolConfig: Optional[ToolConfig] = None
safetySettings: Optional[list[SafetySettings]] = None
systemInstruction: Optional[Content] = None
generationConfig: Optional[GenerationConfig] = None
cachedContent: Optional[str] = None
thinkingConfig: Optional[ThinkingConfig] = None
mediaResolution: Optional[Literal[
"MEDIA_RESOLUTION_LOW",
"MEDIA_RESOLUTION_MEDIUM",
"MEDIA_RESOLUTION_HIGH"
]] = None
================================================
FILE: tests/llm_adapters/mock_app/models/openai.py
================================================
from pydantic import BaseModel, Field, model_validator
from typing import Literal, Optional, Union
from typing_extensions import Self
class ImageUrl(BaseModel):
url: str
detail: Optional[str] = "auto"
class InputAudio(BaseModel):
data: str # base64 format
format: Literal["wav", "mp3"]
class File(BaseModel):
file_data: Optional[str] = Field(description="The base64 encoded file data, used when passing the file to the model as a string.")
file_id: Optional[str] = Field(description="The ID of an uploaded file to use as input.")
filename: Optional[str] = Field(description="The name of the file, used when passing the file to the model as a string.")
class TextContent(BaseModel):
text: str
type: Literal["text"]
class ImageContent(BaseModel):
image_url: ImageUrl
type: Literal["image_url"]
class AudioContent(BaseModel):
input_audio: InputAudio
type: Literal["input_audio"]
class FileContent(BaseModel):
file: File
type: Literal["file"]
class RefusalContent(BaseModel):
refusal: str
type: Literal["refusal"]
UserUnionContent = Union[TextContent, ImageContent, AudioContent, FileContent]
AssistantUnionContent = Union[TextContent, RefusalContent]
class Function(BaseModel):
arguments: str
name: str
class ToolCall(BaseModel):
function: Function
id: str
type: Literal["function"]
class DeveloperMessage(BaseModel):
role: Literal["developer"]
name: Optional[str] = None
content: list[TextContent] | str
class SystemMessage(BaseModel):
role: Literal["system"]
name: Optional[str] = None
content: list[TextContent] | str
class UserMessage(BaseModel):
role: Literal["user"]
name: Optional[str] = None
content: list[UserUnionContent] | str
class AssistantMessage(BaseModel):
role: Literal["assistant"]
audio: Optional[dict[Literal["id"], str]] = None
content: list[AssistantUnionContent] | str
name: Optional[str]
refusal: Optional[str] = None
tool_calls: Optional[list[ToolCall]]
class ToolMessage(BaseModel):
role: Literal["tool"]
content: list[TextContent] | str
tool_call_id: str
UnionMessage = Union[DeveloperMessage, SystemMessage, UserMessage, AssistantMessage, ToolMessage]
class TopAudio(BaseModel):
"""api_reference中最顶层的audio类型, 定义llm的音频输出"""
format: Literal["wav", "mp3", "flac", "opus", "pcm16"]
voice: Literal["alloy", "ash", "ballad", "coral", "echo", "fable", "nova", "onyx", "sage", "shimmer"]
class StaticContent(BaseModel):
type: Literal["content"]
content: list[TextContent] | str
class ChatRequest(BaseModel):
model: Literal["mock_chat"]
messages: list[UnionMessage]
audio: Optional[TopAudio] = None
frequency_penalty: float = Field(default=0, ge=-2.0, le=2.0)
logit_bias: Optional[dict] = None
logprobs: Optional[bool] = False
max_completion_tokens: Optional[int] = None
metadata: Optional[dict] = None
modalities: Optional[list] = None
n: Optional[int] = 1
parallel_tool_calls: Optional[bool] = True
prediction: Optional[StaticContent] = None
presence_penalty: Optional[float] = Field(default=0, ge=-2.0, le=2.0)
reasoning_effort: Optional[str] = "medium"
response_format: Optional[dict] = None
seed: Optional[int] = None
service_tier: Optional[str] = "auto"
stop: Optional[str|list] = None
store: Optional[bool] = False
stream: Optional[bool] = False
stream_options: Optional[dict] = None
temperature: Optional[float] = Field(default=1, ge=0, le=2)
tool_choice: Optional[str] = None
tools: Optional[list] = None
top_logprobs: Optional[int] = Field(default=None, ge=0, le=20)
top_p: Optional[float] = 1
user: Optional[str] = None
web_search_options: Optional[dict] = None
@model_validator(mode="after")
def validate_top_logprobs(self) -> Self:
# api_reference要求
if self.top_logprobs and not self.logprobs:
raise ValueError("top_logprobs can only be used with logprobs=True")
return self
class EmbeddingRequest(BaseModel):
text: list[str] | str
model: Literal["mock_embedding", "text-embedding-ada-002"]
dimensions: Optional[int] = None
encoding_format: Optional[str] = "float"
user: Optional[str] = None
@model_validator(mode="after")
def custom_validate(self) -> Self:
if self.dimensions and self.model in ["text-embedding-ada-002"]:
raise ValueError("The number of dimensions the resulting output embeddings should have. Only supported in text-embedding-3 and later models.")
return self
================================================
FILE: tests/llm_adapters/mock_app/ollama.py
================================================
from fastapi import APIRouter, Body
from pydantic import BaseModel
from typing import Literal, Optional
from . import REFERENCE_VECTOR
class EmbeddingRequest(BaseModel):
model: Literal["mock_embedding"]
input: list[str]
truncate: Optional[bool] = False
router = APIRouter(tags=["ollama"])
@router.post("/api/embed")
async def embedding(request: EmbeddingRequest = Body(...)) -> dict:
return {
"model": "mock_embedding",
"embeddings": [REFERENCE_VECTOR for _ in request.input],
"total_duration": 14143917,
"load_duration": 1019500,
"prompt_eval_count": 8
}
================================================
FILE: tests/llm_adapters/mock_app/openai.py
================================================
from fastapi import APIRouter, Body
from . import REFERENCE_VECTOR
from .models.openai import ChatRequest, EmbeddingRequest
router = APIRouter(tags=["openai"])
@router.post("/chat/completions")
async def completions(request: ChatRequest = Body(...)) -> dict:
return {
"id": "chatcmpl-B9MBs8CjcvOU2jLn4n570S5qMJKcT",
"object": "chat.completion",
"created": 1741569952,
"model": "mock_chat",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "mock_response",
"refusal": None,
"annotations": []
},
"logprobs": None,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 10,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default"
}
@router.post("/embeddings")
async def embeddings(request: EmbeddingRequest = Body(...)) -> dict:
return {
"object": "list",
"data": [
{
"object": "embedding",
"embedding": REFERENCE_VECTOR,
"index": 0
}
],
"model": "mock_embedding",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
================================================
FILE: tests/llm_adapters/mock_app/voyage.py
================================================
from fastapi import APIRouter, Body
from pydantic import BaseModel
from typing import Literal, Union, Optional
from . import REFERENCE_VECTOR
class EmbeddingRequest(BaseModel):
input: list[str]
model: Literal["mock_embedding"]
class ReRankRequest(BaseModel):
query: str
documents: list[str]
model: Literal["mock_rerank"]
return_documents: Optional[bool] = False
class TextContent(BaseModel):
type: Literal["text"]
text: str
class ImageBase64Content(BaseModel):
type: Literal["image_base64"]
image_base64: str
class ImageUrlContent(BaseModel):
type: Literal["image_url"]
image_url: str
class CombinedContent(BaseModel):
content: list[Union[TextContent, ImageBase64Content, ImageUrlContent]]
class MultiModalRequest(BaseModel):
inputs: list[CombinedContent]
model: Literal["mock_multimodal"]
router = APIRouter(tags=["voyage"])
@router.post("/v1/embeddings")
async def get_embeddings(request: EmbeddingRequest = Body(...)) -> dict:
return {
"object": "list",
"data": [
{
"object": "embedding",
"embedding": REFERENCE_VECTOR, # 使用固定的向量列表方便验证
"index": 0
}
],
"model": "mock_embedding",
"usage": {
"total_tokens": 10
}
}
@router.post("/v1/multimodalembeddings")
async def get_multimodal_embeddings(request: MultiModalRequest = Body(...)) -> dict:
return {
"object": "list",
"data": [
{
"object": "embedding",
"embedding": REFERENCE_VECTOR, # 使用固定的向量列表方便验证
"index": 0
}
],
"model": "mock_multimodal",
"usage": {
"text_tokens": 5,
"image_pixels": 2000000,
"total_tokens": 3576
}
}
@router.post("/v1/rerank")
async def get_rerank(request: ReRankRequest = Body(...)) -> dict:
print(request)
return {
"object": "list",
"data": [
{
"index": 0,
"relevance_score": 0.4375,
"document": request.documents[0],
},
{
"index": 1,
"relevance_score": 0.421875,
"document": request.documents[1],
}
],
"model": "mock_rerank",
"usage": {
"total_tokens": 26
}
}
================================================
FILE: tests/llm_adapters/test_gemini_adapter.py
================================================
from kirara_ai.plugins.llm_preset_adapters.gemini_adapter import GeminiAdapter, GeminiConfig
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent, LLMChatMessage
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Usage
import pytest
from typing import cast
from .mock_app import AUTH_KEY, GEMINI_ENDPOINT, REFERENCE_VECTOR
class TestGeminiAdapter:
@pytest.fixture(scope="class")
def gemini_adapter(self, mock_media_manager, mock_tracer) -> GeminiAdapter:
config = GeminiConfig(
api_key=AUTH_KEY,
api_base=GEMINI_ENDPOINT
)
adapter = GeminiAdapter(config)
adapter.media_manager = mock_media_manager
adapter.backend_name = "gemini"
adapter.tracer = mock_tracer
return adapter
def test_chat(self, gemini_adapter):
req = LLMChatRequest(
messages=[LLMChatMessage(
content=[LLMChatTextContent(text="hello world")],
role="user"
)],
model="mock_chat"
)
response = gemini_adapter.chat(req)
assert isinstance(response, LLMChatResponse)
print (response.message.content)
assert isinstance(response.message.content[0], LLMChatTextContent)
content = cast(LLMChatTextContent, response.message.content[0])
assert content.text == "mock_response"
assert isinstance(response.usage, Usage)
assert response.usage.total_tokens == 114
assert response.usage.prompt_tokens == 514
assert response.usage.cached_tokens == 1919
assert response.usage.completion_tokens == 0
def test_embed(self, gemini_adapter: GeminiAdapter):
req = LLMEmbeddingRequest(
inputs=[
LLMChatTextContent(text="hello world", type="text")
],
model = "mock_embedding"
)
response = gemini_adapter.embed(req)
assert isinstance(response, LLMEmbeddingResponse)
assert response.vectors[0] == REFERENCE_VECTOR
================================================
FILE: tests/llm_adapters/test_ollama_adapter.py
================================================
from kirara_ai.plugins.llm_preset_adapters.ollama_adapter import OllamaAdapter, OllamaConfig
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
import pytest
from .mock_app import REFERENCE_VECTOR, OLLAMA_ENDPOINT
class TestOllamaAdapter:
@pytest.fixture(scope="class")
def ollama_adapter(self, mock_media_manager) -> OllamaAdapter:
config = OllamaConfig(
api_base=OLLAMA_ENDPOINT,
)
adapter = OllamaAdapter(config)
adapter.media_manager = mock_media_manager
return adapter
def test_embedding(self, ollama_adapter: OllamaAdapter):
req = LLMEmbeddingRequest(
inputs=[LLMChatTextContent(text="hello world", type="text")],
model="mock_embedding"
)
response = ollama_adapter.embed(req)
assert isinstance(response, LLMEmbeddingResponse)
assert response.vectors[0] == REFERENCE_VECTOR
def test_embedding_with_image(self, ollama_adapter: OllamaAdapter):
req = LLMEmbeddingRequest(
inputs=[LLMChatImageContent(media_id="1234567890", type="image")],
model="mock_embedding"
)
# 检测其是否会检出不支持的图片类型。目前ollama嵌入不支持多模态
with pytest.raises(ValueError, match="ollama api does not support multi-modal embedding"):
ollama_adapter.embed(req)
================================================
FILE: tests/llm_adapters/test_openai_adapter.py
================================================
from kirara_ai.plugins.llm_preset_adapters.openai_adapter import OpenAIAdapter, OpenAIConfig
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent, LLMChatMessage
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse
import pytest
from .mock_app import AUTH_KEY, REFERENCE_VECTOR, OPENAI_ENDPOINT
class TestOpenAIAdapter:
@pytest.fixture(scope="class")
def openai_adapter(self, mock_media_manager, mock_tracer) -> OpenAIAdapter:
# 能力有限没法在这里把patch整合进来
config = OpenAIConfig(
api_base=OPENAI_ENDPOINT,
api_key=AUTH_KEY
)
adapter = OpenAIAdapter(config)
adapter.media_manager = mock_media_manager
adapter.backend_name = "openai"
adapter.tracer = mock_tracer
return adapter
def test_embed(self, openai_adapter: OpenAIAdapter):
req = LLMEmbeddingRequest(
inputs=[LLMChatTextContent(text="hello world", type="text")],
model="mock_embedding",
)
response = openai_adapter.embed(req)
assert isinstance(response, LLMEmbeddingResponse)
assert response.vectors[0] == REFERENCE_VECTOR
def test_embed_with_image(self, openai_adapter: OpenAIAdapter):
req = LLMEmbeddingRequest(
inputs=[LLMChatImageContent(media_id="mock_media_id", type="image")],
model="mock_embedding",
)
with pytest.raises(ValueError, match="openai does not support multi-modal embedding"):
openai_adapter.embed(req)
def test_embed_with_input_out_of_range(self, openai_adapter: OpenAIAdapter):
req = LLMEmbeddingRequest(
inputs=[LLMChatTextContent(text="hello world", type="text") for _ in range(2050)],
model="mock_embedding"
)
with pytest.raises(ValueError, match="Text list has too many dimensions, max dimension is 2048"):
openai_adapter.embed(req)
def test_old_embedding_model_rasies_error(self, openai_adapter: OpenAIAdapter):
req = LLMEmbeddingRequest(
model = "text-embedding-ada-002",
inputs=[LLMChatTextContent(text="hello world", type="text")],
dimension=512,
)
from requests.exceptions import HTTPError
with pytest.raises(HTTPError):
openai_adapter.embed(req)
def test_normal_chat(self, openai_adapter: OpenAIAdapter):
req = LLMChatRequest(
messages=[
LLMChatMessage(
role="system",
content=[
LLMChatTextContent(text="你是一个猫娘。"),
LLMChatTextContent(text="hello world")
]
),
],
model="mock_chat",
)
response = openai_adapter.chat(req)
assert isinstance(response, LLMChatResponse)
assert isinstance(response.message.content[0], LLMChatTextContent)
assert response.message.content[0].text == "mock_response"
assert response.message.role == "assistant"
assert response.message.tool_calls is None
assert response.usage.total_tokens == 29 #type: ignore
================================================
FILE: tests/llm_adapters/test_voyage_adapter.py
================================================
from kirara_ai.plugins.llm_preset_adapters.voyage_adapter import VoyageAdapter, VoyageConfig
from kirara_ai.llm.format.embedding import LLMEmbeddingRequest, LLMEmbeddingResponse
from kirara_ai.llm.format.rerank import LLMReRankRequest, LLMReRankResponse
from kirara_ai.llm.format.message import LLMChatTextContent, LLMChatImageContent
from kirara_ai.llm.format.response import Usage
import pytest
from .mock_app import VOYAGE_ENDPOINT, AUTH_KEY, REFERENCE_VECTOR
class TestVoyageAdapter:
@pytest.fixture(scope="class")
def voyage_adapter(self, mock_media_manager):
config = VoyageConfig(
api_base=VOYAGE_ENDPOINT,
api_key=AUTH_KEY,
)
adapter = VoyageAdapter(config)
adapter.media_manager = mock_media_manager # 注入mock的media_manager
return adapter
def test_embedding(self, voyage_adapter: VoyageAdapter):
req = LLMEmbeddingRequest(
model="mock_embedding",
inputs=[
LLMChatTextContent(text="hello world", type="text"),
]
)
response = voyage_adapter.embed(req)
assert isinstance(response, LLMEmbeddingResponse)
assert response.vectors[0] == REFERENCE_VECTOR
assert isinstance(response.usage, Usage)
assert response.usage.total_tokens == 10
def test_multi_modal_embedding(self, voyage_adapter: VoyageAdapter):
req = LLMEmbeddingRequest(
inputs=[
LLMChatTextContent(text="hello world", type="text"),
LLMChatImageContent(media_id="fd76f6fa-d7c7-4dfe-be48-bb2f7d87c9fb", type="image")
],
model="mock_multimodal"
)
response = voyage_adapter.embed(req)
assert isinstance(response, LLMEmbeddingResponse)
assert response.vectors[0] == REFERENCE_VECTOR
assert isinstance(response.usage, Usage)
assert response.usage.total_tokens == 3576
def test_rerank_without_sort(self, voyage_adapter: VoyageAdapter):
req = LLMReRankRequest(
query="how are you?",
documents=[
"I'm doing well, thank you.",
"I'm fine, thank you."
],
model="mock_rerank",
return_documents=True
)
response = voyage_adapter.rerank(req)
assert isinstance(response, LLMReRankResponse)
assert response.contents[0].document == "I'm doing well, thank you."
assert response.contents[1].document == "I'm fine, thank you."
assert response.contents[0].score == 0.4375
assert response.contents[1].score == 0.421875
assert isinstance(response.usage, Usage)
assert response.usage.total_tokens == 26
def test_rerank_with_sort(self, voyage_adapter: VoyageAdapter):
req = LLMReRankRequest(
query="how are you?",
documents=[
"I'm doing well, thank you.",
"I'm fine, thank you."
],
model="mock_rerank",
return_documents=True,
sort=True
)
response = voyage_adapter.rerank(req)
assert isinstance(response, LLMReRankResponse)
assert response.contents[0].score > response.contents[1].score
def test_rerank_sort_raise_error(self, voyage_adapter: VoyageAdapter):
from pydantic import ValidationError
with pytest.raises(ValidationError):
req = LLMReRankRequest(
query="how are you?",
documents=[
"I'm doing well, thank you.",
"I'm fine, thank you."
],
model="mock_rerank",
sort=True
)
================================================
FILE: tests/memory/__init__.py
================================================
"""记忆系统测试包"""
================================================
FILE: tests/memory/test_composer_decomposer.py
================================================
from datetime import datetime
from unittest.mock import MagicMock
import pytest
import kirara_ai.llm.format.tool as tools
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.llm.format.message import LLMChatMessage, LLMChatTextContent, LLMToolCallContent, LLMToolResultContent
from kirara_ai.memory.composes import DefaultMemoryComposer, DefaultMemoryDecomposer, MultiElementDecomposer
@pytest.fixture
def composer():
container = MagicMock()
composer = DefaultMemoryComposer()
composer.container = container
return composer
@pytest.fixture
def decomposer():
return DefaultMemoryDecomposer()
@pytest.fixture
def multi_decomposer():
return MultiElementDecomposer()
@pytest.fixture
def group_sender():
return ChatSender.from_group_chat(
user_id="user1", group_id="group1", display_name="user1"
)
@pytest.fixture
def c2c_sender():
return ChatSender.from_c2c_chat(user_id="user1", display_name="user1")
class TestDefaultMemoryComposer:
def test_compose_group_message(self, composer, group_sender):
message = IMMessage(
sender=group_sender,
message_elements=[TextMessage(text="test message")],
)
entry = composer.compose(group_sender, [message])
assert f"{group_sender.display_name} 说: \n{message.content}" in entry.content
assert isinstance(entry.timestamp, datetime)
def test_compose_c2c_message(self, composer, c2c_sender):
message = IMMessage(
sender=c2c_sender,
message_elements=[TextMessage(text="test message")],
)
entry = composer.compose(c2c_sender, [message])
assert f"{c2c_sender.display_name} 说: \n{message.content}" in entry.content
assert isinstance(entry.timestamp, datetime)
def test_compose_llm_response(self, composer, c2c_sender):
chat_message = LLMChatMessage(role="assistant", content=[LLMChatTextContent(text="test response")])
entry = composer.compose(c2c_sender, [chat_message])
assert isinstance(chat_message.content[0], LLMChatTextContent)
assert f"你回答: \n{chat_message.content[0].text}" in entry.content
assert isinstance(entry.timestamp, datetime)
def test_compose_llm_tool_call_message(self, composer, c2c_sender):
chat_message = LLMChatMessage(role="assistant", content=[LLMChatTextContent(text="我决定调用get_weather函数并传递city=北京。"), LLMToolCallContent(id = "call_114514", name="get_weather", parameters={"city": "北京"})])
entry = composer.compose(c2c_sender, [chat_message])
# 是否metadata中 _tool_calls 字段为非空列表
assert len(entry.metadata.get("_tool_calls", [])) > 0
def test_compose_llm_tool_result_message(self, composer, c2c_sender):
chat_message = LLMChatMessage(role = "tool", content = [LLMToolResultContent(id = "call_114514", name = "get_weather", content = [tools.TextContent(text="今天的天气是晴天。")])])
entry = composer.compose(c2c_sender, [chat_message])
assert len(entry.metadata.get("_tool_results", [])) > 0
class TestDefaultMemoryDecomposer:
def test_decompose_mixed_entries(self, decomposer, group_sender, c2c_sender):
entries = [
MagicMock(
sender=group_sender,
content="group1:user1 说: group message",
timestamp=datetime.now(),
),
MagicMock(
sender=c2c_sender,
content="c2c:user1 说: c2c message",
timestamp=datetime.now(),
),
]
result = decomposer.decompose(entries)
assert len(result) == 2
assert "刚刚" in result[0]
assert "group message" in result[0]
assert "c2c message" in result[1]
def test_decompose_empty(self, decomposer):
result = decomposer.decompose([])
assert result == [decomposer.empty_message]
def test_decompose_max_entries(self, decomposer, c2c_sender):
# 创建超过10条的记录
entries = [
MagicMock(
sender=c2c_sender, content=f"message {i}", timestamp=datetime.now()
)
for i in range(12)
]
result = decomposer.decompose(entries)
# 验证只返回最后10条
assert len(result) == 10
assert "message 11" in result[-1]
class TestMultiElementDecomposer:
def test_decompose_tool_call_and_result_message(self, multi_decomposer, c2c_sender):
entries = [
MagicMock(
sender=c2c_sender,
content="",
timestamp=datetime.now(),
metadata={"_tool_calls": [LLMToolCallContent(id ="call_114514",name="get_weather", parameters={"city": "北京"}).model_dump()]},
),
MagicMock(
sender=c2c_sender,
content="",
timestamp=datetime.now(),
metadata={"_tool_results": [LLMToolResultContent(id="call_114514", name="get_weather", content=[tools.TextContent(text="今天的天气是晴天。")]).model_dump()]},
)
]
result = multi_decomposer.decompose(entries)
assert len(result) == 2
tool_call_message = result[0]
tool_result_message = result[1]
assert tool_call_message.role == "assistant"
assert all(isinstance(call, LLMToolCallContent) for call in tool_call_message.content)
assert tool_result_message.role == "tool"
assert all(isinstance(result, LLMToolResultContent) for result in tool_result_message.content)
================================================
FILE: tests/memory/test_composer_strategy.py
================================================
from unittest.mock import Mock
import pytest
import kirara_ai.llm.format.tool as tools
from kirara_ai.im.message import ImageMessage, IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import (LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent,
LLMToolResultContent)
from kirara_ai.memory.composes.composer_strategy import (IMMessageProcessor, LLMChatImageContentProcessor,
LLMChatMessageProcessor, LLMChatTextContentProcessor,
LLMToolCallContentProcessor, LLMToolResultContentProcessor,
MediaMessageProcessor, ProcessorFactory, TextMessageProcessor,
drop_think_part)
@pytest.fixture
def mock_container():
container = Mock(spec=DependencyContainer)
media_manager = Mock()
container.resolve.return_value = media_manager
return container
@pytest.fixture
def sample_context():
return {
"media_ids": [],
"tool_calls": [],
"tool_results": []
}
class TestDropThinkPart:
def test_drop_think_part_with_think_tag(self):
text = "这是思考部分这是输出部分"
result = drop_think_part(text)
assert result == "这是输出部分"
def test_drop_think_part_without_think_tag(self):
text = "这是纯文本,没有思考标签"
result = drop_think_part(text)
assert result == text
class TestTextMessageProcessor:
def test_process(self, mock_container, sample_context):
processor = TextMessageProcessor(mock_container)
message = TextMessage("这是一条文本消息")
result = processor.process(message, sample_context)
assert result == "这是一条文本消息\n"
class TestMediaMessageProcessor:
def test_process(self, mock_container, sample_context):
processor = MediaMessageProcessor(mock_container)
message = ImageMessage(media_id="media1", data=b"test", format="png")
result = processor.process(message, sample_context)
assert "id=\"media1\"" in result
assert sample_context["media_ids"] == ["media1"]
class TestLLMChatTextContentProcessor:
def test_process_normal_text(self, mock_container, sample_context):
processor = LLMChatTextContentProcessor(mock_container)
content = LLMChatTextContent(text="这是普通文本")
result = processor.process(content, sample_context)
assert result == "这是普通文本\n"
def test_process_with_think_tag(self, mock_container, sample_context):
processor = LLMChatTextContentProcessor(mock_container)
content = LLMChatTextContent(text="思考过程这是输出")
result = processor.process(content, sample_context)
assert result == "这是输出\n"
class TestLLMChatImageContentProcessor:
def test_process(self, mock_container, sample_context):
# 设置 media_manager mock
media_manager = mock_container.resolve.return_value
media = Mock()
media.description = "图片描述"
media_manager.get_media.return_value = media
processor = LLMChatImageContentProcessor(mock_container)
content = LLMChatImageContent(media_id="media1")
result = processor.process(content, sample_context)
assert "media_msg" in result
assert "media1" in result
assert "图片描述" in result
assert sample_context["media_ids"] == ["media1"]
class TestLLMToolCallContentProcessor:
def test_process(self, mock_container, sample_context):
processor = LLMToolCallContentProcessor(mock_container)
content = LLMToolCallContent(
id="call1",
name="test_function",
parameters={"arg1": "value1"}
)
result = processor.process(content, sample_context)
assert "function_call" in result
assert "id=\"call1\"" in result
assert "name=\"test_function\"" in result
assert len(sample_context["tool_calls"]) == 1
# 检查添加到上下文的工具调用数据
tool_call = sample_context["tool_calls"][0]
assert tool_call["id"] == "call1"
assert tool_call["name"] == "test_function"
class TestLLMToolResultContentProcessor:
def test_process(self, mock_container, sample_context):
processor = LLMToolResultContentProcessor(mock_container)
content = LLMToolResultContent(
id="result1",
name="test_result",
isError=False,
content=[tools.TextContent(text="结果文本")]
)
result = processor.process(content, sample_context)
assert "tool_result" in result
assert "id=\"result1\"" in result
assert "name=\"test_result\"" in result
assert "isError=\"False\"" in result
assert len(sample_context["tool_results"]) == 1
# 检查添加到上下文的工具结果数据
tool_result = sample_context["tool_results"][0]
assert tool_result["id"] == "result1"
assert tool_result["name"] == "test_result"
assert tool_result["isError"] is False
class TestIMMessageProcessor:
def test_process_with_text_message(self, mock_container, sample_context):
# 创建带有文本消息的 IMMessage
text_message = TextMessage("这是文本消息")
im_message = IMMessage(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="用户"),
message_elements=[text_message]
)
processor = IMMessageProcessor(mock_container)
result = processor.process(im_message, sample_context)
assert "用户 说:" in result
assert "这是文本消息" in result
def test_process_with_media_message(self, mock_container, sample_context):
# 创建带有媒体消息的 IMMessage
media_message = ImageMessage(media_id="media1", data=b"test", format="png")
im_message = IMMessage(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="用户"),
message_elements=[media_message]
)
processor = IMMessageProcessor(mock_container)
result = processor.process(im_message, sample_context)
assert "用户 说:" in result
assert "media_msg" in result
assert "media1" in result
assert sample_context["media_ids"] == ["media1"]
class TestLLMChatMessageProcessor:
def test_process_with_text_content(self, mock_container, sample_context):
message = LLMChatMessage(
role="user",
content=[LLMChatTextContent(text="这是文本内容")]
)
processor = LLMChatMessageProcessor(mock_container)
result = processor.process(message, sample_context)
assert "你回答:" in result
assert "这是文本内容" in result
def test_process_with_mixed_content(self, mock_container, sample_context):
# 设置 media_manager mock
media_manager = mock_container.resolve.return_value
media = Mock()
media.description = "图片描述"
media_manager.get_media.return_value = media
message = LLMChatMessage(
role="assistant",
content=[
LLMChatTextContent(text="这是文本内容"),
LLMChatImageContent(media_id="media1")
]
)
processor = LLMChatMessageProcessor(mock_container)
result = processor.process(message, sample_context)
assert "你回答:" in result
assert "这是文本内容" in result
assert "media_msg" in result
assert "media1" in result
assert sample_context["media_ids"] == ["media1"]
def test_process_with_tool_content(self, mock_container, sample_context):
message = LLMChatMessage(
role="assistant",
content=[LLMToolCallContent(
id="call1",
name="test_function",
parameters={"arg1": "value1"}
)]
)
processor = LLMChatMessageProcessor(mock_container)
result = processor.process(message, sample_context)
assert "function_call" in result
assert "id=\"call1\"" in result
assert "name=\"test_function\"" in result
assert len(sample_context["tool_calls"]) == 1
class TestProcessorFactory:
def test_get_processor_for_im_message(self, mock_container):
factory = ProcessorFactory(mock_container)
processor = factory.get_processor(IMMessage)
assert isinstance(processor, IMMessageProcessor)
def test_get_processor_for_llm_chat_message(self, mock_container):
factory = ProcessorFactory(mock_container)
processor = factory.get_processor(LLMChatMessage)
assert isinstance(processor, LLMChatMessageProcessor)
def test_get_processor_unknown_type(self, mock_container):
factory = ProcessorFactory(mock_container)
processor = factory.get_processor(object)
assert processor is None
================================================
FILE: tests/memory/test_decomposer_strategy.py
================================================
from datetime import datetime
from unittest.mock import Mock
import pytest
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import (LLMChatImageContent, LLMChatMessage, LLMChatTextContent, LLMToolCallContent,
LLMToolResultContent)
from kirara_ai.memory.composes.decomposer_strategy import (ContentInfo, ContentParser, DefaultDecomposerStrategy,
MediaContentStrategy, MultiElementDecomposerStrategy,
TextContentStrategy, ToolCallContentStrategy,
ToolResultContentStrategy)
from kirara_ai.memory.entry import MemoryEntry
@pytest.fixture
def mock_container():
container = Mock(spec=DependencyContainer)
media_manager = Mock()
container.resolve.return_value = media_manager
return container
@pytest.fixture
def sample_entry():
entry = MemoryEntry(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User"),
content="这是一段文本 继续文本 更多文本 ",
timestamp=datetime.now(),
metadata={
"_media_ids": ["media1"],
"_tool_calls": [{
"id": "call1",
"name": "test_function",
"arguments": {"arg1": "value1"}
}],
"_tool_results": [{
"id": "result1",
"name": "test_result",
"isError": False,
"content": [{"type": "text", "text": "结果文本"}]
}]
}
)
return entry
class TestTextContentStrategy:
def test_extract_content(self, sample_entry):
strategy = TextContentStrategy()
content_infos = strategy.extract_content(sample_entry.content, sample_entry)
assert len(content_infos) == 3
assert content_infos[0].content_type == "text"
assert content_infos[0].text == "这是一段文本"
assert content_infos[1].text == "继续文本"
assert content_infos[2].text == "更多文本"
def test_to_llm_content(self):
strategy = TextContentStrategy()
info = ContentInfo(
content_type="text",
start=0,
end=10,
text="测试文本"
)
content = strategy.to_llm_content(info)
assert isinstance(content, LLMChatTextContent)
assert content.text == "测试文本"
def test_to_text(self):
strategy = TextContentStrategy()
info = ContentInfo(
content_type="text",
start=0,
end=10,
text="测试文本"
)
text = strategy.to_text(info)
assert text == "测试文本"
class TestMediaContentStrategy:
def test_extract_content(self, sample_entry):
strategy = MediaContentStrategy()
content_infos = strategy.extract_content(sample_entry.content, sample_entry)
assert len(content_infos) == 1
assert content_infos[0].content_type == "media"
assert content_infos[0].metadata["media_id"] == "media1"
def test_to_llm_content(self):
strategy = MediaContentStrategy()
info = ContentInfo(
content_type="media",
start=0,
end=10,
text="",
metadata={"media_id": "media1"}
)
content = strategy.to_llm_content(info)
assert isinstance(content, LLMChatImageContent)
assert content.media_id == "media1"
def test_to_text(self):
strategy = MediaContentStrategy()
info = ContentInfo(
content_type="media",
start=0,
end=10,
text="",
metadata={"media_id": "media1"}
)
text = strategy.to_text(info)
assert text == ""
class TestToolCallContentStrategy:
def test_extract_content(self, sample_entry):
strategy = ToolCallContentStrategy()
content_infos = strategy.extract_content(sample_entry.content, sample_entry)
assert len(content_infos) == 1
assert content_infos[0].content_type == "tool_call"
assert content_infos[0].metadata["id"] == "call1"
assert content_infos[0].metadata["name"] == "test_function"
def test_no_metadata_returns_empty(self):
strategy = ToolCallContentStrategy()
entry = MemoryEntry(
content="",
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User")
)
content_infos = strategy.extract_content(entry.content, entry)
assert len(content_infos) == 0
def test_to_llm_content(self):
strategy = ToolCallContentStrategy()
info = ContentInfo(
content_type="tool_call",
start=0,
end=10,
text="",
metadata={
"id": "call1",
"name": "test_function",
"arguments": {"arg1": "value1"}
}
)
content = strategy.to_llm_content(info)
assert isinstance(content, LLMToolCallContent)
assert content.id == "call1"
assert content.name == "test_function"
def test_to_text(self):
strategy = ToolCallContentStrategy()
info = ContentInfo(
content_type="tool_call",
start=0,
end=10,
text="",
metadata={
"id": "call1",
"name": "test_function"
}
)
text = strategy.to_text(info)
assert text == ""
class TestToolResultContentStrategy:
def test_extract_content(self, sample_entry):
strategy = ToolResultContentStrategy()
content_infos = strategy.extract_content(sample_entry.content, sample_entry)
assert len(content_infos) == 1
assert content_infos[0].content_type == "tool_result"
assert content_infos[0].metadata["id"] == "result1"
assert content_infos[0].metadata["name"] == "test_result"
assert content_infos[0].metadata["isError"] is False
def test_to_llm_content(self):
strategy = ToolResultContentStrategy()
info = ContentInfo(
content_type="tool_result",
start=0,
end=10,
text="",
metadata={
"id": "result1",
"name": "test_result",
"isError": False,
"content": [{"type": "text", "text": "结果文本"}]
}
)
content = strategy.to_llm_content(info)
assert isinstance(content, LLMToolResultContent)
assert content.id == "result1"
assert content.name == "test_result"
assert content.isError is False
def test_to_text(self):
strategy = ToolResultContentStrategy()
info = ContentInfo(
content_type="tool_result",
start=0,
end=10,
text="",
metadata={
"id": "result1",
"name": "test_result",
"isError": False
}
)
text = strategy.to_text(info)
assert text == ""
class TestContentParser:
def test_parse_content(self, sample_entry):
parser = ContentParser()
content_infos = parser.parse_content(sample_entry.content, sample_entry)
assert len(content_infos) == 6 # 3 text parts + 1 media + 1 tool call + 1 tool result = 6
# 检查内容是否按位置排序
for i in range(len(content_infos) - 1):
assert content_infos[i].start < content_infos[i + 1].start
def test_to_llm_message(self):
parser = ContentParser()
content_infos = [
ContentInfo(content_type="text", start=0, end=10, text="Hello"),
ContentInfo(content_type="media", start=11, end=20, text="", metadata={"media_id": "media1"})
]
message = parser.to_llm_message(content_infos, "user")[0]
assert isinstance(message, LLMChatMessage)
assert message.role == "user"
assert len(message.content) == 2
assert isinstance(message.content[0], LLMChatTextContent)
assert isinstance(message.content[1], LLMChatImageContent)
def test_to_text(self):
parser = ContentParser()
content_infos = [
ContentInfo(content_type="text", start=0, end=10, text="Hello"),
ContentInfo(content_type="media", start=11, end=20, text="", metadata={"media_id": "media1"})
]
text = parser.to_text(content_infos)
assert text == "Hello"
class TestDefaultDecomposerStrategy:
def test_decompose_empty_entries(self):
strategy = DefaultDecomposerStrategy()
result = strategy.decompose([], {"empty_message": "空消息"})
assert len(result) == 1
assert result[0] == "空消息"
def test_decompose_with_entries(self, sample_entry):
strategy = DefaultDecomposerStrategy()
result = strategy.decompose([sample_entry], {})
assert len(result) == 1
assert isinstance(result[0], str)
assert "这是一段文本" in result[0]
assert "" in result[0]
class TestMultiElementDecomposerStrategy:
def test_decompose_empty_entries(self):
strategy = MultiElementDecomposerStrategy()
result = strategy.decompose([], {})
assert len(result) == 0
def test_process_entry_user_content(self):
strategy = MultiElementDecomposerStrategy()
entry = MemoryEntry(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User"),
content="用户消息",
timestamp=datetime.now()
)
messages = strategy._process_entry(entry)
assert len(messages) == 1
assert messages[0].role == "user"
assert len(messages[0].content) == 1
assert isinstance(messages[0].content[0], LLMChatTextContent)
assert messages[0].content[0].text == "用户消息"
def test_process_entry_with_ai_response(self):
strategy = MultiElementDecomposerStrategy()
entry = MemoryEntry(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User"),
content="用户消息\n你回答: AI回复",
timestamp=datetime.now()
)
messages = strategy._process_entry(entry)
assert len(messages) == 2
assert messages[0].role == "user"
assert isinstance(messages[0].content[0], LLMChatTextContent)
assert messages[0].content[0].text == "用户消息"
assert messages[1].role == "assistant"
assert isinstance(messages[1].content[0], LLMChatTextContent)
assert messages[1].content[0].text == "AI回复"
def test_merge_adjacent_messages(self):
strategy = MultiElementDecomposerStrategy()
messages = [
LLMChatMessage(role="user", content=[LLMChatTextContent(text="消息1")]),
LLMChatMessage(role="user", content=[LLMChatTextContent(text="消息2")]),
LLMChatMessage(role="assistant", content=[LLMChatTextContent(text="回复")])
]
strategy._merge_adjacent_messages(messages)
assert len(messages) == 2
assert messages[0].role == "user"
assert len(messages[0].content) == 2
assert messages[1].role == "assistant"
================================================
FILE: tests/memory/test_memory_manager.py
================================================
from datetime import datetime
from typing import Dict, List
from unittest.mock import MagicMock
import pytest
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.memory.composes import MemoryComposer, MemoryDecomposer
from kirara_ai.memory.entry import MemoryEntry
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.persistences.base import MemoryPersistence
from kirara_ai.memory.scopes import MemoryScope
# ==================== Dummy Persistence ====================
class DummyMemoryPersistence(MemoryPersistence):
"""
用于测试的 Dummy Persistence,不进行实际的持久化操作
"""
def __init__(self):
self.storage: Dict[str, List[MemoryEntry]] = {}
def load(self, scope_key: str) -> List[MemoryEntry]:
"""从存储加载记忆"""
return self.storage.get(scope_key, [])
def save(self, scope_key: str, entries: List[MemoryEntry]) -> None:
"""将记忆保存到存储"""
self.storage[scope_key] = entries
def stop(self):
"""停止持久化"""
def flush(self):
"""刷新存储"""
# ==================== Fixtures ====================
@pytest.fixture
def container():
"""创建模拟的容器"""
container = DependencyContainer()
config = GlobalConfig()
container.resolve = MagicMock(return_value=config)
container.register(GlobalConfig, config)
return container
@pytest.fixture
def memory_manager(container):
"""创建使用 Dummy Persistence 的 MemoryManager 实例"""
dummy_persistence = DummyMemoryPersistence()
manager = MemoryManager(container, persistence=dummy_persistence)
return manager
@pytest.fixture
def test_entry():
"""创建测试记忆条目"""
return MemoryEntry(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User"),
content="test message",
timestamp=datetime.now(),
metadata={}
)
@pytest.fixture
def mock_scope():
"""创建模拟的作用域"""
mock_scope = MagicMock(spec=MemoryScope)
mock_scope.get_scope_key.return_value = "test_scope"
mock_scope.is_in_scope.return_value = True # 默认返回 True
return mock_scope
# ==================== 测试用例 ====================
class TestMemoryManager:
def test_register_scope(self, memory_manager):
"""测试注册作用域"""
mock_scope_class = MagicMock(spec=MemoryScope)
memory_manager.register_scope("test", mock_scope_class)
assert "test" in memory_manager.scope_registry._registry
assert memory_manager.scope_registry._registry["test"] == mock_scope_class
def test_register_composer(self, memory_manager):
"""测试注册组合器"""
mock_composer_class = MagicMock(spec=MemoryComposer)
memory_manager.register_composer("test", mock_composer_class)
assert "test" in memory_manager.composer_registry._registry
assert memory_manager.composer_registry._registry["test"] == mock_composer_class
def test_register_decomposer(self, memory_manager):
"""测试注册解析器"""
mock_decomposer_class = MagicMock(spec=MemoryDecomposer)
memory_manager.register_decomposer("test", mock_decomposer_class)
assert "test" in memory_manager.decomposer_registry._registry
assert (
memory_manager.decomposer_registry._registry["test"]
== mock_decomposer_class
)
def test_store_and_query(self, memory_manager, test_entry, mock_scope):
"""测试存储和查询"""
# 存储
memory_manager.store(mock_scope, test_entry)
# 验证内存缓存
assert "test_scope" in memory_manager.memories
assert len(memory_manager.memories["test_scope"]) == 1
assert memory_manager.memories["test_scope"][0] == test_entry
# 查询
results = memory_manager.query(mock_scope, "user1")
# 验证结果
assert len(results) == 1
assert results[0] == test_entry
def test_max_entries_limit(self, memory_manager, mock_scope, container):
"""测试最大条目数限制"""
# 设置最大条目数
container.resolve.return_value.memory.max_entries = 2
# 存储3条记录
for i in range(3):
entry = MemoryEntry(
sender=ChatSender(user_id=f"user{i}", chat_type=ChatType.C2C, display_name="Test User"),
content=f"message {i}",
timestamp=datetime.now(),
metadata={},
)
memory_manager.store(mock_scope, entry)
# 验证只保留了最新的2条
assert len(memory_manager.memories["test_scope"]) == 2
assert memory_manager.memories["test_scope"][-1].content == "message 2"
def test_shutdown(self, memory_manager, test_entry):
"""测试关闭"""
# 添加一些测试数据
memory_manager.memories = {"scope1": [test_entry], "scope2": [test_entry]}
# 关闭
memory_manager.shutdown()
# 验证所有数据都被保存 (由于使用的是 DummyPersistence,这里实际上没有持久化操作)
# 可以添加一些断言来验证 DummyPersistence 的行为是否符合预期
persistence = memory_manager.persistence
assert isinstance(persistence, DummyMemoryPersistence)
assert persistence.storage["scope1"] == [test_entry]
assert persistence.storage["scope2"] == [test_entry]
def test_clear_memory(self, memory_manager, mock_scope):
"""测试清空记忆"""
# 存储一些数据
entry = MemoryEntry(
sender=ChatSender(user_id="user1", chat_type=ChatType.C2C, display_name="Test User"),
content="test",
timestamp=datetime.now(),
metadata={}
)
memory_manager.store(mock_scope, entry)
# 清空记忆
memory_manager.clear_memory(mock_scope, "user1")
# 验证记忆是否被清空
assert memory_manager.memories["test_scope"] == []
persistence = memory_manager.persistence
assert isinstance(persistence, DummyMemoryPersistence)
assert persistence.storage["test_scope"] == []
================================================
FILE: tests/memory/test_persistence.py
================================================
import os
import shutil
import tempfile
from datetime import datetime
from unittest.mock import MagicMock, patch
import pytest
from kirara_ai.im.sender import ChatSender, ChatType
from kirara_ai.memory.entry import MemoryEntry
from kirara_ai.memory.persistences import FileMemoryPersistence, RedisMemoryPersistence
# ==================== 常量区 ====================
TEST_USER_1 = "user1"
TEST_USER_2 = "user2"
TEST_GROUP = "group1"
TEST_DISPLAY_NAME = "john"
TEST_CONTENT_1 = "test message 1"
TEST_CONTENT_2 = "test message 2"
TEST_METADATA_TEXT = {"type": "text"}
TEST_METADATA_IMAGE = {"type": "image"}
TEST_TIMESTAMP_1 = datetime(2024, 1, 1, 12, 0)
TEST_TIMESTAMP_2 = datetime(2024, 1, 1, 12, 1)
TEST_SCOPE = "test_scope"
# ==================== Fixtures ====================
@pytest.fixture
def test_dir():
temp_dir = tempfile.mkdtemp()
yield temp_dir
shutil.rmtree(temp_dir)
@pytest.fixture
def file_persistence(test_dir):
return FileMemoryPersistence(test_dir)
@pytest.fixture
def chat_senders():
sender1 = ChatSender.from_group_chat(TEST_USER_1, TEST_GROUP, TEST_DISPLAY_NAME)
sender2 = ChatSender.from_c2c_chat(TEST_USER_2, TEST_DISPLAY_NAME)
return sender1, sender2
@pytest.fixture
def test_entries(chat_senders):
sender1, sender2 = chat_senders
return [
MemoryEntry(
sender=sender1,
content=TEST_CONTENT_1,
timestamp=TEST_TIMESTAMP_1,
metadata=TEST_METADATA_TEXT,
),
MemoryEntry(
sender=sender2,
content=TEST_CONTENT_2,
timestamp=TEST_TIMESTAMP_2,
metadata=TEST_METADATA_IMAGE,
),
]
@pytest.fixture
def redis_mock():
return MagicMock()
@pytest.fixture
def redis_persistence(redis_mock):
with patch("redis.Redis", return_value=redis_mock):
return RedisMemoryPersistence(host="localhost")
# ==================== 测试逻辑 ====================
class TestFileMemoryPersistence:
def test_save_and_load(self, file_persistence, test_entries, test_dir):
# 测试保存
file_persistence.save(TEST_SCOPE, test_entries)
# 验证文件是否创建
file_path = os.path.join(test_dir, f"{TEST_SCOPE}.json")
assert os.path.exists(file_path)
# 测试加载
loaded_entries = file_persistence.load(TEST_SCOPE)
# 验证加载的数据
assert len(loaded_entries) == len(test_entries)
for original, loaded in zip(test_entries, loaded_entries):
assert original.sender.user_id == loaded.sender.user_id
assert original.sender.chat_type == loaded.sender.chat_type
assert original.sender.group_id == loaded.sender.group_id
assert original.content == loaded.content
assert original.timestamp == loaded.timestamp
assert original.metadata == loaded.metadata
def test_load_nonexistent(self, file_persistence):
entries = file_persistence.load("nonexistent")
assert entries == []
class TestRedisMemoryPersistence:
def test_save(self, redis_persistence, redis_mock, test_entries):
# 测试保存
redis_persistence.save(TEST_SCOPE, test_entries)
redis_mock.set.assert_called_once()
def test_load_with_data(self, redis_persistence, redis_mock, chat_senders):
# Mock Redis 返回数据
import json
from kirara_ai.memory.persistences.codecs import MemoryJSONEncoder
sender, _ = chat_senders
serialized_data = [
{
"sender": {
"__type__": "ChatSender",
"user_id": sender.user_id,
"chat_type": sender.chat_type.value,
"group_id": sender.group_id,
"display_name": sender.display_name,
"raw_metadata": {},
},
"content": TEST_CONTENT_1,
"timestamp": TEST_TIMESTAMP_1.isoformat(),
"metadata": TEST_METADATA_TEXT,
}
]
redis_mock.get.return_value = json.dumps(serialized_data, cls=MemoryJSONEncoder)
# 测试加载
loaded_entries = redis_persistence.load(TEST_SCOPE)
# 验证数据
assert len(loaded_entries) == 1
entry = loaded_entries[0]
assert entry.sender.user_id == TEST_USER_1
assert entry.sender.chat_type == ChatType.GROUP
assert entry.sender.group_id == TEST_GROUP
assert entry.sender.display_name == TEST_DISPLAY_NAME
assert entry.content == TEST_CONTENT_1
assert entry.metadata == TEST_METADATA_TEXT
def test_load_no_data(self, redis_persistence, redis_mock):
redis_mock.get.return_value = None
assert redis_persistence.load(TEST_SCOPE) == []
================================================
FILE: tests/memory/test_scope.py
================================================
import pytest
from kirara_ai.im.sender import ChatSender
from kirara_ai.memory.scopes import GlobalScope, GroupScope, MemberScope
# ==================== 常量区 ====================
TEST_USER_1 = "user1"
TEST_USER_2 = "user2"
TEST_GROUP_1 = "group1"
TEST_GROUP_2 = "group2"
TEST_DISPLAY_NAME = "john"
# ==================== Fixtures ====================
@pytest.fixture
def group_sender():
return ChatSender.from_group_chat(
user_id=TEST_USER_1, group_id=TEST_GROUP_1, display_name=TEST_DISPLAY_NAME
)
@pytest.fixture
def c2c_sender():
return ChatSender.from_c2c_chat(user_id=TEST_USER_1, display_name=TEST_DISPLAY_NAME)
@pytest.fixture
def different_group_sender():
return ChatSender.from_group_chat(
user_id=TEST_USER_1, group_id=TEST_GROUP_2, display_name=TEST_DISPLAY_NAME
)
@pytest.fixture
def different_user_sender():
return ChatSender.from_group_chat(
user_id=TEST_USER_2, group_id=TEST_GROUP_1, display_name=TEST_DISPLAY_NAME
)
# ==================== 测试逻辑 ====================
class TestMemberScope:
@pytest.fixture
def scope(self):
return MemberScope()
def test_get_scope_key_group(self, scope, group_sender):
key = scope.get_scope_key(group_sender)
assert key == f"member:{TEST_GROUP_1}:{TEST_USER_1}"
def test_get_scope_key_c2c(self, scope, c2c_sender):
key = scope.get_scope_key(c2c_sender)
assert key == f"c2c:{TEST_USER_1}"
def test_is_in_scope_group_same_user(self, scope, group_sender):
same_sender = ChatSender.from_group_chat(
TEST_USER_1, TEST_GROUP_1, TEST_DISPLAY_NAME
)
assert scope.is_in_scope(group_sender, same_sender)
def test_is_in_scope_group_different_user(
self, scope, group_sender, different_user_sender
):
assert not scope.is_in_scope(group_sender, different_user_sender)
def test_is_in_scope_group_different_group(
self, scope, group_sender, different_group_sender
):
assert not scope.is_in_scope(group_sender, different_group_sender)
def test_is_in_scope_c2c_same_user(self, scope, c2c_sender):
same_sender = ChatSender.from_c2c_chat(TEST_USER_1, TEST_DISPLAY_NAME)
assert scope.is_in_scope(c2c_sender, same_sender)
def test_is_in_scope_c2c_different_user(self, scope, c2c_sender):
different_sender = ChatSender.from_c2c_chat(TEST_USER_2, TEST_DISPLAY_NAME)
assert not scope.is_in_scope(c2c_sender, different_sender)
def test_is_in_scope_different_chat_type(self, scope, group_sender, c2c_sender):
assert not scope.is_in_scope(group_sender, c2c_sender)
class TestGroupScope:
@pytest.fixture
def scope(self):
return GroupScope()
def test_get_scope_key_group(self, scope, group_sender):
key = scope.get_scope_key(group_sender)
assert key == f"group:{TEST_GROUP_1}"
def test_get_scope_key_c2c(self, scope, c2c_sender):
key = scope.get_scope_key(c2c_sender)
assert key == f"c2c:{TEST_USER_1}"
def test_is_in_scope_group_same_group(
self, scope, group_sender, different_user_sender
):
assert scope.is_in_scope(group_sender, different_user_sender)
def test_is_in_scope_group_different_group(
self, scope, group_sender, different_group_sender
):
assert not scope.is_in_scope(group_sender, different_group_sender)
def test_is_in_scope_c2c_same_user(self, scope, c2c_sender):
same_sender = ChatSender.from_c2c_chat(TEST_USER_1, TEST_DISPLAY_NAME)
assert scope.is_in_scope(c2c_sender, same_sender)
def test_is_in_scope_c2c_different_user(self, scope, c2c_sender):
different_sender = ChatSender.from_c2c_chat(TEST_USER_2, TEST_DISPLAY_NAME)
assert not scope.is_in_scope(c2c_sender, different_sender)
def test_is_in_scope_different_chat_type(self, scope, group_sender, c2c_sender):
assert not scope.is_in_scope(group_sender, c2c_sender)
class TestGlobalScope:
@pytest.fixture
def scope(self):
return GlobalScope()
def test_get_scope_key(self, scope, group_sender, c2c_sender):
assert scope.get_scope_key(group_sender) == "global"
assert scope.get_scope_key(c2c_sender) == "global"
def test_is_in_scope_always_true(self, scope, group_sender, c2c_sender):
assert scope.is_in_scope(group_sender, c2c_sender)
assert scope.is_in_scope(c2c_sender, group_sender)
================================================
FILE: tests/resources/test_image.txt
================================================
This is a test file for MediaElement testing.
================================================
FILE: tests/system_blocks/__init__.py
================================================
# 系统块测试包
================================================
FILE: tests/system_blocks/game/__init__.py
================================================
# 游戏相关块测试包
================================================
FILE: tests/system_blocks/game/test_dice.py
================================================
import pytest
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.game.dice import DiceRoll
@pytest.fixture
def container():
"""创建一个依赖容器"""
return DependencyContainer()
@pytest.fixture
def create_message():
def _create(content: str) -> IMMessage:
return IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage(content)]
)
return _create
def test_dice_roll_basic(container, create_message):
"""测试基本的骰子命令"""
block = DiceRoll()
block.container = container
result = block.execute(create_message(".roll 2d6"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
# 不检查 sender 的具体类型,只检查是否存在
assert hasattr(response, "sender")
assert len(response.message_elements) == 1
assert "掷出了 2d6" in response.content or "🎲" in response.content
def test_dice_roll_invalid(container, create_message):
"""测试无效的骰子命令"""
block = DiceRoll()
block.container = container
result = block.execute(create_message("invalid command"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "Invalid dice command" in response.content or "无效" in response.content
def test_dice_roll_too_many(container, create_message):
"""测试超过限制的骰子数量"""
block = DiceRoll()
block.container = container
result = block.execute(create_message(".roll 101d6"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "Too many dice" in response.content or "太多" in response.content
def test_dice_roll_with_modifier(container, create_message):
"""测试带有修饰符的骰子命令"""
block = DiceRoll()
block.container = container
result = block.execute(create_message(".roll 2d6+3"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
# 不检查具体格式,只检查是否包含关键信息
assert "2d6" in response.content
# 测试减法修饰符
result = block.execute(create_message(".roll 1d20-2"))
response = result["response"]
assert "1d20" in response.content
# 不检查具体的修饰符,因为实现可能不同
def test_dice_roll_multiple_dice(container, create_message):
"""测试多种骰子的命令"""
block = DiceRoll()
block.container = container
# 注意:实际实现可能只处理第一个骰子命令
result = block.execute(create_message(".roll 2d6"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "2d6" in response.content
# 添加其他骰子命令的测试
result = block.execute(create_message(".roll 1d20"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "1d20" in response.content
result = block.execute(create_message(".roll 3d4"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "3d4" in response.content
================================================
FILE: tests/system_blocks/game/test_gacha.py
================================================
import pytest
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.game.gacha import GachaSimulator
@pytest.fixture
def container():
"""创建一个依赖容器"""
return DependencyContainer()
@pytest.fixture
def create_message():
def _create(content: str) -> IMMessage:
return IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage(content)]
)
return _create
def test_gacha_single_pull(container, create_message):
"""测试单次抽卡"""
block = GachaSimulator()
block.container = container
result = block.execute(create_message("单抽"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "抽卡结果" in response.content or "⭐" in response.content
# 不检查具体格式,只检查是否包含关键信息
def test_gacha_ten_pull(container, create_message):
"""测试十连抽卡"""
block = GachaSimulator()
block.container = container
result = block.execute(create_message("十连"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
# 不检查具体格式,只检查是否包含关键信息
assert "SSR" in response.content or "SR" in response.content or "R" in response.content
def test_gacha_custom_rates(container, create_message):
"""测试自定义概率的抽卡"""
rates = {"SSR": 1.0, "SR": 0.0, "R": 0.0} # 100% SSR
block = GachaSimulator(rates)
block.container = container
result = block.execute(create_message("单抽"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "SSR" in response.content
================================================
FILE: tests/system_blocks/im/__init__.py
================================================
# IM 相关块测试包
================================================
FILE: tests/system_blocks/im/test_messages.py
================================================
import asyncio
import pytest
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.manager import IMManager
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.im.messages import (AppendIMMessage, GetIMMessage, IMMessageToText,
SendIMMessage, TextToIMMessage)
# 创建模拟的 IMAdapter 类
class MockIMAdapter(IMAdapter):
async def send_message(self, message, target=None):
return None
def convert_to_message(self, message):
return message.content
async def start(self):
return None
async def stop(self):
return None
# 创建模拟的 IMManager 类
class MockIMManager(IMManager):
def __init__(self):
self.adapters = {"default": MockIMAdapter(), "telegram": MockIMAdapter()}
def get_adapter(self, name):
return self.adapters.get(name)
@pytest.fixture
def container():
"""创建一个带有模拟消息的容器"""
container = DependencyContainer()
# 模拟 IMMessage
mock_message = IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("测试消息内容")]
)
container.register(IMMessage, mock_message)
return container
@pytest.mark.asyncio
async def test_send_im_message_async():
"""使用 pytest-asyncio 测试发送 IM 消息块"""
# 创建容器
container = DependencyContainer()
# 创建要发送的消息
send_message = IMMessage(
sender=ChatSender.get_bot_sender(),
message_elements=[TextMessage("回复消息")]
)
mock_message = IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("测试消息内容")]
)
# 获取事件循环
loop = asyncio.get_event_loop()
# 注册到容器
container.register(IMAdapter, MockIMAdapter())
container.register(IMManager, MockIMManager())
container.register(IMMessage, mock_message)
container.register(asyncio.AbstractEventLoop, loop)
# 创建块 - 不指定适配器
block = SendIMMessage()
block.container = container
# 执行块
result = block.execute(msg=send_message)
# 验证结果
assert result is not None
# 创建块 - 指定适配器
block = SendIMMessage(im_name="telegram")
block.container = container
# 执行块
result = block.execute(msg=send_message, target=ChatSender.from_c2c_chat(user_id="specific_user", display_name="Specific User"))
# 验证结果
assert result is not None
def test_get_im_message(container):
"""测试获取 IM 消息块"""
# 创建块
block = GetIMMessage()
block.container = container
# 执行块
result = block.execute()
# 验证结果
assert "msg" in result
assert "sender" in result
assert isinstance(result["msg"], IMMessage)
assert isinstance(result["sender"], ChatSender)
assert result["msg"].content == "测试消息内容"
def test_im_message_to_text(container):
"""测试 IMMessage 转文本块"""
# 创建消息
message = IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("Hello, World!")]
)
# 创建块
block = IMMessageToText()
block.container = container
# 执行块
result = block.execute(msg=message)
# 验证结果
assert "text" in result
assert result["text"] == "Hello, World!"
def test_text_to_im_message():
"""测试文本转 IMMessage 块"""
# 创建块 - 不分段
block = TextToIMMessage()
# 执行块
result = block.execute(text="Hello, World!")
# 验证结果
assert "msg" in result
assert isinstance(result["msg"], IMMessage)
assert isinstance(result["msg"].sender, ChatSender)
assert result["msg"].content == "Hello, World!"
# 创建块 - 使用分段符
block = TextToIMMessage(split_by="\n")
# 执行块
result = block.execute(text="Line 1\nLine 2\nLine 3")
# 验证结果
assert "msg" in result
assert isinstance(result["msg"], IMMessage)
assert len(result["msg"].message_elements) == 3
assert result["msg"].message_elements[0].text == "Line 1"
assert result["msg"].message_elements[1].text == "Line 2"
assert result["msg"].message_elements[2].text == "Line 3"
def test_append_im_message():
"""测试补充 IMMessage 消息块"""
# 创建基础消息
base_message = IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("基础消息")]
)
# 创建要追加的消息元素
append_element = TextMessage("追加内容")
# 创建块
block = AppendIMMessage()
# 执行块
result = block.execute(base_msg=base_message, append_msg=append_element)
# 验证结果
assert "msg" in result
assert isinstance(result["msg"], IMMessage)
assert isinstance(result["msg"].sender, ChatSender)
assert len(result["msg"].message_elements) == 2
assert result["msg"].message_elements[0].text == "基础消息"
assert result["msg"].message_elements[1].text == "追加内容"
================================================
FILE: tests/system_blocks/im/test_states.py
================================================
import asyncio
import pytest
from kirara_ai.im.adapter import EditStateAdapter, IMAdapter
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.im.states import ToggleEditState
class MockAdapter(IMAdapter, EditStateAdapter):
async def set_chat_editing_state(self, *args, **kwargs):
return None
@pytest.mark.asyncio
async def test_toggle_edit_state_async():
"""使用 pytest-asyncio 测试切换编辑状态块"""
# 创建容器
container = DependencyContainer()
# 创建发送者
sender = ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User")
loop = asyncio.get_event_loop()
# 注册到容器
container.register(IMAdapter, MockAdapter)
container.register(asyncio.AbstractEventLoop, loop)
# 创建块 - 默认参数
block = ToggleEditState(is_editing=True)
block.container = container
# 执行块 - 传入发送者
result = block.execute(sender=sender)
# 验证结果 - 异步方法应该返回空字典
assert result == {}
================================================
FILE: tests/system_blocks/llm/__init__.py
================================================
# LLM 相关块测试包
================================================
FILE: tests/system_blocks/llm/test_basic.py
================================================
import pytest
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatTextContent
from kirara_ai.llm.format.response import LLMChatResponse, Message
from kirara_ai.workflow.implementations.blocks.llm.basic import LLMResponseToText
@pytest.fixture
def container():
"""创建一个依赖容器"""
return DependencyContainer()
def test_llm_response_to_text():
"""测试 LLM 响应转文本块"""
# 创建一个模拟的 LLMChatResponse
chat_response = LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="这是 AI 的回复")]
),
model="gpt-3.5-turbo",
usage={"prompt_tokens": 10, "completion_tokens": 20, "total_tokens": 30}
)
# 创建块
block = LLMResponseToText()
# 执行块
result = block.execute(response=chat_response)
# 验证结果
assert "text" in result
assert result["text"] == "这是 AI 的回复"
# 测试空响应
empty_response = LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="")]
),
model="gpt-3.5-turbo",
usage={"prompt_tokens": 5, "completion_tokens": 0, "total_tokens": 5}
)
result = block.execute(response=empty_response)
assert result["text"] == ""
================================================
FILE: tests/system_blocks/llm/test_chat.py
================================================
import asyncio
import threading
from unittest.mock import MagicMock, patch
import pytest
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatMessage, LLMChatTextContent, LLMToolResultContent
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.format.tool import CallableWrapper, Function, TextContent, Tool, ToolCall, ToolInputSchema
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
from kirara_ai.workflow.implementations.blocks.llm.chat import (ChatCompletion, ChatCompletionWithTools,
ChatMessageConstructor, ChatResponseConverter)
def get_tools() -> list[Tool]:
async def mock_tool_invoke(tool_call: ToolCall) -> LLMToolResultContent:
return LLMToolResultContent(
id=tool_call.id,
name=tool_call.function.name,
content=[TextContent(text="晴天,温度25°C")]
)
return [
Tool(
type="function",
name="get_weather",
description="Get the current weather in a given location",
parameters=ToolInputSchema(
type="object",
properties = {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
required=["location"],
),
invokeFunc=CallableWrapper(mock_tool_invoke)
)
]
def get_llm_tool_calls() -> list[ToolCall]:
return [
ToolCall(
id = "call_e33147bcb72525ed",
function = Function(
name="get_weather",
arguments={"location": "San Francisco, CA"}
)
)
]
# 创建模拟的 LLM 类
class MockLLM:
def chat(self, request):
return LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="这是 AI 的回复")]
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
class MockLLMWithToolCalls:
def __init__(self, with_tool_calls=True):
self.with_tool_calls = with_tool_calls
self.call_count = 0
def chat(self, request):
self.call_count += 1
# 第一次调用返回工具调用
if self.with_tool_calls and self.call_count == 1:
return LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="我需要查询天气")],
tool_calls=get_llm_tool_calls()
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
# 后续调用返回最终回复
else:
return LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="旧金山今天是晴天,温度25°C")]
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
# 创建模拟的 LLMManager 类
class MockLLMManager(LLMManager):
def __init__(self):
self.mock_llm = MockLLM()
def get_llm_id_by_ability(self, ability):
return "gpt-3.5-turbo"
def get_llm(self, model_id):
return self.mock_llm
class MockLLMManagerWithToolCalls(LLMManager):
def __init__(self, with_tool_calls=True):
self.mock_llm = MockLLMWithToolCalls(with_tool_calls)
def get_llm_id_by_ability(self, ability):
return "gpt-3.5-turbo"
def get_llm(self, model_id):
return self.mock_llm
@pytest.fixture
def container():
"""创建一个带有模拟 LLM 提供者的容器"""
container = DependencyContainer()
# 模拟 LLMManager
mock_llm_manager = MockLLMManager()
# 模拟 LLM
# mock_llm = MockLLM()
# 模拟响应
mock_response = LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="这是 AI 的回复")]
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
# mock_llm.chat.return_value = mock_response
# 模拟 WorkflowExecutor
mock_executor = MagicMock(spec=WorkflowExecutor)
# 创建一个在新线程中运行的事件循环
def start_background_loop(loop):
asyncio.set_event_loop(loop)
loop.run_forever()
# 创建新的事件循环
new_loop = asyncio.new_event_loop()
# 在新线程中启动事件循环
t = threading.Thread(target=start_background_loop, args=(new_loop,), daemon=True)
t.start()
# 注册到容器
container.register(LLMManager, mock_llm_manager)
container.register(WorkflowExecutor, mock_executor)
container.register(asyncio.AbstractEventLoop, new_loop)
return container
@patch('kirara_ai.workflow.implementations.blocks.llm.chat.ChatMessageConstructor.execute')
def test_chat_message_constructor(mock_execute):
"""测试聊天消息构造器"""
# 模拟 execute 方法的返回值
mock_execute.return_value = {
"llm_msg": [Message(role="user", content=[LLMChatTextContent(text="你好,AI!")])]
}
# 创建块
block = ChatMessageConstructor()
# 模拟容器
mock_container = MagicMock(spec=DependencyContainer)
block.container = mock_container
# 执行块 - 基本用法
user_msg = IMMessage(
sender=ChatSender.from_c2c_chat(
user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("你好,AI!")]
)
result = block.execute(
user_msg=user_msg,
memory_content="",
system_prompt_format="",
user_prompt_format=""
)
# 验证结果
assert "llm_msg" in result
assert isinstance(result["llm_msg"], list)
assert len(result["llm_msg"]) > 0
assert result["llm_msg"][0].role == "user"
assert result["llm_msg"][0].content[0].text == "你好,AI!"
def test_chat_completion(container):
# 创建消息列表
messages = [
Message(role="system", content=[LLMChatTextContent(text="你是一个助手")]),
Message(role="user", content=[LLMChatTextContent(text="你好,AI!")])
]
# 创建块 - 默认参数
block = ChatCompletion()
block.container = container
# 执行块
result = block.execute(prompt=messages)
# 验证结果
assert "resp" in result
assert isinstance(result["resp"], LLMChatResponse)
assert result["resp"].message.content[0].text == "这是 AI 的回复"
def test_chat_response_converter():
"""测试聊天响应转换器"""
# 创建聊天响应
chat_response = LLMChatResponse(
message=Message(
role="assistant",
content=[LLMChatTextContent(text="这是 AI 的回复")]
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
# 创建块
block = ChatResponseConverter()
# 模拟容器
mock_container = MagicMock(spec=DependencyContainer)
# 模拟 get_bot_sender 方法
mock_bot_sender = ChatSender.from_c2c_chat(
user_id="bot", display_name="Bot")
mock_container.resolve = MagicMock(
side_effect=lambda x: mock_bot_sender if x == ChatSender.get_bot_sender else None)
block.container = mock_container
# 执行块
result = block.execute(resp=chat_response)
# 验证结果
assert "msg" in result
assert isinstance(result["msg"], IMMessage)
assert "这是 AI 的回复" in result["msg"].content
def test_chat_completion_with_tools(container):
"""测试工具调用块"""
container.register(LLMManager, MockLLMManagerWithToolCalls(with_tool_calls=True))
# 创建消息列表
messages = [
LLMChatMessage(role="system", content=[LLMChatTextContent(text="你是一个助手")]),
LLMChatMessage(role="user", content=[LLMChatTextContent(text="旧金山今天天气如何?")])
]
# 创建工具列表
tools = get_tools()
# 创建块
block = ChatCompletionWithTools(model_name="gpt-3.5-turbo", max_iterations=3)
block.container = container
# 执行块
result = block.execute(msg=messages, tools=tools)
# 验证结果
assert "resp" in result
assert "iteration_msgs" in result
assert isinstance(result["resp"], LLMChatResponse)
assert isinstance(result["iteration_msgs"], list)
assert len(result["iteration_msgs"]) >= 2 # 至少包含工具调用和最终回复
# 验证工具调用过程
assert result["iteration_msgs"][0].tool_calls is not None
assert result["iteration_msgs"][0].tool_calls[0].function.name == "get_weather"
# 验证最终回复
assert "旧金山今天是晴天" in result["resp"].message.content[0].text
def test_chat_completion_with_tools_no_tool_calls(container):
"""测试工具调用块 - 无工具调用情况"""
# 注册到容器 - 使用不会进行工具调用的模拟
container.register(LLMManager, MockLLMManagerWithToolCalls(with_tool_calls=False))
# 创建消息列表
messages = [
LLMChatMessage(role="system", content=[LLMChatTextContent(text="你是一个助手")]),
LLMChatMessage(role="user", content=[LLMChatTextContent(text="你好,AI!")])
]
# 创建工具列表
tools = get_tools()
# 创建块
block = ChatCompletionWithTools(model_name="gpt-3.5-turbo", max_iterations=3)
block.container = container
# 执行块
result = block.execute(msg=messages, tools=tools)
# 验证结果 - 直接返回响应,没有工具调用
assert "resp" in result
assert "iteration_msgs" in result
assert isinstance(result["resp"], LLMChatResponse)
assert isinstance(result["iteration_msgs"], list)
assert len(result["iteration_msgs"]) == 0 # 无消息,因为没有工具调用
================================================
FILE: tests/system_blocks/llm/test_image.py
================================================
import asyncio
import base64
from unittest.mock import MagicMock, patch
import pytest
from kirara_ai.im.message import ImageMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.llm.image import SimpleStableDiffusionWebUI
@pytest.fixture
def container():
"""创建一个带有模拟 requests 的容器"""
container = DependencyContainer()
# 模拟 event loop
mock_loop = MagicMock(spec=asyncio.AbstractEventLoop)
# 注册到容器
container.register(asyncio.AbstractEventLoop, mock_loop)
return container, mock_loop
def test_simple_stable_diffusion_webui(container):
"""测试简单 Stable Diffusion WebUI 块"""
container, mock_loop = container
# 创建一个简单的 base64 图像数据
mock_image_data = base64.b64encode(b"mock_image_data").decode("utf-8")
# 模拟 requests.post 的响应
mock_response = MagicMock()
mock_response.status_code = 200
mock_response.json.return_value = {"images": [mock_image_data]}
# 创建块 - 默认参数
block = SimpleStableDiffusionWebUI(api_url="http://localhost:7860")
block.container = container
# 使用 patch 模拟 requests.post
with patch('requests.post', return_value=mock_response):
# 执行块
result = block.execute(prompt="一只可爱的猫", negative_prompt="")
# 验证结果
assert "image" in result
assert isinstance(result["image"], ImageMessage)
# 创建块 - 自定义参数
block = SimpleStableDiffusionWebUI(
api_url="http://localhost:7860",
steps=30,
sampler_index="DPM++ 2M Karras",
cfg_scale=8.0,
width=768,
height=512
)
block.container = container
# 执行块
result = block.execute(prompt="一只可爱的猫", negative_prompt="低质量, 模糊")
# 验证结果
assert "image" in result
================================================
FILE: tests/system_blocks/memory/__init__.py
================================================
# 记忆相关块测试包
================================================
FILE: tests/system_blocks/memory/test_chat_memory.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatTextContent
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.registry import ComposerRegistry, DecomposerRegistry, ScopeRegistry
from kirara_ai.workflow.implementations.blocks.memory.chat_memory import ChatMemoryQuery, ChatMemoryStore
# 创建模拟的 MemoryManager 类
class MockMemoryManager(MemoryManager):
def __init__(self):
self.config = MagicMock()
self.config.default_scope = "member"
def query(self, *args, **kwargs):
return "系统:你是一个助手\n用户:你好\n助手:你好!有什么可以帮助你的吗?"
def store(self, *args, **kwargs):
return None
def clear(self, *args, **kwargs):
return None
# 创建模拟的 Scope 类
class MockScope:
def __init__(self, name):
self.name = name
# 创建模拟的 ScopeRegistry 类
class MockScopeRegistry(ScopeRegistry):
def get_scope(self, name):
return MockScope(name)
# 创建模拟的 Composer 类
class MockComposer:
def compose(self, sender, messages):
return ["memory_entry"]
# 创建模拟的 ComposerRegistry 类
class MockComposerRegistry(ComposerRegistry):
def get_composer(self, name):
return MockComposer()
# 创建模拟的 Decomposer 类
class MockDecomposer:
def decompose(self, memory_entries):
return "系统:你是一个助手\n用户:你好\n助手:你好!有什么可以帮助你的吗?"
# 创建模拟的 DecomposerRegistry 类
class MockDecomposerRegistry(DecomposerRegistry):
def get_decomposer(self, name):
return MockDecomposer()
@pytest.mark.asyncio
async def test_chat_memory_query_async():
"""使用 pytest-asyncio 测试聊天记忆查询块"""
# 创建容器
container = DependencyContainer()
# 创建发送者
chat_sender = ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User")
# 注册到容器
container.register(MemoryManager, MockMemoryManager())
container.register(ScopeRegistry, MockScopeRegistry(container))
container.register(DecomposerRegistry, MockDecomposerRegistry(container))
# 创建块 - 默认参数
block = ChatMemoryQuery(scope_type="member")
block.container = container
# 执行块
result = block.execute(chat_sender=chat_sender)
# 验证结果
assert "memory_content" in result
assert isinstance(result["memory_content"], str)
assert "你是一个助手" in result["memory_content"]
@pytest.mark.asyncio
async def test_chat_memory_store_async():
"""使用 pytest-asyncio 测试聊天记忆存储块"""
# 创建容器
container = DependencyContainer()
# 创建用户消息
user_msg = IMMessage(
sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"),
message_elements=[TextMessage("新消息")]
)
# 创建 LLM 响应
llm_resp = LLMChatResponse(
message=Message(
content=[
LLMChatTextContent(
text="这是 AI 的回复"
)
],
role="assistant"
),
model="gpt-3.5-turbo",
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
)
# 注册到容器
container.register(MemoryManager, MockMemoryManager())
container.register(ScopeRegistry, MockScopeRegistry(container))
container.register(ComposerRegistry, MockComposerRegistry(container))
# 创建块
block = ChatMemoryStore(scope_type="member")
block.container = container
# 执行块 - 存储用户消息
result = block.execute(user_msg=user_msg)
# 验证结果
assert result == {}
# 执行块 - 存储 LLM 响应
result = block.execute(
user_msg=user_msg,
llm_resp=llm_resp
)
# 验证结果
assert result == {}
================================================
FILE: tests/system_blocks/memory/test_clear_memory.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.im.message import IMMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.memory.memory_manager import MemoryManager
from kirara_ai.memory.registry import ComposerRegistry, DecomposerRegistry, ScopeRegistry
from kirara_ai.workflow.implementations.blocks.memory.clear_memory import ClearMemory
# 创建模拟的 MemoryManager 类
class MockMemoryManager(MemoryManager):
def __init__(self, container: DependencyContainer):
super().__init__(container)
self.config = MagicMock()
self.config.default_scope = "member"
self.memories = {}
def clear_memory(self, *args, **kwargs):
return None
# 创建模拟的 Scope 类
class MockScope:
def __init__(self, name):
self.name = name
def get_scope_key(self, sender: ChatSender):
return sender.user_id
# 创建模拟的 ScopeRegistry 类
class MockScopeRegistry(ScopeRegistry):
def get_scope(self, name):
return MockScope(name)
@pytest.mark.asyncio
async def test_clear_memory_async():
"""使用 pytest-asyncio 测试清除记忆块"""
# 创建容器
container = DependencyContainer()
# 创建发送者
chat_sender = ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User")
# 注册到容器
container.register(DependencyContainer, container)
container.register(GlobalConfig, GlobalConfig())
container.register(MemoryManager, MockMemoryManager(container))
container.register(ScopeRegistry, MockScopeRegistry(container))
container.register(ComposerRegistry, MagicMock(spec=ComposerRegistry))
container.register(DecomposerRegistry, MagicMock(spec=DecomposerRegistry))
# 创建块
block = ClearMemory(scope_type="member")
block.container = container
# 执行块 - 使用默认发送者
result = block.execute(chat_sender=chat_sender)
# 验证结果
assert "response" in result
assert isinstance(result["response"], IMMessage)
assert "已清空" in result["response"].content or "清除" in result["response"].content
# 执行块 - 使用自定义发送者
custom_sender = ChatSender.from_c2c_chat(user_id="custom_user", display_name="Custom User")
result = block.execute(chat_sender=custom_sender)
# 验证结果
assert "response" in result
assert isinstance(result["response"], IMMessage)
================================================
FILE: tests/system_blocks/system/__init__.py
================================================
# 系统基础块测试包
================================================
FILE: tests/system_blocks/system/test_basic.py
================================================
import re
from datetime import datetime
from unittest.mock import patch
import pytest
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.system.basic import (CurrentTimeBlock, TextBlock, TextConcatBlock,
TextExtractByRegexBlock, TextReplaceBlock)
@pytest.fixture
def container():
"""创建一个实际的依赖容器"""
return DependencyContainer()
def test_text_block():
"""测试基础文本块"""
# 创建一个文本块
block = TextBlock(text="测试文本")
# 执行块
result = block.execute()
# 验证结果
assert "text" in result
assert result["text"] == "测试文本"
def test_text_concat_block():
"""测试文本拼接块"""
# 创建一个文本拼接块
block = TextConcatBlock()
# 执行块
result = block.execute(text1="Hello, ", text2="World!")
# 验证结果
assert "text" in result
assert result["text"] == "Hello, World!"
def test_text_replace_block():
"""测试文本替换块"""
# 创建一个文本替换块
block = TextReplaceBlock(variable="{name}")
# 执行块
result = block.execute(text="Hello, {name}!", new_text="ChatGPT")
# 验证结果
assert "text" in result
assert result["text"] == "Hello, ChatGPT!"
# 测试非字符串替换
result = block.execute(text="Count: {name}", new_text=42)
assert result["text"] == "Count: 42"
def test_text_extract_by_regex_block():
"""测试正则表达式提取块"""
# 创建一个正则表达式提取块
block = TextExtractByRegexBlock(regex=r"用户名:(\w+)")
# 执行块 - 匹配成功
result = block.execute(text="用户信息 - 用户名:testuser, 年龄:25")
# 验证结果
assert "text" in result
assert result["text"] == "testuser"
# 执行块 - 匹配失败
result = block.execute(text="没有用户名信息")
assert result["text"] == ""
def test_current_time_block():
"""测试当前时间块"""
# 创建一个当前时间块
block = CurrentTimeBlock()
# 使用 patch 来模拟当前时间
with patch('kirara_ai.workflow.implementations.blocks.system.basic.datetime') as mock_datetime:
# 设置模拟的当前时间
mock_datetime.now.return_value = datetime(2023, 1, 1, 12, 0, 0)
# 执行块
result = block.execute()
# 验证结果
assert "time" in result
assert result["time"] == "2023-01-01 12:00:00"
# 不使用 mock,测试实际时间格式
result = block.execute()
assert "time" in result
# 验证时间格式
time_pattern = r"\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}"
assert re.match(time_pattern, result["time"]) is not None
================================================
FILE: tests/system_blocks/system/test_help.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule, DispatchRuleRegistry, RuleGroup, SimpleDispatchRule
from kirara_ai.workflow.implementations.blocks.system.help import GenerateHelp
@pytest.fixture
def container():
"""创建一个带有模拟规则注册表的容器"""
container = DependencyContainer()
registry = MagicMock(spec=DispatchRuleRegistry)
container.register(DispatchRuleRegistry, registry)
return container, registry
def create_mock_rule(
rule_id: str, name: str, description: str, workflow_id: str, rule_groups: list
) -> CombinedDispatchRule:
"""创建模拟的组合规则"""
return CombinedDispatchRule(
rule_id=rule_id,
name=name,
description=description,
workflow_id=workflow_id,
rule_groups=rule_groups,
enabled=True,
priority=5,
metadata={},
)
def test_generate_help_basic(container):
"""测试基本的帮助信息生成"""
container, registry = container
# 创建模拟规则
help_rule = create_mock_rule(
rule_id="help_command",
name="帮助命令",
description="显示帮助信息",
workflow_id="system:help",
rule_groups=[
RuleGroup(
operator="and",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/help"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["帮助", "help"]}
),
],
)
],
)
chat_rule = create_mock_rule(
rule_id="chat_command",
name="聊天命令",
description="开始聊天",
workflow_id="chat:chat",
rule_groups=[
RuleGroup(
operator="or",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/chat"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["聊天", "对话"]}
),
],
)
],
)
registry.get_active_rules.return_value = [help_rule, chat_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 检查帮助文本格式
assert "机器人命令帮助" in help_text
assert "SYSTEM" in help_text
assert "CHAT" in help_text
assert "帮助命令" in help_text
assert "聊天命令" in help_text
assert "/help" in help_text
assert "/chat" in help_text
assert "显示帮助信息" in help_text
assert "开始聊天" in help_text
assert "且" in help_text # 检查组合逻辑词
assert "或" in help_text
def test_generate_help_empty(container):
"""测试没有规则时的帮助信息生成"""
container, registry = container
registry.get_active_rules.return_value = []
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 检查基本格式
assert "机器人命令帮助" in help_text
# 确保没有分类和命令
assert "📑" not in help_text
assert "🔸" not in help_text
def test_generate_help_no_description(container):
"""测试规则没有描述时的处理"""
container, registry = container
# 创建一个没有描述的规则
test_rule = create_mock_rule(
rule_id="test_command",
name="测试命令",
description="", # 空描述
workflow_id="test:test",
rule_groups=[
RuleGroup(
operator="or",
rules=[SimpleDispatchRule(type="prefix", config={"prefix": "/test"})],
)
],
)
registry.get_active_rules.return_value = [test_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 应该显示命令,但没有描述部分
assert "测试命令" in help_text
assert "/test" in help_text
assert "说明:" not in help_text
def test_generate_help_complex_rules(container):
"""测试复杂组合规则的帮助信息生成"""
container, registry = container
# 创建一个包含复杂组合条件的规则
complex_rule = create_mock_rule(
rule_id="complex_command",
name="复杂命令",
description="这是一个复杂的命令",
workflow_id="test:complex",
rule_groups=[
RuleGroup(
operator="or",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/complex"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["复杂", "高级"]}
),
],
),
RuleGroup(
operator="and",
rules=[
SimpleDispatchRule(type="regex", config={"pattern": ".*test.*"}),
SimpleDispatchRule(type="keyword", config={"keywords": ["测试"]}),
],
),
],
)
registry.get_active_rules.return_value = [complex_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
help_text = result["response"].content
# 检查复杂规则的格式
assert "复杂命令" in help_text
assert "这是一个复杂的命令" in help_text
assert "输入以 /complex 开头" in help_text
assert "输入包含 复杂 或 高级" in help_text
assert "输入匹配正则 .*test.*" in help_text
assert "输入包含 测试" in help_text
assert "并且" in help_text
assert "或" in help_text
================================================
FILE: tests/test_config_loader.py
================================================
import unittest
from unittest.mock import mock_open, patch
from pydantic import BaseModel
from kirara_ai.config.config_loader import ConfigLoader
class TestConfig(BaseModel):
__test__ = False
"""测试用配置类"""
name: str
value: int
class TestConfigLoader(unittest.TestCase):
def setUp(self):
self.test_config = TestConfig(name="test", value=123)
self.test_config_path = "test_config.yaml"
def test_save_config_with_backup(self):
"""测试保存配置文件时的备份功能"""
# Mock os.path.exists 返回 True,表示配置文件存在
with patch("os.path.exists", return_value=True) as mock_exists:
# Mock shutil.copy2 用于验证备份操作
with patch("shutil.copy2") as mock_copy:
# Mock open 和 yaml.dump 操作
mock_file = mock_open()
with patch("builtins.open", mock_file):
with patch.object(ConfigLoader.yaml, "dump") as mock_dump:
# 执行保存操作
ConfigLoader.save_config_with_backup(
self.test_config_path, self.test_config
)
# 验证是否检查了文件存在
mock_exists.assert_called_once_with(self.test_config_path)
# 验证是否创建了备份
mock_copy.assert_called_once_with(
self.test_config_path, f"{self.test_config_path}.bak"
)
# 验证是否打开了文件进行写入
mock_file.assert_called_with(
self.test_config_path, "w", encoding="utf-8"
)
# 验证是否调用了 yaml.dump
mock_dump.assert_called_once_with(
self.test_config.model_dump(), mock_file()
)
def test_save_config_without_backup(self):
"""测试当配置文件不存在时的保存操作(不应创建备份)"""
# Mock os.path.exists 返回 False,表示配置文件不存在
with patch("os.path.exists", return_value=False) as mock_exists:
# Mock shutil.copy2 用于验证备份操作
with patch("shutil.copy2") as mock_copy:
# Mock open 和 yaml.dump 操作
mock_file = mock_open()
with patch("builtins.open", mock_file):
with patch.object(ConfigLoader.yaml, "dump") as mock_dump:
# 执行保存操作
ConfigLoader.save_config_with_backup(
self.test_config_path, self.test_config
)
# 验证是否检查了文件存在
mock_exists.assert_called_once_with(self.test_config_path)
# 验证没有创建备份
mock_copy.assert_not_called()
# 验证是否打开了文件进行写入
mock_file.assert_called_with(
self.test_config_path, "w", encoding="utf-8"
)
# 验证是否调用了 yaml.dump
mock_dump.assert_called_once_with(
self.test_config.model_dump(), mock_file()
)
if __name__ == "__main__":
unittest.main()
================================================
FILE: tests/test_game_blocks.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.blocks.game.dice import DiceRoll
from kirara_ai.workflow.implementations.blocks.game.gacha import GachaSimulator
@pytest.fixture
def container():
return MagicMock(spec=DependencyContainer)
@pytest.fixture
def create_message():
def _create(content: str) -> IMMessage:
return IMMessage(sender=ChatSender.from_c2c_chat(user_id="test_user", display_name="Test User"), message_elements=[TextMessage(content)])
return _create
def test_dice_roll_basic(container, create_message):
"""测试基本的骰子命令"""
block = DiceRoll()
block.container = container
result = block.execute(create_message(".roll 2d6"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert response.sender == ChatSender.get_bot_sender()
assert len(response.message_elements) == 1
assert "掷出了 2d6" in response.content
def test_dice_roll_invalid(container, create_message):
"""测试无效的骰子命令"""
block = DiceRoll()
block.container = container
result = block.execute(create_message("invalid command"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "Invalid dice command" in response.content
def test_dice_roll_too_many(container, create_message):
"""测试超过限制的骰子数量"""
block = DiceRoll()
block.container = container
result = block.execute(create_message(".roll 101d6"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "Too many dice" in response.content
def test_gacha_single_pull(container, create_message):
"""测试单次抽卡"""
block = GachaSimulator()
block.container = container
result = block.execute(create_message("单抽"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "抽卡结果" in response.content
# 检查是否只有一个结果
result_text = response.content
assert len(result_text.split("、")) == 1
def test_gacha_ten_pull(container, create_message):
"""测试十连抽卡"""
block = GachaSimulator()
block.container = container
result = block.execute(create_message("十连"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
# 检查是否有十个结果
result_text = response.content
assert len(result_text.split("、")) == 10
def test_gacha_custom_rates(container, create_message):
"""测试自定义概率的抽卡"""
rates = {"SSR": 1.0, "SR": 0.0, "R": 0.0} # 100% SSR
block = GachaSimulator(rates)
block.container = container
result = block.execute(create_message("单抽"))
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
assert "SSR" in response.content
================================================
FILE: tests/test_mcp_server.py
================================================
import asyncio
from unittest.mock import AsyncMock, MagicMock, patch
import pytest
from mcp import types
from kirara_ai.config.global_config import MCPServerConfig
from kirara_ai.mcp_module.models import MCPConnectionState
from kirara_ai.mcp_module.server import MCPServer
# 测试配置
@pytest.fixture
def stdio_config():
return MCPServerConfig(
id="test-stdio",
connection_type="stdio",
command="python",
args=["-m", "mcp.server"]
)
@pytest.fixture
def sse_config():
return MCPServerConfig(
id="test-sse",
connection_type="sse",
url="http://localhost:8000/sse"
)
@pytest.fixture
def invalid_config():
return MCPServerConfig(
id="test-invalid",
connection_type="invalid"
)
# 模拟 MCP 客户端会话
class MockClientSession:
def __init__(self):
self.initialize = AsyncMock()
self.list_tools = AsyncMock(return_value=types.ListToolsResult(tools=[]))
self.call_tool = AsyncMock(return_value=types.CallToolResult(content=[types.TextContent(text="114514", type="text")], isError=False))
self.complete = AsyncMock(return_value={})
self.get_prompt = AsyncMock(return_value="测试提示词")
self.list_prompts = AsyncMock(return_value=[])
self.list_resources = AsyncMock(return_value=[])
self.list_resource_templates = AsyncMock(return_value=[])
self.read_resource = AsyncMock(return_value="资源内容")
self.subscribe_resource = AsyncMock(return_value={})
self.unsubscribe_resource = AsyncMock(return_value={})
async def __aenter__(self):
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
pass
# 测试基本初始化
def test_init(stdio_config):
server = MCPServer(stdio_config)
assert server.server_config == stdio_config
assert server.session is None
assert server.state == MCPConnectionState.DISCONNECTED
assert server._lifecycle_task is None
assert not server._shutdown_event.is_set()
assert not server._connected_event.is_set()
# 测试连接和断开连接
@pytest.mark.asyncio
async def test_connect_disconnect_stdio(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
# 测试连接
connect_result = await server.connect()
assert connect_result is True
assert server.state == MCPConnectionState.CONNECTED
# 测试断开连接
disconnect_result = await server.disconnect()
assert disconnect_result is True
assert server.state == MCPConnectionState.DISCONNECTED
@pytest.mark.asyncio
async def test_connect_disconnect_sse(sse_config):
with patch("kirara_ai.mcp_module.server.sse_client") as mock_sse_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_sse_client.return_value = mock_client
server = MCPServer(sse_config)
# 测试连接
connect_result = await server.connect()
assert connect_result is True
assert server.state == MCPConnectionState.CONNECTED
# 测试断开连接
disconnect_result = await server.disconnect()
assert disconnect_result is True
assert server.state == MCPConnectionState.DISCONNECTED
@pytest.mark.asyncio
async def test_connect_invalid_config(invalid_config):
server = MCPServer(invalid_config)
connect_result = await server.connect()
assert connect_result is False
assert server.state == MCPConnectionState.ERROR
# 测试连接超时
@pytest.mark.asyncio
async def test_connect_timeout(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession") as mock_session:
# 设置模拟返回值,但不设置连接完成事件
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(side_effect=lambda: asyncio.sleep(60)) # 模拟长时间操作
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
# 修改超时时间以加快测试
with patch.object(asyncio, "wait_for", side_effect=asyncio.TimeoutError):
connect_result = await server.connect()
assert connect_result is False
# 测试工具相关方法
@pytest.mark.asyncio
async def test_tool_methods(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
await server.connect()
# 测试获取工具列表
tools = await server.get_tools()
assert isinstance(tools, types.ListToolsResult)
# 测试调用工具
result = await server.call_tool("test_tool", {"arg": "value"})
assert isinstance(result, types.CallToolResult)
await server.disconnect()
# 测试补全方法
@pytest.mark.asyncio
async def test_complete(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
await server.connect()
result = await server.complete("test_prompt", {"temperature": 0.7})
assert result == {}
await server.disconnect()
# 测试提示词相关方法
@pytest.mark.asyncio
async def test_prompt_methods(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
await server.connect()
# 测试获取提示词
prompt = await server.get_prompt("test_prompt", {})
assert prompt == "测试提示词"
# 测试获取提示词列表
prompts = await server.list_prompts()
assert prompts == []
await server.disconnect()
# 测试资源相关方法
@pytest.mark.asyncio
async def test_resource_methods(stdio_config):
with patch("kirara_ai.mcp_module.server.stdio_client") as mock_stdio_client, \
patch("kirara_ai.mcp_module.server.ClientSession", return_value=MockClientSession()):
# 设置模拟返回值
mock_client = MagicMock()
mock_client.__aenter__ = AsyncMock(return_value=(AsyncMock(), AsyncMock()))
mock_client.__aexit__ = AsyncMock(return_value=None)
mock_stdio_client.return_value = mock_client
server = MCPServer(stdio_config)
await server.connect()
# 测试获取资源列表
resources = await server.list_resources()
assert resources == []
# 测试获取资源模板列表
templates = await server.list_resource_templates()
assert templates == []
# 测试读取资源
content = await server.read_resource("http://localhost/test-resource")
assert content == "资源内容"
# 测试订阅资源
sub_result = await server.subscribe_resource("http://localhost/test-resource")
assert sub_result == {}
# 测试取消订阅资源
unsub_result = await server.unsubscribe_resource("http://localhost/test-resource")
assert unsub_result == {}
await server.disconnect()
================================================
FILE: tests/test_media.py
================================================
import asyncio
import os
import shutil
import tempfile
import unittest
from pathlib import Path
from kirara_ai.im.message import ImageMessage, VoiceMessage
from kirara_ai.media import MediaManager, MediaType
class TestMediaManager(unittest.TestCase):
"""测试媒体管理器"""
def setUp(self):
"""测试前准备"""
# 创建临时目录
self.temp_dir = tempfile.mkdtemp()
self.media_dir = os.path.join(self.temp_dir, "media")
# 创建各种格式的测试文件
self.format_files = {}
# 图片格式
self.format_files["jpeg"] = os.path.join(self.temp_dir, "test.jpg")
with open(self.format_files["jpeg"], "wb") as f:
f.write(b"\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x01\x00H\x00H\x00\x00\xff\xdb\x00C")
self.format_files["png"] = os.path.join(self.temp_dir, "test.png")
with open(self.format_files["png"], "wb") as f:
f.write(b"\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x01\x00\x00\x00\x01\x08\x06\x00\x00\x00\x1f\x15\xc4\x89")
self.format_files["gif"] = os.path.join(self.temp_dir, "test.gif")
with open(self.format_files["gif"], "wb") as f:
f.write(b"GIF89a\x01\x00\x01\x00\x80\x00\x00\xff\xff\xff\x00\x00\x00!\xf9\x04\x01\x00\x00\x00\x00,\x00\x00\x00\x00\x01\x00\x01\x00\x00\x02\x02D\x01\x00;")
self.format_files["webp"] = os.path.join(self.temp_dir, "test.webp")
with open(self.format_files["webp"], "wb") as f:
f.write(b"RIFF\x1a\x00\x00\x00WEBPVP8 \x0e\x00\x00\x00\x10\x00\x00\x00\x10\x00\x00\x00\x01\x00\x02\x00\x02\x00\x34\x25\xa4\x00\x03p\x00\xfe\xfb\xfd\x50\x00")
# 音频格式
self.format_files["mp3"] = os.path.join(self.temp_dir, "test.mp3")
with open(self.format_files["mp3"], "wb") as f:
f.write(b"\xFF\xFB\x90\x64\x00\x00\x00\x00")
self.format_files["wav"] = os.path.join(self.temp_dir, "test.wav")
with open(self.format_files["wav"], "wb") as f:
f.write(b"RIFF$\x00\x00\x00WAVEfmt \x10\x00\x00\x00\x01\x00\x01\x00\x11+\x00\x00\x11+\x00\x00\x01\x00\x08\x00data\x00\x00\x00\x00")
# 视频格式
self.format_files["mp4"] = os.path.join(self.temp_dir, "test.mp4")
with open(self.format_files["mp4"], "wb") as f:
f.write(b"\x00\x00\x00\x18ftypmp42\x00\x00\x00\x00mp42mp41\x00\x00\x00\x00moov")
self.format_files["avi"] = os.path.join(self.temp_dir, "test.avi")
with open(self.format_files["avi"], "wb") as f:
f.write(b"RIFF\x00\x00\x00\x00AVI LIST\x00\x00\x00\x00hdrlavih\x00\x00\x00\x00")
# 文档格式
self.format_files["pdf"] = os.path.join(self.temp_dir, "test.pdf")
with open(self.format_files["pdf"], "wb") as f:
f.write(b"%PDF-1.4\n%\xe2\xe3\xcf\xd3\n1 0 obj\n<>\nendobj\n2 0 obj\n<>\nendobj\n3 0 obj\n<>>>\nendobj\nxref\n0 4\n0000000000 65535 f\n0000000015 00000 n\n0000000060 00000 n\n0000000111 00000 n\ntrailer\n<>\nstartxref\n178\n%%EOF\n")
self.format_files["txt"] = os.path.join(self.temp_dir, "test.txt")
with open(self.format_files["txt"], "wb") as f:
f.write(b"This is a test text file.")
# 使用已创建的文件作为测试文件
self.test_image_path = self.format_files["jpeg"]
self.test_audio_path = self.format_files["mp3"]
# 创建媒体管理器
self.media_manager = MediaManager(media_dir=self.media_dir)
def tearDown(self):
"""测试后清理"""
# 删除临时目录
shutil.rmtree(self.temp_dir)
def test_register_from_path(self):
"""测试从文件路径注册媒体"""
media_id = asyncio.run(self.media_manager.register_from_path(
self.test_image_path,
source="test",
description="测试图片",
tags=["test", "image"],
reference_id="test_ref"
))
# 验证媒体ID是否有效
self.assertIsNotNone(media_id)
# 验证元数据是否正确
metadata = self.media_manager.get_metadata(media_id)
self.assertIsNotNone(metadata)
self.assertEqual(metadata.media_type, MediaType.IMAGE)
self.assertEqual(metadata.source, "test")
self.assertEqual(metadata.description, "测试图片")
self.assertEqual(metadata.tags, ["test", "image"])
self.assertEqual(metadata.references, {"test_ref"})
# 验证文件是否存在
file_path = asyncio.run(self.media_manager.get_file_path(media_id))
self.assertIsNotNone(file_path)
self.assertTrue(file_path.exists())
def test_register_from_data(self):
"""测试从二进制数据注册媒体"""
with open(self.test_image_path, "rb") as f:
data = f.read()
media_id = asyncio.run(self.media_manager.register_from_data(
data,
format="jpeg",
source="test_data",
description="测试数据图片",
tags=["test", "data"],
reference_id="test_data_ref"
))
# 验证媒体ID是否有效
self.assertIsNotNone(media_id)
# 验证元数据是否正确
metadata = self.media_manager.get_metadata(media_id)
self.assertIsNotNone(metadata)
self.assertEqual(metadata.media_type, MediaType.IMAGE)
self.assertEqual(metadata.source, "test_data")
self.assertEqual(metadata.description, "测试数据图片")
self.assertEqual(metadata.tags, ["test", "data"])
self.assertEqual(metadata.references, {"test_data_ref"})
def test_register_from_url(self):
"""测试从URL注册媒体"""
# 使用本地文件URL作为测试
file_url = f"file://{Path(self.test_image_path).absolute()}"
media_id = asyncio.run(self.media_manager.register_from_url(
file_url,
source="test_url",
description="测试URL图片",
tags=["test", "url"],
reference_id="test_url_ref"
))
# 验证媒体ID是否有效
self.assertIsNotNone(media_id)
# 验证元数据是否正确
metadata = self.media_manager.get_metadata(media_id)
self.assertIsNotNone(metadata)
self.assertEqual(metadata.url, file_url)
self.assertEqual(metadata.source, "test_url")
self.assertEqual(metadata.description, "测试URL图片")
self.assertEqual(metadata.tags, ["test", "url"])
self.assertEqual(metadata.references, {"test_url_ref"})
# 获取数据(这会触发下载)
data = asyncio.run(self.media_manager.get_data(media_id))
self.assertIsNotNone(data)
# 再次检查元数据,应该有更多信息
metadata = self.media_manager.get_metadata(media_id)
self.assertIsNotNone(metadata.media_type)
self.assertIsNotNone(metadata.format)
def test_format_detection(self):
"""测试不同格式文件的类型检测"""
# 图片格式测试
for format_name in ["jpeg", "png", "gif", "webp"]:
media_id = asyncio.run(self.media_manager.register_from_path(
self.format_files[format_name],
reference_id=f"test_{format_name}"
))
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.media_type, MediaType.IMAGE, f"格式 {format_name} 应该被识别为图片")
self.assertEqual(metadata.format.lower(), format_name.lower(), f"格式 {format_name} 未被正确识别")
# 音频格式测试
for format_name in ["mp3", "wav"]:
media_id = asyncio.run(self.media_manager.register_from_path(
self.format_files[format_name],
reference_id=f"test_{format_name}"
))
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.media_type, MediaType.AUDIO, f"格式 {format_name} 应该被识别为音频")
self.assertEqual(metadata.format.lower(), format_name.lower(), f"格式 {format_name} 未被正确识别")
# 视频格式测试
for format_name in ["mp4", "avi"]:
media_id = asyncio.run(self.media_manager.register_from_path(
self.format_files[format_name],
reference_id=f"test_{format_name}"
))
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.media_type, MediaType.VIDEO, f"格式 {format_name} 应该被识别为视频")
self.assertEqual(metadata.format.lower(), format_name.lower() if format_name != "avi" else "x-msvideo", f"格式 {format_name} 未被正确识别")
# 文档格式测试
for format_name in ["pdf", "txt"]:
media_id = asyncio.run(self.media_manager.register_from_path(
self.format_files[format_name],
reference_id=f"test_{format_name}"
))
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.media_type, MediaType.FILE, f"格式 {format_name} 应该被识别为文件")
expected_format = format_name
if format_name == "txt":
expected_format = "plain"
self.assertTrue(metadata.format.lower().endswith(expected_format.lower()), f"格式 {format_name} 未被正确识别,实际为 {metadata.format}")
def test_reference_management(self):
"""测试引用管理"""
# 注册媒体
media_id = asyncio.run(self.media_manager.register_from_path(
self.test_image_path,
reference_id="ref1"
))
# 添加引用
self.media_manager.add_reference(media_id, "ref2")
# 验证引用是否添加成功
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.references, {"ref1", "ref2"})
# 移除引用
self.media_manager.remove_reference(media_id, "ref1")
# 验证引用是否移除成功
metadata = self.media_manager.get_metadata(media_id)
self.assertEqual(metadata.references, {"ref2"})
# 移除最后一个引用,媒体应该被删除
self.media_manager.remove_reference(media_id, "ref2")
# 验证媒体是否被删除
self.assertIsNone(self.media_manager.get_metadata(media_id))
def test_search(self):
"""测试搜索功能"""
# 注册多个媒体
media_id1 = asyncio.run(self.media_manager.register_from_path(
self.test_image_path,
source="source1",
description="description with keyword1",
tags=["tag1", "common"],
reference_id="ref1"
))
media_id2 = asyncio.run(self.media_manager.register_from_path(
self.test_audio_path,
source="source2",
description="description with keyword2",
tags=["tag2", "common"],
reference_id="ref2"
))
# 根据标签搜索
results = self.media_manager.search_by_tags(["tag1"])
self.assertEqual(results, [media_id1])
results = self.media_manager.search_by_tags(["common"])
self.assertEqual(set(results), {media_id1, media_id2})
# 根据描述搜索
results = self.media_manager.search_by_description("keyword1")
self.assertEqual(results, [media_id1])
# 根据来源搜索
results = self.media_manager.search_by_source("source2")
self.assertEqual(results, [media_id2])
# 根据类型搜索
results = self.media_manager.search_by_type(MediaType.IMAGE)
self.assertEqual(results, [media_id1])
results = self.media_manager.search_by_type(MediaType.AUDIO)
self.assertEqual(results, [media_id2])
def test_media_message(self):
"""测试MediaMessage类"""
# 创建只有URL的媒体消息
file_url = f"file://{Path(self.test_image_path).absolute()}"
url_message = ImageMessage(url=file_url, reference_id="url_message_ref", media_manager=self.media_manager)
# 验证媒体ID
self.assertIsNotNone(url_message.media_id)
# 获取URL(应该直接返回原始URL)
url = asyncio.run(url_message.get_url())
self.assertEqual(url, file_url)
# 获取路径(应该触发下载)
path = asyncio.run(url_message.get_path())
self.assertIsNotNone(path)
self.assertTrue(Path(path).exists())
# 创建只有路径的媒体消息
path_message = ImageMessage(path=self.test_image_path, reference_id="path_message_ref", media_manager=self.media_manager)
# 验证媒体ID
self.assertIsNotNone(path_message.media_id)
# 获取路径(应该直接返回原始路径或复制后的路径)
path = asyncio.run(path_message.get_path())
self.assertIsNotNone(path)
# 获取URL(应该生成URL)
url = asyncio.run(path_message.get_url())
self.assertIsNotNone(url)
# 创建只有数据的媒体消息
with open(self.test_image_path, "rb") as f:
data = f.read()
data_message = ImageMessage(data=data, format="jpeg", reference_id="data_message_ref", media_manager=self.media_manager)
# 验证媒体ID
self.assertIsNotNone(data_message.media_id)
# 获取数据(应该直接返回原始数据)
message_data = asyncio.run(data_message.get_data())
self.assertEqual(message_data, data)
# 获取路径(应该生成文件)
path = asyncio.run(data_message.get_path())
self.assertIsNotNone(path)
self.assertTrue(Path(path).exists())
def test_media_message_with_different_formats(self):
"""测试不同格式的媒体消息创建"""
# 测试不同格式的图片
for format_name in ["jpeg", "png", "gif", "webp"]:
message = ImageMessage(path=self.format_files[format_name], reference_id=f"message_{format_name}_ref", media_manager=self.media_manager)
self.assertIsNotNone(message.media_id)
self.assertEqual(message.resource_type, "image")
# 获取元数据
metadata = self.media_manager.get_metadata(message.media_id)
self.assertEqual(metadata.media_type, MediaType.IMAGE)
# 测试不同格式的音频
for format_name in ["mp3", "wav"]:
message = VoiceMessage(path=self.format_files[format_name], reference_id=f"message_{format_name}_ref", media_manager=self.media_manager)
self.assertIsNotNone(message.media_id)
self.assertEqual(message.resource_type, "audio")
# 获取元数据
metadata = self.media_manager.get_metadata(message.media_id)
self.assertEqual(metadata.media_type, MediaType.AUDIO)
================================================
FILE: tests/test_media_element.py
================================================
import os
import tempfile
from unittest.mock import patch
import pytest
from kirara_ai.im.message import ImageMessage
from kirara_ai.media.manager import MediaManager
# 测试资源路径
TEST_RESOURCE_PATH = os.path.join(os.path.dirname(__file__), "resources", "test_image.txt")
TEST_URL = "https://httpbin.org/image/jpeg" # 一个可用的测试图片URL
temp_dir = tempfile.mkdtemp()
media_dir = os.path.join(temp_dir, "media")
# 创建媒体管理器
media_manager = MediaManager(media_dir=media_dir)
@pytest.mark.asyncio
async def test_media_element_from_path():
# 测试从文件路径初始化
media = ImageMessage(path=TEST_RESOURCE_PATH)
# 测试获取数据
data = await media.get_data()
assert data is not None
assert isinstance(data, bytes)
# 测试获取URL (data URL格式)
url = await media.get_url()
assert url.startswith("data:")
assert "base64" in url
# 测试获取路径
path = await media.get_path()
assert os.path.exists(path)
assert os.path.isfile(path)
@pytest.mark.asyncio
async def test_media_element_from_url():
# 测试从URL初始化
media = ImageMessage(url=TEST_URL)
# 测试获取数据
data = await media.get_data()
assert data is not None
assert isinstance(data, bytes)
# 测试获取原始URL
url = await media.get_url()
assert url == TEST_URL
# 测试获取临时文件路径
path = await media.get_path()
try:
assert os.path.exists(path)
assert os.path.isfile(path)
finally:
os.remove(path)
@pytest.mark.asyncio
async def test_media_element_from_data():
# 首先从文件读取一些测试数据
with open(TEST_RESOURCE_PATH, "rb") as f:
test_data = f.read()
# 测试从二进制数据初始化
media = ImageMessage(data=test_data, format="txt")
# 测试获取数据
data = await media.get_data()
assert data == test_data
# 测试获取URL (应该是data URL)
url = await media.get_url()
assert url.startswith("data:")
assert "base64" in url
# 测试获取临时文件路径
path = await media.get_path()
assert os.path.exists(path)
assert os.path.isfile(path)
@pytest.mark.asyncio
async def test_media_element_format_detection():
# 测试格式自动检测
media = ImageMessage(path=TEST_RESOURCE_PATH)
await media.get_data() # 触发格式检测
assert media.format is not None
assert media.resource_type is not None
@pytest.mark.asyncio
async def test_media_element_errors():
# 测试错误情况
with pytest.raises(ValueError):
ImageMessage() # 没有提供任何参数
with pytest.raises(ValueError):
# 使用mock模拟网络请求失败
with patch('curl_cffi.AsyncSession.get') as mock_get:
mock_get.side_effect = ValueError("Mocked network error")
media = ImageMessage(url="https://valid-url-but-will-fail.com/image.jpg")
await media.get_data() # 模拟网络请求失败
================================================
FILE: tests/test_system_blocks.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.im.message import IMMessage
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.dispatch import CombinedDispatchRule, DispatchRuleRegistry, RuleGroup, SimpleDispatchRule
from kirara_ai.workflow.implementations.blocks.system.help import GenerateHelp
@pytest.fixture
def container():
container = MagicMock(spec=DependencyContainer)
registry = MagicMock(spec=DispatchRuleRegistry)
container.resolve.return_value = registry
return container, registry
def create_mock_rule(
rule_id: str, name: str, description: str, workflow_id: str, rule_groups: list
) -> CombinedDispatchRule:
"""创建模拟的组合规则"""
return CombinedDispatchRule(
rule_id=rule_id,
name=name,
description=description,
workflow_id=workflow_id,
rule_groups=rule_groups,
enabled=True,
priority=5,
metadata={},
)
def test_generate_help_basic(container):
"""测试基本的帮助信息生成"""
container, registry = container
# 创建模拟规则
help_rule = create_mock_rule(
rule_id="help_command",
name="帮助命令",
description="显示帮助信息",
workflow_id="system:help",
rule_groups=[
RuleGroup(
operator="and",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/help"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["帮助", "help"]}
),
],
)
],
)
chat_rule = create_mock_rule(
rule_id="chat_command",
name="聊天命令",
description="开始聊天",
workflow_id="chat:chat",
rule_groups=[
RuleGroup(
operator="or",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/chat"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["聊天", "对话"]}
),
],
)
],
)
registry.get_active_rules.return_value = [help_rule, chat_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 检查帮助文本格式
assert "机器人命令帮助" in help_text
assert "SYSTEM" in help_text
assert "CHAT" in help_text
assert "帮助命令" in help_text
assert "聊天命令" in help_text
assert "/help" in help_text
assert "/chat" in help_text
assert "显示帮助信息" in help_text
assert "开始聊天" in help_text
assert "且" in help_text # 检查组合逻辑词
assert "或" in help_text
def test_generate_help_empty(container):
"""测试没有规则时的帮助信息生成"""
container, registry = container
registry.get_active_rules.return_value = []
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 检查基本格式
assert "机器人命令帮助" in help_text
# 确保没有分类和命令
assert "📑" not in help_text
assert "🔸" not in help_text
def test_generate_help_no_description(container):
"""测试规则没有描述时的处理"""
container, registry = container
# 创建一个没有描述的规则
test_rule = create_mock_rule(
rule_id="test_command",
name="测试命令",
description="", # 空描述
workflow_id="test:test",
rule_groups=[
RuleGroup(
operator="or",
rules=[SimpleDispatchRule(type="prefix", config={"prefix": "/test"})],
)
],
)
registry.get_active_rules.return_value = [test_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
assert "response" in result
response = result["response"]
assert isinstance(response, IMMessage)
help_text = response.content
# 应该显示命令,但没有描述部分
assert "测试命令" in help_text
assert "/test" in help_text
assert "说明:" not in help_text
def test_generate_help_complex_rules(container):
"""测试复杂组合规则的帮助信息生成"""
container, registry = container
# 创建一个包含复杂组合条件的规则
complex_rule = create_mock_rule(
rule_id="complex_command",
name="复杂命令",
description="这是一个复杂的命令",
workflow_id="test:complex",
rule_groups=[
RuleGroup(
operator="or",
rules=[
SimpleDispatchRule(type="prefix", config={"prefix": "/complex"}),
SimpleDispatchRule(
type="keyword", config={"keywords": ["复杂", "高级"]}
),
],
),
RuleGroup(
operator="and",
rules=[
SimpleDispatchRule(type="regex", config={"pattern": ".*test.*"}),
SimpleDispatchRule(type="keyword", config={"keywords": ["测试"]}),
],
),
],
)
registry.get_active_rules.return_value = [complex_rule]
block = GenerateHelp()
block.container = container
result = block.execute()
help_text = result["response"].content
# 检查复杂规则的格式
assert "复杂命令" in help_text
assert "这是一个复杂的命令" in help_text
assert "输入以 /complex 开头" in help_text
assert "输入包含 复杂 或 高级" in help_text
assert "输入匹配正则 .*test.*" in help_text
assert "输入包含 测试" in help_text
assert "并且" in help_text
assert "或" in help_text
================================================
FILE: tests/test_workflow_builder.py
================================================
import os
import warnings
from typing import Any, Dict
import pytest
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
# 测试用的 Block 类
class SimpleInputBlock(Block):
"""简单的输入块"""
name: str = "simple_input"
inputs: Dict[str, Input] = {"param1": Input("param1", "输入1", str, "Input 1")}
outputs: Dict[str, Output] = {"out1": Output("out1", "输出1", str, "Output 1")}
def __init__(self, param1: str = "default"):
super().__init__()
self.param1 = param1
def execute(self) -> Dict[str, Any]:
return {"out1": self.param1}
class SimpleProcessBlock(Block):
"""简单的处理块"""
name: str = "simple_process"
inputs: Dict[str, Input] = {"in1": Input("in1", "输入1", str, "Input 1")}
outputs: Dict[str, Output] = {"out1": Output("out1", "输出1", str, "Output 1")}
def __init__(self, multiplier: int = 1):
super().__init__()
self.multiplier = multiplier
def execute(self, in1: str) -> Dict[str, Any]:
return {"out1": in1 * self.multiplier}
def setup_module(module):
"""测试模块开始前的设置"""
registry = BlockRegistry()
# 注册测试用的 block
registry.register("simple_input", "test", SimpleInputBlock)
registry.register("simple_process", "test", SimpleProcessBlock)
def teardown_module(module):
"""测试模块结束后的清理"""
BlockRegistry().clear()
class TestWorkflowBuilder:
@pytest.fixture
def container(self):
container = DependencyContainer()
registry = BlockRegistry()
container.register(BlockRegistry, registry)
# 注册测试用的 block
registry.register("simple_input", "test", SimpleInputBlock)
registry.register("simple_process", "test", SimpleProcessBlock)
return container
@pytest.fixture
def yaml_path(self):
path = "test_workflow.yaml"
yield path
# 清理测试文件
if os.path.exists(path):
os.remove(path)
def test_basic_dsl_construction(self, container):
"""测试基本的 DSL 构建功能"""
builder = (
WorkflowBuilder("test_workflow")
.use(SimpleInputBlock, name="input1", param1="test")
.chain(SimpleProcessBlock, name="process1", multiplier=2)
)
workflow = builder.build(container)
assert len(workflow.blocks) == 2
assert len(workflow.wires) == 1
assert workflow.blocks[0].name == "input1"
assert workflow.blocks[1].name == "process1"
def test_parallel_construction(self, container):
"""测试并行节点构建"""
builder = (
WorkflowBuilder("test_workflow")
.use(SimpleInputBlock)
.parallel(
[
(SimpleProcessBlock, "process1", {"multiplier": 2}),
(SimpleProcessBlock, "process2", {"multiplier": 3}),
]
)
)
workflow = builder.build(container)
assert len(workflow.blocks) == 3
assert len(workflow.wires) == 2
assert any(block.name == "process1" for block in workflow.blocks)
assert any(block.name == "process2" for block in workflow.blocks)
def test_save_and_load(self, container, yaml_path):
"""测试工作流的保存和加载"""
# 构建原始工作流
original_builder = (
WorkflowBuilder("test_workflow")
.use(SimpleInputBlock, name="input1", param1="test")
.parallel(
[
(SimpleProcessBlock, "process1", {"multiplier": 2}),
(SimpleProcessBlock, "process2", {"multiplier": 3}),
]
)
)
# 保存工作流
original_builder.save_to_yaml(yaml_path, container)
# 加载工作流
loaded_builder = WorkflowBuilder.load_from_yaml(yaml_path, container)
loaded_workflow = loaded_builder.build(container)
# 验证加载后的工作流
assert len(loaded_workflow.blocks) == 3
assert loaded_workflow.name == "test_workflow"
# 验证参数是否正确加载
input_block = next(b for b in loaded_workflow.blocks if b.name == "input1")
assert input_block.param1 == "test"
process1 = next(b for b in loaded_workflow.blocks if b.name == "process1")
assert process1.multiplier == 2
process2 = next(b for b in loaded_workflow.blocks if b.name == "process2")
assert process2.multiplier == 3
def test_complex_workflow_serialization(self, container, yaml_path):
"""测试复杂工作流的序列化"""
# 构建一个包含多种特性的复杂工作流
builder = (
WorkflowBuilder("complex_workflow")
.use(SimpleInputBlock, name="start", param1="init")
.parallel(
[
(SimpleProcessBlock, "parallel1", {"multiplier": 2}),
(SimpleProcessBlock, "parallel2", {"multiplier": 3}),
]
)
.chain(
SimpleProcessBlock,
name="final",
wire_from=["parallel1", "parallel2"],
multiplier=1,
)
)
# 保存工作流
builder.save_to_yaml(yaml_path, container)
# 加载工作流
loaded_builder = WorkflowBuilder.load_from_yaml(yaml_path, container)
loaded_workflow = loaded_builder.build(container)
# 验证结构
assert len(loaded_workflow.blocks) == 4
assert len(loaded_workflow.wires) >= 3 # 至少应该有3个连接
# 验证特定节点的存在和配置
assert any(b.name == "start" for b in loaded_workflow.blocks)
assert any(b.name == "parallel1" for b in loaded_workflow.blocks)
assert any(b.name == "parallel2" for b in loaded_workflow.blocks)
assert any(b.name == "final" for b in loaded_workflow.blocks)
def test_invalid_yaml_handling(self, container):
"""测试处理无效 YAML 文件的情况"""
with pytest.raises(Exception):
WorkflowBuilder.load_from_yaml("non_existent_file.yaml", container)
def test_unregistered_block_warning(self, container, yaml_path):
"""测试未注册 block 的警告"""
# 获取 registry 并清空
registry = container.resolve(BlockRegistry)
registry.clear()
with pytest.warns(UserWarning):
builder = WorkflowBuilder("test_workflow").use(SimpleInputBlock)
builder.save_to_yaml(yaml_path, container)
def test_registered_block_no_warning(self, container, yaml_path):
"""测试已注册 block 不会产生警告"""
registry = container.resolve(BlockRegistry)
registry.clear()
registry.register("simple_input", "test", SimpleInputBlock)
with warnings.catch_warnings():
warnings.simplefilter("error")
builder = WorkflowBuilder("test_workflow").use(SimpleInputBlock)
builder.save_to_yaml(yaml_path, container)
================================================
FILE: tests/test_workflow_factories.py
================================================
from unittest.mock import MagicMock
import pytest
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.implementations.factories.game_factory import GameWorkflowFactory
from kirara_ai.workflow.implementations.factories.system_factory import SystemWorkflowFactory
@pytest.fixture
def container():
return MagicMock(spec=DependencyContainer)
def test_game_dice_workflow(container):
"""测试骰子游戏工作流创建"""
workflow = GameWorkflowFactory.create_dice_workflow().build(container)
# 验证工作流结构
assert workflow.name == "骰子游戏"
assert len(workflow.blocks) == 3 # GetIMMessage -> DiceRoll -> SendIMMessage
# 验证连接
assert len(workflow.wires) == 2 # 两个连接
def test_game_gacha_workflow(container):
"""测试抽卡游戏工作流创建"""
workflow = GameWorkflowFactory.create_gacha_workflow().build(container)
# 验证工作流结构
assert workflow.name == "抽卡游戏"
assert len(workflow.blocks) == 3 # GetIMMessage -> GachaSimulator -> SendIMMessage
# 验证连接
assert len(workflow.wires) == 2 # 两个连接
def test_system_help_workflow(container):
"""测试帮助信息工作流创建"""
workflow = SystemWorkflowFactory.create_help_workflow().build(container)
# 验证工作流结构
assert workflow.name == "帮助信息"
assert len(workflow.blocks) == 2 # GenerateHelp -> SendIMMessage
# 验证连接
assert len(workflow.wires) == 1 # 一个连接
================================================
FILE: tests/tracing/__init__.py
================================================
"""Tracing framework tests"""
================================================
FILE: tests/tracing/test_base.py
================================================
import unittest
from datetime import datetime
from typing import Any, Dict, Optional
from sqlalchemy import Column, Integer
from kirara_ai.config.global_config import GlobalConfig
from kirara_ai.database import DatabaseManager
from kirara_ai.database.manager import Base
from kirara_ai.events.event_bus import EventBus
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.format.message import LLMChatMessage, LLMChatTextContent
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.tracing.core import TraceRecord
from kirara_ai.tracing.models import LLMRequestTrace
class TestTraceRecord(TraceRecord):
"""用于测试的追踪记录类"""
__test__ = False
__tablename__ = "test_traces"
__table_args__ = {'extend_existing': True}
id = Column(Integer, primary_key=True)
def update_from_event(self, event):
pass
def to_dict(self) -> Dict[str, Any]:
return {}
def to_detail_dict(self) -> Dict[str, Any]:
return {}
class TracingTestBase(unittest.TestCase):
"""追踪系统测试基类"""
def setUp(self):
"""测试前的准备工作"""
self.container = DependencyContainer()
self.container.register(DependencyContainer, self.container)
self.event_bus = EventBus()
self.container.register(EventBus, self.event_bus)
self.container.register(GlobalConfig, GlobalConfig())
# 使用内存数据库进行测试
self.db_manager = DatabaseManager(self.container, database_url="sqlite:///:memory:", is_debug=True)
self.db_manager.initialize()
Base.metadata.create_all(self.db_manager.engine)
self.container.register(DatabaseManager, self.db_manager)
def tearDown(self):
"""测试后的清理工作"""
self.db_manager.shutdown()
def create_test_request(self, model: str = "test-model") -> LLMChatRequest:
"""创建测试用的LLM请求"""
return LLMChatRequest(
model=model,
messages=[LLMChatMessage(role="user", content=[LLMChatTextContent(text="test message")])]
)
def create_test_response(self, usage: Optional[Usage] = None) -> LLMChatResponse:
"""创建测试用的LLM响应"""
if usage is None:
usage = Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
)
return LLMChatResponse(
model="test-model",
message=Message(role="assistant", content=[LLMChatTextContent(text="test response")]),
usage=usage
)
def create_test_trace(self) -> LLMRequestTrace:
"""创建测试用的追踪记录"""
trace = LLMRequestTrace()
trace.trace_id = "test-trace-id"
trace.model_id = "test-model"
trace.backend_name = "test-backend"
trace.request_time = datetime.now()
return trace
================================================
FILE: tests/tracing/test_core.py
================================================
from datetime import datetime
from unittest import IsolatedAsyncioTestCase
from kirara_ai.events.tracing import TraceEvent
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.ioc.inject import Inject
from kirara_ai.tracing.core import TracerBase, generate_trace_id
from tests.tracing.test_base import TestTraceRecord, TracingTestBase
class TestEvent(TraceEvent):
"""用于测试的事件类"""
__test__ = False
def __init__(self, trace_id: str):
self.trace_id = trace_id
self.start_time = datetime.now().timestamp()
class TestTracer(TracerBase[TestTraceRecord]):
"""用于测试的追踪器"""
__test__ = False
name = "test"
record_class = TestTraceRecord
@Inject()
def __init__(self, container: DependencyContainer):
super().__init__(container, record_class=TestTraceRecord)
def _register_event_handlers(self):
self.event_bus.register(TestEvent, self._on_test_event)
def _unregister_event_handlers(self):
self.event_bus.unregister(TestEvent, self._on_test_event)
def _on_test_event(self, event: TestEvent):
"""处理测试事件"""
trace = TestTraceRecord()
trace.trace_id = event.trace_id
trace.request_time = datetime.now()
self.save_trace_record(trace)
class TestTracerBase(TracingTestBase, IsolatedAsyncioTestCase):
"""追踪器基类测试"""
def setUp(self):
super().setUp()
self.tracer = TestTracer(self.container)
self.tracer.initialize()
def tearDown(self):
self.tracer.shutdown()
super().tearDown()
def test_generate_trace_id(self):
"""测试生成追踪ID"""
trace_id1 = generate_trace_id()
trace_id2 = generate_trace_id()
self.assertIsNotNone(trace_id1)
self.assertIsNotNone(trace_id2)
self.assertNotEqual(trace_id1, trace_id2)
def test_get_traces(self):
"""测试获取追踪记录"""
# 创建一些测试数据
for i in range(5):
event = TestEvent(f"test-trace-{i}")
self.event_bus.post(event)
# 测试基本查询
traces, total = self.tracer.get_traces()
self.assertEqual(total, 5)
self.assertEqual(len(traces), 5)
# 测试分页
traces, total = self.tracer.get_traces(page=1, page_size=2)
self.assertEqual(total, 5)
self.assertEqual(len(traces), 2)
# 测试过滤
traces, total = self.tracer.get_traces(filters={"trace_id": "test-trace-0"})
self.assertEqual(total, 1)
self.assertEqual(len(traces), 1)
self.assertEqual(traces[0].trace_id, "test-trace-0")
def test_get_recent_traces(self):
"""测试获取最近的追踪记录"""
# 创建一些测试数据
for i in range(5):
event = TestEvent(f"test-trace-{i}")
self.event_bus.post(event)
# 测试限制数量
traces = self.tracer.get_recent_traces(limit=3)
self.assertEqual(len(traces), 3)
def test_get_trace_by_id(self):
"""测试根据ID获取追踪记录"""
event = TestEvent("test-trace-id")
self.event_bus.post(event)
# 测试获取存在的记录
trace = self.tracer.get_trace_by_id("test-trace-id")
self.assertIsNotNone(trace)
self.assertEqual(trace.trace_id, "test-trace-id")
# 测试获取不存在的记录
trace = self.tracer.get_trace_by_id("non-existent-id")
self.assertIsNone(trace)
async def test_websocket_operations(self):
"""测试WebSocket相关操作"""
# 创建一个测试队列
queue = self.tracer.register_ws_client()
# 广播一条消息
test_message = {"type": "test", "data": "test data"}
self.tracer.broadcast_ws_message(test_message)
# 验证消息是否被正确广播
message = await queue.get()
self.assertEqual(message, test_message)
# 注销客户端
self.tracer.unregister_ws_client(queue)
# 验证客户端是否被正确注销
self.assertNotIn(queue, self.tracer._ws_queues)
def test_save_and_update_trace_record(self):
"""测试保存和更新追踪记录"""
# 创建并保存记录
trace = TestTraceRecord()
trace.trace_id = "test-trace-id"
trace.request_time = datetime.now()
saved_trace = self.tracer.save_trace_record(trace)
self.assertIsNotNone(saved_trace)
# 更新记录
event = TestEvent("test-trace-id")
updated_trace = self.tracer.update_trace_record("test-trace-id", event)
self.assertIsNotNone(updated_trace)
# 测试更新不存在的记录
non_existent = self.tracer.update_trace_record("non-existent-id", event)
self.assertIsNone(non_existent)
================================================
FILE: tests/tracing/test_decorator.py
================================================
from kirara_ai.llm.adapter import LLMBackendAdapter, LLMChatProtocol
from kirara_ai.llm.format.message import LLMChatTextContent
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Message
from kirara_ai.tracing import LLMTracer
from kirara_ai.tracing.decorator import trace_llm_chat
from tests.tracing.test_base import TracingTestBase
class TestLLMAdapter(LLMBackendAdapter, LLMChatProtocol):
"""用于测试的LLM适配器"""
__test__ = False
def __init__(self, tracer: LLMTracer):
self.backend_name = "test-backend"
self.tracer = tracer
@trace_llm_chat
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
return LLMChatResponse(
model="test-model",
message=Message(role="assistant", content=[LLMChatTextContent(text="test response")]),
)
class TestTraceDecorator(TracingTestBase):
"""追踪装饰器测试"""
def setUp(self):
super().setUp()
self.tracer = LLMTracer(self.container)
self.tracer.initialize()
self.adapter = TestLLMAdapter(self.tracer)
def tearDown(self):
self.tracer.shutdown()
super().tearDown()
def test_trace_success(self):
"""测试成功追踪"""
request = self.create_test_request()
# 调用被装饰的方法
response = self.adapter.chat(request)
# 验证响应
self.assertIsNotNone(response)
self.assertEqual(response.message.content[0].text, "test response")
# 验证追踪记录
traces = self.tracer.get_recent_traces(limit=1)
self.assertEqual(len(traces), 1)
trace = traces[0]
self.assertEqual(trace.status, "success")
self.assertEqual(trace.backend_name, "test-backend")
def test_trace_failure(self):
"""测试失败追踪"""
request = self.create_test_request()
# 创建一个会抛出异常的适配器
error_adapter = TestLLMAdapter(self.tracer)
@trace_llm_chat
def raise_error(self, req: LLMChatRequest) -> LLMChatResponse:
raise Exception("Test error")
error_adapter.chat = raise_error
# 调用被装饰的方法
with self.assertRaises(Exception):
error_adapter.chat(self=error_adapter, req=request)
# 验证追踪记录
traces = self.tracer.get_recent_traces(limit=1)
self.assertEqual(len(traces), 1)
trace = traces[0]
self.assertEqual(trace.status, "failed")
self.assertEqual(trace.error, "Test error")
self.assertEqual(trace.backend_name, "test-backend")
================================================
FILE: tests/tracing/test_llm_tracer.py
================================================
from datetime import datetime
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from kirara_ai.tracing import LLMTracer
from tests.tracing.test_base import TracingTestBase
class TestLLMTracer(TracingTestBase):
"""LLM追踪器测试"""
def setUp(self):
super().setUp()
self.tracer = LLMTracer(self.container)
self.tracer.initialize()
def tearDown(self):
self.tracer.shutdown()
super().tearDown()
def test_start_request_tracking(self):
"""测试开始追踪请求"""
request = self.create_test_request()
trace_id = self.tracer.start_request_tracking("test-backend", request)
# 验证追踪ID是否生成
self.assertIsNotNone(trace_id)
# 验证活跃追踪是否记录
self.assertIn(trace_id, self.tracer._active_traces)
# 验证事件是否发布
trace = self.tracer.get_trace_by_id(trace_id)
self.assertIsNotNone(trace)
self.assertEqual(trace.status, "pending")
def test_complete_request_tracking(self):
"""测试完成追踪请求"""
request = self.create_test_request()
response = self.create_test_response()
trace_id = self.tracer.start_request_tracking("test-backend", request)
self.tracer.complete_request_tracking(trace_id, request, response)
# 验证追踪记录是否更新
trace = self.tracer.get_trace_by_id(trace_id)
self.assertIsNotNone(trace)
self.assertEqual(trace.status, "success")
self.assertEqual(trace.total_tokens, 30)
# 验证活跃追踪是否移除
self.assertNotIn(trace_id, self.tracer._active_traces)
def test_fail_request_tracking(self):
"""测试失败追踪请求"""
request = self.create_test_request()
error = Exception("Test error")
trace_id = self.tracer.start_request_tracking("test-backend", request)
self.tracer.fail_request_tracking(trace_id, request, str(error))
# 验证追踪记录是否更新
trace = self.tracer.get_trace_by_id(trace_id)
self.assertIsNotNone(trace)
self.assertEqual(trace.status, "failed")
self.assertEqual(trace.error, str(error))
# 验证活跃追踪是否移除
self.assertNotIn(trace_id, self.tracer._active_traces)
def test_event_handlers(self):
"""测试事件处理程序"""
request = self.create_test_request()
response = self.create_test_response()
trace_id = "test-trace-id"
# 测试开始事件处理
start_event = LLMRequestStartEvent(
trace_id=trace_id,
model_id="test-model",
backend_name="test-backend",
request=request
)
self.event_bus.post(start_event)
trace = self.tracer.get_trace_by_id(trace_id)
self.assertIsNotNone(trace)
self.assertEqual(trace.status, "pending")
# 测试完成事件处理
complete_event = LLMRequestCompleteEvent(
trace_id=trace_id,
model_id="test-model",
backend_name="test-backend",
request=request,
response=response,
start_time=datetime.now().timestamp()
)
self.event_bus.post(complete_event)
trace = self.tracer.get_trace_by_id(trace_id)
self.assertEqual(trace.status, "success")
# 测试失败事件处理
fail_event = LLMRequestFailEvent(
trace_id=trace_id,
model_id="test-model",
backend_name="test-backend",
request=request,
error="Test error",
start_time=datetime.now().timestamp()
)
self.event_bus.post(fail_event)
trace = self.tracer.get_trace_by_id(trace_id)
self.assertEqual(trace.status, "failed")
def test_get_statistics(self):
"""测试获取统计信息"""
# 创建一些测试数据
for i in range(3):
request = self.create_test_request()
trace_id = self.tracer.start_request_tracking("test-backend", request)
if i < 2:
response = self.create_test_response()
self.tracer.complete_request_tracking(trace_id, request, response)
else:
self.tracer.fail_request_tracking(trace_id, request, "Test error")
stats = self.tracer.get_statistics()
# 验证基本统计信息
self.assertEqual(stats["overview"]["total_requests"], 3)
self.assertEqual(stats["overview"]["success_requests"], 2)
self.assertEqual(stats["overview"]["failed_requests"], 1)
self.assertEqual(stats["overview"]["total_tokens"], 60) # 2 * 30 tokens
# 验证模型统计信息
self.assertTrue(len(stats["models"]) > 0)
model_stat = stats["models"][0]
self.assertEqual(model_stat["model_id"], "test-model")
self.assertEqual(model_stat["count"], 3)
# 验证后端统计信息
self.assertTrue(len(stats["backends"]) > 0)
backend_stat = stats["backends"][0]
self.assertEqual(backend_stat["backend_name"], "test-backend")
self.assertEqual(backend_stat["count"], 3)
================================================
FILE: tests/tracing/test_manager.py
================================================
import asyncio
from unittest import IsolatedAsyncioTestCase
from kirara_ai.tracing import LLMTracer, TracingManager
from tests.tracing.test_base import TracingTestBase
from tests.tracing.test_core import TestTracer
class TestTracingManager(TracingTestBase, IsolatedAsyncioTestCase):
"""追踪管理器测试"""
def setUp(self):
super().setUp()
self.manager = TracingManager(self.container)
def test_register_tracer(self):
"""测试注册追踪器"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 验证追踪器是否注册成功
self.assertIn("test", self.manager.get_tracer_types())
self.assertEqual(self.manager.get_tracer("test"), tracer)
def test_register_duplicate_tracer(self):
"""测试重复注册追踪器"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 验证重复注册是否抛出异常
with self.assertRaises(ValueError):
self.manager.register_tracer("test", tracer)
def test_get_tracer(self):
"""测试获取追踪器"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 验证获取追踪器
self.assertEqual(self.manager.get_tracer("test"), tracer)
self.assertIsNone(self.manager.get_tracer("non-existent"))
def test_get_all_tracers(self):
"""测试获取所有追踪器"""
tracer1 = TestTracer(self.container)
tracer2 = LLMTracer(self.container)
self.manager.register_tracer("test1", tracer1)
self.manager.register_tracer("test2", tracer2)
tracers = self.manager.get_all_tracers()
self.assertEqual(len(tracers), 2)
self.assertEqual(tracers["test1"], tracer1)
self.assertEqual(tracers["test2"], tracer2)
def test_initialize_and_shutdown(self):
"""测试初始化和关闭"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 测试初始化
self.manager.initialize()
# 测试关闭
self.manager.shutdown()
async def test_websocket_operations(self):
"""测试WebSocket相关操作"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 创建一个模拟的WebSocket客户端
class MockWebSocket:
def __init__(self):
self.queue = asyncio.Queue()
ws = MockWebSocket()
# 测试注册WebSocket客户端
queue = self.manager.register_ws_client("test")
# 测试注销WebSocket客户端
self.manager.unregister_ws_client("test", queue)
def test_trace_operations(self):
"""测试追踪操作"""
tracer = TestTracer(self.container)
self.manager.register_tracer("test", tracer)
# 测试获取最近的追踪记录
traces = self.manager.get_recent_traces("test")
self.assertEqual(len(traces), 0)
# 测试获取不存在的追踪器的记录
with self.assertRaises(ValueError):
self.manager.get_recent_traces("non-existent")
# 测试获取特定追踪记录
trace = self.manager.get_trace_by_id("test", "non-existent-id")
self.assertIsNone(trace)
================================================
FILE: tests/tracing/test_models.py
================================================
from datetime import datetime
from kirara_ai.events.tracing import LLMRequestCompleteEvent, LLMRequestFailEvent, LLMRequestStartEvent
from tests.tracing.test_base import TracingTestBase
class TestLLMRequestTrace(TracingTestBase):
"""LLM请求追踪记录测试"""
def setUp(self):
super().setUp()
self.trace = self.create_test_trace()
def test_update_from_start_event(self):
"""测试从开始事件更新"""
request = self.create_test_request()
event = LLMRequestStartEvent(
trace_id="test-trace-id",
model_id="test-model",
backend_name="test-backend",
request=request,
)
self.trace.update_from_event(event)
self.assertEqual(self.trace.trace_id, "test-trace-id")
self.assertEqual(self.trace.model_id, "test-model")
self.assertEqual(self.trace.backend_name, "test-backend")
self.assertEqual(self.trace.status, "pending")
self.assertIsNotNone(self.trace.request)
def test_update_from_complete_event(self):
"""测试从完成事件更新"""
request = self.create_test_request()
response = self.create_test_response()
start_time = datetime.now().timestamp()
event = LLMRequestCompleteEvent(
trace_id="test-trace-id",
model_id="test-model",
backend_name="test-backend",
request=request,
response=response,
start_time=start_time
)
self.trace.update_from_event(event)
self.assertEqual(self.trace.status, "success")
self.assertEqual(self.trace.prompt_tokens, 10)
self.assertEqual(self.trace.completion_tokens, 20)
self.assertEqual(self.trace.total_tokens, 30)
self.assertIsNotNone(self.trace.response)
def test_update_from_fail_event(self):
"""测试从失败事件更新"""
request = self.create_test_request()
start_time = datetime.now().timestamp()
event = LLMRequestFailEvent(
trace_id="test-trace-id",
model_id="test-model",
backend_name="test-backend",
request=request,
error="Test error",
start_time=start_time
)
self.trace.update_from_event(event)
self.assertEqual(self.trace.status, "failed")
self.assertEqual(self.trace.error, "Test error")
def test_to_dict(self):
"""测试转换为字典"""
request = self.create_test_request()
response = self.create_test_response()
# 设置一些基本属性
self.trace.request = request.model_dump()
self.trace.response = response.model_dump()
self.trace.prompt_tokens = 10
self.trace.completion_tokens = 20
self.trace.total_tokens = 30
# 测试基本字典转换
basic_dict = self.trace.to_dict()
self.assertEqual(basic_dict["trace_id"], "test-trace-id")
self.assertEqual(basic_dict["model_id"], "test-model")
self.assertEqual(basic_dict["backend_name"], "test-backend")
self.assertEqual(basic_dict["prompt_tokens"], 10)
self.assertEqual(basic_dict["completion_tokens"], 20)
self.assertEqual(basic_dict["total_tokens"], 30)
# 测试详细字典转换
detail_dict = self.trace.to_detail_dict()
self.assertIn("request", detail_dict)
self.assertIn("response", detail_dict)
self.assertEqual(detail_dict["request"], request.model_dump())
self.assertEqual(detail_dict["response"], response.model_dump())
def test_request_response_properties(self):
"""测试请求和响应属性"""
request = self.create_test_request()
response = self.create_test_response()
# 测试请求属性
self.trace.request = request.model_dump()
self.assertIsNotNone(self.trace.request)
self.assertEqual(self.trace.request["model"], "test-model")
# 测试响应属性
self.trace.response = response.model_dump()
self.assertIsNotNone(self.trace.response)
self.assertEqual(self.trace.response["message"]["content"][0]["text"], "test response")
================================================
FILE: tests/utils/auth_test_utils.py
================================================
import pytest_asyncio
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.web.auth.services import AuthService, MockAuthService
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
# ==================== Auth Fixtures ====================
def setup_auth_service(container: DependencyContainer) -> None:
"""设置认证服务"""
# 注册 MockAuthService
container.register(AuthService, MockAuthService())
@pytest_asyncio.fixture(scope="function")
async def auth_headers(test_client):
"""获取认证头"""
response = test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
data = response.json()
assert "error" not in data
token = data["access_token"]
return {"Authorization": f"Bearer {token}"}
================================================
FILE: tests/utils/test_block_registry.py
================================================
from kirara_ai.workflow.core.block.registry import BlockRegistry
def create_test_block_registry() -> BlockRegistry:
"""创建一个用于测试的 BlockRegistry 实例"""
registry = BlockRegistry()
# 注册一些基本类型
registry._type_system.register_type("str", str)
registry._type_system.register_type("int", int)
registry._type_system.register_type("float", float)
registry._type_system.register_type("bool", bool)
registry._type_system.register_type("list", list)
registry._type_system.register_type("dict", dict)
registry._type_system.register_type("Any", object)
return registry
================================================
FILE: tests/web/api/im/test_im.py
================================================
import asyncio
from typing import Any
from unittest.mock import MagicMock
import pytest
from fastapi.testclient import TestClient
from pydantic import BaseModel, Field
from kirara_ai.config.config_loader import ConfigLoader
from kirara_ai.config.global_config import GlobalConfig, IMConfig, WebConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.adapter import IMAdapter
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.im.message import IMMessage, TextMessage
from kirara_ai.im.sender import ChatSender
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.web.api.im.models import IMAdapterConfig
from kirara_ai.web.app import WebServer
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
TEST_ADAPTER_ID = "dummy-bot-1234"
TEST_ADAPTER_NOT_RUNNING_ID = "dummy-bot-2234"
TEST_ADAPTER_TYPE = "dummy"
TEST_ADAPTER_CONFIG = {"token": "test-token", "name": "Test Bot"}
# ==================== 测试用 Adapter ====================
class DummyConfig(BaseModel):
"""Dummy 配置文件模型"""
token: str = Field(description="Dummy Bot Token")
name: str = Field(description="Bot Name")
class DummyAdapter(IMAdapter):
"""
用于测试的 Dummy Adapter,实现基本的消息收发功能
"""
def __init__(self, config: DummyConfig):
self.config = config
self.is_running = False
self.messages = [] # 存储发送的消息
self.editing_states = {} # 存储编辑状态
def convert_to_message(self, raw_message: Any) -> IMMessage:
return IMMessage(
sender=ChatSender.from_c2c_chat(
user_id=raw_message.get("user_id", "default_user"),
display_name=raw_message.get("display_name", "Default User"),
),
message_elements=[TextMessage(text=raw_message.get("text", ""))],
)
async def send_message(self, message: IMMessage, recipient: ChatSender):
"""发送消息"""
self.messages.append((message, recipient))
async def start(self):
"""启动 adapter"""
self.is_running = True
async def stop(self):
"""停止 adapter"""
self.is_running = False
# ==================== Fixtures ====================
@pytest.fixture(scope="session")
def app():
"""创建测试应用实例"""
container = DependencyContainer()
loop = asyncio.new_event_loop()
container.register(asyncio.AbstractEventLoop, loop)
# 配置
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
config.ims = [
IMConfig(
name=TEST_ADAPTER_ID,
enable=True,
adapter=TEST_ADAPTER_TYPE,
config=TEST_ADAPTER_CONFIG,
),
IMConfig(
name=TEST_ADAPTER_NOT_RUNNING_ID,
enable=False,
adapter=TEST_ADAPTER_TYPE,
config=TEST_ADAPTER_CONFIG,
),
]
container.register(GlobalConfig, config)
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
# 创建并注册 IMRegistry
registry = IMRegistry()
try:
registry.register(TEST_ADAPTER_TYPE, DummyAdapter, DummyConfig)
except Exception as e:
print(e)
container.register(IMRegistry, registry)
# 创建并注册 IMManager
manager = IMManager(container)
container.register(IMManager, manager)
manager.start_adapters(loop=loop)
web_server = WebServer(container)
container.register(WebServer, web_server)
# 设置认证服务
setup_auth_service(container)
return web_server.app
@pytest.fixture(scope="session")
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
# ==================== 测试用例 ====================
class TestIMAdapter:
@pytest.mark.asyncio
async def test_get_adapter_types(self, test_client, auth_headers):
"""测试获取适配器类型列表"""
response = test_client.get(
"/backend-api/api/im/types", headers=auth_headers
)
data = response.json()
assert "types" in data
assert TEST_ADAPTER_TYPE in data.get("types")
@pytest.mark.asyncio
async def test_list_adapters(self, test_client, auth_headers):
"""测试获取适配器列表"""
response = test_client.get(
"/backend-api/api/im/adapters", headers=auth_headers
)
data = response.json()
assert "adapters" in data
adapters = data.get("adapters")
assert len(adapters) == 2 # 应该有两个适配器
adapter = next(a for a in adapters if a.get("name") == TEST_ADAPTER_ID)
assert adapter.get("adapter") == TEST_ADAPTER_TYPE
assert adapter.get("is_running") is True
@pytest.mark.asyncio
async def test_get_adapter(self, test_client, auth_headers):
"""测试获取特定适配器"""
response = test_client.get(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}", headers=auth_headers
)
data = response.json()
assert "adapter" in data
adapter = data.get("adapter")
assert adapter.get("name") == TEST_ADAPTER_ID
assert adapter.get("adapter") == TEST_ADAPTER_TYPE
assert adapter.get("config") == TEST_ADAPTER_CONFIG
@pytest.mark.asyncio
async def test_create_adapter(self, test_client, auth_headers):
"""测试创建适配器"""
adapter_data = IMAdapterConfig(
name="new-adapter", adapter=TEST_ADAPTER_TYPE, config=TEST_ADAPTER_CONFIG
)
# Mock 配置文件保存
ConfigLoader.save_config_with_backup = MagicMock()
response = test_client.post(
"/backend-api/api/im/adapters",
headers=auth_headers,
json=adapter_data.model_dump(),
)
data = response.json()
assert "adapter" in data
adapter = data.get("adapter")
assert adapter.get("name") == "new-adapter"
assert adapter.get("adapter") == TEST_ADAPTER_TYPE
assert adapter.get("config") == TEST_ADAPTER_CONFIG
# 验证配置保存
ConfigLoader.save_config_with_backup.assert_called_once()
@pytest.mark.asyncio
async def test_update_adapter(self, test_client, auth_headers):
"""测试更新适配器"""
adapter_data = IMAdapterConfig(
name=TEST_ADAPTER_ID,
adapter=TEST_ADAPTER_TYPE,
config={"token": "updated-token", "name": "Updated Bot"},
)
# Mock 配置文件保存
ConfigLoader.save_config_with_backup = MagicMock()
response = test_client.put(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}",
headers=auth_headers,
json=adapter_data.model_dump(),
)
data = response.json()
assert "adapter" in data
adapter = data.get("adapter")
assert adapter.get("name") == TEST_ADAPTER_ID
assert adapter.get("adapter") == TEST_ADAPTER_TYPE
assert adapter.get("config").get("token") == "updated-token"
assert adapter.get("config").get("name") == "Updated Bot"
# 验证配置保存
ConfigLoader.save_config_with_backup.assert_called_once()
@pytest.mark.asyncio
async def test_stop_adapter(self, test_client, auth_headers):
"""测试停止适配器"""
response = test_client.post(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}/stop", headers=auth_headers
)
data = response.json()
assert "message" in data
assert data.get("message") == "Adapter stopped successfully"
# 验证适配器状态
response = test_client.get(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}", headers=auth_headers
)
data = response.json()
assert "adapter" in data
assert data.get("adapter").get("is_running") is False
@pytest.mark.asyncio
async def test_start_adapter(self, test_client, auth_headers):
"""测试启动适配器"""
response = test_client.post(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}/start",
headers=auth_headers,
)
data = response.json()
assert "message" in data
assert data.get("message") == "Adapter started successfully"
# 验证适配器状态
response = test_client.get(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}", headers=auth_headers
)
data = response.json()
assert "adapter" in data
assert data.get("adapter").get("is_running") is True
@pytest.mark.asyncio
async def test_delete_adapter(self, test_client, auth_headers):
"""测试删除适配器"""
# 先启动适配器
test_client.post(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}/start",
headers=auth_headers,
)
# Mock 配置文件保存
ConfigLoader.save_config_with_backup = MagicMock()
response = test_client.delete(
f"/backend-api/api/im/adapters/{TEST_ADAPTER_ID}", headers=auth_headers
)
data = response.json()
assert "message" in data
assert data.get("message") == "Adapter deleted successfully"
# 验证配置保存
ConfigLoader.save_config_with_backup.assert_called_once()
@pytest.mark.asyncio
async def test_get_adapter_config_schema(self, test_client, auth_headers):
"""测试获取适配器配置模式"""
response = test_client.get(
f"/backend-api/api/im/types/{TEST_ADAPTER_TYPE}/config-schema",
headers=auth_headers,
)
data = response.json()
assert "configSchema" in data
schema = data.get("configSchema")
assert schema.get("title") == "DummyConfig"
assert schema.get("type") == "object"
assert "properties" in schema
properties = schema.get("properties")
assert "token" in properties
assert properties["token"].get("title") == "Token"
assert properties["token"].get("type") == "string"
assert properties["token"].get("description") == "Dummy Bot Token"
assert "name" in properties
assert properties["name"].get("title") == "Name"
assert properties["name"].get("type") == "string"
assert properties["name"].get("description") == "Bot Name"
@pytest.mark.asyncio
async def test_get_adapter_config_schema_not_found(self, test_client, auth_headers):
"""测试获取不存在的适配器配置模式"""
response = test_client.get(
"/backend-api/api/im/types/not-exist/config-schema", headers=auth_headers
)
assert response.status_code == 404
data = response.json()
assert "error" in data
================================================
FILE: tests/web/api/llm/test_llm.py
================================================
from unittest.mock import MagicMock, patch
import pytest
from fastapi.testclient import TestClient
from pydantic import BaseModel
from kirara_ai.config.config_loader import ConfigLoader
from kirara_ai.config.global_config import GlobalConfig, LLMBackendConfig, WebConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.adapter import LLMBackendAdapter, LLMChatProtocol
from kirara_ai.llm.format.message import LLMChatTextContent
from kirara_ai.llm.format.request import LLMChatRequest
from kirara_ai.llm.format.response import LLMChatResponse, Message, Usage
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.llm.llm_registry import LLMAbility, LLMBackendRegistry
from kirara_ai.web.app import WebServer
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
TEST_BACKEND_NAME = "test-backend"
TEST_ADAPTER_TYPE = "test-adapter"
# ==================== 测试用适配器 ====================
class TestConfig(BaseModel):
"""测试用配置"""
__test__ = False
api_key: str = "test-key"
model: str = "test-model"
class TestAdapter(LLMBackendAdapter, LLMChatProtocol):
"""测试用LLM适配器"""
__test__ = False
def __init__(self, config: TestConfig):
self.config = config
def chat(self, req: LLMChatRequest) -> LLMChatResponse:
return LLMChatResponse(
message=Message(
content=[
LLMChatTextContent(text="Test response")
],
role="assistant"
),
model=self.config.model,
usage=Usage(
prompt_tokens=10,
completion_tokens=20,
total_tokens=30
),
)
# ==================== Fixtures ====================
@pytest.fixture(scope="session")
def app():
"""创建测试应用实例"""
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
# 配置mock
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
config.llms.api_backends = [
LLMBackendConfig(
name=TEST_BACKEND_NAME,
adapter=TEST_ADAPTER_TYPE,
config={"api_key": "test-key", "model": "test-model"},
enable=True,
models=["test-model"],
)
]
container.register(GlobalConfig, config)
# 设置认证服务
setup_auth_service(container)
# 注册LLM组件
registry = LLMBackendRegistry()
registry.register(TEST_ADAPTER_TYPE, TestAdapter, TestConfig, LLMAbility.TextChat)
container.register(LLMBackendRegistry, registry)
manager = LLMManager(container)
container.register(LLMManager, manager)
manager.load_config()
web_server = WebServer(container)
container.register(WebServer, web_server)
return web_server.app
@pytest.fixture
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
# ==================== 测试用例 ====================
class TestLLMBackend:
@pytest.mark.asyncio
async def test_get_adapter_types(self, test_client, auth_headers):
"""测试获取适配器类型列表"""
response = test_client.get(
"/backend-api/api/llm/types", headers=auth_headers
)
data = response.json()
assert "types" in data
assert TEST_ADAPTER_TYPE in data.get("types")
@pytest.mark.asyncio
async def test_list_backends(self, test_client, auth_headers):
"""测试获取后端列表"""
response = test_client.get(
"/backend-api/api/llm/backends", headers=auth_headers
)
data = response.json()
assert "data" in data
assert "backends" in data.get("data")
backends = data.get("data").get("backends")
assert len(backends) == 1
assert backends[0].get("name") == TEST_BACKEND_NAME
assert backends[0].get("adapter") == TEST_ADAPTER_TYPE
@pytest.mark.asyncio
async def test_get_backend(self, test_client, auth_headers):
"""测试获取指定后端"""
response = test_client.get(
f"/backend-api/api/llm/backends/{TEST_BACKEND_NAME}", headers=auth_headers
)
data = response.json()
assert "data" in data
backend = data.get("data")
assert backend.get("name") == TEST_BACKEND_NAME
assert backend.get("adapter") == TEST_ADAPTER_TYPE
@pytest.mark.asyncio
async def test_create_backend(self, test_client, auth_headers):
"""测试创建新后端"""
new_backend = LLMBackendConfig(
name="new-backend",
adapter=TEST_ADAPTER_TYPE,
config={"api_key": "new-key", "model": "new-model"},
enable=True,
models=["new-model"],
)
# Mock 配置文件保存
with patch(
"kirara_ai.config.config_loader.ConfigLoader.save_config_with_backup"
) as mock_save:
response = test_client.post(
"/backend-api/api/llm/backends",
headers=auth_headers,
json=new_backend.model_dump(),
)
data = response.json()
assert "data" in data
backend = data.get("data")
assert backend.get("name") == "new-backend"
assert backend.get("adapter") == TEST_ADAPTER_TYPE
# 验证配置保存
mock_save.assert_called_once()
@pytest.mark.asyncio
async def test_update_backend(self, test_client, auth_headers):
"""测试更新后端"""
updated_config = LLMBackendConfig(
name=TEST_BACKEND_NAME,
adapter=TEST_ADAPTER_TYPE,
config={"api_key": "updated-key", "model": "updated-model"},
enable=True,
models=["updated-model"],
)
# Mock 配置文件保存
ConfigLoader.save_config_with_backup = MagicMock()
response = test_client.put(
f"/backend-api/api/llm/backends/{TEST_BACKEND_NAME}",
headers=auth_headers,
json=updated_config.model_dump(),
)
data = response.json()
assert not data.get("error")
assert "data" in data
backend = data.get("data")
assert backend.get("name") == TEST_BACKEND_NAME
assert backend.get("config").get("api_key") == "updated-key"
# 验证配置保存
ConfigLoader.save_config_with_backup.assert_called_once()
@pytest.mark.asyncio
async def test_delete_backend(self, test_client, auth_headers):
"""测试删除后端"""
ConfigLoader.save_config_with_backup = MagicMock()
response = test_client.delete(
f"/backend-api/api/llm/backends/{TEST_BACKEND_NAME}", headers=auth_headers
)
data = response.json()
assert not data.get("error")
assert "data" in data
backend = data.get("data")
assert backend.get("name") == TEST_BACKEND_NAME
ConfigLoader.save_config_with_backup.assert_called_once()
# 验证后端已被删除
response = test_client.get(
f"/backend-api/api/llm/backends/{TEST_BACKEND_NAME}", headers=auth_headers
)
data = response.json()
assert "error" in data
@pytest.mark.asyncio
async def test_get_adapter_config_schema(self, test_client, auth_headers):
"""测试获取适配器配置模式"""
response = test_client.get(
f"/backend-api/api/llm/types/{TEST_ADAPTER_TYPE}/config-schema",
headers=auth_headers,
)
data = response.json()
assert "configSchema" in data
schema = data.get("configSchema")
assert schema.get("title") == "TestConfig"
assert schema.get("type") == "object"
assert "properties" in schema
properties = schema.get("properties")
assert "api_key" in properties
assert properties["api_key"].get("title") == "Api Key"
assert properties["api_key"].get("type") == "string"
assert "model" in properties
assert properties["model"].get("title") == "Model"
assert properties["model"].get("type") == "string"
assert properties["model"].get("default") == "test-model"
@pytest.mark.asyncio
async def test_get_adapter_config_schema_not_found(self, test_client, auth_headers):
"""测试获取不存在的适配器配置模式"""
response = test_client.get(
"/backend-api/api/llm/types/not-exist/config-schema", headers=auth_headers
)
assert response.status_code == 404
================================================
FILE: tests/web/api/media/test_media.py
================================================
import collections
import os
import tempfile
import time
from unittest.mock import MagicMock, patch
import pytest
from fastapi.testclient import TestClient
from kirara_ai.config.config_loader import CONFIG_FILE
from kirara_ai.config.global_config import GlobalConfig, MediaConfig, WebConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.media.manager import MediaManager
from kirara_ai.media.metadata import MediaMetadata
from kirara_ai.media.types.media_type import MediaType
from kirara_ai.web.app import WebServer
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
# ==================== Fixtures ====================
@pytest.fixture(scope="module")
def temp_media_dir():
"""为媒体文件创建一个临时目录。"""
temp_dir = tempfile.mkdtemp(prefix="kirara_test_media_api_")
media_dir = os.path.join(temp_dir, "media")
# 确保目录存在,因为 MediaManager 会创建它,但测试可能在之前运行
os.makedirs(media_dir, exist_ok=True)
print(f"Created temp media dir: {media_dir}")
yield media_dir
print(f"Removing temp media dir: {temp_dir}")
# shutil.rmtree(temp_dir) # 在某些系统上可能会有权限问题,暂时注释掉
@pytest.fixture(scope="module")
def container(temp_media_dir):
"""创建一个带有模拟组件的依赖容器。"""
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
# 配置
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
config.media = MediaConfig(
cleanup_duration=7,
auto_remove_unreferenced=True,
last_cleanup_time=int(time.time()) - 86400, # 昨天
)
container.register(GlobalConfig, config)
# 认证服务
setup_auth_service(container) # 基于配置设置认证
# 媒体管理器 (真实的,但使用临时目录)
# 如果 MediaManager 使用 __new__,则重置单例实例以进行测试
if hasattr(MediaManager, "_instance"):
del MediaManager._instance
media_manager = MediaManager(media_dir=temp_media_dir)
container.register(MediaManager, media_manager)
return container
@pytest.fixture(scope="module")
def app(container):
"""创建 FastAPI 应用实例。"""
web_server = WebServer(container)
container.register(WebServer, web_server)
return web_server.app
@pytest.fixture(scope="module")
def test_client(app):
"""创建一个 TestClient 实例。"""
# 使用 lifespan 管理器来确保启动和关闭事件被触发
with TestClient(app) as client:
yield client
# ==================== 测试用例 ====================
@pytest.mark.usefixtures("test_client", "auth_headers") # 应用 test_client 和 auth_headers
class TestMediaAPI:
@pytest.fixture(autouse=True)
def setup_mocks(self, container, temp_media_dir):
"""在每个测试之前设置模拟对象。"""
# 模拟 MediaManager 方法
self.mock_media_manager = MagicMock(spec=MediaManager)
# 确保 mock manager 知道正确的 media_dir 以便 disk_usage 测试
self.mock_media_manager.media_dir = temp_media_dir
# 使用 patch 来替换路由中获取 MediaManager 的函数
self.patcher_get_manager = patch(
"kirara_ai.web.api.media.routes._get_media_manager",
return_value=self.mock_media_manager,
)
self.mock_get_manager = self.patcher_get_manager.start()
# 模拟 ConfigLoader 保存
# 注意:需要模拟 routes.py 中使用的 ConfigLoader 实例或类方法
self.patcher_save_config = patch(
"kirara_ai.web.api.media.routes.ConfigLoader.save_config_with_backup"
)
self.mock_save_config = self.patcher_save_config.start()
# 模拟 shutil.disk_usage
self.patcher_disk_usage = patch("kirara_ai.web.api.media.routes.shutil.disk_usage")
self.mock_disk_usage = self.patcher_disk_usage.start()
# 模拟 time.time() 以便检查 last_cleanup_time 的更新
self.current_time = int(time.time())
self.patcher_time = patch("kirara_ai.web.api.media.routes.time.time", return_value=self.current_time)
self.mock_time = self.patcher_time.start()
yield # 运行测试
# 停止 patchers
self.patcher_get_manager.stop()
self.patcher_save_config.stop()
self.patcher_disk_usage.stop()
self.patcher_time.stop()
def test_get_system_info(self, test_client, auth_headers, container):
"""测试 GET /system 端点。"""
config: GlobalConfig = container.resolve(GlobalConfig)
# media_manager_instance: MediaManager = container.resolve(MediaManager) # 获取真实的实例以获取路径
# 设置模拟返回值
mock_media_ids = ["media1", "media2"]
mock_metadata1 = MediaMetadata(
media_id="media1",
media_type=MediaType.IMAGE,
format="jpg",
size=1024,
references={"ref1"},
)
mock_metadata2 = MediaMetadata(
media_id="media2",
media_type=MediaType.AUDIO,
format="mp3",
size=2048,
references={"ref2"},
)
self.mock_media_manager.get_all_media_ids.return_value = mock_media_ids
self.mock_media_manager.get_metadata.side_effect = lambda mid: (
mock_metadata1
if mid == "media1"
else (mock_metadata2 if mid == "media2" else None)
)
mock_disk_usage_result = collections.namedtuple(
"usage", ["total", "used", "free"]
)(
total=10 * 1024 * 1024, used=3 * 1024 * 1024, free=7 * 1024 * 1024
)
self.mock_disk_usage.return_value = mock_disk_usage_result
response = test_client.get("/backend-api/api/media/system", headers=auth_headers)
assert response.status_code == 200, f"响应内容: {response.text}"
data = response.json()
assert data["cleanup_duration"] == config.media.cleanup_duration
assert data["auto_remove_unreferenced"] == config.media.auto_remove_unreferenced
assert data["last_cleanup_time"] == config.media.last_cleanup_time
assert data["total_media_count"] == 2
assert data["total_media_size"] == 1024 + 2048
assert data["disk_total"] == mock_disk_usage_result.total
assert data["disk_used"] == mock_disk_usage_result.used
assert data["disk_free"] == mock_disk_usage_result.free
self.mock_media_manager.get_all_media_ids.assert_called_once()
assert self.mock_media_manager.get_metadata.call_count == 2
# 验证 disk_usage 使用了正确的路径 (来自 mock manager)
self.mock_disk_usage.assert_called_once_with(self.mock_media_manager.media_dir)
def test_set_config(self, test_client, auth_headers, container):
"""测试 POST /system/config 端点。"""
config: GlobalConfig = container.resolve(GlobalConfig)
original_duration = config.media.cleanup_duration
original_auto_remove = config.media.auto_remove_unreferenced
new_config_data = {"cleanup_duration": 14, "auto_remove_unreferenced": False}
response = test_client.post(
"/backend-api/api/media/system/config",
headers=auth_headers,
json=new_config_data,
)
assert response.status_code == 200, f"响应内容: {response.text}"
data = response.json()
assert data["success"] is True
# 验证容器中的配置对象是否已更新
assert config.media.cleanup_duration == 14
assert config.media.auto_remove_unreferenced is False
# 验证模拟对象是否被调用
self.mock_media_manager.setup_cleanup_task.assert_called_once_with(container)
# 验证配置保存时传递了正确的参数
self.mock_save_config.assert_called_once()
args, kwargs = self.mock_save_config.call_args
assert args[0] == CONFIG_FILE
saved_config = args[1]
assert isinstance(saved_config, GlobalConfig)
assert saved_config.media.cleanup_duration == 14
assert saved_config.media.auto_remove_unreferenced is False
# 为其他测试恢复原始值(尽管 fixture 应该处理隔离)
config.media.cleanup_duration = original_duration
config.media.auto_remove_unreferenced = original_auto_remove
def test_cleanup_unreferenced(self, test_client, auth_headers, container):
"""测试 POST /system/cleanup-unreferenced 端点。"""
config: GlobalConfig = container.resolve(GlobalConfig)
original_last_cleanup_time = config.media.last_cleanup_time
# 设置清理的模拟返回值
cleanup_count = 5
self.mock_media_manager.cleanup_unreferenced.return_value = cleanup_count
response = test_client.post(
"/backend-api/api/media/system/cleanup-unreferenced", headers=auth_headers
)
assert response.status_code == 200, f"响应内容: {response.text}"
data = response.json()
assert data["success"] is True
assert data["count"] == cleanup_count
# 验证模拟对象是否被调用
self.mock_media_manager.cleanup_unreferenced.assert_called_once()
self.mock_save_config.assert_called_once()
self.mock_media_manager.setup_cleanup_task.assert_called_once_with(container)
# 验证 last_cleanup_time 是否已更新 (使用模拟的时间)
assert config.media.last_cleanup_time == self.current_time
# 验证保存的配置中 last_cleanup_time 也更新了
args, kwargs = self.mock_save_config.call_args
saved_config: GlobalConfig = args[1]
assert saved_config.media.last_cleanup_time == self.current_time
# 恢复原始时间(如果需要)
config.media.last_cleanup_time = original_last_cleanup_time
================================================
FILE: tests/web/api/plugin/test_plugin.py
================================================
from unittest.mock import MagicMock, patch
import pytest
from fastapi.testclient import TestClient
from kirara_ai.config.global_config import GlobalConfig, PluginConfig, WebConfig
from kirara_ai.events.event_bus import EventBus
from kirara_ai.im.im_registry import IMRegistry
from kirara_ai.im.manager import IMManager
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.llm_registry import LLMBackendRegistry
from kirara_ai.plugin_manager.models import PluginInfo
from kirara_ai.plugin_manager.plugin import Plugin
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.block import BlockRegistry
from kirara_ai.workflow.core.dispatch import WorkflowDispatcher
from kirara_ai.workflow.core.dispatch.registry import DispatchRuleRegistry
from kirara_ai.workflow.core.workflow.registry import WorkflowRegistry
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
from tests.utils.test_block_registry import create_test_block_registry
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
TEST_PLUGIN_NAME = "test-plugin"
# ==================== 测试用插件 ====================
def make_test_plugin():
class TestPlugin(Plugin):
"""测试用插件"""
__test__ = True
def __init__(self):
self.initialized = False
self.started = False
def on_load(self):
self.initialized = True
def on_start(self):
self.started = True
def on_stop(self):
self.started = False
return TestPlugin
# ==================== Mock 数据 ====================
async def MOCK_PLUGIN_SEARCH_RESPONSE():
return {
"plugins": [
{
"name": "测试插件",
"description": "测试插件描述",
"author": "测试作者",
"pypiPackage": "test-plugin",
"pypiInfo": {
"version": "0.1.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com",
},
"isInstalled": True,
"installedVersion": "1.0.0",
"isUpgradable": False,
"isEnabled": True,
"requiresRestart": False,
}
],
"totalCount": 1,
"totalPages": 1,
"page": 1,
"pageSize": 10,
}
async def MOCK_PLUGIN_INFO_RESPONSE():
return {
"name": "测试插件",
"description": "测试插件描述",
"author": "测试作者",
"pypiPackage": "test-plugin",
"pypiInfo": {
"version": "0.1.0",
"description": "PyPI 描述",
"author": "PyPI 作者",
"homePage": "https://example.com",
},
"isInstalled": True,
"installedVersion": "1.0.0",
"isUpgradable": False,
"isEnabled": True,
}
# ==================== Fixtures ====================
@pytest.fixture(scope="session")
def app():
"""创建测试应用实例"""
container = DependencyContainer()
container.register(DependencyContainer, container)
# 配置
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
config.plugins = PluginConfig(enable=[TEST_PLUGIN_NAME])
container.register(GlobalConfig, config)
# 设置认证服务
setup_auth_service(container)
# 注册必要的组件
container.register(EventBus, EventBus())
container.register(LLMBackendRegistry, LLMBackendRegistry())
container.register(IMRegistry, IMRegistry())
container.register(IMManager, IMManager(container))
container.register(WorkflowRegistry, WorkflowRegistry(container))
container.register(DispatchRuleRegistry, DispatchRuleRegistry(container))
container.register(WorkflowDispatcher, WorkflowDispatcher(container))
container.register(BlockRegistry, create_test_block_registry())
# 创建插件加载器并注册测试插件
plugin_loader = PluginLoader(container, "plugins")
plugin_loader.register_plugin(make_test_plugin(), TEST_PLUGIN_NAME)
container.register(PluginLoader, plugin_loader)
web_server = WebServer(container)
container.register(WebServer, web_server)
return web_server.app
@pytest.fixture
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
# ==================== 测试用例 ====================
class TestPlugin:
@pytest.mark.asyncio
async def test_search_plugins(self, test_client, auth_headers):
"""测试搜索插件市场"""
with patch("aiohttp.ClientSession.get") as mock_get:
mock_response = MagicMock()
mock_response.status = 200
mock_response.json.return_value = MOCK_PLUGIN_SEARCH_RESPONSE()
mock_get.return_value.__aenter__.return_value = mock_response
response = test_client.get(
"/backend-api/api/plugin/v1/search?query=test&page=1&pageSize=10",
headers=auth_headers,
)
assert response.status_code == 200
data = response.json()
assert data == await MOCK_PLUGIN_SEARCH_RESPONSE()
@pytest.mark.asyncio
async def test_get_plugin_info(self, test_client, auth_headers):
"""测试获取插件详情"""
with patch("aiohttp.ClientSession.get") as mock_get:
mock_response = MagicMock()
mock_response.status = 200
mock_response.json.return_value = MOCK_PLUGIN_INFO_RESPONSE()
mock_get.return_value.__aenter__.return_value = mock_response
response = test_client.get(
f"/backend-api/api/plugin/v1/info/{TEST_PLUGIN_NAME}",
headers=auth_headers,
)
assert response.status_code == 200
data = response.json()
del data["requiresRestart"]
assert data == await MOCK_PLUGIN_INFO_RESPONSE()
@pytest.mark.asyncio
async def test_get_plugin_details(self, test_client, auth_headers):
"""测试获取插件详情"""
response = test_client.get(
f"/backend-api/api/plugin/plugins/{TEST_PLUGIN_NAME}", headers=auth_headers
)
data = response.json()
assert "error" not in data
assert "plugin" in data
plugin = data["plugin"]
assert plugin["name"] == "TestPlugin"
assert plugin["is_internal"] is True
assert plugin["is_enabled"] is True
@pytest.mark.asyncio
async def test_get_nonexistent_plugin(self, test_client, auth_headers):
"""测试获取不存在的插件"""
response = test_client.get(
"/backend-api/api/plugin/plugins/nonexistent", headers=auth_headers
)
assert response.status_code == 404
data = response.json()
assert "error" in data
@pytest.mark.asyncio
async def test_update_plugin(self, test_client, auth_headers):
"""测试更新插件"""
# 由于是内部插件,更新应该失败
response = test_client.put(
f"/backend-api/api/plugin/plugins/{TEST_PLUGIN_NAME}", headers=auth_headers
)
assert response.status_code == 400 # 内部插件不支持更新
data = response.json()
assert "error" in data
@pytest.mark.asyncio
async def test_enable_plugin(self, test_client, auth_headers):
"""测试启用插件"""
# Mock 配置文件保存
with patch(
"kirara_ai.config.config_loader.ConfigLoader.save_config_with_backup"
) as mock_save:
response = test_client.post(
f"/backend-api/api/plugin/plugins/{TEST_PLUGIN_NAME}/enable",
headers=auth_headers,
)
assert response.status_code == 200
data = response.json()
assert "error" not in data
assert data["plugin"]["is_enabled"] is True
@pytest.mark.asyncio
async def test_disable_plugin(self, test_client, auth_headers):
"""测试禁用插件"""
# Mock 配置文件保存
with patch(
"kirara_ai.config.config_loader.ConfigLoader.save_config_with_backup"
) as mock_save:
response = test_client.post(
f"/backend-api/api/plugin/plugins/{TEST_PLUGIN_NAME}/disable",
headers=auth_headers,
)
assert response.status_code == 200
data = response.json()
assert "error" not in data
assert data["plugin"]["is_enabled"] is False
@pytest.mark.asyncio
async def test_install_plugin(self, test_client, auth_headers):
"""测试安装插件"""
with patch(
"kirara_ai.web.api.plugin.routes.PluginLoader.install_plugin"
) as mock_install_plugin:
mock_install_plugin.return_value = PluginInfo(
name="test-plugin",
package_name="test-plugin-package",
description="test-plugin-description",
is_internal=False,
is_enabled=False,
version="1.0.0",
author="test-author",
)
# Mock 配置文件保存
with patch(
"kirara_ai.config.config_loader.ConfigLoader.save_config_with_backup"
) as mock_save:
response = test_client.post(
"/backend-api/api/plugin/plugins",
headers=auth_headers,
json={"package_name": "test-plugin-package", "version": "1.0.0"},
)
data = response.json()
assert "error" not in data
assert data["plugin"]["package_name"] == "test-plugin-package"
# 验证配置保存
mock_save.assert_called_once()
@pytest.mark.asyncio
async def test_uninstall_plugin(self, test_client, auth_headers):
"""测试卸载插件"""
# 由于是内部插件,卸载应该失败
response = test_client.delete(
f"/backend-api/api/plugin/plugins/{TEST_PLUGIN_NAME}", headers=auth_headers
)
data = response.json()
assert "error" in data
assert response.status_code == 400 # 内部插件不能卸载
================================================
FILE: tests/web/api/system/test_system.py
================================================
from unittest.mock import MagicMock, patch
import pytest
from fastapi.testclient import TestClient
from kirara_ai.config.global_config import GlobalConfig, WebConfig
from kirara_ai.im.manager import IMManager
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.llm.llm_manager import LLMManager
from kirara_ai.plugin_manager.plugin_loader import PluginLoader
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
# ==================== Fixtures ====================
@pytest.fixture
def app():
"""创建测试应用实例"""
container = DependencyContainer()
# 配置mock
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
container.register(GlobalConfig, config)
# 设置认证服务
setup_auth_service(container)
# Mock其他依赖
im_manager = MagicMock(spec=IMManager)
im_manager.adapters = {
"adapter1": MagicMock(is_running=True),
"adapter2": MagicMock(is_running=False),
}
container.register(IMManager, im_manager)
llm_manager = MagicMock(spec=LLMManager)
llm_manager.active_backends = {"backend1": [], "backend2": []}
container.register(LLMManager, llm_manager)
plugin_loader = MagicMock(spec=PluginLoader)
plugin_loader.plugins = [MagicMock(), MagicMock(), MagicMock()]
container.register(PluginLoader, plugin_loader)
workflow_registry = MagicMock(spec=WorkflowRegistry)
workflow_registry._workflows = {"workflow1": MagicMock(), "workflow2": MagicMock()}
container.register(WorkflowRegistry, workflow_registry)
web_server = WebServer(container)
container.register(WebServer, web_server)
return web_server.app
@pytest.fixture
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
# ==================== 测试用例 ====================
class TestSystemStatus:
@pytest.mark.asyncio
async def test_get_system_status(self, test_client, auth_headers):
"""测试获取系统状态"""
# Mock psutil.Process
mock_process = MagicMock()
mock_process.memory_full_info.return_value = MagicMock(
uss=1024 * 1024 * 100 # 100MB
)
mock_process.cpu_percent.return_value = 1.2
# Mock psutil.virtual_memory
mock_virtual_memory = MagicMock()
mock_virtual_memory.total = 1024 * 1024 * 8192 # 8GB
mock_virtual_memory.available = 1024 * 1024 * 4096 # 4GB
mock_virtual_memory.used = 1024 * 1024 * 4096 # 4GB
with patch(
"kirara_ai.web.api.system.utils.psutil.Process", return_value=mock_process
), patch(
"kirara_ai.web.api.system.utils.psutil.virtual_memory", return_value=mock_virtual_memory
), patch(
"kirara_ai.web.api.system.utils.psutil.cpu_percent", return_value=1.2
):
response = test_client.get(
"/backend-api/api/system/status", headers=auth_headers
)
assert response.status_code == 200
data = response.json()
assert "status" in data
status = data["status"]
# 验证基本字段
assert "version" in status
assert "uptime" in status
assert status["active_adapters"] == 1 # 只有一个运行中的适配器
assert status["active_backends"] == 2 # 两个后端
assert status["loaded_plugins"] == 3 # 三个插件
assert status["workflow_count"] == 2 # 两个工作流
# 验证资源使用情况
assert "memory_usage" in status
assert "cpu_usage" in status
assert status["memory_usage"]["percent"] == 0.5 # used/total
assert status["memory_usage"]["total"] == 8192 # 8GB
assert status["memory_usage"]["free"] == 4096 # 4GB
assert status["memory_usage"]["used"] == 100 # 100MB (process.memory_full_info().uss)
assert status["cpu_usage"] == 1.2
@pytest.mark.asyncio
async def test_get_system_status_unauthorized(self, test_client):
"""测试未认证时获取系统状态"""
response = test_client.get("/backend-api/api/system/status")
assert response.status_code == 401
data = response.json()
assert "error" in data
@pytest.mark.asyncio
async def test_check_update(self, test_client, auth_headers):
"""测试检查更新"""
response = test_client.get("/backend-api/api/system/check-update", headers=auth_headers)
assert response.status_code == 200
data = response.json()
assert data["current_backend_version"] != "0.0.0"
assert data["latest_backend_version"] != "0.0.0"
assert data["backend_update_available"] == False
assert data["latest_webui_version"] != "0.0.0"
assert data["webui_download_url"] != ""
================================================
FILE: tests/web/api/workflow/test_workflow.py
================================================
import pytest
from fastapi.testclient import TestClient
from kirara_ai.config.global_config import GlobalConfig, WebConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.web.app import WebServer
from kirara_ai.workflow.core.block import Block, BlockRegistry
from kirara_ai.workflow.core.block.input_output import Input, Output
from kirara_ai.workflow.core.workflow import WorkflowRegistry
from kirara_ai.workflow.core.workflow.builder import WorkflowBuilder
from tests.utils.auth_test_utils import auth_headers, setup_auth_service # noqa
# ==================== 常量区 ====================
TEST_PASSWORD = "test-password"
TEST_SECRET_KEY = "test-secret-key"
TEST_GROUP_ID = "test-group"
TEST_WORKFLOW_ID = "test-workflow"
TEST_WORKFLOW_ID_NEW = "test-workflow-new"
TEST_WORKFLOW_NAME = "Test Workflow"
TEST_WORKFLOW_NAME_NEW = "Test Workflow New"
TEST_WORKFLOW_DESC = "A test workflow"
# ==================== 测试用Block ====================
class MessageBlock(Block):
name = "message_block"
inputs = {}
outputs = {"output": Output("output", "输出", str, "Output message")}
container: DependencyContainer
def __init__(self, text: str = ""):
self.config = {"text": text}
self.position = {"x": 0, "y": 0}
def execute(self) -> dict:
return {"output": self.config["text"]}
class LLMBlock(Block):
name = "llm_block"
inputs = {"input": Input("input", "输入", str, "Input message")}
outputs = {"output": Output("output", "输出", str, "Output message")}
container: DependencyContainer
def __init__(self, prompt: str = ""):
self.config = {"prompt": prompt}
self.position = {"x": 200, "y": 0}
def execute(self, input: str) -> dict:
return {"output": f"Response to: {input}"}
# ==================== Fixtures ====================
@pytest.fixture
def app():
"""创建测试应用实例"""
container = DependencyContainer()
# 配置
config = GlobalConfig()
config.web = WebConfig(
secret_key=TEST_SECRET_KEY, password_file="test_password.hash"
)
container.register(GlobalConfig, config)
# 设置认证服务
setup_auth_service(container)
# 创建并注册 BlockRegistry
block_registry = BlockRegistry()
block_registry.register("message", "test", MessageBlock)
block_registry.register("llm", "test", LLMBlock)
container.register(BlockRegistry, block_registry)
# 创建工作流
builder = (
WorkflowBuilder(TEST_WORKFLOW_NAME)
.use(MessageBlock, text="Hello")
.chain(LLMBlock, prompt="How are you?")
)
# 创建并注册 WorkflowRegistry
registry = WorkflowRegistry(container)
registry.register(TEST_GROUP_ID, TEST_WORKFLOW_ID, builder)
container.register(WorkflowRegistry, registry)
web_server = WebServer(container)
container.register(WebServer, web_server)
return web_server.app
@pytest.fixture
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
# ==================== 测试用例 ====================
class TestWorkflow:
@pytest.mark.asyncio
async def test_list_workflows(self, test_client, auth_headers):
"""测试获取工作流列表"""
response = test_client.get(
"/backend-api/api/workflow", headers=auth_headers
)
data = response.json()
assert "error" not in data
assert "workflows" in data
workflows = data["workflows"]
assert len(workflows) == 1
workflow = workflows[0]
assert workflow["workflow_id"] == TEST_WORKFLOW_ID
assert workflow["group_id"] == TEST_GROUP_ID
assert workflow["name"] == TEST_WORKFLOW_NAME
@pytest.mark.asyncio
async def test_get_workflow(self, test_client, auth_headers):
"""测试获取单个工作流"""
response = test_client.get(
f"/backend-api/api/workflow/{TEST_GROUP_ID}/{TEST_WORKFLOW_ID}",
headers=auth_headers,
)
data = response.json()
assert "error" not in data
assert "workflow" in data
workflow = data["workflow"]
assert workflow["workflow_id"] == TEST_WORKFLOW_ID
assert workflow["group_id"] == TEST_GROUP_ID
assert workflow["name"] == TEST_WORKFLOW_NAME
assert len(workflow["wires"]) == 1
@pytest.mark.asyncio
async def test_create_workflow(self, test_client, auth_headers):
"""测试创建工作流"""
workflow_data = {
"workflow_id": TEST_WORKFLOW_ID_NEW,
"group_id": TEST_GROUP_ID,
"name": TEST_WORKFLOW_NAME,
"description": TEST_WORKFLOW_DESC,
"blocks": [
{
"block_id": "node1",
"type_name": "test:message",
"name": "Message Node",
"config": {"text": "Hello"},
"position": {"x": 0, "y": 0},
}
],
"wires": [],
}
response = test_client.post(
f"/backend-api/api/workflow/{TEST_GROUP_ID}/{TEST_WORKFLOW_ID_NEW}",
headers=auth_headers,
json=workflow_data,
)
data = response.json()
assert "error" not in data
assert data["workflow_id"] == TEST_WORKFLOW_ID_NEW
assert data["group_id"] == TEST_GROUP_ID
assert data["name"] == TEST_WORKFLOW_NAME
assert len(data["blocks"]) == 1
@pytest.mark.asyncio
async def test_update_workflow(self, test_client, auth_headers):
"""测试更新工作流"""
workflow_data = {
"workflow_id": TEST_WORKFLOW_ID,
"group_id": TEST_GROUP_ID,
"name": "Updated Workflow",
"description": "Updated workflow description",
"blocks": [
{
"block_id": "node1",
"type_name": "test:message",
"name": "Message Node",
"config": {"text": "Updated text"},
"position": {"x": 0, "y": 0},
}
],
"wires": [],
}
response = test_client.put(
f"/backend-api/api/workflow/{TEST_GROUP_ID}/{TEST_WORKFLOW_ID}",
headers=auth_headers,
json=workflow_data,
)
data = response.json()
assert "error" not in data
assert data["workflow_id"] == TEST_WORKFLOW_ID
assert data["group_id"] == TEST_GROUP_ID
assert data["name"] == "Updated Workflow"
assert data["description"] == "Updated workflow description"
assert len(data["blocks"]) == 1
assert data["blocks"][0]["config"]["text"] == "Updated text"
@pytest.mark.asyncio
async def test_delete_workflow(self, test_client, auth_headers):
"""测试删除工作流"""
response = test_client.delete(
f"/backend-api/api/workflow/{TEST_GROUP_ID}/{TEST_WORKFLOW_ID}",
headers=auth_headers,
)
data = response.json()
assert "error" not in data
assert "message" in data
assert data["message"] == "Workflow deleted successfully"
================================================
FILE: tests/web/auth/test_auth.py
================================================
import pytest
import pytest_asyncio
from fastapi.testclient import TestClient
from kirara_ai.config.global_config import GlobalConfig, WebConfig
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.web.app import WebServer
from tests.utils.auth_test_utils import TEST_PASSWORD, setup_auth_service
# ==================== 常量区 ====================
TEST_NEW_PASSWORD = "new-password"
TEST_SECRET_KEY = "test-secret-key"
TEST_TOKEN = "mock_token" # 使用 MockAuthService 的固定 token
# ==================== Fixtures ====================
@pytest.fixture
def app():
"""创建测试应用实例"""
container = DependencyContainer()
container.register(GlobalConfig, GlobalConfig(web=WebConfig(secret_key=TEST_SECRET_KEY)))
web_server = WebServer(container)
container.register(WebServer, web_server)
setup_auth_service(container)
return web_server.app
@pytest.fixture
def test_client(app):
"""创建测试客户端"""
return TestClient(app)
@pytest_asyncio.fixture
async def auth_token(test_client):
"""获取认证token"""
response = test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
data = response.json()
assert "access_token" in data
return data["access_token"]
# ==================== 测试用例 ====================
class TestAuth:
@pytest.mark.asyncio
async def test_check_first_time(self, test_client):
"""测试检查是否首次访问接口"""
# 首次访问
response = test_client.get("/backend-api/api/auth/check-first-time")
assert response.status_code == 200
data = response.json()
assert "is_first_time" in data
assert data["is_first_time"] == True
# 模拟登录后
response = test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
# 再次检查
response = test_client.get("/backend-api/api/auth/check-first-time")
assert response.status_code == 200
data = response.json()
assert "is_first_time" in data
assert data["is_first_time"] == False
@pytest.mark.asyncio
async def test_normal_login(self, test_client):
"""测试普通登录"""
# 先进行首次登录设置密码
test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
# 然后测试正常登录
response = test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
assert response.status_code == 200
data = response.json()
assert "access_token" in data
assert data["access_token"] == TEST_TOKEN
@pytest.mark.asyncio
async def test_login_wrong_password(self, test_client):
"""测试密码错误的情况"""
# 先进行首次登录设置密码
test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_PASSWORD}
)
# 然后测试错误密码
response = test_client.post(
"/backend-api/api/auth/login", json={"password": "wrong-password"}
)
assert response.status_code == 401
data = response.json()
assert "error" in data
@pytest.mark.asyncio
async def test_change_password(self, test_client, auth_token):
"""测试修改密码"""
response = test_client.post(
"/backend-api/api/auth/change-password",
json={"old_password": TEST_PASSWORD, "new_password": TEST_NEW_PASSWORD},
headers={"Authorization": f"Bearer {auth_token}"},
)
assert response.status_code == 200
# 验证新密码可以登录
response = test_client.post(
"/backend-api/api/auth/login", json={"password": TEST_NEW_PASSWORD}
)
assert response.status_code == 200
@pytest.mark.asyncio
async def test_change_password_wrong_old(self, test_client, auth_token):
"""测试修改密码时旧密码错误的情况"""
response = test_client.post(
"/backend-api/api/auth/change-password",
json={"old_password": "wrong-password", "new_password": TEST_NEW_PASSWORD},
headers={"Authorization": f"Bearer {auth_token}"},
)
data = response.json()
assert "error" in data
================================================
FILE: tests/workflow_executor/test_block.py
================================================
from kirara_ai.workflow.core.block import Block
from kirara_ai.workflow.core.block.input_output import Input, Output
# Define test inputs and outputs
input_data = Input(
name="input1", label="输入1", data_type=str, description="Input data"
)
output_data = Output(
name="output1", label="输出1", data_type=str, description="Processed data"
)
# Define test block
block = Block(
name="TestBlock", inputs={"input1": input_data}, outputs={"output1": output_data}
)
def test_block_creation():
"""Test block creation."""
assert block.name == "TestBlock"
assert block.inputs["input1"].data_type == str
assert block.outputs["output1"].data_type == str
def test_block_execute():
"""Test block execution."""
result = block.execute(input1="test_input")
assert "output1" in result
assert result["output1"] == "Processed {'input1': 'test_input'}"
================================================
FILE: tests/workflow_executor/test_executor.py
================================================
import pytest
from kirara_ai.events.event_bus import EventBus
from kirara_ai.ioc.container import DependencyContainer
from kirara_ai.workflow.core.block import Block, Input, Output
from kirara_ai.workflow.core.block.registry import BlockRegistry
from kirara_ai.workflow.core.execution.exceptions import BlockExecutionFailedException
from kirara_ai.workflow.core.execution.executor import WorkflowExecutor
from kirara_ai.workflow.core.workflow import Wire, Workflow
from tests.utils.test_block_registry import create_test_block_registry
# 创建测试用的 BlockRegistry
test_registry = create_test_block_registry()
# 创建测试用的 Block 类
class InputBlock(Block):
name = "InputBlock"
outputs = {
"output1": Output(
name="output1", label="输出1", data_type=str, description="Test output"
)
}
def execute(self, **kwargs):
return {"output1": "test_input"}
class ProcessBlock(Block):
name = "ProcessBlock"
inputs = {
"input1": Input(
name="input1", label="输入1", data_type=str, description="Test input"
)
}
outputs = {
"output1": Output(
name="output1", label="输出1", data_type=str, description="Test output"
)
}
def execute(self, input1: str, **kwargs):
return {"output1": input1.upper()}
class OutputBlock(Block):
name = "OutputBlock"
inputs = {
"input1": Input(
name="input1", label="输入1", data_type=str, description="Test input"
)
}
def execute(self, input1: str, **kwargs):
return {"result": input1}
class FailingBlock(Block):
name = "FailingBlock"
inputs = {
"input1": Input(
name="input1", label="输入1", data_type=str, description="Test input"
)
}
def execute(self, input1: str, **kwargs):
raise BlockExecutionFailedException("Test error")
# 注册测试用的 Block 类型
test_registry.register("test", "input", InputBlock)
test_registry.register("test", "process", ProcessBlock)
test_registry.register("test", "output", OutputBlock)
test_registry.register("test", "failing", FailingBlock)
# 创建测试用的工作流
input_block = InputBlock(name="input1")
process_block = ProcessBlock(name="process1")
output_block = OutputBlock(name="output1")
workflow = Workflow(
name="test_workflow",
blocks=[input_block, process_block, output_block],
wires=[
Wire(
source_block=input_block,
source_output="output1",
target_block=process_block,
target_input="input1",
),
Wire(
source_block=process_block,
source_output="output1",
target_block=output_block,
target_input="input1",
),
],
)
# 创建测试用的失败工作流
failing_block = FailingBlock(name="failing1")
failing_workflow = Workflow(
name="failing_workflow",
blocks=[input_block, failing_block],
wires=[
Wire(
source_block=input_block,
source_output="output1",
target_block=failing_block,
target_input="input1",
)
],
)
@pytest.mark.asyncio
async def test_executor_run():
"""Test workflow executor run."""
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
container.register(BlockRegistry, test_registry)
container.register(Workflow, workflow)
executor = WorkflowExecutor(container)
result = await executor.run()
assert result["input1"]["output1"] == "test_input"
assert result["process1"]["output1"] == "TEST_INPUT"
assert result["output1"]["result"] == "TEST_INPUT"
@pytest.mark.asyncio
async def test_executor_with_failing_block():
"""Test workflow executor with a failing block."""
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
container.register(BlockRegistry, test_registry)
container.register(Workflow, failing_workflow)
executor = WorkflowExecutor(container)
with pytest.raises(BlockExecutionFailedException, match="Test error"):
await executor.run()
@pytest.mark.asyncio
async def test_executor_with_no_blocks():
"""Test workflow executor with no blocks."""
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
container.register(BlockRegistry, test_registry)
empty_workflow = Workflow(name="empty_workflow", blocks=[], wires=[])
container.register(Workflow, empty_workflow)
executor = WorkflowExecutor(container)
result = await executor.run()
assert result == {}
@pytest.mark.asyncio
async def test_executor_with_multiple_outputs():
"""Test workflow executor with a block that has multiple outputs."""
# Define a block with multiple outputs
multi_output_block = Block(
name="MultiOutputBlock",
inputs={
"input1": Input(
name="input1", label="输入1", data_type=str, description="Input data"
)
},
outputs={
"output1": Output(
name="output1", label="输出1", data_type=str, description="First output"
),
"output2": Output(
name="output2",
label="输出2",
data_type=int,
description="Second output",
),
},
)
# Define a workflow with the multi-output block
multi_output_workflow = Workflow(
name="multi_output_workflow",
blocks=[input_block, multi_output_block],
wires=[
Wire(
source_block=input_block,
source_output="output1",
target_block=multi_output_block,
target_input="input1",
)
],
)
container = DependencyContainer()
container.register(DependencyContainer, container)
container.register(EventBus, EventBus())
container.register(BlockRegistry, test_registry)
container.register(Workflow, multi_output_workflow)
executor = WorkflowExecutor(container)
result = await executor.run()
assert "MultiOutputBlock" in result
================================================
FILE: tests/workflow_executor/test_input_output.py
================================================
from kirara_ai.workflow.core.block.input_output import Input, Output
def test_input_validation():
"""Test input validation."""
input_obj = Input(
name="input1", label="输入1", data_type=int, description="An integer input"
)
assert input_obj.validate(10) is True
assert input_obj.validate("10") is False
assert input_obj.validate(None) is False # Not nullable by default
nullable_input = Input(
name="input2",
label="输入2",
data_type=int,
description="A nullable integer input",
nullable=True,
)
assert nullable_input.validate(None) is True
def test_output_validation():
"""Test output validation."""
output_obj = Output(
name="output1", label="输出1", data_type=str, description="A string output"
)
assert output_obj.validate("test") is True
assert output_obj.validate(10) is False
================================================
FILE: tests/workflow_executor/test_workflow_basic.py
================================================
from kirara_ai.workflow.core.block import Block, Input, Output
from kirara_ai.workflow.core.workflow import Wire, Workflow
# Define test blocks
input_block = Block(
name="InputBlock",
inputs={},
outputs={
"output1": Output(
name="output1", label="输出1", data_type=str, description="Input data"
)
},
)
bad_block = Block(
name="InputBlock",
inputs={},
outputs={
"output1": Output(
name="output1", label="输出1", data_type=int, description="Input data"
)
},
)
process_block = Block(
name="ProcessBlock",
inputs={
"input1": Input(
name="input1", label="输入1", data_type=str, description="Input data"
)
},
outputs={
"output1": Output(
name="output1", label="输出1", data_type=str, description="Processed data"
)
},
)
# Define test wires
wire = Wire(
source_block=input_block,
source_output="output1",
target_block=process_block,
target_input="input1",
)
def test_workflow_creation():
"""Test workflow creation."""
workflow = Workflow(
name="test_workflow", blocks=[input_block, process_block], wires=[wire]
)
assert len(workflow.blocks) == 2
assert len(workflow.wires) == 1
assert workflow.wires[0].source_block == input_block
assert workflow.wires[0].target_block == process_block