
_Declarative deep learning framework built for scale and efficiency._
[](https://badge.fury.io/py/ludwig)
[](https://discord.gg/CBgdrGnZjy)
[](https://hub.docker.com/r/ludwigai)
[](https://pepy.tech/project/ludwig)
[](https://github.com/ludwig-ai/ludwig/blob/main/LICENSE)
[](https://twitter.com/ludwig_ai)
# 📖 What is Ludwig?
Ludwig is a **low-code** framework for building **custom** AI models like **LLMs** and other deep neural networks.
Key features:
- 🛠 **Build custom models with ease:** a declarative YAML configuration file is all you need to train a state-of-the-art LLM on your data. Support for multi-task and multi-modality learning. Comprehensive config validation detects invalid parameter combinations and prevents runtime failures.
- ⚡ **Optimized for scale and efficiency:** automatic batch size selection, distributed training ([DDP](https://pytorch.org/tutorials/beginner/ddp_series_theory.html), [DeepSpeed](https://github.com/microsoft/DeepSpeed)), parameter efficient fine-tuning ([PEFT](https://github.com/huggingface/peft)), 4-bit quantization (QLoRA), paged and 8-bit optimizers, and larger-than-memory datasets.
- 📐 **Expert level control:** retain full control of your models down to the activation functions. Support for hyperparameter optimization, explainability, and rich metric visualizations.
- 🧱 **Modular and extensible:** experiment with different model architectures, tasks, features, and modalities with just a few parameter changes in the config. Think building blocks for deep learning.
- 🚢 **Engineered for production:** prebuilt [Docker](https://hub.docker.com/u/ludwigai) containers, native support for running with [Ray](https://www.ray.io/) on [Kubernetes](https://github.com/ray-project/kuberay), export models to [Torchscript](https://pytorch.org/docs/stable/jit.html) and [Triton](https://developer.nvidia.com/triton-inference-server), upload to [HuggingFace](https://huggingface.co/models) with one command.
Ludwig is hosted by the
[Linux Foundation AI & Data](https://lfaidata.foundation/).
**Tech stack:** Python 3.12 | PyTorch 2.6 | Pydantic 2 | Transformers 5 | Ray 2.54
# 💾 Installation
Install from PyPI. Be aware that Ludwig requires Python 3.12+.
```shell
pip install ludwig
```
Or install with all optional dependencies:
```shell
pip install ludwig[full]
```
Please see [contributing](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md) for more detailed installation instructions.
# 🚂 Getting Started
Want to take a quick peek at some of Ludwig's features? Check out this Colab Notebook 🚀 [](https://colab.research.google.com/drive/1lB4ALmEyvcMycE3Mlnsd7I3bc0zxvk39)
Looking to fine-tune LLMs? Check out these notebooks:
1. Fine-Tune Llama-2-7b: [](https://colab.research.google.com/drive/1r4oSEwRJpYKBPM0M0RSh0pBEYK_gBKbe)
1. Fine-Tune Llama-2-13b: [](https://colab.research.google.com/drive/1zmSEzqZ7v4twBrXagj1TE_C--RNyVAyu)
1. Fine-Tune Mistral-7b: [](https://colab.research.google.com/drive/1i_8A1n__b7ljRWHzIsAdhO7u7r49vUm4)
For a full tutorial, check out the official [getting started guide](https://ludwig.ai/latest/getting_started/), or take a look at end-to-end [Examples](https://ludwig.ai/latest/examples).
## Large Language Model Fine-Tuning
[](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
Let's fine-tune a pretrained LLM to follow instructions like a chatbot ("instruction tuning").
### Prerequisites
- [HuggingFace API Token](https://huggingface.co/docs/hub/security-tokens)
- Access approval to your chosen base model (e.g., [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B))
- GPU with at least 12 GiB of VRAM (in our tests, we used an Nvidia T4)
### Running
We'll use the [Stanford Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) dataset, which will be formatted as a table-like file that looks like this:
| instruction | input | output |
| :-----------------------------------------------: | :--------------: | :-----------------------------------------------: |
| Give three tips for staying healthy. | | 1.Eat a balanced diet and make sure to include... |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
Create a YAML config file named `model.yaml` with the following:
```yaml
model_type: llm
base_model: meta-llama/Llama-3.1-8B
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
Below is an instruction that describes a task, paired with an input that may provide further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
decay: cosine
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
backend:
type: local
```
And now let's train the model:
```bash
export HUGGING_FACE_HUB_TOKEN = "## Star History [](https://star-history.com/#ludwig-ai/ludwig&Date) # 👋 Getting Involved - [Discord](https://discord.gg/CBgdrGnZjy) - [X (Twitter)](https://twitter.com/ludwig_ai) - [Medium](https://medium.com/ludwig-ai) - [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues) ================================================ FILE: README_KR.md ================================================
_확장성과 효율성을 위해 설계된 선언적 딥러닝 프레임워크_
[](https://badge.fury.io/py/ludwig)
[](https://discord.gg/CBgdrGnZjy)
[](https://hub.docker.com/r/ludwigai)
[](https://pepy.tech/project/ludwig)
[](https://github.com/ludwig-ai/ludwig/blob/main/LICENSE)
[](https://twitter.com/ludwig_ai)
# 📖 Ludwig란?
Ludwig는 **LLM** 및 기타 심층 신경망과 같은 **맞춤형** AI 모델을 구축하기 위한 **로우코드** 프레임워크입니다.
주요 기능:
- 🛠 **손쉬운 맞춤형 모델 구축:** 선언적 YAML 설정 파일만으로 최신 LLM을 데이터에 맞춰 학습시킬 수 있습니다. 멀티태스크 및 멀티모달 학습을 지원합니다. 포괄적인 설정 검증으로 잘못된 매개변수 조합을 감지하고 런타임 오류를 방지합니다.
- ⚡ **확장성과 효율성 최적화:** 자동 배치 크기 선택, 분산 학습([DDP](https://pytorch.org/tutorials/beginner/ddp_series_theory.html), [DeepSpeed](https://github.com/microsoft/DeepSpeed)), 매개변수 효율적 미세 조정([PEFT](https://github.com/huggingface/peft)), 4비트 양자화(QLoRA), 페이지 및 8비트 옵티마이저, 메모리 초과 데이터셋 지원.
- 📐 **전문가 수준의 제어:** 활성화 함수까지 모델을 완전히 제어할 수 있습니다. 하이퍼파라미터 최적화, 설명 가능성, 풍부한 메트릭 시각화를 지원합니다.
- 🧱 **모듈식 및 확장 가능:** 설정에서 몇 가지 매개변수만 변경하여 다양한 모델 아키텍처, 태스크, 피처, 모달리티를 실험할 수 있습니다. 딥러닝을 위한 빌딩 블록이라고 생각하세요.
- 🚢 **프로덕션을 위한 설계:** 사전 빌드된 [Docker](https://hub.docker.com/u/ludwigai) 컨테이너, [Kubernetes](https://github.com/ray-project/kuberay)에서 [Ray](https://www.ray.io/) 실행 네이티브 지원, [Torchscript](https://pytorch.org/docs/stable/jit.html) 및 [Triton](https://developer.nvidia.com/triton-inference-server)으로 모델 내보내기, 한 번의 명령으로 [HuggingFace](https://huggingface.co/models)에 업로드.
Ludwig는 [Linux Foundation AI & Data](https://lfaidata.foundation/)에서 호스팅합니다.
**기술 스택:** Python 3.12 | PyTorch 2.6 | Pydantic 2 | Transformers 5 | Ray 2.54
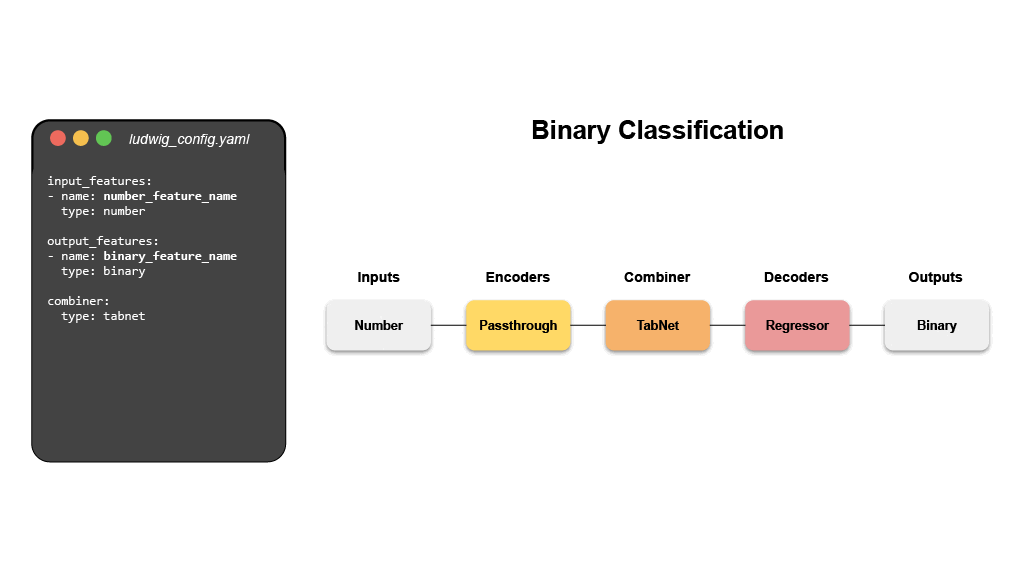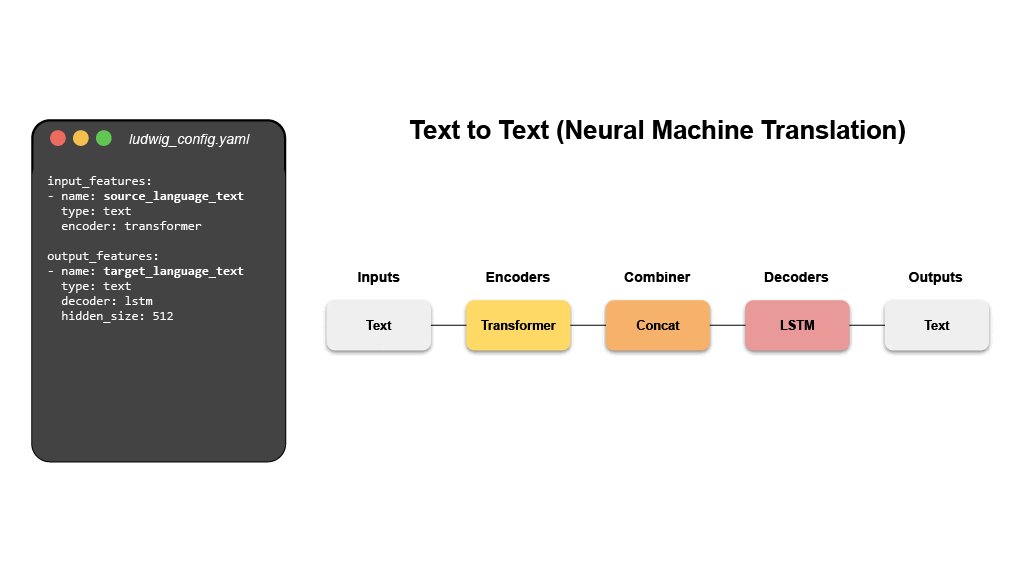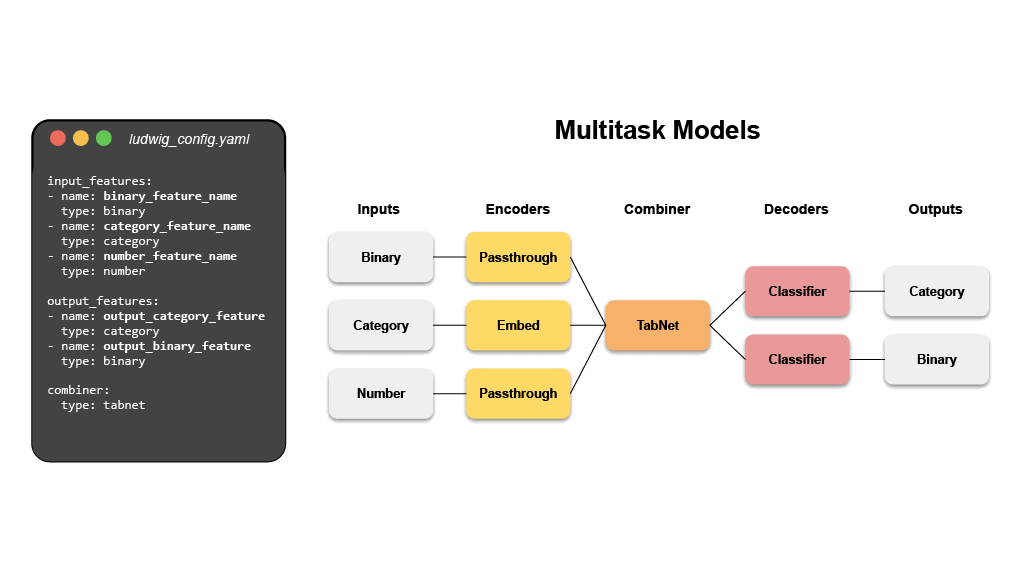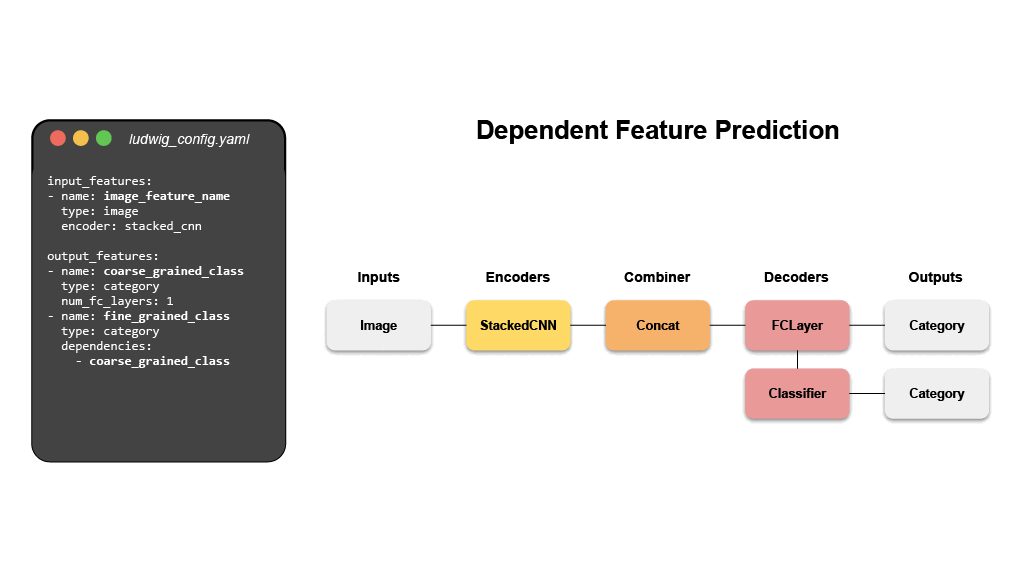
# 💾 설치
PyPI에서 설치합니다. Ludwig는 Python 3.12 이상을 요구합니다.
```shell
pip install ludwig
```
모든 선택적 의존성을 포함하여 설치:
```shell
pip install ludwig[full]
```
더 자세한 설치 방법은 [기여 가이드](https://github.com/ludwig-ai/ludwig/blob/main/CONTRIBUTING.md)를 참조하세요.
# 🚂 시작하기
Ludwig의 기능을 빠르게 살펴보고 싶으시다면 이 Colab 노트북을 확인하세요 🚀 [](https://colab.research.google.com/drive/1lB4ALmEyvcMycE3Mlnsd7I3bc0zxvk39)
LLM 미세 조정을 원하시나요? 다음 노트북을 확인하세요:
1. Fine-Tune Llama-2-7b: [](https://colab.research.google.com/drive/1r4oSEwRJpYKBPM0M0RSh0pBEYK_gBKbe)
1. Fine-Tune Llama-2-13b: [](https://colab.research.google.com/drive/1zmSEzqZ7v4twBrXagj1TE_C--RNyVAyu)
1. Fine-Tune Mistral-7b: [](https://colab.research.google.com/drive/1i_8A1n__b7ljRWHzIsAdhO7u7r49vUm4)
전체 튜토리얼은 공식 [시작 가이드](https://ludwig.ai/latest/getting_started/)를 확인하시거나, 엔드투엔드 [예제](https://ludwig.ai/latest/examples)를 살펴보세요.
## 대규모 언어 모델 미세 조정
[](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
사전 학습된 LLM을 챗봇처럼 지시를 따르도록 미세 조정("인스트럭션 튜닝")해 봅시다.
### 사전 요구 사항
- [HuggingFace API 토큰](https://huggingface.co/docs/hub/security-tokens)
- 선택한 베이스 모델에 대한 접근 승인 (예: [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B))
- 최소 12 GiB VRAM의 GPU (테스트에서는 Nvidia T4를 사용했습니다)
### 실행
[Stanford Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) 데이터셋을 사용합니다. 다음과 같은 테이블 형식의 파일로 구성됩니다:
| instruction | input | output |
| :-----------------------------------------------: | :--------------: | :-----------------------------------------------: |
| Give three tips for staying healthy. | | 1.Eat a balanced diet and make sure to include... |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
`model.yaml`이라는 YAML 설정 파일을 다음 내용으로 생성하세요:
```yaml
model_type: llm
base_model: meta-llama/Llama-3.1-8B
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
Below is an instruction that describes a task, paired with an input that may provide further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
decay: cosine
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
backend:
type: local
```
이제 모델을 학습시켜 봅시다:
```bash
export HUGGING_FACE_HUB_TOKEN = "## Star History [](https://star-history.com/#ludwig-ai/ludwig&Date) # 👋 참여하기 - [Discord](https://discord.gg/CBgdrGnZjy) - [X (Twitter)](https://twitter.com/ludwig_ai) - [Medium](https://medium.com/ludwig-ai) - [GitHub Issues](https://github.com/ludwig-ai/ludwig/issues) ================================================ FILE: RELEASES.md ================================================ # Releasing ## Release procedure 1. Update version number in `ludwig/globals.py` 1. Update version number in `setup.py` 1. Commit 1. Tag the commit with the version number `vX.Y.Z` with a meaningful message 1. Push with `--tags` 1. If a non-patch release, edit the release notes 1. Create a release for Pypi: `python setup.py sdist` 1. Release on Pypi: `twine upaload --repository pypi dist/ludwig-X.Y.Z.tar.gz` ## Release policy Ludwig follows [Semantic Versioning](https://semver.org). In general, for major and minor releases, maintainers should all agree on the release. For patches, in particular time sensitive ones, a single maintainer can release without a full consensus, but this practice should be reserved for critical situations. ================================================ FILE: docker/README.md ================================================ # Ludwig Docker Images These images provide Ludwig, a toolbox to train and evaluate deep learning models without the need to write code. Ludwig Docker images contain the full set of pre-requisite packages to support these capabilities - text features - image features - audio features - visualizations - hyperparameter optimization - distributed training - model serving ## Repositories These four repositories contain a version of Ludwig with full features built from the project's `master` branch. - `ludwigai/ludwig` Ludwig packaged with PyTorch - `ludwigai/ludwig-gpu` Ludwig packaged with gpu-enabled version of PyTorch - `ludwigai/ludwig-ray` Ludwig packaged with PyTorch and Ray 2.3.1 (https://github.com/ray-project/ray) - `ludwigai/ludwig-ray-gpu` Ludwig packaged with gpu-enabled versions of PyTorch and Ray 2.3.1 (https://github.com/ray-project/ray) ## Image Tags - `master` - built from Ludwig's `master` branch - `nightly` - nightly build of Ludwig's software. - `sha-
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"fig = plt.figure(figsize=(10,6))\n",
"sns.set_style(style='dark')\n",
"ax = sns.lineplot(x='epoch', y='accuracy',\n",
" style='split',\n",
" hue='model',\n",
" data=accuracy_learning_curves)\n",
"ax.set_title('Accuracy Learning Curves', fontdict={'fontsize': 16})\n",
"ax.grid(visible=True, which='major', color='black', linewidth=0.075)\n",
"ax.grid(visible=True, which='minor', color='black', linewidth=0.075)\n",
"ax.set_xlabel(\"Epoch\", fontsize = 15)\n",
"ax.set_ylabel(\"Accuracy\", fontsize = 15);"
]
},
{
"cell_type": "code",
"execution_count": 230,
"id": "b6ef7fce-b49e-49a6-a4b0-436d078f72ed",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAmMAAAGICAYAAAANo+ehAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAB3l0lEQVR4nO3dd3gUxRvA8e9eSy69J9RAAoTeBBGkFwsIwk/sYkMRFQuKBbuAiogI9oaKigKioKCIogiKiNI7CIQSIL1ecrm2+/vj4DQmgQDJXcr7eR4ekp0t704W7s3M7IyiaZqGEEIIIYTwCZ2vAxBCCCGEqMskGRNCCCGE8CFJxoQQQgghfEiSMSGEEEIIH5JkTAghhBDChyQZE0IIIYTwIUnGhKhmRo0aRVJSUok/rVu35oILLuDOO+9k//79pY7Jzc1l+vTpXHzxxbRr146ePXsyduxY1q5dW+51VqxYwejRo+nevTudOnVi+PDhzJ07F4fDUaE4n3vuOZKSknj//ffLLO/fvz+TJk0q99pJSUmkpKSU2H748GGeffZZBgwYQPv27RkwYABPPvkkx44dO2UsX331FUlJSWRnZ1codl949NFHueyyy7x2vV27dvHwww/Tt29f2rdvz8UXX8yLL75YretIiLrK4OsAhBClde7cmUceecTzvd1uZ/fu3bzxxhuMHj2a5cuX4+fnB8DBgwe55ZZbcDqd3HLLLbRp04bc3FwWL17MzTffzLhx47jnnntKnP/ZZ59l3rx5DB8+nGuvvZaAgAD+/PNPXnzxRf744w9mzpyJXq8vNz6n08m3335L8+bNWbhwIbfddts53/Pvv//OPffcQ6NGjbjzzjtp2LAhR48e5f3332fkyJF8+umnJCQknPN1fOWuu+6iqKjIK9f6+uuvefzxx+nUqRMPPPAAMTEx7N+/n3fffZeff/6ZuXPnEhUV5ZVYhBAVoAkhqpUbbrhBGzNmTJll8+fP11q0aKH98ssvmqZpmtPp1C677DJt0KBBWlZWVqn9Z86cqbVo0UL76aefPNsWLVqktWjRQps3b16p/b/99lutRYsW2qJFi04Z488//6y1bNlS+/3337UWLVpof/31V6l9+vXrpz377LNlHv/jjz9qLVq00I4cOaJpmqZlZWVpF1xwgXbDDTdoNputxL7Z2dlar169tBtvvLHceL788kutRYsWZdZBXbN//36tXbt22oMPPqipqlqi7NChQ1rHjh21iRMn+ig6IURZpJtSiBokKCioxPcrV65k7969TJgwgYiIiFL7jxs3jsaNG/P22297ts2ePZukpCSuvvrqUvsPHjyYW2+9lfDw8FPGsXjxYtq3b0/37t1JSEjgiy++OMs7+ud82dnZTJw4EZPJVKIsPDycRx55hO7du+N0Os/pOmvWrOHKK6+kffv29O7dm1mzZuFyuTzlDoeDV199lYsvvpi2bdvStWtXxo0bx/Hjxz379O/fn+nTp3PVVVfRpUsXPvroI1577TX+97//sXTpUk9X8RVXXMHGjRs9x/27mzIlJYWkpCR+/vlnRo8eTYcOHejVqxdvvfVWiXhTUlK488476dy5Mz179mT27NncfPPNPProo+Xe49y5c1FVlUcffRRFUUqUNW7cmAkTJtCqVasScXz//fcl9rv88ss911i3bh1JSUnMmzePnj170qdPHx599FE6d+6M3W4vcdy9997L9ddf7/l+6dKlDB06lHbt2jFw4EA++eSTEvtv2bKF66+/nk6dOnH++edz7733cvTo0XLvTYjaSpIxIaohTdNwOp2eP4WFhaxbt45XXnmF+vXr06VLF8CdXOh0Onr27FnmefR6PQMGDGDLli1kZ2eTnp7O3r176dOnT7nXfuSRR05ZXlBQwMqVKxk6dCjg/uD+/vvvKSgoOOv7XbNmDdHR0bRu3brM8iFDhjB27FgMhrMfWbF27Vpuv/12GjZsyOuvv87o0aP58MMPmTJlimefF154gU8//ZTbb7+dDz74gPvvv5+1a9fy/PPPlzjXhx9+SO/evXnppZfo3bs34O4ufvXVVxk3bhyvvfYaNpuN++6775QJ5MSJE+nQoQNvv/02/fr1Y+bMmaxatQoAm83GzTffTHJyMi+88AIPP/wwH3/8MRs2bDjlff7222+0adOm3G7I66+/nlGjRlWozv7tzTffZNKkSYwfP5477riDwsJCfv31V095UVERq1evZsiQIQAsWrSIBx98kK5du/LWW28xfPhwXnjhBc8YQ6vVypgxY4iNjeXNN99k8uTJ7Ny5kwceeOCMYxOippMxY0JUQ6tWraJNmzYltvn7+9O9e3cmTpxIYGAgAEePHiU8PJyAgIByz9WwYUMAjh8/7mkFql+//lnH9t1336GqKoMHDwbcydjMmTNZsmQJ11133VmdMzU19ZxiqoiZM2fSoUMHXnnlFQB69+5NaGgoEydOZPTo0TRs2JDs7GwefvhhRo4cCcD5559PcnIyS5YsKXGupk2bMm7cuBLbCgsL+eijj2jfvj0ALpeLu+66i927d9O2bdsyY7r00ku59957AejWrRvLly9n9erV9OnTh6+//ppjx46xbNky4uPjAUhISOCKK6445X2mpaWVm9Sei5tuuon+/ft7vm/Tpg3ff/89AwYMANyttA6Hg0suuQRVVZkxYwZDhw7lqaeeAqBnz54oisKbb77Jddddx759+8jNzWXUqFF06tQJcLeC/vHHH6iqik4nbQWi7pBkTIhq6LzzzmPixIkA/P3337z44ot0796dadOmlejG0zTtlAPtgRLlJ79WVfWsY1u8eDHdunXDYDCQn59PYGAgnTp1YuHChWecjJ3sRtPpdOcU0+lYrVa2bt3K+PHjS7RU9e7dG1VVWbduHQ0bNmTmzJmAO6E5cOAABw4cYOPGjaW64xITE0tdw2AwlEi64uLiPNcuT8eOHT1f63Q6YmJiPIP8161bR/PmzT2JGEDbtm09yXV5qqoumzVrVuL7oUOH8vrrr2O32zGZTCxbtowePXoQERHB/v37SU9Pp2/fvqXq+9VXX2Xr1q20bduWsLAwxo4dy5AhQ+jTpw/du3fn/PPPr/TYhajuJBkTohoKDg6mXbt2ALRr14569epxyy23YDKZmDZtmme/Bg0asHbtWmw2m+ftyv86OQanXr16nm3/HgP1X+np6URFRZXZMnHkyBHPOKiuXbuWKt+5c6enVcZsNpdKYk46ud1sNnvuY9u2beXGZLFY0DSN4ODgcvc5lfz8fFRV5eWXX+bll18uVZ6RkQHAxo0beeaZZ9izZw/BwcG0atWqzHqNjIwstc1kMpWos5Nfnyox8vf3L/G9TqdD0zTAPV1JWeMAT/cWZIMGDU75883NzcXPz89T9xX131gGDx7MtGnT+O233+jWrRu//vorzz77rOcaAA8++CAPPvhgqXNlZGQQFBTEp59+yhtvvMGiRYuYO3cuISEhjB8//qxbWIWoqSQZE6IG6N69OyNHjuSLL77gkksu8XQX9evXj88//5yVK1dyySWXlDpO0zR+/vln2rVr5/kwbd26Nb/++isTJkwo81q33HILUVFRzJkzp1TZ4sWL8ff35+233y6ReLhcLsaOHcsXX3zB008/DbgTlszMzDKvkZaWhtFoJCQkBIAePXqwcuVKdu3a5Rlc/m/z5s3jlVde4fvvv6dRo0anqqoynezWvfPOOz3dav8WExNDQUEBY8eOpXPnzrz22mueFqlp06axe/fuM77muYqJiWHnzp2ltmdnZ9O0adNyj+vRoweffvop2dnZZSZzs2bN4ptvvmH16tWelsn/JowVmYIjNjaWLl268MMPP3j2HzhwIIAnaX7qqac83bb/drJ1r3nz5sycORO73c6GDRuYM2cOzz77LG3atKFDhw6njUGI2kI65YWoIR544AGCg4OZOnWqp2WpZ8+etGvXjmnTpnlad/7tnXfeYf/+/YwZM8az7aabbmL37t1lvgH59ddfs2/fPs/g/P/65ptvPN1J3bp18/zp0aMHffv2ZenSpRQXFwPulrP169eXOcnoihUr6NSpk2dA/uWXX05YWBgvvvhiqda0zMxM5syZQ8eOHc8qEQP3W6gtW7bkyJEjtGvXzvPHaDQyY8YMUlNTOXDgAHl5edx0002eRExVVX7//XdPa5U3denShb///psjR454tu3du7fE92W57rrrUBSFF198sVTc+/fvZ/HixQwYMIDAwEDP27np6emefdLS0kpNxlueoUOHsnr1apYvX07fvn0950tISCAsLIy0tLQS9Z2bm8usWbOwWCysXr2a7t27k52djclkonv37jz55JMAp53kV4jaRlrGhKghIiIiuOOOO5g+fTqffPIJo0ePRq/XM2PGDEaPHs2IESO47bbbaN26Nfn5+SxdupRly5YxduxYLrroIs95Lr/8cn755Reeeuoptm7dyoABA1AUhd9++43PP/+cSy+9tMxB4uvXr+fw4cOMHz++zPiGDRvG8uXL+f777xk+fDg33HAD8+fPZ9SoUdx22200aNCA9PR0Fi1axNatW/nwww89x4aGhvLcc89x//33c80113DDDTdQv3599u/fz/vvv4/L5WLq1KmnraP58+eX6n5r2LAhAwcO5N577+Xuu+8mKCiIQYMGkZOTw8yZM9HpdLRo0QKn00lgYCBvvvkmqqpSXFzMZ599xu7du1EUBU3TSk0VUZWGDRvG22+/zdixY7n33ntxuVy88sorKIpyyjji4+OZOHEikydPJi0tjSuvvJKIiAh27NjB+++/T2xsLI899hjgrvcOHTrwwQcfUK9ePfR6Pa+//rqnxfJ0Lr74YiZNmsRPP/3ErFmzPNsNBgP33HOP52fWvXt3UlJSePnll2nSpAkNGzYkODgYTdMYN24ct99+O0ajkTlz5hASEkK3bt3OoeaEqHkkGROiBrnpppv4/PPPeeuttxgxYgQRERE0btyYhQsX8vHHH/PFF1+QkpJCYGAg7du358MPP6RHjx4lzqEoCjNmzGDBggV89dVX/PDDD9jtdpo2bcoTTzzByJEjy/yw/+abb/D39y932ouTbycuXLiQ4cOHEx4ezsKFC3nttdeYNWsWmZmZhISE0L59e+bOnVuq+2rgwIF89tlnzJ49m1mzZpGdnU1sbCy9evXi7rvvJjY29rT1c3IA/r/17NmTgQMHMmDAAN58803eeOMNvvrqK4KCgujRowcTJkzwJHCvvfYa06ZN48477yQ8PJwuXbowa9Ys7r33XrZs2VJiwH1VMxqNzJ49m2effZaHH36Y4OBgxowZw0cffeTpdi3P9ddfT5MmTZgzZw4vvPAC+fn51K9fn5EjR3L77bcTGhrq2feFF17gmWeeYcKECURHRzNmzBh+//33CsUYGhpKr169+Ouvv0o9FzfccAP+/v589NFHfPDBB4SFhXHJJZcwfvx4FEUhLCyM999/n5dffpmHH34Yh8PheWbL6l4VojZTNF+0vwshhDilPXv2kJKSUmKMm8VioXv37jz00EPceOONPoxOCFGZpGVMCCGqoYKCAu666y7Gjh1Ljx49sFgsnlaxkxOrCiFqB2kZE0KIauqbb77hgw8+4ODBgxiNRrp06cKECRPKnOdMCFFzSTImhBBCCOFDMrWFEEIIIYQPSTImhBBCCOFDNXYAv6qquFyn72E9ObO0LDp7alJPFSd1VTFSTxUndVVxUlcVI/VUcd6qK6Ox/HWEa2wy5nJp5OaefsmOk8t0BAQEVHVINZrUU8VJXVWM1FPFSV1VnNRVxUg9VZy36io6uvy1dSVlFkIIIYTwIUnGhBBCCCF8SJIxIYQQQggfqrFjxsricjnJycnA6bR7tqmqe5B/fr73FvitiXxVTwaDifDwaPT6WvUoCiGEEBVWqz4Bc3Iy8PcPIDAwzrPQscvlAkCvL/8tBuGbetI0jcLCfHJyMoiKque16wohhBDVSa3qpnQ67QQGhngSMVG9KYpCYGBIiZZMIYQQoq6pVckYIIlYDSM/LyGEEHVdrUvGvM1mszFy5NByyzduXM/TT0/0YkRCCCGEqEkkGRNCCCGE8KFaNYD/bHz33RLWrFmNzWYjKyuTK6+8ll9/XUVy8n7uvvs+rFYrCxZ8jtFopFGjxjz88OPY7XYmTXqCgoICGjRo6DnX/v37mDnzJTRNIzQ0lIkTn/bhnQkhhBCiJqjzyRi4l0J45ZU3WLFiOfPnf8a7737Epk0bmDdvLocOJfPhh3MJCAjk1Vdf5uuvvwSgadNE7rjjbnbs2M7GjesBePHFKUyc+BRNmyawdOli5s6dQ9eu3Xx5a0IIIYSo5iQZA5o3TwIgKCiYJk2aoigKwcHB2GzFNG2aQEBAIAAdOnTmr7/+AKBbt+4AtGnTFoPBXY2HDiXz8stTAfecZ40axXv7VoQQQlQjWYV2UgtstI4NOvcXljT1xB8XqCqK5vrne00F1YWCCqqKvsiCagoBWZvytBR7AZreD/BdXUkyxqne6FM4eDAZq9WK2Wxm8+aNNGrUGEXRsX37Nnr16svevbtxOp0ANG4czxNPTCIuLo6tWzeTlZXpvZsQQghv0zRQ7SjOYhRnMZz4W3HZ3F+7ikuWuWzur102UPRoBj/Qm9D0/qD3QzP4uT8UT/zt/tofTWc6sa8fuFTQGX195+XKKbKz8UgOB/bvIe/YLoIsyTRS0rEFQodYf8JMGorLfqKO7CiqDZw2FNUBqhPFYQWXDcVlB82B4nKCprqTrDOk6QwUnXcvRZ3vBIO5Cu62hnPZCdj0FlF/vkJO14dwdb3bZ6FIMnYKer2eW2+9g3vvvQNF0dGwYSPGjh2HXq/nhRee5c47RxMf3wSj0f0fw4MPTmTKlKdQVfc/mkcffZLMzAxf3oIQwls0DRxFKE4rirMIxWE98bUVxVEETuuJxOTfZUXgsOJfXICiOt2t7J5fDt1/ayf+xvM748nv/7Wf3oRmDDzxJ6Ccv//5WjUEkGvTSC+w42/U0SBYj9Geh86Wi1Kce+LvHHTFuSi2XHTFOe7txTnu7dZsFHue+x68VL0nRQEqYMOEAz8cigmn3h+Xzg+X3h/N4P6DwR+d0YzO6I/OFIDBZMboF4g+KBLVHIVmjkA1R7m/9g8D5SzeZ3NaKUrdy7Hk7ViO7cSQs48GjoP8T0nFpLgn0sYITk1HdnEotoMG9LocDLjLFDTPqWyN+qD5hWJM24S+MKvUpYqbXowrui2GjG34Jf9Qqtwedx62pJEo1iyC/pzuPr/qJPCvGfjvmoelz/PYmww883s8Azanync709CAYW3jMOiq79RFhrTNBK+cgCFrN6oxkMKmQ/D3YTyKpmna6XerfhwOF7m5RSW2paYeIi6uZNegzMBfMb6sp7J+btVZUZH7uQuQ5v9TqvX15CjCmL4ZQ+pGjEfXYUzbgM6ef0an0HQmNJ0BxWkFlBN51okkzGBG8wsB1YWuOPvEEf8kZpqiQzOFAho6Wx64HGfUemLX9BTihxGVIKW4/BgVPZopGMVecKKF5p+PDNUvDGvHO9AM/gT8NQOdvaDU8dMjprCpIJiri+fRQ7eDYs2EDSNGRcUfG6+o13DA3J7hyi9ca1tQ6vjfXG1ZF9iPNuYcLsn5tFR5vhbAb3TErDg4T9uOARcaiieV1aFhw4A/TvwUR5n3qKJgM4bj9I+EgCh0QdEoAZFoAVGo5hPJmzEQff4hXBl/Y03dSUDeXoKdWZ4pCVRNIVMfRYz6zy/gNkxk+TXkaFB7tEEvsnRHOlGbXyGIYlrWj6BNgygMRj80vZHiNtejmYIxHPsTveUoms7obi3UuRN0V2RL1MA4dJbj6HP2/5OMKwqgoAbG4gpLAKcVQ8Z2bMU2/I/9RujWd9wtbmjYmgzC0utZ1JDG5f68z0axw8VXW4/z0boj5Fjdddw6NpjnLmtJw7Bq1iLnKCLwj2mYt85GDYylsPtjqJl7yG93B+aQiCq9dHR0cLllkowJQJKxM1Hrk4xKUqvqSdPQ5yVjSNuI4eif6I+uw1Rw0D1mpxwfBtzGEV19+thW0s65DRsmijFRjB9Fmh+fcBk/a+fRWtvHMG0lKjr8dC78dComRWW3Poll5suIVvJ5sGgGRsWFERdGxYUBF1Z9CB81eRmTQcfNe8cSYT+KXrVj1BwYcaJTNG63PYBFMTNOv5gL9TtKxfi7qzVpAc1J8suldf4qwN2KY8FMgRbAd2o33jKMol24i7GuzzAFhuEfHEFISCQhYZEU6sPYZurI35mFFKZs42BOMftynBS4jBRjxIYJ9CZ6NI2iZWwQq/ZnsTO1gHohfoSZjRh0Oox6hfv6JNA6Nohf9h7ntz1HCdA5CFDsmBUHTmMQrZolcWEDI0X7VrPxwDFwWtG5bGj2QvI0M/saXsk9vRMIWPkIf+zch1Etxg8bARQTgI3h9smMG9ieftsfokXuqlL1sNR1PvlaEB11+2ihpKABOkVDT+mPR1Vzp8T/Ht2yxtWaDd3e5NrzEyla9x7JWj0aN2tPcFTjEjuqmsaw9/4k02LHpWlEB5m4v08Cg5KiK30C7JP//oKc2QSteRbVHIn/nq9AdVJ03jiKOt8FhnNrCyq0O1m4+Thz16eQY3WgAM10xzDiZJfaGKNeYUL/ZgxvF1ctJvg2HvmV4J/Goy9MRdP7kX3dKtSQhl77v0qSMSQZOx1JxiquViUZVaim1ZOmaRTaXeRaHWTlZMOxjfhnbKJ+zjrqWfdg1opP7Ofe/03XUP5SW9JR2Y8NE1u0RPar9bDihxU/HOhpEGamUZiZ/GIHO1Mtpa4ZF+xH3+ZROB0OFm5LB9wf9DrFPZZVr1PoUD8Eu0vlQFYRNoeKhoZ2Ig5Nc38daDJg1CsUFDtxqBqgYcCFEz23dY/ntg4hbD+UwmfrkokyK0T5a0T5gxbWlAYNGtMl1kBKWjr3fnuYw4UK/+oTJdTfQEJkAAezrZ5WD3BPUvnvdrgwsxG7U6XI4SpxbPPoQJ69tCUxwX6kF9gI8jMQYDr7/2cq+lw5XCoWm5NCu4tCu4ukmCAAlm87xNG0NArzsrAVZuEozOXXosY8NKwHDfM3krtlMVZLNuFKEeGKhXAKWK11ZIXWhUYRIQy2fsNfRdEcUOtjD00kqnFL2sXXo3PDUMLMpx/LdjC7iDd/O8jKvzPR6xRcqka7esE82L8ZbeLK/7A+U2XVk67gKGFfDEFvzcQVWA9L36nYmww443MXFDuZt+koc9enUGh3MayhjXHRmwlJXkpc8X4AdpPAR47+fOPqQeeE+jx+UQuiAk2Vc3NnSCnOIejXp/Hf+5X7344xiMKez1Dc6ipQdJKMnQtJxiqXJGMVV9OSDF+pzHpSNQ1V1XBp7q9dqoamgUvTyixzujQKbE7ybU4sxSf+tjnJL3ZSYHNSUOwkr9hBkd1FfrETi9VKa+dOBuv+oK9uCw2UTE4Od3FqOgyKSrFmZJfWmD/U1mxWm/GL2oH7B7Sid2IUW47ls/FILiFmIydTGUWBbvHhdGgQypEcKz/sSUdB+ad3CWgYZmZgUjT5BRbmb0kDvQGHS8Xu1HCeGHs6oX8zAGatOsDB7CIcLhWHS/P8/ezgJBIiA/lhdzrrj+QSFWgiKtBEZKAfUUEmGoX5E+Jf8QHvNqfKsbxijuRaScm1YtTruLJjfZwulT6vrcHuKvmRoVNg8W3nExfsx9wNR9EpkBgZSGJ0IJEBxipr8anMf38Ol4ruRPK7MSWXLUfzSSuwkZpvI7WgmNR8Gw/1b8aQNrEcyi7iQFYRnRqEEhZw9i8SbDmax6urk9l6LB+jXsHh0hjSOoa7ejYlJtjvnO+pzHrSVPy3f0zg2hdQHIUogK1RPyx9n6tQ12VukYPPNqbw+YajhDizuEz/B5cb1tJB2ec+vd4fxXXilxa9H4rLhl1n5gtnL75SBnHNxYPo2zzqnO+twjQN0/5vCV75iHuMI2BNGknhhU+hmf/pkpRk7BxIMla5JBmrOEnGcI9BKTHQOwfFmo2uMA295Ri47KjF+eitWej0Cqo5GjUwDldIA7SAWFRzBJp/BKp/BKo5vNSbXou3HmfmqgMUO1y4KvF/KM+QLA1ijEXcGLGXPvaVNCvajL/iQNPcSZRD0/OI7iFuu+pK6lv/5pdUPYd1DYkJ9ic6yI+YIHfCY9BXziImNeWZcqka6RYbKblWjuUVE+JvJDEqkIZh/ui81A3lq7pSNa3S71HTNFbty8KgU9h0NJ/PNhxBpyjc0q0xN3RpiL+xaloQFWs2gX+8iP/OzwANFANFXe+nqNPYMrsuMwvtfPpXCis272IAfzJU9zvddLvQKeD0j6S40x3Y4vsT/PtkbE0GAQr+u+ZhzNiGM7QJ5B/DoNnZoDZje8z/6HPZrQQGBp31vVWEznKcoFWP43fwB5xhiaA6sQx4GUf9C0rtK8nYOZBkrHJJMlZxNeWD85xpGsZjf+C34zMMBUdQirPR2fLBXoDOZTvloaoxGGdADIrTirHw2OkvpTOgGYNQ/ULJ1oLZkOuP1dwAU3QzVmSGsSYvkgxC+Xf32ZDWMbSMDWZzSh4//V16GpkeTSMYfUFjimxOXv01mVB/I80NaVxg/50uhauoV7wfnWewt0ZRQENy4wfjanoRfg07oBi9N/C4zjxTlaA219VDX+/gl33uNykjA4080DexQuPJXOo/LaV2l4rDpZJvKUIDIkODCDLp8TPoSp1Hn7GD4F8eAZcNY9YuXMGNsfSZgj2+PwCp+cV8sW4PxTuXMkT5jZ76HehRUdGhQ0XTmyhuPgLLgJfLjEufuRMM/lh0waQtmkDHgpUYFZV8zGQnjCTkgtG4wpude8X9m6biv/0TAtdMQlEdFF4wEWvH291vy5bzxqwkY+dAkrHKJclYxdXmDwMANBXTge8J2PgmxvTNZe5S1PZmXOGJGI//hT7vIGpANGpgLGpwA1yB9XE0uACLIRKdLY8gRzq6okx0hanoClLQFxzFGdoEV1RrDBlbCdj0jnvOpX+xaQZ0eiNG1erZ5tL74wisjy2sBdbItuijW6KPbkGhuQFFLgXdibcRFcCgVwgw6lE0FUPqBvz3LsKU/D36IvebbhpgbX87tuaXoTiLcYUloAbVq6IKPb1a/0xVotpcV0V2F3PXpzDnryPYnO5u6gah/oT4G7C7VKwOFYfThf1EV7zDpeJ0aRV6h1avQIBJj79RT5DJQLCfniB/A4FGPcEmhbaObVyT8gwBrnxSwi5gpV8/4o4tp49uCybFhS2gHqaiNDSDP/amF2FLvBR7o75gCqzQvRmPrsX220yiM9e4xxtq7i5uW73zsbW7CVvCJe555M6BPvcAwcvvwpi5HQB7/QvIH/IhmunUY/EkGTsHkoxVLknGKq7Wfhi4bPjvmEvA+lnorVm4QuJxhsbjjG6LK6otakCUu7sxIArNL/S08zKdUT05rexNPsj0pWuJIpfL2jWkx4Ar0eUlE7r0RvSWY+5JMMugKXpUcxSu0CY4o9vijG4HOiOmwysxHfoJXXGOZ1/VLwx7kwEUNx+Oo+GFoPfNgOL/qrXPVBWoC3WVWWjnvd8PsWjbcfz0Ojo3CsWk1/F7cg52V+nU6/rzGhBmNrJibwZ70gtLlV/SMpr6of5sPprPxpQ8z3ZFcb+IYTLo0DQYoy3kXsNX6FFRFPdLIjbFxMrOb9HlgoswpG/BGdX6nP7dWDIOsWn5e3TLXUoDJZNsQokgD9U/guKWV+Fo0N29ooDLjqI6QXW4J8R1/ftvJ6h293AJpw00F4o1G/99X4OmoplCKOg3DXvikJKvvZZDkrFzUJOSsS+/nM8VV1x9TucYM+Zmnn32eerVq39Gxx06dJCXXnqe119/95T7nWs9DRt2Md98s7zMsuPHj/H004/x7rsflVkuyZhvKbZ8zOtnYt7+CTqnuyWqqONYCrtPBF3Vv/UGcCCzkBs+2YhD1RjTvTG392hScgdNQ1eUjj73APrcA+gsx7HH90efu5+g355xz7P1H6op1P2mmKbiCkvAljgEV0SLCv3n7G217ZmqSnWprg5mF7ExJY//tXe32v64JwOXqmHSK5gMOox6HX56Ha3jgjEZdGQW2nG6VIx6HS67eyC9qjcR7G8g0GTgcI6V7cfzKSh2YrE7KSh2YbE56dwolMGtY/k7w8LLi37mXvv7tFCOkFl/IPW6XoHW4PyzmxT3FLILi0nb8QsP/uVPa/s2Xg+cTZAj84wmEdYAdAY0g9k9B56jkOJW11LY86nTtob9W3VIxmrtDPzf7kjjm+2pnMw1K+ONnmFt4xjSJvaMj5sz54NzTsaEqGy6wjQCf5+C39/foGjusVP2hr0ovOARnLEd0TSNA5mFHMgqomdCBOZzGEx8Kqn5xdwxfwsOVeOazg1KJ2IAintSSzUw1v2b8wnOuM7YWoxAV3DUnajl7MOYvhXFno+l9+RKn9xSCG9qEhFAk4h/EoRBSdGn3P/fU0cUKe5l+gIC/hmQ3zjcTOPw8sdCNo8O4u0xw4BhAMRBGTOtVY6IQH8izr+Ey2zJfPinjklF/2OM/0801WeiGPxPLInlj+XCJ3FFJGE68B2mlDVohgA0oxnNGAAGM7b4ATjrn48uPwXFno8rqnUVRVy1am0y5iuHDx/i+eefxWAwoNfr6dy5C/n5eUyfPpU77xzH1KlTsFgKyMvLZejQEYwYMZJx48bQvHkSBw7sp6jIwuTJLxIXV4933nmDdevWEhsbS15eLgDp6WlMnz4Vu91Gfn4eN998O71792XUqKto1Cgeo9HIPfc8wKRJT6BpGhERkaeMd+PG9Xz66UcYDEbS09MYPvwKNm5cz759e7nyymsZMWIkf/31B++++xZ+fn6EhIQyceJTBAQEMG3acyQnH6BBg4bY7e4upLS0VKZNex673YbJ5MfDDz9W1VUuzpAhbQvmLe/gt/97UB2gN2FteR2F5z9IjhLK7weyWPbrVranFmCxuVtMw81Gpl3eio4Nwio1ltwiB/d8uQ2HqvHMJUkMbh1z5ifRGVBD41FD43HE96P8ueSFENXNnT2bUC/Un+k/K3xR2Je+zSJ56fI2pfYr7nAbxR1uK/c8akjDqgyzytXaZGxIm1iGtIn1ejflX3+tIympJffc8wBbtmwiPDycL79cwIQJj7Jnz24GDryIPn36k5mZwbhxYxgxYiQArVq14b77HuSdd97gxx+Xc+GFPdmyZRPvv/8xVmsR11zzP8Dd7XjNNdfTuXMXtm3bwuzZ79C7d1+sVis33zyaFi1a8vrrMxk48GKGDRvBTz/9wKJFC08Zc3p6OrNnf8KePbt45pnHmT9/MRkZ6Tz22EMMH34F06Y9z5tvvk90dAwLFnzOnDmz6dTpPOx2O++++xGpqan88stPALzxxixGjrya7t0vZP36P3n77dcZM+auqq10USGmvYsJWvciuvwjgI7itjdQ0OYWthSF89O+XFbN3c/x/H8G0ut1Co8MSMTqUHl1dTK3z9vKVR3r8WD/ZpXyin+R3cV1n2wgu9DOG1e257xGYed8TiFEzaIoCiPa1+P8+DA+/vMIYy9s4uuQfKLWJmO+ctlllzN37hwefPAeAgODuOOOf1aBj4yMZMGCz1i1aiUBAYE4nU5PWYsWSQDExsaSlZVFcvIBWrZshU6nIzAwiISEZifOEcWcObP59tuvAaXEORo3bgJAcvIBLr54MADt2nU4bTKWkJCIwWAgKCiY+vUbYDQaCQ4OwW63kZubS0BAINHR7haLjh078c47bxIWFkarVu7fXuLi4oiJcXffHjiwj08++ZC5c+cAuBc+FudMn7ED85bZ6KzpKKoTTWcCgwkcxehsOaA6QXWhaO6/NYMZNSgOXE4M2btQHIXoHO5X3a1hSfxQbxyfpiWwa2s6hfbjnusEmvR0bRzGkNaxdGsS7umajA8389i3u1mw+Ti/Hcjmnas7EBdy9kup2J0qoz7dQIbFTpdGoXRuGHquVSSEqMEahJqZOKiFr8PwGfmkrGS//baKDh06ceutY/jxx++ZO3eOZ9za559/Qtu27RkxYiQbN65n7drfPMf9d0xb48bxLFw4D1VVsdlsHDx4AID333+boUOH0737hXz77TcsW7a01Dni4+PZsWMrzZu3YNeunaeN+VSNHGFhYRQVFZKZmUlUVBSbN2+kUaPGxMc3YcWK5cC1ZGZmkJGRcSLuJlx77Q20a9eBQ4cOsmnThgrVmyibIXUDAWtfxO/Y72j8M8uWyxyFZo5EcRSiL0gpdZxqCgadAdBQbPm40LPLfD4PW29kR2oEpALkMaxtLD0TIrE5VBKjA2gWFVjm+MrezaJYdkc37vtqO9uOFzD8/T95/KIWDG0bd8b35FI1Rn++mcM5xbSKDeK1ke2rxbp1QgjhK5KMVbKWLVszadKT6PV6dDod99zzAMePH2PSpCe57LLLmT79BX74YRmhoaHo9XrPWKv/at48iX79BnLbbTcSFRVNeLh76YZ+/QYwa9Z0PvnkQ2JiYsnNzS117G233cnTT09kxYofqF+/wTndj6IoPPzw4zz++EPodArBwSE89tgzhIWFsXXrFm6//Sbi4uoRFhYGwN1338fLL0/FbrdjsxVz330Tzun6dZKmYUxZQ8CGVzEddSdhmqKnOGkkjvrngyEAZ1RrXOGJKHYLuoIUNGMAmsGMZgigWDOyJbWQdYdy2HAkj91FBagacOKNd7NRR9fGYQxKiqZf82j8DBV7SyrY38gH13Xisw0pvLPmEJOW72VHagH390mo8EzhmqZxz5fb2J1uoUmEmdnXdsSgk0RMCFG3ydQWApB5xs5Elb0GrWmYDq4gYN2LGLN24wqIxdruJnTWTKyd7ix3UlKnS2VnmoV1h7JZtS+LvzMK3ckX0K5eMN3iwzmSayU22I/eiZG0rReC/hwTIJvDxdu/H+LT9SkEmPS8fHlrujQOL7FPWfX0+uoDzPkrhdhgPxbe0uWclnupTerSdA3nSuqqYqSeKk6mthBe8+GH77Fhw1+ltj/22NPn3HomzpHqwm//twSsewlDXjIauJcFun4VmEqv36ZqGvsyCvnrcA7rj+SxKSWPQrurxD71Qvzo0TSCsT2anNNixuXxM+q5r08CRp3Ch38e4c4vtnF5uzgeH9S83C7H+RuPMuevFPo1i+SpS1pIIiaEECdIy5gApGXsTFTab1EuO/57vsL81wwMFvf6jZrej6IOt2HteAeaOcKzq6ZpLN+dztId6Ww9lofV4Z6Fu2GYP93iw0krsBFuNtKjaQTnNQolPMB7M8tvSsll/KIdFNpdxASZeOfqDjQMM5eop3fWHOT9Pw7Ts2kELw1vI12T/yGtGBUndVUxUk8VJy1jQtRFTiv+O+cRsOlt9JajqMYgNEMARZ3uwNp+NJp/WKlDFm4+xrSf93u+Dzcb6RofxoP9EonwYuJVlk4Nw1g+9gIe/HoH6w7lMvKDv3jp8jacV889ueTnG1J4/4/D+Bl0PDKwuSRiQgjxH5KMCeEtmoZ562wC/nwFnT0PZ0QL8i77GGd4czT/sHKX70grsPHKqgMowKODmtO9STj1zmFaiargZ9Tz+sj2LN2eyju/H+KBxTsY3iaaxEgzM1YfxqhT+OSGTsSFnNtCwEIIURtJMiaEN7jsBP9wD/4HvgXcY8KKutyPPb7/KQ/TNI3Jy/egA6YObUX/FqdeDsXXLmsbx6CWMbz+azLzNh4FQK/Ae9d0oGlkoI+jE0KI6kmSMSGqmGLLJ2TpKEypG9AUA4U9Hsfa9gYwlL9G3ElvrznEukO5PDqwWbVPxE7yM+h4sF8iBs3F0l2ZTLmsJW3qhfg6LCGEqLYqdxl2wXffLeGtt1477X4bN67n6acneiEit2HDLq7yazz99EQ2blxfbvnIkUOx2WzlltdGOstxwr76H8bUDaiGAHJHLMTa8fYKJWL7Mix8uO4wJr3C0LNYoN7Xbr+gIV/f0pFu8RGn31kIIeqwWtsy5rd7If675v2z5HwljBkubnUNtpYjz/1Eok7QZ+0mdMkNKHYLBX1ewNmgB67wxAod61Q17vlyOxrwyMBmmAzyNrAQQtRWtTYZ86UdO7Zx3313UlhYyK23jsFmK+arr77wLIs0Zcq0Evt/+eV8Vq1aidPpJCgoiOeee4kff/yetWvXYLMVc/RoCtdffxODBw9lx47tzJo1HU3TiI6O4emnJ5OSksLMmS+haRqhoaFMnPg0ZrOZadOeIzn5AA0aNCx3pv+TrrvuCtq0acfRoyl07tyFwkILu3btoHHjeJ58cjLHjx9j6tTJOJ1OFEXhvvsm0Lx5C778cgFLly4mMjKKnJwcAJxOJy+99DwpKUdQVZXbb7+Tzp27VE1lV1PGo78TsuRGFE0lZ8RXuOI6ntHxU3/cS2ahe93GYW3LnuxVCCFE7VBrkzFby5HYWo70yfxZ/v7+vPTSLHJzcxgz5maGDh3OSy/Nwt/fn2nTnuPPP9cSFeUe/6OqKnl5ecyc+SY6nY4HHhjHrl07ACgstDBjxuscOXKYRx4Zz+DBQ5k27TmeffZ5mjRpyldffcHBgwd5+eWpTJz4FE2bJrB06WLmzp1D27btsdvtvPvuR6SmpvLLLz+dMubU1OO88sobxMTEcuml/Xn33Y8YP/5hrrrqcgoKCnjjjZmMHHk1vXr15e+/9zB16mRmzXqLL76Yx8cfz0On0zF69A0ALFmymNDQMCZOfIq8vFzuvnsMn366oGorvRrx27OI4BX3oaBib9ADV+SZLX674UguX29Pw2zU8fLwtlUUpRBCiOqi1iZjvtS+fUcURSE8PILAwCAMBgNTpjxNQEAAhw4dpG3b9p59dTodRqORZ555HLPZTHp6Ok6nE4Bmzdwf4jExsZ6WrZycbJo0aQrA//53JQCHDiXz8stTAXC5nDRqFE9y8n5atWoDQFxcHDExpx5zFBISQmxsHHq9HrPZTNOmCQAEBgZht9s4ePAgHTp0BtzrZqanp3Ho0EGaNk3AZHLPc3Xyevv372Pr1k3s3LndE1NeXu451GgNoWmYN7xB0Dr3z6I4aSQF/aefWLC7YoodLp5dtgcFeHFoawJM0j0phBC1nSRjVWDXrp0AZGVlUlhoYcGCz/nyy6UAjB9/N/9e9GDfvr9ZvfoX3ntvDsXFxZ7WJaDMZWWioqI4cuQwjRo15tNPP6JRo3gaN47niScmERcXx9atm8nKysRgMLBixXLgWjIzM8jIyDhlzOUtYXNSkyZN2Lp1Ez179uHvv/cQERFJ/foNOHjwADZbMQaDkb1793DRRZcSH9+EmJgYbrzxVmy2YubM+YDg4Fr+Np3qInDV4wTs/BSAwq7jKer6AJymXv/rrTUHOV5g46VhrejeVAa+CyFEXSDJWBWw2Wzce+9YrNYiHnnkCb7++ituvfUGzGYzwcHBZGZmUK9efQAaNmyE2Wxm9OhRmExGIiOjyMwsP3F66KHHeOGFSeh0OiIjI7nqquuIjY1jypSnUFX3EjmPPvokjRvHs3XrFm6//Sbi4uoRFhZ2Tvd099338+KLU/j8809xOp1MnPgk4eHh3HbbWMaOvZWwsHDMZvcbgpdf/j9efHEK48aNobDQwogRV6LT1eIXd51WQn68B78D3+MMiaeoy73YWl19xqdZsSeDzzYcZXi7OPo2rxnTWAghhDh3sjalAGRtyjPx73XMFGs2oV9fgyFrJ4U9n8HafvQZt4YB5Bc7uPTtP3C4NObe2Jnm0aUXCK9pZG28ipO6qjipq4qReqo4WZtSeNVvv61i3ry5pbZfeeW19OzZ2wcR1Wy6vEOELh6J3nIcNbjRWSdiAPd8uQ27S+Omro1qRSImhBCi4iQZq0N69uxDz559yiw72TImKsaUuY3w729GcRSgBjUgd/iCs07E5m1IYWeqhcbhZu7u1aRyAxVCCFHtSTImxBnyP/IL0T/fjU514IhuR96wz9D8w8/qXKkFxcxcdQC9ovDmle1O+yKFEEKI2keSMSHOgGIvIPqXe1FUB7b4geRf8jYY/M/qXJqmMfXHfWjAg/0SiA0+u/MIIYSo2SQZE+IM+O3+Ap2zmKzuk1A73QzK2b8lumR7KmuSs7m/TwJXdWpQeUEKIYSoUWrxfAOVa9y4MRw6dJDvvlvCb7+tAtzLGIk6RFMxb34XW1QHLC2vOadEbG+6hed+/JtmUQFce54kYkIIUZdJMnaGBg8e6hkEP2fOBz6ORniT8eBPGApS0M6yW/IkVdMYt3AbqgZjL2yCTsaJCSFEnVbnuykPHz7E888/i8FgQK/XM2TIML77bgk6nY6srCyGDRvBFVdc5dl/9ux3iIyMJC8vj/z8PKZPn8qECY/68A6EtwT+OR2AvHZjzuk8Ty/bQ47VQd9mkfRpFlUZoQkhhKjB6nwy9tdf60hKask99zzAli2bOHjwAJmZGXzwwVw0TeXGG6+hf/+BpY676abRfPnlAknE6ghd3iEMmTtQ/cMpbtDzrM+z7mAO3+9KJ8TPwPOXtarECIUQQtRUdb6b8rLLLic0NIwHH7yHL79cgF6vp23b9phMJvz8/ElISOTo0RRfhyl8LODPl1HgnGbY/2ZbKo8sca9bOuuKthj1df6fnxBCCKRljN9+W0WHDp249dYx/Pjj97z77puEhITicrlwOBwkJx+gYcPGZR5bQ1eSEmfKYcV/3xI0RY+1/S1Qwflxi+wulmxP5YvNx0jJteLSICLAyFWd6tO2Xi1fOF0IIUSF1flkrGXL1kya9CR6vR6dTscVV1zFsmXfMmHCveTl5XHTTaPLXWS7SZOmTJr0JE89Ndm7QQuv8t/7FYrqoKjtTWh+oVBUVO6+NqfKqn2ZfL7hKDvSCjiZr3dsEMr4vgm0ig2SiV2FEEKUIAuF/8fGjev5+usvefbZFyon0BpCFgovh6YRPv8iQCHn6uWgKKUWlXW6VP48nMsPezL4aU8GxU7VXW7UM6BFFLde0JiGYWZf3YHPyELFFSd1VXFSVxUj9VRxslC4ENWc8dgfGLJ2Udh1fImxYi5VY8ORXJZsT+WnvZkUO1WC/PT0bRZJVpGDUV0b0i0+XKatEEIIcVpeS8ZUVeWZZ55hz549mEwmpkyZQnz8P60h33zzDR9++OGJrsIruO6667wVWgmdO3ehc+cuPrm2qH4C1rmns3AF/TMx67zNx/l0YyoFtn8Gj7WKDeL9azpiMsigfCGEEGfGa8nYihUrsNvtzJ8/n82bNzN16lTeeustT/m0adNYunQpAQEBDBkyhCFDhhAaGuqt8IQoRWc5jvH4OjSDP7YWwwFIzS/mrbVHAQg06bmsTSwj2tcjMSrQh5EKIYSoybyWjG3YsIFevXoB0LFjR7Zv316iPCkpiYKCAgwGA5qmnXaQs6qqnn7ef7ZpnrFPJ2mae/yOq4JvwNVVvqwnVdVK/Syrg7A/XwPAkjicIrsK9iK+3nIMgKvaRnJHj3gMJ6anqI7x+5rVKnVSUVJXFSd1VTFSTxXnvbqqBmPGLBYLQUFBnu/1ej1OpxODwR1C8+bNueKKKzCbzQwaNIiQEHn1X/iQy07w3i8AyG93O+CeyuSnv7NpFW3m1i6xnkRMCCGEOBdeS8aCgoIoLCz0fK+qqicR2717N7/88gs//fQTAQEBPPTQQyxbtoxLL7203PPpdLpSbz7k5yul3gY82dLji7cEaxJf1pNOp1S7N378dn+HzmXFEdsJU2wSJmDH8QKSc4oZ3bU+ZnNAtYu5upJ6qjipq4qTuqoYqaeK82Vdee1X+86dO7N69WoANm/eTIsWLTxlwcHB+Pv74+fnh16vJyIigvz8fG+FVmlsNhtLliyu0L7ffbeE335bVW75J598xM6d28stF1XLvH0OzpAm5A+c5dn24Z+HAYgL8fNVWEIIIWohr7WMDRo0iDVr1nDNNdegaRrPP/88S5YsoaioiKuvvpqrr76a6667DqPRSOPGjRkxYoS3Qqs02dlZLFmymKFDh59238GDh56yfNSomysnKHHGDGmbMaZtoqDXZNSwBACcqsba5GwMOoV+ieE+jlAIIURt4rVkTKfTMWnSpBLbEhMTPV9fe+21XHvttZV2vRUrlvPDD8s8SxZVxqznF110KQMHXlxu+ccff8DBg8n06tWVLl3Ox2q18uijT/L999+ye/dOioqKaNKkKY899jSzZ79DZGQkjRs3Ye7cjzEaDRw/foz+/Qdx002jee65Zxgw4CKys7NYu3YNNlsxR4+mcP31NzF48FB27tzOjBnTCAgIIDw8HJPJj8cff+ac71FAwPpZaIAr9J+pV37dn4ndpdEtPlzWlBRCCFGpZNLXSnTjjbeyf/8+unXrTkFBAfffP4HCQgvBwcHMnPkmqqoyatRVZGSklzguLe04H330OQ6Hg+HDL+Gmm0aXKC8stDBjxuscOXKYRx4Zz+DBQ5k+/QWeeGISCQmJvPPOG2RmZnjzVmstpSgT08GfQNHhjOno2f7JX+7F4m/s2tBHkQkhhKitam0yNnDgxQwceLHPlvlp3NjdquLn509OTg5PP/0YAQEBWK1WnE5niX0TEpphMBgwGAz4+fmXOlezZu7xdTExsdjtdgAyMzNJSHC3LHbo0ImffvqhKm+nzjBv+wgFFVuTi9HMEQAU2p1sTy0gwKinS+Mwiq1WH0cphBCiNpH+lkqkKDrPfF06nbtb9I8/1pCensazzz7PmDF3Y7MV89/lQE/Xg1pWF2tMTCzJyQcA2LFjWyVEL1CdmLd9AEBR57s9m3/em4mmwR094mV5IyGEEJWu1raM+UJ4eDgOhxObzebZ1qpVGz76aDZjxtyMyWSifv0GldKl+OCDj/DCC5MwmwMwGg1ER8ec8znrOtOB79HZ8nGGxOOM7eTZ/t2udBqG+XPteQ1OcbQQQghxdhTtv800NYTD4SI3t+Ssuamph4iLiy+xzVfdlFXtyy8X0L//IMLDw3n33TcxGo3ccsvtZ30+X9ZTWT83Xwj9cjjGjG0U9J6CrbX7ZZK0AhuXvbuOfs0jmTasDfDPbPsyf8+pST1VnNRVxUldVYzUU8V5q66io6vBDPyickVERPDAA3djNgcQFBQkb1KeI33WLkyp67F0fxxbq2s82+dtdK9D2SjM7KvQhBBC1HKSjNVQ/foNpF+/gb4Oo9Ywb3wbTWekuNXVnkF8mqaxdEcaAFd3ki5KIYQQVUMG8Is6TynOxX/f1yiqA8WW59m+O62AXKuDxuFmYoJl1n0hhBBVQ5IxUef575qHojpxxHZCDWvq2f7pencX5ZUd6vkqNCGEEHWAJGOibtNUzJveAUpOZ+FUNVbvz0IBhrSJ81FwQggh6gJJxkSdZjq0Er01A9UvHHuTf8bgrTuUQ7FTZUL/RIL9ZWilEEKIqiPJmA+MGzeGQ4cO8t13S/jtt1WlyocNK3/9S4BVq1aSmZlBVlYm06dPraow6wTzxjcAsLa/BXT/JF3f7UglxN/A8HbSRSmEEKJqSTLmQ4MHD6Vnzz5nfNwXX3xOYWEhkZFRTJjwaBVEVjfocw9gOv4ntviBWNvc4NlusTlZsTeTQJMek0H+iQghhKhatbr/5eGH7/csPfTvJYWmTZsJwNtvv86BA/tKHXfHHeNITGzGjz9+z48/fl/quPI89thDXHnlNXTqdB67du3gzTdfJSwsHIulgLy8XIYOHcGIESM9+8+e/Q6RkZEMHTqCadOeIzn5AA0aNPSsP3ngwD5ee+0VVFXDYnEvPF5QUMC+fXuZMuUpnnxyMlOmPM27737EX3/9wbvvvoWfnx8hIaFMnPgUf/+9h7lzP8ZoNHD8+DH69x9UahHyusx/2xw0nZGCftPQAv9ZweD7XemoGjSLDvRhdEIIIeqKWp2MedvQocNZtmwpnTqdx3ffLaVz5y4kJCTSp09/MjMzGDduTIlk7KQ//vgdu93Ou+9+RGpqKr/88hMAyckHGDduPImJzfjhh+/57rslPPLIEzRr1oKHHnoMo9EIuOfDmjbted58832io2NYsOBz5syZTY8ePUlLO85HH32Ow+Fg+PBLJBk7yV6I/465uEIao/mVnBV5wSb3W5TXdZa5xYQQQlS9Wp2MTZs285TL/IwdO+6Uxw8adAmDBl1S4et169adN9+cRX5+Hlu3bmL69Fd5++3XWbVqJQEBgTidzjKPS07eT6tW7qV24uLiiImJBSAqKoaPPnofPz8/ioqKCAwsu6UmNzeXgIBAz/qUHTt24p133qRHj54kJDTDYDBgMBjw8/Ov8L3Udv57FqJzFaOpDtD/Uy+p+cUkZ1sJNOnp3CjMdwEKIYSoM2RATCXS6XT06zeQ6dOn0qtXX+bN+5S2bdvz1FOT6d9/IOUtAxof34QdO7YCkJmZQUaGeyHxWbNeYvToO3jiiWdJTGzmOV6n06Gqquf4sLAwiooKyczMBGDz5o00atQY8EwmL/5N0zBvPjGdRccxJSpp0dbjAAxKikYnlSeEEMILanXLmC8MGTKMq666nHnzFnH8+DGmT3+BH35YRmhoKHq93jMe7N969erL1q1buP32m4iLq0dYWBgAF110KY8++iARERFER8eQl5cLQNu27Zky5WkefvhxwD0e7uGHH+fxxx9Cp1MIDg7hsceeKXM8nADj8T8x5B9G0/thS7rCs13TNJbtSseoU7iyY30fRiiEEKIuUbTymmuqOYfDRW5uUYltqamHiIuLL7HtVN2U4h++rKeyfm5VKXjZGPwOfEdxq2ux9H/Js313WgGjPt3EIwMSuaJD/RIvffxbUZH7uQsICPBKvDWV1FPFSV1VnNRVxUg9VZy36io6OrjcMummFHWKYs3CL/kHQMHa7uYSZYu2pmLQwaCkmHITMSGEEKKySTIm6hT/XQtQNCe5w7/AFd3Gs92paizblYZLBbVmNhYLIYSooSQZE3WHpmLe/jH2eufjbHBBiaI/krOxOlSaRAQQHmDyUYBCCCHqolo3gF/TNOliqkG8OWTRmPIb+oIjoKmgaSXeopx/Ym6xKzvK8kdCCCG8q1a1jBkMJgoL8736AS/OnqZpFBbmYzB4pyXKvOUDNMDeuG+JRMxic/LX4VwUBS5qGVPu8UIIIURVqFUtY+Hh0eTkZGCx5Hq2qerJubmktexUfFVPBoOJ8PDoKr+OznIc06GfUABr2xtLlK3Ym4FLg44NQgg1G6s8FiGEEOLfalUyptcbiIoq2c0kr/dWTG2vJ/+dn6Og4YhsXWLgPsC3O9IINOkZ1bWhj6ITQghRl9WqbkohyqQ68d8+B4Di9reUKErNL2bL0Xyu79KQ3olRvohOCCFEHSfJmKj1TId+Rm/NwhnZkuJmw0qULdmeigb0TozwTXBCCCHqvFrVTSlEWfy3f4IrMJacq74H3T+PvKZpLN6WCkCutexF3IUQQoiqJi1jolbT5R/GdHgl9vgBJRIxgN3pFtItdoJMero0CvNNgEIIIeo8ScZErWbePhcAY9rmUmWLtrpbxS5pFYNe3rYVQgjhI5KMidrLZcd/x6fu6Sz+M3DfqWos350OwOXt4nwQnBBCCOEmyZiotfwOfI/Onodm8C81cH/dwRyK7C5igkwkxQT5KEIhhBBCkjFRi/lv+xANheKkkWAKLFH23c40Aow6HuyXKMtnCSGE8Cl5m1LUSvqcfZiO/wWAtc2oEmUOl8pvB7K5qGUM/VtU/ez/QgghxKlIMiZqJf8dn6IpBiw9Hi814/7WY/kUOVzEBvn5KDohhBDiH9JNKWofpxX/3V9gazaE4o63lypesScTAE2RBeWFEEL4niRjotbx27cUnS0PzVj2wPxfD7iTsT6y/JEQQohqQJIxUeuYt7oH7lPGwPwMi420AjsBRj3NowPLOFoIIYTwLhkzJmoVfcYOjBlbgdID9wHWJGcDcF6jUHmLUgghRLUgyZioVczbP0ZDwRnVptTAfYAfdmUAcFFLeYtSCCFE9SDdlKLWUOwW/PZ8iYJGcbsbS5U7VY3d6QWc3ziMHk0jfBChEEIIUZokY6LW8Nu7CJ2rGM1gprjZ5aXKdxzPp8DmYnj7eoT4G30QoRBCCFGaJGOidtA0zNs/wRHVlqxRa0vNuA/wy74sAMLN0jsvhBCi+pBkTNQKhrSNGLJ2UtzmerSAsqes+GWfe0oLvU4eeyGEENWHfCqJWsG8/RM0dBhT1pRZnlNkJyW3GKNeoV29YC9HJ4QQQpRPkjFR4ynFOfj9/TUKKo7GvcvcZ+1B95QW7euHYNDLYy+EEKL6kE8lUeP57/kSRXWgGQLKHLgP/yyBNDBJprQQQghRvUgyJmo2TcN/60doKBQnXVHmwH1V01h/JBeAHk1kSgshhBDVi7xWJmo049HfMeQfBKC4zfVl7rMn3YLVoTKqS0Pqh/p7MTohhBDi9CQZEzWa/45PUQ1m7E0G4oxuW+Y+v59YAumGrg29GZoQQghRIdJNKWospSgDvwPLKG5zAwUXv1Xufj/uziDE34Cqal6MTgghhKgYaRkTNZb/rvkoqhN7o77l7pNf7GB/VhF6BYL85HEXQghR/UjLmKix/PYtRUPBL3lZufv8dTgXgBYxQfgb9V6KTAghhKg4ScZEzaRp6LP3uhcFb3NDubv9tCcDkCkthBBCVF+SjIkaSVeUhk614wqsV+7AfU3TWHsoB4AeTWVKCyGEENWTJGOiRtLn7AfAGdW63H32ZxZhsbkI9jOQGBngrdCEEEKIMyLJmKiRDOlbAHBGty93n5NLID03pCWKonglLiGEEOJMSTImaiR9XjKqzoQt8dJy9/k9OZtmUYF0ly5KIYQQ1ZgkY6JG0uen4IpqhaucbspCu5ONKXmomoaqyfxiQgghqi+vTbykqirPPPMMe/bswWQyMWXKFOLj4wHIyMjggQce8Oy7a9cuHnzwQa699lpvhSdqGH3WTlyR5Y8XW384D1UDVQOddFEKIYSoxryWjK1YsQK73c78+fPZvHkzU6dO5a233LOmR0dH88knnwCwadMmXnnlFa666ipvhSZqGMVuQW/Nguw95e6zal8mAP2bR3orLCGEEOKsnDYZ27p1K0lJSfj5+Xm2/fDDD0RFRdG5c+cKX2jDhg306tULgI4dO7J9+/ZS+2iaxuTJk5k+fTp6/akn6FRVlaKiotNe12o9/T6iZtWTKXMHAI6ghmU+A5qmsXq/Oxk7r35ghZ6TM1GT6sqXpJ4qTuqq4qSuKkbqqeK8V1fB5ZaccszY008/zdVXX82mTZtKbP/yyy+5/vrree655yocgsViISgoyPO9Xq/H6XSW2Ofnn3+mefPmJCQkVPi8ou4x5rhbxOwRLcssP5JrI6/YhZ9BoWVMoDdDE0IIIc5YuS1j8+bNY+nSpcyYMYNu3bqVKHv77bdZunQpTz31FK1ateJ///vfaS8UFBREYWGh53tVVTEYSl7+m2++4cYbb6xQ4DqdjoCAis8ddSb71mU1oZ4Cst0tYzTsVma8m3a7J3o9r1EYIUFVl4zVhLqqDqSeKk7qquKkripG6qnifFlX5baMzZ8/n0cffZRLL7201BxNiqIwdOhQ7rnnHubOnVuhC3Xu3JnVq1cDsHnzZlq0aFFqnx07dpxR16eom4xZOwFwltMytjY5m0ah/jw6sLk3wxJCCCHOSrnJ2MGDB7ngggtOeXDfvn05ePBghS40aNAgTCYT11xzDS+88AITJ05kyZIlzJ8/H4Ds7GwCAwNlck5xWkphBq7AOFxhTUuVFTtcbEzJ48LESOqF+PsgOiGEEOLMlNtNaTabS3QrlsXpdGI0Git0IZ1Ox6RJk0psS0xM9HwdERHB119/XaFziTpMdaIvSsPa8XYwlm5S3piSh82pklNk90FwQgghxJkrt2Wsffv2fP/996c8+Ntvv6V5c+kKEt6jzz+MojpwBtYrs/zXA1kAhPh7bdYWIYQQ4pyUm4zddNNNvP/++8ybNw+tjBnMP/vsM2bPnl3hAfdCVAZ99j4ATMf/LLN89T53MtYrUeYXE0IIUTOU23zQvXt3xo8fz+TJk3n99ddp27YtISEh5OXlsW3bNvLz87n77rsZNGiQN+MVdZwhbSMAzthOpcqO5llJt9jR6xQ6NQj1dmhCCCHEWTllX87o0aPp3r07X3zxBTt37uTgwYOEh4dz+eWX87///U+6KIXXGTK2AeCMbluqbG2ye0qLtnHB+BtPPWmwEEIIUV2cdmBN69atefrpp70RixCnZcg9AIAzrFmpslUnuij7NY/yakxCCCHEuSg3GUtLSytzu9FoJCQkpNSErUJUOU1DV5iGpjOiBUSXKHK4VLYcy2No21iGtY3zUYBCCCHEmSs3o+rTp0+5c34pikJSUhJ33XWXjBkTXqNYM1FUO46otvCfZ3Pz0TysDpU+iVEEy5uUQgghapByP7U+/vjjMrerqkp+fj7r16/noYceYtasWfTp06fKAhTiJEOO+03Kwu4TS5Wt2Z8NQEahzasxCSGEEOeq3GTs/PPPP+WBF110EVFRUbz77ruSjAmv0GfvBcAVXnq82C/73ePFws0Vm4RYCCGEqC7KnWesIvr06cPevXsrKxYhTsl4Ym4xQ9auEtvTC2wczStGAc5vHO6DyIQQQoizd07JWGBgIE6ns7JiEeKUDNl7AHCFNimxfe1Bdxdl8+hAGS8mhBCixjmnZOzPP/8kPj6+smIR4pR0BUfRUHCFlHzmVp3oouzbTGbdF0IIUfOc8dQWmqZhsVjYsGEDM2bM4J577qmy4ITwcFjR2QtQ/SNA/8+4MKeq8dfhXAC6N43wUXBCCCHE2TurqS00TSMwMJCbbrqJG264ocqCE+Ik/YnJXl0hjUps33E8n2KHylMXt6BVbLAvQhNCCCHOyRlPbWEwGAgNDaVJkybo9bLkjPAOQ87fADgjW5XYvuZAFjqgb7Mo9Lqyf3kQQgghqrOzntoCIDc3l0WLFnHLLbdUalBC/Jc+Zx+aosPSa3KJ7b/sy0KvU9ifWUjHhrI4uBBCiJrnrF49W7duHQsWLODHH3/E4XBIMiaqnD53P2pwIzCaPduyi+wkZ1sBqB/q76vQhBBCiHNS4WQsJyeHRYsWsWDBAg4dOoTBYGDw4MHcfPPNVRieEG7GY3+i2PPBYfUkZH8czAGgYZg/McF+vgxPCCGEOGunTcb++OMPFixYwIoVK7Db7TRr1gxFUfj000/p0KGDN2IUdZ3qQmfNAL1fiZaxXw+45xfrnShTWgghhKi5yk3GZs+e7WkFi4+P55ZbbmHIkCG0aNGCNm3aEBgY6M04RR2mK0hB0VScQfVKbN+UkgtAD5nSQgghRA1WbjL20ksv0bRpU9544w0GDBjgzZiEKOHkAuH/XpOy0O4kq9CBUafQsYEM3BdCCFFzlTsD/4QJEzAYDIwbN45BgwYxffp0duzY4c3YhABAn7EVAEdMR8+2fRmFADw7uCV+hnNaSEIIIYTwqXI/xW677TaWLFnC/Pnz6dmzJ1988QUjR45k4MCBaJpGenq6N+MUdZgx3Z2MuaLberb9fSIZa1dPJnoVQghRs522SaF9+/Y8/fTT/Pbbb8yYMYOEhAQURWH06NGMHj2an376yRtxijpMZ8vDHnse9gY9PNvWH85FAY7mFfsuMCGEEKISVLh/x2g0cumll/Luu++yatUqHnzwQdLS0hg3blxVxicE+px9uCKTwPDPXGJ70i1oQESAyXeBCSGEEJXgrCZ9jYqK4rbbbuO2225j+/btlR2TEB6KNRtdcTb6vEOebS5V43h+MXoFGoWbT3G0EEIIUf2d88jntm3bnn4nIc6SPne/+wvV6dmWkmvFpUFssB8GWY9SCCFEDSevoYlqzZC5EwBndBvPtr3pFgBaxAT5JCYhhBCiMkkyJqo1Q9omAJz/mtZi67F8ADrJwuBCCCFqgdMmY8uWLcNisZTY9vnnn7N06VI0TauywIQAMGTtBsAV0cKzLSWvmCYRZi5vF+ersIQQQohKU24yZrfbGTNmDA888AC7du0qUbZlyxYmTJjAvffei8PhqPIgRd2lLzgCgDMswbPt74xCkmKCCDSd1fsnQgghRLVSbjL20UcfsWvXLubPn0/Xrl1LlE2dOpW5c+eyfv165s6dW+VBijrKWYxiy8eaNBKMAQDkWR2kFdhIzbf5ODghhBCicpSbjH399ddMnDiR9u3bl1l+3nnnMX78eL766qsqC07Ubfq8ZBQ0HPH9PNtOzrwvHeRCCCFqi3KTsaNHj5abiJ3UrVs3jhw5UulBCQGgz/7b/YWtwLNtR6p78H77+iG+CEkIIYSodOUmY8HBweTk5JzyYIvFQmBgYKUHJQSAMW0zAIrrnyWPNqXkAdCxgSRjQgghaodyk7GuXbvy5ZdfnvLgBQsW0KZNm1PuI8TZMmRsA8AV2cqzbV9mEQDNo2WOMSGEELVDua+j3XrrrVxzzTUEBwdzxx13EBT0z4dfQUEB77zzDgsXLuSDDz7wSqCi7tHnHQTAFd4MAKdLJcNiw6hXqBfi58PIhBBCiMpTbjLWtm1bXnzxRZ544gk+/PBDmjZtSkhICHl5eSQnJ2M2m3nuuefo1q2bN+MVdYWmoitKR9MZUQNiADiYbUXV4I4LGqMosgySEEKI2uGUEzUNGTKErl278s0337Bz507y8vKoV68e1157LZdccgmRkZHeilPUMTrLcRTNhSuoPpxIvPZmuCcf7t0sypehCSGEEJXqtLNmxsTEcNttt3kjFiE89DnuNymtbW7wbNuUkodOAadT9VVYQgghRKU7bTJ2+PBhFixYwKZNm8jOziYiIoJOnTpx5ZVXEh8f740YRR1kyNkHQHGrqz3bth/PR9VAkx5KIYQQtcgp16ZctGgRQ4cOZd68eZjNZtq0aUNQUBALFy5k2LBhLFq0yFtxijrGkLYZ1eAP/1r/NCW3GAVIiJTpVIQQQtQe5baMbd68mSeffJLbb7+dO++8E5PJ5ClzOBy8//77PPnkkyQmJp52clghzpQhczs6ZzE6ex6uwGgyC+0UO1UiA434GU67vr0QQghRY5T7qTZ79mxGjBjBfffdVyIRAzAajdx5551cc801zJ49u8qDFHWPruAYGgquEHdX+N8nBu9Lq5gQQojaptxkbNOmTVx99dXlFQMwcuRINmzYUOlBibpNseWhcxah+UeA3gjA1qPuZZA6ycz7Qgghaplyk7H8/HwiIiJOeXBISAiFhYWVHpSo2/QnBu+7Qht7th3KLiLcbGRwm1hfhSWEEEJUiXKTsQYNGrB169ZTHrxt2zYaNWpU6UGJuk2ftRcA57+XQcoqom29YBqEmn0VlhBCCFElyk3GLrnkEmbOnElBQUGZ5bm5ubzyyitcfvnlVRacqJsMOXvRFD225sMAsDlVDmYVIbOLCSGEqI3KTcZuu+02DAYDl19+OZ988gnbtm3jyJEj7N69m7lz5/K///2PsLAwRo0a5c14RR2gzzuEK7wZjoY9ATiQVYgGZBTYfBuYEEIIUQXKndoiMDCQuXPnMmnSJKZOnYqq/tMuYTAYGDFiBA8//HCpNy2FOFf6rJ2owQ3dc4wpCrtT3W9Sto4L9nFkQgghROU75Qz8oaGhvPzyyzzxxBNs27aN/Px8wsLCaN++PSEh8labqAIuO/qCo+is2Z41KTek5ALQuVGoDwMTQgghqsZpl0MCCA8Pp3fv3mWWrVy5kn79+lVqUKLu0ucdQkFzLxB+wq40d8tYUkyQr8ISQgghqswpk7Fly5axbNkyDAYDw4YNo2/fvp6yrKwsJk+ezPLly9m1a1dVxynqCH22+01KV0RzADRN43h+MToFGocH+DI0IYQQokqUO4D/o48+Yvz48ezevZs9e/Zw5513smzZMgC+++47Bg8ezM8//8y4ceO8Fqyo/QwZ2wFwxHQEILXAhsOlcXHLGAw6WSFcCCFE7VNuy9iCBQu44YYbeOKJJwB4//33ee+998jKymLKlCmcd955TJ48mYSEBK8FK2o/Q4Z7bjtnVGsA9qa7JxUe2bF+uccIIYQQNVm5LWPHjh3j2muv9Xx/ww03sHv3bl555RUefvhh5s6dK4mYqHR6yzFU/0hcEUkAbD2WB0CIf4WGNwohhBA1TrnJWHFxMWFhYZ7v/f398fPz46677uLWW2/1RmyirtE0dJbjFDcfhhrsbgnbdGJNypwihy8jE0IIIapMuclYeQYMGFAVcQiBrjAVncOCK6TkmpQAzaMDfRWWEEIIUaXOOBnT6/VVEYcQ6HP2A+CX/AMAhXYn+cVOgv0MBPlJN6UQQoja6ZSfcB9//DFm8z8LM7tcLj777DNCQ0tOvjl27NiqiU7UKfps9xQpzui2AOzLcA/ebxIhi4MLIYSovcpNxurXr8+SJUtKbIuKimL58uUltimKUqFkTFVVnnnmGfbs2YPJZGLKlCnEx8d7yrdu3crUqVPRNI3o6Gheeukl/Pz8zvR+RA1mTNsEgDOmAwA7Ut2L1LerJ6s9CCGEqL3KTcZ+/vnnSr3QihUrsNvtzJ8/n82bNzN16lTeeustwD2x55NPPsmrr75KfHw8X3zxBUePHpW3NesYfZZ7wldnuHvC178zCjHpdQxMivJlWEIIIUSV8tpAnA0bNtCrVy8AOnbsyPbt2z1lycnJhIWFMWfOHPbu3UufPn1Om4ipqkpRUdFpr2u1nn4fUT3qKaLgCAAWvzi0oiIOZFhoHRtAYpixQj9rb6kOdVUTSD1VnNRVxUldVYzUU8V5r66Cyy054wH8Z8tisRAU9M/agnq9HqfTCUBOTg6bNm3iuuuu48MPP+SPP/5g7dq13gpNVAOKw4LeUYgzsD6awYxL1diXVUSE2ejr0IQQQogq5bWWsaCgIAoLCz3fq6qKweC+fFhYGPHx8TRr1gyAXr16sX37drp3717u+XQ6HQEBFV+r8Ez2rct8VU+GNHcXZWHvSQQEBHAouwi7S2NfdnG1/dlV17iqG6mnipO6qjipq4qReqo4X9aV11rGOnfuzOrVqwHYvHkzLVq08JQ1atSIwsJCDh06BMD69etp3ry5t0IT1YA+528AXOHuhHxPugWApJigco8RQgghagOvtYwNGjSINWvWcM0116BpGs8//zxLliyhqKiIq6++mueee44HH3wQTdPo1KkTffv29VZoohowpG9BAwxpm3GFN2NTSi4A5zUKPeVxQgghRE3ntWRMp9MxadKkEtsSExM9X3fv3p2FCxd6KxxRzRgydqCAZxmk7cfdLWOt48of8CiEEELUBl7rphTiVPR5BwFwhrm7KY/kWlGAhEhZBkkIIUTtJsmY8D2XA501C01vQguIJs/qoNDuom29YPwM8ogKIYSo3eSTTvicvuAICiquwHqgKPx9Yhmk23vEn+ZIIYQQouaTZEz4nD5nHwCucPcYwh2p+QA0CZdXsoUQQtR+kowJnzs5rUVB/xkArD+SB8ChHJlBWgghRO0nyZjwOUPOflwBsWgB7jUo92e6uymbR8scY0IIIWo/ScaEzxmO/4XisKArTMPpUskstGM26ogMNPk6NCGEEKLKeW2eMSHKpGnoLcfAZUf1j+BgthVNgwah/r6OTAghhPAKaRkTPqVYM1FcNjRzJOiN7EwrAGSyVyGEEHWHJGPCpwwn16QMdU9jsSu1AAXo2TTCh1EJIYQQ3iPJmPApffZeAJyRbQD3zPtJMUH0axHty7CEEEIIr5FkTPiUIW0zAI7YDgDsSbeQGCnziwkhhKg7JBkTPqXPO4wjsjX2hEvILLSTa3Wy8Wier8MSQgghvEaSMeE7LhvGjC04GvZE8wtlz4nB+7I4uBBCiLpEkjHhM4a0LSguG/r8QwBsPupeBqlzwxBfhiWEEEJ4lSRjwmeMx/8EQLFbANh6zN092a5+qM9iEkIIIbxNkjHhM6YjqwGwN+oFQHKWFYDm0dJNKYQQou6QZEz4hurCkLYRAEf9bticKrlWB1GBJoL8ZGEIIYQQdYckY8InDFm70DmL0XRGnDHtOZBViAZM6J/o69CEEEIIr5JkTPiE8dg6AJzR7UHvx54097ix5tFBvgxLCCGE8DpJxoRPGI+vwxUYR0G/qQD8cSgHgNT8Yl+GJYQQQnidJGPC+zQN47E/cTTogSuyFQB7090tYw3DzL6MTAghhPA6GSktvE6fl4zOmomuMA00DQ04nm/DqFOoF+Ln6/CEEEIIr5KWMeF1J8eLKbZcUBRSC2w4VY3YED8URfFtcEIIIYSXSTImvM6YsgYNcDTqA8DuE4P3k2Jk8L4QQoi6R5Ix4XXGo7+j4J5fDGDriYXBz2sY5rughBBCCB+RZEx4lc5yHH1RurtlrF5XAI7m22gY6seI9nG+DU4IIYTwAUnGhFedXI/SFZaI5udeEPzvDAstYoIx6OVxFEIIUffI25TCq4zH1qEazBQMnAlAod1JSm4xZqPet4EJIYQQPiJNEcKrjMfW4ax3Ps7YTgDsyygEkPUohRBC1FmSjAmvUYpzMGTvQbEXgOoCYOuxfAA61A/xZWhCCCGEz0gyJrzGeHw9ALqidNC5uyU3puQC0LlhqK/CEkIIIXxKkjHhNcajv6MB9oa9PNu2H3fPMdZC5hgTQghRR0kyJrzGeGS1e36xhj0AOJxjJdfqIMCkJzLQ5NvghBBCCB+RZEx4h6MIQ87f7i/ruSd7/T05G4AZw9v4LCwhhBDC1yQZE15hTNuEoqmoAdGowfUBWJOcTXy4mfMahfk2OCGEEMKHJBkTXmE89gcakD9gJgBWh4u/DuVgdbhwulSfxiaEEEL4kiRjwiuMx/7EGdUWR2P34uDrD+fi0sBs1MvM+0IIIeo0+RQUVc/lwHj8L9Bc4LQC8PPfGQAMTIr2ZWRCCCGEz0kyJqqcIWMbimpHX3AU9P5omsav+92D9/s0i/RxdEIIIYRvSTImqpzx6B8AOBpcAIrCgawi8oqdBJr0JMn8YkIIIeo4ScZElTMeWQ2AvZF7vNiaA1kA9GgSjk5RfBaXEEIIUR1IMiaqlqZiTNsAgKP+ifnFDubQLCqAxy5q4cvIhBBCiGpBkjFRpfTZe9A5raiGAFwRLbDYnGxKyePChEiC/Ay+Dk8IIYTwOUnGRJUyHvsTgIJ+L4Ki489DOagaHM8v9nFkQgghRPUgyZioUsbjf+IKjMPefDgAP+5xT2nRMjbYh1EJIYQQ1YckY6LqaBrGI6vRDGYUewGaprH2YA4AvRMifBycEEIIUT3IoB1RZXT5h9EX56A5CtGMAexJt1BodxERYCQ+IsDX4QkhhBDVgrSMiSpjPO4eL+aIbg86A7/sywSgd6JM9CqEEEKcJMmYqDLGw+75xRzx/QFYtS8bvQIDW8gSSEIIIcRJkoyJKmM69jsA9voXkFvkYH9mITd3a0SXxmG+DUwIIYSoRiQZE1VCKUxHX5iGpuhxxnZg7cFsNKBXQiR6ncy6L4QQQpwkyZioEifHi1l6PAF6P5bvdk9pkVXk8GVYQgghRLUjyZioEsbjf6IZzBS3uxmXqrH+SC4ArWJlYXAhhBDi32RqC1ElTId+QfULQ7HnszPHiM2pUi/Ej+ggP1+HJoQQQlQrkoyJSqfY8tHnHQBFh2Yw8/PfxwHo3zzKx5EJIYQQ1Y90U4pKZ0xdjwK4whLAGMDPe93ziw2QKS2EEEKIUiQZE5XOmPI7GmBv1JdMi41j+TbCzEZax8l6lEIIIcR/STImKp3p8C8ogKNRT34/sRbl61e0lSkthBBCiDJIMiYql7MYfc7faIAjrgur9mUSFWikRYy8RSmEEEKUxWsD+FVV5ZlnnmHPnj2YTCamTJlCfHy8p/zDDz9k4cKFREREAPDss8+SkJDgrfBEJTGmb0bRXBR2vgeHMYS1yTmogM2p4m/U+zo8IYQQotrxWjK2YsUK7HY78+fPZ/PmzUydOpW33nrLU75jxw5efPFF2rZt662QRBUwHnNP9mrtNIYtx/JxqBpNIwMkERNCCCHK4bVkbMOGDfTq1QuAjh07sn379hLlO3bs4N133yUjI4O+fftyxx13nPJ8qqpSVFR02utaraffp+zzu0j+/mWCc3eUPqdfDM6QxmAvJDhvV6lyp96MNbYr8ReOwmA0ndX1ve1s6+m/gpNX4PILp7ggh2XbbQD0TQir0M+qpqisuqrtpJ4qTuqq4qSuKkbqqeK8V1flv8TmtWTMYrEQFPTPuCG9Xo/T6cRgcIcwZMgQrrvuOoKCghg3bhwrV66kX79+3gqvFGthHj1S5+CvlLF8jw3IP80Jkn9mhWKgeZ+bqiK86kl1Ysrchk51oOkM/HYwDYA+CeE+DkwIIYSovryWjAUFBVFYWOj5XlVVTyKmaRo33XQTwcHurLFPnz7s3LnzlMmYTqcjICCgwtc/k31P7n981AaslpxSZQajCZNfAC6nC1txQenYFB2Bi6+m+YHZmC6+A4Ou5rwncab19G+G9K3oVAeugFhyjTFkFR0k2M9A6wYRKErte5PyXOqqLpF6qjipq4qTuqoYqaeK82VdeS0Z69y5MytXrmTw4MFs3ryZFi1aeMosFguXXXYZ3333HQEBAaxbt44rrrjCW6GVKyg0gqDQiNPsFVPm1uNBzWhfsJovl7xH78tP3eVaWxiP/QGAo0F31iRnAzCgRVStTMSEEEKIyuK1ZGzQoEGsWbOGa665Bk3TeP7551myZAlFRUVcffXVjB8/nhtvvBGTyUT37t3p06ePt0KrEpGXvYD22YV0OvI+UDeSMdPBFQDY4/uxZmc29UP9eWxQcx9HJYQQQlRvXkvGdDodkyZNKrEtMTHR8/Xw4cMZPny4t8KpcqaIeFKNDWnqSGHuug1c3O08X4dUtTQNQ/pmAApju7FuWTJD2sRKq5gQQghxGjVnMFMNpHZ/AEWBeuuf93UoVU6fux+dowhr6+v5K8eM3aXxd0bh6Q8UQggh6jhJxqqQqf1VWPGnl7aBdclZvg6nShmPrQPA2ukOvt+dAcDFLWVhcCGEEOJ0JBmrYlktR2FSnBze8oOvQ6lSpoM/o+nNaIqB308M3u/bLMrHUQkhhBDVnyRjVcyvzyMU6kJIOPIFmYU2X4dTZYzH16G4rBzPtZBrdRIVaCIuxN/XYQkhhBDVniRjVc3gj6XxAC5S/uTtRUt9HU2V0BUcQ2fLRTUG8X1qIAC9E083JYgQQgghQJIxrzC1vxKdAldlv0t2LWwdMx53jxdzxHZizcFcAox6LmsT5+OohBBCiJpBkjEvcDbqjdUQygW6nbz8405fh1O5nFbMm98BoLDRAHYcz2d4+zja1Q/xcWBCCCFEzSDJmJeo7a5Hr2h0OvQuNofL1+FUDtVJyPK7MGS4F31fr7TG7tI4v3GYb+MSQgghahBJxryk6PwHUdFxtX4lr/2a7Otwzp2mErzyIfwO/kjhBY+SP+AV5h12ry2aXVTG4upCCCGEKJMkY95i8MNR/wIiFAtpf69D0zRfR3T2NI3ANZPx3/0FxS3+h/W8cRQnjWTd4XwAeiVG+jhAIYQQouaQZMyLLP2n4UJPr+Jf2HQ0z9fhnDXzxjcI2PIemsGM8egacFo5kFVEod1Fw1B/wsxGX4cohBBC1BiSjHmRGtqE4sQhXGlYxdsrtvg6nLPiv2MuQX9MRdMZUf1CyRv2ORjM/LgnHYD+LWSiVyGEEOJMSDLmZa4m/QmhiKvy3mfF3gxfh3NGTPuWEvTLo2iKDldQA3L/twhXRAsAVuzJBODiljG+DFEIIYSocQy+DqCusbUYgbryIYbpf+eiVQcY2KJ6rN+4eHs6S3ZmEBXsj6ZqhAcYaRkbTJPIAGKD/Gic9ydRP9wDig5nRAvyhn2GFuCO3WJzciTXSrOoQJpHB/r4ToQQQoiaRZIxb9PpsTcZSOCBZZxn+Ykdx1vRpp5v5+RKzirklV8PE2TSYzIa2JNWgEvDs+B3e2U/n5sms4c43vO7mXTaEvRLFjHBFmKCTGQW2lE1eGRAMxRF8em9CCGEEDWNJGM+UHjhk/gdWMZ9hkWM++kSPr6hs0/jeXDxDgAeG9CEQa0bkGt1sCu1gE0peeQe3cnzWZNxaTrmJcwgXw1jV0oe+akZOFwaJ98JDTTpaRkb5LubEEIIIWooScZ8QA1pjCssgYTcA+SlJZNuaU1MkG8W1V646RhHcotpFRPIhU3CAQgzG+neNIILI4sI3/UAOuwUxQ/g7ku6gs7A+2sPsXp/FvsyC3G43OmYzalSgyfrEEIIIXxGkjEfKewyntAV93CV/hdW7OnGdec19HoMRXYnr6zaj06B5y9NLFGmFKYTPn8QOkchxc2GUnjRG6C43/e4rXs8t3WPx+lSSc4uYk+6hTCzEbNR7/V7EEIIIWo6eZvSR+xJI3DU68pVfn/w+V+HsTu9v0TS5OV7sbs0rj+vIREBJs92xZpNxOf90NkLKE4aScFFb3oSsX8z6HU0jw7isjZx9EyQiV6FEEKIsyHJmA9ZW19PffU4A4qX8eJP+716bYvNyYYjuTQK82dc76b/FLhshHw/BsWWh7X1tRQMnAkyKF8IIYSoMpKM+ZCtyQA0FMYZvmbZrjScLtUr19U0jZm/HCDX6uS5y1qhO5Fs6axZhCy7DdOxPyjoNx1Lv5e8Eo8QQghRl0ky5kv+4Tij2xKnZNPMlcwH6w575bIfrDvM19tT6d8iilax7sW99ZZj1P/qYvwOrcRy4VPYWl/jlViEEEKIuk6SMR8rvGAiCvCE8VM+33i0yhcQzymy897aw+gVeHhAM1BdmNfPosHCgejt+VibD8facUyVxiCEEEKIf0gy5mOOxr1R/cO5QL8bh83K0h1pVXq9R5fswqVq3NKtETGW3UR8eiFB614CzUV+65uxDHqtSq8vhBBCiJIkGasGiltdix6Ve/Vf8e3OqkvG1iZnszElj4gAI2NbFBP84zj0BSk4w5txbPi35HR7TAbrCyGEEF4myVg1UNh1PC5zFJeGHGTz0XxS84sr/RqapvH0sj0M0a3lp5DJRC68FJ01m/zez5Nz7Uqc4c0q/ZpCCCGEOD1JxqoDoxlrxzEkWLeSqB3hxZ/2Vfoljh85wGzXY7xheo3w3K3Ymg0j+/rV2NrdKK1hQgghhA9JMlZNFLe8Eg0dM/3f5bcD2czdkFI5J1adKGum03ZJPzrr/sbpF07u0LkUDHoVzRxROdcQQgghxFmTZKya0AKiUQNjaaXtJ1xXyMxfDnDT3I3kFtnP4aQqwcvGELV5Jmgam+KuIeeW9Tga96m0uIUQQghxbiQZq0aKOtyOgsZPrX+kYag/O1MtDHl3HT/uzjij8yj2Avx2f0HYVyPwP/gDu10NuUr3CnEjXgK9XxVFL4QQQoizIQuFVyPFHUYT9McLhB9cwpJBF/Hxbo3Fu/NY+tMBEmlDs3pRoDOBTgcoqIGxACjFuaA6QVEwHl5N8KpHURyFqH7hPKLexXzHhbw1vD0GnYwNE0IIIaobScaqE50eW9NB+O//jvBlt3EfcN/JhqyfSu6qAWpIPJrRjC7/CDpHYYny4iYDecx1J1/9baN7kzC6NA73xh0IIYQQ4gxJMlbNFAychTOqDSh6XOHNURwWOLiKnUezyC2wYFJc1A+EJmFGCGmI4ihCQ4fmsIDLgWYMwNL7OXaZO/HVnA0YdApPXpzk69sSQgghRDkkGatuDGasXe4ruS3pChI0jfkbj/LKqgOouRBhNzKla0u6ltPidWxfJgC3XdCY6CAZJyaEEEJUVzKAv4ZQFIVrzmvIJzd0Ji7YRHaRg7u+2MaS7aml9j2eV8yMXw7QJMLMjec38kG0QgghhKgoScZqmBYxQSy4pSuXtooBYNHW46TmF2OxOQFIzS/mig/+4mheMRP6N8Oolx+xEEIIUZ1JN2UNZDbqmTS4JRc0CefFFfu47uMNgMLQtrH8nVGIQ9Xo0TScbvEyaF8IIYSo7iQZq8EGt46lbb0QJn6zk72ZhXy24SgAep3CxIHNfRydEEIIISpC+rBquMbhZj68vhNXd6rv2Ta6W2PiQvx9GJUQQgghKkpaxmoBk0HHhP7NOD8+nN+Ts2XQvhBCCFGDSDJWi/ROjKR3YqSvwxBCCCHEGZBuSiGEEEIIH5JkTAghhBDChyQZE0IIIYTwIUnGhBBCCCF8SJIxIYQQQggfkmRMCCGEEMKHJBkTQgghhPAhScaEEEIIIXxIkjEhhBBCCB+SZEwIIYQQwockGRNCCCGE8CFJxoQQQgghfEiSMSGEEEIIH1I0TdN8HYQQQgghRF0lLWNCCCGEED4kyZgQQgghhA9JMiaEEEII4UOSjAkhhBBC+JAkY0IIIYQQPiTJmBBCCCGEDxl8HUBVUVWVZ555hj179mAymZgyZQrx8fG+DqvaGj58OMHBwQA0bNiQF154wccRVS9btmxh+vTpfPLJJxw6dIhHH30URVFo3rw5Tz/9NDqd/F5z0r/raseOHYwdO5YmTZoAcO211zJ48GDfBlgNOBwOHnvsMY4ePYrdbufOO++kWbNm8lz9R1n1FBcXJ89UGVwuF0888QTJycno9XpeeOEFNE2TZ6oMZdVVQUGBT5+rWpuMrVixArvdzvz589m8eTNTp07lrbfe8nVY1ZLNZgPgk08+8XEk1dN7773HN998g9lsBuCFF17g/vvvp1u3bjz11FP89NNPDBo0yMdRVg//raudO3dyyy23cOutt/o4surlm2++ISwsjJdeeomcnBxGjBhBy5Yt5bn6j7Lq6e6775ZnqgwrV64EYN68eaxbt86TjMkzVVpZddW/f3+fPle1NkXesGEDvXr1AqBjx45s377dxxFVX7t378ZqtXLrrbdy4403snnzZl+HVK00btyY1157zfP9jh07OP/88wHo3bs3v//+u69Cq3b+W1fbt2/nl19+4frrr+exxx7DYrH4MLrq45JLLuG+++7zfK/X6+W5KkNZ9STPVNkGDhzI5MmTATh27BhRUVHyTJWjrLry9XNVa5Mxi8VCUFCQ53u9Xo/T6fRhRNWXv78/o0ePZvbs2Tz77LNMmDBB6upfLr74YgyGfxqRNU1DURQAAgMDKSgo8FVo1c5/66p9+/Y8/PDDzJ07l0aNGvHGG2/4MLrqIzAwkKCgICwWC/feey/333+/PFdlKKue5Jkqn8Fg4JFHHmHy5MlcfPHF8kydwn/rytfPVa1NxoKCgigsLPR8r6pqiQ8J8Y+mTZsybNgwFEWhadOmhIWFkZGR4euwqq1/j7koLCwkJCTEh9FUb4MGDaJt27aer3fu3OnjiKqP48ePc+ONN3L55ZczdOhQea7K8d96kmfq1F588UWWL1/Ok08+6RmCAvJMleXfddWzZ0+fPle1Nhnr3Lkzq1evBmDz5s20aNHCxxFVXwsXLmTq1KkApKWlYbFYiI6O9nFU1Vfr1q1Zt24dAKtXr6ZLly4+jqj6Gj16NFu3bgVg7dq1tGnTxscRVQ+ZmZnceuutPPTQQ4wcORKQ56osZdWTPFNlW7x4Me+88w4AZrMZRVFo27atPFNlKKuuxo0b59PnqtYuFH7ybcq9e/eiaRrPP/88iYmJvg6rWrLb7UycOJFjx46hKAoTJkygc+fOvg6rWklJSeGBBx5gwYIFJCcn8+STT+JwOEhISGDKlCno9Xpfh1ht/LuuduzYweTJkzEajURFRTF58uQSwwfqqilTprBs2TISEhI82x5//HGmTJkiz9W/lFVP999/Py+99JI8U/9RVFTExIkTyczMxOl0cvvtt5OYmCj/V5WhrLqqV6+eT/+vqrXJmBBCCCFETVBruymFEEIIIWoCScaEEEIIIXxIkjEhhBBCCB+SZEwIIYQQwockGRNCCCGE8CGZBVUIUaP179+fo0ePllnWvHlzli5dWuUxJCUlMW3aNC6//PIqv5YQovaRZEwIUePdfvvt3HTTTaW2y6obQoiaQP6nEkLUeAEBAbJqhBCixpIxY0KIWi0lJYWkpCSWLFnCpZdeSocOHRg1ahR79uzx7ON0Onnvvfe46KKLaNeuHUOHDuW7774rcZ5Vq1Zx5ZVX0qFDB/r378/7779fonz//v2MGjWKdu3a0b9/fxYuXOiV+xNC1HySjAkh6oSpU6dy//33s3DhQoKDg7nlllsoKCjwlM2ePZsHHniAb775hiFDhvDAAw+wfPlyADZt2sTYsWO58MILWbx4MRMnTuSNN95gwYIFnvPPnTuXa6+9lu+++47+/fvz5JNPcuTIEZ/cqxCiZpHlkIQQNVr//v1JT0/HaDSWKnv00Ue58MILGTBgAE888QSjRo0CoKCggN69e/PII49w2WWX0a1bN5566imuvvpqz7H3338/R44c4csvv+SBBx4gIyODTz75xFO+ePFi9Ho9Q4cOJSkpibFjxzJ+/HgA8vLyOP/883nttde46KKLqrgGhBA1nYwZE0LUeNdffz3XXXddqe0RERHk5eUB0LVrV8/24OBgEhMT2bt3LwcOHMDpdNK5c+cSx3bt2pWff/4ZgL1799K7d+8S5cOHDy/xfZMmTTxfh4aGAlBcXHzW9ySEqDskGRNC1HihoaHEx8eXWXYyGftvy5mqquh0OkwmU5nHuVwuz9uYFXkrU6crPepDOh6EEBUhY8aEEHXC9u3bPV/n5eWRnJxMq1ataNKkCUajkQ0bNpTYf8OGDTRr1gyAxMTEEscDvPLKK9x1111VH7gQotaTljEhRI1XVFRERkZGmWUnW6dmzJhBZGQkMTExvPzyy4SHh3PppZfi7+/PLbfcwsyZMwkLC6Nly5b88MMP/PDDD8yYMQOAW2+9lZEjR/Lmm28yZMgQdu/ezccff8zjjz/utXsUQtRekowJIWq89957j/fee6/MspNTTFx11VVMmjSJ9PR0zj//fObMmUNAQAAA9913Hzqdjueff56cnBwSExOZMWMGl156KQBt2rThtdde49VXX+XNN98kLi6O8ePHM3LkSO/coBCiVpO3KYUQtVpKSgoDBgxg7ty5dOnSxdfhCCFEKTJmTAghhBDChyQZE0IIIYTwIemmFEIIIYTwIWkZE0IIIYTwIUnGhBBCCCF8SJIxIYQQQggfkmRMCCGEEMKHJBkTQgghhPAhScaEEEIIIXzo/7zo2tkU3QuIAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"fig = plt.figure(figsize=(10,6))\n",
"sns.set_style(style='dark')\n",
"ax = sns.lineplot(x='epoch', y='roc_auc',\n",
" style='split',\n",
" hue='model',\n",
" data=roc_auc_learning_curves)\n",
"ax.set_title('ROC AUC Learning Curves', fontdict={'fontsize': 16})\n",
"ax.grid(visible=True, which='major', color='black', linewidth=0.075)\n",
"ax.grid(visible=True, which='minor', color='black', linewidth=0.075)\n",
"ax.set_xlabel(\"Epoch\", fontsize = 15)\n",
"ax.set_ylabel(\"ROC AUC\", fontsize = 15);"
]
},
{
"cell_type": "code",
"execution_count": 231,
"id": "9bfd8dc1-b0e0-451c-8f2b-de9e92e976c0",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAmsAAAGICAYAAAAedKdVAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAABW70lEQVR4nO3dd3xUdf798dedml4JhA5BARUQkPJTARULNiyIuMQvFhTLigoqYqEoglhZFUEEWVFEkV1cu7sKsmBFBNEVQaUqJUBInUkymXJ/fwQiSAgDJLmT5Dwfj13IvXfmvuc9Fzh+bvkYpmmaiIiIiEhEslldgIiIiIgcmsKaiIiISARTWBMRERGJYAprIiIiIhFMYU1EREQkgimsiYiIiEQwhTWReq5v375MmDDB6jIOMmTIEG6++Wary6hUu3btmD17do3syzRN/vWvf3H11VfTo0cPunXrxlVXXcW7775bI/sXEes4rC5ARKS2evPNN2nSpEm17ycQCHD77bfz+eef85e//IUbb7wRu93OsmXLGD16NP/73/948MEHq70OEbGGwpqIyFHq3LlzjexnxowZLFmyhFmzZtG7d+/y5X369KFhw4Y8/fTT9OvXj27dutVIPSJSs3QaVEQOKycnhzFjxtCnTx9OPvlkrrnmGv73v/8dsM1LL73EueeeS8eOHTnnnHOYNm0aoVAo7PVHIxAI8Oyzz3LmmWfSsWNHBgwYwFdffXXANhs3buSOO+7g//2//0eHDh3o27cv06ZNY9/kLcuXL6ddu3bMnz+fXr16ccYZZ7B161b69u3LrFmzGD9+PD169KBr166MHj0aj8dT/t77nwadOnUqAwYM4P3336dfv3507NiRK664glWrVh1Qz0cffcTFF19Mp06dGDhwIIsWLaJdu3YsX768ws/o9/uZO3cuZ5111gFBbZ9rrrmGq6++GpvNVl5Hly5dDthm7dq1B+zjvvvu469//St33303Xbt2ZeTIkZx99tmMGzfugNfl5+fToUMH/vnPfwJQVFTEI488wmmnnUanTp0YMmQIP/300wGvqY7vWaS+U1gTkUp5vV4GDx7Ml19+yd13383f/vY3TNPk//7v//j5558B+PDDD3n22We57rrrmD17NldeeSVTp05lwYIFYa0/WmPHjuXll1/mmmuuYdq0aWRkZDBs2LDygOT1ernmmmvIy8vj8ccf58UXX6Rnz54899xzLFmy5ID3mj59OhMmTGDkyJE0a9YMgBdffJGCggKmTJnCiBEj+OCDD3jhhRcOWc/mzZt57rnnGD58OFOnTsXn83HnnXcSCAQAWLZsGSNHjqRjx45MmzaN0047jbvvvrvSz/jjjz+Sl5fHGWecUeH6qKgoxo0bR9euXcPuG8DSpUvx+XxMmzaNq666iosuuoiPP/6YYDBYvs0nn3wCwHnnnYdpmtx666188MEHjBgxgmeffRaXy8WQIUP47bffgOr7nkXqO50GFZFKvfXWW/z222+89957HHfccQD06tWL888/n+eff56pU6eyYsUKmjZtSmZmJoZh0KNHDxwOBw0bNgQ47PqjsWHDBt566y0mTpzIlVdeCZSdFty9ezfPPPMMr776Kps2baJFixY888wzpKSkAHDqqaeyaNEiVqxYQd++fcvf79prrz3gZ4D09HSmTJmCYRj06tWLb775hmXLljFq1KgKa/J6vcyZM4dOnToBEAwG+etf/8q6devo0KED06dPp3v37kyePBmA3r174/V6ee211w75ObOysgCq/Nq4QCDAhAkTyvuSmprKiy++yDfffMOpp54KlI0C9unTh4SEBD777DO+/vprXn75ZU477bTy+i+66CJeeOEFJk+eXC3fs4hoZE1EDmPFihUcd9xx5UENwOVycc455/DNN98A0KVLFzZt2sQVV1zBzJkz+eWXX7jhhhvKw8/h1h+Nffvu06cPgUCg/H9nnHEGq1atorS0lA4dOvD6668THx/P+vXrWbRoEc8//zyBQIDS0tID3m//z7dPx44dMQyj/Of09HSKiooOWZPD4aBDhw4HbA9QXFyMz+fj+++/5+yzzz7gNeeff36ln9NutwOUn7atKikpKeVBDeD444+nbdu2fPTRRwDk5eWxfPlyLr74YqDsdHF0dDTdu3cv7zWUBfevv/4aqJ7vWUQ0siYih1FQUECDBg0OWt6gQQO8Xi8Al1xyCcFgkHnz5jFlyhSefvpp2rdvz5QpU2jTps1h1x+NvLw8oCysVSQ3N5dGjRoxY8YMXnrpJQoLC2natCldunTB4XAcFH72Dy77REdHH/CzYRiVhiaXy1V+7RhQ/vtQKER+fj6hUOig/aSmph76Q/LHiNr27dsPuc3OnTtp1KhRpe/zZxXtt3///rz88suMHz+eTz75BKfTyVlnnQWU9bu4uPiAMLqP0+kEDn8ciMjRUVgTkUolJiaycePGg5bv3r2bpKSk8p8vv/xyLr/8cvbs2cOnn37KtGnTGD58ePlIzeHWH6n4+HgMw+CNN97A4Tj4r7Lk5GTefvttnnnmGcaPH8/FF19MfHw8QPlpvpqUmpqK0+kkJyfngOV//vnPTjzxRFJSUvjss88YPHjwQetLS0vp378/55xzDo8++iiGYRx0Qf++UH04F110EVOmTOHbb7/l3//+N2effXZ5YI2Pjy8/VVqZqv6eRUSnQUXkME455RTWr1/Phg0bypeVlpayaNGi8ovaH3zwQe644w6gLJRceeWVDBw4kB07doS1/mjrMk0Tr9dLx44dy//31VdfMWfOHBwOB9999x3p6ekMHjy4PKitWbOGnJycKj+teDh2u53OnTvz6aefHrB88eLFlb7OZrNx9dVX8+mnn/Lll18etP6ll14iPz+f/v37AxAXF0dJSQkFBQXl26xcuTKsGps2bUrnzp157733+Prrr8vfE8r6nZOTQ0xMzAH9fu+998ofzFsd37OIaGRNRIB169YxZ86cg5ZfdNFFDBgwgFdeeYVhw4YxYsQI4uPjmTNnDtnZ2dxyyy0AdO/endGjRzNlyhROO+00srKyeOONNzj33HPDWn8oW7durbCuM844gxNOOIF+/foxatQohg8fTps2bfjmm2944YUXuPHGG7HZbHTs2JH58+fz/PPP06NHDzZs2MC0adMwDIOSkpJj7tuRuu2227j++usZM2YM559/PqtXry6/uWD/06d/NmzYML7++mtuvvlm/u///o/TTjuN0tJSPvnkE95++22GDh1aPlrYu3dvJk+ezIMPPsjVV1/NunXreP3118OusX///kyaNIn4+PjyGwkAzjrrLDp27MhNN93E8OHDady4MR9//DHz5s3j4YcfBo7+exaRyimsiQgrV66scPSlc+fOdO7cmXnz5vH4448zYcIEgsFg+bITTzwRgMsuuwyPx8O8efOYM2cO8fHx9OvXr/yxFIdbfyjr168vv3Nyf2lpabRu3ZqnnnqKZ599lpkzZ7Jnzx6aNm3K3XffzQ033ADAgAED2LRpE/Pnz+ell16iadOm3HDDDWzYsCHs0aaqdOqpp/LEE08wbdo03n77bU488UTuvvtuJk+eTExMzCFf53a7mT17NnPnzuX9999nwYIF2Gw22rRpw5QpU7jgggvKt23Tpg0TJ07khRdeYNiwYZx88sk899xzDBo0KKwaL7jgAh599FH69etXfi0alI0Mzp49m6eeeoonn3wSj8dDy5YtmTx5MgMGDACO/nsWkcoZZk2fCxARqacWLVpEixYtaNu2bfmyN998k4ceeojly5eTkJBgYXUiEqk0siYiUkOWLFnC559/zt13303jxo3ZsGEDf/vb37jkkksU1ETkkDSyJiJSQ7xeL08//TSLFy9mz549NGzYkP79+3PbbbfhcrmsLk9EIpTCmoiIiEgE06M7RERERCKYwpqIiIhIBKvTNxiEQiGCwcrP8u570ndlzziSMupVeNSn8KlX4VOvwqM+hU+9Ck9N9snptFe4vE6HtWDQJC/v0JMuA+WTMlf2jCMpo16FR30Kn3oVPvUqPOpT+NSr8NRkn9LS4itcrjgtIiIiEsFqNKx9//33DBkyBIC1a9eSmZnJkCFDuOGGG8jOzgZgwYIFDBgwgEGDBrFkyRIASkpKuP3228nMzGTYsGGHnfhYREREpK6osbA2a9YsxowZg8/nA2DSpEmMHTuWuXPncu655zJr1ix2797N3LlzmT9/PrNnz2bKlCmUlpbyxhtv0LZtW15//XUuu+wypk+fXlNli4iIiFiqxq5Za9GiBVOnTuXee+8FYMqUKTRs2BCAYDCI2+3mhx9+oEuXLrhcLlwuFy1atGDdunWsXLmSG2+8EYA+ffqEHdZCoVD5ueZDKS6ufL38Qb0Kj/oUPvUqfOpVeOpjn0KhIF5vPsFg4Ihet+8xq3l5RnWUVWdUR5/sdgexsYnYbH++oaDia9ZqLKz169ePrVu3lv+8L6itWrWK1157jXnz5vHZZ58RH/9HobGxsXg8HjweT/ny2NhYCgsLa6psERGRiOb15hMdHUtMTDyGEX6gMM2yuxwNQ5evV6aq+2SaJkVFhXi9+cTHp4T1GkvvBv3www954YUXmDlzJikpKcTFxeH1esvXe71e4uPjD1ju9XrDnkPPZrOFffeG7oYJn3oVHvUpfOpV+NSr8NSnPhUU7CY+PumIghpAMFj2q91e8eMipEx19Ck+PomiooKwj1PL4vQ777zDa6+9xty5c2nevDkAnTp1YuXKlfh8PgoLC9mwYQNt27ala9euLF26FIBly5ZxyimnWFW2iIhIxDnSoCbWOtLvy5KwFgwGmTRpEl6vl9tvv50hQ4bw3HPPkZaWxpAhQ8jMzOTaa69l5MiRuN1uBg8ezK+//srgwYN58803GT58uBVli4iICODz+Rg4sP8h169a9S3jx99fgxXVbTV6GrRZs2YsWLAAgG+++abCbQYNGsSgQYMOWBYdHc1zzz1X7fWJiIiIRJo6PYOBiIiIHOzDD9/j88+X4vP5yMnZw5VXDuazz5ayadMGbrvtToqLi1mw4A2cTifNm7fg3nsfpLS0lAkTxlBYWEjTps3K32vDhvU888yTmKZJYmIi998/3sJPVjcprImIiNRDRUVFPP30VJYsWcSbb77OzJlz+O67lcyfP48tWzbx8svziImJ5bnnnuaddxYC0Lp1G26++TbWrPmRVau+BeDxxydy//3jaN06g/fff5t5816he/eeVn60Okdh7RjkF/vxh0waxLqsLkVEROSIHH98OwDi4uJp1ao1hmEQHx+Pz1dC69YZxMTEAnDyyV1ZseJrAHr2PBWAk07qgMNRFiG2bNnE008/BkAwGKB585Y1/VHqPIW1Y/Dcso1szilm9uDOVpciIiJyRA59R6LB5s2bKC4uJjo6mtWrV9G8eQsMw8aPP/6P3r3P5Jdf1hEIlD2Et0WLlowZM4H09HR++GE1e/Zk19yHqCcU1o6BaUJWQYnVZYiIiFQZu93O0KE3c8cdN2MYNpo1a84ttwzHbrczefLD3HrrDbRs2Qqn0wnA3Xffz8SJ4wiFyh4ee999Y8nO3m3lR6hzDHPfPAp1kN8fJC+v8qlH9k1HdTQPUJz08S988NNOvhzR+6jqq22OpVf1ifoUPvUqfOpVeOpjn7KytpCefuSnHoN7n/aqh+JWrrr6VNH3lpZW8XRTmmPiGPyUVYg/aFLiD1pdioiIiNRRCmvHICGqbAi4oOTIJs8VERERCZfC2jFIiim75G9PUanFlYiIiEhdpbB2DFJjyh7ZsSPfZ3ElIiIiUlcprB2Dfc9X21moO0JFRESkeiisHYN++W/ytHM6hT5dsyYiIiLVQ89ZOwYZ9p00sv3IRrsyr4iIiFQPpYxjYItOJgkvubrBQEREpNzChW8e83vcdNN17Nix/Yhft2XLZoYPv+mY9384l1zS75DrduzYzk03XVdl+9LI2jEocSSQYvhZu203cJzV5YiISD33wZqdvPtjVljb7nsm/qGnnSpzSYd0Ljqp0RHV8corf+eKK646otfIoSmsHQNHTHLZb0ryrS1ERETEIr/9toVHH30Yh8OB3W6na9duFBTk89RTj3HrrcN57LGJeDyF5Ofn0b//5Vx++UCGD7+J449vx8aNGygq8vDII4+Tnt6YF1+cxvLlX9GoUSPy8/MA2LVrJ0899RilpT4KCvK57rph9OlzJkOGDKJ585Y4nU5uv/0uJkwYg2mapKSkVlrvqlXf8tprc3A6nezatZNLL72CVau+Zf36X7jyysFcfvlAVqz4mpkzX8DtdhMfn8Do0WOIj4/niScmsWnTRpo2bUZpadlZtZ07s3jiiUcpLfXhcrm5994HqrzHCmvHwIxKAsBVmmdpHSIiIgAXndQo7FGwqppGacWK5bRr157bb7+L77//juTkZBYuXMA999zHzz+v45xzzuOMM/qSnb2b4cNv4vLLBwJwwgknceedd/Pii9P45JP/cPrpvfj+++946aVXKS4u4i9/GQCUndb8y1+upmvXbvzvf98ze/aL9OlzJsXFxVx33Q20bdue559/hnPO6ccll1zO4sUf869//bPSmnft2sWcOa+zbt1axo27jzfffJvdu3fxwAOjuOyyK3jiiUeZPv0l0tIa8uab85g79+907dqd0tJSZs6cQ1ZWFv/972IApk17loEDr+LUU0/n22+/YcaM57nppr8eU0//TGHtGPib/D+uD45lg9HA6lJEREQscfHFlzJv3ivcffftxMbGcfPNt5WvS01NZcGC11m6dAkxMbEEAn88PaFt23YANGrUiD179rBp00batz8Bm81GbGwcGRnH7X2PBrzyymw++OAdwDjgPVq0aAXApk0b6dfvQgA6djz5sGEtI6MNDoeD+Ph4mjRpitPpJD4+gdJSH3l5ecTExJKW1hCATp26MGvWCyQnp3DCCScBkJ6eTsOGZaF448b1zJ37MvPmvQKAw1H10Uo3GBwDM6YB3zs7kRdwW12KiIiIJT7/fCknn9yFZ599gbPOOpt5814pvx7ujTfm0qFDJ8aNe4S+fc8pXw4HXyvXokVL1q5dQygUori4mM2bNwLw0kszOP/8ixg79hG6du12wGv2vUfLli1Zs+YHANau/emwNVd2mV5SUhJFRV6ys7MB+P77VTRv3pyWLVuV7yM7eze7d+/eW3crbr31dp5/fiajRj3AmWeefdj9HymNrB2LUi+32hbygXkiptnrsBdpioiI1DXt25/IhAljsdvt2Gw2br/9Lnbs2M6ECWO5+OJLeeqpyXz88UckJiZit9vLr/X6s+OPb8dZZ53DjTdeQ4MGaSQnpwBw1lln8+yzTzF37ss0bNiIvLy8g1574423Mn78/Sxa9DFNmjQ9ps9jGAb33vsgDz44CpvNIC4unvvuG0dqaio//PA9w4ZdS3p6Y5KSkgC47bY7efrpxygtLcXnK+HOO+85pv1XWJO5f8ytY/z+IHl5RZVuU1RUtj4mJuaI398o9dBgVnsm+TP5v79OJsZ1bOf9I92x9Ko+UZ/Cp16FT70KT33sU1bWFtLTWx7x66rqmrW6rrr6VNH3lpYWX+G2Glk7BqYzlpBhJ8nwkF/ir/NhTUREpLZ4+eVZrFy54qDlDzww/phH32qawtqxMAyKbPEk4SW7sJTGCVFWVyQiIiLA9dcP4/rrh1ldRpXQDQbHqNieQKLhZbsmcxcREZFqoLB2jPyuRBLxsLPQZ3UpIiIiUgfpNOgx+r3FFfxrdRYuhTURERGpBhpZO0Yl7a/irVAfcor8VpciIiIidZDC2jFqbO6kj+178ooV1kREpH768MP3eOGFqYfdbtWqbxk//v4aqKjMJZf0q/Z9jB9/P6tWfXvI9QMH9sfnO7azbzoNeowa//4Or7r+xk1RZ1ldioiI1HPudf8kau388Dbe95TVwzzPveSEv+BrP/CY6pJjo7B2rKKTAbD58i0uRERExDpr1vyPO++8Fa/Xy9ChN+HzlfDWW/8on2Jq4sQnDth+4cI3Wbp0CYFAgLi4OCZNepJPPvk3X331BT5fCdu2beXqq6/lwgv7s2bNjzz77FOYpklaWkPGj3+ErVu38swzT2KaJomJidx//3iio6N54olJbNq0kaZNmx1ytoR9rrrqMjp06MTWrb/TtWs3vF4Pa9euoUWLlowd+wg7dmxn8uQJBAIBbDYbd955D8cf35aFCxfw/vtvk5ragNzcXAACgQBPPvkoW7f+TigUYtiwWw+aHutoKawdI9OdCEBB7m6LKxERkfrO135g2KNgVf1k/qioKJ588lny8nK56abr6N//Mp588lmioqJ44olJfPPNVzRokAZAKBQiPz+fZ56Zjs1m4667hrN27RoAvF4PU6Y8z++//8bo0SO58ML+PPHEJB5++FFatWrNW2/9g82bN/P0049x//3jaN06g/fff5t5816hQ4dOlJaWMnPmHLKysvjvfxdXWnNW1g6efXYGDRo04IIL+jJz5hxGjryXQYMupbCwkGnTnuGKKwbRq9cZbNy4nscee4Rnn32Bf/xjPq++Oh+bzcYNN/wfAO+99zaJiUncf/848vPzuO22m3jttQVV0luFtWNkupMACBbnWluIiIiIhTp16oxhGCQnpxAbG4fD4WDixPHExMSwZctmOnToVL6tzWbD6XTy0EMPEh0dza5duwgEAgAcd1xbABo2bFQ+Mpabm0OrVq0BGDDgSgC2bNnE008/BkAwGKB585Zs2rSBE044CYD09HQaNmxUac0JCYmkp6cDEB0dTevWGQDExsZRWupj8+bNnHxyF6Bs7tJdu3ayZctmWrfOwOVyAZTvb8OG9fzww3f89NOP5TXl5+cdbTsPoLB2jEJRSQDEhjzWFiIiImKhtWt/AmDPnmy8Xg8LFrzBwoXvAzBy5G3sPxX5+vW/smzZf5k16xVKSkrKR6egbCL1P2vQoAG///4bzZu34LXX5tC8eUtatGjJmDETSE9P54cfVrNnTzYOh4NFi/4DDCY7eze7d1d+1quife2vVatW/PDDak4/vQ+//vozKSmpNGnSlM2bN+LzleBwOPnll58577wLaNmyFQ0bNuSaa4bi85Xwyit/Jz4+Idz2VUph7RiFYhqxwnYyBSE3pmke9osXERGpi3w+H3fccQvFxUWMHj2Gd955i6FD/4/o6Gji4+PJzt5N48ZNAGjWrDnR0dHccMMQXC4nqakNyM4+dLAaNeoBJk+egM1mIzU1lUGDMmnUKJ2JE8cRCoUAuO++sbRo0ZIffvieYcOuJT29MUlJScf0mW67bQSPPTaR+fPnEQwGuf/+sSQnJ3Pjjbdwyy1DSUpKJjo6GoBLLx3A449PZPjwm/B6PVx++ZXYbFXz0A3D3D/q1jF+f5C8vKJKtykqKlsfExNz1PsZ+vp3/G9HIUuGn0acu+7m36roVX2gPoVPvQqfehWe+tinrKwtpKe3POLXVfU1a3VVdfWpou8tLS2+wm3rbrKoQclugyh85BaV1umwJiIiUtt8/vlS5s+fd9DyK68czBln1I7HbilZVIFZuwYxz9GHvOKeNE+2uhoRERHZp1evM+jV6wyryzgmmsGgCoTcSSQaHjylAatLERERkTpGYa0KBFyJJOJlR16J1aWIiIhIHaOwVgWKHQkkGV5+zfZaXYqIiIjUMQprVcAWk0wSHnKKNJm7iIjUDcOH38SWLZv58MP3+PzzpUDZFFFS8xTWqoA9NhUDk7xihTUREalbLrywf/kF+q+88neLq6mfdDdoFSg5czJnr/6c40p0g4GIiES2337bwqOPPozdbsdut3PxxZfy4YfvYbPZ2LNnD5dccjlXXDGofPvZs18kNTWV/Px8Cgryeeqpx7jnnvss/AT1T42OrH3//fcMGTIEgC1btjB48GAyMzMZP358+ROIFyxYwIABAxg0aBBLliwBoKSkhNtvv53MzEyGDRtGTk5OTZZ9WA67DZsBXt0NKiIiEW7FiuW0a9eeKVOeZ8iQ6yksLCA7ezePPTaFmTNfZsGC18nNPfjf2WuvvYGEhEQFNQvUWFibNWsWY8aMwefzATB58mRGjBjB66+/jmmaLF68mN27dzN37lzmz5/P7NmzmTJlCqWlpbzxxhu0bduW119/ncsuu4zp06fXVNlhcW1exH/c95Fm7rG6FBERkUpdfPGlJCYmMWrUnbz11j+w2+106NAJl8uF2x1FRkYbtm3banWZsp8aOw3aokULpk6dyr333gvAmjVr6NGjBwB9+vThiy++wGaz0aVLF1wuFy6XixYtWrBu3TpWrlzJjTfeWL5tuGEtFAqVTz1yKMXFla8Ph1lUyPH8RjKFh91fbVYVvaoP1KfwqVfhU6/CUx/7FAqZ5VMihWPZsiV07Hgy11xzPYsXf8ysWTNITEyktLQUv9/Pxo0baNy4KVA21ZJpmuX7MM3QEe2rLjDNsjN/Vf2xQyGzgsxg8XRT/fr1Y+vWP5L6/pOex8bGUlhYiMfjIT7+j0JjY2PxeDwHLN+3bSQJuRMBsPnyrC1ERETkMNq1O4GJE8djt9ux2QwGDBjEf/7zAffeO4KCgnyuuWboISdAb9myNRMnjmfMmIdrtuh6zrIbDPafid7r9ZKQkEBcXBxer/eA5fHx8Qcs37dtuPsIdzLfY5n0156YDoA7UIg7Khq7zTjq96oN6tMEycdCfQqfehU+9So89alPBQXGEU0y3qJFS2bOnFM+Qvb999/x888/8fDDkw/Y7vnnZwKQkdHmoGX1yb4RtaqeyN1mM8I+Ti17dMeJJ57I8uXLAVi2bBndunWjU6dOrFy5Ep/PR2FhIRs2bKBt27Z07dqVpUuXlm97yimnWFV2hUx3EgCJhpdCn24yEBERkapj2cja6NGjGTt2LFOmTCEjI4N+/fpht9sZMmQImZmZmKbJyJEjcbvdDB48mNGjRzN48GCcTidPP/20VWVXaN9p0CQ85Bb5SYp2WlyRiIhIeLp27UbXrt2sLkMqYZimaVpdRHXx+4Pk5VV+sem+i/uOacjcNHn1/Q+Z+ws8POBUTmudcvTvFcGqpFf1gPoUPvUqfOpVeOpjn7KytpCe3vKIX7fvNGhVn96ra6qrTxV9b2lpFd9goBkMqoJhUJJ6EnnEk1Xgs7oaERERqUM0g0EVOTf/HxTbC8gtOvL/uhERERE5FI2sVZGOns+5wPYNMW7lXxEREak6CmtVxIhOJtHwkq/J3EVEpB7x+Xy8997bYW374Yfv8fnnSw+5fu7cOfz0049VVFndoWGgKhJwJZJkeFi9Nd/qUkRERGpMTs4e3nvvbfr3v+yw2154Yf9K1w8Zcl3VFFXHKKxVESM6iUS85BRpZE1ERKyxaNF/+Pjjj8Ladt/DIPbNJnQo5513Aeec0++Q61999e9s3ryJ3r27061bD4qLi7nvvrH8+98fsG7dTxQVFdGqVWseeGA8s2e/SGpqKi1atGLevFdxOh3s2LGdvn3P5dprb2DSpIc4++zzyMnZw1dffYHPV8K2bVu5+uprufDC/vz0049MmfIEMTExJCcn43K5efDBh8LuT22lsFZVopKIN4op8ZVYXYmIiEiNueaaoWzYsJ6ePU+lsLCQESPuwestmybymWemEwqFGDJkELt37zrgdTt37mDOnDfw+/1cdtn5XHvtDQes93o9TJnyPL///hujR4/kwgv789RTkxkzZgIZGW148cVpZGfvrsmPahmFtSpS2vJsHv86n5K9E76KiIjUtHPO6VfpKNj+quP5YS1alD0Rwe2OIjc3l/HjHyAmJobi4mICgQNn+MnIOA6Hw4HD4cDtjjrovY47ri0ADRs2orS0FIDs7Ozy6a9OPrkLixd/XGW1RzKFtSoSaNiJd+0eikoV1kREpP4wDBvm3oEK2965sb/++gt27drJhAmTyc3NZdmyJfz5GfyHOfta4enZhg0bsWnTRlq3zmDNmv9VzQeoBRTWqohRnMOlti/5KNTW6lJERERqTHJyMn5/AJ/vj4fCn3DCScyZM5ubbroOl8tFkyZNq+SU5d13j2by5AlER8fgdDpIS2t4zO9ZG2i6qSqamsSRtYrkhZdwXekoJt9xOw573XsqSn2cxuVoqE/hU6/Cp16Fpz72qT5NN7Vw4QL69j2X5ORkZs6cjtPp5Prrh1XrPiNhuimNrFURMyoJgCS8FPgCpMS4rC1IRESkjklJSeGuu24jOjqGuLi4enEnKCisVZlQVDIASYaHPZ5ShTUREZEqdtZZ53DWWedYXUaNq3vn6ixiuhKAsrC2vUCP7xAREZGqobBWVWx2SuxxJOIlq9B3+O1FREREwqCwVoU2p1/AT2ZLdimsiYiISBVRWKtCv3d7iH8Ez9SUUyIiIlJlFNaqUGN3CY3ZQ25RqdWliIiIRJThw29iy5bNfPjhe3z++dKD1l9ySeUzLyxduoTs7N3s2ZPNU089Vl1lRiSFtSqU8e145rknE+vWTbYiIiIVufDC/vTqdcYRv+4f/3gDr9dLamoD7rnnvmqoLHIpVVQhIzqZZMNDKFRnnzMsIiIR7t57R1S4/IknngFgxozn2bhxffn0T/umdbr55uG0aXMcn3zybz755N8Hve5QHnhgFFde+Re6dDmFtWvXMH36cyQlJePxFJKfn0f//pdz+eUDy7efPftFUlNT6d//cp54YhKbNm2kadNm5fN/bty4nqlT/0YoZOLxlE0MX1hYyPr1vzBx4jjGjn2EiRPHM3PmHFas+JqZM1/A7XaTkJDI/feP49dff2bevFdxOh3s2LGdvn3PPWiS+NpGYa0KhaKSiMfDbzmVz5ogIiJSV/TvfxkfffQ+Xbqcwocfvk/Xrt3IyGjDGWf0JTt7N8OH33RAWNvn66+/pLS0lJkz55CVlcV//7sYgE2bNjJ8+EjatDmOjz/+Nx9++B6jR4/huOPaMmrUAzidTgBM0+SJJx5l+vSXSEtryIIFb/DKK7M57bRe7Ny5gzlz3sDv93PZZecrrMkfTHciDkLkFeRaXYqIiNRThxsJu+WW4cChp1E699zzOffc88PeX8+epzJ9+rMUFOTzww/f8dRTzzFjxvMsXbqEmJhYAoFAha/btGkDJ5xwEgDp6ek0bNgIgAYNGjJnzku43W6KioqIjY2t8PV5eXnExMSWzw/auXMXXnxxOqed1ouMjONwOBw4HA7c7qiwP0uk0jVrVch0JwEQHSy0thAREZEaYrPZOOusc3jqqcfo3ftM5s9/jQ4dOjFu3CP07XsOh5qCvGXLVqxZ8wMA2dm72b27bKL3Z599khtuuJkxYx6mTZvjyl9vs9kIhULlr09KSqKoyEt2djYAq1evonnzFgDsPbNbZ2hkrQqFYtLYbjTCEdJz1kREpP646KJLGDToUubP/xc7dmznqacm8/HHH5GYmIjdbi+/Hm1/vXufyQ8/fM+wYdeSnt6YpKQkAM477wLuu+9uUlJSSEtrSH5+HgAdOnRi4sTx3Hvvg0DZtXb33vsgDz44CpvNID4+gQceeIiNG9fX1MeuMYZ5qMhbB/j9QfLyKr9+rKiobH1MTEyV7POa11axdqeHL+7shctRtwYuq7pXdZX6FD71KnzqVXjqY5+ysraQnt7yiF93qNOgcqDq6lNF31taWnyF29atNBEBEqLKBivzi/WsNRERETl2CmtVyCjew4s51zPQvpSc4oovqBQRERE5EgprVch0xpDk30ka+XhLFdZERETk2CmsVSVHNEGbm0TDo8ncRUSkxtThy8/rpCP9vhTWqpjPEU8iXtbu9FhdioiI1AMOhwuvt0CBrZYwTROvtwCHwxX2a/TojipmRiWRVOxhj1c3GIiISPVLTk4jN3c3Hk/eEb1u39SINlsdeyhZFauOPjkcLpKT08Lfvsr2LGWikknCS26x3+pKRESkHrDbHTRo0PiIX1cfH3NyNCKhTzoNWsUKz3+Bm/0jKSjRDQYiIiJy7BTWqpg9Pp1CYvH4FNZERETk2CmsVTH3r+8x3T2VYEgXeoqIiMixU1irYvb8TVxgfEWSU2FNREREjp3CWhULRSUBYJbkWluIiIiI1AkKa1XMdCcCECjKs7YQERERqRMU1qpYyJ0EQCIeSvxBa4sRERGRWk9hrYqZe0+DJhkePWtNREREjpnCWhULJrbm743G8L9QBjvyS6wuR0RERGo5hbUqZroT+K1RP3aRTFaBJnMXERGRY6PppqrBGZ4PWGs42elpZXUpIiIiUstZGtb8fj/33Xcf27Ztw2az8cgjj+BwOLjvvvswDIPjjz+e8ePHY7PZWLBgAfPnz8fhcHDrrbdy1llnWVl6pXpvncFv9u4UR/W3uhQRERGp5SwNa0uXLiUQCDB//ny++OILnnnmGfx+PyNGjKBnz56MGzeOxYsX07lzZ+bOncvChQvx+XxkZmZy+umn43K5rCz/kMyoRJKKvezU/KAiIiJyjCwNa61btyYYDBIKhfB4PDgcDlavXk2PHj0A6NOnD1988QU2m40uXbrgcrlwuVy0aNGCdevW0alTp0rfPxQKUVRUVOk2xcWVrz8acc4EEvGy+vdcijo2qPL3t0p19KouUp/Cp16FT70Kj/oUPvUqPDXbp/gKl1oa1mJiYti2bRsXXHABubm5zJgxgxUrVmAYBgCxsbEUFhbi8XiIj//jA8TGxuLxeKwq+7BMdyJJxg52eUqtLkVERERqOUvD2pw5c+jVqxd33303O3bs4Nprr8Xv/+PZZF6vl4SEBOLi4vB6vQcs3z+8HYrNZiMmJiasWsLdLhy22FSS+JUif6hK3zdS1MXPVB3Up/CpV+FTr8KjPoVPvQqPlX2y9NEdCQkJ5aErMTGRQCDAiSeeyPLlywFYtmwZ3bp1o1OnTqxcuRKfz0dhYSEbNmygbdu2VpZeqdKWZ/Ou2ZsizWAgIiIix8jSkbXrrruOBx54gMzMTPx+PyNHjqRDhw6MHTuWKVOmkJGRQb9+/bDb7QwZMoTMzExM02TkyJG43W4rS6+Ur90AXlqUTmkgZHUpIiIiUssZpmmaVhdRXfz+IHl5lV8YuO8GhKoc3jRK8rhnzgd8XdyEz0ZG7iNGjlR19KouUp/Cp16FT70Kj/oUPvUqPDXZp7S0ii/x0gwG1cC1+RPmBEeTbmZTh7OwiIiI1ACFtWpguhMBiMer69ZERETkmCisVYOQOwmARMNLTpEe3yEiIiJHT2GtGphRSQAk4WF7Xom1xYiIiEitprBWDfaNrCUZHnYU+qwtRkRERGo1hbVqYEYlkh3bFo8ZzS6FNRERETkGCmvVwe7mqzMX8naoF3u8umZNREREjp7CWjVpkuAGTHKK/IfdVkRERORQFNaqSYdPB/Oi6xncDrVYREREjp6SRDUx7E7S7F4cNsPqUkRERKQWU1irJmZUUtmjO/L16A4RERE5egpr1STkTiI2VMiGPZXPTSoiIiJSGYW1amK6E0k0PPgCIatLERERkVpMYa2ahKKSicKPEdRpUBERETl6CmvVpLjzMPrFvUWJ6SJkmlaXIyIiIrWUwlp1sbuJi3ID4CkJWFyMiIiI1FYKa9XEvmctj3rHcpKxiT1FmsVAREREjo7CWjUxQgHaFa+iibGHIr9uMhAREZGjo7BWTULuRACSDA85mh9UREREjpLCWjUx3UkAJOLlf9sLrC1GREREai2FtWpiuuIJGXaSDA/ZGlkTERGRo6SwVl0Mg5ArgUS85Bb5ra5GREREaimFtWqUc95MZgcvIL9EYU1ERESOjsPqAuoyo8WpbDH9tPTpOWsiIiJydDSyVo1c699nqOM/FOvRHSIiInKUFNaqkXvjvxnm/pgGsS6rSxEREZFaSmGtGplRScSbHl2zJiIiIkdNYa0ahdxJRIc87CootroUERERqaUU1qqRGZWEDZPokJdgyLS6HBEREamFFNaqUWjvLAZJhocCnQoVERGRo6CwVo0CDTvxdtL1eMxoduSXWF2OiIiI1EIKa9UomNKWb5pcxx4S2VHos7ocERERqYUU1qpToIRTgqtpQjY7FdZERETkKCisVSOjtJArfr6TvvbviHXZrS5HREREaiGFtWpkuhMBSMKDtzRocTUiIiJSGymsVSe7i5AzliTDw9qsQqurERERkVpIYa2ame5EEvGyJVcPxhUREZEjp7BWzUx3EkmGF48vYHUpIiIiUguFHdZM0+Sdd94hKysLgNmzZ3PxxRfz4IMPUlRUVG0F1nalzU7nV5pTpGvWRERE5CiEHdaef/55HnroIbKysvj22295+umn6d69O9999x1PPvlkddZYq3l7jWe6MZiSQMjqUkRERKQWCjus/etf/+LJJ5+kc+fOfPTRR3Tu3Jnx48czadIkPvnkk+qssXYzQ6Q6SihVWBMREZGjEHZY2717Nx06dADg888/p3fv3gCkpaXh8Xiqp7o6IParyXwSuhGboYncRURE5Mg5wt2wefPm/Pjjj+Tk5LBlyxb69OkDwJIlS2jevHm1FVjbhaKScOHHCPoIBEM47LqnQ0RERMIXdli78cYbGTlyJDabje7du3PSSScxffp0pk2bxqOPPnrUBbz44ot8+umn+P1+Bg8eTI8ePbjvvvswDIPjjz+e8ePHY7PZWLBgAfPnz8fhcHDrrbdy1llnHfU+a9L+D8bNLfaTFue2uCIRERGpTcIOawMGDODEE09k69at5adAO3fuzJw5c+jevftR7Xz58uV89913vPHGGxQXF/P3v/+dyZMnM2LECHr27Mm4ceNYvHgxnTt3Zu7cuSxcuBCfz0dmZiann346LpfrqPZbk0LuJAASDS/b80sU1kREROSIhB3WANq3b0/79u0ByMnJoaCggJNOOumod/7555/Ttm1bbrvtNjweD/feey8LFiygR48eAPTp04cvvvgCm81Gly5dcLlcuFwuWrRowbp16+jUqVOl7x8KhQ77WJHi4up97EiIaBKBJLxs3p3P8cnOat1fdaruXtUV6lP41KvwqVfhUZ/Cp16Fp2b7FF/h0rDD2rp167jjjjuYNGkS7du358orr2Tbtm04nU5eeOEFevXqdcQl5ebmsn37dmbMmMHWrVu59dZbMU0TwzAAiI2NpbCwEI/HQ3z8Hx8gNja21tzUEHQnUmqLJtrwsdvjt7ocERERqWXCDmuPP/44bdu2pU2bNrz99tsUFxfz5ZdfMn/+fJ555pmjCmtJSUlkZGTgcrnIyMjA7XaXP3QXwOv1kpCQQFxcHF6v94Dl+4e3Q7HZbMTExIRVS7jbHbGYbrx9zpf89921NCo1q28/NagufIaaoD6FT70Kn3oVHvUpfOpVeKzsU9i3Jq5evZp77rmHlJQUli1bxplnnklKSgqXXHIJv/7661Ht/JRTTuGzzz7DNE127txJcXExp556KsuXLwdg2bJldOvWjU6dOrFy5Up8Ph+FhYVs2LCBtm3bHtU+rdA0MRqAnCKNrImIiMiRCXtkzeVyYZompaWlrFixgkmTJgFl167FxsYe1c7POussVqxYwcCBAzFNk3HjxtGsWTPGjh3LlClTyMjIoF+/ftjtdoYMGUJmZiamaTJy5Ejc7tpzof4pSzMZZj+B34zrrC5FREREapmww1qPHj144oknSEhIAOCMM85g3bp1TJo0iVNPPfWoC7j33nsPWvbaa68dtGzQoEEMGjToqPdjJVfhb7RzprLHdUT3c4iIiIiEfxr0oYcewuFwsG7dOh5//HHi4uJ45513iIqK4oEHHqjOGmu9kDuRFJuXXR6f1aWIiIhILRP2UE9qaipTp049YNmoUaOw2fRE/sMxo5Jw5xSyJqvQ6lJERESkljmipPXJJ59w5ZVX0rlzZ7p160ZmZiYff/xxddVWZ4TcSSQbHkr8QatLERERkVom7LD20Ucfcccdd9CsWTNGjRrFnXfeSaNGjRg5cqQC22GY7kSSDC/+oCZzFxERkSMT9mnQ6dOnM2LECG6++ebyZUOGDGHmzJnMmDGD8847r1oKrAu8PUdx7+/nEihRWBMREZEjE/bI2pYtWzj//PMPWt6vXz82bNhQpUXVNaGE5hRGNwfAFwhZXI2IiIjUJmGHtcaNG/PLL78ctHzdunUkJydXaVF1jSNrJSNLXyCeIvZ4dUeoiIiIhC/s06ADBw5k/Pjx5OXl0bVrVwBWrlzJM888w1VXXVVtBdYF9vwtnOn5gAZGX4r8GlkTERGR8IUd1oYOHcrOnTt5+OGHCQaDmKaJ0+lk6NCh3H777dVZY61nuhMBSMRLfrGmnBIREZHwhX0a1G63M2bMGL7++mvefPNN3nnnHb799lvOPvtshgwZUp011nqhqCQAkgwP32/Lt7YYERERqVWOeP6juLg4OnXqVP5zfn4+q1atqtKi6hozquyavkQ87CrUNWsiIiISPk0/UANCe0+DJhlecop0GlRERETCp7BWA0x3IjmnTeDr0AnklSisiYiISPgU1mqCzUGwy1B+NltQWBKwuhoRERGpRSq9Zm3GjBmHfYPNmzdXVS11mnPLEk6z/8JGX2erSxEREZFapNKwtmDBgrDepHHjxlVSTF0Wu/wJRkS7mRTf0+pSREREpBapNKx9+umnNVVHnWe6E0m25eAp1WlQERERCZ+uWashIXcSUYECtuWXWF2KiIiI1CIKazXEjEoiziykxB/CNE2ryxEREZFaQmGthpjuROJML2BS4g9aXY6IiIjUEgprNcTfqDPLY/riIMiOAs1iICIiIuFRWKshpRkX8Hbz+wngYEeBrlsTERGR8Cis1ZRgKW2ce4jCR5bmBxUREZEwKazVEGfWt9z640C62NbjsqvtIiIiEh6lhhoScicBkIgXfzBkbTEiIiJSayis1RAzKgmAJMPDr7u91hYjIiIitYbCWg0JuZMBSMLDLwprIiIiEiaFtZriiMK0uUg0vBSWaMopERERCY/CWk0xDAIpbfEbLryaH1RERETCpLBWg/Ku+jczGESJXzcYiIiISHgU1mqY22nDF1BYExERkfAorNWguCWjedU2AZu6LiIiImFSbKhBRqiU5sYuSoMmpmlaXY6IiIjUAgprNSjkTiI6WEAwZOLRTQYiIiISBoW1GmS6E3GHinEQYFueJnMXERGRw1NYq0GhvbMYJOJlR4HCmoiIiByewloNMvfOD5pkeNhZUGptMSIiIlIrKKzVIF/r8/hHr0/YZDZml8dndTkiIiJSCyis1SRnDClpTQlhY0+RRtZERETk8BTWapBRnEP37+7ldNv/8Af1YFwRERE5PIfVBdQrhkHC5vc5yZFKYazb6mpERESkFtDIWg0yXQmYGDR0FJFXrNOgIiIicngKazXJZsd0J+AOFLDit3yrqxEREZFaICLC2p49ezjjjDPYsGEDW7ZsYfDgwWRmZjJ+/HhCobJruxYsWMCAAQMYNGgQS5Yssbjio2e6k0gyvJT4g1aXIiIiIrWA5des+f1+xo0bR1RUFACTJ09mxIgR9OzZk3HjxrF48WI6d+7M3LlzWbhwIT6fj8zMTE4//XRcLlel7x0KhSgqKqp0m+LiytdXtQRXPMmGF5//8LVFmpruVW2lPoVPvQqfehUe9Sl86lV4arZP8RUutXxk7fHHH+cvf/kLDRs2BGDNmjX06NEDgD59+vDll1/yww8/0KVLF1wuF/Hx8bRo0YJ169ZZWfZRyzvlbl5zDiQQ0kTuIiIicniWjqy99dZbpKSk0Lt3b2bOnAmAaZoYhgFAbGwshYWFeDwe4uP/SJuxsbF4PJ7Dvr/NZiMmJiasWsLd7pgddy6/L1+FWeghKjoa297PWpvUWK9qOfUpfOpV+NSr8KhP4VOvwmNlnywNawsXLsQwDL766ivWrl3L6NGjycnJKV/v9XpJSEggLi4Or9d7wPL9w1tt4tixgiuDH7OG3uQUldJAj/AQERGRSlh6GnTevHm89tprzJ07lxNOOIHHH3+cPn36sHz5cgCWLVtGt27d6NSpEytXrsTn81FYWMiGDRto27atlaUfNdeWT7mmcCZgUuLXg3FFRESkcpbfYPBno0ePZuzYsUyZMoWMjAz69euH3W5nyJAhZGZmYpomI0eOxO2unSNSpjsJG0HiKCa/2E+zpGirSxIREZEIFjFhbe7cueW/f+211w5aP2jQIAYNGlSTJVWLUFQSAEmGlx93FHJS4wRrCxIREZGIZvndoPWN6U4CIBEP2/KLrS1GREREIp7CWg0zy0fWPOR4/dYWIyIiIhFPYa2GBeObk3fS9ew0k8ktVlgTERGRyims1bBQfBNKz5jAerMZBSUBq8sRERGRCKewVtNME0f2TzQzsin0KayJiIhI5RTWapphkLzwEm6L/ZS02MrnNhURERGJmEd31CehqCSaGSXs8visLkVEREQinEbWLGC6k0gwvWwv8FHo000GIiIicmgKaxYIuZOIMwsBWL45z9piREREJKIprFnAjEoi1VY2Mf2K3/KsLUZEREQimq5Zs0AgtT1ObJANP+/yWF2OiIiIRDCFNQsU9RwFgOuXz9iuKadERESkEjoNahXTJDXGSb4ejCsiIiKVUFizQNRP82kwozXntzQImbDHW2p1SSIiIhKhFNYsYDqjMUIBzmxqB2B9ttfiikRERCRSKaxZIOROAqBZdNlDcT/fuMfCakRERCSSKaxZwIxKAiDFKBtR+2ZLnnXFiIiISERTWLPAvpE1e2k+MS47Ows17ZSIiIhUTGHNAqY7EQCbr4BG8W68pUFCpmlxVSIiIhKJFNYsYLoT2X3zrxSffANtUmMA+Cmr0OKqREREJBIprFnBMMARDUCXZmWjbF9vzrGyIhEREYlQCmsWifv0HmKWP0mvjBQA8or1cFwRERE5mMKaRRx71uHc+R1NEqNpkhhFTpHf6pJEREQkAimsWSSY0hbH7h/BNGmS4OaH7QVWlyQiIiIRSGHNIv70rthKcrAVbKHYH2RnoY/i0qDVZYmIiEiEUViziL9RVwCcWStp1zAOgBW/51pZkoiIiEQghTWLBFPaEXLG4sxaRdfmSQCs+C3f2qJEREQk4jisLqDestnJu/wtgomtOC3kAmCtnrUmIiIif6KwZqFg2kkAxANOm8HWvGJrCxIREZGIo9OgFrLlbyHh3zfj2LmaFinRlAZDVpckIiIiEUZhzUKmMxb3hg9wbvuKfu0bUugL4vHp4bgiIiLyB4U1C5kxDQgmtMS5cxWt984RquetiYiIyP4U1izmT++KI2sVcU47AP9Zt8viikRERCSSKKxZzN+oK/ainXRJ8gLw626vxRWJiIhIJFFYs1ggvezhuDG7viPaaSOroMTiikRERCSSKKxZLJB6InmXvomvZV/S4tx4fEFM07S6LBEREYkQCmtWszvxNzsdXLFkpMZgAuuzdSpUREREyiisRQDn9uXEf3wb3ZtGA7A2y2NxRSIiIhIpFNYigFG8h6hf36F/WjYAnlI9a01ERETKKKxFgH03GaTk/UBytIOfdmiOUBERESmjsBYBQrHpBOOa4Nj5HSETlm7YY3VJIiIiEiEU1iKEv1FXnFmrSE9wUxII4dc8oSIiIoLFYc3v9zNq1CgyMzMZOHAgixcvZsuWLQwePJjMzEzGjx9PKFQWWhYsWMCAAQMYNGgQS5YssbLsahFI74q98HdOSS4FYOXvedYWJCIiIhHBYeXO3333XZKSknjyySfJzc3l8ssvp3379owYMYKePXsybtw4Fi9eTOfOnZk7dy4LFy7E5/ORmZnJ6aefjsvlsrL8KuVrcxGB1BM4IbcJ/LyFb7bk8f9apVhdloiIiFjM0rB2/vnn069fv/Kf7XY7a9asoUePHgD06dOHL774ApvNRpcuXXC5XLhcLlq0aMG6devo1KlTpe8fCoUoKiqqdJvi4srX1xh7MqSeQscYP7CF/23PO2ztNS1iehXh1KfwqVfhU6/Coz6FT70KT832Kb7CpZaeBo2NjSUuLg6Px8Mdd9zBiBEjME0TwzDK1xcWFuLxeIiPjz/gdR5P3XsWWcymj2i1bgZOm8GeIr/V5YiIiEgEsHRkDWDHjh3cdtttZGZm0r9/f5588snydV6vl4SEBOLi4vB6vQcs3z+8HYrNZiMmJiasOsLdrjrF5vxA9E/zOL3l+WzJ90dETRWJ1LoijfoUPvUqfOpVeNSn8KlX4bGyT5aOrGVnZzN06FBGjRrFwIEDATjxxBNZvnw5AMuWLaNbt2506tSJlStX4vP5KCwsZMOGDbRt29bK0qtFIL0rRqCE0+Ky2JJThM8ftLokERERsZilI2szZsygoKCA6dOnM336dAAefPBBJk6cyJQpU8jIyKBfv37Y7XaGDBlCZmYmpmkycuRI3G63laVXC3+jsofjtiheQ4hufPprNhec2MjiqkRERMRKhmmaptVFVBe/P0heXuUXBu67iD8ihoFNk9SXu7I1uSd9NmZySYdGjO3XzuqqykVUryKY+hQ+9Sp86lV41KfwqVfhqck+paVF4A0G8ieGgT+9K028awD4ZZf3MC8QERGRus7yGwzkQEVdbsHwF+H+l40dBSVWlyMiIiIWU1iLMIHG3QFoEPsN2wtKDniUiYiIiNQ/Og0agaJ+fJVBMSsxTdier9E1ERGR+kxhLQJFrZnHVcYiALK9pRZXIyIiIlZSWItAgfRTSCv8ERshNmTrJgMREZH6TGEtAvkbdcXu99LWvp1/fr/D6nJERETEQgprESiQXvZw3J729WzNK7a4GhEREbGSwloECia2JuROoqdrI8X+EP5gyOqSRERExCIKa5HIMPD0fpg1DS4C4MftBRYXJCIiIlZRWItQvnZXkHh8LwC+3pJrcTUiIiJiFYW1CGWUFtLf9wHtjd/4cUeh1eWIiIiIRRTWIpVpkv7Nw/R3f0dqrMvqakRERMQiCmsRynQnEExpy6mujWzOKbK6HBEREbGIwloE8zfqQtvAOn7eVUhhScDqckRERMQCCmsRLJDelbhQIS3JYrluMhAREamXFNYimL/RKQB0MX7l29/zrC1GRERELKGwFsGCKceT23UEa8xWrNvpsbocERERsYDCWiQzbAROvYdNtpZszy+xuhoRERGxgMJahLN5tnNj1KeUlhRimqbV5YiIiEgNU1iLcI7stdwbnEVHNuELaI5QERGR+kZhLcL507sC0MX2K1tyiy2uRkRERGqawlqEM6OSKY5rSRfbr3ywJsvqckRERKSGKazVAmaTbnSxrWf5Zj1rTUREpL5RWKsFgo1PIc3Ix+HZanUpIiIiUsMU1moBf7NezHVcSX6pQSCkO0JFRETqE4W1WiCYlMHSJsPYSQrrsgqtLkdERERqkMJaLXFmSh7n277hK123JiIiUq8orNUS55R+wnPOqTjxWV2KiIiI1CCFtVoiqkUPXEaQqD0/WV2KiIiI1CCFtVoiuPfhuOa2by2uRERERGqSwlotEYptxE6jIRmla/H4/FaXIyIiIjVEYa0W2RZ7El1s61n1e77VpYiIiEgNUVirRQpbX8TbwdP5dku21aWIiIhIDXFYXYCEL73bAK5d0YROu0qsLkVERERqiEbWapGUGBcn2LeSlPuD1aWIiIhIDdHIWi3zlHs2AdMArrG6FBEREakBGlmrZXKST6ZdaANBvx6OKyIiUh8orNUyJWmdiTL8rP9phdWliIiISA1QWKtl7E27A7Dtp88srkRERERqgq5Zq2WOzzie7YtSuGDPy1z0Ul/apMUxmP9warsWBFPa4kvIwB4VZ3WZIiIiUkUU1mqZKAc87xxCg+LNFOfv4r/5xTztfomErQUAhEyD7UYa250tebflGFo1aUL7mELaNG2KIyrW4upFRETkSCmsRbpSL86d3+Hc8Q3OHStwZq3k4UAROOF25zv4DRc5tlR+ojGeoINgKES04SPN9xtfrfmFf/yYy8vOJ2hkX0uOszGbjGZk2Rvji25MVrMLaZTegowkO02S43E4dDiIiIhEmlrzr3MoFOKhhx7i559/xuVyMXHiRFq2bGl1WVXO8O7CmbWiLJjtWIFj948YZhATg0CDEyk5YRD+xt0xHTHYCrdi92wjsXA7KYVbsXm2YfPuwsAEYLF7FAAeYskxkgn4S2hj/sTJrMJVHGDczmIWhdqQaV9ER8eXZNsasNNIY7uZSqGzEeuSziCQ1oE2iTZObBhNanwsTrsucxQREalJtSasLVq0iNLSUt58801Wr17NY489xgsvvGB1WcfGNLHnbfhj1Gz7N9gLtpStckThb9SFolOG42/cnUCjrpjuhMO/Z7AUmzcLe+FWbIXbsXu2YS/cRkLhtrIwV7gNWyAAwATnKwe8tFFoJw3I5iTTxBkMsnLHKlZvO46G7KGn4xu8phsv0RSbTkpw87V5Ev+iL/G2Eq6zf4w9Kg6fEcVuv4tSewweRxqr4vsS5XbRMbSO5okubHYne4qD2GwO7E47RfHH4XK5SAjm0TgmhNvpwm8aGDY7bpcTV3QC0e4o7EYIuxnAZneAYSv7HwYYRlV/KyIiIhHFME3TtLqIcEyePJlOnTpx0UUXAdC7d28++6zyOyJ9Pj9ZWTmVblNcXARAdHTMEdcUs+lDEtbMOeLXlTFxFPyG3ZcLQNCdjK/RKZQ0OgVfo26UppwAdtdRvndluzUxAl7sJTnYSnL3/ppz0K+2oj2YxXtw+HJxho5tequgaWDDrDBXFZkuQthwU4rTCFW43o8DJwFijNIK1xcQi40QaeTvHVP8Y0d+7OwwUwFoYmRjN0Jl600T9o5BbjNTCeKggZFPjLH3s5r7fjHYbSZSRBTxFJFiK8TYt3rvNoVEk2Mm4CRAE2PPH7s3/6hhm5kGQHNj194a9paw129mQ4I4SDNyiftTDQA7zSS8RJOAlwa2gvLlZnkNMWSbiTgJ0NzYXV6DWV6Dg617a2hp7Kywht/NhgSx09DIJbaCGrJJ+KMPRuFBNXiJJpd4HARIJ6f8+963PoCDLFLKvguyK6whi1RC2EihgGjDV9br/dbnEYsPF9GUkGgU/bFi7zbFuCkkBjtBUik46LsIYCeXeABSycdmmPvVYOytIYUgdpIpIMbwAQbm3uMFYNd+30Xqft/Fvn14iCZnbx+asAfDKDtiDt2HfTXs+6AG20glhJ1U8ok1fAf1ad93EUcRKYbnoGPSQxQ5JOyt4eDvwo+dHTQAoCm7y7+LP457+N1MI4SdNCPvgONhXyf2/bmIo4hU2x/Hw/5/LnLLa6j4z0VlNQD8bjYghJ0GRl55H/Zff9gazGhyqPzP5tHWsG+TfcdDPF7SDnk8JODAv/d42Lt6v2Ny197jIZ09Ff652E4DgnuPh5hq6sNOUrBh0ni/Y3L/InKJwwBiKcZlBA6qoZAYSnDhppR4o5h9f7/u61VZHxKxm0GaGNkH9aEUJ7+bDQFoZWRhN4IH7WOj2RhsDo535WEPeA78ECaE3ImYdheG34vN7/nT602wOTDtbkzA5t/794dR/n+Yhp1QdCoYNmxFuzHMUNk/F4AvqR27Lv0X1a1ly0YVLq81I2sej4e4uD/ucrTb7QQCAUuvszLtbkLOo7/zsrj5WeUBLZDQumZGiQwD0xlHwBkH8S3Ce0mgGFtJDv78HdiCPqIcNjADGEE/hPwYIT9GKIAR8kPQD8ESQj4vQX8JPpz4/aW4PFuJdZiYoSD5xX5CoRAhM0SuM52AaSO+dCcp9hIMTIr9fgKBEJghdtnS8BixJITyaWZk4zAgGAriDwbBhAIjnl22NNxmMW3M33HZDEwzRGkwhIFJKQ422faeLg+5iLGX/QVQGgyV/yHeaGtJ0HDgM7NItXkxgEDILP/Hc5utEQVGPMlmPoaRjc2AoGkSDJWtzzUS2WE0xGWWEoWJ3TAwMQns/Xvfh5PfbGW9jjEDRNnLVgSCZvnfI9uNJgQNB4Zpw7R5MQwIhkxCe2vYbaRRYMTjM/Nx2QxshkFo/xpIZIctDZdZSoJRurcGCIRCe2twscPWGIAE00eUbW8NIZN9Veww0gkYTmymjZDNCwYEQ5TXsI3G5BkJpJh52Gy79/aB8hpySGKb0Qi36cNtgN0GmODfu96Hi/VGawBcZqisD+a+Gsr8SgZ+w0FLczsN7J6938UfNWymKblGIqlmLq1sO8v7ENi7j2xS+M1oTJTpo6OxAbutrA/+YNn6Elz8ZBwPmJxs/ky0PQSYBIIm+w6In2lD0LDTwtxOms2z97sI7f1HxWSnkUa+kUCRmY9z73cRDJns+0+NPSSy3WiEy/QRY4Sw2YyD+vDrfn2I3ns8+IN/fBebaEnAcOA3t9Og/HgIsfct2Epj8o14Usw87LbdBx0POSSWfxcxRqisD/v1yYeLzca+Y9Jffkz69+vDNqMpAcMBe48HY9/nNP84XvbV4LTZ9vsuKK9he3kNARw2A/NPfdhXQ7Tp/1Mfyv6p32o0I2A4ME0HIZsHwzAO+LNZYQ0hk+Dez5BjJLHdaPinGkz85X82j66G/b+LXfv92XTbDGxAyIS9UeOg76Ki42GdkQGA3aS8hkAwVP7nYuPe4yFgbqeBzQP71WBgHmUfyv5+MAEfbtYbGYQw9tZQ9vlLgybm3iCz2jiBUsNFhvk76fYCDMPAHwwR2vs5NhnNyDMSaBjaQ4ZtB3aDvcdkqLwPO4yGRJslxBule49J9h6TJqW42G0rC2spZhFuewgD8Af/+I/4PCOVKLeLQJQT/O4//s00DEwM/IltCEU3wFa8G2fBFvadfTH3/hqMbYw/6TiMUi/uXd+WfTLzj2PetEdR2qADYOLe9R0E/RiYZf+mxFt72VWtGlk7+eSTufDCCwHo06cPy5Ytq/Q1fn+QvLyiSrcpKipbHxNz5CNr9Y16FR71KXzqVfjUq/CoT+FTr8JTk31KS4uvcHmtuVq8a9eu5eFs9erVtG3b1uKKRERERKpfrTkNeu655/LFF1/wl7/8BdM0efTRR60uSURERKTa1ZqwZrPZmDBhgtVliIiIiNSoWnMaVERERKQ+UlgTERERiWAKayIiIiIRTGFNREREJIIprImIiIhEMIU1ERERkQimsCYiIiISwRTWRERERCKYwpqIiIhIBFNYExEREYlghmmaptVFiIiIiEjFNLImIiIiEsEU1kREREQimMKaiIiISARTWBMRERGJYAprIiIiIhFMYU1EREQkgjmsLsBKoVCIhx56iJ9//hmXy8XEiRNp2bKl1WVFpMsuu4z4+HgAmjVrxuTJky2uKPJ8//33PPXUU8ydO5ctW7Zw3333YRgGxx9/POPHj8dm038bwYF9WrNmDbfccgutWrUCYPDgwVx44YXWFhgB/H4/DzzwANu2baO0tJRbb72V4447TsdUBSrqVXp6uo6rCgSDQcaMGcOmTZuw2+1MnjwZ0zR1XP1JRX0qLCy09Jiq12Ft0aJFlJaW8uabb7J69Woee+wxXnjhBavLijg+nw+AuXPnWlxJ5Jo1axbvvvsu0dHRAEyePJkRI0bQs2dPxo0bx+LFizn33HMtrtJ6f+7TTz/9xPXXX8/QoUMtriyyvPvuuyQlJfHkk0+Sm5vL5ZdfTvv27XVMVaCiXt122206riqwZMkSAObPn8/y5cvLw5qOqwNV1Ke+fftaekzV6/i8cuVKevfuDUDnzp358ccfLa4oMq1bt47i4mKGDh3KNddcw+rVq60uKeK0aNGCqVOnlv+8Zs0aevToAUCfPn348ssvrSotovy5Tz/++CP//e9/ufrqq3nggQfweDwWVhc5zj//fO68887yn+12u46pQ6ioVzquKnbOOefwyCOPALB9+3YaNGig46oCFfXJ6mOqXoc1j8dDXFxc+c92u51AIGBhRZEpKiqKG264gdmzZ/Pwww9zzz33qE9/0q9fPxyOPwaqTdPEMAwAYmNjKSwstKq0iPLnPnXq1Il7772XefPm0bx5c6ZNm2ZhdZEjNjaWuLg4PB4Pd9xxByNGjNAxdQgV9UrH1aE5HA5Gjx7NI488Qr9+/XRcHcKf+2T1MVWvw1pcXBxer7f851AodMA/JFKmdevWXHLJJRiGQevWrUlKSmL37t1WlxXR9r/mw+v1kpCQYGE1kevcc8+lQ4cO5b//6aefLK4ocuzYsYNrrrmGSy+9lP79++uYqsSfe6XjqnKPP/44//nPfxg7dmz5ZS6g4+rP9u9Tr169LD2m6nVY69q1K8uWLQNg9erVtG3b1uKKItM///lPHnvsMQB27tyJx+MhLS3N4qoi24knnsjy5csBWLZsGd26dbO4osh0ww038MMPPwDw1VdfcdJJJ1lcUWTIzs5m6NChjBo1ioEDBwI6pg6lol7puKrY22+/zYsvvghAdHQ0hmHQoUMHHVd/UlGfhg8fbukxVa8nct93N+gvv/yCaZo8+uijtGnTxuqyIk5paSn3338/27dvxzAM7rnnHrp27Wp1WRFn69at3HXXXSxYsIBNmzYxduxY/H4/GRkZTJw4EbvdbnWJEWH/Pq1Zs4ZHHnkEp9NJgwYNeOSRRw64NKG+mjhxIh999BEZGRnlyx588EEmTpyoY+pPKurViBEjePLJJ3Vc/UlRURH3338/2dnZBAIBhg0bRps2bfR31Z9U1KfGjRtb+ndVvQ5rIiIiIpGuXp8GFREREYl0CmsiIiIiEUxhTURERCSCKayJiIiIRDCFNREREZEIpifAikid17dvX7Zt21bhuuOPP57333+/2mto164dTzzxBJdeemm170tE6haFNRGpF4YNG8a111570HLNWiIikU5/S4lIvRATE6OZN0SkVtI1ayJS723dupV27drx3nvvccEFF3DyySczZMgQfv755/JtAoEAs2bN4rzzzqNjx47079+fDz/88ID3Wbp0KVdeeSUnn3wyffv25aWXXjpg/YYNGxgyZAgdO3akb9++/POf/6yRzycitZvCmojIXo899hgjRozgn//8J/Hx8Vx//fUUFhaWr5s9ezZ33XUX7777LhdddBF33XUX//nPfwD47rvvuOWWWzj99NN5++23uf/++5k2bRoLFiwof/958+YxePBgPvzwQ/r27cvYsWP5/fffLfmsIlJ7aLopEanz+vbty65du3A6nQetu++++zj99NM5++yzGTNmDEOGDAGgsLCQPn36MHr0aC6++GJ69uzJuHHjuOqqq8pfO2LECH7//XcWLlzIXXfdxe7du5k7d275+rfffhu73U7//v1p164dt9xyCyNHjgQgPz+fHj16MHXqVM4777xq7oCI1Ga6Zk1E6oWrr76azMzMg5anpKSQn58PQPfu3cuXx8fH06ZNG3755Rc2btxIIBCga9euB7y2e/fufPrppwD88ssv9OnT54D1l1122QE/t2rVqvz3iYmJAJSUlBz1ZxKR+kFhTUTqhcTERFq2bFnhun1h7c8jb6FQCJvNhsvlqvB1wWCw/G7ScO4qtdkOvvJEJzdE5HB0zZqIyF4//vhj+e/z8/PZtGkTJ5xwAq1atcLpdLJy5coDtl+5ciXHHXccAG3atDng9QB/+9vf+Otf/1r9hYtInaaRNRGpF4qKiti9e3eF6/aNbk2ZMoXU1FQaNmzI008/TXJyMhdccAFRUVFcf/31PPPMMyQlJdG+fXs+/vhjPv74Y6ZMmQLA0KFDGThwINOnT+eiiy5i3bp1vPrqqzz44IM19hlFpG5SWBORemHWrFnMmjWrwnX7HqExaNAgJkyYwK5du+jRowevvPIKMTExANx5553YbDYeffRRcnNzadOmDVOmTOGCCy4A4KSTTmLq1Kk899xzTJ8+nfT0dEaOHMnAgQNr5gOKSJ2lu0FFpN7bunUrZ599NvPmzaNbt25WlyMicgBdsyYiIiISwRTWRERERCKYToOKiIiIRDCNrImIiIhEMIU1ERERkQimsCYiIiISwRTWRERERCKYwpqIiIhIBFNYExEREYlg/x/95ioavjW7OwAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"fig = plt.figure(figsize=(10,6))\n",
"sns.set_style(style='dark')\n",
"ax = sns.lineplot(x='epoch', y='loss',\n",
" style='split',\n",
" hue='model',\n",
" data=loss_learning_curves)\n",
"ax.set_title('Loss Learning Curves', fontdict={'fontsize': 16})\n",
"ax.grid(visible=True, which='major', color='black', linewidth=0.075)\n",
"ax.grid(visible=True, which='minor', color='black', linewidth=0.075)\n",
"ax.set_xlabel(\"Epoch\", fontsize = 15)\n",
"ax.set_ylabel(\"Loss\", fontsize = 15);"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "11855d06-552d-4bc2-ba74-668422aace0c",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "base39",
"language": "python",
"name": "base39"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: examples/class_imbalance/standard_model_config.yaml
================================================
input_features:
- name: Gender
type: category
- name: Age
type: number
- name: Driving_License
type: binary
- name: Region_Code
type: number
- name: Previously_Insured
type: binary
- name: Vehicle_Age
type: category
- name: Vehicle_Damage
type: category
- name: Annual_Premium
type: number
- name: Policy_Sales_Channel
type: number
- name: Vintage
type: number
output_features:
- name: Response
type: binary
trainer:
learning_rate: 0.0001
learning_rate_scheduler:
decay: exponential
decay_rate: 0.9
decay_steps: 30000
staircase: True
epochs: 50
================================================
FILE: examples/forecasting/README.md
================================================
- Download and unpack hourly weather data from https://www.kaggle.com/selfishgene/historical-hourly-weather-data
- `ludwig train --config config.yaml --dataset temperature.csv`
- `ludwig forecast -n 10 --model_path results/experiment_run/model --dataset temperature.csv`
================================================
FILE: examples/forecasting/config.yaml
================================================
input_features:
- name: Seattle
type: timeseries
preprocessing:
window_size: 10
encoder:
type: passthrough
output_features:
- name: Seattle_next
type: timeseries
column: Seattle
preprocessing:
horizon: 2
combiner:
type: concat
flatten_inputs: true
preprocessing:
split:
type: datetime
column: datetime
================================================
FILE: examples/getting_started/rotten_tomatoes.yaml
================================================
input_features:
- name: genres
type: set
preprocessing:
tokenizer: comma
- name: content_rating
type: category
- name: top_critic
type: binary
- name: runtime
type: number
- name: review_content
type: text
encoder:
type: embed
output_features:
- name: recommended
type: binary
trainer:
epochs: 3
================================================
FILE: examples/getting_started/run.sh
================================================
#!/usr/bin/env bash
# Fail fast if an error occurs
set -e
# Get the directory of this script, which contains the config file
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
# Download the data
wget https://ludwig.ai/latest/data/rotten_tomatoes.csv
wget https://ludwig.ai/latest/data/rotten_tomatoes_test.csv
# Check the first 5 rows
head -n 5 rotten_tomatoes.csv
# Train
ludwig train --config ${SCRIPT_DIR}/rotten_tomatoes.yaml --dataset rotten_tomatoes.csv
# Predict and Evaluate
ludwig predict --model_path results/experiment_run/model --dataset rotten_tomatoes_test.csv
================================================
FILE: examples/hyperopt/README.md
================================================
# Hyperparameter Optimization
Demonstrates hyperparameter optimization using Ludwig's in-built capabilities.
### Preparatory Steps
- Create `data` directory
- Download [Kaggle wine quality data set](https://www.kaggle.com/rajyellow46/wine-quality) into the `data` directory. Directory should
appear as follows:
```
hyperopt/
data/
winequalityN.csv
```
### Description
Jupyter notebook `model_hyperopt_example.ipynb` demonstrates several hyperparameter optimization capabilities. Key features demonstrated in the notebook:
- Training data is prepared for use
- Programmatically create Ludwig config dictionary from the training data dataframe
- Setup parameter space for hyperparameter optimization
- Perform two hyperparameter runs
- Parallel workers using random search strategy
- Serial processing using random search strategy
- Parallel workers using grid search strategy (Note: takes about 35 minutes)
- Demonstrate various Ludwig visualizations for hyperparameter optimization
================================================
FILE: examples/hyperopt/model_hyperopt_example.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Hyperparameter Optimization In Ludwig\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Demonstrates hyper-parameter tuning capabilities of Ludwig. The following steps occur in this notebook:\n",
"* Training data is prepared for use\n",
"* Programmatically create Ludwig config dictionary from the training data dataframe\n",
"* Setup parameter space for hyperparameter optimization\n",
"* Perform two hyperparameter runs\n",
" * Parallel workers using random search strategy\n",
" * Serial processing using random search strategy\n",
" * Parallel workers using grid search strategy\n",
"* Demonstrate various Ludwig visualizations for hyperparameter optimization"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Import required libraries"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"pycharm": {
"is_executing": false
}
},
"outputs": [],
"source": [
"import warnings\n",
"warnings.simplefilter('ignore')\n",
"\n",
"import shutil\n",
"import datetime\n",
"\n",
"import pandas as pd\n",
"import numpy as np\n",
"\n",
"from ludwig.hyperopt.run import hyperopt\n",
"from ludwig.visualize import hyperopt_results_to_dataframe, hyperopt_hiplot_cli, hyperopt_report_cli\n",
"\n",
"from sklearn.model_selection import train_test_split"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Retrieve data for training"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(6497, 13)"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_df = pd.read_csv('./data/winequalityN.csv')\n",
"train_df.shape"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Standardize column names to replace spaces(\" \") with underscore(\"_\")"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"new_col = []\n",
"for i in range(len(train_df.columns)):\n",
" new_col.append(train_df.columns[i].replace(' ', '_'))\n",
" \n",
"train_df.columns = new_col"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Data Set Overview"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"type object\n",
"fixed_acidity float64\n",
"volatile_acidity float64\n",
"citric_acid float64\n",
"residual_sugar float64\n",
"chlorides float64\n",
"free_sulfur_dioxide float64\n",
"total_sulfur_dioxide float64\n",
"density float64\n",
"pH float64\n",
"sulphates float64\n",
"alcohol float64\n",
"quality int64\n",
"dtype: object"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_df.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create training and test data sets"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"3 30\n",
"4 216\n",
"5 2138\n",
"6 2836\n",
"7 1079\n",
"8 193\n",
"9 5\n",
"Name: quality, dtype: int64"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_df['quality'].value_counts().sort_index()"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"categorical variables: ['type'] \n",
"\n",
"numerical variables: ['sulphates', 'fixed_acidity', 'total_sulfur_dioxide', 'density', 'pH', 'residual_sugar', 'free_sulfur_dioxide', 'alcohol', 'citric_acid', 'volatile_acidity', 'chlorides'] \n",
"\n"
]
}
],
"source": [
"# isolate the predictor variables only\n",
"predictor_vars = list(set(train_df.columns) - set(['quality']))\n",
"\n",
"#extract categorical variables\n",
"categorical_vars = []\n",
"for p in predictor_vars:\n",
" if train_df[p].dtype == 'object':\n",
" categorical_vars.append(p)\n",
" \n",
"print(\"categorical variables:\", categorical_vars,'\\n')\n",
"\n",
"# get numerical variables\n",
"numerical_vars = list(set(predictor_vars) - set(categorical_vars))\n",
"\n",
"print(\"numerical variables:\", numerical_vars,\"\\n\")"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" count mean std min 25% \\\n",
"fixed_acidity 6487.0 7.216579 1.296750 3.80000 6.40000 \n",
"volatile_acidity 6489.0 0.339691 0.164649 0.08000 0.23000 \n",
"citric_acid 6494.0 0.318722 0.145265 0.00000 0.25000 \n",
"residual_sugar 6495.0 5.444326 4.758125 0.60000 1.80000 \n",
"chlorides 6495.0 0.056042 0.035036 0.00900 0.03800 \n",
"free_sulfur_dioxide 6497.0 30.525319 17.749400 1.00000 17.00000 \n",
"total_sulfur_dioxide 6497.0 115.744574 56.521855 6.00000 77.00000 \n",
"density 6497.0 0.994697 0.002999 0.98711 0.99234 \n",
"pH 6488.0 3.218395 0.160748 2.72000 3.11000 \n",
"sulphates 6493.0 0.531215 0.148814 0.22000 0.43000 \n",
"alcohol 6497.0 10.491801 1.192712 8.00000 9.50000 \n",
"quality 6497.0 5.818378 0.873255 3.00000 5.00000 \n",
"\n",
" 50% 75% max \n",
"fixed_acidity 7.00000 7.70000 15.90000 \n",
"volatile_acidity 0.29000 0.40000 1.58000 \n",
"citric_acid 0.31000 0.39000 1.66000 \n",
"residual_sugar 3.00000 8.10000 65.80000 \n",
"chlorides 0.04700 0.06500 0.61100 \n",
"free_sulfur_dioxide 29.00000 41.00000 289.00000 \n",
"total_sulfur_dioxide 118.00000 156.00000 440.00000 \n",
"density 0.99489 0.99699 1.03898 \n",
"pH 3.21000 3.32000 4.01000 \n",
"sulphates 0.51000 0.60000 2.00000 \n",
"alcohol 10.30000 11.30000 14.90000 \n",
"quality 6.00000 6.00000 9.00000 "
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"train_df.describe().T"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"unique values for type is 2\n"
]
}
],
"source": [
"for p in categorical_vars:\n",
" print(\"unique values for\",p,\"is\",train_df[p].nunique())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create config"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"# template for config\n",
"config = {'input_features':[], 'output_features': [], 'trainer':{}}\n",
"\n",
"# setup input features for categorical variables\n",
"for p in categorical_vars:\n",
" a_feature = {'name': p.replace(' ','_'), 'type': 'category', 'representation': 'sparse'}\n",
" config['input_features'].append(a_feature)\n",
"\n",
"\n",
"# setup input features for numerical variables\n",
"for p in numerical_vars:\n",
" a_feature = {'name': p.replace(' ','_'), 'type': 'number', \n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean', 'normalization': 'zscore'}}\n",
" config['input_features'].append(a_feature)\n",
"\n",
"# set up output variable\n",
"config['output_features'].append({'name': 'quality', 'type':'category'})\n",
"\n",
"# set up trainer\n",
"config['trainer'] = {'epochs': 20}"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"config:\n"
]
},
{
"data": {
"text/plain": [
"{'input_features': [{'name': 'type',\n",
" 'type': 'category',\n",
" 'representation': 'sparse'},\n",
" {'name': 'sulphates',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'fixed_acidity',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'total_sulfur_dioxide',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'density',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'pH',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'residual_sugar',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'free_sulfur_dioxide',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'alcohol',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'citric_acid',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'volatile_acidity',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'chlorides',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}}],\n",
" 'output_features': [{'name': 'quality', 'type': 'category'}],\n",
" 'trainer': {'epochs': 20}}"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# View the config\n",
"print(\"config:\")\n",
"config"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define hyperparameter search space"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [],
"source": [
"SEED=13\n",
"\n",
"hyperopt_configs = {\n",
" \"parameters\": {\n",
" \"trainer.learning_rate\": {\n",
" \"type\": \"float\",\n",
" \"space\": \"loguniform\",\n",
" \"lower\": 0.0001,\n",
" \"upper\": 0.01,\n",
" \"q\": 3,\n",
" },\n",
" \"trainer.batch_size\": {\n",
" \"type\": \"int\",\n",
" \"space\": \"qlograndint\",\n",
" \"base\" : 2,\n",
" \"lower\": 32,\n",
" \"upper\": 256,\n",
" \"q\": 5,\n",
" },\n",
" \"quality.fc_size\": {\n",
" \"type\": \"int\",\n",
" 'space': 'qrandint',\n",
" \"lower\": 32,\n",
" \"upper\": 256,\n",
" \"q\": 5,\n",
" },\n",
" \"quality.num_fc_layers\": {\n",
" 'type': 'int',\n",
" 'space': 'qrandint',\n",
" 'lower': 1,\n",
" 'upper': 5,\n",
" 'q': 4,\n",
" }\n",
" },\n",
" \"goal\": \"minimize\",\n",
" 'output_feature': \"quality\",\n",
" 'validation_metrics': 'loss'\n",
"}\n",
"\n",
"# add hyperopt parameter space to the config\n",
"config['hyperopt'] = hyperopt_configs"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Train with optimal hyperparameters on the whole data set"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
"# clean out old results\n",
"shutil.rmtree('./results_ray', ignore_errors=True)\n",
"shutil.rmtree('./results_random_serial', ignore_errors=True)\n",
"shutil.rmtree('./visualizations', ignore_errors=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Random Search with ray executors\n",
"\n",
"This executor will use a local run cluster with 3 samples (should take less than 30 seconds)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{ 'executor': {'time_budget_s': 1000, 'type': 'ray'},\n",
" 'goal': 'minimize',\n",
" 'metric': 'loss',\n",
" 'output_feature': 'quality',\n",
" 'parameters': { 'quality.fc_size': { 'lower': 32,\n",
" 'q': 5,\n",
" 'space': 'qrandint',\n",
" 'type': 'int',\n",
" 'upper': 256},\n",
" 'quality.num_fc_layers': { 'lower': 1,\n",
" 'q': 4,\n",
" 'space': 'qrandint',\n",
" 'type': 'int',\n",
" 'upper': 5},\n",
" 'trainer.batch_size': { 'base': 2,\n",
" 'lower': 32,\n",
" 'q': 5,\n",
" 'space': 'qlograndint',\n",
" 'type': 'int',\n",
" 'upper': 256},\n",
" 'trainer.learning_rate': { 'lower': 0.0001,\n",
" 'q': 3,\n",
" 'space': 'loguniform',\n",
" 'type': 'float',\n",
" 'upper': 0.01}},\n",
" 'sampler': {'num_samples': 3, 'type': 'ray'},\n",
" 'split': 'validation',\n",
" 'validation_metrics': 'loss'}\n",
"\n",
"\n",
"Initializing new Ray cluster...\n",
"CPU times: user 492 ms, sys: 207 ms, total: 699 ms\n",
"Wall time: 12 s\n"
]
}
],
"source": [
"%%time\n",
"%%capture\n",
"print(\"starting:\", datetime.datetime.now())\n",
"config['hyperopt']['executor'] = {'type': 'ray', 'time_budget_s': 1000}\n",
"config['hyperopt']['sampler'] = {'type': 'ray', 'num_samples': 3}\n",
"results_ray = hyperopt(\n",
" config,\n",
" dataset=train_df.sample(4000, random_state=42), # limit number records for demonstration purposes\n",
" output_directory='results_ray' # location to place results\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Random Search with serial executor\n",
"\n",
"Run the serialize executor with 2 samples (should take less then 3 minutes)"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
"hyperopt_configs = {\n",
" \"parameters\": {\n",
" \"trainer.learning_rate\": {\n",
" \"type\": \"float\",\n",
" \"low\": 0.0001,\n",
" \"high\": 0.01,\n",
" \"space\": \"log\",\n",
" \"steps\": 3,\n",
" },\n",
" \"trainer.batch_size\": {\n",
" \"type\": \"int\",\n",
" \"low\": 32,\n",
" \"high\": 256,\n",
" \"space\": \"log\",\n",
" \"steps\": 5,\n",
" \"base\" : 2\n",
" },\n",
" \"quality.fc_size\": {\n",
" \"type\": \"int\",\n",
" \"low\": 32,\n",
" \"high\": 256,\n",
" \"steps\": 5\n",
" },\n",
" \"quality.num_fc_layers\": {\n",
" 'type': 'int',\n",
" 'low': 1,\n",
" 'high': 5,\n",
" 'space': 'linear',\n",
" 'steps': 4\n",
" }\n",
" },\n",
" \"goal\": \"minimize\",\n",
" 'output_feature': \"quality\",\n",
" 'validation_metrics': 'loss'\n",
"}\n",
"\n",
"# add hyperopt parameter space to the config\n",
"config['hyperopt'] = hyperopt_configs"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"starting: 2022-04-09 15:09:04.768901\n",
"Note: steps_per_checkpoint (was 40) is now set to the number of steps per epoch: 40.\n",
"\n",
"Note: steps_per_checkpoint (was 52) is now set to the number of steps per epoch: 52.\n",
"\n",
"CPU times: user 17min 20s, sys: 48 s, total: 18min 8s\n",
"Wall time: 2min 42s\n"
]
}
],
"source": [
"%%time\n",
"print(\"starting:\", datetime.datetime.now())\n",
"config['hyperopt']['executor'] = {'type': 'serial'}\n",
"config['hyperopt']['sampler'] = {'type': 'random', 'num_samples': 2}\n",
"results_random_serial = hyperopt(\n",
" config,\n",
" dataset= train_df.sample(4000, random_state=42), # limit number records for demonstration purposes\n",
" output_directory='hyperopt_results',\n",
" experiment_name='random_serial',\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Note:\n",
"`results_ray`, `results_random_serial` are `HyperoptResults` object with the ordered_trials, so will convert to dictionary to visualize."
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [],
"source": [
"def hyperopt_results_dict(results):\n",
" return [{\"metric_score\": t.metric_score, \"parameters\": t.parameters} for t in results.ordered_trials]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Convert hyperparameter optimization results to dataframe"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Results For Ray executor"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"| \n", " | count | \n", "mean | \n", "std | \n", "min | \n", "25% | \n", "50% | \n", "75% | \n", "max | \n", "
|---|---|---|---|---|---|---|---|---|
| fixed_acidity | \n", "6487.0 | \n", "7.216579 | \n", "1.296750 | \n", "3.80000 | \n", "6.40000 | \n", "7.00000 | \n", "7.70000 | \n", "15.90000 | \n", "
| volatile_acidity | \n", "6489.0 | \n", "0.339691 | \n", "0.164649 | \n", "0.08000 | \n", "0.23000 | \n", "0.29000 | \n", "0.40000 | \n", "1.58000 | \n", "
| citric_acid | \n", "6494.0 | \n", "0.318722 | \n", "0.145265 | \n", "0.00000 | \n", "0.25000 | \n", "0.31000 | \n", "0.39000 | \n", "1.66000 | \n", "
| residual_sugar | \n", "6495.0 | \n", "5.444326 | \n", "4.758125 | \n", "0.60000 | \n", "1.80000 | \n", "3.00000 | \n", "8.10000 | \n", "65.80000 | \n", "
| chlorides | \n", "6495.0 | \n", "0.056042 | \n", "0.035036 | \n", "0.00900 | \n", "0.03800 | \n", "0.04700 | \n", "0.06500 | \n", "0.61100 | \n", "
| free_sulfur_dioxide | \n", "6497.0 | \n", "30.525319 | \n", "17.749400 | \n", "1.00000 | \n", "17.00000 | \n", "29.00000 | \n", "41.00000 | \n", "289.00000 | \n", "
| total_sulfur_dioxide | \n", "6497.0 | \n", "115.744574 | \n", "56.521855 | \n", "6.00000 | \n", "77.00000 | \n", "118.00000 | \n", "156.00000 | \n", "440.00000 | \n", "
| density | \n", "6497.0 | \n", "0.994697 | \n", "0.002999 | \n", "0.98711 | \n", "0.99234 | \n", "0.99489 | \n", "0.99699 | \n", "1.03898 | \n", "
| pH | \n", "6488.0 | \n", "3.218395 | \n", "0.160748 | \n", "2.72000 | \n", "3.11000 | \n", "3.21000 | \n", "3.32000 | \n", "4.01000 | \n", "
| sulphates | \n", "6493.0 | \n", "0.531215 | \n", "0.148814 | \n", "0.22000 | \n", "0.43000 | \n", "0.51000 | \n", "0.60000 | \n", "2.00000 | \n", "
| alcohol | \n", "6497.0 | \n", "10.491801 | \n", "1.192712 | \n", "8.00000 | \n", "9.50000 | \n", "10.30000 | \n", "11.30000 | \n", "14.90000 | \n", "
| quality | \n", "6497.0 | \n", "5.818378 | \n", "0.873255 | \n", "3.00000 | \n", "5.00000 | \n", "6.00000 | \n", "6.00000 | \n", "9.00000 | \n", "
\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" loss trainer.learning_rate trainer.batch_size quality.fc_size \\\n",
"0 1.291179 0.001393 170 60 \n",
"1 1.300332 0.000203 45 100 \n",
"2 1.956202 0.000527 75 45 \n",
"\n",
" quality.num_fc_layers \n",
"0 4 \n",
"1 4 \n",
"2 0 "
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df1 = hyperopt_results_to_dataframe(\n",
" hyperopt_results_dict(results_ray),\n",
" hyperopt_configs['parameters'],\n",
" hyperopt_configs['validation_metrics']\n",
")\n",
"df1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Results for Random Search with serial executor"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"| \n", " | loss | \n", "trainer.learning_rate | \n", "trainer.batch_size | \n", "quality.fc_size | \n", "quality.num_fc_layers | \n", "
|---|---|---|---|---|---|
| 0 | \n", "1.291179 | \n", "0.001393 | \n", "170 | \n", "60 | \n", "4 | \n", "
| 1 | \n", "1.300332 | \n", "0.000203 | \n", "45 | \n", "100 | \n", "4 | \n", "
| 2 | \n", "1.956202 | \n", "0.000527 | \n", "75 | \n", "45 | \n", "0 | \n", "
\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" loss quality.fc_size quality.num_fc_layers trainer.batch_size \\\n",
"0 1.300466 75 4 55 \n",
"1 1.362126 45 1 72 \n",
"\n",
" trainer.learning_rate \n",
"0 0.005918 \n",
"1 0.002479 "
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df2 = hyperopt_results_to_dataframe(\n",
" hyperopt_results_dict(results_random_serial),\n",
" hyperopt_configs['parameters'],\n",
" hyperopt_configs['validation_metrics']\n",
")\n",
"df2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Example Hyperopt Visualizations"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Report results of the a hyperparameter optimization run"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"scrolled": false
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAAsI0lEQVR4nO3df1hUZd4/8PcMyDAwEilIKRpQaiarrLZPGlJamj/ytwiIDLaaWWouat8UQVQMGCx1BZ4VH4M10WQmxHJ7yBKz/JVm6hiY7pOmJKiIPwhBYIaZ+/uHl7MREKgMc6D367q6Luacmc/5nMHpzX3PPWdkQggBIiIiiZHbugEiIqL6MKCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUU20bNnT9y4caPWtuzsbMyaNctGHTUuJSUFubm59e7r2bMnxowZg3HjxmH8+PEYPnw4Jk2ahLy8vBbp7eLFi3jzzTdb5Fi/9uvfWVRUFA4dOgQAiI6ORn5+fpPrLFu2DC+88ALWrl3bbL3l5eVh3rx5zVaPWp69rRsgai2OHDmCJ554osH9H3zwATp06GC5nZaWhnfeeQdardbqvV26dAnnz5+3+nF+T1xcnOXnQ4cOITg4uMmP1Wq1+Oqrr/DII480Wz9/+tOfkJSU1Gz1qOUxoEhyKisr8dxzz0Gn08Hb2xsA8Ne//hVTp05Fbm4uZDIZzp07hxs3bsDf3x/R0dFo164dzp07h7i4OJSWlsJkMkGtViMwMBBHjhxBXFwcnJyccPv2bWRlZWHHjh3IyMiAXC6Hm5sbli5dCm9vbyxevLje+jqdDvn5+Vi1ahXs7OwwbNiw3z2HmpoaXL58GQ899JBl2/r16/HFF1/AbDajS5cuWLZsGTw8PKBWq/H4448jPz8fN2/exLhx4yx/+efm5iIlJQUmkwkqlQqRkZHo06cPkpOTodfrcfXqVXTv3h15eXkoLi7GjBkzkJaWhqioKPj6+mLKlCm1+jIYDIiLi8OhQ4fQsWNH9OrVC5WVldBoNFCr1Zg6dSpGjBgBALVuZ2VlQavVwmg04pdffsHMmTMRGhpaq/bd+58+fRpXr17FW2+9hZUrV2LWrFnYt28f2rdvDyEERowYgXXr1uHJJ58EAISGhkIIgZkzZ2LZsmXo2LEjYmJicOPGDcjlcrzxxhsYNWpUg891RUUFIiMjUVBQALlcjt69eyM2NhZHjx7FypUr8emnn2LGjBm4du0aAOD27du4ePEidu3ahc6dO+O9997D0aNHYTKZ8NRTTyE6Ohoqlaop/1TJ2gSRDfTo0UOMHj1ajB071vLf888/L1577TUhhBDvvPOOSExMFEIIUVBQIJ5//nlRU1MjFi1aJMaPHy/Ky8tFdXW1mDp1qsjIyBBGo1GMGjVK5OfnCyGEKCsrEyNHjhQnTpwQhw8fFk8++aQoLCwUQghx6NAhMXToUHH9+nUhhBDbt28XI0eOFGazucH6QggRFhYmPvvss989nzFjxgh/f3/xwgsviJUrV4pr164JIYTYsWOHiIiIEEajUQghRGZmpnj11VctdWfOnCkMBoP45ZdfxPDhw8WXX34pzp49K5599lnx888/W/r29/cXt27dEklJSWL48OGWeocPHxYvv/xyo897enq6CA8PF9XV1aK8vFyMGzdOLFq0qN7zu3u7vLxcBAUFiRs3bgghhDhx4oTw8/OzPHd3f2e/fvyQIUPE999/L4QQ4o033hBbtmyxnENQUFC9z9/d38f48eMt97906ZJ48cUXxa1btxo8px07dojp06cLIYSoqakRUVFR4sKFC/U+J3d/pxs2bBBCCJGcnCw0Go0wm81CCCFWr14tli1b1ujzSC2DIyiymd9OiWVnZ+Pzzz8HcOev6rCwMMyfPx9arRaBgYGws7MDAEyYMAHOzs4AgHHjxmHPnj0YMGAAfv75ZyxZssRSr6qqCj/88AMef/xxPProo+jSpQsAYP/+/Rg1apTl2BMnTkRcXBwKCwsbrB8WFtbk8/nhhx8wc+ZM/PnPf0bHjh0BAHv37kVeXh4mTZoEADCbzaisrLQ8Njg4GO3atUO7du0wYsQIHDhwAD4+PhgwYAC6du0KABg4cCA6dOhgeW/Hz88P9vb39hI+fPgwRo8eDQcHBzg4OGD8+PE4c+bM7z7G2dkZqamp+Prrr3HhwgWcOXMGt2/fbvIxp06dinfffRdTp06FVqutM6r7tdLSUpw5cwaTJ08GADz66KMNvu93V//+/bF27Vqo1Wo8++yzmDZtGh577DFcuXKl1v3MZjPeeust+Pj44LXXXgMAfPXVV7h165blvTOj0Wj5nZHtMaBIkry9vdGzZ0/s2bMH//rXv/DRRx9Z9t0NKgAQQkAul8NkMsHFxQWffPKJZd+1a9fQvn176PV6ODk51XrMbwkhUFNT02D9e/HUU08hMjIS0dHR6Nu3Lzw9PWE2m/Hqq69apsUMBgN++eUXy2N+HTR3j9lYn78+p6ZSKBS1brdr165O/buMRiMA4MqVKwgODkZQUBD69++PESNGYO/evU0+5rPPPovKykp88803+O6775CYmNjgfe8+DzKZzLLtp59+QufOneHo6FjvY7p27Yrdu3fjyJEjOHz4MP76178iOjoaDz/8cK37xcXFobKystZCDLPZjCVLluD5558HcGe6sLq6usnnRtbFVXwkWaGhoVi1ahX69u0LDw8Py/bPPvsMBoMB1dXV2LFjB4YMGQJvb28oFApLQF2+fBmjR4+udyXZoEGDkJOTY1lFuH37dri6uuKxxx5rsD5wJ7juhkNjRo8eDT8/P8THx1uOmZWVhfLycgDAunXr8Pbbb1vuv3PnTpjNZvzyyy/47LPP8MILL2DAgAE4ePAgLl68CAD45ptvcPnyZfTt27fO8ezs7CyB8nsGDx6M7OxsVFdXw2AwICcnx7Lv16Ozn3/+Gf/+978BAPn5+ejQoQNmz56NgIAASziZTKYGj/Pr50omkyE0NBRRUVEYPXp0nZD8NZVKhd69e+Pjjz8GcOf3OGXKFNy6davBx3z44YeIjIzEoEGD8P/+3//DoEGD8OOPP9a6z//8z//gxIkT+Pvf/17rD5BBgwZh69atMBgMMJvNWLp0KdasWdPgsahlcQRFkjVkyBBER0cjJCSk1nZHR0eEhoairKzMspxbLpfjH//4B+Li4vD++++jpqYGf/vb39C/f38cOXKk1uP9/f3xyiuvYNq0aTCbzejQoQM2bNhgGSnVV/9uP4mJiTAajZgwYUKj/S9duhRjx47F/v37MXnyZBQXFyMoKAgymQyPPvooNBqN5b5VVVUIDAxERUUFQkNDMXDgQAB3ll/PnTsXJpMJjo6OSE1NRfv27escq3v37rCzs0NgYCA++ugjREdH17tIYsKECbh48SImTJgAJyenWlOsb7zxBhYvXoyvv/4aPj4+ePrppy3PV1ZWFkaMGAGlUok+ffqgQ4cOKCgoaPDchw4divnz5+Odd97BoEGDMGHCBCQmJlpW9uXl5SE6OrrWiPeu1atXY8WKFcjIyIBMJkNcXBzc3d0bPNb48ePx7bffYtSoUVAqlejcuTPCw8MtU5fFxcVYvXo1fHx8EBYWBrPZDACYN28eZs+ejcTEREyYMAEmkwm9evXC4sWLGzwWtSyZqG8egUgCjh8/jqVLl+LTTz+1TPksXrwY3bt3x4wZM6xyTGvXr89vV8+1pLS0NPz444+1wtIa/vd//xc7duzA+++/b9XjUNvCERRJ0qJFi/Dtt98iMTGx1vsR1Pqo1Wpcu3YNycnJ910jIiKiwc95rV27Fj4+Pvddm6SLIygiIpIkLpIgIiJJYkAREZEk8T0oAHq9/neXvraU6upqSfRxP1pr7621b6D19t5a+wZab+9S77u6uhp+fn51tjOgcOfDi7169bJ1Gzh9+rQk+rgfrbX31to30Hp7b619A623d6n3ffr06Xq3c4qPiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJXGb+AMxmgQvXK1BcVgUPF0d4dXSGXM7rxhERNQcG1H0ymwV2nbqCBTo9qoxmOLaTY02QH0b0foQhRUTUDDjFd58uXK+whBMAVBnNWKDT48L1Cht3RkTUNjCg7lNxWZUlnO6qMppx9VaVjToiImpbGFD3ycPFEY7taj99ju3k6NTe0UYdERG1LQyo++TV0RlrgvwsIXX3PSivjs427oyIqG3gIon7JJfLMKL3I3hyXgCu3qpCp/ZcxUdE1JwYUA9ALpfBx10FH3eVrVshImpzOMVHRESSxIAiIiJJYkAREZEkMaCIiEiS2vQiiePHj0Or1QIAoqKi4OLiYuOOiIioqdr0CEqn0yE2NhaBgYHIycmxdTtERHQP2nRAmUwmKBQKuLu7o6SkxNbtEBHRPWjTAaVUKmEwGFBSUgI3Nzdbt0NERPfAqgF18uRJqNXqOtsNBgMWLlyIoKAgTJ8+HRcuXHig2mazGTExMQgODoZarUZBQQEAICgoCDExMcjMzMTYsWMf6FyIiKhlWW2RxMaNG7Fz504olco6+3Q6HZycnKDT6fDTTz9h5cqVSEtLs+wvKipCly5d6vzcUO3c3FwYDAZotVro9XpoNBqsX78evr6+0Gg01jpFIiKyIquNoLp164bk5OR69509exbPPfccAMDHxwfnzp2z7KuqqkJERARyc3ORnp6OhISERmsfO3YMAQEBAAA/Pz/k5+c356kQEZENWC2ghg8fDnv7+gdovXr1wt69eyGEgF6vR3FxMUwmEwDA0dERaWlpWLlyJXbt2oW1a9c2Wru8vBwq1X+uh2dnZ4eamppmPiMiImpJNlkkMWnSJKhUKoSGhmL37t3o3bs37OzsAABCCCQlJcHf3x/Ozs7IyspqtJ5KpUJFxX++ydZsNjcYjkRE1DrYJKDy8vIwcOBAbNu2DSNGjEDXrl0t+6qqquDl5YX4+HikpqbCaDQ2Wq9fv37Yt28fAECv16NHjx5W652IiFpGiw0zSktLER0djZSUFDz22GNYt24dUlNT0b59e8TFxVnup1QqERYWBgBQKBQIDw9vtPawYcNw8OBBhISEQAiB+Ph4q50HERG1DKsGlKenJ3Q6HQDA1dUVKSkpAIAOHTpg06ZNzVZbLpcjNjb2geoREZG0tOkP6hIRUevFgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSpDb9tbPHjx+HVqsFAERFRcHFxcXGHRERUVO16RGUTqdDbGwsAgMDkZOTY+t2iIjoHrTpgDKZTFAoFHB3d0dJSYmt2yEionvQpgNKqVTCYDCgpKQEbm5utm6HiIjugVUD6uTJk1Cr1XW2G41GLFy4ECEhIQgNDcW5c+ceqLbZbEZMTAyCg4OhVqtRUFAAAAgKCkJMTAwyMzMxduzYBzsZIiJqUVZbJLFx40bs3LkTSqWyzr6vv/4aNTU1yMzMxMGDB/H3v/8dycnJlv1FRUXo0qVLnZ8bqp2bmwuDwQCtVgu9Xg+NRoP169fD19cXGo3GWqdIRERWZLURVLdu3WqFzq95e3vDZDLBbDajvLwc9vb/ycmqqipEREQgNzcX6enpSEhIaLT2sWPHEBAQAADw8/NDfn5+M58NERG1NKuNoIYPH47CwsJ69zk5OaGoqAgjR47EzZs3kZqaatnn6OiItLQ0jBkzBh4eHti6dWujtcvLy6FSqSy37ezsUFNTUyv4iIiodbHJIolNmzZh0KBB+Pzzz/HJJ59g8eLFqK6uBgAIIZCUlAR/f384OzsjKyur0XoqlQoVFRWW22azmeFERNTK2SSgXFxc0L59ewDAQw89hJqaGphMJgB3pvi8vLwQHx+P1NRUGI3GRuv169cP+/btAwDo9Xr06NHDes0TEVGLaLGAKi0txdy5cwEAr7zyCk6dOoXQ0FBMmzYN8+fPh5OTE4A7S8PDwsIAAAqFAuHh4Y3WHjZsGBwcHBASEoKEhARERkZa70SIiKhFWHUezNPTEzqdDgDg6uqKlJQUAICzszPWrVvXbLXlcjliY2MfrFkiIpKUNv1BXSIiar0YUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkWfULC23t+PHj0Gq1AICoqCi4uLjYuCMiImqqNj2C0ul0iI2NRWBgIHJycmzdDhER3YM2HVAmkwkKhQLu7u4oKSmxdTtERHQP2nRAKZVKGAwGlJSUwM3NzdbtEBHRPbBqQJ08eRJqtbrO9uzsbKjVaqjVagQFBeFPf/oTysrK7ru22WxGTEwMgoODoVarUVBQAAAICgpCTEwMMjMzMXbs2Ac/ISIiajFWWySxceNG7Ny5E0qlss6+iRMnYuLEiQCAFStWYNKkSbUWMBQVFaFLly51fm6odm5uLgwGA7RaLfR6PTQaDdavXw9fX19oNBprnSIREVmR1UZQ3bp1Q3Jy8u/eJy8vD2fPnkVwcLBlW1VVFSIiIpCbm4v09HQkJCQ0WvvYsWMICAgAAPj5+SE/P7+ZzoKIiGzFaiOo4cOHo7Cw8Hfvs2HDBsyZM6fWNkdHR6SlpWHMmDHw8PDA1q1bG61dXl4OlUpluW1nZ4eamhrY27fpVfRERG2azRZJlJWV4fz58xgwYECt7UIIJCUlwd/fH87OzsjKymq0lkqlQkVFheW22WxmOBERtXI2C6ijR49i4MCBdbZXVVXBy8sL8fHxSE1NhdFobLRWv379sG/fPgCAXq9Hjx49mr1fIiJqWS0WUKWlpZg7d67l9vnz5+Hp6VnnfkqlEmFhYQAAhUKB8PDwRmsPGzYMDg4OCAkJQUJCAiIjI5uvcSIisgmrzoN5enpCp9MBAFxdXZGSkmLZ9+qrrzZbbblcjtjY2AeqR0RE0tKmP6hLREStFwOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJMmqX/lua8ePH4dWqwUAREVFwcXFxcYdERFRU7XpEZROp0NsbCwCAwORk5Nj63aIiOgeNCmgiouLcfbsWZw/fx5LlizB6dOnrd1XszCZTFAoFHB3d0dJSYmt2yEionvQpIBauHAhrl27hrVr18Lf3x/x8fHW7qtZKJVKGAwGlJSUwM3NzdbtEBHRPWhSQMlkMvzlL39BWVkZXn75ZcjlTZsZPHnyJNRqdb37NmzYgODgYEycOBEfffRR0zuup7bZbEZMTAyCg4OhVqtRUFAAAAgKCkJMTAwyMzMxduzYez4GERHZTpMWSdTU1ODdd9/F008/jcOHD8NoNDb6mI0bN2Lnzp1QKpV19h05cgQnTpzAtm3bUFlZifT09Fr7i4qK0KVLlzo/N1Q7NzcXBoMBWq0Wer0eGo0G69evh6+vLzQaTVNOkYiIJKZJQ6GEhAR07doVr732Gm7cuIHExMRGH9OtWzckJyfXu+/AgQPo0aMH5syZg9dffx2DBw+27KuqqkJERARyc3ORnp6OhISERmsfO3YMAQEBAAA/Pz/k5+c35bSIiEjCmjSC6tSpE1588UWUlZXh/Pnz6Nu3b6OPGT58OAoLC+vdd/PmTVy6dAmpqakoLCzEG2+8gV27dkEmk8HR0RFpaWkYM2YMPDw8sHXr1kZrl5eXQ6VSWW7b2dmhpqYG9vZtehU9EVGb1qQR1Lx583Dq1CmsWrUK7dq1Q0xMzAMd1NXVFYMGDYKDgwN8fHygUChw48YNAIAQAklJSfD394ezszOysrIaradSqVBRUWG5bTabGU5ERK1ckwKqqqoKL7zwAq5cuYLXXnsNJpPpgQ7av39/7N+/H0IIFBcXo7KyEq6urpZjeXl5IT4+HqmpqU16v6tfv37Yt28fAECv16NHjx4P1B8REdlek4YZRqMRH3zwAXr37o2zZ8+isrLyng9UWlqK6OhopKSkYMiQITh69CgCAwMhhEBMTAzs7OwA3FkaHhYWBgBQKBQIDw9vtPawYcNw8OBBhISEQAjRapbBExFRw5oUUIsWLUJubi5mz56NTz75BFFRUU0q7unpCZ1OB+DOtF5KSopl39tvv30f7dZfWy6XIzY29oHqERGRtDQpoPr164eysjJotVp4eXmhT58+1u6LiIj+4Jr0HtTq1auRnZ0Ne3t7fPzxx/xsERERWV2TRlBHjx5FZmYmAGDatGkICgqyalNERERNGkHV1NTAbDYDuLOEWyaTWbUpIiKiJo2gXn75ZUyZMgV9+/bF999/j1GjRlm7LyIi+oP73YBavXq1ZbTk4eGBvXv3olevXpYP1RIREVnL7waUj4+P5Wdvb28MGTLE6g0REREBjQTUhAkTWqoPIiKiWtr0V74TEVHrxYAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQ16es2Wqvjx49Dq9UCAKKiouDi4mLjjoiIqKna9AhKp9MhNjYWgYGByMnJsXU7RER0D9p0QJlMJigUCri7u6OkpMTW7RAR0T1o0wGlVCphMBhQUlICNzc3W7dDRET3wKoBdfLkSajV6nr3TZgwAWq1Gmq1GpGRkQ9U22w2IyYmBsHBwVCr1SgoKAAABAUFISYmBpmZmRg7duz9nwgREbU4qy2S2LhxI3bu3AmlUllnX3V1NYQQyMjIqPexRUVF6NKlS52fG6qdm5sLg8EArVYLvV4PjUaD9evXw9fXFxqNppnPjIiIWoLVRlDdunVDcnJyvfvOnDmDyspKTJ8+HeHh4dDr9ZZ9VVVViIiIQG5uLtLT05GQkNBo7WPHjiEgIAAA4Ofnh/z8/OY9GSIianFWG0ENHz4chYWF9e5zdHTEjBkzMHnyZFy4cAEzZ87Erl27YG9vD0dHR6SlpWHMmDHw8PDA1q1bG61dXl4OlUpluW1nZ4eamhrY27fpVfRERG2aTRZJeHt7Y+zYsZDJZPD29oarq6tllZ0QAklJSfD394ezszOysrIaradSqVBRUWG5bTabGU5ERK2cTQIqKyvL8t5QcXExysvL4e7uDuDOFJ+Xlxfi4+ORmpoKo9HYaL1+/fph3759AAC9Xo8ePXpYr3kiImoRLRZQpaWlmDt3LgAgMDAQt27dwpQpUzB//nzEx8dbRjxKpRJhYWEAAIVCgfDw8EZrDxs2DA4ODggJCUFCQsJ9rQokIiJpseo8mKenJ3Q6HQDA1dUVKSkpAAAHBwesXr262WrL5XLExsY+WLNERCQpbfqDukRE1HoxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCTJ3tYNWNPx48eh1WoBAFFRUXBxcbFxR0RE1FRtegSl0+kQGxuLwMBA5OTk2LodIiK6B206oEwmExQKBdzd3VFSUmLrdoiI6B606YBSKpUwGAwoKSmBm5ubrdshIqJ7YNWAOnnyJNRqdYP7r1+/jueffx7nzp17oNpmsxkxMTEIDg6GWq1GQUEBACAoKAgxMTHIzMzE2LFj7+8kiIjIJqy2SGLjxo3YuXMnlEplvfuNRiNiYmLg6OhYZ19RURG6dOlS5+eGaufm5sJgMECr1UKv10Oj0WD9+vXw9fWFRqNp5jMjIqKWYLURVLdu3ZCcnNzg/sTERISEhKBTp061tldVVSEiIgK5ublIT09HQkJCo7WPHTuGgIAAAICfnx/y8/Ob6SyIiMhWrBZQw4cPh719/QO07OxsdOjQwRIqv+bo6Ii0tDSsXLkSu3btwtq1axutXV5eDpVKZbltZ2eHmpqaZjgLIiKyFZsskti+fTsOHToEtVqN06dPY9GiRZZVdkIIJCUlwd/fH87OzsjKymq0nkqlQkVFheW22WxuMByJiKh1sMn/xbdu3Wr5Wa1WY/ny5XB3dwdwZ4rPy8sLYWFhqK6utnzQ9vf069cPe/fuxahRo6DX69GjRw+r9U5ERC2jxUZQpaWlmDt3bqP3UyqVCAsLAwAoFAqEh4c3+phhw4bBwcEBISEhSEhIQGRk5AP3S0REtmXVEZSnpyd0Oh0AwNXVFSkpKXXuk5GR8cC15XI5YmNj779RIiKSnDb9QV0iImq9GFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEk2du6AWs6fvw4tFotACAqKgouLi427oiIiJqqTY+gdDodYmNjERgYiJycHFu3Q0RE96BNB5TJZIJCoYC7uztKSkps3Q4RUZtiNgv8VFKOb85dw08l5TCbRbPWb9NTfEqlEgaDASUlJXBzc7N1O0REbYbZLLDr1BUs0OlRZTTDsZ0ca4L8MKL3I5DLZc1yDKuOoE6ePAm1Wl1nu8lkQmRkJEJCQjBlyhT83//93wPVNpvNiImJQXBwMNRqNQoKCgAAQUFBiImJQWZmJsaOHftgJ0NERBYXrldYwgkAqoxmLNDpceF6RbMdw2ojqI0bN2Lnzp1QKpV19u3duxcAkJmZiSNHjmDt2rVYv369ZX9RURG6dOlS5+eGaufm5sJgMECr1UKv10Oj0WD9+vXw9fWFRqOx1ikSEf1hFZdVWcLpriqjGVdvVcHHXdUsx7DaCKpbt25ITk6ud9/QoUOxcuVKAMClS5dqra6rqqpCREQEcnNzkZ6ejoSEhEZrHzt2DAEBAQAAPz8/5OfnN+epkI1Ye36biO6fh4sjHNvVjhDHdnJ0au/YbMew2ghq+PDhKCwsbPjA9vZYtGgRdu/ejaSkJMt2R0dHpKWlYcyYMfDw8MDWrVsbrV1eXg6V6j+JbWdnh5qaGtjbt+m32Nq0lpjfJqL759XRGWuC/Oq8Rr06OjfbMWy6ii8xMRGff/45li5ditu3bwMAhBBISkqCv78/nJ2dkZWV1WgdlUqFior/zHuazWaGUyvXEvPbRHT/5HIZRvR+BDnzApD52jPImRfQ7H9A2iSgPv74Y2zYsAHAnZV2MpkMcvmdVqqqquDl5YX4+HikpqbCaDQ2Wq9fv37Yt28fAECv16NHjx7Wa55axO/NbxORNMjlMvi4qzDAxw0+7qpmn91osYAqLS3F3LlzAQAvvfQSfvjhB0ydOhUzZszAkiVL4Oh4Z95SqVQiLCwMAKBQKBAeHt5o7WHDhsHBwQEhISFISEhAZGSk9U6EWkRLzG8TkbRZdR7M09MTOp0OAODq6oqUlBQAgJOTE9atW9dsteVyOWJjYx+sWZKUlpjfJiJp4xs1JEl357efnBeAq7eq0Km9I7w6OnOBBNEfCAOKJOvu/HZzfaaCiFqXNn0tPiIiar0YUEREJEkMKCIikiQGFBERSRIDioiIJEkmhPjDX4FTr9dDoVDYug0ioj+k6upq+Pn51dnOgCIiIkniFB8REUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJJ4NXMbun79OiZOnIj09HQYDAYsW7YMdnZ28PLyQlxcnOVbhqVmwoQJUKnuXGHc09MTr7/+OpYtWwaj0QgHBwesWbMGDz/8sI27rN+GDRvw5Zdfwmg0YsqUKZg8eTIA4F//+he2bNkCrVZr4w7rl52djR07dgC485mR06dP47333kN6ejrs7e3RsWNHJCYmQqlU2rjT2oxGIxYvXoyioiLI5XKsXLkS9vb2WLx4MWQyGbp3745ly5ZJ8t96fb23htepwWBAZGQkLl68CJVKhZiYGMhkslbzGq1FkE0YDAYxe/Zs8dJLL4mzZ8+K2bNni6+++koIIcSCBQvEnj17bNxh/aqqqsS4ceNqbVOr1eLEiRNCCCF27doljh8/3vKNNcHhw4fFrFmzhMlkEuXl5SIpKUkIIcSpU6dEeHi4mDx5so07bJrly5eLzMxM8dJLL4mSkhIhhBDvvfee+OCDD2zcWV27d+8W8+bNE0IIceDAATF37lwxa9YscfjwYSGEEEuXLhVffPGFLVtsUH29t4bXaUZGhoiOjhZCCHHu3Dkxffr0VvMa/S1pRf8fSGJiIkJCQtCpUycAQK9evVBaWgohBCoqKmBvL83B7ZkzZ1BZWYnp06cjPDwcJ06cwI0bN7B3716o1Wro9Xr06dPH1m3W68CBA+jRowfmzJmD119/HYMHD8bNmzexZs0aLFmyxNbtNUleXh7Onj2L4OBgZGRkwM3NDQBQU1MjyauheHt7w2QywWw2o7y8HPb29jh16hT+67/+CwDw3HPP4dChQzbusn719d4aXqdnz57Fc889BwDw8fHBqVOnWs1r9LcYUDaQnZ2NDh06ICAgwLLt7nTByJEjcf36dTzzzDM27LBhjo6OmDFjBtLS0rBixQosXLgQP/74IwYOHIjNmzfjl19+sUxFSc3NmzeRn5+PdevWWXpfsmQJIiMj4ezcOr5KfsOGDZgzZw4AWP64+eKLL3DkyBGMHz/ehp3Vz8nJCUVFRRg5ciSWLl0KtVoNIQRksjvfjOzs7Ixbt27ZuMv61dd7a3id9urVC3v37oUQAnq9Hjdv3mw1r9Hfkl78/wFs374dMpkM33zzDU6fPo1FixbhzJkz2LFjB7p3746tW7dCo9Fg2bJltm61Dm9vbzz22GOQyWTw9vbGww8/jKKiIgwYMAAAMGTIEBw8eBCBgYE27rQuV1dX+Pj4wMHBAT4+Prhy5Qrs7OywfPlyVFdX4+zZs4iLi0NUVJStW61XWVkZzp8/b3muAWDTpk3YtWsX3n//fUmOoDZt2oRBgwZh4cKFuHz5MqZNmwaj0WjZX1FRARcXFxt22LD6er916xa2bt0q6dfppEmTcO7cOYSGhqJfv37w9fWt9e9Gyq/R3+IIyga2bt2KLVu2ICMjA7169UJiYiI8PT0tCw86deqEsrIyG3dZv6ysLGg0GgBAcXExKioq0Lt3b3z33XcAgKNHj6J79+62bLFB/fv3x/79+yGEQHFxMTw8PPDpp58iIyMDa9aswRNPPCHZcALuPLcDBw603F6/fj2+++47bNq0CR06dLBhZw1zcXFB+/btAQAPPfQQampq8NRTT+HIkSMAgH379uHpp5+2ZYsNqq/39u3bS/51mpeXh4EDB2Lbtm0YMWIEunXrBi8vr1bxGv0tXizWxtRqNZYvX46bN2/ivffeg729Pdq1a4eVK1fC09PT1u3VcXeF0KVLlyCTyfDWW2/ByckJK1asgMlkgqenJzQaDRwcHGzdar1WrVqFI0eOQAiB+fPnW6ZZCwsLsWDBAuh0Oht32LD3338f9vb2eOWVV3Dt2jUMHjwYTz31lGXkNHLkSISGhtq4y9oqKiqwZMkSlJSUwGg0Ijw8HL6+vli6dCmMRiN8fHzwzjvvwM7Oztat1lFf748++qjkX6c3btzAggULUFlZifbt2yMuLg43b95sNa/RX2NAERGRJHGKj4iIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQRBKRnJyMbdu24fTp00hJSQEA7N69G8XFxY0+9t1338WYMWMsny+6X9nZ2dizZ88D1SBqLrySBJHE9OrVC7169QIAbN68GcuXL4eHh8fvPmbXrl345JNPLB8ivV8TJ058oMcTNScGFFEzqaiowMKFC1FWVoYnnngCJ06cgKurK5YvX47HH38c27Ztw7Vr1/Dmm29i9erVyM/PR2lpKZ588kkkJCRY6hw5cgSZmZkYN26c5VJYkydPxoULF7Bo0SKYTCaMHz8eWVlZUCgUSElJwdWrVzFr1iykpaVh1apV+P7772E0GvHmm29i6NCh9fb7xRdfYOPGjbC3t0enTp2wdu1a/Pd//zfc3Nzg5uaGzZs3AwCuXLmCRx55BBkZGVi9ejW+++47mM1mvPLKKxg5cmSLPLf0x8QpPqJm8uGHH6Jnz5748MMPMX78eFRUVNR7v/Lycri4uOCf//wntm/fDr1eX+803uDBgy2Xwnr55ZexZ88emEwm7N+/H88884zlChJz586Fu7s70tPTsX//fty8eRNZWVnYvHkz8vPzG+z3008/xYwZM7Bt2zYMGTIE5eXlln3Dhg1DRkYG4uPj4eLiAo1Gg6+//hqFhYXYtm0bNm/ejNTUVEle6ofaDo6giJpJYWGh5dJJ/fr1q3MpmbsXbVEoFJbL0Tg5OeH27du1LqBaH5VKhb/85S84cOAAsrOzMXv27Hrvd/78efj5+QG4c/24iIiIBmtGRkZiw4YN2LJlC3x8fOqMtEpKSvC3v/0NCQkJ6NKlC3JycnDq1Cmo1WoAd77io6ioSLIXe6XWjyMoombSs2dPHDt2DADw73//GwaDAQ4ODigpKQEA/PDDDwDuXCD18uXLWLNmDRYsWICqqio0dMUxmUxm2RcUFISPPvoI169fx5NPPlnv/X18fJCXlwcAuHXrFmbMmNFgv1qtFm+++Sa2bNkC4M6CjLvKysowZ84cREZGomfPnpbazzzzDDIyMvDBBx9g5MiR6Nq1a5OfH6J7xREUUTOZPHkyoqKiMHXqVHTu3BkAEB4ejhUrVqBz586W72/q06cP/vGPf2Dq1KmQyWTo2rUrrl69Wm/NP//5z3j77beRnp6Ovn37oqCgAFOnTgUA/POf/0S3bt3w4osvWu7/4osv4ptvvsGUKVNgMpks3x1Vnz59+mDWrFlwdnaGk5MTBg8ebAmrtWvX4urVq0hJSYHZbEa7du2QlpaGb7/9FqGhobh9+zaGDh36wIsyiH4PLxZLZAXV1dUYOXIkvvzyy2araTabMWXKFKSlpTEY6A+BIyiiVuDixYuYO3cuJk6ceE/hZDAY6p3m8/b2RmxsbHO2SNTsOIIiIiJJ4iIJIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJ+v8sYvvxGtNxUQAAAABJRU5ErkJggg==",
"text/plain": [
"| \n", " | loss | \n", "quality.fc_size | \n", "quality.num_fc_layers | \n", "trainer.batch_size | \n", "trainer.learning_rate | \n", "
|---|---|---|---|---|---|
| 0 | \n", "1.300466 | \n", "75 | \n", "4 | \n", "55 | \n", "0.005918 | \n", "
| 1 | \n", "1.362126 | \n", "45 | \n", "1 | \n", "72 | \n", "0.002479 | \n", "
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAAqoUlEQVR4nO3dfViT1/0/8HcACYFIrUJpfWCKFWU6ZbTdtMgUq0Wt4kMREAjt6qyztQ5rO0QwtVCe+jCs+Ct0FPbdfCKID/W7Wf0aZbXV6VpprCjt1AqKWkQt0qCQkJzfH15mUkBACLnB9+u6el3Jfec+9+cc07w5d04SmRBCgIiISGLsbF0AERFRcxhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxICiNhk+fDiuXbvWaNu2bduwaNEiG1XUunXr1kGr1Ta7b/jw4Zg5cyZmzZqF2bNnIygoCM8++yyOHz/eJbWdP38er7zySpec6053/pvFx8fj0KFDAICEhASUlJR0eT3t9cYbb2DSpEnIyMho97FHjhzBjBkzrFAVWYuDrQsgspYjR47g0UcfbXH/X//6V/Tt29dyPzc3F2+99RY0Go3Va7t48SLOnj1r9fPcTXJysuX2oUOHEBYWZsNq2kaj0eCf//wnHn74YVuXQl2AAUUddvPmTfzmN79BQUEBhgwZAgD47W9/i8jISGi1WshkMpw5cwbXrl2Dv78/EhIS0KtXL5w5cwbJycmorq6GyWSCSqVCSEgIjhw5guTkZDg7O+PGjRsoLCzE9u3bsX79etjZ2cHNzQ2rVq3CkCFDsGLFimbbLygoQElJCd5++23Y29tjypQpd+1DQ0MDLl26hAceeMCyLSsrC//3f/8Hs9mMAQMG4I033oCHhwdUKhWGDh2KkpIS/PDDD5g1axaWLl0KANBqtVi3bh1MJhOUSiXi4uIwevRoZGZmQqfT4fLlyxg2bBiOHz+OyspKLFiwALm5uYiPj8eoUaMwf/78RnUZDAYkJyfj0KFD6NevH3x8fHDz5k2kpaVBpVIhMjISU6dOBYBG9wsLC6HRaGA0GnH9+nUsXLgQERERjdq+/fjS0lJcvnwZr732GpKSkrBo0SIcOHAAvXv3hhACU6dOxfvvv48RI0YAuBX8GRkZGDRoEE6dOgWDwQC1Wo2xY8dixYoVGDZsGBYsWAAAje5PmjQJM2bMwD//+U9UV1fjlVdeQXFxMU6cOAEHBwdkZWXBw8OjxX+jiIgICCGwcOFCvPHGG+jXrx/UajWuXbsGOzs7LF68GNOnT2/LUxZnz55FYmIibty4gcuXL2PEiBFYs2YN9uzZg02bNiE/Px/ArT8kQkNDsX//fpw/f75Nz9eNGzciPj4e5eXlsLOzw8iRI5GYmAg7O16wajdB1Abe3t5ixowZIjg42PLfhAkTxIsvviiEEOKtt94S6enpQgghysvLxYQJE0RDQ4OIjY0Vs2fPFnq9XtTX14vIyEixfv16YTQaxfTp00VJSYkQQoiamhoxbdo08dVXX4nDhw+LESNGiIqKCiGEEIcOHRKTJ08WV69eFUIIsXXrVjFt2jRhNptbbF8IIaKiosQnn3xy1/7MnDlT+Pv7i0mTJomkpCRx5coVIYQQ27dvFzExMcJoNAohhMjPzxe/+93vLO0uXLhQGAwGcf36dREUFCT2798vTp8+LZ588klx7tw5S93+/v7ixx9/FGvXrhVBQUGW9g4fPiyeeeaZVsc9Ly9PREdHi/r6eqHX68WsWbNEbGxss/27fV+v14vQ0FBx7do1IYQQX331lfD19bWM3e1/szuPDwwMFF9//bUQQojFixeLDRs2WPoQGhraqKbDhw8LHx8fcfLkSSGEELm5uSIyMlIIIURsbKz46KOPLI+9835gYKBISUkRQgjxj3/8Q4wYMUKUlpYKIYR46aWXRFZWVqvj4e3tbXkezJ4921LnxYsXxVNPPSV+/PHHFo+9c8zT0tLEjh07hBBCGAwGMWPGDLF7925RX18vxo0bJ06dOiWEEGLNmjXi3Xffbdfzdfv27eKFF14QQgjR0NAg4uPjRVlZWat9o6Y4g6I2++klsW3btmHPnj0Abv11GxUVhWXLlkGj0SAkJAT29vYAgDlz5sDFxQUAMGvWLOzbtw9jx47FuXPnsHLlSkt7dXV1OHnyJIYOHYpHHnkEAwYMAAB89tlnmD59uuXcc+fORXJyMioqKlpsPyoqqs39OXnyJBYuXIhf/vKX6NevHwCgqKgIx48fx7PPPgsAMJvNuHnzpuXYsLAw9OrVC7169cLUqVPx+eefw8vLC2PHjsWgQYMAAOPGjUPfvn0t7+34+vrCwaF9/8sdPnwYM2bMgKOjIxwdHTF79mx88803dz3GxcUF2dnZ+PTTT1FWVoZvvvkGN27caPM5IyMj8c477yAyMhIajabJrA4A+vfvDx8fHwDAz3/+c2zfvr1NbT/99NMAgEGDBsHNzc0yK/P09MT169fbXGN1dTW++eYbzJs3DwDwyCOPtPh+Y3Nef/11HDx4EDk5OSgrK8Ply5dx48YNODo6Yt68eSgoKEBsbCy2b9+ODRs2oKysrM3P18ceewwZGRlQqVR48skn8dxzz+FnP/tZm2uj/2JAUacYMmQIhg8fjn379uF///d/sWXLFsu+20EFAEII2NnZwWQywdXVFR9//LFl35UrV9C7d2/odDo4Ozs3OuanhBBoaGhosf32+PnPf464uDgkJCRgzJgxGDhwIMxmM373u99ZLosZDIZGL6B3Bs3tc7ZW5519aiu5XN7ofq9evZq0f5vRaAQAfP/99wgLC0NoaCgee+wxTJ06FUVFRW0+55NPPombN2/iX//6F7788kukp6c3eYyTk5Pltkwms9Rx5+07a7rN0dGxxb60x+3xl8lklm3fffcd+vfv36i2lrz66qswmUyYNm0aJk6ciEuXLlnqDgsLw7x58/CrX/0Kw4YNw8CBA/Htt9+2+fk6aNAg7N27F0eOHMHhw4fx29/+FgkJCZZLsdR2vChKnSYiIgJvv/02xowZ0+i9hE8++QQGgwH19fXYvn07AgMDMWTIEMjlcsv/8JcuXcKMGTOaXUk2fvx47Nq1y7KKcOvWrejTp4/lr9Lm2gduBdftcGjNjBkz4Ovri5SUFMs5CwsLodfrAQDvv/8+/vjHP1oev3PnTpjNZly/fh2ffPIJJk2ahLFjx+LgwYM4f/48AOBf//oXLl26hDFjxjQ5n729fZMX7+ZMnDgR27ZtQ319PQwGA3bt2mXZd+fs7Ny5c/j2228BACUlJejbty9eeuklBAQEWMLJZDK1eJ47x0omkyEiIgLx8fGYMWNGk5C8mwcffNBS07Vr1/Dll1+2+dj2UCqVGDlyJHbs2AHg1vNn/vz5+PHHH9t0/Oeff46XX34Z06dPh0wmw7Fjxyzj079/f8tz4fbssT3P102bNiEuLg7jx4/H66+/jvHjx+PUqVOd0Ov7D2dQ1GkCAwORkJCA8PDwRtudnJwQERGBmpoay3JuOzs7fPDBB0hOTsZHH32EhoYG/OEPf8Bjjz2GI0eONDre398fzz//PJ577jmYzWb07dsXH374oWWm1Fz7t+tJT0+H0WjEnDlzWq1/1apVCA4OxmeffYZ58+ahsrISoaGhkMlkeOSRR5CWlmZ5bF1dHUJCQlBbW4uIiAiMGzcOwK1l0EuWLIHJZIKTkxOys7PRu3fvJucaNmwY7O3tERISgi1btiAhIaHZRRJz5szB+fPnMWfOHDg7Oze6xLp48WKsWLECn376Kby8vPD4449bxquwsBBTp06FQqHA6NGj0bdvX5SXl7fY98mTJ2PZsmV46623MH78eMyZMwfp6emWlX3Hjx9HQkJCoxlEc1QqFV577TUEBQVh4MCB+NWvftXKqN+79957D2+++SbWr18PmUyG5ORkuLu7t+nYZcuW4eWXX8YDDzwAhUKBJ554AufOnbPsnzt3LpKSkjBhwgQAt2Z+bX2+zp49G//+978xffp0KBQK9O/fH9HR0Z3X8fuITDR3XYLoHhQXF2PVqlX4+9//brn08tNVXZ3N2u0356er57pSbm4uTp061SgsreEf//gHtm/fjo8++siq55Eis9mMxMRE9O/fHy+++KKty7mvcQZFnSI2Nhb//ve/kZ6e3uh9Aep+VCoVrly5gszMzC4/d0xMTIufD8vIyICXl5dVj9fr9QgMDMTo0aMbXdIl2+AMioiIJImLJIiISJIYUEREJEl8DwqATqdr11Lan6qvr+/Q8cQx7CiOX8dw/Dqmo+NXX18PX1/fJtsZULj1Ycjbn4q/F6WlpR06njiGHcXx6xiOX8d0dPxKS0ub3c5LfEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAdYDZLPBdlR4XjS74rkoPs5nfGkVE1Fn4Oah7ZDYL7D7xPV4t0KHOaIZTLzv8KdQXU0c+DDs7flkqEVFHcQZ1j8qu1lrCCQDqjGa8WqBD2dVaG1dGRNQzMKDuUWVNnSWcbqszmnH5xzobVURE1LMwoO6Rh6sTnHo1Hj6nXnZ4qLeTjSoiIupZGFD3aHA/F/wp1NcSUrffgxrcz8XGlRER9QxcJHGP7OxkmDryYYxYGoCz31/DkIf7YnA/Fy6QICLqJJxBdYCdnQxe7kr0d6iFl7uS4URE1IkYUEREJEkMKCIikiQGFBERSRIDioiIJKlHr+IrLi6GRqMBAMTHx8PV1dXGFRERUVv16BlUQUEBEhMTERISgl27dtm6HCIiaoceHVAmkwlyuRzu7u6oqqqydTlERNQOPTqgFAoFDAYDqqqq4ObmZutyiIioHawaUMeOHYNKpWqy3WAwYPny5QgNDcULL7yAsrKyDrVtNpuhVqsRFhYGlUqF8vJyAEBoaCjUajXy8/MRHBzcob4QEVHXstoiiZycHOzcuRMKhaLJvoKCAjg7O6OgoADfffcdkpKSkJuba9l/4cIFDBgwoMntltrWarUwGAzQaDTQ6XRIS0tDVlYWRo0ahbS0NGt1kYiIrMhqMyhPT09kZmY2u+/06dP4zW9+AwDw8vLCmTNnLPvq6uoQExMDrVaLvLw8pKamttr20aNHERAQAADw9fVFSUlJZ3aFiIhswGoBFRQUBAeH5idoPj4+KCoqghACOp0OlZWVMJlMAAAnJyfk5uYiKSkJu3fvRkZGRqtt6/V6KJVKy317e3s0NDR0co+IiKgr2WSRxLPPPgulUomIiAjs3bsXI0eOhL29PQBACIG1a9fC398fLi4uKCwsbLU9pVKJ2tr//pKt2WxuMRyJiKh7sElAHT9+HOPGjcPmzZsxdepUDBo0yLKvrq4OgwcPRkpKCrKzs2E0Glttz8/PDwcOHAAA6HQ6eHt7W612IiLqGl02zaiurkZCQgLWrVuHn/3sZ3j//feRnZ2N3r17Izk52fI4hUKBqKgoAIBcLkd0dHSrbU+ZMgUHDx5EeHg4hBBISUmxWj+IiKhryIQQwtZF2FppaSl8fHxsdjxxDDuK49cxHL+OsdZraI/+oC4REXVfDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSerRPztbXFwMjUYDAIiPj4erq6uNKyIiorbq0TOogoICJCYmIiQkBLt27bJ1OURE1A49OqBMJhPkcjnc3d1RVVVl63KIiKgdenRAKRQKGAwGVFVVwc3NzdblEBFRO1g1oI4dOwaVStVku9FoxPLlyxEeHo6IiAicOXOmQ22bzWao1WqEhYVBpVKhvLwcABAaGgq1Wo38/HwEBwd3rDNERNSlrLZIIicnBzt37oRCoWiy79NPP0VDQwPy8/Nx8OBBrFmzBpmZmZb9Fy5cwIABA5rcbqltrVYLg8EAjUYDnU6HtLQ0ZGVlYdSoUUhLS7NWF4mIyIqsNoPy9PRsFDp3GjJkCEwmE8xmM/R6PRwc/puTdXV1iImJgVarRV5eHlJTU1tt++jRowgICAAA+Pr6oqSkpJN7Q0REXc1qM6igoCBUVFQ0u8/Z2RkXLlzAtGnT8MMPPyA7O9uyz8nJCbm5uZg5cyY8PDywcePGVtvW6/VQKpWW+/b29mhoaGgUfERE1L3YZJHE//zP/2D8+PHYs2cPPv74Y6xYsQL19fUAACEE1q5dC39/f7i4uKCwsLDV9pRKJWpray33zWYzw4mIqJuzSUC5urqid+/eAIAHHngADQ0NMJlMAG5d4hs8eDBSUlKQnZ0No9HYant+fn44cOAAAECn08Hb29t6xRMRUZfosoCqrq7GkiVLAADPP/88Tpw4gYiICDz33HNYtmwZnJ2dAdxaGh4VFQUAkMvliI6ObrXtKVOmwNHREeHh4UhNTUVcXJz1OkJERF1CJoQQti7C1kpLS+Hj42Oz44lj2FEcv47h+HWMtV5De/QHdYmIqPtiQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESS5GDrAqypuLgYGo0GABAfHw9XV1cbV0RERG3Vo2dQBQUFSExMREhICHbt2mXrcoiIqB16dECZTCbI5XK4u7ujqqrK1uUQEVE79OiAUigUMBgMqKqqgpubm63LISKidrBqQB07dgwqlarJ9m3btkGlUkGlUiE0NBS/+MUvUFNTc89tm81mqNVqhIWFQaVSoby8HAAQGhoKtVqN/Px8BAcHd7xDRETUZay2SCInJwc7d+6EQqFosm/u3LmYO3cuAODNN9/Es88+22gBw4ULFzBgwIAmt1tqW6vVwmAwQKPRQKfTIS0tDVlZWRg1ahTS0tKs1UUiIrIiq82gPD09kZmZedfHHD9+HKdPn0ZYWJhlW11dHWJiYqDVapGXl4fU1NRW2z569CgCAgIAAL6+vigpKemkXhARka1YbQYVFBSEioqKuz7mww8/xMsvv9xom5OTE3JzczFz5kx4eHhg48aNrbat1+uhVCot9+3t7dHQ0AAHhx69ip6IqEez2SKJmpoanD17FmPHjm20XQiBtWvXwt/fHy4uLigsLGy1LaVSidraWst9s9nMcCIi6uZsFlBffPEFxo0b12R7XV0dBg8ejJSUFGRnZ8NoNLbalp+fHw4cOAAA0Ol08Pb27vR6iYioa3VZQFVXV2PJkiWW+2fPnsXAgQObPE6hUCAqKgoAIJfLER0d3WrbU6ZMgaOjI8LDw5Gamoq4uLjOK5yIiGxCJoQQti7C1kpLS+Hj42Oz44lj2FEcv47h+HWMtV5De/QHdYmIqPtiQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkOdi6AGsqLi6GRqMBAMTHx8PV1dXGFRERUVv16BlUQUEBEhMTERISgl27dtm6HCIiaoc2BVRlZSVOnz6Ns2fPYuXKlSgtLbV2XZ3CZDJBLpfD3d0dVVVVti6HiIjaoU0BtXz5cly5cgUZGRnw9/dHSkqKtevqFAqFAgaDAVVVVXBzc7N1OURE1A5tCiiZTIYnnngCNTU1eOaZZ2Bn17Yrg8eOHYNKpWp234cffoiwsDDMnTsXW7ZsaXvFzbRtNpuhVqsRFhYGlUqF8vJyAEBoaCjUajXy8/MRHBzc7nMQEZHttGmRRENDA9555x08/vjjOHz4MIxGY6vH5OTkYOfOnVAoFE32HTlyBF999RU2b96MmzdvIi8vr9H+CxcuYMCAAU1ut9S2VquFwWCARqOBTqdDWloasrKyMGrUKKSlpbWli0REJDFtmgqlpqZi0KBBePHFF3Ht2jWkp6e3eoynpycyMzOb3ff555/D29sbL7/8Mn7/+99j4sSJln11dXWIiYmBVqtFXl4eUlNTW2376NGjCAgIAAD4+vqipKSkLd0iIiIJa9MM6qGHHsJTTz2FmpoanD17FmPGjGn1mKCgIFRUVDS774cffsDFixeRnZ2NiooKLF68GLt374ZMJoOTkxNyc3Mxc+ZMeHh4YOPGja22rdfroVQqLfft7e3R0NAAB4cevYqeiKhHa9MMaunSpThx4gTefvtt9OrVC2q1ukMn7dOnD8aPHw9HR0d4eXlBLpfj2rVrAAAhBNauXQt/f3+4uLigsLCw1faUSiVqa2st981mM8OJiKiba1NA1dXVYdKkSfj+++/x4osvwmQydeikjz32GD777DMIIVBZWYmbN2+iT58+lnMNHjwYKSkpyM7ObtP7XX5+fjhw4AAAQKfTwdvbu0P1ERGR7bVpmmE0GvHXv/4VI0eOxOnTp3Hz5s12n6i6uhoJCQlYt24dAgMD8cUXXyAkJARCCKjVatjb2wO4tTQ8KioKACCXyxEdHd1q21OmTMHBgwcRHh4OIUS3WQZPREQtkwkhRGsPKi4uhlarxeLFi/Hxxx9j9OjRGD16dFfU1yVKS0vh4+Njs+OJY9hRHL+O4fh1jLVeQ9s0g/Lz80NNTQ00Gg0GDx7co8KJiIikqU3vQb333nvYtm0bHBwcsGPHDn62iIiIrK5NM6gvvvgC+fn5AIDnnnsOoaGhVi2KiIioTTOohoYGmM1mALeWcMtkMqsWRURE1KYZ1DPPPIP58+djzJgx+PrrrzF9+nRr10VERPe5uwbUe++9Z5kteXh4oKioCD4+PpYP1RIREVnLXQPKy8vLcnvIkCEIDAy0ekFERERAKwE1Z86crqqDiIiokR79k+9ERNR9MaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJElt+rmN7qq4uBgajQYAEB8fD1dXVxtXREREbdWjZ1AFBQVITExESEgIdu3aZetyiIioHXp0QJlMJsjlcri7u6OqqsrW5RARUTv06IBSKBQwGAyoqqqCm5ubrcshIqJ2sGpAHTt2DCqVqtl9c+bMgUqlgkqlQlxcXIfaNpvNUKvVCAsLg0qlQnl5OQAgNDQUarUa+fn5CA4OvveOEBFRl7PaIomcnBzs3LkTCoWiyb76+noIIbB+/fpmj71w4QIGDBjQ5HZLbWu1WhgMBmg0Guh0OqSlpSErKwujRo1CWlpaJ/eMiIi6gtVmUJ6ensjMzGx23zfffIObN2/ihRdeQHR0NHQ6nWVfXV0dYmJioNVqkZeXh9TU1FbbPnr0KAICAgAAvr6+KCkp6dzOEBFRl7PaDCooKAgVFRXN7nNycsKCBQswb948lJWVYeHChdi9ezccHBzg5OSE3NxczJw5Ex4eHti4cWOrbev1eiiVSst9e3t7NDQ0wMGhR6+iJyLq0WyySGLIkCEIDg6GTCbDkCFD0KdPH8sqOyEE1q5dC39/f7i4uKCwsLDV9pRKJWpray33zWYzw4mIqJuzSUAVFhZa3huqrKyEXq+Hu7s7gFuX+AYPHoyUlBRkZ2fDaDS22p6fnx8OHDgAANDpdPD29rZe8URE1CW6LKCqq6uxZMkSAEBISAh+/PFHzJ8/H8uWLUNKSoplxqNQKBAVFQUAkMvliI6ObrXtKVOmwNHREeHh4UhNTb2nVYFERCQtMiGEsHURtlZaWgofHx+bHU8cw47i+HUMx69jrPUa2qM/qEtERN0XA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSHGxdgDUVFxdDo9EAAOLj4+Hq6mrjioiIqK169AyqoKAAiYmJCAkJwa5du2xdDhERtUOPDiiTyQS5XA53d3dUVVXZuhwiImqHHh1QCoUCBoMBVVVVcHNzs3U5RETUDlYNqGPHjkGlUrW4/+rVq5gwYQLOnDnTobbNZjPUajXCwsKgUqlQXl4OAAgNDYVarUZ+fj6Cg4PvrRNERGQTVlskkZOTg507d0KhUDS732g0Qq1Ww8nJqcm+CxcuYMCAAU1ut9S2VquFwWCARqOBTqdDWloasrKyMGrUKKSlpXVyz4iIqCtYbQbl6emJzMzMFvenp6cjPDwcDz30UKPtdXV1iImJgVarRV5eHlJTU1tt++jRowgICAAA+Pr6oqSkpJN6QUREtmK1gAoKCoKDQ/MTtG3btqFv376WULmTk5MTcnNzkZSUhN27dyMjI6PVtvV6PZRKpeW+vb09GhoaOqEXRERkKzZZJLF161YcOnQIKpUKpaWliI2NtayyE0Jg7dq18Pf3h4uLCwoLC1ttT6lUora21nLfbDa3GI5ERNQ92ORVfOPGjZbbKpUKq1evhru7O4Bbl/gGDx6MqKgo1NfXWz5oezd+fn4oKirC9OnTodPp4O3tbbXaiYioa3TZDKq6uhpLlixp9XEKhQJRUVEAALlcjujo6FaPmTJlChwdHREeHo7U1FTExcV1uF4iIrItq86gBg4ciIKCAgBAnz59sG7duiaPWb9+fYfbtrOzQ2Ji4r0XSkREktOjP6hLRETdFwOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAdbF2BNxcXF0Gg0AID4+Hi4urrauCIiImqrHj2DKigoQGJiIkJCQrBr1y5bl0NERO3QowPKZDJBLpfD3d0dVVVVti6HiKhHMZsFvqvS46LRBd9V6WE2i05tv0df4lMoFDAYDKiqqoKbm5utyyEi6jHMZoHdJ77HqwU61BnNcOplhz+F+mLqyIdhZyfrlHNYdQZ17NgxqFSqJttNJhPi4uIQHh6O+fPn4z//+U+H2jabzVCr1QgLC4NKpUJ5eTkAIDQ0FGq1Gvn5+QgODu5YZ4iIyKLsaq0lnACgzmjGqwU6lF2t7bRzWG0GlZOTg507d0KhUDTZV1RUBADIz8/HkSNHkJGRgaysLMv+CxcuYMCAAU1ut9S2VquFwWCARqOBTqdDWloasrKyMGrUKKSlpVmri0RE963KmjpLON1WZzTj8o918HJXdso5rDaD8vT0RGZmZrP7Jk+ejKSkJADAxYsXG62uq6urQ0xMDLRaLfLy8pCamtpq20ePHkVAQAAAwNfXFyUlJZ3ZFSIi+gkPVyc49WocIU697PBQb6dOO4fVZlBBQUGoqKho+cQODoiNjcXevXuxdu1ay3YnJyfk5uZi5syZ8PDwwMaNG1ttW6/XQ6n8b2Lb29ujoaEBDg49+i02IiKb8XzQGW/NHoWEHSWW96Demj0Kng86d9o5bLqKLz09HXv27MGqVatw48YNAIAQAmvXroW/vz9cXFxQWFjYajtKpRK1tf+97mk2mxlORERWdO6HG8jcfwoLxnthyaRHsWC8FzL3n8K5H2502jls8iq+Y8cOVFZWYtGiRVAoFJDJZLCzu5WVdXV1GDx4MKKiolBfX2/5oO3d+Pn5oaioCNOnT4dOp4O3t7e1u0BEdF+rrKlD+dWb+H9Fpxtt7xbvQf1UdXU1lixZAgB4+umncfLkSURGRmLBggVYuXIlnJxuXbdUKBSIiooCAMjlckRHR7fa9pQpU+Do6Ijw8HCkpqYiLi7Oeh0hIqIueQ9KJoTo3E9WdUOlpaXw8fGx2fHEMewojl/HcPzarzM/B9XS+PONGiIiajc7OxmmjnwYI5YG4Oz31zDk4b4Y3M+l0z6kC/TwrzoiIiLrsbOTwctdif4OtfByV3ZqOAEMKCIikigGFBERSRIDioiIJIkBRUREksSAIiIiSeLnoADodDrI5XJbl0FEdF+qr6+Hr69vk+0MKCIikiRe4iMiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDqgPMZjPUajXCwsKgUqlQXl5u65K6pWPHjkGlUtm6jG7HaDTi9ddfR0REBEJCQrBv3z5bl9StmEwmxMXFITw8HPPnz8d//vMfW5fULV29ehUTJkzAmTNnOr1tBlQHaLVaGAwGaDQaLF++HGlpabYuqdvJyclBQkIC6uvrbV1Kt7Nz50706dMHmzZtwkcffYSkpCRbl9StFBUVAQDy8/MRExODjIwMG1fU/RiNRqjVassvonc2BlQHHD16FAEBAQAAX19flJSU2Lii7sfT0xOZmZm2LqNbmjp1Kv7whz8AAIQQsLe3t3FF3cvkyZMtoX7x4kW4urrauKLuJz09HeHh4XjooYes0j4DqgP0ej2USqXlvr29PRoaGmxYUfcTFBQEBwf+sPO9cHFxgVKphF6vx9KlSxETE2PrkrodBwcHxMbGIikpCTNnzrR1Od3Ktm3b0LdvX8sf6dbAgOoApVKJ2tpay32z2cwXW+pSly5dQnR0NGbNmsUX2HuUnp6OPXv2YNWqVbhx44aty+k2tm7dikOHDkGlUqG0tBSxsbGoqqrq1HPw1bQD/Pz8UFRUhOnTp0On08Hb29vWJdF95MqVK3jhhRegVqsxbtw4W5fT7ezYsQOVlZVYtGgRFAoFZDIZ7Oz4N3tbbdy40XJbpVJh9erVcHd379RzMKA6YMqUKTh48CDCw8MhhEBKSoqtS6L7SHZ2NmpqavDBBx/ggw8+AHBr0Ym13rDuaZ5++mnExcUhMjISDQ0NWLlyJcdOYvht5kREJEmczxIRkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDiqiDMjMzsXnzZpSWlmLdunUAgL1796KystLGld2yd+9ePP300/jb3/7W5mO2bduGd99914pVEbWOAUXUSXx8fLBkyRIAwN/+9jfo9XobV3TL/v37sWLFCkRHR9u6FKJ24Qd16b5XW1uL5cuXo6amBo8++ii++uor9OnTB6tXr8bQoUOxefNmXLlyBa+88gree+89lJSUoLq6GiNGjEBqaqqlnSNHjiA/Px+zZs2yfPXLvHnzUFZWhtjYWJhMJsyePRuFhYWQy+WoqKjA8uXL8fDDD+P8+fP4xS9+gTfffBOZmZlwc3PD/PnzcebMGaxevRrr16/HzJkz8fjjj+Pbb7+Fl5cX+vXrhy+//BKOjo7485//jF69ejXp2759+3DgwAGUlJTgwQcfxOnTp7F582aYzWZMmjQJS5cubXV8mutzeHg4kpKSMGzYMHz66acoKirC8uXLER8fjx9++AEAkJCQgOHDhyMwMBBeXl4YOnQoHn/8ceTk5MDBwQEPPfQQMjIy+O0N1CI+M+i+t2nTJgwfPhybNm3C7NmzG32/4p30ej1cXV3xl7/8BVu3boVOp2v2Mt7EiRPh4+OD9PR0PPPMM9i3bx9MJhM+++wz/PrXv4ZcLrc8tqysDMnJydiyZQsOHDhw1+8yq62txYwZM7Bp0yZ8+eWX8PPzw8aNG2E0GnH69Olmj3nqqacQEBCA119/HZ6ensjJycGmTZuwfft2GAyGFvvaWp/nzZuH7du3A7j1nWzz5s1DdnY2xo4di/Xr1yMpKQmrV68GcOv7At99912sXLkSf//737FgwQJs3rwZgYGBkpllkjRxBkX3vYqKCss3Mvv5+cHR0bHR/ttftiKXy3Ht2jW8+uqrcHZ2xo0bN2A0Gu/atlKpxBNPPIHPP/8c27Ztw0svvdRov6enp+Ub8d3d3Vv9XayRI0cCAFxdXTF06FDL7bb8ntb58+cxbNgwy9f5vPbaa60e01Kfp02bhrlz52LBggWorKzEyJEjsWbNGhw+fBiffPIJAOD69esAgAcffBAPPvggACAuLg4ffvghNmzYAC8vL0yePLnVGuj+xRkU3feGDx+Oo0ePAgC+/fZbGAwGODo6WmYzJ0+eBAAcOHAAly5dwp/+9Ce8+uqrqKurQ0vfFCaTySz7QkNDsWXLFly9ehUjRoxo8rifksvllnOfOHGi1ce3laenJ7777jsYDAYAwNKlS1tdyNFSn52dnfHrX/8aycnJCA4OBgB4eXnh+eefx/r167FmzRrL9jsv4Wk0GrzyyivYsGEDgFsLOIhawhkU3ffmzZuH+Ph4REZGon///gCA6OhovPnmm+jfv7/lx9hGjx6NDz74AJGRkZDJZBg0aBAuX77cbJu//OUv8cc//hF5eXkYM2YMysvLERkZCQD4y1/+Ak9PTwwfPrzZY6dNm4aYmBh88cUXlhlTZ+jbty8WLlyIqKgoyGQyBAYGwsPD467HtNTnQYMGITQ0FBEREZZLeb///e8RHx+PgoIC6PV6y4KRn7a3aNEiuLi4wNnZGRMnTuy0/lHPwy+LJbpDfX09pk2bhv3793dam2azGfPnz0dubm6jH7js7r7++mts2LABb7/9tq1LoR6KMygiKzp//jyWLFmCuXPnWjWcvv76a7zzzjtNtk+bNg0REREtHrd69WqcOXOmyfbWfrZjw4YNKCwsxJo1a+6pXqK24AyKiIgkiYskiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgk6f8D/SAyElMsrasAAAAASUVORK5CYII=",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAAvBElEQVR4nO3dfVhUZd4H8O8ML8PISCyBroGIuJIWq4TV6iKaGqGmmEq8yVCPZmlZabUiguiivFnZCmxgiNte5iMQUtmumeFa5uv6SGOgVqshJipOKiLIMMPM/fzh5WwEBigzc6Tv57q6rplzZn7nd5/B+Xafc2ZGJoQQICIikhi5rRsgIiJqDwOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFDUre69915cunSp1bLS0lI899xzNuqoYzk5OSgrK2t33b333oupU6di2rRpeOKJJxAaGoqZM2eioqLCKr398MMPePHFFzt83NWrVxEXF9fl+jt37sSqVatupbUOLVmyBAUFBV16TmfH0d7f2a1KTEzEvn37uqUWdS97WzdAZGsHDx7E7373u5uu//vf/w43Nzfz/YKCAqxatQpFRUUW7+3s2bOoqqrq8HFXrly5pdCcMGECJkyYcCutWcStjuN2pKamWnV71HkMKLKapqYmjBkzBsXFxRg4cCAA4H/+538wa9YslJWVQSaT4eTJk7h06RKCgoKQlJQEBwcHnDx5Eqmpqairq4PRaIRarUZ4eDgOHjyI1NRU9OrVC9euXUNJSQk++OADbNy4EXK5HO7u7li2bBkGDhyIJUuWtFu/uLgYlZWVWL16Nezs7BASEvKLY2hpacG5c+dw1113mZfl5uZix44dMJlM8PT0xPLly9G3b1+o1WoMGjQIlZWVuHz5MqZNm4aXXnoJAFBWVoacnBwYjUaoVCokJCRg2LBhyM7OhkajwYULFzB48GBUVFSgtrYWc+bMQUFBARITE+Hv74/o6OhWfSUkJECn02HatGkoLS3F8OHDMWHCBHzzzTd444038O2336KoqAgGgwFXrlzB3LlzERMTg9LSUnz66adYt24d1Go1AgICUF5ejnPnzmHEiBHIzMyEXC5HeXk53njjDTQ1NUEmk+HFF1/EuHHjUFpaipKSEjQ1NUGlUmHjxo2t+jp8+DA+/fRTNDQ0ICgoCPHx8bC3t0dJSUm7/fx8HJWVlVi1ahWamprg4OCAxYsXY9SoUQCA7OxsHDlyBHV1dZgzZw5mzZr1i6/djh07kJubC5lMBjs7OyxevBgPPfQQ1Go1Zs2aBTs7O+Tk5Jgff/r0aTz66KN4/fXXbzp+sjBB1I38/PzElClTRFhYmPm/sWPHimeffVYIIcSqVatEZmamEEKI6upqMXbsWNHS0iLi4+PFE088IRoaGkRzc7OYNWuW2LhxozAYDGLy5MmisrJSCCFEfX29mDRpkvjqq6/EgQMHxJAhQ8SZM2eEEELs27dPPProo+LixYtCCCG2bNkiJk2aJEwm003rCyFEbGys+OSTT35xPFOnThVBQUFi/PjxYuXKleLHH38UQgjxwQcfiIULFwqDwSCEEKKwsFA888wz5rpz584Ver1eXLlyRYSGhop//etf4sSJE+KPf/yjOH36tLnvoKAgcfXqVZGVlSVCQ0PN9Q4cOCAef/zxDvf7Dz/8IAICAlr1/cEHHwghhGhoaBARERHi0qVLQgghvvrqK/Njt2zZYn5tYmNjxUsvvSSMRqO4evWqGD16tNi/f7+oq6sTjz32mPjhhx+EEEKcP39ejBkzRtTU1IgtW7aIhx56SFy9erVNT/Hx8WL69OmisbFRNDc3i9jYWLFp06Zf7Oen49Dr9SIoKEjs2rVLCCFERUWFmDJlijAajcLPz08UFBQIIYQ4evSo8Pf3F3q9/hf30YQJE8RXX30lhBDiyy+/FNnZ2eZx//z137lzpwgJCRFarfYXx0+WxRkUdbufHxK78X/pABATE4PY2FgsWrQIRUVFCA8Ph52dHQBg+vTpcHZ2BgBMmzYNO3fuxMiRI3H69GksXbrUXE+n0+HYsWMYNGgQ+vXrB09PTwDAl19+icmTJ5u3PWPGDKSmpuLMmTM3rR8bG9vp8Rw7dgxz587FAw88gLvvvhsAsGvXLlRUVGDmzJkAAJPJhKamJvNzIyMj4eDgAAcHB0ycOBF79uyBr68vRo4cif79+wMARo0aBTc3N1RWVgIAAgICYG9/+/80H3zwQQCAs7Mz8vLy8MUXX+DUqVP45ptvcO3atXafM27cOMjlcqhUKgwYMABXrlyBRqOBVqvFCy+8YH6cTCbDt99+C+D6+SCVStVuvWnTpqFXr14AgLCwMHzxxReIiYnpVD/fffcd5HI5HnnkEQCAv78/Pv74Y/P6KVOmAACGDh0KvV6PhoYG/OY3v7np/nj88cexYMECjB07FkFBQZg7d267j9NoNFixYgX+9re/wd3dHV988cVNx3/PPffcdHt0+xhQZFUDBw7Evffei507d+Ljjz/G+++/b153I6gAQAgBuVwOo9EIFxcXfPTRR+Z1P/74I3r37g2NRmN+87vxnJ8TQqClpeWm9bvivvvuQ0JCApKSkjB8+HB4eXnBZDLhmWeeQUxMDABAr9fjypUr5uf8NGhubLOjPn86pttxo8758+cRGRmJiIgIjBgxAhMnTsSuXbvafY6Tk5P5tkwmgxACRqMRgwYNavVa1dbWws3NDR9//PEv9vvTfQ5c3x+d7cfOzg4ymazVsu+++w6+vr7mWjf6BNp//X9q0aJFCA8Px549e1BaWop33nkHpaWlrR5TVVWFF198EW+88QYGDRoEAL84frIsXsVHVhcTE4PVq1dj+PDh6Nu3r3n5J598Ar1ej+bmZnzwwQcYN24cBg4cCIVCYQ6oc+fOYcqUKebZxk+NHj0a27ZtM1/dtWXLFri6umLAgAE3rQ9cfyO8EQ4dmTJlCgICApCWlmbeZklJCRoaGgAAa9euxeLFi82P37p1K0wmE65cuYJPPvkE48ePx8iRI7F371788MMPAID9+/fj3LlzGD58eJvt2dnZwWAwdNiXvb09jEZju2/SlZWVcHNzw/PPP4/g4GBzGBiNxk6NOSAgANXV1Th06BAA4Pjx4wgNDcWFCxc6fO4///lP8z4vLS3FmDFjfrGfn47D19cXMpkMe/fuBQAcPXoUTz31FEwmU6f6/qmWlhaMHz8e165dQ3R0NJYvX46TJ0+2et21Wi3mzp2LxYsX4w9/+EO3jJ9uD2dQZHXjxo1DUlISoqKiWi13cnJCTEwM6uvrzZdzy+VyvP3220hNTcX69evR0tKCl19+GSNGjMDBgwdbPT8oKAhPP/20+U3Mzc0N69atM8+U2qt/o5/MzEwYDAZMnz69w/6XLVuGsLAwfPnll3jyySdRW1uLiIgIyGQy9OvXDxkZGebH6nQ6hIeHo7GxETExMeYT/MuXL8eCBQtgNBrh5OSEvLw89O7du822Bg8eDDs7O4SHh+P9999HUlJSuxdJeHh44L777sOkSZOwefPmNvulpKQEEydOhFKpxLBhw+Dm5obq6uoOxwoAbm5uyMrKwurVq9Hc3AwhBFavXm0+tPpTa9euBQC8/PLLAAAvLy9ER0fj2rVrCAkJwfTp06HT6W7az4ABA1qNIzs7G2lpaVi9ejUcHByQnZ0NR0fHTvX9U/b29li6dClee+012NvbQyaTIS0trVWt7OxsXLx4Ee+++y7Wr18PAOjTpw/y8/M7PX7qXjLR0byYqJuVl5dj2bJl+Mc//mE+PLNkyRIMHjwYc+bMscg2LV2/PTeuDps4caLVtknUk3AGRVYVHx+Pf//738jMzGxzfoHodhw4cADp6entrvvDH/7Q6kIbujNwBkVERJLEiySIiEiSGFBERCRJPAeF6x/MUygUt/z85ubm23q+JUm1N6n2BUi3N6n2BUi3N/bVdbborbm5GQEBAW2WM6AAKBQKDB069Jaff/z48dt6viVJtTep9gVItzep9gVItzf21XW26O348ePtLuchPiIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgyKpMJoHvtQ04a3DG99oGmEz8pi0iah8/B0VWYzIJbD96Hq8Ua6AzmODkIMeaiABMvP+3kMv5xbFE1BpnUGQ1py42msMJAHQGE14p1uDUxUYbd0ZEUsSAIquprdeZw+kGncGEC1d1NuqIiKSMAUVW09fFCU4Orf/knBzk6NPbyUYdEZGUMaDIanzudsaaiABzSN04B+Vzt7ONOyMiKeJFEmQ1crkME+//LYa8FIyq85cw8Ldu8LnbmRdIEFG7OIMiq5LLZfD1UOEe+0b4eqgYTkR0UwwoIiKSJAYUERFJEgOKiIgkiQFFRESS1KOv4isvL0dRUREAIDExES4uLjbuiIiIOqtHz6CKi4uRkpKC8PBwbNu2zdbtEBFRF/TogDIajVAoFPDw8IBWq7V1O0RE1AU9OqCUSiX0ej20Wi3c3d1t3Q4REXWBRQPqyJEjUKvVbZbr9Xq8+uqriIiIwOzZs3Hq1Knbqm0ymZCcnIzIyEio1WpUV1cDACIiIpCcnIzCwkKEhYXd1liIiMi6LHaRRH5+PrZu3QqlUtlmXXFxMXr16oXi4mJ8//33WLlyJQoKCszra2pq4Onp2eb2zWqXlZVBr9ejqKgIGo0GGRkZyM3Nhb+/PzIyMiw1RCIisiCLzaC8vb2RnZ3d7roTJ05gzJgxAABfX1+cPHnSvE6n02HhwoUoKyvDhg0bkJ6e3mHtw4cPIzg4GAAQEBCAysrK7hwKERHZgMUCKjQ0FPb27U/Qhg4dil27dkEIAY1Gg9raWhiNRgCAk5MTCgoKsHLlSmzfvh1vvfVWh7UbGhqgUqnM9+3s7NDS0tLNIyIiImuyyUUSM2fOhEqlQkxMDD777DPcf//9sLOzAwAIIZCVlYWgoCA4OzujpKSkw3oqlQqNjf/9VVaTyXTTcCQiojuDTQKqoqICo0aNwubNmzFx4kT079/fvE6n08HHxwdpaWnIy8uDwWDosF5gYCB2794NANBoNPDz87NY70REZB1Wm2bU1dUhKSkJOTk5GDBgANauXYu8vDz07t0bqamp5scplUrExsYCABQKBeLi4jqsHRISgr179yIqKgpCCKSlpVlsHEREZB0WDSgvLy8UFxcDAFxdXZGTkwMAcHNzw7vvvtttteVyOVJSUm6rHhERSUuP/qAuERHduRhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLUo392try8HEVFRQCAxMREuLi42LgjIiLqrB49gyouLkZKSgrCw8Oxbds2W7dDRERd0KMDymg0QqFQwMPDA1qt1tbtEBFRF/TogFIqldDr9dBqtXB3d7d1O0RE1AUWDagjR45ArVa3WW4wGPDqq68iKioKMTExOHny5G3VNplMSE5ORmRkJNRqNaqrqwEAERERSE5ORmFhIcLCwm5vMEREZFUWu0giPz8fW7duhVKpbLPuiy++QEtLCwoLC7F371785S9/QXZ2tnl9TU0NPD0929y+We2ysjLo9XoUFRVBo9EgIyMDubm58Pf3R0ZGhqWGSEREFmSxGZS3t3er0PmpgQMHwmg0wmQyoaGhAfb2/81JnU6HhQsXoqysDBs2bEB6enqHtQ8fPozg4GAAQEBAACorK7t5NEREZG0Wm0GFhobizJkz7a7r1asXampqMGnSJFy+fBl5eXnmdU5OTigoKMDUqVPRt29fbNq0qcPaDQ0NUKlU5vt2dnZoaWlpFXxERHRnsclFEu+++y5Gjx6NTz/9FB999BGWLFmC5uZmAIAQAllZWQgKCoKzszNKSko6rKdSqdDY2Gi+bzKZGE5ERHc4mwSUi4sLevfuDQC466670NLSAqPRCOD6IT4fHx+kpaUhLy8PBoOhw3qBgYHYvXs3AECj0cDPz89yzRMRkVVYLaDq6uqwYMECAMDTTz+No0ePIiYmBk899RQWLVqEXr16Abh+aXhsbCwAQKFQIC4ursPaISEhcHR0RFRUFNLT05GQkGC5gRARkVVY9DiYl5cXiouLAQCurq7IyckBADg7O2Pt2rXdVlsulyMlJeX2miUiIknp0R/UJSKiOxcDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIki/5goa2Vl5ejqKgIAJCYmAgXFxcbd0RERJ3Vo2dQxcXFSElJQXh4OLZt22brdoiIqAt6dEAZjUYoFAp4eHhAq9Xauh0iIuqCHh1QSqUSer0eWq0W7u7utm6HiIi6wKIBdeTIEajV6jbLS0tLoVaroVarERERgd///veor6+/5domkwnJycmIjIyEWq1GdXU1ACAiIgLJyckoLCxEWFjY7Q+IiIisxmIXSeTn52Pr1q1QKpVt1s2YMQMzZswAAPz5z3/GzJkzW13AUFNTA09Pzza3b1a7rKwMer0eRUVF0Gg0yMjIQG5uLvz9/ZGRkWGpIRIRkQVZbAbl7e2N7OzsX3xMRUUFTpw4gcjISPMynU6HhQsXoqysDBs2bEB6enqHtQ8fPozg4GAAQEBAACorK7tpFEREZCsWm0GFhobizJkzv/iYdevW4YUXXmi1zMnJCQUFBZg6dSr69u2LTZs2dVi7oaEBKpXKfN/Ozg4tLS2wt+/RV9ETEfVoNrtIor6+HlVVVRg5cmSr5UIIZGVlISgoCM7OzigpKemwlkqlQmNjo/m+yWRiOBER3eFsFlCHDh3CqFGj2izX6XTw8fFBWloa8vLyYDAYOqwVGBiI3bt3AwA0Gg38/Py6vV8iIrIuqwVUXV0dFixYYL5fVVUFLy+vNo9TKpWIjY0FACgUCsTFxXVYOyQkBI6OjoiKikJ6ejoSEhK6r3EiIrIJix4H8/LyQnFxMQDA1dUVOTk55nXPPPNMt9WWy+VISUm5rXpERCQtPfqDukREdOdiQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkWfQn322tvLwcRUVFAIDExES4uLjYuCMiIuqsHj2DKi4uRkpKCsLDw7Ft2zZbt0NERF3QqYCqra3FiRMnUFVVhaVLl+L48eOW7qtbGI1GKBQKeHh4QKvV2rodIiLqgk4F1Kuvvooff/wRb731FoKCgpCWlmbpvrqFUqmEXq+HVquFu7u7rdshIqIu6FRAyWQyPPTQQ6ivr8fjjz8OubxzRwaPHDkCtVrd7rp169YhMjISM2bMwPvvv9/5jtupbTKZkJycjMjISKjValRXVwMAIiIikJycjMLCQoSFhXV5G0REZDudukiipaUFr7/+Oh588EEcOHAABoOhw+fk5+dj69atUCqVbdYdPHgQX331FTZv3oympiZs2LCh1fqamhp4enq2uX2z2mVlZdDr9SgqKoJGo0FGRgZyc3Ph7++PjIyMzgyRiIgkplNTofT0dPTv3x/PPvssLl26hMzMzA6f4+3tjezs7HbX7dmzB35+fnjhhRcwb948PPLII+Z1Op0OCxcuRFlZGTZs2ID09PQOax8+fBjBwcEAgICAAFRWVnZmWEREJGGdmkH16dMHEyZMQH19PaqqqjB8+PAOnxMaGoozZ860u+7y5cs4e/Ys8vLycObMGcyfPx/bt2+HTCaDk5MTCgoKMHXqVPTt2xebNm3qsHZDQwNUKpX5vp2dHVpaWmBv36Ovoici6tE6NYN66aWXcPToUaxevRoODg5ITk6+rY26urpi9OjRcHR0hK+vLxQKBS5dugQAEEIgKysLQUFBcHZ2RklJSYf1VCoVGhsbzfdNJhPDiYjoDtepgNLpdBg/fjzOnz+PZ599Fkaj8bY2OmLECHz55ZcQQqC2thZNTU1wdXU1b8vHxwdpaWnIy8vr1PmuwMBA7N69GwCg0Wjg5+d3W/0REZHtdWqaYTAY8Pe//x33338/Tpw4gaampi5vqK6uDklJScjJycG4ceNw6NAhhIeHQwiB5ORk2NnZAbh+aXhsbCwAQKFQIC4ursPaISEh2Lt3L6KioiCEuGMugyciopvrVEDFx8ejrKwMzz//PD766CMkJiZ2qriXlxeKi4sBXD+sl5OTY163ePHiW2i3/dpyuRwpKSm3VY+IiKSlUwEVGBiI+vp6FBUVwcfHB8OGDbN0X0RE9CvXqXNQb775JkpLS2Fvb48PP/yQny0iIiKL69QM6tChQygsLAQAPPXUU4iIiLBoU0RERJ2aQbW0tMBkMgG4fgm3TCazaFNERESdmkE9/vjjiI6OxvDhw/H1119j8uTJlu6LiIh+5X4xoN58803zbKlv377YtWsXhg4dav5QLRERkaX8YkD5+vqabw8cOBDjxo2zeENERERABwE1ffp0a/VBRETUSo/+yXciIrpzMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEmd+rmNO1V5eTmKiooAAImJiXBxcbFxR0RE1Fk9egZVXFyMlJQUhIeHY9u2bbZuh4iIuqBHB5TRaIRCoYCHhwe0Wq2t2yEioi7o0QGlVCqh1+uh1Wrh7u5u63aIiKgLLBpQR44cgVqtbnfd9OnToVaroVarkZCQcFu1TSYTkpOTERkZCbVajerqagBAREQEkpOTUVhYiLCwsFsfCBERWZ3FLpLIz8/H1q1boVQq26xrbm6GEAIbN25s97k1NTXw9PRsc/tmtcvKyqDX61FUVASNRoOMjAzk5ubC398fGRkZ3TwyIiKyBovNoLy9vZGdnd3uum+++QZNTU2YPXs24uLioNFozOt0Oh0WLlyIsrIybNiwAenp6R3WPnz4MIKDgwEAAQEBqKys7N7BEBGR1VlsBhUaGoozZ860u87JyQlz5szBk08+iVOnTmHu3LnYvn077O3t4eTkhIKCAkydOhV9+/bFpk2bOqzd0NAAlUplvm9nZ4eWlhbY2/foq+iJiHo0m1wkMXDgQISFhUEmk2HgwIFwdXU1X2UnhEBWVhaCgoLg7OyMkpKSDuupVCo0Njaa75tMJoYTEdEdziYBVVJSYj43VFtbi4aGBnh4eAC4fojPx8cHaWlpyMvLg8Fg6LBeYGAgdu/eDQDQaDTw8/OzXPNERGQVVguouro6LFiwAAAQHh6Oq1evIjo6GosWLUJaWpp5xqNUKhEbGwsAUCgUiIuL67B2SEgIHB0dERUVhfT09Fu6KpCIiKTFosfBvLy8UFxcDABwdXVFTk4OAMDR0RFvvvlmt9WWy+VISUm5vWaJiEhSevQHdYmI6M7FgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIke1s3YEnl5eUoKioCACQmJsLFxcXGHRERUWf16BlUcXExUlJSEB4ejm3bttm6HSIi6oIeHVBGoxEKhQIeHh7QarW2boeIiLqgRweUUqmEXq+HVquFu7u7rdshIqIusGhAHTlyBGq1+qbrL168iLFjx+LkyZO3VdtkMiE5ORmRkZFQq9Worq4GAERERCA5ORmFhYUICwu7tUEQEZFNWOwiifz8fGzduhVKpbLd9QaDAcnJyXBycmqzrqamBp6enm1u36x2WVkZ9Ho9ioqKoNFokJGRgdzcXPj7+yMjI6ObR0ZERNZgsRmUt7c3srOzb7o+MzMTUVFR6NOnT6vlOp0OCxcuRFlZGTZs2ID09PQOax8+fBjBwcEAgICAAFRWVnbTKIiIyFYsFlChoaGwt29/glZaWgo3NzdzqPyUk5MTCgoKsHLlSmzfvh1vvfVWh7UbGhqgUqnM9+3s7NDS0tINoyAiIluxyUUSW7Zswb59+6BWq3H8+HHEx8ebr7ITQiArKwtBQUFwdnZGSUlJh/VUKhUaGxvN900m003DkYiI7gw2eRfftGmT+bZarcaKFSvg4eEB4PohPh8fH8TGxqK5udn8QdtfEhgYiF27dmHy5MnQaDTw8/OzWO9ERGQdVptB1dXVYcGCBR0+TqlUIjY2FgCgUCgQFxfX4XNCQkLg6OiIqKgopKenIyEh4bb7JSIi27LoDMrLywvFxcUAAFdXV+Tk5LR5zMaNG2+7tlwuR0pKyq03SkREktOjP6hLRER3LgYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSfa2bsCSysvLUVRUBABITEyEi4uLjTsiIqLO6tEzqOLiYqSkpCA8PBzbtm2zdTtERNQFPTqgjEYjFAoFPDw8oNVqu72+ySTwvbYBZw3O+F7bAJNJdPs2iIh+rXr0IT6lUgm9Xg+tVgt3d/durW0yCWw/eh6vFGugM5jg5CDHmogATLz/t5DLZd26LSKiXyOLzqCOHDkCtVrdZrnRaERCQgKioqIQHR2N77777rZqm0wmJCcnIzIyEmq1GtXV1QCAiIgIJCcno7CwEGFhYbc3mJ85dbHRHE4AoDOY8EqxBqcuNnbrdoiIfq0sNoPKz8/H1q1boVQq26zbtWsXAKCwsBAHDx7EW2+9hdzcXPP6mpoaeHp6trl9s9plZWXQ6/UoKiqCRqNBRkYGcnNz4e/vj4yMDIuMr7ZeZw6nG3QGEy5c1cHXQ2WRbRIR/ZpYbAbl7e2N7Ozsdtc9+uijWLlyJQDg7Nmzra6u0+l0WLhwIcrKyrBhwwakp6d3WPvw4cMIDg4GAAQEBKCysrI7h9Kuvi5OcHJovfucHOTo09vJ4tsmIpKCG+fh95/80SLn4S02gwoNDcWZM2duvmF7e8THx+Ozzz5DVlaWebmTkxMKCgowdepU9O3bF5s2beqwdkNDA1Sq/85a7Ozs0NLSAnt7y51i87nbGWsiAtqcg/K529li2yQikgprnIe36VV8mZmZ+PTTT7Fs2TJcu3YNACCEQFZWFoKCguDs7IySkpIO66hUKjQ2/vfcj8lksmg4AYBcLsPE+3+LbS8Fo2DW77HtpWBeIEFEvxrWOA9vk4D68MMPsW7dOgDXr7STyWSQy6+3otPp4OPjg7S0NOTl5cFgMHRYLzAwELt37wYAaDQa+Pn5Wa75n5DLZfD1UOEe+0b4eqgYTkT0q/FL5+G7i9UCqq6uDgsWLAAAPPbYYzh27BhmzZqFOXPmYOnSpXByun7uRqlUIjY2FgCgUCgQFxfXYe2QkBA4OjoiKioK6enpSEhIsNxAiIjIKufhLXoczMvLC8XFxQAAV1dX5OTkAAB69eqFtWvXdlttuVyOlJSU22uWiIg6zRrn4Xv0B3WJiMgybpyHH/JSMC5c1aFPbyf43O3crac6GFBERHRLbpyHt9RnP3v0d/EREdGdiwFFRESSxIAiIiJJYkAREZEkMaCIiEiSZEKIX/2v7Gk0GigUClu3QUT0q9Tc3IyAgIA2yxlQREQkSTzER0REksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJH6b+S26ePEiZsyYgQ0bNqC5uRnPPfccfHx8AADR0dGYPHmyTfpat24d/vWvf8FgMCA6OhoPP/wwlixZAplMhsGDB2P58uXmXy+2ltLSUnzwwQcArn/e4fjx41izZg0yMzPRr18/AMCLL76Ihx9+2Kp9AYBer0dCQgJ++OEHqFQqJCcno66uDqmpqbCzs8Po0aPNP7RpLUeOHMEbb7yBjRs3orq6ut3Xb/78+bh8+TIcHBygUCiwfv16q/Z1/PhxrFy5EnZ2dnB0dERmZibc3d1RXFyMwsJC2NvbY/78+Rg3bpzF+/p5bydOnMCyZcsghICPjw9WrVoFe3t7rFq1CuXl5XB2vv57RW+//TZ69+5ttb6OHTvW7vtETk4OPv/8c9jb22Pp0qUYNmyYRXtqr7eLFy8iKSkJ9fX1MBqNWL16Nby9vW2yz1oR1GV6vV48//zz4rHHHhMnTpwQxcXFoqCgwNZtiQMHDojnnntOGI1G0dDQILKyssRzzz0nDhw4IIQQYtmyZWLHjh027XHFihWisLBQrFmzRmzfvt2mvQghxMaNG0VSUpIQQoiTJ0+K2bNni7CwMFFdXS1MJpN45plnxNGjR63WzzvvvCOmTJkinnzySSGEuOnrN2nSJGEymWzW16xZs8SxY8eEEEJs3rxZpKWliQsXLogpU6aI5uZmUV9fb75t7d7mz58v/v3vfwshhIiPjzfvs6ioKHHx4kWL93Ozvtp7n6isrBRqtVqYTCZRU1MjZsyYYZPe4uPjxT//+U8hhBD79+8Xu3btEkJYf5/9HA/x3YLMzExERUWhT58+AIDKykp8/vnnmDVrFpYuXYqGhgab9LVnzx74+fnhhRdewLx58/DII4/g6NGj5pnJmDFjsG/fPpv0BgAVFRU4ceIEIiMjcfToUWzZsgUxMTHIyMhAS0uLTXo6ceIExowZAwDw9fVFRUUF9Ho9vL29IZPJMHr0aKvuM29vb2RnZ5vvt/f6/fjjj6ivr8e8efMQHR2NXbt2Wb2vNWvWYOjQoQAAo9EIhUKBr7/+Gg888AAcHR3Ru3dveHt745tvvrF6b9nZ2XjooYeg1+uh1WqhUqlgMplQXV2N5ORkREVFoaSkxOp9tfc+cfjwYYwePRoymQz33HMPjEYjLl26ZPXeysvLUVtbi6effhoff/wxHn74YZvss59jQHVRaWkp3NzcEBwcbF42bNgwLF68GJs2bUL//v3x17/+1Sa9Xb58GZWVlVi7di3+/Oc/47XXXoMQAjLZ9V+4dHZ2xtWrV23SG3D98OMLL7wAAAgKCsKyZcuwadMmXLt2DYWFhTbpaejQodi1axeEENBoNLh69Sp69eplXm/tfRYaGgp7+/8eeW/v9TMYDJg9ezb++te/IicnB+np6bh48aJV+7rxP2fl5eV477338PTTT6OhoaHV4R9nZ2er/M/az3uzs7NDTU0NpkyZgsuXL2PIkCG4du0aYmNj8frrr2P9+vX43//9X4uH58/7au99oqGhASrVf3/sz1p/bz/vraamBi4uLnj33XfRr18/5Ofn22Sf/RwDqou2bNmCffv2Qa1W4/jx44iPj8eYMWPg7+8PAAgJCcGxY8ds0purqytGjx4NR0dH+Pr6QqFQtPpjb2xshIuLi016q6+vR1VVFUaOHAkAmDlzJvr37w+ZTIYJEybYbJ/NnDkTKpUKMTEx+OyzzzBkyBA0NTWZ19tynwFodb7wRi/u7u6IioqCvb097r77bgwdOhRVVVVW723btm1Yvnw53nnnHbi5uUGlUqGxsbFVv1Y9X/ETnp6e2LFjB6Kjo5GRkQGlUom4uDgolUqoVCqMHDnS6m+2ISEhbd4npLLPXF1dMX78eADA+PHjUVlZKYl9xoDqok2bNuG9997Dxo0bMXToUGRmZuL555/H119/DQDYv38/7r//fpv0NmLECHz55ZcQQqC2thZNTU0YNWoUDh48CADYvXs3HnzwQZv0dujQIYwaNQrA9VlBWFgYzp8/D8C2+6yiogKjRo3C5s2bMXHiRPj4+MDBwQGnT5+GEAJ79uyx2T4DgPvuu6/N67dv3z68/PLLAK6/of3nP/+Br6+vVfv66KOPzP8O+vfvD+D6DOHw4cNobm7G1atXcfLkSfj5+Vm1LwCYN28eTp06BeD6jEQul+PUqVOIjo6G0WiEwWBAeXm51f/m5syZ0+Z9IjAwEHv27IHJZMLZs2dhMpng5uZm1b6A6+8dX3zxBYDr/1Z/97vfSWKf8Sq+brBixQqsXLkSDg4OcHd3x8qVK23Sx7hx43Do0CGEh4dDCIHk5GR4eXlh2bJlWLNmDXx9fREaGmqT3qqqquDl5QUAkMlkWLVqFRYsWAAnJycMGjQIERERNulrwIABWLt2LfLy8tC7d2+kpqbi3LlzeO2112A0GjF69GgMHz7cJr0BQHx8fJvXz87ODnv27EFERATkcjleeeUVq76pGY1GpKamol+/fnjxxRcBAA899BBeeuklqNVqxMTEQAiBRYsW2eRXAp599lksWbIEDg4OUCqVWLVqFfr06YNp06YhIiICDg4OmDZtGgYPHmzVvtp7n1CpVHjwwQcRGRkJk8mE5ORkq/Z0Q3x8PJKSklBYWAiVSoU333wTd911l833Gb/NnIiIJImH+IiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRdQJzc3NeP/99zv12NLSUuzcubNbtpudnY3Nmzd36rEd9diVWu05fvw4cnJybvn5RF3FgCLqBK1W2+mAmjFjBiZMmGDhjtrqSo+3YujQoVb/Znf6deMHdYk6IS8vDydOnMCQIUPwxz/+EdeuXUNqaio+/PBDVFZWoq6uDkOGDEF6ejqys7Ph7u4OX19f5Ofnw8HBAWfOnMHkyZMxf/58nDt3DsuWLUNzczMUCgVWrlwJo9GI+fPnw9XVFWPGjMHcuXPN2y4rK8Mnn3wCnU6HpKQkDBs2DO+99x527NiBpqYm/OY3v0FOTo65x5ycHMTExCA+Ph5Xr16FEAKZmZkAgJ07d2L79u2oq6vDyy+/bP56m5+rqqpCQkIC7O3tYTKZ8Oabb+L06dMoLCzEK6+8gqVLlwK4/k0W33//Pfbv34/PP/8c7777LuRyOUaMGIHXXnvN8i8M9WgMKKJOmDdvHr777jsEBwfjypUrSEpKQkNDA1xcXPC3v/0NJpMJjz/+OGpra1s97+zZs9i6dSv0ej2Cg4Mxf/58ZGZmQq1WY+zYsdi/fz/eeOMNLFq0CFqtFlu2bIGjo2OrGp6enkhJScF//vMfLF68GFu2bEFdXZ05DObMmYOKigpzjwsWLMCqVaswfvx4REdHo7y83PwVO3379kVqaioOHjyI9evX3zSg9u3bh2HDhuFPf/oT/u///q/Vdzr2798fGzduhF6vx7x587B27Vo0NzcjOzsbW7ZsgVKpxJ/+9Cfs3bsXQUFB3fxK0K8JA4qoiwYOHAgAUCgUuHTpEl555RX06tUL165dg8FgaPVYPz8/2Nvbw97eHk5OTgCA7777DuvWrcP69eshhDB/q7SXl1ebcAKuf40QAAwePBharRZyuRwODg7m7Z4/f77Nz5VUVVUhPDwcABAYGIjAwEBkZ2ebv0vN3d0dOp3upmMMDw9Hfn4+nnnmGfTu3RuLFi1qtb6lpQWLFi1CWFgYxo4di6+//hqXLl3Cs88+C+D6zOr06dMMKLotDCiiTpDL5TCZTObbwPUvbz137hz+8pe/4NKlS/jss8/w828Ou/FTGT/l6+uL2bNnIzAwECdPnsShQ4da1f25r7/+GlOnTsW3336Le+65B9988w3Kysrw/vvvo6mpCTNmzIAQolWPgwYNQkVFBYYMGYJDhw7h888/h5OTU7v9tGfnzp0YMWIEFixYgH/84x9Yv349nnjiCQDXv+w3MTERDzzwgHmZl5cX+vXrhw0bNsDBwQGlpaXm34siulUMKKJOuPvuu2EwGFrNOoYNG4a3334bs2bNgkwmQ//+/XHhwoUOa8XHx2PFihVobm6GTqdDYmJim8fMnj0beXl5AIAzZ84gLi4Oer0eKSkpGDBgAJRKJaKiogAAHh4euHDhAh544AEYDAa8/vrrmDdvHpYuXYqtW7cCANLS0vDhhx92erz+/v6Ij49Hbm4uTCYTEhISzL/ttH37duzYsQO1tbXmb8Bevnw5nn76aajVahiNRnh6emLSpEmd3h5Re/hlsUREJEmcQRH9iq1YsQInT55sszw/P998zozIVjiDIiIiSeIHdYmISJIYUEREJEkMKCIikiQGFBERSRIDioiIJOn/AZWdVMCZQFUKAAAAAElFTkSuQmCC",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAAtkUlEQVR4nO3de1iUZf4/8DfDYWZkJCIQ+0GGmGhlStBuFqGpGR7RlACRQVezk5aH9isaSi7Gyc1M5CvwVchds2BCK7a1XGgtylMGjUWpJSUpnsYDRx0GZu7fH66zEiAgDPOA79d1dV0zcz/P/Xw+DvHmnueZGRshhAAREZHEyKxdABERUXMYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAonYbNGgQLl682OixHTt24LnnnrNSRa1LTU1FQUFBs2ODBg3C5MmTMWXKFEydOhVBQUGYPn06vv/++y6p7cSJE3jppZda3a66uhpRUVHtnv+zzz7D66+/fjOltWrZsmXIzMy0yNy/N2XKFFRVVXXJsVry/vvvY9u2bVat4VZiZ+0CiLrCgQMHcM8997Q4/re//Q0uLi7m+5mZmXj99deRk5Nj8dpOnTqFX3/9tdXtKisrbyo0x4wZgzFjxtxMaZLy0UcfWbsEFBUVYeDAgdYu45bBgKJOdeXKFYwYMQIajQb9+/cHAPzpT3/CzJkzUVBQABsbG5SWluLixYsICAjAihUrYG9vj9LSUsTHx6OiogJGoxFqtRohISE4cOAA4uPj0atXL1y+fBm5ubn44IMPsHXrVshkMri6umLlypXo378/li1b1uz8Go0GJSUlWLNmDWxtbTF27Ngb9tDQ0IDTp0/jtttuMz+WlpaGf/3rXzCZTPDw8MBrr70Gd3d3qNVqDBgwACUlJbh06RKmTJmCl19+GQBQUFCA1NRUGI1GqFQqLF++HEOHDsWGDRug1Wpx7tw5DBw4EN9//z3Onj2LuXPnIjMzEzExMRgyZAhmzJjRqK7ly5dDr9djypQp2LFjB4YNG4YxY8bgyJEjeOONN3D06FHk5OSgvr4elZWVmDdvHiIiIrBjxw7s2rULGRkZUKvV8PX1RXFxMU6fPg1/f38kJydDJpOhuLgYb7zxBq5cuQIbGxu89NJLGDVqFHbs2IHc3FxcuXIFKpUKW7dubfbfraXn0GQyISEhAYcOHUJtbS2EEHj99dfh7++PZcuWoaKiAidOnMDjjz+OCxcuQKVS4ejRozhz5gy8vb3x5ptvwtHREYMGDcK+ffvw+eefIz8/HzKZDGVlZbC3t0dycjJ8fHxQVlaGV199FZWVlXBzc4MQAsHBwZg2bVqLz/f1z8egQYOwbNkyxMbG4sKFC9DpdPDw8MBbb72F4uJi/Pvf/8aePXugUCgwc+bMFn8uqJMIonby8fERkyZNEsHBweb/Ro4cKZ599lkhhBCvv/66SE5OFkIIUVZWJkaOHCkaGhpEdHS0mDp1qqipqRF1dXVi5syZYuvWraK+vl5MmDBBlJSUCCGEqKqqEuPHjxfffvut2L9/vxg8eLA4efKkEEKIvXv3iieeeEJcuHBBCCHE9u3bxfjx44XJZGpxfiGEiIyMFJ988skN+5k8ebIICAgQo0ePFqtXrxbnz58XQgjxwQcfiEWLFon6+nohhBDZ2dnimWeeMc87b948YTAYRGVlpQgKChL//ve/xbFjx8Sjjz4qfvvtN3PdAQEBorq6WqSkpIigoCDzfPv37xcTJ05s9d/9xIkTwtfXt1HdH3zwgRBCiJqaGhEaGiouXrwohBDi22+/NW+7fft283MTGRkpXn75ZWE0GkV1dbV47LHHxL59+0RFRYV48sknxYkTJ4QQQpw5c0aMGDFClJeXi+3bt4s//OEPorq6uklN0dHRYvPmzTd8DouLi8VLL70kjEajEEKIjIwM8dxzz5n3nzVrVqP5wsLCRF1dnTAYDGLq1KkiNzfX3O+FCxfE9u3bhb+/vzh9+rQQQoi4uDixdOlSIYQQoaGhYtu2bUIIIY4dOyaGDRsmtm/ffsN/198/H1u2bBEZGRlCCCFMJpN45plnRGZmZqN+hbjxzwV1Dq6g6Kb8/iWxa3+lA0BERAQiIyOxePFi5OTkICQkBLa2tgCAp556Co6OjgCunlP47LPPMHz4cPz222949dVXzfPp9Xr8+OOPGDBgAO688054eHgAAL788ktMmDDBfOxp06YhPj4eJ0+ebHH+yMjINvfz448/Yt68eXjwwQdxxx13AAB2796N77//HtOnTwcAmEwmXLlyxbxvWFgY7O3tYW9vj3HjxuGrr76Ct7c3hg8fjrvuugsA8Mgjj8DFxQUlJSUAAF9fX9jZdfx/v4ceeggA4OjoiPT0dHzxxRc4fvw4jhw5gsuXLze7z6hRoyCTyaBSqXD33XejsrISWq0WOp0O8+fPN29nY2ODo0ePArh6nk6lUrVYx/Hjx1t8DiMiInDbbbchOzsbJ06cwIEDB8zPEQD4+/s3miswMBAODg4AAB8fH1RWVjY53v3334++ffsCAO677z7k5+ejsrIS3333Hd555x0AwIABAzB8+PCW//Guc/3zMWvWLHzzzTd4++23cfz4cfz8888YNmxYk31a+7mgjmNAUafr378/Bg0ahM8++wz/+Mc/8P7775vHrgUVAAghIJPJYDQa4eTk1Ogcw/nz59G7d29otVr06tWr0T6/J4RAQ0NDi/O3x3333Yfly5djxYoVGDZsGDw9PWEymfDMM88gIiICAGAwGBr90rw+aK4ds7U6r++pI67Nc+bMGYSFhSE0NBT+/v4YN24cdu/e3ew+CoXCfNvGxgZCCBiNRgwYMKDRc3X27Fm4uLjgH//4R6v13ug5/PzzzxEfH48//elPGDNmDLy9vZGXl9ekhxvV15Yerj33129//c/DjVxfw1//+ld89913mD59Oh5++GE0NDQ0W0NrPxfUcbyKjywiIiICa9aswbBhwxq9Jv/JJ5/AYDCgrq4OH3zwAUaNGoX+/ftDLpebf7mdPn0akyZNMq82rvfYY49h586d5qsIt2/fDmdnZ9x9990tzg9c/UV1LRxaM2nSJPj6+iIhIcF8zNzcXNTU1AAA1q9fj6VLl5q3z8vLg8lkQmVlJT755BOMHj0aw4cPx549e3DixAkAwL59+3D69Olm/xK3tbVFfX19q3XZ2dnBaDQ2+8uypKQELi4uePHFFxEYGGgOJ6PR2KaefX19UVZWhoMHDwIADh8+jKCgIJw7d65N+9/oOdyzZw9GjRqFiIgIPPDAAygoKGhzXe2hUqng5+eHHTt2ALh6deS+fftgY2PTrnm++uorzJo1C1OnTsUdd9yBvXv3muu9/ueotZ8L6jiuoMgiRo0ahRUrViA8PLzR4wqFAhEREaiqqjJfzi2TybBx40bEx8dj8+bNaGhowMKFC+Hv748DBw402j8gIACzZ8/GrFmzYDKZ4OLigoyMDPNKqbn5r9WTnJyM+vp6PPXUU63Wv3LlSgQHB+PLL7/E008/jbNnzyI0NBQ2Nja48847kZSUZN5Wr9cjJCQEtbW1iIiIwCOPPAIAeO2117BgwQIYjUYoFAqkp6ejd+/eTY41cOBA2NraIiQkBO+//z5WrFjR7EUSbm5uuO+++zB+/Hi89957Tf5dcnNzMW7cOCiVSgwdOhQuLi4oKytrtVcAcHFxQUpKCtasWYO6ujoIIbBmzRrzS6vXW79+PQBg4cKF5sccHBxafA6dnZ3x5z//GZMnT4atrS0eeugh84UFnS05ORkxMTF499134e7uDk9Pz0arrbaYP38+1qxZg40bN8LW1hZ+fn747bffAAAjRozA6tWrAQDz5s274c8FdZyNaO7PMaIOKi4uxsqVK/Hxxx+b/4JdtmwZBg4ciLlz51rkmJaevzlqtRozZ87EuHHjuuyY1LK0tDQ8+eSTGDBgAKqrqxEcHIxNmzbd8C0GJF1cQVGni46Oxtdff43k5OR2v7xC1BFeXl5YvHix+dzmvHnz0LdvX0yZMqXZ7R0dHfHuu+92cZXUVlxBERGRJPEiCSIikiQGFBERSRLPQQHQarWQy+U3vX9dXV2H9peintgT0DP76ok9AT2zr57YE3DzfdXV1cHX17fFcQYUALlcjnvvvfem9z98+HCH9peintgT0DP76ok9AT2zr57YE3DzfR0+fPiG43yJj4iIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSbzMnCTJZBI4fqEWZ6v0cHdSwOsOR8hk/Fw/olsJA4okx2QS+PSHM1ii0UJfb4LCXoY3Q30x7v6+DCmiWwhf4iPJOX6h1hxOAKCvN2GJRovjF2qtXBkRdSUGFEnO2Sq9OZyu0debcK5ab6WKiMgaGFAkOe5OCijsG/9oKuxl6NO7fd+MSkTdGwOKJMfrDke8GeprDqlr56C87nC0cmVE1JV4kQRJjkxmg3H398XglwNxrlqPPr15FR/RrYgBRZIkk9nA200FbzeVtUshIivhS3xERCRJDCgiIpIkBhQREUkSA4qIiCSpR18kUVxcjJycHABATEwMnJycrFwRERG1VY9eQWk0GsTFxSEkJAQ7d+60djlERNQOPTqgjEYj5HI53NzcoNPprF0OERG1Q48OKKVSCYPBAJ1OB1dXV2uXQ0RE7WDRgDp06BDUanWTxw0GA1555RWEhoZizpw5OH78eIfmNplMiI2NRVhYGNRqNcrKygAAoaGhiI2NRXZ2NoKDgzvUCxERdS2LXSSxadMm5OXlQalUNhnTaDTo1asXNBoNfvnlF6xevRqZmZnm8fLycnh4eDS53dLcBQUFMBgMyMnJgVarRVJSEtLS0jBkyBAkJSVZqkUiIrIgi62g+vXrhw0bNjQ7duzYMYwYMQIA4O3tjdLSUvOYXq/HokWLUFBQgKysLCQmJrY6d1FREQIDAwEAvr6+KCkp6cxWiIjICiwWUEFBQbCza36Bdu+992L37t0QQkCr1eLs2bMwGo0AAIVCgczMTKxevRqffvop1q1b1+rcNTU1UKn++5lttra2aGho6OSOiIioK1nlIonp06dDpVIhIiIC+fn5uP/++2FrawsAEEIgJSUFAQEBcHR0RG5ubqvzqVQq1Nb+99tWTSZTi+FIRETdg1UC6vvvv8cjjzyC9957D+PGjcNdd91lHtPr9fDy8kJCQgLS09NRX1/f6nx+fn4oLCwEAGi1Wvj4+FisdiIi6hpdtsyoqKjAihUrkJqairvvvhvr169Heno6evfujfj4ePN2SqUSkZGRAAC5XI6oqKhW5x47diz27NmD8PBwCCGQkJBgsT6IiKhrWDSgPD09odFoAADOzs5ITU0FALi4uGDLli2dNrdMJkNcXFyH5iMiImnp0W/UJSKi7osBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJPfprZ4uLi5GTkwMAiImJgZOTk5UrIiKiturRKyiNRoO4uDiEhIRg586d1i6HiIjaoUcHlNFohFwuh5ubG3Q6nbXLISKidujRAaVUKmEwGKDT6eDq6mrtcoiIqB0sGlCHDh2CWq1u8nh9fT1eeeUVhIeHIyIiAqWlpR2a22QyITY2FmFhYVCr1SgrKwMAhIaGIjY2FtnZ2QgODu5YM0RE1KUsdpHEpk2bkJeXB6VS2WTsiy++QENDA7Kzs7Fnzx689dZb2LBhg3m8vLwcHh4eTW63NHdBQQEMBgNycnKg1WqRlJSEtLQ0DBkyBElJSZZqkYiILMhiK6h+/fo1Cp3r9e/fH0ajESaTCTU1NbCz+29O6vV6LFq0CAUFBcjKykJiYmKrcxcVFSEwMBAA4Ovri5KSkk7uhoiIuprFVlBBQUE4efJks2O9evVCeXk5xo8fj0uXLiE9Pd08plAokJmZicmTJ8Pd3R3btm1rde6amhqoVCrzfVtbWzQ0NDQKPiIi6l6scpHEli1b8Nhjj2HXrl346KOPsGzZMtTV1QEAhBBISUlBQEAAHB0dkZub2+p8KpUKtbW15vsmk4nhRETUzVkloJycnNC7d28AwG233YaGhgYYjUYAV1/i8/LyQkJCAtLT01FfX9/qfH5+figsLAQAaLVa+Pj4WK54IiLqEl0WUBUVFViwYAEAYPbs2fjhhx8QERGBWbNmYfHixejVqxeAq5eGR0ZGAgDkcjmioqJanXvs2LFwcHBAeHg4EhMTsXz5css1QkREXcKir4N5enpCo9EAAJydnZGamgoAcHR0xPr16zttbplMhri4uI4VS0REktKj36hLRETdFwOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiSLfmGhtRUXFyMnJwcAEBMTAycnJytXREREbdWjV1AajQZxcXEICQnBzp07rV0OERG1Q48OKKPRCLlcDjc3N+h0OmuXQ0RE7dCjA0qpVMJgMECn08HV1dXa5RARUTtYNKAOHToEtVrd5PEdO3ZArVZDrVYjNDQUDzzwAKqqqm56bpPJhNjYWISFhUGtVqOsrAwAEBoaitjYWGRnZyM4OLjjDRERUZex2EUSmzZtQl5eHpRKZZOxadOmYdq0aQCAv/zlL5g+fXqjCxjKy8vh4eHR5HZLcxcUFMBgMCAnJwdarRZJSUlIS0vDkCFDkJSUZKkWiYjIgiy2gurXrx82bNhww22+//57HDt2DGFhYebH9Ho9Fi1ahIKCAmRlZSExMbHVuYuKihAYGAgA8PX1RUlJSSd1QURE1mKxFVRQUBBOnjx5w20yMjIwf/78Ro8pFApkZmZi8uTJcHd3x7Zt21qdu6amBiqVynzf1tYWDQ0NsLPr0VfRExH1aFa7SKKqqgq//vorhg8f3uhxIQRSUlIQEBAAR0dH5ObmtjqXSqVCbW2t+b7JZGI4ERF1c1YLqIMHD+KRRx5p8rher4eXlxcSEhKQnp6O+vr6Vufy8/NDYWEhAECr1cLHx6fT6yUioq7VZQFVUVGBBQsWmO//+uuv8PT0bLKdUqlEZGQkAEAulyMqKqrVuceOHQsHBweEh4cjMTERy5cv77zCiYjIKiz6Opinpyc0Gg0AwNnZGampqeaxZ555ptPmlslkiIuL69B8REQkLT36jbpERNR9MaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkiz6le/WVlxcjJycHABATEwMnJycrFwRERG1VY9eQWk0GsTFxSEkJAQ7d+60djlERNQObQqos2fP4tixY/j111/x6quv4vDhw5auq1MYjUbI5XK4ublBp9NZuxwiImqHNgXUK6+8gvPnz2PdunUICAhAQkKCpevqFEqlEgaDATqdDq6urtYuh4iI2qFNAWVjY4M//OEPqKqqwsSJEyGTte2VwUOHDkGtVjc7lpGRgbCwMEybNg3vv/9+2ytuZm6TyYTY2FiEhYVBrVajrKwMABAaGorY2FhkZ2cjODi43ccgIiLradNFEg0NDfjrX/+Khx56CPv370d9fX2r+2zatAl5eXlQKpVNxg4cOIBvv/0W7733Hq5cuYKsrKxG4+Xl5fDw8Ghyu6W5CwoKYDAYkJOTA61Wi6SkJKSlpWHIkCFISkpqS4tERCQxbVoKJSYm4q677sKzzz6LixcvIjk5udV9+vXrhw0bNjQ79tVXX8HHxwfz58/H888/j8cff9w8ptfrsWjRIhQUFCArKwuJiYmtzl1UVITAwEAAgK+vL0pKStrSFhERSVibVlB9+vTBmDFjUFVVhV9//RXDhg1rdZ+goCCcPHmy2bFLly7h1KlTSE9Px8mTJ/HCCy/g008/hY2NDRQKBTIzMzF58mS4u7tj27Ztrc5dU1MDlUplvm9ra4uGhgbY2fXoq+iJiHq0Nq2gXn75Zfzwww9Ys2YN7O3tERsb26GDOjs747HHHoODgwO8vb0hl8tx8eJFAIAQAikpKQgICICjoyNyc3NbnU+lUqG2ttZ832QyMZyIiLq5NgWUXq/H6NGjcebMGTz77LMwGo0dOqi/vz++/PJLCCFw9uxZXLlyBc7OzuZjeXl5ISEhAenp6W063+Xn54fCwkIAgFarhY+PT4fqIyIi62vTMqO+vh5/+9vfcP/99+PYsWO4cuVKuw9UUVGBFStWIDU1FaNGjcLBgwcREhICIQRiY2Nha2sL4Oql4ZGRkQAAuVyOqKioVuceO3Ys9uzZg/DwcAghus1l8ERE1LI2BVR0dDQKCgrw4osv4qOPPkJMTEybJvf09IRGowFw9WW91NRU89jSpUtvotzm55bJZIiLi+vQfEREJC1tCig/Pz9UVVUhJycHXl5eGDp0qKXrIiKiW1ybzkGtXbsWO3bsgJ2dHT788EO+t4iIiCyuTSuogwcPIjs7GwAwa9YshIaGWrQoIiKiNq2gGhoaYDKZAFy9hNvGxsaiRREREbVpBTVx4kTMmDEDw4YNw3fffYcJEyZYui4iIrrF3TCg1q5da14tubu7Y/fu3bj33nvNb6olIiKylBsGlLe3t/l2//79MWrUKIsXREREBLQSUE899VRX1UFERNRIj/7KdyIi6r4YUEREJEkMKCIikiQGFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSpDZ93UZ3VVxcjJycHABATEwMnJycrFwRERG1VY9eQWk0GsTFxSEkJAQ7d+60djlERNQOPTqgjEYj5HI53NzcoNPprF0OERG1Q48OKKVSCYPBAJ1OB1dXV2uXQ0RE7WDRgDp06BDUanWzY0899RTUajXUajWWL1/eoblNJhNiY2MRFhYGtVqNsrIyAEBoaChiY2ORnZ2N4ODgm2+EiIi6nMUukti0aRPy8vKgVCqbjNXV1UEIga1btza7b3l5OTw8PJrcbmnugoICGAwG5OTkQKvVIikpCWlpaRgyZAiSkpI6uTMiIuoKFltB9evXDxs2bGh27MiRI7hy5QrmzJmDqKgoaLVa85her8eiRYtQUFCArKwsJCYmtjp3UVERAgMDAQC+vr4oKSnp3GaIiKjLWWwFFRQUhJMnTzY7plAoMHfuXDz99NM4fvw45s2bh08//RR2dnZQKBTIzMzE5MmT4e7ujm3btrU6d01NDVQqlfm+ra0tGhoaYGfXo6+iJyLq0axykUT//v0RHBwMGxsb9O/fH87Ozuar7IQQSElJQUBAABwdHZGbm9vqfCqVCrW1teb7JpOJ4URE1M1ZJaByc3PN54bOnj2LmpoauLm5Abj6Ep+XlxcSEhKQnp6O+vr6Vufz8/NDYWEhAECr1cLHx8dyxRMRUZfosoCqqKjAggULAAAhISGorq7GjBkzsHjxYiQkJJhXPEqlEpGRkQAAuVyOqKioVuceO3YsHBwcEB4ejsTExJu6KpCIiKTFoq+DeXp6QqPRAACcnZ2RmpoKAHBwcMDatWs7bW6ZTIa4uLiOFUtERJLSo9+oS0RE3RcDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJLsrF2AJRUXFyMnJwcAEBMTAycnJytXREREbdWjV1AajQZxcXEICQnBzp07rV0OERG1Q48OKKPRCLlcDjc3N+h0OmuXQ0RE7dCjA0qpVMJgMECn08HV1dXa5RARUTtYNKAOHToEtVrd4viFCxcwcuRIlJaWdmhuk8mE2NhYhIWFQa1Wo6ysDAAQGhqK2NhYZGdnIzg4+OaaICIiq7DYRRKbNm1CXl4elEpls+P19fWIjY2FQqFoMlZeXg4PD48mt1uau6CgAAaDATk5OdBqtUhKSkJaWhqGDBmCpKSkTu6MiIi6gsVWUP369cOGDRtaHE9OTkZ4eDj69OnT6HG9Xo9FixahoKAAWVlZSExMbHXuoqIiBAYGAgB8fX1RUlLSSV0QEZG1WCyggoKCYGfX/AJtx44dcHFxMYfK9RQKBTIzM7F69Wp8+umnWLduXatz19TUQKVSme/b2tqioaGhE7ogIiJrscpFEtu3b8fevXuhVqtx+PBhREdHm6+yE0IgJSUFAQEBcHR0RG5ubqvzqVQq1NbWmu+bTKYWw5GIiLoHq/wW37Ztm/m2Wq3GqlWr4ObmBuDqS3xeXl6IjIxEXV2d+Y22N+Ln54fdu3djwoQJ0Gq18PHxsVjtRETUNbpsBVVRUYEFCxa0up1SqURkZCQAQC6XIyoqqtV9xo4dCwcHB4SHhyMxMRHLly/vcL1ERGRdFl1BeXp6QqPRAACcnZ2RmpraZJutW7d2eG6ZTIa4uLibL5SIiCSnR79Rl4iIui8GFBERSRIDioiIJIkBRUREksSAIiIiSWJAERGRJDGgiIhIkhhQREQkSQwoIiKSJAYUERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEkMaCIiEiSGFBERCRJDCgiIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoIiISJIYUEREJEl21i7AkoqLi5GTkwMAiImJgZOTk5UrIiKiturRKyiNRoO4uDiEhIRg586d1i6HiIjaoUcHlNFohFwuh5ubG3Q6XafPbzIJ/KKrwal6R/yiq4HJJDr9GEREt6oe/RKfUqmEwWCATqeDq6trp85tMgl8+sMZLNFooa83QWEvw5uhvhh3f1/IZDadeiwioluRRVdQhw4dglqtbvK40WjE8uXLER4ejhkzZuCnn37q0NwmkwmxsbEICwuDWq1GWVkZACA0NBSxsbHIzs5GcHBwx5r5neMXas3hBAD6ehOWaLQ4fqG2U49DRHSrstgKatOmTcjLy4NSqWwytnv3bgBAdnY2Dhw4gHXr1iEtLc08Xl5eDg8Pjya3W5q7oKAABoMBOTk50Gq1SEpKQlpaGoYMGYKkpCSL9He2Sm8Op2v09Sacq9bD201lkWMSEd1KLLaC6tevHzZs2NDs2BNPPIHVq1cDAE6dOtXo6jq9Xo9FixahoKAAWVlZSExMbHXuoqIiBAYGAgB8fX1RUlLSma00y91JAYV9438+hb0MfXorLH5sIiJrunb+fV/pefyiq4HM1tYix7HYCiooKAgnT55s+cB2doiOjkZ+fj5SUlLMjysUCmRmZmLy5Mlwd3fHtm3bWp27pqYGKtV/Vy22trZoaGiAnZ3lTrF53eGIN0N9m5yD8rrD0WLHJCKytubOvydNvQ8DTaLTz79b9Sq+5ORk7Nq1CytXrsTly5cBAEIIpKSkICAgAI6OjsjNzW11HpVKhdra/577MZlMFg0nAJDJbDDu/r7Y+XIgMmc+gJ0vB/ICCSLq8Zo7/77swx8tcv7dKgH14YcfIiMjA8DVK+1sbGwgk10tRa/Xw8vLCwkJCUhPT0d9fX2r8/n5+aGwsBAAoNVq4ePjY7niryOT2cDbTYX/Z1cLbzcVw4mIerwbnX/vbF0WUBUVFViwYAEA4Mknn8SPP/6ImTNnYu7cuXj11VehUFw9d6NUKhEZGQkAkMvliIqKanXusWPHwsHBAeHh4UhMTMTy5cst1wgR0S2sK8+/W/R1ME9PT2g0GgCAs7MzUlNTAQC9evXC+vXrO21umUyGuLi4jhVLREStau78e9LU+yxy/r1Hv1GXiIg617Xz74NfDsS5aj369Fag/tIpi5ziYEAREVG7XDv/fu09n4fPGy1zHIvMSkRE1EEMKCIikiQGFBERSRIDioiIJIkBRUREkmQjhLjlv2VPq9VCLpdbuwwioltKXV0dfH19WxxnQBERkSTxJT4iIpIkBhQREUkSA4qIiCSJAUVERJLEgCIiIkliQBERkSQxoP7DZDIhNjYWYWFhUKvVKCsrazSu0Wgwbdo0hIaGYvfu3QCAixcvYs6cOYiIiMCiRYtw5cqVFrc9deoUZs+eDbVajcjISPzyyy/dvqdrvv76a4wcOdLi/Vxj6b4uX76MpUuXIiIiAk8//TS+++67bt/TqVOnEBkZiZkzZ+LFF180b9ud+ro2FhQUhLq6OgBXv4H7pZdeQkREBObNm4eLFy92+56qq6vx/PPPIzIyEmFhYfj2228t3lNX9HVNaWkp/P39mzzeLEFCCCF27doloqOjhRBCfPvtt+L55583j507d05MmjRJ1NXViaqqKvPt1atXi+3btwshhMjIyBBvv/12i9suXbpU5OfnCyGEKCwsFPPnz+/2PQkhxKlTp8Tzzz8vHn30UYv301V9paSkiP/7v/8TQghx+PBh8cEHH3T7nuLj48U777wjhBDizTffFH//+98t3lNn9iXE1f9vpkyZIh588EGh1+uFEEJkZWWJlJQUIYQQH3/8sVi9enW372n9+vXm8dLSUjF16lSL99QVfQkhRHV1tZg3b54YPnx4o8dbwhXUfxQVFSEwMBAA4Ovri5KSEvPYd999hwcffBAODg7o3bs3+vXrhyNHjjTaZ8SIEdi7d2+L20ZHR5tXGUajsUs+ucLSPdXV1eG1117DqlWrLN5LV/b11Vdfwd7eHnPnzsXGjRvN+3Xnnu69915UVVUBAGpqamBn1zVfBddZfQFXvzn77bffhrOzc7PzjxgxAvv27ev2Pc2ePRvh4eEAuu53RVf0JYTAypUrsWTJEiiVyjbVxID6j5qaGqhUKvN9W1tbNDQ0mMd69+5tHnN0dERNTU2jxx0dHVFdXd3iti4uLrC3t8cvv/yC5ORkzJ8/v9v3FBcXhzlz5sDd3d3ivVzP0n1dunQJVVVVyMzMxOjRo5GcnNzte+rbty+2bduGiRMnorCwEOPGjbN4T53ZFwAEBATg9ttvbzJ/c9takqV7cnJygkKhgE6nw//8z/9gyZIllm7JXLsl+0pNTcXIkSMxePDgNtfEgPoPlUqF2tpa832TyWT+K/P3Y7W1tejdu3ejx2tra+Hk5NTitgCwf/9+zJ8/H2vWrIG3t3e37sne3h7ffPMN/vd//xdqtRqVlZVYvHixxXuydF+9e/eGs7MzRo8eDQAYNWpUo78ku2tPa9asQWJiIv75z38iJiYG0dHRFu+pM/tqy/ytbdtZLN0TABw9ehSzZ8/G4sWL8cc//tECXTRl6b7y8vKwfft2qNVq6HQ6zJkzp9WaGFD/4efnh8LCQgBXPzzWx8fHPDZ06FAUFRWhrq4O1dXVKC0thY+PD/z8/PDFF18AAAoLC+Hv79/itvv370d8fDw2b96MBx54oNv3NHToUOzatQtbt27F1q1bcdttt2HdunXdvi8fHx/4+/ubtz148CDuueeebt+Tk5OT+Q+lPn36mF/u6y593Wj+tm7bWSzd07Fjx7Bw4UKsXbu2Sy8+snRf+fn55t8Xbm5uyMrKarUmfljsf5hMJqxatQo//fQThBBISEhAYWEh+vXrhzFjxkCj0SAnJwdCCDz33HMICgrC+fPnER0djdraWtx+++1Yu3YtevXq1ey2wcHBMBgMcHNzAwD0798fcXFx3bqn6wUEBGDPnj0W7aer+qqoqMCKFSug0+lgZ2eH5ORkeHp6duuejh07hri4OJhMJgghEBMTg/vuu8+iPXV2X9eMHj0an3zyCeRyOa5cuYLo6GjodDrY29tj7dq15v/HumtPL7zwAo4ePQoPDw8AV1cvaWlpFu2pK/q6XkuP/x4DioiIJIkv8RERkSQxoIiISJIYUEREJEkMKCIikiQGFBERSRIDiug6dXV1eP/999u07Y4dO/DZZ591ynE3bNiA9957r1Pmup5Op+vyj6LKz8/H2bNnu/SY1DMxoIiuo9Pp2hxQ06ZNw5gxYyxcUce4ubl1eUD9/e9/R01NTZcek3qmrvnESKJuIj09HceOHcPgwYPx6KOP4vLly4iPj8eHH36IkpISVFRUYPDgwUhMTMSGDRvg6uoKb29vbNq0Cfb29jh58iQmTJiAF154AadPn8bKlStRV1cHuVyO1atXw2g04oUXXoCzszNGjBiBefPmNalh7dq1+Oabb2AymTB79myMHz8eX3/9NVJTUyGEQG1tLdauXQt7e/tGcxUWFmLw4MH4+eefUVNTg/Xr10MIgSVLlkCj0WDy5Mn44x//iKNHj8LGxgYbN26ESqXCX/7yF5SUlMDV1RXl5eVIS0tr8Y3Jo0aNgre3NwYMGICQkBAkJSXBaDTi0qVLWLVqFaqqqnD48GFER0fj3XffRU5ODj7++GPY2NhgwoQJiIqKsvRTSD1Juz+TnagHO3HihHj66adFSkqK+asbqqurzV+/YTQaxbhx48SZM2dESkqKePfdd8X+/fvF+PHjRX19vaitrRV+fn5CCCEWLlwoPv/8cyGEEHv37hVLliwRJ06cEA8//LD560quuTbX559/LhYtWiSEEEKv14vg4GBRWVkp3nnnHXHmzBkhhBBpaWli48aNTeaKjIwUeXl5QoirX6mRkZFh7kcIIUaNGiWKioqEEEIsWbJEfPzxxyI/P18sXLhQCCHEhQsXhL+/vzhx4kSL/z6DBg0SFy9eFEII8c9//lMcOXJECCFEXl6eiImJMddx7Ngx8fPPP4vw8HDR0NAgGhoahFqtFqWlpTf1vNCtiSsoohb0798fACCXy3Hx4kUsWbIEvXr1wuXLl1FfX99oWx8fH9jZ2cHOzg4KhQIA8NNPPyEjIwObN2+GEML8wZuenp5wcHBo9pg//fQTfvjhB6jVagBAQ0MDysvL4e7ujvj4ePTq1Qtnz56Fn59fs3Nd+/iivn374vz5803mvzZ+5513oq6uDuXl5fD19QUAuLi4tPohxrfffrv5U6r79OmDjRs3QqFQoLa2ttEnYV/r5doXdQJAZWUlysrKuuSDkqlnYEARXUcmk8FkMplvA1c/BPP06dN46623cPHiReTn50P87hPCbGxsmszl7e2NOXPmwM/PD6WlpTh48GCjeZvj7e2Nhx9+GKtXr4bJZMLGjRtx1113Yc6cOcjPz4dKpUJ0dLT5+Deaqzm/r3PgwIH46KOPAFwNkOPHj99w/+uPFx8fjzfeeAMDBgxASkoKysvLzccQQsDb2xv33HMPNm/eDBsbG2zZsgWDBg1qV710a2NAEV3njjvuQH19PfR6vfmxoUOHYuPGjZg5cyZsbGxw11134dy5c63OFR0djVWrVqGurg56vR4xMTFNtpkzZw7S09PN90ePHo2vv/4aERERuHz5Mp544gmoVCoEBwdj5syZUCqVcHV1bdPx2+Lxxx9HYWEhwsPD4erqCoVCAXt7+zbtGxwcjIULF8LJyQl9+/bFpUuXAAAPPvggli5diqysLDzyyCOYMWMGDAYDhg4d2uXfHUbdGz8slugWVlpaiiNHjmDixIm4dOkSJk2ahN27d7f4EiRRV2JAEd3CLl++jFdeeQUXLlyA0WhEZGQknJycsGXLlibbRkVFYezYsV1fJN2yGFBERCRJfKMuERFJEgOKiIgkiQFFRESSxIAiIiJJYkAREZEk/X926JKees9tIwAAAABJRU5ErkJggg==",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABVIAAAVfCAYAAABY3ROgAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAAEAAElEQVR4nOzdd3hUdfr+8XtCQghJ6IqFIiCEoiCIbWmCIAqCUgNIENsqLhZAQaQjCCgoGlAUcQX8AgFhEWwrTYpiASWIFClRiSAttCRASGZ+f3jt/IwkmYnM5JzPmffruuZa5szknGdkuXl4zueccXk8Ho8AAAAAAAAAAPkKs7oAAAAAAAAAALA7BqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAACwSFxcnNLS0nJtW7JkiR555BGLKvJt2rRpWrlyZZ6vxcXFqUOHDrr77rt1zz33qG3bturSpYt++OGHIqlt//79evzxx4Oy70OHDqlHjx4XtY/ExESNHTvW5/seeOCBC/5/AQAAAOuFW10AAAAAzPH111/r6quvzvf12bNnq1y5ct7ns2bN0rhx45SUlBT02g4cOKCUlJSg7LtixYpasGBBUPb9V1988UWRHAcAAACFwyAVAADAhs6cOaPmzZtr4cKFqlatmiTp/vvv17333quVK1fK5XJp7969SktLU5MmTTR8+HBFRERo7969Gj9+vE6cOKGcnBwlJCSoa9eu+vrrrzV+/HiVLFlSmZmZev/99/Wf//xHc+fOVVhYmCpUqKARI0aoWrVqevbZZ/Pc/8KFC7Vt2za9+OKLKlasmNq0aVPgZ8jOztbBgwdVunRp77Y33nhDn332mdxut6688kqNGjVKFStWVEJCgmrUqKFt27bp+PHjuvvuu/XEE09IklauXKlp06YpJydHMTExGjp0qOrXr6/ExERt2bJFhw8fVs2aNfXDDz/o0KFDevDBBzVr1iwNGzZM11xzjXr27JmrriVLluijjz6S2+3WoUOHVLFiRU2cOFEVK1bUli1b9NJLLykrK0tHjhzRP/7xD73wwgtKTU1Vhw4d9P333+c6blxcnCZPnuzdd2pqqhISEnTjjTdq586d8ng8GjlypBo3bpyrht27d2vs2LE6ceKEXC6XHnjgAd1zzz0aOnSoJOm+++7TW2+9pcsvv/zv/58IAAAAAcUgFQAAwEL33XefwsL+/92WTp48qbi4OEVFRemee+7RokWLNHjwYP36669KSUlRy5YttXLlSu3cuVPvvfeeIiIi9MADDygpKUk9evTQE088oRdffFH16tXT6dOnFR8f711Bunv3bq1cuVJXXnmlNm7cqLfffltJSUkqV66clixZon/961/66KOPJCnP/ffu3Vuffvqp7r333nyHqPfdd59cLpfS0tIUGRmpli1basKECZKkpUuX6qefftKiRYsUHh6upKQkDR8+XDNnzpT0x4rS+fPn68yZM+revbuuvfZaValSRaNGjdKCBQtUuXJlbdy4UY899pg+/fRTSdJvv/2mDz/8UOHh4fr666/1/PPPa9asWZKk8ePH5/vf/bvvvtOSJUtUrVo1TZ48WePHj9drr72mOXPm6IknntBNN92kjIwM3Xbbbdq2bZvKlCmT6+f/fNy/OnDggJo2bapJkyZp7dq1euqpp7RmzRrv69nZ2erXr58GDx6s22+/XYcOHVK3bt1UtWpVTZgwQUuWLLlgZS8AAACsxyAVAADAQn8dmC1ZskT//e9/JUm9evVS7969NWDAACUlJalr164qVqyYJKlTp06Kjo6WJN19991atWqVbr75Zv3666967rnnvPs7e/astm/frho1aujyyy/XlVdeKUlav3692rVr5z12586dNX78eKWmpua7/969e/v9ebZv366HH35YDRs2VPny5SVJa9as0Q8//KAuXbpIktxut86cOeP92fj4eEVERCgiIkJ33HGHNmzYoOrVq+vmm29W5cqVJUm33HKLypUrp23btkmSrrvuujyHmb40adLEu9K3e/fuuvvuuyVJEydO1Lp16zRjxgzt27dPZ8+eVWZm5gWD1IKOW7p0aXXo0EGS1KJFCxUrVky7du3yvv7zzz/r3Llzuv322yX9cduA22+/XevXr1fDhg0L/VkAAABQNBikAgAA2FS1atUUFxenVatWafny5Vq0aJH3tf8NVCXJ4/EoLCxMOTk5KlWqlD744APva0ePHlVsbKy2bNmikiVL5vqZv/J4PMrOzs53/4VRt25dDR06VMOHD1eDBg1UqVIlud1uPfTQQ+rVq5ckKSsrSydPnvT+zJ8Hk/87pq86//yZCuPPn8/tdnuf33vvvapdu7aaNWumO++8U8nJyXnWUNBx/7zvv+7/f8//6s+fCQAAAPZUuI4YAAAARapXr1568cUX1aBBA1WsWNG7/ZNPPlFWVpbOnTun//znP2rZsqWqVaumyMhI7yD14MGDuuuuu7yrN/+sadOm+vjjj73fDr948WKVKVNGVatWzXf/0h9DQn8HfnfddZeuu+46vfDCC95jvv/++0pPT5ckvfrqqxo8eLD3/cuWLZPb7dbJkyf1ySefqFWrVrr55pv1xRdfaP/+/ZKkjRs36uDBg2rQoMEFxytWrJjOnz/vV21fffWVDh06JElasGCBWrZsqZMnT2rbtm16+umnvZfc//rrr3kOPguSlpamdevWSZJWr16tiIgI1apVy/t6tWrVFBERoc8++0ySdOjQIf33v//VP/7xD+/nYKgKAABgP6xIBQAAsLGWLVtq+PDh6tGjR67tJUqUUK9evXTq1Cm1bdtWXbp0UVhYmF5//XWNHz9eb7/9trKzs/Xkk0/q+uuv19dff53r55s0aaK+ffvqvvvuk9vtVrly5fTmm296V57mtf//1TNp0iSdP39enTp18ln/iBEj1LFjR61fv17dunXToUOH1L17d7lcLl1++eWaOHGi971nz55V165dlZGRoV69eumWW26RJI0aNUr9+/dXTk6OSpQooRkzZig2NvaCY9WsWVPFihVT165dtWjRIg0fPjzPL5uS/ric/plnntGRI0d09dVXa+zYsSpdurT++c9/qlOnTipTpozKli2rRo0a6ZdffvHeWsAf/xtmT548WSVKlND06dNzrUiNiIjQ66+/rnHjxikxMVE5OTn617/+pZtvvlmS1KZNG/Xq1Uuvv/56rgEsAAAArOXy5HWtEgAAAGzhu+++04gRI/Thhx/K5XJJkp599lnVrFlTDz74YFCOGez95yUhIUH33nuv7rjjjqAf63/3oX3zzTcDvu/U1FR16NBB33//fcD3DQAAAGuxIhUAAMCmhgwZom+++UaTJk3yDlEBAAAAWIMVqQAAAAAAAADgA182BQAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwgUEqAAAAAAAAAPjAIBUAAAAAAAAAfGCQCgAAAAAAAAA+MEgFAAAAAAAAAB8YpAIAAAAAAACADwxSAQAAAAAAAMAHBqkAAAAAAAAA4AODVAAAAAAAAADwIdzqAgAAAHAh9++1/Hpf2GU/BbkSAHA2f/KWrAWAi+OU3pZBKgAAQeRvwxAK7N4U2c15T7Zf74sMch0AgsPEvx+cmuP+5C1ZC5jLtLwN5ayV7J+3DFIBAABsyC2P1SUAQEggbwEg+JyStQxSAQAAbOi8J8ev90UFuQ4AcDp/8pasBYCL45TelkEqAACADTnlrD0A2B15CwDB55SsZZAKAABgQzkOaTYBwO7IWwAIPqdkLYNUAAAAGzrvcVtdAgCEBPIWAILPKVnLIBUAAMCGnNFqAoD9kbcAEHxOyVoGqQAAADbklMufAMDuyFsACD6nZC2DVAAAABs674xeEwBsj7wFgOBzStYySAUAALChHLmsLgEAQgJ5CwDB55SsZZAKAABgQ26HnLUHALsjbwEg+JyStQxSAQAAbChLYVaXAAAhgbwFgOBzStY641MAAAA4jNvj8uvhj+TkZCUkJFywfenSperQoYN69eqlRYsWBfojAIARyFoACD6n9LasSAUAALChLBULyH5mzpypZcuWKSoqKtf2tLQ0vfbaa1qyZIlKlSqlvn376pZbblGlSpUCclwAMEUg8pasBYCCOaW3ZUUqAACADQXqrH2VKlWUmJh4wfbU1FTFxcWpTJkyCgsL07XXXqvk5ORgfBQAsDWyFgCCzym9LStSAQAAbMjfbzZNSkpSUlKS93l8fLzi4+O9z9u2bavU1NQLfq5q1aras2ePjh49qujoaG3cuFFXXXXVRdcNAKbxJ2/JWgC4OE7pbRmkAgAA2NB5j39t2l+bS3+VLl1aQ4cO1eOPP64yZcqoXr16Klu2bKH3AwCm8ydvyVoAuDhO6W25tB8AAMCGcuTy6/F3ZWdna/v27Zo3b55effVV7du3T40aNQrgJwAAM5C1ABB8TultWZEKAABgQzme4JzvXr58uTIzM71n+jt16qTIyEjdf//9KleuXFCOCQB2Foy8JWsBIDen9LYuj8fjCfheAQCAJMn9ey2rS7CNsMt+sroEo3ycco1f72tXbVuQKwEQDCb+/eDUHPcnb8lawFym5W0oZ61k/7xlRSoAAIANBeusPQAgN/IWAILPKVnLIBUAAMCGznuKWV0CAIQE8hYAgs8pWcsgFQAAwIZy+E5QACgS5C0ABJ9TspZBKgAAgA25HXL5EwDYHXkLAMHnlKxlkAoAAGBDWQ65/AkA7I68BYDgc0rWMkgFAACwIbdDLn8CALsjbwEg+JyStQxSAQAAbMgp32wKAHZH3gJA8Dkla53xKQAACLBPPvlEkpSZmalJkybp/vvv1+TJk5WRkWFxZQgV5z3F/HoAJiNrYQdkLUIBeQurOaW3ZZAKAEAe5s+fL0kaP368SpcureHDh+uyyy7TyJEjLa4MoSJHYX49AJORtbADshahgLyF1ZzS23JpPwAABfjll180fvx4SVKNGjX02WefWVwRQoUJZ+SBQCFrYSXyFqGEvIVVnJK19h/1AgBggZ9//lnvvvuuwsPDtX37dknS1q1bdf78eYsrQ6hwe8L8egAmI2thB2QtQgF5C6s5pbe1f4UAAFjgzTffVHR0tK666irt2rVLx44d07hx47j8CUUmRy6/HoDJyFrYAVmLUEDewmpO6W25tB8AgDyUKFFCjRs3VuPGjeXxeNSvXz9NmjTJ6rIQQpxy+RNQELIWdkDeIhSQt7CaU7KWQSoAAHm4//77VaJECV166aXyeDxKSUnRqFGjJElz5syxuDqEAhMubQIuFlkLOyBvEQrIW1jNKVnLIBUAgDwsXrxYo0aNUs+ePdWkSRMlJCTQZKJI5Tik2QQKQtbCDshbhALyFlZzStYySAUAIA/ly5fX1KlTNWnSJP3www9Wl4MQ5JTLn4CCkLWwA/IWoYC8hdWckrXOGAcDABAE4eHhGjZsmPcSKKAouT0uvx6A6chaWI2sRaggb2Elp/S2rEgFAMCHzp07q3PnzlaXgRCTw/luhBiyFlYhbxFqyFtYwSlZyyAVAADAhrIdcvkTANgdeQsAweeUrGWQCgAAYEM5BlzaBABOQN4CQPA5JWudsa4WAADAYbLdxfx6+CM5OVkJCQkXbF+2bJk6deqkLl26aN68eYH+CABgBLIWAILPKb0tK1IBAABsKEeBOWs/c+ZMLVu2TFFRURe89uKLL+rDDz9UyZIl1b59e7Vv316lS5cOyHEBwBSByFuyFgAK5pTelhWpAAAANhSobzatUqWKEhMT83wtLi5Op0+fVlZWljwej1wuZ1xyBQCFQdYCQPA5pbdlRSoAAIAN+XtD/qSkJCUlJXmfx8fHKz4+3vu8bdu2Sk1NzfNna9asqS5duigqKkpt2rRRqVKlLq5oADCQP3lL1gLAxXFKb8sgFQAAwIb8vSH/X5tLf+3cuVOff/65Vq1apZIlS+qZZ57RJ598ojvvvLPQ+wIAk/mTt2QtAFwcp/S2DFIBAABsyO0J7h2YYmNjVaJECUVGRqpYsWIqV66cTp06FdRjAoAdBTNvyVoA+INTelsGqQAAADaUHaRmc/ny5crMzPSe7e/Vq5ciIiJUpUoVderUKSjHBAA7C0bekrUAkJtTeluXx+PxBHyvAABAkuT+vZbVJdhG2GU/WV2CUXp+9U+/3jf/5reCXAmAYDDx7wen5rg/eUvWAuYyLW9DOWsl++ctK1IBAABsKNvt3w35AQAXh7wFgOBzStYySAUAALAht/y7IT8A4OKQtwAQfE7JWgapAAAANuT285tNAQAXh7wFgOBzStYySAUAALChbHdwv9kUAPAH8hYAgs8pWcsgFQAAwIacctYeAOyOvAWA4HNK1jJIBQAAsCGn3EcKAOyOvAWA4HNK1jJIBQAAsCGnXP4EAHZH3gJA8DklaxmkAgAA2JBTLn8CALsjbwEg+JyStQxSAQAAbMgpzSYA2B15CwDB55SsZZAKAABgQzkeZ1z+BAB2R94CQPA5JWsZpAIAANiQU87aA4DdkbcAEHxOyVoGqQAAADaU45Ab8gOA3ZG3ABB8TslaBqkAAAA25HHIWXsAsDvyFgCCzylZyyAVAIAgCrvsJ6tLgKGccvkTgLzx94N9kLeAs5G39uCUrGWQCgAAikybsG5Wl2AbK9yLCnw9xyHNJgBnMS3HfWWtRN4CsB/TslYKnd7WGTcoAADAT+np6dq5c6cyMzOtLgUokMfj8usB2BFZC5OQtTAZeQtTOKW3ZUUqACBkfPrpp5oxY4ZycnJ0xx13yOVy6bHHHrO6LCBPTrn8CaGHrIVpyFuYiryFSZyStaxIBQCEjHfffVcLFy5UmTJl9Nhjj2nlypVWlwTky+12+fUA7IashWnIWpiKvIVJnNLbsiIVABAyihUrpuLFi8vlcsnlcikqKsrqkoB8mXBpE5AXshamIW9hKvIWJnFK1jJIBQCEjOuvv16DBg3SoUOHNHLkSF177bVWlwTkK8eAM/JAXshamIa8hanIW5jEKVnLIBUAEDIGDhyodevWqU6dOqpevbpatWpldUlAvgJ51j45OVmTJ0/W3LlzvduOHDmigQMHep/v2LFDgwYNUs+ePQN2XIQmshamCVTekrUoauQtTOKU3pZBKgAgZNx3332aNGmSmjdvLkl68MEHNWvWLIurAvIWqGZz5syZWrZs2QWX+11yySXe5vP777/XK6+8ou7duwfkmAhtZC1ME4i8JWthBfIWJnFKb8uXTQEAQsbBgwf1+OOPa8+ePZKkrKwsiysC8uf2uPx6+FKlShUlJibm+7rH49Hzzz+v0aNHq1ixYoH8CAhRZC1MQ9bCVOQtTOKU3pZBKgAgZFx22WV65ZVXNGTIEG3atEnh4VyYARvz+PdISkpS586dvY+kpKRcu2nbtm2B/19fvXq1atasqerVqwfpgyDUkLUwDlkLQ5G3MIpDelv+lAEAQobH41GlSpU0Y8YM9e/fX0eOHLG6JCBf/l7+FB8fr/j4+L99nGXLlqlPnz5/++eBvyJrYRp/8pashR2RtzCJU3pbVqQCAELGfffdJ+mP++e8/fbbuvXWW60tCCiA2+3y63Gxtm3bpkaNGgWgYuAPZC1MQ9bCVOQtTOKU3pYVqQAAx1uzZo1atmypo0eP5ro0JC4uzsKqAB8C+M2mf7Z8+XJlZmYqPj5eaWlpiomJkcsVnGMhtJC1MFYQ8pasRTCRtzCSQ3pbBqkAAMc7ceKEJOno0aPWFgIUgscduH1VqlRJCxculCR16NDBu71cuXL64IMPAncghDSyFqYKVN6StSgq5C1M5JTelkEqAMDxOnXqJEnq37+/Tp8+LZfLpZUrV6ply5YWVwbkz9/7SAF2QdbCVOQtTEPewkROyVoGqQCAkDFgwADdeuut+v777+V2u7VixQpNnz7d6rKAvHmsLgD4e8haGIe8haHIWxjFIVnLl00BAELG4cOHdffdd2vv3r0aO3asMjIyrC4JyJfH7fLrAdgNWQvTkLUwFXkLkzilt2VFKgAgZJw/f16fffaZrr76aqWlpdFswubs30gCeSFrYR7yFmYib2EWZ2QtK1IBACHjoYce0scff6xHHnlEc+fO1WOPPWZ1SUD+PH4+AJsha2EcshaGIm9hFIf0tqxIBQCEjNtvv1233367JOnJJ5/0bh81apTGjBljVVlA3gy4tAnIC1kL45C3MBR5C6M4JGsZpAIAQl5KSorVJQAX8BhwRh4oDLIWdkXewmnIW9iRU7KWQSoAAIAdOaTZBADbI28BIPgckrUMUgEAAGzI5ZDLnwDA7shbAAg+p2Qtg1QAAAA7cshZewCwPfIWAILPIVkbZnUBAABYzeOUG/bAWdwu/x5F5NChQ9qzZ49SUlL03HPPaceOHUV2bDgDWQvbslHWSuQtLh55C1tySG/LIBUAEDJWr16t1157TZL04IMPasOGDZKkd955x8qygLx5/HwUkUGDBuno0aN65ZVX1KRJE73wwgtFd3AYhayFcWyUtRJ5C/+RtzCKQ3pbBqkAgJCRmJio+++/X5I0depUTZs2TZIUERFhZVlA3mzWbLpcLt1www06deqU2rdvr7Aw2kjkjayFcWyUtRJ5C/+RtzCKQ3pb7pEKAAgZ4eHhio2NlSTFxsb6/Mty5cqV2rhxo06fPq1SpUrp+uuv1x133CGXyxk3Soe92e2G/NnZ2XrppZfUuHFjffXVVzp//rzVJcGmyFqYhryFqchbmMQpWcsgFQAQMurXr69Bgwbpuuuu0w8//KC6devm+94xY8bI7XarefPmio6OVkZGhtatW6cNGzZo/PjxRVg1QpbNbm82YcIEffHFF+rWrZtWrlypSZMmWV0SbIqshXHIWxiKvIVRHJK1DFIBAI737bff6oYbbtDgwYO1fv167du3T23bttVtt92W78/s3r1b7733Xq5tt912m3r06BHscgFbuvTSS3Xbbbfp1KlTSklJUYMGDawuCTZD1gKBQd7CF/IWuHh/N2u52QoAwPHGjRunzMxMPfTQQ2rRooX69u2rZs2aKSsrK9+fcbvd2rRpU65t33zzDfecQpFxuV1+PYrKE088oR9//FEvvviiIiIiNHLkyCI7NsxA1sJUdspaibyFb+QtTOSU3pYVqQAAx2vatKk6duyow4cP64477pAkeTweuVwurVq1Ks+fmThxoiZMmKBBgwbJ7XYrPT1dN998s8aNG1eUpSOU2ezyp7Nnz6pVq1aaPXu2XnzxRX355ZdWlwSbIWthLPIWhiFvYSSHZC0rUgEAjvfMM89o5cqVeuSRR7Rq1SqtWrVKq1evzrfRlP64ZKpevXqaPn26oqOjVaVKFe3du1e//fZbEVaOUOZy+/coKufPn9fs2bNVr1497dmzR2fOnCm6g8MIZC1MZaeslchb+EbewkRO6W0ZpAIAQsa//vWvXM/XrFmT73vnzZunBx54QC+99JLeeOMNffDBB5o7d66mTJkS7DKBP3j8fBSRIUOG6PDhw3rsscf01VdfadiwYUV3cBiFrIVxbJS1EnkL/5G3MIpDelsGqQCAkPHX+0b98ssv+b43IiJCJUuWVHR0tCpXrixJqlixolyuor1PGkJYAJvN5ORkJSQkXLB969at6tWrl3r27KknnnhC586dy3cfjRo10o033qikpCRddtllql+/fiE/EEIFWQvj2ChrJfIW/iNvYRSH9LbcIxUAEDK6dOmim2++Wd26dVOtWrXUt2/ffN/bqlUr9evXT7Vq1dIjjzyiZs2aaf369br55puLrmCEtEDdbH/mzJlatmyZoqKicm33eDwaMWKEXnvtNVWtWlWLFi3Sb7/9purVq+e5nylTpuiXX35Ro0aNtHTpUm3atEnPPvtsQGqEs5C1ME0g8jZQWSuRt/AfeQuTOKW3ZZAKAAgZH3zwgdavX69p06bp+PHj6tixo9q1a6fo6OgL3vvPf/5T33zzjTZs2KArrrhCx44dU0JCgm699daiLxyhKUCXNlWpUkWJiYkaPHhwru0pKSkqU6aM3n33Xe3evVstWrQo8B/23377rRYsWCBJuu+++9S9e/fAFAjHIWthnADkbaCyViJv4T/yFkZxSG/LIBUAEDLCwsLUvHlzSdL777+vuXPnavHixbrrrrvUu3fvC95/44036sYbbyzqMgFJksvPZjMpKUlJSUne5/Hx8YqPj/c+b9u2rVJTUy/4uePHj+v777/XyJEjVaVKFT366KO65pprdMstt+R5nOzsbLndboWFhcntdnMpIPJF1sI0/uRtUWWtRN7Cf+QtTOKU3pZBKgAgZLz44otatWqVbrzxRj388MOqX7++3G63OnfunGezCVjJ328t/Wtz6a8yZcqoatWqqlGjhiSpWbNm2rZtW77NZvv27dWzZ081aNBAW7duVbt27Qp9TIQGsham8SdviyprJfIW/iNvYRKn9LYMUgEAIaNatWpasmSJ93KnU6dOqVSpUpo2bZrFlQF5CPK3llauXFkZGRn65ZdfVLVqVW3atEldu3a94H1TpkzxnqGvWLGi1qxZozp16igtLS24BcJYZC2ME8S89TdrJfIWhUfewigO6W0ZpAIAHO/IkSNKT0/XokWLdMMNN+jw4cNyu90aMmSI3n//fVWqVMnqEoEL+HvWvrCWL1+uzMxMxcfHa/z48Ro0aJA8Ho8aNmyY533S/nxvqWrVqqlly5bBKQzGI2thqmDkbWGzViJv4T/yFiZySm/r8ng8QZ4JAwBgrZUrV2r27NnauXOnateuLemPe0o1bNhQTz31lLXFhZg2Yd2sLsE2VrgXFfh63POv+LWfXSMGBKIc4KKRtaHBtBz3lbWSf3lL1sJOyFvnMy1rpdDpbVmRCgBwvNatW6t169Zau3atWrRoYXU5gH841Q3DkLUwFnkLw5C3MJJDspZBKgDA8V5//XU99thj+uCDD7Rs2bJcr02ZMsWiqoCCBevyJyBYyFqYiryFachbmMgpWcsgFQDgeK1atZIk9ejRw+JKgEJwyFl7hA6yFsYib2EY8hZGckjWMkgFADhecnKykpOT83ztxhtvLOJqAP+4HNJsInSQtTAVeQvTkLcwkVOylkEqAMDxjhw5YnUJQKE55fInhA6yFqYib2Ea8hYmckrWMkgFADhe//79vb8+fPiwsrOz5fF4dPjwYQurAnxwyFl7hA6yFsYib2EY8hZGckjWMkgFAISM5557Tlu2bNGZM2d09uxZVa5cWQsXLrS6LCBvDmk2EXrIWhiHvIWhyFsYxSFZG2Z1AQAAFJWdO3fqo48+UtOmTfXRRx8pMjLS6pKAfLnc/j0AuyFrYRqyFqYib2ESp/S2rEgFAISMsmXLyuVyKTMzU+XKlbO6HKBgDjlrj9BD1sI45C0MRd7CKA7JWgapAICQUa9ePc2aNUuXXnqpBgwYoDNnzlhdEpAvE87IA3kha2Ea8hamIm9hEqdkLYNUAEDIGDhwoNLT01WiRAmtW7dODRo0sLokIF8uh5y1R+gha2Ea8hamIm9hEqdkLYNUAEDImDZtWq7n27dvz/Wtp4CtOKTZROgha2Ec8haGIm9hFIdkLYNUAEDIqFChgiTJ4/Fo+/btcrsdcn0JHMkpZ+0ReshamIa8hanIW5jEKVnLIBUAEDJ69OiR6/lDDz1kUSWAHxzSbCL0kLUwDnkLQ5G3MIpDspZBKgAgZKSkpHh/ffjwYR04cMDCaoCCOeWsPUIPWQvTkLcwFXkLkzglaxmkAgBCxsiRI+VyuSRJkZGRevbZZy2uCCgAV+fBUGQtjEPewlDkLYzikKxlkAoACBknT55Uenq6IiMjde7cOY0ZM0Yej0cul0urVq2yujwgF6ectUfoIWthGvIWpiJvYRKnZC2DVABAyGjYsKHuueceNWzYULt27dKsWbM0btw4q8sC8uRyyFl7hB6yFqYhb2Eq8hYmcUrWMkgFAISMvXv3qmHDhpKkuLg4HTx4UMWLF7e4KiAfDjlrj9BD1sI45C0MRd7CKA7JWgapAICQERsbq6lTp6p+/fratGmTrrjiCqtLCjkr3IusLsEYTrn8CaGHrHU2J+Y4eQtTkbfORdbaF4NUAEDImDJliubNm6d169YpLi5OAwcOtLqkkHN78V5Wl2Abn2XNK/gNAbz8KTk5WZMnT9bcuXNzbX/33Xe1aNEilStXTpI0ZswYVa9ePXAHRkiyImtNyxaff/5RtAKUt2Qtihp56xt5ayMO6W0ZpAIAQkbJkiX10EMPWV0G4JdAnbWfOXOmli1bpqioqAte27ZtmyZNmqRrrrkmMAcDRNbCPIHIW7IWViBvYRKn9LZhQdszAAAA/j6Pnw8fqlSposTExDxf+/HHH/XWW2+pZ8+eevPNNwNTNwCYhqwFgOBzSG/LilQAAAAbcrn9O22flJSkpKQk7/P4+HjFx8d7n7dt21apqal5/mz79u3Vq1cvxcTEqH///lqzZo1atmx5cYUDgGH8yVuyFgAujlN6WwapAAAANuTv5U9/bS795fF4dN999yk2NlaS1KJFC23fvp1/3AMIOf7kLVkLABfHKb0tl/YDAADYkMvt3+PvSk9P11133aWMjAx5PB59/fXX3L8PQEgiawEg+JzS27IiFQAAwI4CdEP+v1q+fLkyMzMVHx+vAQMGqE+fPipevLhuueUWtWjRIjgHBQA7C0LekrUA8BcO6W1dHo8nSB8FAAAgt9uL97K6BNv4LGtega/f1Odlv/bz9ZyBgSgHMJpp2eLrzz+Klj95S9YCfyBv8Xc5pbdlRSoAAIANXcylTQAA/5G3ABB8TslaBqkAAAB2xEVDAFA0yFsACD6HZC2DVAAAABvy95tNAQAXh7wFgOBzStYySAUAALAhV47VFQBAaCBvASD4nJK1DFIBAADsyCFn7QHA9shbAAg+h2Qtg1QAAAAbcsrlTwBgd+QtAASfU7KWQSoAAIANudwO6TYBwObIWwAIPqdkLYNUAAAAO3JGrwkA9kfeAkDwOSRrGaQCAADYkFPO2gOA3ZG3ABB8TslaBqkAAAA25JT7SAGA3ZG3ABB8TslaBqkAAAB25JBmEwBsj7wFgOBzSNYySAUAALAhV45Duk0AsDnyFgCCzylZyyAVAADAjpzRawKA/ZG3ABB8DslaBqkAAAA25JT7SAGA3ZG3ABB8TslaBqkAAAA25JRvNgUAuyNvASD4nJK1DFIBAADsyBm9JgDYH3kLAMHnkKxlkAoAAGBDTrkhPwDYHXkLAMHnlKxlkAoAgA/Hjx9Xenq6YmNjVaZMGavLQYhweZzRbAL+ImthFfIWoYa8hRWckrUMUgEAyMfWrVs1duxYud1ulSxZUhkZGfJ4PBo5cqQaNWpkdXlwOmf0moBPZC0sR94iRJC3sJRDspZBKgAA+ZgwYYISExN1+eWXe7cdOHBATz75pBYtWmRhZQgFTrkhP+ALWQurkbcIFeQtrOSUrA2zugAAAOwqOzs7V6MpSZdffrlcLpdFFSGkeDz+PfyQnJyshISEfF8fMWKEJk+eHKjKgUIha2E5shYhgryFpRzS27IiFQCAfLRo0UJ9+/ZVkyZNFBsbq/T0dH3xxRdq3ry51aUhBLjcgdnPzJkztWzZMkVFReX5+oIFC/TTTz/phhtuCMwBgUIia2G1QOQtWQsTkLewklN6W1akAgCQj/79+2vw4MEqUaKETpw4oRIlSujpp59W//79rS4NocDt8e/hQ5UqVZSYmJjna999952Sk5MVHx8f6OoBv5G1sBxZixBB3sJSDultWZEKAEABDhw4oJSUFJ0+fVqlS5dW+fLlVbduXS6BQtD5+82mSUlJSkpK8j6Pj4/P1Ty2bdtWqampF/zc4cOHNX36dE2bNk2ffPLJxRcMXASyFlbyJ2/JWjgFeQurOKW3ZZAKAEA+xowZI7fbrebNmys6OloZGRlat26dNmzYoPHjx1tdHpwux79m86/Npb8+/fRTHT9+XP/85z915MgRnT17VtWrV1fnzp0LvS/gYpC1sJwfeUvWwgnIW1jKIb0tg1QAAPKxe/duvffee7m23XbbberRo4dFFSGU+HvW/u/q06eP+vTpI0lasmSJ9u3bxz/sYQmyFlYLZt6StbAT8hZWckpvyz1SAQDIh9vt1qZNm3Jt+/bbbxUREWFRRQgpAfxm0z9bvnx5rsulAKuRtbAcWYsQQd7CUg7pbV0eT5BHwgAAGOrXX3/VhAkT9OOPP8rj8SgsLEx169bVkCFDdNVVV1ldnpFuL97L6hJs47OseQW+3rbhKL/289/vxwSiHMAygcha07LF159/FC1/8pashROQt7CSU3pbLu0HACAfVapU0RtvvGF1GQhRwb78CbALshZWI28RKshbWMkpWcsgFQCAfCQkJOj8+fN5vrZgwYIirgYhxyHNJuALWQvLkbcIEeQtLOWQrGWQCgBAPp5++mkNHz5c06dPV7FixawuB6HG7ba6AqBIkLWwHHmLEEHewlIOyVoGqQAA5KNBgwa6++67tWvXLrVp08bqchBqnNFrAj6RtbAceYsQQd7CUg7JWgapAAAU4KGHHrK6BIQop9xHCvAHWQsrkbcIJeQtrOKUrGWQCgAAYEc5DjltDwB2R94CQPA5JGsZpAIAANiRQ87aA4DtkbcAEHwOyVoGqQAAAHbkkBvyA4DtkbcAEHwOyVoGqQAAAHbkdsZZewCwPfIWAILPIVnLIBUAAMCOPM44aw8AtkfeAkDwOSRrGaQCAADYkUNuyA8AtkfeAkDwOSRrGaQCAADYkUNuyA8AtkfeAkDwOSRrGaQCAADYkUOaTQCwPfIWAILPIVnLIBUAAMCOcnKsrgAAQgN5CwDB55CsZZAKAABgRw45aw8AtkfeAkDwOSRrGaQCAADYkUNuyA8AtkfeAkDwOSRrGaQCAADYkMfjjGYTAOyOvAWA4HNK1jJIBQAAsCO3My5/AgDbI28BIPgckrUMUgEAAOzIITfkBwDbI28BIPgckrUMUgEAAOzIITfkBwDbI28BIPgckrVhVhcAAACAC3ncbr8e/khOTlZCQsIF2//73/+qS5cu6tq1q2bPnh3ojwAARiBrASD4nNLbsiIVAADAjgL0zaYzZ87UsmXLFBUVlXv3OTmaMmWKFi9erJIlS6pdu3bq0KGDypUrF5DjAoAxApC3ZC0A+OCQ3pYVqQAAAHbkcfv38KFKlSpKTEy8YHuxYsX08ccfKzY2VidOnJDb7Vbx4sWD8UkAwN7IWgAIPof0tqxIBQAAsCGPnzfkT0pKUlJSkvd5fHy84uPjvc/btm2r1NTUPH82PDxcn332mcaOHasWLVpccGYfAEKBP3lL1gLAxXFKb8sgFQAAwIY8bv9uyP/X5rKwbr/9drVu3VrPPvusli5dqi5duvztfQGAifzJW7IWAC6OU3pbLu0HAACwowBd/pSf9PR09e7dW1lZWQoLC1NUVJTCwmgNAYQgshYAgs8hvS0rUgEAQJH5LGue1SUYY4V7UVD2u3z5cmVmZio+Pl4dOnTQvffeq/DwcMXFxaljx45BOSYQbGQLLkYw8pashVORt/i7nNLbujwej39rawEAAAAAAAAgRHFNAQAAAAAAAAD4wCAVAAAAAAAAAHxgkAoAAAAAAAAAPjBIBQAAAAAAAAAfGKQCAAAAAAAAgA/hVhcAAAACz+12a/To0dq1a5eKFy+ucePGqWrVqlaXZbljx46pc+fOeuedd1SjRg2rywFgM3/OiHPnzumRRx7RVVddJUnq2bOn2rVrZ22Bf7FkyRL95z//kSSdO3dOO3bs0Msvv6xJkybp8ssvlyQ9/vjjuvHGG60s0ys5OVmTJ0/W3LlzNWDAAB09elSS9Ntvv6lBgwZ65ZVXNG3aNH3++ecKDw/Xc889p/r161tcNQAA/5/L4/F4rC4CAAAE1meffabVq1dr4sSJ2rJli95880298cYbVpdlqfPnz+upp57Snj179PrrrzNIBZDLXzPiu+++0+nTp/XAAw9YXZpfxowZo9q1a+vAgQOqW7eu2rZta3VJucycOVPLli1TVFSUFi5c6N1+8uRJ9enTRzNnztSRI0c0adIkzZ49WwcPHtTjjz+uxYsXW1g1gEDbsGGDz/c0bdq0CCrxX1ZWls/3FC9evAgqKZyUlBSf76lWrVoRVOIsrEgFAMCBNm/erGbNmkmSrrvuOm3bts3iiqw3adIk9ejRQ2+99ZbVpQCwob9mxLZt25SSkqJVq1apatWqeu655xQTE2NxlXn74YcftGfPHo0aNUoPPfSQduzYodmzZ6t+/fp6+umnFR5u/T/7qlSposTERA0ePDjX9sTERPXu3VuXXnqpPv30UzVt2lQul0tXXHGFcnJylJaWpnLlyllUNYBAe/bZZ709al7Wr1/v17C1KDVu3FiXXHKJPB6PXC6XJHl/7fF4lJaWpi1btlhbZB66d++uOnXqKL/1k7t27dI333xTxFWZz/q/UQEAQMClp6fn+gd/sWLFlJ2dbYt/TFthyZIlKleunJo1a8YgFcAF8sqI+vXrq1u3brrmmmv0xhtvaPr06RoyZIjFlebtzTff1L/+9S9JUpMmTdS6dWtVqlRJo0aN0oIFC9S7d2+LK5Tatm2r1NTUXNuOHTumjRs3aujQoZL++LurTJky3tejo6N1+vRpBqmAg3Tt2lVPPfVUvq9PnTq1yGrx1z/+8Q/NmDEj39cfffTRIqzGf23bttW4cePyfX348OFFWI1zhOa/pgAAcLiYmBhlZGR4n7vd7pAdokrS4sWL5XK5tHHjRu3YsUNDhgzRG2+8oUsuucTq0gDYgK+MaNOmjZ5//nmLq8zbqVOnlJKSoptvvlmS1KVLF5UqVUqSdNttt+m///2vleUV6NNPP9Vdd92lYsWKSbrw766MjAzFxsZaVR6AIHjqqae0e/duhYWFqUaNGnrnnXd08uRJPfTQQ4qNjS1wyGqVli1b5lqN+lcFDVmtNG7cOH333XfavHmzzpw5o7Jly+of//iH9/ZWBQ1Zkb8wqwsAAACB16hRI61bt06StGXLFtWqVcviiqz1f//3f3rvvfc0d+5c1alTR5MmTWKICsArr4x47LHHtHXrVknSxo0bVa9ePYurzNu3336rW265RdIfl5p27NhRv//+uyR71y39UV/z5s29zxs1aqQNGzbI7XbrwIEDcrvdrEYFHObVV1/VqFGjNHjwYD3++OM6duyYypYtq2effdbq0vI1efJk3X///fr555+tLqVQZsyYofnz5ysmJkbbt2/XwYMH9corr+j//u//rC7NaKG7NAUAAAdr06aNvvjiC/Xo0UMej0cvvPCC1SUBgFFGjx6t559/XhEREapQoYJtV6SmpKSoUqVKkiSXy6Vx48apf//+KlGihGrUqKHu3btbXGH+UlJSVLlyZe/za665Ro0bN1Z8fLzcbrdGjhxpYXUAgmHjxo1asGCBsrKydNdddykxMVGStGrVKosry1/t2rX11FNPadCgQapVq5a6d++uhg0bWl2WT+vXr/cOTbt3765HH31UM2fOVI8ePXTvvfdaXJ25XJ787joLAAAAAAAABEiXLl300ksv6fjx43r00Uf18ccfKyoqSg888IAWLlxodXl56tOnj+bMmSNJWr16tZYtW6Zt27YpNjZW//nPfyyuLn+dOnXStGnTdOWVVyolJUWjRo3SO++8o65du2rp0qVWl2csBqkAAAAAAAAIui+//FIvvfSS6tatq5o1a+qtt95SdHS0hgwZotatW1tdXp4SEhI0d+7cC7anpaXZ+vYjGzZs0IgRI1SqVCmdPXtWL774otavX6+KFSuqW7duVpdnLAapAAAAAAAAKHKnT59WZGSkihcvbnUp+Tp69KgqVKhgdRl/i8fj0fHjx2098DUNXzYFAAAAAACAoFu7dq3mzJmj/fv3q3fv3rrzzjvVu3dv7dixw+rS8pWenq7HH39cTz/9dK4vnBo1apR1Rfnh8OHDmjBhgubNm6edO3eqTZs2uuOOO7RlyxarSzMag1QAAAAAAAAEXWJiotq2batx48bpySef1IYNGzR27FiNHj3a6tLyNWLECMXHx+uuu+7Sv/71L23fvl2StG/fPosrK9izzz6rOnXqyOVy6YEHHtCbb76pd999V5MnT7a6NKOFW10AAAAAAAAAnK948eKqWLGiJOmGG26QJNWuXdvKkvzStGlTSVKVKlX0+OOP6+2335bL5bK4qoJlZWWpU6dOkqRvvvlG1atXlyTb1213rEgFACBEJCYmav78+dqxY4emTZsmSVqxYoUOHTpkcWV/WLFihW6//Xbvt6L6Y8mSJZxVBwAAMES9evU0duxYNWzYUM8995xWrFih4cOHq0aNGlaXlq/w8HCtXr1aOTk5ql69ukaMGKFHHnlER48etbq0ApUqVUqvv/66PB6PZs+eLUn64IMPFBkZaXFlZmOQCgBAiKlTp4769+8vSZozZ47S09MtrugPq1ev1rPPPqs+ffpYXQoAFOjcuXNatGiRX+9dsmSJVq1aFZDj/u+EmD981ViYfeXlzyflAMBfQ4cO1bXXXqvdu3fr999/1yeffKI6derY+tL+8ePH67PPPtPp06clSTfffLOee+45RUREWFxZwaZMmaLo6OhcK1APHTqkSZMmWViV+bi0HwAAQ2RkZGjQoEE6deqUrr76an3//fcqU6aMRo8erRo1amj+/Pk6evSoHn/8cU2ZMkXbtm3TiRMnVLt2bU2YMMG7n6+//loLFizQ3XffrR07dmjIkCHq1q2bfv75Zw0ZMkQ5OTm655579P777ysyMlKpqakaNGiQLrvsMu3fv1/XXnutxowZo8TERFWoUEE9e/bU3r17NXr0aM2dO1cdOnRQ48aNtWvXLlWvXl3ly5fXpk2bVLx4cb311lt5Np2rVq3SunXrtG3bNpUtW1Z79uzR/Pnz5Xa71apVKz3xxBM+//vk9Zl79Oih559/XjVr1tTatWu1Zs0aDRo0SMOGDdPx48clScOHD1dcXJxatmyp6tWrq0aNGmrcuLFmzpyp8PBwXXrppXrllVcUFsb5ZwB/OHLkiBYtWqRu3br5fG/nzp2LoKILFabGv6NOnTqqU6dOUPYNwLnCwsJUr149NWrUSFWrVvVuT05OVoMGDSysLH+lSpXSxIkTJUk//fSTdu7cqXr16umDDz6wuLKCRUVF6b777su17Z///KdF1TgHg1QAAAwxb948xcXFacCAAfruu++0YcMGlSlT5oL3paenq1SpUvr3v/8tt9ut9u3b53n5/q233updAVCxYkV17txZTz/9tNavX6+bbrop12U/P//8s2bNmqWoqCi1bt1aR44cybfOjIwM3XXXXRo1apTuuOMODR06VAMGDFDv3r21Z8+ePP/hfdttt2nFihVq166dqlSpoiFDhmjZsmWKjIzUlClTlJGRoejo6HyPmd9n7tatm/7zn/9o8ODBWrx4sR555BHNmDFDN998s3r16qWff/5ZQ4cO1fz583Xw4EEtWbJEZcuW1RNPPKEHH3xQd9xxh5YuXerdPwBI0owZM7Rnzx7Vrl1b//jHP5SZmanx48dr6dKlF5zQ+d9Jp+rVq2vmzJmKiIhQamqq2rVrp379+ungwYMaMWKEzp07p8jISD3//PPKyclRv379VKZMGTVv3lwPP/yw99grV67UJ598orNnz2r48OGqX7++3nvvPX322Wc6c+aMypYtq2nTpnlrnDZtmnr16qUhQ4bo9OnT8ng83tVIq1at0qeffqoTJ07oySefVKtWrfL8vCkpKRo6dKjCw8Pldrs1ZcoU/frrr1qwYIEGDhyo5557TtIf+b9v3z5t3LhRn3/+ud59912FhYXp+uuv19NPPx383xgAtjd9+nRt2LBBOTk5qlu3rkaNGiWXy6UpU6YU6vZORemxxx7TnDlztHjxYs2bN08333yz5s2bp86dO6t79+5Wl5evrKysfF8rXrx4EVbiLAxSAQAwRGpqqpo1ayZJatSo0QUNkMfjkSRFRkYqLS1NAwcOVMmSJZWZmanz588XuO+YmBjdcMMN2rBhg5YsWaLHHnss1+tVqlRRTEyMJOmSSy7RuXPnCtxfvXr1JP1xBv9/97wqVaqUz5+TpP3796tmzZoqUaKEJPn1j+/8PvOdd96pzp0768EHH9ShQ4dUr149TZ06VV999ZU++eQTSdLJkyclSWXLllXZsmUl/XHZ2Ztvvqn33ntP1atXV+vWrX3WACB0PProo/rpp5/UrFkznTx5UsOHD/frJNaBAwe0bNkyZWVlqVmzZurXr58mTZqkhIQEtWjRQhs3btTkyZM1YMAAHTlyRIsXL74g66+88kqNHTtWu3fv9p4kOnHihHdo+eCDD+qHH37w1ti/f3+NGzdOrVq1Us+ePfXdd99p69atkqSKFStq/Pjx+vrrr/X222/nO0j98ssvVb9+fT3zzDPatGmT9/JWSapcubLmzp2rrKwsPfroo3r11Vd17tw5JSYmavHixYqKitIzzzyjL774Qk2aNAnw7wQA06xbt05JSUmSpEmTJmnMmDEaPXq0t4+1s/fff19z5sxRdHS0zp8/rz59+th6kNqhQwcdO3ZMpUuXlsfjkcvl8v5voG45E4oYpAIAYIi4uDht3rxZrVu31q5du5SVlaXixYvryJEjqlGjhrZv366KFStq3bp1OnjwoKZOnaq0tDStWLEi3+b0fw2VJHXv3l0zZ87U8ePHL/j21Ly+3TMyMtK7MvXHH3/0+X5/ValSRfv27fN+vieeeELDhg3zfsNrXvL7zCVLltRNN92k8ePHq2PHjpKk6tWrq2PHjt7m8n/3EPzzpftJSUl6/PHHVb58eY0cOVIrVqzwfuspAPxZtWrVJPl3EqtWrVoKDw9XeHi492TRTz/9pDfffFNvv/22PB6PwsP/+CdapUqV8lwx9L9vua5Zs6aOHDmisLAwRUREeI/7+++/Kzs7O9fPpKSkqGvXrpL+OBHXqFEjJSYmek96VahQQWfPns33M3bt2lUzZ87UQw89pNjYWA0YMCDX69nZ2RowYIA6duyoFi1aaOvWrUpLS/NeQpqRkaFff/2VQSqAXD3pkCFDNGjQIL399tu2/ib5jIwMnThxQpdccok3o8PDw30uVLDa/Pnz9eCDD+rdd99V6dKlrS7HMbjZFwAAhujWrZuOHTume++9V2+//bYkqU+fPhozZowefPBB5eTkSJLq16+v/fv3695779UTTzyhypUr6/Dhw3nus2HDhho8eLBOnDihBg0a6JdfflGHDh0kSf/+978LPFt95513au3atUpISND27dsD9jnLlSunhx9+WL1791Z8fLzq1q1b4BBVKvgzd+/eXatWrfJ+rkcffVSffPKJEhIS9NBDD6lmzZp57u+RRx7RfffdpyNHjujWW28N2OcDYL6wsDC53W7vr6X/f0Ln5Zdf1sCBA3X27NkLTmLlNSioXr26nn76ac2dO1djxozRHXfckWu/f/W/1aS7du3SFVdcoZ07d2rlypWaOnWqRowYIbfbLY/Hk6vGGjVq6IcffpAkffvtt3rppZfyrScvq1at0vXXX6/Zs2frjjvu8P4dJP0xFBk2bJgaNmyoe+65R9IfQ+DLL79c77zzjubOnavevXvruuuu8+tYAJytXbt26tq1q06cOCFJmjBhgjZu3Kjk5GRrCytAo0aN9Nhjj2nz5s3697//rYyMDN19991q166d1aUVqFy5cho0aFBA+3RILo8J66cBAEAu586d05133qnVq1cHbJ9ut1s9e/bUrFmzvJfxO8HWrVv13nvv6cUXX7S6FAAOce7cOXXv3l1NmzZVpUqV1LNnTx05ckSPPvqoSpQoIZfLpbNnz2ro0KH68ssvvfdIXbBggV555RVJUpMmTfTFF19o//79Gj16tM6dO6ezZ89q2LBhuuSSSzRw4EAtXLhQkvTAAw9oxowZevPNN7V9+3ZlZGQoKytLo0ePVtWqVfXII49474VXvHhxde3aVW3btvXW+OCDD+q5555TRkaGJOmFF17Q0qVL8/zCwLz8+uuvGjJkiCIiIuR2uzV06FClp6drwYIFuv322/Xcc8+pQYMG3hN6o0aN0o8//qj58+crJydHV155pSZMmKCoqKhg/9YAMMD+/ft1xRVXqFixYt5tK1eutP2tlDwej86cOaOoqCjt27fPe/sqhBYGqQAAGCjQg9T9+/erf//+6ty58wXf7hlIW7du9a6E+rM777xTvXr1yvfnRo8erb17916wfebMmd7LY/Py3nvv6f3339fUqVN11VVX/a2aAQAAEBjnzp3TggULtHHjRp0+fVqxsbFq3LixevfuXWBPZyUTa5b+qHv+/Pn66quvjKrb7hikAgAAAAD+9kkrAPDXwIEDVbt2bTVv3lzR0dHKyMjQunXrlJycrOnTp1tdXp5MrFkyt26748umAAAAAAAaPXq01SUAcLjDhw/r5ZdfzrWtdu3aBV6ZZDUTa5bMrdvu+LIpAAAAAAAABF1kZKSWLl2qY8eOKSsrS2lpafrPf/6jkiVLWl1avkysWTK3brvj0n4AAAAAAAAE3fHjxzV9+nR99913ysjIUHR0tBo1aqR+/fqpfPnyVpeXJxNrlsyt2+4YpAIAAAAAAKBInD9/Xjt37lR6erpKlSqlmjVrqnjx4laXVSATa5bMrdvOuEcqAAAAAAAAgu7zzz/XlClTdNVVVyk6Olrp6enat2+fBg4cqNatW1tdXp5MrFkyt267Y5AKAAAAAACAoJsxY4bmz5+vmJgY77bTp0+rb9++th3umVizZG7ddseXTQEAAAAAACDozp8/rxIlSuTaFhkZKZfLZVFFvplYs2Ru3XbHilQAAAAAAAAEXXx8vDp16qTrr79esbGxSk9P1+bNm5WQkGB1afkysWbJ3Lrtji+bAgAAAAAAQJE4evSotm7dqoyMDMXExOjaa69VhQoVrC6rQCbWLP3/utPT0xUTE6P69esbUbedMUgFAAAAAABA0J07d04LFizQl19+qdOnT6tUqVJq3LixevfufcFl6HZhYs0FWbNmjVq2bGl1GcZikAoAAAAAAICgGzhwoGrXrq3mzZsrOjpaGRkZWrdunZKTkzV9+nSry8uTiTUX5N1331Xfvn2tLsNY3CMVAAAAAAAAQXf48GG9/PLLubbVrl1bvXr1sqgi30ys+a/cbrfCwv74vnmGqBeHQSoAAAAAAACCLjIyUkuXLlWzZs28X4C0bt06lSxZ0urS8mVizZK0f/9+TZgwQdu2bVN4eLjcbrdq1aqloUOHqlq1alaXZywu7QcAAAAAAEDQHT9+XNOnT9d3332njIwMRUdHq1GjRurXr5/Kly9vdXl5MrFmSerTp48GDRqkBg0aeLdt2bJFEydO1IIFCyyszGwMUgEAAAAAAAAH6dGjR54D0/y2wz9hVhcAAAAAAACA0PXEE09YXUKh2b3muLg4DR06VB9//LHWr1+vTz/9VEOHDlVcXJzVpRmNFakAAAAAAACwzMmTJ1W6dGmryygUu9fs8Xi0cuVKbd68Wenp6YqJiVGjRo3Upk0buVwuq8szFoNUAAAAAAAAFImdO3fqyy+/1OnTp1WqVCldf/31ql+/vtVlFcjEmhEcDFIBAAAAAAAQdNOmTdPWrVvVtGlTRUdHKyMjQxs2bFDdunX11FNPWV1enkysGcHDIBUAAAAAAABB16tXL82bNy/XNo/Ho+7du2vRokUWVVUwE2tG8PBlUwAAAAAAAAi67Oxspaam5tqWmpqqsDD7jqdMrLkgGzZs0Ndff211GcYKt7oAAAAAAAAAON+wYcPUv39/nT9/XjExMUpPT1fx4sU1ZswYq0vLl4k1F2T79u2qWbOmfv/9d1122WVWl2McLu0HAAAAAABAkUlPT1dGRoaio6MVExNjdTl+MbFmBJ6Z65ABAAAAAABgpJiYGFWsWNGogaRpNW/ZskWdO3dWz549tWnTJu/2f/3rXxZWZT4u7QcAAAAAAAAcZOLEiZoyZYqys7M1ePBgDRo0SE2bNtWpU6esLs1oDFIBAAAAAAAAB4mIiFC1atUkSW+99ZYeeOABXXLJJXK5XBZXZjYu7QcAAAAAAIBlBg4cqEmTJunYsWNWl+I3u9ccHR2tOXPmKCsrS5dccokmT56sp556Sr/99pvVpRmNL5sCAAAAAACAZY4ePaqyZcvK4/EoPNyMi6ftXnN6err+/e9/6/777/fe13XPnj16+eWX9frrr1tcnbkYpAIAAAAAACDoXn75ZfXr109RUVFWl1IoJ06cUEREhEqWLKmlS5fK5XLp7rvvtv1l8j/99JMiIyNVtWpV77bk5GQ1aNDAwqrMxiAVAAAAAAAAQde0aVNddtllevrpp3XzzTdbXY5f5syZo3nz5snj8ejGG29UVlaWoqKiFBYWppEjR1pdXr6mT5+uDRs2KDs7W3Xr1tXo0aPlcrnUp08fzZkzx+ryjMU9UgEAAAAAABB01apV0yuvvKLZs2erT58++vDDD3Xy5EmryyrQhx9+qI8//ljz5s3TmjVrNGnSJI0ePVq7du2yurQCrVu3TvPnz9eiRYtUsmRJjRkzRpLEesqLwyAVAAAAAAAAQedyuVS5cmW98cYbGjZsmHbs2KH7779fLVq0sLq0fLndbp05c0bly5fXqFGjJElZWVk6f/68xZUV7M8D0yFDhuj06dN6++23bX87ArtjkAoAAAAAAICg+/NwLy4uTs8884yWLFmitWvXWlhVwR5++GF17txZbrdbbdq0kSQ9+OCD6tatm8WVFaxdu3bq2rWrTpw4IUmaMGGCNm7cqOTkZGsLMxz3SAUAAAAAAECR8ng8xqyOdLvdCgv7/2sR09PTFRMTY2FF/tm/f78uv/xyhYeHe7etXLlSrVu3trAqszFIBQAAAAAAQND9+uuvGjNmjPbt26fDhw+rXr16qly5sp599lldcsklVpeXpx9++EEpKSlq2rSpJk2apB9//FFXX321Bg8erCuuuMLq8lDEGKQCAAAAAAAg6B588EENHz5c1apV05YtW7Rq1Sq1bdtWr732mt566y2ry8tTfHy8xo4dqzfeeEO33nqrWrVqpW+++UazZ8/W3LlzrS4vX0lJSfm+Fh8fX4SVOAv3SAUAAAAAAEDQpaenq1q1apKk6667Tt99952uueYanTp1yuLK8hcREaG4uDidPn1a99xzj0qVKqXWrVvb/sum9u3bp1mzZunIkSMXPPD3hft+CwAAAAAAAHBxKlWqpJEjR6p58+b6/PPPdc011+jzzz9XVFSU1aXl68orr9SsWbPUokULTZs2Ta1atdLatWtteyuC/xk6dKj27dun5s2bq379+laX4xhc2g8AAAAAAICgy8rK0qJFi7Rnzx7VqVNHXbp00Q8//KCqVauqbNmyVpeXpzNnzmjWrFnasGGDjh8/rrJly6pRo0Z65JFHVLp0aavLK1BaWpoyMzNVqVIlq0txDAapAAAAAAAACLqXX35Z/fr1s/UKVF927typ2rVrW12G344fP6709HTFxsaqTJkyVpdjPAapAAAAAAAACLqmTZvqsssu0zPPPKObbrrJ6nL8smHDhlzPX3rpJT3zzDOS/vg8drV161aNHTtWbrdbJUuWVEZGhjwej0aOHKlGjRpZXZ6xGKQCAAAAAAAg6BISEvTCCy/ohRdeUEZGhrp3765mzZrZ+hL5e+65R2FhYYqLi5MkrV+/Xs2aNZMkTZgwwcrSCtSzZ0+9/PLLuvzyy73bDhw4oCeffFKLFi2ysDKz8WVTAAAAAAAACDqXy6XKlSvrjTfe0K5du7Rs2TK98847OnbsmNauXWt1eXmaP3++xo4dq0aNGqlbt25KSEiw9QD1f7Kzs3MNUSXp8ssvl8vlsqgiZ2CQCgAAAAAAgKD780XRcXFx3kvk7SwqKkoTJkzQO++8o5EjRyonJ8fqkvzSokUL9e3bV02aNFFsbKzS09P1xRdfqHnz5laXZjQu7QcAAAAAAECRcrvdCgsLs7qMQtm4caMWL16syZMnW12KX7Zv367NmzcrIyNDMTExatiwoerVq2d1WUZjRSoAAAAAAACCbv/+/ZowYYK2bdum8PBwud1u1apVS0OHDlW1atWsLi9fK1eu1MaNG3X69GmVLl1an3zyie644w7bXyZ/4MABpaSkeOsuX7686tata/u67YwVqQAAAAAAAAi6Pn36aNCgQWrQoIF325YtWzRx4kQtWLDAwsryN2bMGLndbjVv3lzR0dHKyMjQunXrlJ2drfHjx1tdXr5MrdvuWJEKAAAAAACAoMvKyso1RJWk6667zppi/LR792699957ubbddttt6tGjh0UV+cfUuu2OQSoAAAAAAACCLi4uTkOHDlWzZs0UGxurjIwMrV27VnFxcVaXli+3261NmzapcePG3m3ffvutIiIiLKzKN1Prtjsu7QcAAAAAAEDQeTwerVy58oIvQGrTpo1t79v566+/asKECfrxxx8lSWFhYapTp46GDBmiq666ytriCmBq3XbHIBUAAAAAAABFYufOnfriiy+8X4B0/fXXq379+laX5VNaWprS09MVGxursmXLWl0OLMIgFQAAAAAAAEE3bdo0bd26VU2bNvV+AdKGDRtUt25dPfXUU1aXl6etW7dq7Nixcrvd3prdbrdGjRqlhg0bWl1eoY0dO1YjR460ugxjMUgFAAAAAABA0PXq1Uvz5s3Ltc3j8ah79+5atGiRRVUVrGfPnnr55Zd1+eWXe7cdOHBATz75pG1rLsjevXtVo0YNq8swFl82BQAAAAAAgKDLzs5WamqqKlWq5N2WmpqqsLAwC6sqWHZ2dq4hqiRdfvnltr2n65+lpaXp22+/1enTp1WqVCldd911DFEvEoNUAAAAAAAABN1zzz2n/v376/z584qJiVF6erqKFy+u0aNHW11avlq0aKG+ffuqSZMmio2NVXp6ur744gs1b97c6tIKtGjRIiUlJen6669XdHS0du/erRkzZqhbt27q2bOn1eUZi0v7AQAAAAAAUGTS09OVkZGhmJgYRUdHW12OT9u3b9fmzZu9NTds2FD16tWzuqwC9ejRQ3PnzlVERIR3W1ZWlnr27KnFixdbWJnZWJEKAAAAAACAoNu/f78mTJigH3/8UcWKFZPb7VatWrU0dOhQVatWzery8nXgwAGlpKTo9OnTKl26tMqXL6+6deva+vL+7OxsnTt3Ltcg9ezZs7au2QSsSAUAAAAAAEDQ9enTR4MGDVKDBg2827Zs2aKJEydqwYIFFlaWvzFjxsjtdqt58+aKjo5WRkaG1q1bp+zsbI0fP97q8vK1evVqTZw4UVWrVvXekuCXX37R0KFDdeutt1pdnrFYkQoAAAAAAICgy8rKyjVElaTrrrvOmmL8tHv3br333nu5tt12223q0aOHRRX5p1WrVmrevLn27t2r9PR0xcTEqEaNGgoPZxR4MfivBwAAAAAAgKCLi4vT0KFD1axZM8XGxiojI0Nr165VXFyc1aXly+12a9OmTWrcuLF327fffpvrknk7GjlypBISEvL8b7tjxw7Nnz9fY8eOtaAys3FpPwAAAAAAAILO4/Fo5cqV2rx5s3eVZKNGjdSmTRvb3rvz119/9d7XVZLCwsJUp04dDRkyRFdddZW1xRXgxIkTmjp1qrZt26Zq1aqpQoUKOnXqlHbs2KH69evriSeeULly5awu0zgMUgEAAAAAAGCZ33//XZdddpnVZThSenq6kpOTdfz4cZUvX14NGjRQyZIlrS7LWGFWFwAAAAAAAIDQ9corr1hdQqGZcll8TEyMmjRporvuuku33HILQ9SLxIpUAAAAAAAAoBD27t2rGjVqWF0GihiDVAAAAAAAAATduXPnNH/+fH311Vc6ffq0YmNj1bhxY/Xu3VslSpSwurx8paWl6dtvv9Xp06dVqlQpXXfddbr00kutLgsWYJAKAAAAAACAoBs4cKBq166t5s2bKzo6WhkZGVq3bp2Sk5M1ffp0q8vL06JFi5SUlKTrr7/eW/O3336rbt26qWfPnlaXhyIWbnUBAAAAAAAAcL7Dhw/r5ZdfzrWtdu3a6tWrl0UV+bZ48WLNnz9fERER3m1ZWVnq2bMng9QQxJdNAQAAAAAAIOgiIyO1dOlSHTt2TFlZWUpLS9PSpUtt/QVI2dnZOnfuXK5tZ8+elcvlsqgiWIlL+wEAAAAAABB0x48f1/Tp0/Xdd98pIyND0dHRatSokfr166fy5ctbXV6eVq9erYkTJ6pq1aqKjY1Venq6fvnlFw0dOlS33nqr1eWhiDFIBQAAAAAAQJFbu3atWrRoYXUZPmVnZ2vv3r1KT09XTEyMatSoofBw7pYZiri0HwAAAAAAAEVu1qxZVpfg08iRI5WSkqK4uDhdf/31iouL8w5Rd+zYoZEjR1pcIYoS43MAAAAAAAAUORMukh44cKCmTp2qbdu2qVq1aqpQoYJOnTqlHTt2qH79+nrqqaesLhFFiEv7AQAAAAAAUOQ2b96s66+/3uoy/JKenq7k5GQdP35c5cuXV4MGDWz9JVkIDgapAAAAAAAACLqRI0eqd+/eqlWr1gWv7dixQ/Pnz9fYsWMtqAzwD4NUAAAAAAAABN2JEyfyvEx+586duvbaa/XEE0+oXLlyVpcJ5ItBKgAAAAAAAIoMl8nDVAxSAQAAAAAAAMCHMKsLAAAAAAAAAAC7Y5AKAAAAAAAAAD4wSAUAAAAAAIBlzp07p0WLFvn13iVLlmjVqlUBOW5iYqLmz58fkH392ZEjRzR69OiA77cgK1as0KFDh4r0mKGIQSoAAAAAAAAsc+TIEb8HqZ07d9Ztt90W5IouziWXXFLkg9Q5c+YoPT29SI8ZisKtLgAAAAAAAACha8aMGdqzZ49q166tf/zjH8rMzNT48eO1dOlSbdu2TSdOnFDt2rU1YcIEJSYmqkKFCqpevbpmzpypiIgIpaamql27durXr58OHjyoESNG6Ny5c4qMjNTzzz+vnJwc9evXT2XKlFHz5s318MMPX1DDlClTtGnTJrndbvXt21d33nmnvvnmG02bNk0ej0cZGRmaMmWKIiIicu1r3bp1ql27tnbv3q309HS9+uqr8ng8GjhwoBYuXKgOHTroxhtv1K5du+RyufT6668rJiZGY8aM0bZt21ShQgX99ttveuONN1SpUqU8//u0bNlS1atXV40aNdS1a1dNnDhROTk5On78uEaPHq1Tp05px44dGjJkiObNm6ekpCR9+OGHcrlcateunfr06RPs38KQwSAVAAAAAAAAlnn00Uf1008/qVmzZjp58qSGDx+u9PR0lSpVSv/+97/ldrvVvn37Cy5dP3DggJYtW6asrCw1a9ZM/fr106RJk5SQkKAWLVpo48aNmjx5sgYMGKAjR45o8eLFKl68+AXHX7t2rVJTUzV//nydO3dO3bt3V5MmTbR792699NJLqlixombMmKFPP/1UHTp0yLWvdevWqX79+ho2bJheeeUVffTRR2rXrp133xkZGWrfvr1GjBihQYMGad26dYqMjNSJEyf0/vvvKy0tTbfffnuB/30OHjyoJUuWqGzZsvr44481ZMgQxcXFafny5VqyZInGjRunOnXqaPTo0fr111/18ccfa968eZKk+++/X02bNlX16tUD8DsFBqkAAAAAAACwhWrVqkmSIiMjlZaWpoEDB6pkyZLKzMzU+fPnc723Vq1aCg8PV3h4uEqUKCFJ+umnn/Tmm2/q7bfflsfjUXj4H6OvSpUq5TlE/d/P/Pjjj0pISJAkZWdn67ffflPFihU1fvx4lSxZUocOHVKjRo3y3FfdunUlSZdddpmOHj16wf7/9/rll1+uc+fO6bffftN1110nSSpXrpzPIWfZsmVVtmxZSdKll16q119/XSVKlFBGRoZiYmIu+CwHDhxQ3759JUknT57UL7/8wiA1QBikAgAAAAAAwDJhYWFyu93eX0vSunXrdPDgQU2dOlVpaWlasWKFPB5Prp9zuVwX7Kt69ep64IEH1KhRI+3du1fffvttrv3mpXr16rrpppv0/PPPy+126/XXX1flypX1wAMPaMWKFYqJidGQIUO8xy9oX3n5a501a9bUBx98IOmPQefPP/9c4M//+Xjjx4/X5MmTVaNGDb322mv67bffvMfweDyqXr26rr76ar399ttyuVx69913FRcXV6h6kT8GqQAAAAAAALBM+fLldf78eZ09e9a7rX79+nr99dd17733yuVyqXLlyjp8+LDPfQ0ZMkSjR4/WuXPndPbsWQ0bNuyC9zzwwAOaMWOG93mrVq30zTffqFevXsrMzFTr1q0VExOjjh076t5771VUVJQqVKjg1/H9ceutt2rdunXq0aOHKlSooBIlSigiIsKvn+3YsaOefPJJlSpVSpdddpmOHz8uSWrYsKEGDx6sd955R7fccot69uyprKws1a9fXxUrVgxI3ZBcnr+O8wEAAAAAAAAExd69e7Vz5061b99ex48f11133aU1a9bke+sB2AeDVAAAAAAAAKCIZGZmatCgQTp27JhycnLUu3dvlSpVSu++++4F7+3Tp4/atGlT9EUiTwxSAQAAAAAAAMCHwt0dFwAAAAAAAABCEINUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgA4NUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgA4NUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgA4NUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgA4NUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgA4NUAAAAAAAAAPCBQSoAAAAAAAAA+MAgFQAAAAAAAAB8YJAKAAAAAAAAAD4wSAUAAAAAAAAAHxikAgAAAAAAAIAPDFIBAAAAAAAAwAcGqQAAAAAAAADgQ7jVBQAwT/bvV/t8T/hle4qgEgAAAODi0NsCQPD5k7WS/fOWQWqIcv9ey+oSCiXssp+sLgF/kuNx+3wP4QIAAJA/0/pxybk9Ob0t4Gym5W0oZ61k/7y1e30AbChbOT7fE1kEdQAAAAAXi94WAILPn6yV7J+3DFIBFFqOx2N1CQAAAEBA0NsCQPA5JWsZpAIoNLecEYAAAAAAvS0ABJ9TspZBKoBCOy//7m0CAAAA2B29LQAEn1OylkEqgEJzypJ8AAAAgN4WAILPKVnLIBVAoTnjPBIAAABAbwsARcEpWcsgFUChZTnkTBIAAABAbwsAweeUrGWQCqDQnHImCQAAAKC3BYDgc0rWMkgFUGg5clldAgAAABAQ9LYAEHxOyVoGqQAK7bzHGQEIAAAA0NsCQPA5JWvDrC4AgHly5PL58EdycrISEhIu2L506VJ16NBBvXr10qJFiwJdPgAAAOBFbwsAwedP1pqQt6xIBVBo5z0Xfw5m5syZWrZsmaKionJtT0tL02uvvaYlS5aoVKlS6tu3r2655RZVqlTpoo8JAAAA/BW9LQAEXyCyVrI+b1mRCqDQchTm8+FLlSpVlJiYeMH21NRUxcXFqUyZMgoLC9O1116r5OTkYHwMAAAAgN4WAIqAP1lrQt6yIhVAobn9uLdJUlKSkpKSvM/j4+MVHx/vfd62bVulpqZe8HNVq1bVnj17dPToUUVHR2vjxo266qqrAlI3AAAA8Ff0tgAQfP5krWT/vGWQCqDQsjzFfL7nr2Hnr9KlS2vo0KF6/PHHVaZMGdWrV09ly5b9O2UCAAAAPtHbAkDw+ZO1kv3zlkv7ARSaW2E+H39Xdna2tm/frnnz5unVV1/Vvn371KhRowBWDwAAAPx/9LYAEHz+ZK0JecuKVACF5u836RXG8uXLlZmZ6T3z1KlTJ0VGRur+++9XuXLlAn48AAAAQKK3BYCiEIyslYo+b10ej8cT8L3C9ty/17K6hEIJu+wnq0vAn/w3pa7P97Sttr0IKgEAADCTaf245NyenN4WcDbT8jaUs1ayf96yIhVAofnzTXoAAACACehtASD4nJK1DFIBFNp5D9EBAAAAZ6C3BYDgc0rWOuNTAChSOZ7g3NsEAAAAKGr0tgAQfE7JWgapAArNKUvyAQAAAHpbAAg+p2Qtg1QAheaUJfkAAAAAvS0ABJ9TstYZnwJAkXLKknwAAACA3hYAgs8pWcsgFUChuR2yJB8AAACgtwWA4HNK1jJIBVBo5z3FrC4BAAAACAh6WwAIPqdkLYNUAIWW43HGmSQAAACA3hYAgs8pWcsgFUChOeVMEgAAAEBvCwDB55SsZZAKoNByHHJvEwAAAIDeFgCCzylZyyAVQKG5HbIkHwAAAKC3BYDgc0rWMkgFUGhOWZIPAAAA0NsCQPA5JWsZpAIotBy5rC4BAAAACAh6WwAIPqdkLYNUAIXmlCX5AAAAAL0tAASfU7KWQSqAQnPKknwAAACA3hYAgs8pWcsgFUCh5TjkTBIAAABAbwsAweeUrGWQCqDQ3B5n3NsEAAAAoLcFgOBzStYySAVQaE5Zkg8AAADQ2wJA8DklaxmkAig0t5yxJB8AAACgtwWA4HNK1jJIBVBo593OCEAAAACA3hYAgs8pWeuMTwGgSLk9YT4f/khOTlZCQsIF25ctW6ZOnTqpS5cumjdvXqDLBwAAALzobQEg+PzJWhPylhWpAAotRxd/k+iZM2dq2bJlioqKuuC1F198UR9++KFKliyp9u3bq3379ipduvRFHxMAAAD4K3pbAAi+QGStZH3esiIVQKFlu4v5fCQlJalz587eR1JSUq59VKlSRYmJiXnuPy4uTqdPn1ZWVpY8Ho9cLmd8ux8AAADsh94WAILPn6w1IW9ZkQqg0Nx+nEmKj49XfHx8vq+3bdtWqampeb5Ws2ZNdenSRVFRUWrTpo1KlSr1t2sFAAAACkJvCwDB50/WSvbPW1akGsztdltdAkJUjsfl8/F37dy5U59//rlWrVql1atXKy0tTZ988kkAqwcAAHZEbwur0Nsi1JC3sII/WWtC3rIi1TD79+/XhAkTtG3bNoWHh8vtdqtWrVoaOnSoqlWrZnV5CBHZ7mJB23dsbKxKlCihyMhIFStWTOXKldOpU6eCdjwAAGAdelvYAb0tQgF5C6sFM2ulostbBqk2kZ6eLpfLpRUrVqhly5b53gx32LBhGjRokBo0aODdtmXLFg0dOlQLFiwoqnIR4vxdkl8Yy5cvV2ZmpncZf69evRQREaEqVaqoU6dOAT8eAAAIHnpbmITeFiYjb2GKYGStVPR5yyDVBgYMGKBbb71V33//vdxut1asWKHp06fn+d6srKxcwSdJ1113XRFUCfx/gTqTVKlSJS1cuFCS1KFDB+/2nj17qmfPngE5BgAAKFr0tjANvS1MRd7CJIFckWpl3jJItYHDhw/r7rvv1vvvv6+5c+eqb9+++b43Li5OQ4cOVbNmzRQbG6uMjAytXbtWcXFxRVcwQp77Iu5bAgAAnI3eFqaht4WpyFuYxClZyyDVBs6fP6/PPvtMV199tdLS0pSRkZHve0ePHq2VK1dq8+bNSk9PV0xMjFq2bKk2bdoUYcUIdcFakg8AAMxHbwvT0NvCVOQtTOKUrGWQagMPP/ywPvzwQw0dOlRz587VY489lu97XS6X2rRpQ9jBUtnuMKtLAAAANkVvC9PQ28JU5C1M4pSsZZBqA5s3b9arr74qSXryySctrgbwzSlL8gEAQODR28I09LYwFXkLkzgla50xDjbcnj17dOrUKavLAPzm9rh8PgAAQGiit4Vp6G1hKvIWJvEna03IW1ak2sDevXt10003qVy5cnK5/vg/zYYNGyyuCshftodzMAAAIG/0tjANvS1MRd7CJE7JWgapNrBmzRqrSwAKxYSzRAAAwBr0tjANvS1MRd7CJE7JWgapNrB7926NGjVKp06dUseOHVWzZk21bNnS6rKAfDnlJtEAACDw6G1hGnpbmIq8hUmckrXO+BSGGzdunCZMmKCyZcuqa9euSkxMtLokoEAej8vnAwAAhCZ6W5iG3hamIm9hEn+y1oS8ZUWqTVStWlUul0vlypVTdHS01eUABXLL/uEGAACsQ28Lk9DbwmTkLUzhlKxlkGoDpUuX1oIFC3TmzBl99NFHKlWqlNUlAQXKcciSfAAAEHj0tjANvS1MRd7CJE7JWmd8CsO98MILSk1NVdmyZbVt2zaNHz/e6pKAArk9Lp8PAAAQmuhtYRp6W5iKvIVJ/MlaE/KWFak28PLLL6tbt256+umnrS4F8IsJ9y0BAADWoLeFaehtYSryFiZxStYySLWBW2+9VTNmzNChQ4fUsWNHdezYUTExMVaXBeQrx+2MAAQAAIFHbwvT0NvCVOQtTOKUrOXSfhto3ry5Xn31Vb3++uvavHmzmjVrpmeffVa//vqr1aUBeXLL5fMBAABCE70tTENvC1ORtzCJP1lrQt6yItUG9u7dqyVLlmjNmjW68cYb9X//93/Kzs7WU089pSVLllhdHnABpyzJBwAAgUdvC9PQ28JU5C1M4pSsZZBqA8OHD1f37t3Vv39/RUVFebd36dLFwqqA/DllST4AAAg8eluYht4WpiJvYRKnZK3L4/F4rC4C0uHDh5WdnS2Px6PDhw+rYcOGQT2e+/daQd1/oIVd9pPVJeBP6i8f6fM9WzuMLYJKAACAHRV1b2si0/pxybk9Ob0tTEbe+mZa3oZy1kr2z1tWpNrAc889py1btujMmTM6c+aMqlSpooULF1pdFpCvHDe3VwYAAHmjt4Vp6G1hKvIWJnFK1jrjUxhu586d+uijj9S0aVN9/PHHioyMtLokoEAej+8HAAAITfS2MA29LUxF3sIk/mStCXnLINUGypYtK5fLpczMTJUrV87qcgCfPB6Xz4c/kpOTlZCQkGvbkSNHlJCQ4H00btxY8+fPD8bHAAAAQUBvC9PQ28JU5C1M4k/WmpC3XNpvA/Xq1dOsWbN06aWXasCAATpz5ozVJQEFcgfg2/ZmzpypZcuW5bopuiRdcsklmjt3riTp+++/1yuvvKLu3btf9PEAAEDRoLeFaehtYSryFiYJRNZK1uctg1QbGDhwoDIyMhQZGal169apQYMGVpcEFMjfs0QFqVKlihITEzV48OB8juHR888/r8mTJ6tYsWIXfTwAAFA06G1hGnpbmIq8hUkCkbWS9XnLINVCU6ZMkct14f+RtmzZooEDB1pQEeAnP+5bkpSUpKSkJO/z+Ph4xcfHe5+3bdtWqamp+f786tWrVbNmTVWvXv2iSgUAAEWD3hbGoreFYchbGMnP+5/aPW8ZpFrI129qVlaWihcvXkTVAP5zu32fSfpr2BXWsmXL1KdPn7/98wAAoGjR28JU9LYwDXkLE/mTtZL985ZBqoU6depU4OsPPfSQ5syZU0TVAP4L1JL8gmzbtk2NGjUK+nEAAEBg0NvCVPS2MA15CxMVRdZKwc9bBqk25vH4ue4ZKGIeP88kFcby5cuVmZmp+Ph4paWlKSYmJs/LVQAAgJnobWFX9LZwGvIWdhSMrJWKPm8ZpNoYf9HCtgL093KlSpW0cOFCSVKHDh2828uVK6cPPvggMAcBAAC2QG8L26K3hcOQt7ClAM73rcxbBqkACq2oluQDAAAAwUZvCwDB55SsZZBqYyzHh10Fa0k+AABwLnpb2BW9LZyGvIUdOSVrw6wuAH84c+aMJOnw4cPebVdffbVV5QAF8/jxAAAAIYveFkaht4XByFsYw5+sNSBvGaTawLRp0/TGG29IksaNG6e33npLkjRq1CgrywIK4PLjAQAAQhG9LcxDbwszkbcwiz9Za/+8ZZBqA6tXr9bAgQMlSa+99ppWr15tcUWAD24/HgAAICTR28I49LYwFHkLo/iTtQbkLYNUG3C5XMrKypIknT9/nvuZwP48Lt8PAAAQkuhtYRx6WxiKvIVR/MlaA/KWL5uygZ49e6pDhw6qVauW9u3bp4cfftjqkoACeQw4SwQAAKxBbwvT0NvCVOQtTOKUrGWQaqH33ntPvXv3Vs2aNTV//nzt379flStXVrly5awuDSiYAWeJAABA0aK3hbHobWEY8hZGckjWcmm/hebOnavPP/9cI0eO1Pbt23X69Glt375dGzZssLo0oEAuj+8HAAAILfS2MBW9LUxD3sJE/mStCXnLilQLPfPMM/rss8907NgxffTRR7lea9q0qUVVAX5wO+NMEgAACBx6WxiL3haGIW9hJIdkLYNUC7Vu3VqtW7fW6tWr1apVqwteX7BggXr06GFBZYAPNjtLdOjQIZ0+fVrFihXTzJkzlZCQoDp16lhdFgAAIYXeFsait4VhyFsYySFZy6X9NpBX8EnSxx9/XMSVAH7y+PEoQoMGDdLRo0f1yiuvqEmTJnrhhReKtgAAAOBFbwvj0NvCUOQtjOJP1hZh3v7drGWQamMej83G9cD/uF2+H0XI5XLphhtu0KlTp9S+fXuFhRFtAADYDb0tbIveFg5D3sKW/MnaIszbv5u1XNpvYy6XM+4fAeex2w2gs7Oz9dJLL6lx48b66quvdP78eatLAgAAf0FvC7uit4XTkLewI6dkLae2ABSejZbjS9KECRNUuXJl/fOf/1RaWpomTZpUtAUAAADAXPS2ABB8Nru0/+9mLYNUG2M5PuzK5fH9KEqXXnqpbrvtNp06dUopKSlc/gQAgA3R28Ku6G3hNOQt7MifrC3KvP27Wcul/TaQk5Oj3bt3Kysry7utfv36euaZZ4J2zLDLfgravhECPPa6VOSJJ55Qz5499d///ldXX321Ro4cqVmzZlldFgAAIcmK3tZE9OM2Qm8LQ5G3/iFvbcIhWcsg1Qb++c9/KisrS6VKlZL0x/1Mpk2bpvr161tcmb20CetmdQmFtsK9SLcX72V1GYXyWdY8329yB7+Owjh79qxatWql2bNn68UXX9SXX35pdUkAAIQsK3pbR/ZbNmVaT77Cvcj3m+htYSjy1jdT89a0rJX8yFuHZC2DVBs4d+6c3nvvPavLAPxmt5tEnz9/XrNnz1a9evW0Z88enTlzxuqSAAAIWfS2MA29LUxF3sIkTslabrZiA40bN9b69et14MAB7wOwNRvdIFqShgwZosOHD+uxxx7TV199pWHDhhVtAQAAwIveFsaht4WhyFsYxWZfNvV3s5YVqTZw7NgxvfDCC7mW4y9YsMDiqoD8uQK0JD85OVmTJ0/W3Llzc23funWrJk6cKI/Ho0suuUQvvfSSIiMj891Po0aNdOrUKSUlJemqq67ithgAAFiI3hamobeFqchbmCRQWSsFJm//btYySLWBffv26ZNPPrG6DMB/AbhJ9MyZM7Vs2TJFRUXl3rXHoxEjRui1115T1apVtWjRIv3222+qXr16vvuaMmWKfvnlFzVq1EhLly7Vpk2b9Oyzz150jQAAoPDobWEcelsYiryFUQL0ZVOBytu/m7Vc2m8DcXFx2rJli7KysrwPwNYCsBy/SpUqSkxMvGB7SkqKypQpo3fffVe9e/fWiRMnCmw0Jenbb7/Va6+9pr59+yoxMVGbN28u7CcCAAABQm8L49DbwlDkLYwSoEv7A5W3fzdrWZFqA99++60+//xz73OXy6VVq1ZZVxDggz9L8pOSkpSUlOR9Hh8fr/j4eO/ztm3bKjU19YKfO378uL7//nuNHDlSVapU0aOPPqprrrlGt9xyS77Hys7OltvtVlhYmNxut1yuwJzpAgAAhUdvC9PQ28JU5C1M4u+l/UWVt383axmk2sDy5cutLgEoFH++be+vYeevMmXKqGrVqqpRo4YkqVmzZtq2bVuBzWb79u3Vs2dPNWjQQFu3blW7du0KfVwAABAY9LYwDb0tTEXewiT+ZK1UdHn7d7OWQaoNJCQkXDD5njNnjkXVAH4I4E2i/6py5crKyMjQL7/8oqpVq2rTpk3q2rVrnu+dMmWK989OxYoVtWbNGtWpU0dpaWnBKxAAABSI3hbGobeFochbGCWIWSv5n7cXm7UMUm1gzJgxkv64Me6PP/6oHTt2WFwRUDB/zyQVxvLly5WZman4+HiNHz9egwYNksfjUcOGDXXrrbfm+TN/vt9JtWrV1LJly8AXBgAACoXeFqaht4WpyFuYJBhZKxU+by82axmk2sCffxNr1Kih999/38JqgKJTqVIlLVy4UJLUoUMH7/ZbbrnFrz8HnTp1ClptAADg76G3Raiit0VRI28Rqi4mby82axmk2sCfb6J75MgRZWZmWlgN4Ju/N4kGAAChh94WpqG3hanIW5jEKVnLINUGjhw54v118eLFNXXqVOuKAfwRpCX5AADAfPS2MA69LQxF3sIoDslaBqk20L9/fx07dkznzp2zuhTAPw4JQAAAEHj0tjAOvS0MRd7CKA7JWgapNjBmzBitXbtWl156qTwej1wulxYsWGB1WUC+nLIkHwAABB69LUxDbwtTkbcwiVOylkGqDSQnJ2vlypUKCwuzuhTAL8H6tj0AAGA+eluYht4WpiJvYRKnZC1/2mygatWqLMWHWdx+PAAAQEiit4Vx6G1hKPIWRvEnaw3IW1ak2sDBgwfVsmVLVa1aVZJYjg/bc8qZJAAAEHj0tjANvS1MRd7CJE7JWgapNjBlyhSrSwAKxyEBCAAAAo/eFsaht4WhyFsYxSFZyyDVBq688spcz9esWXPBNsBOnHKTaAAAEHj0tjANvS1MRd7CJE7JWu6RagNZWVm5nv/yyy8WVQL4yePHAwAAhCR6WxiH3haGIm9hFH+y1oC8ZZBqA126dNH48eP1008/SZL69u1rbUGADy6P7wcAAAhN9LYwDb0tTEXewiT+ZK0Jecul/TbwwQcfaP369Zo2bZqOHz+ujh07ql27doqOjra6NCBvDlmSDwAAAo/eFsaht4WhyFsYxSFZy4pUGwgLC1Pz5s3VpUsXlSlTRnPnztWDDz6o9957z+rSgDy5/HgAAIDQRG8L09DbwlTkLUziT9aakLesSLWBF198UatWrdKNN96ohx9+WPXr15fb7Vbnzp3Vu3dvq8sDLmTAcnsAAGANelsYh94WhiJvYRSHZC2DVBuoVq2alixZ4l1+f+rUKZUqVUrTpk2zuDIgb075tj0AABB49LYwDb0tTEXewiROyVou7bfQkSNHlJKSokWLFnl/vXfvXj3wwAOSpEqVKllcIZAPB3zTHgAACCx6WxiL3haGIW9hJH+y1oC8ZUWqhZKTkzV79mylpKRoxIgRkv64x0nTpk0trgwomFPOJAEAgMCht4Wp6G1hGvIWJnJK1jJItVDr1q3VunVrrV27Vi1atLC6HMBvLgPOEgEAgKJFbwtT0dvCNOQtTOSUrGWQaqHXX39djz32mD744AMtW7Ys12tTpkyxqCrADw4JQAAAEDj0tjAWvS0MQ97CSA7JWgapFmrVqpUkqUePHhZXAhSOU5bkAwCAwKG3hanobWEa8hYmckrWMki1UHJyspKTk/N87cYbbyziaoBCCNCZpOTkZE2ePFlz587Ntf3dd9/VokWLVK5cOUnSmDFjVL169cAcFAAABAW9LYxFbwvDkLcwUgBXpFqZtwxSLXTkyBGrSwD+lkDc22TmzJlatmyZoqKiLnht27ZtmjRpkq655pqLPxAAACgS9LYwFb0tTEPewkSBukeq1XnLINVC/fv39/768OHDys7Olsfj0eHDhy2sCvDN5b74BKxSpYoSExM1ePDgC1778ccf9dZbb+nIkSO69dZb9cgjj1z08QAAQHDR28JU9LYwDXkLEwUiayXr85ZBqg0899xz2rJli86cOaOzZ8+qcuXKWrhwodVlAfnzI/+SkpKUlJTkfR4fH6/4+Hjv87Zt2yo1NTXPn23fvr169eqlmJgY9e/fX2vWrFHLli0vumwAABB89LYwDr0tDEXewih+zlHtnrdhAd0b/padO3fqo48+UtOmTfXRRx8pMjLS6pKAArncvh/x8fFasmSJ9/Hn4CuIx+PRfffdp3Llyql48eJq0aKFtm/fHuRPBAAAAoXeFqaht4WpyFuYxJ+sNSFvGaTaQNmyZeVyuZSZmem9IS5gZy6P78fflZ6errvuuksZGRnyeDz6+uuvuZ8UAAAGobeFaehtYSryFibxJ2tNyFsu7beBevXqadasWbr00ks1YMAAnTlzxuqSgIIF8Nv2/mf58uXKzMxUfHy8BgwYoD59+qh48eK65ZZb1KJFi8AfEAAABAW9LYxDbwtDkbcwShCyVir6vHV5PJ4gfRQURnp6ukqUKKF169apQYMGKl++vNUl2U6bsG5Wl1BoK9yLdHvxXlaXUSifZc3z+Z6bEl72+Z6v5w4MRDkAAMBARd3bOrHfsivTevIV7kU+30NvC5ORtwUzNW9Ny1rJd976k7WS/fOWFak2MG3atFzPt2/fnutb+AC7uZjl9gAAwNnobWEaeluYiryFSZyStQxSbaBChQqS/rgx7vbt2+V2uy2uCPCBhewAACAf9LYwDr0tDEXewigOyVoGqTbQo0ePXM8feughiyoB/OPi72cAAJAPeluYht4WpiJvYRKnZC2DVBtISUnx/vrw4cM6cOCAhdUAvjklAAEAQODR28I09LYwFXkLkzglaxmk2sDIkSPlcrkkSZGRkXr22WctrggomFMCEAAABB69LUxDbwtTkbcwiVOylkGqDZw8eVLp6emKjIzUuXPnNGbMGHk8HrlcLq1atarAnz127FjQv5UPuIBD7m0CAAACj94WxqG3haHIWxjFIVnLINUGGjZsqHvuuUcNGzbUrl27NGvWLI0bNy7P9/556b4kDRkyRJMmTZIkVatWLei1ApJzvm0PAAAEHr0tTENvC1ORtzCJU7KWQaoN7N27Vw0bNpQkxcXF6eDBgypevHie773//vtVokQJXXrppfJ4PEpJSfEu558zZ05Rlo0Q5pQl+QAAIPDobWEaeluYiryFSZyStQxSbSA2NlZTp05V/fr1tWnTJl1xxRX5vnfx4sUaNWqUevbsqSZNmighIUFz584twmoBOWZJPgAACDx6WxiH3haGIm9hFIdkbZjVBUCaMmWKYmJitG7dOlWuXFnjx4/P973ly5fX1KlT9fnnn2vGjBlFWCXw/7k8vh8AACA00dvCNPS2MBV5C5P4k7Um5C0rUm2gZMmSeuihh/x+f3h4uIYNG6YlS5bI45CJPszilCX5AAAg8OhtYRp6W5iKvIVJnJK1DFIN1rlzZ3Xu3NnqMhCK3PylCwAAAoveFpaht0WIIW9hCYdkLYNUAIXnjPwDAAAA6G0BoCg4JGsZpAIoNJdDziQBAAAA9LYAEHxOyVoGqQAKzYQbQAMAAAD+oLcFgOBzStYySAVQaE45kwQAAADQ2wJA8DklaxmkAig8h3zbHgAAAEBvCwBFwCFZyyAVQKG5PM44kwQAAADQ2wJA8DklaxmkAig8hyzJBwAAAOhtAaAIOCRrGaQCKDSn3CQaAAAAoLcFgOBzStaGWV0AAAN5PL4ffkhOTlZCQkK+r48YMUKTJ08OVNUAAADAhehtASD4/MlaA/KWFakACs2Vc/GnkmbOnKlly5YpKioqz9cXLFign376STfccMNFHwsAAADID70tAARfILJWsj5vWZEKoPA8fjx8qFKlihITE/N87bvvvlNycrLi4+MDVDAAAACQD3pbAAg+f7LWgLxlRSqAQnO53T7fk5SUpKSkJO/z+Pj4/8fencdVWef//38eZJHVvbRcAlNQywVtdSvTsSxbTEVM/FjNTFpaJiWhiWg5aG6VS5ZLqY1IpONYU01pJVJWZiPmWi6pZOWGyUFlO+f3R7/4RoLnoByuc1087rfbuU1c53DOE2tevnhd7+t9lSpmvXv3VnZ29nnfd/ToUc2bN09z587V+++/XzmBAQAAgHLQ2wKA57lTayXvr7cMUgFUnBv178/Fzl0ffPCBcnJy9Pe//13Hjh3TuXPnFBERoX79+l1EUAAAAMAFelsA8Dz35qheX28ZpAKoMJubG0BfjKFDh2ro0KGSpNWrV2v//v00mgAAAPAYelsA8DxP1lqp6uotg1QAFefmkvyKeOedd3TmzBn2jgIAAEDVorcFAM/zQK2Vqr7eMkgFUHGVVP8aN26st956S5LUt2/f857nbD0AAAA8jt4WADyvEueoRtZbBqkAKszTS/IBAACAqkJvCwCeZ5VayyAVQMV5aEk+AAAAUOXobQHA8yxSaxmkAqg4i5xJAgAAAOhtAaAKWKTWMkgFUGG2YmsUQAAAAIDeFgA8zyq1lkEqgIqzyJkkAAAAgN4WAKqARWotg1QAFeewRgEEAAAA6G0BoApYpNYySAVQcRbZJBoAAACgtwWAKmCRWssgFUDFWWRJPgAAAEBvCwBVwCK1lkEqgIqzyJJ8AAAAgN4WAKqARWotg1QAFecoNjoBAAAAUDnobQHA8yxSaxmkAqg4i5xJAgAAAOhtAaAKWKTWMkgFUHEW2dsEAAAAoLcFgCpgkVrLIBVAxVnkbnsAAAAAvS0AVAGL1FoGqQAqziIFEAAAAKC3BYAqYJFayyAVQMVZpAACAAAA9LYAUAUsUmsZpAKoOItsEg0AAADQ2wJAFbBIrWWQCqDCnE5rnEkCAAAA6G0BwPOsUmsZpAKouGJrFEAAAACA3hYAqoBFai2DVAAVZ5G9TQAAAAB6WwCoAhaptQxSAVSc0xp7mwAAAAD0tgBQBSxSa32MDgDAfJzFxS4f7sjKylJcXNx5x//73//q/vvvV//+/bV06dLKjg8AAACUoLcFAM9zp9aaod6yIhVAxVXC3fYWLlyotWvXKjAwsNTx4uJizZw5U6tWrVJQUJD69Omjvn37qm7dupf8mQAAAMB56G0BwPMqodZKxtdbVqQCqLDKOIvUtGlTzZkz57zjNWrU0HvvvafQ0FCdOnVKDodD/v7+nvgxAAAAAHpbAKgClbUi1eh6y4pUABXndL1JdFpamtLS0kq+jomJUUxMTMnXvXv3VnZ2dpnf6+vrqw8//FCTJ09W9+7dzzvTBAAAAFQaelsA8Dw3aq3k/fWWQSqACnO6sST/z8Wuov7yl7+oZ8+eeuaZZ7RmzRrdf//9F/1eAAAAQHnobQHA89yptZL311sGqTCNjxzpRke4KB8WrDA6QqX7qDjN9Ysukt1u1/Dhw7VkyRL5+/srMDBQPj7sQgIAAMpnxX7LW5m1J78QelvAfdTbqkGtrbiqqrcMUgF4hXfeeUdnzpxRTEyM+vbtqwceeEC+vr6KjIzU3XffbXQ8AAAAwG30tgBQNaq63tqcTmfl3DYLAAAAAAAAACyKawoAAAAAAAAAwAUGqQAAAAAAAADgAoNUAAAAAAAAAHCBQSoAAAAAAAAAuMAgFQAAAAAAAABc8DU6AMztxIkT6tevn5YsWaL8/Hw98sgjuuqqqyRJsbGx6tOnj7EBy/Dqq6/q448/VmFhoWJjY3X99dfrmWeekc1mU4sWLTRx4kT5+HjHOYasrCzNmDFDy5cv18GDB8vMOXfuXH366afy9fXVuHHj1LZtW6NjAwAAmJLZetvVq1frX//6lyQpPz9fu3bt0qxZszRt2jQ1atRIkjRq1Chdf/31RsYs8cfe9sknn9Tx48clST/++KPatWun2bNn09sCALyazel0Oo0OAXMqLCzU6NGjtXfvXs2fP1/ffPONcnNz9dBDDxkdrVxffvmlXn/9dc2fP19nz57VkiVLtGPHDj344IO64YYblJSUpK5du6pXr15GR9XChQu1du1aBQYG6q233tLw4cPPy3nFFVdo2rRpWrp0qX766SeNGjVKq1atMjo6AACA6Zixt/2jSZMmKSoqSkeOHFHr1q3Vu3dvoyOV8ufe9ne//vqrhg4dqoULF+rYsWP0toDFZWZmunxNly5dqiCJ+woKCly+xt/fvwqSVMyBAwdcviY8PLwKklgLK1Jx0aZNm6ZBgwbptddekyRt375dBw4c0Pr169WsWTONGzdOISEhBqcsLTMzUy1bttRjjz0mu92usWPH6q233io5S9+tWzd99tlnXjFIbdq0qebMmaOxY8dKknbs2HFezvDwcHXp0kU2m01XXHGFiouLdfLkSdWtW9fI6AAAAKZjxt72d99++6327t2riRMn6q9//at27dqlpUuXqm3btnrqqafk62v8r31/7m1/N2fOHA0ZMkSXXXaZPvjgA3pbwOKeeeYZde3atdznN27c6NawtSp16tRJDRo0kNPplM1mk6SSf3Y6nTp58qS2bt1qbMgyDBw4UK1atVJ56yf37Nmjr776qopTmZ/xf6PClFavXq26deuqa9euJc1m27ZtNWDAAF1zzTV65ZVXNG/ePCUkJBictLScnBwdOXJECxYsUHZ2tkaMGFGqGAYHBys3N9fglL/p3bu3srOzS74uK6fdblft2rVLXvP7cZpNAAAA95m1t/3dq6++qscee0yS1LlzZ/Xs2VONGzfWxIkTtXLlSg0ZMsTghOf3ttJvWyls2rRJiYmJkkRvC1QD/fv31+jRo8t9/sUXX6yyLO66+eabtWDBgnKfHz58eBWmcV/v3r31/PPPl/v8s88+W4VprINBKi7KqlWrZLPZtGnTJu3atUsJCQl65ZVX1KBBA0lSr1699Nxzzxmc8ny1a9dWRESE/P39FRERoYCAAP38888lz+fl5SksLMzAhOX7476tv+cMCQlRXl5eqeOhoaFGxAMAADAts/a2knT69GkdOHBAN954oyTp/vvvL+lnb7vtNv33v/81Mt4FffDBB7rrrrtUo0YNSaK3BaqB0aNH6/vvv5ePj4+aN2+uJUuW6Ndff9Vf//pXhYaGXnDIapRbb7211MKmP7vQkNVIzz//vL755htt2bJFZ8+eVZ06dXTzzTerefPmJc+j4rzjjjownX/+85968803tXz5crVq1UrTpk3To48+qm3btkmSNm3apDZt2hic8nwdO3bUxo0b5XQ69csvv+js2bO66aab9OWXX0qSMjIy1KlTJ4NTlq1169bn5YyOjlZmZqYcDoeOHDkih8PBGXsAAIAKMmtvK0mbN2/WTTfdJOm3K5juvvvukoUC3pxb+i1ft27dSr6mtwWs76WXXtLEiRM1duxYjRo1SidOnFCdOnX0zDPPGB2tXDNmzNCDDz6oH374wegoFbJgwQKlpqYqJCREO3fu1E8//aTZs2frn//8p9HRTI0Vqag0ycnJeu655+Tn56f69et75Vn7W2+9VZs3b1b//v3ldDqVlJSkxo0ba8KECZo1a5YiIiK8bmP+3yUkJJyXs0aNGurUqZNiYmLkcDiUlJRkdEwAAABLMENvK/12M5HGjRtLkmw2m55//nmNHDlSNWvWVPPmzTVw4ECDE5bvwIEDatKkScnX11xzDb0tYHGbNm3SypUrVVBQoLvuuktz5syRJK1fv97gZOWLiorS6NGjFR8fr5YtW2rgwIHq0KGD0bFc2rhxY8nQdODAgRo+fLgWLlyoQYMG6YEHHjA4nXnZnOXtOgsAAAAAAABUkvvvv1/Tp09XTk6Ohg8frvfee0+BgYF66KGH9NZbbxkdr0xDhw7VsmXLJEkff/yx1q5dq+3btys0NFT/+te/DE5Xvvvuu09z587VlVdeqQMHDmjixIlasmSJ+vfvrzVr1hgdz7QYpAIAAAAAAMDjPv/8c02fPl2tW7dWixYt9Nprryk4OFgJCQnq2bOn0fHKFBcXp+XLl593/OTJk169/UhmZqYmTJigsLAwnTt3Ti+88II2btyoyy+/XAMGDDA6nmkxSAUAAAAAAECVy83NVUBAgPz9/Y2OUq7jx4+rfv36Rse4KE6nUzk5OV498DUbbjYFAAAAAAAAj9uwYYOWLVumw4cPa8iQIbrjjjs0ZMgQ7dq1y+ho5bLb7Ro1apSeeuqpUjecmjhxonGh3HD06FGlpKRoxYoV2r17t3r16qXbb79dW7duNTqaqTFIBQAAAAAAgMfNmTNHvXv31vPPP68nnnhCmZmZmjx5spKTk42OVq4JEyYoJiZGd911lx577DHt3LlTkrR//36Dk13YM888o1atWslms+mhhx7Sq6++qjfeeEMzZswwOpqp+RodAAAAAAAAANbn7++vyy+/XJJ03XXXSZKioqKMjOSWLl26SJKaNm2qUaNGadGiRbLZbAanurCCggLdd999kqSvvvpKERERkuT1ub0dK1JhCXPmzFFqaqp27dqluXPnSpI++ugj/fLLLy6/d/r06erbt6++/PLLS8qwevVqrV+//pLeAwAAAAAAq2rTpo0mT56sDh06aNy4cfroo4/07LPPqnnz5kZHK5evr68+/vhjFRcXKyIiQhMmTNAjjzyi48ePGx3tgsLCwjR//nw5nU4tXbpUkvTvf/9bAQEBBiczNwapsJRWrVpp5MiRkqRly5bJbre7/J4PPvhAqampuuGGGy7ps/v166fbbrvtkt4DAAAA3i8/P1/p6eluvbYyT7b/vnjAHa4yVuS9yvLHBQwA4K7ExERde+21+v777/Xzzz/r/fffV6tWrbz60v4pU6boww8/VG5uriTpxhtv1Lhx4+Tn52dwsgubOXOmgoODS61A/eWXXzRt2jQDU5kfl/bDK+Tl5Sk+Pl6nT5/W1Vdfrf/973+qXbu2kpOT1bx5c6Wmpur48eMaNWqUZs6cqe3bt+vUqVOKiopSSkpKyft8+eWXWrlype655x7t2rVLCQkJGjBggH744QclJCSouLhY9957r95++20FBARo7ty5Onr0qB555BEtXrxYL7zwgrZt26bCwkKNGjVKPXv2LDPvhx9+qIULF8rX11eXXXaZZs+erXnz5ql+/fqqX7++li1bJkn6+eef1bBhQy1fvlwzZ87U119/LYfDoWHDhumOO+6okj9bAAAAVK5jx44pPT1dAwYMcPnafv36VUGi81Uk48Vo1aqVWrVq5ZH3BmBdPj4+atOmjaKjo9WsWbOS41lZWWrXrp2BycoXFhamqVOnSpK+++477d69W23atNG///1vg5NdWGBgoP7v//6v1LG///3vBqWxDgap8AorVqxQZGSknnzySX3zzTfKzMxU7dq1z3ud3W5XWFiYXn/9dTkcDt15551lXr5/yy23lJzVuvzyy9WvXz899dRT2rhxo2644YaSpewjR47U6tWrtWTJEmVkZCgnJ0dvv/22fv31V73++uvlDlLfffddPfzww7r99tu1Zs2aUitfe/XqpV69eunw4cMaPXq0pk6dqg0bNig7O1upqanKz8/XwIED1blzZ4WFhVXOHyAAAACqzIIFC7R3715FRUXp5ptv1pkzZzRlyhStWbPmvBP+c+bMUf369RUREaGFCxfKz89P2dnZ6tOnj0aMGKGffvpJEyZMUH5+vgICAvTcc8+puLhYI0aMUO3atdWtWzf97W9/K/nsdevW6f3339e5c+f07LPPqm3btnrzzTf14Ycf6uzZs6pTp47mzp1bknHu3LkaPHiwEhISlJubK6fTWbIaaf369frggw906tQpPfHEE+rRo0eZP++BAweUmJgoX19fORwOzZw5U4cOHdLKlSs1ZswYjRs3TtJviyP279+vTZs26dNPP9Ubb7whHx8fdezYUU899ZTn/8UA8Hrz5s1TZmamiouL1bp1a02cOFE2m00zZ84sWZDkbR599FEtW7ZMq1at0ooVK3TjjTdqxYoV6tevnwYOHGh0vHIVFBSU+5y/v38VJrEWBqnwCtnZ2erataskKTo6+rz/UzudTklSQECATp48qTFjxigoKEhnzpxRYWHhBd87JCRE1113nTIzM7V69Wo9+uijZb7uwIEDat++vSSpVq1aGj16dLnvmZiYqFdffVVvvvmmIiIizhu4Hjt2TE888YRSUlJ05ZVX6r333tOOHTsUFxcnSSoqKtKPP/7IIBUAAMCEhg8fru+++05du3bVr7/+qmeffdatE/5HjhzR2rVrVVBQoK5du2rEiBGaNm2a4uLi1L17d23atEkzZszQk08+qWPHjmnVqlXn9cVXXnmlJk+erO+//15jx47VqlWrdOrUqZKh5cMPP6xvv/22JOPIkSP1/PPPq0ePHoqNjdU333yjbdu2SZIuv/xyTZkyRV9++aUWLVpU7iD1888/V9u2bfX000/r66+/Lrm8VZKaNGmi5cuXq6CgQMOHD9dLL72k/Px8zZkzR6tWrVJgYKCefvppffbZZ+rcuXMl/5sAYDYZGRlKS0uTJE2bNk2TJk1ScnJyye/83uztt9/WsmXLFBwcrMLCQg0dOtSrB6l9+/bViRMnVKtWLTmdTtlstpL/5f4uF489UuEVIiMjtWXLFknSnj17VFBQIH9/fx07dkyStHPnTkm/Fd2ffvpJs2bN0pgxY3Tu3LlyC+7vRUKSBg4cqPT0dJ04caLcOwJGRETo22+/lSTl5ubq4YcfLjdvWlqaRo0apTfffFPSbze2+t3p06f12GOPKTExUZGRkSXvfcMNN2j58uVaunSp7rjjDjVp0sTtPx8AAAB4p/DwcEmlT/gnJSWVecK/ZcuW8vX1VVBQkGrWrCnpt8tEX331VcXFxWnevHk6ceKEJKlx48Zlrhj6/S7XLVq00LFjx+Tj4yM/P7+SlaE///yzioqKSn3PgQMH1KFDB0m/LVq4++67Jf120xdJql+/vs6dO1fuz9i/f3+FhYXpr3/9q/75z3+qRo0apZ4vKirSk08+qbvvvlvdu3fXoUOHdPLkSf39739XXFyc9u3bp0OHDrn3BwrA0v74+/vvK+UXLVrk1XeSz8vL06lTp9SgQQP5+v62HtHX19floi6jpaamqkmTJlq9erU+/vhjrV+/vuR/cfFYkQqvMGDAAI0fP14PPPCArrjiCknS0KFDNWnSJF1xxRW67LLLJElt27bV/Pnz9cADD8hms6lJkyY6evRome/ZoUMHjR07VkuWLFG7du108OBBPfDAA5Kk119/XU2bNi11c6jbbrtNmzZtUmxsrIqLi/XYY4+Vm7dt27Z65JFHFBwcrKCgIN1yyy0lQ9XZs2fr6NGjmjt3rhwOh/z8/LR48WJ99dVXGjx4sM6cOaOePXsqJCSkUv7sAAAAULV8fHzkcDhK/ln6fyf8X3zxRZ08eVIfffTReSf8yxoURERE6KGHHlJ0dLT27dunzZs3l3rfP9u2bZv69u2rPXv26IorrtDu3bu1bt06paen6+zZs+rXr5+cTmepjM2bN9e3336rqKgobd68WZ9++qlq1qzp9uBi/fr16tixo0aOHKl3331XixYt0r333ivpt6HI+PHj1aFDh5JjjRs3VqNGjbRkyRL5+flp9erV7KcKQJLUp08f9e/fX4sWLVLt2rWVkpKiESNGKCsry+ho5YqOjtajjz6qgwcP6vXXX1dcXJxiY2NLap63qlu3ruLj47Vz507ddNNNRsexDJvTDOunUa3k5+frjjvu0Mcff1xp7+lwOBQbG6vFixczwAQAAMAl+X3P+y5duqhx48aKjY3VsWPHNHz48JIB5blz55SYmKjPP/+8ZI/UlStXavbs2ZKkzp0767PPPtPhw4eVnJys/Px8nTt3TuPHj1eDBg00ZswYvfXWW5Kkhx56SAsWLNCrr76qnTt3Ki8vTwUFBUpOTlazZs30yCOPlOyF5+/vr/79+6t3794lGR9++GGNGzdOeXl5kqR//OMfWrNmjerXr6/Y2Fjt27dPycnJWr58eZk/76FDh5SQkCA/Pz85HA4lJibKbrdr5cqV+stf/qJx48apXbt2Ki4uliRNnDhRO3bsUGpqqoqLi3XllVcqJSVFgYGBnv5XA8AEDh8+rCuuuKLU6vZ169aVe48Sb+F0OnX27FkFBgZq//79at68udGRYAAGqfA6lT1IPXz4sEaOHKl+/fqdd8e6CykoKCjz8v7w8HBNnjy5UrIBAAAAAFBd5Ofna+XKldq0aZNyc3MVGhqqTp06aciQISVbnngbM2aWfsudmpqqL774wlS5vR2DVAAAAACAkpOTtW/fvvOOL1y4kF+6AVSKMWPGKCoqSt26dVNwcLDy8vKUkZGhrKwszZs3z+h4ZTJjZsm8ub0de6QCAAAAAJScnGx0BAAWd/ToUc2aNavUsaioKA0ePNigRK6ZMbNk3tzeruwdzAEAAAAAAIBKFBAQoDVr1ujEiRMqKCjQyZMn9a9//UtBQUFGRyuXGTNL5s3t7bi0HwAAAAAAAB6Xk5OjefPm6ZtvvlFeXp6Cg4MVHR2tESNGqF69ekbHK5MZM0vmze3tGKQCAAAAAACgShQWFmr37t2y2+0KCwtTixYt5O/vb3SsCzJjZsm8ub0Ze6QCAAAAAADA4z799FPNnDlTV111lYKDg2W327V//36NGTNGPXv2NDpemcyYWTJvbm/HIBUAAAAAAAAet2DBAqWmpiokJKTkWG5uroYNG+a1wz0zZpbMm9vbcbMpAAAAAAAAeFxhYaFq1qxZ6lhAQIBsNptBiVwzY2bJvLm9HStSAQAAAAAA4HExMTG677771LFjR4WGhsput2vLli2Ki4szOlq5zJhZMm9ub8fNpgAAAAAAAFAljh8/rm3btikvL08hISG69tprVb9+faNjXZAZM0v/L7fdbldISIjatm1ritzejEEqAAAAAAAAPC4/P18rV67U559/rtzcXIWFhalTp04aMmTIeZehewszZr6QTz75RLfeeqvRMUyLQSoAAAAAAAA8bsyYMYqKilK3bt0UHBysvLw8ZWRkKCsrS/PmzTM6XpnMmPlC3njjDQ0bNszoGKbFHqkAAAAAAADwuKNHj2rWrFmljkVFRWnw4MEGJXLNjJn/zOFwyMfnt/vNM0S9NAxSAQAAAAAA4HEBAQFas2aNunbtWnIDpIyMDAUFBRkdrVxmzCxJhw8fVkpKirZv3y5fX185HA61bNlSiYmJCg8PNzqeaXFpPwAAAAAAADwuJydH8+bN0zfffKO8vDwFBwcrOjpaI0aMUL169YyOVyYzZpakoUOHKj4+Xu3atSs5tnXrVk2dOlUrV640MJm5MUgFAAAAAAAALGTQoEFlDkzLOw73+BgdAAAAAAAAANXX448/bnSECvP2zJGRkUpMTNR7772njRs36oMPPlBiYqIiIyONjmZqrEgFAAAAAACAYX799VfVqlXL6BgV4u2ZnU6n1q1bpy1btshutyskJETR0dHq1auXbDab0fFMi0EqAAAAAAAAqsTu3bv1+eefKzc3V2FhYerYsaPatm1rdKwLMmNmeAaDVAAAAAAAAHjc3LlztW3bNnXp0kXBwcHKy8tTZmamWrdurdGjRxsdr0xmzAzPYZAKAAAAAAAAjxs8eLBWrFhR6pjT6dTAgQOVnp5uUKoLM2NmeA43mwIAAAAAAIDHFRUVKTs7u9Sx7Oxs+fh473jKjJkvJDMzU19++aXRMUzL1+gAAAAAAAAAsL7x48dr5MiRKiwsVEhIiOx2u/z9/TVp0iSjo5XLjJkvZOfOnWrRooV+/vlnNWzY0Og4psOl/QAAAAAAAKgydrtdeXl5Cg4OVkhIiNFx3GLGzKh85lyHDAAAAAAAAFMKCQnR5ZdfbqqBpNkyb926Vf369VNsbKy+/vrrkuOPPfaYganMj0v7AQAAAAAAAAuZOnWqZs6cqaKiIo0dO1bx8fHq0qWLTp8+bXQ0U2OQCgAAAAAAAFiIn5+fwsPDJUmvvfaaHnroITVo0EA2m83gZObGpf0AAAAAAAAwzJgxYzRt2jSdOHHC6Chu8/bMwcHBWrZsmQoKCtSgQQPNmDFDo0eP1o8//mh0NFPjZlMAAAAAAAAwzPHjx1WnTh05nU75+prj4mlvz2y32/X666/rwQcfLNnXde/evZo1a5bmz59vcDrzYpAKAAAAAAAAj5s1a5ZGjBihwMBAo6NUyKlTp+Tn56egoCCtWbNGNptN99xzj9dfJv/dd98pICBAzZo1KzmWlZWldu3aGZjK3BikAgAAAAAAwOO6dOmihg0b6qmnntKNN95odBy3LFu2TCtWrJDT6dT111+vgoICBQYGysfHR0lJSUbHK9e8efOUmZmpoqIitW7dWsnJybLZbBo6dKiWLVtmdDzTYo9UAAAAAAAAeFx4eLhmz56tpUuXaujQoXr33Xf166+/Gh3rgt5991299957WrFihT755BNNmzZNycnJ2rNnj9HRLigjI0OpqalKT09XUFCQJk2aJEliPeWlYZAKAAAAAAAAj7PZbGrSpIleeeUVjR8/Xrt27dKDDz6o7t27Gx2tXA6HQ2fPnlW9evU0ceJESVJBQYEKCwsNTnZhfxyYJiQkKDc3V4sWLfL67Qi8HYNUAAAAAAAAeNwfh3uRkZF6+umntXr1am3YsMHAVBf2t7/9Tf369ZPD4VCvXr0kSQ8//LAGDBhgcLIL69Onj/r3769Tp05JklJSUrRp0yZlZWUZG8zk2CMVAAAAAAAAVcrpdJpmdaTD4ZCPz/9bi2i32xUSEmJgIvccPnxYjRo1kq+vb8mxdevWqWfPngamMjcGqQAAAAAAAPC4Q4cOadKkSdq/f7+OHj2qNm3aqEmTJnrmmWfUoEEDo+OV6dtvv9WBAwfUpUsXTZs2TTt27NDVV1+tsWPH6oorrjA6HqoYg1QAAAAAAAB43MMPP6xnn31W4eHh2rp1q9avX6/evXvr5Zdf1muvvWZ0vDLFxMRo8uTJeuWVV3TLLbeoR48e+uqrr7R06VItX77c6HjlSktLK/e5mJiYKkxiLeyRCgAAAAAAAI+z2+0KDw+XJLVv317ffPONrrnmGp0+fdrgZOXz8/NTZGSkcnNzde+99yosLEw9e/b0+ptN7d+/X4sXL9axY8fOe+Di+bp+CQAAAAAAAHBpGjdurKSkJHXr1k2ffvqprrnmGn366acKDAw0Olq5rrzySi1evFjdu3fX3Llz1aNHD23YsMFrtyL4XWJiovbv369u3bqpbdu2RsexDC7tBwAAAAAAgMcVFBQoPT1de/fuVatWrXT//ffr22+/VbNmzVSnTh2j45Xp7NmzWrx4sTIzM5WTk6M6deooOjpajzzyiGrVqmV0vAs6efKkzpw5o8aNGxsdxTIYpAIAAAAAAMDjZs2apREjRnj1ClRXdu/eraioKKNjuC0nJ0d2u12hoaGqXbu20XFMj0EqAAAAAAAAPK5Lly5q2LChnn76ad1www1Gx3FLZmZmqa+nT5+up59+WtJvP4+32rZtmyZPniyHw6GgoCDl5eXJ6XQqKSlJ0dHRRsczLQapAAAAAAAA8Li4uDj94x//0D/+8Q/l5eVp4MCB6tq1q1dfIn/vvffKx8dHkZGRkqSNGzeqa9eukqSUlBQjo11QbGysZs2apUaNGpUcO3LkiJ544gmlp6cbmMzcuNkUAAAAAAAAPM5ms6lJkyZ65ZVXtGfPHq1du1ZLlizRiRMntGHDBqPjlSk1NVWTJ09WdHS0BgwYoLi4OK8eoP6uqKio1BBVkho1aiSbzWZQImtgkAoAAAAAAACP++NF0ZGRkSWXyHuzwMBApaSkaMmSJUpKSlJxcbHRkdzSvXt3DRs2TJ07d1ZoaKjsdrs+++wzdevWzehopsal/QAAAAAAAKhSDodDPj4+RseokE2bNmnVqlWaMWOG0VHcsnPnTm3ZskV5eXkKCQlRhw4d1KZNG6NjmRorUgEAAAAAAOBxhw8fVkpKirZv3y5fX185HA61bNlSiYmJCg8PNzpeudatW6dNmzYpNzdXtWrV0vvvv6/bb7/d6y+TP3LkiA4cOFCSu169emrdurXX5/ZmrEgFAAAAAACAxw0dOlTx8fFq165dybGtW7dq6tSpWrlypYHJyjdp0iQ5HA5169ZNwcHBysvLU0ZGhoqKijRlyhSj45XLrLm9HStSAQAAAAAA4HEFBQWlhqiS1L59e2PCuOn777/Xm2++WerYbbfdpkGDBhmUyD1mze3tGKQCAAAAAADA4yIjI5WYmKiuXbsqNDRUeXl52rBhgyIjI42OVi6Hw6Gvv/5anTp1Kjm2efNm+fn5GZjKNbPm9nZc2g8AAAAAAACPczqdWrdu3Xk3QOrVq5fX7tt56NAhpaSkaMeOHZIkHx8ftWrVSgkJCbrqqquMDXcBZs3t7RikAgAAAAAAoErs3r1bn332WckNkDp27Ki2bdsaHculkydPym63KzQ0VHXq1DE6DgzCIBUAAAAAAAAeN3fuXG3btk1dunQpuQFSZmamWrdurdGjRxsdr0zbtm3T5MmT5XA4SjI7HA5NnDhRHTp0MDpehU2ePFlJSUlGxzAtBqkAAAAAAADwuMGDB2vFihWljjmdTg0cOFDp6ekGpbqw2NhYzZo1S40aNSo5duTIET3xxBNem/lC9u3bp+bNmxsdw7S42RQAAAAAAAA8rqioSNnZ2WrcuHHJsezsbPn4+BiY6sKKiopKDVElqVGjRl67p+sfnTx5Ups3b1Zubq7CwsLUvn17hqiXiEEqAAAAAAAAPG7cuHEaOXKkCgsLFRISIrvdLn9/fyUnJxsdrVzdu3fXsGHD1LlzZ4WGhsput+uzzz5Tt27djI52Qenp6UpLS1PHjh0VHBys77//XgsWLNCAAQMUGxtrdDzT4tJ+AAAAAAAAVBm73a68vDyFhIQoODjY6Dgu7dy5U1u2bCnJ3KFDB7Vp08boWBc0aNAgLV++XH5+fiXHCgoKFBsbq1WrVhmYzNxYkQoAAAAAAACPO3z4sFJSUrRjxw7VqFFDDodDLVu2VGJiosLDw42OV64jR47owIEDys3NVa1atVSvXj21bt3aqy/vLyoqUn5+fqlB6rlz57w6sxmwIhUAAAAAAAAeN3ToUMXHx6tdu3Ylx7Zu3aqpU6dq5cqVBiYr36RJk+RwONStWzcFBwcrLy9PGRkZKioq0pQpU4yOV66PP/5YU6dOVbNmzUq2JDh48KASExN1yy23GB3PtFiRCgAAAAAAAI8rKCgoNUSVpPbt2xsTxk3ff/+93nzzzVLHbrvtNg0aNMigRO7p0aOHunXrpn379slutyskJETNmzeXry+jwEvBnx4AAAAAAAA8LjIyUomJieratatCQ0OVl5enDRs2KDIy0uho5XI4HPr666/VqVOnkmObN28udcm8N0pKSlJcXFyZf7a7du1SamqqJk+ebEAyc+PSfgAAAAAAAHic0+nUunXrtGXLlpJVktHR0erVq5fX7t156NChkn1dJcnHx0etWrVSQkKCrrrqKmPDXcCpU6f04osvavv27QoPD1f9+vV1+vRp7dq1S23bttXjjz+uunXrGh3TdBikAgAAAAAAwDA///yzGjZsaHQMS7Lb7crKylJOTo7q1aundu3aKSgoyOhYpuVjdAAAAAAAAABUX7NnzzY6QoWZ5bL4kJAQde7cWXfddZduuukmhqiXiBWpAAAAAAAAQAXs27dPzZs3NzoGqhiDVAAAAAAAAHhcfn6+UlNT9cUXXyg3N1ehoaHq1KmThgwZopo1axodr1wnT57U5s2blZubq7CwMLVv316XXXaZ0bFgAAapAAAAAAAA8LgxY8YoKipK3bp1U3BwsPLy8pSRkaGsrCzNmzfP6HhlSk9PV1pamjp27FiSefPmzRowYIBiY2ONjocq5mt0AAAAAAAAAFjf0aNHNWvWrFLHoqKiNHjwYIMSubZq1SqlpqbKz8+v5FhBQYFiY2MZpFZD3GwKAAAAAAAAHhcQEKA1a9boxIkTKigo0MmTJ7VmzRqvvgFSUVGR8vPzSx07d+6cbDabQYlgJC7tBwAAAAAAgMfl5ORo3rx5+uabb5SXl6fg4GBFR0drxIgRqlevntHxyvTxxx9r6tSpatasmUJDQ2W323Xw4EElJibqlltuMToeqhiDVAAAAAAAAFS5DRs2qHv37kbHcKmoqEj79u2T3W5XSEiImjdvLl9fdsusjri0HwAAAAAAAFVu8eLFRkdwKSkpSQcOHFBkZKQ6duyoyMjIkiHqrl27lJSUZHBCVCXG5wAAAAAAAKhyZrhIesyYMXrxxRe1fft2hYeHq379+jp9+rR27dqltm3bavTo0UZHRBXi0n4AAAAAAABUuS1btqhjx45Gx3CL3W5XVlaWcnJyVK9ePbVr186rb5IFz2CQCgAAAAAAAI9LSkrSkCFD1LJly/Oe27Vrl1JTUzV58mQDkgHuYZAKAAAAAAAAjzt16lSZl8nv3r1b1157rR5//HHVrVvX6JhAuRikAgAAAAAAoMpwmTzMikEqAAAAAAAAALjgY3QAAAAAAAAAAPB2DFIBAAAAAAAAwAUGqQAAAAAAADBMfn6+0tPT3Xrt6tWrtX79+kr53Dlz5ig1NbVS3uuPjh07puTk5Ep/3wv56KOP9Msvv1TpZ1ZHDFIBAAAAAABgmGPHjrk9SO3Xr59uu+02Dye6NA0aNKjyQeqyZctkt9ur9DOrI1+jAwAAAAAAAKD6WrBggfbu3auoqCjdfPPNOnPmjKZMmaI1a9Zo+/btOnXqlKKiopSSkqI5c+aofv36ioiI0MKFC+Xn56fs7Gz16dNHI0aM0E8//aQJEyYoPz9fAQEBeu6551RcXKwRI0aodu3a6tatm/72t7+dl2HmzJn6+uuv5XA4NGzYMN1xxx366quvNHfuXDmdTuXl5WnmzJny8/Mr9V4ZGRmKiorS999/L7vdrpdeeklOp1NjxozRW2+9pb59++r666/Xnj17ZLPZNH/+fIWEhGjSpEnavn276tevrx9//FGvvPKKGjduXOafz6233qqIiAg1b95c/fv319SpU1VcXKycnBwlJyfr9OnT2rVrlxISErRixQqlpaXp3Xfflc1mU58+fTR06FBP/yusNhikAgAAAAAAwDDDhw/Xd999p65du+rXX3/Vs88+K7vdrrCwML3++utyOBy68847z7t0/ciRI1q7dq0KCgrUtWtXjRgxQtOmTVNcXJy6d++uTZs2acaMGXryySd17NgxrVq1Sv7+/ud9/oYNG5Sdna3U1FTl5+dr4MCB6ty5s77//ntNnz5dl19+uRYsWKAPPvhAffv2LfVeGRkZatu2rcaPH6/Zs2frP//5j/r06VPy3nl5ebrzzjs1YcIExcfHKyMjQwEBATp16pTefvttnTx5Un/5y18u+Ofz008/afXq1apTp47ee+89JSQkKDIyUu+8845Wr16t559/Xq1atVJycrIOHTqk9957TytWrJAkPfjgg+rSpYsiIiIq4d8UGKQCAAAAAADAK4SHh0uSAgICdPLkSY0ZM0ZBQUE6c+aMCgsLS722ZcuW8vX1la+vr2rWrClJ+u677/Tqq69q0aJFcjqd8vX9bfTVuHHjMoeov3/Pjh07FBcXJ0kqKirSjz/+qMsvv1xTpkxRUFCQfvnlF0VHR5f5Xq1bt5YkNWzYUMePHz/v/X9/vlGjRsrPz9ePP/6o9u3bS5Lq1q3rcshZp04d1alTR5J02WWXaf78+apZs6by8vIUEhJy3s9y5MgRDRs2TJL066+/6uDBgwxSKwmDVAAAAAAAABjGx8dHDoej5J8lKSMjQz/99JNefPFFnTx5Uh999JGcTmep77PZbOe9V0REhB566CFFR0dr37592rx5c6n3LUtERIRuuOEGPffcc3I4HJo/f76aNGmihx56SB999JFCQkKUkJBQ8vkXeq+y/DlnixYt9O9//1vSb4POH3744YLf/8fPmzJlimbMmKHmzZvr5Zdf1o8//ljyGU6nUxEREbr66qu1aNEi2Ww2vfHGG4qMjKxQXpSPQSoAAAAAAAAMU69ePRUWFurcuXMlx9q2bav58+frgQcekM1mU5MmTXT06FGX75WQkKDk5GTl5+fr3LlzGj9+/Hmveeihh7RgwYKSr3v06KGvvvpKgwcP1pkzZ9SzZ0+FhITo7rvv1gMPPKDAwEDVr1/frc93xy233KKMjAwNGjRI9evXV82aNeXn5+fW995999164oknFBYWpoYNGyonJ0eS1KFDB40dO1ZLlizRTTfdpNjYWBUUFKht27a6/PLLKyU3JJvzz+N8AAAAAAAAAB6xb98+7d69W3feeadycnJ011136ZNPPil36wF4DwapAAAAAAAAQBU5c+aM4uPjdeLECRUXF2vIkCEKCwvTG2+8cd5rhw4dql69elV9SJSJQSoAAAAAAAAAuFCx3XEBAAAAAAAAoBpikAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALjBIBQAAAAAAAAAXGKQCAAAAAAAAgAsMUgEAAAAAAADABQapAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC44Gt0AADm4/i5pcvX+DT8rgqSAIB1uVNrJeotAAAAvJ9VelsGqYCH/cV/sNERKuTDghUuX+OQw+VrWO4OoCxmq4me5KreulNrJeotAACoOmbr5dz5/RZVwyq9LYNUABVW6Cx2+RqKCwBcGndqrUS9BQAAgPezSm/r7fkAeCF3zyQBAC4etRYAAABWYZXelkEqgAordjqNjgAAlketBQAAgFVYpbdlkAqgwgotciYJALwZtRYAAABWYZXelkEqgApzyBpnkgDAm1FrAQAAYBVW6W0ZpAKoMKssyQcAb0atBQAAgFVYpbdlkAqgwgotciYJALwZtRYAAABWYZXelkEqgAortkb9AwCvRq0FAACAVVilt2WQCqDCCmUzOgIAWB61FgAAAFZhld6WQSqACnNY5EwSAHgzai0AAACswiq9LYNUABVWbJEzSQDgzai1AAAAsAqr9LY+RgcAYD6FTh+XD3dkZWUpLi7uvONr1qxR3759NXjwYKWnp1d2fAAwBXdqLfUWAAAAZmCV3pYVqQAqrDLOJC1cuFBr165VYGBgqeMnT57Uyy+/rNWrVyssLEzDhg3TTTfdpMaNG1/yZwKAmVTWWXvqLQAAAIxmld6WFakAKqxYPi4frjRt2lRz5sw573h2drYiIyNVu3Zt+fj46Nprr1VWVpYnfgwA8Gru1FrqLQAAAMzAKr0tK1IBVJg7y+3T0tKUlpZW8nVMTIxiYmJKvu7du7eys7PP+75mzZpp7969On78uIKDg7Vp0yZdddVVlZIbAMzE3UubqLcAAADwdlbpbRmkAqiwYjcK4J+Lnbtq1aqlxMREjRo1SrVr11abNm1Up06di4kJAKbmTq2VqLcAAADwflbpbbm0H0CFOeTj8nGxioqKtHPnTq1YsUIvvfSS9u/fr+jo6EpMDwDm4E6tpd4CAADADKzS27IiFUCFFThrVPp7vvPOOzpz5kzJmaf77rtPAQEBevDBB1W3bt1K/zwA8HaeqLUS9RYAAABVzyq9rc3pdDor/V0BlPiL/2CjI1TIhwUrXL7mvwdau3xN7/CdlREHgMWYrSZ6kqt6606tlai3AACg6pitl3Pn91tUDav0tqxIBVBhBU5KBwB4GrUWAAAAVmGV3tYaPwWAKnUp+5YAANxDrQUAAIBVWKW3ZZAKoMKKnTajIwCA5VFrAQAAYBVW6W0ZpAKosEKLLMkHAG9GrQUAAIBVWKW3tcZPAaBKFVtkST4AeDNqLQAAAKzCKr0tg1QAFWaVJfkA4M2otQAAALAKq/S2DFIBVJhVluQDgDej1gIAAMAqrNLbWuOnAFClHLLGmSQA8GbUWgAAAFiFVXpba2xQUI28//77kqQzZ85o2rRpevDBBzVjxgzl5eUZnAzVSYHT1+UDMDvqLYzmTq2l3gIAAHfQ28JoVultGaSaTGpqqiRpypQpqlWrlp599lk1bNhQSUlJBidDdeJw2lw+ALOj3sJo7tRa6i0AAHAHvS2MZpXe1vtHvSjTwYMHNWXKFElS8+bN9eGHHxqcCNWJVe62B7iDegujUGsBAEBlo7eFUazS21rjp6hGfvjhB73xxhvy9fXVzp07JUnbtm1TYWGhwclQnRQ6a7h8AGZHvYXR3Km11FsAAOAOelsYzSq9LYNUk3n11VcVHBysq666Snv27NGJEyf0/PPPsxwfVcrh9HH5AMyOegujuVNrqbcAAMAd9LYwmlV6Wy7tN5maNWuqU6dO6tSpk5xOp0aMGKFp06YZHQvVTLFF7rYHXAj1Fkaj1gIAgMpCbwujWaW3ZZBqMg8++KBq1qypyy67TE6nUwcOHNDEiRMlScuWLTM4HaqLQgelA9ZHvYXRqLUAAKCy0NvCaFbpba3xU1Qjq1at0sSJExUbG6vOnTsrLi6Ooocq57DImSTgQqi3MBq1FgAAVBZ6WxjNKr0tg1STqVevnl588UVNmzZN3377rdFxUE0VOrx/A2jgUlFvYTRqLQAAqCz0tjCaVXpb79/FFefx9fXV+PHjS5bkA1WtWD4uH4AVUG9hJHdqLfUWAAC4i94WRrJKb8uKVBPr16+f+vXrZ3QMVEMOpzWW5APuot7CCNRaAADgCfS2MIJVelsGqQAqrNBpjSX5AODNqLUAAACwCqv0tt6/ZhaA13E4bS4f7sjKylJcXNx5x9euXav77rtP999/v1asWFHZ8QHAFNyptdRbAAAAmIFVeltWpAKoMIfz0s/BLFy4UGvXrlVgYOB5z73wwgt69913FRQUpDvvvFN33nmnatWqdcmfCQBmUhm1VqLeAgAAwHhW6W1ZkQqgwgqdPi4frjRt2lRz5swp87nIyEjl5uaqoKBATqdTNps19lIBgIpwp9ZSbwEAAGAGVultWZEKoMLcOZOUlpamtLS0kq9jYmIUExNT8nXv3r2VnZ1d5ve2aNFC999/vwIDA9WrVy+FhYVdemgAMBl3z9pTbwEAAODtrNLbMkgFUGEOuT6r8+di567du3fr008/1fr16xUUFKSnn35a77//vu64446LiQoApuVOrZWotwAAAPB+VultGaQCqLBCh+futhcaGqqaNWsqICBANWrUUN26dXX69GmPfR4AeCtP1lqJegsAAICqY5XelkEqgApz9056FfHOO+/ozJkzJWefBg8eLD8/PzVt2lT33XdfpX8eAHg7T9RaiXoLAACAqmeV3tbmdDqdlf6uAEr8xX+w0REq5MOCFS5fE/vF312+JvXG1yojDgCLMVtN9CRX9dadWitRbwEAQNUxWy/nzu+3qBpW6W1ZkQqgwtzdJBoAcPGotQAAALAKq/S2DFIBVJinluQDAP4fai0AAACswiq9LYNUABVWZJEzSQDgzai1AAAAsAqr9LYMUgFUmFXOJAGAN6PWAgAAwCqs0tsySAVQYVYpgADgzai1AAAAsAqr9LYMUgFUmFWW5AOAN6PWAgAAwCqs0tsySAVQYVY5kwQA3oxaCwAAAKuwSm/LIBVAhRU5rHEmCQC8GbUWAAAAVmGV3pZBqhfZtGmTDh06pHbt2ik8PFwBAQFGRwLKZJUzSai+qLcwA2otAABwB70tzMAqvS2DVC8xa9Ys/fzzz9q3b5/8/f312muvadasWUbHAsrktEgBRPVEvYVZUGsBAIAr9LYwC6v0ttZYV2sBW7Zs0QsvvKCgoCDdd999ys7ONjoSUK4ip4/LB+CtqLcwC3dqLfUWAIDqjd4WZmGV3pYVqV6iuLhY+fn5stlsKi4ulo+P9//Hg+rLKmeSUD1Rb2EW1FoAAOAKvS3Mwiq9LYNUL/F///d/6tevn06ePKkBAwbowQcfNDoSUC6r7G2C6ol6C7Og1gIAAFfobWEWVultGaR6iR49eujmm2/WwYMH1bhxY+Xk5BgdCShXsUXutofqiXoLs6DWAgAAV+htYRZW6W0ZpHqJG2+8US+//LK6du0qSRo9erSWLVtmcCpUhg8LVhgdodI5nUYnAC4e9dZYVqyJnkKtBQAArlR1b0svh4tlld6WQaqXiIiI0BtvvKGcnBzdfffdcnr4vzDHzy09+v6Vzafhd0ZHwB8Um2ADaKA81FvjUMsrhloLAABcqere1ozM1o9btWe2Sm/LINVLBAcH65VXXtGYMWN0/Phx+fn5GR0JKJdV9jZB9US9hVlQawEAgCv0tjALq/S21hgHW4DT6ZS/v79eeukl7dmzR1u3bjU6ElAup9P1A/BW1FuYhTu1lnoLAED1Rm8Ls7BKb8uKVC+RkpIiSapRo4amTZumW2+91eBEQPkcFtkkGtUT9RZmQa0FAACu0NvCLKzS2zJINdj8+fP16KOPatasWbLZSi9zvv322w1KBVyYVZbko3qh3sJsqLUAAKA89LYwG6v0tgxSDdajRw9J0qBBgwxOArivspbbZ2VlacaMGVq+fHnJsWPHjmnMmDElX+/atUvx8fGKjY2tnA9FtUW9hdlU5qVN1FsAAKyF3hZmY5XelkGqwaKioiRJzZo1U25urnx8fLRo0SLFxcUZnAwoX2UsyV+4cKHWrl2rwMDAUscbNGhQUgz/97//afbs2Ro4cOAlfx5AvYXZVNblT9RbAACsh94WZmOV3tYaGxRYQHx8vI4fP64XX3xRnTt31j/+8Q+jIwHlcrrxcKVp06aaM2dO+Z/hdOq5555TcnKyatSocemhgf8f9RZm4U6tpd4CAFC90dvCLKzS2zJI9RI2m03XXXedTp8+rTvvvFM+PvyrgfdyOm0uH2lpaerXr1/JIy0trdR79O7dW76+5S+K//jjj9WiRQtFRER4+sdBNUO9hVm4U2uptwAAVG/0tjALq/S2XNrvJYqKijR9+nR16tRJX3zxhQoLC42OBJTL6XC9SXRMTIxiYmIu+jPWrl2roUOHXvT3A+Wh3sIs3Km1EvUWAIDqjN4WZmGV3pZTFV4iJSVFTZo00d///nedPHlS06ZNkyQVFBQYnAw4n9Pp+nGptm/frujo6Et/I+BPqLcwC3dqLfUWAIDqjd4WZmGV3pYVqV7iqquu0lVXXSVJ6tOnT8nxv/71r1q2bJlBqYCyOStpk+g/euedd3TmzBnFxMTo5MmTCgkJkc3m3hkroCKotzALT9RaiXoLAICV0NvCLKzS2zJI9XLOyhjHA5Wssv6zbNy4sd566y1JUt++fUuO161bV//+978r50MAN1Fv4W0q8z9J6i0AANULvS28jVV6WwapXo4VIvBK/J0MC6LewutQawEAwEWit4XXsUhvyyAVQIW5u0k0AODiUWsBAABgFVbpbRmkejmW48MbOZ3WKIDAH1Fv4W2otQAA4GLR28LbWKW3ZZDq5a6++mqjIwDn4+9kWBD1Fl6HWgsAAC4SvS28jkV6WwapXuLTTz/VihUrdO7cuZJjy5Yt08SJEw1MBZTDImeSUD1Rb2Ea1FoAAOACvS1MwyK9LYNUL/HSSy8pMTFR9evXNzoK4JpFziSheqLewjSotQAAwAV6W5iGRXpbBqleolatWrr++uuNjgG4xSqbRKN6ot7CLKi1AADAFXpbmIVVelsGqQZLS0uTJPn5+WnChAlq06aNbLbf/uOKiYkxMhpQPoucSUL1Qr2F6VBrAQBAOehtYToW6W0ZpBrs2LFjkqR27dpJko4fP25kHMA9FtnbBNUL9RamQ60FAADloLeF6Vikt2WQarCRI0dKkg4ePKhvv/1Wd911l2bMmKFBgwYZnAwon81hdAKg4qi3MBtqLQAAKA+9LczGKr2tj9EB8JuEhAQ1btxYktS9e3eNHz/e4ETABThtrh9V6JdfftHevXt14MABjRs3Trt27arSz4e5UG9hGu7U2iqst9RaAAC8D70tTMMivS2DVC/Svn17SdJ1110nh8Mio3pYk9ONRxWKj4/X8ePHNXv2bHXu3Fn/+Mc/qjYATId6C1Nwp9ZWYb2l1gIA4J3obWEKFultGaR6ibCwMKWlpWnPnj1KT09XcHCw0ZGA8jnceFQhm82m6667TqdPn9add94pHx9KG8pHvYVpuFNrq7DeUmsBAPA+9LYwDYv0tnTAXmLq1Knau3evpk+frn379iklJcXoSED5vGg5viQVFRVp+vTp6tSpk7744gsVFhZW6efDXKi3MA0vu/yJWgsAgPeht4VpWKS35WZTXmLlypWl9jKZOXOm4uPjy3zt119/rU6dOsnhcCg1NVW7du1SmzZtNHDgQNWoUaOqIqMa87ZNolNSUvTZZ59pwIABWrdunaZNm2Z0JHgxd+sttRZGo9YCAABX6G1hFlbpbVmRarD09HTFxMRoyZIlGjRokAYNGqSBAwcqMzOz3O95+eWXJUnTp0/Xnj171KtXLx06dEjPP/98VcUGvMpll12m2267TadPn9aBAwe43BRlqmi9pdYCpVFrAQDwHvS2wKW52N6WFakGu+eee3TTTTfp1Vdf1fDhwyVJPj4+qlevnsvv3bZtm/75z39K+u3ufHFxcR7NCvzOVsU3k3Ll8ccfV2xsrP773//q6quvVlJSkhYvXmx0LHiZi6231FoYhVoLAADKQ28Ls7FKb8tSAoP5+/urcePGSkpK0tGjR3XkyBEdPnxYH374Ybnf89NPP+mjjz5SaGiosrOzJUm//PKLzp07V1WxUd05bK4fVejcuXPq0aOHfv75Z/39739XcXFxlX4+zKGi9ZZaC8O5U2ursN5SawEA8B70tjAdi/S2rEj1EqNGjVJhYaGOHj2q4uJiXXbZZbrrrrvKfG1CQoK2b9+u4uJirVu3Tvfff78GDRqkKVOmVHFqVFtediapsLBQS5cuVZs2bbR3716dPXvW6EjwYu7WW2otDEetBQAALtDbwjQs0tuyItVL5OTkaPHixWrbtq1Wr16t/Pz8cl8bHx+vK6+8UgsXLtSwYcMUGhqqTz75RDfffHMVJkZ1ZnO6flSlhIQEHT16VI8++qi++OKLUputA3/mbr2l1sJo7tTaqqy31FoAALwPvS3Mwiq9LYNUL1GzZk1J0tmzZ1WzZk3ZbOUvZ46KitKuXbs0dOhQbd68uaoiAv+Pw42HG7Kyssrck2fbtm0aPHiwYmNj9fjjj1/wxIIkRUdH6/rrr1daWpoaNmyotm3bVuSnQTXjbr2l1sJw7tTaKqy31FoAALwPvS1MwyK9LZf2e4m//OUvmjt3rqKiojRw4EAFBQWV+9qAgAAlJSXp22+/1WuvvabJkyfrxhtvVJMmTTR06NAqTI3qqjLOEi1cuFBr165VYGBgqeNOp1MTJkzQyy+/rGbNmik9PV0//vijIiIiyn2vmTNn6uDBg4qOjtaaNWv09ddf65lnnrn0kLAkd+sttRZGq6wz8pVVb6m1AAB4H3pbmIVVelsGqV7igQceKPnn7t27q1mzZuW+1un87b++a6+9VnPmzFFubq42b96sAwcOeDwnIElyXvoG0E2bNtWcOXM0duzYUscPHDig2rVr64033tD333+v7t27X3CIKkmbN2/WypUrJUn/93//p4EDB15yPliXu/WWWgvDVUKtlSqv3lJrAQDwPvS2MA2L9LYMUr3Et99+q4kTJ+r48eO64oorNHnyZLVs2bLM1/br16/U16GhoerRo0dVxAQkSTY3ltunpaUpLS2t5OuYmBjFxMSUfN27d++Su0X+UU5Ojv73v/8pKSlJTZs21fDhw3XNNdfopptuKvezioqK5HA45OPjI4fDccGtMQB36y21FkZzp9ZKVVdvqbUAAHgfeluYhVV6WwapXmLKlCl64YUXdPXVV2vPnj1KTk7WihUrynztfffdV8XpgD9xY0n+n4udu2rXrq1mzZqpefPmkqSuXbtq+/btFxyk3nnnnYqNjVW7du20bds29enTp8Kfi+rD3XpLrYXh3Lz8qarqLbUWAADvQ28L07BIb8sg1UsEBATo6quvliRFRkbKz8/P4ERA+dw9k3QxmjRpory8PB08eFDNmjXT119/rf79+5f52pkzZ5acNbr88sv1ySefqFWrVjp58qTnAsL0qLcwC0/WWsn9ekutBQDAe9Hbwiys0tsySDXY78uVfX19lZycrOuuu07btm1TSEiIwcmAC6ikTaL/6J133tGZM2cUExOjKVOmKD4+Xk6nUx06dNAtt9xS5vf8cb+T8PBw3XrrrZUfDJZBvYXpeKDWShWvt9RaAAC8D70tTMciva3N+fuOwzDE3Llzy31u5MiRHvtcx89l77/qrXwafmd0BPxB5HOzXb5mz4QnqyAJ4D7qrfGo5RXjTq2VqLcAAFRHRvW2ZmS2ftyqPbNVeltWpBqsvAJXVFRUxUmACuD0C0yIegvTodYCAIBy0NvCdCzS2/oYHQBle+SRR4yOAJTL5nT9AMyCegtv5U6tpd4CAIA/oreFt7JKb8sg1UssXrz4gl8DXsXpxgPwUtRbmIY7tZZ6CwBAtUZvC9OwSG/LINVLbNiwQcXFxUbHANxic7h+AN6KeguzcKfWUm8BAKje6G1hFlbpbdkj1Uvk5OSoa9euaty4sWw2m2w2m1auXGl0LKBsJjhLBJSHegvToNYCAAAX6G1hGhbpbRmkeokFCxYYHQFwmxnOEgHlod7CLKi1AADAFXpbmIVVelsGqV7C19dX06dP18mTJ3X77bcrMjJSV155pdGxgLJZ5EwSqifqLUyDWgsAAFygt4VpWKS3ZY9ULzFhwgTdf//9KiwsVKdOnTRlyhSjIwHlssKd9lB9UW9hFla5sykAAPAceluYhVV6WwapXuLcuXO66aabZLPZFBERoYCAAKMjAeVzuPEAvBT1FqbhTq2l3gIAUK3R28I0LNLbcmm/lwgICNDGjRvlcDi0detW+fv7Gx0JKJcZzhIB5aHewiyotQAAwBV6W5iFVXpbVqR6ieeee06rV69WTk6OlixZouTkZKMjAeVzuvEAvBT1FqbhTq2l3gIAUK3R28I0LNLbsiLVSzRs2FCzZ882OgbgFqvcbQ/VE/UWZkGtBQAArtDbwiys0tsySPUSCxYs0KJFi1SzZs2SY5mZmQYmAi7ABGeJgPJQb2Ea1FoAAOACvS1MwyK9LYNUL/Hee+9p48aNCgwMNDoK4JJV9jZB9US9hVlQawEAgCv0tjALq/S2DFK9ROPGjUudQQK8mVUKIKon6i3MgloLAABcobeFWVilt2WQ6iUKCwvVt29ftWzZUpJks9k0c+ZMg1MB5bBIAUT1RL2FaVBrAQCAC/S2MA2L9LYMUr3E3/72N6MjAG6zyibRqJ6otzALai0AAHCF3hZmYZXelkGqwT755BPdeuutOnDgwHnPXX/99QYkAtxgkTNJqF6otzAdai0AACgHvS1MxyK9LYNUg506dUqSdOzYMWODABVglb1NUL1Qb2E21FoAAFAeeluYjVV6WwapBrvvvvskSSNHjtTRo0dVVFQkp9Opo0ePGpwMKJ9VluSjeqHewmyotQAAoDz0tjAbq/S2DFK9xLhx47R161adPXtW586dU5MmTfTWW2957PN8Gn7nsfdGNWCRM0monqi3MA1qLQAAcKGqe1szoh/3EhbpbRmkeondu3frP//5j5KSkvTkk0/qiSeeMDqS1+nlM8DoCBX2kSPd6AieUUkFMCsrSzNmzNDy5ctLHX/jjTeUnp6uunXrSpImTZqkiIiIyvlQVHvUW2OZsZZ7isu/Iyqx2aTeAgBgTfS21mTGnrm69LYMUr1EnTp1ZLPZdObMmZJ/4YC3qowl+QsXLtTatWsVGBh43nPbt2/XtGnTdM0111z6BwF/Qr2FWVTW5U/UWwAArIveFmZhld7Wx2PvjApp06aNFi9erMsuu0xPPvmkzp07Z3QkoFw2p9PlIy0tTf369St5pKWllXqPpk2bas6cOWW+/44dO/Taa68pNjZWr776alX8SKhGqLcwC3dqLfUWAIDqjd4WZmGV3pYVqV7i3nvv1WWXXaaaNWsqIyNDbdu2NToSUC53ziTFxMQoJiam3Od79+6t7OzsMp+78847NXjwYIWEhGjkyJH65JNPdOutt15sXKAU6i3Mwt2z9tRbAACqL3pbmIVVeltWpHqJ8ePHKyQkRL6+vurRo4fq169vdCSgfE43Hhf71k6n/u///k9169aVv7+/unfvrp07d156ZuD/R72FabhTa6m3AABUa/S2MA2L9LasSPUSQUFB+sc//qHw8HD5+Pw2377QBB4wks2Dd9uz2+2666679N577ykoKEhffvml7r//fs99IKod6i3MwpO1VqLeAgBgBfS2MAur9LYMUr3E559/rg4dOujEiROSpPz8fIMTAeWrrE2i/+idd97RmTNnFBMToyeffFJDhw6Vv7+/brrpJnXv3r3yPxDVFvUWZuGJWitRbwEAsBJ6W5iFVXpbm9Pp9PBMGBeSnp6ut99+W3v37tXVV18tSXI4HCoqKtK//vUvg9N5l14+A4yOUGEfOdKNjuARN8TNcvmaL5ePqYIkgPuot97BjLXcU1z9HeFOrZWotwAAVEf0ttZmxp65uvS2rEg12D333KObbrpJr776qoYPHy5J8vHxUb169QxOBpTP00vyAU+g3sJsqLUAAKA89LYwG6v0tgxSDebv76/GjRvrueeeMzoK4DabwyIVENUK9RZmQ60FAADlobeF2Vilt2WQCqDirFH/AMC7UWsBAABgFRbpbRmkAqgwW7HRCQDA+qi1AAAAsAqr9LYMUgFUmFX2NgEAb0atBQAAgFVYpbdlkAqg4pwWqYAA4M2otQAAALAKi/S2DFIBVJjNYXQCALA+ai0AAACswiq9LYNUABVmlSX5AODNqLUAAACwCqv0tgxSAVScRZbkA4BXo9YCAADAKizS2zJIBVBhVlmSDwDejFoLAAAAq7BKb8sgFUCFWWVJPgB4M2otAAAArMIqvS2DVAAVV2yRCggA3oxaCwAAAKuwSG/LIBVAhVnlTBIAeDNqLQAAAKzCKr0tg1QAFWeRTaIBwKtRawEAAGAVFultGaQCqDCrbBINAN6MWgsAAACrsEpvyyAVQIXZLHImCQC8GbUWAAAAVmGV3pZBKoCKs8iZJADwatRaAAAAWIVFelsGqSaWk5Mju92u0NBQ1a5d2+g4qEZsDmucSQLcRb2FEai1AADAE+htYQSr9LYMUk1o27Ztmjx5shwOh4KCgpSXlyen06mkpCRFR0cbHQ/VgUWW5AOuUG9hKGotAACoRPS2MJRFelsGqSaUkpKiOXPmqFGjRiXHjhw5oieeeELp6ekGJkN1YbNG/QNcot7CSNRaAABQmehtYSSr9LY+RgdAxRUVFZUqfJLUqFEj2Ww2gxKhurEVO10+3JGVlaW4uLhyn58wYYJmzJhRWbGBCqPewkju1FrqLQAAcBe9LYxkld6WFakm1L17dw0bNkydO3dWaGio8vLylJmZqW7duhkdDdVFJSzJX7hwodauXavAwMAyn1+5cqW+++47XXfddZf8WcDFot7CUJV0+RP1FgAASPS2MJhFeltWpJrQyJEjNXbsWNWsWVM5OTny9/fXU089pZEjRxodDdWEzeF0+XCladOmmjNnTpnPffPNN8rKylJMTExlRwcqhHoLI7lTa6m3AADAXfS2MJJVeltWpJpQfHy8xo0bd8FlzIBHuXEmKS0tTWlpaSVfx8TElCpmvXv3VnZ29nnfd/ToUc2bN09z587V+++/Xzl5gYtEvYWh3DxrT70FAADuoLeFoSzS2zJINaH//e9/+utf/6ohQ4aoX79+7GeCqudw/ZI/Fzt3ffDBB8rJydHf//53HTt2TOfOnVNERIT69et3EUGBS0O9haHcqLUS9RYAALiH3haGskhvyyDVhK688krNmzdPL7/8su6++27ddddd6tatm5o0aaKQkBCj46EasDncrIAXYejQoRo6dKgkafXq1dq/fz+/1MMw1FsYyZO1VqLeAgBQ3dDbwkhW6W3ZI9WEbDabwsLC9Oyzz2rp0qUKDQ3V/PnzFRsba3Q0VBdOp+tHBb3zzjullu8D3oB6C0O5U2uptwAAwE30tjCURXpbVqSaUP369Uv+uW7duho8eLAGDx5sYCJUO5V0Iqlx48Z66623JEl9+/Y973lWRsFo1FsYqhJP2lNvAQAAvS0MZZHelkGqCc2aNcvoCKjmPL0kH/AW1FsYiVoLAAAqE70tjGSV3pZBqgnFxcWpsLCw1DGn0ymbzaaVK1calArVykUstwfMiHoLQ1FrAQBAJaK3haEs0tsySDWhp556Ss8++6zmzZunGjVqGB0H1VGxNQog4Ar1Foai1gIAgEpEbwtDWaS3ZZBqQu3atdM999yjPXv2qFevXkbHQTVks8iZJMAV6i2MRK0FAACVid4WRrJKb8sg1aT++te/Gh0B1ZlFCiDgDuotDEOtBQAAlYzeFoaxSG/LIBVAxRVbY5NoAPBq1FoAAABYhUV6WwapACrOImeSAMCrUWsBAABgFRbpbRmkAqg4ixRAAPBq1FoAAABYhUV6WwapACquuNjoBABgfdRaAAAAWIVFelsGqQAqziJnkgDAq1FrAQAAYBUW6W0ZpAKoOItsEg0AXo1aCwAAAKuwSG/LIBVAxVnkTBIAeDVqLQAAAKzCIr0tg1QAFWeRAggAXo1aCwAAAKuwSG/LIBVAxVlkk2gA8GrUWgAAAFiFRXpbBqkAKs4iZ5IAwKtRawEAAGAVFultGaQCqDiHNQogAHg1ai0AAACswiK9LYNUABXmtMiSfADwZtRaAAAAWIVVelsGqQAqziJL8gHAq1FrAQAAYBUW6W0ZpAKoOIfD6AQAYH3UWgAAAFiFRXpbBqkAKswqS/IBwJtRawEAAGAVVultfYwOAMCEnE7XDzdkZWUpLi7uvOP//e9/df/996t///5aunRpZacHAHNwp9ZSbwEAAGAGFultWZEKoOIq4UzSwoULtXbtWgUGBv7prYs1c+ZMrVq1SkFBQerTp4/69u2runXrXvJnAoCpVNJZe+otAAAADGeR3pYVqQAqzOlwuny40rRpU82ZM+e84zVq1NB7772n0NBQnTp1Sg6HQ/7+/p74MQDAq7lTa6m3AAAAMAOr9LasSAVQcU7Xm0SnpaUpLS2t5OuYmBjFxMSUfN27d29lZ2eX+b2+vr768MMPNXnyZHXv3v28M00AUC24UWsl6i0AAABMwCK9LYNUABXmzibRfy52FfWXv/xFPXv21DPPPKM1a9bo/vvvv+j3AgAzcndDfuotAAAAvJ1VelsGqTCNjxzpRkfA/8+T/y7sdruGDx+uJUuWyN/fX4GBgfLxYRcSwCqo5e7z9J8V9RYAAMA7WbFntkpvyyAVgFd45513dObMGcXExKhv37564IEH5Ovrq8jISN19991GxwMAy6DeAgAAwCqqure1OZ1O1zu5AgAAAAAAAEA1xvVbAAAAAAAAAOACg1QAAAAAAAAAcIFBKgAAAAAAAAC4wCAVAAAAAAAAAFxgkAoAAAAAAAAALvgaHQDmduLECfXr109LlixRfn6+HnnkEV111VWSpNjYWPXp08fYgGV49dVX9fHHH6uwsFCxsbG6/vrr9cwzz8hms6lFixaaOHGifHy84xxDVlaWZsyYoeXLl+vgwYNl5pw7d64+/fRT+fr6aty4cWrbtq3RsQF4AYfDoeTkZO3Zs0f+/v56/vnn1axZM6NjGe6Pf281b97c6DgAAADwcgUFBS5f4+/vXwVJKubAgQMuXxMeHl4FSayFQSouWmFhoZKSklSzZk1J0o4dO/Tggw/qoYceMjhZ+b788kv973//U2pqqs6ePaslS5YoJSVFo0eP1g033KCkpCStX79evXr1MjqqFi5cqLVr1yowMFCSysx5xRVX6KuvvlJ6erp++uknjRo1SqtWrTI4OQBvsG7dOhUUFCgtLU1bt27V1KlT9corrxgdy1B//nsLAAAAVSszM9Pla7p06VIFSdzXqVMnNWjQQE6nUzabTZJK/tnpdOrkyZPaunWrsSHLMHDgQLVq1UpOp7PM5/fs2aOvvvqqilOZH4NUXLRp06Zp0KBBeu211yRJ27dv14EDB7R+/Xo1a9ZM48aNU0hIiMEpS8vMzFTLli312GOPyW63a+zYsXrrrbd0/fXXS5K6deumzz77zCsGqU2bNtWcOXM0duxYSb8Nqv+cMzw8XF26dJHNZtMVV1yh4uJinTx5UnXr1jUyOgAvsGXLFnXt2lWS1L59e23fvt3gRMb7899bAAAAqFrPPPNMSY9alo0bN7o1bK1KN998sxYsWFDu88OHD6/CNO7r3bu3nn/++XKff/bZZ6swjXUwSMVFWb16terWrauuXbuW/ELatm1bDRgwQNdcc41eeeUVzZs3TwkJCQYnLS0nJ0dHjhzRggULlJ2drREjRpQ6qxQcHKzc3FyDU/6md+/eys7OLvm6rJx2u121a9cuec3vxxmkArDb7aVOZtWoUUNFRUXy9a2ef/WX9fcWAAAAqlb//v01evTocp9/8cUXqyyLu2699dZSv4//2YWGrEZ6/vnn9c0332jLli06e/as6tSpo5tvvrlke6sLDVlRPu/YCBKms2rVKn3++eeKi4vTrl27lJCQoG7duumaa66RJPXq1Us7d+40OOX5ateurS5dusjf318REREKCAgoNTjNy8tTWFiYgQnL98d9W3/PGRISory8vFLHQ0NDjYgHwMv8uT44HI5qO0SVyv5769ixY0bHAgAAqFZGjx6t77//Xvv27ZMkLVmyRLNnzy75vfxCQ1ajzJgxQw8++KB++OEHo6NUyIIFC5SamqqQkBDt3LlTP/30k2bPnq1//vOfRkczNQapuCj//Oc/9eabb2r58uVq1aqVpk2bpkcffVTbtm2TJG3atElt2rQxOOX5OnbsqI0bN8rpdOqXX37R2bNnddNNN+nLL7+UJGVkZKhTp04Gpyxb69atz8sZHR2tzMxMORwOHTlyRA6Hg9WoACRJ0dHRysjIkCRt3bpVLVu2NDiRscr6e6tBgwZGxwIAAKhWXnrpJU2cOFFjx47VqFGjdOLECdWpU0fPPPOM0dHKFRUVpdGjRys+Pl6JiYn63//+Z3Qkt2zcuFHTp09XbGys5s2bp++//15z587VO++8Y3Q0U6u+S1NQ6ZKTk/Xcc8/Jz89P9evX13PPPWd0pPPceuut2rx5s/r37y+n06mkpCQ1btxYEyZM0KxZsxQREaHevXsbHbNMCQkJ5+WsUaOGOnXqpJiYGDkcDiUlJRkdE4CX6NWrlz777DMNGjRITqdT//jHP4yOBAAAgGpu06ZNWrlypQoKCnTXXXdpzpw5kqT169cbnKx8NptN7du316pVq/Txxx9r6dKlevrppxUaGqp//etfRscr15kzZ/Tjjz/qyiuv1KFDh5Sfn6+ioiKdO3fO6GimZnOWd/suAAAAAAAAoJLcf//9mj59unJycjR8+HC99957CgwM1EMPPaS33nrL6HhliouL0/Lly8877u03es7MzNSECRMUFhamc+fO6YUXXtDGjRt1+eWXa8CAAUbHMy0GqQAAAAAAAPC4zz//XNOnT1fr1q3VokULvfbaawoODlZCQoJ69uxpdLwyHT9+XPXr1zc6xkVxOp3Kycnx6oGv2TBIBQAAAAAAQJXLzc1VQECA/P39jY5Srh9++EEzZ85UQECARo4cqauuukqSNHHiRE2aNMnYcBdw9OhRLVq0SGFhYerZs6dGjRqlGjVqaOrUqWrfvr3R8UyLm00BAAAAAADA4zZs2KBly5bp8OHDGjJkiO644w4NGTJEu3btMjpauSZMmKCYmBjdddddeuyxx7Rz505J0v79+w1OdmHPPPOMWrVqJZvNpoceekivvvqq3njjDc2YMcPoaKbGzaYAAAAAAADgcXPmzNG8efOUlJSkJ554Qtddd512796tiRMnKi0tzeh45erSpYskqWnTpho1apQWLVokm81mcKoLKygo0H333SdJ+uqrrxQRESFJXp/b27EiFQAAAAAAAB7n7++vyy+/XJJ03XXXSZKioqKMjOSSr6+vPv74YxUXFysiIkITJkzQI488ouPHjxsd7YLCwsI0f/58OZ1OLV26VJL073//WwEBAQYnMzcGqbCEOXPmKDU1Vbt27dLcuXMlSR999JF++eUXl987ffp09e3bV19++eUlZVi9erXWr19/Se8BAJ50KbWyKnz00Uf6y1/+omXLlrn9PatXr+byJAAAAJNo06aNJk+erA4dOmjcuHH66KOP9Oyzz6p58+ZGRyvXlClT9OGHHyo3N1eSdOONN2rcuHHy8/MzONmFzZw5U8HBwaVWoP7yyy+aNm2aganMj5tNwRLmzJmj+vXrKzY2tuRYXFyckpOTXRbk2267Tf/+978VEhLi6ZgAYKhLqZVVITExUb169VKPHj3c/p7Vq1dr//79euqppzyYDAAAAJXB4XDo3//+tzIzM5WTk6PatWurY8eOGjBggNfecMput5fMC7777jvt3r1bbdq08Yr+GVWPPVLhFfLy8hQfH6/Tp0/r6quv1v/+9z/Vrl275Jf71NRUHT9+XKNGjdLMmTO1fft2nTp1SlFRUUpJSSl5ny+//FIrV67UPffco127dikhIUEDBgzQDz/8oISEBBUXF+vee+/V22+/rYCAAM2dO1dHjx7VI488osWLF+uFF17Qtm3bVFhYqFGjRqlnz55l5v3www+1cOFC+fr66rLLLtPs2bM1b9481a9fX/Xr1y9ZTfXzzz+rYcOGWr58uWbOnKmvv/5aDodDw4YN0x133FElf7YArMOoWpmdna34+Hg1bNhQhw8f1rXXXqtJkyaVGszu27dPycnJWr58ufr27atOnTppz549ioiIUL169fT111/L399fr732Wpln79evX6+MjAxt375dderU0d69e5WamiqHw6EePXro8ccfd/nnU9bPPGjQID333HNq0aKFNmzYoE8++UTx8fEaP368cnJyJEnPPvusIiMjdeuttyoiIkLNmzdXp06dzqvzPj5cyAMAAHApfHx81KZNG0VHR6tZs2Ylx7OystSuXTsDk5Xv0Ucf1bJly7Rq1SqtWLFCN954o1asWKF+/fpp4MCBRscrV0FBQbnPeevQ2gwYpMIrrFixQpGRkXryySf1zTffKDMzU7Vr1z7vdXa7XWFhYXr99dflcDh05513lnlJ6i233KJWrVopOTlZl19+ufr166ennnpKGzdu1A033FCyJ8jIkSO1evVqLVmyRBkZGcrJydHbb7+tX3/9Va+//nq5g9R3331XDz/8sG6//XatWbNGdru95LlevXqpV69eOnz4sEaPHq2pU6dqw4YNys7OVmpqqvLz8zVw4EB17txZYWFhlfMHCKBaMKpWStIPP/ygxYsXKzAwUD179tSxY8fKzZmXl6e77rpLEydO1O23367ExEQ9+eSTGjJkiPbu3atWrVqd9z233XabPvroI/Xp00dNmzZVQkKC1q5dq4CAAM2cOVN5eXkKDg4u9zPL+5kHDBigf/3rXxo7dqxWrVqlRx55RAsWLNCNN96owYMH64cfflBiYqJSU1P1008/afXq1apTp44ef/zx8+o8NRsAAODSzJs3T5mZmSouLlbr1q01ceJE2Ww2zZw5s0LbOxnh7bff1rJlyxQcHKzCwkINHTrUqwepffv21YkTJ1SrVi05nU7ZbLaS/2VbwovHIBVeITs7W127dpUkRUdHn3d25PcdKAICAnTy5EmNGTNGQUFBOnPmjAoLCy/43iEhIbruuuuUmZmp1atX69FHHy3zdQcOHFD79u0lSbVq1dLo0aPLfc/ExES9+uqrevPNNxUREXHewPXYsWN64oknlJKSoiuvvFLvvfeeduzYobi4OElSUVGRfvzxR34pB1AhRtbKpk2bllzS1KBBA+Xn51/w/dq0aSPpt03uf7/sKSwszOX3SdLhw4fVokUL1axZU5Lcumy/vJ/5jjvuUL9+/fTwww/rl19+UZs2bfTiiy/qiy++0Pvvvy9J+vXXXyVJderUUZ06dSS5rvMAAACouIyMDKWlpUmSpk2bpkmTJik5OVnevOtkXl6eTp06pQYNGsjX97cxmq+vr8v+2mipqal6+OGH9cYbb6hWrVpGx7EMrlGDV4iMjNSWLVskSXv27FFBQYH8/f1LVjzt3LlT0m9F96efftKsWbM0ZswYnTt3rtyC+/vZFkkaOHCg0tPTdeLEiXLvCBgREaFvv/1WkpSbm6uHH3643LxpaWkaNWqU3nzzTUm/3SDld6dPn9Zjjz2mxMRERUZGlrz3DTfcoOXLl2vp0qW644471KRJE7f/fABAMrZW/nGT+t8FBASUfPaOHTtcvt5dTZs21f79+0suR3r88cdd3hCrvJ85KChIN9xwg6ZMmaK7775b0m81ediwYVq+fLlefPHFkuN/vHT/QnUeAAAAF+ePPWlCQoJyc3O1aNGiS+odPS06OlqPPvqotmzZotdff115eXm655571KdPH6OjXVDdunUVHx9f8jsCKgcrUuEVBgwYoPHjx+uBBx7QFVdcIUkaOnSoJk2apCuuuEKXXXaZJKlt27aaP3++HnjgAdlsNjVp0kRHjx4t8z07dOigsWPHasmSJWrXrp0OHjyoBx54QJL0+uuvq2nTprrttttKXn/bbbdp06ZNio2NVXFxsR577LFy87Zt21aPPPKIgoODFRQUpFtuuaXkl+3Zs2fr6NGjmjt3rhwOh/z8/LR48WJ99dVXGjx4sM6cOaOePXtycysAFWZUrfz9pNCf3XHHHRo9erQ2b95csgK1MtStW1d/+9vfNGTIENlsNt166626/PLLL/g95f3MTZo00cCBAzV48GAlJydLkoYPH67x48frrbfekt1u18iRI8t8vz/XeQAAAFyaPn36qH///lq0aJFq166tlJQUjRgxQllZWUZHK9f48eMl/TYEPnv2rAIDAzV79mxT3GyqS5cuRkewHJvTm9dPo1rKz8/XHXfcoY8//rjS3tPhcCg2NlaLFy9mgAnAEqiV7tu2bZvefPNNvfDCC0ZHAQAAqPYOHz6sK664QjVq1Cg5tm7dOq/dSik/P18rV67Upk2blJubq9DQUHXq1ElDhgwp2YrKG+Xn5ys1NVVffPGFqXJ7O1akwvIOHz6skSNHql+/fhUaDBQUFJR5eX94eLgmT55cmREBwHAXWysratu2bZo+ffp5x++44w4NHjy43O9LTk7Wvn37zju+cOHCCzaCb775pt5++229+OKLF5UXAAAAlSc/P18ff/xxmUNJb5WYmKioqCiNHj1awcHBysvLU0ZGhuLj4zVv3jyj45XLrLm9HStSAQAAAAAA4HFjxoxRVFSUunXrVmq4l5WV5bXDvSFDhpRs5fdHgwcP1ooVKwxI5B6z5vZ2rEgFAAAAAACAxx09elSzZs0qdSwqKuqCVyYZLSAgQGvWrFHXrl0VGhoqu92uDRs2KCgoyOhoF2TW3N6OFakAAAAAAADwuIcfflh9+/Y9b7j3n//8R4sWLTI6XplycnI0b948ffPNN8rLy1NwcLCio6M1YsQI1atXz+h45TJrbm/HIBUAAAAAAAAeZ9bhXmFhoXbv3i273a6wsDC1aNFC/v7+Rsdyyay5vRmDVAAAAAAAAFQJsw33Pv30U82cOVNXXXWVgoODZbfbtX//fo0ZM0Y9e/Y0Ol65zJrb27FHKgAAAAAAADzOjMO9BQsWKDU1VSEhISXHcnNzNWzYMK/NLJk3t7djkAoAAAAAAACPM+Nwr7CwUDVr1ix1LCAgQDabzaBE7jFrbm/HIBUAAAAAAAAeZ8bhXkxMjO677z517Nix5AZZW7ZsUVxcnNHRLsisub0de6QCAAAAAADA49566y0tX768zOHegAEDjI5XruPHj2vbtm3Ky8tTSEiIrr32WtWvX9/oWC79nttutyskJERt27Y1RW5vxiAVAAAAAAAAVcJsQ8n8/HytXLlSn3/+uXJzcxUWFqZOnTppyJAh562uNYNPPvlEt956q9ExTItL+wEAAAAAAOBx+fn5+s9//lNqKLlv3z6vHkomJiYqKipKTz75pIKDg5WXl6eMjAzFx8dr3rx5RsersIMHDxodwdRYkQoAAAAAAACPGzNmjKKiotStW7dSQ8msrCyvHUoOGTJEb7755nnHBw8erBUrVhiQqOIcDod8fHyMjmEJrEgFAAAAAACAxx09elSzZs0qdSwqKkqDBw82KJFrAQEBWrNmjbp27Vqyr2tGRoaCgoKMjnZBhw8fVkpKirZv3y5fX185HA61bNlSiYmJCg8PNzqeaTFIBQAAAAAAgMeZcSg5Y8YMzZs3T8uWLVNeXp6Cg4MVHR2tadOmGR3tgsaPH6/4+Hi1a9eu5NjWrVuVmJiolStXGpjM3Li0HwAAAAAAAB6Xk5OjefPm6Ztvvik1lBwxYoTq1atndDxLGTRoUJkD0/KOwz0MUgEAAAAAAIAKePzxx/Xyyy8bHaNcEydOVEFBQcnq37y8PG3YsEH+/v6aNGmS0fFMi0EqAAAAAAAADOPtQ8my/Prrr6pVq5bRMcrldDq1bt06bdmyRXa7XSEhIYqOjlavXr1ks9mMjmdaDFIBAAAAAABgGG8fSu7evVuff/65cnNzFRYWpo4dO6pt27ZGx4IBGKQCAAAAAACgSphtKDl37lxt27ZNXbp0UXBwsPLy8pSZmanWrVtr9OjRRsdDFWOQCgAAAAAAAI8z41By8ODBWrFiRaljTqdTAwcOVHp6ukGpYBRfowMAAAAAAADA+j7//PPzhpJxcXEaOHCg1w5Si4qKlJ2drcaNG5ccy87Olo+Pj4GpLl5mZqb8/Px0ww03GB3FlBikAgAAAAAAwOPMOJQcP368Ro4cqcLCQoWEhMhut5v6zvc7d+5UixYt9PPPP6thw4ZGxzEdLu0HAAAAAACAx2VlZWnixIllDiW9eZ9USbLb7crLy1NwcLBCQkKMjgODMEgFAAAAAABAlWEo6Xlbt27V5MmTFRAQoPj4eHXq1EmS9Nhjj2nevHkGpzMvLu0HAAAAAABAlQkJCWGA6mFTp07VzJkzVVRUpLFjxyo+Pl5dunTR6dOnjY5magxSAQAAAAAAAAvx8/NTeHi4JOm1117TQw89pAYNGshmsxmczNy8dzdfAAAAAAAAwAuNGTNG06ZN04kTJ4yOUqbg4GAtW7ZMBQUFatCggWbMmKHRo0frxx9/NDqaqbFHKgAAAAAAAAwzZswYXX755frrX/+qevXqGR3HLcePH1edOnXkdDrl6+t9F3zb7Xa9/vrrevDBB0u2Udi7d69mzZql+fPnG5zOvBikAgAAAAAAwDDePpQ8deqU/Pz8FBQUpDVr1shms+mee+7x+svkv/vuOwUEBKhZs2Ylx7KystSuXTsDU5kbg1QAAAAAAAB43KxZszRixAgFBgYaHcVty5Yt04oVK+R0OnX99deroKBAgYGB8vHxUVJSktHxyjVv3jxlZmaqqKhIrVu3VnJysmw2m4YOHaply5YZHc+02CMVAAAAAAAAHrd69WrFxcXpiy++MDqK295991299957WrFihT755BNNmzZNycnJ2rNnj9HRLigjI0OpqalKT09XUFCQJk2aJEliPeWlYZAKAAAAAAAAjwsPD9fs2bO1dOlSDR06VO+++65+/fVXo2NdkMPh0NmzZ1WvXj1NnDhRklRQUKDCwkKDk13YHwemCQkJys3N1aJFi7x+OwJvxyAVAAAAAAAAHmez2dSkSRO98sorGj9+vHbt2qUHH3xQ3bt3Nzpauf72t7+pX79+cjgc6tWrlyTp4Ycf1oABAwxOdmF9+vRR//79derUKUlSSkqKNm3apKysLGODmRx7pAIAAAAAAMDj4uLitHz5cqNjVJjD4ZCPz/9bi2i32xUSEmJgIvccPnxYjRo1KnUDr3Xr1qlnz54GpjI3BqkAAAAAAACoUk6n0xSXmX/77bc6cOCAunTpomnTpmnHjh26+uqrNXbsWF1xxRVGx0MVY5AKAAAAAAAAjzt06JAmTZqk/fv36+jRo2rTpo2aNGmiZ555Rg0aNDA6XpliYmI0efJkvfLKK7rlllvUo0cPffXVV1q6dKlXr65NS0sr97mYmJgqTGIt7JEKAAAAAAAAj5s0aZKeffZZffLJJ/rnP/+pG264QQ8++KDGjx9vdLRy+fn5KTIyUrm5ubr33nsVFhamnj17ev3Npvbv36/Fixfr2LFj5z1w8XxdvwQAAAAAAAC4NHa7XeHh4ZKk9u3ba/r06YqPj9fp06cNTla+K6+8UosXL1b37t01d+5c9ejRQxs2bPDaFbS/S0xM1P79+9WtWze1bdvW6DiWwaX9AAAAAAAA8Lj4+HgFBwerW7du+vTTTxUcHKybbrpJS5cu1euvv250vDKdPXtWixcvVmZmpnJyclSnTh1FR0frkUceUa1atYyOd0EnT57UmTNn1LhxY6OjWAaDVAAAAAAAAHhcQUGB0tPTtXfvXrVq1Ur333+/vv32WzVr1kx16tQxOp5bdu/eraioKKNjuC0nJ0d2u12hoaGqXbu20XFMj0EqAAAAAAAAPG7WrFkaMWKEAgMDjY7itszMzFJfT58+XU8//bQkqUuXLkZEcsu2bds0efJkORwOBQUFKS8vT06nU0lJSYqOjjY6nmkxSAUAAAAAAIDHdenSRQ0bNtTTTz+tG264weg4brn33nvl4+OjyMhISdLGjRvVtWtXSVJKSoqR0S4oNjZWs2bNUqNGjUqOHTlyRE888YTS09MNTGZuPkYHAAAAAAAAgPWFh4dr9uzZeuONNzR06FC9++67+vXXX42OdUGpqamKjIxUdHS0UlJSFB4erpSUFK8eokpSUVFRqSGqJDVq1Eg2m82gRNbga3QAAAAAAAAAWJ/NZlOTJk30yiuvaM+ePVq7dq2WLFmiEydOaMOGDUbHK1NgYKBSUlK0ZMkSJSUlqbi42OhIbunevbuGDRumzp07KzQ0VHa7XZ999pm6detmdDRT49J+AAAAAAAAeFxcXJyWL19udIyLtmnTJq1atUozZswwOopbdu7cqS1btigvL08hISHq0KGD2rRpY3QsU2NFKgAAAAAAADzuj0NUh8MhHx9z7Di5bt06bdq0Sbm5uapVq5bef/993X777V5/mfyRI0d04MCBktz16tVT69atvT63N2NFKgAAAAAAADzu8OHDSklJ0fbt2+Xr6yuHw6GWLVsqMTFR4eHhRscr06RJk+RwONStWzcFBwcrLy9PGRkZKioq0pQpU4yOVy6z5vZ2rEgFAAAAAACAx40fP17x8fFq165dybGtW7cqMTFRK1euNDBZ+b7//nu9+eabpY7ddtttGjRokEGJ3GPW3N7OHGuoAQAAAAAAYGoFBQWlhqiS1L59e2PCuMnhcOjrr78udWzz5s3y8/MzKJF7zJrb23FpPwAAAAAAADxu4sSJKigoUNeuXRUaGqq8vDxt2LBB/v7+mjRpktHxynTo0CGlpKRox44dkiQfHx+1atVKCQkJuuqqq4wNdwFmze3tGKQCAAAAAADA45xOp9atW3feneR79erl9TdAOnnypOx2u0JDQ1WnTh2j48Ag7JEKAAAAAAAAj7PZbGrSpIkOHTqkmjVrqlatWmrYsKFXD1G3bdumyZMny+FwlNy0yeFwaOLEierQoYPR8Sps8uTJSkpKMjqGabEiFQAAAAAAAB43d+5cbdu2TV26dCkZSmZmZqp169YaPXq00fHKFBsbq1mzZqlRo0Ylx44cOaInnnhC6enpBia7OPv27VPz5s2NjmFarEgFAAAAAACAx33++edasWJFqWNxcXEaOHCg1w5Si4qKSg1RJalRo0ZevYr2dydPntTmzZuVm5ursLAwtW/fniHqJWKQCgAAAAAAAI8rKipSdna2GjduXHIsOztbPj4+Bqa6sO7du2vYsGHq3LmzQkNDZbfb9dlnn6lbt25GR7ug9PR0paWlqWPHjgoODtb333+vBQsWaMCAAYqNjTU6nmlxaT8AAAAAAAA8buvWrUpOTlZhYaFCQkJkt9vl7++v5ORktWvXzuh45dq5c+d5N8hq06aN0bEuaNCgQVq+fLn8/PxKjhUUFCg2NlarVq0yMJm5sSIVAAAAAAAAHte+fXutWbNGdru9ZCgZHBxsdCyXjhw5ogMHDig3N1e1atVSvXr11Lp1a6++vL+oqEj5+fmlBqnnzp3z6sxmwCAVAAAAAAAAHnf48GGlpKRox44dqlGjhhwOh1q2bKnExESFh4cbHa9MkyZNksPhULdu3UpukJWRkaHMzExNmTLF6HjlevTRR9WvXz81a9asZEuCgwcPKjEx0ehopsal/QAAAAAAAPC4oUOHKj4+vtRl/Fu3btXUqVO1cuVKA5OVb8iQIXrzzTfPOz5o0CCvzfy7oqIi7du3T3a7XSEhIWrevLl8fVlTeSm8dzdfAAAAAAAAWEZBQcF5e6G2b9/emDBucjgc+vrrr0sd27x5c6lL5r1RUlKSDhw4oMjISHXs2FGRkZElQ9Rdu3YpKSnJ4ITmxIpUAAAAAAAAeNzEiRNVUFCgrl27KjQ0VHl5edqwYYP8/f01adIko+OV6dChQyXbEUiSj4+PWrVqpYSEBF111VXGhruAU6dO6cUXX9T27dsVHh6u+vXr6/Tp09q1a5fatm2rxx9/XHXr1jU6pukwSAUAAAAAAIDHOZ1OrVu3Tlu2bCm53Dw6Olq9evXiJkgeYrfblZWVpZycHNWrV0/t2rVTUFCQ0bFMi0EqAAAAAAAADPPzzz+rYcOGRseokMmTJ3N5fDXEHqkAAAAAAAAwzOzZs42OUGEPPPCA0RFgAFakAgAAAAAAAOU4efKkNm/erNzcXIWFhal9+/a67LLLjI4FAzBIBQAAAAAAgMfl5+crNTVVX3zxhXJzcxUaGqpOnTppyJAhqlmzptHxypSenq60tDR17NhRwcHBysvL0+bNmzVgwADFxsYaHQ9VjEEqAAAAAAAAPG7MmDGKiopSt27dSoaSGRkZysrK0rx584yOV6ZBgwZp+fLl8vPzKzlWUFCg2NhYrVq1ysBkMIKv0QEAAAAAAABgfUePHtWsWbNKHYuKitLgwYMNSuRaUVGR8vPzSw1Sz507J5vNZmAqGIVBKgAAAAAAADwuICBAa9asUdeuXRUaGiq73a6MjAwFBQUZHa1cjz76qPr166dmzZqVZD548KASExONjgYDcGk/AAAAAAAAPC4nJ0fz5s3TN998o7y8PAUHBys6OlojRoxQvXr1jI5XrqKiIu3bt092u10hISFq3ry5fH1Zm1gdMUgFAAAAAABAlduwYYO6d+9udIwLSkpKUlxcnFq0aHHec7t27VJqaqomT55sQDIYgUEqAAAAAAAAqtzQoUO1bNkyo2Nc0KlTp/Tiiy9q+/btCg8PV/369XX69Gnt2rVLbdu21eOPP666desaHRNVhEEqAAAAAAAAqlxcXJyWL19udAy32O12ZWVlKScnR/Xq1VO7du28em9XeAaDVAAAAAAAAFS5LVu2qGPHjkbHANzmY3QAAAAAAAAAWF9SUpK+++67kq//OETdtWuXkpKSjIgFuI0VqQAAAAAAAPC48vYb3b17t6699lr2G4XXY5AKAAAAAACAKsN+ozArBqkAAAAAAAAA4AJ7pAIAAAAAAACACwxSAQAAAAAAAMAFBqkAAAAAAAAwTH5+vtLT09167erVq7V+/fpK+dw5c+YoNTW1Ut7rj44dO6bk5ORKf98L+eijj/TLL79U6WdWRwxSAQAAAAAAYJhjx465PUjt16+fbrvtNg8nujQNGjSo8kHqsmXLZLfbq/QzqyNfowMAAAAAAACg+lqwYIH27t2rqKgo3XzzzTpz5oymTJmiNWvWaPv27Tp16pSioqKUkpKiOXPmqH79+oqIiNDChQvl5+en7Oxs9enTRyNGjNBPP/2kCRMmKD8/XwEBAXruuedUXFysESNGqHbt2urWrZv+9re/nZdh5syZ+vrrr+VwODRs2DDdcccd+uqrrzR37lw5nU7l5eVp5syZ8vPzK/VeGRkZioqK0vfffy+73a6XXnpJTqdTY8aM0VtvvaW+ffvq+uuv1549e2Sz2TR//nyFhIRo0qRJ2r59u+rXr68ff/xRr7zyiho3blzmn8+tt96qiIgINW/eXP3799fUqVNVXFysnJwcJScn6/Tp09q1a5cSEhK0YsUK/X/t3XuYjfX+//HXmqMZQ0ZCYtrGdt6RYVe2U0SKpJzGDGOLb0mRYyGnQYhIe5OdkGoUMw7ZKrVDaohyKIRkG3JIMTUjZoY5rfX7w8/ac1jjvhdrrVkzno/ruq+rWes+vNfM1Wt9vO/7c9/x8fH66KOPZLFY1KlTJ/Xr18/df8KbBo1UAAAAAAAAFJunn35aR44cUatWrfTHH39owoQJSktLU/ny5bVs2TJZrVZ17ty50NT1M2fOaP369crKylKrVq00ePBgzZo1SzExMWrTpo127NihOXPmaMSIEUpOTtaaNWsUEBBQ6PhffvmlTp8+rRUrVigzM1O9evVSixYt9N///levvPKKqlSpojfeeEOffvqpunTpkm9fiYmJatSokcaPH6958+bp448/VqdOnez7Tk9PV+fOnTVx4kSNGjVKiYmJCgwM1Pnz57V69WqlpKTowQcfvObv55dfftHatWsVGhqqDRs2aMyYMapbt64+/PBDrV27Vi+99JLq16+v2NhYnTx5Uhs2bND7778vSXriiSfUsmVLhYeHu+AvBRqpAAAAAAAA8Ao1a9aUJAUGBiolJUUjR45UcHCwMjIylJ2dnW/dOnXqyM/PT35+fipTpowk6ciRI1q0aJGWLFkim80mP78rra/q1as7bKJe3ebgwYOKiYmRJOXk5Ojnn39WlSpVNH36dAUHB+vs2bOKiIhwuK8GDRpIkqpWrarffvut0P6vvn/77bcrMzNTP//8s+6++25JUsWKFQ2bnKGhoQoNDZUkVa5cWQsXLlSZMmWUnp6ukJCQQp/lzJkz6t+/vyTpjz/+0IkTJ2ikugiNVAAAAAAAABQbHx8fWa1W+39LUmJion755Re99tprSklJ0caNG2Wz2fJtZ7FYCu0rPDxcAwYMUEREhJKSkrRr1658+3UkPDxc9957r6ZNmyar1aqFCxeqRo0aGjBggDZu3KiQkBCNGTPGfvxr7cuRgnXWrl1b//73vyVdaXT+9NNP19w+7/GmT5+uOXPmqFatWvrnP/+pn3/+2X4Mm82m8PBw/fnPf9aSJUtksVj09ttvq27duk7Vi6LRSAUAAAAAAECxufXWW5Wdna3Lly/bX2vUqJEWLlyoPn36yGKxqEaNGjp37pzhvsaMGaPY2FhlZmbq8uXLGj9+fKF1BgwYoDfeeMP+c7t27bRz505FR0crIyND7du3V0hIiB599FH16dNHQUFBqlSpkqnjm3H//fcrMTFRvXv3VqVKlVSmTBn5+/ub2vbRRx/VsGHDVL58eVWtWlWpqamSpCZNmuiFF17QW2+9pebNmysqKkpZWVlq1KiRqlSp4pK6IVlsBdv5AAAAAAAAANwiKSlJhw8fVufOnZWamqpHHnlEW7ZsKfLWA/AeNFIBAAAAAAAAD8nIyNCoUaP0+++/Kzc3V3379lX58uX19ttvF1q3X79+6tChg+eLhEM0UgEAAAAAAADAgHN3xwUAAAAAAACAmxCNVAAAAAAAAAAwQCMVAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMEAjFQAAAAAAAAAM0EgFAAAAAAAAAAM0UgEAAAAAAADAAI1UAAAAAAAAADBAIxUAAAAAAAAADNBIBQAAAAAAAAADNFIBAAAAAAAAwACNVAAAAAAAAAAwQCMVAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMEAjFQAAAAAAAAAM0EgFAAAAAAAAAAM0UgEAAAAAAADAAI1UAAAAAAAAADBAIxUAAAAAAAAADNBIBQAAAAAAAAADNFIBAAAAAAAAwACNVAAAAAAAAAAwQCMVAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMEAjFQAAAAAAAAAM0EgFAAAAAAAAGlZqjwAAR3hJREFUAAM0UgEAAAAAAADAAI1UAAAAAAAAADBAIxUAAAAAAAAADNBIBQAAAAAAAAADNFIBAAAAAAAAwACNVAAAAAAAAAAwQCMVAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMEAjFQAAAAAAAAAM0EgFAAAAAAAAAAM0UgEAAAAAAADAAI1UAAAAAAAAADBAIxUAAAAAAAAADNBIBQAAAAAAAAADfsVdAICSx/prHcN1fKoe8UAlAFB6mclaibwFgBvF2BYAYBaNVMDNHgyILu4SnPJZ1vuG62TbcgzXCXRFMQBKnZKWie5klLdmslYibwGp5GWLmfEWPIexLQDALBqpAJxmla24SwCAUo+sBQDPIG8BAGbRSAXgNKusxV0CAJR6ZC0AeAZ5CwAwi0YqAKdl2xhsAoC7kbUA4BnkLQDALBqpAJyWy/QnAHA7shYAPIO8BQCYRSMVgNO4jxQAuB9ZCwCeQd4CAMyikQrAadk2BpsA4G5kLQB4BnkLADCLRioApzH9CQDcj6wFAM8gbwEAZtFIBeC0bMaaAOB2ZC0AeAZ5CwAwi0YqAKflylLcJQBAqUfWAoBnkLcAALNopAJwmpWz9gDgdmQtAHgGeQsAMItGKgCnZcmnuEsAgFKPrAUAzyBvAQBm8Y0BwGlWm8VwMWPfvn2KiYkp9Pq6devUpUsXRUdHa9WqVa4uHwBKBDNZS94CwI0jawEAZnFFKgCnueI+UosXL9b69esVFBSU7/WUlBT985//1Nq1a1W+fHn1799fzZs3V/Xq1W/4mABQkrjqnn3kLQBcG2NbAIBZXJEKwGnZNl/DxUhYWJjmz59f6PXTp0+rbt26qlChgnx8fHTXXXdp37597vgYAODVzGQteQsAN46sBQCYxRWpAJxm5qx9fHy84uPj7T9HRkYqMjLS/nPHjh11+vTpQtvdeeedOnr0qH777TeVLVtWO3bs0J/+9CeX1A0AJYnZK6TIWwC4MYxtAQBm0UgF4LRsm3F0FBxcmnXLLbdo3LhxGjp0qCpUqKCGDRsqNDT0esoEgBLNTNZK5C0A3CjGtgAAs5jaD8BpubIYLtcrJydHhw4d0vvvv69//OMfOnbsmCIiIlxYPQCUDGaylrwFgBtH1gIAzOKKVABOy7W5/hzMhx9+qIyMDPuZ/scff1yBgYF64oknVLFiRZcfDwC8nTuyViJvAaAgxrYAALMsNpvNVtxFAKXZgwHRxV2CUz7Let9wnQ3H/2K4TqeaB1xRDoBSpqRlojsZ5a2ZrJXIW0AqedliZrwFz2FsCwAwiytSATjNXVdJAQD+h6wFAM8gbwEAZtFIBeA0K7dXBgC3I2sBwDPIWwCAWTRSATgty+Zb3CUAQKlH1gKAZ5C3AACzaKQCcJqV6U8A4HZkLQB4BnkLADCLRioAp+Uy/QkA3I6sBQDPIG8BAGbRSAXgtGymPwGA25G1AOAZ5C0AwCy3NFJTU1M1b948TZ06Nd/rKSkpGj16tC5fvqzKlStr5syZCgoKsr9vtVoVGxurH3/8UQEBAXrppZd05513au/evZo+fbp8fX3VsmVLDRkypMh1Y2Ji7Ps7duyYHn/8cT333HMaN26cTp06pZCQEE2aNEl/+tOfHK47evRoh5/JUQ1mPltCQoJWrlwpPz8/DR48WG3bti1y3bffflsff/yxJKlNmzYaMmSIcnNzNXPmTB04cEBZWVkaOnSo2rZtq+3bt2vOnDny8/NT8+bNNWLECM2bN0+rV6/WzJkz1bp16xv+OwJF4cmm3oO8JW9RepG13oOsJWtRupG3AACz3NJIfe211xQdHV3o9YULF+qRRx5Rt27d9Oabbyo+Pl79+/e3v79p0yZlZWUpPj5ee/fu1csvv6x//etfmjx5subPn68aNWroqaee0qFDh3T69GmH68bFxUmSTp06pWHDhmnw4MFKSEhQcHCwEhISdOzYMU2bNk1Lly51uG5RHNXQoEGDa362zp07Ky4uTmvWrFFmZqaio6PVokULh+s+8MADWr9+vVatWiUfHx9FRUWpffv2OnTokHJycrRy5UqdPXtWn3zyiSRp9uzZmjNnjmrVqqXo6Gj9+OOPGjFihM6ePeuKPyFwTZy19x7kLXmL0ous9R5kLVmL0o28BQCY5fJTb2lpafr+++9Vr169Qu/t2bNHrVq1kiS1bt1a27dvL/L9u+++WwcOHFBaWpqysrIUFhYmi8Wili1bavv27Q7XzWv69Ol6/vnnVbZsWR09etR+Fjs8PFxJSUlFrlvUZ3JUg9Fn279/v5o0aaKAgACVK1dOYWFhOnz4sMN1q1atqiVLlsjX11cWi0U5OTkKDAzUtm3bVKVKFT311FOaMGGC2rVrJ0mqX7++zp8/r+zsbGVmZsrXly9/eE6ufAwXuB95S96idDOTteSt+5G1ZC1KP7IWAGCWy78R9u7dq5o1azp8Ly0tTeXKlZMklS1bVhcvXiz0fkhIiP1nX1/fQq9d3c7Rujk5OZKkw4cPKz09Xc2bN5d0ZWC2ZcsW2Ww27d27V2fPnlVubq7DdYuq21ENRp8t72tXX09LS3O4rr+/vypWrCibzaZZs2apQYMGqlmzplJTU3Xy5EktWrRITz75pMaNGydJqlu3rp5++ml16tRJt99+u8LDw4usH3A1q81iuMD9yFvyFqWbmawlb92PrCVrUfqRtQAAs1zeSE1NTVWlSpUkSbt371ZMTIxiYmL0xRdfKCQkROnp6ZKk9PR0lS9fPt+2ed+XrtxXquBrV7dztK6f35U7Faxfv149e/a0v9e9e3eFhIQoOjpaGzduVMOGDe1nuQuu60hRNRS1TlE1pqenq1y5ckX+HjIzMzV69Gilp6dr8uTJkqQKFSro/vvvl8Vi0T333KOffvpJFy5c0KJFi/Txxx9r06ZNuvPOO/XWW29d8zMArpRt8zNc4H7kLXmL0s1M1pK37kfWkrUo/chaAIBZLm+k3nrrrbpw4YIkqVmzZoqLi1NcXJzuv/9+RURE6Msvv5QkJSYmqmnTpvm2jYiIUGJioqQrZ//r1KmjkJAQ+fv76+TJk7LZbNq2bZuaNWvmcN2rvv76a/v0Ikn6/vvv1bx5c61YsUIPPfSQatSoUeS6jhRVQ8HaC362Ro0aac+ePcrMzNTFixeVlJSkOnXqOFzXZrPpmWeeUd26dTV16lT7YLhp06b2dQ8fPqzbb79dZcqUUXBwsIKDgyVJlStXtv/OAU/IlcVwgfuRt+QtSjczWUveuh9ZS9ai9CNrAQBmufzUWuPGjTVnzhyH7w0ePFhjxoxRQkKCQkNDNXfuXEnSCy+8oOHDh6tDhw766quv1Lt3b9lsNs2YMUOSNGXKFI0ePVq5ublq2bKlGjdurLvuusvhupKUnJys0NBQ+8933nmn/vGPf+iNN95QuXLlNH369CLXTU5O1owZMzRv3rx8tTuq4fz585owYYIWLFjg8LMFBwcrJiZG0dHRstlsGjFihAIDAx2uu2nTJu3cuVNZWVnaunWrJGnkyJHq1auXJk+erF69eslms2nKlCkKCAjQ2LFjNWDAAAUGBqpcuXJ6+eWXb/AvB5hn5cmmXoG8JW9RupG13oGsJWtR+pG3AACzLDabzebqnU6aNEm9e/fO9+TPkiInJ0dz5szR2LFji7uU6zJ27Fh16tTJ/gACFL8HAwo/5debfZb1vuE60w8+YrjO+IYfuaIcGCBviw95e31KWia6k1Hemslaibz1BLK2+JjN2pKWLWbGW/AcxrYAALPccupt2LBhev/9kjk4sNlsGjhwYHGXcV3mzZtnP+MPuFOuzcdwgWeQt8WDvIUnmMla8tYzyNriQdbCU8haAIBZbrkiFcD/lMYrJCZ+/7jhOtPu+sAV5QAoZUpaJrqTUd6ayVqJvAWkkpctXJHqXRjbAgDM4vGDAJxmtXHDfQBwN7IWADyDvAUAmEUjFYDTct1zVxAAQB5kLQB4BnkLADCLRioAp+XYfIu7BAAo9chaAPAM8hYAYBaNVABOy2X6EwC4HVkLAJ5B3gIAzGIOAwCnWW0Ww8WMffv2KSYmptDr69ev1+OPP67u3buX2KckA8CNMpO15C0A3DiyFgBgFlekAnBatgumPy1evFjr169XUFBQofdmz56tjz76SMHBwercubM6d+6sW2655YaPCQAliSuyViJvAcAIY1sAgFlckQrAaa44ax8WFqb58+c7fK9u3bq6ePGisrKyZLPZZLEw3QrAzcdVV6SStwBwbWQtAMAsrkgF4DQzN+SPj49XfHy8/efIyEhFRkbaf+7YsaNOnz7tcNvatWure/fuCgoKUocOHVS+fPkbLxoAShizDz8hbwHgxjC2BQCYRSMVgNPM3JC/4ODSrMOHD+uLL77Q5s2bFRwcrOeff16ffPKJHn744espFQBKLLMPPyFvAeDGMLYFAJhFIxWA06w2990VpFy5cipTpowCAwPl6+urihUr6sKFC247HgB4K3dmrUTeAsBVjG0BAGbRSAXgtBw3DDY//PBDZWRk2M/2R0dHy9/fX2FhYXr88cddfjwA8HbuyFqJvAWAghjbAgDMsthsNltxFwGUZg8GRBd3CU75LOt9w3Wivn7KcJ0V973pinIAlDIlLRPdyShvzWStRN4CUsnLFjPjLXgOY1sAgFlckQrAae6ebgoAIGsBwFPIWwCAWTRSATjNXdNNAQD/Q9YCgGeQtwAAs0w1Un/66SedOHFCdevWVZUqVWSxmHuKLIDSyWrySdJwHnkL4Cqy1n3IWgB5kbcAALMMG6nLly/Xxo0b9ccff+ixxx7TyZMnNWnSJE/UBsBLMdh0D/IWQF5krXuQtQAKIm8BAGYZzmH4+OOPtWzZMpUrV079+/fXvn37PFEXAC+WY/UxXOA88hZAXmaylrx1HlkLoCCyFgBgluEVqTabTRaLxT7lKSAgwO1FAfBuVnHW3h3IWwB5kbXuQdYCKIi8BQCYZdhI7dy5s/r06aMzZ87oySefVPv27T1RFwAvxll59yBvAeRF1roHWQugIPIWAGCWYSM1KipKf/vb33TkyBHVrFlT1apV80RdALwY95FyD/IWQF5krXuQtQAKIm8BAGYVeeotOTlZx48fV3R0tHx9fVWvXj35+/trwIABnqwPgBey2iyGC8wjbwE4YiZryVvzyFoARSFrAQBmFXlF6r59+/TOO+/o+PHjmjhxoiTJx8dHLVu29FhxALxTro3pT65E3gJwhKx1LbIWQFHIWwCAWUU2Utu3b6/27dvryy+/VJs2bTxZEwAvx1l51yJvAThC1roWWQugKOQtAMAsw3uk3nLLLZo0aZKys7MlSefOndPSpUvdXhgA72VjsOkW5C2AvMha9yBrARRE3gIAzDKcwxAbG6t77rlHaWlpqlatmipUqOCBsgB4s1yrj+EC55G3APIyk7XkrfPIWgAFkbUAALMMr0gNDQ3VI488oq+++kpDhw5V3759PVEXUGp8lvV+cZfgckx/cg/yFjeD0piJ7kLWugdZWzqRLbgR5C0AwCzDRqqPj4/++9//6tKlSzp27Jj++OMPT9QFN7P+Wqe4S3CKT9UjxV0C8shlsOkW5G3pVNLy1p3IcueQte5B1sJblMTvh9Ka4+QtAMAsw0bq2LFj9d///lcxMTEaPXq0unfv7om6AHgx7iPlHuQtgLzIWvcgawEURN4CAMwybKSuWbNGY8eOlSStXbvW7QUB8H5Mf3IP8hZAXmSte5C1AAoibwEAZhneNfvo0aO6cOGCJ2oBUEJYrRbDBc4jbwHkZSZryVvnkbUACiJrAQBmGV6RmpSUpPvuu0+hoaGyWK58gWzbts3thQHwXkx/cg/yFkBeZK17kLUACiJvAQBmGTZSt2zZ4vD1TZs2qX379i4vCID3Y/qTe5C3APIia92DrAVQEHkLADDLcGp/Ud59911X1gGgBHHV9Kd9+/YpJiYm32vJycmKiYmxL82aNdOKFSvc8TFKDPIWuDm5cmo/eWuMrAVuXmQtAMAswytSi2Kz2VxZB4ASxBXTnxYvXqz169crKCgo3+u33Xab4uLiJEnfffed5s2bp169et3w8Uoy8ha4Oblqqil5aw5ZC9y8GNsCAMy67itSr95TCsDNx2qzGC5GwsLCNH/+/CLft9lsmjZtmmJjY+Xr6+vK8ksc8ha4OZnJWvLWdcha4OZF1gIAzLruK1IB3MRMXLQTHx+v+Ph4+8+RkZGKjIy0/9yxY0edPn26yO0///xz1a5dW+Hh4TdUKgCUWCYvkCRvAeAGMbYFAJjE1H4ATjMz/ang4NJZ69evV79+/a57+9KEvAVuTmanmpK3rkHWAjcvxrYAALMMG6lnzpzJv4Gfn0JDQ/XEE0+4rSgA3s3sDfdvxIEDBxQREeH243gT8hZAXp7IWunmy1uyFkBBjG0BAGYZNlIHDRqks2fPqmbNmvrpp58UFBSknJwcjR492hP1AfBGLnoASl4ffvihMjIyFBkZqZSUFIWEhNx096sjbwHk44aslchbshZAIYxtAQAmGT5sqnr16vr0008VHx+vzz77THfddZc++ugjvffee56oD4AXstmMFzOqV6+uhIQESVKXLl3s06UqVqyof//73+4q32uRtwDyMpO15K3zyFoABZG1AACzDK9I/f3331WxYkVJ0i233KLffvtNFSpUkI+PYQ8WQCll89B005sNeQsgL7LWPchaAAWRtwAAswwbqQ0bNtTIkSN19913a+/evapfv742bNigW2+91RP1AfBGPI/DLchbAPmQtW5B1gIohLwFAJhk2EidPHmyNm/erKSkJHXt2lVt2rTRsWPH1LZtW0/UB8ALmX2SNJxD3gLIi6x1D7IWQEHkLQDALMM5TGlpacrMzFTlypWVmpqqdevWKTw8XEFBQZ6oD4A3slmMFziNvAWQj5msJW+dRtYCKISsBQCYZHhF6jPPPKPKlSvr9ttvlySeNAiA6U9uQt4CyIesdQuyFkAh5C0AwCTDRqrNZtOcOXM8UQuAkoIb8rsFeQsgH7LWLchaAIWQtwAAkwyn9tetW1f79u1TVlaWfQFwc7PZjBc4j7wFkJeZrCVvnUfWAiiIrAUAmGV4RerOnTv1+eef23+2WCzavHmzW4sC4OUYTLoFeQsgH7LWLchaAIWQtwAAkwwbqevXr/dEHQBKEAvTn9yCvAWQF1nrHmQtgILIWwCAWUU2UqdOnapJkyYpMjKy0E34V65c6fbCAHgxztq7FHkLwCGy1qXIWgBFIm8BACYV2Uh95plnJEmvvvqqx4oBUELYvOus/dmzZ3Xx4kX5+vpq8eLFiomJUf369Yu7LNPIWwAOkbUuRdYCKBJ5CwAwqciHTVWqVOnKCj4+2rBhgz744AP7AuAmZzWxeNCoUaP022+/ad68eWrRooVmzJjh2QJuEHkLwCEzWevBvCVrAZRaXpS1UsnPWwAozYpspF41bNgwpaWlqVKlSvbFGampqZo0aZIk6fPPP1f37t0VGRmphISEQuueOHFCUVFRio6O1uTJk2W1XvnGWrBggXr06KHevXtr//7911xXki5duqSuXbsqMTFRkpSRkaEXXnhB0dHR6tmzp30f//nPf9S9e3f16NFD77zzzjU/x969e9WzZ0/17t1bCxYsKPR+SkqKBgwYoOjoaA0fPlyXLl2SJCUkJKhbt27q1auXtmzZcs11X3rpJXXr1k0xMTGKiYnRxYsXdebMGfXv318xMTHq27evjh07puTkZPs6MTExatasmVasWKFBgwbprrvuUmZmpvk/EHA9bCYWD7JYLPrrX/+qCxcuqHPnzvLxMYw2r0TeXkHeAv+fmaz1YN6StVeQtWQtSiEvylqp9OQtAJRGhg+bKlu2rEaMGHHdB3jttdcUHR2t7OxszZw5U6tXr1ZQUJCioqLUrl27fIPXmTNnavjw4br33ns1adIkbd68WdWqVdPOnTu1atUq/fLLLxo6dKjWrFnjcN0OHTpIunIPrLz3vlq6dKlq166t2bNn6/Dhwzp8+LAaNmyouXPnas2aNQoODlanTp3UpUsXVaxY0eHnmDx5subPn68aNWroqaee0qFDh9SgQQP7+wsXLtQjjzyibt266c0331R8fLw6d+6suLg4rVmzRpmZmYqOjlaLFi0crtu/f38dPHhQS5YsyVfDSy+9pL59+6p9+/baunWrXn31VS1YsEBxcXGSpO+++07z5s1Tr1697L9TwN287Yb8OTk5euWVV9SsWTN9/fXXys7OLu6Srgt5ewV5C1xB1roHWXsFWQv8D3kLADDL8NRW7dq19fHHH+vYsWM6fvy4jh8/bnrnaWlp+v7771WvXj0lJSUpLCxMt9xyiwICAtS0aVPt2rUr3/oHDx7UPffcI0lq3bq1tm/frj179qhly5ayWCyqVq2acnNzlZKS4nBd6crAskmTJqpXr559v9u2bZO/v78GDhyohQsXqlWrVvL19dWGDRtUrlw5nT9/XlarVQEBAUV+jqysLIWFhclisahly5b24121Z88etWrVKl89+/fvV5MmTRQQEKBy5copLCxMhw8fdriu1WrViRMnNGnSJPXu3VurV6+WJI0ZM0Zt2rSRJOXm5iowMNB+TJvNpmnTpik2Nla+vr6m/y7ADfOys/YzZ860/0MwJSVFs2bN8mwBLkLekrdAPl52RSpZS9aStSi1vChrpdKTtwBQGhlekfrDDz/ohx9+sP9ssVj07rvvmtr53r17VbNmTUlXBmzlypWzv1e2bFmlpaXlW99ms9nPtpctW1YXL15UWlqaKlSokG+7ixcvOlx3x44dOnHihKZOnapvv/3Wvk1qaqouXLigpUuXat26dZo1a5Zmz54tPz8/ffbZZ5o6daratGmjoKAgh58jLS1NISEh+Wo4depUoXWufr68tTv6zI7WzcjIUN++ffXEE08oNzdX/fr101/+8hf7oPnYsWOaNWuWXn/9dfv+Pv/8c9WuXVvh4eHX+jMApV7lypX1wAMP6MKFCzp+/LgaN25c3CVdF/KWvAW8GVlL1pK1gGeUlrwFgNLI8IrUNm3aKC4uzr6YHWhKVwZ5V6c3hYSEKD093f5eenp6voGYpHz3fklPT1f58uWL3M7RuqtXr9aRI0cUExOjrVu36pVXXtEPP/ygChUq2KcFtW3bVgcOHLBv++CDDyoxMVHZ2dlat26dw8/hqIby5csXuY5R7Y7WDQoKUr9+/RQUFKSQkBDdd999Onz4sCTp66+/1rPPPqvZs2fnG1iuX79evXr1clgz4E4Wq8Vw8aTnnntOBw8e1OzZs+Xv72+/d11JQ96St0BeZrLWk3lL1pK1ZC1KK2/KWqn05C0AlEaGjdTExETl5uZe185vvfVWXbhwQZJUq1YtnThxQufPn1dWVpZ2796tJk2a5Fu/QYMG+uabb+zHbdasmSIiIrRt2zZZrVadOXNGVqtVFStWdLju3LlztXLlSsXFxalVq1Z6/vnnVb9+fTVt2lRffvmlJGnXrl3685//rLS0NPXt21dZWVny8fFRUFBQkTfxDgkJkb+/v06ePCmbzaZt27apWbNm+daJiIiwHyMxMVFNmzZVo0aNtGfPHmVmZurixYtKSkpSnTp1HK77008/KSoqSrm5ucrOzta3336rhg0b6uuvv9b06dO1ZMkS3XXXXfmOeeDAAUVERFzX3wa4IV42/eny5ctq166dfv31Vz311FPXnVnFjbwlb4F8vGxqP1lL1pK1KLW8KGul0pO3AFAaGU7tT01NVatWrVS9enVZLBZZLBatXLnS1M4bN26sOXPmSJL8/f01duxYDRw4UDabTd27d1eVKlV09OhRLV++XLGxsRozZowmTpyoV199VeHh4erYsaN8fX3VrFkzRUZGymq12s/GOVq3KIMGDdKECRMUGRkpPz8/zZo1SyEhIerSpYv69OkjPz8/1a1bV48++qiSk5M1Y8YMzZs3L98+pkyZotGjRys3N1ctW7ZU48aNdf78eU2YMEELFizQ4MGDNWbMGCUkJCg0NFRz585VcHCwYmJiFB0dLZvNphEjRigwMLDIdbt27apevXrJ399fXbt2Ve3atTVq1ChlZ2dr7NixkqSaNWtq6tSpSklJUUhISL4HDwAe4+HBpJHs7Gy98847atiwoY4ePWp/WnBJQ95eQd4C/x9Z6xZk7RVkLZAHeQsAMMlis9mu+bXx888/F3rtjjvuMH2AqzeYz/sUUG+Wk5OjOXPm2Ad3JU27du30ySef5LtxvyPWX+t4qCLX8Kl6pLhLQB615r5quE7SqJEeqOSKb7/9Vps2bdLgwYP173//W40aNVKjRo08dnxXIW9LltKat+5EljvHTNZKnstbsvYKstazzGZtSVQSvx9Ka44ztgUAmGU4tT8nJ0cfffSRPvjgA33wwQdatGiRUwcYNmyY3n///esu0NNsNpsGDhxY3GVcl0GDBik5Obm4y8DNwEXTn/bt26eYmJhCr+/fv1/R0dGKiorSc889p8zMzGvuJyIiQvfcc4/i4+NVtWrVEjvQJG9LDvIWHuHCqf2uyFuy9gqy1nPIWniMF2WtVHryFgBKI8Op/aNGjVKHDh307bffqnLlysrIyHDqALfeeqteeuml6y7Q0/z9/XXbbbcVdxnXxdl/CADXyxU33F+8eLHWr19f6InCNptNEydO1D//+U/deeedWrVqlX7++edrPsF37ty5OnHihCIiIrRu3Trt3r27RF55Q96WHOQtPMFVDzdxVd6StVeQtZ5D1sJTGNsCAMwyvCI1ODhYgwYNUpUqVfTyyy/rt99+80RdALyZC87ah4WFaf78+YVeP378uCpUqKC3335bffv21fnz56850JSuPGjjn//8p/r376/58+drz549zn4ir0DeAsjHRVekuipvyVoApZYXZa1UevIWAEojw0aqxWJRcnKy0tPTlZGR4fRZewClj8VmvMTHx6tbt272JT4+Pt8+OnbsKD+/whfFp6am6rvvvlPfvn21bNkyff3119qxY8c168nJyZHVapUkWa3WEvugCvIWQF5mstaTeUvWAiitvClrpdKTtwBQGhlO7R8yZIg2btyorl27qn379uratasn6gLgxSxW43UiIyMVGRnp9L4rVKigO++8U7Vq1ZIktWrVSgcOHFDz5s2L3KZz586KiopS48aNtX//fnXq1Mnp43oD8hZAXmayVvJc3pK1AEorxrYAALMMG6l//etfVb9+fZ0+fVobN25U2bJlPVEXAG9m8ob716NGjRpKT0/XiRMndOedd2r37t3q0aOHw3Xnzp1rP0NfpUoVbdmyRfXr11dKSor7CnQj8hZAPm7MWsl83pK1AEo9xrYAAJMMG6n/+c9/9K9//Uu5ubl66KGHZLFY9Mwzz3iiNgDeyg2DzQ8//FAZGRmKjIzU9OnTNWrUKNlsNjVp0kT333+/w23y3l+qZs2aatu2resL8yDyFkA+bvqHvbN5S9YCKPUY2wIATLLYbLZrfm307t1b7777rgYOHKh3331X3bt319q1az1VH9zE+mud4i7BKT5VjxR3Ccij7rR5huv8OHGEByopXcjb0qmk5a07keXOMZO1EnnrLLIW3qIkfj+U1hxnbAsAMMvwilRfX18FBATIYrHIYrEoKCjIE3UB8GZunm56syJvAeRD1roFWQugEPIWAGCSYSO1adOmGjlypM6ePatJkybprrvu8kRdALyYhcGmW5C3APIia92DrAVQEHkLADDLsJE6cuRIJSYmqkGDBqpVqxb3aQEgmXySNJxD3gLIh6x1C7IWQCHkLQDApCIbqfHx8fl+LleunM6dO6f4+HhFRka6vTAA3ouz9q5F3gJwhKx1LbIWQFHIWwCAWUU2UpOTkz1ZB4ASxMJZe5cibwE4Qta6FlkLoCjkLQDArCIbqUOGDHH4ek5OjtuKAVBCcNbepchbAA6RtS5F1gIoEnkLADDJx9kNBg0a5I46AJQkNhMLbhh5C9zkzGQteXvDyFoAZC0AwCzDRurSpUuv+TOAm4/FarzAeeQtgLzMZC156zyyFkBBZC0AwCzDRuqXX36p3NxcT9QCoKTgrL1bkLcA8uGKVLcgawEUQtYCAEwq8h6pV6WmpqpVq1aqXr26LBaLLBaLVq5c6YnaAHgpnmzqHuQtgLzIWvcgawEURN4CAMwybKS+8cYbnqgDQAnC9Cb3IG8B5EXWugdZC6Ag8hYAYJZhI9XPz0+vvPKKUlJS9NBDD6lu3bq64447PFEbAG/FWXu3IG8B5EPWugVZC6AQ8hYAYJLhPVInTpyo7t27Kzs7W82aNdP06dM9URcAL2axGS9wHnkLIC8zWUveOo+sBVAQWQsAMMuwkXr58mU1b95cFotF4eHhCgwM9ERdALwZN+R3C/IWQD48bMotyFoAhZC1AACTDKf2BwYGauvWrbJardq7d68CAgI8URcAL8ZZefcgbwHkRda6B1kLoCDyFgBgluEVqdOmTdPatWuVmpqqt956S7GxsR4oC4BXs5pY4DTyFkA+ZrKWvHUaWQugELIWAGCS4RWpVatW1bx58zxRC4ASgrP27kHeAsiLrHUPshZAQeQtAMAsw0bqG2+8oSVLlqhMmTL217Zt2+bWogB4OQabbkHeAsiHrHULshZAIeQtAMAkw0bqhg0btHXrVgUFBXmiHgAlgIXpTW5B3gLIi6x1D7IWQEHkLQDALMNGavXq1fOdsQcApj+5B3kLIC+y1j3IWgAFkbcAALMMG6nZ2dnq0qWL6tSpI0myWCyaO3eu2wuDe/lUPVLcJaAkc9FZ+3379mnOnDmKi4vL9/rbb7+tVatWqWLFipKkKVOmKDw83DUH9WLkbelE3uK6ufAKKfL2f8haeAu+H7wIY1sAgEmGjdQnn3zSE3UAhjr49CzuEpy20bqquEtwC1ectV+8eLHWr1/vcGrlgQMHNGvWLP3lL3+58QOVIOQtbgYlMcvdxeg7wlVXSJG3+ZG1wI0paTluZjzO2BYAYJZPUW9s2bJFknT8+PFCC4CbnM3EYiAsLEzz5893+N7Bgwf15ptvKioqSosWLXJR0d6LvAXgkJmsJW9NI2sBFImsBQCYVOQVqefPn5ckJScne6oWACWExWo8moyPj1d8fLz958jISEVGRtp/7tixo06fPu1w286dOys6OlohISEaMmSItmzZorZt29544V6KvAXgiJmslchbs8haAEVhbAsAMKvIRurjjz8uSRoyZIjOnTunnJwc2Ww2nTt3zmPFAfBOZqY/FRxcmmWz2fT3v/9d5cqVkyS1adNGhw4dKtWDTfIWgCNmp5qSt+aQtQCKwtgWAGCW4T1SX3zxRe3du1eXLl3S5cuXVaNGDSUkJHiiNgDeyo1PNk1LS9MjjzyiDRs2KDg4WN988426d+/uvgN6EfIWQD5ufor0zZq3ZC2AQhjbAgBMKvIeqVcdPnxYH3/8sVq2bKmPP/5YgYGBnqgLgBezWI0XZ3344YeKj49XuXLlNGLECPXr10/R0dH685//rDZt2rj+Q3gh8hZAXmaylrx1HlkLoCCyFgBgluEVqaGhobJYLMrIyFDFihU9URMAL+eqJ0lXr17dfhVQly5d7K8/9thjeuyxx1xzkBKEvAWQl6uyViJv8yJrARTE2BYAYJZhI7Vhw4ZaunSpKleurBEjRujy5cueqAuAN3PzdNObFXkLIB+y1i3IWgCFkLcAAJMMG6mPPfaYKleurDJlyigxMVGNGjXyRF0AvJjZJ0nDOeQtgLzIWvcgawEURN4CAMwyvEfq+PHjFRISIj8/P7Vr106VKlXyRF0AvJjFZrzAeeQtgLzMZC156zyyFkBBZC0AwCzDK1KDg4M1Y8YM1axZUz4+V/qukZGRbi8MgPey5BZ3BaUTeQsgL7LWPchaAAWRtwAAswwbqdu3b1eTJk30+++/S5IyMzPdXhQAL8dZebcgbwHkQ9a6BVkLoBDyFgBgUpGN1FWrVmn16tUKDg7W1q1bJUlWq1U5OTkaNWqUxwoE4H2Y3uRa5C0AR8ha1yJrARSFvAUAmFVkI7Vr165q3ry5Fi1apKefflqS5OPjo1tvvdVjxQHwTtyQ37XIWwCOkLWuRdYCKAp5CwAwq8hGakBAgKpXr65p06Z5sh4AJQFjTZcibwE4RNa6FFkLoEjkLQDAJMN7pAJAQUx/AgD3I2sBwDPIWwCAWTRSATiN6U8A4H5kLQB4BnkLADCLRioA5zHWBAD3I2sBwDPIWwCASTRSATjNkstoEwDcjawFAM8gbwEAZtFIBeA8xpoA4H5kLQB4BnkLADCJRioAp3FDfgBwP7IWADyDvAUAmEUjFYDTuCE/ALgfWQsAnkHeAgDMopEKwHmMNQHA/chaAPAM8hYAYBKNVABOs9gYbQKAu5G1AOAZ5C0AwCwaqQCcxpNNAcD9yFoA8AzyFgBgFo1UAM5jrAkA7kfWAoBnkLcAAJN8iruAvFJTUzVp0iRJ0ueff67u3bsrMjJSCQkJhdY9ceKEoqKiFB0drcmTJ8tqtUqSFixYoB49eqh3797av39/vm1mzJihFStW2H9+++231bNnT/Xs2VMLFiyQJF28eFFPP/20+vbtq8jISH333XdF1mu1WjVp0iRFRkYqJiZGJ06cKLROQkKCunXrpl69emnLli2SpJSUFA0YMEDR0dEaPny4Ll26ZF8/JSVFHTt2VGZmpiQpIyNDgwcPVp8+fdS/f3+dPXtWkrRt2zY99thjioqK0sKFCyVJ48ePV7NmzZSUlGTwmwZujMVqM1zg3chb8hbez0zWkrfejawla1EykLUAALO8qpH62muvKTo6WtnZ2Zo5c6beeustxcXFKT4+Xr/99lu+dWfOnKnhw4fr/fffl81m0+bNm3Xw4EHt3LlTq1at0quvvqopU6ZIujKA+7//+z99/vnn9u1PnTql9evXa+XKlUpISNC2bdt0+PBhLVu2TPfdd5+WL1+umTNnaurUqUXWu2nTJmVlZSk+Pl6jRo3Syy+/nO/95ORkxcXFaeXKlVq6dKleffVVZWVlaeHChXrkkUf0/vvvq0GDBoqPj5ckbd26VQMGDFBycrJ9HwkJCWrYsKHee+89Pfroo1q8eLGsVqsmTJig+fPna8WKFTp27Jh2796t6dOnq379+jf8dwAM2WzGiwn79u1TTExMke9PnDhRc+bMcVXVyIO8JW9RApjJWvLWq5G1ZC1KCLIWAGCS1zRS09LS9P3336tevXpKSkpSWFiYbrnlFgUEBKhp06batWtXvvUPHjyoe+65R5LUunVrbd++XXv27FHLli1lsVhUrVo15ebmKiUlRenp6Ro6dKi6du1q375q1apasmSJfH19ZbFYlJOTo8DAQPXv31+9e/eWJOXm5iowMLDImvfs2aNWrVpJku6++24dOHAg3/v79+9XkyZNFBAQoHLlyiksLEyHDx/Ot93V2iXJx8dHy5YtU4UKFez76N+/vwYPHixJOnPmjMqXL6/U1FSVL19eNWrUkCRFRETo22+/dfp3Dlwvi9V4MbJ48WJNmDDBfoVKQStXrtSRI0dcXDkk8lYib1EymMla8tZ7kbVkLUoOshYAYJbXNFL37t2rmjVrSroy8CxXrpz9vbJlyyotLS3f+jabTRaLxf7+xYsXlZaWppCQkHzbXbx4UTVq1FDjxo3zbe/v76+KFSvKZrNp1qxZatCggWrWrKny5curTJkySk5O1vPPP6+RI0cWWXPB4/n6+ionJyff+44+R97Xr9YoSS1atFBoaGih4/j6+qpfv35avny5OnTooIoVK+ry5ctKSkpSbm6uEhMTlZGRUWSdgMtZbcaLgbCwMM2fP9/he99++6327dunyMhIV1cOkbcSeYsSwkzWkrdei6wla1GCkLUAAJO85mFTqampqlSpkiQpJCRE6enp9vfS09PzDdqkK2e4875fvnx5U9vllZmZqRdffFFly5bV5MmT7a//+OOPGjlypF544QX7lQGOFDye1WqVn59fke9frefq62XKlLHXbuTdd99VUlKSBg0apE2bNmn27NmKjY1VQECA6tSp43CQCriLxcT0pvj4ePvUPkmKjIzMN3js2LGjTp8+XWi7c+fO6fXXX9eCBQv0ySefuKZg5EPeXht5C29hJmsl8tZbkbXXRtbCmzC2BQCY5TVXpN566626cOGCJKlWrVo6ceKEzp8/r6ysLO3evVtNmjTJt36DBg30zTffSJISExPVrFkzRUREaNu2bbJarTpz5oysVqsqVqzo8Hg2m03PPPOM6tatq6lTp8rX11eSdPToUQ0bNkxz585VmzZtrllzRESEEhMTJV256qBOnTr53m/UqJH27NmjzMxMXbx4UUlJSapTp44iIiL05Zdf2mtv2rRpkcdYtGiR1q1bJ+nKGf6rdW7btk1Lly7VkiVLdPLkSf3tb3+7Zq2AS5m4j1RkZKTWrl1rX8yegf/000+Vmpqqp556Sm+++aY++ugjrV271s0f6OZC3jpG3sLrmLxHKnnrnchax8haeCWyFgBgktdckdq4cWP7jbf9/f01duxYDRw4UDabTd27d1eVKlV09OhRLV++XLGxsRozZowmTpyoV199VeHh4erYsaN8fX3VrFkzRUZG2p86WpRNmzZp586dysrK0tatWyVJI0eO1JtvvqmsrCxNnz5d0pUz7//617/05ptvql69emrdurV9Hx06dNBXX32l3r17y2azacaMGZKkZcuWKSwsTA888IBiYmIUHR0tm82mESNGKDAwUIMHD9aYMWOUkJCg0NBQzZ07t8g6u3fvrjFjxmjNmjXKzc21H6Ny5crq2bOnypQpoy5duqh27do39gcAnGDJdd+TS/v166d+/fpJktauXatjx46pW7dubjvezYi8dYy8hbdxZ9ZK5K27kbWOkbXwRoxtAQBmWWw2k/PGPGDSpEnq3bu3GjRoUNylFLJ582YFBwerefPmxV3KNcXExCg2Nla1atUq7lJcroNPz+IuwWkbrauKuwS36Ngs1nCd/+w2Xuf06dMaOXKkEhIS9OGHHyojIyPf2f2rg83Ro0ffQLVwhLy9caU5b92pJGa5uxh9R5jJWom89WZk7Y0ja71PSctxM+NxxrYAALO85opUSRo2bJjmzZunl156qbhLKaR+/fqqVq1acZdxTePHj9cPP/xQ3GXgZuCi8y/Vq1dXQkKCJKlLly6F3udsvfuQtzeGvIVHuPBcN3lbPMjaG0PWwmMY2wIATPKqK1KBaylpZ7+l0ntF6kN3Fz218KpP9071QCUASpqSmOXuYvQdYSZrJfIWgGeVtBw3Mx5nbAsAMMurrkgFUEJw/gUA3I+sBQDPIG8BACbRSAXgPKu1uCsAgNKPrAUAzyBvAQAm0UgF4DzGmgDgfmQtAHgGeQsAMIlGKgCnWZj+BABuR9YCgGeQtwAAs2ikAnBeLqftAcDtyFoA8AzyFgBgEo1UAM7jrD0AuB9ZCwCeQd4CAEyikQrAeQw2AcD9yFoA8AzyFgBgEo1UAM5j+hMAuB9ZCwCeQd4CAEyikQrAeTYGmwDgdmQtAHgGeQsAMIlGKgDncdYeANyPrAUAzyBvAQAm0UgF4DzuIwUA7kfWAoBnkLcAAJNopAJwHoNNAHA/shYAPIO8BQCYRCMVgPNyc4u7AgAo/chaAPAM8hYAYBKNVADO46w9ALgfWQsAnkHeAgBMopEKwHkMNgHA/chaAPAM8hYAYBKNVABOszH9CQDcjqwFAM8gbwEAZtFIBeA8K2ftAcDtyFoA8AzyFgBgEo1UAM5j+hMAuB9ZCwCeQd4CAEyikQrAeUx/AgD3I2sBwDPIWwCAST7FXQCAksdmtRouZuzbt08xMTGFXv/Pf/6j7t27q0ePHnrnnXdcXT4AlAhmspa8BYAbR9YCAMziilQAzss1N5i8lsWLF2v9+vUKCgrKv+vcXM2dO1dr1qxRcHCwOnXqpC5duqhixYo3fEwAKFFckLUSeQsAhhjbAgBM4opUAM6zWY0XA2FhYZo/f36h1319fbVhwwaVK1dO58+fl9VqVUBAgDs+BQB4NzNZS94CwI0jawEAJnFFKgCn2Uw82TQ+Pl7x8fH2nyMjIxUZGWn/uWPHjjp9+rTDbf38/PTZZ59p6tSpatOmTaEz+wBwMzCTtRJ5CwA3irEtAMAsGqkAnGYzcUP+goNLZz344INq3769xo4dq3Xr1ql79+7XvS8AKInMZK1E3gLAjWJsCwAwi6n9AJzngulPRUlLS1Pfvn2VlZUlHx8fBQUFyceHqAJwE3LR1P6ikLcA8P+RtQAAk7giFSXGRuuq4i4B/587/hYffvihMjIyFBkZqS5duqhPnz7y8/NT3bp19eijj7r8eACKB1lunrt+V+QtgBtRGnOcsS0AwCyLzWYzdwMuAAAAAAAAALhJMacAAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMEAjFQAAAAAAAAAM0EjFDfn999/Vpk0bJSUl6dChQ2rVqpViYmIUExOjDRs2FHd5Di1atEiRkZHq1q2bVq1apRMnTigqKkrR0dGaPHmyrFZrcZdot2/fPsXExEhSkXUuWLBAPXr0UO/evbV///7iLBeAF7FarZo0aZIiIyMVExOjEydOFHdJXiHv9xYAFFTSxrZr166119erVy/ddddd2rhxo9q3b29/fefOncVdpl3ese2IESPsNbZr104jRoyQxNgWAODd/Iq7AJRc2dnZmjRpksqUKSNJOnjwoJ544gkNGDCgmCsr2jfffKPvvvtOK1as0KVLl/TWW29p5syZGj58uO69915NmjRJmzdvVocOHYq7VC1evFjr169XUFCQJDmss1q1atq5c6dWrVqlX375RUOHDtWaNWuKuXIA3mDTpk3KyspSfHy89u7dq5dffln/+te/irusYlXwewsA8iqJY9tu3bqpW7dukqQpU6aoe/fuOnDggJ5//nl17NixmKvLr+DYdt68eZKkP/74Q/369dO4ceN08OBBxrYAAK/GFam4brNmzVLv3r1VuXJlSdKBAwf0xRdfqE+fPnrxxReVlpZWzBUWtm3bNtWpU0fPPvusnn76ad1///06ePCg7rnnHklS69attX379mKu8oqwsDDNnz/f/rOjOvfs2aOWLVvKYrGoWrVqys3NVUpKSnGVDMCL7NmzR61atZIk3X333Tpw4EAxV1T8Cn5vAUBeJXFse9X333+vo0ePKjIyUgcPHtSaNWsUHR2tl19+WTk5OcVdnqTCY9ur5s+fr759+6py5cqMbQEAXo9GKq7L2rVrVbFiRfs/0iWpUaNGeuGFF/Tee++pRo0aev3114uxQsdSU1N14MAB/eMf/9CUKVM0evRo2Ww2WSwWSVLZsmV18eLFYq7yio4dO8rP738XjTuqMy0tTSEhIfZ1vKl+AMWrYD74+vp6zT+mi4Oj7y0AuKqkjm2vWrRokZ599llJUosWLTRx4kS99957ysjI0MqVK4u5uisKjm2lK7dS2LFjh/2qWsa2AABvRyMV12XNmjXavn27YmJi9MMPP2jMmDFq3bq1/vKXv0iSOnTooEOHDhVzlYVVqFBBLVu2VEBAgMLDwxUYGJhvcJaenq7y5csXY4VF8/H53/+uV+sMCQlRenp6vtfLlStXHOUB8DIF88FqtRb6B+zNxNH3VnJycnGXBcBLlNSxrSRduHBBx48f13333SdJ6t69u2rUqCGLxaIHHnjAa+uWpE8//VSPPPKIfH19JRX+7mJsCwDwNjRScV3ee+89LV++XHFxcapfv75mzZqlZ555xn5D+B07dqhhw4bFXGVhTZs21datW2Wz2XT27FldunRJzZs31zfffCNJSkxMVLNmzYq5SscaNGhQqM6IiAht27ZNVqtVZ86ckdVqVcWKFYu5UgDeICIiQomJiZKkvXv3qk6dOsVcUfFy9L112223FXdZALxESR3bStKuXbvUvHlzSVdmMD366KP69ddfJXl33dKV+lq3bm3/mbEtAMDb3byXpsDlYmNjNW3aNPn7+6tSpUqaNm1acZdUSNu2bbVr1y716NFDNptNkyZNUvXq1TVx4kS9+uqrCg8P97ob8181ZsyYQnX6+vqqWbNmioyMtD+hGwCkK1dPffXVV+rdu7dsNptmzJhR3CUBQIlSEsa2knT8+HFVr15dkmSxWPTSSy9pyJAhKlOmjGrVqqVevXoVc4VFO378uGrUqGH/+S9/+QtjWwCAV7PYbDZbcRcBAAAAAAAAAN6Mqf0AAAAAAAAAYIBGKgAAAAAAAAAYoJEKAAAAAAAAAAZopAIAAAAAAACAARqpAAAAAAAAAGCARipKhfnz52vFihX64YcftGDBAknSxo0bdfbsWcNtX3nlFXXp0kXffPPNDdWwdu1abd68+Yb2AQDudCNZ6QkbN27Ugw8+qHfffdf0NmvXrtWcOXPcWBUAAAAAXEEjFaVK/fr1NWTIEEnSu+++q7S0NMNtPv30U61YsUL33nvvDR27W7dueuCBB25oHwDgCdeTlZ7w+eefa+zYserXr19xlwIA15SZmalVq1aZWteVJ9uvnhAzw6hGZ/blSN6TcgAA3Cz8irsAQJLS09M1atQoXbhwQX/+85/13XffqUKFCoqNjVWtWrW0YsUK/fbbbxo6dKjmzp2rAwcO6Pz586pXr55mzpxp388333yjlStXqmvXrvrhhx80ZswY9ezZUz/99JPGjBmj3NxcPfbYY1q9erUCAwO1YMECnTt3ToMGDdLSpUs1e/Zs7d+/X9nZ2Ro6dKjat2/vsN7PPvtMixcvlp+fnypXrqx58+bp9ddfV6VKlVSpUiX71VS//vqrqlatqri4OM2dO1e7d++W1WpV//799fDDD3vkdwug9CiurDx9+rRGjRqlqlWr6tSpU7rrrrs0ZcoUzZ8/X5UqVVJUVJSSkpIUGxuruLg4denSRc2aNdOPP/6o8PBw3Xrrrdq9e7cCAgL05ptvyt/fv9Bn27x5sxITE3XgwAGFhobq6NGjWrFihaxWq9q1a6fnnnvO8Pfj6DP37t1b06ZNU+3atfXll19qy5YtGjVqlMaPH6/U1FRJ0oQJE1S3bl21bdtW4eHhqlWrlpo1a1Yo5318OP8M4Irk5GStWrVKPXv2NFy3W7duHqioMGdqvB7169dX/fr13bJvAAC8FY1UeIX3339fdevW1YgRI/Ttt99q27ZtqlChQqH10tLSVL58eS1btkxWq1WdO3d2OCX1/vvvV/369RUbG6sqVaqoW7duGj16tLZu3ap7771XgYGBkqQhQ4Zo7dq1euutt5SYmKjU1FStXr1af/zxh5YtW1ZkI/Wjjz7SwIED9dBDD2ndunX5rubq0KGDOnTooFOnTmn48OF6+eWX9eWXX+r06dNasWKFMjMz1atXL7Vo0ULly5d3zS8QwE2huLJSkn766SctXbpUQUFBat++vZKTk4usMz09XY888ogmT56shx56SOPGjdOIESPUt29fHT161OE/vB944AFt3LhRnTp1UlhYmMaMGaP169crMDBQc+fOVXp6usqWLVvkMYv6zD179tQHH3ygF154QWvWrNGgQYP0xhtv6L777lN0dLR++uknjRs3TitWrNAvv/yitWvXKjQ0VM8991yhnCezAVz1xhtv6OjRo6pXr57+9re/KSMjQ9OnT9e6desKndC5etIpPDxcixcvlr+/v06fPq1OnTpp8ODB+uWXXzRx4kRlZmYqMDBQ06ZNU25urgYPHqwKFSqodevWevLJJ+3H3rRpkz755BNdvnxZEyZMUKNGjbR8+XJ99tlnunTpkkJDQ7VgwQJ7jQsWLFB0dLTGjBmjixcvymazadasWZKunMT69NNPdf78eQ0bNkzt2rVz+HmPHz+ucePGyc/PT1arVXPnztXJkye1cuVKjRw5Ui+++KKkK/l/7Ngx7dixQ1988YXefvtt+fj4qGnTpho9erT7/zAAALgZjVR4hdOnT6tVq1aSpIiICAUEBOR732azSZICAwOVkpKikSNHKjg4WBkZGcrOzr7mvkNCQvTXv/5V27Zt09q1a/XMM884XO/48eO6++67JUm33HKLhg8fXuQ+x40bp0WLFmn58uUKDw8v1HBNTk7WsGHDNHPmTN1xxx3asGGDDh48qJiYGElSTk6Ofv75Z/5RDsApxZmVYWFhCgkJkSTddtttyszMvOb+GjZsKEkqX768atWqZf9vo+0k6dSpU6pdu7bKlCkjSab+8V3UZ3744YfVrVs3DRw4UGfPnlXDhg312muv6euvv9Ynn3wiSfrjjz8kSaGhoQoNDZVknPMAbm5PP/20jhw5olatWumPP/7QhAkTTJ3EOnPmjNavX6+srCy1atVKgwcP1qxZsxQTE6M2bdpox44dmjNnjkaMGKHk5GStWbOmUNbfcccdmjp1qv773//aTxKdP3/e3rQcOHCgvv/+e3uNQ4YM0UsvvaR27dopKipK3377rfbv3y9JqlKliqZPn65vvvlGS5YsKbKRun37djVq1EjPP/+8du/erYsXL9rfq1GjhuLi4pSVlaWnn35a//jHP5SZman58+drzZo1CgoK0vPPP6+vvvpKLVq0cPFfAgAAz2KOGrxC3bp1tWfPHknSjz/+qKysLAUEBNiveDp06JAkKTExUb/88oteffVVjRw5UpcvX7Y3DgqyWCz293r16qVVq1bp999/V7169RyuHx4eru+//16SdPHiRQ0cOLDIeuPj4zV06FAtX75c0pUHpFx14cIFPfvssxo3bpzq1q1r3/e9996ruLg4vfPOO3r44YdVo0YN078fAJCKNystFkuhbQMDA+3HPnjwoOH6ZoWFhenYsWPKysqSJD333HOGD8Qq6jMHBwfr3nvv1fTp0/Xoo49KupLJ/fv3V1xcnF577TX763mn7l8r5wEgr5o1a0rKf0Jn0qRJDk9i1alTR35+fgoODrafLDpy5IgWLVqkmJgYvf766/r9998lSdWrVy/URJWkv/71r5Kk2rVrKzk5WT4+PvL397dfGfrrr78qJycn3zbHjx9XkyZNJF05EXc1966e9KpUqZIuX75c5Gfs0aOHypcvr//7v//Te++9J19f33zv5+TkaMSIEXr00UfVpk0bnTx5UikpKXrqqacUExOjpKQknTx50twvFAAAL8YVqfAKPXv21Pjx49WnTx9Vq1ZNktSvXz9NmTJF1apVU+XKlSVJjRo10sKFC9WnTx9ZLBbVqFFD586dc7jPJk2a6IUXXtBbb72lxo0b68SJE+rTp48kadmyZQoLC8v3cKgHHnhAO3bsUFRUlHJzc/Xss88WWW+jRo00aNAglS1bVsHBwbr//vvt/9ieN2+ezp07pwULFshqtcrf319Lly7Vzp07FR0drYyMDLVv395+ZRcAmFVcWXn1pFBBDz/8sIYPH65du3bZ/zHuChUrVtSTTz6pvn37ymKxqG3btqpSpco1tynqM9eoUUO9evVSdHS0YmNjJV25kmz8+PFKSEhQWlqa/cFbBfdXMOcB4CofHx9ZrVb7f0v/O6Hz2muvKSUlRRs3bix0EsvRSabw8HANGDBAERERSkpK0q5du/Ltt6D9+/erS5cu+vHHH1WtWjUdPnxYmzZt0qpVq3Tp0iV169ZNNpstX421atXS999/r3r16mnXrl364osvVKZMGdMnvTZv3qymTZtqyJAh+uijj7RkyRI99thjkq7Mhhg/fryaNGlif6169eq6/fbb9dZbb8nf319r167lfqoAgFLBYivqEhWgmGRmZurhhx/W559/7rJ9Wq1WRUVFaenSpTQwAZQKZKV5+/fv1/LlyzV79uziLgVAKXH1nvctW7ZU9erVFRUVpeTkZD399NP2BuXly5c1btw4bd++3X6P1JUrV2revHmSpBYtWuirr77SqVOnFBsbq8zMTF2+fFnjx4/XbbfdppEjRyohIUGSNGDAAL3xxhtatGiRDh06pPT0dGVlZSk2NlZ33nmnBg0aZL+KPyAgQD169FDHjh3tNQ4cOFAvvvii0tPTJUkzZszQunXrHD4w0JGTJ09qzJgx8vf3l9Vq1bhx45SWlqaVK1fqwQcf1IsvvqjGjRsrNzdXkjR58mQdPHhQK1asUG5uru644w7NnDlTQUFB7v7TAADgVjRS4XVc3Rw4deqUhgwZom7duunvf/+76e2ysrIcTu+vWbOmpk6d6pLaAOB6eUtWOmv//v165ZVXCr3+8MMPKzo6usjtYmNjlZSUVOj1xYsX26fHOrJ8+XKtXr1ar732mv70pz9dV80AAAAAINFIBQAAAADo+k9aAQBws6CRCgAAAAAAAAAGHN/BHAAAAAAAAABgRyMVAAAAAAAAAAzQSAUAAAAAAAAAAzRSAQAAAAAAAMAAjVQAAAAAAAAAMPD/ABx0Bm1a9q54AAAAAElFTkSuQmCC",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"hyperopt_report_cli(\n",
" 'hyperopt_results/random_serial/hyperopt_statistics.json',\n",
" output_directory='./visualizations'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Generate parallel coordinates plot on hyperparameter optimization"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [],
"source": [
"hyperopt_hiplot_cli(\n",
" 'hyperopt_results/random_serial/hyperopt_statistics.json',\n",
" output_directory='./visualizations'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To view parallel coordinates plot, using your browser open html page in the `visualizations` directory, i.e, `visualizations/hyperopt_hiplot.html`. The browser should display something similar to the image below."
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAACrIAAAXgCAYAAAAXW0u3AAAMY2lDQ1BJQ0MgUHJvZmlsZQAASImVlwdYU8kWgOeWVBJaIAJSQm+iSA0gJYQWQUCqICohCSSUGBKCih1dVsG1iyhWdFVE0dUVkLUgYmdR7K5lsaCysi4WbKi8CQnouq98b75v7vw5c+bMOScz984AoNPBl8lyUV0A8qQF8rjwYNaElFQW6REgg+HAANgBFl+gkHFiY6MALIPt38ub6wBRtVdcVLb+2f9fi75QpBAAgKRBzhAqBHmQmwDAiwUyeQEAxBAot55WIFOxGLKBHDoIeZaKs9S8XMUZat4+oJMQx4XcAACZxufLswDQboFyVqEgC9rRfgTZVSqUSAHQMYAcIBDzhZATII/Iy5uq4nmQHaC+DPIuyOyMr2xm/c1+xpB9Pj9riNVxDRRyiEQhy+XP+D9T879LXq5ycA47WGlieUScKn6Yw5s5UyNVTIPcLc2IjlHlGvI7iVCddwBQqlgZkajWR00FCi7MH2BCdhXyQyIhm0IOk+ZGR2nkGZmSMB5kuFrQ6ZICXoJm7CKRIjReY3ODfGpczCBnyrkczdhavnxgXpV+izInkaOxf1Ms4g3af10kTkiGTAUAoxZKkqIha0M2UOTER6p1MKsiMTd6UEeujFP5bwOZLZKGB6vtY2mZ8rA4jb4sTzEYL1YilvCiNVxRIE6IUOcH2y3gD/hvBLlOJOUkDtoRKSZEDcYiFIWEqmPH2kTSRE282D1ZQXCcZmyPLDdWo4+TRbnhKrkVZBNFYbxmLD6mAC5OtX08SlYQm6D2E0/P5o+NVfuDF4IowAUhgAWUsGaAqSAbSNq667vhL3VPGOADOcgCIuCikQyOSB7okcJnPCgCf0ISAcXQuOCBXhEohPJPQ1L10wVkDvQWDozIAY8h54FIkAt/KwdGSYdmSwKPoETyj9kF0NdcWFV9/5RxoCRKI1EO2mXpDGoSQ4khxAhiGNERN8EDcD88Cj6DYHXD2bjPoLdf9AmPCe2EB4RrhA7CrSmSYvk3vowDHdB+mCbijK8jxu2gTU88GPeH1qFlnImbABfcA87DwQPhzJ5QytX4rYqd9W/iHIrgq5xr9CiuFJQyjBJEcfh2pLaTtueQFVVGv86P2teMoaxyh3q+nZ/7VZ6FsI38VhNbhB3EzmAnsHPYEawesLDjWAPWih1V8dAaejSwhgZnixvwJwfakfxjPr5mTlUmFa41rl2uHzV9oEA0vUC1wbhTZTPkkixxAYsDvwIiFk8qGDmC5ebq5gqA6puifk29Yg58KxDm+S+y/CYAfEqhMOuLjG8NwOHHADDefJFZv4TbA77rj14SKOWFahmuehDg20AH7ihjYA6sgQOMyA14AT8QBELBWBADEkAKmAzzLIbrWQ6mgVlgPigBZWA5WAPWg81gG9gF9oIDoB4cASfAaXABXALXwG24fjrBM9AD3oA+BEFICB1hIMaIBWKLOCNuCBsJQEKRKCQOSUHSkSxEiiiRWcgCpAxZiaxHtiLVyE/IYeQEcg5pR24h95Eu5CXyAcVQGmqAmqF26CiUjXLQSDQBnYRmofloEboQXYpWoFXoHrQOPYFeQK+hHegztBcDmBbGxCwxF4yNcbEYLBXLxOTYHKwUK8eqsFqsEf7TV7AOrBt7jxNxBs7CXeAajsATcQGej8/Bl+Dr8V14Hd6CX8Hv4z34ZwKdYEpwJvgSeIQJhCzCNEIJoZywg3CIcArupk7CGyKRyCTaE73hbkwhZhNnEpcQNxL3EZuI7cSHxF4SiWRMcib5k2JIfFIBqYS0jrSHdJx0mdRJekfWIluQ3chh5FSylFxMLifvJh8jXyY/IfdRdCm2FF9KDEVImUFZRtlOaaRcpHRS+qh6VHuqPzWBmk2dT62g1lJPUe9QX2lpaVlp+WiN15JozdOq0NqvdVbrvtZ7mj7NicalpdGUtKW0nbQm2i3aKzqdbkcPoqfSC+hL6dX0k/R79HfaDO2R2jxtofZc7UrtOu3L2s91KDq2OhydyTpFOuU6B3Uu6nTrUnTtdLm6fN05upW6h3Vv6PbqMfRG68Xo5ekt0dutd07vqT5J304/VF+ov1B/m/5J/YcMjGHN4DIEjAWM7YxTjE4DooG9Ac8g26DMYK9Bm0GPob6hh2GS4XTDSsOjhh1MjGnH5DFzmcuYB5jXmR+GmQ3jDBMNWzysdtjlYW+NhhsFGYmMSo32GV0z+mDMMg41zjFeYVxvfNcEN3EyGW8yzWSTySmT7uEGw/2GC4aXDj8w/DdT1NTJNM50puk201bTXjNzs3Azmdk6s5Nm3eZM8yDzbPPV5sfMuywYFgEWEovVFsct/mAZsjisXFYFq4XVY2lqGWGptNxq2WbZZ2VvlWhVbLXP6q411ZptnWm92rrZusfGwmaczSybGpvfbCm2bFux7VrbM7Zv7eztku2+t6u3e2pvZM+zL7Kvsb/jQHcIdMh3qHK46kh0ZDvmOG50vOSEOnk6iZ0qnS46o85ezhLnjc7tIwgjfEZIR1SNuOFCc+G4FLrUuNwfyRwZNbJ4ZP3I56NsRqWOWjHqzKjPrp6uua7bXW+P1h89dnTx6MbRL92c3ARulW5X3enuYe5z3RvcX3g4e4g8Nnnc9GR4jvP83rPZ85OXt5fcq9ary9vGO917g/cNtgE7lr2EfdaH4BPsM9fniM97Xy/fAt8Dvn/5ufjl+O32ezrGfoxozPYxD/2t/Pn+W/07AlgB6QFbAjoCLQP5gVWBD4Ksg4RBO4KecBw52Zw9nOfBrsHy4EPBb7m+3NncphAsJDykNKQtVD80MXR96L0wq7CssJqwnnDP8JnhTRGEiMiIFRE3eGY8Aa+a1zPWe+zssS2RtMj4yPWRD6KcouRRjePQcWPHrRp3J9o2WhpdHwNieDGrYu7G2sfmx/4ynjg+dnzl+Mdxo+NmxZ2JZ8RPid8d/yYhOGFZwu1Eh0RlYnOSTlJaUnXS2+SQ5JXJHRNGTZg94UKKSYokpSGVlJqUuiO1d2LoxDUTO9M800rSrk+ynzR90rnJJpNzJx+dojOFP+VgOiE9OX13+kd+DL+K35vBy9iQ0SPgCtYKngmDhKuFXSJ/0UrRk0z/zJWZT7P8s1ZldYkDxeXibglXsl7yIjsie3P225yYnJ05/bnJufvyyHnpeYel+tIcactU86nTp7bLnGUlso583/w1+T3ySPkOBaKYpGgoMICH91alg/I75f3CgMLKwnfTkqYdnK43XTq9dYbTjMUznhSFFf04E58pmNk8y3LW/Fn3Z3Nmb52DzMmY0zzXeu7CuZ3zwuftmk+dnzP/12LX4pXFrxckL2hcaLZw3sKH34V/V1OiXSIvufG93/ebF+GLJIvaFrsvXrf4c6mw9HyZa1l52cclgiXnfxj9Q8UP/Uszl7Yt81q2aTlxuXT59RWBK3at1FtZtPLhqnGr6lazVpeufr1myppz5R7lm9dS1yrXdlREVTSss1m3fN3H9eL11yqDK/dtMN2weMPbjcKNlzcFbardbLa5bPOHLZItN7eGb62rsqsq30bcVrjt8fak7Wd+ZP9YvcNkR9mOTzulOzt2xe1qqfaurt5tuntZDVqjrOnak7bn0t6QvQ21LrVb9zH3le0H+5X7//gp/afrByIPNB9kH6z92fbnDYcYh0rrkLoZdT314vqOhpSG9sNjDzc3+jUe+mXkLzuPWB6pPGp4dNkx6rGFx/qPFx3vbZI1dZ/IOvGweUrz7ZMTTl5tGd/Sdiry1NnTYadPnuGcOX7W/+yRc77nDp9nn6+/4HWhrtWz9dCvnr8eavNqq7vofbHhks+lxvYx7ccuB14+cSXkyumrvKsXrkVfa7+eeP3mjbQbHTeFN5/eyr314rfC3/puz7tDuFN6V/du+T3Te1W/O/6+r8Or4+j9kPutD+If3H4oePjskeLRx86Fj+mPy59YPKl+6vb0SFdY16U/Jv7R+Uz2rK+75E+9Pzc8d3j+819Bf7X2TOjpfCF/0f9yySvjVztfe7xu7o3tvfcm703f29J3xu92vWe/P/Mh+cOTvmkfSR8rPjl+avwc+flOf15/v4wv5w8cBTBY0cxMAF7uBICeAs8Ol+A1YaL6zjdQEPU9dYDAf2L1vXCgeAGwMwiAxHkARMEzyiZYbSHTYKs6qicEAdTdfahqiiLT3U1tiwZvPIR3/f2vzAAgNQLwSd7f37exv/8TvKNitwBoylffNVWFCO8GW4xV1HpDF3xb1PfQr2L8tgUqDzzAt+2/AFoGh9r+AwoRAAAAimVYSWZNTQAqAAAACAAEARoABQAAAAEAAAA+ARsABQAAAAEAAABGASgAAwAAAAEAAgAAh2kABAAAAAEAAABOAAAAAAAAAJAAAAABAAAAkAAAAAEAA5KGAAcAAAASAAAAeKACAAQAAAABAAAKsqADAAQAAAABAAAF4AAAAABBU0NJSQAAAFNjcmVlbnNob3Q+xNfQAAAACXBIWXMAABYlAAAWJQFJUiTwAAAB2GlUWHRYTUw6Y29tLmFkb2JlLnhtcAAAAAAAPHg6eG1wbWV0YSB4bWxuczp4PSJhZG9iZTpuczptZXRhLyIgeDp4bXB0az0iWE1QIENvcmUgNS40LjAiPgogICA8cmRmOlJERiB4bWxuczpyZGY9Imh0dHA6Ly93d3cudzMub3JnLzE5OTkvMDIvMjItcmRmLXN5bnRheC1ucyMiPgogICAgICA8cmRmOkRlc2NyaXB0aW9uIHJkZjphYm91dD0iIgogICAgICAgICAgICB4bWxuczpleGlmPSJodHRwOi8vbnMuYWRvYmUuY29tL2V4aWYvMS4wLyI+CiAgICAgICAgIDxleGlmOlBpeGVsWERpbWVuc2lvbj4yNzM4PC9leGlmOlBpeGVsWERpbWVuc2lvbj4KICAgICAgICAgPGV4aWY6VXNlckNvbW1lbnQ+U2NyZWVuc2hvdDwvZXhpZjpVc2VyQ29tbWVudD4KICAgICAgICAgPGV4aWY6UGl4ZWxZRGltZW5zaW9uPjE1MDQ8L2V4aWY6UGl4ZWxZRGltZW5zaW9uPgogICAgICA8L3JkZjpEZXNjcmlwdGlvbj4KICAgPC9yZGY6UkRGPgo8L3g6eG1wbWV0YT4KAhYPZAAAABxpRE9UAAAAAgAAAAAAAALwAAAAKAAAAvAAAALwAAbZj15up6kAAEAASURBVHgB7J0HfBRFG4ff9B6SkITee5EO0lRUioCKqDRBBKV8VDsWLCCIBUEQC9IUG1ZA6SBSpEjvvRNKEiCkkUqSb9455jJ3ueQul0uD//gjOzttZ5+d3Qvy3LtOK1asyHByciJOGRkZpPKywMIP1UbfcjNL/VQbNYy+z+3T09Nlleqr16s+5lvVRt9yGzWG3l61UWX6vjp+dHS07FujRo078vx1djofxcx8q9roW30Mvb1qo8r0fcVf76vXqz7mW9VG3+pj6O1VG1Wm7+P4ReP+06+dfn3UNTPfqjb6Vh9Db6/aqDJ9H9cf178ofP7oa1dfn2rNmm9VG32rj6G3V21Umb6P9Y/1j/Vf+L9/6veufn+qe9Z8q9roW30Mvb1qo8r0fdz/uP9x/+P+158d+vNBPTPMt6qNvtXH0NurNqpM38fzB88fPH/w/NGfHfrzQT0zzLeqjb7Vx9DbqzaqTN/H8wfPHzx/8PzRnx3680E9M8y3qo2+1cfQ26s2qkzfx/MHzx88f/D80Z8d+vNBPTPMt6qNvtXH0NurNqpM38fzB88fPH/w/NGfHfrzQT0zzLeqjb7Vx9DbqzaqTN/H8wfPHzx/8PzRnx3680E9M8y3qo2+1cfQ26s2qkzfx/MHzx88f2x//pw4cUIIokRe3l7qdjLxJfne4uTs7CzLeV/luV8G/+AkVFMn/nErGe5J7pOexeFUY/K9KhMPkdnV5PhOK1euFO0zBVaV1wfRy3hQtX9rLsaNLBd78niaHMsN1GQs9dXLVJ63qp9e5ujjs8jK49esWVMeTz9WQRyfj6GOqee5jJN+vqqd2soG2g9ZLvaLE3+evn4+Ks9bTjj/zPtNZ6PuJwnp1g9ZL/K4/qbPG8ajeCmGt5DJjV6m8rzlhPWH9aevCX09yAWi/ZDtxD7uP9P7jRHh/jP8BqbWkrZs8PknnrXm6wPPX3z+qOeGumfMt/o9xHlZz1vxR19PXKfvqzyXc1Lj6nku48RtVb35VjbQfsh6sY/jm/JmRIq5YqhhM/LlMlXPW07gj/Wnrwl9PcgFov2Q7cQ+7j/T+40R4f7D71+8DtS9xHmV9DKV5y0n/X7T69R6UmPwVtbzVvxR9fo4xjbqf0xygUhqXD2v91P15lvZWfsh63k88QfHz1zvjEjnofJczklx1fNcxonbqnrzrWyg/ZD1Yh/8TXkzIsVcMdSwGflymarnLSfwx/rT14S+HuQC0X7IdmIf95/p/caIcP9lfh4oFmrpqPXF+yrPW076etPrzMfgtrKet7f6qTLeqvZqDC5TSS9Ted5ywvHx/NPXhL4e1PpRW9lO7GD9md5vzAf3H55/vA7UvcR5lfQylectJ/1+0+vUelJj8FbW81b8UfX6OMY2+PsfozAmxZULVF7nppfp18M4wK2MbMdjiD/gn3m/Mx6dh8pzOSfFV8+DP+5/Xg/6/abWidpyvZ5kuSjA/Wd6vzEjdc9ZYqeXqTxvVT+9TL8esoH2Q7YT++Bvyltx5K1iyXmV9DKV5y0nxVuKrGLf29tbjqHXqTZcppJexnmVLI3PdXq5aV+uU70z58Mlqh1vndauXSvGMIgEqiKzW2ZjVaa3UXne6onH46Tq9To9r+pxfPDntaDWg6U1osr0NirPWz1h/eH+4/Wg1oe+NvS8qsfzB88fXgtqPVhaI6pMb6PyvNUTnj94/vB6UOtDXxt6XtXj+YPnD68FtR4srRFVprdRed7qCc8fPH94Paj1oa8NPa/q8fzB84fXgloPltaIKtPbqDxv9YTnD54/vB7U+tDXhp5X9Xj+4PnDa0GtB0trRJXpbVSet3rC8wfPH14Pan3oa0PPq3o8f/D84bWg1oOlNaLK9DYqz1s94fmD5w+vB7U+9LWh51U9nj94/vBaUOvB0hpRZXobleetnvD8wfOH14NaH/ra0POqHs8fPH94Laj1YGmNqDK9jcrzVk94/uD5w+tBrQ99beh5VY/nD54/vBbUerC0RlSZ3kbleasnPH/w/OH1oNaHvjb0vKrH86f4P3+cFixYkKEuqLrIlva5Tj0gVDvzLdcbw8mqSn7GiPvKfExVzVvzOkv73A7HNzygmIWlBP5Yf7j/DKGtjfcHnj94/uLzJ8tnrPH+EBlLn7f6Zy3Xc9LLZIHZD3z+4PMHnz/4/DF5TuDzF5+/+PzN8hmrf3Ti89cQdUgxscSD60yeK6qxtsXvH/j9A79/4PcPk+cEfv/A7x/4/QO/f4j/h2HyXNB+b7D0+4beFv//A///h5eLvia05WPMcj1+/8DvHybrBL9/4PcP/P6B3z/w+0e2n5/4/cv0d1NLPPD7B37/Mvm9wvhbZ2YGv3/i92/8/QN//zB5Ttwhf/9wenDOTfFrNhIIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIOIZAte3D5UBNmzaV227dulFYWBjFxMRQcnKyLPPw8CCIrI7hjVFAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARuEdBF1ipVqlBqaqpFNhBZLWJBIQiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAgL0ElMjao0cPSklJyXYYp/Pnz2dkW4sKEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABELCDwIULF+j69es59oTImiMeVIIACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACOSWQHx8PJ05c8ZqN4isVhGhAQiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAQG4I2BKNlceDyJobqmgLAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiBglcCxY8coJSXFajuIrFYRoQEIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgEBuCBw4cMCm5hBZbcKERiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAArYSgMhqKym0AwEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQcCgBiKwOxYnBQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEbCUAkdVWUmgHAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiDgUAIQWR2KE4OBAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAjYSgAiq62k0A4EQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQMChBCCyOhTnnTvY5cQU2n49nk7FJVFCWvqdC6KInrm3izNV8/OkFoG+VMbL3WSW4UlXaff1Q3T2xgVx7ZJM6rCTlYC3iydV9ilPTQLrUWnPYJMGGVeuUfreQ5R+9gJRQqJJHXaKEAFvL3KuXJ6cG9Ujp5CSJhM7ffo0zZo1i/bu3UvHjx+nmzdvmtRjx3EEXF1dqWbNmtSoUSMaMmQIVa1a1WTws2fPymuxZ88eOnbsGK6FRofZ1apVixo3bizZVa5cWatFFgRAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAASKFwGIrMXrehXJ2e69foOWXr5eJOeGSWUl8HCZQGoU6CMrDsQco1Xhm7I2QolNBDqVbkt3lagl26YfPkFpazba1A+Nig4Blw73knPdGnJCy5cvp9GjR1NKSkrRmeAdMhN3d3f67LPPqEuXLvKMV61aRaNGjaKkJMj11paAp6cnzZgxgzp16mStKepBAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAoEgSgMhaJC9L8ZnUJRGJdd6ZyOIzYcxUEni2Sig5OcXQj+f+ApE8Euhb6VEqHeNEN3/+M48joXthEXDt3Y3OJcZLETAxMZGaN28uolwOpSd79CAvL6/CmtZtf1xm/ftvv4moq1/Tjh07JGsWWJ2cnOS1SEhIoKZNm9LgwUOoZ69e5O3tfdszsfUEmc2vv/xCs2fPol27dkk2zK5SpUq2DoF2IAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIFBkCEBkLTKXonhOZPHFKDoYk1A8J38Hz7p+CW9yc95PR2JP3cEUHHPqdfyrUad9RBnHwNIxRAt+FKda1eiVlYtp4cKF1EsIk/O/+77gJ3GHH/GZ/k/TL0LMfPzxx6XI+scff1APIRJ//8OPdzgZ66ff/+l+9Ouvv0p206ZNs94BLUAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABECgiBGAyFrELkhxm87U45co4WZ6cZv2HT9fb1dn8nReRwlpeG13XheDt4snDVpL5IRXoOcVZaH1zxCvZm/x1WSKioqiffsPUK1atQptLnfqgY8dO0YNG9xFQUFBEgGuhe0rQWe3d+9e2zuiJQiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAgUEQIQWYvIhSiu05h4+EJxnfodP29Pl1V3PANHAXh+paNGwjiFRaDalPHy0EnJKYU1hTv+uJ4e7iYMcC1McOS4o9idP38+x3aoBAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAIGiSAAia1G8KsVoThBZi9HFMpsqRFYzIHnYhciaB3hFpCtE1sK/EErGVDOByKpIWN8qdhBZrbNCCxAAARAAgYIl4Be5p2APmIejxYU2zkNvdAUBEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEMgLAYiseaGHvgSRtfguAoisjrt2EFkdx7KwRoLIWljkM4+rZExVApFVkbC+VewgslpnhRYgAAIgAAIFSwAia8HyxtFAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAoLgSgMhaXK9cEZk3RNYiciHsmAZEVjugZdMFIms2YIpRMUTWwr9YSsZUM4HIqkhY3yp2EFmts0ILEAABEACBgiUAkbVgeeNoIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIFBcCUBkLa5XrojMGyJrEbkQdkwDIqsd0LLpApE1GzDFqBgia+FfLCVjqplAZFUkrG8VO4is1lmhBQiAAAiAQMESgMhasLxxNBAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAorgQgshbXK1dE5g2RtYhcCDumAZHVDmjZdIHImg2YYlQMkbXwL5aSMdVMILIqEta3ih1EVuus0AIEQIDo5s2b5OrqChQgUCAEILIWCGYcBARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAASKPQGIrMX+EhbuCUBkLVz+eTk6RNa80DPtC5HVlEdx3IPIWvhXTcmYaiYQWRUJ61vFDiKrdVZoAQJ3OoHPP/+c+C+AkydPJn9//zsdB86/AAhAZC0AyDgECIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACNwGBCCyFvOLeGzvRQo7eY2SElLIx9+TKtUMoap1SxXYWUFkLTDUDj8QRFbHIYXI6jiWhTUSRNbCIp95XCVjqhKIrIqE9a1iV9xF1vXr19PJkydNTrhSpUrUoUMHkzLsZBK4cuUKLV++nFJTU2Vh+fLl6aGHHspsgFyRIhAeHk7Hjh0jDw8PatmypU1z4+ip586dowsXLlBAQABVrVqV/Pz8bOpr3ujEiRM0YcIEcnd3p+nTp5OPj495E+N+SkoKHT9+XB63WbNmFBwcbKzLLuPIuWZ3DJQXPwKWRNb0jAw6dSGSrkXHUcu7qtt8UonJKXT49EWKjk+g+tXKU6mgEjb1tbVfXGhjk/HS09MpKSmJvL29TcqxAwIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIg4HgCEFkdz7RARvxn0QFauWAPRV6MyXK8ijWCqfNTTahVx1pZ6hxdAJHV0UQLbjyIrI5jDZHVcSwLaySIrIVFPvO4SsZUJRBZFQnrW8UuP0TWU6dO0enTpykyMpK8vLyoYsWKVLZsWdqzZw+1aNGCQkJCrE/QxhYvvvgiXbt2zaR1hQoV6P333zcpKyo7LCUePnyY2rRpI8XEwpgXy7/z5s0zHppF1kmTJhn3kSl8AmfPnqV169bRwYMHicVjlb766qscRVJut3HjRpo/f75RVFZ9mzdvTkOGDMn1uvv000/lvdu+fXvq37+/Gs64TUxMpA0bNtC+ffukcMtiKqeOHTtSv379jO0sZRw9V0vHQJntBPbu3UsJCQnUunVr2zvlU0slsqaK9bRu5xHae+wcHTgVRvEJSfKI3703jPy8Pa0efdPeYzR9wUq6mZZubNu8blUa88wj5OribCwzz+SmnxJZY2Nj6YcffqBdu3bJ+4/l8UceecTmLwrwZ+aWLVvkvQMJ1vyKYB8EQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAELBMoViLroR1hQt7cbflMsil9/mPxD1uu2f/DVjbd7Co+eTCc/py3LVd9h77biXxLWP+HO33Qr8evpq2rj+lFFvMdnmxIfV+812KdowohsjqKZMGPA5HVccwhsjqOZWGNBJG1sMhnHlfJmKoEIqsiYX2r2DlSZL1+/boUJFloyy517dqVevXqlV11rssvXbpE/Ieji16+fJkWL15MRVlk/frrr2nz5s3EAm7jxqZR/HJ98nZ24KiZR44ckbLxokWLCCKrnSDzqRuLoSNGjCAlhOqHYam0ZMmSepFJntf/woULTcr0HY5W/MYbb9gcKZLvLW7v5OREkydPtiih//LLL7Rs2TL9MDJ/77330qBBg7KUqwJHz1WNi619BFhGnjt3Lj344IP0zDPP2DeIA3spkXXdzsP02c+rsoz8zbtDKcAv54inu4+eoUnz/qI0ESG1eoVSFOjvQ/uOn6eU1JvUpmFNeuXprlnG5YLc9lMiK3+BgqMnlyhRQj5XOc/38bPPPkvt2rWzeCy9kL8EMn78eKpZsya9/vrr4v9HuOrVyIMACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACFggUKxE1s0rjtLsiWssnEb2RbPXDSc3d5fsGziwZu/mMzRtzNJcjfjp4oEUGOJrc5857/9Nm5Yfsbl9135Nqcew/IvEA5HV5ktR5BpCZHXcJYHI6jiWhTUSRNbCIp95XCVjqhKIrIqE9a1i5yiRNTk5md577z0KCwsjT09Puuuuu+SfuLg42rRpk5RMeVbW5DbrM8++xcmTJ+UcirLI+tlnn9HOnTtp4MCBdP/992d/MgVQo3hBZC0A2Lk4BL+W/OWXX6aoqCgpZev3aE4i69WrV+nVV1+ltLQ0eTSOBtmwYUMpenOEZJW6d+9O/MeWNHv2bPr333+pVatWNGzYMItdOHLst99+K+VYFu9iYgxvfsjpXs+PuVqcHAptIsBfAnj77beJJfd3332XqlWrZlO//GykRNY4EYF1vZBZQ4P8qWq5UBry/lx5WFtE1tc+W0DHz4dTi3rV6I2Bj8p+u46coffn/UkZGRk07eWnqVKZ4Cynkdt+LLJy5GS+b0NDQ+njjz8mZ2dn4sjK77zzDtWqVYvGjh2b5TiWClhgZYGcv/DBX/xAAgEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQyJkARNac+eSqNr9F1v/WHKeZ47JGsbE2yTe+eJxqNSpnrZld9RBZ7cJWJDpBZHXcZYDI6jiWhTUSRNbCIp95XCVjqhKIrIqE9a1ip0ty1ntl34KjjHK0UR8fH5o4caJJ1EiOMPnhhx/SmTNnqGnTpvT8889bHIgFPhbcWOLhVzSXKlWKypUrR76+tn15R4mZuRFZ83JMPq8LFy4Qvw6aI/CVLVuWgoKCKD4+XgphnDdPeRFZ8zJXngfPlyVHxVPxgshqfpUKf5+vE0dy9PDwoP79+xsnlJPIOn/+fFq7dq1s6+7uLsVEjsDKY3E01cOHD8s6vkd5HBbOc0os0rKYx/0nTJhAPFZ2idcWj8dRVjnKL6ecRFZHzzW7eaHcNgKzZs2SXzioUaOGXDe29crfVkpk1Y+SnJJKvd/8XBZZE1nPXb5KL0z5XradNfY5Cgn0Nw713uyFtOfYOeratjENeqydsZwz9vRjkZW/xMGyar169ei1116TY/J9MXz4cCm3fvTRRybHyW6HxfBvvvmG/P39acqUKfIZkF1blIMACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACBBBZHXgKshvkXXi0N/p5MHLuZ5xiwdq0PAJD+W6ny0dHCGyuosoN+ItpyYpXUTWSU3PMCnDjmMJOEJkdXN2JWcnZ/GaTyFpZBiihpnP0tXJhVycDVGRc2pn3q847TtEZBU3gZObja8dFYJYxk3LvB3FzfeBNuRZt5aMcnX9218o/UaCo4bOMk7Akw+Ta+lQSk9Kpqg5P2apL4gCiKwFQTnnYygZU7UqbiLrF1/OlJJY2zatqUmTgn3NvGLnKJFViWmNGzemF198UV0S45YlOo5Sx1FILb22+tChQ8RjhIeHG/twhqPatW/fnp544gny8vIyqTPfUWKmrSKrvcdMSEigBQsW0MaNG+XzTs2DX79eu3Zt4tdDs/w3Z84ccnFxkXIun/+NGzeIX9/Nom6zZs2IpTE9BQQEyMiXepnK2ztXliH5VfPbt2+XEQM5CiG/mr5Ro0bUokUL+uCDD+QrsCdNmqQOlWXLghbPmyXj5s2byznydUEqGAK2iqwszLFEzck8gurRo0dJv8ajR4+WazCnM+A1vmLFChlZmSO92pJYYrVFZHX0XG2ZG9pYJhAdHS2f2fzMevrpp6lDhw6WGxZwaV5F1j837KJvl2ykCqVK0mevZsrgfBrLNu2hOYvXU9mQQPritQEmZ2ZPPxZZU1NTaeTIkcTRyR9//HEpfvNnxI4dO+iee+6hwYMHmxwnux2OisvjJCUlISprdpBQDgIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIaAYisGoy8ZvNTZL0WHkcvP/GtXVN0dXOhOeuH29XXWqe8iqyuzk70Yeu7yMXcZBUHZkHjenIq7b4STVvDr1FUUoq16TisvqKfN1Ur4SPH+y88ihLzWRp02MRzMVBeRVYXIaiOb/mCuHYudC3pOn2ye3aWowd5BtCwu/qRr5u3rDsSdZK+O7owS7viXuAIkdX3/jbEf2xJGckpFPH+NFua2t0moOej5Fm/tux/ZdosSouKtnssax2DRz5LrqHBlCHEi4jxU6w1z5f6vIqs24RYNmv2PJvmVrFSBXr3LdteS2vTgIXQKEFEJuMIfyz7lRORKx2RlIypxsqLyPrmW+9QREQk3VW/Hr3w/Cg1ZJbtn38tob+WLJPnMX3aFPLxNjyrsjS0oaBO/Yay1fOjR9L/htgmudgwrE1NFDtHiawciZGFSY7KOHXqVGPUT30yHJ3Okoy6atUq+vHHH2VTjkLHMixHDeXXMrPAyYmjho4bN4440mR2KTciq73H5Eix/KpoXsuc+HzKlCkj1k6EFFX1uanomd9//z2tWbNGr8o2//nnn8tIfHoDe+fKr3hnUZXFWU5877m5uclosbzPr4Fn0TWniKzqNffXrl3jLjK99NJLUoRV+9jmLwFbRFaW3oYMGWKcyLBhw0ykaL6OXMb3IKennnqKHnoo+y+ssazNQjq351ed161b1zh2ThlbRFZHzzWn+aDOOoHff/+d/vrrL8Nn2vTpxEJ9UUh5FVm/+WsD/bVxN93XtA690Md0rR85c5He/OJX8nB3o58njTQ5XXv6scjKib8wwJHJWWpVqXTp0jRw4EDavXs37dy5k3r27Glyb6p2+nbGjBlSgOXPQ/4c4ec2EgiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAgGUCEFktc7GrND9F1gP/naMpL/9l17y406Qf+1LZyllfi2v3gLc6OkJkndymgdVpJKSm0RcHTtGlG4Z/tLfaIY8NulcrR/eWDZajzNh/kk7H3MjjiEWve15FVo60OqHVy/LEYpLj6MNdX5mcpI+QV4fd1ZdKegbK8ujkWJp54EeKSYkzaXc77DhCZPXrcC/53NPSJhwFIXxCZLXpUhgbsRD5+ptvGfdzytSqWZMWL/wtpyZFvu6XX3+nce9NkPPcummDQ2QZJWOqk8+LyNqhUxe6cPEitW7ViubOnqmGzLKdNn0GfT17jkPO43YSWU+cOEETJ06UXyjhV5dz5M4GDRrIVyqXKlUq29cjX7hwQYqhLFTWr1+fnn/+eZO2e/bsoelCrmIR78EHH7QYzVVdJFtF1rwckyXdvXv3SgmUhaSOHTvKqLE8v3379hGLqEpi4rbBwcF0+fJlKTDxl202b94s9zkiavXq1dXU5ZYjpbZpY/rlhLzMlbnt2rVL8uzduze1bdtWisAXxTrn6LfHjh2Tx81JZGUJlkVGPVm7Dnpb5PNOwBaR1fw68SvOa9WqZXJwft05r0VOHHWTo29ml5YsWUK//fYbVa1aVQrk2bUzL7dFZHX0XM3ngP3cERgzZoyMhM3rhddNUUl5FVmn/LCcNu09Rl3bNqJBj91vcloXIqJo1OT5suzHicPJ29PDWG9PPyWy8iBXrlyh/fv3ywjW/EWRuLg4+aUMruMvPbBwXq1aNd7NNm3atIlmzZol69977z2qXLlytm1RAQIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAJ3OgGIrA5cAfkpsu5Yd5K+eGuF3bMdN7cXVa4danf/7Do6UmTNEAdZfyFSRhHydnWhMj5eVME389XDcak3afz2w+I19twyfxNEVut8cxJZ3V3caFC93uL6lZEDxacm0NdCYr0qIrfejsnRImvq5Ui6ecn0ldw6twzxqtPYlev0IofnIbLmDqkust4rBLOQUiHZDlBGRPQaMex/2dYXhwqIrFmv0u0ksvLZrVy5Ur5WXEV9VGfs4uIixZ2uXbvKaKuqnLfz5s2j9evXS8GSo4eGhGS9D3744QdavXo1eYvot1999ZX8zNfHUHlbRVZ7j6kLeH369KHOnTurQxu3LLlyBD2WVlkkDQw0fDFDNfjss8+k1MoR+u6/31SuUm30rb1zZbF4wgSDOD506NAsgiyLwyytsdiYk8jK58GiG0ecVSk3ETpVH2ztJ2CLyHrkyBEZfVcdhaXyihUrql25HT9+PJ06dUrmW7ZsScOHW37zAovYHI2Vow+PGjVKSukmA+WwY4vI6si55jAVVNlAgAX85557jtJEdPsuXboQC+9FJeVVZB0/ayHtPX6OnnywBfXtbPoFgavRcTR4ouELKV+/+RyFBvkbT9uefrrIGhYWJj/T+EsLHNmYI1/zFzv4eV+7dm3jcXLKsAz78suGL/6ZR1fOqR/qQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQOBOJACR1YFXPT9F1qN7LtKHI+1/Jfsnfwyg4NJ+Djxbw1COFFmjk1OlqKpPsklIAPWrXYmcbhVO23uCzsUl6E1M8u7OznRTiBrp4k9ekj0iq7uLM6WkpeflsFn6OotXB7uKPyniH6cdnfIrIquzkzM9Xbs71Q40RChKSkum2QcXiGi6kdmegpuzeCVyRpqUhbJtpFXwK5VZpE1Nv6mVWs86iZXk6pz7ftZGdrTIGvPnSkrctd/aYfO1Pl9FVnFDOwkZIEPI6ZyCRz5LrqHBZC3SrJMQ3LkN5e32tsit2pTxstzeKKC6yPrT9/OF4NfI4nFul0KIrFmv5O0msvIZsrizbt06OnjwIHHkT369PcuQKvXt25c6deqkdknJdfzq5OxeXx4ZGWmMJPnJJ5/IKK/GAbSMrSKrvcdUUfJYzJ09e7YUlLTDG7Pbtm2ja9euSTHMWHgrk1uR1d65rlmzhr7//nsp0rJQaynxdfrmm29yFFm5H0tVLGVFRUVRs2bNZKRdS+OhLH8I2CKyspDMEVdVevPNN7NIcyryJrfhe5DvRUtJrQt+JfqHH34oIw5bamepzBaR1ZFztTQHlNlO4OrVq/TSSy/JDubPZttHyZ+WeRVZp/64nP7dwxFZG4uIrO1MJhkWcY1GT/5Oli14fyR5ergZ6+3pxyIry8AfffQRHT16VI5VtmxZ+cWM0NBQ8vT0lNGNmzRpku0XMYwTEBn+osGzzz4ri7p37078BwkEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQMAyAYislrnYVZqfImtyYioNbZ/965FzmnBQqC9NXTQwpyZ21+W3yMoTG35XNaoR4CvnuOjURdp46arJfKv4e1O7cqFUXkRvDfJ0F3JjBl1JTKb9V2Po7wsRJhFcPYRsym3vKulPwV7uxOJrTMpNupaUTIeiYmnv1Wh6pHJZeTxfN1d5nIvxiXRdSLYqLT17iSISkuVuYyHa3l0qiMqJY3P7hNQ0unAjkXZFXqft4lWXempXLoSqlfCltIx0+ul4GAV5uMt5lPf1pqjkFPrz9CXZ3NXZiTpWLEXVS/hROR9PYkE2NiWVeB7LzoXLrT6uvfn8ElmfqPYQNSvVQE6LRdNvDv9KZ2IvZJlmJb9y1LZscyrrU0pctxJ0U7S9mhRFB68dF5F5twlOQljUEour91doLRhWpDLeoYKLG8WlxNPlhEhadW6jiSjr7+5L3ap2kL0PXTshROBUahZanyqKY3q5esrIsCeiz9CKs+tzLcNqUzJmC1pkdRLiVYknugoZ1EXO4ca23ZRy6pxxPpxxLR1Kfg8YolZlJKVQ9MJlxnrXMqXIp2UT2YYFUhJC6c1rUZR6/iIlCIH2ZuRVsiSyuoYEkV+H++Q43C75mCEanBrY2c+X/B/uIP5hnyjx0DFK2ndYVcmtZ92a5NW8EbmXL0tOYv1nJCVRStgl8qhRVdZbElndKpQlnzYtyK1MKLkEBlCGEAJ4rsmHjtONjf9RhoMk74IWWc+cPSteV3tAnnfFCuWzRLbkiqPHjhtfF96sWVMqLV7pvmzZCuHxZlBDfs17qVD65591tGfPPgqPuEx16tSh+9u1o3p168hxzX/sP3CQtm3fTkePHBWyf7oUo5o3bUpNmjQ2acoCh36cypUryder83wvXQ4Xr4VPoy1b/6O/liyV/d4a+zr5+hie0VzQqWMHKXqYDGrDjqdYE3qyVyrmMTp06kIXhHjZulUrmjs7+8/OadNn0NezDZHctm7aQAEBAfoU6Pz5MNq0ZTMdOnyEoq5dp8qVKlHDhg3EObbPIrBYElkPC9YcTdPDw5Me6tSBeH/zli3y2vOxGjdsSF27dpavizc5cC53FDt+9XF+pmQRDXq7WENLly6VMqq7uzvNnDnTKIGOGDFCvnrZljlw3xkzZpCXV2bkdb2frSKrvcdUkl7JkiVl1FX92Lbmcyuy2jvX7777jv7++2+qUaMGvf322xand+jQISle5RSR1WJHFBYoAVtEVr7PBg8ebJyXeRRefkZzZMck8RnKKTtpkSN0shDLEXhZpGsnPh9yk9Q9wn3uvfdeGjRoUJbujpprloFRkGsChw8flrIydxw5ciS1aNEi12PkV4e8iqzfLtlIf27YRfc0rkUv9e1iMs3Dpy/S2C9/JS/xO8RP748wqbOnH4usLJ9OmjSJSonfuzj66noRaZy//KCnBuL3MBaHncXfJa0lvl9v3LhBrcTvJJxHAgEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQsEwAIqtlLnaV5qfIyhOaOW4V/bfmeK7n1qVvU+o5vHWu+9nSoSBE1mFCZK15S2RdcuYy/XMhM7Jn+wqh1LlSaeLIpZZSmJA/Z+w7IeVWX3dXeqFhdSrp6WGpqSzbIeTT5kJMzSnNPnSGjonXWPaoXl5KrNm13XMlmhYcPy+PzW0G16tCdW+97nLDxStC4gwml1vzDk9Ioo92HaMQLw8aUKeykDs9LQ6bJiLh8Zi7IqMt1uemMD9E1vYV2tCD4g8nFuW+P7qIjl43lR25rl25ltShYltx3Sz/4+/F+AiaefBHKbdy+2DPQHqqdjcpsPK+eWLp9fcTK4SIbBAny/uKV7c36G/eLMt+WNwlmitE2+S0lCx1uSkoaJGV5xb4TE/yqFZZTjMtJpauzphLGUJ45uQkZOigoc9I+ZP3k/YfpujfDdKhb7tW5HNfa2IZ1lLiKKkRE6ZaFFk9alWjwL5PyG7x6zYT/9GTW7kyVHLo07IoYcceil2yxljt3/kB8m7VzLhvKWMusvreezf5PHCPOB/L6yT1UgRFzflByK1plobLVVlBi6wXL12ibt2flGIDv2J96Z+LqEyZ0sY5x8XF0cPdHieOXsmi3ZJFv5OHEP6aNm8p23Ts0J6OiEhhYWGmkji/9nbSxAn0yMOZogcLGSxszvt2vkk0TXWwPn160WuvvGyUKRMSE43HeeP1MeTr7UOTPvpYzlX1yWm7ZtVyKl+uXE5NLNYpGVNVFrbIylFnP/x4slEWU/Pibcu776Ypkz+goKCSxmJLIuvkT6ZK7hyhtHfPHvTDTwuyXAMWib+c8RmVKOFvHCu3GcXOUSIrC5oc3Y9fV+/hkfUzk6PUseTDSX/t+TvvvENnhaTNwlxOUec4Ciqve16v2SVbRVZ7j8mRVr/44guyFpE1u/lxuRJZ+/XrRx07dsypqayzd65//vkn/fHHHxQcHExTp061eBwVedMWkTU6OlpGZK1SpUoWIdvi4Ch0GAFbRFY+mC4986vMR40aZZwDR0j++OOPjfsvvPCC+EJCE+O+yrB0/vnnn4tnSwkpa+d0v6k++tYWkZXbO2Ku+nGRt4+ALrKOHj1aRly2byTH98qryPrXxt30zV8bqFxIIH3+2gCTCRrrQoPo8zHPWK7LRT8WWfWk7jeWWnv16iU/ExcuXEinTp2Swvk999yjN7eYVyKr+b1ssTEKQQAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQOAOJgCR1YEXP79F1vMnrtI7Axbkasbevh704c9Pk3+g5YhnuRrMQuP8FllZUH2tSS0K9TaINN8cEVEMRaRVTvVFVNXn6laReX7R8T4RTfWSEFf9xCslWwoZ1e2W/LbyXAStOh9OvWtWMIqnyWnpdComXkRjTaVQIY9W8feRMuzWy9eohOhfWex734p2GSmir0bfEgT5YItF5J8aIrJq92qZotaJ6HgKT0yiUCHJ1gr0k3PiH8vPXqY1YQbxVhdZjQ1uZVhk/ViIrC82rkkVRHRXTlEiiibLsBxhtrYYs7KIPMuJo76+v+uI3MoCO384WmT958IWwaSTnA1HjPz1xDLae8U0IidX1gmqTv1rP25sd+DqMQpPuEJ+bj4ykqubs0Fs+jtsE60N20JO4j+WUsv5lpJ9rifHiDVwVEZSrRlQRURZLSvLE1KTaMqe2ZRwM1FE580qsrLsGpFwVVxXLwrwyBTGVp7bQBsubpNj2PvD0SJrwpYdlLj/SLbTuXnlKjl5e1HIiGfJ6ZaYnSCissYu+1v2YVnVVwignKTk+sU3IvppMnFE1IDej8lyWRcdS6lhF0mYXCIqqhCahGyXHyKrZ71aFNCrm+lxL4XLiLLuVSrK43KlLrJ61KoupFnDOhHmHyWJCK83wyOJo756NWkg+hjWSfw/myh+/Rbj2PZmClpk5Xn+/sdCevvd8XLK97ZtS1/P/MI4/bHvvEsLFy6W+19/9TndK0QJXTBVDVkGrCsisEaJKLWnz5yRxU7iublEiLHVqhqej+Mnvk8///yrrKsgor+2bdtGSPTOtGnzFjp77pwsf+SRrvTxBwYxUT+Oj49PFoG1Vs2alJScROfOnZd9GzduTB4iuqZK5oKnKre2VTKmaleYIitLvyyhcqpbp7aIyNZORg7dsWMXbdi4UZazLPzxhx/IPP/ISWQ1NhKZSpUqUqnQUiLK62Ej2y4PdaIpn2SKaXp7W/KKnaNEVo68mJKSQizdtW/fPssUOLKciio3YcIEcU6VZJvZs2fTv//+S/waZhZcsxPnOKIkj59dNFYezFaR1d5jhoeHE7+enVOPHj3okUcekXn9B0e03Lp1K50+fVpGvTSPvPf111/T5s2bZV8ew1qyd667d++madOmyeFZaGQZSk8sq7N0zK95tyayfvvtt8TSa4Z4rrIk/9Zbb8mtPh7y+UfAVpH1p59+opUrV8qJsGzN17d69erGSJF8f3Dy8/OTkipHODZP7777Lp0Rnws9e/akhx9+2Lza6r6tIqsj5mp1MmhglcC1a9foxRdflO2eeeYZevDBB632KagGeRVZL0ZG0ciP58vpfvn6QCoTHGCc+jszf6cDJ8Oo231NacAj9xrLOWNPP3ORddmyZfTLL79Qnz59qHPnznL8ffv20ZQpUyRjZp1TSk1Npeeee0426dq1q5Rhc2qPOhAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARC4kwlAZHXQ1XeNjqIzW4/R2xN35mrETxcPpMCQzFcyW+u85rd99OM0g0RjrS3Xj5jYmZrfX92Wpna1yU+RlSXWhyqVog4VDAJjshBf3tthEDhdRMTJ15rWohAh8bHEOu/wGfFK+ljjOVTw8xLRV2tIOZX7vbHlII27uy75u7vJNt8eOSvEV4MQywWlhCj7cJWydDb2hpAnI6Wkeq+ImMppxv6TdDrmhszzDy8huI5tVpt8bol0i05dpI2XrhrrW5UuST1rlJf7SeLYE3ccpRsiyqW5yHpSiLS7RWTV8IREERE0Q8iXXtRHyLacWLLlyK8s3HJiFs/UrkQNgkvI/b/OXKJ1F67IvL0/HCmy8hxYimGBjtOSM3/Tlsu7ZV7/4eLkQi80flZGWGXZlSO2HokyyBjcrhwLqHc9LcfhKKnjt02nxiH1qEeNLnKYM7FhNP/IH8YIqny8p2p2E1JzTVm//Ox6+vfSdhORlee16fJOYjE2JS1VirGPVetILUo1lH1iU+JFNNyZMoKsLLDjh6NFVmtTiPlzJSXu2k9ejepRice7GpqL84ya+xOli1cSl/zfM4aIq1z27c+UciZMSqPBoweTS4BB4mUxNGbhMimu8gAsxPrd35a8GteniEnTHRaRlSO/Bo9+jlwCDdJB4u79FPvXasoQgpg8rngVbPCIgWJeJYwiK0dgDR4l+pQM5IVF139aRMnHMteJa9lSFDxURNwV1z8jOYUi3jcIXnJAO384UmQNCAwkJRZams7nn02nekI+5fS/4aOMYiRLkSxHbhJi3OChw2V979496d23xsq8Lph6eXnS86NGCrnuKXIVjDnN/+57EUH0E5l/4onuNHH8OCm3PvrYE8TiYJvWrWn6tCnkI+RXTvxa6pdeGUPr1m+Q99zvv/4spU39ONwuJDiE+vXrTQ3Fa3Tdhexcp04d+vOvpTTuvQlcTVs3baCAgEypRBba8cOcmSNEVhYpg4Mzo6aaTytWRDPm8+WkziMq6hp16vIoxcfHU/fHutF74981MuZ2n06bQbPmzOEsLfz9V6pTu5bMWxNZOfLqBDFWVREFkxNHPO0/4Dk6c/ascMmdadWKZVROCKD2JMXOUSKrirDI0Vj51cl8zVViaZJfdb9+/Xop0XFUUhbtOJ0TYvS4cePkertbRK1laY9FO07cj4XQnTt3StmVRdbp06eTr6/l34FsFVnzcsxZs2bJ10Xz/Fn269Spk/E10cePHxcC+M9SqOXPGp6r+TpnuYklp9KlS9PLL78sX0PNr1o/ceIE7dixQ54rS6cDBgyQDOydK4tQLDKyfOvp6Sml2jZt2khR+JKI7sxyKkfJ5ZSTyMqRWJ9//nn5eS0bix+PPfYYPf74rS8NqEJsHUaA1/xff/1FHGWbE68NlVgAZwGVI+2yCM1bla5fvy7vPX52c2Lpu169enTx4kUpLKt22UmqR44coQ8++ECuF167OUnjaize8prme48l7itXrhCvGU58n5YpU0bm+ZX1fK+olNe5qnGwzRsB/n138ODB8ksCRe2+zqvIymTGfvkrHRZfJmxcqxK9Pai7/L1ly/4TNPm7pRIcR2rliK3mKbf9zEXWjeLLK3PEZz4/c4cOHSqH54isixcvlpHHc4o+zo35PuLPB04DBw4UX4y5X+bxAwRAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAICsBiKxZmdhU4pyYQB5hZ8nz/GlyP3eKXGNjKDKgPPWdkyk82jJQbkVWHnPd4oP03SccTSv7I/j4e9KAMffnq8TKR3ekyJouTmj5uXByFZEC/dxdRNRTP2MkVj7WkjOX6Z8LkZyl6iIi6ogG1WR+R0QU/XQ8TOb1HxytlaO2chq37TCNEeKrirI6Zc9xuiCit2aXONpqdiKrHgn2ohjjEzGWeRotJNoqtyKofnf0nIysqousfC7rxLnol3CkOJ9q4ry47H0hv14TETT1VE6Irq+IiK2ctoZfExFPL+jVuc47WmTVJzDn0M9CxjVEa9TLq/pXoMH1+8ii3ZEH6beTy/VqmX+6dneqG1RD5j/Y+aWIpPuIYFlBcMmgT3bPFpFqDVKF6ljWJ5RGNRwgd3dE7KOFp1aZiKw7I/bTH6cMUc1UHzdnNxrbfAR5uLjLosm7Z2UZV7W1ZVvQImusEFkThMjKKaBPd/KsY+CVdu06pQtZzK1UiKy7sXk7xa1aL/PulcpT0HNPyXy6kKevTJ1JGVqkYVkhfjgJ2ZvLA3o+Sp71a8viK9NmUVpUNHnUqiaipD4hy+LXbSb+oye3cmWo5NCnZVHCjj0Uu2QNuVcWx33WcNy02Hi6+qk47i1BW/UNHvksuYYGG0VW98oVRB/DOkncc5BiFmVdJ4FPdSeP2obzjpz8JaXHxavh7No6UmS1NoGfvv+WOIoppytXr9Cj3Z6g6JgYYgH21wU/0DMDnxOiUjhVqVyZ/vjtFyEgecq2umA65tWXaKCFKGCPPPa4kJBOSXlw+9ZNpKKxsoi3bMliOaYc7NaPi0KC69S5qxAP06W0OWnieyaRX1l+/WTyhxQgXk2tp19+/b1YiKz6nK3llcg6/bPPaeas2fJ6/L1quVH8Vf1vJCRQy9b3SDHzvXHvUI8nDfdETiIrS2B8PZTsr8ZatXoNvfDSK3L39ddepWee7qeqcrV1tMj66quvUkREhJwDS541atSQUVcjIyOJX1/NsianZ599ltq1ayfz6seSJUvot99+k7sswlasWFHKoSz0sZCpEkt8LL0qCXb//v00d+5cKWFxGxZf1XE4MrBK3P6VV16hyuL+UMneYyYKifm9996TciCPxZIovz46RtyPSuDja8aiZ7dumVGl1XHDwsKII9KyFM4pJCSEoqKipMir2rC0xPKSSvbOlUVVfp08c+HE0WFZglTHZi5KevT396fhw4eLaM111WHlNjY2Voqsqh0X8quyOUogUv4QYAGORThrSY/2qNquWrWKONopC4qWUk0RHZvvBV635onXCr8SPTcRIHXhznw8fZ/XHZ+XnvIyV30c5PNGgCMs8xca6tevb4w4nbcRHdNbiayr/ztAC//ZQTfE33FYlk4Qb5/g5CW+1MRf6PAUv4M+3aUt3dvE8PunfnSOujphziJKvZlG5cWbN0IC/GQk1pvi95cHm9ejkb066s2N+dz2MxdZWULnLxLwZwI/493EF3r4CwT8+cbPf/4iQ06Jv9QwY8YM2eSNN94w+WJITv1QBwIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAJ3IgGIrDZedSchDrhfCiMPIa16sLx6RQgeZv+wXFAiK0854kIMcXTWnetOUvS1THk2uIw/tXigOnXu04T8Ar1sPDv7mzlSZM1uFnEimulvQto8cC0zgmprEfW0x62opzHJqXT4emY0VjVO45AA8hRiB6fP95+SYqqKaMqRUv8Lj6JDIorr+fgEEanTEB1S9c1JZG1XLoS6VS0rm+pyrerL23tENNfHhQzLafnZy7RGRHnVRdZ3hVgbayYRjtcixrKoap5chUzTXPzDLacT0fH05YFT5k1ytZ+fIuuN1ATB/DuKTja9LhwFtXs1QxQvjoR67HrWc7gruLa4bh7yXGYdXCCi1D4ixGZDxD4WVc0TR3ltElpfFrM8yxJteY7s2kBE7BRpW8ReWnxqtczrP3RhNjvxVm+fU97RImvyidOUcjqrCKzmkHT4GKVdN9wPzj7eInrps+R8K8qmapMaEUlRM78zSqPeTRuQf7eHZLUuuKr25ltHiaz6ceM3bKX4tf+aH4rMRVbvZg3J/1HDOmH5NflE1nXiVa+2jCLLg0XN+4lSzuZN7HakyNqrVw+qWKFClvNUBY8+3NUk8t6yFSvplVdfk9UsJLGYxpFEF/z4HdUXEfhU0kXWN14fQ/379VVVxq0eLXTHf5tp5OgXadv27SKSX136/ZcFxnZ6pm//AbR79x5q1LgRLfh+vonImt1xiovIWqFCeerdq6d+uib59Rs2isiZO2WZEllHjBpN/6zbQDWFvPnKyy+atFc7r455nWKEFDjo2YH08ksvyOKcRFZ/fz/atmWT6m7csqjZpHlLKfQ80/9pen2MQWo1NrAx42iR9cMPP5TCKr96nuUdXXzkKbHMwxEkW7ZsaXGGLND98MMPUvbRG7Bs2UBE9uXIdk2aNJHrXNXzq5o5uqsuu6o6fcsS3ZgxY4glPj3Zc0zuz2IoR8zk17grKZTLWRRt2LAhdenShWrVqsVFFtOpU6ek1MdikxIO+T7m82Q+fJ48lp7snSuLsxxFliO7qsSRNh944AGqWrWqUZZizvyKcZ6DeeIogsuXL5eSMAvKL7zwQrZRcc37Yj/3BLaL5+/8+fONEVktjcD32ahRo+Q1NK9nCW7evHl040bm7/p8ffkeGjBggMk9pPry+nj77belJD516lQKFF+SsCWxWMhyOfdXa9m8H382cbRlFZlSr7dnrnp/5PNOgNfa2rVr5bX/8ssvbY7Em/cj5zyCEllXbtlHsxb9Y/5XaGNnVyGzDu7+AHVseZexTM/sPHyapvy4nJLE3/048RcN7mtSh0b17ijfXqG31fO56WcusvI4/HxnqZwjKvNnRmXxRQqWz6tXr64fxmKer8N///0nv2D06aefyi8gWGyIQhAAARAAARAAARAAARAAARAAARAAARCLi5pgAABAAElEQVQAARAAARAAARAAARAAAYLImt0iEJIqy6ocbVVGXRUSK8usOaWCFFn1eURFxFNiQgr5+HlQQHBm1DK9TX7lC0JkXRMWIWTQcJNTeLRqGbq/XKhJWU47cw6fIQ8hkjxdu1KWZhwJ9qAQWpcK4fRKoiHKXE4i6xPVy1HbMsFynO9FtNXdV0wjhHIFC7MD61SWbVT01JxEVg/xD7cftrb8j7ZyELMfYSIS7FQLkWDNmuW460iRlaOlbg/fS81KNSAWSzldjA+nmQd+pJsZacZ5dKl8v5B8mxv3rWUWHF8iRVZr7VT9xfgIIdDOt0lkfaLaQ3K+3Hfe4d+EHHxGDZPrraNF1hgRcTXxVsRVWybjWbcmBfR+LLOpWNNXv/yGbkZcNZb5dbqffNoY2OsRXY0NzDKOEln9Ot5HPm3vlqNzZFWOsGqezEVWv07txFxbmDfLdv/6j39Q8rGssmu2HSxUOFJk/UnIoI2FFJqb9NLLr9KKVZnC9fOjR9L/hgw2GcIWkXXBgl/ovfcnyX4cgXXwkGF06fJlav/gAzRj+qcm46mdV4SUuWz5CmKZatOGf24rkbV1q1Y0d/ZMdapZttOmz6CvZxsiCyqR9eFHH6NTp217Hjz6yMP00Qfvy3HtEVm5Y+t776frIopnl4c60ZRPPs4yR1sKHC2yssjGEVJZkGSJ9ezZs8SvD+fIqCyx8uvrWaazlhJE9FoWgFJSUmS/oKAgm/pZGzenenuPyeLe1atXZSRaPz8RET40NFcSGEvJHMWWGbE4aC6vWpqzvXPlCIEstfJxOBqgeaRfS8fSy1jE4mNz5Fakok+A1+Zl8Rzn+5Kf0xzNmKNBZpf+/fdfmj17NrVv35769zd8qSe7to4uz+1cHX38O308foZxRG1+brMc3by57b9z5yc7JbI64hgcgfX4ucsUn5hEtSqVoRK+3jYNa2s/SyKrfgBe47Y+c/mLGSNGjJBfknjsscdkdG99LORBAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARMCUBk1Xi4xsbcEleF9Bh2hpwTE7Ra69lLPmXpmfnZv67e0gifLh5IgSGGaJOW6ot6mSNF1ngReXXSzqPylPvVqiheL28QLFg0nXXotIjeGW/E0aN6eWpdpqTc58imZ2NzvlbLz4VTREIScTTVDhVKkbdbVgEnTRxn/pFzMvJrTiJr75oV6O5bkVG/OXKW9l81RMY0Tk5kmpUKpL41K8qijZeu0qJTF3OMyOrn7krv3Z0ZedHSmPr4l8W5rBTnlJfkSJGVo6t+sPNLalW6CT1atb1xWjsj99MfJ1ca9x+r1lGwMwh+caLP+fjLxjpLmS2XdtLg+oZXzHP9oagTlpoZy8JvRNLfYZttEll7i0ivDYPryL4/HF1kdWzjQSxkCltkdS4hpKuXhxlnliGiql2Z+jWlx8YZy/wf6UDezRvL/eg/llLSvsPGOksZqyLr+s0U/89mk65u5cpQyaFPy7KEHXsodska8n+koziu4ZpH//InJR06ZtKHd8xFVr1PWlw8pYZdytJHL4hfu5FuXonSi3KdL2yRdauI1vXsoKHGef/2y08m0Vi5whaR9eeff6XxEw1i5fKlf9KTPftIYe2xbo/SB+9PMI6vZ8a+8y4tXLhYvp56z85tNh2nuERktUdkbdXmXooWr5ZnYaxxw6wRLXV2d7dsQf2eekoW2SuythEiK7+Ovmvnh+iTyR/pw9ucd7TIavOB0RAEQKDIEWBR+ejRozJqMUcwRrqzCMydO5c2bNhA9evXl9Gri8LZO1Jkze/zsSay5ub4HKV4xowZMnLytGnT8OWB3MBDWxAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAgTuSwB0tsjonJ5H7+TMi4qoQV8+fJtfovIlQ591L0XM/peRqIUFkdaLJbQyiULR4TeT47Qa5zstVvBa3cQ0K8TREnEq4mUbT9p4wRkx9oHwoPVKljGTNkijLorYmN2cnqlrCl6r6+1CdID+qoEXyORgVS3MPnSFdZP18/yk6FZMp0XasWIo6VyotD/eHOPYmC8e+u3QQ9a5RQbb5OyySlp29nKPI6iRackRWdxGZlc917NasUSttPT9b2zlSZI1JjqMPd30lD92zRldqHJIp5S4+tZq2ReyVdfeVu5seqnSfzC85s5a2XN6V43SdyInGt3yB3JzdKPFmEr23/bMc26vK8r6laUQDQxQyPjbPwTz1r/24uP6GV4LO2PctXRISrL2psEXWoIG9yb2KQZxW55B88gxd/+43tSuiorYgv47t5H783xsofuM2Y52ljDWR9ca/2yhuzQaTrpZEVt92rcn3gbayXeyS1ZSww7AW9I7mIqs+19jlaynhv5zXiT6WvfnCFFk5kuOTPXvTyVOnjdPn19r//usCcnNzM5bZIrJ+/uVX9MWXM2W0MJZSn+zVh06ePEVtxWuoZ3/9pXEsPTNy9PO09p/1VKFCeVq9YlnuRdZ/11OAja+u1o9rnlcypipPSs7d56nqx9sOnbrQhYsXyR6Rla/FocNHqE3r1jRnluG5po+dXd4ekZWj5jVs0kxEz0unwYOeo5deGJ3d8DmWK3bnz5/PsR0qQQAEQAAEbm8CV65ckQIrf75MmjRJRtAu7DO+U0XWCRMm0IkTJ6hjx47Ur1+/wr4MOD4IgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIFHkCd5TI6pSeRm4Xwwziathpco8Q0SBF5EJHJYisuSfpKqRSSyIrj1TGx5Oeb1iDPITcyYkjqk7bd5KShOh5V8kS9GzdyrKcJVOWTe1NdQL9aEj9qrJ7anoGvbn1gJBky9K9ZYNl2VcHTtHx6EyRtWloAPWrVUnWHbgWI15Lf1bm9R8cUbZpaKAs+vlEGG0Lj8pRZOWGrzapRWXFOXP6QpzPSU2elYUO/pFfIqubsysNa9CPyniHyhmnZaTRrIML6HzcJaoXVIP61e4uy8/Ehslya6c1utEA41izxTinRT9ryZrI6uXqSa83HSbEYYMkOG7bdEpOS7Y2bLb1hSmy+rRuTn4P3W+Ym4gqLAxG4zx1cdSjdnUKfOpxWZd6KYKuzZxvbGcpY0lkda9emYL695TNE3ftp5g/M6PtcqElkdWrcX0q0b2L7JN04AhF/7ZE5vUf5iKrZ50aFNDHsE5SzoZR1LwFevN8yRemyPrBhx/Tdz/8KOXTB+6/T0qlfJLmYqMtIuvgocNp0+bNFCpe/75h3d80YtRo+mfdBipVKpTWrl6Z5bXu/Irch7o+QufPhxnFTVuOo0dk/Xf9WgoONjwv83JxlIypxigskfWVMa/TsuUrZETWtatX5PgKbzVX3tojsu7bt5969zVEMX5v3DvU48kn9CFtzit2EFltRoaGIAACIHDbEli6dCn9+uuv9MADD9CAAQMK/TzvRJE1LCyMxo4dK74kVIHGjRtn8sWkQr8gmAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIFFECt73IOv/3HuRz6Sx5srh64Tw5pdof4c3aNYTIao1Q1vqcRFZu3TC4BA2oU9nY8TBHTBXiqL+7K41tVoe4P6fsIqPWDPClByuUklFWhzeoRmvCIujQtVjjeJxxFuLfh63ri6ifzpQmpK7Xthyg9uVLicihpWS7xacv0YaLV4x9gr086I2mtWQ/lsA+3XeCwuISjfWlvT3plSY1yUWMK7RC+mT3cRHtM9GqyPpk9XLUpoxBBgsX0u6XQqCNS7lpHJczHKn2IRENNvxGEm0Nv2ZSl9ud/BJZeR5BngE0qsEz5OlqiKgbmyJk433zyVkwfqXJEHJ1cpHT/fP0GvovfE+WqVcrUYnalWtJ84/8Tl2rPEAtSzeWbSISrtKcQ79QfOoNkz6eLh7UvmJbihT12yP2kS6y8v6iU6uM7Z3EdXmsakdqUaqhLGMxlgXZvKTCElldS4VQyf/1JycXwVOsxai5P5F71YoiAuo98nQyUlLp6hffUNr1aHIu4UchLw4lJ3ENOMUsXkGJuw/IvPrhWacmeTVrSNe//40siayuJQMp+PnBsnladCxdnT6LMkQkSU7O/n5CWO1MHtUqy/2EHXsodskaIbeWppJD+8uyDPG642tfzaebVzLXrmeDuhTw5MOGehE9LGL8FDlWyItDDOclamKXrqGE7VnXCZ+rzz0tKfqHP8Q80uQY9v4oLJF1y9atNGjIMHH5Mujpvk+JKGqvUE8RRfXI0WNCOnWmH+Z/S40aGdaqNcH00KHDMgIrM+jduye9+9ZYmjPvG5oydZrEMm3qJ9SpYwcTRBs3baKh/xshy4YNHUKjR42wKSLripWr6aVXXpX9/vjtF6pbp7bJuPbsKBlT9S0skfWnn3+mCRM/kNMYNXI4Df/fUDUlky1Huk0XX4apWbOGLM+tyMrXnKPhsmjMr/9etXwplS5t+NwxOZANO4odRFYbYKEJCIAACNwBBFavXi1/t+jUqVOhn+2dKLJeunSJ1qxZQ926daOAgIBCvwaYAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAgUBwK3vci6ulccOaWZyoD5dWEKQmTdtOwIHdx+3uZTaNmxFjVqU9nm9rltOPHwhdx2MWlvTWTlxl0rl6H2FQzRPXl/bVgkLT17mbpULk0dhKSq0iEhuR4UEVLjU29SSU8PKcFW8feR1W9uPUiTWtWX+TOxCbQzMopYFvUUAmDrMiVFpFB/WXcuLoGm7T1BzUoFUt+aFWVZkhDkVp2LoBQh7FUt4SNl2HblQ6llqSBZnyzKV5wLp8sJiRTq5UldhGjKwimn3Vei6fuj52R+cL0qVPfWcd7ddphihWSoJ18h577RtDZ53+qbkJpGGy5dkZFoWbatXsKXGoUEyPr1Qqz9Uwi2eUn5KbLyvGoHVqP+dR4nJ/EfpzOxF4RQ/As9UKE1PVC+lSzjH0eiTtKR6yfFdUugII8AEW23FlXyLyfrx22bJmRlV3q58SDB1BCtNiE1iTaH7xTS6jUhEzuLa1KBGpSsLev/vbSDlp9dZyKypmek02FxDI4Ay9FiawVWpSr+FYzHn3nwRzoXe9G4b0/G0SIri543IzLlafM5pYtX0cct/ZuChMTqJmRWTglbd1HsirVSVC05bAC5ljJI0SnnLoiIpj8J0ZXIv8uD5N2yqXG4hF37iCOeOvt4SwHVo0ZVyhD3T8SEqRZFVichVoa++QI5ubnKMbhv8onT5BpSkjiKqpOHR+bYt0RWLig5uB+5VSgr69LFfZIojpshBECPqpVEueFacyXLqCyycvJ9sC353tda5vlH8rGTlHz0JKXFJ5BLUAB51qtF7hUNfSMmfkos7eYlOVJkHTl8GFWpWiXb6QSU8JevvI+OiaFujz1BkeI1wBXKl6M/Fy0kL/EMYSG111N95evmK1WqSIt+/02W6yIry63/GzKI6terR7zG//tvB70/6QOKiY2VEURXr1wmo7ImJiZRx4e60tVrV8lfyMaTP/qA7mnbVs5t+44d9OIrr9H1qCgKKFGCVq1YJtvox3nj9THUv1/fLOdy8NAh6tHrKVneqWN7Gvf2W+Th6UW7du+ipk2ayvlm6WSlQMmYqllhiaw3hXDd/cmexKIqi+8sBT874BkqV7asFFcPHT5CCxctoj8WLqZ33x5LTz5hiHSck8jqIj5rhg4eRJ0f6iSj454Pu0Bz5s6llavWyNPt91QfGvvm6+rUc71V7CCy5hodOoAACIAACOQzgTtRZM1npBgeBEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABG5LAhBZHXhZC0Jk/X7KBlq7cL/Ns+45vDV16Zsprtnc0caGBSGyssTJEmjtQD/jrFgOPSgiq/7vLpYSDbKqsdJCRhdZLVTLonQRHe/z/Sw8JkgR9c1mtcn3lrCn95l96AxdjE+k0Q2ri8ij7nqVSZ5F1en7TlJUUoostyaycqPGQlTtU7OCjA5rMpjZTnEQWXnK7Su0ERFx2xhnv/XybiH9rqfn6vYyyqrGSgsZFlmT01KoQXAderJ6ZymiWmhmLLIkshorLWRUewtVuSpytMhq7eAsfCZs200+rZvLpmlR0SLy6jwpoXKBW/kyUh4VFp6sj1u5jm5s2UFOQvAuOeRpcg02SNiy0uxHTiIrN/V9QAim7TIFU7Puxl0VkZUL3KtXocB+TxijwRobmWV0kdVJCN2BA3obZVWzpia7RU1kNZmchZ1aNWvS4oW/0YsvvyJFRpYl58+bQ82bNzO2nvzJVJr37Xy5ryRHXTA1NjTLcBTXt8WrbHv1fNJYw9FTX3vjTUpNNci+Pj4+MjpyXFycbMN9JojX3nbv3k3u68fJTmTlSKQ9ROTYw0eOGo+jMmtWLafy5cqpXZu3SsZUHQpLZOXj7927j4aNep6ir19X05GCMEuuaeL+U2nC+HdtEllVe0vbOrVr0dxZMykwKPv70lI/vUyxg8iqU0EeBEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABECguBCAyOrAKwWRNfcwXZyd6AMRKdVNvO48MjGZPtiZVYriUTlK6YuNa1CwEPE4cdRVjmrKiSOqdhARW/3d3eS++iECUFKYiN64M+I6bb58TbZrVboklfUxRPZU7XjLYupiEeH0ZEy8sbiaiIDap2Z5Gd1VFfKYMw+eouPX46Xs2qtGeRENtISM2qe34eiwPx8Poxtinio9U6cSNQoOoDQhzL6z7RBxxFVLKdjLg56oVo5qBPiSyy0RUbVLvJlG+0XU2Q0iIuvlG0mq2K5tXiOyuji50Lt3Py/l0iuJUTR1z5ws82BBb0CdJ6hmQFVj3eTdX9P15FgR0bYx3V++Jfm5+xrrOJMh/rsYH057rhyireF75GtRuTzIM4C6Ve1A1UpUFFwMEW+5nFPSzWQhNh8T13mniLR71SQiK9enpKWSu0vm+ohNiae/wzbRjgjbpXAeJ7vkCJHV975WIgrpPdkdwrRcrCGOaOokojwKQBT1zc8ysqreyL+ziL7ayiCxp99IoMiPPpfVLIj63t+WvO9uTE7ideZ6YiE2YedeurFpO5V47CHyatJAjh85ZSalxxqkR+7v17UDeTcVdVpKjYiU/QIe70os0N7YvJ3iVq03tnCvXpkCejxKziLiqDGJuXNUWPeK5ck1NJjSRfTQyA8+M1ZzMF/v5o3JR7Bx8TNdJ3zeqZfCKXGvuJe275HzzOyY+1xeI7IuWbKMxghZ1JbE4uKwYf+j0c+/KJv36dOL3hlr2jcpKYke7f4EhYnInXwf/fzTD1S9ejVq2ryl7MNjhEdekdFU1TE5euvbY9+gNq2zisYHDh6kV197g86dM43ozcLpRx+8T02aNFbDEEdxbdqipbz3xr75GvV76iljnZ45feYMvf7GWDpw8JCxmCOPrlm5nMqUKW0sszWjZEzVPi8ia8fOXSW7tm3a0Oyvv1RDZtl+NuML+urrWbL8v83/UgkRLVclllg/nDyFVotXAzMTPYWGhFCXzp1pwDP9RIRVQ2Tweg0ay4itL74wioYMGiSb60IyX5fNW7YYh/H28qIOHdqLqK5v2RXB1jiQyCh2EFl1KsiDAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAgUFwK3vci6qmccOadnyoT5eWEgsuYnXetje7u5UCkhgaYJ29RVCLIRCUlCJM0qi3oKES9YRFJlSZRF2muJKcTRU1lSNU8cDZajrnJbDxG18IqQbVkm1ZO7KGc5tqSQbK8np9AlIZgmmbXR29ua52MHe7nL47LIG5siXvmekCxeI25ppraOmtkuryJr5kh5y3m7elGIV5C4buniurkIofmakHwTsx3U2cmZgjwCyMPVXQjOnhQnpNQI0SdD41LetzSNaNBfjrEtYi8tPfOP6FNCRNj1pqjkGIoWIq0jkyNEVkfOx9axXAL8RZRWTyGXivsmOpbSrsfY2pW4r2upUCHTOlPKxcuUHmMQXXMcQKxp19Ih5BpSkjJEpOJU7ickW1sSC7AuHEn2lsB782oUpSdkv05sGVNvk1eRVR8rv/LmkVKf6tObLl26TFevXKGqVYQoHBho9dBXrl6hI0ePUbqIKlqndm2jhGm1Yw4NIiIiKDw8gtw9PKhK5UrkKdaUPUnJmKpvXkRWNYYjtvxsuXw5nC5cvCBF1TKlyxBLw7YkJbL6+/vRti2bKDomhi5cuECurm5UQ4jJLP46Iil2EFkdQRNjgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIFDSB215kXdkjllwyTMVDR0O+6eJKMSXK0FGPcjRuxrFcDf/p4oEUGGIWaTCHEb6fsoHWLrQ9imTP4a2pS19DVMYchrW7auLhC3b3RcfCJVBURNb8oGAusi4+tTo/DmMcs7iKrMYTQIaKo8jav1/f2+rKKRlTnVRREVnVfOzZmous9oxhSx/FDiKrLbTQBgRAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAoKgRuO1F1lVPRpEzv5/agSlDjBfjF0w3SlektGo1yLlGVXJydaW9m8/QtDFLc3UkiKy5woXGDiQAkdVxMCGyOo5lYY0EkbWwyGceV8mYqgQiqyJhfavYQWS1zgotQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEih4BiKw2XpMbnv4UF1qBkitXI+faQl718cnSEyJrFiQoKMIEILI67uJAZHUcy8IaCSJrYZHPPK6SMVUJRFZFwvpWsYPIap0VWoAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACBQ9AhBZs7kmya6eFBtcjhIrVCGqVZNcQoKzaZlZDJE1kwVyRZ/A7SyyBnmWoKdrPy5iJzvRrsiD9O+l7fl6QSCy5iveAhm8OIisycnJ1LN3X8oQ/w0dPIi6dulcIGwK6iBKxlTHux1E1vnffU9/LFpMfn5+9ON336pTc/hWsYPI6nC0GBAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQKAACEBkvQU53SmdYlxS6KoHUUJoCHnVb0he5RuTs2egzZcBIqvNqNCwCBC4nUXWgsYLkbWgiTv+eMVBZHX8WRetEZWMqWZ1O4is6lzye6vYQWTNb9IYHwRAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAID8I3LEia4agGSfE1etuSXTdNUlIrMmU7sSlmcnJmcgjIJh8S9cg7/INyaNUfXISkVqzSxBZsyOD8qJIACKr464KRFbHsSyskSCyFhb5zOMqGVOVQGRVJKxvFTuIrNZZoQUIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgAAIgEDRI3BHiayJzjeluBolxNVolyRKdU636Yq4umZQCb9kKhmYRkEVq1GKXyNK8W1MKR5ViNh2vZUgsioS2BYHAhBZHXeVILI6jmVhjQSRtbDIZx5XyZiqBCKrImF9q9hBZLXOCi1AAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAARAAASKHoHbXmT94amLFC3EVY66yiKrLclJRGb190mhwBIpFOSfTH6+qeRsFq2Vx0l3LUHJPo0oSfxhsXXn9hs0bcxSWw5hbPPp4oEUGOJr3LeW+X7KBlq7cL+1Zsb6nsNbU5e+TY37js5MPHzB0UNivAIiAJHVcaAhsjqOZWGNBJG1sMhnHlfJmKoEIqsiYX2r2EFktc4KLUAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABEAABIoegdteZH1ziJA+0zOskvf2vCnE1SQK9BcCq5BXXV2s9zEf9EJKSxo4MtC8OMd9iKw54kFlPhKAyOo4uBBZHceysEaCyFpY5DOPq2RMVQKRVZGwvlXsILJaZ4UWIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACIAACRY/AHSuyurulUYCQVoOkvJpMnu7peb46kal3Ud8R5XM1DkTWXOFCYwcSgMjqOJgQWR3HsrBGgshaWOQzj6tkTFUCkVWRsL5V7CCyWmeFFiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAiAAAkWPwB0jsrq4pFMJX0O01aCAFPL1SnX41YDI6nCkGDAfCUBkdRxciKyOY1lYI0FkLSzymcdVMqYqgciqSFjfKnYQWa2zQgsQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAAEQAIGiR+C2F1lnvvMfBfndENFXU8nJKSNfr8CdKLJOPX6JEm7mPZptvl4YDJ6FgLerM3k6r6OEtKQsdSjIHQFvF08atPb/7N0HmFXluTfuFxCkqNgrGnvvilEjxpiiUfNZsRMl9gJq7L1r7LEbNXaJFVskfz3xiJpY0Ch2QUXsigI2qgL/ed5z1pzNsAf2zOzBYbjf65JZe62137XWvfb1fdd58lvPSqnNeJYNk2s5e0/p2DFtcPUFadSoUenlV15NK620Uss5udnkTIYMGZLWWnONNP/88+crdi8qv/GldoMHD678i/YkQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECLQQgVYfZL3j6nfT/G3fqQmxNn/Y8oNvVk77HLVMg27tJff3TvMtNFfF37n1oifSY/1fqXj/nQ/eOG21x3oV79/QHe//eFR67euxDf2a/X9kgdW7dk7t276S3vzm3R/5TGb9w68yz3Jpi5dTmjKE5ax6N9ustFw66v+7P/Xv3z/tsssu6eZbbp1VL2WWPe+9ft8r3XnnnWmHHXao+f+v26R777039ezZM9162+2z7DXNrBPvtece6e6770477rhjuuSSS2bWYR2HAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFA1gVYfZL3u8YPTHG3GpUmfv5A6fPtimvv719Jc7T6rGmDpRB98XRNkPXr2CrJ+Mm5iuuG9EaUMlmcBgT8ss3Bq2/abdNvwB2aBs23Zp7jHT/5fWvTrNumHO1i27DtV/9nNseu26f1x36UtttgijRs3LnXv3j3tv/8BaaeaIGWnTp3q/6ItTRII63tqApjXXvuX9Pzzz2frRx55JAdZ416MHTs2rbfeemm//fZPO9cEjDt37tyk47WmL4fNXTXB3+uuuzb95z//yTZh95Of/KQ1XaZrIUCAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBGYTgdkiyNq+Q7upbuek72qCrF8+nzqOeSl1nfx6mrPtt1Ntb+yHl75ePh1z9AoN+vqs3pE1Lnbw6DHp75+ObtB12/nHE9hmsfnS2vN1ySfw6tdD0iOf/evHO5lZ/MhbLLpJWqPr/7yGfvIbb6dJ//XkLH5Fs9/pt/vNpqntKv/z/24PGDAg9e3bN02cOHH2g/iRr7hDhw7psssuS1tttVU+kwhl9unTJ40fP/5HPrOWf/iOHTumyy+/PAexW/7ZOkMCBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAwLQCs2WQdWqGKWnSqKGpzaiajmbjBqeubYbWdHBtXIjpha+XS8cfveLU08/gU2sIssYlflrTmXXQ6O/Su9+OT2MnTZ7BVds8swU6t2ublpu7Y9pgvrnSYp06THX4z8Z/mV4c/XoaPuajmnsnNDYVTpkPndt1TEt36ZbWnW+1tGjHBafaY8oXI9Pkwa+nycM/SmnsuKm2+dCCBDp3Sm2X7pbarr1aarPQAlOd2LBhw2o6hF6bBg8enIYOHZp++OGHqbb7UD2BOeaYI6244opp7bXXrumAu39adtllp5p8+PDh+V689NJLaciQIe5FiU7YrbTSSmmdddbJdksvvXTJVosECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAgVlLQJC17v2aNDFN+vKV1O6rF9JcE15N87QbntqkKXX3Kvt5dg6ylgWxkgABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECAwHQFB1jo4EVl967uv03MjR6VXR49OI78ekdZu93766Zw1/3V4Py05x+g63/i/j4Ks/2dhiQABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECAwIwFB1hqhj8ePTc99NSq9PGp0GjryqzRmwvf1ui3e7uu0QYRa5/wgbdDhgzRv27G1+wqy1lJYIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAjMUGC2DLKObTM5vZzGpBdr/vtP+i59NGZMavvlhNR21MTU7qvvU5sfoi/rjEfbNCWt1P6LmmDr8NytddLYjunUY5ed8RdL9rjk/t5pvoXmKlkz/cVbL3oiPdb/lenvVLJ154M3TlvtsV7JGosECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAgZYhMFsEWdt2aJfeajO2JrT6P8HVt9LYNKlN+RtQk3FNbb+a+D+h1pE1f7+p6c5aWa41LfvZ5PTV1W+Wn7ietYKs9cBYTYAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECLR6gVYfZF36if+XXmw/NkUX1kaNmu6s7UZOSO2iW2vNf23GTKp3mmU+m5K+vvqNereX2yDIWk7FOgIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQGB2EGj1QdYvnvhFmtChnvarjbjDbcZNyoHWtjXdWnOwdeL/BWQFWRsB6isECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIDAbCsgyNqUWz9lSmrz3aQ0x5cTUtuabq3LvzEhfX2VjqxNIfVdAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAYPYREGSt4r1e+6kx6ctjnmvQjJfc3zvNt9BcFX/n1oueSI/1f6Xi/Xc+eOO01R7rVby/HQkQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECM0tAkLWK0t2fGps+PebZBs0oyNogLjsTIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECrUhAkLUJN3PO1CatMaVLWid1SevV/P3235+lS4/5e4NmFGRtEJedCRAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAgVYkIMjagJvZtia4uvyUjmndCK6mudJqUzqnDjXrijH43++lPwuyFhz+EiBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgSmKyDIOl2elBariaquW9NtNYKra9f8nSe1q/cbgqz10thAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEJhGQJC1DsncNUHVCKxGcHW9mr8RZK10CLJWKmU/AgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgEBKs32QtX1qk1ab0jkHV6Pz6vKpY02UtU2jfhuCrI1i8yUCBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIEBgNhWY7YKsEVFdLnVKEVqN/1ZPnWuiq22rcvsFWavCaBICBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIEBgNhGYLYKsXTt0qAmtzpXWTTXh1TRXmndKu2a5vYKszcJqUgIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQKCVCrT6IOvpj++bftKh00y5fYKsM4XZQQgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAIFWItDqg6zXPX5wat+heTqw1v0NCLLWFfGZAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFC/gCBr/TYN3iLI2mAyXyBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgRmYwFB1irefEHWKmKaigABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEGj1AoKsVbzFgqxVxDQVAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAg0OoFBFmreIsFWauIaSoCBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECg1QsIslbxFguyVhHTVAQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgECrFxBkreItFmStIqapCBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAgVYvIMhaxVssyFpFTFMRIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECrV5AkLWKt1iQtYqYpiJAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgRavcAsFWQd9sbn6elH3mrQTdmtb4/Url3bBn2nsTt/NGxkGvjAaw36+o77b5Q6delQ8Xeef/ydNGTwxxXvv26P5dKq63ereH87EiBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgRmlsAsFWSdWSiOQ4AAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAg0PwCgqzNb+wIBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECZQQEWcugWEWAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIND8AoKszW/sCAQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAmUEBFnLoFhFgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECDQ/AKCrM1v7AgECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQJlBARZy6BYRYAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAg0PwCgqzNb+wIBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECZQQEWcugWEWAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIND8AoKszW/sCAQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAmUEBFnLoFhFgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECDQ/AKCrM1v7AgECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQJlBARZy6BYRYAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAg0PwCgqzNb+wIBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECZQQEWcugWEWAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIND8AoKszW/sCAQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAmUEBFnLoFhFgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECDQ/AKCrM1v7AgECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQJlBCoOsr799ttTynzfKgIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQKNEhg6dGhF32szYMAAQdaKqOxEgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQicCUKZXFU9s89thjle1ZyVHtQ4AAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgMNsLjB8/viKDNuPGjRNkrYjKTgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABApUI/Pd//3cluyVB1oqY7ESAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIEKiqgCBrVTlNRoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgUKmAIGulUvYjQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBCoqoAga1U5TUaAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIFCpgCBrpVL2I0CAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQqKqAIGtVOU1GgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBQqYAga6VS9iNAgAABAgQIECBAgACBLDBy5Mj8d/75509t2rRJU6ZMSaNGjcrrFlhggZmiNGLEiPTBBx/kY3fv3n2mHLOSg/wYFpWcl30IECBAgAABAgQIECBAgAABAgRmT4ExY8ak8ePHp44dO6YuXbo0CqEaczTqwPV8aezYsWncuHFNuqZ6pp5pq1ua6Uy7cAciQIAAAQL1CAiy1gNjNQECBAgQIECAAAECBAhMK/Dxxx+nfffdN2/o379/6tSpU3r77bdT375987oHH3wwtW/fPgdMJ0yYkIOuc84557QTNWHNTTfdlO688848Q4Rpb7/99ibMVt2vlrOo7hHMRoAAAQIECBAgQIAAAQIECBAg0FoEvv/++zRp0qRcT2vXrl2zXNapp56aBg0alHbeeefUu3fvRh2jGnM06sD1fOm8885LAwcOTDvssEPab7/96tmrZa9uaaYzS2tm/OZn1rU4DgECBAhUV0CQtbqeZiNAgAABAgQIECBAgECrFqg0yPrss8+m008/Pc0333ypX79+VTOJQueOO+6Y4m+EaKMb6/HHH1+1+Zs6kSBrUwV9nwABAgQIECBAgAABAgQIECAw+wgceuih6d133019+vRJW221VbNceDUCk9WYo5oXJ8haTc2ZO9fM+M3P3CtyNAIECBColoAga7UkzUOAAAECBAgQIECAAIHZQKBckDVeg/X888/nq990001T27Zt0zPPPJPOOOOMqgdZo7Afxc4Y0Zl1kUUWycst5Z9yFi3l3JwHAQIECBAgQIAAAQIECBAgQIBAyxI45JBD0rBhw5o1yPrmm2+mzz//PC211FJp2WWXbRRANeZo1IHr+VJrCLK2NNN6qKu+emb85qt+0iYkQIAAgZkiIMg6U5gdhAABAgQIECBAgAABAk0XmDx5cp4kgqLNNcaOHZtfZda+ffuyhygXZC23Y3MFWYcMGZIOP/zwfMiHH344h2bLHf/bb79N4dW1a9dym5u0LuYOn44dOzZpnkq/HN1n67sflc5hPwIECBAgQIAAAQIECBAgQIAAgZYnUGmoL+pDUeuac845p7mIGdXzpvlCPSsmTZqUj9GUOlQ15qjn9KZaXUmQdcqUKSnOZ4455pjqu/V9aIzj9O5LHGf8+PFNriHOLNP6XMqtj4f5O3funNq0aTPV5koMG/Kbb8pvcaoT84EAAQIEZgkBQdZZ4jY5SQIECBAgQIAAAQIEZmeBwYMHp379+qWhQ4emdu3apbXXXjv96le/Su+880569tlnU8+ePdNmm22Wia644ooUT/NvvfXW07yOLMKlt912W+68cOSRR9aSjhw5Mv3tb39LTz31VPrmm29yaHLFFVdMq622WooOq8stt1ztvuWCrB999FG69NJL8/fOOuusFK8a+/DDD3Onh/hidHpYYYUV8lx//etf81zHH3986tatW+28sTBq1Kh08skn53UHHHBAWnPNNafaftFFF+UOFdGlIsbqq6+eFlxwwXTsscfmzxMnTkw33HBD+te//pXimmJ06dIlbbnllmm33XbLy3llI/756quv0i233JKefPLJFIXaKNJGN9hNNtkk7bXXXrUF8boWETq+995704z+j++NN9447bHHHrVnFmHZsHrttdfSJ598kuaZZ558P+K+rrvuurX7WSBAgAABAgQIECBAgAABAgQIEJj1BIo6XdSSoqY199xzp4UWWig/wB0PZp9++uk5tHraaaflutugQYNyrezss8/OF9uQel7Uy6JeGDWyX/7yl/n711xzTXr11VdzPSrqXFG/ilpjhCaXXnrptP3226fNN9+8FrYacxSTvfHGG7kW+dZbb+V6YtS64ljvv/9+ijpoHDvqn9Mb0wuyRo3zwQcfzHXECRMmpGWWWSbPt/vuu6dOnTpNNW1DHEeMGFHvfYlaZpxT3LsTTzwxXXfddflaohPu/PPPn+t6ffv2TXPNNVft8atlGmHaW2+9Nb8xK+qIUctdf/31cy02zmPeeedNRxxxRO1xG7pw4403phdeeCHtsMMOuQYac4bbxRdfnFZZZZW8XElteXq/+agdx1ATbejdsT8BAgRal8CM/re04mrbjBs3bkrxwV8CBAgQIECAAAECBAgQmDkCjz32WPrzn/+cfvjhh3zACEZG94UoMEcHhniqf++990677LJL3h6hzldeeSX16tUrRXG2dDzyyCN5rgiWXnnllXlTzBuh1gjJxlhggQVSzf/9l+Lp+RhR3L3wwgtrXztWLsj69ttvpyjExogi8UEHHZRiv9Kxxhpr5IBrnFMU58ud30MPPZSuuuqqztK+mAAAQABJREFUXMCO4meEUEtHzDt8+PDSVbkQfPvtt+dw6THHHJML1LFDPK0f1xadF2J07949F5rrdgnIG2fwT1hEF9gI58aI4m8U9aOwGmOdddZJ55xzTl6uaxHnce2116b77rsvb6/vn5///OfpuOOOy5sjqBth4C+//DJ/jvscRfcYcf5RGN92223zZ/8QIECAAAECBAgQIECAAAECBAjMegIDBw7Mwce6Zx5hyKjP7bvvvrm+tfLKK+fAaewXgc8Isja0nhd1pgjC7rzzzql37975kMW6qBO+9957uYYWdaeilhbLEcj82c9+NtX+TZkjJvrnP/+Zg7lFrTNPXvNPHC/qkFGHO/jgg9Pvfve7YlPZv/UFWa+++upcn4wvRR01/iuOFdcaAeF4MD5GQx2LumjU++rel6jPRn00ti222GLpgw8+yMcoNY2w5iWXXJIbFcTG4h40xTQeuD/hhBNqa7v5oP/7T4Sjo34ZD8jfeeedpZsatFxYRw00gsbFbySCrHFNldaWp/ebj4YGaqINui12JkCAQKsUEGRtlbfVRREgQIAAAQIECBAg0BoEotAYRdAo4EYXgj/+8Y85RBndEqKAGN1TY8Q+jQ2yPvDAAyk6MEQ3gHPPPTctv/zyOSgbgcwIhkboNOaOY8QoCrax3L9//1xgrhvejALx008/ncOdEfqMTqZRtI3XeEXgM7oiRCeECK2WjjheXFsUyE866aTSTXk5ugtEp4bYL8Kdd999d14fBeLoYBCf4zhHHXVU6tGjRxo9enSKcOw999yT94tjR8G1oaMIAMcxo0AbRe8Yzz33XDrjjDOyV3QiiA6zdS3i3OI+FqHU4thR8I3/4SG6JITXmWeemf/HiAgpR9H73XffTUvXdL+Ia4kuCtGtNrofRLE/xuWXX57vVTGfvwQIECBAgAABAgQIECBAgAABArOOQNSGIkgZdaDhNQ9uxwPcv/3tb3P9LOpFEWQtxoYbbph+8Ytf5FrRUkstlRpaz5teYDKOEXNGx86VVlophwlPOeWUXIuKtyFdcMEF+TSqMUe88WifffaprXX+/ve/zzXCqAdGwDNqeTEaG2SNjp9Rq4v64J577pl23HHHHBqNh/6j7vndd9+ln/70pym63MZoqGNpXTS+X3pf4iH04kH/qPXttNNO+Q1RUeuLh/CjjhrjT3/6U1prrbXycjVM441OUfuMt3iF20YbbZR/V/FWrkcffTQfp1pB1pgsGg/suuuu+b5F44J//OMfFdeWp/ebj21qovl2+YcAAQKztYAg62x9+108AQIECBAgQIAAAQItWSBeCdWvX7/81PzNN9+cOnbsWHu6L7/8cm0Hz6YEWf/yl7+khx9+OG211VbpwAMPrJ0/ForQ6aabbpqOP/74vK20YFtfkDXCm0XheL755svXUEz87LPP5s4H8fn6669PSyyxRN4Uheo99tgjP9F/8sknp4033rj4ylR/hwwZkrujRqj0/vvvz9siKBrF6Qjd7rbbbimK4MWIIuj++++f4jVtUWTda6+9ik0V/43AbQRi4zVgESbt0KFD7XcjBBzh1eicEIXwckHW2p1LFuJ+3nHHHXlNdFjdbrvt8vLjjz+ezj///BzUjXuzyCKL1H6rNOQaXSmiOG0QIECAAAECBAgQIECAAAECBAjMugKHHHJIDo/26dMn1+fiSkrrb6VvAiqusqH1vOkFJiOYGPWu6N5ZjKhZRe0qHlCPtybFqMYcUQu89957c8fZ6JxaeszSWmdjg6wR/g27bbbZJoVr6ShqlREyjZBn1Cwb6ji9+1JaE6xbg4ya3vbbb59rl4ceemjaeuut86k11bS0JvqHP/wh9ezZs/SS09FHH51ee+21qnVkjcnjzV2rrbZa7XEaahhfLPebVxOtJbVAgACB2VpAkHW2vv0ungABAgQIECBAgACBliwQr5qPIm50DyjtwhDnHAHNeLI/urU2Jcha9/qjE0R0D42OoFGI/OKLL3J303hFVYzSgm1jgqwx/+677567lJae99///vd05ZVX5s6wEd6NMGy5US7IGl0boktrjMsuuyy/0qr0u/F6tOhksfjii+duAaXbKlmOEGvRPTZe4RYh0uicEK87qztKi9YPPvhg2esofY3WlltumQ477LDaaeL8o5NBdHSIYnbdEd1t439AWHLJJdO1115bd7PPBAgQIECAAAECBAgQIECAAAECs5BAuVBfaf0tal7RjXV6Y0b1vOkFJn/1q1/lV8OXzl88iB71uahvxajGHEWts1zQNI6x33775YfRGxNkjbcZxUPyMa644or8hqP84X//GT9+fH4QPd74FOfx85//vHRzXp6R4/TuS2lN8Kabbprq4fSYPAKsUW/t3bt3Po9Y11TTCKlGWDVG1AsjeFw6nnjiidwBtlodWaO2Gh1gpzdmZBjfLfebVxOdnqptBAgQmH0EBFlnn3vtSgkQIECAAAECBAgQmMUEonvoiBEjUmlHhtJLOPLII9Mbb7zR5CDrsGHDcnfQCIlGcDVCsqWjR48eqVpB1pg3AqsRXF1uueVyYTnWFYXseIVa8RquWF93lAuyxmuy4vVj8dqw++67L3czrfu9pnyOsPBJJ52U3nzzzdpp4nVdq6yySu0rxKJba4zSonW5IOvQoUNz6DZeNxavZ4vXms0xxxy18x577LEpXncWI7rO1h3xvRhzzTVXuvvuu+tu9pkAAQIECBAgQIAAAQIECBAgQGAWEigX6isNTN51111TdS4tLq0h9bzpBSaji2d08ywdRXfUqFnFA94xqjFHvEUpao+lbycqPe4pp5ySnn/++fwWoniQfHrjvPPOS/Gw+A477JADsKUPusd5R+2u7ijqavFWqm233TZvbojj9O5LaU3wgQcemOqNTnGgojtq6YP9TTUtaqLRVfeee+6pe7kp6pDxAH21gqxhVveNXnHQhhjG/uV+82qiIWMQIECAgCCr3wABAgQIECBAgAABAgRaqEC8bj4KrFFwjM6ddUd0ZIgibWkBtCj69erVK3c+Lf1O8VqwZZddNodJY1s8mR+F3yK8uuCCC6Zu3brlzqUfffRRLh5XO8gagdA//vGP+dTi1WUdO3bMHRPiNVsXXHBBDniWnnfpcrkgaxT0i1egxXJzjOjWEFZPPvlkNo8uDsXo3LlzOv/883Mwt7RoXTfIOnLkyBzSjQ4RiyyySLr00ktT165di2ny34MOOigNHz48h1sXW2yxqbaVfogg68UXX1y6yjIBAgQIECBAgAABAgQIECBAgMAsJlAu1FcamCzeiFR6WQ2t500vMFmuhtjQIGulc8Rbp+KB8XhgPuqNdUcR9mxMR9Z///vf6ayzzspTRk2t9MHxuseJt0VtttlmVamLFnMXNcF40H7AgAHF6tq/xbWV1nGbel/igf54Y9NSSy2V36xVe7D/XSjuY7WCrEVouPQ4Df0txnfL/ebVREtVLRMgQGD2FRBknX3vvSsnQIAAAQIECBAgQKCFC+y///7pww8/TOU6I8Sp77bbbumrr74qG2Tdc889a1+nVVzmhRdemB577LFUBFkjvBpFwvfffz917949d0NYYoklit1rO6dWO8gaB4hOD59++mnaZ599UqdOnXJn1oUXXjjFq7ei4FvfKBdkje4LEcaNEYHWRRdddKqvx2u7IpQbAd3oAtvUEa/Iio4GzzzzTIoOCxFy3XDDDXNniqJoHccoDbJOnDgxd16I78X1XnTRRTksXPdcTj/99BSvb4turRHqNQgQIECAAAECBAgQIECAAAECBFqvQLlQ3/SCrI2p5zU1MBn61ZgjAqrvvfdevR1Xowb63Xff1bu99FdQtyNr1P8OPfTQvMuf/vSntNZaa5XuPs1yYxynd1+KmuDMDLI+/fTT6cwzz6y342rULa+55pp6t0+DUs+KutbFbo0xjO+W+82riRaq/hIgQGD2FhBknb3vv6snQIAAAQIECBAgQKAFC5x22mnpueeey4XXKMCWjs8++yz17t07ryp9kr8o+v3mN79JRxxxRO1XottphFY/+OCD2iBr8Xqp2Omqq66aJlhZFJebI8h66623pn79+qUVV1wxBzujQ8Cuu+6a9tprr9pzLrdQLshaWqg+/PDD0xZbbFH71UmTJuWw7Oeff57KdYeo3XE6C9H5NrzDb6ONNppqz7/+9a/51V2LL754iuWiaB07lQZZi4JvFLNPPvnkaeYpJr3++uvTvffem9q2bZvuvPPOFJ1XS0ccIzodrLnmmumoo44q3WSZAAECBAgQIECAAAECBAgQIEBgFhMoF+qbXmCyMfW8aoRQqzHHGWeckR8M32CDDVLUMEvHG2+8kY488si8qjEdWceNG5eiY2iM7bffPkWDgNLx5Zdf5ofMo1YY1xJ/4y1YMZpSFy2OUdQEZ2aQddiwYTkUGucQb36KOmsxImR60kknpRdffLHZgqyN+S3G+ZX7zauJFnfOXwIECMzeAoKss/f9d/UECBAgQIAAAQIECLRggX/+85+5c2ecYmlAMzqARrjyrbfeymdfGmS97bbb0u23357mn3/+dPnll+e/EWKNYmC8bipG0ZH1k08+ySHPWHfggQembbfdNhZT3f032WSTdOKJJ+Zt5QrpRaE2dijCm9FVNArSc845Zz6fLl265O8X/5TOU6yLcyw6wsb2e+65J2+K4nO8IitGuSBrrI/QbnhEx9Vzzz03zT333LkgHa9fu+GGG2KXdNlll6UVVlghLzfkn6LIvt5666UIF5e+muySSy5Jjz76aO5oG/uVs4hAanSajVF6r/KKOv9Ed9wo5kYxPV5zFuHbYgwePDiHYKMjbBTat9xyy2KTvwQIECBAgAABAgQIECBAgAABArOgQHQRjYe0d9lll1w3iksorZtFbSve7lOMxtTzqhFCrcYcTz75ZK7bxbX88Y9/TL/+9a/zZcX1Rq1z1KhR+XNpkDWuP95Ytdhii6Wdd945b49/iofGS193X6xbcMEFc0013v4UY/z48SmaBETDgIUWWijX6eKh9XhTVIym1EXzBDX/FDXBmRlkjfph/H6GDx+eQ6xRm+zatWt+e1TUh6MmGWOeeeapXc4rGvhP4VpqHVM05rcY3yv3m1cTDRmDAAECBARZ/QYIECBAgAABAgQIECDQQgXiyfnouhkdCaIIuswyy6RFFlkkvfrqq/k1W8Vpl4YjX3nllXTcccel+G5084xOoVFUjNdyFaMIssY+URiOYme7du1y59cojL/++uvpq6++yoXPr7/+Os8TheXoZFCukF4UamP+Isgahec99tgjHzLOuXv37rUdAorziDBmPLkfY5VVVkkXX3xxsSm99tpruUtCrDj77LPTuuuum7fVF2R9880307HHHpsLtfPOO29aeeWVc+h19OjR+Xu//OUvG93BNLrFhmmMn/zkJ2nttddO0eUhgrPR4TZGFPM33HDD2qJ1rAuLiRMnpngtWljHiPtYbsR9iiBvjKIDQSxHJ4UI50ZH2ZdeeinPs/rqq+difXRtNQgQIECAAAECBAgQIECAAAECBGZdgXgQfcCAAal9+/a59te3b9/UsWPHtO++++aLqhtkbUw9rxoh1GrMERcUD8tHl9AYpQ+0R82sqJ+VBlmjJhe1ubq1w3LhypEjR6YDDjggjRkzJtcz11lnndShQ4cU9dIvvvgi1+XOOuusXGdsjGO5umi+kJp/ivpoXEfcz7rj6KOPzvXO0jpuNUyjTnz88cfnh+KjrtutW7cc/I3wbjGaK8jaGMM4p3K/+ah/qokWd8xfAgQIzL4Cgqyz77135QQIECBAgAABAgQIzAICUXi9+uqr02OPPVZ7tlEQjW6cUTyNQmxpATR2+sc//pG/E51bi7H++uunCHNGkbcIssa2CGJGATc6GxSjc+fOabvttsvHOOWUU3LQNdbFK+9Ln7QvCunRNSKepI9RBFljuehkGstrrLFGOv/882OxdjzwwAPpmmuuyZ+jo+pvfvOb2m2lrxOLjglrrbVW3vbOO++kPn365E6v999/f+3+sRCh2Ai9jhgxonZ9dE/dZptt0l577ZX/R4DaDQ1ciGNFZ9dS05giwsLhv/XWW+cZ61pEkHWnnXaa4dGWXHLJdO211+b9oggcx7vxxhunOl5cS48ePdJBBx2UO87OcFI7ECBAgAABAgQIECBAgAABAgQItGiBeFD6nHPOyUHLONGo3UVH0aJbaFF/K72Ihtbz4q1J8fak6Gjau3fvPFWxrm5dMTYWD5hHLeqhhx6aav+mzBETRW0tOoU+/PDDKR6gjxF1saifxVuP4tildcITTjghP9wdD3ZfcMEFef/4J+qMjz/+eKrbJfTTTz/N24o3WRVfiIfI41qjtlaMhjqWq4sWcxU1wVKzYlv8LQK5pd7FPWiqaRw76sfRACC6tEYdN2qxm2++ef5tRRfaW265pfR0GrRcn3VM0lDD+E653/yaa66Zg8xqoiFkECBAYPYVEGSdfe+9KydAgAABAgQIECBAYBYSiI4C0Tk1iqHLL7986tKlS37aPl43X1oALS4pXj8fr2SKzqrR3WDRRRctNk3zNwrIEQKNrp/RcTQ6vxbdPiNUGR0F4nhFl4RpJpjOijjvCHPGk/8xR+l4+umn05lnnpmLq/G6q+g2UY0RBeu49niVVhTCI2xajRGh4uhyEB0coktGvNKsuBfVmL/uHHG8KETH9cS1rLDCCmmBBRaou5vPBAgQIECAAAECBAgQIECAAAECs7BA1Oai3hRvTFp44YXrfaNP6SU2Zz2v9DjNuRy1r7jmoiYYIdvPPvus9s1HjT121DOjAUDU1SLYGXXReHtTUe8snbc1OBbXE9cyduzYXEeMddEY4cILL8xve7riiiuK3ar+tzGG8Z36fvNqolW/RSYkQIDALCMgyDrL3ConSoAAAQIECBAgQIAAgakF4rVR9QVZp96zZX46+eST0wsvvJC23XbbdOCBBzb7SX777bcN7j7w61//Oq244orNfm4OQIAAAQIECBAgQIAAAQIECBAgQKA1C9xzzz0pAirdunVL0Wm1dBQdTeNNVNE9NLrSGtMXiNDqUUcdlXc64IADat9oFSsizBtvy4pOvPFmr8MOOywHW+t2qp3eEaIxQa9evaa3i20ECBAgQKCqAoKsVeU0GQECBAgQIECAAAECBGaewKwYZB0xYkTuhvDhhx+mm266KXeYuP7663N30+aWi+60Z511VoMOE68n23jjjRv0HTsTIECAAAECBAgQIECAAAECBAgQIDC1QPF2pli7/fbbp8022yx3oI1w5WWXXZZGjx6dunfvngOYU3/Tp/oEDj744PTee+/lt2z17NkzrbfeemnUqFFpwIAB6eGHH84dby+44IK0yiqrpLvuuisNGjSovqmmWR9vuTrttNOmWW8FAQIECBBoLgFB1uaSNS8BAgQIECBAgAABAgSaWWBWDLIOHDgwnXfeebUy22yzTTrkkENqP1sgQIAAAQIECBAgQIAAAQIECBAgQKD1CUyePDk/ZP7MM8+UvbhVV101b+/UqVPZ7VZOK/D666+nE088MU2YMGGajW3btk3HHXdc6tGjxzTbrCBAgAABAi1RQJC1Jd4V50SAAAECBAgQIECAAIEKBO677770wQcf5I6h0a1gVhjRYeH2229PUZBeffXVUwRZo6hqECBAgAABAgQIECBAgAABAgQIECDQugUmTZqUnnzyyfTEE0+kTz/9NHcMXWGFFVL8t/nmm6fOnTu3boBmuLpPPvkkPfTQQ2nIkCG5q+3iiy+eVlpppbT++uunCAcbBAgQIEBgVhEQZJ1V7pTzJECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAi0MgFB1lZ2Q10OAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQGBWERBknVXulPMkQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECLQyAUHWVnZDXQ4BAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAYFYREGSdVe6U8yRAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQItDIBQdZWdkNdDgECBAi0DoGxY8emcePGpY4dO6YuXbq0jotyFQQIECBAgAABAgQIECBAgAABAgRaocCUKVPSqFGj8pUtsMACjbrCaszRqAPX86URI0ak8ePHp4UWWih16tSpnr1+/NXh/t1336V55503zTPPPD/qCbW0e/ijYjg4AQIECBAgQIAAAQIEGiggyNpAMLsTIECAAIGZIXDeeeelgQMHph122CHtt99+M+OQjkGAAAECBAgQIECAAAECBAgQIECg1Ql8//33adKkSal9+/apXbt2zXJ9b7/9durbt2+e+8EHH8zHauiBqjFHQ485vf333Xff9PHHH6czzjgjde/efXq7NnpbBD8nTJiQ2rRpk+acc85GzXPqqaemQYMGpV69eqXdd9+9UXNU60st7R5W67rMQ4AAAQIECBAgQIAAgZkhIMg6M5QdgwABAgQINFBAkLWBYHYnQIAAAQIECBAgQIAAAQIECBAgUEbg0EMPTe+++27q06dP2mqrrcrs0fRV1QgwVmOOpl/J/80wM4Kszz77bDr99NPTfPPNl/r16/d/B2/AkiBrA7DsSoAAAQIECBAgQIAAgRYsIMjagm+OUyNAgACB2VdAkHX2vfeunAABAgQIECBAgAABAgQIECBAoHoChxxySBo2bFizBlnHjBmTnn/++XzSm266aWrbtm2DL6AaczT4oNP5wswIsj7zzDO542trCbK2tHs4ndtrEwECBAgQIECAAAECBFqcgCBri7slTogAAQIECKRUSZA1CqPxarR55523IrJvv/02v9asY8eOM9y/IfvOcDI7ECBAgAABAgQIECBAgAABAgQIEPiRBCoNskadbfLkyWVfcT927NhcV2vfvn2Tr2L8+PGpkvrc9A5UjTmmN39sKxdk/frrr9Pcc89dUVA3LMNtrrnmqvdQlQZZo1YZ83Xt2nWaucp1ZJ04cWJq06ZNvmfTfKGJK2Z23TR+l9X43TXxsn2dAAECBAgQIECAAAECzS4gyNrsxA5AgAABAgQaLlBfkPWHH35It956a3ryySfTZ599lieOAu6GG26Y9tlnn1xILj3aV199lW655Za8fwRfo4C7yCKLpE022STttddeaY455qjdvSH71n7JAgECBAgQIECAAAECBAgQIECAAIEWKBAhydtuuy199NFHKYKNEcBcaKGF0uGHH54DkfFK+znnnDOddtpp6dJLL02DBg1Ka665Zjr77LPz1YwcOTL97W9/S0899VT65ptvcphwxRVXTKuttlqKrqvLLbdc7VXHMWKOCByeddZZOej5wQcf5IfVo3Z34oknpuuuuy4NHjw4ff7552n++efP8/Tt27c26FmNOYoTivBj1BCjS+wnn3ySz3X99dfP5x3nEQ/GH3HEEcXuZf8WQdaTTz45vfLKK+lf//pXCpMwW2GFFdJBBx2Ull122Wm+O3DgwHTfffflLrhRywzzMFt99dXTFltsUVuPjHk//PDD7BGTxFwxb9yfGHHPbrjhhtrjxrouXbqkLbfcMu222255OdaVBlmjs2sc/80330xTpkxJSy+9dNp5551Tjx49YtdGj0rrpuXu4b333ptm9D/GbrzxxmmPPfaoPb8Iy/71r39Nr732Wr5/88wzTzbceuut07rrrlu7nwUCBAgQIECAAAECBAi0JoEZ/d9OxbW2GTdu3JTig78ECBAgQIBA8wqUC7JGEDWK3kOGDMkH79y5cw6mxvoYUYC+5JJL0qKLLpo/R8eDKPxGQbjYPmnSpBSF0BjrrLNOOuecc/JyQ/bNX/APAQIECBAgQIAAAQIECBAgQIAAgRYsEIHGqLHVHbFugQUWyB1HI3i68sorp1dffTXvFiHBCLJGAPPII49MQ4cOzetj/5r/nSx3GI0VnTp1ShdeeGFtkPPtt99OEUqN8eCDD+ZAa7EujrHYYoulCLbGiAfNI2QZI4KbUc9r165dKvaP9Y2dI74btcITTjih9txjXTEizBu1wQhG3nnnncXqsn+LIGvUIKN2GCNCrBMmTMjLcV0RAi4NVhYdVot94zhffPFF3j/+2XzzzdPRRx+dPxfz126sWVhjjTXS+eefn6/hmGOOyWHY2B7HintSuHXv3j1FEDksiyBr1EYjcFp3tG3bNu+zwQYb1N1U0eeG1E3L3cNrr702B3und7Cf//zn6bjjjsu7DBs2LJ/vl19+mT+Xmsf1HnDAAWnbbbed3nS2ESBAgAABAgQIECBAYJYUEGSdJW+bkyZAgACB1i5QLsh68803pzvuuCN16NAhFzZ/+tOf5mLtG2+8kYvG3333XVpvvfVy14fweeSRR9Kf//znXGC++OKLawvrzz33XDrjjDPy67iiA0O3bt0atG9rt3d9BAgQIECAAAECBAgQIECAAAECs75AhB4j/BgB0+HDh+cOor/97W9zR9DoUhpBymLE245+8YtfpKVrOngutdRS6YEHHkjXXHNN7pZ67rnnpuWXXz7X0iKoGAHL6Ba6yy67pL333jtPUS7AWLouwpQ77bRT7iQ6efLkdPvtt6f+/fvn7/7pT39Ka6211nSDrLFjJXPEftHJ85577snh2IMPPjhttNFG2SG60z766KOxS4OCrLH/Zpttlvbff//8IH2Ee6O2OGrUqLTkkktmpzi3uK5dd901B2Wja+ohhxySrSM4e/311+djx37RobRjx44pHrh/+umn84P2EUKNt0pFUDPeIBWdWO++++78+aijjsodVUePHp0eeuihfG1xTvGAfjyoXwRZY110fe3Tp0++h/Fw/ymnnJLfalUaoI39GjIaUmMtvedFGDmuvwilFseN32YEpuN3GCZnnnlmDgSHYfxe33333fxbjGuPzr9hfeONN6Z//vOfeYrLL788/yaL+fwlQIAAAQIECBAgQIBAaxAQZG0Nd9E1ECBAgECrE6gbZI2CZ69evXLHgygab7/99lNd87PPPpu7EMTKK6+8ModWr7rqqlzcjVeVRaEzArDFiEJ8FFbj1VoRiG3IvsUc/hIgQIAAAQIECBAgQIAAAQIECBBo6QIRqIwulxFw3GqrrfLpfvzxx7VB1tK3FhXX8pe//CU9/PDDef8DDzywWJ3/RoDyqaeeSptuumk6/vjj87pyAcbSdRHw3GuvvWrnicBi1PciEHvooYemeGV86f5FCLJ0XSVzRA1xzz33zPP+4Q9/SD179qw9ZixEN9R4XX1DOrJGkPKyyy7Lgctisrj+4k1PEciMrqxff/11+v3vf5/DpzfddFMOvRb7f/7557Wh3+hQGgHYGEUH1/nmmy/169cvryu9ht122y3PmTfU/BMB0KiNfvTRRzk0G6ZFkHWuuebKId64tmLEnLfeemtaZpllcv2zWN+Qvw2pm5ber+IeljtW0bAgtkWH1e222y7v9vjjj+eOtNGFNX6DiyyySO3XS0Ouv/vd71KElA0CBAgQIECAAAECBAi0JgFB1tZ0N10LAQIECLQagbpB1ni9WXR7iI4E0ZW1S5cuU11rvDIsCtNRzD322GPTZjVdEqJDQRRaY0QxOQqc0d0hXn1WdzRk37rf9ZkAAQIECBAgQIAAAQIECBAgQIBASxWYUZA1am7RjXV6Izq7RlfN6JQZAcMvvvgidwk94YQT8tfKBRhL10WwszSUGF+KAGvM17t37/yween+RQiydF0lc0RINcKqMf72t79NFSaNdU888USKDrANCbIedthhKTqslo4IrUbINGqR4bvNNtuUbq5djlDqiBEj0j/+8Y8cDI4N4Rddb2OUC7IWddDYHgHaFVZYIRZrx3vvvZc7mS6++OI5oFoEWTfZZJN04okn1u4XC//+97/z26siGHr//fdPta3SDw2pm5ber+Ie1j3OwIEDU9R+Y4Rr+BYjrjesokNwXFfdEV1r475GEDgCwQYBAgQIECBAgAABAgRak4Aga2u6m66FAAECBFqNQN0ga/EKq0UXXTR3Vy13odFl4dNPP82dW3ffffc0duzYdNJJJ6U333yzdvd27dqlVVZZJRdDo0Af3VpjNGTf2sksECBAgAABAgQIECBAgAABAgQIEGjhAjMKst51111p7rnnnuYqootrPFA+ZMiQHFyN0Gbp6NGjR6o0yPrAAw9M9bakmKfojrr33nunXXbZZYYdWSuZ49FHH02XXHJJfgj+nnvuKT3dvDx06NAcnGxIkDWCr/FwfN0RHUEjVLrTTjulffbZJ2/+/vvv88P1EZiNrqlRc6w7ZhRkLa6hTZs26b777ksRQp3eKIKsO+64Y22X3WL///znP7k+Gs0BIpDamNGQuumMgqzhH8HpCRMmpNVXXz2de+65uXFBcV7RoOCVV17JH8tdd3wvRnSfvfvuu/OyfwgQIECAAAECBAgQINBaBARZW8uddB0ECBAg0KoE6gZZo6B+4403pmWXXTZdeeWVZa81Xi8W3RBKXxsWxeMoHD/55JMpuhmMHz++9rudO3fOr6qK14PFaMi+tZNYIECAAAECBAgQIECAAAECBAgQINCCBWYUZO3fv/80bzCKelrU54rw6oILLpi6deuWO4BGQPP555+vuCNrBDIHDBgwjVBDgqyVzhHBz+jUGR1PIzBad7z88svpuOOOa1BH1jPPPDOtv/76dafKr7aPIGs8UN+rV680efLk3J11+PDhed/27dvn8wi3FVdcMV133XV5/YyCrEUdNMLFsTyjUQRZ4xziXEpHNYKsMV+lddPpBVlHjhyZ+vbtm0aNGpW781566aWpa9eupaebDjrooBR+EbxdbLHFptpW+iGCrBdffHHpKssECBAgQIAAAQIECBCY5QUEWWf5W+gCCBAgQKA1CtQNss7otV+fffZZfg1ZWMQrtOJVWnVHvAItnvqPV3ZFB4cowNb3mqqG7Fv3OD4TIECAAAECBAgQIECAAAECBAgQaCkCDQ2yRng1AoXvv/9+6t69ezrggAPSEkssUXs58ZD53//+9xYZZH366adTBE/r67gaNcFrrrmm3u21F1mzsO+++6aPP/44X/92221XuimNGTMm9ezZMwd9jzjiiPSb3/wmPfXUU+mcc87JHVQPO+ywtNFGG6WOHTvm78XD9/EQfowZBVkHDhyYQ8SxbzzYH2+oKh3vvvtu7vYaAdl4QH9mBFlLjz+9uml9QdaJEyfmDrxRm+3UqVO66KKLcii6dN5YPv3009Ozzz6bu7VecMEFdTf7TIAAAQIECBAgQIAAgVYtIMjaqm+viyNAgACBWVWgbpD1nXfeSX369MmXc+GFF6bVVlttqksrLfAWxeB4TVUEXKPwHoXj0vHXv/41xevFFl988RTLDdm3dB7LBAgQIECAAAECBAgQIECAAAECBFqyQEODrBE2jCBmjKuuumqawOHBBx+cohNpjx490gknnJD3KxdgLNZV2k212D8mfPDBB1N0NC3WVTrHsGHDclfUmCM6fkYn1GJEQPekk05KL774YoOCrD/72c/y94p54u+gQYNygDSWL7vssrTCCiukU045JXeqjTpkLJeOImAb64raZSzHA/dnnHFGmm+++VK/fv1iVYqg6qGHHpqXDz/88LTFFlvk5fhn0qRJaZ999kmff/557gIbHVibO8jakLppcb/iXIt7GMtFrTfu48knnzxNrTb2iXH99dene++9N7Vt2zbdeeedKTqvlo6o40bDgzXXXDMdddRRpZssEyBAgAABAgQIECBAYJYXEGSd5W+hCyBAgACB1ihQFDd32GGHtN9+++VXc0WQNYrRUYA+66yzUrxeK8a3336bC5cffPBBfs1XdF2IEUXgKAavt9566bTTTsuvpMobav655JJL0qOPPpq7SsR+Ddm3mMNfAgQIECBAgAABAgQIECBAgAABAi1dIEKREY7cZZdd0t57751PNzqNRsfRGP37989dMvOHmn8++eSTHJaMzwceeGDadttt86bJkyfnoOF9992XP8cbkeLNSDHKBRiLdZWGUIv9Y74iBFmsq3SOCHrG9cbr6aOGGDW/eH19vJnp9ttvz+HImL+0Y2tYxAPvMbbffvu01FJL5eWiI2t8KLquxnJ0Y40w5ptvvpkfto+H7mOcf/756fHHH0/zzz9/uummm3IQN9ZH6DfCpl988UV8zB1hf/KTn+Tl6D4aXUjnnHPOfH5dunTJ6+N4b731Vu64eu655+Y6aFxb3Ksbbrgh71MEaJs7yNqQumlxv+IEi3sYgdTwiBG/v/gd1jeiC3AEr+NaI6Tbq1ev2l0HDx6c3aMjbAStt9xyy9ptFggQIECAAAECBAgQINAaBARZW8NddA0ECBAg0OoE6gZZ4wJffvnldPzxx+dXdkVBOJ68jwL6a6+9lkaNGpVf1RUF4+iAUOx/3HHH5eUoDq+99tpp3LhxuQgcodcYUejdcMMN89yV7pu/6B8CBAgQIECAAAECBAgQIECAAAECs4DA5ZdfngYMGJCDlcsss0zq27dvrqPVF2SNzqXRdTXCoO3atUtrrbVWDrq+/vrr6auvvsrB0K+//jp3y/z1r3+d9t9//xYTZI3b8eqrr+YaYoQh4zX23bp1Sx9++GEaP3587d0qDbJGbfHoo4/O284+++y07rrr5uXSIGusWGyxxfJ/EQqO64+Oseecc05affXV8/5PPfVU/hwfFlpooVy7jOPG/h06dMh1zAkTJmTPPfbYI62xxhq5phnLMRZZZJH80H0EOSMke+yxx+YA7rzzzptWXnnlNGTIkDR69Oi87y9/+cvajqTNHWSNmmylddO6QdaJEyemnj175npunHgEksuNeGtWdGONUXRljeUIIy+33HK5A+1LL72U5wnvqB1H11aDAAECBAgQIECAAAECrUlAkLU13U3XQoAAAQKtRqDoYFB0ZC0u7JVXXsmFygiulo4lllgiv+Jr6aWXLl2d7r///tylILoulI54LVV0ANh6661rVzdk39ovWSBAgAABAgQIECBAgAABAgQIECDQggWis2cELouOoBECXHDBBWu7rtbtyBqXEg+BxxuRIohZjM6dO6ftttsud8I85ZRTctA11sWr4COsGZ1QYxSdOIt1c8wxR3rooYeKaWr/RjgyQpJRo4suncX+TZmjmDzmuvrqq3P4MwKtcZ4RHN18882zRQRNb7nllrz7G2+8kY488si8/Kc//SkHTeNDvCXqo48+yoHRO+64Iy/nnWr+iXBpGKyyyirFqvw3Oo/efffdObRabFh++eVzUHbQoEH5mFGnjPBvdH+NUXQ8jeU4x6iLxhg6dGiKYO2IESPy5/gnLLfZZpu011575TByrIuOrtHZtXCMdcX4z3/+k2um9d2DYr8Z/a20blr3HkaQdaeddprR9GnJJZdM1157bd4vgtRxvBtvvDEHeYsvxzX06NEjHXTQQbVv6iq2+UuAAAECBAgQIECAAIHWICDI2hruomsgQIAAgdlKIIq9UUyP13JFETo6SSy66KL1PtEfr/uKTgxRrI9OCdE9IQrIxau6SvEasm/p9ywTIECAAAECBAgQIECAAAECBAgQaKkCUU+L2lh0WF144YXrraOVnn98J8KUn3/+eYq3HUUNruiCGWHD6L4Z9bV4wLyljriGsWPH5i6ycY6PPfZYuvDCC3OXzyuuuKJBp/3ZZ5/law6L6PJaWNSdJIKn77zzTt6+6qqrpuj+Wox4OD8842H86BZbjJEjR6YIfca+dWuWn376aXr//ffzNUTgMx7Q/zHGzK6bxvEiGBvX37Vr1/wWrgUWWODHuHTHJECAAAECBAgQIECAwEwREGSdKcwOQoAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQKD5BCK0etRRR+UDHHDAAbXdVWNFhG+j+2l0L91yyy3TYYcd1nwn0kJnjiBvdOitdESwtlevXpXubj8CBAgQIECAAAECBAgQaIKAIGsT8HyVAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAQEsROPjgg/ObnKJzas+ePdN6662XohPqgAED0sMPP5y70l5wwQVplVVWaSmnPNPO46677kqDBg2q+HjR/fW0006reH87EiBAgAABAgQIECBAgEDjBQRZG2/nmwQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgRajMDrr7+eTjzxxDRhwoRpzqlt27bpuOOOSz169JhmmxUECBAgQIAAAQIECBAgQODHFBBk/TH1HZsAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIBAFQU++eST9NBDD6UhQ4ak0aNHp8UXXzyttNJKaf3110+rrrpqFY9kKgIECBAgQIAAAQIECBAgUB0BQdbqOJqFAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECggQKCrA0EszsBAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgEB1BARZq+NoFgIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAgQYKCLI2EMzuBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAECBAgQIECAAAEC1REQZK2Oo1kIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQIECBAgAABAgQaKCDI2kAwuxMgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECBAgQIAAAQIECFRHQJC1juOYMWPS+PHjU8eOHVOXLl3qbJ324/fff58+/fTT1KZNm7TkkktOu4M1BAgQIECAAAECBAgQIECAAAECBAikkSNHZoX5558/19KmTJmSRo0aldctsMAChJooMGHChPT++++nL774Iq2wwgpp4YUXbuKM0//62LFj07hx4yquo05/NlsJECBAgAABAgQIECBAgAABAgQIEJidBQRZ69z9U089NQ0aNCjtvPPOqXfv3nW2Tvvx448/Tvvuu2+aY4450kMPPTTtDtYQIECAAAECBAgQIECAAAECBAgQmM0FihpaMPTv3z916tQpvf3226lv375Z5sEHH0zt27fPy/Hg+KRJk/Lndu3a5XX+mb5A+J544onp888/zzuG629/+9vpf6mJW88777w0cODAtMMOO6T99tuvibP5OgECBAgQIECAAAECBAgQIECAAAECs7OAIGuduy/IWgfERwIECBAgQIAAAQIECBAgQIAAAQJNFGhIkPXQQw9N7777burTp0/aaqutmnjk2ePrt99+e7rtttvyxS6zzDJp7733ThtssEGzXrwga7PympwAAQIECBAgQIAAAQIECBAgQIDAbCUgyFrndr/55pu5c8FSSy2Vll122Tpbp/1YFOF1ZJ3WxhoCBAgQIECAAAECBAgQIECAAAECIVDU0GK56Mg6ZsyY9Pzzz8eqtOmmm6a2bdvm5UMOOSQNGzZMkDVrVPbP6aefnp599tn0q1/9Kh155JGVfamJewmyNhHQ1wkQIECAAAECBAgQIECAAAECBAgQqBUQZK2laNxCUYQXZG2cn28RIECAAAECBAgQIECAAAECBAg0r8DkyZPzAYqgaHMcLY4xduzYNNdcc5WdvqihxcYiyFp2x5qVMyvIOmnSpBTn3b59+/pOpcnrJ06cmDp06DDNPLE+6onVuicnn3xyeuGFF9Luu++eevXqNc3xYsUPP/yQvvrqq9S1a9eqXHMlQdb4TYRvcxhPmTIlxT0Mx0rH999/n+/5nHPOOdVXvv3223yOHTt2nGq9DwQIECBAgAABAgQIECBAgAABAgQIzByBVh9kveKKK1J0Wd16662neRXZM888k1+5FZ1Xi04FN9xwQ95/yy23TL/85S9r78KECRPSzTffnF5++eX00UcfpSWWWCKttdZauVvEH//4x1wwfeihh2r3t0CAAAECBAgQIECAAAECBAgQIEDgxxQYPHhw6tevXxo6dGhq165dWnvttXPHznfeeSd37+zZs2fabLPN8ik2tIZWXNfAgQPTfffdlzuoRlByoYUWSquttlpaffXV0xZbbFEbMiwXZI0a26WXXpoDhGeddVZ67rnncq0u1kfQc+65587zxTyPPPJIPuTxxx+funXrVhw+/x01alSKIGeMAw44IK255pp5ufSfa665Jr366qtpjz32SG3atEn33ntvCocIQi699NJp++23T5tvvnntV6Ij7EUXXZQ/X3nllbXri4WTTjopjR49OneNXXnlldMHH3yQItjZuXPnFOd45513ZuORI0emNdZYI7tHrfG//uu/UtQQY/4IuK644orp4IMPTvF2qMaMuKZbbrklDR8+PH333Xc5pLrkkkum3XbbLa277rp5ytdffz1dd911+ZgR5Izrj+P+/ve/r92nMceuL8ga1/y3v/0tPfXUU+mbb77J9zeOF7+L6Ly73HLL5cOdeeaZ6bPPPsv3K+5b3XHrrbdmw7jfYVqMmPfBBx/M1xM122WWWSb/tiPE26lTp2K3NGLEiBSdaiO0etppp+Xf2qBBg/Lxzj777BzqDbsnn3wyRXfgcFlkkUXSJptskvbaa6/a327thBYIECBAgAABAgQIECBAgAABAgQIEGg2gVYfZD322GPTK6+8kjsRRDGzdEQB/M9//nOKIGtRkD711FNTFDR33nnn1Lt377x7PJF/yimnpLfeeqv063k5ukxEkVhH1mlorCBAgAABAgQIECBAgAABAgQIEPiRBB577LFc94pwaYzo/BndRyOsF8G+8ePHp7333jvtsssueXtDa2jxpXhI/IwzzsjfjznnmWee9MUXX+TP8U8EQ48++uj8uVyQ9e233059+/bN2yOY+O9//zuHQfOKkn8ijBjBwwi3RrfRujW+CIZeddVVOTAZAcouXbqUfPt/FouaX9QB33vvvRTdPMMi/saI5RNPPDH97Gc/y58jIHrMMcfk9QMGDMjrSv+J8/jyyy9zzXCjjTZKpdcSD8DH9ZbOH9+NueMa6475558/n390Sm3oiPBvhDTrjnD97W9/mwPAl19+eQ7sxj5xnyL8GSPCzRFGjYBpY0a5IGv83qJhQISnYyywwAJp3LhxuVtvfI6g6YUXXpjrsTfddFMO/Ma6uG9xbsWI32qEjqOD7E477ZT22WefvOnqq6/OIdb4EL/p+K/4jce9jd/KggsumPctfnPRDTbCxnFPY0TAN+714Ycfnj788MO8bt55581GUQeOsc4666RzzjknL/uHAAECBAgQIECAAAECBAgQIECAAIHmFxBkrSDIeu211+bOEhFW3XfffXMHhSiQRoH1gQceyHdJkLX5f6yOQIAAAQIECBAgQIAAAQIECBAgMGOBCONFSDVe6x5dWONtQhHUiyBfhA+jS2aM2KexQdYIGu66664pjhVvNjrkkEPyg97x+frrr0+PPvpoDhlG59N4XXsRKozj9u/fPwcaS8OfEWSN+lrU3CKEObymw+hBBx2Uw5ix/txzz80dPqP7ZoRWS0cETuPaIiganVLLjSLIGtui++kRRxyRVlpppdzVMx5gj66u0UX2ggsuyF9vSpA1ApnRZXWzmm63Eew94YQTcnfQmDi6i0Yn3J/+9Ke5A+0ll1ySjxfnEIHYxozoshrX99JLL+V7usMOO+SQatznCIDG7yC61MY1R8fcF198MUW9MzrfrrrqqrWdZxt67HJB1qiVRvfbePg/7tnyyy+fA9Rxr+M+RRg5fnPx24sutkUn1uiou/HGG9eeQjQmiHB1jAivLl3TNbcITkdAeM8990w77rhjvs7YN44VzQbC9bT/DfaW/uZing033DD94he/yHPFG7yiwUHcq4svvjgHa2OfCAZHODt+39HFtm7339jHIECAAAECBAgQIECAAAECBAgQIECg+gKCrDMIskbxPV6zVbdLRXErosj8/PPP68hagPhLgAABAgQIECBAgAABAgQIECDwowrEK9n79euXO6TefPPNOUhanNDLL7+cjjvuuPyxKUHWr7/+OtfMIlQYnTUjKFuMzz//PAcV43MEJuNV96WhwvqCrNE5M0aEYocNG5b69OmTttpqq7zu2Wefzd0240MEZaPraYzRo0fnzp3RWbVuGDLv8L//FEHW6NZ64403prnnnrt28x133JHCKa4hHlyP0ZQga92usfEmqL///e953iKUmT/U/LP//vvnrqDRfTTCmY0dce0vvPBCDq5GB9MY4RRB4giVRiiz9B4NHDgwh5ojJHz33XdP9Rup9BzKBVn/8pe/pIcffjjftwMPPHCqqaLD6VNPPZU23XTTdPzxx+dthx56aHr33Xdz6LcIrsaGwqw0uBwNBuJ3tM022+TfSOnkRcg1OrTedtttab755pvqN1e3w2qEoaOTb3TDjd9Dhw4daqeLIG4Eb+ONXRGMNQgQIECAAAECBAgQIECAAAECBAgQaH4BQdYZBFkjpBph1SiCRlG3c+fOU92V4vVdOrJOxeIDAQIECBAgQIAAAQIECBAgQIDAjyQQQdUIrEbHygj/lY4IfEbQMbp0NiXIWjpnsRwPhI8YMSL94x//yGHGWB/BxuiA2tQga3Rq3X333XMH2NLzjoBohB4jrBnh3SIMW5xT8bcIsv7qV79KRx55ZLE6/y1CsvHd6AwboylB1iK8myeq+ee+++7Lgd7SoGyx7eyzz07/+te/cufZ6ETb2FEuyBrB0OhWusEGG9SGgIv5J02alOK6I4jcvXv3et2K/cv9LRdkrbtf3Lcvv/wyh1XjtxAdanv06JG71Ma+hU3UXCNQHPcguqFGqDdCytFRNn6v0TE3wr4xrrjiirTccsvl5eKfaEIQwdPoThu//5///Of/P3vvARhHda5/P9oqadV7b+69G5tOqAkQwJAACTWkEQgpf/KRhEBIIwkkkHaB3EsCIaFcQiimY7BNt40r2JZlW5IlWb33rdL3vses7rrJkizZlvWcZDyzO7NTfjNods/8znP2uuY0DVbTWINFJdZgsu/cuXNx4YUXYtasWSYpOLgMxyRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAkeOAEXWQ4iswe6wtNutxx57bL8zE+wCiyLrfmj4BgmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQwFEgcO211xqhNDTRNHQ3VOTcunXrYYusKg2qEPj222+bbupVjt23DJfIqusNpnSqxKgyo5agtPvZz34W/YmgQZH1C1/4Ar7yla+Yzwb/CabUhtbvHY7IqnJmeHh4cPUI1i8WFBSYY+ibIRMjKbJqL1Mqjl5++eXmXIdudzimDyayapquSqlFRUVm+ypPh5ZQkVUFVU2wVXlVz9GiRYuwefNm/OAHPzCSraYLJyYm9onFuh49T1arNXSVZtrj8ZixJsFedNFFe4msTz/99F4pvHqt/uQnP0FhYWHfenSdU6ZMMfug0qumtbKQAAmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQAAkcGQJjWmQNdhsWWokcrNTWFvzXX3+96Yrq8ccf36trsdBTU11dbSq/Qyu6Q+dzmgRIgARIgARIgARIgARIgARIgARIgARIgASOJIGLL74YKvV95zvfwXnnnbffpjWdUkXN6667zkiOukAwvVOlQk0+DS0HqkNT8fCmm27Crl27zKKapKnJq1lZWZg4caLpyl5nDKfIqtLh97//fbM97Q5eZVFN6dR9uffeezF9+nQz70D/BOv8DnR8gxVZdXvKWEVe7clp8eLFpqnGv2gAAEAASURBVCt6FWk14fSVV17ZaxeCImuogBtc4Je//CXef//9EUlk/fznP2/2MSh2Brc5XOMDiawqNev7QXk1KSnJXBP5+flGdtber0JFVt2X22+/HevXr8eZZ56JW2+9FQ8++KBJxtWE1N/85jdmd5WRstKSnp5uZFbz4gD/6PV7+umn7yWyPvvss/ulrer50/195513zH8PmuoaLJoQe8899+yX/BqczzEJkAAJkAAJkAAJkAAJkAAJkAAJkAAJkAAJkMDwEhgzIqt2RxXsfiqI8He/+x3eeust9Ceyvvnmm/j9739vPvL3v//dVJQGP69j7Z5LK/opsoZS4TQJkAAJkAAJkAAJkAAJkAAJkAAJkAAJkMDRIvD1r38dFRUVOFD6qO7TlVdeiZaWlgOKrAOtQ3v33Xdx9913w+l0GmFWZc5gCmlrayuuuOIKc/jDKbLqCjVNVRuWa5fzERERJpk1JSUFjz76qJFIzUYP8M9wiqw1NTWmAbxu5lgWWb/61a8amTMoiIZiUYnzgw8+MMz03KmIPNiyr8iq8uqNN96IsrIyLFiwAN/4xjeQmZnZt9pgou6+IqvWz2o9rcvlwhNPPGHYalLr9773PZxzzjnm88XFxbj55pvNtMqtKrkeqlRWVkIZaDmQyBr6eb/fj+3bt+PDDz80CbrKR9Nh9bphIQESIAESIAESIAESIAESIAESIAESIAESIAESGHkCx73I+rOf/QyrVq0ylZ5a+RksmpygFavl5eX9iqyhSQ8HSrEIJgRQZA2S5ZgESIAESIAESIAESIAESIAESIAESIAESOBoErjrrruwevVqI/sFEy2D+xMqYYYmsg62Dk0FTk3XVAlSp0OLCpK/+MUvzFvDLbJqV/MqO2rqq4qsmqaq0uy1114bugv7TQ9WZA0VJ//xj39AZdlgWblypUkd1dfHssgaPKeaiqrcQstrr72GP/7xj0ZEfvrpp+FwOEJnD2h6X5FVRVCtP9XywAMPQFNYQ8u3vvUtlJaW7pfI2t3dbeRqTRFW+frf//632S/tJUvlVi26zJIlS8z0JZdcApW1Q0tDQwN+8IMfIBAIGPlU02/7E1k1lVj/W9D6Yb2GQ8vf/vY3PPPMM8jIyIBOs5AACZAACZAACZAACZAACZAACZAACZAACZAACYw8geNeZP3Xv/4FrfRMSEjAn//8ZzNWifXhhx/Gc889Zwj3l8iqy2prf61k1cpXTZqIi4szn9u8eTN+8pOfmK7aKLKO/MXKLZAACZAACZAACZAACZAACZAACZAACZAACRyaQGgPQ9/97ndx7rnnmg9pyqQKfNu2bTOvQ0XWwdahabfrK1asMHVtmoYaTPTUOjSVRuvr6802HnroIeTm5h5QKtyxYwduueUWs9zSpUv71qF1cSqSXn755SY11izw6T+hcmLwfa3nCyZ/6nyVELWo8JiTk2OmByuyKisVJzWpMzSlVtNgVdZsb2836z2WRda1a9fijjvuMPsZmm5aV1eHH/7whybZduHChVDhdShlX5G1qqrKJOXqur75zW/ioosuMqvdty725JNPxu23377XJoPrCr55+umnm16wgq91HFxGxVztQSsoF7vdbqiwrfJ2cnKySee1WCwHvOaC6/v5z39u0lfnzZsHFb+1bjdY7r//frzxxhsmVVaXYyEBEiABEiABEiABEiABEiABEiABEiABEiABEhh5Ase9yPrxxx+bilnt2ioqKsq0pNdK1Y6Ojj66/YmsutDGjRvx4x//GLqO2NhYzJgxw1Rir1u3zlSwd3V1mcrOF198sW+dnCABEiABEiABEiABEiABEiABEiABEiABEiCBo0FA67BuvfVWbN261XQdr42zU1NT8cknn+xVJxYqsg62Du3dd981Db71+FQenDlzJioqKoyAqumeKi9qwqZ2Af/lL3/ZCK/7dvN+MJFVG6O/8sorpt5N911lV03YDBYVSTX9U8uUKVNw3333BWdBG55rMqeWX/3qV5g7d66ZHqzIqh+67bbboFy0aP2hyq27d+82r5WxlmNZZNX9U0lTBc+wsDBMnjzZMNXrQPff6XTiD3/4A/Ly8nTRQZegWKrC79e+9jWzTk1d3bVrF6xWqzn3mpq7ZcsWtLS0mHrV1tZWU0d79tln75Wqqum+ocm+oecuuGONjY34xje+gc7OTrOOOXPmmCRZPUcqTusx/vKXv+w756HS87PPPmsSfIPr0iRflXm1qGg9e/Zsk/qqkrf24KVFr5lFixaZaf5DAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiQwsgSOe5FV8b366qt48MEHTWVzEOf8+fNx5plnmpb8oSJrsMutL37xi7j++uuDi0OlVW3ZHyrAasqrtsr/9re/bSpnKbL24eIECZAACZAACZAACZAACZAACZAACZAACZDAUSSgsp/Wh7311lt9e6Gi33nnnWeSKlX+CxVZdaHB1KHp8prEqt3Aq7QaLOPHjzci6Zo1a/DYY4+Z+jjtBv6EE07oS+sMSoWauqrpq1pCE1lVJtRekYKpripMqigbLC+88AI06VVLaNKovlZ59//9v/+nk6YuT0VaLcE6v32PWecF5dd9e1xqa2sziaZBaVaX1YbyKm0uW7bMfC4osgaPZd916GeC+ztx4kT88Y9/1Lf6itY3vv322/jsZz/bl07bN3MQE0Fh9YYbbsBll13W90lNlP2f//kfaL1lUL7VmSqvampqkE/fBwYxEUzlDYqs+lGVQFUmVak5WCIjI3HxxReba095qeiq7/3nP/8JLoJAIGCEZxVdNWn1kUcegaaq7ls0EVe3G0wVDs7PyMgw1/Mpp5wSfAuhCbHBa65vpkw8//zz+Pvf/75XnbHO13Os18n5558fujinSYAESIAESIAESIAESIAESIAESIAESIAESIAERpDAmBBZlZ9W2paVlZnW/9rVWFpa2qCxaoqEJkXU1NSYFAat8D1QheqgV8wPkAAJkAAJkAAJkAAJkAAJkAAJkAAJkAAJkMAIENAUSxUHVbBUydTlcuFHP/qR6YHoQFLnYOvQtJv6nTt3mjqyqVOnIiYmpu8ompqaUFtba6RJTeYcTNH0UxVZNdlTxUaVcIPlgw8+wC9+8QsjQz7++OMIDw8PzhqRsaaJlpSUGMExJydnxLc3EgfhdrtNWq72LKXSZ3p6+ojVa+q5U/lXz72mnWqqbrAOVWVarV/V61DraEOLprmWlpbi6quvxpe+9KXQWXtN6zo0bVXlYRVgtZ5X02aD29hr4UO8UOFbE2r1WrPb7YZL8L+TQ3yUs0mABEiABEiABEiABEiABEiABEiABEiABEiABIaRwJgRWYeRGVdFAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAsckgf5k9WNyh/fZqTvuuANr167FRRddZJKD95k9al+2t7ebpOrBHMDZZ58NTXM+nKLJ3PumGPe3Pm2QoEL5cJaioiJ897vfNY0qNK07Pj5+OFfPdZEACZAACZAACZAACZAACZAACZAACRwHBCiyHgcnkYdAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiRAAkpgNIqsmu6sKbsVFRV49NFHTQrzww8/bFJyj5ezqunOv/zlLwd1OEuWLMGJJ544qM/su/DTTz+NNWvW7Pv2QV9HRUXhrrvuOuj8wcxYvXo1NEX5iSeeMGnMKuZ+//vfH8wquCwJkAAJkAAJkAAJkAAJkAAJkAAJkMAYIUCRdYycaB4mCZAACZAACZAACZAACZAACZAACZAACZAACZAACZDA8U9gNIqsK1euxG9/+9u+k3PBBRfgpptu6nvNidFJ4Ktf/SoqKyvNzkdEROCBBx5AWlra6DwY7jUJkAAJkAAJkAAJkAAJkAAJkAAJkMCIEqDIOqJ4uXISIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESOHIEnnvuOZSXl5skzwULFhy5DR/GlrZt24bHH38cKjtOnz4dKrJaLJbDWCM/eiwQeOihh7B7925kZGSYc5qTk3Ms7Bb3gQRIgARIgARIgARIgARIgARIgARI4BgkQJH1GDwp3CUSIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESGAsEKLKOhbPMYyQBEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiCBY5DAqBVZtVsh7W7o/fffx9atW5GWlobTTz8d8+fPN5h7e3uPQdzcJRIgARIgARIgARIgARIgARIgARIgARIgARIgARIgARIggaESaGtrw7Jly/r9+JIlSxAWFtbvMjpTl+ns7MS///1v7NixA1FRUVi8eDEWLlyIyMhI8DnDIRFyARIgARIgARIgARIgARIgARIgARIgARIYFgKjUmRVifUPf/gD7rnnHvT09OwFIiYmBq+99hry8vL2ep8vSIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAERjeBt956C1dffXW/B1FcXIyIiIh+l1GJdfXq1bjmmmugcmxoiY6OxgsvvIDJkyeHvs1pEiABEiABEiABEiABEiABEiABEiABEiCBESIwKkXWZ555BrfccotBoi2jzz//fHg8HvzrX/9CeXk5xo0bhzfffBNOp3OEsHG1JEACJEACJEACJEACJEACJEACJEACJEACJEACJEACJEACR5rAww8/jDvvvBM5OTnIzc3db/M2mw2PPvoo7Hb7fvNC32hsbDTpqx0dHabHt0svvdTIr0uXLsX27duRkJCAV199FdnZ2aEf4zQJkAAJkAAJkAAJkAAJkAAJkAAJkAAJkMAIEBiVIuvcuXNRU1ODCy+8EA899FBfF0Eqs5555pkoKSkxrah/85vfjAAyrpIESIAESIAESIAESIAESIAESIAESIAESIAESIAESIAESOBoEPjxj39sRNX7778fl19++ZB3QWVYlWJjY2NNL29BKba9vR1nnHEGqqqqcMUVV+C+++4b8jb4QRIgARIgARIgARIgARIgARIgARIgARIggYERGHUia1lZmWklrYen3f7s2xr6iSeewK233oqkpCRs3boVfr9/YCS4FAmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQAAmQwDFN4Morr8Tbb78NTU6dP3/+kPbVYrGY5wylpaX49re/jR/96Ed7reeRRx7B7bffjujoaGzbtq0vTGOvhfiCBEiABEiABEiABEiABEiABEiABEiABEhg2AiMOpFVd/iqq66CVjRVV1cjEAjsBeP999/HF77wBfPemjVrkJWVtdd8viABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEhh9BKxWK+bNm4fdu3ejsLAQcXFx2LVrlxknJyfD5/Oht7f3kAemy+Tk5JjnCy+99BK0F7jQUlRUZFJZ9b1ly5Zh2rRpobM5TQIkQAIkQAIkQAIkQAIkQAIkQAIkQAIkMMwERp3Iun79elxwwQUGw4oVKzBp0qS9kDz77LO4+eabzXuvvvoqZs2atdd8viABEiABEiABEiABEiABEiABEiABEiABEiABEiABEiABEhh9BHp6eoyAquNTTjkFq1atMvKqHomKrN/97nfx1a9+db8AjH2PtLy8HIsWLTJv79ixAy6Xa69FNEAj2BvcU089hVNPPXWv+XxBAiRAAiRAAiRAAiRAAiRAAiRAAiRAAiQwvARGncja0dFh5FVtMX3bbbeZiqlgC2ubzYYlS5bgvffeM5SefPJJnHbaafsRq62thUquAyl5eXlISkrC9OnTB7I4lyEBEiABEiABEhjFBLZu3Yq6uroBH8Hs2bNN6suAP8AFSYAESIAESIAERh0Bt9ttJJmB7nhMTMx+qW4D/SyXIwESIAESIAES6J9AWVkZFi9e3LeQPhPIzMxEZWUl/H6/ef/888/HI4880ve6b+GQiUP1/Kbr1d7evF4v/vznP+PSSy8N+fSeSQ3a0P05VImKijLPGDTVVWVbFhIgARIgARIggeOXgDaGeffddwd8gOHh4X2Nawb8IS5IAiRAAiRAAiQw6ghobzI6DLRosGd6evpAFz9ulht1IquSv/XWW/HEE09Av9ipzHrCCSeYboRUXF27dm3fyXlGXtvXrOp7HZyo9Aew0eMNvjzkOMVqwYJw5yGX4wIkQAIkQAIkQAKjm8B6txfVUtE00DKuaCssJcXwd3cjZc5cZCw+CTmfORMu+VLpiI4e6Gq4HAmQAAmQAAmQwDFMoKWlBX/4wx8GvofSm3FHQys62jvQ1taGdh23tu2RaaRRbkZWpgwZyMjMQGZ2lhln52QjPTPd1HPY7PaBb4tLkgAJkAAJkMAYI7By5Up86UtfgsViwc9+9jNcffXVcDgc5p774x//GNpjm5Y//elPuOyyyw5K55///Kd5thAbG4vVH65DZUWD3Lu7+4b8celYcvk50GCNe+65F5s/7JL7eTfa27rR2dENj9QfTFtsR2R02EG3EZyhQRxhYWHYUeNEfbUPvR1eWBxWOMfHoWB2FuacMB5zpB5hQkISHLDAGmYJfpRjEiABEiABEiCBUUbA5/PhV7/61YD32ulxI+PVFxEeG49YCdjKPfc8edYwD/ETJsAiDWtYSIAESIAESIAERi8BrQ/Q7wZ1Erj51ptvonQAjWGDRxsT6UK4Y2RcxfknLMTCxXt6qQlu71gZj0qRVR8EXXnlldiwYcN+HBcsWICPPvrIvL/i9dfhqKzYbxmPtMyubGnd7/0DvfHuzmJkxcXhzMkTDzSb75EACZAACZAACRxHBNo9Hng/TXA56GGJnPLJ7kqUidRyUnQUXB3t8HV2wCZfJB0x0QiXB08xUuEUVzAOEZK0YpfkFX1gxUICJEACJEACJDA6CWi6W0lxCRobGlFVWSWVTnVob239tBvjMETL/V8HV5QLW4sK4ZIKppyMbHjle0W3NHbp7nZDU139Xp/IrD7Y5TuD3WE30o3TKd8fZFrHka5IRElDmGgdZH1mWsb6vs7n94nRef1wr0mABEiABIaXQGdnJ3ZJgoneG8ePH7/XyjUB7bzzzsOWLVtw1lln4YH/+ivc3V65F3vhdfvM2N3tgcfjR0PLTtz4rRvN/Xj5Gx9i07piBHp60BPokXt8AAtPmoLTPjPfrP9//vthvLG0WQRWTXztheRewCbtThwxIqS6/Oi0BeC19SDK6UCk3NddMrbbrLKcDCKletub4G6pQWTCRIT1utDe4EGzSLP1YV5EJYRLomwMctISkJkaj4TUWCTHRSNFvk84wqywU2rd6xzzBQmQAAmQAAkcqwR65XuIr6sLnSKq7CoshLuhDl319fBKoxgE9DuEBTZXBOzRMXDIMwOLzYHXiovhksY5JwV86PFpCFcYHNLIJkrS5vX5QnRODlxp6bBYrTKLzxiO1XPP/SIBEiABEiCBUAIqrrrluYA+T9ChuakJreIVtLQ0m0a4nZ1dUj/Rhd6eXkRERCAiMkKeLYhzIM8XIsIj0S7eQfnuCkwcNx5pqWmhqx626fxx+cgfN27Y1jecKxqVIqsC6JFKpccffxyrV69GaWkpcuSLnEqs2sXvBRdcYB7wFG3bhkg56YdTfv7LX2KCVIhdecUVh7MafpYESIAESIAESOA4IvDhqlVYJq2mrr3qKmSkpMDT3ITqVR+aoW79eiRMnYrsMz6D1PkLEJdfwEqm4+jc81BIgARIgATGFgFtMa1D4ZZCrHl/FdZ9tM5UOi06aTHmLJiLmbNmwC4ijYoqWu67/z7Ex8fj+uuuN5+TZ1B7xjLP4/aI0NqN6qpqVO+WQcY1VVVGjq2qrEZLczMSkxIloTVTKpG0IikfeQX5JsE1ThrYWsSaocxqMPMfEiABEiABEjgogXvvvRf3338/MjIy8Pory1FaXI2G+jY01LWiUcaNdW2ol+lLr5uJa679slnP6y+/i7//5XW4osPhcoXDKb2zfW7JPHzm7BPN/Ccefwb/erQF3e4wJCdHISU1Su7X0XBkW+DP8qPQ1YyGCDcm2WIx05GA2fYkuMJssIuwovfuTZs24qUXX8Sll14m8u0kFBe34ZPCWry7frt8J6iCt6kRlhQHXPmxGH9iPmZPzMEJaVlItIcjMoxJ7Qc92ZxBAiRAAiRAAscQgYA0YO2orkKNuguvviyNWFpgldT47NPPQJo4DAmTpsAqvc2qkBr8bf/AX/8KbYhz8ze/iebtRajdsB7lby4zPcDFiPuQc865yDrlVFmPk+msx9C55q6QAAmQAAmQQH8EOtrb0djYiA1r1+HjDRuxo2g7fF4vUtJSpYe2bORKIFZObi7SpIe2ZAnFcsr3A/1uYP4nzxO279iB//3f/8X555+PuXPm9LepIc8Lk4Y02tPNsVhGnciqJ8/+aTd7moqiQmtoeeyxx/DDH/4Q06dPx7Jly/oeGIUuM5jpu+66CxMnTjTdFQ3mc1yWBEiABEiABEjg+CXwwQcf4I033sD111+PnKws+EVKaZeU1vbyMrRJA5vOulqT0upKz0CctGZKmTNXkloTYdOKKhYSIAESIAESIIFjnoDKq16pXKqtrsXHGzehoqxCBJh6JKUkIy09zUimaRnpSJHXWukTfAh1zz33ICEhAV/96lf3O8YeTWeReoyO9g7TTXFXR+eeaanYamtrl66K2802dbua3Orz+SW0xQ+rJK9EulxITE40FVvJqSlITkmS1FZJcZGHYsdqhdN+APgGCZAACZAACRwmAb0/V1ZWSqKqB6kpaWhu1HupW5JSdZDf5W3d2FH+IVRmnTJlCq794g/lYZFfGoOEyf1SBmkUovdVq7yeOicN5553ptmjZ599DoWb/Ghv70F7R48Iq704//MRuPSyS8w9/o3XV2PL5i65H9sQGeVEQLIzasLdaI7yotXVjSRJT0l1SrKqxYUMayRSLJK2Jkmq8g3BrF97lnvhhRdw+eWXY9KkyWht9aFe9r2sqhFlJY3YtaMR1a0taPV1IirJiqQMF9JzEpE1LgXZOUnIc8YgyabrtH66xsMEyY+TAAmQAAmQAAkMC4Fe8RQ0iVUl1CYJ2GreUQSf/Na3yG/1yNRUREnDmpicXETJc4JwqSsIs9n22u5//dd/GZH1lltugVvS2jpra9BaUizPGcrlecNuI766JEgjbeEJJqHV9P6m6awsJEACJEACJEACxxQBrdtvkCT2kp07USn3cO3ZTdNWtdc1HWsvbJq4GiPJ61qvHxsXKw1po0xvbFpPEVqKiorw5JNP4sILL8S8efNCZ42J6VEnsrZI6yVNXdWyYsUK5Ofn950oPbmnnnoq9KTqFz4VWg+3UGQ9XIL8PAmQAAmQAAkcfwRCRdZcaTEVLNrq2iNdDe9+9x1UrFwugqsbLqmwyjnjTMRNmLCnGyCprArb5wtp8PMckwAJkAAJkAAJHH0Cmoai3f/U1dShqHAb3l7+tqSpuqGpqGeccyZmzp6J8Ihw2PZ5AKV73p/I2t+RaSNdTWytqa6Wiq5KlJeVG3m2SqabG5uNRJOakSbpb+kmoTUjM0PS4FIQJV0OaYttFVrt0pWxNvxVsTUo1va3Tc4jARIgARIggWONgIqqkP/7Az1G6vD7AhJk0SvT+lpEEZm+6pov4pNPPsHXvvY1fObkS+U+2SYNQrrR1tKFuQsn4Ff3/gAqjl588cWIt81HfGKUDNFIkHFcQrQZomNdiE+IwcWXnCvpqMW45pprcMWVPxJZtQXV1W65n1pl/DA0NGPu3Ln49a8fl887kJzqQCf8qOrtwjpvA6p6OtHZ68fJjjTMsSciNswBp8im+5ZQkVUFWy16qHpMFRXdcjwt2LK1HKUllWhpqIE3wofeHAcyZ6Vh/KwszE2URjTRcYhzRiBc1i/NWHiv3xcyX5MACZAACZDAkSQgN3JteOrv6EC3CKjVqz5A3cYNaK+oMPJq1imnIWnGTBNyITftg+5ZqMhqFpL19sh6m0SMrZRnDI1btojg2oicM89C6tx5iJXe36wiw2jSKwsJkAAJkAAJkMDRI6D1FwF/wPTA1tXVjdqaGpTvKsPmTZuMyNrcLG7j3DmYu2A+pkoQZ7IEYgw0kIIi6/IBndiw7u5uqVo5+kVl1QkigrS1tZmEk7vvvluSSvzmAdJDDz2EO++80zzAWS2x/akijhxuoch6uAT5eRIgARIgARI4/ggcTGTVpLUeEV+0cqlTugqu/3gTWqQFdbd0H5Aycxbyzv0sIpKS4JCWViwkQAIkQAIkQALHJoFg6+k3X39TUtJ2mRbSEyZNwLQZ00RgSUGstJrWRLcDyaJDFVm14ku/R3g8Xkj9C9wyaAVYd1eXpMO1o7WlTUSdJjTJd4rmpmZJcms1PdRoBVhGViZy8nKQJd0SpUtKrLbwttn3Tnk5Nklzr0iABEiABEhgbwJ+eQjk9UgyamuX3Ps60dLUsWcs06063dqJ7rAiPPDAA4iR39WaUOLvjsSu4hqceuYsPPPc4/jVr35lVvr00/9GYmyWPCuw4+33X8NOSUUZJz2mfPbcy9DS2oO6ei82bnxKGqH81tzTn332WUk+nynd/UKSU9bh6quvNsmv99xzr6SgfBE2ZxgCjh6s9tVjR6AVnt4A0i2RmGqLMwms8RbnXimsoUd2IJFV58vtX+77fnnW4UdZWQtKSlqwfm0NmtqaYY/ugN/iQU9kD+LmSQPZKemYJo1axoXHIc8WLbup/2MhARIgARIgARI4GgQCkg7vFVeh5qPVKJMeYvWm7IiJRdL0GZKcWmACLRyxMbBL0lp/ZT+RVReWLwgeqQdwNzaguWgbGgsLJaW1BM74eOSefQ7ix0tgRnp6f6vlPBIgARIgARI4qgS03ryzsxP//ve/sWPHDhPGsHjxYixcuBCRkZED7ll9KOvR8Al9jv/OO++grq4OM2fOxIknnmh6Yle3cN+iAROvvvoqNm/ejIaGBpxwwgk444wzjG94oOUPtE+LFi3C1ClT8aff3SeNZuORlZON7NwcJCUlS6PYhL6e1Q70PGHf/dHXFFlHmciqJ02/1AUrpE477TTMmTNHKp02YuXKlTobt912G77zne+Y6cP9hyLr4RLk50mABEiABEjg+CNwMJE1eKRGRhGhtWnrFtRt2oja9evhkO4CYgvGIWXWbMRJZZNdugi2SGoaCwmQAAmQAAmQwLFBwO/zG2Fl5/YdKNxSiB1F282OzZg1E5OnTcGkKZMOKK+G7v1QRdbQdYRO63cKt6TBtra0oqaqRoZq0y2RtvBuk+6KNIk10hVp0mJj5CFZvDzYio2Pla6J4kTwiUa0vBclD84OJt6GbovTJEACJEACJDCSBMzvZElU9Xn1fuuTJHIZZOz9dOx2e+HploahMnZ3y7S+r9OfzjfT8v4Jp4zH9/6/r0tiarVJItdu9rKysrB161Yz6DFo93sPPPCguW97vT2SuHol3nvvPZx00kn47ncfFCHWh7Z2P9LTLCKyft0kuOrn9AFXuCSdr5ff8PrASlNd/0uk2YDExFb7O1HR24mtvma09HiRaY3ERFssZkgSq603DJZ+0tYOJrLqNoOludlr0mA3bmxC2S5puNJYh67OZnT3tKMz34qYghhMKMhAQXoy8pMTkGyNQII13CS0Wqm0BjFyTAIkQAIkQAIjS0B+o3tFMu2orkLTtm1o3r7NjLXeP3HyFKQuWIDI1DSTmDoQWeWAImvIEXRUSVq7NMapeHslPM1NiMrMMkmvqbPnSKOXaNikISsLCZAACZAACRxLBPT+p8GT2vOJBlSGlmi5d73wwguYPHly6NsHnB7KevQzX//61/Hiiy/ut84vfvGL+Mtf/mJ+6wdnlpeX47rrrsM2uafvW7Rx6+9+9zvTW0xwnqaxr5P6goMd2/PPPYfioh0YP3EC8seP6+s9Lfj5gY4pso5CkVWN6F//+tf461//utdF5nQ6jcD6ve99b8AG96EuFIqshyLE+SRAAiRAAiQw9ggcSmRVIuYhnVceukk6a6N8Aa58712Uv/kGxl+8xHQFFJOXDyeTWcfexcMjJgESIAESOGYJdHZ0oqGuHq+/8hpWLFuBxaeciLnz5xqJNTYu1lQ8HWrnh1tk1e3pd4qApLWaQSrLtBtij6S/tEkqa0VZBXaVlqF0ZzHKZbqluRkpaSnIL8gX8XYyJop8m5efB60vsdr27+r4UMfD+SRAAiRAAiQwXAS0Tl/lVE1abahrRVNDGxrr21Ff1yLjNnmvDR3tmkrulUYZLkkxiUZcQpSkl0QjPlHHMYhNcCFO5nW5W/DTn95pElZC90+TV2699VbcdNPN0mVfGFRibW8P4OabrzHLaihGVtaPEBtjR3p6OHJyIjF+glWeKXwFa9eu7VuVNhTRBBZ9/mCRlHNNX/3AX4c3PbuRJimsBdZozLMnI9kSDkfYoTXSgYisPSL56v42t3ixZXML3l5ZB5ulGw67CLSVpWjt7YAjLwbOOQmInZ+KxRFpmBWeZFJhw2UfWEiABEiABEiABEaeQI/8Jm/eXoTaj9ag5OWXEJ6YiIyTTjbhFbGSxGp1hiPMKt8N+mngErqXhxJZdXt+6bGlrbwM1as+RPHS503qa9455yFBJCCVZllIgARIgARI4Fgi0Cg9imn6akdHB9LS0nDppZeaHsSWLl2K7du3IyEhwSSgZkvvYv2Vwa5H770///nP8eCDD5rVnnPOOWY/tmzZgueff964hTfccIMJzdT6Ca1zP/nkk1FaWmoatF5//fVSR5BjGrY+88wzZr6KrF/+8pfNtK5UE1s13TV4bJdccgkiwiPwknwnCB7bK6+8IvUN6aZX+YF+H9iXA0XWUSiyBk+ixgCrGb17924T66vJrHrRD2ehyDqcNLkuEiABEiABEjg+CAxEZA0eaUBS1LpFZq3ftAnVq1ehV0QUhwisWsEVP248IpKTEWaxBBfnmARIgARIgARI4AgTUEG0u6sbJSKDrnrvQ5N+qsFm809YgElTJyMpOckknw5kt0ZCZD3QdrWyTZNam5uaRf6RRjP1DaarpJbmFpFgvKZiTivK7CL0qMSalJJsBNeU1FQkJiWKBBRnVjvUyrQD7RPfIwESIAESGNsEtKGF1+tDd6dXHup0o6vDjc6QobvLYyRVXU4fGOlg+uENYpPXmiCuDS9cLidcUeGSOq6DTEdHSPeDTkTKexGRDrkv20RUtUDTU3ZKSpneF/UhWF5eHnw+K1pafHJfdMtDJq+Z9vl6ZJlekUqAcKdVksvtkmJuR3JSuEzbpJtDm6S0tsgDq3XmAdYCSVNzhjtNEmtdoBub/c2o7OlEU48HU23xmCBJrBkitEaG2YJ73+94ICKrrkCRqMxaXd0tXQm2Y3dFO+pq2iSpthFeSWb1OrvRHi1CcLIdeVPSkZebguzoWOQ4opFtccEeJvyYztrvueBMEiABEiABEhgqgY7K3WgpKZF6/o3olKRUi92B+IkTkTJ3HqLSM+CUnlEGWw4lsur69HmCV2Sglp07UPXB++iqr5c3e5B58qlInjETEUlJsEgjHBYSIAESIAESOBYI3HnnnXj44YcRGxuL1157Dbm5uWa32iXRXBuMVlVV4YorrsB9993X7+4Odj1NTU2YO3euqRtXKfXuu+/uE1C1kerPfvYzsz3tgUUF28cffxw/+MEPjHD6+uuvY8qUKX3789RTT+H73/++CbZYs2YNLPI7u2xXGZa+/GLfsf394b9h49p1yMzOwvRZs/DFy7844GPr29BBJiiyjmKR9SDndFjfpsg6rDi5MhIgARIgARI4LggMRmQNHrBbEtI65Mt50VNPoHHrFmSf8RmkLVyIxGnTYZfWWtpSm4UESIAESIAESODIElCJRoXQ6soqfLTqI7z83IuYMWcmzjzvbOTl50n62+Aayx4pkfVAlLQL5G5JaiktLsWObUXYtmUbSktKUV9bj+zcbOQW5GHi5D0JrfrabrfDJilzdpvdiEMqBLGQAAmQAAmQwMEIGPFURMuASKM9IqP2yD20J7BHSFVJ1OP2oktk1ebGdklb1UESV2XYM92O9tYuSRT3GRE1KSUOickxSEiKkcYWMsh0UnIs4iR5NSbWZVLMVDodSOmVbftlP/z+HgT8QG2dBxUVXSje2YGqarcIql55SBWO8eOjMH5cFDKzIhAdLfdAW/8bCIgg0gE/Cv0teN1dgWiLA5NEYJ1pS0C2NWogu9a3zEBF1uAH9Fi8It9+8H4T1q1rFtE2DFZJZO1qrUR9QyPq2lrhPikB4bOTkJ2WgBmxKVgQnoxY2UeVa1Vm1QdtLCRAAiRAAiRAAodPoMfnQ0B6RalZ+xGq3n8PTdsKYYt0YdLlVyBJ6vYjpcHoUMtARNbguv3dXeiWlLvipS+g+MUXkH36Z5Cx+EST0OoUWYjPF4KkOCYBEiABEjhaBLR+WdNYNeX029/+Nn70ox/ttSuPPPIIbr/9dvlNHm1CKw8WsjCU9Wji6ze/+U1T562BmBEREX3b1u2oqNrS0oI77rgDN954I771rW+ZpNYlS5bgL3/5S9+yOqHLzxI5VcM1f/vb32KiBFM1ym/xX/321+bYbr75ZsyS7wDz5Tm/Pj+wS4OSgR7bXhs6yAuKrBRZD3Jp7HmbImu/eDiTBEiABEiABMYkgaGIrFrZpUPdxg1o+ORjNBVtgystHTmfOROx+fnsBmhMXkk8aBIgARIggaNNoKuzE7U1tVj26huora6VbozjpQX1DMycM0uS4FwmzXQw+3g0RVYVjFRm7ezoRFtrmwytJrG1VSromiS5VdNbW1tazTI2SbvLzctFdl6OjPNEIkpCjCTGH6zycDAMuCwJkAAJkMDxR0BuMSKJBoyo2trcgbaWLnkA1ImWpg65t8jQLGJFl9uIqg6nXVJNHXIPlXGEjMODY4c8SJI0VX1tBpl2SnJ4yLJ2u1UeANlNcupAKIpTKymvAVTXdEuvbd0oL+uURh0itAYgQqwNcZK8mpDgkHucXQabEVgjI3Qbonn243lKZiw6e/1Y5a1FaaADbslmHW+NwSyRWOPCHHBZ7APZvb5lBiuyqhiszGtq3JI624XCQhGCGzsRFemHNaxdJOI2FEoaW6PNh/TZ6YgqiEN4djSm2uONbJthjYQrbHD72LeznCABEiABEiABEjAE9De2pqG2V5Sj6sMP0CzdIXdWVyF51mwkTJmKxMmTJYU1HrYQUWaw6AYjsvbI7/2A14OmwkLzjKFZni9YHU7kf/ZziJ8wEREpKYPdPJcnARIgARIggWEloPfOnJwc+U0ewEsvvWQSUkM3oIKmprJqWbZsGaZNmxY6u296KOu5//77ce+99+LUU0+FJqruW2644Qa8+uqrOPvss/GPf/wD5557Lj755BPcdttt+M53vrPX4rr9z3/+89KwdB0uu+wyxIZH4oqrvozzzv+cObbnn38emRkZIrEmmucHKt4O9Nj22tBBXlBkpch6kEtjz9sUWfvFw5kkQAIkQAIkMCYJDEVkDYLySDJr847tKHlpKTxt7YgVeUS7H9JugGwul1Q+sRugICuOSYAESIAESGCkCGgXxJomV7xjJ4oKt2HNh2skIS4Sp595OgomjEN6RvqQNn00RdYD7bDX6xWxqAtlpWUmqbVkZzHq6xvQId9BVF5NlgddKakpkoKXhMSkROm6Ocq0iFeJ1yHfSaxMjD8QVr5HAiRAAsclAZUn/T4/fD7pvlaSU70ev4ipXvi8ASOouiVxtbvTg04d2rvRJeOO9i557ZZGFNJwU0RXLXHxUYiNdyEuIUoaiESbcZy8jpX3XVHhko4ieaH9WaT90FW5MyD3b4+nR7YrYkm7Dy3NXtTVy1DnRkODR9ZvMeJqfn4UsrMjkJ4eLuKsbrOfFYfMkk2gsceNChFYV3vr0CFC6wRbDKbY4jFRElmHUgYrsga3oUmzHe0i1K5qlJTZbug5ior0ItrlRmlRGWqkfsGX5kR3rgwTIjApKQUT4xJQYI9BmsisKt1K7josAz344IY5JgESIAESIIExTkAFVp+7Gx27K03valUfvAcVSVVczTvnPCTPnAHbMPSyNhiRNXhKvG1t6Kiuxs7n/4O2sjIkTp1m5NqUOXNgc4bDIr2vsJAACZAACZDA0SBQXl6ORYsWmU3v2LEDLnnuHVpUcM3OzjZvqWyq0umBylDWc9NNN+G5557DN77xDfz0pz/db7W/+c1v8Kc//Qlz5H758ssv44orrsA777yD8847z6Sp6r5pXXqbBEFAGrdeeNFF8ju8Aqeffjpy0zJw9Q3X4yyRYLVsl8YtUVF799Qy0GMzKzjEPxRZKbL2e4lQZO0XD2eSAAmQAAmQwJgkcDgiq1Z4+Toksaak2LTkLn3tFdMFUPYZn0H8xMmIkNZbLCRAAiRAAiRAAiNLwAie3d148T9LsfrD1Rgn8ur0mdMxZ/5ck0yqaXBDKceayKqtx3ukEs4jqfBer8+MW0R6aRCZdVdJKcpLy81Yu4fWRNaJUyZhkgwTJk2QLp+TTIvyocpGQ+HHz5AACZAACRwdAnq/UBG1pbkTzY0daKhrlXuFDHUtaKxvl1RvTV3tgCZ6R8eKIClSakycC/GJUXvEVZmOkff3iKrStb3IqlarxSxvsYSZsdVmMQ0kDsepDIjY6XZLAmu1Gzt3dpihttaNmGgbUtPCkZvrQpqMk5Kccg+zGKnVbg+D7sNAikqsPb09WO2vx2pPnbzqRabVhcWONCRbnAgPsw1kNfstM1SRVU6LiLu9kn7rRfHOTrz/foMcE5CaakNKYo+k0TbjvfcL0dbjRWRmFPzz42GfEockR4SRbhc7UhEtyazOMOt++8Q3SIAESIAESIAEDk7AL/UFXbU12PHcs6ZnNYvNhrSFJyD7tNPhjE+AQ+UV+VJzuL+XhyKyqmTr97hNMmvt+nWoWLHcyKyTLr8SkdJY1Rk7tIY3B6fBOSRAAiRAAiQwMALLly/HVVddJb/BLfK7vdqkl4Z+0ib306ysLCOM/vnPf8all14aOrtverDr0dTUc845xySs/vCHP8Qtt9zSt67gxEMPPYSf//znZvtr167FnXfeif/+7/+Whq/hUrewUxr1+qQnlEZoEITN6cCSJUukp5RezJ49G7+462doaW/D1VdffVjHpnUDOhyqqABcKAnsF154IebNm3eoxY+7+Xr+B1LCuru7tR5nzBWKrGPulPOASYAESIAESOCQBA5HZNWVB2XW+k8+RsXyt0yXQHap/Mo8+VQkTJyEcJFZtXKMhQRIgARIgARIYHgJ7BE7e1C2qwwfb9iEHUU70CZpJiedejKmTJuCjMwM06XxULd6rImsBzoOqd9BV0cnqiqrUCXpMjpubW0zkqtD7BiH04lISaeNiY0xSa3JmtialCTiUrSp2DvcB3UH2ie+RwIkQAIkMPIENMnUJ4mre1JV3ZKo6pUk1T3JqnsSVt3w+/cs0yPypC7v1y5s5T1t8KAlIsKBqOhIGcKN0BoVHSHTESK1Rsq9Q0RPmT/c9wmfTxJYvb0i1nokcVVTV73o6JDj6BaJQ/ZTJdWkRAdSUpzIyIhAXJxDUl+GJm4293qwy9+Orf4WlAXaMVlSWCdYYzBeElkjhiixKrehiqz6WUWvSaw1NW5s2dKKGpF4W9t8yM9zIjbKj/qaGtTWNqKhuR1N6VZ4c8KRPEFS15NikBLuQp41Grk2EY8lnTWcQqsiZSEBEiABEiCBgxLoEYnF75bvG5s/QcOmTWjdVYIwqw0JU6ZICussI4xatOeSw2mZE7L1oYis+vFe6WXGrT2/bS/CrjdeR48kyIUnJMjzhZORNH140mJDdpOTJEACJEACJDAgAv/85z9x2223IVYaVWhqqaaUhhYVWQsKCuQ3fQd+//vf48orrwyd3Tc92PWoPDtF7tVNTU24++67cd111/WtKzjxyCOP4Pbbb0dycrIRXnft2mUSYTXwYvHixfjOd75jeih76aWX8Mwzz5hnBvrZE088EX97+GEsffHFwz629957DzocqqRIwxRNpaXI2j8piqxf+lL/hDiXBEiABEiABEhgzBA4XJE1CMoj4kx3XR0Kn/gXdr+9EgUXXGgqmxKnTYctInLYHwAGt8sxCZAACZAACYxVAlp55u524/133sMT/3gCeQV5Jon1xFNOREZW5mFjGQ0ia+hBqtirQ11tHUpLSrF50yfY8vFmlO4sNel5+ePyMX3WTEybMQ05eTlIkMY2YSIMaat6FZWGW1YK3TdOkwAJkAAJDI3Anr/t4lfIx+WvvBEh9T2P2yfypxd11c2oDRnqalpEhmyR1NV2uERKjUuIQlp6AlLT45CSFi/jeCSlxiIpJdaIrJq0OtJFdtcUFTg7OwNobvZiy+ZWFG1vR1lZl0izVuTnuzB9ehzGjXchNsYmCaxDk1d1Q4aTjLcH2vCWezc6en1GXD03PAsTrXGGpdmhIf5zOCJrcJOazOrxBrDqwyYsX16HrMwIFIxzYcaMaFTuqsSK1zdIekwHPI5eJH+uAO6JkdgV2Y154cmSKJuCfBFyEyRVVq8LuYMHV8sxCZAACZAACZDApwT0+5L2pNbdUI+ip59C2ZvLkDJ7DtIXnYi8s8+BQ3oxGe4yVJE1uB/e1lY0bis0+7rz+Wcx44avIf/8CxApko4tPCK4GMckQAIkQAIkcEQIvCiy5ze+8Q0jhO7evds0jg3dsNYlp6enm7ceffRRk6IaOj84Pdj1nHvuuTjppJNQUlKCO+64AzfeeGNwVX3j++67D7/73e8wefJk+U293NSJP/3000ZOVZk1tDgl6EGTY4uLi41M+te//hWD3SdNiB1qKSoqwpNPPkmR9RAAKbJSZD3EJcLZJEACJEACJDB2CAyXyBqQL8YBaeGtXQDVb9yA1rJdUsmUgtyzzkZsfgEipMKJhQRIgARIgARIYHgI6EOppoZGrHr/Q5PEqkmkCxafgPkL5yElNVW6Q3Yd9oZGm8iqB6xcNKW1o71DJKYmNAoj5dTS0op2SWrVFvIet8cktSYkJSAnNxfZudnIzM40Ca0Oh+OwuXEFJEACJEACh09ApU9NXO1o60Zbaydam7vQ2tIhY5lu6ZS/891GZrXZrfJQySYJ5DLYbfL3fc+0jiMiw+Vvux2RrnCZdsrgMEmrOu1w2k0jh2EKIDvoAetxtLdL0qgksFZUdKOuzo3GJi8iwq1GYI2KsiE+3oGEBLsZx8ba5TgssFqHLmd29/pRIgmsRYFWbPY2YpwtFtMkjTXXGoU4STI93IYbwyGyKhcJX0NVVbc8nOtASXGniK09mDo1GjFRAVjQjeLtVSgtq0Gd3w1rtguJ89PRk2iHJdqOAhFZx0k66zgZR1hssvzQeR305HEGCZAACZAACYxSAprE6hEptP7jTahY8Rb0tT0qGqnz5yNh0mREZ2bBMgK/fQ9XZA14PGa/azesM0EZ+p0lMiUV+ed9DjF5eWafD/d7zCg9pdxtEiABEiCBo0Dgww8/xKWXXmq2XFZWJr/V7XvthfaMpiKplqVLl2K+3GcPVIaynksuuQSrV6/GTTfdZJJX912vCq5/+9vfcLKkl2via5vUfRdu3Ype+Wm8fMUKqDyqQuusWbOMQKqJsSvkfRVzf/rTn2Io+7TvPgz0NUXW5QNCRZGVIuuALhQuRAIkQAIkQAJjgcBwiaxBVm6RRlpLS1D07/+FR7oESp0zD8mzZyNp5kxYHU5YpKsFFhIgARIgARIggaETUFmztaUFxTuK8fpLr8ItYmZOfi4WnbhIEkdnDH3F+3xyNIqs+xyCSDLShbM0tNGU1hLhVbStCCU7S6QL6i7Tmj4rJ9uIrFk5WYhPiEe0pNK4XC44w6VL6fDww5Z99t0fviYBEiABEvg/Antkxh74vH5JNtkz1mmvCKxej09Sx73SCEEF1k6RWbvRIimrrSK1trd0wSPzewI9SJAu5xOSY5Ckg6SsJiZFy+tYxMW7jKx6JBJX/++I9kz5/b3ywEhS0909ksAqEmuDB7U1buze7ZaGFV55PyDdD0bJ4DLjuDi7JLAOTzKsWyTW+h431vjqUdXTBW9vAIscqVhoS4ZVZJDhED6HQ2QNMvP5etDdFcDKt+tFaO2ULhttGD8hGrNmxqG8tAo7CsvxyfpS9DjDkD0rE7X5VjRmWJAS4UKeMwYz7IlIsYQjVgTd4Tq+4L5xTAIkQAIkQAKjkUBQBm0q2obatR9h9ztvI2XOXGSdfAqSps9AhHTvO1LlcEXW4H61V5SjYctmI7N21tZiwkWXIFlEnKisbIRZrfydHgTFMQmQAAmQwIgSKC8vx6JFi8w2DiSqfvTRR7jooovMfWnLli2Ii4s74P4MZT0qsD733HMmmfWZZ54x4Q3BlWvvYkuWLIE+3//KV76C66+9DtHR0dLA145yEW6feeIpjJs4AYtPPglZOTmIkfruadOmoaGhwUivZ555JoayT8HtD3ZMkZUia7/XzF133YWJEyfiSxRZ++XEmSRAAiRAAiQwlggMt8iqLby97e2msqlu3VpUfvA+0heegIILLkRURuaIdFs0ls4Xj5UESIAESIAEVM784J33sGHtBlRKt0YF48fhrM+eg2RJP4+OiR42QMeDyKrSr/LSFujubrcIrJri1yHJeA3SFXUNdpdXoLqq2oiu6RnpyMnLxYRJE5FfkGcEV6s0wGHiy7BdUlwRCZAACexFYI+s6kN9XQua6tvQUC/dydbLb0kZN0u38u5uTdC2Iyo6AjFxkSI5uhAdGykPh1xwyXtRMRF7UliDiawy1nRWTWm1y6B/v4/033C57Yi8GkBNjSSKFnegtLQLbW1eSX8NQ0ZmpHQ7GI6M9AhpNGGDprGGh1vMPItleBJFS/3t2CFJrOtEZI2yOHCyPQ3ZVkkzFdlzeLYADKfI2ivJrOIjy71YkllLO7FmTZNIyA7MnhWLpEQL7FafNESpxratFdiytRxpM9KQuTALjZkWuGNkPqwisybgBHsKIsPk/IcNjxC814XKFyRAAiRAAiQwigh01dagQRLZil94HgGPG0nTphuRNXHqNNil0eZIJLEG8QyXyKq9vvnkt/uuZW+gbuN6kyibPHMWJiy5DLbISFhEZmUhARIgARIggZEmoMLoSSedJL/ti3HNNddA68q1nlmL1jXcdttteOyxxzB37ly8/PLLe8mmofs2lPW8+OKLJj1Vew9btWoV0tLS+lbZ2NiImRIepfXeTzzxBIo+2YLK+lqzL+effz6u+fJVUq+dY8RapwQ1vPHGG7jhhhtMouy2bdsQERGBoexT3w4McoIiK0XWfi8Ziqz94uFMEiABEiABEhiTBIZbZFWIPX4/NJlVuy/a9erLsDqdiJIuizJOPAlxEybAFsEKpzF5sfGgSYAESIAEDptAm3QPWFtdi7eXvy3JosXIyc02KawLFy8yra6HU9g5HkTWAwEPBAKS7Ncm8motyneVo6KsQoTgSlOBZ5NuqbUFe2xsLBISEyTZLxHxn45dUZLuJ5WHw8n4QPvH90iABEjgeCJgElYlPbVb0lW7Oj2SvunpG3eLqKqpq16P3ySsetzSKFKW9Ukiq37OYrUgMtIpEqsLsTpIymp8gnQ9LzJrtEiskVHHRnL2HnnVL2mxPjQ1edHcrGOPCKx63AFJW7XKAyQHsrIijMiamhoOq1Ul2+E70x5JXu2CH2u9DdguIqs+0MqzRuFkZzpcsME+jILncIqsSkD31evtFfnXjdVrGuUeLedexN7p02OQnxch10sHynZWYf2anZDYVdjjnPBPiYE/OxzeBCuSHJHItLgwzhaDdItcFyK02obxeIfvLHFNJEACJEA6wcD1AABAAElEQVQCJDByBHzdXfBJo826dR+hTurkOyqrJME0EzmnfwYxuXmITE0duY1/uubhElmDO9ooqax1GzegRrpWdkjKXfbpZyBeAruiJZmVhQRIgARIgASOBIE//vGP+O1vf2vqg5999lmcfPLJ5jfsypUrcfXVV0tdhgf33nsvvvzlL5vd2S2hEw888ICZvvHGG5GdveeeNdj1aCjD1KlT0dXVhdNOOw1PPfWUqbv2SZjUtddei7feeguZmZm475575TnBSqTnZeOOO+4w6avLly838/S3drP0nPr5z3/eyLjXXXcd7r777j5sg92nvg8OcoIiK0XWfi8Ziqz94uFMEiABEiABEhiTBEZCZDUg5Qtyt3RT0LS9SGTWV1Dx9gpMu/4G5J51NlypaUZuHZPAedAkQAIkQAIkcBgEigq34aNVH+HjDZtMpdlV112FiVMmIVxaUg+3YHm8iqyKXyvydNBuqb0+r6l03FG4HYVbCrFp/UZUyUO/9rZ2TJk+FbPmzMLMOTNNWmtMbIzIR0x/OYxLmB8lARIYQwT072xnhxvNDe2SuNmEmqpmaYzRjOrdjaiV1x0yz+8PIDk1Fqlp8UhJj0daxp5xaloc4hKiTCKrVVJQwkRs1PuccT9N0uqeBJSjjVMO0dxPysu7sH1HOz75uFW66/PKe5Ce0aIxZUo08vJcSEiQ7FARc4dbYA0ef3OvF5WBTrzpqUSZpLJ+PjwX023xSLCKNDtsWax7tjbcIquuVa8VlVmbm7346KNmvPZaDRYvTsD8+QnyAC5cWsv6UFfTgrde24C1HxZh5sLxSJmdDsyKQ7GzEzv9rTjLmYkFjhSRWiMRITIrCwmQAAmQAAmMJQJd0lCzdVcptj35BJq2bcWESy5D+uLFIn5Ogk1CJoa1Bc1BwA63yNorjVA7dldg2/8+iTbpKtlid2Cc9PqWc+ZZR+R4DnKYfJsESIAESGAMEeju7sZll11meibRw9Yk1HBJOV2/fr3UZ/hx8cUX48EHHzS/aXX+2rVrjTiq0y+88AIWLFigk9LIdXDr0c9oKqvKsJoCq6ELc+bMQWFhIWrlnu+Ue/vfH/4bnnz0nxg/aQIuu/IKXLLkEumFrN702nbhhReaOpSlS5ea9zTRddmyZUhMTNRVmzKUfQp+djBjiqwUWfu9Xiiy9ouHM0mABEiABEhgTBIYMZFVaPrli7mnpQU1a1aj6oP3ECbd80bn5BqZNSojU5JZI8Ykcx40CZAACZAACQyWgFYsNdQ1iMS6xrSyLhhXgMlTp2DO/DlITE4aEbnyeBZZQ/lrZaAKrdotU2N9A2pratHYINMyaKt6n7SAD4hopYmsyakiyGRnSvfQmUgS7lHRUcMuEIfuG6dJgARI4FgmYBoESNfwmqza2dYtDQDckkraifbWLrS2dKJD3vN4vPD7AiZdVRNWrSKkaoMAnXY6pSt4h03+vmq6qtOMo6LDzdglaavO8D3y53A31DhcpiqpdnX5jbCqKaJVVV3o7AzIQ6xeOTbI/tsRH2dHUpJTBoc8cLJL1322EfFHAuiFW9JYt/qa8IG/DnZYkGQJx3x7EjJE6HSK0DmMwa8G3UiIrLriQKBXrpcAdu3qwqZNLYap3RGGhQsSkZoq14KlBzu37cb2wt1Gag04LYifmgTku0w6qwc9iBBtd7I9HjmWKGRZXcN+7Id77fDzJEACJEACJDDcBPxuNzzNTahdtxbly9+CXerbI1JS9/SMVjAOzvh4aRBkGe7NHnB9wy2y6kY8bW1o2roFdRvWo3rVh0iZO0+O7UTEj59oju2AO8I3SYAESIAESGAYCbTJveiqq64ykmpwtdpr1xlnnIG//vWvpgev4PsquF5wwQXm5csvv2zk0+C8wawn+BlNYtWk1c7OzuBb0ttLFm6//XZs+3gz8gsKUDB+HPLlWUFVdTVuueUWqDgaWmbMmGH2My8vL/RtMz2UfdpvJYd4gyIrRdZ+LxGKrP3i4UwSIAESIAESGJMERlJkDQJtk9bgjVLhVPLKy/DJl+1JX7wcidOm7+kGyKTpDPejteCWOSYBEiABEiCB0U8gIK2760Ww3CKVU+tWr8WmDRtxxdVfwqlnnCayjHQYbB+Z1LGxIrIe6ArpkC4Zm5uaJaF1Kwo/2YqibUXS/XW3dG0dJ5WDBRg/cTyycnOMzBoRIbKVtIJ3yGDR1ED5bsNCAiRAAscTgR6RVVX61/RUHXpE2AxOq6gaTF1tauxAk6SvNjW2obmxXRoEtBt5MzzcYVJXk1PjzDhF0leT02IlpTQa0TGRkqh1bKSr9nfOVF71+ZSBirsBkxxaISmsu8q6UFLSAVekTe4JTkyaFI3c3EhkZETAZhvZ+4HsErp6/ajt7cZabz2We6pwqiMNi+wpSLVGwBVm7++QhjxvpETW4A61t/ulcYkHK9+ux67STkmwScDkyTHSJWOEaVzSWN+GZS+tw+7yeiQkxyBzVgbS5mditaUB9TaPkVgnSxrtDEcC5FuSyLzDnUkb3FOOSYAESIAESODoEuiR7oXdTdIIc8sWVH7wPipEZB1/yRKTWBqdkwNHVPQR3cGREFk15r5H6kSqRGLd9vi/YJc6EA3K0FTW+PETYBWRaERaCx1RctwYCZAACZDAaCDQ1NSEdevWmURWTVrVZNahlIGux4QvSF1MZ0cntm+XnsQKtyI5MQlPP/4kJkyciEUnnYipM6YhLV16K/m0BCTNfOvWrSguLpb6Cz/Gjx+P2bNnB2cfdDzQfTroCvqZQZGVIms/lwdAkbVfPJxJAiRAAiRAAmOSwJEQWX1dnVKp1mRahTdJtwea1Jp+wgkYf/ElpksgiyS1spAACZAACZAACexPQCus2qXV99bNW7H0Py9IolsEpkkF1Qzp7j6/IB9Wm6TajVC6ylgWWTWB1StJrO1t7ZIu2Io2GRo+TWutqa4RUavRnKz4hHgjtarYqi3gw+X8OJzyII2FBEiABI4jAt1dHnR0uI2k2ljf+qms2o4WEVc1gVXvVSqraoqqpquaVFVXOKJiIuTvogORMq3pqpq+qss5Pp12OO0iex77DQA0eVaeBUn3fW5UVHQbcbW+3mPSZWMleTU1xYlESV9NTHQiKsoKl0vkSUkLtUj67EgWv6SxVgU6jcDaCi8iJY10rj0Zk62xCLfY5NXIbH+kRVa/v0eSWXvkIV07du7sMNxVDD7t9GREuSzo7QmgqqIB27fuxsa1OxERF4nU8UlImJWKQFY4ivytsEijkhRLBObYEzHBFmtYyJU2kqeD6yYBEiABEiCBI0qgV75/ddfXof7jj1Hy4lKpY7chYdIUSSydi7iJk2CPjMSRrnMfEZFVqOqxdtbUoHl7ESpWrkDLzu0ouOAipIlEFJ2ds0dmPaL0uTESIAESIAESGHkC2lNYl4RDrVm1GhvWrkOLhC7ExsVi8rSpyMvPR5Y0WomOiR6yUDvyR7BnCxRZKbL2e61RZO0XD2eSAAmQAAmQwJgkcCREVgWrLcQbpbVY7fp1qHrvXURlZSNXWk7HSWuwyLR0ppeNyauPB00CJEACJNAfARWDPNJN4GZJYv1k4ycmiXXq9Kk474LPISExwVRU9ff5w503lkXWUHZ7BKaAqSzcXbEbJTuLsatkF1qaW4y8peciKTlJJCYdEs25UcHVFRUl8pYkDbKQAAmQwDFOQP/O+bx+Efj9kj7tlcRRL7xunxm7uz3o7vLKwxMZm2l9kOLZs5wIrj5fwAiq0bERiE+MQXx8FBKSohGXECV/E+WBSqRTpM6RSQYdSayawKpCpaaDtrb6TAJrY6MXDQ1e81rnJSQ4pEu/CORL1/bx8Q6RWI9cA80e2cGqni7sEGlzla8WcRYn5tmSkGeLNgLnSLIZaZE1uO8qC+8q68RHa5pN0Nq0abEoKHAhPT0cfqlf2F3WgFXvbpXk3zb45HxMnCMP8SYloiLRjxaHH529PkwUiXWcNQZZtihESzqrnemsQbwckwAJkAAJjGICARFb/F1dqP5otYism9AiKW0JkyYj73PnIyo9A07pSeRolJESWfVYeqShqYZjFL+0FLvffcccZ9L0Gcg85VRzvCaZ9WgcNLdJAiRAAiRAAsNMwO/TeogWVFdVo7S4BMU7dsh0ldRBJEigwgQsPHGx1D8nSiNa1zBveWRWR5GVImu/VxZF1n7xcCYJkAAJkAAJjEkCR0pk1YejWuHUUlIsrcRfQPvuSukWyIfJl19pKpz0yRS74h2TlyAPmgRIgARI4CAEfF4fWlta8fg//mXkyanTp2H2vDmYt2AeLFZNerMc5JPD8zZF1v/jaL7HiFisXTLpedEW8XU1tSjfVWbSckt2lsh0OfLG5ZmE1llzZiN/nLaMz+b3m//DyCkSIIFjkID+fZNgT7nfdErSahtqqppRW9Msf+NaUFvVhHoZqySo6aLJqXEi7scgKTUWiTpOiZWHJ9GIjo6A3WGXe1OYuTfp2Cr3KOunaauj8Xeeiqrd3T3SfV87ira1Y5sMVjmu+Hg7Jk+JkfQTFxJFZI2MtMJu13syDKMjdYp96MEKTxW2+JrRI0GjU2xxOM2eNqJJrMFjO1IiayDQa6ThjRtbJAW3U65LN046KQknnpxo0nB9IrO2t3Vj9buFeHf5J0iQazJnQirmnzEV9Qk9+KinAc09Hjglj/UsR6ZJZo2xODCy356ClDgmARIgARIggZEj4Glulrr1Cmx57FG0l5cj56yzkTZ/ARKnTpNkVjvCRriu4GBHNpIi657vrL1oka6SGzd/jJ0vPA9HdDRm3PA1xOQXwBkbe7Dd4vskQAIkQAIkMKoIaA9hhVu2YM2Hq7DizbcwbsJ4zJg1E/MXLjR1zdpjm8U6cr20DTcsiqwUWfu9piiy9ouHM0mABEiABEhgTBI4UiJrEK6npQWNW7eg5qM1qF69Cpknn4L0BQsRL63GHTExwcU4JgESIAESIIExT2BH0Q5sMWmsHxsx6PSzzzAVV2npaUeEDUXWg2PWtNzODpW+GlFVWWVayNdU10gyoQ8BkV1V2nJFuRAXH4+MzAykZaQjJS3FtJS3SkUjCwmQAAkcSQL64D8Q6DEpqh3t3dBBBcAOHT59rYmsmq6qxYgCn461M3a7w4bwCKckgUfIEIkoGUeJvKoprFFRESaRVRtYjOaiPq+Kkx0dftTVeUx39nWSCOruDphkVv27Hh9nR3JyOFLTnUhKdCJCJFabyK1HujSJnFnV04lVnjo09rgx3Z6ASfY4FFijRdIc+f05UiKrcvV4AnIuPEYo3rChBZmZERg/PkoGSf2Ns5nreldxDQo/KTMJrV5Jrhk/KQPRExNhk2V29XSgvteNSJFZsyWVdaoIvwmWcESHjb6U4CN9nXF7JEACJEACxx4B7fHML722aL165fvvwd/ZAaf85sw540zEjRuPcElnO5plJEXW4HF52trQIRJvycsvorOmBlEZGUg/YTHSFy02Uo+GZbCQAAmQAAmQwGgjEAgETL3yzu07TAJrqfQI1tXVLQ2ErZg4eZIZsnJyECPP0UdbY2GKrBRZ+/3vkSJrv3g4kwRIgARIgATGJIEjLbLqQ9FekT8qVixH4RP/gjMmFrH5+Sg4/0LE5OaaVuNj8kTwoEmABEiABEjgUwIqSaoQueKN5Vj26hsiQ8ZhwuSJOPuz55iu648UKIqsAyetKa1ueaC49ZMt2Czy8ccbNqGxsdGsYNqM6Zg6fSomTZ2ElNRUhIeHw2a3wWazmYrH0Vb5OHAqXJIESOBIEzDhqr09RsjsEXFV7yc9PXskVq/Hh5bmTtTXtsjQ+ulYputa0VTfBofTbiTVlLQ4ke/jRdZMkCEOqTIdE+tCpMs56h6WDIT/HoFV77u98nc8gOpqN3bs6JChHVVVbtONvXZnP3OmsEh1ykOjoydAimuLHjm/2wNt2OBvQIW/A5EiZF7ozEG2NQrWIyRuHEmRNXgOS0s78f77DZLQ6pcHeWE47dRkkVldci+1mOu8u9uLN178CFs2lZmPzJiTjzPOnY0yexd2WDuw1lePcJFZFztSMc4aY6RWuQsfEfE3eAwckwAJkAAJkMBhEZAvLZ72dnRVV6NYejsrefkl5J9/PrJOOc0ksWo66dEuR0Jk1WP0icBbu24datasQuV77yH37HMw5UtXwRYpTVeczqONgdsnARIgARIggQET0GfmPSKxdnZ2oUWCoFZKAuuGteuk8XGb1CVPwfkXfR7pEpIQLw1XRmuhyEqRtd9rlyJrv3g4kwRIgARIgATGJIEjLbIqZP1i3lG5G03btmH3yhXoqqtF3rmfRfKs2UZqDWNS2Zi8FnnQJEACJEACewg0NTahWFpfr/lwjREjzzjnM5gzfy4ys7OMBHmkOFFkHThplcUC/oAINq0iirWguakZjfUNqK+vN6mtbVL5qLJrbFws8scVSLLuOOQV5EmaX6QkGToGviEuSQIkQAIHIaBCZneXxySstjR1oKmxXYY26HRrc5c8BOkyn3SG26FDZKQmijrNtI4jXeGSuupAhAw61kGX0WU1kdUmKSDHW9EEVr+/B5WVbpSXd6GsrBNdnQHY7Rb5e21HQoIDiYkOM46Pd8DptMjf7KOXPOvulftMjxdrfHV4z1tjklin2uIx0RaLKBFaj1T+2NEQWdvb/SYld/36ZpSUdGL69FhMnBiN3Fy9j1rkPAZQWV6P0h3V2LS+1ISxqYxdMC9ben9JQmlPOyokxbYy0IEC4TVZhgIRWhMslF2Ot/+ueTwkQAIkcDwS0FCIgMeNpsJCkViXwtfVCbsrClmnnobkGTNNL2cW+9FrbBNkfqRE1h7pBcXT1ITajetRvPQFhMfFI2HKFGQsPhGxBeOCu8MxCZAACZAACRzzBLq6utBQV4+PN26SZwGrpFe2MERL45RJcl/LLchHTl6u1NNoTzijt/6YIitF1n7/Q6TI2i8eziQBEiABEiCBMUngaIisClq7Qgp4PNj21BOoXbsWUZmZSJk9G5nSitzucjGZdUxejTxoEiABEhjbBFSG9Hq90n1QMd5ZvlJEyEaTfnf+JRdixswZ0k2edBh8hNLW9ExQZB369aiNdlqlFX1NVQ2KCrdh5/adqK6sgpo1/z977wEeV3Xm/38lzUgzozLqXVaX5d47LjhgbJopDpCEsBCylJCwu8+zCSQsyz88AcKSwAbYHxBCCZCEAKHYBgPG2BhjG3dbXbZ67xrNjKaP/u97ZCmyVbBsbLX3PM+de+e2ued7z9xyzud83+iYaMRTT/qEpASEU+jHsPBwcjsMJmhMf0FB5bPPnWwpCogCI6UAX1vcLg+FW6ewsjy2u9S0y+kmN1EnrBY7gZgOBa0yuGrusCmwtZPmO2kdhlPDwoMQEUUAX2RI9zgimMZGBaz6E7A63hMDvy6Xl9xO3OjoIJfadhfqyYW1rp7gkBYnAbs+5MKqR1p6IFJTAxEUpBlReLXnfHjpwJu9dhR5TChwtaHMY8ZluiTM00ZCT06jGp8LB9iOBMjKzsL0mIQDB9pwmGBWLcGr8fE6zJ8fhtBQf3WO2IW4ob4d+3YVoLK8iZ6jOjB/SRYmz54E30gdKnV27HE2IMDHD5G+OkzVUihmcrIN8/GHluZdKBC455zKWBQQBUQBUUAUGEwBfu/n5z5OPRCrqbQU9Qf2o/KzrTCmZ5AT6wqET52KoLj4wXZzwedfKJC1J2OsScW2regoL4PD1IGMa65F3IKF0HDbAkVAkSQKiAKigCggCoxGBfgezy6s7MBaz07rx0+o+uPjhcXIyp6MaTOnk6nFPERGRamIXqMxD8M5JgFZBWQdsrwIyDqkPLJQFBAFRAFRQBSYkAqMFMhKtXGqIq61uBhNRw+j/KMPEZSYiOwf/BDBCYkICA2dkOdDMi0KiAKigCgwcRVwUSePZnLx3L/na7zz5juYNWcWLlm7BknJ5CYWHnZBIVY+CwKynltZ9JBLjJPOqcPuILjMolxaqyurcLzoOMpKSimcdxMSk5KQnpWBGbNnIDk1BbFxsef2o7K1KCAKjFsFFMxAPEN7G11PyG21kYA9NTS0o6nBhFaC9lwut3JPDSM4lYFVhlV7pkPpOzuvarV+NLDDqi+FaCcAkgea5+vLnSXGrXy9GXO5uqixyIkTJ6woLupA8XEzjEYtoqJ0FKo+iCBWHYXsY2daP4IjfeDn53PB77+9B3tygjEWJ7mxFrlN2GivQLCvFpP9jJiiCUWiJgh05i4ohDkSICtLwTxPS4sD1VU27NzZRGBrF1auisKkSYHKOZf/Iwx1M8Cdc6QMX23PVWU9MsaIiy6dCWOyEW0+LhxyNyPf3YYIglkzyJV1qX8sjORoeyFh4JOnVkaigCggCogCooBSgMHVxsZG7N27F3yfbWhoQHp6OjmQT8e6tWthqq5C0d//hvbjx6ELj0DS6tWIXLQEb7/zDo7TvKCgICxZsgQLFy4kR31DLwTbV14NgZ3cDrBz5071WzNnzsTSpUvJ4TyLnM3dfVc96+kLDbKyMy07s7JLbcnmTRTxbS0Sli5DWHY2/IOCzzofsqEoIAqIAqKAKHA+FWAzC1unDfv5vn/gIHJzcpXpwYJFiyiKF3VWmZREUXMCFcR6IU0tzleeBWQVkHXIsiUg65DyyEJRQBQQBUQBUWBCKjBiIOtJtR0UatdMvaaPv/8eXOYOBCdNQhyFAYqePQc+fuSKQg2qkkQBUUAUEAVEgfGuAFdgdVBY+j279qAwvxANdfVYtHQxvnPZJeSgpxuR8EECsn57pc5DveztNjuByk3kEleBqooq1NXWwUPucRwyikNEhYaFISo6EtEEs0ZFR5Fba7hyaB0PFZbfnpKyJ1FgfCugXDkIzrPbHMpZ1WJmh1W7clplt1WrxQanw02wnkdBq3wN4ZDqHh5oWkuOqgyrGkMNNAQhJDSQHJ/1NAQiMJjvJVp1zRnfKp6aO4YfGXhk99XWVieBIQ6CIZ0EO7rIpZb083QhOjoAMTE6JCbquyFWHaGhdG0eLckFL0rcZuXEeszdggwNgZnaGET46RBEAOaFTiMFsnI+XXTOTCYXgTgtqCcX3UByzJ08OYic643QEpzNMDaf85rKJhTkVKL0eJ1yKM7MTkRqdjwmTY5Fqa8FxV4TOdw6FLw6yS8QaQS0ppA7K/1DBGi90AVKfk8UEAVEgQmuAL/vffXVV7j55pvJYd/eT41ly5bhuT/8Afn/+3tVV560YhUaIyJxyy230PNNxynrcyjiDz74ANkEcvZN/Bt33HEHNm3a1He2mr7hhhvw7LPPfisw64UGWdmt1ksQbu1Xu1D5+TZ0edwU9S0RKWsvJ6OMBPjpdP3yKzNEAVFAFBAFRIGRUsBNhgd8r68oK6foXcdRUV5O77cmBAQEIHNyFmbPmYPI6GgEh4yvzhgCsgrIOuR/TkDWIeWRhaKAKCAKiAKiwIRUYKRBVhbdSZVujUcOo2bXl6jc9hkmf+/7mHzjTdDqDRIGaEKWSsm0KCAKiAITTwGn04ma6hq88sLL6Gg3YcXqleTSOZMqsTJHTAwBWc+f9FxxabVacezwMRw5dAQH9u4nWM2qoOV5ixZgzrw5mDp9GoFoRnJK1Cg3QAFaz9/5kD2LAiOhgHJYJR/NbqdVIu8IwPO4vcpRsoUdV+vaUFfTQkP3uIG+swOrgUDVEKMBcYkRiEsIPzlEICY+jK4ZgQpkHYn8jMbf7IFYGVgtL7ciP9+MvDwTWghoTaSw9FOnGqmhKFTBqwaD32jMAqhkwAo3PrFXodRjhsFHgzmaCHIRjRmx4x1JkJUz7XJ5UVNjo3NpxhdfNGLOnDBcfnnsSRfd7o6w/L/qIoB5+6dHsH93ESxmG7KmJOKK6xbDQHC3XduFHY5a5Lna0NxlwwJtFC4JSEQwgcF60nj0YMwjdprlh0UBUUAUEAUukAK5ubm48sorqYONE2lpabj66qsV0PIOua2WlJSoo1i3bh3uv2wNHORAGnfl1VhCTqoWivoRGxuL66+/XnWM3LhxI4op8ll4eDi2bNmCJIr+wYnfIx9++GE899xz6vuaNWuUe2teXh7ef/99BbDefvvteOSRR6jzj1etc7YfFxpk7TlOW3MzTKUlyHn5T3ASEDTrrp8gcvoM6CIielaRsSggCogCooAoMKIK8DsqR+xqbWnFZx9/gs8++RQhISH0njoFV6y/CkknXVhH9CDP048LyCog65BFS0DWIeWRhaKAKCAKiAKiwIRUYDSArB6qqLO3kKPK/n0UBmij6jkdOW0a4hYvQXBid6XbhDw5kmlRQBQQBUSBCaNAfm4+QY1HkZ+Th9DwMKy76nIkJMYTrGQcMQ0EZD1/0nMDoYtgVq68bG1uQUN9A1pozIPFYiaQzUXhrDWIi49DcloKklOTERMbQyGStTR/dMJW508t2bMoML4UYHdQp4NgdnJYbW+zwNTWqcbtbWaYTTYF3DGAp9H4EchO4e0DNMppld1Utf5+ClQ1BOoU0GoIDKBwczzo1Hxel7eb6IkBVie51tbV2VFbS24nFVbYbB7l1BlEDp5GowZRUTpERviTAzY71ZILp2Z0oovNXjsqPRbsdjXA0eXBYgJYU32DEE8uoiOVRhpk5f9QZ6cHZWVWfP11q3IZjiZH3ZkzQjBpkqFXFm4orKlsRnlpA3IOlcJBbsZR0SGYNicVGTOS0AAbqrqsOO42we7jBcWDUZBwJjneGn38ofWR6DC9YsqEKCAKiAKiwHlT4LHHHsMzzzyD9PR05ZgaGhqqfstcWYEX3nobTz75pPq+47PPEEFQ6h/+9jf86U9/oucZIz7++GMkJyd3r2824+KLL6Znn1rcdNNNvdu1trZi7ty5CpS97bbb8Oijj3Z3pKKtXnjhBfz6179W2x86dEiBserLWX6MFMjqttlgb2tD6eZNaD9ehIDQMMTMX4DkS9cwyatg3rPMkmwmCogCooAoIAqcswLcWaW6shLFhUU4cvAw1Qk7qQ5Hj4ysLKRlZCA5JRmBgYFUB3ThI66cc+bOYAcCsgrIOmQxEZB1SHlkoSggCogCooAoMCEVGA0ga4/wrQUFqNrxOUzlZSosUOZ1GxA1cxa09ADv4yuNSD06yVgUEAVEAVFg/CjgdrkJrHBg2yefYf/efQSuhmDqjGlY9Z2LKVzuyEEqrLCArBeunDFs09TQhMqKCuQdy6XwUifQ3NSsQkklp6YgNSONHHUSKUy4UfXWNwQaCLrSCNR64U6R/JIoMGwF3G4POVzR4PIol1Wn09077rQ60GGykgM3Q6zWk0CrRUGsvIzh1PDwYETEGAm8M1Joue4hOjb0JNSqGfbxjPcN+DrqdnfRPdVLHQLcFGrXheoqAhWrOlFdbSNN/QjO0FGoXQohn2xAUDABwtrR+47ppfx4yY+1wNOOHFcraj1WRPrqsZZcQ6N8dfAbQchypEHWnrLc3Owgl90OlJZa0dDowMoVUZg+3Qid7p9gMpcLE/3P9u8uxPGCGtRWN2P2ggzMW5yl/ls2PXDc24FcdyuKXO2YoQ1HtiYUKZpghPoEQOcjYHiP3jIWBUQBUUAU+PYVYLfUa665hjpmfI0HH3wQd999t6oTZ1fR+gP74UvuqovXX6N++P+efVa5r7Iba1lZGX72s5/hl7/85SkH9corr+CBBx5AcHAwCgsLFcDJTq133XWX6hTJ8/R6uvmdTPz7U8gJrr29vff3e5adzXikQFY+VjbKaKKIb42HDqJ27x5Ez56D7O/9AP6khcbwz44uZ5Mv2UYUEAVEAVFAFBiuAvwuykYGFupo0tTYiIK8fOTn5imYNWtyFhYsWYQpZOgUGxc37jtcCMgqIOuQ/x8BWYeURxaKAqKAKCAKiAITUoHRBLI6zR3obGpC6cYPlDtrwvIViKXe0xHTpkPTp5JtQp4oybQoIAqIAqLAuFSgva2dQJtqbP3oExQVFuOqa67CnPlzEB0To0LKj2SmBWS9sOpz73y73Q5LhxkmUwca6uqpt34Vyssq0EJQq4cqPzOy0pE9dQqmEewcGhZKsHPQhT1I+TVRQBQ4IwW4wcLSYUNbq4WgdBOaG0zUcEEh7Zs60NZspv+6U7mthhgN1IHBAGNYEIHrBvpfByIoRK/cVv0D2IFVQ46sWgTQuNudVasaOHx9R6d76BmJc55WIsnR1uZEZWUnjh+3KLdOrdYHYaH+5G4SSA6s/oiMDCCXE0036OhH7lyjWEdXl5f8Qj3Y5qjBHmc95moJ0tSEI40AS72PhrxDRy6NFpDV6fTCbHbjwIFWAoDaCFIORlZWEDIzg+k8/xNAdVGnIYbGi/KrCGgtUnB5ULAeKy+dhcSMaLj8gWoChUs8HSgmd1YXOd/OI72zyJk1lfSmkjJyYssviwKigCggCox7BVJTU1Xn1n/84x9YsmQJHASV1n61C40EZaZeez1mX3KJ0uDpp59WIOukSZPg8XiwefNm5bTaVyAGRdiVldPWrVsxjQCZp556Ck888QRWrFiBN998s+/qavr222/Hli1bcOmll+LPf/5zv+XDmTGSICtb7zs7OtCUm4OiN/8GLXUMjpm3ADHkRmtMSx9ONmRdUUAUEAVEAVHgnBXwuN1wUjSufXv24tC+/aiiOt6g4CCq95+HdHJhTZyUpOp1AwICzvm3RvsOBGQVkHXIMiog65DyyEJRQBQQBUQBUWBCKjCaQNYuAjS8VBFX9flnqKEKOy8BHaFpFFZh7VroI6Ogld7TE7KMSqZFAVFAFBiPCjDkxI1PxQSvfvXFl8p905dCxl9JICv3ytZoCVIhd5SRTAKyjpz6LqeL3AQ7FMhacrwEVRVV4JCQer1OubRyGMmomGjExMYgMioSRgo/yS6tflSGJIkCosD5V4Cv4QxOOh0u2G1O2DodNDhhtdgo5DlPd3+32Ry0Djtvu+Cwu5QjKzu0+hJEqdcHIDQ8UEGsoQSyhoUHnQRa9QggeHU0Q5bnX+Ez/4Ue99WmJgeam51oaXHAbPGQ3m4FrsbH6ZGSYkB4RAABwmPnGtnstaPcY0GRux0nCK68VJeIqX5hCPbVwm+EwcrRArKq/yFpUVjQgSNH2um/5yXXcg0WLgxT7rs63annu76mFQW5lThRVIPG+nZywE9GZnYCUjPj4NQBLT5OHHI1o9ptgZ50TvQ1YLI2FNE+Ohh9A0ZY9TP/T8iaooAoIAqIAmNLARO5r3JiF1V7czPaS0pQuW0rOYkG4XCQUTml8vLt27crN9XFixfzV+q4c1yFIVZfTn5wHUNSUpL6xtAqw6v33HMP3nvvPdx555146KGH+q6upn/729+CIdk5c+bgww8/7Ld8ODNGFGQ9eaDm6ipUfPoJTORa6yBt06+6GnFLlkKj08GXoppIEgVEAVFAFBAFzqcCfC/utFpRV1uHMrqnl9D9up6mDWRGkJaejvmLFyI6OkZBrefzOEbTvgVkFZB1yPIoIOuQ8shCUUAUEAVEAVFgQiowmkDWnhNgI1fW1qJC5Lz0ooJ4pt36I4RPzoaB3OkkiQKigCggCogC40EBrtSy2Wz4YtsOvPz8S1i6fBlWXXIx0jPTldPmaMijgKwjexY4/FTPYCaX1sb6Bhw+cAjHjhxD3rFcRERGIi0jDQsWL6BQVFMRn5QAf3+ylZMkCogC510Br7c7RFxbiwVNDe2oq2kBQ3J1NNTXdo/9yUXVEKhDTHwY4hLCERNHcF18OEHoRoRFBEOn94cvdVjw8fWldx6g22WVvtP0SHdkOO8Cfks/wDBxRaUVpSVWHCRXzrY2F/QGDaZODaEQ8yHkwhqgwEbWljVlbcdComyhpOQE/ufx/6E8RGHlQz/BZN8QTFLuoEPnwJfKU3l5uXJWO3HihLqPpKWlYS11Ds3KylKdaIbewzcvHS0ga8+RWq1utDQ78NFHDWCg+TuXRCMjI0id/77n3Ovxwk3PXwf2FGPfrkK0kjtyfFIErtywGJH0v9QQQN5CAHGxx4RP7dX0RwRSfIOwxD8WUzSh9HNdNGuMFKIecWQsCogCooAoMKYUqNu7BzzEL1yEbWXl+NWvfgUXubmxW+prr72Gbdu24eabb6bnRl/U1dX1u69rCNRMTEwER/t45plnsGHDBqxZswY5OTm4//77ce+99/bT4/nnn8fDDz+stjtw4IB6dui7Er+T5ubm9p016PTOnTvV9gP9zqAbfcsL3FTPYm9pQcmmD3Dsj89jxo/vQNqVV0EfFS0mGd+y1rI7UUAUEAVEgf4KcLSterpH7975JTa++x7V30Yhc3ImVtO9PD0zg+qC9Oo+PpHqfQRkFZC1/z+lzxwBWfuIIZOigCggCogCooAooBQYjSCrx2GHtaEBFZ98jPbSEuotrUXCsouQtHo1fPw05GB0qrOKnEpRQBQQBUQBUWCsKWCicIFHDh5BXk4eivIKsOrS1bho1XIKMR1CTnyjI6SQgKyjp1Q5HeT4aOukitB61FbXqp78HQS3Wi0WuClUlZYA1kgCWxMIZp2UkkygXBTBWyECw42eUyhHMgYVYEiS/1/stGo2daKDBlO7tXu6o/u7h9xVObHDKgMFfn7/HBhUZZA1MEiHoBB995jCmfP3AJ0WWnLeljR8BVwuLzlWuwnesKOSIFaTyU1OnHQd1PjQPZSuhRH+5FatI4eTAHIt8yPA33f4PzKCWzgorD0DI+u+cymKi4uRkpKCN3dtRZiPP4J9tEMeGbtyP/vss2BnNYZe+iZe9tOf/lQBMdyZ5lzSaANZ3W4v7HYv9u1rRXmZlUlwZGYGYcGCMPqf8X/yVPi0troF5SX1yDtSTvdRO6JjQ5E9YxKmzUqBm/6WbXCgmFxwq7xW1Ho6kegXiBS/IEwmmDWcnFmpRuJc5JNtRQFRQBQQBUSBfgo4qH7AUlcLc2kpvGTmcD8BrLt27VLrTZs2DW+99RbCwsLw+uuv47777gNH6ODnhNPv6QyycgcWC70n/v73v1fQ65QpU1R0j0cffRS33nprv99+5ZVX8MADD6jOMwy88nNI38TPFI888kjfWYNO8zEymDOSIGsXPee4CSKq3bMbpZs2wp/ei0OSk5Fy2VoEJSSqTmSDZkAWiAKigCggCogCZ6kARwypLK9ACXUozTuWQ3UVJvhRPVEawasZWZlIpfszR9SaiNG0BGQVkHXIv5WArEPKIwtFAVFAFBAFRIEJqcBoBFn5RHDv6bbiItRSL/SyDzcjceUqTL7hRujCw6ENDJqQ50oyLQqIAqKAKDA+FOCGoKqKSmx6dyPa29oRTSHil65YhllzZ4+qDArIOqpOR+/BeKlhjstQyfES5JIz69FDR9BAbq3sxpqcloIpU6cghcYxsTHQGThEeYBa1u1GeCrM07tTmRAFJrACPe6qbjc1ehOY2kVuqzztomm73YmO9k5ybuxAc1MHWmjg6bYWM9pbreT+6Y/Q8EAC4cKU4yoDcWog91W9PkABqxNY2m8t63yOPJ4uchfrIojVqSDW0lIrigrNysk2xKjFzJkhBG4EISaGQEPN2AQNvdTw5aQ+mw/f/wBeffVVpR+DrLv37AE3in3TFfzLL7/EjTfeqLaLj4/HtddeS5BvJzZt2oRmClXM6bnnnsP69evV9Nl+jDaQlfPBZaSmxkZQjxl79rYiMUGHNZfGIjRUS0B5f2icAdb9e4qQf7QCVeVNmDEnBcsvmYlwcksOoP+1y8eLHFcrdjjrwHBxsK8WS7UxSNeGwEhQMfkoq+FsNZTtRAFRQBQQBUQBVqCLoNEu6jjVduI4dLGxePx//wAGSxlQZSj1rrvuws9//nPqmNHdmYXv6Xfeead6v6uurladrvoqye98cXFxahY/S1x22WVYtmwZSgmQffDBB3H33Xf3XV1NP/nkk/jd736H7OxsfP55f9CCwdb8/Px+2w00Y8eOHSPuyNpzXKbyMrQQmFv1xXY4Ojow/bbbETl9BvwptPOYsenvyYyMRQFRQBQQBUalAvyezgO7sFotVoqkdZAiaR1BYV4+4uid/OI130EWdVBJnJQ0Ko//Qh2UgKz9n68G0t6HwvdxhJ4JlwRknXCnXDIsCogCooAoIAp8owKjFWTl3tMuqxWNR49Q7+kP4EOVd9xretJ3LkFE9pRvzJesIAqIAqKAKCAKjEYFuHKrqqIK+bn52LrlU4INo3H51VeQk2YiwsLDRtUhC8g6qk5H78FwGeLGRCs9J5lNBNQRDN3c2IS62jrl1MqurX4aP+XYkz01GxkUvio1PU01fk7EXv+9wsmEKDCAAqrBweaExWxTYcZbCFJlWJWH9laLcmElHoCA1YCTzqoGBJGjao/Lqk7nr5axwypP++s0ahwQoFXurL7k0Crp3BXg0PFmsxtFRWaUlVnQ3u4iUFijXFfj4vQqhLwCFg2+BO/7Kbj13H/1wu+hs8uN3dt24JZbbun98W6QdTdHtf/G9K//+q/48MMPobbZTducTOwsvGDBAjRQ1JNVq1bhr3/9a8+isxqPRpCVbo3kXO5Gba0du3c3w+HwIpQceufMDUVGRv+OsB6PF60EpJcW1+HQ18fJedmh/ssXrZ6OzKmJ8CMnVzPcaPTakOduQ7mHoGmCV1N8g7HUPwZGAlt1Pv0B2bMSVDYSBUQBUUAUmLAKuCjqRmdjI+o6bbj9xz+m55wypcWlFH74of/+b+Xe1jf08B7q3HL99derdSoqKnoB1x4BOwjYZCCV08aNGzF//nzVseXrr7/GPffco5xXe9btGTPg+tJLL+Giiy5Szq89889m/H//938Kwh1JR9ae43Z1WuGk9+Wit/+OlrxcRM+Zi+jZcxAzbz58T4LBPevKWBQQBUQBUUAUOBsFuOOJw+FAAYGre7/arepl2YBg2szp5MKahZTUVIrQEwyDwXA2ux832wjIKiDrkIVZQNYh5ZGFooAoIAqIAqLAhFRgtIKsPSfDUl1FoYD2oDk3B5baGmSsvwZxCxfDn0MwkPOYJFFAFBAFRAFRYKwowJVbDJN8tfMrHDt8lKCpFmRPm4Krr1tP8IR+1IUWEpB1bJQsBvHMHWbUkCNPSfEJFBcWU/hzkypr7PbLQ0x8LCIiIshpLgKhYaEEgFF5I9i1b6Po2MitHKUocHYKsLuq0+GCw+4i2M0BO8Gr3dNOBbB1kjtjJ4FsnVYHbNbuaVunUzmz6vTkuhoWiDByaoyIDEE4DWHkwhoaTs6NBLBq6L8k6dtVgK9rdMtU4eJbW+1oaXGisdFBIKadQuV6VKj4uDgd0glQjIvVEbjvP+aNtcjHBc0tLVi1YiWBuu34wQ9+gDfeeENBqQytsCZDJb6eM4BSUlKiwvnef//9p6z+KwpRzM5sDLds3779G/d3ysanfRmNIGvPIZpMLhSSU29JiRmVFTYsXhKBWbOMCCRXVn///mB5c6OJwj5WoDivisJANmHOggxkT09CUko0DEEBFH7YB3muNhR62lHutkDv64dMvxCkakKQ4GtAAMGsmm/0yu05OhmLAqKAKCAKiALdCqhnHQJfrPV1sPj5Ye3lV9DzTgt1zonC7554AhevWAGNTtdPrsrKSixevFjN7wFV+660f/9+5bzOzwV5eXnkTB6qANb33ntPObO+8847pzwD+FLI4+uuu446gezGj370I/zmN7/pu7thT48mkJUPnnWu+PQT1O/fB0d7G8LJHCP96msQYDTCjyKXSBIFRAFRQBQQBc5GAb6/2CmqaGtrK8pKy3C8sEi5sAYFByE+MRHLll+kTCuCgoOl7pUEFpBVQNYh/2cCsg4pjywUBUQBUUAUEAUmpAKjHWT1Op3KmbX43XdwYuP7SFi6TIGs3HvaPyRkQp4zybQoIAqIAqLA2FSAe2hzmKFXX3yFKrcKcOm6NZg1dzaBOGkEFY4+Vy8BWcdOOWOHVoaknQ4nhd52ora6BqUlZcg9mkNgTgWayLF12oxpmDFrBmZSmUtITKBQywZyLewP9YydXMuRigJnroC5w0YOq2Zyx2hDQ10bjVvV0NRgUkCrH4Wij4o2IiomVI0jYoyIjOqGVg3kxqrV+p2Ev6E6HfD6/P8hRkAaJc78NJzxmsxsWq0ecte04chRAgjJhbWp0YnMrCAagpGWGojwcH9yX/VVUKufH52IMZwYYmXH7A3Xb8CuXbvw05/+FNNnzsBdd9x5xiArZ3/Dhg0KROEwwq+//rq6L/B83ve8efPAIYg5pDA7r51LGs0gq9vtVW6sBw604ZOP65E9JRjTpoZQuQlBSEj/Zy12ZnXYnTh2qBT7viqkjiCdClhfu34BEiZFEvyqgRNetHkdyCFnVgZaiwhsXUyurMu0sYj2I4dmn+5wz+eiqWwrCogCooAoMLEU6KL3NzvBL01HDuPx994Hg6ZBFPL+808+QXxSEnzp3j1QLx1+/ly2bJnquMIO7vzOzu+CnBheve+++/Daa69h7ty5yqWdQZtNmzbhzjvvpHuaP/bu3YvY2NhesRmenTlzpgI+//73v2P58uW9y85mYrSBrJwHW1MTmo4dRd6rL0NHHTun3XIrQpJT1PTZ5FG2EQVEAVFAFBAF2Kyioa4Ox44cxUcbN4NdWBMnJWEJdS6dMXsmRfEJUq7pUu/aXVYEZBWQdcirhoCsQ8ojC0UBUUAUEAVEgQmpwGgHWakmDVy5V39gH2p2fYlOCoeoCw9H+lXrEUyVTv70QiBJFBAFRAFRQBQYCwqUlZSSE+sx5OXkweVy4Yr1VyArOwvB1DFjNDpjCsg6FkpV/2PkxkqTyUSh0VsUxFpfW4eG+gYV4pErULXUgBkWFkYOAfFqiIuPI0dgQ7+wlP33LHNEgdGrAJd7htHYRZWhVXNHpxosZrv67iAHVpfLrRrpvV52tqR3DBrxlL9WA3ZdDTEa6HqsR7AxsHfaEKij/4xmzIaqH71nrP+R8XlhF9bmZgfq622oq7OTMym56FKIeH8K8643+CEhQQ92Yo2M9IdO5zduzouFQti/9v/+qFzQZsyYgd9ufAPVW/fizmGCrJs3b8Ydd9yhxF21ahWuvvpqFebw7bffxqFDh9SzxkcffUQOpbP6n4BhzBnNICtfC/i/XVZmxZEjJipDTgJ5gWVLo5CYpFflhgH00xPD7WXH65B7pJxgVqtyZM2akoBps1KU67LT14sGrw0lbjMKPG3kweqDQPJinaYNwyS/IIT76sSZ9XRR5bsoIAqIAqLAgAp4qS7ATS5uVV9sR2BEJNb+5B5ynm8Eu6n/6LbbBgRYeUcclpjf5/7whz/g8ccfV/f1d999Vzmy8/1vx44d+OEPf6ju/U+Qqyu7u3Pijo5Tp06l6AOdWLlyJd588021H+4IyTDstm3b6BkrAewArznHDrajEWT1UIfiDnKyLfngPdiam6ALC0fiilWIXbgQJMSorItRJ04+RAFRQBQQBUalAo0NjaipqkLusRwyEqhW990EcmHNmpKN9MwMxMbFqXvLaKzrHylBBWQVkHXIsicg65DyyEJRQBQQBUQBUWBCKjDqQdaTZ8XZ0YGOqkrkvPiCglkn3/g9RM+erWBWeSGYkEVXMi0KiAKiwJhRgB1SPG4Pdn3xJT54533EJcRRxVY6ll+8EjGxMaM2HwKyjtpTM6wDYxdgDlN9+MAhHDlwGIX5hapxNDUtRbkETJ81nRwoo5QDkEarVc594hgwLIll5QuoAMOO3FDvJRdFnubra890h6kTrS0daKxvJ2eMdhq3oanepL4zuBag0yI2PhyxCScHno4LQ2h4EDkUUwjxgei2C5i3ifpT3eeRIQsvubC6UXLCioLCDgUiMmicPTmY4ItgTJkSQnCFDw3jx0laQZdUNvPz8nH5unUKHvnb1s2ISk1C/kdfKCg1JSVFgSW87pkkhlb/7d/+bcBV+b7OgMtg+9q3b58K+Tfgxn1m6ijUMYcrvvHGG+m8TOmzZPRMclkym934mFxZT5yw4DvficaU7BC63wXQfY5EHyC5XB7s+SIfOYdLUV3RhOzpSVi3fiGCCHDXkzMzXyPYmbXKa8WXznrkuVoxXxuFmdpwZGlCYYAfND7jp3wOIJHMEgVEAVFAFDhHBfgezHXcltpa5P/5FcR9/wdYsXbdGe312WefxXXXXQcbQbDsws4dSzixoyrfm7nTCsOp11xzDZ577rlT7vfsysqu7PzsbDQaMWfOHBQUFKCBDCMCAgLAHV2+jXv6aARZWSMHad6Sl4var3ah4rNPwe0Kmdd/F1q9Hr70DixJFBAFRAFRQBQYSgG+f3voHuugziH5uXk4+PU+HD7InUWBNZevw8zZs5CRlTXULib0MgFZBWQd8g8gIOuQ8shCUUAUEAVEAVFgQiowVkBWD70guMxmqmzaiubcHLg6rYhbtBjp66+hMJ9a+LDNiiRRQBQQBUQBUWAUKmDuMFNP7Rrs2bUb2z/7HGuvXIvFy5agxwlzFB6yOiQBWUfrmRnecbnJhZJdeFopbGRLcyuaKbQiuwe0NDejva1dOfOwW8Ck5EnImJypymVEZMTwfkTWFgUugAIMrNpsDiq3BGe3WmiworXZhDaa5sFNEBo3Iuj0ATRo1VhPTqsMoOkNJ8f0nV1W2YGV5zPcyoNGI+8SF+AU9vsJZjM7O92orbWjvNzaDa8SoBwQ4IvIKHJejQpAVGQAuUhrCbqgdz46v76+A0OI/XY+BmaQRzBcDie+c/HFlP9yPPb4b5F941qCIo346qOtwwZZeR/srHbixAmVewZVGFgx03s0p+DgYLz44otYsWKF+n76x8cff4z9+/efPrvf9yQKecy/NZpBVo+HQCGCow8ebENxsYXcfruQkmLA0qWR0Ot9ByxHDFU3NbSjvKQeh74+DqfDTSEhdVh4UTaypyVBQ+7NLh8vOrvcKHV3oNRrQaXHDH8CWKcSyJruF4IUTXA/vWSGKCAKiAKigCjACnDEMS9BMHV796Dy821wU9122+JluPunPz0jgV544QVcddVVat0OAjNvvvlmHDhwoHdbf4q8cTE9U/B6PH16YifWBx98kDoOWXsXJZKD3MMPP4y1a9f2zjuXidEKsrILroM6d9bu2Y0T776D0MwsRM+Zq4ZAeheWJAqIAqKAKCAKDKYAQ6wuqletqqzCof0HUFZaSu+NDWRSkXlyyKAOk9EU4UfeBQfTUEBWAVkHKxtqvoCsQ8ojC0UBUUAUEAVEgQmpwFgBWfnkcKVTOzXKNRw6gPJPPkYYVTplXnc9AuPioQsPn5DnTzItCogCooAoMLoVYEeUupo67P7yK5SXlqG5sQnrv3stlly0VIXzG80OgAKyju6ydTZHx0CTw25HfV09iguLUZBXoMolO/iER1CIRYKTYuPjEJ8Yp4CnEGMIAT/kMUeQ32guq2ejhWwzOhVgkMxDwKrT4aKGAnK7sHNoeRcBaW7YOx3U8G6HxWwDu69aOmwwd3TSYIPVbIevny+CgvWIiAxGRHQIIqON3UOUEYYgglt1/Rv0R6cK4/+onA4P7HYv2k0E2be6UFNjQ329ncLqOhBJ4OokCgGfRU6sMTF83vwGhA7Hg0ou4qd//rN/x1tvvYVLLrkE//7KU8jyM0JPYOSWzR/2gqx79+5VrmqDOamyFhwKeP78+aik0LmZ1KDG7QDLly9X23311VcKUiksLERUVBTYeZXd1842sQPcBx98MKpB1p68VVV1oqTEiiNH2hESoiGIN4rKlY7ucZqeVfqNW5vNOHqwBMX5VQS1NmDB0mzMnJuq3JwZhGeY2kwwa73Hiq9cDTTuhNHXH5l07qYQ0BrqQ8C8L4HX/fYsM0QBUUAUEAUmsgLsCmqhEMTVX+xA1Y7PFUQZM28+YhcsREBo6FlJ09raSp02DipH1gULFqjxUDvyeDzIz89XHVJmzJhBnTxShlp92MtGK8jakxF2ZS3/eAts1MmTnVjTr16P8KlTodXpVdSSIIxsrQAAQABJREFUnvVkLAqIAqKAKCAKsAIupwudtk7UVlVTPWoRDlEHEjYMYGh1xeqLMXXG9O4IV/Q+LmlwBQRkFZB18NJBS7gCK4ssjb///e8PuZ4sFAVEAVFAFBAFRIGJo8BYAlmpFQ5ugi/ajxfj+Lv/gMtqoYq+MKSuuxzRc+dNnJMmORUFRAFRQBQYEwowcNJp7URRQRFe/ePLBFRFYsXFK5GZnYX4hPghwcAeaHAoaOV8iyAg6/lWeGT2zzArO7Qy0Gq1kLNluwmlJ0pQUnwCx4uOK+gpKDgIs+bMxrQZ05CWkYZA+u7rK+GSR+aMTaxf5dDe9k4nuQa3o6m+DY317Wioa1Muia0tZgrl5qXyqEdoWCDCIoJpCCJwNURNs3Miu6xqtRTem5wT1ZggbA195/I7npw8x3SpIBfWlhYnAZedyM0zoaKik6ALX8TG6qjeOhjR5MIaFu6vXFn9/X2VC2vPPXFM5/u0g+f7e5vNgukZk9USDvEbTS4uPamurg7Hjh2jzgT6XgfVp556CqGDgC4MsC5evFhtvmXLFsyaNatnV2rMEOvq1avV9Lvvvtu77ikrneGXsQSysisrA9I7djSho8Olytf06SHInhIyaG7dbg86LXbkHi3H3i8LFFQfGhaESy6fi0mp0eqa4iVK1e51o9Frx3GPCXucDdD7apDkF4SF/tFI9Q1SIKuP4KyD6iwLRAFRQBSYUArQfb+1qAglG9+Hpa4WXgJKM65aj7iFi6AJDITvOAFgRjvI6mSYuLYWxe+8hYYD+5H9/R8gfslSBMbGKbB1QpVJyawoIAqIAqLANyrQ3taGyvIKfPzhR6imd+5Qao+ePW8u5i1aQPUW4TAYqPM/RQsdj3UW3yjOMFYQkFVA1iGLi4CsQ8ojC0UBUUAUEAVEgQmpwJgCWU+eIRuFxK2nyqamI4fRlHMMaVdejURym9FHRkFDDX2SRAFRQBQQBUSBkVSAK68aGxvBDmoMezRwuKH0dEyfPh2rL16tIEJDoGHQQ+QKsMcff5xC4RbjzjvvxLx5/TtrsPMa38N37typfmvmzJkULnep6rzKLrDfRhKQ9dtQcXTvQzm0OhzkGlyLqgpynisrR2tLK2ydDJbpyN0ymIDBUETHRCOOnFojo6MURMXOl1JJO7rP7Wg+OnZcdZGDRaeFHFYt5KZqdZC7aieB/zQmt1W7rduNlWEyXo/HPHR5Aa2/HzlfGGAMNSAkNJDKZxBNB8JI44AAglf9xQVjtJ57q9VD4LxTOa82NznQTDCr0+FV8HxUtA7xcTpMSjYgOEgDnZ6sSsdxIpaXAEgbXJ12LMyadsY5Zce1uEHC377zzju499571b5qamr6XaP5uSEhIYH+Uy48/fTT2LBhwxn/7ukrjiWQlY+dy15+fgdKSyxgh9ZZs0Ixd14YOef40XVj8LJWW92CE4U1KMyrAru0Zk1NpM5ICWoICNCii2BWZ5cHtd5O5LhbUUfOrB1dLmRqjMjQhCDFLxiBPhrQHfN0CeW7KCAKiAKiwARSwEPvW6ayMjQdO4Kq7Z9DHxWNqFmzEUPv+caU1HGlxGgHWb1UV+JxOlCyaSNqvtyporxFTp+BpFUXw5/efX2k8+a4Ko+SGVFAFBAFzlYBi9mMluYWMqcoUE6sLc3N1HHagMlTsqlT5BSkZ2UKwDoMcQVkFZB1yOIiIOuQ8shCUUAUEAVEAVFgQiowFkFW7rXuJSexko0f4Ohz/4eEFSuReNFy5cqqj4yckOdRMi0KiAKigCgwOhRguI9D+N58880UNtne76CWLVuGF198cVBHNd6endLuuecete1zzz2H9evXn7IfXueOO+7Apk2bTpnPX2644QY8++yzBH2dO8wqIGs/ecf9DAZba6o4XFYxvt79NQry8mE2mcmBLhkLyG1g1tzZSM9MVyGp/cjpUmDWcV8kzjmD/3SV9lHAIuNcdruToFUnaqubUV/Tihoa1xEwxtBYe4uFYH83omPDKIx3GOKTIpGQGIE4HhLCEWI0KFhVyt45n5oLtgMyIFPnvqbGhtJSK4W1b0Fbq0s55DJMOGuWkeBMPTmZDA4UXrCDvUA/RFg2Druo3LuscOaWE+yoRaRvAOGO/wQe9+zZg0cffVQ9L7z++uvqesuurYOVfe48c91116kc8HNIauqpYIzJZMIUanDjtHnzZsydO1dNn83HWANZvd4uOBwe6lxkwnvv1mDK1BDMnx+GZAKnjUbtkBLwNeyLrcdwcG8xdfQwK4j1qu8uoe0ClTMrb0w4NgGtXuxxNWC7o46+exHvF4i1AUlI8DMgABOnbA8ppiwUBUQBUWACKsD3EXYBLf1wExoPHiA31jqkXLYW2d/7gXJhHW/g5GgHWXuKYEthARoPHUTFp5/AQI74s396L4Li4sWVtUcgGYsCooAoMEEV6KnDqq6sQs7RY9i+9TOCWQtxydo1WHLRMkyfNVNFTZmg8px1tgVkFZB1yMIjIOuQ8shCUUAUEAVEAVFgQiowFkFWaglVIZhaC/JRS2507aUnVI/prOu/i7DJ2fAPCgK18E3I8ymZFgVEAVFAFBhZBXJzc3HllVcq19W0tDQ1HRAQoODUkpISdXDr1q3Dq6++Cg91zDg9sYvaqlWryD3MqhadDrIywPLwww+D53Nas4Yq0pYsQV5eHt5//30FsN5+++145JFHwFDiuSQBWc9FvbG5LVfYWi1WdBDw1FDfQOHdm9BE7sLtrW2w0HzC0VSFbXJqClLSU5FMgGsghcL09/cfmxmWoz5vCrCTqsPuhqndAlObhcqQFe00NrVZYVauq05otX7QEBDNLqr+PJDDIY8DdP7kBqyDPjCAHBP1ahwYqIOBvvuT6ypfBweD+c5bhmTHw1bA5fKSu7MH1QSwlpVZ0UIOrDabh4BVX4SFBSAqKgAx5MQaHuGvIFaNZmK8v9nJwdPc5cSnjhpUuM3I1oZisiYUU2jo69y5detW/Mu//AtSUlLAUGtPgxqfiJdffhknTpxQbu98z+dksVgwbdo05bjKnWZee+01dX32JWexNgqH+J//+Z+qA4zRaFRu8ey6fbZprIGsdGuDh2DWanJjPXrUpMqi2+3F8uWRSEsLpGuRrwKrB9OjpqoFFaX1OHqghK5rLoLswzFjTiomT0ui7eis+foomLWeHFkrPBYUu9vR2uWA0ScAWeTOOlcbCX+ClLU+ArQOprHMFwVEAVFgvCrQUVmBVnJzq/5iO9w2G2IXLkLUzFkInzJV1V2Pt2fasQKyOtrbYSovw/F3/wGXxYzYBXReyCU3YiqdF0migCggCogCE1IBrkc3mzqQm5NLHfwLUZifj7DwcCQmJWEKvWsnpyQjNDyM6rEkEtBwC4iArAKyDllmBGQdUh5ZKAqIAqKAKCAKTEgFxiTIevJMcY/2ToIr8t94DW1FhUi78ioKyzQfoRmZqlf7hDyhkmlRQBQQBUSBEVXgsccewzPPPKPgksceeQyfbP6YIJ1w3HTz9/CXv/0FTz75pDq+L7/8Uq1z+sFeccUVCjDpmX86yNra2qpc1JzkTH7bbbcpt7YeuOWFF17Ar3/9a7XpoUOHEBsb27ObsxoLyHpWso2rjdhVuIlg1uNFxTh2+CiqKqoIQiSH1pRJSElLRXpGOsIjI6hiN4xANAMYjBKn1nFVBIbMjILDCMh3uzwEz9FATqo8sKOqg1xXrVaHglfbmjtobEUbuRkyyGqzOQi69yAy2ojomFBE8RAbqlxYIyKDERSipxBtBIcRsCppbCnAZYIBQZvNC5PJqYDByopOlFBIdxfNDw7WYuq0EKSlBlKYe/2Q8ODYyvmZH22j16Zgx13Oeli8LlytS0aG1ggDuXb2dWQdCmRl9/Vdu3aBgdW3336798cZXr3//vvV90iKVLJo0SI0UwjEAwcO9Haeefrpp7Fhw4bebc5mYqyBrD15tFo9pIcdu79qQX5+B1auisJUcmdlqJph1sESP2fxNezrXQU4XlCDxvo2zF2YiYXLsqkhM0hB9ny9ouIPB4HKh8htN8/ViuquTiT6GrDIPxqxNA4jsNWP1usLLA/2mzJfFBAFRAFRYGwr4HW54HbYUf/116jduxvm6moEEwgz9fs3q3D2ftTZdTymsQKysvYMs7JTbguBxm67DUkU8W3SpWvgp/WXdoXxWDglT6KAKCAKDKIAA6xej5cicLSgsqIS+/bspXE5LGYLVly8CstWLldAK9d7Sjo7BQRkFZB1yJIjIOuQ8shCUUAUEAVEAVFgQiowlkFWL4VN9jgdqPp8G+r27YPD1K56tU++8SZoDYHKpXVCnlTJtCggCogCosCIKMAQwzXXXIOvqbHqv/7rv3Bg5z4sWrYYc+bPpZ7bU5RjV1ZWljo2buC59tpre4+THb04hDADJsuXL0c1NXSVlZUp59X169f3rrdx40bcddddBFxoUUi9w/V6fe8y/n0OG9xODTIPPvgg7r777t5lZzMhIOvZqDa+tuHKXIfDQa6KNgWwtjQ1o6GuHuVlFRQGvoZcWxuRkJSA9Mx0TJs5XbkTGI0hBLOKO8H4KgkD54bhVSu5q3K47ab6djQ3mmjoICffdqrwtymYNShYj5DQQBhpCDbqKUx6EI0NCCZYld1VAwL8e51Y2ZmVB41GINaBFR/9cx0OL517FwqLzApera11kCuoH+LjdEiaZEB0tD+FZPene5cfnXsCNycYq8yg4wFXE3Y46xDko0GcjwGLA2IQ5UudAAhj7Zs+//xz3HzzzarTC0OrPZ1WeJ2bbroJO3fuxMqVK/G3v/2tdzN+DvjrX/+Kxx9/HI3U4bNvCg0NxW9+8xtcf/31p+yr7zpnOj1WQVaPh8I7Oz04cqQDOTntBMz7KKB62bJIgqyHvm/x9a691YyivCrs2Zmv3KQZxl+2ipx50mMVlM36ewl67ehyodZrRQ7BrLXk0tpG7qzL/eMwRxuBEB9ynhZn1jMtarKeKCAKiAJjVgEHuaGzG2vZlg9RTx1KUgiQjF2wEKFUHzCe66zHEsjqofdcc1WVAo2P/+MdxFGkm8zrNsAQHYOAkJAxW/bkwEUBUUAUEAWGpwDXe3ZSZLTPP/0MRw4dBnfqZ/fVBYsXUZ1nEiKjIlU9vJ+fRNgYnrL/XFtAVgFZ/1kaBpgSkHUAUWSWKCAKiAKigCgwwRUYyyBrz6lrKy5Gc84xVGzbCn1EJFLJzS40NR2GmJieVWQsCogCooAoIApcEAVSU1MV+PfXv/wFf3/1TVzz3WsxbxG5hRNA4u3yIiUlRR3H6Y5oDL9ed911BPgYFZzCkGtJSUk/kPWpp57CE088gRUrVuDNN9/slycOMbxlyxZceuml+POf/9xv+XBmCMg6HLUmxrpcsdvW2oYTxScIZi2nUMvlquOQTs/hwcMRERFBrprR5G4XRW6bUeRSZyBYbXy6DU2MMw54KRy30+mCw+Yih1U7Qc1OdHbSmNxWO9VgV6G2HQ4X7LTMTk6sPM3WhL4EiTHAGhoeTOUjWDkXhpF7IYOtQUEU1py4PQa/JI1dBRiu7OryoTLhpvD1ToInHWhqtNM0lZdOD7mAdpE7uA6pqQbEx+sRHk4B1ifoebeTU2drlx1fOxux29WIhZoozPSPQCLBrIG+2m+1ELBrez6FQeTnCO6QkJGRgezs7FM6v5zLD45VkLUnz5WVVtLGioJCM92jfLF0aaSCrY3Goc8Dl/eaymbkHC6j+1+DcpmeNS8dk6clISE5kval7b2mWeBGmasDRR4TcgloTfAzIFkTjCw/I6J8dDDQOZerX88ZkbEoIAqIAuNHAS9FK/CQu2dbURGqd34BS10tPRd3Ie2q9Yim0PWawEB6Rh6/IMxYAlm76BmJYdbGI4dR+Le/ErxK7ysU5S1+6UU0zhCDjPHzt5SciAKigCgwoAJuck+3WjvJfbUCxQWFOHH8ODpMJiSyg/qM6Zg7f76KPsWRp8Zq4jq3vp1iRyofArIKyDpk2ROQdUh5ZKEoIAqIAqKAKDAhFRgPIGsXVRJ20MtG3ut/hq2pCYEUSjmZAJ64RUsm5DmVTIsCooAoIAqMnAK5ObnYs2sPOtraCeILxOpLVyMzO4ucuzR48cUXlVMqH9327dsxefJkdaAWi0W5sDY0NODll1/GunXrcNFFFw0Ist5zzz147733cOedd+Khhx7ql9Hf/va3ytV1zpw5+PDDD/stH84MAVmHo9bEWLcbWuuCh8LCK8eCTityj+Xi6KGjOHbkGCwdZiQkJmDWvNmYv3A+EiclUfitsIkhzjjNpZvOtanVgqYGE2prWsiJt3uoq26Fqc3C7fIEqAYiNj68e0joHkdGhShw1Y/cVX2p4tyHXKd9fbsDp/vwWADWcVFiGHR2u7tQW2snh0sT8gtMqK6yk4toIN3jgjB9ulHBq+y+yu6XE/m0N3ltOOZuQ7G7HZUeC64OSMZ8bRQ0PmMv0PxYB1m5zLa3O7F5cy2amhzImhyCKdkEmWYFf+P/0kMhJ11ON3ZuO6acWf38fJE5OQGXXkmdlgjU5+scJ3bf9VAHpmqPVcGs+wlebvXYsUaXhOmaMMT5BsJvIv8hlEryIQqIAqLA+FOAwcjOxgZUbvsMuS+/hMSVqwhivQqhaRlkvhDBvbjGX6b75Ggsgax82Px+ayXYuPHwIdTt3o3m/DzMuvseTLp4NXw5ysg4P199Tp1MigKigCgw4RSwUn18VWUVvtj2OT549z3MmDUTs+fOxbIVyxEXHw+NVtNbd8V1WFbq3P/222/jOAGvQUFBWEJO3gsXLlSw65nComezH25T4HZ8jsrCkVdmzpxJnTGX0vtrFtXHuPudN4769v777yM3Nxc1NTXUuTgW06ZNUwYa/VamGXv37lXrDbSM53H0t6lTpw62+IzmC8gqIOuQBUVA1iHlkYWigCggCogCosAFVeBse0L1NPqe6YPxN2VqPICsnEcn9ZSrP3QQjTQ00JD8nUswiQY9OYJxyCZJooAoIAqIAqLA+VTARb24G+oaVAiiTzZ/jCyCVy9atRzJqSmIiY3Bq6++il/96lfg9dgt9bXXXlONJlwZdcstt+Djjz9WoYLZcZXTQCArPwOsWbOGYKEc3H///bj33nvVun0/nn/+eTz88MNITEzEAQphyE5sfROHR2L31zNJvF54eDh+/OMfn8nqss4EU8BDHYm4wrSpoRH1dfUEOdahpakZHR0dBPk4VdmLiIxQ5X8SheSKjY9T4bi4QlXS6FJANeCS26rVbEdHuxUmGsymTrS3WSlMvI0cWd3oImDRl4AtHrg914/Oo1brB53BH4FBehp0CA4xIChYj6AQPVXkB0Cn1xLUJed7dJ3tcz8ahpfJh5X+707UN9hQVUWuY+TA6nR6qUz4IChQQ40+esTE6Mid2R86XTfEeu6/PDb3wKHm7fCgxN2Bz5w1CKCw8pMIYpxJYeaT/ALJlXPsAS1jHWTlMmy3e6hhz4TSUiuB2DZqnAumhshI6HW+8CfwerDE10vevqKsASVFtSjIqYSX4NbMKQnKmTUtM663sZP3YelyocXrQB65slZ4LXAR3BpH7qyztZHKmTXU13+wn5L5ooAoIAqIAmNMAYZYrfV1qNj6KUylpXCTM2vCRStoWK5C1fvpKCLBOE9jDWTl0+GyWpQxRsWnn6Ji+zYkrViJ2AULEUZu9v5B39zJZZyfUsmeKCAKiALjTgGuy6ypqkYJAalHDh2mCDOdyoBi2vTpZEYxGUnUKT+QQNWexPXxXEfO9fdc59k3BQcH44MPPlARUPrOH2j6bPbD29xxxx3YtGlTv13ecMMNePbZZ0+BWevr6/HDH/4QeXl5/dZPT0/HG2+8geTk5N5lvH9up2DodbB099139xpzDLbON80XkFVA1iHLiICsQ8ojC0UBUUAUEAVEgW9UwI9C/zAc4u/vj/vuu68fHPKNO6AV9u/fD274YQglJCREhflbu3YthVqMV0DLUPvg33/88cdRXFysnNjmzZs31OpntGy8gKzsyuqydaJ6x3Yc++PziJo1BwlLlyGSwjaxQyu7QEkSBUQBUUAUEAXOhwIMNVjMFhzcdwA5R3JQkJeP1WtW4/qbvovy8nL1zLBr1y7109wD+q233kJYWJgCHV5//XX84he/UJVI7NKqo8YtrkQaCGTl5wDuBd3a2opHH30Ut956a7/svPLKK3jggQdUaHd+1jgdZG1vb8f//u//9ttuoBl8LJGRkQKyDiSOzDtFAf4PMNjaSFBrYX4hjh06gtyjOeDwW+ER4Zg6fRrSszKQkpaqnAoCAvzV8zSH1eTyLunCKMDXA4/bS5XcHPKdppWzIAPJ5LpK7qqtLR1oaexAcxONm0xopmmGWv0pXHZIqAGxceGIiQ9DTFyYcl+NiAxBsFFPFf6DQ18XJmfyKxdCgR73VQZWbTYP3d+sKC/rxPETZrrXgN5n9eTyEUINOMEw6P2g9Zf3Lz4vbnhR77Eh192KTxzV5MYZjqt0kxDiQ5AvQa1jMY11kJU15/JsMbtRUGjGRx/VIXlSIBYvCVfl2Gj8p/POYOeHr5/mDhs+//gwThTVKJfWOQsysOziGdATxM/Xzb6pztuJEwQzb3fUKHh5hjYc2ZpQJPsFwZ/KAd0N+64u06KAKCAKiAJjTAF+H+okeKSFHD0L3/wrfPw0SLlsLaLINS00PWOM5ebsD3csgqw9uWUX3fKPP1JOrCEpaUi78koYYmK7nVl7VpKxKCAKiAKiwJhVgO/VbPBgpmhSRw4ewrHDVHd5LIfMKCZjzeVrMSklBdEx0f3y19LSotxXOaIau5tef/319M6nx8aNG1VbPZtAbNmyBUlJSf227TtjuPvh+lLmEZ577jm1Gza3YBdYhlTZcZWB3Ntvvx2PPPKIqv/njuRXkQs8MwjchrBy5UosXrwYn3/+uQJxOf/s4srtDz11sWywkZqaqtxmly9f3vdwe6c3bNiA7373u73fz2ZCQFYBWYcsNwKyDimPLBQFRAFRQBQQBb5RgYMHD6oHQYY6uIfS6XDIUDvgdW+77TZs3bq132r80PvYY48pJ7bB9skPlu+++y44pDAnfnhdv359v30Nd8a4AVnpIZxh1vaSE6jbsxstBflwWazI/sHNiJ49GxqdXmDW4RYOWV8UEAVEAVHgjBTgEOt1tXV4+69voa2ljUIRTcfVG65RnU8YLGXAjyuG7rrrLvz85z8nx7puuKGsrAyrV69WFU+bN2/GbLpfceJ7/rJly1BSUqLu99dcc03vcfD8UnJ3efDBB8E9ok9PTz75JH73u9+pnuBcUXV64mNpaGg4ffaA37mXtjiyDiiNzBxAAX6G5f+ChSqE29rayc2zDXXk0sr/jQZybHU6Xep/MHnKZEyeOllBrcZQo5o3wO5k1reoAFdWczJ3kMtqqwUtzQyqmtGqxjxNjhLEUGkpbJpyVCV31SByV2WXVR4MgQHQk8NqgI7dNbUI0HeP/f01KtRaTyjtb/GQZVejUAF2sGxsdKCMANbiIotyYNVofBAXqyP31QBEResQGqqlEHtULmi+lItu59rOLgpD76xHmcesnDyna8OwSBsN8ises6HlxwPIypdFN4H97MZ66GA7WlqdBPp3YfmKSEyeHKzK71D9LPi66iK36vraNhTlV2H/7iJypdYjOS0Gs+ankyN/zCn/YnsX1VWQM2splYMTHhOOezqQ6WcksDkMaX4hEGfWU+SSL6KAKCAKjCkFuug9yEswSdlHH6Ju7x6adiEsKxvJBJwYOFJY4D9d3cZUxs7iYMcyyGqprqL2hAKUbfkQHocT2d//ASKyp0AXEXEWSsgmooAoIAqIAqNJAX5/40ga+QSBHt5/ACfIjZW/T5tBLqxTspGekU71XgZlMHH6cf/3f/83/vSnP8FoNKqIaj2OpmazGRdffDG9U9aqtn2ukx8qDXc/bGQxd+5cqntxKraATS166vdeeOEF/PrXv1Y/d+jQIQXYHqc8MbzKie/H1157rZrmjz//+c/45S9/qb5zVLiZ1NGGExteTJ06lep0YnD06NFhMQ9qB2f4ISBr/zaagaTzsdls3TW4Ay0dx/MEZB3HJ1eyJgqIAqKAKHDeFOBeTNx7iV1QOXQAQyXDBVl5Hwyxcq8shlP4AZIfQLlnFM/jB1Fe57PPPhs0BEFNTQ1WrVqlekZxZgVkHfiUOym0g4VeHEo2vo/Gw4eQfOkaxC5chLCMTEyEEE4DqyJzRQFRQBQQBc6nApXllSgqKMS2T7chODgI13//u6pHNIOqnDhED7+Pcw/nvol7VT///PMICAhQ9/i+y7788ksV2mjGjBnKtX3FihXqWYKfITicEXdsYefV0xMDri+99JJydGXn13NJ//M//yMg67kIOIG35YpVhqZrq2tRXlqG4sIign3qVQUpuxtEUwVpTFwMgW9RiIiMQCg5FPN/hx1a+ZlY0tkpoBwzXW4Cit2w2xw0OMltwqXGtk4HOq00WOz0PkEDjXkej3k+w6oMrUZGGxERFUJOusE0NiI0PAg6Ale12rHpHHl2SspWPQq4XF56V+1CW6sDzS1O1Nfb0dTkUIPR6I/oqABkZgUiLk5P/2GNwKs9wp0cc1j5Bq8Nn9qr0EFA61wKJ59J0GKKZmyHqR0PIGvPqbJYKKxktQ1Hj7WTs00HPT9FYvp0ug5GsHP40Pej7sbQLlRVNOHrXQXUaaNNXXsXLM1G9vQkur8ZyZlV0/NTcHWRiytcKHS1Y4+rgVxYfRHuG4BpBLOyMyvDrPQv6l1fJkQBUUAUEAXGhgK25mZ0VFag/JMtaCOIJH7RYkTPmUvRwmbDj971J1IayyCrm1z67G2tKHj9NWWUETNnHqIpGl7s/AVgqKTHvW4inU/JqyggCogCY10BVT9JnU1MJhOqK6uUA2tBXi51vtUiITERyy9epcbBIQO/o3MdJbugch3/z372s14YtEeXnshowcHBKCwsHPRecTb7YcdXNsVgQwzeNxti9SS+J3HUNgZRe8wu2CTjjjvuUPWqHCGOTTV6Euef1+f06quvgt1dOfG7/RVXXPGttCOoHQ7yISCrgKyDFI3u2QKyDimPLBQFRAFRQBQQBfopwA+XP/zhDxXEWlFR0bt8uCArg6rp6emqQZ9t/hlq7Uncq4p7SXFYAbb9555UAyV+mOSHyp4kIGuPEqeOVS94lwsV27aihiAgt82mek9PvvEmBBAkIUkUEAVEAVFAFPi2Fdj2yWfY/eVXqqLohz/+F1UBxPf1KHJfYXdUBlkHStxzerD7/unr33TTTeCe3Qywvvfee8qx9Z133untic3r83PLddddB3Zb/9GPfoTf/OY3p+9mWN8FZB2WXLLyAAq46JnMRU6sPG5saERNVTXycnIJbD1OYexbFMQ6e+5szJg9k1xas6Gjhl4NVdBKGr4C3fAwQVKmTjQ3mpRLYH1tqxo31rehqcFEnfN8FawaFROqgNXoGCOiYrunGWTV6QPUOuyk6afp7sznR9M+PAxlTTj8w5UtxogCZgq93kIA66GDrdSh00oQtBuxcTpy7AihsHkGus/pqFEF1EDiS/cgaeA//bSWkOtmgbsNee52BPlocVVAEmJ9DSqU/OnrjqXv4wlkVR0AyIn1wIE27NrVhGhyFk5ODsScOaHKYfibzgtfex0OF6xmO3bvyMPObceQlBKNrKmJWLQsG2HUKaAnMQTjpfUZZm0iwHmXox457lblzDpDG445BDoH+vyzsbFnOxmLAqKAKCAKjGIF6Lpev/9rnNj4ARztJgSQW1vWhu8ifHI2NAycTLBn6LEMsrJ1vovaEeq+3ovGgwfQnHMM8csuwowf/ZgrWyTS2yj+G8qhiQKigCgwmAIcParTalV1kR++vxEdHXSv1ulw6drLMJMio4VQpCh/f39Vpz7QPvh9b9KkSaptn0FRNqjqmxjQZFdWThyNddq0aX0X906fzX6eeuopPPHEE2BzizfffLN3Xz0Tt99+uzLK4nYHdlzdt28feqK6cZQ2Blf5d7k+7+9//zv+/d//XcGt+fn5FEmn2y3+H//4hwJ0b731VtWG0dTUpODYlJQUZfDlJgj420gCsgrIOmQ5EpB1SHlkoSggCogCooAo0E8BfshLSEjoN3+4IOvevXsVWMI9pjgcMO+3b+J79B//+Ef1QMwurexg1ZMYSuGQAU8//TSWL1+O6upq1ftLQNYehQYet584gRbqWVe143NodHqkrLscYZmZCIyLH3gDmSsKiAKigCggCgxTAYuZQ3S3YOuWT5Fz9BgWL1uCXV9/pUBTrhBiV1UOzTNY4nt6Q0PDgIu5lzf3nv7JT36CdevWKVfWuLg4bNq0CXfeeaeqZOPni9jY2N7tGZ7l0ED8nMEVVPzccC5JQNZzUU+2PV2BTmsnTOQUUFVRhaqqKnKua6DK5E5q3O1SobsCKeRmfGI8OSEkICEpkRxCDcqt+PT9TPTvHgp95rA7yUnVAXNHpxosBFDxNINUDFR53B51HWBAi6Epn5OisbNqYJAextBACoFtoLEBQRQKO8RogNafw8GL6+pEL1/8mup0esmthNxX6xyob7DTfcquQq4zqGoM9af7WoCCWENDtQgMFOhuoDLjJudNJ7zY62rEfmcjInx1SNcYMd8/EkHkuUlo+ECbjZl54wlk7RG9osKKoiIzPXt1UiOmj3JmTUzUUwPfN5dxda2lBtIThTXIO1aBmspm1RA6e0E6UtNjkTApsudn1JidWbl85LtaUeQxobXLCV2XL6ZoQ5HiF4xEcmcd2yXklOzKF1FAFBAFxq0CTosZHfTOXrtnD6qp/jlq5ixEzZ6DmLnzoKdOrRMxjWmQlU5YF7XJWOpq0Xz0CI6//x6CE5OQctlaGFPTYBiibmcinmvJsyggCogCo10BBli53v7Y4SMoofbipsZG6pgbh4ysTEwh4DQ+IZ46cdP7+RCdTiorK7F48WKV1ePkuh4YGHhKtrktPykpSc1j2JSh04HS2eynx8yC2wEeeuihfrv97W9/q7iBOXPm4MMPP1RcAUOt7N7KDMMNN9ygwNudO3eqtgqz2YzVq1fjjTfe6N0XG3CwcQaDq1bSi0FWTuzmetFFF4HbBjh/pzMNvTs4wwkBWQVkHbKoCMg6pDyyUBQQBUQBUUAUGFCBZgoPxL22OLHzGbubDRdkfeaZZ/DYY49h4cKFeP/99/v9Dru0ckUPQ7MHDx7s/T1ekcMHs7uakXp08wMnhxQuKSmBgKz9ZDxlBjuzdtbX49if/ggLgULh2dmIX7oMMQsWdveuG+Ll5JQdyRdRQBQQBUQBUWAABbgCp7aagYU87P1qDxrqG/DQo/8f1lCP7kaqGLv//vuVK+oAm6pZBoNh0N7evMIll1wC7iF9+v2eXd6nTp2Kzs5O5ejOlWTc6YV7SN9yyy3Ytm2bep7YQ41pfUMIDXYcQ80XkHUodWTZuSjADq1cmVxcUIT9e/eRQ2sxOYfWI2tKFmbMmoFZ5NIaExdL0JwRGj8NVSxTAGam6CZI4usLA4U8ZnC1i4DUnmkGVRlabSaHVQ5j3VjXTsBhKzmutqO12az+92ERQYiND0dcYrgax8aHITYhnCrcdRTmWhxvJ0gxGlY2ubx5PORC5SJXX3Jhray0IienQ4Vcb2tzYeasEMyYYURGehBB0EM39Azrh8fpyp1dbrR5HfjUWYO9zgZcq0vFfHLbNPr4Q+sz9q9l4xFk5bLfQWV/4we11HnYhkWLwjF5cjA12unp/nNmWKnL6VbX503v7KX7WzV1yojEzHlpWLiUXPnYtZhcsfsme5cHzV47tjgqUeW1qvIxj8rJIm00lRM/hTz3XV+mRQFRQBQQBUaPAgp4rKlGxWdb0UxGCmaK5DbtX25F8pq18CW7ep8J9O7S96yMdZC1Jy9txcXIf+M1uKwWBEZHI/nSyxSkzA67QwFPPdvLWBQQBUQBUWDkFOD2fC/VpdXV1uI4OaZuJidWc0cHZs6ZjSUXLcO8hQvO+FrOzqY333yzqpOsq6s7xYSKc8h174mJidQh2AnmAK6//voBMz7c/WzYsAFr1qyhepkc1cZw77339tvv888/j4cfflj9/oEDBxRX0E4GAldeeaUy1Dp9Az5OZgx05Ejbk9hAoy+zwNHlGM7lSLKc2K2WIdnBnGZNJhN1hDb17G7QcT211X/00UcqKu28efMGXW+8LuDzfybJx2azUfXcxEsCsk68cy45FgVEAVFAFPh2FWB3s//4j/8YNsjqcDhgt9vVQx+7svZNPJ97NtXSQzU7rr300ku9iy0Wi3JTY7e2l19+WS3ndQVk7ZVo0Alu7OfKpqbDh9FA4YAayOk2YeVKpF+1HgEMRegNg24rC0QBUUAUEAVEgaEU4AoxrqA6uO8A3nvrXQpDG430yRmYv3gBlixZMtSmvcueffZZ1VGld8ZpE4OBrLwau7LefffdqoKKO7pwz+uCggLl7hoQEKAqhjh80LkmAVnPVUHZfjAF+D/Ez8DmDrMCWhsJBG9qaAJ3IGtva1PzIyIjkJQ8CVmTs2icRK6hRnINnRgQJsNQdrsLbS0daG2x0NiM9lYLTZsVJMXLGUgNoIFdVvWGAAqNpoWBxgaCVfWG7nlqrA9Qy3lao51YQPBg5U/mn6qACq3u6kJNjQ0VFZ0KYrVYPTDo/RAe7o/oGB29//qraXan1GqlAf9UBft/q/CY8bWLrmkEKXIjxEr/OAofH6IgVgpM23+DMTZnPIKs/D9gN+KjR004cYLuTS1OZGUGYdUqgkr9fSms4jefN24sdbrcKD1ej+L8KuQdLUdkVAjmLMxAclosddAIO+VMe8iZlfyOUemx4oTbhAJPOwJ9NEjyDcJMbTiNA+FL4PM3//Ipu5UvooAoIAqIAudZAS+7dlZXqdDzpR99CF1oKGIXLkbkjJkISUlREOtEhR3HC8jqoHfSptwc1O3ZjZpdXyL7BzcjefUl8Kd3Uj+CeiSJAqKAKCAKjF4FOBpUdWU1dZzfi4K8fIRHhCM5NQXTKYpZHLmwRpBb6Zmm119/Hffdd58ymiqmTg59o6nyPhhkTUtLA7fl//73v8f3vve9AXc93P0wPMt1+wyUcsTWW2+9td9+X3nlFTzwwANg+JSBVz62X/ziF/jLX/7Suy6bZ9XU1PR+5/aG1157TX3nZ5W1a9fSO/BRBaq++OKLSKHnGE7bt28HR4vj309NTVVR5wYyGNixYwd4+KbEUeYYBL7qqqv+f/beA7yOs0z/vqXTdHSOeu+yJUuy3HuN7dhxCuk9JCEsZElggVzLB/sBWcJ/YQMXXPDBbv6wCSyQEEISUh1cUu0k7lVualbvvZ9e9T3P68i4SLIky7ak87yXxzOamTPlfuecmXnf33M/EJB1aLUEZH3wwaHVkSWigCggCogCooAoMKQCYwVZB9sgPySyTf+XvvQl5cKq0WgUeDJnzhy1Oj8As7Pae++9hwceeAC//vWv1fyRgqzsxMbpCi5WeL+FhYXqODIyMi62+qRaztHxLooGaz6wD8V/eVGlAUqhNMtx1LBoTk6hVLbSJTSpKlQOVhQQBUSBCaIABceSA2IL9u3ai81vvYMNN2ykYQNOkhPLV7/61REd5e9+9zvVeDPUytyQdOLECfz+979XkdTnr8dOrE899ZRK+zOwjCOrORKbPzseRUDW8VBRtjESBfg71dvdi+LCInJnPaWcWjm9VyR1CqdnZiA1LQXxiQmIio4iN8hwgjdDCKab3FArA0/stuomKNVF0Krb7fls7IXD7oLNSqBvr53AVQf6em000DQNvD67A0bFhCGGAKnY+AgFSsXwODYcRpOBGtI1I5Fd1glgBU47/PbD4WAHVoKmyXWVQVYeurrcBEkHU2dFKLKzw2hsomsqaMSulAEsKyWL7we7sRZSyvj3XPVIDA5Fvi4KedpIxAefG9A6mXWaiiAr1wc7E7e2Oilw2IrduzsoUCmEAotjqWPQQB2XI7vn8HeLAxHqa9qwfVuB+i2PiDRh/pJs5M1KQwgFFeh02jPVz6Czh4BWdmTd52lFm88BNzm1LtbFIUcTgXiNEXqCWQVnPSOZTIgCooAocFUV8FNmCQ9lR2natwdtRwvQQ6mKExYuQt4DD0JH6YY1Z7mcXdUDvUo7nyogq6pnSrFc/e42FL34PNLWrUfKqtWImTUbIVHnBqZcJallt6KAKCAKiALnKeAh04k+cl6tqapG0clCVJSVg6HWNdeuw5z585A5fZoymzrvY8P+yWYSjz/+uPpcA2X+5IxoZxfu52dIk8sLL7ygXFTPXj4wPdrt3HDDDVi1apVyVuX2fza0OL/86le/wi9/+UvkUTZSdvx8++238fWvf12txg6uzBckJycrkPWVV14Br8/lhz/84Zn+i5qaGgWrMjR7vgkXswlf/vKX1Wc+/PDDQV1ZmUEYCYfA7b579uwRkFWpOfR/ArIKyDr01SFLRAFRQBQQBUSBYRQYL5CVH27/8Ic/4Gc/+5kCUBgmffrpp/HFL35R7Z2Xc4QWR08xXMrRT2z3z/NHCrK+/vrrKCoqGuZsTi/i7ddS+iMGaqccyEqdSAyz9lZVoWHXp+gpL4Ojs5NSPX0JSctXIIh0Z02liAKigCggCogCo1Ggo60dOz7coRrGent6cd2NG7HimpUKrON7+pUqHGldXFwMbnTiQJjMz6Kmx2v/ArKOl5KynYspwA6tPq8PDqcDVouVgM0+1NbUUqNzBSpp4BRgDLLmzZqJeZQKLDmVHRRiLrbZCb3c4XDBbnWhva0XbS09aG/pVuPW5m7SwAl2XY2KMStgNSr69DiGQNWIKBPMYUZyCNRSQ7pWuawyFKWhtNU8ZshVnm8ndNVPiINj90mHw6eAvfJyG7l695HLbzDiCdjLzjYjJcWowD0jubIy1MqvTHJdXbzqHASx1visOOntxEF3O1bqE7DekIJQaAhGvHLPBxc/0ktbY+qCrJTVhdyJm5ud2LunA30WL7ldB2P5shjqHAwbsWj8/bLbnGhu7ELB/jLs3H6SXPtzlDNrVk4ywiLOzQ7DMKuTrp3efg+OujtwmNx8Q4I1SCVH1jXk5ssQtI5gVimigCggCogCV18BFwEx1sYGlPz1JVjqapG+8XoFskbl5iGYAvGCggP793qqgKwc3cLOux0njqNux3bYWpqhDTUh/+FHEJmdHfD1fPW/iXIEooAoIApcqEAP3aMLDh5CwaEjOF5wFAuXLMKS5csxLWsaosmFlbOYDeYqeuGW/jGHDaPuvvtuNYP70c8PqmdwlkFSLn//+9+xePFiNX3+f2PZzp133okDBw4oOJWdV88vDLhyhldmBl577TW1HsOs69atA4OrHGQ5ULg9hxkAhlOXLl2Kd95555zlA+udPeZ+B2YGuM32mWeewT333HP24lFNnzp1Sh2TOLIOL5uArAKyDn+FyFJRQBQQBUQBUWAIBS4VZGW4haOOGFCtoIhtLvyQyykHOC3wQKmursb69etVdNeWLVswf/58tYgfNjkKq7KyEs8++yzuuOMONf/sB9KBbfDDJQ8XK/wgzNFUUxFkHTh3N7my9tXWqIanpv37kEGNjMkEsoZTSgQdNUJJEQVEAVFAFBAFRqpAHwF2VRVV2Lpps2rwmTN/LmbNnY3snOyRbmLSrCcg66Spqil1oPz86iF30taWVtTX1aOavm9tra0EF3kotbMGJrMZcfFxakhMTiQ30jhERkWqZRNNCC/Buey2yu6qNquDBnZadRDgRBArDU6HWwGrHnJ08HnpvCkltdfjV9CgVqeh8zKDnfwYXh2YNocbyZFWL8DqRKvsSXI8DK+yA2trq0s5T7ITq83mVSnVY2MNCmBNSzMiJsZAoPRpgHWSnNpVP0wv+bF2+d3Y7W5Gs98OTX8QFuliaYhTEPBUCp+cqiDrwEVkIYC1osKKsjILysutWLE8GvPmRyE8nAMIRgYoseM2u2ufKqrH/l0lqm0mjIIQFq/MRVpmPLmLh57jcsxdjH5yZq3xW1Hs6VYOrW76O0sThmxtOI0joKX2IHFmHaglGYsCooAocGUVYKiRXTrbjx0lN9a9CmbVmczIvu12RGRlw0CZJKQAUwZk/awy7fQe2ltdhaptWxXMOuOOOxE7d57K9Bbo0LJc76KAKCAKTAQFBvrBqyvpt5r63NmJ1Wa1UaCuHouXLqFg+AUUSBiuINaxHC+7jS4nGJbLYKDqoUOHcPvtt6t3fjaW4sxSg5WxbIfdVRlMZSbgjTfeOAc8ZSD3rrvuwt69e5Vr6k9/+lMsWrRIua9+61vfwr/9279dcBi/+c1vwOtxRrfDhw8rk63m5mblNpuenn4BT8DcAc9noHU4t9kLdjTIDAFZdwyiyoWzBGQVkPXCq0LmiAKigCggCogCI1DgUkBW7nj/0Y9+pABUfgCMjo5WQOvDDz98QRQYpwV+7rnn1MM1R0+dXXbt2gU7pTBi5zVOC7BmzRoFoZ69zmim+UH3gw8+mNIg64Ae1du2oPztt1QKII6Uz771dhjj4wcWy1gUEAVEAVFAFBhWAb5/c8PYsSPHsO3vW5E1IxuPfeNxAhvCyR1xZClnh93BBFsoIOsEq5AAPRxuMO3s6MTJYydx+MAhHNi7X0Gr8QnxWL56BeYSTJ6bn6caXjno62q5Rp4bWBakGpjZka+7y4oWcuVrauigoVM59LU0dFHDuhM+cu1LTo1GSlosklJonE7j1BiCdCMUwBok7qoBetVfntNmM472dhdqam04crhbAXrh4TpkZ5mwdFk0EhNCED7C9OmX5wgn91bt5KjJ6eFfdVQgiLS+LSQT6VozooMMk/vEBjn6qQ6y8nfFQ8EFB/Z3UcdhI+bNi6D2lwhkZVFwwSi/I/xb39XRh01/24uSwjqsv2E+5i2ajszsROWifb68DLS66Fr6mIDoE54udPqdmKuLxq2GDBiDCKQVZ9bzJZO/RQFRQBS4Igr4XC54KNX8qddeRfFf/oxpN92M1LXrED9vPvTUHiDltAJTDWRVZ0WBlsd//xyaCWCOnpmPxKXLkLL6Gmj0eql2UUAUEAVEgausAAe9u91ubHn7HeylvnNLnwVz5s/DvQ8+gOiYGISGnpsNY7SHy8DogLnUI488Am4rHzCQ4vbH7373u3jxxRexcOFCbN269RzY9Ox9jWU7mzdvxuOPP67aO/fv34/ExMQzm+ykzKNz585V+2Nu4ZprrlFgK6/Hrqf/+7//e+Y4+UN8rE8++SSef/55xRS8+uqr2LFjB5hPYHahsLCQ3nUjzmyfJ3bu3IkHHnhAzWNH2UvJ6Cogq4Cs51xc5//xH//xH8jJycGDArKeL438LQqIAqKAKCAKjEiBsYKsAxDr//zP/6j9cCqCn/zkJwp8GWzHDLz+7ne/G2zRBfP4QfJXv/rVBfNHOiOQQNYeisjrOHkCjbt3qgf8GXfdg2gCWo3k5CVFFBAFRAFRQBQYTgGG6bzkmrjtna04cew4NYSZMGfeHKzdsI7Szo4+NdFw+5ooywRknSg1EdjHwQ3ELieBQJ1d5MzajpbmFnS2d6i/7XabCggzUsN0xrQMTM+aTlBoKsF44VfEoZXTR3vJRdXS50Bfrw293Tb0dFvR00XTPTaVWprX0WiCCXbXKmiJnVb1NG0I0SlnVZMphFxmTw9GkwFmcuzjZQaD7qpBuYF9xU29s7daKS1qhwtVVVa0tbnQ0+OG0aihd1Ed4uIMSIgPQXyCgeYF07WpmXoCXKEzKiTosMTXgzqvFYmUCn59SIqCWA1BU0/TQABZGWatJej7+PEeBYAHU2DB2rVxSEsLpe/JyN2KPW52PPbi+OFKnCqup/tXHwUuxGDF2nzEJUQoZ9azL9F+UCpjmtHos6HGZ0WRtxsecmYND9JhgS4GOdoI8DUlzqxnqybTooAoIApcXgX66X2EXTnrPt4BS00NXL09yLzhRsQvWgxjdAw0lKpYymkFpiTISg8FLYcOoPXIEbSfOI6oGTnIfeBBZZShNRql6kUBUUAUEAWuggLcRu90OFBaXEpB7wdUADxnuMidmYec3FzKnDaD2tyM0Gq1l3x0//3f/42f//znqo3urbfewurVq1X/8ieffIIvfOELcFGwyy9+8Qs89NBDal8NDQ0YYAG+9rWv0Ttkmpo/2u0woJufn6+MrdauXQuGTxmI5XNnqHb79u2UVScFDJnyeT799NNqvwytsoPqTTfdpNxUmU/49NNPFbTKx/r9738f3/zmN9V2mR3kdldmFtixlQt/vqmpCffee6/KDrts2TJs2rRpSEhXfegi/wnIKiDrsJeIgKzDyiMLRQFRQBQQBUSBiyowVpD17LQBjz32GPiePFzhB91WSl0zWOEHzBpqNPuXf/kX9SDKrqxJSUmDrTqieYEEsnL0vLOLHL3++Af0VFYgafkKJFKjY/yChVDpgOgBXYooIAqIAqKAKDCYAhzR3UXRzq+//BqqyJX1pltuwtwF85CannZFgLnBjulyzxOQ9XIrLNsfrQLsespDfU0dKssrcazgKBrrGwgktSI9M51ckrMwLXs6QXnxKmCMAdcQY4hq6OWG2LEUtU+CUT0ehtl9NPYSvOpTYJLb5SHI1vMZvGpVIGtXp+X03wS18rpGo55cIMIRnxiJWIKW4hIi1XRklJkAJun4HEudyGeGV4ABPJ+vn65RP6WK8yp4tanRgXJKlW6zehGsCcKsWeHIywtDfLyBAjMuvWNn+COa2ku9BB66/Oyg2aQcNFM0JuQSbDhfF4uQKQixcm1OdZB14Iq12cgRvNNFTjVtqKuzK5A1NzdMAeAa+h6NpnR1WFBd0YwPtxaAgai55MqaNysdaZlx1OlIYCoFPJxfOv0uHPV0oMzXh0pPL1aGJGCeNgYJBEqHQgONuLOeL5n8LQqIAqLAuCvQTwGtzq4utBw5jLI3XlPwYhyllk9esQqR2dnjvr/JvsEpCbJSpTi7u9FVUowTf/g9DGHhmHH3PYjKngET9ctIEQVEAVFAFLhyCnAbHYOcfb29lPWoEUcOHsLuT3eqoPacvFysufZaChxMHheAdeCsHATM3nPPPeo9mOexE2pISAgKCgrUsdxxxx1nMrHy8sOHD+O2227jSbzzzjtYsmSJmh7tdvhD7MrKMCzDpuyYumDBApSUlCh+wECBNNu2bcPMmTPV9m3kHL9x40bFD/CMxYsXK3bg4MGDZ3iDrKws5cSq053OLDcA1/L6DMUuWrQIfJwMx1qtVpU1dsuWLdSGNItXGXMRkFVA1mEvHgFZh5VHFooCooAoIAqIAhdVYCQg65/+9CdUkPMnPxA++uijapuvvPIKvv3tbyMyMhIcpTVUOgOOpjKZTMNGNl133XUoLi5WD8a33377RY/5YisEEsjKHUZepwMtFKHXWnBEubMyzJr30MPQGkIkJdDFLhZZLgqIAqJAACtwiiK8D+0/hJqqagUb3H73HZhOwBxHd48VkJvocgrIOtFrKHCPz2G3k3OAgwDWPnSQO2tTYxPqqmvRSI3YTnJvjYyKQv7sfOTl5yErJ1ul4RqrC4OCV8lNjyGkjvZe5abX3tpL030qXbTd5lTuqSazkZxgQxEeyYOJGphNZ5xW2Y3VYKCU0CF6GGia/2ZnVoaXpIgC462Al1Ki2+0+VFfbUFpqQWuLkxxC/EhJNSIlOUQ5SoaRG6vJpKHrkmC4UQJ54328k317Pf1uNPvs+NTVhHq/DTca0jBTG4noYHJrx+hgx8miRaCArF4vd5L6ceBAF06dslBQRBCys8xYviKaOi5H9/vNzqzs1F1aWIdTRfUoK2nA8mvysZycWTmwgYMezi/sxNrX70G5t1cBrVZ4YQrSYq0+EZmaMISSS+vUvMLOV0L+FgVEAVHg6ingtlrQ8Okn1I5cgL6aaiQtW4HpN7efCTwAAEAASURBVN8MA71v6ChLi5RzFZiqIKufUldbmxpRvW0rLPV1CiiadtPNSFu77lwB5C9RQBQQBUSBy6oAZ0zjLE0l1Ef+0Xsf0PuaB3HxcVhAAGbeLH63ilKQ6Xi31fdR++PDDz+sINWBE9Tr9biWwFnOrsrTA4UB11tuuUX9uXXrVgWfDiwbzXYGPsNOrE899RQFKtsGZiE1NRU//vGPceONN56ZxxONjY3gjK8Mn55feF12lo07L0Ppc889h2eeeYay9/Sc8xGGV/ncpk+ffs78sfwhIKuArMNeNwKyDiuPLBQFRAFRQBQQBS6qwEhA1vvuuw+7d+/GqlWr8Prrr6ttPvHEE3jjjTcuun1OMcDRURxVNlQRkHUoZUY2nyPprS3N6Dh+DOVvvQkzRU6nrluP6Lw8mk4Z2UZkLVFAFBAFRIGAUYDThnMk8v49+7Dtna1Iy0hDzsxcLF+5HLHUUDaVi4CsU7l2p865WS1WcszrJIfWCnK7qyZor5WcKN3kdhqGmNgYxMbGkgtqPLm0xiGWGmuNnFpMd64Dpd9HwU7ktup0uOGwuwkCdKqxw+6C3XZ6cDrdYAdWJzmwumia/2YwicwYYQozIoLg1ahoMyKjwxAdG0ZjM8zmEOgNOgU/TR3F5UwmogJ+5Rrsp44HD30f3OS24VTjri43gsmNmKHVrGwzdXYYkZDALsWn08VNxHOZLMfEb+x+em+v8ltwwN2Kbr8bjBVuDElVkKFmCiOGgQKyDlyL1dV2Cla2kPNNH6Ki9LjmGrqfxOrpN/7ce8nA+kON+Z7Brt1Fx2uw5+NCcumORPq0eMyam0GuQTHqfjGYeXir34FKbx+KPF3o6Hciixx/szXkBkdjCseFTpxZh5Jc5osCooAocEkKuMiFs6+uFlXbtsBG7xjhGfR7TYYIKStW8oPUJW17qn54qoKsXF8ugpi6SorQQn03Dbt2YtqNNyGThpCoaGjpHVOKKCAKiAKiwOVVgLOldXZ0oLiwCBVlZRTU3ohkchGdv2ghsnNmqOnLewRAF7m0HzlyRMGy7LTKzqxjKaPdDgO8bHDF2VrnzJmDzMzMYXfLQGsZacTZXzmr64wZM5Cenj7kZ9gUYMDplZ1fs8l1/nzgdcgPj2CBgKwCsg57mQjIOqw8slAUEAVEAVFAFLioAgyjMpTKHeKFhYUq+vb8Dz3wwAPYuXMnpZ1bC3Zi5cgvhlqrqqrOX/WCvzmyac+ePcOCrBw1deLECfz+978/E9V1wYZGMSOQHFkHZGFn1p7KSlRtfkdFU/sJUsq9/wEkr1w1sIqMRQFRQBQQBUQBpYDdZkdLczNFeX+It159E1/8yj/h+ptvJOfFcAyk4ZmqUgnIOlVrdmqdFweAcYotbtR1OV1ob2sjqLWS0osdoYbtcuXWOm/BXMxbuABLli1GQlISzGHmc0RgQNVBEGtbczeaG3noREvT6XE3QUd9vXaCYsMJOgpHYlIUbYOGZB7HICrGTM4Lpx1WgwkmCiLHPnbt43cA+qfG5+xM/hAFLoMCHo8fNnJhLTzZi6KiPpSXWQms1iEnJwz5+WHIyDDRdRpMLsCnr8/LcAgBt0kGWV39Puz1tOJvjkos1sVhGQ0Z5JQZEfwPN5apKEyggaz8/WomZ+OtW5opiMFH36lw5OaGITNz9E58HDjR2tKDU8X1OLz3FBpq23HHA6sxb3GWcvXWaIgyP6/4KWLCR/e6E94unPB0otTbgzStGTfr0xCvCVUured9RP4UBUQBUUAUGAcF2skEoZmyejXt3Y2Q6GjM/ufHEEEwq8507rvEOOxqymxiKoOs3J/gc7lQ9/F2HH/2t4ibvxCpq69B/PwFCE1ImDJ1KCciCogCosBEVaCK+nRPHjuB7e9/AKvFgg03XE8Q6wLkkEkRZzvVaEaXNWOinudUPC4BWQVkHfa6FpB1WHlkoSggCogCooAoEJAKBCLIyhXtojQJXadK0bxvL+opRdT0W29D2pp1MCUnSWqogPwmyEmLAqKAKHChAgzINdTV45PtnxDY1gSblVIG33oTFi5ZpCBWbiSbykVA1qlcu1Pz3BhoZfi8q7MLTQ2NaG5qViC6kwBXr9dL/ohBCA+PQHQMO7NGUCO3EXYrQ6w0kPsqF4ZQ+bs9AKPqPoNUzWYjAbBGmMwGhEUQOERuq+awUBhD9WfWn5qqyllNVAXoFgWrzUvwtotcNhyUQs5ObsR+dbhGowbx8SFISgqhsYGu+9POwAxXSxkfBTjNO6d8L/Z0o9DXjTXaRCw1xCOMfFn1U9whM9BAVv6uWSxenDjZg+pqm/rOLVoUhSVLogkQDyJAfHTPgzarEz1dVhw9VI7Swnp1b8nMSsTiFbmIiDLRM+bgHbBt5Mza4LPhJDmz9vW7lRvrHF008nVRMCpn1sE/Nz5XvGxFFBAFRIHAUcBjt8FJjmu1H36A5v37EJaegdjZc5B6zRoYyKUsSECZIS+GqQyy8kkzzNpVWoL6j3fAQi53XHLuuRcxs2ZDazCIU69SRP4TBUQBUWD8FOC2+W66J1dWVKKEnFjLSk+pDEyplN2UnViTU5IpiDd6/HYoW7osCgjIKiDrsBeWgKzDyiMLRQFRQBQQBUSBgFQgUEFWbnjyezyofu9dFD3/R8TOmYv4hYuQTCmiOIo6aIrDSQF5sctJiwKigCgwCgW4ocxht6PoZBFefuGvqlFs9brVyJ2Zh5S0lFFsafKuKiDr5K27QD1yho3YmdXnZYdWPzjtWEdHJwoOFuDYkaMoLSol6FRDqdUTEWqKg5acEy19HlqfnFSDaH5iFBJTotU4/jPn1dh4Al9jwwRWDdSLagKet9fbD3aIdLn8aGt3oarSQmnPbaivdyAt1YisbDPmzqXrlhxZjcbRpT6fgKc7IQ/JRw6ZzT47PnU3o6vfBV0/ZWExJGKONjA60AINZOWLkL93vb0eHD3Wg/ffbcGCBZFYuSpWgeKhoWMDSCtONaH4RA2OHqygoAgDbrhtCdIz4xEZbRrSzdvm96Dc16ecWQ962rFIF4tl+ngka0wICyJgnY6VgzakiAKigCggCoxeAW4D4PZiW3MTOouLFKzYVVKCWV96VGXxComKQrBWnq3UO5efsmL4yDHcB9AkZcjgcT9efOFZ9R72+OPfoKBBChLUUJAg3ZY4SHCqFHdfH2V4a0Lpqy+j9fBBzP7yV+j6WAljbJxcH1OlkuU8RAFR4KorwPdkP91kbBSsXlVRgb27dlPbRyV6urtx2113YumK5RSkHkOBhVM7G8pVr4hxOgABWQVkHfZSEpB1WHlkoSggCogCooAoEJAKBCzIyq1uNHSXlaGt4AhajhwisNWL/Ie/gOj8fJUmilPCShEFRAFRQBQITAU8FOxQUliME0dP4PCBQ5g9dzZuu+cOhFFKcmNoaECIIiBrQFTzlDlJP/Wgej0+9PZYya3Biq4OC9pbutHS1EGN3Q3kqtxCrsp91InqgT7ERy6sNupk9VIq5yhkTp9O3/FZSE5NQkJSHAwheoSE6GjQQ2fQUsO4jqAiNtiRZ8Mpc8FM4hPp7HSjqcmB0lICtWnaS1BrXKxBua/GkftqdLQeERHkCqrn1HpyzY53VdNbJHrIDbPc04v3XfWIDDZgrT4RKRozYmg6EEoggqzckerx9CtH1gP7O+GmaZNJg5UrYpCeETqm+wM7s7a19uDQnlNoqu8g2CcYC5ZkY9nqPHJ51ai/z7+evP1+WPu9qPNZUOTtAbu0euHHKl0CcrSRiAjWkzerfO/P103+FgVEAVFgJAr0EzDjsdnQRC6sZa//Dca4OETn5CJp+UpETJsGDcMyAf4+wM3pHExlc/jR0+tFbx+9f302uN39qDr1Ekntx8Ybv4KoSC0iwjUwhwar59KpIh0bY3idTlRt3YymPbsRmpiE+LlzkXrteujNYSO51GQdUUAUEAVEgYso4KXf2j4KHGCAtaSoiNr2WpCZNQ3zFixAJt2T4xLiYSAn7KmeLe0iMk2axQKyCsg67MUqIOuw8shCUUAUEAVEAVEgIBUIVJB1oLJd9DLk7GhHySsvo/tUKdLWb0DSkqWIys2TKOoBkWQsCogCokCAKeClwAar1YoPtr1PKYvKoNfpsHjZEqy/YUNAKSEga0BV96Q4WYZVGSZyOtxwuzwEo7rhcrrhdHrgtLtht7vISdlFwKoTDhuNbU7YaZrHHvpe6w0MBrmpoduOnp52Wr9PuTdExUQhlZyWE1MSyY01kRyYoygVezhB65SsWVKHToprYyofJF/3bjcBAzYfurvdaGlxorWVALg2F7lf9SMyUo9scmHNyjLBbNYSgD02d8iprOF4nZtyhSFGsMjTjVJfD04RzJqtDcetxgwY+oOhCxpdivnxOq4rvZ1ABFkHNGaQvKbaiqKiPjS3uLB2bSxyc8Mo0ElL8Ono699J97BTRQ0oLaxT7qzTZyRh0fIcpKbHISJqaGdWhqkbyRX4qKcDFd5eZGnC1bWYo42AmZxZDeQyLkUUEAVEAVFgFArQO4bLYkEnwTLsstmw81OkXLMGGRtvgDklBQZ6NwjUwpkA3B6gz+JTg8XKDnk+2J2cIYAy2Xw29pB7eVv9KySTD7Pm/RM9kwYhlCDWMLMGkRFaRBPYGmIIIvBo9PfLiah965HD4KGzuJiyu8Uj977Pw5SUCF2oaSIerhyTKCAKiAKTQgHOsuT1etFYX4/qikocLShAT1c3BaFHqrb5ZStXKIBVS231UiaPAgKyCsg67NUqIOuw8shCUUAUEAVEAVEgIBUIdJCVU0ZxJHXth++j+cABOLu7ED9/AWY+9AVojcaAvCbkpEUBUUAUCHQFOB15c1MzXnr+L+Tq2IG7778HebPzkZScFFDSCMgaUNU9KU7W6/UpgLWthVzoWnvR1tyF1uZuGvego70Pll47Qs0hiIwiZ8T4cMTG8RCBGBpHEhBkDicwVctOdQQGupzk3tqD4sISlBYV07gI5rAwJNL3fPGyxZg5K59AolTVQD4pxJGDnLIKMMTKKc3Ly60oONJNrlce5beYPysc06abkJoSSpCABjpdMEHaUyt160SrVE6Z6yGXsU2uWpS4u5Gji0C+NgqzadAQxBooPpiBDLL6CNJxuX349NMOHD7cjRkzzApkzcsLg9E4eniUYXSXy02dtC3Y+eEJ9PXa6Lusw3U3LyQIKEM5vQ7mBu6n+5iH3FmryJm11NOD475O0B0OG/WpyNSGITpA3IEn2m+EHI8oIApMXgX8BM1Y6imo4MU/w9bSjLC0dKQSyJq4dBmC6Xc5iB+yArRYbX60tlPGmjIHyiud6OgiL3AOporQICZKR86rGuW+GkKA6u5P/wQfvbPFpT6Mzm7S1OqFjgI9MtIMWDjXhOQkHWKjtVNCSTbHsNTW4PjvnoOP3i1n3HUPYmfPVtfOlDhBOQlRQBQQBa6CAk5yvLbQ7+t7W7Zhz86dKsg8N38m1pLrdQIFC5jMp4P9BntHugqHK7scoQICsgrIOuylIiDrsPLIQlFAFBAFRAFRICAVCHSQdaDSu8vL0XHiOGq3fwhjbByybrkVEZnTYIyPH1hFxqKAKCAKiAIBokBxYTEKDh5BRXkFuduZcNvddyAtI40AhcAKcBCQNUAu+Al2mj4fOfuQQ52dHFYZTLVaHGpgl1UbTbPrqs9LgUgElPVTB6oKSqJpLtyQbQ4zqiE80oQwAlfDI0JpHEqN3SHkvqo9k6rZTy4PdrsDTQ2N5PTQiNqaWpW2zOlwkKueVjWOx8TFIjklGSlpqZSuPZq2ax5T+ugJJrEcziRQwEuwnIeu81ZyfGxqcigHVgsBrJza3EyuVlHRBqSnGxEfH4KICB05BwcKQnl1K6/T7yIXTCv2etrQTdPr9EnkghmB2OCQgIFYuQYCGWTl82dn3pJiC4pL+tDR4ab7gw6rV8UiJlZPwQ+jh1l5m92dFpSfakTpyTpUlbdg9oJM5OanYVp2orqn8TqDFXZmbfE7cMzdgTYaGwhmzaVrcraO7lkg57vgqQELDXbuMk8UEAVEgfFUoIOcWLlduGnfXoRERiB13XpE5+aSG2vqeO5m0mzL7vDBYvGjqcWDtg4Punu89Gx6+p1LS4GBoSHB6pmU3VZN5LrKg04XhNf/9nty0vNhzfp/ps/7YLX7FczKz7Zael6NIYg1IV6H1CQDIsJPfyY4eHI+x/bT+6Sjk5zRN21Cb1WlAp6Viy9le+PoskCGnyfNhS4HKgqIAhNGAS+ZDVnIGb2qshLHC46iraWVAv5c9E40E3kzZyInLxch1C4fHMCBJROmssZwIAKyCsg67GUjIOuw8shCUUAUEAVEAVEgIBUQkPV0tTME0VtdhcI//gGu3l5EUWNl6uprEEfurEQsCLQQkN8OOWlRQBQINAX87NJNEN27FPX97t+3YUbuDMyeNwfLVi4jGC4i0OSAgKwBV+VX7IQZAiIzOQWj8neOHX1Uym4auylvJTvSdbb1UcM1Oa/SoFxXadzbYyNnBjviEiIRT0NCchQ5JUcjMSWKnBmiEU3OqwYDQ32jc0zi7z5DseWnylF0shAH9x0guLWBGsg1yJ+Tj/mLFqjfg0Ryf+D0ZVqNhpxdBQ66YhdMAO2Ivxo+Xz9B1py61YOTJ3pRWtqHlmYnYgmSmz8/CjNyzASxhqr3E3pNkXKFFGAHzFJvDw6729HZ70IYpW//nCENyZrASx8b6CArX3JWcpjj7+XmzU0KMN+4MR4ZmSaCWvVjuiL5Hsjf/307i/HJB8fUfSwlPRbrb1ig7nVa7dCArLvfhwafjVxZu/CRswE5BLKu1iciXROGGHJmpdaMgAKtx1QB8iFRQBQIWAUGMnWVv/UmGvfspqA3DRIWLsSMe+6FzmQOKF1Ov48FqWfRdoJXG5s9OHrShpY2D5wuP3JnGDEr14hpGXpER1KA4CAA6m9/+1v6vA9PPPGE0o4/19LmRVGJHYeO2ihgMIjulRosnmfCtHQDwsM4q0DQoNuaDOJ7KQiyp6IcTXv2END6FjJv+hxm/9OXoSHYSqMf2zPBZDhvOUZRQBQQBcZTAb5v2Kw21NXWYt/uPdj2982YRQ7Xy1auwKJlSyjAPGU8dyfbugoKCMgqIOuwl52ArMPKIwtFAVFAFBAFRIGAVEBA1tPVzo11Lkov23rkMNoKjqjxdHJlnXbTzdBTmlmNwRCQ14ectCggCogCgaRAHwUy1NXWY9fHO3Hk4GHcfPstWLpiKUFz8eTkGHidEAKyBtLVf+XOlUEdr4fSTPY5CEy1kgudFT3dNHTRNA02i5OgIC8BoxqCUslNLoQc7ox6NQ7hMQ3GUD1CTSE0Nqhpo9EAQ4hO/c3uDKOF+04DRP3k/GpBV1c3Otra0d7ajhZygOjq6CSwtlc5P8TExiigdVrWNHJpTlcgobhBXLlrZ6rviQFWi8VL9yE7autoqLHRda+ha12DuDiDGuLjqcM/XAeTSTvq63yq63c5z49TuDvhwx53Cz5yNWKeLgaztAQVEzDIQOvlKgPpEvk3aqyFt3Epnx9svwKygu5TfnLx9uLA/k5yTXZScEMQZs8Ox+LFUUqygbobTL+h5nE1tzZ3oaayBUcPVaKPgjdmzydn1lnpyM5NHupjKijEBi+aCGYtJti6xW9Hj9+NZfp45GkjERtEjuRBowvwGHJnskAUEAVEgSmmgLW5Cd1lZaj/eAcs9XXIuO56ZWoQlZ2tHDan2OkOeTqc7cLvA5pbPaiqdaG+0YXePh/CzMGIidIhPk6HKIJXIyM0MJuCYdAP/s51PsjKz7cOZz+6ejzkYu5Fc5sbHZ0+AmP7EREWjJk5RiQn6REXMzmDBNmV1U3vkK2HD+HUa6/ClJSMhEWLFQxtTk0bUm9ZIAqIAqKAKPAPBeooQ1JFWTkFle+noF4KXo+PQz6BrOzCGkuZkoyhof9YWaYmpQICsgrIOuyFKyDrsPLIQlFAFBAFRAFRICAVEJD1H9Xup/QV7MbKjZdFf34eSctXIG3tOkTPzEdITIyCFf6xtkyJAqKAKCAKTBUFGPBgR8ba6hrs3bUXdTV1cFDD2Z333YUF5MQYqCnhBGSdKlf4lT8PhnH4O+V2USp0t5dcVmmgaR67nOTo43CT24KTAFG7cljlsZqmMa+v0QYjItKE2PgIRMeG05iGuAhERpvVwIDQYA5A43Wm/JvQ19uH+rp6lBaVoLiwWP3NTq/pBLCmZaQhPTODjjFCuTWbzCYFuwvUOl41EFjbcTopLSmlb+3t9aK9ncCBejtaW5zUye/CNHJ4nJ5txgwaIiN15FglMNrVuDos/R7U+a3KjfUQObLeHpKhIMHQIC0lb788dVJJKRV//vOfE8Ach5/+9KejglE15Ca3idLcHjx4kCDLJnI+i8ayZctw5513ktPn0M6eI9VWQNbTSrndflRX21BWZsWJEz3Izw/HmjWxCjRnCH0sxUcu5XyP/Pj9YzhVVE/3Qw3yZqVh6ao8hJoNKqhjqO3a6Dpt9zlxxNuBw552TNeEK9g6R0P30mAKBKHrVYooIAqIAqLAaQUYQPS6nGg/fhx1O7bD1dWpHFhz7rsfUTm5CmIdS1DCZNOX33sohpCeRf3o7Paitt5FIKsbFnIe11GQRt6MEEzPDEFasp6eIThj2fBneD7IOrA2vx/yvmrq3aisdqK80gU3BYUkJ+qRSc6smWl6Bc2GhDAge5GdDGx0Ao17ystR8/67sDY3c3oFZN1+J+IXLEAwBUQHanvSBKoeORRRQBSYoArYrBTUTuZChcdPoKSomNrlq5FE7qvrN15HbW6ZlIkpfoIeuRzWaBUQkFVA1mGvGQFZh5VHFooCooAoIAqIAgGpgICsZ1U7Naj5vV50ldBL00cfUuNTk0opO/PhLyBm1mxpeDpLKpkUBUQBUWAqKcDAncvpxOEDh/CX51/CtOmZWHnNKgIHZiIhMWEqneqozkVA1lHJJSufpYDXS840Li85m/ago72Pxr1ob6FpGvPflj47ua3qYA4zIjomHBFRJkTGmGk6DGHhoTCHGwkM1RK0xwOlm6RpTqvMgCuPr0TnppeeCd0ut3KDsFLjelNDI2qqalBxqly5tNoIdp8zfw5mz5uLmfRbERsbSy6y7JI5+Tpez6o6mbzSClCnflOzA7XkwlpY2If2DhdMoRqkp4cim+DVqCg9IiJ0BK/xtT+489WVPuRA3F+t14KP3I2wkyuridDVFeR0OYPgQA25XF6Obzw/l6xfv54AyTJkUgfevn37Rgyy8u/VXXfdRddT4QVVlZeXhzfffJOuq9OuoResMMIZArKeFoqhHIfDi/JyKz76qE19V3NywpCTY0ZiYsgI1Tx3tdPBVf3kzNqNsuIGfPLBMURGmbFkZS6m5yRTx270uR846y8/+uEm9+BGcmat8vXhqLsDLrpmV+uTkE1Qa5o2sFJknyWNTIoCooAocIECHrsNtqZmglg/wqlXX8G0z30OadduQGRWNgwREbgosXnBFifnDL6XdfV4UVPnwqECG7mn+hFqPO2Umk5waXgYZQegvw2GkT3zDAWysjp8j3O5++n9yo+2Ti8BrQ4UlTrJ4ZWefVP0mJNvRHoqZ0Trn3TvVO6+PlgbG1G5+R3UfPg+Zn/pUaStuxbG2DhoAjC7z+T8NshRiwKiwJVUgO8Jp0pKqS3+IIpOnqRgdytWrV2DWXNmK4jVaDRSe+Dly35yJc9V9gUIyCog67DfAwFZh5VHFooCooAoIAqIAgGpgICsF1a7o70dPZUVKiK/+1Qppt9yG+IXLUJ4WnpApZW6UBmZIwqIAqLA1FTASRBreWkZjhUcU46sy1Ysw4233kRAQnhApy8SkHVqXu/jdVbsGscuqw67G1arAw6bCzabE3Ya28ltlccKBnX74COw1UNWP14PTdPnGPY0hhoIWjUSxGomV9NQBbOyC6spLIQ6Sw0IJvfTiVIYKuvq7CKwqAVVFZVoJKi1raUNBiMdqylUQWHx8fFITE5EHDlGxMTGEHRIPo3BE+ccJoqWchzsVswd+D50dbnQws6r7ZxilVypqGOfLhskJIQQyGpCRoaJoIEgcWG9ihcNg4E9/W6Uurux3d2E+OAQLCGINV1jRixNX47Cjqnf/e538cILL6jNjwZk5d+dW265RTmx6gmaePzxxzF//nxyCz2B3/zmN/T768O9996LZ555ZsRg7GDnKCDruarw97igoBttlC7ZZvNi5coY5OWFKehnLO7h3KnroXtnU0MHDuwuRXtrD91H/VhMMGv+nHQVBMIBHkMVdmbt8hOQ5OlAvc8CAzmxZgabMUcXjcggPUzB0iE8lHYyXxQQBQJDAb/bjb6GejR8+gl6q6pgb29D9q23IXnVNeTKagqItl8GWPssPnoGJRfWBnombfXAYvMhgsDV1GQDMtL1SIzT0bPpxV1Yz75qhgNZB9bjZ2GHsx9NLR6UljvQ2UUZ0lz9yEij/RI8m5ZiUPDsZHqVYmMMr9OB6m3baNiiXH3j6RksecUqGC4xgGhANxmLAqKAKDAVFOB30j7Kislta6dKOANSEcxmM+LJSGL5qpVIS+f3nbBJF9AwFermcp6DgKwCsg57fQnIOqw8slAUEAVEAVFAFAhIBQRkHaLaqUWv+KUXUUtR1OHTspC4eDFF5q+H3hw2xAdktiggCogCosBkVaCnuwdbNm1GZXmlivZetWYV1m5YN1lPZ9yOW0DWcZNySm7I6aQO4F5Kgd7UTbBNJ5p5aOyioRPdnRZYLU6COiMI7oxGckoMEpKjkJwWo9zkYuIjVHpkzQSCVUdTST3d3WghqHXfrr04fPAw6mrqCGaNxKKli7Fk+RJyap2LEHGPGI2kAbUupyNvaXGgtNSK/fu7CAb3wmjUYPnyaMyk1OQMsur1AkFPhIvC3e9DmbcXhd5uHCEocIkuDneFZII9yYIJyL8c5aOPPsIjjzxyZtOjAVk/+eQTPPjggwqif/nllynN/Zoz2/nDH/6AH/7whwqyr62tvaSOQQFZz8iqJvg7benz4OOP27F9extuuTUZS5ZGIZLclC/lu8zO5j3dVuz86ATe/OsurL9xPlaum4WM6QkKZj33KM79y0/tGe39ThTRtft3Rw1iCLy+Rp+IHG0kkjWh564sf4kCooAoEEgK0O+j22JB29ECHP3NM+SYGYusO+5CbH4+wsjAYCIUDmr58Y9/TPcQvQpu4aC68wsHzJWWlmLPnj0oLi4mJ/BErFu3Doup/ZoLB0WcXzjghfsBdu7cScEXbZg7dy6WLV8Biz0Fb2/pwKrlZuRlhyAzfezBOiMBWQeOi4FWr7cfh4/ZsXt/H/z9QUiM12HDGnoejtNe0j10YB9Xetxx8gSa9+9H65HDytl37tf+BREZmQHj8Hul9Zb9iQKiwORSgO9NbgomqSqvwKY33qS2tFrKcOHAPZ+/n9rh18MYEkKZjiTobnLV6siOVkDWHSMSKoi+EBc+wY3oo5N7JQFZJ3f9ydGLAqKAKCAKiAKXQwEBWYdWtf34MbRQw1PbkSMIJZet3PsegDk1FXqKCJQiCogCooAoMDUUYCCttroW77yxiRwjPQpgzcnLpTRGE6MT62qqLCDr1VT/6u+bOxY9bi8BqQ709dgUtMrjboJqGGC1k/sqO8ax25xWpyUIXHN6IJc4doozGHQwmdmxdGDQq2meZwjRgTtox+JUd/WVATkGuQg+tCuYtaWpRY0ZiGdXCW6Y12i0yJiWQUMmpmdNgzk8jMDdsXcIT4RzlmO4NAU8Hj9clKq1ts6OujobwQMu+v7003chCNHRBsTHhxDAqlfTDLVqNJcHkry0swisT3spRbuFnC0/cDWggVK1JwQbka+Nwnx9DGGsxCOo/8dXk87OTgWf9vT04KGHHsJLL72E0YCs//zP/4xt5AS2ceNG/PnPfz7n4Poo5e0PfvADBbA+/fTTCLuEd1oBWc+Rlpxu+X7px8nCPhw61IXQUA2Sksi9d0k0BTnoSfNz1x/pXwwuuZweVJQ24tjhSgoSsdL9VYPV62cjMytJ3WOHuo9y55ej34s2vxPFBLM2+Kxo8zkwXxeLmQSzJhHMGkpOrVJEAVFAFAgkBfg53UfP8fUf70DbsQLYKDAtZtYsTP/czco1c6KYFxyhduhbb70VsQTZFhYWkpu//5xqYoj1v/7rv8Dv6+cvCw8Px3vvvaeeH87+EGfEeOyxx7B58+azZ6vp++67D0/+4FcEE3kQE62D2TT2gKrRgKzM2vI7Zzu5wjY0EdhU40Jvnw8m2n/2tBDMnklppelWpdON/XguONnLPMNJz3J9dbUof/MNOLu6MO2mmxAzew4ipk2/zHuWzYsCooAoMLEV4HY0C72THtp/ACVFxeim38gECsLIo0CSrBnZSElLlcxGE7sKL+noBGQVkHXYC0hA1mHlkYWigCggCogCokBAKiAg69DV7rL0wUJuNSf/9/fw2G2YfjM1InLjU1bWJTnYDL1HWSIKiAKigChwJRXgjqyy0lM4eewE9u3eRyBRPL7w6COIo7FOLxHgArJeyavx6uyLOw75e+DxeFXaYh57PT762we3ywOnw43ebht6e6zkCkcQKzmt9nSdnna7Pep5KDo2XDmvxpHLalxiJE1HIjo2DJFRZuUKOFaA5+ooMvq9ekmz3s/Soh0vOI7yU+VopU7xtIw0ZE6fhpy8HEqRFo/omGhy3QxVQKtGq5FnydFLPek+wd8v5g6cTh96etzUUeNBZZUNtbU22O0+ghMMmD07HBkZoQS9GccMu006YSbJAff63Wjy27DVWUdAoA83GdIwTRtOzpaGy3IGDPfffffd2L17N77xjW8olzQGTjIzM7Fv375BndXOPhD+/MyZM9FFHYIvvPACbrzxRtUR2E0BOxEREWpVL6W9HY8iIOvgKjY2OlBRaUURAa1cNm5MQEoKBXOEXhowaqHgkbbWHny09QhqKlux7JqZyJ9LwRLkzKojwmcomJWPwQ0/evwuHCZH4e2uRmRqw5CtCVdQdjy5tIYQzDpGzpY3L0UUEAVEgUmlgNtqgaO9HadeexXdZWWImzsPCUuWImXFyqvumMlwKt/Ly+i42Jm9srJySJD1jTfewBNPPKG0X7p0KW6++WYVaMcBMHV1dciidmt2eDcYTj+zMMTKDq/PPvus+sz111+PpUuXk6NrMTZt2kSuqF48+uij+M///AktPxeaHW0FjwZkHdg2A63szHqiyI5TFU7UNbqRkqTD4vmUajpWi4hwDoDEsPe7gW1d7bF6t7ZZUfrXv6KzqBChBGkl0jXGWd6C6CR4kCIKiAKiQCAp4PNxG6MH7a1tqKutwc6PP6VMTk3KQGIR3cOuWbsWwZStie+DUqauAgKyCsg67NUtIOuw8shCUUAUEAVEAVEgIBUQkHXoavdTQ56LOv7qdnyEDoqAd3R1IvO66zH91tvo5Upz1Rs5hz5yWSIKiAKigChwMQXYuYQ7Gf7+5jvY/ekugs7SMWvOLCxftYIcrkzSgEYCCsh6sato8i9nx1Unub11tPWiq6MPne00fDZmaJVBVnZXZRfVsHAjIiLN5C5qRHhEqJpnMhuhN1DaR3Jf1dN6Z8Y0rSWHVu40neqFf0cYZrU77LD09qGrs4sa6NtRXVWNxvoGtLa0EtwbTw4TWZg1dzamEdzKTknsYitlaivALqy9veSmWGEjGMGKmmobAd46Sv0agvQ0EwVN6Akw1BHgrCHAmd4tpEwoBTgl+zGC/zrI0TKK4NUN+hTEEfinDxr/uuLfSgY/2Cl1zpw5ylX13XffVc5pIwVZW1tbsWDBAqXh+++/j+eee05Bse0E7BiNRpVq+P/8n/9D8PTsC9zbRiu8gKyDK+Zw+NDX58WOHa1obnYiLy8MOTlhBBSZLwlU93p9ypm18Fg1Sk7W0b2lgzp+43H9rYsREWWi3w/94AdEc9mZ1UNQUiu5sdb5rXRNd6KdphfoYpCvi8K04DBog6TTeEgBZYEoIApMKQVOp33fh87iYmgMemTfeReicvIQEhV1Vc+T4Z0vfOELCmKtJUOFgTKUI+vChQvR0tKiXFv5fj/wzsVudxs2bEBVVZWCYX/2s5+pTXGQC3+G0zl/6UtfQtqMfyWn0yBkputQUfIqfvSjH6n1CgoK6Dk1cWD3YxqPBWTlHXEAmMVK96t2D0rKHGht86KH3FlXLjErZ1ZTaDAFb0yOd0sf6dxVXITmgwdR/8kOJC5egjmPfgUaytCh+QwuHpO48iFRQBQQBSahAnabDe1t7di7axd279xFmWgSMI0CLuYvWoiU1BRERUersxq4l03CU5RDHoECArIKyDrsZSIg67DyyEJRQBQQBUQBUSAgFRCQdfhq9zqd6K2qpManA6h5/z3V+DTtppthTkmB4TNnm+G3IEtFAVFAFBAFJqICnGK3rbkV7299DyePn8SNt9yE+YsXqEY0nU7cWLnOBGSdiFfu6I+JXVbdLgJWCUp12F1nxna7myDW0/NclEbSRdP8N4Otbh7IcZXJG5PJQKCMGZHRNBAwExUdpv42h5HLnClkUjjjjF61sX/CSc+O1j4LKsoqUFleierKKgKJ+gnyNShXpbj4OMQT2BqXEKfcn0OMBMbph4aQxn4k8smroQA7SjHMxgBrW5sT7e0uNdis9B10+ZGRbkJ6hhFpaaEKYmXTEemwuRo1NfQ+vQT9sQPrblczDnnakakhGFEbgTkE/pkuUyr2oqIi3ESpZ7VaLbZv345p06Zhy5YtowJZS0pKFLzCZ5aenq4c2XiatzngxMrXGru1bty4kReNuQjIOrR0DLAfPtSD8nJy/SM35qwsE1asiCFXvGCqi0sDRlubu1FZ1oT9O0uUa9HMOenImZmC9GnxKgBruN8SJ13TDviwz92KU94e6AheTQ0y0XUdjXiNEWFB8uw7dK3KElFAFJjsCnDbrpsyKDTs/BS1H30AU2ISosnFPP3aDTBSNpbhfj+vxLlzYFwKtTOfXwYDWRl0XbFihVr1wIED9EyZds7HXn75ZXznO99R7x3FBOxarW588MEWfPWrXyUQVIe/bzmGw8d9mJ5pwPQMPTLSDMintM49PT146qmn8LWvfe2c7Y32j7GCrAP7sdn9qGtwoaLahZJTDqQk65GeolfHGx2lRQjdT+lxZkKXfgqadpGebceOouSvf6HrLRHpGzYiOi8P5uQL63lCn4wcnCggCogCY1SA30H7+N5bV4+ik4Woq6mhtpF2LCCAdfbcucjOmUEB8uYxbl0+NtkUEJBVQNZhr1kBWYeVRxaKAqKAKCAKiAIBqYCArMNXOzcm9lP6i9aCwyh64XnoTSZEzshF2rprKWo/Z/gPy1JRQBQQBUSBCatAZXkFDuzZr0AzBs/uf/gB5ZbIbihXuyNroogmIOtEqYmxHwc/x9itTvR0W9FCAExrUw+Nu2jM013UsUmdui4PYuPCCayMREJSFOISIxFPQ1xCBIGrZhhCdCrNJX8vOH1xEA3BNK1SI07wTsSxKzf2T6pnR9LdRw56/Ntit9tQWlSK40eP4+SxE1QX3coBesHihVi2YhlpnkBOt5Fj36F8csIowHXPpaHBgfIycj481oPmFieSkgzIzQ3D3HmRlBpVp9KMazT0HZLvz4Spu7MPxNpPEDK5sG53NqDA24n7QqZjsT4OodBAcxmcK9kdbd26daihjr2f//znypGNj2e0IOu+fftw9913nzmVb33rWwpGYTdWBmUfe+wxBbdGk+MNgy8meq89v7CT65EjR86ffcHfDNtUV1fj/vvvx0wCgaT8QwH+GejqcpOrnpWcdSllJsHrN9+cRL/zOphCL83N1+/zo7vLiiP7y+i+Uo+66jZc97mFWHfDPOWKPlw6Tv514qCKLr8L1b4+bHPW019QgPZccmadoYn4x0nIlCggCogCU0wBR0cHubAWEcT6IRp378Lcxx5HBmXcYoOC4AkSxNpBx8hZY7i88cYbyqV9MJB1x44dePjhh1UAQ3NzMzhl89llz549uPfee9Wsg+QIqjck4q8v/V/84he/wJo1a3DvQ89iZk6IAlhDDEH0nheERx99FOwEz4Euf/7zn8/e3KinLxVk9dONlGVoanajstqNoyetyql1w5pw5GSHIDZaOykCKRlm7a2uQtXWLbA2NcJPabVz7rkPyStWjlpT+YAoIAqIApNRAYfDQe8sxTiwdx8+ev8D5FHQxPqNGzCDoP6kpERoKOBS2t8nY82O7ZgFZBWQddgrR0DWYeWRhaKAKCAKiAKiQEAqICDryKrd0lCPFmoAbDt+DJb6OuTedz+Sl62ALiwMwfTSJUUUEAVEAVFgcijAHT1OhxOH9h/EptffRmp6KmbOysfCpYuQlJw0OU7iCh2lgKxXSOhL3A1f0y5yULVanLD02ckN1EFjBzkf2NSYnVbdbu8Zt7YBGJUhOp1WQ6CqnpxVDTCHkyNbWCjMYUZyRTDARGOGWLW0jjQuj62SuDOaXSg6KI1aU2MTpYNupJRqbbBYrPBSZyZTRPEEsvJvT8a0DHJqZaiVOtTZplPKpFGAwTV2YGX31bo6Ozo7XVTHPvp+gb5LOuqkCaE0racHPbsyEjAgZWIqwGBfjdeCfZ5W9PS7EUQzrjUkI0sTrtKvj3fNaTQafPOb38Rrr72G6667Di+99BIGgOjNmzefcWTdv3+/mj+wbDD1zgZZGTD99a9/fc5q7PTKaYu5vP7661i1atU5y/kP3k9paekF88+fwXAsO8AKyHq+MvSzTteM2+1HY6MDu3a103Q/YmL0mE8g+7TpoZd8P2Xn9JbGLpQU1uHQnlIkpcYgOzeFgrEyVCDKxe7XLnJm7aZru9DThVqfBe0EbefoIpFHIGuaxizOrBdWqcwRBUSBSawAw4QemxWdJcWoovtqPz2Xh8TGIn39BsTkz1IQKwfnTbTyt7/9DRyQMhjIWlBQgFtuuUUd8scff0zBUrnnHP5bb72Fb3zjG2reli3voq0rE5vffhJvv/02Hn/8cdz7wP+LpEQ9ws0UoPNZfMXPfvYzPPPMM1iwYAG2bt16zvZG+8elgqwD+2Nn1u4eL4rJlbW+0U2zg5CcqMXcWaGIjNBScMjEq7eBYx8Ysytr16lSNO3dg/pPqa7uvR9p166HMToGmpCQgdVkLAqIAqLAlFOgrqaWshSVUQa0E9RW0guzyYz8ObMwe948REVFihPrlKvxi5+QgKyTFGTlBmqOuuaIp4qKChV1NX36dNx4443IIaev8yOqLn4pDL6GgKyD6yJzRQFRQBQQBUSBQFZAQNaR1b7P5YLHakXp315B2ZtvYMaddyFtzVpEZGVBRy9iUkQBUUAUEAUmhwLskNjS1Izdn+zCG6+8jtvuvh233nkbwgkeMxgMk+MkrtBRCsh6hYQewW78fnam8ZPLJw0Erqq/ff0ESfoIkjkNsXa296G70wIed3bQQOOO9l7002cZSI2LJ5fVxAhyW41SjqvsuhpDTqwREeTKR3TWxeCXERymrHIRBdh5saO9A0UnCnH08FEcLziKsPBw5co6Z94clVotJTUFIQSJ6Q16lRKcQTcpE08BhtX4e8hpxB0OH5qaHKiqtqO4qI++p/3UMaPBwgVRyMk1U0eNntwSJ35n+8RT+coeEUOsnH79uKcDm1y1yAw2YyE5sWZpwxETdHmeD+x2O7Kzs9WJMjwST+mNBwq7rJ04cQIMjbKDGheGUyOHcHCur6/HsmXL1HovvviiAmPVH5/952EnMOpncNF77dNPP40vf/nLZy8e1fTRo0fxzjvvCMg6jGq9fR6cOmVBGQ08vv76BCxZHE2/7cHj4iRXWdaEPR8Xoq2lh+BZPzbctAi5s9LoetEjWDP8742Poihs/V661jvxvqsB4UE6ZGjNWKSLQ2pwKPRBGlB+gmHOThaJAqKAKDDxFeDgDz89e/fW1qJ53x6UvfEaEhYtQe79n6f07snKjXWinsVwIKuV2qYZXuXz++53v4t//dd/VdN8LloyWrjrrruwe/dudWov/uVlNHXMwV//9CBOnjyJ733ve/jqV79Jz6Xn/sY/99xz+PGPf4zU1FQcPnxYvXeerQ2/h5aXl589a8jpDz/8UH3+iSeeGHKd0SxoamFnVhf2HLTCQMe9ZIGZ3GT1SIzngMuJneGAQWofXYOVm/+OE79/FunXbkDyqtWImzMXIeSQL0UUEAVEgamkAN+XuM2LnVgPHziIIzTUVNcgkQK377j7LqRnZiBKfvumUpWP6lwEZJ2EICs3SP/mN78BRzxxg9LZhZdx5NSTTz45LjCrgKxnqyvTooAoIAqIAqKAKMAKCMg6suuAG584DVDTvr0URf0JQa0WhKWmUVqge2FKSlbpdUe2JVlLFBAFRAFR4GoqwM6I2z/YjtqqGkr5bce6667F8tXksE0pBQUYO7dmBGQ9V4+r+ZfD7oLV6kQPpRTuIki1u9OqoNXuLgs5r9qpPcmHkM+cVRliYVfVkFByVTWHwBhKjquhITAYdQRr00BQK68bQuvp9VpodeK4eqXqljuBGSLr66U67OpSUGszObU2NzajrbVNwcSR5E6Rm5+HnLxc5dQaFh52pQ5P9jMKBdhx0W73oarKiopycvqiVOKU9RvxcdSxnmgkpysDIglgNZu19L0bH3BtFIcnq45BAYffiyq/BcXebhwjwG+xLhZryY3VBKpDAvsuR7HZbJgxY8aIN33kyBFy+B3cPZ6DHNLS0tS22OF19erVF2yXwReLxaL6IR555JELlo90hoCsF1eKfyMsFg+OH+vBx5+0Y86cCOTnhyMz06R+Fy6+heHXsFocCmI9SK6spUX1yJ6RpEDWWfMzyWV9eJc3hra98KOD3FhrfVYUkTtrg8+GPF0U8rQRyNVEIuQyXfPDn5UsFQVEAVFg/BTwk/uqmxwxy956Ez3lp6AxhCBp+XKkrFkHLblhavT68dvZOG9pOJCVd/Wd73wHL7/8Mr3ThSiYlQNZ2Cn9lVdeUSDqwOG8+urb0IXOwVf+aSm66N3jpz/9KR555J8ooGJgjdPj559/Hv/+7/+OuLg4BbzyO8vZhdmFn/zkJ2fPGnI6KipKvdOMF8jqcJAza68PFVV0z6p3oanFg9kzjZibbyTHcx1CjeedzJBHduUXMNTF/QmdJ0+ovgRrYwO0oSbkPfAgouj5L0gCFq98pcgeRQFR4LIowL93nI2osrwCB/ftRy0ZOFr7LJi7YB61b81EFgVvmsxmaoOcuPfeyyKMbPSMAgKyTkKQddeuXSp6mWsxmaLA7rzzTtWZxumDOjo6VOU+++yzuP32289U9FgnBGQdq3LyOVFAFBAFRAFRYOoqICDr6Oq2r64WXdQ4WPPBexRVTa42996HmLyZCD3LPWd0W5S1RQFRQBQQBa6UAlZK511TVY23XntT7XLh4oWUinU2pmVNv1KHMKn2IyDrlasudnb0EozK7qpOpwcuh5vGbrhdNE1/2wlktdtcsBHM6uCx7fTYbnfSOl5otBpERJnI3YDcH6PDEBMbjujYMETS3wyzMrQqZWIpwB3EPNQQVF9Fjf0lRSXkpNtJULKXHHPjFcSaRM4VPM2uFWFhYVSX5J4r5aopcNqBtZ9S43kIBiB33Q4XmpsJJmt1kQNikHJezc0NIzcrI4EAl8fB86qd/BTfMTtUdvtd2OVuQRMBfexQvYTcKRfTcK5n2fgKwb8BDIUOVvbt26eAE3Zg/ctf/qKOiV1bh3LP5oxvS5YsATuzfvOb31TGGNyhOFD279+vXNr4702bNmHp0qUDi0Y9FpB1hJKR/CWlfdizp5PqDQpuX7okimBko0rnPFRdjmTrCo6h+j28rwzHDldQR7FTua2vWJtPLt9RKqDlYtvxkJOrO8iPQ+525c7K6ycEGzFfF4NEDaVuDpJnh4tpKMtFAVFg4ipga2pCT2UFuWG+Ay9lZUlbtx6x5ITJAOFELxcDWfv6+vD5z39+0GcIfhY4dOiQOsVt735KYQspeOLr11PwVRWeeuopfO1rX7vg9H/1q1/hl7/8JfLy8rBjx4WgBT+vFBQUXPC5wWbw8wvfo8YLZOV9uD30nNbtRWmFEwePWBEdpUVqsh65M4yIj9XCGEI+4pfzgW2wEx3FPEd7O3prqlH5ziZYCGbNI1fg+PkLYKS+hKDzqeJRbFdWFQVEAVFgIijgI4DVarWhob4OxSeLcJSCLznjWXxiItZcu5ba3LNU4AW/r0oJXAUEZL3w+WqwqyGILI3/0Yoz2BpXcN5XvvIVbN26laJxM5Uj2sCumVrnB87W1lasW7dORVcNLBvrWEDWsSonnxMFRAFRQBQQBaauAgKyjq5uOSWQiyL6i//yZ3SXlSGKXG2SllFEP6UGkiIKiAKigCgwcRXgzpSqiiqcPHYC29//CGmZ6Xjk0S8SVECuU+RkIuVCBQRkvVCTyzGH4TjuHOzttim31bbWXrQ2d6Od0gW3t9KY/vZ6/QS9BCM6LhyxNMQQpBpFsKoCVmMYcAyBjt1VCWjVaE+7P3JqSZ5mUCY4eAL37F0OUSfJNvl3iR2OXE4XgctOqvcWVJRVoIga/9nJwkBuFanpaVi0bDFyZ+YiY1qmqs9LgZ8miTQT8jDZYbGvz4vCwl6UlVlQXWVDfIKBUsOHkcOIiVxYCRoP0ZDDdxB9F6WTZkJW4hAHZac0641+G153VNEaQdhoSEGmJgxxwVfv+YBT837xi19UfQYDUMjA4f/pT39CRUUFsqhT8NFHHx2YrZzYvv3tb6uOQ3ZlXbFihcryxvcY3tZHH32ktrdz506VfvjMB0c5ISDryAVj8L2lxYmdOzvQ3OTAzbeQcyoB7ybTpbuh8z3E2udAU0Mn3nvnIHroOWLeoumYNW8aZsxMuehBcgcZb6O3340muv53uJvRRS6t6cFmLNDHYp425rKC3Bc9QFlBFBAFRIFLUKBux3bUf7wDboI+wzMyVEat0IREcmad+MFGFwNZWRa+t//1r3/FgQMHUF1djfT0dCxatBhz5s7HnXfcqt4ZCo6WUDCcGQ89eLda7+tf/7pyXj1fVgZc//jHPyo3d35+uJTy29/+Vj17jCfISrcq2mY/ughmrWt04egJB+oaXFi9PAz5uUYkxuvU8/elHPfl/Cy7A/tcTpS89BJajhxCdG4eEqiuuC8hmDIDSREFRAFRYDIrYLNaUVdTi82b3qH3kgbKAhWC1WvXYPmqlcqFldvcBWKdzDU8PscuIOskA1m54ZnT/FRWVqropO9973vnXAlPPvkkXnjhBRUF9fHHH6uGhXNWGOUfArKOUjBZXRQQBUQBUUAUCAAFBGQdfSVzJH/T3j1oKziiovvjFyzCjLvuhs5EiSeNxtFvUD4hCogCooAocFkV4E4eTrn7wbb3caLgOLleBGHWnNnYeNNG1cAmUNjg8gvIOrguY5nbT7Cqi9xVHeSsaiVXVTsNFkoLrFxWacxOq+zE6SNglaGSAbiVr13+rN6gI1dVA8LCjQiLCD09punwCBOlEDYQPKdX17Vcy2OpnYnxGa53C6Vea21pRX1tHerr6tHd1Q03Qa5anRbhkRGUPjMGKWmpyq01Lj5Wfr+uQNVxx7nV6lXuq00EoTGQZrf7VGc6A6uJBK+mpZuQEG9AeLhuQrtBXQG5Ju0uyn29KPH0oJTGsUEG3GhIQxS5URqDtVftnIYDWe+77z7s3r0bq1atwuuvv37mGPl3ZMOGDSgtLVWdhStXriSn4CgcO3ZMObVyByJDL2vXrj3zmbFMCMg6ctUYgHc6/QpkLS/rI9AoFDNmhGFmfvi4QDc+n1/BrEf2l6GyjNwHu63Im52OJStz6RkhlJ4RLg5jszOrDV6c8HSiymtBu9+BNK0ZeZpIpNM4mr4TUkQBUUAUmCwKuAhctbc0o/ajD9F88AASCRhKmnP+AABAAElEQVSMX7CQhgXUbmueFKcxHMjK73u6z+BHNsSy2ek5tdOLUxUONLd40O/aBmYNZs+ejbc3vYdQYzC+8Y2v4+2331bPDW+88cY5rAE/G9x1113KaOvLX/4ynn766UvS6HKArAMH5HTRPc/qQ2GpA+WVLgr0DEJCnBZz8o2IjdYhNHQCB5LRM1oj9SW0HDqIXmJCosn9Nufe+2GIiJgUcPVAHchYFBAFRIEBBTgYmyHW4wVHcaq4lMwZW6hNJBw5M/Mwc1Y+MqdPV++k0k45oFhgjwVknWQgK1+u99xzj3pAvOGGG1SaIDc5MXCoq1ajxeJFi9BA5Dpb/T/5gx9c4tXdj//80Y8xI2cGHnzwIQ63VRFZl7hR+bgoIAqIAqKAKCAKTHIFBGQdfQX2E1TisVjQdGA/jv32/yIyOxv5D30BYWnpMMbFjX6D8glRQBQQBUSBy6qAy+UigNCOP/zP/1Kao2Lcdtdt5Fg1H+mZGdT5obms+57MGxeQdXS1xwARQ6d+HhP8xs8LPE0Zq8lR1Ye+HhuBiVblsNrWctppld1WO9p60dNlUaBqVIxZpQSOp7TAnBo4MZmGpGiYCVpl11UpgaMAdwqwi/SJo8dxYO9+dHZ0wkuw8+JlSzCffr/y8vPIUTpKdWQHk1uv/JaN77XBX112fvJ4/GhuduLUqT4UFfWiqcmFzIxQMh0Iw4KFUdRRoyX3S7mPjK/6V25rVM3qd/ojVwOOejsRQ8Beri4SS3XxCAm6uvXKqX0ffvhh5brK0CrfYwbKAw88QGDkTgWkvvLKKwOz1dhOzzvf//73zwFceUFCQgKee+45LFu27Jz1x/KHgKyjV+3kyV4CjC2oq7MrmPWmm5IUcDMejul+hlkpKOb4kSq89coupGXEYfk1+cjKSUZcYqQC7C/WgUxhM3D3+1Di7cE2Zz2lou5XjsSrDeQgqyXIhjqsyON99CcunxAFRAFR4AoqwO9ffZTCnQHWFhqszc2Y9/jXkLxiJTSU6WCyRBwNB7L2UJaw+fPnK1XZACvUnIqKahd27OzDLTdE4/954iZ6bj11jnnW5s2b8fjjj0NPGuzfv58CsRLP1EpnZyfmzp2rnjN4v9dcc82ZZWOZuJwg68DxdHZ5UVPvwvZPe+k5LgirlpoxPTMESQlaxT0Q6zshC2d46zh5Asf+5zcwxsZh7mOPIyw1DQZ6p5MiCogCosBkUYDfSznovrO9A43EsW1+axNKS0qwcMliLF2xXDmx8v1GiihwtgICsk5CkHXLli147LHHVD2uW7cOt912G7l0uFRjU0FBgXro2rxtKyJnTT+7rkc9HUQNDX9++v9Dxows3Pfg56Gnpgdd0ASOThr1GcoHRAFRQBQQBUQBUWAsCgjIOnrV1Mua241eSt1U/e5WONrbVGNo1q23I3EpdQxSi9nFOopGv1f5hCggCogCosBYFaipqkbh8ZM4eewEvW+7cfs9/z977wEe11mm/d/SdM2Meu+9WpYl926nJ8SkJxBCFhaWwMcFu/yv3Q0sV1jIB7mWZZe9luXbkIUlIbQE0psNSRzHibtsy0W9Wr2X6V3/530VGduxZJWRNCM9rz06Z86c+nvPnDnnfe/nfu5ELgV5GijNHl+vp6bKQtap2Vz5iRCqushx1TRmwxil9h0j0ap4ifejJF4VjqtemkecbxqdijoRyWGVXFQ1WhoXbqs01IWRs6qOHABpODEuXGUmpqnUSkoDvbSiqiuPmd8vLAHhIm2hwKnhoWEM9A9Ip9b+3n6IzmYniVyVShW5s6YgryAPGVmZlOI+XopZ+Zrmn3oZGnKR+yq5PTVaMDzsJkdFLzlbqhAbqyb3VXJ9omF0jJqExEJEHKC95f5BsazXYhknFzNKpf6eqxvNnjHsUiejSBmJhFAdlEHebj48PIxz586Rcxk5dJLrV2Zmpt8E7yxknf3XYmTEjQsXrOSkO0j3AKFYvz4KaWlhdC2Zv9upaJ9wuzzo7aY6P92K9lb6rRg0YdeNa1BSliGDYVTk7D1doRAcEq8CIz4n2rxm1JOgtcljQpbCiDwSsq5SU1ANSCDEYtbpMPJnTIAJLCEBkb7dNTZGItajqP/D81IgGLe6jNppN8BAYsHQIApgnU7IKoLX8vLyYCLn2S9+8Yv467/5Z7z19iC2b47CsUPP4jvf+Y4UrB47dkwGsYgqcVEbdnFxMWUVsMkgmOeee0665AlH14cffhjvvvsuUlJScOTIEXrGmP734lpVvBhCVuHMajJR8EWDA+2dTghha0GeFhVlekQYFfRsHZjaBy9pP0zt7Wh65SU4hgahjY5B2q7dE30J1wLLnzMBJsAEAoSAzWpFd1e3dGI9eugwoqKjKWtQMlaVlSI9IwNx1DYl3L65MIFLCbCQNQiFrKICRQqgv/3bv720Li+Oi46j1Puvh5MiYq9WvOTGYOsbutpHl00TjQznfv0aYnMzsPGB22VUuTZEKQWtIsI87KNxNY1z8+tl6PgNE2ACTIAJMIFlTYCFrHOvXsfICIZra9B16AN0HHgPxQ89jPTrboAmMpLTAs0dKy/JBJgAE/AbAREh7qasJyeOnsC+19+iFKvh5FKVhl03XCdTc/ttQ8t0RSxk/UvF+shpVQhRXSQUEaJVIRgR42LocXtJ5OYi11+ndEQzm+yXD0nM6nS4SfCmgN6oRVSMETFxEYiNCychnFG+F06sGhK2KshZkwsTuBoB4cja3dmNs1Vn0NzYhMGBIUSIa1pmOjKzMpGSmkLXuAhERIaTAFoPBQmfWdR6NZJXnybMLoX7qt1O7slmEoSRC2tnp43SsdukM2tUpAaFRQYSDhhgNAoxOn9Xr04yeKYKf9NOjwXnPSNo8lEaYp8bd2gzkSvdJ0XCNG4hn6o2Wcg6FZmpp4v7CCGQ37+/HyMjLkRGqlBaGoGCgnDq6AW95n++ifuQkSEzjhysxZH3q1G2LgfFqzOQU5AMY3jYjO4xhBOrmyStp12DOO4ZgIvupaNDNVivikOqQo9IGp//nk7NiT9hAkyACcyJAN3IOSkAbKj6PHope5Zoo8269TZk7/kktOR2qdSFzWm1S7XQdEJWuizjySf/H37wgx/I3du5cyfKy8tRVVWFAwcOyGmPPvroxzQHwpVVZH8VbSQR9MwglqklB72+vj7KLqDBW2+9haKionkf8mIIWcVOejz0uzriRX2jHYdPWBAbrURBrpacWTWIj1PRbx79tlIQaaAV4craW3kC/adOov/0aeTecSeybvsEnaM6hKpUgba7vD9MgAkwgYsERPCcCKLoIRFr9bnzaKitQyM5gO/YvQvrN22SWc+M4caL8/MIE7iUAAtZg1DI2tbWJiOempqaZF2KG0hxI2mmm25RjEYjfv7zn+NIRbh8f+UfX98onL8+cOXkKd/7suNhubNcNsZpSLSapAhDWqgeGRRdm0zjcaFa+Vng3d5NeUj8ARNgAkyACTABJjAPAixknTu8cYpcd1M0+4W3/4y6536HuLI1SKioQOL6jdDFxc19xbwkE2ACTIAJ+IWAyHYyMjyCd/a9jT/85jnc/cA92HHdTili1YUFV2eWX4DMciUsZJ0AJsQnQqxqtdjJHZMcMsnlbGjAREMxTh2m9F44rgoxa0SkXopFwiPDEBltJGEhDWmaGOr0GuokVJGgldxVSdQqhgplqHRaVaknRIcsPJzlSbqCZvdQILu4ptnp3nOYrmu93T1obW5BPXUemE0WOqeUWL2mDCWlJShaVQwddYaKaVxmRsDlEm2xHunAeu78GDkpO6UQODtHT2nA9eRSpZUCVo1GfGcpwTY3nM4MbIDOJUSsPuqIq3QP4DXnBdk2XkBOrKtU0YiVbeMBuuMBslssZJ1bRdhsHrS321FTY8KJE0PYtj0Wu3Ym0L1BiLyuzG2tf1nK5/XJYJvmhh7UnmtHY10nie6VuO2ujUjNiIPeoP3LzFOMCWdWUcbG3ej32nHI1YtOn5X6jHRYTd+PTap47juagh1PZgJMYOkI+Ch41dzRjupnfwX74CAis7ORvHkr4qmNVogDQ4LMGe6FF17A17/+dXLtjsX58+elZmCSrsNB96xWD/7nZz/CU089Rdd9z+RHUpAqTLO+8Y1vQAiOrizCifWxxx6Dldz0Jktqaioef/xx3HLLLZOT5jVcLCGrODw3iVkHhzxoarWjodmJrm43dm83orQoDEaDuGcPvBt2ca46yTm44739OPfLn0tH1swbbkJETq40xpgXfF6YCTABJrCABDx0/Tp96jROV55EFb0Sk5OwadtWZOfQby65emu0Wr9lAFnAw+BVLxEBFrIGmZBVWPSvW7eOGjDaZSqAf/7ud5GzuQKdXgvGjtfi3/7vE6irq0McCSH2Hf0Ax0OGP3Zqua3UkXK28WPTr5wgbll73j+FsJwURN2zHR6KrKXALSjoA03ohDOrIUSFiFA1YiiyNiaEXEJoXA1KkRXkqZSuZMHvmQATYAJMgAkwgb8QYCHrX1jMdWzgTBXa978La28PVOSAlXf3PdQAlSMj/lmQMleqvBwTYAJMYP4EBikd96nKU6g+S5HidQ2451P3Ysv2Ldy4NkO0K0XIKt1WSfwhXFNtVod0VnXYJxxWbeRu5qDpDpuLRIQucmX1kROrWwpbpTMrCVx9NE3Yk4nffCMJVo3hOoR/JF4Nj5gQsQrxiFbHjqszPPV4tmsQEOlBx0ZG0X6hndxZm9FDolbhjKGljoPw8HBERkUiMSlRdiwkJCbAYDTIDgW+L70crHC0crm8GBx0YWDAiZ4eO0ZHSQhBglaRkjQ6Wo3sbAOlZaV20hhyIQy8vvDLD4jfzZiAw+dBn8+OKs8QDji7sU2ThA3kOClErDrKWsZlegIsZJ2ez1SfCvc4K4lZq8+b8N57/cjM1JP7nRFZWQZERfnPhW1k2IK+rmEcPliDATJByclPRkFxKorInVWk+ZyJ+6twZnVQhsCz7iE0ek3oJVFrPH0/ilVRSFcYEEd9R4HodDcVe57OBJjA8iYw0tCAwfPnpDhQTffCwo01koSB+qSkZXPgQrhpt/vQ0+9GXYMD/YNuJMZZEOJro8DKbrpfTUBFRTndv0ZPe8xer5cCKmogTLZKS0vptyhz2vln++FiCVkn90swGRnz4lyNDedqbUiMVyMjVY3iAh0iwhUBJ2aVAmN6COk7WYnGl1+k32TKmJuYiIybbkFUXl7Qia4n64GHTIAJLE8C4polXj3d3bjQ2obzZ89RUHU3XVtVKCwpwqatW6TLt95gWJ4A+Kj8RoCFrEEmZBUC1k1ktSzK3r17UVZWJscnI1/r6+px3XXXyWkvvfQSNm7aKMfn+ud73/0e8vLz8OCDn4GNompHfC60+yxocI+inhokRsad8I77KLo2BquUUShRRElhq3Bu5cIEmAATYAJMgAksTwIsZJ1/vbosZhnxX/XTn2C4rhZlX/4/SFi3AWHx5FYSZFH/86fBa2ACTIAJBA6Bhtp6/ObpX8tO+1x6Ft6wZSPyC/MDZwcDfE9WipDVTWJUl9NNYo8xKfjo7x1Ff+8IvWhIAhDhumoes0FNbqoxsUYkJEUhPjEScfRKoFdicjSiYsh9lcSrQiACEn+wYDDAT+5ltHuiU2GgbwCtLa0kWvqQUrxVS6fWktWrsG7jekrxtl6meBMOrRPn5zI6+HkeitPpg83mxcmTw+R2ZUJLi5UEwFqUrY5AcXEE0tJ0JACmBPMsYJ0n6cBbfNjnlG6sLR5KjThux83qVGxRJwTejgboHrGQdX4V09ZmJUfWEXLXdkkx6PU3xJNoXj+/lV6xtNvlwcljjTh3ugUNNZ1YXZGNez6zXd7LKJUz6+sRvy/ekHG0kenKW44ODI87oKTInZvo+7JWFUv7Tu7UV2yX3zIBJsAEloJA44svoOPgAbnphPIK5N93P1T65SWqEcEQQrx6ttqOtw+YkJ2hxuYNBmSkUcBVVOAE4Sy2kHXyfOvocqG+2Y6TVTb5LL7n5ggStGoQFiaezwOv2Pr6MNLYgJbXXsUQ9SWs/f/+Hslbtk44CPPDR+BVGO8RE1ihBEQWcZH14YMDB/D23j9RG2kf4qjP874HP4Xc/HzKPnX1jOIrFBcf9jQEWMgaZELWyfQAok67uro+1tEhHFtTyIrZTVbNP/nJT3DvvfdOU/3X/ui75PiaTxeVBx98EG4SrJKXCEw+N6WKcZGo1YlRGo6SuNU+7qHPyJaAGisSFWHIoCjblFA9YhQUaSuTx1x7WzwHE2ACTIAJMAEmEBwEWMg6/3rykiuWx+FA86svo//0KUoFFIUESl+VcePNUGg0898Ar4EJMAEmwARmRUC4jPR09eD8mXPY+8ZbyMjMwCfuuJ0EiAnkVBg1q3Wt5JmXg5BVuK2KlOwOO7ksmmywmO0fDR0X39us5LpKDqzCoUxB4g6FYiJ1uBB6iHYZpVoBFY1ryFE1TK8hp8aJoS6MOsbofRgNhchVo6W0ldzptJK/Mkt27DYbndsmC7rJGaOX3Fl7e3phGjPReW2X+yQ6F7Kys5CZk4XUtDSZdlSpCpwO78UEJ64JFgu5cfY5ceGCFR0dgpFI6w1ERqqpU0aDpEStdGPV6xXyurCY+8fbWngCDmr37qBU6UKYJ1R4BYoIFJGhg2j/5jIzAixknRmnqeYymTzSAfrUyRG0XbBh27ZYFBQY5HVHqfSP4EZ0OIsAnZbGbhw7VE/XuFCkZsRJQWtWbuKM71dElr8x6i9qJdF3k8+MGvcw0pUGZCvCUULfm6gQDWXzYznrVHXN05kAE1hYAvbBQZg72tG69y2MNjfJNO0J5WsRVVAgBYELu/XFW7vF6sPgkBunztowQGJWjToEudk6FOZpYTCEQqvxz2+HP45oqYSsktGwG1XnbOjtcxMXBfJztCgvDaPnewTcPb3HboNzdEy6svYeO4rkrduRSBl8Y4pLoKAsG1yYABNgAktJQAS0iUxAnWTKeOrESenGOjg4QOYQhcin39iC4iLpxKrWqJdyN3nbQUSAhaxBJmQ9evQo7r77bnmKHTp0iNLIZF12uo2NjVF6mSI57Y033qC0ABWXfT7bN5cKWa+2rJlcWgcoTUyNZxQt5NDaSY16kSAbfmqcyKHGiVRq0AsPUUEbqqSpgXNjfLVj4WlMgAkwASbABJjAzAiwkHVmnK41l3TDqjqN3soT6D5ymNIB5aPkrz4HbVQ0lOSAxYUJMAEmwAQWh4C4HjsouKDy6AmcqzqLJkq7vX7jOjzw0KekSzYLDWdeD8EgZB0XQlUSLns8Ey4BXhp6POL9Ry9yW3U6XCRcc5Cwz0bp2C3SXdVkssM0apXjNpsTwrksKjYcUdF6RMfQMMZA7qsRiCYH1mjpthoGLQlZ+fyZ+fnDcy4NASFqNY2aZMo3cQ1saWqh74MHGVkZ5JiRK10zoqIpA1NkBHRhOinWVoje3WVe3G4fGQUIESu1fQ640NZqJQGZFb29DqSn65GToycXVvruU3pvjWb581jm1T3l4QlRXp/PhnrPGP7k7KS2bj3u0mYiIoQCFEJWprh7SljTfMBC1mngzOAjIaj3esfx3nv9qKwcldefvDwDiVmNFBxDnqd+1IUKMevRD2pwoaUPfT0j2H3TGqzdmAe9ka7/qpld68T3RmTxq/aM4EN3HywkbA0LVWGLKgFZCqP8/lAsENufzKDueRYmwAT8Q2BcOMTR/a3IitX94YcYaWqQKy5++HNSCBiqWh4BhuK3QjixdvW60dLmkG6sKmUINq3TIyNdg/hYlX+A+nEtSyVkFYcgWNU3OdBAr7omO7KI0bbNRkRFKKEPUGfWtn170fXBQZm6O5KMyHL33EEGGZEIWQHPZ3487XhVTIAJ+JGAaD9yOZ3o6+1FzbnzeO/d/RQQoKDsNYm47qabULyqRLYjcfuoH6Ev4KpEPYm+kqUuLGQNMiGrxWJBSUmJdFzdunUrnn32Wej1E6noRkZG8Pd///d4/fXXpaJdNBBp5xmFcy0hq3RpHffCSk6tY+TQOjzuRKfXinZKH+OixopwaqAoU8UgI9SAZGro82ObylJ/d3j7TIAJMAEmwARWLAEWsvqv6l0mk2xErf3dbxBKtk6p23YgpnQ1InNy/LcRXhMTYAJMgAlMS0C4b5roevz7X/1WptcuW1uOsvIylK5ZzSLEacl9/MNAF7KKhjinww3hqDoybMYYCVNNozaMDJkxOmyR78U0F4lURXrwML0OBqNWuqjqDTroDRp66S6+V6uVUAn3VTEkt0rxXjitCqGHeC+EJdxQ+/HzhKcEFgHhSC06Hswm+h6MjGJoYBDdXd1obWnFQP8AfUfGkEOC1qKSIhSXliAuLo6+A2GBdRALsDfDQy5yrLXjfPUY+vtdECL4hESNFLHGx2vJjVUJo1F890MDzrFpAXCs2FUKMd5hd790lXRSNrI8cmPdqUmChgwbFJQmncvMCLCQdWacpppL9iNSX2JziwX19WY0NVsQRY7Qt9ySSK6sdN/hJ1dWsX2n043hQRPOVLbg4DtnkZEdj9yCFKxZn4uYuJmnAhVdn2YSsA76HDjhHkCr1wwjGZ4UKCOwRZ0IbQg5WHNv0VRVztOZABPwMwEvCWyc1Ife/t67qP3tb2RK9qRNmxG7qhS62FgZwOrnTS7J6mw2H4ZG3Dhx2oa6Rjsy0zTIydIiN0sDIzmOqsmZNdDKUgpZffQDa7ONo6PLiWOVFjgpiE0IWDdUGJCXrQnIZ3nThTYMVZ9H4ysvQ200ovQLfwNjWrocD7S65f1hAkxgZRAwm83o7uzC2/v2oeNCO7WbGlBSugpr1lZQ+1E8tasaqM1k5T07i/Zgq9WKP/7xj2hsbCTnbwM2b96MDRs2UDBi2IzFonNZj8gWJvrxDx48SO1Z/Vi9ejW2bNkiM7GL9r8ri6ifV155BefPn5dZ4RMTE6UmcdJg88r557JPV67jWu9ZyBpkQlZRoUK8+s1vflPWbSzdYG/cuBGDlA6hsrKSInO9cvpPfvIT3HvvvXJ8Pn+uJWS9dN1C1OogQesFapRodI+hb9wBO6VeiqQI9YRQHVLJpTUuRIuoUEqhRw193FBxKT0eZwJMgAkwASYQPARYyOq/uhKCGhtFKja/8TpMba3wuV1Iv+EmpG7fAYWaXNw4mtp/sHlNTIAJMIEpCPT39qONBFt7X3+L0mo7cOd9d1GHfR65a8ZMsQRPnorAUgtZhWOZm4TJLiFWJddUh90lBRnivYNeTie9t4shvei9mHdy3OUU4y54yJFV6Cp0Og3CI8JgpFd4hJ5eOoRHimEYNcIKUetE+j4Wqk51NvD0YCTgI7cqm9WG/r5+NNQ1SHF/x4UOOt/1MIYbEEsiVuGqEZ8Qj9j4OOnSqqZ71uXg0CqEYi6XF2azl1KxCjcRB3Eg0fuoS1ZldJQamVlhyM42kKmAgl1Yg/EEn+U+O8i8QQjx/uzqku3dIi16oSoKeaHhCPWnBeYs9ysYZ2chq39qbWzMjZ4eOw68P0j3Kz7qF4pGZqaeOog1/tkArUW0UYj7qeb6bhw/VIfhIRMJZRXYuL0I2blJiIwykOBrZkIoIWYdp39n3EOoI1fjTjI/iQxVY5UyGhmUyS9RESZdWWe2Nr8dIq+ICTCBFUZAuLHaBwbQd/IE+sgAavDcWeTedTcydl8PdUQEFBr/XUOXCq1wYqVHWXR1O6XDaC8FYTkcPqwrNyA7U4voSAVdywPzaruUQtbJ+hod85Lw14HmNjvaO11Yt0aPonwdYqOVZBgWWOIrj8im0dGB2l//Co7RUaSQ6VncmnLEFBVPHg4PmQATYAKLQsBJQSJWMmFsqKtHXW0tWpuaKbBfJR1YS0pLUVBUGJABAYsBR7QVHzt2DA8//LA0z7h0m0YKQnj11VdRWFh46eSrjs9lPWKZL33pS9L88sqV3n///fjpT38qg9knP+ul/unPfvazqK6unpx0cZhDhku/+c1vkJGRcXHaXPbp4sKzGGEhaxAKWcXJ8bvf/Q4//OEPpYL60vqOJPv473//+7jnnntmrOK+dPkrx2cjZBWNEqJxwkt/XT4vesbtaKQGiuMUcWvzeWAU6WPUCVhNDRXhFH2rpqhbLkyACTABJsAEmEDwEWAhq3/rzOOww0IRi+3v/Bnnf/U0ij7zWRTc94BsTFXO013fv3vKa2MCTIAJLE8CJ49X4vAHh8h9ahjxiQm44947pVBrJUaLz7eGl1rI6vF4pcPq0MAYerqHMUjpcQf7TRgiZ7HhAXqR86rX65OOqTGxlBI8xoBoGkbHGEm4PPE+kqaFh4dBoxXpJSecFoVgQ4iW5FCKN+j9DEUc82XKyzOBxSYgRUz0PXF73NQpYaXvzTCqTp7CuapzqK2uITF3BPILC7B+03qsWl2KiKgIEnUGvwBApBY1mdzklGHBicphum64ZCrv8vJIcq0wkhMrXRc0oVIEINpm6T+XZU5AOEm2eyx4z9UNMzy4X5uNbBLfaahNm86AZX70/j08FrL6h6cQ3JvNHnLWGUBnp42CbhQoLY1ARUWUfzZwyVocdidsFide++NhShHajtUV2Sgtz0JxWSY5Uc+uX8dJovA+nx3vu3roO0XfppBx7FInY5MqHio2PLmEOo8yASawEAS8LheGa2tw9qmfyYDF+LVrkbRx84TwT97TBf9vutPpQ2+/G2erKdjhQxNKinRYW6ZHeqoGEeHkgB1YWszLqjkQhKykdSYhsA+nzlqx/6AZ8XEqZKSqSNBKgXwxysv2d6nfiGc119gYLrz7NgbPnoWtrw+Zt9yK3DvvWupd4+0zASawwggMDw3hQmsb/vTmXlQeP47N27Zi7Yb1WFNRLt1Hhah1pZYhYiPcV0W2deFuKrR7Op0Or732GhoaGiirRjT27t2LtLS0aRHNdj2irerxxx/Hk08+Kdd70003yf0QIlXhuCrcWL/whS/gBz/4AQUv+qRT7p49e3DixAkZoL5z505s2rQJ+/fvl0Jc8ZuTn5+P995776Ioebb7NO0BTvMhC1mDUMg6WZ8uuvmuqalBc3OzPNFyc3Olclt8CfxVZiNkvXSbQtBqGXdjwEvRSz6rbKgYosa/UPrAQILWLGU4UkP1SA4Ng5IaK4L/MeHSo+dxJsAEmAATYALLmwALWf1bvz56eHBTNHXPkcNoePGP0CclI7akRKa5MqZO/yDj3z3htTEBJsAEVhYBt1ukmLfinX1v490/vYuytWuwek0ZCbNWkfOgcWXB8NPRLoSQVbiCCZdUh4NcZchh1U5OqxMvGieRhZg26b7qsE04qvooY0wI9dZJ8Sk1OIhxIToT71VqJaVUVCKMHFXD9PQK09Bw4qWjoY7eazQiTe/sRBp+QsirYQIBRcBDrsV2u12mieuiwKvuri6MjYzRd84mG7FFOrSklGSkZaQhMysTekoZ5892yYWGIa8vJGDt7raTy6GDUqhRgJnFQ+YAITAaFdS5oEZqahi5HapJ4K6ihn1uwVzoOgmE9YvOGjoFcM49jMPuPjofgDiFFttUiTLrGLuxzr6WWMg6e2ZTLeEioU1LixVNTRbUVJtQVByOrVtjyClaKcX2Uy032+k+CmgQwT9Vlc2or25HX88oEpOjsWlHEQV+RdG98sz7oERfkY36itrIkbWBjE/q3CP0ndJJV1bhdBxP2fwU3Ec02yri+ZkAE5gBAdHmOlB1Gv3kxNp3qhIRmVnIvn2PbHvVkohkORSLxYe+ATeqztswPOKh+1WgME+HglwtDPpQv/42LASvQBCyyns/Uip09bjQ2OxAWztlcqFMDRWr9chM0yAuVhlQgaweh4Myu7Wh5/hRtL71JpI3bUbOJ++AjlJ4q8npjwsTYAJMYCEJOOga1NXZiYbaOpyuPEmNriFSuLpmbQVy8nIRH59Aba8rV8Qq2H/nO9/BL37xC0RQIPi+ffsuOpqazWbs3r2b2qC68alPfQo//vGPp62q2a5neHiYghwrKNuQC5///OfxxBNPXDS/fOqpp/C9731Pbu/UqVNSYNvY2AghXhVF/B7fdddfgiJ+9atf4Vvf+pb8TBzD6tWr5fhs90kuNIc/LGQNYiHrHOp71ovMVcg6uSHRSCF8WjuokaKaGijOeobR67UhTxWJQmUESsid1UjurFoRyU4zc0PgJDkeMgEmwASYABMIXAIsZF2YuhmmSLzuwx9KlwAhbC357F8hrmwNFJSuVapvFmazvFYmwASYwIolYDKZ0NXRSZHjf8Kh9z/A57/0BWzfvYOEjDoSMQaW60awVNKVQlbZISQaBqhdQAjGxEsognxCFUT/RfS3GBXl4mc0j5gkUkCKaUJEIUSsVosDFpMdZpMNY6PWi+OmMRtNo+k0FKJWIVSNjNJLsUV0XLh0WpVDcl0V7qs6vZrSA9JvKxcmwARmRcBLQgAham1ubMaZU1Xy1dPdK4WsBUX5KCtfg4SkBPqexZBYXC2vo4F6LRXXFuHAard7YbF6KA2eSYrCujod5DirRDEJwwoLw6mzQScdKoQQnsvKISCyjdkpu9hBco983XkB29RJqFDFIp1MGfRk0MBl9gRYyDp7ZlMtIa5fLtc4GZyMkaNPN7n46LF+fRQNwxAV5f/z02K240JzH14lZ1ZxX7duUz7yilKQnpUgXXtmc30U93fNXhM+dPWih/qIPBR4dL0mBUUqEsZSHxF7HU9V6zydCTCBuRDwUeCqmwJXG178AwbOnIHaYEQSCf6EkFUEOgZ7mXhWBjq7KaNAix0nTlsRQYFYO7aEIyVJhZjo4GjTCAQh6+S5IJ4PRMDIvv1jqG9ykqOtigTBOpQU6KQgOFBOG9nO4qXMuMeO4uyT/w/G9HQkb96KuDVrYCBTDOHIx4UJMAEmsBAEhIh1aHCQBKyncPZ0FapOncTO66/HdTfdgFRyFzWymF62IQk31tbWVnzta1+7KAadrI+nn34a3/72tyWrurq6Ka/ZIlPcbNcjHF+//OUvUwYNFcS6Lw00F78NRUVFGB0dxWOPPYavfOUreOONN/ClL31J7nMbBUhc2oY3Ru7fYn5RnnnmGQh317ns0+Rxz3bIQlYWsk57zsxXyCpWLhoobOMemMZd6KUUMl0eK9pJ2OqglEy6EGocpqhb8ZoUtE67Q/whE2ACTIAJMAEmsOQEWMi6MFXgJEGVfWAATS+/SC4BJ5F1621IWLcBkdnZUCyDdK0LQ43XygSYABOYO4Gmhibpxjo6MgIFuW/efNstKF5VIse54X9uXK8Usno8XrjJTdUp3VTdcuh00tDuluJUF407HPQil1U5/aP5hHDV6fRcnF/sjYrqSKNVyZcQqwrXVPleo4ZaTBfvP5qm05FYlZxVhfOqmEdNTgBiqFIpqVGOnFoVwd9xObca4qWYwNwJiA5TIWa1kiBgZHgEgwODGOgbIJfWbvT19tF4PwnIE5FGHaklpSVIJZfWyMgIuqYGVie6OA6r1SvdV4WjoXipVeQgYlQhKUlL7iEaxMZSGtYINTX60/UilDuC537WBOeSY+Qc2eQexXnPCGq9o7hFk4a1JGQlz0iZWSw4j2pp95qFrP7jL65hIgWycJI+fXoUg4MuEt14yUknDvkFRjIKEXGw/rtuucmZ2zRqQ83ZC+S61InWph5s3FaETduLYIwIm3VwkIX6hAY8dpzxDKGR3Fl1oUpkhBqwWZ2AiBA1VOTMyoUJMAEm4A8C5s4ODNfVov3dd+AkMUbOJ/YgtrQUhrR0v14n/bGvc1mHxeojB1Y3Tpyyoq3DSeJVNbIztMjL0UAfpqBnYP/9Fsxl/2a6TCAJWeknVgbTtlwQzqx2ErM6pCB46wajdGUNJ6FwwBTa2bG2VnQefB+j5KjnIBe+ooceRuKGDQghW15/3gsEzDHzjjABJrBkBMQziChnTp3G2aozqKuukSLJ4tJVyC8qRGZ2FrQa7Yp3YhWMBKt0ahfzUsCBEIoKh9RLixBoCldWUd5++22UUHbOq5W5rOc//uM/8KMf/Qg7duzAc88997HVfuELX8DevXtx4403QjiuHj9+HHfeeaecb//+/VK4KrYrfkOef/55/N3f/Z0Ut4os8QaDwW/H9rEdu8oEFrKykPUqp8VfJvlDyPqXtZGglaLZh8edsqFCiFmHvA4kK/QyjUwKDeMppUw4NVgoycKfCxNgAkyACTABJhCYBFjIukD1Qg8Iwn2u6ZWX0X7gPYTFxiJ2VSnSrrsemvBw2Qi1QFvm1TIBJsAEVhQB0ZAk0mJXVZ7Gi8+9gNT0NKzbuA6FJUVITEpcUSzmcrDS+YUEqkJ46iKx6YTolNxuaPzFV39DnWZGcoG5WTqpCjfVSTGrSFEuRK1u18TQ+5HIVbz30HSXyw2fVzig0LrovZgmxBOirVQIycL01CFn1FLEuo6GOhKdTbyM4WET02kYFqYmwaqaHMJYBDGXuuVlmMBsCLjpuyqcrRvrGtBQV4/a6lrpzqCnxu3UtBTp1JqQSA6tMTGIIEGrcIJQkph8qYpwV3I6fSTCdWJgwInuHif6+x1SBJacrEVGehhy8wyIiREi+FBquF+qPeXtLhUB0WEj3Fg7fVZ8QI6RFhK0KsdDsF2bhEJF5FLt1rLYLgtZ/V+NFouXrmN2VJ0ewblzY7juugSUloaTCF8E7vj3Pkjcq40MW3DudCve+1MV0jJiUbgqHfnFaYhLoIAFuu+ajWBGdIPXeUgs7h5Gm9css/VVqOKk63GSIkxm7aM1+h8ar5EJMIEVQcBHgVdelxN9J07I9lWPxYwwSnOcd8+9CE/PQEiABVnNtlK89MzsoHva7l4PCS1t6Oxyw0PTNlYYkJWhQXSUIqgCsQJJyDpZF1ab4OvCwcMW6dCakqxGYZ4OmWkqEvSEBAxfFz2LmTs60LbvLXmuFz34EFJJvKSLjWNTjMnK5CETYALzIiCekUU2LWEC0dvTg1MnTqKJMkuOU5aIvMIC7L7hemrziaY2W/28trOcFm5vb8emTZvkITU2NkJ/BRvRL5FG7rWiCLGpEJ1ercxlPV/96lfx8ssv45FHHsE///M/f2y1//Iv/4Kf/OQnKC8vx5tvvinFtkLUKtxbY6k/+v7775fC24MHD8r1mM1mes68Dr/5zW/kuuayTx/biRlOYCErC1mnPVX8LWSlpIHw0gXPQc2CvT4bGijqtoYaLTo9FpSqorFKGY1SNV3sWMo6bb3wh0yACTABJsAElpIAC1kXjr54MBxtaqKUV1VoefN1aniKRdmXvwpDcjKU1PnPhQkwASbABOZPQKRBam1uReWxE3h339uUAmk37v3UvdDSdVZFzp1cpicghKlWC6WSGhhDf694jdBrlN6Ts3hII7zuUAx1GKSwVYheleSkqtYoiS+5G34kNBXjWhKcCpdUrU4zMV3OQ+P0mRCjyvlpXE0uq2q1QjrlihRGoYoQKORwQjQhjLsm34vPhfhsNmKK6Y+WP2UCTGAqArJDg8TqTqcDdrsDVrMFjQ2NqCFnjrrztTTNLsWsZeVlqFhXgfikBIRTcNZSldFRN3p6HDh5chgdHfaPnCTCsKokArFx1OkfTdcbErAKHXwIu7AuVTUt6XZFu7WdsopVU1v1C/YWpCsMuEGbgsTQMESS8QKXuRNgIevc2U21pLjHcrt9OHp0GB9+OIisLD3y8ozkomMktxz/Bg1IkTdd77s7BlF7voPcWdsw1D+GPfdtwao1WfLebbZu945xL4Z9Thzz9KPZPQYr9RetV8ZihzoJmhAFO7NOVfE8nQkwgWsScNussPXTteW1Vynr1UvIv/c+pO3aDWNGBlR6Q9A/KzocPvQPenD6rBUHj5hRtkqH1cV6pKeqERFOz830vBxMJRCFrOI31mYfR+sFJ6rr7Dh11oIdmyOweYMeRn2ofGYIBMbjJIbyud1ofuN1tLzxGqIKChC/phzJm7dCE8lBWIFQR7wPTCDYCQgRq8vlIgFrJf781l6IdPN6+i298ZabUUBOrNGxMdKxU7THcpkgIJxNH3roIRno3UPiXyFcvbQoKaAmNTVVcv2v//ov3HPPPZd+fHF8tuu59957cdNNN1GQ4zl885vfxNe//vWL65oc+dnPfobHH39cbr+ysnJCpDw6ittvvx0tLS2Ts10civ0UolatViunzXafrnZsYv/Onz9/cRtTjajVankse/bswdq1a6eabdlOF6xnUkKo8XXCL3kmcy+jefwtZL0UjUgj0++1o8lrQpvHBDc1FooUTckUdZupMCItVA8NpZZhd9ZLqfE4E2ACTIAJMIGlJ8BC1oWtAxFNLVIDNfzhebitFiRt2oK4sjWILixc2A3z2pkAE2ACK4DARBT5KN7e+2e0NLVI0ePGLZtIzLpLdmixAPLqJ4FwSBVOqV3tQ+jpHMRgvwkOuxPUvyMbvUQkvigdA5VQKjSICy+W74WTqhSykkBYiFlV6omXEKeqVCLdoZJeE5/JaR+JXifEq+R2Qo5iYhmxDq4biZT/MIGAJCCurV5yv+rt6UVnRyfaWtowODAgBa5KSm2p1mik43VicpJ0axWdHQstap0UeY2NTQhYe3snnFiF8Et08AvhakqKDhkZws1ZQQ3zAZQqNCBrefnvFPmCy1TntSRkPecaxioyW7hJkwotSLBAwjoucyfAQta5s7vWks3NVuoIHENfn0Omkt6+Iw6JidoFEdmIQKaBvlFUHmlAfU0H0jPjkVuYgtLyLHJhom/KLIMA6E4SreTI2ugeRZ13FOFQI0NpJAfkCKQo9VCQI3Io22Nf6xTgz5kAE/iIgBDdC2Gfqa0Nne+/h7HWVjhInJF7x51I2rARSnJECyXxSLAWOjxYbV709XtwtsaG4RGPdAtdU6pHfo7IXEL33KrgErGKughEIavYL49nHCazFw3NFHRx0oJwYyiSk9RYVaRDQpyKgt9CZHuSmHepS3/VafQcPYLR5iYSsEah8IFPw0hufwp6BuPCBJgAE5gLAfGbKgSsgxQYcu7MWTQ1NuEC/a5mZGYiryAfq8pWI57czkXWHW6vvZzwr3/9azz66KOUKSMCDeReezUha3Z2NiwWC/793/8dn/70py9fwUfvZrseIZ4tKirC8PAwnnjiCXzuc5/72HqffvppfPvb30ZcXJwUiYp9+8d//Ef89re/vThvSkoKurq6Lr6/4YYb8Oyzz8r3s92nqx3bgQMHIF7XKklJSRSM3gMWsk5PioWsDz44PaF5fGqlSPcBnwMHXN1S1OqmaNw1yhhsp+jbiFA19CF0AaQbdL4IzgMyL8oEmAATYAJMwI8EWMjqR5hTrMpJDa0tb72B4ZoaOEnYmknpHbJuu53coYRFVPA1Sk5xmDyZCTABJrDoBJxOJ7o6u/DLJ39BrqJW7Lnrk8gvykdq+kRKn0XfoQDfoOgsE41aNqsTI0NmHD9cj/OUVra3a5hcU5VISo2lVzS5LsYgITEK+979IzXUReHBTz9EojAhRFXKdLMBfpi8e0yACfiRwIRznxc9Xd3U4XFOul9XnaxCJLkCpWdmYMOWDcjNz6PU1GkXnTsm3JT9d48rUq4KwarZ7EFbmxVVVWPo7rbTdd+DdeujpAtrRmYYOYkEr5jBj1XGqyICIhzDOu7G245OXPBZYQxRoVQZhQ3qeObjBwIsZPUDxClWYbV5MDzkwmuvdVOnpRu33ZqAnFwjXXMXLsvA+ao2nD3ZgobaDsQlRJIz62bEJ0ZKt/0pdnPayZ1eq3RmbSRn1sFxJ27TpKGc+ocMoXQvCRIK0T8uTIAJMIFrERinwCq31YqeY0dx9qknpZAv/fobELu6DOFp6ddaPKA/n3guH0dXjwt1jQ58eNSMxAQVdm0xkrhSg6jI4A24CVQh6+QJ0dvvRn2jnZxZHRgk8fBtN0SguCAMOm3gCFmFKYa5swNV//1TOIdHUPaV/4OYklXQRkdPHgYPmQATYAIzJiDbdChQeWRkFNXknvnKCy/C5XRRUHIqbrz1Zsq4s46yZbHhwFRAX3/9dTzyyCMUWKhGZ2cnBUZ4LptVaN6ESFOUZ555RrqoXjbDR29mu56bb74ZW7dulc6qjz32GL7yla98bLU//vGP8W//9m8oJNMk4fj58ssv46tf/aqcTzi4Pvzww0im7KBCyPr73/8eYn5RvvOd7+DLX/4yZrtPwiF2rqW+vl7uAwtZpyfIQtYFFLJ6qKnQSeLVbp8NnV4LWsmd1ULiVpHOabUyGvlKSvEVqoWWBK1cmAATYAJMgAkwgaUnwELWha8DD6W9Nl1oQy81vor0QMmbtyBnzx0IS0iA2mhc+B3gLTABJsAElimBhroGSolaI4VV4RQZfdf9dyOJHAL1Bv0yPeK5H5ZouDSP2XGhpQ9NDV1oaeiBTq8hF8UwKVYIj9ST+5ZGvnQ6DXRhGvz8f59EVFQUPvdXn4OCXFQnxGlz3wdekgkwgeAkIBxa7TY7RsgJYqB/EH29feTi1y9dWkepM0QXpkN0DLX5FRYgKzcb8QnxlJpaN++Dnezk7+y0oaPDLkWsVquXxFWh0oE1IUFLzhMaOW4wKEhIy+nv5g19mazATCLWPp8d+5wdMPtc2KlJQXaoAYmUOYzL/AmwkHX+DKdag8dD11u7Dx9+OIj2dhuMBiXyCwyUfjF6wWJgR4ct6O4cwuH3q2EatVJQUwy5MmViVXn2nLYpjE4G6ftX4xmh1yi5IFPWPnJk3aCKR2yIBhp2RJ6q+nk6E2AClxBw26zoOvQhBsidcrSpCQlr15MpwG3Q0vOpitIgB3Ox2nwYomCFyiobuknMKoSrWRlaFOVrEaYLhUYTvPe0gS5kFb+xY+TMevqsDfXNDsRGK5GdqcGaEhKzEvtA8Jvwkmuii9J9N7zwB4w0NsCYmoaE9RuQun1HMJ/2vO9MgAksEQEzieMHBwfx4YGDaG5spHYTFTKyMlFWvgbJqSmIiY2lax8Hmk1VPUeOHME999wjP75w4QJlJLs8wNBEfIWQVJTXXnsN60gYfLUyl/XcddddOHbsmBSnCufVK4sQuP7v//4vtm3bhj/84Q9yPiFm3bVrlxSNir6AySLq+POf/zz27duHDRs24NVXX4XQBvjj2Ca3Md2Qhaz7p8Nz8TMWsi6gkHWSMiV9wPC4C/WUSkY0WjR5xpClDEeOwohsGsaF6mCgaHi+LE4S4yETYAJMgAkwgaUhwELWReBODwxetwt9J07g3C9/AX1iIuLXVCBx/XqEZ2SyK+siVAFvggkwgeVFQKa9JmfR9989gGOHj1EjklKmQrrhlhthDOcAgUtrW7Byu70YGTSTo+Iwmuu7KVX4IAZ6R1GwKg2FJWkoKE5DeGTYxxou//Vf/5UEYtH44he/eOkqeZwJMIEVTEBeU1xutDS3oK66VqalGxsdIyIhyM7JQkZ2JlLI2SOWOkPCI8Kh1WmpM352aTCFA6vD4YUQrY6NudF+gYSsJGbt73dQB7MSubkG+crMpFTVZFg12/TXK7j6Vsyht1F683pqi65yD0JPLpB3aDKQGBoGVUjwCkMCqfJYyLqwtSHSHzc2Wijlp4XSV5qkI+v118dLYZNavTDnsNXiQOWRerqud6C/Z5RErJnYsrOEruMk7KHgprmUFq8J513DaPCOkckJsF4dR31D4Uii76KSvovcLzQXqrwME1gZBNxWC6wUONX0yotkDNBODqxpSCJTgJRt24MagMwyQNf4rh43mlsdaCQhpZi2ab1BClnjYoLfACrQhayTJ1Btgx21DQ50dpOQOEKBrRsNiI9TwaAPDDdcL2Uf6jl6BP2nT2GorhaJ69Yj/4FPQaXVIfQKEdXkMfGQCTABJnApAY/bTQFyDlxoa0VDXT1OV56U2czWbViP1RVrsGr16ktn5/EpCLS3t2PTpk3y06sJVU9Qn+8dd9wh29Srq6tl9qKrrWou6xHuqkKYKpxZX3jhBVwqTBVmE3fffbcUo/71X/81nnjiCQp+XCvdV7/xjW/gH/7hHz62Gz/96U/lfKmpqaisrKRg8Ta/HNvHNnSVCSxkZSHrVU6Lv0z67ne/i/z8fDy4CEJWsVU3NVE4yJ21lyJw26kB8ax7GGMkbs1VRKBEGYnVqhiIJgtutPhLHfEYE2ACTIAJMIHFJsBC1sUhLlJimTva0XviOAbOVNF4B0o+/wUkb9mKUCUl2OOox8WpCN4KE2ACy4KAkxr1rRYr/vDb53H44CHsuXsP1m5YR6mt0z8WGb0sDngeB2G3OTE6YsXhA9VSxOp2e5CZk4hVazIRHReOqGgDCc3UFJH/8Q4bFrLOAzwvygSWMQEhZnVQh4jNZoPFLJz8utDW0orGhkb09fSRs3MYsnKyUb62gq43mdIpezb3una7lxrf7aivN+PcORNUyhBEUFrtPBKwpqSGkVO0CmFhCinqErfQs1n3Mq4WPrSPCAjPkYOuHnzg7JEOrLlkqFChioORDRX8do6wkNVvKK+6ImGcY7N5KY2kBXv39tA1T0OuOVFIpetfTIz6qsvMd6LXSw515MZad74d7+2rgsGoRWZuEso35CI9M35Oqxf9QqIv6LR7CI0kLB8dd6JYGYUbyCFZuLSyM+ucsPJCTGBFEBiur5Ntp50H34dSq0XBA59GZE5u0KdWF/e4I2NenCQn1uOnLCjI1SI/V4cccgQNNyqoLSP4e8uDRchqI1fcvkEP3j9kwpjJg9RkNUoKdSjMm39WCX98SUU/goOyYfRWnkDNM79EZF6e/B4Ykuk3lIKNuTABJsAErkVgbHRUttN8+P5BMoE4gtI1ZSgtW42ikhLExsVSNrPgdje/1vH763MhGBVC0ubmZjz88MMQbeWiTUwU0Rb16KOP4tlnn0VFRQXefPPNy8Sml+7DXNbz+uuv45FHHoFarcbRo0eRSAZJk2VoaAirSYwsxK3PP/88tm/fLoWtYr49e/bg5z//+cX9FMuIff2nf/onPP3009ixYweee+45mXnNH8c2uU/TDVnIykLW6c4PLLaQdXJnrJTOaYTSOJ3zDOOC1wInNWLEhWqRTRG4aQo94smdVUFfHo7DnSTGQybABJgAE2ACi0eAhayLx9plNpOjQA/a9u1Fx/sHkHP7HiRu2oKIjAwo/ZB+dfGOhLfEBJgAE1haAj3dPaglJ8ATR4+jj8bve/ABrC4vk+mtRcMQFwosdXlgszrR1tyLlsYe9PaMwEvpahOSIpGdl4QCcmLVaFRQqad2fWEhK59JTIAJXIuAaDQfHhomx+duNDU0oYPcKixmq3RJ1ev1iI2PQ3xiPIlZkxFHnSWRlA5WQcL5K8WnLpcP4tXb60Bfn1O6rwo3Vjt1MsfGqpGURKKqLL0UcWm1Iu1n8Hf0X4stfz57AjZKaT7qc+IDVy9Oe4awTZ2IUmU0ubHqWDQ3e5xTLsFC1inR+O0DcW0V18NDh4bImdpDAUchWL8+CgUFRnl9XYhLoM83ToEJgzh1tBFdnUMwj1mxaXuxvGeMjjFOe8841YF7KWuf6A8SQtbzlLVPF6JARqgBhapIpNJQ5OsLXYiDmWqHeDoTYAIBTcBHKdU9djs63tuPzg8PQhkWhsjcPGTf+gkp3gsRVvxBWESAgt1Bwsl+N2rIBVQMLVYPKlbrkZ+jJfc2BdSq5dGOESxCVlEnNrsPZ6ttaL3gxMCQW9ZFeakeEeTQqqPnjaUuPo8HQtRd/9zv4fO4YUhNQ/qu3YguLuFnoaWuHN4+EwhgAh4yMOilPsjWphacraoic4NReOgasmHzJhSvWoXE5KRZZ80J4MNdlF37z//8T/zwhz+U196XXnoJ27ZtkwLSAwcO4LOf/SyE4caPfvQjfOYzn5H709nZif/+7/+W41/5yleQRs7yosx2PS66LyouLpZB5Dt37rwoPvXQ74MQ1b777rtISUnBkSNH6HlRie9///tyu6K97JlnnsGtt95Kzu9ejFFJmQAAQABJREFUymSkwPvvv4+HHnpI7uu3vvUtfO1rX5vTPsmF5vCHhawsZJ32tFkqIavYKRENb6fGRJHa6W1nF/rJpVWUGzWpWKeMhS5USXG43AgtofAfJsAEmAATYAKLSICFrIsImzYlOqRa33wdTa+9Cn1CImJLViHjxpugjYlZ3B3hrTEBJsAEgpjA6ZOn8fIfXqIU01py50vBjut3kcApM4iPyP+7bjbZSYwwhAN/Oo2jH9Ri7aZ8rFmXi9Vrs2EM182o44OFrP6vF14jE1iuBMQ9rniZKXCrobYep06cwuH3P4TD6SCHVj227tiK8nUVKCguJDfVMOn8cCkLs9mDoSEXjhweRG2tCS73ODIzw7B5cww1zOtIwDqR2pr1TpdS4/ErCfT7HKjzjuI8ZQXr9lpxjzYbaygjGLc4X0lqfu9ZyDo/fjNd2mbzoKfHSWkfh3HgwADuuSeVOk1jyJEnVIpZZ7qe2czndnvhdLjw9hsn8afXT6B8fR7K1uWgpCxT3j/OZl2XzjtA381T7kFpdCK+o59UZ0ihuXBKVoUsvVjo0n3lcSbABJaOgMtkgqW7G3W//y06D7yH0ke+jLTd1yEsNi6o06l7veMYHPLgXI0d+/aPIStdg60bDCRsUSMmaurA0qWriblvOViErOIIhZjV4fDifK0dr+4bRVKCCmtW6ZGXrUF8nGruEPy4pH1wEP2nT6Hr8CH0HDmE8q/9LbJI2B3CAdx+pMyrYgLLi4DVYsHRQ4elC+vxI0exaesW3HnvPTK4ODwyYkbtwcuLyPyPxk5BNvfeey/Ec7AowglVS47xp06dIpGwB3feeSeefPJJ2SYmPq+srMQnP/lJMYpXX32VAhLXy/HZrkcsJFxZhRhWuMBGRESgvLyc2sxqKQC8TwqS33rrLRQVFcn1W61W3HjjjWhra5Pv161bR0HhSTh+nIxAaH5RcnJysH///osZ7eayT3JFs/zDQlYWsk57yiylkFXsmGecUuqSO6uIwm31mNBKotawUBViyZ21TBWNZHJnJW9Wdmadthb5QybABJgAE2AC/iXAQlb/8pzJ2kbq69FfdRo9xyhSjh54Cj/9GURkZUPF6Txmgo/nYQJMYAUTcLsp2welVzt26KgUsm7YshHbdm6nlKfpCKfGHC703E0ChIH+MbSSC2tVZZMUixkjdMgtSEEapYaNi4+YsaMWC1n5jGICTGC2BIRjhHD8GOjrh3DP7u/tJ4HqEDmr2mRnsd6gR0ZWBrKysxFHQV0hoXp0dJDwvtshXyKlaliYgtxbtUhI0FCjuw56eq/VBacD12z58fxzIyAMFITzY71nFH9ydVL7spLcHsNQropFKrU3c/EvARay+pfnVGvzkJO+SH1cVTVCDjoDyM830stAnY9GhIcvjPBJuLJ6PF4013fhfFUbujqGpIP/1t0l8j4yKnpuKUiFwYkQszZ4x3CWhOZacmYVGfsqyOAkWRFG75UsOJ/qRODpTGAlECBFoZee9Yeqz6N171twkwhHuLFm3nwLuU8WQ6ULC1rhns3uxcioF6fO2tHT64KKHLazszQoKdDBYAiFVrO8xPzBJmT10u9ePznkVtfZ0dXrxpjJg03rDCjI1cFI9aNQLG04lJueoRxDg7jw9p/R8OIfkbPnDqRu3wEjZXdTG4wr4erAx8gEmMAMCIigYiF0bKpvQPX58xRcXEcZb1xk/pCGopIiFJeuoixmYezEOgOWU81iomAb4WgqRKqTRa1WY/fu3Xjqqaco2FA9OVkKXG+//Xb5/s0335Ti08kPZ7OeyWWee+45PPbYYxBC1cmSmpqKxx9/HLfccsvkJDns6urC9773PbzxxhuXTRdvxLzCWTYuLu6yz+ayT5etYAZvWMjKQtZpT5OlFrJO7hx5NJCQ1YwqzzCaKK2MjZoa1ypjkK+MmBCzUkOGkuSsXJgAE2ACTIAJMIGFJ8BC1oVnfOUWPNQIZe3rxbmfPyWdBnI+eSfiytYgkqLhuDABJsAEmMDUBMwmM+qqa3HyeCUOf3AYd913F26783aZPkekyVnpxUEOWuYxOxprO1F7vl0OSyuysHlHCaX2joTBqJsVIhayzgoXz8wEmMBVCHR1dqG1uRWnyaG1taUVZmr8T6EG95z8fKSmZyFUEYWmZhIuDAEmUwhKSyNRWGgkoauBOvcp2D10aTuPr3JIPCkACUjzBHik4+OrjjZUkIB1tzpJmifoyfGRi38JsJDVvzyvtbbGRgu56AyRa5xPCv23biXxZzLJtUkMtVDFanFgaGAMe185IR3+V1dko6g0HXmFKSTqIUdYes2ldJDBST31B51xD8EMN7aoElFAfUKJoTqoqD8olG2354KVl2ECQU/AS2Ib++AAuj78AHW/+y3iyiuQcf0NiC4ohO4KsUWwHKxw+xROrD0kkmxrJ3ft0xPiEyGSzCRHVuH+uRxLMAlZJ/k7nWTCZfHh8HEzjlZasGa1HsX5OllP+rBQci+cnHOJhnQyXXj3HelUbExJRVRBgXQq1icmBa3Ae4lI8maZwLIkIASsNhI4jo2OShfWkycq6bnBIYOHb739E0hKSZZZcpblwS/BQQ2TwcbJkyelI6twWhXOrHMps12P1+tFTU2NdFstLS2lDEaZ025WCFobGhrQ2dlJz47JyMvLQ3p6+rTLzHafpl3ZFR+ykJWFrFecEpe/DSQhq83nocYKDxqp4UKIWbt8NsSGaLBBHY80ipSPo8YLLkyACTABJsAEmMDCE2Ah68IzvnIL4/TQ4aaHy9Z9ezF0/hw8lHI1edMW5N55F5a+dezKveX3TIAJMIHAICCiy7u7uvHy8y9ieGiYhJkJ2LhlE8oqymRapJAl711Yek5tzb1obiAn1hNN9HsCrKI0sFl5SUhJi4VGqyLBw+zEvixkXfo65T1gAsFOQHSg2Kw2mMbGyC16EELY2tTQhpbGdrjJ9S+UnPjCo7JRUFiANWuLEBurRXS0FjpyYFWp5iaUCnZmvP+zJ2ClDGDC5bHJa0IbmSdspPbl7epEqMksQcE+j7MHeo0lWMh6DUB+/nhszE1ucU58+OEgevscuPGGBOqINJArq2rBmg+8Xh8cNicFkHWgnl4NFCSVV5iKG29fC2O4jhydNHM6Sse4F5aPvq8N5KA87HMiWxWOnSQ8jwxRQ0fOrFyYABNYeQQcFNHU9s6fyZG1GvaBAaRfdz3SSciq0uuh0MzterPUFJ3OcVhsXimMFKnrEyhVfVaGBkV5Wrp+U7aBZebEOsk7GIWsE27k42i54ERtgwOd3U4Y9Ars3haORBIcB0JdjbW0YODsGRJ7H4SbUlyv/ptHEFNUHLTfj8nzhYdMgAnMj4AQsQrn1fqaWhx4dz+1uQzI9PYbN29CYUkxkknEqtWJADi+x54faV56vgRYyMpC1mnPoUARsl66kz1em2xgPOMZImdWD6JJzJqtDEe2IhzRoRqEcePFpbh4nAkwASbABJiA3wmwkNXvSGe0Qp9Ij91Qj96TlejY/y7iSlcj/777oY2Ogcowt3R9M9owz8QEmAATCFICI8MjaKirxyt/eAl6uk7eeOtNyMzOQkJSQpAekf92W7pmDZpQRy6sQsjqcrqleHXjtkJEx4YTr7lFh7OQ1X91xGtiAiuZgOgcFk6CPd1jqK3pRM35BhJFNRASE7nveUhoH46MTHLlK0qjjpYEJCTGIyo6ijpctOT8NzsB/krmvFKP3Q0fBrx27Hd1Y3jciYQQHUpV0ShWRq1UJAt+3CxkXXDEl23A4xEd1D68++4A6utNyM01SCFrQUH4grqyjtO1e3jITPeW3Tj4zllKl6lELjmyFq5KQ1pmvLw+z9U1u52cWZtJeC6cWcnrTvYF5asikB5qkM6sCg5Qu+wc4DdMYDkTcJCz2VhzE5peexUeuw3RhUVI2rgJsdROGoxFOLG63T70DZCRU4sDFzpcGBn1oKJMj9wsjRS0qlRLbfG5cGSDUcg6SWN0zItectA9WmnGmMkrXVlzsrTkzKr+KHh6cs7FH7rMZjiGBlH962cx2thAZhh3I27NGoRnZFJgID8vLX6N8BaZwNITEAJWETDc3Ngkhaznz56jNuAYZGZlYcPmjUgj902lSgS+Ld/fnKWvBd6DmRJgISsLWac9VwJRyOrDOOwUidtDjqxV1HBxwNmNNKUBq6ixsVwZiyRyZuDL67TVyh8yASbABJgAE5gXARayzgvfnBcWzoI+etgcOFOFs//zM2giI5G6fSfiysoQnpk15/XygkyACTCB5Urg/JlzqDpZhZPHK5FXkIfPfP6zMBgNLHKiCr/Q0kdpuxtRe66DGjFtuHnPOhSvziAhmIEaLZVzdutiIety/TbxcTGBxSXgdo+jt9eO2lrTRHpsu4vSr40jPdUBRWgfas6eJsftDhJMDWLthnWoWF+BsvI15LwdT8KpiY7jxd1j3lowEbCQMYJwYX3B0QI1SeLu1WbL9mRjyPJM2RsIdcNC1sWtBdF2IKz2q6vHUF9nRkenDRkZetx8cyLCwhZWvOIjZ1YhZq0+04bzVeLVijsf2Iptu0uhDVPTffjcnLM94z6MkTNrtWcE5zzDqCZH5V3qZOzSJCGcnFm15KbMhQkwgZVBoP/0KfRVniCnyQ9gJFFe6Rf/BmFx8VCSg1wwFq93XKapP3Pehn37x+h+Vy0FkQW5WsTFqhBKl83lrCkKZiGrDL5z+lB13o76Jgf6SNS6qkiHm6+LoGeWEFl3S3VOjpProsjwVv/H5+X3RRMVjYSKCmTceDMU9LzEhQkwgZVHYIxErC0kYn3x+T9ieHAQSeS+unXnDqzftBE6SnevIBdWFrGuvPMiUI+YhawsZJ323AxEIavYYS+JWW3jHnRQJG4tpZTppyh6B03NpAhc4c6aq4yAjhJBhS7nu/tpa44/ZAJMgAkwASawcARYyLpwbK+5ZuqQMnd2oJ0cWUebmymyegh599yLlC1bESo67UXrJhcmwASYwAon4KXGeo/Hg9dffh1nT1UhNi4WpWWl2LpruxQ4rWQ8NqsT7a395GzYgVpyY42KNkon1lVrMpGQHAWNRgjA5k6IhaxzZ8dLMoGVTkA4CDpd4yRQtaOLXr29DtgovWoI3d5GR6kRF6dGVCS9hwW9PZ3o7+0lx9YeeNwemQpPq9UgNj4O6ZnpSE1Lk6JWFbmJsEPrSj+zPn78Qggn2pOFmFUYItysSUVEqFq6On587uCaMtnxOCFknPu++2s9k3vAQtZJEos7HBp0oa3NgsNHhqGnlMdbtsQiMVGLyMiFFW07KPhgaMAkRaxHD9YiJT0WWXmJWF2RTfflEXRdn9vNppPMTQbHHWj0mHCWsvUpSYgusvWVq2OREhKGsFASfC0uYt4aE2ACi0jAQ+nR3RYLObG+AiFmNaSkIH5NOVK274AqTB+UbaIuCt4S7qtCxNrd64bF6kNBrgZF+Tq6/1UgTLf8RfrBLGQVp78QIgs33ZYLTpw6Y4XRoEBhng5ZGWokxi/s7+21vn7ifnCQDDH6Tp1E74njiMzNQ9FnHoImIjJohd/XOmb+nAkwgY8TsFmtMJlMqDx2HHU1NbBZbbLtpKS0FDm5OdQunMYC1o9j4ylLTICFrCxknfYUDFQh6+ROi1RQdhK0fuDswXH3gGy8yFAYsU2TiLhQLfQ0RTS8za1pZHIrPGQCTIAJMAEmwAQuJcBC1ktpLP6422aFtacXLW++jvrnfofSL/wNsj9xO0RktUKjWfwd4i0yASbABAKMgN1mg9lkwTO/eJpSJdXhvk/fjzVr1yAuYSKlaYDt7qLtjtPhRn/fKI4fqkNrY48UGOy6eQ0JfFdROm4VpZqdfycZC1kXrTp5Q0xgWRAQnav0X6bAtlq9GBtzo6bGJFNhWyxexMSoUVERjcxMHZKTL3fZMpvMGBgYQOXREzhXdRZtLa0wGAwoKC7EKgpeyM3PhTE8nNwHdTKIQaTQnBTnLQt4fBCzJiA8Kj3Ulvy2swun3YNIUxiQr4jAGlXMsnBzbKZAxx/+8Ick+o7DE088IQXes4ZECwjxt1hPQ0MDHnnkEaxdu3Yuq7lsGRayXoZj0d6Ia+xAvxP7/tQLcU1NTwtDYZER2dl6colb+B6T5vpunDzagNbmXnnMt965ATn5ydCFaea1/T4yNWnyjuEE9Qd1eK3kzJqEUvoeJ1J/kCaE+oMWjTBviAkwgUUjQNczW18fxlpb0fDSH+Ww9AtfRMK6DdBGRwddqnRx/yvK0IgHF9odeO+QGeTfhLJVYcjP0SIjbeW07wa7kFXUo6jPXnJjPXjEjKFhD7yecWzdRJlkC8OonQXz+s0T659PcZH4e7imGlU//QnUkVEo/uxnEZGZDR3dL3JhAkxgeRPwkTOzMHropQDg1pYW7P/z22ij39GtO7Zj7fp1WF1eDhH8y4UJBCIBFrKykHXa8zLQhaziXt9NkbgDFInb7iZ3Vu8IRsYp3RgJWFepolChiqVxBVTCvoELE2ACTIAJMAEm4BcCLGT1C8Y5r8RHD58eBzlVfXAQjS+/BGNqGmIKi5C6cxfCEhLmvF5ekAkwASawXAi0NrfgzKkzqK2uoQ4EL+687y7qNM+ltNTaFStiEinvas5eIGFvB5rquhARGYbVa3OQkZWA+KQomebVH4IGFrIul28RHwcTWBwCwsHIYqU0761WtLba6GUh5yklXaNUJFzVIj5ei9hYNTkJKqG7wpFKOLE6nU5KYT2MIcpS0N/bhz56dXd2w2I2Q3Ta5OTlIq8gDwVFBQiPjJC/A4tzZLyVQCRgJRnroMeOd11daPaacSM5sRYrIxFD4jeSOQfiLs94n8T5ft1110nxaWZmJo4cOTInIasQe7/00kv46le/Krf95JNP4o477pjxfkw1IwtZpyKz8NOtdI1taDDTi1wMGy3YsjVGOrMqlSF0/7ew573FbKe0pSYcPlCD1qYe6cxauCod5etzoVKTsmeOxe7zQHyfa8hZuY4clk3jbsSH6rBNlYAEclnWk5iVCxNgAsuHgEiR7vO40X34MBpffAEaClQyppMD/87dCKffPBHUH2zBSh4SOjpdPhw7aUVdox0qZShSk1VYXRKGyAgl9GErp097OQhZxbfNSpkkhDNrdZ0dlaetKCvRoZCcdYUoeSnrU/QjWCi7W9Orr8A+0A8luRdnXH8DEjduWj4XCT4SJsAErkrASkL2jvZ2nDpRiUMHP0RaehoysrOwavVqymJDWUkiI0lov3J+b64KiScGLAEWsrKQddqTM9CFrJM776NQNRs5s57xDKPePYounxXJlE6mSB2F9FADYqlBUk2JZUKpMY4LE2ACTIAJMAEmMD8CLGSdHz9/LT1UW4OeI4cx0thADbahKLj/AUTm5ckGqWBrwPUXE14PE2ACK5vAZKT5scPH8NZrb5L4KYaEmpnYvnsHEhJXrtDfbLJJ99XTx5ukI5ZSEYr8kjRyYi2Rjlj+cGKdPPNYyDpJgodMgAlMR8Dp9MJu92F42IXBARc6O20YHHJidMSF9Aw9uQWG0cuAqChqzaN+lWvd24qgBQt10rS3XUD1uWrpztrX04cY+h2IJzfu5FRKPZsYj7j4OERGRUFvoBxOSkpKzZ0201XTsvusw2uRwrcmrwl2nxu3azOQp4xAKDklXOscC2QYwkH10UcfxTPPPCN3cz5C1q6uLuzatQtWSj8pCgtZJYag/iPEUiaTG2fPjOKdd/qxuiwCGzZEk3MvCWsoSGChi3CFrTxcj/NVbRigzACpGXHYQvegsfERMBgvd9qe7b50kRtrG32vK8mZ1UVmJ4UkTM9VhiOTMvapQxRBL1CfLQ+enwksVwJuqwXmjg50UkB/82uvIuOGG5G2YycicnKhJlFrMBXh3CmCTIVrZ2ePC2fP2zAw5EFJoQ555MSala6he9SV1Y+9XISsVK0USO1Ddb0Dh46aKSNEKGKjFago0yMhXgUNvV8qiYKLUor3nT6F/pOV6D1+HLl33oWs2z4BpU6HUHZjDKZLCO8rE5gRAdE+Pjoygq6OTpw7c4baR9povAPbdu/Eug0bkJySTG0ihhmti2diAktFgIWsLGSd9twLFiGrOAgfPQHYScza5bPhrHsILT4zRJqZ6zXJKCdn1ugQDaWWmX+qxGmB8YdMgAkwASbABFYAARayBkYli4ZcJz2Qnv35/2C4vg4F9z2A+IoKhGdkIoQ75QOjkngvmAATWFQCLpcLFko1ve+Nvfj1L5/FAw99GtfddD3iEuLIyW9+HeWLeiB+3lhDTSeOH6pDR1s/pVwMxXU3r0FOQQoio/VSuONP8Q4LWf1cebw6JrBMCQwOusgZxIaqqlG009BgVCAzw4DiYiOiYzQw0nuNRjEjEatAJIRSorNG/A64yKV1ZHgU/X39qCFRa0OdSGvdgsSkRBQUF6B83Vrkkkt3REQElKqFF3Et0yoMusMSWb1OktjtNccFpCj0yCcB6yplNJkfkItbkLuxvvPOO3j44Ycv1sl8hKyf+MQnINxTJwsLWSdJBO9QiKaE+3VzkwUffjhI19UQREersW59FFJSFuf+WDizXmjpw75XT9B12o2CknSsrshGbkHyvMCKTH1WeFHjHkEtObNW06tcGYvd6iRE0XdbH8qpUucFmBdmAgFCwNzRjpY338BYawvcVhty9nwSKdt3QCmcWCmYI5gK3a7SddCHKhKw7v/AjIhwBVKSVFhTGoYkEjsK8eNSiR2XiuNyEbIKfuI3d3TMg/5BD94/ZEZvvwu7toYjP5cyTcSKILqlESkLV1YXBf1d+POfcOapJ5F18y3IJiGrMT0j6MTgS3We8naZQDAR8LjdOHHsuHRiPV15Upo87L7xRmRkZlCAbwJUJGDnoN5gqtGVua8sZGUh67RnfjAJWScPxEypZDopGreBUss0eUwylUyCMgyFiggkUUNlZIh6clYeMgEmwASYABNgAnMgwELWOUBbgEXGvV543S40vfIy+k+dhEpvQHx5BTJuvGkirRaLWReAOq+SCTCBQCYwNDj0/7P3HvB1VVe6+CfpNvXee7Uky7Il9woYbDC9OAmPEAJhAunzn/+8N8PL/N7LwEt45CUD708yA5lk0sgAAUKxwaYb3Ktc1Lus3rtuv1f/tbYj4yKr6+pKWhtkXZ2zzz77fHvfc/ZZ61vfwrnTZ1F0rhBFZ4uw8798CRu3bILeoKfUqfPLwTUTOA8NmtFU34mSc3WERx2RuIIphVQklq9MRUh4ACm9zDwmQmSdiZGTNgSBhYcAO3XNZgf6+2xoajahtdWMjnYLHOTMZ9WpyEg94uJ8kJDgA4PBkxwr00tvZyEy69DgEOprz6P+fD0ptdbT+c3kXHaqwIaAILIRxkQrpdZYUmv19vEm4qx+4QEvV6QQsBDZrWvYggJbJz61NGG9LhJrtREI8zDAx3N+k5m7urqwZcsW9Pb24qtf/Sr+9Kc/YSpEVnZkPv3003j++eexefNmUkluRG1trSiyLqDvUGenBdXVQygvH0BXlxXXXReGjAx/+Phw0MDsEmucdLPv7RlCwfEK1FW1KWXWFavTsHwVrUlD/WHwnrq/xkb39U6nWYmanLJ2KBVWJrHmakKRpPGDN23xogw2UgQBQWD+ITBMrE9jWys6i4qIyLqb7J6kbLlyNcKXr0BQauq8uyAmsfb121FRTfes8xY0NNmQlWFABimxxsXo5jT9/FyCuZCIrIyj1cbBdcCREwOorrOQEqsHUhINpMzqA296z5kLxV0O+qOoP7SeOI7KN98gv4EBAQkJSLjxJgQkp8zrzARzOXfl3IKAOyHA33P+YRXW6spKCuotQkdHBwUJB1BAbxZWr1sL/wD/RS304E7jJX0ZHwEhsgqRdcxZMh+JrCMX1Exk1lrHAPZZmtFNxko2UuZoQ5DmSQ47Ml7MrnlmpBfyWxAQBAQBQUAQWHgICJHVjcaUXk67SI2VUwPVvLsbwRmkMvX9v1XR1F66qTuD3OgKpSuCgCAgCEwIAVbiq6mqwZuvvUFqfDZEx0YrEmtmduaEjl9olRxEGGhq6MSRz4pJibAVXR0DuGPnOqzesITIWhR5T8qss1GEyDobqEqbgsD8ReCCUuoFNcCuLgvOnzfixIluRaKykZN37dpQ5OYGISJCR2Sq2SEU2kiNxGQyoZgCHApOnMLpU6eJUNWL+MR4LM9bgVXrVtP5I0ilOgheRObjzAaiTjJ/59xoPe9zWlHs6EUZqTWW2/twmz4Bm3VR8942zEE69913H6lsHsT3vvc9+i7l4rHHHpsSkfXYsWO49957lVLx/v37cc899xDpsVqIrKNNqHm6zW4fBt939+xpxfHj3dhCRNacnABER3krBcDZvixem5qMFsoSUIo3/rQfWcsSkb8mHRnZcQgND5w2mbbHaUGVow/HibB+2tqJHYZ45BOZNcqTAiSIsC6+oNkeYWlfEJhZBNQaktZwLceOEvnuGNpOnkRk/kosf/w78PI2wFMzO+vGmb2KL1pjHqHZ4kB9ow0ffNoLi3UYUaTAuibfD0tIrXMxl4VGZB0Zy6YWqyIt7z88gPAwLW69KRBhoRr4+c58QPHIOcf7PdjUqIjhDZ99Cv68/NvfQ9TqNUrZeCYz9YzXD9kvCAgCM4+Ag5SXOaD36KHD+OSDjyhLTTfCIsJJ5OF+pFDwh5+/38yfVFoUBGYRASGyCpF1zOk1n4msxmE7+slQWensR62tHy1OE8K9DKTMGoQUTQAZMVyTOmdMgGWnICAICAKCgCAwDxEQIqt7DZqlrw+9FeUof/3PyvEetWYdwnKXIzgtzb06Kr0RBAQBQWCWEGASa3dXN6mOFuKt199EXHwcdtx5G1hlLzgkeJbO6r7N2mx2UrtqRVlxA4pO1yIkLIDIAglIzYhBVGyIIgrMlpNCiKzuOy+kZ4KAqxFwOodhtw2jucWMurohNDQYMTBoJ7UpL4SG6REZoScCqZ5SXOvh402KeaTMOhuFnxEOymTQQ8+JTlLubmtpJTXYDnR2dKKvtw8DAwNKnZWfHRmZGYgipVZ+dgiZdTZGw/VtOkCqNCR2sMdcD6uHEwmefsjVhiLFy9/1nZnBM/JznIkfP/7xj7Fs2TIiJ+7B3r17p0RkHaRUs6zC2tbWht/+9rfYsWMHNm3aJETWGRwvd2iK78l0O8TZs70oLuqHze5ETIw3Nm4MJaUm7aynsubzO+wONNZ3oJDWpw11HRgaMGHLtlxSiYpHQJAvZVCYeqAVKy9zpj4mq5fYejBIn1mZdZ0uArGUpc/fQ+sOwyB9EAQEgQkiYBsahIlUxytefw09lRUIW5pDaqyrELlqtSKxcuDRfClMYrVanThbbERVrQWdXXbERGmxPMdHERyDAuaO2OgOGC5UIuuQ0Yn2DjuOnx5Eb58d3npP5C33RfYSb3rPwJwEWPD3ykIq/vy9aiF11uQdtyoiaxCpsnqKIIY7fB2kD4LApBHgwA+b1YaG8+dx7MgR+l2PbiKxLqV3xExSYk3LSEdAQCA02vkVADJpIOSABYeAEFmFyDrmpJ7PRFa+MCfdvPuGrUqZdb+1FWYitwZ76LFMF4pUMlgGeuig9/CakwXjmMDLTkFAEBAEBAFBwI0RECKr+w2OsbUVNXveRR+lf7SbjEi6eQdiN2+Bp5ZV9xa3QdT9Rkt6JAgIAjONABvsiguLcfb0GZw6dgJ5q/LxwMMPUso2DTnEF9c9kJWu+nqHcPJIOWoqW2EcMmNZfgqu37YcOr2G0nXPruFSiKwzPbulPUFg/iHAZCWz2UkEUTspn1pRTwTW+noTenosMBi8kJnpj9RUP1KN9KGL85h18tSlCI44eTgde1lxKUqKSlBKPwZvb0pvHYKk5ETEJcQrYmtAUCB8KYWtN+3z0iyuZ8mlmM3nz5RcEb0kclDl6MceSwNCidS2Qx+PCBI3mO+ktuLiYkU45bXOJ598guTkZLz77ruTJrLy8Q899BDef/993H///XjuuefUkE+UyMpEcKPROO40qampwQcffICvfOUryMrKGre+VJg9BFopuIDVsY+TOraeSDXbtkUpVWxf39ldI45cEa9Nea362Ydnce5kNXJXpiCT1FnTM2Ph46ufdhBBO4mZ1BN5/YitDb0OCxHXQ5CuCUQy+YLIOqIy9Y30RX4LAoKA+yHAazXKjazsm13Fhaj/9BPYSWEu+8GHEJa9FLqgoHmVBp2vZ3BomMirNhw5OYiWVispseqQlWHAimW+itDofqPg2h4tVCIro8hk1opqEyqqLCirNGHVCj/kr/ABk5e9DXNExqY5WfnWm2j4bB98wsMRtiwXCVtvhM6fgrwoUEqKICAIzB8E7KzCajajqbGJ7BrFOHLoEDReGgrOjcKWrVsVkZXf9yRId/6MqfT0CwSEyCpE1i9mwyif/vmf/xkZGRl44IEHRtk7PzbZhp0wwo42MmIUUwqp49Z2RFJKmUSKwF+rC0eUlw+ZMGRxNj9GU3opCAgCgoAg4A4ICJHVHUbh8j7YyHk42NiojFDlf34FGTu/hNQ774IhJBQacr5LEQQEAUFgISNgHBrCm6+9ifKSMkTHxmDFyhVYt3G9cnDNlvKou+JZX9tOODTg9PEqUt0axuYblyE5LYqMmMGEB735zvKrrxBZ3XVmSL8EAdcgwM56i8VJxFUjKiuHUFLcpxz0IaF6pBF5NTbeG4EBWiKIeikC1Vzco1mhlR0+JqMJA/0D6O+nTE7VNaip4p9qpd4aSqTWpbk5yFm+jPocR2qF81u90zWj735nISoMCm3dKHP0os4xgDQis92sj4N+eH6T2axWK66//npSOq7DT3/6U3zta19T4E+WyMrfv5deegn/8A//gMTEROzbt4/I5ga1fpookZWVYI8fPz7u4MfHx5Mqc4MQWcdFavYrsCpgd7cVH31ERM9eG5Zk+JH/J4CI/BxcMPvF6eB7sIPWq40op+wBvG4NCfXHLXevQWRUEJFZp5die8QXVGYjxTlHHypIoTXZyw9b9bFEZjfMexL77I+QnEEQmFsEhmmd5rTZUPfB+6j8y+vwT0hEKBFY47ZsgU9EpArYn9seTvzsipRL1YvKTDh1Zgj9Aw74+2mwfpUv4mL1lKVg9t/PJ97buau5kImslBQCJgrwK60w4cCRfvj5eSE2WoeVpMwaFTF3SuHdpaVoP3Ma9fs+gW9kFJZ/6zvwjoiAFwliSBEEBIH5g8AgBRW2tLRg7+73cL6mFv4B/lien4dVa9cgODiY1tUcMDFHpPn5A6P01E0RECKrEFnHnJoLgcjKF+ikCHxOL1NDRsuzti50Oy1qW6pXAFI1AUgkYwYrswqhdczpIDsFAUFAEBAEBAGFgBBZ3W8iDJNlzGY2ofngQZS98p8ITE5BeO5yRK1dC7+YWPfrsPRIEBAEBIEZQqC/rx+tzS14+4230EUpo7fdejNFnGeCU0QvpmI2W9Hfa6RUrTUoOl1H6oGeRL4Kw9rNWQgLDyA1Vtc4JITIuphmnVyrIPAFAkyMYhXWjg4LWltNaG8ndeg+G8wmB0KJxBob501EOUqfGq4nZWj3cdozqZV/GusbcL72PKorq9WzxErKX94+3pTqOhCRkRGIiIxEJKmaBIcEU1q+AEX0++Lq5ZM7IuAgW7DZacdHliZUOfsRTaIGmURkXaEJhRcFdszXwkrz3//+9/Haa6/hpptuwp/+9CcSrmPKLrB79+6LiqxHjx5V20f2jXa9tZTNYysp9TCxm0mwK1asUNWY4Lpx40ZUV1fjhRdewN133622j9ZWWVkZGimgcrzC5FsmvIoi63hIuWa/0WhHQUEvztcRsarfjqU5AVi7loJgNR6UzWCWo57+eok9XQNoPN+BQ58VY3DAhJSMaGT9VZmVHe6enlPvB/uCOsn/U2vvx0l7J2XtcyKEFJmXaUKQQvcBA/mBNCJs4prJJmcRBCaJgLmnB72VFWg+dBBNRw5TxqlbELN+IwKSEqH18Z1ka3NbfXDIiZY2myIxshpnHBEYU5L0pMZKa0x/yhQ69dvc3F7YDJ99IRNZR6BqarGipNyEhiYbKdk7sXalL1KS9aTMylmERmq57reltxd9NdUo+c+XMEwBJil33InQzEz4xS4uO5rrEJczCQIzi4CF7BUs6lBWUopSytTRcL4eOh09X3KykbV0KTIyl4jNYmYhl9bmAAEhsgqRdcxpt1CIrCMXyRG5NqKwfkJGzAJbJ8xwkBEzSKWVCvLQQzePDZkj1yi/BQFBQBAQBASB2UZAiKyzjfDU2++tqkLzkUPoOHsG1sFBrHj82whfkSepgaYOqRwpCAgCbo4AK+gVnyvC4QOHoTfo8PA3v4GEpIRFF3He3TmA6vImHN5fguIztbj7/k1YszETgcF+RBpznWdEiKxu/oWR7gkCs4TA4KBdkVePH+9GUWEfrT2HkRDvi7XrQhAX54OQEJ06s7s67Jmgp0itFBym0vIVl+LY4aPq+cKp+RJTkrBh8wZyDC1FanqqcgrNhZrsLA3fgmzWPGxHn9OKV8zVaKA041/2TkGWJlipMc5n3oiRMnGkpaWpMcvLy6OU8BEXx4/VeM6dOwdvysixhZTruDz33HMIojTMo5WnnnoKL774Iqkj65XC66V1Dhw4QEQLI5YtW4aYmBjV3iOPPHJplUl9Pn36NN555x0hsk4Ktdmr7HAMKzXWQrpfv/duC5avCMStt0WTOiCrZbtm3cj3XeOQBWdOVqOwoAYVpNC64YaluO2etSoAy8treoRzpncPDttQS8ImR61t+Nzaglt18digi6Jsfd7w8dTMHsDSsiAgCEwZge7ycqXEamxvgweR2pd85X5Er1k37+yaHGPS0GTBwaODaOuwwWIdxvbrA7As20cFDbjrmnjKAzeNAxcDkdVOz10O/PvgEwqwIHXenCwfZC8xYEm6AQb99J53U4Xe1NGBsldfRv/5OqXGGrtxM2I3bppqc3KcICAIuBCBPiKjN1Ew4a4338bRQ4ewnoIQ16xfR0qsJGrj7yckVheOhZxq9hAQIqsQWcecXQuNyOqkt4dhslbW2wdx3jmgUsuYSanVz0ODpWTMzNaGqIhcLWmzShEEBAFBQBAQBASB0REQIuvouLjDVktfHwabm1Hz7i50FZ5D0q23ITJ/FSkXJMFLd4FA4A79lD4IAoKAIDBdBNj57SDC0f5PP8fH73+M8IgwpC1Jx8Ytmyg9ach0m583xztIPaO/dwgVpY04TIpWWp0GUTEhyF2ZQoTecCIC6KalaDVZIITIOlnEpL4gMH8RYGcsE1jPnzeiqcmMlmYTqUF7UGpyT1IxNRDBTk8EOAN8fTW0zTXEqOmiyc+WwYFBSrvdjbbmVrQSMbCjvRP9tMY2mcx0HXoEEikwOZXvsQmIiY2Bwduw6IInpouzK46vsw+g2N6jSGyexBa5RR+POE/feS9iMETKO+np6ROG8NSpU4iOjh61/pNPPolf/epXo+67cuP999+PZ5999srNE/5biKwThsolFZ3OC4Sa2loj9u/vIPKqJ80TAxGXA+m+7e2SPvBJbDY7Otv71Tr22IFSSofqg4TkCCyndWxsQti0nfBW8vsMwI5KWy9l6etWAife8MIafQTiPf0Q4MleoPlMbXfZUMmJBIFZR8Bps2GgqREdFPhQ895u+CckInbTJoRmZcM3OmbWzz+TJ7DQGrmh0YaKGhPKKswID9MiPUWP5AQ9IsK1dG+bybPN/7YWA5GVuQmUBAIVVRaUkzpvMyn1Bgd6YsMafzUnfLxdz0mwGYdICOMs2k6dRMuxo0i88Sak3/claAz0bqN1TUaf+T975QoEAdciwEqsnJWsrKQEJ44eU0EeQcHByF2xnAJu08gGE0l2Yfn+unZU5GyzhYAQWYXIOubcWmhE1pGLJTorBigyv8BKEUeOPlTZ+5BLqWXydWGIolRTgR5aaCjFjLxPjCAmvwUBQUAQEAQEgS8QECLrF1i42yd2vlMOSZS/9mc0frYPvrGxiCRF1rjrrofWj6IxSc1AiiAgCAgCCwEBTlHLZKPdb+3Cnnfew1333YX1pJYXzaQiMrwvhuIkEqvJZEFNRSuKztbixKEy5K1Jx9YdeQgiJVZfP9fjIETWxTDz5BoXMwK81rTZLhCgenutSoW1vHwALS1mInvakbHED0uXBiAx0ReBgfPfUW82m3G+po4cRWUoOFmA7s4uWMwWLMnORDoFT7A6a3BIMHxJ9YSfPToKHBOl1rn9hnBKcQf9nCKb76fWZkSQ8mKyJgD52jAEe8z/wD5WDmZS6GjlyJEjePrpp5UC60svvaTmIqu2XmtONpKKT1tb22hN4fvf/z7q6urwne98Bzt27FCqrNcixI7awBUbhch6BSBu8mdHhwXFxX001kPo7rJh640RyM4OIDV/j2vOm9noeuP5DhyndWx9XTsG+oy4cUc+luUlw4fWstNVZuX+djstaHYSaZdUWRtJ4GSlLlxl6UsiMquBlFnFCzQboyptCgITR2CYAlRtFKjRdOgg2s/QeosIOnHX34CsB75KhDoKzNTMHwVlKymv9vbbcfL0EM43WmE0OZG3zJcIi77QUsCXl9fseJ29KD89K63zWvQf//EfVaaBK0fAk2zC/Gzfu3cvqiijF68pUlJScMsttyAjI0MFCl95jIawZz/A/v37ad3fjtzcXGzYsEHVt9vtV1af0t+Lgcg6AszgkBMtRGL9cF8vzJZhrMz1QUqSHnExF94hXEly5u+dpb8fjQc+x7kXX0DMho3IICKrH/kSdAEBI12W34KAIOAmCHC2jO7OThQXFuHcmbM4W3Aa6zdtxJatN1CQbSLZXwLdpKfSDUFgZhAQIqsQWcecSQuVyMoXbRsm5RpKL1PvGESJvRutThPMTge26KOxRBNIxk09tB5C9hhzgshOQUAQEAQEAZciwA4oRVScxFmncsx4zQuRdTyE5n5/Z0kxOs6cRuPnn8GHIjFzvvEofKOioaE0k1IEAUFAEFgICLS3taPoXBEZ7s6grroW992/k1IorYKeiETsxFkMxThkRltLDz569xSRDwaQlBqFrGWJyMiOIwcWOeWnmZJ1KhgKkXUqqMkxgsD8QOBCvNQwEd8sivRUUTGAdvocGKRFVJQBCQk+CAnREYlOS6nNvYgINf9taqz8bTKawCqYfT29pNDaiuamZiJb1StSq91uQzw5jZYuW4q0jDTExMVSuliNKLTO4ZS2kAIj23sPWlvxoaURN+tilfpiiAelbiXRgoVcPvroI3z9619HUlISmNR6qe3gt7/9rSKtpKam4tFHHx0XhptuugklRCR64YUXcNddd41bf7wKQmQdD6G52W820/eFCFdHj3bj2LEubNwYqlRZWVFbr3fd98VktKCrcwAnDlPQwLFKtaZdsjQey/NT4B/oM21wbHCCs/KV2XpQ4egnpeZ+RJKYyXXkB4oksnvgAiC5TxskaUAQmEMErAP9pMbahLL//BOMHe2IWb+BskutRGj20gsB+a5k900Th3oir1bXmlFURpkKPD2wcoUvEmJ1iIzQqACB2boUVmC/4447EBYWhqKioquIrGwj+eUvf4lnnnmGgtJsl10l7/ve976HH/7wh5eRWdmn8Nhjj2H37t2X1ec/vvzlL6v2ZoLMupiIrHbHML1XOFFUakJNHWW0aLMiL9cXG0mZVa+fPaLzVQNIG3idyErInUWFqHrrTVXFj9SPE0iZNXjJktEOkW2CgCAwhwiU0L397OkzOHPyFGXfMtA6OQ9LsjKRlJIMb4M3NNr5E/QxhzDKqecRAkJkFSLrmNN1IRNZRy68d9iK85RuqojSTdXY+xHj5YMkL39kEJk1xFMPX1JnlSIICAKCgCAgCEwVATYGjRcRPV7bJ06cUKorhYWFCKCI2LS0NBUtHRMTc5lzitthIxNHSB89elQdwwor7KzKycnBrbfeipkwMAmRdbwRm/v9Voqo7q2pRul/vgQHqUYl3XwzQpfmIDA5Ze47Jz0QBAQBQWAaCLCx3WF3oLysHHt37VGOlrDwMGy+YQsyMjOm0fL8OXSETFZd0Yzy4nqUnKunVKze2HhDDuISwhES5j9nFyNE1jmDXk4sCMwaAnzPMRrtGBiwg9X7mLza0mpSf7MzPiHeB8nJvkhM8lHEp9lSmpq1C5xEw71EZm1raUN5aRnqSKm1g967dHodqbKGICIyAuER4YiIikRIaIj6YVIrvw9KcR0CPaS8WGrvRRn9VBNZ7TZ9AlaRGquGxAoWegrxsYisTDg5ePAgERU34vXXXx93QITIOi5EC6IC398dpPBfUNBLintdCA3VIT7eGytWBCMwgEhXRMJyReH1Pf8UnakjImsFeruHFIF1/ZZsWtuGISDId0a60UX3hzry/xyzd4BJ71FEYs3UBCGN/EAUCieiJjOCsjQiCEwcAf7e05cf3aUlaKX05m0nT0JHKvdLvvQVZb/UzSN1ObPFeYGgSATWiiqzAiE6Sou1+X4ICuQAr5m/n7LCKq8zKyoq8NBDD6G6uvqaRNYDBw7gK1/5iuoX+xPuueceWt8bFUm1kxT+uFwavML+BfZn8DYu27dvx/r160nFuxhvv/228i9wYMxPfvKTq0iz6oBJ/LOYiKwMi83mRHunHRXVFhw7NYi4aC1ysryREKdHcBBphPMLlgvLYHMT2gtOoY0U/wfqzyPz/gcQvW4dvIgY5ynvMS4cCTmVIHA1Avyc7OkmMb6WFpwhBdbqyirYKENZKvmHWYk1LDyc7MFzZwO+useyRRCYOQSEyCpE1jFn02IgstKrEuykztpAyqyVZOA8bGtThpNNrMzqFYhEL78xMZKdgoAgIAgIAoLAWAiMFxE91rGc4ueRRx4BO6SuLN6krPm///f/xv3333/RYMSGjkOHDuHBBx8Ep8G8srDT6te//rVKNXjlvsn8LUTWyaA1N3WHae6Y6SW35r3d6CGDpsNiRsJN25B8y61z0yE5qyAgCAgCM4QAq+MZh4w4fuQYfv2v/65UWO/aeQ+ioqMWlPGOn+nKsTcKbkw4sNvs2PPWcUrDWo6U9CgsX5WK7NxE+PjoydkwdyqIQmQdZcBkkyAwzxGgZSWam02k5jiIkye6MThkV4qrK1YEYUlmAEKCLyiwajREE3St39XlyPL7mZPuwTZSYh3sH1AKrcWFxTh9sgCtzS3qvYyVUfJX55NCygr4ERlDr9e7vJ+L+YQsUvCetUFBEOflixVeIUjSBGCBT011vZ9++qmyBXAgK5NWL11HsN2A0wJfd911eOWVV8adIpxm+Ny5c/j3f/933H777ePWH6+CKLKOh9Dc7ud7fG2tEadOdlN0NHD3XTGIjfWBF6XBdmUZGjST2nU/dr1+BM2NXchbnYacFUnIzEmYkW44QUp4w3bUOQZw2tqJQ+QHWqeLwGZdFJFafeAngiYzgrM0IghMFAG2XTopPX35a6+i5t3dCM3KRkR+PuI2bQGTWD2IqDlfSle3nRQ2LSg4Z8T5Rgu2XRdA5EQfRUzkIK+ZXiMzifVrX/uaIrGeP3/+IkzXUmT95je/iffeew9JSUkUuHD4Yn0WvFi9ejVlXGjD9ddfj5dfflnt6yabcj6NhZUIU+ybePrppy+uK371q1/hySefVPUKCgooM0PUxfam8mGxEVl5feZ0eqChyYLjBUPopLnjIKXWm2jOZKYbXE5kdVgssA1S5loSw6h68y/IfujriN96I1id1UveY6YypeUYQWBGELhwr3DiHKmwfvzBh2igez0/F++6917KCJNDgbOhtFb3kmwwM4K2NOKOCAiRVYisY87LxUBkHQFggIwYHQ6jUmZtdg6pdDOJpMyapQ1GNBkyAsWQMQKV/BYEBAFBQBAYB4HJRERfqylugw1Fe/fuVQYMjpRmAxKrs/I2NiRxnY8//hiZmZmqGU4dxE4m3peSkoI777xTOU7feOMNFZXNlXbs2IHf//73l6UKulYfrrVdiKzXQsa9ttsosr6vqhItx4+hgZyaMZs2IeX2O+BNL7laXwnUca/Rkt4IAoLARBFg1ZDic0UoOluIM6fOYP3mDbjtrtthMBig1c3fbBpMXJ2oonpLUzfO17QhPiUIp0i55syZ08rxNJ4COysD8jOciSx8rtzcXGzYsAEZGRkzotjOYyhE1onOZKknCLg3Anb7MCwWB90rrGhoMNI9xozBQbvqdFCQFhHhesTG+ZACKaWf1nmASayLrXBa1qHBIUVmbaxvQAsRWbu7ulWgARPB9DodYuJiERcfh7jEeFJtDVbvZvwOJ2XmEWCCGquxljv68JG5EXEkTLDlr2nDA8SmO/OAT7JFIbJOEjAXVzcaHejqtODzzzvQ1U1pjilQISXFj+5f3i7tCQdrmUwWnDlejYrSRnR19CNtSQzWkTJrQKAPfP0M0+6PjQRNBoZtqLL34Yy9CzY4lRprvjYcyRp/+EMLr5lmnE2719KAILAwETASebKrpBjNRw+jp5wCNG+9HRErV8E/Lm7eEOh4zdw34EB1rRkFZ41KeTU0RIPcpT6IJUVWLa2TPWfhnsIEp9jY2KsmxmhEVrY1bCKbMCu2/uAHP8ATTzxx2XE//OEPla+A/Qv79u1ThNVdu3bhW9/6Fl2PFmVlZRTE9sXzgNvLyspCb28v/sf/+B/49re/fVl7k/1jsRFZR/Dpp3nT1GJFUSkFDNZaaM4YiMhK84YUWg16170vjBDKz3/0Aeo+eB8+EZRdIjMLCURmNVDWCSmCgCDgegQcFGTQ2dGJIsrQWVVeQUqslZSlIAEppMSau2K5ygLDAbN8P5YiCCxUBITIKkTWMef2YiKyMhAOMnp2Oc0otvfgQ0ujisJNp9Qyy7WhSPT0g24RpKEac0LITkFAEBAEBIFxEWDH5GQioq/VIJNRmZDCynOcpodJrSOFo6JZSaWrqwt33HEHOBKaCyu0/uIXv1DH7d69+zLl1Z///Od49tlnVT1OJ8RtT7UIkXWqyLn4OI7wJgd70+FDOPtv/4ogetGN3bwF4cuXw5eiquVF18XjIacTBASBaSPASnhMEnr37d0Uid6A4OBgrF6/Bms3rJ1223PZAN+PJ6KoHuAfACspsVaVNaFvqIXWGxNXYOdzPPbYYyp14JXXyumGf/nLX84ImVWIrFeiK38LAvMLAVo+qnSXQ0MO9PVaUVrWTylE+0kJ20Gq1xqsXBl8gdwU94Uze35d4ez1trenF40NjTh1/BQFXBSisrwSCYkJyMjMwNLcHCQmJxKZNQQ6vU6RXDlVp6zHZ248rJQmvJyIaaX2XhTaSUVMG4a7DElKiVXcezOH81RbEiLrVJFz3XEWqwMHD3ShumYQWgpOyCTF7TVrguk+BQqidt23yOkcxkC/EaWF9dj9xhEEBfthPRFZU9KjERVD/aG+zMS9s2/YilanCfvMTSh19GIDqbLmaIKRRCR4A7yIzOo6EpHrRlnOJAi4CQK04HSQvbKz8Byqdr0D+xDddyjgPuNLX0ZYzjI36eT43eCsBUaTE9V1JpSUmXHq7BDWr/bHpnV+CAzwmnUyYmdn58UsbSxi8eMf/xijEVn5Snbu3KmCWm+++Wa89NJLF9/9vWg9unLlSjQ2NipCKhNTuTz33HP42c9+hi1btuDVV19V2y7959FHH1VCG9u2bcMf/vCHS3dN+vNiJbLyexcTko+dGsKh4wMI8PNCfKwOq/P8SMlXAxoal5auslK0F5xCy7Fj0Pn5Iucb30QAEec8icwsRRAQBFyDgFJhJX8wBwpUEoH1g/f2oId8wd7ePrjljtvI/r1eBRjwvVuKILDQERAiqxBZx5zji43ISutGWMjwyWRWTjFTQQbQ885BpJAya4ZXILK1IfD30JAR1HXGmzEHSHYKAoKAICAIuB0Ck4mIHqvzR48exb2UJiIg65QAAEAASURBVIIjnmtqai6m7xk5hp/RnOYvgQwKrNLK5J67774bx8jYMFo09NDQENLT09XhbCBihdepFiGyThU51x/HUdV9NH8a93+mfpv7+pD9wFcRsWo1PDW0ppGoTdcPipxREBAEpoxAf18/EVjr8drLr8FGAR+33nk70jLSyKk9vVR2U+7QDB04UUX1X/3q1yg6UwsP7RDuuuvOCSuw873+qaeewgsvvKB6vH37dqxfv57IacV4++23lROLHVEcOMPriekUIbJOBz05VhCYWwQ4paXF4qR3j0HU1RkpzfQQKa16IDBQi+hoAyIjDeQc18PPTwMfH3GcXDlaHIhoMpkoLXaXUk/paOtAW2srOto7yPnUQ5j5ICEpAelEbE1fkg4/f//L1K2ubE/+njgCI+nC37c0oN4+iBgvH2QTIS2XhAnEgjtxHGezphBZZxPdmWmbnwGNpMBdWTWIUyd7kJTki23bI9X93mBw3T2fbWp2mwMdbX0oPF2L2qoWNDV04oabVyB/bTqpsnqTA3/6/WFlVjPJmpQT+b2SfECNTqPKyLdBF4lYT18Ee+pnBlhpRRAQBK5CwE7rpQEiTrYcO4Ka3bsQSUTK+BtuRFBq2rxSgBxR1Dx8fBBmWkPHxeiRkWpAUoIOOq0HERFdtwr585//jL/7u7+7JpH13XffVYGtPBjXX3+9yuJmoZTyr7/+OgoKCpR9eM+ePVhO4gdcvvvd7+Ktt97C448/jh/96Edq26X/PPPMM3j++eeRl5eH995779Jdk/68WImsDBSTWdvabairt+B04RAJmgDr1/ghMV6PMFL2dWWx9vfT97IBZa/8J4xEkk67626ELc2Bf3yCK7sh5xIEFjUCZrMZ/fRd3P/JPpSVlJB9xoqklCTkr1pFGXHiEBoeprJ0ik9vUU+TRXPxQmQVIuuYk32xEVlHwLBTShkTEVrP2Lpw3NquFvEhZLxYRkbQeIrKDfMwqG2uew0Z6Zn8FgQEAUFAEJgPCEwmIvpa18PKqqywumbNGkUyubIek03Y0MNphE6dOqWIJ8nJyfRyY8Ff/vIXRVC59Bh2rCYlJalNbGjiSOypFiGyThW5uTmODVH99fWoe38Pmg4eQMaX70fc5s0qVZAXpSCRIggIAoLAfEGgorQcxYXFOHr4qHLQPPAwEfMjIihd3/xWiJioovpnn32OU4caUNd67KIC+zvv7FLKtMRVVWU0BXZWcs/Pz1fEV1Z4f/rppy8GyLCq+5NPPqmOZQdWVNT0SMFCZJ0v3ybppyDwBQJWiwMmsxM9PTZ0dJjR1GSi31ZSAbEiJsabMjn4KkJTeLheqfKN3G++aEE+XYmAlRxOZiJpVJCKSnlJGaoqqzA0OESqtv6IjolGdGwMIiIjEBoWqlRavX28YTBMP2X2lf1YLH9zmvA2hwl7rQ0YdNpwoz4GySRKEO4pysHuMgeEyOouI3HtfjCZxmJ2oLZuCB+830aEUQ1WrAhCYqI3rbddf38ym6zo6ujHyaMV+OzDs8jNT8HS5UlIWxKDoBBf5cS/9tVMfE+P04JGxxAO2lox4LQikQVNKENfGv2wMqtWlFknDqbUFAQmgICT0iWbiCTH9snO4iIM1J9H8o7bkHLbbaT8qFNB9xNoZk6rMPHfbh+mdPBmVFNKeP4dGqLF5nW09gjTwt/P9YrO4xFZGTAmrf7t3/7tqNjxezxnmONgAiZIcfBrIaW0fuKJJ/CDH/zgqmNefPFFFSwbR8SqkydPXhUQy+00NDRcddxoG3bt2qWOH+08o9VfaNusNicGB53Yd4ACt5utiI7SISNFj+xMb2iIDO0yQjSNmWVgAOV/fgVdJcXwi4lF1Oo1iNtyHWhSqHmx0LCX6xEE3AUBOz0breTXbahvQHVlJc6cKqAMOb207l2C5XkrsHINidJQJlAhsLrLiEk/XIGAEFmFyDrmPFusRFay22CY/usn42cnqbMesLainpRZAz10yNWEYBNF5mrgCU+x3o85f2SnICAICAKCADARQ9JoODEhlSPwdDrdVUo9vH3Tpk1obm7Gjh078B//8R+qiT5S2+TiT+o+/GIzUvjzr3/9a6XUytv27duHJfQSNNUiRNapIjc3xw1TOLeDiMy1e/egZu97CExMQtiyXMRfdz30QUFz0yk5qyAgCAgCU0Bg7+492L/vcyL/RCJraRY2btlEinZ+89qQx0bIiSqq//KXv0R9KfD5yZcuKrB/61vfuuz6R1NgZ8cQ19NSSriysrLL1hV8/qysLJW2ajRF98kOkxBZJ4uY1BcE5hYBJi719FjJ0WzC2bM9qK5msqUGcbGkaJkdACavsiKrTuep0luK42Ri48XOe1a4ttB7m8l0QVWlubEJ5aVlqCitQH1dPZFZo5Uya/7qlUhMSkRk9PQCCSbWs4VZq8Y5gCJrF6oc/fCDFrcbEhHhRc5/0WN1mwEXIqvbDMWYHeFnQmeHhdT5etDSaqb1oQ1bb4hA7vLAMY+bjZ1OJ6UetztQU9WKcwU1SpmV3DW4fed6pKRHQa/XXrYGnmof7KzM6uFEra0fxfYeHLe1I8srCJsNMYj28Eagp26qTctxgoAgMAoC1oF+9FZV4dxv/h0sP5l08w6E5iwjNdbUeUOWM5kcGBhy4pPP+1FRbcZSIhyyEmtaigF6nQuJh5fgO57/oa6uDg899BCqCHsugYGBaq06QMRFLuxLYN/Bli1baM3vpWwEHBDLQbAPP/ywqnPpP7/73e/wT//0T/SuEK4Ir1dmdrHZbCrjy6XHXOtzcHCwup8vViIrP3ttRIw+32BFWaUJp84Mqfl0y41BpIruAYP+Cx/PtTCcqe0O8kd1FhWilbL/NX7+GWLJ/7Tsm49fyOp2ia9pps4n7QgCgsAFBIyUTZMzuXz28Sf4aO8HKotL1tKlWLVujRIc8PH1FagEgUWHgBBZhcg65qRfrETWEVActII0D9tRQilm2BjaRNG5AR5apGoDkOoZgFgvX3iR449iIEYOkd+CgCAgCAgCgsBlCIxnSLqs8jh/sOO4o6MDrKbGKqxsWOK0P8uWLbvmkUxa+f3vf48f/vCHYCPStm3b8Mc//vGiEtulB7a1tYEJMOOVGkpVf/DgQdWPxMTE8arLfjdBoLPwHFqOH0N3WSl0/gHI+NKXEUDjp/WRF2E3GSLphiAgCFwDAeOQkdIyd2MPEVlPnyjAjTffhLxVeYhLiFcBH9c4bN5sHktRnQNbeD+X5577v1iWvRa33Xn9pBTYn3vuOfzsZz9TTqlXX331KlweffRR7N27V60R/vCHP1y1fzIbhMg6GbSkriAwdwiYTHYMDDiU+mp7m5neMSxgNSBPTw9ERuqVEmtioq9KKc0kVilTR4BJrfwe1tvTg8b6RkViZYUqq9miCAR6UmINCQ0hxcNwxMTFIiIqEoFBgUTSkswJ46HuJGw5q9YRIp4dtbYRedUHKaSmmK8Ngz/Zb6W4DwJCZHWfsRivJ0ajA61EYi0q6sPx493YvDmMUkcHE+lJQ/clr/EOn/H9vT1DaGvuxrGDpWiqp1THWXFYkh2HrJwEaLReM0JmdRBDlpWda+ykAGvtgM1jmNRYPbFcE0p+oEB1PxFi/IwPrTS4GBGg5zbbJdsLTpHiYwn8aN2Tfs998ImKhj4gwO0Roe4rJVYmHBaVGdHZZWd+PVYu90VinA7BQV5qLT0XFzKW/0Gj0WAVpaWup2xd6enpYL//ZsrUxWvUQ4cOKWVVDnhlUurx48dVloCNGzeC7f/XCnZ99tlnwdlgMjMz8emnVxMtHERSPnr06ISg4DUCE2EXK5GVQeK51U/vZnX1Fhw5OQgvev2Ki9Ehe4k34mN16llHbqFZL04aN3NXF9pPF6Ds1ZcRkJSM1NvvUKIYhrCwWT+/nEAQWGwI8L2S7d11tXVKhbWjrZ0CYU1YsTIPS3NyEJ+YACGxLrZZIdc7goAQWa9eX41gc+lvD7pp8Hp00ZXFTmQdGXA2ZjTah/CJtQkNjkEMkmHjZn081mjD4e2pURH+JKw/Ul1+CwKCgCAgCAgCFxEYy5B0sdIEPjCJ9Te/+Q2eeeYZRTZlEuuPf/xjfP3rXx/1aFZhra6uxj/+4z8q0ilXWkpRfK+99ppKQTzaQZxiqLi4eLRdl21j8ur58+eFyHoZKu7/h804BGNLKwqe/78wdrRj6dcfQXhuLnyjY9y/89JDQUAQWNQItDS3oLSoBEcOHkZTQxMe/fbfII+Mep70LFwIZaKK6n95YxesQ1okpoUiKMgPAYEBE1Jg/+53v4u33noLjz/+OH70ox9dBRmvLZ5//nkiKeThvffeu2r/ZDYIkXUyaEldQcC1CLCzmp2krHLX2ckqrEZKBdqjCEt2uxMrV4aoNNKRkQb4+i6M+6trEZ7Y2ThtIDunCs+cU8EZx48epzSCVrqn+2P1+rUqdWByavLFezy/112abWNiZ1kctWxEYh1y2rHHUo991mbco0/Cal0EgiijlqQDd685IERW9xqPsXrDzwl+Xhw/3oNdu5pJlc+ffigQNsMfAaTYPVflyOfFOHOyGm0tlGY1MwZ3fmkDOfb10Ghm7nnFPp82pwn7zM1EkG/DFl00VunCkeTlB9Z4lux8czX6ct6FgABni3JSYE/xH36PxgOfIyQrG1FrKG35pi3QeHvPi0u02YYxZHTieMEg9nzch2VZ3hRo6qPUM4MCZ+5eNBUwxvI/MIF13bp1qlkOYF2+fPllp2AS69atW9W2N998U9W95557VBYYtiWw8uqVhQmunCGOM8axr2E65V//9V9JnNexqImsI/h199hRVGoipV8TauosuG17MFat8KHsOiSoRQGHrio95eUo+dMf1XfWLzYWCVtvREj20hkJHnHVNch5BAF3R4AJ/GayC1SUleP40WP44L09lH1sKbbvuAVLsjIlY4u7D6D0b9YRECKrEFnHnGRCZL0AD0f4GynGv9lhRAWps5Y6+uDjoUGEpwH5mjBSZvWBnv523TJyzGGTnYKAICAICAJuhMBYhqSJdJMJqxwd/Q//8A8X0/9wtPO//Mu/KMLJaG2w4s//+l//C5zmhw1BHHnNKYX/23/7byqt8GjH8LaKigpw2qDxCtfhCG1WhhVF1vHQcp/9TnKa2yhlVNWut5Uqq5fegGgyZCZTGi+yRLlPR6UngoAgIAj8FYELpKthclqfxjtvvkPKgD5ISIzHxus2U1R6/II2oms0WvyBnHyXKqrvvP3byM5NQHRcKLx9LqhyjEyWaymw8/7t27erdH9PPPHEqM6hF198UamwxMXFEantpFJDGWmXfw8ODuKll166dNM1P3NqwpCQEPzN3/zNNevIDkFAEHA9AkxeZed7a6sJdXVGNDYa0ddrJxKQF0JD9UqFNSLCQJ91pMLkSe8MosI6W6PEDqsR5ZXODlI8am2jNILt9NOJgf5+pbjN6V1j4+OQnpFOv2MRRmqtHNjIP1K+QKCdCGfFth5UUxatzmEztuvikK0Jhs6DyL9ipf0CKDf4JERWNxiESXSByaznzw+hpHgAzS1mInACW2+MQFycgexLc/N8aGvpQW1VC44fKldE29SMaFoXJyElPXoSVzZ2VdswKdERQb7S3odSew86nGZSZvXCWl0kEigzXyj5gqQIAoLA1BAYaKhXKcubDx+GqbMDKXfciYjlK+BLaqwe8yBA1UFr6fYOGwrOGtHabiNCqwN5y3yRmeGNQH8vyhQzt2u0sfwPb7zxxkU7QFNT01XrSfYbxBJZkf0JHOC6c+dOjATDsjIrH8+2mZHCAVb33nsvDtNYfuMb31BCGyP7pvJbiKxfoGaxDKOb3tEKS4w4UTCE1GQ90lIMiiwdQPPMVcXU2Ym20wVoO3mcFJQLkPPwI4i7YSs05EuYD99XV+Ek5xEEpoNAw/l6VJE/9uTxE+jv60d0TDQys7ORnbMUAZShhW3gUgSBxYyAEFmFyDrm/Bci6+Xw8FK9loyjZ23dqKHfJor6X0WqrBnaIER5eEPv6UWmjbl9Ybm8x/KXICAICAKCwFwjMJYhaby+MYn1ySefxAsvvKAMRkwMYULrgw8+eE1VHl7csRGptrZWNb9t2zbw83wkLfF455zIfjZUffjhh0JknQhYblbHYbWiq7gIrSdOoOngfkStWo3MBx6E1td33igguBmk0h1BQBCYRQTsNk59PYBDnx/EKy+9jI1bNmHr9q2K3MMkn4VYrqWo/pOnnoNeRymTyVnvH/CFYs216o8osPNaIisrSwWqPP3003j44Yevgo0DX1hlhVMJFhYWXkVk5TFgVfiJFCs9Z0JDQ4XIOhGwpI4g4AIE2OdsNNkxNEgp63qsisBaW0sk1j4bvU8A2dkBSEv1oyABHyInCVHSBUNy2SlUwAYRW1spa0JNVQ2KzhWhtroGZrMZwfTux8qs8QnxiKXUu6zC7RfgDx9SLWNF8sVMamX7rP2vZLNPSIlVO+yBKBIZYBttHJHNpLgfAkJkdb8xGa9Hg/Tc6OoyY9+nHWhqNuHGGyOVKmtwsJbuP+MdPfP7+X7Z3TmAg58Wob62jQKtTFi7MQsr12eQo18PrU4zYyftG7aihQRNPrM0gwnz7PvJ8ArEEk2QIspriSovRRAQBCaGACux2i1mtJ06hdo972KY1j0+ERFIu+teBKamzov1DHVZkQtrzltw+NiAIq2mJRuQRSRWTvvuDmUs/8PRo0cV8ZT7yWIZV/oIOEMM2wy4vPvuu8jPz8fu3btVRhedTgc+PioqSu3nf7oo9XwuZfji+zKfd/PmzRf3TeWDEFkvR43f38orzThGyr9ms5MyZXhiwxp/REdqYdBTqJYLnsEOiwWWvl4Sw3gHpS/9EVkPfBUJN26DLxHttD6y1r58xOQvQWByCBiNRhXAWnSukLK0nEE9EVrZHrv91h1ISklGaFjY5BqU2oLAAkVAiKxCZB1zaguR9Wp4zBSZy2lmzhGZtZyUWTvIqBFP6WVu0MUg3IvSr3lorz5ItggCgoAgIAgsWgTGMiSNBcoIifXf/u3fVLX77rsPP/nJTyiVW8A1D2ttbQUTV9mgxC8/P//5z9Xf1zxgijuEyDpF4NzgMDYY24aG0H7mNEr++Ht40zyJ23IdwpbmwD8+wQ16KF0QBAQBQeALBJhAyamXz50+h7MFZ3DL7Tuwbcc26PScRnTmnNVfnHFuP42mqP74448jPWEDKdBGIjc/BQZvHby8LjjPR6t/pQI7E51YRaWmpgac/u/b3/72VRf57LPPqjUDK75/+unEjCRXNfLXDf/n//wfUWS9FjiyXRBwMQLsBLXZnBTgNkSZHQZRUtKvHJ8hIXqkpvoiPt4HgQFapcqqJ6eoK9NVuhgKtz4dkwA4CMBC5NWBgUH09vSiqb4RNURora6sVvv0eh1y85ZTqsEsZGQtgTeRWRfic3CiA+XAMPrJNnva2om3zXXI14bhRn0sqSXqVQatibYj9VyHgBBZXYf1TJ3J4WAlbyf27+9AZcUgOdV1SEvzp5TUQSrF8UydZzLtWC02dHWSyMipGny69zRSSJV1WV4KlmTHk3L1tW1lkzkH17XTPcZCPqBqUmZl/89ZWxfiPX2xSR+NGCLNB3voJ9uk1BcEFi0CNuMQBhub0PDZpyj78ytIu/NuJG7brmyQunkQnMrraavViaMnBynduwUmIhamJumxbpWfIhgysdAdylj+B86wspTSVbP9gG0Df/zjH6nvvkoko6enB//1v/5XRVwNDAwEP68NBoNaf2aTMiATrq677jq8+uqrqr6dsn099NBD+OSTT5SK65EjR6a9JhUi69UzaICCSbq7Hdh3qA/NrTaszfdDeqoecTF6FYx49REzu4X9B5zZrenAflS98za8KVg5iIjnCTcRmZVUlKUIAoLA1BDgd/86EiA6fuQoSouK0dHWjg0k2pCbtwIJSUkUtOpDwVnCM5oaunLUQkNAiKwT89F4mEwmWq4uviJE1muPeb1jkFJXDVAKq26wATWajBgcmZuqCYDBwwsSmXtt7GSPICAICAKLCYGxDElj4VBfX491lPady2OPPQZ+Jo9XRtL++Pn54cCBA5QiNHK8Q6a0X4isU4LNbQ7iF+b+ulrU7t2DweZmDDvsSLn9TqXO6qkldRWW55IiCAgCgsAcI+Ago3lzUzP27t5DDusuBAYFYf3mDchbmTfHPZud04+mqP7IQ99GyZl2pGfGIisnAXGJ4RdPPlp9Xitcqa7CB9xzzz04duyYSg/IyqtXFia4/sd//Ac2bdoEVnKdThEi63TQk2MFgZlBgJ3tRkp32tlpQVubBe3tZvSSAqvF7EBQkE4RWBMTvBERaSAykmtUfWbmyhZHK6zG2tHWoZRZqiurlHOLCQhMOAiiZ2FwWAgiSMksMioS4ZER8PP3UwSCxaTQahy2o8zei3IimfHvdboI3KAlhSiyx3q5QqZqcUzFGb1KIbLOKJwubay8bAAVlQM4f96ImBhvbNkShgB/DQWWuS7F8cgFsy3DbnegtrIVR/aXkJqViQK8PLBuczZSM2LofmggxeqZsWc4/0qYP28fwFFrGyykAu3nocEyTQjStIHwI++P1mNmzjVyffJbEFhoCDiJODnY0oyGfZ+it6oKxs4OpN91N2I3b4EXpSj31Lh/cGpXD9klWqw4XWik9bQDKYlfpHp3J/PpeP4HJq8+8cQTaoqFkdrf2rVr6V2hEydPnoSDVHO5PP/889i5c6f6zP+wKisHwjqJ1Mgk17y8PJSWltL7RRv0FFy8Z8+ei0quFw+awgchsl4N2kgwyZGTQ0SgNkNLmTOSE/RYucIX3gYP9Q539VEzv6WnshLtBSfRcfaMUlPOvP8BBGVkUFY3n3mhpjzziEiLgsDUEOD7qJHEZc7X1qGM7qNFZ8/RO7wWIaEhRGTdjNS0VHj7+NC61vXr66ldkRwlCMw+AkJkFSLrmLOMHWEZtCh54IEHxqy3GHcys5mVWUvtPSggBYDjtg5s0EXiBlIAiPLyBiXoXYywyDULAoKAICAIXIHAeIYkrv7b3/6WVJKqSBkpFY8++qhq4ZVXXsHf//3fK2flZ599RqnSfK5o+cKfnFKYnZr8kpOTk0OO6nZlmPrGN74xan3eyG3xcVMtQmSdKnLuc5xtaBCDRBCr3vU2Sl/+E1b+P/8vUu+6B1qOyJ8HhmT3QVJ6IggIArOFgImUPyrKK/Dvv/iVSqf81YcfRFxCHIKCg2frlHPW7pWK6s8881O0VA+jqrwZK1an4a4vb1DpUkfUEq+sP54C+0igC6uvvPHGGyoF4MjF8nrg3nvvBT/bee3w4x//eGTXlH4LkXVKsMlBgsCMIjAwQOo5TSYUFPSQqlIPrf01pJjkTQ7rUMTFeyM4iNNCeyh11hk9sTQ2YwgwWYt/2OHV1tKq1FmPHTqKspIyNDU0IiNzCfLXrMLK1fmUfjBp0Tm9up0WvGs+j85hC6I9vZGrDcVSzcJbH8zYhHKDhoTI6gaDMMUumEx2NDSY8Zc3m4g844lbbolETLQ3rc/nTi3KZLSgn0is775xBCePlOOGm/NozZxK98MoItjOnE+G7sQYctrRPmzCQWsr3jc3YCv5ftaTDyiRMvT5SWa+Kc4qOWwxIKCI56TG2nHuHE7/4v+Dgd7j2e4YSins51NGqHPFRqXG2k8KmSHBGmy7PoBSvOugIRK9OxV+z//BD34AJqkWFRWpNeSl/eO1/8svv4yf/vSnyndw6T4OlGI7AGeD43G7tLASKwe+DhEBa6TExcXhqaeeoufBLSObpvVbiKyjw8dD0dFpR2WNGR/u60N4mAZ33ByEsFAtfH2m7tcZ/Wyjb3VQgJ2VMiWd+r//gk6aV7mPPY7I/FXwIfEUEcIYHTPZKgiMhgCrWbNYw+433yYiawmGBodwy2234mb64WwrOsrAImXhIcDPXn5+vv7666ikwAAWoFq/fj3WrFmjfPRXPnOvhcBU2uEMPmzr379/v3ru5+bmYsOGDYr3x/NxpLDCem9v78ifY/6+4447oNNdmKtHjx4lu2PTNetn0XqPld2nU4TIKkTWMeePEFnHhAe2YSd6yGhaQ5G5xY4eGMmwoaWbUp4mTCmzBnnQC41E5o4NouwVBAQBQWCBIzARIuuXv/xlHDx4UKX34UUtFzY+sRFqvBIfH4/jx4+TY6FBLYDHq8/7f/nLXyrSykTqjlZHiKyjoTK/trEqgo1IYqyKUPnWGwjJykbE8hWIWr0W3mT0lCIICAKCwFwiwIacksJiFJ45h7P0k5iUiHu/cq9SZWXlj4VWRoimbND64P2P8Nn7paTA14uU9BhkkhJr1rIECkBh0tkFZ9ml9SeiwM5KKo8//rgyNrGhKSoq6iKEXV1dYGMWY85rls2bN1/cN5UPQmSdCmpyjCAwfQQsFicGBm04X2dEc7OZDNUWRVQ1EOkokpRXIyL0SknP19eL0oWKysf0EXddC+zk6u/vRws5vlqJ1NrW0gZWaDWbTHDSvTsgIADxifFISk5CQnKiSgc74lxwXS9dd6a+YSsaHEP40NII0hPGdbooJGj8ESqpvl03CFM4kxBZpwCamxxitzvR1WUlR2g3pTm2krPdE8uXB5JjMuDi2tTVXXU4nLBabDhXUIOiM3Xo7x1CVEwINt6Qg7CIQPj4ztz7Avt/zJSPr5IUoAspM98AbNAMe2CVNhxJdO8J8aQ0z3QvkiIICAKXI8B2x+bDh9BWcAp91dUIzsxE6p13wRASAp2f/+WV3fCvwSEnGpstKK0wo6LKTGndDUhL1iMlyaBIhH99NXfDno/dJavVipKSElTTmHDAVFpaGjJpbJhIda3Ciq18TF1dHZYtW4akpKRrVZ3SdiGyXhs2k9mJ1nabIlMPDJAyuC89g3N8kJlOisbKRnTtY2dizzCNvcNqQeVf3kD76QJ4U1aI8BV5SNx6EzirmxRBQBAYGwE7PQv5vltw8hSKzxUSmbWJMgj4YwmR/JZkZSI5JQUarWZaokNj90D2zhUCbMPn7GgPPfSQsudc2g9/mgPvvPOOev5eun20z1Nph4/hLK/sD7iyMBeB+QEjZNabbrpJPeOvrDfa36dOnUJ0dLR6B9y2bZsKnBmtHm9jRXcOhJlOESKrEFnHnD9CZB0Tnos7e8mI2khG1COUZoZTWi2nFDNZ2mCkeQWoyFxJM3MRKvkgCAgCgsCiQ2C8iGgG5P7771eRUddddx1YiZUXmqyaVlNTMy5eKfSyc+jQIezatUuRVMY9gCr86le/AkdPTbUIkXWqyLnfcR3nzqLx888w0Nig0gIt+cr9CE5Ng+dfI+vcr8fSI0FAEFjoCLCThH/27tqDs6fPkNpTIJYtX4bNN2y5GPW7kDDgCOlLFdW/+sDXYLPZ1VpAb9CR4voXab9ZUZ3JSZfWn4gCOxtNOQraSAEMvNZgVRVWYmWjFRvUOPo6NjYWR44cUempp4OvEFmng54cKwhMDgFW6bHZHLBYholcZEFHh4XUPQbQ2mZW21LTfImoHqiU84JIhVXK/EeAyau9vX0q2ONswRnUVNXARNsSkhKQlpGmnGGcnjCQlLW8vQ30zNDDS7OwiMtV9n6VHavQ3o1IUmO915CCQFJF9KR3aCnui4AQWd13bCbSM6PRgdraIZSV9ePcuX5s2kik0Y1hlFrai+4xc/fd6+4cQH1tGz7cfZJIAnZs2roMqRnRiI0PI6W4L4LAJnKN49Xpp8x8nU4zPiESfS2JmrAKNPt/MjSBoDstiZu4Rh1vvH7KfkHAHRBQKo4UhFP66svoIhXHICJLRq5eg/jrrnd7FccL6+thNLfacKbIiJZWK4ZMTty4JQBLlxhUSndZcszsLBMi69h4DhmdqCJV1tIKE4rLTFi/hhT9VvlThj5P6LQueAbTl6KdCOmtRGBqKziJ0MwsLP36I9BSILaQWcceO9m7eBFgsQAH2VxZ6bKttRX7PvoEpcUliIyOwvL8PGzddpNS5OQsm1IWJgIsHMHqqxyEzIISrHrOQSPsx6+oqEAIBfbs3bsXLFQ1VplsO8wtYNX0F154QTW7fft21Y/i4mK8/fbbyhfAWWF/8pOfqIAWFr4Yi4dQX1+PAVLmNhgMlPHpNALJT8O+jOTkZKU2ey1BjJ07d+JLX/rSWJc27j4hsgqRdcxJIkTWMeG5uFNF5nqQQYeMGFUUnVtJRlU9GS/W6CKQ7OVPaa5GTwd9sQH5IAgIAoKAICAIzCMEhMg6jwZrnK6ae3owSJGg5X9+Bf0N57HkS19BBEVW+0bHuL1xeZxLk92CgCAwTxEwUsqdvr5+/PmlV1BeWo477r0TuSuWIzo2mkidC8/A19jYOClFdU4/xD8TKZcqsHMUNkdDs+oKG53y8vJQWlqKtrY2IiHosWfPHnDan+kWIbJOF0E5XhCYGAJOJzlGHKDvsJkUlQYVwaitzULpRPWkwKpHXJw3QsN0CA7S0XfcUzndJ9ay1HJnBDjQw0aqLoP9A4rQ2tXRqRxjjfWNSq21k/5mUmtKWiqWLltKz84YBIcEz5lq4kxieSHR7TA+sjThtK0LUV7eSCcCWZ4mFAYPL9JDdIEjfyYvaJG1JUTW+T3gDscwBUQ5UFjYh48/bkd6uh+p8gWS49Wb1pVzFyhhI/JqH6mxnjlZjeqKZnS09iJ/bTq23LQceoOGnn2aGQOe/T+WYQdqHP2ocPShzNaLMLoPrddGIM7LF6Gehhk7lzQkCMx3BPpqqtFZWIimQwdgN5mRsfNLCM1eCgNlgGKChTsXu30YTS1WVFSbcfKMEdGRGuQt80VcDK+rab1B3Xf3a3BnfEfrmxBZR0Pli2129QweVkTW/Uf6ER6qRXysDrnZPggPm7nn3BdnvPqThfwHXSXFKPrD72AIpiCOe3ciMDlFKbReXVu2CAKCgM1qI/JfP04eO4GP33+f1qXeiIiMwMo1q9W7elhYuAo4lefJwp0r//N//k/85je/UTb492kOJCYmqotlUugNN9xAmZSalcDVs88+OyYIk22nu7sb+fn5Sgn4kUcewdNPP62ysPFJWODqySefVOcrKCi4LGPbaJ1gQYxNmzahlcjYv//978GkWC5M0GbBjMjISJw9e1b5GkY7frrbhMgqRNYx55AQWceE56qdHJnb4jDiKCmzdg6bSRFAp4yqmZogBJA6gLeHaxaVV3VMNggCgoAgIAgIAjOIgBBZZxDMOW6KUwTZLaTe9fKf0EYpggKTkhGZvxKxmzbDi1VZ3dzAPMfwyekFAUFgFhBoON+A0qJinDh6QkX23v+1/4KMrCWKbLkQDXxMMOXo54kUNjhxmUz9SxXYWYmV0/oMEVl4pMTFxalI7VtuuWVk07R+C5F1WvDJwYLAuAiwssfQoAO9faQM12lBe7uFiIxmDBntZJwGUlJ8kZTkq8hF3t4aWcqNi+j8rcBzgRVaO9o7UF1ZhaqKatRW16jnpS8pJIVHhNFPBKm+RBKpORQhoaHw9vEmYtfckc6mg7Zx2I5+yojFRNZyEhG4XheNLLK3siqrRpQQpwOtS44VIqtLYJ7Vk/A9p6Z6CIcOd5KSD+Dvr8Hq1cH0vPEhpf+5I3YxmbW5sYveH+pxdH8pYhPCkJufguS0KIRFBKrUyzMJTJ/KzDeIg5ZWDMGOEA89skmdlYn1fuT/EWXWmURb2ppvCDjp5mCntUnz4UOo/+QjeGq0CCDiRvJtt8MvJtbtA+YtFif6B504WzSEhiYbvTc7kJ3pjbUr/ZTypdYV6pfzbdBnoL9CZJ0YiA1NVpqbRrS22+g5PIz1q32RkmSAr4/njD/rruzRMAVED9SfRwn5D6x9ffCPi0fsxk2IyMsX38GVYMnfixoBXi+biPzX3tZO4gyl9FOGirJyLM3NQU5uLgWb5qj38kUN0iK4eM6CxmqstbW1+P73v4///t//+2VX/bvf/Q7/9E//RO9T/pTxouyaATJTaYcVX7/1rW8puw+3zSqwI4X9KixiwURU9g+w4MW1CouJfPOb31QKso899hiYMzhS+N3+tttuUyTX1157bWTzjP8WIqsQWcecVEJkHROeq3ayOoCFDKutThOKbD34xNqkInLzteHKuBpFxlUpgoAgIAgIAoLAfEdAiKzzfQQv7z8bozrOnkHryRNo2v85QpfmYMV3vw8tpbD2WIDqh5dfvfwlCAgC7obAkYOH8fbrbyEsPAxJKUnYeN1mRMdEX9Oo4279n0x/2MDpcDhRcu48dr12CD6+BiSmRJGSVBoSkiOVM2Kmybus5ldSUoK6ujpS0lpGhLekyXR53LpCZB0XIqkgCEwZAb5ngP6vrTWirLwfZ8/0wWx2IDxcj6U5AcjI8FfKeKzAyqmeJdX6lKGeNwfynHDSfd1KKq1mUjwborR1xYUlKDpbSD/n1DMmIioC+atXYsXKPMQnxMM/wH/eXN+lHW0m4YByey9KHL3oc1pwjyFZpfTmZN6ixnopUu75WYis7jkuk+1Vfz/5PVpMRGbtQlXVIO6+OwbLcgJJZcpzztbqI+vp+to2HDtYhuaGLhiHLLjtvrWK0OrlNbN9Y/8PE+ubHUMosHfiU0szVmrCsE4XiSSNvxIzmSyuUl8QWCgI2IYGMdTSiupdb6PyzTeQ/dDDSLxpG3yio6H1dv+sld09DiKwWvDJ/j7YKfPB9RsCkJigQ0TYhSAg4n9ImQUEhMg6MVAtVlZHd+LDfX04V2LE2nxfIlr7ICFOp4jWE2tl6rWYwNp25jRajx8l/8F+9f1Ov/c+cDTLTNutpt5LOVIQmFsEOAtWM2XeOnv6DN75y5tk5/XF6rVr6F08H6np6YpcuBCzjc0t6u53dn4/SUhIIHuMA++++65SSL20l0zQZFVWLh999BGWLl166e6Ln6fSznPPPYef/exn2LJlC1jQ4sry6KOPYu/evdi2bRv+8Ic/XLn74t9vvfUWvvvd71K2pzgcOnTosoDov/zlL4qg+/DDD+PnP/85Ojo6FDmWfQw8v+0c9TgDRYisQmQdcxoJkXVMeEbdOWLMaHIO4Zy9Gx0OM4xOG3K0IUj3CkAMpZrhlFdSBAFBQBAQBASB+YqAEFnn68iN3m9+ITJ3dqKTUgRVvvE6dBQJmECG5pAlS+AXGzf6QbJVEBAEBIEZRsBC6tC93b048Nl+vPPGW7jx5puwbtN6xMXHw8/fb4bP5h7NmU1WlQa1jBSkCk/XIiM7HqvWZyAqJgQBge7v6BsNRSGyjoaKbBMEpocAK+4MDtpIedWC+nojunus9LcDGkr6ExSkQ3SUAVHRekREGMi4TCRWL/GyTw/x+Xk0O0nsNjtamlvQ0tSMxoZGdHd1YXBgkFK9DUNDKbY5SCQqOgrxifFKrTUkNMTtHc9sZ3UQg7uIbKwfkxorZ7yK9fTFKl24UmOdn6O1+HotRNaFMeZWqxMmkwOHDnaisKifFH38kZbmp9TADYa59Xf09xnRVN+Bs6dqUFpYj+xlCcjMSUDqkhh6l5hZcRH7MOFAd6Zqez9O2zqVMqt22AMsZpJMZNZgTz0oAfnCGHS5CkFgggiwGmtfTY1SYh0kEo/dYkbK7XcictUqRWJ150B5XmtbiSRYWGpCcZlJrZsiw7XIX+6D0GANDETWlzJ7CAiRdWLY8nqelvs4Q4rBpRXEOzA5EROpJWVWCmYM8IJON7vPHQfZ7ExdnWgkEYzyV19B/NYbkXjjTfCLT4A+IGBiFyG1BIEFjEBvTw/aKJjj5PETqKuppSsdJoGGZAoqXa3ewYNDQhbw1culXYpAfX091q1bpzZVVlbClwjNlxa23cSTv4MLk02ZdDpamUo7TD5lEipnc/vRj350VbPPPPMMnn/+eeTl5eG99967aj9vaGtrU30aGBjAr3/9a6W+emlFJq8+++yzShyDs74xkZWLhoyUmzZtAvsG+PrY7zydIkRWIbKOOX+EyDomPGPutAw7MDBswwFrK/ZRZG6KhtQxvAKRrwtDKKWckTQzY8InOwUBQUAQEATcGAEhsrrx4EyjawONDSj/86swtrVCFxCIBDJGRa9ZK5HV08BUDhUEBIGJI9DX24fykjIcO3IUBz87gEcefxTbdmwncYeFqe5gJ4mXnq4B7PvgDOpr21XE8trNmdhw3ehR2BNHcm5rCpF1bvGXsy8cBNjey0ZfJg1xWtP2NjOpsA7g7Nk+RVQNDdWplM5JSb7gz56es+u4XDjILo4r4bnDzpGmxiaUFZei4MQpesaWq5S+sXGkoLgiF+mZGUhKTiKnN6k46XXK6cDPXHcrTBgzEmHsMNlXXzfXYKsuFlt00Qgjopi3B7G5pcwLBITIOi+GacKdPHumF0VEZB0y2hEd7Y3Nm8MQEKCZ82cR3/tOHC7HoX3FsJFSNQeHbb0lD5HRwdDqZv5+MQQ7OuxGysrXjHO2LqwiImuONhTp5AfyJiqrl4f73VMnPMhSURCYBAKc6clKZIfW48dQ9NvfwJ/ICwk3bkNYTo7bB8jzmnuIVC47u8iXe2QARWVGbF4XgJwsb8REaWmdJN/jSUyFKVUVIuvkYOvutaO+wYKPPutnMVRsvyEIcTFaBAfN/HNutJ41Hz6E4j/+Hj7hEQjKyED8luvgn5Do9sFxo12LbBMEZgIBfu/mdWdNVRUKKSvKkQMHYbVYceuddyBneS4Sk5Pk+zETQM+jNj799FM8+OCDyqfR0tKibDOXdp8Jn6x0arVa8Ytf/AL33Ufq1qOUybazc+dObN++HYWFhXjiiSfwgx/84KpWX3zxRTz11FPq/CdPnqTgHedlddgm9J3vfAdvvvkmVlEw0q5duy7bz3/w/rfffvvi9vDwcHWN3d3dahvbmJgkey2lWaPRSMH5gxePv9aHpqYmvPPOO7jjjjuwcuXKa1VbsNt5/CdSPEwm0/QowxM5ixvWESLr1AfFSZEWVjK2cpqZGscAyij9FaedWaIJRKYmWP2eeutypCAgCAgCgoAgMHcICJF17rCfzTNb+vvRXVaKliOHSUHhY6TftxOppJ6g9fODl14/m6eWtgUBQWCRI8BO59rqGux6cxelAjUiNCwUm6/fjKyc7AVr7GuitKe1lS04eqCEyENeWH9dNkXqRyEyJnhezwYhss7r4ZPOuxECTGD9/9l77+C4jivt+wEmB+Sccw4ECGZSTKJysJKV5SDXWvbrdW19f2xpyy595fX6lctlr/dbW2Wv1ru2ypZXsqxoKlESxZwRSOScc8YAg8mD73RzKZEUCQHgDDADnKsacTD3Tt/up+/c0P07z5mddaG52YSuLgs5IlihUgYinKDVWOHASq/wcDU5Oyig0ZDvG3OsPtR7vlEVMSFhmbXAJO7xx8YxOjxCrr5DGKbXCL0Xx4xOr0d2bg4yszORmpEGPf3ta6kOhUlAA42pNjun6DWJPZp4bFJGQRuoZMdD3zjUFlQLBlkXJJPfbDQ6etEh/OTJMRlcsXdvNOLjdQgKWh6IZj6hRoenZJDYmeMNME2aUbQ+HbkFyUjPjpvva0ta56C5HzuB9q3kzNrsMqHTOY2gQJU8RyUrjQTca5dULn+JFfA3BZwEJPQeP4YRSjs+QSBPLLnPifFETWgIlDrfzTTiFoE/lP22rdOGk2dnCMKYg0EfiNJiPVISNeTEGrDigL6/HQtLqS+DrItTTTwnTky5cK7KjIFBh7ynLy7QYUOJQY6fefu50NTVieGqKgyVn8UsZXgr+ObTiClZj0AClwK8vfPFScVbswLLooDIgtJY34ALlVWor62jZ+ss5OTlIjc/n7KgRMFAc2u8rC0F/vSnP+HZZ59FSEgIjek1XxNkTU9PlzDnv/7rv+Kxxx67pkCLLUfAs3l5eRBA6fPPP49vfOMbXyj3D3/4A374wx9CwKcCeL0aZBXg7aZNm2SdDxw4gKKioivKEOf522+/nYLsL0hQVTi2pqamym0OHTqE73//+3L/aWlpOHbsmIR5ryiA/jh8+LB8Xf351X/HxcVB1IdB1quVufJvBlkff/xKRfivBStwyZn1ODkHtNGAhpIicdMDg1BC0bkizYyRUmLxwgqwAqwAK8AK+JMCDLL6U28tvK4iDZgYfO7+9KB0UIil9BeJO3cjMi8f2oiIhRfEW7ICrAArsAgFxICJgGzqqmvx+it/RVx8nHRiTUpOQiQN+K22RTix2m0OnC9vQ+35TkybLJTiOQo331GK0HAKHFD4t+MLg6yr7Yjl9iynAnOULtJqEw6sThr4tWN01I6enlmMjdmkM6uAhPLygiUsJCBWnidczt7x732JgBEbpQPt6+kjp5g21FfX0fFF6bApDVxcQjziE+IQn5ggJzPCwsMQTOCJXqdDoEJA0itHSQs31kG3BYfI7dDkdiA0UE2puyORpwz17w5Zg7VnkHV1dbrTSRDNhAMffjgo/83ONiI7OwhpafoVPWcIld0uAfHbceijKrQ19cvJ05yCJGzakQudTgON1vNzMQK47yMzkyO2AUzM2ZGo0CNHEYocVSg5Ryuggn/f36+uo5db42kFHOYZmClIpvXtNzHd001urMmI27IVCdt3eHpXHi1P3hvZ5zA45EBjiwXl52eRnqJBQa4WKUlahIYoPLo/Luz6CjDIen1trrdGPDN2ddvR2GpFTf0s8nN12FJmkMetXufdY9c+Mw0bQVINr/wZg+fOIfeRxxC7eTOMcfEIVHn+Gns9DfhzVmClFRAurOOjY2hva6MMKOWURWcIVosVe2+9BaUbyhAWJjIC8G9ipftpJfa/f/9+PPPMMzL7TW9vL5w073r5IsZYBKQplpdeekm6qF6+/tL7xZZz2223Yfv27Whvb8dzzz2H7373u5eK+uzfX/7yl/jFL36B3NxcXO34Ker1gx/8AAJ23bZtG9544w2ZKeqzL//vm87OTgmrCmhWR+NGly8ffvghnn76afnRxx9/fE1XVlE/8fqyRfzGzpw5wyDrlwjFICuDrF9yiFx/tXBmddGA8bjbijb3NA7TgIYYAk5SGLBJHY0sRYj8+/ol8BpWgBVgBVgBVsC3FGCQ1bf6w1O1EYO4FIKH0bpadH38ESyjIzQApUbuY48jgmBWXlgBVoAV8IYCTodTRqxXV1Xj3JmzWFdagkefepQGezRQqlbe1cnTbTbPWGigcxofvVtBIGsH9txWgsKSNCQmR9EA58oCQ55oK4OsnlCRy1iLCsjbMHKBGhmxoaGRnN2aZ9DRYaZ0XzqkphqQlUXObpEacsxUyBSnCsXKwYVrsX9WQ5tF4IiYCBBpDq0Wcvkl6KSvtw/1NXXo6uzC5MQkEpMSKf1hEYpLRArEFAK+tOQavnLXYjNltmolJ9Y3rJ1kBqDG3ZpkxBAgFsymAH53SDLI6nddNm+FxTXLYnGhrm4KbW1m9HSbUbYhHHv2RMvvrSD/Lidb3RQYMjI0iYaabnzyXgWi48Jw081FSE6NpkC5kHnbtpSVLoLureTM2k0wa51zAiftQ8hWBGOrOhbJNAckzEx4YQVWqwJTBPCM1FSj88AHcgyx4OvfQFhmFtTkQubLizhPjE+6cOTENAaG7DLzQUmRHsX5OqhUAXT/w/fay9V/DLIuXmlxHRYwa2u7DZ8eM0n34MQ4NdYV6pEYr158gYv4xhw9UwgzjNa330IfOTEbYmMRtW4dknbvgcrAzpOLkJI39WMFxDzazPQ0jh0+Qk6s5ylYtBXFNJ69Z98+xJJBQygFhiroOXolg0L9WF6/r/qpU6fw4IMPynZ0dXXRfcWVQLMw9BAgqVj+9re/YcOGDfL91f9bSjn333+/hD+/973vSefVq8sUgOt///d/Y8eOHXjttdeuWD01NYWSkhIZBP2b3/wG99133xXrF/KHy+VCSkqKdHr91a9+hYceemghX7vmNk1NTXjllVcYZL2mOp9/yCArg6yfHw1LfCdSzYzMWXDBMY5eGtQYIUeBPGWYjMwVAxoGis3lR6MlistfYwVYAVaAFVhWBRhkXVa5l31ns8PDmGxrRffBT+S/OV99GNGlZdBRuonAFZzIXnYheIesACvgdQUEVGOeMePDdz9AU0MTjEFGlJaVYtfNu72+7+XegZhoEBHYXe1DqDjVTJPrUxTyOIed+4qRmZNAcJoGAYH+/0TIIOtyH1m8v9WgwPQ0ObCO2dE/YCWQ1UrudnYCcXAxCDqZJiMJZhVurDpy12GAdTX0uG+0YZom3oSDTGd7J3p7ejA0MCSvUwqFUl6PQ2jyTbiki1csObZqCWpVU8rQ5VpEut8WtwmNjgnUOyeRqgjCndok6EHuhuRwyIt/KcAgq3/110JqK1xZR0fsaGqexsmTY8jIMGDz5nBERFAGOuPKAfCi7gIusNuc5EI9ilNH6jAxPiObtGl7LvKKUqDTqwlS8+x5RJiZzBB83+40ocIxCgu9V5MTq8jKl64MRkiAms5d7My6kGOLt/EPBdwUHOO0WtF7+BDBbEclxBqalYW02++ELjISAeTq7stLX78dnT126WapIGg1L1srHVnjY5fvXseX9VnOujHIunS1h0ecqGucRVevDRNTLmzfFITsDC2CjIFef24crqrEYEU5xskQw0BurLmPPwF9VDQUGg7eWHqP8jd9XQExji1Avc72DrQQZFdfW0/j2tMyo1jxuhKUlK2Xz83sxOrrPend+nV3d2MLZbsUy7VA1XPkZv2Vr3xFgs51dXUEPl8748xSyhEA61tvvSWdWV9//fUrHFUDAwPxwAMP0LPbSema+pOf/OQKIV544QU8//zzCAoKQm1t7RcAXLGxhYKiBwYG5NhQcnKyBFYvL0Q8h4nPxe9kPrfZy79zvfcMsn56PWmu+JxBVgZZrzgglvqHGNCwzblQ7hzFe9YuGMlBICHQgN2aeCTRvwoazPD/qculqsPfYwVYAVaAFfAXBRhk9ZeeWmI96WHDTQ8atX/4b+nMGr91G+I2b0FUSSlUev0SC+WvsQKsACvwRQXsdjvBW+P43Qsvop9c4b76xCPILypAbFzsFzf2809cMs2pDaePNeCNl4+iuCwDG7ZkISsvEaHhq8e1gkFWPz9QufrLpgDdbtGAL91zuYGeHgtamk2orJzElMmB6GgNiotDULo+DAZyYNVqfRsEWDbReEdeU0BMRkzQ9bj2Qg3OnDqD5oZmmEzTyCvMRcn6UpRtLJOTc2JCQwRdiAkQb7rL0M+DvA3d+MjWiwaCWMMCNGQGECozW5F3udd04IK9pwCDrN7TdiVLFtey1tYZfPDBIMGhCqQk6yh9ZLAMvvDmOWKhbbbM2qQz6/FDtXj39dO468Et2La7ADGxYRJm9UYdhZP0KGXm+9TWh+PkzLqDXFnXE8yaQTCrHkoErqRd7UKF4+1YgQUoINKLW0dH0fDnl9H10QEUfPNpJO3ZS+6McT4NsolAGfIcwqlzM6iut8BqdSEjTYtbdgXLoDH+iS6g8z28CYOsSxfU6STmwD6Hg0dNOHx8Cls3BqG4QI/kBDUdz94NnhDnAOHIXPH//RKBBK6v++73EJqeAQ2lU+eFFViNCghATxgUWC1WfPTBhzhy8FMJ8WXn5uC+hx6gsew4qBnkXo1dv+g2ifGS7du3U+aKNnzta1+DGCsXELRYxPPHs88+iz/+8Y9Yv3493nvvvStg08t3tpRy9u/fj2eeeUaCpqdPn0YsuWZfWsbGxmissVju7y9/+QtuuummS6tkvYQD65kzZ/DUU0/hZz/72WfrLn/z6aef4sknn6RgCYWEXUOucuA/evQoHn30UfkV4Sgr3FmXujDIyiDrvMfOj370I2RnZ+NxBlnn1WmhK+VALD0lDZMba6d7BvXkKjBGAxspSoqSUoSgQBUuI3V5SHahivJ2rAArwAqwAiuhAIOsK6H68u1TPJSLe5H+06cwcOY0TJ2dCElNRc5jj0MbHgHFVakwlq9mvCdWgBXp2ZsaAABAAElEQVRYbQp0tLWjrroO5yuqZMql+x9+AMkp5LZmMKy2plLK5hlUnG5BR8sABvvHsWFrDsoIZA0ONUCjuTLFkD83nkFWf+49rvtyKeByzUG4sPb3WyQAND5uI1cDN0JCVAgPV9NAsxZRUWrpaqdSed9NZ7nazfvxXQVcYkLOSk5O4+MYGR7B8OCw/HdiYlw6p1tmZxFDE3OJyYnIyMqULq3CsVVMXnhjESDY1Jwd71u70UdZrYQBQBaNm8YqdORvyKOm3tDc22UyyOpthVeu/LHRi66sLS3TGBqy4uabY1BYGEKTpwJ4X7l6iT07nS7YrA401vWg/GQTubQ6EBSix86bixCfHCnvwT0Ns4qsfPYAN1qcU2hwTGKI5oG0dObaoIqiOSAjogJ1KysK750V8IACIrX4eEMDOg98AAvBrAEEbKTddTeiioqh0NG12kv3Bx6oOsYnyK15wI7ztbMQbpZF+TpkEsialKAi5zHvgn+eqP9qLINB1qX3qggoETBrU6uVnFkpMG3SidAQBW7aEkTPkyqoVd67EAtX5tnhITT/9TWYB/phiE+AMMOI3bR56Q3ib7ICPqqAgBCt5ELe3tqKU8dP0vPyEIQ5Q2FxEXIL8pGWnkZBUpQ7xIevfz4q7aqt1r//+79LGFQ8a7z55pvYsWOHBEgPHz4sQVGbzYaf//zneOKJJ6QGvb29+M1vfiPff/e730VSUpJ8v9hyxHGZn5+PWRrD2bVrF1599VUZiCwgbAHVHjx4EAkJCRCQqfKy7Jvie5mZmRLWns9JVZQr2EHxm3jwwQchXFzFItrZ39+Pr371qxLg3bx5M95+++3rQrryS1/yPwZZGWSd9xBhkHVeeZa8UjizOsiZ9YRjGDXOcVjpfZLCgC2qGEQGku0/ObV67/ZyydXmL7ICrAArwAqwAlIBBlnXxoFgGR7GWGMDGl/5MxRqDXLpoSo0PVOmCFsbCnArWQFWwFsKiMEO8Tp59ASOfnoEWprsSklPxZ59exAZFemt3a5YuTPTFvR2jeDgB1U08GlHUnIUSjZmIjs/ccXq5K0dM8jqLWW5XH9XQEwyusiBddbswtSUXcI+fX1WtLVOS4fLoCAViopCkJqqJ4BVpDzmiXR/73N/rv+s2YyxkTHU1dShoa4eTfWN0BsNiI6JRipN0iUkJZKjYQwEzGqg4BOtVgulynOpxPsJXm1zTaOCMlrZacz0AW0qUhVBwsvQn2Vd03VnkHX1dr/N5pLBGSdOjOHEiRHs3h2NdetCCaDRSJjVF1o+OjyFns4RnDxSh+GBCdxEIGtOQRLiEilQV+Edh2nTnAMjLgsOkjOrgFnT6ByWQ87SeapQaKCAijLz8cIK+KMCAl6zTU5S4PspGi/8H4RmZiF+y1bK4lQi04v7apto+IGgIzfau2w4X2OmLAhuOkcFYM+OYIJYxb13wIrD976qnbfrxSDrjSssANaBISeOnjRhZtaFnVuDkZqkRjTBrN5cHDMz0gRj5MJ5jNbVImXfLcj4yn1yHiHwMkDKm3XgslkBbyvgFND2LI3r9nTjQuV5nDx2DBGRkcjMysK2m3bI52NfDuDwtj5c/rUVEFlvHnroIYjnYLEIJ1QxblJZWSlhUeF++tvf/vYz0LO8vBz33nuv3Padd97Bxo0b5fvFliO+JFxZBQwr5l6EY2ppaSkaKABpaGiIAvk0eP/995GXlyfLv/S/I0eO4LHHHpN/1tfXIzQ09NKqL/x7Ca4VKwQUW1ZWRsH5FgnHztB1Qezj3XffpUwdBV/47mI+YJCVQdZ5jxcGWeeVZ8krhTMrJbDAuNuGHtcMThPQanLbEUqpsjapo1GsDJdpZhhmXbLE/EVWgBVgBVgBLyrAIKsXxfWhol0UhWceHEDz63+VkdXGuHjEU0qMuM1bfaiWXBVWgBXwRwVElO+seRb73/ob3n1rP+554F5s2b6VwJgESn+2ulyKhMu1cIFqqO5C7flOamMk9t21nlI0E/xj1Ppj981bZwZZ55WHV65hBcTEuc3mRn29Cc3NJnIqsMnJ85RkAzkt6GjwVwejUUlgv0JOpAdS+nZeWIGVUsDlcsFBE3bmGTOmTSZMTZrQ1dmFzvZ2dLV30cSLA2ER4cgj95mCogJyak2SUKunnA3LHaP4xNaLMBonTSYHw43kZBhBgf/8q1ipI+LG98sg641r6KsliEANh8ON8+cnUF4xAaNeiYREPU1ohtEEqHcBmoVq4rA76RrsxOlj9Wis6aLAMgey8xJx8x2l5J6lIfdIz0OlTnJmFeYlnTT30+SaxHnHGOID9diujkWCgoJW6JzGCyvgjwrY6b6g/+QJDJ+vxFh9HYFrtyL9rnugMhqh8OGUylarG0MjDlTXW3D89DTK1hmwrlCPhFg1ZYQJkPOx/tgfq6HODLLeeC8KV1bzrBuny2fQ1WOXUHZ+rg7bNhq9Cmi7yeHPRhkd+k4cR+0f/gvx27Yj84GHYIiNgyY4+MYbxiWwAj6gwNTkFD0Ld+L9v+3HKBm/REZHYz2Be8XrSxBMkKAYx/bUc7APNJer4EEFTHTP9OSTT0JAqpcWtVqNPXv24MUXX6QxQfWljyXgevfdd8u/33vvPQmfXlq5mHIufUc4sT733HMwU5DypSUxMRE//vGPcfvtt1/66LN/f/rTn+LXv/41kpOTcfbsWQnBfrbyGm/+4z/+A7/61a8wScFNly8CXhVtS09Pv/zjJb1nkJVB1nkPHAZZ55Xnhle6aKTHBHp4so+hnZwG+t1mZCiCkUfRuckKI0IC1Zwy64ZV5gJYAVaAFWAFPK0Ag6yeVtR3y7NNmzBIDy6jFFktBqiTdu9B+t33QkkP6L48QO27inLNWAFWQCgwNjqGpoZGnDt9Fg21DXj4yUewactmmkimc8sqSsMk3FdnZ2w4fqgWrU19ElzNK0zGph25NFilotQ+qw/JYZCVf+OswOcKuMmBVcCr4+N2jIzYMDhoxcQEBQqRK2ugIgCR5LyanmZAXJwO4RGUmWelczB/XnV+xwp8poCAWkUaut7uXjmB19HaQddxckq1O6Cn63YwTVJHkVNrVEwUomhSLyIyAqFhofJ4XuwxLdxXhYuhCPj/hFwMbyLgq0QVgTiCv/QBnnN8/axxq/DNJc1FIM1SF1HGjXz/WvtlkPVaqqyuz3p7LWgll/GWFjMEF7qLnFnj47U0ua/wmYa2t/SjpaEP1ZXtCArWo3RTJrloxSAmPtwrdRRZ+WbonNZFMOsp2xAscMFA5zJhYpKpDJFZ+diZ1SvSc6FeUsA+PQ1Tdxfa978DC90LGBMSkUCpcmM3+m4qcXE9s9vnMDxK87B1FgmzTs+4sHVjEApz9aAEVFDSfTkvK6cAg6ye0V7ArB3ddrS0WVDfZEFKkhabyyhwIlwFg97zARui1vJ+kZ4VhqsqUf/nl6EOCkIYuVTGb78JoRkZnmkYl8IKrJACVquVAjtnUFtdQxlKGtDd1UXBm6FYR+6WOXm5SElLXaGa8W79TYFxAv4rKiqkI6twWhXOrEtZFluOGMsR7qqdBGIXFRVRBqjUpez2ut8Rv5FLTq/C+TUzM5OyckRdd/vFrmCQlUHWeY8ZBlnnlccjK8WAhojQrXVOSLcBCw3ahgRqcJsmEVkEtSoozQw/RnlEai6EFWAFWAFWwEMKMMjqISH9oJg5ethxUNRez+FDqPz3f6MB6puQ8/CjCEpKgpojq/2gB7mKrIBvKiBSFL/79n7p9iZglz379pIrUs6qg7jGRylYsXcM7791BkODE3joiZ3IK0qmiH3DqoRYxdHGIKtv/ua4ViujgJhMHBu3oa7WhNraKflvRqaBUngF0yByCKKjNTSAraRzH+RrZWrJe2UFFqaASEs3R3C2cGodGhySASnlZ8pRXXVBTmLHxsdi09bNKC5Zh9yCXBmYEhi4uElzAbG2OadQRc6FFY4RPKrLxDbKXBXIYf4L6qS2tjb87Gc/k5NHzz///IJhVAGuDpO70OnTp2XqQ5FyMIPgg8LCQtx5550SZF5QBebZiEHWecRZJauE8/j0tBNvvtVH5wgr9u6NpuPIgJiYpU3UekMWEWAyNDCOj/ZXyHt0pTIQO/cVY9P2XK89hwikfHbOiWGXBSfsg/jA1oPd6nhspnNbuioYRjCk742+5jK9o4CpswPDFy6g6S+vQBcZhZLvfZ9g1niojUHe2aEHSnUTyDo15UZLuwXvfTSJ8DAl9u4MRnyMWr4X9+G8rKwCDLJ6Tn+naw6dXXbs/2gCKgK001M1KMzTITmRiG0vLjN9vRg8dw5D5ecgzhPF3/k/SNi+gx9yvag5F+19BUTwZm93D9766+uoq6nBTnLR3EgmDMWlJezC6n35eQ+sABhkZZB13p8Bg6zzyuOxlQJmHXPb0OE0UaqZKfS5zEgiR1bhzlqkDgf5EvGQrcfU5oJYAVaAFWAFblQBBllvVEE/+j4N+Lposnqc3Fhb33kbbnqvCQtD2u13IiI/nwek/KgruaqsgC8oICKBp03TqCyvxFt/eQMZ2ZnYtWcXUtJTyY3QO05IK9Fut8tNri8u1FS14wS5sSpVCnKqC8WWm/IQlxABlVrhtcnylWjv5ftkkPVyNfj9WlVgyuTEKDmwdnbMEBxmg8XqgkoVCKNRhdhYLb00BJpppEudgh2g1uph4rftFkDrrHmWnIbHMdg/iMGBQYyT07pIKWe32qBQKunY1iI5LQUpqSlITE5CELkzKVXzw1pibLTbOYOD9n6ZjjskUEWgVwwyFUEU4M+UyZcdMKJf9u7di+bmZqSmpuLUqVMLAlkFxHrixAmZ8lA4qly9bN++Hb/73e8oRXzo1asW9TeDrIuSyy83FpCoSN195swYOtpnQd4cyM0NwpYtF+/xL7kFr3TjzDNWdLQOoqGmCzXkzJpLQWZFpenkqhWD4FC9V6rnpPObhWDWVgL1a8jMZGrODtVcIMpUkUhTBiGcTE3YysQr0nOhHlJApA93OezooFS3g2dPU4YmLSIp2CHlltugomu8QqXy0J48W4yA+mzWOZSfN6Ojywa7Yw6pSSqUlRhhMARCq1lcwI1na8elXVKAQdZLStz4v8KQf3zCiYYWutZ1WtE36MBNW8h9OF8Hgy4QSqV37qntM9OYHRpGx/vvSjOMrAceRMK27dDHxUO5ROfBG1eDS2AFlqbA7Owshimwr+5CDc7QM5Vwz4yIjERJ2Xpy8k9DJDlOrqZsYktTib/FCnhfAQZZGWSd9yhjkHVeeTy6UkTnusmZ9ax9BJWuMUy4rIhR6LCLInRjFXqZasY7t5gebQYXxgqwAqwAK7AGFGCQdQ108lVNnKWH99G6WvQdO4qxujoUfPNpJN60E0qdDgGrKA34Vc3mP1kBVsDDCthsNrS1tKHibDk+/eggdt+8B488+SgBXioCX3wn7eiNNttqoTTiQ1M4faweH79XiT23rsOGbTmIT4yAweg7rlQ32s5rfZ9B1mupwp+tdgXEhKGLJsqFG52VoNWBASu6u80ElM3ANOWgiQ4NcnKCsK44lCbNFdD6UJrl1d433D7vK+B0OKVTTUtzC6rKq9DX0wvhXpOVk33xlZuNqOgociMPlpOAao1aTvxdDrUJtzSRcrvROYk3rZ1ICNRjj4bGQwN1CCPAi5f5FRATqc8++yxeeuklueFiQNba2lrcfffddP6yIz09Hffeey80Gg1ef/11CIdXsdxxxx2ybBGQtNSFQdalKudf3xPXwp4eC7nnmFBZOUmOrEZy9Y2FWh0oX77QGnHNdjpdqK3qwAfvnIVer0FMfBi5suYReB9JacaFU7p3ZmGmyXV6lOZ8Prb1odM1jUJVGHKVocihlyZAQd6s3tmvL+jOdfBvBewmE8w0Ltj4yp8xUn0BAlKL3bgZIampCKRneV9cxG99esaF0VEnDp0wYWTMifVFemRn6ijlupqzIfhQpzHI6tnOcBCwbZ5143T5DD46NIXNZQaUFBqQmKCGnmBWL13iQBFUaHnrTTLCeBMRefmIKilF/JZtUFO6aW9dVz2rHJe21hWYE8+kFgtGh0dQW12NC5Xn6fm2ArfceTt27NqJxKREBHGGwrV+mHD7l1EBBlkZZJ33cGOQdV55PL6Snq0wMWdDPzmyniOgddRtRVCgGiXKcGxQU4QHx+Z6XHMukBVgBVgBVmDxCjDIunjN/P0bTnLncUxPo/Vvb6PzowNI2rUbsRs2IpxcWX05hZi/6871ZwVWmwKmqSm8+9Z+dLZ3QKfXUwriTdiyYxtE6uHVMrAtBj77esakE+vwILnT2R3YsacQhSVpBK8JeGd1u74wyLrafrXcnoUoIMCdKQJWe3pmUV8/jYkJO02AuJCQoJOvGHJhDQ9TITiYoH1yYGUX1oWoytv4iwLCCdRKE37mGTP9Dkxy4k842PT2iPTiQwRzm6Treia5sOcW5CEtI42AboMMYrnURgcF9re5TGhwTKLaOUZwVzhu0yZBQ46FKmHryMu8CnzyySf42te+9tk2iwFZf/rTn+LXv/41AYcZ2L9//xXOq7/4xS/wy1/+UpZ77Ngxuc1nO1nkGwZZFymYn25Ot8GYnXWiq3MWBz8dhkGvRGFRMFJTDYiO9h0oXbjHjo9Oo6dzGOdONaGrfUjer+cXp8jAM5V6fgfppXaPcGa1zbnk+a6Vznn19nFEBmqxTROLBIUBEQG+o9FS28jfW50KjFw4j44PP4B1YpzcFXXIvPcrCMvJgUpv8MlMTeJcJH7ndY0WlFfNwuF0IyxUgY2lRkRHKenctHqCaFfDEccgq2d7URz/Tucc2jptuFA7i8kpJ2VLCMSeHcGIjxVjUp7d3+WljdZUY/DcWQLeq6EhN/9CMsIISkxiE4zLReL3PquAk9zHG+sbKLvWeZSfPYeQ0BAUl5YgOzcHScnJ9DvSUZYR3wze8FlRuWKswA0owCArg6zzHj4Mss4rj1dWCph1llLNXHCMocU1hR6CWlMDjShWRcgBDZFqRkQ2rZaJXq+IyIWyAqwAK8AKeFUBBlm9Kq/vFk73Hz1HDqP74CeYownrkJRUpN11F/QxsQhUemeix3fF4JqxAqzAYhWYmZ5BX28f3vzL6zIl8c69u5CTl4vk1OTFFuWz27tdboyPzaC5oQdHP6mGMUgHMSGek5+EBHJ4WgsLg6xroZe5jUIBMTkuJggFwDo+bsfQkBUjIxf/VSoDZbrSnJxgJCfrCQxT+YwTHfceK+BtBcT1fmpyEk0NzWhvbUNPdzc9O8zRNTEIUTFRiI6JJofWaHIqjqAUjRFQU6pGl0aBI7YBdLlnKN12AIoIZN2ijvF2VVdF+WNjY9i5cycmSfMnnngCL7/8MkGDqThFaTBFcM18ixhbvu+++ygV/Bk899xz+O53v3vF5mazGVlZWfIzAZncf//9V6xfzB8Msi5GLf/fdnjYRsfVOLkz2yBSe2/ZHI7cvCAKXguQL19oocPhgt3mwNGD5LhV3obQMAPSs+KxfnMWOUjryZnVe6CCiZxZu50zOG4fkPNAkZSVL59cWTMVITAEKBng94UDhOsgFXBRRhUBr/YdP462t9+kYPYCRJeUIKZsI40F+u51WrhRjow6UNtgQXXdLLIytBdf6VqCWDlAxtcObwZZvdMj4xNODAw5cK7SjDF6v3WjEempGkRHKr12LbbSfampqxONr/4P7PRMkPPoY9KdVU/3/rywAr6qgHhmmhgfx+DAgHRg7WjrkIGauQX52L3vZoSFUWYdo9FXq8/1YgVWrQIMsjLIOu/BzSDrvPJ4baX7f6Nz2ynFzBEa0Jh028iNNQC3ahJRSO6s4n0gDTbywgqwAqwAK8AKrIQCDLKuhOq+sU/z4AAmmpvR8D8vw+1wYP33/wGhNLmpMvDDvG/0ENeCFfBdBTrbO9FQ14CDBz6mieIwfOPvvoGY2Fio1N6bJF5uNcRkeNW5VtRXd6GjdRBFpWm48/7NciJcpfKi7cVyN3Se/THIOo84vGpVKWC3CxdKN2pqJ1FbZyJQ30LpuANRkB+MzEwjgWTkOEmplJXKi9AOD+Gsqu7nxsyjgHBoFUFvdnpWsFltclKwnSYDq8nZppng1pHhYaSmp6GwuBBlmzYgKjEOIIDsVWsbxmn883Ya+8xUhiA6UDfPXniVUEBBlloPPvggjhNg9Pd///coLi7Gt7/9bTr/LAxkFWWkpaXBRqDSG2+8ga1bt4qPPlvsdrssS3zwq1/9Cg899NBn6xb7hkHWxSrm39tbrS4ImLX83AQ+OTiEr3wlHjt2RMnrpLgu+sIioAXBeg/2jaOtuR8H36+ke3Yl7npwC5LTYhAW7r0xjktGJv1uMyooK98hmv/ZoIzEVnJmTVYYERywep6PfKGvuQ5LV8BKYM9QRTkGzpxG/8njyP/aN5B2591Qkiudwodd6foG7DhVbsbQsB1Wmxt7yYkyP5cAdVUAGQQtXQ/+pncUYJDVO7rS7TgcDjcOn5hGY4sFwUFKZBPUvbnMIJ9RvbFXt8slM7rV/fElTLS0IJycm0VGt7gtV95jemPfXCYrsFQFxPNrVXkFjh06jPa2NgpC1uDu+7+C3Pw8REVFIYCyiIlMYrywAqzA8irAICuDrPMecQyyziuPV1eKAY2JORvaHFNoJmfWDuc00pTByFAEIVcVJgc0KAGnV+vAhbMCrAArwAqwAtdSgEHWa6myNj5zWmYxS5PPTa++AlNPD2JKSxG9vgzRpevXhgDcSlaAFVi0Ahcniedw+JPDOHPyNBRKBUR64Ztv20dptoNpIml1PNOYZ6yUTnmKXJ1q5IR4UkoU8siNVcCsoomrpZ1fdgAwyPplCvF6f1ZAuLBarW4Mk/vqwIAVvX0W+tsl3eb0OgUiItRISjLQZIeaXDtUa+Z37899ynX3rgIumsy2EyQ5OjKGfnJl7+3ppd/PMAGuVnI0dsoJQW1ECBRRweiIVSGUHFsfjC9EoiYIOnIl5OX6Coj7CgF+/OQnP0FRURHef/99fPDBB4sGWaempuROgsgx9/IJWvH+d7/7nXRqFRscOnQIOQQjLHVhkHWpyvnn94RjuY3gsfPnJ+nYGSZnX6MM8sjKCqL7f9/6bYt7+LERE04dqcNA/zj0Bg3dv6ejZGMmgQxKAsa9Ay4459yYhRNtThOqKDOfBS6oaa6nVBUp54BC6S/FKnlO8s+jeG3XWjzDO8zksE5AT+vbb0GMBRpi45C4cxci15VIqMcXn2/FuWd4xEEp1e2oqJ5BaIgSmWkaemkREyXuzdd2v/pq6xlk9V7PiICN1g4rWtro1W6l34Ea2zYZERGu9Jo7sZPu8wdOncRwVaWEWeO2bEHOI49SNjcVZ3TzXldzyUtQQDyrjo6MkOlCPZrqGyTEmpCYiPTMTJSsL0VkdBS0lD2EF1aAFVgZBRhkZZB13iOPQdZ55fH6SooLpn0E0GDGKE7ahzBBzgRhgRrs0yQgiaJz9TSoy89eXu8G3gErwAqwAqzAVQowyHqVIGvsT8fsLHoOHcTI+fMQDq1xW7ch+6GH5WCUiFDlhRVgBViByxVwOpwEelnxl5dfxZGDh3H7PXdgw+aN5MaWSpPD6ss39cv3l9yc+rpHpZvT8UO1MpXvg4/vREp6NKWfWluDngyy+uVhzJX+EgUEwHoJypmYsKOhwYTWVjNNdMwgMUlPcFcQCgqDER+nJXcbCjnmgZovUZRXr1UF7DY7TARO1lyoRlXFeVSWV2I6kGDwUB1ii7NRlJ+Pu7NLERMcJh3blUol/aZ8C3rzlb6rq6vDHXfcIfU5ePCgdFZ99913Fw2yXqs9KnLZe+mll/CDH/yAnLwcuOWWW/DHP/5R3t9cvX13dzc5bw5f/fEX/p6YmMCJEyfwyCOPIC8v7wvr+YPVqUBbmxmVlROYmnJIN9bdu6OQkKAnaNq32mujrAoim8KF8jacOFSD9ZuzccvdZZRFwuj1e/mZOQdGXVZ8Yu9FjWMcmzQxKFSEkTN1sAT62cjEt46VtVIb4ao43dNNbqwVaHrlzzITU+HTfwdDTAzUFIzqi4twnzTPulBdZ0EzQXsDgw6UFOlw865gKBUBBKXzDbov9puoE4Os3u0ZkUmkt9+B/QcmJE9QXKBHBsHdCfEElnrhwVWcP6xjYxg8exoXXvwPaX6x7pnvQBMayhndvNvVXPoCFRDjuAJiNZvNaKitw4H33pdZRIQT670P3I/1lDVEo9HI7BcLLJI3YwVYAS8owCArg6zzHlYMss4rz7KsFCjruJsevFyzqHKOYchlQWigGvnkyipSzigDyNKccdZl6QveCSvACrACrMBFBRhkXdtHgpvck8z9fXJAu+WNvyI8Lx9ZD34Vxrg4qENC1rY43HpWgBX4ggLDg8NoaWohN9ZT6O7sxoOPPYSSslLo9fpVMSjodAq3OSdOH63H8cO1iIkLQ1pGLE2AZyGUUpIqyYF2LS0Msq6l3l47bZ2YcGBw0IKWlhn091up4XMIClIhOlpDL610YA0NVZNbx0WI1RcdqtZOb3FLfVkBkbZRpKufmpzC0OgouocHcaq/FeX97QgetyPSqUC8MRQZqanIys1BUkoSIqMi5f0C/64+71mh4e7du9HZ2Ymf/exneOqpp+TKGwVZhQtrG7nvPfvsszh+/Lgss6CgAK+99hq5TId9XoHL3gkn2LNnz172ybXfJiUloYcyejDIem19VuunJpMTIyM2Op5GMDRkw5490cjIMNDxRN6jPsSUiXPTjMlCQWkDOH2snoJX3DAG67B9dwEysuIQSK6s3joHOciZ1Q43mp2TaHGZ0EkOrSFkZLJVHYMEhQERAZrVenhwu3xUgTn6PbgoELX1b29juLICgQTzRK8rReqtt0Gp0yGQgh18cZmYdKFvwI4zFWbMEtCam61FZroWKYkaeb7xpXOOL+q3knVikNW76ougzCmTC3WNFrR3WTE47MTWjUZsWKen4PJAj0PeAhJ0U0aGsQZyuXztVcrKRFkXsrMRt3krwuhfXliBlVZAPo9OTOLYkSNoaWzC5OSkdGFdX1ZGz5/JCI+M4OfPle4k3j8rQAowyMog67w/BAZZ55Vn2VYKZ1YxqFFJzqyNzin0usj1gwYyNqijEEf/honEMzT4E8BA67L1Ce+IFWAFWIG1rACDrGu59wndoAGpOYJZx+rrUPfS76GgQe2I/ALE0oBUuBiQ4tHhtX2AcOtZgf9VQA5e0yRYY10DPjnwiUwjbDQacetdtyMzO3PV6GSanEVv1wjOnmxEbVUHdt9WguKydAm0ajS+OcnnTfEZZPWmulz2cikgzl/CucZicUsXueFhG/r7LOgfsMiJ8ehoNbkfGpGbGwSjUUkA69oC1perH3g/q1uBCZcNXc5pnOhqRHlrAyKaJ6AbmIZlxozwiHDExschPjGBrqcxCA0NQQi5OAUFB8lJRQFcrtVFoVDg+9//voRL9+3bh5dffvkzp9T9+/d/5sh6+vTpi89tdD5byCKcV//lX/4Ff/jDH6RDkXDC/c53voN//Md/hHBovd4yNDQkJ3+vt/7S54ODg5Ri/hCDrJcEWSP/ulzC0dyNjz4eRiO5mWdlBdHLKJ3MlUofIln/tz9Gh6fImasbDTXd6OkcwY49hSgsSUVUTAjUXr6vN5Eza5/LjCO2fkzN2WU2vhxlKLKVIdCSjYkqgO811sjPZsWbaSMH7em+XrS88TpM3V1I2XcLokpKEZ6TC1/MwiTOMw7n3MXU6W10zz5oR3BwIHZvD0ZUpBI6vk9f8WPqyyrAIOuXKXTj6+2OOYxPOHGhbhZHT5ogXFnXFxsQF6OC0eCd68sMmWD0HT+G8aYmiPcim1vC9h1QUGYmXzyX3LjKXIKvKyBcWJ00p9VHwXUdbe1kuHAaJtOUhFfXb9iATVu20LEZQJkD1u6zpq/3IddvbSnAICuDrPMe8QyyzivPsq5008CjJcCFbhrkPekYkilnxFDkXk08SlTkzEoDGnxpXdYu4Z2xAqwAK7BmFWCQdc12/ecNp/sSM01GDlWcw2B5OcbqalH4rb+TA9wBNLnqLbeSzyvA71gBVsDXFRDORjZyYTh++Bh+/x//jS07tmL3zXuQmp4iYRRfr/9C6ifYkPbmfnz8XgWsFjv0Rq2c8M7MiYdSRU9oNAC61hYGWddaj6/O9orf9uioDd3dZly4YJLvBdiakxMkneRiY7U0Qa6SAKtIU8oxPKvzOOBWeVeBdnIdPETAltVB108HUOQMQvCUHX3dfWimCe/mBpr0JqhVpHUsXFeIgmICyuilI0d3NU2Ar9VldnYWmZkXA4JKS0vJFTr6MykGBgZQXV0NHTnm7dy5U37+b//2bwQCh362zbXeiAmip59+Gh0dHXL1LbfcAjEnkJaWdq3Nl/RZVVUV3nnnHQZZl6Se/35JBsHSNbWhcRrNzTPo7DQjNUWP22+PlddQX7t+OhxOeU9/5ngjTlG2hZAwg8y0sGNvEcIo04I3FxcZmVjmXOhyTaPeOYFT9iHkKUKxTRNLhiZGhARcHyj3Zr247LWnwHBVJXoOH5IQq9oYhJxHH0NoeoZ0Y/VFNSwWF0wzcxLOO19rxoYSI/KydUhOVBPEejFbgi/Wm+v0uQIMsn6uhbfeCb7A5QRaO6zkWjwDO917Gw2BuGmLEUkJ3nH+dlpmMTsygvZ396Phz3+S8wbpd90NbWiYNMXwVlu5XFbgegpYLBZMT5nw0Qcf4sSRoxSoFI2snBxs27kDMTExMJD5As9pXU89/pwVWH4FGGRlkHXeo45B1nnlWfaVwplVROc2Oy6mmmkmd9ZMisrNVFA0M0XohgWqCWZde5Oly94RvENWgBVgBda4AgyyrvED4H+b75ildF0Es3YdPIj2/e8g/e57Eb9jB0JSUqAyeHeSh3uAFWAFfF+BWfMs2lvbUFleiSMHD+OWO27FrXfeBmOQcVUAKHa7E8MDk6iv6cKpI3VISI7Eug0ZSKf0oxGRwb7fQV6qIYOsXhKWi/W6AsLNye5wY2zUjqFBK4aGrRgfdxCQ7yIXtkCEhaqRkmJAfLwWQUFKmYbR65XiHbACq1ABN41tzsw5UesYxwFbL1II0CpVRSCVxja1NjcmxsbR292Lrs5ODA8OY3p6BkqlAnoCWMU9RExsLGLiYxEbF4vgkGAJba6lCUez2UyOllkLPjIqKioQFxd33e2FU6oAV8fGxhAVFYVf/OIX8u/rfmGJKxhkXaJwq+RrY2N2CbGeODEqncy3b4+ECAoJCfFNOLONAtXqq7vQ3jIgXbk27cghoDUO0bHzQ+E32l0uysg3AyfaCWY9Zx+GA25yY1WQiUkE0hXBCKK5HyXP/dyozPz96yjgslphJTfWniOH0HngA4SRA2t08TrEbdkGbXj4db61ch+LwDMnObH2DdhRSynTh0ec8r598wYjMtO0MOg9nzJ95Vq7uvfMIOvy9e/YuBNdvTbUid/MqBPbNhqRla6loCcFlBSg6cnFTe6XbgpY6/r4IzT95RVEFhUjal0JYjdsgi4y0pO74rJYgXkVEC6sIhiwk1xYz1dWYaCvTwZMFq0rRl5hAWUNy5LPlPMWwitZAVZg2RVgkJVB1nkPOgZZ55VnxVaKQd86isw9bB/AmMsKfYASd2tTaEAjCBpKM+PZ280VaybvmBVgBVgBVsBHFWCQ1Uc7ZoWq1UkDUo2v/BlBCYkIz81F8s37YIi9/mTpClWTd8sKsALLrMDo8Ag+/uAj9HT3QKSrFW6s23ftWOZaeGd3wl3KPGNF+almmXq0u3MYO/YW4vZ7N8rJbl9zl/KOCtculUHWa+vCn/quAmISXPymBbA6PeNCXe0UqionMEJAq1qjwMYNYcjNDUZ6uoF+377bDq4ZK+AvCtgJzOpzzuC8axwfW3sp01QC7tUkQxkgMk19PqIpfpcjdC/R2d6Jc6fOoLa6Fi2NLcjIzpQOrRs2bUBaZjq5JIYR6Cpc0IXr2uff9xc9FltP4XgvoNBrLadOncLzzz8vHVj/9Kc/ST2Ea+t8unzve9/DW2+9RXChEceOHZNuRNcq+0Y/Y5D1RhX0/+8PU4DI++8Pwmx2IjnJgIICurZmGHyyYU4n3ROYZvH2qycgoFYRqFa8Ph3rN2fT7wnz/qY80SAzwf6DrlkcsvfhNAGtuygjX5kqSoL/Yh5o9Z/pPKEil7FYBawU0DDW0ICuT+gZ/tBBlH7/H5B62+1Q6Q0QmZd8bRFBaBbrHKqqzdh/YIJgPB3WFeoIYtUhPMz36utr+vlSfRhkXb7eEM++4rdz4FMTys/PICdTSy8dcrO10sHYGzUZq61B77GjmOrsgFKrQ96TX0MoZReY7/7UG/XgMtemAuKZUjix9vf24sSx43jzL68hv7AQ2yl7xfqNZYhPSFibwnCrWQE/UIBBVgZZ5z1MGWSdV54VWymcWSfmKN2W04wa5zj6XGZEBGqQpQrFemWkjNRVrIHB2xXrAN4xK8AKsAJrXAEGWdf4AXBV8yfbWjFy4QIGzpyCy2ZH/pNPEdCaB6WBBrv5fuQqtfhPVmBtKDBLbmFdHV149eVXEEhgyo7dNyE7NxtJKcmrQgDT1CwGesfw6YdVmJm2Iq8oGbmFSQTXJMjJ7VXRyCU2gkHWJQrHX1sRBcQkno0cILu6zQTdW9DbY4HLPUduqwGIjFRTym4dvdQIC9NIF1a+rVmRbuKdrjIFRKapI7YB9LnNEiJfr4rERnUUgVnivysXMek4Y5rGyMgohgYGMTw0jKnJKUxNTcE6a4FWp0NcfJwEWlPSUhBOjnF6g/7KQtbQXx9//DG+/vWvIzU1FQJqFRO3l5bf//73aG1tRUZGBr71rW/JjwUAXEgTucPDw/inf/onPP3005c2/8K/whFXwMJLXRhkXapyq+d7ZrMLjY0mOg5n0N5uxrZtEdi0KVw6nCs87AJ3o6q56V7ATnmXm+t75auhthspaTHYvqeA0tCGkhu0d88zwonVQjBrC2Xja6DMfKNzZGRCXqyb1dFIUhoRHuCdNNA3qht/308VoGuFk9xYxxvq0fLm6xAuiiI4PWn3HkTkFyCQrhW+9pArLm+maRcqq2fR1WOV7wty9Sgu0CPIGAgtZVPgxX8UYJB1+frq0q1hc5sVTa1WdPfYCPxWYveOYAmAe+O3IyB5U083Wt54HTP9fch97AlEkduznjIB+Nq5Zfl6gve0XAqI58eujg6cOHoMk+Q6HhQchIKiIgmzRkZF0rOjbwZVLZc+vB9WwJcVYJCVQdZ5j08GWeeVZ0VXCphVDEdWOkZRQ+m4BMwao9BhmzoWcQo9QmlAI4C2+OIw8IpWm3fOCrACrAArsAoUYJB1FXSiB5vgIGDNNjmJmv/6T0w0NyHjK/cjpmwDQtLSEHADk50erCIXxQqwAsusQE9XNxpq6/He395DQmICnvrW16VjmlarXeaaeHZ3AggRL5FmtLGuB+fPtiI03Ii7H9yCmLgw6PQ8qcwgq2ePOS7NOwo4HG4JsJpMDoyPU7rjDjN6+ywEy9kRR6mOMzINyMw0UjpuHQRcwwCrd/qBS117CljnXBh0z2K/rRs2er+RHAYzKF12ouLLJxDtdjsslBKysa4R9XX19G8DZs2zBJQFy0CZtIx0xMbFICIyAgZyF9XqtBD3HWspsG4+kPXhhx/G8ePHsX37dvz1r3+VB18vORNt2rRpQQfiCy+8gAceeGBB215rIwZZr6XK2vrM6XQTbObE+fOTOPDhIMo2hGPL5nAKHNFAr/c990QB+8yarWhr6scH75wl52cFMnPiUViShuS0aCjo78DAq/F7z/bpFIH/wpn1U3s/hsjQJF8VjmxlCLLovKmmrHwqChjkhRW4UQXclD1lurcHg2fPovmNvyKioBDZDz4ksy5pwsJutHivfN807UZvvw3Hz8zAanUjI1UrHSUzUvl53CuCe7lQBlm9LPA1iheZSAaGHPjo0BQ5tAJbNhiRkqRGTBS5fnv44VfA8S6bTc4bDFVWIGHrdsRs2ICodSUXQflr1I8/YgVuVAEbHXPi2bG+tg51NbWoq66Rz4l79t1MJgRZFAwZf6O74O+zAqyAlxVgkJVB1nkPMQZZ55XHJ1ZO04BGPw0Cn7YNYcRtkTeZW9UxKCNnVjGYcXlaLp+oMFeCFWAFWAFWwO8VYJDV77vQow2YEwNSNLHc8f57GK6qoPy8QFTpemTc+xUo1GqP7osLYwVYAf9Q4OCBT1BVUQmnw4nc/DzccsetBHnqbsjJyxdaLtKMOuxOfPRuBcpPNyMtI4acWJNRVJpO0IzG79vnCY0ZZPWEilyGNxUQMLqEVzvNaGqaQWfnLIwGBaXT1iI93YjIKDWl5VZDpwuULnHehlS82VYumxXwNQWEC2uby4ST9iEEB6hxjyYZkYGUypRSZX/Z4na7ySXOjVnLLKX8nqaXCYP9gxDBMx3tHfR+gBx2ghGfGI+ikmK6RqcjJTVFjpN6ekL+y+q6Uus//fRTPPnkk9J1VUCrlzuyPvroozh69Ch27dqFV155RVZx//79eOaZZxZU3RdffBH33HPPgra91kYMsl5LlbX1mQBDBcza2mrG8RMjBIYGIipSi/XrQxAfr/NJMVx0zpkcn0FLYy/qzneiuqIdt927ARu35yIk1AC1RuXVejtpcMUKF1rJlbWJ3FlrnBNIURixUx2HmEAdQgN5vMWrHbBGCrdPT6Nt/zsYramB2+lA/JZtSLntNig1WgSqvHuML1XiqppZNDRZMDxK9Y1VY9smcioOU0Cv8z0ofqltXEvfY5B1+XvbSZlJpsnVuPw8ZSbpc9D9tQtl6wwEtF4MLvPkvbMMCKe5g75jRzFYfg7TPT2ILC5GwVNfh0LD8Pny9/7a2GN/Xx+a6htx6vgJ9FGwRtnGjSgoLkJWTrYMetTwsbc2DgRupV8rwCArg6zzHsAMss4rj8+sNMOJevsEWlxTaHWakKYMQg5F56YrgxEGNaXzFL6s3o0Q9hkxuCKsACvACrACXleAQVavS+x/O6BZqbH6Ogyfr0IvDUyFpqUj55FHoY2MhNoY5H/t4RqzAqzAkhS4GPFuwRuvvk6OrHUo27wRxQST5OTlQqn6ckhlSTtdxi+Njkyhq20IFWda0N8zhp37iiTIGh0bKl2alrEqPrsrBll9tmvWfMXMZidN1jnJddVGabRt8t+ZGSdBNXPkvKpFUqIOqWkGglqVBKaww9maP2BYAI8qIDJKibxSZ+3DqKasUo4AN8FYQdijiad02YpFj1mKCXGX04mJ8Qn0dPego60dne2d5LRsk+BqMAGtoeFhiIqOole0/Dc8IhwarYZclhly8WjnLrAwBlkXKNQa2Exch1tbZ9DcPI3JSSd2745EZpaRADThAud7AthtDpimZlF1rhXHPqlGYgo5SWcTMF+ahvCoYK8/A4jz59ScHe0053PGMQIHuVmHUiBAoTIcGTT3o6dAAHZm9b3jxl9qZB0fh6mrE63vvA3xPm7zZkSVlCKSXFl9cTHPujE27kBltQVdlBI9LkaFjDQNCvP00Kh98ATiiyL6YJ0YZF2ZTrHb59A7YEdjswUX6izIydRiY6keEWEqckr38PMw3bubursImK9GC51vghOTkPvYEzDExkJN9+28sAKeUmCWXFiHBgcJYm3Ahcoq+XxopGwdO3bvQkZWJkLJaZyfBz2lNpfDCnhXAQZZGWSd9whjkHVeeXxmpRjQcNOAcDNF5h629UtnVgGv3kXOBnnKUEJZKdWNL44E+YyCXBFWgBVgBViBxSjAIOti1Fo72wpX1onmJlT++79RRDW5mt19NyLyCxCcnLJ2ROCWsgJrXAEBlAz09eOv//Maent68e2/f0aCrGqKdPeko8NKyVx3oRMH3jkHMcseFmHE7lvXISU91utpRVeqvUvZL4OsS1GNv7McCvT3W9DebsbZs2MYHbVDo1FgXXEI1pWEISJCBQMBrMJ9lYdOlqM3eB9rTQExZumiCezXre0Es46Qm2AsitURSA403hCAJYDWS06tVqsVrc0tlDqyDudOncXw0BClG7Zh45ZNWL9hPYpLixFJYKuaM0asyOHHIOuKyO6TOxUBJHa7G+++O4Bz58axb180iuh6HB2lJSjUN0E0OtWQ+/MwGmt7UH6qCdZZOx588iZk5yVCq1N7/TlHzP2Y55zoc5lxwj6IT219uFWTiC2UlS9BYYBhAa7WPnkwcKVWXIGR6gsYOHMag2fPQBcRgeJnvosgAsx81Ym1u9eG2gYLmtussDvmcNctochM10CtoryUvnn6WPE+9ocKMMi6Mr0krm1uejW1WPD+J5MIMiqRkqhGUb4OCXGed/yeo+wKky0tOP+bF2SDE3buQvS6EoRmZq6MALzXVaeAeDYcHhzC8SNHUVlejpoLF3D/Vx/CzbfeSpl3IilTmN7r92yrTlRuECuwggowyMog67yHH4Os88rjcysn3Db0UJquOscEul3TiFHoZWRuMUXoGgNU0uPA5yrNFWIFWAFWgBXwOwUYZPW7LluWCosBKTNFvHZ99CEm29vhmJlG2p13I2n3HgQK5yMeVV6WfuCdsAIrqUDthRoc+vhTiAh4kd73jnvukGl95TlgJSt2g/u2Wu0Y7JtATVU7Th6po3RUqVhXRimLCWINDtXfYOmr6+sMsq6u/vTn1ghQxmp1Y3CQHJu6zBJeNZkcBLEpEBysRFSURjqxRkdrodUGQkUT4LywAqyAdxSYmLOh12nGaXJk7adxy9s1SchThYIwVo8E3kuHVkpZOkkBNaOjY+jv7cPI8AjGRkalC4/T6ZKuiQJkTUhMQHJqCmLjYqHT6aBQskOrd3r9ylIZZL1Sj7X810UAHSgvn0B19RRdf4HkZD02b46UDnC+Gvw2M23B+KgJp442oKt9ELHx4cgpSELpxkyo1MJN1rsUnYNsTATM2kJGJucdY7CSM6s+QIENqigkU3a+EJr7IZRvLR9a3PZFKOAiB3PHzAw6Pnwf3Yc+lSBZdPE6xG/bAU1IiM+N3wn4fXLKjfomC85UTpMTqxppyRrkZuvIPVIEoy2i8bypzynAIOvKdYmAWUfHHGhssaKji7KW0PubtgYjj35bel0gOVd6tm6W4WF0ffoJxpuaYBkdRcY99yLl5n0IED9iL19HPdsSLs2XFBD3lg4HHcd19TI7WGNDAwUua5CYnETmCiXSiVWr1dJzn/9nCvMl3bkurIC3FWCQ1c9A1mG6yB87dmxBx0V6ejpKS0sXtO31NmKQ9XrK+O7nIkJXDGZUUaqZPtcsIhRa7FbHIZ6g1mBKOyOGM8hjxHcbwDVjBVgBVoAV8HkFGGT1+S5asQo6Zs0wdXah98ghNL/+V+Q88iiy7n9QpglS0AACL6wAK7A6FXARPCIGDY98chh/fullbN6+Rbqf5RcVICSUJsL8eBFOb+NjM6g624rWpj70do1g353rsWNvoUxHJRwceflcAQZZP9eC3y2/AtJVhmxlrFYXzGYX/XZtaO8wo7FxmmA2twRW160LRUaGEQkJwvmNZ72Xv5d4j2tNAeHG2k7B9mcIYjXNOQhdDcA+dQJSCbzy5jI5MYnB/gFUVVShgSY1ezq7YaC0kilpKeSimIP0jHSEhYdR4E0QhHO8WkX5rBhq9VqXMMjqNWn9tuDe3lnplF5ZOYGgIBXuvCOWHNLV9Hv0MDXjQYUEKFF1rhW1VR3oaBuk80kMbr1nA51LjOTytTzjHZNzdgy5LThIrqw9rhmUEcgqMvKlKYKgIbBVwfM+Huzx1VmUOI6tY2OYbGtFxwfvY6jiHAq+8S0k3rQTGpFyWdDlPrS4XJSSfNqN1nYrGigFej299u0MxqYyowTtfNXJ2Yck9PmqMMi6sl0k3I0tFjeOnJzGybPT2Ey/rcI8HRLJlVUEfHqSL3VaZjFN2Zt6CKBv/MsryH3scWQ/+FWo6B5dwVkTVvZA8NO9i2vazPQ0JiYmcOTgIdTX1MBGWTlKN5Th7vu/Ar3BIKFWP20eV5sVWNMKMMjqZyDrxx9/jK9//esLOmgfffRR/PKXv1zQttfbiEHW6ynj259P0cDwoHsW5ZSuS/yrpkGMUlUkNigjhNcBFAE8WePbPci1YwVYAVbAtxVgkNW3+2clazcnYDZyYuw7cQxNr75Crg5ZiKbI15iyjTDExa1k1XjfrAAr4EUFZqZn0NfTh5PHTuDD9z7AVx9/GHv27b0Ih/j5YPS0idwcyXXpg3fOyWnh0k2ZyMpNRGJKlBzQ97b7khe7zStFM8jqFVm50AUq4HC4JbDa3Dwt4ZieHgs5vQUgMlKD+HgtObDqEBKigpHSJopJOQbRFygsb8YKLFEBEWxvIwfBCsco3rJ2okAVjhLKGpWmCEZooOdTll5eTRFgY7VYYZqawgQ5tQqH1sGBQQz09cv3NqsVCUmJ0qEnJy+X3BVjJdh6eRn83nMKMMjqOS1XS0kWiwvDwzYcPDhM2RycKCkhGDPNQIEmOp9u4uSEWT4bHDtYC7vdgSR6JlhXloHs/MRlqbdjzg0rXGh0Tkp31nanCXFkYHKTOlZm5wshIxNeWIHrKSCAHzFuN3rhPJpef01upo+OQcq+WxCWnXMRJPMktXa9iizwc6ouZig4rbPHjqMnTVBQEGl6qgbZGSL1uVIGpflQdRfYKt7sagUYZL1akeX9W/zORDaTplYraupnMWVyIZycjndvD0JEuJICuD0XvC3nDQhm7T9+DPV/+iMiC4sQvWEjoteVQB8dvbwN5735vQLCeEA8852vqMSJo8fIOX9MZtzYuG0LMrOzkJiUJA0IFJ62FvZ75bgBrIB/KMAgq5+BrKdPn8Zzzz133aNLOOE0NjbK9d/73vfwwx/+8LrbLmQFg6wLUck3t7HQQHGdYwJNrimIAY0UcjooVIYhSWFEOA1oBBLM6rnbT9/UgGvFCrACrAAr4B0FGGT1jq6rqdTR+jr0Hj4Ec3+/TA2U9cCDCM/Lh1K4svIo82rqam4LKwAxGSbAkOOHjqGLHJlHKT3YfQ/dh01bNxMk5r8BdHKSj5wdm+p70VjbjdrzHUhIjsRt92xEWEQQRfUvj+uSvx1iDLL6W4/5f33d9DsV6UZNJgfGKBXi6KgNg4NWTE44YLO7EBWlQXq6AUlJekRHa+g2hHLU8GCI/3c8t8AvFLDS2OSAy4LzrjEcsvZhLzmx7tTEwkgpsEXQ/XItLqeTQLlZ9FLQTWtzC9pb2zFE9y4arYaCboLpPBGFqJhoREVHSpg1JDQUwSHBBMh4P134cmmw0vthkHWle8A39y/c00+eHEVvr0Ven/Pzg7B+fShBB551gPNk68UzwsT4DMpPNklX1tGhKWzYmo2SjZkICTNQoMzygKRjbiu6yO36JLld2wlsTVAYkKcIRboyGNoAAvx45seT3b5qynLZbJju68Xg2TNo/9s7iCguRtLuPQjLzIYuMtKn2inu8R3kFNnSbkNrhxVtnVYkxWuwfbMRYaFK6cbqUxVe4coIUOvHP/4x1BRI/Oyzz0IAXpeWG8n0Ku6FxDzA0aNHKfhgGMV0zGzbtg3Z2dkEPzov7eKG/mWQ9Ybk89iXR8ec6O2341yVGVbKZrJtI2UySNYgkmBWTy+jtTXoOvAhrJOTUOi0yLrvAQnTB9BxzMHinlZ79ZUn7sXE851wYe1sb0f1+QuoOV+NuIR4ZOVkY+uO7fRcFy2f5VZf67lFrMDaUYBBVj8DWec7NMXF/be//a28WS0tLcXbb79NzhM3lgaCQdb5FPftdSJ1l50idDvFgIZjCEM0cOxwu3CHLgnFqghQwiwezvDtLuTasQKsACvgswowyOqzXeMzFbOZTLCMjKD+jy/JNGXF3/4O4rZsgy4iAmJQihdWgBVYPQq4XW401jfi9y/+F4xBRuzYdRNy83ORmJzk140UbdSz0AAAQABJREFU7XI6XXjntZMEsXYiNSMG+cUpcpJapVKyk+N1epdB1usIwx97RQExgSHmaAW82tQ0jbo6E1pbZhBPbm4CXs3PDyFATQ29XkGTGAHStckrFeFCWQFW4JoKjLttOEOQlUh/PQMHdqhisUFNjubyv2t+xSsfyuAUOl8I4MJBDooWglrHx8bR1NiMhpo61NfWy0nz4NBglJSVorC4ENl5OTBQKkoBcPBy4wowyHrjGq7GEoST+tCQDbW1UzhyZAQbNoThjjviCMTy7Wu2eEYwz1hRcboZ775+CunZ8SguTUf+uhRERocsS1eJuZ8ZysrXSefXKnK9PuUYxjZlNLaTM2usQgcDBQzwwgpcrYCNoJ+ugx9j5MIFzPT3Ie2Ou5B+193SidXXxupEuvNZsxvvfTyJrl4bcrJ0yMnUIidDK+/rOTDtyt6tqKjAPffcQ5koIumcWnsFyLrUTK+COfj2t7+N/fv3X7kz+uvhhx/GCy+84BGYlUHWL8i7Ih+4XPSbs8zh8AkTOrttCAlWID9Hhw0lBo/XR5yLpnt70PSXVzFSfQHr/+H/oXmDLVDq9Ajw44B4jwvFBV5TAQHqz5rN9AxXi7dee0MGLIZHRuDmW2/ButIS6cqq4IDEa2rHH7IC/qQAg6yrCGRtbm7GLbfcQlGfWhw+fJhSpt14+lYGWf3p53ztuk7O2WV0boNjEm0uExIpOjeDUnjlq8IgUs0wznpt3fhTVoAVYAVYgesrwCDr9bXhNRcVcFNaF6fNita33kQ/Re6HZKQjitIEJWzfAZXe8wNgrDsrwAqsjAIiI0gfuZvVXqjBgfc+lOl573/kfoSFhUuodWVq5Zm9Dg1QZH/bICrPtJKz4wxu2luEzNx4RMeEIpBconi5tgIMsl5bF/7U8wqYppwYG7ejp8eMkRFyl5p2yJ1o1ArExmlpTEyH+HgduScTxOrBdIiebwmXyAqsTgWsc3SP4J7F+9ZuysgA5CtDka0IkZmiVrrFAmi1WqwYGhzCQF8/ObX2YoocoWamZyTQqiRjCL1BL5184hPiEBcfhwgCQ9QaGkfloLwldR+DrEuSbdV/STguWq1uGYxy6NAIAVhq5OUGIY2CUSIjfTf7gXQCo6C3rvYhnD/XisH+CRkAt21XATJz4hEcapCust7uQAeZmExTkEAzzftUOccg4FYjVFiviqTsfEbpfs05+bzdC/5TvpXAsan2NrS+8xacFNARWVSMWErpHVFQ6FONoLgTmfWlq8eOxhaLdIgUQGVZiR7JiRqEkxsrQ6wXu0xkwBH3JYIN+NrXvoa2trZrgqxLyfQqNBcOr8I8Syy33nortm7dSoGDddJES9xLfetb38L//b//9wpo9mLNFvd/BlkXp5c3txYuyG2dNrS0WdHcbkV6igZbyZk1OEjhURdk4Q4tzkONr72KgVMnEU/zBbFlGxCeXwAlMS68sALXU8BqtWJqYhIV586hpakZw0NDSExKQn4RBSLm5iAmNtavs4Ndr938OSuwFhVgkHWVgKwi+mDv3r3yhvXnP/85Hn/iiRs/numB4Z//+UcyRcDjjz9+4+VxCSumAHUlapzj5IJAA7SuWQQFqnGrJgHJiiA5oMFZ9Vasa3jHrAArwAr4pQIMsvplt61IpYfKz2GQXiM11QhOSUHh15+GllxZA9nZaEX6g3fKCnhaARsNPp86Ro6lBLL29/Zj/aYyPPTYVz29m2UtT0ycCUC3tqoDxw/VUspyJ8LDg3DrPRsQnxSxrHXxx50xyOqPveYfdb7kvupyClfFOfT0zqK93YyamkmYTE6CzNQoyA9GaUkYpQpXUpA3O8D7R89yLVejAnMEU41TYH0TwVV/s3XJlNePaNMRTAH12gDf+m1ecmsVgTltLa04X1FFk6ItNCk6jJi4WOSRy3xeUT7SKDAvLCwMGoJZlUoVFEoFT5Iu4uBlkHURYq3BTfv7LTh3bgLjFKAi4NYdOyKRlWWUYLkvA2s2qx3TJgvef+sMyk81Y9vuQhSvT0N6FrnKalTLlsFBGJn0Oc044hhAo2MCuzXxKFKGIzHQAG0gQX9r8JjiJn+ugLjOiWNgrKEeQ5UV6Pr4AIzxCVj3nf8DfXQMOSDqPt/YB94JV0ibbQ5nK2dw9OQ0EuLVyEjVoKTIgNAQ37qHWEm5BMT61FNPSSagq6vrs6pcy5H1s5XXeHO9TK/j4+NYv349jYfY8c1vfhPPP/+8BIxFES+++CKxA/8sS6usrEQsgWM3sjDIeiPqefa7YjzMbnejtcOK/QemJMBaVmxAaooa0ZEqj0PknR8dIAOME3A77AjLzkHWfQ9AHRxMQXB85fJsz/p/aXI8iMZqR4ZH0NHejv1vvY2x0VEUrVuHTdu2YtOWzf7fSG4BK8AKXKEAg6x+DrKKm4qAgED86Ef/L/7zP/8TOTk5/z977wEdx3GljX4DTEDOOQcSIACCAcwkSFGUSElWsNL6lyU5ai1Za1vv7dvzjr3rI9urI2vt53Sc7XXOCpQoUaKoxCRSZo4gMpFzDgNMDu/emmlgAIIkACLMAFXgsHu6K9z6Okx31Xe/i3ffP0jDhTf/I881vPD8t2jQIAePPSaJrGOuHB/80uewoMNpxDlLF9odRgTRwHG+OhIbNHFQ0zkklVl98KBKkyUCEgGJwDwhIIms8wS8DzZrpAGFvuoqVJKHNQ+yZt1zHyLpeZUHzWWSCEgEfBsBO4XU1Ov1+Mef/47aKzUoWluEwlUrsHxloU93zGgw08DogJiMPvL+RWzcmodVa7ORlhmP4BCpDHGjgyuJrDdCSO6fLgJMXh0YsJICqwHVVUNi3WS2IzqaJtXiAhAfrxPrERFaCknM6kQ3Py42XVtlOYnAYkeAVQHP0PhjhX0AfU4zsvxCsUObJEis/jQG6W2JJ0YNwwYMDQ2hv7cP3d096KZJ0h5edneRUuuwIG8kJSchIzODFOizEZcQj/CIcEG087b+eKM9ksjqjUfFe2waHrYTedyEM2f6hIPK7TsTUFgYhtBQNRHHve+eoSBnJ1VWq9WGsksNKL/USJEquhFL0Rt23LmKluGk7Dw37w4WUsA2wo5yIrFW2gbQSXNAMaoAFOsSkeAXiFCVRjFZLhchAhwxyW4hhcVXd6OVlA9DSbkubtVqJBdvgyY4GCovUxrv6aVrqtKIOgpt3t5hxbqiYOQtDUBUpFo84y/CQzhhl/nZJTn56rHVqRJZrxXpde/evfjiF78IDanUV1RUiFDdiiFMfs3Ly0M/qdk/++yzePrpp5Vd01pKIuu0YJu1QqSbhu4eK0rKjWhqofGxbhtuLQ5DYX4QnQ+YUSeNgfo69JReRu1bbyKAHMYKPvcEzRkk0b0pZNb6Jyv2TQQMw8Po7enFP48ewzlSYw0lwnNaRgZWFtHvWUqyiJ7hmz2TVksEJALXQkASWX2YyMoqmxaKnNbe1oTNmzaKAbV/vPgyglOLr3W8p7RdRYOOb/7pv5GYloPb7n4UWjWg8XdCp1FBp3YigJZ+NC8gHWOmBOu8ZuZwM5cozEy5rR91NvJm9A/GWk0skvyDEOWnI/oz/8kkEZAISAQkAhKB6yMgiazXx0fuHUXASaNfhs5OVPz9rxhqaUZwYpIIF5S4fgNURGyVD5KjWMk1iYCvIdBHRI/mxibseeU1Csc7iEcefwRLl+UgIjLC17oyYq+DJqOZxHrpXC1qKltFuNC7H9yAtZtyadJMDT9/751IH+nEPK9IIus8H4AF1jxPotmsTJq3o59IrB1EcmHVtmYis6o1foLgkpcXhvT0ICKx6ojsIkc0FtgpILvjgwjw2KOZCFXvWppRbR3AUnU4lqkjsMw/HN5IYp0IYlac1w8MktpPHaoqKlFbXStIraFhoYiOjUFiUiKFrYwnoloc3YdCaSKVIl6FhEiV1onAdG+TRNbrgCN3kQoriBDqwEfHunH0aBcKCsKRuywU2dkhCAryfgXG3m49muo7cfCd86QkaaUoFUvpvYii4WXGifcHJn3NRep2mNBg1+OYpR1muhfn0P03RxOBDFUItOREwGImMi0+BIxdXRhsqBdEsf6aamTf/xAS1q5FSHKKV0VLYjVmg9GJugYTTp4dFvcFVmBduzpYhDdffEfuxj3uJvEAjtbKaffu3Xj++ecxFSLr+Eivj3lEev3Rj34Ejv66bds2vPjii1cZ88QTT2D//v3YuXMn/vSnP121fyobJJF1KmjNTV6jyQEmlZ+/ZMBHJ/XYvCEUK/IDER+rJlLzzP0u24xGDDY2ouQ3v4KV1rM/djei8gsQnpk1Nx2VrXg9Ahwxy2gwoKW5BRVlZSgruUyOQ83YWLwZq9YUkYPh0jFEe6/vkDRQIiARmDQCksjqw0RWmmOD3qTC89/4D/z973/Hjh07kH7/XzBgYIrrtZO/uR3hrX+8dgaPPX4UlsQeshRBuZ9EbJgK0SFOxIf7ISEcSKQPk1vlXJ4HYF6+ymfGsMOKFocBJ6wd6LQbYSKP3dso3MwabSwo4A39zc3AipdDJc2TCEgEJAISgesgIIms1wFH7roKAcvwEHrJu7r1+HE0HTqIrHvvQ95jj8Nfo/U65YerjJcbJAISgWsicPliCU6dOIXW5lZERkXgvgfvR1JyIpE46CXRBxMrmpiMFlRXtOD1F48hJDQQq9YtwdK8ZKSkxhLxnrn38l3pRodWEllvhJDcPxUETDSBNjxsI3W2AVRW6tHZaUJwsBpLloQgPS2IlDcCxUQaK7CyYpu8RKeCrswrEZgdBPROK7ooEtQ+UxM6aPzxgYAMIlNFIIQUAX3lV5SfCVh5ngmtJpOJFFnpfaanB7U15OhSXYMrVVeoLyp6VgjB8hXLkVeQh9y8ZaTcHkzhxLWzA6yP1yqJrD5+AGfZfL7m+GG7ulqPy5cHxe99WJiGCFJEGI/VzXLrN1+9je4XQ4NGnD99BVXlzWhp6MaG4mXYcddquidoSCV+bgik7EgwDBs5EfSjzEbqtvRZpYnGVk0CYvwDECyVWW/+YPtgDe2nT6Hmjddhp9DdAVFRyKZISRFLlsJPS2NyXvTwzOHMq2pMqLxiRlmVEctIhXXrxlAKbe6HoBkkzvngIZyUyS+99BL+/d//fdJEVo6a9Y1vjEZ6PXjw4Jjz4Utf+hL27NmDp556Ct/85jevsuE73/kOfvKTn2D16tXYt2/fVfunskESWaeC1tzk5Z9lK0VEKasw4NQ5g3jPjolWYwsRWuNiZm7MjwUwTL29qNu/jyK6VcNhsyJ1+w5k7LpjbjoqW/F6BIxEcG6oq8fpEyfx/v53sCQ3B2vWrRPvXwmk3hsQECCiAHp9R6SBEgGJwJQRkERWHyaysodaL/3AryGPAyuFh3hp9+uotq274UlgNXSjt+KtG+bjDOb+BuiiliJ2xSdFWDY/lRNqkmFlAiu9gyM2lD5EcI0hlfcQGlPgKBS+Mig5KQAWaKZBGlS+QmFmqijEF4ebyfQLwRLy0M3VhCNCpYO/PIoL9MjLbkkEJAISgZlBQBJZZwbHxVILhzHjQam2kydQ+fI/EF1QiLQdtyEiewkCY2IWCwyynxKBBYOAzWaDxWLB4Q8O0SDie1hKg4j5y/NJeWgNwii0k68mDgtaXU4e/pdJDeJ8HbJzk7B910oi6YYQMSXQV7s153ZLIuucQ77gGrTZaDKLCKxdXRROtN2EjnZSRtRbxUSaVqsShBZWYI2PD0BEBBHjvGgCfsEdDNkhicA0EKglNcAL1m60EolVS+7yd+hSkOIX7DNqrBN1mUmtBsMwWltaSY2+GU0NjRROd4AcYIyk2K5FQGCgUGSNIbXW2PhYxJFSa0RUpEul1ctCNk/Uv7nYJomsc4Gy77fR22sRyusnT/bCaLRj69YYUl0PFr/33t47q8WGtpZeVJY24cTRMiQkRSF/RbpQZo1NiJiz5xUbRVnsJWXWK7ZBnLV1010YiKL5nhVEaM1QhyKQZn6kkIm3n00zYx8rHRo6O9Dy0TGhxhpfVIT4tesRs7zQ68biDAYHunutOHvRgI4uK0JD/AWRdWVBkJiXlo/7Nz4npkpkbWpqwsaNrkivL7/8MoqLRyO98vvVrl27yJmwBF/72tfwzDPPXGXAr371Kzz33HNISUnBmTNnRpRhlYzsoNBJEbomk1555RVRfqJ2JlNe5pk9BNo7raSSbEY5kcsNRge2rA9FRpoO4SR45jdDF6bNaEBfZSXaTp1C05GDgsia88BD0HC0AyIpyrR4Eejq7KJ3r0ZcOHcO7a3twsFwZdEqFK1bS+NCsTRWS+QkmSQCEoEFi4AksvowkZUfJvlB8Ze//CUyMjJwnFSuXN6rM3O+Ek8Wz/33t5CelYMNtz2KtgGgrd+J1j6gc9CJriEgKw7ITwKWJ6uQEqVCAJFb/f2cM/YAMzM9kbVMhAD7ObNn7lFzGykk0MCryh/3BKQh2z8MgSq1pLJOBJrcJhGQCEgEJAICAUlklSfCdBDoLrmEyldehoMIcKwCkXn3PYimcEGSgDIdNGUZicD8IcDKZANE3tjz8mvY++rr+Nd/exI7dt4mVMnUmplTZpjLHvJ7tGHYjLf3nBRk1sjoEKxck43N2wvm0owF0ZYksi6IwzgvnWDVF74WjSY7ujotuHSpHxUVelwhdba8/HAsXx5Gn3DExmhJ+Zm0EGdo4mxeOisblQgsQATEmDRdlx9ZOrDXVI9l/uFYRkqsBdoohKsWnkoph7SsvVKLc2fOoby0DFcqr5BKdDIps+bSM8Qq4ejD33UBOqESxPesxXzfkkTWBXjRz0KXxHOAwY639rWhsdGA3NxQ+oQhJ8d3iAr1Ne04euAy2pq7yfnPhrsf3IDC1Vn07MLK8XMnAdPnNKPBPoRjlnZcsHTjY4HpWOsfgzj/QATQPJBMCxsBvpZMpCTefuoEWk+cQMeZUyj8/BeQdd/H4UcRVFSkxuktid8B2jqILFdvxlEKYc7+Hx+/MxLJSVoEB3mPnd6C17XsmAqRle9F//Efo5Fe//a3v43hFvjTQcjLyxNCWi+88AI++9nPXtXsH/7wB3z9618XZDImvDpIWdMzsfjWt7/9bc9N11yPjIwU90dJZL0mRPO2gwXVrFYn9u7vI8VkM/JyA7FsSQBySDFZ7T9Dv2l0E7DT+dJ0+BDO/vB7SFi/AUvvfxBhGZli/mDeOi8bnjcE+DeM7ykXz13AWSI4Hz18mBwFE/Avjz6CzOxs4TQ4b8bJhiUCEoE5Q0ASWX2YyMo38ZycHPIIN4gHRpb6n8nELxD/TUTWbAozcc8Dj8FgASjSIobMTuhNKvQNOaA3qzBkoocMB4VTIseYzFgVUqOA5EgmtIIIrTNpkaxrphHoc5DCCZFYL9p60GIfFmqsS9VhWKONRQB550pl1plGXNYnEZAISAQWBgKSyLowjuNc98JInvjd5WVoOfohesvKkPf440jatAWa0FAxkD7X9sj2JAISgekh0NrcQiGdTlNY3Wr0dPfg4w/dj1VrV0Oj0fhsOKeujgE01Lbj+IflRGg1oXhHIbKWJiAxOXp6IC3iUpLIuogP/jS7zmNPPFHR3W0mFTYTGhoMYp3DdgcH+wsVtrg4HWLpExmpRVAQTb7LsaZpoi2LSQRmDwGj04ZuGmc8be3EEXKa36lLxlpNLCL9dNAtQNLU8NAwBgcH0UvPQp0d9J5Dy0Fy9NHr9fQsMSwIGaxUn5ichLSMNCSnpiA6Ohrs9MPhfBdbkkTWxXbEp99fq9WB0ssDuHJlGC2tRiKyhuDWHfHQEBHUFy4d/aCRSKw9OH+qGmWXGoQqa+7yNKHMGswTaHOUzE47hmBDha0fly09MMGBaL8AbNTGIdE/CMHwTQfEOYLPp5vh52rLkB79VVWo2k3O5BRRJXpZHhI3bkJUXj6F1PQexwoLEeSMFInh3AUDLpUa6FnfH2nJWhTmByEs1I/GGBbf7+V0T76pEFl7iORcRAq9TDZ9/fXXsX79+jHNMtF1y5YtqK2txbPPPounn356zH7+8sMf/hDf//73sWzZMhw8eDXRwm6349ChQ1eVm2hDRUWFVGSdCBgv2Mbv6na7kxRZTURkNdLvshWpdI1uLw6j93IVdNqZuUYddL70VZTjyt7XYTMYaa4gBFl334uYguVegII0Ya4RaGttRVVFJRFZz6OluRnpGRnIoXtN4aoVCAsPRyBFw5BJIiARWPgISCLr1c9XEx11ldFopJ9r70onyJPuwQcfFEZdunQJMbMQmvVb3/qWIMs++uijYzpvtgEkWIMr7U5UdwB13S4ya2IEkVkpQmwGEVojg0DkVie05JXjC4MMYzq4iL7wiX2eiKyXrb1osOkR5xeIYl08EvyCEElhZ/ilRc4RLaITQnZVIiARkAhMAgFJZJ0ESDLLVQjYSYmVQ5tVvfSiGJjK/NjdSN68BRHkmKUJCr4qv9wgEZAIeBcCPCHGEx1lJWV4ffdrNHAYhCVLs7FmwzpkZGV4l7GTtIbVJRx2By5frBeTzT1dg4iKDcNd968nD/8IUoOZmUH5SZqzILJJIuuCOIxz0gm+/iwWh5i81g9a0NZGymENw2huNortKSmBNB4VSmpAYdDp/Ch8t7we5+TAyEYkAtNEoJtCWV+29qHaPoAmUgG8R5eGdeQovxhGFW1WG4VBN6K+tg6V5ZWook9nRwdN/DuIhB+L9Mx0pKanIS4hHqHkxBccEkyT/0F0X9MKYus0IfepYpLI6lOHa16NZdJMb69ZEFk/+KADycmB2LkrHpER7Mzi/Uqi/M7En9P/rMSJD8toHUhIisKmW/IRlxhJ71Bzq1DdYTei0TEk1LL1DguKNDFYqg5Hun8INCoiB8uZn3k932ejcScTwq5Uo+PcWdTtewsR2UuQ/6nPIDAuDjpysPCWxNdGX78NTa0WnL80jPpGC7ZtDkXBskBER6qhpggMMk0egckSWXm+dzKRXh944AGcPHkSLKDFyqvjExNcf/e736G4uBgvv/zy+N1T+v7zn/+cnpnskIqsU4JtTjMP6O10jZrx/qEB+i32w+Z1oYLQGh01c04RBhLA6CkrRcuxo2JZ8NnPI5kI1Woae/QmFek5BX6RNWahuSOOAFZeWopT/zyOrq4u8b70sfvuRV5BviCxLkaHwEV2GsjuSgRGEJBEVh8msn73u9/Fj3/8Y+HxxJ5N/II80+laRFZuykZeOEYrKbISobVvGGjtd6KGSK0DxPm12oG1GSrkJwPxYeSVo5lpy2R9M4nAoNOKNrsBp0g1oYOW7JW5SROHtTTgTLpKckBjJsGWdUkEJAISgQWAgCSyLoCDOB9doAdI9rBu+eiYUGW1kkJEaFo6ch/+hBhQnw+TZJsSAYnA5BGw2+zoJeUOVmN9+e8vYc36tUKNNTomWhAyJl+T9+Q0m6wY0htx+L0L+PBACTZuzcOKoixkZCcgKNjl1Oc91vqGJZLI6hvHyRustNmcaGkxoK7OgNLSAZhIjUmjUSEzMxgpRFqJidUhLEyDkGBSLyQHaRqmkEkiIBHwUgR4RLrWPoi9pgbS+PPDEor2VKCORBoRpRZD4jF5dozhqGlMaB0eGkJfbx/aW9vR3NSElqYW9PX1C7oYk1qX5C4lVaFcJCQmICKSVCEWQZJE1kVwkGeoi3w98TMCO7YcOdxFKn0gBzMdCgvDkJ7uGw6w3IfeHj2aG7pw5P1LRMoYxobiPOTkJYv3jBmCalLVWJwODMOKclJmrbQNoJ6ETHKJyLpdl4hwFYVuV8mJu0kB6SOZnHTB2M1mVL78IjqJyKqNiETCmjVI3XEb1AGBXhMNiS4R4bhWecWEg0cHERToj8QEDQrzgpBESzWdln7y4X9KZ91kiayTjfTKBNY9e/YIZdbdu3eP4R8wkYxFtnh+4POf/zyef/75Kdk6PrMkso5HxPu+8+9yd68NZy8Mo63DCrPFSWTWYKwqJEUzSkyQvtnE9y4rRTWo2v0Kave9iax77xWR3MKzsqAhMqtMCxsBfnbqaO/A8WPHUFFahrqaWmwq3oKi9euQQpEtwsNJbEBNcYRn4Fxb2EjK3nkTAny+DtN97ZVXXkF1dTVCQkKwadMmoYTOjq183k8mTacetVotfqc//PBDdJKjwIoVK7B582YhYGkjtX4lHThwAP39/crX6y7vpfsyO+Nymo5N1618gp2SyOqjRFZ+ULzzzjtx4cIFfO5zn8O3v/3tCQ7vzW+6FpHVs2YS0QArtHYNEpG1E2jqcaJTD0SQsndMKJAarUJCuApx5OzHgjZ+N/8849m8XJ8hBIY51AwpJ1TRwHOVtR+ZNOic6x+ObFpG0qAGe+fKB4QZAltWIxGQCEgEfBwBSWT18QM4z+YPNtSjp7wMjR+8LyzJ/T+fRMSSpQiIjJxny2TzEgGJwPUQ4DC5F85ewOVLJeQdX44tt2zFvQ/cS0opalIu9X51pPF948GizvZ+lJc0orK0Ea3Nvdh5zxqsWJ2J4NBAqcY6HrBJfpdE1kkCtUizcbhgs9lBIbjNNJBqJoUNi1Bd0+ttCA72p0hDOmRnhyApKQDBQXRvkUpMi/RMkd32JQQccKKPVP4q7P14z9QsyKs7dEmIoRDWoYuYIMXPTd1dPWhqbERjXQPaWtugH9QjIDAAgTRpxcqsUdFRrg85BUVGRQpSq44mhvzp2WqhJUlkXWhHdPb709dH5MvyQdTXu9Tat2+PFWRWnY7o8j4g0m4jJ8DhIROOHSxBTVWbeLfILUjFuk25dB/QQhcwdwRSO7/3OI2osQ3itLWLHA5USFGHIM8/Aml+IQjw85dCJrN/Ss9JC0ZSr+Mxt5q33sRwWxvSb9+J2JWraMxtidcoGjJnw2iyo6HJgupaM0orDFiaHYCVBUFIjNeSE5sPXOBzcjSn1shkiayTjfT65ptv4qmnnhKEFS6TkJAwYlAPOTgzIYbHVLjdrVu3juybzooksk4HtbkvYzA60NxCz/xEQL9QYkDRyiCsJiJrVISa1MZn5rrlc6rhvXdR/947pCAdjkiK4pa+8w4EREdLfsLcH/I5aZHJ9azIzJEtqisrcfHceXJosiE8IgIbt2zG8hWF0Op0Yux5TgySjUgEZggB5lSxsvmnP/1pDA4OjqmVxwLeeOMNIVY5ZscEX6ZTD5d58sknwb/l49MnPvEJ/OxnPxPXGe+7/fbbUVZWNj7bhN/Pnj2LxMREcT+eib5N2IjHRklk9VEiK8trZ5EXCt/g+SGPZf5nI02GyMrt8ssHf0ikFd1EYm3oduBYNUBzgUiJUmFlKrB5qQpaGofT+N4c52xA63V10qGDnQafOQTYUXMbOhxGOqjAvQFpyNNEQuMkZVbp6eJ1x00aJBGQCEgE5gMBSWSdD9QXTpsc5szU24sLv/gZBurrkHbrDsSvWYvoguULp5OyJxKBBYgAK4u9+Jd/kKpYM7KXLsHqdUVYVbTKZ3vK79Jllxrw6t+OIjQsCEuWJVGfliAlncIgy/eeaR9XSWSdNnSLouDQkE2QV8+f70NJyYBQYoqN1aKoKBIZGTR5nUhKUeT9zB95GS6KU0J2cgEgYHHahdJfGan9VdFnpToK9wVmsDs8/S3exBPx4kMKEHYHE9qG0dnRgdJLpbh8sQQlF0oIHCfCIsJRuGoFOdKsREFhAYXMDCMyAKlDLLAkiawL7IDOQXdsNlY5duDo0S688Xor7r4nEZs3RROxQUPEqpkhzMx2N+yk1NzdOYCS83V485V/InNJIu56YD3iE5m4PreK1ex00O+0CAGTc3aKsmHpxL26dGzWxCPSTwedSk7azfb5MBf1d5w9g8aDB6AnNXBdeDjyP/UZRGRnQ+VFjqcsjNTTY8V7hwfR2W1FeKiaVB0DsWp5sHj+l+8A0ztTJktknWykV+Yg5OfnC7X5W265BS+++CK9o/kJ4guTcljBLTk5GcePH79pgpkksk7vmM91KeaAOOgCvlhqwDsHBhAXo0FmOimm5weK9ZmyZ6C2Bl0lJajb/zYpSQeg6P/6vxGWTu8WvuDFMlMgLKJ6mLRqNBjxxquv4TSR/qxWK9asW4v7H36Ion+FQEckVjlGu4hOiAXUVXb6YPXVIYrWws4gDz30kHjP37t3L6qqqhAVFYX9+/cjNZVIdNdJU62Hr5fnnnsOv/zlL0Wtu3btEnaUlpbi9ddfF7/jTzzxhBDJ5LkRdlqpra29pgWN5Jir15NDLt2P+Z0+nJ4vp2rTNSu/wQ5JZPVRIusNjuuM7Z4skdWzQQNJyuuNKtR3UwiYPhUptTpIXxgI1qqQmwhkxqoQFuCEjkLGyeR9CPCARpN9CKW2PjRQqJl4v0Bka8KxggaiQ0hJgYTbvc9oaZFEQCIgEZAIzCkCksg6p3AvuMZ4QtdmNKDp0EF0XbwAQ0cnkiisxZIHHqTBdQ4fLCdQFtxBlx3yeQT6KRxufV0d3njldeEp/7H77iYyazZi4+N8sm9mkxWN9Z0ou1iPsyerwepIm7blIS4hEiGkxirT9BGQRNbpY7dQS5pIcWloyI7GRgpD2GYSSqzcV43GjwZuNYiPC0AiKbCGh2tIlXXhqRAu1OMq+yURYASYGDXstOFdSzMaaQwx0S8I+epIrNRES4DGIcCTsqzS2tXZTZ9OUoXvpHDj/UKdxWKxwkHOfjyAHk3qrPEJ8UhKSSayWzyiSYFKo9X4/ASuJLKOOyHk1xsiwIQZVnK/fHkAH37YRc8MOqQkB2Llqgi6LlwhLW9YyTxn4LEPk9FCjoDdOHm0HP19w0KYZvMtBcgrTKMJYYqCxyEM5yiZyPFggOZ+Ksjp4KK1B/400R1N6tnrNLFIUAUiyI/uNXNki2xmZhGwGY0w99N83oEPUPf2PsSvLkIsfRLIaVznZdGP6hvNqG0wo6LKhKAgP6woCERqkhaxRIqTafoITIbIOtVIr6zk9vTTT4v7FhNXVq9eTUrZ5eggxxwml7399tvIy8ubvtHukpLIetMQzlkF/Nvc1mFBJamy1jdaKGS2HVs3hyI7IwBBgS6H1Js1xkLKhfrmZlT8428w9vYg+557EZ1Pzl5EZpVp4SDAKqz8flRZVo7z584J0QTelpefh2UF+cilewtHAOP7lkwSAV9E4Bvf+AZ++9vfCuLnO++8g/T0dNENJoXeeuutaG1txSOPPIIf/vCH1+3eVOvpJQGhoqIiEg6wiKjuL7zwgnCw5UZ+/etf47//+79Fe+fouvNUW5/ICIPBgOLiYrS3t+OPf/wjmBTLaao2TVT3ZLZJIqsksl73PJkOkVWp0Erjb12kznq23okrHRDE1lVpKhQkO5Ea5YeIIBCZFaTyqZSQS29BgJ5Fcd7ajYu2HjTbhxHtH4hbNYlI8qfQV0Rm5UO2uHUVvOVISTskAhIBicD8ICCJrPOD+0Jq1UHetkOtLWg7dRIVf/urUGQt+NznEUBhYzTBc6tMspBwlX2RCMwWApXlFbh04RKRPs8gJjYWn/nXzyA6NsYnBxRZGWmwfxgfHS5FfU07KYyYsaF4GbbdtsLnSSKzdfynUq8ksk4FrYWb18FOK1YnzGYH+vstNOhpQmXlEBFZjUTasiInJ5QUfsKQmRmMqEgio8hxoYV7MsieLWgEDERi7bIbscdSjwGHBXfr0pDlH4YoUveT6foIMMGtva0dTQ1NKC8tQ1V5Jepq6kglPozI/QnCYSgtIx0paSng0IMBgQFEaNVCq9EIxz9fUyaSRNbrnw9y77URaGkxoqpajyvVw6Qg5KAJ1HikpQURuYFmJ3xEunF4yITmhi6c/mcljh64hNvvXoP1W5aRU2A4AoPmXmmsnSLx1doGccLaiV6nGVtJlTXXP0LM/ahVFJVPPphd+4T0xj30e2LsJieJyyVoOfohWj46ihVf+CIydt0BdVAQ/IgI5A3JZnPCQuT00+cMKCMSq5OUHbMydNi6KYQIcCSfI98Hbuow7d69G8888wxiYmLIAeCyIJ+Or3A6kV5ZifXZZ58lwuLwSHUpKSlC7e3OO+8c2XYzK5LIejPozX1ZC4mZGYx2vHtwAJfLjdi4Lhj5uUFITtRCQ7ebmfhttgzpicj6d/SWlyGIlAwT129EyrZbuPIZqX/uUZMteiLAhFXDsAHdXZ346MNjOPTBASQmJ2EZkVd37LydnPkS4C+FTjwhk+s+hgATsFmNtY5EQb7yla/gP//zP8f04A9/+AO+/vWvi/f8ioqKa97XplMPK75+8YtfJPEADbhuz2gvfH9mB5R+cqjl33Z2VrlW4mvwC1/4Ari+J598EswZ5DQdm0TBafwniaySyHrd04ZPypycHDz66KPXzTfRTnoPgcUG9A070TYANHQDzb2A3uTEkngVlsYDeaTQqiVlVklmnQjB+d3Gyqw8qHHW0oUOWmppEGOVOhprNTGgIVPy2JVeMPN7hGTrEgGJgERg/hCQRNb5w37BtMwEF5MRPRTSovJlCk9Fk7KROblI2riZljkLppuyIxKBhYAAEy3e3rsPRw8fRVJSEvIL87Fh80ZSLg255kCLN/d7gJSQmhu78O7eM+SdbMWW7cuRtTQRyWkx3my2z9gmiaw+c6hmzVAON8gKam1tZtTUDKG+fhi9vRZST9MhLk6HxMQAoaQWEaGlSWs/aHVSiX3WDoasWCIwywjU2gdRaRtAFan7BUKNOwNSkUCRnbQyRPWkkDeZTCKUpn5Qj8GBAfSRAn53ZxeptXbQxG63COHHRJ8EIrZmZmcJcisrtYaFh4mJqUk14iWZJJHVSw6ED5phMJAT7JANH3zQiaYmI00KR2HJkhBSEAqgiVTfYL7ZbHahzFp2qQGnPqqgCBcOUl8OxS07V5L6cgz81XM7z2Jy2DAMO0pIxKSK7uE9DhOy1GHYrk1CGImYBKq8g/jog6frnJvM7+oOUtzqLr2M8r//VTg6hGdmIbl4K6Jyl7lIrF7CEO3ptaGpxYLzJaRO3mPD+qIQLMnUISFeA7W/b1zLc36AvaRBJp2VlZXRe109CgsLkZGRMaOWSSLrjMI565Xx+77N7kRJmRHlVUbohxxIStBie3EoQoP96bf55k3g+1rXpYvoOHdWEPSTthSj4LOfo3sasRPU8jfq5hGevxo4lPkwhVqvqqzEgXfeo/edIVKo12Htxg3ILyhATFysCGE+E4To+eulbHmxI8DPZ2lpaSKq3VtvvSUUUj0xYYImq7Jyev/991FA5/5EaTr1/OhHP8L3vvc9bNu2DeyMMj498cQT2L9/P3bu3Ik//elP43ePfN+zZw++9KUvgZ1XPvroo5Hxh+nYNFLpFFckkVUSWa97ytwMkdWzYr3Jpc56sRGo7XRCq3YiLkyFbIpEmRihAr23Q0NzFz4y9uDZtQW9bqBBjVJbHw1K96PWoUeGfwgK1VFIpSWrK/DrpVRmXdCngOycREAiIBGYEAFJZJ0QFrlxGgjoW5rRfOQI+qqrYOhox9IHH0byli3w19JzhvS8nQaisohEYGYR4BAygwODeHPPXpw+fgp33nMXitYWISk1GVoioPtS4oEW/lSWNqHsUiOuVLaICeS77t9A6rJhpHTmW/3xVuwlkdVbj8zs2kWXlri+9HqbUGDt7rags9NESqxmImnZwX6wrL6akRFM4bSCKBTlzExwzW6vZO0SAYnAtRBw0A47HDhl7cJJSyfCifiUoQ4V4anDVPL39Fq4XW+7El6zrbkVjQ2NaKirR1trG/p6ehEQFIhICg0dFRONqOgo8Ymg72FhRBggUmsQKe6xYoo3T/hKIuv1jr7cdz0ElGeMQ4e6SN1dj4gIDbKzQyjENUVz0ZB2KE9Q+Ehqa+lFTVUrLp6pEREiNt1SgKXLkkmFLIoIiDPA/JkCDhyRr4Ui8dU4BnGGhExYuCRHHY6l9EnxC4ZGKrNOAc35y+qgsMwD9XVoP3MadfveQlR+PoXhvg+hKakIiIqaP8M8WrYT4c1sdqKm3oxzl4bFelCQCsUbw5CcQCRWoa7sUUCuLjoEJJHVNw95R5cVDU0WnDw7ROODKmxZH4rkJBKqCL95R1UHkafNfX3i3lb+1z8hYkkOcv/lEwhJSoaOnoFl8k0EzGYzhiiselVFJSooIsXlSyWIS4hH4coV9FmJ1PQ03+yYtFoiMA6BxsZGbNy4UWytrq5GcHDwmBz87p+amiq2MdmUSacTpenUw+RTJqE+9dRT+OY3v3lVtd/5znfwk5/8hN6lVmPfvn1X7ecNHR0dwiY9Xa+/+c1vcPfdd4/km45NI4WnuCKJrJLIet1TZqaIrORgAXpfgd7oRGs/cPwKqbT2q0DOp1ifDWzMViEkwAkdvbTI5D0IOEDhPpwO1Nn1OGZuQzd55zroEN2pS8VydaQc0PCeQyUtkQhIBCQCc4qAJLLOKdwLujGb0Qhjbw9q3ngdZX/+I5Z//gvIohejgOgYqAMCFnTfZeckAr6AABMoyi+X4czJ02glYsVjn3scq4pWQ03xwryZLDERtuz1z2pIb716EiePlZOybDoKVmYgrzANQcEBPjUJPlH/vGWbJLJ6y5GYWzsUFdaq6iEKXaWncJYDQiUtkdTS8vPDkEUk1tAwDRFY/ej+wVF55NjP3B4h2ZpEYGYRsBKJ1ei0Y7+5CYcsrbhbm0oRnGIR4xcgxgpntrXFUxs73NjpWcVqtZDSlZ0meofQ292D2is1NOFbhRpa9tD3yMgIZGRlIn95AXKW5SA1I43urzoiA3mvQpUksi6e83i2esoK71VVQzh/vh/JyQG4/+PJCAzyJxK37zxT8LuIxWzFwXcu4PKFOrpuNeJ95JadK6ALmHsnACvN+3BUvlJrL8rt/SgnMZMdpMq6VZuAUHJK4Ah9Mnk3Ahx++8rre9BdcgkOm40cw7fSmNo9UNHvgZ+XOIebTA4w4e3cJQMOH9MTgTWE1FiDEROtpugM7ITh3RhL62YfAUlknX2MZ6MFVmXt67fj0NFBdHZbERWpxor8ICzPC5yR5pz0LNxbWYGKl/4BXg9JTkHqLdsRnT+xcuGMNCormVUEent6UF9bh9d3v4qOtnYUrlqB1WvX0DhzketdhkKhyyQRWAgIHDx4EI8//jiNi/pRtKo2oczq2S9+b2elUwupT//0pz/FQw895Ll7ZH2q9Tz88MPYtWsXSkpK8LWvfQ3PPPPMSF3Kyq9+9Ss899xzov0zZ86A50s8E9v8b//2b3jttdewdu1a7N2713M3pmrTRH2rqKgQSu9jKp7gCzvr8jjCvffeizVr1kyQY2FvYqwnk1RGIzEwF2GaKSKrAp2VHmyGzSrUdDjR0ENen32A1t+JyBAVchKA1CgVwoOAOY6mopgnl9dAoM9hFmRWVmatsQ2SygJNRJHSQh6RWSmYFfzl2+Y1kJObJQISAYnAwkRAElkX5nGdj17xQJSNvHGbjxxC9WuvIiw9A9F5+Ujeug1BcSTdL5NEQCIwLwgwkYIHMi5duIT9b+wj4pkGSclJKN6+lYgTGfNi08022t01iLrqNlw8W4OWpm5sp1CeecvTEEVqrGr1zStG3Kx9C6W8JLIulCM5uX4YjXahwMrKqy2tRgwOWkllySGi7URF6RAfryWySSBiYnRCNc1XQgBPrvcyl0Rg8SLAju5XaHyw1NaLZscw7tKlUQSnSOhAastyjHDGTgyrxQqj0YDOjk6002RvZ3uHILIaDEY46TmNJytYIZ8VWaNjo+meG4/Y+FhSnI8m54Ew4XTkLY5Hksg6Y6fFoq2IVd8bGw04coTUQ0mJde2aCKSkBiE2VudTmPB7VnVFi4gSUX6pAZHRoVi/ZRlS0unapfeSuU4mckrgezrP+5y39SCEFLYT/AKxgqLyJfkHQ6ciouFcGyXbmxQCxu5uDDbU4wo5hpv7ieC9eQtiVqwkklf+pMrPdiY+1y0Wp5vEakRPr1UIGxWtCEJ+TiC0OhXUPkREn228FnP9ksjqu0efxwMqa8yoqaNPvRHLlwVhw5oQhIT4Q0cqrTebjJ30DHzmFDounEdvOTmkP/YpJG+7Bf7kwOUtZP2b7eNiKM/RvvpJYbfkwkUaZ75IUXuMFGEiGkXr1iAzOwuJSUmLAQbZx0WEwF/+8hd89atfRXh4ODniVU1IZM3KysLQ0BB+8IMf4JOf/OSE6Ey1HibP5uXlobe3Fy+88AI++9nPXlXvH/7wB3z961+nd6hYQXgdT2Rl4u369euFze+++y4KCwvH1DFVmybq2+HDh8GfG6XExERBBJZE1usjJYmsjz56fYSmuJfeYdA+AJS2ABcanKjvdmLjEhUKU4DMWD8Eah3QyJeYKaI6u9l5cPSitQcnrZ3ocBjBocLu0KUgTR2CIJAi0+w2L2uXCEgEJAISAS9CQBJZvehgLBBTeskLjwemOs+fEz0qfOILiMzJhZ8XqwotEOhlNyQCEyLAIW5MRhM+PHgEv//177Dt1m244567aHAxkYgRoROW8daNLlKuU0wWH3n/olBBCgkLwo47VyFzSaK3mu2zdkkiq88eukkbzuM5dgqvY7WSAkuflUJgG8iTfgBlFYNg8mpqaiDWFEUJtbQwUmGVnLZJQyszSgR8AgGmT9ZQ5KaDphY4aTAw0k+LDeo4cnr3recDnwB7nJFMXmWV1vq6elSWV6C0pBT1NXU0MdyPlLQUMRGcm78MGZkZSEpJIkcdCtlMKvoaWnLYclZXma8kiazzhfzCarenxyKIrL20DAj0o5CYkUL5HXRf8hbS9mQQ5+eolsYuvLn7BAb7h+l6JTLHhhzkrUgT1+l8OP60OQwot/bhnLUbnURs5Yh8BeoIRPsHsIuCnPuZzIGdozz8fgv69FwuQdupk2g/fQoBFGp7xZNPI5TC1Pp5iaIdR2zo7bPjChHc3jvUj+goNW7ZHIqkBK1QbpwjuGQzPoCAJLL6wEG6hol8OzKS6vLlcgPefKcfGWk6rFkVjLRkLSIjOJLTNQpOcrOdxC8sg4Oo2v0KSn73v1jx1L8hm1SnA4gEyWRWmbwbAf694mgTHR3tuFJVjSMHD+HS+QvY9bG7sHHLZizJWSoc8ry7F9I6icDUEXjzzTfx1FNPCafT5uZmihBnG1MJv7cwSZPTH//4R6GiOiaD+8tU67njjjuwZcsW1NbW4tlnn8XTTz99VbU//OEP8f3vfx/Lli0T6qqeGdiu//qv/wKTXTdv3oxXX32VHjmZITaapmoTK8SOT4zHeEzG5+HvNTU1eOWVV6Qi60TgeGyTRNYZJrIytgazEwNGFSmzkjprN6uzOom8CqHMujRehcw4lXxB9jgJvWG1j0LNtNmHxYBGu92IcD8N8jWRWKeOhZpCzcghDW84StIGiYBEQCIw+whIIuvsY7zYWuBBqSHy9qt8+UUM1tch+96PI3blSqHQqprHCdfFdhxkfyUCCgL6Qb0gSFw8dxFnT57G7Xftwu137kRgYCA0Wt8K9cThO3u69bhw+goO7j+PwqJMrNlIYXhJ9SgsIljpslzOEAKSyDpDQHpxNYODNjCRpLpaj1ZSYR0esiEoWC1UV+PjdUIZLSpKS/cLfxq0nT/SlBdDKE2TCPgsAkxiHXLaUEJhqPea6pFLJKfN2nih2hdGKn4yzS4CPIlks9owPDyMgYEBDBCBta+3TxBZWeWoj77rBwZhs9ug1WjpWSeVCK6pSE5JRlxCPCIiI+aN7CeJrLN7biyW2g0GG5oajSgvH8T5C/3YsjkaW4pjKRwtKTv6UIg/JvgNDxlRU9mKUlJlvXy+Tryf8DtKXEIEgkMC5vyQGujePui04hIJmVTZB2Cn+02qfwi2aOIQ4acTyqxzbpRscEIEHBSG1krqdjVvvoGG999DTMFyxK5ajcQNG6FlNW4vGEOzU2ROs8WBk2eGBZGVyWyZ6ToUrQxGUICKrln5jjDhwV2kGyWR1XcPPPOb+Hpv67DgUqmRFJhtMJnsuGVLGHKWkCMEXeo345zhICd7vuc1HaZIbnteRXgGR3IrQNKWYhnJzQdOG4p2jaaGRpRcvIQTxz6id5FIpGemo5DmfNIzMxASGkrPb2of6Ik0USIwNQSOHz+Ohx56SBRqaGigaBJjx0oGaS6UiaSc9u7di7Vr14r18f9Np54HHngAJ0+exJe+9CWhvDq+Tia4/u53v0NxcTFefvnlMbt5jGHVqlUUacuMX/ziF7j//vvH7Ocv07HpqkomuaGyshL/+Mc/JJH1BnhJIussEFkVzAeMpM7a78TxK6zS6kRooArZFEl2GRHRo0NUCBFONb7lVav0bSEurU4HzpNnbjmFm2kkBYZUUlxYr4lFvF8QomhQQ3hASwryQjz0sk8SAYmARGAEAUlkHYFCrswUAjTyZbdaUfni39Fx9iyCExMQt7oIqdt3wJ/CZd60C/dM2SnrkQgsAgRYjZVD2L739rtob20Tgy3F27dh/ab1Ptd7niQeHDCg9EIdyi83oraqDdvvWIWtO5ZTKEMN/HlUXaYZRUASWWcUTq+ojK8jnpwyGuwYHLSis8tMoZ1MgsQ6RCTWwAB/ZGYF0yBsGKKjtRRGUE5EeMWBk0ZIBGYBAQ5B3WgfwmVbH45bO7BZE0+qfSnQUuhpGXx6FgCfRJUWs0UQWxtIpbWutg4dre3o7elDOzkJRsdGI4ZCBsbFxyE6JoY+UeR4EIzg4CCx1AXoEBAQMCfkVklkncTBlFluiAA/j5hI+e0CkVjffrsNy5eHo6goglTgA33u+YPfuYwGIv6crcW7b52h6zQCGdkJKFydgcTkaFJTprvqzUrZ3RDRqzPU2QZRbR/EBSK0aki4ZA3N+2QQoTWR5n78yR4pZHI1ZnO5hR0ajF1d6KMwtU2HDqDr4gXkPfo4EjdtRiDd571FjbV/wI72TitOnNGju8eGFQVBWJodiPRUUgifh/NaOUaeqmLKurLkPCPrHuJjyjYnOfOMyeORfyQPs/qUJNZVo3VOkF/JykulDrHOKtPjt7mrVvIpS8+yyjZlOVIHrSjbaIB1ZH102+j+8dtG6uCGKLn2X6cOd1sTl1PKc02uOpjk+Mabe8GhjT/z6c8I9Tp2nmZym7///NwH2TqZpobAsMGBrm4bTp8fQkm5EcUbQrA8Lwgx0WpyruKz4eZST1kp2k4cR191tbjP5T7ySURmL5GqrDcH66yWZqIejylfunBRqLE2NzbSuPJGbNm2FfHkYMckVpkkAgsVgUY63zdu3Ci6NxFR9fTp0/j4xz8unvVLS0sRERExIRTTqYcJrHv27BHKrLt37x75zecGOELLgw8+CJ7f//znP4/nn39+TLs/+9nP8MILLyCUrs/Lly9fRcDlzNOxaUwjU/giiawHJ4WWJLLOIpHVxt55pKjcM0QSwZ3AyRrXK0EUieMU5/hhaTygJqVWep6VyQsQ4PclA8j7mQauPzK3o8dhBisy3KZLxko1DbIIZVYvMFSaIBGQCEgEJAKzhoAkss4atIu6Yg6V2VN6Ge1nTosB+aj8Aqx++stQBwV5zWD8oj5AsvOLBgGTyYS6KzX4/a9/T0opOtx9/73IXpJN6kDkbehjyWKxobmhE2+89E/wesGqTOQtT0XWEvKapPfL+Zgc9jEIp2yuJLJOGTKvL2C3OaHXW1HfYEBJyQCFhTNhmEitS7JDkJkZhNTUIISFaYgM5SfU0Pz95eCN1x9UaaBEYJoIsFrfIXMLWigENZNXV6mjUKSOEb+n8sqfJqg3WYwJJRyyk1VT2trbwL/DsUReffDjD6KqvILUK5uEEpLJZBYqfVnZmcjIyqRnoSykpKYgnhwImShiIHU/DttXTQSBkJAQbNq0CevXrxfhPj1JLdM1VxJZp4ucLOeJAPPC2MGmrm4YJ070wGp1IogU4DdviRbPI555vX2drysn9aWzo1842509UYXW5h587IENWL4qQ0SOmA+nOzM5LPTRfM95Ww9qScSkw2EUIia36BIR4PQX5KImgDsAAEAASURBVFZvx3Yh28fjZp3nz6HypX/wyyyCExKQvvMORObkwp/VvuaRJOqJ+6UyI06cHoLV5kBUpBqb1oUgIY7eF+ZRiVVcc3zdeXyYPCl+42gb31t43UFCPpxG8rnzjOyn77TTtZ/ycR383VXXuHI0b6qU42On1Mn1O9x1KOWVfaIej3qV7Xy/4HXXfqU9uinyP95OdtNC2DJSxp2f87jsGy3nykp1jvRvFAvaOtIfxT5XeaqfH/gUO8TSjQWvM3Yj+1x2KTaL7cJGbtNVhmqi90cNBk16odq5ZeMWcsKJQWRUpCD1sMMNP6PI5P0IsKMJR84+d4kiul4cpudHf6QkabC+KAThYTd/DDmSm6GzE5d//xsM1NVh+RNfQDwJYARERXnNfc/7j9LcWnjp/AWcJ7GSs6fOCFLc9tt3YEnOUnLWSRbkOHltz+3xkK3NLQJMGN2yZQtqamrw6U9/Wryji99TMoPnIr761a/iz3/+MznkFWHfvn30E8m/ylen6dTz5ptv4qmnnhKOISdOnEACPSsqqaenBytWrBDtvfTSS9i6dauyS9jFCqys5vqpT30K3/3ud0f2ea5MxybP8lNZl0TWg5OCSxJZZ5HIykeAL0+aV0QHKbKWtQAt/URs1TuRFqNCRgywhOZMw4NUIEdUmbwEgQGnBVW2AfGppnAzS/3D6ROGJepwCjejld65XnKcpBkSAYmARGA2EJBE1tlAVdbJL2xmConJXtYV//g7dOFhSN91Jw3I5yAkKVkCJBGQCMwRAjXVV1BWUoqjh48iiULR/sujn0BUdBSFCQ+cIwtmrpm6K+2oKmvGuZNViI4Lx447VxEhNxJh4UEz14isaQwCksg6Bg6f/eKaiCJVFVJf7ew0C/LqwACHs7bRpIOfUD1LSwsUCmgxMQG0TVLYfPZgS8MlApNEYNhhRYfThP3mJliI6LSOVPqy/EOR5E9KBDLNOwI8MbZjxw5UkUpfRkYG9r21Dy1NzWgjJST+DPT3UyjzYbpfa8XkMSvTB5HDYERkBBJSk8QEGysneSZWYnnjjTdGwh567pvquiSyThUxmf96CPT2WtDQMIzSy6T21WHG9u2xyM0NJbVh/5sKYXy9Nmdrn8loEREkjh8pRXlJI+ISI7B0WQpWrslCcGjgvESQYDJri2OY5n0GcZGUWcNVGmRQVL48dSSSSJmVhUx89clPIQrwUvkoREA+xmIbbVD28fKq/W6yAeXiAiIvs/s8yyjr4rzhPKJOd/3uMpzHxQl01eEqMzYPcR1G6rVbrDD19qCr5BLq338PoelpiF2xEhHZOQiIjhYEQ67D1Q9XOcU+xZ6RNth2d8ax+67uj2cdoojoC+ejbx59EfWoAmC1h6K+2Q9VNXYEaLoQFTaMrHQNgoNc0VA822MzlO8MhrKuLF2NKNuVpWLjWNxc3fHcJiqnzaPHhvOI5G7L9cWNhTga7v3uBdvhmcZ/5328jY+jksbncX33zOEqo+Tn5fgyE20bk8fDfs+ax+SZoN7R/aOlnG7iLrepYOVa57678o2Wc+0ZOS7ur2IxGayU804UcB0XbmHAMCj2JETH0T3cnxSp1cKpOpLCkLNDdQyRW6NjosU2fxmG3BN1r1tvbDajpt5M17+JBMpU2LIhFMmJWoSG3Fw0JAexZG0mIyr+9ld0khJ1zPJCxBetQfzadfCT54TXnAd8r+gm1fDG+gaUXLyIuppa8b6RvXQpNhVvJpK6KzqE1xgsDZEIzCICP/7xjwUZlImrr732GoqLi8Xv/eHDhwVRlB1Rv/e97+Gxxx4TVjQ3N+MXv/iFWH/66afJSS9VrE+1HovFgvz8fOGoesstt+DFF18USqw2uo8yqfbAgQM0lpuM48ePC/VzBQIut2TJEnJKsOGPf/wjdu3apey6ajlVm66qYJIbJJFVElmve6p861vfQg6RBx6dZSKrYgQ5YpHXFnC+wYl/VruIrWE0X3r3KhUyYlUIocj1o4/YSim5nC8E+FWmxNaLw+ZW9JKnbohKjXsC05HpF0rKDDygIY/WfB0b2a5EQCIgEZhNBCSRdTbRlXXrm5tQ9crLMLS3w58mVzNIXSJp82YJjERAIjBHCLz39ru4cOY8T0+RemkBdn1slwg7O0fNz0gzPHjK8ygH9p9Dyfk6GkD3x7LCNGzfuRJanQx7PiMgX6MSSWS9BjA+stk1SamisL02mIwUuvdiv1BhbWw0IjjEHysLw1FQEE4qzcFErKA3fp5dl0kiIBFYFAi02w2oIXW+98zNCCcH9scDlyBaRUpZNP4n0/wiwIpGrOrCE06cMjIyxMSUJ/FkoJ8Utds7UFleicqyCqHW2tXZhf/vZz/A3ffcjaGhIaHWwqEGmeDKIRCZFBtFE85vv/22mEi7mXu+JLKKQyP/myEEWOGQFePf2teGk6d6sbU4hp5PwoSDDTvc+FJSrtOaylaUXqzH6eNViIwOwcOPbSNSayS9h5HK5gwlpa3JVtdiH8ZZazfKbf3g34D7AzNQpIlBEM0BUcDvG1Yz1fZuWOE1MlyvnfFWcl4+f1g50qUwSe+N/N1DLdNutwuigdjG5xp/5z/Kw9tEeZF/dJ1fPsU+99KlcqmoYI6WG6lDad/dNpfl5KrflV/Y5ZHPPKRHb3kZBhrqMdzViZjClYhdvUbYw/3iP1EPrdvtSh20FHV47HP3Y8Rm93ehkumuQ8FE6dOI3WwnvWfbHXZ3W7RO+HA+tsHqCIfRkQmbI5qiOAZB6zwHtbMWTrvNlccDe1GGvnM5F+auOuir67u7TqE06oGTUm7kGHruo77ynCTn4TrZVlGeKuV2WEWM96so/KdY53cZ+vBidJ+fex/vcuejcn4838nZuQ5RxrXPj+viZyGRl+vy+LjLcR7er9TnWZfLDldbXLdrH9ftql8pR6XH2M3laNOI3fxd1EVLpR1q0sM2134uo9io2KGU5bZEHe5yvK5sY3u4HDeq5GcclbrE0sNGVz2U191vBTexXekb1WYxW1BWVSaIM0O9enS2daKvt4/eRY1ISE5E4cpCrF5bhLyCPOF8E0AO1kqbfM3I5F0IcARevd6OPfvod6PTijUrg5C7NBAZqdqbNpTvQ81HP0Tn2TPou3IFcatWI//Tn4E6IOCm65YV3DwCyr2clVjf2/8OmojMytf7Jx57FCtXr0JIWKj4fvMtyRokAr6BgJF+xx5++GHwezAnVkINoPvVuXPnxG8eq5/+8pe/FM8nvP/MmTO47777eFU4k65bt06sT7UeLsSqrEyG5eeh8PBwrF69GuXl5SRS0CGcQvj9Pi8vT9Sv/HfkyBF88pOfFF/LysqEMrqyb/xyOjaNr2My3yWRVRJZr3uezDWRlV9S6B96hoBWUmWtanOifYDCC5ASa1YssDaTwmXonOTJxw/MMnkDAj1EYG0lD132zm2j0GKxqkDkkCrrKnU0Ash7jl8NZZIISAQkAhKBhYWAJLIurOPpbb0xkxJQL6mytp86icZDB5Hz0MPIvOtuaCjEpT+FOZdJIiARmB0E2BPYSGFlX/rriyi7XIbi7duwYtUKLFm6BP78QuZDST9gIBWAARx85wKaG7uwoTgPywpSkZoRNy+qRj4E3U2bKomsNw3hvFXAKqzDw3Y0NxvQ2GigpVFMPGq0Kpo01CI2Rov4+ABE0np4uItUIeYy581i2bBEQCIwlwgct3TgEoWadtKFn+YXjG26JARRmGkmKMg0vwh88MEHQl1FsSIj42oiKz/nmUwm9Pf1Y4A+YjkwgNPnz+C3v/2tmOD6/e9+jyPvH4LNasO2227B//P//gdaW1vxyCOP4JkvPyMIJOEUNYNJLS4yi9LijZeSyHpjjGSOySMg5pBoEun8+T6Ulg7CYnEIEmsxEVpDQtR8is5ZYuIGf+g/sVTChfM2njwWRDpaKvkol8gryHi06srjRF/fENqae3D2RBX0gwYicEWSMmsysnISRV9GynvWJdpQ2uamlDbdtrjzjoQ2J5Lf2HrcREsu6VGXyzYnhkiJu5MIrPVWPVptw4j3C0ACKbIm00fnJIIaWabUrZQRZMgRLLj/bJNSv6t91zZe5930n9tuJZ/SD2Grm6TImV02UjmR3+P7uPr5+LM9XB+XU2xjQqOSxD2Mm6ak3M/GL907J8jDCpzUiPs8m7CcKOWqm7uo5OHNyrpr6TJi7LbRPMrJ7CCVLKuexsoqK2AjYgSH0w5NTkFwouv8EPZ41K20w7WPr1vZ51ry/640Pp/yXdTh7qyyTVlySV530PkwOOSH3sFgdPRGIypSg7QkJ7R+XdD66zkT5STc3BensnS17Ppf6QN/c2cbyT9RPzzrUI6Hsk1ZcptKZco2zjuyTg2NX+fzi7d5bhc2jSvnstN1HlyVd1x53s99EIlOiPH1e5YfXafcVI7TyDYPG3jfyPaR9avrVspzXgVHUc5th+d+pT7PdpVtrqX7GLo7I7Z52OiZ1715jI0T1esgwvGe1/fARsutm7eKMSmjwSgcbIb0Q3Q/HBTPL0xMTqaIQWmZ6cjJzaFnkkhytJRRAfj4eVPi+53JZEdJuQlX6kzo6rYiLycQxRtCiDzlJ5xhp2sv/wYMt7ag69IlVL36irgHLnv0MQQnJFJUt/DpVivLzQACfH32dvfg/Nmz5DRXgdorNchZlovcvGU0FpuPmJhYaLSakfvBDDQpq5AI+AQCHPHk8ccfFyRVxWCtVotbb70Vv/71r8HrSmKC6z333CO+7tu3T5BPlX1TqUcpw0qszz77LI3zDiubkJKSgueeew533nnnyDZl5X/+53/w05/+FGlpaTh16pR4flb2TbScjk0T1XO9bZLIKoms1zs/MNdEVk9jyGkQFW1AWStQ2uxATIgKazJVSIl0Ii5cBY0fe9C53xY9C8r1OUWAX+z4veW0tQsl1l60E5k1mQa0i3WJRGoNQBiFnpGD2nN6SGRjEgGJgERg1hGQRNZZh3hRN8DhgqxEpmugUGkXf/0LpO+4Dem37UTE0hzoIiIWNTay8xKB2USgu6sbzQ2N2Ld3H9opBO2n//WzKChcjsAgl+LFbLY9U3Urk50NdR1C0aiqvAUOerG87xNbkJkdTyHqSDtImVGZqUZlPWMQkETWMXB4/Re+ZqxWp5hs0uttRAA3o8FNYm1vMyEtPQhZWcEiXG8MEVm1Wr6GvL5b0kCJgERgBhGwEvHHQmGm37E24wI5sa9Rk/KhJhLpfiEUjcm3HF1mEBavqaqnpwfbtm1Df3+/CEv417/+FRkZVxNZJzKYwwZyuMG6ujp85StfQXhAKDkxNIvnQK1Wh3XbNojJr9DQUBw5dJjCg9ZRSNBIMRGt0WhF6F+NWiOWarWaQhNyOGAaByb1JVaJ9Uy+RGTl30YlXW+dKEQi25g8o1QlN0GPeXSTrc/V6mh+V9jlG9mi7OflSFkyjdfZwpFtYp1zudLY7Te2kSpSio6rk7dTS+42lUxK/cqStyvrV9s1Ud037n97u1E435ReHkRQsD9uvz2eSNmkFkqq8UpbynK0fW591JbrrV+rz6ICj/5yG4oCJ68rhEwmUFJLo0RKN+HSlZfKcF7GVZRxEIHLjPKSRnonI0XCPj1y81OxfFUm/Kg/PL8yQshkgir/Ubmx7bq3jyN2Ku0JYqfbbs9tLpuZWMp1upZKH9i2bruRCK1G9NjNwtYkv0BEQIsAIi/yKa+QVzkv/ylllf676ue66TNCrnW3x7aKMm4FUVGf2wY38VSp37P/3LCdynKbYruodywxl9sabwsfO34fVAl1TcKV7leKWqaihOmp1inUJCkPlxFKku4lb6fW3eV5P9XrmU+su/d7qHW62mPpFxcJUShwKkqXVAlVM1on18H20t9wa7MgcFkG+hFABL6Y5SugCwmFmggQ4+sYtZON4nPHrdTJ9VOdok+83cNGkU/sUxQ4lf1sJ1OWXWqmXGYkL9tNf0xitVj90NDih84eHfQGiqyUasPyHDN0JEikVrvadWHoKqPUMYorVztqp1D/ZPvoT1ECdfWTsXbb5sbNlce1XVEIVXAmw939pFxUTibvRODnP/+5UNB95plnhIF2mx16UiBurGsQTtZVFZVoaWoRDjXJqcmCHMek1riEeHJeIIJkgG7kOHtnDxeXVXTrRW+fDZVXjDh0TI/kRA1u2RRKZEYNwkLHPh9OFRknESb7qqtx6X9/Ke5FSZu2CGXWCAqHLdPcI8C/63y9dnd3oab6Cj48dEg4zLFy8o6dO7Fu0wZB1Bv/XjD3lsoWJQLzi0Bvby/OEtGbFVlZaZWX00lTrYdJ5qyuWl9fj8LCQmRkZEyn2euWmapN161s3E5JZJVE1nGnxNiv80lkpd8/GCxAx4ATle1AXRfQ2OPElhwVitKBaCK2zmBklbEdl9+mjMCA04JmCjdz0tKJXlJpZTXWdepYEW5GTS+h8jVxypDKAhIBiYBEwGsRkERWrz00C8IwMblBL1ldly6i4b13YKUwl6zGuuSBhxGVm7sg+ig7IRHwRgQunb+Ig+8dIEUjiyAp7LxrF1LT064iInij7YpNPIlpMVtx/MNyvPXqCeQtT0NeIX/SEREVIibBlLxyOTsISCLr7OA6G7XymAv/5nZ0mNFE5NWy8kF0dpoppLQ/hZcOIC/8QMTGBlA4KS0CA/1oAsI90T8bxsg6JQISAa9FoJ/H+0iJ7yNLG1qcBtyjTRNE1kB2XPdaqxeHYTwp/NBDD+HYsWP48pe/LMIVPvnkk2KC6vjx4+Iefz0k+LkpPT1dkEf27t2L+Nh4lxKayUiqSr0Ij44YUYV57dVX8Zff/Bms7BoRGUHPilHieZHXo9zrTHLlTwgRXwMCA8aQhnyByMq/iZwYF2aoeYajFkQ52i8IdbRTvLPydy5DH9d+pSxvHyXUiX0KgXEkLxMYuR1XHQrZjhtW6uZto/uZ2MdfaT/Zx8tR+zzbddtC9Yz0g/K71qkCInK5bPVol9t01ynqFf1X9rvaVcrTVirv2je2DNftss9VP6272+UyY+z27JcgTY6W406O2ufGkLbxvMJIf4WtrjImk41UhmykHGwUbcTFu59ZiDzH+a/G0G0L40gfbk/YRkulX57tK6TOUVxGbaLCoqzAhnAV5DqeAxHro+Q5xlwh/9GqIBW68owSBTkP76MqMTxkxpDeiIH+YbqWAhEeGUpErQC6poiwyHlEXio70pZSj2ufsp3zKURFYRsTEEVStrvaHLWNt9M2/nOXdbUF2Mgwk8pBUfmIzOo0w05VJfoHiah8apoD8ncTDpV+8QFT6lC2KbbwieJad7UjuuQ/SmDk9hVi6Ziywn4+F0bLu/pI38dhQVnGtM/7lb4odTIUvD7Rkg7DuH1uFUqRm/ZxAx5JqYfbUJKybexyXD0TtM+npVJG1MXnOzkdVO5+SUQtilu5CrErViKmcAXU40Ksczm2nZNSx4RLakTZ7plXsX+ifcq2sUtXa/ohBzq6bDh6fBhGsx+KVoYRkVWNhDjQueEilY8tN2qfOOknwGGMXeP744GRUi9djSN9UrYpy/F18XeZvAuB8URWvucyOY5DF7OS3ODAIPp6+4TKYyOFK2+gT2xcHJbmLMWaDWuQkZlBZNYAcW/xrp4tTmv4Pma1OdHaZsWJs0OkrmuHRg1sWheKnCXTI28pSPK5YezsRNORw+itKMdQS4uI5Ja+cxffWJRscjlHCFitVnGNvr//HZRcuEjjsWYspbmbLdu2CqJ5OAmSKL/5c2SSbEYiIBFYQAhIIqsksl73dJ5PIqtimMFMEyuDQHmrE+cbiMAaCiRHqpBHUTPiSZk1WMcDAEpuuZwvBPhlUe+0oczWh2rbAGqtg8jRRmCZfzjS/UMR6acb94o/X5bKdiUCEgGJgETgZhGQRNabRVCWnwwCw21t5GVdhaZDBzHY2IBljzyK+KI1QpVVNU7hZzL1yTwSAYnAxAjwBIGBVJA/OnIMr760G0XrirB6bRGW5S8T4domLuWdW3nSt7GuE+dPX8Hpjypx28dWkwJALiLpJVInvSDn5KBJIuucwHxTjTBRw2CwU1hpC4X6ow+psHZ1mWgCwi4m5uOJxJqaGoCs7BBSCfCDjlRYZZIISAQWJwJMUam1Dwqn9QGnFRQQErdpk5ChDhX3i8WJinf0mgk6TPx4/vnnhbrK22+/jf3792MqRNbGxkZs3LhRdKia1K2Cg4MFiZCJef19/WLieTmp83P6y1/+grMfnYZer4dWpwUrsmpIfZXXOSSiTqcb853Dh/J+Nb23sUprW0cbyohwsGJ5IeJi45g/KMaJmZDAiZee68o215L/V9Joft4yUZmx22jSgOt207vG7htbXtnnzjpSN+XiKkRS8oxfigyiKcU+V37+n/OOz+/5XZnWuKoNNsTdrqjH/WXismPb9cyjrI+vg9tV9o1dKmqmit0uCz3zTFh2xD5uaWy/3RtGtiv7PZee6+OxUPAVFdB/nrbYiCzT32dG/4ANvb0WxJKCfHIyEZpIxZSTp638/apzgYm1I9uVvrva8CyrtCnyug1UtvH1yB+FFKoQQhXyhqdKpCBBjuR3lWOlSaU877dYrDAMm9Ha3Iuu9gGkpMciISmK3s2CR0Lzjq/bZQP3l/486+O23MqVCuFzjJ1st5sIqhBIlbr5O6PD+x0ERg85NrSRQ0ODc5h+D/wQpyblTfo9SKAlC5lwudG6WdiEMaH/3f112eWqj3H0zMv5Rr4r+dk27stIf1y2MllJbOd8XI6Jqu76aNNoPWyPu28KBmyLLyUDEbYG62pRTxGL+q9UI/vejyNu9WqEpqbBj+6t85n4nYKGEnCl1oSqGjpf28wIJbXF4g2h5BihIec4hTw9n1bKtn0BgfFE1vE2s6Kc0WBEfW0dqT7WoJIUWq10n2Ql+MTkJKSkpiAlLRVx8XHC2WZ8efl9fhAY1DtQ22BCZbUR1bVmbNkQghX5QeI+oSWHk+kmy/AQBonM3PrRMdS+tRfZH78fWXffA114hCD4T7deWW7yCPA1ySIIDXX1qKqsRPnlUugphHpmdhYKV67E6jVr4E/Xp/hdn3y1MqdEQCIgERiDgCSySiLrmBNi/BdvILLyuAC/MHcOOtHQDRypJE+ePuDWPBUKU4C0GApPId+Jxh+6efnOoXDsKifKrf04TEoNA6TMGuSnwZ26FOQSodWfBw7mxTLZqERAIiARkAjMJAKSyDqTaMq6roUAhwuyk2dvyW//F00HDyDjjjuRsH4DovML4E8TpTJJBCQCM4MAk1jb29px8N0DePlvL+LJLz+Fu+79mAhz409hYn0ptTR248A750lFTC9Cit6ycyUKKRwnv4T42qSlL+Huaasksnqi4Z3rVquDQkcbUUEKrGfO9pG6noOUvtRYvSoCucvCSIVVR4QkDgvNb++j6kbe2RtplURAIjBbCDDZi8djT1g78ZKxBoXqKKzRxCKTnNUj/LSz1aysd5IIlJaW4q677iIShxoHDhxAZmYm3nrrrSkRWQ8ePIjHH39cTDK3kRMhT0oricmsXHdaWpqYqP7pT3+KXaR2ZaTnxp6eXnR3dlEY0W40NjVhUD8Ak9EMs8kkFFttpB7IBD8urxBZ/YjQGhQahN62HhiHDOLsUsKFc16hgsnKg2SAWFe2iaWLUMn8s9F9PGHgKie2cY30XVEJdeVz5effMqUcZRlVCuX8ohw1yuv0UQh3jMMoUW6UZKhMyPNS2e9aKvmVvOLhU+RRSHaCcOcup5S5FkGP9wuyHhP16MPfFUIgbxfbeJzdTRJ07ecybjtohetW2lH2sy28PpKP63LndbXjYTfXTX9KWWEPlaUcV9U9uo9KuG1Qtgm1Tm5nxB5e53wuAuJ4e0R7CvmQK3PX58qn2OMqz6HI6bQhFVM7amqGcPJ0P/LzwlBcHEvvMmoifapd7VB7nEZDl7txEv1x1enZjoIFtTKx3e5yI32luvncVRKXn0y6Vj4bsQMtZhve33cWB/efR9H6pShcnSmiTASFXHss5Fr1jbfluvk8OjImH3WJ537aHOQAaelAvU2PHocJ9wSmYZ0mDlo6Fv7i7HC15lHNSPNj6hvZOnZlMnm4xGTyTSbP2Na971vH2TO48sbrFKmInAjCwpH7fx6hSEXLxHk539ay4qLR6MAHRwZw/PQw1q4KQiGR1DLSdAgkZ7hJXgbz3Q3ZvhcgcCMiK5vIv9H8nMIKkGaTGedOn8Op4ydQWV5F761+2H77rcIhu6CwwAt6JE1gBJjszveJE2eG8fYH/VieG4h8+izNDkAYkd6nnfhcoGfNpgPv4/zPf4rEDZuQsu0WMV8QGBMz7WplwckjwBEaBvr78f477+KN3XsEgXX5ikLcevttSEhMEE5sk69N5pQISAQkAhMjIImsksg68Znh3vqtb30LOTk5ePTRR6+bby52GixODJlUuNzsRE0nvSRZgLgwFVakUSgTUmYlh1SZvAABHgDspRAz9bYhlNv60WTXI40GuZf4h2G5JgqBKvLC8RjU8AKTpQkSAYmARMBnEOBBWB64me8kiazzfQQWR/viXKfzvenwIbQd/yfMA/2IWJpDIYP+hbyswyFVWRfHeSB7OfsItLW24djho8KTntW37r7/HqzfuJ5UjGgq0kdmnxx2B3p7hlBV3oTD714kBdYQrN2Ug/SsBApnFTH7IMoWRhCQRNYRKLxqxWy2k+IqE1iHBYmVFcssFP2GOEYUBlpL5NUAJCToEBNDoWsDyFlYegt71fGTxkgE5gMBk9OONrsBF209OGppx1ZNAop1CQhVaaCjsT2Z5g8BVkDavn076uvr8d3vfhef+tSnhDFTJbKyyupXv/pVhNO7VVVV1RgiK1fIRNSsrCwKCTuEH/zgB/jEJz4Bm9UmQv0yoXV42IDjJ/6JmtraG4KhVWtgsVkRHR6JQF0gs9CuLuMx1HG9Z9Dr7eNKXftdlRE1dcwo9NVlRxsd2Ue28bry+f/Zew/4OKsrffiZPuq9995ly1VypdkYQi8OoS6BDeSfZb8vv/3tkvyzSTYJIT3ZlC9ZEpIQYEOvBkyzccPdstWbrd57GWn6zHfOFXJkbMtWnRnpXhjP6C23PPeded97znOeM9FR8TfX9lnXJ/ZPvE+0Pf636MjZ1ieOOfd9nPx4zrbPKudtjNH423hfzq1/fNuEfWhyHRPHjZ//j3FwXcy2nHzsxGdGYfzzxPv4ICf287vojDj/H8eI7eMNTqqXN4wfM7k9Pn+iPu7IxOezdfM5/N85x403O3GMeP+sbnEcHc99t9BzTlOzEZ9+2gt/fy0SEryRmuqH8HAvUd9Ee/SHaINOEeWctsaHfE77E23wwaJtAcN4Hye2ie2itrn7h0neTGatrmhG6Yl69HQNwdffC5uuzkd0XAh8/eg75KIyShn5Wh2jqLT0o4Iy80WpiLhIvp98TQiCKSPfZDKri7q4KJq1UUr1sZ5uoTh4hois4aRuF7WmEKGkaq0PCXHpGPl3h03TbR0WlFUa0dVjw5jRjtUFPkhNIoKaPylxf6aI7NKOysY9BoHLIbJODIYDU9j+09XZiZamFtSfqafPXaRiPUbPM/5CoTU7NxtxCfHw8tKTKqRnBWdPjHMxvIvfChpIY7MFpfRb0dNL2R1oOjYV+SM6itYT2n/cT6c7Xq67r7wMTaRWbervh9qb7vu33IbgTPcg+k93PJ5yPH//DMMjaGxowOGDh9DX0yMC3vKWL0N2To743vn4+nrKcGQ/JQISATdHQBJZJZF1ykvUnYisEx3tNTjRQETW3VVkpLAB2dEKZEQByeGATq0ABV/J4mIE2IDE5QhF5xZb+wSxNVLphSt10Yigdx8yen9mGxo/UP4rEZAISAQWMQIqIgJ9//vfF+n22EnEC77plmPHjuHkyZMoKysjg6A/GeRTsW3bNkRHR59HbGUj+ujoKF555RVwekBfWjwWFRVhzZo1lNbJ+7zjp9sXPl4SWWeCmjxnpggY2lrRW1GO6hdfgD4wEPn//Ch8KW2U1tdvplXK8yQCEgFCgA2/rJhVW12LF5/9O3R6PVauWYlsUrBISEzwGIx4HFZaGFZXtKCypAnlpxpIsSgZt35pvUhlxeocsiwcApLIunBYX6olVkCx251CcXVw0ILubgsRlUbQ0DAq1FHCw/VYtixAkD0iIvSXqk7ulwhIBJYQAmzXG6Qg9WJrLxpIda+bVPeu0kahUBuxhFBwz6GyfeGxxx7Dyy+/jGuuuQbPP//82TX+jh07ziqyHj58WGzn56SLFT7+kUceEbaK1tZW8Vw4+Vi2LURFkdGdyjPPPIOtW7dO3i0+M6l2spIrb7SzmiRtNxIRi18mk5HuPY04UXwC6wqLEBcbN67I+Zl1mNs5q0zKnyderHpJnz+vRDp5Gytsnj1eHDuuAjih3sn9OZtanPZzk7xvvA56p/3i/M+28fGyeCYC7e1GFBcPklKwmRT7HNi4MYxsZz5CqY+n3hOLYcSI7o4BvPPaYVJBHkLR5hykZ8ciMSXys+vYNaPiX5Ua+xCOmLvQbh+FRqnClXSPSCYhk0Ais3oo3K4B8wKtsrK0qa8PncXH0UX24I7Dh5B9/wNIufEmqLSEL90HXFl4fTFmdKKyxohd+4YQFqIhAqsO2ZleiAjTuLJrsm0PRWA6RNbJQ2QfS093NwU01+CTjz5BX28f7VagaEMhlq1YhvCICPj4+VK2EfreeOqNYPKAPfTz6JgDA4M2fLB7CO2dVlyxwQ8ZKV4IC2XV9JkPykiZAYYaG8Bk/8G6WuR95VFSZ10LtZe3W6hWz3xk7nmmjdSQ+bm+iQLpTp04Sd+5jxEdG4PC9euQv3y5ILG6Z89lryQCEgFPRUASWSWRdcpr1x2JrGarEyNmBeqJzFrXBdR2OAWJNSdGQe8KBEtl1inndKF2CmVWhxltpN5wnNKQsUprgEKLZeoQrNCEClVW5WyeUhdqILIdiYBEQCIwSwROnDiBG2+8kRSuQlFeXj4tIisbZB588EF89NFH5/XCy8sLP/rRj3DXXXedrZONMkeOHMH999+P4eHhc87x8/PDW2+9hUyKTJ1tkUTW2SIoz58OAjbjGEZaWlHz0gswDQ4gLC8fEatWCyWK6dQjj5UISATORYBJB53tnSg9VYr33noHKemp2H73dgQQYdzH13MWVaxWNDJsxM43jpCqbDeltIpEVn4CkVkTx4kJcs1x7sTP81+SyDrPAE+j+tFRGwYGLBTYZEALqZR1dZsQGKgh9VUdBUN507OpFkFBWlJgVZJajWsd4tMYljxUIiARWAAEbE5ScCbFvbfNzZRK2oFcdTDS1QGUcUkq7CwA/FM2MUZKqBzYyqWgoIAUJ0nZ4bPS0dGB0tJS+k0n5cZNm8TWX/3qV/Tbf2F1+kOHDuH2228XxzU1NUGjOZeAxDaFCfvB22+/jVWrVk00NeU7k2f5OZPtGRw0xcTWMlLN+vDDD4VtJC0tjWgm5zIXJggmE+/cwPjnceVOJs6dv+8f26bcR22xnfofdZ5/3uTzxYHyH49DYGzMTkE7Jhw7NoBTpwaJeB1BATuBFNxN6pAeqjTP6xzjqBklpMrKmSfaW/uRTeuca65fQc9vGmh1535nF3LSRkiZtc9hxDFrD5rsBngr1MhUBaCIAh5YtXucJr6QPVocbYlgU7KBDZIwQeXzz8JJv6UhpMIavbaQlAazxslZLl7fGijLQ0nFKBqaLOjssiAv2xsF+T6UKlwJvU4GkS6OK3FhRzFTIit/XzjFuWHEgO6uLjScbqBA7Rr09vQKsv+K1SuRlZuF1LRUmep8Yaf0nNZsnwXXHisexZlGs1CHT0vRo2iNr1BvnulPmp3mntWrq1/8O9oPforYTZuFvyAkKxsqIi/LMrcI9BJpvIkC03Z/vIsI5D2Ii49DFqmw5i7LE9kdvEhARxaJgERAIjCXCEgiqySyTnk9uSORlTvMDz6jFgVqiMR66DRvcSLQW4GcGCAhlFLj+VAqPLlmYmBcWthEOEZGjVOUhqzGOkik1lGkkeF7GaWaiVR6E7FVQ1Hx5xouXdph2bhEQCIgEZgjBFjhg5VSOD0fk0rPnDkzbSIr18Ek1p07dwqHza233ooVK1aQUf6Y2MYKJ3zMxx9/fNa51EcR+6y+yqn/IiMjhVOKnVjsdOK+BAcHi3Pj4uJmNVJJZJ0VfPLkGSBgGRpC8+5d6K2swBgZJ+OvuhqJ114LpUYLpVqmiZoBpPIUiYBQyjr86WFUlJaLlGwFqwpw2/bboKT7lyc583u6Bqn/Pdi/qwzGMTM5dlciKTUSIWH+cpZdgIAksroA9M+aZNE9O6mwjhpsGBqyoqfHRE48C7q6zBglcgc7+uLjvZGS4ktEVk77SZlS5HLcdRMmW5YIuCkC/FvRR8Hop21D+NDShjClHtdr4xCq4gxL8rnb1dPG2VeYCHq5hQNrJ1RVP39Oc3MzCgsLxeYLEVXZ9nDzzTeL58KKioqLEmI/X++F/uYMMxxY+8UvfhFZWVkXOkRukwjMCgHiTQsl1oMH+3DgQC/ZyUjxLd2PCEy+lJ3IcwN2mBDe1TGI2soW7Pu4FCGhAVi+OgXJaVEIjwoSz3KuWrsR5CijbHxV9kE0knp3KN0vWMAkVuUjPivo2dRVfZvVxeTCk1mNtb+6Gt2nitH88UfwT0xC+p3b4RsVDd1FghIWsrsjBgeRV604fHwEBlJZDA9RIyfLGxmpermuWMiJWGRtzZTIOhkG/q1sIxGEupo6lJ4sQUd7B/1ehgiVyPTMdETFRAvfjJpy27M/RZaFRYBtFU0tFGRbb0R5pRER4RpsLPJDcJAaPt6zm4/GD3ai9cABESIVTM+YKV+4ERoSdGG1f1lmjwCrsI5QcFtVRSUqy8rR2twCX8J3/aaNSM1IQ3QMEXNkkQhIBCQC84CAJLJKIuuUl5W7Eln5oYf+h8EE9I44caDOidJmIC0SyI1VYHk84KOTHpkpJ3eBdjposoywkQF8GHss7Rhz2OCj1OAqXYyI0lVxCqgF6otsRiIgEZAILAQCbAy57777BHGUVU0mynQVWZmompKSIpRMfvjDHwpS60Rd/f392Lx5M5i4ymqvTz31lNj1ne98B08//bSIgnz//fcpVWyC2D4yMoIrr7wS7e3tQsH1l7/85URVM3qXRNYZwSZPmgUCdvo+jHV3oXXfXpT/+WkkXXcdMu++F/qgIJEyaBZVy1MlAksSASapMBHi+b88Jwz9BSsLkF+wDHnL8zzO2Vh8pA5HD1TBbLEhIjoIV25ZjtCIAJFGdElOrosHLYmsrpsATvNpMtnR2DSG8rIhNDaMCUIrE1c5tW5qqi/8iLzKCqwqlUK8XNdb2bJEQCLgrgg4yOJaYutHNQekkyprCqWKvlYbAy+y5Un7netnjYkaTAq9UGGF1SeffFIQTp977jnxTMeqrRcjkrHtYv369SLwlgNw+R7O9XPhcx5//HE8++yzIqD23XffFQERF2r3crZJIuvloCSPmS0CDgroOX3agIqKYRHI4++nxtZrI4i85LnKbLxus9uJPNjWj2MHq9FMGSh6u4dx/W1rsaooXQTRK5Wu+3U2kohJB2Xk22fpRKdjTPjsNmujsEYbDiU58KSIyfSuagfZvqopG1EnBRJoiSjE2YgSt22DSqsTAafTq23uj645bUJ1nQk1dUaEh2pwzRX+CCEimpeXJIzNPdpLp8a5ILIyWjarTQRsd3V24kzdGez5+BMM9A8Q6c4XV1x9JYo2FlFggw+pWWuXDrhuNFIrZdtt67Di/d2DdF8DUhJ1yErXIyFudvfo4aZG9JaVova1V+EdFoaCf/1/4RMRSeIXrlMtdyPYZ90V/j5VlJbh4P4DKC8pxZbrt2Hl6tUkIJBCJGRvqXY8a4RlBRIBicDFEJBEVklkvdi1Iba7K5F1otM2sq1ZrEAVKbNW06vfAHjRs0lWjBIJIU7EBFGiItet4ye6ueTfmXTc5zCh1jYoCK3NDgOlJAtEKhnDWaHVBxQFJydqyV8nEgCJwGJBgI3MMReIRJwukfXw4cO47bbbRFrA+vr685xGfI/+4x//SMpa8UKlldtlNdaGhgY89thj+OY3v3kOpH/961/xrW99C35kCK2m6P6LObPOOekif0gi60WAkZvnDQFWpbCbTOgqPiFSBumDQxBC6WuiC4vgn5A4b+3KiiUCixWB/r5+oVbxzps7iOg2jJtuvQkZWRmkYkrpLTykmEwWDA2M4vC+SnLq1iBvRTKl2owndaJo+PjqPWQUi6+bksi6sHNKj3+UttlBqXTNRNgwoaPDJMirZrODUkQrKJ2uhp5LvRARoSO1fj1to0BSaSNZ2EmSrUkEPAgB0m6GxWnH++ZWsuENIUlNioaUKjpHTcFjFIgui3sj8NFHH+GBBx5AYmIimNTKNoKJ8pe//IUIfqdFsOxDDz00sRm//vWv8ZOf/ETYB15//XVs2LBBnLdnzx4RoMspe3/2s5/hnnvuOXvOTD5IIutMUJPnzASBgQELBXGb6DvQJwJ8Nm0KE4r0gYGeTWgZHTGirbUPZcX1OHn0NLKXJVDK7HikZsZSoJLXTKCak3OcdN8YJTIri5jwfaPaNoBElZ/w+bDfJ1hJBEwZBnFZWBt7esCErIad78FAQgSciSg0fxmCSIXb1cqCRpMDw8N2HD81ivomM0KC1YKElpvlBW8vzuhyWUOUB0kELojAXBFZJyofo6Dt3p4+VJOCZFNjEzraOuHt442wiDBk52YjgZ6TWK1VpfZcte6JsXrSOz+WDo84UFY5hsYWsl90W7B2lR+W53pBr1NCrZ7ZD4mFBFz4t7Pq+WfBQhiJW69FcFa29BfM8uIwkR+mmb4/NVXVKDlZTHdyBQJJUGRNUSFS0lKFkI5KLbN1zBJmebpEQCIwBQKSyCqJrFNcHgCTZNLT03H33XdPeZyrd5opkqd3VIGdJQ609tPN1NuJFYlKrEp0QkvOG7W0tbp6ikQ0Lhs2jlq6ccDaBSMps0ZQWrIt2lhE0btepidz+RzJDkgEJAJzh0Bvb+9ZJZNXX30VTzzxhEhfU15efnb7pVr77W9/ix/96EdYs2YN3nzzzfMOZ5VWNvQwaZbTBdoplJVJrfz+zjvvCNWUySfxQx+rsnJhB1cOkQBnWiSRdabIyfNmi8BQYwPaPz2A/qoqjNH3LOf+f0IkfUcUHpYKfbY4yPMlArNFoKaqBsVHiRhOBklviqC/55/uQWx83GyrXbDzmZgx0GfA6Zo2nDhcSw6KFmy//wqsJlWi8VRxMzOAL9gAFnFDksi6MJPLTiBWYLVYHBgbs1GQ0ghqakZQV2sgJ50aycneyMsPQFqqH7TamTuFFmY0shWJgETAXRBgZb1hpwUvGxvAQeh36JORpQmEH6Qaq7vM0VT9mIrIun37dkq3fkAosL7yyitnq+F0oXfcccdZldf8/HxS7tajuLiYAiVsuOWWW/CHP/zhHFLs2ZOn8UESWacBljx0VgjwM5LRaMOOHR1oaRlDVlYA+bfG1elnE9A9q07N0cm8Bio5fgaffHgKVqudiFj+uPq6AsQmhBEByLWELPb7VFoH8ImlA0MOC7yValxDat4sZKJTqiSZdYprQAQd0Nz2lJagjexdAyQ+oKE1eu5D/4zA1FSXkljHAyIU6O61irTgx04a0Ntvxw1bApCRpic1PklinWJq5a7LRGCuiazcLF+7LIpw5nQ9jhw8jOJjxWhvbcPmq6/AitUrkZmdCR8fkljSSCLeZU7TnBxmszlhGHXgWLEBOz4YxLo1viha7YvQELX4PZlpIybKWlj7+qsYbqiHmlR3YzduQuymzZxiYKZVLunzrKQg19fXiwN796H05CnK5FWLq7ZuwXU3fgHBISHCjrykAZKDlwhIBBYEAUlklUTWKS80TyGy2iltjImUWVuIxFrX6SCFVgX8vRSIC3YiLxaIDVaQ4ueUQ5U7FwABsiOhx25Eq92AU5SmrM9pQpTSG1mk7FCgCRERPXKaFmAiZBMSAYnAgiLw0ksv4etf//q0iaysfMKRj1qtVqiyTu40b2ellHaK0L+OUqz/+c9/RnNzMwoLC8VhdXV1whgz+RwmuMbFjZOUXnzxRWzatGny7ml9lkTWacElD55DBDjKepRS2tS/uwNt+/ch/fY7EFW0Dr7RMVDpZpeKaA67KauSCLgtAmzM5/vBx+9/jJ073kNqeipy8nKwcs1KBAQGum2/J3eMx2Ajx21tVSs+eucEpYXTIComGAVrUhGfGE6OPs7KIVcVkzFbyM+SyDr/aHPWZ4PBRs+BpGTSyK9Rcc2ziklomJ6eObUID9dRamktKfETcUDF9hD5nZj/mZEtSAQ8H4Em+wjKrf1octDvCg3nWl0c4lQ+RGOVCgGeMLu7d+/GvffeK1RXmbQ6TkAa7/ldd92Fffv2YfPmzXjhhRfOGc7w8LA47/jx42e3sx2CA2GfeuopYZM4u2OGHySRdYbAydNmhAAH+lRUDKOuzkBq9UZkZvjh6qvDSX3P85Xpe3uG0Nbci8P7q9DTNYgVa9KQkROPxBQaHwX4uqowkZUJrO32MZTY+tBI/h/2+6RrArBMTaQXEjGRT6MXnh072X/NQ0No+ugDnH7zDURSyubwFasQsWIldKR+58q1LQfOjRmdqKg2Yt/BYYSFqhEXo0V2hhfCQjRCQVEuMy48r3Lr5SMwH0RWbp2fgwwjRL4mteN6IrTWn2lAS1OzeK5Jz0xHbn4uMojQqlTyvUH+Ql3+jM38SJoSCsQggnGjBUdOGMg+Cfj6KFBEhNbYaFLwnuE0WMdGRRBAx9EjaPlkNxJIlTXji3dBrdNDqfFsRfaZoz39M/k74yCDE5NXy0pKicBaAx35W3Ly8yiLVyYSkpLE32qpxDp9cOUZEgGJwLQRkERWSWSd8qLxFCIrD4JJkjZ66GnuAz6tc6JvhJy0TgVWJgIZUQqE+ABaCq6Sz6OMluuKgx6EzJSm7KitB1UUpdvvNCOZ0s2s0YQjjJRZfRVS5cF1syNblghIBOYDgZkSWS/UFzaq9JDx5cEHHxQqrGykfu+995CXl4cJpxUbXzo6OgRRaXIdvMCMjY0l5S4LWO319ttvn7xbfN65c6dIN3jejs9tCKHIy9raWtGPhISEz+2Vf0oE5hEBNqiQlYuN+0xmDU7PQPiy5Yhatx7agABpeJxH6GXViwMBVt0aHBjEB+/sxPvvvI/bvng71m1cL1KssXHSEwqrD/V0DqLsVD127zxFKTXjsPGafEREBcHXz3VpNT0Bu7nqI8WRCjVQVtOw2RXkiOB3etHfzz7zSwQGBONL93xZODZZ4IQFongdLp1Ds5sBk8lOCmMODA1byRlnouc9Ezo7TejuNiMyUk8BS97IIMWxMCKzenlLZ9zs0JZnSwSWFgIOsqra6Tn7hLWH1PTaEa70QoLaDys0oQhWeMbzwdKasfkZbX9/v7AzsCLraiJS8ftcFUlknSskZT2Xg4CDHlb7+iyCyLpnTw89I3nhmmsiEOCvIeV615E9L6fvlzqGCSa8Htq98yQqS5ug99IiNSMGazdk0th0IsjvUnXM1372zzmcDhyne0kpBUX0k8J3mFKPdboIRCq8EKDUCiGT+WrfE+tl0pCJsg31lJeh49BBtNMr5/4HEHfl1dD6+0NFQQWuKtQ1Uk60o7HZjKpaE0orxkg50Q8F+d4IClTBSy+DXFw1N4ut3fkisk7Gqa+3j0isLdi7e49QZvX28SZV1izkFyxDeET4Z2nSWWF4hkzKyY3Jz5dEoG/ATirPZpSUj6Kn14YrNvojPVkPfw7EncFPi5N8BVaDAa3796L0T39E1NpCpNx0M/xi46DzkKD9S4I2jwfwvYhfwxRU0dnRiWOHD1PmqyoKilYiPTMDW7ZtQ2Bw0JyuDeZxOLJqiYBEYJEgIImsksg65aXsSURWHgg71EwWiv4cA042A8cbKZpH50RiqALr0xQI88eMI3qmBErunBYCbCAfdlhRbx/GAUsnjERsDSAC60ZdFKmzBgqDhlwuTAtSebBEQCLgxgjMFZGVDSlPP/00fvzjH2N0dFQoLTzxxBN44IEHxOife+45PP7448LwwiRTVtybXJjImpycTApeBvziF7/Al770pcm7xWdJZD0PErnBDRFgw0pfZQW6TxxHx9Gj0JNBKvfhf4Z/XDwULlQgcUOoZJckAuch0NXZhZITJ1FeWo7mxmbcec92rC5cQ4RDtVChOO8EN9wwajDh0z3lOFPbDv68cm06ijZnQ0OMSRUZWWWZfwQo0zBGmVA54sDA8Pj7MH3mbXWnfk8kykBsvPp+BAeoEBSghC+RKjUamSVlVjNDto62diMp8I8JhbGeHrMgCsfHe9PznQ+RV3UICtKSY0FFWCtn5PyZVf/kyRIBiYBHI2Al4pEBNuwxtWGHuRk36hNQSAHnwUoddArPJn159MQsos5LIusimkwPGArbDDjAqrXViF27ugUxKS7WC1nZfiLwxwOGcNEujpNNgI62PpyubsMnH5RQZg1vXHntcsQmhCE0POCi5y7EDlZmHXHa0OkYw15zh8jOx/eSVdowrNSEiS5Iv88/ZoLJV70V5ah87m8sH4mApGSRDjs4MwtKWqOLaMB/HL6gnywUrNjWYcVHe4ZIFMGBqAgtcrO8kJSgE4GKyplKJy7oKGRjnoDAQhBZbVabyHzX29OLmqpqHNx3AGOjY2S78Ma1X9iGvOX5IrudiqNwZZl3BFiVlbRWsJeUnstJ8TkhVou0FL1Qe+ZMM9Mt4t5Iv6d9FBRQ+/pr4nSfyEgkXL0FQRkZ061uyR0/HiRjRUnxSXz43vtEaB2kQBkvXHnN1cjMyUZIaKhH2Y2X3ATKAUsEFikCksgqiaxTXtr/9V//hfT0dNx9991THudOO8m/Q9LnQH0PUNFGi62B8b/TIoDUCAUSab3Mayy5znLtrDGZdYDSzZRRqpl62whaKN1MniYE6Sp/JJLqg49UZnXtBMnWJQISgTlDYLZEVlZd/fTTT/Ef//EfZ9VSMzMzBRm1oKDgbD937NiBRx55RKTHaW1tJaM9sUwmFSbCRkVFiS3PPPMMtm7dOmnv9D4ePHgQH374oVRknR5s8ug5RMBEakHDTY2oefklWEZGkHLjTQjJyRGR1nPYjKxKIrBoEGCjrp3SV9RU12DH628J0mp0TDSKNq5DSlqqx4zTMGJEZ/sAKRAVY4Q+Z+XGUyrNOKSkR3vMGC63o3zf5nlzdeEucD9GKaXkIJFW+waJvDpkFykmSQxKKLNy7AwfZ6fI0jMl/x+0+iCk5N4D5hWr1QpS61EgNEiFsGAVQgLHSa2Sc3zpmWUChsFgQ3+/BV1dJqEsNjBgEY5kxjUkRIeYGD3i433I6aYSJNZL1yqPkAhIBCQC5yMwSKp5tbZBVNGrml436OIF4UgLIsbT/UgWicBsEZBE1tkiKM+fCQL83FRWNoQWCgTq7DRj8xWhlNEo4LOgH8/+bTOZLERm7ceB3eUY6Buh50ANVlCAX3Z+AnT02ZUBfuz3GSUya5mVyLa2YbQ5RpFIGflyNcGIU/kKQRMFSZks9eKwWjFYX4/uk8Vo/PB9BKWlIXHrNvgnJMKLSEOuKrz2Y/9qQ7MFpxtMqK41IjREjZXLfBAZrhVqrK7qm2x3cSKwEERWRo6vbavFio72DgruLkP96TP0O9qBmNgYJCYnIScvh4IBwijTj+/iBNoNR1VRY6TfGMoy02NFWKgaGwr9KMMP2TZmQGbl4Rna29BTcgqdx49jhPwGWffch8i1a6HWe0ExE6lXN8RsrrtkJUZxf18/qiorUUskbyZ6xyXEIzU9DQWrViIiIgIqCqyQasVzjbysTyIgEbgUApLIKomsU14jnkhknRiQnRZbJooa3FUJlLVQig5WC/nJAABAAElEQVQrsCxegW15CugpI4d6+kE9E1XL9zlCgN2y9s/Szew0t4B0oBCp8sJWXSxiyahBiRzmqCVZjURAIiARcB0CsyGyMon1e9/7Hv7whz8IY0twcLAgtN57773nKecdOnQIt99+uxhoU1MTGeY15wx6eHgYTIDl8vbbb2PVqlXn7J/OH5LIOh205LHzhQATWKuefxZ9VVXwJUJeVOE6xG2+Yr6ak/VKBDwaAY6uNxqNOPLpYfzPb34vVFi33/NFEVXvSUb65oZu1Fa2ksO2DP6kPHT3l69GSLg/3fNIrcbDCxuFu7u7cZhSeDHZo6urCykpKcjNzcX1119/wQAVVmh/5ZVXKG1qHXx9fVFUVIQ1a9bAm1RFLkSCZeVdvofv27dPtJWfn49169aJ4NXPB8AwnExO5dSsNlpbt3fZcabJirJaC5rb7WCFHm/KOBwarCaSqlKor/r5KHBk72+h0gRCH3YXevtJEWPQLsisqQlq5KVrsSxTCx9SaNVpea3nlMbwC1y3jDvPn8lkR0uLEZWVw5TqeUAoi/n6qukZLhBZWf4UoORFAUzSsHEBCOUmiYBEYJoINFGA+UeWNljgQJBCizXacKRQoLksEoG5QkASWecKSVnPdBBgxTdOjX5gfw/efLMdt90ai/XrQ+DjO65gP5263PFYk9GC9pZeWuPVYOebR7D1xlW45vqVCAzyISU1coC5sLDfx0Z+nyr7IN4xNQsfUKia1N20UUhTBkAlgyRgMYyg8b330EVEVg7WjrvyKmTedX72rIWeRl6HmEmB9aNPRlB92gh/fzVyM7xQtNpXZn1Y6MlYIu0tFJF1Mpx8nZeeLMFhspEdO3yUAreUuO2uOwSZNTY+VtopJoM1j5+NJodQfn59Rz9Zh4BrrwpAfKwOwYEzU8a1EynTTrbPsj//CXWvvYK8R76KhC1b4R0aBuXnfGXzOCyPqZq/ByPkM2Ty6kvP/x0G8rVEkY9ly3XbsHZdkfA/SgKrx0yn7KhEYNEhIImsksg65UXtyURWsVi2O9HSBzT2AlXt7CYDwvwURGgFUsIhFGKkMuuUl8C87uSHJCf5L7sdJjRSdG6FbQC99DlZ7Y8MNTnnVIFQ0wJC0lnndRpk5RIBicA8IzBTIusEifX3v/+96CGTVH/4wx+SAfHCDsXm5mYUFhaKYy9EVD127BhuvvlmYYipqKhAIKVjn2mRRNaZIifPm0sE7GYzek4R2evECXQcO4LowiJkfukeirLWQ6l1rdNmLscp65IIzAUCTGKtKq9E2alSnDx+EoUbivCFm28gB6f+vMCHuWhvruuwk+SnleQ/WXHo5NHTCAr2JRXWKKxal0kETj0pK3j2ioENw6y+zoEqJpPpPPjWr1+PP/3pT2fv3Xz8kSNHcP/994MDVSYXPz8/vPXWW2eDVyb28Tlf+cpXwAruny/bt2/H7373u7NkWbGWJjXQjh47OrrtRFy1wTBG2kq0ePMmdVVvLwV8iYzK7zr6uWW1DL1OAeYTP//ML0nBJAibrnkAJrNTKLcaxpwYNthhNjtgsysQF6WilxqxkWr4+ijFuvzzfVqqf4+N2cHqYc2kHNbWZqT5JYV9Wjd7easQHKxFaKgO4eE6BAVp4eWlIrUtz772l+o8y3FLBNwFgQnVvCrrAN6jAPMolTc26aIQqfQiQqvOXbop+7EIEJBE1kUwiR44BA7IYjJraekQ9u7tQWSkHgkJPsjLDSCy57nB3x44PMqM4MCYgRQzK1pweH8VEU4UYp1UtDkbcYnhQpXVlQQUvsf0O8yotw+T2vcQOGgiXR2ANHqlqwLgq/T8OZjpdcPE1ZGWZiJavSpIrNG03gtbthwh2TkzrXLOzuvosqChyYIqUmLl9VxBnjeSEnSkxqohm/KcNSMrkgicRcAVRFZuvK+3jxRZ21FRVoHmxmZB6EtOTcGqtasQTSqtwSHBZ/soP8wPAnbicHDGn6MnDOjoIjUyKvk5XlixzJd+b5zTzgzhpCB+Vrtu/OB9NHywE/5xcQjNyUXspiugDQiYn0F4aK3GsTFhT/x0335BZLWQnyU2Ph75y5chPiEB4ZERktDtoXMruy0RWCwISCKrJLJOeS17MpF1YmDk80HvCHCk3ikIrR2DwNpkUmdNoPSGlCGAg1M93O85MVSPfSeBHxGVu9/aiVJKOWN22pFEZNYiTTiClTr4KJauUcNjJ1V2XCIgETiLwEyJrJOJqUw84XvyVEVJ6VGY6HLmzBlBbPnpT39KKmr8Cwux6Hz88cfx7LPPYsWKFXj33XeF0tdU9U21TxJZp0JH7lsoBNg4ZSECV+fRIyLSOigtHel33Am/uHjoQ0IWqhuyHYmA2yPAJNChwSHs3PEeGeebKAW5j1BkLdq4zu37PtHBUXLQ9nYPYvfOU6goacQ1X1iJ/BVJCIsMXBRqrOXl5bjhhhsoZbwFycnJuOmmm6DT6fDqq6+K+zrjcN111+GZZ54hhzWpnPb1CfVVg8FADvlIocju5eUlFNdra2uJ8BiMnTt3Io6M9lzYgf39739fKLzz31u3bhXnc2DLm2++KQisDz30EH7wgx+Ss9KGMeLSDg4zgZVeHTa0EJFVSwqqIYFKZCRpkBiroc+U6eQC6d74+YPbf/jhh5l/Sf11kiqrA7WNVpwmRdf6Zisiw9SIiVAjKU6N8BAVAnyZEEuE1pmJbvCQPLowwcJiIdLvmI3m1kKpb41oaBhFT49FqB5FRemRk+1PKQ+9ERYmiWUePdmy8xIBN0PASmp5zQ4DKojIetjahXxNCG7RJYCSUku1PDebK0/vjiSyevoMenb/OUCIFe5bW42CFHPV1eGIidGLrAGuJHrOFapdHQM4U9suAv462/tx9XUrkJ2fgOBQPxqjax+wHbQgsJHa91FrD91nusWQIxVeWKeLRAQFTfgoPD+zxrTmkfBgW1Z/VSU6TxxH55HD0JJgQc6DD8E/PgFqWtO5qtgokJGzblRSqu/i0jE4aB0XFqLGxiI/hNI7E6VlkQjMBwKuIrLyWDgzTWtzCypKy/HxBx+LYO/M7CzkLctDSlqqyHaj0Ur/9HzM+0SdHPDc1mEl8rwJR4sNWJ7ng42FvhS0zgHTM8tA01dehg7yF/BvrTaARLPuuRd+sXFSlZVAZ5si2x4729vRcKYeB/buQw9lh1pGPsOClfRatVIosU7Mj3yXCEgEJAKuQkASWSWRdcprbzEQWXmAZlqADRkVqOl04ngDLRbJoRZAa8JNmaQGQ0FVOrWCnHtTQiF3ziMCNCNiTvqcrMw6gsO2HpgcNkSSEsQKTSiy1UFSlXUe8ZdVSwQkAvOLwOUQWf/yl7/g9OnTIoUwE0m4vPDCC/i3f/s3ob62Z88eYTi5UE+ZwMqkJFa5/vWvf42f/OQngrDy+uuvY8OGDWI7n3/fffeREpoZP/vZz3DPPfdcqKrL3iaJrJcNlTxwHhEQyu5kcOyvq0X9jreI1DoCrZ8vErddj/DlBfPYsqxaIuBZCBjHjGhrbcNzf/kbxkbHcOOtNyEtMx1R0VEeM5D6unYcOVCNvp5hUu9U4oprlyMpLZLIlZpF4VD70Y9+hN/+9rfiOYAVUyerpv/85z/HL3/5SzFX+/fvF8d85zvfwdNPP40AUpR4//33SVkqQewfoTRgV155JdrJIH3XXXedPa+fFH84kIWN1Q8++CCefPJJ8XzAJz311FP43ve+J84/caIYVmcIKurIiXDGKkiU/pR6NT5aJQinwQFKocTK6qvsy7mQM3MykZUrFc5rEhUdNdKafJictqS20dBqQ2evndRnnUKZdUWOlpykTGidmZNCdN5D/2HbRG+vmeaMVJOrRoi8asaIwYZoUgyLifFCdLReKLH6+mmI7Eu461xLRvBQmGW3JQISgYsgYCTb2ycWcmI6RqAj8mquJhhr1GFiPSnNpBcBTW6eEQKSyDoj2ORJc4QAK94PDlrx0UedQvH+qqsikJrqi5AQ7aLwCVk4EG3MjEN7K1BWXA+/AG/KXhGNdVfkwsdXJ37T5wjKaVcj/D50Vr/TgjabAQctXRggldZkjT+yVUEUQLG0FA8dZMOym02oe+N1NOx8D6G5uWS/WoGotYXQUeYsBa11XVVGKINGW7sVpZVj4lW0yhc5WV4UhKiBXu+6frkKD9nuwiHgSiIr25ZNlMGov6+fSH0NKCk+hRPHTggi67IVy5FfsAyhYaELB8YSbInV01n9ue6MCXsPjsCPbFBxMVrkZtLvT8TMSMTmwUGhel3xzF9gITtZ1n0PICQzC15hYUsQ4XOHPEoB8Z2dXThISqz7dn+CpJQUpGWkI4+UWFmJ+GLZIM+tRf4lEZAISATmHwFJZJVE1imvssVCZJ0YZGu/E7VdCtR1OjA0BlA2SqSGK5AURmoy9DykkuuxCahc8s7pZtiQUWztRaPdgG67EdmaQDKkh4j0Zr5YYhG6LpkF2ahEQCIw1whcDpGVU/oeOHBAKKq+8sorogv/+q//KpTYLtUfVls7evSoIKRw6ug77rgD7CTikp+fT8ZGPYqLi0WE8S233CLU2NhIM5siiayzQU+eO9cImHp70V1agq5jR9FdcgoZX/wS4jZfAQ0RvJWamRm85rqPsj6JgCsRaKhvQE1lDRko98A/wB933fslRMZEifuDK/t1OW3bbHYYRowoP9mAXTuLERMXioyceGTlxSM0fHGkBWMVKL4/HzlyBN/+9rfx1a9+9RxoRkdHkZaWJraxg+f2228XaqoNDQ147LHH8M1vfvOc4//617/iW9/6Fvz8/FBdXS0c12+//TYeffRRUq/ViG2s3vqPokA2KY4MkqGf24/NeAC9A3ZBPA0JVCEqTEXKqSqEBqrh431pWtPniaz/aAewCpUf4AwpszaR2mtHt02QB4KIIBsXpUZspArBASp46S/dzuR6Pe2zzeYgEq8DAwMWocDKRNb+fguGhojxS0VHROGkJF9S1PVCOCmwenmrXEpA8DR8ZX8lAhKBy0OASaz9TjN2mlvQ6zChUBuBFKUf4tSUvkoWicAcIyCJrHMMqKxuWggwSYYEyLBrVxdqa0coo4EXPV/7IjfXn56PF49DqKaiBVVlzUKd1cdPj/WbcxETHyqUWacF2DwcbCe/z5jThmOkzFpnHYIBViSq/LBcHYIwlRf8l0hGPmNPDwZqa9Cyby96y0qResttiCoshE9EJFSUkcMVhQMPzRRg2E5pvU+WjmKQAg/ZbFy42hfpyToKHlWKNZsr+ibbXBoIuJLIOoGwldLRj5BAAhNZDx04SIrEDviSWELe8nwkpyZTyvU4UrhWy3X5BGDz8N5Jv0GlFWPit8gwasf6Nb7ISPUSRPrpcvyddNNnMmvFs89gqL4eITm5iFi5EpGr18xDzz2jSlZiHR4aQktTM0pOnhJKxL10Typcv06QWOMT4uFNvhRZJAISAYmAuyAgiaySyDrltbjYiKycYZkyYuDIGSdKmoH2QScSKQDnhuUKBPkQmVXyJKe8HhZiJ5NZ2ZheYuvHB5ZW6EkRIorSzFyhi0YCGTcWt0tzIRCWbUgEJAILjQCnBWZSamhoKDh1sINvRp8rrJq2b98+bN68WSixMqll/fr1qKeF9qUKpyD+9NNPzyqrDVOq9XvvvRfHjx8/e6pWqxUKbay6xp9nWySRdbYIyvPnEgFWtLARibv2tVdQ/qc/In37F5FwzRb4kUKh1tdvLpuSdUkEPBKBTz7ejcMHDkNFaSVT01NxzbXXwI/SF/K9xt3L2KgZTfWdIk3mvl1luPamVdhyw0oyZGtdniZzLrFLSkoSqumvvfaaIKlOrptVVBMTE8Wm3/zmN4LIGh8fL9KBvfPOO0JpdfLxbORhVVYuH330EXJycvCrX/1KKLJv2rQJL7744uTDKdDFiUceeRg7d+7Eli1bEJr5S2SlaFFAKqmxkWoE+SuhVo1nMLmcS2YqIut4II2CnoXGFVrbumwoq7HgcIlZqL5mJGlQkK1DZOjiVh1lVbCuLrNIcVtaSkohIzboSOUoLy9AkCpSkimEk2wTKoq0ZdXby8H9nEmVf0gEJAISgctAoJvIq432Eew2t4mj79KnIEblA41i8ZC6LgMGecgCISCJrAsEtGzmoggwMa+uboSIrAZSwR9GUqIPbrghSjyDecK66KIDm7TDYrGhp2sIb7/8KXq7hxCfFI6CNWnIX5E86SjXfWTC5BjsqLEN4h1TE9R0v0kif89aDqSg96VQeij4uvbVl4UNi9Ndp958iyBYKVWuW//YyGHaT4GMFVVj+PCTIaQk6XHVxgCEharh6yNJrEvhunT1GN2ByMoYsM+GsxgNEQHy7dfeQvHxYoSEhmDlmlXYduN1IlueyoXfVVfP03y3b7EQ/mNOfLx/CAePGnDVBn8sy/VGRJhaEOqn2z77CtoPforuU8XopyDvmI2bkHP/P023mkVzPNsWqysqcfTwEXz47k6kZ2Xi2i9cR0TtFEREUjAFXduL5Xlo0UyaHIhEYIkjIImsuy/rClCQwtnspMsuqxn3O2ixEVknEG4fBJp6gfJWUkKxKhDo7URurAKZUZSqjx1G0mY7AdWCv/MXzeF0oIsM6rX2QdTZhtFHnzPVAUhXByJZ5Q+9wnUL+wUHRDYoEZAISARmiACnET5x4oRQ3Fu9evWcKu9JIusMJ0WeNj8IkDPEScbGNjJONVJqNk7F5kdKxUnXfwF+sXGQDKD5gV3W6v4ImM1mMsKPYscbO4jIeggbrtiIglUrhJqEzkVqL9NBzWq1obtjEHs/KkFf7zApA+ixqigDucsTPyP3uT8R93LHO0SqCFxYRVU5SWqCP//pT38SSqm8/5NPPgGrqRaSag+Xuro6+HxOMYFVFlitnQuTVpm8+rWvfQ1vvPEGEVYfwXe/+12xj1O3GcYcqG+xY/d7vwSTZAsKCvC1f38NUeFKoY7qR45LPamDTqdMRWSdXA8TaA3kpOjosVMfrOgj56nJAkFijY9WIzVBLdpmEu1iKKOkKDI4aEF7u1GQWPtIhZUJFSq1gpSSNQgO0pI6mF6kuA2iz6AAT+lEWAwzL8cgEXBfBDgb0nFSxuMwywilHpspgDxIQSmo3bfLsmcejIAksnrw5C2irrMafnPzGPbu7SGCnhqFRZQFLkqP8Wcvzx8oP1uOjppQcaoRdVWtaDjdgez8RKxen4HgED9SF5yclWHhx8tBbazM2kdq4JW2ATSQ36fVPop8ysaXpQ5CjNIbvsrFmVXHTmtzQ3sbOimjVsO7OxBMwYYxGzYhOD3DpamurVaHWJMdKzagpc0i1ifpqXoU5HlDpyVfKamxyiIRmG8E3IXIyuO0U1Ygi9WCqvJK1FRV48zpegrsVQlF1mUFy5CWmS4y3UhC69xfFayeTvCjtHwMJaTMyvaQiHC6V6/yRVCAmmxl02uThS/4d7eb/GMsfhGal4f0O78Ir9Aw6Ci4fymVtlZ6JjhzBqdOnCT7ai+JGwQgOzcby1YUICAgQCqxLqWLQY5VIuBBCEgiqySyTnm5LlYiKw/aYFLgVLMTFURmrekEVicrUJgChPop4KN1CufolODInfOKACuzWonQutfSgWOWbmiVlNKSSKzrNBEIVuokmXVe0ZeVSwQkAhKBqRGQRNap8ZF7XYPASGsL+quq0Pj+ezCPjGDZVx5FcFY2NJ8jebmmd7JVicDCIzA4MECpolrx3o53UVFagYcefRiri9ZQ2nLdOWTJhe/Z5bU4NDiK0zVteOfVw/Dx1ePam1cjJjaEUmMuDYOzRqPBM888g//7f/8vOM0dq6U+++yzlBJ1l1BeZ5JrR0eHUGadjCinu4uNjQWrLfz2t7/FHXfcga1bt6KsrAzf+MY38C//8q/kmCEH8qAdnUQiLa2xwtT9PH7wg++L8/bsPQatxikUQSfqZWWSAbqeLqf8+c9/RnBwMB5++OHLOVwowpqpP8dKLSiptlC/HYiO0GBNvg5hwUoiGSjE2pyEST2qMJHATupG7BzmMfX2jpNY6+oMRGQ1UfpOOxJICSwnJwAJCV4ICyPyGI1Rklc9applZyUCHomAnWxtVrK5fWxuxR6yua3VhiOXCESc4tlLIVNVeeSkekCnJZHVAyZpiXSxu9uMDz/sFIr40dF68SyWkuIrnsMWAwROIgKNjZlRdrIeO145hPDIQOQsT0JmThyiaC01rvbv2gdrJrOaKCPfUVsPPjC1IkLlJe5BqzRhCKfACt0iEzHhwGsLBS62H/oUnUSo6q+sQPKNNyH9ju1Q0tqNg7FdUXi9MjxiR3unBbv3DWPU6EDRal8kJ+gQEzX7bF6uGJNs0zMRcCci6wSCNiJBdnZ0YtcHH6O2qobIf33YSMHh6zdvIJXWUCL+eQu7mly/TyA2d+/dPVY0tZhx6JiB7hbAddcEIjZaC2+v6f9W8u8vK2Gf+v3voCc7VcyGjQjLXwb/hMS567Ab12S1WEFCfThVXIwTx46hvu4MAgMDcfOdtyM5JZmCXELcuPeyaxIBicBSR0ASWSWRdcrvwGImslopsmfYCNR3O1HSQtGqZkBDQp8b0hVICXfCS8MOsynhkTvnEQF+QCV9NXQ6jGiyjeAEKUWYYEOy2h/ZqiBkkDqra00u8zh4WbVEQCIgEXBzBCSR1c0naIl2z2Ycg5mcA5XPP4sBSq0dSymDIlasRBCRWV2Zpm2JToccthsgUFNZjV0f7oKBiN1e3l7Yet21SM1I8whjO6v1HD9Ui8rSJvT2DCExORJXXrucVIT00OoWp0rPxCXDBNUzpJTw+OOP48CBA2JzDin2vPzyy6QWFYTnnntO7GPVhNra2gsSWZOTk2EwGPCLX/xCkF6zsrLASu1PPvkk7rjzAZxusuJ0sxVnmu0IJbKoYvgV/Od/fovIlGE4eaqM1lmOc5z5g5Ra77//+78nujjlu16vRyg5di6XyEq+dkrhR+ksBykrR68dtY029PbbYSXF1uxUDZZl6eDrrRCKQFM27GY7mcDa329BS8sYzeeo+Dw2ZheE1fBwHfjF6l8BpMbq7a0igjmncXOzQcjuSAQkAosSgWGnFe2kgHeU1FgrSBHvC7p4LCc1PB8isdIv0aIcsxyU6xGQRFbXz4HswTgCrJJfVzdCz9EG1NSMUPaCUKHMqiGVfCZ5enrhdRQ/W3e296OmokW8Otv6cc31K5BbkAS/AG8KWHNttjv2+3BQRTf5fRrtBpyy9WHQYUaeOhiZmkCkkJgJrVA8fSrO9t9iGMFwYxOq//48LLQ2j1qzBuFkq+LAa14AuIIIx9cI8btwqmyUlA+NtKYkdfZwDVYu86b1IWXG0EvH6NkJlB/mHQF3JLLybykTALu7usG2tZPHiylIwCgy4ly55SpkZGWQfcpXpGOfd4CWWAMmswNDw3bsPzSCLiK1RkdqkUFK0dkZ01cV53k0kPBF8ye7MVRfD2NvDzLvuhsx6zcs+gxuHJDe2twiCKw1lVXoaG/HilWrkJWbg5S0VFJl9SfVbRm0sMS+XnK4EgGPQkASWSWRdcoLdjETWScG3jPixOkuoLINaBtwIitGgfQIIClMAW8doJZrtgmoXPLOEbpDDgsOWbrQ6BiB0WlHhioAy9QhCFHpyNC+uB3ZLgFdNioRkAhIBC6BgCSyXgIgudtlCDjJ+n5mx9uUNug4OOo6dNlyJN9wA9Q6PRSUCkoWicBSQIBTy5uMJhw7fBSvvvgq0jJSyVi5Elk5WQgND3N7CEyUX95IUYa7dp4k5YtWJKdFCQWhnOWJlMJtcSvFsfLqD37wA/z1r38VBFVWV3300Ufx7//+7yJ9HU/ejh078MgjjwiDcyulB2OlkMmFHaFRUVFiEyu6XnvttVi/fj3qyWj/7W9/G6s3fBn1LTYMDDswOuYQZNHK4/+Dn//858jMzMTu3ecbSUwmE/bs2TO5mYt+LikpQQipOlwukXWiIvIvwGimtXkjkWyJaFtPRNuwEBUSYtRIjNEgnD7rde4dbMrKqyYTOV2GLBgctAoV1p4eE3p6zMJBrderkJzsQwqs3oikNLY6StW5GAgTE3Mo3yUCEgH3R4DJQ61EGjpu60WXfUwos27RxiCTgsVlkQjMJwKSyDqf6Mq6p4OAjYKlhodtKCkZxEcfd2LFiiCsXhVMgVhaIigtnrWGyUjPowOjOLi3HMcP1iIzN45e8cjIjiPyihcF+7re6cXZ+EwKB/aZ2lFrH4JGoUSC0hcrNKEIVNB8KBeB34cWOX2UOajn1Em07t8Lb0ppnXHXl+AXFw+tC1Nb8zqwp9eKk6VjqD5tRGaaF9JT9EhJpEyIksQ6nZ8UeewcIOCORNbJw2IyYFlJGcpLytHe1o7c/FyyUWUhPSOdggP86Dujn3y4/DwHCLBtpaSCgoIbLWCFVv59Wr/WlwKAlZRBaHqBDubhYRiam9C8excaPtiJ7PseQMLVW6Cl4HDVIiRyMoGVbXjtbW1kU63G8SPHyL5og3+AP664+moiYWeS2IG3JGHPwXUqq5AISATmFwFJZD3fR3MhxBUUecO2viVXlgKR1cbp/uwKVLY7Ud4KNPYCwb4kV59PDsAAwIfIrLK4DgFWZWUy6zCRWavIoMGpz7xAzkxKebaG0s0kqv1c1znZskRAIiARWKIISCLrEp14Txg2OQmGmhrRTSlzal56AUHpGSigNNo6Nk5Jw6InzKDs4xwgwAbLjrYOHNx/EG++8jpuuPVG3Lr9Nnh5eZ0lQ85BM/NWRU/XIJrqu3Bgdzn6+0Zwy13rkU4OV2+KMlzMpD82znz5y19GQ0ODwHbLli3g9XhSUtI5WB86dAi333672NbU1HTenA6TkZ4JqVzefvttrCLFhVtvvRVHjhzB1772NWjC/0Wo7yTGqrA6T4/gACV++fPv4s9//jM2bNgglF/FyTP856c//SmCKWXbdIms3ByTWc3ksOjpd5BarA2Vpy1o7rBh/Qo9ctO1iA4n5VLt9JwWMxzGtE/jvjN5tb3diIqKISIOj5Jii51UVzVIT/dDfLw3YmK9iIyrIhUshXgt5ut52gDKEyQCEoF5R4AViZz0E1pq7cMr5gbEKn2wgoLEU9UBCKFUzrJIBOYTAUlknU90Zd3TQYCf2ViNktVY9+7tIQKSCpGRehQUBIr36dTlzseOK246cLq6HRWljagqa4KPrxdu3r4OMfGhRAZyPUmUpgIOmpA+pwmnbcPk92kjr48Cy7UhyFYHCf+PO2N8yb7xfZcIRWybatnzCXyiohFesALxV10NtY+PSzMHNVLa7qPFo+jts4o12KYiPyKKeVGwJCvEXnJk8oBFggAHwfLzoauLuxNZbVabIAaWE5n1VPFJlFEWm0DKlnPDLTcgNT0NYRHuHzDu6jmebvt8WY4Y7Kg5bcLOj4dIlVWDjYV+pBytRmDA9IJO+HfYbjaj/p0dKH/mL4i/8ipErVuP0Jxc4S+Ybt/c/XgOkO/u6sLOHe+ihoisY6Oj2LB5IzZddSUCAwMFiZUzQckiEZAISATcHQFJZJVE1imv0aVAZJ0AoHsYaO5zoozIrMPEWw7xJWXWSCCHFFq19FykkSJeE1At+DsvpeyU3rKT1CLKKO1ZC6VA63eYkK8JRgapRsSQ8V2vkBO04BMjG5QISASWLAKSyLpkp94jBs5p2waIEFb9wv9CqVYjqnAdQvPyEZiS4hH9l52UCMwWgYH+ARzYewB1NbXo6+nF1du2YNOVm0S0vSvSFl7ueNjZarfZSeWiEft3lYqUl6HhgVh/RQ6iYoOJxLp4Da2dnZ1g4mpfXx+lng8T6qj894VKc3MzCgsLxa4Jourk444dO4abb75ZKICWlVUASn98+1uP4Y033hDKrHc8+Df4UEa2hGg1UuI18CLFnTvvvB18b2ci7RNPPDG5uml/ng2RdaKxMVqP9w3ahTLrGVKPpbhGBPorkZGsQVSYGqFB7nEtOOmaHRyyor/fgq4us3gfGLCQ2oUTnJnW108j1L2io71IpVaHAHK4sGPYnb+HE3Mg3yUCEoHFhwAr33U5xlBhG8QnlnYUaEJwhTYa/qB7gXJ6DuHFh44c0XwjIIms842wrH+6CHR1mVBXZ8Dp0wah0HrVVeFITfGBjp6NF9Oz2mC/gYIc+/HpnnIMUJBgSgapcJM6axaps3Jxh7GaKQNfn9OMYkuvUA0fdlqQR4EWOZoghFKghbfCM+9Rxt5eDDc2oOmjDzFQV4uErdsQsWIlAihQUalxDZHYYnUSedWGujMmHD9lQHiYBilJOqQl6ykbhmv6NN3vrjz+wgioKAvV97//fZG55fHHHyfCvuOCB/Jxb775Jo4ePUpBmO0iCHXt2rUi+JX3fb5wlhi2Fezbtw/d3d3Iz8/HunXrKFgz/bzsMJ8/93L/dnci68Q4ujq7KOi6ESdPnBRY6LQ6ZOdlI79gmchK4+PrM3GofJ8lAkywttMl3N5hxeHjBiK1OshGCKxd6YtU+s1SqaZPuu88egSNH34AOwX/e5HdLfWWW4U6tmKR2Bo5W5PFYkFleTmqyivRQFmZtBotEpOTkLssjxSEM6Cme89itq3O8rKTp0sEJAJuhoAkskoi65SX5FIisjIQJosTFe0QZNZTTU7kxgLX5CgQ6quEt27cGTUlYHLnvCLAyqxs2Nhn6RRG93AyZKSq/FGoCUeISk8Ru+7h0JxXEGTlEgGJgETADRCQRFY3mATZhSkRGO3sQOP7OzF45gzMQ0NIuelmEXEtjFNSXmJK7OROz0bAbrejpakFz//1OVhIcWDlmlXIobRnqempbj8wi8WGUYMJ+z4uwWv/ux/bblqNwk3ZiIwOhvciT5PBSqlMNPX19cX+/fsRERFx0flio/P69etxhn7f7r//fjBxdMJJxY5odlo9++yzlCZ1BZ5/YQea2qxoqH4f/+f/PCqcWgcOHIKPXwSCSImVC5Nn2RnFjoKXXnoJGzduvGjbl7NjLoisE+0MDDvQ1mXDJ4dN6B2wIzNZi+xUDbJSNOBsqOy8WOjChGvigsFqI1UPSk3b1DxGKrpEDKsYFCQIvsXk5AQgK9MPiUk+8Pdn8urC93OhcZHtSQQkAu6PwKjTihJbP2ptQ2i1GbBOG4mrdNHu33HZw0WBgCSyLoppXFSD4LTFJpMD777bjpPFg9h2XSTycv2J1EUEGVLPX0zFZLLgyP4qVJY2oatjAPkrk3HdzWugIfUWtfp84porxs7BFqNOG47auvGWsRFpJF6SQ6qsuURmDVd6Ca8P0ZZc0bVptykU0IlE2FdRjuZdH2OYUlqriDyU88CDCMnOYfbwtOucixN4HcNksPKqMdQSkbWpxSJSdW9e50fXgZLITXPRiqzDVQicOHECN954IwVShqKciGwTNoLJ/TEYDLjtttvE/snb+TNndXnttdcoo0jQ2V28jv3KV76CHTt2nN028WH79u343e9+NydkVk8hsvLYzWRnayQy69FDR/Dum+8gLSMNG67YiMycLERHRxNRUK7/J66RuXjnIOf2DgsR70dxiAitN14bKMisXl5KTPf2NUoB5EMN9ah95SWY+vtR8Nj/gxBSZVXpdB5tsxH3HLLnjdL3e3BgAO+8+TaOHzmKyKgoFKxaiWuv30Y2QD9JYJ2LC1LWIRGQCCwoApLIKomsU15wS43IyhE+g2OszEqptloonb1xHJ4i8vtmRCngrSVnmVzQTXnNzOdOTjXjIDJrGylINNhHSEViACYycGSqApGhCRSk1vlsX9YtEZAISAQkAuMISCKrvBLcHQHrKKmqUMrttgP7cfqtNyjK+jYkX/cF6ENCoKb06rJIBBYrAp0dnaiprCbD5Q6EhIbg1u23Iyo6Cv4B/m4/5N6eYZw8WofG052kGtSHq7YVYPnqVOi9tG7jYJ0PEFnhJDc3Vyh6fOMb3xCqqBdrx9vbWxiff/3rX+MnP/mJMLa//vrr2LBhgyCi7tmzB/fdd59wrvz0pz9DeNJtqG2wojBfibtuW06p7sewefNmvPDCC0KhlxUbmAy7a9cuxMTE4NChQ4T17BSP5pLIyopBo+S4aGy1obHNJki5QQEqJMerkUZqshGhqgX1A7OozeiojdK0mdHcPIrmljHC2iH64O+vIeKDVrxCiAAREKiGj48aGg0rhbjGWX2x60hulwhIBJYeAnYiCPWS2t07piYMEaE1jYLCs4gcxMHhskgEFgIBSWRdCJRlG9NBgEl9NgpKOnq0nwKShuHjrUJiog8KVgSKZ7jp1OXux9rJ6dXTOYi66jYc3FsOvwAfIl3FISM7DjHxoW7Rffb52OjVTpn4OODijH0Ygw4zVmnCkE6k1milNzQKz3DMcQprM5GJWvbtFYSpcAowjFpbhDDKFMQqgK4qg0N2tLZbcOiYQVz7qcmkxJrihfgYrVjPyCWLq2Zm5u1ykCurqNbW1op1PQe7XozIyuv8G264QSixarVaPPLII1i+fDlKS0sFIZWDou+880785je/EbYFXsOywusf/vAH0cGtW7eiqKiIfi8rhKIr2xIeeugh/PCHP7wgaXY6o/IkIivjxITg1uZWVJaVo+FMA1ipdeXqlchbno+UtFQKxPaezvDlsVMgwPdpo8mJkvIxHDw6gpgoLZIT9cjO0CPAf3qBGFbjGKxDw6h47m8YqK1B3FVXI3xZAYJIqVR5ATXiKbrlVrtsVitGRkZQVlKK/Z/soQxBdnqOoecZIrGmpKUhOoYJ1hppl3KrWZOdkQhIBC4HAUlklUTWKa+T//qv/xIpAu6+++4pj1tsO5nMWt/jRGmzE9UdwPIEBbKiKP1iqAK+eoACFGVxIQJWorMaHFbsMbej3jEilFjTyfi+ggwb/kpKieah6WZcCKlsWiIgEZAITAsBSWSdFlzyYBcg4CS2kcNqQfPuXSj90x9F+rbINWsRsbwAXuHhLuiRbFIisDAIHD9yDCXFJThTdxrpmem48+7tZET3cWuDJasHmIwWNJ7pxMfvnRRAxSaEYhkpBSWnLX6luNbWVqxZs+ayLhBWPGEFFaPRiDvuuANMCuHCiqp6vR7FxcVCEeWWW27Blx78FaobLBggh2VynAZay25SZf2qcDIFBASgoKAAVVVV6Orqgo4UKN577z1kZWVdVj+mOmguiazcDl0ewnHR1G7D4ZMmGIjYqtMqkJehRQqNK8APlC6NU8BO1auZ7eO2uRiNdhjHbKRgZEd/nxmdlIq2i8is3d0meBPpITRUh9RUX8TGeiE8Qk/Br/PQmfGuyH8lAhIBicCMEBiiNM0tdgPeNbeQDU2B63XxiFX5wE8h0wjPCFB50rQRkETWaUMmT1ggBBqbxlBXZ0BtzQgCAtS45hrKXBCkoefj6RFkFqi7M26G11ztLX3Yv7sMPV2DsFI2jHVX5CBnWSK8vHVuEzhoomx8Y0Rp3WvuQJm1T6ixpqoDkEfqrAEKLfTK2QXdzRjAyz2R17ak9Nddcgqcxrrj8CGkb/8ikq+/AWoKSlQRgXChCwfj2YjMfPqMGbX1JjQ0mREWqsFVG0mBOFBF60jp7FzoOZmL9pjEykGsTGJtokD+iXIxIisHvbKfn8/7+9//jk2bNk2cgqeffhrf+c53RFAr18Uk1n66jjnLC6cqf/DBB/Hkk08Kgiuf9NRTT+F73/ueOJ9tEJGRkWfrmskHTyKyTozPSEHC/X39OLD3AA7u+5TsAOFISErEijUrBXEwMChw4lD5PgcI1DeaUVZlRHePVQQLbyryQ3QU3avJNjSdwGEHEbDPvPUmuk+egFKjRRj5CRKv3QY12cTmxag0B2OfqgqTyYQB+q6eJhtweUkJKbEeQ3ZuDpavKEA+2fzCwl0XPDFVv+U+iYBEQCJwOQhIIqsksk55nSxVIitlCYTZCpzuAspbnWjpd0JPtt0tuQrEhyjgR2RWWVyHAPsTbURm7XWYRITuXiK0+pDxPZNUWXPVwUhQ+bquc7JliYBEQCKwBBCQRNYlMMmLYIhMZu2vrkLrvn0idRAbtrLvux/BlMptOkauRQCFHMISQGAildQLz/4dJ44cR3ZeDqlB5FEE/gqRTt6dIWCFoNamHlSVNWH/rnIkpUXiC7cXkiPZh0i4ZExe5IXT9LEayuUUdhhxukAuw8PDuPfee3H8+PGzp7KyypVXXol/evQ3OFbmIBUGJVZkaxEbqUJIoBJvvvEyvv3tb5Oq6OjZc2JjY4XSyrZt285um82HuSaycl/Y+coqHP1Eyi2rseBEuRmhQSrER6uxOl+HkCBSopkH8uiEUld7mxH1DaQOVWtAHxFZWWU1OtobCQne5LTTC7KDXq+i75pSvGaDnzxXIiARkAjMBwLVtkFUUlajRiKzRqi8sE0bi0Alpc/2kDTN84GJrHNhEZBE1oXFW7Z2+QiMUbASByjt3NkJq9VBmQ5C6BnPRwQqXX4tnnGkccwMzoJx9EA1dr9/EoUbs1CwJg1JqZHwYfUWNyiszGpn0i0pszY4DDho6YSalFgLNeFIISGTGArCcOfiIGW8wdNEKPrbX2AzmhCanY3oonXCDiUU/+Yj+u4SgJgog8TYmAO79g2jus6E3CxvpJEaa0qSTpDAlPOwjrpEl+TuOUCAbUCcVeXz5WJE1ocfflgEr27ZsgV/+9vfzjmNbQv/+Z//KWylTzzxBPwoDfnbb7+NRx99lNa+GlRXV8NrUnYrtqlyEOzg4KCwL3z1q189p77p/uGJRFYHGSlYlbarowuNDY3Yu2sPerq7KaA8Q6izrlm3VuAp7c/TvRoufPwo/YYNDtnw0Z4htHdasX6Nn/gdi4ocV5S+8Fnnb2VfwQCRv5nI2rDzXQRnZmP51x6DhgQAlKRa7EmFr8GO9g5UkUryzh3vQEn3yqycbOST0nJaVga8vUjJXCuDFj1pTmVfJQISgXMRkERWSWQ994r43F9Llcg6AUOfAWglEuspUmbtHQEiA4DUCAVyYxXQ0jONZnEF5k4M2yPenWTUsFJqtE6HESesveJ9xGHBck0IsijdTJjSC3qFnCCPmEzZSYmARMDjEJBEVo+bsiXbYVNfH0ZamnHm3XcwWFeL9DvuRMTKVZTOLdzjDFRLdhLlwC8LgZHhEXJK9uDNV99EY30Dbrz1JuQuyxPR95xqzl0Lk1hZjfXQ3gqcrmkn57FNqAJtvDpPpMiTTrVLz1wfqYCcOHECKrUOYVEFpMKqRGePXZA7YyPVyEph1VKlcFJybZxmrLKyEo2NjcjLy0NiYuKlG5nGEfNBZOXmyU8HK6WVa2y1ofK0FT39drEtNUGNxFgN4qPUlA7OScZ7xTR6e/6hdrsTZjMpr/ZbiLQ6/hoetsEwYiU1GifhDCKuahEVpSfHoRcRrjWLLv3s+ajILRIBiYCnIiBSNZPtbC8RgU7Z+hBJtrJUIgIVaEKlzcxTJ9VD+y2JrB46cUug20wG42e9ffvIv0Cq+74+KuTkBCA311+Isy0mEpKD1l5Wqx0VpY04vK+SgsWcCAr2xdoNWYiOCyVlViYEze5Zeq4uGaPTJkRMjtp60W4bpWd8IFNFIiaaYPiDMvK5oTIrE6QG6+qEGmvz7o/hExWNtJtuhm9cPLxCQ+cKmsuuh9dPPMdtHRZBYG1ps8BkdqJwlQ9SKDW3v5+K1Dkvuzp5oBsi0NvbKzKucNdeffVVMAn1QkRWtgkx8ZRVVp955hlwEKuaSHsDAwO0niWnNxUmZU4uv/rVr/Czn/1MKLe++OKLk3eJzw899BAFAOzEhYix5x18iQ2eSGSdGBIrYg5Tuvqjh46gprIaQ/Q5Ni5G2OOSUpIRERkhCa0TYM3inX/LrFYnPj1qwGlSltaSEmtqkhdWLfcWwcTT+S0zDw2hv6oSlc8+Ay1d/yk33oyA5GT4RFJaXg8pbAPu6elG6ckSnCZi7tDgEBISE7Bq7RrExschNEwqsXrIVMpuSgTcEoGJ9QCvk1xZJJFVElmnvP6WOpGVwWF11so2J0qIzHq03onMKCVuXqlAkDewBASCprw+3GEnk1mNsGM/pZt5y9KEDCUZmsigsYqM8iFK94gkdgecZB8kAhIBicBcIiCJrHOJpqxr3hGgBVfZ039C8+5diFy9GpFr1goyq3qSmsC890E2IBGYZwSaSAGi9GQpTp04CTakP/DwPyGdIvDdvVjMNkrHNoIX/7obHW192HbLGmRkxyE6NsTdu+42/SN/KcZIrbTytAUf7DcKh3tEiAobV+vBJE9WKl1If/R8EVknABdEU3Jg7D5kQnmtVZBZc9I0uHodBTJSpk6VaubOdzbQWUixaHDQiorKISL8jqCqaoQUadSCtLp8GTk5Un2FQherr8oiEZAISATcHQG2mZnIZvaKsR7HrD24U59EAeChlJ5ZAxWp9sgiEVgoBCSRdaGQlu3MBAGLxUGpucfo2Y/ISEf7UFQUiuuuiySS38I+R8+k7zM5Z2RoDD1dg3jzxU/R3NiNm+5cJ4IJwyIDxZhnUud8nMP3sH6nGScsPXjL3IRMEi8pImXWVHUAQt3Q78Mpq0+/8To6jh6G3WJF1Bpa226/i9JXu0YRj7kHTPw6dmoUb+8cIPKqDlnp3sjO1FPQo2cpD87H9bXY6nzppZfw9a9//YJE1q6uLhRQmnEuH3zwAf7nf/4HBw4cICJcj1BaXbVqFb773e8SgT/3LDH2a1/7Gt544w2RPYb3fb78+Mc/xm9+8xtR77vvvvv53dP625OJrDxQtiMYjUZUE5H1lf99mUiFg/Dz98ONt92EtesKPwvS/v/Zew/ouK7rangPMA2D3ivROwiQAMHeSZHqlVS1ZMtyUWQ79r9WkmXJXk5iR/GyY8X+ojiRtdwiy7K6VSiSoljFXsACohC99w7MYHr5z7k0KBYQBEBwMADu5RpOee2+/R7ee/ecffaWz90TOilGmZmvae2dNlTVmHDgiB7zYtV46O5g4UQ00fjMUFMjKt9+E2Yid/uEhmHe+g0iVzDKZj3yp7raWpQQiXXPrs/QT/vw0CMPYyE5ciUmJdF9XJ5rHnnQZKfmJAJMCGVXtHfffRfVVOzk5+dH44zlWELPiDqdTtw/xgPMZNbDBSucxz9IbpVdpBiel5eHFStWID09/ZriFe4DXzva2trAxSs15C5gtVqpuC9HFKxc/nww0t/jx4+jtbV15Os171xAk03OBDfTJJFVElnHPH8kkZWqFunhqJ+cF5tJmZXJrHqzQlSAFiYB2bEKaGkcqpTPBWOeR7dyIuVtYXc50OIcBlulsU2amSp2F5Aya4pXAOKVfvCSVmm38hDIdUsEJAJzEAFJZJ2DB32G73L7sWPoKDqJQQr0BFBQJ/PxL0EbEiJVWWf4cZXdvxgwZzupY4eP4YN3/orYuBikpqdh2arliIiM8HiIakmFtfRcPRrru6DRqLDhznxBYvUUa0tPB9BkpuTuoAvnKyxo63JQohKII2XS5HneiIlQCiVWd5JYGa9bTWR1UvaCybst7Q40ttlRWWcVCicRRN7NTlUjKY6UhYjMOl6HTEGMJRx7egjDdjPa201CjZUJsSqVAjpfFUKCVQgNUSM0TCMUWLVaL49K8nv6eSr7JxGQCEwfAuxiVGUfxAVbPwZdVtypmYc0IgBpyMFo8rT/6dsfueWZi4Akss7cYzcXes7PgwYDPVdWGrB/fxfmzfPBwoVBl9T3ZxsGVotNuGKcPFKBqvIW2MmxITUjFqs25ApVVpXKM0iOlJaDyWlHK+V9Su39aHcaYaS8z2JVONK9L5JZVR5SlMFkKENbK2o+/ABMkIonUlT4goVkW50FxTSRigaHHLhQZUZdoxktpMaan6fD/CwdgoO8odXIhOZs+7sei8h64cIFbNy4UexyfHw8mpqaxGcmuYwosTJJhtVaWWGVP2/evBklJSV4/vnn8d3vfvcauJgM+5Of/ARxcXEoKiq6RIAdmfGi2vXQyNcx319//XWx/GjbGXNBD5rIOPb39aOqohIVZRVk915O8blYJKemkEpmIcXnIqXN+xQcr2GjE20dNhw+rqdz14W4GBWyM3yQME8zobVbSZW1q/gcOk6dRMeJ48h49HEk3XUXvNUaKDzY1YpJ0jXVNRRHLUbp+RJExUSDyavzF+QhJjYWfv5+4u93QmDImSUCEoFbggDfS0+cOIEvf/nL5P5w5f3Q398fH330ETIzM2+47cmsh5f55je/iW3btl2z/kceeQS//vWvL93/eQYmsfK9+Ac/+AHlFii5cFnjaf/2b/+GZ5555hLxltfPzwulpaWXzXnlx+eeew4/+tGPrvxxgt8kkVUSWcc8ZSSR9Qt49GagppOShM0unG4AlqYokJ+gQGww4EfPSN5y7PcFWNPwyUJkVlaZ2G1pRbmtDxHeOqT9zS7NV6EUQfpp6JbcpERAIiARmJUISCLrrDyss3qnTKQy0FtxAeWvvwaVjw45T38VAYlJ0AbTg5xsEoEZjAAHFwx6A/bu2oM//+F13L/1Aay7bR3Zl0URAY8sJDy0OcjWkhOoxw9dwJEDpdTfYCRnxKBwWToCg3w9tNee0y1OthOEaO+yE5nTgbNlFkpAAxnJKmSlqJESP33J51tNZB05Clxw2tfvwKkSC5oIg54BBxblqJGXqUZwgJdIzlJcbdTG+NnJesVMBNbhYTvZ/9kFgbW52UhV6mYYjQ7Ez/NFYhKNKdP8EUIkVp3Oe9R1yR8lAhIBiYAnIsDkHydcgsC639oONZV4R5B63VJNJGK8PPf5wBOxlH2aGgQkkXVqcJRrubUINDQYceBAF5z0rBgYpMKiRcGIj9cJdwNO2M6mxiSzZlJjrSxrpvFYGRVsBWDjXQWIjg1BUIhnEWFMRF4doGKMQ5YOoS7OyqwjrwAvFVR0j5uuxjhylR3Hm5gQ1XX2DBXVeWP+M19HMCleMSlqOtowjWfaOuw4ckIvxjYhISoU5OqQniodDKfjeLhjm2MRWY9Rcf+WLVsudYOVW5lg4kNOVWVlZYLswuTWECr4Z9JNQEAAWEmtjwjaP/3pT/H0009fWnbkwx//+Ef88Ic/RDhZmDPhlQusL28cq/r3f//3y3+67udgis3yNXYmE1l55xgDfrFT0r7P9pH7UC/UGg3WbVyPjKx0hEdEQEmFAlIx87qnwrgmDFD85lyJCY0tFnT32rBisT8KiKjPhcjjdehxkNKglYhlDbt24vyrv0H61oeRfO990DHhWOd5MUkHFZzo9Xo01tXj1PETaKD33p5e3HXfPVhCqr/B9LerVpNFkWwSAYmAxyDQS/cAVl81GAyIojwN34f5vvvxxx+jqqpK3HN37txJBXTzxuzzRNfD91MuNHnllVfEerkwhfvB9/sPP/xQEFi/9rWviXv0yL37yJEjYIIrP9eySvsTTzwBLnb5/e9/j+LiYvGZ5xnpK09LIhI9q82uXr161P5v3boVDz/88KjTxvujJLJKIuuY54oksn4BD+W5YLICtURmLWkBuoZcUJFKy/psBZLCAR09I4xX9eWLtcpPU4UAB+ntZDfTQoqstQ49Tlq74EME1nx1GFKJ0Brn7XkPn1O173I9EgGJgETA3QhIIqu7EZfbu1kEHBYLDO1tqHr3HZi6uxCQkIjopcsQWbj4Zlctl5cITCsCA/0DVIVfivNkKXW26Ay2PvYw1mxYI4Ll3h6sImDQm9DW0iuIrGdOVOP2+wpRsCQNIaH+pFIxfSTMaT2YE9j4sMmJ/kEnkTitpEhqQ1S4FymRqpCWqCIVVgV8faYvmesuIisH17hIfEDvRHWDDWfKrJS0AEKCvLBsoQbzoiilTTCMxjkYHnZQUs6C2lqDsJHt7LRQUE5BNoxqREf7IDJSS8qrSvj7qwSBlacppQ3LBM5QOatEQCIw3Qg4iMRqooLvE7YuvG+swwoisC5XRSLKywe+RPqRTSLgbgQkkdXdiMvtTQaBwUEbKRUaKWE7kb/zrwAAQABJREFUQPafBtxzTwxycwPIOYJUrGcXj1XAY6ZkV3trL44dLEd35yDZfQAr1uVg0bI0QSrzFPKug3I+NupcMymz1pDK+HlbL1hXfJU6Gkne/oj09pnM4Z6SZZykwmg3GVFPRISKt/5CMaZCRBYsQtSixdCGhk6LGquTKv6qai3Cfruq1oyYaDVWLvEjhwkV/Hynb5w4JYDLlVwXgfESWR999FH86le/umI9e/fuxVNPPSV+Y/vjVatWYeXKlairqxNqakx6vbr98pe/xEsvvSTU5Pbtu5ZowcS7Tz/99OrFRv3O2+Hx/UwnsvLO8X7oiSDZ3dUtnJMqL1RScYQTWTlZ2HzXZgQEBUKrlYTyUU+Ecf5otblwkcxqxP7DQ0Ri9SXFaV9ER6rgqxvfNc7FpGO6frcfP4bKd96GjkjGwWlpiF29Bv5xY5PKxtnNKZuNzykmwp08egznzpwlR6sGJKWkYOmK5YhPTCCCdDiReDn+Nb59n7KOyRVJBCQCYyLwz//8z/jd735H8eVAcT9MSEgQ8zMpff369Whra8Njjz0Gvp+O1Sa6Hi5CKSgogJUI+1/96ldFQQpfR7i9+uqr+PGPfyw+nzlzRhBsmZTKZNdz586J+/8bb7whrik8ExelLFq0iFzMevBP//RP4EIYbgOkDp2dnU3x80hBdB0hxIqJU/ifJLJe+3w1GrwKk8l08QiPNnUW/yaJrNce3F4DDZr7gHONpIAz4EJyhAJpkUB6tAJaigXL/Na1mLnzF7ab6STrtGO2TnQ7zSKokaMKQRbZzQR6aaAl+zTZJAISAYmARODmEJBE1pvDTy49PQhYKJDYfuwous8XY6C6CvEbbyPboHugpACiFwV8ZJMIzDQEODHQ3NiEndt2ikC5r68v1m5cR5ZSuR67Kxw44cRaS2M3Th2tRGdHPymz2kn9Jx/ZuQlERPQSSVOP3YFp7hirsBopNNHWaUd1IwXdu+2wWF3ITVcheZ4K0eHegpA5nd10F5F1ZB85FtdGyrQVdaRO22qHftiJ7FQVUhNUiInwEqocnJQ3Enl1SG+jYJsN/f1Wsv2zie9MamWF4OAgNeLIRjY21gcRERpBWBivmsdIX+S7REAiIBHwFASGSb2ukYq8S8iKmQu9b9PEYg0RfjgmxuQf2SQC7kZAElndjbjc3mQQsFlJrZ+ULI8c6SZVwj4sXRqKnOwAREVriXg0O3MKwwYzqi60oKK0GaVn61GwNA0LF6eSXXEQfP2mjyA62vEbhh1ddiPlfbrQ4TQiUKFGOqmz5lLux4fubpppyPuYiSzQU16GtqNHBCGKVf3i1qyFT1i4iDWNth+38jd2nNAbyLXi7DCaWqyk/OWF9BQtFi30hYqK82YjIftW4jmT1j0WkbW5uZmuZ0vF7vzpT3/CbbfddsWuMVElnRSELSQC8OKLLwr74AcffFCos377298WyqtXLEBf2C6YldqY9PrOO+9cPXlC3//nf/6HxuSOWUFkHdlxJvWcP3seZSWlqCi7AB+dD5FZs5GRnYmEpASKN2iEwt3I/PJ9/AhwDMhBccWKKhMOHdMTll4ID1Mhn1SnoyJUosB5vIUYAzU1aD95HH0XLsBuNiHzsScQNj+X1LRJuWyaL5h8DjHhtqW5BXW1tXQ+nUMPOc75+wcgv3ARlq1cIUjRKrXMaYz/7JFzSgTcgwATy1kFtb6+Hn//93+PF1544YoNj6ia+/v7o6Ki4rq5kMmshxVf/+7v/k6QUXndrAI70vjayIrrTETl+zgXqrA67Lp168Qsu3fvRk5Ozsjs4p2fL1iNlZVXRxRWeWx/9913T8kzwBUbu+qLJLJKIutVp8SVXyWR9Uo8+Bs/JNnpIam0FShppoelNgViyJX2vgIFQn1d8NXIgPC1qLnvFzo8sJLqRD/ZzZyiYP0OazORWIOQrwpDNgU2QslKTTaJgERAIiARuDkEJJH15vCTS08PAlxpzbZBTfv24tz//Dfib9uEzMefEFXXaj//6emU3KpEYJIIMCGUK2vLSI31lZdfIQJeHLY+/jBiYmPIUooGJx7amMRqtdhwrqgGb7/2OZJSo7B6w3zEJ0UiNDzAQ3vtOd0yWVxo73KQ+qgFB0+asSBLjYIcNRJiLiqxegLx0t1EVj46nMSgSzyOnTWjuIIs4kihg4m9G5f7wE+nuBj8bzGjts6AslJSR+mxwGR0UrLOD+kZfkhJIYWiUI0gvTKGXmS1Ms05C8856WRPJAISgRmJQA8Vdh+wtlOBtwlKlwJL1ZGC6CMjljPycM6KTksi66w4jLN+J0bUis6dG8Dp0/1CkT8qUoNly8MQFDQ7iSI8PrPbHSguqsWOD08QQUaH2HlhWLk+B3EJZEPoQY3zPjbK+7Q6hlFKhRp7LK1IVgZggzoGseTGF0IiJu5uvUR+qvjLn2EbNpACaxiS77wLYQsWCiXW8RKpprLPXd02Ybd99KRBFEDesTEQKYla+PtxwehUbkmuy9MQGIvIyiTRETtgJp0y+fTqlpGRIazLf/azn+HLX/4ymMD6wQcfCGXW9957TyiNjizDxJqHHnoInB945plnBPl1ZNpk3mcjkZVxsNvs6Cbi4bFDR1B85hwuEKH1rvvvweY7b0dwaPAV5KLJ4DbXl+kbsKOt3YojdL1rbbfhgbuCkZWuJWIrxXTGecGzGYdhIULX+Vd/g7bjR5H/999D7IpVUJOCotc0u1w5KMjF5PI9u3Zh767dJArgRFJyMu554H66T8dBR2IG03Gfmevnndx/icB4EOAxRXx8vCjS+OSTT4RC6uXLMUGTVVm5jUYeHZl3Muth1fVf/OIXWLNmDd56662RVV16/9rXvoad5CSwadMmvPbaa+ACl+eff14QXPfv30/FAN4i52SnaxCLpnCxy8gYaWQl77//viDoPv3000Kdne91TI5NTEwUy/OyU9EkkVUSWcc8jySR9frwdOtJmbUXKG4iWXeLAn5aUsKJUyA7VgENuWGSmJBs04SAk24QFgpqNJHdzHl7r1Bm5SBHgSocqRTcCFNooVLIAzRNh0duViIgEZgFCEgi6yw4iHNxF+j5wEHEv+7ic6h67x14ayiYTwPK+PUbEZSaOhcRkfs8gxHggGZNVQ1Kiktw5OARZM3PwsOPPyJUHjzZpoztKyvLmsWrvLQJeQXJWLMxF34BPqQkQIoHso2KAF2+MDDkRCspsZZU2YTqqJrGnJkpaqTGK0ViUqP2jMzkdBBZGTTGqKXDjoZWBy7UWinQ5kRMuBeUTiucVgsMpMZqt7sESVWn8yaFKSVZIGkRFqYWJFZW8fAEIvCoJ4D8USIgEZAITAABIzkVNTkN2G5pAplMYokqAklKsl72+kKJYwKrk7NKBKYEAUlknRIY5UrchEB7u5kUlIZRUjIoyH8bN0YgmlRZdTp6AJ+FjZPTHW39NEZrEsqs/b16LF+bg/TsOEREBRGh13PUaEmfDkY40GI34CzlffocZvrmQiHlfTJUQQigO5878j5OSuoPNTehm2xY63Z8gsDEJMRvuA1BZPesI5tVdzce55hIjbWswoTT54bpXPVGZIRSWG6HBisvulS4u1Nye25FYCwiKxNPFy9eDFZmZWW4H/zgB1eQUo4fPy6IqdzhDz/8EEuWLMG2bdvw7LPPQk3KlDw9Kirq0v709vYiLy9PrIO3yyptN9NmK5GVMTEajWhpaiHl6wqcLToLpUqJkNBQLFmxFMkpyfDz9xOkn5vBb64ua7E4BWH/6CkDKqqNSIrXIjVZg8xUHzpvxxcfY9ELp82KirffEi5urMYavjAfUYWLobxMxdCdGDNh1Ww2o7mhEadPnRKKrEODQ8jIykRmdhbSMzPleePOAyK3JRGYBAJNTU1YtmyZWLK6uloQQi9fzeUFJkw2ZdLpaG0y6xkpROF7+L/8y79cs1ouWHn55ZeRn5+P7du34x/+4R/w5ptvYsuWLbjjjjvw3//93ygvL6cYuh1xcXH40pe+JJ4d+FlipL300kv45S9/KYirw8PDomiDpymVSlEsw7kBLqC5mgA7svx43yWRVRJZxzxXJJF1THgwTATW8lYnSlpcON8MLE5WYDnxICICFNBRHpaEXGSbRgTMRF7Vw4Y95hacsfUggxRZs1XByPYOhq+CBvCSzDqNR0duWiIgEZjJCEgi60w+erLvhtYWdJ4uQkdREfRNjcj56tcQvXSZsA1SXDYgk0hJBDwVAQ4CcFBz32d7UX6+DE6XEwsX5WPzXbd7dDU+27f39xmwd/tptLX0ISBIJ2wrF5F9pWzXR8DucBEp04XaJjuq6m0orbYhKswba5b40LsXggK+CCRdfy3umzIdRFZWkmIiq5XsYHv6Hfj8hAm1jUT4JVtNJylsKKzDCPBXIiZGi4wMfyQk6Cig5iP+XhRyzO6+k0NuSSIgEXALAu0OI6ocg/jM0oJ5Xr541CcVfl4UAyNSq2wSgelCQBJZpwt5ud3JIMDP3oNDNnz0URu6Os2UXA5DSrIvoqJnb0EAq7Kyc8auj4tw6mglUjJiqFgyHnmLkkn1TUPFYJ51Dxl22tDlMuO4tROfkwL5UiraWKgKpcKNAPgryFoat+4hn62erQYD2o4cotjSafTXVGPe2nXIfuorF5VY3YwVj4OGyW2io9OKIiKxnjo7jA2ryXo6TwcmsXLBnmyzH4GxiKy890xSYbIKW9qzKitbHjORhklzX/nKV7Bnzx5BSDl48KAgorADUHZ2tiBirl27Vqi68XWAiS2s2Lp3717Exsbi2LFjYv6bQXg2E1lHcGlraUVZSRkVoh9GfW09Nt25GQsKFiIxKZGI5zp4e1DBwEifZ8r7+XIjyonE39NnR0yUGutX+ZO6uDeU5LYz3tZ29AjaT56AoaUZQcmpyHjs8WlRZeW/SbPJhM6OTpyj+8uuHTsRFByMtPQMrN24HilpqR53Px4vxnI+icBcQmDfvn148sknxd9re3u7uN9evv9M+GSSKN9rmTjKJNLR2kTXs3XrVmzevJmK8UqEyup3v/vda1b7m9/8Bj/5yU/E9osoP8rPALtI+ZnvRSa6/nDeSaVSCSXWkYVHSK8j37/1rW+JwpeR7+Hh4WIf+/r6xE9cBMMk2ZycnJFZrnjnvBYrvd6oNTQ0gNVf7733XixatOhGs8+66Xz8x9MUdOBoODD3miSyjn3MbZRUZDXWui7gbIMTw1YFWBlndTqQHAH4qKQl4dgI3tqpDkrqk+A1Ghx6VNsHUUGBfK3CG4uVYUgkNYooL92t7YBcu0RAIiARmKUISCLrLD2wc2S3hG1Qfz9qPvwAjXv3IOXe+xC9fAUCExKnrdp6jkAvd3OKEOAgx2D/AN74vz+jqaEJ6zatx/y8+UhOTZmiLdya1fR0D6KxrhMHdhXTBlxYdzsF7ZOjEBoecGs2OEvW2tPvFEqjxRUWdPc5kBKvRlKcEsnzVNCSe6aaxpye1KaDyGqxOGAyOtDcYkJdvQnnywzopNiZQ+kDnRYIoVNs8QIfpCZqKKGhFApFrKglSayedObIvkgEJAJTgQAHr48RqaecLJdtcCLZ2x9r1dFQUyyMTIWnYhNyHR6EAKt8MYHkzJkzaGtrE4QSThbdfffdgpgy3q4yMYWTRGwxWFNTI5ZNJutSVmRJT0+/JvE23vVePp8ksl6Ohvzs6QgwMdBkcuDEiV40Nl5M6GZlBZCyUoind33S/btYGOZCXVUbKshBo+xcPQKD/LDhznxEx4ZQEaLvpNd9KxZkFVYzKZDXkwJ5JeV8mux6cZdbqYpEMpFZQ7y0t+yuZzXoYWglnN58A8PtbYhZsRKRBYvASn58H3an1TOfq+xE0dJmw+dHh0QBpL+fNxbm6kidUEOqhF5EorgVR0Cu09MQuBGRlYkpGzduREVFhSDWrFixAsFEkDtHqsKs1MrPAm+88QaYtDrSWJX1ueeeE88FgWS1zkSWCxcuoLOzUxBid+zYIayIR+af7PtcILKa6JltaFCPciKzMqG1rbVVKLNu2LwBCYkJFBcLmyx8c365/gFyo2i14vBxPYmLKbC00BfxsRqEhY5fRX24ox199LdR8dZfoPb3R87Tz8B/Xjw0Ae6NVw6SNXdzYxP27d6DLiKzsmJvTm4ucvJIKTYinL77u/UeM+dPLgmARGCSCLz++uv4/ve/D753VlVVXTOeZiIrj7cNVBj1n//5n3j88cdH3dJE18Pk2aysLDCh9Kc//Smefvrpa9b7xz/+ET/84Q/B5FMmvN5///005jkh5ktLS8OvfvUrcb8fGhrCK6+8ItRbeSLvz/e+9z1xDeI4QXFxsSCq/va3vxWFMDzP/v37hXorbz8pKQmHDh0Szxc87fJ24MAB8OtGLTo6GkwElkTWsZGSRNYnnhgboTk+tUcP1Ha5hDJra78CefOAjGggIZTIrCRhL5VZp/cEMVCFbjdV6H5uaUO300yBDA2yWJlVGQwdKbOqpSrF9B4guXWJgERgxiEgiawz7pDJDl+GgLC0oABu/c7taPh0J3zCIxCalU02cBuhoSCuVGW9DCz50SMR6OrsQl1NHXZt30nkPRO+9PSTgsTq6+dZycUR8Di5xiofpZQMLTvXgPbWPkRGB+OO+xcjONSfbNRkZm0Eq8vfraQEpR+ma1WzDRV1ZF1pcBFxVYEleWrExyjh70uUJA/kJN1qIiufT3wdNxJx1Wi0Y3jYgcFBwodUs/r6bBgYsNF3K6wuJZQ6P1gddH4RTisW6ZCZoiEFWwVUSg8E7vKDLz9LBCQCEoFJIGAjVyIzkVd3WJpQax9CDsW8OPaV4kX3WulINAlEPXsRTujcd999aCUixNWNk0ZsUch2fjdq3t7e+PWvfw22GLxaFYWnfec73xEWxKwQdTNNEllvBj257HQgwFbtzc2kcF2lx/nzg5Rs9sNtt0VAq/UiApf3dHTJLdsc1pvQ0daPzz4pgmHIdFGZNTceqRmxpLpIOqcelugacllFvucIFXEwmZUVWdPolUX3QC3psk65Ix+NQ3qJ7NR9/hwpsh6BkioLs554EoHJKVC7mfDEJwSTWNs6bKipM+P0eROiI5XIz/VFXIwaQYGz9zx1yx/DDNvIe++9B1ZeCwsLQ2lp6agFLVwA88ILL+Ddd9+9Yu8iIyPBCm1Lly694nf+ws8TP/rRj2jcPXxpGqvIsZobE1mmos0FIusITu1t7VQwUIuDBz6Hnuzik1KTSf06B1k5WYK0yIq5sk0MAQo3gsms+w8PobvXjuBAJbIztPTyoXjj+MTGnKQMqG9pRunvfwvLkB5xq9cgfMFCBFNBlzuaxWKBkf7GKi9UoLL8AiropfP1RX5hAbKpSC2ZlFhlkwhIBGYOAlwI8uyzz1JBkRotLS1Czfzy3nPRE5M0uf3f//2fUFG9fPrI54mu5/bbb8fKlStRV1cn7t1cjHJ1++Uvf4mXXnoJmZmZYMXPBx98UBBZWYWVVdkTEhIuLcL93LRpk3iuYEXUTz75RMTkuQiWyapMmvXxudKx4tNPP8Uzzzwj1rF79+5RVVmZ3Muv8TRWjZVE1rGRkkRWSWQd8wwhl0xYKNF4vhni1TnkQmQgcGeeAuH+gNbDVHLG3JlZOJFynTC77GhzGlFi6yNCa7sIaCxXRyKBlFlDFHJwMAsPu9wliYBE4BYiIImstxBcuWq3IdBfXY2ekvNo2L0LKhpwLfzW3yOABmpeNGiTTSLgyQicOXUahz8/REFOIyIo4XDHvXeSzWXUqBWunrAfDhosWcimcsdfT+DYwXIsWZmJnAWJlAyNgUarkmoC1zlIAzSmrKizorzGhvJqC1YWarEwS4PwEG9SGaViSQ/l/95qIisnKWxWBxF3zGhoHEZ9vREdHSZKXNgQE62lgJsvvchGM0wLjY8Sp0utOF1mxbxoJdISVMjPUQsS8HVglz9LBCQCEoEZi8CQi2yWKe6109KMTocJD/skI9UrADovUqBmRr9sswYBtvVlsgmTWYOCgvDII48gJiZGJKKOELGKSaecVGJFFC4mGquxSsqjjz4qZuF1cCKLiS6cNOvp6RG/sxILK7XcTJNE1ptBTy47HQhw8RSr/tfWDWP7J+0IDlFjyeIQsuH0QWioejq65JZtupwuIqyZUVHahLLiRpwrqsHKdTnYfE8hfHQaqNiO0IOakzRQreTKV0+OfKxGftrWg2gvH9yunYdIeg9UTOGxopPCSdfXmg/+itptHwnyanjeAsStWSuKor2I/O/OxueokZSDDxzWo77JQkRjBeZn6VC4UCcK95jAJZtEYDQEmHzCKmysBMdElsTERCL8Xf/85eeK8vJyod6eS+qQPP9UtrlEZLXbuBjXgJqqGpwtOoMDe/Yjd2Ee2cavQyqRFcNIdVO2iSHAhc4WKxWfkCprWYUJJ88MY9kiP2xcGwANCY3xtfFGjddhJTXUxj27SZn1Asx9vUjYfDuS7rz7RotOyfTurm40EjFs945PcaGM4qbLl2FhQT4psc6Hr5+fIMNNyYbkSiQCEgG3IMCuKVu2bBHbamxsBJNEL2+sdsr3X24ff/wxCgsLL5986fNk1jNCTP32t78tlFcvrexvH7g45fe//z1WrVqFd955Ryiovv/++4JwysTTq9sI8dWPrkVMkOVYxFiNnxmYDMtxiJdffhlbt24da/Yxp1VWVuLNN9+URNYxUSL9DpPJxFy4Odf+9V//VVgIPSGJrOM69u0DQGOvC8VNLpisCsSR20wmEerTowAlVat6arJxXDs3w2fioIYJDjRQZW6RtRsG2IWtWr4yFGmqAASQLuuUV+jOcMxk9yUCEgGJwPUQkETW6yEjf59JCFhpwDjU3ITKt9+kAFUfEjffQVZw80UyYibth+zr3EHAQYECk8mMvbt2kxrrLhQUFiAvfwGpN2TDP4Cq5zy09XQNopYsKotP16GD1Fhvu3sR9Tme7Cl1Uo11lGPGRZIdXWSN1u7AhVorBX4AX50CuRlqJMWphCqrJ4vYTjWRlW1ODQa7UF3t77dioP+i6qrF6oSVXkyUViq9KCjoRbZIRPQNVyMiQgs/P1Jkpd/qmu2CENzR7aSELrAgU0WkVhUiQq+fqBvlsMifJAISAYmAxyNQ4xjCGYp39ZAjkRZK3KaORZzSV8S+PL7zsoMTQoCt/zhB5UtKTax4kpKScmn5jz76SNgA8w8nT54k0l3cpWmjffjGN76B7du3C1IKj/NHGieoFi9eLOyD161bh7/85S8jkyb1Lomsk4JNLjTNCDBRsLPTjOPH+8DPoWyHsGxpMDIy2NqXv96YHDPNuzCpzdvtDvSRBWFlWTMO7y9BULAfqcHFYP7CRETHhVKOy7P220V5n0Eq5mhxGETeR095Hy3d/fIo78PK5D4KUmadAkc+c28vBmpr0Pz5AfQUn0PinXchavFSBMTHw1urnRTWN7NQV7dN2GkXlxrBbh6sQJiUoBGW2jezXrmsRMDdCMwlIitjy7G9/v4BipPV4PjR4zDoDULxetGSQmRkZSIiKoKUv6X40kTOQ4eDijCMVAxebcShY3qEhaqQmeaDlEQNfR5fAYbdZMIgkbTaThxDw65PhXNb2oMPCbVtpfZKxcGJ9G2seYl7RCro7aTEegHFZ87CTgQwfr4vXLIEqelpgtjMFuSySQQkAjMLgaamJixbtkx0ejSi6qlTp0ShKI8lysrKRHHqaHs4mfUwgfWDDz4Qyqys1i7cKf+2ci8iqj300EPgcT+rpr744ov4+c9/jv/6r/9CQUGBiAtcPj8v9uqrr+LHP/4xgsnJsoJcCbgIhgtqWW02np6Bry6c5eX5dya0/t8YarOj7e/Vv0ki676rIRn1uySySiLrqCfGaD8OW1woqgfK24C6LicKk7ywab4CvlT8yQWrszS+MRoUHvmbkZRZ+5wW7Le24TBZzixXhSNfHYZk7wD4KUgRyiN7LTslEZAISAQ8CwFJZPWs4yF7M3kErHo9qt59W1RbK3W+iFm+AgmbNosHttmalJo8WnLJ6UaAbaZ6e3qx7YNt2LltB77xrW9i/aYNZDfFhFDPI+Vx4IIVfSooAbp/1zkR2OAk6Jrb8pCQHDndcHrk9jn4bqYc+ZkyC5EvbWhusyM7TYXNq3RChVWr8fzRys0QWcU5Q4QBJu8ygdVJJFVyeENnl5kUWE2kvjpMlkxGtLeZEUak1ZhYH6Sm+iEpkewz44i2RYTWqxPrNrKFHdA7sfOACa2dDsRFeSOHMM0jYvB4beY88mSRnZIISAQkAn9DgJUXnKRGd8zejW3mBmR6ByFbGYRMIu9MqRKdRNxjEOBEEyecNmzYgD//+c9X9IsTSSPkVbYOZmvB6zUe77ASS21trbAjfv7556+Y9Qc/+IFIPrFaDKu7Xp3UumLmG3yRRNYbACQneywCRqOdkrVk2366H0eO9uKB+2OwfHkoJW+vfe702J2YZMdam3pw6lgl2WC3o7/XgHu2LkXeohQiWBEt1MPIrLyLw04aPzmHUWTrxj5LK1aro7FSE00KrTr4EpnV6yYyPy66trJKX8OnO2Foa6VxrhNZTzyJyEWkoOXmhJ+Txtk8XjpfZsS5EiOGaKwTGa7EpvWBCAmm/XRzfyZ5esnFJAKXEJhrRNaRHWcCa2dHJ3Z+sgP7du3FspXLsGjpYlLiXEikpkB4SwLjCFTjfm9ps+JM8TA6e+zk5OPChjUBSEvWCJGxG8X5RTyKSMZcrHD6v36JqIJCJN11F4JS0uATFjbuPox3RjsFu3q6e3CGbLOLTpyk1wncee+92Hj7Zop1xcDP33MFC8a7j3I+icBcRYAJozwO53H2l7/8ZXCsfITwydei73//+/jTn/50XfLoCG6TWQ87qzz77LOCaHr8+HFERZHa4t9aLxVl5eXliXH922+/jdWrV+Ovf/0rvvOd78CHHCuLi4tJGMJvZHa6dnrhvvvuEwWyK1asABNj9+3bhyeffFLkokpLSxEYSBbll7WDBw/iscceE7+woiyrs062SSKrJLKOee5IRdYx4Rl1op0GkT16F+q7FTjdwOFkFwKpWGdJihdSyBWAc8yen34cdddmxY92Cu5bXGQL5NSjwj6AVscwtBTIWKqKQIK3P0K9ZKXbrDjQcickAhKBW4qAJLLeUnjlyt2IgMNiEcmIjqJTaN6/D9FLl4lkhIqqn6dDUcONuy43NQMRaGlqxvEjx9FY34ChIT3ueeAeYTWlJJnJGwVkp2N3rRYb+nr1KC6qxd4dZ5BbkIzFKzIQGx9OCrK3Rs1gOvZzqrbJik/N7XbUNNlR22gTqjqpCSokzVMhIcZb2KF5shLrCA6TJbJy0oCJvIODVHjYaxXk1e4uC3r7rOJ3Jp3qfL1JnUIJf34FKClYpoa/P32ml07nLf4Ors7bMiGWTkXUN9tQS9gyQTg2UomFWSpEU8I3ONBrpOvyXSIgEZAIzEgEzBTj6nGaccLWJYg7d2jmYak6AkEU31JPgQLdjARllnf6d7/7HZHqTuPuu+/GPffcc8XecrJn/fr1wr7wAqk76XS6K6Zf/YWt/nh8f/vtt+P111+/ZBXIRVKLFi2iApIWofDKFoQ30ySR9WbQk8tOJwJ2SvaYTE6cOdNPhO5uzJ8fQFag/kikQip2AJjNbdhgJpLNIM4crxbuGikZMcjIjkPOgkSyOna/AumNsLbDCSPdE+vsQzhv6xUqrUzqXKGKJBETf/h7sS7rxDNzTiIbmXp70E5kgKr33kZIRhZiV61GaFY2dJeRA27Uv6mabjA40EUkrbMlw6isMSMvW4e0FC0psZJ7h5bHRFO1JbkeiYB7EJirRFa7jVyXzCZUV1ajvLScFFqrBeCszJqZnUWKnKnuOQCzaCvDRie6e+0oOmvAhSozli7yJbVqH0SEq6BW3fjiyEUKvRfKUb9jO9jJTUXP0Sn33Y/QnPlThtLF2JeDjnkZyopL6L0UPrydtBQ67tlIIqcFfn7nWK9sEgGJwMxFYKT4lHM2TBblAlL++z9w4ACeeuopWCgv+Ytf/AJf+tKXxE7yuPt///d/xefnnnsO8+bNE58nuh6r1YpsupYYjUasXbsWb731liCksuMKk2r37t2L2NhYMMmUFZ/5dybdNjc3i9jCb37zG0FSZRIrz8MKrkzC5X48/PDDYr3p6enity1btuDXv/616CfvZ1tbm5iHCbxLly7Fhx9+eFPFsJLIKoms4uS63n+SyHo9ZG78e9cQUNzkQk0X0NbvwvJUBebHKhAe4IJWrZjEkPnG25RzjB8BPdnNdDpN2E/VuR0OI9JIrSJdGYgMepE2D1QKmdAcP5pyTomARGCuISCJrHPtiM/e/eUAlY1ULjtPF6Hkt68iMCkZSXfejaDUVOgipWLk7D3yM2vPOMjBQYgLJeX46zvvi6r8zJwsodIQnxjvkTvD5EH9kJGCsg3CkrL6QgvW35GPNRvziFhBKjEzgZHpRmTN5OoxSEo6F2pt4sWEzvBQb6ws0CA8xBsaGj/OlDZeIivvo83mpHPbReQAO8wmBwXDHETSJiIrWbf2EYG1n156vYOC+l4ICVGRwpyOgm0+9NJRZblCKGGNBxdWLbIQxg2tDnx+0iwUjMKDvTA/nWyQYr3F+JyJsrJJBCQCEoGZiEAvkVjL7P2otg+inmyV79XGYwkVa3NhvYw+zsQjOrE+c8KIbfuGKNl+7tw5vPDCC2hsbMRtt90mVF5utLZPPvkE3/zmN8Vs69atE4ornFRjNdczZ86IIpEdO3ZgwYIFN1rVmNMlkXVMeOTEGYBARYUex4/1iCtrcJAKS5eFIiJCIxT+Z0D3J91FHouePVkjlFmH9eSKEBGAVRtyERUTQkVmnikIMuCyoo3ES45bu+i+qEeuMkTkfJKVAfAhQRPlBIo8OGbETj5dZ06j4/QpdJJyXuLm25G+9RFR/OxNtqruajymIa4B2tqtKK8kxwp6H6Yx1IZVAUhP1dKYkWi6ckjjrsMhtzOFCMxVIusIhKzM2t3djU+37URtdY2wk5+fNx9MaGWlO3Zhkm18CFAoUsR7jp3S40SRAZERVBwer0Fejg5+vuNTUjd2daGvsgKtBz9HT1kp5j/9DKJJiVDpo6NY5uTdsPh+yi9+Zu/u7MTJYydQVVFJsTATcnLnY9Ndd/ztePuOb2flXBIBiYBHI2Civ20uGuVxMDdWQtVqtWKMzeTRBx54AK+88solomcRPWOy+im3jz76CIsXLxafJ7oeXohVWZkMywRUvo/k5+eDi1w76dqj0WjA4/usrCyxfv5v+/bt+MY3viG+x8TECKVYPT3/HjlyRBBdCwsL8fHHH1+af4Rcyz8wKZYLYLmfTHw1GAxiGxxnyMnJubTMZD5IIqskso553kgi65jwjDnR5iA7E4sC55qcKKqj4DENImOCFFiXpQCN9yFzt2PCd8snOijsxKoV9VShW+EYwBmq0k3w8sN6bQwiFD6kXOG+IMQt31m5AYmAREAiMMUISCLrFAMqVzetCLgo8TtAVYL1n+6AiYJVNHpEygMPImrxkmntl9y4RGAEAQcFN3p7eslmqghv/flNFJLV2MOPP4zAoCCPDWjbSFmirbkXH759hAiENmTnxiMrNwFJqdFiXOSJCrIjeE/HextZ3p8ps6KxzYYhgwtL8tTITFEhNOgiiXUmJSTHQ2SlyyydF6Qg2GMRVq2trSaq2jbTeW4F1xMGkMJqeIQW4eFE5CWCQGCASiiussKQilQ02MqVMZmIpSmTqw1GSvx22lFcQXZzZRYsW6hFXqaalFm9oPORhYzTce7LbUoEJAI3jwArz31iaRa0nERvP8wnwk6C0k+SWG8e2hmxBlZKYZIpJ6VGWlJSkkhGBdGz4ngak1a/973vjTor39dZMYYT76O1zz//HOfPnx9t0hW/hYSEoLq6Go8++ugVSbMrZpJfJAIejMBAv42eW004dLhHFFzde28MkpN1lJBmdwwP7vgUdG2wfxjtrb3Yvf0M+slxo3B5OjLnxyM5LXoK1j71q2BlViu58lVRgQc78lXSK8zLB5u1cYiid3+FatwbdVBBqb6lGaV//AMsfX0Ip+ttVOFihOUtuEhocuPBt9up+HHIgdILRuw9OITkRA0W5vpSYZ4awUGz/zwc90GTM844BOY6kZULkrh4vaWpBeUlZdi3ey8CAgIwf0GuILNKZdaJndL8yMpE/9oGM4pLTSKGdOdtgYgmUqtGc+O4D1/37aRkWPX2W6j95GOk3P8gYlasJPGLJCKzTt5digllfKzPnCrCgb370E05CFZeXbdxA9IyMhAZHSVUENkVQTaJgERgdiDAxPUnn3wSTFIdaWoqgmIHlVdffZXi219wkbiIdMRthYmlTD4daRNZz8gyrMTKrirDJOIz0uLi4vCTn/wEd9xxx8hPl94PHTqE73znO6Kw4tKP9IEVY1988UVBTr38d1ZuffnllzEwMHD5z4K8yvuWnJx8xe+T+SKJrJLIOuZ5I4msY8IzromNPS5UdQDVFE+02FzIJlXWNBL4SgwjXQQKcrhxrDuu/s6lmZxEZh0iZdZGux7HrJ2wK1zwpZrcBapQpHoHQEd2MxQCmEuQyH2VCEgEJALjQkASWccFk5xpBiFgpoQEV1u3Hz2C1mNHkfnYE5i3dh3UVLHoToWNGQSZ7KobETBRAPXs6bMoJcupivJKrFizEvc9dJ9HBzibGrpQW9GG44fLERzqj413FiAyKggBQVJZYOTU4eC6lcaHbV1kf9lkE5b3WgqqR5ASa266CjGRpBZETmJsh+npjfeFCS422p//9/9eomrvYKosf4qSMU6q3GY1VAcs9NnGL5rHSt/NFv7shNnMqqycuGF1CsBX500kbSVCQ4nEGq4lJVY1EQS8xq2+OhZW3BezFSivseJ0qZWs5YDQYG8syNQQ7kRm1V4co4+1DjlNIiARkAh4CgJ0ycSA0yJIOrusLYhV+GIDFWeHe2kRoPgiIeIp/ZX9uDUIcHHQ/fffL5RebGR/PdIef/xx/OxnP6Pk/diErYaGBmExWFNTIxZlxRZOtLMCCzd/f3/89re/xZo1a8T3q/+TRNarEZHfZysC/FxrIvXLPXu6UFdnIFWlQKSn+yM+XjfrVVkdDieMwxYcPVBG1tdt9AxvF0TWpasy4eOjgUY79nVmus4JVixvJmXWU7ZuGCgHFOmtQ6Y3O/IFQSOUWW88zuonAn5PyXk0H9gPNV0PU0k9KzAxGT7h4W7dLR7H6A1OQWJtaDajh6yz87J1KFjgR0QohVBjdWuH5MYkAlOIwFwnsjKUHE9hNbvmxmYcPXQUne3tYKXWgsUFyCF11lgiH/n5+00h6rN7VUajE919Nnx+RI+BQQdyMn2QmqRBwrwbK4mL4i06Hg2ffYrGz3ZBExiE4IxMocatpcKsiTZen52e0Xt7e1F5oUK8qisrEU2qh6npaURWXkwF3BFXENomug05v0RAIuDZCPRR7vH06dNCkZWVVlmZdTJtouth8nx5eTl4zJ+bm4vExMQxN8tKsRwXqKioQFRUFDIzMzFWcazZbL6k9MpxhFRyuQyfwmdkSWSVRNYxT1hJZB0TnnFN5GSchSw/PiulgWYLwEqt+QkK3JmnEKqsXjceL49rO3KmySMwTIGMNqcRhyzt2GVpwd2aBKzSRIkKXZ2CsseySQQkAhIBicAVCEgi6xVwyC+zAAG2i3PSQK3ynbdw/jevUHLiQcxbvwHB6RkiWTELdlHuwgxGYKB/AG//+S1SZ2hGUkoy8gsL6PVFVa4n7trB3edx/mw9kRNtyMiOw213L6LKXc9McE4Xfmx5NqR34cAJE6ob2BYSWJ6vwdolWqiUNFacQSIMvC92IqUahx34zau/gq9vIAoXbSXFIFKYHbLTy4bBQSvtrx16/j5og4MWCgnRICZGQ1XafhRM80VcrA8CAsenknEzx21Q70RXrxM7DxrR3mXHppU+yExWIyrCm4jDN7NmuaxEQCIgEXAfAjZSm6txDKHc3k8uQz3IV4VhizZJlmO77xB41JYsFgvOnTuHTz/9VKi7cOdeeuklPPHEE9ftp5IqZtgmsKmpCWlpaeA8wOrVqwWZgm0EWa2Fk1icjDp58uQ1KizXXfEoE9hSkS0SpSLrKODIn2YMApznOXWqH+UXBqkwyyUUWdesCZ+SgitPB8FJZNb+PgNKz9Xj3dc/F04b92xZhsiYYAQFey65yuSyC2XWs+TGd8jWjhWqSNyumYcQLw3Gk/ep+fADtHy+n60gEJabh/QtD09LjIiLANs7bPhgez8VQzqxtMAPaSlaxMXIwhVP/9uR/bsxApLI+gVGdioUGDYOY8/O3Xj79bcQnxSP+URk3XTnZsTExZIwlgxYfIHW2J/4unnqrBE1dWahZr1gvg7rV/mPvdBlUweIzNV9vhgNu3dB7euL/O/+f/CfFz/hY8AFYsNktV16voRctt6AhYhfofRsfe8D9wsSKz+Py+N6GfDyo0RAIiAR+BsCksgqiaxj/jFwACs9PX3MoNeYK5ATBQI0zkdjrwu1pMp6vtkFnUaBpDAgi9RZ46mARz57Tu+JwnYzBqcd1WQzU2zvg5ECHDrSYl2uicQ8smVjuxk5PJjeYyS3LhGQCHgWApLI6lnHQ/bm5hEYqbbuOHUSjbs/g42ChrrwCKQ9tOVikIqSFrJJBKYDgUGyZ2FFhr++8z6pWdpw1/13i4r98Aj3KsCMd98NBhOGBozYs/006mvayXYyQ6j1JKawRZb8O2IcOQHO15yaJgeq6sk+rt0hiKspCUokxikRF0VkSoLKE5VYue9MSh0YsNLrC5KqngiqrKzKrbn5TVJ/80dc3D3imPO+eHszMVdB+zXyAs1DCqikvurvryTbPBX8/JTipVZ7iXnFym7Rf6z+ajS7UFxhRX2zTXyOj1Fi6QIN/EjRyIcUYGWTCEgEJAKejABdjkXsag8VYzc6DQiCGtnKYBSqPfP5wJOxnGl986IbKye8ubHCCr8ub5wI/8pXvoLPPvsMmzdvxmuvvSaeOy6fZ+QzE1iXLVsmvu7cuRMLyDL78sYk1g0bNoif/vrXv16a9/J5xvtZElnHi5Scz5MR4Gf4tjYz6uuHidzdh7AwNTZujERwsIqea2e3GAbvu9lMYiDNPTh1pBJ9vXpRtLh6Qy5yFiQSmVcJLw8c73HeZ9BpQ519COfsvbDAAbXLC8vUkUhRBcAHNPYaJfNjoXG4oa0V9ds/QU9ZKeZt2IiogkIEEenfW3NjRb+pOo95/MWtpNyIyhozunttCAtVYkm+L73TGMp3BlU/XtwV+b9E4BoEJJH1C0iY9MgK+w11DagouyDUO9lSOjM7SxBac3LnQ6mSxMcvELv+J7vDhY5OG6rrLDh1xoB5sWosX+z3t2vnjWM+VsJ9qLkJFW/8GZbBQaTe/wBCc3LgFxt3/Y1eNcVIlt59pMR6/MhR1FTXwEyqu/GJieDjmJicJJRY+dldElmvAk5+lQhIBCQChIAkskoi65h/CJLIOiY8E5pIz59oG3DhSDW991PijCwNV6YrsCBeAT8a+6rkmHNCeN6KmfvJkq3dacIBS5tQaF2kDiO7mSAkEplVTUENb8k4vhWwy3VKBCQCMxABSWSdgQdNdnlcCBja28AV17Uffwhzfz9yn/kGwubPh4os5GRQaVwQypmmGIGqiiqUl5RR0PMYgkND8JWvP02BznAi+nne4IGTbJzYrK5owbmiWgzrTXjw8VVIyYgViU35N3SRxGom9aZBg0NY21fU2qDlIkcisK5c5EMkyoukzyk+jSa9Ok5YOyj4z1aqTFRlO9WeHgtZolnR33+RzMqkVgPtj8XsIFtRPi8/IoLNRSIrk1N9/S6SVH2JtCq++14krGqJLKokMut0KaA6ad+6SZW1ptGGQ0Vm+Pt6YXGeRhCJI8MoEU+VjHL4N+lTRy4oEZAI3GIELC4H+iiG9YGlHr30vlEdixRvf2GbfIs3LVc/zQiw7WxGRoboxQcffIBFixZd06Nf/epX+MUvfkGq5zE4c+YMmBQxWnvvvffw3e9+V0xqbW29ZrzDhNnY2FhBqHj55ZexdevW0VYzrt8kkXVcMMmZZgACNlLDbG014+OPW8ltT0GqxiGIT9AhOnpyFqEzYJev6OKwwUxOId0oOlqFw/tLcNudBVi0LA0R0cHw0WmuuY5csfA0ful3WYjMqhcK5pWOAaxQRyHHOxhx3r7wUXxBZuXxD1000VddhY4Tx9FTWgLbsBHzv/oMwhcshJeKBE/cOEhgRcHhYScOH9ejgoisCXFqocSam6WjMbaUXpnGU0puegoRkETWa8HkQna2bN65bQfOFp0R153MnCysWb8WoWGh8PP3c+u16NoezoxfWGSsvtGCXfsGKE7lhfg4FbLTfQSpla/lN7qcW/V6XHj9NfRXVSEgKQlRi5cgevmKG2LP9txMSG5tbkZdTS0O7jsAvX4Iefn5F1226PndnfeSmXG0ZC8lAhIBicCVCEgiqySyXnlGXPVNElmvAuQmvvIYmIpW0UP2keebgWM1LswLVSAlQoGF8UDY+BXtb6IXctGxEGBbNgtV6ZaTKmulfRANDj1ivXyxQR2NMG9KLJMyq2wSAYmAREAiAEgiqzwLZisCdgoS2ihIVf7nP6G3vBxRS5YgalEhwjhh4YHEwdl6HOR+fYHAru2f4tD+g2Q7RQVWFLReuWYlKVh6HrHaSTbxrAh26mgldn54EnHxYUhOi8aCwlSEhQd4pDrPFyi755PIidJ/9S2E03kz+gedlCN1oTBXK4isIUFE7CTV0hsF0t3T24tboe7BQGqrra1GoTxVW2uA3e4SiqnBwWoEkpKqf8BFYiqrULGa6vvv/y+do0G4//4nRaKAlViVSlZkZQU5VmTFpd+J2jutwXsLKbP2DjhQVm1DMynjdvTYsbJAi4IcDXyo2JT7K5tEQCIgEfBEBFocw6h1DOEsqcuRJhPuVscjxlsHDZFxZJvdCLAia25uLrq7u/Ev//IvePbZZ6/YYZ7Ov3300UdYv3493njjjSumX/7l+PHjeOihh8RPR44cQRIl6C9vg6Q+lZWVJX765JNPUFBQcPnkCX2WRNYJwSVn9mAEmOjY328jkviAeEbmgq5ly0Lo7yPYo57jbxWEDmIFmY0WlBY34OThCnBxWGhYANbfvhBRsSHimf9Wbftm1st5HxPsqCBHvnLbALpcJgRChQ2aWHH/9P1b3sfJ5COjES0H9qHsT68hPDcP0UuXEok1H7rISCh4MOPG1txKWF8wobnNBguRWlct9UNKEuWpfC86XbixK3JTEoFbhoAksl4LLRchOel6297Wjpqqahw6cFAQW2PiYrFy9UosyF8grkeSDHktdpf/wnG4/kE7aurMqKw2o6bBgts3BCJ/Po2bNFRYfYNLOucJus6cRufpInTSe+yq1cj5ylcvYj/GwvohPR27Nhz+/CCKjp9AQlIiuWulE5F1ISKjo8iVKODybsrPEgGJgERAIjAKApLIKomso5wWX/wkiaxfYDEVn+iZiQs6UdMJnKqnoMcwKe7Qg9KiRCCZCK2hfmwhORVbkuu4GQS6XWQRZBvCCVsXmc0Q4ZgUWTOVQUjy8ofGi5RZR7GbuZntyWUlAhIBicBMQ0ASWWfaEZP9nQgCnLho2vMZBalOwzI0iPC8BUi5/0EotVp4kSqRbBIBdyDAygsGCnxu+2Abjh0+Sko3m1BQWIB5CfEUbCWGnYc147AZnW39OHOyBgf3FGPd5oUoWErKPFFBQpnHw7rr9u4wIdREVvZtnRRAb7IRcdKKkEAvzItSYn6GBpGhpAJ0gwC6OzttNNpJ+ceBri5WX7WIZP1F5VU72aZ6U9BdRVaqGoSEqBEUpBLfWW3Viwazv/jFf9DvIfj617/uzi5PelsmSgh39jjB6rinSy1IiFUiLVGFlHgVggOYgCsH6JMGVy4oEZAITDkCHFd00b/T1m6csvfAi36IU/phpYqsrb087/lgygGQKxQIsIoqq6mGh4fjnXfeQQ7ZnHJBESuovvXWW0Jllcl2P/7xj/GNb3xDLPOHP/wBNeQ8kZKSgq997WviN4PBIJZlxaiVK1fiT3/6E3x9fel+7kX3/n784z/+I7Zt24bAwEAwEVVL46HJNklknSxycjlPRIBdCjo6zCgrG0LRqX4sWRpMZNYwch/wFoVdntjnqe5TW0svaivbUHK2HvohI5avySEnjmjExIYSwcdzn587yY2vyWEQ91G9y4YUZQBSvQORRu8qeMGpNwgV1nZSY209fAjJ99yLhE2boQ0NhcqH7DPc1Gw2F/REkq4g4tVJssQOpOLBGBo75uf6IjyMVWHd1BG5GYmAGxCQRNbrg2y32UXx0rFDF63puzo6iQy5AAsLFpJFfQICgwKntTj4+j33nClWKmAe0jtQdM6AIycMyM/zRU6mD+Ji1PDVjR2Ic9HztbGrUxBZK978C0LpmTtt66Pwi4qCehQyqp2eqfv7B9BYX4/S8+fR2tJK90g9lq5YhhwqRONjdjPP056DquyJREAiIBG49QhIIqskso55lkki65jwTHoiK7MarcDOYhfKWp1IDFNgfhxZ0SQpoJb8iEnjOlULOikpwIGMKqrOLSZ1Via0sk3bWk00ghVqaBXyIE0V1nI9EgGJwMxEQBJZZ+Zxk70eJwKU9B3uaBeV1qV//ANCqGJ64Xe+C21QMJQ69yUuxtlbOdssRaC7qxt11bU4QPZTtVU1+OqzX0Ph0kJBUPBExYWujgEcP1iO5sZu9PfqsfneQrKYTBfERk/sr7tPG7vDRWRJB/YeM6Gz2yESj8vztcjPVgtLSFZi9aTW3m5CQ4MRRUX94M++vipSafNFdrY/oqK0RGhRCYInE1c5icok3JHj/B//MbOIrKzQwUTjpjY7zldYSTGX1I4o0XH3Oh1SE5TQkMqsTBR70tkp+yIRmNsIcLzKTheu7ZZG7La2ilhVgSoM0V46ilVJNda5cna0t7dj+fLlsFqt9ByhxsKFC8nWPBqc6KmoqBAw5OXlYceOHYKUyj888sgjOHz4sCCsvvvuu5egYvLq888/L76HhYVhKSkP9vT00DNAkSDH8oSXX34ZW7duvbTMZD5IIutkUJPLeCoC/PzosDtx5mw/kb07kJbmi7w8EsGg52V+Tp4LjcnzFosdn350EuXFjQgO8UfOwkSsXJ8Dlcpzcyd8HzW5yJGBcj6ltj6U2PuRpwrFXZp58CeNc3tjMzn0vA4TXQdZgTV+422IKlwsBjwj4x13HF9W+q2pJzXWChPOlRixYTUVrSz1h87Hm/D1rLGjO/CQ25jdCEgi69jH12EnMqWJ4jPHT+Hj9z8SxQKRRKS8b8v9SM/kuBvHLOR14Xoo8j2bC7wuVJlx6qyR4j0OhAQpsWaFPyLDb3zPdtL9rq+sFJwj8PbRIoyVuhcvRVBq6jWbHKYisdLzJThx9BgO7NmHgiWF2LjpNnKsIrcqes5mtzd5rK6BTf4gEZAISARGRUASWSWRddQTY+RHSWQdQWJq31mV1U7ZsgttQFWHC819QDDxIvITFIgLUSDMf2q3J9c2cQRscKLfaUENWbUVkdKFUuGFIC81ClXhiFXo4ONFikNSmXXiwMolJAISgVmBgCSyzorDKHdiDARsxmEMkGIRV1tTtEsEqTh5EZyRMcZScpJEYGoQ4ABreWk5dm3/FKyQFRwchI23U+AzNcXjAp5OGtMMG8yoq2rD7u2nofVRIzsvERnZcYiND5saQGbwWjhgziTWynobahvtaOmww48UH1jxMyHWG9ERbAjtmvbjyv1kq8qeHgsaG4eFEmt/v1WQVZnEGhamJtU3Uo6N1BKp1Rs+lEC9XptpRNaR/dAPu9DV60AxkVkbW22IjVQieZ4S2akqUswgyzmZFxqBSnArKOEAAEAASURBVL5LBCQC04jAoMuKFscwTtt6hD3yXdp5WEhEVh/yDpLuQdN4YKZh0+Xl5XjuuedQXV19xdaZzPDUU0/hhRdeuMK29LHHHsPBgwexdu1avPnmm5eW4WT6X/7yF/z85z+n+3/Xpd/5Q1BQEF588UVs2bJFEACumDjBL5LIOkHA5OwejwCP2RobjTh9uh9DQ3bhurd2bQTmxfuIYj6P34Ep6CCPBavKm1FZ1oKKsiaERwZh2ZpsRMeGELGVrAc9tDno2PWQMmuD04CzdD+103jMz6VEepsBweUNaP1sN3xCQpGw+XZBVPKLjnHbnvC4zGhyorXNiuOnDWKMFhSoRG62D1KTtGJ8JvlqbjscckNuQkASWccGmu83TiIVtLW04UJZuYgXdrRREUVGGrLmZyFv4QLofHWXipfGXtvcndrTa0czXVvPlRqhJ4XWlUv9kBSvQVAgOySNHfAxtLUKle4+KhgztLYg8/EvIWblKniTGwIF9ASo9bV1qKVcQjG5GBhI3Zufo+dTYdn8BbkIIHcDHx+fuQu+3HOJgERAIjAJBCSRVRJZxzxtJJF1THhueqKZLEJa+4EdpMw6ZALiQxXImwdkxiigotzgDZ6dbnr7cgU3RqDbaUatfYgs27rRaNdjgyYW85XBiPTygYrIrZLMemMM5RwSAYnA7ENAElln3zGVe3QtAsbOTjTt34e+ygoMk+pR6gMPIn7DRnhRkErB8oOySQRuAQIcnGZ1raNkG/bab/+I/MICrN2wFkkpyQgiQqunNTspQzTVdwkVnoN7S5A5fx62PrmGiH8qqDU3VjbwtP2Zyv5wEtJkdsJgdOHQKTOqGmwICvBGVooKrMbKQkWecCmx210iQcrE1fr6YZw7N4DhYQclSYGCgmCkp/sJAqualEnH02YqkXVk35jIWlJpQVuXA1HhSmxYpkVIoBepH41v/0fWI98lAhIBicBUI0C3FbJD1pNrUDf6HGaRNN2gjkG6MnCqNyXXN0MQYEXExsZGQWY1Go2Ii4tDSkoKQkJCJrwH/PzJ5Nja2lpBlkgllanMzMwpS7pLIuuED4lcYAYgwKqZXV1mIol3o75uGPfcG42cbCKr6FhxbQbswBR00Wa1o6mhC9vePQaz2YqU9Bjk5ichNTNWkKpuRA6agi5MehX9Lgsq2JHP2oNiUyfyj9Yg5XwTLE2tiClcgpynvgKlVuu2+A+PHx1EDm4holV1rRnHThkQF63G5g2BQj1QdwML7EkDIReUCEwzApLIOr4DwPFCfu3dtQdHPj8sLOuTUpNx5713ISo6Cn7+ftNeJD2+PZmeuQg6WImTsf2zflTXWZCRqkVGmg8yUrQiNjfWfZsFLzhPULftY1S89Rcs+NZ3kHz3vVD5+gq3DJPJhBNHjuL0qSJyqmpEQmIi7t+6BbH0bB4QGDA9Oyy3KhGQCEgEZjgCksgqiaxjnsKSyDomPDc9kQemwxYF6rtdqGgHSlqAbCrwvKjMCvhrb3oTcgU3iYCZrGaMVJfLVjMV9gEMOa2I8fbFGnU0Qr008FFQBlo2iYBEQCIwxxCQRNY5dsDn6O7ayLZpuK0dzfv3ovK9d5D24BYk3XEnfMLDodL5zlFU5G7fagRMREJoqG9E0YlT2L97HzbduVkEpVldga1jPamxAo/JaMEeUmKtrW6Hf4AOOXkJWLwyE0pvKveaw1V5BA3ZjZJCUYMdp8ssGCYyq5p4vXmZaiTEqBAapBBqOtN9PDlZ2tZmQnOziayIh2Aw2Em9TYXYWB/xCg5Wwd//b4qk4zyeM53IOjBESidEYj153gwDqbRGhHpjfjopDZMyq2wSAYmARGC6EGASq9XpQKmjDx+ZGxHr5Yt8skJOVgYgzEsGD6fruMjtjh8BSWQdP1ZyzpmDwEhB2KFD3SgpGaQCMH+kpvrSyw8azfUdDGbOHt64pzwm1A8aUXWhBRdKGlFW3IAVa3OwdHUWAoN9iQyvufFKpmkOK+V99C47Lgy24lxnHdRvb0NQXQfiVq9G7KIliMvNJ7U9940BbESw4kLIg8cMqK03ISxUKVRY52f5QKvx8ojx4zQdKrnZWY6AJLKO7wCzMiu/Ojs60VBbTwXwR9Df14/QsFAULluCZSuX0XWC1UVlEe5oiI4UC1RWU6F5nRn1jRYkkiLrprVUgKJVQKm8fgWK026Hw2JG42efofLdtxG5qBAR+QUIJcXV5q4enDp2HI0NDRRTM2BBQT6ysrNJkCAFOp0OKg4GyiYRkAhIBCQCE0ZAElklkXXMk0YSWceEZ0omMpnVbFOgrNWJzysU0KpciKQCnQUJXogLdkGnVsyZCt4pAfQWraSVrNtqSfnitK0LDtpGrjIEaaR6Eeelg5J0Wb3GKte6RX2Sq5UISAQkAtOFgCSyThfycrvuRMDFle52G5oP7EfZa39ESEYWBanyEbV4CXyjot3ZFbmtOYIAB6R7e3pxcN/nqKupI1VMAzZs2ojV69d4JAJDlLDs6hjAbiKy9vUMYdX6XKRmxCA2Pswj++uuTnFwfNjkQnuXHRV1dpwndc/YSG8kxamQm6FGcACRfK8fH7/l3eT+iYSz3o6+PiuamoxobTWhp9cCfz+VSLwnJelI1e2i7RlbDk+kzXQiqzh+RifOXrCirtmGrl6nILHmZ6lJUVcqs07kXJDzSgQkAlOHgM3lRBfZIJ+392GPpRWL1eHYpI6Fn0IFjWJukKWmDk25pulAQBJZpwN1uU13IXD+/CDKygaFq0FUlBarVoVRMZhyzhAP2aXDoDehuKhWFDnGJYQjPTuO3DriER4ZRDjw+GdiYwp3HTtihaGq6jyKzxyB/tgJOG02hD3+CBJzFiIjOBZqusd6kyvfrW48BunusaGpxUK21yYMkdrv8kKyvU5QIzJcPa3jx1u973L9EgFJZJ3YOcCxQ/3gEI4ePorykjJSAG1Gdm42Fi9fgnnx8QgOCZZk1utAytfagSG7ILEeOKyne7U3lhX6IjZKjZDgG4tWdZ0uQuO+PbAODcGhJqGrRYvRODCEIlJi9fHRkjJuNNZt3ID4pERyqiJFb0+9910HH/mzREAiIBHwJAQkkVUSWcc8HyWRdUx4pmTixSoqBQZMQPsAcKjKiSpSZ12bSYo98xSIDQbUY1QCTUkn5EpuiIANTqHGWkJJgwr7IOrtQ1iijgTbuPmSKqvaDQGNG3ZSziARkAhIBNyEgCSyuglouZnpR4AiXH1VVeg4cQw9ZaVUfW3B/Ge+jvDcPGHnOv0dlD2YTQjYqcK/ubEJf/jN78lS0EnBz3XIzMlCfEK8R+4mq+4UF9Whqb4TvmQlcdcDSxAdFwaVau4SajgozspMzR0OHDhuwoDeKZRYly3UIitVDQ2J6iq9pzeJ63C4YLE4UVk5hFOn+jEwYKUkhwIFBcFITvZFWJiGFKS86DhOLmE704ms/MfGGBnNLlyotWLfcTP8ycYznpR087NViIu6cXLDI/9gZackAhKBGY3AMCnGFdm6qcB6CP1OCwpV4ViljoKC7juysHpGH9o503lJZJ0zh3pO7mh/PxWHNRux+7NOocR6333RiIgggovP3Hhu5PwWF8q1tfSisqwZJWfr0d+jx32PLEdWbgJ8dBox3vC4k4P77XCgZucnOPf6H2FLnYfB7CQ0Ls5AZkwK7tIlItCL3ClusSMfjyEZv9PFwzh4VI8AIkHHRKtQuIDGZqTKOpZKoMdhKjskEZgEApLIOnHQHHTtMg4bUV5ajt07P4OeiJVarQb3PnQ/8vIX0HWD5JekMuuowHK8p4sKB44XDaOnzwZvioctWeSH+ZkXi7lHXehvP5p7ejDUROrjr7+G6tOn0RIXD2NAEBQqDdYSgXXJ8qXkVhVAzwJ835tcTG2s7ctpEgGJgERgLiEgiaySyDrm+S6JrGPCM6UTrXbAZAPONoLUWV3g9GZMELAoEQj1V5Ay65RuTq5sEggwmbWdlFmricR6zt5LBFYVokmRdb4yGPO8/aCk6iqqL57EmuUiEgGJgERgZiEgiawz63jJ3t4cApaBARhaW1Dz8Yfor6hA6oNbyEJoEXyjY+BFgUHZJAJThUBbSysqLlTi0207EBYehoce3YrIqEgKgvpP1SamZD02mwNmkxXHD5Xj2OdlmJcYgbSsOOQVJCMgUDcl25iJKyHuMaxkB1ndYCMlTzsaW+0IDvRCWqKK1FiVwqJ+OsUYhGqH3oHubrJQqx+mdwuGSIkiKEiF8HANUpjESu86nfKmFH9mA5GVzz9OJnf0OFBWTcrc7TZSRYIgsvLxDAv2JoKyHPfNxL9T2WeJwExEwE6xqB4ir+6wNGHQaUWqdwCyVSFI8fas54OZiK3ss/sQkERW92Ett+R+BKxWB3p6rNi7twt6vQ1paf708kNioq/7OzONWxw2mIVTx7GD5ai+0IrE1ChkkDJrzgJSpvNhVVHPen62DA5ioKYarUcOo/ngAYTccRtsyxaiLIrITKys5+2DHHLlS6b7LYuY3Kq8j2HYiebW/5+99wCP6zivhs92LBa99947QLCAXWyiRBWTVLElW5ZL7DiJk8+P/3yOe4rtx/ns2E8cJbb/2J9sybasalWKauwVJEj03ntv2/v3zjCgSQIkURe72BkJxJZ7586cubj3zjvnPceMhmYT/ynMVSMzXY1YIrP6qgURahVPaXFoFyEgiKyLA5rFeIYHh1FXU4sGIrR2tncgIzsT2bk5yC3Io/hcAClie2+i+Z1QNZALT2ePGU2tJtQ2GLChRIMSSh4I8JPxxO7b7WskwvDE4ADK//MZNJCDmzEyCiEFhUjbvI0SN/KQmJzEMXe3+93t+iM+FwgIBAQC7oyAILIKIusdz09BZL0jPCvy5SgtkHWMOHG02gm7U4I9OUBKBBAVKOEUSTeb768IBu5e6SCzc7OOodY2gS6bFg+qE1EsD0MAEVtp2dftgjLujqdon0BAIOB5CAgiq+eNmWjxEhGg4GDdb59FDwWpQvPyEFlSipiyMsjV3kvaWyKiYvdbEGAB6ItnL6DySiUp2fTx4PPhxw+Teo37nWNsgXJoYAIn36/C2RO1eOypndi0PRcaPxW3jbyla17xlo2fyeLElNaJD88a0NVvR2iQDIVZSmwqUnEMVnMex0i2NpsD3d2Ga0qs5RNccTUzyx8FBUFIS9PwOcxytHGtEFnZoDGlDpPZiZPlJpy9akZqvBwZyQoUZKrgr2HzPq84vUUnBQICgVVGQAdSbLfr8KKhDQqi0XzcNw1REh9oSCVOFIGApyAgiKyeMlKinYtFQK+3obJyEu3tOnI8sHG3g7KykGV7xl5su1Zjv6vlLaiqaENX+zBiE8Lw0KObERzq71bOHU6aIE22t6Pz6BFoSV3PSsqGWU88Cc3mDbTuM07rPuNgznx7lLHYRgrobN1HRcqsy/34z+Zpvf0WnC3XYnzczpPp7tkeMC9lwNUYW3FMgcBKICCIrItHlcWi2M/ZU2dw4sPjGB0ZQxQlxH/ssUPc3clX4yvWq+eAl2FGpli4XKnH60cmkJOhRn6OGilJPggMoLSFW4I9bHsHXbAnxscx1NePi8/+Gl1nTiM4JBj5992P7V/6a8h9fGbtN8ehxUcCAYGAQEAgME8EBJFVEFnveKoIIusd4VmRL02k4jNpAKp6gK5RYIpe58cDZWkSqClGrRTCXyuC+0IqNThsmHCaUUdEVkZmVUlkiJH4YpMyAmFSHygoQ1cUgYBAQCCwlhEQRNa1PLqib7dDYKjiMoYuX8ZobQ38yeo951OfhjokFFKFIBHcDjPx+fwQYJZgNoqgvvyHl3Dl0hVuA1ZQlI/8ogJa7HOv84sFb7vaBnH6WA1Zlxkhk8uwbVc+0rNi+WtmUe9thSCBzQ5uQ1/bbCUyqx1qlQR5mUrER5MSa4iMgtmrgwprGxuz/n4TX1Tv7DSQCqsVYWEqxMaoEZ/gi+BgBQICFMvWxrVEZGX4MTJr94CdK+22dlshl5HtXMG1sWXKrKIIBAQCAoGVRqDBNokG+yS6bTpEUsxpnyqeWx2TYehKH1rULxBYNgQEkXXZoBQVuSkCNpsTQ0NGNDZqcfbcGHJzA7F1SygCA8ma3se7nhnHRqbR0zmMcyfrYTJZkEnuHdn5iUjJiHaL0XMyS+6RYQxXXkXTyy/BPyYWcdt3IDQnB8rYGEyQCnqzbQqVJGTC5nGBEiXKlJGII2e+5SSzsnlG/6AFre1mVFTpERGuQGGuL+JilQgJWppLhlsALRohEJgnAoLIOk+gbrMZi/kMDw2TImsnLl24SInnQwgll6eikiKUbdsMObmJCWXWm8FjmLF4T0+fBTX1RgwOW/n7nVv8kZSgIsxuTlw2GAwYGxnFFVoXuHj2HEIlTgTopgFS9U4loYuNX/5fUAUGcjLrzUcS7wQCAgGBgEBgsQgIIqsgst7x3BFE1jvCs2JfsoXQgSmgro8yqVqAuGAnihMlSAwFwvzJvp4m0Ku1GLpinfbAitvt02iwTqKeyKw0IhTQiEAyWc1EyyjLjf/ngZ0STRYICAQEAvNAQBBZ5wGS2GTNIWAcG8NkczNqn3sWcpUKWZ94AkEpaVCHh6+5vooOuRYB7bQWY6OjeImIrG0tbfj4Jz/Oyawss18qdR+SisPugE5rRG1lB46+eRmx8aEo2ZiB5PRosqQPcC1obnI0cp+HnizJxiacqGykRDeyoY+NkCItUYnCbCVX7VytpjIFVpPJQco+ZjACa1OTFgaDHRpfOdaVBiPhf0isy00+XktE1pmxM5qcmJhy4PhFWuAYtSOBCMppiXJkpyppgQOc3DqzrfgtEBAICASWCwEHSCnI6cAJywAn08TINEiTBaCQbI7VUpHlvlw4i3pcg4AgsroGZ3GU1UPgWgKUg565dXjnyACREilmkBWA1FQNwum1NxVGEJompZYzx2vRSUmQRoMZRevTsGFzJjmOqKBYRaUWpsRqMxl5kvLwlQqwhOWYzVuQ/eSnICM1PZlSyYeq327gZNY6+wRGHSasV4QjSx6EGKkaSshofW5pmYqM+MzmkVW1BnR0mTE+ZScVVh9s3xxAcwsQ6Wxp9XvT+Sb66vkICCLr0seQXXdNJhMunDmPyoqr6OroooTzDOzcvRNRMdFcOZSpjN6qNLr0I3t2DTo9xcwmrDh5TovObgtdg/2QlaZGaKicx3mYCqtep8fQ4CAa6xtQV13Nf2/etAHJfr6Y/vB9hMTFIePQowhMSYEmKsqzARGtFwgIBAQCboSAILIKIusdT0dBZL0jPCv2Ja2HwkzKrAOTQHUPKcCMSTCmB+7NAwpIndWHhJlkXqh2tGKAL7Jik9OOKacF5dYRtFGWroHeF8iDsVsVy+3e5EKZdZHIit0EAgIBd0dAEFndfYRE+1YCAYfVCt3gAFpeeRl6+q2JjELs1q2I2rBpJQ4n6vQiBFqbW1FRfhkdbR1cPfPQ44eQmpYGucK9SCpGowVNtd2or+5CY20PijemYc/9JaQwpFzVxcjVOlXYYjVbgOzos+PMZSNYANxHJcW6PBUnOWp8JatGcHQSw9ZIJNaebgPOXyAS/qQVDiJDFRYGIy3VDyEhSho3KSn+Lj9Rei0SWR2Ep8VKjin9djS2W3C1zkxjrMD29SqEBsuhUYuF5tX6OxTHFQisZQRM5Aakgw1vm7pRRapwD6kTkU8k1mCpiig04rqzlsd+LfZNEFnX4qiKPt2KAJsfDA2ZUF09RY4IRu6EsHdvJCe0LpH3eOuh3P691WrH2PAUT4J8/+3LSM2IwbqyTKSkRSMkzH/V2m+3WGCeGEfN//0Vpjo6EFlUgsjSUkSUrINURgzS/xkoC82djE4bqmzjXMRkzG5Egtwfe1Vx/D6sWqIq+tS0HQNDVpw4M02EVjs2rPNHcoISsdHXiLTedr6s2gkhDuwWCAgi6/IMAyNdTk9N8QT54x8cw8T4BE+Ov+/B+7FuYyl3fHKnZPnl6fXSamHK2FaK612s0KOu0QhftRSpSSqUFmmgptdWWgtobmwk96wKnD11GhGRkSjduB6ZmZkIgAN9778H8/g45Go1EvfspTWCjUtrkNhbICAQEAgIBK4jIIisgsh6/WSY64Ugss6Fius+05mBQU5mBWp6nUiLAFIjnMiOlcHfx8mVWV3XGnGkuRCwUlCjw65FE1m91ZPVWxBZzWRSdi5TyWDKrFKhzDoXbOIzgYBAwMMREERWDx9A0fxFI2DRajF4qRwjZEE3UlONpL37kPLAQzcpdyy6crGj1yHAgsw2m41sqS7g9Vf+hPjEBKRnpGM9ZfZHRNGDvxsVi9mKiTEdTnxQhYG+cVJz8ENBSQop66R6paIDW6Q2EFG0i0isbWQ339JpRVgIKbHS4iNT6owIXT37UKPRBq3Who52A3p6DRgeNkPjJ0N0tBoZ6X6IiVFzAutKLY6uRSIr+1NkZFa9EejoteJipZnbzoUGSZGfqURCjAxKBTmniGRTN7pqiaYIBDwfgSGH8VqsyTqBSUqifkCVwONNLGla0Fg9f3y9rQeCyOptI+69/dXrbRgesaDi8jjq6qaxc2c48nIDERik4FbF3oIMUwe0k+1gR9sQzhyrIUU7E09+LNuew0mtarWSiKPLn1R3N3yn2tsw1lCPnuPXFoZTHz6IkIxM+BI5aa7SY9ehndZ+aojQ6qANkqR+yJAHIoXWfuQ0oVroHZlCABQDIOXeVhMamk2kBGhDUKAMZRv8EBGmgJqSDUURCHgbAoLIunwjzq6942NE1q+sRl1NHZoampBfmI/cglxk5WTTvSiQFJ9XL161fD1d3po6uixobjOipd2EYLomb93kBwdd98dGelFbVY2+3j7YiNSalZODjZvLEBoWBhVxA0aqqzB4+RIGyy8i4/CjSLx3Pye1Spl1jygCAYGAQEAgsCQEBJFVEFnveAIJIusd4XHJl2yRtGEAuNLpRPswoCEnmoOlUsQFO7GKLiwu6bsnHaTfYcAp8wAntY45TXhIlYQNirBlsZrxJBxEWwUCAgHvQEAQWb1jnEUvZyPgtNthNRjQ/eEHqPjpvyGBsq2zPvEktw5S+q+eqsjslopPPAEBm9UGg9GAd15/G7/8j5/j6b/4DO576H4EBQdDpXIv+0ntFJ33nSN4+fkTHNpHP7UD8UkRCAj09QSol72NTIl1bNKBd08a0DdkR4CfFBsKVFhPP4wgulIk0fl0ZGTEjK4uPY4fHyEFDgtycgOQnx9IP0EuadtaJbLOYD+tYwRmGy7VWnCpyoyHdquxsUgFfw0p3MoFtWwGJ/FbICAQWDoCtbYJvG/uhS/pr8bINCglW+MYSpgWRSDgiQgIIqsnjppo82IQYGs5jEh06uQoPY8PIycnAFnZ/khP94evr/eRhxiBdWx0Gu+/dRlnj9fiocc2Y8PmLIRHBkKpIttBF5eOo0fQefRdyBQKBKdnIu3gIajDw+/YCq3TikvkyFdLiSVN1kns9InBvaTMqqb7s2KBjnwWKym9mpz48MQ0zl7UYjMRWAtyfREfqxQk1juOgvhyLSMgiKzLP7p2il+Xny/H0bff5cqswcFB+PinPk6JBOlQKq8pPy//UT23RitdmwdHrHj1rQlSYXXya/NI31W0NpxDfU0tAogA/PiTTyAjK5OTWFlP2RqBhdYIOt5+E5d+9K/I+eRTSD/8CHwjIojMKuZsnns2iJYLBAQC7oKAILIKIusdz0VBZL0jPC77ckIPDEwBlzsow0crQXQgkBUDFMYz1RdaKHVZS8SBboeA3mEFI7PW00JDtXWcq7EmyvxQqAhFmNRnwdm5tzuO+FwgIBAQCLgDAoLI6g6jINqwKgjQgpSdMrBHKeO69fU/cSVK3+hosg/ah+CMjFVpkjio5yLAbL6YSkJtVQ1qq2vxsUcPYtvObbSgR5bBbqaQcPVSK6oq2jBFE5Oo6GDs3FeE4FC/VVl8XM0RZwvTTEWnoc1CFvNWDI/Zua18broScVFyRIWv3uK0jlRYBwZNaGnWor1DD42GlGEjfJCU7IuoSB+EhrpmsWKtE1kttKih0ztRT+dAVYMFPioJosLkKMlVIDxE5lVKW6v5tyiOLRBYywjYSPNN57Dhim0U75i7sU4ehg3KCERLfaGRCHWftTz2a7lvgsi6lkdX9G0uBFpadFyRlbkjBPjLsPOeCISHs3med63kWCl502K28blk5aU2rtIaHR+KrffkERkogKu0zoXfcn9mmZ6Gtq8XXR+8j4EL55Gwaw9ZQG8gMmv6XQlHzJGPqaS3kTJrpXUUclqNC5WqsI4STBJo/YeRWeejzMocHvoHraiqNWJ41AqT2YH1xRqkp/jQ3E0KuZedG8s9xqI+z0VAEFmXf+xYQsXQ4BA62ztRcfES+vv6ERcfR8qseSjdtJ4nz7tb3HH5UZh/jSzWN00xtUtXtOjoNmJy0gztaDlM01eQnEKuGFkZyMnLQ1BIMHx8fK5VTDs5yGWrn+4pzS+9CDWptAalpSFux074x8XP/+BiS4GAQEAgIBCYEwFBZF0jRFYJSb6wB5PlLoLIutyILr4+q50RWYG6PprwTjiRHiXBPdkS+Ps4SaXVuwIgi0dxZfdkf4FNtkmUU4buoN1AObkS7FBGI1URAMoxhnQ1pZlWtuuidoGAQMDLEBBEVi8bcNHdWQjo+vswUlVJCyAXMN3ViZynnkZMWRlkKh9IWJaRKAKBuyDA1BG6O7tw5I13oNPpSIU1CFt3bkdufu5d9nTt12zh0Wyy4sMjV1BxoRnZ+YnIzkug3wnwITtIbypsum0wOTCldeBiFRFZ26xk/yhDeqIcpXkqUtCRrIoSq93uhIna1d9vRHOTFp2kxjo+ZsXGTSGkAOXPyaxKpeuuS2udyDpzzjMl3tYuK2qaLHwRescGNVLiFQgJomVsMT2fgUn8FggIBBaBgMFpQzdZGVfZxnDGPIj7fRKwWxlDxBkiyogLzCIQFbu4AwKCyOoOoyDa4EoEpqasGBoy48MPhmA02rH/vigkJPjC3987ExIG+sbQ0TKI08dryJ7Zjr0H1iElPRphEaTYsoKFr5lSJuJUZyfFb85htLYG+sFB5H3mc4jZVAYpKbPO9+F9gNZ7akjEhK3/DDj02EbrPnnyYIRL1VDehczK5mx6gxMNzQacOKNFWKgcqck+yM7wQWS465VpVxByUbVAYMEICCLrgiGb1w7s+ueg69/JYydw5dIV9HX30nU3BXvvuxfRMVHksBTIBRrmVdka34jhZDBQnK9xEFerp3H+shkOUz2CNR04/Oh9KFmXRzFQNQmLzY6tTba1YvDSJYzR/cVq0COblFnD8vL5/YVxd0QRCAgEBAICgcUhIIisHkxkZdkyr7/+OsrLy2nRqh8hISHYuHEjDh48uGwKPoLIurg/rJXYixI2MWkAOkecONcK2IjYGubvxIYUKZFahSrrSmC+mDr1sGHcbsIFyzDa7dPwlyqRTQGNTfJwqKSyeWXnLua4Yh+BgEBAIOBKBASR1ZVoi2O5IwI2oxFM0aP5tVe4okfy/QeIyLoZQSmppOahdscmiza5EQIsmKzT6lBfW4/fP/scomKi8dChhxETF4uQ0BA3aikwOjyFjtZBUnBoRn/PGPY/tB65hUnwD6AArmx2ANetGr+MjWEkVjspsbb3WHGx0gxmLy8nG/l1uUokx8sR6L86CjrsXDIa7KirnwZTferuNiAuTo2sTH/ExPpSjEBBtnFEfJK6LnjuLURWk9kJrd6B8mozOnttUND5kJmiQFmRCgrF6pCal/GUF1UJBAQCq4jAqMOEE5YBjNBvBSVIryfFt3xFCHdjoqvLKrZMHFogsHgEBJF18diJPT0TAZuN5nw6G44fH8EAJZzFE4k1I8MPmfSc7o3FZLJwd4+zJ+rQ1T4EpUKG/JIUbNuVzxe2Vorsw62f9Xquwlr/3G8QmJSMaFpDDS8qhl9s3IISkU1OO3ROK2qJzFpjG4fZYeeufDuJ0BouIzIrrfzcrugNDlTXGdDaYcLgkBX5OWqUFvvBn5RYVarb73e7+sTnAoG1hIAgsq7caLKY0djoGCmzduDUsZNgzlAaPw2279qB9Zs2cC7JXOTMlWuRe9ZspDj/4MAgjr79ASUcaKGzZiA42A8J8X7YuysJGenBHKu57lUWnRamsTE0/P53GLpSgVwSu4havwG+ERGQuJnblnuiL1olEBAICATmRkAQWT2UyMpUew4dOoTa2tpZI5uVlYVXX32VbrLBs75b6AeCyLpQxFZ2e7aAOqYDrnY50TnqxMAkUJoM5MVJEU6kVrVSBLRXdgTmV7ud7GZYdm4jZed2kYpGmNQHxYpQxEk1PKghRml+OIqtBAICAfdFQBBZ3XdsRMtcgwALBJIdArreP4rO99+DMiAQwZmZSNp7L3wouUyosrpmHDz1KDaynmpraUX11SqcOXmGq7B+4qknuT2VQukeaizM9tBOmXOtTf04c6wGFouNk1fZQmNSWpRXqTbQXzuMJnLFIAXO5k4LV+CMDJUhKU6O3HQVwoJdr8B57RLkxMiImSzijGhq1pH1mYUWhKXIzg5Abl4gnU9STmJ19d+JtxBZGa7s76S500bKrDY0d1gQHiLFOlLnjQ6XIzhQLEi7+twTxxMIrAUEmBprD6m8vWPshpwUfNZTUnSy3B9RMt+10D3RBy9GQBBZvXjwvbjrFgutEVRPorVNj7ExCxFZ/bF1ayglPUmJEON9KwRWmlM21feiqa4H9dWdSEqNxJadeQiPDIJ/4Mrc56x6Hamw1mKo4jL6Tp9C3PYdSHngQfiE0jj4ahZ1dnbZtGghAZN6Wv+xwYkceRDS5IFIkvmRQx/NDW+pVUdJkIPDVlyoIHIUvQ4PUyA3U43MdHL0uXXjW/YVbwUC3oCAILKu7CizGPbU5CQqyisoob4Orc2tKCgqRMn6EiSlJCMwKHBOpdGVbZV71G61WGE2mylG24KmhkY01NfDYtUgMmELbM5wSOjavr3MH1kZvuTCxJLEZ7fbSWquDorzNr7we/SeOonwgkJEFJdwMqsQu5iNl/hEICAQEAjMFwFBZPVAIqtcLscDDzzAlViVSiW++MUvoqioCNXV1XjmmWfAbCofffRR/OxnP6P1dbbstvgiiKyLx26l9rSRDYnZJsGlDuDdKieigpxICZegLE2CiICVOqqod6EImClDd8BhwAemPgw7jFCQvcwOys5dr6SHX/7fQmsU2wsEBAICAfdBQBBZ3WcsREtWF4GpjnaM1dWi9c03IPdRo+Rv/xcCEhOv2dOtbtPE0d0YARYkPfrWu6irqSWioRLFpSW4Z+8uTg6dK7t/NbpiJ/lRvY5cBk434JXnT2Djtmzcs68IkTEhpN7gsxpNWrVj2omsODxqx7ELZgyO2MjWGSgr9kFhtpKIoxJahHZ90zjRmOaFFy6M4+rVCbJAs3Ml1u3bwhAW7gO1+lqjVmNh1JuIrGzkrTYQydmGY+dNmNTa4e8rxaZiFfIylK4/McQRBQICAY9GwElkmEGKHzHL4g/NfTwZ+uPqNGgkch5T8ujOicZ7PQKCyOr1p4BXAsCW5qanrWhs0OKtt/uRluaPAw9Ewc9PToSYVZhErPIosLVKRmZtax7AkT9doHVMJ7mShGITzTXTsmJXpHWGwUHUPf8baHt6SB0vkhNZY7dsvZZ8vMjJkp3u13pSZi23jqDeOoF+WgMqJfX0/ap4qIjIytaBbixtnWY0tRhRXW9EaIgc9+8JRGiwnCce3rideC0Q8FYEBJF15UfeQWRLFousvHwVR958ByZSIA0OCcbDjxxEVm42J7K6Szxy5dH48xG001qMjo7gjVdeQ/mFC8jMykZB8TqUlm3HxSsOXLhswI7NAVxFOzpScVsFbXZ/Gyy/QD/lmGhuRnB6OnKf/iwJXwjSxp/RFq8EAgIBgcDCEBBEVg8ksp44cQJPPPEEf7D4wx/+gO3bt18f9V/96lf4zne+QzaHcnR1dS1ZKUcQWa9D6zYvWACE0ZO7SZG1vh/oot9GK1NmlRKh1YnoIEDmQutItwHGzRrCxohZzbTayObTPoVG6yRX0ciQBSJdQaptEqWgs7rZmInmCAQEAvNHQBBZ54+V2HJtI2CenoaurxeNf3wBpvExJNyzG2H5BTxgtbZ7Lnq3WASYXRWz8nr5Dy+ht7uH23nl5uciOTVlyXO3xbZprv2000bUXGlHS2MfOtsGsXlHLl9gVPuqICcbSG8ofN5FD/WtXVa00A+zj1f7kH18soKrscZEyF2uoMPaxEjG/QMmtJAKax+psWq1ViSQVWlSkgapqX48sL6aCk/eRmRlY6LTO/g50tpN6qydVk5izUlTIiZCBl+1kFnyhuuF6KNAYDkQcFC074JlGA32SRhJmTVNGoCdqhioJLJZ6m7LcTxRh0DAlQgIIqsr0RbHchcE2HOixWJHb48Jx44PcxXWuDg1OSj4Iz5+ZRRI3aXvt2sHI/uMj2rRUNOF5oZedLUNYfPOXOQXJyMkPIDIncuXDKbt6cZ4QwM6jh7hycaJ5KATQm6W/nHxt2vevD+3kiMfI7C20dpPjX0cCiKwRpN6ep48BInkyicnMqvFTIRXgwOXrujQ0m7m5NXkRBUKcm+v7DfvBogNBQJrCAFBZHXNYLLr70D/AF17m1BTWU33pl5k5WQjJy8H+UUFUPuq3SouuZKoWCwWuheNUaJJAynVXiJirwlKlZJwKERqWjriEhJR32xFdZ2RGbIhMlyGTaX+CA6Sz6nKytqqH+jHGNXX+tqrUPj7IfuJT8I/PgGqICJtiCIQEAgIBAQCC0ZAEFk9kMj6+c9/HkeOHMHevXvx29/+9qZBn6bF9G9961v8YeN73/se/P39b/p+oW8EkXWhiLlue3L6JGVWJ45UATW9TsSFSJAVDZQkSaAmR1LZzYmfrmuYONJ1BOj5Fg56yq0jm5mPSE3DAgf8pAquzJpCVjM+pKox22zm+u7ihUBAICAQcFsEBJHVbYdGNGwVELDoyFaOglQTjQ2QyhWI2bwZbIFEwvyGFqnwsQrdEId0EQLDg8PoaO/Am6++DqPBiL/4my9SkDSVB0xd1IS7HsZGE42BvnG8+3o5tFMGxCeFo3BdKjJzl77gd9eDu9EGZgslDJqcOH3ZhMY2C7cRy0pRYGupD1dinctSbCWbz1RYrTYHtNM2NJCq09mzo6S8Kkd0lAqbykIRG+tDi+OrPwn0NiIrG3O2sMGUWSsbzPjgLCmbBEiREKNAYRaNT7ickxbE7WAl/zpE3QIBz0fAToQYK8WMXjd1oYmSoYvlocgiq+JUWQBk4gLi+QMsekAK8lfxxhtv4PHHHycSX7ZARCDgVQiMj1tQUzNFwjMGDA2asGt3BAoLA/mzuzde4llintlkxZljNXjrlfPIK0pCbmESsvMTSSHQD9IlzmmYzTP76TtzGgMXzmOaBH+CMzKQR+p4nFC0jKAzJ77LllE00727267DXlUsSuRhCCBqq27Sib4BKy5W6DA4ZMX+3UHISveBvx+zpxbJbl51ERCdvSMCgsh6R3iW9UtGZmXXx4/e/wjnTp2l+JKWEuuTceDhBxARFQlfzdpPsmAk1kkSGGhubMSli+U4ffwEyrZtxRYSjcsmddrgkBCO+ciYDd09Zpy5qOXiYvfvCUJstBIacuGZqzBcmdhF5X89A/PUNIld7EJYQSFCMjPn2lx8JhAQCAgEBAJ3QUAQWT2MyCoj30IW7BkfH8dvfvMb7N+/n6uvTkxMIDAwkA+3zUYrKMtUBJF1mYBcgWpoHZNIkkDHCNAy6EQ1kVkDSe1lYwoQHypB+NI4zCvQYu+skpFZJx1mDFBQ44plBB12LZLk/mDKrAWKEKiJzCqKQEAgIBDwNAQEkdXTRky0dyURsLMAWEszBi+Vo/P99xC9YSNyPvVpKDQayHy8y4J9JXFeK3VXlF/GqeOnSJnHgsjICOw7sB9R0VHcbcNd+tjfO4ZWUmI9c6wWwaF+2HVfCaJjQhAQtPYD2jNjwIiJHaTAWtVoweAomUfSxKs4R4WkWBkiQpkCg9PlShVmsx3DI2ZUXJ7E0JCJW3FmpPshnX7CI3yI1EqKfW6wHuqtRFZ2zoyM29HVb0NdixXDtOixqcgH6UkKOmekkMvcYHBmTnDxWyAgEHA7BCYddL8hZbfj5n6MOkw44JOANHkA/Lmbj9s1VzRIILBgBASRdcGQiR3WEAImk51cOSy4cmUSJ04O4557IlBSEozgYGZT7B1uFzcOJ3tuttvt6O4YRmNtN1pImZWRW3fTvDM5LRr+gUtTBbQa9LBMTaH55ZcwcPECYrdtR+S6UoTl5UOuVt/YlCW/NjlpbJ1mNNgmUWkdIyVWCcKgRqkzAuMtEpw7r0NQICW3kZtHXrYakREKKOQkbSKmBkvGXlSwdhAQRFbXjiUjsw4NDKKtpQ1nT53hZNa4hDis21CKkvXreKxLskYvUg4im7a1tKK+phaXLlyATC4ncYE0ZOXmIIV+BwQGQKm8pgxuMjswNe3AqXPTFIuzIj5WhYxUFbIy5r6PMFzNk5Po/uhDUmath2l0FEn33ovk+w4IoQvXnuLiaAIBgcAaQUAQWT2MyDo0NITi4mJ++r333nv4xS9+gTNnzmBkZIQWrmiCVFqK73znuwgKy8a0bmmEVvac8sfnvk8S6mnYf+DjUMolXHlGqZAQeRY04ZKICZcbXAiMFmCAsjuPNzgxZQRC/STIjQWyYiRQyZ1QiAWzVR8lRmZl6hqXrCOoooCGHjZESNVYrwhHlNQXQdLls8xZ9c6KBggEBAJegYAgsnrFMItOzhMBlnFt1esxdKUC9c/+Gn5kU5ewZy8pfmTCLyZmnrWIzdY6AjaSazSZTPjovQ/x7ltHsG5jKQqLCynbPwf+Ae6RgcYUP1lQ99K5Jm71ODmuQ3J6NPY9UEoWYyqvUY0xkQXk2IQdDe1WXKkzI4Ssw2IjpFiXp0JYsOvVc+x2UmK1kqJQnwmdXXo01E9DoZAiMdEX2VkB/Lc7eU57I5F15vplJccUM50/pytMqG+1IjRIirQEBXIzlPDzlfAYysy24rdAQCAgELgRgTb7NK5SvGiIkqCZPfF9qjjEyTR0eRdMlxtxEq89FwFBZPXcsRMtXzoCbJ5FSwOoICLrB+8PIjHJF2mpfsjKDkBQEFnreWnR6YyYmtDhw3euorNtEHmkyspcQDJy4iBXsOTBRdwDiUg03d2F0epq9J0/C+PwMLKf/BQiS9aR1bP/NeecFcC7i9RYG8iVr9k2Ba3BjuyxCOhbZWiqsaC0SIOiXF+Eh8lJyc/7iMsrALeoco0hIIisrh9QFvubJtXQ05Ro31BXj5HhERSWFGFD2UaebM8InWupMJIpczQeIY5N1dVKtDQ1Y5yIpqnp6dixexeiYqLpfhw0q8tmIrNW1xvR1mECU2jNJCLrlk1EdiWejIJ+bi02I93XOjswSGrgbW+/RY5t+5Bx+FEo6f4jxC5uRUu8FwgIBAQCd0ZAEFk9jMja0NCA3bt381FNSEhAd3c3fy0nZumMEivLlHmW1Fovtaynhcg5TgCyuXDoz8zxxc0fMSKrw9wCH78UpOUf5vZ4zCIvJFCGoAAZAvywuMnkzYcR75aIAFNlNZLt5cCUBJVdwMlGB0qTgc3pUkTTc5efaokHELsvCwKMzKpzWtHn0OMYKWyMkcJGvFSDEmUYCsgyThSBgEBAIOBJCAgiqyeNlmirKxBgZNap9nZ0vX8U+oEB2K0WpB96BFGkziqKQIAhoNOSnSCdGx+8+wEnsz79hc9g+64d8PX15Q4b7oCS1WonEp4Vr/6OAtk1XSjbnkM2j8lITI2kNnrPghtTYC2vMqNnwIYJUl/Yvt4H+ZmrR0Q0Gm3Qau04cWIEra06UvJVcRXWgoIg+KqlULqZipM3E1lpbQTsp2/IjrYeKy5cNXMC6+7NasREyhFISaeiCAQEAgKBWxFg8aKzlkG8YepEDjn35MjJelgWhECR9HwrVOK9ByMgiKwePHii6cuCAHtG7OkxoKFhGl2dBq54d+/+CMTH+/LXy3IQD6vEQSqsNpsdtZWdqK/uQgu5gqRmROOhxzZDo/GBQrkwJztumU1Krz0nT6D+uWfhT0nGoTm5iNmyFQHxCZCQ2+VKFSscMDhtuGAeRs3gNPrPSKHR+yAx0BfrC/yQna4mhwaxnrpS+It6PRsBQWRdnfGz0/WXkTurr1bhyJvvgDkCx8bHYfe+3cjMyVoz9yZ+b6CbcE1VNSnQnkJrUwtP4t93/30kLpCN6NhYIqUqeP9vHQmWiKLVOdDYYsTRj6ZIlVWJHZsDeGJCgP/sewpbH7Cbzeg/dxZVv/w5QnPzkLBrN0Iys+AbEXFr9eK9QEAgIBAQCNwBAUFk9TAi6/nz53H48OHrQ/qVr3wFhx/7Apo6ZdDIWvG//7+/5OTWkJAQvPv+eZy6PHuhxGwYQnfj89fruNsLTWAK4tIPQUrMVomUFNBpB5ZtoiEb++BAKUJJlSaUVGrU5JwqoyxJRoAVxbUI0JwfBlJmbRl0orydCMgUGPGn8ShNliCBOJJqhVOQjl07JHMezQEnkVltqLaNo42yc/vterKKC0SePBgxRGoVixRzwiY+FAgIBNwQAUFkdcNBEU1adQRMExOYbGlG75nT6D97BpmPfwLxO3ZCFRwM2f/YEq16I0UDVg2B3u4enD9zDp3tndy266HDD6O4tISe0ZmtoHtMoAb6xtDW1I/qKx1EnDRi74ESpGXGws9f7RVzCRspnzICYgcREJk1vI9KgrgoObJSFYin32yYXDlUNq7u6UBnpx6NDVpMTFr4OGRm+iMhQY3YWPccF28mss5cYPRGJ6l12HGxykRkaCf8NRLkpCmQTecSc7aRCdeUGajEb4GA1yNgohjRGFkSl1uGedLzPlJiXa8MR7BEBZVk9uKo1wMmAPBYBASR1WOHTjR8GRHQaumaP2bBqVPDGB42Y/v2CKSk+CI0VOXSecYydmnJVTGC0cjQFDpaB3D+ZD3ZPEuJQBXPlVkTkiMWNFe26LSYamvDANlFd374PicPsZiMP5FYmRreShc7Lcqd7R3H5fZpdDRYIfV1ICpbgnsSw1ASEQQ5La7S7H+lmyHqFwh4HAKCyLp6Q2Yn8n9/bz8qr1ylZIJmSsAfRMn6daSQnY+U1GT4ajSr17hlOLLdZsP42Dga6+vR3NSE1uYWhIWFIyEpEaUb15P6bDR8yO34dnFZdo8iiNDbb8HZizqYSKFV40uOTaS0nZJ4zblqrjjhWH0d2t95C5ZpLeS+aqQ99DGeWOG1N/tlGEtRhUBAIOB9CAgiqwcTWR9//HH86Mc/IdUcYFpPWR608NZQcwKf/vRT/Ex+6aWXkZQ2WwXq2o3XdteznS3k/e7Z/4PwyFQkZh3GKNkrjk06MDpOSj1EmpQRqTU5To60JDlSyS4vIkQGpVJyPbNwrpv3XQ8qNlgSAlNGYHASONbgRG2vE/sLJChKkCCSXAAUFP8WY7IkeJdlZ0ZmtVBWVi2RWd+2dIMedUmZ1Q+bVJFIlvnzYIYIZywL1KISgYBAYAUREETWFQRXVO2xCLCsawcFyJpffgk1v/5vpNx/ALHbtiMkOweqgLVlyeSxg7RKDWeWXTWV1TS3eh6hYaEoLC5CflE+4hLiV6lFNx+WqxPQoltlRRs+PHKFVGJViIkLw+adOWSvFXLzxmv0HQ0RBaRp4fGKCU0dVkzrnCjIVGDvFlLOYcRDmvu6sjDVB6PJjtFRCy6Vj+PkyREUFwcjLz8AmRn+CAx0XwtSQWS9dqYYaYGjq9+OmkYLLlSasaFAiV1laiK1SjlJ2pXnkziWQEAg4L4IjDvMqKP4ELMibrVP42FVIjYpI923waJlAoFFIiCIrIsETuy25hBg84533x0kZdYpIrH6caeF7OwAPudYc51dQIfGRqdx9ngtOlsHidg6iT33r0PZzlzuDCIl8Zy7FRaP0Q/0o/3IO5hsbYV5chLphx9B0r5777brsnzPhGWsVgfOX9KhusmAfrKX1ifpgDId9vvGYosyChqJHAqmFCSKQEAgcBMCgsh6Exwuf8PIrMzx9713juK9t48igGLYmTmZ2HdgPyIiI+g6vDB1bJd3YI4Dsjgni8Ua9Ho01TfgrdffwPjoGCVLyPHw4UPYsHkTfHx85lRhnaM66IiD091rwZVqPa5WGfDw/UFYX+xLnBjpnInKprExTLS2oOPdIxi6fAklf/cVxFFihYyUXwVRYy6ExWcCAYGAQGA2AoLI6mFE1p6eHmzceI2c+txzz2HX7j2wk1KLlX6clM0ngRW59IBhJnbr9773PTz+ic/MHvV5fsJu9D/+P/+MxKR07Ln3cU5eNVkcVDepShpITp1u3Oy33kAWIER61ZCtYXy0HAn0ExMp44RWoTQyT7CXaTMLnQdGq4RIrEB9H03eLRLEBAGb04AwSjr1ISVdUVYXAfaXSvEqjDlMpMo6jUbbJLrtOuQrQpFN9nGJRGr1lXrexGB1URVHFwgIBFyNgCCyuhpxcTxPQIA9OzNPaRag6jlxDEyh1SckFJmPPgb/hERyNhALFp4wjsvdRpvVhqGhISKJXsWbr76BwpIiPHjwQYSEhkLj5x7KBiaTBWMj07h0rgnHjl7Ftl35KF6fhug41kayefCC0jtoQ3uPDU3tVpr3Orl6Zko8KbFGy7grCXMncVVhl5KpKSs5rehRcWUSFpqDa3xlyMoKQFKSLy0qKHiw3FXtWehxBJH1GmLMNUVHsZL2bhsu15hpFggE+UvJWlTFYybsluDC02qhwyi2FwgIBFyAAIsNdVJc6KiFgnhUYqW+KJSHIEkuEqA4IOKfNYWAILKuqeEUnVkCAuxZv6FhGi0tOnR16ZGYoMHuPRFQq2VzkmGWcCiP2pXNSYf6J1Bb2YHzpxrIGSQGOfmJSM+ORXDondVUWSzGODICpoDX8uorXP2OKbGG5OQiMCnZJTiMT9jQP2RFRaWOBIFsRAJTwRRvREf4KF/riZCpUSoPQ5zMjyuzum526ZLui4O4AQLMFv6f//mfKVagxNe+9jVO4ru1WRdIrbivr+/Wj6+/z87ORk5OzvX37AUjMbJ1gFNkyT48PIyCggJs3rwZGRkZnPx408aLfCOIrIsEbpl2myF9dnd2obmxBVcuVXACKFNlZT+5+bnLdCTXVWMymTBJcfnzp89Qn5q4M1ZichJyC/KRlJKMiIhIIrVSvG+eQRmr9RoX5mqNAefLdUhLUfGfjFQ1/ChZ+dZio+NbtVq0/Ok1dJNCeOK9+xG9qQyBKSlQqH1v3Vy8FwgIBAQCAoE5EBBE1mNzoDL7I4nRSN5wblBYZkx8/DXlnpdeeglbt26d1arMzEyygtTihz/8IZ566qlZ3y/kg3/8x3/kD6RPPPHETbvpjQ5MTDnR2WdFV58NAyM2Lq8eTqqssURiZRaMQQFSBPjJoPa5ptJ6UwXizYoiMDBFwfAR4FwLyd7TmbsxBUiJuEZq5QtmK3p0Ufl8ELA5iRTutKPcNoLzliH4SWihXO6HYgpohJOFnEbqvipL8+mf2EYgIBBY2wgIIuvaHl/Ru6UhoB8cwCTZ2bW9+TpM4+PIffqzCMvNgzIwcN4BsqW1QOztTggYDAZcvXyVK7I21jVg2z3bcfCxQ/xcmG/AdCX7w5Q/J8a0qKvqRGNdN1ob+/HgI2XYuDULcoWcW9mv5PFXu24LBaMNNNWvb7WSco6FJ4hGhcmwdZ0KYcEyKFycCMhIqyaTAx0dOrS3k3JEkw7R0SqUrAtGbIwaISHK1YbsrscXRNabIRoZd6CZVH6Z0u/giB1b6NzKSlEgNIiSf0X+4s1giXcCAS9CgLn16Jw2NFon8Ka5G3FEYt2nikMYEV0CKD4kikBgrSF6OQ9NAABAAElEQVQgiKxrbURFf5aCwOSklZ739fjwwyEEBSmxZ08kwsOV8PPz3odDnhhMoDbUdOPEe5U0L7PDz1+NLTvzkJAcTtbP1yycZ+FOJFbmjDN0pQJDFZcxSInFoeSKk0dxGCWpCspUqlm7LOcHbD7NCE5tnWbUNhgwMmaDLwn+7NoeAHu4BbXOcbST4rrOYeWK6xmyQETJfCEnSSJXJksuZ59FXe6JQEVFBR588EGyTQ9DbW3tLCIriz/t3buXf3e7HnzpS1/Ct7/97etfs32+8IUv4K233rr+2cyLxx57DM8888yykFkFkXUG1dX9zRLxGbfk6FvvopFUTFnmbV5BHo9jBgYGQO3r/gRMpixrsVjQ39uLjvYOXDx7DuNj40hNT0PJ+lJsKNtEcU7pouPzTa0mXKnSc4E3P+K/bF6vQVQkJZsrZpNZ2Wh2HD2CrvffozWBILo3ZSNxzz6ogoMXffzVPUPE0QUCAgFvQWBmzWrm+Xy1+i2IrB5GZGU32PXr14Mps375y1/GN77xDRJ++jPHlmVUHTp0iJ9Pr7/+OjZs2LCkc+t2RFY7sSNpLslVWo200DaldWBo1E7EVhuGabLGlFqzU5V8gSaZlGz8fEktVqQZLmksFrKzxQZMm4CrnTSJJkLr8JQDpckSbM+ScFVW+dzPVAs5hNh2iQiwv1qmzjpKyqw9dj3OEpl1iizlipgyqyIYaTKhwLFEiMXuAgGBwAoiIIisKwiuqNrjEXBQwMyi06H++d9itK4WUaUbEFFSgojiEkhJIUEU70JgYnwCL/7uBfR29yI9Mx2F64pRRKqs7lJsVjs6Wgfw+otnuW1jVl4CsvMTaLEwcs2TWNkYjE04iGBoQSMpsXb327C5xIfmsQqwBE0SMnH54uLYGAXc+4y4cJFsyCasXIU1JUVDtqMarsIql7v/pFoQWW/+62ZkaaPJicu1ZlTWWxBAqqxJsXJsKvKBv8b9x/Pm3oh3AgGBwHIhYCWvnmbbFHfpqbdS4hPFgu4nIqtCQop8RG4RRSCw1hAQRNa1NqKiP0tBwGajtbQhM06eHIHBYCdlOB/k5PojLdVvKdV6/L5snVM7ZcTw4ASOE5m1tbkfW+/JQ25hEhKSyN5aMTue4rBaYTMaUfeb/4tBIrNGFBVTDGY9IulHRhO6lXbGMZlJ8IcUWC9XGnDmopaspjXIz/FFXIwSMh9KmpTQd5YR1NsmuKhJCqmu36OMRSCJmCggFuk8/qRd5Q4wvgBTYm1ubuaiVm2UVH87IitTVk1OToaerNa3bds2Z8sfeeQRPProo/w7RmJhCq8///nP+ft9+/ahrKwMdXV1YNwDRhj83Oc+h+9///uzSLNzVn6HDwWR9Q7guPArdg3mrlKDg6irqcP77xylhAI/UsfOQ+nGUk4GdWFzFnUoHRFxmXLwqWPHcfbUGSQkJiAzK4tcp0oRFR3N+zND0FrMAbQ6B09YOHZqCiPjNuzeFoCUJBVCgyk9YY4p3GRrK0aqq9B97EMoNBoU/uVfwT8+AVL6exRFICAQWPsIsOsNu+++/PLL5MbQQklrfvxeyvh7vpQccCPH705oLKaehSqqs2eK/v5+/PGPf0QrXbtYUkBubi5PgsnLy5t1r19Mm+7Ux7m+E0RWDyOyskF84YUX8NWvfhUqyiZkqqzs4ZEptTocDnz605+mTM4PkZSUxKX+2Um6lPKP/zi3IuuNdTro4cZsJiUfIkv2DjrQN2TD4KgNPkopWSBKEBEqQySp2kSHX1NnVSnnuJvfWKF4vSwI0Jo0esacaB4ErnQ5EU4OLFkxEqSRMmskcSTZQxX7EWV1EWCLFzqnFRcsw+iwa8GUWpNl/ihWhCFYqoRGKHGs7gCJowsEBAJzIiCIrHPCIj4UCFxHgCmCdH/0ASmCVMA0MY7wgkKkHTwEuY9aBKuuo7T2X0xPTaG7sxuvvfgqn/wf+NgDPPAbERnhFp23k/d5X/cImut7cfZEHeKTwrFrfwlCwwPgH6B2izauVCNYUubkNCmf9lpQ3UhP5JRlxpIv1+WqOMmQKbG6cq5kNtuh09kpUKRDS7OW1B2YApEMxcUhiIn2IaUmz1HnE0TWuc/atm4rGtss6B5wkFoHUJqnQly0nJRZxQL23IiJTwUCaxcBpsZqJDXWY+Z+dFIcyF+iJCJrMNYrwtdup0XPPAoBtig130W1+XZMEFnni5TYzlsQ0GpJlbtRi7Z2HXq6DbTGF4p1pcFc1U0m895FGxtN1Kyk0nLuZD1qrrZTMp8ciZRkuWFrNgICfaHyuXlepO3twXhDA3pOHKfYywTSHv4YwvMLoCHC0kpO6Ji2EBP7GR61oqbegP5BKyanyH1hoz9yMtXw4S6V18axzTaNVjtLXpki6qoEGfJApNNPvFQDGV1v2WeiCAQWigAjnHzqU5/iJNaurq7ru9+OyDo5OYmcnBxERkaiqqpqFiHlegX/82KcHKZKKCmfEVk+85nP4Ac/+MH1Z4Nf/vKX+Kd/+ie+5ZUrVxAVFXXr7gt6L4isC4JrRTeeIbP2dvcQEfQs+kjZdHpqGpu2bEJ+UQEio6OgVrtfvNBGSQ0TE5Po6uhAbXUNBvr6odPrUEzncC4RcZNSU5al3Ta67jM+zMlz02jrMCM8TI70FB8UUAIDSzy/NY5omZ7GdHc3Gn7/HMwUI04/9AjCcnKhiYlZ0XEUlQsEBAKrjwCbU1+8eJEnmkzTteDG4u/vjzfeeIMELLJu/HjO14uph+2zEEV19kzx/PPPcwFNK11Pbyzsu3/5l3/BZz/72evPAYtp0411zve1ILJ6IJGVPUjs3r2bJrqNXAJ98+bNCCYp8srKSq7Uyk6o3//+99ixY8d8z4PbbjcfIuvMzmzyRv8Ts9yBsUkHzl81kbqNjdRHHMhIVpCFng+YTWNQgFiomcFspX+zMekZd+JCG9A5SiqtRuAhEoAqTpRQph5TGFrpFoj654MA+7uZclooM3cSfzJ2IIjIqxuVkciSByFOpplPFWIbgYBAQCDgUgQEkdWlcIuDeSIC9BBmGB7i9nZVv/g5gjMzse4rlIhGVkIKD7Bi8kTI3bHNLY3NqKmqwcVzFxAaFoqn/+IzCCcSK5vsu0OxmK1EYK1FY20PDHoT8otTsPeB0lmBV3do63K3gc1RG9ttqG22oLLBjA0FPti7VQ2NWoLVSLxk6qsdnXqUl4+Twsk09uyOQFFREC0I+VACq2fNnwWRde6zlS14TGmdePu4AX2DdiTGypCfoURBFkn/iiIQEAh4FQJWSmBmMaDfGVswbDfiAVUiMhSBCJP6eBUOorNLR8BgMOD8+fNgJBKmnhIbG8tVUw4cOHBXgsqtR2eKbkxhrby8nNcVEhKCjRs34uDBg1zt7dbtF/peEFkXipjYfq0jYLNRUoPRRgvc43jttT7s3ElJhbsi4O8vp+f/2cqjax2PW/s3MjSF1qY+vPPqBShVchz8xDZyDYlAYNDNayU9J0+g9U+v8oRhpnLHEojZ75WeczNxH6OR3D1aTHjj3UlOZtpQ4oekBCUiwm4m286s/ZwxD6CRCK0DdgN2KKOxWxULFdFY5RLPmu/dOlbi/eogwHgC7L5/a7kdkZXdh9nzwdatW7lA1q373fr+zTffxF/+5V9CoVBwLsKN5EX295VNNumMHPvtb38bX/rSl27dfUHvBZF1QXC5ZGNGZDLoDXj/yHv44/MvIL8wD0XrSrBl+xYe13RJIxZwEAMpHjbW1+Pc6bN4750jKCEF1j337UcGxeOZmMBy3hMY76K9y4zGFiOuVBm4IuvBA8Hwodgd0XNmFUZmbfjdcxgn5eRAUkVmzm0xW7bM2k58IBAQCKwtBMbGxrgYpY6cG1nCx+HDhzmhnt1fmZI6m2+/++67iI+Pv2PHF1oPu94tVFH97NmzeOyxxzhRtbS0FE888QSR8+X49a9/zZNf2Gu2zUxbF9qmO3bwDl8KIqsHElnZeLJA1de//nUuRXzj+LJsql/84hc80HTj54t9vRAi68wxrGRrzzJS+oeZMqsdgyN2UpRxwmRxIDZSjrgoGS3aKBDod41MuZwPEDNtEL//jIDODAxOAtU9TtT1OZEYxlRZgbw4CfwpRu4m6+h/brAXvmLBDIvTjmGHCbW2cXTbdBhxmrgaRw6RWcNpMcNHsjR1ZS+EVXRZICAQWEEEBJF1BcEVVa8ZBGxGAybIMqTpxRfgJOeE0Nw8RK5bj1AK9oqythFgCwrMLeOjox/gzMkzCAkNQVZONrbs2EpKp2ST4AZFrzNhYlSL996+jKH+CRRvSENGThxSM9a+KsA4JV32D9tRUWcihQYndw5hiZdpiXIoSEHBlQpIVivZkg2b0d6hR23tFCkOySiQpaSMbH9alFKTzRBZTHuYIpMgss79B85Uf5n1aEunDa1dNnT0WJEcJ8f6AmZDJ+Mk6rn3FJ8KBAQCaw2BPrsebaTEetU6ylXYDvgkIFqihloq4j5rbaxXsj8DAwN46KGH0NfXN+swybRIziwBZxaaZm1wywdsce3QoUP0LFJ7yzfk7kUqMa+++ioX0Zj15QI+EETWBYAlNvUKBBgR0mZ1clXWUydHaJ4o58//BQWBiIgQiQ1GgxmjI9O4cKoeg33jkClkKCpNRWlZJi2sS2GneIuufwA9x4+h8713kbBrN6I3lSEoPQOqALIjXMHCSEwmkx01DUa0kiLf6JgNqWQtvb5YA38/cqVUz2YymWnthxFYW4jIWk3rP2rIESXzRZE8BPEyP05mdY901xUETlS97AiMjo5eT1x55ZVX8L3vfQ+3I7Kye/mXv/xlPP300/jxj3+MkZERTkRNSkriCSs2cpa6sfz0pz/Fj370I2zfvp0/U9z4HXv9uc99jhNw9u7di9/+9re3fr2g94LIuiC4XLIxi2myc6K9tQ3VV6rQ1kI202YLNm4pQ2ZOJhKSEvl545LG3OUgHW3taCVSWNXVSiLf6hESFoac3Bxk5+VS8kMQt+++SxUL+prdA6a1dvT0WXD6gpbI3lLkZfkgMV6F6MibExlYxXaTCYOXL2Gk8iqGqyoRU7YZWU9+EjK5AhKmOCaKQEAgsCYR+M53voNf/epXCAwMxNGjR5GYmMj7qdVqcc899/Dk0Y9//OP4yU9+csf+L7SehSqqM5Lqvn37uGAmS3ZhYpksiYUVltSwbt06sOeNv//7v8dXvvIV/vlC28R3WsQ/gsjqoUTWmbFmJ2NNTQ3ZEOp4YGnmoXPm+6X+XgyR9cZj6o1OrjZS12ompRsrAihhMpKk1rNTFYiJkCPAnxRv6CZPfyOirCAC7MGqphcob3diQg8EqJ24J0uK2BAJNCr6UhS3QICRWaedVpRbR/CBuZfbzGQSkTVbFoRQqQoKtsQhmMduMVaiEQIBb0dAEFm9/QwQ/Z8vAoahIfScPI5xclLQ0SJz2scO8gUWKU0GJXOlac+3YrGdWyPArNeYcsFrf3wFJ4+dxAMHH8T6TesRExdLRMXVV19kRNv+njG0NfXjwukGctVw4hAp3MQnh5MF4uq3b6UG1+5gARgnkQit3DmkrdtCtu5y7C7zQXiolIiEsxccV6otrF6z2Q4tBb8bG8mSrE2HTlJkLSgIwqZNoRTkklOw3TMnyYLIevuzhpFZmRowOwffO23k51xGkgKZKSw+QqRlZkV3+93FNwIBgYCHI8Cib+wefNU2hksU92GFEVh3+MSQM8/avf/yjop/lhUBRixgaqmMzBpEC/RMPSWGLEqPHTvGlVLsdjtXSjt+/Ph1gsvtGsAWrh544AGuxMqeU7/4xS+SKnwRqqur8cwzz5B1th2PPvoofvazn123ErxdXXf6XBBZ74SO+M6bERgYMHEyK5sL6PU27syQmuY/p0Wxt+FkNJrR2TaEmivtuHimkSdf7thTQImifnBMjWGQ7FqHiRg00dyEvKc/i3gis7oi1sKUWMfIUePEWS2GRig5LUGFrHQ1cjLvbrfdS8ksFZTI0kEJLeMkasKUWbPlwXztRymRibmAt53ky9jfF198kRNMbkdkZeRVRpZhHAI9kf0YkZUV9hzAiCtsHs8SYNizKit//dd/jT/96U/8ueC73/0u/+zGf374wx/yZ4Pi4mK88847N3614NeCyLpgyFy2g4lImAadHq+9+CpqyXEqJj4OhcWF2LB5IzR+mlWLcbLz1Gg0QqfVoYLcBKqJxNrX28fjrgcefghxCfFLTsK6G8hj4zacK9dhaNRKz9tOnsyQl+U76/7tpGdpE3F5BsovoOa//3+EF5cg7zOfhQ+pMSr93EPs4G59Fd8LBAQCC0OAuaeXlZWho6ODJ5Ewccoby7PPPotvfvOb5MTgz1XPb8f9WUw9C1VUZ+qwO3fu5M374IMPuMPLjW1lzxdMjXXbtm08LrCYNt1Y30JeCyKrhxNZFzLYi9l2qURWZp9HSTqYnHZgfMrBVUf6h0ihlRZvIkNlKCQbvRhSaQ0Ncu2i4WKw8PR9pgzA8DRwpsWJoSknEkIlyCHBpaJEsVTmLmPLpohWIrP2OwxcnaPGOg4DEVu3KKOQLgtAtEwjghnuMliiHQIBL0dAEFm9/AQQ3Z83AjaTEXpaYO4+9iEaX/gDMh55DMn3H4BvWDjkvr7zrkds6FkIDA8No7mhCeXnL6K7sxuPPfk4WXAVw0ftQzZTqzvvYcFe9nP+VANOfVCN4DA/JKdGY92mDL4gKJWtbvtWcqS1pL46Om7HhSoT2kgRM5ds3ZkKa3KcgizAaAHHxcqn3d0GtLdfU2Jl/c7NDaRFJQ2ioymBjZI9PU2JdWbsBJF1BonZv9nfnsMpwfikHa3dNjS1WdDRa8POjT4ozFbBXyPhqsCz9xSfCAQEAmsBATsljpgddnxo6cNxSz+2qqJRwJTYpBpy4RFqPGthjF3Vh4tE3jp48CA0Gg1Xd0lNTb1+6DfeeOO6xW85LezHxcVd/26uFydOnODWgewZ9Q9/+ANXXpvZjinIMLUVRnLp6upaUnK9ILLOoCp+CwRuRsBotGF62oYTJ0Y4oXXHjnAiogcgNFTJyTA3b+1d7xyUiWggZdaWhj6cOV7LiflBwRps3JACf+MQ6p//LVSkcsVsmhkxKCglhdsP3o4MsFzotbab0NBiQlevGRpy0Ni60Z+r8Plp7j6XNjpovGFFlXWMnPkm+FpPHCmyblNEEpnVBwrJ3etYrn6IetYWAncjsv7VX/0VXn/99eudDg8P58kqTCyLFZbMwgipubm5/H7P1NmYiNY//MM/4G//9m+v7zfzgjnDMuti9pxx+fLlWYkzbO5rNpNd6DwKsy5miTNzHWceu4tNVhABNi7shymz1lXX4fyZ85REFYgt27cgPSuDE0ZX8PBzVs3jKqQY29LUhHOnz6Cro5Mrsa7ftImrsCaQ6qEvxdwVytnqqHNWuMgPWZIyS2aoqTPi7EUttpYFYEOxLyWmy6BS/vlazttLggdj9XW0NvB7yFQ+CCG3tugNmxCUlrbIo4vdBAICAXdGgP3dJyQk8Ovn22+/jZKSkpuaywiaTJWVlbnIozMbL6aehSqqP/fcc/xen03XJZYIKyOlaCbSwpJnWbyBqbKydsyUxbRpZt+F/hZEVkFkveM5s1Qi60zldiK00rMO2npsYMo3vYMOOumBkEBSBSUia0ykDGHBTAVHQou7pEIiuJUz0C3bb3aJMVmcuNIpQeOAAxMGCZLCgA0pEoT4AX60eCuKeyBgcFihhQ1nLINotU0jhNRY0+QByJeHwk8iFwsc7jFMohUCgXkjwB78WGCHBYS+9rWvzQrszLsi2vDChQt8oerhhx8Gy3ieq7AFqM7OTm7v09rayo+XQsHc/fv3IyMjgz88z7XfQj4TRNaFoCW29WYEnBRYc9ispMp6Ag3P/Zbb3IUXFlGwijLXo6O9GZo12Xc2kWf2W431jfjgyHsUtLcgOCQYu+/dg9T0PxMMVrPzBr0JY6NabtFYTqo2W+7JQ+G6FETFhZAF4tqcENCQwEiW7n2DdtS1WDFMqgnEI0JZiQop8Qr4+UppDuq6UWFKS5OTVjQ364jIqqOAkANRUWqsXx+MkBAljYNnk5kEkfXu55KFlIGntA5crbfgIhGrGZk6NeGaMmugn8RjScx377nYQiDg3QhonTayFdbjvIXU5chW+CGfJJQow6B2kiKzCIR698mxwN7/+7//O/71X/8Vu3btwu9+97ub9mbPojPk1Zdffhlbtmy56ftb33z+85/HkSNHMJc18PT0NL71rW9xQguzK2aKMYstgsi6WOTEfmsdAabixtbJTp0eQVXlJJ8XpKRokJ8f6PHzguUau+HBSdTXdKGprgcDPSMoygxBmI1s0c+fQFRRIdIPPwJ1aCiU/gHLdcg56zHTnFKnd6Cy1oDaBiOCiKyURGqsJQW+8NOQmuoC1jTbaM2n2T6FZtsUpbkAeaTKmizzR6Lcnzz5wHz55myD+FAgcDsE7kRkZeRuti5QVVXFiar//d//jaSkJF4VI618+ctfBiO0Jicn4/Tp09xSmBFa2Gc/+MEP8PTTT8867IyaHCPEMsIre/64sTDiy/e///0bP7rt6+DgYP6sIYist4Vo1b9grlM93T348OgHGB0eofuTGqUb1yO/KB8BRGxVqVwTT7QTsYrZcjPyan1dHWoqq+BLRKvomGgi125HQlIiOU25RkSA3b9ZbKem3oiPTk0jJkqBlEQVsjPUCAmWz7on6Pp60XvqFCZaW2AkB7eMxx5H9KYySClhTLi2rfopLhogEFhWBLq7u8lxbROvs6WlhRNCbzwASxBgKuis/PGPf7wpmfTG7RZTz0IV1b/61a/ihRdewOHDh/mzwn/8x3+gvr6eE1lZXOHJJ5/kzwkz4iyLadONfVrIa0FkFUTWO54vy0VkZQdhE3Km0Go0AQMjNlpEtOBSjQUBflLER8mwoVCFhGgZEX1oIVHM0+44Lov9kp6rQEmsaB0CjlQ5aIEMyIiSojDeiZQIAfpicV3u/Vjwgqje6KMFjiYKaHxk7uNk1j3KOCSQKmsYZeeKIhAQCHgOAhUVFXjwwQdxO2uf+faEEWLZw+SZM2fwox/9iD9A3rov24bZ/zF7HxYwurGw7/7mb/4G3/jGN5ZMZhVE1huRFa8FAndGgJEbJ2nC2n/hHMZqa2EjW6aCv/gCwvLyuVrInfcW33oSAixwz7JVT584hV/+7BfYtLUMe+/bh4TEeASS7as7lMG+cVReaiM1hQGM0ILgA49sQmFpKs0LaKlsIStv7tCZebbBbHFgdOIaafDDs0YUZSuxvkCF2Cg5Amku6upu9/UZaaFnCk1NWk5o3XlPOLKy/CnQrZplQTbPLrrVZoLIevfhYLER9tPdT6qsHRZOsGZzwAd3+VJMhBIXVWJufncUxRYCAc9DoMemw0Ui3ozajZy0co8qBhnyQEFW8byhXPUWM6VUFmc4cOAAHnjggZvaM6PuolAo0NDQwBWpbtrghjcsRjBDVPnNb37DF66Y+urExASpSQXyLdmz7XIUQWRdDhRFHWsZgY4OWgdo1hIxZ5rih0o8/HAsAgIULp+ruCPGNpsdFjOp1r5fiZNHK6Ce7kek0oDMBH+kbN2EhN17IaXr2UqDNT5hQ3uXGVVEZG3vNOO+3YHIz/UlVVbpgtVzbU4ixZKQyTlKbmmwTmDCacE6RRj2qeKgpCcDoczqjmeie7fpTkRW1nImesGIqey+z0iIN5ajR4/is5/9LP+IKcPl5eXxRJj29nZ8+9vfvq70fuM+P/nJT/DjH/+YYhlZOHZsNtGCPT8wlfj5lP7+fpofO4Ui63zAWqVt2PgYDUYMDgzi3KmzeO2lV7Fp8yZs3r6VVFCzERoW6pKWGfR6dJJV9+uvvIaBvn4uHLNn/z6Ubd3CCa3s+deVsU0W1+kftKC51UyOO+TKprfjof0hSElSzkpQthkMMI6OoOVPr6H+d8+h5O++gtQHH4aCiLiMzCqKQEAgsHYQYPfFT37yk9yZb4DcGhlx9cbC5tyMJMqUTxlxlK37z1UWWs8jjzyChSqqf/rTn8Z7773H4wZGI8Wq6MLGrqU38guYqBZTbWdloW2aq2/Nzc1gIlzzKcxlhvEr1q1bN5/N19Q2cz1fzdVBCQ0cW1fwurKcRNYZ8BiZVW8EBodtZKNnxdikA3qDkyZ8EkSFy5CeqEBosIyrs87sI34vHwLkyIIxHVDT60TnCJElJ4D1KZT1GSdFOCXW+6ys2v7ydcQLatKTWsegw4AK6yhGHSYwG7oiUmXNpQxdpsyqFNZzXnAWiC56KgIsO4ktCrEHsqeeegptbW2LIrKyiTerhz3Q/td//RfPgmaY3I7IyrKmH3/8cQ5bTEwMtxs00CT5rbfewujoKP/85z//OQXEH+avF/uPILIuFjmxn7ciYJ6chK6vD21vvo7xxgakHTyMCLIU8YuJFcGqNXRSsOttV0cXKi5exomPjmP3vt2494H7oPHTuEyd4HZwMqUAk9FCtoy9eP/tCvj5q5GcHkXqCcmITSCbhjVaTGYnhsfsuFJnwcg4PU3TrD4vQ4HsVCWffyoVriMMMtvQvj4TV2FtbNTRwrScFJd8aCHJH5GRPtcSOtdARqcgss7/j0lLik6MZF1eZcbgqJ2TWNMS5chOo0UPkmJyNcl6/i0XWwoEBAILQYAlKluIsFJPRJUj5m5EynwprhOEdPoJF4nKC4FSbDsHAixmwBbGmHpqZWUlvv71r6Orqwt79uwBswm8UxkiNagZpxe2eMVsglni7MjI/yhtlZbiu9/9Lie03Kq0dqd65/pOEFnnQkV8JhD4MwLT0zb09xtx4sQI/7CsLASxcWqEhbpG5e7PLXG/V2xBnc3jqk5exuUPLqKjuQ9KuZQSRzORtakQSaWFK9poJjRpMNrR1mHGxQodkVallIQoQ1GeBnExCk5WWsxzu5WeDbrtOrTZp1Fnm+AufNESXxQoQxEv9YWMCK3SxVS8omiIyt0VgbsRWe/UbvYckUh27Oxe/7Of/QyMCHPw4EFcvHgRTNntm9/85qzdGcH117/+NbZu3YqXXnpp1vcL+eA///M/+bOMUGRdCGqu35adJ4zM2tzYjIvnLmBifII77G7etgUZ2ZkIDw+DbIUImYxcpdfpceXyZTTVN2B8bIwcsEKQmZON9MwMEhBI5GtoriSxzoyAgehDY+NWXLhMrktdJlLp1iA9xYfuD8qbkhwcRO62m03opGfuphdfQPTGTYhYV4oIcm5TuYn4wUyfxG+BgEBgaQg8//zz3J2VJYcyjsBcRFbmoqrT6fBv//Zv+MQnPjHnARdaDyPPziSqzldRnXEF2P2elfT0dPz0pz/lMQIWX2BcAvZcwApzm/27v/s7LLRNc/XtxIkTNOc5weu90z/R5GjJiMCCyHonlGj9QBBZn7gzQov4lk0AbTYnasnesbrJzNVI1D5SrMtTcmu9qDDKPFRQNqNnOysuApn/x957AMdxXVnDZ4AJGOScc04EiMAE5ihZlqgcLFmytVrJq8+2/Ll2q6zVlstrl9Ylr132rsq1tj//TvIqWDlRpCiSYo4AiJxzznEwOfz3Nj0SmECkAWaA91jghE7vnW6g+9177jmO38RM2OuNwLkmGz68bENGJOhHhqwoGQK9bIT50iV0HT9a1z6CnsmspNZRYh7CZ4YuFMiDsV4ZSsqs3vBzU0JGQZzleDh3bVRF7wUCjkWASayPP/649IDKCSR7m48iK1c58cNiXV0dmCBlbzcjsj799NNSZVR8fDyYbGpvXAW9bt06cKJqx44deO211+yL5vUqiKzzgk1stNoRoMxL9St/RufxzxGUmYWw/AJEFhXB3UMt7uUr4Nrg5NrI8AhOHD1OaqctFGDVYMeendi+e4dTjM5ksmCgdxTlJc04+MFFFGxIxV0PbIKXjwfZbimdoo+L2QlOdPIPk1ibO0i956IO3qSUs6WAXEAi5QgJXNpJppFUYYeHjSgtHSUllCkMDhgo4ROMDRuDCP8r897FHP9y7ksQWeeGvoUKfUuIaF3XYkJvvxnJpNyxp0gNNZlwLCXRem69FmsLBAQCc0GAVddYaa2UipQ/0LVikyoc+z3ioCaKiihQnguSYt0bIcDxh9zcXGmub1+eQNbAHEvwv0VSnBVbd+/eLW0WGxsLtgnkxgoxdiVWjjmyWuvevXulZdf+x0W31ybmrl2HP1eT/evHH38sFd5yck00gYBA4HoExsdNOHy4n8jkhr8XvPlKzg2rnstIEzsrEai6KMle//lpnK2dwpTcF4Xb1yKrIBnp2bFSTMXNAUWBPKdkh4++fhOqanU4eXYC+Wu9sb3IB/5+7vTMTtVnC2y9Fi0uGgfQRITWPqsOe1VRyCd1Vl+ZUlJmFZm6BQK8SjaficjKJEAmgiiVSvD9/triFI5n8fd8P+d7Pqu52a2JN2/ejLfffltSaLNDyc8e9913n5R7YCXXF1980b5oXq+CyDov2JZtI82kRop/vv/2eyi+cAkbN29EXmE+snPXSGq//By5WI2vVb4uBwcG0N3ZhYMfH0BbcwsV5eeicMN6bNpcBLnCOdS5Tp2fREW1Fp5qN8THqrA+31t6f+09vL/4EjqOfgbD5CTUQcEkdnEffGPjIKPfK9EEAgKBlYEAC0t961vfku67XV1dX8yt7aPjOTaTNLnZ77v2ZdNf57qf2267bc6K6vbCFVZhPXnypFTYYu8D95PjAFXkMsmKqDyf//DDDxc8Nj05VvLPrRrHJ959911BZL0FUILI+ujiE1l5Esg/4xpK6pEqa0e3Cd2k0to/ZEVYkDuSYuX0o0AIvXfAHPQWp3xlLyZBJpqsgNRYbWjsl6G21wqdUYbNKUBymAwh3qBKqpWNgauMzkIJD73Ngg7rlFSZ22OZItMZK7YqwpFMFnRMZiVDVFcZjuinQGBVIMDBn6ioqOvGOh8iK1dj8c+17UZEVn6o5CpoVn/lCubnn3/+qs1eeOEF6aGYLX8+//zzqwJQV604iw+CyDoLkMQqAoEbIDBQWoI+qh4fLLsM34R4ZH3zH+AREChUWW+Alat9ZTKa0N7Wjtf/8qoUnNi0tQgZWRmIo/PsDE0zSUm3IxVob+mnJKAVOQVJWL85HQolzbVW4IO/0WSjhCNwuliHxnYzkVhlSIhRYA2psfJ7D9XSTXZYDbexUSP9tLRo4O1NirCkwhoT40lKrCpJ0efawLYzXDPz7YMgss4NOY6JjIxbJbeaC6TMykWliTFypCUoJNL13PYm1hYICAScEYEpqwlllhE0mycwQGSVAmUItlBMx51iOUJpzRnPmGv1ieMArKLCiqfT7f9Y+eSll16SbAFvNqJz585dZWP4/e9/X7IPZsthJp4+88wzErk1kBSvWKXFi6xPr22ffPIJ2O7vVi0mJgadnZ2CyHoroMTyVY2AjlQ/m5quzBvq6yZRUBiA7duDJbEXR5A0XQVsM5HwjKQK1fjhB2g6eAiWjI2Y8IlFV78WmWsTsfP2PHIc8YDac/HVa000rxweNeM0EZSGhs3w8XZDZpoa6SlqmkvLFkUQRmc1Y8RmQI15DOXmYajIhS9cpsYmZRjC3Og4sqWbu7rKNSH6eT0CMxFZ7TbA7PrGZBRWiJvemLjyyCOPSF/xswGrs04nz5w/f57I9eFfbDJMapg5OTlSboGPu3Xr1i+WzeeNILLOB7Xl28ZsMkvugTVV1aiuqEJ9bT38A/yxc+9uioHGITQsdNE6xyIBfb19KKZnzbMnT9O+wxATF4vsnDX0Goeg4CCniWl29xol5e6Scg38fBXYtdUHocEKsuu++m+4tq8PY60taP7gPejod2nNU88gKCsLCm9vIXSxaFeO2JFAYHkRmD7PZrErJolOb6x2ynl6bkwMLSQnlBu1+ezHTkydraL6d7/7XbzzzjvIor9Dn3322XXd+OUvf4lf/OIXlM/wJpe5FrAr7P333y+tt5CxXXegG3xRX1+P119/XRBZb4DN9K8EkdUBRNbpAFNBjWT12NJpRlmtAUy09FbLkJJAFWIR7gj0p+pGFQV4r77fT9+FeD8PBHRGG6aIwHqsxoaGPhtigmRIJSJrFvGv1AobFHJBkJwHrA7ZZNJmQj9V5J439qPRPI50BdnQufshlcisashFQMMhqIudCgTmj8DQ0NAX1c1ctcyVyfMhsnJVEj/UcmOi0Y4dOzAyMoIbEVl5Hbb+YZIpV16xxL9dRYUDVVwxxdVfzz77LNj+ZyFNEFkXgp7YdjUjoKO/DSM0Aat77a9wV6mQ+tDD8E9Mhmfo4gX5VjO+yzn2/t5+1JG91YfvvI9ACqQ++o3HEELn1duHKsSWuTGJtZ/UWA9/VAzNhA5r1yUhJSMa8UlfJiKWuYuLdngmBTJxdGDEis5eMyrrTUQSNKMw2wNJZNkeFeouWT8u2gFvsSONxozRUSMqKsbJ5ldL93IiKSZ6kRJrICkzuEtJ6VvswuUWCyLr3E8ZX7dc3Hu+TIe+QSu0ehvWrVEhK0UpKbOKefncMRVbCAScBQG2DWZyyqfksDNqNSDWzQtZikApluMsfRT9WBkIGAwGlJWV4dChQ/jd734nDYoTTo/OENOfnhh7+OGHJRvB6WgcPXpUcpvh79566y1J3WX6cn5fUVEhJbSu/f7az0y4ZbItH0cosl6LjvgsELiCACv1T0yYUFMzgc8ODyA1zRtFm4MQEqwiIvniKdy5FN70oDzV14vBygr0UrxziJSkI++6Dxr/eJw4UY+AID9k5yUgOT0KkdFUJEyxU/57sxiNhQr6Bkxo6zSi+PKUlCtbX+CFmCgVie8s/vlotUyi2jRKyqzj4OeHfEUIktx9ECX3ulL8IsRMFuO0rth9zERkZZe31NRUKVfB5JNf//rXEg78u9LT04MHH3xQEsbYsGED3n//fYmgyorrmZmZkkPc9u3b8cYbb0i/X5xreOKJJ8DPCCzkwc8SC1XgFERW17wsx8fG0NHWgUMfH6R81SgSEhOQk5eDrJxsch7yuI64NZdRsgrrJOXEuru6UV1ZiZbGZrS3tqJo21ZSfy1APLkPOEO8dfqYDAYb+gdN+Oz4OLRUmJKR6onkRBXiolV0X/pyTQs9s5umplDx/36DEbqnJXzlqwjNy4c/WXoLVdYvcRLvBAKujAAriW7cuFEawo2IqpcuXZKKUfk+zAWkN3NSmc9+5qqo/rOf/Qz//d//jfz8fMnVhZ9/pzeOLfz4xz9GQECA5BzbSn+LF2Ns049xs/eCyHrsZtBc9b0gss4Q9LoKqXl+4N8JM03UdZSwGRm3oLqBkn31ZrLSAyLD5NiUp0R4sJyUc6bd7ed5LLHZlwgwYZh/2gZtqO+14UILqbH6ALevkSHMTwZf9dV/rL7cUrxbagSssEkBDCax1lMwo8o8ggA3FW5XxSDCzRM+squrOZa6f+J4AgGBwM0RmCmQdPOtrl/CwVi7ZeDNiKws7c+qKdyY9Lp//35wQouTTqWlpVIwlxVTeD8LaYLIuhD0xLarGQErBXw5CdPw5t+kV6/wCERt3oLwDVcmtqsZG1cf+/kz51BWUoaBvn4kpSRh//33wMvbSwr0L/fYWpt6UV/dicsXm+Dr74W7HyxCSLg/VB4r7/mRk78mEySr9iNndTSHdEcMFUbmpCsRSk4fTAicHkB25LnhOS4rKl0uHaXkkA5upLS5eXMw4uO9SAFFIRFql6ovjhzntfsWRNZrEZndZwMVmbJbTWm1AUfO6JFL1+zaDCXiouTwJeUn0QQCAgHXRICLkjvNGrxnaJNIKPerEymGo4a3iOG45gl1gl5zXMBOGOEkP/9Mb5wM+8Y3vkH25Icla+C//OUvN3VjYYVUJq1we+WVV7Bnz57pu5IUXpn4wjEFLs5l++D5NiaxfvDBB4LIOl8AxXarAgFOHLOLXmurlqw9B6V5S0iIimJ4fpKbw6oAYdogpUQ6AcI2zNWv/BkKUoX2T0lFRNEWmH1DUVXejobabrQ29WH/Q5uwvigdSpV8Uebg9hw+K7GWk1W0QuFGZCQFNhb6wNuL/w4vfp7SSORVLXnxsZBJHamzTpKie4bcH/s8YqAmlVYF+fKJJhC4GQK3yj8wSYXJKtyYgMqCFzpSO2YiqoZUL1VUbM95BVZkszdWZWVBDLZ3ZxXXvLw81BLxrr+/X1qfcwyLUZwiiKx2xF3rlUnNfA011Teh5GIxThz9HAUb1mHfHfsQHRMN32uUf+cyOiZSl5deRumlYpynIgYmrm7dsR0JSUkIj4yQrj9+JnamxvcNzZQFVXWESYsePb0mumd4YesmHykn90X8j1a00PhaD36CfnJuI+9ihOUVIPGu/cKxzZlOqOiLQGABCPDfp82bN0tFIlz8wbFyvpdy4/n6D37wA2n+fTPyqP3Q89nPXBXV3333XXznO98Bu7KUl5dLyqvTj88cA3ZgKSoqAot2zadP9v3N9VUQWQWRdcZr5t///d+lSq2Zqrdn3MEcF0qJRzMk9ZymdlKgHLLAQInIoACaKEbKkRxHMuweMqjItkO0xUOAhJnQOwaca7JiUs8EVmBNNJAeSVhTcam7cz0PLt7AXXBPo6Tk0W2ZwkXjACYosBEkU0kBjUx5AJQUzJALqxkXPKuiyysdgVsFkmY7fn5AvBWRlffFpNXvfe97N9wtPzA//vjjN01kNTY2gu2BbtVYFZYfXp988knJbuhW64vlAgGBwJcIGCcnpURM/+VSDJGqSNzefUi6cz/kNFl0u8Zm5MutxDtnRcBMrEm2cX3vzXdRVlqGjKwMZOeuwdqCvAWpDyzGeJnYYDJZcO5EDZFYG0mtQI2ElAhs2pZJJFsPKXCyGMdxln1w0HhsworGNhOaOkxo77ZgTZoCGUlKRJASK88jl6JxwlU7ZSUVdC0FrKZQXz+BYEpAx8R4kqKJLwIDFZT4XLkTLEFknd9VxtevyWxDc4cZxZUG6EnNgwt5N+SqEBXO1y+rS81v32IrgYBAYPkQaKBi5FoiozTRawgRWO+gYmR/N6WI3SzfKXH5IzNhIC0tTRrHe++9JxFRrh3Ur371K8nFJTIyUipotSfNrl2PnxVjYmKkr998801s2bLl2lWkY03S/OWll16SFNiuW2GWXwgi6yyBEqsJBAiBoWEjmho1aGycxEC/Hrt2hSI9w4eIO+6UPF49D4QWcqkaIwvTvuKL6Dj8KUJIsS5uz174xMbBqvTEYP8Yyi414eLZeqRnxSA9OwZpmbHw8VMveK47PmFBb58RZVVasF10ZpoaKUlqIrMqaZ7vuHPAYiZt5klSZZ1AjXkUSiKwxrl7I50IrTGk6s65H5oViN8TgcB1CDC55LnnnpvREe63v/0tXn75ZYyRkub0xuRVVlxLTEyc/rX0npVY2dltihQk7S06Oho/+clPcPvtt9u/WtCrILIuCL5l3dhCZNbx8QnU19Th1PGTFIM0w8/fFxuKNiI1PVUiRLnLZ6dgzbE0/ukhFdbmpiZJiXVoYJCK8D2QmZ2NgvWFkmqhJxU1OGszmqwYHDajrkGHC8VTkiJrwVpvhIUopCIIe79tRGgbqavFQNlldJ04jgAq0sh8/BtQ+vpK+QH7euJVICAQcF0E7AUkTFxlsijPtflv3PHjx6UcPReLThesYjfV//mf/5EGzEUk9nn6XPczV0V1Lkpg0i0Xud55553gZwV2eGU+Ahe73HfffRIJl/vBCu7c5tonaaN5/CeIrILIOuNls9REVntnOIlDvzcorTGgktRZmdQaF6XAtnUqRITI4e9zJYkjEjl2xBb+qjVStS8ps15uB07WA9spJrozU4YAT8BDYVvw5H/hPRR7sCOgs5nByZBy8zDOGQawQRWKvcooSoao4EnBDdKZsq8qXgUCAgEnQGApiaxtbW1ScqmJJvvcuFqak1aceOLm4+OD3//+99i2bZv0+dr/mATLVga3anFxcWSR3C6IrLcCSiwXCNwAARuTCykA3HH0CEr/+1eIpURM2sNfg1d4OJT0OyqaayGgpXM5MTaBP/3+j6ipqsFTz/4j2VzlS39vecK/nE2vM0AzqceHb53FpTP1uPuhIuRtSEFQCAVG5e7L2bVFPzbPHzlg3NZlwaendJLbRxipsa7PUSElfumUZ7kfFrNVUmA9c3YYvaTEOqW1YO/ecKxd6welkhKPKzz5LIisC7u8p7Q2DI9Z8Bmpsta3GLB3iyeyUkhRONAxyk8L663YWiAgELgZApSGpX/A58YeFBuHEO5OBBh3P6yVB8LTbenuSzfrn/jedRHg58s1a9ZgcHAQP/rRj/Ctb33rqsHwcv6O1U937tyJV1999arl0z/wuuvWrZOSVt/97nfxwgsvXFX0ev78eSlxxduw1fD69eunbz6n94LIOie4xMqrHAEzFTfpyJb4yJF+SnYP4o6vhJPdZwD8AxSSMuiqgIcmVjoqom8/fIgKgCuhGxpE4h13Iunue1jK6gsIqsvbcPZ4NYYGx0n9zwt33LMeMQmh857vXiFSAS1tRly6PIXhEbOkvrpvpy/iY0lGZInmckNWPc6SMivngDotGtymisZmVTg8IYdCCJl8cf7Fm7kjoCeCuF1VlfMGycnJCAkJmXFHXPhSU1MDzjvwM0h8fPyM6891oSCyzhUx51t/fGwc7a3tOHTgIM6eOI17HrwXm7YUISaOFKU9PWfFL2AyFROwzp06jRPHPkdfby/CwsLwwKNfIyXWRPgSydMVGscFG5v1OPT5GBUnu5PrsBK52WpERyqn375gNugxXFWF4l/+HJ4hoch64ptSoYY6ONgVhin6KBAQCNwCAS5AfeCBB8DzYG45OTnwIGI+O6fy37t77rkHv/nNb76YfxcXF0sOq7wuz+V5ns5trvvhbeaqqH7gwAE8/fTTvCm4GJaVYplTcObMGamvhYWF+PDDD6Xl/N98+vTFxnN4I4isgsg64+WyXERW7hQrLA+PWdE7YEZLl4ne20iW3YrMJAVSExQIoUSOp3p5k8MzgudiCynfCo2e7C/7bShpIzUYsuX0IdWiohQgLkhGNpwUI3CxMa3U7prJZmYCJrRSdW6paQh6mwUqqsUtUoYhSe4LD5lcnKuVevLFuFwSgaUisrK9ID9QdnR0ICUlBXwP37p1q/QgzA+cXCldV1cnBadYTZUtg65tbA00vcL62uX2zy2kiHD69GlBZLUDIl4FAnNBgCJaFlLwHKooR+N770JGCWSviAhSFtmHALLuFM21EGhubMLl4lI0NzZLhQN3P3AvklOTJTVWrrhdztbRNoDLFxrR0z0Co96InbfnISU9itQMli4BtxTj5yAxJ3uvFECa0UPzx6gwOfIylQgJcoffEtmycz9YAbe+XkPqERq0d2hJfVVJSmY+iI31pPsvPbFT4nOZLwuHnxJBZF0YxFzQayRXmstU1NtA6sIGgxXREe7YnK+Gj5dMSqQv7Ahia4GAQGApEOA4zYTNiMOGLlSTotouZSSyiMQaSoRWEbFZijOwso/BimusvMbEE1ZSZSU1JplwTICV03g5k7F+/OMff5GQ+uMf/wgueE0iS9annnrqC4Bef/11/PM//7MUH+B9bdq0SdoXF8R+4xvfICLdEYmwcvLkSWn/X2w4xzeCyDpHwMTqqxoB+/zm8uUxFBePwNdHjhiaTzCZ1Yfer4amJxLreEszGt5+E2Yi3kVt3orgnFwE/l2R2o7B6PAkqfcN4/wpUrbrHUVmbjwysmORnBYJt3nYDBrIFWFoxITqOj0ulmqQkuiB9BQPxMUo4edLd/AlmuLrScik36JDg4XFTEagpnxPGCm7F8qDEeV+RZl1ibpih1q8CgQchoAgsjoM2iXbMRNQNZMaVFwuR1nJZTCxNSg4CLv27UZ0bAwVGtychMrPrEaDER0kmnKJiqg62zsk1eBMer5NSU9DSloqfIjEqlQql2w8Cz3Q8KgZza0G1DXq0Ntvwq4tPshI9STrbhkpHV75681CF5OdHWh49x0Y6J6nJGJ57K7dCCsoXOjhxfYCAYGAkyAwMTGBr3/96/Q8X/xFj/hvGRecshL69L9rTHBlRVRuTCzNy8v7Ypu57Me+0VwV1U+dOoXvfOc7UsGsfR/8+thjj+HFF1+8jk8wnz5N3+9s3gsiqyCyznidMAkmlRLqjz766IzrOXKhVmdF35AVVaTMWlJlQHS4HHGRciSTsk5ooDu8PFd+MtCR+F6770ES7WMya0Un0DUKbCEia3okEE7PmUq5wPpavJbz8zBV5rI9XQUlRZrJbmajIhTZikBEuHmSMqtIjSznuRHHFghMR2CpiKxMYN24caN06IMHDyI3N3d6NyQS665du6Tv2MrAvu5VK83yw9mzZ3H48GFBZJ0lXmI1gcCNEND0dGOQKjJ7L13EREc7sshCKJxUjuRqqlQncqtozo0AJ/ctZgsunLuAD995HxGREUgiAuuGog0II3Xd5WxWixV6Iq5WlbXj8MfFZGvviyRK5OXkJyIsImA5u+aQY2t1VxQsz182oLvfjAA/N2SmKFCYzQUbSzN/4cD71JQFQ0MGqqweQ1eXFiqlOzIyyVJtQ6BEPrQHqx0CghPtVBBZF+dk9AxY0NppxoVyPal4yLC5wEOKhQTS9b1UCfTFGYnYi0BgdSIwaNWhhYuPyUlngN7fq4pHpiIAwkNndV4Piz3qXlKoYsIpkwY4+bV27VpEUGEcJ3q4eJUbK7588sknVERzZV7x0EMPScWobBvITiz2xs8wu3fvlrbjdYuKihAQEICysjJJqZW/Y1XX7du32zeZ16sgss4LNrHRKkegvX0KTc3006ihuYUbdu8JJXU6D/q9X8HxAvqbxH+Xhior0F9agp5zZ+EdEYnsbz4JdVg4FKTsN73RqjCTlfXxz8pRU9EubZtMxZubd2TDy4uwUs2e+GshYZdRckaoqdehtcOArh4jtm3yQeFaL8L8S/LR9OM7+n27ZRLlxmG0WDXQWE3YpAwlhXdfhLl7SsqsNDNwdBfE/gUCDkdAEFkdDvGSHaC/rx+tzS347OBhjI2MYT3FSLNzsqV4qUKhkOyqp3fGQpW8Wq2OCvC7UVtVjXOnz0iFU+EUY925dzeRWNMkoQD78+z0bZ35PTtG6ShWeercJM6XaLA+zxsZaR6IiVJSfOfLe7hhbAz9l0sxQPe7/pJipD34MOJuuw1ylQdkZO0tmkBAILAyEBghsnpJSYmkyMpKq6zMOp821/3MVVGdlWK5+JVjCuGU30pPT4e/v/+MXZ1rn2bc2TULBZFVEFmvuSSu/ugMRFZWZjUYrRgaZXVWCyntmNA3aEZynAJpiQpkJpOliiBYXn3iFvCJRISgN8lIldWKSiKz8ufYIGBXpgx+amAehawL6I3YdCYETKCHYVL5qDaNoMI0jDFS+wihytw9qiipQlclEw+6M+EnlgkElgqBpSKysiILK69w66bJ/7VKgKzOEhUVRWpxJrz88suSrcF8MRBE1vkiJ7YTCHyJgIVURYxUlVn/1t/Q9ukhySIvsmgL/OLjicxKD12iOTUC/Ld0YnwCRw59hlf/9Ffc9/D92H3bHgSHhlCF/fKePyaxdncMoaKkBZ8fLsfWXdnYsW8tfOhh3oPUWFdaa2g1oarRhK4+s0T420KEv6gwUmL1+TI47Mgxc6KVW3X1BJE+xiQyq483EWnXByIm2pPIIApp+WohHwoiq3S6F/yf0UQEbYqBnC83oI9Uht1ItSM/S/l3gvZVjqoLPpbYgUBAILD4CNSax3DU2A2FTYZQuSfWyUMkBTVBN1l8rFfrHtni99lnn0VjY+NVEHCi//HHH8e//uu/XmXB+sgjj4BVVZmQyiqs05tWq5XWn05w5eVs5/rb3/6WinI2TF99Xu8FkXVesImNVjkCWq0ZIyNGHDrUT+p0Rvr9DUVc4WIKFQAAQABJREFUnBqhofNLfrsCnFZKoFvNJtS99iq6ThxHECnyheTlI2LDJii9vW9Y9Gu12jDYN4bGum4c+/QyKfd5YvPOLMQlhM26kJOndBoqTGzrMOLoyXGJLJyb7Yl4UmKNIFtonsstx3yOFd41NhNKyJWvxjQKIyxIJEe+naT07idTSmRWVzivoo8CgZkQEETWmdBxrWV2Zday0suorqhGfU0dcvJycOc9d8GPyFBe3l5XDWhyYhJdJM5y8KMD6O7qonX8kJufh7zCAnI4CoSnl9cXRVlXbejkH/iewsURXBhRWavFpMZKjlEK7NrqC38/Km38+6TQSrFlw/g42g4fQuX/93uk3HsfEr7yVXJuo8INL28nH6XonkBAICAQcCwCgsgqiKwzXmHOQGS1d1BPth5aPVlG1hvR0mGGgRI7rEaSGEPEHEpUhgbJ6YFmeSaU9j6upNf2IaCRlFmruwFywERODJAUKkMUiTjZH7JW0nhdeSy9Fi1auTqXlD6mrGakyf2QQj/JFNS4ovYhUiWufH5F310fgaUisp4n65X77rtPAuzMmTNISEi4CrxxmhRnZGRI33388cdkSZZ/1fK5fBBE1rmgJdYVCNwEAYpq2ahii4NV7Z8dhtLXj2zy0hG3dx/UQVRFJB64bgKcc3w9NjqGGlILKCspQ+mlEjz4tQexbfcOSRXLfRmr5lmNdWSEKv5P1qCzbRA6rRGbtmVg3eZ0KfjL1vYrpelobjgyRsV35NxR3UgFXYFuiItSIDedbB+JxLoUv0IcnJ6YMKG3V4+Ghkk0N2sQEqxCXLwXsrP94OenkOaoKwXz2YxDEFlng9Ls1tHprWjptKChzYi6FhPSE5TIy1RRAsQNXmRJJ5pAQCDgfAiYbVRwLLOgxDiEg/oO5CiCkE8/0e7e8JFdKWxwvl6LHrkqAqyw0k42rExmZTJqdHQ0kpKSpMT/fMbEaiqVlZXQaDSS+kp8fPx1ylnz2S9vI4is80VObLeaEeCCOZ3Ogs8/HySFZC0VyCnJPdGHHJj8pLnOtQXsKwErbT+Rdpsa0XHsKMaam5B8z30Ipfglq7K6kZrfzZrJaEZfzwhOHavC8OA4Kfq5o2BjKrJy4qFSK6TPN9uW53QmsxW1DeR+16JHd68RURFKbN7gA1+aV3qql18spNk8gSZy5KslZz7O93DuJ0Xuj1g3L8hlQpf1ZudWfO8aCAgiq2ucp9n2klVW+3r7UEck1pOfn5TsqGPjY5FXkIeklCQoyE3ATnitra5GQ20dOjs64empRkZ2FjKogCEpJZnuc+yw5Npxj4EhEzq7yW24TAsuuiha7y2psgb4X1ELlwrjKTfQdfoUFXD8L7yjohFI+buozVvgHRk1W8jFegIBgYBAYEUiIIisgsg644XtTERW7ihPKjlh2TdowbHzevSSMquK5q+b8j2wbg1VIJIy62qxbJzxxC3CQnqmwoQOOFJtQxMRWiknjqIUGbanXbHndPHnx0VAyHl2QacKepsZ50z9qKLK3G6rFgWKYNypjIHSzR1E8XaezoqeCARWIQKzIbL+8Y9/lCT7Oen01FNP3RAlVlbJzc1FPwV1f/7zn+Oxxx67aj1ONmXRRJ9VAtku8JVXXiEbrStVq6Ojo/iXf/kXfPTRR0Sq8ZOSSPO1L+CDCiLrVdCLDwKBBSEw3tKMQUoYt3z8IdnkeSH/e/8XPrFxcCMVZdGcF4H2tnZ8+M770ExqEBAYgK07tlGSLHvZO8wJvM62Abz6h6M0L3LDztvWIjElEmGRVI22wlr/ELl1UJFjfasZ3X0m3LXbi0isCsmmiwscl6JxILq1VYsTJwYxPGSQEsp79oRR4YgP2Vh+qbKwFH1xlmMIIuvinQmOf/A8vK7ZhE9OTFES3Q0x4XJJmTUmQtwjFg9psSeBwOIhwMppPTYtio2DOGbowVcpLnO7R4xEOnETgbTFA1rsyeUQEERWlztlosNOgoCZCJZtbTrU1k3gcumoVCx3992R0rxjJRUp2uFma+Wm996FWaeFyj8AqQ88hACyNZ0NmUmnM2Kwf4yKOmvx0VtnsO/OddhB8+HgUF+oPVX2Q1z3ajbboDfa8MEnI2hsMWBNJpGpUtVIS1LTnPq61ZflCytNDCbIje+MkchhlnF0W6awTRlBznzRUFHuR0FkVtEEAq6KgCCyuuqZu3m/maA5NDCIyvJKnDt1FufPnMNj3/y65GTlF+BPDlekQtraho/fex/lpWUUU92ODUWbsJbIrmpPT5dUYb0RGhzT0UxZceCzMXT3GJAQ54H0FA9kpl3t5DXW3Iz+4osYKLsM85QWa55+BsFrcm60S/GdQEAgIBBYNQgIIqsgss54sTsbkZU7ayY5di0RLDt6zGjrNqG92wy1B1l1kSJrZpICEaFuUvJSxIdnPLWzWmgwEc4jQH2vDRWdNoT7ARmRbqTMCtD8XzQnQsACG1iZtYUqcy+bhqkSV4YId0rmywMR7+5D4QwiIDtRf0VXBAKrCYHZEFkfeughnD59WiKgXmvnZ8fqVkRWXo/Jq88//7y0SXBwsGQBODQ0hOLiYrIzsUjfv/zyy3jggQek9/P9TxBZ54uc2E4gcD0ChokJaMg+qe6N12Ag0nnMrt0IoWCVf3Ly9SuLb5YdAQ7GsvVVXXUt3nztTYSEBmPP7XtJgTOOEmQhy94/tlOsr+5EdXkbwiMCsPuOfAQG+5Id180Td8ve6Tl2gBONg2S5zi4dxVUG+HjJEEukvnSaC4aHuMOdVGcdPRfkYLROZ0ZjgwbNLRq0t2kRFu6BlGRvxJMaa1Cw3X5y9T2BCyLrHC/oW6zO19rgiAVN7XS9tZnQP2zGpjwPpCYoEESWdKLm4RYAisUCgSVGYNhqwCljL/qsOorSABsUIVgrD5LiMbMh4Sxxd8XhBAJLhoAgsi4Z1OJAKwwBfhZkB4imJg0psw4gJESF9esDERGhhr//zRVKXQ0Gs06Hqf4+9Jw9g+YP3kdY4TpEFm1GUEYmPMheejbNQhVgeiKz1tF8+MKpGkkUx8/fC0U7shATFwK5ggsNr5+ftXUaJDXW7h6jdO9en+eF2Ggl2T/LHT6vnM247OsYqFimjwRMGs3jqCBlVrXMHSFualJ+D0a0m6ckZiKKZuxoiVdXQkAQWV3pbM2+rzr6uz48OIyKsnJcPHsBHmoPSQggKTkJo6PkAlBeDg8PNYJDgrFmbS7iExMQGhoK9xUW5DAYrahrvKL43d5pRFqyCtuL/MjRC/RzpQjBQMReLd0DG995G8PVVUh75GsIyy+EmvAQQhezv+bEmgIBgcDKQkAQWQWRdcYr2hmJrNxhTiDzJL6j14LSaiO6+syY0tpQkEX2KpTQCQ1ylx4C5O7XT0xnHLBYeBUCjDFXe7YOyXC02oopowweJPxSRLyKlHAZ1PSgtYLcSa8au6t+GKBkyQXjAFotk+ilwMZOZSTyKJjhSxZ2Sqaz3iBY46pjFf0WCLgKAm+//Taee+45MLG0qqqKbERIWuua9sgjj+DkyZPYvn07Xn/99WuWXvnIv7+FhYXo7u7Gr371Kzz88MPXrcfrvPbaa/jZz36GgYGBq5b7+/vjxRdfxP333y/dR69aOMcPgsg6R8DE6gKBWyBgnJykYNVbGKmrhVztifCNGxG3ey/cWP5D3Ltvgd7SLuaigNbmVkkx4LNDh7EmZw2++cw/UPDVg4KtyyfXYqWkndlswfHPKiQSq5oe1NOyYlC0PQsqjxWU4KSajCmdDfWkUFnfaiQyqwn52SpsW+chFTcqFY6f//FcVKez0n1WjwsXRtDbq4OSkqJ5+QF0n/aXHEJWojrSbH/TBJF1tkjNfj0mbxuMwImLNNcrNyAtQYmUBCJvJyrgRSqtS6VAPPseizUFAqsTAROs6DBr8IGhXSKurleGIpEKiyOIXCKaQGC1IyCIrKv9ChDjXygCXV1aHDs2ABMphzKBleceCfF0f6Hpj6vH+20UJ9UND6O/5BIp0hXTzyWkP/p1JO3fD3cFFQjOURZ1aICU/pr7cOF0HbraB3Hb/nXIzImjAk8fKgL7cs7OgjkGcn+8XDmFs5emEBTgjrgYFfJzPBEY4LzuB6zGetk0hCbK/wxSLmiHKhJZ7gEIdFNJ+R9BZl3ob5vYfqkREETWpUZ8aY/HyqtVpMx66vOT6GzvQGp6KoxGPcVWm7Fr315s27UTkVFR8PH1WdqOLdHR2MmJ+Su1DVocPDKO6EgVtmzwQniYEn6+f78nMRmDfir/+Ad0nzyO8PUbEEpE1tC8PMoTXK3eukTdFocRCAgEBALLjoAgsgoi64wXobMSWbnTfF/X6a0Y19gkNZ7GdiPGJmwI8HXDuhwVIkPd4U/vRVsYAoyzxgD0jwMlbTaUkzJrdpQMmZEyIrMCK0jcaWFAOcnWepsZY2QzU2kawUWysvNxUyDG3RsbFaEIowpdEchwkhMluiEQcDACRqMRNTU1aKaAABNnk0nZMZ2suNSLNPEVRFYHn0Cx+1WHgJV+Z0cbG9B74TzaPj2EyE1FyPrGk5CTnZK7auUoaa6EE8t/Xz89cAg1ldWS1RXbXu3cs0sisS5nAnFKo8fo0CQOfnAR7a0D2EkWihlrYhEeGbBiLLn4+hmdsKKr14wzpXroDTZkJhOhL06B6HBWplwaJVYmslZWjtN9dgKDAwb4+V1JJEdGeiAokH5fpWTySrja5zcGQWSdH24zbUV5D3qes5EbjQUNROBubCNXGrUMuzepERbsJpFZZ9peLBMICASWBgF2yWkku98TpMjK8Ze7VHEIIFKJBymmiSYQWO0ICCLrar8CxPgXisDkpBmt5ARRXTNJRfJj+OpXI1FQ4A+FgouaHF/Mt9D+z7S9SavFeHMTql/5M6xmM0LX5kmKrIHpGZBRxdZc59lGshnUag2kylpH5KlWqFQKJKVFEllqDTy9Pb7Y3/gEPVs361HfpENTqwFbN/ggO1ONAFJiVSqdF1M9KbNOUP6ngvI/1aTMaqZCmihy5tumCEewmweU4rljpstNLHNCBASR1QlPyiJ2STs1RQqsY3jn9bdw5uRpIrEakUDqq5u2bELmmizEJcRLOauVpsRqh5A5FhYqnOjpM+HSZQ1Gxy1S0eOWjT5ITeJ70pU1OdbIquT9ly5ioqMdASmpyHjscSh9hT2uHUvxKhAQCKwuBASRVRBZZ7zinZnIOr3jPQNmtPdYUNtkIoUeKyLIUjIuUo6EGDm8Pd3goXLeief0cTjrexYPNNPP5XYbkVnpoYsevIK9gcJ4INxfBh8PZ+356uwXnR60mCckMmunbQpmmxUFZGdnVwJxtz8Zr054xKgFAgKBRUBAEFkXAUSxC4HANARYgcSk0ZACSTGq//In+MTEInbPXgSmpcErPGLamuLtciKg1+sxPjaOt177GzraOlC0dTOycrKRnJr8RTJsOfrHwc72lgFUXW5BS2OfVMDwlXs3ICEpDAol2yG6/lyI1XJMJpAKq4mIfCb0DZkR5O+OzfkqhJAbB6tSOroxzhMTZlJiNVDymFR+2ki1J0iJxERv5Ob6w8vL3eWTyIuBoSCyLgaKN96HhlQ8BoctOHFJR0W8VqTGK8iRhq5Binvwr/kK+FW/8cDFtwIBF0DASmbExVRMXGcewwiMSHLzwV5VFFREJqEyCxcYgeiiQMCxCAgiq2PxFXtf+QgYyZp4asqMS5dGceRIP7ZuCSF3EF+EhZEzhdp1CyY4FjJSV4fBijJ0HD0Cn+gYpD74ELwj6R5KzlILaY113aitbEd9dRcp/amxZWc2omKD4RfoIzlsdPUYiVQ0Jb1XUf5wY4E3khOvkIpc4bm6jRRZ6+m5o848DguRWbPlgUiS+yLWzQs0MxWCJgu5eMS2S4qAILIuKdxLdjCOobGr1WD/ADo7OnD86OeSMqtuSo+YuFgUbihE3roCpKSmLLs4wFKAMqmxor3LgNp6HarpZ3uRD3KyPOHr7U5FKVfmi5NdnRiuqUbzB+9L98CMrz8h3ReVPitTrXYpcBfHEAgIBFwXAUFkFUTWGa9eVyGykpMmDKQa2kaTTyazXiS7vbgoOQrJZpLJrCGBrjuZn/EELeFCeubEpJ6UWUn19pNyYIBeNyUBmdFuSAxZwo6IQ80KAba04+rcI8ZuVBtHpOQJBzN2e0RCQaEMkUaZFYxiJYGAQOAmCAgi602AEV8LBBaAACdwxkhFufXgAegGBsh9wIqUe++XlEgWsFux6SIiMEjnpa2lDR+8/T4lEafw9P95BklEYlUto2ouB4b559zJWrzz6kmkZkYTuTYeWbnxCAjyXhEkVj6FWipWZCeOo2e1qKw3YVO+B6mxkvMAKbFy0nEpXAcY58ZGDU6fHiY1CaMUaN6xIwRJSd5S8tjVlZAW61dFEFkXC8nr98Nzch3Zn1Y1mlDXbEBHrwV5mSrs3ewBuTv9Hjiez319p8Q3AgGBAFFY+R/wpq4FNaSMlqcIRobcHylyPxF9EdeHQODvCAgiq7gUBAILQ4CfA3k+UkXOEKfPDMOTCvnCI9QoLAxAcLDrurjYiORU98Zr5E5zAUpvb4QVFCLhjjvImYYIpQt8uDUZqQixbwyfvH+BiFTj5FYSiPwNKcjOS0QvKePV1Gtx6pwGKURe3bPDFwH+cgnXhZ2ppdualVg15M530TiAWiK09lm1kpjJbapoSQ1eQWRW0QQCroCAILK6wlmaex+ZxMqCABfOnMOBDz4gDodRilEGBYVAr9NjgAiudz9wD/bcvg8qDxW5LMnnfhAX2oJddkwmG86XaHDk+CTSU1RIS1EjLdkDPkRm5caq5JOdHSj/7W9gorhz3K7dCFqTQ+qsKS40UtFVgYBAQCCwOAgIIqsgss54JbkKkZUHwdLsk6RQ0tVnpqSOERMawGgiAgBZTSbEKEil1Q1qDzF5m/GE32KhyUKJMyNQ2g409VklYmtiKLAhyQ1U1ApP5S12IBYvGQKcROFUSgNV5DbSTwPZ23lBjixFACmz+kp2M0vWGXEggYBAYMUhIIisK+6UigE5CQKG0VGMNNSj+/RJshM6i/RHH0PMth1Q+hERQiketJb7NF0uLsXZk2cwOTmJ4NAQ3HHXHZQMiyDy2PLNMaY0evR2j6DsUhPOHK/Cjn1rUbAxFUEhPkSudN2Epv1cc8LWQOpD7L5RVmsEKxgwYbQgS4G4aAV8PGVwJwKfIxv3QatlK88ptLROoaFhEpGRaiQmkGJPihcCA5VCiXXaCRBE1mlgOOAtqxMPjljQ0mHBxQoDWZ/KkJGklAp4Q0UBrwMQF7sUCNwagQmbCYNWHY7ouzBg0+M2FanJEYnVV8YUEsfeo27dO7GGQMA5EBBEVuc4D6IXro9AX58eLTQvqaubJFKQBbt3hyE2Vk3FfSRc4WK3HN3QEDSkPtf88UeYIOJO3K49CMldC38i7Li5L1yYhom/WpovV5Mqa2NNF5rqe5C+JgEZuSloapdhZNxNmksyiSgvxxNKUsRz9Nxysa9AExVAd1un0ETufFVUTKOUEcHZTY01iiBJmVVBn8WzyGKjLva32AgIIutiI7q8++O/vTqtFj3dPSgrvUyOVm1UVNAvCQFEx8TA29sX3Z1dKL5wCZHRUZIia966fERwfJX+9q8EV6mbnQGOL7a0G1BRrcXQsJnu3cC2Tb6IDFdCqbxyE9ePjKDt0EGMNjbArNMiZuduxO3dJ1nwrGRsboaZ+F4gIBBYvQgIIqsgss549bsSkdU+EL2B1HomrbhUacKZEj0iw9wlq721GSqyn5RBpaSpm4tN6u1jc4ZXftAa1ZKtZy9woNyGQC9gY7IM8UE2hPlBUkMS+DrDmbrSBwudsF6qxv3M0IV+m46orG7YpAxDnjxIUmkV2qzOc65ETwQCroSAILK60tkSfXUlBFiNxGIyouHtt1D9xz8g4c47EbN9JyVyUqHy9XWloayovlpJLZeVBA599Anee+s9bCjagLzCfGRkZZJF4fLZO3E1/yApzFw4U4fujkEMD03g9v3rULgpbUXgz/MOVisYJQv1y7UGUmPVSYS9vEy2UlfCz2dpJnV6vQX9/XqcPTuMfkoc24iUtLkoCHn5/qQY4Zi5pTsF73/yk59QIFuJH/zgB+Br8NrGBOo2SggcPHgQTU1N0jqJiYm4/fbbkZqaKl2z127DChd8Dz958iQGSGE4JycHRUVF0vpmUn5YjCaIrIuB4q33wQW8Z0oMGB4jI1H6XdlW6IH0JAUUcjIxX5pfjVt3UqwhEFglCLSaJ1FpGUE7WfzKbDLs94hDrLv3Khm9GKZAYHYICCLr7HASawkEboWAkYr89Hor3nuvSyq027MvHKkp3ggJUbnMMyCTnNiRZoTsk3vOnsEQvborFMj+h6cRmJYG2SKQWO048pzZaDChvKQZ7//tDPyDQxAeG4fmbi94enth1zY/JMSpEBLk2kqA/VRQU2IcJDGTCbQRqXUvqbIWkEK8v5tKygGJ6YH9ihCvzoiAILI641mZX584dmo0GtHf24eq8goc/PgAuRkpkJyWgu27diIzO1sSA2iorceJo8fR2txKcT8j7nnwXqxZmwNvHx8qKFh4IcP8er80W2m1VgyPmnDwyDj6Bky4bRc5eSR5UJHylYIUs06HCYr1dZ8+hcb33kby/nuR8fjjklK5G8X0RBMICAQEAqsFAUFkFUTWGa91VySysjKr0WxD/5AF3aQa2tBGyj1TNoSHuJM6qxzZqUrJdk8kd2Y89TddyAllIymzDk7YUN0NtA/Z0DMmw/Z0GXJjAR8PQLGynzNvio0zLqDThSmrCb02LapNoyg1DUkJlTSyucuUByCIghmiCQQEAgKBuSIgiKxzRUysLxCYJQJ/T+j0FV9Cx9EjMGkmoQ4JRcr9D8AnJnZFV6XPEqFlWU0zqZGUBE4eOy4FWh949CFs3rYFfqSUq1AqlqVPkrrMlAHNDT048M55eJM9Qt76FFI4iEBEVNCy9GmxD2qmOd3QqBXnyw0YoLkdj3lNmgoZyQp4qWWSYs5iH3P6/vh47BVdXT0hqbB2dukQGKDEmhw/REWpv7DwdMS8sqSkBHfddRcdIxhVVVXXEVk5sP/rX/8aL730EgX9TdO7LQX9v/Od7+CFF164iszKyg3PPPMMPvroo6vW5w8PPfSQtL/FILMKIut18DrkC63Ohr5BC8rrjBLRuzBbhcxkJSJD3VzKEtUh4IidCgSWCAGOt7ATznmy9D1o6ESCuw9SFH5YIw+Ev0wo6S/RaRCHcREEBJHVRU6U6KbTI8DETJ4nnT07hOamKShVbkhO9sa6dYFUZOcadEULkZxMGg3ajxxG/d/eQNi6dQjLL6SfAqiDaC67iBMsntMxZn09I6it6CQnRwtau2UICPJGUqIvtmwKREiwAh6Eoys3vc2CEasBdZYxVJpGpKGEkjLrRkUoItw94SETCTtXPr8rve+CyLpyzvAoqYl2d3Xj5Oefo7O9A37+RNJMS8Wa3FyEhodJcVSOTU2MT1CheD/OnzmHmqoaBAYFklhABrbu3EaKrd4rmszK93CDke7jFyfR0mYgNy03pCWrUbjWU1IFZ5EL09QUes6dQc1fX0FQZhZiduxEAIlcqENCVs7FIkYiEBAICARugYAgsgoi64yXiCsSWe0DMtHDACd3iqsMZLtnhpYqVaPC5MhMUYAt9/x9yTqEbCkXcV5sP/SqeNWTOtKwBihtA07W25AZBaRHyJAaLoOf2iaRhVcFEC4wSE6umGFFvXkMpw190NN7D1JmXa8MlRItfm5khyrs7lzgTIouCgScBwFBZHWecyF6sjIR0PR0Y7ShAe2fHoR+fBwZX38CIVnZUJAqq7ARWvpz3kNB2IvnLqKxvhFDg4O4/5EHsG7j+mU9FxaLFW3Nfaglm8QLp+tI3SASdz2wiVRlPODh4drkGYlASqeZSXrt3RZy2jCQggNIjVWBpFgFosOXRoFAozFjZIRIgpfH0NE+BS9vOVKSfVC4LoDsv8iikeaSi9lYYZUJqg30u//EE0+gubn5pkTWU6dO4eGHH5YOHxkZiXvvvRdasm5jkuoQWXRy+81vfoO7775bes9/N1jhlb/jtm/fPmzatIlIutV4//33KRluxlNPPYX/+I//uI40K20wh/8EkXUOYC1gVeZZm6mIt6zGiLOXDfD2JBvRYBnyMlUIpngHW6OKJhAQCDgWASPZ+U7YjDhj7MchYyf2KaOxQRGCQDe6FwvCiGPBF3t3OQQEkdXlTpnosBMjwM+Bra1TaGycRG3tJCIjPbBnTxi8vNxpnuL8hEX98DCGa2vQfeYUumlek/H1xxG7czdURHhyZ59lB7TRUQMp2I7j3KVxlJRNIDrMjDWZPtixMw5BQWqys3ZtIqsdsg6LhnJA46g1j0JrMyOPVFmT5b6IIaV4OeV/RA7IjpR4dSYEBJHVmc7G/Pqi1+sxOTGJJopn1dfWoqGunvgXlIOmuFNGdhaSU1Ou2zHH/kouFqO0uFRSZg0IDMCO3TsQGx+HMCK9ruT4N9/Hm1oNaGzWoa5Rj+goJXZu8YW3lxvUHlfuR0NVlWh6711w8QcXecTuuw1B6RmQEa6iCQQEAgKB1YCAILIKIuuM17krE1n5QcBC1ZZTWhs6yXbvUoUeo+NUgUnfby1UkzKrXKq0XCFz1BnPoyMWMo6UP0f7MFDTZUN935VE2h1rZUgOBTxVRBJ2xIHFPueFAJ0uKXjBlbknjD2opmBGKqmyZtFPDqmFeMiWhhAwr86LjQQCAgGnQ0AQWZ3ulIgOrTAEOEhlpurryj/8XrLZi9q8BeGF6xC8JkcErJb4XHNgtaq8Eq/++X9JSYBU1nJzkJufi5g4siJYxmbQm/DZgRI01HaR9ZYaWbnx2LAlXbLoWmyC5VIPU5rHEUHv5CU9qhtNNCYgMUaOTXkepDTpeCVWHi/3obFRg+LiEQwMGCR1oy1bgpCQ4A0fH0oB0kRnMYPqTGJ9nKzCmMTa3t7+BeQ3U2R9+umnceDAAcTHx5Ma09kv1mdC6jpSNOrv78eOHTvw2muvSctGSBUjPz9fsnh78skn8dOf/lRSuOWFv/vd7/DjH/9YWq+0tBTh4eHS+/n+J4is80Vu7tvxdTo8ZkUXxTvOlFDiiJxo9hR5SIRvLtzl61Q0gYBAwHEIjLLyGRUM808jWfne6RGLdfIQuNMvnyCKOA53sWfXREAQWV3zvIleOy8COp0ZnZ06KmTrgdpTjq1bgiXXiMBA5y5qtFmtGKmrRe3//pXIOQZ4hkcgbvceBGevgWSZ7KAH2LYOPc4XT6KjQ4OB/nHoh+oRFy3H/V/bjIiYQFLEc27cZnslGkmZVUs/JeZBej4Zx6BVhzR3P9zmEQMvorKqRKHNbKEU6y0hAoLIuoRgO+hQA6SuWl1ZKSmsVpSVYcv2bcgryCcCayp8KZbq4UFWrjdo7IDV29OLTz85hK72TvpbrJZUWbfv2iEVGCxm3O0Gh1+2rzjWrCfxtc4eEw4eGYdSKcPaLC8kxCkRHnbF+UtHQgqj9fVoI/XyocoKrP0/30HU1m1w50p/B90rlw0QcWCBgEBAIHADBASRVRBZb3BZfPmVKxNZ7aNg65AJjQ1N7Ua097Cqjxlhwe6SOmtKnByB/m4SoVXc9+2Ize11QgcMaWS40GxFx7ANNO+XVFmzomRQETeSE8+iOQcCVrK8M9MDcrlpGLVkMzNi1ZNSiAp58mBEksVMEKmGiCYQEAgIBGaDgCCyzgYlsY5AYGEI2IiQ1vbZp+gnYplhbBSha/OQfO99pFBCuuqk2iia4xGwmC0YHBhEWellfPDO+2Qpvwa33/UVhISGwsfXx/EduMkRJsa1GOgbw7FDpRgenMDGrZlITo8icu3KsJgaGLago8eMmiYjRsatSE9UICVeibgo9yVxfZiasqCnW4cGUjiqqZlARIQasbGeyCTFnoAApWT1dZNTM++vOYgdFUUWF9e0GxFZOZC/ZcsWSbH1ueeew/PPP3/VVi+88AL+/Oc/Iz09HZ+TnRvv+8MPP8Q//dM/kbKtAnV1dVJywL4R7y8jIwNjY2P44Q9/iGeffda+aF6vgsg6L9jmvRFb0k2RE83ZUgPaukwI9CN7WYpzrM1QEQGb5+OCzTpvcMWGAoEZEOD4CqueHTX0gEkjge4qFJIaa5K77wxbiUUCgdWLgCCyrt5zL0buGAT4GX9w0IDTp4fpOd5EJCE3rF3rT3MAH6d9/rNSjGOyowMDl0l97+AB+MTFI37vPvgnJkFNc2xHNLZwHh41o7HFgIslk/DzkSHI34TW6iqY9ZNIImeT9OwYpGfFLnqxoiPGM5t92p9RWswTqCIxEy6wiXTzQqYiAHH0qiQyqyi4mQ2SYp2lQkAQWZcK6cU9zhUyph7trW1oqm+QiKwmkxmenp5YX7QRqWlpCAgMhEJ5hZh5o6PzPqY0JORQVoGaqhrUVdciMTkROflrafsUBIeGLGoR+Y36sFzf0dCl+9Olyxr09ZugN9iwLs8LazLUFLuTwaLXwTQxgcb33kHH0SNIvGs/IjYWwS8uDu43IQYv11jEcQUCAgGBgCMQEERWQWSd8bpaCURW+wD5oaC104ySagOaOsykRmPD7iI10hKIzOpHkzciXAoyqx2tub+WtdtQ0QXU99oQHwzsz3eDvyckMuvc9ya2cCQCOqsZPVYtPjC0Y4xs8NJJlTWXVFkz6JV1dEWq05Hoi30LBFYGAoLIujLOoxiFcyPASiWa3h4MlBSj+s9/QlBmJvKe+79Q+vpC7qF27s6vkN7pdDpUXK5A5eVyIrOWYduu7XjosSt27ss1RA7ytjX3o7ayHRWlrVS1L8eDT2xHdGywywd3eb5Glz0qG4w4eVFPtulWaZ7Gc7bo8CsqqI7EnbHl4/f2klrPuWF0dWkxPmHGbbeHI4+SwhxIdiQpcGhoiI5PHaD29ttv48UXX8SNiKy8/IEHHpCUWG+77Tb89a9/BSuxcnMnkntBQQH1vUsipDIxlduvfvUr/PznP8e2bdvwxhtvSN9N/++pp57CwYMHsXfvXvzlL3+ZvmjO7wWRdc6QLXgDvmxausyoazahuNIgKRjv3+1FlnQ0HydlD9EEAgKBxUWAblcwkF1vLSmxvqprQizZ9d6pikUwFQf7uq0MRbfFRUzsTSAACCKruAoEAouPgFZLBYAdWlRVjePSpRHs2xdOz/vBVMzkfMr8PNcy67ToPHYUfcXFmOhoR/S27ch64ptSUs4Rqns8v9TqrKiu16G+UUcWznoUrfdG0To1Ll9sQG1FGzrbB1GwIQV33LeB5nvu0nxq8c/U8uyRnflKTUNEZh1BnWUctymisFUVAR+ZgsisTGUV84TlOTPiqNciIIis1yLiGp9NJhNGhkdw7PBhlJMAQFtLG3bu3Y2v3nM3AgMD4OnlNauB8P3BRoJkleSG9d6b70Cj0UjiAXfddzcJCmRDTgXZjrhHzKpzDl7JaCSVciq2uHh5ipRZx3D7bn9s3eQDby83KBVXVMJaPv4QrZ98As/ISISQennMjp1Q+fs7uGdi9wIBgYBAYPkREETWY7M6CTJKYnKcctW1lURk5ZM3qbFiiKz3GttMZL9noQoXKyJC3UmtRIngAHf40MOBaPNDYFgDdJIi68VWksQ3yRDsDayNkyE94gpBWEyL54erI7aykHKIxmZCvWkMTWR/10g2M2kKf6xVkDKrmyd8KZghmkBAICAQmAkBQWSdCR2xTCCwOAhwIM+kncJ4YyPq/va69EAVkpOLsPxCBJA1k2iORYAJheNj43j3b++gk1RjomNjkF+Yj/x1BY498Ax75z4ZjWacP1mL44fLEJsQiqTUKKxdlwRfP0+XD+xOTlmlwsP6VnpOpZ/sFKWkxhodIYeXmtJsDp5QmM1WtLRo0dQ0icYGDfz9FUjP8EVcnCdCQlQSidXRfbCf/r/97W/4/ve/f1Mi68cff4xnnnlGWn3Hjh3Yv38/DAYD3nrrLZSSijMH+T+hQHdubq60zre//W289957+Na3voUf/ehH9sN88frSSy/h5ZdfRl5eHg4cOPDF9/N5I4is80FtYdtwkp5/fzp6zbhQZoTFQgq/YXJkpSoRT0rGogkEBAKLi4CZYiqsclZHKmdl5HiToQjE7apoeMAdCiKGiCYQEAhcj4Agsl6PifhGILBQBHj+wm4SlZXjOHp0ABnkIJGT44/oKDW8vUma34magVTlpnp6UP/mG5jq60X4+g0U2yhA8Joch81jNfR83NNnxJkLGujIwjk+RonUZA/ERinI2WQcTXXdOHeyBj40l04hh5OM7FhEUYHoSml6KrphMmsD5X8q6HmFp9PszrdeEYoYKsJRkTKrg6fYKwVKMQ4HIyCIrA4GeJF3b7FYwCTWy8UlqCgrR293N6mCeyCVnH5S09OQkJgAlYocYoiAOtvGMfDhoWG0NLVI+60lZdbM7ExkrslCbt7aZXXFmu0Y5rMeFyXrDRbUNuhx5vwk/P3kiIxQIDfbCyFBV+7jw7U1kpJ5/6WLJG7hh6xvPgmf6Bi4zQHf+fRNbCMQEAgIBJYbAUFkFUTWGa/BlUZktQ+WrSqbSZX1co2BqiyBNLKrTIhWIJqSPSoST5DLxRTOjtVcXsd1VGHfDjT0WtE1ChQmyLAuAZIyq1oowcwFSoevyxYzWgpm1JhGccTYDbVMLgUwcigBEy3zggdbzCxVpt7hoxUHEAgIBBYbAUFkXWxExf4EAjdHYKq3F+3HjmCsqQn64SEk3rkfMdt3SAErGVsKiOYQBDSTGvR0deO1V16FTqvD/vvvRgrZWoWGhTnkeLPZ6ZRGTwm3CZw+Vokzx6txxz3rUbgpDYHBPmTV5VyJytmMx74Ok/A4sdg7aEVJlQHDYxZSYwW2FnogK0Uhzdcc/Vyq01kwQeqrJSUjaG/XksKpDRkZPti8OYiUedwkVSN7f5fi9VZEVu4Dk1a/973v3bA7TCZ9/PHHwckAJrXu27ePEtyVeP755/Hcc89dt81vf/tb/OQnP0F0dDSKSSHJrgxrX1Gv10vf2z/P9MrPCIFkH/eP//iPM60mljkAgZFxK8prjWjtMmJwxIaifBUV7aqgVokYhwPgFrtcpQhwLEVvs+CUsRetFg3c6B6WrQxEkWL5ng9W6akQw3YxBASR1cVOmOiuSyHQ0DCJEyeGJAeJwCAVCvL9ERmpdngh4GxBYreZMSrQHSwvQ+eJ43Anm+msJ5+CX2IilN4+s93NrNfjORDxrNDeaURDix41dToEBsixe5sPgoMU8FS7SfOk7o4hnP68GgN9ozDojdiyaw3W5CXAQ62k+d/KKQbrsWip+GZMUmYdtRmwTh6CdBI1iZB5QuVGOSBBZ531tSVWdAwCgsjqGFwXe6/8t9VsMmN0dBS9VJhw4ew51FZVwz/AH+nkIrZz7x4EBARQfHL2BNbpfeQ4FJNkz5w4jVPHT8JoMCI8MoL2u4vEBaLhSw5lK7V19xpRR2TWtk4D9BQf3bnVFwmxSqg83GCenJRUzKv+8HsYSa026xtPIjA9A+rglVN4sVLPqxiXQEAgsDAEBJFVEFlnvIJWKpFVb7BhYopsObtMkjprfYsJ6UlK5KQrEEO2lX4+ghQw44Vxk4UmUn7R6GWo7rbhZL0NPqScFBXAZFYbogNYSEwQhG8C3ZJ/TWYNoGIvjFJVbodlimxmBqWAxmZlOJjMGuV2hcy65B0TBxQICARcAgFBZHWJ0yQ6uUIQYPs9TU8vOo8eQc1r/4uMRx9D4l374eEfALlavUJG6XzDaKxvRE1lNUouFpPaqS8e/vrXEBYRBqVy+SyDOdF24XQt+nso0WYwYedta5GxJpZUDuQOtbx39Nlh0mpbtxn1LUaJhBdJjhmbC9QICXST5mVLMYVoa9OipmaC1Fg1UsJ348ZAUmL1IkVUpTSHWYo+TMf5VkTWtrY2PPHEE9TfJmkzPz8/iXw6SQFubj4+Pvj9739P1qLbJHvMDFLGGBkZwU9/+lN885vflNaZ/t+f/vQn/Nu//Rspz4ZIhNdriaxjY2P4r//6r+mb3PQ9K3EEU0BdEFlvCpHDFhhNFOfQ2Oj3yIBj53XISCKSQIoKibEK+HmLubjDgBc7XlUIGG2k2G4z4h19K/qIGLJTGYlUhR8iyN1GNIGAQODmCAgi682xEUsEAgtFYGTEiM5OLRXljaGvT4877wxHepovkYmIorjMj4BMYrWazWj56EM0f/QB/BISJRXW6K3b4EHFbzJWmVnkZqJnYgPZNR8/PYnKWh0S4pRITvBARqoaHioZzY+ugKLTGjA0MIGLZ+pw8kiFVCSaU5BIricR8PZZObEWAxXg6GBBOamy1pKoyTDlg2Lk3thNzzCBMip6c3PdothFvnTE7pYJAUFkXSbg53hYJrFOTIyj9FIJDn18QCKscuxnw+YiJJNzGBc0X4lPzp9fYVdm7e7owqefHEJ/3wDSMtKQRw5Z6zaum2OPXWd1Jq+yivixU+Sg2mxAwVo10lPUiI5UUrGBBQYiD9eTW9tYawv8k5IRVlCIiA0bXWeAoqcCAYGAQGAeCAgiqyCyznjZrFQiKw/aRCo7YxNX7CtZmVXmJoOPlxtS40mZkuwrA/1YeWeZZ/oznh3nXMiKSp2k/lLRya/AFJGG1yXIkBImQ4ivDYq/Bwqcs/err1cmSsKQ5hRKjUMoNQ9JSqyRlIDJUwQjROYBL7f5Vc+tPiTFiAUCqwsBQWRdXedbjHZ5EbBSNbrVaEAXKZdUv/IKgqjKPSw/n4JW6+C5jOqgy4uK445+Rb3FghPHTpDN4Bl4enlSQDYZO0gBYLmq/60Wel6jJFt9dSeOfFIKP38vpGXFSCTW8MhAx4GxBHvW6qwS8a6U5mPdfRaJkMvzsXVr2IaMVCQdPHfQallNwoTa2knU1U3Cy0uOiAgV8vMDKAjPSjzLMx+cicgql8tRWFiIjo4OpKSkgOfsW7dulVSFzpw5Iymr1tXVSaTUixcvShZvmzdvRktLC374wx/i2Wefve7M/vKXv8QvfvELpKen49ix64MkZko+95DixmzaG2+8IRRZZwOUA9bhubjVakMTuc9cKNcT4R2kOCXD+hwPRIe7k70fhOuGA3AXu1xdCAxY9Wi3TOKMsQ8W+qXbr45DFLnaeAoSyOq6EMRo54yAILLOGTKxgUBg1ggYyJZYq7Xg888HpXnN+vUBSEv1RgSpsrK7xHI2PZFvxol40/n5MfQXX0LiV+9E+PqN8I2NhTsVwC124+fhgSETWtoMqGvUYWzcgk3rfJAYr0RQwBW3D/sx+bnZTFWVVZdbqWC0TnofEOiNjVszEREdSLEA1YoSZukkJfkWeoapNI/SM4wVce7eSJX7IdGdHF7gDvflZj3bT4x4XXUICCKr85/yyYlJDPT3obqiCq0UW+rq6ERSSjLSMjOQtSYbwVQU7bZIrmEW+rs8NTWFs6fOkOJrDYaHhpGSnoaNmzcgPCKCYqJ+zg/YHHvI9yO+f10smUJ1vU6KhcZEK7E+31uK6VgNOvSeOyspm48R/hGbNiH1/gfhrlA4pCBkjt0XqwsEBAICAYcgIIis1+dobgS0TKfT0S1k9TVOiqVSJc2jjz66IgfPDwZavQ1DIxYcv6BDGdnwZaUokZ2qxJo0BbzIZkS0uSPAqkpG+jlcZcO5Jitig2TIjKQEWqIMNP8XzckQYHXWEVZmNWvwibEDk1YT9qiikebuJ1XnOll3RXcEAgIBJ0BAEFmd4CSILqw6BEZqa9F16iTGmhrAqiZsxReclb3qcHD0gNnGymQy4a9/eAWHDxzCA48+ROoCGxEZFblsaqwmoxndnUMoL27GZx+XYMO2TNz3tS1QqhSUmFx8BRtHYzx9//1DFnLJMOPEJR3hDtyxwxOJMaQe6bM0BNL+fgMqKsdQX6dBd7cWd9wRgbVr/aFWuy8biZXxmYnIygTWjRuvKC8cPHgQubm50yElQm4ddu3aJX337rvvSuvee++9uHDhAr797W9LyqtXbUAfmOD6hz/8AVu2bMGbb7557eI5ff7P//xPQWSdE2KLv/IUEcS5aPfQSZ2kdHz7dk9JmTU4wA3uIsSx+ICLPa4qBCrNIygmRxudzYxQNzV2kJpZsNviE3FWFahisKsCAUFkXRWnWQxyGRHgPNeFCyOoqBijeasb4uM9sX59EDw9l3e+OFxXi7ZPPiaXmR4pjpH+tccQXkiqeg4gTTIGXJhaVqXFp8cm4O/rDiYCFeR6IjyUnTZufIImJ3QY7B/F+2+cJXLWIL5yz3pk5sQjIirQpZ1Prh0tJ7gnSVW+3ETXCamzVhGhdbsyAns9ouEFuSRwcu024rNAYCkQEETWpUB5/sfgv6ttra0oL72M9996l+JlamzZsQ0F6wolgikTWBfbjZVdgrRaLSrLK/H6X16j2KcCmWsysWX7FlJoTZ//YJx8y0EuxGg34OjJCfj5ynHvVwOoCMMdSrkNXBjSc/Y0Sn/9MqKKtiDvu9+Dwov+ejugKMTJYRLdEwgIBFYJAoLIKoisM17qK53IyoMncRnoyWqkhVRLWimJ2kfJVAUp7yTGyBEfLUdspBw8x73ZRHdGAFfpQp4U03MmmgaAuh7CdhBQkwtrYbyMSK1AqO9NogarFC9nGLaeLGYmKJBRRkGMVqrMnaKkTIq7L9YrQuAjU5C6iFBmdYbzJPogEHAWBASR1VnOhOjHakKAbYQmu7vQ9MH7GGuoR+oDDyGUlFk9w8LhJhdWcIt1LQwNDqGpoQnnTp9FW0srHnjkQawtzKMEoKdk0b5Yx5ntfmxUlT85ocXxz8rR2TYoJdJyC5Kwfku6pHbgRq4SrtgMRhsVFAIVdQaU04+PpwyRYXLkpJNSjh8FaZX/P3vfAd3GdWZ9QaKx9957bxLVuyzLVZZtKd124nizjpONz+45OanHmz85Ts76ZNe78WY3yZYUx4kdt9iyJFf1ShVSlEix994bQKLj/76npaxCgRUkQb5nQwQwM2/e3BkA877vfvc697jMZhtZlBlQV69H6eUh+PooERVF1l3pPggP1wq7yYXE1hGR9c0338Szzz4rTntbW9ttCQNWbI2KihKE7Jdeegl79+4VBNa//vWvYGVW3p4TEeONkw6PPvoo+Lf9q1/9Kp5//vnxRTP6K4msM4JtTjeykPuMkSxVi8tNRGQlhjgFM+Ii3bE2T0NqHkRmXVg+w5weq+xMIjBfCFipAJiteY+bOujRiTxlILJUAUhw85FONvN1EuR+XBoBSWR16dMnB+8iCLS2jJILg54K9YbgQ/ObHTvCEBSkJoeG+b/5s1GV4lhvr1BhrX7rDfglJiGSFOSCsnPgHRHpFETZ7aOhyYDqWgMqqo3IyfRANj3Cgim34Xnnai4uHDWMmVB0qhI1la0wk0JLcmokNmzLFqqsKvXSibeYYUOPdQx1lP8ppTwQz7p9FWoUqkMQ6+YFD4VSOjg45eqUnTpCQBJZHaGzsMt6urrR3NSISxdL6G8TuRh5ISEpCbn5eQiLCId/QIBTBjjultXV2YXLJZdRVVGJxroGITSQtyIfcfFx8PL2csq+F7LTMYMN3T1mHD+jg56U1mOj1EhP8UBinBoWgwG9ZVdQ8adXoPbxoZzASoQVFMA3PmEhhyz3LRGQCEgEnIaAJLJKIqvDi2s5EFnHATAYbegftAs1oNYOi0jwZCSpkJehIWVWBTSUTJVk1nG0pvbXSCTh3hHg4GU7uofsiAtWICtKgYwIuyALSzWYqeE4X2uxLV6PnQI9VI37iaENIe5arCIiazzZy7DSiFJBlXXzNRi5H4mARGBRIyCJrIv69MjBLVUE6HealVjLfv9btJMya0hePkJXFiJ81WooqRpettkjwBX/NVXVOPThIYyMjJDKgBb3Png/UtNTZ9/5DHsY1RvR2d6Pfa+fJmstAzbdlSOSapExwTPscWE342A0F7wNjdjR0mlBSbkRVQ1mbF2jRT7NuwL83KBWOfeO00wEv+FhE8rLh0Wit7V1FAUFAdi0KYSSvLR/UjBa6OaIyHr27FlBPOUxnjp1CgkJNweth4aGkJGRIQ5h//79WEGE9/feew9PP/20UBXm7cPDw68fYl9fH3JzcwW5lfe7adOm68tm8kQSWWeCmnO2aaPPWF2LBWcvGeDr7Y4d6zmR7w4fL+d+xpxzNLJXicDCIqAn55p+uxFHjO04Y+nGZ7SJVPgbCg8QOZxiJbJJBCQCjhGQRFbH+MilEoG5QMBotKK724h977bDTIVNGzcFIy7WEyEh82yRR3M+I82ney+XoqPoLNpPnUT8ffcj/fNfFMpxbqSsN9fNRHO87h4TzhWPghXtqB4U61Z5Iz/bc0q7oiGjvbUXVeUtOPpRKdlk+2L7vQXgeXdAkPdtxYNT6nQRr9RtI+cGy5AgszZbddigDkOOKhDhbp5CmVVmgRbxyVuCQ5NE1sV3Us0mMymi6gWB9NLFYnIxqoSNHKzu2/UgMrOzERkdJYrrnT1yi9kCckzGscNHse/NdxETF0MqsKlYS85Z4ZER0Gg0S+77Wae34XL5KOoaibjaZ8bKfG+sXuElOBWjbc1oOvQJRsipyTQyjJRH9yJ89RooqFp5rlVxnX1uZf8SAYmARGAyBCSRVRJZHV4jy4nIarXawRNetrdsaLXicpVR3BiEBrmjIFONuCgl2fBJMqvDC+aWhZykHiNMG3sVqOywo6QJSKOc6bpkBcL8AB/pvnYLYgv7knWZWGGkhwIZV80DqLeNoNWiwzZNJAqI0OpLyqwqmaBZ2JMk9y4RWCQISCLrIjkRchjLDgEmAXaeK0LXxQvoKy+HP1XBZ33lq1D7+cFNSuzN6npgEqvJZBJKrH/835eRW5CHDZs3ICklGYFBgbPqezYb11S2oeJyk1CG8fX3wj27ChEaHgAt2x24YLNRRnHMCFQ3mHDsnBEeWgWiSIk1M1mFyNBrJFZnK6F2khJrY4MeF4sHiFRrR06OP9h6kxVZlUq2RFt4YB0RWXU6HbKysoTiKiusvvzyy0IVg5VVB0i5+dvf/rYgrvrR9wKTRrRkM8bXdmZmprBm27JlC1577TWRdLCQPckTTzyBQ4cOCRXXM2fOEAazUxySRNaFv37GR2AwUqFivxVnSozoG7KS8rEb8kj1ODv1ztaq49vKvxIBicDNCLRb9bhg7kWndRRjsOIudSTSVf5wJyLrIvjZuHmw8pVEYBEiIImsi/CkyCEtOQR4bjM8bEHR2T60dxjEvCYvz5+K9vzn9VitRiN07TSPJdW40e4uBKVniALckIIV1+IWczzhYhJqRxfZMRPp5+xFHRVHKrGm0BsRYSqyZJ7a3IZjLUaDWRSRFp2sRHfnACmzWrBxew4KVicLdxZnz1Pn8yRxDkhnN6PSOiTyQAM2I4LdtNiqjkC4uyc8SZlVNonAfCEgiazzhfTU9sPx0c72DlwoOoeKq1fRUFeHgpUrkU0F0AnJiQgIDBRxpvkgTgplVosV7EbE7llnT55Bf1+/iNdm5WZTof+17+epHZlrrMUOOwMUvymvHMPRk8NIS9ESkdUboaQurrHrMdLagqYPP0Dd/veQ+7WnEX/PvVCRUq4zikRcAzE5SomARGCpIiCJrJLI6vDaXk5EVgaCJ718k9BJZNbLlWZ09FgwQtUv6YkqJMWpRJLVQ6OgpJ9D2OTCGxBgMusouRnWdJLabSWgJCebMF8gN0aB2CBAQ3NiiecNgC2Cp2N2C3ptBlwie5mz5m4kkiJrkrsfMpT+CHTXQEWJGtkkAhKB5Y2AJLIu7/Mvj35hEdB3dqK/sgLVb7xOgSpPpH3288JGyCPYNRU6FxbNT/duIIumtpZWnDtzDgf3HcDO++/B/Q89AG8fb1Hh/+ma8/PMQoFaTpydPlaOkmY2WV4AAEAASURBVHO18A/0RhLZG67ekE72Wa5ZDcbzAibW1TabUdtkJjKrBck0x1qRpQYXD3p7OpcKZDLZiMhpRUXFCGqqh0nh1oqwMC3WrA1EUCBZbnrMv+Xmna4mR0RW3obJq9/73vfE5sH02V+zZg16ybrzwoULsJJKBreXXnoJe/fuFc/5H1ZlfeaZZ4i8awOTXAvIgqyiogJdXV3iGj948OB1JdfrG83giSSyzgA0J26iJ4vVynoz6posVLBrQU4qfeayNfDzVhCRXM7rnAi97HqJIMAFv2a7jVTLBvGhqRU+FBFJUvoiSxmACCJ6yCYRkAhMDQFJZJ0aTnIticBsEWBV1qamUVRX61BWNoycXF9s2ji/zhNDDfWi8Lbhw/eh8vREyiN74JeYBM/Q0Nke3m3bcy7PaLKjtEyP2gYi0OqsSIjTYPN6X5rjKCgXNb05pl5nQH1NB8pLyUr7fC1WrElFwapkUmYNctl5+G2g3fAGF+o02nQiD8Tq86lKPyTTI9HNB2o3dyrYmR5+N3Qtn0oEpoyAJLJOGSqnrsixJC6CbmlqItJoDS5fKoWB1FC5OHojFURzwb+npxeUqvknunPMVq/T46ODH6KivIKKuT3JPSsNq9evgb+/P30/ezkVm/nsnHkqrCpeW28QRFaVyg0hwUrkZXkiIkQBu9mI+v37UPHKHxF3905Ert+AgLR0aHyJeCGbREAiIBFYQghIIqsksjq8nJcbkZXBGCezGol8WVpBdiSXDaTUCpFc3bZGg4hQJTRqOYFzeOHcspBvuobHgJY+O87U2nGpRYH7coDCBAXImQXq+b/vvWWE8uWNCHCixkqJmhaylam0DlIgox8GUhzZpYlFChFafd1IwefGDeRziYBEYNkhIImsy+6UywNeRAjYKbDI6iZXX3kZYz098E9OQcSatQhbWbiIRul6QxnoH8DJo8dFhf9Afz+27tiOLXdtFaqV86EycCtio3ojhgZ0OPDXIhQX1eDhz28UCTS2NVRyZZgLNiM5NfQN2PD+sVH0kkpkQoxKKLFy0aA7JRjnWJjnNoQGBigg3zKKoqJ+1NfrsW1bKKmU+pLVphpqNdtw3bbJgr3x5ptv4tlnnwWTVMvKygT59MbB8DX55z//GS+88ALZh3bfuEgE8Z9//nns2bOH5rZ8Z/9pYyXW5557jki8+utvRkdH4yc/+Qnuvffe6+/N5okkss4GvbnflpW5OLlfVmPGB8fGEBbijjT6zGXQgwnkskkEJAKOEbDCjhFSLCsmNdY3RuuxWh2Kh7Sx8CLHGq1CfoYcoyeXSgQ+RUASWT/FQj6TCDgTAaEsarTRHGII+97rQFKiFxW9BSEiQkvFbCpn7vp630ywaTl6BApSLwnMyETy7kegoUI6tj6e66YftaF/gO5zDw+RCq2ZCKw+SE3SIjyUpDioZmu6c3m+d2Yr68slDfjkYDE5NrojhKwFt92Tj5j4uSfizjUe0+2P73NGSdSkjPI/5ZYBlJNLX74qCPdoosmdTw1PN5m4my6mcv3pIyCJrNPHzBlbGElNm11+9v/1XVy5dElwJQpXr8Ld990LXz9feFBhAn+nTvd7dS7Gyr9tXJTdQUqxV6+U4503/gpfIm7uuO9upGWkISYudi52s6j6GBi0oqXNiIulo1SoMYaH7wtALpFZ2USp63wRmj76kEitZniGhSP5kUfgHRW9qMYvByMRkAhIBGaLgCSySiKrw2toORJZGRDO9/GNUXu3Fc3tVtS1mDGisyE40A2J0ZT0SVZDo6KKTjmPc3j93LiQBKWgIwWmK0RiLWm2CyXWSD8isyYCwT4K8frG9eXzhUeAkzV9pMzK9nnN1hH4Qo0UqshdoQ6GlupxVQqp4LPwZ0mOQCKwMAhIIuvC4C73KhEYR8A0PIyOs2fQc7kUfRVXhY1Q4gMPwl2jhZu8QR2Hacp/WXGgtbkFb776BrjKPzc/D9l5OcKiasqdzPGKzQ3duFhUja72AWFxeNf9K5CSHgUVVYC5mqUhz604IVhDipDVDWa0dlrg5aFAQZaWHC/cEeTv3HtKi8WGkREL6upIaebSkCCs+vqqwDabUVFaUpRQivfm+BTOS3d87V4lq7c6snrjoH5ycjLS09Ph4eFxx/2zygZv09jYiJycHMTHx99x3ZkskETWmaDm3G34M9hGn7vLVSbhPjNqsGN9gQYp8Sp4ahWCSO7cEcjeJQKuiwA71pQRsaPGMoR6iousUoUI212Oh7jJEl/XPbFy5POOgCSyzjvkcofLGAHOa7Eq6+nTfaSuZyM1PXdyoQhCfByTkJwHDMcp9B0dqD+4X8QqojZuQnjhKgSmZ1CsQjOnO7bRMdrIiKK2gVzlykZpvmelOZAb1hb6ICJMCU9y25jNsXa296Omog3llxsx0DuC1RvTkZoRjYjoIJctLL3TCbCQoEkP5YAa6D6n1NJHSoB2IWTChNZEd19RuCOVWe+Ennx/LhCQRNa5QHHmfXBcaWx0FFfLynGl9DJ6uropRuCGpJQUpGVmID0jHe4Ua3Z3QjHCdEc9SuPsJDLr6eOn0d7WBt2ITqiyrihcgYCgQIexsOnua6HXN1JRio6KNYou6HC5fAzpqVqkJGqQGKeFpa8N/eSw1HLkEEykVJv1xJcRQLFAlZc3/fY58Yd+oUGR+5cISASWFQKSyCqJrA4v+OVKZL0RFDMpB5WQMmtZtQlNbRbERyuxZbUHAinh6utFYWu6J5D3BTci5vh5xxDQ0AMcr7TBaFHgHlJmTaJiVlZmpVouiaVj+OZ9qY2qcqspYXOVEjfnzT2IdPPCvVSRG+ruISz13OTFP+/nRO5QIrAYEJBE1sVwFuQYljMCdosFxsFBNB8+hNJf/yfidu5E2ue+AI+QEKi9fZYzNDM6dlZjrbpaiVd+9zICg4Lw1a8/hdCwMHiSVdV8t3EFmJILddj3+mlExwYjMzeOHvFCCWa+xzMX+zPRfGqMiHMnLhhRctVA5FUl0hJUyM9UE6HVuSRWxnOUAr8tzXpcvjKE8+cHSJEoEOvWBSIwkBRmiMQq29wiIImsc4vnXPVmJBKDfhQ4dGYU50qN2LjKA9kpKvF5ZMcZOa2bK6RlP0sJAda0HrAb8YGhBd22MUS4eyFbGYAsesgmEZAITA8BSWSdHl5ybYnAbBEYGragldwoioupGKNGh127IpGbSzIVTnKisFNR3VB9PbounEPn+XMwULwi92tPI3TFSripVHSvObfEGrPFTve2Npw9r8Oh40MoyKHf6AwPIvho4O09e+VXm9UGi8WK9985h+JztQiPCkBGdiwK16XRHFIDNyJ5LbU2YDOKPFAJkVmZ0HqXJgorlEEIVXjAy43O4VI7YHk8iwYBSWRdmFPBRQ9Wii8PDQ2hg0ihRz45jFPHTyAzOwv5K1Zg07Yt8A8ImPPv79keLSvH9nb34MSR43jztTexau0qrFm/lr6jM8nVKEiQbme7j8W0/eXyUZRSwYZ+zIbQEBU2r/WGnzcVc4zqcfHfXhQCFxlffAyhBQXwiYkVauiLafxyLBIBiYBEYKYISCKrJLI6vHYkkfWaOmv/kA1tXRZU1pnRP2Qlaz5gVY4GGUkqeHspyGJETuMcXkg3LBwj7IbGgIuNVBncC5BAEjIjgY2ppHDrZoeSbEVlWzwI2InIqiMFkjYr3RSTMisrtHIyZ40qFHnKQKhJhcRdKrMunhMmRyIRmCcEJJF1noCWu5EI3AkBCjZaKHDXQ1ZPNW+/IZRYfePiEbNtO/yTku60lXz/DghcKDpP1oGX0dzUhISkROze8zB8fHwo+Dn7BNgddnnHtw10s9zc2I2ykkacPXEVazdlYP3WbPgFeJGygPqO2y3WBXSpCgVWVoJs77LCQA4NhTSPSo5TIsDXjdRsnHvvz0qsra1jOHOml9R2rQgL05JiqS/i4z2h0bg7ff+L9bw4c1ySyOpMdGfeN3ELYKbJdwXFNK7WmDE4YkNIoDsV6WoR6MefhZn3LbeUCCxVBHTkUtNuG8V7hiahTrZTG40Yd28EKuZWVW6p4iePSyJwIwKSyHojGvK5RMD5CLASq8Fgw6lTPbhwgezi8/2RkeGL6CgPaEmtdC6bjYhQZlLJaz91ApV//hP8kpIRmpePsFWr4B0Z5RRSTXevGZeujKKtw4TBIYtQYs1IJcKlJ+XqVLMnmTLBy05FkY11XVT02oLSi3Vkre2FzXflIIqKTQOCll4BsYmUWYftJqFCX27pxwjlhLwVKmzShCOa7n+8yKGPhWhkkwjMNQKSyDrXiE6tP1ZiZXXT8itXBIFVSUEBLurPzstFErn9hISFUvHD4otDssuQiWLiDfWNuHShGPW19RgbG8WOe3ciMydryZFZ+wYortlmwhkq3LBY7di8zgfREUr4epKb8DvvoKf0EpReXghbuRJxd98jndqmdvnLtSQCEgEXQEASWSWR1eFlKomsn8KjG7WjocWMynozymtMIvmaEq9GXCQlYf3coFZJFZNP0XL8jMmrjURivdpmw6VmIMKPiJFJCkQFKBDgZYdU+XSM30Is5QQOW+lVWAdx2dyPXCKx8iNa6Q1fqOQ5W4iTIvcpEVhABCSRdQHBl7uWCNyAwEhLMzrPnRO2fWM93Uj7/BcRVlgIpdbDKcmiG3a9JJ5aKOHGj/fe3ocSCn4mJCUgKzcbhWtWLUiwloOxA306IrCSPVRjD1l7GQSJdc3GDJdUS2SVnCEiy1U1mFF0yQgfbzdEhrqjgJRYI0KUTj0mKwV3LbT/ujodamt1qK4eQUiIBuvXByM0VAM/P9WSuIYX40FIIutiPCufjqlvwIbmdjPO0GeSP6PrCrSIj6KEVdDcEho+3aN8JhFwXQQaLSOotg6hmIp6A4i8+qhHAv1VQymLeV33pMqRTxmBcfVEJnPNRZNE1rlAUfYhEZg+AiUlAyi+OEiW0ApERGqxenUg/P3VczoXM42MYLCmGu2nT6Hhw/eRtOthJNx/PzwCg6D0nFuXE3bc0OkpT9dkwKlzIyQw44aoCBVyMj0REzX3hKuxUSMRvfrx0f6LGBrUIzYuFJl5cUjLiiHCrDvc3GZPmp3+WXXuFt0kZNJkHcYFIWpiFEr0KUpfJLj7QkP3QEosvWN2LqKy98kQkETWyRCa++XDw8Po7uxExdUK1FRWERm0DplZWVi9bi0SkhMRFBw89zud4x5HhkfQ19uLT97/GFdKLyMtIx0ZOZnIzc+Dj6/PgsR15/gQRXcc29TpbPj42BA6u81EYlUhNdkDaUlq9JddRnfJRXScK0JQRiaynviKILW6L0ICsjOwkX1KBCQCSxsBSWSVRFaHV7gksn4KDyuYGE12tJIyazUlY/nBFpmbScEkJU4l1EyW4Lz1UwDm8BnHQI0WoH0QOF1jR/ewHWYrsCNTgbxYBQVWIGs75xDvuejKRjqsBrsVtRTEKDJ1o5+sZjQKd9xDFjNJFMhQiYrcudiT7EMiIBFwBQQkkdUVzpIc43JAwDI2BiNZQFW99mc0UsIo7QtfQvSmzUL1xF0j1cImuwZG9Xpw8PaV3/4RV6+U40tPPkb2WQXwDwyg+9H5J3WNkRprC6mxvvnHY2L/m3fkUgA5nGwMAyc7lEW5fIQSjCVXjahtMpMqqxWr8zRYnUtWj6SSw0WAzmyjoxYK9FrxySddgszK6kMpKd708CElVnIUkC4QToNfElmdBu2cdMxJkBEq0j1dbEBzh5XS0HbkpmuwNl8zp4SGORms7EQisMAInDB1EomjB76kRpZI5I3V6hB40nPn/oIt8EHL3bsUAqOkgHjmzBmyDi9Ge3s7oqKikEUkhAceeAA2DmTPsPF98AsvvECFQNV4+umnsZIUnmbbJJF1tgjK7SUCM0Ogp8eIpqZRnD5FqiL0A7b7oUgitHoQwWfuyIhcYFv1l1eh7+iAytcPcXftQPjqNUIVTjHHCTOT2Y6qmjFU1RpQXWdEWrIG2zf5wdNDIeZ5M0PpzluxKusokVnrqttxpaQB509VkmtKJu66nyyc/Tyh1c49efbOo5mfJWZSZjXCigrLICr/7xFPiqw7NdEIctMKldb5GYncy3JBQBJZ5/9MM/Gz+MIFXCw6R9+dWmzcuhlp6emIjY8TBFClavEXf7MYAIsT1FRW48qlyyg6fRb+AQHY/ZlHEEfHERjkmrHUW68G5lOwynpdo4l++8ZwtWpMFG/s3ErK4EY9+squ4PJv/gOeYeHIfPzL8ImOgTZwaRz7rVjI1xIBicDyQkASWSWR1eEVL4mst8Mzorehp99KqqxmtHRY4KFVIDpcicwkFSmzuotJ8+1byXcmQmDEANR121HZweqsQHY0kB4BJIQo4KOdaAv53kIj0EsVuaxKUkb2Mu3WUaSq/JFCCR1+aN24HlemdBb6HMn9SwTmAwFJZJ0PlOU+JAKTI2CnBDXb+DV+8D6aPvkInqFhCMrMQuz2u6Dx95+8g2W+RnNjswh2cgB3bHQMn/niZ5GakUbKKkRSUcz/PU1tVRsqy2hMJY2UXAzEzl2FZFnoDQ9P1yMl9w1aBXm1uMwIExWwsdpjVooaybHXlFidBS8r9JjNNkrWjqG8fIjUGUykTgwUFPgjLs4LgYFzqz60zD9CEx6+JLJOCMuietNMn8mGVnLcaDTjaq0JcVEqrMrRIDjAHT5e8//dt6jAkYORCBACRiriHSUCxyfGVpSSI806FamvKf2Fra5KqrHKa2SRINBBhLGHHnoIbW0UUL2lJSQk4LXXXkNMTMwtSyZ/yffAb7/9Nr75zW+KlX/1q19h9+7dk284yRqSyDoJQHKxRMBJCBgM5PrRb8Ynh7rQ32+ieVEAEhO9EB3tMes9smKzvr0NvWVlaDiwH2pSwIvZuh0BRIZiIs1ct9ExGwYGLThXrEdHlwkB/kpkpHggN8tTFGQ5a45psVgxMjSKCpqrnzxcRkp/HoiKDUbeyiTx192dMiLO2vlcgzjF/mx0bnvt1/JAxZZemGAT6vRZygAkK/3gQaIm8p5oimDK1SZFQBJZJ4Vo1ivw9zUXOfV0d6OuphZVFRVobmyC1sMDcQnxWLVmNcLCI4SS6ax3Ns8dDA4MoqWpGccPH0Nvbx+RWf1RsLIA+YUF8KDj4xivqzd2nRoathKZ1Yhjp4cREqREfo4Xooib4j7QjMpX/wTLqB6+sfGI2rgRwTm5rn7IcvwSAYmARACSyCqJrA4/BpLIemd4Wjup0ocSP8fOGaAlVZ9NhWTJF60Udpm81RKbu94ZiFkuoVwzSprs+KTMDjvlzEK8SZk1S4GYQAVZs8yyc7m50xA4beoSyiR9pMwa6+aFXR5xIpghAxhOg1x2LBFYVAhIIuuiOh1yMBIB9FdWovtSMVqPHYXGzw953/g7eEdFw20BVEVd5XRwEPfc6SK8++Y7CAwOQkJSAtZv3kAEUqqqmufGY6H/8fH+Cyi9WAe/AG+kZ8diHSm9qDXKeR7N7HbHx8GtrNpEBDkzqsjFIibCHbu2e8LX283pSqysUqDTWXD2bB/e/6ALK4jAmpPDaqw+8PNz/eD1NXQX97+SyLq4z8/46DgRUttswf4jo+JzmUCxjJxUFWIjmcg/vpb8KxFYnggM2k1os+pxzNSBBnKl+aI2BTlE3HCnDwf/J5tEYKERYPWpNWvWgMms/lS89tnPfhaRkZE4fPgwTp06BVaoysjIwJEjR6atzMrE2K1bt0JPzgXcJJF1oc+23L9EYPYIMJn19Ok+NDToKd+ioO8HX/oOCZz1PZ+dvmtaTxxHJ1ka910tR9iKlch56mtQenrOeXKM55ldPWY0tZgEiYdReehef8REaeDlOT9JpK6OAVy93ITSC3Voqu/Cnsc2o2BVMhGl1BR7mZ8xzP5qmF4POlhQaxnCOWM3Tpq7cJc6EhvV5Brj7iFV6qcHpVzbAQKSyOoAnDlYxDFHvjc0Go0oLS7BB/sPoKerGyqyn9/zuc8KZypvKkRYCGeqOTg80QW7FNRW1eLMqTP4cP/72LhlIx7asxthEeHw9vZeMsUGre0mnDw7gmGdjQi6Cqxf5Y3YAD06z59Dd8lFepQg64kvI+H+B6mof2n+Ls3VNSP7kQjMBwJc6MTz6jfeeAM1NTXi+2jdunVYvXo1POl+mb+fp9Jm0o9SqaT7/9M4fvw4uqmIITc3F+vXr0dqaqpQs75xv+xY+PHHH9/41m3PH3300Zu+S8+ePTthUe34hhyPyMzMHH85o7+SyCqJrA4vHElkvTM8+jE7WGmoup6tMi3oG7IhLUGFrGS1UBzyIstM2SZHgL+je3VASx8RWpvt6Bm2IzMKSAtXICkUUErbz8lBXIA1ukiNtcmqQ7G5F2OkVBJJZNZsSuxkkEoJ/6DKq38BTorcpURgHhGQRNZ5BFvuSiIwBQRMQ0MYbm5C5Wt/hnFoGIlkJ8rKrL5x8VPYevmtYjaZwRP0Y4eO4vU//QU7779HBDkjo6Pg7UNVVfPcRobH0NszhMPvl6ClsRub7spBelYswqOINONiZGR2r+gbJJJwqUHMkRKiyY45xh2pNE/SkH2ls+Ko1wLzQGfHGC4WD5IKg4mC9BYU5AcgJdUbvr6qObXPnOdLxKV2J4msrnG6eB4+MGyj4lwLqsmirrndgk0rNchO1cDHWwGVUs7oXONMylE6A4EaImycMHXCRMqsPu5qbFCFIZYsdaUDjTPQln3OBIGioiI88sgj8PLywgcffICkpKTr3bz77rt45plnxOtz586R6iLZX02jPUDzCFZPHW+SyDqOhPwrEXBdBCwWO1pbR1FdPYKS4iEkJ3thx91hRMB0n/EcyUzKbxyHqHzt1esk1rCVKxFasBJuc6x+xwVYBqMdxaV6FF/Ww99XSQRWNXKzPem5O5TzdN86NmokdVsdLp6txuXieoSTi0pyepQgs7JK61JTZeUr3kz3QsN2M+qtI7hCKvU6ek60XaxVhyHe3Qe+ChXcZBWc6345LJKRSyKrc08Ekzy7OjtRRCTPxoYGDA0OIiklBWkZ6fQ3GcHBIURqXRhnqrk6cispZw/Rb1JNVQ2KTp/FMMXGVSoltt+9neKrmfD08nS5+OpE2OiIwNrSbkRZxRiu0GPrBh9kJlL8xtCHzpNHhDJryqN7Eb/zHniEhkLl6TVRN/I9iYBEYB4Q4PtCnrc/8cQTIg914y59fHzA8/Z0cjGYrM2kH97mb//2b/Hee+/d1j0Xwf7yl7+8icx66NAhPP7447ete+MbdXV1QuWa3+P+7777bpSRK8OdGscknnvuuTstntL7ksgqiawOLxRJZHUID9iSb2DIivIaE05dNCLI3w3xUUqkJakRHuxOSq1SVdQxgteWkqMBKB6BIxWk3tRqJ/IqBIl1Dd2AeWsBrRRPmgqM87oO6YaBK3LPmrpFVW63dQz5qiCsJss9Pzc1VeS6lnrYvIIndyYRWAIISCLrEjiJ8hCWHAImImZWvvpnDNRUwSM4GBFr1iF685ZrFdgysXDT+R4ZHkFtda0Ibh7+mCbqX/0ykVl3CrspN2cxLW8awacvbGRP0NzQhXJSdqmtaKUggg0PfWY9ElLCKSFHN8Uu0pgUZzbb0dJpRWW9CQ0tFljp2O5a5wEms3pSkZ+zaHG8b6uVCLREXq2r1+PM6V74+KiQlu5DSqzepFA2e9tMFzkNi2KYksi6KE7DlAZhJlLDqMGOsyUGcpoxCkXW9EQVkuJU8PFii9QpdSNXkggsGQTYRtdIhI0Sax/2GZqQToW6eRTnSCCihr9CvWSOUx6I6yPwi1/8Ai+88AK2b9+OV1555aYDYtvYcfIqK79s2LDhpuV3esH3wD/72c/w0ksvYdOmTUR6ayX1xgapyHonwOT7EgEXQoDnS6zKWlurw8GDnQgKUmPt2kBERXkgIGD6v29cRKhraUZfxVU0fvQhjESKyn7yKWFlrPH1nVM1Vh77iM6Kzi4zzl/SoarWiI1rvJGV7oGQYCpWJEW6+W7lpY24RKqsbS29VDDpie33FSAqJhhenMhaoq2fXPlaSa3+DLn0Ndt0KKD7o1R3PyQofaGFO6RLn+ueeCajcJuqKpwzjlQSWZ2BKsXoqIjfaKQic7qnq6mqxtkTJwVxKZKKnNZv2oj8lSsEuXO+46DOOdprvfb19ol47+kTp1BWegXbdmyj4yxAXEL8kiCzcmEHx3HOntfh0IlhZKRokU6PpHgNBs4dQdn//jeCsrIRXlhIKumF8AwLcybcsm+JgETAAQJ9fX1g9VWdTofw8HDs2bNHEEH37dtHxWXVCAwMxPvvv4+YmBgHvQDT7Yd/13/yk5+IeTx3vHPnTjGO8vJyvPPOO+J34KmnnsJPf/rT6+4t//M//4N//Md/RGxsLOLi4m4bD6u7/v73vxe5M17IrxMSEoTaLMcOJmp79+7FZz7zmYkWTfk9SWSVRFaHF4sksjqER1iAmsw2UjKhpG2HmSw0zfTXSiomaqQnKkl9SElkVinf7hhFniTRg1bqHgbqe4BjlTYiryqwgr4rk0mVNSpw/gMSk41ZLgfRWO0YoiBGlZXUSoyd0CjcyFbGE2tUIVSR6+s0soLEXiIgEVh4BCSRdeHPgRyBROBWBCwGg1BC6Tp/Hs2HPxEk1syvPAmlRgs3mlzK9ikCbS2tOLjvAPr7+qHRarFl+1bkrci7pio/j8wtJrEyAbPoZAX2vX4aKaTmkp4di8zcOAQG+7iUoovRZBcFfsXlJhw/bxDzocwkFeJpPuTn4w5nOi0yjmMGG06e6EE9EVl55pBMBNbCwkAKELlBo3EdQvCnV6nrPpNEVtc5d/TRgY0SIU3tVlTUmdHQaiIygBt2bvRAZKg7qSjLebjrnE050rlAgEmsHbZRlJj7cMTYju2aSNyljYIHETSUpD4mm0RgsSDAiaaLFy+C1VMffPDBm4bFyZ5t27aJJFNFRYWwLLxphTu8YLUYtgv08/MT9oOs+MqqK1KR9Q6AybclAi6GAM+ZOjoMuHBhAAMDZkpc28leNIiUoHymdySUyLGRRXXzoU9Q9fpr8I6KQkByCqK3boN3ZNScxh6YWGe3K1DXaMSxU8M0d7YTcdQdK/O8EBetFmqy8zh9v46TbmQMXR0DOPxBCdlzk7JhahSy8uKRnR9/fZ2l9oSuGFKqt6HKMigetZZhBLtrsVUdiQg3UsYlYRPZFhYBdvNh4oqa7OK/+93vXienOBoVb8OFMUyoefrpp7GSVJVvbdOxJr5126m+lkTWqSI1vfUG+vvR0d6Bj9//QBBZo2Io5kg2zwV0noNIAMHL24tck5bWHMdsNmNsbAyXLl5C8fmL9F3dieCQYOze8zAVHNC8jqy8XbkJLgX909RixtWqUTSLGI4CO7dTUcFQHTpOnsBQQ704xMzHnxBuba58vHLsEgFXRoCJoTxv5/k1u6iME0RHRkbEfL29vR2f//zn8eKLLzo8zOn200/f/StWrIDJZMKTTz4pilXHi1V+85vf4Mc//rHYX3FxsSDY8osf/OAHgqj6r//6r/jc5z7ncDy8cJCK2DLp9ySMyPKlpaVTuueYtNMJVpBEVklkneCy+PQtSWT9FAtHz0yUuNWTksmVSiMq6kmmlVpIoDsyKHkbHuKOAN+ldTPoCIvZLDNTMKJnBDhTC3QNUVKNEmt5sQpkkwuWF82F1ZKDMRt4nbKtjcisHdZRXKJET7NVh0G7ESuIyJqq9EMkBTE0CkkccArwslOJwAIjIImsC3wC5O4lAhMgYKdkEiuhdF44j8o/vwLfhETE33sv/BOT4Ul2QrJdU5jQ6/SorqzCG6++QYEEX2zYsgnJqcmIiIyYd4hG9UZ0tPWh+FwNTh4qw/Z787FqfRoCQygAqXWNRBAHUVkNoLffijJyqWjrsqKHnq8r0CI7RQ1vUnUkNy+nNd5/V5cBLS2jKC8fhl5nESTWlBQfJCZKCy2nAe+gY0lkdQDOIl00NGJDz4ANpy+OoZf+5qSpkRKvRmykO1mFLtJBy2FJBJyAwKDdhAvmHjRadBiwGbBZE0GuMyFUICE/CE6AW3Y5Rwiw4oqV5gHD5M5w6dIlfP/730dTUxN27NiBl19+eUp7YZUYVlLp6urCb3/7W9x3333YuHGjJLJOCT25kkTAdRDQ6a30/aDHVZo3lZcNkapzKPIL/InwTgUbyqnlr0yUfB9pbkbriWNo/PADijnch+gNG+ETFw812aTOZTOR40dnlwnVdQYUXx5DTKRKKLHGRmvg77dwOQeeg47qDbhYVI3q8lYM9OtEUeq6zZnw8fMk1T/NXMKwqPrqpfsjVmY9Ty59epI5CVJokaHyRwrlgjyp7Ecqsy7c6eICl127dpFNfLCw+mWFdkeN7x/efvttfPOb3xSrTVS4wutMx5rY0f4cLZNEVkfoTH8ZEzl7u3tImbSGvu/Lyb2oVxTK568oQCrZWCenpggl1un37DpbtLW2oY6cuM6eOgN25crIykBmTpZ4MIGbH67choYp9tprwamiYfQNWLC20AeRvjp4jnWg7r13MVhbg8zHnkDYykKo/f3h5uLH68rnSo59eSLARQKsxtrQ0IBvfetbYo5+IxK/+93v8MMf/pAc5XxQWVl5RzGTmfTDiq9f//rXRWEr9+3h8alTHf+uZ2RkCCLqc889h2eeeUYM6wtf+AKOHTsG3raQFJ0nayUlJaKolmMGr7/++mSrz3i5JLJKIqvDi0cSWR3Cc9NCnsCO6G3o6LHiwxNj6B+0IjVBjbx0NbJSVDetK1/cGQGzFRjQ21FUD+wrtqMwQYENKQrEBivgqyWQZVt0CFipGtdEVblHjR04bupAoJtGBC+2qCMQQM9lkwhIBJYeApLIuvTOqTyipYEAV1cOkApTzdtvwqwbgYomw4n3P4iQvPylcYCzPApO8re1tKG0pBRv/+Ut5ORl4+vPfoMUOzVwV85/ELO7cxCnj5WjrbkXw0N67HywEAWrU0gRwXUIM1x4pqM5UFW9CfuPGODvS/fuKzwQF+WO0CB3CsTM8qQ52JznX3zNnz8/gNOne4XFQ1S0B7ZsDkFIqMalcHRwmC63SBJZXe6UCYcUCxWVnr1kRCUps+pGbaIod8cGSkfP/1ej6wEoR7wkEOBoUxsRM9401Av3mQJlkIhrxLp7L4njkwexdBHg5FZeXp4goY4fJdv8HThwAP6UuJ6ssdLaE088IVRiWBGGVVi4TZXIyuRXVmSZrHV2duLIkSNC4YWTZ7JJBCQC848Aq7BaqAjxBDlZ7NvXgU0bg1Gwwh8RER6CzDqVEQ03NwkC62BNDUZ7upH1xFcQvWUreOLHyfG5bCM6K06fG0FDs0nMOVev8MKG1d5injfHu5r2sO2EpZ7IrOWlTXjjlWMIiwjAeiKyJqdFISwyYNr9ucoGfL80ZregiQRNLpp6cNTcgUJlMKnYRyFC6QkfyDzofJ5LvgdgQh4rqvJvOSupT5XI2tbWhq1btwpbYB7zrURW/jxP15p4pscuiawzRW7i7Xq6unG+6BzOnDhJRM7TeODhh7B521YkpiSTqrXvklNhnQgFjhWO6kdx+sQpocxaUV6B9ZvW4wtPfFE4c7FysSs3jodyDOfQsWFR7OFHYmrpyR5YmatF2f/8Gi1HjyD+7p0IX7UagRmZcKe4t2wSAYnA/CHA30GxsbGi4HT//v1CIfXGvY+7qPB7H3/8MbKysm5cfP35TPrh+fzPf/5zbN68Ga+99tr1vsafPPXUU3j//fdx99134w9/+IO4j2BF9tbWVrCjC8cQGhsbxd+QkBCw0jWP48b21ltvCYLuV77yFfzzP/8zenp6REwgPj5e9GexXBN9vHGbmTyXRFZJZHV43Ugiq0N4blvIVaL6UTtqmsiWr8UiSK0RpMiaHKdEfLQKQf5Tq2y9reNl9AYXChopoNJAueiSJpKnHoVQgVmXrEASiYlxQasL5faXxZnjny8y+kGDZQS11iFUW4dJTdeObGUAkqkaN04mfpbFdSAPcnkhIImsy+t8y6N1LQQMfX3oLS9D+5lT6CJFhowvPY4YSiypvCnhQ4nq5dx44n30kyMoK72C0dEx5Bbk4r5d94sJ9lwn3RzhzJN/vc6A+poOfLjvglBsySlIRHJ6JCKjgxxtuqiWcdDUaAIulhlp7mOGfsyO+CglVmZr4OOlgKeHc+c+AwMm1NfrUVM9gubmUQr6+CElxRvRMZyIXd7X+kJeKJLIupDoz3zfHJNs67KgnuIYxfSZDiCVq4IsNaLC3CmOIdmsM0dWbukqCPTaDag1D+EIFecGkD3uPZoYhLh5wFshf09c5Rwu13HyPezu3bvBqih8rzveWFXln/7pn4QSy/h7t/7lbf/4xz/iO9/5jrA6ZKKpVqsVZLSpElkPHjyIc+fO3dr1ba9jYmJIQb9FEllvQ0a+IRGYPwR4Hsr3fFWVIyg61y+eBwSoSTEqEKGh/Nm/81hs7AAzMICey6WoeetNaCjJzQSZ0Px8+MYn3HnDGS5hhbnWdhPOF5PuJ+WK0lM9kBivQWzU4iAfMZYWiw2d7f0oOVcrilOHBkaw6a5cZOUnkGW3hr5/l+Y9hIVETUbsZjTadCg19UEHM6iEFSuJ0JpEuSA/hQpKhXNjATO8rJbUZkxiffzxxwWJlZXYx9tUiawPPPCAuHcY3+5WIutMrInH+5ruX0lknS5it6/PhfsGgwEVpMBadbUCtTW1UKtUCCHb55y8XCQmJ8GPvrddncB5+5Hf+R2rhcQMSJm1qqJSKLMy6TsyKgqr169BalqqEDSYz1jwnUc6syVcnFLfaERNPZ33GgOiI1TYusEXA0WHMFB6XghcBKaRAu+je4Viuisf68wQkltJBBYOgWZyL1i7dq0YQA0Vf3l53ewax9/ZPD/mxmRTJp1O1GbSDyut//Wvf8XTTz+NH/3oR7d1yzGCl156CQUFBaL4lRXcmXTLf9ml5ezZs9fjCkxk/fu//3v8zd/8jSDljnfG5NUXX3wR8fHxoiCGiazcuEiW4wicG+Dju5UAO779VP9KIqsksjq8ViSR1SE8Ey7kYMCY0Ya6ZguOnjWIqhh/qoZZkaVBUqwKWiJiKt0dRAUm7HX5vakzAj3DdhytsKO8DVif6oasKCA2ENBSYaejwMryQ2txHLGFyKwjNhM+MrWh3jIMbzey+yEy62p1KDR2spWVAYzFcaLkKCQCc4CAJLLOAYiyC4mAkxCwUQLbQjZS1W+9gasv/wGpe/YiZtt2Si7FQ+W1fFXFLGaLmFj/+Q9/EvZSazasRU5+LtIy0uZcOWayU2u12tDU0IXKK804fugKUjOisfdLm6H1UEGtcQ0FE57zjJCLQlefBcfPGdDTT3bkqSqkJ6lpzuPchB3v22AgW8xGPc4W9UOns1Aw3o2CPsGCyMoJHTlXmOwqdN5ySWR1HrbO7pkTIe3dVhw6bcAIqbIGEpk1P0OFlHhKRlMMQ36unH0GZP8LhQD9rKDM0o8KywDqzSNIUvlhlyYWWoUkcS/UOZH7nT4CRqMRly5dEsqqv/nNb0QHnGD64he/eMfO2Opw+/btRMaygJVi8omQxo0T3Rs2bBDKbkxsefjhh8X7EyWiOLnW3d0tljv6Z4AIcKdOnZJEVkcgyWUSgXlCoK/PRMTyUSKh92NkxELWoBGIj/ckp5I7OGrQBMxK3zFcMNt14TyaDn2CyLXrkP3Vv4GS7ErnUumN53pWKpisrBlDVZ0RTc1GhIUqcc82f/j7KSlBPk8gTXE3BoMJg306nDpajk8OXMD6rdkoWJWMuKRwIrNql7RLCJNZO6yjOGXqxGW6j1qpCkYm5YKSlL4gXweZC5riNTTT1fg3OYpIebe2yYisHC/52c9+JkgsTFhhBTa+H7iVyDoTa+JbxzLV15LIOlWkbl+PiUdcaDA8PIxuUmI9cfQYETcrYKSq88LVq3DPA/fB18+Pir09b994mbzT0d6B08dPoZJUWRvqG/DA7gexduM6BAQGCIcuVyV48neAgbgoza1mvPfhIDy0Cqxe4Q1/SxvcOitR887b8A4LR97Xn4FnaBjcqVhNNomARGB+EDh8+DAee+wxoYDd0dFxEwmUR8CEz+joaJhMJvz7v/879uzZM+HAptvP3r17sXPnTly5cgXf+9738Oyzz97W769//WuhuM77v3DhgrgHWLdu3fX1eGx8f8HK7ePKqlz88rvf/e7662984xt45513rm/DhFcm53IRDDcummCHmDspzfK6/JissdL8X/7yF+zatQusGrvcGp//qTTF2BjJyyzDJoms0z/pPNmm/A9GdDa091hRUWtCVYMF0WFugsiak6YmhSKZXJ0MWSpohZEUbivaIR4dQ0CYL7Cd3KdCyLKUyayyLS4EWIWVyaytZC1TbRnCeXMPgt21RGYNJEs+X0S4Ld/J0uI6U3I0EoHZIyCJrLPHUPYgEXAaAvR7bKNkdPvZM2j68APKRAM+0TFI3PUQvCNvD3I7bRyLrOPenl40NzXj4Dv7MTQ0THZSX0ByagoFdOkGcx4bBxqNBjMOvV+Cmso2ocaalRdPigBpQg3AzQWsB3hizC4Kl6tMpMZqoiCGHQF0f76KLKzCgtzh5encoj0msdbVXVNirarSISHRi4gXfggP18LHRyXJdvN4PU+0K0lknQgV13iPYxmjFPpqbjejvMaMi+VGbCzUCpXlACrO1aid+9l2DZTkKJcaAuI3jeIY+w1NuEpE1gR3X6Qp/ZGjCiQKhrzml9r5XgrHwwQUTi5xmygBxMn4L3/5y/joo49EEovtAicioPL2bBnMiSwN2Y1uJXvhG9uJEyfIwWAUOTk5iIyMFCoxTz755I2rTOs5K8a+++67ksg6LdTkyhIB5yBgMtno820lK9Musg7VIy/fH6kpPqTG5DEh8ZKLZY2Dg6j48ysYIAtz/6REhK5chaj1G6AghTsFfS/NVTMYbBjWWXHizAiqag3ISvdESqIWCSwQo70D0Xaudj6DfmxUpGqiotnaijZcLq4XCq0enhrc/eBKRMeF0JgXh4LsDA5t0k3MpMxqUpCgDwmaVFkGhbCJFwmbrFeFIZYc+oLdJGlqUhBnuUJvb69QUONu3nzzTTz//POYjMhaVFSERx99FH5Ebjx+/DgeeeSR64UrrPA+3qZrTTy+3Uz+SiLrTFC7tg0XMo0Mj+A8KeidOXlK3BsGBAWigAg/rMIaQfdwKlJmZTXS5dqI34P+vn4Un7+I08dOUZGBF2IT4rD97rsQERXh0thw4Uf/oBUlV/RoIxXz4REb1uW5I8GnCxV/+B1sZhPiduxEENmWO0M9fbleU/K4JQKTIcCuJ9/97nfFb2013TvfStrk+XxiYiKJc+jwL//yL2A3lYnadPth8mxGRoYglHLRyle+8pXbumVC6g9/+EMw+ZQJr0yW5OJXjjP8+Mc/FmrvTETlAokf/OAHePvtt0UfrOLKRFmON9x7770oLS0VRNX//u//poK4eLEOO7x861vfEvtPSEgAxxS431vb0aNHwY/JWkREBJgILImsjpGSRFYH1duOoVu+Szm5azLbUFFvQWmFCWMGO9lrKpCdokJspApBAW5wgTz1gp/AnhGguc+O07UAxQSQEWlHWoQbKbPaRWBFYrjgp+imAXASyGS3otWmx2lTFwbtJpH6WUEVuWnufvAliz4Vbv/RuqkT+UIiIBFY9AhIIuuiP0VygBIBDDc1oo8spVpPHIOV7KXSv/gYAshSSO3jIyacyw2isstlOH/mHNrJVsqHyKt7PrcHkdFR846FbmQM3Z2D+PjARfR2D2Hdliwkp0UiNj7UZU6JnohunT0WXKk24yqR3ZLjlUiJUyItQS3mO848EL3egt5eI1ngDZH6l4GIHOTakOVLdjj+9FwxYeLVmeORfd+OgCSy3o6JK71DuXhSPLYLovpRUluOCHZDfLQSmSkaBPkr4C4n4K50OuVYp4CA3mbGECmKvW9sRrNVjx2aKCKy+iHEzUPSWKeAn1xl/hHgZHxaWprYMVsGTqRMMk4+YQJqcXHxdZLLraPlRNW4euuty259/fnPf17YB976/lRfSyLrVJGS60kE5gcBLmA6c6YPVVWUfKGWlOSN1atZne52sqiurVUQWBvePwDz6BiSdz8sSDFzWSjL42F3gI4uM9kkG8kumRwCiNC6Zb0PkhM9RLHkYi767O8doVhDH04duYKeriHkr05GelYM4kmZ1d2dRW2WbnEM539YmfUs5YJ6bAaE0z1UCuWBMlT+8FAooZEK9/PyoWbFsn/4h39wSGRlwgyrsHZ1deG3v/0t7rvvPmEBzIpntyqyTteaeDYHKYms00ePSVF8Pjvb2lFTVU2PKrS2tCCOiEPpWZlYuaoQfv4cJ1tkMtbTP9Q52YKLuqorq1FyoZhEBaqJu2HGxi0bhUtXbFysKMhw1e/psTEbxWjNKKsYQ9FFHdat8kZ6hB79R9+FqbMVbkRIi96yFdGbNgurW1c9zjm5EGQnEoF5QuC9997D008/LZRJWfl8XNl0fPf8OWSSJrff//73ogB1fNmNf6fbzz333COcVerr6/Hcc8/hmWeeubE78fzFF18EO7ekp6cLEqter6fCtkZR3JqcnHzT+vxbw6TVcsox7tixAy+//LJYzuuz+iqTZj3IneHG9sEHH+CrX/2qeOvjjz+eUJW1gpTDuc/JGv+GseuMJLI6RkoSWSWR1fEVcoelTOobpZuIoRE7jhWNobHNCj8fBXLTNFibr6FJrLhvuMPW8m1GgBNpOiNQ0mRHVQfQ1GvH2mQFdmQqoKZ7cOXyLSRbtBcIX/cGu0WQWJnM+omxDQWqIOSSMmsmqZr4KqSc7qI9eXJgEoEpIiCJrFMESq4mEVhABGxkTWIaGUHJf/4S/VUVSHxgF8JWrERgKiW+l3ASZSLIOWD54f4P8NZf3kReQR7yVxYgpyBXVMVOtL4z32uo7cDV0iZUlDVDrVHhoc+sQ1RsMCkkuEZwmROMrNZ48qKRqv5tQuFryxoPIrGqhFqjsy8tVgyqqdERkXWQrNHccffdYQiP0MJXKrE687KdVt+SyDotuBbdytdU+xToILJ6XbMFlytNGNHb8cA2SkjHzc/nfNGBIge0pBFoJfIqO8qUkyWumZRZd2vjEO/uA6LxLOnjlgfnugiwogmrpPb09OBHP/qRSJDdeDS8nJNmrH66bds2/OlPf7px8U3POanGZJaJGiupcIKKbQOZ6MKk2PFk20TrT/aeJLJOhpBcLhGYXwT4nq+z0yDmVieO95KFqAceeTQKXl7uoljwxtG0HDmMpo8/gtVkhG9cPJIfeRRe4RFwm0OCFJNYTeTOd6lsDPs/JIX0WC3SUuiRrCVBGPdFX7AolFlNFhSdrMDVy02iaDUzNx73P7qGiAEk67GEi8EoKgAjCZu00D1VGanbHze2I4mKgraowxFNyqyBbpobLyf53EkITEZkZTLIE088ASaYcHEKF71w27hx422KrEywma41MVvcz7RJIuv0kTOQYEF9bS0V7BfhgwMHER0Tg4LCFVhBBNZYUsZjtf3lrMI6EaImown6UT0OkFPX5ZJSQfJdQZjteuQhqDRq+p52TQEmdkq1kUN3abkenxwbQWiwClHBFsQom2GsPIf6/e8hZc9eZD7xFbgRKWUuVdQnwlm+JxGQCHCx2Bns2bNHQNHU1CSUsW/EhdVOmUjKbd++fSgsLLxx8fXnM+mHldZZfZ0LUlh59dbGBNf//d//Fb//r7/++q2Lb3v985//XNwzcDyA5/S3qsveugEvj4uLE8W04yqut64z1ddVVKTx6quvSiLrJIBJIqsksk5yidx58TVlVjtqGi2obzGjucMCP283JMaQbDRZokSEXGNiOjvpe+cRLv4lZrIr7RwCqim2erHRDj8i9yeGuiEzwo6IAFJekvmFRXcSOYDByqy11hFcMvdigCpz1XYFVqhCEK9kaxmpbrLoTpockERgGghIIus0wJKrSgQWCgEKZFmJzNpw8AA6iy+SvIkVoQUrkbTrIbhTNfZyIbOOUlVpd1cPjh06gkMfHsLuvbuxbuN6BIUEi8DufJ0eK1VnmYxmnDtdhZOHrxD5MgCJKREoWJMC/wDv+RrGrPbDicX2Litqmsyk1mhECCUUU+LVSIpVIiTwduWeWe3slo3HxqwYGqb9lg5RsnUEPkRcZevLvDx/8ZzVWGVbHAhIIuviOA+zHYX+/wpyiy6RIlaLiT7nKiQTkTWVSOtqlfy8zRZfuf3CI8AFuHb6r8Tch0NUfBugUFOyzxuFFLOQVrgLf37kCBwj8OyzzwoLYbYD5ORTFtmFcsKISSqvvfYaeDmT1Fhx9Wtf+5rojJXXaonwkJSUhKeeesrxDmgpK65cvXr1NoW2STe8wwqSyHoHYOTbEoEFRGB01Iq21jEcOtxNYiEK5OT6UeLZE+Hh1yzhTboRjHZ3o5nUlNrI6SVi/QZRHBuUnQ21t8+cjnxEZ0N13RjqGlmN1Yi8bA/kZnoSiVUJrdY1yEX0tYvWpm7UVrXj4tlqeHprkZOfgCRyYImMDppTvBZbZ0yk0sGCZgsVU1v6MExq93ynla8MQorSH/4kbKKWyqxOPW2OiKxMTGV74u985zuCXMLWv1qtVigFT0RkZQLkdK2JbyWymknxkm2Np9L8STmUx8j3L7LdGQG+t+NHc2OTILFWll/FQP8A3EntKTk1Fdl5OYiMioKvn9+dO1nGSxg7vk4ryq6CXbvK6eHj64O8FflIz8wgNds4l0anrcOEymoDmlrJIXjUhLVZVqiai9D41quIWLUK8ffcK4pRNPR5k00iIBFwLgLNzc1Yu3at2MlERNXz589j9+7d4rePlUn5d3CiNpN+xhXVN2zYIGIG/N033piw/+ijj4Lz+6ya+vzzz4OLW02UQ+Si1VvVVXm7cbcXvi84fPgwRkdH0dHRIdRmY2Njb3N/4f3x+xyfcKQ2Oz4mR38lkfWwI3iuL5NEVklkvX4xzPSJhSpi2jotOErKrD39rF4EbCqkyWyaGloNWfRJZdFJoW3ps6OoQYFmUmUdMQD3ZAM5MQp4EBdDklknhW9BVhglZdYhIrG+Z6DJFZFac4QqawAy3P0peOEGMtZZkHHJnUoEJAKzQ0ASWWeHn9xaIjBfCNgpQDdIFmFdFy+g9p23EZSRiYK/exYqb2+4U3X+cmjdpDJVWlxKj0sU6K3Hl558DOs3bRCBgvk8/rExEwb7dTj8fgkOf1iCRz6/AWs3ZsIvwAsqthlY5M1ipcQUqTKev2JEbRPd341YUZijwZbVWrIap3txJ92M85yJ1Xl6e42kCjZKlb8D6Gg34J57w5GZ6UskViXNo+T95GK6fCSRdTGdjdmP5WKZEVdrTegjBeaYCBXuWqeFt5ebdEaZPbSyhwVGwEo/MOwkc9TcgTcNDbhXHYO1qlCEumnh4bb4f5cXGD65+wVGgBNH69atEwknNRWo5efni8QTJ3oqKyvF6HJzc3Hw4MHr6lKf/exncfLkSWE1+MYbb0x6BJLIOilEcgWJwJJAoK/PiLNn+9HdTckWEqFYWRiA7GxfEbHXtbeiu6QY7WdOY4C+X/K+/g1EkTUxF8bOpaKbmQomO7pMOHJiBCM6K/z93LEy3wsZqTdblboC4Jy87+oYwMcHLqKrfUAMeeP2bKxYnULFBqQsy5PnJdz0NjN67AacIpe+46Z2rKJ7qzwisyYrfeHrppaK9048946IrA0NDdi+fbuwNt6/f7+4b+ChMHmUiS51FDf81a9+hYcffvj6CPn96VgTX9/w/56wjfJUlN549d7eXrGVJLL+H3gT/GECJhONDGMGFJ0+g/Nnz6KxvgFh4eF48JHdSCI76NDwsAm2lG/digAraDM5bN9b71AxRztxCxS4+76dFKNdJ4hZXBjmis1otAmH4P3slhCQAABAAElEQVQfDaCCCK3bN/kiSF+OgY/fgMbbU5BYY7Zugx8VtfFnXzaJgETAeQgwYXT895XV0DlWPl7wwZ+/7373u3j55ZexYsUKHDhwQBQpTDSamfTz3nvvCYcWjhOcpd+KcPqdGG99fX3gOAHfr/J9w+bNm68rsHMBLBfC3tj4+/Cee+4RSqx8j/Cf//mfgsz62GOPCdXvsrKy2xwPjx8/LpTfuR9WlGV11pk2SWSVRFaH187/+3//D6lUyfNFSWR1iNNUFlL+FWNjNCnvsaKqwYjyajNCgpSIDHNDfrpGqBi5qHL9VA5/TtbRG+zoGQFKmu243ALEUiFrKuGXG6uAj5YAlm3RIWCx0wQLVFFNVn211mHxN4wSQ+vUYYhw80SAtJZZdOdMDkgiMBUEJJF1KijJdSQCC48AT0rNOh36KytQ8edXoPLwQMS69QjOzoFfQuLCD9DJI+AAQeXVCrz12lsUjFRRdX08Vq9bjcTkJCfv+fbu21p6ce5UpUhmMal16915yMiNhYbGpXASCfT2Ucz8nU6awzS2WXCpwgQrTWzy0jSIi3JHdPi1AK+zYqBmsw3DwxYiZQzj1OlehIZ4ICbaA2npPggJVZMypHOVYGeO2PLdUhJZl9a5ZwJrc7sZZy+ZKNN57bMfH+2OyFDXTO4srbMjj2Y2CIyQUli9ZRhXyAK3lFRZ79fGYLUyBFoisdIvy2y6lttKBOYFAVZLfeaZZ0ipvuam/XGy6/HHH8f3v/99+Pr6Xl/GNsKcVNqyZYuw57u+4A5P7r33Xly+fBn/9V//hQcffPAOa039banIOnWs5JoSgflEYGzMgnYqFCwvH0bR2T5s2hyCdWsDoKaIft/lYlS8+id4BAYiKDML4WvWURwhQZBY54oEQyELNJL6f239GMoqxhAUqMTaQm+Ehajg5+uayi+jeiN4/n+luB5FJyuQU5CI3BWJiE8Kg6+/13ye3nnfF+eCjKDYgVVHeaBBNFn1giyxRhOKBHdfhEuXPqedE0dE1p/85Cf49a9/LVyJtm7detMYTpw4IdTVcnJIzZNsg5nU8uSTT2KurYlv2uktL/7jP/5DKLdJIustwPzfS1a1YwJrDRUUnDl5igoPugWpNSMzEylpqYLE6k3KoqyyK9vkCHCsXDeiQ3NTM0ouFOPsyTNISk1Gdm42qbPmITTMNQnBFAInsroNFy6NorLGIMTUgty6kaKuxtCVixhubkLOU19DxJq1cGOyrrMCuZOfArmGRGBZIPCLX/wCL7zwgiCOv/3222AFdP7+OXr0qJivG41G/PznP8eXvvQlgQcrozJRlBvP82NiYsTz6fbDRQ+Z9PvAyqk892fHFo4RcIEJk2oPHTqEKFLvZpIpE1VZlZX3y7EDXrewsPC628u//du/4ac//akYx1tvvSWKablf5g5y3m3Pnj345S9/KZbz3KC9vR2f+cxnRIHMmjVr8M4774hjFivM4B9JZJVEVoeXjSSyOoRn2gt5Ys6E1rpmM1jZpH/IJsLjBZkaxEdfs+Tkokx5/zAxtIwftyutdlxstGNwVAFfDzvWJ7shKgD0/Npy+e/iQoDt+vR2DmAM44ixA0Z6Hu3uhUxVAJLcfaChNJGS1FllkwhIBFwHAUlkdZ1zJUcqEWAEdO1tqCfVhZGWZtgsZiTc9wAi1q4Tgau5VFJZTGhzoHdkeBjF54vxl1f+gvSsdNy/635EREXMq80Wq4mOjRpRXdGKD/edJwVWb6RlRiM9O9Yl7AXNFjuMxF+7WmtGRZ0Jw6SQExGixOZVWgSQUo7KiVw2DsCOjFiIoKGjAIie/o5g5coAqlYOIMsdFdnduGZiczF9TpwxFklkdQaqC9cnz8E5bnHyggGdvWRbTR+7XHKVyU4le1C1m1BkXrjRyT1LBGaGAOX40EHEilPmLvTbjMzRxiYNKX0rKbAkm0TAhRDg+92mpiZBZuWEUnR0NJJIZSmQSGeLrUki62I7I3I8EoFrCPB81WCworR0CPv3dwg11mwSXfE2tEF39SIaDh5A1MZNSHroYXiGhkLt4zNn0LESq9Fkx7liHeobif5IY0lJ0GLDGm9xn+mqOTLG1Er2jGWljcKRRU0OLEGhvli9Ph1RscHQaNVOczSZs5Mzy450VDDUZzOQKmsnmi06RLh7IkXphyzKB3lCCa1CzuVnCfFtmzsisrLC2m9+85vbtpnoDS58efHFFzFda+KJ+prqe5LIemekxsbGMDRIpPDGJlSWXyW3qRL4EGk1ighOm7ZuRnxioiAoM0lJtqkjwGQyJnVdKb2Cjw9+RCJko/Dy8sLmbVuQnJYC/wB/oTY49R4Xz5qtbSbU0W/qpbJReLobsC7ThP7Db6L37DFkPvZl8ZvOv+esri6bREAi4DwE+Pt77969Qs2U98JKqFxwUFxcLL5/WOGU1dD5+4jbhQsX8NBDD4nn7777LlatWiWeT7cf3ohVWZkMy2RTPz8/FBQUoKKiAl3kXKghl0Z2bsnIyBD9s0rrzp07wa4vKpWKci8rRVyBC2f5wW3Xrl2iwHV8rOPkWl7GpFjehsfJ5FgdierwPlgBPisri1eZcZNEVklkdXjxSCKrQ3hmtJC/j8ZI4l1P6qxFlyip3WimZJACKfGUEC70gJZcXqU9pmNodeR00zNix6FyUrgdogBHuBuyIoGcGKma4Ri5hVtqpWpcPVXjNllGUGrpwxmyl1mvDscaspfhQIaXwoksiIU7bLlnicCSRUASWZfsqZUHtkQRMOt1VHndjJbDh1D12qvIevKrSHl0L1QUpHOjCepSbAaDARVlFbh8qZQst85h/cb1eORze8SEfD5toswmC1qaelB2qQHHP7mMglXJuP+RNfD00lICa/FjPzRiE+S1syUG1DZbsL5Ag8xkNcJD3K4lF5148eh0FrL7GsUnH3dR4MWOzCw/JCd7U0WyB1UMu8niPydiP5uuJZF1Nugtzm2ZYNDdZ8PlKiOOnzOgIEuNDSs0CPR3h5eHTJgtzrMmR3UnBLjQ1kKPKnKNeX2sHsHkGLNVE4EocowJoueySQQkAs5BQBJZnYOr7FUiMFsEOCHN+aqGej3Onx/AGJFaFfp+hLR/BG+K37trPRC9aTPYjpgV3BTuc0dAHByyoqvHgmOnhtHbb8aW9T5ITtQKF0M3F3AtcYQ9Yzo0oENHWx+OfXwZddXtuOv+FcjOj0d4ZCDNZ+cOR0fjWKhlNrrXMlE+qM2mR6V5EGfN3QhQaLBWHYpE5TVl1oUa21LdryMiK6u8MXllovatb30LjY2N+MY3voH77rtPqLJGREQIEszTTz9NcZ/JrYk3bdo0UddTfk8SWSeGir+f21rbUFFejg8PHISJ1PtiyaJ5xepVpB6aC28fb0GKkiTWifGb7F3Gl5VZe7q68cGBD3ClpBSZuVnIX7kChWsKqXjeNZWzjCYbuum39ZNjw3R8ZiTHKeFWfhCKymMISEtDcE4uotZtgPoG54bJsJLLJQISgZkhMEwiK4899pggqY73wL+r27ZtEwUm/Hy8McF13AnlwIEDgnw6vmw6/Yxvw+qqzz33HPR6/fhbgqDKKu3svnJjq6+vxw9+8APh4HLj+5xD+/a3v42/+7u/E6quNy5jpfeXXnoJg1RscWNj8ioXzyRSocVsmySySiKrw2tIElkdwjPjhTyR5ZukmiYL6prMwqZTq3FDYoxSPKLIopPn6q5adTpjYKa4IUvkGyzApSagqtOGPh2QGKJAYQIQ5O0GLw0BLNuiQ8AsyKwWVJgHcI6CF0qqvA1QqLFCFSwUWj2JzEqUhEU3bjkgiYBE4HYEJJH1dkzkOxKBxYyAjarMLaTS1HL0CCpeeRlhKwsRvnqNCF55BAcv5qHPaGxcbcpqrAf3HURjfQORRj0pCLkKGzZvnFF/M93IZrVR0NCAk0euoLmhGxazFfmrkrBuS5aY/C/me32r9ZoSa32rGZeuGqkQD1AT73Z1rhZxkUp4aBVOm6vwvs1mG1X9DqO2loLKPSaEhWpQuIosLYPU8PGRBVAzvSbnYztJZJ0PlOd3H0wkZ2XmGopdnC42CiXm4EB35KerEc2xC+KyLubvs/lFS+5tsSNgpVicIFWQ3e1pIugkE5nifk0sOB4h1cEW+9mT43NlBCSR1ZXPnhz7ckBgYMCElpYxlJ+tRWtJOcL6jiM6yhtxlGgPooS0f1LynMHA95asxlrTYETJ5VEYSPTF19sdawu9EB7Kqv8813T9HAEXtRqNZpw5dhXlpM7KhazxyeFYvSGd5rQeUGsWf2HrbE46Z+hG7Ra0kwr+eXMP+u1GkRPNUQUhjdRZmdgq771mg/DN2zoist685s2vduzYIRTXWBVu9+7d1xdO15r4+oYzeCKJrDeDxtyBvt5eQWJlFdYmIhqPUUw3hFQ0M3OykZyagihS4V8K35M3H/n8v2J3A1ZmPX/mHC5dLEFvbx9Cw0KxjsQQYuJiEBzimjFznd6Gkiv6/8/eewbHlV1Xo6tzA42cc86RAJjBzOFwch5ljSxL/vTJVXY91/uq/Meyq1x+dvk51LPsZ+vZsj/JlhVGM9IkzpDD4TAME4iccwYauZEancPb51IzIjkkSIQGbqP3meoh0Dedu85B9z17r70WhkftmF8gZy1HB1KcbbCMDiE0MQ4FX/oKDAmJUoHK1qPOV2QEAg8Bk8mE+vp6qfhAKK0KZdb1tLWeR3zGCVVVUbBSWlqKjIyMVS87QkI4fX19kpJrKil/Z2ZmSgUtDzpIEpL5jdKrUH7NyclBbGzsg3Zf8/tMZGUi66qThomsq8Kz4Y30PIq5eQ+ukE3f4KhTUmmtrtLjwC4dfTBAUmrd8EV26AnEQnjF7kXPJPCrOi9CSMm2MkOBgkQgNZqCHTv0vnfCbS14HJjwWHDePkYqKAs4rU1BGQUwklUGIreKsePR2wnjzPewsxFgIuvOHl++u52LwExLM4bOnYWNLEPUpMaa/+oXEUXV2DuNgeR0OjE9OYX/7x9/gKWFRUmJNb+oAAmJCVs6uHYb9WNqAT//3xeJ0GrFqWeqyKIqSVJg2dKOrONiQoFxdt6NhnYHPrxqxZ5SLQ7vCUJ8tBrBPhYlENaWQo31zJkJsso1UwVyBIqKwpGXF8LOFesYy60+hImsW4341l1vftGDISK317U5SKHZgRcfC0FZgYZcZZQSmXXresJXYgTWj4ADHqmwtpvUwcxErijRROGklix+uDECjIBPEWAiq0/h5ZMzAhtGQJBLXS4PPvqPc6h78yPEuQaQf6AEe/+PP0QwFb8qNtG22kEkVrPZjWu3zHj/owUcPxSGqrJgJCZoaK2585RKhSprb+c4zr1TBwMRWF/8cjWR0KIRFmHY8Lj5wwnsXjfmicR6wzGNd+zD2EV5oEpNLIrUEZLICQubbM4objaRVfRqLdbEG7kLJrL+Fj1BOnITsbK9tQ1XL19Ba3MzBFHo2RdfROXuSmSQwp1qE5Wxf3vlwP7JskLiD8Mj+K//+E8sUhy5rKIce/bvpX/LJMKwv5GGXSQQsLzspmKRFbxzdgHlOW7syTBh4Mf/L7QKF6r+6P9EOBHOtIaQwB54vntGgBGQNQJMZGUi66oTlImsq8Kz4Y2CyCqSxBMzbkmZtb3PiVCDAvExKpTla5EYp4aK1U0eiLOTHsbmzAq0j3sxOO3F2DxQnatAWZoCEcGAjsWaHojddm4QwQsr3Gh1mtBFRFaz14kkVTD2a+IQo9DDoNzZ1cjbiT1fmxHYLASYyLpZSPJ5GIGtRcA6M4OloUH0n3lP+rfgK19FfEUV9FFRm2oRuLV39fmrDQ8No7ujC9euXCMrKD1e/tKrlChKImXWrU0U9XUb0dU2ip6OUbL8CsKppysRTzaCwQaqwJJxu20j7kZNsx1zVLmv1ShQkqtFYbaWCGsKskH0TeeF6oTL5ZVUWBsa5mGxeKAjgpwgsqamBiM8nKwsd4Ayj2/Qk89Zmcgqn7HY7J6IzwazxYv6Njvaeh1IoLhFdpoWJXkaGIK4GHGz8ebzbT4Cn7rEvGMdIlVWC8qJxJpPJIpsVdjmX4zPyAgwAnchwETWu+DgXxgB2SHgtFphX1pGzQ9/gua3L8Adl4/sIwdw6lunERoVumnFr8SXxdS0Aw3NFkzPurBicWNvpQEFuUEwBCt3ZOHiitlG1tULqLnaRQW381Br1Kggp5bKvbm0tlZBKRKAO7h54IWN8kGjbjM59S1Iyvg2yg3tUkdLyvjJSiFusrMx2IrhfeONN/CHf/iHiCHieVtbm6Sm9ijXFfbCLS0t+Nd//dfPLI3vPG4t1sR3HreWn5nIetvBVRBWJ8aNaKyrw/DgECYnJ5FG6nlZ2VnIKyhAfEICxRZDOC62lsn1iPu6nC4I6+6WxmZ0tneit6sHJeWl2HdwH1LSUhEeEf6IZ5LHboJ74nB4MDBMRQS1ZnicDgS5FxDc+joivCbEVVJ8urJKcmqTR4+5F4wAI8AIfB4BJrIykfXzs+KOd5jIegcYPv5xeNyFxg4HxqdcZKfixb5yPXLS1YiKUJJ1H2lUcl7oviPgoGT3sl2BW/1efNTuRSEJaRQmKZFHgluRxFVQ8xr4vrjJ4c0pjxUDriV84pyUbGUqqBo3WxWONBWpbZEqq5InvRyGifvACNwXASay3hcWfpMRkD0CHqrq97icaPv3H2L82lWkHDmKhN17pMCVSidvcuWjgCuIkOJ1/ZPrqLl2A0663/SMdDz57FOIiIx4lFNsyj5ut4esEl2ShWB9TS9Cw4KQnZeEA0eKYAhZn3XMpnTsIScRgU7xmphxkVuEGzebbFIycU+ZFulJasSSlbivmhg3m80Dk8lBSRSye74+h7zcUOQX0Cs/lEisXOjkK+w3+7xMZN1sROV3vq4BJzqoCFfELsJDlTi6R4e4aBWC9Lz4lt9ocY/uRGCR3GEmvVacsY1ghdRYX9RnIFMVCoPCRxUad16cf2YEAhwBJrIG+ATg25c1AmItZpmaxHx3NwbOnsVgbSsmUp5Bwt79OPVsLqJjg8gCdeNrQaH6ukx2x/2DNly6toSQYBXysoOQl6NDUgLZE+7gZrXY0d9jRFvTIBpq+rBrTw7FBwoRlxAp6xjBZg6JlZ69lj1OXHJOoMM1jwRlEHKpoKhEFYlwJRXNKjY+xzazv3yu3yKwVmvi3x75aD8FOpHV4XDAZrXBOD6Onq4usrmvgd1uJ9JqKI4/dhK7qioRRNZIal9VlT/aMO34vcQ8X1lZQWNtA95+822EhYchOzcbVXt3IyMzA3oSSlBuojr5VgA6Z3Khj75zO3usGBtaRJ7rJuIc/YB1GSnVB5H1zLOSsMVmqq5vxX3xNRgBRiAwEGAiKxNZV53pTGRdFZ5N3WilxK3ZAjR12NHZ75SqT9MoYXywUiclh6g4k9t9EBBVvMQVwJjJi+5JoNNIKrdkT/N4iRLZ8UAocQWUTAK+D3Lb/5bD68Gi1yEFLnpImXXIY8ZuspU5rKHKQgVZVHLwYvsHiXvACDwAASayPgAYfpsRkDsClKASSaqxK5cxeasGKxNGRBUUoeDLX4E2zP/VyETQ0el04o2f/RIXzn6Ek088hso9VcjKyaLE29YRSIXiyvycGRc+aEBTXT9OP1uF8qpsxMRHQKOR70O9eKZ20nP05VsU5OxzIDREhaxUFXYV6SS1RaHM6qvmpof6qUlSCrgxh5kZO/WDlHn2RqOwMAzBlOBUU2EfN/9AgIms/jFOG+nlipX+XslV5hJ9Viwue1Ccq0ZephYZyUwG3AiufKzvEeh2LaLFOYdprw1hFHM4qU1CPLnDiEJabowAI+BbBJjI6lt8+eyMwHoREPEBkm7ERM1NdP38p9CQzbDDEIt2eylUsekor4xBZqYByclB673EZ8cJdbiWdgt6B+wYn3QQiVWPQ/vDaK2pJCeOnf1d7CGMrRYHOceM4tpFUsukxXdEVAgOnShFVm5SQIjYCGVWF+WDxtwrGHAvo9Y5Aw0psZaTMmsuqeNnqEn5l1tAIhDoRNbpySkMk3vWxY8+xvjoKBHcE1BYVISyyl2Swq4gtKpUtGJh4R+f/n2I70O3y43Z2Vn09fSSQMJNdLR14OTpU0RmrSJ13DRy/dr4d6FPb+Kek4vvXYvVg2u3VlBbt4Cc6EWEzzXC+snryDx+BGXf/h9QB9N6eAeIW9xz6/wrI8AI7AAEmMjKRNZVpzETWVeFxycbB0Zd6Bl0YnDMRQ+nQH6mRkoIpSSQlabSyyqVD0B9hVRZTVTRe70XGJz2IjVagVxSZS1JVkBHAk473KHlAajI/21h7TdNyqzd7kXUOKYQqdIjTRmCIqrGTVQGS8EMJSeV5D+Q3MOAQ4CJrAE35HzDOwyBpZFhzLW3Y+C9d6GPjET+F7+E0NQ06CK2TrXUF5AuLixibHQMF859hPaWNnzhq1/E7n17JOstEfTdiiYCn+MjsxKBdWRwGuZlK558YS/yi1Kg0Wpkm6AS+csZkxvCJaKdlBbnF90ozdeSQ4QGqYlqnz5Lu91eGI02DA6uoLl5AQYD2ZVnhyAnJ2RTEqZbMe58jd8iwETW32KxU38SnxcWIrPeaqG/W4pbOJxAQZYau0t0EglBOMpwYwTkhIAgTojYw3XnFK7aJyWihCBMlGijEQImYMtprLgvOxcBJrLu3LHlO/NvBFxWC5ZpDT1x4xr6KT6QdLAa4bsOoHsuGjNmneC4orQ0DBUVEaRERw5q61QMsVg8mDU5UVO/gplZJ+JiNaTEqkdpYbBs18i+GNmpiXl0tY1IhFbx875DRSgqTSfiWji0IokVAE0os854bKhxTmPSbaU79iKfckEFqghEK6mIVhkYOATAUD/yLQYikVXEDpeXljFhNKK/t1ciTprm5qQi/KLSEuQVFNArXyKvMoH1kafSpuwo1HBXzCu4duWqRGYNDQtFano69h3ch/iEeCnGvCkX2oKTSMUqdJ3mdiuaWs1wUEEFxlsR0vzfSC3OQsaJ44jMz0dIIlndcmMEGAFGQGYIMJGViayrTkkmsq4Kj082CiUkYbFytc6GvmGy26Cf95TqcGyfHiIhtEU5eJ/cmy9PKpJp4tVFqqzt417UD3qRHqPAS1UKhAd5oddyMs2X+G/k3CKpJMisnaTK2uCcxaBrGS8GZaJKEyMlldRUmcuNEWAE5IUAE1nlNR7cG0ZgrQh4KRu1PDqC5n/5ZziWl5G4/wDiq3Yjmir+/bn19/ZLgcYJ4wTEPT738gsoLC7cUtUCLymL1tf04I2fXEFqRhxKdmWgUEpMyZck/OlzdCM5Q5y/bkMwidcmxt52hkiMVa07Wfmoc8lu9+DKlRl0dy/DZnOjpDQcJ07EQa1af6L0Ua/N+20+Akxk3XxM5XhGQUBfIDXW9l4nzly0IDdDg8cOBiEmUokQA6/f5Dhmgdwnh5dsIok08b59BOcd4/iiPhsHtfEwkCorlYwHMjR874zAliHARNYtg5ovxAisCQHL9DRGLpzHXFsbRMFr/he+hJTHnsQ0kU1b2xZx4eNpVB+MwZNPJpC7iFJyEVzTBX6z85jRgf5BO2obV2idBzz3ZCSSEsiRTR9Yz41CmVW4j3z8QSM++bgVCclRKChKxYEjRQgND14PtH53DPkEwU2vBY9DygW9ax1GssqAUk0UKrUxkriJ390Ud3hDCAQakVWQC0XMcrB/AJcvXkJTfQNGhobw1HPP4sDhQ2RjnwlDiMHvbOw3NAlkdrAYoylSyhVx5jfJ9ctqseC5V15ESVkJkVpTZdbbh3dngcQKxifs+OCjBcwPDqFCcxNRynnoqW4g5/kXEFdZ9fCT8B6MACPACGwxAkxkZSLrqlOOiayrwuOzjQ4HKTlNuzEw4kTngJOSyUokxqlQlKNBcryKFJEUAVWpuhag5y3A6Bxwa8ALKxUXRYcA5WmkbJsgEuGsaLsWLLdyXwsllUweO1qdJnS45imhpEaKKgS7icwaRZW4WsXWqKht5T3ztRgBf0aAiaz+PHrcd0bgNgL2hQWMXrqI2fY2rIyPI/30E8h88iko1cIFwL+SSbeTQU7U1dTil//9OtIz07GrahcpmxRTtTxJ9G9Rs9HDp3F0Fi0NA6i52omqA/kUhC5CJD2QBhuIHSrTtrziRd+QA70jLvQOOVGap0VBtgYp8WoEB/mW4DM5acPwMBU0dS7BYnEhPz9UUmNNTw8sZR6ZTo11dYuJrOuCze8OEgR4h9OLsUkXKbOSYonFC/r6wP5deuSkaaBU8drb7wZ1B3d4htS+usgFpoeKZyc8FjypS5PIEoLEyg4wO3jg+dZkhQATWWU1HNwZRkBCwD4/j7nuLvT96g3p97iKKsRVVCIiL58KDD3SGu3Cx1NISgpCUSFZv2cYEBWlXRN6TnpetNm9aGg2kxqcBZGRKqSn6FFWHISwUMpzUfFiIDWJwEbP0YO9E+hsH0Fvx5ikxLrvcCHSs+IRGxceEHAIYRMHqeUb3SuUC1rAGP275HWgRB2JXE245Nin43xQQMwFcZOBRGS1Wq1YoM/elsYmIkn2YXJiAuHh4UhKSaZC/GKyr09HWFgY1BpWJt7uPwALkVfnTfO4cfU6BojQarFYJSLr4eNHaIxCERTsP8UHgnOyuOTGlRvLGOmdQZBtDKHj1xFivIWSb34LKceOQ0P3I3IC3BgBRoARkAsCTGRlIuuqc5GJrKvC4/ON41Mu1LY6MD7pxpLZg0O79SjMViOcFvmiclURWOv8R8Z72aZAy6gXnUYveie9OJgLeikRqidlVg2D9shAbsOOQo1VKLM2kTKrkib4cV0SMlWhiFHob9tobEOf+JKMACPweQSYyPp5TPgdRsDfEHALq6TJCYxdvoSOn/wnMp96BgVf+jJ0ERFQ64P86nacTidMcyZcvfwJfvbjn+L006fx4qsvIYQCi3r91hBIhRLrvMmMW9c6Mdg3iaVFCw6fLMXBo8WyxVIQ0ewUzDRSAd21ehsWSV1RJBIPVelQQmRW0Xy13nC5hBKNF22k8tPcvAjLiguxseRCcTwOcXG6gEtoynaSrKNjTGRdB2h+fMgyEVhHjE40dTrRTKrOj1UHobJYSzELpeQo48e3xl3fAQgIsoggSgx4lnGeknWCtBqvDkaVOgZpVDjLjRFgBLYOASaybh3WfCVG4GEIiO9HkBqgqbMDk3W1kiJrRE4eSv/Hd6CPiIQ66HY8YGRkBTU18zCbXVSwpMDBg9HIzDRIa8RHsboWl1mmnJZx0o46UmJt77bi1LFwlBYFITJcLZ3zYX3dqdvtNifm55bx7hs3ME7FsHmkylpUlo5ieqlUSioK86/i4vWOk5PIrELg5LLDiJvOGcQpqShOHY5KIW6i0EHPZNb1QutXxwUCkdXtckFY1guVz2FSX71CSqwzU9MSifXgkUM4dOwoguizV8MEVlnNXbeLlEzHxiXV3Pfeeg8paSk4dvI4snOzkZCYKH1WP8r3oRxuSrhhddD3cE8/CQqMWKFufhOx3b9E8Ve/gsxTjyE0JYW+//2HnCsHTLkPjAAj4FsEmMjKRNZVZxgTWVeFx+cbrVT5Or/kRUefA209pMwapEQSKbPuKdMiOkIp2W36vBN+eAF6tsSiFeiaAK71eGDQK5AYrsDeLC+SI1nNVs5DKuz+5kmZtZ4CF6OeFdg8bpSRrcwhsv3TQAWNIjCCOHIeI+4bIyAQYCIrzwNGwP8REDZWLlICmKqvQ/fPf4aguDjEFJcgcf9+hKaSnL0ftaWlJdTerEVXeyeGySLp+KmTOPH4CUqMqSkJtDWq7pYVG8ZGZvHOL6+DODPYe6iAAptJSE6LkS2SLrIG7xcqrMMudPTayQFCjT2lOiTEiMI53z4zLyw4SYmV1Ffal9A/sIKKiggUFoRSIFhPwXvSyOPaM9nOm4d1jImsD0NoZ213uW47obR0OUiZ1YbwECVSE9XYTZ8lkWG8dttZo+1/dyNIrCseF1rdJvzaOoRCIkYc1SZJZNYQsNqM/40o99ifEWAiqz+PHvd9pyHgIUKV225D50//G9ONDdL6P76yEsmHj0CtIzGJ36yhBYF1wmhDbZ2J1FmX8dRTiSgrC6diUeVDCw8FiVU8J/YP2XDlulla30VFqLCr1ICUJA20WiovCeA1n8ftIdVbJ/q6xtDVNoq2pkGJzHr89C5ERBpgCPWv4uL1/o2QwTrc9DK6LRjymNHomIXN60Y+PbMVaSKRpwoMhdr14rdTjgsEIuvc7CwGBwZw6/pNdHd2Ii4+gdykMlBcSnHYpCTExMYQKVJFrqK8hpbTvBaFHzaKnY+N3iaz9vX0wThmxNMvPIM9+/ciLDzMb8jHlAYgAQM3eonIevGTRSjGmpC4XIcE4pyk5KUi/dTjCKZ5yY0RYAQYAbkgwERWJrKuOheZyLoqPFu2cXCUksv9ToxOuCCCAKX5WqQnqZBMdp9iwR/Ii/7VBmF0zovmUWDUBJhtXuzPUSI3HogJBdS8HlgNum3d5qRgxYDbjC7XPFqdJsSrglCmjka6OgSxiiBJqTWA41zbOjZ8cUbgUwSYyPopEvwvI+D/CCz09WHsyiUskSKAy2ZF7kuvIG5XBVQ6nV88ZLqcIrk2gbfe+DWpoC6RDVcaKnZXSnZPWzk6g30T6OkcQ+31HsQlROCZl/YjMjqErKYIRxk2Kz0bCwXW+nY7WYO7pfVEQZYG+8p1koqir2LnHlKutVg8EOo+zc0LpO7jpkA92ZHvj0ZOjoESmipe28hwvqylS0xkXQtaO2ffoXEXOvsdpM56+2+6ulIvEVpDgn1Lit85CPKd+AIBO8UWBt3LkmVtHRXL7tXE4rQ2BVolWRmTOis3RoAR2DoEmMi6dVjzlRiBhyFgmZrC4tAA+t97DyvGceQ8/yJiy8slQqvijoWgmwofhYLblcszuHlzDpVVUSgoCEFaWjCRWVcvGHWQ+8bEpBPdfVbUNq0gK02HijIDEuM1CA9b/diH9X+nbBdkVvOyjeIIo7h4tgk6vQZZVAxbVJ6O1Iy428qsysB4XnGQMuui14Hr9kmMkLgJUa2RQyRWIXASrQxCiIILkHbKvL/ffexUIquHmINWsqefnJzE8MAgerq6SZF1ElYiRlZQ8UBxWSly8vO2zEnqftjze4+GgHnZDOO4Ebdu1OCTS58QAbmI4s6lNIYliIqO8h8yK/FLxsYduHJjGaYRI9wzw4idu47UWKD4K19BRHb2Z6rsj4YM78UIMAKMgO8QYCIrE1lXnV1MZF0Vni3bKBb+Fhtwo8GG3iGnZAFanKfBif3CakCBAHEaWTPeTlJmtTqAi51e1A8BCVTAWZgklFkBgzw5BWu+x514AD1LU7DCgzGXGTW/UWZd8DjwtD4VlURo1ZKljLAE5MYIMALbhwATWbcPe74yI7DZCDhXzLCSMoBQYxn56DzK/ud3kXr0OHSRkVD5gaXV8vIy+nv78R8/+CFCQkLw9d99DcmpKVJV/GZjtdr5zr9Xh+b6AYSEBSO/KAX7DxdSIkpLJE15PrNMTFPhEBXL3Wqxw04Pzaeqg5GZoiYFRd8SSR0OD0ZHrWhrWySbShMKC0Nx6HA0YmP0MBhYiXW1OeYv25jI6i8jtbn9FDELs8WLDy6vEJnVg6IcDQQ5Pi9Tw+T0zYWaz7YGBJbhxAXbOIweC/REXRVkiEp1jBRN8BcLyDXcLu/KCMgaASayynp4uHMBhsDEzRvoP/Me3FTIqo+KlopZI7KyoLxn/S+U6Ki6VVq7iSJEG7kHxsXpcPhwLCIjNauitkRFk5/cWMIoEWZcVMxYSUqsuysM5DAI2a6RV70hH20UZNZ5kxndHaMUT+hHW8MgXvhSNfYdLkIwJbDUArAAaGKmCWXWRcoBdbsWcN4xBoqmIF0Viv3k1JdJ/8ozshIAg7MFt7hTiawOu10qvL904QLamlsxPjqK6iNHcPDIIaSkpiIsIpyKubW0XubZvQXTbEOXEKRkN1nB9vX2orGukV4NEJ/fX/z6l1FQXIDQUPqM8pNxNK94YJx0kNr6Im5cm0HawI+QGzaJ8m+8hsSKXdDHxvrNvWxoUPlgRoARkD0CTGRlIuuqk5SJrKvCs6Ub3UTKFConQp21e8iBYLJwSUlQIZ8SQ8kJalKp9AvRrC3FTMRaxCK4ewLomvBieFYQWL3Yk6VASpQCMSFb2h2+2BoRWPY6MeYmy1lSZm0jZdYMdSiy1WEoVEUiUilCGbzAWyOkvDsjsGkIMJF106DkEzEC246AZCvosGPgnXcwfOE8IvPyEVtWjsQDB6ELC9v2/j2sAx1tHWhtakFLYzNS0lLxypdfRUREBDTa1RNrDzvvo25fMdswN7OIi+eaSGFhSko45RelkoJKrKSg8qjn2ar9BNlshchmbb1OtHTZERykREKsEhVFOkSFK6GlIjlfNYvFjZkZGxobFzE9bYNOpyQiaxiKS8KgI2tJNVsm+Ar6LT0vE1m3FG7ZXMxDi29yqUVzl0MqvjUteIgcr8HBSh19zijob9x3ny2yAYE7IisErF4XptxWnLGPwErUiP2aOGQRCSJJZZBVP7kzjECgIMBE1kAZab5POSPgslpgmZnB2OVLGCQia8LefYjfvQcxpWXQUyHrg9r0tJ0cNSyorzNJuZYTJ+KRnHy7EPF+x8zOuTAybkdDswXE80FRnh4ZaVqkJrOyyP3wspESiyCzNtf14da1biSlRpMyayLKq7JJ6Y/IUTItjr3fvWzkPZHHc5Ey65THinaXCaOUF5rx2FCgikC+JpxIrSEIJmVW8nvYyGX4WBkisNOIrJaVFSwvLaO9tRV9Pb0UB5umeJcG8fHxKCwpRi6psIYQ8VGQWLn5FwLzpnlMTkzg6qWrGBkaRnxCPIpKS7D3wF5JWVetkb96tJPiwlYqTKkntfRrNxagGbiEKFs/3UcM0veWI+lgNZSqwCii8K/Zx71lBAIPASayMpF11VnPRNZV4dmWjVOzbtxopOCB0QXTogfH9+ulxHOQHlJFq79U/WwleA5KqM0sA+82eulfLzJJJr80VYEiUmcVarYBEgvYSsg39VrtRGS96ZzChMuCYKUap3WpyKAEVBApqij9pMptUwHhkzECMkCAiawyGATuAiOwyQhMNdRjsqYGpu5OBMfFo/gbvwNDQiIUMg1eCXUYURF/5u330HCrHlEx0WTtVIzqo4e2zJZL9GFseAZd7aNobRiAzerEy187QtZgSbIksYoiryWzF6MTLtS22tDa7cDpw0HSWiKSSKwatW8SQuK6Aiuj0YqBgRXcuDFHAXslTp2KR2pqMMLDt4Z0vMl/Mny6ByDARNYHABMAb4u/9WVS9+gbduLMJSspPCtxjFxkkuJU0s+8dAuASSCjW5wm4sOgawnn7KMwKDT4clAOYpV6aBQUBOLGCDACW44AE1m3HHK+ICNwNwL0oGYlEutkYz2M16/T2v8Gyr/z+8h48kmotDoiSz74+9HtJuV9swu/+tW4VJC4f380cnJCiMwadNc1RGETLdHR3mlFR48VxgknkhI0ePKxCISFUhz/wZe46zyB+kt/txFNdf3o6RyleIIKz768H+nZ8QgKpvEJoAdpN80ju9dN+aBpXLCPI5Se49JJ4OSgNg4JymDoyK2P285CYKcQWd2kRuWi6s7pySkMDw7h4/Pn0dvdg4ysTOzZvw/HTp6kv2fhssoxMH+ewWKcm+obpVh0XU0dFR5kS6IKsfGxfqXM2tNvQ1PrCsb7puAY7ULG0mUUHChG8de/DpVu9ecCfx4/7jsjwAj4DwJMZGUi66qzlYmsq8KzLRtFpcyMyYOeIaekdhIeokRirAqVxTrERpOSkco3CehtudlNuqgIoFidCvROEm5TQMe4FwWJCuzNViA2FAglEjA3+SKwSMqsU2QFWO+cxajLjGhKPhVqIlGljpaSUKzMKt+x457tXASYyLpzx5bvLHARsM7OYnGgH12v/5wsBu3Ie+VVRBcUIjghQZagWK1WSqaZ8Yv/+jnaW9rw5HNPobxyF5JTkknpwPcV8B6yR3Q5Xai72YNz79QhOS0G2XmJKKvMQkxcBCWa5AWb6K/VDolgdq3eTokxICFGheI8LVLiVaTE6juLR7vdDYvFg5pbc+hoX0JsrBYZGSEoKgqjIK9aIrXKCy3uzUYQYCLrRtDz/2OdLioepXhFQ7sdU7MeWKweHKzSoSyfrFHpc0dun43+jzjfwYMQqHXMoMU5B4fCg2RFMI7qkyQiBMcPHoQYv88I+BYBJrL6Fl8+OyOwKgJEDHSSGqupowNdP/+pVKwamZsnubCINb9gmK5GlKTDYbO5UF+/gP5+M+x2j7SWq66OuevZboUcOBaXPLhRa0bvgA1F+UHIzdIhK11Paz7S0ZTZGnlVzLZh4/KSFbNTC7h+uR1jI7PkOBOD/JI0VOzOhko8SAdIo+kG92+UWYfdZrTS89yC10GKrKGUE4pAiTpKcurj6bRzJsROILKKQvuF+Xl0tnego62d4pQtpNaZgOTUVEmBVThIJZBYgPhbVjKr368nryjUF8qsQwODuHb5qvSzTq/DkeNHUbm3SiIq+8MYLy65MT3jxOUrsxhq7Ebc+FkUVSSh8gtPI4TmrtYPXNr8eiJx5xkBRuChCDCRlYmsq04SJrKuCs+2bhwad0t2oONTVOVFVbGVRVpkpmoQF6WkxDQHBu4dHEFmtTiBLqMHFzoUMJCTTWoUUJKiQDI552iJ78DKrPeiJp/fPWRcJIisna4FjBGZNVltwD5NPOKVQYhQatlQRj5DxT0JEASYyBogA823GVAIeOlhyWYyoeM/f4TFwUFEFRRINoOJZDcox4zTFCkc9Pf24dJHF0ntYBqvffsbKC4rkay5VkvCbdagCvu/aUoy1d/owYfv1ePU01XYd6gA0bFh0AfJyx5MkFhtdi+GjW70DDrR2uNETroa+8v1iKG1Q0iwb1JAIuHpoXXKzKwdQ0MWdHQskYKPHQcPRiEvLwQxMURsU7Msz2bNSbmch4mschmJ7euHIK8ap91oo8+ammYbDlTosatQi9goFYL0vvm82b675SvLDQEXPJKK13nbOJpccyjTRCFfHYFsFX0/s4KX3IaL+xNACDCRNYAGm29Vdgh4nE4s9PdjqqEOA2feRVRhMfK/8EUY4hOgCw9/pP66qFhJOGz09CyjtnYeubkheOwxUgsNUtIaXAU3rTknJh0QCm/9g3asUCHjiSNhyM3US/swifWRYCY1Rzdqr3ejo2UYMxRvyMxJxOGTpQiPMMAQElhqLG7KB1k9Ltwgp74u1yJscJNLXwiqNDGIIaGTUAXnhB5tVsl/L38msrpJgdVut1N8cBrDQ0NEYG2VrOfnKb568PAhVFRVESk9FSGhpKjEbUchsDC/gOaGJrQ2taCFXgcOHcS+6v1EXk5GGJFAtyI2vRFABWfC4SC+xJUltNwcgqPzCrIS3NhTnYb4XeWIzMnZyOn5WEaAEWAENowAE1mZyLrqJGIi66rwbOtGG1W+Wm2QEkM9Qy6pLzlpahzZG0TJIUDFrMy7xkdKpItKqRVgaBaoH/KiawI4XarArjQFokMATeAUtt6FjT/8IipxV7wujFEV7mX7BBapCjdYqUY1kVnLNdFEZBX/cWMEGIGtQoCJrFuFNF+HEdhaBFyk0jJVV4fJulpMN9Qj9fgJFL32O5LN4GpWg1vby9tXa6Jg4dl336dCJCXiEuJw/NRJpKanbpmygUgq1VzrwtjQDBbpAfPY6XJU7MmBWqOmPsjrqcTh8MK06MGHV62YNrmRkqBCYbYWBVkaSSFRFMH5ogkLShu5SbS1LuKjC9OIi9OREmswCgvDEB9/m8TKCU1fIL+952Qi6/biL4erSwkRpxed/U5crbdBTwpcsUSa37dLL7nJyKGP3Iedi4AZZOfpskhWtN3uRbyky0S5NhpBIPUj/tLZuQPPdyZ7BJjIKvsh4g7uYAScKyvoeeN1zLa2QK3TI4GKVdMfPw0l2VsrH9HNRORWBOFlYGAFH7w/gfBwDcrKw2h9F4KoKC3stOZsarXg7IUFSYG1IC8IOZk6REWK9fEOBneTb00o/S0tWDDQO4EP362DktbqhaTKWlyegczcxE2+mrxPJ/JBHsJD5IEG3cu44piAzetGlFKHg9oEFFOhEueE5D2Gj9o7fyaympfNmJ2ZwUfnPkRHaxuJTrlRUFSIg4eqKVYZj8ioKKngXiVskbjtKAQEidlisaK5sRkXz1+AjWywwiPC8fwrzyM7N4cEx1SyJrOK7xsRuxkctqOzcxE1V0ZhmGtBqbIOxV98GZknT+6o8eKbYQQYAf9DgImsTGRdddYykXVVeGSxsW/ERRahDgzQvzqdEoLMmpWqRhJZhIogPcfp7x4mO3F+zTYvGoeBBiKzRhgUSCNl1ooMBaIMTGa9Gy15/SaCF0sUuOh0zqPXtYQB9xIKyE6mUB1J1jIhCFNomM4qryHj3uxgBJjIuoMHl28toBHwiCDc9JREZhWJLqHKmvPcCwhJToEukiTsZdDcpFCyQok4Yd/0+k9/gf1U7b573x6y6spF2COqyWzkNkSgz7Jix2DfJD56v4Eso1TIK0xBQUkqUjPiNnLqTT+WugrxGhyj9cKQE/2jLuh1ClQUaZCaqEZMpO8C6YLEurzsQnf3MgYHzRgdsaKoOAwlJWGSEqvBQHYI3HYkAkxk3ZHDuq6bmpgRsQrx+ePCMqly7S/XIitNg6hwYae4rlPyQYzAQxEYoeLXRnJzMbotpNvlxeO6FOSQGiuTWB8KHe/ACPgUASay+hRePjkj8EAErESwWhoeQv+778BKCoEph48gtqxcWus/8KBVNkxN2XHrlgmz5LohnD8OHIhGUnIwegdsGBA5qiEbKssMKC8JRgQ98+kpX8VtbQh43B4ixi2h7kY3RoamMT9nxt7qApRVZlLMwwCdXrO2E/r53m6vByavHW3k1DdIOaFx94qUE8ojImu68nZOiJ/z/HuQ/ZHIumI2Y2Z6BgN9fejt7sHc7Jw0CEmkxllQWIji0lLo9XpotIH19+rfM3F9vR8fG0dXRxea6xsh3MN2Ve1CSVkpcgvyiLOhkzmZFVg2ezA0bMXFT0xY7mxC+Phl7H3xMEpP7YeW4uxqmsfcGAFGgBHYDgSYyMpE1lXnHRNZV4VHNhtNCx5cqaVgwZhTeug4sicI+yu00KoVVPXjG4Ul2dz8OjsyPg/0TgGXu0RqQ4kXqxTIjAHCgtZ5Qj5sSxC4XYnrQbPLhPdtI2R1DMlK5nF9KjIocKEUb3BjBBgBnyPARFafQ8wXYAS2FYG5tla0/u9/h4oUWsKzcyjZdXTdia7NvhGrxYKJ8Qlc/OiiRGT99nd/D8+99BwpoWqkavfNvt695xNJpYlxE9mFDeHsW7XIK0rBV751kuwStRSglhc5U9g7OkkV8eJNG2612JEYp0Z+pgZ7SnUIDvLtM5Od3CPGx604c2YCVqsLOTmhKC0Nlywo78WUf99ZCDCRdWeN50buRqh7OMmG9r2LFjR3OlCUo6GXFvlZaui0TGrYCLZ87P0REPECQWL9tW0IqUoDCjWRVPgaIcUM7n8Ev8sIMAJbhQATWbcKab4OI/BbBEQR5mxzE4w3rmOqsRFBpAxY9p3/ibD0DMl15bd7PvpPFgspn8/YUVNjwuXLM3jppWRkZoXj/KVFcg/0IjVJRyTWIORmM/Hl0VH9/J4uKuC1mG24erENv/yvK9h7qIAsqwuQlZeIiEiyFgywJpRZRRZPPOedtY/ST3fnhNRC3oQVffx2VvgTkfW2iqUHk0Yj2co34sqly2isa0D10cM4UF2NPQf2kWJ1OM9Hv52Na++4mBPi9QG5hl299Ak5U9lQVFKEl7/4iqTQqnpE5fO1X3nzjpiZdeJGrRm99X0wNjbh6KFo7KlORlRePnQREZt3IT4TI8AIMAJrQICJrExkXXW6MJF1VXhks9Fm92Jy1oPeIQfa+5wII5XR5Hg1SvI0SIgRaieszHrvYK0QZiYzUDukwJjJC53Ki+IUJfZmQbJYlZkj7L3dD+jfRaBixm3FMCmttBGhdYKqcHMoOSXUWfNU4dArfKcuFtDA880zAncgwETWO8DgHxmBHYiAZWoSU/V1mGpogKmrE4Vfew2pR49CRTaEim2W0RPV7ZcvXMLo8AjMpIBw+uknsIcUWZVbYNkkApMOhwtXzregu2OMiLNKSYm1+lgx1Gp65qbf5dSM0y7J2nt43IUlqrCvKtEhm5wb4qLV1F/f9JQgImUeD1paltDTsywp9cTF6VBREYnYWJ1kQembK/NZ5YIAE1nlMhLb3w/xeSBeXQNO9Aw6MWJ0IjZahaN79YgMUyJIL6/PzO1HjHuwEQQcZDVr8tjRQASH8/ZxHNTF45AmAREKLYKUPvrS20iH+VhGIMAQYCJrgA043+62I+C22+FYJneMD85g5KPziCoqRuyuCiTtu62wtl7Sn3DesNo8qKsz4cqVWSQkGRBk0GFyxo2kRB32VoYgLkaN8DCOz29kEgi1W5fThaGBKTTV9mHKOE/kTS+OPlZOZNYkGEL0Us5vI9fwp2PFvXuJrHo7J7SMLvcC5YSsSFIGI1cdhlJ1FIIUalbg96dBvaOv/kJkdTgcWJhfQGtTM6mwdmNsbAyhoaGkSp0sWcmnZWQgNi5WUuG84/b4xwBAQMSLR4ZG0NPVjVvXa+Byu5BfWIDyynIUFBXKnthssboxMelEQ80kxbwHkR8yguIMB0qfexwx2ekBMIJ8i4wAIyBHBJjIykTWVeclE1lXhUd2G0WSur7dAWHhZyei5v5deuRmqBERqqRkNZNZ7x0wpxvomfSi0wi0jnqREavA0XwglpJqITpaGvtWqOre7vDva0DAQ6ELNy0OrjkpmEOJKidZzKSpQnBAG49opR4GClxwYwQYAd8hwERW32HLZ2YE5ICAy2qFfWEefW+/hZ7Xf4H8L38V6Y89BkNCItRB2ydfL4LG/b39+MVPfgaNRovK3ZUoLitGWsbWBNWsFjsFrVfw7hs3MDE6hwNHiyRF1vSseFkFJV1SchFEYrXjRqMDWi0QF6XCvnKdVOzmy2dcodCzuOjEtWtzGBxcQVKSHvn5oSgvj6AxY9KaHP6+fd0HJrL6GmH/O7/Z4sXYpAvnPrFIxNa9ZXpkpKiQECu0k8S6mxfe/jeq8uuxGS50OEwSsaGLrGcf16XiqDZB6ihFw+TXYe4RIxBgCDCRNcAGnG93WxEQhBrb7Czme3swTCTWqbpaFH3jm0g9clRSVlOSm8lGW2vbEq5dn8P0nBd2p1IqWiwrMeDw/lDOQ20U3DuOXyFV1rmZJVx4v4GKaUex71AhisrSkZ4dT+t8TUCRWQUsIick1FlrXDNocZow77YhURVMBUwJiFcGIUyhkZ76+NnvjknkBz/KncjqdDgllc2Z6SkMDw2jobaenJrGpXXs7v17cejoEURGRiLYYPADtLmLvkJAFPWbZufw4fvn0NvTC8uKBfurD9D8OITQ8DDo9fJVKqePVbjITae+cRlnPpiBdvQGEtQTOPba48goz4EmOJjcUXlN7au5w+dlBBiB+yPARFY/JbLevHmTrBrH7z+q9G5hIS1oiooeuP1RNzCR9VGRksd+ohp2yUwWGx12SX1Jr1MgI1mNAxV6hJJKq0rFDxp3jhQVtsLqAIYp4HK9FzCT/Y1eo8ChPAWKk2/vyc9mdyImn5+lKlwavzmvDSOkzHrdOQ2Lx4UMIrOWaaLIPjBSPp3lnjACOxABJrLuwEHlW2IE7kDAS8E3j9OJ0csXMXDmPQRFxyAyLw9px08iOD7+jj237kcREBRqrO0tbfj1679CZk4WvvqNr5JNUwQFiymgtgVtqH9SSh51toxARQqsTzy/B6npsdAHEVNURk2Qxjr6HOgZcmJgkCEJGAAAQABJREFUxImKIh2psWoRQcVawT5UQBSBz4GBFUmdxzTnIIwUOHAgGunpwQgJIXUUtjyQ0SzxXVeYyOo7bP31zIJcv7TsRUu3A4NjTszNe7Bvl44Kb3XkhsIFt/46rnLr95THivdswzB7XUhWGVBGylxCoYuJDHIbKe5PoCLARNZAHXm+7+1AwOt2Y6a5CV2/+Jl0+ZCkZKSdOInI/AKoBIl1ExIeA4NWtLQto7HVCrH+PHEkDEX5wUhPFUqh23HXO/OabrcHTnKFaWkYQGfrCIyjs0hOi6FYxF5ERBqg1W2clOxvyFHYAYteB8bJpa/GMY1Zj43UWFXYrYlBlSYWFHlgZVY/G1S5E1nnqDBgeHAYN65eRUdrG2Lj45CZnY3S8nIkJiciKjqaCPxqyr+zErWfTb1N7e5tFy8HZqam0dTQhPPvf4g4mitCmXXvwX0kwpC2qdfbzJOJvtPDAcbGiVvSvYLWGwNYGJ/E40cNKChLQFRODlRUPMGNEWAEGIGtRICJrH5IZBVqFadOnUJbW9sD58p3v/tdfO9733vg9kfdwETWR0VKXvv1UtK6W7Luc0FLxMyiHC1Sk1RIjlNJVWKbEKuQ1w1vsDcLFlKsMnrROwn0TXlRlalAaaoC8WFeGIgMzE2+CLipClcELmopaDFEhNZFshLMV0dISas4qsZlZVb5jh33zL8RYCKrf48f954ReFQETN1dmKqvw2xrCyWjVMj/0pcRTsFaTfDWqwwIW73amltk4dWCIQogl5aX4uUvvSIFi5U+zpQJEq1IHtXX9OL6pXaqpKcEXWY8qaEUIDI69FHh3JL9lswecmdwo67VjuUVDxWzKVFeoEUhrQcETL56srWSDdXsrB1dXZTMbJxHYmIQ0tMMKC4JQ1SUdjNypVuCH19k4wgwkXXjGO7EMzicXkxMu9A1QJ/lLXbJOWYXkeyT4tRS0e1OvGe+p61DYJnUWIdcy3ifiKzBpMR1XJckWc1GKXVb1wm+EiPACKyKABNZV4WHNzICm4aA226HmQRwJm/VYOD9dxFdRA4mRGINz8pBUEzMhq/jpgIlh8ODzh4bahvMME7aICT3q8qCUVhgQFZmMIupbBjlz59g0miCKKy9eaWT4PaitDILOflJSKO4hMj1BZrDgaBcmb1OtJEqa597CcP0HJihDqW8UDgJnYQiihz7BJ+aC5o+P5fk+I4ciaxuKggQiprjY2NkGT+Evt4+zM/N0eefQ7KKLyAhsbyCfASRUqWvY5JyHDPu0/0REJ/PLpcLA30DuH7lGiaME3DQ9/LBI9UoLi2WSNBaYZsl02ZeccNkcuLiBSO6mowojJlBcXksSk5UQWfYPoc2mcLF3WIEGAEfI8BEVj8ksorKnszMTKysrODw4cP3nSKvvPIKXn311ftuW8ubTGRdC1ry2fdTxZMrtTYMjDpBeX/sLtXiyB49VLSCYzWku8dKKLPSugS1g8C5Vg/CghRIjQaO5CuQEH73vvyb/BAQljIWr5vsZObwrn0YEQotcihosYcqcNNIoZUbIxDoCIhg5u2qys1Dgomsm4cln4kRkDMCLpsVNpMJjd//fzDf14fS3/0W4nZVIjgxccsTJXYK/P3kP/4Lne2dEom1rKIM5ZW7tiRgbLc5YV6y4tx7tTj3Ti1e/NJhHDhahMioENkpoPQOE1Gs3yk5NCQSQezpo0GIDFciSO8rCuvtGTwzY5eUWIeGLDAarXjidAIqKyOh06skAq2c5zn3bXMRYCLr5uK5U84mBD7E86j4jLpUY4OIWYSFKHG4So+MFPVOuU2+j21CYIAIDF2uBdxyzCCdyAuvBmVKhFYWhNumAeHLMgL3QYCJrPcBhd9iBHyAgGOJSH3nP8R0UyOWx0aR+cRTyHv5FSiEUuAmqJvY7R4sLrlxrWYZZz9eREq8AtHhtNb0uFGQH4LDR2Kg0fA38GYPrYcSWEsLK7hGhbX93UZMTy3gyMlSnHiyUsr1BWK+T+SE3GJ94V7EZcckZtxWUmIFntKloVgTCY1QZvVZKe9mj3Bgn0+ORFabzYbx0TF8/OF5tDa3wEiE1iMnjuPYyRNISUtFWHi4pMAaaCTywJ6pj373DrsDK+YVvPvWOzh35qwUx66oqsCBwwelufPoZ9raPT+N21w4N45bnwzDPt6PwtIYPPftozCQqMNmPEds7R3x1RgBRsCfEWAiqx8SWRcWFlBE1T7xZOvZ3NwMoRDkq8ZEVl8h69vziocNoXgyOuFGP9mJdg84pCRRapIa+VkaJMWqpeeNTYhd+PZGtvDsAjPjPC18p4GuCWDFDlSmA9lxQEqUQloEb2F3+FJrQICGDkKZddJtQadrnpRZl8lSxo5yTbRUhZusNEBP9jLcGIHtQkDYyvz5n/85RLXlH//xH2/oe/vmzZs4e/Ysnn/+eVRUVDzwlsQ133rrLdy6dYsIRUZSw4vCvn378OKLL26KzQ0TWR8IPW9gBHYUAsKS0Gm1oPdXb0qqrPrISMRX7UHaY6egFImwLWpLi4uYGJ/A22++RQmbaTz30vOkgFAgVbJvRdB4yjiPxto+shKbgml2CY89VYWSXRnQkY2fUlSJyaCtWD1YNntR20rW3VTIFhOlRHaaBqV5WuqnQipm80U3RUJtklR4hoctpMS6AL1eiYx0A3LzQpCcHMxrDl+ALvNzMpFV5gO0zd0zLXgwNO5Ce68dxik39lfokZepRkykChq1bwn323zrfHkfIOClOIDQ2vrYYUQHxQKCQOrx5NCyXxsnkRd8cEk+JSPACKwTASayrhM4PowRWAMCDlo3Lw4NoueNX8JpNiN21y5av+9GTEnpGs7y4F1dLi+mZ5yob7FgZtYJQWpNp4IkrcqD5qZ5JCTocfJkHMLDNQgK2rp4wYN7vLO2iAJb4+gcutpHUHu9G8lpMUQwSkNeYQpi4gJTjUU8Cy6QMusIOfWJvNAw/RtHaqxZqjCUaaIQSoInlAndWRNhB96NnIisy0uUW5yZQRuRV/upoF+QEYXqakJSAimwFiArOwshoaFSnmcHDgXf0iYhIHg7wlmso60DLU3NGOwfoO/FIBw4dBA5eTlITE7apCv55jQD/cv0XWPCrcsDCAv24OTxGKTmJSEqJdY3F+SzMgKMACNwHwSYyOqHRFYR+Hn66adx6NAhvP766/cZ1s17i4msm4fldpxJkDNHJ1yoabZjctYNq82Dw7uDUJCtQWgwJbSlQlxeyH06Nm7ihJNrLM62etE66kE8VRMXJCpRlQnoNYBaHjyFT7vL/96DgNPrgYMorZftE7jmnEK8MhjZpMayWxuLSLIUJEPde47gXxmBrUGgvr4ezz77LGLIwqutrW3dRFZBTn355Zdx9epV/M3f/A2++tWv3vcGzBSsfumll6Rr3btDAQVc3nzzTUQSGW0jjYmsG0GPj2UE/AsBD1kizbY0Y6q+DuPXryGufBdKfvfbUFMATqmhB6QtaMKSqa25FQ219VCpVfjaN19Dema6z9VYxbO00+FET+c4zvzqJgwhemTnJaK0Igsp6fII3ok+ugWZdMZN5DA3mjrsWLZ48Xi1nqy7tZJlt6+K10QiUyQv29oW0d29hIkJO/JJhefxxxNIhUfBSjxb8Lchx0swkVWOoyKfPok6bFF0K9xjbrXYkZGkIiKrFoU5GhjIGSUQ1aTkMzr+1xMXPLDT6w3rAHpcizimTUIBubMkqwyswOV/w8k9lhECvnB1YSKrjAaYu7LjEJBcmGhhaOruwkxzE4Y/PIeg2FiUfvs7CE1JprU7qahtsIkCxmWzB739Nnx0ZQmREWqUlwQhNUkLp92FX/96jIhdKuzdG4l0KmyMi9Nt8Ip8+P0QEOv/vq5xfHyukVxjLOSAosPRU2XILUiW3GIC9VmaYJHc+hqcsxhzryBcqcVRbSJS1SGSe5+CyKycBb3fjJLHe9tNZJXs4Il0aKFCfiOpsPb39qLm+k0Yx8cl8uqu3ZU4SHyMoOAgCMdcbozAoyJgtVgwOz2LX/7sdQwPDSM3Pxe7qipRtadSIkOrZDqf7A4PxXht+NWbY1ianEZRwhJKD2ajYG+eqCMl0QL+RH3UOcD7MQKMwPoRYCKrHxJZBQHlD/7gD/A7v/M7+Nu//VvMUHWQUGnNyMiQVNZclGzerMZE1s1CcnvOIxa2FiKvCtWT9l6H9AoPUyE1QYXdpXpEhnGi6M6REQtekVgbnvWiZxJoGPYi0qDEgRxSZY30IiaUH87uxEtuPws7GQ9NeqPHggHXEpqcc3AQubVCG41cVTgy1KFy6zL3ZwcjoFQqpe/knp4evPbaa+jv718XkVUsCgWB1eFw4J//+Z/xl3/5lxJqDyKyimDKM888IymxCgXY73znO9hFCgwtLS34p3/6J7hJXfHVV1/F97//fcnedb1DwETW9SLHxzECfogAfbfaaa0x29aKjp/8J4KIlJ/51DOIyM6GISHR5zckAsqXL1zC+++cQRJVrOdQ0E9UsEfHRPv82k6qcBofnUVHyzCuXmxDUVk6TjxRgYjIEAQb5JGYcxKZ1LziRXOXnYhhdqQmqpBFSqwFmRpERShBvF+fBRhNJgfGx62orZ2n9agDpaXhyM4OQXpaMCnVUqKIH519PkfleAEmsspxVOTTJxGjEK9howu9Qw509bsQTATWkweCEBejJDIrFx/KZ7Tk35MZj40UuJZR45zBoseBZ/XppMAViiAFa2/Jf/S4h5uBgIWS4zdu3EBDQ4PkxJKcnIzi4mJJAGMtDm4i7jA9PQ3hACMIp1NTU/RMl42SkhI89dRT2IxcAxNZN2PE+RyMwP0REE4qbqcDPW++gbHLlxCWnkEFqOVIPnQEWlIOVFBccaPNbveisdWCnn4rFhbdyMnUYf/uEATpFbBY3KirM2GSSC9WGynu749GeXkErwc3CvoDjl9atGDKaELNtS4pVlG5N1eKVWTmJBDRTh5xigd03advL3odmPZY0Ug5ISORWUWur4wc+/ZrYknghNwfFLzO8OkAbODk20lkFTFHJ+VdpunZp7G+AV0dnRgi9cxMeg7KJuXMLPo3MYmUKKOjqLBeOJ1yoGsDQx1wh4pcnNViRU9XN9pa2lB38xaycnNw9OQxpKWnbUlsez2gi+KVBZMNN6+Mor/LhOlJM46cyqDCiXSoNSrZuJOt5974GEaAEfAfBJjI6odEVkFe/fu//3tkZGRgZWVFIrKKKSfIK0Kl9a//+v8mdaR4Ir0QI28DTTyO/eg//oq+THPw3HNfklR11GT1JtR11JSYJI4ONz9AQCSJROsbdqKt14mJaRfNFSXKCzRIo0R3QuztCjJ+/r6Nk/g/ubSAHGRxqcuLJasXUSEKlKQA+QmAjv4GBCGAm3wRsHvdEIGLq44pspNZho6SWLmUzCqnwEWogqyN6HdujIAvERAk1q9//esQJNbh4eHPLrUeRdYzZ87gX/7lX9DV1UWBYctn53oQkfXSpUv4yle+IqkU/vSnP8WRI0c+O+aHP/wh/vRP/1R6XhD92kjghYmsn8HKPzACgYEAPVDetih8Hbb5eehJ1Tn12AnJplBkpzbyebIagHY7qYuSrdeH75/DB0RkfeLZp7D3wD6kpCZL1l6rHbvRbV4K2pnNVtyi5FB/jxFLCxZU7svFscfLpfv11T2vpd8uN43Lshd9Q07pWb9vxIX9u7QoL9RRwZoSOq1Y0W1+E0qsYq3Z00tWU53LEITWsFANrUVjEJ+gYxvJzYfcr87IRFa/Gq5t66yF1tnTc258fNOKpWUPKbJqSUVag0yypxWN4xPbNjR+c2ER6upyLeAGubGIAtYwWusLRdYk1cZV5/wGBO5oQCMwMTFB8frnqKho/HM4ZGZm4uc//zlSU1M/t+3eN8Qz7bVr1/C1r30NNpvt3s2orq7Gv/3bvyEiIuJz29byBhNZ14IW78sIrA0B29yctF4f/OB9mDo7kP3Ci9JaPTQlFSoqct9oM694MDvnxI1aM/3rQmqKFvk5ehTmBUmntlrdmDDa0N6+SITWeRysjsa+fdEIDlaR4hwnETeK/73He8hW0OVyo/ZGN2qvd0uuNUkp0dh7MB8xceEBTWa1eV3oJpX+bvcCup2LSKTnwiJ1pCRwEqvQEZ1VCSUvNO6dUtv++3YRWS3ErxAxx7HRUYxQrqSvpxfm5WWIeOC+gwdQUl6G2Pg4+izj9cW2TxI/7oAoLlsxr6C7swsfnjknFYiJebVn/x5S/M2HwWCQPsfldos2iwMjfbNobpjB1U9mUFEVg8NHExGfEo6QcL3cusv9YQQYgR2IABNZ/ZDI+vu///t46623PpuOsWQTIqo6TCaT9J5QYHv33ffQ0E6su/s0t9sKy/Lgfbbc/ZYgqk4bPybFoUxKGL+M0BAlJShViAhXQ69TSItQfua/GzM5/yaqZoXN6LUGm5ToJi4rSvLIYmOfnhZvYAu/OwaP1imwOkjZc16BelJlvdwFVOd6cThfgZgQwEDzn5t8ERAJLReRWWe9dnRQYuu8fQyxCj12a2ORR8qsIoDBjRHwJQKiklcoodzb1kNk/bu/+zuI173tQUTWb3/723j//fdx6tQp/PjHP77rsKWlJfzJn/yJRMD6i7/4C4SSKsN6GxNZ14scH8cI+C8C9sVFmLo6MPbJFQx98AFKf+87yH3xJSqg00Dhowq3edO8FOgTll5NdU34+re/gUNHD0mEfFE04Msm1FjnZhbxix9fwsK8GYeOlyKvKAWpGXG+vOwjn1sUq9no+X5g1IUPLq8QJgrkkwqrIIOlJKhJzZuIYI98trXtuLJC2Mw6cOPmnKTGWk2JyrKyCCQQiVUkK+VA8l3bHfHem4kAE1k3E82dey7xGWa1edHa7UA3kfHHJlyoLNbiseogqChAwbGmnTv2m3FnYs0vHFmu2Cfwun0AB6mYv1ITg3RVCEKI0MqNEdjpCAiF1H379pHl54REMP3CF76AJFIL+/jjjyVSqsgTFBYW4uLFi+Q8tbrQRVtbm+TqIlxgsrKyJHKsTqfDG2+8ITnLCCyffPJJ/OhHP5LyD+vFloms60WOj2MEHo7AdFMjBt59B/alRWgMIch96WVEFxZBsUnqgYPDdrR3W9DbbyMlfRUeP05rvzjVZwWM4rnO6XCTovMC3n1vgj5/QqX1YXq6AWFhLCjx8BFc+x4i9jw/Z8bo8DTOvl1Lin8Oco/ZhZyCZAhSa6A24dbngFty7Kt3zmLQtYw5yhE9pUtFBT0rBhOVVc3KrLKbHttFZB0nAqtQyrx4/gJGR0aQSC5QuyorcfBwNcLCwym+dZtgyDEu2U0Zv+uQeB5fWlyiz+wRXProIj7+8AKeeeFZVFOMO5WUWQ0hBtndkyB0O51utNRN4K2ftktOOplZ4Th4KhfpuYH7PSO7geIOMQI7GAEmsvoZkVU8MD3xxBNobm6WrIJ+8IN/JWuQJHT32qBw1+N//a8/lAitovL6v392Abcafqve9uk8tlmnMdD9809/fei/htAMpGQ8K9m/iWyoID3q9UoitqoQGUEvIrZGRqjpS4ysKylezBVtD4V0W3YQAQUq1KRktxP9I+LlQphBIVmPZqWqkRQnggpeTjz/ZnSEwpXVqUCX0YtbA7fnfYTBiz2ZSqREeaEluHiub8tUfqSLisSWnSpwjW4LGlxzmCYCv5WCGFXqaORrIhBFFbg6BUvrPhKYvNO6EJidnf0sYSQSQII4uh4iq1BEEQRU0QRp69ixY9L3/P2IrCpiLYlklShsEUkm8bwg1NrnST0xnIIvom2GJaA4DxNZBQrcGIHAQsBN6qj2hQWMXPoY3T/7KSmyHkfy4SOIzMmF9jefMZuJiEjM9Pf24ex7Z6XK9RAK6p04/RgKiws38zIPPNfwwBT6usfRXNcvKZqceroKiZQQMoRsf9W5KLpyOr1o73NgYMSN8SmnRF6tKtYhOpLWaQbfkHzFesJGVpFjY1Y0NS1gedlFa0QvqqoikZNDVs60HlSRcwe3wEaAiayBPf5ruXsRn5gmVa++YRdutdgRH62iYltyjklSI5piTdwYgQchYKG1/iSt8Rtcs0RmNeJJfRr2aeIkBxa2jX0Qavz+TkKgpqYGL774oqTgdPbsWWST7e2n7e2338Z3v/td6ddbt24hJYUsplZpf/VXf4V//Md/lM7x7rvv3qW8+qkrnDj8k08+ues6q5zyvpuYyHpfWPhNRmBDCIg1unVmGsbr19H/zluILilF/J69iC0tQ3Dcxgsw7XYPhBprU5sFzfSKI2e/zDQdSgqDJcGbOwuPxLpwcNCCW7dMtGb0QEdCIAcPxpAydBALqGxolB98sMPuxOKihayfOzAyOE1xaC+Ky9Kxp7qA8rcaaEQCK0DbsteJcfcKOl3z6HEvIgo6pKlDUaqJpLyQHnrOC8lqZmwVkVWQCUWuZXZ6huKNvRKp0Cgp2ysQEhqCrJxsZOfkIDM7ixQyRYE4r0llNVH8vDNOh1NyWW6sa0DNtZtSPDU6NhqHjx1BSlqqNAflSJoe7ZtB7cVeDI25YHZocfqZDBSXx0jFLBwD9vNJyd1nBGSOABNZ/YzIKubT0NCQRFIpKCgg0qEe84uUTDQ6pAXi8vxV/N7vfUuadh98cB6LK2mfm4JOpw2L8+Ofe//eN0T1Wlvz2xBE1pDIp+g6LizQtZaW3dBoFIiixEJKkhapyVqkJesQE62mAJoKGlIDUtLznZLyp0z0uxfV7f9dJKDHp9y4WmfFxIwbNlIePbYvCOX5GgowUPLZN3nv7b/xdfZgzuzF6BxwtZdIwNNePFmmQBk5c0WFKCBUbe8M2KzzEnyYDxGwkzLrEgUuPnFM4qx9lFRaSDGMyKwF6giEk1KLiitwfYg+n/pTBH7xi1/gj/7oj9ZFZP30HOJfQWQtLy/H1NQU7kdkFe9XVFRIh5w7dw4/+MEPcPXqVczMzNDCMgi7d+/Gn/3Zn6GkpOQzku2d51/Lz0xkXQtavC8jsLMQmLh5Az1vvA61PgihZFea/vhphGdkbupDkUiCOewONNU34t//5YfIzsvG40+eRlpmOqJjfFv1La4tEkAiGSRs+rQ6DdKz4nHksTKEht22TtzuEbXT8/ui2YMPr1oxanQjPVmFohwNdhXqfNY1sYZwuTyYm3OgrW0RFz6apgB/CA4ciCKCRDAVTFBFIzdGgBBgIitPg7UiMGJ04fItG5aJKKGlWFN1lR65GZQ4ZGXWtUIZMPvPeIjE6pzDCKlsTXtteJJUtoQiKzdGIFAQ+Id/+Af89V//NU6cOIGf/OQnd922IGl8Sl795S9/ierq6ru23/mLSJa/8MILEMTY733ve58RYD/dZ4Usd3Nzc6VfBclEkGfX25jIul7k+DhG4AEI0AJNFJpO1tdh8lYNxsk5pfBrr0lqrEpybFRukIAl1n8LlA8cHXegrsmCrl4rnjkdgV0lwVIO8H45pMVFJ8Us7RSLnMXwyApeeD5ZUmfVasnOXajjcNt0BFxUGTZpNKGlYRDn3qklF5lUIhntRlxCBELDgwJetGbAs4xmemZsdcyRmj9wWpeCbHUYYpR60mwS/3GTAwK+JrKKOJ+b/lZsNitMcyZ0dXbiyseXME25FCcp0p968gns3rdXUsYUORRujIAvEZibmcUIKbP++vVfwTg2jqdJmbWsohzpGelEoJafy5VlfgmzwxO4cHUFtW0ucoJMQGVVFBISg4hTwmRvX84VPjcjEOgIMJHVD4msn05a6eGLFCwcTg8sFg8lXMnynByz8/MzJYLK97//fRw5+vynu6/5X6H084N//r+QkpqDo8deJetKN+wOD71A13PDYvXAQUlUG1VmOp2CYOOlSkw1khO19NIQ0ZVUWoOZFblm4H18gAhCWKgqdmrWg+5BJ1q67Igj5ZN0Uj0pzdeSipNKUt31cTf85vR2F+FlBxpHvOj4Df87LQo4lKeA4DLQcyU3GSMg7AYdHjdGvFSB65zHsNtMuqxeSa0li6pw4xRUFc5sZBmP4M7o2lYRWTspCHPy5EkJtLS0NIyQJY5oQpX1UyVWkagSaq2nTp2Stt37P5H0Es8XD2s3btzARx99hG9+85tIT09/2O68nRFgBHYQAubxMcx1dGDs8iWYJydQ8s1vIZZI9lpDyKaRWYW16VD/IJobm8hy6RKq9u7GC6+S6hSpsgqrU182y4oNC/MruPRhM1rq+1F9vASlFZmSPZ8gtcqh9ZINd2sPJQnn3NAR6Wt3qVZSZI0K993ay0HrwMUFJ27eNMFotBDBV0XrzlByCQmTqvBFcpIbIyAQYCIrz4O1IiAIrEYqtm2m2EQbfbYdqCClrzytFKfQaTm9vFY8d/r+Lq8Hg0RKeNc2Ai0VphaqIpCvCkeKmp5DuDECAYLAD3/4Q9TX1+Ppp5/GM888c9ddi2TP8ePHSYRCAxEjCA6mZMEqTbi62UnV8c0336QCpQN37SmeyTMyMqT3RJ7hlVdeuWv7Wn5hIuta0OJ9GYGHI+CyWLA4OIAucktxWi2Iyi9E0v79iC4uEYm6DREYRVhQ5Pz6Bm24cn0ZOlrrxcdqUFoUjKRENcUZScjmPvF0sWYUKq6XL8+go2OR1ooRRIY30OeIAbxefPiYrmcPUYRrpeTV2MgM6qgQ12Si3AcR9o6dKkchqbNqNOqAJhELZVaTx4ZWpwkjnhXYSNU/h54bD2rjEQI19MrAVa1dz3zz1TG+JLK63W6I10BfH7o6OqWXeWkZIWGhSCbV+vRMcqRNTUFsfLwkBCLyKNwYAV8iIFSB/3/23gPMruI8A37v3r699960vUirLhASQojesSkmGGIIwfGf/HYebBwSTIzLbxtiggM4IdjYMZgOAiFABdTbqu5qe++9317+75vVFStptdp2t2hn9Fzdc+bMmTPnnbP3zMz3fu83NDiEIwcOofhUMTo7u5CWvogI1Rvh5+8HTy8vd15+wnVbiRRkNZiw+9MSHPyyBt7R8UjMisLadWEUyUEjxb4mjKg8QSIgERgvApLIOs+IrEYjqWi2tNDEj1RQiaTChJORicknnM8DMyaqbNy4ceThCW8//fTTSE1Nxb333ivOZZVWGxH7Bgft6Oqxo6PTis5uG7roYzCSUitJVAaQUmtggArBgSoEECnS15smBDoFdKT2KdPcQIAXI/hZqay3obDIjO5eB4VJAJZkaREfpSISMnnJkr1oLsrYzxaCtZ1OVLQRobXOCS3NZVanKBAbpECIz7RxNmbr1hbEdYdokaLPacEOCjtYY+tHjNIbqWo/ZKoCoIeSDGCSkbwgHoRZusmZIrIyufSOO+44e5esAsshBdmTuLi4GI888oggtwYGBgrFFa9RJsWs2MJlL5WYvFpXVyeJrJcCSh6XCFyGCNhoPmIldaai115F25HDSLr5FoQuWYoACmnqQQbzqSYeow4ODGL3zl0oKykV28tXr8DG66+datWXPJ+v3dbSg9Kiepw+WY/21h7cfPcqCpkUPycMQGxMHBgCjpeYcey0BcEBHkiIVmFxphZ+Pu6Za7nmDaysU19vINJEDxx2B/IXByCBDJKRUVKt4pIP1gIrIImsC6zDp+F2eVnLSg7aR4ooksYRM8KDFYiPVgsyq78vRUJRSjLrNMB8WVTB7nY9DjNK7b34xFSHOKUPbtTGwlehgbfH1McglwVI8iYWHAK8dst2gP7+fhw/fhw/+tGPxFx9w4YNeP311y+JR19fnyjj4+NDZKevx5O8/d///d9CqZUL7Ny5k5yYFl2yvosVkETWiyEj8yUCk0CAJmk9RMrqOHEc1Z9shk9UNNK+eS+8oqKgCwiYRIVfn8LzPxazaWm14XS5gdRYh5CeoseyxV4ICVaTkM7XvxNfn3Xu1pEj3Thd3A/iU5JCtJ5I8kFCxVWqsp6L03TuDfQZUFvdiuOHq3D8SBXWkENuzpJEREQFQe/JRKOFO55moZNq+wBKrb04Zu2Ev1IrIvbFeXghQuUJtZNtoQsXn+l8DidblzuIrDZS32Jl+a6uLnQRUZCJrLVV1WhrbaMQ7j7Izs1BZk4WUinyLY95Ro6BJnsf8jyJwHgR4PXnxvpGlBSfxratXwjhhmUrl9PzmIpYVmYlwsZceyaLvzqBYzuKUNkTDN+oCFx/cxxiYr3F+3289y3LSQQkAhKBiSAgiazzjMi6Y8cO3H///eIlVlRURCEc/c7p7127duGb3/ymyGNCy1RV0s4nsnLFTGYlgUNYbSTHz99kcOBJ6eDQMLG1utaMimoTeWoSyY8mt5mL9IiJ0iA8THpmnNNZs7zDAyWjiYgCBif2H6c+q7HA24uUlRJUWJ6nFcRjGfHl605iZVZyaMW+SqC+y0lEYGBpArCKCK28ziunul9jNRe3eMHCSsot7HnLixaHre0ihMxabSSilV4IUrhX3W0uYiLbNHMIzAaR9Rvf+Aaef/75c25y+/bt+Na3viXyLhZikMcOLiXXc04+b4cn0zwOkYqs5wEjdyUCCwABJys30ySg9rNP0XLgAL1hgeCsLEFoVXtO3WucDfFdnZ34w+9fozBf7bhy3ZVicTkpJdnt6PL4+ERhNTa/vR/Bob5ISA4n408SwiMDabw3+6M9VmA9VWZBTaMd7V02rF2mR2aKGj6eRPQiVRx3JFZ44fnevn1dOHq0lyJwqBEbp8cSCiPl66uSyjruAH2e1ymJrPO8A2eh+fzbyzPqlg4bapvswtmWo/9cd6VeEFo99e75fZuFW5WXnCICVgoKW0yRVkptvaglQkIGOaZuohCxKlJmJe25KdYuT5cIzE8E2MidS9ER2ig8rislkMrqJ598QipJ/q6sCX2zmusfSCDjySefpHGgVUR0YVLs8O/1uVWVlpaisbHx3MxR9ljd9dChQ+C1ivT09FFKyCyJgERgvAjwfLz8nbfQfGA/1KS6HJKbj/hN14ltjymqCfL8r7fPjh27+9HaboM3zTWzSIk1O10v5pzKcTgYdXSYUVMziF27OuFNIjc33xSBoGCtDEE83g6eRDk7OZuaTRR98Wg1Duw+TaqsDoSE+2PD9YvnzHrGJG5rWk4hSx7MTrJdkzJrCTlDldv6UEVCJ+s1kViqCUGABz2bJHQi0+whMN1EVh6vDJDqagmJdZw4egyHDhwkQreeHLEjkZOXB15fDA4JJeVLTyEAspCJ3rPX6/LKPDbuoHXvwsOFOF10GmWnS3HT7Tdj3Yb1RLb2FtEV5hJKvY0taKpowufbutFrVCNvdRIysgOxKFVGRplL/STbMrcQ4PcLO1WwPb6iooLGxd4iCsqyZctE5JTR5tej3cFk6mGF8X379tF4fBfa29uRk5ODVatWCQFLVwRX17XYKfaLL75w7Y76ffvtt5/jGDWZNo1a8RiZksg6z4isBgoZwgqprMTKqmsvvvii6F5+WJqbm3HXXXehqqoKy5cvxwcffDDqAtMYz8MFh54+T5H1ggIjMlghqK/fjoZGM+oaLRgyOATRlQmtfmTkDCR11lAKQcKh6708lfQSlovMI+CblU22F/GPZFmNDeVEZG1stVPfKJCWRIq/EUpEhKikLPyInjFZnahqV6CsFShudCCBlGJyYxWICQL8x47UNaIWuTlbCPCixSApszbZh3DQ0o4BWIXHba46EGnqAHhROBk1GcBkkghMNwIzRWRtaGgQ739uPxuZWIFlZGIDFI8hOGzgT3/6Uzz00EMjD09omwfAn3/+uSSyTgg1WVgicHkh0EWhSlkBpnnvbuhDw5B+7/3wCg+D2mtqC1hMXq2urMKnH20R49A7vnkX4hLjiTTp61YA2ejT3taLU0drsGvbSeQVJGH5FWkIDacxgrfOrde+VOU2OxsTHahutJFioRlatQeF3PZATpoGMeHD43V3CIjwXKGry4zaWnIEKh2gRQ8zhYf0RXKyN2JiPCWJ9VIdt0CPSyLrAu34abhtg5HWlAYcpMpqQnO7Q0SLSYlXIS1RLZwJ3PE7Nw3NllXMEALsnGogEsIX5kbUEYk1XOmJNKU/8tS0ICOTRGABI8A2gVtuuQWseMpzfle655578Itf/GJCRnAmxbJd4YknnsCePXtEVZmZmXjrrbco6troKo9btmwRBFXXdS/2HRMTA16zkETWiyEk8yUC40PA1N2NoeYmVG7+EH01NYheexVC8/IRlJYOBYfcm2JqbbOiroEigBQZoCRnzpxMT8RGaxARNn7lc5OJHC/bTdi2rQO8nZPth/gET1JnlQaUKXbPJU9vbuhEZVkzio7XwDBkxpLlqUhOi0RUbMiccM695A24sYCR7EKtdgPK7P1CmTXAg55rD09kkW0oXKGHXqGSyqxuxH+sqqeLyMrk1R76jWysr0dzU7NQXx0Y6IeFbCERpFgdlxCPlEWpCAsLg44i2M01xcuxMJLHLk8EmPPTQs/qscJj2PPlHhIOiEFK2iLkLc6lZzZSiNrxWH8uJCu1ta+1CzvfLURVrQnKmGzkFoRhzapAWh92n8DCXLh32QaJwGQQ4L/dgwcP4oEHHhDRU0bWwdFQPvzwQ6SRKvil0mTq4XM4QuvmzZsvqP7uu+8W/MKRZNaRIlgXnHAmg9cJOPorp8m06Uw1E/qSRNZ5RmTl3v3tb3+LX/7yl6Kjo2jwtWTJEhgpxCerqA0ODpJnoxYff/wxGRkzJ/QwjFZ4IkRW1/ls8OTQcDX1JpRVGHG8yEh/oDZaOPNAfg5NDNI8ERWhIbnxYcLYHHkHu5q/IL+5v9q7ySCw14DmNrsgDVxRoMfSbC08aP1jDghQzZl+4ee7rAXYctIBC6m0BngpsC5dgZRwqco6ZzrpEg0xkfGrhcmspMr6ibkBV6rDsUYbIZRZvWnBQiGVXC6BoDw8UQRmisjKKoZsHOLEhqY1a9Zc0FQOBTgwMCAMWjyAnmySRNbJIifPkwhcPgjYyXO8r7oaR577lbipRXd/A0HpGfCmsIZTScePHkfhoSNorKtHWEQ47rqX6g12P0mlv5fCJh4oQ2VpE5obu7Hu2lysvSZ3KrcybecazU6UVllQXGFBUbkVBTk6bLpCTxEwALWblFh5zGsnAm1JST8ZINvE/CAkRIc1q4MQFz915d1pA0dWNOcQkETWOdcl86pBJCYllKdL6DevusFGEWPUuHG9HhoVh3ucV7ciGzvNCFgowkqv04w/GymUMilq3aGNR7LaD/4KehnKJBGQCAiH1ePHj2Pr1q145ZVXBCK//vWvce+9944LHSbB/vu//ztee+01GgPaSXlRhb/7u7/DP//zP49JhuX1BTbCXypV07zhs88+k0TWSwElj0sELoFAV3ERmoho3nHyhCCu5jzydwjKyIBiGgZKPAc8dHQQJ4jEyg5G8bE6XH2lL3y8Jz4IGxy0k/G+Cw31Q2ABHI7oUVDgLwzfl7hFeXgKCLBojZWMVp+8dxCnjlXDx88L2fkJtLaRQ7/rSok/YdvqMKKSyKy7zC1kIzLgRl0sskjlP8yDVIelyMkUnr7JnzoVIis/8/xh8a9GcpgppVDtu3Z+iXJSt/T29UF2Xg7Wb7yGQqDHkgpryOQbKc+UCLgRgaqKKhzcfwDHDh/FQN8A7n/ofuQuyScejdecIlybBwZx6u2PcPxoJwpNS5C/Mg433RBK4hPDAnZuhEhWLRGYdwh0dXUJ9VXm7oWHhwuBSiaCfvTRRygvL0dgYCA+/fTTszb9i93gROthkukzzzyDl156SVS5ceNG0Y5iUilnEUwmsD788MN49tlnxbuTC/3P//wP/vVf/xWx9K4cLdo7rw1wxBaO3MJpom0SJ03iP0lk3TEu1BREFKVp3NxJL7/8Ml544QX09vae0ygmr/JiVWJi4jn5k92ZDJGVr8WT3gGarPb02tDZbUN3D4UI7bbSBNhJi2EOUmdVCzJrfIwGPj4eQqF1sm2U500dAe4vg4kG+qTIWlFrQWm1DWFBSsRFqZBO6qzBARSkbW44/Uz9ZqdYA2PVQ+uzNR1OFDcB1e1O5MUpkBGpQCxxLHTjd06eYkvk6ZNFwEYGMCPsqKEQMids3ehzWigMIbBCFYZElS98PUjxR5JZJwuvPG8UBGaKyMpexEuXLhUqJ//wD/8gwgDyQo4rHaAQ4Cz/z4kHrBy+YLJJElkni5w8TyJw+SDgpEViA4UlqdnysVCCcTrsiL2aFofXrZ+UcYQXnXkiveXDT/Dl9p3IyMpAVi55d+fnkSKqe4mTJqMFTaRc8tlHR0gxxoL0rFikZcYgISVi1jusf9CJ1k4bDh43o2/QIRRYWaEwJV5NCjnkcOYmjzODgcJVlg+gsnIQ1dVDSE3xRgapsUZG6kV4yFkHRjZgziIgiaxztmvmRcMomi26e2muRgrUB46Z4an3oIgxKiTGqClizNRVxuYFCLKRoyJQbxtEhb0PpykkLNEwcJ0mBpGkyqpVyOdiVMBk5mWLAM/72ZDEiQmn/BmZ2HD1N3/zNyKCChut/vjHP14yYhsbiDhiSw2pO3K65pprwDaBhISEkVVPaZsVY1l1RiqyTglGefICRoAdSS0U9rNh5w5UvP8ugrOzEZqbh7CCZdATOYv/9qeS+gco9DrNOwtPDKG2niJxpOuRmqRHHNnvNJOIrGixOCiCpJEie/Tj8KFe5OX5Y80VwUTKUcrIHlPpqHGc6yD7a3VFC4WpbqSIM9UIDPHF0pWLEB0fgpBQv3HUcHkXMZAya5+DHIVtPagk+5ARNkTRmHKpKgTBSj18FNLAN9NPwGSJrDwGam1pQQM5wleUlZMSdBuRAPuJc+CLgMAAREZHIZLEwPjbi8I5u5TkZvr+5PUkApdCgMN6t7W04eC+A0TGLkFgUCCtTWdg9ZVrBJlVSY4IcyHZSN24vagEJUdqsWt3J/RR8UhYnoNlS/yQEKedC02UbZAIzBkEmBjKBFE/Pz/hbOoiiLIj6Lp160Sk9W9+85t47rnnxmzzROvpJmXyxYsXw0Jzh29/+9v42c9+dnY9gDmEP/nJT8T1jh49Kgi2vPPkk08Kourzzz8v5utjNogOTrRNl6rvYsclkXWeElm5Q00mEynklKCtrU38ESQnJyNkmj2KJktkPf+B6yIya2OzBSXlRtQ3EmmMjK4hQSokJegRGqxCEG176jyE/DgbY6c47z7/8nJ/HAgw14mNRqx6sq+QVHSHnOCx0bJcLZJowYL5Ayrl1BZExtGMeVGEFWyttE58oMqJPeUO+HkOk1gL4hUI8lFAO7yePC/uZSE3cgBWtNmN+MrcLBYtOCRhuspfkFl1ZBqTHrgL+emY3nsfD5H1f//3f4ksVImkpCThDTVaC9hglZubK977v/rVr3DfffddUOyNN97A97//faHOzqqsK1euFIYtJoixMWvbtm2Ij4/Hrl27zhq/LqhkHBmSyDoOkGQRicACQMBqGEJvRQVaDuxH7dZPEX/9jUi98y6oyWNcqZmYQprRYERvTw/ef/t97PlqD+554B4sX7VCeKeq1O4dXDU3dgkl1h1bjyGIjDy33L0awWTg8fSavUU4Bw3MbTTerCUyV3mtFWXVVqGEc/UqPcKDydNd775xucFgIwOABQdIQaer0ywMjQVLApBLxkc2kMq52gL4457CLUoi6xTAk6eeRaCt0469hSZ09jjEOsXSbA0yU4aJFLyeJNPCQYCWqegZcKLQ2iGiqmhprh6j8sYKdSgCPGbvPb1wekDe6VxDgKOycaQVTu+//76I1HZ+G9kAxWsGkZGRYAMVrwdcLLW2tgriKquqsF2BVVyZyDrdSRJZpxtRWd9CQoCd1C0kaNNdVorGXV+i9vPPkPXthxG/cRO0ZBz3mODceyR2PO9kPjzb7opKjGhqtZCDqRMbrvJDIpFSOALIZOZ/XK/V6kBxcT8+3txC4ZI9yageQEpPnvD3l0TBkX3gjm0LqbI21Lbj882FGBo0ivWN/GXJWJQRAw0Zr2RIdaCJIvZV2wewm5RZlfSQZ6sCkUJq/9EeXtCQoxQ7Tsk0MwhMhMjKDvBMzhkkZcg++l2sq6lFNYU7Li8phcVqIcdrbyxZthRZOTmIjokWBNaZuQt5FYnA1BE4ergQR48cJTJrKULDQnDt9ZsQHRcjiK1TdViZeutIxI7mFFZSl6wpPI2vXv8cbYpYWOJWY9PGEOTn+pFNElBKHsl0QC3rmOcI8DiLbfPsKMqiUz/60Y/OuSOOgvLjH/+YHC98yOmrVNhbzilwZmcy9bDiK0dWYfVUrnukEwf/jqSnpwuhzKeeegqPPfaYuNI999yDr776SqjFFhQUjNaUs3mTadPZkye4IYms85jIOsG+nlTx6SKyWmjSSmNL9A/YhEprE02Mm1uJ3NpiQVCgCtERGmQs0iMiTA2dTuE2ZaFJgbCATmIyq8HkFAoox06zMquV1FiVSI5TY0mmhtRQJrdwcblByDhxau1zoq6LCK2VgNHixOpUDySFOhEVICe5wwjN7f9tcMLsIHIIqbqUUziZCmsvgj10WK+NQgR54Urv27ndf/OpdeMhst59993YQ6HBVq9ejbfffnvU2+MB4qWIrLy4ffXVV4sBKpdftWoVAgICwCEGGyi8Duf93//9H9auXTvqNcabKYms40VKlpMIXN4IOMniZR0aQtO+PTj9+h8ppGEmIlevQXBmFjxDQyd08431jRSa6LjwPO/p7sFtd9+GnPxcMel292Ldrm0nKexejVg0SEwJx5r12dB7ElWGJU9nKZnMTopw4cDeo2acLDNTeG0NqbCSEit9e9J8yZ1NqyAl1vKKQaGeExiooYWXYPLQ1ZHzpHpSRsxZglBedpYQkETWWQL+MruskdYl2rvsOFlqxa7DBqxarEM+rUmEBiqFSutldrvydsZAQMzbnXZ8bm7ENvps0EYjX03vJQr/qpNqrGMgJw9drgjwnD6blBg7Ojrwb//2b3j00UfPuVU+znmsfspKLzz/Hys9/vjjghDLxI/du3cjLCxsrOKTPiaJrJOGTp4oEYCD5t09pJxc+sb/wWYywpPCk8ZetR4h2TlQqFRQ0N/9ZJPVyvNOO04UGbBjdz9Sk3XITvdEXKwW/hQqeDIkVldb2IbS0GDA0cIeMphbRfYVV4aQE797I664rr+Qv5lIPDRoQn1NG04UVuPg7tNYvS4bS1elIjQ8gMh9uoUMj7h3E40vOVJfhY1sQ+JDysGaYBSQMms4KbN6S2XWGXtGJkJkHegfECqsx44U4lhhIcwms1CsTExJQhyJd0RTWGR/f38R2UlHIZyVyrmhZDljYMoLzWsEWJmV18d3btuB1qYWEljwIlXW1Vi9do2w67l7ffxS4LHtkW0BXeUVKHp3M0o6AlCtXIyCFWHIyQ1CPI0dPD0nPya51PXlcYnAfEGA/1Zi6X3EyuEff/yxUEgd2XYmaPJcndMXX3wBjrg+WppMPS6n1iuvvBJvvvnmBdU+/PDD+PTTT4XzKkdv4ffkkiVL0NjYKAQ0+R1aW1sr3qXs6Gq1Ws8qunJlk2nTBY0YZ4Ykskoi65iPynQRWV0X4cmryWRHW4cNdaTMWl1rIg/PYQ+NICJMhgSrERaqRmCASkyU+bypTJZd15Xf40eAlS64n0qrbDhdaUFHt4MMRUB2qgYxESqEkOFI9skwnmZe6DGBVFlJLYsIrXq1E2kRCiwmZVatygkNeSzLNPcR6Haa0UgeuPstbeDQMuEenkKZNVnpC50HKbNCDrznfi/O7Ra+8847+N73vofg4GAUFRWNqobCIQRYJZUJpqyqOlriiSp7QzU1NWEsiX+DwSA8vM4nxLJB6uWXX8by5ctHq35CeZLIOiG4ZGGJwGWPQFdxEao/3iy8sj30OiTfdAsC0zOgoInwpRbZePJrpwnBqROn8NF7H9ICtDdi42OxYvVK8e1O8IwGM/r7DNi25SgqShuxeFkK0rPjkJAcTqrVs7PYzeNwu92J5nY7ympsqG+2oZ8Mi6sW65ESp4Ivqf+7K0oCK7EOkOPhsWO9tGAxRJ70SiQmetG7J5CcDT2kV707H8bLqG5JZL2MOnMWb0WoeNFaUXGFBXuOmClCjAfCghTIy9DSNykkkcqHXJeYxQ6awUv3O62otw8KRVYOAXuzNg75qmDoaa7uIZWyZrAn5KXmEgK8vsDrDGxY4kgsbPhiI5mKCG1srOLjPMbmsIHf+c53RNNHiwLD5bOyskiJvx0//OEP8dBDD130Nj09Paek4CeJrBeFVh6QCIyJgIPmygMN9eggB/Wqjz+CTyzNVzdtgl98IjynSDzneWf/gENEUaypo/VxEp1Zmu+FJblepN6kgEY99TXx/n4brWMacOJ4LyqrBrFhQzgyMnwF0UWlmnr9Y4K3wA/a7Q7wmsepozX4atsJ+Pp5ITwqEPlLkxEZE0SRV4gEvcAH1FanA2wbYiLrIWu7cJIKVuiQqQ5EtNILPlALtdYF/ii5/fZHI7LyOMZMYcwN5Dzf39ePQVKB7O/rwwAR/Xp7etFOkWq7yKnHx9cXEVGRpDacTgqsMaRiGbbgn2u3d5i8gFsRYLI2Cz2cPlUsxB4ysjNQsHwp4hMTEBAY4NZrj7fyodYWtB4+jBNH21BYRIJ1OQWIz0vB8gJvhIWoaU4iuRHjxVKWuzwRqK+vx4oVK8TNVVA0Qy8ipY9MPHePoXcWJ56/M+l0tDSZelyOquzcyo6v56df/OIXeOGFF5Cfn49PPvlE8BWYdMtRXK644gocOHBAkFf5PF5v+Md//Ef87d/+rVhv4LzJtInPm0ySRFZJZB3zuZluIitfjI2zw0YJColCKpalFUYUlxpRWW0Whogs8vjMStcjLYWCe0vjxJj9486DFiJpdvU6sG2fAU1tdviQF01BthbLckgbntICn+MKDATRgJ7n1j6gqNGJz045kRiiwHW5QCiRDHyJACzT3EfAQcqsRiKwVtn6cczahf20aMFhCjfoohAADbw8ZLijud+LsoWjIdDd3Y1Tp06JhZ60tDTEk1fydHkhSyLraIjLPInAwkXA1NODQTKulb3zNloO7seSf/o+otdeBZVWd0l1GJ64myhE6q6dX+GVF17G+o0bcMudtyI4JFgoKLgT1baWHlSVN+PgnhL0dg/h7gfWIiU9mlRgL03AdVe7OPKrkdRYOTrCxzuGEB+tEg5lKfFqtzuUtbaaUEXGxSOkmDNABsdNm8KQkuJDYW449KBchHRXn19u9Uoi6+XWo7N3Pzzf7uq1o5Gi+ewrNKONFFpv2eCJRYlq6DmSj1yUmL3OmcErM4l1Lzmd9hHJgOgWuFITiRSVn6SwzmAfyEvNPQRaWlpEqEIOrauhkOJ5eXmIiIgAG3o4fCCnHAqpu2XLlrPk09GiwLDqyrJly8Z1gy+++CJuv/32cZUdrZAkso6GisyTCFwaARvNles+/wytRw7D0N6GKIqAsuie++DBTqNTUGLlK5vNDjQ0WbD5s17RkNxMTyQnahEdpZm2cRbbAW02J3bsaKeQpR1YtjyQCPQUvj1KT2TZ2XEevTTql08JMZ7u6EN9bTu+/PwEKbS24/Z71iA7PwF+/l70HEkyMU050EvjzCa7AV+Zm3HK1o0rNBFYTOqsiR4+0M6TCAC85v/MM8+IccETTzwxqpAGO7CwyMaRI0dw4sQJcl7WCnvBJiLHx8XFnSWpjPwL4HPYDsACHOz4wuMLjgCXmppKf9vkeTgN6XwiK5NYWYm6l9YaGxsaUV1ZhaqKStRWV5Pz9QC8KRRzRmYGRXHKQ2JyEoIpIpTqzG8iK9PLJBGYzwgwmcxqsZLgw0l88Pb7xKMhomhwEG649SZkZmfOCaK2nUjmZiKWnyRV1n2vvo3m5Hvhu3gdbrsxCEnxOuEMs9AdJebzMyjbPnUEduzYgfvvv1/MxXnuzvavkYnfrdHR0eLv+z//8z9xxx13jDx8dnui9dx5553YuHGj4AWwoyo7uMth/xcAAEAASURBVJ6fWOyKxwt8fR4P1NTUiLUFVzluW1RUlBDUcr3nb7jhBrz22mvivT/RNo12b3zNanqnXyqxGiwTa2+66SahGnup8pfbccZ6PElhNBp5PLvg0tNPPy0GpPfee++03zsrf7KhtqvbhvYOK5pbrejqsYGhpjU4+PmqkBCrQVSEBj7eHmRQlgPQae+EMSqkNQZSz3WgqsGGmkYi+dVZEUrKJ2xETyCDejAp6Eq7ERGzCUMDkQ0aexQ4XO1EnxG00AMsTwTSIoeVWZXS8D/GkzY3DtngQK+DVKIFmbUTVoUTXhQ+ZikpvSQofUjthXVZJYFjbvSWbMVcQEASWedCL8g2SATmDgK8gGUldYSKD95D45c7EbFyFcIoJEkwhTpUe57rcXp+q4cGh1B6ugQnj53AkYNHsO6a9dh043WkAKqDSq06v/i07LMxzW6z49SxGmz79Ch8fT0RER2E5WvSEBYROGtjXG5X/6ATp8qtqGmwoLPHgSyKisCREfx9FUTccs98yGKxg5VySkoGaAGjm0LHqGnBQk8GRn/yvNWSJz07sclx0LQ8fAugEklkXQCdPIO3aKK59hCtEe0/RkR7WpMID1EiOU6N7EUaUgmTv0sz2BUzfil2OLWQStZpUmHdbKpDhNKTlFiDkKjyRZCHDIc74x0iLzjnEDh9+jQee+wxsMLLyMQEjm9961siSosvqZS50mhRYDZv3gxWahlPeuWVV4QBaTxlRysjiayjoSLzJAJjI8AkkcHmJlS+9y59NyOMojSFLV6CkNy8sU8cx1Gee5aUm1BRbUJjswWhpKC2bLEXggPVQgl/HFWMqwgT0phMWVzcT8S5XkGeDQ3VYc2aYDHvlNPMccE4pUImowWDA0Zy4C1FWXEDharWIjktCstWLYKnN627zFI0mind1DSfbHbaYYAdpbZelFi6MQAb/Dw0yFEGIEblg5B5MPYsLCwU7+mLRYRjYsrPf/5zEeXtfPiYBPvd734XTz755DlkG14HeuSRR8DjhfMTO8iwk4uL5MJ/60zUcX0zGc9BqsDi22EXx1gl2Enjey7H20xWZZLKR5s/onrsyCOS7CAprg4ODArlVZPJTOfboSbCgJYc5XV6DlvuRSRsP4SFhyM8MkKEPtaTarxMEoHLCQH+O2pvaxeKrCePn0BtVQ3yChYjKzcbi9Lot9trdp95/tt1EMG2evtOFL/7IapUi2EKzUFqXhzSM/1JrM5z1tbWL6fnQN7L/EXgT3/6E9ipxM/PD+Xl5eK9N/Ju+J2cmJgoRKh+85vf4J577hl5+Oz2ROth8mx6ejpY5OpnP/sZHnzwwbN1uTaYkPrjH/9YqK2yEBaTJZkHyOsIHNGF1xLYWbaf3sc8LnjvvffEqaziykTZibZptHv78ssvwZ9LJXbWZSKwJLKOjZQksrqByDoScp44DxmcqG804+jJIbS00eRqyIFsetmlJOkQGa6GD4WS0+mGvTTlBHckeu7b5kUGG4WYqW2y48uDRjIgOaDTeGBFrgapCVqaPADSaXMY/0Ez0NDlxJEaYF+FE1dnUgjweFJm9QP0ZGCTz6z7ntPprLnbYUYNkVkP2zrFwsVV5H2brQoURjOdgsmsMkkEJAKMgCSyyudAIiARGA2BBiKxNu76CnaTEX4JiUi6+VbogoOFWsxo5XlBu7O9A59t+QzNjU1CDWLVFavJoLJ8tOLTlme12CgkmQH7vizCB3/diw03LMGqtZkIDfeH3nM4+sC0XWwCFfF8qLHNhh37jDBR5IrEGDUyUzRE2nIPoZebNhxOkhzXqgfPGBf7cPXVIVi2NIhCtKlo4UKOfibQhbIoISCJrPIxcAcCxRUWlFZbUUtOtpGhSlyzxhN+wuHZHVeTdc4FBDjUa5fDhBOkivUxEVmXa0Jxiy4eFLsJaoV8N82FPpJtmH0EmAhSV1cnyKwGg0GoqiQlJSEwMHD2G3deCySR9TxA5K5EYAwEmMDC7M8eIqp3nDiOhp3b4aFSI+fRv4Mf/Y2r9VMjsHAkPhYw2blnQBBZw0NVWJSsw+Icb4rkNEbDpnCos9NCoUiHsHdvlyC63XRTFClJa8/a+6ZQtTx1nAhUl7eg+GQtCg+UIyDIB9fdspRCstO8329qz9M4Lz8vivU5LWiyDeFzSyO6SaU1RemHDKU/0tQBQpmVowPMduLfB9eHSScatRrl9FvxwAMPUISdKjCRld+5TBB1lePfk7feflsQUrj9HMKYwwezwiqTVFtbW8VtMbll2dKl4jyu+z+JqPrSSy+JY6zwxmGS2ZHmgw8+EATWhx9+GN///veJeDogzmGHcTuTVumb1/vEvt0myvKYhUmvwyRW3uZyNljIMf7k6WLKt0FBed2d3UKJldVYVXRvgUGBSEpJQSqR91LoExEZSc7ovtMWdU7cnPxPIjAHERB/Q/R3s+Ozbdj++XaxZs4KxOs3Xk0iDGFCAGK2m915kpS+d+9GaY0NTYZA2CKJbFsQhauv9INGqyCl5Nn/zZxtjOT1FyYCLodRJoRyFBSX04cLDXYUYZImpz/84Q9CRdV1bOT3ROu59tprsXr1aqF2+tRTTwnH15H18fZzzz2HX//61+AorkxiHRoaQm1trfiNSU5OPqc4v7NZtb24uBgbNmzA66+/LsYN7Aw7lXvja7LC+qVSU1OTuJ4kso6NlCSyupnIynNzNqIaTTRB77Witd2KpharILTarEBUpBrJRJxclKKHWqWgQap8+Y39yE7fUeIYC1Jxe5cDRWQ8KqmyIjqcVFBi1UIhysdL9gWjbeMwsBYFSpodOFpHoXloQSiAsFm7CIgMUIAi1Mo0DxCwsPet00aqL71C+aWXFi+CFFqsJUJrOCnAeBKZVSaJgERAElnlMyARkAiMjsBgUyO6SkpQ+cH7grya+e2H4J+YBM0INaiRZxrJ4F5XU4c/v/Ynofi56YZNSExNpoXp4Yn8yLLTud3d2Y/jR6pQXdGCpvpOXH3dYuQvSyZ1Bw3NM2aHHMPzoeMlPNYmJdZuh1AdXJajQUiQCl5694y32ZlwcNBOixVD2L27gzxvFRROjsJ2L/JFTIyelFkodLeMLDCdj96CqEsSWRdEN8/4TfYNONDUZsfuwyYyjjqRnqRGEimzxkbI+dmMd8YMXXDIYUUhOZhWkaMpz8vz1UFYrQ6Hkhb8ZbSUGeoEeRmJwDQiIIms0wimrOqyR8BJRmO7xYzqLZ+g+uPNYk7N0U4iV62GPigIiimyTZtaLILAWl5lIhKZEyuXeVNkRC0pGyop0px75p5msx19fTZs+6INHZ1miv7hh6QkL8THjx3B5bLv7Bm8waFBE9qae7DvqyJyKO4nJ14NClYuEmshTKiQUVgAdqQykBprtW0AlfY+nLb2INzDE1nqQKRQVIBQD/0M9ti5l3KRUpn8yYQYVillIikrvbFTiysxkXXrp1vR3dUJm5XK0u8Jk12f/vdnRHje++67Dzdff4NQWuN6WNX0yX/5F4rQUyKU1vIys+k8K6698QasvWqtCHv87W9/GyF+AUIllQmykQlxIiwxX/PLnTvxwv/3G0FgpacICiLAssIrc36ZDMvbHuSEpqC1Jd7nbQ/OO7OvJFU6B63D8U9PaEAQrcuR8ipFaGKVVR8fH/gHBsDb2wfePt607yuOs5KdfF5dPS6/L1cEXH/zLU3NqCyvxJ6vdgu14rwl+cjJzyXl0/RZv3VTVxf6Gupx7C/voqyoA12p9yAmLw0rlvkhMkKNoAC5XjPrnSQbMCsI7N+/H3fccYe4Nr+j1fQeHplY7ZSJpJw++ugjFFDUhdHSZOq57bbbcPDgQTz++ONCefX8epng+uqrr1J0hDV46623zj98wf6vfvUroeYeSY4kPKffs2fPtNzbBRcaJaOsrAxvvPGGVGQdBZuRWZLI6mYi60iwebunz462dgtOl5mIzGqlwS4NYoPViInSICxEhSAKcaKV3hznw+a2fTasszLr6UqrMLAPGhzw8fRAXoYG0WEqBPrPjsHfbTc8hYpb+4CaDiIi1DvRO+TEskQFUsKJjE1k1lniRUzhbhbuqa0OI2ppweKIrUMQWzNUAUhW+iJB6SPUX6ThbOE+G/LOhxGQiqzySZAISARGQ8BmMsHQ3oai/31VfEddcSVC8/IRlJ4xWnHU19ajpKgYn3/6OULDQvGthx5AYDAtXNOitTsSLwKaTBY01nVi25ZCUn9wIDImGLlLSD02NdIdlxxXnazEyvOfw6csqGm0IoJCZ6fEk+JOmpYMDuOqYsKF2InQYnGgsnLwzGcAsbFeWLkyiFS8NGQokIuNEwZVniAQkERW+SC4AwFek+jtd+DgCZMgtFrI4Tk3XYO8NAozqWFnZ3dcVdY5WwhY4QBHS9lqakAPqWEl0Vw8TeVPBAIKeSOTREAiMC8RkETWedltstGzhICZlAj7aqpRt/0LNB84gJTbbkcUkVi9IqOgmsJc2Waj+TARV0+XGXHk+BC0FEUuLFSNpfleCAmmSGRELHNnMpnsOHSoR0QDIW4d0tJ9sGxZAI3jhkls7ry2rHsYgaFBI06fqEPZ6QZUlDYjOz+ByKypCAnzh5e3e9Zh5hv2Dpp4DBGZtYZsQ/usbTA6bNCTuEk2kVmTiMwaSKInmotEB+A1J1YvcykpivDb5ITHaqMi3+4gO+u52w7K42NOVjClD5NLh887o1p6QX1c3oHY+FisJ3W08xMTWV9+8b+I3Fp7ph4n1q5fhyvPkFI5RPCJw7QexvVSe/laRrsVv/3tb7FkyRKsWbZCtCWNQpj//d//vSDf/PUvb2DLhx+J6zqI7FuwbBmeeuZp9Pb24l+IBFt6/CQ1Y9gR2sNDCaWKPjRBY5Kqir/FRyX+1pnEqmSCKx3jclqNFp19PYKYurxgKXwpDLMPOcP7B/jTupQ3hVD3kqTV8ztZ7i8oBJiQ3tfXh21bv6Df7XL6u3UgMycLK9esIgcUf/obmT1VbTsR220kUnHyv3+Psv1FaAy5Btr4LIQlRyM/xwupFHGZSeruHl8sqAdC3uy8QKC+vl6omHNjRyOqHj58GLfccot4v7HaKf8tj5YmUw8TWN9//32hzPrOO+8IxXRX3exQcvvtt4uIqw899BB++tOfCsVYi8UiFGL1+gsddp5//nkwmTU9PV0ouDIxlxXaOU3l3lxtGutbEll3jAXP2WOSyDrDRFY2rNL4GUNEmGwhddaTxQY0NpnR1WPDssXeyMv2JGIrqRN5SmvF2afUzRtsODKwYi4Z2b86ZEJ9iw1hpBCVlaLC0pzhwYibmzAvqqfoFzDTotCecqC4iZ5jUmrNiFJgQ4YCGuID8KBNprmPgI0mA0bYcZLCGLLnbaWtD7mkALNJGyNUWXUK+dsz93tRttCdCEgiqzvRlXVLBOYxAjRgNFNYkMadO9BB4YUMFKYs+qp1SL3jzlFvaucXO3DsyFER8ixlUSo2Xn8tGU/ct0jNCqQdbb0oLarHlvcPIT4pDLd+czX8/L1o4W/2jDa1TXZyFjOjvolCvxFSG1bpER+thl5HhgA3jR3ZiNjXZ8Wnn7agpcVMXsA+pMTqg5QUDic5bIAYtdNkpkTgEghIIuslAJKHJ42AlebZPX0O4Vz7+R4j8smxdvViHUKDlPB0k3L1pBsrT5wSAv2kwNpoH8L7plqhvnqnPhGRCj28PNzk3TGl1sqTJQISgfEgIIms40FJlpEIDCPQRWG2OcqJubcHSq0OybfciuCcXChZzWkKxgW2tbEa69ETQzhYOIRrrvJFQZ4X/P1UFB7UTRPPEZ3KNr/2djNKS/vJEN5BBnEfMuJH0rU9iCwnhVJGQOW2TSZNsnPv6ZN1+HzzERGVhp17V1yRTusjpMYik0CACZ5GhR1ddhMOWNqI0NouBE7YsWqpOgSBHtoLkHKpJ5rIwdtiNsNkNBHWJpjpYzQaxYe3OY8/nCeOGYb3+Ryj0TB8nI7x+VzGVQeTTFgNVakcJoCqVURCX7VCEE2ZKKrz8cKzzz4LJrL+P489juKiIoqyo6bjKtxw6y14/c9/EorLdxAx/tTxE+I8VjbNXZyP37/6P9i6dSu++93vIi05haKiqlFZVyOIK1deeSX+4e8fF2RUFf0GqZmcSnU+9x//QetJn+Kaa67Bz+i6KmqXUEml3yiXWqrr54r3v84b/q1x7fNvGocqZvLvI9/5zllFVya7srork25kkggsZAQEQZ6IB52dnTheeAwfvvM+iUGEYcWalcjKyUZMXMyswcNtc9DvUv22L1B/+BhaOp1ocCah0XslbtgYiDUrfMT4giN+ySQRWEgI8Ltr9erVqKqqwgMPPABeK+f3HCd+/z3xxBPi3bd48WJ88skn55BNR+I0mXo2b96MRx99lP72NEKJPTz86/FdF6ko5+TkiOv99a9/Bb/jN27ciFOnTuE79A7+yU9+MvLyNI5Q4dprrxVKrLfeeiv+67/+S7yXp+PezrnQRXYkkVUSWS/yaAxnP/3000hNTcW9M0xkdTWKVUA53GVDMy1iN1loom0VnhtspIiJ0iIqQoMIUgTlya5rUOw6V35PPwL8G2u2OlFKIU+rG2xoptB+IYFKpFFYv+hwJYIDJLmPUWcCAquyVrQ6UdTohA/xInJiFYgPViBcCohM/4PpphrJDxatdgOq7f04Zu2CijxtOXxMDnnfxnp4Q0tkVjn8dhP4sto5j4Akss75LpINlAjMGgJ2Wlzvq6lB25HDqNm6BWGLlyDl9jugoxCIGgoHxokX33lR/r2/vkOLcMexdMVSWjzPQ2r6IrGY7o7G8+Ka1WLDoX1lgsg60GfEosxorN+URyHZWBli5sexZosT3b0OlFRZcaTILJRYYyPZUUwjIh64Y34jFkDJ8aq6egilJf1obTMR5gpS3ghETIwnAgIkScgdz99CqlMSWRdSb8/svdLPOMykJM1rEQeOW2jhFfD1UaAgS4sYWo9gEr47fjdn9i7l1RiBcg7laiHFNpqLByv1uI4cSgOIMCBn4PL5kAjMXwQkkXX+9p1s+cwhwHNpjnDSduQIqj76AL4JiYhYsRIhWdnwioiYdENcY6hmsq0dPjaEAbK3MamkIM8TKYk6MR+cCbU0diw1mWgsVz2I7dvb4eerRlaWL+LiSRE25EJi4KRvWJ44JgK8JtDaTOIdRGatLGtGV0c/lq9Jx6KMaIRFBIj1kTErmKcHBeGKDJysRMprUnYihtlspCZIaofWM9+8b6V9VlA1U5khixllNCYttvdAFRYAX1rTirXp4NkxBGVDF2z0N2ujcjaqi8/hc/k6YqJyBiexT9vnf7NhiYty4mNsZxouw5mKC8tzLk12ziqasrIpEUyY5MLrWSq9Ft///vcFkfV/Xvk9Wlta6Bjln1FHdZXj8zMyM+Hl402qrXV499138bvf/Y5qB7Zs2QIdKaSySvJ/vPCCUHRjMgwTTAWBlq9Jx/h6vyMyywtUJj8/XyiyTWVNja/P/fK9731PtEP+JxGQCJyLAP82MJm9oa4BB/buR3NjEwb6B7Bm7Rpk5+UgKCSYohjPznuU1aR7KyvRevw4yj7bgQZrDDoS78CiNH9SXvdFcoKW3vczv+Z+LoJyTyIw8wiw0vkvf/lL8e5mNfQ1a9aId/uXX36Jb33rWzCTAwsrnd53332icY2NjYIoyjuPPfYY2WmGSeoTrYd/KzIyMmAgteS1a9fizTffFGMFVnxnUu327dsRFRWF/fv3C6Iqq7IyQdWX1NC5bEFBgXgnM4n1P8hphZ1kOPF4YeXKlWJ7om0SJ03iP0lklUTWMR+b2SayjmxcT69deIweODKIqhoTwsM15B2mQ16WJ3x8PKDT0pI2jfal4WIkatO/zZMrVkJpaLbj870GUs11wo/wX56nRVoie+RJ4xGjzji19gFbTzrQPgB4ahVYkQTk0XtHqFxJBuT0P5xuqrHTYcIpazeKaMGilNRZr9PFYrkmFL5QUxgZaUpzE+yy2jmOgCSyzvEOks2TCMwyAk5agG4rPILjv/tPeIVHIHrtVQjOzoZPTKxoWX9fPzpIrfWvf34T5SVl+M53H0X+knzoPT3F5N4dzWfDwtCgCe/8eRfqqttE+LyM7DgkLYp02zXHug92EOMw2UxiLa220MeK667UY0WejhYfKUy2m0QnLEQCMxrt2LO3E3v3dJLTog8p4fghM9OXwrbJhcWx+kweGx8Cksg6Ppxkqckj0DdA6xGtNhw8YUJFrRU3rfdEdqoGXuTwzHNtmeYvAmy2d9K/neZmHLZ2INKDCDYqPxEdxZNCusokEZAIzF8EJJF1/vadbPkMIUDGBI5uwg6hrYcOooU+idffgPT7HxBKrAoijk02sRIqRzosqzDh8539iI3W4OorfRFM0fZ8fSZf72Tb09ZqwsFD3ejuJjIhtW3VqkCKEOJL1RGZTxr3JgvrhM7j0PQWsxWff1yI3TtOITk1Ehk5ccgrSIY3qbJ4uGtBYhytZMLWMKFzmNgpttnYdobcyWPF84/zvosIyttfHx++IO9zOG4mr1qInMqO1UwgcSmkGg1Gkc95LiVVoapKyqlDFhMMClIzzghCb6gn7INGeJxugnJ/OWxDRjhMw+cwccRisQoFNCaU6T310Ol0Yp2LQ/XytlY3nK/X0T7liXw951M52udvT1oXc23zObzPZblOjVZz0b8RVlb7p3/6J0FkLSI1Vpfy22iQu8qOPPbzn/8cDz74oMCO/w5dCm0//OEPRyWYvvzyy3jmmWcQHR2NI0S+H+t6I68z2rYkso6GisyTCFyIAP9G9fX04rNPtuK9t97D6itXY9nK5cjMyYJ/gL8gmV94lvtz2BGnq7gIhc//Bu1Wf1iWPgCzJgjeQf64ajU5AERriUjn/nbIK0gE5hICrKp+5513CjVTbhcrofJ7/ejRo+QAYwMrnL700ktnxyz8Lr355pvFLXz44YdYunSp2J5oPXwSq7IyGZbfzX5+fsLppKSkBG1tbWI8wY4r6enpon5WaeV3fgs5wKhJeX3JkiXi3X769Gnwh9NNN92E3//+92fbOpk2iYom+J8kskoi65iPzFwisprNZHSl0PYtbVY0U/jLplYr7TuE9+giIrQuStKfIbTKt+GYnToNB9nwPjDkQEOLDeW1NpRUWpAUp0JKnBop8RryTJTGI55bGy1AXRdwusmJ4/VAehSQHa1AXBApx+inoSNkFTOCgMlpR6/TjBJrL07YhpVZQzx0WKEKRbjSUyizzkhD5EUkAnMIAUlknUOdIZsiEZiLCNBAqL++Dg07d6C3qopCIvZi0TfvEWoyHBqsorQc+/bsQ1trmwhLduOtNyEpJUmoSbjrdloau1BV3oxjhyvJuGDDxhsLROg8n1kYlPE4safPjppGG/YfMxMGQEIsjaNpPB0TTooaZEv0cIMBj8fwLa1GHD/Wh3ZSYh0cstHiRIAgs/pROEkZztFdT9/CqlcSWRdWf8/G3bKaNa8NFZKS9alyC4L8PZAYo0F+hgYcvUem+YsAz737HRZ8YWnCSYqKco0uGlmqQATT/JuClc7fG5MtlwhIBIQBjw1y3/jGN84azSQsEgGJwNcIWIeGMNjUhLK/vgFDRweCM7MQRopIoXn5Irw2sde+LjyBLZ4Dsg1t36EB1NabBQkuJUmHxTleZMgGNOqZt6UZDHY0Nxtx4kQvCo/0kPE8DIspQoinpwfZ+ma+PROA87Ipyuq4TO6sqWhBWXEDSovr6XnQYM3V2YiND0Vg8HA0nZm8YW6PSy3VSoTQYWKomQi3TBBl5VMbfdO+IIxSHhG6WFl1+PhwPu+bRXk6Rt9mKuuqi9VWuX4mabJ6KKuV8reSFUtpm8m7Yp/zR6iYetCCjQdF8TGH+GAgSIdGLwfMRIT16BrEIpsn4mxaqJUqqOgj1EpJwUxF9fLaF6uZcZ38zYqo4lvsD1+f1VJZIVWce6YdfG1xHp9DEQLFPtXtat/F+sRFTg0ODsaliKyfffaZUG/t7u4+Wx2HHn7xxReJWL5KtJkJLnz8Zz/7GR4kguv56bXXXsOPf/xjUlMOESGJzyeycl/85je/Of+0UfeZrMtJKrKOCo/MlAicRYB/w/g3sLKsAieOHkdVZZX4Tbv62muQuigVwaHBYv/sCTO0waqsAw31qNr8EdprW9Bn9USj5zLYInKxerk3qb9rERTIv4eTG8vM0G3Iy0gEph2B/v5+3H///cLhw1W5RqPBunXr8MorrwjnF1c+E1xvvPFGsfvJJ58I8qnr2ETqcZ3D6qpPPfUUhmiO4UrsfMJOKJs2bXJlie/q6mo8+eST2LVr1zn5PB75wQ9+gO9+97tiHDPy4GTaNPL88WxLIqskso75nDz99NNk2EzFvffeO2a5mTxopdD2ff12FJUaUFNnRluHDZHhajL+ahEVoREvQy8vGuDTnFd6cLqvZ3iyS3NHIrFase+YSVzIl5RZF2dQP4QpiczqQfi77/rzoWaCSGBUTETWnSVOaClsa7A3sCRBgSh/J4XpoFAgCxyj+dCPrjY22AdRRiEOi0mV1eC0Yak6BMlKX0QpvaCkh52eeFdR+S0RuOwRkETWy76L5Q1KBKaMgJkm6gP19aj74jPUfrYVmQ88iKir1kHp7Y1Dhwrx/tvvC/JqZnYmcvNzabEtZMrXHK0CHrOyGuvJwioc3ldGnqhOhEUG4Kpr+Jp+o53i1jwSPiHDikM4g1XWWVFFn4QYNa5aroOPlwJ6nXsMdzaKqNDbS4udlYM4sL+L1FfVFKJGj6xsPwonIz2s3NrpC6xySWRdYB0+i7dbwU61VRbUN9vE7+faZXqEBHrAi0gQMs1PBDgaSqW1D8ftXWhzGHGbNh4Z6kBwHBQ5256ffSpbLRFwISAVWV1IyG+JwOgIsANoV9Ep1GzdAg3NmdPuvR++8QnQBQSMfsI4c3vJgbKl3YJ9BwfRP2BHLkU3TKIwv3GkjjZbiVVYLRY7Dh7swdatLRTCNBBZWb6IjfUiMuvMK8TOFg5z4bpGgxmd7X34bPMRtLf0IJGUWdOyYpGWGQM1kTeZmDkyCWVTIiw5aV3F7rALYqiDiFXsrMv7TGZitVfOEwqo/M37nD/yOO07aJ/XZ0RZcZ5dKJQxAZKVylg91WodJrBaiYTKhFTOt9Fxq+ubjlvJSOnK528+X9Qh8nl7+BwbtYWTmkgZrGyq1eroW0vqaEREJVIJK55yHqumsiKZ2KdtlxKqio4bfdSoDfJAp4ZIWwob0h0+SFP4IlrnhwAtCZ5QPUxYnQ279ESIrK4+5TDGhw4dwvPPP48q+g0KDQ09S0pdvXo1mNjCJBhWdTs/Pffcc/j1r39Naspp2LHjQqIF98Uf//jH808bdd9FspFE1lHhkZkSgQsQGOgfQEdbOz758GNUVVSRImumUGXNzs0Ris4qVkyY4WTp60MHjWOaDx5E4969aIq8AYb49YiJJSJriiey0vT0m8ucCDmzn+GukZebAwiwY0hhYaFQZGWlVVZmnUyaaD1MfmdV1draWmRTtMT4+PgxL1tPtrzKykoxbouJiUFCQsI5ZNvRTp5om0ar42J5ksh64fhqNKwUJJFLQ/GFl+YikZUnNzzZZQWOjk4bahvMqKgykVKrhbw6dEglddbMNA6/4CFJgm58ZHnSyuE8Boac6O61Y+9RE+pb7IiPUiEtUS1C+9GccMEnelzRZwRoHQC7yx2o7gDWLlIgi5RZI/1B3pYLHqJ5A4CZ1GEMsOGwpZMIrb1CKSZd5Y8NmijoKcyhmjxkZZIILBQEJJF1ofS0vE+JwOQRcNJE2UZh2Gq3foryd94mJZk8+GdlQ5OQiL2HjuGNP/0Fd9/3DVx7/Sb4BfgJ48Dkr3bxM62kvjo0ZMLOrcfx2cdHcPWmfCxenoKomGAKz6a5+IluOjJkdKC334kv9hjQ2ulAZgorsapFdAO2EXm4yctpaMhO3r/dZJwYJFUNCxkK/bB8OaveKAl7OSB1U3cvyGolkXVBdvus3DT/nnZ227Ftnwm9Aw5kpWiQGk9OzjFyIWJWOmQaLlpq68U2c5NQXw2j6CcF6mBEK70liXUasJVVSARmGwFJZJ3tHpDXn6sICBsL2VkqP3gf9Tu2E3HVH0EZmYi75lpo/f3hMUUDy8liA46eHIKBzJtBASqsWuaN0GAVzQFnbx2bzUp83+UVg2TU76Hw7g74+qpwxRXBCAubnGF/rvbvXG8Xk0xNJnKwLW/C6ZP1KDxYgay8eFx74xL4+ntB73ku4dlFFLWYzHSe6eyH1VF530z5HPqatznsLOdznslkFHmuciZSNBXl+TiXp7JcjhOTZ5lgyopl/FFr1MPbI/PUdIzIqKLMmXwup6NttWb43K/PGyatMjmVFVBZKZXJpqx2Kr5pmwebI/NYoYfXZr4+Tk5VlOcgNUEjTTXKnP04YGmHjci4/h5arNdGIl7lA52HetZIWmMRWfneXeRaVnM8PzHJZcOGDSJ7+/btQjn9tttuI7L5QTz++ONCefX8c5jg+uqrr2LNmjV46623zj88of3f/e53ghQtiawTgk0WXsAIuH6LS4tLcPL4SRzce4CijiXg1rtuQ1h4mAglPtPwONiJgJQfqz/9BCdJaVK17CbY069FTZcPImN9cMM1/vD1YcVpSWSd6b6R15MIzFcEJJFVElnHfHbnIpF1ZIMNbLjooolWjRl1DeSdRwRXDkESHqpGdKQG0aTQqiHVS/liHIna9G4zqZicI3Gy1IJyUpTq7XcgNFCJrFQNwoOVCPCbvUWR6b3TyddmJQUsk02BQ9VOFDVSyB6a7MYGAgUJCvhT1AytevJ1yzNnFgGmb9fY+lFpH0CRrRs6hRJJpMqaqvJDDCuzSl3Wme0QebVZQ0ASWWcNenlhicC8Q6D92FE07voKQy0tpGhOYQ2TF6GhdwBlpeVigW3t+qtEqDQ2ELgjdXX0U5i8BjLK1KKhtgPX3rwUeQVJgsR6vrqIO67vqpONdTxXqWmw4TRFNGjttAu1/mW5WkSHK+FHkQ3clbo6LWii0I3Hj/XCYLAhOsaTom74IDnFS5CDXAYNd11f1ruwEJBE1oXV37N5t0yAYFJGYbEF1Q1WDNFLJiNZg4JsUlYim7taGkhms3smdG3S7xJRT45Zu7DFVIcsUmFdogpGlMobvgq5YDIhMGVhicAcRUASWedox8hmzToCpp4eDDY1CgfQTlIyi1m3HuEFS+GfnAIlkfImm4YMdnT32HCi2IjTpUYkxmuRnKBDSpJuzqjXd3aa0dhIRNujvRgctGH9+lDEx3vDy4vIhpLnMqmu5/GxUD9lNVNSMWW1UyY8uT52VizlfSIcMYmVy5jNFnR39qG6ohWFB6oQQqGp0zIS4O3nhEbHqqvDKqc2UjZlFVVWXOXriA8rqzp5H+K6Z/OE4iqV4X+07WoXt214n8rTeWKfTz5TH68LKYm8zcRLQUQlwqogoJK6oPoMeVUcE/mUx0RXLivKky34zHlclvOY7MplODSu6zPV9Q++pya7AeW2PlTZ+9HrMCOWxqyJHj5IVfvDk1yyZkPwZCwi67PPPitCGLPK6htvvHHBs8W4R0REiH564YUXcOeddwoC6/vvvw8+55133hHHXCdy+dtvvx1sH3jooYfw05/+1HVoUt+SyDop2ORJCxwB/l3t6e4hRdZKfLltp3AKCA4JRsHypUjPzBDq0vy7N1PJ9fvfvHcPSt98A07fUBh8ElGpyINXZCQW53ghNpp4I8TfkUkiIBGQCIwHAUlklUTWMZ+TuU5kdTXeRF6bXTQx331gEJWkzsoT9bxsL6xZ4U1ESpVQZ5WTXxda7vk2mZ1obLVjy1cGDBociI1QYXGmBulJGrnwcAZy4lGgqt2JLSdJiZW4CjfnKxAXokCAJ03WZZpXCHRQyMO9llaxYNFoH8SN+jisUYdDS8RWDnsok0TgckdAElkv9x6W9ycRmD4EzBRaaLC5Ccf/63copZBl9bHJ8E5ORXxKEpatXIZF6WnTd7FRaqoobcLH7x4Q49HouBAUrKBrJ4WPUtK9WTZ2bCLhiy8PGrGD1ANz0tTk+KVGWpIW3p7uGzuwTejUqV6cPNlHRkKjULi54YYIBAVpSOnEfdd1L5qy9rmMgCSyzuXeufzaxo61/YPkMFphwYdfDNFvqgYbVusRHKB062/r5Yfk7N6RyWFDs8OIQlsnvjA34kZtLK7Xxgg3URl6cHb7Rl5dIjBdCEgi63QhKeu53BDoKi1B41dforukBHaLGTl/+whC8xeTQuTU5mqtFL3wVIkRFdVmimpoxU3X+iM7kyh2NAecYtXT1gUcedFqdRBJrpEihwxh5cogLFrkg+hovVDDnLYLzaOKmAg0kXR+eSanchhZVkNlFVSDwQAzqZ9y6HZWPeV8Ax8z0Ie36bgoQwqq/X0mdHeY0U+RBQd6ySlMT6EFPbrP1DMkzuXrsUOwTq8nQSGOiqkX28P7erGvP5Ov13uKY3ovytcNl+dy4hxP2j9zLtfD+Tq9TpBNlcr5ETGGe+ogqbIepfFrJZFaYymKwM36eIR66OFNZNaZTmMRWf/yl7/gBz/4gVBpZPXV88m8dXV19Pe3UjR569atyMnJwebNm/Hoo48K1dsDBw4gPPzrdbSuri5Rhp8Hvu4VV1wxpduVRNYpwSdPXuAI9Pf3o+x0GfZ+tRtbP/4Ud937DVx38/UICAwQv7czDU9fTTXajx5F6+GDaG/oRH/uA7CGZYmxx5JcTyzO9ZrpJsnrSQQkAvMUAUlklUTWMR/d+UJkZXUji8WJllZSG2qxorHZQhMy9uhzIiVRj/hY9vJgQuv8mASN2Slz9CDNkTEw6EAlqbLWNNpIbcpKIVI1WJSgRkyEe1Wm5igkFzTLSOSF7iHgMCmztvQphCpXXiywJEEBDT2aFNlEpnmCgMlpR4t9CGX2Phy3dcEfpAJNnrf5FPowTKEXZNbzFwTmya3JZkoExoWAJLKOCyZZSCIgESAE7BQmzjIwgCN/fA1Hv/oKJ8jhLHn5ctx89x2IiokWC2vuAMpGCiQdbX0oOVmHL784gYSUCFyxPhuh4RTKyI8k8WcwsS2qpcOG4yUWtHY4hNNXQZYWKfEq+Pt6uE01cGDAhrY2E06eIHWV6kEkJXsjKYk/XmR0Us0ZA+YMdsVlfSkee55vyJyNG5ZE1tlAfeFek39fLVZ2qrXh0EmzUGXlefXKfB2tR6hBdnb5WzcPHo9uUrJiR9EmmmM7iLezXB1Kc+ugYdVw6Sg6D3pQNlEicGkEJJH10hjJEgsLATuF97aQ02fzvr0of/ctUmBNRdiSJQhbXABPIoxNdl2Z7WT9/XaUk9jL/sOD8CeRF1ZjXURKrGGkgjZXSKzc2zyOY0XOw4d7UF4+SPY9B5ISvbB6TTCpaQ6Hcr9cnwpWN7VYKcIkf/OzQCRmq8Uqtq2Uf3Zb5NExUlG1kHLqyHKssmrh9RY638p1kMoqK67aaS1EQYqZ/AyJKDT0zQqa4qOgfI8R+0QaZachPuZ00sehRGebGS2klGu1DsDT2wOLsiLhR2EFlTTIVnrQh75d6qb8zcRTD/qoSTVVqRxWU+U8cYzPoTxXeVZbVZ3Jc5UX+656zrR7vvR7Gzli8fi1xN6LbrtJTDyyVQHIUgXCW6GiaH4zR2gdi8haX18vlFWZ5Pzggw/il7/8pVg74Gekh1Sh77vvPhQWFiIgIAAnTpwQ/cXPVUZGhiA6r127Fm+++aZ4Tvi5e+CBB7B9+3ZERUVh//79ovxU+kwSWaeCnjx3oSPAf6t9vb0oOlGE/bv3it+hwKAgXHX1VYhLjIdOp5v0mGIy2FqIWGtob0fZW2+i6dhJeF9xO7p9s1He7ov8HB8sX+IFX18lRdFxX2SyybRbniMRkAjMPQQkkVUSWcd8KucLkXXkTfTRRL2mzoyiUgPKKk2IjdIiLkYjQqcEBaooNAlP2siZkAbpMk0vArTuADMRik9XWbDrkJlCeQDBgUrkpWtEyFRPHU+gp/ea8602sw1o6AKKmoD9FU6kRzqxOkWBMD8FfPQ0xpxvN7TA21tt6xdet3WkymohcusVmgikqPwQ5KEbJrMucHzk7V++CEgi6+Xbt/LOJALuQMBKxpU9tOh98IsvcKy8GsvWr8ejT/y/0Hl6QTWFcIkXayuT+QxDZpw6Vo2yYgrTWNWCgpVpuPbmgmHjDRluZiqxWuDAkBMVtVbsOmwSYRzjopTITuXxsXuMGoLYZbGjudmEoqI+NDWx2ooD668ORXKKN6mhyFCNM9X/k70OG/6eeeYZoX7yxBNPCAPvaHVxuQ8++ACHSO24ubkZgYGBWE5E8dtuu00YFM8/hw2I/A7ftWsX2mlhmZVWVq1ahdTUVBFu8vzyk9mXRNbJoCbPmSoC/Dtb12TFyVILqbNacfVKPXLT1fDzcZ+zwFTbLM8fRoDn0Y1EANhsrqdArcBiIrAmKX0RpZRKLfIZkQhcTghIIuvl1JvyXqaKAM9XreTs2VlcJIis9du/QOoddyH51tuh9vaGcpJzZBZ1MZmBiiqjILIWlxqF8tnaVT5EZFFAq5l7pBGeuzY3G1FZOYiDB7sRGanDdddHwNtLCa12dlU/uJ+YaOskXB1OFs3h7eFvxpqPO8/kM0FQ5PHxs2WHz+fzOG/43OE8m41Iq0RMtRL5dJigytsWERralc/kVDN9xPd5JFYmtLrKCSLsGULrcDscgrikJfKSlp4l/rDaqWufSU380eoo/8y2hsuQairndXeY0FjXh5amXpqPqnHF1ZlITIlESFjgWULqVP8GLqfzh5xWVNr7UWTtxjESPElR+iGHiKzxKh8EKLTQEHmYrKJuv+WxiKx88R/+8Id4/fXXRTtiYmLEWoCJlHhZbZUVezn94Q9/wMaNG8U2/8eqrI899ph49v38/JCfn48SUo9ua2sTz9WWLVuQnp5+tvxkNySRdbLIyfMkAl8j0NzYRMqspdhHZNbmphZsvH4jsvNzEU0iEmo1O7K4/3dItIZf7PQ59dqraNyzB4E5+ejQZ6CwOxlx8b7ISCOn43gdAgOkwMLXvSe3JAISgdEQkERWSWQd7bk4mzcfiawcttNocqKzy4rWNitKicza3WMT3qcpFLozP9uTBtmkgKmeexP3s8DP0w0en/CEvW/AidZOO46dtqC2yYa0RJVQZk2JV9OCyQwNluYohoyRgZRZ6zqBQ9XkIW2kcCz0KK5L90AqReeQijFztOMu0iyD04Z+hwWHbR0opRAyNB1AMi1WXKmNAFFzoJypycFF2iezJQLuQkASWd2FrKxXInB5IsCGlff+8CccoBBllvpaLFm9CrdQiDKfyEho/f2n/aatpGrS0zWIj97ah472PmTkxCE9OxYpadEz7lTFUSKOkRJrJRFZO7odFPZajeW5WjLMKaB3k/c5K9m0t5tQXNyP/fu6kZzshaxsP8TGesLfX0MYOGduAXPae3dhVMhqKDfddBOCg4OJjFwkDEfn3/ng4CBuv/12cfz8Y2lpaXj33XeFoorrGC9aP/LII8IY5cpzfd9999148cUXp4XMKomsLlTl90wiwOtAJnKqPU5rEAdPmBHo74HYSBWWZGqF8vVMtkVea2IIsJIVh2Pdbm5CqFKPW3TxwuivU8wueWVidyFLSwQkApdCQBJZL4WQPL6QEHCQomF/bS1K/vJnmHq64Rsbh8hVqxGavxge5HjGapqTSUaTAx2dVmzf1U/2GYqEQkSRFFJiTaSoeSrV3BUYMZnswvny88/aSO1TgWyauyYkeFEoc91kYJiWcwT5lAioZmIGM2mUCX/8sdC+mUijvM3Hzm5TnpnzznyL40wu5bLGM/l8jPOoPqGWSuqmGi33DauUqqEm0iiTjdQaDdnQKJ+36cPHOY9JpeK4WnO2rIbLieN87Mw2ncMKqayyquRnieaBQjWVlVg5n4iVvO9SZmWVVX7mWL2Vz+H1hMF+E3ZvL0JdTRvCIvyRlZeA5WvSh8+T9o5znjE7uWKxjajZQcJK1h5U2wfQ47RgJUUYSFf6I0LpSWRW949r33nnHXzve9+76BoCK6k+99xzeOGFFy5YX4iPj8ezzz6LdevWnXNvvMNKrE899dRZsivnRUdHC8fbTZs28e6UkySyThlCWYFEQLyXDEMGQWQ9eewECTwYaB08FTfcciOtBfvTO8U9YgqjQc+OHs3796Ht8CH0VFfD7BcHZ8E30Nqvo98SOzZc5YdFKXp6H4lX1GhVyDyJgERAIgBJZJVE1jH/DJ5++mmhznLvvfeOWW4uHjSZHfRCdOB0mRG1DWYMUth7b1JjjYzQIIZUWsNCVPDUkzoHhSmRaXoRoOglYsJ7nNRQTldSSBPaDwn0QM4iDX0rhSrK9F5x/tXWTU6ONe2szOpATacCi2OdyIjyQHQgoCMlW5nmDwLETUaZrRcl9Kki71tPIrDmaoIQ5+GNCA9Pof4sf2XmT3/Klo4PAUlkHR9OspREQCJADjwGA4U46sNbf34TJfsPIFnlQHJcLJKzMhGxbAWCKFTZdKe2lh7UVLZg75fF4j18zY0FiIkPoXB4M6vu1jfgQGuHHYdPmYSjV3iIEulJGmQku2+wZzbbKTScVSixNjYa0Uvb+Yv9kZcfQHMfDvcnRyXT/bxNV33C0EgGxfLychGqr6qq6qJGKDZW3njjjUKJlY2XjxIxPC8vDydPnhSEVFbiueuuu4SRiheQ2VDKCq8vvfSSaC6rrKxcuZLIzsVC0ZWNWg8//LAwXrHRdipJElmngp48d6oI1DbaUEIRYupbbFApFVi1WCfUr33IeUCmuYnAUWsnTtNcuoMIrQlKH1yrjRZhWGWPzc3+kq2SCEwWAUlknSxy8rzLDQEemw/U1aLj1EnUfLoFuoBAJN5AJJPEJHiGk8rFJBILZ3CqrTejssaE0goTvL2VWFlAa9NhpFBPIXzneurutpAyZBcpPZqIZKdAQYE/MjN9BblyLN6ki3DK8x87zWnsdgc551mFgx7n8TzHTsYqu91G26Saynm0zXlnv0eU+fr84XOGFU6dw3U7+PwziqyiHi4zXKedVVdpe3if2kDXEG0T5YfzuW4+ziquTCRlUirP5ZjAqtGQcqcgq369z+qo4jgTWukYK6uKMkR+ZdKqa3v4WztcH5VV0lxxKsp7/IxyW48erERpUR0ps3YhNiEMK67IQHCoH3x8KaygTBcgMEhk1ja7ASft3Si19pJjFkXhUXkjXeWPEA89fBXuWwe6oDFjZPT09IDXGmr+f/beM7qu67oWnsAtuBe9g+iFJCrBXsUiUlSzLMuWFffnGr/YjmOPLyM/Xpy8OEqGh4eTeNgjeS/fs1/sz1WWbMmWJatLJCVKFIvYSYAgAAIgeu/A7RffXPvcg0KxgCBAouxDHpxd195nnXPv3WWuuerrISyr+fn56pQ1hmsd8t5WVlaigQD88vJyCPB1Ng8NZJ1NbWpZS10D1VXVqKqoxIljJ9TvxKatmxSgNTc/T/023Mrvw83odrilGT2VFah59g8I2KOR+tBnUNmRgPqOCGzbHI3iQgdSk/n7RgMWfWgNaA1oDVxNAxrIqoGsV3svxtMWMpBVJvAy6eI8FF1kZz1zfhTVZGetu+zBlg3Ryq1KdqZdgVvHb1gHZk0Dov9hso22dvjx2tsuDBJIXLaSG/c8C/OuPSmatQ7Mc0EkruWCxhhZWcNwqCaoLI9yksJwb1kYkqLneed1996nAS5NoSfowX5vK+r9Q/DRPeIO+zLs5Gm9Te5j3tcpnaA1MIca0EDWOVSuFq01sMg00NHegbraOrz03AvobWzEh7asRczQIHrOn0P5F7+E/A98cNbNr48fvshNlxq4XF5k5iRj74PrEJcQTXaR27s4JmCqCrq4rm30Iineig/sciqjrrn0UNDf7+OmxDBee62DC5Zh2LUrRTGxpqRECBHLLW1oLbJXc17djoBYP/vZzyoQ6+XLl8f7di1G1jfffBNibCr1fvOb3/A57xqv85Of/ATf/va3FTOPyJJF6t7eXqxfv57Ghl588YtfxHe/+101V5ZKP/7xj/FP//RPqv7JkyfJfDSzDXSzAxrIampCX++EBry+MYyMjuG5N0bQ1B7AulIbjQcikJ+l3dbdiedxozYFd/N7dz3O+3tRbktSrFUrLbGwcQ6tD60BrYHFpQENZF1cz1PfzS1ogJsmdS/+CW1Hj8AzMICUNWtR9IlPwhYZNWMmVtmHCXCf4Y23BnDizCgySeSyskA8E0bRpTxZOGUiOM8PYWXt6vLg5Ml+7HujEw9+II3skKmc0wpT6LX7L0BVmeO4XS5lROuiIa0woI4yLmmT012jLq4RyGmUkbAY3qoyI0xnWFhVR5nv9ZKchbIdTgecTiciHA445AzFjbBT5alwpBGWclI+MlK8QkbAyavEJ5cXgKrBkCosuWHk85yYp5sAo8lXFWYh8zFerc7k8rP1qEdH3DQQbscfnzqkGhdPN6vX52N5YcZsNbGo5MhzDBKkLN4G6gPDeMPTDBcC2GRLQbk1EYXWuEV1v7N5MxrIOpva1LKWugYEeN7d1Y3XX36NgNYLGORY4/6HHsADD39g/LfnduhojP0YbLyMM//nP+Hj72/m3XtQ61mOmqEMJCZYkZdjx4Y10Rqjczsehm5Da2CBakADWTWQ9bqv7kIGspo3JhP5UVcAnV1+NLfS1X0jXXn4oNg5cghkzcmKQHYWLRjJTmROBs26+nprGqBhK4ZHyYpbQ72TGaWzN8ANJJsCtKYlW6BZUYDmXi5eKWZWwEd9rc4GlqcCAmrVx8LSgItWtw1cpKimW8QKbsSJpe1ybsKJ1W0aXcjorbiF9Tx1b6+vAQ1kvb5+dK7WgNbAhAZOHDuOg/vfgs/nQ2JMDHZsXANfdRVq//B7FDz8CHLu2YuojHTYo2MmKs0w5HZ7MTLkxsE3zuLUsVqs3liAklU5aqPF4bTPUOrNVxuhMVdvfwBnqny4WEcw7TILlmfbUEIm1ih6hJiLOYffT7eH9Ehx6lQ/amuHufEWpLs3J8GL8WTZsHPzbP6z8Ny8phdPDTHAzMzMfN8NXQvI+uUvfxkvvfQS7rvvPvziF7+YUm9wcBD/83/+T7Up+p3vfAcx/Nw9//zz+OpXv6pYeqqqqtRmqllJNj1LSkrQ39+vXAZ+7WtfM7NmdNVA1hmpTVeaJQ3I+o+AWU9f8KL2sg99A0EUZFv520MAQQTUus8sNaXF3KIGhuBHT8DFTf4WtARGcD+ZWAs5d04Mp+HFLcrW1bUGtAbmnwY0kHX+PRPdo9uvAQGujnZ04NJzz6KvtgbLNm9B2voNSC5fjfDrsCHeqKddPX7UNXjIxDqK3j6/AoasKBCmM3FZPz9+VRUzKkEtPoJOfQI+9fDKNQIV51Xm8oMDLs5lvTh5yoe8PAdyc62wWXrJVjNqlPVJHT9P73h9xYBKNtTJQE4JTz6V/sbTGON4UQwC5TDLhSLjcTGCDadhjbCb2uiOWdgqrWQ7laswoMpV8ibHJV/KCkjVahWWVSnPk2nCvqpYWFl3MohVtTtP/wijbG/3EM6erEdddStamrqxZUcx1mxcgQQysTgct2+NZZ6q6KrdGuUeUR8JTyr8fWjkXlE/w8LMKsZaedYYJIbJWHd+fC6vegN3IFEDWe+A0nWTi1oDYqhRf6ke506fxXtHjiErOwslZaUoX7ca6VyDN38z51oJ7p4eNLz2Cnrpeco/MgwU7YRv+W6ulXvgdIRj945Yek+2Ke/Jc90XLV9rQGtg4WlAA1k1kPW6b+3jjz+OwsJCxfZy3YILJHOIrKBd3T4cfm8INfyhTKLVR0FeBFaXRSKBLEkOByeonMMuBCvVBaJyulABXO4xVHET//VDbg5IwpCXacWqQjsy08K5kTQ3m/kLST8XIUTNAABAAElEQVSjXuDV80BNexCx1M+qLGBzQRisfBetGnOwUB6l6ucYV8LqgsN4y9OG7qC4Qgpitz0dpTa68w3j4pZmlllQz1N39toa0EDWa+tG52gNaA0YGpANJdmsevWFl/H73z6DHXfvxIbNG7GycCX6jh9Dxc9+irgVK9WmXeZdd9GN4q0vpPX1DKOhrgNHDlbiUnULHvvMLqzdtIJMKLbbwsaqmHBIu9/RFUB1gx8X633o7gvggZ0OxQjoJIhqLlhhpd3BQR9ZN714860uNDWOYtOmBBSXxNJgz8nNM21OsxA+l93d3WrsKH195plnICDUqwFZZeNTgKfCsvrzn/8cDz74oNpAFReB4hpQDvnsTT5++MMf4t/+7d8Uc+tTTz01OUuF//zP/xwvv/zyVYGx7ys8KSHIl4+kM2rOF+S7L+/if/zH9xEfn0iG2S+qxXEZH6tFcuZx/1gd5tWI8K/Kk8xQWckwy0qYh7HQPinfSObfq6WNZ+rAEtSAeD/pHwwqIOtr77iQHB+Ou7c4sYzGtPGxBrBhCapl3t2ybOxf8PejOjCAAL9IPhyRpzb3Qx/9eddf3SGtAa2BW9OABrLemv507YWtATFak4Fyf20tOk+dROu7h+An8+fqv/gKklatgoVu5WcCKhGxYsAo+1yHjg6RDRIc64Rjx9ZYZGXYx8feN6M96aucsqYtY3RhmDTj5n1InrStykqhUPmJckySMvIvlOcjw6nX6+Ep7KkkmvF4CF51w0dAq1zllLzuHgtaWqMYD1CGC5ERTdyr62V5lwKvmvVUedYV+TI/MhlPhTFVwooFdRKbqsSdZE21C0uqCkcadWjpJHHFuBpiTpW4gFUlbakffjLVjI54cOTtSvzp6cMQVtby9QUoKs1CYnIsda/XGq72jsjbPxj0oYpg1je8LapIGklPNpKddQWZWZ1hFlgUnFWPfEU5Gsh6tbdIp2kN3JoG5PexqvICXnnhFXR3dikDjoce+SBWrSlHZFSk+u28tRZuXNtHpvPBhga0vPM2ap/7A7IffASpD34KL73pxqArDHdtjsZyYnQylmnDiBtrU5fQGlh6GtBAVg1kve5bv9iArD5fkOwcQEenjy7v6Xaz3oVhglvFMrWsOBLFhQ6yhIZzs1tPwK77YtxEJsdKyrVNHzeShJVVNvQvt/ixutiO4uV2ZJOhyhGxdCdsoh8/Xf800bj4YhtwvH4My+KBTQSyZieGgcat+lhAGpAFuhG6jOkIjOIsWVkrvGRmtTixgha3m+ypiCaYldDtBXRHuqtaA1fXgAayXl0vOlVrQGtgQgNDg0NobW7BwQNv4a19b+Lj/+2T2Ll7F6KjozFC10LtBLN2nTkNPzexVn3hi0gqW4UwMprMZANPWpXNtIsVzXjjpZNcjOMYKiUOm7cXISc/TYFHZyp34o5uHBLs4ADnFpVkkXn7PTcyUi1YkWfHCjLJJCeQzYWsLlMAfDcWecMSMpaUOc6FqiEcfrdb3Xt8vB3r1sUjI0NcGIbPCXj2hh3TBW5JA7/97W/x13/911cFsnaQxWndunVK/quvvoof/ehHeOedd+iKs0ttwm7cuBH/+I//iFXcFFcb0Cz59a9/Hc8++yy+8pWvqLwrO/e9732PANT/UHJffPHFK7OvGRcWYDeNFodH/HTLGVSeUF584T8RFRmPu3d/xvjscWotAO6wsDF1NdiNjDT5TCAsGMo30lR+qI5Zz0JrUyPM4uHcrA59lsbTKEbC+tAaMDXg8Y6hsyeA4+e96OkL0vvJGLavi6B3GMOwYba/i8129XV6GpB583veLrzkaUKWJQoFnC+vsSUhiWys+tAa0BpYnBrQQNbF+Vz1XU1PA0FOFAMeNxr37UPVk08gobgEqavXIH3rVjhTOV8lEHMmh8sVRHObDxeqXTh1dhSrSx1YWx6FVLKbRUXe/P6WgF78ZDwVQKmH/RXQqMfNk1eVxrA3lK4AqQSfTuQb5cy4MK0aYFMj3bRSU6ykNoPZVJhKFYsp1wFEBzZeg2NOjtti0NkdD5eL3s7yB5GS7OU8x0JwqbCdSh2ewnRKBhCTFVXkyhlOYKWVZUSegCzDw410MywMqlLGwnQpIzLkKsQ2RpxtyNxD0oTxZokfYqwYIJi16XIXKs9dxqWLrXCNerD3A+tRSDBrTIyTutJ6uvI14TIN/ASB9495leeBCwEab9GAKy3Mqca96+3JSCAzq0VPSpTqNJD1yjdIx7UGZkcDA2SCb2tpxbtvv4szJ08rcomy1auwccsmxMTeume0G/VyjCQX3pERGvC8g4pf/Jxr/6uRtGUX6kaz0D4ao0jQyksjcdemKLUfoL8Sb6RRna81sLQ0oIGsGsh63Tf+8UXGyGrerN8/hoGhACovutDQ6EE7Qa3LUm1kLCKwMiMCyUlWRBPQKpvg+pgdDcjGvtszhlMXPDhx3qMWU9JTLFi10o6URAvjS1fXAkDwBoDGHuDAhTG4CbaOcYxhfW4YVqQBDlsYF1Bm5zloKXOvAVmokIW/87S4PePvQRetx6NgwwYuUORYYpAS7tBQ1rl/DLqFOdaABrLOsYK1eK2BRaCBFoJYD3OhrKGuHj09vXjsE48pRlYBlHrp+ny0sxMXf/skei5UovDPPo40gu+iyMo6E5eK4l5wsG8Ep49fwmsvHCdLSB423VWErJxkxMZH3RZtimHS0MgYqut8igWwodWP9aV2bFodYRjK2Wd/rCtjSJcrgNZWFyorh3DqVB9KS2IUE2t+fjRBwzPbEL0tCtONXFcD1wOyXrhwAXv37lX1c3Jy0NjYqMKyKWsyscrnTNha77vvPrUYfP/99+PcuXP427/9W3zzm998X9sChv3nf/5nZGVl4fjx4+MAWHnHfP4g+vqG8PvfP2WwrzJtLMS+KqxPElZXCbOCxzNIQ8V4svR8TLUj+7/q7ecfuZoOChQIlXEFQBWQa2jF2ohPlJX0UNY4WNXcU5ay0qaSFfqISVm5f+Nq3Or78iVZlWP7oYKqeghsK2EFfpcyZlmVFqoXCpvtKFmhNEOe1J+oa26CT01jH1lncl0JG3qgMiVLCoTSVDiUpnSkwhO6MfOZrI+QBkZdY2igEa0YF5zmOsRd6wjuKI1AYlz4kjamvdMviI+b+kNj9JTk68AL7kbcG5GJTWSnknmyk4af+tAa0BpYnBrQQNbF+Vz1XU1PAx4CSQZqa9B08C1cfuM1rHzsY8i9Zy8i09JgdUZOT8ikUjL+dbn9yvPg2Qo3GUxd6B9wYQPnnmUlZGKlwUgw6EcwECTBSIAngbQMi5GbhCVd5g0BxoMhTyqSJ2lGXLyr+BSoVcrLfNsvMghoDEg91vH5mM+weUq6X2SF0pWHFgmH6iqQKAGmEWRAjSArqpw2xXpqxh2KBdVmdxCo6kRdPcGsXU5kZXqQnW1Bfl4MoqJYlvXtEQ5V3x5hV+BVmQfpY241MDLsgnjAOfjGWVRfaEZRWTaBrNko5tUZadeg32uoP8DPqncsgIpAH076ujFEllZnOL1VWhOQy32iDAtZEccIol7ikzkNZL3GC6STtQZuUQPy2y5jhiOHDuPooSMYHBhEUnIS7t67G9m5OUhITLjFFqZXvfscfzv+8HuIYY89Pgm21fegy5KHE2ddNFiJwM6t0YiNEZyIXseenkZ1Ka2BpaEBDWTVQNbrvumLFcjK321O1GWTLcgJf4DuV1yoqnGjtd2LtWWRKC12YmWBuCHR6MHrviA3kSk6l7N3IIC2zoBiqRKW1vVldhQV2FGQvbQXHGSrkl5a0D4AHKkdw8GLY7ivLIzMrEBaLOCcA/DDTTw+XXQGGnCN+dEdcOOAtw3iNjEm3Ib1tmRst6dxQTG0cT0DubqK1sB80IAGss6Hp6D7oDUwfzUgi2QVZ8/jFz/5uVoUW79xvXJdlJWTrTotbgZl8ar66d+i9chhxBA8l7J6LbJ37+FGnvOmb2xk2I3zp+tRdb4J1ZXN2Lm3HLsfWAM7mVpuFzvICNlwWjqCePmtUW7mjWF1kR0rycaalS4sMCY47aZv7boVhB2ltZVjjQOd6O/zccMvDFu3JKKkNJabgAaD5XUF6Mx5q4HrAVkPHz6Mxx57bLzvwtz6ta99TbGxVlRU4C/+4i8UuDUxMRFHjx5FbGwsSkpK0Nvbi+9+97v4whe+MF7XDPzsZz/D3//93yMlJUUBXo3FbrLI8F0eJVi6qbEXzz//c25+G6BVuRKLxi1yA6wp+24mqFOAqlZrLFLTP6LKyxyQH3kVljn4eJiGfOYcUdoz0o1yqg7B4Waa2mSXNrnJp/pAeSLLlC0dkb4IwFN93tgHMUqdGpYNQiPdzJOr9F3KSVilh8qILGFuMphkzTKGsaswwqo6vMr9mvKM9gw5Ztp4Wcoy+2O0Z7A0m2lTy79fruQbzLRGeybDrVnP1L/5TPXVeJeInVAg1gNH3EimAW12upVGBhE0puWD08cd0YCAWGv8gzjn68FpGn5+1JGPrbZUxUilvZfckUeiG9UauC0a0EDW26Jm3cg81UB/bS0u/u4puPt6YXWQkfGDDyN1/QZlxBkmg8GbOGSuLSDRtvZRtaf1Dsc4ljA3SlaMIi7aS1ZTF1lTPTR4HOXpgtvl4elSYYlL3ihd/brpGUUYU12jUsbFfTIjLqBQOU3AqcNB0Cj7LMBTh1PCBohUpUsa4wJIjYx0EmAqcaOslFPlmSZ1FYsqgayGsZiMpWUcbpzK6EvC8o/pMsOoqBjFxYsjGBn20tjOgV27UugKmfP7UB0ZxE8Yi0kdfcylBmQOJmDoKrKyVp7lea4RyzIT8MjH7qI3nFg+d+0W+mr6l88rp7BwBQMYIDvrIV87mVkHIIZd5bZE7LVnIpKGXHbT2vNqQpZAmgayLoGHrG/xjmlAvocGSSjR3tKGZ5/+Axla29Qa/fpN6xXhxO3o2Cg9S/VerKIxz+vo4brlqq/+FdxZm7HvnRH+fliQl21HaZETmen6t+R2PA/dhtbAQtGABrJqIOt139XFCmSdfNMjdIHY3eNDXYMHl5s8tBwFIp3htPYkOytP+eGkhxE1uZ5cT4dnpgGPly4n3cCZC17UN/vI0gpuJlnUZn9ifDiiZ+D2ZmY9mX+1SHYElxc430w3e3XgwhOQTHb/TfnAMoJZIwhO4BqNPhaIBoKcIHhocVsVGEAtzzr/ENIsThRb4lFgNZlZ9QNdII9Td/MKDWgg6xUK0VGtAa2BcQ0IS0sn2VbFZdHzf3gOZavK8NBHHlYu0q90W9Rx4jg6TpxAz/lziMnNRcmnPoMIgu+s3PSa7uH1+NDR1od9L5/CQP8IlqUnoHxDAUrLc6cr4pbK8eeeGzpABRn/quvZFxrJpSZZFBNrSoKFXh7m5rc+QJBfY6MLly4NkY11EPFxNoIVY5GbR1eSqdo18y091HlQebpA1k984hP44Q9/OKXH++iy9LOf/axKe/rpp7Fjxw5s374ddXV1+Id/+AcFep1SgZEf/OAH+P73v4/i4mK8/PIban7c1e0jC5IXw8PCyGSARgUsKu+8LITLRrPVGsaN6XCeYcrdp4MA6jde/3/JlhSPu3Z82mBqNQGnrKPAr6wv42QBqaqNPblSblCAqyKcck2WVwkr0GyozjgTrKpryDEBtUqI8YcyDJlqo1zFzBQDcKuSpKnxg/dzrYnWVT7CKknKq/6GhDA+UXRC+GS51IAqPJ42Ueyq87zxcpPuKyQg1CgFhGQollZ2QPb+ZVNfuidgV7kaQAEjT2TKPqmkCzBWwlLHTDfChniznoBlDXlSdqL+leFwljPYhMx2DbmCz1DyVV8mwgLyNfpiAIOlDbP+lDqT5Kr7DN39dC/N7X5UkS37cmuA6w9BbF/vQH6WlWzZBohiunJ0uVvXgLyuLYERHPC0YgR+OGDBNnsqiqzxty5cS9Aa0BqY1xrQQNZ5/Xh05+ZAA4oJlYykg81N6Dp7Bg0vvYjwmFjErVuP6IICRKSkhphNyXjq9RrMpizvo8GnsJsqxtNQ3OcV9lM5hV2VzKkBejkZW47+kVh6QGmB3dKL/MxhGjMGuI8VGhzK2JtjK3O4OsZBM6Nq/C23K+kyFjfCoTqMWLkRZrXaCE7labPztPIMhSWNoFUBukqanWGVF0qzm3XUdaK+lWVlfGoCT1WjN/jT1uZGQ8MoTpzo5Zzaij17UpCcEsF5xtImQ7mB2uY8u6drEE0NnTh8sJJAaB9yC9JQtjoXK4szFQh5Yv4y511ZUA3IPDfAiVttYBC1BLLWk/TEyslPSrgTJRwH55Gd1cGJEaHaC+q+ZquzGsg6W5rUcrQGrq4BYU8fHRnFscNHUVVxgaQIrSgqLsLWHduQnpGO2Li4q1ecpVQ/jWs8/f2oIStr05sHsPzDH4F1+QY0jqaipQvo6fNj17ZYgllpBBNh4XhhlhrWYrQGtAYWtAY0kHX/tJ5fGK0VJ2Zz06qyOAotBSCr+aSGR4LcqPPhrXeH0Nzq5UQcWE121k3roglsDeOPp2wGGRs4Zh19nZkGZI1kcDiIi3VevPKOG1HU71q6vVmZZ0NmmljWyubWzGQvhlr00oKm3jHsrwS6hoCH1oShaNkYQa2yMbgY7nDp3INsVosLmbrAEF71NGMw6IWD7mN229OxypYALuPxn36oS+eNWDx3qoGsi+dZ6jvRGphtDQjLy9mTZ3D21BmcP3sO2+/eiY9/5hNXbcY7NITeqgs485//Cxa6VCz/8n9HfD439Qhmne4x0DeCupo2/OHJtxET68RHP7WTzCCJiI65eWbX6bY5uZzXJ24dgVfeHkXVJa/yNFBcYEXZSm7qEeQ3F4cA+9zuIN5+uws11cPc0AxiVXkc7rknVc9X5kLhd0Dm9YCsTU1N2LJli+rVL3/5S9x7771Teiib3oWFhWRV8uA73/kOvvSlL+HRRx9V7Kxf//rXFfPq5AoyN/v2t/8BP/3pTxXo9X//5xOovUSPJdX8bNW7FZA1Pt6KlGQbUlPktCMt1U72Vhs3lS2cN8sceeJd/9d//VcIG+yXv/zlyc3MaVjuQTbix9laFSg2jBv9TOOprvzcCHhWmFwFfG6kydVgg1UMr5IveaoMR/KUOx5WeYYsqavSmaZYY6WdUL7apAzJN9tQcsx2VJ64dZ2QocC4Uj/U7njeJLmCRJicbspWV/ZTDpkrCtDTZGm1WoVBVtKMPIPV1QCNWpgn6QImVekCVpU4rySPVVdhxDLDpkyTYVZAqyLblGnmmzLDJY8RM12VE0BqSPbEVdqYkCVAVlV3SlnJN+qyqForCN2yum/1+oUSjHfRiJjvpRiMejxjeOGAfE/7sGVtBIqX25CzzKruYdLrG1qIYH3+N+tLZCIsTRpx1Yoqp7oR6ot8FlTOeB2ZE1K7E4XeJ29S1iIOih78/DBU+/vxpLsOqeEO3BeRhWV0qZoQpplXFvGj17emNaA0oIGs+kWYrxpQhlUyWONhhtWvOdNUMiNm+uQykqYOVW5qfY4iFPDUOzKM9iNH0HHyOLrOnEFEUTGSP/AwDWvIkion587CiirsqDKP9khYWFIlHGJMNdlUVbpbmFMJYvXZkJD5YcQkFMESOA9bWAuctn6ymglrqlOxowpTqjMyUsWdoTQVn5LOMswbT2c4nAO8mwGcGkqY/b8yxu3s9ODZZ1uokwDuuisZeXmRWLZs+kavs98rLVE0MDTowokj1bhAVta6mlbsunc17nlgLewOAS9roPH13hL5pugJunHc143zvl5Uk/zkHnsGNttTODbmZ1egrFMmJ9eTtnjyNJB18TxLfSfzVwPiCWlkeARnT5/Bk7/4DdfQY7Bm/Vqs37QBy1cUqN//qeses38vl577I+po2BOXl4uYwjIkbNiJIxUWvPHWAB7cG48NayORlECWahrJ60NrQGtAa0ADWfdP6yXQQNZPf3pailrIhXy+IDxkw2xr96KJQFZhZ6Wxq2JjXV0aifxcO+Jixdp08gbEQr7jO9d3WeeRTf++waBirrrc4kdjmx8byiJQstyKtGQrgcNLV88kFsMwmWrfqx/DpQ5j22tFKrCziGxH1jH1Tt65p6dbvlkNBLlhJ+4Tm8k8U+HrQ2WgD/m0sl1hiSOYNRFxYbabFanLaw3ccQ1oIOsdfwS6A1oD81IDspk32D+AZ556Bk2XG5Gdm4N1G9epRbGrdThIwN1IWytqnv0DRtrb4EhMQtbOXUjfuu1qxa+advzwRbq2a0Rv96BiA9l9/xpEx0ZyzE4U1RwfxJyhodlPt9VedPcRncZjU7kduZk2xIsBkiCu5uAQdpr6+hFcuDDETU8/1qyNR25uJF0uRiqA1xw0qUXeZg1cD8gq7E7Z2dmqR7/73e8U+PTK7hUVFWGIQPHvfe97+NznPgcBsD777LOKmfWZZ55Rm/FmHX4M8alP/Rnkt11Ar5m5f6nmvE5HOOLjLYrtN5JeM5x09+VgmpyRTotiYRVGVgEYTj7uBJBV2pc5pnk1wAYCMjUSzauUkSQBFUqOyfA6HlZpTDfz5CoRHqYMdSWoVJIlPLmsRKS8pMkf1by6GolG+0ZYsc8awXHZYyKXhZSM8avIDAEppN8SlmuobdXO5LCqbPTBZMBlM+PlVXZI3hQZkkG5cggoVw5JMu9bheWP8d9Ilyo8DD1M7dPk8sa9Ujb/G/JC96H6bbDuihwlnn+Mq8TN+w71yRChvucMYKvxPWuCYmXPV8Ly3StXK99NAePKZozIutxKbzwDY3BE2pAcH4acNHo9IX7SbiOol3UnZBoyhNF2apqRbiG612hHwLpGWwr0G5IRxnblY2H2xSwv8iaAxtIvqoTnUjmEhaqR7FNVBLIe83ZipTUOH3TkKFbWiLC5/81eKnrW96k1MF81oIGs8/XJLN1+ydggSEMjr8+rGFG93AgSQzCvlyc3iXxMl6uRZpZhGtlTjXS3Yk2VsEpjujCrSnlhUA0P+GH3e5HS1gyQhYzDEIxl0I34ikIFFrGQ1VQAo8JuKuBRqwBI5cq4GANJ2KLSaBhEKx8Jy+CikZ7cKqroBSSjAOnpiSjIdiE2ysX6PlVGyl0p0yIsqxYr0ylH5IfKWJgm4xSVRtlylXHTXANZpvPWyXhwaMiH48f70NQ0qgw516+Lx6ZNNHpdQuOn6ejqdpfxef0QZtaqiia8+1YFEpJikEdm1jUblyMjK+l2d2fBteemBz8BszYEh3GBe0XD3Deycyy83pqs9oxSLI4lR3yigawL7jXWHV6AGpBxj/Ki1tGBc2fOofJcBWprarHn3nvUun16xjJl2DKXt9ZTcR7t9M7WdeokbPGJKPrMF1A/kICT5z1clwnDMhrNb14fhaREbRQxl89By9YaWCga0EBWDWS97rv6+OOPKzaXTy8BIKupCNm06erxo/LiKOove9Da7kMBQawFeQ5kptuQmGBDFDfy9HHrGhAwK9nsufnvwdvH3YqNNSfDguICbiwlcpOUVjdLaWNnskZlT7C+cwxVbcCJhiBSYsKxozAMGQlAQuTS2vCarJeFGhYwq2zgnvX34rC3A246k4kl68xWexqyLVEEs9r1GtxCfbhLtN8ayLpEH7y+ba2BG2hgeGgYbS0tePKXT2JkZASPPPYRrCxcidRltMi5xuEZHETnyRPo5CKWnPkfeAgFDz8CK5liwumC8FqHbJ6IK7vX/nScTCCXsbIkC0Vl2cqtnc0+9wteMo4dHArifI0Ph095sCzFAhnHrimOQHLC3MwVxL272xUggHUQZ88NcMOUY0S6V9y+PYlXBzcm9Y7etd6XhZZ+PSCrbHhv2rSJG7pN+MY3voG/+7u/UyA98x6PkPXpox/9qIr+8Y9/xObNm/GnP/0JX/nKV5T7z8OHjyApOY1MTwHFtmq1DGH9+jVKxq9+9RSOncpTjKt5ORFYXuBAWloEwX7Tn5fdKSCref9L9arApJxECqurrGkISJXYDBWW+DjzrGJ5NcoIWy2zVBmD4XVSuqpLBk2WkTwBEyg5IfnSnkoPtTOljJQPlTOZayfkSxsGeFX1Ufog/VOnwY4rcXU/kqbyJ+5Fnq8JCFWAVX7tGcBVBggUlfUDBRZVAFYCRxXolGBT5vmD4Rj1hKOtjwANzs+SY4OIjwZioiYAsaYsfsyULAGqmjKNq5E+Xk7aI2p1cnnJM+tInxgd76OkK/CrgGwlnadMBNVF6qn7kzaMfAHIivKlrCHLSGdMyZx8NeSxoPxXZ0iGVJX7kcL8IyxPhjwjzKc1kcYici9Khlyu0icm3/Qh6xsebtof8XWihkBWD1HWZfRQsocMVPrQGtAaWBoa0EDWpfGcZ/suFdiUA4MxngGewiYWpFGXjBOC/C1R6RJXzPdShmYTaowS4BiCYZYxxkBGWamj4syTfAF0+Pw+BVr1+ximhZeKE5DqlzBPv89PsKtZxq/Aqj666DXymE7QqoBeJS7yFBCWacGeLoR1tqMkguypCQnozytAMDEZ4ZFRsEeQOZXz3YgInmRRjWA8QsXlasQl327msVwYiRBcHiuqagI4ccaLFRynr1juQBHPuNjFaRAi8922VjcqKwdw7L0+zlnicfeuFLLMileIuZlzz/Y7vFjlKSOxug4cfacK7a29fO/92HnPKhSvyiHLX6QCSC/We5+t++ommPUyjbyOe7vQNjaKAkssVtDQa3l4NGLD7XCGzf261mzdy63K0UDWW9Wgrq81MH0NiPHN0OAQDu5/C6++9CoKluejuLSERBTrkZLG31iOP+bqcPf1YbChHhW/+Bn8NPxZ9fkvwhWbh7bhGFRccKn1p727YpGVYdc4nLl6CFqu1sAC0oAGsu6f1tPSjKxLCMgqGzQ+2SR2jxHE6kV9oxsXa8StyxhKCp0oWulA4fIILh5MbCBM6y3Shd6nAQH2cX0JXX1BNJOR9fh5r2Jp3UpXf4V5NqSnGK4I31dxiSS4vWNoHwQOVVNHQ2r/CtsLgY15oQ0ptRO1RJSxCG5TNu+GxrzoCrhw0NtONpohZIZHkZU1CZvoPsZibC0ugjvVt7AUNKCBrEvhKet71Bq4eQ3UVtcoi+7jR48jKiYan/rsp5GemU52x2sDUoPcBPQSzNr01ps495P/i6wdOwlk/RBic3Jhj4u7ZieEAaS5sQvv7Kc1NzdOHvmzbSguz0VUNAGwAvyZ46O3P4gzVR7UNwfQTMO3nRsdWFNiRzQN3sSKfC6OgQEfmhpHceZMv2JjvYsA1vLyOAVmjYjgSGJump2LW9Eyb6CB6wFZpeqTTz6Jv/mbv1Gb3sLKum3bNrUZL5v7n//85/HGG28gLy8PBw8eVIxMslBdWlqK0dFR3H333XjiiSfR3OJFXFwY/urrX8K+ffuQmZmJn/18Hz8/VqZbEBNtpfwwxc56M58pDWS9wcOdw2xZyxBQImeLCpis4kyT7wYzLJvOMi+RrwujvFyvqBPKl1JGmVANqavaCN2EhCVNRY02JSIpUk61EsqXckZ8cr7UV5WVHLM9VWI8XfJD7TJNyhOfQpCKCdo1ALV89RWoxQC+hoCwZLg1gL2y7iCgXHo+GR1DvTCz8jvc7Q4id1k4cniKXClrgmsFWDsOxg2BaUVLYlAwDrIVEI3qx1QArtGX9/dHgW6kPOUZ982nQKArsbZkQAtTDLLCAGsVZjReQ8RrykiBRGwqXbEg8zfOiLOMsCKP1zfqhYeLFxepb5xSRz7DxpVypI6Zz7pSVsC4qo7KM9hppR/SznhZCbP8TFjaxLBzZMyP37ouoSU4gm22VBRZySZOTyX60BrQGlgaGtBA1qXxnGfzLmXsIGNbAYjKWNblcsHjkj0at4q73YwzLAyobqZLWMpIWSkjaaqs5IfiUlbKGTIEeOqHzW7jmNfOa4Qy+rJz7ipgUrvdrgCncrXZGA6lRUhc8ngKANUudSVf4lKG9cW9evNrr6ozk2PwtDVrEL9+A6zxCQjjD7wYpoXTyiRMruqUtX6eZjrDyjBmPD8cPfQAcrbChSZ6tuvq9mP3jliU04ug02H8rs+m7ueLLBkveTxBZcj56ivtSM9wYPXqeOTlRREcfO01hvnS/8XeD9eoBwN9I3h7/zmcOFpDIFQWSlbnomxNHqJjnIv99m/5/nw08vJyjHyZe0TV/gGc9vUoTwXr7Mkooie/POvSGSdrIOstv05agNbAtDVgGAUFub7ciJqLtXj7wFsK2Pqhjz6CklWl/K1Nn9GcfzodkD0Ad08PLjzxKww2XkZS2SokrFqHqJINeG1/P8c4XpSXOLFyhRP5OXY1FpqOXF1Ga0BrYHFqQANZ90/rwWog6xICsk5+I4aGucHR40MF2VnbO/xqsyE5yYZsugvNWGZDCsOyCSAbQ/qYuQbcHm5quII4fs6Luia63eE6RHa6BauLIhAbHUbXldwtWaLHiCcMNe1Bxcwq7KxlmUB5dhgyycwaM3eGUUtU23N/27KB5+Wu62lfN6oDA+gMuLHM4sRqaxIyycyaFB4x953QLWgNzIIGNJB1FpSoRWgNLCINmJuMB/e9iUMHDyEyKhLLV67Anvv2IPY6YFRRgQI3cYNS2Firn/kdWVjtiMnKQvaevUhYuVIQM1M0ZbQ1hot0Y3eYbuyElTWag6Ld969Fdm4KQTdzO26UzbS+gQBdVPtxgkZYEk9NCkd5cQTyMumKkb29ostT+j+TiICfRkeDaGwcwenT/QwHFLhw02a6ksyP4gaqBrHORK/zuc6NgKzyOdi7dy+qqqrU5vddd92lmJ5Onz6tmFplQ/yJJ55QoFW5T2EzeuWVF/GXf/k1BQiI4+dy3bp13BS+gA66FZNN+N///gXExtNFqTCwckNcQG0zOTSQdSZa03WmqwEBicr3rgEKDYFKCViVuMlGa+aNhdLH8whk9fhoJNobRF2zD5W1fmSnhSM/MxxJ8RY4CNw268p1cn0FTlXtsu0QsHVc7nifjL4J05vUNYCxE4BbJVuBWA2AsBj28hdj/DfD/O0wPnnMY8D4TTECkj8lLrVVgqSH5IyXkTzJNMoY5aTU1Drs8fjmkJIfqiPpcl4pQ+JiKyLAVymqQDa8jjPXCihWgLZMM+QZ4FcvwbWDYx4c8ndgBD5sj0hDpjUScdaI8brj5a+UfWWcws22DSCwGWebzJO+TO47I/rQGtAamAca0EDWefAQ5qALMiZVzKaK3dRPgw9hOjWufjKdKsZTYSplvp/gBYMFVdhMJcxyvPrVVcoEWYYMqKYM1pOwsKgK46q0pU7+KCs2Vv5UiTxhZZV0BcyQMpI/6RTDlIl840ebxZgWVL9zVgU8Jfg0BE5VQFRuTgg4VUCudgJcxTBTwpKmQK+T6yggayiPMoKjI3C1tqLl4JtoP3YMufffj/QtWxFfUACrk27WbvKQvvYPBtBAspX3To4qQ5f0NBtWEeiRnSlkKzcpcAEWb6Qx53tkZB0a8qlxxvbtycjLixwfhyzAW1oUXTbGzUGcO1mPMycuob9vGAmJMdi6s4QGzYmcW0Ytivuc65sYHPOhLcC1HnryEwIUGYXnWaKxkuysGdwviiEb82L/mGsg61y/ZVq+1sD7NTAyPIK+3j4ceGM/ai/WIC4+DqWryrBl+1a1ri/rhHNx+DhOaj74FrrPncVwcwsytm9H3ocexclzHtTU0fiIeJHl9JC8bXM0x2AzX5uci75rmVoDWgO3VwMayKqBrNd94x5//HEUFhbi00sUyCrKkcWCEW4c11/24MDbg2rjWsCrd98Vg7XlYvUqrBfXVaPOnKYGhJn10mU/XnprBFHOMOze4lSAgLTkpatgef/kON0IvHA6iAi+e+nxwN3FQE7SYp/CGve+GP8KmPVycBjPuRswHPQhjWDW7fZlBLQmLsbb1fe0CDWggayL8KHqW9IauAUNmBuTT/zs13jp+Rfx2Ccew7addyEjK1Mx00xH9Eh7G7rPn0fTgX3oJThv3Tf/H8XOKow1kw/ZxPRyw/Pg62fxm/9vH3bftwbb7i5DFkGswsY614e42a66REO3Wh/OX/SieLkNH76XYFI7YOM4bS4Ony+I1lYXzp8fwv79nVhVHov77ktTLDRRkUvH3dxc6Ha+ynzmmWfwzW9+E8nJyXzu59Vm/JV9FXbVb33rW3j66aenZKWlpeFHP/oRtmzZotJl435kZIwGml68e+hZ/OM/fpvxkfE6WQSO/9M//TMeeOABtRk8njHDgAayzlBxutpt04DMsc/y+/vFN12IjwlTaw7rSiOQnjr192auOySfTeJvlPs8ufr8AuBhGk915e8N8TsE+YgbZF6Z7/MZacLqKqeUM+uJtxuJqzoiS+UbdaWeWd5sy5SpyjFf5ASDBOD6Q22pfhj1zbLEAilWVmFplXWxiTNcGVhYLAYbrM0WzjymsYz8jI9YfBgM46aUJQCn1YIVjlhEW62qvlFWZBlraySxU2FDtshhm5RhY76ZZsq1qLJhNIY28qScwSBLlrsZ/ySHFmGu8gKYwN6rZOkkrQGtgRtoQANZb6CgeZYtv1HTOWQeKIypJhvq6MioCo+6RuEadanTTZZUGbcKC6owprolPZTmMtN5VXlMl6ukC3uql7Kt/HKPiHDAGRmJSJ4Op0NdJRxB97dOGlGqdAk7nQp8IVcpL1cpI/lG3Yl8SRcW1dn+bu+rqUHDqy9jsL4OXoJEVn3hS0jfujVkSTIdrU4tI3PB2noPKqtcBHlQXnEkPvyBBAPcMUfzz6k9uPOxkZEAurs8eOtgF72TDOBjH8uiUV68GnuIAY0+7qwGhJm1o60Pz/z6IHq6B7kWVIpVa/NRUJh+Zzu2gFr3ca9oiIDWk/5u/Ml1GXHhdoJZY3B3RAbywqMNI7FFDGfVQNYF9LLqri4qDYjhT/2lOpx67xSe+/2zyCvIx2e+8FnlXU2ArXNxGKys3Wh++22c/fH/QdbuPWoPYNBlwaWmIF54pZ+GOnY8+nACPUVZFAZnLvqhZWoNaA3Mfw1oIKsGsl73LdVAVgGyckGfi/rCztrc6uHpQyPpze32cMTHWlBS6EBmuh2xMZoJ6bov0zQyXbS06ekPoLLGhxa6aO0fCipW1rJCO+LIzCqg4aV4yNph1xBQ2zmGCy1Ax+AYNuSFoXAZmWsTxSJpKWplYd+zMLMOcHGixteP2sAgasjOupIuY4rpXrHAEot4LlboQ2tgPmtAA1nn89PRfdMauP0a6OnuQV3tJcXGeqm6Bn/2qY9j/aYNahPRIqiSaRxike3p68Ol55/jYtZB5N57n2KuiStYTuaaCbd0gwOjqK5sQtX5JlScbcA9D6zFpu3FiIpykCVnbkGd4pK6my4dj572oJ3uHLOWWbEy16bArDIem4tNNJfLj95eH44d60NHpxvRURYUFsVgVVmcmo8IqEcfS1sDvb29OHfuHIaHh1FcXEx2ojy+ixblhrO3z4emZg9a2zzo7KLnC7IZJCeGIy62Ba0tl1G+uhxZWbnqvTKZFW9VmxrIeqsa1PXnWgNqfk1W1up6zscue5Wr3l2bI1GYZ+VGCcGUt2nZwcQImcytEg9wI0mlm2yyTOO+dohlzjC0Voywks7TYMISpjkjTJQMWepCrLFMNNOVjEl1JK7aZQEpj1B7RnlDlqyFSdzsn5STNGlTDskTyih1MZJUmqqnCrCulOdZ4xtErX8QGeGRSOOZGBYBxWEu9UMylKzxsNG2iFVMelPaM/JUw0SrSn+Ea1aVlfoUKKcws44zx/KnUgCuEleMsXzG6sp0EliH0iSf5VSaAHCl7KQ8FTZwSFLXyDfLGOVUm+N1rpB9RbqFL5rxvSusuNI/490z0kSB+tAauLEGBBx4+PBhnDx5kkZPrcjMzERZWRk++MEPqu+NG0swSgiQT4xcxDimhiC86OhobNu2DZs3b1bgP/lM3eqhgay3qsGZ1Tfdx3q8Hho7kAnV61XAU69Hrl7FiCpgUS/zfV6fyhOWVBVX6ZLGsqE8qa/KE2SqGFYpU9hRw8OMfRHxCiCWBHIND6NRgXwXSzh0qjjTzbhRlmVCaWFmOZEh35NMt3KiZRHjB1ovWGntYJFrKM3GdMmzMG61iuc8Xpmv4mRNFRCsqssywqoqdUWuEWbeNOeq09G+ADNc3d3oPHkcF595GrE5uUjfvAUpa9YgOjNrOiLeV2bUFVCkKu8eHVJj+bRUG1Yud6CsyEkdGr8976u0CBMEzOt2B/Huu904eaIPpaVxnBNHIy8vimDl6a03LEK1zJtbEubk0WE3WVnrUFvVgvbWXhSX5+AuGhzHxhFQHjk3rH7zRgGz0BEOzenFL4COwCjqgkO4HBimJz8XPflFosAaizJrAqI5erbxO3ExHhrIuhifqr6nhaABGeMPDQ6h6XIj3n37ELo6u8mCH8DOPbvUur4YBMnYa1YPtumjwVPXmTO48KtfwpmSQoOfbYhZWYohWzrePjzEseYYUlNsKC9xIj9X/4bMqv61MK2BBaQBDWTVQNbrvq6PP64ZWU0FGYvhQCM3As/TAraeGx7DBLeWFjmQnxeB7Aw7Ip3htBBenJMJUw9zfZUBSm9/EOervXjzmAv52XaUFNh4tSh3f8K8wbWsJXeQfAw+MqzsrxzDyYYgUmLDUZAKBWilN13Y9JrNgnsnZEPPiyDO+nqw39vKpYhwpIQ7sNmeihy6j3FyEZhLvgvuvnSHl4YGNJB1aTxnfZdaA9PRgGyO1tAF0Zv7DtCVXD+BcnY89KGHUFRK+vgZHPUvvYCG115DBF2fJ5WU0hXjA4iIj+cmaDg3SwNoberGm6+dhQBaHU6b2hwpXZ07g5amX4U/2YrJrrkjoIBPF8jIKr/Q922nO8cMK6IjZ//3WtoUcE57uxsNDaM49l6vAlft3JmCnJxIJCVpo5fpP8GlUVLeGTncbm4kuoLo6/OjvcOL2rpR9PT4MTwSROEKB1Ysd/KMVIaYAsSa7UMDWWdbo1reXGhA1h3cHuDAUReO04XdmmI7SlfYkZ9lhSNiaa45TEfP5u+hyQgr6xTCICtsrorxlWsWAQmrdDKxEtTT7/fijJuAe08fNoWnoiAsFrZAOLhXP4klloyxIVnCEDshw0gXNlpJV6yzISZaow8hGaqOsNFKGQHbTgBOBehjglIN8KgBMJVwWBhBpPwaNEGpFq43TcQNcKkCCrGMAr5eUxYL8L9VwK9m2RAQVqUpINckYCvLSJsC6JLreP8oXwBWAg+WdS/+N66hRTBzLWziaryrUk5+AlQdibCmGVZMg/LgRB4TTZmqgLRjFL9mntQhNNgsrq4iWwJTZLENSVftyVUVkb/Gj5NqW6L6mDUNtLW14ZFHHkFLCy3erzjy8/Px1FNPITs7+4qc90fl2Rw9ehSf+9znMDg4OKVATEwMnnvuOWUoMyVjBhENZL2+0mRONcZTDBoM8GlAXeXja+xJhNJVPj+VciWAVPKMusZV1ZX0UDlhTA1wDjUBTCXLqYBYCUz1KlCrFx65mnEBqoZOYVr1ErBqXCfSzXpSJ0Aa7zACq4QxNcIRAQdZTsUVrVzltNFthRlWcc4VhVHVTJOy6mSayBhPF7ZU1pW55WyCTa//FG4hl8/BOzyErrNn0f7eMbS88zbyOI8t+sSnlFGmhfdxM4f53Ns6fKhv9OLE6WFV/d7dccjJjFCGNzcjb7GUPXt2AKdO9fG9A9LSHNi6NVF5KZHfaH3cWQ3Id01/7wgunGvEK88dQ8qyeGzcWoj8lelIS09Q4yg1Rriz3Zz3rQc4bvJxkHzC34MT3i4MBr1ItnC/yJaqDMKSuHdEswGONxfXO6+BrPP+1dQdXOQaEDBrXW0djr57GAdeP4Dd9+7B9l3bkZ2bjZjYWGWANNsqGKivQ8Mrr2C4rVUGu1jxyIcRsXItqmq8uNTgwWVicXZvj8U6ekYWo3yZM+tDa0BrYGlpQANZ90/rgYfRpYmx8jat4ounkAayTn2Wsogg1p9DdGdyuclDUKsPdZfdiCKAtaQoEivyI5BFQOsim0dMVcIcx0THsqnU3hXApUYfai/70TcYxPb1DqwkQ0pSglhWz3En5qF4+QIS3TT1jOFSJ3CsbgwOWxh2FgE5SWFIiZmHndZduq4GZDNInmsfFyTaAiM45utCY3CEzKyxKCUza5k1EfZFamV7XcXozAWhAQ1kXRCPSXdSa2DONSAbp7KxefTQEfzyp79AcVkJF7p2YGXRSiQlJ82o/f7aWm4AnkHjvtdhi4pC+X//KmK5CR/Ojc3+vmFUX2jGS384iuTUONz70Hosy+TmVWL0jNqabiUZmwob67EzbhwmG+vKXCsK8+1YQTbWWHoNEJDKbB8C2vF6x3DoUDdOn+5DSgqN5/KjsGpVHGJirFzEE6CLPrQGJjRAvIICk11udKOmVgwv3XTjGkBqsh3py+wEszgIXg3naSNzkeGGey7mrRrIOvFMdGj+akDm1gKErG7wQ4wTWtr9XGsIx713OWlAa3w+5m/v72zPRHemobcRnoiLsaZMcoW0VWCOHX4Xznl70cx5bl+AG1H2TBTRE0k4GWDlMNlWTZZX+R5T6SJDhPAwrxNtqSbUHykxIUMi0jbn2bxKutQdY1vCKithkS95RjrfAcYlLO+CmS5hs55ZTq5Sl5cQUDYUZ4JZbzxflTXSlfyQvHEZk2QZdY0+TLQlfSSjLMcWJtueAHQMQCz1aoJpqcKpIFhhOAyBZUN1TeCuEA5amDmeLzJCIFpJmygX2iAkwNdklzXakLrCHDsBuhUAhcidnGay4Boy+QaYfWQ9o20jTZ6rPm5NA8KEuWXLFgiYNZ4GXx//+MeRkZGB/fv3c+x4iO90ACUlJThw4ADf3dAH6xpN9vT0KPZVYXZftmwZHnvsMeWO/fnnn0d1dTUSExPx8ssvTwsUe40mVLIGsl5bO/KZd7vdCjQqLLvch4KHcQ8tLjwEksop4FMBo6pyTBcwqZnn8UjdSfFJ+QG+K3JYhZ00xEqqrnYbWUntimXLLkyloTwbAZfCcmpjvp354VyEl3ypLyymki8sp1JXyghLlzCgitGhAE7lO0E8AxiMqwxLGr+4JM9kZ7VIfqiskW4wr6q6Kl0YqifKLwTwW4DPY6S9DZW/+gVG2tqRSC8JyzZtRtr6DQhT984v25s4BKjp8QZx7MQwjp4cQVqKFQW5ZGIlM1kcvQIuVa8c3d0eNDWN4p13epQ2P/hQOtIzHJqV9SberbkqKt9jfrKwdLT14dzpetTXtKG1uQcPPLIJazeuoLeeCDXemKv2F4tcDjXVjlE/94s6gxxH+3vR5B/BKD37rbYlYSsJUGLDaBBAApTFdGgg62J6mvpeFqIGxOhJxqAXzleSmfVdGsb3KeOihz/yMFYWFyqjo9kej3lpQKfArK+9iobXX8W6r/0VMvbcB1cgAqfPu7Hv4ADWr4nC6rJI5RU5KvLmxlIL8TnoPmsNaA1M1YAGsu6fqpBrxDSQ9dOfvoZqlm5yL92KNtNFY8UFFwYGA2ozOSvDhrzsCIibl+goY5F4tn/cl4rGhUVoYGgMJyo8qKHLv+REC3LIeCUsKQIYiKAFzlI83D6gi3o5WCVXgN5ZsCoTKM2kTmxcmNRjuQX3WoilrZdsCcf9Xajw9cFNq9tl4U6ssyfT7aIT8Vyc0IfWwHzTgAayzrcnovujNXBnNCCbp20trXjvyHt44Y9/wj3378UHyMYaGxerFrxm0ivv0BCGmptw4de/hKe/H/kfeAiJpasQTdeM50834GJFE2ovtqCwJAsPPbqFTD3iJnKW3RyFOi4AEwG/9PQZLqgvNfmUsdW2dQ6OSW2Ij+Um7iw3bYKDenq8qK8fQVXVoGJl3bAhAYWFMYp5RoNYZ/JmLd46frIhDtPQslcxsHrQ3e1DT6+f4IagAqzm5jiQk+VAdpZsHhpgornUhgayzqV2tezZ1kDvQFCBWN89RVAQjRY2rIpAfqYV6amLa3N4tvV2I3myCR/gHFdco77hboGFiEaZ4663JSOb3kdux2EAUgWwLKyFAg4loDUEKjXzBN8nYfmtN4Cvxu++mc9bMPI5IJA0YZEVWSYoVckOlVFAVhU22jPjUtaUJ+VVWMYXIo99mppvAGAFjCsgUFn1kjVF45Q40wkSkzw5BPQlh8QVMxevZp5R1mCdlVKqnips1HtfmmpHnlxIrsgyw7yOy5V0yeAh4FQpJXHpiplu9lH6NJEmJXlK/1VdyZNzok0ZA6l7miRPyhj3NsH4KjLNNPO+J66qSxP6kCjbGNehalPSjLbNeka/hKGXwsflh3RBvUu/mDwuByJT4pPuR6Ank5+J2SaLzfohDKqPPvooomj09QqZjJYvXz7ehjCofu1rX1PxY8eOISvr+i7Nv/3tb+MnP/kJ4ugNQWTl5uaqukMck+/Zswetra345Cc/iR/84AfjbcwksJCArMZ4XD67BiuqgEGNz7uwogaUlwhxuxpgOMjPtQCLzbBRh3ny3cMyfjKWShmVruKSx5VAfkkY3wki20hTcggkkDoCKDCZWRVLK8tIXNqRvCvbMfKMNg15Rl/5WvK9DA+xm0YoMKvJdGonG6oCpxKgaqRFGNdQXMCqwogqpwK2SljVmUiT+guCMXUmL+1N1BEgRk/FeVx+/XUaYNqx8sMfRfwKgvfS0m5CilFU3r9+7jVdbvKismpUMbJuXh+FkkIHDdT4rJawQaOX4N7+fi9ee62Dcx4v1qyOw/IV0cpjyU0rWleYEw2MjnjQ1dGPk0er8d7haho7Z6N4VQ4KS7MRG+sMMc/PSdOLSqiMjjwceFb7B1AbGEQNr7HhNmSHR2G5NQ6ZlihEkpvVukhIUDSQdVG9vvpmFrAGOto6cKmmFscOH0VzYzPWb1qPVWvKx8GsMqacrSNIYgwfwbO1zz2Li799EgUf/BAyd+xCbH4B6lotePvIEMep4TQ4tmLD2kgsSxWW/tlqXcvRGtAaWAga0EDW/dN6TBrIqoGs73tRZLFZNjqGhoKouEhL0MPDtF4mM2aSDTu2RCEvl65xCLaUhUt93LwGuGajmC1aOvyoa/Lj0Am3AgrcSxeuAmhNil+aIxbRi4fvXUt/GM40jmFfJbAxfwz3l4cj3jmGKLpB1MfC04AsTgzTsrYpMIwX3U0YgU8xs67lRl+ZNWHh3ZDu8aLXgAayLvpHrG9Qa2BaGhgcGKCl9iFcvHARHa0duOeBvQrMamzcz3BMwsGOh3JlIavvYhUZbKzIuGsH0nfvxbNPvYOaCy1YSRBr6epclK/Nm9ONEAGreMiKepFsfS8cGCX7TbgCsBYV2JBBkNNcABQMQAtw/nw/N+g6CVCwEIBA8M/6eGRmRnIj2gBRTOsB6UJLQgMuVwB1DW6crxzBiZNDirE3iy5Hy8lakJ/rVO+QsDYJiPV2TE01kHVJvHaL5iZlfi2M2+8cd+FyqwCRgHUldtxFjzD6mLkG6NQaboKtTtMt6hOuWqwhg9RDEdlICLcjKowWuLfpEDCQQiXyr4SN70BjfGLkSUcI+VTlJGysQwlCUUpdWV8VmFxeieKfK+sbBSfqqyIG8HFqe0qAUS4kS7WpQLcCWCPzK8GzchXgK3FsKiwAWzFimEg3GGKljDC6B03QrtRR4FrWY7qSF4pPBtBKHUOWgHR5huqpdBUO9YNhGRtJP/wKpDfRJ1VH+hcqL9eJvpvgX+MZCAOsbEKaDK4qzN8okzU2jOyvBhOswURrsseaxhgmKy3FGOUIJjXLq7qMh4u8yWeojAB8pT0z3xrqi4oLKJUAVaMds36oDdU/wxhE2jXrqzbG2+eD53M00uQaAhLPwY/vv//7v+Nf/uVfcM899+DXv/516I0zLgJoNMGrTz/9NLZv3z4lf3JENqO3bdtG46l6fOMb38C3vvWtydn42c9+hr//+7/n2CKGxlUcl9/CvSwkIKsChfJFN5hQhQWVxg7CkEoj2uIP3AAAQABJREFUPmFEVVeXcfV43XC7JN0FH1lRTWZVs9zksmba5LKS7/N5CU6MgMPpRCRPZ2QkInk6nA5lHBjhEMZJJ9mwHIhgmhFmeaZLGclX4dDViHNfgqBTAZ4KA6sc5vNT19CzNOYzxnfR5HwV5uddiklYfZtep86UF2cJRupe/BOaDuxXd55YUooVH/koHAkJBLvfPOBDfgdq6jx4/c0B9fOSlGjFlvXRyM0mQ+4SnwvKz63HE8Dx432oqxsme3EQZWVx2LFjZt5gluCrOue3LO+vjDHEk87p92pxqbqN31l2fOSTO5CTl0JQ/CxbAs/5Hd25BuR7VwhQOgMuXAz045SvBxf8ffRwkIGN9hQFao0MWxz61EDWO/ee6Za1BiZrwDCUCuLg/rdw7N0jZNnuQFFpMT72mU8gLj5OGUBNLn+rYTHsan77IOpffhFWjnNj8/IUoYXXmYL2Dh8OHh5CW7sPjz5McoflHO9GyPzqVlvV9bUGtAYWigY0kNWYX97oeWkgqwayXvUdUZNnWoJ29/jputFLJg8v+vr9ZAwNV1TnRSvJpkimJnHdqI+ZaWDUReZRMgqdvehFRzetzzmDKyZ4oLyIGyDOMLo3WnqjFtlgGPWG4VLnGI5e4oSWGw00aMWmAiA/WRb6uai+9NQysxdsHtUiRwMG6Tamwt+POlratgRGsJIWtmXWRFrZRiJOM7POo6elu6KBrPod0BrQGhDGoJbmFjzzm99BXJGWrVpFYGm5WuC6Ve34uUHcV3UB7cePo/ngm3AUliNmx4M4criWgCMf9jywFssLM5CUEqs2Vm+1vavVlw0Yl3sMFTU+XGr0obUzgBW5NqwlwCmZ1uCRHHvN9iFtjo4GcfHiIC7VjRBUMIyioliUlcbS1asD0dGLY5NitvW2FOV5fUECJYJobPSgsclNBlYfwUvgojINK1NsSF8WgfQ0Oxeaxd0r5wa3cXKggaxL8Y1c2PcsBsrN7WQ8qvfiTJUX+VlWbCp3IIVeYaKj9MR6Jk9XvIzInPYi2aPOcNN9HYGse+2ZcITzO0lBRGcidenUkbVGAwhiYGQFVCdrYQJgFaSkMLYKSETiKj1UXsCjRl0DkGqCSQScKmGjrgFUFRmqrMqTdSWJT8gU+ZPrSVlhj5TreJsMGPWMvhl5AmDlqfoU6i8jKk+uqheSPtEnI2bGGTN3J6XS+HEl4HiypFBd1jM/scb9SmUjZTyuolfKMhqZWjcU42W8rin9Ov2SIio71HV1K0wTplcB4MrPsaQJk6uEDffrkmbEFdPrFWEB8o4zxobCFyufxsmTJ/DAgw9hWfrd6nde5LJ1REe2Yu/ee9RG8+HD59DdK67dpc1QO+pq9GnZMhtKS/L5bAN47vkXkJpaGuqfkT/QX497771HKejVV1+nC+9Coy22o+6Bgg0W2xCbrUo379MA/hrMTWM4ffoUnn/+eTz22GNYSaZKtVFOZcmcQphLTdbS9zObCvuovHsG86kqJ6ykoTqT6wlzquhfWFMlXzGeMm2yTDOsPlcs5zfZTVX5EAuqfOZ4msBOUYCErxY309QbqcqoxzBe9nr1jDqGbKvVxmdmVYBWYT8V8KmwncrVwnNy3Mp0Wyhd6khdCwd8Nl6tU+JG3dlkz1Ivg/4zrgExwBwha3HDqy+jk+945s5dSNuwEUnFJbAQWHyzh3hUaG714WKtC+erXMrzX3mpExnpHNfHcFCvD36uSfDR4kJNzRABrf1kpI7C7j0piIq0cg9O62i+vCJ9PQQftfTi2KEqdLb3o2BlOorIzlpanqOMkc3vzvnS3/ncj9GgHz1jblwKDKHa1w9vWJBsrFYUW+ORQ08Hws6qhgDz+SZu0DcNZL2BgnS21sBt1kBjQyNqLlbjyKHDaoy+srgQa9avQVFJ8fvGxLfaNcVqf/4cWg69gyDH7WWf/yIic1fQi6mdrKzDqLnkxvJ8B1bkk/GeYFY7WVr1oTWgNbA0NKCBrPun9aA1kFUDWa/7osiipizwygLD2QoXmlu8nDiHYeuGaGRl2LiZaFcbiGKVr4+b14BsLLV1BXC+2quYWZfn2LGx3I6sZVYChY1FU2PB9uZlL+QavSNAHcGsJxrGUNUGPLg6DOtygARuttn0us2CfLTCXOPipt85Xy9e8TapRYlcazTWWw0XjHbuPNDmbEHem+704tKABrIuruep70ZrYCYaEDbWmos1+OVPf0GAZTQ+/+UvID0zAzGxMTMRN7WObGqT1ajtyBGc+F//gcHIVHjLdqN3OICE1EQ8/Gdb2dbcsq64CBLs6Q9i37suGlWR2SrdilUrbVhVaJ/a11mMud0BdHa48dbBbvT2euni1UYm1gSUl8dxoXAWG9KiFqwGZONWQKxDQwGCV2nsd34YtZdciv0tK4NzpA0EPRPAGh9350DPGsi6YF+vJdtxAT0JGK/2sh8vvzWqWD5yMywoWylrDgSACXBMfwdP+/0QgOQw/HjL04rm4AhsZAdda0/GRlvKtGXogotTA/JZE4Cs/JbJZ07WUeUUQK7EJV3iKj8UVp9PKR86Vf0ryo4JA62ZpsoZoFsmjctUcplgyldgW7ZlMNga/ZA2JtoTIKPUN2WwrpLHuNmWyjfKmfJM+aYs+TwI0FO+R8JDhiUGo6IB9pSwypN8dRpxYX1VwFf5/uHrMKU+EwzWWJERRlfNVnzwwQQauAyjsvKMYlW9fPkyAaj34qFHvj9FrmqP9UWesM+uKBjGnt13qRfu8OFKkjRIXqg9XgvyIjgWLVD5TzzxJOIS16t8Ba4NyVF9oyyj/3IfAsyckGEw0wJVF07jwIGXyCL7AWRmZFH3NMIhE6nP62HYa8SZFggQeMpNbD+V76fLUb9PwpIWgE/yBZjKPB/zFFhV0ieVM4CtfqZJudBV5IXqqXZZR65KpsiReKgNSTdArOFkM7UrMGmEQ9hNDfZTAZcK06kwoCrGUzKpGvlyDaUxX/Ik3W63G+FQmsSFedXMF1CqhAVsqoFdC+e7T/aChEVsoK4O7ceOoIsgVldvL1Z/+SsEsm5AOJ/rzQ4e5HujfzCAo8eH0UQwq4BaN9KV7rZNxvxaj0WM98P8nhYg63PPtSIxyY7NmxKRle1EclLEwnmJlkBPxVDg8FuVOH+6Ad2d/ShelYP7P7gBzihhi759DP2LRdX9JEBpC45iv6dFjbFzw6NRakug54Nk8FcEEWH0GrRAb1YDWRfog9PdXtQa6O3pxWsvvYqqygvo6yUb9D27sef+e+g1IEqNkWfr5n2jo/D29+EU1//76+uw6gtfQsradYhKS8Op8y5cqHahnwRy4nlq9/YYGq6Id4+F+m03W1rTcrQGloYGNJB1/7QetAayaiDrdV8UtXjBEkNDZGflhmL9ZQ+tZz2KqTU3OwKlRU7F0Bofp9GF11XkNTJlgWKUYIL2riAu0LWrgFoHuXm7fYNDsbPGRBluya5RfdEme8m6NOIBTjeO4QxPG12GZsYDO4vCkBBpLD4v2ptfpDfGVx0B7uL0jnnQQCvb8wS0Xg4Oo9yahBKysy63xMHBRQl9aA3caQ1oIOudfgK6fa2BO6+B0ydPc0PirAKzZufm4NGPf5TAyzjFAjQbvRvjBnVPdTWq//QCzlwaRGV/JDbuWo3yTYUoLMlCdMwcUKJO6nhVnRcXan1o6QiQ2YoGauscSE+1II6eF+bquFg1hIvVQ2RiHUFioh2bNiUgLc2BhIS5A8/O1b1oubOvAQHvDI8EydY7igbONy/Vu+gJxILkZBuysxxIJRNrYgLBEA7xWjF37+mN7kwDWW+kIZ0/HzUgYLP+AQGz+lBV50N9sw97tzlRXiyeYMKVYfJ87Pd87JObrFFdZI161t2A0TE/dtmWocBKkD29jOhDa0DW99QaqlxFHSp+9TT5XAqMU8rJb6Aqa9aZkmYAUCVLgKRmucl1pF3JkLRQ0GDuVB2SPGMzVNWRkkZzStaUOsx7v1wjzWgjVHdSO3IfRp55L1LGaEDlqbLMC9URYK/K5h/Jlw7LffFitM2+mv2UxORkO776F7vQ0dHBEsaRn5+PX/36OZw4LRUNFl8lR8kz4tJeWnIFPv/5zyoQ5Wuv1+DYCboyZxWz3bVr4vDYo6Xwer3493//D3T336XalvYVIyo75nZVwu9tNJsO3et4VAWM52ij7CZ2o5zMTk6eIxiTk2teGBsl5s9NYK6PZ4Cb0zTiJrAznOhf40oJEhfjbothYGDhNYzxibIEghKgO5Eu+QL6NcuFZIlskSPyQrIkHsZ0C9tTIFymG/UMeSrM8hY5RZ66hsqLnFBcyVN9NMqZ9zDRx0l9D8kyymgQ69Q3Zv7HhDHMT+BFyzsHceGJXyN+xUrFxCog1qj0DPWO3OxddHb50UBPC8dPkbmCL+KmdVHIzrQjLYVc5hrFOkWd8h3a0eHBiRN96OrywMN9o527klFSEqN1NUVTdzYivxXdnQO4VN2Kd9+s4FqRBSvoWad0TR7yVyy7s51bgK17SX7ipke/Rj/XjLhvVEWvfjbuE6WHO5XRWIElBvyFWpAkKBrIugBfSN3lRa8Bj8dDZu02nD9zFgde34+UtFQIM+vmrVuQnZs9a/cv6/8+F5nWn/kdusnMKuOo1PUbkH03CS0Ggrjc5FHMrA57GHZujaEHKhsS6H1KH1oDWgOLXwMayLp/Wg9ZA1k1kHVaL4oU8gl7aIcXdZe9ZGcdpeU23TsmWpFPK3ZhyYmPtdAaWxaopi1SFwxpYGR0DJ1kxDp9wYMKsrOKe9flORaedsREk4WUQM6leNR3jeEiGVmFlVXeq20rgPxkvnexS1Ebi+Oefdw5EDcxx7ydOOHtQgQX0zPoJmYdmVlTwh2ICdNWy4vjSS/cu9BA1oX77HTPtQZuVQOGm84AXn7+JZx87wTS0pehdFUptu7YppiJblX+5PpdDc2oOHAYx4/W4FxlBz7y3/Zg6561SMpaBrvz5l01TpZ9rbDbM4bB4SBOVnpRWeNBAg3RCrKt9AbgQCQBgnMxhne5/Bgm2+zx432oqxtGVJQVBQVRCsjqcMiG+tIc417rGS21dJlferw0mOz2oaPTh6ZmNxl7fXxPA2RSc2IFXWvlZDkRQ3ej8+FV0UDWpfaGLp77FU8wsuZw7IwHh066FQN3UYGsOdgIZp2b7//Fo72JO2kPjKLOP4i3fe1whlnxqCNPzWEdDOtDa2ApamCcnVXAnzwV2DYERhWQj8SNqwBeDZCqMLxKWcGdSp4AbUWOArSG0gxZY3QrH45v/Y9P49SpU4qZ1NTxpz71KbKzfgdV1Z7xekom2zP70dn2Iv72b/+HMkZ75g8n6bpzhABTox2v14fioih88uObOE4dxr/+6/dx4mQ8RoZHx+UJoDM+vh2Rzm6zWePKAcnE6NUIhVuSCFrt4JimHKOjDjKxjvB0kXF1hIyovPK0hPu5jh5EXGwEmWa51htjJ+uTjV7PxNMZQaAhgKnVauV922CxWngl6FTioTxJs1gk36pAp6qszapAsarspDypZ2OelWkKnMq6wriqwaVTH6eOvV8DnsFB9F6oRPvRI2jcvw/5Dz3M8yE4E5Ngjbw5ww0/P3M+7xgqLrpwscaFAbKyioeFXXfFIC4mnO/knTNQe/+dz5+UkZEAWlpGce7cIL//+shCnYZ16+I5l5bvBa2z+fKk5Desq6OfQNbzaG3uxfCQC1t2lGA12b6jY+giWjOz3tSjkhGBm4ZirRxvH/N1oTPogotGZCW2eKyg4VhGeBSiw23gr5r6d1PC72BhDWS9g8rXTWsNXEcDsgdwqboWB/e/hfa2dnpH8OPuvbtRVl5GAoZE2Oyzs08tBkIdx99D56mT6KmsRHL5ahRzLhNmd6J3ENh3cNAYH9GAv4TEcYVcB5X1z/mwBnod9eksrQGtgVvUgAayaiDrdV+hxx9/HIWFhfi0BrJeV0+TM2WR0e832HI6udl4+twIAa0uBWJdURCBDWuilKtHrvXp4yY1IBNfeiRBY2sAF+sNliyuU+K+7U7kZFjJSLQ0lSrMrIMuYP+FMdR1jiGWm2xrcoDtKyeWjW9S1br4HdaALEqIdXnfmBfNgWHso1vGAYbX2JJQRpcxRWRm1YfWwJ3UgAay3knt67a1Bu6sBsQie3RkFD//r5/h1Hsn8enPfwbrNq5Hcmqy2iyezd411LRi3wvH0Hz6HEYaarH7oU1Ys2sDksvKEBE7NxY77d0BVNEDgDDy9fQFcC/HmcUEMkWLB4A5Gmq2ttDyvHYE58/3U7cB7LknBStWxChXseKmVR9LWwOymd3V5cXR9wZR1+AmYDwM+blOrF4VzYVjK99Nw1ByvswvNZB1ab+vC/nuFWCME7FLZGWtqPGhud1P8FQ4HtxFRu4UAqP09/G0Hu9xGmKe9nXDR1fjmWGR2O3IRDS308UFuj60BpaiBhT7agjWKXywAi0x04yrrP9QM/IRGQ8Ya0KSqMowT7KMT5FZf6K4lPH7+N1VcQavvvoKfvzjHytVf//738eHP/KJ8XqSaLYtifveeBFf/epXSLhgpzFVE0ZGvKoRaau/r5+kATaUrSpWsv7r//4XfverP6KpsUkBPSMcEYjheDw2No5XGbfyGmfEY+mlIXZSODIqGpcuVePQoVewZt1DiIjIpotQL/r6fWTD9qrwwICP2hmD0xGuxjl5uQ7k5TmRlGgjsDW0Sc7vERMiO2HoRZ1Keug7Rl0nhSenj5cTXfL+Ja5Uz+uV5dRN6z9aA1fRgHyGhpoaceHXv8RoZ5dyfZtF1rD/n733jo/rOq9F1wBT0HvvlWgEe6dEqlJSLNmyJcuyLdmWlWtZcez78v5xcvN8/bOf7cSRY984fi6xHcslUYmsLlGNpESRYu8EQPTeOzDA9Jm3vg1RgSgSRBkAA2JvaTiDmTPn7LPOOXP2/r71rZWycROVfScUey/ztSu+NTbu4XXgwb4DdCEhmfW6zZHK3S+NimNCYn3/dL7i95frB5Incrm8OHx4gL97XVizNhZlpZHIyYlQZNbliksg7rfT4cLw0BiOHqzGq88dIYk1F6vX56N4ZRZi4iICscsB3Scv71wigjJGQmulexBHKIQyyrxRRJAZN5vTSGiNRjgLyPjrEdD7Mblzmsg6GQ39WiMQWAjYxllkMzSE1199He/u24/i0mKsXrcGW7ZvVXMAv/SWYysHt9F98gTO/OoXiMnPx6pHHkVofAJcdHZpaqHYBMdIZ86P4zqqst54XRSLVsR5Yen8zvkFJ70SjcAyQ0ATWTWRdcpTXhNZp4Rnyg9lIi2KTo28wdbW21W1iEQdRfY8O9OC3CwLA4ViUaRvtFMCeZkPh0e96B3w4DSVsnr4HMPq5Hyqs5avMDPAg2WpzOoiwbeqw4fabgNqu7zIjDdgQ44ByeQ7xsysEPwyiOu3FgsBCUqMwoVTzj6lajPicyHPFIXVxjgk0DYmSiuzLtahWfbb1UTWZX8KaACWMQLtbe2orqrGscNHMTQwhPs+/xkUlxUrNdaLCeC5wuP1eDE8PI7q8y1485UTCLUPIjPcjhjfCJLSk5D/8U8gMj1DJQrnuq2L35dCtJExsZV24+hZu1JfTU4IxmraSqcmCQFnIuF9cXl/PDupsjk66saFC6M4SVvEiEgjUlIsWLMmFom0iQ2m24C/MPVHf/U6Fg4BUV0bG/Ois8uBtg4H2vlwuyRICyQnm2gzGoJsEjwsnE8GmkqTJrIu3HmitzQ/CAyNeNHV68HhM3bI6zUlFuRlGZGZohWyp0LczaS6nYpQe50dOEki6yoWYRYzkZ4XHIUQ2p7qphHQCPgHAVELFZVRaRedEiavWcaOX/ziF/HGG29g165d+P3vf/8+eXXyUhOvDx06hHvuuUf9UUX1owuVVSpRPTg4CBsL17buuI4FVjepz5968kkcP3RErUtIrKGhoWr8H8Lnj7x+/z153xLC8YrFgrPnKvDqqy/h9tvvQUpqIVVZPRi3eWHjQ17baA1ud9CdiONjGXcHs4JMinSi6Y4QH2dGQsKEjagU8BiXqSPXR4+gfmcxEBhpbkJfxXk07d4NMwnb2bfsQiyFYCLS0mfUHS/zRB7OQVvaXYqYMTjkVnO/TevCSebmNcbiNV3UeHVIZS59/PgAfzso7hFtxPZt8ZwvhWjsrg7dgi0hpGMP1Wnqajp4H6lmHGlMqeZu3VmGnPxk/s6HUxVb50hnckCkCEOKPzrFCcEzikY++r12lSvKDo7kGDwGsSS2hi+R3JEmss7k6OtlNQILi4CXlhDyG37m1GmcOnEKHa3tisC6fef1yM3PRVJykl865HGyuK2uFpUsFBIuTeKq1UhatwFR+SswMupBVY0d+w+NIof8mrJixkT5HE0HZN00AhqB+UPgYl5qohh2/rZzpTVrIqsmsl7p3FDvayLrlPBM60NJiktg7sDhUXWjtVJlqaggFDu2RiiVpTBlUSdJ6mmtTi/0PgJUtEddiwuVdS4cP+tQiaWbt4UgPiYYEWHLr1qZ4zq4vaAiK/DiKdZl8m8hs64nmTWf48j5IF/ok3FhEJDA5hjcqHAN4CVHCyJYUVtqjEW5KQ5ZQREINiyl+tqFwUxvZf4R0ETW+cdYb0EjEIgIyKT11PGT2P3SbpLnTEjLSMMNN9+IjKwMv3bXYXehsa4L50814tD+CpQVxODGzamof+ZpuK2jWPv1/4n4ktIZ2zZeqZNyr7XbqcLX6sL5Go4tzzlw/cYQ3LAphFapBphN/h+oC5YjI240Nlpx9swwjp8YYmI/GVu3JiAiQmxN50n+9Uog6PcDAgGeFso62MGCyM4uJ06eHkFTs0MRWjdtZDFTeQSys0IQzvlOoDZNZA3UI6P7NRMEXIzj7DtsR02jS90DSvJN2LrWQltrmVv7/54wk74F6rJjLLoc9Drxqr0FZ9wD+HxoAdYY4xFC0PSMNVCPmu7XUkTAZrOhqKhIdf25557D+vXrP7IbP/nJT/DYY48hLS0NJ0+ehCSgZewpz1Iw5mXRtJBgu7u7sX37dvX9Z599Fu++tY+Kqy1oaWrisj588zvfwqc//WlFrtu7Zw+dA8aQnZOD8IgIRU79yIaneOPUqVN44YUX8JnPfAYlJSWXXVKS1H10N6trGEdjkwP1jeMIsQQhNtaE4hWhyKVCa2qKWb0nBV+ilK1/ki8LpX5zPhCQa4jXTcu+Peg6ckSpsiauXoOyLz6k5qUXE73T3bQUrlnHvTh5ZhyvvjlEUkYo1qwMQw7FT2JI4NZteggMUdm5i8V/e/d2sxjWhbvvTkdeXjgFZJZffmh6iC3eUuNjdsZAbHjhqYOoPNuMHTevwsq1uSRCpdCeWheMzeXInGfe6BzVWU+wmCyaBNYd5hRVTJZCIRTJHQVu9GBirzWRdS5HX39XI7AwCMgcpLurG088/h9oa23DqrWrsW7jOqzbsF4VI0ix3VzbOOcmrfvfxsCFC7C2tWLFpz+DrJtuVsoSzYzZHzg8oorfxMFhOxXsZcyk5wJzRV1/fz4RkPnBGOfQ//Vf/4Xa2lrmfCKY+9mKTZs2ISwsTM3Rp7P92axHil8lj79//3709PRg1apV2LZtm3Jid7tp9XyVVl9fjx/+8IdITEzED37wg4/09fDhw2hvb7/iWmTOX1paesXPp/OBJrJqIuuU54kmsk4Jz7Q+lGSkJEG6e1xo73SinnaQY1R7kmDFagYnCvIYnIgyKnXWaa1QL6QQEFxHiWN7txvnqh0YokqrkFs3rbKgJN/CgCqr9+c+blpSaDPGjKFxEny7fUqdtbrTgK0FwOosICnKgJD3nbiW1E7pzrK2liRlJhn6WFVb4xlGvXsELV4r1gTHoZRk1ozgcISR3KqbRmAhEdBE1oVEW29LIxAYCHg4wZWg1dt73sYTv/8P7Lz5RmzfsR1ZOdn+sxLirkpyfWTYhreoxNra3IO4hCgUFyWjpDAe1U89geH6OqRu2oyktetUdbY/IlZjNpIGezw4cMKGsXEf0pKCUZRnQkGWSSk++SEW96GDKMQAq5VJ0JZxHDrUpwqQUlNDUVwcSZXNsPe3qYlSHwJtmfwxPOxGLwkcF2psKiErpJOYGFHqpTJwskWpkQW6Epkmsi6Tk/Ua301yvdDS4UJ9ixsnKxxKmXvbuhAkxgUjMlz/Pl/u8Ld6rEqJVZShCB9utqQjn4pQuvDycmjp9zQCs0dAksTl5eXo7e3Ft7/9bTzyyCMfWpl8Lu8JafTGG2/Ef/zHf6jPR0dGlNpqZ0cnujo7VSI6NDQEv/ztbyBJqi984QvYumEz+vt6ERoehuSkZLxBwt4f/vAHrFu3Dr/8+S8QxveFxCpJsWCRiZ9Bmw6R1Ul3MynmGaFjgZWkViG2DpKkJkqVolTvZgV/aGgwx0RmZGZYqLpoViIRBkbOZkoinEHX9aIaAYWAc3QU9oF+VD/9FAaqKpG6dTuSeW2IYliQWMTNoEleY4hFjafOjqO1nQpkwx5FYi0vDUVEeJAiYc5gdct6UVFxHqNwzN69PWhuGUNpSRQT9CS35IRpVdYAOzPcVPRzOZnLY8Fy1bkWdHcOIj0zATt3rUJcfBTvMUzo6TYrBAa9DvQyd1TnHkabZwx9PjvyjFEoojJrLsfjMQbzrNa7UF/SRNaFQlpvRyMwewSE+GYbt+Hc6bOopNNC5flKFJUWYceNNyihi+gY2sPOsbnGx2AlMa717X0cbz2Jks89gLyP3QVLdDTGHEa0kWNz+hwL3locuGE78wWFIcq9waidj+eIvP76fCAg89MjLH6TefYI5+KTW2RkpJqvFxcXT377sq9nsx75zle+8hW89NJLH1nnfffdh5/97GecW1+ZzCoFsDfRmaWmpoZj6hzmrw59iMgq67/11ltx/vz5j6z/4huPPvoovvWtb138c1bPmsiqiaxTnjiayDolPDP+cHjEg9p6ktHqbaius6MgNwR5uRZkpZlpk2SiJZO2jJkpqFaSDZppwVNR68SZC05l+1dWaEZ6siizsjp/mQ1gGA+Anfeeo/U+7K30UZUVyEsyoDzDgPgIwBikg7szPccCZXkXyazj8OC4qwfvOruQYAhBZnAEVpPMmsjq2nBNZg2UQ7Us+qGJrMviMOud1Ah8CIEx65hSaDr4zkG89vKruP/Bz+H2O+9QlqLBxpklsj+04kv+GB0eR3trP3Y/fwSizHrj7WuQW5DKsXIYml7fjW6qSnls4ySyrkfeXR+HkdVLhhkm0i9uUhKIQlZqbHOjrtmliqPiY4Oxk0qsyfFGJhH9T1YSEqsk2xqpMFVXZ0VF5TCyssKw4/oEqk1ZEE67VN2WDwJCVJXz0E47XSFrdFJNqL3DySSsg0QOD9LTLCikm0dpcTiMVAZeCsFZTWRdPufvtbyncm26OK9u6/LgzYM2da/ITA1GaYGZ8ZtgrQI46eBT55GzVB9ECWq3vRXJwWGKwFpqikUS56m6aQQ0Av5H4Bvf+AaeeeYZpY7y9NNPo6ysTCmsCsH0ySefhHwuv2Pf+c53cAtVjOwsRjt09AjHnnXIz8/HUHcvlU/7MGa1Iq+0GHLvlmSUqLIWFhQihARXUXJ98MEHOR5xKHXXz3/+83PakekQWSdvQMZHsg9d3U60tYs6q419ZgLd7lEx9OQkM8m2Jhb5WNSYPTwsWJFcZR3cFd00An5DQM5DGbAPNzSg98xpdBw6CBeVlUq/8CUkrFwJc0TkjE+6UasXLW12HDxqVcIcmelmKrKGITcrsMlmfgPVzyuSOfbRYwOoqR5lUp65ECqybtkSpwjBQdqy3s9oz311/X2jaKztxN7XTqmVrd9SiPzCNGTmJql7kT5ms8PY6aOqOQmtVZ5BHHR0ITzIhJSgMJSQzCpCKLEGC4wB6uyniayzO+b6WxqBhUZAyG1WFvZUnK3Ai8++QEGxEBSsKFDKrLn5uTAzRj/TYrfJ++Dj+r1uF+P/r+HML3+OjB03IP36HUgQV7aoGLhcPrzz3iiOnRqj83EIVuSHoJAPUWjV4//JSOrXgYBAf3+/Ul+1cs6dkpKCe+65h/PVULz44ouKIBoXF4fdu3cjMzNzyu7OdD0yr//ud7+LX/ziF2q9u3btUv2oqKjA888/rwisDz/8ML7//e8rx5ZLNy7X8De/+U08/vjj6qOcyxBZJe6Qm5ur1Gavv/76S1eh/r733nuVu8tlP5zmm5rIqomsU54qmsg6JTwz/lBUWG12BuGoztrU6kA1lXaGqSS6itW2RawcyaUMupHWSLpNHwGKdsHuIBmg1U0rWCe6+z3K+u/GLaHIYqJpuQ1gGFpTSbauIR+a+g042sCBpd2AXeUGFCYDMWFihTh9fPWSgYOAHFuPKLP6HBC1m0PObgzw9XpjApVZY1V1rbZsDJzjda33RBNZr/UjrPdPI/BRBLo6u7D39bfQ3tbOwJELt9x2K9Zv3kCVEwkW+W9wcYHKHOdON9LSlGqs8ZG47eMbkZgUzTFykLJv7GFS/QKVWWOLirH6kUdVVbYpPPyjHZ7GO04GwJwukKQ0jqp6F3LSTSjMMaI036zU/eeDNKgIiyMuvPVWN9rabMjLj8CKwnBaxEapecByK8KaxmG6phcRRwUn5zIdVBU4e97Kc4JOE1RlXVE4YZ+bnmqmuoCJgS6xzl0a9rmayHpNn7LLaueEtzJCokkDYw2VdbxGq1247fpQbKYLjDjAzMc9YikCLAWXIz4XjrHg8kVHM3aaU3GTOQ1RVH6yGHRxxlI8prrPgY9AJxVVxZLQ6XSSqGXGmjVrkJqaCkn0XKAVpzSxDvw2FVAOv3sQjQ2N6Brqx4EDB7B9+3YqGF2vlk9KTkZmThb+6mtfgxBNL34vJGSCyCoqLXfffbdKgikyn1pidv/MlMgqW5FtSsLa6ZR4On9rqGDZ3SPEVidaSQIUB7RwKrQWMqaenxuG7Pfj6poENbtjpL91eQQUqYLz35Y9b6LiD79H7IoiEljLkX7ddQhPTplxUaWML85XjeNCrZ1kVgcyKHCyc1skoqP+m4x9+Z7od6+EgGDa00M1ShaK7n+nDympFnz8rjRERBo5ZtNjkSvhtljvu1weDA9aceZEA2qrWtHa1IftN5Zh5y2rYQkVVxx9zGZzbKS4zM3HsJc5UjoknHaT3O0eQnwQiV7BUdhsTkY0ya1GBJ6NpSayzuaI6+9oBBYHAXFsG+gfQPWFGhx97zBOHD2BO+++E1uv34bk1BRF1JtLz2Tc1Xf2DBpf260Kh8xRUSj45D2IyS9Qc4O6Rsf7Yygnx05BuP2maFXk5m83tbnsg/6uRkAQ+N//+3/jN7/5DeP60XjttdfowpetgBklGVycUzo6OnD//ffjxz/+8ZSAzXQ9AwMDylFFYgUPPfQQfvCDH6hrRzbyq1/9ShW7ymspXBWC7aXtrbfeUiqyF9+/HJF1aGgIpaWldEhJxpkzZy5LiL34/bk8ayKrJrJOef5oIuuU8Mz6w7FxLwYGXQxa2NBGuzppSQkm5GbTMjLFxJuuEUIH8CcpQG3kGv5nYMiDDlrCnqtxoZsV+llpRuTTDrYwWwIWQVRMuYZ3/jK7Nk4rrlE7cLDWgPpeH5JYHL4ixYBVLOywGH066XYZzJbKWw5W144xLHHE2YMGzyhtG33IDorAGlM84oKoRGGYmZ3VUtlv3c/AQkATWQPreOjeaATmEwFJINuo4tRQW49nnvwvjqss2LB5I4pLS5CZPXXF6Ez65aL0ndPhxoF953HiUDXSsxJQWJyB1RvyaWEaoibc7vFxDFZfQOUff49gJthTNm2hleMqFcyaybYk0SX71dlLt4QmWke38t467sGmVSwsyzAiIZZjRz+r+otKDGNxaGkZJ8lglOq248rqcP2GWKXIGh+v1XdmcgyvhWWttMAc5JywnfNBUWIdGHAhmEWNoigmKqyZ6e9bZC2xQkdNZL0Wzk69DxcRkIKH0TEfzl5w4MAJJ2MMvD5Z8LAihyTzyGUWZLgIyiXPMjetdA0yUT6MGs8QiaxpuN6copLk/itzuWSj+k+NgEYAlZWVELu+2traD6EhRWaipHorlVgrzp6j6rudY2wn46VV2L9/P3bu3IlHv/IIhMSakEhHACrBjFFd8oEHHsDx48c/WJcQZCXBJskueT3XNhsi66XbFCGDoSE3x01OVQQ0MOCkYqyP6k8GRJGwFhUZTJVaqrRyXB0TzXgw1Zl0Mf+lKOq/Z4qAk1agg7U16HjvIFr27qHF7Z1UB9uJiIx0mMNpfzaDJnPOUYqaHDlpJYnViUTmgwro1reqLBQmjvl1LmgGYF6yqJ1qze3tNrzxRjfzHkEoWxlFpagwkva1OvwlUAXEn+K+0905QHvqFhx5twrpmQkoKsvEitIM3p9iYNA/3rM+TlJk5mTGqMo9iGqOzweo0mpitjnTGKGEULLp8GdGMExUZw2UpomsgXIkdD80AtNDQBwbxCr92KGj2L/3HQpRxCErOwubt29BSlrqnMmsYyzak7FX81tvYqyrE6UPfhGJq9dQBT8CQxxHdXa5lKq9FLttXheOrEyz4thMr/d6KY3A/CMgc3IpPG1sbMTXv/51/N3f/d2HNvq73/0Of//3f4/IyEhViHqlOcBs1iOKr1/96ldhMpnUukUF9mKT7ZSUlHBOPYRvsehV4gmTm6i/7tixQ30ujix/+tOfcDkiq8ztP/axj+E6FvaJQ8xsm+To3MyZOemowKEhHPLga4fbwNc+tDeTML/nCazaeheyVqyb7Wam/F5arAFpMVMusmgf7t2riaxTgq+JrFPCM+cPxT6yibaRb749wiCGBynJJmzkTXdNeZhKbOug/8wglh+8MxcYnK12oLbZjZwME+68IVQlmCzm5Ycm4UB9N6u8230ktJLsGG/ApzcZEM17VojmOs7s5AqwpeXYDjEIcYFVtc/bmxBmMGKrOQnFRpJhGIzQTSMw3whoIut8I6zXrxEIHATENmigrx9nTp3GH//9jygqKcJf/c+/Rlh4GExm/w0oxqx2DA6M4tXnjuL4e9W4/6EbsWFrEVVUQpTq60VEJIDVwkDWABWnxrq7UHz/55DFRP1MmpeDRq/HgGPnHHh57zjSkoNVAdT6lWYkxs2P+oc4MzhdXry7vw97qMa6YkUkSkqjsHJlNKKijDPpvl72GkGglQpMNbXjOHh4GONMaucx0bpmdTgT2REMNhn8TqZeKNg0kXWhkNbbWUgEGlnwcOK8nQUQbnVt/sUNYVTx1r/dcgx6vDbsdrRR/cmB5OBQrDbGc14aoFHghTxp9LY0AguAgMfjoRrSBdTV12NocBARTO42VNfi7bf2qKRYycoyFp+VoqSsBKnp6YhPSJiSKCfqLSdOnIAosm7cuFE9+2s3/EFkndwXKRLr6XWhucWO02esSqG1f9CN8rJwlK+MoPNZGOJijdr5bDJo+vWsEBhqqEf9889htL0NHiqzFt93P9VYL2+hebUNdHW70NBsx5ETY6qQ8hN3xFJNWFviXg236X4u5PZjxwbQ2WknQd+DbdvisXatHpNMF7/FWK6xrgtHDlShuaGbc2IHPvmZ7Vi5Npfjbf86/yzGvi32Nj3vq7Pud3biPEmtnZ4xbGL+6BZzOmLonBBOddZAaZrIGihHQvdDIzAzBDraO1DHuceLf36eMf1BfP7LX8Cq1asQnxg/5Zzjalvxco7j5ZjrxP/5Z3QceBcln38QqVu2IjIzC0G0NBexuLfeGeH430G1y2CsLAnF2vLZubVdrS/6c43AbBAQAZWsrCzIfP3ll19WCqmT1yNKo1I0Ku3NN99EWVnZ5I8/eD2b9fzkJz/BY489pgipTz755Afruvji4Ycfxu7du3Hrrbfi97///cW3OfYKxj333KNcXP76r/9aObx85StfuSyR9c9//rMi6H7pS1/Cj370I/T29iryq5BeZT3i7DKdxik9bC4DhnlN91uBwTFgQB5WKszbAGtPNTz1TyEo604gfn6IrDuLDNhZHJgcMk1kvcpZpImsVwFojh87nV6M0qpOyKyttEVq63Ay0BhEVVYzSmgnmZxoZBJTJm1z3NAy+nrfoAdtXW6SWZ0Yt/sQERaE8iIzivNom0FlreUkLy/E3hGqsrYNAIfrvBh3GhAT5sPabFZcpE1goU+tpXlxyOBFlFkHWF97ztWPVgYiumgZs5qqrCtJZk0KCg2oYMTSRFn3eioENJF1KnT0ZxqBawsBN5VSDx88hLOnz6K7qxsrV63EXZ/6uFJmkqpQfzVJYBw9eIGk2REV7Np562oUFKXBaKJTwaQBi2vMipHmZrS/+y7qX3weBffci+xbdyEsIRHGSRWmU/VrmJPh6non6lqY/G53Y02JGaWFrN6OC0IolZv83STR3tvLe/a5YarEjFN504n162MVmTUuzkws/b9Nf++DXt/cEZCxuYtkZrHEbWgkIa7bqVTFIiKClSNHZkYIkqgiFh9nmihqnHTez33r87MGCTiJ0rBUSTtJDqdLJH73i39CTGwcHvzSw3SCEGUpH9XQlsDOzA9Eeq3XCAIjvG/09ntw+IxdOcGsLTUr95f0FJKkGGdYrs1KNdYm1whedbQiNMiIG8ypSA8OR5zBslwh0futEZg3BCQOZKUN4dDgEDra29FJK0J5HrOOcXzhpGtCiCKeWkIsTOjGIDo2BnFUW42Ni1Wqq6FhYXNWR5rLzvmbyCrjKpvNA+uYF719TvT3u/hwU0XbzcQZGE8HEqnMmpPN8VWSGbExH55TzGVf9HeXBwI+Jp6lcLL3zGnUvfA8whKTkE5F4/jiEkRmzMyZxO32YczmxfnKcRw6ZqVqsJHuC2aUl5BwTWe+5TyW8OfZJKqsXXS6OH9+GIcP91MlKgGbN8XR4cWo59z+BNqP6xodsaGrox+njtbjwvkWFQMqLMlA6aps5czjx00tu1XxNqnyR53MGbV4rah3j2CcY3dmm1X+KD84CglBIbAY5qeYeyaAayLrTNDSy2oEAgcBmYdIMd3B/QdRc6FGxfMlb3DDzTciNCyUrgmzdHXgQN/HYGP9Sy+i8+hhmELDkFC+Cjm33cbYfxiFInxoaLKjrsGByhobigtCcP3WKISFGpRDb+AgpHuyXBFoaWnBli1b1O6Lg0p4+IeJ1kJwzcycmE8I2VRUUC/XZrOer33ta3juuefwyCOP4Nvf/vZHVvuP//iP+OlPf8pir7V45ZVX1Oei1Cr34u9973soLy/Hq6++qsiuVyKyCnn1xz/+MXJycpS7ixBZpRlJNBeVVhG5kP2TGMbFJjkEphnBoR96RoHuYRamjpCs6uD7zCcEB9FNmor8RqbJjByaSNpxrKcGrSeeQFr5XYjJnB8ia2kasDIjMOO6msh68ey5wrMmsl4BGD++LRexXLiNzQ4cPTmGAVaPS7J73apw5OVYVGDDTDIrCey6TRMBK63/KklOuMCHKLOuX2nBulJaS7ESn6ICyy6RKjeFinagqoOkjU4vthcasKUgCFFamXWaZ1TgLiZWMSM+J064+vCms12psRYyCFEaTDIr1XAkEBGYt9/AxVT3bHoIaCLr9HDSS2kEljoCUj1pG7fh2aeeQXVlNYrLilG+ZhVWr1vzIZXUueyn1+Ol5akTZ040KDXWjOwEbiNXWcolJEV/ZNUSyPKyX81vvI6z//ZLpGzegtRNm5G0Zi1CExM/svzkN1TC2+5Fe7cXB47bVNFTeBjHRWtCUJRLs7V5uGnKuN5q9aC+3ko7116VQEtPD8WaNTGszA2b3D39+hpGQIKsQrYYHHSpIsaqC+NUEHDDTOXVTRuiqcYaGpBJbA/PX6/PADcDShQVnnjmex4v3yOBVeax8iz2P3Zaejm50L5nfoTwyDjc+sm/VC4QJgaiZD9NnM8KsdUU7J0oMJyH6+0aPoX0ri0yAhdjr/sO21BR50I4EyR5mSZsKLewAIIKysu0HqHZM0rL0iG85+xBBgmsnwnNRzjdQiRBrptGQCMwNwQkueWiEpFYdzpsdo4jbBig1V9vTw9amlvQxuRYW0srgpnliaAlYcGKFSgoLEA+HwlJSVT8j5pbB/z8bX8TWS/t3jhVXAY4zqq6MIZ6FgwNDLgRxnG+jLEyMyxIS7EwgRjMsTjHIlo04lL49N+XICBzTredBLtjx9B94jh6T59SSmBlX3oIwSYzgoQpPc0mY4hRzgdFwORsxTiOnx7DLTujsJ5ODNFRck4u00HENPGbyWKCtZuTkxMnhvDCC+10P4mimlQMsrPDtQvKTIBc4GUlP3r8UI16jI6MIzk1BlLYnJwaSyKULo7yx+EYYv6ozjWM0+5+VFKdtSg4GkUmKkIHRyIuyEK3P8bD/LGhWa5DE1lnCZz+mkYgABAQJ7fa6hqcPXUW7+x5G2kZ6bjtL25DZnYW5yQTbhBXsk2/Wvf7Ks6j59RJdLx3EFFUtyxjwXxoPNVejSbYWLxSXWfHK28MITXZzHFVGIuELEoo4Grr1Z9rBOYbASEgPvDAAyp/1tnZqZRZJ29TCJ8ZGRlwOp3413/9V6WEOvnzi69nup57770Xu3btopjKOfzt3/4tvvGNb1xc1QfPv/zlL/Hd735Xbf/48ePkpHlRUVGBO+64QxFR9+zZg9zcXKUkeyUi61/91V/h+eef/2CdiczJSfxCHF6kmc1mRZItKS1TuQSH24AxB8UdKb7XN+pD13AQOoZ8iszqYG5BCKwxTJNFhfoQGz7hLB3JWOtQVzWO7nkCa7bfhZyi9R9sz58vkqN8SI1ZzFHQlfdGE1mvjI36RBNZrwKQnz6WSfY4q3IHh9yoZQVJXQPtT/h3Iqtzt2yIQFKCCZEROqgxXbj5WwkrA5h1LW6cqnTyRuBVyaXr1ocgm/Z/JqUMNN21Lf3lpJKBbr0ks/pwoMaLyNAgpNNVZ1OeAWmxS3//lvMeeGkRIzYx3R4bGj0jOOseQJ/Xjk3GJJTQzjHDGAFqTixniPS+zxMCmsg6T8Dq1WoEAgyBkZERdLZ34pkn/gs9VGO974HPoJQWpTFUeJptEOrSXbTRPq65sRvnTjXi2MFqbNlRght3rVXqG2bL5W2bJbHYX1Wp7IWGGhsQxIqv0ge+gDiq40zFRiVnFjWNLtQ2uVFV70BGqhHb1rJwLCZ43sbaQl48e3YEtbUjVIexo7g4ilatsUykmaiKpSvVLj0frsW/JTEnNqJNtBE9e95KIooXUZFGKoRZ+AhFLIvtwsOCSaoQ9dLAQYB8Vdjo6DDC/o7YGTxisaDY+qjH+6/HWDU97mSAShFUfYqs6jj9IzJW4+DO+zIJr0AkCwnjwn1IYVAoPdaAjDgD3/Mh3BJAOxs4sOueBDACErfp6GFhAtW8j5xxIIZuOjduCUFyAu8h4cszXrPP2YEK1yBCWEBZYIzGFlOSLqYM4HNYd23pICDJpDGrFX29fWisr0djQwMfjRjl2JyyJiT3pCIpORkpqcmIi09QyqthVHlRD1E/YuLIOAOi3UIgM99EVlG8FAKbKLSOjLjR0+NCeycd0Gg5KuMrGXuVUv1SFFpF/d7IsYtuGoErIeAmcdw+QMLXH3+Pwbo6pGzchOR169XDIPJA0xy0y9hBHBla2l3Yd2CUCV4f8z3BSok1J8vC81DUhvS5eKXjMNP3J1SfDGhqGieZdUD9Fsi1fsMNibqIdKZgLvDyg/2jLM7ow7t7zmF4aIxF1JkoW52jCpwXuCvX5OZEDMXGLFI7Xf1aPFZUsRDN6nMh1xiJkuAYlBvjEGwIYjHa4jRNZF0c3PVWNQL+QEDuvaLM2t7Whvf2v6cK7axjY4rMuvX6bWpeIlbjs2kOzn2G62px9je/hpHqrivuux+x+QUIIWmO0yV0cbx/6tw4enpdimNz43WRKC0S0Qgfh2p6fDUbzPV3/IPAH//4R3zzm9+kU0o0ampqLktkzcvLo/iJFf/8z/+Mz372s5fd8EzXI+TZkpISRSj9wQ9+gC996UsfWe/vfvc7/P3f/z2EfCqEV7vdzrHyDRw/N+GHP/whHnzwQfWdl19+GZcjssq1dfvtt+PMmTMoKyvDr3/9a+Tk5Kjv7Nu3D1//+tfV9oUM+/Y776LXGoS6Lh/qe33oGBRxDCBk8F2Mt+z/MHtl0iV78WVSciq6Ottx6+13YdWa+SGymoJ9FOK4uMWPwLWob2gi61Xg10TWqwA0Dx83t9FqssmBesqiCwEzPdWCrAxaIWWaKYsepGXRZ4B5D63/6ls8qGlyopeV+KUFYv9nJmkhGCGswF9u45iWfh/OtgKtLIgYd/iwtTAIBUlAfIRIds8AWL1owCFg97kxxschV7cKREQazMgKisAqE23kWFUrqji6aQT8iYAmsvoTTb0ujUDgIlBbXYszp06j6lwlk+FGfOaB+5GVk62qM/3Raw9nrgN9Izj4dgU62voh6qybthdj47biq47T7FSkGm1tUTaPwySzFt//WaqyrlOqrIbLBMhsdpLwrF4cP+dAW5eHCpFAcb4ZG8uZ6Kct9HyMCyWJ3tVlU4owg4NOBggsDCZEcpIfpeDTQTV/nEWBuQ5JWoua6fCwG320uW1rs5PM6lSFi5ERwYrAmkv3jfQ0C5gvWnTHCHaXQbUJZdUR2/uE1fEJkqqNRFUXFVgdVJV1skpaPbisk4QRUWYV1WGZW1mMVF5lorhl/2MIColDZPmX1bJSVS1BoVA6igl5NZyiOtFUSItmlXU0HSLkdQTfE06AzuMH5vmse/XfCNg5j+7u82DfERtVlX3IZEFEcb4J+Vkmdf7Ox73kv7ceOK8cPg/sTIa/Ym9BrXsYm8xJKGYhZVZwBLQnSOAcJ92TpYGAJH9FvURcEEZGhkngGaJFpzwG1WN4eBgjwyOwjlrVeDwiIgKZVCTKyMrkcyYLzGIRGWDqq5dDfr6JrJO3KaTW4WESdjrEctSOIY7HbDY34mLp1kWxiNRkcUAzTajh07tQxiC6aQQmIzBEAnn/+XNo3f82hClReO99iCsqRmhCwuTFrvpazsXWdjrG8Tw8W2FDagrV3NeEIyXJpNRYr7oCvcCsEBgacqGzw4bjJwbR2WnHTTclYcWKSERwHqaJw7OCdN6/JLEgK5VYDr1TiYbaToyPswi4LIuxoSJERYchRCaTus0ZgTGSVwe9dPdz9qLFO8bRvBfJQaHIocNfelAYEoNDVFHaQrsraCLrnA+tXoFGYNERGB0ZVcqsp46fwrEjR7FuwzqsWb+WrhGFShAjaDYDbs6TrJ0dLCz6A2x9vYjOzVMK+VJcJG2MgmYdXXR54xjrXOU4rt8cgfKyMMTGGJUz1KKDojuwbBF46aWX8MgjjygidxtJ3uJ6OLlJTiiVxanSHn/8caWiOvnzi69nup7bbrsN27dvRwMLYb/1rW/h0UcfvbiqD55//OMf40c/+hHFVorxzjvvKOLp008/jVtuuQV/+tOfWDcrWQJAtn2RyHr48GH1/sXPhPQq6qtCmg0NZXB/Utv92mt4+MtfVu/sfv1NNLtLMcQcwyjzDSK8J2L75pFzGO8+Bwvzcybm5a7EUQqhzbaQbe+66y6sXz8/RNZJXQ+4l5rIepVDoomsVwFoHj6WylxJtAuRtaqaie8zYyjIC8GW9REktFp4A55d5co8dDXgVykVOW7ieeK8E6cvODA84kVWmhG7rgtDTFQQSQsBvwt+7aCLwTOHx4DXzxGTJh/yEg0oTTdgbZYklgOz2sCvAFzDK5NhhQwgerw2NHhH8bqjDXRxxQ5LGgpoEZPJhKJuGgF/IqCJrP5EU69LIxC4COx9Yw9eevZFZOdmo6ikGJu2bUZ8QrzfOmwnQ661uRdP/m4fgjlj3XXXemTnJSMxmdLxV2miyupj0v/84/+OjoMHkLR2HVI2bEQyH8EWzogvaV29HjS2sejjNIvFaIN+x45Q5GbQ9YB2JfNFPKquHrU02IAAAEAASURBVKU1ywjqakcZtDPjttuSkZQUopVYLzk21+KfMqdzkPBWVT2GYydG0dfnovWvAVs2RiqL22TaXolLRDCDNYHQRH1VlFW7h4H6Hh+qO4HaLi+cnDtIMCmO10ksVVXjwidex0fy7zASUUlCjaLFepBB1A64JxyP/uxfHuP5HofPf+F/MEDlQ5+V66VdUOuAD839QFMfBVtJeo2PmJiLFCaDxXUGkmBpJbTM5meBcOx1H2aGgMRzxxl8raMqa0UtLYKrnbhhUyhu2BzCa5oFogFyTc9sr2a+9CDtSbs843iT884eOoLcH5KHIhJZjfwhkP900whoBKaPgKivigpKV0cnk7/VqDx3HtVVF6go2sPfFKodM/m7oriIj2Kk035QxuKitiqfyUOSwkuhOGohiazyWz1BEGayjLHQdhIJG5psOHtujLFhNxITjFi1MgJr10Qq0Qht7T7983VZLMkTqHH3K6h97lmEUakolgTWnNvuQFhSEgvQps96lvNQbG/37B9FfaMdEeF0ESkKxaZ14Wq8MF9z0GVxjK6yk1Jo56FC8+7XunH69BDWrotFcVEkcnLC6IIx/WN4lc3oj/2MgBQ6ixprxZkmvPD0e7SnjseW60qRX5RKJXJtK+gPuPmzBM/76qzN7lEccHWhg2P6MbhxgykVG1mcFmMw0W1hYUVRNJHVH0dXr0MjsLgIyNhbyHpnT53BW6+9iYH+AbqthePez97HnEKRmrfMpoeiytp9/Bi6TxxHz8kTKPzUvVjx6fvUquR+LzyQw8etePu9UWSlm1GQG4Ky4lBdMDQbsPV3/IbAoUOHcM8996j1NTc3c/xJxuakJi6IQiSV9uKLL2LDhg2TPv3vl7NZzyc/+UkcOXIEX/va15Ty6n+vbeKVEFx/+9vf4rrrrlMk2oKCAvXB2rVrmbdK+mDxzs5OugyeVUTVHTt2qPd/8pOfICbmynk7Nf9xerAiP5vXphf/519+in1jn0IBY/8laQasSDEgkfouZgpeiLCM5BOkyOxKUcRqxkeeeOIJTWT94Khc/oXBZmOkehk2TWRdnIMu5MshqRzvdKKmzo5RqkdJMrQgz4JcWiClJBkRYtGT7ukenU7a/zV3uFFZ5yJxwYeMlGAU5phQQNUUA9l+QcskciQ/YjKoq+rw4UKnDy1MJMcy+bylwECrT3k9XUT1coGKgI2qrP1eB065+pRVjJV/l5piaQ8Ti/igEIQtcBAiUHHS/Zo7AprIOncM9Ro0AoGMgCTTRfnprd1v4LWXd+P2O+9gAmEbUtNTP1JlOZf9qK1qp9prMy5UtKrExK471yM2PnJGahvtJLFKQGuksRGxK1YomyELbVuC3g8QyNhvnEViFTUunKxw0MIdSE82Yk2JBXExQYpMOJd9uNx3x8bdGBxw0WJlCLUksaakkDSbG47S0iiEM4GpVWAuh9q18Z4EUUUBrKvHifoGm1JgHR/3KAvb5CQzsjMtiI+n00aYkE4WZ58lqMRuYtQODIyRaDriQ7/VgEGqSzrcBkX8kL4JgTWMxW5hFL+RordQk08pqoaSJy7vyUMIqRba70xWUv2nf/onZXH88MN/qbYjiq6i8jpkAwbHZJtUTeA1Ke9zaqLmYmYSWGU+kh7LeUk0lEKrbH+xMFqcI6O3ulQQECGFoVEvLtQ7cfCkXd1TVHwh24R43leWQ6umHekhZ49SZQ2HETeygDI9OPyKweflgIneR43AdBGQhI6oq/ZTVairswvdfPT29tKS08qYnYf3xSAWvxhhofpIVHSUSiYlJicjITFBWROGhoUtCeLqpXgsJJH10m2PjHqoGOOiQqtDWY8ODbvUGMNiCebYLIQK+WYkJZK4E0JN6UUan13aZ/334iDgpALycHMT2t7eh47Dh5B5081I37oN0Xl5MIbOLHAudreixnqWCmEOhxerqRCWm2VBWioH0brNOwJCqDl9ehiVlcMYH/OwECAU11+fSFKN8UNzl3nviN7AtBGQY+ai/Ye49Zw6WscCjwHeG+3YtrMMJeVZiIgKJRFkYQmW0+78ElvQTTLrCNVZmzyjaPVY0Up1VlFhjSCJtcAYpZz+UqjUahT7mAVomsi6ACDrTWgEFgiBnu5uNNQ14Njho2hraUXZqnKUlZdh5epyOg5/VHjiat3yOBwY7+lG+4EDqH76SWRxbJZ3513Kkc0cEam+3tTqRGX1OMf6LrrIGXDD9iikMPYfGrIwv2FX2wf9+fJDoKWlBVu2bFE7fjmi6rFjx/CJT3xCzesrKiquSA6dzXqEwPrcc88pZdZnnnlGxfkvHgEpgv3Upz4Fye9/maqpf/d3f4fCwsKLH1/1+cSJE6qvQnI1m+kMTKcYF4vHHCwe7RkB2gYMyEmgI/TqLOU685vfPg5n0q1IJnk1mfH+xKiJPMOEIMbVJ96ayLr3qsdEFtBE1s99blpA6YX8i4DN7kX/gBvHT4/jCJV8RJE1nxaUK0vCaIcUDIt58RKg/t3T+V+blYnZo2ccqG12oW/Qg9XFZmxda0EEk8iWZaZGanP60EW1pZdOM6lMXMoyJtSQ8lloIUnoyYno+T8yegv+RsBFSsCgkFmd/XjN2YpsKrKuNsVhRXA0koNDafUoYQndNAJzQ0ATWeeGn/62RiDQERgcGERddS0OvnsQxxl4evir/wM7b76BBUCskPRDdlds40RtY+9rp3HuVAPVGyOwoiwDm7YXM4E8s8Seva8PfZUVOP/bX8MSE4tVX3kEkZlZMNNiVQh7I2NetHd5qNDvwOkqB27dHop1ZRalzm8mAc+fTbYnxWc9PXbU1Fhx4cIIlTidtIdJQllZtFJi1SRWfyIeOOuSY+9yeWlb60VrG+cc9TacOW8lcToIuTmhWL0yXD1TOM0v19BM91ypFPgMVFhlP/mwUS1WlFLbBieK2zqHSGTltRLKayIrIQiFyT7I3CCJLhbhFu7cDNpFIutf/uVfXvZbQqKVuUhLH4vrurh9KrR2j3C78SzcTJ6ozpYAVzjj20JwFZVWP/zsXLYv+k2NwFwQaGpz4dg5J/qHvOoc3bkpBHmZRlUgca2es9RCp4qTD4ddPXjW3og1xniUm+KZ8I5ElGFm9++5YK+/qxFYSgh46CAg5FWX08mxggt2mx29TMY2NzUzyVuPxvoGWmB3MBFkQlZONpVXS5QTQk5eLuLi45V6kT/G34uN2WISWWXfZawm46EeFhtVXhjHhZpxNLXYKRoRioJ8PvgcF2dSCW8R3dRj9sU+YxZ2+0KgE/WHIdpwtr2zD0N1tbD196PsS19WFraixDrd61DOMzeTuUJgPXPeRiV3WncnmXDTdVEsbjPqce0CHtreXgcaG8fwztu9iIwyUc0pVRUVCmldt8BFwG5zsDDYinffOseY0Slsv2El1mzMR05BKiIiQlRcKnB7v7R6Jr9r7W4rakloPcYitQ4SWleYYlAcHINSui2EUxRF1Fklm+Tf6NmHcdJE1g/jof/SCCxlBGRMJY83KY5x+OAhFpOMo7BoBf7iEx/j3CaOcf+Qme8e19f+3kGc/dXPEZWTh9TNm5UzW0RaulqXcGlEHO6VN4bQ3evCTddHkUsTolwYrtXYzMxB1N9YSASEMLp9+3bU19fjC1/4AiRWLjEBaXLv/eY3v4k//OEPWLduHV555ZUPkU0n93M263nppZfwyCOPKKLp4cOHKbCS8sEq+zm/WbVqldreU089pfoo8/TLNVGD/cEPfqCIq3/84x9Vv0W1dd++fXjggQdUnOIc3WR85mgMUSijthuoaAfWhryLz332frXKffsPISc7GyYOvWWOPdOmiayayDrlOaMVWaeEZ94/ZKwTDmYbe/s8aGmjqk8T1bFG3UhLsSh11pWURxfrOn0jvvqhENWU/iEPGlrdOEE1LrHyTIwLxrpSVgykTQSRlguO5I1gzAGlylrTJbahPqzONmAblVmjQ0Vx6ep46iUCFwFJLjpZVStWjzWeYdQzENHD11vMySoAkcxqWrNBB+wC9wgujZ5pIuvSOE66lxqB2SJQX1uPV154GbbxcUTHRJPEeiOKS4vVhHW265z8PeuoDX09w3jr1ZNoqu/CzbevQzEVNpIoyRgsMowzaG6qx1rb2lDzzFOwDw4iOjcPaVu2In71WtipfNPU5sb+Y3YW6hiQEBuE8iIzMlONIFfA7wlqITIOU+GpqmqEla0DVNCipVFBJCtbI5CQYFb7tlzGmzM4hEt+UZWs5rytiXO12job2jrscDq9SEsLQQYVvtLTSJyONio1XtIo/HYdzQQ4CtkoxdVWVka3DfjQMQg4mWC38DqIoUNDDAWmYsMNoMgNmBtEJB8RJLCaKXhj4nxzJu1qRFbhCdhdJNPyMcyiuqFxUWo1kNw6Qa6lCA/7Aqyg7VB2PFVa4ybmu7rYbiZHQS+7EAhIsWzvgAdHzzpQ0+jCxlVmFOeZkEYHHX8XSizE/kxnG+IA0uu145irF2852nFnSBa2mpIRSfUmk2Fm9+/pbE8voxG4FhAYpW3gwMCAIqy2NDaRwNqkEroy5o2Ni0d8QrwirMYysRsTG4vISBLDqcQaFh6ukk+SvLoW2mITWQVDSarbmegWhdbePpcitYob2vCIWzmfZVE5v7QoDLGxpvfHbdcC8nofpoOAl4kDUWPtOnYEF574T0RmZSONyeeEleWISM+Y0fjdyuKwrm4XTp0bQ1WNDetWR6C40IIMKrGGaGWw6RwOvy0jSrg93Xbs2UsVeZsHRcWRyM+PoHrUzNR1/dYhvaJpISAFIC7mRGur2nD+dBM62/sRGhaCm25fg4xsUdWdBQlqWlte2gsFs2r2u9/9rho7CEHmImFm8l4JeaanpwdCbJH7cjeVE/Pz87Fy5Upsvf0W7BtvRbPXytySR6mzllMcZVNoCk6+dwT79+9X3xUCzLZt27CCjkhiI+6Ppoms/kBRr0MjEDgIyJi7o71DiWS8u28/fytczCuUYM36tSguK5lVR4fq6tDKYqOR5ia4bTaUfO4BJK5Zq8ZownlwcIx/+IQVjc0OvgcUFYRi68aIWZHnZtVB/SWNwCUI/Mu//At++MMfqnP02WefxXXXXafmo2+//TYefPBBOjY48Nhjj+Hzn/+8+mYb81s///nP1etHH30UmZmZ6vVM1+NkAW1paSnGmdfbuXMnnnzySV4HQeqeLaTaPXv2ID09HUJUNdIJ5krtzTffxBe/+EXk5OSoZeW6librlTGAjDPuuecefP+ffobnTzK/wFj+usROfPb+TysC72YSzv/01AsUzWDxP78n1+VMmyayaiLrlOeMJrJOCc+CfSiJ0HEmSY6fsbJa3AmpLklLYZKkMERV9MZEUWNR2Oyz+RVYsL1Y/A3Jb2xXrxtnLrjQ1uVWdoCiyLUix6hIrZJsWi4QuqkWNmI3oKrdhz2VPiXnXZhiQDELM5KjfVQ+mt8qy8U/G679HtgZcBjxOXGY1bSnnH1ICaaFFZVyVhrjEBtkRiiraXXTCMwWAU1knS1y+nsagcBGQCagY9YxnDtzFk/98UlkZmcqJVZRhEpMSvRL52U81tzQpRISDbUdcJP8eec9W5BbmMrJ8/SVbiZ3RpKO7e8dQN+5sxhkYCvntjuQdtPtaB8IRl2Lj2M/J3IyjNi0yoKk+GBERfifEOCmjYrV6kF1zSjq6qxobh7HurUx2LBBCAkm2if5f5uTMdCvFx4BOZftdg/JDxNkiNZWB1pa7fBQhSk21ohVKyNoHWqhk8bCjrlE8VQeUrg2avPx2YABVkYPWH0ksxoUcXSE74eQxCqWPhmxE2RRUUGNoArqdO19roT41Yisl37PwdyXzQnUsLiuoReKZCv9jw/3ITXGgBRaD8VHkGzLgFgYC+5myHW/dHP6b42A3xCQ3wCZVx+h88tJFstGhgepItl1pRZ1nxEF5mut9dP544yrHw2eEbR5xvAXlkxsNCfOs0bTtYai3p9rGQFFvqHqqpBXJx6jGKDqST8dBPr7Jp4H+gcUyUQUiXLy8vjIRRZVSqJjYmC2mFWi61rEKBCIrJNxFULrKMfuVRfGmPC2KRWnKFqOp6SYkMqYe1KimeozJkVwvUa4xJN3X7+ejABv6M4xK3rPnEH38WPoOnoE6Tt2ovBT98BMYrkxhJVe02hS3OZy+dDZzdxDxRjJ0m5VWLljayTJFCG87mWuO40V6UX8ioDVSrfD44NoaRlTRPY1a2Kxdm30+7EHv25Kr8zPCIgqa1f7AN556wz6uodRvjYXxSuzkLciTRUJa+XsDwMudr933XUXi6gTcP78+Y8QWYXEevDgQaWiZmdB+KVNlON++et/w7sWxtd84xjyOPCF8BX43qP/N0Td7dJ233334Wc/+5lfyKyayHopuvpvjcDSR0DmRTIP2vvGXtTX1ql8w8Ytm7B5+xYW78XQtWx646uLSDiGhjDa2oKGV15CN3/vyr70ENK2bleObEEk48k4rLnVidoGO85WjCMz3YIbr4tEZEQwt6Vj8hdx1M8Lh4CNhOt7771XFY7IVqUQRBSJT548qe6dd999N37xi198oMZ6/PhxfPzjH1cdfOGFF7Bx40b1eqbrkS/JfVvIsJLri46O5th3LYVXqlQBi8ViwauvvoqSkqlJ5Zcjsor4xDhj+L//9QRJV7YlpNj169fTpc6mCK9Wq5V5MAtefvllOhSWySKzbprIqomsU548msg6JTwL9qEkSOQmLBW9bR1OHD1pxcCgm9alwPUMhqwqC+OPgkGRDxesU0t0Q04GlOxM6oq97LFzdmUZlZ1mwrZ1TDLHBDFxu0R3bIbdVucUz6uekQllVpH7bu334ePrgrA6i6qsJh+TxMsEjBlit1QWF2VWFqKhw82gvHcUB51dcFOpdYc5DYXGKKQHkw2gm0ZglghoIussgdNf0wgEOAJid9rU0IRTx0/ijVdfx+ZtW/DZL3yWk+xQGE1zJ+NNjGm9OHKgCs/95wEUlKSjtDwbpauyEZcQOevEvVdsWgcH0LJ3D84x8J5FImvSrntwsCYSPdYQxHOMV1powqoisxovi6OBv9vYmBttrTa8/kY3iU1elJdHo7AggtWzYSphqZMs/kZ88dcnCry9/S7U1Npw+OiwUvhNoCVteVk4cnJCEUFSm8kUxCSp/8+3qfaenGo4XAaSQr2o6waqOydUTylqg9wEg1I5zaLSaXykEFcNSnXVSMIdeeRqLjTXBPtMiaxe/jD4fAYIoVWUWvtGqW7b66Md0QTxVoiC63N4DacDOQnaPWKqY68/W3gE5L7WRaJKc7sH7x63KSXWv9gZhvRkI8JCF/ban++9566iyT2KFxxNCKb66orgaJTQcjQrOGK+N63XrxFYMghI8maESdYLlRf4qERlRQX/Hia5zYW8gnw+CpDPR1JKslJhFeKqyWTibweV+3kzFpLJtdoCjcg6MS/xUQmHxT6DLhYjUV27bhwVVVYmvkOQnxuK8pXhFJAwawLitXpSvr9fPiZYxqlKeO53v8VoWyviioqVw0fyho0UDuEgeZrXpYxZh2lrW3GBc8K9QyjIDcGm9VLYZkZ0lOQcrt3rO5BPEZmz9fU5cfbsEPa81YMtW+Nx663JSh1X5mq6BS4CHsZVHJwgnj5eh8qzLWht6iGRNRN33bsVlhC5f16DVWMzPByisCZKrDU1Ncq6WCyMr0RkFXLrnXfeSfcYJ/JYSCNkGSGaPPPMM0o5TTZ9xx134Bf8Lax3DqLVO44jP/x3RbKRz3bt2sXrZ6sa2zz//POKhPPwww/j+9///kdIs7L8TJomss4ELb2sRmDpICC/N4P9gzh2+Cief+Y55OTmYM2GtVi3YR3SMhjkm0GT8ZqH67vwxH+gcferyLrpZqRs3IQ4Kk+awiZy3aLE3tLuwu63Bjm/YhyxKJRjegvSORbTTSOwGAiMsMD1gQceYFHV8Q82bzabceONN+JXv/qVKnC9+IEQXOU+Le2VV15R5NOLn81kPRe/I0qs3/rWtzA2NnbxLWRkZCj19ttvv/2D9670Yu/evarvotx+4MABxVMbpKtaQ49XCVH0Hv83/H8/+ymGGP+Y3IS8KvsmY425Nk1k3TstCA0MREnMdtk1TWQNrENO4rxS/GlstqO5zYnWdidiY4KRmmxGYb4FCXGSLJHAZ2D1O5B6I4FKebR0ulHbRLJG+wQhuCjXhFwqdWWnG5cVfmMM2A7yHnaiyYfzbQZkxvlQkBKEsjQoa1F9LgXS2Tu7vox5XRikMutx2j+2eXmwef4LkXWVMR7RVGYN08qsswN2mX9LE1mX+Qmgd/+aRcA6asXbe/ahmsl3Byt/Nm7dhFtuv1Xtrz8S6+OUiOykooYkIg7uO48dt6zCxm1FtFSNQkjoHIJKHNxJMKuLCjrVTz4BW0IRbBmb0e5KQxirvFeXmJGVGoyUxLmTcS89+FJs5mHSsqJiBHW1VvT0OpCYaGHVbCzi4y1UY/X/Ni/tg/574RCYmEvQTpx2tB2dDrRyTibkB1FfSkwwIYMV/1mZJE9zXibk5YUYS/MUhIskVVFZ7WWRWg+JoH2jBqqckpzh5vnJOWQIT8MIWpkm0XkhmSqsiSSxhlN91RTsYx/9O3mcKZF18tGTfbE5aXc44kXrgAFdwz70WUmw5QBW+psYaUA6FWQz4g2q8C6Ejhq6aQQWGwFxzBkY9uLdY3b0D9E9hyTW4jwTiviQM9TPl9ii7C4vTQxQjbXGPYQ3HG2qKPIWSzrig0NBrbpF6ZPeqEZgsREQaz2ng8nZgQH0U22ou7MTfb19SnlIkrZuklfdbg/tkFncEhmB1LQ0pKSmqueo6Ci+v7ysrQONyDr5/BGFfRGMaKd4hKiz2mhBLjH4KI7jRZk1M8PMcb1ZKTpN/p5+fW0gMNzQgP7K86ooMpikrtw7PoaYwkJEpDI4Ps0mJFar1Ysz58eYs3FghGNZIU+sXxNOEQ0WjlGNVbfFQUDmb3KNX7gwirfe6qbqcgiKiiORnxehruvF6ZXe6nQRkHhLV8cAGmo6ceRgFQnIZuQXpaGEyqyZOUlqnO3v+ex0+7bYywmJVayJhcTa3Nz8QXeuRGT9h3/4B/zrv/4rhJAiSm0xVIK/2H70ox/hxz/+sfrz3XffRWJeFovFh7Fp3QZFfH3ooYdQ+v88xDxSMDKCInDyd8/iO9/5jlpeiDcpKbR5nEPTRNY5gKe/qhEIYARkvuR2udFQV49DBw/x97xT2alff8MO/o6XKuK9yUy7qBm01rf3oW3/O/ByvhWZk4PCuz+FkPh4FduUe/7AkBunzo4pUbiRUQ+2boxAeWmYIrZql4UZAK0X9SsCA4wZiHK6KLKK0qo8z6bNdD2ijFzJAtumpiaKrpQjh9fMTJuITlgp5N5MMbyOQaB7hNe118DV+FCabEfQSDUJ692Ij6WoS2EB82KJM93EFZfXRFZNZL3iySEfaCLrlPAs2odyM26iRLrIo1+gApDN5sXO7VFYUWBBYrwRJmXLumjdWxIblkmwze7DnkN21JDQKuKjq4stuG6DhapJYlkpP8LLp13oBM60AnVdXkTy/nnX2iCkMUls0Tmpa+IkECXWXq8d59z9eMXegkxjJLaZU5AXHImkoBBlBbm8zvhr4rAu6k5oIuuiwq83rhGYFwQmLH8G8Ltf/RY9Xd3YcdMNKFu1EvmF+X7ZngSv+igFL8mH1sYeDPSNYNddG0hkLfbL+mUlQ5yUdxw+gqMXDKjojkHiijyqvaZgx+YwZfPstw1NWpHD4YFt3IPdr3Wp5FhZWRRKSqNQXBSp1DgnLapfLnEEJkjLJI1S1edc5RjO0zJUyA7RUUZs2xyD3JwQpbi0ELsp80H+D0VipZLpKANKbQM+VHX4UNNtoNMCkMq8VE6CD2XpBogCa3rswhBr50JkvRS73lEfCa3AkXqgsYfKrVygJM2ATfxZSo4CYsMMnLfJt/xPyL20L/pvjcBUCNhZIFpVT3WQeqo0M76wbqUFt24LUfeBiXN0qm8H/mduXmM17mFUeYZwztWPlcY43BOSq4i6gd973UONgP8QEGu+iw+X0wXr6CjqmZitoU1fxbnzaG9tJbF1ECtKilFSVoqVq1chJy8X6VQ+Wa5Em4voBzKR9WIfXZS1l+Kk00x+nztvRRPHeTExJqxZFUGnhTBkpFE5l84OC1WsdLFf+nmeEOCA2sdruunN19H+7n64rGOIo8Vm8Wc+C0ssg+IzaGOcD3b3uPHyG4MkTfqwYW04CvMsytZ2BqvRi84jAm1tNlq5DrHwwKEUpXbuTCKhT9xTdER8HmH326p7uoZw8O3zaKzrQk/nIO64exM2XVcMCwlQQdfCYHsWSEmMTex8L22XI7LKeS4WxkeOHFHqbGI3PLmJWlshCfzShFT6yU9+Ei+++CK++tWvKuX41yqO4Wm0osdjQ4kpFh8LycbHVm5SKmyi9vZVrm8uV5Imsk4+Gvq1RuDaQ8But7Pgx4rnn34Wb+1+E1uv344Nmzdg1drVCI8I59h6+gU/Vqrn99H1ovbZZxBsCcG6/+tvEJWZhSC6XEhzOL1KEO7oiTG88sYQbr85Gts3R7BALVgXFl17p5beo3lEQOVB6KAmYnjtgz68Vzfh7CyCGWuzDdicb0ASY/PCKZqvpomsmsg65bmliaxTwrOoH1rHvOin+k9DI5WAWDE+avUgiSpA5aWhyvYoNlpba0x1gCT566ZCUVu3G41tHpyvcSI8NIiKrMEoyTfTCnB54TdEOXBRPDpc50M/VY8yqXJUkmrAyoxrQ0FmqnNhOXzmZeLR7vWgi5Ywle5BKrOOo4+Bh83mJJQaY5FAMquFFbW6aQSmi4Amsk4XKb2cRmDpINBN8mp9bR1ee/k1lcz59Gc/jey8HCqKUrpxjk0C7KLGKkmHV58/glCqr65an4fConSkZdIr3E+ts3UIlac7cP7cMJUyx7G21IzyVQkoXJeL0Aj/zqplLCmW6E2NYzh9agiDQyyMYmJ7/TraLGeFMeltJo5+2jG9mkVHQFSWxse9aG6xoerCOEZZ1e8hizQ1xaLIqxlpVN8loTWM84mFaA6SV8cdrIbu4znIimjm9eB0G1iE5kM0yZ1RoUAcnbXiIgyICfMhwmJAGBVNF6L5k8hqJ5lkXCm0+tA9DHRyP8XGaJQEgQzyC3ISg5Cf5COhFTAb9QW3EMdXb+PyCEggd4h2wrXNbhw8aUd8dBCKGVfIy6SaX/zSnmcJgdzhc+M1KrE2ekaRGBTKOWQM1pn8d/++PKr6XY1AYCEgxNXR0RF0dXahubGRjyb09vTQ9ckHM1Uco6KiEB0Tjdi4OPWIe/9Z1FjDwifsLgNrjxa2N0uByCrjexnfDQy4aEXuVur7Pb2ivu/mnChYqbMWFYYhhc5oIVTZFEKrbksXASetPse6utDw8ovoOXUSGTfcqCxqY1cUwThNlSQ5Z6SdrWS89YKNYwE3EuJN2LguXOVpFmpuMNEL/e9UCFiZO+vuseP4sQFUVY3g1ltTIEWoERFGiproa3kq7ALhMxsnv90ksJ4/1cji6GrGqpKwojSDxdc5iE8ki2KZtr6+PlVgI7v/zDPP4Hvf+55SODx//vwH71+EJjc3Vykh/vnPf8bWrVsvvq2eRUk+JydHvf7pT3+Ke++9Fz/5yU/w2GOPYceOHfiHP/0bOr02dNDtr89jx4jPher/+VPs3r2b19Kt+PnvfoPwoJmpKk7ugCayTkZDv9YIXHsIiHiGi24VVecrce70WdTV1CnHiptvu0UV/cUnsPp+ms01ZsUYlV0r/vA4HIODyKFFenzZSkTn5qk1iKuCkFmrqm04eNRKR4UguhqbsHbVxNhsmpvRi2kEli0CMr+RKU4fHd8ae32o7zFQidWLcM5/4yNEKEPEMybc3kKYhzDN4zhaE1k1kXXKC1ETWaeEJyA+7OhyKnXWk6fHlCJPFu2OcrNpaZluRng4K0y03eKUx0mS0l29Hhw65UDfIAdTTApvoHqKWAHKAMe0jBRJRR78WCNwoYMkaZJZi0lkvW6FgTaktCOd/Tx0Svz1hwuLgN1HuzQqsx5z9eI9ZzfyjVRyZhJyRXA04oIsCNFk1oU9IEt4a5rIuoQPnu66RuAyCEgC/vSJ0zhx9DiVpNqQkpaKT33mHiQm+ccKxMeEcEtTD6rOtSgVjey8ZHziM9tI/AtT1nCX6dKM3pIglc1BNZ02N46dtWGgpRuu3jaUx7agcEUssnbuhCU62q/VOarCm+TVcyTNHjrUh4yMMOTlhWPlSt5T48wz6r9eOLAREIUlIa52djlIZHWgumZckRmExCoKXakpZlb1zz+ZweURsqrY+fgwbDOgz8qiPKqVCrlzmOTOUJOPxE4DiZ1AbpIB4TwNzYswl/EnkXXymTFqNyjibiVVZyvbgXAScxPIsy9InlCfjSdpN4z7rB0lJqOmXy80Am1dbhVbGKKlsLQtaywozDExLoMlS3iSOeSQz4Hn7U1KhelmSzoKjNFIJqFVN43AtYqAjI3lIepBtvFxjFGpcYSkNyGudpP41t7Wjq72DqXIGk/rvMysTBZorUA2SSIZfG2k1VNw8NImsfv72C4FIuvkfRYFfilQaGy0U6F1VM01RI21IDeE4/4QRWoNDw9iEVOwLl6bDNwSeC3XNhleGGpoQNexI+g7ewY22n2WffEhJK1bB1MI72/TrEi02ThPsHpxmKpfVTU25GTyvk8l1pKiUISGLEyB2xKAPCC6KDEDua7ffruH8/d+rF4dg+LiKJL3eKxCF2HSFBCoLK1OSFzpQkUrDuw7D+vIOEJYqXndjSuRk59CRb+QJTvW9tdReOqpp/A3f/M3VySyDg+zMpRNitUnqx/K61//+tdKqVU+37dvH4qKivC1r30Nzz33HB555BF8+9vfxhgL20Qk5bxrABUUSgn62esQ0uvatWvx2PN/QnxwCCIMJvBI0P0yaEYKrZrIKsjrphG49hGQ+VRHWwde/PPz6O3uYTFCOcrXlKO0vIwxExOCOYeaTnNwPTX/9RSG62phYjFh6uatyGRBkozfLiqtt3c6UVPvQEOTnXM6L268nvf8LDPHZ3rsPh2M9TLLEwHJPTgolDHAnIM4pNV2UVhixAcH+UPlmUEoSgHyEn2wkHs2zenSnIDURFZNZJ3yBNJE1inhCYgPnU4frGMeyE25us6uKoCzMywoKgxBcUEo4uOMC/JjEhBgzKITEruyk/gwyB/is9VOHD5lR2aaSSmnrCk2I5ZKKsulMRagkuA1vDHtrfKpRHBxahBK03xKoXW54HAt76cox7kNPrS7aYXrGcEJVx8kMbnDkopCJiNTg2ipdC0DoPfNbwhoIqvfoNQr0ggsOgIqUc+szvPPPI83d7+BNevWYDUf5WtWKXsff3TQxUqhvbtPo7qylYQ/I0pWZdNGqARGVgz5Q8lILJ3bujyorHPiyGk78qP7UBDShJEDLyImIQqr/sdXEJlOS9dpBsSms8/9/U4cPz6A1lYSZwecVLSIx6ryaCpuBSsr6emsQy8T+AiIjU5jkwM1dUzYVFqVnWx2ZghJy6EsHLTweAfRzpCJmgVQ5Bqy0UGBpNXKdqqwsiK6g69TYoAsOilkUbwgiaTOyND3yZxCmuOgbgG69ZGDOF9EVilAFCVaIbSKm8SFTsGBFeIMrqWxEnxNNpBLgUipCtdNI7BYCIzbfKpA9uhZB46ecWDn5hCsZlwhMS6YvxVL89xs94yhwTuKE84+NVe8y5KFjOBwmHUR5GKdZnq7C4CAqAa53W4SVtvQUFeHqooqNDc0KgvdyKhIElezJkirmRlKfTUqOopEqFClzGqhOqskUC8mURegu0tiE0uNyKqsFJnIE6KiKDk2tdhR32hDZ6eLcxi6WK0IQyHj7nkktk4c7yVxGHQniYBPrm+7DW3738H5f/8t4opLkLJpE5LXrUd4ahoMM7C3bW134EzFONo7XLAzR7NjawSJrKEkOM9/kZs+mDNDQHJA0iqpxlpZMYLBQSfi4824+eZkuqloBY8JdAL/X+so4y+UCNv3+mnUVbejlLEl9SjPhmkxqjgDCLKrEVkv11UTiWOPP/44/tf/+l9KLVHUVf/whz+oRXft2sXC7XP427/9W3zjG9+AhxeRC15YqcY67HXijd/8J/7f736XxR0Z+OaBp8WySDn/ZQdHwIJgeDmOEoLqdNpFYq1sRzeNgEbg2kXAw9+FcZsNlWcrcPb0GRw9dBTrNqzDx+6+C3HxcUqldTp772ax4UBVJbqPHUPznjeRddPNKHvoYQQx7n9xHCe8D4nP7HlnmIRWO9avDidvJlTxP7QS+3RQ1sssRwSGmXtopfPb4XofekYmEBDRuxUksCZEGhAZ4qOQxsIV6msiqyayTnkdaiLrlPAEzIeS1Buj1WUTFYLOMnjiYDLfyCrx3BwzJNGakmScUAlaCHp8wKAy/Y4IgdNDDBta3Th7wYnBYS8rfwwoX2FCdpqRSaeFSU5Pv8fzt6Rg0cXizGMNXj4bwNgANheAZNYJi1KTFpSYP/AXcM1jXhcGfU4cdfWg2WNFGIxKnXWVKQ6RrJwNNUyv8m0Bu6w3FWAIaCJrgB0Q3R2NwBwQsI5a0dfTi9dffQ3HDh/DJ+69Gxs2b1QqDiaRkJtjG7MyuNQ3gjdfOYHujkGs37IChbSAy8lLYdJ3jivn10WJtZ/2Jqcqnejp95J04ENx2hhyQzvR8Mx/wmsbR96ddyGhrAwRGZlz3qAkwPr6HGhqGsOpU0NqH9LTabNcGoXsbBaE+GOn5txLvYK5ICDHWM6jPtrKdnY60N7uRG+/Cx6+l5BgJGkhTKmwxsfN/fqYqp9ukifsJG4O0Cmhh0V3/VZWRP//7H1ndFzXee0ezGBm0HvvvbF3ilWFqpZkSY4tNzlOseM4cVZ+xM7KW17rxc8ty3G8VuLuWHEsJ7EjRbKianUWsRMkABK9996BqZh5+zsQZJACARAAwcHgHGk4gzszt+xz595zvm9/e094OT73MkdEggy/nBINVXCWQkJrRND0HPBWn4I3i8g6g5VYuEuFeHP/tMVR6wCVavm32BmlRBmUxZE8RwSDc2IKMsx8UT9rBFYBAYkriMvLpSoWVpTZEUaye2qiCdtKLIgMN6g4zSrsxopsgnqUyk7somsAZzhvDOC1MYUE1n3mROXmsSIb0SvRCPgQAjYmVSfGxzHQ14++vj708zEyPKKUWEWV1U07zEAziekJ8UhLS0cKSaxJyckIDg7m8ps7JvAhmJa8K2uNyDpzoDPkt+4eJ9o67GhusWOESq2SAI+OMtGq1IxEqvPHkhBnsRhU0dPMd/WzbyIgKl6DlVfQdfYMOt49gcwjdyPjriOwUl3ZHEK/zEU0l8uLUTo2iKjI2dJxRIQbkZpsxsbiICTEmVdknruI3dAfWQIC/f38LbdN4ty5QXg4h7j99jikpAYhNFTHwpcA56p/xcPJ4BQf507W4EpZM5XRbUhJj8WufYW8P0cqZdZV3ykf2eCNEFmFONrQ0ICvfOUrOHHihDqCEsbM/vu//xtRUVFKVb6oqIhF24P45je/iT/8wz98/yhFKGWKs4Rf/eLf8X/+z/9BHK+d3zr/Elqdo4g0cs5jMCPGYEGUx4xXfv4f1GcVkcT5Z+VSQCRF9prI+j7M+oVGwG8RkGLBoYFBVSj49htvUQwiULlbbN+1A9l5OeSymK9SjZ4LCClKsg8NUVn/LKp+9UvEFJcg9+FHEJKSAiuvYdJkDC/XlbOlk0o1X4rUMqicv3t7qCo4EqcF3TQCGoFpBMbszHeNUTCCsfaOIS/zD9OOZ4kRBuTRCS2DwhGiwmpaZe0/TWTVRNZ5f6OayDovPD73puO9CpNjJ0dx/tIkwsMCkJ9rxYG9YQyo0NZqlS8wPgfQAjvkYnJaFL1eeocVQVT0yqAya0meGTs2BKoA5QJf95u3BYdJJ21Eqrx4/iKwLw/YkRWgbErDrH5zmOv+QDiOR9cU1cXcg3jF3oo4YxCOmFMhVbPxfK2bRmA+BDSRdT509HsagbWFQCetUctKy1BRVo7uzi58+o8/g62shl6p1t7ah7rqDpw9UU0HRw8+9pnDyvptRnFhudvpH5xiMZILrxyzISTYgPsPhSA53oggzyiq/us/MFxXiyAG1pP37pu2GVrmBt1uDy5dGkZV5RiVOidQVBSG++9PYuLauK7Gi8uE0ae/LkWCdrsXZbSRPfbuCF9PqbnUof0RVGINVonq1VBgtXE8TrEZVLR7caHZyyIzGb0Bm9NZcJdqwAY+rOTNSBBpgbzQquJ9s4msMwcjQWlRaBWS78UWzl0qPSqoFh8O3FFM699EA0LNvoXNzL7rZ/9HQAormjtcOH7OTnUj4MN3ByMzxQQrSU5rpUmS2sMk9cuONrzoaMERSxq2m2KRHBAEa4Ame6yVftT7uXgE+np70dHWjtLz51F28RLtiytJiAlFWkaGGhtvoPVlTl4ewmlfOTOOXYiYsfit+/8n1yqRdXbPSLHCGNVZGxptOHFqhAQfFjpx2YF9kdhYEkJXtEDOCXTwfTZmvvh6rL0NlU/9OyY497VERyHz7nuRsm//De2qCIrUN047410sn8SdB8NwO+cKmsx8QzDekg8LqUVUlp97rgPd3XZs2xqJ3LxQZGaG3JL90RtdGgJSMN1U341nfnVUkZX237EBhSVpSMuMX9oK/eBbiyWyujg5+X//7//h3/7t33gPk8IME/7sz/4Mf/M3f6MIZQKFjG/27duHxsZGfPWrX8UXvvCFDyD0T//0T/jHf/xHFBYW4juv/gbn3H2ocY9gmOIpucZwFBsjsdkcgzjOHUQ4Zb4myq2yL5rIOh9K+j2NgH8h0M/iwcrLlTjxzjGcOn4KT/zJZ3DH3XdCnC6E3LqYNnDlMip/+QsYjCZE5OQgZf9BRBcUXPXV/gE3Gui09drbI4iKNOIjD0Xz2bRmHXOuOjj9h0ZgBRCQ+Hojnd/K2yT/YMAQRTT25ND5LB0Ui5G8g7jNrMCGlrAKTWTVRNZ5TxtNZJ0XHp97U4Jnoh7UTpujljYHWtsdKmkiN+e8bKsitQYKY15XmszZd1KRI8pH9S0uEiKm0NTuQngok8Qks6YlmRAfsz7kSOWm5eR51NhnwKVWUX8CAo0MzOYHUPEJCCWZ9Rbds+bsN71waQgIFWKSyqzdHhvKqbLT7bVhjH9vD4xFCZVZpXrWqu0ilwbuOviWJrKug07Wh+j3CEgCR4il5ZfK8dx/P0sFklBk52Zj197dSM/kTHWZTY2rOLA6f6oGR18vR0xcmFJh3bG3AFExoQsqMiy0eRnzOqiEc67cidomlyrYSqeS/laq3oUxB2WccqCvvAw9F86jm2o7ybftR8FHPwYTbV+NtHxdShsZcaGnx4EL5wfRP8CiJyqw5uaGIj8/FAEcXwfcqln9Ug5Gf+cDCMg5O0yFrY5OO2pqbUplyeXyICXZguQkM1JTLIrQajYH3LQAzgQJtKN2AyugvegaBvpIZBXHBAs5YxGsM4rm3ESImrFhQFTwtAIr40k+1VaLyCoHLeqsNpIEe0nybR9kkRadJfo5dxFMBCexP0qiWm20zkv71DmyHnbGxt/y8JgHJ0sd6OxxI4WqrPmZJlUou1ZuFaNeFzrc47jg7keFaxAPWEnmC4xBMN07jDoisB5OY78+RiFLiMpqd1eXIq+2trRioL+fiqwTMFvMCOJ4MTg4hGPWKMSyICouPp52lzGIiIxQKkGawHrjp4c/EFlVvNTpwcioG13dTj4c6Ol1Mfbu4XkRoFzR0umMlpZKU2XODdbK9f7Ge3PtfmO0pRn9JD00v/IKzCRKZBy5B1EkqIcmpyz6oCYmveika8PJs2OwO72Ijw1EcUEQcjJ1vy8axFv4QYmDiBiMuKs0No5Tddut3FX2749Vv9nVKFi8hYfvN5t2Ot0YGZrApXP1aGrowgD9b7fuyoXEm0LDWXRlZUXjOmuLIbIKIeSP/uiP0NTUpNA5cuQIhAOQlZX1AbQeeeQRnDlzBl/84heV8uq1HxCC689//nPs378f3//1v6OXOaZejx0DfEx63XB4p+BiWVwYc0yRJLIKoTU6wIoIvg4zmukQOJ1rFa8ZTWS9Fl39t0bA/xEQN4yhwSGUnruAM++eRmhYKNIz0nHg9oNISEpcFJl1oruLMf+zKv4/3FCP4k9/hmTWAzAKEfa9gbjNNoWePjeOnxrDJOM0qRQwK8oLQjbHbbppBNYrAjKvFbczUWGt6YaKqXMopeLnCRFAVpwBCYyrRzKefivzDprIqoms8/5GNZF1Xnh89k1yEjDOyuBzpWNoaHLSFtNNIqsFWzYGIzbahLBQow6ozdN7Dgahunqn8PZp2kWNexAVEYCN+YEozDYzMCkWlT6WLZ7nWJbzlkiJD4x78WqFl1LiBuzKBoqYDBYJcVH3vZU3r+Ucl/7u1QjYPW70eR0odfXhTUcHSkxR2MBq2ZyAMMQYrTAxmCD/6aYRmI2AJrLORkO/1gisTQSmaOUzMTGBk8dP4pf/+u+47eA+3Puh+5CQmICwcLLkltnsdqdKLBx7oxxvvnIR9zy4AztvK0BcYiSVahZXWX29XZDJtozR+gc9OHbOxiIuN/ZutaAgOxDJCSY1VvNyQOwcG0PnqZOo+OmPEVOyAXmPfQTh6RmwRtOP/QbaNCmX9iotk6ipHkVT4yRJDgE4ciQBySlWBFnXR7HTDUC2pj4q55PdMcXfgwdt7VR2abajskbcLUzIZTFgcWEIhJQgMdCVJiRw01QemVYWFQVWKSDrYeCorpsJ8mEPSZoBSKErVhEroHMpLpMUSctaHx+HryaRdeZEExylH6u7gCsdXlR1SuGdl7gFIDvOi0wG4EI4jwskIVjPYWZQ0883GwH5bV+qdqC20YVOxhfyswJxeDcT68yXBNKS2peb/KY6piZwjnPEHrp4uPl7usuSgkITmeG6aQTWIAJCXJKxr8PhgCRNx8fGMUw7ypbmZhJgGtFYXw+H3aESpoUlxSiivW5BUSHJq9EIDtHVECvR5f5AZL0Wh+4eJ5pb7SirGEdfn0sRGrMyg1CQT/U5jiNDggOUY4Mmxl2L3Or/7eFN2ctrQPuxo+i+cA5jra2I3bgJRZ/8FMyhYTDQZnuhJmNNmRe2UXG9jqq8F8om2ecmqrGGIzYmUPX3QuvQ7/sGAiIG09fnQHX1GI4e7VOFqffck8gCBiMJkHpu7xu9tPBeuMnAGBwYw8WzdXjtxQvILUjGtt15tKZOQjQrP0U9fT0VnixEZO3u7mYM6wgGBgYQxyIdUVOVv6/XhMD63HPPKWXWZ555Rll0z3xWsH300Uch+QEhxn79619Xb9lJXh1inqnePYq6qRE0TI2CvYAgZpgSSWSNI5E1io/IADMJrlIcF8D/gKd/9KQqtP/Dv/yCKpgzMvASwGuuie+aDLIG3TQCGgF/RaChrkG5xJ0/fQ5OpxP3P/wACouLEJ8Qr67h813H3bZJ2FiMWP/b51D7zNPY+Kefo9L+PbBERsEoZI73mjgqVFTa0NhiRzeL0HZtC8XOrSEwU/hNis900wisJwSEwCpidpKDaBkwoLTZAwrdU9COauz5BpSwvi+UcUuTDwyJNZFVE1nn/W1qIuu88PjsmxJYkQn5yOgUgytOVNXZMDgkAVvKQe8MRUGulUqjAQzQLhyk8dmDvIk7JkRgG7HqoHJKdb0LF6toh5FuQnFuILLTAxERtj5wo3Mulc6g5MRrWZHRSVWoHCbQ7yqRm5gBZiaCdVv7CIhdpMMzhU4vyTmuYQYZRjFG9Z2D5iTkmyIQZ7BCgge6rW0EZiZ8ksBbiaaJrCuBol6HRuDWIiCKU1W0TC2/WI4LZ8/jjnvuxL0P3MfEDa/7KzBT7ekaYkKhHi1NPRjsG8Wd92/Dpm3ZLApiKFqYeEtsapzLMUplnRMnLjgYcGK1KIuOtm+wICkuQNk5ijKqXO8kWTlUW4OGF56Hi8cbSNXZrPsfQNymzTe0dRut5YeHnLhQOoxzZwdRUhKhkl1ZWSFUsmXwXQe9bghPX/qwnE+SkG5mMLO6dhJNLTa4WNSWnRWkFFhFUSs0xEhlNuoP3oThkIy3xbKnjWqi1SRgdlNRdITBo2QSVhMjvEjhc3Qo1ViDDQhmDFY44L5OxLwVRFY5p6QvJ5y0QCLJvYPzlqY+EoJ7vIikkm1aTAA2pXmRFi3uJL6PoS/9RvS+LB0BUVOWmExjmwvHzjp4LQnA5kIzMlJNSPBhtxeZLZDug0r3EJ6zNyGBSectphjkcm4Yy8SzbhqBtYiA2OiODA8r4mptVTUkYdpDQkdIKO3gY2ORlJysHvEs6BKXgrDwcPWe2FqK5a5uy0fAH4msds4RRIG7v9+FLpJaG1nsNsbCqCkmBjdtDEF+XjBiKCihi96Wf/4sdw3OiXE4R0ZQ+dS/Y+DyZaQcOozEHTsRU1yCAP7OZ2Jm823HRTcQEb94+/goi1TsSEoIRG6WFRsKg1jkqB3w5sPO196TeYODhYzNzZN4440eXvcDkZMTgjy6rSQm6bGOr/XX9fZH5vEuKrN2tNE94GITWhq7MT5qw50PbEPJpkwSky3Lij1db7u+unwhIusMMVXGOcePH0dCQsK8h/LCCy/g85//vFKiP336NBITE9//vJBhN23apOJust0DBw6o9yTP5PR6lCLrOPNLEyyHG/Q40D9lx7DXiVGPUzkCOjjbELVW9hBCAgJhf/INGNifJZ9/DOGK5BqIcCq3RgZYEG2g2jWprNoB6X349QuNgF8hMDkxSWXWQRx98yjFI2pY9Gti/mAz7r7/HlVkaJTA/3Wal4VKUyS/trz2O9Q99wxiNmxE/OYtHOPtgiWKqgDvNXF1EweuiiqbGseVFAWRyBqqCpIkTqObRmA9ISAE1o4hLy40k/fD58gQAzIpYFeQaEAUa3jDrV6V6/KF/IMmsr61qFPTwGptieWuu6aJrGu/y+Xm3MTEbH2TAy1tTgZZTMriKCvdzGAaLRyCbkJGdu3DxoQ2Axq0i6pvceNsmUNZeoYQq41MPKUn0f6CF/ZFFGuveSQksCOqUI1MBJ+s88BK5ZiNaQZFaBV1KGk3I6k/vWb972oiMMHgggQWzlJ1p9Y9oipkc0zhVGiNZuDABCsfui0NAZlsfe1rX1OBn6985SuqwnhpawIkcPTqq6/i4YcfxtatWxe1Gtn+P/zDP6C2tlYFoLZv376o7833IU1knQ8d/Z5GwPcR8HCgM9A3gFdfegWd7R2w0j71tv23YefeXcveeUkmOKjGWl/TibeoxGom8y49Kw4bSWJNz2RFzDLbpM2Drn4PqlhsVHrFgcIcUc0PRBaJQWFzBJ8me3vRX1GOrnNnMFBRgcKPfwKpBw7BRHWtgAWICTIOEqvQ3l47qqjW0t7O4rABBxUp4lBUFIYQEhxNJh3wWmaX3pKvz/StWMOKmlZrmwPtHQ61L9FRJmwoCUVSogWREdcPmC51x92sfLa7gUE6H0jwqHeMSqx8DJLQ6vUaWAENZPOnkhEDpJJ4GSTk1TV0mt0qIutMf7hZ0DlmN6C534uy1unX8l468ZSHYBpm8cJq1vPgGcz0881DQM2n+6dw6qIdgyNM7fK+IoUXct+y8Bz0xd+2qK/20xL0smsQrzvasSkwBkeoxhpOW1CrYeWviTcPfb3m9YyAFDRN0nlgbHQMg4MDGOgfQH9fH8dxA8rCcpyq/W7ekBOTk5SFZVZODslLSYiNE2tpfX+4GeeOPxJZBSc515wkOA5RQKKunk4RHE8KqVUIrPFxgUhJtiIhPhBRkSYlKKFPr5txdi2wTvbREFWX+y6WKjVW96QNBY9/HHEkO5hJWl9MYFsSgz1U8Gptd1LRi4RlKnvt2RGGrAwz4mJYqOkLmd5MvBmRAABAAElEQVQFYNBvfxABUWW9cH6IfUsr9MkpWqTHorAwbDp5r/v0g4D56JLxMVrad7Po+GQ1KstbUFCSNv0oTltXZNb5iKxSlLNhwwbGtnrxt3/7t0pF9XrdGRwczGtagFJGLC4u5m9jEocOHcKvf/1rtdzNgvEnnngCb775JlJSUnDq1Kk5i37kuiltkPOKvvceA3weIplVSK6TXjfVVqmGSJLq2JOvs5LOg8TPfQiBVGANJMFVnoP4bsR7xFZ5DuU7QnyV5ZrYOo2v/lcj4A8IyHXlctllpcxacamcBYZJdI7bj8zszPeVWec7zl6O8TpOHMdkTzfMERSfeOyjCEtPfz/uL3EY4XzUNdpx9N0xjskNiKOq/pYNwUhO5BWH93w9Rp8PYf3eWkdA7smTTHv0j3nRSjGN1gGgb9Sr3KJEwC43wYBsklnld+BLvwVNZNVE1nl/e5rIOi88a+JNuUG7KPXTScvVhiY7SssnaJ3pwd6dYcjPsSI99ffy6mvigFZxJwW7SVbWD5EM/M4ZO65Q+WtbiYXKrGbkZhiZeFpDGeVl4DZFQsrghAFnGrxK2aiHSlFHNgD78qYTbzquswxwfeirHp7w5E6gbWpcEVmPOrsQQvLqEUsqMoysTqMSj25LQ+DChQt48MEHEUull8tUfhAC2VKaEFIfe+wxnDhxAt/5znfwyU9+csHVSBLu2WefhVRdS/vRj36kSLALfnGBD2gi6wIA6bc1Aj6OgMvpoiJVC376/R9zcmrAhz/yCHLychGfuHyiqZAC+lkFU17aiBf/5xQ278jBhx/fR1UrK9VelzfulLFZDwlBx87b1bNUVB/YYcUmFhoplcU5BiUeBsNcDLzXPv0bVP3qKeQ99hGk3X4HwjMzYQ6h1OU8TUi540xSVlWN4qWXOpGUFITt26ORmRlMKzaLT03s5zkM/dYcCIh7hSSghXBw7MSwUleSKvw9u8KRmxOkVFjFveJmBG/GHQb0MXAkJMuKNpLKx0mspPDPhlQD8ilykhPPpI3Rq85pES+e47Se44h8Z9GtJrJOq88b4CBZ2K7cJaBsknpGDVS29eKOIgOy4hi0DvMdzPSe+DcCNjt/58MenCt34rUTk7j3YDD2bqWlZjhdTphA8bU26XGjzD2AOhY3dnomsTMwDrdbkplilv900wj4PgJyH5A5dweLtepqanHp/AXU1lSTyNqviKpFJSVUatuI3Pw8REZGqoIuIXgIaWM+xR/fP3Lf3kN/JbIK6jJHkXmDzE36+p1oI9nxfOkoOkhqTU8PQlFhMLZvDaOYBC2SKRCg2yoiINcDqnW1/O5VVDz5r4guLELc5s1I2X8AIYlJMCyiokT1L/8pLZvAG0fHSEo2Ii3ZjO1bQhSJVbtzrGJ/rvCmbDbaoNN55dSpAbz1Zh8eeTQFe/ZEM24hv9X1kfdZYUhvyerk+iv3fSGxShxKiqrj4iPw0B/sRUJSlCquviU7tsobnY/I2t7ejl27di1qj77//e/j0UcfVZ8VVdYvfOELCt8IksNEVKOqqgo9PT10Q7Lg5ZdfZpF30bzrlZyTuD2IWuv0Y9r9wT2j3ErV1hd/9Au4eK1O+/xDGJpyYNDrwMCUDTYv1RZ520wPCEE2BVdyjeFIY54q0RikyK7zbli/qRHQCKwZBGT+Jg4aTQ1NePG5/0Vfb59SY73/oQewe98eNU+b72AcQ0MYa29Dxb/+DPaBfmz7q79GNOd8gcGUl5zVhoanWJTkwPlLE2hudeDh+6OwsSgYgVJkrIfos5DSL/0Jgem5DNBOAuv5Zi+qu+gIRyez/fkGupcZIKJ1FLGHLw59NZFVE1nn/S1qIuu88KypN8dosTgw5EJdgx0dXS6VrE1kZXhutoUVJ2YVhFlTB7RKOyuKSU4qs1Y2ELtmWpEx6RwZHoCtRRYkxAao16u0K7d0MzZaJ3UNG3Clw6PkxrPjDZQZB5Pt01Ljt3Tn9MZXFAGpiO1hoOASk5c9HhtDCR6UGDmgDxRlVq3Cs1iwZ5JgooIqVcoNDQ1LIrIKwUySaU5aZPzwhz/EN7/5TbULiyWydnR04PDhw5igGo00TWRVMOh/NALrHoHmxiZUXanCsbePkZAZi498/KMM9MciiMoLy2kSeJqccODMiWomDzowQWWMTdtzcOCOjTCRFCjXxqU2qQHo7HXTotmNS1UOqq8a31diTYy7vkKcIrXxy+3Hj9Fq6FUYjFRuZVV2zoceVMnL6zEVhegoqixll4bR1DxBe2gXCY6hDNxHIjycChC0mtdtbSIwNOxGb5+T92Y7ekk2cLLILy7OjNQUC4v8aF1HBS1JSK+kstKEgzZWk9NBo64RkhxIqpSEjhBVw+n6EM3YakqUAfEUhYriz1AItDeDRLsaPXariawzx0hOCRNuQBeL8NoHWJDXD9UHsjwpwstq8wAVrJvBe+Z7+lkjsNIIUFxIFROLkvjJUrl/GRhLMCpl1rhouTf6TsZEksySPH7F2aZUWbMCwlBsjkK+MWKlYdHr0wisKAIuzpfppobOjk66DbQrEusobcTFqtLIm62J1uFh4WGck8cpFdYE2uOK+qqZJAwhsep28xHwZyLrbPQmOH8YHWWSvI3x904HRscYWOaYLzTUhIx0CzJJbA0LN8JqWfq8aPb29Ov5EXDyOjBQXYXuM6fRfuwoMu+7H6n7DyI0NQWBCxQ1zqx5fMKj3O5qGx2orrVjy8ZgFOVbkUilXSEn67Z2EZA5v8MxhdLSYRw71o/c3FA+QpCfH87frJ7vr7We7e8bRXtzL85SmXVs1IasnEQUbkjjI+O9+bXvjLlvBrbPPPMMvvSlL82ZfxBC6uc///lFbfYnP/mJEuSY+bAosX71q199P7cgy1NTU5X73L333jvzsRt6nhFUcZKo6uT84xc/+DHcJLLe88XPYNLjgo3UV1FstfEhz7ObKLWavQGINwYrQmscxVdCDaLhqptGQCOwlhGQ+P0Ix23VzFdcLqtAWWkZNm/bgi3btyCvIA8RLEC8XptyOOAcHcWVX/4CQ3W1SNm3H/FbtyG2hIpcs4KrDsZ/ZVx35sI4LlfZUZBnIUfGiuwMC4JYxKKbRsDfELDTOURcy2pJXm0jkbWXHKdg6szEhhmQRxVWIbFSe8YnSazSF5rIqoms8/4mNZF1XnjW3JtSnSgVJ/VNDhw9OUY1DS/SUszYWBxMKxyLUhglX0q3ORAYn/Qq8sRrx22YsHmVKmtBViAyU2kpS8x8Kfk0x+6vyCKOI1WlxtFqQJLxIRzY3V4IZMYBZsb9/TsUsCIQrpmVOBhEEBLrRdcA7STbUBQYpZR4Mo1hiDZYYGTAQPf39btTiFqf/vSnISTWlpaW9z+4FEXWl156SZFPq6urlZXPzMoWS2R94IEHIAmjmaaJrDNI6GeNwPpEQIJC8jj29lFcPFcKu92O/MJ83Puh+6mYenWV8lIQcjndGOwfw7P/dQIDfSPYviePSYN0ZOUmLWV1739HJZhYVHOx0oWaJieLs6ZQlGvBkX1WZYGyGH7sWGsL+iuvoPnVVzHldGDzn/05ovLyYQqaW3F8YoL3wh47Xn+9h4E0J0o2RFBNKRzZ2cvH6f0D0y9WDQEZx7rpUsECf7S02lncN4nLtAWVc2fzhlAU5HM+lGmdHd9c1r4JWVK26aQyl3sqAL2jVIZTRWGcUwwJodKLomQDNqZOF4bFUBxYuGyz4qvL2v6t/LKvEFlnY+Aih0QCdpfbvThVD1gDvchhwG4TVXCzaJ0kYtFrUf129jHq176PQDcVxRta3CivcWKUitD3Hw5GdpqJCRNR//CN2dUEE8ddXhuetjViiipJjwZlIdUYogoafR9hvYfrCQEZz06J6j4fbpebxMERDA0OMvFZiZqqGlRXVikCa1R0NJOf27Bh0wbk5OYhLCJcFYquJ6x85VjXC5F1Bm+ny0OlRzcuXBxDA21MOzqYLM8PwQbG4FNYPBUdFQgz1Z+keNlHbgEzu+43z+LMMdrcjKZXXsJYWytdOmwofPzjitywGNCn5w8cu3c7cfLcOPtTyj28OHRbGDZQvUs3/0Ggrm6MBawjGB5xIYQFswcPxtGNxbou8j3+04vTRyKF1adPVKG6ohU9XUPYsjMHd92/TbkDBUoCS7clITBFkmllZSWaeU3duHEjMjMzl7Se633pBz/4AWQbQsSd3SRHJUTW9qkJtHrG1aPXbVPLUjhHyWauKscUgQSSWS0GI8yks5rkvqozV7Nh1K81AmsGATXH47XgzMnTeO43/6MEN5JTknHH3XciMyeLY2ezGjvPdUAeBnwbX34JvRdLIa8Ttu9AzoMPIUCKFq8ZbJddnkTZlUnY6MibGG/CgT1hiGChmVbZnwtZvWwtIkA6GJXOyQmjC1zbEGPhdRTVGAOdyoAdWQbs5MNs8tIRzjdikdfDWBNZNZH1eueGWq6JrPPCs+beVMlUqouOjnnQRnujplYn6hlMS0okITPNguKCIAbSxE5rzR3aTd9hsYcaJ4G1voWDISqBSQIqn0TWbSVmxEYFUFVlfYAmSlI9VDU60+hFc58Xm9IDlDJrDp2IdSzgpp+Gq7YBsXkR65ZOzwSqXMNoY6BgxOPEPjMrmRkciDaQOEQyq25zIyATrpSUlA+8uRQi63e/+13I49q2EJFVyLSi3vrP//zPOHDgAMRCqKmpSSuyXguk/lsjsM4QEJseUXj+zVP/hQtnL2Dfof3YumMbcvNyaaMTuGw02pr70FDbifOna2GxBuLeh3YiOTWGJFmWdi6jDY540EU11rO0ZR6kmubmQjNyM8xITzapWNQ18ag5t+SanKC90AAq/+MpjPJ6mHroMOK3bEV0UfFVQTAZL8t1vLx8BJcvj2CcZKPo6EDs3BlN1U6LUlOacwN6oc8iIH0qBX2dXQ7U1NrUPGho2IX0NCuL+qxIoTVoFMkEIcErN7YhpwYTTqC534u6nunx87gdVF71Ij7CgESKG8aEGhBJq/swC1hQ6D+pFl8ksrL7YWN/DIx70U4icQvVWZs4l4kKNiAp0ostGVTIpBqulTbvi7me+OzJrnfMpxGwUf1jkvPp4xfsaGx1ISPFhPzMQBTmBKqiDF/Y+To3FVDcw2iYGkVUgAX3WtIQzWetceQLvaP3YTYCLqcL/f19aGtpRV1NLdpaW9HX00ulnghERkUhNj4O8fEJSnVV1HsioyJJTgpV410hDuq2+gisNyKrjD0djMEPU1Cip9eJzk4nurqp0Eq1Vhl7ZmUFUQUqGMGMJ5t8PIG4+mfL8rfoIQlisqcbfWWXUPv0fyMkKRkZR+5GVH4+QpM/GK+ba4tuJn/b2W/1VGK9WD6BeDrb7dgaguQE7Ww3F15redkICaxSxHri+AAGhxy4664EFrCGIixsOt6wlo9tve27m/aKA72jqK1qx8mjV1QsKis3UTkFpWVQjUU3n0TgekRWyVG5WVw3o9AqpNYxFt6Nw4XOqUn18PD9sAAz8pizyggIQZoxVBUJahkWn+xqvVMagQUR8NBaqa+3D031jTh5/F20t7Zj556d2LR1M/KLChBIp425mpffG6ErZk/pBTS+9IKK92/+3J/BFBICk/XqvET/IAnyHU68e5bMPjYpUkpNtiAyQiu9zYWtXrb2EBAuT+cwUNHmRWMvnabpDJVEUeMcDoUSmJOIZk5CBDV8yCBqTpA1kVUTWec8MWYWaiLrDBL+9cxYDm1TPKipt+FC2SSVibywWAwksgbzZh2I+FgTrbVW1k7THxAUS8Axys7XNbvw7gUHbaAou51gQhETT8nxYgslmPnDkV7/GIQIQDErVb1R1jZdyJRK6fHdObRB5Y2QnBXd/AgBUeTp99pxztWPCvegCgbkBUYiPyACEQwQWFnpqtvcCPT395M0wx8Lm1j7fP3rX5/T2mfub/9+qagljtIWQ5qQUw8fPoxBKs0sRGQ9c+YMHn30UURERNAe6xgeeeQRWig3aCLr76HVrzQC6xKBkeFhdHV24YXn/heNdY34+Gc+iS206QkNY6CX15ilNi8TtS4mDC6QwHrpXIMigqakxeDw3VsQEbV0BVNRYhVFy8ZWN67UOdHPCtJgxp4O7w5CEsdeQv67kSZWQw0v/C8TmhfJVuXEndXZWfc/gAAGwQzvHb/YgQ4OOJS9YE3NGDIygpXFYFFRGIKDtYLHjeDtC591UQ1LKuz7+pxKibW+wUaFVCgb0C2bQ5CZQXtX2kauRNW9zBXkfB2xAUMTBlXp3D3iRdcwiQwktgaRJJmfSAVQBo0yqAIayJ/cMn52vgDvnPvgi0TWmR2VeYzDbUBVhweXWgE6Tiol1rxEID2aFonRBgRRndWif+ozkOnnm4BA6RVaEze6MUyl5tREI27bZmVhrOGG72kruWuSJJ7iZP9dV7dy5Yg0mJETGIHtRhajBOhJ/kpirde1NARkbm232TA+Nk5i4DCGh4bQ092D3u5u9SyKrEJuzcrJRnZuDu0nCxCfmKDmw0vb4tr7lhB0pRjLV9t6I7LO7ocJxpL7+h2orJokKdKmYu5RkSZkZQYhMdGC2JhAdQ8I5FhRt+UjIEQGt20SXYyL9ZLMMFBdhcQdO1H4iU8pIoORal4LNVHUnaSDwsWKCSUEYpv0oDDfiv17QhXxeCXmDgvtg35/9RAQ5w7Jlf3u1R4qKI+juDgc+flUeswJ4XxN/y5XrydWZktyL+xo7cfp45Xoph2KqLTedqgERRvTER4ZQhKUzmesDNIrt5brEVnn2oILvD6T0FpD8ZVKFuBJ7kqcJOKoypooD2MwojiXiTJaEWJgnlvps+rf8VxY6mUaAV9FwE1VfRHieO3l11B67gK5FxZk5+Vg/6EDiI6JZiHYB5Xx5drvpojFwOXLKP/ZTxAUG4vchx9BRFY2ghMZ9JvVpFhphMVlb7wzit4+FhlT6C0/14r8HIsSu9B1j7PA0i/XDAISCXDQiW5oguMgijg09gmZlaJlFHbYkGKAxL7Flcyyhuacmsj61qLOP4PNRinGddg0kdU/O13imnJTl6Tu2Lgb5y5O0l7TDg+X5WUzKLM7jGpTAQyiLZ3Q4I/ICW6i5iMDnPYeD0ov21HV4MKBnUHYmG9CYpzpliafVgtzwWFwYlph6rUKrxrY7S8wsJLDy4oOPSlcrX5Yje3INWHK4EXb1Djq3KM46+yBkUqsd5iTkW0KRzyDA7otjMBvfvMb/PVf//WSiKyz1y4ks82bN1MloGdeIuv4+LhSYZXPPfnkk7jvvvuwf/9+TWSdDaZ+rRFYpwjU0mpVqpkl8W8ymfChRx5Cbn7usi1WXU63Sg68/NszePedK7jrvm3Kwi05NRbmZTDCRL1uZJT2JxepjkIFu71bg7CpwKyIP2LFfKOBJS+rucResvv8WdT9zzOI3bgJW774lwhkdbaRQTFpLS0TOH9+mNdaaj6QlHjwUBzy8kJpRWfUSaw1+LsZo6JuW7sdJ0+NUF3HzeK9AGzaEIriwmClsCPFfJKcvNFzaS4oJh207GHFczmLvWq6gNYBKn6Sx51LC3txL5Dir1CetxZywiR35q85UV8msso8hv/DzsAe85moaPeqvhLl3NQoA27LJaE11oC4sLl6WC/TCKwMAqNUBm7pcOHV45Mq5rJ/mxlpLCiOi751SXUXk79MAeN5ezNOc873oDUTm03RiAnQThwr0+t6LctBQEiskszsaGun+moNyi+Vob62lsRWO6Kio1FQVETiaj4ys7IQFh6mLCjNFrMa6xqNt+53tZxjvpHvnjt3DkISraioQHh4OAuwcnHvvfciOTl50cRWiTWIXfArr7yC+vp6VZSbnZ2t1pNPBUux+11uW89EVlFnFQjHGYOX8WhF5QTnHHYM0WkiPzcIO7aFIyEhkJamupJmueeZfF+KF+1Dg6j42U8xVF+HlH0HSGTdgdjNWzjuZ65jEQP/4RG6VHU78faJMYyTiHxwbyiyMyx06HiPEqXD3yvRVT6zDpkjTLEqsYKuLLV14yyCdCgS65EjiYp47jM7qndk0Qg4yOQYHZ7Au29fwTuvl6FkcwYfmdjAh5BZdfMtBG6EyCrzeSnCc9BNUBwF+zw2tDJ3Ja4SfR47JkhylXlMSWA0VVrDEU5Sq75k+1Z/673RCCyEgPBX5CH5i5qqarz47Aswmoy448idKCwpQkZWxpyrkGKmsdYW1D//W9goNGSkEmvm3fcgceeuqz4v931xTqgnL6amnjyPWju2bgrGkdsjWLAkogP6qnEVYPqPNYGACHcId+dcoxe1dIdrZaxbHMjkIWqs4VaKGpLEupbObk1k1UTWeX98msg6Lzxr/k25WUswraHZicZmu7LLkVhOXGwgcjItqgpFVEZFnVW33yPgpILtBLntlXUuVNQ6lQ1gXDST4rS5jWfyKTjI//EStSlRmjrVQJtWVnYIwXdTmgFbeUO0BnpVcv73iOlXax2BMa8LvVM2lLr70UXbFjMCUEBl1k0MCoQaqByhlVnn7eLVJLIKMe2JJ57Aq6++iscffxzf+9731L4tlsh6/vx5dHR0zHs88qYkE8vKyvDZz36WaoVzTxwXXIn+gEZAI7BqCMhvViqZT584hef++3+Qk5eLDZs2YuPWTYij9epyW2/3MGqutKGyogV9fH3PgztQvCmTRALeMYw3XhglY1Spju7qneJYizZ//STKcuy1e7MZBdkWNdaSwNINN67YSbL/YNUVVP3qVwgMDUHK/gOIKdkAS2IaLWqdqGPiqrR0iMUHZmRmhqCoKJyvpSL7hremv3ALERDlq6FhmeM4FJF1goTWECqvpqVYkZFuoaWrRamwLqdfeZpSidiLUbsBPO2pvOpB75gBNhJap7wGmMlFiKddfRqVPhMjDIhmvkz4NP5+KvkykXX2KSkKulKh3joA1PVMV6gbA7zIiDEgk5fFFBJbQ8hv1/Hr2ajp1yuBgJCZ+mk1ffqSA30DU+patKkgEBvyzSq2IByb1W4DTPo2snDxontAzfcetGagyBgJSwCLOPz+qrXaaOvtLQYBGbcKUbWrs5MJTKqudnUrJdaJ8QmOaVmJwCakzfiEBKSmpyE5JUW9lgTneiCvyvHL+F7m46+//rr8eVULCgrCt771LRUTkM/N1wSv73//+/j2t79Nxy5Wesxq8t5f/MVf4O/+7u+WTWZdz0TWGUjFbUJUH1vbOT5ts6Oj04Up9o+ZLhNpqVakpliQRIXWIGsAE+gz39LPN4rAEInufeWXqMh6mnM4FpRRjSs6vwBBcQvPe6WPZHxfTUJDBRV0bTYPoqMCsXt7CJVzTapvbnR/9OfXBgISg+jp4XiocQKnTw+QtGzBIRa1xsRYEBKylODD2jhuf93L6QKCKcap2nHxbB2GBsdVfGrPgWKkZsQhkhWncn3QzTcQuBEi6+w9FhGWCbgxMGVHq2ccPZzTCLGVuizKSTAqwIIECrGkGkOp0GoBNbVnf12/1ghoBHwcAXGr7Ovpw7G3jqKttRVOhxM79uzEjl07ERbBAkbOea5tDrp39FeUo/vcWXSdPoWCxz+BjLvvpip/EAKYO51pMuaTwqX6RgeOnxpDIt13t2wU12ILIiP0fX8GJ/3s+wi4GGMUwYYGxrab+jmepcGrjGsj+PPIpwqrCGxIfHstCtJrIqsmss77C9RE1nnh8Zs3pbJlhLZ2lyomWXliQ32TA7u2hbwXpAlESDBTF3pe94H+HhzxoK3LjbdO2TBGqe5Du6zITTchmQMeaf6OmQT2+pisL23x4uUyYHO6F3eVBKiEfShviv5+/B84Ifx8gaj0dExNoNw9iNcc7chlReshcxLSGAiIZlBAJzivfwKsFpFVAnBPPfUUvvzlLyty6dtvv00FQasKzC2WyPr000/jypUr1z+Y994R8mpLS4smsi6IlP6ARsA3EBAywOjwCF5/5TX8/Mc/x6f/+Ak8SDXW0NBQKqYubK14vaOQMaTIGwqB9ZXnzzGAZEFyajR23FaANCYHltok3z5OK8crdU68+PYEUhJN2LnRjKyUQMSugGLdeEc7Gl9+CWO8jrloO5Tz8KMI37yXBP0R1NWP8/o2iYMH46huHUvbOZ1IXmo/3orvySkpwcjOLgcammy4cHEcA4MubN8ShuKiYOTnBSs70OXs23unPaSwa9JhQAuVVy9yPNzQCxJavdiQalAPKfISRVYhtK6ntlaIrDN9IsE+6bfSFuDNSiAh3KuCfLtzDEiOZLU6izplXqPnNjOI6eeVQMDh9KK7z41L1S68fcqOAzusOLzHirBgkuBJaFrNxssm6qdGcNTRyTSwFxGc2+0LTEA653m6aQRWEwEhXHrI9BZi39joGPr7+lBWSqXRsnJUcY5qJLE6NSMNW7dvx8Ytm5GVk63IrOuRiCKqkkJiFQVVOf5HHnkE27Ztg6izyjIZ+8tn3njjDRQWFs7bjcePH8fHPvYx9RlRcZV1TU5O4oUXXmCRFzNhbD/60Y/w8MMPq9dL/UcTWa9GbpxFVp1dTpwrHVXj1aREM3JzgrB1cyji4wJpoSqx+JVxDbh6y378Fwfpcg1p/h2VhanEFRQTg6iCQmTf/yEEx9MeYRHNTqLx2LgHx06O4cTpUezfE4bNG4KRkmTWJNZF4LfWPyLxjfZ2G55/vlP9/ko2hCMvNxQpKR8kyqz1Y10v+2+bdGBoYBzP/foEmhu6sZdE1mKqsuYVpSjFvfU4hvDFvl8qkfXaYxn2OtFLIutZZy8qqdAq4iwpASHYYY5DjjEMKUa6MbFIT4iuAXqCfy18+m+NgE8iIIV2fb19OHnsXfz6l/+JHbt34vYjd1CkIwfRsTFqzjN7xz108nBxLtPw/HMo/d53UfyZzyL3w4+osaApKHj2R9VrKTCTcZ84GFvporV3Z5gSetOXiA9ApRf4GAIz+YlRG4vlx4G3Kuk61u1FLHMRG5mTOEQnZSvTfmuRwDoDtSayaiLrzLkw57Mmss4Ji18udFJGfWDQjTZWg9c30oJhcrpiX4I1mWlmxESblFKIXx78Eg9KglvjJLBWNrjQ1Ea7EloEZqWZqBZmRSjHQ1JB789NSCY2qtO2DhhwoZlkaN4s5YgP8OaYm+Bl0p5Wraubg/NnuG/5sckVwcbUZifJrBWuQVa42jDicWKPOQHFpkhE0qbFrJVZ5+yn1SKyNjU14Y477lC2iy+++CK2bNmi9keCcvv27UNDQ4NKQH34wx9WyxUB7Zo9lirHxdgGlpaW4s0339RE1mvw039qBHwVgcGBQVw8X4rqK1W0ZK3Dg48+hP2HD5CkGfiBgM+NHIPL6SbJYATlpY148+WL2Lw9G3sOFiMxOZrql9YbWdX7n5VJ+CSDR+crHGhqdylCa36mCduKqZ4QEsCk7vIHF86xMYw0NaLj+DE0vvQCEu95FKaSwyit5sZNZuTlhdJKMBRpacHvJTfe3z39wocRENWVEVVNP4mWVgdaqHQlRABRtspMt1JZd9qydTnBSHEhcLmBtkEoAmtzHxVAKAxnpjVPFMf/0SFeFnUZEEtr+ugQA0mQHB/795TgA2fEWiOyijKrjWTWXlast5KU3ELrJeY6EcZLWFacARtTWcXOvrWyj3XTCKwUAkK4tzuB2iYXTpU6GDswIC4mgPc68/uFsSu1rfnWI7acNs8ULk0N4Hl7M0pMUdgeGKdIrOF03tBNI7AaCMi81M2EY29PDzrbO9BQV6+UWPuZsAwNC0VIWBgiIyMRExuL2LhYPscgmgS1UC43m5dekLUax3aztiFE1ZycHDV3/8Y3vqHm5TPbGhwcpIrgIQwMDODBBx/ET37yk5m35nz+0z/9U7z00kvIzMzEyZMn3/+M9MnOnTupUNiDw4cP4z//8z/ff28pLzSR9WrUXIynitpnT68THSzA6qKN/djYlFLmTkuzoLggmOd9IIIpLqHb4hAQBa6Rxga0HX1HKXBl3nc/knbvRTgLsQODP0hcmL1WuQ5JnLud5OLzFyeUQpf8vX1LMPKyg1iwScc6ox4LzsbMH1/LeTA87EJ5+QhVkyfR1+fA/v2xLBSI0nGBNdrhbvrsOmxOVFxqQn11B9pb+pGZk4gDd25ARHQoi7s1SdkXunaliKxOeGD3TilV1h66C/Z4JjHgcUAIrjK3iTNYlctgMgmt8rcWZvGF3tf7oBGYHwHJVTrszBE0NuHcqTOcL3ZCcphH7rsbGzZvZGFjGIyzlFa9HMAJmbXz5Luoefo3CElMojJ/PlIOHERocsoHNiYFTG3tvE9UTVDozY7b94dhY3EwwkIDlLjFB76gF2gEfASBCTrC9YyA5FXgcjs5SWavykVkxXqREm1AEt3hxBluLfN0NJH1rUWdbQabjV6WPt5mqsfmIqYsddc1kXWpyK3d74mUenunE2WXJ9DU6kR2pgVZGXzQgjMizMjAjQ6gze5dSUD1DXpQ1+LGyVIbIolRSZ4ZGSlGJMQaVQByOcny2dvy1ddCYG1nMv9cI62XuoDb8kAVKlDBaDp57+/H76v9crP2a8LjYmWrHRfc/Tjj7EEhSazyyHufzKqvEddiv1pE1q997Wv48Y9/DIvFohJNs/dDVFZEVWXjxo0QlZWDBw9eleya/dnFvJYE12uvvaaJrIsBS39GI3CLEXCTdddK5dHn/+d5FfhJTk3Grr27UVg8vzrTQrstc47xMVouXmykXVsbGuu6cPCuTTh892Zl6RqwxFnyKANI3f1TePeCAyNM5uZmBKIwmwpFGSsnaylKPR7a0jZSsaqUClPm/O3wpO1AmzsDSblJLAqIR0REIK+n+p620HngC+8LgVXIAEPDblq0OlBdM4lBJiDFunXXjnASAZikiDApsulS9penOtxCdiTpbJRhgaGJacJj25ABvXRosJDgmBNvmLbr4bOZ3C/TOj511hqRdeackD4Wld1LrQaUt7LIk0WKUSTPlzDOncoAYEIEFDF5LVeyzxyrfvYdBLr7plDV4ERj2xSGec87TJeXAt7zgklsXQ0SvCR6u1mgeNHVjzfounGXJRV382FhgaKJakW6aQRuFgIqIelwwMY5qqivjo6OKvJqR1sb2lpaMTw0zHGrHXmFBSgoKkQ+HwkJCYq8OhP/vln7thbWe/r0aTz66KPKTrOxsZHWgVenLSSe/9Of/hTp6elKpfV6xaqC5Yx7y5e+9CX87d/+7VWH/3d/93f4xS9+oVRdxfHl2u1c9eEF/tBE1rkBcjOu7GAS8vKVcdTW29BNQmskx605JE+mJJsRH29WTmniEqHjq3NjKN6ZU1TrGiaJtYMk1tGWZjh4XSn8xCeRuHOXspFd6Loh/TA8TBvyejvePTvG4pJAFOTSeS3bgngWw+m2fhCQOWR/vwOXLg3j6NE+FgbEYe9eFk+Ecj5pXseTvDV8CqiC16FxRWR9/aULsAaZsWlbNnIKkqn0Hs/4lbjw6HHvrezilSKyzj4Gmef0TE2ibmoUFXQYtHndMBkCqMwawaK9ECQGBNGJgvdYkNDKG6w+A2ajp19rBHwPgTGKUnR1dOGt197A+TPnsXffXl7LN3OeWICQkBCYZpFZZe+H6urQfe4MBqsqMcUiwKJPfArRRcUIoKjH7HEhUwQci0/h9IUJvHNiDCVFVhTmBiEny6rdin3vNFj3eyTTfhHZGKdDXM+IF3VUYG0eYJ6CRiqb04WbY0A2cxOhlqvjA2sVOE1k9RMiq5GU6n/4h39AbW0tPv/5z2M7bZZWomki60qguLbW4Wbyzkmbu45uF5pb7bhcRZYiR/ElBUHIz7FSzYie8bq9j4DcNJxMnA8w2FXX7EZDq5tJKBdu3xOELYVmVu1IMtu/p0GS9HUQg/I2AxO/oizjRRJJrHcWGxBDN8LVSMC93yH6xU1HQFR7nAwEtLGitY4WLZddQ9Rp9eBwYBJyAyMQxyCAf5/xNw7xahFZ//7v/35BtZWZvX/88cfxT//0TzN/3vCzJrLeMGT6CxqBW4KAJJuFHFB1uRJPPflLJCYl4g8++TEkJSeR2Be+rH2a4gCgu2sQ//ubkxgft6OgJBUlmzKRnZ90VUDoRjdSXuNEebUTQ6MeREcEYP92C+KijQhewWIqlYQnNh1Uqa156TV017bAPhWItIc/gcwdG5GeEaySVDqZcaO9d2s+b7NPKQWrM+fG0Nhkk1w2sjKt2FAcgqgoE8fjJgY0l27NKoqdPMVRy+BQDYu2KvkIYUAoluPcvMQAZT8v6qshnCZZA73Taj23Bgqf2OpaJbJKiE/OHenr/jGgqsuD5j4D2oeAwiRgW6YBadFA5PyCXj7RB3on1g4CDs6dJya9OH7eDrn/FeeSOJMdiNx0sZW++bOqISoUnXb1om1qHA7O8XYHxitFVp3MXTvn0FrcUw9VchwksfZ0daO2qhpXLl9WKqxyLBGREcjMykJGViZS09NIHApTqqxBVFMUJ4FrE5Rr8fhXYp//5V/+Bd/61rewa9cu/Pa3v/3AKkWlVUghKSkpuHDhApUmOZi5TvvIRz6ilFjvuecePPXUU0odVz4quQbJL7S3t+MLX/gCvvrVr15nDYtbrImsc+MkYw8hWU1SnXVgwIXWdjuamuyob7AhKyuIREorigpDEM0xrVErgs4JoqhuOUdG0HXmFC7/25OILihE+l1H1HNIYiLzGgvfTyfpTHfu4jiaWpwYHHFhE+cRO7eGKEEPf4/rzwnqOl44XSTpQUXFKN54swepKUF0bAlDfn4Y55aa1LxWTw0XC7wHOcmrqmhB9eU21FW14+4Hd2D3gSKlymrS1Yq3tGtvBpFV5vcyv7GB8SK6CrZ5eI13M2bkHmV2C8g0hik3iuLAKOUyqIv4bukpoDeuEVgQgSkZ75GQern8MspKy1BbXUOXjmg88tFHkZqWRmc4+qnPao6xUTjoVHHlF/+GvopybPzjP0Hijl2w0tnDMIu0IGNxeTS2OHCl2kanBKdyzLnn9ggkJoiT3cLjyFmb1S81AjcVASGx2hhHLCMf50o71YQHDUiMJIk1zaDyE+ISZ+VwlTU6ftE0kfWtRfWjTyuySuXAs88+iy9+8YvqYH5EVaGHH354UQe20Ic0kXUhhPz3/fEJVp8ygFZeSQuGPnot8uKYmhyIHCaFE+IDKddu1GS1Wd1vszPgOOyhmooLFyudSKAtYFqSiYkoM0kYBiVBv4i42aw1rr2XHYNeNPSBhFZAEv5b06XyQxSM1t6x6D1eGIExrwv9U3acc/eh1T2OSFaw5poisDGQdtLU77FSxUe3aQRWi8gqCSax/Zur/eVf/iWam5vx53/+57jvvvuUKmtSElkZS2yayLpE4PTXNAKrjICoL1VfqUJFWQXOnT6LwpIiPP7pjzMgEwRT4PIUTrs7BpUK6/G3KkgwCMJd929DUkoMwpfI8pqg0uXA0BTKSGKtbnSqcVQOiTwlHEsF08pxJZsEqFwuD2pLm3Hud2Vwlr0Bi60HxVTtSd+7E3GZSbQl0vexlcT8ZqxLiskmJugm0eFACwvw+jhnETWlxAQzslk5n5fD85zSqLPik4veDTlHJqnAOjRBmx5azvfSqmeASqxCcrRzapRIdU6x6cmKhSrcsjBIpGOb0/CuVSLr7JND+riDBNbGXtBxwqv4D2FWKOXd1GieYwwMmoW07O8TvNmg6Nc3BQG51kiTe18FiaxCZIqLMWLvVqsq5rCYV/b+N7216X8lsdtJlaJXnG2qMLHEGIU8USgykaWvm0ZghRGQpKNt0ob+vl709fahr6cXQ0wsjpB8NjkxoYitkVFRiKfqamZ2lkpGJrLwKoA3cXnodjUCQgQWS02z2axUWWe/K8tFZbWzs1PN/X/+85/PfvsDr1988UV87nOfU8sPHz6Mhx56SPXH008/jdLSUlWg9vLLL2Pz5s0f+O6NLNBE1oXRsktsedDFca0DNbWTEBewQDOQlGghmc6KlCQzlQQDYNGqkL8HkzdS5/g4us+eQe/FUvRdrkDq/gPIeejDMIeFwRS0sG24uNN19bhwtnSMTkZepKWap9VYsyzq/P/9xvSr9YRAS8sEyspGSDDnpJCJsUOH4qlyHaTUO/UUYG2eCXa7EwO9VOekq9DJdyqRnhWP3MIUFG/KQExcuOrbtXlka3+vbwaRdTYqMuUSddYOCrPUu/m79jqoaOdBhMGMOGMwUgOo0GqcVmglbW32V/VrjYBGwMcQkHlkc1Mzjr75DkaGR5Qi64ZNGyiusUEV4kkxnjQvcyJTbheqnvoli51OI37LVsRt3YbE7TtgpKPltU3Ggz29Lpw6P47hETdu2xWmnIpjY0hzv3lhmWt3Q/+tEZgTAeHciItY14gBLf1UYeVjzG5AEPMROQnAJhJZQ5XAxpxfX7MLNZHVD4isHR0dkEDTBAN/0jSRdc3+Hn1ux0VSfWycVne1Nrz+zgjJmAYksQJFbuA5mRZViaJv4L/vNklCdfS4Ud/iwrlyB4SQ8aE7qGSbaUYoVZr8PdE5k/D/3WVRq2KwlUoB2zKAO6jMqpt/IjDFCX/r1AQqp4bwmr0dKbRludeahpSAYMQEMNuvm0JgMUTWJ598EvX19cjJycEf//Efz4mcJPAkeSRk1e985zv45Cc/Oefn5lp41113obKycsXGCJrIOhfKeplGwPcQcDld+N9nn8cVViuHU+Fq09ZNOHTHYRXYWe7enj1BguzFJpIQxpGdl4R7HtrJ6uelX/s7e6eoxOrgOMpNe2UP7j8UhA35ZgQuQ0nzesfopprsBFV3Tp/sw/8+34H09qeRbahBzpE7kbx7N+K2bIGRxADdfBsBmae0t1NN8NwoLlwcw4aiYGzcEKqUWMPCTJyrLH3/pcK5Y8irVFjPNNCiZ2DaaaAoGdidY0B8GBD+Xl5cz4euxtkfiKxyRJLsEuKyEJmPVXtwthHIIHG5mOfA/vwApczqLxXuV/eg/utWIDDOe1JHzxSef2OCxCXggcPBSE82ITJ8GReyBQ5k2OtEvWsE/+NoRqzBgk8H5yGSz2ZabuqmEVhpBEZHRtHLeWzpufO4SIXQqstXFEEsKzcHW6n6uW3HdiSnptAxIEItF9EGeei2eAQEr76+Pnz2s59VKqySxBUC6saNGxdciZBW/+qv/mrOz8l9/dOf/jSViuTOuPSmiayLw05gFmtzIbW+e5ouSJWTynkgk8ISh/ZHUlzCjPAwXXA3g6aHN83J7m6U/eRHGO9o5zxuK5L37EXCjp2LvoZU19lQWWNHXaODxSQmPHB3BGKogCuODrqtXwQmJtwYHXXhlZe7SSwfw0ceowNNSTiCginuou9Pa/bEkHtZcz2vGRcacKWsBU6HC4998iAKilNhpoSZ7ttb07U3m8gqR+VV/1HJzuNGm3cCZ5y9qKbbYPeUDbeZE+hKEYsCirSEGLTy8q05C/RWNQKLQ0Cu41IgeebkaVw4ex5lF8tw8PaDSrjDYrWqQr/Za+p89wS6WPA02tKC6MJCFH3q0zDT9ePaJmNwEb147Z1R1DfaOSYMRGF+ELZtCua94dpP6781AquLgLgij5K4eqLWi6OMUYdT9CUn3oBDhSK2YYCFejX+eJ5qIqsfEFkfeOABSDBopmki6wwS+nm5CIiVCtXa0c9q8GZWg7e2O5U6qyiypqdaUJhrVcEzHdj5PdKTJK8OsnJHFFXauqZYJW9AVqoJW4un1cSEjOHPzcWKkOZ+A2povVre5kVSBJVZM6lOS1XWGC3s4nddrxL8VGbt9thQ5hpAL58nvW5sN8ViA5VZwznxt2hlViyGyPrRj34UJ06cwL59+yBJpLmaJrLOhYpephHQCFwPgcnJSVWZ/Jtf/RqtTS24694jKN5YgvTM9GUpWzkY6LdNOPDaiyQh0JZt07ZsFG5IR25BMhWDblzlVcYOQyNUR21y4XSZA7FRRmRy7FRIa+X4aOOyyIhzYSPKRv39TlwsHUJXt42JYTcyp8oR76iDradLBbUKP/ZxpeBjeK+Ke6716GW3BgEJLDqdJHx1Ojg/saOh0cZzhFXHoUZkZVipoGRFTLSJgcsbJ2LJ3GfYZkD3sLgM8DyhvbxUNwdTeVMCRImRfHBsm8CHVDwv4XS/NaCt8lb9hcgqsLlIKLRRhKl1gOqsPCe6h3n+cVk0Hcty6TxRnEpVNJMU8K0yyHpzfoeAKEyPjrPA4pIDUtgh55QUc2wtMatr3M1QfL7E+Vv1lCRvJ5FhCsMRcyqCOXcL0N47fnd+rfYBSXJRrOyFuNpJ8YXW5hb0dHVjoH9AOQJYmWAU68coKrDGUYFVVFgTEhMQHBICyxzqOKu9/2txe0K8+dd//Vd8+9vfVkIXQmL9+te/js985jMLHo44tzzxxBOqsFY+HEEysfTf2BgHQmxhVLX82c9+hoMHD6q/r/3n1Vdfxblz565d/IG/02j5Kdv62Mc+hqKiog+8rxf8HgGZr8ijs8vB+YpLuQ+Mcs4iy9LTrMgiqTU5yULRBCHU/f576/HVUE0N+srL0HnqXaqvBiPnwYcQkZ2D4HgO1BZoooI+MjqF8xcnUNtgU7mOHKqwFuYGUemYd8N1ju0C8Pn921L86iSp/PjxflRVjSEzk+dXbigKCkI519SD/7V8AoyN2qgMP4TzJ2vRVN+F5LRYpcy6dWcuLJrMeku6djWIrHJgQmb18HmUBX1CYO30TKDdPYFxuDgHCkA8hVmyjGEktEaCtGYW+Onf+i05IfRGNQILIOB2udVcs7qyGieOHqcIWyBSWBS5e98e5OTlKgGPmcIEKXTqv3wZ9b99FkHRMSj81BMITUmBJTz8A1uRsXZDs5PFTTbU1NmRkWbB4X1hCAkJgNVy43HmD2xAL9AI3CACHI5iYEx4N8CVjmmXOIkPZsbxEWtQjsjB1GK5GTHDG9zVm/JxTWRdw0RWIbR885vfxD//8z/jwIEDVKNpR1NT04qprckZ93//7/9Ffn4+PvGJT9yUE1CvdG0gwPilqkSpqLShtJyV4ONuRISbsH0zbReSzYiKNHFgIGoJa+N4bvZeSoK9qd2tbHHLqlys4g7Avm1WJMYZEUVFFcHJX7GSYxeJ82Yme1+r8MLu9CIq1ICdWQbkUt5c4jzLUce62X2n1780BGwkr8rkv9Tdj7cdndhkisYmElmzTeGIokWLiao+vEIsbeV+8K1nnnkGX/rSlxAbG4vLnDRJUuja9vjjj+PYsWO0qjqE//qv/7r2bfW3TL527NgBUWL/3ve+pxJAc35wjoX33nsvysvL8dOf/hQf+tCH5vjEjS3Siqw3hpf+tEbgViDQ092DxvoG/O7FVzE2OoY/+sKfIC8/D2bL8pRGB8nua2vpxbE3ytHVMYjHPnFAEVmDgqfV+m/kWCVANE77xrpmF2pIZK1ucGHPVgv277AiyCLW3St77/CSqDgy6kZj4ziOvtNHsoQRhUXhSA4bgXW4AVX/8SsE81q98U8+h9DkFJjnCGrdyPHpz64cAjLGFGKMJJyHhtyorBpXhXbdPU4UF4Zgx/YwxMUGqoT+jWyVpwTvyyQr0kqe/Gx0UoVVgkNVnSzo8xjAPBa2ZgCFSUA87eTlb93mR8CfiKwzR8oYOcadBpyu96Ca58bQpAHZDBpu5xwnLsxLdVb/rX6fwUA/33wEHJw7SzFsFe+FFy7bUZJnxuHdVoSppMnK3Q89TOC66azxqqMdle4hZKpkbYQqRNRWmje/n/11CzLHdbMS3m6zUyFnEuO0+m6l6k0L49R11bUYHBzkezYqnhVhAxVCizYUIzEpicp2wYwR6aTgUs8LIay+++67+PKXv/w+EbWQSkPf/e53sXXr1gVXazKZVIyhtbUVeXl5Kg8gOQYZc8l6v/a1r6G6uhpxcXE4e/bsnERjWS4JpoWaEJivXLmiiawLAXXN+5OTU2hh8VZVzSQulY+zLwKRQXvzfJItExNENCGAyfv1R7r08HrjcTnR8sbr6GRRuFhERxcUIv+xP4AlMvIaFK/+U+YVMv7v6XOikWSFK9WTGBh04+7bw5XylmAqhXK6aQQEgSuXR1FVPcpiDAeSk4Nw6HAcCS3TuTCN0NpG4MLpWpRfaERHWx9S0uNw531bERNHRc5lOA2tbURu3d6vFpH12iMcIaG1lzmtU65eNLnHVPZK8llbmNsSt8HIALMSaZHMlm4aAY2A7yHQ2d6BU++eottHFdpb2/DAhz+EXXt3ISo6+n1lVhkzjrY0o+yH38eU04mMu+9BTMkGRLLw6domY0QbXRGaWhx46bVhCrkFYM+OMKSlmJVowrWf139rBG4mAjbGCEVgo7HXi2q6IFd2AukxBmxKAwoSRWjD/+9Nmsj61qJOMYPNRplFH2tnzpzBo48+qiqlhfzyyCOPoKGhQRNZfayf/GF35OYtQczRsSkV2LlSY6MKkhOioJWXbcXu7aEIDtYVKbP7eoJJ9r4Bj1Jm7e6jzREHP3u2WLG5kAqVrNzxZxtKuViO8+bayuO/1AqUNnuxj/abW9JF4tyLYKrU6uZfCEwxYOxgPWuHZxLVriE0TI1RmdWFg+Yk5NOSJYYWlUZtUelXna6JrH7Vnfpg/BSB82fO4e3X31ZJvaTkJKXImpiUuCyygIwHxX7t7d9dpNWiEdGx4bjtULFSsDAuYXAjJNbOHjfePmOnyibHlZmB6pGebIRphYukZN/dtAg6d25IWQOOszArJzsMO3dFcWwyBWdPO6p//Z9wjo0yCVqEpN27Ebtxk5+eHWvvsNycd4jFU8WVCZXIHxlxIyzUREWcYCQnmlVSX6rjpbjuRpqdBNYx2sfXMCBUzYDQwAQLzkjySo2WqmYDkpkHjwgGQi2AhSRWndNeGF1/JLIK4VmK9YZ4fnQMelHbA3RRuXeYhNYdWVRmTQGdKAwIWl6dwMLg6k/4NQISd7HZvahvdeH4ORvdXQKQkmjERiqzpibeuOL59cAa97iUCtGLjla0cN72gDUDhcZIRAVYdIr2eqDp5fMiIGMsxs3R39uH+tpa1FRVo7a6RinhhIaFIpmKN/JI5Hg0IjKCcexIpcgq1o9CpNRtaQgIifXv//7vVR5A+iCaCVshtH7qU59a9HhfCKx79uxRO/DKK69g8+bNV+2MkFjvuOMOtezZZ599/7NXfWiRf4ib3PPPP6+JrIvEa+ZjUvgn94aBAZJt+lzKjaCDSq3hYSalILplUyh/UyZYreuLEO4cGcFoexsaX3gevaWlyKYSa9KuPQjPzIRxAWVnt2DKuL0IdrxzYgxJiYEQJdb8bIsqjBMSq78KUMycV/p58QgMDTlZmDGJd6QQ1mrEkbupJB5vUXPRxa9Ff9IXERgeGkd7cx+Ov3UZ42OTSKEy6xaqshZvyvDF3fXrfbpVRFYXc1pO5rQGPXTFmJpQOa0e5rfk780UaSk2RSnnihDo8apfn4D64NYsAna7HUODQzjz7mkcf/sYYuNjlSLr4TsP0/kjnuM5Rng5T7L396P59d9hiHNV9+QEMo7cw8fdcx63jL37WeB04dIEenrdFODw4ODeUGwqCVKfn1F6nfPLeqFGYAUQkNigtNpuEdrwoI4xaJmb5CYYkBXHfEUU8xRW5inWwa1JE1nXKJFVKtulQrqHNk0///mTDCTdiYceukMRWX/4wx/htn33TZ/ly/rXgB/+4BvIysrFH/zBJxiABAOMBlWRqifzywJ2zX5ZLp6SRK5voo1ns0NVpYQEGxk4MyOTEusS+LFQPUuIB7qBilFetHa5lcLYlTonslIDUZBlol1uICKoUiqiE/466JFEr6ixXmoz4HiNqBQByby5CplV1KzEgtNfj309n/vjcKN/yo4zrh40uEeRFEDbJRJZi/gIozKrVdux+M3poYmsftOV+kD8EAGx1xEywduvv4UXn3sBu27bja07tiK/sABh4WFLPmKXkxXMI5MQ1YrXXjyPrTvzsHl7NjJyErne6WDOjVLGDAAAQABJREFUYlcuY0oJDNW3uFHXwoQsSTuxUUbs225FXLQRoVQ3XOk2OuJiAMqB8+eH0NdrR3pGMPLzwlBUHK6CAY6hIbQdO4qBSiYx2tqRec+9SD9yBEYzlWY1yWKlu2PR6/OQQeigpWP/gIv2qi6qsNrYj05E0h1CrFU3bAhhEtGoCF+LXamMUx1U2BwkKbFvlHbxI/JMEuu4l/MYIDbMgDw6CaSxyjmePxk9910sstOf80ci62wE6ESJ5j4vahhIrCUBOpYKDQkRHuTEByCJxOfoYK+Kmcz+jn6tEbgRBHoHplBe46Q6qwsjtBATd5fCnEAEWVcm1tLuHkfN1AiqpobhZPL2QWs6sgLClIvGjeyn/uz6RsDldEESh8McPw0ODKC/r4+PfirW9XPZMIaHhxAdE4Ok5GTk0hEgLT0dSSnJiriqY0HLP3dmSKw//OEP1coee+wxfOMb30D4DboJzLjHyErE+eXavhGicQpJyC6XSznCfeQjH1nyzmsi65KhU190uZiE55i4umYCtfU2Om64qTQVgNRUC1KSLSzssiiRCRFP8OvGiaQoaw3W1qDz3RMYbW7ClMOB/I8+jrhNm0hitcIwj8qzzC0mxBGElrH1jQ7UNtixdVMwtm8KISHYyHutn+Pn1yfHzTk4IT5L/OD113sxNuZCbm4oHSzDmDMNuTkb1GtdNQSE3DQ6PB3jqq/pRG/3MDbvyGasK1cVbQeHsJpVt1VB4FYRWWcOThwrRinK0sh8Vv3UKGpdw6rIL85oRTrnScnMcclrM1g8rcVaZmDTzxoBn0BAruVVV6pw4ex5NNU3qnHggcMHkFeYz2LKZDW/cZG8Olxfj64zp9Hy2u+Qee99yHvkMQSGhMxZADVBR4SubjdV+204d2kc+3aFYtvmEMaiGX/297G2T/Tq+twJ4a9KzmJ4QnIVBtT30LWJYgqyLDnKgG0ZzFOEAzeYhlvTYGoi61uL6j+fUmSVINITTzyBV199FWJF/OWvfJuEVhf+4ov3KiLrD37wQ1ogHL7ugXmlysgxed33Z94IIBnx+NGfMeiYg3vv+wNV6SuBcwmSaHuVGZTW37MQD9xuVqkNT6GmjtZGtXZlwXNoXzi280YeH2ekrREzwLpRAW2apPH/2XsP4Miu61p0NYDuRs45DHKcASbnYRpmUhIpkuZTpG3JpWBZqv/Lri/p68mPVsksy7KlZ1lfwc+WqGBRgZJIDuOQQ3Jy4ORBzoOcYzc6d/+1TxMUBkQeYAbhnKqLbty+fe+5+5zuPnvvtddqbmP1ToWTjGMuVv8YcM8tlIAi45hRsTotPlBjuZjey8nSbzGgbQB4q4pVTBbgwY0GRXkeJ6CA5dJR3Y9Fs4A4/TLuVz3+5OhxZxcBrEbcbU5HZmA44inJotvqsIAGsq6OcdR3sTotYLVY0dXZhddfOYhXXngJf/WFz2D/3XciOCRYMWMt9K5HCWKtqWxF+YUmnH+nHh/6sz24ZX8p1zOBCJgnG6uw+otU98tvj6G81omiHKMC6RRmGyGsmksBHKyqGsGFC8PoYRIqnEyed92VRGlABqLp20gTeSEHZW+b3ziIyz/+EfIf/jAKP/oxBMfEICiEFTm63RQLSNJ+gJXwl8tHcfjYEKKjjYp9asumCCbtTe/5pvOZM8LCKiDWc00MdpKFtakPrGb2YUM6UJwaoFhYTaxqDgzwcdMr1vkO/GoHso6zs/aNAm2DPhxh0V7HIFBAWaeyDAO2ZxuU+sZ85uR8bayPX90WkN9IAdkcPWvH22Qs373ZjI3FZqQnBSwKwOa8qw+vOFqRaGBiNigCW4xxSAiYX0HK6h4BfXdzscDoyCjXm524cukyLpENsaGunrFmB3Ly87C+tBQbykqRmJzE3+1oBDH4JcBL2SYDJedyLX3M+y0wkUn1M5/5DJ588sn3HzSHPadOnVJqb3Lo8ePHCczKvuZdw2S9LC4uVvtefPFFbNmy5ZrX5/OPBrLOx1rvP1bi8dKcTi9GqSxRTpWC6toxNDbbkZ8biu1bI1SRV2zM6qbm8Xk8cLNos+XQG7j4g39HMllY1+2/E3El6xGamDhrBZr4Fh1dTrzyxrBST8vNMqOECg85mYQnaSZW/yTTf6+xgABkxsjGVl4+jIZ6Mni2jWH3nniSDMVfc5z+Z2VawEN0iG3MiYuMcb30h9Nk8ItCfnEatu7MV8pDK/OuVl6vbzaQVSwmOS032VkHvU70+uw45uhEg3cUkcxtbSA76z4ji/j5XBO1rLz5pXu8+i3goB9qGR3FH37ze5RfKkcSFem279qOO++9i+u7APi8XhX3b3vrTZz/3v9Gyp69yHnwA4jKzlFx/8kWksInLjlx8coYXn1zGBmpwt4fjPVFIVjta+3JttD/3zgLSLxZCOLK23x4q9oALk+oIujDrYVAYUoA1eKEgIMkeWsoVaGBrCsMyCoBv1/84hdKKigzMxOvvfYmWPBOZhoHnvz6BxWQ9fvf/wEXXHum/WTZbb1orPvdtK9PfiE8IhMZmQ8q+m1x6KXaICQkAMLEqbYwAhcpKy+b/D/O2jr5PPr/1WUBm92LfiaVm1ucqGElOPk1Of4BKMxjgoVJ5fjYIA14fnfIh0e96OjxoKLeibZOD1LJ1pOdYURJrkmxqsxQKL7iJ42dAUKLw4BT9T409vqpziXJuz3HgGACeYN0ofuKH+OpbmDU50YXZVguMkna47WrQEApHf71QdGamXUqg63AfRrIugIHTXd5zVigvbUNxw4fQ+vVFjL1jOCDjzxERtYtKnCzUPCAi6jT9pY+vPnqBVgtDjJsRWDrrnwUrs+YNyCBsSO0saq5ulHY5rxw0EHfVmpCDtdGsVFSMLe4Q2W1ki28z6kSTxUVI8gkE2t2diiKiiIREWF8DzSrgloMfHWffQfVv/4VQhISEVtUhFQGtyLXZS5up/TZ5mQB8TU6KJ1aVz+GoWGmFDh30tOoBJEZgtQUkXMUQMzsp5LEv2zDZNIU9tWr/T4lC0+SYQVUDaUcvDBpjjOwijzPWgoKzW7B+R2x2oGs49awMaA46gBqyMoqDK2DrBUO41xKjSajb4pIPflgEkWbOczR8XPqR20BsYB8XwlreWW9CxcqHZDvqliyxAmgNSE2AEbOq4U0kc4cJdPQaVcPXrG34FZzKrYExSM5MAShhtUNfFqIvfR7/mQBAfF4+SPczwC0KIO1t7aiu6tbsa/K/gD+GJvJghgZHYXklBSkpqcqJtZQMtwEB+ti1j9ZcvGePfPMM/jbv/1bBRR+++23GZOfuuhKErdhHAcZw5/85CeoJxNRbm4uPv3pT6vOiOLb+vXrFePq3r178fOf/1wdL+8bJNvu3/3d3+HAgQNkqoxiQdiF6xpPDWRdnPGXsZSCh+5uJ9o7nFRLs1GNg2XlJE7IoGJaRnqw2kJD/Kp6i3PV5XMWx9AQOs+cRu+lixioKEc6QayZd95FEEIsgqb5HIz3Xn5f68jCWtdgQ+NV+rQE/W7bFIakhCBER+nfwXE76cf3W8DlokIIYwqVlSME/fdRFSQKO3fGIibGyO9fPXfeb7GVs8e/xvEx3tWLy+eb0Nrci9FhK3bsK0ZBSTqBrdGqeHvl3NHK7OlyALKOW87u9cAOD5lZh9HisTK3JblvH0IQhLygSGQHRiA2wIwQ7T+Nm0w/agvcdAuo9TEVJC5fuITKKxUk4qhGUmoydu3djaycLCQmUXaLC8Hey5dQ94ffK982NCEB2fc9gJiCgmn739LmQGWNHe1Uy5HCByF0E4XipSLhmLYj+oVVbwEr48s9VI2r7gA6hnwYYg5D4ssZsUBekgFx4cTTkENwYdHAlWs+DWRdYUDWpqYm7N+/n4yYbkgldEFBGXp6nZAv0//3yw++x8gaZL5FBb5HRhnxntTclBEbGrgwae/7/xXnfnS4gpXzGfAF3aUkaxys+jUaDUwaBiEm+t2NDps8j5aNTn8owawmk0EF1wMFGc7MzVwSjO/vgd6zEiwwyKRyV48Lx05aOA+dKC4IRmE+t7wQ/phT+m6BSZaVcO/z7ePFKiclAh3oJKg1MS4Qd+zyy+eGkul4ocCS+fbhZhwvVSTNfX7Gq5N1QHK0Dw+UBSAh0qAqSPT3w80YlaW/pt3nUWDWC65+vOFow3oCWXcEJSCTrD8xBpOSYVlri66lt/qNu4IGst44W+sraQvMxwJuAk4ryyvwzM9/hSiCCTZt2YQNG0uRvi5jPqe55lgJBo0SAShsrH985hgSU2Lwocd2K6aKiKipk+bXnGDCP1LNLJKYl2tceOOEDYkE5GSmBWHLerNaG0049Lqfii8jQaZe+koVFcNobCRTbZcd996bjLKNUUqKfiqVieGmRnSePIG+igrYmcBf/8SfI2nrNhiCglb1eu26Db5IJ5D5RleXgAofZVPHUFtnQxUlVMXf3Lk9kiDWYCQlEi04x+bmnHPJvCMLq6gEVHdJUIjJ/xFWMycbUJIGbFpH/zbYDzqc42n1YTNYYK0AWcdNYCMYv2PIgMPVPs4xgks8BuzIBTZnAjGh/uK9eZJWj59aP65xCwyNcm5R1eXQSTsslBa795ZgVfQRHbmwig8LQayinCGMrCdc3XjcnEMwawoFMhmPWOO21rf/fgsIQNXLhZuTCUEXWevtNjsaGxpQX1uHiitX0E32f2G+KSwuQtmmTVhPBlZZbwpwVUCQui2tBb70pS/h2WefnfUiGRkZOHPmjAKyPv744zh27BgEsPq73/2J4ELAq1/5ylfUueLj4wnO2knAVh/Onj3LtTQXUWzf+9738Nhjj6nnC/2jgawLtdz07xuzeThWLpy/ZMG5c6ME1QUp5YLNVC5ITCB5AolISIS8anwYUdAYaW5G9TP/DVt/P4sN1yHjttuRtH3H9EZ69xU3wb9O+hdvHR1BNf2LGKo8CBnH9i1hMBn1d9asBtQHqO9RAbK+9FIX4uNNzMtGcAtHQoJ51XzG1vIwO1k5Zmel4sEDZ3Hi7QoUl65DycYsxtOyEE4N30Dt0C3p9FhOQNbxGxXlQWFnvejuR7lrANXuIZQYY7AxKJZg1kgqD5phNrC4mm/Q3tS41fSjtsDNtYCTa8WG2gY8+8xvYbVakUww677bbkHppjJiVYJg7+lBf2UF2o4cxlBDPco+8zmk7tqNAJHPnQKoYCehm8XqxUuvD6G+yY47b40kBiZEEbkJ/kk3bYHrtQBTV5DcRccQUN/tw3FiaGQq5iX5sCUzAEUp/itMMT2v99Ir4v0ayLrCgKzf+MY38KMf/YiV7mbcfvvt10yyo0ePUuZiDKWUcEpNTcWtt96KO/Z/9Jpj5vOPJH9/9vQ/ITUtF3v2PsJkopebX8LGZvcwYOmDfInLc3l0MCktScc4MnGmpZqRlmZmRauJ0p1+ltb5XFsfu3IsIOBmmQtXW51olq3FruTusinJk58ToqpTVs7dLG1Ph1hN0dHrxoUKB4bI0hoVHoANBSaUFpr4w+RTLBZL24Obc3b5LhEKdPkhPtMAshWJTKsPu3IDUJpOxivGCzVT0c0Zm6W8qjj7NoJZ271WVLoG0cbHUTr/e03JKCIza4zBDKNBB4uXcgyW8twayLqU1tXn1hZYmAU89Hp7yJJ18dxFPP/scwy4b8CHH38E0THRCAtn2eYCm4BBRWaturwFHUQC5hWm4s4HtjAxaoJR9Nfn0WT9U9PoRv1VrhnbPdi63oiyIrNiYpUCqMVskqwcHHSirs6CE2RNiY0zo7AwHDk5YUhMFJDF1MV2TkoRjfV0o/65P6Lz1EnkP/IYUnfvRnhqGgJMcwdQLua9rJVzyZpR5JtaWaRZTfCqVLyPjbmVTGpGulk9hlMNJDh47usHYWBtIQOrVDQLY6aH50+KMpCB1YCkSB/iIwyICiGIVRVgrhVLL+19rjUgqwQdxdfpITi6icystd2MmTBuwq9IbM0CshMNiOYcC9QOz9JOvFV4dmEst9p8OHXBjhYqu4SYgWKqumwvE8DE/G+4wzOGt50dGCGg1UQ/bLcxSfllCzjV/C+u37HiLGCjdPfgwAAa6urRSBbPBgJY5XfaZDYhLiGewJ1EFjUlIi4+juC5GBZQxSAkVIAewpauZ9VSDrjYV8CojY2Ns14mJyeH7IHHFQDrIx/5CI4cOYLbbrsNwug63uR8v/rVr/Ctb30LPUzuTmzR0dH45je/iUcffVSdY+Jr832ugazztdjsx7vJ3i35GGGK7OpykZ3VjoFBlyKVyMkOQdmGMKVgEBJCNOsqaAPV1YpJq/WtQ0o9I++hhxGZmYUQArBna50sDBEAQk29XcnE79wajux1VJSL04pys9lOv+63gBRcdnc7VJFsS8sYRkkgdNddSYwxREwbW9C2WzkWkDiEmzG15vou1FS0oKq8FcF06G7ZX4qMrATEJ0atnJtZgT1djkBWLnvhZG5ryOdEJ/2oVq+Fea4xDHjsSAsIQ54xiuqDMQg3GMnVqte+K3Da6S6vQgtIMebI8Ahqq2uYH7mAMyfPYPe+Pdi2cxuy83IQQjCrc3gYtb//Hdrefgt5D38YKbv2IILFf4HEXU1uUtMn6+0z5yxqDSng1exMM3Zto/KIee6x6cnn1f9rC4xboM8CtDJvcakFVI8DCeCAzDgBshJvFy7EG1NirMffvuofNZB1hQFZ/+Ef/gE//vGP5zQxJUD1ne98Z07HTnfQk08+ycrCAnzsYx9Th0hCWORqhOl1mEycwyNcyA27MDTk5j4PRkbcTGoHIjIigIBWk6oEjiJLa3hYALcgLv4DFMhRgmQ6rjmd1VfmfuuYVzGznjlvxcCAi8y9AQSympGbbeZcoMwKJY1k3Nd6k0RUeY0T9S0uJatbkG3CxiITJQIDEU7GntVsolE7JZy6gMp2LyoIJtiebVBMRYlkZg17/xpxrU+VVXP/Vp8bvV473qGEZbl7EFkB4cino58fEIWoAMowsHJVt5VnAQ1kXXljpnu8+i0ggIPz75xHxeVyJaGze99uPPI/HoWBFSMLXYO5yEphsdhx6JXzaKztREZmgmKmKNuaq5I1c7WqAB9kDdTe5capi3bYKJci655tpQSXZhsXff3jdntZee1BdfUo2cMsaGuzoWR9JPbuiSPIIpBFgTP89rCzwkBWT6mh5tdfQ0xuHuLLNiJt3y0wRkQs2JZztdVaPU78TOuYn1WqsdlOADJRp3QdRPFj6+YIVSgZGhow67xjzBJOBhpl3TnEUwhDZvsgC6oGBUgIJBLEWpTMgBDZWMO5/jTOMBXW6lhMvm/5/PoTez4CgQ2qwFXGS1hzXQzoynMpaFWPRHW++Nz3ER4RjXvvf0LZXNhrhA1MAr5BAhjmc3kcfy7jIq/JtpJ9IbFTO+dZLf0d2XrJppmdAOQkBiCL+IqoEGifZ/Lk0v/PagFJmtQ2EXzT4kZtowtZ6UG4ZRsl3FkUG0Jll7k0ScLa6ZM1eEZwwN6ifLCdxgSsoyxmQgCj4rppC9ACovzlsJP9l1LzQ4ND6CcjZ19vH7o6OlShlBRLxcbFIYXECQVFhZRozCHxQZoCti50nakNv7wsIAxGlZWVSu1NksB5eXkoKipinJ8/YIvQNJB1EYw4zSlkDSZEE5VVY6hvtKGzy6HW0NlZIUhNMSk1gzCuoyVWvxKbl8wqHqcDV19/Hd3nzsJtG1P+Wf4jj8IYGqb83enuSwAINhKwVNWO4ewFK0G+krMKwu7t4SRg0SDW6eym909tAavVzbyXE6dO9ePKlREqZyZgw4YoKlUSyMa5pdvKt4B11IaeriEcevUCeruH34uBFZdmcs0TxHHWAYSlGOXlCGSdeJ+S3xpkfusilQdrPKyWZoszBCMvKBIpAaFICgxR7KxGal3opi2gLXBzLSB+raiJvHPqDF458DILLqORnpGGHXt2IYMKIqEsvmw88AKaD76q2P0TSsuQdsttMEUSQThNa25xoKHZgSuVY2odefveiHdxL/ozP43J9O4ZLCAxOgcJEAapvNRMQoT6HgO6h0l2RwKEbVkSRwZSScAhJHA3u43HeqSg62Y0DWRdYUDWtrY2Vv6R4mOK9sUvfhHNzc3467/+a9x///2KlTUl5V3O4SmOn8uuyUDW8SSWh8F0SWZ5mchyM1klQQFhbBWQa2cXGZau2tDW4VDg1tDgQCQnm5CbE4zMDL8UpNEoH8C5Bd3n0k99zM23gEoaM2g2QIBzTR0XCQS0mkxkOkowsjolHBlplBJf4cnJxbCy2Mlm5w8TgazHz9lVwleSUHu3hiB3nUjW+lYtQEIYsETWtbwNOFwjzFdQjFj78oH02JWduF6MubFazyHMrG7+eLSSkbWWEixnnb0IIkrhDnMacpg8TQxYnKTIarXfcr0vDWRdriOj+7WWLTDMiuLf/OLXaGluQX5hPjZu3ohN2zZfl0kGByzoIgvrqy+cISuXBQ89vgf5xemIoLTauCM7lwuI79DYyjUiQTgXq53ISAnEnbuCEUu5eCl2WuxmsbjpM9lx8GA3mVJc2LIlhsn4CKSnBytWRMMsfog45/0V5SpR2nnqlGL5Kfvs5xFG3ypAEHm6LaoFvLT3GIviWlodOH5yWBVMskgeWwhgLSrwM0mJXyG+xGzNQUDlMAGsFe0+nG0CiMMmYNKL0owABSpMjxGpdx83f0Bo9jPOdsXV/7p8fkWKVQoXR1jIKgWsoxb/o3pOmS0paB0leHyMgPVQ/DcBBZEIjnxYSdqGETwu0rbyKJ/3UHkkAC9Uilwn7DeZAhSD2Eq2qIvzz+ExMBDppSSUARdbfJx/IgdFADVDMzlkZ9VNW2A+FpAYnJ0KOE1tbhw8Nkb5Y86lHBOLQKiElDw3VnTxx9rJIlTFosK3nZ0oDIrCYyE5MDPRSgjPfLqjj13FFhij9GJXZydqqqpx+cJFNDc2cQ1lQWZ2FvLy81BYUoSExCSCWWMZ66OUarCZ39kCAtNzaBVPi0W9NQ1kXVRzXnMy+a0Q/0UAm4ODLFxosqGu3oaaWitZWcOxvoTMcVRNi4yc2+/GNSdfBv84RkZg6+tF+U9/gsHqKuQ/+hiSt+1AZFYWAsRpmKHJ+rW13YlL5WMQ8o07bonAlrJQxMaQcEUzac1gOf3SVBYYL+47ebIfp08PIDMzFLm54SgpiVQ+zlTv0ftWlgW8zHXbbMxvN3Sh/GIzTh+twvpNWbj7wa1kpI+k2pEuAluKEV3uQFaJWXnoU1ngQp/XgYvOPjR5RtHns2NDUCx2m5KQxALBSINWcVqK+aHPqS0wHwvImliK8vpZlNna0oaDL79GhZEG3Pvgfdi0dTOysrMwVFutYv5dZ86omP9GxvxDk5OnzXWIAkJXjwuvvTnC4jEP1heFIo8kbuuoHqabtsBMFpD8mZWxlt/97nck7aijink4dlP5b9v2HThcH4xq5i9aSYqwO8+vYJxMAg5Zakh91ESyh+nOs2PHDq5BQ6dUT5F4jeTxRZVFlFfKysqwZ88eRWApgO/ZWkNDg1JtSUhIwFNPPfW+ayykT7Ndc/LrGsi6woCskwdw4v933XWXqpz+4Q9/iIceemjiSwt+/uST1zKyznSicUduYMDNL3QHZW1YpTTkUkEUQtSYeISSgQyhFGR8vEkFDGJZARtKBlezDhzMZNoV85os6OW7T8DMtQ12iGyPhUnONFZ/r8sgmJmV4JK8DApa2wk8mgn9Q17UNjvRSEBrV5+XySgjCrJMCtgxV2aVFTMxJnVU6NGrOn1kZ/Vh2AZsyzagIMmA5Gj/j/Okw/W/q8QCo5Sw7PXaFJC1i48mJk0LjdEopbMfbmAAmZtuK8cCGsi6csZK93RtWEBArG0Mzjz32z8QbDaGBx96EPlUVUhMZgnnApoEfWS9UnXlKs6eqsUIqS2josOw/75NSE6LnRcLhSRUR1hh+s5lB1o73WotKIz0m4uNBOQIw+YCOjjNW5Q/QtBdDZlYq6pGlEqAqEPs2BGHpKRgBgvmDkK19/djuKkRNb/7DTx2B3I++CHEFRcjPC19mqvr3QuxwBhZWIdYCCcsrG3tDqX0ERUZiPS0YGRnBauCSJFknxi8mXwd1krBSSaqDjKvdo0YFAvrCNeYUkAlLJgJEVAg1kQW10eRCXgWHPPk06+p/6XoTgpUR+jDDY+wSJHytKMWrwIau2hj+V5QQWF55LH+5/798l5pzbX/RcavKGTk/JkaNxk7AY+LB+j/vLPKnLLmsmP88y9jEkSAnpmAZYkPCMh1HOiqHgl8lZiBFMPONBdUB5bBH2EDFp9HANU9o1CFv+mxnIdkZl0XF4DoUClevDYouQy6rbuwTC2g4geDHlyocqK9m0xgjCXs3RqMDQUmfmYErC+frumbC16ccvawqHAYY3CjhBKY+02pfAPnofpkTv9e/crqtIB/ncd4zNAQ2VZ7FIC1l4/CwjrGdaSL7IeBpM8ODQtFanq6Yq5Zl7kOYWSmXyx2ztVpWX1XM1lAA1lnss7ivWaze9Df7yLJiJ3srA54qFRhMhuQwYK+jDQz0rhJUcRKIBiR7yoiEVSBYeuRw7C0tSLAaFIysDGFhTCFhU+7mJK3ii06+bt59oJFrWfl93Lr5jAUUEFOk6ws3pxbi2eqq7Mw3jCKri4bAeJG3H47peeZ79SsrKtjNgiYdYQBhcbaDpw8UqkAUTGxBMHvzKc0dTL9UvJuiqyIbotmgeUOZB2/USkQtHndaPZa0OwexVU+8ucGocxrZZOwJSMwTDG0igIhtbHG36YftQW0BW6CBRwOB2xjNhx56wiuXLjEuGQAcvJysO+2fQhmQNPd042a3zwDLyvSC//HRxCTX4AQAvamarKulIL+c5esqkBKivqlMGpzWZhaV8+FeGGq8+p9q9sCAvQ8ffo0nnjiCa4rRq652QjGVp577nkc6SxkrgJYnwZkJRgQIjG+SUuM2c7z/PPPKyWViReQ93zmM5/BgQMHJu5Wzx9//HF8//vfV6o873vx3R0CBt+/fz9qa2uRlZWFkydPqhzA+PEL6dP4e+fzqIGsGsg643yZD5B1qhMJs05HJym3WQlcS3lIeW4jS0tGOoMOuaEozA+lk2dEFCuCJYm1UhJTU92r3vcnC/jjTAQsULLn/GUr+gluTiYz6/5bo5CcaKSkq6RLVkYS8k93tbjPxMERsMWpiw4cO2uHkeDejBQjbtthRly0yG+uXkdHktzEmODlS17FlJVKZixhKNqR4/+RlkS2bqvTApJE7SAb0CXKsLzmaEUu5VduZxJ1XWA4YgOEE0gP/koZeQ1kXSkjpfu5VizQUNeA8svlOHn0ONlSI/Gpz30aySnTVxLPZhcJ3LvdHrzxygUcePYkdt9SQnbXXOQWps6LgULWhL0DHrQQwHr4tA1jZMd88PYQ5GWaEBG2+GtBJ9UBrGNuvHmoF2fO9GPz5hisXx+J/PxwFtTNHcQ6bh8HAR4VP38aQ6xAjSCQI3XPXrWJs67b9Vlg3F/o7nHiKiWaFBMrWT1L14dhA1mjSorDZr2ArKflPDYnmTHsBpxt9pH5n7I8fQakRPmwnWvLklQDgYP+U+lhm9qkUozoB6WSTZSfIVFZae0gAEJJZ9nRxeJECdgGmwMRFRWIaAKNowkQj4wgIJP/C/DY/3+gYl39wf/3L0zoxuC+B55QLK4SE7CQrVUYsawELlvI4Cr/C3ur2v/ua+L/SNFrHBmyRPJVtnjZ4oJYBCvXMRJ0AD+rsnwEuQXIoIqixTL0LYkbgQCqL7f6cLCczKyMd6TQzxM1irwkgMqUGsw69ZTUe6ewgADJR/nZOXnegeffGMPd+0Kwa5MZ8TFkNubnZrom+PIxFhQ+a29SydYdpgQUBUVTGWN62bzpzqX3r3wLCCjMQ0kt2VxOfs83NKKyogLnz57F1aZmiLR8dm4utu7Yho2bNiMzJ4vrJ7LZazb6lT/4y+AONJD1xg6CrLlGmWQ/fHQIldVWhIcFoSA/BLt3RSIiPIhALFk9yVpE/i7P5pPvKpsNTS+9iCv/8SOk3nKr8sWStmxV7Fkz9ZpvRS8BvdVUjXv9rSGqBJpx7x3RiOO6Mjxs+t/Nmc6pX9MWGLeA1epXgHnhhU7YCZh++OFUZGSEIoyfM91WjwWGBq1oIpj11LFqFnjX4EOP7cGuW4oRHRtOZno6protmgVWCpB14g2P0Mdq8VhwwtmFd1y9yAogO7MxFjuMBLZTgdD4bozC/2s78Z36ubaAtsCNtEBnRyeqyyvx21/9lsyVIXjosYeRW5CP2JBgXPk/P8LI1RYkcm2Zsn07EugDT9fcjMkMUaXq3EULXn59GHt2hGP/LVGIYGxUs/xPZ7W1vb+fJCnCvmqxWEjUkYxHH30UwSEhOPDCCwogGhsbiwMvvoyk1HUwcQk5GcA6br2pziMFxi9MOM8rr7zCtWiGeov4d9/4xjcgxJfS7rnnHtWPCsZ+nnvuOQVg/fSnP41//Md/VMU66qAJfyT+8+UvfxlPP/202puV9X4g63z7NOH083qqgayrCMh633334fLly/iP//gPfOADH5jXRJju4OsFssoX+xgTYaOjbiURKVUKwtIqLJ1WlbzyMngSyCSViRXBJiQnkak11qgYJZZxHGU6c+n971pAEsrSJGDU2eVCfZODYFaXCo4V5JI5pCSESc61/eOuGDBoo26ysbZ2elBR54SVydyc9EAUZBsJ8Fi9zrACHTCj1tgH1HR6UdUBUqUbsDvXgLQYIJ6sWbqtTgvI2AsLUIfHinJKW3YR1DrsdWKnMZGOfgxiKL9iYsWqbsvfAhrIuvzHSPdw7VhA1hRvHjyEt994C3HxccgvKsC+228h4CxqwUYYHmLAvr4Ll88T4HD5Ku6hjNqm7XmIYImo0Ti372lJHtqdwMUqB85cciAqgr/zSYEoK/IX7QgT0GI1ta7ij0xLyxguXhwmCxHZh1g1s3VrDHJywhlUClqQIoCbidPeSxfflRs6jdR9t6LoIx9FEEEdAYKo021BFhBfYZig1ZYWYYqyoaXVTqCiUbGvZmeGICHBpACSM51czmFxGNAx5Gf5b+K6UmZUiNGHxEgDkjj9U7jFhBsQxmpm7Vu+35pSVOfzGcju6EYf/bauHrfy3waHPASLEmhJgIMA5IQRNSzUr6Ji4rQ3mQL8mzzn59j/v0ExWwnT1Xe/+21ER8fiYx//lGJ3JSaeQTKfei7fCy4XVTz4+ZRHAeeN7xMgugBpReHDSVZYp7xOkLL/vWRx5bmD2afICAHUCpD2XRAtgbSh7/qWy2mcx5mC+y38buoHmnqh5msEJaLWxRmwaR3nJ6vug8lCq5u2wGwWkM8riUJQ0+TCuStO9RkSUPnuzSakJAROWwg7QOnLDu8Y3nZ2wkq/64HgTGQFRSACGmgxm81X2+vCSDM6QuaopiY0EcDa1NgIBxnnhTFb2ECiY2IQnxDPLYHSufEEe8Vxf6RiHFvOQLfVNk6r+X40kPXGjq6sn2Q91dnpVKoHrVQ+kGIlUUkrKghFfl6IysksZ5U8W28v/bB30HPxAvquXEHuhx5CGsGsIbFxCKQ/Nl3z56N8OHGG33ltDrVezcsOxubSUMVOK6ogumkLXI8FZI6NjLhw+HAvWVntzGuGqOLZ4mJdKHQ9dl1u73VQ4sUyakP5pWZcfKde5TaTUmKw57b1SEqJ5veJjgkt1pitRCCr08fiXHhUnusq2Vnb6HNZCW4NMxiRHxSFUoJaw+hzCTurbtoC2gI3zwI2Ko6ICsnpE6fR3NiEwcEh7N63Gzu3bcYwY/7DVZVUZGtC+m23o/DPHlfMrVMFkSUObXd4iXex48Rpi4qFJsQHqfWlqBLrpi0w2QJ///d/j//8z/9UOboDL72KVsc6VLQBG1NG8X//xX50dHTgIx/5CL79L99RU246kreJ53n11VeRmZmpLjU6Ooo77rjjvfN85zvfUfsHBgawZcsWVaj8l3/5l3jqqafeY1P98Y9/jH/4h39Qx50/f14BbCf3+4033lAssuP7pwKyzrdP4+ea76MGsq4iIOt8B38ux18vkHXyNRz8khcwa/NVm2LekUf58g9mgiw1xYyUZDMSydwZwaSUSAqauV+YKpdTQmryPen/Z7aA/LDXNThQU2/j5kBqshElhSFII/toHJl1xiUiZz7L6n1V2Eltdh+OnbOjoYV8lfw/P8uIbaVmhDImNxO7ykq3ip3JaZHafO0yK5nGDBC5zZI0AwqSfKw+MagE+kq/R93/qS1g9brQ67XjrLsPp53dKKS8ZREd/AJuUQSzmrWDP7XhltFeDWRdRoOhu7KmLSDMWSIB+/yzz+Gtg2/ivg/ej207tyMjM4NrLPO8beNn6vKirbkXxw9XYGjQoiTAb79nI4pLibqaYxOGR4vVRwlkjwKyXq5x4ZatZpQWmpAYx/XfIgO3JJE0NOREdfUojh/vJxDSTABrKEpKIpGYOH2Sc7bbERYgx/AwOk+fxJX//D9IKNuI/EceJTsr7UvAh27zs4D4fSJbL1L1be121NQymNjLOcyk+o6tEUyqhyE2zqiSzdOd2UUgpJNgLmG67B4h+yrBgVcHgC7KuGdRtl2YLkWOJ4aErmauJ3W71gIC8HYSHCo+mthdNlHP6Ot3o6fPhaFhYUr1KjbU1GQTMlKNSFHFpvK5nVvS/5//+Z9ZnBqLv/qrv7r24rP8J9e1knFSGA6GhimfPuhmEawUxPJ/7hOQq5Hl6WFk0YogQDkyQuIGAYgkq5gwa0mhpODLTaZANYdEMlaAtkIkeDPlc8W/E3bWK2QLvtTiQ/ewj1JRBLJmki2Y/k9yNPvMuTpd5f0sZtMvrzEL9JHlvLWLLCDlTvTz83HHLgInGD+I4mdi8jwnVB117hFcdg8QzGpVidQPEMiaRIYg3Va/BUQKTtaJdhblWEYtTNgNqgReW0sLWq9eRSsfBaianJqCkg3rkVdQgPR1GRBmDw1cXf3z42bcoQay3gyrixqYv4CsosqK+oYxtLU5sW6dWankpXCtJ+QiISxaEqW85dLEJ3XbxjBUV4e65/4Iz5gVpqhoZN//ABI3b5mxm+JvSFFWBwG8J89aMExylR1bwpGTaUZ6qgYZzGg8/eK8LCBFeOXlI6ivt5DIxUZFkUjcemuCAouvZqW9eRlplRzcdrUXddXtOH+mjusqJ/bdUYo8qhWlMJklaya9brr+gV6JQNbxu3ZR3sbqc+McWVmrPcPo89qQaAjBBlMc0gJCkRAQjBADi+tV6fX4u/SjtoC2wI20gN1uR1tLG86efgcHXz6IDWXrsX3HViSHhcDV1IC63/0Wqbv3YP0TfwEjizyNoaw6n6b19LpQ22BHXaOdxAAe3HlLJAry+DknnkljmaYx2hrcHUDnSthYmwiS/uIXv4hbHv0KKjt8JDkwoDDZB2/dz/A//+fXGJOJYD6retq1xOTzfPWrX73Gmj/96U/xta9dex5hav3c5z7HGLlRnVtiPONN1izFxcXMow3h61//Oj7/+c+Pv6QehWn11ltvVa9//OMfxy9/+UtkZV3LyLqQPl1zkXn8o4Gsb87JWgabjVSJa7AtNpBVWCQk0SzJM0lU2WweiJxkV7cT7R1kBxj1qsBJBuVe8nNDkJEerJJofodgDQ7AKrhlGXOSPKhxlkqV5hYnOjne2zZTMrQghCy8xjVNuy4BNqr3MgnlQWOLGycv2JU9cjKCUJJnxLrU1cuUIvc+Rqa2ZjJoVbYDZxq92MyE7i0FQKywZ80ff7MKPjFr4xa8TKo6vR60+caYXB3GFdcAeVq9uM2UglzKXCYFMnmmnftlPRk0kHVZD4/u3BqyQG9PLxrq6nHi6AnU19Tho3/+cWxjIMYsjKELyEb6uG6zWOwov9iE5397nJKyybj1zlKkZcQr+bS5mFatbQiWa253481TdrX2j6Wc9uZiM7LSgwhEW3xQ2QjZPc+eHUBz8xgGyMa6eXO0YmMVaT/jHMF3U92bYnolPeRATTXqJYnKwJc5OhpZ992P+A2lU71F75vBAsLAqcbqwijHys4CRzeDIaLWEK7k46MiOV5kSGJMZdo2OAZ0koX1fLMPbQSwOghqzYxnIVQyWVhJgBMXDoQyRx0k4MUZzjPtBVb5C6NURuknEK6pxYGrZMJtbXcR+GkgEDQQSYlGJJFNIDHeqMCiUmwq8lgCBhVQ6EzjMtFsCwWyKsAnHSOJFwhLqzCzynNhbXURCWq3+0HQIpMrxbHD8kiAqzwKQFcSxvGxQQSyG5FA2Vi5D3kcZ2ud2Mcb+Vy+EyWYNOY0oJ/xjqpOoKGb4OthcN4CewsMSKAihTC16qYtMJsF5PPgoA995IwNtc0uJMQGKiDrpmIqW/BzOt4ExCrtMKUuDzpaWTTIwsHAKJSYYhGu2VjHzbSqH4WBVZhnGggEqyCTobCwDvQPICU1Fesy1yE7NweJSUmKgTU0LFRJ3EkRlMjI6aYtsBQW0EDWpbDq7Occ983GxrzMvzjQRFKRRsbnpZCppCgUhWRnzSFbaUjw8vnse7kIHCZrtLCxNh44gGgC7QupihGenKJ8senuWu5V8hAXrozhnQtWlWNK4rpwO3MQskZczuyz092T3r98LSBzbXjYpYppDx7sRnZ2GO66K5HKFCb6H8vn87R8Lbhyeman1JCFlbRnjlcrQKuAWdeXZeGuB7cw3hTEtdMyqgRYOWa9pqcrGcgqeS6md2EhG2u3x8Zc1xCaPBY0ekawMSgW6+mHFQRFIypAF1NcM+j6H22BG2gBKfJ0MKbf3HRVgVkb6xsxMjSMDz30AJINXjQ/+1uEJSUTzLob8aVliMxYN23vhLDPSnzTkROjuFxuw9ZNYSjKD2bBlFGvNae12tp7QXJK69atY7zag98/9yJebNnE2K8B+YwDCwmHd6gWd+6/Qxnm9ddfx/r166c00sTzvPjii4ppdeKBAvQUVlZp4+f57ne/i29/+9sKkPrrX/964uHq+ac//Wm88soruPvuu/Gzn/3svdclFvToo4/i2LFj+Ju/+RuUlZXhM5/5DHM31wJZF9Kn9y4yzycayKqBrDNOmcUGsk68mEro8M8gmVaE/aWdEje9fU7F0COJMqkGjokOUltiolnJS4p8oAa1TrTiynluHfMopp+aerIvkZ1V5CkTmFzMzwmGBJVioteugy9f+pKs7e734mKlQz2OWj3YRMBHflYQ4mibxWYuWy4zR0C8VsrC1nSRlbbWh2CyKCVTBnbjOjK0kuhMgxCWy0gtTT8srFbtJzPrGVcPrrotZGM1Is9I6RU6+eF8rqVXlsbui3FWDWRdDCvqc2gLXJ8FJAhTV1OL1185SBbDMQLPwnDPA/eioIgVIQtsIp1WV9WGqvIWVFy6itLN2bjnAwKMJUvmHGXTRA68jWxxdQTYXK52Ii0pEBu5pknlY0zk4gf4BwYol9lmw/nzQ3A4PEhPZ0K2MBy5uWHTVrPO1zy2nh50U9JSkqkDVVUo+ujHkLpnH4y0eUDQ6i06mq+dpjtewIgOhw+tbXa0cBOGJAG1RkcFoiDfL20q8vQiSz+5CRRL1snDioGV0uyDPgIACYi1+YGV0SySz06QIBDBmCyCkrWkbn4LiL8tdrYIyykZTge5yaMw4kpRqYyJsJxGhgciNiYIyQSyCvgzlsA4AcRNZnecq10XCmSd6fz+e/HCQhDGe0DWd0Gs8r8oXAjbrwChBSxvmgDAFb9T2FpDGV+QR/8WSFUYmUP+eTTTtRfzNTfncks/gaw9PlR1CKifBXxkD5Yg5ro4g3rOXKhu2gKzWqCizkkgq5u/t24kxwdizxaz+o2VeS7N5uXn3efEMVcXTji6cXdwOrYExSE2wAyTVr+Y1b4r8QBZF1otVgxSRq6X65ZeSnL3seBpeHgIoyOj8PALKJABlnWUoVuXlamArNEszgkLZwWIbtoCN8ACGsh6A4w8yyWsXEf1Ug2hpm5MKeXJOkRyL+sygqmUZ2JRk0kVBs21eGmWyy3oZa/LBZfViquvv4bey5cVM2vyjp3I/dBD9LuMM/pesubt6nHhSuUYcw92FJNAIz+HxZRkoB3/fVxQp/SbtAWmsIA/n+PDVYLD33ijW/khGRkhShUmLe1PzFdTvFXvWoEWECBKY10XaipaVeF3dEw4SrdkIzsvhez2wsyKRYs/rUDzXHeXVzKQdeLNCzNrl3cMta5hVLkHYTRQQYbqg5lBEcgIDEMqGVrFFyPKYeLb9HNtAW2BG2SBYYJX21pacfL4SeY9ylFSWoK08BBEdDNAR5l2A8mX8h76MJK2blMBO4kZTm4Sn5Q1wPnLY7hcwWA1W0pSEHZuDUdkZOCUse3J59D/r24LyBxpvtqCvXt2qRt9/WQdXqsKVbHfDVSRS4wiBi7Ig4yMDPW6gE2FBXWq1kIlnV27/OepY5Gy5P8mNlmfTD7PF77wBfzxj3/EZz/7Wfyv//W/Jh6unv/TP/0Tvve975EIZjNeeukltU/muvwWf/Ob30RpaSlefvllBXadCsi6kD69rxNz3KGBrBrIOuNUWUog6/iF5QMtTb74JanWycRmZbUVFZUWxdIjFYybN4rUZCgT0iGUG5ekmv89+u/KsoCMtchDtnOMDx0ZUQDmjevDsL6IUgvF2sGXJL+N7LXCyvraURvyM40ozjWitIgJZSb6V2tT84LsWpLQPVUPVJOl6BGuE7dl+wEJuqh1tY68/748nADtlLosJyvrQWcbkunQ32NOx7pAsrNRekW35WkBDWRdnuOie7V2LCDrZgEsHD98DD/63g+wefsW3HXfPcjKzkJM7MIl7y2jNrz4+1Nobe5BYnKMArJu3pE3r4C8xerDoZM2NLW6mcwBC3NMBNj4v8+niP9c96BdvjyMyooRSrVYkc7E0YMPpjJwRNmuRZSVF1Ygj8OO6l/9N6789L9Q8oknkHnX3YhgwCEoZHq5oeu+uVVyAmGA6ifg+MixYVy8zHFKN6GkMBTbt0YinCDKmcbKI+oOLgPqyGB5sp5Mv73AiB3YmcvCJ8Z78gkADCWjqMytpZhfK3kIhCVI/OvmVgcBC3ZU1droX3thCPCpYkIpKCzMDUZUFFlLCX4bt9/440LvfSmArON9Eb9hvMn3IEddxREEyCosraL80dnlQge3zm7ZnGp+hYcFICONkrIEaaSlGJGS7AftCvHgQgG74/2Y76P0epRA7JZ+H07UeVnMB2zPMVCZAijNCEBUyISbnO/J9fFrxgJ2KQ4giPW5g1b12b1lewgyUwORnOBHQvexWLCabECVrkG00td62JyJLaYEnTJdpTNErQuZwLjafBVVFZV45/Rp1FRWYYxgsDSuVbbt2I6yTZuQX1RI5tVgrs+MnDd+MP8qNYm+rWVoAQ1kvfmDIt8VsnyyEvApCnlvHRlSCnmyDty6JQK7d0Qppv6Z1uZLfRdOyyjGurpx4fvfg6W9DcUf+wQSmWSNzMqe9dKt7U6cODNKohS3YvS/+/YogllFqeTGFi7N2lF9wKqygBTWVlePoq5uFK2tNsYjkgkMWHhMZlUZZ5XdjPjXnW39ePO1C4yZ9XKdZcf9D+/Ezn1FitH+ev3oVWaued3OagGyyk2LNy/srIMeBw4521FOQGuIIUgxs+43p5LIxaTJW+Y1O/TB2gKLZwH/Wpgg1HfO4dTxU/SZqxEdFoKH792PsbNn0H7wVWz72/8HWfc/gECTifHT6cFIom4ga8+Dbw0rzNKjH4wloJXkTFS30m3tWkB8LfkdePPNN/HEJz/BuRGAPxztgCmQgNNYA2LCfIzLifJZEPMj6VQwd+Lf//3fFRPqVFaT83ziE/7zdHZ2KobXiccFkWBl4nkee+wx3HPPPbhCVZ6vfOUr+NKXvjTxcPX8Rz/6Eb7xjW+o9509e1blGCsqKnD//fczhh6EQ4cOITs7G8IAOxWQdb59EpbXya21tZXr5tbJu9/3v81mw9GjR/HBD36Q6otb3/f6at8htp5LM9BQMu/WXLsRQNaJRnWSRUWCKQMDLrJ3+jeRn3Q4+cFmclJYWqVKOI0JqLg4o5K90Q7CRAsu/+d20q5LhXQDZYyaKWkp0pbCxirV0dncEpl4udHJxOViNfmBc1MWs7XTg5omshSTzczt9qKsyITsdCOTUsJIvFx6u7j9sPMzPkpm1gvNPlxuAyKDfchKMBDM6k/majDr4tp7OZ1NflytdO67vDZcdvWjm48WMghtMcZhvTEW0dq5X07D9V5fNJD1PVPoJ9oCN8UCdsrhtBCscO7MObx58BBuu/N23PeB+xERGUEZG9JSLqAN9o+ivaUPbx28SLkdF/btLyW7RDKSUuaehOns8aC53Y0rtU54uaYpLTQhKz2IrKyLTzFoEYn0fgfOnRskC4oVmZlhyMsNR0Gh2OBPoLwFmOL9b+EiTcCsbUePoJlBLQlmRWZlIeeBDyCU0kNTVWi//yRrb4+TbJ+9VN5ovkpFhjobfEz8iD+XnRWCtFQTkpNMirlm8vpWBX24QOgcBtrJwNpE8OoQAdIenwFRxA3Hh5O5P9aHJFYwR7MWThj8dZPCUPoS9B36Bz3o7iWIs8uJgSGPYl6V2KsoPISFBSIiPABxZGAVBq5YbibuX0zAwlICWacbZ8X6y/kmTGOyyfeDdczH2IIH4mfYydbscYt9yNxKGwkAlpgGBeKNJmNCFDdhCBabBJsNtMnSBp6d7IeFvk9znw91LOLrt1JWigOYHS/srAHISfTPa3ZRN22BKS0gIP+hESZgKhwqbiBsxVs3mLGpxMjPM9DkG8XrTJwSt47UwFBsIhurMAHptnos4GLCw253oPXqVbQxASAg1tHhYSZCXPwOMyqm1eiYGCQkJpApLAUJCZQ75v/CyirJFN20BW60BTSQ9UZbfPrrCWO/FJpdJeiurc2hCn8kFi+s9UUsNpPcixQBBQXd4O8KroW6z76DtmNHYe1kwjcqGnlkYhUQqyli+t8wuR9Z+9Y12nHukhVJVBgoIhtr1joT4mMFuD+9LfQr2gLXawGbzYOBQScuUiHm1Kl+7LslHqVl0Yjj3DObtaN6vfZdbu+3WhiLa+pB1ZWruHi2Adn5KSgoTkfxhnWIiQvXsaEFDthqArKKCdygAo6PRcXuEbSwqLCNSoROgw9BjEMUG2OQFxCBGIMZIQGLHytd4BDot2kLrCkL9LBoSvzn40eOo5/PE2OjEdXdjsiOFmTdeTdSd+1GdH7BjOtPwboMUHH66MlRFYeVwvnCfBIG5GlypjU1md69WcE5iAqXKMkJWVv3hV8SSPplxp2j8OrxWoQa3YigMti4kpwARnNychi/tuBf//Vf8dGPfnRKs/3iF7/Al7/sP09tbe2UQNaJ5xHQa3FxMXF2A3jqqafwF3/xF+87709/+lN87WtfY4woQQFeJc94++23o7m5Gd/61rfwyU9+Ur1nOiDrfPs01b29/fbbkG22lpKSQgLMTg1kncVQGsj6sY/NYqLFf1kScX39TrSzoqGiyqqCKgJqzclmICIzGOvSgxHDBFwwE9XC9nTDgyuLf8tr5owytja7BMyc/JEfUcBWqf7eVBqKArICSbBMZCHXaqBJJHnHyCr0xnEb6q66kZYYgIJsE9bnE7zN+S6JqdXaGglUqGr3obydkqBBPty9nuxJcUwya8Le1Trk792XndIrvV4Hzrp6ccjRjg106ksJZs0LjFQSmIS409XXbblYQANZl8tI6H6sRQtI9bBI4Rx9+wjqa+ow0D+A/ffciTvu3r8gc4wz89RVtVFWp5nnbGcAPgIf+rM9iE+MIrPE7AlMD3Fhsn65UuNEea0LVsqWp7AA545dXK9HBixqkZKwYJCMlklXSkbWjKK+3kKgnhf33J2E7JwwAiUFoLE0vxjDTY3or6xAy6E34CPz2YZP/RViCgo0K+ukmedf63swxICeFK/VN25NyTgAABgXSURBVI6hvsGOkmKCqUrDKXkTjMiI9yf15H0uAqBtZGC1UqWgvtuntqZeAgu5LsxLMmBDurCwyv9k0lyaYZ50N8v7X7GZANocZGcU/0qAm8JEKqwAV8nEKqBO8a0yafNc+hPpqWYFYhU/a6l8rZsBZJ1plIZHCHrnXOym1KzYRiRnBwZdkP0CXBVQb1xskAI6xMcFKXuFEsgh/qiRzM7C2up/XHw2rzGO24jdgMPVPtR2EehNUHFeog9bs6VK38BAp3+clmqsZrKbfm35W0AKvvsGvbhU5cDbp+3YXhaMHZuMCI0C6gIH8AdHEwoDo3CnOQ0JgZTLM3BC6bZiLSDrNbfLTaCqgwBWO4YJWh3kGrC+tg6N9fWor6tXAFYBrG7YWEZARQmZ+rMRTvCXLrhZscO+qjqugazLazj9PqAB3d0OXC63oLGZgNYuB8o2sDAwX4rOghWw9UaxSnkcDrjHxtDw4gtofPEA4jduVLKuqTt3wxwdPa3xhBBCSFHKK22op9/RwbXe1o2huHVPxHvrt2nfrF/QFlgEC8hnSdo77wzh0BvdWLcuBDkssC0piaRSjAZSL4KJl9Up1HhzyCV2dviNy7BabCweCsGtd21ETn4yQkLNSxaPWlaGWOTOrDYg67h5yIOOIa8Tl90DqPIMoZpqGYVB0SgJikGWUiMMIVsrY5g66zVuMv2oLXDDLDBmHcOxw0dx6cJFFihcRYrbhgLGAGPj45HIWH82WVnDklNmDJ7aGYe9XMn1a5MUhrlQWhKCfbu4BjWSMCBQB61v2GDe5AsxLA+Hi4rUJOEQEOvpRh+K3C/hC3/9WcZoTCT1ayPhi/uaPIbEaASkKe3pp59WLKpT3caBAwfw2c/6z9PW1kaCBrI0TGiTz3Pvvfdi7969aGxsxNe//nV8/vOfn3C0/+l3vvMd/Mu//AuKiopw+PBhfPGLX8Rvf/tb3HXXXfjlL3+plM/kSLn2OCPrqVOn1H5ZB823T8IQO7kNDQ2pmNbk/ZP/7+rqwiuvvKKBrJMNM+l/DWS9KUBWsqUwIW5XMoFuMne60NNLYGuHQ8nTC0tKarKZFQ4hSOZjLBNQuq0cC0igSaq/e3rdqG2woaLGhkhKiwr1+paNYUhK8DOJrMWAuwA0pHKjtZPJ/xaymhEUEhVBmacNTD4nByEh9v2J/5Uz8jP3dIyghT6LyGyycmXIz8xammHAjlwu+rgY0Encme23kl/1coAdPg/avWOodQ2hzkOQu5eMgOZk5DMBmxQQgkA9AZbNEGsg67IZCt2RNWgBcVg72jrw30//gkFzK3bs2YX1peuRm5+7IGt4iUJ1uTx489ULOPF2BQpK0lFENomSskyEhpnnBH4YpaPe0ePGuXIH6q+6sK3UjKIcE1JZjGPmmn0xv76F5XN42IVLl4Zw5Ggf8vPDUVgYiVyCWKOjjQSdLV2gyDVmhb2/HxU//xlGmpuw7s67kLhpM2IKi+ZkpwUN0Ap7kwQ0vGROray0oI5r/BaCKQUUmJ8XqqTdkxJNipV1KgZQO32/fotBAfoutfjg5HrYzCBiZpyPDKwGJJOBVRhZOS1VmH8x59UKM/N73RV/WcCqjWS9bW5xoomP8hkIJ/NqIv2pBAIzxU+OoJ8lLFshlLiSgOpS2m65AVldwsJKwJ+A/oQxwQ/6JWMrQb+jFq/ahlkw63/uYZDRz0gm9ksko1dCvB/sKqytiy1NK0UA4vd1jwBXyc4qxXziD4Vwjm/PBkpSwWp9gmlnryd4b07oJ2vHAhI3cDjBmIELpy461O9QcLgXcesJYk+w4AoTpsLEendwGsyUsxQGIN1WrgXcLkqUDgySkb8Z1VXVaGpoRGd7O2Lj4pCQlIg0ytIlJichMTEREVGRiIiI5O9tMIKk8l83bYFlYAENZF0GgzCpC4K/E9Z6y6iXRVBkGSQ7a1ubnWt5kNE0FHk5ocjOCl7SdeN4lyxkYO05fw5dlLccqq9FwaOPI3X3HpiFSZoJ4Ona0DDjiJ1OHDtlYVGXB5s2hLHPZmRQ/UHWu0u55p2uT3r/2rOA+MCtZDiWQtvGRqvyGe67LwmpqYxlL2F8Yu1ZenncsYz3yNAYeruHcPJIJQuKupCVk4Ti0nXYtC0XJrNee813pFYzkNXN+TLsc1KFcAxXPSwccZO90WdHDslbCpjzEjKXEPpqGsw631mjj9cWuD4LeJhf6e/rR2V5Jd58/RCcA/0IdzmQPNSHnIwMlH3u84jOy0fQDMp35LigUo4bNfV2vHV0hHFvE3ZuDUdyolEpP11fD/W7V4oFrCQp6B4x4HgtMU+M70robXv4aXzk8UfVLTRTRcc0KS4zMjKigKRywAsvvIBt27apYyf/OXnyJB591H+eqzyPcQ7n+fCHP4zTp0/jC1/4gmJenXxOAbj+13/9F/bt24enn34aeXl56pDNmzereNL48cKEevnyZcaVWLBz661q93e/+11UVVXNu0/j55zvY01NDZ555hkNZJ3FcBrIehOArJPHRBJ0g2ROaWiShKhdyQUKS4qwqCQyIZoQZ0QsJTvCKZUYErx6Jdgn22Ul/y8BM5F3bGpxoLzKRrCym7TYZFvKCSZrkJlA5SAlDbtWK1eEVamrz4sT5+wQgEgoWUlL8kzIzzKp58IMtBqbgwn58jagpgtKbjMnkUDWHCAhwkDq9dV4x/qeJlrA6mOCjpWqJ53dqPcMI95ABrGgKKxntWqkgeAXLbky0Vw37bkGst400+sLawugp7sHdTW1eOH3zxOkEIE/+/jjSElLJdtH5IKsMzpiQ1fHAI6/VY7q8hbc/YFtKN2crWTRjMaZC8VkLSfAsPZuMsJVO9FPGXMpPNm3LZhBH79k+WKyZopsuvgDkiBqaraitcWG3XviUFYqgA0jAWhLj/YStqCG559D76WLpAQNUExBUqUdwECCYQ1L9Y6v64XpsptV6OKzCcNTABN3Ik8qTKxRUUEKxDpxogqQjzhqAlgJ5hsmIHrIH/zp4fOYMEpiRxtQkiYgVgJYuQ5cnavfiRaZ+bnYWRiJxU8YHCKzKD9z4kMNDLkJ8CYQgYxUUWRBlqCp+FPJ9JOF/VZYRW9UW25A1qnuW4oqXQTFDwxSCpQ27GPRrDzv63eR4dYPegih5FNoqACAAxlf8IODQ0IIciXrs6iJhKjNz7JwvSzQAmYdtAKXWukb9/IzMAxk0wfKSfAhK56MEGRnpVL4mp//U42l3gf0DnhQzwLYmgYnWihtG1I6itBMJ8xhPmw0x2K7KUGbaQVaQEASNpuNADML2ff7mWTrQ19PL/rksbcXY1arYmjNzM5CVm4O8vLzEE821kiCWHXTFliOFtBA1uU4Kn/q09CwG13dVNeosJLFnr8lXOckJ5mQkxVC2UmTSsYLIG+xgaE+Lmxd/D7rrywnE+uLVL1wIzguHtn33Y/YkvW83tSrf8kfSE6hlqoPAh4Qxn1h2RcWrHgy7Uv/ddMWuJEWsFg86O21Uya1h7/VTtx2WzwlY8OZrzRphs4bORA36Fp+pSAvzhyrRjnZWQXYmpwagx37ipCUEoOoaAYzdJuzBVYrkHWiAawkbBnwOXDJ1Y9a5ryIYKAKIWOnBLSmBYQimQoaRrKzyn7dtAW0BW6MBcTnbm9rx+kTp1BfVYO2+gYkdF5FVmw0dnzik0jbsgXh6RnTrkfl/RKjvdrmxJETI6pQPZpF8FvKwlRMVtIE0yxlb8wN6qssqQWcJEe1k4m1iUrDTX1AY48PUssihBxFkW24dd8udf2pgKrvvPMOHnroITW3KioqSM4ytQJFS0sLdu2a33kEwPrHP/5RMbM+++yz7zGsSmcCOCkfeeQRSH7/U5/6FL761a+SJCZ/znY6d+4cCXFc8+7TnC8w6UANZH1zkkWm/lcDWZcBkNWftCMzj8tLJk8f2lgpXFs3RukYqXIEopkY3bQxAnm5IYo5RUCuui1/C8i4ughKcJJJ5J0LFlTV2plEdCNrnRl37ItATBQThUwersXmpXGIlUBPv4fgEBcOnbRhS4kROygZmJ4cSGal1TnH1X3zx7++G3j1MicIfbf0GJCVNQC5iWtxJqytexZmVpkDbR4rat3DOOLqQiid+DtMqcgJilTMrGvLIsvzbjWQdXmOi+7V2rDAuTNncfHcRVwlI1d2TjYe+chjCtAqjuhCWhPZI04drUR/74hynu+8fzPyi9NVsmW6xOH4dYTpcHDYi4tVTrx2dAxlhWbs3hyM5ASuUwi8WsxgjawZbWNuNDZZ8fLLXTCzcG1jWRRyc8OQlhaqrrWY1xu/x8mPPpZbDzc1oeudM6h99rdIICPr1i/9XwhkdepMbEGTz7Pa/heQsc3mw+UKC44cY1CeiW6Ra9+5PQIZ6ZQmJUOogJonA/4k4DNM3+5Mow+VHWTkHwTSuO7bkkUQH4F8AmA10RUQRsobMb7LfVwkYeYks2hbhxNVdXb6TmPo7vWwANCI3Ey/WklcjPgJgRDWWz/gwKc+2zfq3lYCkFWCzfKdIoxjEnQWMIQ8yqYAwgS1dnSRNYVM0x0EdQhjqzBfCkA4JSkI6almSu4akUZlmGCCXE1kTb2eNt4XCYI29ADnmr1kaGXRp9eAuzcYUES1qViCEgMXszLgejqs37usLCDAbAeB2W+ecuDtSxYMZwwhPceAe/OikRsWgUQmSHVbeRbw8gupp4vFnbV1OH/2HKqY3BgcGGCCIwYlZOLfsLEM+YWFXAOGc00UTAltMjmxamGh68GVZyHd45VmAQ1kXd4jptTB6NsNsTiqucWOk6eH1do+JNSAvbsog1wUqsgmFptdUooER1tb0X78KKqf+W+k3XIbij/2cYQkJMAUHjGt0RwsphTSk9cPD+PilTHs2BKO4oIQggZMVAQxvM/nmPZE+gVtgUWygKznnZQUeeONbjQ2ENSYYkZBQQRKS6P0fFwkGy+304hPabWQzbqpB688d4bES3bkFaRi8448pXC03Pq7nPuzFoCs4zkvi8+NHq8Nx13dZGgdpUKhF9uNCdhnTEJkgAnBzIPppi2gLXDjLCCgPCkgfevgm3jxD8/BONiPlBATdm8qRcHefci4Y/+sxBUjox4Vpz13yYpL5VY8/EAstm0KU4pPk+PgN+7O9JWW2gKsYUEXiTjeqBBSAipaMHa7Id2gtjBzAG67dS8aGhrwxBNPQGLlEuORJvm2L3/5y/j5z3+OLQRLv/TSS9eATSf2W+I7e/fO7zwHDhzAZz/7Wc4/E06dOkVV8+T3TtnPIumysjJ1vd/85jfq3OKnT9WEDfapp55SINtf/OIXqt/C2hrIuNN8+zTV+eeyTwNZ35yLmaCBrMsAyDpxpKTidpiVwj19LnR0OFSySaoepYWFUXqdEoApdBZTU/zBixvBzjSxf/r5/CwgTp+gFSUh28LKlYZmu5J8DGWwrDAvBHnZwUqS9HoThPPr1fI4WpKqkjRtanPjQqUDNlKUm0iOtnm9GZlpRkTQRgvErSyPG5ymF5JUHiAzlwAa6sny1jYA7MwlI1cqkBhpUFUt07xV714lFrDSqe/2jOGiux9dlF5xE+BaEhiD9ZRbiRZmVkqu6HbzLKCBrDfP9vrKa9cCHgIo3S43XvjD8xAwa15BHtaXbcCW7VuZVKQO9Tybh7SDY1YHrpxvxMGXziE9I04F2wtKMhCfSPTgLE3W40OUoTxX7iDQy6PWKKWFJoJZhTme8uWL+DUtS0UHZS/Ly4cZALCS6cSB9PRQyq7EICbGpECSs3R38V5mZ5yjlAIjoKSKyVZzZARS9+yllPMGRGZmLd51VsiZZB0vLKDdBPvVsMhQGC2t/D89zczNhGyyOEWQEXSiwoKs86wOgwr2tPRThpHrPJF9F6BqJNe2qSxCzooncI9FW+Fm8RPWdlPAArq6Pb1kuyXbVCfBlSMEVkqBZ1CQqJEEsJAzCElkX01KIAOVACtvADvxdKOyEoCs0/Vd9o/ZpHDWixF+vw2NuDDKR5nj1jEPg45+wCthsCqAF8BJGx4WoOZ4ZESAKq4V9gVhAQtm0HIhTXygjiGgtovMEAR2y3dpCr+SJRiaQDxHJFU6dNMWmGgB+Y2Ub8ojdaM4XDOMVrKApfK38cM7opEdF4xo8yL+IE+8sH6+qBaQdZ4k0TrbO9DZ0YH21jbFxDrKNYc0SRZEkH0/Pj4eaRnpZP1KRWJSIn8HgtRri9oZfTJtgSWwgAayLoFRF/mU8nviZGHEIMGsTYzNd3Q6FDtrZEQQ4uOCUJAfhsQEI0K59pE10PU2L7/z7AToN736MgbrauGjxGsaAQPp+++kjGswAvj9NrlJH1Xxe7sTVyqpAMH1sTDbb98USvbYYEX6sNhg28l90P9rC0xnAZmfVZUjqK+3oPmqlb5wOPbvT2TBCVUc6LfptvosIHG14UELrlxoRmMd128tfSguzUTZ1hwqJ8UhXMsLzmnQ1wKQddwQbgJXbfCg0T1CIKsFbV4rM+NUfiGAtSAwCplBEYgzmGHSgNZxk+lHbYEltYDEtQVgKAWkl0gccvn4CQw2NbIo2IQtd96J3Z98AkEsHA2cJOk+sVNOqsxKgdU5krWduTBGXEswlYfNyM8JYY7k+tfME6+ln998CwgpR9+oD/UkIqgihkXyHJK/KE41ICPWT8ohrtK//du/4Vvf+paKH//hD3/Avn37FID07bffxic/+Unmuhz49re/jY9//OPqptra2vCDH/xAPf/85z+PjIwM9Xy+53GSObCkpISx7TEqBNyGX//616rg2U1fS0C1hw4dIilMGgSoKvGk6drrr7+OP//zP0dWVpY61o/l8h893z5Nd43Z9msgqwayzjhHnnzySVYOFuBjywzIOt5pcQ6ltbbZKV9px+UrFkorulQiKT83FMWsFo6NIdiPjDTC0CqAv0WIs/gvqv8uiQUkSVhTZ0N5tQ1XqmzYuD5E0bCnJpveC0atxTG0kuGqj7Khh8+QeamBtN1kOyvKoWRoapCqNF+NNhFZTzsXgCfqgZcuelGYYkAxN0niitSsMHPptrot4PRRlslnx3lXH16zt6HQGI2trFDNDaRDH2Cm1EoA3XzdboYFNJD1ZlhdX3OtW0Cqg0dHRvHLn/ycjKwX8MlPPaFArNGxMQsCMNjtThVkv/BOPQ69fAHCxHr/w9uZZDHRiZ2dAWDEQgBipxuvHqEeNtvOjSHIWReE1MTZ3zvfsbTZPATuufD6691oa7MhL4+MO8WR3CJuGrvJaGsLml5+mQxCLfA4Hcj54ENII6BVHI7ZmGzne//L9XgBMwuYsqPTqZQyzpwdVX5XcWEINqwPV0ysE9eoEtiRRLODrJOdBOpVdfjU1kzmyeI0rvHSgNJ0cJ1ngHHxp9FyNeOU/fIHUoUplOthMk4JuFKkUxuaHMrvNZIBdF26CeuLQlBARRIpADTR3x2fexODS1NeYAl3rnQg61SmEVDHGP0xmevtZGpt7yTYrFuAxU4F3I+ODlJsrcLYmpxkRCz/j3wXwB3AuSxMqhKLmA+wQj4XNZ0+HK/z+z3bsoGCZI57LAgM177QVOO0Vvepzzu/bE+N9OMEaa1bjgUjzhOC+3aHIzvdiPgYYUjXXtNynB+SMPPwh9HlcjLJYIOFoNXqikrFvlpZXgG73Y7IqChs3LwJZdzyCvIRGxfH7xMdDFmO46n7NLMFNJB1Zvssp1cVWJQLdwGzXrhsUY8Ouwc7tkUgPy8MSVzrmFmwM7FQbSH9dw4PY6ixAVd+8p9wWa3I//AjSCgtQ2QWFz3TNIkVj7G46HKFDQffGkYGC+eK8kO4BSuw7TRv07u1BW6IBeSzM2b1EMg6igMHOll8YsIDD6YgLs58Y4tvb8jd6ouMW8ArReJjTgKgGnDgdydUYXgumVk3bc9DemaCAjHrtfi4taZ+XEtA1nELCLShl8ysVa4hXCCRS41nCBsDY1Fmikd+YCQiDUYFZtVe3LjF9KO2wNJawOUUYgYrfv30L3HmjTcQ0NaMnbffhof+5guITEpGMItKZ2tVtTacvzzGYngPoljkfvueSBLvSeGp/iTPZruV8Lqs81yM0/czFSbx2ittQHkrcFsxi+qyhZjDhzDzn8ZacnmPPfYYxhlPhQk1mKDo8+fPQ0ClDz/8MH74wx++x8Z69uxZfOhDH1KmeP7557F9+3b1fL7nkTcJK6uAYSXmFMWYkjCpVlVVkYikWxHivMycVnExOz5DmwnIupA+zXCpaV/SQNa5AVn/fwAAAP//zWSBPQAAQABJREFU7L13eJzXdSb+Dqaj994IgGgE2ElRbKJqJEuyLclxUbGjxGtH8dq/J/+sd5+sU7ROc+Jk14lX1sZ27PUmlqt6pboosReQ6L33Dgymz/zecyEwLAAIgAAJDu7lM5zBN189937fnHvOe97X4HQ6g1iD7c///M9RWFiIhx9+eNVefZA943QGMD7hw8ioD4NDXvT1ezAy4sPEpA8ZaVZkZ9mwLteG2BgTbLawVXst+sQAny/Ifgugs8eDplY3+tmXbk8QmzbYkb/OhuREE8zmtdeHYhePF6hv9aKhzYuefh/iY4zYvcWGpIQwREWEnk3koev3B9E5wuvuBep6AI8P2FcYRH5KGOIjAYO+aULaAgE+4F3wozfgRI13BG2BSYwE3LjJnIxiUyxSwuwwG0Jv7N8InfrRRx/hjTfewOOPP46cnJwb4ZT1OWoL3PAWaGttw9nTFaiprIZzyokHPvsgikqLYbFYYDAs7hcxyOfryNAk3nn9DLo7h7gPE7btKsTmHfkICwvja+79ie8trxOVblQ1iJ8GpCcbsb3cgtioMITbl/m5zGM1NEzg7NkxDAx6YLWG4aab4pGRYUdMjPm69atnYgLjrS3oeO9dNL/4PEoeeQzr7v4ELDExMFqt1+28ruWBe/s8aO9wo7rWgfFxH1KSLWrelZttY9+YEB5+8VgYcQC9Y0BVVxA9fPfSr0uIDCI9zoC0GAMSo4DYcIDDEfMMwWt5idftWGFhRvyP//Gkur/33/41HDk+DqslDHa7gb6/Wb0S4k2IiTYiKsoIkxGcI5nwt3/7t6ivr8dXv/pVbNu27bLzN5lMkN/w999/n/OsfmzcuBG7d+9Wc36fjx2yDO073/kO4uPj8eUvf3kZ9rY6dhEIcJ7KeYnEHZxOP5yuIKb42THlh8Mh7wFM8iV/T076YTKxrxh3SOLcNSnBhET2WUKcEdHsK3m+LuSR7XADw5NBNA8Y0DIQRPtwEDkJQGm6AfnJBjUXWh3W0WdxvS3gRxDeYACvTHXiveF+JNUnI3owGuaAEZuLrdi5ycoxF+Rzde7f9ut9DWvx+AE+WCYnJtHb04PG+gY0NzahtaUFERHhiIqORlJyEhKTkpCckoI4PlNj42IRGRVFP0j6U/flWhwzN/o1nz59Gs8//zw+97nPoaSk5Ea/nJA/f5nvORx+DI940dbuRmeXi3MxL6Lpexatj0BOthVpqfI8Wropug59gO6PPoSjrxeR6Rko+OSnEZGeBnMEA75ztLFxPyoqp9DKOUj/gA9bysOxsSxc+VhWy1WczBzH04u1BRZrAcnh9PQ4Od8agJtzhnjOA8rLY5GfH7HYXen1bxALSHzN7w+gv3cUTXVdqD7bhp6uEey4uRDF5dnIzE6C1Xb9Ylc3ghm///3v04Z+fOMb37gRTnfZztEV9GM86EGn34E2/yQ6Ag7O6/zINkaiiLmvEmMsjMyA6nncsplc70hbYE4LyPxc4qL1NXU4c/go3vnNbxEXbmMOYju23HUXCrZvn3PbmS8Eo9Tb78WHxyaJWfJj/64orMuxQuK3ut34FvD6maPqE6xKQGFWomwGrEsC8pIMzG0AdgvAcPBFbXx8HI8++ihOnDhxfrnk8m699VY8/fTTKu4/88WpU6dw3333qT9ffvllbNmyZeYr5l0Wvp+ZjZ555hl861vf4pyOCZmPW2ZmJp588kncfffdM4vmfH/77bfVuefn5+PQoUPMB3KCeEFbyjldsPmCPtbV1eHnP/857r///lnzHAvayQ28kvTBQppBA1lXL5D1wg6UBNPomA+t7U60tLjQ3OpkMt2IuFgz0tMsSEqyqB+MqEiTSgJK8PdqAi4XHlt/Xl4LTDIh2D/gxelzDjSxL1OTzcjKtKJgnRXxcWZEXJIYX96jr969jYwT5Nvrw+FTLjjdQRRkm1GQY0ZupkklsI3G0AvaOQmQmXABByuDKombx8RtYSqTuBkGWOn/GS9xDFZv7+kzW6oFpoI+jBLAetQ7gArvEDLCwpFnikapOQ6xsMAepicCS7XtUrfTQNalWk5vpy2weAuooLjPj5PHT+KVF15m8jAK2bk52LN/D9IzMxa/Q24xOeFER+sAXn3umNr+pr0lWLc+lfsjSuoKzcH6vkEWjB2t8KClw4vCdRaszzHx3QyLeXn9ELc7gLFRD86eG8OpU6NITWVx2roIbNoUSztc32d/kEF2r8uJNoL6K3/0L8jYtw/pN+9BYlk5bASchGqTmMUUgXyjDM61tnG+1eLECOdfkREmbN4UgexMmwLtyfVLeEPAf1MeA0YdQXSNCIDVgI4hKU5iUo856pL0MALzJNgThG2Zx8+N1Adyn4ttna4ApqaCaGutwCc/eT8SExPx3e99hBNnxpGWwvlQhpXFfVYkMyFqJ2h8Zi4r89rf/va3+NrXvqYu+6mnnsKnPvWpi0wg63zlK1/Biy++eNFy+eOzn/0s/vmf/1kFbS/7cpELQhHIOpsJpOBK4g8SqB4a9itwRx/nr/2DPrjYj9KiIo0KbCwAVgF+RPNvAbjaGOyUdwHm26xMTM0BbvXy/hmbMqCORX2HGwWIKPeNARsIZs1JFOB3EGbO/2bGwWznqZeFvgUm4UO/bwrverpx1jmKnSNZsHVGo6rajyL+Nu/ZakUsx18EgfC6XV8LeFmdzPgyJsbH+Ds6ioH+AfT19KK7qwuDA4MYHRlBVk428gryUVxaivSMdAJgElSR0fU9c310bYGrt4AGsl69Da/XHiQ+397hQsW5SfqpfoJGTchbZ1dgVonRh4cTZkMfRXzNhTSfcwrusTE0vfgCug9/hISSUiRv2cq51M3zglgV8UW3B0dOTCpfS3IFZaXhWJ+3NooIF2Jbvc7qsMD4uBd1dZNobp5EW9sU9u5NxNatsYqcJRRzN6vD6tf/LDxu8fM8+PCdSpw62oCExGjk5Kdi8/Z8xCVEwh6un1Vz9dJaBbLO2GMy6MVgwIXjzH0JoFV+TWfArMkGG+LCrDCDpAML/J2d2a9+1xbQFlicBSQ2K/P15vpGPP/vv0BfUyPMUw7c9cjD2Hn3XYiIiobFSrTiHE2IuVzEbbz53jhaGDPPTLegMN+G0mI7cQw6djeH2Vb94gDj9eNTwMBEEFXdBrQPsZ9JwFeYZsDuAsZ+JcY797BQ1zc8PIyTJ08yHmzDjh071PtSLnyx+5EikerqarS2trKwqhy5ublLOey82yz2nObd2SVfaiCrBrJeMiQu/vNGYGS98Iwl+efnE8XDpLcwpAgzUEMTE8xtrBzudiGWgNb1+XaUFDHJmmUlUwrZftY63c+FBlxFn+UHXypYJRnY3unB8dMOMpIGUVoYjpJCGwrWaJBKgQEIIGls86GuxYvKeg+2llqxb4eNiVGDSoSuom5cllOR+9rHXHBTP1DbQwa4liCyE4K4d1MYK6IAHQNYFjOv6p1wCMBHlqEuVqe2BCbwkbtXgWP2WdNQYIxGhlFXtV/rDtRA1mttcX28tWwBqQYWBtY3XzuIf336R7j/wU/ijrvvREpqKsLJ2rWU1lDThZpzbaisaEVqejzu/8wuMn1FwixUmFdozR0+HD/nxiCBW5KEuWWnFTnponqw/CwB/f1uMrGOcrI9hf4+Nw7cmoSyshiylRnVsa9wqiv6tapCpZMyeO4sOt55WzEJmWx2FH/hEcRR0SIUm/LJ6JR1dXtx/OQ4unvdcFBJYdtWskWsDyfo0kJflNXHH5cfk5SEIFbx4YLKf+se5d9kmSzLMmB9CgPz8QZE2wEryUlkSraWp2UCigwzGMlSS6BveyO+9KUvoqmpSQFZf/jTowQ9AvGxBEUSOMDCbWVjkiefb10EQR04cOB8lfWlQFYBFkjFtSyXdhfZBG4mWKCqqgrPPfecArD+wR/8Af7yL/+S4MxpEOb5nS/yw1oBsopZ5J5Q81Y1d6W/yvmrvARoMTxKUOvHwNZ+MpgJU6uHgc60FAvS0szIZKFtWqoFKUlmJrXZp7MUJKr98xiTLOobmASONwVwrhOKwZi1B9iVP30P6cK+RQ7SEFu9ncnOk95B9PmnIHfv/jBWB3SF470jLo4tA1KTjNhUbOZvtWaCup5dL37DOIFbHW1tOHfmLCrPnkNfb48CqeavX4+CokIUFhcxbhmrGFktZF618OFgkgeEbtoCIWABDWS9cTtRfBsp0hkc8qCh0YlTFQ7luyTT99+5I5qFbHxesThnob78REc7+snQ2334Q0x2daLk0S8h/aZdMEVGIsxImYE5WlWtE7UNLkV4kUE/6rb90apQQ4q7dNMWWE0W8HHOLL7/iRMjePnlHuzbl4hdu+KpWsH5sm3uMb6arkGfy+ItIHM3mUv3dQ+jtbEX7x6s4NwwgH23l9PPS0dWbvLid7qILYx8fsqcX5jevvnNb847rz9y5Ahee+01Vfx6IePbhYeTGIKwuP3qV7+iSlIDIvmMlhjCzp07WcAQfhkz24XbLvbzWgeyBj5W2BgnoFXmdsc9/QrY6ubsbr+FYGhzImIMJA9gzEg3bQFtgZW1gDzHx1l02lxdiw8OvoWXf/Ms7rr/Xuz/nTtQtLEcMfOQV8zECJuJSaqjz3queoqYJBvuvTNG+cqzxf1W9mr03q/WAgJiJTQBZ9qDON7KPNA4EMkc2O71UKpZQjYgaRD+ZOq2AhbQQNa3F2RVzcj68MMLMtRqWkkSSl4CH7spUd/dIxI4bhV04TNHVQ7HxZpU4igx0UzGVpNKhusHzWrqwelzmWZ88qOSwaou9qWbye90Jv7yciyQoFVMDOUZ11jHSQBRmFkFSHKSsr4iM5oUF4ayIgulfcnsw79DzSTiAI45gQ5Kan7UQClaUrinxBAIQSK6AsYABEiz0IDp6hvl+owWagFHwIuhoBsnmKjtotRKGMdFgSkG5WRmjTFYEMEJvW7XxgIayHpt7KyPoi0gFpighL3I2pwiI+uRQ4fxqd99ALfdeTvZGFnNK3rii2gid+b1+FRAvepMK1khorC+OAPbdxdyf/OzQ7gJwBoeZRVnkxcnznnocxiRl2VGSQF96ejl9T3Ejx8lCEwYTE6eHGEg3oiUFCtBrNHIygpXfs5CGX8WYZ4lrTrV14ex1ha0vPqKSsQW/e7nkLx5C6zCoDZPInZJB7uOG8m8anLSR8ULl5pX9fR6FCOoSKYXs0gwPdWs2CUNdMgEBzlI0F3vaBCdI/zMiuVJtzDpB8kgOS2LnkHJHWFkvVRy5zpe4jU/tICaxK8fpV9vNofh//v646ivr2cRZtv5cxFG1ldfP0VmT2HvJOiXfv5s7d5774UARGbapUBWqY7eunUrgZQePP744/irv/qr84knkTL6i7/4C7WpyBilEiR/NW0tAVnnspOAPRxTAbK1UpKXjK0jfJ4JuNVB1REDu1CApyYTg518Wfl8k/6VVwyZpqOj+JkMrmbeHDOPECnqc/MerO8zoLY7gKFJbsvHfy5JtPNTyM7KIj8T770Lwc1znZteHjoWkISnj69z3mG85u5AapgdhZSgLObLMGZBdSOZ0zsJqB7yY992FnTnTyvbLNJ1CB2DXeMrkQSYvIYGh8i2OoDe7h709/dhZGgYLrK8eLxeFn+QLTc+jiysOcigxFtWdhaf9Sy61+DVa9xb+nDXwgIayHotrLxyxwgwiytqGb19ZJpsmMLAgEf5OjIXyEi3KtlUUcwQdta5WoAFmr6pKfSePIHml14g+2oEIjMykX3bHYilZKVhDkfGQRbY8YkATpDkorXDjUTKs4pCwaYNESzElGI4nTmey+Z6+fWxwDSQJUAGrHG8886AItfJzLRj48ZYKkbOH3e5Pmesj7qcFnCRlXWYSJejh2rQ1U45GraiDVnYuC0P0THhK8bMKkxvIr0rMYTKyso5gawCeH3ooYeUTPDf/d3f4ZFHHrns8iXedvToUXzxi19UcsYXrhAVFYXnn38excXFFy6+qs9rHcg6Yzw/53ajzH01esfRGphEh28SUcx3JXOet57qhGmmCMQxB8YI7Mwm+l1bQFtgBSzgdXswOTaKowJk/dm/ITw5GWkFBThwz13IZwFqhBRfzeG3ClHBOOO8Le1uvH94Qikzbdxgp8KWBcnEI+l2Y1hAfDkf5z/DDgOa+qDUgkVpLjmasdikMGwgNiWW/DLmuac+N8aFrvKz1EBWDWSdd4jeaIysc12MJAgladTQOMWq4QkmXwUQ6Uc5Ax4lxREoIsun1SKJpOnEoI5/zGXJ67NcgmVOspDW1E/hzfcnlJuewKDV7psikZ9LWQUmANcis66ASRrbvThd7UV9sxd332LD5hKRDQxTNrk+vbWyR50gG1F1VxAVrH453Q7cXQ4cKDEgnPevdhhW1varZe/CzDrICX2FdwgvudqRSTbWm63JZGaNQVqYMBNSzkxP5le8uzSQdcVNrA+gLaAsIEC3nq5uvPbSq0p+1kxgw6133oYt27cuyUISUJ8Yd+LX//Y+qs+24sGH92Hj1jzEEVE4VwBGDiSFYAK2q27wopY+R22zB5+4JRw3bxG2sOUFT0mgwOXyk/FhQiV+zp0dw+YtsfjEJ9IJaOXvPQF/q6rxhAOUaal46vvo+vAQMvffgtQdO5G0aTOMQp15gzfpD2ljVLroYXHgO+9TCpksk1IMuG1LFF+R0wVFAmDlusLCKgVHZzuCqCRzpPhs4TRDWaYBm7OZwEllH5L4dy3Pt8Smcm8LYFvmOA3NdHApx3r/PYXTxr7g/ysloeS+FVDq9773PTL97ENnZydaWloU8+qnPvWp83t64YUX8Id/+Ie8f8yora1VQPiZLyVJVVJSomSuv/Wtb+GJJ56Y+WpJ7xrIOrvZ5LnmmAqig7GIdnkRiNFNQHj/oA9JiSakkqk1h4xmWWTNlAC3ME9LjELcWt5evGcMSqVigsV9b9VwbtxNdjSvAdtygds4H7JbggSLa6my2a0fmksFxOoga89Hnj780tWMOyzp+IQ1m8V9JoQFjJAClLePOPHWh07s2WbDphILMlOMCNfMdSs6IGYArMKoL8UDtVXVOFdxlgVJJ8gu38ffTCPKN2/Cth3bUVpehvSMDLVstRTorKhx9M7XtAU0kDU0ul9i9MGgAWfPTaDinAPNLU5VgHPL3ljkZNvUHEFi9LP5+l6CWCepItDx9puo/MmPUfiZz6Loc5+HnQWAJvvsSiPiN/f2szCjzYNjpyYxyfzO/XfHooBA1nC7cdbjhIal9VWEggV6e52Ma0xy/jWhikLvuy8d+fkRazKPFQr9uZhr8Pn8GOwfw9mTTXj+Fx8hrzANe2/fiHX5qUhMjlm2MSDxAPEtpSBWQKczqi6XAlnFz5T1xDf93//7f6sYglzPXEDWoaEhxb46OTmpCl0F+CrF9BJXkGPFk5Hw1VdfZaF51mLMMue6Gsh6uWk6yMxa4xvFYbKzDgSc2GVJwUZzPAqZAxMoqy7iuNxmeom2wHJboOXYMZx5/jm8fboSPS4vHnzsC9i5+2bk5OUST2RScbq5jilqw4eOTGJo2KtWuXlHJMpKpsk55tpGL18dFpD5h+Q4RGVOYq+vn2MROfMdohB8Wylj6GnT5AS6pGDl+0sDWTWQdd5RFipAVnnoeL0BJmD9GBqalvgb5PvYmI/J1iAlPcKQm2NjwMWKhHizCoTMaxj95TW1gPSfYitif7V1utHa7kFnt4d9ZVLyRWXFdrLXGBWjzTU9set8MBcr4SccTGKSGa2WL0lypiYasXOjFXExwswaej+jAowYcQC1PcCRxgBiyOqVHgsmcCmZyHdJ8uoW2hYQ5iFX0I9eSmfKZF4m9YMBF7ZZklBijEWq0Q4bk7e6rawFNJB1Ze2r964tIBYQoJuTyb6G2no88/9+ThmvKNx6123IK8hHatrSGBNbKG92+ngjeruGuH/g9k9sRW5+Ctm/zHMGX7gafegAWrt8OHzarZgEczNNKMw1KcDVNMBq+fpsYsJHoKQbhw8PYmTEqxhY1xdEYn3hfwAml+9oV78n6SdxPzrffw+9x4+p5Gx8cQmKPv8FmK8gj3n1R1/5PTgcnD8x6FZd60AL2VgtZAQV5qVcJqrT0qz8PB24c/umfbSWwSAZI8nY5DOoMZZA1tXUGPprZGBN5OcYuwDypl8rf/ar8wjCzDk07OOchqohVJxwuYJMKgGZqVMELxoQGRGGQ+8/j29/+9tXZFMRlpQHH3yQKhUxeP/99/HAAw+o5NWljKz/+I//qJJU+/fvxzPPPHOZYf7gD/5AJaLuvPNO/PSnP73s+8Us0EDW2a2lFGOkwJZMrSI1qt4JxpjgZyfHgJNAV5eTrNmc1rk9AQUKiaX6iLCOJRE4Lu9WyvbKhEdYANpI7lPHOZEEUyMIFt+aQ6UCAsXtJHgQxlfdQt8Ck+RjrfQMocFPxh7fBPZaU7HbnAIzaX8NBBmxxgJ1LV6crXVjnHGDGEqe7dthQ3KCMP7qifNKjBAnmVZHh0fQ0tysXu0tbYoNS4ADUTHRiIuLQ1JKMtnYkpDIV2xcLMLJSDhfMdFKnKfep7bA9bCABrJeD6sv/zFl7iPzyOERH/rJytrW5kIfgabiz2Rm2FCQb0cmGVrj4i6Oywkbq6OnG00vvoDJzg6yrxqRecsBpO/eDaPVhjCCAS5toggh/pKotH10dAIpSZx/suhnQ3E4EuLWXh7gUvvov1e/BabIJjw25sEH7w+iqdmB3bsTUFgYpVhZRZlBt9C1gID+XU43Y2/DBLM2o5sxuNGRSey+ZQNKynMQT3Uks+Xy595iLCL+42OPPTarqsulQNaXX35ZFbtKUesU44wzbS4g65/+6Z/ihz/8oYozvPbaa8iheoA0UYy69dZb0d3djc9//vP4h3/4h5ldXdW7BrJebj5HkMouATea/RNo56uf+S8pWMwxMj5KMGuuKUoxs+onyeW200u0BZbLAuO9vehvbMCb//ZzVBDUai8uw4Y9e3AHmVkTkxLJzBox56Gm6MOKyrD4sSfPTGLvrmhs3RRBIjKjIuqYc0P9xXW3ADHLCodyomVaac7FIvGcJAPWpwAZcQbE6tzGNesjDWTVQNZ5B1uoAFkvvUhhFOrv96KqxoGubrcCuIocZk6OnbKYFlaUTUuuSaJIJMt1Wx0WkAmgj8xF1bUunGHV9xhlhcLDwyglFK6AFJJUlyTwWmNn7eqjzGu7H2eYoJJk1U2brMjJMBLUKsCC0AQKtA0FyfQ1Tefu9BhwSxFQmEYHghUxGsy6Ou7XlT4LAbOOBz044u7DR95+5HDynseJfKkpDolhNtg1mHVFu0ADWVfUvHrn2gLKAsLo1dHWoVi8Xn3hFRQUFuBL/+lxREZFMuCxOKbPAGky3W6yuB9rxBsvnUBmdhLyyQixcVs+EpKoiTJHE4l4L4FXjW1kf2/1oY5srLkZJty+20awHQFTAqpapiYJUQF6tbURvEs21pqacfp5Jtx2G+V70ni8yKsL8i/Tac65m8nuLgyeO4e6Xz5DVqFElH7pcUSTncISPbd959zZKvhCfG5JvPVxztTS6lQgVgG0lpdGMPkWroCswo4rMjvCmD9CqZ3OEaC5P4CmfkAArJnxwsIqIFZhzw+sacYID4sq3W5QJcSPgSGfYuIUZs5Bfo6KNFKS1YzSIruSmRLw4i9+8Qv88R//8bxAVmFHERbWPjL8/fjHP8Y999yDvXv3zgpk/drXvoZnn30WX/3qV/Fnf/Znl42wv/mbv1Gsrlu2bIEkua6maSDrwq03A24Vpob+gelx0cu5nTCP2WxG2G0GBRaPjyWglXNdGSsRnP9KnGLcHYZayls1DwLdo9OMx6XpDKryvouyaXmrhffCjbmmyE72sbDvLU8350ReJBnIuGpOQJEp5qILGmEhSk+/H+8fd5LFLohbdtqwLsuERAKAdLt6C/gZgPESfS6FR5MTkxgme1Vfbx9aW1row7Whu7NLAVezc3NRWrYB+ZQjTEtPh0moyXXTFlhjFtBA1tDrcAGa9va50dDkwslT47CSKCSNDPMCZs0iqDUqShL1LK5gbHqK/upgdRXqf/kLsq+STOTO30FCaSmic3JnNYzkAKT4S2RZq+ucOFs1hQN7oj4GAJg0AGBWq+mFq80C00WvBrz9Th/OUmkmJcXO+yMC5Rtj6M9rRuHV1l8rcT5TDheGBsZx9FAtPnq3Chs25xLImo3CkkzExEZcFZhVxlcGmf0vbbOpunz3u9+FvC5tswFZBSB78803K6WXr3/96/hv/+2/XbTZv/7rv+JP/uRP+IyPUmovy6EqoIGsF5n4oj/GmP/q8DtwyN2DYQJbbWEm5r9iOe+LPZ8D49NEFdhftKH+Q1tAW+CqLeDnXN/vcePDH/wAR557HrUEOCaXlePAffegqLQEOetyFNv1bIWp4suKr3zq7BRefXMU6/NsKFpv5ztVdWOmsRtXfYJ6B8tqAaUyxzxYz5iB5AHsu9YgPCTuKEgxYAOV5orJxKoRY8tq8ivuTANZNZB13kESqkBWH2lLRGZNKiKEobWLMpntDIz09HkUs2dWpk0laUUyU4Iuuq0OC6iqb/5MqH4jQ1dltVMxtAqDTVGBDbtJzS7AVtsygipWx5XPfxYyloWZ9XQ12Wq7/KoKfsN6M/bvsCu5XwH3hlqTipgJ9vuHDQZUdQaQTIxIcXoYtucGKaupXYlQ6+/Zrod4J3gJZu1hArctMImT3kFMMIm73ZSIYnMs1hmj9BR+NsMt0zINZF0mQ+rdaAvMYwE/WWveefMdnDtzlgA4NzaUb8Bd996tpMFnC5DMsysCLOjnkgHi1NFGvPXqKdx133bsva0M0TERTDiSvm+O5nQFFIvbm5Ql7uz1k4XVjMJ1JqzPMSsmfMa3l625PWQlJHDyww95nqdGKLlHloH1kSgqilYS26u9uMzPPhonaKX2mX+HZ2IccUXFSL9pFxLLNy6bja7VjgRU7CBTZE3dJOobKYfYOIV1uXYUE8Cans6iv7hpBQs3gzsCYj3TDtT3BtHPQI8AWEnyi6z4aSbWCCvVL8yUsVvGsXKt7LCcxxHAqqrEr5lSUvIudxCZaWZkZ1mRzoR/LNUUREreQlsJO8+VgKwiYSXSgcKOIkwowrgqbTYgqySW7rrrLpwj0Pq//tf/im984xuXXdoPGJR98sknkZmZiRMnTigGwQtXEmC9sK8spD399NNKavDLX/7yQlZf0+vIvSZzXGFgFSZWD+d1orrh5vgY4nx3ZJSSlBw7w6N8kfnMTnBrDIHOGSzCTUq2IDrWjEGXEa3DZIXmS0h99hUZkJ9sQDzvRT0rCt3hJQw9LWTmedbVqph57rVmIzWMSjVhFxe60JWAg0y/wqje2ukj8AcoLbCo4lcBFul2dRYQBtaBvn401NWj8uxZtLe2YWJ8HOmZGcjOzUHuujwFZI2Lj2NBTiRslGS1Wq1zsuBf3dnorbUFVrcFNJB1dffPUs4uQB9GfJcJKuD1kZ21rp4FiZw3xDA5n51lw9bNUUpNTcCsbQffQA+VBJz9fYgrLsb6Bx6CNTaWoFZSGl3SxD8S36i904u33h9DkMWVmRkWVfSVnWHmfHgaHHvJZvpPbYFVa4GWFocq1q2sHEdyshX33puO6GiTJtBZtT22fCcm82gPUTDtzf2orWpH9dm2j9WRtiB/ffq8heULOYvBwcHzc/df//rXc6q6uFwujNNHlSbxxAMHDmB4eFiptjzyyCMXHUrmp9nZ2Sw09+Oll17C1q1bL/peQCXCyirt4MGD2LBhw0XfL+UPDWSd22o+FjA6OfcTRcImKnGc8QxSlyOIKM77RI2jwMyYKUyKnXXuvehvtAW0BZZkAT4Pg3yON772Kurfew81La3odZNgKTIad973Cdxx952KlXU2whHxZ+V5KiQGNfUutHWQiIw+7d23xyInU0jZdEBmSX2yghs5GIsdpiLwRw1AZSeLRUgUsC4R2JABxJF8N8Kq+2wFzT/rrjWQVQNZZx0YMwtDFcg6c33yLkxDwi7U2kYwa4eLkn4B9QMiUvUi4ZeaYkUCJTOF/cRk0oGSC213vT6LA+Bj4lyqsptaXHz3MKkXpiSG8tfZkJFmIYMNk8BryBEQe7T3+BVjWnUjAdlRYSjOs5A1zYiUEGVm5TDAuY4garpBeU1xJILYVcDqf5LQCDOrbmvDAjKRFwDrEU+/SuZKBWouQaxlZGZNMJIBwjA3QGttWGhlrlIDWVfGrnqv2gIzFvB4PIrZ6zfP/AqN9Y3YumMbNm7eyGrf4kXLz0oF8GD/GI59WIvOtgFMjJHN5q5N2HLTelU1PBuQRXwtYWPt6CELa4tHFcrIue3abEV2ugmx9DNm227m/BfzPn0sgiD73ZREm0Bz8yRGCODatStBAVnjCJoUH/xGaO6REXR+8D4Gq85hoqMDuXfdTbahuyiXaZ1VLnO1XZOMFen3bhb5dVP+qLnFqeQ8medQINZCVo4LM26AstVDk2RgGuO69MEG+dntNcBsDCIrwYCiVCApepoVcrVd47U6H2HalGKzUQIQhYG1f9DLOadPMSKKPYVVMyfLQnlUAoMJTLTbL648mw/IKsDUn/3sZ/gv/+W/KIm/d955h3MfmwJGzQZkFUnrkpISlaj6q7/6K/ze7/3eZWaYYVURuWsBvErC7cI2OjqK//k//+eFi+b8LOciLDAayDqnieb9Qu5DeS6OkUlTAKxDHD+DHDsDgx6qk0yrbVgZPJXiTRvnwE5/GMa8RnRPhMELI7LJFFDIOaCoVUQTG6IDrfOa+4b9UpKYdb5RVHiHkREWjvttOYjkvMfM5/OlTRi2m9t9ZFYnu3qLF1lpJuzZZlMxgwi7DsRfaq/5/pZElDCvjjDxPzDQr0CsA/0DfNaPwsHlkvAXoGrOulzk5q3jK08x6dtnAWrNdxz9nbZAKFpAA1lDsVenr0kRhjDx28S5Q32DE6NjPqWWlkbVu9RYL19kk3v5NxirrUJiWRmSt2xF6s6bYJxFZUR8oJmYvzC91jW6yPJqxo6tkVQuMCFaE46E7kAK4SsbHyeRTpcTb7/dr/KOu3cnsoDQzuK/iwuQQtgEa/7SxhmHG+gbxZH3a8jYP4jElFjFylpGhla73QKL9erzF/PFEC7sAAGybtq0SSm7zMbI2t7eznjcLrVJQ0MDC24vls4WfzeL6kPSnnnmGezfv199vpr/NJB1futJHtSHALpJ6FLjZdwx4MAImVqlkDGbCoV5YVGIZx4sQisUzm9I/a22wBItMFxbi+7Tp1H5xutopAJLd1QC1hHEX7KpDOXM1wg7ttEkTOuXx1dEYUAwSB8em0Rntwe7tpG4g6ysKckazLrE7lj2zch9iEkSdQhBQE1PECRSh5tF4eWZJOtInlacM18ctl/2c9A7nN0CGsj69uyGuWSpgVX24iusubYWgKwSiBauEkk2OslUUVPvQFW1A+eqHGRnNVE204qtW6KRR4CkJIt0lcTquQ0kyTdMlpqaeifOVU+hssaJ2/bHYMeWcII3zSqxt3rOduXPRIZyT78PR88SlN3tV7b5xIEIbC4xK3anWXyolT+pFT6Cm9T8PQRRPH8qCMYDVMJ2EyVsS0jxrtvasYCwQAwHCYDyj+FFVxusQSO2WRIVmHWdKXrtGOIaXqkGsl5DY+tDrUkLjI+Nk0G1B//2k5+hn0xfX/nPX0VJWSkD3Jcz1lzJQD4in5rre/DzH7+N8AirYmLNI/NDSnrcnJsKhs3LIplDJ904eGgK63MtKMozo4yM71Iss5w+hfjiIrVTUTFKtocexVBSVMSChLIYSu8JOG/O01x1XwREXpjglrY3XkPFU99HAZmGSh55DLa4uFnZhlbbBUjS2EP2o/c+GKV8p0MxLEmR2IH9cYiltLlInSt/k75XRVuQTKxB1FPaXCqTy/jamhOGOLJASnBHuu1G6rvl7gth1BwZ9aKKUqgnK6b42QczmVa3bIygkoQdeTkWygjKvRT82FYXD/T5klAtLS247bbbmOT3KYaUzZs3q9OXgOmePXvQ1NSEp556Cp/+9KfPX5Ysb25uxre+9S088cQT55fPfPiHf/gH/P3f/z2KyZD19tuXB0mEdVAAswtplZWVmpF1IYa6wjpyr0mbAbZKvEJA0d29XsXkIGwO7Z1uhJHuWIDRMYlW+K0WtE4RIJ1qwq3lZuQlAWmx0/vR/4eWBd7ydKOSINZIJiuLqEaxw5QEq2HuyLr8preQkfX5gw4VJykrtJBl3YSMFC1xv9CRIf6KgPxb+Sytq67FsSNHFBPrJNmqcwha3b5zJ4uONiGvIJ9s9zYW4ZAZiUCB2ZJZCz2mXk9bIJQsoIGsodSbl1+L+C3iq7ionnXi1DiqahyKMCTNPoLNqb0YP/IKzO4xbP6j/4zEjZvU3Gi25yND/Ypk5DVKsDa1uJGUwDloSTi2M9YvbS3PLy63ul5yo1hA7o/RUQ/eeqsfg4NukuZYGe+IZrGhjlnfKH14tecpfqSfVHwtjb2oPN2Cd944g9z8VHzys7uptBGDmNiLwaJLOd58MYQL93clIKvEAx599FHlx/b09KhCrQu3Fx9XlFykAP+f/umf8NBDD1349fnPEq/4l3/5l/N/z/fBK/IkbLOpx8y33Vr7LkAmVsmD1filoHEIp/kK53zwgCUdRaYYZBqvfhytNZvq69UWWIgFRIVttLERx7/7HXQNDMKzeQea+wYx4pjCo48/hh27dsAeHj4r+Yj4ANLePTSOylonIqnGtT7fhh2bw1kEe3kh8vTa+v9raYEpD9A2CJxoCeLdWmBLDslc8oE8ql0JaVrYxSH7a3lqa/5YGsh6eY5mtkGhgawPPzybXUJqmfyYSAWxJBn7B7zo7fWo5OPkpB9CahFF9qGsTCsy0q1kabWoymIdPLn+Q0CkF0VmsbXDo6RPBQhht4dhQ3E4MtPNSIw3r6kgl8gG9g0SkE1W1iq+0pNNyMkwYUOBGXFkewq1MStU/FMeA5lZ/WjqN6B1MIjyrDACKYAEMrRGkJlXt9C3AHmr4KbWmEisVPlG0OGfRC8rVDeY41FiilWTeGEo0m35LKCBrMtnS70nbYHZLFB1rgrHDx9DT3e3YvK674FPIis7S4EiZlt/rmWBjwPldVUdOH2ikTK3ybjj3m0qSC6g1tma+MRDowHUNnnR0uVVRTI7ym1kejcjIS5MFcfMtt1SlsmxRB2hunqM4DtWJnc6mcyJwsaNsYqdJCLixgLYiNyQBLd6TxxH3S+egT0hAXFFRcjYsxfROblLMdE12UYArFNOPxUqXKipm4Ka/9BpFAnP7Ewb2Tas8ATCMOI0oKF3mol10g3Y+NMaE25AemwAGbFhZGENcplhzQZ4BCgmyXuRjepilX1PPxk0WcEdFhZEXKyJ94+JjFJkYI03KUB42DyRsPmSUE8++SR+8IMfKNa/AwcOXDRGPvjgA95TUygvL0d6erpiR3n88cfxwAMP4CjlXL/2ta/hT/7kTy7aRv4QgOuPfvQjCKPrL3/5y8u+X8yC73znOxrIuhiDLWBdSXzK81LG16QjgLEJH8bIdjY24WcxLu9fqso4+D4wxuToAMgEYUBaghG5ZNBeRwnedelGxfwr0r6hNh9cgPlCahVX0I8pKlK84m5Ho28cuy0pKOZ8J4NJS1GmmKvN/Lafq3OjrZsxr6EA9m23YVMxGaBIBraW1GzmstFsy31eH+8xJ7rIst7R3oFWFhJMUpbVzd96i8WqZARjWaySlJKMND5zk/keExPDe9DEe23u/pjtWHqZtkCoW0ADWUO9h0U+dRrM2kcfuLNjimD/EQxTvmFycARJ6EJWShBbPn0rkvMyYaBiwGxNmKoaqb7W0ORWxTxSBJZDBQNhrdJNW+BGtoCT8+3Gxgk0NDiUEs327fHYvTuB/kQY4zzaZ7iR+3ah5y7PyPFRBzrbB3DqaANGR6hfzLZtVyHKNpGZlTE6s1QFL7HNF0O4cJdXArKK+ss3v/lN5dPW19fPCmTNo+rA5OQkvvvd7+ILX/jChbs//1nAqQJ0XUgTcKw0DWRdiLUYs2UOrNfv5HxwDD2BKThAllzOB/ON0VQqjER8GEkBFrYrvZa2gLbAAiwg8X5Hbw8afvsb9JKpeoL5lnbGyYesJFVLZUymtAQ37dnF52Y0i81nf463Ulm4odmJ6joXEuKNuGU3mZQZJ44In339BZyWXmUZLCBqc4IrqeoUrEkQkTaq0lHhqoBqV1G26TzHMhxG72KJFtBAVg1knXfo/Pmf/zkKCwvx8BoAsl5oCKkg9noDlNN0obp2Cs2tUwxUQ7Gz5q0jg06unZIKwkpE+XpONOdLQl64X/155SwgAOSePi8On5hUiePi9TYU5PElTLqUXLQwqb5WmkyKRTLwZKUHAyN+lZjaR+lAAbRGkq0n1PIpUq0vFTNnyQr2ckUQqTEGFKcDJekGfmYil0D0tdP7a2WUz36dXoJZHRRaOeEZwEF3J5KNdk7eo7DFnKikVmxM74aF2g0wuylWfKkGsq64ifUB1qgFhOlLWAveffMdvPjbF1BUWowNGzdgy7atiI1bHK2egFg9Hh8+eOsc6ms4G2crKc/Ggbs2zVohLN+LD+Ekk2RLhxfvH2fykAsS44zYUW5FXtZ0YFnWW642NUUwTZ8b770/QFCWF0lJVkqcxaK09MZmJhlraUb34Y8wXF0N99gYih9+FClbt07LZ66i3yHFhkugpQBXe9kPNZz3nKqYJHjVinW5NpSXRSI6xgyP34Du0aCqTq7qCmKccjvxrEguzzJga64BEZYgrGvI175w/Ms9I7LdwsA6TlChzEnqKYHaTjDrEOXg01PNKCmyIz/XqmRRZd64kCEwXxLqL/7iL/D0009feBpzfv785z8PYVsVAOuzzz6rGFt//etf817niX/cJJH14IMPQn7bf//3fx/f/va3Z75a0rsGsi7JbIveSLpQ+nGECiX9g150csx1dHsJpCZTBHOiDq8BMQo8bcb2YiuyydIaETE9LzbzfhWGYIllLGQ8Lvrk9AYrZgFJWnYxWfmuu0cV8X3WnqfYdwibVP/mO7CbjNvjk0Ecq3Dj9UNO7N9hw7YyK5ITyOrLYmDdpu+pAOVS3WSYcrtcmBifwPDQEBrrG/iqR31tHeMrFiQmJWLjli0oLS9D7rpcAlojNXBVD6DrbgEBT1/4+341J7Sc+5o5Dw1knbFE6L/LOByjJmfd8UacPTeJ07UB5OVHoaAwFmVbU5CaHgE7cyoX+sXiT3uYPD5bNYUTZxyqwCI9zYI9NxGQw4Iw7a+E/rgJ9SuUfKOAWc+coRLNi92qeHfvvkQkJFoIYln+WEuo2/NGvj4H9YvbW/pw4nA9Pny3GrtvKcXWm9YjKzeJhex2KoIuzS+fL4Zwob2uBGR98cUX8dWvflX5vJ2dnSpGeeH24iOkpaWpRT/5yU9w1113Xfj1kj5///vfV4BZDWRduPkkDyakLtW+Ubzn7aFCYRjSTVTnNMWrfJiQukiho86FLdymek1tgfks4KESy0DFGUVe0Xv8KCbSMjGSmoXGplYkMD5w76fvQ866HJKHxM4aG3CTlE0Ull5+Y5T5FlBZOEJhjlJZrKX93PksvzLfMWUGF8nAJc9R081c2KABGRQvvLUECmMSs3hRxJU50TW+Vw1k1UDWeW+BtQpklaSQSPgJu8nYuBcDTAxJcreLySEnGS+F/a+0OALrKQuZSImbcF0xMe84uhZfesjEKo5Ae6fnPDurVLIUFdiQv85KdlbSjKyhNuGg1DqTmsfPudHR42PQz4jidWZs2UAZ0xBLWEoaXphZ+8em5W1re4CeEeC2UgPKMoUpjAwzS5v/r6ERExqXKk9nPx/gAwEn2snKeobyKn38LHKbwsxaaoyDWSi2dbtqC2gg61WbUO9AW2BWCzjJpDg0OIQ3XzuIl597CZ999PPYf9stiIuPU0HkWTeaY6EEx0eHJ/HSb46gu3MIt9y5EYUlmUjPSpyzCEv8qbpmL+pbvWhs8yE/24SdGy1IYPIwgsyby91qaydQVzeB1laHkte7+eZ4BWaNjr6xGXc8kxOYGhhAIyu1uz/6EIWf+V2k7boZkRmZ02DW5TbkEvdH3DR6et2qeO/M2QlWjbMIiIyheQSxpqWRDcRmQt+kgUEdgGRKGOfcKCseyEow8N2AOKqWSWDHxOLxechFl3h2q38zmTMKm+3gkBfNbR40tRJgxqBkPFUQEhMo2U0lj0QCCWPph0fYDSyuW7g6wnxJKEkm9fX1zWqgr3/967yfWvFHf/RHuOeeexQrqySZLkxGHaEcdmpq6vnthwjS2rhxowK/yHH37dt3/rulfNBA1qVYbWnbyBj0sABXlBiFVXmKsQqJV/SPBNDJsdjU7UffkB/RJr+6XxPJBixB8rQUM+91M2JjTLBRykwHzZdm/+uxVTXVJz5w9yLIn+T4MCv2mFOQRvadhcxwJMbl808XvUqcQBijoyPDsJfMrGlJLPhbyE6ux0Vfw2P6eDMJu1RHWztqqqrRRLaVbrLjR0fHUPY1CRmUUU0m40pKSgqiyLYiy+3h9kUz5l/DS9KHWgMWOH78OAQkeu7cOY7JaBQUFODuu+9WPsBigK1Gsgc999xzOHbsmBr38fHxuOmmmxSru3x3tU0DWa/WgjfO9kEWBAyyAKDy57/A8LgB3uQSDCATLmsykpPtWL8+EhvLIj4mCJn+8RkbpzpEu5uSq1NoanFj17ZIlLIYLCnJDKtl+eehN4419ZmGigXEbxdp+eZmBz76cIgRbKrJJViwdWscZdo1WiJU+nkh1+GjQ+5yMn5Q341zp1rQ1ztCIpYwVXSeV5iuwKxLIU6aL4Zw4XldCch6+PBhPPTQQ2qTtrY2ssReHJ8bpzpBcXGx+v6FF17A9u3bL9z9kj5rIOvizSZ5MAGzjgTc6GahY71/DA1kaI3lHDEnLBI7LUmIN9hg0bmwxRtXb6EtMIsFAowVuEdH0fHeu6j6yY8RvWUr7Fu24XhVHQbHJ0kEEY2dN9+EfQf2U+VZisYv9l8lHiP+bkWVE20dLoXfuHl7pAK0XljcNcuh9aJltoD4ZB3DAmCFUp6bIGFHaQYUC2s2cx52/uxJrkO3628BDWTVQNZ5R+FaBbJeaBR5oE1NBTAwROn6hikme8muw2RlAgGsSYmSALIgOYkSkUxSaimQCy13fT6L1KIws55k9bYwIkmfCJA1L8dKunYTwsk0con/cH1OdIWPKuNWwAln6zyoa/GgbzCAFMpLbimlHFOiEbHRoZelkuqZcSdwuDGAM+0G5CYC61MNKCU7q9DBazDrCg+6VbR7mcS7KalyxNOnqlL9nNinh4VjkzkBKWF2TugtV2QsWkWXsypPRQNZV2W36JMKAQsM9PWj4nQFKivOkfmrEZ8jkPXmfbvJyCAAuIsDIFe6XGF4qK3qQHVFm0qS3PfQLsXwYLPNXtwjAKhhylKfIKN7b7+P4CYDNqw3Y+sG60VsOVc67kK+dzp9igX0xIkRNDUx2BNlJktPBAPgcZRLXzjYbyHHuh7riOSQMLo1Pfcs2t46iOicHCRv2oyMvfthjopadF8u9zWInzhOafJhMoY2tzrJ5EgGx1GvAq9uKI1EeLQFQbMJIq/TPRJED9lYpVpcAjllWWHKx0qKAq5C9W65L+ma7k/sN+nwY4IMrAO04cCgD339XkxwHuIh42FOFhMHmWZW1tsQSQbMpUhFLjQJdemF33HHHagmE/BTTz2FT33qU+e/9pBdsLS0lPPaKdxyyy145plneF+HKXaVL37xi3jrrbeQkZEBSVrNyPqd33iRHzSQdZEGW8bVBbAk43OEwfG+AT9qWJRQ307lEo5PPwGv0cyRZxCwmM75oIzNqCgjoqg0I59FcUZYOa189usg+jJ2yjLtSuYzzoAPx30DeMXVoeY15aY45JmiEUW2ncW0QQKd28jee7bWi5ExH/Zuo+oQC1fiY8JU3y9mX6GwrpvyS1MOh2JelWKigf4BDLEYpb+/D+Nj4/B5fcjMyaKfkk82wfVIIog1JobSL7ppC1xnC4iSw+OPP46DBw9ediZ2ux1//dd/DWFml/Wu1ATALezslZWVl60qYJXf/OY3iIsjRc1VNA1kvQrj3UCbCoh1oqsTgxUVaHzxeViT0pCy/060OVLQMxWjciwxLKRZl2NDOgvnkphTkcS+MFSdOjul5ohCwHDzjkgW11k1e/wN1Pf6VBdmgcFBNxobHWhomKCv4cZttyWjqChSFT0uBby4sKPqtVajBYYHx1l0PozjH9Wis20A64szsb40UxWg2xh8MTMms5i20BjClYCs7e3t2LVrlzr0bEBVKaCRWIPEKKuqqli4uzj1qNmuSQNZZ7PKwpbJPNEd8KPWP4pzvmEME9gqRC4FYdHINUUhyxipwKzmBZU+LuyYei1tgbVqAYn39x49iuqf/RS2xETYc3LRbTSjY3QSDczjFJcWYc/+vcjIypxVWU/UB3r7Paiuc+HoSQc2brArIGs81fDC7Ro5udLjiuFSTFF9m8IRaOgLoppsrAI6jgsP4qb8MDKyBhHOmOjiMnArfdZre/8ayKqBrPPeARrIOm0eSQaJ/IeXLFUDgx5K17txtpIsDZ1uxESbyMwajm1bIgmUtJCdNfQAgvMOklX2pfSVSOaNjflVFfcHhwUcEaYkUndujVDMrGspKOAiS21XXwDvHHFijMn2uGgjdm6yEphCIF+I/RqLEyLx+dZBoLYniNOt0zK3n95mQHpsEBF0QHRbGxaQsSDM2eNBL9p9Ezjo6cZE0IM0g53VqMkq8UtI+9owxgpdpQayrpBh9W7XvAXqamrxq3//pQKurstbhx0370T++oJF20XATB+9V4XXnj+OjOxEFRDfsqMAcQlzS9929vnQRMDTsTMulTC8e384MilFHRWx/M/L3l4XpXcmcbZijD6bl1JkKWTmiUJkpDDCLf/xFm3AZdhA+mCougp9J08oVtbwJP7+/OEfIYLsmIbrSHsnvrKcW239FCrOTqKNzEdhjJXt2RWDHAIvhRWmtpfBnB4DKtqDLAQyID85iA2sTC5MDYPNHISFyWVRuws1X3Ih3T5jvxbara7BiXPVLgVqFabL4kI7SgptnHtMByBnZNuXYqeFJqEuPee5gKyynrCyPvHEEwrQIiCsLZTFrqmpUeyuVqsVr7zyCkpKSi7d5aL/1kDWRZts2TeQ2IUoVkiAtpssA29VUrmk1weDx4sYgxfhARYsDBDcSkZhKc7NonqJALCzMsxI5t8WMp+FyrN42Y17nXboCvrRT6WJwyzUe83Tic/Y1uGAOQ02gwnGRT5kiDEiM2sQBw85Ud3kQUYKlWzWWbCphEzci8uXXydrLO9hBwcG0dHRjtPHT6Dy7DkCCToQHRuDkg2lKNtYjsKiIvW3PTwcFjJShbG4SAAAumkLXE8LyBh8nCDWV199VQFJHnjgAbL6bYWAS2SZFLDIOm+++eZ51rS5zlcKWO677z7FxGqxWJSc8ObNm3H27Fn88z//s5L6/d3f/V1873vfUz7kXPu50nINZL2ShULje5/LhbY3Xkfv8WNUqOhH2s5dKPz8w/AGTBga8eNUxSTVA5wYoB+yY3s0Nm+KJLs8lELEOx9OoKwkHPtvlhyLmYoga4OMIjR6Xl/FQi3gZXGZ5GvePNhHZtZB3H5HCjZtjEFColURsix0P3q9G98CAU7YhJ215lw7qipaUXmmFemZCbiXRejJqbGIEGaWRbSFxhCuBGSV7/fs2cOi8yZI0avM72eKYgS8+s1vfhP/9//+X+V3vPzyy1flG8xcngayzlhi8e+qmJWbeRHAJP8/7hlQxC6dVCssZeHj7ZYMJBptiy5+XPyZ6C20BdaGBcbbWtFDBYvBijNw0Ndd//CjGLZH4iG6CIsAAEAASURBVMXfvkDVYDdV9eJxz/33oGxTuZqnXWgViSlLvK6m3om33h9ncTnVvJh72USlAlFO0m1lLeCX4jkqzn1QH0T7EEkAHMCtVPbdmku1IpuB+Y61qTi3sla/ur1rIKsGss47gjSQ9XLzOKam2Xc6Ol3o7vGo5HuAum4mSnGmpVqUhGQq36NUIl4SvKGRjL/cEqt3iTgDwoYkzKz1zS7FousgQ1JmBtmRsiwoWGdTLGNG9lmoN5nIjE8GlURwc7sXrV0+laQqyjOvGDjlettUWFn7WFFztCmI/vEgUkmWUpJuQFkm79M1Crq43n1yvY4vzKzjnMCLBGcLAa2dvklkmyJRaIpBnjGa8ipkGdTP6CV1jwayLslseiNtgTkt4CeqZHRkFBWnzuDZXz1L8Go+7v7E7yA1I40VvItjP3JMujDQN4oTR+px5L1q7LtjIzZvz0dyWhzs9svZWD0s1HK6gjhT40FVoxd2K5SPIEysMZH87SRocbmaJG0mJ/2oq5vAsePDBPyZKM9rw6ZNMZSZtBLAe7n0znId+3rsxzU8jLGWZtT96hfwOV3Iv/c+xBMoGJWVfc1PR/xjny+AIcXC6kJXlwv9TCDHxZqYNLMgLSscU0ET+hxhGJ0iAM4jjKtBJEYZkJMApJFkI4mfBbuzfCPimpthyQeUsTtBn7qPNuug7UbJXiysrALoFVbL1GTaMJVqHZQ/NRMEKHPDq2m//vWv8Y1vfAOJrPAXdrSZxNGV9ilSwgI8+T//5/8oUMql6wsT67e+9S04yD440zIplf3kk08qGeKZZVfzroGsV2O95d1WwKyTbgPqewJo7A6gqdsHn9sPE6v/ku0+RJi4glQCyl3Nh4Q8g23WMBbrUsGDz4a4GKN6RkSSrdVgCGpw6/J2z6L2Nhhw4bh3AJ1+Ks+QZed2awa2UG1CuCKW+rSpaWK8pMWLti4yciebsHe7DbEsArYzgB+qTeIjfp+PDGj96OvpRVdHp2JgHR6mxC+/k8S9MFkmJiUpFpV0MlWnpKYQWGKBkWA/3bQFVosFBKiaT5ZgmUP85V/+pQK1zpzbMP1PYV8fGhrC/fffj6effnrmq1nf3333XTz88MNq/P/7v/879u/ff369H/7wh/jTP/1TxdYu8sJXE+PWQNbzZg3ZDyK3Okk21iYysU52diGRihQpBFinbNuunrFOKoCIEkQ7cyrtHZxsSKMv7fPL746wglPWs8iOzWUsHBB/ehnnoepY+j9tgVVgAWEgFvf75MlRnDo1TFUEE7KzSZKzLU4BWlbBKepTuMYWGOwfQ0frAE4da8DkhJPy1OEo35KHkrJsWMnMalqgvvFyAVnl8v/X//pf+Nu//Vv1u//b3/4We/fuVc9x8Rkee+wxBdb6u7/7OzzyyCPLYi0NZL16Mwqpi7CzdnC+2EYQa713FB5DAOZgGErMVPIwRiExjHlxg2Z9vHpr6z2sZQu4x8fh6OlBM/1dKdwq/OznYVqXh+aeftTU1qO5oQnbb9qBjVs2Iq8gn0UJEZeZS2LLtQ0uqqS5qJjmxy27o7E+36ZiMbqo/DJzXfUCAbC6vYyNkoW1eQBoHxTmVea/4gwoJnYkk0ysEscPEW6Vq7bXatqBBrK+vaDuMDidTqb+1l7TQNa5+1wmnJKIr6l38MdpCpXVDiQzcZm3zo7S4gikE8xqpzSfBF3WAmBybktdv2+kskWYRoSi/fRZB5lamYRngnnfLjrtZE2Sym5poY5j4280gQtBVNZ78eaHU5SqCUMq5SR3brSqah+ZC4eaDdw+4FwH2cS6yc7aHVQg1rvLDQi3BGFjMFS3tWOBACfwHjIY1fhG8bq7EwJujQ2zYr8lFQUEs9rDTAyX6zGx2BGhgayLtZheX1tgfgtIMrquuhanT5zGoXc/wJ4De/HY448p5s7FJIwFhNHfS0DsyWY01Xeju2MQn/rsbmzbVTTrb32A609MkrGv34cjp12obfbizr12bCq2kMV9aZLoc12pJGympgJk4HEQaDdKIOsI7rgjmZJlCQrQarFM+2VzbX+jLpeEbs2//QyjjQ1kY01H2q6bkbF3n3K+FtO3V3P97GYqSwgQ06/Yjj48PEa/mEEb+sI7d8YgLTMcA8Q1VtFvOtUKMG9COR1gVz5BrIkGRJEIZC0Gc2TMKtvRj55kUZwUMdY1unCuZooyf2FIoPTT9s2RlEa1EuxnvGrw6tX08WK2FdBLdXU178VWlJeXIzc3dzGbX3FdDWS9oomu6QoyhmU+KMHa9+soYzYqc2QD9hfxPo/yY3zEjZ4eArSpNtPd6yFDFMiCZiI420SGVhbqMq6RmGBScqcmgtuNrAwUALcE10NtDnlNO2YRB5OEpCQjn3O1wsx5ywZTvCrMyzRenhBZxG5VEUtHjw/PvzWlnl97ttmQk25EcoIAlxezp9W9rvhGAT73PF4vvKT9c1BCvaGuHrVkpK6sOIsxFhLJOpu3b8WmrVuwobyMBR6JfM5rRpTV3bNr++yOHDmCBx98UAGvm5ub1Ri+0CISz5eiluzsbMXSKr/9c7Uvf/nLipX9zjvvxE9/+tOLVhtnova///f/zmeCAd/+9rcJsoq66PvF/KGBrIux1o21rjxDxWkerqtF/6mT6Dr0AQxGskv94ROILSiAyWa/6IKGR3xUhXDi0JFxxdAaCBqRm2PD7ftjkL/OqnIqofQ7dNHF6z+0BT62QEfHFJqbHaigSo2dcsL33pvK4l6bBnCv0REiBem1VR2oONGI4x/V4eb9G7DvtnIkkZk1PIJEHAsIyCwnkJV4CHzmM5+B/HZL27hxI+eDNoKvTzHP6MOnP/1pPPXUU5f5H0vtPg1kXarlZt9ugiqFLf4Jxc562NuHzeZElJOdtcgUi3jmxagxobNhs5tOL9UWuKIFZvxeifW3vPIyUm8iizaLtuLLynHoo6N4+fmXICpYeesLcPtdtyONJCWXxhY8jNG7SCry+ttjOHHGgVuoRlBWGo7UFAtVYEIoGHNFa67sCmqKwkOIWtUQ81/v1QqQleq9LN7enAXcUixEFGsz57Gyll++vWsgqwayzjuaNJB1bvPIA9BLVqMJVksIs1F/P+X5+Boa8krsBvFxlJcsClcsrUlkOdLt2ltA+kES0EMMkHUx8SwVLmPjAfXDJBXeGzeEw0pQoznEHQP1Y83/hsdYkcdEVWW9Bz0ErGxYb8H6XDNyM00h5xxJslZo4Zv7gzhCZlYJuidHA9tyDchLCj3g7rW/u26cI0o1KocDRoIedJGRtYqA1mbfOJJZgVpAZtatlkQlraKn74vrUw1kXZy99NraAleywMT4BF589gU0NzYjOjoKW3duw579e9Xv15W2nfleAilulxeNtV146bdHEBkVjqINmSgtz0FGduLMauffxT9wk8G+oc2HD467KCdsQGJcGDYSxJqRYlI+0nIlEOVYTqcfnUzWHPpwSDHnCxNrSWkU1uVGKF9sIYH58yd/A33wuSidebYC/Senk7pZt9xKec0vMKFrg5EMb9eiCXPo4KAXpysm0NfvVWxHKak2BtNsGPSaMOgykcUesNInTiA+ISvegHQysCZEAsyZrFlGe5F8FFWHBio8tLS7IUl3KVJMpNRpSrJIsJPNlnO+iIiwaSn25bphrsWgWMFjaCDrChp3ibsWX5jkPhiYAOp6gmjkHEmeywnhQZSnM4hLgGrAS+UZPitkzI8T9C5xDgeLD+R3QpzpxAQzkjjmUzn2kxLNiCdjq2Jo1jH2JfbKwjaTvhM21nr/GN5wdSKb4NV7rNmIMVByOezqgJZS9DvK+Mjpajc6ewlqngjgps02bNtgUc+6UHikKd+I8n5Dg4P0sZpY5NOAlo9BfzYCqxKTEpGUkkx2+BTEJyQoGcDo2BhYrQIYCM0Cm4WNPL3WarfAP/3TP+Gv//qvWZC0E88999xlpyssrQIKySCr8En6oHMxuxuNRpRQLUBYXH/yk58odnaTyYSRkRGVgJUdC2BlOZoGsi6HFVfnPvwsyvRNTaH19VfR8vJLiC0qRhJBT2k33Qw7n60GjrMLm8wLxycDOPjOGD4kmFWIKMSvKCqgUkd5BMo3RChSEP0YvtBq+nOoWcDh8HGO7sHbb/eThdOHHTfFE9BNEAvn6bqtPQv4fHwuUhqnuaEHZ040KWZWCzWO99xahoKidIKdLQiTasJ52kJVXSRPtn37dqr0dOEf//Ef8bnPfW7WvUoxy6OPPooTJ06c/15UCm699VbF9i6fl6tpIOtyWXJ6P16SukwGfegOcEwxD9YecMBBcGs+SV1EqbCYgFZN7bK8Ntd7W1sWkDhDz9HD6Dl8GJPdXUp5rfBzn8ew04PGhgYcI6B1dHSMv+07ULaxDIUlQjDyH8Ezwa1InWFFFUnySJYg0y0hYdt7UxTJPkKrsPh6jgwv5xhun0GRnp1pYx6MNo9mfd2GDCCbuY8UYkakWy7omut5uvrYs1hAA1k1kHWWYfEfizSQ9T9sMd8nYTjykNWovnEKjU2Usu8TeZwgK4jJeJkuMpNWJc0nrEeS/NRS1vNZc/m/kyTdFINkNfUuNLaIhJEbGWkWFOZbkZk+zaBkJQtYqP9YSaLKR/ngIxVuxc4qIN6MFCM2lUyzroWTQTjUmoAyTrcF0ToI9PHz7gJWkGYZEEumMcYCdFtDFhA4q58Pg9PeIVT4hjBMSc4YJn+3mpOQGRZBYKtdVaLq5/PCBoUGsi7MTnotbYGFWMDJpF9vbx9++f+ewcgwWUrvvhNFDHBk5WQvZPPz60jgu6drGJVnWvDuGxVKhux3PrkDMbERisHh/Ir8IL6Ri+Ck7r4AaiktfKLSjeI8M7aVWZFC1vaoiP8Irly43VI+Twdngmhvm0JDw6RiY01Ns1OaLJGy6VYCd0P7BznIyJR7bAy9x46g8l9/jITSDci7737E5K6DjYndlWwe9vEUJTy7ut1kPSIYk5JFbi+QnG5DXIod0Yl2tFBOZ5DgNl/AgGyeTnnmNIg17uqI/lbyslZ03zJeZV4n0k7Do370U+6po5vFiixclGR6WooZJYV2BeaTwkXdLreABrJebpPVskSe/cLMWtMdQH2vRCwMKE0H1rHQL4sszJIbdbsCEJkzKdLt6WWCnYW6AmgVwHZUZBjZh82IizEhJtqoWJ3D7VS9IIuUSADbrDKfnC4iXC3XfKOfh4/2PMf5S51vDK1k1Slh0vE+W47i0FmOX2ph5+4d8KOqwYPDZ9zYXGLFjnILQfphiLhB4wPCPOkl+6oUCY0SjDdCgF4f/azuzk70dHdjeGhYAVgzyVRZXFqCnHW5SCfY78LE0o0+bvT5h74F3ARou1wuPntFDexitktZLhLA3Rzv99xzD370ox/NaZC+vj5s2bJFff/666/jBz/4AQ4dOoSBgQG1XwG6/Nmf/RnKysrmBMPOufNLvtBA1ksMEiJ/SiLfxWKB4dpadH7wLiVWj1Ni9XPI3Lcf4UnJMLIw4MIm608QxCq+xvFTDlTXUUabPobZTNZ3QxA52Sw6z7dT9c6ifA1RQQj1eP2F9tGf15YFpqb8ePfdfnR2uhAZKYUFUdi0KVb5JHrcr62xMHO1gwNjaGnoJTNrE9pa+rBpWz6KSjOxbn0a7NRBNl4BzDqzn+V8l2IXKYoRRtYdO3ao9+Xcv+xLA1mX26LT+5simHWc5C6HPf2oJ7mLxWCEqHpsIDtrCnNholoo5C7LMa9cmSvQe9UWWL0WEACr+L+Nzz0Lo9mEDb/3+7BnZMLDH/DXXnwV1ZXVaj5VsqEEe27ZS2WLSD7HCUy4oPX0edFK4oSTFQ5FNnZgbzTSycoaydibbku3gBSEewkOHpkCOoZEuTeIpj4gl7HPorQwlBHIKupz2tdauo2v1ZYayKqBrPOONQ1kndc857+UhJAkPYW1RyRTe3rd/PFxoaZ2Sj0IJdmzZVMk8vPsTP5QdpJgVt2urQUCAQI2mJQTx6Cm3klWJRdZlfzYf3MUNpSEKzlQYSIL5SbjVNoQr7ut24dDJ92q6l3kgwtyTMjJuDpGl+m9r67/SSwEhws41hzEe5TSzGSVTUHKNDNr/BoFaKyuHrq2ZyO3gFSfDvid+Mjbj3Ymg6VtI5h1rzmVk3kWG/Cl25UtoIGsV7aRXkNbYKEW6GjrQH1tHd5+4y3FAPbo7z+GzOwslZhe6D5kvSn+4H34ThUa67oJxPOqgPeeAxtUoPtS5gbxi4YI0nv7sAt9g35EErgq/oCwtTP2ohhwFnPs+dYVhh0nwZRvvNFL6bxJFnjZsL4witJkMUxYUqLaGOr+F0spCKoZodRmIxmzfE7K0kdGKjBrImWHVrINDTMg1upERSUZktqcKFwfjviUcHiYgGgdDUPrkAGZBK/mJRlQnAYkRRsQaQ0qdl6qh6+5Jr6yl0Vf/WTGqa5zoYkFcMLEui7HinXZVuTxPYES6+E2SbZTfijE5w5LHQAayLpUy12b7Vwc4xOcH9V0G8jOGkBTP1CSbsC+Ij4DoghK5ZRQlGfkXvD5giq+MUGWVgG29g34GOvwUOWEAH0CIKU4NJOFu5npZgXyTkmiSCFlL3UwePn60kU2nRfd7WgikDXPFEUgaxzKTPHLlmxUzz32c32LF+/PsLPHG7GTYNaM1BsTrD/FAqGxkVFUnavEuYqzqKupoV/kQXp6OtYXFZLVqhDJZGCNi49TiXgrfxMvlfpbvh7Ue9IWuHYWEDC2AFAff/xxBTgRttVXXnkF5eVz+5s1vD9uv/12dZLZBHe3t7erz8LKOsPEKvsVttY777xz1osZY8GW3HdXas1kQz548KBifhMWWN1CwwIyzxH1idqf/xuCnGRGpKUj+/Y7VPGe0Uyn4hKnQICsjc1ufHB0UsXpxa8uL7Xxd42FG1UOKt2R3ZWJ5927YlBSHK5YqWTOqJu2QChaQMhx2tudqK0dx8kTI4yRxOLuT6RwPh76cZJQ7M/luCYpUBelpeqzbag83cKC8AEkJcfgdz65Hanp8YiIDE3GXg1kXY7Rc/k+AvzN9SNAQhcPOgKTOEpA63DQDUKisceaii3GBFjDjPwrtOOyl1tGL9EWuHoLiCLBVH8fKn/4L3zvR9aBW5FQvhExBetZQNuDyopzeOXFV1TcYf+t+0laUkzSkqyLDuxh3G2U+Zk33h1VKmB5OTYUUqGgMD80n/UXXfwK/iGkbmNOAwGswNvVQZDUHDlC3kGSs5wEFuFLAZ2eXqxgDyzfrjWQVQNZ5x1NGsg6r3lm/VKS9ROU4uslK2sLE8ciQakYTMjGGhdnVsmelGSLkuPTSZ5ZTbiiC1XfUFK1vsmJ5laPYpVJYZW3yBeJVKIAjUO9iXM0RtnA09WUWu/zwekKomidGRsKWe0eaYCdQcRQaZKYE/BiMxO0ZzuD6B4JKkbknXlSfWOAgFmZa9VtDVlAxoOL1agN/nE0MCHcRHmV2DALcoxRKDLGIM0YDjPBrFKNqtvcFtBA1rlto7/RFliMBSSR99EHH+Kj9z8kS2pQsbD+zr13U942fjG7gWPShYG+MRx86QTZxxwo37qOsjWZyCNrw2yto8eH5g6vYmi3WQ0oL+JzMN2k2FhnW3+py+R3uKuLUlbN02ysXo+frE9xyMmxIyWVTNhr6FErQa3BynPoITPrcGUlir/wMNJ274UlKgphBAssVxObu1wyF/GivUNYWJ3g8IAnaEBEImU6IyzwM6kc4O+c+EA5iZTTYTAni8U+ESRMWot+kdhM5gjCutrV48HAIFkryMgqPoOwsOZkWpGVYUEKJdVFwWAtjduljEsNZF2K1a7tNsSponcMaCU76znOkViTiyiC2EszwhRDQQzJ/cwfT4slvuF2B1kM6VX3yCDvk9ExShXyngljIYKRDw0jH2HCxiq/J7Fka40l03ZMjJFFEmHqJVen2S4X38eTUoAXcOF1d4dSk7jNko4CcwwSDcuf1Ogf8qOh1atew2MB7N3OopNcM6LJBHIjBPgnJiYwPDiE3p4e9PX0QlgmpxwOjl23YpGMjo5GRmYmsnNz6GvlIJJsKMIqpZu2QKhYQJ6xP/zhD/E3f/M3cHDsC4j129/+Nr70pS/Ne4mHKYf50EMPnV/nj//4j/HEE08o9qCqqip85StfUeDW+Ph4HD16lOzcl1eEC1j22LFj5/cx14esrCx0dHRoIOtcBroBl/v5jB0jQLnv1Am0vXkQ8UXFyLzlAOKYwLcnkfLokiYEIL39PtQ1OHGGhXY5mRasz7MhlwVjEr2Vwrv2DmGEd6v4fGKiGXnrOG9k3D42dvnmS5eclv5TW+C6WUCIccSnbmiYwNtv9bHQxkbJ93gW31BBJW75ZNuv2wXqAy/ZAn09I2hr7kPFySaqDDiRlhGPog1ZKObLYjWzqDa0cpgayLrkobKgDb3BAMbIzFrnp8oHc2GdfgeSyMgq7KyFphilVGgjW6vOhy3InHolbYHzFvAwDtHyyssYrqmGAFszqIrx/7P3HkByXde16OrpODnnnCNyBggwB4lBgSKlp69kq74syyX9qu9fLssu2Zaq5JLLtlQOz5L9/JQsWXpMoihSpEiBASDyIMwMJuecY890Dn/t0xhgAAKDAdAz6Om5B+jpG8+9d5/b956z99pr5T/6IZVIO9A/iPffPUofxYhS0th3zz5s3bENCYkJishksRIh/2hotpNMgbGdSQ+qyyOxd1cMRFFXI1BYtNLKvxecJG+Z9zN5n2ysUwBfoSruIQn8QnQWHynefq2sFwtoQFYNyLrsvaoBWZc1z7IrJSAqgIQuvnwaycxa1zDPQYcH5eXRzDSORk1VJJm2AtmVAmjVytpaYFiAxr0uvH/KqhwG+9kxqCiNRF6uSQXZwj1A7WXwUqSc6ltdePUdOg+zDdhRbUZxnhEplBEMt+sXZlabC3ip1k/mIT+qswnayQFqmIEjRHDhdr1r+2tan0eT7mo/GVmFmbWDA/gJsrSKTOcOYwpiI4zQE/CjBdxv3LYakPXGttHWaBZYqQV8ZKwR+dvnfvZL/PaV1/Dwhx/F7n17UFhc+AGJ0JvVOTQwia72Ybz9+jnl1P70Hz6ArJwUGBaRSJcqCPRPgaO1DtQ1O9lXBVnZjbh/byQBesHtj0o/WABQp89MUy5vXIGb8vOjsXdvMlktN15QxkdqIa/Lieb//jmafvIjVHzq08h94EHEEVBjjPogKOBmbX699QGb02FDJtbTtVa0ddgUe2JpVRxySuJwfliPSZsAVnXYXqjD3mLQgQM1f736wn2Z3P8SPPTy08ugeWu7A+cbyORHtkkJqG+qjMT2LdF0MOqUxFO42yNY16cBWYNlydWvR5hZeymzdazNjxMdwMEyPhsK+F5IXx7YLkCUebK09vQKa7ELXb10uE+4Oa72IY+glLxcshiTwVgYPTMzTArsKuOtRb+HNvZaWdv2M8AoEpDnPZOKJecZSxGyGWwM7ts6cC7sjpCJ1483jjpw8oIdO2vMqC4xojDXqADKKzvjtdtK3nfykb6Un8/wvt5etLe24syp0+hoa8fQwCCqaqqxfdcO7Ni9C/kFBYgiAE/AfVrRLBBOFpB7+tixY/izP/szdHTwQc5SUVGBf/zHf2Ty2LabXupSIOsnP/lJfO9737tqn8OHD+Ozn/2sWvb888/jwIEDV62Xmba2NiauDX5g+bULHA6HAsPKcTRG1mutsw7n+Qx2zc2h67VXMUFGVtvEOAoeeQxlzzx7XSer9LunZzw4dXaeKnYBdveDVEnbt4vvNXYMFvsGA4NOtJN84vSZOcwR4LdjawyqKqNRWhypsb6vw9tEO+WVWWCg34Z33xtnAg5ZjaPJjL87GYWFUZpfemXmC9ut7DYn6snKWlfbgbozndixrwyPfWQX4hNi2K81h9X9oQFZ1+Y25ggKnSR3OUlmViF5mfe58ag5Ryl+pEZYlFLhaow11+bqtKNoFlh7Cwh4dba7G8MnjqH1uf/DvvCj2Pzlr0BUCVyMA0xNTuHw736Pn/3ov/DAIw/i0H1kZq2qUGDWxdizqObNL3hxkWDWX702RSBrFB66Lw5JJMYLdqxm7S20dkeUsYaUAZKZdY7pcJhMrOLvP1gWQRU6PwpJbKaV9WcBDciqAVmXvWs1IOuy5rnpSnlwCrvPFIPJwtA6Nu7GxKRbOdwFxFpWEon8XMmwNDBAGj4smDc1TAhssGDzKiBnR5cDfYMuShe5kZFuUmBWkUhMSgzvAIfISohU0zDlIVu6PBga9WKGQftdm80oKzQhkdKyxjCSS5XOINV6mIVD2cQRoJvsQ1kJwIFSHWV0yUCkkbGEwK9y7U9hAR6Mem1occ+gjYN3PT3n6cxG3WFIQUZEFKIjNMaHG7WKBmS9kWW05ZoFVm6B2ZlZ9PX04r3D71Ju5iI+8elnsHPPLsUSJnKeKynS1xQQx4kjTThzvBVRUWbkF6Vh78EqOrcZFLwmWWqScjX9w17UtzgxNuXDlgqy4BDImpOhD3qW78yMG52d8wxuWylvb2MwPYFB61ikk2XEYgnvftZ1246N5SNSaPDY++gjY5GgiGNz81D05FOU4My84yCESIC72Nlpal5AJ/u3Exx/WN0RcBop1RlNh3S0EUlxeqSx35MZ70dGgo7TOpDMA1Qu3HBFZIasZF0VBtZOqjRMkW3S4fAhkWxPyRybCftqKlmgkpMMMDDrSZhZtbIyC2hA1pXZKRS2kmQ/YWzungDaOUYanaV6Be91SfgrJJGasBVc8xpRpy1JCvK8WVgIqNHM8rckINY5q/yO/FT88MFBFlcpUp/8ltL4ke9EMrXGxZLtRftNKfvc6I8EGU+5xnHUNYxEBhXz9THYZUpFgm51EkHEP+D36dDc6eLHzT6CFykJEbhvTyTbLCKkwPzS71mYn8cgwarSj+ps78Acpc2dTgdiYmKRkJSo5PvS0tKRmp5GOdZULo9hco/xjt+1N2ovbblmgbthAQGxfvOb38T3v/995WcW1lQBtH7mM5/hM3ZlD1lhSN2zZ486/Z/+9Kd46KGHrroUt9uNsrIyxW4sDK9/+Id/eNX6W5k5f/48fv3rX2uMrLditBDe1j4+jpnOTnS+8iu4F2zIPnAPUjZvQRKB1Ncro4yJSOJY7YUFGI06VJZFojDPhCwmvCyCWGU/m81HwCu37XNgYMjJOIpHsbvnZltQTPbWrCwKIrNzsnSf6x1PW6ZZYD1ZYI7kN709C2hsnEVL6zweeSQdW7YmKMUDvTBwaGVDWsDj8WJ6ch5dHcMKzOqwu0iMZFD+vpKKbAVmXen7PtQNqAFZ16aFZIRuperHmM+ulAp7PFY4wXEfx5tbDcnINkQjUScs6VrRLKBZYCUW8NM34aZvYqT2DJr+6yeILyxC3oMPKXUCc0oKnA4maDHR9uzpWgyRoVXK/Y88gIpKglnpt5DxnMR2JKm4f8CJE7WiKsOkFio879kRS5KFq/vJKzmnjbqNMK+OzlGZt0+ArH4kkjMkN1lHEKsOyTEaBmS93hcakFUDsi5772pA1mXNs+KV8iKy270KyNrQuADJLh4bd6GY8jiFBXTCZJoVmDWGGZcyONWcMSs27R1tKAxMM5TN6+px4PiZeeX4laB1JZlZ88kiI50Fca6Fc5EA4xzZdE6ed+Jso1OBWQTIWpJvQGx0eIFZ5Xe4QFbW7nE/ftfAGf6vIJ28UMqLpK6AOLTfXjjf7Te+th4ysza5p9HomYbT78VOUxpKDJSfJJjVSFEVg25lQaAbHyH81mhA1vBrU+2K1tYCwiLW09WNY0eOKdYwt8uNjz7zMVRvrrmlE3E4XLDO2sjEeh6nCWQ99NAmbN5epNhYzRYiFC8VSehwuqkU0OfGuSbuQ/CRhViY+wlQycsyKEBRsN6Bcm3S7+3vJ5PO6SkGI70EwERg/4EUBsLpOeALeDHrePH8NtL3XG8Pppqa0PP7N+Fze1DzB3+IhNJSmAi+uZ0i/Rs3AWWzlPoem3DhXN08OnoopUytb2NCJKIzYmD38j3GgO/2fB3K6cDJTQIY/9hwRYBa8luw29n/tXowPOpGPxPaJLFN5JpEDn0TVTOKCswKaKdJON3eLaIBWW/PbndzLwGzjlv9ONJKhlaCWtMJdi/LjEB1FhBj8SOKkmY3K+JsXyD4RMDhA0MuDI24CRD3qGUCCE9JovJHsp7gcIJZCRiPJNOxYjtm3fKOkN9bsN5DNzvXUF/vgQ92BhTfdgzisHMI95uzsM2YjEyOTcyUfFzNMjPHNhzz4vBxngEBywd3EkRL9ZbUpNU97nLXtMi86rDb2aews98zi8mJSfSShbWXfaluylrrI/QqEFS9qYaSq1UoKSvl/UWwk8bAupxptXXr2AKLINZ/+7d/U1fx9NNP49vf/jbi4pixdAtF1CFyc3PVHs899xzuoRzmtaW8vJzJP1Z85zvfwec+97lrV694XgOyrthUIb2hBOz9vG/G6y5gtLYWY3XnEcXEgerPfwExWdnQW65mCpDkMTfHoY0tdrR1OjAy5kY+2dsfPBR/Q7+7PPdFRaxXxpNUmZDkMyFbqKbCXXGhEIKQLdzCvoMG8Avpe0U7uZVbwONhEhgTwd5/fwKHfz+Gew6mYMuWeGRkbNAk4JWbbkNsOTVBtZ3mAdSf60Rb4wD2HqpCzdYCZOelKjCrXr/+4xYakHXtb+UBqn+0e2dxhsmTbr8PZcYElOjjUGiIRRQMMGnxsLVvFO2I69YCU60taH/xBXgddpgTEhUza1JVNQlGItQ4anx0DK/9+lU0NzRh595dqNm8CZU1VSQkiYLeEPC1zNCvL1iVplY7CReceOT+BOWjtlh0Wp93mTtD1IftLh36pwJqvJKobyWo9Z5yoJIxkBSGW64RLFymNm1VqFlAA7K+vaIm0dkl2rUBiwZkDV6jSxBAHDdCET465sIgs4p7KMEnbK3paWaUUCJnUzVlIaIYyCFbq1ZW3wIS+Bf2KmmTkTEPmtvsaGi0KSnEYgawqyknmsQgWzgH1CSYL07FAbKzdRDc0tzhQgQdgYd2mQlsYZAxLrzuRenUzLIT0z7iJzsr0DAA3EeygL0lOsRRWte8AUEdq/9LC/0jOAhenfOTfYjSnW1kZx3w2VBMIOshYwaS9RbE6q6AwUL/atbmDDUg69rYWTtKeFpgEZBx5uRp/OyH/4X8wgLFxFq9qRppGWm3dNEjQ1O4eKEH7XRqT01aKTO2G1Wb8mAmSnVRwlkqlMSVEbKw17e6ceycQ0kGb600ITPNwAAiwUO3dNTlN3a5fOjrs6G11YoL52dQVBSNfftSkJxiIiOafkODWMVyHgJxHNNTaPrJjzHT1Ymce+9D2rbtSBYH1210OgU8NkOZzotNCzhJCU6/0QCXwYgJXTSi44zIzzRQJhwoSotAQlQAlGZhotb1WBaXb9n1v1bGYvJbaGm3o7XDQSCrSzkDC/LMyMkyQVQZYnmPWgiwE+zT0t/Q+r/6tbsCDci6drYO1pFkPOgStY5ZnWIuONvjh4m/gaI0HTbn6vjNhL+bHEySRANMrXznKEbWALBVwCfCpjZGBRT5drokmQHI4PtHfnPy2xO21jgyRmuAlICRZzgu6WaiXZ1rAi0MLj5lycc2fbICsUbcxnviJk131Wrxj8wx2eXkBTLhjXjY7rwHyN6+m8otq3zoq85j6YyHUjIuSvb1ELDa0tSMxvqLGB0ZYdKxERlZmSgqLkZ2bg4yMjMUI2tUdBQiGRAShqrbea8uPbY2rVkgVC3Q19eHvXv3qtP70pe+BPHf306R38muXbuYgNaPr371q/iLv/gLleS/WNfJkyfx8Y9/XM2+/PLLlLvevbjqlr81IOstmywkd/A6nWRgXUDb8/8HfW8fRuaevUjfuQupW7cxMS9GBeyXnvg8yRMmqXxw5LiVTFMubNschXIq1OVkm5jEIrl21+9hSJ/Cbue+jJt0dTvQ2DzPfgYQF2/AbjJU5edGqhiK1l9fam1ter1aQGJUXgYtmpqsqK2dVn2utDQLGbMTkZKisSOu13YN1nm7KaNhX3CgpbEfF893Y2x0BrFxlJ7+8Hbk5KUgOpZBrXVeNCDr2jegxMPmyc4qBC9tnllcJMFLtj4aNYZEVBgSlGrh2p+VdkTNAuvTAvaJCUy1NKP/vXcxcvoUtn75K4qZNYI+C3m/u1xONDY0UpGvAXXn6pCZk4WnPv4RZGVnsW8bSEQUX4z0fU+dXcDx01ZUlkeyz2xBSRH7vJHX7y+vT2sF96wlMb+VClONg340DfhRTuKy6myQvEynWFmFyEOzXnBtvpa1aUBWDci67P2mAVmXNc9tr1ROnEkX2jvtip1VgqqRzKpIZYA/k5I66ZS4l0BO5EaUXb1tq97+jipwx6B2Bx1jdRdtKsBNDADBxRbkMrAmMkcktbqhc+32jxw6e87b/JiY9uJMvRMjE16kJupRTFbW6hKTkhEU52K4FJHQnLFJxwY42upDOvuJhans3FBCMzWW2U3E7t7AjxouJtCu4zoWEJa2IQJYu7xzuOCe4hZ+pOk5WNAnqEzUaGaiGrVM1MuW04Csl02hTWgWuGULCBhjbGQMAmT9zUuv4MC99+DRJx6DyIEK+GIlRQBDLrK4tpKN4Z03zhO4alQsrDv2liInn3rQS4qAhsYpEXyhmYoAkz7IO3/vVguqSw0Bqbog5qw4yMQqUpDnz09jaMih3qdVlXHYviOBgcoIpTyw5NQ27KTX4UD3b1/D2IXz8Hk9SN++E0VPPAkdO1wRK2SPE0D07BxZWMlq1NlNhqMeJmT0uhGTzASM5EhYEiyqP1fA26EwhRLhiZLBvfH6OBIUFMZayWwfm3BjhCysE2SJtFp9tDX7fslGSAJbBlUZkhLDO4FtrX5wGpB1rSwd3OPIb8VBv8TILHCuFxijJJeNY+QyMhiUEgyfzWdINOPotwKCl8QGu4PvIP72xiY8/PZghtKpAnSV5F1hlrCYIxQjm4DIY6IjEBurR3wsGVvpqDcJ6P5WDhhck9yV2shzhz7vPI65R2H1ucG0FBw0ZaDUEL9m5+Niv6F70IP2Hjca2ykrXmDErs0mJMazrSKD2GlY5opEzpyEAhgfHWWwfoz9plFMT02R5XcKC9YF9i/IrJGagryCfBSVlCCdINaEhAS1fJlqtVWaBcLGAr/4xS/wp3/6p+q+f/fddxWbz/UuToCq0dHRCpz6wx/+EB0dHSgm+PuLX/zi5c0X6xIWY2Fl3bdvHwOuXrLY+/D5z38ev//971FQUIAjR46wP3/7zkENyHrZ5Ot3gp0F60C/YmMdPn0a84MDKP3400jfsRORKamIWHJ/yHhVZFJ7+l0EodoJSPWoseD+XdHIyzHzPS/JBsubQuqQj5CBtHfYMUTWd2F/T001MhHGjHwmo8VRUSE6ip16rWgWCAMLjIw40NNtQ2PTHP09Xjz4YDqysy18xmsJwWHQvHd8CaPD01QjGEXd2U5MT86joDgDJeVZKK/OVT5BwyVWvzs+0F2oQAOy3gWj85Bejj2F3KXLM4dzTKJ0cImRCiClZGYt0MdSEYS+RR39lDd7Yd+d09eOqlkgZCwgpBUuKsd0vPJrdPz6JfaPP4HcQ/chOjsbRibZSpkYn0B3ZxfeeettKs3YkM/x1ZbtW1BZXUn/mGBQAuOs5jaHUlsTX1pCvB77dsUQO0SWZCoZaeWKBcSHOUq/Zf+kkJYxRkICM/EfbmEyfk2OjspSTNC//aHrlQNpU3fVAhqQVQOyLnsD/s3f/A0lQMvw6U9/etnttJW3ZgF5wEoRBqVpMijV1c+jpc1GYKsNVRXR2LYlBmWlUUp2T+sjBmy12n+lTSTQJixN7xydU5JHRsocVjPr5b574i4xM93Ew7baJ7mK9cv1i4Oxf9iDxg433q91qIDVowctSGK2u7C1hVORn+DQdIBq/mwPMLUAfGxHIFMnku2+weKl4dS0d3QtEjiWgLGAWU9TVuWoewT3mTKxz5SOfMqqxBDMqpWABTQgq3YnaBa4fQtY56wEsZ5BEzNxOxlMfvhDj+CxJz6kwBcrZQ7zeLyYnV7A6WMteOHnR3Dwwc348Ed3M4s3CpZI0+WTk/f7DOWiBYzy6jsLSEnQ44H9kchK1StASrD7mePjTkr92vD222N8ogKPPZbBAGMUg+was/XlRuGESHJa+/uYpX0ajf/1E8XIuuv//f9giIxEBJ1XKynCUtTGgO7FxnmcouTmHOFO+tR4mGIDSXEHyyNQnObf8Ek68huYIyNkEx2BDU02Jq0tIC/bjDJmtW+ujmLCmlEB6qTvF+zfw0raMRy30YCs67dV5ffiIWDE6dGhttuPNxsAi9GPrETggaoIMhoAouJ7K78VqVOA94FvgmMpdjRFH0hvHwH9fU5+XJid9ahkh6xMI4oILC/Ot0Cm4whuNRLMulEKrQQvDdVANpz/drSjkAHEezkWEWacBN3K3g3BsJW0lbxjWrs9ePVtG+KY7FkqSa6lZjK5rw1YyDo3h5HhYdSeOo3ztWfRUN+gEn5Ky8uwk4yQFQz2ZGRmEgxtUQkg0n9aaR8qGDbS6tAscLct8LWvfQ0vvPDCTU8jNzcXp9nflOfws88+S9nq93HgwAE8//zzl/eVdQ8++CBaWloUk/H+/fsp3Z6ICxcuKKZWAcP+/Oc/x7333nt5n9uZ0ICst2O10NpHxjBDx95Hw//+XwSupiCxvAJ5DzyEhKKiD3QOJJFsge/8E2SUeuWNGQbho7F9czQK8iwqgeVW+xJe9k9aGTtpal7ABcZR4uON2Lc7DkWFFmQT1KoVzQLhYAEPfzcOAldefGkAvT0LuPe+VMZmY0l6Y95wyV3h0J7BvgaVIEAZjfpzXWggM2v9uU6UV+Xio5+8B3GU34mOsQT7kGtWnwZkXTNTf+BAHPrB6fdgjjGx9xkLO+oaQVIEfWZkZb2XaoWpJHohlP4D+2kLNAtoFrjGAhxT9bz5BtpfehGxuXlIrqxSKmzSZ5YiY65567xiZT114iTe+/27+PBTj+PJp59CPJNyIxkTkGKlmoEkg//2zRlM01f21GOJyk8myd9aCViAplQ+xmMdwPleJr0R61FEsrLHNgEp9F9FcWigPbXC427RgKwakHXZO1kDsi5rnjteKYMPB8Gs4+NuDI+4VIaxdd5DuXsoEGsWHTFFBWRVIiuJMJVoZXUtIO0h7Kx9A2509zr47VIHTEkyKAr3gnwzjAaRGg3PV6C8/K2UERQJwfNNThVklCSgHTUMJuaRtY0Az3C69gWClokBQm0P0DYiQA+gLCMCW/PAbJ0P+GBX9+bTag8ZC7jhw6zPhU5mojZ6yPhDmRXys2GLKRkFEXQeMhNVfyse95C5suCeiAZkDa49tdo2jgW8BKCKHO4Lv3yBzGLTKCktwdad21C9qfqWjGCds6P2RCu62ocxMTaL3QcqsPcgM3jNRr6rA31G6dMIG+vZBj7T+txKNjo/S09WNQYP6RsJZt/S4/ExQcuvmFgbL87yPPTIzLRg27YEBsLJ7k7mPa0ssQA7Xa75eUw1N6Hll/+tAKwZu/YgdcsWxBcyEHyDEnDU0EFDNqKeXifVBOzoZhLS0LwB8cnsrxUTmEmQcmZSBHIpocNYBgTXHJ491xsY6dJiG9mB5+d97NM7MUB7zZGBlW4ustlEIIvqF6K4IBntMdF6BgWXr0tbe2sW0ICst2avUNtaVAq8Ph2ZWf3oGgO6xgNjpox4HYrSQIkuHSIJbjXc5phY1GgkeXTOSnZWOuVn5nyYI0ursE24uE6ALz6+v2TcKX6QBCZVyng8mYzJ8VStMYXZmHRp+7v9PgyQjbXJM4OT7jFsoqzjw5ZcRDF0aNatbdBC3jdjk14mubrQO+DB5IwX9+6ORCUVW0RN6FJXY+np39G0myzzcwSvDg8Nobe7B0ODg5ikPJ8A6ISdJIosJilpqQq8KgDWlNRUxWJ/J+yQd3TC2s6aBe6iBQS0LWDUrq6um55FEQGGx44dU4HTT33qU4pVVQCpwsK6tAgr0Ne//vWrAK6yPj09HT/4wQ8ob71n6ea3Na0BWW/LbCGzk2veipnWVozUnsHA0feQte+ACs7H5eXDFBeQRF08WUmGmCAD64UGG4YY75hlP3z3tmhUlFoQE8Pn+m0ySgkZyOgox7YcA41PuMhm5VMg1rxcMwryI1WfQXPXLbaC9r0eLeBnbEr6yidPTaGzc56XQHWEsjjs3ZNIpjZt0Loe2zTY5yz3yNjoDPq6x1B/tovPQYfyA+7cW6aYWSWxfT0ys2pA1mDfKbdWn5fjUBmL9vsX0O6eo0KIFU7GyNIYBys1xKGK41ITlQrJzXprFWtbaxbYYBaYbGnG2NlajNfXwUC1i8rPfA5xBYXQXyKtEOWZyYlJRW5y/MgxJuVGUGkgFffcfwiFxYUQhQyGjlQf9+hJK/oHXcoXVkr14C01URuegEv8VHwNYmDKj5ZhoI9srPNOHZPu6a+kIl1phiTjQ6nubrBbL+QuV4DbgrlS314f/cykEWNo5so813O5qMDIduqbY0jZTi2XdaxjYLAP77z3BvbuPoTS4opVuc7E5FgkpRAgFILl7bffXtFZ6ShpxZ/GxisakHXt2txup+TlnBsX6uYpubPAHy2l0ih1WVMVjYx0owK2StDGeJvOnrW7kvV/JMnynmagpvbCPLp7KMNLCcRtm6KxpdrCdmDghjKHEvAOV8aPeYJZewbdqGtx4XyjE/fsisSWChPSkvUqaBVubKUXB/xoHATaRyhPFafDw9U6pDNQK9KZWtm4FpgjmHXC78Bh5xA6CGoVSZVKYwIqOXCPpqTKWgeTQ60lNCBrqLWIdj7rxQLCxtrV0YWf/OePFYvY//j8p5Gbn6tkQVd6DS6nGyIp9uqLJ7Ew70BFTR6qNlFatyzzchUyKLTaJIDowzsnHRglGGV7lRHlRSbkZ4ss1OVN73hCnAhWK2Wjx5w4eXISLc1WHDyYguqaOKSlWTQQ6zIWFjnO7jdex1xvL1wE8JR89GPIPnBPQJbzmiis2FnkuOcXvGhotuFs3QJG2Edd8BlgzIhHKVkMt5foycIKCODsmt2XOYvwWSUODg8VBlzMRZuYdGNkzI2mFsqQjroV81NJkYVMUGQIVmoDmgN+tVpeA7KulmXXtl555tBviJOdflwgw8G0Dcikuv2Bcp16xsSR8EeNie/wtOQ4dj7bpqY9BOm70dvvVM76GYJbTWRjTU40IpP+kEyCz9NSjAQ0EkhriVAJpgaul0RTKev9mUczwOZ3K1UIUYeY4/QOYwoOkZH1bhVJhllgX+Io1Vrkc2CHBVsrzMgg04W0wZ0WD4M4Lj6wnU4n5mYDINaujk60NDH4w6Qfh8OByppqbNqyGZu3bkVSchLBq9F3elhtf80CmgWWscDU1BQaGhqYDDSPiooKFBQUMLEgOEB6Dci6jOFDfJWXz+qFkWH0vP46Zro64LE7UPj44yh85LEPvIAluGyd9xJs6lCKZ1GRegJYI5UaQjbZ1u+0CMhPAK3NrTYcPznLgL8OaalGbK6JQV6OSLCzj8DYyXrvF9ypnbT9168FpG/c10flxnYrztZOIz8/Co8/nkXlncC9vX6vTDvzYFpgbsaG1uZ+1Nd2ovZkGw4+sAk7CGbNzE5CdCxJOIKddRbMk79OXRqQ9TpGuQuLBNBqgxfHXaNoZnLlpM+BYsbE9pvTkawzI44qIcLOGqG9ZO9C62iHXA8WcNK3b6Mvo/5//QA2Ksxs+r//CKmbNsOclHTV6Q8NDqGx/iJOHz+Fnq4ePPGxJ7F91w6kZaSpRF7BB7VSha2t04H2LgdKCiPx8H1xMCuMUBCDOledVWjPyBhDkt/nHDoIpuN4u1/5A1OZT3dvOZCbRP8gh60b7fEkMUDpO8pdoaYXv7lMVixdJvKJi9vLt6wXg31gGWsTxShZLX+WrpdF1y5T9artA/sE6hafsoBSBbDqvTztpaPZy3lZHpi+Mr8IaPWSMMcjQFZ+pmaG0dp1FkV5m4hRypWjB70Ul2ejtCI76PUGo0INyHoTK2pA1psYKIirJVtZpN1n6IyZnGIAh1J7I8wyliCsBG1KybBUSHbWVAZv5EEcriDKIJr0tquSh/OiY6yXrKzNrXYGcHzMZgT27IhBIZlZw5m9SQAAdieBnT0uNLS5sUAq+5joCBwkoDUzNUJ1lsKpM0BSOwzNQHV86ANAcowf2/J12JRLEMht30XajuvdAsLM6vJ50eObR6d7Fs1eMgwy87SKsirl+gQUGEIzQ2et7K4BWdfK0tpxws0C4qSov9DAzNuLyMrJxtOf/AQSkxJhNK08qDfQO46O1kGcONKMhMRoPPrUTqRn0ll9SUZM+jEyYGxsd6P2oosgET/lmXXYvUXAJ3pEEXwSrPe4HEvYWDs7F3D06IRqLpF5FCbWnJxIgnXp4tRepje8jYXZaH5gAP1vH0b7iy+g4jOfReFjH4aZcq4GyiUvFgFoOgn0kn7pyVoruocIHJ7xIz4tElnZFlQVm5GTwizu+AiViCPZxxutyL3oIpPj5JQXre0O9PQ7MEwAqwLAEQSXnUUG1iSjYnQ00vF3u2ySG82ut3O9GpD1dqwWevvIb4r/lYLF0DRQT0fx+JwomADbC3XYyU8knzXiKL7TQh8m31WUUqVajY0JvvKZJwhmds5L1lYvpvk9S2CrjNETyMoqgFZhVZaE35RkgwK8rnflEA+DhtN+F16yd2Pa58R2gljLDPF3dcwhTmTxUbV0uVHfQr8A8/uTEyLIzGpBSmIEgcy3/4KXfsrE+DgG+wfQdPEiujq7MD05RZAGfQ7ZWchmH0mYVxMZ8BGJ89j4OBXQ0RhY7/TXpu2vWeDuWUADst4929/pkSX5brKxEe0vvwQjEwryCWBNItA5jrKp1xYJMJ+vtzHwbldJKsUMvO/ZEYWYKJIjEIh3p0X1+dlnEFb30XGys/I4/QNOpTaSk2PGti0xTBI1MOEiCB2UOz1ZbX/NArdhAekj2Wxe9Pfb8dZbo+pe3rotHnl5USpR+Daq1HYJQwt43KJA40AnfYMN57sxNTGnmFjve2QLCksyFZj1Tvrqa20yDci61ha//vFk/C/j0ik/lY28C1QKmcYEwaw2nwf7TOnYZExCvM7IGJn2jr2+BbWlG90CPibruhcWlPraZFMTkisrkbZtBzJF3WJJgITkiZgn2cmpE6dw/sw5xUZZVFKEhz/0KNVnUsjCblCJYaIc/M77VsTG6Em0FglRIRB/2EYrqv9PDJX4Jk91AaOzTIhnvGtLng7lzP1OJ0HZRlTZlT6j+O1EAXIRFCr9A5mXeJ1HfS9ZJ9txeWC9bBNYJ/vItABH3bKPUsoKAEyX1uG+VLc61tL6l9S5eB5Slyq87yW5RmHa6EKURAhhIhb1JflJqHX0LV5ezoU6zutlPb9dTPSfdXQizpIHiyFlVW79nfvKlNrlqlR+h5VqQNabGFADst7EQKuwetEhMzjkQlePHe3MupAfs7yosrPNDMaSiSSN0mp0/pjNd+4AWoVLCKsqxyc9bAencsCNktWpII9yRewsCJg1muDOYMryhprhxgkE6B/24kKzk4FDP6pKjSjKNSgmN2G+kfsyXArH/ajrF1ZWUpWTlr46B9hRoENSDBDD7H6tbFwLLJANaZQDdslEHffZVdZpuYBZGVhOpbxKFNlZN+IdogFZN+5vQrvy27OAyGNItuHvXnsDtadqkUxWscqaKuw/dEDJ5a6kVjUwZR1njrcqR7Uws+YXpePBx7YhiiDWxSQnAQBNTPtQ3+riO9yF0nwjPwaUFhoRy75LMIvD4cXIiBPNzbO4cGEWhYVRqK4OBFkE0KqV5S3gZ3t6nA70/f73aPzxD5GxazfSd+6ik2s7IlMCg3Mb5bbnrF4MDjnQykzsc01OowIqAABAAElEQVTMwCEzVnyiCXmF0Shin7SCUt8JZCkMBqBs+TMOzbULDPTNM/FqbNxD8KoLwyNuxfAov5lyMkAVk602Pc0YFAbB0LRAaJ2VBmQNrfa407MR/4SNLMctw360jQAdo35kJVCyKzMChXxMpTK3y8SEzzvANH7gFOWYTqeXmfdeSgd7FLvy2IRbgVoFsCrS9pJYGkt54rg4g3q3ib8kmiAZYWITtlAZq66n8aoEC/u983jTMaAcuE9a8pEVQeAPA4V3u4yR1b1v2IOzF52K8Xr/dvpEcgwEta48gCkOdq/Hg9nZWcxMTys5vbHRUUqjcow1OqbYH4X1MTMrC6Xl5SgoLkRObi4D8mSRF+pfrWgW0Cyw7i2gAVnXXxPKWMXLgPzg+0cxSplU60A/ksorUP7MJ2FOSICe8qdLizCxTvCdceqsVamb5TCRrIxSqDWVkUs3C8q0EIIIEUMb4yatbTb2F1yKiVUC/LlkZs3ONCsGS2F314pmgfVogfFxJ44fn8TUlEv1aXfuTERlZZxKJFpPfdz1aPv1dM6T45SB7x7DudPtGBqYRBkZxYrLs1BWmYPIKDOT5jlQWwdFA7KGXiPNMibWTlbWVs8s2vjJ1UejQB+rGFpT9ZFKsVB7w4Zeu2lndPctIGDWgaNHMH7hPKz9fcrHX/qJZ2Fgv1l3jdJFW0sbyU4acf7seQXc23vPPj7Hy5BXkK8cWuLnPnFmHtNUMJJ3/85t0SgvsWwo9QEP+/wONzAwrUPnmB/NQ35Y2L/PSQQ2E8haQL+kPItCtW8ksQmJCwqwU03zW1ShVayQANDFb2EvvcJU6gVzCtS8bCvAUxUXvPQt+whQVXynql5OCOtpYB9ZLvOsW765v/LHcd5/aXpx2eI2Aj5duk7Nc19Z5iXZl9TLQ126hsB1yDpVvxxnsd5Lx1ysS2KVEfThiq9PkmsEwKqmZRn9fOLrC6yPUMk4ahsu0xsC6/Tcx2qfQu9QHXLSK5EUvzqsqZWb8iCfUCwakPUmraIBWW9ioFVazeeDcsaIxN7MjBuNzQtoaLSRgcRHNgoD9u6OQ36uyNzf/aDGKpkgZKrls58ZCL5LYFYHGlscSpr00P5Y5GWbFANMyJxskE+E7xzFenO+yaVYWEYnvCghEObRe6IYHARfLOEzVOF7H3a3Dg39Prx5kcBx+lgLUwlmZX8xNzl8rjPIt8iGqI5dOLjYU5thcLnePYV3XMOIAQHdZGQ9wEzUfH0MGCrfELZYepEakHWpNbRpzQI3t4CSzqVE7o/+44dKNuaTn/0f2LGbTKrpaSrL9uY1yDvZS2CPGy/9/AizdTtw/yNbsWkbgR4FqXRgXHFOD48xeFjvxNCYh+A+Px7Yx+Ahk1FMlFgMJhZEBsHT02689y4Z1YZsKoNyx45EbN2aoPoI64n9YSX2X7VtaMeJxosYOPIe5nq6EWE0ouqzX1AsR3LMfoIyO3pdOHFilkysLngtZBqqicb+7VHITIpAItl2TeyTCYgsVJ02q2Y7VizjpgHapbPbiXP1CwS+eRi4NinHXk0FE04IbDObpN8aALat5rlodQcsoAFZw+9OoE8SLoJFhmZ0qO/3o5Wg1sl5HR6uoeOYKhZJVHsPNpBeftvKuXtpPE4MpFJJGRlzYWjYjb5BJ5nYPAT6+5CeaiBDqxGFeRaCV0xM/jUo1uX1xNLaSLabi/wMk/kmjclyj1lykUj5xlAYZYhfQJJkDh93oHvATTkvAyqLjdhezYfrCouHDegg60jjxUZcrKvD2dO1BK9a+Ww2Ysu2rajevAlFxcVISk6GiQ9tk5GylQZhdQ8FC6zwIrXNNAtoFljWAhqQdVnzhORKD5/brvl51P/HDxSQVZQjhFEqqaISESbTB57R7V1ONDTZ0EeGVEkqefj+BGTxnWzh9GoU6SsIo7uVSX/NBLMKoLWjy46Ksijs3hlLRQaLUmNYjWNrdWoWWG0L2O1eDA87cOH8DNVvxvHhxzNx8GAKGeoFDLDaR9fqXy8WELCJsKU11feqz8UL3UwMS8KHP7aHyk2iahC1Li5FA7KGXjMtxsQGOT5tp1LhOdcEZuHCAWMGasjMWrBBY2Kh11LaGYWaBfwEG9ipPjNaewb1//kfSKmuwbav/j8wxsbCGHX1M9lN0Ov05DTeev1NtDQ1w0Y214P334sPf+RxBfhzMal8lMndZy8s4F0ys37ooXgc2BOrMCrhhM9Yrg0XnH5MLUDhNrrH/UiP16GGeMbdRREw6f1YEhJbrpq7sk5iZ/KOdrsCMT0XEblOp4sfD5X3OO2QaX7bXXBw3sF5l1on85e24zrZRghtHJe2C0y7yZzqUSBSAX4a6D8TH5ownBrpoDXIh/OXv2Wa2wmQVC2j4dQ+BJUGtjOo/aQO2e7KfoG6Jfa4WP/ldUyWMUqdap9L+3FazfP4wrK6GKxadO0pHx/HcAFfn199c/byuPKq7bi8s7MDL/3qBTxKRZDNm7euSjuKvUzm0MTbaUDWmzS5BmS9iYFWebVkF4tDZoSymH2Ux5Sgjci8y2A1lfThOcLQSkk9AbQKWGDxB77Kp7Uhq5+mpOEo26G53U7JUsl+0ZGV1YRSSrkmJxgV80s4GkZeIEOjHmY8eNHQ4lL3Xk6mHhVFZAHjdzjddwJmHSYl/UXKZvZM+DFjk84Qqekz+HsjNT3fZVrZoBaQgbubYNYhn01Jqgx5bZj1uVBojEVhRCzKjAmIIlfrRgK0akDWDfpj0C77ti0wPDSM1qYWnDlxGhMTE3jm08+iioyskXRgBAZuN696ZGgKHS1Dio11dmYejzyxE6VkWYgmG6u8jyVDdXzKh84+t2JNiyP7ajH7KmUFBqSnCBjk5se4lS2GBu3o6bGhvmFGDXCrquJQUBCFrKzgM+7cynmtx23tvCfm+/vQ8ZtXMNvTg9JPPAPkbcKIKxm9Ay4MMhg8RxBRdIwR+QRqSbsWUyUg2hzIQl6P13wn5yxBa0n4m5xyo3+QzOlUTRAAq4yRYmMNyMk0EshmVIBWWaaBqu/E2re+rwZkvXWbrZc9rFSxGJ0Dmgd96J4QED2QEQ9sIpg1LVaHWIuMHlenyO/eTbniWatHMbNOk61VfvfCWK2YCDiWk6InsF8SNxLJFpoQr0cS5YXj4/SIiw2AIoP9Lgwc9fb/yjjDw4t7xzWEM+5xFJHlppTKDzWGRERS+SFUCn3vaO0iK0+vG13sZxTmGHHPTjOlooUh94NoCnHYSxLP3Mws32EDGOgfwNDgIOw2SdBmNIYQ3bi4OAVczcnLRXZODpIpoRcZGbniflGo2EY7D80CmgVWZgENyLoyO4XMVnyOTzY3Y/jkcUy3t0HYWYue/AhSqqphTkyk1OOVZ78A7sRv3kDlCAGyZjFWUVRgQVWZhX1zSSYL8kD0GiNJ7GRsnOxXTHIRIKuLUqNyegX5FkUEksFxgcUS/PHwNaehzWoWCKoFJC5oo/JIfd0sfn94lGyssRCfS35+tBrzBvVgWmXr3gLjY+xz946jrraTCgg2+hpNqNlSgMrN+VSVJHtfiDOzakDW0L0FrWRmnfQ6VEysjwoibp1fJV6KWmF2RDQVC8l4pBXNApoFLltAsV+SzGS6tQWNP/0x9BYLMnfvRcrmzUgoKr683eKE0+lEe2s7Gusv4nztOaSR9KR6cw1q+EnLzGK/Fqgn0d2RE1ZkM4Fb+tiV7GMn0tcVzoV8LlSH0jGR3kcWVjAuIjEQoCJLh/xkhk3ukIBM2on/FdupgE0XE0NkWnyMXp5AYJpsqCppxEdflkdt53Z51Dof+2qL2whrqufyPoEkk0WmU59Qml5KU9fRB3i15zQwTpLzubZcO4KSbRbHVYvTMi/g1SvsphzzcBykGE8vsaGq9cKGyvjhFVbUAOGHrFvcf5EJVbGkcjAl81K/1C1EAQE21Uvbq2MGQLABnJCsv7JNYL9rr+DaK7z5fGtrK37xi1/gySefxI4dO26+Q5htoQFZb9KgGpD1JgZaw9Uil9Pb51AZxmfPWdUDQYCsm2tiUFxogZny50YGbNYT68gami8oh3KREVcC5Reb7Thy3Iossj1tqoqiXKlJyZVK5sEq++aCch23U8n0rA+n6pzo7idYgCCZgzst2LXJhEh13935y+h2zmk19nELeNyjw1uNPhxtBSozgaqcCFQzwyeWYzK+57WygS3gZUfRDR+OuUZwyjXGgbtPDdjvN2cjg5IqkQSzMqXgUpc0vA2lAVnDu321qwuuBUTuo/58PX732zdAfx9S6ZB44JEHkV+Yv6IDycBUJDounu/G4TfOMwjHfgeZFfYeqkR2bkB+XpIxHMxQbWh1obXbzQQUD7ZWmvHwAUqJSf/wSpxxRcdcbiM5F+mXnj07jcbGOcxbCWgpisGDD6YxsUckgJfbW1t3XQuwjSVj+8K//wD97x9Dyq59mEjYjAZnOSWXPbDPuVHCwNVmMrHu28SAMIFD4drnvK59Li2U34KoJbgIZpPEss5uB87WLRDUygxsOrP27oghA1OkArAJkE0rd8cCGpD17th9LY86MOVH57gOR1p8cHl12FcClGUEnMn0W67Ze8DNd5GT7z5hfpNPd5+Lyb8Etk97FSurAGlE1jib4HYBschzQZTcxHkrfhMdX8qLTuC1tN/SYzn9Xsz7PfiNo1eNL56JKsJ2YwpidUY1sli67d2c5uMXTgKDOno9eOWwDXFkA9+7zczkVgNSkwLgoEB/RRz2HrJFEMQ6N4uBvn4ysNbjYkMDOts6kEvQanFZKXbt2Y2i0hIFYL2b16UdW7OAZoG1s4AGZF07W9/pkQS06mEAvv/tw7j44x8iubKSwfctyDl0L6Iz6ChdUmRsOMF+eQfZWBtb7Ojtd+JDDydga00kLOa1jVPYbAS0TrhwptaK2nNzigCkpDgSWzfFIJEkIGaTOHU35jhqSZNpk+vMAm1tVpw4PkmfEBDDxKx9+5KRna0l/qyzZlyT07UtcDzUPoxzVHA6/u5F7NhThv33VSGLfsO4OCbRcwx0t8c+NzKEBmS9kWVCY7nAriZ9TnR65vCmc0DFxApI7rLVmIwKQwJMpHdRUbGN6KgMjSbSziIELTA/NIie372Bud5euOgbKfnox5F9z0GhnvzAs1h8KQJmff03v8XI8LACVz758aewfdcOxoEsVCLzKFyKKJJJX/bh+0S1mSo24oALwyKqQJJIPzTjx8kOP850+bEll5+8CFRmAdEmbnAJ9ym+KnlGiQ1lmXyradop8C0bBqbVJvwjVvOyYyX4UmE3dbmE8ZQsqfRjBb4D84F1AfbUK9vI9uLzkuWyvZuMq7Kv7COMqzIfYGAVdcXk1Dj85d9+Cr976zW0t7cjJiYGe/fuRXXVZvz3/35XnbPJTAWLSBNxXhyvMO5n5ryZ8xIDVMsijUxiikJqZixeeunFy/Xs27cPu3fvZjwu6tK1Xn0zGAwGSBz/yJEjGBsbI6PpZuzfvx9lZWXKb3f11gQOM/H8xIkTOHfuHIaGhtjfzEZ1dTUef/xx9kNprGvKyZMnMciE9RuVSo4hq6qqbrR6Rcs1IOvbK7KTzm4n1HsDFg3IGjqN7uPD1UY21ukZN4ZHXApQOTjkVMC6WA5iqyqilYMmMVEABOH58rrbrSHOOQmUj0+4GSQLBMvGSOteXhKJ0kIzM73N12UjudvnHYzjC2BgYtqHNoJjzjY6kUhWm8y0CGyrMiONgatwAa2wiZWEZc8EGWeGgbYRP8xGHe4pBXKZ4SOymVrZuBaQjoBkT435HRigrEqjewpTficsZEsS1qTtxlSIAKhRF/70vRqQdeP+DrQrvzULSDamzW7D0XeO4Oc//hnuufcgDhw6gMLiQsSSiWwlRQbGU5MMxp1oxZuv1mL/oWrsOlBBMGsCAxkB9tNZSisPj3tx4ryTbHVeMqcbUZJPmeVcI50jZKQJojNxeppAIUrcnT03w0GtHVu3JqC0NEYFUwQ0G8RDrcQ84bMN+/oX3zqK9lONGJsExnxZGI2qRkFBDMoYgFVKDGlGpJBlMJRlc1arQaSPJn3x/kEXenoDgDUb2Z+EZTGTdslkVrooVsRz3sQgtTYeWq2WuHm9GpD15jZa71uItNecXYf2UT+6xvx0LpMNIUVHxzKQk6hD4hqNmdTYjWBWGxmaRblmfoGg0HkvrJy2yjffhws2JioyIdXPjdNSjUjnJ4PPjORkAxlb6Tuh6+RuvreGqfTQ5JlBJ+Ua58h286gpB+UMBhpJoRBqXh0JJoxPelHX4qRqC1mxZz24b3ckNleY+F7S0WHvgHVuDp3tHQzCtKGPDOO2BRti4mJp72Q68FMVu0haWhoSOR8TG6Mc7uv996Cdv2YBzQIrs4AGZF2ZnUJhK8fUFMYunFeSqCKLWvTkU8g5eAhR6ekwRF6RRBXGSGFGb+9y4NipeTKgG1CQR/WyooCCnCSOrOU7VpItJcFFFO0GBhwcM9hV/yCe46ey4mgGjKM4ThB5zFB7w4ZCq2vnEKoWmJkWtmEbas9MMR7owiOPpBGAEKuSiNfy9xWq9tHO64oFhBVu3mpHX/cYGut6MTYyrZji9h2qQnlVLhKSYgh6Cs2EXw3IeqUdQ3XK4aMaCileesnK2uW1oo1j2LSISORFxGCzMQnpnNbzoST/tKJZQLMAAZLzVlgJYu1/9x10vPwSqj7/Byh+/EkYoqOhN5k+YKI5+lIG+gZQe/I0zp4+ywTgEsXMuoNgVoMpTmGDjp6cZ5/AhV3botnfJtMrfeHhBmYlGSomrEyeHwVOd3qpCuFBnMmDwiQv0mM8iDSQ4YLPI2E/VSBSsqQKsFTm3XwPuhlHk3lhT1XLOL10Xk1fWu/lwSR+oDcIxoWspopRVAhh+OEy6WcJK6liIpXtLrGXLm6vmExlH7WvbCfMqIv16RQY1Ri5gM997nNM9Ka81ZISGxuLl1/+NSJ80YolVe13+Rz06rgBJlSOXSgX3NrWeMN6fv3rX6OiomJJ7eLn1OFLX/oSfvOb31y1XGaeffZZ/Ou//utVYNZhAqifeuqp6wJTCwsL8ctf/hK5uXT6XipS/8MPP4yLFy8uLvrA9x//8R/jG9/4xgeW38oCDciqAVmXvV80IOuy5rkrKwX0LpI5vf1kZ22xEdTqhJ1So3m5lkCAm6wjiYlGREcFHpjyoNVKcC0gEkVWBsnqLtpwvmEBMdF6ZDAgVkkGqHQGxQKyhcE9ZqjU1jPgxoVmN0YmpFPgx+7NFhTlimQjX6yhOQ6+LdPZnAzSsbN0uMmPsTkdClNJWU/SgfJMghQVi89tVavtFCYWEECrjYHmOgJZWzlolwF8nj4G1QSz5uqjkUxJFQk+h174OXgNoAFZg2dLrabwtsDC/ALldPtx/Mhx/PaV1/Ds//UsHnviw0o617ACNKJkjs7OLKCJTujWxn608PPYR3Zh/73VZKDkC4nPGgnYdfZ7lORv75AbsdEReGCvBWnJekRFBu/lLCBCl9PHgKAN9fUzmJpyKbbXe+9NJcMag4IaiPWWb2YBYUnffp79jmmCkdvr+9DJtu5v6CMwKwLmtBzsub8Auw9kIZkS2deTb77lg66zHcQ+DqeA03yYomRpH1meBofdyoEXG2NgQpkFhfkB1kW5tFBlGFlnZr+j09WArHdkvnWzs4AapxagwKzvt/lB3y4yE3RqzJRPUGsc1Szo913z4mYCJskUMEQ/yRATgIdHPIrBeWbOQ4CNnuBVPRIJYJUEYPmOtOjUuzIqiiB4MjsLuGUtgPAynqBAGVrcMzjsGkIkE+EyIqKwk2ysWRxPhGqxEzQ8NukjmNWFo7V27N9mQkWhl873GczPjZNFfAyDAwP8DGJ6ckoBVYV5tbyyAmV0rMcS1BoZGUjCCdVr1M5Ls4BmgdWxgAZkXR27BrVWjj1dtgXMdXej67evwklAa4TRhKInnlCSqEtRqQJiFUWQDoJY2zodCsxaVR6J/btjERsTcVfHLdIXEHbW83VWKjjYCbb1MInFhPLSaKSToT2JfQCzOXxIGYJ6D2iVhZwF3EzIkljg7343iqamOcqqJqCiPE75YDRQdsg1V0ic0NyMDUODkzh9rAVtTQMoq8pBWWUOSiuy2Ren745Mb6FWNCBrqLXI9c+H6aFwUFGkzTOLk+4xzPvcKga22ZCEQn0sga1UjuW4Vk9ftVY0C2x0C4jCgZfJvt2vv466f/83FDz6GHLvewCJpWUwXYfcRGJAwnpZe/IMjrz9HpOz55GQmID7H7of+UWFiE9IwJFjVjS1OVRfu7jAQtUBqoRa7k6fVs5XEsaFhM9HB6HEjbziKGSRb7kWH8cLV9YHtglsK9MSEwkknQfYUWV/PmMISB0lE2v7iA9nu7zIiPWiKsOH5GgfooxUACJAVeqX5A35SH3CfCqg1cXlAmJV5yPbCMBV1l/aVr5lOyGfkbiMyWSgH5CkIfyW96OJ8brAtJHfeio6GAkkDqyXaRNZU2W9kduZuFzm1TJVx6V5qZNxO7tjgUz6+xjTmEdGRgaefvpp5Q975ZVX0NbWhqSkJLzO+2MpQPR6v5vJyclbqkdiI9/61rfw/e9/X1X3yCOPqP0bGxsJnn2ZtvDgi1/8Ir797W+rNpD5PXv2QMCsCbzPBOialZUFkbU/duwY7eWFsKu+8847anupVNheBeC6sLCAgwcPXu+08YlPfALPPPPMddetdKEGZH17RabSGFk//ekVGUrbaPUtEKDCFrYLHx+CPmZfONHb50BTM6NILCJ3X1MdTedMIMs43LIxVt/CNz8C38t8cPsxQwaS0XE3Tp+zYYzfwuxSXRGJ7Vso1cEXRTiCiB287xZIUC2Mb00dbgb/9CjNNxDQamYAMHxQ09KJctDx2TUONA0B53qAKlLWP7wJiOd1Rn0wYermN462RVhZQAbudoafhZm1zj2JXo8Vk2RnfcCUjS0cvCdFUM47jAftGpA1rG5n7WJW0QKjI6N4+83DGOwfYN/NhQcffRC79u5WWZ4rAdzJwLq/ZwyvPH9CDbyLy7JQs60AhSWZCmgj7+X5BT/BJE6caXBga6UJlSUmFJOJ1WIWeefgvZsdDq8Cr54jE+u7745h584kbNuWoJhYBQAUzGOtYpOEVNVu9iftbh2a+umo6vBhsHUC02xvw/QgsswTqEyfQcUDe1B8zy4FCNuINhZWpdFxF1rbyQJcb+N9BsWiWFVmQV62iQ4WCUQzy5nsSloJDQtoQNbQaIfVPgsZEwtTgsh9DZOR9Xwvncw9geS/mpwIbMoVMKvANde2yHmJw1qSLumLVYH/BSb+ClPr8CjVbfgZGXOreRnzZdN/kpttpCybmWytBsQT3GpYA3k2L1Ue7ASynmYA8HlHF/YZ03G/KRNJOjOiI4ioDdEithW7Xmx34f2zTrJjcETkGIFj8hgmh1swTPmx3Pw8FJeWErhajuycHOUItxC8KgDWCMVQoT2vQ7R5tdPSLLCqFtCArKtq3qBULgH3WbJpj56tRftLLyChpAQVn/o0YrKyYWGgdWlxMCYxMenBm+/OqQQzpVZWTLIDqpUJuO5u+sQX/fY2vv9HmNjS2GyjqoMD4/Td79sdh8010UihkoOFgX+taBYIdQvI/SzxQPHDNDfPQX57eUwkPngwWbGyhvr5a+e39hYQP6LIHHd1DCsg64UzHYiOtuC+R7fSl5iBlLT4tT+pmxxRA7LexEAhsjog3w2OY8nO6vfgjGsMTe5p8rT6UGiIxX0mJuFzPBsZEXpg6RAxoXYaG8gCCsvD9/cY+9Vdr71KP5UXUalpKKbSQVxB4XUtIftY56wYHR7Bqy//Bj3dPUwKLse2nduxZ/8+DI64maTlwKmzNqRSZejxh+NVsrbZvPY+FgUgFbZTgkZdDjfjXvzwWxhPr5q+vM7Fd1OARVW2k21czEIPTHMdmVRtdjc/gW87Y14uxkyE1COOZHLRUdJ3FwBpACy6CCQVUKkAURWgVACml0CkZgGcLgGlClZKLeN6AaQK06qATYX1VMf4mYxdIiSeL99qXpZdSnS/9C1RNp1sz4mrpmV7/lNxG7V/gOLqb775N/jP//xP+hnj8cYbbyA/P1+1u9Vqxf3330+lwyF86lOfwne/+93r3g+LC//qr/7qluqZYjLi9u3baV8X/uAP/gB/+7d/q/qSUt+///u/45vf/Kaq+ty5cwpge+rUKXzsYx9jXyFanWdxcfHioSFsr8KsKuX06dPIoY9PyszMDKqqqpgkmI66urrLAFe1Moh/NCCrBmRd9nbSGFmXNU9IrBQw5RhlRTq67HQgycPfpxhBU5LJTJRN2XdmHAtDqAZoDX5zSUas3eFHMzNgunsdmJr2MoNCT6ddILCewo6E2F1eauFSFp0nbT0etHW70T/sQTSBnZvKGQDMNCj2t3C5VglsztqBzjEfTnayE8J2TOc4fwuDsnnJZB1i28oyrWxsC1jJzNrnmUebb1Zlo8bDiGyyKFVRUkWyUGN1oRuIvpOW04Csd2I9bd+NYgG73U7HcRde+O/nODA2YOfeXaioqkR+QWDQejM7yDt3ZGgKbc0DOHq4HqnpzMKl4zk9IxFxCdHwEkwyPOZFY7sbQ/wWtvh92ywoYYJJHFlwggnEEQaQ8XEnmVhnGQx0EADkwa5diaipSaATQUeHwdo7TG5mv1BdL+0qGb/jVqgM4/5xL7r7XejsssHscSNG50BW5AziZ+ph7jqCsg8/hsLHHqOMJwFAzHbdCEUSxoRpeJhgs9Exj2JVlDGPk6oIKclGZJFJqSDPjGSyKRn5mt2IAN9Qvg80IGsot07wz43EBkwABFqG/WjoJwOaSwcLf5flGeCYCchNCoyH7+aYOMDS6sc4/SUCupmc8mCWUsgLCyIjBhgJuJFPJFnMo8lqHk//iYDkxY8Sw3mT8ZJDOojmWyB7TbfPikYG/uo8UzhoysC9BLIqBhvlEg/iwYJUlQRVHA76PcgGUX9xmDLS/bB5MwloNiDK14ho4yR9AwRXEMiaX1igAK2JBD6ZKJu3kuSdIJ2mVo1mAc0CIWoBDcgaog1z6bR8bjfcZNTpfetNjDfUw2O3IX37DrKxPgWDxUJm1oBvS41lOJjp6nGSiZUS1lTuElW4XdujkZnOJDMSHoRKkXNd4Bi5nyQg3T12fhwE/omqGBmEyGKVmcHxBH332lgiVFpMO4/lLDA07CCgZQFnz04jNtaABx5I4/1rYt91Y/gIlrONtu76FpiZnsfo0DTOnmyjasIMIqPMKK/ORdXmAjKzRsISGTpMLRqQ9fptGKpL+XpVLIud3jm0k5211zcPL1+66fpIlOjjUGyIBz2YMJGdVSuaBTa6BeYHBzDZ3ISBI+/BTl9K1Wc/h5SaTTBFxxAN+UGAgbBfOh1OnDp+EhfrGwhqHUVhcSH2HTyAuPg0ODyxeI/MrG5mlksiWXGhiUQPZDO5pkg/WOpSLKV03C1lKFXLLjGTLjKULmU0FZCqsHR6eYwr24qvnvVx2eI6ptoQIBlIJpfDK4ZVzgtTq3pOCMhC5rmRMLMGwL2BeZkO7MvEc+JspuaBMarkzpNILZf5cymxIKGYTrGeBhhQ9QqwqhfmUwJQ5SPxtsB3YN3l+UvbBMCqss2V7WTawARrPffX83u1fFUCkBU21u7ubnz1q1/F17/+9ata6Ec/+hH+8i//kn26WLS0tNzwPG6nHmF8/fKXv8zrNqq6l6oiyfUKu6oAUb/xjW8okOo//dM/4e/+7u/Yt3wAP/vZz646T2nTRfDq888/jwMHDqj1MrZ//PHHcc899+C55567ap9gzmhAVg3Iuuz9pAFZlzVPyKyUYLiAKnv7nKg9N8dAuB2zc17s3hmLmqpoBnotDMpIp9F/w4dhyFzMOjsRedF6GGzvH3ThnaNzGJ9g/hmXPXCQGd7VUczs0IUliFiueXLGh9ffXcDopB/JCXpsqzLyY1Z9r+v0v9ZZy1453WmSHbeOMPO5F6jr9eNjO3XYV6JDNPuGGm7nip02+lS/dx7tHLwfdY1gzudiBmomqo2JKKCsSiAfK7wspAFZw6s9tasJvgVkMD4xMYH68/X4+Q9/iuKyEnz5a19RkroC6FhJEefAmeOtaKrvpdNiGtWb8/H403vVoF38AA6C+uqanXjlbRvyMo2oKTOiosiIVCbVBLNIX2duzo2O9nm8+ltKjMQbcehQCmVPoshk80FHSTCPHW510ZR0AAFOsr7XE/BV1+PDuTYXrMNWmKdmUV0exXakukIxHTe1v8eFf/0nFH/ko4oJKTIlBUZxcoV5kftNmIbtZFA6fXYeDc12gs88SnVi/64YsiaayJoYnkki4dK0GpA1XFry1q5D1CzmyM762wtM9KSiRTIfV1vzdThUTpAoX0v0D4dUEZa26RkPeplIILLIXb1OKq54+Y7VISvDyGCAWQHmhbFVwKwCdF0EugRjrDvhc+Bd1xDGfHZE6gzYYUyFSDKGYlFBB3Y8vAxkTE1No6WpCefOnMOZU7XwxT6KyKStKMhcwI5N8bjvYLEKkhv0we2LhKJdtHPSLKBZ4NYsoAFZb81ea721i8xAC5STrPvB/8RcX58af6STySe+qPiqU5GxjMQgDh+14sy5eb4rqQhCVbhN1ZFU6gqxl/2SM59kMouwsh45Nov+fgeqK6OVol1NVQwD5Ffe8Ut20SY1C4SUBQSAMjrqwIsvDirFgf37U1BQEEUmLUtInad2MqFlAWFmHeibgLCyvvmbWpRWZOPQw1tQUJyOpJS4y+Obu33WGpD1brfA7R9/gSQv56hWWOdhsiO/ZVx7vzkL6bpIxEUwofH2q9b21CwQFhaQZDGvy4mz3/suBk8cQ80XvojMvXsRS8UD3SW/iQJ4Xr5anQJ82mwLaLnYjJ/96KeKBXTT1s3Yu38vMnJKcY6KZeLLmqRP68DuWOxhQplCjF6qQ/oMAiZ1ky1VmE8ddleALZVZ6A5+7HZngAlVmFEdXEc2VLVMtuO0AGllO2FatXOZg9u4pB7ZXm1DHAwxIhH0k5nNJpKc8BNpVKyoFma2WyLNiv3UzISJSH6ECdWslnOa3/KR5AoT2VFN3HfKYUL3lAHd0ybMewz48HYzthQYkRJHgOo6dS1Jm+bl5Skw8auvvqoYUi83MScEoCmsrFLeeustVFdXq+lr/9xOPd/73vfw93//94zfHcIvf/nLa6vEF7/4Rbz++ut4+OGH8ZOf/ESxvZ49e1YBU5944omrtl88TwHFNjc3MykwSq1/8cUXFUD3C1/4Av7hH/6BBDjjChxbUFBATJRegZ2vqug2ZzQgqwZkXfbW0YCsy5onZFZKwFdeTPPMMhYg5dCQk5J5LsySuUgYstLJylpYwEAMmUJNlN0MJkNXyBjhLp5IwPaUgx12kZnViY5uJ5nQ9EhNMWBLTRS/+QIni0swAl538TKvOjRvN7LR+tAz4EFHrxutZGcVEE1FMWUZsw1IjAtd5+VVF7KCGRWUJTNrwwBwrsevJDJzksk2UKhTWUEaK+sKjLgBNpFB+zQBrK1eZqF65jDpcyKTzKzV+gTkUVolOSK8wF4akHUD3NTaJd6RBSQz9cT7x9FwoQFjo6OoqqnGEx97kgN3sxrM3axykVWZt9rx+sun0dM1okCslZvyUVaZo5wX8zaCIFvY7+h3Y3zKi+pSEzZXGPn+1cNCmfVgFenjCNt/be00Ojvn6cjwkVE2Cjt2JCoWEE2OceWWlv7ErF2HrlEf2kaA6Sk6nMbYZ+9fQHKUHxU5epQWRyE/R9qRgLDG8+j41YvQR0Yhjo6P3AceRELR1YHklR99fWy5YPNiTBhq+xzoJMuT3MmSFCZ96gyysGZlBABlUSpBb31c00Y8Sw3IuhFbnSB9Jli4yKTcM6GjooUfnaPgGBjITABqsnXITwmAWUNl7CSsz8LybJ0noznZWYWhVaYXFvwc53oVoN7ppGOew1oBsqYkGZFGEL2orgjbnMkYodbdTmvbyMY66LfhFUcvKGSGA8Z0jhdikB4ReTvVrdo+wrzgYdBleGgYfT296O7sJCv7COXg3JRrMzE5Jw6WxO3wGvKp1OJAYY4Zjz+YSiZbkWoLH3/AqhlYq1izwAazgAZkDc0GV4FzBhZGTp+6xBQ1AXNCAorJxBqbXwAzn/VLy9CICy1UJusjocMc3507t0ajpNCCpERhQgreOHTpMYMxLe92m41+bDKzDvDcR6luZ+Q4Q2ImZQTi5uWaVbxkMWklGMfU6tAsEEwLSPzPanXjzJlpDAzYCCzxEhSRSKWcQCJUOMWdgmm3jV6XsOrZbC4M9o2rJPnhwUnMM/tw+95SVFTnITUjXgGM7radNCDr3W6B2z++2+/DpN9JxUIr2hgXm2F8zENCrS1M0iwhM6uwtJo45tWKZoGNagE//Sp+ZoJ1/vplDJ06QR9KIlK3bEXeAw9RHsgEL9lS3SQzkcQDt0zz20WfiwBMR8jGKiQpA/09TCoeQUXlZmRmlxALFIlJawzG5+KQkexGRhIBDO55+m8can8hR5G6pG8gjJ7CwrnIPip9XR0/EVymvpl1fnmayyJkXra5dp9L2y/WI9/qQwxSYJreLarYXl5OMKMwosq8gWhUATdeXq+W62H3ME4yHoHeqQj0z0QgKzECRel6lGREIC0+Ahb6lULFh3ir928fEwP3ErAspb29nQz6Aja+UoQtNzc3Vy0QsKmATq9XbqeeP/mTP8GvfvUr/NEf/RH++q//+gPVfuc738E///M/Y9u2bXjttdeuWi/tLuc2NzeHCxcuKCbZ3t5ePPTQQ/jpT396eVsBr373u99FQUEB/agLCsgqKw1UExSWVokNyPVdDdK+vPuKJzQgqwZkXfZm0YCsy5onZFeK9ObwiBPnLlA+goDWCGYsFORHMjgeiWQGYGIpkWcxywskdB1MIWvcG5zY4sO4q9eF+kabcooJa+n2zWTEzTeTOYrU5XTohZPNhQpeZBo7+7x495Rd0cAnEMAqrKwFBLMKkEYCf+FSusf9aBzwo41BWQHy3lehQ1GaDonsf2i/pHBp5Tu7Dg5JFIC1g5IqR1zDYDwfWRFRqDYkotgYR7loI4xhMnDXgKx3dq9oe4e3Bbx0FthsNrz03ItoaWymc7gSNVs2Yev2rWrQvpKrF9mv/p5xvPdWHYMVdnzk2f0oKc9GFOnAF+ibGB7z4v2zDjouKO+RYUBVqRHlhcFnqbRaPUyScuLokXGMEXRZVRWHsrJYFBdHK6fGSq5lI28j/QUv+4MitT1JhvehafYl2G9q7PFQ59IBvd0Bs8uB8iIL5ThjFetoUmKgHa19ZOJlNuzoubOwjY0p6SGR99RT2lMXRh0ssY8Ayqy8l0Xyu7efDvABFz9OFFHys6SI8nclFiQnGsKqHx3OvwsNyBrOrXvza+MrECOzwPF2Pwb4zJt3AjsKdASzijSYDiRpCNkxoo2AgKlpL30pZG1jcvDgsFsp3QggNzGBQFaC6iVJNZHPoxjKKEda6Fjnh8pkjD8wOLBCBZxhnw1t7lm8Q0bWDH0UnrYUIl5novTi3R88i8PaTfCqnf2Yudk5JkfPkMWpHz2d3ZSz7WaSjRVJyckoLS9TfZvYxFy2cSIOn6BcM5n4Du2yIIuBB1Fs0YpmAc0CmgWWWkADsi61RuhMe+x2OGdn0fO719H129eQxoCmjDkyd+9VgNbFM5X+uhAatLTbcfz0PN+BeoJAjdi1LUolmy1uF+rf8q4fG3Pj1Jk5JtC51Fitojwa5QSzJvH9HsX3u5CCMIarFc0CIWcBl8uH4WE7GhvncPLkFHbuTMR996aR+YwS3loSUci1VyidkI3+p8mJOZx+vxUnjjQpZlZJlC+ryiEza6xixrub56sBWe+m9YNzbCtJXga9C6h1U52MzKxFVCksJZC1TB+PRBK8xEQE32cdnDPXatEscGMLCO5DEknke5Hl1Ovzku1UljEaLOvo/PcKWJXfapvFbfntZTKBWs7psQvnMFZXh9meHsQVFKLoyY/CbyCQ1eMjcNVDECp9MXSoeciiujjvIHOqgATb2xpx/uxxYnuSkJCQjrS0PPiNOZh2ZsNls8LvnkG0cRZGnV2BEKUuAbMaKI9kokNLMZ+ayX6qmFGFIZXTwobKefkYOa2YUrmt8fI6LiPbqunSvJnMqcKsKvOyvZF1C+hRPrdSlM24w5zEt2b8ON8b+CbhK/aV6hSBGA+jlJ1upd5Q2/btt9/GZz7zGfo/I9h3G1btsvQcBfCZk5PDtnbhX/7lX/D0008vXX15+lbr+cQnPoFHHnkEDQ0N+PM//3N87Wtfu1zX4sQPfvADfOtb31LHr62l0hLv38Ui57tlyxZiywiEuVQKCwsV4DWByY6L5Stf+QpefvnlxVmkpqaqa5yamlLLRJFSQLI3Ypq9vONNJjQgqwZkXfYW0YCsy5onZFeKxI+L7CIBQKsLnd12OmfcBEJ4UFMVjbKSKOSSLSM6WgsuBLsRxSE2P+9HU6tdyRNOTZOplLbetztGBeBDWWbpdmwhnY65eR9GJrw438Ss/E43NpUbUVlMFmAyi0lwL1wKGfMxSwa899uBLrIMxUX6UcNr3EtyNCYVaU7OcGnoO7gODmsgWahWP2V7vPNo9s7gAgfu+foYZqDGMRM1GWkhxrR0u5erAVlv13LafhvBApKxODI0ghd+8RwzZ0fwyc98SjGyJiQmrHhwf/50B44ebqBjQI+0jETsv6+a3wkE8kXgIqXomzpcGBrzITVJj3t2mNV3VOStOQ5u2hZ8xzc2zeIM2VjtZMoUhrV9+1KQniF9SKJ2tHJTC9BvRMeMX7G6Cwtr/ySBrQQmG+YXYJt2Ip5qLDs3R6GYgM3sbConkMHfyI8Uj90Gx/QM2p77JfrfexclH/s4svbuR1x+PvRk9g2XskBmpOkZN+ou2tHT54TIfacxAUwS8NIJGEtOYkCZ97aR7Ie36BsLFxOtu+vQgKzrrsmCesIC4KcPHjM2oGUYONsjjn8/Evm8O1iuQ14ymZb5nAvyGyso1yDAejeBOvQjUzKNSSkE7CwQZD855cEEP/I9Tek2F5M5U5KNyEij4znLhEwyRgtztCjfrITJ7bh7FI3uKfAVoQJ895gyYNEJN+vdt4qNQRJxPDddbEQzP20trQx+GJCSQvnaoiLk5uUiIzMTcQnxDKJQjlRvxJzNgNN1LoyRIV4CN7s3mbGVya3aMzsot6VWiWaBsLGABmQNzaacHxzA0PHjGK+vw1xfD8qf+STlTvfDHB+PCEpILhbps7e0O9DeyU8X2fy2RJO8IUqxlK8n36+860VxRGImkkDX3LKg4iUy1ti9kwmbhVTDoMpJOBFRLLah9r3+LSBxGKfTS2lXK956c5R9MgsqKyXROAZJSab1f4HaFayaBQSkIsCowb4JJqiNoK62E7YFJ7bvKUV5dS6Ky7JW7dgrqVgDsq7ESqG9jYeULk4C/IaYtNnLuFi9ZxI23//P3ntAWXJVV8P7db/YOec8nbtnpifPaKSZkYSEDAiQhAgSmd8GFj/497eWl4xZ2IAxfFiEZcwyBmyLYIwEQqCAJJQ1M9Lk1Gk655zTy+/1+/e5b95MT+g4nbvu6uqqunXvrapT9eree84++3hQZIhGkT6KS/QqmO2ubhlqV7f6JKCi1BAQ6nZ5yZDq5ndUmFJl7blqX9hPhUHV5ZR8l2JDdRGZ6XRyW+pye2JgCOP9ZMXu68ckgd2mhBQEEziqox7JQJ2LLMJgauRaAKj+ff+Y1O6gk/FIP5qba2CdGENxyTYkpRfBEpGNti6SZwxPYndZMLIzghFqkbbocM12/OyqfoZV+QEKSHEqI6s6LmBU0p6KzUkBUy+xtQaYWeWpBI5J3UAdaW++IFZpS3RGkz4dTjT5UEnisMEJIClSh51ZXBMnGRMqejVGR1rjCqVf/epXeOSRRxDJOVVdXd0Ngaw51LFNTEzge9/7Hj7ykY+IeK5L821HwLNFRUVKr/etb30Ln/zkJ69r87HHHsNXvvIVBT4VwOtUIKs80/e9732Qubs4uQeSXJ8wuRo4P5Qy99xzDy4QmC1A1Z/97GfIyspSRV9//XV88YtfVOcXAOyRI0fUexdoJ7B+6623cPTo0cDutOuEhAQII+y9997LCJE7pi23Xg8IkHkuSWe30wK5AZMGZF3bD11A9Eoxw/Ccopxpb7cjNCSYHhsMzZliouHFoLynxWNTU9As3rMWpUI7wxS1UOai5BO3HAlDKKGW0tOMCBHWlksghcU768q1JGEkJSxjZR1BCBdJucMRTCwp4LcWGpEQG4xwDjzWS5J7lcFVLcEorQM+JHKAtStbBlhkZqVxVkuaBEQCHoJZHTRN15GZ9Sy9UOkHBz1/F+KBmk1Aq7C0SkiVtTwY14Cs2ruuSWB6CdTX1uP8mXOora5R4I8HH/ogMrOzVGiN6Wv5j4gyZHzMhuNHLuLwK+XYuTcfJWVZyNqURK2BkcxwkzhLx5HGNjfiGL4xN9Og+lsJv8455KIlm41MrP1OVFaOoqJyDNmZIcihcaSwMILAFQ3EOpuglfPLJc9iYWHtoYdxz4AHPYyUYHE7yUbgQhTHR2lJBmwuDaPiwKDG6Fe1y/GjhB9qeu5ZtL32KsxkwIsrKUXGne9QhuVFfeBXnXjpdwToZidgVUBhPWRE6qZchAVRmP4jwoOQydCeeZvMlImf8XDpr0g7w2JKQAOyLqY0125b8jvvHPLhIsGsEtmCGH5kM5pFTjywiWuLwacilqzmO5R7cBAsMDLiJTu5B30DbsUcPTbhVYp8YWoV8I6wt4XRSTiCkW9kCQ8LUt90cWKd2jeLw5vMEV50duAigaxlhlgU0qCXw/mBzBVWIgkDq4BXR0dG0UfGhX4ygPf19vGeR2Al+6rVakNcfBzSGBIsNz8PqelpiCQLgyivA0kcEFo6OfdpcStnm7IiI3aUmAhu4jecUVq0pElAk4AmAZGABmRdXe+BhDh10QGzv6IcTX96FkFkBQpLTUP67XcgprCI/deV77dEAenpdeP0eSvGSJIhxBhbS0JQVGChYVK0wGsrBdi1hPSjieQfrXSm6x9wqTlZarIJmZkSDcKAsDCNAGRtPdmNc7Xt7TacpsPx6KhbjTX3749HVlaIsu9N+eluHIFodzpnCVgnHBgZnsCpt2rQ2tSnwFLpWfEo2ZKF+MQoOqutjIFLA7LO+RGu+oLWSTeGJ1044+5H+6SVs18f0oJDkUe7WAqjkcSQnVXcWtfa2GHVC34DX2CALVUi5AkDqgAlheXU4/GofdmWfP/iL3M571KdwHFhMZ28XJZ15DjbkzwFwJRt6uoDLKySL3gQVYf5qowqK9tc6EAlkW0D5d02B8Y7O2EfpM14eBgxubmI5mLQE7h6ieVUrS9tC2unMKdCJ+fxoObiebS1NLFtHVLSclCydTfaesPRPWBCYa6RGBRZQqij8gNh5Yc2dUy/kq8JxcRnAPSPE1sxyMi3xFj0jfkQz8hNuYk6lGUAZqqZiKddF+nZZ5/FZz/7WT4/Izo6OtT7OPXG5Lkk00lc0s9//nPFojr1eGB7vu28853vxP79+9HU1ISvfvWr+PznPx9o6vL6+9//Pr773e/SzleI6YCSTqcT58+fx4svvoif/OQnqq7Ueeihh9R2S0uLAqsKaNZisVxuWzakzqc//WmV9/LLL9+QlfXs2bOQZbYUFhaGmpoaDcg6i6A0IOulF3MWOWmHV6EE/J0rmSTHBJDgxtsnRtHcyjCmBK+WFoXilr0Md03FjHRsWlo8CYjcRdHX0OxARRWVC1T27d4Rhj1cUpKMNHStk974kshksDZBttLeQRrm3rRhkMa+3Vs4eFLMrOsL8CIMQ8Ko9twFH6xOH1KjCWbNAYpTtOnX4v2C1n5LMjB3+rw0VnvwirMTFzxDYLAF5YF6lykN4WCYhmUKHyqDYpnQLWbSgKyLKU2trfUmgddfeg1PP/lHgk+zUFhSjF17dyE2jhR0c0gjw1Y01HTi7Ml6lJ9txIc+cTv23lpEj9xgdPd7UdtEkEg9wa4cY7zroAX5WQYVynexjRU9PQ4aRobQ1mbjpNTNyXQCysqiCVy5GpQzh1vacEXkc9s3BtT1+nCy0acYCdMjvbC4HLB2jkJHJZgAn26/jYwEBSEqLLU4lE33DIfptTtAhqTmF5+HOSYGZV/8a4SlpNIDem2O3UU+1Omhq8eFco6RJYpBG52/yjaHoqTQgoJcs2L/DQr2KdX2dHLZcC/WGrphDci6hh7WEl8q9fag3h6nmydR3qFDE7+LqTE6vKdMh4QIIGwNkEsHhtAyv5dtYWyVeX5bh5POwnQsaXEQ4OpRzK3pqUZkpRuRk2UiU6swttJ1jYwVge/YGA16A5MOPOdsQxtZah625Kq5gUm3UjBWYZ51kD2+W7Gvnjx2Ag3S5wwMoHTLFmwp24qde3YhITGR7HRk5qNFQRg8rjWEiGFm0qvDhRonnnvdhpREsmpn6lGSJ4zx60vvscQ/Ga15TQLrWgIakHV1PV4Pv/8jDfXoIhNO3VO/Qyad5Yo/8WnlMKe/xhgpURNqG+w4ccaGREZOePfdkYiJYtSENW5LUP0XxyptvL+aWitOnRunwzkjZmwPR1FhGLIy1sBAZXW9VtrVLJMExPF4YMCJN97oJxvWKD7wgTTqa6KoW5Awv8t0Edpp1qQE/EB+H4YGxlFb1Y4/PXVCgVkLitOwa38h8gpTrxvrL8eNakDW5ZDy8pyDs2YC9wArbWJC8vKSsx122sgidUbcbkrBZjpy6mkT46xyeS5IO8u6loCyefJ987Ofekia4ISD7BKyb7e51L6Qhkieg2thS7VzW9aX8y8dc0jdS2UcrOtgGdED8ZWGyWyE2WKAkTHvzdw2cVvWZiIvzRbuc9to1lPfb+I22VYv53ObdQL1g0huMVZXjdHqcoxUXUDBAx9A/n0f4DPiSZgu61oud+bUjV/eBrq7ulBdUY3fP/47hBLgd98H72ckuBT0j0TxvrxIZcSg22+NUA7WqsFV9E9sAU4SWJxt1eGF8kmYCBtJJgPrHUVBSIsBwbxrn4V1qriPHTuGBx54QGUJo+hUZ3DJlIiOAiSV9Mwzz2Dnzp1q+9p/C2nnvvvuw4kTJ/CFL3xBMa9e26YAXP/rv/4Lt956K5588snL5Dvi6C7L1CTv3yc+8Qm89NJLCmz7i1/8YlasgbSRyYiCAub+4Q9/yHGqvOMLS7W1tfjNb36jAVlnEZ8GZNWArLO8Iqv/sITNEeaj9k4HuroZ9q3PRQ8Adoy0K2RlmJHBRRhaLRZtwrtYT1NYpUbHvGRmdaCuwQkJw6TX61BMj/WMNAMS4oz0lF2ss618O2LUs5G8WphZmzvcGBqdRHa6HtsZVjA6gkw1ix3yeIVuWQyYo2QUuthFoHKfDo19wNZ0HxcdGVqBUI11ZoWezOo7rSjF6cMHB3/nP/yn/6u8r4r+vw9jxONAMSft+fpImAhvnQ+g9fjx48qjSej9t23bdsOblsFlH9mUpKwYi3rJrrRp0yaUlpbiXe9613XeXzdsZJZMDcg6i4C0wxtSAgIGGR4ahgBZn3/mObzrve/BLQduQWJy0nWeidcKSBQvHnoIS4ivV/50RilKYuMjsGtfAdKzkwhcBaobXDhxwUkm1iCkpxAgQk/beDKfL6anqod9+eCgi16bZGg4NUTFhwHZOfSczwujl6j5KuXJtfew0fep48Kw1Yemfh06yEI4OE71LRFcPnrAjPXZ4LM5EWGgUinZqBhHM9LJ9BPDsEF8gFN0UteJ0Tk6ivG2VtQ+/hu4yZqX8Y53IJbMrJHZ9KJZY2mcLIbCwtrY4lTMhlbKy2zWIYrhO0XZlsy5SAyZhiVahJbWrgQ0IOvafXZLdeU9o3QEFHbWLh+VXrWgnwAAQABJREFU7AybRqB6SVoQihjBUsCsosBeK0kMGS7O88fGvWquPzLqX4uDidvFhcfc7M9l3m+k80dcrF596+P4ve8PsaLGOESGGieMumDcSUNeRnDYshrxZLwhCvN+zg/aWlrR0d6BAc4bJGSYXk928LBQRERGICklBSmpKUjm2hLCaBJkkZgpyRy5q8+DajrbtPcQ2Eu9wIFdZgJaadjhMxZAr5Y0CWgS2NgS0ICsq+f5ezlvtfX3qcgPo81NMISFI3nvXqTddpBBQIwMcepXVjtoSxBd9onTE2giKUZkhF5FG9tCNlYTdZ96OuOthyTkH4ODbjQ22RktwsUQn5OIjzMgk7YSWaQvl/naVCDBerhv7R7WrgREb+NweHHs2CDZrEaQXxCGXEbQyc0Npe5pDQ2s1+4jWNNXLvMBCX/d3zuCGoJZ25p70dM1TGf8ROTkJSO/KB1R0aHKiW25blQDsi6XpJfnPAJmFSbWQc57Gz1jaPGOo91rRXyQWbGzltAuFsdtiVio9a3L80xW+ix+x2DqSqgjF/ZTl8sNj1sic3kvrZlPPYrb7VFl/PkeZSuRbannkWMkhxDWVNmXfGFMlXbku6YTJ2IBSF8as10Zu/mdi+VdU3nK2dhfVvYlU+Wrf1JdQttLnqz5jlJFrSfBiOjvZa22DZfWHAsLa6rKp/5HiEhkW+oHyupZ1p/PtrweOMnG2nviGBr/4Hck2/See2GJj4chNGzWx2SdsNIRuQfHjr6NTupybDYbsvJ2IjGtDHXNEhnIjP17wpTtIZK69tWQRFfk5LhFSD8qOqg3GgaGaA/IT/IzsWaS+yXcrB7DarjcRbuGtrY27OX8StKNgKqnTp2C2PjlPauqqmIkbaJ6b5AW0o4AWP/whz8oZlYBqsrvI5Dknb7//vsh9n1hTf3KV76CgoICdVjq7NixI1D08voHP/gBHn30UUb6TlEsqlbap7rpEC96woyMDAVYvVyYG3I+yRdA60xss1PrTLetAVlfm040V+VrQFYNyHrVC7GWdwRYNUZjS229DRdrbaiqnkBWlgWbssnqlWuhcsYPZhWdlWZsWJwnLUZ7CUX49skJerA7GCrVRLYpC/JyTIqZdT0Z62VAOjZBFjKGFXzlLTsiwnQoLSArDQGtyXEyYOPgTwaHazyJI5aDRsqzLcDzF8RzyIecBAJaMwhmDefAdgZmtTV+69rlL0ACZ86cUR5DcXFx+L9nnser9g5sM8RhpzEOCToLwnUG5Yk6208jmB9m8eI6SsYMGTg+/PDD112NDHzfeustfPSjH6VS03HdcQkr8LOf/WzagfF1FabJ0ICs0whGy97QEhgaHEJNdQ2E0ezc6bP45P/zKRy885BfkcLf5kxJQtCMjdpQcb4ZTz/xFjblp+Due3ciNj4KOoOFhkMXqhvdOFftwh37zNhbxjEEQxkbDTO3O9M5rz3mJehSvHerq8fQ0DCB5iYrNm+JxJ13JtBQKYqYxTvXtedeq/uiB6C+DNSfoZfhcDpHdDjf6sMAt0UBlxnuQYKeDEaUqYBaZbxdXBSC4sJQdcuzvBaXxeIimLX2t09guKFOKbZSbtmPjNvv4LtFbdpcG7nc2vJuKBlxzCSG8G6GJBUWw6oauzKKx3PeUVpkweZiMYZDgb6W9+q0sy2FBDQg61JIde23KWD/+h6fUlyfafEpEOuOLB3SooEYzhmp6xd7w5pMLhcjdRDo09bpQnuHSzmyDg176eQ5iaREAyOyGJDMdWfEKM6F9CLLHIZ8cyQ2W6IQZzBT77J0ty0KZFkkLJiLi91OkE5XN1qamzlmuYjW5hYykTgUYHXr9m0MK1qKbDrAiUJaDDLzSfKdlygtr77tIDurC7fuMJGVVZwU6KCwiOOV+VyTVlaTgCaB1SMBDci6Op6F9AlWGh6H62pR+8RvlOGx8EMfQQzDQoYl08OEScbvUm5g0IP2LjeZSicwNOzBnQciqMs2IyrSb6BfHXe0OFchc2EBtDY0OnD07RElgyiyzm5l1Ihs2k3CQiVEqx/YsDhn1FrRJHDzEqiqGkNFxSjB1x7Ex5vIrBWH6GiDZtO7edFuiBYETCaMhRfONOLV588qkJY41O87UIyM7ASER4bwXZKIDEs/S9OArOvzlRPolJfjiSpGKjzh7kOv164cOm8xEjQdHK7ArELwQnjf+hTAGrwrpT+g8VuenbApyoYCoXLDJ/kyRmS+HJ+6LWUkQ9aCQQlsq/qSz++NAFAFdCpsqS4q0p0Es7pd3OdawPWSL/tOpzCqcl/yWc6/zTUZUtVxVd5fJwB+FbCo0aj3M6GSHdVAb2lhQvWzp5ItlccUcyrzFauqsKjyuJRTZaQs8wxSTjGt+rcNRj8wdTEfpciv8+gRlP/0x4jalIeUPXsRX7YNoQQJziWJzbezvRPHjx7Dn55+Dtt27sDm7ftxsSkGk7oIFOSFqGhnudlEhzKtpNlAXiE334l+gliFFOytOjp9U/eXFaeD6APpP7Fuf/3Sf4otvrGxER//+MchunL1m1LPRIdHHnkEv/zlL7F9+3b86U9/4k9GflXXp4W08+yzz+Kzn/2s0usJ2VVSUtLlhgcHB7GFEZjkfE888QQOHjyIzZs3M6J3P/7xH/9R1btcmBtyfmnr6aefxu23345f//rXeO211xT+QPAKlZWViIwkw9uUdPjwYXz4wx9WOcIoK+ysC00akFUDss747nzta19Dfn4+HtKArDPKaa0ddJEpxGr1UiHlRm+fG61tDrUdQkBEJtmhNpcIC4ee3hurw2Njrcn32usVL1kxbrV30ajFcEV1VIpJCNmCTWbkEsyamU7L/TpJ0tcKM+vQCNlK26gAbHGhtcuDW7bzvconMyv7M9M6YNmS+5SxuYBWhHmtvJ0KXjKvHSjgc01mqEyCWReTIW+dvB4b6jZkgCcDuTqG55SBqgxYBcj6h/Nv4S1ntwor6uaLdIspEfnBDMumM92QmVWAqdKOy+XCv//7v+Nb3/qWkuN0QFYZOL7nPe9R5XNycvDe976XkzKTChEg1yDpL/7iL5Qn1LVhAtTBOf7TgKxzFJRWbENJoKGuAc/8/o+K1SyWv/dbD96KguJC5Vk5myAkXM25kw2ov9iB7s4hlJZl49DdWznZD0Z3P/DGCTsnu0Bmqh4FOWSHISOrgcDSxVRGjNFw19vrwJEjA2Rrc6OoKJyMHgypmEUmBoWX1BSLU58jhwH0LAU6h32o7xWFDKiY8alw2RH6SRjdLnS3WTHcZ2eIaY730ujYQyBrLMGbYaFU087j4Qlr0hCNzd0njqPt5ZeQdvAQCh/6KAxkyQsWBOgqTaLAdHIMLADWi7V2dPW4lYFY2FdTkozKQzyahnDxEpex8TxEskrvWLsskYAGZNXegxtJgHYLWF3CWD2Jum4fOoZ1GCXocc8mHQqTwcgWwtR6o5qrP0++dbTJ0IlskowYXAhgFWfWcTK6DY+S5W1EFhd63QSRBtlRkhyKklSGLU4JRWK0iaGZxdlzafpYD8PwCIi1pakJ9bV1dKy4iJGRETVWEbbVlLRUBWKNixfgQzTCIyIVK6vMZebTT8lTknGK6D4u1NL5pp4h+xw+pCTqcXC3mQ6u0t7qf5baFWoS0CSwdBLQgKxLJ9s5t0wdlBjPW1/6M9reoFGMH+aoTbnIeuc9CIlPgN5iUU3JHEciu5VX23D47Qmyk+o5bvc7oAkBxmLPQ+d8/UtYMKDPHifjel+/Cw1kZ21uIeCG7FpJiUZsLwtT5B8hmq1kCZ+C1vR8JTA05EJHh03pcGQc9s53JiI1NQShBF5rSZPAbBKQ757YBkaGJtBDPWT5uSa0t/QrMFduQSr23FrIuQGdjhkie6mTBmRdagmvXPsCapyAh7YwO6rdI2glO+u4z41sfTj2GhIQS2bWMJK8aGnlJSDfBAGbKkAp2U8V4FQBSoUN1Z/vEBAqF88lAKrzEuBUAVKZ71RgVAGh+plVA20IcN7Ljkp/idU0wFAaTCWQweBnNBXG02D9FdbTAJPpFSbUK8eknmJGDbTHdRD1ysHUYwTJtlr794WpVQD50k4g32+7vX5fdBZSX9qR8kIgsdh6DAEQjtTXo/3N11UENi/tvkXU8cdvLZvTSyDfbYfdgebGJpw9dYZEJC3U8diRV3oXzOH56B0MxrbNYTi4P1yNY2laXrFkdfoYvQ54q0GH1v5JRDBqb3Y8qA/TITpUx+i2Yl1Zv+lf//Vf8Z3vfEfp1p566ik6HN2qAKRvvPEGPvaxjyld3VQ7f0dHh8IAiEQ+//nPIz09XQlnvu0IlqC4uFgx9gpQ9fHHH1fvvugHBavw6quvcryYSmb/Y8qB/Utf+pLCD8STGfi3v/0tSkpK1PhAnNulrhyX9/brX/86/vIv/1K1K9hBAeYK8daPfvQjdZ2iQ+zq6sKDDz6o8BB79uzBH//4x2lBuqrSLP80ICvn7HNIGiOrBmSdw2uy9oqIUspOI0t1jVWFzxkb9xC8SuZMGpaTGfY0Id6oDMtmc/Cid9ZrT1o3f8Vi1OonePjMBZsKVWTgoCwn06TArKIIDLEs/qDo5q96YS1IuMXRcSo9ycQiYZBTyMIi4JuiTUaCWSXMop+af2Gtr55aHKeDkYLxZi1/R51AEoG6uYlB2MLxRSijL3IMrqUNKAGZCMlAVECsra2tlyUgQNbjFedR4xpCpXuIYVUmGE4lBFn6CGyiF+qNJu7ijfXjH/8YNTU1aoAYaGzqADeQJ+tvf/vb+Ld/+zdsIpOSeF5NDUnw3e9+F9///vdV8SNHjqgyU+vOZ1sDss5HWlrZ9S4BmbRNjE+g/Hw5fve/TyA9Ix133HUnGQwyIcCQ2ZLT4VaK41dfOMvwMMNIy4hD0eYsFJRmorGNIQ7pGHKx0cW+VI/9OxjakKHXwwh6WaykADjuSY4FrfxuMdxTux1h4XocuC2eHptmAmxWUOOxWDe5iO2IisXOvn/MLg4tBLISlNXBsDgTJMGWSX1SiBdmjwseFhgZphKPDmRbSsPIxmqmEZROCwtgpRODs3tiQgFZq37xmDI4Z7zjLsTkFyAkke7LqzBNMMy2sBqJ05wAWTsJYpV3zWxiOPF8CzII7I1nmE6N6XcVPrybvCQNyHqTAlzn1Sf4/ewbBc61+XCx06cArBkMJVZAgoC4CB3CVi82f15PRthJ7XYfunoJhumx4STjp40S3Brk4rw43ILUCDMiw4MRxTDN4twQHkZHYq5DqNg38TsZTEPLQgwm0g9JyD0JMTc8NITBgQGGSx5EL8PPDTCMdH9fP/shAx2XI1FA9r3c/FykpqURvBqmFNvzuslpCvf0e9HS4cGZKqf6xgszayoBrVERS0g9O821aNmaBDQJrB4JaEDWlX8WrrExTHR1ovnFF9B35jRSb70NCdt3ILa0FAZLiLpAdiPKEaO13YmaOjsqGUlh9/ZQlBZbkEDdtYW66/Wc5P7FKaOx2Y4aRrLr7XMpIgMhochIM9OgbOZ8xt9Xr2c5aPe2NiQg7+roiBsvvEjChAEXgQdkTc7zOyOvjTvQrnI1SED0NAIyE2bW2sp2Mv0NEMDKCJ4Es2bmEBydHqvArQIaW6qkAVmXSrKrp13RpTZ6xlDvHcVFzzCCycSaERRKm1gEMghqDQUJG5inpZklIPN9/1jFq0BkwkgqebIW+4TS8ROMqn7XgTWBjz5xOuVamFHl9x447uXv/3LepWMClFTAU7ap1pLPtqSsP/9KOwJw9Uh70jaPe1SdqfX924rClQoOYUY1EIRqIuupfFOMZEQVhlQjDenCfirbwoqqyklZLoo5depxqS91uAjYVdoRoOp8HXFnlvTSHnUOD2OsrRVNzz+HvvPnUfqJTyJ57y0wUU+jmyPydHRklN/rDhx98ygdESqQsakUxpA89I2lozA/Grt3hNOxmLofkkcsd3Iz0oHTrUP7ECMz9U6imWRg8v6UpumQRzNGdvzi2bWW+97mcz6JiPSBD3wAMg+WJEyoZrMZZ8+e5W/Fg/e///3K9i+/YUmnT59WxFSyLQyou3btkk0VWWk+7UgdwQYIGFa+C8KYum3bNly8eJEkNr2K+Or5558niU2RFEU3o3Xs27dPkWNJdKaysjJixJIhIFLBJUiSa5c6gn2QFADXyraAYnfs2KGuU8CxE7RhCbnWc889p0CxUmahSQOyakDWGd8djZF1RvGs+YPybZTF6aTn3ahXgVlr621kTLIhM8OEogIyhRSFEtAqIUnEUXtjdC5L9WBF1m4CRUbHJlHbYMeR4+PKmJ9Mz+49O0LJzGpUxqr1IGe5V45L0NPvQWunFyfLHbDSkPeOWyzIzdQjJorg6KUS9DK2y1tUv6G2QT8b25FaH6IILnr3Vh2So0APo2W8GO1Uq0YCMvCUwdu1SYCs5ZUVcHjd6KIXaoNnFMfcveA8Ejv0sSgxxKjJ+9R63/ve9yDLtelGQFb5dsjg98SJE/jqV7+qBqpT61mtVio081SWKIjuu+++qYfnta0BWeclLq3wOpeA2+1GUz29YE+fxesvv4o9+/fioU88rIAicwnLO8j4Km3NfXjx6ZNqcvnAwweQlBqHIKMZL7xhU0DW7DQ9CjcZVIhe0R0vZmivAFP/G2/04eTJQZRti0ZJcSRyckJpqNScma59fWV800FFTB1DZB+r98FBpxbp77czJE5qmBfNDRMM1WxHS4uNoSjDsGNbOBITjAQp3RzrqIBZh+kg0fzi83AQmCSDxrz77lfG52uvcaX3ZRzY1OpU493z5XYqNX1kpTWiuJDRCAjoFecto1E84xcG1Frp+9POP7MENCDrzPLZ6Efl+0AbCLpHfWjhp+xIHSBOkLuygeI0OnqSnWE9JDHiyL1KqOJmtxVPW1vgIGt36ngkgnpNcPYEobObofF47xF0HklPMSCbOpjMDCNiY/SwLNCZWIxONqsNbS2tOH/2DCoulKOuphYJiQnIys5G6dYtyN6Uo8CrAmg1UEktY5WAMnoxZC/f/JHRSbxyzIHeAQ+S4oJRyugsJXka085iyFdrQ5PAWpWABmRd+Sc3WHMR7a++gpGmRngZtrXo4Y8igaFM9TSoKoU0L5HdCNo7nfjz66OKlTWe4NVtWwg0yTKSJWvpGMRXXjpXrkD6b4k2Zrd5lY2kps6K+ka7imK3b08kUkj+ERuj9WlXJKZtrZQE5F0Vu175hVE0NE4wLKwTW7dG4dChdTKgXinBbsDzii1DIkUNUT957nQj6qo70Fjbhb23FeGWQyVISomh45s/TPVSiEcDsi6FVFdfm26iKUd9dPQkoLXCM4QzngHaxOKw28i5anAYInVkBtLSjBIQ0KnrEjuqsJ86yLTgomJafr+y77T7WVHVvt2f59/25wtDqoP5LjI0Sb6D5BpqnwyqckzsDQI0NRgNio1ZAKPCyizAUiPXAQCp7Jsl32Tk4gebSjkFOr28z2MCRGV+gHVV2TMIDBA7psIHyJrLVDuHOnapjBSSkiyiysm+6C5kXx1R9WcU2ao86BPgL+1J1f/zS7T8+UVk3HEnknbvQSxZNPWXnMtmu3A/4NiLygsVtEmdw/kzF+D0RmNT6f2IiEpAWJgR+/eEcwy//N7iVjqw91Ln9xbtJscbgK0ZZGEliFUc2CNpQ5HoDhsljdGR8KMf/agCqQbuWcCit99+O37yk5/wN3LluycAV4m2KkkIrgR8GkjzaSdQR9hUBScguIBASqMj+ze+8Q3cc889gSy1rq6uVniCerIFT00B0q4vf/nLBEVHTD2E//iP/8APf/hDFfVp6gFhdJV7y8nJmZq9oG0NyKoBWWd8cTQg64ziWVcHhZ11gGyhXTSmtLQSdGjzEEyhQwyNKMlJNKjQ8ziSbCHr3fN6qR+q3yvJh14CPOuoBJMQqwIizkwTGTPkbJaZrLhCab/UV7I87VvJ+DtGZtZz1S60dnmU13pOugFlRUYa5/zMrMtzJUt7FmEWEla24xyYDXFMEEZK/M3pOuVhxHE/gRpLe36t9dUngQGCjMTbSdKTTz6Jb37zmxAga2VlpcqXECoDXjuq6IHaOWmD3edBajCNA2RnzQwKQwzDqshw3sFw0jJIlSSDxkOHDmGI7Eo3ArJKmezsbE5anfj973+vvKgkL5AkpEBWVpbalQGmeHEtNGlA1oVKTqu33iQgyl7rhBUvv/CSCtlLOwJ27d2N299xu1/BMsMNS10xPAjrwdkT9QSeOJCYFI2Dd5fB6g5BQ7uXziAyHiPYvcSIjBQ94mI4RvBra2ZoeW6H5NwyLunqsqOiYpQemU56Tnqxc2c0cnPDODmlZ/MGUizMJDUBr7pozOweoWGXIFZZS2gcyY8KIaMg5/E+UrI6x5xkvXPyufpUVIPcTSHI5tguhIDghTCxXntNDrLqCZi148ib6CGLUtGHH1JMSkZ61gZPUXxcW2859sXoLQyEff1utHW40Md5xdgY2QepBBVQloQjTWXUhziGJmV3tmjv8XLcm3aO+UlAA7LOT14btbREtRiy+lDR4f+u0paCjFgd8pMI9oxmqGM/MdyaFg+5UTDGMX8dndf+7GhDrDcE+70p8I0Gwz2qw+CQh3qXSY73/XMG6d4lHJ7FHKT6EHH+jI7SM6JJsNLDyPf0RkMAGftPjI+ju6sbXQxF1t3ZpRTJHhpGdGS1kbB9iclJSKGjXVpGOmJj4xAZxVAiS5jsvKeaJj+rvLCzFtEZZ9926jqEcZaODFrSJKBJYONJQAOyrtwzn6QuyEYdVc+pk2h45o+IzMxC/JatSCLLT1hq2uULE0eE5hYX6umUV9fgQDzH7ds2hzKqhIGEBBsv5JQ4o/QPuNHe4VDkH9Jnyxxa5ndZGWZlLxE7yY365stC1TY0CSyxBLzUU/T2OVFfP47jx4eUQ/Ktt8ZRnyNs/xvvd7vE4l73zdsJiutqH6SDdg/qLnaQxdEHS4gJ+cVpjDqVgGQCWoUhcbGTBmRdbImu3vZcPi+GCWZtIpi1kmBWF+fMep8ORYZoZBLMmsLohaTVWr03MMuViT5YbILCkCrspB5hMuUi225GTlHbBKIKs6lb1jwm+YrJVMpeypd6ahHGU8mXtqQ+j4suf2ry712TJwMWZV30l5QZuFybgERl7T92dR0pKfZHYTjVkx1VrWVbgK3CfEpWVH/epTJqP0iBVIMZfVaOXVVO6kh9OcZtaVtLV0ug7fXX0PXWUXjJ3BlJ0F/u+++HKSZGPaerS06/19/bh1Y6Mr91+C20t9FoYUiBgcysIdEFOLgvgmR1IYgIk+e09PLn64lhG9Da70MlI9gKoFX0WJs53ciJ9yE2jJiQxe9CphfOKjoiNv0zZ84oRlZhWhVm1oWk+bYjgGcBqba0tGDz5s3Iysqa9rRSViLMCphVojwJ6FUiv8bwnZwuCX4hwPQqzK+5ubmIj188hyoNyPradKK/Kl9H+t/rv+hXFVmfOxqQdX0+15nuSli55HU/c24MFyomCEL0Ki/jXTvDyaRkQhw9sQXUEEwDi5YWLgEBpbjIznq23IYTZybgdvmQQAXhbbdEKAWhGK9EwutBGSbj6rYuGvCaPTh2lorQmGDcSWbWBDKzRIbLffoH0AuX5uqoKcbXpn4Ckhgm81iDD3tzdbijSIdIAlwsDCO8Hp7l6pD02ruKJ554An/zN39zFZBV7sLLSeMYJ+4XvSM0brfzt6BDUrAF+4yJyAuOhJGTdgmzEvjaymRv69ativ5/OiDr6ChjtTKFh4dfNTmUuj/72c+UB5Ycf/3111FQUCCbC0oakHVBYtMqrUMJCBvr0MAgfv6zxwhg7MVdf3E3ikqLkJWTPevdivLJSe/nF585jaOvVWD3/kKUbCVLWlYSKtmPvHlS+swgZKcZsGuzicbDxVU4iGHORpaZqioCbP7ci6QkM4oKI1BYFIaEhIVNpme96TVWQHR71BWCDuoY4/i4ssOHc63ACJUyoXRo3pcLZEYTzGry4viJMVyssbG/92FTjgUHb43it5hhkYyL99wCHts1T/xGeW3nvOs9SDtwENH5BTDyu78SSWQk75Ld4SMoy42aejtOnxdPX46BGEZ6365wGnrl/fWHelqJa9TOubwS0ICsyyvvtXw2mSeO2YHqLuDFch+MwT6GGAsiw7WswX2/0nut3iMD+KGeINaLnhGc9wyiKDgKH7TkqLG9jPvFgCTRWrp73Whuc6ClzYWOTrKjUE8gTG9pdAAQh2JhtI6JlhB8OtAOpPQxk5MSuo9GLY5DRkZGOAbpQWV5BRlYL6C9tY1lyeK+uRTbdu7Alm1liIqKohF6+dDB0jdIv1BZ78LTr9iQRWb5PVtMSE/WI4p9gzY3XqtvtXbdmgQWLgENyLpw2d1UTX6QnXSOHqgoRycN5W2vvYKCD34I+Q9+GAaLBUHsLyRJiHI7yQjefHscDc0OMmoFYXMxHTB2h/KbHdBK3dSVrNnK4uwpgNaz58dx9NgY0lKNyM0JwZZSfxQ7k4mdM9MGF9Oafb7r4cJl3FVfP4Fnnulk+FgDSkslwk4YEhOXn4VtPchTuwcCkYYm0NHahyOvVaLyfAuKN2dQX5mF0rIsRESGKBbGxfzmaUDWjffWWeFBv8eO19xduOAaxCZDpJov7zDGIZxQVj3ny0s5/pC5uHw75Z+sJF2VFzjOIZACfrKQ/7i/nmwHri9QL3BcgKfCbuok66l/7SZrqp8R1cm1sKE6yYwvTKqKRZXbku8mK6qshSnVX2ZKHWFMZb6AWAUYaDL7mVDNXJssRsWOKmyoZtnmIoBzi8XEY342VTO3VVmzMKmyjixkTjWHSF3ZFnZVPXEfjMzG9rW0PBIYb2/DYFUV6v/we4JPQ1H2/34R4ekZ8yarsJFx8/SJ04qZ9cLZCniNZYhIegf2kqxk6+YI5GQKycbS/qYExGojRqKxD3RY9+FUo09FXTqQz9DztJ2w69CSJoF5S0ADsmpA1hlfGg3IOqN41uVBxRhKRqVhGqL7qKTpYDihvn4XhofdSIg3IivTghyGBBU2pWACoxZzwrIuBTrNTckgWWQ9OOxRhquaOju3vYppJT/HrMI2GfS+ZfGSmeYSFy1bBvB2BxlLB72oqCFD15CX+5PYtcWMzQUcJJORRQxyaz3JQG2c9ykDtVNNPrgJ6ojg4HB/ng5ZcX5WVu33staf8sKufzogq0ySxQt1hGDWdu+EMnQ3e8cVG2sGPVC362MRS2ZWA8GskuYCZFUFr/knhuyf//zn+Pu//3t6eLpx11134Ze//KV/En5N2eHhYcUCe032dbviZXX48GF86lOfQmZm5nXHtQxNAhtFAl0dnWRircfrr7yuGCYffPhDSCfbWVh42KwiGGTIrsb6LpSfbiLopB9337sTKVkZ6OgPRkvnJDp6vOwrjYrFLC46eFEZzKRvnhj34PyFEXpk2jAw4FTGji1bIhUTq4UMohs9yVhNWFjbh3R0VPGhpsuv3KQOEGlUwMQTNxph9KGvy8Z3gCpYlhVS1DyysIpxMzHBxP2rwyPdtEx5UT56Q3WfPIH2N1+Hi+ClkMQkGqI/iLCUVCobFw80O5drlfdIwmK3tDOiQ7sTTS1ko+X4Noye3mkMuZlMBtb4OAPCQoNgpOe3Ng6ai1TXfhkNyLr2n+Fy3YGMhUkqgsEJfkcGfJxH6bgIiFWHvEQdilP5naVfxVr8dkiP4WLoxJecDMs5yfE9wyQWEsi60xhPVzW/YSjwDXUQ8Dlh9WKCTG/iSDw+McmFa24L+5ubwFZxikiI1yMx3oCkBD1DBvZjdLATdbW16OrsxCCZ9iIiIhEdG032gwTEJcQjPiEBMbExiIqO5hhCQkIvH/WF9KEyP+7q9eCC6AAGyTxL1u5DeyzIzxYmF4HyakmTgCaBjSQBDci6Mk/bTcP2GBl4an77OFxjo4jOzVOhSxPKtkGnwAr++UNXN1m0W8ioQ/20jO93bAtDFiOHJSX4ga4rc/Wr46wyz3ORgKKX9hGxk7Qykt3IqAfRdDKRyGqlxWFKn69FM1kdz2sjXoWMu/r7nSgvH0Fnpx1DtOPdeUcCSkoiFOBpLY6lN+JzXE33LCA6G0NotLf0oqXRvwjILiklGoUEtRZtzuT8REBvi6OD0oCsq+npL8+1uDlXdsGLNtrEmmgPk0VIX9IYsbBIH4UCkrzIvHmxopJNvSs/6ylZUMl26nZ54XT5QaTyjkuei2vZVgtBqYFtyXexrL+ebLOMsKlyvi6AVdkXECuNbkqJIbY8YSOVqCsCEJXfS5AsBIrquZbIKbItx6aWESCpHJeyUufKcf++ypd6U+oLI6pqi3mqDs8tbco1qP1AWa5V25J/qY4qw23Be8gkPQDQnSozbXtpJOCyTsDKiDrVv/oFnNTxZ951N+JKNyt21vmc0evxYJBR3Gqra/H2kbfR2RuEcXsCktJLUFySjTtui1C6pKUcq3YOi14PKG+jUzMJQdJJ4rkpkUsCow5xOrFRmVjn8xy1stdLQAOyakDW69+KKTkakHWKMDbgprCzdjE8aiM9sSurrBz00JBEZqmc7BCkpppUmFBhDl1MpqmNJmYZ0zqdXlTWOFDfaEcHmUsTqSQsLbQghcb/GIZiNYiRZx1YeWxkMhNQTnWDC2ernShmeMGSfCPSkvSICF0/LL99Y2Te6dWRtY2/n2Fgf34QilOABIYd1gZrG+0X7r/f6YCsAWlI2FExdFd7hnHG1Y8RTuNNCMZmfcylkCqhygvVGKyflZE10KasZRLa2NiIRx55BEePHlWHSkpK8Nvf/pYKd6KwbpB+97vfkZ2x6gZHrs4S8KqEGdCArFfLRdvbWBIQAIp4u558+zjZ0EaRmpaKe+9/L2LjYmcUhNSTkEHN9d04/Gq58rIWz+idt25GcEgcTpbTE5uGsrAQHfaWmbEpg37oizwOGCeItavLjmNvD8BG5p3kZIsycuTnzw7AnfHm1sFBAd5Qb6lYVwcngGaCWDuHdegZ9SGRfXluApAV44NZR2ckjpNbaPCta7Ar8GpOtgXFBSHKqCkKxKVKE12dGK6rQ9OfnoWboV5KPvYJxBQWwUTGveVIjDRDBe0kRgmyGqJTVnObEz0EKw0Ou5BI4GphfghZBA1KSaYpQJfjiayuc2hA1tX1PNbC1UgoY5KRoKIdOEHWBu4immwNZRk6pMfqGH7MD2Zduq/q4kvJoZzVnHjG0YreSTsOGpNVxIVkhkqcLoluQBiuxwlqlW9qV4+L+hgX+gfdZMnzwGxyk800mFFyjHBY+zAy1I6m+iqMj/bTyOdCQVEuWViLkF9YqECsRpNxxY1QVhuBPwNenK50KkDrgV1+Z9a4aHFwWEtPdLqnpuVrEtAkMFcJaEDWuUpq8crJvHOEoSH7L5xH859fQAgdHAoe/BAiMjJhjvXPWQWk6XD6UFVjR3mVTZEuJNBpYv+ecMRRJy22AC35JSCOJcSv4ByZWevqbaq/jiODen5eiHLgkyh2wp6uRbHT3piVkIDN5qGDsotha4dx/PggSQwSsW1blHJUXo5wwitxz9o5l14CdoJZxQn/1Nu1CtAq7JFZOYkoKElHIkGt0TFhislRgHU3kzQg681Ib23XlXnzkM+BY64+Er1Y4eR+PkGsxUGRiKGFLNRHZ0w6zE9SWSvzZXGe99LB37/PbeZPcp+mtcv5cmyShaWsrCc5x5YyQiwla6kjYFQBnXqpn5e1AFID23IsAHb18pjo8KWMv7x/XwFYpT7HBir/UptybQK+NRjovEmHfuMlplMT5+YGhpwxGv3Mp5IvZYQFVZWh4VhYVAUgHmBHleMmszCqSh2y1LI9yRN9s6ZrXdvv/dSrdzFyQv3vf4fh+joEW4i9uWU/0m+/QynB5vucexip5/yZc6gob0ZNbR90lp1IyyrAPe9IRC5tFrEc28+3zanXeqNtO21Y4w4darp9qOuho/q4D3HhOtxaoENKlA7hZv5wtaRJYIES0ICsGpB1xldHA7LOKJ51f1AGeRLy3kYWkJExj1LS1NbZyNY3iahIPXZsD0NmhoWGFM07+2ZeBhmAS/im7j43Kqtt6FDGKg8O7AvH1pIQBR4WRdhaTxzDE5gzibYuL8prXejpl2CLwJ37BKQjA3IC7xYbqbMCQhPwCyNAKFbW0y0+mAhEzqR++GChDlG0W66DW1wBqa7tU84GZBXGJvkt2MXgPenEOfcAGrxjGOR2gT4Sh4wpiA4yITzYOGcgqzCv/tM//RMee+wxTry99P7U43Of+xz+9m//lhPe6b/Z1dXV6O3tnVXgExMTVI6e0YCss0pKK7BeJeBXgE3iqSd+jxeffQH7D92KHbt2EDxSgJDQ6UEqIg9RhllJ4X32ZD2e+t8j2LIjB7cc3IJxdxi6Bo2oqHMhP8uA2wj2kPC7oWT3XuxUWclQxxfH0dZmQ1KSGQcOxCE21oSQEI2J1UpD7rAVONsqoCoBVPlBVFvSdSoUTkwIDcKMXCBMtidOjSkgjjh55edakJ4moZrE437xn9nUd8DrYpip0VFU/eIxpehK3LkLSVwStm2fWmzJtq02LwYGPai8KAZvO/sVyigmGCWFNOIm6hkCm+M65q2H8euSCXEdN6wBWdfxw12iW5P5sIyFJbqFKL3fbhAngkkqvHUoTaMCPJ/fE3ZPN2kfXaKrv3Gz3ZM2xSpzkgY5ubf3mTKRoQ9jkMSZjbwiCy8NbG7Omz1eHZ1eqYsZdaKzaxQVlV10fHUwWo4OPh0NY5RJWMgEHQdMKC2KpbMxWTboPWkym9TYX5zaVjoJMNdNkNT5ix6cuOBAOBm605KCsJvRWWSMoyVNApoENo4ENCDrMj9rdigSyaHm8f9F51tvwUKG7vitZci6653Qh4Yi6BJLtzCBt3e6cL7SRjCrDQf2hmMLddFi6BbiCk2HeeW5qfEK+2mZC/WTnbXqog1t7Q7Oi9xksI1A2ZZQys2g2Fmv1NK2NAksjwRUlEWOuU6dGsLhNweQRR1F7qYwFBZFIDx8+Vj5l+dutbMslwQECCgskxMTdrQ19eLCmSZ0dwxifMxOPWgJNm/PRkJytApNfjPXpAFZb0Z6a7uuELx42MGOMmJhvWcUJ939sFLnaaB9dbcvFpmeEOhkbkyWYHkXnTS8CqB66rab+5LnP0Z9qZTl4nTKNsuqbf9xtxhvmQQMqoCkAh4VUCnXeiodBGxqInA0sK9Apsz3A0n9QFQ/4FTKCgnVlfpS1yCMpyyv5uJUDcs6QHSgAKjcF41xYFvZw1W5K+BU/zGJYOKP8iUMrQI+9C8aY6p6gOvon8dBpv+6WnQfP64cz4SVtfRTn4GO71YQ2Xrnk8QmbGM0huNvncTrr76NYVsWjCFZKCnNwvayOOxixIXFHtt3DPlQTvtJLUGsA+PALXk6FCXrkBhJEhDaBtaSHm8+stbKLo8ENCCrBmSd8U372te+hvz8fDz00EMzltMOrm8JCADRRYp9CTPU3GonO4gLVrKEhFgY3i7BiNRkE5ISjYgkuFW8jhe7I1zf0r1ydxI2sJ0hihqbnahvciA6Sq/CBhYQGCFhWUXe60G2I2NkKu0jCy2BOp09HoaqMiA7TY+8LD0sJhnYX5HJWt6SMMR13UBdr08BdLdn6hgmE0heHrK0tSy6dXftswFZAzcscFaZSjcTxNrkGUMDF/nRRzIUaUFwBApNMThQtksBTR999FE8/PDDgapXrWVw9+lPfxrNzc0q/6677oL059nZ2VeVu5mdt99+Gy+99JIGZL0ZIWp117QExsfHqbztwqsvvYozJ0/jgQ9/ALv27FLhe/X0jp4pWScYsrGiFbVV7ai72InNOwtQurMUlfWTGBzTkXGNE/4cPcqKCURRYYBmam1+x2w0ug2TNfPs2RF+I6wcx5mwKScUpZsjqXgOXhfjjPlJxF9axrrihCKsq90jQAdBQiMSzpkgophQhraKCUIuw+EIBY+VbLYNjTb00gHJ4fAiNcWMArLwJJBRXxy9lit5nQzz9vqr6D13Fg6GlE7YvgN5938AQXRWCBimF/NaBIwkDkl9/WSi7XWjk45XEvpaWIkSOE5NTeZ4LtOEiLAgsgesk8HcYgpwA7WlAVk30MNe5FulnRS0TaG6UyJcgGzYjAhjAXI4h5JwZCnRPirBJbzgIp94EZsT9jveBs57BnGCRji51KQgC24jI2ssHdPmksQJzclv/NDAIHp7etDe1kUG8GH0DbjhIzONOSQZRksMDWehZJdxEzDD/icqFOFhekRGGLgEIzoyWOlnTEaGJVxi54q53FNbtwf1LQxb3eZRY41bd5gIaDUQ2LqKH+Zcbkwro0lAk8CcJaABWecsqkUpaKOD8mhLM1pffgljba3IILNTfNk2ROflq7mCgDKFVKGNINazFyZgd/jYXxA0QtKKHI7pNRDr9I/BLzsCgDucyk7S3OJUzoyix8/OMit21hgCWmUuryVNAsstgcZGK8RxeWDA/14ePBhP52XLqhgPLrcstPMtngQEKD0yNI7mxl60NHSjtbmPjvBGxCVEIjMnCanpcUgiQ2sAcDffM2tA1vlKbOXKX2Y1vcRS6gfR+5lNhb1U5rKK8VRtk/30UjnJC2wLg6nUU+WECZXHnFz3uOlU4xzCOOe43kkv8oLoqKmzwKILRjBJBgRYLUnqyqRbMbFyXxx3pG+eFFpWlc85uWRcylObrBOYq4tOIZgAQQVcpQ7fQOCp6PKD9cJ4SjAqt/3HeF4CU4UlNVBW1vpLYNUrZXlc8lR9AR+uDzu+Erb2b8kl4BP9z8gIuk+ewMVf/xIxRSXIefd7/BEUYmIWdP6mhkZUllfjfPkQegaod4kpxrayZNx5IAZhYcGQSMs3k9RY2O1jRFodGvt8io3VSL1TbJiPkZWCSATiQwh1UesBz3IzctLq3rwENCCrBmSd8S3SgKwzimdDHpSQQ+0dDlTXWHHsxJgCrmamm7F9W7gKpWNk5yQDQa2DWvjrIcAAAbMePz2B0TEv7rgtggAJKsISCUzg+EI8r9ZDOn/RhfIaJxlaPUghe9e7DoYgJpLhFvgOrYck8ylhFXr2nE+FJY6ikU7ArPty+Qx5g+vkMa6HR7Xk9zBXIOvUCxnzuVHnGcEpGsCPOLtxmykZd5nT8eCOAzMCWXto7Bbg6uDgIOLj4/Hd735X7U9tezG2NSDrYkhRa2MtS6CtpQ0n3z6BpsZGjI2O4cGHPoSt27fOekuiNJOwXM/87hgG+kaRlhmPhIwsWKJTcfi0Q3mp3ntHCDKS9QgNWdz+UJQM3d0O1NWNo/zCKMcYLrz33hQUFITTs/yKh/isN7GOCohMpFMWMOYgWVhPNk6iqhNo6BUWQB925+hQQC/iOIa1lmfX0OhAeeUEaupYmOnOQzFkORGHo8UPzaNOMMM/UdTa+/vQc/IkLvz0x4jfshU7/vr/QB9Oxj+GIlqsFFD0usgKOEpnpNPnraiutSsga0Gehd7coQrAGhu9fCDexbo3rZ2lkYAGZF0auW6kVsW5oItOBW/U+OdRIzbg7lLOo8jsQMymYmddrfKQqDYSd+RFRzuec7XjTlMKdhrjkawMcNN/J+VbK0nWDrsdYwwvV1VeidP8xlecv0AnlGFkZWdhS1kZdu/bi/CoFIJaY6g3cKCBugNZSxLn19xsM3KyTcjOMCrn2IBDrF+P4FsRfQJtlZiwTuIPLzMCDZ1Zd5YaUbjJqBxa1YVr/zQJaBK4aQnIbzzwLbnpxthAQPe4WG1qQNbFeCpzbIN9Se+Z02h64XkIoNUUEY6ij30CsYVFl5WRbhqfxUGinJHBXn1zHKWFFtxxMAJxHNOHhNyccXuOV7kuig0NexQrq9hIauut2Lo5DJtLQlFUGMo+eeM6iq6Lh7tGb0I5Lw+58PQzXWQOduL9709BXl64YgoOfNfX6K1plz2LBASY941vfIO2NSMeeeQRBfK7toq8A1ay9f3ud79DfX09AU1h2LdvH3bv3s1vf8gNxxES5U3sAIcPH0ZfXx+2bNmCvXv3YYJOh//5b88jrzAV23bnYvf+QgX2C1YgvvnpMzUg67VP6ub3rx+/XT9OlKd0XTlm+vOufoaSJ4sCrpLVVLGfOlyw25yK8dTBbccltlSnXbb9bKgqj/tOh0flBfL99d10qpH6QhTgZ0wV9lSQhFJHdlMP7cQGkx5RFgvCLYxWaDEz+ogBZm6bZW02+vcDawv3qTCQfHWc5UxyjG2YQ/x1FCiVoFMBm2pJk8BqksBgVSWqf/0rzsGCEJ6egbSDhxBbxLH7ApL8Vm02O/745LM4ebITQ45tKC7JwN13JiAjzYz4m4yyTOw5+sm+eriWthISeQ1NAId4qYeKgmCm2os/MS1pElgUCWhAVg3IOuOLpAFZZxTPhjwohhnrBBnDOCHuIuBS2Kj6B1wMHxqkGD8krGoyGVrFC1kD6i3sFbGRAWyEANa6BobsoGf8BNmuksh8u7mEQIlYDtyXke1rYXcwt1qDI5OKkfX8RSfDMvlU2KqiTXoUbRLA7upm2pnLHfKnohiFmvqB2u5JVJJZKJ2MbmWZQFq0P0zxXNrRyqx9CSwEyOryeSFg1lbvBAGtoxjyOZDGcKRf2/P+y0DWh8jIerVKAfjCF76AP/zhD0oRdeTIESQmCoXg4icNyLr4MtVaXBsSEEWAeJifO3MOT/7mt4hPSEBxaTHKdpQhJS111pvo7yUTKtkL3ny5QjHh7DmwFT1jEegYMCIqPAgZKQZsKSSbGrcNi8ig5iKT5vi4G9XV4zh2bIDfBjMyM2lgKwpHXKyJCrwrxupZb2IdFRCHkwGGsZbwN61kUvdMEiRl9CngalqMTrGoRzC0tZWyq2uwKdadXkYmSE4yIp2KnyyyFUVHrUz4SHkXPXYbhsnCXfvbx8l8EYQYGqeTdu3hunDRnpIAjwaGhIXWjvYut1Jamwl8josNppOVESnJRoKug27am3vRLlhraMUloAFZV/wRrPkLkHmUzUUwK42j9b0Mi8woF8LmIOwO27OC+G328VtN59lVeKfjHL93cPx+1j2IC1zeZc7ADmMcLD4ytNAgMV0S4OpAfz9aGpvR1tKCzg56VTCZzDTYRUQghkwc8YkJSExKVGMPo4keFjBilCGhxfl1jDqDcW5LlBcHHQ+cXBhVTn2fo8jOmhCvV+zZcTRYrARLqzxTua6KOjcaWqlDGppEPiOyHNhNYyTDza0G1lglcO2fJoE1KIFTp05BQKIVFRWI4PciNzcX99xzD1JSCHiXH98CkoBhvvOd79ABrg6f/exnsWPHjgW0cnUVDch6tTyWak/mBxNd3eg8ehiNzz6DlL17kbhzN+I2b4ElNladVuaGI6NeHD8zge4et+oXivItKC0OWZE+YqlksRztSt9mZR/c2u5AGxla+/pciok1NYWRT+jwmJVhIgmIxsy2HM9CO4dfAkJCI5FjXn+9D62tNqSlhRDIGqZ0P2Jv0dL6lcCZM2dw7733Ii4ujqy8ldcBWQXEeuLECXz84x9XTnNTJREeHo6nn34ahdfokqTOX/3VX+HZZ5+dWlxtf/CDH8T/+euv4E9PHVP7IaFmFG3OQHZuEiKjwugwP70T37WNaUDWayWysP2AztpNoKlHmFDJcirbboY9kbWwpV7Z98DDKKwe5nl4zEUPf1mr41wH6kre5W3qw4U9VVIQ3w1h4JU+TpJgASQMunxmFCMpZ+uB4/Ieybbf5ss168i25MukXtry50k+FzKae4N86NE50OGzoVVnRYqRjiKmWCQaQxCllwhmQYpBVcaswpoq7QmjqspXedxmvuqDWdafzzrcXihzsLpR7Z8mgSWSgI0ERX3nz9IZ7QyGai6i+BOfQtptB1TkNdH5zzfJ77aR+qWqyg4cfqsPk7popKRvouNaLLZtjuDvRTAY/AHOIwl5lzieV3UxEm2PDx1DoqvzIZcRlCQabXosdTu81Hk2O48r0IpuNAloQFYNyDrjO68BWWcUz4Y+KJ5XovhqbSOrZtUEQa3iOcUOi0qazHQTFaYMLRpOTyca/9VAdX794YaWrdy86Jr76Rnf3OZnZpW8nEwzNpFZJSON3mMMO7wejD0CYL1Q40JdC4HRfZMoyTModpZohkO0qHdH7nztJnmOnOuhqQ94uYqTRw7y4sLIzJqlUyEyTWQUksmdlta3BOYCZP3v//5vNDQ0UNG9CZ/5zGcuC8QKDwa9Dhx19WCSL8v39n5AAVn/5dFH8Z6HHkS4jsBvUQywhnhIl5aWKu/ov/u7v8OnP/3py+1cuyFe1qIYWGjSgKwLlZxWb61LQJQAI8MjOHb0bTz+q9/g1kO34d777kUMjYIhodOzYIoyUUIgVZyjAuFCC1pb+hARE4+t+3ehvj0Ize0eBeYoyWNorujFBbFKSPjxMSovmsZRUzNBMOsYDhyIw65dEk5Gr8JGrvXnMp/rF6WLkwxEE06gZxRoHxSgFJlyJ3QMfaNDfhLD4JBB3aInax2f28iIh4ZJp2JiFXYTA5239u7yRyIwMxRP8AqHjLT2dKP9zTcUoHW8ox35DzyIdHptB5GFYyGKLpGlKKVcbhplCYjq63cro2xzqwv9gx6kE2ydx/F+cQEZEcJEMawNZObz/m2EshqQdSM85eW5R5lLtQ36UN5OpmyGKxPng51ZIFN2EJIifTATAEk71KpJvFx0eq045elHn8cGt86HO42pKNJHXXeNYkQU5lW73UEAzIQav3d1dKCpoQmyHhoaQiodZPJpTC7ZshlZOdn85oaR5YgTyBskkZWAkvoH/d/sdjrEdhGcJAa9EM6rE+kYK+zhCVzCGUouNERCJOr8i8hxGfoy0SENj/pQRyDrq2/bkRQfjIO7zEigY4Q48GhJk4AmgflJQMKpfupTn8LLL798XUULmau+/e1v48Mf/vB1QJbrCl+TITrcp556SjnJyqEf//jHeN/73ndNqfnvakDW+ctsvjUmPR7Y+npVxIbec2cwSHBz0Uc/jsy774bebIEu2A8qEiZWAV0eP21Vc9R9nNtkphvp9HDjPma+17ERy1s5TxSij5OnxgkOdrH/hbKRFJOZNTraoBxL/KCdjSgd7Z6XWwIy5qqoGKUzgowxncjODsGhQwlkJVx5/cVyy2K9n090+wLkE8cTAag2MmrUdEBWid4m7KsTnHskJSXhgQceIFOvBc8884yqL45zL7zwAtLT05XYZDwgDK8yDpB0N/sSqV9VVYU//vGPBEp6lA3j3nd+FG+9WYE+KtiKStORW5CKxJRo6knDqSc1X2ZpVY1M828jAVmVfphzNxnHiZ5YiKNkHQCIyu83kD9J0KgqxzIqX9Yq70o9fz7bYptSz029dQCQ6iHwVACtfiBrANTqJkGDOD1eAagGjss1SL6LwNfL4NVr2pNzCBhUgMpGGjeNRi6ybdQrdlSDwb++ku8/LkyqcixQz8S6BrKuSjlhTZX6ap/58l5Psh9t84zjIiMWnuT8OoI2sELOq3P1kUgJCoGFtK0zOYpO86pp2ZoEVq0EPA47nIzEU//U71H/+ydR8slPIeMdd9ERLQ7BJtOCrlv0Tm2tvXjhT8dR1wz0jaTg3fck4rZ9cdQPWdgHzM3hQH1f+I2ZcOpoP/HhVLOfiTWUOJWCJODWfDKxGiaVM9eCLlSrpElgGgloQFYNyDrNq+HP1oCsM4pnQx/0d1zi4UmD0oQHHZ1OLi40NduUsSSFrKxFhSFKaSOMYsthGFlvD0SAwmNkvxW51jc5UMUwrrlZlCu95DcxXKAwq6z15BFwjdWHxjY3Tl4g7Q7DMAqIdU+ZEVmpflZfmTSv5cS5nTK6dgz5cLbFh3OtMrDTYWuGML35FLvQWr4/7dpnl8BcgKzixXz06FHs379fhfcJtCqhSd1kZ+2dtMOqm8TDOw4pIOt3Hv0X5HzwHdiij4WZE799mQ4AAEAASURBVHcDGZ46aPSWUEBzST/60Y9w//33z6XoDctoQNYbikXL3AASGB8bx3mysVZVVKG+pg6H3nE77nrX3VTGGZTyeDoRKGUgvdv/9NQJnDvViMLNWQgKTUHHaBwiI4wKzLGlkI5ACQSxElCyWE4OMl6z28kQ02rF66+RIpwpOyeELAuRZOagQplusmu8m51O5DfMV/IgQ13PiA/nCYwSEGvfmA+bEugwRO9hYUyPIclduJnfXpcPo6MenDg1RkOvg6BWlskxo6QojMZIPcJC9cpAudLyc5N1yc7wbi0v/RkX/+dXKHroo8giC1dIfAL0dFpYSLLxnRkgaLWimiysHIcOEcybkcow1WSgTU40IIb3LyysYgufr/f2Qq5Hq7O2JKABWdfW81rtV2vnt1iU5dWMbiGMD71jQApxoRKyLD5cvter4w7YRUDG7dXuYfzB2YKEIAu2G2KRExyOeG5PTWKMtDGkZ1trK2ov1qC6sgqDAwN0DHYhPTMD6RkZyMzOQizZlCKjIul0Ek4HYbLOcKwx09xYwkTL4qCDsZ1MXHY7Q7zx+z1AcKswaw+PkLWVrHHihJDEb7l81+WbnhAn4Rc59liswcfUm52yLX2wmyxh3X0eHOfcf3R8Up3zlm3UcTAqy0r3p1MuVdvUJLDqJSAGfgGxCuBEvgv33Xcftm/fDmFnlTyXS4B0QXjllVeuY1eb7eY6Oztx6NAhFXpYympA1tkktkqO8yPrHB/HIFn4qn71cwJXzUjesxcJ23Ygig7TwpIm+knRw544Y8W5cpsaz6elGLF9SwjnpAIm0ZwKFvo0xXlU9PhDwwISdqGq2gqZU4nT354dEchjBLsQOpFoToALlbBWbz4SkDHXyKgbjQ0TePXVXsTHm3HnnfEEOJoRGrr27UnzkcV6Liv9/Mc+9jEFQm3lvCKQpgOy/sM//AP+8z//k1E1I/Hiiy8ySlOmqjLOvuP2229HV1eXcoD5/ve/r/LFsU7GFjKmkDHHt771rctM7z/5yU/w9a9/XZU7ffoM+jqtaG3uQ1NdF0YYYzoxNQa5+ako3pqJaCrZQsNmnrRtJCCrHyzq4dxPFjecDpcCjsq+U+27FfDU6XBzXueCW8oRWBo4JnXUIiyrkn9pLXkCYBU2UwGa6gkaFeCo6H1lW9hJDQZZ9Aimg76e4wK92pe1/3igrABKVXmCS4Up1aDqXirDuvLuKQZVmcDxL7AtTKfBPCZrv/OG/1pkrKr2pxyXlyfAjjqV3VXCqkuz/IzBPulhlEInWidJysB5dp13FKX6aJRwKSCoVQhetKRJYL1IwEc9kZff27aX/4yGZ57m+D0X8Vu2IHnvLTDT0WAhSYDzNpsDPd0DOHaiD8/9uZNEaRHE7sTgrjuzkZZKpdockswhhBSkuhM4Wu8n7xJd3HZ2I5lxfluKOJnzp6slTQKLKgENyKoBWWd8oTQg64zi0Q5OkYAoanoYarW2zq6UNhLGJJ4GkeQkGkcYcjQ2RryPheJ/SiVtc1YJiBwnyIbV1OLE+QobPfPIPEMjU0GehYxYZFWJlQnE2h4eiHKlb9CLi40Mo95JQ9uwF1sKjMjL5vtDlhYJfbjWkzCxci6J823AsQYfQulAlUwD7LYMICECik1IJmhaWp8SePLJJ/GlL31pWo9ouWthSjl8+DAOHjyI3/zmN9cJgsGcIaFK37n7Vohh6V++/z2437sd6cGhyKSBPCHYgsPP/VmF/buu8g0yROEk4YYWmjQg60Ilp9VbyxLw0pO9j4DBZ596Gv19Ayq87849u1C2o2zW2xoaGENH6wCOH6kmQ8IACraVEciajM4BAwpyTNhaxPES+7yw0MXrDKR/dZNVs75+guecQFOTleMyM/bsjeH3yKTYWGe98HVSQGQhDKxD9BruGtUxXLUPfWSFm6SKxRTsQ1GKDpsSdYgi7jOY6lK7YxLtBK+2khm/s8uhmA1SOe7K2xSKHLLjiwJWltWQRNE16aHB9PXXUPPr/0FUXj7iSzcjZd8tCCHLxlyTyMhmnyTQyUMWPxeZWD0QtiYSMpAlPwi5BPFuIpA1nKx5ZjK5aEmTwHQS0ICs00lGy78ZCYhTYPMAUNHhV5onR+qQm+hjlAudmlvRBreiycO+o89rR5VnCK+5upRx7W5TGpljjGCvQdYbgkjHxxRgtb+vHwP9Axjs7yfL+7AK7SmRFcIY0jMnN1exr2ZmZSqGpOkYWGe7WfmmCzvP6JgXg5xf9zDU8QDn3INDnFXwuy7EriEWYWYN4tiDC8GtkRF6RtUJRjgBDiYyayyVM/IEo7KII2ttsxvV9W7s32FS8//oCDL7rIO5/2zPRjuuSWAxJCCgEonmIiw7//zP/6wAJoF2BXgiegVhXpM5v8z955Pe/e53Q9hTA0kDsgYksXrXYqSe5DvRd+4sl3PoOXMKsYVFyL3vATq3xcMYEaHARyNjnOOQiKLqoh1tXG8pDkE+AZYScUEDsd7881XPgX2sOJDUN1DG7Q7FlC6s6GmMXJeZYaJDoJFAQm0udfPS1lqYTQJiQ+rosOO11/rIyOhDRoaFjg0RBC8uzNl1tvNpx5dfAvLNSU1Nve7ENwKyCvBQ2FSbm5vxxS9+EV/+8pevqvfYY4/hK1/5CvU94YzkVKOcZISp9XOf+xznDQaVJ+ytgSTAxKKiIkYwGsFXv/pVPPSRj6O/dxQXK1qp++xX7KKWEH7zyMoaGx+BuIRIxMSFIzyCTJrMv1aftlRAVpGRf17kZz/1ciKk2E5Fj8a5ko/fbHEyFHCp/xvuZzy9utzV7KmKEVX63Ut15Ld2ZdvfjmpP2me5QNuq3KXzS/t+ZlVZs8ylfP+1sD11nOtL51H5bE/VkfPyQQS2L5dhWbk3AaAKQDUARFXgVWE7FQCrMKlyW6/YT5l3qayUETCrnxVV7M2XgLBSTkCsUmcKIPba5xd4L5Zi7STByxhtYtWeYZxzD1Bnq0NkkBH5wZHICA5DYjCjDvLE/niFS3EFWpuaBJZXAgMV5eg+dgyjzU0w8Jtc8MEPI4KOB0GixFlAku+Qx+1mpLlevPFmK3r6ffwGB+POg7EoJqA1OSWG34YbK9RU3UkdRmwSddaHJnKkNDCqXUYs7SgkBClKAaJDheRiARemVdEkMAcJaEDW1+YgJfaBdqEy2IBJA7JuwIe+wFuWgT/H1/QAE9Clg0rPccVeZSMIc+/uCJQWh3FiRSOO5t09bwmLbAVQMUbGksNvj+NClRXpZE8RZtbd20MVuGCtgyDl3RH2mBMXnDh2zq5C3WSSkfXQbguiaNBa6/cnD53jRQxZGW5yGPhzxSQGJoB3lwWhkCGM4yO0qda8fxgbsIIMRDyEXbV6J3CWE/dqhlYRg/khUzK26mOQRUCrSXfjScdii0sDsi62RLX21oIE7DY7Wlta8R//+u9KwfexTzNMY3YmoqKjZ738msp2HHm1nEz29JafNMEVUgBjSDRiyWxZVmTAlkKj8ppfzHm/GCvsBCY++2wnGfOtNHaHoriIY7LSSKU0Xg9966yCZwHpfyWJsqWiY5Ls6FTAkA2+kMqWLelBdCrRkYlgEsZLjkFW6yR6Cfg58vYIKqttKKTzUHFRKEpLQv0spMsQftl/xfP7P8xQcj2nTqL37Gkast3Y8rnPI664hDPZ2d8qUUxJkhCjNfUOXKi0KxCruvcCMzbz/k10pJIoC5Lm0KQqp/3bmBLQgKwb87kv9V3LZ0ocEkRp7ncOBHZkAQcKgFSyaUdcsasu9aXcsH27z0PD2iDqyRLTw/H5TmMcbjem0KDmNzI6HA401TfiAkFGZ06eJmNRM8GjYcjJy8WOXbuQV1ig2FgNeoZSpIFRDAkzsa/e8CJukOkPVenvC9W4gHqFHjKitrTxeugs29XjhpVjhUjOuXPorJDLyC8SXlqYtwXouhRJnqUws54qd+HZ12x06NGTkdWIwhyDmvsvxTm1NjUJrDcJHD9+XEVYEVBJU1OTAkpMvUfR5//0pz8lcClDsbQK4HW2JCAXYVv74Q9/iNtuu01FfBHAiwZknU1yK398ks/XbZ1Axc9+CjF+i2ObOLWlHzxEVjTCOy4N3ms5zn/tyJj6Bovjwm37wpHFb/5SOS6svGRW5gqknxPAUnOrAzV1Nlwon1CAqVv2RCA/LwQZ6TMzE67MVWtnXY8SGCMr68WL4wRWjxPAaGVo+CRG8ooJfBLW4y1vuHsaYFQHATlKEiKNb37zmzck0hCdj4wJZDzw3HPPKabVqcISoIiwskp6+eWXUVJSgh/84Ad49NFHceDAATz++ONTi6vtz3zmM4oF/q677sJjj/2ceWQGJ4vo0OA4qstbUXm+BRXnmhAbG4GM7ARs3ZWLTXnJSEiOJqjy6nnG0gFZaUuhQ6GbOjIPmWaEsVRYTF0EdcnayzyXy5/ndvsZTqWcHJM6bta9XEfakPrS3qV2pJzkuVhXHZM12xMGVdVeIP9ynpuAL5nrBcFkYVQMi4l2UD0dGLmWfTPt51zM3DaZuKht2edi9u8bzXp/OTnOxcj6Us/IRZhUA+ym8pDUfJJ9kn9e6bu0liNMamxwJS8w97yUPaXM5WHE1fX9JZb8P+G5Crhr5Xx7aNKBl5wdqPWMIjkoBGWMgLLfkAgjQXm0IC/5tWgn0CSwHBJwjY1hggzZ5//9R7D192HHX/8NYktLYWSknptJExMOOjpO4KlnB3G+fAib0oexa0c87rizTH1LbtQ2Px+wOoB66uGeO0/QPTNSSdC1d5OOdhVhYNZArDeSm5a3eBLQgKwakHXGt0kDss4oHu3gNRIQRY2ALoX1o6fHiQ4yWPX2MTwCQ9sJi2hKMr2PqaxJIwhTWEQ1Rdk1ApxhV0I/SYii5lYXmskOJgYnPYEU6akGGpssVILR4EW3l7U6XJd3R5bOXg+aOzyob+Fkj8atvEw9NmUYkJXG2LXrIAkrqxhgTzXTe6lPpvdALsMZ783VwWLwXQbRrINb1W5hiSQgU3dhZu3lxL3Jw3DXnnE4CG4NIYBVmFmz9eFIDwqDQcKwLNE1SLMakHUJhas1vWolUFtdg8qKKpw7dUaxsT7wkQcZ9jeWk33SbE+TRLk5MWbDmRP1ePm5MwhPSEdYfCYcuhgkJoairNCA1CQ9EmKvVuJO09ycs6VPbW210WhBJliycEiPs2NHNBXXIVQim/z6yjm3tjYLii7f6oIKQ93QM4k+hqMetesQYvQhlqyi6dE+sqPrkBhJpQsVL26Os4SBtIUGx7p6mxqXCIgnd5NFjV3jyIJvYAit1Zpco6OY6O5G/VNPYri+Dpve+34kbtuG8PT/n733AK/zKrNG15FOk456782qtmVLttydHlKAIQQyIUNCCXMHHgaGe7nDP8wz8/DM/NxhGH6mXJhCGdo/cAmQDBBKSC923LssN/Xe++n9rnfLCrIjq1iSrSPvnRyf8p3zlfV9+vbe77vetQpguGZlNa26SGoaGgmoQjRRYR2bCMAWE4XkJCNys03Kfjo91aTG7ZrAulrP/uraL01kXV3nYy3tDbtU3seBdipInOuhc4lH1LGBzSxIKE4H0uPAOfKNP+IApXzGwz485+nCUMiNUmMiigNW5Hqi0dXRqR7dXV1wOpxU2wmqcYPNZqM6URqyqJydmZ3N8UQaEpMSVzQ5yFANk7XEzRlkzEYUuP0YZ+zG7gix0IaJXS6TuIMkuuNsRpJKoyF9X2qKURFbxSlluWI4apxCN5ZzVGTtJbFWEqe31VmQnx29Jgp1b/xVqLd4qyHwr//6r/jyl79MQtJ2/PKXv3zb4YtKq5BCRKntxIkTb5Fc3vbFGR8cOXJEkWPFcljcYh5++GG6OrRoIusMjFbry/HmZkVg7TtymJakXhTd/yDSSEKKy8tXu+ymxX13rx+NLV6cveDCuqIpcYR8Ck4k8l6v28ogMMk+dmjYh+ZWNwboYidFpunpZhQR/4I8q3Kv0/OrlcFer3UKAckljY74UF8/jn37h7FjRypqahKVQ0/MChUsaexvHgI//elP8dnPfnZWImtnZyd27typdq6pqYnK0JTQm9GE4JqfP9VnCGlVyKuf+tSn8Itf/EK5v/3N3/zNjG9PvfyHf/gHVfxSy7jTb3/7W/Wh5Ia9Hh9drCYw0DuGvp4ROOxuuF0+RSiV/KWQL2NtVlhjRaHaSrKmCQePvqDGKnu2P6DUSUWldEqdlOqjXGeQj98rmE6pnsq21IMKpdMKp9Pfk/nM71VRuWsGEjblP7npXk6Y/J64OfWB+pfL1Vcu35wvP/1+jqZ+fnk9jLNOre/y76eeLm9HyJ8Glfu7cjuihBilhAyUcionr9GieHpZQVUIrtNqqtGigKqWUUlVvqeWTX0mn6v3fDYQU/mNvJ8qhpza9ttOWIR/4Oec24cgGklibQs50MWcmMVgJKGV4gOmZBSqfJjoteqmEYhsBIJ0WfDbWRDwo//CaOMlxva3IHNrHTJqauWP+7oPTnJUPhIU9h+iuvGZEeXekZcdhd0UoissymGui0G1Gc1D4bFJxtzOdAqXIQxPgBwf5lAqs4EcFpOnMv6mm0ZgpRHQRFZNZJ3zGtNE1jnh0QvnQUBs67p7PDh2wkF7Uh8nJtG0LIqlXHkMEhM5YWGSXAgBS+h759mDtbdYAhBj40HsP2ynHZRPTdaqaQW1ZfOUSpgkl26ktcNyIyykEwcDe/uOetHc6WNFjwEbSs3YvplViWZaIF5WAlvu7d7I9XGOje5R4GJfGPsvhZGRANy9PgpZHASKDL9McacnuDdyv/S2Ig+BkZAXXVRn3e/rQz+T5slRFqw3JqHamKosVmJotiLTd6nEXe6miazLjahe32pGYCoAGsTLz7+M40eOMeAai8r1VbjznjvV67n23clq19amPpw82oL9r15ARtkWZKzbwPEPLZELTSRtWJedsCHqAUJIOXlyDG8eGEFGOguJaB9XRyJrcgo70zXe2M1SDQFgnFyRWFsYbDnVIYFvA+IsYewojUIVgy4J1vBb4wq3h6SeCQZEm11oafWgqcWFTRvjsLU2HtmZZqrmRUiCl8H6c//1A/QeOojEkhJkMNiVd9vtiLZYrxhbCIHI7+d1wmIzIbF2dHlRf86t3gsve3ttHJX/rcpq2ryKybtr/FKO2MPTRNaIPXURs+N2KkIMsDjhQGMY9V1hrM81YD3VIMqzgHiKnNH58IY2B4vMeoMuPONqgdvrxX3BDMRN+OAbGcfFc+fReKkR7a1ttNJk0dm6EtRs3aLGEekZGYiNvbn2rqIYJ0TW/gE/C2Y97A986OVrmT3Ex0WpQo7cLBNysqaskGOsEsNhspQYm5hclUKZ6527ujjvd7jCeO51F9pIar19m5XqrCZkpzNZu3rrRm7otaU3phG4FgJe3mtE6dlsNlPF60pJavl879696KWSz4MPPojvfve711rNW587HA6lwjowMIDvfe976neyDk1kfQuiVfkiTOJRwOtBz7430P7CCyxei0JCUTHK3vd+xOVM2U2L+9XIWAAnTrvQ1euFOKft3h6Pulpa8fJmH8kx5FV5Uq7aKSFZjYwGOMd04006fshcNYNk1k0bbSgpiuHfr5CSIjuWf9Uh67erDQFedKdOjeH5FwaQk2NFSUkc1q9PQApjQysQLl5tR39L7c9cRNZXX30VTzzxBO/5UehjAfTVSu1GDu7z8vIopOODFMs88sgjVPC9D2fPnsVf/uVf4jOf+czbsPzmN7+JL37xi+p3x4/TGeiyMuz0F2VdP/rRj+Bxk8jv8sLp9CoSldwXZT/Eql4ImtIPhTmfkvtjmm2j2jchoaoH1U/l+6KcGmCfN01OFVLr9PKAvOZyOaap5aKKzdf8nZBg5To3cYIo2zOapEA9+vfP3P40WVTIoFPLZPnUw8TvT33OZ/ax0+9/vx75/e/XK8tlHXJcZtnmjPdCTJXlQjjVfe/0VbL4Zz8FXQbogLKP+bBO5sWc9C/cbkxHLdVZkw0WxEQZtTrr4mHVv1hlCAiZtfPVlzFIRx/P6Ciy6rah9OH3I4r3auW2sIT9bWu3o+HcON44OIqgfxQVRaOo21aODRtL1dwyigrHvKViyB5G1wgFjZrDdJo10NUO2KBib0vYuP6pRmCRCGgiqyayznnJaCLrnPDohfMgIKRLUXkaYYK8h+qsHVQSnbSLrUIYG9fbsK7ESpUnsUWIEHLAPMd7IxYL8cBLXIeoGCbqrA2spJeJj1TQb62xKUuoSCYHy/GJCkz/UAgtXX6cbPAh3jZF9pGkVk5G5F8rcoxuEmwGJsI40Q70T/C9L4y95QZsKaRtLw+Rc3ndNALzIuBjJaqLk/UBkliF0NpMhVanBH54kW0xp6MsOgEZrEq1UK11uZsmsi43onp9qxkBSRS7XW785IdP4STVWB/8g3eipq5WqRVIUPJaTYKtfd0jePE3x9HT50XAmIKQNRu25DTs3GxFaZERWWkSxLzWGq7v8xEqbogSa0uLkwFqt1LdqKqKp5qaWE4t88aubxdX7FeMXzNYDbQNScEIleyHDPAGmCxMoI1aqgEFKQYks2I4noRWKY4Roo7cM8XysbHJjc4uD5OJVGEtiUF+noVKeRynWqaSiyu208u84sHTp9B//BhEkSm5tBTVH/sTWJKSEGUyqS3JOESIS929VAdq86jxpN0RQHqaCXnZZqr9W6jGGq0ITJE8plxmWPXqFoGAJrIuAiz91etCQJRZ6daITgbVm2lx1jQwtRoJrIvbRVG63N1vXBNVmHO+EZyfHMBkZz9STvXAyefxoRGkZ6QjIzMTWTk5fM5ASioTbCnJLBSIo/qQVanm3Lg9ffuWQuwURImVeRKl1CpqcXYqtk5SsXWcCt0jY37Y7ZxzeMJIToxGBsctOewrsjNNJOJMJXSvd+4q/bUUVZzgnL+x3Q8P58Ql+UZV5GO1rEwx3tsR0J9oBNYOAkIqHxoawpNPPqlUWEWV67nnnkN1dfWcBynklQ9/+MN4/vnn8dhjjykrYfnBQoms7e3tVJu8fCOeY0vj4+M4dOgQPvCBD6CqqmqOb+pFC0XAMzaGiZZmdL3+GnoPvInid70b2bv3ILGoCKbYKbW93j4fWikUcOK0gwWU0diyidb2nOek836uSWwLRfr6vydzL8mP2B3iXsdz0e6mzbubAh9UkWNOZFO1TRFbzWYt9HH9KOtfzodAL/Nyly7ZGSNysHg1iAfuz0JRkU3Foq63IGm+berlNx6BuYisP/zhD/H5z3+e955ENDY2KqLnzD2UsUBJSQmksOWf/umfFOlV+upREqj+/u//Hh/96Ednfl29/v73v4+//uu/ptJ0uiK8zkZk/epXv6q+K/dCKYBTz/zn8tupZ/5rMrKimh+WFe5UCqMiyiFKo289C/mTnwkBVq7ZqMtkUHktjhHqM/k+P5eNqOWXvyekr6nfzlzn78mkkludua3pdb31rPaD6+UUU31X7Ydsc2od07+dXo/MRNU2Z6x36rdT+86fq/1VwOh/Fo0A9XjhCQcxTLfCluAkzgXG4OX7OBixy5yl3ArjDCYV7130yvUPNAKrBIEwCwPsXZ0YPHkSjf/9M6RUrsem/+PjMCckwLjEYmink3ydPg9eem0YLc1dcE20om5LGnZsz0dBUQHMsUkkroooCBR/QZzs8pLBAvIoJcolIiG6aQRuFAKayKqJrHNea5rIOic8euECEJDJyVT1sV8pXLUxYNNLMkd6mhkZGSZlpZPGxLmQK4TIIQN+3eZGQAgX4bBBqaaIJVRvv58qrQFUlrGqtpAWhjlmqt0un+3f3Huz/EvlmhGCRe9gEEfrvRgdn7I4rF1v5mTWiATaAZupAhPpjUWo6BgGGmiLKUpxNbTErM4zIC+FBBsKakT+EUb6GYqM/ZdpQ4CVqIOsRL0QHEc7bVX6qAiVFRWLPKMNeVEMipPMmkK1ViMDLMt1XWkia2RcH3ovlweBocFBtLW04fWXX0N3Vzce/+iHUF1TrdSPJLA5W5O+enzUgaZLfXj+N2dohRyLhLwqxCfGMWEVi121FuRmCQFEgp+zrWHxn8l4y8GCofYOF44dG+X4C0oBv64uGUXFNqW4s/i1RsYvhAwjRSKjjjAGJw3oHgN6Rqk46mexT0wYG/KjSGINIydpCm811iBeEyTpDA35qcDqJrHTq5Tg8ziO2rolnkVCRhZbRV5liVRqj1y8gAu0IDIxuFX63vchiYTW2MxsVWCmLC5H/AxaUXWPY0hRxLPFRnEcGcNxuVmp7i3XNRkZV4/ey+VGQBNZlxtRvb5rISDzKVGJONQE9LE4kK6UKM2csjpLjTPAxnzoSjVJ1Lrcbkw47DgWNY7ToVHYW3sQaulHXPMwwlRklxRtaXk51pWV8rmMBNaUtyknrtT+LWW9Ulg6TheYIfYV0k+IWusw1eQoLKSKPUSpNYmkVuknpf+Q93F03xG1Vuk3F9uHdPVRqa7Tj1PnfUhKMOC2bTHISIlGAterm0ZAI7AwBGRO8p3vfAdi8+t0OhVJ/u/+7u/wkY98ZM4VyO+E3PIXf/EXdHAoxGuvvca/4ykl/4USWYUse/To0Tm3IwvFsrirq0sTWedFagFf4GQmQOXdidYWdL32Kuzd3ep9+SN/iMxt2xBtMlMkgAV9LBCoP+dScx0nFbALCyzYuyNOxYylYE23G4eAzM19LN5opTLr2XNOVSwiWy8psqIg38oiETqRsYhDCK26aQSWGwEXi5TGxnx4Y98Q2ttduOOOdJSXs9g5RfJxyxSQWu6d1utbNAJzEVl//etf4xOf+IRS2+uWPiPAqsAZTcYD2dm0LmL7wQ9+gPvvvx979uzhPasVX/jCF/DJT35yxrenXv7zP/8z/vEf/xGVlZUQxdeFtAAVVr0eP2OX7ssPDxVbvdh36HdUTw3hzr3vVmqmon4qeWJRNhUlUyGwqvf8XAp1ppbNeM3Ppr4n+WX5nN+/vA55r9vaQ0Dm2j3MgV0MjFPcZQKjYR9KKepSHB2PEmM8bCSzWldA3GXtIamPaDUiIHmlIMf6I+fP4ex3vg0LixAK770PybzfxuexgnuJbWJS3BomceJkD06dbEF+lhMVpeQnbKmBJSUPXROx6B6PVmJcW4qmHJBySGaVmJtuGoEbiYAmsi5sfGVwu93CFbnlmiay3nKnfEUOWHW6DNj4WYEsCRCpQD5xyo7BQR+Sk41YX2nDtroElfgQmzrdFoaAKKdIUPL8JTfONLgwSquo5CQj7tobr0gIsUwqRWoTgokoz9pZ+SNk1v3HPCgvNqGyxIwNZSYkkswa6Y38Gfh5Di/1G5Q8v53dTByDlvdVG1CUBm2nGOkn+AbuvwxQAlRn9bH6dCDsRlvAgRP+IQyxMjU3OhbVxlTsoEKrBbTIIZl1OZomsi4HinodkYLA2dP1ePG5F1lkEUASVdTe8cA7UFhcpIKj1zoGsbmqP9mKhrO9VPu0Y9yfgmBsCe7ZE4edJLGmkgAiamOMFS9bE6WXpiYHLl60Uw1hHFWVCbj7btobxxsV8WTZNrQKVyQqbt3jBjR0g4SmMAMrYWQmRaG2IITidJJsrGFYxAr58i1QCmZknHH+vBP7D00gQLcAUcXZsS2BCV6rIuRIrDsSC6zEYtTR14um/34GTj6b4uJRcPc9SN+2CwNDATS2eHDkhFMp0SZR0b+GKkAlhRYWCon1mdhFL+NFuQqvFb1LK4+AJrKuPMZ6C1MIqPkU1VlHSGa90Ae8fjGsyKulGeJ0Ad7/l7efncZd4huS/O3iPfZs40UcTaFTipVOKb87g5whH2pLylFZUYESKSJgQYHZYmEhponJVEm6Ls9YfHpfVuJZ5uJCuJG+0i82nsxzi9NOL+M4vX1+dHR7MUzXndGxIPJypDjZjGL2I6LqncliZek7FzO+Ecee/uEgXj7ohpNz4qz0aGyqMKO8SGdJVuL86nWuLQSEzHHgwAFFRG1ublYHJ4QSUVOrra2d92Db2to4X7hb3dN+85vfoKamRv1GCC1CYGlpacE3vvENvPe971Wfy/3v6iYqsJOTk1d//Lb3QpwRoqxWZH0bNIv+IMQbs3toEL0HD6Lh+99F+qbNKH3Pe5FQUoJYKuPJTXhiUgoSAnht/4QqYLttV7wqXMtMnyKuLeY+vegd1D+YFQEpPJU+z8M+tZ5k1kt0BelhMaU4YuzdnUjXOs7JOD/TTSOw3AjIrVss1/e9MYyGhgm6BFAMpcSGzZuTSKBe/WPT5cZjra5vLiKrKKK///3vV4fe0dFBi/srx9nSj8v4QdqvfvUr1NXV4eGHH8aRI0fwqU99SimvqoUz/hGC63e/+12l4P6zn/1sxpJrv5RxxNRcg7qavCeKO4Q8/yeJWqFQEB//+CffmkdwRsHXEp8KX37my8ud13QfNrV8hiDMNZZfe4/0kkhGwH85H9YYnMB5ElpFnTXJYMbdlhwURschneIuumkEIhYB3h8nqcra/sLzVGftQijgx7o/eAg5u3Yv+ZCEWzJpD+LYiQn88rkhjPUdQHTwArbs3Q1LzgZcchSiNMeCbSUGxVVIj5/iK2gduiVDr1ewSAQ0kVUTWee8ZDSRdU549MLrQEBZ1dFOp7VtSplV7Oqk8lMUPKQyPJedo6iz6kn0wsCVid8glcQkmdTc5qXtX5DKKNGqolsUWoUkE6nV3HJsQvRs6w7gXCNVYKgKI8p1myqYLMsxIi2FlZXTs9aFwbUqvyUqQqLMWt8VxgBj/xtyDCjPNmAdY89zOFavymPRO3XzEXBSn3U06GEl6iR6Qk7Yw35EU8E5IcqsJvB5nMSnUZ01xnBtO/SFHIUmsi4EJf2dSEcgyAShy+XGof0H8PRTT6O2bgvqdmxDeWU5kpKTrnl4fvodu1xevPz8WZw6NYiJQDoS09JRUpYJURevLDEpwmD0Ms7+XS7aKg15lRLrIJ+TkkyoqIjHxo2JipgYiYTMawJ8eYEoxgVCBnSNkMQqCqx82D1TCzMTgFxWChemGZBiE5syCYErhzGVOBwe8SlLx/4BH4k4firgWJFPi81iKuIksShIxhuR3LxMQgzXn0E/LYj6jh2Hdes7ELPtXSQKMVDlnHJLSGExWXYWx1RMnKZR+U5UmdbAsCqST9ua2XdNZF0zpzIiDkQoVVLc2c95VEN3GH3jwLhrSpm1NDNKkVlttD5b6l094A/A6/Wgr7ePj1709vQoR4Rhzr3Hsm3wJ8WgvN2D0mAM8rKykZWVhfSMDEVcjQTy6lwnm7llhNjnjk8E6ZYiBNYARviY4Hsh5UjnIf2HuKbExkQxnmNECvvS5KRoxFFVVays5+tfpID1QrMPLV0BdPb6sXWjBVs2WBAXy3iGLnae6/ToZbcwAkJi/Z//838qoqkQQ1Ko+izKqk888cSCSfNf/OIX8c1vfpMxWAvuvPPOK9Dcv38/5zQuVFdXIycnB7fffjuefPLJK76zmDenTp3Cs88+q4msiwFtlu8KidU7MaGUWEfONcA9PIzsnTtRdN8DLGCLg8FsVQV7za1enDzjVHHV+Lho1NXalOiBqGfPd0+eZbP6o2VCYJoMLm4g3d0+iHOdOGQYGaIrKY5hYUgMUlON7E81oXWZINermYFAU6MDjSx+bmtzIJNk1rvvykACC3q1QvMMkCL45VxE1s7OTuxkXyFtmqg681CPHTuGhx56iP2DAefOnWNcLEkRWH/xi1+owpZnnnlGFUNP/0bmN+973/sg+YGPfexjEBX4pbR///d/J9k6iM985jNLWY3+7S2KwFDIrdRZz5PIOhryKkeyUmMiyqMSkR5tVeqstyg0+rAjHAEf4/ujly6i99BBdL7yMqoef2JqzG+j895VBQmLOVSJ40jBcjOdAt484sCFc+fR1XER8Ql2JGVnIrFkJ2qrsrCduaXEWCCWwhe6aQRuBgKayKqJrHNed5rIOic8euESEOC8hCoePtQ3sJO85EIzLV03V8cpddZ1JTHKqm56Eq0DbPMDLfZEFxs9Sp214YIbRZftojJYaS/E1sWqosy/xRv3DUlMOpwh/G6fG82dAaXMIiSg9aVGldSKdHKOEHYlASsKQifbWSHNQWQZk653VYEKclAWjjcObb2ltYCABMYDCGGAk/gT/mGc94+hKWjHZlMK1VlTUMGJfGqUVamzyhSEaYxFH7Ymsi4aMv2DCESAjgwY6OvH6y+/hmdIZH38yQ/hPe97CBarhYmma5PB7RMuDLIy4b+fPo2T9ZOw5dZgS20m7rstFhlptOJdRqtc1Yfwn54eqjG3OnH48AhMtCN85zuzkZsbQwLJtfczAk+J2mXhzFBMBG4fMEnltuNtQl4KYcJtQF6KAbtLaZtJAmsG7YlnNhWkkfEn1fJa2jx48+AEi6kAIa/WbI5H2bq1U6kfol2bjyTs5pdewZGv/wccxffAV/VujHusSMuIxc6tcWqsKERW3TQCy42AJrIuN6J6fQtBQIobvAzEH2mReRVgMYZVn3BbOZCTZKAq91sCPgtZnfqOJFNFYd1P5QuX04WJsXE01NfjXEMDFdfPYiLTBut9tSyEyEN5Rh7ekVqK0tgUlQBe8EYi9IuiAu/1htFC8m57l/SrXkVulc9y2LcU5VtYqEyF1nQhtIr6n8xrDYxLTKmdXx3jEfVXD/v1Ew1ePPsyiXPlJtRVW5CfbUJC3BRRNkKh0rutEVgRBKZJrP/xH/+h1i8qa1/60peo5shqrkU0IcJ+61vfWtAvHnvsMYiN8PU2TWS9XuSu/J3PPolJEpIaqF7nHRtDHp0XMrfUIW3jRqVy5/GGMEo3tOOnXXjp9QnspRJrXU0ssjPNsEWwc9eVKKyNd1KM2tPrw+mzdhw6YieR1aryIhVlMUhPN6t4cKTHvNfGmVo7R+FyBtDd48Evf9HNuFY03vkgi69Y1BtPFx/dIh+BuYisQjydVlr/8Ic/DJmzh8SCgU3Iq5///OfxX//1X9iyZQt++9vfKtLqr3/9a3ziE59gIb6ZscbDqlBvGqWRkRFs2rRJfU+2e9ttt00vuq5nTWS9Ltj0j2Yg4KVTYW/QidP+Ebzi7UGBMR415lRUkMyaY7QpoZe1IIo045D1y1sAgRBjUkGfFy2/ehYn/uWfUPnoYyh84EHE5+fDEr+4ed9scImDckuHDwePTVCdtRuDbc8gPcWDex68D9u2VmFjVaEqkJxWv55tHfozjcBKIqCJrJrIOuf1pYmsc8KjFy4BASFeeDxBjFHRY2DQhz5a1A2QWOByB5GWalIVyJXlsbDGiAKHtjiZD2ohZ0zYQ+gf8CvL2KFhP+yOALZssqG81KoUUSJV5XbK0jCM1q4gWkhkbebAKpV2wVs3WpFNu+AUKr1EepO/h97xMNqHDTjWFlJKs+tzgPIsAwpSI/3o9P7fDARozANXiIpJYR/6g7QrozrrQJB2naS4xhuowEdl1vXGJKSQ0Gq7DnVWTWS9GWdVb/NGIzA0MIh9r72BjrYO2mXace8D78DO3TsRbRRlsStJkjP3reFMFw692YxLnSb+HSZg/YZsbFrPANp6C5XSpxTLZn5/Ka993qBScDl2bBT19ePIyLCiqMiGDRsSVDJiuihoKdtYbb91eoHu0TCaBsK41MdxInMucVTbExJrNoVys0lYshFn61UcTXEBkDFnfQPvhwNehU8e1UjXUfkmlWNPcQeY47SuNhjm3B8ZY8sxnj3cioO/PgGD0YyEtCSs312FwooMZNH6OT4+mip5eow9J5B64XUhoIms1wWb/tESEZAiB3kMTISp1A1c6ANGHIBYoFVkA7UFBuV2sVAxdEnsjo2OKgXW5sZGdLZ3oJt2bnHx8bAlxCOW99Sh3DhcLLRgV1IBbo/LQ6E1CUlGViLeAk3y3oFACA4XH3TckcJTsaaTh7y28zMnlwneosqakWYiicoEKbRNYqGtuMbM7HNlPizz/s7eIE5doFr6OH/LLuq2OgtK8qeIsDO/fwtArA9RIzAnAjOV1T7+8Y9D4vfX07q7uzlmHJj1p3/2Z3+G9vZ2/Omf/ikefPBBpcqanc0b6nU2TWS9TuBm/ow3y97Dh9B74E04qAwek5GOUlqMxucXwEQSs7haSVz48HEnJiaD6j5aUx2L8nVWNe430qVCt9WDgBThCJl1YNCPzk4PRKV1fNyPvFyrKrasYF5E5muazLp6zlmk74mM3UZH/di/nzbCdKYRJx9x8ams5IBZt4hHYC4iqxzc1772NXzlK19R8cyf//zn2Lt3ryKivv766/jQhz7EIjUvvvrVr+Lxxx9XWPh8Pqxfv16ps99xxx34yU9+oghNAcr4CRn2lVdeYQF9Lg4dOjRnsf9CgNVE1oWgpL8zFwIh5sLcCKo8WHNgAh0BBwZDHlSYElFGUZfSqATYooyUc9Fjoblw1MtWFwIiWBQmmbXv6BG0/uqXiLJYEcf7bjHJrAkFhUve2Z6REOrbgzh5ioJzDUOwBBoR7W+BIdjN4odavOO+u+hKmIiYWMqy6qYRuAkIaCKrJrLOedlpIuuc8OiFy4SABG3Elu5UvR1tHR6VwEhLMUGUWTMzzLTHMjFww8STJrTOi7iLyaJe2uSev+jBqbNOFOabsY5KY8VMsInFXyRbSDlptdTTH8T+Yx64qfSSnhKFqlIeHxNbFosh4pVLRV1ulHa/+y7RIpkEHakQ3MyE66Z8ke4Pk6ijJ1nz/gHoL8yKgCNEYnvYj1NUZ20J2eHk60SDGUUks2ZFUSEyKgYJUWZYEQ2jYWH6rJrIOivU+sM1hIAEcNtb2/DMj59WEm6bajdj46YNKF5Xcs2j9PuDcLu8ePPNDrzwfDMM8UVIz8nGnrpYlBVbkJ3BJNQysTBUIIOkjxGq27e3O2n9NUllDTf27klDVVU8x07mNTVuosAoCK+yi6bYLdqH2FeOgRbSYazLMKAsi0QlFn+kxgHRV3EzRTVOSDVdXR41zhQFEmmbN8VzfGRFbo7lCjLNNU/wKl8gRU3ieDBBEpHYPnfSqlKOtbPTCUPXKSR52nH7o3tRurUMMUkJiCIhWzeNwEogoImsK4GqXudCERCCpSizHmulVX1vWM2vclnosKXQgCwWOyQz/i4EyatnVtKv+v1+9uMuTE5Q7W5yQqmy9/X2oYcEVlEdks9L1q1DXkUJEtYXYzDdgtNmB+6x5uFecy4sUdEcTV+95oXueeR/z+2ZIrD2ski5Rz18mGRxbTTZrOISk5psYkyCyvSJ0RCb69iYKPWw0KZOYj0yRLI7wxgYDuLwaY8qZL1tmwVV68xIY5GKJmBF/jWij2D5EHjqqafw53/+58r6VwgosddILooCm43Wk3KP+973vofm5mas433sj//4j+fdmXvvvRfnz5/HN77xDWU3PO8P5vmCJrLOA9A8i/0uJ3zj42h97jn0HNiP5LJyZNTWInfv7TDFxVNZD+hn0Z44Txw96aTTmRGbNtCqvsCK9DSttjgPvDd1sZcquhLPP3XGrlzrZGfSWABSVRGLLCrpTiuba0LrTT1Na2bjTqqyNjba0dLiRCtdferqkmk5n8IiI8aEde4hos/zfERWcZ165JFHIP2xNFFUtVqtOHnyJAvUAnjve9+r+nwZM0w3UWX95Cc/qdRbExMTUct+58KFC6oIxmKx4Dn2SVVVtBVcYtNE1iUCqH/+FgKizOoIU5neN4gTgRHEGKKRydzXJlMqspkHS4mi8gHbrTtrfwsq/SKCEJjsaMfw2Xr0UR3bOzmJDR/+CFLpxhBNYutcYivXOkQpfhNnu1bmVxq6gaEeOhANsBLcbYdn9AKGO19EeXk26rbXomJ9BXLz81TBgswtddMI3EgENJFVE1nnvN40kXVOePTCZUJAqXmwCtnBJMfICCfTzW50dLrR1+9DJYM2G9fbaH8aoxIey7TJNbsawdLnF2VWH7p6/DhzzkVcw6jdFIMKKrMW5FlU4i4SAZBjc3lon9wfQEOjH0frPdiy0YLa9WbkZBgRFxvZ0w+JEfg4gByyA2c5eHztfBglGcDWYgOfSc6xReJZ0/u8GhCQitRAOEQCK1Www160BeyQytSm4ARSqciaH21DtTEFhbRciQcVjxZAtNNE1tVwZvU+rBQCErQdGhzCuTNn8fRTT6OwuBCPP/khkkOTEctE8LXa5IQLbS0DOMzE4YETPpRT+XLj+iTUbbIiI0XUx5avn5I+w+sJMIBsx0svDyIxyYyC/BilxJqdHaMSEAv4U77Woay6z0WFVYo9jpKY1NRPVX8/kJvMwDuLPTITDUij7bDYSAs3c+ZxC05irXmx0cWHE23tbkVgrSyPIYGVVcy2KKUKt+oO+Dp2SBKgbo6TTtU7cbHJg3GqMCUnsuinzAL7G0/DfeZ1rLvrduRs24rUDRtgiom5jq3on2gE5kdAE1nnx0h/Y+UQkPu+POysWehhwYP0GzK/knnWnVUG1BSIYrfhbUUPYtk2SgXWtpZWnDt7Fg0cA9hp32w2U7m7dB1KSkvVIyGRindxZpwwTmI42g8DA/nbzRmoNaaqBMLy9fQrh9FKrXm6oMLnD0OKSLy+MJVZQxge8aOP8Yn+QcZ72CfLvD4j3Yj8XDMK88zK7jqZLitC0GFNBuMZYRw940X9JR/iSHYtzjdi+yYLSa+3Mrorddb0eiMVgc985jN45pln5t39fNpOHj16VBFZH330URbcvamshZ9+msV68zRNZJ0HoBu8eLK9TakxDZw4Dld/Pyoe+yCyt++AmcQiQ7SRrmchvHFwEk2tXjqbGZQ717baOEwVC+j75w0+XYvanIxbRJV8cjKAwSHG8s86mBPxQhRbN1fHo24L1eBj1868dVHg6C8vOwJyrTmdQZytn8Bvn+ujImsCdu9ORToLtGw2TXpfdsBv4AplXCDjg7S0NDQ0NCjy6dWbnyQB6oknnsDx48ffWmQ2m3HXXXfhW9/6Fuc+5rc+n34hSqxf+MIXeN0wKHe55eXl4Ytf/CIeeOCB6Y+W9KyJrEuCT/94BgKSBwuyYx2nS2EfXQoP+wbQH3IjmQTWzSSz7jRlUMjFgIVJucxYsX6pEbiJCPhZcO13OFD/7W9h6MwpVP7R48jatg1xObmcByxOqELGnRNu4ER7GI10MuqkqFZlWgAFNro6HJrA+PAActPo2tF9Fv09TXj40fdh595d5OcksgD5Kvu7m4iJ3vStgYAmsr66oBNtYLUS/7RXTzMajWowKgPOM2fOUI3QgqKiIjVwLCws5OSXcjzL0DSRdRlA1KtYMALSgbqpuinqUR1Uzero9CrSpZU2OtlZFuRkm5GbbWWloFbjmA9UsfETW78ztM8VQitFFqkEZyKZNUYljRJoJxuJTYJ4HiYlG9v9OHHOx8q5MBJoVbip0oy8TCOTW6KwE7kBWkncieJc+xBwuIXkbhJ3jFFhbCsxKMW5OBYMXq00F4nnUe/zzUPAQzLrICfvXSEnWkhmlffMJcNmMCqV1rRoWmwbLCS4WhDHz6x8zNY0kXU2VPRnawUBGUcfO3wUZ0/XU5W1HRuqN+C9nLSLUsFsladCfA1SVruzaxL73uxBG4sRRh2x2L09CbUb45GfEw0biRjL1abGS0E0NU2paDQ3O1glG4/NmxNV8iEubva/2+Xa/o1ajxyn02fA4OSUUnn3KDDJQItMypKoqFeUBpRnG2CjarmQkmY2+a0QO3v7fFQm9aD9suK/jClVgRSVWCUZaDQu33mZuf0b+drD4xQFVrER7aYC3hjtKOkAR7W7KORkmVFabMbE8dcwduIgglQaTqQKV9lDD8OakrLoYNeNPC69rchFQBNZI/fcraU9l35A+oymgTBaBoHmgRBEmbUw1YAK9h3JMUEYqNQyOjKMoYFBpb46PDRES99xqqJR9c7rU/ZpKampKCwqRD7jbKJCEaBS1aDBh996OjmGZsGoKQ3rouORy8Iw3a5EQM6BEKvE3nqYBNbBYR9GxqiQ4+CEl922iVgK2So2luMk9smi2pqcZEQSn/tpcdfVx7FOh59jKAP2bqVbT1oU4lmAoptG4FZHQFR39uzZQyW91nmhKCkpwYEDBxSR9bHHHsO+ffsg9sCi6DpfE3JKfX09vv3tb+Pd7373fF+fd7lWZJ0Xolm/EKJauJd908DJE2j73XMwsbAyobAI+XfdjUSeXymoGByecmNouOCCxIOryq1YVxyDIrp06RY5CCgBB3cQLa1uxha86OI81maLpqKuCSVFMcyNmGGjorkx+sq5b+Qcod7T1YCAjM+k+EjiSPv2DXM8FoV0OiLW1CQhJyfmisLg1bC/eh9WBgEp4Dtx4oSKc24jGUrinXM1iZOKSnt7ezuqq6sVF2Gu7y92mSayLhYx/f35EAhwru7mfP+sfxStwUkMhDxIpkNhMefu8sgx2ijnYlD/zbcuvVwjcLMRCHOQKI9LP/0J+o8eQTyLCdI31yD39jtgnOf+Pb3v0v/zf3SNhNE+DFwkiVW4CEkxYbrcAVm2IA4dcaC7exJR4QlMDp/BxNBpxsFyUFZRhq3b65CWnjZrwcP0NvSzRmC5EdBE1ggksgqJ9ctf/jL+5V/+5W3XQzSZ95/+9KfxV3/1V8tCZtVE1rdBrD+4QQiIpc7IqI8d5ySVpeyIiTEyaGPF3l1C0jArCzrGbnWbAwEh1oxNMADW7sWLr06ob1aWWbF5o41YmiV3dF2y83Ns8oYtEsvBYSbBXjrgxqVWH+7eGYON5VRmzYxWCbEbtiMrtCEX1WtE2v/5+jAONYdxz3oDthYZkJciCkIrtFG92lsKgSAVWv2culwMjOMMJ/Rn/MOwh/3IjI5FlTEJ643JSql1ym5F7hbhGRN7XpcHD+HFF1/Ek08+CSmg0U0jsJYQEGvhH//gRzhLNTYhsW6q3YyarbWQcfZsTQIBbjeVw85N4EdPd5HYQgX0wlTcf0cCajbELnsiIBCgutmwF7/73YB6zsy00t4ricHkxNl2LyI/k8BKgOp5vePAyY4ppfKm/jC2rxN7aGBjngEJLF651lDQT3X6SRJn9h2k+nQzE7pU/d9Sm4A7bkvkGFLUcSOfCCPjvHDYgHGO9c5dcqOexUunzrqwoZLKvHxs5rWXlmrkdWuAo7cXIxfO48IP/zeiGeDa+n9/Dom8d4sFkW4ageVGQBNZlxtRvb6lItA8AByhMmsj+xEJ1P9BDR0vUr0wBp1KffXU8RM4eew4xkbHkJKagk01m1G3cwdKy8uQlZ19RRHLMBNgjf4J/MbbgQwWgD0RU6aKwUxSOarbnAjIeMlPtVVRDG/r8KK51UPlQCqIsx8TQkVxoQWlJSRfFbGoLsVIJZ0o/OJFJyap6rqtmsuKjCjK1ZPhOUHWCzUCqxgBTWS9vpPjc9gx3tiIztdeRdPPn0HFo48pFSZzQoIay8u86eRpOoIcdSDIe2kWRQzuvT2BIgb6fnl9iK+OX4ky67nzDqqz0v693YPb9yTSWSQOeTkWEs6oI3etifDq2H29FxGAwMiIjwURDpw9O4mebhceeigHGxlTimSBkAiAXe/iNRDQRNZrAKM/XjICos7aGXTgVW+PEnaZCHnxzphCbDOlKxEXI7VZddMIRAoCg6dOov/YMfQfP4qU8gps+sQnYY6PX9Duc5pAtX/g1QthnGwPw0URjEoWeT+4KQoJ1jBCFGlpaffhPHMMIpCWEteH7OQ2HNz/JvMPIXzoYx9GRVUFXQHXTv5pQcDpL91UBDSRNQKJrD/4wQ8UUVWunNtvv109BgYG8Otf/xr9tJaR9v3vfx/333+/er2UfzSRdSno6d8uBQEhIPhoG9vX50Uv7XT6aUVnp8KoVCfn5lBdal0ssjLNiFRl0aVgs5jfip3f+ESAQS8vFcl86O71oiDPQiIrLRJJDBbVk0gMfondoJfXx/kmP5qp0jLBayMjNRp11WakM+kuupstAABAAElEQVQlqi2R3MhRUtf/+d4wzvXwHLoMHDgCe0rFQpnqmZbIPr5IPjdrZd8l2SEqUmOcvI/yMRj2YDTowWTIBzeC8HGpkQSp2CgjElitmhBlQhzrVOOjzGqSf/HwCbz50qv4yJMfRVFBYcSS4tfK+dTHsXwITE5MUJVtAL94+hfo7+3DQ4+8F+s3rkdaRvo1r3O3O4Djp0ZIIpxAQ6MfFWXxuIPWbEXsb9PYJy13a2pyKDXWtjYX4qjIsnVLMrJzrEhNtSz3pm7K+sQOeogqrBf7wugbNzCwEkYc+ZZpcQbkU0kvi/1gsi0MC5Xcrm5CfpWxT2OTC5caXVSBC9C5wkByTAwK8q1qDCnETnlEcnNT4U7UlhpbPFTq8SoSkMUSheTEaDoYmJRNs5CAxEpUElF+WsAJmfXST5+Ce3gImVvrkLllK1I3bIxkGPS+r1IENJF1lZ6YW3i3xDZN+pUTjbRc7hhGcLwVcHTy0U1VMyhFibi4OCQlJyMjM5OPDNXvi3VaTKwUpPy+zzjmH8I5/xgLwHwoopLL3ZYcxNDBQFsTLuwCEztbmctLbEcIqhOMVYhiq4N9mpsqdB4vl7MfZ/0+++oojDmosO6PAqcl2LrRgt1brErF1TjLGGBhe6C/pRHQCNwsBDSRdfHI+5wO2Ds70fLsLziGH0ZMejpydu9VY3kj3fnsjBW20XniUrMHrSwQ2MhitrJ1VpIdTVS6nr0Ic/F7oX9xMxAQx7qx8cBlxzrG6thXiuO35EMK8y3Iy7VGZDz/ZmCptzk7Ah5PkOOxAA4dGqH69gS21SWjqiqBRVwca62Bwt/Zj1p/uloR0ETW1XpmIn+/QiSyOhFAb9CFZroTNgUnYDJEKzfCLcY0ZFPUJc4g2qy6aQRWPwJuugiNXryAi0/9GJbEBJT/4QeUU4OVTkLXakJgFV6NqLDWd4UxMEnuQYAud1RhLUkX1yLGxBh/EcGMSXuIBcdevEFhEKvZjfQkFru0H4djohsWCmNsZtH3bXfdrlzCjablz3ld6xj057cuAprI+uqCTr7B7XYL5+OmNwmgP/zwwzh8+DAef/xxfPWrX31rn0Q9Smx/Lly4gEceeQRf//rX31p2vS80kfV6kdO/Wy4ERJlDkvWNTW5FSmhsdtNuLhpFJCQU01YnK1OCc1GcYEczUb9cW11b66HzBxNCIVVJ8+ZhO5NCBiSR6FCzMZakVlrr2kjoIMlhRn4uYgAYHQ+ho8eP/cc9VB4AqivMWFdgQi6VWSUpGelVxKNOoHs0jNcuMM9KYs/2dcC6DKCARB6eMvWImJOld3TVIiADnACr6saZkO8I2tEa4IOWK07ar8iyRJJXExSJ1URCqxnxJLb2H67HhVcP4r6PPIqc/HwYqUKlHpz2kx6vXktC33j5fTSX64DAqr0E9I7NQKC1uQVnT5/F6ROn1KdPfOxDKF5Xwv5k9kGGm8H/4REvfvNCHy61uGCJsWHvjmQ8eFeSIksuZ9/q802RPI4eHeV4X9Tqo5nIsmHnzhRY+Xom0WbGIUXES1Fp85DY4vIZqMIaRtcoLW562fd5gXQWFm/IBWoKDFQlDzO48va7iQQmA5eJMYPDfpxl5XAzz0dmJot3iq3YsjkO8fEkGs1+GiMGIz8rXTyeMK2ZAxigSs8FVknL8cZao1XSessmG8nNLELg9XB1805OouOlFzFyrgG+iXHk3nYHih54ENEmBmyvoTZ89Tr0e43AQhDQRNaFoKS/cyMQCAQC8Hm9JEi64XK6cOJCP05f6EXjpRYM9XXCO9mPyrJ81GwqR01tNdaxv0+lIquR98WrW5CjYn84iOe83SSyjmC9KQWVdDEoNyZylBzBncvVB3oT3kthhhTfdnFe30kbZSnAZXhTJVISE01weg1o6Q5hU5UZd+6IQWoSFUPiopg84dgnKsw58dvHBTfhMPQmNQIagXkQ0ETWeQCasVgSybwJYryF/dXZM2j91bOQBHXFox9AYvE6ElozOCcIobvPjxOnHcqNiyEd3L47nv2addnnoTN2Tb+8wQhI/9g/4MXho5MQldb0NMa9i2NQWRHLeH7U5XkfHZR0X3iDz8za2dzhwyOQGFNSkpn5tljUslDaZpM8mx5frZ2zvPqPRBNZV/85Wgt72M6c14XgOM4HWJga8mOrKQ1lnM/nRdtgIblVz+vXwlle48fA+YG9qxP13/lP+O12pG/ejKxt268pVCFTClFeHWWB8NnuMI62MtcbC+TT+XUnuQbZScINuRKzrh4vDhyhIIYryHxuEDZjKxxjF3GKLkZFJUW4/10PICc3GylpqWr8qcegV+Kn3y0vAprIGmFEVglkFBcXU6HAhxdeeIEWotVXXBFf+cpX8LWvfQ1bt25VCq1XLLyON5rIeh2g6Z8sOwKi2uFicmN03I/BQT9aWt3oYIIjgYQEsdTZXG2jdaoJsbrafFbsZbAi9lJ2Kp4MDQdofexEW6cXqckmBr8s2LrZxsDXlGLXrCtYxR+KmovDSeW1dj+aKHvf3hPE5kozdtRYkECCbgztliK5ifWlkyQeqZRqoiVmD0mtm/INuHsDyTzG2ck8kXy8et9vHgKKBEYVVi8fTk7khcQ6GfYrhVYHn12sXHXy2cHPZbn7WCPwxnl4PrAD1rwMRXBNYPVqolJvJfGVr0XJNTFaiK+8P5PSamRgXf7TTSOwWhGQcfYbr7yOX/38V8gvzEd5ZTl27N6JtPS0a+5ya4cL5y5M4tBJF6TC9c5dCUweSqFIjLrelzOf1N/vQXOzAxcv0l5y3Ifdu9NQWmpTSqyRrDAquPmopNpD9dWzXawQHgphhAGWkgwDigh9YZoByQyyxNHmRgpvZsuniFXx2JgfF6nEeuTYJIucjMpOs7I8liqsFpI7SbY3RrYFo1RPj4wGlA1zY4ubRB8/crJMSnGpqEDUf3nfjY9SievZrocQWUH2nm70HT6ESz95Cjl79qDysQ/CmpICk42y77ppBJYJAU1kXSYg9WqWhID06Q4G9rs6unCJihUXGs6hp28Y43Yf4tPy4I8twKihADs2pGHvxiSU5CYgLSkGJiH3z9J52+HHUMCNF0lk7Q658B5LASpNycqpQJdrLelUQeI9flFUpxqrFDELOWt8Isj4D4s2GP/p6gviEuf7sezbM2mZXV1mRHmxiX2gmXGMKJ4zPb9Y2hnQv9YI3BgENJF14TiHqUggY/dLT/8UvYcOIiYlFWnVm1Bwz73KPjTIAuPOLi+VWL10BXGimHOBrTWxypUhnvMeTUBbONar/ZviOCLiFEJi7eh049x5lyr0SGFMf0ttPOP6ViVYoc/5aj+Tq3f/urtdaG114vTpceZRovGud2UjPcPC8VVk51RWL+J6z2ZDQBNZZ0NFf7bcCLiZ15LclqiyNlGdVYitWVRk3WXORG4U4+tRa8PpbLlx0+tbXQh4x8bQc/BNDJ+tx1hjI0rf+z6s+4P3gIGsK3ZUeCE+8gu6KRay7xL5NY6p5VuLDKjMBpJsgIU13Ff+inwEcnEGBgM4dsqBU/V27NwajeS4YdSfOICR4QF43R48+J53Yduu7crdKFqLY1yBu36zvAhoImuEEVkHBgYg5FIJrP/bv/0brwaDkoT28W5k4R3nT/7kSTz//PP49Kc/jf/z//qLJV0tQjb5X//r/2GCvAwf/OAHLzPrl7RK/WONwJIQENKi0xkkkdWFJlqpOhwBFZzLzDAjm0mMnGySpxJoK68JrbPiLAQISRCdv0S7XdpOjY0HFYG1ojRWkSCyqW4rSmWzJe5mXeEq+VCOSZRZm5jcOnbWi8T4aCqyRqGihNdFerSyHrxqDLdK9nxhu0HxNfRPCJHVgCPNIdopG1CRbUBpRlhVTAmhJ5KPb2Eo6G/daAQ4z4FLJvckrU4ycT8Z9MJhCLBa1acqVgeONGD89dOI+SNaSZDIKsqrYqpqpvKqSR58Lc/yuVS0WvkQNddE8MHnOC4xR7HCn8t10wisBgS8VGybHJ/Ayy+8jOee/Q3uf/eD2LlnF3LzaBlMW+Grm/Q9Yn979NSkejicJBWSXPHg3alMIFqolrp89iqSvHI6A7h0yY5Tp8ZVoio1lcnKrUnIpu2bkBYjre+extNOtfExqo/3jIXRN8H+bpx2N7wBWVissSEvShFZ0+PCMM2iwvrWOmhPLAqlrRwf9vR5qZDrR1GB2GrGID/PgsTE5TsX09u8kc+SuJSCrn6SefoH/OjtZ3EB7ZcFp1IWJJUUWjkONs1fvMMIVsDjweDpUzj/w/+tEuIZNbXIrKtDQlHxjTwkva01joAmsq7xE7xKDy/EyW6IFh0TVJweHRnFMC3XhoeGMUor5tHRUdipSh3Fsac1Ng6Z+etIZC1Gf7gQiQk2ZJEMUsn5VW4yEG+lpf0seft2uhacoRJrD0ms0h4w56HImMCxrG4rgYDdEcQ4bZQHBnzoHw6hdyCA7gESecZCKM2PRn5WNJIS6DTD+I8UccTHRatHDAt0TRFeuLISeOp1agRWAwKayLrws+Ds68NYcxO6Xn0Fk1Rdyr/rbmTWbkFyWTk8gSgWNQYVgbV/MIgAiwE2VFiVSIHJzLgM54a6rS0EhIjg9QYpTuFHw3mn6hsnOQcuKLAiP9ei3NYSEhj/5vmP1LjA2jpjkXU0EmsaGvLi1VeGVK5tBx1/CqnMmpXFQbFuGoEbhIAmst4goPVmlPvgAOf0QmI9HRyFh64rSRRjKafbSnF0HJL52mqI7DiyPs1rG4EgY/v27m70HNiPpp//N4offKcislqT6S50OYclnAIvXW5aBsNo5aN5UGJdBhSnT5FY86jIOptQiCAneSjh4hw76cDh406ONU10xfEgKtCBtuYGnDp+ElvqtqC6drMSgUlKTmKsTUfG1vZVd/OOThNZI4zIOvNSEYUJmcjKc3NzM5555mnIgE/a88+/SHUm6kIvoQkx6tvf/gqKi0sVkVWS5Lq6cwmA6p8uGQG51qWJ6paodTRccODCRTcfDk6upfo8HmWlMSS0WjSx7xpoC4Zi0zdKwsf+w3a0U5lV8Ny+xYbdO+JgMU8peV3j56vy4+l74TCTWq1dAZw67+WzH++8w6bUWROVOtmq3PUF75SQkPtJ8DnRPjXo7KPt8kO1BmwtJkmQ8ypNZF0wlPqLi0Bg6o4rpDKONwxT79RrruPwwUN47aWX8YGPfghx+ZkYD/swFvJefvB1mK/52WjQAzfVXKXwRmxaKqMTUcZHkTFeqbaaSXDVTSOwGhAYGx3DpQsXcfjAYZw4cgxPfuKPcfvdd5AkStvaWW6ydierU6ly/vKbdhw6YUdtmQ816zkW2ZJN9U/zst6XXbRy6aDy66nTYzh8aBT33JOBPbtTEU/yhtjqRnKTYApdnnGoBfD4wiigAuuWwihszAOsrAo28/AE/llOwVuH3drGsSCLdI7xPMTGRmHX9gQUF8VwbGhWBTqRbjk8MhZEJ219Dh1xoI+EnjiSdaqrYrFlcyzJO9Ecu03N0ebCaBosGTM5ursY7HoTIw0NmOTr6j/+E+TtvW1ukKdXoJ81AgtAQBNZFwCS/sqyIxAIBOChMkTjxYuoP30aJ4+dQC+D+7E2G8oqylGzdQufK5BXkM+CEBPs3mj0TkThzUYDzvUAt1UYUFMABvan+p+rd/CIbxC/9LajNDqBSa5EbDCmIEUrtlwN07K9l9DP9Dxfiod4evH6UQ9e3O9iMRznJsEAXA4/iaxRyM02sbDDqhQJc/jaxrGAjl0u26nQK9IILBsCmsi6QCh5A+w9eACXfvZThENBxGRkouLRDyCZQiMGzk2lsK21w4t9h+yq8OL+uxMVmTEpUeatC9yG/lrEISD9YoiVjD5fCJfoQnKc5AIp9jAzjn/n7YkoLYmlNfzssYuIO1i9wzcUAbm2XC7mifYNoavLzRhTFNZvSEBdHVkuumkEbhACmsh6g4DWm1EISJZLBFx6Q04c9w/jFW8P1kcnodachmrO89OiNJFfXyqrFwGJk4jCYdcbr6P+W99AStV65Ozeg4zNNYjNzFQ77iR/ZpTCIc+dgSKyFtP1rpq5lm3FLHoj53Q+3qlsoqPLR0E0txJFM1Fw5MF74zHYcw6vvPCSKhqPT0jAo49/gHG2MsbYKGekJyKr96KJ4D3TRNaIJrICP2NQ47Of/ewVl+CXv/xl2Gz3qIntFQsuv/F6x9DX9/psi972mc83xoRwHi053wETJ8aSLJfJTExMtHpYaTdhpZWX2E6I8pR8LrZeMonWTSOwUghIJyr2c0PDPvT1+9DV7aX1XABud4g2smZFXBB1KgngyDWr+88rz4QEvrwki3T1MPjZ7lYB0BhrFDLSTFhfEaNUvYTQGmm4iTLeuD2Ec00cYLX6YeW9KicjGrXrzSrBJUSPSG4y+BQya0N3GPVdQEEqVVkzDdiYCyRQLDCyjy6Sz8ytue8HDx7Eiy++iI989KPIKMyDF0G4QyQQyDMDAW4mXN56Le9Z3erlI8i6V3nwzqyUWYUAkBkVQ+sWq6p4FVXXSCed3ZpXRGQftQQAWptb8Ntf/pZ2tm7Ex8fjznfcjaoNVW87MBmDiEKmFEwcPuVGW+sw7GMTuPeOVNRuSkZGRhzHwctDLpVtCYm1t9eNo0dHVXIhLo6WutUJdEyQ7UQeUUNURD0soOkfN6BlSJ6BCVdYWdmkxZPwzlxJThKQQZU1UcS7VnWwYDMy6qelpgetbR6lwhpnI5mFijRlVJpPSTIpUuvbTmAEfCDHFiRQUnTU3evjw49Bqu/IvVGIq1lU/s3L4Xg3w6js/pjPXlTz0WrbQXJX5ysvofO1V2lB9DADXnsRl5MDY0zMotalv6wRmA0BTWSdDRX92Uog4HI6qcA6ge7OLnR3daG3q4f9uIdFWCHeH0loJIk1NT2N8YEsZOfmICUtjQ4uCSrALn2R02vApT7gYp+8pkIFb4Eyt5J5VkbC1B7L+FUKtCTB9YKnC3dbcrDdnIFUg0UrtazESZ1lndIvSgyjqcOPs5d8uNhMhwgqthbnRCGO50z6wRDjQ/I9iVuKrXZ6KlVDUowcD0TzOphyaZll1fojjYBG4AYioIms84PtpXr4ZGsL+o4cRifVWLN37kLW9h1IW78BBlsSrT6DONPgxvlGl8rF5JG8v3kjCYx0oBA1Tt3WNgLTBR4yT+zp9aKD4hSDQz5VvJFFl7XKchvSGNuXOaNuGoHFICAEaSmebmy041zDJKqqEnDHnemwMl+k87yLQVJ/93oR0ETW60VO/+56EQiA7lec63cGKZYVGMdQiFIsjCOUsmi1JDoexXRfoTyCzrleL8D6dyuOwOiFC+h49WW4+vuVOEXFHz6KhMqNcPmn4lxnySNw83WcBajKYZxLci7JC58v2B0h5Qbw5hE73X0DzHvZYLOMw+/upgjMccbgulFaXoYN1RuweWsNxwxWTWZd8bN+621AE1kjmMgqCn0vvPA8/sf/+JyySpu+fCVI/6//+m949VVmgWdp4fAEg8BvzrJkto+cVD7Ioq3ETmVjKsRVSaBLIDg+ngliPk+/Fjv3+HiSWYXUGisBFFF2lKAyGf6k+E9Zlsv9dOE3ytn2SH+mEZiJgEy0xU6n4bwDR4/ZucjA6zAaNZvilJ1sCm0CJZhnnMOSdub6brXXPX0+nG5woY3V/BII27UtDlXlJJUlT5GA56vMWY14dfUF0NwZwMlzzEay3b7NisIcI9J4THL7ifRb0PmeMI60hjFsNyCWg9B71xuQz0FojDnyj201Xk96n2ZHYJrI+uSTT9JyqnD2L13+1MegwCTJrB20ZG1kYKCV1i3DYY9K/qeTwFpI25acqFhk8xEXZYI1yghjmLagBo4jdLhgTmz1wqUjIMkgj9uN+lP1+MF/fh9FxUW4/90PIr8wH6lpqVdsQAgSYq0yNBrEibMu/PblUcRgFHmpdrz73VWoWp9xxfeX8kYIG/Lo7nYzmcAxDoms2dlW3HtPJvfLzPF4ZNkcKeyCgNtHVXhWBF/sDeNUJxVlqLAmAZXdZVEszgDS4kh0vxZ7lYDKegL0x3F7wmhpceHMWSeGSWg1cs5x294krCuOUYm7SFVik0ItIUo7XUwkdftwns4DA0MsBvAEUVcTh8pSi1JcWkqiWlVuE8iWXz2Lxmd+ysrtDcioqUHOzt2wpnBAEekDpaX84enfLgsCmsi6LDDqlcyCQIhBMD/tRXxeLwu3fRgaHEI/7Zcbqaje3NiIzvYOpGVkoKRsHWq21KKsvBzpVKSQgPq12oQb6B0DXj7H+ZUjjBJara1nkH99Lgu02dW6DCROBsdx3j+G84ExPGQtwh5zlh6hXgvQFfzcxcLl0YkQnntjqm/cWWNRRNaAL6icZnqpUjgxGUQsi+1zqMqek2VCdqaRhFYT4hi7lKJ7GS9IbEjGCbq7W8GTpVetEZgFAU1knQWUyx/J+DzE/s3OooxOJqTHGy/B2d+Hqsc/hLy77qUSq1EV7vewyO3YKaeK4d61Nx4bKmORlsr4iY55XxvcNbpE5sXtnVSipzrrydMO9nHAhiob58OxyGNxp8XCwlDm5HTTCCwEAYk9SY7twgU7fvVsL/LyYnDb7enIzLQgMZEXl24agRVGQBNZVxhgvfprIuBh3srJvNXrvl6cDowiAXT7MCVimzFNia7EGKg0yV9rXss1IdQLbhIC3rExTHZ2oPnZX2LgxAls/tNPw1azGwM+G463Ayf52MK0bXW+AZU5U4TWxe6ql2ODNw7Y0dLupXAY11MWw/xELF5/5VUcP3xExeTEAemdD72LxVRpsMXZFrsJ/X2NwJwIaCJrBBNZVSLXL4lOSqD39uDcuZP4+tf/XyZ1W6gGlYE33qCVWi8zxdfdDPjpT/+J6hXF2LnzIfh5w5KbltdLVTUmWGVyI88eJlZ9fJZl8lomyaLMmp5mQXq6BWl8pKSakUxlJJMp8pSjrhs+/cMbgoBMtP0klUxOBpQyl1QjCzlzYsKPVKpwVFbEoiDPisyM5bX5vSEHdwM24vaEqGYbRHOrRw1GHM4gUpKN2LE1Til+iS1fpDVJcE0wCXnmohfdfUG4SHZZX2rGrloG8iR5FVncn7fBL8nWYXK2DzTRbmyMNsxUDKriQFSsMHUy7m1w6Q9WCIHFEFkZX4eQWUWV1R72gSUymAj6lLrVWMjLZx8cIT/81GoVMmtutA1FrHpNN1CllYqtOvS+QidRr1YhIISYlsZmnDl1Bm++sR9b6rbifR94Hx0HYpj8IcNyRgvQ2lYIFPuOuXGmfhitF9tRtzkBt+1MRUlpGse7yzdZl/G2KM2/8cYQ2qmMkUbyalkpk5W0eBN3hEhKVsqchcM1tA0Dzf1hXCCJNUiyegJV1IrTwGIMA9LiqYRHnpGZOZK5/ublHAyP+HH6jIPjvakinIqyWJTQUjgnm4QWqrCZWEAXqf3hEI9NEtQNJLDK+MzIeZWor4ptcka6SaktxVinCDgzLs1Fv5Rk+eiF8wx0HcfgqZNKiXXDR55EQlExos2sjNFNI7AEBDSRdQng6Z9eEwG5b7lZeNJLRen21nY0XryoSKx2qkxL/CsjKxNZ2dks9pD+OBXJycmwxcepvjx6DulqP4ssXD4DOobDaB4EzveEVJ9UlW1AWRYVsuOd+J23W41ls6JjUWtKxbroy3Kt19xbvWAlEAiymF9cWKRgtZnqrKIQUpJvQt1GE2ORVNThuEmKnIXMKn2ouPaIeqG4zSQlGdmXktxKxbqsTDPJzSQqMzagm0ZAI3DjENBE1mtjHQoG6ZjQhaEzZ9D8q18iNj0d+XfcxYKzKsTm5PPeZ6AatRv7DtkRT2J+Nu9lG6pilUODuFFF6tzn2ojoJQtBwMXix9ExOnj0+KjO6lHE1lzOiWVuXC4uJVQmj9QCz4Ucv/7O8iGgyPQcZ/X00A3oyCgczoDK8e7alarcgJZvS3pNGoHZEdBE1tlx0Z+uPAIhOgcG+OgLuqjOakcDRVicIR9SKL6yyZSCamOKElvR2qwrfy70FhaHQJDF3QHGyC7RuVsc15J33gZ7/nacCa+HNY7zhEQST7PDKEwjiZU5F6ZLFt1EcKO7z4+mFjdOnHZRPM5MV8IEuOzDdERqxb7X3oDT6UJuXg527NmJzbU1nJdI0bCOtSwabP2DWRHQRNYII7KKPdr0DUAUKK5u58+fx7333qs+fuWVV2gDUXX1Vxb1/m//9m9RThWLP/qjD8JLkqoEh2Ui43QEpp7lNYlvTvU89VpUkiRhLUpRNps8RLV16jmWqq22WKqtUSEhJobqrXyWRLwotuqmEVgKAnLNSWvvEItZN4mZtAIg2UESFlKJnJ9rVdZysSRmyvWm+9EpvKb/7e33oZWqrBcbPVT9CqG40IKifDOKCqxM/FAZMcKSPAEqvHXQirepfcp+MD0lGuvLzFPKrHwtYm+Reg3IpR5gwvVYG3CBidYxlwGFFA3csQ5IJYHHZrn8xzB9cvWzRmAFEFgMkfXqzcsV6mWl6zBJrL1BJ3pCLvTxMc73sVRkjYeRBFYhsZqRyud4VsImRFOBkhWwpjALYiL1j/dqIPT7m46ABOsddgdee+kVqrldgp+dx/ZdO3DP/VNj6Zk7KOOM/qEgWjp92Hd4Aj2dgzDQSuWeu/Jxz93r6EZgpp3t0islZDuyX/39HmXt1kBbN5c7gB07UlFcZGORGI2N5lAsnbnPN/u1EE58HIuNs58anAyTJETVuwlgnHV2QlwtyzJgHUVscxKn+uS5/rQDDJxIUV0fxysdXR40NdM6muzYRNpobtpgQ+m6WDVWiTQleTnfQR6H08kk5HhQFWP1kqArKqyiupqbZUFpCcdj+RZ1fMupquMdH4e9pxuXnvr/4BwYQNn73o/06k2Iy8u/2ZeO3n6EI6CJrBF+AlfJ7ktfGCSxx8Wg+ATvV2NUmxgZHsZg/wBVHwbVI8hJkYkVEOvKSmlpVs6iknVISEycU4F1tsOTe7GL4bV29lMHm0iI5GsTlTsrijipTJ3EPkMXskxW3GXORhaLrpI4RtXt5iAgY4vegYCa5x+r95KYasTeOqtyX4klOdXlDqoC5/7BICTGMTjMYjkWPosSq1gty7ghkc/xceIoJfFJzp/5kNikKMLPNRa5OUest6oRWDsIaCLr7OdSlFgDLhd6DuzH4OnTSlkpc8tWVDzyKAzWGHhDFrS2c/5DAYILTW5soGBDbbWNRW7MtUSg+MDsKOhPrxcByX3YHRSooFvJKRZ7ioOjFD6Wl9mQy4LIdBZDWsyMg+vU2/VCfEv9ToRiOjqcuHB+Ehcv2ZlnzsSmTTK2jo6oYupb6qStkYPVRNY1ciIj+DACYFFk2I/j/iHlJjga8qCYQisVLGLNjYojsdUCI90DNT0vgk/yGt31pudfRBNzWz7mTsaTKtC57j1YV5KCLcXRyEk2IDGGAa/rbBIrE0HD9i4vXnljUuUmKkpjUFJkQozJgYP7D+ASHZL6evtQt2Mbtu3czgLzLMQnMPGjm0ZgGRDQRNYII7J+6Utfwre+9S3s2bMHTz311NsugSjOSrOpQiFB/69//et45JFH3vadxXwwTWT94Ac/iDCTrKKmJEljuXmFeFOU9+r15c+CjCo7SHIdH/djcJBJ2AGPeh5jdeiUQqaZlhRW5ObGIDvHSoIhbYQZQI6NXXrifzHHpb+7dhHwUaXY46ZaF21mLzU6GcRxKjUrqULeUZdAEoiV15tWBr76CpDAlxBYm1o8uERyyPlLHg5GzLh9N1URaVMlSZ9IanJf8vOYhHR0+oIPXVRmHaUqyzv2xGBzpQTx5BqIpCO6cl95eHB4gJbBMF44G1YTqDKqBm2mTUBJ+pXf1e80AiuBwFKIrLI/If6RBqXiNRxCwBCGi4qsdta/tgUm+bCjLeSAn8tMzCZXRieh3JiIMj4SDCaYDZF1P1oJ/PU6lweBAImroyOj+N43v4P+3n7c9877sb56PYpKiq/YgPQp8th/3IMjpxxUgxuGFeNYl+1B3fYCVpsWwaDID0sPZ8k4W/rko0dH8fprQ8jMtqKgIAa1NclUVDFHVPLAQ+LIKEmrpzrCONZqUPOGFIrW1hUbqCZOMmsciUKcAghZaL4mxBRRVntj/wTamMhNTIhGBe1sttYmkEQcpVTVIoXgO/NYpbLZw4BQc6sXJ+td6B/0kbgF1GyMpS0kVWZpiyyJyGkb5Jm/XerrMDfkczrR9MzPMHyuAdaUVGRt347Ce+97q3ByqdvQv781EdBE1lvzvC/3UQuJ1ePxoLOtHQ31Z1FPck9baysVVhlPystF1cYNKCWBtaCwUKmom6miLoXfor46Xfy9mH2Sft7lk+ILFgy20v2iOQRbDm0wMkj6TxlGXVwyHrYWsryKhEcmsHS7OQjIeZLilu7+IF477IGPY43kBAPqqq1UZ41W4zXpR2UsJd+TYvyRsSD6BxgToOJ5b78fQ8MBjiOikMnioMICPvKk8HkqRhBJivc35wzorWoErh8BTWSdHTvf5CQc4rT3g+9hsqMDRQ88iMy6bUitrILXD/QNBvD8KxNUmKboAIvbqiqsLHSzch6lyfezI3prfSr9osQQJKY/wfnyydMkIV50Iprz7OJCK/bsSlSuHuLqoptGYD4EJD4hLpxvvjmMl17sx85daaiuTmQuV/JpOn87H356+fUjoIms14+d/uXyIMDulO5h5BYYQmjxT+CwjwW0FF0Rgut91jxsNNLxhXkpRhuWZ4N6LRqBZUKgpaENTUfq0f+7Z2CIiUP2Rz+H4soCFNDBQXIuS9VDkbHm6HgA5+ge19LmQTcFxO6/OxGbN5jhdjlx8tgJPPvfv1Tk1YKiQtxz370sMi+5rrjcMkGyqlYj8Ukn8y9PP/00mpqayImLw65du7CdOZjY2FjGsOTuM3+7nvUYjUZIHn/fvn3k6g2yOGkTdu/erQQsJS96dXOxuPLQoUM4efIkHd97Of7LpTvkBrzrXe/ifIPVcle169mnq1Yx71tNZI0wIuuPf/xjfO5zn6OKQCJEffXqAH0HAx7yByDt+eefVxflvFfBHF+YSWSd42tXLPJQuVVNnsenyKtCYLXbA3z4SYadIq/IfguJTJ7jRK2V6q2ijJCcbFHPMTHRqtLvihXrNxqBBSIgk24vLef6BrwkO7gxzESFg8rBMdYoWvOaUMRATgYtepOT9QR8JqTSD42MBdDV7cV5KrNK0kcIJlWs9heFViGNRJr9npOkZlFsudTmx/lmH/KyjCjOM6GyhAqPcQZlkzMTg0h6LWo0I44wznRS5W5kSu1uS5EB1XkGKrMCVtoz66YRWCkElkpkvXq/hNDqCQep0uphkIBFMCE3JsI+2FkJKwECIQxYSGBNNrAgJioGmdExfG2BRZMJroZSv18EAlIt2tLUjJeff0n96pHH/hCFxUVvqxodoVKmFEScOudikcwEHAOtyMsM487bc1FckoHMnORFbPXaX5WJ6wSLwZpbHGhudqCDY5jNNYmorExAFpU5RQVjtTcpchMV1r5xKqaN06p5BJhk0pWGDciIN7ASGFRhNSAplkoxCxC0kySKKMy0UXG/mTY2Dr7mHJx2ibEoIPGkgMlcmU/w/4hqEqMY43U1MORDZ5dPjb8cVGWNo7J6SlI0i4msJNhwrMJCopU8NlGAGjx9CoMMUPSfOIaMzTWo+MAfwWSzwRgTE1GY6p1dPQhoIuvqOReRtidu2qKJAmtvTw8VHXpZZNKHyYlJugO5VRGUBGHTaLecSYWH/IJ8pGdkICU19XI/sPSOQPowP0mQrSwWPMt+v8HCfTBNsnglGnuTUvBwegbHpIxlLX1TkXZqVt3+TthDuNTKMVOnH21dAezZakV1BZ0d/n/23gNKsqs6G/2qu1LnnHOYns6Tg0ajMMoJCQWyjAHZCD09s57fW16AWTK/ZRBgsDBhGfRjfgXAFkhYEpKQhNIoTNLEns455xwqV3W9b5+mR62ZnplO013VdY90p6or3HvuvrfuPWfvL4TNkFtmOyy5IQF/jU+IUqtb3W9HWYQRAKy8J04PMy5RHJtEca7Be3AMXX2iI/VUbBUnCBZ+tAM+G07tUYvAsiKgAVk/Gj4vk7AyFu8/eRw9779Ph4Q+GCMowHDLrYjOy4c+Ihp1VGBtanWwYOxEDOsmW8pCkZLMfDavVVrTIjA3ApLTd3HS3dHhoIKvDb10+ZC8sZw3IuqRmxvCfALzahR20JoWgfNFQHJSkquooSLrsaMjlB/QIT7OiN274zgGN6ox9/m+q72uRWA5EdCArMuJnvbdlYwAL4EY8RJX4JpAs2cCnXQTjKIjS0ZwGIoJZhX3wDC6BmpNi8BaR8DiAIYmmbtqnEBDZTvC3n8ccXor0q6/FZlby5G2MXvFuiiYL8mnnGZt7PAxC7ZtDkVZUShrF8F0S+pCxfFTaKhvUIIx23duR2l5KbLzckhEN61YH/xxRVKzOnLkCD7/+c9jguTFuS0iIgIvvPAC636Fc1+e9/lS1iPf+fKXv4wXX3zxnHV+8pOfxM9+9jMSwD8Es/b29uL2229HN/OxZ7ecnBw8/fTTyMj40MVvKX06e70L+VsDsr61kDDROdRGNJQPtI6ODqXGKuoUX/jCF/D9739fobXlhBGrtc997nM4fvw4AXoxqKioYEJ2eTfUpQBZ5wuTUkPgZLqvj8mXLiu6Orl024jotitAa0SEARnpoUgluy8zI5TFCCMimTgW+8zg4BnlRNlH/q81LQILjoBMvGUC3sDEX3WtBVU1FlWEKKUFbQHlzyWRYzTMnF9aceLDsFpZ6BEbvmNkcR/8YBJbN4WhvFjArGYFqKDIjd81AbKeqHKgmxaDJlr1XrcnBFmpeibxhJHkvxcWpTLj0uFwkxfPn/CiKJVAVo4l5DGOqnf+rDrrdydZgHV4pYGs84VvmEmDHiYLqt2jaHSPo2vaiigyX3ODIlBsiEFOcAStXWfArDPWLhwnzLci7TUtAvNEQMYHwhg9cvAwhgeHkZKWio9/4k4m5+PPfFrGEVIQknvIwZN2AmumMDIwhOmRGtrZR+ETf3UFQa+hKwJwkG25iZ5pa7PibSqx2h0ejoUNZEnGkSXp+3YsMlGSWDk4/53gtKmiA6jtARr7vciOp1JaDlBI5fDkKCGynQnxeZ9IPDxEFE1OEkTcZVc2iWKVuLk8HGWlYVRjDSMZzv+KcKKWI8AZF+PU0uZQKvgnT1uUpXFutknZhOZmGakqSLuqBcTpvAFc4BvyO3CTPd1PIOvJn/4YkZmZKPzM5/iYhRCCxbSmRWApEdCArEuJWmB+R65BktsSZr+bYJ7R0TH09/ZRffUkqqnC2tLUTNJzGPILCrB5+zYUl5YiNTUFoQTbX8pmJ/JjlP359VQzToxNInEgDbujonFrbrgiC9Khd1Wu0ZdyH/193XIvFTDqoZMOvPCmFTvKTNhUZEJ2WjDCqdR+vnuoAivTxaeXyqzttMdraXcqgJjkP4RAkkLVkiySZDLSjFRFN6rcwYwq+szcWssb+fuZo/V/LSOgAVk/Gn03VcedkxNoev45NPz+aaRftQ+pey5H0tZtZPxFwkaBhjf2j6OWQgOiGl1MkYHNBLL6m8DAR/da++tSR0Dm0VYr3clOT6GmzorGJitKisOUS11SopH5i2AEk6Bxvvvkpe6ftn7/iMDwMMdHrOGKMquF7pt33pWOrKwQGGUQrDUtApcgAhqQ9RIEVVvlsiPQSCBrpWsEJ11DSmTlamMK8oIjkRLMWgDXzlnnsrehrUCLwGIjIDUYNwnYvWNeVXtRQlcdYyhv/S2ynS2ITIxDOucUGVddveKJq4oqK17n/ETIv+Iit43YkdiYIObznHjxuT9i/xv7EcfaWklZCa654Vq6C8bSJSBwxw7Dw8NKfHJqaooiNcm4++67WQMKwR//+Ec0NDSo+LzyyisfAYjOdz4sdj2Cp3v44Yfx85//XK3uhhtuUP2orq7G888/rwCs9913H8QFXuVjCWjdtWsXiXC9iI6OhgBdU1NT8dZbb+HAgQMqb1tUVMSa5dvq87LSxfZpvv1ayGsakNXPgKxyUL/+9a/jqaeeUsdX0M8iBSyWa4cPH1byxPLGE088ATkxl9tWCsgqFsKixmqzTXMy7eIyzb7ykSqZU5wMWeTR4ub7HjXZNpIdGhoajOQkqhElc0kyIYKqrWYqtWpNi8BiIiAJHAFBjIy60E02cg+XftrKiR1KQpwBG5kITEs1Uq01WAP9/SWwAjwXhk1nt5OFHYcq8shrJUUE/9J6Ly3FuCKgncUcx+V+dmJqGkOj0zhZw3OAYNZoqqtsyDZgcxFtyg2iEO2fkw4pxEkRr2sUqOsV9SCxxAT2FgD5STrEhnlVgnK58dO+r0Xg7AisBpBVFFptXrdSZh2ddmKESq2jVGkdpa2LhUqtnIkhmcqsmUHhyNNHIoIg11CNEXv2odL+nicCAppxEaDyp+dfwuuv/hnbd+1E+ZZyAmRKFGBm9itW+4x1bS0VvU/W2DHS0YDpqW5sKouhUmoayreSWUr5a5kcLreJ8mgzVVgbuTQ0TCIzMxRbtsRwDEwSCcldvt4sLLSOWmbuRY39M4p2Zr0XabFUYY0GUqJ1iKTAZ6hxYXviIjilu0fUZOzKGtFkCkZCvJ5KrCFI5ThElEoF7OlPTcgnTsaptcOOhmYHhobdyvpY9kuAM7JfcXQLEIDuahL4ppmsGG9tReufXoKVNjNBZCzl3nobknft9qfwan31oQhoQFYfOhg+3BUBsbqcLqW82tHWTtBqk0qajpGgLYnTKC6itioEk1nlVXktJMQMveHSWk/0uK1o9UzhsH0QHXQsiezIRKwrDPG854sDxoYkQHLxfjqF9OGzYuFdkzyPEF7auzyoqHdicMSj5vVX7TTThYVjhPNYbsv35NyzknRjIdBninmCCaq9i/q75I1EHV0UXJ0Eu0oOMz5OrwCuSYkGxMfSSYoAIAG2ak2LgBaBxUdAA7LOiRmvQzL+7nj7DfXoIJEj++abkbx9J4zRMejoA05WWjDCa5tMNUWJNTvTxEKxXstdzwmj9nT+CEgOX+ogPb1O5VQnClpW1txKCsOQlxeKZN7TRJ1Va1oEzhcBh2Na1WzfenOAYkQEQ5dEYsOGCGRnh65I/ut829VeD9wIaEDWwD32vrzn4hQ46LGhngIrndMWVZPK0UdgsyEOSboQpdTqy/3X+rY+I2B1etE2pENDH9VYO6eRFKVDZoQdiSOnqShyHL0H3iOIdR+K7r0XwUb6WS5T8HBuFAcGXWijs1xljRUTdOK+9spohRkRU7e2lhbU19bj+AfHCHb0Yuv2rSgmoDW/IH/uKgLq+T/90z/hP//zP5XLurioZ2Vlqf2fnJzEvn37KPbYg09/+tN49NFHLxiXxa5nZGQEW7duhdPpxBe/+EU88sgjKg8mG3nsscfwz//8z2p7JyhsIgBbUY298847EUbRAOlnXl7emf6IauwDDzyg/v7ggw+Qnp6uni+2T2dWuMgnGpDVD4GsIvUrJ/VPfvKTM8jn2eOenZ2tENTyA1iJtlJA1vP2hUnk0TGCU0ZYwOil7QkVWnv7yEhmMZ/pZSaNmaSJNSqF1ugo2oSxkC8AxBACWk2mIKXY6q8AtPPGRHvjkkRAwH4WFiXaO+04VTGprOVEOSwvlyrAtKZNFFZyBM+vEC2RM3sABHA+Ou7GoaNTHJw4FLgil6qsGzfMKLP6W6zkHKhkkau+1U2LaDdSEoOxo5zHPi4YUbTyXQEc0mzoVv3RRvDqJK0E3qrxoq7Hq0CsBclAcWoQzEYv9NppverHZL1vcDWArHNj6GYl2Q4PuqnK2sTkgYALhglspfk1EglmTaO9SwKtXeJ0JL4EMSlPC1iDjpbcc1eiPdci8JcITE1O0fZkEK+8+CccfPd9fPYL92LXnt1qUqk36NXEzsGkwODINCrqXGhus9BWYxK2vhqEBw3h5tupCleegZi4COUcsNzA2u0ejI25cJTWbd10LNATHVNaGokdO2IU0cJX70/MSSgL5kk70D9O4ClJFWLH3DcOKq/qkENBz01UCY+hcJ6JpJGFNAGYCMFteMSJxmY7OjhuE8Bnfl4IbWvCEUcSUniYfxHbZLwpBKExjqkGh0QBjgVFWj6K80QcQTGbS+lKQdU3sTReq+YYG8NwTTV6Dh5A5zv7UXzv55F9w43QM4ERbFwg+nitOq9t1+cioAFZfe6Q+ESHBDwoTH+7zUZlJwtttcYxRuBOb08vujs70d3VRaKzFdMc8xWS6b+hcCMKuMTFxyvFgtXYCdKv+R+U6spR1yCc7IvOGoLQriRMjYSoe93WrCAUp8l9DgijSxoNhLS2hhFQhFWO1945akPfoAeXbzMrwmpSnDjvLGzsIUQTIdD0D7hJfhaF1hmyydi4hzmiIGXLHBsTTACZQSmPhIboSISeId8LKVYcaxa6rTUMlbZpLQJrHgENyDpzCIREZqc6z8CpE2h64XmYIiMRs7EQqZdfgbDsfNZJPKius+HIcSr3MFedlW7AJjpSCLBea1oEFhMBIWmImEdltQW19RZ1PqWzBpJPMKvMQyNZB5H620oQcxfTL+2z/hEBAUR/8MGIIlpLTiM/P5xqXTGKUKyNe/zjGPpTLzUgqz8drcDqq9Skej1WNHjGcdg5gJAgPbLpEriBoioZweGqNmXQaUmBwDor1m5vJ+06lZeqpPt714gXYxYvduTQCS97GkbHOIaPHcLpX/5vJG3Zig33fALhqWkwRTF5tULNQeyWgyIdr701hqYWBx0LQ7AxXwh3Rub7XBgeGsarL72C1qYWir+YsXnbZuy6bBfCIyNIoqI9bgC1INrlXnbZZWglefHv/u7v8I1vfOMje//444/jm9/8JnNOEairqzvveHwp6xHF16985SscsxnUukUFdrbJuF/UVcdYC3rooYcUSPXHP/6xcoC/5ppr8Jvf/Gb2o+pR8riz4NVnnnlGucYvpU8fWeki/tCArG8tKFo6m410fR9ro1SqaG5uVj+CKF6IcnJy1KJfQXT9JQeyMqYCLhPgqkyO5FGW8XFe8Ghh0UdQa3+/HQMDDjVJimHiOCsrFFnZYUhPC1HAQ7HO1ibcPnZy+mB3BBghih1OYZQSINFGpVGx1xF2si7Ii/LScBTkhyGLDHdfBYysdlglSSG/y74BAVw4ceykheAaJi5yzCgu5OAkw+hXsZJzwEawTTcLVAeP2zA+5VVWgbs2GVFWMKMy66/HXo6VnN8tg7TAJhPrVDvVYyJ0uKFMh6RIICKwxoir/VMJyO2tNpBVBmECbHCCkyUuk5wYjVCZtc0zqZZ2AlvjCWTNIKC1RB+DLLJjo3VGwlkXVsAOyIMYwDvd0daBDw4eQVtrG8E0U7jjno+jtLxMWZ3ImFKcBPoHp9HU7sKBEw6MDw0idLoL+ulJxEUH49qbtyAzJ5H3xBnlzOWGsquTAO3mKVRUjClg7JVXxtNSJJSKdL59n3W5SUizUi2o3YuGfqBjyIvsBB2ESJEdr0NCxAzIR8gUC7m/yn1agE41dRZUk9nb2W1X5LVtWyKonk/iSbyBMRfAiH/9rkXNRMZRdY02VNXYSMoLUm4A+bm0LuZ+hYXqFEFPv4b7JQV1l9WK9tdeRdX/+U9k7LuG1qZ7EVdSAnNMzHJPce37ARYBDcgaYAd8gbs7C2Lt7upGXW0tak5XoqmxiSqaBsQSrLqhYAPvrdlUJM9EKEH0sphFfZUTUEmSrkaT+7+b48w3nT34k70Dl5uSUYI4xLrDqY4XjGOtM+4XAmC9pgjIiqfSuIn2vKvROW0b80ZgFoR6pEIIq051ruRn6XH5VtOC7bdl/CFNijK8HapHIfUqABAVR/oGuPS7FDFaoM4pSUbafAu4zAhRao0I11RaZyKo/atF4MIR0ICsM/FxTk2i+9130HfsGMZbmtSYO+9jd8DI2s6Y1YgPTljQSUC9gOn37AxHGd2xhMhnWCAx8MJHQXs3kCKgam5UGB8mmVKIGhWnLYpcKU4gxUWhdJoJV0SMhczVAylu2r7OREDGRwOsyzY2TmH//kHlGnTbx1Ko1iUCQ2tHwtWOz/qMgAZkXZ/HdT3slUwVnXQNHKNbYBdVWU+7R1DhGkKpPpZLDIoNsYikS6DWtAhc6gjIfflUhxfVBLGKkEgc6/+X5QNpMRTKoIiIbtqNkZoq1P/+d8S8BCGCjt7pVGaN3bhxxbomOTPBIlRWW1HfRPfjQadyjbj+6kiYmRsTBVAhq1ccP4XXXn4VaRnp2LF7J+tuJer5inXED1YkNS7Jb4oz5EsvvaQUUud2WwCas6KUr7/+OtXvS+a+feb5Utbzox/9CD/4wQ9w5ZVX4umnnz6zrtkn9913H1555RVcf/31ePLJJ5Vq7PHjx3Hrrbfitttum/2Yepztp4Bia5nLDQ0NVfW7ldi3j2zoPH9oQFY/BrKe55iu6MurAWSdr8NWWnyNUal1aNCBQS5DBLXabMwoI0glbkSNVVRZIyMNLPLPLFFRtIenmqa/2YzOt//aa5c2AiJrLopYXd0OtLbTqpp2gQKMEJUvUcRKYUInPtagzjWNYQrYqSI2RBuiiiorBoZoR8TfZ262iYtZxWvGAvfSHrOVWrsM9qasVC1tdqKl0422bjcKcgwoyNYjM5UqbwST+HMCb9wG9I4BBxq9mCJoV0CsxWkCKvLCyHN8gaI0KxVubT3rOAKrDWQ9O5QeFpEtXjd6PBZ0cREgqyQVBEgQSkVWAbEmBoUolVZRbDXL+IEKrVoL7AjIxM/lcuH0yQo8/8xziCZAb2PRRmzdsfXMZNpJRS47maUnqh1obndSEceBqcEOWHpr+dkkFJemoag0U6mxLjeaQt6yWNyoqpxATc04jCwGpKaYsH1HnBrf+ipg00oV8AnebzqGZ1RYh6eY1OMw3UiyS24iCS+JkkDxIsy8MGiP3JtlbDZMh4bOLgfaO+wEjDgRTmCIAFhLisIYDz0TIqsDZFrucZXvS9FQVH37CX7p6WMShySaiQm3IgglEwCTRTJQeqpRKbv5yr1Zfh/9x46i9U8vw+NwIITAstzbbkdUbu6K2hCtRHy1dfh2BDQgq28fn9XsnYPXEhtB8v19/SyE92OQy9jYOCYnJpQyq9vtoftOLJJTU5Cdk4OU1FQkJCUqMOJakJVlbNlL9f8PqLRy3D2EW0wZ2KZPQJhOj6FxHZoHoOzbRiw6pMfynkfl8Y0pOoRSuNqgDTNX89Q6Z1utXW5FQKppciGWqvCXbwtRzisyv19KE0Kv3MeHhmknSWV4UYcfn/DAQoCr4KqNRpJQCCozc6wjinYREcGIjqTTS5SeBBXOOzj39ue8wlJipn1Hi8DFIqABWUmuHxrCRHsb2v78KqwDA4jMzELyrt1I3rmbqtLMUXa4aNUpDh1Qc4WiApJ1CZyX68la3Bcvdky19/0jAnYSKycnPaitI3Gxg8r4vJfFxOg5Jw2hUAxzZwlSA/FvpzL/OBL+1UvJDzhYE+rssuH11/vVOVJaEomc3DDa0GqKGf51NH2/txqQ1fePUaD3UOpOU8wX1LnHFJhVCLAhlFDZqI9GFpVZxS1QKK5Lm30GenS1/b9QBARMPTxJBVY64dX3etHD+n+E2Ys81l+2ZEk+aqb2L+uw9Pagj/bvQ1WVGG9rRdFn70XK7ssQbKKA2woSxKXe0d7lxOFjkyTc6bF7exgJv6zJ0m1O8oCtza149+13MDI0Ag/ZwpddsYf1tGLEJ8QzlxIYzm8dHR3YvXu3OrSNjY0kAhFtPKcJwDWDYGNpAjYV0Ol8bSnrefDBB/Hcc8/h/vvvx7e+9a1zVvu9731Pub5v2bIFL7/88kfelzmn9G2CedtTp04pJdn29nZcd911eOqpp9Rnl9Kn4M3yKQAAQABJREFUj2xkEX9oQFYNyHrB02WtgKxzOzVT3J4moNWJDk626+sn0NpioUorVZpCg5GdHU71jnBlb5GQYFIXTfm+ljSeG0Xt+XwRENCEMNybW2x4+91RpbhhpkXclXuiUVYSphimGuN9JnIzgAyqrlVaKBs/TsDnjJrY5bvCkZlmUsWc+WLsi6/JNUWWygYn3jxIs3KeB7GisHeZGZkpwYqN7ov9XmifLARgNVEZ72QHcLgJuIqEqxvLdbS+pAItC2pa0yKwEhFYayDr3H3wUKlVqC51nlGcdo3gJFmxAkRIDgrFZmMctgTHIZ5gVgEhaL+AuZELvOcyCZuanMJ7b7+L//2zX+C6m6/HZz7/OUTMsTdRFrWj03j5bSvaqJS6pYBg1q4mHN1/FHd/7gpcf9s2qk/oqQq6fMSKABu7uqw4eGAYNbUTZDymYMuWaAIiDFSH9c2zVZIn/eNA6xDwXh1VawnqyaEiXXmGDnsKghDO5ImBhdfFNBmPCWmmtt6Kt/aPQsDEkQSE7LsqBhvyQmAgWCTIjwb2Msaw2WXCP60sQU9UWOHhixkErl65h+qyJEzJ/vliE5vTya5OVD/5OMZbW7Ht7/8/JG3fDn1IqFY898UD5qN90oCsPnpgVrFbUviWNkYXof7ePhw78gFOHj+Bhto6XtNJIiwqxLYdO7Bp62YFXo2grbIvtB5aBh5zDSqiFK/cuNGUrpT+5/btRDtVMKhEXtPjRWq0Drdv1Rww5sZnrZ6LKkh3vxsvvGGBw0UyZ54BRVyyacm9Us1q85AE7aHKOt19WuxoaXNgdNytiDZCTsmjc00eCb9ynw8lyV7I0tL8aAizUqHS1qNFYN4IaEBWYLDiFHqPHEbn/rdJGkvApv/rQURmZcOrN7MQPIXqOhtGKCRQSrXMm66Lgp5TBl8lN857kLUXfTYCMjRzUZ21q9uJ/e+NobfPQaDBNK65OgZbymmNTJXN2fuWz+6E1rE1iYC4Zh47NoKeHjsmJl248op45q0015Y1ORjreKMakHUdH9x1tms21pwm6BT4oqMdtZ4xJOjM2GqIx1XGFBgpouKb2fx1dhACaHdk/Cb4hapuHd6uJZ6FznhhxIHevEmERAAzayZzzzkRpnASgFj7X79B9VNPYNv/8/8i5+ZbYaLzQxAVNVeqSb+E8CtYkTHmRJIS9CgvCUXhhhkLe7udYwb248U//BEvPPs8rth3JXbt2YXN2zYjkn0JhPbWW2/h3nvvVUT93t5eBQ6du9/iPpWenq5UbH/605/i7rvvnvv2meeLXc8999yDG264AZWVlfj617+Or371q2fWNfvkF7/4BR5++GG1/WN0CREHrdkmjlibNm2iWzpBJn9pOTk5CvAaHR2tXllsn+bbN4lJT0/P7CbO+zg5OUlngP342Mc+hm3btp33c+v1DYn1QprOZrPNZOIX8ul19BlfALJKOKUQIiqQFlrCj4+7WBBxqkf520qlVpl4i2KCWHWKDWtSEu1HE81E94udWJCW9FlH5+RK7orcbMU+boLKGt20berptSvlLHk9lIq/+XlmMpPNyi4u0JVZRTLeQ6SYDE7aO0XJlkrJTK6mJrM4lElLooJQpUbiL3GSYzw8No2OHhdqm13oH6LKbKYB+Zl6qrMalMLKSp5rq7kuF1XgJmw6NPZ5cayNSW8qxsSQ7LMzR4eMOC/0lH7TimmreUTW57Z8CcgqAzS5Ro16HRjh0u+xYYjLmNcJQtXhItA1iUBWYcZmBUUgNshIUOvKTdzW5xFen3slINZTJ06iprIaddV1uOraq3H9LTcoJqiOySYXx5Ki5HWs0qEC4LFPYrK3DsHTUwgjIOGyK4tRsjlbgViXcx0VcoiNYIjm5ikcPjJC4GcQYmOMKCuPRFpaiLJpW876V/royT3TwdiMWXlv4Ry2k0qsveNehNNaOS5cRwubGRubROKQjCy2Lobga7PR6pBKrFXVU8q210ZAazoJMlmZBIJQjTWaymYytvCleJwvvhInAbD29nGsRGVZGSvJayZa66RShTWFY6YUKv/LuSRKbr7Y3DYb3FRPrP/90+g/dRJJW7YikezcxC3bEBwgjGlfPC7+1icNyOpvR2xl+is5G1Fa6GMysrurG20Eww9QiXWEAHmT2azUByIiOA6Li1Oqq4lUXo1PSFS2VAJuXcsmY0k3x4v1VFd5ydGhlP2LDVRtp7pKEhX+57YhqpB3UwmjptuLEcvMOxRrR2m6DuEUpyLXRWtrEAG53woZScZxLVQ07Or3YOcmqtyXmRDCe66oGy63zaq0TkzOqLNOcnsTVLibskyrcZ2TAFr5jIxZRIkkPlaPxHgDnX/0iKJaqz7YP8Yzy42T9n0tAueLQCADWZ1TkxDCWPuf/0wg6yFE5+cjoXwT1Vgvw5gzFJ29HgVinZryoIC56LycEOQQGC/ODf4wDzrfMdde960ISI16corq871Oqv/a0dFpVzUzURMvpQtKCt1hIsKD/F7gwbei7v+9EZfM/n4HqqomcOjQEK64IgHbt8cop0yjkUUHrWkRWIEIaEDWFQiitopViYDkDZxUY23xTKDZPYE2ugQadEFICQ5FsT4GucERECkV+U9rWgSWEwHiVzHC/FM1c08iKNLFesyG5CC64XnpDqRDVAhr/cwxzG1eirh4nE7OOV5D0wvPIbaIKqilZUqV1UxnwpVsVir8N7ba0dhsR32THTu3hmHHlnCF0woOmlbKrHU1dcoZsaOtXdXf9l59JfI25JHQnrKSXfHJdf3617/G1772Nbr2RKGhoWFeIGsuXfCmpqbwb//2b/jMZz4z734sdj0Cni0qKiI5cgSPPPIIvvCFL5yz3scffxzf/OY3kZCQoACvc4Gsosh6xx13QObu4mw526R/ouRqICB6sX2ab98EnCrLxVpKSgrnLr0akPUigdKArJ/97EVCtLpvy8TbzkKxqLKKSmtbmwW9ZAV6+EZoqJ72FiZOvglATKYCG1VbwyhtbTbPMEtFYVOz41nd4+XrW5OihxTeunucaGi0oL7RRithNwGaZiYOJXloplWcHiG0jfMXMMWlirn89lzuaRynulhltZVA8mkWZ/RqgJLAx6hIDtM5dvKHRKscd9mfQ6fsqKx3cr9o3ZUcjJ3lJtoRBikVlUsVx9VYb/8EFSpJaJGBrgCOrt6oUwXW2HDN+nI14r/et+FLQNa5sebPWgERhglobXKPo8Y1imYmFsIJXBUwa25wJFIJaI0LMimFVhMtYIQr609qj3P3V3u+8Ai4Ca4ZGhzCS8/9kepw/UhMTsL23TuwZdsWBTa02b0YGPHgeJUDRyrsKM4hUDOICr/vfUByVCgu31eKrNwkgm+WxxqVe4+AWEWJta52EkePjaKsLAo7d8YoElYox62+1BxUR7W7dbSw8SoLm1reV4anvHB5gO3ZOpTRASUhQkeQyOJ67SaY18119w0wuUJls4rTk5zQe9W4q5hFtA0s4ErzhzG7jCVkf6TwPDxKa2OqtHXQXqenz4UcIfsUhiqFtjgCWvyltb/xOvqOHlEFd0l6bbjrHhgJQAtaCSSQvwTBD/spv5dZJcy17L4GZF3L6K/utkXp3MkkuZ0geKvFolTPxXKqvbWNVmLNGB8b57XejcKSIhSXlaKQyVQBsJpDQnzq+u4BCVHTDlS6R/BHWzs2GeJwmzmT40fmkbic3axOoGXQi+ou4FirFwXJM8rkmXFALAmERsk5nf0l7e9LHgEO9TBp8eJkjR2vvWdDWaER20tJjEnS01Fm5ccUakxHAs7gkEvd82fu/STdkygdFhaEuBjOP2jXnEh1klhaOEs+KYQOQCaCPvTEbguRyR/yJpf8wGkbCJgIBCSQlReKaV6cxPFg8PRp9Bx8H5O0mRSbz4TtuyipFIP6Fhcqa2wKYCgg+H17I5WggghzaE2LwKWIgNy/uroJOmig8yHrIELMKOEcXOofmelmJVShARQvReT9c53ioCO5muPHR6nG1YvCjREoKo5EXl44wRlrS0bzz4hqvZ4vAhqQdb6oaK/5cgRcBLOKmMpBZx86p3kvpVLrVn0cyglmFWfAEKk5EeCqNS0Ci42A1Del1jBK4nQbAayHmyn0R82VUAqKXL4BKEkjUVeERC6QdBIXiO4D72OqsxPG6CgUfOJTiMzMWtG8vowN7HSHraiy4uXXR5Ua6+ayMDr4ihOd5Dp0mJyYpNv2IJ5/5jmVJywsLkL5lnJs2rKZ400z8yLn5tsWGy9f/fyLL76I+++/XwF4u7q6SHoWT9EPm8RHQJrSnnjiCaWi+uG7Hz5b7HpuvPFGXH755WhpacFDDz2EBx544MOV/eXZo48+ih/+8IcoLCzE+RQ/HVT3PXXqFF599VU89thj6pvync8SL7jYPolC7NltaGgIslysjdLp67XXXtOArBcJlAZk9TEgq0y4ZRLlpJqmWJHarG6qILhp8+XC8DDV2PrtGBtzKQXXpCQzUglqzcgMQTKfJ1ClVaoK/lAYv8h5qb29ghGQc0qUfS1U/u3rc6KLCq1NzVSloqKGYiaXhKGwIIy2caLmcYERwgr2yRdXJXGSJhZ6ff0unCaYVZRZxepqc2koNnERlbGzmUAz3/Ktf6XQL7szQmXWLqqnHT3tpJKaF+kpwSgtMCplVt/q8eJ64+C4yMIB7vFWDiY7vTCzoJpFRda9tH6OYiHvQgPdxW1J+3QgRsBXgaxyLESd1UklVpuX1t5eqrgTmNBJdmyXx4I+r10lEtL0YSgKjkYOWbIRBLkKc1Zr6zsCMnEWYM1vn/gNSSlBuOtTdyMrJxtx8XEkQlFllCo47x21wUITBgGgmD09cE/2oqO5G/kFKbjpjh0ICw+BcZlSazJ2HRx04O23B9RYVcalRYWR2FAQTkajjDF851yUe37vmLB+dagkWGeApIj4CECAOvlJOsSEehFJoToT+73Ye4oomAnw4+jxcZLSHHRTMJBAFIIN+SFUMTMgJMR/iGdC6pH9OVVpQTNthp1OL+Jig7EhN5RFaD2BLASviAor4+QvbaqnG4OVp1H/u6cRlpiI4r/6a4SnpcP0FwsZf9kPf+5ncHCwsvkxGo2KwT2XHT27XzKfHRgYwOHDhxVTWmx/8vLyUFpailtuueWcJJl8T6yL5B7+7rvvqu+Wl5djz549KCgomPfzs9tazKMGZF1MtPz3s3JO2qw2pcDaWF+P+to6NFFlwGAwIoqJ8oysLKSmpSKVVlmixBoRGcn7aJhK4sr57UvNNu1GBUGsTSQ/9XC8uJlA1qtpDajn+JDp93O6KuMGG4UJRJm1oXdGHUMs3i7foENRKpDIe6UUFrS2uhEQxRJiq9HW5cLxaqdSaDUwd3PVTjOy04IvicKcFG9kbOcguFlyk1Yuk0JsYY5ElhESXCb4t9QsBNSazHFBeqqRj1RqJcFFpiAaoW51zxNta2sXgUAEsgqIVew9ew4dQN3T/4WI9AwqsW5G8o6d8ESloqOXStL1VDJqcWDb5jC6XYUghfMimTtoQPe1O1cDYctyzxKnQ1FmbWu3o6XNpsQpykrCkZ1lVk4igRAHbR8XFgHJs3a021B5epx1VxvrQEG45toEZGaGadeqhYVQ+9RFIqABWS8SIO1tn4vANCvLTqqzikNgI/MIp1xDcEx7KIphwBWGZOToIxFC97f58gk+tzNah3wqAtQRg435hQMNXjT0Mc9AIZCcRB22Zc0440WwFiNZqgvNFRxU45zoaEfNb56Cjc/L//Z+xBeXwEh10JVqUjfyMAnT2e1SNRHBiUi75opIJewhonAC3nTYHWioq0dVRSU+OPQBsnNzcP3NNyAtI03V5VaqP762nkOHDuHuu+9W3RLCvyiZzm0TnCMKkFTaH//4R6rdb5/79pnnS1nPnXfeiSNHjuDBBx9UyqtnVvaXJwJw/dWvfoW9e/fi2WefVbUCeUvECmSZ26T28Nd//df4M51FBJD65JNPqrrCSuzb3O2c73k9883//d//rQFZzxegv7yuAVl9DMg63/ESwOHEhIsIbgdlhmkRTzDr8JBTgQ5NVGMVVdZIqmpGRRvUYySL5JGRBqL+gxQITwO2zhfVwHzNQmu4QZ47NXUW9FMpTCTS42kJl0Kl37QUI58bEU6FDQFvBmqTBIadoM9asrfFOrez26mKMTlMdmWmM0YEcOgJ2PCHoowUn2aUW2itxKLXOJnoBTkGlG7gfsQEU5nVv49z8wBQ2+NFU78XBp6z27KBbFoPJK/cmDVQfwYBvd++DGSde2BmkwpdZMa2uyeV5Qv12znZIwiPqqxxOhMSg8yIlyXYDCPZshqodW4E18/zhroGVJ+uwpGDh5GckoxPf/4znCzHE0BgQFevC00dBLHUOhFN8ElOKkEp1VWYGOpHdEw4CkszsPPyQpWsX2pEZHIvBApxEmhunkJtzbhyEdi6LQbp6SEcW5Bo5QON3YSosE7YgP4JHbpHRInVS2KEDkaSZHMTuDB5khMPsHZxwaTJfLvj5LrHSYbp6nagucWmAB4iiSsqrNlUgElONKqx+3zf9aXXhFAnBKiRMTpEDLrRQ3LPwOAMISY2OhiZGSZszDer8aIor/lb85B1O97Whtrf/hpuq0VZEaXs2o24klIec/8eF/nLsTh+/LhK0sTzOlVVVUUSJzOZc5ochwMHDkAsg+x2+5x3Zp4K+/qXv/wloueAj+U7X/7ylxVz+uwvfPKTn8TPfvazFQGzakDWs6O7fv4W9VWb1co8yxCXYSqdDyq18zEy5CfGxzlvtqp7awoBrHm0TU7LSOc9N0URSHz12uGmksr4tAt/dnSif9qOTH24IjsV6aMveuCmeG8cGJ8maVCHeoKR4uh8kRmnw0aKKiRQgSLMJHdVra12BMYmOHYhUfVUrQPd/R7s3mzi/F6PRAJHLzWGWi7Vdo4PhkZczCnRindQyPYCZp1WSqxmDvdEfV/ySeFhwcxNBisb54jwYKXWKuA1rWkRWK8RCDQgq1h72sfGMHDyOAZOnYQoI6XvvQppV1+D6fAEzrXMqBCnK+acJb+8g3ac+TkmXitm3MDW63mg7ZfvREByFCMUhemmmEdlNdXkSM40m4KQxdy+uNQlkIARyvuSABG0pkVgYtzFOpmDJMphVXu9+uoEbNgwo8qqnSPa+bHcCGhA1uVGUPv+WkVAZvxChq33jLPuNI4RCqpk6yOQHRSBfH2UcnkxEdCqNS0CF4uAjMsExNrDOkzrIFDfR/c3pnszmGMqTNFRiZUkWKnFXGxFfH+alvDOyUlUPf6fGCEQMHXP5Ujaug3xZeUrntcXR5pe1kWOV0wph7rLd0WomogIe4gonOSzJwnabGpowpuvvaFy2CIss33nDhSVFjE/ErYulVk76MKxe/dudbTmA6oePXoUd9xxhzoe1dXVH8nfzz3ES1mPAFife+45pcwqQNW57m1K4OeuuxQY9Utf+pICum7cuFFtUr6zbdu2uZtXz3/0ox/hBz/4AVJTU3HixAm6pLetyL6ds6F5XtCArG/NE5VzX9KArH4AZJXDJhd6AaVJcdnFQrmVSq2trVP8UVnR3GShxZeLr0+rSZZMtPLzwxGfYFYJY23Cde6JH6ivzJ5HLoKju7okmTOFxiYbFTWc2LEtEqXFYcjNCYGJyZ1AbjPWMlSiIQDo+CmCxDoJeph044Z9USgtClV2ev6gzCrHUMngO3WobnTShtCCCBaWctIN2FZqRHqyf8vbu3hNnLDq8FqVDIC9iKCloYBZ91AxSMOiBPIveHn77i9AVtlLSSgIoNVFlqwotbYS0FrjGUO1awRDAlgIDkexPhbbDfEK3Bo2j4Xs8qKlfdsXIvDay6/i8IFDJDFF0uK4EFfuuxqhYWFKifvtIzY0tZM1ygFAbpoHJTluPP/f76G3Zwh3feYKfj4D0bHhy5roz9wzvXjzzQHacowp4OqGDRHYsSNGkap8ZRwqKnOiKtfQN433G3QYmZJfEO8ZBTqUZ+gQH66DST+9ZOX1CSY36hqsqKyaIlt3Crt3RGL71kiShQwID9erhIwvnC8X64OQU4cJUjldbUMN96e+0Y5yqtKXcfyTl21CTLReKezKevzxXisJDicL771HDqGPgMrB0xXY+MlPY8Odd6kd8lVA2sWOm6+/L8kkUapsoKrl5z//eYLem3mtmB/IKuDW2267Tdm65+bm4vbbb+fcxKSY1PI9aTfffLOyJxI2tRyzhx9+GD//+c/Ve8KivuyyyyDJsueff14BWO+77z585zvfOQc0q76wiH80IOsiguVnHx0nWLWnswunmLg8deIUWpp4rvF6sbG4EKXlZbQI20LQQwIioiJJdqD6CBkPvqa+enbILQSximL/09YmiD3gp0LzkMGxYTguPgdUY0zeN0W9XMiD79QBLt4f9hZAgVmz4xdSYji7R9rfy43ATD4H2M/x3YlqBxLjg5GfZcDWYqMC5Cx3/Rf7vmxfxn0zjzPAVlFpFaUSyZm0UYl+mMAhIQYLCTiXRJ6cLCNSk43sq8Evxw0Xi4n2vhYBiUCgAVndDjvGaelY+cvHFKA1actWpFy2B9Elm9He5UZVnR1Hjk+q/Om+vZGIZbFXQIP+OHfQznD/jYDcq4SAIWTT05yjv/P+OJVZg5GRbsJlOyORnmZWQGvtvPTfY7xSPReyjocJoz//uR9VlRPKVUichTYWRNBxIbBrZCsV40BejwZkDeSj7//7LnUnN+tO1e5RnGa9qYqPCRRNucmcgfSgMMRSTEVrWgQuFgE3c0lWKrG+TyXWt2q9JEfrkJc4U8dPoPCKYZF4aBGp6HjrDZLqTsI2NIjknbtQ+KnPrHihgqkPlf9458Ckwokk011iQ54Zm0pCz+RfBMw6NUWga2s73nlzP1587kXccc/Hcc0N1yCNLk7hEWSFr7MmOX4RmZAcveT4JVc+K1IhOfqvfe1reOqpp7B161a8/PLLzB9JhvHctpT1vPjii7j//vuVI5a4uCUnJ59Z8fDwMMSdTbb3u9/9DldddRXKysroIDmIb33rW+p7Zz7MJ7J9WdcLL7yAffv24be//a16bSX2be52zvdcA7JqQNbznRvq9f/1v/6Xshn8rJ8AWefujAKzEog4NurEKJPEIyMOZeE6MeFWky55X7gLooYQF2tEQiLV2Ki0GUWVVhNVWrUC7dxoBuZzuW8IG1kUtto77WSbOpjc8SrgcyKt4LLITs5IN0Ps6oRZEqhtigq2vX1OWmHZGSfnTHwS9CgrDmUilmrI/I35epNjLTL4/UMe1Le60NHtxiiVXMoKDMjPNiKFCqb+qKgmcZd9c3IQ3EgGV2O/DnU900iLATZl6pAeO2NH4OvHR+uf70XAn4Css9GTu74kFsamnRiYtqF32ooBD63kvW4FchU6Y0pQCFKDQpFOAIMothppAOMPytKz+6g9nhsBm43HeHIKzz37HCqOn1IT5PItm5CVk43hsSC097CI2OCiJew0ivIN8Ez1Y7irDYN9YzCHGnHNTVuoKBfPseFH7T/O3dKFX+nrs6OJpKrm5klVJNq0KYoW4OGcSJrXfAwh9wlZ+sZFfZWWvGT9jpAA4eV9MSaMVrhROmRRgTUpEpAwiBLrYpq6x5JU0UFykNgWttG2UH6PUZF6FOSHqvFUaGjQGeDnYta92p+12jxMvEyjuY0qb71OkuQ8LOxBuT0IGCWVgFwpQouSjb83D1U+LX296D54AE3P/Q/S9l6BzGuvQ2RmFowEhGttZSMgiaG/+qu/UiBWsRyabecDsn73u9/FT3/6U15H8pTC6lzl1R/+8Id49NFH1Sree+899ZkRWklJckwUNb/4xS/ikUceOZMke+yxx/DP//zP6vPCrJ6b4Jrtx2IeNSDrYqLlu5+VBKuAoAf6+9HX24uujk4+H2B+ZVTlSoKDCbgJDaHjTTRSUlOU8moyH80hQvj0n0JNs4cEJxabmmgHGBVkxC2mTCr1mwhjXfh13MIcwcgUUNUNdA7PqJiL9VsxFd6TeQ+NpPWb1lY/As1U229odaKl060UUK/YbkZSnOQnVjd3IyQhJ8eZ4+MejHHcMDrm5vjBjUmOJ4RQ6+Yij0ZDkCI3iXJJHB1u4mINVGsVhxgN2Lb6Z4+2xUsRgUABsqoiJCdAvR8cRj8JYaNUQQpNTkL2dTfAG5sOS1A8Tpy2UAnToxSZN24wo6iA904qsQZybvlSnHPaOhcWAamRidtIP51GxDWlr99B10MP62QGOo2YqaoVQhJwkLpPLWyN2qfWcwSqqydQVzeJgQE7UlJCCGpIUE6Y2vVrPR/1S79vGpD10sdY28Klj8Ag6009XGoJZB2mMiupjSgIjkKRPgaxOiPC6AqnNS0CZ0dAoEp2pxc9Y0BlFzAwQUCrY4YcvSFZp2r5LFEtuok7xHhrK4GsJ9Dy8ot0WytC8b1/DVNMNAxUQV3p1sJaSV2jTRF3I+g8c9WeCCTEGTDrOuNyuhSYtfLUaSU243a5ERkdiSv2XYXs3GxEREQogORK92st1/fjH/8Y3//+91UO9X/+53+wd+9elYvfv3+/qgE4CDYWpdPPfe5zqptdXV34j//4D/X8gQceQEZGhnq+2PVI7r+4uFi5ZglQ9emnn1axdbvdClT75ptvIi0tDYcOHeL8U4+vfvWrShhDhAl+//vfo6SkROWD5T35rrwvc1ypHfzt3/7tkvqkvrSEfzQgqwZkveBp489A1vl2bGrKTUArE9nNFiq1UkGy3aISxrEEsmZmhnIJQyItTaOijYpJKBMwA5PJ0jTm6XwRDZzXJIHT00u2/NFJyqQ7FWihcCOVt0rCER0lRbwglXAMZMCTqIs0NDtojWUhswTYtS0MOZkmJCfRJpg2WazP+3wT1pOAmQ6ecODIKQcHWsHITddjc7EJ0ZG8HvgpYFlARKLM2jJIZdbKaRbLgFiOVXfm6ZCfRLtognC0a5zPn54+1UF/BLKeHUBR3RpjUmFGnXWUCq1kywabyZQNZYIhlmDWMEQT0GBCMEw6uYBRxfjslWh/+3wEhgaH0N7Shtf+9Bo62tpx31fuQxkV40Dl3dP1TlTVE0hg8SAhNghXbNej7lQd3nz5GAqK06nEmomSTdmIEjTnEttsUaimZgLvvT+kxpUJCSbs2ROHtNSQNb32CphUwBUOcTGgKnlDH1DbM6PebeT9bnMmUJQKdZ+Qc38p94lp3oAcVBwTJbITpyZVYUxIQvlk5l61N4ZJimAF2lhieFfla3IPFYCJjA+GR9wcB9KuuNKi7IJjCDYp2hCC7ZvDFNDEyAL0umrc+d7Dh1D15OMIjU9ATEEB0q64EpFZ2dD5w8DOjw6GJIQkiXR2mw/IKoTLj3/84zhy5AgeeughSHJrbrNYLHQg2aBekoLQnXfeCbEx+spXvsJrkIGFxzomEj9E1sn6ipjQHKMK73zrm7vuhTzXgKwLiZJvfkbAq5LYdDqcyu7LynOpheoBTVQJrq2uwSgB0XKuFvJ8Kdu8GYXFRUhJS1XAVQFj+1OT+5OXl+z3nX045hpUBKa8YKqEG1iMX4I6v9xPRyxATbcXb1SDLhgsWin7N5IHY7xUM/eP+bA/HcOL9VVIyAPDHry834YpjvW2l5mRl6lHekqwGtOvJXndJsQYEoLbmENp7yJxmiqtAmwVVTxRZk1LoTNMqhHxcXrEMN8k4wshEkmOUpaljMkuFi/tfS0ClzoCgQJkFTKYk4pD9c/8Dn1HDiMiIxOJ23cg49ob0c2cXGPLTN401ByMa6+i4mWqiaQ4/7qHXupzRVv/2kRA5ryyHD85iQq6p4yRgBFPAMIuuqhIbl/qH9o9aG2OjS9tdXycCvPtVrz6ah8BznrceksKkpJMSizIl/qp9cW/IqABWf3reGm9PX8E7F4PuqYtSpn1XWcPspljKCeQNV8fhUQKqBhZYyJN8fwr0N4JqAgIjsLJsVf/OFDXC7xbPyMqUsRcUjkxjBlxyztXPAQ0DldV4sRP/h0hdPzK/dgdiN1QgDBaxK90s9mmMTjsxouvjUKe790dofAhiRQ9m5t7GWatrrO9Ey+/8BJaW1px7Y3XYcv2rQrMajRSVsjPcosXiqMI7Nxzzz3KmUQ+J0qoZrMZIiIhuVfJ7YtzmiJC8v1jx44pxzX5rCig7tixQ54ynotbj3xHVFmlXiB53qioKGxhPbS2thb9FCsQ8YE//elPqhYgn+2leIG4tgkAVo7BZuZ7U1JSICBSqSFIk77Ld2aPz1L6pFa0yH80IOtbC4qYjgdEar0B19YbkNXtnlYMUwuT2FYu4xNOpdIqiq2jVG6dmHApwF10tAEZBLamp4VSWcTMH7VY4i3vhhFwJ88622EXQR52+zSGhl3oofpoK9XEJiep4sfXi2kjm58bSltcAp7WgQLXUg+dxSq/KY9SZu2gMms/lWxzsszYtikc8bF6Wgb7fmJW2E8COuod8KCDKn0CchLQZ2mBEXkZemSmXtxicqnxu9Tfk32bsAEdVAk63elFFdldO3J0KE2HUmYNM2nXuEt9DNbT+tcDkFUGdk4mFya8Lox5nRiiOmufl4vHinGqtoYQxJAVFI4CQxSTDrTKYppBrwCt6+lIrv99qaqoxGsvv6pYhLFxsVRkvRaxidno7p9W13hR69pcSFBDggfT9hFUn2rCySONuPFj27H9so1khobCYFz6tV9IVI2Nk1wsnPxNctIYjdKySCQmmNc80S/2xyMWkhwGeF/oACy0r5HxbhbVukWxOzkKiKbySrhpadMgSca4XNNoaLLh1OlJpXIv6uYbC0KVVaEiuhCM4ctjbOKclGL7CAGsUnRuoaJsb7+LRBc9UljMy0ijqwOfR0cH/4W0s/7upZOdHRisOEVA62FM9XSj5AtfQhITKXqTWQOzrvAldGho6IzN0LPPPotvf/vbVEKKR1VV1ZnXZzeZk5PDea0Df/jDH1SyafZ1eZTEU3Z2tnrpJz/5iUqa/ehHP1Is7yuvvFKxqdWbc/6577778Morr+D666/Hk08+OeedxT/VgKyLj5kvfEMSp1OTUxgaHEBjQyOaG5vQwsVgNFBlKRwJSYksUichKSUZ0TExXKKVYoIosEoic25i2hf252J9cHAMOMUx4OvObhx1DuI6UxoLTLGquGRYwnhPjSvdvK9SmbVtCKjvFRKhl4QQHTamAAVU0gj3H6Hai4XPL94XMI7VDjXea+l0YYDuK1uKjbh8q6jhz4x51mpHpG+SZ5AcitU6rQo94yT6CPFHgEOi2Cq5FWmhIcFqzJGcJGMPwwyRWlNpXatDp213GREIFCDrCIt9PQffx3BdLdwEtebecitC80rgMCXgRJUTdQ02ZGeZkMtFbDfD/cSZYhmHXvuqn0RA5r4yHhTl8IFBFxqb6GI04MIEcxqFnMOXl9K5iEROf3Be85OQ+2U3RWV+eNiJd94ZVLVUUWUtLIwgkXL92QL75QHy005rQFY/PXBat8+JgLgB2uBR9aUW9wSa6fzST5XWMuYaNuqjkcsak9SctKZFQCIwReXVfjrkHWzkI5VYI4UQnRyEQuJMxdlnKUqscyPrZXFG8vptr76Cye5ueD1u5N1+B1J2XTb3YyvyXHIcFuY2jp+iiCBd+STPsbksDLu3hysi7iwZV3LZdpsdxz84BqnbdXd1E8Sag5s+djNEETQ8Yn2NJyYmJnDvvfcqkOpsoAUsum/fPohDmjyfbQJwve2229SfL7/8sgKfzr63mPXMfkfUVEWwQgQvZlt6ejoefvhh3HTTTbMvqceamhoFfG1s5Mk4p0m+VxzkvvGNbyDyLIe+pfRpzqoX9FQDsmpA1gueKOsNyDp3Z1VhmhfWsTEn0eZ2dHRY0Nfn4A/arQrqAmaNiTEiLs7EAo2eP1DaevHRTMZ0IIMV58YwEJ8LyFHUuFra7FQVs6K7h6qd8UbFTBa7HZFKl6SOgDJmb8yBFCeq1SsAq8jIn6y0KpvgNAJ883KocphqUGplwt729eYkQHmCiiiizNrZ6+ZvnsqlVG8RQKskmc1+CvpUynsssJ5sp/pQg1cVU9NiRXXPi0S6BIeuNyU5Xz/R/Lh/6wHIOjf8bu80RKG1zTOFJvc4Wmkza/O6EaEzICmYRAWqtMZTrTVGxzEBXzPqghdhODt3S9rz1YqAsBptVhsOvX8Qz/zX77Fl2xZs3bEdGTkbMOWMREUdyUzjTC+xWHPZFoJ0gidw/FAdATxjcNpduPbmLSjZnH2GZbjYfksBSCbsvb02sizH1HhTrw8ikzKGbMcIjhPWxiZWSA2yz2NWYIhgm+4RL7pGZx4jQ3RIiSF5g6KQaTE6hNDxaCkkWFm/i+SxyYlpdHOM3dwii01ZE6anmbCJBbBY2uUGUw3cl5vYK1rJIB4im1hITB1UTBP1Xrfbi5LCUORlz4z/zOucxOSyTMFBK/H6Z36P7gPvq4RX8s7diCaQMtiP7MN9+Vybr2+/+93v8Pd///fnBbKOj5Ouz3a29ZIkmH75y1+qRJW8//bbb2Pjxo148MEH8dxzz+H+++/Ht771LXnrI+173/seBPQqDG1Jli2naUDW5URvdb8r1l5WKwk8VOOVZWhwEIMDgxggQ39keBgCrk5JSUVaRjryCzYgKzsLScnJ0FPZ19/b0LQdre5JnHANoZuKKXeYs1AaHAtj0Ixa51L3z8V7hNWlQ0WHFx+00C6ec9945uHL0nVI5T02ls99fza81L33ve9xOIhB2nfXNjlxgHN7IaduLzMhJVGPiDDfOhI2EqdFlbWHeUkhzfRRAV6UZKeZtxQF+6hI5iWp2iiPEeHBzK3oCCYKUlZ9ZhPnJuQNB2IOyvfOOq1H54vAegeyeqQoS+Xyvg+OoOWVl2GOjaWLQQ6Sr74eFpIlGppYe+h2su4wjT07w5VDRVTkDBnufDHTXtcisFYREDGPto6ZuXxdvYXETb1SC8+mYEVysoliFdq5u1bHxhe2ayURp6pqgkpqU3QwtGHbtliV6zKSuOzLRGVfiJ3Wh/kjoAFZ54+L9qr/RsA2TWIihVNOuodxijmHcLr+SX2pKDgaKfpQVWPyrdmo/8baH3su4iJO5iqEBN3U70XTAGBgnWRTBpCXSFcfCoysVHMwfzxKgl3PoYPoePstFN/7eWTfeBP0Qkpf4dye5MO6e5yo57zneIUVBXkm7N4RplxmziZCCYC1obYeb7/xttrV0vJSlHDJ25Cn3MSCfb1wtMgDNMJ54vHjx5UiqyitijLrUtpi1+MhaEdAqm1tbSgrK0N2dvZ5NyufbW9vpyBPo8oVC+g1Ly+PdbwLn5CL7dN5OzDPGxqQVQOyznNafPjSegayyl5KoV0pIbDYLkVpKVgPDTnQ02Pnj1qArXb1d1paCLKo0JpPZmEqbWDFElZrgRsBNwsJLqcXQyNOniMuWu5MYHDIhdgYA0qKwrB9WyRMBAQaDIE3FBXgjoBZJ6gm0sUBS0W1lfa7Vmyj5W55cSiyM5nsorqbrze5Nsg1YWiMSnKtLrzzgR3xMUHYUmRELgGtSfH+yZqT/eL/SimoZwx4s4bAbAKZ9hXNKAWlsbgaeGetr5+Nvtm/9QZkpbms+m24CGh1EtA6Nu1Al8eCGvcYOghuFbBDiSEWxUw2lBpjEEl9VrGC0ZrvRsBGYE5XZzcOvPMeXvjDC/jUvZ/GjWQ0jk0ZUNM8jf1HyIYu4GR6swnR4VThburAs799l2CdeFx5bRnSsxIQl0CE/xKbXG/b2qy035ggkHWUQKAQXHNtIglSJETQfm2tgAai/iXJklNUYBV17laqxYWR+LkpU4e8JCCLljUiQKtn8iRoiTcEUWKdoGp9I5VY9783yn3VkfRjwBYqtOflhJxxOlirGCz0kApxqZNjmQ+OWWhN7FLK8oX5IQSxmgkk0StyTjBjFeTrO7LQHT7P54S97ZVExp9fRec7+wleNSOuuBg5t9wGE61ptHZpInAxIOt8WzUwAfnEE0/gH//xH6mG7FLqqk899ZT66A033IDKykp8/etfx1e/+tVzvv6LX/xCMbIlSSVWRmI9NLfZqSgmAJSFtHfffZfXujj8zd/8zUI+rn1mjSIg87aJ8Ql0MJlZfboSp09VoIcKDZK4FNBqQWEhikpLVMIyiuqrcn4ZuQRTytLf1FfnC3EDiUtvOXr4lhexJCvtMiQgk+ooS7z1ndnE7HxLnDAGJrx4u5aJ/FEWImK8KMvQYWeuTt1f1/mt40w81vqJHA/J+bX3ePD+MRvsVJ83M513xfYQ5BLU6ktN9ZWMI8lDSE5F3H9EmVXGI929LrUIyFXejyaYNZ2q8FkZRmSmm5QDjpBvg5Y6ePOlQGh9WXIE5Nos1/aVaCu5rtn+rHcgq53kj96jR1gkPoTeI4dQ9JnPIe2aG6n+HYFqzj/ffm+CCqwhJPUxN5phQgyBgRoAffbs0B59LQLTvJZI7WN0zEVCpwOVVRY1vy8rDUNxYRg2bghZc4cZX4tZIPVHxiKTky5UVIzjpZd6sH17LK68MoHiLgYSbHycsRxIB8qP9lUDsvrRwdK6uqAIiDKrLKOsMfVMW/GOow+DVGZNDwrDZkMcdhgTmHuQ/7QWiBGYcugwQIGVd+pZnyEJupy5omIKi2xMmXHykbrMSrVpsnvFJaLlpRdR8R8/Q/6ddyHr+htIuMuGMSJipTaj1iNTUcHPNFHU5M13JlQNKC3FgPISOmCnfqg8Kh92u9wYJbjz9KnTOHH0BE4eO05V1ltw06030yExcslAzxXdIW1lax4BDciqAVkveBKudyDr2TsvapsWKh6MjjppoeKgIokDIwQrigKCJAODqLIZFmagOque6jgmBUaIlgkaVVq1hPHZ0Vz/f9tsM9Zvza12pcw6Tgs4A2shopCRRYZyWqqJz4MpDR54YCdRNJ2iLV4TY1NTZ1O2eaG0vyvIF2VWIy2VmbD18eqdDLoctMvpG5xWyn3DYx7YHV5sKqL9V5YBURE6BVj2xzPdQbaXhbYFohLUMsg94L7mJQI7coOoyuqF2f9FlvzxsPhVn9cbkHVu8FXCXsCsZM12uqfQTUCrWMAIpEfP61a4UmkNQXpwGOJ1ZkSRUavjb2g9gDrmxsHfnw/2D+Dd/e+irbmVKnPjuOr6G1FYtgsna1zoHxY712mUbjChiNe9zpZuNNd34fTJFjI/s3DNTVsQFmHmhPmjE+yFxsRmczOp7yYYbBSdnTauJwj5+RHYvDmKE3gql6yBMrmwfEWFtXvUq9i+oxZaHVExTq75KVFUHU+iYhxzF9GhC93L+T8nKrTDHEc3NMrYyK4Uh5KTjMjJNiMj3UzSz9qBeOfv8Yevyn3fw7mAWPr2UoFVQCP9tFSUIk0Ij2FaihEZBI1IAkaOYaApjYzUU7H4dIVSZTVGRqHw059BREbmiie9Pjwigf1sMUBWUWFtbm7G1772Nbz//vsqcCUlJfj973/PYmIMz9VgKkEXcV47gkceeQRf+MIXzgnu448/jm9+85vKxkkAr2cDWceo1vnv//7v53xvvheEVR4fH68BWecLzhq+JgBVD9kMQ0NUXO3rR29PD/MdQxgfpRK508nrn4f3KBMioyKRmpaOdKqwpnIJoUqDvL5emocTH7H6E1WUV+ydyt5vmyFejeuidEu7788XGxdzSA63DpUkjbRQXaOfoNa4cB1t4nTIivcimfdeQs608eN8wbsEr41RJb6l04XaZhcdVzxU4+cYMM9AQGgQAdq+Wz4UlVZRbxwedWOEyrLDoy71t8vFmQm7LXlIGZOEcpwSFaVX+xMVFUzFEwGScKzC93087XIJjnbgrfLo0aOKbCL3b7H7y8/PV1aBqampCwa2ylx2YGAAhw8fVuvqpzK3qK+Ulpbilltu4XiYk4lltvUKZBXSl50q5jJWbnvtVXicDoQmJiFu514EZZSiqt5FUtw0bHR6KN5oJikuRKksr3dXh2WeLtrXfSQCdoq+TE540NxqI5DVyjw558bM72dnMSfG/L44rsi9SLvX+MgBW6VuKKAKhYEaGy14550BBV4V8nZ5eRRJ3EtTGFulrmub8dEIaEBWHz0wWreWHQGn10NSkxvVnlE6wlAQy0PBpCAzcvURyNNHISmIqpgaoHXZcfaXFUieaMKmQxuFRSq76ObjlDk7UJ4O5LA+H0cHHwNxSCvZFNGRN+7ew4fQ8IdnmMePZD4/A9k33Kjy+iu5rdl1DdLdrrbehlaq+w+PeHDFZREoKghR9ZW5QqsOOlr09/aTXF+F9ylGI/nINAos7NyzC5nZmSoXqdVcZ6MamI8akFUDsl7wzA80IOvZwRAFBLudYLzGSU7Wp1BfP8WksUslgzds4EAjP5yAxVCqlBiV+qZYxsrEfWZZ2ZvN2X3T/vadCIhaxuAQbQIqJgncsKGF4M0tm8NRVhLOxA6LgbSBE7BDIIKdLQS0jIy48Ma7tJvpcCKH8SjZGIKyohACfP0DBOJkkm6CxaNDJx1485Ad5RsNKC0woiCboPbwIB5X3zkXF9MTYnWoEgTU9nrx6mkvkiJ1uK5kxk46JozAfS0LuZhwBtxn1zOQ9eyDOTXtwqjXgWPOQdR4xtBFFm0SAazlVGgtpEJrpj4cBqYcDFRolcSD1tY+AgLWaWlqwa9/9SSv0UHYtecyJKVvxLQhTV3Hg4K8uGZ3CDJSghFi4D3q5eNobe5DRCQT71tzsWtv0ZJ2YlYBaZBEqI4OKw4eHFbKpDfemIQNBLJGEVSwmpdWKS7wf4KTgHHrDHGhgoCaY620N472KjDNrjwCNPncSALDcs5eBQJlMqaXSmGt7XYcOjJBYNQ0tm1homJjGATI6stN+i/2NwIYaWt34CTV5AXIKpZ5l+0IZ9FZCnVUIwxActLscRO71CmqNZ74yb/DMTaKgns+gbjSMkRl58x+RHtcwQgsFMgqyqv/8i//AgGiyrVPT7XMr3zlK/iHf/gHpaApXZKk3+WXX46WlhY89NBDeOCBB87p6aOPPoof/vCHKKQK51tvnZskEQBLZ2fnOd+b74VnnnlGqXhqiqzzRWd1XxNAsixybjgdtDOemkJDXT1qq6tRSQVWAS2ZzSEoKinG5m1bUMhHSRrLeST3z/XY7Cwk9XIsd4JA1jcc3biBds+3mrIUWWmlx3FybxEiSceIDn+upPvP5LRSPb+qMAibqYRu4r1XihZau/QRkGMhqvTvUJF//xE7Cgli3ZirR2EuHWNC/QOAI+NMr1eHcZKlejlGae3gmIuLOOHw542EOD1SSbbJShfiDVVa+beAdAXoKj9nDdR66c+z1d6CXN+/+MUv4vXXXz9n00JC+O53v4tPf/rT55BTzv6wjBMOHDiAe++9lzlw+9lvqzHEL3/5S1qLR5/z3mJeWJdAVv4uPSSDDFWeRt/RDxSQNa5sE8r+5suYmI5A94jxL2pEOuzdFUGXKiOSEzXm+GLOG+2zvhEBmReLQvj+d0fRzntPBIU7SulKt3M7/YqoCG40zNTEfKO3Wi9WKwIDA3aCWTm/aJiC5MFuvjmZBMpIVQdbzdzXau2vtp1LFwENyHrpYqutee0jILl5AbS2TU/ideYghglmlXatOQ3l+liEQM98xEpnI9QmtH98KAJSj7dSibWFwlmn2r042KTD1iwvLi/QISNWB5alLmmb6GjHcHUVOve/DfvIKLY8+H+rvH4Q838r3QRbJTWWt9+fVK4U+/ZS4KUsFEmcB81H5uumq2LFyVM49N5BdLR34JOf+xS279qB2LhYlZ/UwKwrfYT8Z30akPXcGs18R09ns9nkXhNwLdCBrKLQKipMU1NuTNDSa3zciTFaqsgi9hnCppbPiL1oaloI0rgkJ4uC19qobQXcCeojOyzngJ035dExFhQI4OhmIWGIjBMBcKQk0+4t00TLnTCV2NGvMJvGR0Jw3m7I70eAoFJgaZOl06EUjCV5m59jUspmvj4IYW0ATiqeiHJLQ5sTXX00heAdYVsJj20a1ZljCV7zw+yM7IPdJepAYjFN8NG4DpO81e3ZAFVYFVVWYvO1pkVg3ggEEpDV5Z2Gg8mG4Wk7hgho7fdYaQVjxwifC3iVaXts0EfSjjYcKcGhGph13jNm9V6UIn9vTy9qq2rw8gsvITk1HbfffTeae8LR2W9WxKO0pCBsLTHB67ZhdHAErxPIapmy48rrypG3IRVJqTFL6rDc80St/fTpcaoZDSvlfhkblpZGqeerDYJ0Sn+oulrTPY3WQR36xwWwSuXVcC/See9KIYA1gerioRSgWy6QZnyctrc9DtSR0NPWbkNCvEEp0+flhCAu1oDw8BX0xFnS0bnwl0aodNbb70RtA3/bVDyT8ygxwaDGcSlJBsTR+jM01H/JKxfe+4W9Oy1AOKpytv35VQzX1NCWyIaMq/ch5+ZbFYvP18dzC9tL3/nUQoCsksz50pe+hNbWVtXx66+/HjJ/z8k5F1x855134siRI3jwwQeV8urZeyoA11/96lfYu3evUnI9+/3F/P2v//qvGpB1MQG7hJ+dGKfix0A/yRqtaGttQScTwgJQNRPgJICk2Lg4xCfEIy4hQSWIo6KiEBYersDP6/U3LdZ+B1z96KLqvpdzuO36OGy7hLZ+TBVgyq5D54gXDX1eVHfLvRfIjNOpOZc8X0nbuEt4Ovn1qmXuK/f21i4P6lucaOt2KzWQq3eZkZxAYhNBOP7QZD+kKGRlLnKSeUoLiUoTdMKZnKTSD8m3FgKNRB1fyDkGTubjYoPVeCY50UhV/GC6ygQrUpUfpi/84fCsah/lWi4g1ldeeUVds+U+v3XrVog6q7wmStvymTfeeEORVC7UuaqqKtx2223qO7m5ubj99tuV+s2zzz6rFN/luzfffDOeeOIJRYy40Lou9N56BLI6JiZgpXpt8x+fx1hzE2Ly8hFVXI6oTbtxtNJFJWgPQmmznUmAeSkJ/fIbFDVLrWkR8LcISK7DQZcycV3p6GJ+n+RVuSfJPL+8lMRVOtOZTEEB51rib8dxpftrZ/5rfMKFQyRxV1aOY9dlsQrImpRoDmgS8ErHORDWpwFZA+EoB/Y+sqKMSSqzivNfo3sM9e5xhAcZkBwUim3MSSSxpmTW+XbuPLCP4PL3vm8cdMnz4mSHDnbBjkQBBSk65CbQCZomSIZLfPhdlinYR0dR+5unMMK8fv7H70Ii54/h6RlYaTCryltQub223q7EQmQcGR+rx+W7IxDHvMTZom+WKQtGCa49duQoKk9XKo3i3Lxc7LvhGpWrXE8uUcs/kwJrDRqQVQOyXvCMD3Qg69nBkYuvAFqHhqh80GpBV5eNhSG7mqTHxhmQyElaYoIJMbFUdQjXIyxsxlZ+tYELZ/db+3v1IjBl8SgF0lOnp9DaJucGkJxkQl5uiAJ1iKWukYmdQAO0CtC3b8CNw8emMESFVlEDKSowE+DLIipZ3GK77OvFFKvdS/WTabz7gR3tPS5kpuiRl2lQai7CIjKsPHFpVU5cK9VbejmIrmgH3m+cxpasmaJqRiwQSQE91j60pkXgnAgEEpB17s4LoHXC60ITkw1V7lEFbhWL2vSgMGVJm0lbmEgdQXtk0pqD9GCpeO7XteerEAFRnTt66AOyOCvQ3tqOtOwi7L3uLlTUe9HVz2tcEa/bubSHTw5Ge3MPqk61oqm2GxFRIbj9E3uQmBJDpufiMwdCapExoiix1lSPo7pmEpcxiS/WavHxJkVyWoXdV5twUXHM4gBGLCQrELza0O9F39iM4mo2kyPbcnQKRCPX+OU2SURMEkDR1U0ljiYb+vqF6OXBrh2RVKENIWhCT/Cw791IZEwvi7CDx3ncuntJVOl2KvV4GbuJklkhxyh5JN0Y/qJkttxYrYfvu6nSJUX6viOHleJU6p7LUfCJT8FMQJw+NHQ97KLP7MPFgKx9fX0Q4OowrS/4SXgAAEAASURBVGwTCEIUNVX5+3xNAKzPPfecUlUTYIoAumabAF3uuusuqkgfVMDYb3/727NvLelRA7IuKWzL/pIcU7fLzWuwjUTcSdrATmJoYBD9fb3o6uyiXVcfhoeGkJSSjOzcHGwsKlKPCQmJMIgsdwA0Gcf1kJD0srMDbo7fthjikRcUocZwl3L35dfG4Qka+4EjzbSJ5/05mJPfbdlATgKQGClgVqpmasPGS3kY1LoF+DlIwsqbB20YHvNgR7kJ+ZzTpyfrfT4fMV9w1O+eivhW7lcvx2A9fRzPcEwzTGK1nYAjcQeKjgomoFWPWJJy5HkIcy9qIZjOQIKTkJy05n8REKBqXl6eApZ+5zvfUaDW2b0YGRnBVVddpcYIH/vYx/DYY4/NvjXvoyi3/vSnP1Xre/HFFz+ivCrjC1Ftl/bee++pz8y7kgW8uJ6ArF4y3qepVj/a2IChigr0cmzs4d95d94DT2IBhl0xqKyxYYSCB9s2haIgL4QEOUPA5YIXcFpoH/GzCLh5zxkcdOHU6ckZIY8hF4oKw1j3MPMcNyGCzmUy//f1HL+fhd23u8uB7sGDQzh6bFQRuLOzw7BpU7Sqi54NVPHtHdF6t5YR0ICsaxl9bdurFQHJC9BjA02eCZxyDaPTMwUP8zibDXHIDY5AKutLRoqmiDqr1tZPBERMSmrwdb3MCZHc3DUKuqN6ceVGHZKidGBJavUaz7ea3/4avYcP0WEtGwmbtiD9iisRbF6BItE8ezEwxFoZCVDHTlmU8Nu+vRQDSjchipiQ+Vp9bT2qK6tY2zuq8pRXX3s1RWfykZaRRqyNkHK13MV8cVvPr2lAVg3IesHzWwOynhseKdi7ySRwOKh2YHGzQORGf7+dxW8bFcBsqhiekGhCZkYoE3xhSqFVAAxaC4wIeJjQcVG9c3JqmlaNVPaqt7KY4KCKr5sM5XCUlcg5YUIYVb0CqQnAx0Fl1tFxD+oabBy4WKlKoFOWWju3hiONFniS3PDlcYgos7r42+/snUZDqxMVdS7ExwRhz1YTUhJZGIryz2MqKkFiedkyCJykpUHvmFcp891UFsTCqpeWlzwugXSyavu6oAgEKpBV2LMeKrTaMQ0rWbQ9tKZtd0+SSTsOC//mlQxlhliUcEkOMiOMoFatrV4EpJjvcrrw30/9FqdPnUZJeTn04UUYdW9kkX7mOr29jNdsgjkNwV68+epJvPfGaRQUZ2BjSTpKN+dQic686EkxN6sm40JyeuP1fgQRjJKaYkYJlVgzM0OoRDGjfrUakZCk2CgBMpIYqepicqIbSCUxITteh4IkJkqYIBGrGlHcXgJe9yO7IPd2AbFWVpFN3mxFJxMTGzeEcqwTrqxixG5Q1MB88d4ufXdS0ay13YFTVValxko8AMGrZmRlEOicYlRjNVFQkuaL+/CRg7FKf0jRXpRY+4///+y9B3SkV3k//BtpqjTqvXdp1bb3XdtrGxsb2wktBAh/EwhfjA/5SPKlwEkOSf4OEM4JKYdDCE5CSAjFgA0GjLGNu73r7VW76r13jWY0fTTf77nDOja7q5W0knZGuvfsu5Jm3nnL877z3nuf51dO4dK3/guJObnI2blLMbiTi0vW6Cg2xm6uB2S9DEy1Uz1TgCU5OfyCL9AEmPLQQw/xeWSmYvRRzkdy31xbwLCb+byUZ6js95ZbbnnzveX8ooGsy4najX9GiBxOKrB2dXahheoKl6iwNz05xdxFCGUVZQq0Wl5ZSdJtGlJSUmEj+NxiJVjfZFpyv3fjR3tztiCq+p0hJ17wDyIjzoL3WMuQbrDAsgbKJ9I/e0gymaWL4ImuMIsYYcg8rCrHgEO1QJJVxiY3Jy4baa+Sr/Gxvz910YeOXjotMW9TV2XGnfsi1aNY7O9lHBqScQ1VXYJBqrv4IqqssyThjo77uQS4BJVSq7B4CvLNKOQiBaTsTI6PSTrSLfYiIH25kFBsVNju6up6G0FFzkby+f/2b//GuUixUmmVPuJqTYqB7373u5Vqu6izP/zww29bbW5uDlVVVeo1AZmI8uty23oCsoZ8PvidTnQ//RTaf/QEi8BbkcFCcFL9LqpvJ+KlNzwoLKCLE+cVddUUNsigqIE5OudFy72e+nMbMwLS54jq9xyFPMSJpZU5fql7SP+5b0+KUmbNzjLr+fMGuz0GBjjG7pzDuXMO9kvxVPnOI9nSQpK4rihssFth2aergazLDp3+YIxFQICsXhJsnRRKOR+YQlvIgdF5D8ri7LjdnI+MeCvsup4UY1d14cMdpriIkJrFFXXCCewqiyixFtEQ0Myp+I3WZxbe+5Xvjp05jZGTJzDKJa26Bpv/n4dgEmemVVC0kjGjOMe89Nos+unkV8h6S3WlFY21VxfDcLvdmJqYwusvv4q2ljY4Zhw4cNtBvPO+e1T+0mjUuYsrr+j6fkUDWTWQdcE7XANZFwwPpAguqlPT036MjHi5+JRaqxQpRE3Dao1HcrIRaWkW2iuakJZqRnJKRJlKMxIXjm2svyv3xhwt3SSp09fv4+KF1RKPpKQ4JjOFpWymgq8JFiYyN8q9MM9s1zxz5wNDflxq9WBMiin8/oj9UGkxwd+FJsYoum2IJGE35wljaJSKfxe8ahBmpQ1hQ7UZlSUmBc4V5bZYbKLcN0DLyzO9wODUPDblx6GKGAcprsqAWp5puukIXI7ARgWyXj7/yz9nwn6MhTwERcxilD8d8MNKHVZRZc2lJYzYw+TG2ZBgMK4JSOLycW3Unw6HAyNDI/jpEz9hQXcI2/bfh7iESqqSpqG61ISachNKC/hAC3HMNjiFo69fQvP5Ptxx7zY0EsSakZ1CQM/SUCTSL/gIGOjqmlOJ+/Y2JwoKbdi2LZVAMZsaB67F9fCRkCAqrPIclwSJLML2DZGEUU61t7JsA4oJaBWrmhsFacg5CxBEVFj7B6hiyrGO2AzaE+NQU03FoapE9ueGqCxayPhMEiiTVGMbGPRxLBKgUnyQNogGjtONqBQlmRyTUovfKOOz5dyfM12d6H/xBcz29iLocaPqve9HzvYdiCNIcjUSX8s5xlj/zEJAVkncNTQ0kDQ3hs9+9rNKRfVa55tAsKIoropyW11dHYFMbqXS9thjj6nXg1QPe/DBB/HCCy+goKAAb7zxBr+7N5YY1EDWa12NlX1dQEk+AmmmqbwnyqvjXCZ4T0hfKLZcXioomy1mzj+TUFJWiqKSYhQS0CT3hIBXN2I76R/HJSrqz3C8VsJC0V2WQtg4RluraY70n9LaWMRoI5C1azzMeZYBJRlAJedcxRmRv/W8KxKn1fpfxjCDo0ECWYM4TUBrXpYRe7daaXUXR9vv2CSn/nqshFztoaPMJMc4Ms6R8Y5jNsT85Tzi+Yg3Uy1PLKATqMoqJGtRbk2hWmtKklHlNMQxR7fojoAoqIqS6u7du/Hkk09ecbCi0iqgEOnbT5GANC/M7Gu0srIy1Z888cQTdJTY97a1ZPxQWlqqXvvKV76C97///W97fyl/rAcgq5B+wux/XYMDGDlxAhNNF9R4uODOu2Gp3I4BdwYGJ+II7AtgS71NOTxkZ0muUH+nlnKv6HVjIwKTkwGqsvrQRmeWcf4u/UlBXsSVLoPOhUn2peVWYuOs9VFeLQICbB4f9+LFF8ZYDwuxb0pHSQnzobmro/B2tWPQr8V2BDSQNbavnz76pUdAxFL6qMjaRYGU5tAMJVPCyCDJttqYQnXWZIJZSYJaA8Lt0o9cf2KxEfBQ2GvMaUAn8z8XB+dZXzcglfjNnWUGFLBGk2C+OTV3N/OGUy3NaHnsu7CkpKDmAx+EiFNYM5iYWoUm4oAXmt3o6PIpIZGKMhsO7rErlxiz+cpsnOQyO9s6cOHcBZw+cQo5uTmo39JAwZgG5BfkU0BGyIFXfm4VDl1vMgoioIGsGsi64G2ogawLhueKNyUh7uZkrY0ghtZWJ5qaHPDRstRIRcPGxhTU1iZTpdUOOyfyRpHC0m1DRMDhoGofLd4Ov0Gr4eY5qrSRkb/Jjr27aEFNoLPYuW2kdhkAc+S4C6fOzSkVlJIiE955Ryrt7uKVSkG0x8NDReaxiXmCWX149jUPbt1lxb5tFuRTmVWUZmO5vdERxtleYMRB8FM28O4dcbBbIiqtsXxe+thXNgIayPr2eAouYYzsWbGGOeofRXNgGmlU+qoxpuKAJRd5BLSmGjg71W1VI9DZ3onzZ87hHJfxSSpO1b0ftpQSpXh2224rdtRbFIizt2sUR19rxuiQKNXN413v2YNNDUXLOjYBRjqdATz99Ah6e91UIrWgcXMKdu5kRmIN27QbGCJ49aVmAmPG+MxmV7StxIBbaoD0RAGwrlzfJAkIH1W/XnltBmfZj0urqrThjkOpBEJE97hGxuq9/STUUDnm8FEnwRwGlJNQs3NrglJjFcUQDWC9/o0bcM/BQ4tySXq1P/5DbP+j/w9l97wLZgLm4jYoQO76UVvaGgsBWQcGBhRwZTFb/OpXv6oU22RdUWUVpTUBs6QwWblt2zY0N/NZODpKQJOFz7GnOV+tXcxmF1xHA1kXDM+KvSkg1pmZGTQ3XWRy9yTOnj6NseERZFGdt66hHrv27kFVTTUBrCUqybvRE70yVnvC240zgQlsN2WizpiGSmOyUtNfsYuyyA3JfHiG/fYRzrsuDYbRQ0DrHfVxuKPOgEQOF4VEqNvqRkCuQe9gAM+85lXKcnmZ8djeYEF50foNvhCtp2cC6OzxobvHj/ZuL8ewIYhNdEUpgUdlVrXkkXCdSfVI3aI7AtIHKMICSUSiyvrWJq8fPHgQQ0NDuPfee/GNb3zjrW9f8bsQIKQJ8UHIL5eb/P7v//7vEKVWaS+99BJqaji5WGZbF0BWcSfwkRR57BjO/uu/wJpOJ5adu5G24wAm4ovxs2dnlGBBY10C8750eqDysW46Aus5AtKfKjBru5tqW3L/x2PbFjvqqbRVynm2bhsnAuJc+cqr4xjo9yhxn/r6ZOzYQbk53XQEFhEBDWRdRJD0KusyAi4E0RacwXGSbl/1D+MWUy5useShON6uhFLW5UlvkJMS9dXjXRHHvLYR4L6tUqehU541QmC+mWFw9vfh/L89qhwmsrduRc6u3cisb1iVQ5KxosdL3FSHFz96agY5JBLfdXsKf5qQQje/a7Wujk788pnn0dEqyqwz+PBHP4K9B/cpp7G3zlmv9Xn9+vqIgAayaiDrgneyBrIuGJ4r3pQHsigfOBwBFpUCmJryK7XW2dkgvJ6gUsUSdY2MTNra0nJWWIkZGWYF3NNF8yvCuW5e8BH06KbyhSR2ZBkd89P6mIMVsk3KSm2orLCxwzYy+fy/CeN1c/JXORH5nkgTcO/gcABtnR6lXisKBWLpW1dDm0vGJprtZ6TY46XyXXd/AE3tfjip7iZKrDtY/CrJNyIpMXaBMKOsYfRMhHG6l88zKuiKQlB9gQEVBLVqolPk3tX/s/B+5Aiee+45fOxjHyPLvkSHhBFwh4NwzFOhfd6tLGEm5qnazNd8CCHLYFUJiJL4JGTFWRWjdmM88dfm1hBlHFGme+2lV/HUk08RTFdOS5RKGO21KCxMQ2MNVb/5bM5MNcBN2dKmM1145qcnUVCcoZRYq2oLkUk11uW07h432lpn0cuf8USPbt2aQgvPRGQR0LqaTfpSYmgx6Yo8s3snWUCaDsPCvkjYvfk81wLWDPJSI4CYJQrNXvXQBQQqyquiwNp0cY7Kpuwk2GQsI/a0BbTPjEaleRGg8nN8LmOO7l6yfzn+cJNoZqdijCRNCgssyKK1biqTJzIe133dVS//214MBQIUNqbrwPPPo4uWqqkVFchsaET+/oOqoP+2lfUfy4rA448/jk9/+tPIzMwkObLpbUpqAkh96KGHFrXdRx99FA888MCb64oSqwBSxCr4cissLMQjjzyCe+655/JLN/RTA1lvKHxX/bBSgOODX9RXxwg87uvpxSABzaMjlHbg62YCkUVpNTklmf1PNjKzspCdk42U1FTYCUza6CDWWSroj3Nc9qJ3CIPhObzTXIhNJBulkGQkqhg3o3kDoGI8+9RxUeeIzLOSiEXbWSrKrICNorlvwZPdjENc9/t0OOepysp8RDeXnqAip26pNXN8QEeSdUg2jhCRwlRmDWKW5z5LEKsAWV0EuErOShY/Ff7j48Ik58YrMKuMj7KUqp6ot8brMVKUfyvkWT8+Pq7m6KLCGh8fr0gqjY2NSz5yUe7+r//6L/zFX/wF89wB3HXXXfjWt77FLudXCb23bPHs2bPo6Oh4yytX/1WO59y5c/jt3/7tFSHOXH0vq/dqmJMKv8uFoddfxdi5s3D29yOtrhEZe25D61gKhhw25gnnUcS5RWOdDRlpJuVYsXpHpLesIxAdERCixOQknVp6vKruIeqs+XSiKym2opyqW+lpRjXPjo6j1UexWhHwk+ws5O62tlnOX518zifh0O3ZBLXGKSX41dqv3u76iIAGsq6P66jPYukRCISJJ2G+oifkRAsBrTOsLYllTKMxncqsSciLT8Taecgs/fj1J66MgLjjdYwB7SPzaB81wMrcjuR4qul+WkTdE3HludkuPN7paQwdeR3jF87D0dmJigd+E2X3vgsGztdWw2lNchEjYwGcODNHcm1IuV3v3WlHbbVN5b2ulpabnZ1Ff28/zpw4TdGas8gvLEBNbQ1J+7uRnpGu5rpXRl+/st4ioIGsGsi64D2tgawLhue6b0p+b3razwKTD+0dLvT1zamJvd1uRH6+leCKBAVolb8TE2k7TGsvrQR13bDG7ArSWbtc8zjHyXwHwZuDtLQtLLTSgjcBBflmWtnRboqgio0EopBkl8jKCxunu8+Halr6bmlIeJONI6Cgqw1iouUmmOX1HJ+ax+FTHoJag9haR/uHUiOKaV1t5feZKvcx2UQh6HDbPAGtBkzzGu0si8OeCq0QFJMXc5UOWgNZrx3YeXb+HoJXW5l8aA050BSYAmESyIm30R4mFUVk1KZTrdUWjoctjmpHXH+jA0yuHc3FvSOWly6nC7946jl8/ztPomLre5Bfvh/xJirhsI+9bY8FFgIS/P4ABnrHcfZkJ1574QIO3t6Aux/Yyb7XAtMS5c8kSe8lGPL06WmcPTvDbcSzUJNAO84MJJGcsprXNCCKqKE4ONxh9FN5tmUkjGGqsbq8BNKWAHX5VBnNIghmBUWAhajl9oSp3OhHS5sbp886aRtoRmkp++1GO4GgtJS/OViga94k8l1k3Z2APSqQUR2/o8uLVtoeegnGTUsxYseWBAJwOf4iQEO35UVg4vw5Jr6OYKazncDxJNR+6HeQTHJDPEF1ukVvBAT4f+nSJfT09NA1pJHf49IVPVgNZF2ZcMp1CgaFEOuFx+2m84sbw1TXG+jrR3dXF0b4u2PGgTxaa9Vs2oRaqrCWEVQuartmywp2ACtzOjdtKzSBRm/QhabQNHpo28eaAu63FKGcaqzR0MQFo2WYYNYB2t2TkLKnAtjEfrwgjQUPYxhGkVjXbVUiIORUilri2DkfnnnVDQGx1lWaUFFMMCvV7G8WyHlVTvYaG3Vzru+YDaGPuam+QT/6uchrUnwTpRQh/MgizjnJJPwIYUkI2QL0jeQuBYSt79FrhHdNX5br8B//8R/40pe+pMgqAhr9/Oc/j49+9KNLOg5Rt+lkMfMzn/kMXn/9dfXZ+vp6/OAHP0Ba2tWV9UTR/fjx49fdT1FREfoJ/oxVIKuPyrWiXtT+xONwsQ9OKiuHrXYX4qsP4NgpFyamgqiv4Zy/wooqLvqrcd1bQq+wjiIgpFfJ8be0unHkKAc37BpEZWtzgx0lRVbVh5hMYgW7jk5an8rbIiD5F3GmbGmZxc9/PkKisw1796az9mlDaqrOubwtWDfxD+nnW1pacPjwYZUTyM3NxaFDh+gqtVMd1dUIK0ajUQlavPoqiRy0pN68eTP279+P6upqNV9didPRQNaViKLeRixHwBkOYDzkwWv+EVVPKomzs46UgjpTGsRHRtWQYvkEN8CxsxuEmzhkhwc42TWPznEDPBQ0q6NIlLjvWFkGXGL5adWiFmIixDUyjIGXX0Lzt/8Hle9+D6rf/wGYk5Nh/DW3j5U6CMkz9A/5ceGSG0c5d7r7UAp2bbMTGyX5hasDKaRPOnPyDI68dpiK7/1ItNtxz333oLyyQoFZdS5ipa5O9G5HA1k1kHXBu1MDWRcMz6LeFKCDLG53UKkdTE/7qKIiqpw+KrZSp40TfQG0lpQkoKLCTiunCKh1URvXK8VUBMR+mPVIOF1BjE8QTDPgRS/Bm8MEhRQXWVBZbsOmmkTa8sYrVbeYOrllHuzleIhKWjNtfscYFw/Va/fvTkJ1pRUpjEVUK7MKmCgQVkounb1BdFGhNSs9nmouNiqXxCs1l2WG5qZ+LEAllikKdV0aAl5tnUdWUkSRdXOxAXnLEy28qeejd77yEdBA1mvHVAATIU6yBMw6M+/DNFm1fQRO9IVcmOTfFoJXN8WnoIrJiMr4ZFrAk4UpWX7dlh2ByYlJNJ1vwpmzPThzbgSJOftRVFaH/ds5tioxIS8rorQ5M+3CC0+fxtDAJGwJZmzbVYUtO8sVg1NIJEtp4+MkKbW7qDbhJLjThz170pXiRFpaRGl/Kdta6rpjswSwTgGne8JKkdXEREhZVgS8mmkHUpkA4OmtGLtXkgaTLMz2UIn1BBMNwSD7hUwTqiptKC22cewaDxMBDdGWPAiwfx6k+moXLXTPX3Sr40tJjkMlrXNFhTWNoAybUgdZ2rVf6vVaz+v7aO3jpCpky3f+B3Njo6hh0iuDwMikwqL1fNr63K4TAQ1kvU6AFvm2m6q501RJaGtpRUdbO9r5U1TxTGYTCqiiK4soEqTT1tienEQSRTKfaTYY2Slom61IkGVMJkiK44ExPOXrQymLQTL+qjemIYMK+dHQfJx3USyeYFaqdYwYSEwh2YLK6rfVxilV9ZS3O4ZHwyGvm2OQQlOIOZq+oRAutPkxNBpSaiB3HUhAUV6cclxZNyd7jRORfEyA4zpR3PcQfCIkLVFqnSG4VcZ+UzNcpoPCu6MiaxwKqLAnJOy8HBMy0ukqxHGUBiVdI7hr9LIAVgWM8ud//udvqqJuIrnhH/7hH7Bt27YlHYX0MX/7t3+Lb37zm8rtQoArn/zkJ/Fnf/ZnHOtfG4QkpAshX1yvicK8qMrHJJCVX4LBI4cxdPg1zJJQYknPROE770OHIwcXeqxISIxDbrYJm+tJzOc8SUQKdNMR2EgRUH0qa1yi9D0xxRx/i1vlD0SgQoCsu3YmKWCr1XptC9mNFK/1eK6SNxI3nKEh5o1OTNOx0q8ynfsPZBLwmLQeTznmzknmiP/8z/8Mma/Py8V6S0vmXPKZZ55BaWnpW16NEJZ+//d/X/Xfb3uDf3zgAx/AV7/61RUBs2og669HV/+90SIQJOXWT3XWwdAcuqnOei4wyWxGWImi1DF/IXkMnb2O3rtCxkGyNA8TeNkLjFBwxMghz84yA0ozSRJlTV1Er5ZYflq1ExanCQGzDnF+c+nb36LTWiVytu9A9rbtSMzLW5X9CpHYz7zDOdZoXjlCgZRcE+tKFjTUJqgazbV2KgR+caN6+fkXServITkmBdt37cAdd91J9VhxxtXzrmvFbj28roGsGsi64H2sgawLhmfJb0rhX1gHY6Ne9PVTUWXYw0ldgEqs8UqRNZkg1vQMM1nuZsVUFKVWG+27lgquWPKB6Q+seQTcHhYGaLXTTmVWUWeVlpgYj8J8C/LzLMjNoT2vhUwUKl5shOZgomuAbJzWdi8BJ17kcRBTTJBJBcEmqSnxqmgSzXGYohz+IAtfJy744OFgrDDXiMpiE8qLjEz4y6A1tqYZlwfevRNhnOgBxp0scHGguafcgMocA9KoUGPcGLdmNN92N/XYNJB1ceGfZ8LBH+bzLeRGV2hW2cQ4w0EkIh5ZVGjNieMSn4BMKrTaaRRjMuik/uIi+79rSdG0q7MXzz79EnqG4jDjzUVxWRVqqvOwd6sZuVSTslA5anZmjlbMY3ieQFbmhbDnllqUVuQQBERvlyU0GcvNzXGfXS6qsTqUvWYK1T137cogMcmmiCiGFX7ki7JFaJ7nwOGCPI8HpqjASpGTCQJaRWk2LxWooj1NOcGs5viVVW9zuwlmcPB8ezxUUPJigmOXTBZn62sTqchqQUaUqZkKaUgSI1PTIYyNkzTEscX4ZFCpjYk9bimLaKXsn7OzxE5akvJLuPh61SsiMM/vX5Bgu9bHvoeJSxdVsitn5y4UHbo9kkjSAb4iZhvhBQ1kXfpVlsJvgKrhLpcTMwSvTk9NY4okjYmJCfW3Q1TgHLOwJ9mRkZnJ/qscxVQ/LiwqJDEjQREylr7X9f8JP4tBQio65h/Ds74B3G7Jxx5TNsddVlijbMw14qBy7CRwtpeKZr6IImtFdpj9uwE2ziejRbljPd41s64wXVZCOHLai+HxIHY1WlFJIlR+Nh1WYmwevxLXx01isYBZRzmOkrGU/PRQlV8chmxWurQwbyUgvSR7fGQhgE9ek7+tzGFFu6vOSsQoWrYhINb/+3//L/71X/9VzUmE2CCA1o985CNLLuhJgejjH/84uru71endddddkJpAWVnZip3umTNn8JOf/CTmgKx+2lq6Bgcx8NorGDl5EomFxTAV1yJQuh+9ExYqGQewqZpuWxU2uj2YkEinDt10BDZqBCIiHmE6E3pUzWOYxFIRqCgqtChAqxBKpd4h6qy6rc8IOJ1B9PbOUe1zlsqfTtxxRzZdQFI5VhAnSn3db+ZVf/zxx/HpT39aHcLu3btx3333kczkw7e//W06ifZRZKkCzz//PL+jEYcdIas/8sgjapwhH7r77rvpQrUPFy9exJNPPqkArL/3e7+HL3zhC1cAY5d6nhrIutSI6fXXawTcrBuJMuup0KQCtYZYxCiLT8ImKrPmso6URHXWjeAcEkvXl6UIuuRBOey0kpzcPDiPdIqMFLHktKPUgHSKjpiidHow1dKMvheex9zoKEGhcah67/uQUVcPA+eZqyVY0kNxtwvNFDVjnkGwTwf22ImLMV+TJCv5UnFjPHnsBJrOXUB3ZzeKiouw58BelJSWIDM7a9WONZbuw/V6rBrIqoGsC97bGsi6YHiW9WaYvZrYdMnE3kMw4/Q0wXutTqXq1dnhQnIK1Q3yrGhoSEZpKZncOVY9uV9WpKP7QwIUlHtAlC+mZwI4dcZJEKebwOYQlUhtOLAvBVkEWYg660ZoEg9RJxbASTutf0+dnYMMAG/Zl6SU00TxI5qbHL/bG0ZnbwBN7X6cavJj12YLbttNIC7VTEWpJBabKAS5/Qa8cHEeRzpog5APNBQa0FhA4DWLWLpt3AhoIOvirz0fD4RREKBCQOv0vJ+2trNvJiNm+PceUxa2mTNRTnXWJEN0P+sWf9Zrs6ZMZCXpevZMK77x7z/GtK8EyQV34b47UrBnawIyUmnbYokoRbVdGuBktxsXz/UiNz8d7/vwLUghKj9e6LBLaF6vgFjn0NTkwMmT09i9Ox233pbJ4j1tfkg+Wo0m40ZvgImQoXkc7aTCBa2HgwS27q0An8uRxIiFt46cyko/mQdoNSukm1OnnXDNBbFvdzJBwgSxknjDnEbUka38AVETC+P0uTmcueAmCDeI9DQj9u60o4hJkUyCWeOZJNmIwJTVuDdlm/NU75pouoCREyfQ9/xzyN2zF1s/9f8ijkyeOLlJdNtwEdBA1qVfclHEcc460dnejktUrDt/5hz6WUz0uN2orKlBHW2d67c0Ir+ggEDWDD7D6FrBRb5jq5VcXvpZRN8nHFTFbwlM41JwBi1cHrCVYp8xi4Wf6NPCl7mv2M51jQPn+4Ej7fOoL4jD7bURwkoqVVp1W50ISOznmYt4/ZQPzZ1+VRisKjXi4E4rLe5WemS1OuewkluV3MZlVTXJ0cg4dJYKrQJo7R/kXIaFJ8nbBAhsFdvoIoKSykosJAtZkM1xlpW5Dy2KspJX5Orbugxi/drXvqZWeN/73qeAJKKottQ2MjICAa5OTk4yD5mFL3/5y+rvpW7neuvHKpB1iiDf/pdewCSBO166EVR+8EE4M7bh+aOikh6nnB52bE4kSM+s5hiax3W9O0G/v94jIH2IiDSLOuuFS3NoaXUT2DqHzY12HNibiuxsM+wENeq2PiMg9S7Jy7z22gR++dyIIn03NqagqMhGMCvthHS7aRHYvn07pM9/4IEH8PWvf/3NeaTkVe+8807mOrvw4IMP4ktf+pI6xqmpKchnBED0sY99DF/84hfVGFHefPTRRxWZRn4/ffo0cnPJrr+BpoGsNxA8/dF1FQGpIwUJXp1DEE2BKTzvH+TkDMilEMohEnMr45Lo7hd9+Yx1dRGWcDIyd+aUGd3M4zx/UZzz+Af/3VlvwOYiAyzGlRUcWcKhLWpVH0nzrqFBJVAxfOwNbP/jP0HhrbfBaLEqYOuiNrLElbw+EYmZx8+emUYnXfTuuIW1pior3S0oOnKN4eHlGmB3eyeefOJJiDuj1WbD/e++H7v37VH9mc6NLvFCxMjqGsiqgawL3qoayLpgeG74TUkKC5h1YsIHsagdG/NhjspXXk/EukvUOFOSqRpFMKuAW9NSyUqg8oF+IN9w6KNmA3IP+FmwGhzyYXCYBYEBn/pbBkBFTIIWUzmsIN9KRn8EiBM1B75KB+J0zdPCLoCWdg+GRwO0z4Ri49TV2JCZYYzqRJcolDg4UO3qD+B8M/V/eA2T7HHYXmehQmucUieJNXVluQ8pPohWWiJcGiJ4ilaXdpJyRZm1IJ1sMiqz6rYxI6CBrEu/7vw6wUcw60yYz3raxAxTpXVk3sO0xDz1WQ1KobUwLhGl8XaqsxIUGacTvNeLsp/qda0t3SSDDOLlNyaRmlmIzVvqsKPBgqrSiLJ5eD5ElbsgXnr2LC6c7kIOQazVdYXYtruKwFPz9XbxtvddrqAaqx0/PkniSRApKSbU1pIVvSlZqYysNDhS+pHx2Qijt3vCgCn2kb4gVbEJZsmgM5sosGazVp1Md+RrTfTfdgKL/EOe/U5XCP0DXtoBRhZRzxAV000EsWZnmWCn6lY0NSmUTFJNbXDYj65en3JAEKe09LR42t+aUVJIclByHBXeo+u4oymGyz0WsSPyEvgwfuE8Wn/wfSQQAFF0x51IJ/jOnk/mi24bLgIayHr9Sx4MBPmcctOpZQTDg8MYotLbJNVXvR6P5LwJuOfcgUlZe1IScmnrlZ2bo36KImsCFVh1u34EhEQktny/9A3Cy9FWFtVLtpkyUUniULQ2AQzOUH29j64YF/rDcFGZVQBRUgCpzAH7/zCVWTcesHItrpcURnqHgpzLE3TT6kdaShz2b7MiK505uaRrVFPW4sCiYB8yLlTFJrpLCUFoejqIGQJb5/i3vC5gJQGtSLMwhymOOmmp8chIM9FtijmcBIMaJ+s85speTFFO27t3r9qoWP5K/n657VOf+hR+/OMfc3xvJ/DoNQoq8IGzCi3WgKxB9smugQGMnD6J/hdfgC0nH5aSKkwlbcVEOAeTM/NKZbJ+E11Wsk18Vuh5xircNnqTMRwBfyDM/IkfQo7t6HTDx/qH5C2EGFtMhVYBtG5EwkgMX9JFHbqMqcJhA9VYZ3HmzAyJxvPKefLgwQySJSy8B/RYdlGBXOGVent7lZqqbPbYsWOsOxa9bQ/f/e538ad/+qckf2dSTfeSUlv96U9/ik9+8pMUWTLxerYwh2p78zMyrqutrcUMCR6f+9zn8PDDD7/53nJ+0UDW5URNf2a9RkBmVgJmHWPdqC3koCiKE+PzXuTHJaDclIJaY4qqHZkIaNXt5kVA8jceCo9cogJr1xgd9KaBLNZrKrK5ZAE5KZF8TjST3EIkMsicp/WHP8Dgqy+j4JbbkLNzJzJq62B8yzN/JaMsmBhx0ztx2o1WKvhLf1JWbMbuHYlKEOxa4wQZX8xMz+DihSY0N13CBaqzNpLwX7+5AXUN9UhNo2WhbusuAhrI+uKirqnBIz5KG7BpIOvaXXRJDotdbX+/B520q22l9cbkhF+xuQtoVVtRSXntAhstXM2cPEQsWMSOI5o7wbWL3vrYk4tWxf0Esp5vol0xFVrzadlbWkJ13jo7J/omgi8iyhbX6sjXRxREmZV2yVNBNYh55bBTqdJWV9Cmq9KK/FyTsoiO5hhMOzhw7ffjbHMQ7b1+3LbLivpqM7LT49Wxx+J31s1ko4CpnjrLa+MC1YGYrKA6azXJtuK2uJIAqvVyH6/389BA1hu/wtO0uh2edyu7246QU/XnRYYEbCXIIo8s2wza3lqYkIhjAlhbxlwZbymYz8158cwzx3H2kgtjc+XY1piFdxxMQW6WEcn2SHJ8zuWhPbMTT//4GFov9uM3PnAAm7eVITXDzmfX4hI+si8Zp/X3u9HZ6aIS6wySkoy01cqm6gCBRvaVAx3LhEMAmD4WfSQZ0j4SRtsImBQJI4EWfFV87m4p5k/Wl0WBdSVrAHKOcq4CShik0tbZ8y4MDnppdR3CrQdTlYKKKKdEiw2gHG+EkRvGLI9RAKytJMI0t3oVCUbGDQ21tjcZvbHY/15550fvK47uLrQ9/kP4pqcQZ6Y6273vQu7OXWqQoMEr0XvdVuPINJD1yqjKsyoYDMIvSWL+dDqdmJqcQk9nF9qp9NbV0YlpKt6kU221jJaODZsbUVFdheKSEgLAjIvur67c88Z8hb023PNBdIRm8UMvSSzxNtxrKUY2wazJMaB+P+cDRhzAG3TEkGVbScQVoyrHQPJKGCYNZl2VG1vyEINjQfziFY8aC1WWkLBUYUZpgVGN0/U4IhL2CECFKq1U2hthvPqYwxJrdRk7uknUT0kxcuxlIpHIqPI3mRkR1wIBK4lQu1hMizq+jueN3cbf+9738Cd/8icEB6Xi5ZdfvibJQeY7iYmJasz8n//5n+jo6FDWwb9HK2Bp0sc0NDQQbDaGz372s/j4xz9+zQMTIsVi509X20gsAVnFccAzOYGhI0cwduYU3QcuIvvO+5C47zdw5GwIs3PxKGXBVUCssuimI6AjcO0IiDLr8CgtYU/P4kLTHCrpRFddmUD1LRsFXIwwm6VP0ODGa0cwNt+Zng5gaMiDV14ZZ+4uiPvvz0NJSYJyMtLXe+2v6YsvvoiPfOQjqh8fHh5m/Y0D37e0w4cP47d+67fUK8ePH0dhYSH+6Z/+CX//93+PW2+9FY899thb1o78KmOJX/ziF0rF/b//+7+veH8pL2gg61KipdfdKBEQcm6Iy0nfGE4EJzAV8iEz3opbzXkoNCYixUAFS4qj6B50be8IqUdIc3qBUdbMX26eVwJQGSJqxdzNnorIXHclazaRPa7e/73P/xKDr70KEatIraxExQO/CQvnmYZF1s6Wc2RDI+LO68PREy6KmJlwz53JylVvIXdbyUVI/3XsyDE89aOfqvFjVk4W7r7vHuZSyxThQo8xlnM1ovczGsiqgawL3p0ayLpgeFb0zcudn5uKrE5nAC6nKB0EMD7hpWKrn+w2vwIOiPpXebkdBQVUac23KRCDfjCv6KW4aRsTRU8PWaqTk0EmeHzo7fVQXSyornsJbdoaGzg4ZVEgMWF9s/zluyAgmukZKYr40dntRS+BoQJIqSq3orzUQqXT6I2BKOzOeebR1hNU1oSiVJJBRZID20XRJZ5We7E3tYiwy6jMOkRA1SgUqEpArPsrgUwq3CWafzV6v2nfHr3jtY6ABrLeeMT9VGf1Mh0xEfIqVu1gmAqtVGkdC3lQQIZtmYm2GvEpVBATQCsL6De+y3W1hTmiPEbH5/CTXwygmwX0kpIsbK1PxZ6tKbAQ8Gn6Fba0s20IJ460Esw6y4StAXfcsx0l5TkwWwSUsLio+nwh2jvP4/CRSbQ0O6iKZ2XxJUmpsSYkGFVBfqWC6+dYYI4KbG0EsF6ke5DDLaolBhRSBbsgNYw8kkvTmRhJtITVPbHIU1jU4ck4RJwBpLjU1U0AMBW38nLNqGKhScg16VTVEhDrSu5zUQd2jZUCBPtKn3tJrAq7fUrR3WaNV6AJIb7kUolVlJHE4jZajvkap7IuXhY7opm2Vgww8dX97C/Q8LsfR8nd98BMRcl489LUj9dFQDbwSWgg69svviRZBbw6NDCIPirh9NCycZC/T9EKS1Rt0jMykJmdhcysTPV7CpPFoiQgyngJBB9JX7XY/urte964f4WoXtI570RLYAZNwSlUGJMVkNXGMo/JEL3zyMtXTBwxfCSz9E2G0T4aVjZ1Mh/bXhpR9yjimEC3lY+AiIrOcdzV2sWCSi9JqT1+7KMq696tFtgscRzvrfw+Y3WLkrMJ8Eb1+WTsOE+nKSoIk5gtiv6O2SBBrvNwMKfpZV5EWgbddXKo7C8A1xyStFOpeKuJ+Td29T/96U/j8ccfv+5GRHFNAClS9PvABz6A119/HQcOHMAPf/hD9dkBKo7u3r37utuRFb761a/ive9976LWvdpKsQRkdQ70Y6r5Erqe/rkiGWZu34V+QxUGAkUIsx/Jpqrg5noqsfK+Tt7gqs1Xu9b6NR2Bt0YgQPcU6S+G6ETXR9eXbtrI+pj3L6Iqa1WFjQqtCQRKCElXj2/eGrdY/12usdsdxIsvjtOB0M0cmh1VVZFFz23W/uqePn2aYOL71Y5feukl1NBB563tRz/6Ef7gD/5AvSTg1C1btuCyYvtDDz2Ev/7rv37r6ur3L33pS/jKV76Cbdu24ec///kV7y/lBQ1kXUq09LobJQJC0JWq63TYj+GgGxdD03T4m6O3H1BnTMMecxYSWDOy0OtPt7WLQCRfE8bZPgPO9rI2QV5Apl2cdICCNINy0Yu1EY2jpxtTFy+i8+dPMY9vR+MnHkISCQ2rpcoqV0uwMCN05X31DSfV28N0JjajttqKCuI/FmrzBNtOjI2jv68fh189jL6ePtTU1VCddTN27N7B2pVpoY/r92IsAhrI+uKirphWZP3whxcVKL3SykVAkoxzTASPjQmgcQ69PXMKXCAJ44wMC20ezFwsypojOZlqnQQ3Wphcj2alypWLzvrekiR46JaMS81zaKf1zsREQF1fSfAU5Jlp8yVAzjh1vdfzxF8AKm4WPppaPDh11kWGdpwC0dRWEcRNYE06waHRfL+PTITQOxjEuWY/gblh1FaaUFFsQlFefERFj8CkWGpS2HPS6rKV4KpXWgArx4PFGWE0FMZxgE4bQRb2dM4xlq7ojR2rBrLeWPze+mlJSLjDAfQxEdEedOBSYBomsh3tMKLYaEcuQa2iIJYSZ0aiArTG1rPjree6Er/LOEhi1t3rJIBxGkdOOcjENOC2/Vmoq05CWVHEcjlExIfH7cPZEx147qlTCrxaU1eE2sZiZGQtzlZY9iUKpaOjXvT0uAlipYLetA/799OauDJRjcfiRZb6Bpucj1iqOL0GjDvDGJkR8ApVUacNSLTSioaHKyqseakGJAmA9cZ3+bYjFgVYcQUYGxc1LaqatrkJQAgq1dm6mkSqNCXQ8o99V5TkxSKAWxJ/SPYZHQugl0DmCZKATFRyKWLSQ1RYM9JNJP4sTnH3bcHQfyw7AqJcJXZEPc8+gwv/+R8ovuMO5O07gMz6BljTOFDQbcNEQANZ2a+73eyD+Cx1zHJxwEHLxYnxcYwz2ToxMUHSqlMpHeTm5SkF1rLKChQWFSIpOVknXW/wmyKqJUIWesU/jE4q3otGiRR59pqzlVrJDW5+TT8uxJZJVxiH28PoJ6g1LREozzYod4wkKrMmkrij28pGgJhzpfJ+oS2AF9/woKrUhAa6q5QVitq/JsYsFG0R9hJF1vGJIJVaA0p9T5x2RNnfRnche2I8Uqm8l0wibDKJRvK3uA7JeM3KXKYQj6St9Dh3oWOO1fckDyhg1C4SI67XysvLISprkmP+4Ac/iFdffRW33XYbRNFV2s9+9jMIQGUx7dFHH8UDDzywmFWvuk4sAFnn/X4EvV4MHaUSK0E/MySgGLJKkLD3N9E5mcR5mpnFVTMqyyyoIdnv8n171RPWL+oI6Ai8LQJiMe9wBHGSLnTiSCf5FgEtVFGdNZskh5RkyTnovvZtQYvxPyR3c+bMDNraZjHH8UB5RSIOHsxUBOmVyKXFeHjW9PBdLpcCr8p44DOf+Qz+6I/+SI0N5CBEnV2IKkJ2kSZjhEOHDtGF6m5cuHBBKbYLgebX29e//nU88sgjSr315MmTzJ8KvO5/m5A5F0O6kU+IMry0q+1HvaH/0xHY4BHwMcfREppBK2tHbVwyDRyLmlJRGp+EHAPHpHGslWsZlFW9S6R+I3NeydH0T4t7HtAzHkZZVsS5tJ518kTqOMTifDYwNwcnCY5N//nv8M3OovI33o2M+nokF5esakydrnmcv+hGT58I1gSwc1sitm9OZH7AsKBwjAgGyPLSL1/E2VNnmHOYQ1l5GQ7cdoACNLkQgQDd1kcENJBVA1kXvJO1IuuC4Vn1NwU8IcACSaZ7vbTtGvHS4tWDjs45TE74OAEMomZTkmIzVlTYkZZmItgvPiY7ylUPZgztQBI5MqmUBM8MEzzdPV60tbtxqYX2OxUJqK3hsimRcuuLV5OLodN/81AlDvIdcM3NK1W4149JosuPnOwIM2fntgQYCSCKVjCrAtpQmaSpPUBVFx8GR+dVEeyOfVZYOaC1EJgba02UgGbcQOcYE1G9wIX+edy3NQ47ygxII3aMOCfdNkgENJB1ZS/0PB94fvJpRaF1NuRHMxm2LSEHBoNzSKIF7lZTBmpNaaiIjwAwNzJsQfqGEEGfz7w8hue4hAKcXJfY8N4HqklyEMBl5NnqpmLrYP8ETh1tw8vPncO9v7kLh+7eigS7lUnzxT2spA8SFYmzZ2fw7LMjKCygUm55IurqkpFF9Z2VKrJwN/D4DTjPZ2rTQBgtw2Tv2kmAyI+DqF8XpgtZIAwzrVhXgwMh5yhKrMeOz+I0iSNJBBeUFNuwbYuAdUmWskXiFS2JGBkXdPf60NTsxunzcyT50K2g1AYhuuRQ6UuUz6N5fLCyT4/o2ZqMXUWyavzcWfTQksgzMU4WdzJqP/Q7ypYoeo5UH8lqR2CjA1nluzA0OIje7h60XGxGW0sLumjlnJySghwmVCurq9iXlKO4pISvJcNitRGIb1IFxHgyBtYzUXG17z3ZfoDjKdd8EN/3dGBgfg53WQpRTYX73HgbyzqxNYKSWjA5rhh1AO0jwCutYXAYg8ZCKDBrccZaRHRj7UONMzkw6xsK4fRFEmWmCY3mi3cfTEB5keRfNlY8lnK2EjtZRKlVciFCNBOnHVFpHaZt4CCXoeGAct7xUVE/n+TkQgKYigtNVP4nYZtkfSFN6RgvJeqxtW4sAFl909NwDg2i9fvfw/iFJhS/835MpzTi9HAuTDYzsrMt2LXVznkh5xwEYOv7NbbuQX20NzcC0kdInUvm8719Xpw87WTdI6CUWG85kIq6TQkKHK4Bjjf3Oq3k3iWnNj3lV7XMZ59hTq3QRlXQPJL3jCS5aKn7lYz1Yrb1p3/6p/jud7/L75lVgVn37NmD5uZmBVwVIOrl9uSTT2Lfvn10oarF1NQUvvjFL+J3f/d3L7/95s9vfvOb+Mu//EvmR7MU4PXXgawBkp2/8IUvvLn+Qr+kkfws82ANZF0oSvq9jRyBy7WjkXniBCiC0sq6UXfQiTss+dhJZdZMA2vOMeA+E8vXUGrjbr/UxMN4rimMBNb4C+iWs7OUwhoUfLKZxE0pNs8wzOSTjwT89id/BEdXJ4wWK/IPHKRIxZ2rekIi7CLjwjOs7zz9yxlsbUzEnh0U9mF9x564MH5C8jQz0zPoaOvAT3/0E7rBkIhcU4W9B/Zh87Ytq3rceuNrFwENZH1xUcHWiqxakXVRN8pqrqQAfQSuTk0FMDREy/lJP9VcvFR2JKiBYD4bQQapqZGkWhYtjtLSzIrdSFE33WI4AgIumeQ1Hxj0cdLvgST8ZTCUlWkka9mKkiILEqlkIWql67UJYEnOu6XNgy4yc8bHRSWOIJsiM0q5iDqrfA+icZAoA7FRKrP2DIRwrsVH8KqBBZo41FdRXTcnntbX0XncC91LXirlznoEcBXG6R4gNTGMQlombCuhWjQtFARopdv6j4AGsq7ONRYVsSAnYYMEXgj4oi/ogpNqrTIxS6UiaxaVWUuo0ioKrYlUbDWK/9oGa5O0u+8giPH1Y0M4e34E2xvI1GxMx/at+VQrj9iXS/J0bGQGr7/UhLHhGUWK2HdbHbbuqOCYaXEFR4n5LK1RW1udVDty0Q7ag4bGZNTXpzBJa1FK6Tcaei/V110+UGUN6J2Yx/QciUtBA0kBtFPhc1VU13JSgBSCVlajj5P+VexgB4e8aO/wqjGmzz9PEKsVpSWRMYbVGh0EKQFE+DkW6ON4aGiEKl9cZIwkmKTiQgFBWBQgQlS9ViNWN3qtN9Ln50ZG4OjuQvczv4B7ZBhV730/srdshS07m5aRG++ZtZGu/eVz3WhAVg+Tpa5Zp1KRGeP9PzY6phRX56hoECIjld0JWxgZmZnIyslBXn4esnNz6K6SBbPFzGeWHjtfvndW4ufovEcVdI4HxhSo9T5LMYrj7EiIi81iudw/Hs6/OKxR86/RWQMV3El2yaPqR14c8ik0kbiw89pKhHXDbcNBlZXhsSDOXKJD0lAAuxqtqKYKYy7n8iYWqHRbXASk2CfjtekZ5jI5hp+aDmF6NkTFlMizUUjJkssRVX0BBaZSjS+Fiq1pqVRuZc5Hcl0Sbf2YXFy8o32taAayzrO/FmeB8fPn0P/yS1QiosVl2AJv2a2YtZVjzGVFWWkCbdCtau6RwvtTNx0BHYGlR0DyLKJmJsqsXRTu6B+gaMuwTz33cylcUV2VQOEOs1Ly1s/+pcc32j4h19vPHNPgoBcvvjim5kXyLK2usaO4mFYDuq1pBGapsvehD32IKrlnrtjvrl27cOLECfW6KLNWVFS8qf7+uc99Dg8//PAVn/nHf/xHfPnLX8amTZt4fa8OtJB7YDHta1/7mlLX00DWxURLr7ORIzAXpvsFXf3agrNoDk7DFmdCRpwFDcZ05McnIMXAHNNGDtAqnbuPNRyp21wcCrOGE8aEM+KWU8O8THGGASm2VdrxGm426PVggirco6dPYfiNIyg4eAtqPvBBxJP8EG+O1NxW+nCki5D6VGePD2+ccLKGRzdCOuHsojJrUQH9la6D+wgFQxT9m8CJYycoItCG4cEhBWLdvms7CouL6AazOFfGlT4vvb2Vi4AGsl59fPXrEdZAVg1k/fV74qb/LYnf6Wk/mppmFchiYMCtwKyizFpbm4yyskQmfY0EODIxTKCrFMh0AuCmX7ZlH4Ak/92eeRw97sD5Jjd8VOgtyLdg755k5OaYkZpivG6nvuydR8kHAyzgDdOi7uXXZ5VVnRRF9u+yYzsV46y8z41RDAqdmArhQhtVFjsD6B4M4p0HbARfWZBEVpGRgKVYLGAPToeVMtARWl36qbZy/1agMjcyaNeTpSj50qziYWgg6yoG91ebZnkX0/O0eadtzGHfCCbnvQizI99rymZyIg158YlIMBgh5d2N8J2Tia2QA1q7vHjuVbItO/rhnBnFR397E5maeUhITFAKqRI+r8ePzrYh/OBbryAxyYo7792O4tIsAogWbyvi84VUsl2UWEUhPZ/kkW3bUlFdnXRDF/9yDlfOZdptwMBUGMe7qN5NO5qsJAMqs8PYXwVkJxtW1TJYCFJyXqKQdeHiHF4/4mBx1orNjXbUsHgk1n7R0FRCg8fqJuB2eiaAY6fdaO/0KlBrVYUFB/fYkZlOlq5dF5Oj4XqpY+BFm2d18tya7PH+AABAAElEQVTXv6ZsWfP37EMOiyK523cibpUSX1Fz7vpAVATWM5BVCnGyyD0eImlCgKpTU9NMlg5SffUSLjY1oa25FUaTEekZ6ahvbOTSgDouYm1ls62D7HYU3+dSJr0QmMIx/yiChjCyqMJ6yJSHzDgyQmK8BQj6oNg8jnWG8fQ5jktIeKnKMWBXmQG5HN4YyRPQ+Z6Vu8gy/pD28jEPTjT5kElgZUWxETsbLbDxdorTwY4EaBn/S27LKWp8/T5aCPrRw5/jtBEUJZaCfJNS2i8jqUpUWkWJRTgworQv/L1oJTAvIwwb8iPRCmSVfj3gnsPc8Ah6n3sGl77138i/+wEYG+/AyYFs+GjZWpBrwjbaXNZv0v34hrx59UmvSgSkr+3q8bDO4UIrxSsE8HjL/hQCxpmP4PPfRLcd3d2uSujXfKMzzOWcPz+Dnh43hkmkvuPObOzYIQqcevy61hdDiP/f+c53cOzYMXR3dxNQXAwBsW7dupVquferGpWARux2O97znveo9T71qU8p5dVfP1YBuH7jG9/AwYMH8YMf/ODX317S3//yL/+igaxLipheeaNHYOxXBN6X/cMQMu9+cw7qWS8SNz/6iOj56grdIJIWCBOHMEkQaxddSp+7wDxgOA6bi+iUUyQ5mRXaURRsRlRZZU40+PprOPVP/4A85vNr/8+DsOfkwrzKgFCHM0ThEj+OHHehs9uLd9/LfGqtjbkX3ssEsy7UQszPetxuHD18FI/9z/coHJCNTXW1OHDrAZSWlf1K1GbhbSy0ff3ezY2ABrJqIOuCd+Df/M3fsGBfjQ9rIOuCcboZbwboMSfAvqkpHwGtAf70Y5Zs1ulpn7LvkmRAbi6TvwReFBcnkHlgUkDXm3Gsep83HgFhpYga2fhEAKNjfvRTkWxqKkgltSCKi6yoLLfRls2KlJT1C+QQ0I2H6jMCuumkGp8AWUS1I4u2x1sabEqZ1Ryl8v1eH2XuZ+fR0kXweXtAAW+zM+Oxk2DWrHSqusSgiqmbhdRpdxgnu4E+qgnGE5C7Kc+AfRUGqrJKkenG73u9heiNgAayrv61EXVWfziEWSqyjhHEOkS27RBVWmfCfsSHDSggkLXCmIxK2uWSnwjTOldn9bDo3dUXRFOrC8fPTFDeqQ+ZSZN41z07UV9XgnhjxI5Z+oqWpj60XuwnqKgPJeW5uOu+HbQus8FKO8jFNOlzL12aRXu7CwP9buRwPCVJ9mwqsSan3BjA08++3OkF2kYM6CGDV4CsdosBGcTHigprXkoY2SlUpeJuBJSyWm1klGOJAR8uNrvYt84jPdVEICsVf4stVMIyKku/1dr3UrYroIZhHqskMTq4mM3xVOiKI8jBjHwSeXJzTJC+X6ujLSWqq7uugAEkPTR4+HWMnjqJ6Y52pNdsQu2HP6ISX3HG2FRFXN2ora+tr1cgq9zbfr8fjhkHBvr6uPSjv7+fVlbTysIqkcW+5JQUOkckISMjA2npaVzSkcqf8rqZQG6jvv9X7WYPcdzk5bjpVRZynvcNYrc5G40s5JQQgJRI4k+sNw5vSOgBhh1hjh84jhjm/NINlGVFiie1+aCiuyYvr+R1lpxaH9VYu/pJSm31I8FmwKE9NjqsxJOQqgshy421jLMDHA+LK4DLRXVWjvVkcdAJQcjb8rrHQ7IA73cBuAi5KpuORNmZZqSn0YmKOS9N1F9u9G/u56IRyCp9e4hKrDPiJvDzp+Aa5wPWaMFYynbMJNUjYEykknoiGmoTkMN7Ue4/3XQEdARWLgIulzjR+RWgVdzoZqjgnZVlJnghUREaMkha1S32IyAkFqldnjs3g1deGcf+/ZnYvj2VcyYzc0/6uboWV1jGTiZT5PsUJBlTAK1vbd/61rfw2c9+Fg0NDfjlL3+pyJsCYP3xj3+slFkff/xx9drlz8SRafTe974XUh/4+Mc/js9//vOX31rWTw1kXVbY9Ic2cAQ880G4EER7yIGuoFPVjITAK8qspfERN78NHJ4VO3U33eFcXgOOdYXRMQLW9UF30jDqC4lLoCBJkpVJg3XSZF4UFrJ+8yW0/jBCTrAXFqLo0O0qr7+ap+kn1knqU8dOOnGp1auwHuUlZjSQRChu1As1NZ/jcQ8NDqPlUjPOnzlH0swwdu/bg8atm1FRVQGLRdsYLRTDaH5PA1k1kHXB+1MDWRcMT9S8KYlgDxU6R4a96Oyg/W2/h9aGXqSm0oaYoIu8PCsVYcy0aTEh0W4ki4GW5prVGjXXb6kHIte6h0DOjk4PLrXMwU67tTwCOspKbCrJk0wAioA6RIl3vTUZlLCcodQ7mpo9BPT61QBnc70NFVSSk8SymYAgUeyIxtY3RJvq7gDaegIEJkMpupQVsiiTEa+An7HGNA+xotrGAXwrAVnnWeDLI/jqQFUc8lINSE2MAFmi8TroY7rxCGgg643HcKlbEHZtDxMT54OTimlrIyijiFa5AmYVC5l0LjZybtcjoNVDMsAkrUhPUhHrwsURtDS3obrIhx0NZmzbsRUFhURvsAWJ8PBRjfWl586hvXkASSkJqNtcgj0Ha99Ua71e3N0kiDjJAj16dJJ97RwtTk20yUomkDWVYFkBiCyvfxELGg+XSRcwOitAVpJTZgm64Wt1BQY0FhLESkU1CsiuahNggJOgAQGGdnV7MEJySHq6Ebt3JiM/14K0tJsP9pF8uhC2ZlnUGqNCV0+fDwNDfoyRzFNVYUNlmUXZeiZRhfU6pNxVjaXe+MIRmBulkjTVKZu/+21YCebb9KHfQUpJKawE+Om2viOwXoCsMu8IBAIEVHngnqNSm8sFsWOcmpxSdlXDQ0MYHRlBgOBWW0ICymm/WFFVhcqqSmRkZZFAcWMK3uv7Lln5s5ubD2CEY6U3AqM44hvF+xLKsYdgVhu16yPm5Cu/z5uxRVFm9XM53BbGxQGqA3N6XEQru51lBmTaOY6gWODyRio342yif58+Fq7G6a7y3OteiErIpnLaHpeR/MM5vAwJlzksjP4TX+Mj9DPOAmIVFZbBYT+GuEzNRECuAhxMT41HBseo6QQ0pSbHE/RiUAUtG4nN4kIlHIHrKbWs8Snp3V0lAtEGZBXVoXkm5hxdXRg7ewbdzz2LgCUNli23o8dXDIchG6Uk+VVXWlFXY2OedRVZhleJl35JR2CjREBS/SOjotLtw6nTs8piNj/PggqKdpRQvEPcV8xmrc4ay/eDXGMBTp4758Czz45Sgd2KsnI76uqS2bfTBlsPXlf98s7MzCjVVdnRSy+9hDKq1F1u8fHxuPXWW+n62YpPf/rTCtAq7/3sZz/DQw89pAiZR48epWhS7uWPYHJyEps3b1bg1u9///u45ZZb3nxvOb9oIOtyoqY/s9EjIJXyGbr5dYeceM1PR7kwySBxNtQZU1FpJMnaYILFsDAIcKPH8FrnL3kWP+v3wzNCJDbQSY/Oeq4wdpQasCnfgOKMsCISX+vzsfz63PAQRk6ewPi5c3B0d6H2d/4P8vftRzzBoAaxS1nF1kyF/uY2L8eFfgiZ6db9SSoXYOG8/3rN7/PTfZBOjk8/S3XWN4iJykBldSX2HNhLnFSWcnO83jb0+9EXAQ1k1UDWBe9KDWRdMDxR82ZkMigKMSFlE+tyBakMQ6UtAloHBj0YomWHPYlgRyqKiSVuSUkiQa4E/DEJoFvsReCyHfAsFStEobW13Y0OWi0nJsShqNCK7dvsVCk1M7G/Pq+vFJWloOTxsHjXIhbDPkxMBZQq2y17k5CVScA2YxGNTY57jiqmpwjG6uwLUD05jGoWww7ttkYKMDE2r5BnjwCzhmaAI+0EmhGgJffnoU0GbCkWMLUupEbjfbgSx6SBrCsRxaVtI4B5pTTmoCLrUHAObWTcDlKldZxqrZtN6UxSpKGKSYpkmJYNtlzaEa3d2kICaO8N4OR5PvObL2C4/adUYt2O973vHbRqTiGAKGLx6Jx1Y3J8Fk89cRQjQ1O45zd3o6auEJnZKYuOSU/PnFJj7e52MyEL3HpLJkpKI8r2y02uy3bGnRELmnP9QC+VWLOTDSjJhFKyzhDgCQGsq61mLf1nX7+XYGA3QboEZlHxausWgqHLbExIW2BRQICbX0EQws6MI4TTvN7dJO44CWgtpNVsXbVNqXKl0d5XAAzRSlpZu29GdO8pRHCfs78PbY//EN6pSSTQiqjo1tuQs3NXdB+4ProbjsB6ALLK81LsqaanptDb3YOOtjYSRjsw2D8ASY5m5WSjoKgIRcVFyCsoUAqsCYkJSCCg1WK1KuVVrb56w7fSkjYwNO/GMQJYRcXezzHT7eY81JrSqFlPEsqSthTdK3NIocYnMu/qmwzjaAcwS9eS9ERgV1lkDia1hfV0zjfzisgYzs34Xurwo6M3yDl8UBGpbt9jVa4qMt/V7cYjIHEWgr6PttLkDyh7aTfzPbPOIIlMXEhsGuUiYFdxKsrLNXNsaEYRl5wsAbga9bjwxi/Dqm8h2oCsMlYNkKjS+v3vYfTsWZjSszBqqUGXaRcSUxORk2fHjs2JBFyZ1NwjbrmTwVWPrN6BjkDsR0Ce/27lxkIHtnYPzp53KdGO0hIrNjdQWY7CFZqwENvXWfr64SEP2uh8JO5HQiK///48lJYmrksxlmi7WgJWrSLpUoiZn/jEJ/DFL36RY6qgmrd+/etfx1/91V8pwOqxY8eQkxPxyhY3krq6Ol4rN2677TY89thj/B7Gqc89+OCDeOGFF1DAufAbb7xxw84jGsgabXeMPp5YiUCQzjRzdPMbCXlwMTiFo/4xFNHFT4Cs200ZyI5L0LmBZVxMrxBaWcs53Qu80sIafi6dcLhU54aVEquFAtfrNecSJJnfR/JD+48e5/IE6h78KIrvfAcSsrIVmHUZ4Vz0Ry478z3/yixEzX3vTrsiFuZmX1+h/3Ied5jKrO1t7XjhmeeZW/Bj3y370bC5EVU1VYs+Dr1i9ERAA1k1kHXBu1EDWRcMT9S+GQzOw8dk+xAnh4OyDLpVIli6VgE3JiWZFNtR7DsyMiwsuMVfV547ak92Ax+YqJV5eZ27ezwEsrrhcFBNgFmBjAwTlVktKCowQ9RZE3l912sThbbefh/aCGb1M+klINbyEgvVaalMyHtdlGmjrQnQs2eQRTAWwlq6ArATdFtZKqouBJtnUV2O8nKxlh+P2GSH0UqLS1FnbSgQhUGQmcbnzTqyV4i2e+lmHo8Gst686AfDtN4kmFXUWXvn59AbnIUlzgg7FVpzmZzIi09AQVwiEvi3NcZZtwL+lyL2uRY/zjc70dfdDedkK0yBS7j7noO45767VLJUEqkyWe1sHcK5U50EGk1Qed6Iux/YiaKSLCp1X3+y6/OF2I8GFYhV7M5SUkwoLEygYkGKGjMtp2giKqyzHlqsT3NMRsD/EFm8vqBBqYgKiLU004BSilNaeXirSWgVYMCcO0Rykw+9fV6CWL20VImjPasJjQ2JJIJEyC83uzjrplqsY5ZqXFThGqQi1+RUUNnKJiXFoYxqSKLGmkAA62JYuDfvG6r3/NYI+B0ODB8/Rhb3WUw0XUDZu+5D6d33wEiwXzxt1nVbnxGIRSCr9CGivOpyujBNdZkpLpNUXnUweStKrFK8E2a/qLdZbTbaDOcpAGsBbbYE1JqUlKSKeuvzikb3WQmw0xcOoT3owC98/UgxmBWAtZqFm1yqkazXFqJ6+YwbaBogUWZ8HiMOoCyLxRXWnWV8kZbA7I+BDhmxNrGMwgsmwMkp5lrEWeXIaR/n7HHYvMmC4nwCKFOik0AbhWFc8iGJvaAotQp5e3ySJO7JgBqry9xA3Ick12OhG4/NGqeIzKLUn5piRJI9TrkWWfn6ao6vl3xC+gOIFiCr9PnCCJghQWXiwnkMnzqFSVpmeAt3w2GvhsNSQgcIKyrLqRjIOUgyhSF00xHQEVj9CEh/66WtbC/Jt00X5+CaC6k8TzFVWUuKrSgssEYN+Xb1o7E+9+BmXmpqyo/XXhtHX58H+/alK9EdcZRcj86C0XYVBSz6hS98QR2WAFO3bduGsyRyvPzyy+q1z3zmM/jDP/zDtx22qLI+/PDDSlE3JSVFfaa5uRmjo6Mch1nw9NNPo7a29m2fWc4fGsi6nKjpz+gIRCIQYq3IB7qvsVZ0hk5+s6wbSVW8Oj4F5XTyKzAkwBzHurN6VUdtoQhIfsnlpVI88ysXByTPYoCDtZ1txUAtHfXEBce2ztPZl10run/xNNp//AQy+IzP3rIVeXv2wZKWtlD4bvg9wU6IoMnh404MjwQ5nw+jfpMNWxsTFXF1MfN7yd1Ojk/glRdfRU9XN2tLQQVk3blnp1JpTbSTBa5bzERAA1k1kHXBm1UDWRcMT0y8KeAFATz29rrR0upE0wUHxsf9LLYJC8+OLVtSyZyzITPTEhPnow/yyghI5y7slAtNbpxvcuFi8xwVA8zYuzsFlQR9CEBlPTdR5WinIu15KsydOOPG1oYE3LovCTnZUsSI3oSzWBRKIayrP4DJmXncdcCGfVstBGUR5BSD9TDehjjbF8az56VgCojC4DvqCdJiQTX64MTr+RuxNuemgaxrE+fr7cWJACbIuH2V9jEXAlNKgayG9jG3mXORTzBrelxs9+3TBA0Mj4Xw8nEvTp8bhcHxArJTZlBTk4/tO7eiYUujClGkGAm8/NxZ/Pix17F5ewUatpWirrEUyalEciyiTU8H0EFViHPnpnHx4iwe+I187NmTQfWduGUl1CXxMU21tM7xMF5plgRIGOQZ4dYasf8FMuk4nUAF1LVoom4i4NAXX55W1ixhPrBvuyVNKbhbLbRcjoKuUurJorbV1unFybMudHb7lIXn5voEyGJPFDDC2sRrLa7JRtlHmIqWAQIAe579BU790z8QyHo/qt7zPtgJ/rMkJ2+UMGy484w1IKv0IbKMj41TfbUbly40oen8BbQ2t1Bthq4PeVT2bKhXic9NdbUEseaTIGHhM0ksTvVz6Wbf4FK0cVCB5GxgAj/0dmOXKQu/ZSuHFfEwGWJwUrWEgMpYg49ZXBwEnmuikpmfoD5TGPdsjqPiO6gYun5VQpYQphVbtZdk1NdPeeFwhhUp6Y79NlSXMsi6rUkEZKwopCencx7dtJ/u7GEupYdFqumgAryKQmt5KcGHBCAW5JmQmWGMSmLzmgQrSncSNUBWklLmqULX9bOfovl734E5uwCulBpcMh6AOTNP3T+7t9tRU0nLDN10BHQE1jwCSqCFRIbXjzhw+iyzXiQ2lNNF5o5DaSTjkrC9CHvZNT9ovcMlReDFF8dwgTVKEdmpqkpSBHILc1O6rW4E5tn//d3f/R0effRRpap6eW8CSBUA6x//8R+refHl1y//FCXWz33uc5ijivnlVsicziOPPIJ77rnn8ks39FMDWW8ofPrDOgIqAgHmRsSd5jnfAI4HxihwYkQt60R3WwqRZDAxQ6LzV9e7VaTG3UMnvaaBMJ6/COSnAnexxl1MsnAWazkbqYkgxdAbRzDV0gyzPQkNv/cJJBeXrHoIZNwnbiwXLnnwwquz2LElAffdnaocMsymxeX4QkFx2JrG0cNv4Nvf/B+UV5bjtjsPqVpiQSEVuHSLmQhoIKsGsi54s2og64LhiYk3JdmrWAy05Jqe8bNA54OANWZnactFCw8BQNrtYsVlRkGhjeA/K3/noIYKB7owFxOXWE0wRZFlkgoVI1QwE5XSiQkfmcvzCsRaWGhVCX1RpzBFoULpjUZZinfTVNEb5HkLAMYxK4xtoKHWRtl5MzJ5P0fjeXvIMh+ZoLJLlx8X2wPISItDUZ4R9VVmZKeLMuuNRmZtPy8xnyBoq3ssjAsc6Iv1Qm0+UJNnQEWWFFL1RGltr8jq7k0DWVc3vovdup8KZD4mKAZDbi4ujMx7FOvWy9fzqc5aRDBrhSkFaVQnM1GdNVa+hUGScEiepGq1H8fO+RDwUQ1vdhDdF36O/BwjfuM996KkrASZWZQ1ZXM5PRjoGcfpE+04c6wDd9y7Ddt3VyI1PYkWzwurscoYyeEIoLt7DsePT5FMEEdVcytq65KpyGpT46HFAij5GOSYK8LaFbvfboJYp+YM4CaRRrJnXqoBhelANvF7cljy+mo2USp3u+cVwaWbKqxOVxBpqVQApz1fEccGyp6PtYKbqcQq49BZMm0FuDow5KPqVhAJVFRPS4tHYZ5ZWcdm0C5W+hCNF1vNu2WVts3BQYgewaLI2vnTnyj1K2tGBsoJaE2rrha5wFXasd7szYxALABZXU4nZmYcGBkawtDgIIYHhwiOmkXAH6ClooUJUqtSXk1KTkJGZiZZ++mKuZ+Wno7ExATEkQGg58o38y77333LmOcMQawdoVk1DtpqzFCEHiNBrBtBcUTmYJOuMPomgbYRoH8qTLKMAeWcf20uMiCJorSrPd7436uxvn9zzoUxQFWQ861+tFOddQ9JqLUVJjV3N68ROWl9R/j6ZydqfULQcnHsKHkfh5PAVldI5b5kTCljX1FylSZKrampRuaD4lVOKJ2/J9ANR4jDut2cCEQFkJUPTdfQIEaOH8coiSsTXb2YSN0BV3oDJ2xFKC5LRR1Vf3JoY56aokFVN+dO0Xvd6BGQsY0IswwO++gy6EMPXWXmWOMQJe6qqgTUVNmU8rZ2aondO6Wraw7t7U60trqQlWXGO96RQ1ckElDM+rm7Fld1bGwMLS0tGBgYQE5OjlJZTec8d6EWYgHu0qVL6OnpQWNjI0pLSxdafcnvaSDrkkOmP6AjcEUExK01RFeWPtaIuujg18ElCOYH4qyoM6WihgqtAmeN17nYK2InL4jjzSiVWM/0hjHMn8nMpVRkG1DPGred/Lb1rsT660HxTEzA2deLtid+CM/UFGo/9DtUZ62DLYvJplVsUqvz0Im4s9tLZVYXCUwGEg3NSplVfi6mCXHD5/Ohv6cPp0+eRl9Pr3LduvX2W9G4dTNycnOUqvhitqXXubkR0EBWDWRd8A7UQNYFwxOTb4bYCcwx0dvfP4fOzjlOWpwqOSCT/5LSRNq00CqRtvSJiSZas8dzAhlRItNjm9i43JK8l4R+0yUXTp52KgBOBkHK9QR15vO6SiLfwmu6HpP3AtwVNTdRcmtq9qCCShxVFVTkKKUVWHJ8VDK2JTnXMxDEySY/Qa1BBTrfv82CcgJwU1iAjCfIKZaK5ALgEtbaS81hpc4qwKPyzDD2VhqQkkDrPy1YExsPkkUcpQayLiJIa7zKHNXIepiouBScxikCOuxk3ebQUrfOlI5CAlpTCWa1Esxq4RLNTZ6Lc7QMHRgOEuTvx9GzXmQnDSEBHWhveoPJ0lw8+InfRWpaqlLDk4npYP8kThxuJSBpCu45L+66fwdVWcuv+/yU4ojXG0Ikic6+g0qsm2qScPuhLNipXG+zLe6hxUNGIAh4AoCDIIcegklahsMYmSFuj+9tIZBkU37E7ldERVd7TCUTfmGvTlGhamTUjzPnnKp/LCyw8PzEjiXpV4Slm3cniFtAIGjAxCT7vzFe6xYPJqcCKjaiwLqFS7T23TcvarG7ZxfBgpOXLmLglZfh6OlC/Uc/jrzde2Cy22GINeZO7F6GNTvyaAOyBqm6JoskMX0eL5/7XkxNTtKlZBz9vb0Y6OvHIIt40p8kUym4oqoK1TU1ZOxXIIuFPbGdEvVV3aIvAqQvYmbeh2f8AxilQn1pvB11xjRsourIRmoydpJ2plcWkiVnicfi3GtfZZgEGgPSEyOOHxq+F4nTcv+Xea4AKY+e9eHwKR/ysuNQWWJGQ5UJybSz14+J5Ub2xj7nFVIUVVrFfWBwOIA+gp6mZ6gIz7FmCvNA2VmcExEkk0ViVEpqPAlTzHMSDCVkZ/kZIfHf2DHoTy8uAjcbyCpOAT6HA2PnzqHzqZ/xvgnCbc7GUOoBhLI3oZxkv03VLPTXWPl91k/MxV1VvZaOwOpFQMY3HrqwNTW70NbmQWeXB8XFFjTW21WNQ9RZhUiiv6+rdw1Wa8tzc0EMDXnx86eGSRAEDh3KpmOklQqtse0qtVrx2gjb1UDWjXCV9TmuVQQE0OoI+/GGfxQd86wJMFfSyPrQDlMmMg1WJMWZFOlXj3YjV0QEVXys6/RMCDnYgNbheYrBGHCoNgJkFefR1a7lrNW9sZT9hJkj9btcuPBvX8ckVVnz9+1H7o6dyNq6bSmbWfa6gvW40OxG/yAdbaeCuP2WJNRWWQlAXbxrn8fjwcz0DF549nm11G9uwGYCWQXMmpGZwXHk4oCxyz4J/cEbjoAGsmog64I3kQayLhiemHxTkgAC3PAQuOGeo3IB1bnGx30YHfVieNjDBAHlLdlJl5YmoLw8EUVFCWREcmATY4C6mLw4K3DQl8Ers1SmmCIgpINJHmEvi0pFPtkqWzbbkZdjodLZ4sA5K3BIa7YJBUhiEWN4hGCufj9aO7yq0FRbbSGg1YYyJruisQlgS5REzlwMoL03ADtVQiqKjUrhxcpxVCwl5OT5wn9krlGJcMKAI23z6tmxpZhFvuwwSmjBoNv6iIAGskbfdRQwh4eqZNPzBOgQ1CHM24GwG/8/e+8BXNlVZQ2vJ72op5xzzuqc3e2MEwZnA2aMPRjmh/HwQdXUVI2HomA+KMIwBk/B8ONhBgYGvv/DYxuw2xGHtt3unFtqtVo55yy9HPT+tY8sTwdJVnySXt9T9fTSfeees8/VuefsvfZaoxMexIeZsI7AjrzwKGQS5LGa/xNd7gC6+vx47xhZNxx+JJKturXmTfS3nyRDajLWb6zANdfuhiXCoti3nQ4XLpxrx97nDiM5NRY79pQityCF4KOPBrE4WH9fvwvvvddPUJOX655IFBZayfIRqYLaEtieSxGHR9+4Do1kpD7TymCLR1ioA5z3RHoGSKLDQ8D8EbwNza3GuZx15mMk2DPA/lRV23GmcpwBfKNaAxSTvSQ50YgognRX0gEj9wpxQAjQQACs3b1eCEtWeqqBDPImMpTrEc02GigXo4FCZh7ntfSNn8BBL51ftczi7jqwHxl7rkMKnV8J69ZBb4lYS13R2joHC6w2IOvY6BjVKvrR0tiEluZmNPPZNm7jntjPLPxU3i+SkcrneDoxE8gYHGG1ErwaSeY+i8rQ19hX5zDoK3TIOJN4Ovx2vOpuU0wjnzBlIYvrnBgm71xtRe6t4y6d2oedaSOL2TCTbLg+2ZQN7C4KgzE8oClkLPKimNrrdpKVtbHNh6o6j0o8vXUPk4ZTwmElo7xWgm8BSaYVgLEAWl1UvRHlGzsVCSTBe2jEpxK7hvnsIquLAJ5knZmWYlBrY2HdjCIIWRL4tbL8FlhpIKsEYjv3v4uuk6cx1NyGLkMxeglijeUeMzMvHhsqrEhNNpDpUbselv9q0M6gWWBuFuByXcWuevqootPiRHuHWyXAblhnJTNrBMGPVFIgoEEra8sCEsMZHmbi+uEh+uTcyv+2eXMsNmyIWVsd0Vq7ZBbQgKxLZkqtIs0CjBAF4OPmdTjgRrNvHFW+IQVsFdNcb0hFCdlZrcLNupLBgVU0TqNOqoxSVa+yPYDqDmA9CUlK0oC8JB2iycRqDD0oxZysH+A1NOHxoP3dd9B3+hRVLbqQumMHyh9+JCjIXpWwyj39sdMOHD9lw9aNViYcWsjOqlckfHPphPh9vVSKa2lsRk11DdUcTyoSg4/dfgtKykqQkZU5l2q0Y1bQAhqQVQOyznr5aUDWWc0TEl+KM35wyIM+AllbWmwM8nmUxG5kpIHsBZRSijMQ9GhEPOXZY2KMiIzUK1DBWgLXhcRAzbMTMq7iFGhqdtLRw7Ftp0YzP4sjUETkhNMIFkkkmEXke0NtLAX4JAwcpysptd3jgZ5ApKwMI4rJzpqYoFdO6dXIclrT6KWMtpdt9qk2ri82IIuLssT4SVHM1djmmS5LHx2NAzbgUAMBaQyiSlmXqcN6rgtFhuFqY2YNp/zsd77zHZXh9cQTT6jF8qRV5v/3yJEjeP3113HPPfco6Z/papBrxW6347nnnqNUUz3n7Uhcc8012MGNRkREBMF/nAwWWTQg6yINuIw/9wcm4KOMjDgqRGa3lSytHgJco3QM2IbR0R9uRXK4RTG0migns5Ky8hebQa7KCc4dzWSpbiCov6bBA4vJg6IsJ4699xLam6pw2523Y9PWTcjMyoLeoIfP60dDbSdqqtpw5kQjyjfk4DaysUZwojGZDBdXf8lrSfqQe2RziwP1deNobXVQRjocu3YlKBYISeD5qKKC5qxnkHNd/zjQMUQQPxnQBsYDSnomnTja0vQwZMQFYCbbUzBIfaRNo2M+Jid5KL/iVCysErgvL41gQkeECthbVhBkISADB0G2klHbxaST9i63koKV9YkAWPOyzcjOMiqgjeZL+6grcA1+z3tP69tvoevgAfjdLsTkFSD/rrthIXAwzPDR/3NrsMdXbZNXEsgqbKsuZtyPjoxibGwMY3weGRlhBv4wxuU9H/Js4DUXEUE1kuws9cjKzkY8r8XIKCZ7aBPQmrl2ZZ1T4x1GPZ9juM75pDmHDCNc3eiuXkCDyxNAXa8wiQD1vQEkRQHFqToVhEmOJpiVe+NgrEnWzEW0gIY6CIgcor/hnSNO9A9PoDTfgOJco0pGFaeLNocswKhL/BMPlQlsTOYeGPKjt5/+zn4fhkd9SrFAVGPED2aNIDsrE82io/R8HaZ8MFYCGOU7AUXNNaFtiZse0tWtJJDV3tONkaYmtL67Hz1NPeifSIQjaTO86VtRTGafwjwqI5GRNYLXglY0C2gWWH0WsJOMpZ/JuudrKEnf6CQTup6S9Abk5ZoJQDcqwg5Zwmv34NU3djO1SMh0mps5nvVUlqI60uYtsdi9O5G+OS3BZCabhfLnGpA1lEdX69tKWmCAhCf1vlHU+kbQMWEnyUm0Ijop4HMMmVnNVPS7WoufcZRhO9A2SABrFzBClb2JgA47C0Agqw6Rpkn/ydVqH+m3KFqMtrag//RpNL70IuJLS1H2uUdhjouDwUrmlmUsEsKWx5lzDqrw2hXOI4VqK9s2W1Vy6nxUh8fHxjHQ1499b7yN5qZmJCYlonx9Bbbu2KZUuMxmgha0siotoAFZNSDrrBemBmSd1Twh86UAOiZZDCjJpQAQLtTWEgDTYGPgjwyRdOyWl0WjhHK7BQVWytKHpjR9yAzoRR3x+SbZKLoJ6Dx33o4jx0YVM1t+ngXbtkQpUIuB4xlK8VpZ3AhASVhO6xtdePfguGJKyUw3qkWOOKilrDbnloeS1BJo2X+cLLq9PhU42bnJjB0bjApsHAwWv4sunUW9lDEQBiDZCJxqBV49G0AZZbV35OuQnwzKWy6q+jX345MnT+Kuu+4ieDwR586dWzCQVQCxDzzwAA4cOIAnn3wSDz/88BW2kOv66NGjePTRRxVY4+IDoqKi8OKLL6KUG47FFg3IulgLLu/v+S/IzFvKf+gm0Otz4AKdFUd9/XAT0BpBB8W1zL4tp+xuQpgZhlUC9hDngdszgTfe5xqkyYfkhDDEWgYRpW/BUQLf+hh8/PyXvkBG1g0I1wujKAHbNhf+vPc4mhu6ERMXifWb87BjN6/vjwhgiNSoi07zd98bwKFDA6hYF8P/iyi1zom06ud0TySGFg4yr55uDeB4ExlZCWKNssg8BxSm6JAZG+A8DrXJDtb87aH9ausdqD7vUEysuTkW7NxOFl5KtAkTeziRKyt1v5f7gjBkdXR6cOjYOLrIwuogW9Z2Oh82kk0lPo5MZgwcS3LNSrVxef8rtdrFAgIiGKqpQfVvfwM9nUSb/9fXEJWTA2MkkVZaCRkLrCSQdXBgEN1kCairuYDaDx52MrBJKS4tQVFJMQqLi5CRmamYWIVtVa+XRE2ZfyYfITMQV0FH3vF04aC7B5n6SBTrY7BRHw8rAa1Xc1FrQCaOdI5M7sPqeybXKHdu1GFLDoMxZi0Ys9jrQ9Y0smatrPWgrtnHvbsf64oMuOP6CM4jQSEnWWwXQv73MkaKQYb7i8kENq5Dydg6NOxHZzdZZbge7ejyoH/Ax3sA/RNch+ZmmdRD/EaybhZAq1aW1gIrCWQVJqHWffsw1N6NLncSWpM/iYTcTOQXRnMvEoGcTKPywWn7kKUdc602zQJLZYGp2JWwbXdSkv7AoVEqDHoVWcd6+hM2b4xU9+BQI+tYKvutxnrUesrtR2XlKF54oVP543bsiGdyeQSio69eYNVqHKtgtEkDsgbDyto5rkYLTHzAzipg1vP+YZz1DJKLNQy3m7kOJphVyE6u1uJi8mNlG1DZEUBVuxAxAR+r0DEZWAcrIQRaAvDklRHw+TBQfQ5nfv4zGKOjkf2xW5BQXoHo7JygXDpDw/S5kBBl3/5RpbJy98djkZPFBETG4eZaxDcgzKytza04feIUXnnxZeQV5OPuB+5BFgkOkpKT5lqVdlyQLaABWTUg66yXnAZkndU8IfmlmxtIleVKWY++PhcGBz3qvQAihZHAZAqn9CKzXflITjYxW31S+jUkjREinRIGNBlTAbM2UYZHbvwiuRbF7OVUMrMW5lvI1CqsRKHjqBdniACVBihd3NDkVkGKvgEvsjNNfLDPeWbFvCGBptVSpM3CVNfa5adUoZdBMQ9SE8NRqNhdDEiIXVuAY+WQ4maglSyFpwlmHSKGgF3E9jygiCCvaO6RwleR/Zf6OhAwhABP6+rqFKi0sbFxQUBWAetJPR7KOPz85z/H97//fdXUmYCsg4ODin3VRtCGyOQK8NVisWDv3r2qLfHx8XjttdeQRUbLxRQNyLoY6wXvt+KscMKPPr9TMbP2TjgwOOFW8vbRlN0V+d1MsrRmEQBCaCjdGHPfAC5lL2S+6CAbdV0L5eLIyOohm9jGUiNG+7hJPvJnBTJKTUvBjbfcjOzcbHXqkWEbukmD+s6fT5NxyYXdN1QgvygN6ZkJMzZNziMBkO5uJ6rPjfG+6FIydVu3xqOw0KoY6GfL5pTfewhg7R1le8k23dxHtie3ZOuS8ZyMTilUQctNBBLp8IgKUiKntEkeXd1uyuy5eJ938Z4v9/gw5OZaUFwYAWGXWkm5PQk2CXuKtE0kAek3UKDVhHg9crNNlHc1wmKWuW5lrr8ZLxjtiyW3gM/poBRRN+qeewb23l4klq9DyrZtSN68ZcnPpVW4chZYbiCrAicx+2FkZBhDXPcIeHVwYAAD/QOc08eZqOBCGBeZYUzUkPVYhNUKSeaRjPuklBS1HouOiWbW/fKyB6zcCIT+mZ0TPozBi3fcXTjjG8RNxnRUMEEnhWua1ZKgs9KjYHMDPVyvXOgiQyvBrBKISYvVYVO2jusUIMK40i1c2+eXRPC+QR+a2v04etaNuBjatsyEzNRwJBIUqZXVZwEfE22dTiY8M3l/ZNSPEa5PR0a9cPN/RZLBuJxW+wS5x1gjJpV84mLDCXKlShWfp5haV1/P1k6LVgLI6uB6c+hCDToYsOysbkRnIAfO2BKY8tahoDgBpcUWpJDVMToqhJ1Ta+cS0VqqWeAjLeBmUoKNMY7GJpfyf/TT1x9Jf0dqqknFN9LTqPBiWFv+84/sdAgfIL4sUUg6enSQic5+xh3DcM3uBORkS3KQ5h8K4aG/omsakPUKk2gfaBZYUgsMMx7Uw7hQtW8YPYwTSQhIWFkr9HGK6MR6lTGzdg0zbj0AnKe/xOae9JEUpwLlJGMyMpfCoG3pL7n+xjva0fL6axhrb4fPYUfhvfcj/Zrd0AUBYOFm7G2MaisHjpAYhRgXiSMV5ZuwvjzikjZ+1JsJOnEkZt5GMOvhA4eUD9nn9WH39ddiw+YNiImNUYqqH1WP9n1wLaABWTUg66xXnAZkndU8If+lgFfFydve5qB0y5h67u/zICc3Anl5VrKzRiIhwUjZaj1BJjr1ENCVlsG+Oi8NssDDyzGtPGdHFR/dBL1ERYVj62ZhazORqdWgHAahBCSRAJOHgNaq804cODpOplYo2vlrtkUiI93AAIWw+q0e1hQJmgQoXyBA1v3HCbCinAHVs3HtNjMKcvSU2ZaA/Oq8vmZqlZ0LzRGHDvvOB3CyJYBdBTqV3ZaXpIPFEAhJx5SAJh555BEFHG1tbf3QNAthZH3llVfw9NNP48KFC3TqOT6sayYg67e+9S388pe/RExMDF5//XXkkOlOyvj4OG666SZ0kaXsoYcewlNPPfVhXQt5oQFZF2K1lf2NhGfb/DYlJXPSOwBxYKSHW1FG4Md6QzwiyWBmIZxVL8CfIAJaFRMrgxFnamTeE4m4MKQnh2FLGWVdTr2P//zFrwhgvQk3fuxGglhzEBUdpYCbjbVdqD7bgppzrdxoWnHvQ9ciOTWWYMiZJ0lh6xbn+PnzY3j77V7Ex1MGlmuZ9etjVILOTCMkQFV5uL06ysyQ9bSHwJBuOjs6A8gibrYsDdiQpUNGPNdCPH2w1kECymVSLIPyE2Rdt6Gq2sZ12wSSEg244Vr2KcWkQKwz9Ws5P5eAhKw5BLTa3ulGQ7Mb52sdCmRbXhKBsmIzykt5xTE4ESx7LWd/tbrnbgEP70ed77+H3jOnMdbSghxmcosDLIyUaDombmhl7VtgKYGs4mic4ALeJw9OKH6+97g98Ljcak3T3dnJPWor2lrb0M6HlAhrBFlXi1HEh7CvpmdkIJHZ9bJP1UpoWGCQ8ngNZBQ57RtC+4QNnzLlYYMhATree7RxvnSMJThT0x3AKe7DfBM6XFeiQyEVMlKZfBPMNculrQqNd7LWESWVd45O7tvNBAvvoqJKEfft4fSPaTPO6h9nAbAOj/ipFCAsrV60dfDewuCYoFqt1nCkpxoZKDOoRzxZWqMihcWbyVdhorwgPtC1559ZyVEJJpA1wPWCl/6TASriNP35dfS2DTAZUY+e9DsRkb8OFWURKC3i/2t+kLIPV9Lw2rk1C4SYBZSvgcQJHZ0uHDoyit5+j0pKEDWa8jIrYqLDmcgbvub85yE2THPujqhDdnU5FZi1sdFORbM0VFREw2yWMdRWU3M25Bo/UAOyrvEB1Jq/JizgpXpf54Qd5whmfY9JwclhFmw2JqKQgNY0SQpmRCgsxP1mDFUwvkMmVjKwnqULsW8cSI4GblsnPhKdlvA7w5UsvvzRlma0vf0WGv74B2x8/G9QcPc9CDeZlT9/hp8t2cdC1lZd60QdFXibW90oKbTgthujYTByTz5PYhS7zY7O9g7sf3c/Xv7jXtx028ew+7o9KCgqgJAeiGqXViZ9q4JXWemiAVk1IOus16AGZJ3VPCH/5SRAYhL0MUqmgpERD4aHvBgYcPO1F+M2L5kJjJT8sCCXwNa0NAvMlN+a740j5A25Sjoo9xwZU2FGG2DGsjC3CYNbL8HJKckE8+RH8GFRABgdo4ChEASc6vMwGTd6KTlUU0c2OAYphJmuMM+ELZusBIfqVLb2KhkmBdCyUW65d8CPc3VkZm3xENSlR2GOAetLjIgga91a2k8I84nXr1NMQAL8IoEi2VgDuLEsTLECRZpWfjG01GMvC7wMgiYuLwsBsv74xz+GPC4v0wFZBUB7zTXXoLm5GV/96lfx9a9//ZKf/frXv8Y3vvENxUomwNjF/I9rQNZLTLtm3tgDXozxIQytXczCbffbYeN7HyawLjwOJYZY5biICGIW7tAogaFNXjQQwN9GRupt6wzITvFgbLCJQNXTOPDe+/jkvXfhljtuIbtwhGIo9nr9ePeNMzj0bjXyyMJaUp6JdZvzEUka1Jmua/m/tDN789TpYbQ0k5l2yI2ysmhs2hRL4DcTBSwzb1IdjGePEUd+jlIz9WRhdTBTV5jNMuOB9DidAoPEUKpX7ifB8rPL/U2C7x0EiZ6pHMcQGchF5ra4iMlGORakMfBuNnNNxmB7sMsEG+dhEoOwr1ZfcKKnX5ivfMiiVGsGGVLSyQYvYIBoJtOspftZsO0YquebIBjR3tuD7iNHyMz630jetBkFd92DSEq9m2JjQ7XbV1W/lhLIame2/OjIKHq6u9Hb0/PBcy/6e/vosGQCBlnnJXknJi6WDscYxPIaiuYjimyrkWRhleQHk9nM+VADqoTSRXjBN4I3PZ0wMAEwRR+BbfpEZJJlPvh3vNVv1cmkQoJZu8gk3w8M2AIoSNZhd9Ekm7ysZ7SycAvYyfDZ0e1DZa0Hp6rduH67GZvKjYiPCYeJQRWtrG4LiH9MlCBcXLdKspuD42lz+FRCsQBrbExgG5fHuE+BVi30dyYn6hWDpzzHxU6uZwX5OtMeZHVbILitCyaQ1TM6iq4jh9F19hw6zzehA4Xot1YgoywP+aXJTKqzIDHBoJgcg2sF7WyaBTQLLIUFZP4WVbMBKr+0UPmlocmp5nMh7NiyicpD6SYlT6/5G5bC2stbhyjqiXLgwYMDOHt2FCUlUSgqikR+PmM2Fi3RdXmtv3pq14Csq2cstJaErgWUch/VbfolMdg/hiY+OhgbEoITITrJC4+ClUQnoVokliKqNdWdQGPfBPrHAiRc0qE4VYfsRCFdCm0F0cWMq/jyJUmw9c03cP63v0HWTTcjffduxJeUBcWXL2MnsaXmNjfeOziukpY2VEQgJ8uEpISZY3rT9dnv476ffWmoq8cpqna0t7ar+NRtd96O4tISxMXHMZFmZqKc6eqc7TPxE9jtdjz33HOor68nMWCkiuHv2LGDKskRxIPMDR+xkHoElCtx/P3791OBuw8bNmzAbo5bMYkffMKOM005fvw4ZN9eVVXFtXQ0VSwLcccddyA9Pf2Kth5hbKeTBBMzlbKyMpSXl8/09Zw+14CsGpB11gtFA7LOap6r7kuXy08QCG8WLXYy3zjR3k5UB33z0VEGJCWbKNNooiyvgcFEI4FSetJwTzIUXHWGWgMdFvCLyO80NjsVO6uEWCLJLpFHGWJhZxWHrgBgDIbQCL4IqMbPrJ1zBNTUNZJlo9uj5OHEeS2gmmSy10mizWrJ9JX2CpvsuToPKi8Q0MWAYwylqreuMyMtORxx0Uu3kArW5TrC6aJjKIAD9ToCwgIoIYOhyDVIIFVPv1SwwF/B6u8AJW6FRUzK888/j+9+97tKyvYcGUGmPp9LW1wuF8bGxtShsoC+8cYbCVgbwnRAVln0Zmdnk3nYj5dffhlbtlwq1SyLPmFllfLmm28yw71CvV7IHw3IuhCrrY7fyNbIE6DUO50WNf4RNPvGmI3rUABWyb7NJktrEjNy43UmGMnOKgyty1FkjyaB4bYuH45XucmeDcrLAzvWcw1hHMQ7b72Nzo5Ozt1+fOz2W7Bz907VDNu4E71dwzj47jlUnmrC7Xdtx4at+YhPZBbmLLovkpDT2enEsWND3Dz6VPJNeXm0cpJPF9yQ9rmYoStzV/+4DiI50845bMjGdU8EHRxkYt2QRRCIlfdPAliDWcTRL0GbHjJGNbXwvlbv4MY3nEkpJmxYZyXjuEkBWKfr13K308kAhM3GtjFJppP32pZ2j7qfiRzrujIL8nPNinV3JQC2y913rf65WUDuVQHep/rPnkHN//c76Jm9HUOnSMae6xBHR0owZInm1lLtqIVaYL5AVlm3KEei0wEnnYniUHQ5nXztxDjXQONjzPwnIGVsdISg1jGui0bhoBMwLj4eiUlJyMjMQDqB0PKIi4tT4NWFtl373eq2gJ9gMXvAhzPeQbzibqMMXix2GJIVw3x0CAdcFjsqxHqofVhDL3CiBTBx35ufFEBxWhgy4wCzFrBZsImF7V/WsKeqPdh3xInstHDkZxtQVsCkHYJZuX3TyhqzgGzhx8b9GBr2MRnap9a0khQtkoayP5BErCgqSMgjJlqvgJCyDpeENgG6ih9NQMwSaFqJtfhqNncwgKyyznQw8WW4qRnN7x9CZ9MgusYscKVtgT5vCzZQgrKYDD6ZTLATn7VWNAtoFlj7FpDkXgGyNjbRf8rEg9xsM7IzjVSosnCOJjsr52WtrH4LVFaOEDQxpkCtSUlG7N6TiNgYiddoc/XqH73Ft1ADsi7ehloNmgXmagEX40KjEx6c9Q3imKcP0WFGpDImVG6IQzqfY3XGkGJmlT2ch9iAIbsODX3AmVYqPzEpOoqkJLuLdMgjiFVUUUMtPj3X62E+x3UfPYLGvS9QUY37YAIb8+74OKKyc4Liy5dxlHjToWM2glr9CsuxfbMVxQXmBWE7hoeG0U310n1vvI3GukaUb6hAxXo+NqxDBMl0hDxhsUV8AkePHsWjjz76YYx/qs4oki+8+OKLKC0tnfpoxueF1CO/+dKXvoSXXnrpino//elP42c/+9klYFbBLDz22GMKN3D5D4RE4gc/+IFSep3CNkj9t956KwTvMFN5/PHH8c1vfnOmr+f0uQZk1YCss14oGpB1VvNcdV+KQ5BxRma4+uEmUGGcoNaODgeamux8lkCjl4FEsnoWWDn5RiEhwURw5PyyIa46o65Qh+WmL3TsDicXrcxkOX/BgerzdvVZMtlZd22PVkCYaMrxhEqRPkuGbx8BvFU1TrS2k42WgYk9OyKxlcysImdtNK4e55a01+EKYGDIj/dPkD23z4ekuHDFyrp1nWnNBUVEPlxYDWu6AooRSFiBNmYDt68XyYYAA6ih65j67//+b/zt3/7tgoCsF///CZB148aN6O3tnRbI2tbWhl27dqmfSHaX1UqE3UVFgCJZWUTesTzzzDO4/vrrL/p2fi81IOv87LXajlbgfrKwuvnoJztrN4GspwkKaae8TCTZWMvouNipT0YcHRfWsMVv2qbrv4cg0fpWH2oaPaiu9yoZ1ht3mmE1T6CrrQG/evo/KA9txa3MhiwsLkRaOtHvLK1NvTj83nkMDkwCvG++YxOKyjLJ1BqmAsbTnUs+q6wc5caKrH49LqSkmAgKT0J8vHFGJlZxcAwQwHq6LYBaskk3kolVAPhl6TqCP4AkJhdYjMzUJYN5sJMgJDjT2eXG/gOjKhs1ickYFWWRKCuJYJBmkmV8pQLn7QwiNbW4caqSbL8EtGYxOaaYsp3iVLCwbVMSfyvVvpmuD+3z4FpA9hRO3sv6CGbtPHgAg9XnsOFLf42sG29CuJH/WNoFEtwBWeKzzRfIKkk7wrza3tqG1tZWSjy1K5mnjrZ27js9nGPDkJ6RjlQ6SdMJWk3jc1paGhlXI6kGYqFz0cikqHAmMxgp5y3AsdWznl9i01711TkJYm3xjyspvKMMuNxoSsctxgxK4FHqe5kSb0LB6Grvz73YMJNzGntFRi+AM2063Eh/+fY8strGBMg0H7p7seUcQ7GtlE7u1Rtb6WeomwQ8fuImMuRnMrmbe1ztljZpo7XyV9YoAmYVkLKX+wHxgcrzGJWNBqlQ1dvvV6oDEkQTFlcpSnGACdIZaQakpRipcqRnMJRKDVo09JJhX3YgK8cuwMFrfePPaDlwiFLVLnR4M9ERuQOlm9KxYXMC8rInWXsMBtk7XtI87Y1mAc0Ca9QCXvqW3GTXbmaSb0OjE+cY34il6s6WTVHIzyMhBNVqtLL6LTA87KHikBNvvUmUEctdd6Vx30cfYYQWW1z9o7f4FmpA1sXbUKtBs8BcLaBIlLgOHplgfHzCif2eHqr22RQj63p9HLYbkyFeNe5k51rlqj5OEnuH7cChhgAkuXeQJCXb80imUqBDjGUysVfbts1tCG0Efo401KPp5b1w0K+/6X99DUkbNyHMQK9cEDZXThK7CL7j5FkH3j0whjs+FoOdWyNJrBeufC9z68XkUcJIKo/zVdWoPH0Wxw4fQ2Z2Fu7/zANIy0hT6l/zqW+6YwcHBxX7qo0+79TUVDzwwANKWWzv3r2oq6tjbDIer7322ocx++nqkM/mW4+MxXe+8x08/fTTqsrbbrtNtaO6uhovvPCC6vcXv/hFfO9731OkW+JHFxCrtEV+e9999ymSLGFnnRWlQwAAQABJREFUlc+mfPNvvfXWh8BbYXvNy8tTbLPXXXfdtE1/8MEH8alPfWra7+b6oQZk3TcnU+mcTuoLXYVFA7JehYM+xy6LhIswgg0NeQgKcStgiLz2+yaYfaHjTSOMLDlGglnJdkmGsPg4EywRYZojd472DdZhU855AcS0tLrQ0+uBLAYszFZOJ6NbtlCzJ5Idj2ytQViHBKXbwmInLHFNlB6qb3LTIRLOPhpQWmgmm52e71fPdSqBMWnvBcpuN7X70dXrJSMrQWaFBmSmUMouZm0F6kmsiEFuGmTDcLwpABPxcWkMnG7I1iErfpKZNTS2R5deysECsu7btw+f+9znFICjmxK8Aly9uMjiMpNsZbLw/Nd//Ve1cL74e3n99tvMQGtsvPzjK96LrMCFCxfUAjcnJ+eK77UP1o4FHASFjDMLt3FiHG10WogTQwrzDpGptyIzzIrUcDJZ8H3YEt0IRIa1f8hH9ioGgwf8iLLqUJJvwPpiPbra23DhfDXefv0tZOXm4MGHHkR8QoKShraPu1Bd2YK3XjnFDSVlbzZko5gg1qSUmeXIbUy6GRjw4MzpYd7n7MjIYMINJcrKK6JhNHG+v6xPNreOrKsBtA0CXSMBOjoYEKU9hL1MGKSFiTUpCisC+JBg+bjNT7YRF/viJFDUr+TyCvIsyMo0IZWB88u6o8ZyOf+I80uUSIZHfGjv9KC7x4t+yvuJu0uYqnKyjErWT+6vYutgt285+67VvTgLeB12OMle3vL662h96w3kfOxWpDEZI5bsrAZr5OIq1369YhaQtcePf/xj5fC7n44vN0GqAlT1uD3qefK1m8x2bvXe7frgNRlYxYHon/BjgtlP8lqezaTqlqSG+IR4dS+YehbmVSMBrOFc22jl6rCA3IuHA5QRc3cx2OJSgZVthiRsMSReHQZYgl665X7NvVhtD4GsrQEYCbSTwM36LJCZla8jNBaShZpZJOmHCHQ8dNKN9m6fWtcW5RpQmGMAc620ssYtoBJwmBRtp5rE8CgfI17F2Grje/GfSf6EgFaZU0E2mElGVvGhyVpY2OQiI3VMnA5XrHJXM7PccgFZZXwEwDrOfeTwhRo0na5HW9MwenyUAEoqQGxxGUrLolViXVysXvk71/glqTVfs4BmgcssIP7zEfokuhijqq1zkLTDDx8TErLpJ8nNMSM9zcRk/9Xj77+s+dpbWsDDOOMIwaz79vURsOElOIIM2sVRlLTVfANXwwWiAVmvhlHW+rjaLOAlwYkkC1d6h9DoH8OQ34X4cDMKw2OQGx6JtPAIBWZdq/Fa8SEFmKDYwhhPAxN6JSYtn6XH6khUwjhPEglKQlApdDmvM/Hle0bHcP7//FaRUuR9/BNI3rwFMfn5CAuCf1bC3S73BM6RqOy9g6MqFiYs/OvKIpAQr18Q9Lq/rx8tTc048N4BpQgWFxeLrTu3Yf2mDdw3WqAXut4Flm9961v45S9/qXzkrzP+MRVHHx8fV8qpXQQGP/TQQ3jqqadmPcN86xFFV1FrFRyAAFS///3vU11Grn7gF7/4Bb797W+r16dOnVIAWzmuoKBA4QkE3Cq/mSpS1w033KDAtHfddZf6vXw3MjKC8vJyEgal4OzZs/NSoZ2qey7PGpBVA7LOep1oQNZZzaN9eZEFRKpemD1rL4wR3DROds9RyrfoOYmZUbEumptPKwGtZiVVHx4uQAYNzHCR+VbFS8lgFikeYWY9cWoMsbEGlJdZUVFqVQAZtaijcz5UQCjCxipgoBOnbeju8+K6XVHsq4UMGgbFzLpa+inrC3G+CZD1jfcdcHOc4mPDsWsjWe4YHAtbg4vt/nGgikxA5zplEzGBu7eEYUe+MLMy8BOCgb5gAVl/97vf4YknnlALY8nomg7Ims9NhWSACcjks5/97BVzj0gN1NTUXPH55R+kkw2toaFBA7Jebpg1/F62MqMBj2I5O+MdwEnPgHJalDMTd7MhAWmUljFxwiF3jXospKsf7JfQ0cP5t82H42fdKvArrFVZlGK1GCfw3jvvqSzI0ZFRrNu4Hnfffw/XDgYCnihV3zqA08cbse+1U7jx9o345AO7CEYVqbEr2cPlXLJBa29z4Fz1GBobbKzDjzvvTEMRneHCwD01z0vfJ+faSendRhJAHCPYvnsUyCFwdSPB9juZpStzlOHKUy3EFPP6jbRNEk8G6MxvbXPh6Ikxxci6c1sM79ME5hLIalgBVmtpl6wdbHaCa5vdOHx8nFJ+k8H8a3lPLSs2836lV0H7eXVYO/iqskDrm2+g6dWXYYiwIpZOk/w7P4kIOkE+/Ae9qqyx+jo75egS6SD1mv/48r8vEH95f8mDx/joVZSM70iCkXft2IGx0VE+xpSE0ihfj/O1PMvn42Py+agCuUqd2bnZyOM6JYsJMlk52crBl5CUhOiY6NVnGK1FQbeAlxGITr8dz7gmE65uNmUgh8GVlDAiMbUyLwsImFWSdd6qBpr7A9hTHIaKDJBxfhLcyi2/VhZgAZnHjlW6cb7eg1Guh4pyjbhpFxO6mSQ8teZcQLXaT1axBexMMhsb96O9w4u2DjfaqEzQRz/TCEHNyWRlTaVvKSvDjAwmIaeTsdVKiWsT5ezlehAS6fAP/tmulutjuYCsfq8XPibEdB06hJrnnkOnNxU9YfkYjduIbCY93nzdpOJUXMwKbORW8fWrNU2zQChaQPwTo6NenK2y4+33hhUza3aWGTu2yjxgVH4g2ckEgzUsFO273H0Sn11V1Sga6hmroZrSpo2xuPGm5Mn7prY+XW7zr2j9GpB1Rc2vnfwqt4ArwP3MhA1/dnVgIOASKhPcYErDpvAEmHXhIMXVmrxviqqGx6/D2+cnqEgjlBsBAljDcGuFDpFm2Ytd5QO/iO7XPfcsuo4cgjkuHsmbNiGb5BR6KmYFqwhRWW29EzV1LqWecuetscjLMVGta2H4lfGxcdTWXMCRA4fx1utv4jYqRN72iduRQhZVUQNbyLpRWE6vueYaNDc346tf/Sq+/vWvX2KeX//61/jGN75BNtkoRRg10zkWUo8wvv71X/+1iqkKGZXlorGR85SVlSkg6je/+U08/vjjOHLkCO6//351XFNT06T//6LWClbw3//935GdnQ1haRXcgeztP/GJT+Daa6/Fs88+e9HRS/tSA7JqQNZZrygNyDqrebQvL7KAMLROglm9zJ70UnLLA5EEGRnxKMYwYScQYGRmJsEqmQQ2xJvIrqM5ES8y4Yq/lDEcpwzwAKnZ2zsn2Vn7KJcWF2dQDviyEisSE/QwkcFuppvqindiHg0Q5owxstk1tXjQTDbaYQKxhZ1hfZkF6ZQdkgye1VJkbMYoedDa5UVds1cBwAqz9ZTiJssLwayREWvLm+MiWZ8EUKs6RNYyQCYgYWSlpAPBrAlMtA614GmwgKwCQv3yl7+sGMo6OjoUm9nF17D834oUr5Tf/OY3EEmBhZZDDBK98cYbGpB1oQZchb9j7B0eOi5GCGYVWZkugkX6+DxMtlYDI62pBIqU6WPJzhqBOJ1pQT0QubdxMpyeqnbjbI0baUl65GToUV5kRITJT1CkE//9u99T0uM8du7ZpTIfS8tLec8Jw8iQjQDW0+juHCTDuwmbthfwUagYiGWNcXlxuyn/OejB+fNjOH5smBIdFhSQyUHYHOLJGC9JNVI4vcLJdvUStFrTHUDPqA6D4wEkknVVHplki04hhiopiqzRdHCshGK1wzGBtnYXGplsUltvV+2XwHgBGSpSko1keVoZZpG+AZ9iOK+td2GUAXtJvE1JNiCD99BUBuxjo8NhNocOo/vl15j2fmksMNbSjEGyMLftexsBOkJK/+JziC8phZHM31pZWQsISFWYU4VV1c4kGJvNDofdrhJiHHYHmels/Px/PqOKjTo2zMJ7BH9rCISRMTVcOc6EFV6y2A16Jh8wOUG953d6vhdmVWFejYyMJGg1RjGwiqPQSjCsyWRiwoImB7qyV8LqOHsH1yUNZAk54ulFYpgZHzdlIZ7rEUvY6tmzrQ5LfXQrhJnVyf1YTSeTJfuB7hEg3hrAllydYmaV9Y9W5m8BmTP7Bilr3unDESZrWc06bF1HZvpUPRLjNd/X/C26+n/hk+AoQVN2JnXZuV6X5C67YzLJy0kGVxF3czr9SvJamOYiqf4TQ7nrhDg+4g3quogkU2uE5eqIoi4HkNXPdcp4Zyc63n8fLXV9aO4Ox5glm5MalTs2ZiK/KAb5ZGOMoM9JfJla0SygWSC0LaDiU5yX+/tFpt6jEoEH6BeK5dybk23GugruMTgXS2KzVlafBXxUehQ/Xl3dOA68P4hc+rz27Emk4qMw6mprqdU3YkvXIg3IunS21GrSLDBfC/iZNGwjM2v7hB313hFc8I0iNsyIdMaARAEnleQmesZmroy+zPdMwTleYlyiDNpCX4fEnnvHqCZHZtaKDB1ZWOnzYBxaOFGmCScFp4EhcJbB6nPoPXUSnQfeV2ys6x77K5hiYxFO/24wiuy9R8d8OHDEhvYuD8pJplJUYEZu9iSYdb5t8Hq8inRBwKzHDh1Vvm6z2YyP3XELCouLYI20qhjkfOoV/5AAPwX0+fLLLyuG1It/LwDNm266SX305ptvoqKi4uKvP3y9kHr+5V/+BU8++SSuv/56PPPMMx/WNfXii1/8Il577TXceuut+K//+i+l3vqDH/wAO0hI8cILL0wd9uGzsLTKfTojIwMnT55U7Kt/+MMfFED385//PH70ox9x7d2vwLG5ubmMu4ZfgU34sLJ5vtCArBqQddZLRgOyzmoe7csZLCCgED+lILs6nHQYOMjaZ1egVmEZSE4yUbLerNhZ4+i4tZK1VUAO8tDK6rCAOOMF5Hmhzo4zlTaIlLGMT3FhBIHIJjJLGJiZETpOn0HKWwt7xrFTDMSz31kZRoKDzMjjokec3avFuUWSK978A6is8+LoGUp/6wJIiA3D1gozUpMoW0dp7rVWhPWwsn2CTECTmVJ7CskEROnuBAZP115vZrZ+sICshw8fxgMPPKAa0traqoAjF7dqjMxnpaWl6iPJytq2bdvFX8/rtQZknZe51tzBwnrmApkQKC1zno8eAlpNBIoUhEcjk86LTD3BRjoCj5ihGz4HRwb3bZSLDmBwZAItHX5U17sVK+sNOyyoKDQS8BhGZr5hglS78Kdn/4ienh587vOPoGxdOaKio2Abd6G9tR+v/vGIYKNw7c3rkF+YhpT0uGlt6xVJMkp+1tSMoamJG1qCQK+9NhFbt8ap+5fBEMYcXMDhJrDWpYOwRLcPBlBHiRkXQa3CuipgjhKqUSYQwGpaAYyM9FM2qsLy1EvW8Au1djJSSJKQF1s3R2HD+kgmCHENFcSArLRJAkNO12S72iUw1E72qQ4PA8M6FOaRKbzQgtwsIzf3C8uAnXZAtQ9D2gJ+giSdQ4Oo+uV/YLS5iVnctyBly1YklE/vwAlpY6xQ52SuEcZVAa16KSckgFSHwwEXnxVQ9YPX8pmdAFYBtjr5euoYeZb3Ln7u8/qQUZinJH51AtohIFUeUVHRBKpaYWWmeWRklJrbrVaryjy3RFgUeFUSbkIhWW6FhjFkTyv3a7lGj3n7FGu8m+uTvLAo3GRM10Csixz1EQcTJbn+2X+BayKufyR5p4Q5b0UpYWShn1wPLfIUV93PZc/eN+THO0dcipUzhslGG0qNKM4jgF+CZVq0LOSviUlwK9Db71VreFnH9xJQ1T/oYzKHjr41HeJiDEyiDlfKBZKQJmBWM0FVsp42krFVfFDGD9QWxI8aKmUpgayS/OTzuDHW3one83U4/8YBdI1HYThuKyLSM5Gcm4JdWyOVf89Mv15YKBkyVC4IrR+aBZbRAqJoo3zo5+yorrHTP+RT/pPy0gikMfE2ibEN8QtNJTgvY1O0qudpARm75mY7/vznXpWAkJMTQeYwMupmWLhXnGdl2uFrxgIakHXNDJXW0BC1gPhdqMOEBh8JQeh76fE76XmZwDZjEvLpfxEw65RS32o2gcQuJN4jsZ7qLuBEsyTtgiRKAUWilBYr+4LV3IO10TYP48xDtTWo/PdfwEhSAiGliMnLhyUxMWgdkLE+fMJGHAujmFw75GYbsWtbpFLE0XPfvZDS39tHVvgGHHzvIJr4vPv6Pdi4ZRNy8/Pot45QAM251tvW1oZdu3apw+vr64mF4oV4URGAa1ZWlvpEwKYCOp2uLKSer3zlK/jTn/6kSK/+8R//8Ypq/+mf/gk//elPsXnzZrzyyisqHiA+fSGauJi9VX4onwvraldXFz7+8Y/jV7/6lapPwKtPPfUUcnNzGSuwKyCrfCHEFXL8P//zP6v+iT93MUUDsmpA1lmvHw3IOqt5tC9nsYDMTcKG5nZPKCDkEBlau7qc6CC4tavLpRy0iYkmgqqiFUtaehq53Hlv0YKXsxg1SF/J2AlQRUCdIsfT2ORSjKXd3W4k0tGzaUMUsrNMigUuSE1a1tOI7JD0tZMAofpGN85UOZBJuaHSIgJymMUjzq3VUKbu9yJT2Dfox+EzZM3t9yM/04CSAgPWFVH0YY2twp0eSpk7gQN1ZAPqC1DSQadkLa8tntxQhIqDKlhA1osXtdMBVYX2/5577lHzbHV1NZ24sQu+tDUg64JNtyZ+KI6LCU464rIYmXCjnSxoTWRBu+AfhRV6pNF5sZWOjFxK+nILp8Css3VMgvoOgh/PN3jw9mEX4mPCOHeFoyTfgLRkPTeBwIVz53H4/UNq02PlBviT934S2ZSXFja/mqpWnK9sQ2NdF1LS4nDHPdsRFx9Jlr4r52eZK0fICN9Ex/e77/apRIxNm2IpUR2B1FQL50m2lJOLtElYyM53BXChW1hZ6dSIC6AgRUdpXSCGTNcWA0Ec3PiuxNSqmEQ8Ezh91s4NuUOxpQvb6aaNlFEmC6swiMumPJjzvjgFhFW3qUXuldygMhGEe26UFZmRw3VBGllihd1kkrl9titC+06zwP9YIMB/Rp/TgfZ39qGPsjQOZvCm0dFT+tBfqP9VbW/wP7ZarlcCYvUQxNrT3cNExA50tLWjmVJCrS2tCqAq55V52UqnnTxH0PkmDjh5locAVNUzGVTNEWbsZaZ5NAGrn7jzE8qBFUa9Ln24HuqZDq2wMN43+FkYJ/+pz0UqSRvr5RrhtV2vnzd2L9cjf3K1oMo3hF2GFFQY4pAdFqkY49d271a29V7e1x0enUrmOf9BkKcwOYD19KUXp4YppYyVbeHaO7usQ50MnHX2+FFZ68bRsy5ct82C3VvMKvF0Cpy49nqmtXiuFpBrYIoR0Ef2YzfX86Je5eZ1ISpAwyNUjRiiitWwH0PDPiZ+QAFXU5icLGv9tBQjCQAMiI8joznlIFZCDWKufZ3vcUsJZPWSFd45MIiava+g7lQLWlAOX1werASxbt4cS9BTFG1IRSkCgzWg2nxHSjtes8Dat4DMxVLsdirPDXpxvoYJzp1uxdS6fl0kttCvkpBgQESERqwyaanV81fGbmjIjXqqEdXVjlGdyEngRCo2biTT2wIlg1dP77SWzGQBDcg6k2W0zzULBM8Ccut0THhhgw9nvFxn+4ZhJ1NrDuM/NzKROCGMiji6FWD7mIcJPNx/dQ4H8B6TdQXMKvHlbbnCxgpEM9Zj5G0/VGLO8zDLkh86wY2uvasTtc89C9fgACKSU5Bx7XVI2bZ9yc81W4V9VBdubvXg3YNjTBbV4+bro5DCvXQUE0UXUrxeryJ3OH38FM6cOkNinTZkZGbg7gfuRVp6Gn3fEXOudt++ffjc5z7H/XwYuru7FTPrxT8WwGdmZiZ9BR7FiDpFUHXxMfJ6vvU8+OCDSom1qqoK//AP/4Cvfe1rl1eJf/u3f8N3vvMddf4TJ04ocovLDxIfvbCsPvbYY4qFVVhWX331Vaxfv14d+jd/8zeXsLcmJSWpPg4NDanvBRQrINmZmGaPHDmCo0ePXn7aK94nJCSQLLEBd911F0mKtl7xfah/IOM/l6IjK8kH25+5HB46x2hA1tAZy5XsiQJFktVzoN+NToJYOzuF5UfADwEyXuopIWlQWbEiEyJyv9HRIl+vSdGu5JjJuSVTQpwHHXT0tJOxtLGZcqF0vhuJG8pINyEzg0ygzGKWRYEAadbyAlCuRQGztpJV7izBOQ5O+eIcKco3ITuTEskMKAgrxmroI8mOFUD8zAUPGlq8lOkG5bknmV6SEvSIiVxYttFKXW8i81DzAZCsuT+AZCoJb8nRIYNEi8KEGAolWEBWWRTv2bMHjY2NePTRR1XWk4BTpMjC84knnsBvf/tbJWMgi8jFZENpQNZQuDLn1gdhZx0OTIJZa30jGJvwEFASQDydF8lhFmSRnTVJZ0YcJWfkP5Z3g0sqlkvQzjm1tpng0jYfWjq9KM03YlMZ5TRVcHESQLX/nf145YWXUFJehnIysW7etoWAqSh4XB7sf7sKVaebkJwah+KyTGzZWUQZ6iulSkSGTBJozlePo6HRRkkyN5NlIrBzZ/zk2sKsh52E1gN0ZHTQqdE7BgzahC0WiGI+TUEykE15GWEkk7ISc76smYQ5pKfXo+69La1OsrJOUAovHPl5ZLAtsyqgqOEDlqZLjL1Mb2QtMG6ToDtlhrgm6O33YYCvRQZVZFGLCwTEakSkdXXcJ5fJDFq1y2gBcYCNNjej//QpNL3+KuKKilB8/6dgTU2FkVLzWlk6C/hoa2FUFZb20ZFRPkYwOsy5fWyUoFWnctgJM6uwsoozTRxr4nyaAq5OPkfAEiGg1klAq7yOiCCYlcyqIr30FCWM4uPj8Vd/9VdL13CtpqvWArIGEWb4993d6PI7cKcpC2UEsloZQFk74nard/hkDWRnMk8jkwpPNpNtgUmeEtxZnxWGXJJpJFIpQ5jqtTJ3C4hNhb2+up5r2GMuyseHIY/Jp+VMPE0iOHEl1pdzb7125HJYQNbSsveWNf0IwaxDZAYUEOsQwayihuTl2t/AmLD4nAwEXpr4bCY7q/jaJEksMlKvnlXCGL9fKMPMcvRtPnUuBZDVzzWKl4wvfXVN6DxXj5oz3egZ1kOXtw1J+RnIzotVCemZVFoSELDGxDqfEdKO1SwQmhZwuSaUH6OlxYmGJifn13DE0ReVl2tGeprpwyTh0Oz92uyVjJkkqJ88OUyQAxPZdsVj3foYKjyaVLL62uyV1urZLKABWWezjvadZoHgWoBbFzSRmVXYWetJaiKEJxl6K4rCY5AXHgWzjgl39MaspiJ7cA/3VKIAOvkIwMrQkRCWFKfqyMi6MnGe1WSjpW6LsLJ2HzuK/rNnMFBVifxP3o28j9+JcJMJYfQlB6NI0qgooew/OA6bY4JqwnpUlFqoGkgdyUVgVjrbO9BQ14Cjh47AZrOjqKQI6zasQ2lFmVJBFV/5R5Xf/e53Kh4fw7hGXV3dtEDW/Px81m/Dj3/8Y3z2s5+dtsr51iPg2bKyMiYFDeH73/8+Pv/5z19R769//Wt84xvfgIBPBfA6hSGYOlCwBL/85S8hzK3Ctiog1u9+97v4y7/8S3WIfH/HHXfg7NmzCqj6H//xH8jNzVXfvfPOO/jqV7+qzp+Xl4f3339fgXmn6p56PnbsGIR466OKkHEJo60GZJ3dUhqQ9S/IiKMVzQKLtMCk81bk0elAaHdw8rHh7JlRlWUpjtv13JBWVESjsFDkctceu+QizbNqfy7jJsCgIbJGnD1nw/73R1TGcnq6GXt2RSMnW5wIocGiJP20c8Hz/hEbDh8fRwrZWIsLzbhmR6TK6OH9eVUUGRMXQcUtnT68tM+hmAXzs/TYXG5EUe6VDIWrotGzNIJTAloHAnj1LDBGwFsss+OuL9EpNqBZfrZmvpoLkPU///M/VWZRQUEBvvjFL07bNwGqbty4Eb29vXjyySfx8MMPX3HcT37yE/zwhz9UwNU//vGPisZfgmbvvvsuHnnkEf4vu2f87RWVzfKBBmSdxTgh+pWfgFZyBuE8waynvQOKFU3ebzUkYpMhAev18QpQcvk06SEgondA5ioCMm0BzlHcUBYZUUKJVZlT5ZoUENVLf3oJ//e//g/+n698GXfc9XGCIiMJtvJieMiGvc8dQvXZFjz0+ZuxcWsBZaq5GSWb3+VFkmRGx3x4eW8XWlodBHYnKAkyYWOVzauAM7pGdDjbxv+JC5OSuanEyAkLdGmaDlZTAPpFbHIvb89C3nspxS0B7aPHx/Au77fRUXqCcU24fk+MYmKVwLVsFoNZBIzc0uZGda0Th46NM6ElDIVM9NiygU4sMpdrUrnBHI3QPZcwsw6er8bZp3+OcGZNSRZ36vadiCsuDt1Or0DPHA4Hg4LDdMjVo6G2niw3FyiX1Ih+ri3iExOYaZ6J/KJClNDpVVhcxASCFAJoIq+Ydy6fhy5+L/JBGpB1BQY3RE/ZSEb4Y54+JtV4QFgSbjVmIEdPdKVWltQCwkw/RqWMP58L4GjjBMrSmSiZrcPWHAaACKjTyvwt0N3nx4VGD2oavRjlGvjuWyK4/qUSwQqvNeffE+0XS2kB8eVcXMbGJ5lZ27skic2Djm4Pevt4zYz5qQ5EJQwmj2dRMSgz3YCsDBP3BmEEta5NdPlSAFklYDrW2oLK197HyVeOoCvlDoTnb8eGjdFYvy4K68tE8nFtJ9pffH1orzULaBZYGgvI3CuJBO0dLhw5Noaqaju2buacUWFFWYkk5F3pX1qaM2u1LNQCMmYnTgwRADFAhm0jFZsiFON2HF9rJfQsoAFZQ29MtR6tbQvIlsUW8KLSN4gznkGc5vM1hmTcTH9McriZicWrKwYtMZ9xF7D3VAB1PSTiitNhE8mSdheC+28NxLocV6OQUngJwmwmIcXJf/kxSj71GZT9xedgiouD3mJZjlNOW6eDeI6mVjeqzjtwqtKOj10fjZuvi16UkqHE023jNhw9fBSnjp3g4yRuuvVmPPhZkm5EUY2MJA4fVV566SV8+ctfVuQQHVQ/E2KJi4v40dPS0tRHv/nNbxSL6sXfT72ebz233367IrtqotLaN7/5TTz++ONTVX34/NRTT+FHP/oRFbNLFePr1BcCWD148CD+/u//XmEV5HM5RoC2mzdvnjpMPbe0tCiwqoBmLZeN9+uvv44vfOEL6rg333xzRlbWSyqc4U1tbS1+//vfa0DWGewz9bEGZNWArFPXgva8BBaQjej4OCW1mFk5MODmZOdRDwERikStkQwDCWRmzVCMnxbKBxvoiNRYvpbA9AuuQskJc3z6+ulY7/QoprhhskgII5zIn5UUWZFI0Gd01Np0qE8ZRvopDKHSx2aCdtr57OUiODVFjwJmagvrnDjFBRC10sXHto6OB9DQ6kNzuxetXT6UFRB4S5BYZpoBkQSDrpVCAkK10WjoDaCeGw2R+l6fqUN5hg7ZCZNMiWulL9O1cy5A1k9/+tM4cOCAWmQ+99xz01WjMpc+CsgqDGoiHyBBIikbNmxQC+tTp06pxfK9996Lp59+elFsrFKvBmQVK1xdRRwYE7yBCzNa34QL7f5x9PJ5lAytRl0YYnQEp+pjkE25mWi+Fp402fSdb/CitsmLngE/4qLDsGWdCamJ4Yjlaym9Pb04fviYAlV1dnQqqY6du3cqFsBmTghHD9QQdGXn+zDcdPsm5OSnkKmIrDsXgTllXSEA0Lq6cV77wwTAkvGdgYgtW+MIwrLARPb3lgFAWJ+7Rwie9elgMQSQQhCrODbS+YilMogwjq3U9C5MrDbK3nV2ETB63k7GJr9irs/NMTFhxKKY0IUB9aJuK/st1x8Br4pNu3q8aGpxo5sBdTvZ9SNpV7nvSyA9mfd9YYqVEqx2LVd/tXpXhwXslNrpOnwIg9XnMNJQj5KHPovMG26E3mSGjs4UrczdAjL/CqPqOAEfvT096O3uRXdXF4YGB2GnozGM9jQYqDhgMpLlWZLSzIiJiUV0bAwTCmMRS8djbHwc59IIddzczwzFCK8BWedjMe3Y6Swgaw4PuT9OevvxsrsNJeGxKDeQaU/P65PrDK0srQVkbykyfI39Ou7HAoq53sB9b0nqJGN9TuLa2VsurWUWXpudiUnDoxM4XulBPeXuyuhLKMwJR0E2594gMusvvAfaL4NhAQ9ZZNwEkov6gc3uV3sAeZYEa48noNhaxScl63JhGjKbBMgaphKtY2O5p+JaPJaqVlYqI6x2BtLFAFn9sqZpb0N3XTtqK7vR0u5B97ABmZvKkFORg3z661KpECFqEdq+JBhXrnYOzQJrzwKKvII+l2aq3rS1uxiL8ql5MzPTxDnEgtwc7jm53FkNPv+1Z93labGoOjY22nHhwhj9i8Att1C6mPFCs1nzDSyPxVeuVg3IunK2186sWWAmC4hK3wBjPy2MAdWQ2MQe8DHeo8NmEprk66MRpzPBwJjQShbZHwmItZYx5co2gm9J/kRBPlQwtpyTQKAgVT81T8byjJAQUkx4GfM7fgwXnvk9IpKTEV9SivTduxGVlb08J52mVlE2HGUcrabOiYNHbQobIeRkwsoaF/vRzKnTVKk+8rJvvd09qLtQhyMHj6g4Z3xCPK694VoUkqFVfOlCPDVTOXz4MB544AH1dWtr6xW+dVFKE5ColL1792Lbtm3q9eV/FlLPfffdR0b7o/jKV76imFcvr1MArr/61a8UCdazzz6rvhYQ67e//e0PsQPi1xdAqzC8ztbPy+uW934CvXJychTT609/+lOFV5juuLl8pgFZ983FTNCArBqQdU4XinbQwiwwOupFX58btbXjaG6yY2TEQ7Y1A7KzLMjOjmBWggUR1nC1STXRaSsOBc0xuTBbL/ZX4jQQsGdNrUM9minLI2DWspIIAm3MyKAkj8UigfG1PUbSRwEUHT5uQ2OzCw4GoYoKLWSfsyCebMFTYKKVvg6lnS4GN87VefH2YSdiIsOQQdDtxjIj0pLCKUm3dsZBri0Jnp5tD+DPVROItnCjEavDtlwgPRaTfVnsBbxCv3/++efxta99jWDvRJw7d+4Kqn5p1kMPPYT9+/fjhhtuUBlG0zVVgHuyoO3s7MS/ULb3M5/5zHSHKblgWWCeOHHiw+9FFvimm27CL37xC5UF9uEXC3yhAVkXaLgQ+Rn/XTFOZrQ2v02xpHX7nXzvxXpDPGVmopEeboXZa0DAGY5DJ11kovKpOakk36DmJwuZvQRk5WfmQF1tHf707B9VwkpeQT627dyOvPw8spJ6cOpoPV7+w2EUlWaiYmMOSiqyyRh4KQub1CMBiWEmxZw6NYKDhwawriIGxSVRyMqLwgQ3YSMOnQLINxIsb3NDzS3CMJaTSFDmKlAtlwC2sGx3dLropHcp9vOEeD1KeW+VRBFhYgrW/UbmYgmWy31vhAkr9U1unKcjQKRa4mL02LqJ93syxMbTERCsNoXIv43WjTlYwMdkDOfgAJpffRXnf/trlD38CHJuuwPWtFQYKF2vlZktIHOhz+vjfOhSAFZJbLGNjWOgvx/tbe3oYqJAR3u7YmMNiCxYZgaycnKRy/k2JzcX6RnpCrSqJ7h1sUVjZF2sBbXfiwXcAb9iYT3s6cVLrlbcbc7BDaZ0RDJ0stLBklAeIdlbDtqAt2uY3DkUQBT3ZOuYXLgxC4ggc71ZA2DOe/iPV7pxttbDpEIwqKLHNZuMat++VuXh520A7QfztoAAy2V/0z/oR0+fJJIzQMiHyCZKErD4eRIoi52YoCdLnYGPcMRE02dKf6mApA1UTxC1Qz3B6JNqDvNuwrL8YCFAVpWYQzlHx9AIOs5eQOO5LpyrHoMzMheG7ApcsysG68ojkci9k/iLtaJZQLOAZoGPsoCDCbpDwz4cOjKKVgJaZe4sKoxQ7Kwx9HlYqDqnxZ4+yorB+d7l8isynFde6WFSphPXXp+IoqJIJldPgo6D0wrtLMGwgAZkDYaVtXNoFliYBUYkBuQbxzEmGQugdQPjP6VMMC5kDCiSzKwmXfCTC2SPMBHQwc44T+8YGbybmQTdDBQzEbciMwzrMoGY4JGCLsywIfKr0aZGdB46iOG6OvjsNpR+9mEkbtiIMPqXLyaiWe7uNrd5cPSkjesGP/fDwJ6dUSqGZVDqhgs/e3dXN86cOI3TJ0+TiKcBd3zyDmzdsRVp6ekwW6gaOQOYta2tDbt27VInng6oevz4cdxzzz3KRtXV1YpUYrpWLqQeAbD+6U9/UqRZgk2Q/5epIu29//77FVGVsKZ+97vfZVx2EsT685//XB0mANzvfe97iI6OnvrZJc8Sc+gmGYlgDrKzs6/AO8j55HMBtP5mFrbZSyqd4Y0GZNWArDNcGpMf/+///b9RTDnHv9CArLPaSftycRYQZgEBTdhslAQmqHVwkGxvBLZ2dxFASJlgHYGrBfmRyM2LQG6ulUBJccpqDsrFWX1hv5YbkNzz7AR5Do940UnZs3Y6fZpbXEhIIEMbs5jLSwk+Tp1kLl2rIBdhxhN2YHFsCStrVY1DgXqEjXXnFitKCGo1EYgl71eyyFhIIGNoxI/OXj/O1LjR0+/HumIj5bsNyM9ioJcLtbVQpC/yGLQDncOUtGwIoGeMcpa5ASVtmZPIQIz2bz+voRwaGsLJkycVy9r27dvV87wqmOVgDcg6i3Gugq8EBOXjP6wLfsXI2kFAa9uEnSytNjgmfMgiK2tEHwGn9ZEEUQnbug67NgoLFZm7IyfnTtnIDA0OofL0WTz3f59FcWkJ7v/MA0igtHWYTo+mhh6cO9OME4frFBPr7hsrKG9tJnvgpSArma+76NA+fHhIgVnl/dZtcUjLikSvQ4/GAYJYO4XZOYAk7r0KksMUkDXeGoCFhG6mhSdmLtlI9/TSIcR76dmqyc12NhND8sgGIgkikZGTQeklO9lHVCRZrD1kX21sdqOSkiwyL4uEaQGzWDMpayoAVlmHaUxiH2FI7esFWWCC88IEGbeElbXxxRdgjIlBTF4ecm+7HZEZ9EJqZVoLyPrcS7vJnNre2oamxkYmBzahv7ePeyyvYldNTEpEYlIyklOSEZcQR+Y2ztNkW7XIg443YWQNJ+plKZyMGpB12mHSPpynBYbIAH/KM4BWsn/0TThxEyXsthoSEc4NJvnJ51mbdvhcLSB7S7cXZLCfQH2vDidaAog2UyUjPqCk+bLJarJW9/hztcFSHzcw5Edrtw8HmdwlwJhrt3JNlRqORIIPtaJZYDoLyPrbz39GYWQVQKubzy4+y3tRbRD21vFxJp2N+fh+gn5Trp9YUUaaUbG1CqgziSDXRProotReYnXMmfMGstIQwvTTfuIMmo5X40KXFb02ymiYI1FQnor1W9MIZjIy6KdXexONRXG6q0n7TLOAZoHLLSCkEJJMPDDoRXuHB9U1NjXPSpLAti3RKC6KUAkDWsLJ5ZYL/nvx70lS9dEjQ2gi+Y2sQYuLI3HNNfQbrpScUvDNcFWcUQOyXhXDrHVyjVpAmFmdjAG10TfT6BvDBd+o8stsMyShIJxEIowDBbuIkpyNqhaNfcD+C4zl830cYz0bsnTIT9Yh0jSpvBfsdl2N5/OMj8NJEoXaZ3+P7iNHUP6XjyFj9x6YE3ivluzKIBUhJpO13aFj42hgXOu6a6JRWmRW++LFrOlcLhfGR8dw6sQpnDh6Ai6COFNJuHHHXXciPTOdPvXpEdMCGN2zZw9Jaxrx6KOPKvWyCblwWcT3/sQTT+C3v/0ttmzZgldeeeUSsOnFJltIPS+99BK+/OUvK6DpEY5JaioR3h+UQSq1iYqrxBJESfa6667DxWDZL33pSxBs4Gxl3759iqlVALBC3BXD+M3FRQi7hLhLijDKCjvrQosGZN03J9NpjKwakHVOF4p20OItIACKsTEv0fykrG+2U8qeNwk6aqOjDZwMDYgj60B8vInPlLONNTIAG65lyS7e7AuqQcZqmGxtrW1OOn0cysEuwM5Myg1npFM6mrJekZQ3W8tyL+IwEZBoHRnymlvdCribT3BRbpaRACMTYqLCuRhY+aCAjIWHAcdjlS7UNhP8zRFNJzPruiIGLxjEiIxY+TbO9SIjQSNlv4EDdWT+7WKMgpi17ARgcy6lv7kmFOCZVlbeAhqQdeXHYDW1YJiZuV1+O2r8I2hz2uEZC4enzQx3TQTlLsM4H4XjOjLlZCYaCVKdbLnbTaAkQaxVZ6pQdbYS23ftwAMPPcj5KwwDfaM48M459SwCMLtvqMDGbflXAKxk7uvrc6GhwYbTp0dgjtAjIzsSMal0oBCU1TEMDBMcP+YEcgmGz0uCcmbEk9hR2rGSQAzZLDqdAW6wPWhpc/FeOrXe0WPDOitBo2aud4Kz2VfBcgZzhnhP7x/woaPLoxif5B4vAXC554lcZ3KSYcXttpque60ty2eBETp5+k6dRP+Z0/C5nCj+1GcQX14BUxQB8iv5j7t8XZ53zTKHOh0ODA8PY2RomEB+AfMPkUl5FKN82MbHCGL1KYBqGtlWhYE1IysLKXRexcbFMilwaUCr0zVcA7JOZxXts/lYgJyDTI6x4w13B1+RQT3Migp9PHL1l7Kyz6dO7di5W4AYOiVn3jEEHG8OoH98Ety6nvJ8RSlAKlUzZI+mTcdzs6msV4dGJ7D/uAt9gxOI59q4rNCAsgIDGTM1CeO5WVE7Siwga3a7YwKjBLAOUhJ7kInXJUUWdLSewRmumaqqqhRrSmFhIW699Xa0dsVwJ0UmZYLRI8gwKMlowjQoKkoC2LpYSUmCaXa7Hc899xzq6+uZTCdAoWuwY8cOlfgie5fFlrkCWQW86meCzvjAKPpb+9BQ2Y7mun6M69NgSkxFWk48SkoZmCyJhIH9EOZZrWgW0CygWWA+FpA5TQgsBoe8SnGuvYP3aDJg52RTHTCLCScZBMkLOyvnS229Mx/LLv2xEpuR2FNd3RjOVY0iKyuCimPJvE9Njs/Sn1GrcSUsoAFZV8Lq2jk1C8zPAqLG18sk4yPuXvVsJRFJvp5rcrKzJoSZIe+DUTzcXzs8OtT1BNDUTzArFfgy46kkQ39FDuPIl4n5BaNJV/U5AkJK4ffhwjO/R/vbbyF5y9YPHltgJIlCsIokKonv5RBVdiurHYqMJZ/ELBvKLUz2FBzR4lrS3NiEC+cv4PTxU2rfvGnrZpStKyc5T7FiNBVQ5+XlJz/5CX74wx9yLanDH//4R1x77bUKQPruu+/ikUceIabGjSeffBIPP/yw+mlHRwemWFEff/xxrnkojcQy33o83EuXl5cz4dWhFGCfeeYZ9j+M9vEpUO3bb7+NjIwMBTKV+MDvf/97/N3f/Z1ihZW2CfHFdEXqsFqtqv9CginAXGFv/dnPfqYOl352dXXhU5/6lALw7ty5Ey+88MKMIN3pznH5ZxqQVQOyXn5NXPJeUNcaI+slJtHeLLMFxJEg/tGpm84oQa19vW7U1IwR2OqgnJYLaZSvLyuLQWlZFNLTzMqpoGVhLvPAzFC9JJC43X44XROU93LgTNU4A+o+OnvCseeaGOSSTS6RwKW1XKSPPt8EGlsmmVmbWtwKyPOxG6KRn2NSjq2VdmrJ/4wwJI6NB9BGtpc3DziVdOG6EgPKC43IywzOJmIpxnmyL3QmUtKysS+A1yoDMHINeFN5GPISA4pJcSnOo9WxOAtoQNbF2S/Ufj3Bf1y/jsDMAFmsR914o3qUmY8+DHWHYeN2HbZTQnW9NRZJBhODqZNlnJLXf3jmeUpy1CMnLwcbt2wmmHU7HNSEaazrwrP/9S5iYq24876dSMtMQPw0XghhbT94cBAN9TaCQv3IKohByaYEHGnSobGfzK/coBalkA22UKecGCIpowADU41YwYGQ9U57B9nmztjIfuokA7gX1++JRXlZBBMQKMtDebtgrW1kky9MT6er7LyPOwiu9ZGFNRw7t0UiO9OIlEQDN+RYcRbyFRwu7dRBtoCP2c4+OlvOPv3/opeA1sL77kfq9p2ILSgIajZ3kLs959PJ/DFCAGtHWzuqKitxvuoc59I6BVzNyMxEQVGhYrnOKyxAcnKyysDWU1cpPIyOO06M0znX5nzyORyoAVnnYCTtkBktIFCpcRBU4B3B884mZJPd49OWPETrjLAEKTAyY+Ouoi9kT+YlwMPJANGhhgmVZBhpCqiEoBtLw5BETPFiAwFXiznFlh4qEHX0+FFV68Gh0y5sX2/C7ddZKGes01jur5YLYYn6KdeT+KgE2BMWFsAXvvAY3nzzzStqF2aYH/zgB+gZuRG9VLxKSTYgleylaSl8ZtJ5Qnw4lTLCmdgiLMs6HD16VAW1xsaozXlRiWIS0YsvvojS0tKLPl3Yy7kCWSfIJu9kck7jiVocfekYml2ZGI0oInNMHCrWx6CsNApRJDtYrEzkwnqh/UqzgGaBULKAxJ9EJbCl1UWSDjsaGulP5/rnut0xKCwwK8W5lfb5h5K9F9IX2fuqMWpxYO/eTkVqs307E9yo2piURMo9rYSEBTQga0gMo9aJELeAJBkLO+vAhAvnfSN4k4nHMWFGlOvjsNmQgFyyswajjJKwRBQ9Xz1Loi0SmEjCbUUGUJo+GQuaIlEJRlu0c0xaQO7VPceOovvoEYw2NyE6OwcVj35esbIG00ayV+7ockMwHEdP2pTS4T0fjyNRi56JnItDsvq5QLQ77Ni/7z2cOXGaLKbt2LZzGz7z8EMwU+nMZLpyTeIke+uDDz5IAp7TygzChCqKaKdOnVKg0nvvvRdPP/30h0DPEydO4O6771bHyh5cVFalzLce+Y2wsgoYVsCmwpi6efNm4qxq0Nvbq9r66quvEmdVJofia1/7Gp5//nn1erY/Aqw9duyYau8UuFaOF1Ds1q1bVTuFgdVms6lzvPzyy6ioqJityo/8TgOyakDWWS8SDcg6q3m0L4NgAZfLr2Syenpc6O93q4d85idXvJ5oFMm+TEkxkV3ITMcsJYclG1/THw/CyPzPKWRxIEDPHmYud5HFraPTTYYIen1YROYrO8tEwLERcbFkclvcWuF/TroCr4Sprpdyy8LO2tvvVU7zLLLPlpWYERetpyNl5TsnAbIxWwBVdR60d/kwPDaBopxwgllNSGKgwrqGmFlF0nKAYNYTzROUttTBRZbWjVlQ8hCRlAg3MeCilZWzgAZkXTnbr9Yzy72gnwzWDbwPvFtpg2PCh6Rkzos5dhjS3UjVW5ARFqEydSdGySLY1YsXnv8TmQPHcPsnbkdJealiCjx/tgUXqtvRUNuJ3PxU3PqJLbBGM9BvvjQpoo8B2bY2O5mHxtFLyVZDbAQMcZEwEvwqwH4TmcJSosgSHs8mJOpgMchnKz9vCGjU6ZxAQ5MDbe1k+ubmOpJB5GQmfYiEXQqDy8KUFAwQq7RleNSv2MaFdVykSiVAEE95zlS2I4dMrMJCYl0F97fVet1r7VoeCwgTl2R0N736CnqPTzpIEtetR8Fdd0PPrGDdWl5QLsBkPgI6JJu6p7sHPcxs7u7qxhClgEZHR5lcRQAK7WE0Uj44OhoJiUlITklGYnISXyeqTGnJmBaQSrCKBmQNlqVD8zx+3sPPeYdQ6x9Fs28cxfoY3GHKhFEXDnJihWanV2mviJODPNoGgHqynbQMTjKz5jC5sDg1TLGzynSsBYo+egAFKGNnwK2OybGHTrmomBKGnHQ99+kGpCWvnaTTj+6pdkSwLCD39sceewyvvfaausffd999DE5twYkTx9Vnsm6QY9544036h1IU8JXTqyIOkL2S7DXMDOYJS+umCibUXb9bBZxEdlBYVQQIu3fvXjLg1VElIl7VOcUIs9A+zgpk5WZSgmz9TZ3oaelHe7cXnW1j6G0bRmxONlJL8gha4n6S6k/JBC4Jm6xWNAtoFtAssFQWEDWavn6PArL29nrU+iclyYiCfDPlWI2IpzKgVlbOAuJvHBhw4/jxIQIwXNwbB/5/9t4D3K6rvBYd++xeTu+9Fx0d9WZZwpYwroBtSjAhJrlcAiE3CXnv5XsJH7m8BL6QkI+bL98FEjCQdyHkBS4BQsAFAq6ybElWPUen997r7v2Nfx5kZFk6Vjllb5257KW9zy5rzTXm2mvN+f/jHwN33JFFckQaizRlrrtxbdN7Xh0ENJF1dXDUW9EIrDUCQmYNxKOYiPrQGpnHeMyHBSq11hrTUE0ia5U5HU7QAWoNGiIuntQ/Qeso0DYaY+GtAZl03dteQnfSTCDbtRZ7XYMDuU036R0fw1xnJ3p+/COkUExhy2/+FtIqq2DLZOes4yIOJlPkbxw7sQSPN6ZcBuur7agsf2Nu8WaaFKWi6eDAILrau3D65GsUizCiiC5oQmitpTKrmcctc/DLFykUffzxxzlPP/36yxaLheryR/HEE08o8YlLbwjB9V3vepf686mnnlLk00vv3ch2Ln1HlFg/85nPKAXVS6+VUADjc5/7HB544AH1kuQLDh06hL6+vksfueZjVVUVRYWOv068/drXvoYvfelLdIdbeMN3hLwqxyafv9VFE1k1kXXFc0gTWVeER7+5zgiEQjFecCNKea29gwqtrMQMktRaWkZiTJUTtbWsyk8VQqHYvTPRRXspPZFd304SUswoSUxtHR68dsatFOXEjqeJltIV5VTPJTlHFB/Wg6CzFkcugZPB4RA6un147ZyPinUp2L3DhXIq1hUwAZUIx0aONyuDSGbtDOIXx/2KwFpbvmxduNxGMepOjkVsIoTMenYgjp+3gPYQwIEqA0ppEZHp5O+bh6F/4xvTl5rIujG4J+pemXNkQUMc7X0hdPZFmKQniZWVsAcOp6DVPI0Ow5yyBi42OrHXlINw/xRmWnvxykvHSeJ04Xd+979ArK8jlP762U9eQyeJrIXF2WjYVoa9d4g9x68ngMv7ipHAuogLzYsYnQgjaGSxRE0evAYrpnnN2Mc50o5Sg1INS7UlBmpy/xDlJC8n0BNMjLxyclElSswsvtmzy8U1Vd0z5T6ylou0g/8z8C9jqhgGSKbt6Pajpc2vlJpqxXJlqx1FTNbocdRa9oTe9vUgsNjXi0lWLfcyCJbKau7tv/cJ2LNzYKaNze28SCW7BMfCXCPhCH+rHiwtLqGbAcGu9g50dXTC4/bQTtfMIoAt2MaKbikGKCgshJ1E3yuDZuuNlSayrjfit8/+5P4UoLr7z6js0RtdgowbxKZuhykLTFHfPgeaZEciYy8/CQMvdADtY8vPtxQbcKTBACdFJ2zkdug52fV16sRMFM0dIVq+s+iUxUT3HnKgsZrKkizI1oTg68NQf2oZASGqVlOpPsrCn89//vOK1HoJmzmqmd59992YZdHLu9/9bvz5Z76sCs8np1mczaSeFGgvLEYUqdXlNCLmfQLf/OY3lVLLD374FMzWIj6nijt8ePCBe5Q94Ac/+EH8zRf+hyqgUQR2nrA3+ru/GpE1xgBWJBRGOBRlfDeMzuMt6Dw7iL4ZF3wpaXBlZ2L/wQLs25/DeG8KVYx/PS+8dLz6USOgEdAIrAYCEiuZpEiHqLK+QvKDXOMq6MTWUO9AdaVDiafoGMlqIH1z2wjQhUkUxs+eXcBLL07j/vvzcehwjirI0KI2N4dpIn1LE1kTqTd0WzQCb42AKLMGDFGcCE7hhdCYIq+Wmly401KAAgN5ACmmVYvhyP1Zct4LPqptzgMne4XMGsOh2hSKHkG5eNo4n9bLxiIgohQ+qn1e+MevwDs1idIjb0fuzl3I/pXq53q2zkcy69lmH10QA4y7RLCjyYFD+11KBO8KnulNNWtyYlLlNVvON6OzvRMPv+8RHL77bcji3NXGgtCriUnIHP3MmTNKkVWUVkWZ9WaWG92OxAva2trIpxrAtm3bUFFRcTO7veZ3AnTVu6T0KsqvNTU1VMzPvebnb/QNTWR97rogM1C2V2Lqm27RRNZN1+UJfcBCAFYr5oMAAEAASURBVBGijNsd5hphUDbENagel/i3h2thoQ0lJXZUVDqRnW2Bw87qHz2GWbd+lcS7DBKkknl8IqjUWcU62W43Kvn2bVtdysbMyWB5MvaLDJp9VNKbnYtQnj6AoVGq0JJEtaXWjoY6G4qpPOtybmxgXW5W5D1ghgqF/SMklPWHMDkbw44GMxqqqI6bT9WuJFGvkKSpVNrJBOXiyLJlhCRRj2wxoKEwBQ5LjDa5+ge+bj/wy3akiayXgaGfwu3hdXEhToUpP0anIqirtKCizIgyrgsGP6bhx0jMi4mYH7MRP9wvtCD0Yist63PRSJvKuzjRi8eMVBqcx0u/bMb05ALueXAXareUIDs3/Q3FD4uLVOcZ9ePchUU0t3ngtqUrJdayMjtKc00kuhuQlwbk0M3GwUJLszExOigYJHGU94/zF9zoInFUlpxsM2pr7LT4pMJH1rJq+VoXekSoCCbqFV09fvT0B1UiW8izosBawntYYYEZGVQZF3WmZLxPJ0Zv61asFgIhjxuLrAju+v7/RjQURM72HcjfvRfZjY2rtYuE3E6EA7kpBv9Gh0nm6+7BCO2KxkZG4EpLRUYGLZFyc5TaajYfMzIykJaRjjSqsYp6mlSDXy1gtp4Hqoms64n27bUvL0msMxwrPB0cxjTt6u61FKOWiqzZLFTZ6PP69kL6xo7mUuJoYjGOwVkDLgzRUpAGLFIstJ9FhvUFYPGLVma9HlT9AcZKFmM40xrG+fYgttVZUF9lRkUxx142Pa+9Hgz1Z5YROHHiBN773veqe7+op0gs7vJF4vlf//rXOR8rw8svn6TzQgR+CgEEg3SH4HkY4NzEH4gjlS5X/+3j96C/vx9/9Ed/hMzCj6q5QpiuSy6nCebok/jv//3PSSJNxclTrYoAK25Lcr5abtCe8WpEVt+iFyMdgxjsc6OXMTb5fQTCBuQXulBckYGyqky6djiYFKQKK+csQiLTi0ZAI6ARWCsEArw+CtFfnHMGhwIq9p+TZWKuycbYlYOJeQtMWjhlreBfcbuibh9k/0hR+/PPT6G8nATjGheFbVzIzLx1lbUVd67fXHMENJF1zSHWO9AIrCoCoswqbjpTUeZ8ol5cjMwxlhNEbooNDcZ07Lbk0lWHjnOrUJAcJidk3mdAx3gcr/ZAFdMWZQANRUBJ5nJx7WUaKKt6nHpj14+AzEfDbjcGn/0lZlsvwj89jbK334Pqhx9Z98pn4RHNkMPR2R3AK6fcdB20UpDMwbyXBempt54sJGcQczOzaD7XjBOvnFAiPHn5+Xj7vW9HWWU5xWp0DPP6z5yVP6mJrJrIuuIZoomsK8Kj39xABCRGG2AQdn4+pJRZh4Zo0ctVCJLp6Rbk0dI+m4HOrCwLE7tm9brZnKKDnuvUZyq4wMC4kD1b270kfoaV2kN5KYnGtAIrLLRShS+FdsW3PmhYp0N6w25EyW6eFtqdPQGcPONBepqRSnYW1JIoWkgyUDpJQKtR2fOGnd7gHyHaQ0ti4rWWIM63BZVVdDFJrFtrSZhKJwmUJKVkWdwBWpa7gRM9VHwcB7ZS6bGh0IDqvGWimp6orH9PaiLr+mOeiHsUsrkEE4bGomjvDWFkIqLIj3fvt6OMdqlOOxONhmXLmcGoBxe9Uzg1N4zBp1/B0ovN2PfAUezdvxc7ymowT+vIjtP9mByfp6KgFQ88vBfFpTkwmpbvE8uWrDEMD/vRfGEBPSPc32wc6RU5yCt2oiLfqCxu63ltEPJqolwXlu+HcaofhTA8wkQIK0GlEKei3K5s6urrHFQWWvviDiGwBnhPmJsXJSYqgVFdXNSYhBhURAKrqLBKgiZtFSbziXiu6jYlLwIS+Bp67peY6+hAgMpi5fffj9Kjb4fRYkWKKfntmCXQF2N1tATB3Az4LS4sUn2Vis2TU5hmBfsUq7zlNQ/fK6+sREVVJWrqamldVEyif86Gq69e7czSRNaroaJfux4EhjhW6I4uoiU8R9W/FDxsLUNJCo3p+FwvG48A64oxwznZeRJZ+6elyBDYVW5AIxNIhUwkuUhs1TWGK/eTxLHkun++PYQzF0NqHJaXnYJ9263IzkiegtOVj1K/ux4IfPnLX8bf/M3fYP/+/fjxj3/8pl2KSquQQoo5XhDll5hM3C5bLs0NJG5VX1eulF1/+KOfomewXBUpur1RRRx92/45PPLwO9Q3f/rkf2JuqYyxJINykrBS+UicM4TILgXGitDO7aVw/idzMQMfU+jLIX8baEHa2n4Rz7/0Cxw59ACTiJWIxE1wU1pppG2QBY1uTM9GYM3KRUZhDupZLF5V5aIDVyrng7rA7rKu0081AhqBNUZAYjhCaO3t8+PMebeKo0jxrxQhS14jP8+sroGaWL/GHXGNzQ/0e3Hu/AIW5sMwUajjMFVZi4vttPPV94prQJYUL2sia1J0k26kRuBNCEQ5tw1ynH86Mo328ALmSWYtNDqww5yNwhQHslMYuyWZNeUm1TJo2IB5bxzdk0DP5HJhbRNzw7srWPiWboDL+sZivjc1UL+wrghEg0EsskBy4rWT6Hvypyg6dBgNj/0mzCyKNNNBbL0WibvE+M/AUAgvHl/iXJgOr5lG7NrmRBkdhFdLYb+/tw8t51vQTGVW99IS9t95AI1NWxm7r2DRp+xnOa+5Xsd9O+5HE1k1kXXF81oTWVeER7+5wQjIzShClYAwCXteL203PVTJ5GR2YICk1kGvmsAWFlEpsyGVctYuElpNlOvWN4716DbpG0nQiOqbn9YvPQz+yNpNBbhUkmS2bqFNZB0HDayEScZF1IFl8LO4FMXUTIRkVlYaDYdRWU7VUwbctzeSmGTb2ISrDOGljaLMOjQewfEzQQTZH/u2kXDLdpaSZJYsiyRNwwwkdpLE2joK9E7Fkekw4MHtcSZNU2DXhdfr3pWayLrukCfkDoUwv+iO4eSFIJ4/EcDurRaS5c2oLLUglb/RS4R+qdIN0XJmaGocZ9pbcfL4CVxsb0fBbx5F/b4dOGgpxPALAzj9g/PYd6gBO/dWo7q+GC5KfV1SYPOzOKKHxRHNLUs4+coMgk4XnMWZOLjNgS3lJhQweOFk8MLKQLbo9NxkfGTVcfZThXV8MoTmix68enIRVRUO1FbbUFNtR26OWY1L1qOtXl8Uo7wXXGz34fR5L3KzqSpSZEFj/bIirJP9JckZnYxZ9VNAb/AWEZAgmI+EziFWdLd9+1uoYiV37XvfBzttaswO5y1ufeO/LsSSAEmsY6Oj6GhtQ2vLRXR1dKqGZWRmoLa+DtW1tQyCVcHpcnJ1cY5jprq+mYk7+nkn4KKJrAnYKUnSpBOhSTwXHkceregqTanYZcpBJhMfWn8vcTpQlFhFLVGs/E70cq4fBNLswD1bDSjPAWwcS6zHuCZxELm5lswvxTFKZxcZP4vjy31vc6CixIzMNH223xyim+9bQY6PxMZPEmSiyH75Iq8fPnwYY2NjePDBB/FP//RPl7+tnkvMTuJaI6PDOHjHHeq19vZu0k5tKsYqxdviusGhCHbvrFLvf+dfvksCdp2yZ5Q4rFycHYx7iZODzcqVKq1i62mzcE5minGNwpIShtkQRgqT2sOj3egeb0ZGSgP87ix4ok74w0ZEwxEIobuqzIy67UUoraZVNLdr4TYtlrUv+HsTOPoFjYBGYFMjcCmnIerVHk+UsRwvOrt8yoGuiDGUwwfTlDJrsopzJHvn+hjbmpsL4Re/mMTggBcPPlSI+nrJ+4nLkR5HJWv/aiJrsvacbvdmRyDOnI9MCjzxMEYizH2EpzAZ9ak80FFbEfaYc2CF8aaLk8cXSGBlLviF9uVCub2VBtTkG8CUkBIy0Zf9BDsDOYiSOP7Ea6fQ/I0nkFZegZK7jyBn61Y4C1kBvY6LjOdkPjtClf0zF7xo7fDjoXszSGZ1qPmrKOzf6hIKhVRM/9jzx3D+zFkKUkyjYWsj3vvY+5CWnsb5Mau99XJLCGgiqyayrngCaSLrivDoNxMIAamWDYdjmJwMYIKW9uPjAQYbwuo1qch00No+O8fKQIOVaq2iBqpJrevVfTJgmJ4JYWw8RKKxX5E/pb9EwTSf6qVltOfJzDApW7JkS3qFeM5xrIL2TrFoDmCJAS6XIwXVlbS4LjYru2g5po08LrGMW/LEca5N1BKjJH/HUVVqwtY6KsemUhU3iZRZZz3AyFwcFG3Ekj+OElqINxRw5RhYxp2XSHPrdW5v5v1oIutm7n0pVFhWYp2aZVC/M4SJ6SivMzHsp5qU2KOmUXFbrB8vX4Ss1d7WjqeeegbeUACmdCfsdzfBnJeDSJ8HUxfGMX5+DA+/6wAOHqinKlUq7wtmREnIH5sRQn4YXW0LvMf74eHvv6gyDRU1aahl0r8oi9cyJkxF+SdRluV7X5iWdAEqefD+4Jbrb4wkVlFipfppthmONVYlV2OjCPHj/VfIEvLo9cUgCkylRSxoKLHykaRjl1FfPxPlxNHteBMCcV47IiRkTDII1vn978GWTWJbXR1K3nYXUsvKXye7v+mLCfyCUl9dclN1dYIq1BN8nKQK65JSZY1EIkoVLSMjA7l5uSgqKUFhUREKCgtJXDUlRTW3JrIm8MmXoE0TBQ83Ex8vBydwLDyBt1kKsMNEBQ8qedgMuhA10bpNxjgTi1RlnTGw0DCGOc7RirOW3TK2FJHERo49BRT1sgICUgzmobLM8bMBDLPQSBxe6itM2NnINB+x28j4wQrN1m8lOAJSADhNJfuPfOQjSoVVFGCefvppbNu27Zotf+655/D4449zLpDCOOq4GoNIIbHMI3yeEC20GTvaVs24Vwj/839+CcGRbCzMePleAOEgJZJYrBhzzSLmWOI+fjX/UzEweX6J2L78upEk2RAW4AxVwRRnQVJaOiyuVDjTbchjvLYg34TCkjRk5TrV+E7/Dq7ZbfoNjYBGYB0QELK/jHmGR4IYGAxgaDgAuX+7GD+prGDRVblNiXXYtWjKOvTGr3ch8axwKIqXXpxBe4dbqbHWVDvRuDVdKeX++pP6WTIhoImsydRbuq0agTcjIOqXHkTQTVXW3qgbfdEl5KbYUGpyYYsxk8+tsBpMl2YLb97AFa94gxRP8RtwcWRZ1EjyQ0Ukr+4qA3LTUrQS6xV4Jdqf811dGPj5MxSmmFLBjZpHHkXert3q+SXRmvVos/A3/MwjiqiLkFlFjbWqwkphFwdcztULWvV296CzrRPnTp9Vh1VORdbtO7ejtqFOFZ5qZdab721NZNVE1hXPHk1kXREe/WaCIiBBhhAntEJobWtbJHHGTStiH7KyLaigElpTUzqt7e3I5t8SGF2WEV8OrCboId0WzRICpVQyt7Z78fIri68Hfw4fTEdlpY3EJ2PS2sCI5dDUTBjPveTG2GSYgRNg3y4X9uxwwGpZtlpbzwHalSeMJCEW3XG0dofws5f8TBIYsafJiupSI/L5XH4HG9m+K9u70t9+qsqeHwInMVRonQD2VhjwwHaDUmW1Jo/I7EqHmBTvaSJrUnTTmjVS1J7d3hg6+8N48nkfcmjNsX+7TZHkRU3nykVIrOFwGK8cO45v/sM3qLi6C/e+6wHEijLQP+fG0z8/A/e8F6m8eL77vr24c2ctqDlI2fUUhLieaA1Q/Ydq6xenlOpP455cqks7sb2G93HuLNGSnHLNFUXyi21etPGe19njU0UbR+/KYAGHBRnpa3uxknGQqKIvK4jE8No5H1o7vVhcjKpCi8MHXMoOLyNdk4OuPFf134mLwNLgACu6X8Pk6VPwTkxg++/9N+Tv3YsUEwOhiXYRuAqM0WiUXI8Yyfkkfc3OYnRoGC3NzbQfuoDBvn7OR0yoa6jH9l07GezageLSElZvp19lS4n/kiayJn4fJVoLF2Ih9DPZcSY8jebwHD7oqMYd5jyhQKn7fKK1V7fn1wic7GXB5BAt/maAchYZPrgDyGGxpIMFRjrC8mucrvZM4iMDo1G094bwWnMQDdVmPHyPk/EDqstcURB2te/r1zQClyMgY6FvfvOb+MIXvkDHKq8qfPmrv/or/M7v/M7lH3vjc84XvvMv/4I/+7M/QzrHHB10zIhQQUeYW/JfNEgiK9Xft+zcyVieB//ji19Ek3sJvtkZ+Bc98C554FmimECqC540B9VcDfyqBJdSEGcRQlwqjaUYQf3N16K0V7QtIiulDmX5RSiuykEBpZxzS7Jgc2ibnTd2jv5LI6ARSCQERAW0i3GdllYSIc556DJnx55dqagotyMr06SUQJNgSppIkN5yWzpJYu3oJFmqz6vIrA8+WAinUxdp3zKwG7QBTWTdIOD1bjUCq4wAUxIksi7hNGM7nSS1+hHFg9ZSNJozkQGLUmZdKU7AaYjSeJ1Y5HYm43ilO84iWjDOYEBTiQH5aeRzvDn1tMpHoTd3qwiEFhexONCP3id/qhzW9vwf/yfK770fRub+DBugRtXTH1QuhUMjITgpRPbgO9KRn2tW3KBbPdZL35+dmcXxF4/h3JlzaGtuxUOPvgv3P/QA0jPTlTJrMuQuLh1LIj1qIqsmsq54Pmoi64rw6DcTFAEZ7EjVrFjaLyyEld3IPC1H5uZDJHGEaAUT5cTWhBxW/JeXO0lqtTFoS3tOnSxY0x6VfhF7sgUSaSYmg7QwC2JyKqxey2TQp77WgeIiqubSajnZFiEt+QO0ZaNMff9QkMqzQQ5OUtSxbG90oKhA7F+pGLpBUS2FPavGRT2xi8SzIaq+TM9FsbfJRvVE/hZIQrPSAi4ZFqm8nvcZ0MOJzOkB5kTY6ByXAfuqDKjIiRNjvpYch5IMcF+zjZrIek1obvs31PWO+c3TLbzejUQQYIVsJUnxu6kgleokqZzXvisXUR/s7erB+bPnFZn18N2HcS8ncgtU8WntGsPPnnwNhgI7Sg6VwVTiRGp2GgrD6QhPOTAzZMdk7wI8E0soyDKiqtKBhkYWpHCymZmaWFaTl8YfQ8NBdHR5MU4V1CDveyW8t5WVWlFRZqd1iUEpkF+J0Wr+LRa10yyu6BsIorsvqK6Jst+iAguVwqlgy0dl15kk1/3VxEZvK3kRCJFA4Z+eQt9Pf4KJUydRdu99JLLuQ2ZNrQqEJeqRCYFVVFZHhoYwNDCIgf5+KrBOwev2wOFy0gIxDelUX83JyaF7RA5VyLJZbJcNu8OhqrYT9bhWapcmsq6Ejn7vSgSELDUQcePZ0BjCfJ5uMOOAJQ9VxjRNhLwSrAT8e9q97JhxcRRY8IpDRhy7yg3YxiSTKLOadc3MNXtNxo1SGDYwGsErZ4Is6jWgpMCIxhqq5heubdHTNRul30g6BETd5fjx4/jTP/1T9PT0qPY3NDTg7/7u77Br166rHo8qrKHCaphjq1+88go+8YlPqDFHy7O/xOBLLyLIxGNwYQERvw91730/dr/nvWo7//SNbyCr+RxSzBa1go8ws4rbbEOKxQ6D1QHIarQg/voqgTAzYikmjIx340LrMRze/w7UVdfA7rLCkWojiZVKxFrG+ap9pV/UCGgEEgMBJRCxFKVyNdVZGfefmg4psY4qCnMsq7PaVR5Ax6PXr78k5yfCNS+9NKPGUAcOZKGkxKGEa9avFXpPq4WAJrKuFpJ6OxqBjUdA3Hamon50RBcwwIJlifOUGJ3YZ8pBjtEOJ6491/UxzzRO4mrHWBxnB4E8ElfLxJWzcPm5ndOPjcqxbzyyydOCKIsjwyyu7H3yJ+hlHL/s6D0oPHAAmfX1ypFjvY9EnBInp8M4ftJNx+AYdmylY2IlnQqLOZddpSVAN7mpiSm0X2zFqROnGM80ICMrE0fuOYKqmmrY7JwzbwCJd5UOb8M2o4msmsi64smniawrwqPfTBIEJNggiplDgz4SDL3o6l5ClOoXNlq/FBfbUUR11tw8EnBSTazGMMJiNWpS6xr2rSRsJLDTPxBQ1cwdnT5lW1ZaYkN5mU2RfdLYF1arIakqmuW4oiRQD4+GcL7FR7JuWJGmdzQ51aBIKnys1mV11jWEd8VNC6HKTQvDMxeDePV8EOVFJioomlFXaUZWekrSkFnlIKfoXHduMI5euhNIVd7hOlblFQNZLv62mQTUy9oioImsa4tvom5drnOL7hjGpqJ49VxAPa+vMqOe15CaciYpr7KIGuvC/AKe/fkv0N/XT0XCOA4evhMHDt2JztZhtDYPou3CIFK356Hy3Q24EHJjPBJGbsyJwARJrD1MCIy4kRsI4tCBbGytT0N5qV0Fqq+yuw15SdRPeZgca8Qxy8KZrh6/UmJNIbM+J9uMO/azyjPPRBLr2rE5pG+E6O/mxHxmLgKpMB0goXZ0LITKMipwc3K+hbYp6ST/Mt+tF41AciLAE10CYEPPPQsrlcOyt25F+TvuU88NCXJiy/VAiKsBEvh9Xh+WlpbgJiFkiETW0eERklkHWGzn5zXMgtr6OtRtaeBjPeciuRwnsjL9Nsh+aiJrcv68NqLVMSY0/PEIWsPzeDI0hGKDA4ethShmkiPDoNX5NqJPbmaf3pAB7aMxtDHZ1EZC65YiYEcZSZlZBqTbQWvy5eLDm9n2ZvjOzHwMZ1s5ZpuMYnYhirfttaGpzgIb4yFabWYznAE3f4xCYv3sZz+Lr371q8qNISsrSxFaH3/8cQanoohxThUNcWUiMRoKIkbyaoQqqzE+D/t8CLndGLXZ8Rsf/KBqRPOLL6Dtm19HiGOXEJVXY+EImv7k/8adj75Hvf+j730Pjo42WFmAY0lNhdmVCisLcswuF//mI4twjHYSWpmgu9p45ty5c/iP//gPPPbYY9iyZcvNH7j+pkZAI6AR2CAE/CwaXliI4OwFt3LgSUszobjQgoZ6J93PzMwtiSIoqQs6LL3mPSQxsDnG3375y0nMz4cVgbWpKQ319anqHqT7YM27YFV3oImsqwqn3phGICEQENedrsgCzoZnwLsjtpmyUG1OQ0mKExY6NlDP/PV2yjXdR3e7aeZ8Ja4wMGvA8CzwtnpgDwtl0x065/s6WEn0ZPiF5zHw85+xrtGMtIoKVD74EJz5BeuuyirnVzAYxYuvetA/GFQuunU1VuzdQVo1Be7EtXm1luHBYSXmc4GCPpPjEzhEQZ8du3eirLxMkVllDq+X60dAE1k1kXXFs0UTWVeER7+ZJAjITUoUWoOBKFUzo7TZimByMoTRUT8GB73wUqFViJMVFU7U16UiL9+qFFqT5PCStplCLvZ4RZ01xH4IoK3DRxUIA1VMTdi9M00RWkXVVAJAybLIuRYIxniOxdDRE6Ainx9S7ZOdZcLhO1JRkGdW0vUbdTzSPiE6TUxHlSrrhfYQz/847thJklOZCYUkWiVLoCcUATxUhTw7EMep3hicNgOr81JwqDZOO0uSoJPntNmo0+GW9quJrLcEX1J+Wa4fsp7jdUPI8OEwkJuVggM7rMjLNlLh8+o/uiATp6Mjo/j2N77F+3AA9z10H2rqapGRkYuf/OAVkrqmUFlTiKL6UuTUFePFMT9aqFToS6f9DKt3Q74YqhYc2BpLxaHGXJTnO2CVe0MCXawEF0loDA0H8OrJJV73I2oSvGObC9VVNmRQ9f1SccZadb4UKnh475FCil4qsU7PhnlNJ8m4lgU7+Rba3RnhsDNIxMl5AkG3VnDo7d7GCCz09mKmpRl9Tz+pyBPbP/YJuEpLSJ5wJsRRC3l/kSpmoyMjJOpfRFdHJ3q6upDJKuy8gnyUV1SgpKwMhUVFcNGK1+F0kuQu5HzzbVOZrYmsCXEqJkUjwjSiFoUOIbKeicxgpzkbD5hLmNQwwszEhl6SA4Eoi3n8YQMGZ+K4OEKXkjkWEnOc+PZGAxqLDXBZ4yRkXn2cmBxHuLatDNE5ZWGJbiMXA3jhhB97t1mxvYFq/lRldVBRXy8agashcInE+o//+I/q7fe97334/Oc/r5TeZdImZFT/7Ay8E5PwTS2v3okJPp9CYGaGRFYvTBx/VP7x/4V73/9+tY0f//CHy0TVdBJVM9JhJVF1iPOcR9/zHkUKunDmDGzxGNVTzZACohQT1ZT4204xMo4kf0tS7hokVtmBJrIqmPU/GgGNQBIjIAXMEYqjzJE4KfmMlose5YbjclFRvcHJfEaqym1o17/16WSfL4KBAR/a25dw4cIiDh3Kxt135VIwXIRE9BhqfXphdfaiiayrg6PeikYgkRAIxOmYGw+hJ7qI9tACuqjQuoMxn/3mPBSyeDnV8GtlVtI3lGBRO0ms5wYpVsQQ757KZTXWvNQ4i2N1vjeR+vZ62+IeHsJcRwf6nnpSFVnu/P0/QDqdOUw22/VuYtU+xzpPjHPs1kXexvFTbgrlWHDf0QykulKUwN1q7UiUWb0eL86cOo1zp89hmvPvkrJSvPs970ZBYSGcdGfTy/UjoImsmsi64tmiiawrwqPfTEIElok4VEybDZHMGqA6kk89D5J8KDFYp9OsKjizsix8tJJoQ+Khc7maNgkPN+GbrCyq/XGM0pqnkzbMs3O0YWZf5OVaUEDiTQml3bMyzZCAULItI2O0GxrmQL0vQIJTnMdjRnmJhap4NkX4sjCoslGLn6qBYmN4qjmIobGIUnupLDEp5ReX4+rW4BvV1pX2K7/n/uk42sf4OEPCOv/eSfWfyhzaVVABSJO1VkLv1t7TRNZbwy8Zvy1qzmOTVE3rCaOrP4Tacl7Pyk2oraCaOQmS11qGBoYUkevZn/+S9tnp+I0PfYD3Wwdmp7049txFzC+F0HRwJyxZ+QhZ0jETZLFJwI2pCBOuFjdizjCyqFxYzETrnsJsVFP9Jz+FpC8SXKj1c63drtvrUpTh9kQxwGrOoWG/SmakpRmVNUlNtR2FBVZVkLFW1yMpnnB7qJI7wQKd8RCTKBEIIcJOsm8FlVjrqm1IdaaQKHftPlo3sPSONAKrgIDY4C4NDaLju/+qrG+L7zyE3B07kbVByl6iwCpBKvfiEmZmpjE1OYWZqWmqwszDTRKJEPhDVECTYFVRSTHKKyvV85zcnNuGuHplt2oi65WI6L+vhkCMvx0fIngpOI6hmJd39Di2m7Jx0JJ/tY/r15IAgQUfMDIfR+vI8hytMAOozKUNYJEBacxT2K4u3p8ER7a2TZTfQoxJlfa+CE7Q8UDc5jLTjSS0mlHIIl9dhLS2+Cfl1nnODA0P44477lDN//jHP44/fO97EKACfMTroZqqB2G/DzE6WogSq1JkDYeW1Vk5JolHI4qYamIRUHZ9A/7rl76MXhYK/fZv/zY+/bHfVXEVUb63pKXiz//iL/HP//zP2L17N5566iml/HqzmGki680ip7+nEdAIJBoC4XAMPsb6JZcxQHGOGRYSK3XWIivjMDY68lhUMbMmU65tz0leyc1C8tbWJTz//BSqq53YuTODDowO1R9ru3e99dVEQBNZVxNNvS2NQOIgEGYR3EwsgG6SWUWZVVRYM1OsaDRnoszoQjqdeHx+A6Y9wMVhFsXOLwupVOcB+6sMcLIoVrtvJk5/3mhLwpyb+qencfHb34JndARVD70Ludu3I72q+kY3dcuf5xSa8fsohsmHePE4pX8ZgywqNKOpwYGyEqv6+2quIje7Y3Gm7O7owtnXzqi8QVVNNbZu24qGxi3Kkc1k/jWR+2b3sRm+p4msmsi64nmuiawrwqPfTGIE5Ka1bAUcp+VnBH19XlxsXURL86JKFAiJdceODNTVuVBa6lCvJfHhJnzTRTFXKprbO3043+xBdy8tV6kad8f+VKrJOVBRTk/CJFvkHBOFPKnwaWnz4WyzH3U1Nhw5tKzMmk6i00Yugvn0XAydfWH8/GUfsjKMOLLfhrIiE1UWN7ZtN4KLkFf9VGZ9unmZ0GqnC+ku2k0cpVOdtmK8ESRv7LOayHpjeN0Onx4YieDYaQbo52lTyd/d/YftaKgyK5WDlUiaLz33Il47cUpN2Kpra/DOR96Fvu4pnDnZjdkZElVttAfftg/jwXR0TggZncR/axBjbRPwWHyIVkQxU+ZFuDCCWlMaK3ezcIclDzSzJJl1469VMzNhDI0E8dwLc5hfpP1moxPbGl3YykdZVsJmNc6L2XmOYQYCOH2eKhSdflRVWLGVE/Bd2x3I4H1GEidr3YbVOA69DY3AjSAgKmP9P3tGKbP6qSpWft/9qH3Pe29kE6v2WZlPzDAo19vVjbNnzuI81ykqnlmsFuzcswc7SfzYuXsX0tLTlPrqpaDYpcdVa0gCbUgTWROoMxK4KVEmNObiQfyLvweLVOm411KMamMaCoyOBG61btpbISBjxL4pJqGozHqqT8ircbx7VwrKc5ZVVd7q+5v5/UU3k3zzMTzzog8TLEx69B1O1FWyqNcp6jMbX7y1mfsm0Y49TjmZ733/+/iTP/kTFt9n4Llnfwkri/zk9RjXuDCjWR4gYw0jFd87vvl12Pi5c6409PT0kOhTjQ8/9hiMFotSUf3SV76Cv/3bv1Wf/9GPfoTDhw4xrQe88MIL+PCHP8xi8yC++MUv4rd+67duCQpNZL0l+PSXNQIagQRDQOaBou4lyqxnztI+uceHMRYX33M0Uymzijub1aoLite626QfJK/38sszKrfkdJpw8GA2ysv1nGKtsV/N7Wsi62qiqbelEUgsBGRe4Y6HMRb14vnQOM6Ep3EHVVl3m3PQYMrA2JQJF4aBFhJZ5bPv3gnU5BuQzsu4ngUnVl/eTGsifj+6fvhvmGluhpkCNQV796HywYduZlOr8p0F5u+6+4JopUNwa4cfjz6UhQN7nKqgeDXdgWV84qEYx2uvnsKpV09SofUM7jp6N973wfcjIzODOQI9TrmeDtVEVk1kXfE80UTWFeHRb94GCMjNJBSKY3EpTEJNkInoIBYWIvw7pF4X9YvUVBOKimjNW2RTaq12e/LYrydLF0k/8H9a80QwNR3G8EhAPfq8UQbmaXlfaEFl+XJFs9lMDb4kGcFKZfDCYlSp5MngaHEpSnJrVJGMqsqtyMk2UQ11Y4JagrefSoJTc1G0dYcxOROlSmscO7ZY0FBtRkZqCqyWxAdajiMSY8J0Gugaj6NjHEgn73lriQFVuXEUZiT+MSTL7/Tydmoi6+Vo3N7PRd1zZCKK7oEwWjqpKphrVEl1UXHOoV39ta7H4XBYkVf//fs/wmkSWfcfPIAtW5topVGOE8c68dLzHQhnVcBWUIb8imIqT1n52zXAT3Krf86LxSkPsmipWrffBV9GCEuOEOZYwRvlT9oSN6DCmIoaUzpyUmxwXmZFs1694aEK6+SU2JH4MDgUhI0KqNlZZtRU2ZFPRfGszLWrqgyzTzy8P/YOBDE6FsLEdARWs4xXUpQSbEGeicrmZlraUbVWXwLX65TQ+1lHBERZbLG/HxOnT2HgmaeRL0Gwd74LroJCqoelrWlLosxWRiIRjI2MYnR4BIMD/Zw/zMDv89Fq10T1YzvSqWKWmZ2F/IIC5OblIS8/j79HC0wkk2yGRRNZN0Mv3/oxShKjP+bBqdAUSKXCgzaOBwy8p6dsjt/JrSOYuFtY9AOTi3FcHCW5YwGIcq5WXwjsKJN5mkErs16j6yQuFQgBr5z1o48FZKkksIoDwq5GCywc511rzH2NzemXkxyBOP2rw14v1VWXEJibu2ydRXBhAd+m68UPfvCDtzzK0tJSPPn1J9Tn/uDzf02iz8u0Xj6E//3d7yoSq5xYfiYX3//+90OIprJsp0qOjXaPZ8+eVWOeRx99FF/96ldvSY1VtquJrIKCXjQCGoHbCQGJSft8EhtigfNwAANDAUQYr3E4UlBf51BOc7mMzeiClLXt9fl55pKGfWhuXsDYaABHjuaioSFNuSxqVdy1xX61tq6JrKuFpN6ORiAxEQjFo3TkiaIrvICuyCI4o0FKhHn/YAaWRl2YGHYwjwtU5BiwhY4umc44rORm6CX5EYgxhj7behGTZ05j5OVjyN+1G42//V9g4nzTaBUl1PVdxBF4gTyNljY/Xj3lRkOdDfU1dorD2FhEvLpcDcmPTo5PoquzSwn9REJhOF1O3HnXISqzNnCc4lS5hPVFILn2pomsmsi64hmriawrwqPfvM0QEDKllPyMjvkxNORHe7tYhAqhNYaSEhsqK5woLqHCWYaZAQkTzEwmyHo7KyptRBcL+VMIrf1UmDv12iLENlnwbmp0sA9syEg3K8KQYJ8si5dBLbF7Ptvso2qeB7UkOlVX2lBdYUE2yU5W68adR0EmzOYWojjfHsILJwOop8JiY40VVaVGEstSYEoSNT8hs47MxvFsGzBPW0szhRoPVANNJLTayCczbbxwY7KcrtfVTk1kvS6Ykv5DQmIVdahzbSEM0nZDJnl7t9lw5y6rUs0W69NrLYtMsI6PTeA/fvhjdFxsx29/7L+isrqeltseHHuhE6+cGETmLlqC19aiKMeKGlrG1OVE0XxmFkODXhLpGfhvSFVKCnGqeS1Qre1ceBZd0QUMRTwoN1Gx25iOCj7mpdjhIJnVRILrWicI5B4lRQDjEySxdvtoI+fH7FwEB/alobHBiQKSWNfq/iTK5dInUjkqiRKpGp1g8UckzGtdox07ttoVgdbp0Be8a52X+vXbAwEZs0sgbPL0a2j5p2/AkZuLPAbCCvbtR3pF5apLIQtxVdYAiR4ejxceKsL20YK3t7sHPV1d8JJokuriNYn2QE0kf1TX1ZC8ms9qbim+Sp7x6mqdHZrIulpI3p7b4XRbkaHORmZwnvf1EGIoTnHgqLUYaQZNYr1dej0U4dxs3kBVlRhe7QFKs8U1AyjnY26qQc3NdLHNm3tbQlI9g2F0DkRYbBpCUV4K3nGIBRIsVrJvUAHsm1upX1ktBFRBN8cXUSa44nyM8TEa4lWRg/tIIIjQ4gIL/GaVHaNYMsrqnZqEiQm//+d8CxXo+t6yKVVVVTh+/Li67n7wgx/ESy+9hLvvvhvfJZH18mWJY5vHH38cp0+ffv1lKcI5evQonnjiCVWQ8/obN/lEE1lvEjj9NY2ARiApEJimW48Ic5ymOquIdAghoqbaztWhiK0S49qEU8N16TuJlYXDMTz77BROnpjFvn1Z2NKYhrIyO3MuOj62Lp1wizvRRNZbBFB/XSOQJAh4qMw6EfXjSc8YOqlWafbbEZ/MgHEqCw83WbC3zAgH80CSk9bLbYIAgxwh9vXUObqYffUfkFZeji0fehyu4hLYsxkg2qClvYtE1te8VNePIT3NhDv2OlGYTwdICqmt9jI9NYXWllaceuUkWjiPf/t9b8ee/XtRUVVBMquLZFY9VrkW5prIqoms1zo31OuayLoiPPrN2xABCSQHAlGucSxRpXVuLoSpqQAmJgLquZHZlpxcK2prXCS12lFQYFMJah2IWL2TQZI3y2pzrNQhOWhwkBXNXH3+KAM/RuzY5kJ5mQ25OeakCQCJ1VAgGGUgK0IL6hA6evwkPcRQV2NDnQS1Kq1Kun71ULz+LVHoQxGjJqZj6B4MoXcoDK8vjjt3k2hbZkJ2Roqypr7+LW7MJ8XG0k8Fm3Gq/rSMACd6Y6gvABoKL1XxbUy7bte9aiLr7dqzbzyusakIBkYjONMSVNeB3VutKC8yIT9nmZy10r2vs70DLzz7Ihbn56lCaMHb7n2QtpR2PPuz8xib5zXR6ML+w1vQuKUAJdkp8C0EMDnsRm+vWylYHDiQhQoWkOTynivGMmESXcR6eJqqrKOi4hZZwkTMjxyjHWUpTuw0ZyOb6qxCaF2rRa6XooTa1u5FT59fqaGWFFt4Ladqe6GVJNLlQouVcLmVts2z6GCUVnVCYB0aCSItzagm2FVULM+hbV16WgqTzEb21a3sRX9XI5AkCHDA6B4ZxsSpU5g8fw6ekSFWdH8ExVQZM/Kas5qDRPeSG5MTE+hoa0c3q6j7aMtrd5A4npWFEiqdFRQVKuJqGpVY09LTaA/kZMLMquYISYLmqjZTE1lXFc7bbmM0vYaocfwsOIJXQpM4aMlHkykTZRwX2Az6Bna7dHiMkzM/C20mFw3onIijn+4Zk0vAnTVxFhqmICdVK6xcq6+9/jiGxyM4djqICAuoKoqN2FJt4ePajXGv1Rb9+hoiwHFMjIEiUVv1MbHlnZyAT1aON9Rzvia2RSlUc7dlZMCSnvGrx3RY+VwU6M0cb5ioBG+02qhoY+VqRwrHH0J0NVAlPuUmJgVzbM+ZM2eUIuu+ffvU42qhoImsq4Wk3o5GQCOQiAiIEIqf+aQRKoIOUpm1p9evyBAlRRbGvZyoKOc1mtyItYoXJSIm69UmySXJ2LO1dUmtktPLz7fi6JE8zs/FWVETotarL252P5rIerPI6e9pBJILgQgv2IvhCJ4d9eKshyratjm4WNBcakjFfTnZ2J5KUh+v2broNbn69a1aK2IUixSE6P73HyJMUqs1MxPl77gXuTt2vtVX1+x9cdKdZOHRK1RlnaII2V0HUyk+Rhdd5thSVvkEDNJZzuP2oLX5Ii6cu0D1+DHm9VLxwDsfREV1JTKzMtfsOJN9w5rIqomsK57Dmsi6Ijz6zU2AgFgHz8wwADHow8iIH253WKm9pVMVNCubappcszItSM+wwOUywmTS1bWrdVpIAELW0bEgevuDDAKJClYUOdlmFJIwVFpsI4FAiDsSkEiOQJDfH4ObBNYzVGUdJKFVlAOLCi1UaLUqG+gMkpA2KrjiZdsWl2J47SLJrCS05mWbUFliVgqtYmtotSR+0EcCVyFWYXeMC5F1+bmD7d5TCZRlG5BhZyJolQehq3W+J9t2NJE12Xrsxtorqp+BIC1hu6kI1RdSwfjifBMJ7lalCCX2ptdaxHY74A/gJCsMf/T9HyKvrA6FlY3IzKvA5KgHrz1/FlklRajZWY+dTXkoybPDEo9Q2dCNCxcWSf5KYZGIHXv2ZCgS65U2YL5YWKmzdkRoRROl1SbJMCwFQKHRQUU3Vk7yMTPFqgit127ltVp/9dflXiQFCZNTIXVPEhKr2x0laTQFjfUOJiUcSilc/l7tRQgMARIaplnYISqwI2MhzHOiHeW1rqLMgspyKx+tsBE3HZtfbfT19hIdgbDXAy8JH/3PPI3BX/4CNY88iqJDh5FKcqnZ7rjp5kcYVPX6vJifncPc7CxmqIA2NTmF2ZkZLC4scjzqRkFhIcrKy1BbX8/ithIVdDKSNKIXQBNZ9VmwEgJLLEoZi/oUibUruoh3W8uxzZzF5AWDxVitO/dKLdDvrScCXo4nZzxA8xBwYThONVaqsopdYCFIZjXAuf5Ocut5+De9rwXOy8+0BklojWKB7gh7m6zY0WChKivVbPWt5qZxXe8vKtcnVsJFAn5EfH7IuCVEFfcIV1GliXCsEabSe5DjiihV35df8yHip/EmFVmNJKeaqfjuyMuDIycXdirQy3NbVjasJLeKFaNhJYuM9T7gt9ifJrK+BUD6bY2ARiDpEZC4tAhxTEyGcKHZS4GOsFIKraAghxBZC5kDENtanT9am66enpL8kQ+nTs1BxGiOHM1FUZEdqal68HQJcXGNGRgYwDPPPIMeFujGOE4R9fYHHngAdXV1jH0y+HnFYuLgU/IAouo+xUKb7XShufPOO9XnxblmNRZNZF0NFPU2NAKJjYDcI2e9oMBJHOfHohiJcj5UNAWDK8QcSwzbLZmoN2cgn0IldjA+pBMdid2hN9g6P2Pqk2fPYJpiFFPnzqHhQx9C6dG3LxdjbkCQQ3JuYbrVvnB8CV29AeRROE2IrNvpDGwhp2AteATjY+Po7+3HK8eOM9cwg5qaajQ0bcG2Hdths9uUKMYNwnrbf1wTWTWRdcWT/C//8i/VgPRDvKDoRSOwGRFQ1qVUYBN7kiAt7ifGA+jt86Cjw43FRdp+8Wa3dWsaGhrSeNNxUQbcuCY3uM2IvRzzJfylqnlsIsxqZh/O0KJHBr3FxVbs3kkb1zoHLa6RFLhLu6MkRAkBamA4iGOveiDk1mwScg/scZEQZVPHsRFjdDZL4To6EaEyaxivngvCaTfg6AEbSgpNyMlMDoUkFTSkMusCVWV/1hJHJ0mt20oNaCqm9XaJAebkOIyE/8lrImvCd9EtNXDRw/vddFQpQfUMhPD2gzY01lioxMqCDVq7rHSNCgQCmCbh60WqsX73O99F490fQMWuB9DeNomFsQmkzI/gvgea8M5HdsNG9VC/L0qLbjcutiwrJ7zj3jySWLNYlWhSRNErD4SXKmqzxhEkgdVDAmxLZA5t4TkIsbXQuKzMus2UhVI+Z0tXhRIT4hhAiL0vH19A80WPuk5XVdhxcH86MjNNsNuXCawr4XLlcVzP33I98wdiGJ8M48RpjyKxLpLEumenE9sa7VQmN8FFpXKTaeU+uZ596c9oBJISAf5IRM1s8Bc/R9+TT8JGS6KshgZU3Hu/Invc7DFJlfTw0CCaWSV9lha7YyOjDG6F0bhtK7Zu24am7dtY0JYNp4tKaFRKM1LxTFa9LCOgiaz6TFgJgcGoGyfCU5iPccDO3/A9thJUG1M1iXUl0JL4PZljyjqxGMfgjAEvdsTgDRpwVz2dM4pIamWxoV7ejIBwAqQA9vTFIJ5+0a+IrPu3W1DEwjKZo+slORCQMUosFIJvegqe0VG4ObZYHBzg4xCV5EfgGRuFJTWNxFSS+YuKaa9YDCfXVNosOguLYKPSu8nBwhxOMgzGFM5BONYgAUWUVhWBdbUnH2sMqyayrjHAevMaAY1AQiAguQzWRap4f0enDydOLaq4joNxoyNvy0R1lZ2Oc7oQeS06S/J0kq97+ulxEkSCzGu7UM+cXXW1ay12l3TblJjFV77yFXzhC19grpPWCZct8t4f/uEf4tOf/vQbyKwiuPLxj38cP/3pTy/79PLTD3zgA2p7q0Fm1UTWN8GrX9AI3FYISI6D/+NMfxynB8W5JY7MtBju2hbGkH0aJ+OTcMCIClMqjlqKUEChEs54bisMNvvBRDkvloLO7h//COf/4cto+shHUfXOd7FQM395zrvOAMl4Tc7JweEwuuige/q8F0UFZjz6EOfmLDoyryDkc7NNlftlkAWrrS2tOHf6DI6/+DIatjbikfdTmKO4SCuzXgVYTWTVRNarnBa/fkkTWX+NhX6mEZDJsMcTwdxcCBMTAczOUhVtPqRUQ6U6Q2zvxQK5qMhBpVYzSTjmDSMl3m69JQNdpY7LSua+fj+mp0NYojKJkwOK7CxWylTZkJ9nVQOMtaiUWW08w1TSW1iM0JqaKiujVCWiyl5BHi0USqjOWkmlWRKjRIVwI/ISYmU4NRtFc0cIM/NMvJDIvaXajC01ZhKmRJl19RUHVxvfqJDP+Xu9MAx0kcg64xH1HyqzVhhQkA5kOld7j5tve5rIenv2ufx2hLDZTfLq2Vbe33jtld/97q1WlBSQsEkVqLe6Ls1Mz+KlF47j1LluNHdNoXrXUeSXNaH3dAsccQ92bs3Fvv2VJIOVKZXzYaolnDmzoO6lmZlmVvZnoKxMKh9XDuzLRDMSJ8kzRsV0VvAORb1YiocRQhRZrNwtSLGjMsWFXKMdTlrU3EzoQ+77XhJth0eC6Oz2MyAeUUqoJbxWl5fZqYQqlZKSVF7980HucTO85/UPBDAxFWG/xJTqazaLCmS/MrG220jON6/Bzlf/cPQWNQJrisBcRwemL5zH5JnXlJVuw2O/ifSqapJDKP33FosKXHGgKcqrUxOTGBkehlRIz1GNNRIRJ4YU2EkiycjMQCGDSkUkmMhqs9lgtpjfYuub821NZN2c/f5WRy337YAUoLD45JnQMEqoot5oykStKR05vG/r5fZGQJRZF/1UZR0ChmaBIAkeZdnAjtJlZdZUfQq84QSQMXiEMYO+4QhOXQgqQgwFOnDHThtKWWRqIp/xrcbkb9ig/mPtEOAYIkoySMTnQ2B+DsGFBfjn+Dg/z+dcFxcRU2QRJsrYr8qBh50nimgyibCkpanxio0Kq5b0DFhJXhW1VXndZKMN9Qao06wVWJrIulbI6u1qBDQCiYaAXO/F2WealrVDjCcNDUseKawEUAoLLKirtTP2b1Z/J1rbk709gUAULSyU72XB/ORkEE1NaTh0KEfFzq50fEr2Y73R9h87dgyPPfaY+lpRURHe8573wMfxi5BUZ6iUJ8tXv/pVPPLII+q5jFk+97nPqdfkhfvuuw8HDx5Ea2srfvzjH3OsGsFHP/pRfP7zn+f5zoDyLSyayHoL4OmvagQSHAGJBc24gZ7JOFcqsi7ElXtmRW4cdSxunTd70Uu3ngEWPfsZMyoxulSxc4OJcyKWPBsZl9VL8iMQ530ixvvG6LGX0PH976nizUy6nJXcdTdcLOLcqMVNQZ8RugIfP+lRXAhRZRUH3bIS65o0SZTPxfGtv6cfp06cwhKd31JYtHrHnQeVgEZGFmMCdF7RyzICmsj63HWdCga/n8yeTbhoIusm7HR9yNeNwPx8mBPiACfHi+jvF7uYIO3hrWioT0dFpYN2MTYmuZeV0oRoohMN1w3tNT8ogSBRZ+0lmfXsOTfGxsMk91Cdblcqamto0ZNPe2WbWPT8KkFwzS1t/BtCnOC4DR0kR736mheLSxFFiLpzvxPVVPpLdS2TozaCmBuipP74DBPNnWG8cNJPIqsVe5osKmmWQUKotCkZzmdvkInSOeCp83H4eUxbigzYWmxATT44AVJ5o40/EZK0BZrImqQdt0Kz5foq6p9TczGcawvhRf72D+yw4gAT5gVUYnWsoP4kg2T5foCshN6eAXznW9/FIBVdDbnbkJNXTttYJ2YvnERNiQ3v+9DbUFCURQKYhXZWPqVwfvbMPOrqUxkUzVeWX3b7jSkbhkhoddOq+ALVWU+EJkHDTmVBs8+cg2pTmlJqtcR5b2Dg43oJrcsk1hjv8yG0tHnx6olFVFbYUF/rwPZtJMjSbmS1FyEtRElaCIfjGBkPsdghgNYOP5Y8UdTXUBW3zk4lVodWYF1t4PX2kh6BCO14A7MzOPuVL1HhbBh17/sA8nbuRFpl1VWPTcZgkmgRFZIwK8KDVJIe7B9AV0cXmkmIHRsd47XCgOraGuzetxcNjQ0oLS/nb4/WVmvBXL9qK5P3RU1kTd6+W8uWh3mvnokFcDo8g6dCQ0pl40FrKewGI1j+uZa71ttOEAQkvy1Wgh0sNPzPi3E4LXFsp3NGA+doxRlxWLTC/Jt6apGFTZMzyy4JfVQKefBuB7bWsmiasQLmOvSyjgiowheexHFRWY1GEI/Qepd/K2UZP0msJK96xsawxHGIl4+e0RH4JifV62aXC46CAqSVlas1tbQUrpJSyKOJhTFGzos2w6KJrJuhl/UxagQ0AlciILGyzm7GvqjOepGxJTvzFpLHqCi3ooB5DFH82uwEyysxu5W/L6mytrUtKWXWhoZU3H8f78HpLAa/wVjjrbQjEb/7sY99DE899RQqKiogcf1LixBS9+3bx/jnJI4cOYJ//dd/VW/NcWyze/du5uJC+MhHPoK//uu/ZuxXIsDAE088gc9+9rPq+dmzZ1HAcc6tLJrIeivo6e9qBBIXASWaQgHozok4jnUB3gDjABRKuacRqCugQAfz+HJVCZLA+nJoAs0sfJ6PU1HbmI6jVipUsujZYTAxQhtXcdrEPVLdsutFYL67WwlRTJ0/pwo+RZk1q2HLhhZwLtAB8fR5urONhjG3EMGd+1x0RBQn4LXj9biX3Bjo68ex51/Cz558BkfvfTvuOHQQtfW1FNPIpAMcfxx6gSayaiLrij8DTWRdER795iZHIEgCZVCURRZDSqVVFFplFcXWKEdodruJE0OHUpYrLrYrdbmNICXeTt0kc2VZPd4ocQ5jdCzENYBJKrTaSRouK7WippqYs1pGeAaJjPfyxN9AZdkopmcjSu1P1FmFIFpSZMHeXU6kpRpVgGu9+1CSjH6q/41Px9DRG+ZjhKqqtVqcAABAAElEQVSEMaUAU1thRnoqCWE3xjNb70NQ+xNVVk/AoKr9Osfj6JwUIiuwu8KAonQDXLbl4MuGNC7Jd6qJrEnegVdpflAI7PytHz8TJHEyhlRanW2tM6Ou0gKbRQLrV/nSr14KkHjpC9EepnUcp8+248zzP0VWbiEO3v9ezI7MYnF8BqnmMG298nDXPdthNFuwwEnh8eOzVKgIorTUgZoaF2prXSqIb+Ik8UYWppQhBJlFklmnSZIZingwFvNiJh5AWooFZVRmrWcVb5mRNuAktKbIhXaFJcYbzQSVsgeHgmi+uFyNmZPNe3q5jfcZO9LTjbBRiXU1F9lnwE8iMckKbUxwTLIv5qkAW0zl1SIqdsialWVS119RRXiLQ1jNpultaQQSHgEhlYRoTzTw82cw09zMQFgIhQcOoubR91xVsi5Cr0evx0PifQ96urpJYO1EKBikTa8Befn5yM3PQz4TMTm5ucrWJy0tHQ6ng787+e2tfP1IeLDWoYGayLoOICfhLpZ4j34tPI2BiJv36zAOWPKw35xLuzjel5PweHSTbxwBmceHWMg566Eay1QcvVRj6ZumKmsZVLFhKRVaXVp44g3AijVxgIVmp1qCaO8JI5WONJWlJuzZaoGTY3W9rB8CUY4TwhxreKcm4ZuYIElVVj6fniJZdZ5xqhjMVHC3uFIhxFVLqiitcm5DdXizk387nXx0wmhnQoyfk+cmux0GTrIMm6RIRhNZ1+981XvSCGgEEgsBN2P/s8xjDAwFMDoapDNbkLkLGy3vbahi7kic2fSyOgjIeDMcjmFwwItjL8+q2FlujgXbdyy7P63OXpJvKxLHOHz4MJVqe/HJT34Sn/rUp95wEJ/+9KfxrW99Cw0NDXj++ecVYfUnP/kJPvGJTzBOa6YIQQdznfbXvyPb27JlC2O7C/jMZz6D3//933/9vZt5oomsN4Oa/o5GILERkBzzEnOzZwcoTMX5/xRVWevyDWgqMaAwA0ij44hMgyRDG+NcapoE1kHGiy5G5rEUC1GIyIB9plxss2TDRnESSgsk9gHr1l0XAqGlJfhnptH2//0LFro6UfeBx5C/ew8LPwupTLpCAvK6tn5zHxLxtOm5iBKUefWUB1sb7NjRRLG6fItyAb65ra78LZWbYHyht7sHLeeb0d/Xz4LZGN529C4KamxBUUkR87Ebg8fKLV/fdzWRVRNZVzzjNJF1RXj0mxqB1xGQG93iIu1iaJHc2+uhHUcIfn8Eubk25HCyXFBgQ0aGheSXZdsYsUxOZJLl6weW4E+mZ8IYGaUqbisVTUn4kcra0mIrLZ+tyM42U9XUSJVTJgYSmHMghFaZ/Hf2BNDVG0D/YBBWksbqqL4nhNyCPJNSajWJhOg6Lz7aP8oATizG23pDqGLSrLrMgppyk7Ibt7BqPNGXiFiDhwxoG43jhY44k6MksWYC2zhhKuajnaKKmyRvtKpdpYmsqwrnhm5MggWiWDAyEUXvUBgX2kOKLCkJ8pICE3Kyrj5hku+FWFG7FKA9DAkJE/NRvHL8FDpaLiC60IctDXU4cv+70XayFWO9Q9i+uwr1W8tQWVOECaqc9vZ60dXlVvZeYvNVUmLnffLWVU6lXSMksvbHPKzinYWPZBlHihnltKUp45prsCE9xaoU4K7UZ5XrsY8mDKK43j9AhUbav02xUKIgz4qd250oLLAicw0SDD4SWD1UXZ2k7dwICzSGRkKQa5cUaGxrZHKDSrByPxOlDr1oBDQCV0dAbHvnGACbOnMaQ8/+EjlN21D/mx+CTaqYHU6qHUfhZYBokYmWudlZzEzPYGxkBONUTRunAmsqLXzzCvKxpWkrKqurUFRc/IZEzdX3ql+9GgKayHo1VDb3a6E473ExP54JDMNviCp1jXpTOqqMaZsbmE169GEKWbo5frwwFMfLXXFkOJYTWZcSWqmS0NJDnjecHb2DLHzt5/h5KKLG6XftsyEve2XHhDdsQP9xXQiI3aEUx4Sp9B7lGqbSapiWu/I8xAKYsHsJwcVFBDiWCHINLfKRiTghuZpJULXn5SGVVr2O/AI4CwvgyMuHLSeX7y0TVq+rEbfxhzSR9TbuXH1oGgGNwFsiIOTKufkInXfEZc6jnHakSLqWghyljP9nZpiUCEoi5zDe8iAT6AMiNtPR4SYxxMMYZABHjuShsTFNOflt1pzc+9//fqXEev/99+M73/kOnQJZMcVFiDJ79uzBCOMjQkgVYqosf//3f48vfvGLuOuuu/C9731PvXb5Px/96EfxzDPP4N5778W3v/3ty9+64eeayHrDkOkvaAQSFgEpKJBViKtDM3GcG6TYEJ0zM53ArnIDttGVReb7V5vzL7AAujU8j87IAnqjS9hizFDiJOWmVGQYLDDfgNtewgK02RvGkyPGOXfrt/8XJl47hWyqsebu2o2iOw7CaN2YymY5X8UpUdxzX3h5SeXkcnNM2NlkV+IyMm5Yq/GZ5Ckmxyfx7H8+i246xZVXlisi67Zd25krzVDCGpv5lNFE1tuEyCokqEuy/qt5Qmsi62qiqbd1OyMQ411OVrFkF1KrqLKOj/vR3e3B1FQQ8wshVFe5qEbnoupcqiK3ms1rJ0t+O2N9+bFFaMEsmAuJeHA4iAstHiwuRdQg+MD+dFpA21UgSLBO9CVABdTFpSiVWQPopp20EFq3b7Vj/x4X8mhh7bCv/zFI1ZyQqYbHo+geCKG5MwQhrx69w4bSQhOyGHBL9OXSIHTBBwzPxXGyl1YWVGe9q96A7WUptLGMwarJYTfcjZrIesOQJewX5Dcu19FnXw2ioy+E7IwUpcK6q9HC3wZUcP1qjRc3TbGHbR2Jo5VE8fbRCKZPfweW+WbceWAHiotK4XTloe18H+ZnlvDIb9yJ6voSRONGEl5nceLELOpp8VVXl4r6+lS4XKZVs1MTddYAoliIBdEfdStbmmmqs8pYeR/V3xrNmYrYenkl76VxdG9/AM0tXhJZmcDmfX3f7jRUkkian2dWpFsTbW9Xc5Fr1NBIED39VH9t9ZFoF0NJMZVwq+2orbJSbcsICwn4xjWcMK/m8ehtaQQ2CgH5DUeDAcy2tODi//p/qYbmRMH+O5C3axdSyyvg8/rQR/WR5nPn0dLcguHBQRSQZFJRVYWt27aRuFpEJVYSTmjxa7EyOErVkRRd6XJT3amJrDcF2239pTnej/sii3gqNIw0Jh/ea61ArtGuLOJu6wPXB3dVBDj0YREVIPOzySXgWGccQ7NxpcraxKRWYxFgTvxp5lWPba1e9NOCcXouil8c98PtjXOsbsKWagsqS7SC22piHqV1biQQgHt4mOuQWpeGBuHhc//MLGIRFsiRrOokUdVRWAgnVWNcXB0cP4gKq9Fi5WpBCscQBlrYpBg52+BzyXpJ3H6zL5rIutnPAH38GoHNjYDEfqSIXBzPhGR5gXGn9g4fUunGJjGnfXtSqcwqcSd9v1iNM0Xycz5fFC+/PIMXX5jGXXfnYvv2NOTn2zjn35wDzSeffBIf//jHFbxHjhzBww8/TLfJIP7t3/4NZ8+eVWOVp59+Gjt27FCf+YM/+AP8+7//O37v934Pf/EXf/GmbvnCF76AL33pS9jFmMtTTz31pvdv5AVNZL0RtPRnNQKJjQBFJZlTBl7iPP88i1fl74oc4FBtCsmscTiZ57jW1ChKfdZAPIJ+KrM2R+YwGPVACqPvtZWQ0JqOTAOdWKHvk4l9Brx16ySGP3HqJCYpRjHT0owsklmbPvq7yslko+bNMk4Td0RxAT51zqvyde+8N4PqrCxYtZF8fTXm9Vsf6lt+QopKZB3oG8DF5ot48ZfPw5WWiruP3k2xjS0ktla85TZu5w9oIutz19W9Br+f8kwJtMgPeWpqiiSAE5BA0CTtjKqrq9HU1ISHHnro9WqqW22yJrLeKoL6+5sVAZ8vQmuNMO1i/Px9BqnQypIjLmbaJTucRqU6JxPn3BwrMhikEBvlaw3eNiuG13vcMsCQqmax6BEbaBlozMyGqaJlQHaWmVXNywQksZERjBMZ5xDtuSenaGc9HEI7Ca0yNkp1kVRGQlNpMRV904zXJJVdL1438zk3iVXTczGcawuqRwexrS03o7HGDDsnHhYqyCb6IjaWYn1+bnCZeCfnQWGGATvL4shLN2gbyxvsQE1kvUHAEvTjcv0cm4qij0qs3VR68tG6dFu9BVVMihfnM/l6lQmaN2jAPK8Jw3MGTCzGlT3s3BwVDqcmMHH+p7CHR/HwI++EIe5Ee/MYbHYryWEZ2HdnAxO7LrS3u9W9cYkFCLv3ZKK21oWsLCGNrS5Zn3pKJM3StoYKcANUZx1mAGQ6FmDlrhGZKRYUpTi50iKEa0rUAK87znuIH8MklYoqqlx783jf2MLJas6viglWayItuAel6IUqtrKviakwRGFcti/7LS+lGm4RFbnzmQTnuZPI960EPbV1szYxAu6RYQxTkXWepFXf9DSstCeKlpTRvnGCY3PaF4myWizK8RSvcyXFKCktJZm1kuPxTLho/6uXW0dAE1lvHcPbbQsXqJDeTkWNsZgXpVRHf8DKYheDlJMk/hziduuLRDqeEItSgxGDUmjpmiCxgyGTXF6GG4sNKMk0IEdfkl/vLhk7ehmWPt8WwsAoFcgXY2iqNWPvNitsMh/XpJfXsXqrJ5I0E+XVMBVWg1RUDYnC6vy8UlcVpdWQ2w1ReZc1SuJqnFlYUWnlxAgmKsTYsrJgz86BLTubj7S55N9WKqUYrTYYdAHMivBrIuuK8Og3NQIagU2CgIhyhBn/l+LpXgpZTDOHIfemvFw6CZXZUFVhV3F2cfPTy80jsCw6QweACws4dXIOdhaJFxbasHdvFjKZL0rZpIE2Ia3+8R//8VWBlXn8hz/8YXU+SnzyvvvuQwsLhT/1qU/hk5/85Ju+87WvfQ2f+9zn6LBVgtOnT1Pkh2y1y5Yox08/+clPLnvl2k9FDVZ+B1fbz7W/pd/RCGgEEgkBTlkVgXV8AeiZBHqnYnTyM6Aq14DqXBZjFhqUaMr1RIHm40GMRX24GJ7DCONIaQZx20vFVlMmMpjXcfJvvSQ3At6Jccy2tqLrh/9GN7Us1H/gMaSWlqn59UYdWZBiYz4WEb96yo3WTj8qy62oqbShnu65dtvajsuW6PQyNjKGV4+9Qve4cfL8wti2Yzu2bm9CYVEhneQ2Z4BME1mTkMgqg8jjx4/j8ccfR4CV4lcuhw4dwje+8Q0lOXzlezf6tyay3ihi+vMagTcjINWfohh6sWURrW2LGB3xw8rKz/p6Fxoa0lBXm0rlp5TX7WOuRhx681b1K9dCYHQsiO4eP06eXsICK2hqaxxoanRydTDBk6IU/xI9VrHojipC7qunPbjY5seeHQ7aSztQUyUDprWr/rkWpvJ6mIE2sR5v7QrjhVM+pdh4ZD9JwjlGpKUmTxp6lhbog7S0eLoZ8FOF8u4GA+oLgLLs5SlUop8bK/XRer6niazrifba7EuCulIde+ZiGM+96keay6CUlu/cbVVWpZfvVZLnsvIrGGUwom8qjhO9rJzk85xUWsKG++BcPIvejlYY+VN65H3vw9iwDz/4zot4xzt34657d1Kd1ckgfRBPPz2OvDwrtmxJo61XKgoK7Jfvas2eT8Z86I0s4aXghCK3pjLosduUjb2mXFgCZkyQzPvSywtK1VsUMI68LYP3DResvD+vZk5acJekxaI7hq7eAF7hxFjq5awsCDh8MBUNNSxwSTdtSNHCmoGvN6wRWCcEJPER8nrhJWm1+8c/woVvfh3uLY2YyspD1+AwnCSabNu+DfvuOIAmBoPS0tOVAus6NW/T7EYTWTdNV7/lgUoig5Qx/MT//7P3JmB2VWW68HvqzKdOzfM8V6pSSchMCIRRIKiogK22bdMt/L9oq7f7+f/+W1sv3tZW6b7a9v0d2uuI2raCIiCgIiCEDISEzEmlKjXP81x15um+3yoCGSpJpcZTVWslu/Y5++xh7W8Pa63ve7/3bcFxsmmUmxIVK3qlMQEWJpbooi0gFnD5hJEVeO5YBON0ceYlA1uKDBB2VsmpmiKvakUaTphsJtwRnKjx4+mXJlBVZsFNW+2q3x4XO51w4Mozm/QL1CCGcwGvqomgCgGoTnR0KqbV0dYWjDY3Yay5GRPd3fCNDMNJQEZ8fgESydoeX1iMBM6dObkKvGpkIozOMpvZvaSBrDOzm95KW0BbYHlaQHxDwrh+kPGL0zUutHf6UFFux403JCKVyd5OJjlLHFj7qWd3/Xt7vWhtdStVKAER33MPk1lz7XOeTD+7Wi7M1i0tLbj//vvR0NCgDphAf4iAT8eZxCMljom9giu48cYbGT8z0m9bSdXJIXz1q1/FX//1X6t1zv3z6KOP4vOf/zzS0tIU4PVCIGuASUFf+cpXzt3kkp+TmFgs97sGsl7SRPoHbYGot0CArOPegAGHW4A/HA8jwSFMrAbsKGeiKsf4M2nPJJZTHRjG3kC3Aq++g8ysRUyOziQxCVtInRod9XfFpSsoY/Xxtlac+P73VJJp+qZNyNi0GalVay690QL9IiDW07UedHT7kcFEo523JSIxXmKE8+t38VMhZpBKMHt37cbjP38cZRXl2Lh5I7Zuv1aRcQgpx0orGsi6BIGsp06dwrvf/W7KwPpRTGeaSABYmRX+xBNPoJHMM1Luuusu/OQnP6FcBREKsygayDoL4+lNtQXetEAwGKZMR1gxtA4NSUPkx/CIX4FbBcwibV8OB9B5eQ41kHYwQ3SumelW0sVwU6JndCxIVj0venr9ZDgNKPBqrCOGzHqxZLqjVDNZcedaHnoubSzMrHIeLW1eTpNsfZKJXVZiQ0EuWWZzrDPq+M+mjuJgc3sIYusL4nR9AIMjIXgZdNx6jRXlhWY4HYaotunZc/cGoAKkJzsEjBfGAH01Fdkx2FwYobQFlLTF2XX1/NIW0EDWS9tmqfwyTCanM80BNLYG0EaQ+voKso+WmBU4XQDzZ4sk1Hv4TuoZNeBMd1jNhylpKs6IVCeQ7gyi/ugeHHjxaZSVF5PhIJdOhESMkZW8v2cY229eg1VripVkWgcTOYStfFV5HMFkCYqd3OFYmAGYh7I0Y5EAs3ld6CZLayfnHk+I7EvMBj5DJ3avhYxLQHamFSLrlsV5UpIJRjbSM3G0nLXfhfMuDoDbOv1obPZRGjZEAGsMB8QmHteiGFgTE4xq2Vwe88I66O/aAsvRAhI0GSOrWldbO04fO4auvbsx+Oou2Cn96ywqQtKmLUgvLUNGZiZS09PIwpLMJDKLCtAsR3ss5jlpIOtiWj+6jj3OdneAbOgv+7rQRnb0O6y5qCCYNclA6W0dcoiui7WItZGA1wSZWhqZKNXQJ+wtEYJZDSjNYMJhFpDCMZruFwkoHPQDTyaXHjrpZT8yovqp2zdZUZzHJChmk2k7nX8jB1zCujoKN1XMJMnF1dsDT38fPAMDasUYI/v6do4DOJkcDpg4t8Q6YSaQwxIfD4vM1RQPM3832jTr6vkWvrpvGsh6dfbSa2sLaAssbwtIroXEjESdR/xEza30l5GQw09f++rKWJSQASw93ULm9fllAFveVqY/k34/IZjZtasfPT1eKprGU9nUicLC2BXVbxLwy+bNm9HW1kZlrDJI3H/Hjh2KBVVIs4RZtba2VoFSDx48qBJ+hTCrqakJDz/8MD7xiU9cdKt84xvfwNe//nUS9VTg5ZcvBloISGkqIq6LdsQFP/7xjxWWQQNZp7KOXqYtEP0W8DF21DdGwpQWxpDGYjBB0o7K7AjH8zFKFdNhiczonSuxnP6Qhwo/w+gkSclQ2IdK+pTWWVKQbrDBqZlZo//muEwNvUyW6HptL/pPnsAI8W2l730fiu56F2KYTDGjG+Yyx7qan4ZHhWjMh9fecKm+2oZ1sSjMtTBeaLma3Vz1uoLp85HAsp2xjeoT1aivq8fw4BDWrp9kZq1YXbHiCDk0kPXi/tVUN5bBI1RJUVIeeeQRfOtb32KHuwTPPvvsecyr0nGUDqSUPXv2qHVmU20NZJ2N9fS22gIXWyDEII0wtHZ1eVBfP8HBoxsD/T5kZNiQSXmTnBwbUlKsiI83wW43vckEpwMSF1vy8ksEdCng4e4eP46dmFDzsbEQ2W/tkwClDCsSyHhnWyR208vX/u1fXQSz9g8Eydg3hu7eAJISzSgptKoMbSdZVxx244L35wTM2t0fxNHTPjWtLbegothCgK0JcUsEzCoslIMuoKYrgl01QDLBeBUMkpZlQA2srMTV6SDg2/fhVJ80kHUqqyyNZeIsF2nStq4ADhzzwUMnuQBXt2+wkWn5bVkW6fh6/MAYn/mBca4/BNRT9tVDMLgEyjfkAwVJPlhDI9j94gt48ldP4l3vfQ+KS1bjyIFWgsNMKCrNQn4x2YtiE/Haa0NwuYKUSrOjcjXZyAlmXegirHByXp0+N467hnCElLInW8dga7AjJehAfj5ZWisSsJWTReRDDbMPGIRp8BABsh4vQXZk225u9TFBwcd3uh+xTFypKLcpiZJ8DoalCAOBLtoC2gLTs0AwyEAfkztdEy6CWEfQQ+kdcfY0M9gS6GyHta8X9olxMj9n4JqPPojcjRvhSEjU0r/TM++M19JA1hmbbtlt2BacQHVoGA1k0QgijPfYClBsjNcQ1mV3pWd/QjJ+94cMqOmOYHftpGpALPunmwuBIkoRJpDA36RJfJWhxybCTC4N4Ui1H7UNfty8zYY1ZGdNToyB2bTy+pFnWVaDPi/CPj+CXg+CHi9C/C4gVu/wENx9BK/29xPA2g83Qay+4WHKFybBkZZO+cI8xOXmITYnB87sbLXMQLCHYS4lGWb/iCyLPWgg67K4jPoktAW0BebBAuMTk4CJU6ddOFXtQj5JOArybCgppq8qmeQRTukECQho5bXzc2FuYWLdv3+QTKQTZCCNEMgZh2uvTVJEMvPNrjYX9Z+LfQiAddu2bWpXf/jDH3DNNdect1sBsd56661q2ZNPPqnWveeee3DgwAF88pOfVMyr523ALwJw/dGPfoQbbrgBv/rVry78+aq+f+c739FA1quymF5ZWyA6LCAEKMzJQPdIBE39wMGmCMyMGxWlAeuosFLM+WybLn8kRHU9L6qp8rPX34PUGMb4jVS1I6A12xQLphvqROnouB2uuhZBgjZdPd3oIBFFzS9+TiDrPSh9371qrC5JpotVJH4qfbNd+8bRRYyJ3RaDqgo7VXOZBGuaW/XGqc5RkkDcLjdeev5FHHjtAOLi41BSVoKt112LzOxM4ofoV53tgzXVgaNwmQayLjEgq9yY73vf+1QHcqpMKBelFCWjSop0/qSzOZuigayzsZ7eVlvgYgtIAxgWin0f2SwJahFmuqEhHwGtHpUVOjzsJ5DVgsJChxpUZ2fbCGY1KkbRi/eml1zOAmfBrBNkvOugPE9LK6Vk2n0EPIQJHIpFWamdDKd2ZdtobfOFVNvH+vb3B9BE4NPRk24VnMpMN2OjZAHlW5Xk9ULWXyQNhQmmrSuIumY/mjpCajBy81Yb8nNMSFDSR5e7Mov/mwDZAgSWCTivoRc43QXFAHRLpQHX5ItUOmBdgUHAq7kyGsh6NdaKrnUDdODWNgYUG2tDSxCFZHC6boMVKYlGxNonEyekrZJnvY7PRy0B37UEFQgAPDvJgJJ0A2VhoBhZXSN9qDl+DDXV1Wioa8TWa3cgOSkPB/bVITsvBe+6Zxta20JoavZimAwImUzauO66ZKQyYcMRuzBMrBdaX57/gTE/6jtdOHB8BEfrxmDJjcCaH4aN08bUZNyYkIHkGLJ3G2Zfx0AgDBdlYOsbvThywkVm67Bir64otSGP4NX0VDMTVwwcEGt0xoXXSn/XFriSBSYogddDGeDqE6dw8vgJ9JFpTdDqRaUlKC0sQGluDtqe+g3cLc0oY1Z31tZrkVRSihgCVHSZPwtoIOv82XYp7VlSRw4FBvCstxV5lH4rMyVgjSmJQQfbUjoNXdcFsoD0PVWwwCdjNOCN5giVAMj8H29AeWYE1xYzidMKpWazQFWK2sNIn9zH8fiRah+OnPIjzmlAfrYJW9YyWTdu9klYUXvil6hYiAktQbcb4x0dGG9v47x9ck7ARsjHG4rQeUd6OuxvTs6MTNgpgWtxOsnCGguTzQqTlUyrwtL+5iQOjpUSGLqEWedlsQayzotZ9U61BbQFloEFgowVCSHHwJvsrNUEtA4NB+gzsmJVmQNr17DNop96If3/y8Csb52C9DGFjbW+bhy79wxQFdGOd76Tyi1xJJJZIb44UXM9y3ba2dl5UT9HGFtzmNQTCATwzW9+E+9///sVgPWpp56CMLPK9sKwerbEMOHn3nvvJWnBa3jggQfw5S9/+exPM5prIOuMzKY30hZYdAv4RP2SQ65XTjP2QQKUBBIdlWZEsKEgBnF0/djngMAyTN+SPxJWbKytwXGcCA6iOTSOdeYUVJmSUW6Kh30OYjiLbswVWAFJSpUxe9f+11Dz858hoagY6es3IIMM4rFZ2YtqEcFldPcEUF3rxuuHXFhX5cBN18fT/xKjgK3zWTlRnRN21t7uXjQ1NOLVl3eRwGMM+Yx1bL1uK7Zs26ra8ZXgs9BA1iUGZJUHo4jSiD4+2L/5zW8IBrjuvGdFGGkKCwvVsrMdzvNWuMovGsh6lQbTq2sLXKUFfAS0esi62dbuRkeHG729PjZQEUqdxjCrwqxklwXYKlNyskVlihqZ0aTL1VlgZCSo2O/qG9zoIQueiVkzSYmUcs6apINPS7XQ5oaoBAyLj0DAt70Es56s8RDUSnnsiSAlhuwEoFmQm22BM1bAzldnk9muPTpOgO0gmWBO+9EzEEJ6SgyKycpaWWqhLLYBFnP036deSl6MkJn1RAdlLxgsTWYQMCcpgrXMFkyLY8BrDgZas7VztG6vgazRemUuX68JAioHhoIMfAfQy+dXgKsVJWZsqBR5bYJXIwa46HwQKZguZtLKfGiCwG8GzBMp6yog1jw+I9lJXJdMiM0cSD3z5G8psRFCKhmNIqEEhIM2BPxBZOZmompDBWpqXGhv9yAn106lgFhUkY3VQmm0xRho+QkqHSDLtUiDNDa5MeEKw8tBob2MqN28AMaSPbCbjUg2WJHLjN4sgwPpRptyhlyNBLI4d+XdPTQcVO/JDh5vYDCIQX5PjDciPc2M8hLKxL0JYl0MW1z+TtG/agtErwXGx8bovBlFN9lX+ygV3Nvdw8SwEUyMT7AvZ0ZScjKzlMuQX5CHXLKsNT/zNAaOHqEcsF05wwrvvJPSwQ7NtDaPl1gDWefRuEtk1z4yZgxT8u1QcAAvejtwkzULm01pSHuzTV0ip6GruQgWoL9eMbpUd0ZUsqGAWu3mCKpyY1CQwqSqRMISidWM/pHm/BuvpSOoEtOaOWfzx8Q0G3IzqZJC5ZblVhRwgjdHwONGgO29MK36x0Yn50xq8fFziKwlAQJahZE15KVfjYysRjN9aM5YAlfTEZuRQUBrhgK0OghkNVqYFGx+W41iudksGs9HA1mj8aroOmkLaAtEkwWE9EQIOYSZtaXVwxhwRMUvCvKp4pdtRRp9SGb621cKi+hcXRvxz3m9JDrp8OCll3pVXKicJCelpU6CNx1zdZio3s/rr7+ugKdSyX379imMwbkVHmXfqrKyUi167rnnsJFqNqIG+9BDD9HPYoFsn5mZ+dYmg4ODWLdunQK3Pv7449ixY8dbv83kgwayzsRqehttgcWzgCI7IlFQ2yABrCRCaRuU+FEEldkEsqYDhVRViZnjYan4mSYiAQJZh1AdGBIeAxKR2FBJZtZcYyzS+JkpH4tnFH3kGVtg+MwZtL/6ChNS27mPCMrv+zMkr65S4/XFipsJUZooLDY0+fDqa+MKg5GXY8bqVXZkZ5oXJLYpmL/RkVHs3/Ma6s/UYXBgkDGPUqxdvxZFxUVISUtln3B5JzNrIOsSBLJKp1JKXFzceTeo3Kw/+MEPFKW//P7KK69g1apV8nHGRQNZZ2w6vaG2wLQtIINpccwLWNFFuvLGxgmcPDmK5hYXZZhDlF92ciAZj7XrEpQMsW2FZIpO24DTWPGsjScow9fe4cW+1wmAICV8kLoH27clYNOGOCTEm8h+G72NPrFWzIoN43i1B3v2M3DDbLeUJBNuuylegVltC1x3sWmInbnm9iCqGyhRftyHAjLB7LzRjlTKGjpjo9eW594yMuDpZbPa1B/Bn6ojGPcC71pvwKpMAzLiGSTVY59zzfXWZw1kfcsUS+pDS0eATMoEshKALvKs777VgbwskwK0yom46CRvHQCOtEawr96AeFsEeSkGXFcKFBPE6iQTlmwn2ZIib3HkjcP4/rf/N0rLV+HeD30Qf/ztMfR0juKOd2+GPS4VnT0xZD3wKVDnXXdlKiCr2Swg1oU3mzzr0gYcPjLGTEoX21oPNq6Pw/XbE5ksYoLPQZba0AgO+wfIINePciOZ48zJ2GJOQ4aRsiEUqZlukYGuSJedYvKBTCcYhEhKMGP9WgcqOdjNz7G8xaa9WIPx6Z6LXk9bINos0NrcgrqaGuzbsxcN9fWYGBtH5ZoqZiRfx77yOuTm5zG4Z0LMmxk+Iw0N6DtyCHW/eQKJpaXY9Hf/D2yJSYhhMEaX+bGABrLOj12X0l5HI35U+4fYro6iJjiC99gKcb0lQ1Fu6nZvKV3JxaurqGcMMuHwhZMcb7JvajBEsL3UgJsqmHzKfuQy99VPy/CisjDGvu0zf/Kgqy+I9ZVmVBRbUJK//MCZiqmFQRxPXx9GybI+0lCPkcYGjLAf4OrpgXd0BM7sbCQVlyKhpASJZF+XSVhYbUnMwOPgQ717zplPy8h6pTm1gAayzqk59c60BbQFlqkFxN8uxCdd3X7s3jei5gLCvOmGJGzeGA+HI0aBWZfp6c/raQ2T5fbYsRG0MObW1+fFO96RgU2b2E9YAWViYgJVVVWKcVUYVn/2s58hNjZW4QuGh4fx93//9wq4mpCQAGmvbTYbY5V+rF69Gm4mCt1000147LHH1PpBEhvcf//9+NOf/qRYXPfv309w8OxUbzSQdQXchPoUl5UFfByvj7qBPXUR/JFj9qocA9bmAusLDEhkfsBcg1jPGk/iOy6CWXvCHjxH9Z+ukBsFVADaZE7FVku6grFqMOtZay2duZ/JqW6O9U//7Cfo2LsHW/7+/0P2DTtgiXUuOhFFP8lpauu8qKnzoJN9s/felYRrGOOTe3whYpzCzOpjou6Jo8fx5OO/gcfjJYlHIu6+9z1Yv2mDan+Xs59VA1mXIJD17KsnzJSHiQkvOtr6ydzoxKt7n8fnPvc51Rm9/fbb8e53PIgxoZq7oITCfox7ui9YOsVXPoTjnh6CG5JRmr8RZosJNvKA22zMaJfPNjOs/Gy1CfiLn/mbzCVwaLGaJp2EU+xWL9IW0BaY2gICfBEw6+goGdz6vRjo95PNzc/BYojPNVGM7IZlZFiZ/UimjVwHEgiKEebWhWgsp67x0lsq9hUGPmHj6+ryKjCrZI8JG2tJkQO5BBdlZVJajmPvaGv8J8G4QD9lhto6/Whu9Sl2PwGMFhXYsKbCDoc9Rp3LQl0ZqdMog2fdfSGcrPNjbFxERDlgqTBjVbEZDluMsuVC1WemxxHw3pjHgKME77UNGeBjULA4DdhaZECcPUJm1kVA3c30ZBZoOw1kXSBDz9FhvLzHh8cIhK/xKeB5WpIRhWRQXlMm/ToDAmRibeiNoJ33f+9oBGyOYDVFkJVoUMxXwn4VTyeERaTMWCdxZsrgaVLO+yRSknMJZt2A9pYBBAmyr9pYxecoFvUNXkp2OQhgdZLpIFYxiy90m6WYvZi00NjsRRMnYeWWOmSQFbWA787CfDv7rwaETMIe50dHiAyy4QnFJOdDGORqYlYvJZGN8UgloDXecGlwQIAsz24PWdY7yPja4sMI23P6d5koYURmuhl5OVYk0/ZxTqNuu+fo3ta7Wd4WkEQvUSLp7+1DW0sLmhqbmH08wMSvCT63NsQlxCM5JRnZBK9k5WQrZmhnnFMFV85axk8G15H6OtT++nGAL4SMTZvJzLoRSbNM+Dy7fz2/2AIayHqxTVbSkhAl3zrCLvzR16Hk37KNDqxnUKHYGLeSzKDPdZYWkL6o1x9By4D0UcOK5SWWCVWSYFVFhbmcZEmuWtkhKgV0oY1OnPGjoTWA/qEwygpM2LGFfVvmaiwFhZQLbxNp90VaUNpuz+AAPP39k9MA52T+kt+kEy1MqjH0PQvjqolACyMnSVKxEHwhwFVrYqL6brLb1W8XHkd/XxwLaCDr4thdH1VbQFtg6VlA1PqE3ETUfdrpX5JJWFjFl1S5yqHYWRMSjGrZ0ju7xauxMN72E8AqBDKv7R+k2mkK1q9ncjtVEG12Zu0v8yLg1c9+9rPqLFNTU3HttddStYrJ/IcOKQlj+eFClVdhZf3EJz5BV0qYscgEbNiwgcpbNVSV7KVPxorf//73bzG5zsZ8Gsg6G+vpbbUFFs4CMgZ1+Q1kYA3jSAsYU50k6VqTy/g6mVhT6faxzbNSZ4DMrC5OdUyabgqNK/9TksGCQvqcVpGdVXxQEr9a2d6Chbsn5uJIIcYag1RYaXjyCTKz7kLm5i1I27CR/vv1MDsoE7mIxcNY3/AolWmPu3CCJGOrK2xYVWpHAdVyBY8x30V8JIIH7Kdv5MzpWtRyamZ8JCcvB2WMbWzawhgH1elM9I8sx6KBrEsYyBrijet2+3nzdqkO6N69e9U9KplVf/uJL+B3vzky5T1rtoWQnEet2GmWkI8hfH+2ArHaHdbJuQBaOdll4jI79ZcVyFUt5zoEuQqg1Uh5VhOpu4zGGCXZrT7zuwy8og0kNk1z6NW0BRbMAh5PCIODfpw5M65YWpubXUhNtTBYb0dxsVOBWgXMKiyiVuvZ52rBqrekDyQd7j4ChZtb6LyoJmip04sCgplKiuwoo9xzIu0q4C5heom2d5XUXRxaJ2vcqK0nMItgqcx0CzZdY0dmhoUgKRPMAjZbQOylyxNBR3cQx2v9OHjCi81rbFhHMGtOhkkxs7IJiPoiYLeuEaC2O4LdZyijTtDe1hIDJSwjyCQzq5GB0vnKJIx640xRQQ1kncIoUbhI3hdybw8Mk+27jezJ9X60d4dw23YbVhPEamH7Mcbnd4B5T6faBSwQoQyMAYWpBmwtngSxJjvPPzHJAhQQ2bNPPouGunomUyVyMOWEx+VAYlIcnAkMHMdlweUxo7vbgxtvTMOWLQwsM/FCnqOFKpPnPun8Hx4h68IJF+oa3Azqx6Ck2I5tW8jEzXe9yLKdWwIEr3oiQRwODFCmZhidBOOkUJqmypSkHCJZdIYwJA6zge3umxtKIorXFyaYP8RkA8q8EsB7mpmakmiQQ6mRTetjkc33s52D24V8N597XvqztsBSskCAtPM+SgK73R4MDw1BWFjra8+gprpaBVBiKRO8cesWVK1dSxB9GZ8t+2X7a24GWZr/+AfF3OanuknRO9+J3JtvnQTCvMncupTsE+111UDWaL9C81c/djuU1JsEFJ7ytiCTbeY7rXmUeLMj7jKJIPNXI73npW4B6ce2Uq5wf4OM1Sjt5gduKI9BZVYEiYxnSJLVSh6jSR90hMmkdc0BvLDHTb8AgaybbJwbkRgX3f3OCMcUYWZ8Bf1UbyAFb1iCV/wsbCweSVrp6YarqwsTXZ1wk3VVgKwCTHVQ1ja+oIBTIRI4OXNyEJuRqdp03dGO7ideA1mj+/ro2mkLaAtEnwXEryWKcmfq3aipdWNgMIA1VbGMX9iQn2ejcp8QWpz1TEVf/aOtRmJPmY4cHsLzz/ciX2JBJXGoqIxblMT7hbaPxLh+8Ytf4F//9V/JSNt33uETmQT05S9/Gffdd59Sjjz3R2Fiffjhhwmufps0Kzc3F1/60pewc+fOc1ed8WcNZJ2x6fSG2gILZgEhhPKSxKNz2ICarjAONBpIggJsKgJKqeSXzhjqQhW+yuFj/KYlNIFd/m5FSMLRL7ZbM1FpTKT/iYR7jN2cH/VZqNrp48zUAh17dqNz3x6I7z6hqBhl99wHG0Gahijw3R896cKho6QhZkknQc62zbFKMddEn9RCFAVopYPswGuvY++uPejr6WMsNhG33fkOFJUUIy09jey1gmlZXv3Cc4GsGzdumidTRy4bV5qng05rty+//PK01jN4PIzyR1kJBAL453/+Zzz66KMqY0ro+z/+0Mdxz3s+jIlxZqlfooTDIXi8kw/bJVZRi+WheHXf75iRlomKki3wkyvcz6Di2XlAvp9dxuVebwABf4hys3LBCQJKiUMi0Q9JnJL5OSmZ31OcSKC32UEqBQG16qItoC1waQsIWFExiE4EMT4exNCQT0k09/aS5W3ET6ClUTHdFRU7UFQYqwCtItmsy/Qs4CPoyO0Oo7fPj24y9Albn7DfihNodUUsJ4KVFMNp9NlU3s9j42H0kZ21rlGYZQP8HMTGdXasXe1QHSgb2VAXqgR5rwrjY1tXCDUNfvQyI0+oWa/fZEVRnglxBHNFO3hLHFkyEOsfJ5i1C0rCsnUQ2FEObCiYBLbOdzbhQl2vuTiOBrLOhRXnfx/ybI5PRHCmKYBX3/AgJdGIYsqNFvO5NLENEanWBvouG/sidDbQ+ZAA5KeQrTTBgBSnQbGykoT/vDIxPoGe7h489rNfoKujB9t33IIRAgxqTvZg3ZYqpGbm8X0aYn/PimvIbJBPRlZhE59MYjpvV/P6JRAI08kaVg7/g4fH1PHj40xYVWZHXq6V/Vsz+6IyuDt/sCm80kFOo2RnHQhT+YAOkVaZyNIqQJy8mFisMyVDAK1WAlrlXefj+6+hWVhYmTna5FXZmJJYkK9Yvs1IShC1AoNiDpvXk9Y71xZYBhYQpo++nl60NDfj1ImTaG5oVKysiWRYy8vPY8ZxLrJzc/iOSSSQPoHjSgdB8pcfVwa9Hoy3d6Bj9y7U/+bXKLrrXWpyZGbA4tQskXN922gg61xbdOnsT9hYa0OjqCWQtT44ilJTAnZac1V7aTYs3Nhk6VhM1/RKFpAxGvP3MeSKoLqDiVedZGKNiSCbKrDbyxgsizMQzHqlvSzf38U+AaqJ9A6EcPgU+67DYZVcddNWJq2VkrWU/dxoHIeHCWINEAzhJevqREcnxjvbOe/ARGcHvCMjSj7QGh/PoFWKClxJ8MoqTKtMmLM4nWRZtcPM9t9kZx+AbGDCympYZgGb5XjXaiDrcryq+py0BbQF5tsCHm9IxS/a2r1U/xFSDo+KAa0qpfpR8SSgNRrb+vm2y0z3L32nri7PW8QxEh/auTMTBYXsVwjb/wowpqhsnT59msQ5jSpRuLS0FBUVFSpB+FJ2FVID2aaFSjlrmVBcWFh4qVVntFwDWWdkNr2RtsCCWmCU7Ku9oyAJENkhGUPNoZJfWSawKstARcvIvDOxXniyYQZlXASz9oY8OB0cxsnAIJwxVMSjst615nSkk5hEiEh0WToWcHV3YZCs33VP/AomjvPX/l8fQ1x+ASxxi++7HxwOopNKufsPueByB3Hj9jgqPVqRyhjjQhXBhQwPDaO7qxsHXzuAlqZmhQ9cv2k9Aa23qxiJsKUvhyL9NSm1JDZ5/PFf4p3vupus8BsnF87xX6MCAM/xTudod0sWyCoI5AceeADNDPBJuf322/GFL/wPymLnzZFphMErjH/9n4+gsKAIt91yF3wEqno8PnhJgeD18LP77Gc/l3OS71zH7wtQRjUIq02Yp6wM3Js5n2RstdpMZG61KiDrWQbXs7/ZHTYOwkyc6GxdCvR9c2ZpvSNtgStbIEhZZAG1trV5OLnR0eHhcxdSQMukJLJwpliUDEoypVASE8myRyl0k0kHC69sWSg7Do9wMF7rQgeZWUfHgkgj821OlhVZmRb1OY6y0OLMiLbi5j3Q1RMky6CHDK0epKeakZVhRikdWempk2yoF4K05vMcRskG09MfxNHTlOdmvUS6vDiP9aHEoZ0grguZD+ezLjPdN5sx9FFa/WRHBAebhZEygmJmFK7ioEyAfmyidCYfjauBrDO9wxZuu2CIrGgE69c1B9HUHkBLRwBFBWZUlNngDRsw5jMoZqtRj0GxW5XT6VCSFkFhWgyc1sgl2a2aCCqrOXUa+/fux/ioD6sqtrCPaKY8lwtZhWVkZE3HBMEGRUVObN+ejNhYI/t2C+c0kAGdJCkMDQfQ2n5Whs2rwKslRZOO/qRE00UA1qmujI8yNYMEszZSpuZUcIiZviGwl4ocYywyIw6kBR3wD8dgvF9Yqf2QAa2XQYa8bCvKye4tbUgSwcO6aAtoC1zaAvLMCqBllNnWQ4NDGKBUjgBZu8jCNsjPbpcb8QnxyC8sQCWVRwTEmpaeflUBpgjHteGAn1nd+1D7i58jNisbKbKv67YjLi9fg18ufXlm9IsGss7IbEt+IwGxetlOvhLoZrs5hiSDFRWUddtsTmXLGX3jqCVv8BV2AuLDbmLy1elOURCgQgnzJiuzgZIMA/KSIkqR5ILcpBVloQl3hKoLk+oLJ6iSsm2DFetWWZCaZISN4/DFKpPtL33Ebjf8E+PwkW01SGUHYV2VyTc2igC/yzxIYKt/bJzkCGFY4uNgT01je50FJ9tsYWF1ZmbB5HBMMq8u1gnp487KAhrIOivz6Y21BbQFVrgFRkaDip31+MkJDNP3JLGffCZpFxXaGbsww+nUan3TvUWEyGR42I9du/rQToDw9denoKzMibQ0pqtHYfxnuue1lNfTQNalfPV03Ze7BQKMMYkyihChCCFKG8l/7IyRbi4ECqjql0FilMUq4icQX1QDfVAnAkPoDrsJb42gksp6xaZ4RUgisRzjCkhSWKxrMJfHDfl8EDDryR/9EN7hIeTedDPS1l2D5FUVc3mYGe0ryATiCZLmvLJ3jAq/PmSQlXVVqR1rKqndqBJhZrTbq95I4iiSkHLi6HFUnzhF9boapKSmoGrdGqVal1+QT1ye5YqkH1c6sCT2yLFmU2RzunfgJ74pRBVQIe+TmLXYUgiYGA5Svj2ZB9Q6/E2WyW/cjryc6O2ux9GDT2D1NXcht2D9bKpzyW1zM43Iz47ODPklCWTtoaSSAFcHKauUlpaGr3/963jHO95xyQsw8x8M+OIX/4md+DJ88IMfUrIL8kekq9Q/mfMmPHsjqyAklwUoCSWg14G+UQYfxxiMHMPgOZ/HR90EqhoUM2tGVjIyyD2eQTqFzOxkpGUk8oGLg5mUCish+23m10ZvudIsIM+X6pTxBS+AVpeLAMZuL+rOjBHQ7iZTq5eZkA416F5TlYDUVAGMa/DMdO4TeafxP99dBGFSrqe2zsXJTfv6sW5NLNasdqK8zKGYWqezv4VcR97B0qgPDAUJwvXjwBEXOlnvzZSxXl1BeZwC64KCR8WW0sGobwmglgyQ1fUBFTy7c4cd6SlGOB2LF0Sb7nVRzxnPoZvSlY0cmB1sAgbJaLlzrQFVOQawibokwG+6x1gO62kga/RfRZcnTGB5GL/f5YbbG8G6Cjq2E80ImU28ryPoGwOSKMlalWvA+nxhHZbsWWG54j1+mTyIl194CS89/yKlK5IpB2pDR0uI/bhslFeVor45hoMOK266KU21R1lZCzuQk6si7WUbAaxn6j14/eAY2csNfJfzPU62ipxsi2Jhna5jWt4Hkt0rAFYvQszsHUI1M3wbyDJn9RAUPJ6KkZMmDNRAAXZzs83YdE2sGsjGxRkheVkLmUwQ/XelrqG2wMUWEGYPPx1VApA/dvQo3nj9dSVZ5yDL2sYtm7Fm3VoUFBcxUSuRY8RJR8yVGFgvPsrku2G8tQW9R46ga/8+uHt7se6hv0Hm1q2IobKJHntOZbWZLdNA1pnZbalvJSDWsYgfj3ua0Bl24T3WAqwyJyLZYCGMNfrHAEvd/iuh/hJAc/sNONgYxmkqaPSORbCW/didaxlIYx92JatniF9AHP6SUPrK6x4kJ8QgL8uIzWvJEEIw62KVEAMsAlwdaWnGGBm8RpoaMNLYiIn2NgJZJxSrqiSUxBcWIr5gcnJkZMCWmIQYtvlCchBjZBtN5nUlJ8hgim6vF+tqzv64Gsg6exvqPWgLaAusXAuIz93vF4U2ElrQ37XvwKjqYSfRz3f9tngUF9thtUS/Ilo0XEHxGwpoYvfufpyuGUNivBklpU5s2pREgPBlHKLRUPllWgcNZF2mF1af1rKwwBiZWLsYK91zJoJjbcB1pQY1Di8h+Y+dTKyLzUsn7/QAIzgexm72+3vJzjqiVPZWE8x6pyUHcTEk2tPMrEviXlTXkgmvrS/+EYPV1VRrGUb+Lbeh+O73LHr9lc+FYMtWEgbV1Hlw+LhLEQa9564kJlaDOIyp+w/iv3AxaffXv/416uvrmXjkxHXXXYetjEc4mKgr5zydcqn9rCNL+n/8+3dw7Mgx3POBe3HTbTcrYKuNqjWi5C5x/N27d6Ovrw/r1q0j8dB2lJeXK0LKqY77xhtvQMbtJ0+epBJePIS1fefOnchm/PfCul6qTmfPTfqubi/xTBSJd1H43sVEIolTyySfvRSXd5GQiByaF8ypAMztBPBqi2lBiul3VM+8Ba5w1VRVnvWyd9/iwHtuc8x6P/OxgyUJZP3kJz+Jp556St3se/bsoVxrxnzYRu3zn/7pn9QN/eEPf3jaxwgRxRSkB9U17oFrwosJmdjSuV1ejHMuzK0CdJWgpfDanb3xJbRhIIWCiU98rNOmgK7xiQ7OnZwcBOXZYCfCQjstp30p9IrL1ALSrolk8jgdF729XjX19fnozAjxeQIzLWIgLK0Z6RZkZtkgLK3ChqfBNJe/IcR20mj29/sp1UM56Q6xKdldzAYmDZgpj21DAadJttvoCsZKoz6uJLS9aGr1kmU2TBZAE0qKrMglcEuYWtlfWrAyPBZGV28QJ88EMDYRhp1AssoSgr5KOGgQoBzlvKO9uNh5GiGzzZGWCOXXySbL+F8BJdc3FAAJ7NM4mPm+kosGskbv1ZcsN8loq64nML85QKlRZryxXUjkeyzMIHAwhu0Bb99Ysq5mUwImL8WAHMqziizr5Yi8PR4PxkbH8MLv/4iX//gnFJdUcbCVgb5uH8z2dCSkFbCfRtB6Ziw2bUxGFtsfu51B5wV6VOQdPkRWCmHWbm7xon8goN7fwooqyQgpySbEx/EkZ1DC3HmE59ERcKHJPYE3OkfQ3xWEqdcKP5MgIoYIqrLiCAqOQ3mOHXEO44ImEczglPQm2gKLagEZB07QMdXd2YX21ja0t7WzXzsGHwGtMtZLpHxwOllXhYU1OycHicmUE54DaRzf2Bg8dNw0PfcMAa2HkXvzLcjaei0SS8uULPGiGmUZHVwDWZfRxbyKU2kPTaAuNIoaJnuIj+edtnzkxDh0wOAqbKhXvbIFpI/bMUR2VrKy1hLMKv3MJI7N1uYZUJQaoXqGYdEDaVc+i/lbQ1RR6tj/b2wLKmDrdRssKMwxsw9sYP9//jrlwqIqzKoSaPKSdEEmz9AgfJS987N9D1G16+zh2WWnb4qKNwysmBnEsaWkwp6SAmtyMuzJKUo20GS3a7b0+btNFm3PGsi6aKbXB9YW0BZYJhaQPrbEKvoH/Gii36ubZBaiRpSYYKIPjspAZAaTzw76pHS5sgUaGyZQz6mubpz+BytuuSVdKR1arVODUa68R73GTC2ggawztZzeTltg/iwgiaQjBKA1kYn1eBsZFKnwZyMT6zX5BhSmTsZILxdLmr+aTb1nYWZtY1J1M5X16uiXIloC8QYz1piSUUJ2VtKtwGzQ7/eprRc9S4NequY2N6H3jYNofv4PyNl+Pcre/2ewJiTARNKLuIXxjwAAQABJREFUxSwSfxwbD6G51Yd9B8dJoGNESaEFZVTIzcki8OGCIjGOAwcO4P7778cYYxLnlri4OPz2t79FRcWV2WavtJ+nn34aj//sMdbHigyq2Wy+djNV7Vbjk5/6JJ599tlzD6s+f+ADH8C3v/3t88CsotL+0Y9+FC+++OJF69vpn3nkkUfwoQ99SKm5ywoR4vveOHjpc3v66d+irjNfxU6FjE0cQmd9QhcdgIaVc3y7vP19YrQRrbVPIqf4TiSnr3t7lTn8VFlqxurSi6/fHB5ixrtackBWQU+vWbNGIac/+9nP4oEHHrjkyQuSO+ZylFqX3PLtH2YCZH1766k/Cch1giBXYWvt7R5Gbxcnznu6hjA8OM7fvJSPpFxrZiJZWpPI8iWsrUlIJg1eUrKTACgyXBGIIayuAtiTz3J/n3+TT31svVRbYDlaQACswtBaUzOO2lp20urHEWs3MfBvx6pVThQUEBCeYFZgVskKmXxelqMl5u6cxJ4DgwHsPzCG1jby8DFzRJxBmzbEK4dQbGyMyrA5r22du8PPeE/jBI0KI+vLu0cxOh5GZjo76qS2r6pwMCsoogCkC/Wu9DCrprlDwKw+vHHSjw2VFly30Ya0ZMqWO5ZOhnjbYARnupmlXUfgHzMMb6owTEpmxE+yVp7bvZrxhVuCG2oga/ReNI8Ctkfwp/1eHKnxKRZSY6wZw2ETfHQ4SJasZM6uphxrJoGs1mliOwf6B9BQV489r+zGwf1HmI23hW1LHgcjBsrLJMETTMMNO1KxfkMisglidTimueNZmlIGkDIYEmd+faMbIrPW1eXn+w64aUciiimzlpw8OzD/2WOIbfsJln2jehxnmj1K1s1Q7Efc6gB2FCRjdXI80ox22ChZY9aZvrO8snrz5WYBCboFCWQR9lWPx4uuzk6cPnUKJymFU3u6ho6WDBSXlmDrddtQUl6GnNzceTNB07O/RdvLL9MBxvfD6tUofue7YSXjq2GWY+d5q/AS27EGsi6xCzbL6gooTbRDDvn7sTfQAyfMyDM6ca0lHckx1lnuXW+uLTC1BQYngFMdMkUUO+utlcCmQiAtnqww5siKTeINkLHC64vg2ZfdaGgNYj3H4KuKyTKWZ6Lv9DKBg6nNfPFStuUCWg2zPQ+HOAkNLJNTRALQ3d+HCbbt42RbHWtrxWhrCzxkPw/5/HBkZSGhoAAJxSVkXy1SkzMrExYn5U6izaly8VnrJXNkAQ1knSND6t1oC2gLrHgLiI9KWK5O17hw4tQEYxc+ghdicO2WBBTkW5HORHYT0UV6eHv5W8XrCaGz04Onnu5k3CSGQNY0+iGYCJ8SnWCGy5/N0v5VA1mX9vXTtV9+FiDxJITop6EngpMcc7/RDGwuMuCGcsaTEgyIs0XvOY9QKehUcAgnqKx3gvMbzBnYak5HppGqqwaOi7ViUPRePNZM4gfhQADdr+/HkW/+L6QQ6Fl4511IKl8FUW+JhtI/yPjgUcYguwMqoejWHfFK3ddMAq9z3RuirC7sqxNM+s0kwPS+++4j8Y8dzzzzDJNo6hizTMYf/vAH5OXlXfa0prMfAaz+4FvfI96uB+99//tw/PRJfPe731X7veOOO1Q9qslyK6BXic88+OCD+MpXvqKAqYIlFBCr1EXwI/fccw82btwIYWeVZX4q7cg6L730EvIKVqk+qM8zTHbXt8/t3nsnz+3ZZ98+t6ee/j2+8xiTl60GKh5TDdTOOSc7+6wOkp857DGKBG1yGb+/uUzmso2VZGJ1dWfwy1/+EnfffTeZ8zdd1k7L8cclB2Tt6OhQdMPTuRiCpr733nuns+ol15kPIKsMsoIBBjH9QXg9frjfZGiVz8LWKsytromzczILcpkwu8oATQZgqekJCuSalpGINH5OSY8nQE8GZzrT8JIXUv+wrC2gnikGLEZHA2oaGvJjYMCHgX4fJgjIlMBiTrYD+fl2FBU5CS6KUaDWZW2UWZ6cUJYLKKqP7KzdPT60k511ZCQINx0cq8jsV1riIJW6hY1vdL13AmQGdJONtb3Tj2Y6sRqavZTHYVZ2hplgVhuEmdBIKsZzO1OzNNUlNxe2HBcZTdvIWljd4CewVsLcwLXXWFCab1YdlOnKe1/yIAvwA5sgDExEcKoTaB8E+nkeGwsM2Fg4KcUuWYgrsWgga/RddeXI5p/m9iAOHPehrT+MvnEO/shmn5BkRk6qAbnJwr5qAHODQLJ7JcPKV8K0igDNnnnyGcW4j4gZ4yM2soMnwuTIYdJROnLyUyhPkUA5M6diYl0I5mU5Z3lf9/b5UX3aha4eP4bJRlFcZFfO+9wcGxmojIpJezYg/gkyXg8OTcqGtLT7EeKBnWS2knZgLNmN/sQJjFm9cJD9vMyYgFJTAgpjnMotMp/sV9O6cHolbYEosIAwsIqTpKWpGY2U0TlTU8MExiEmJhqRTBa2dIJYMwlyEadOcmoqny/pr85flvVIQwMGTp6gVNELMPNYlR/+CBIKi2Bhdrcus7eABrLO3oZLaQ/+CBOVIwHs9vXgZX8nbrHlYL0xBVmS2MEggS7aAvNhAV+Q7DCuCJr6DQysheH2i2IGsL00hkmHojzApMNp9nHno36LtU/VN+Y4vLo+gPqWADqpklJARtZbtjHJjMEACxlrZ1OCVGgQ5lVXTzfGCVp1dXdx6oabbOcRtvUxVNgyE5xqTYiHJT4BVkrRWTipZWQcMcU6CV4lQUFsLBUd7Fx/hQ6mZ3MRlvC2Gsi6hC+errq2gLZA1FlA2vzR0aDyVTVTna2ry6c+ix+sgoQWuWRoTUrSffHLXThJih8e9pMtbUgpHorfcOPGRPo2meQ6uy7T5Q6rf5vCAhrIOoVR9CJtgUW0QPdIBC1UqTzcwjg5x97CwFqaYUBRGhQrq6hXRmsRH5WAWVvIzFobHCG5C0F4fKdvMaWRmZWYIiZck2YpWquv60ULSPLsMOMHLS88r5TV5GqVESiZtmFjVNhHFHIFzHqi2o39b0xg03qnwl/kkpVV8Ddnyxe+8AX88Ic/JBlQAp5//nmSzhWon8apUnfLLbew79alWE6/8Y1vnN1kyvl09/Oed96NU8dP4q73vQu33XabAqAKQPWrX/2qAgjLzr/3ve/hi1/8ojrOkSNHVCxGgKolJSVKSV3ArbKNFB8xMsPDQ7j9HTdDwLQCJn33B/9dkajVHf6fb53bT3/+O5xqTiX4NAaVRX783399x1vn9hcP/iuMVLMU0iGJF5sUSSWVpWkmhoXe+n7ucgEESzJWDB9cDWR9WV2LK/0xUE51EoFzpTXn+XdBVD/00EPTOorcjHJTzabMB5D1cvUJhcLweQOKmbW/dwQDfaPo7x1FHz+7yNTq9wcQR7bW+HhOibEEZsQq9tZYpw2xsTbY7JStpvfazrnFYoZZdHJ10RZYQRYQUKvfF0JPLyVmmlxoaXExI8QPp9OE1BQrGyUrszwsdGRYEEeJZcnWFWZjPTif+iZRTqGxoJKprm9wo4nA0NRUswKE5ueRXZSfk+kUiqYsZ6mzgHBb2n04csKNETq1wnTMrK4gkDnfouosHYqFApEKM2xnbwjHyAzZ3BHC6hIywhSYUJQ7CWZdCjkIEihlU4Tqzgj2NwAkC0dZRkQN3jLIzGqRjtUKG/toIOvU74zFXOrxhdE7GMaJugD2HiYC20JWUCcTfcjGmplqREUWUExnQx7BrPLOn+57X0mAM2B9+MBhPP5fjzFrjqCz9GJ0tPnpyIhHUmYpKlan09mbgty8hWMuEACrT865P4DWVg9q6zxqQBbnNGLj+jgCau0qa08GPDMpqj3lu3SUciG9fQQCkO26k1mWI0wayWZbWlxoRUW5DUNWD9oNE6gODmMk5EOS0YZcSikXU7ImJYZAWjLT2Sifqh0kM7kKepulbAF5d4gjZHx0DENDQxgaGEBHewc6O9qpxNHNd5ABWTk5SuqmYnUlUghgjSW4ZSFKwO1WrHGnf/qokj7Ovm47MjZuQsrqqum/HBeiokv0GBrIukQv3AyrPcKgQHNoDMfIdFFNxov32Qqx2ZwKK0GsM2uBZ1gRvdmKtEAf1dmambx1tI0Jh/y8OicGJekRTiJ7GIGZTvKVWIZHw2jqIMD8oE8lkG5ea0Y+E7DSqY5ypSIMKMIkEPC4Efb64HdNIOByI8TvPsrh+Tl5hgbhGx6Gl0ENL+cBBmJE5s/O5BQnGdXj2L7H5uQilkkqsizGRHUETQt3JdMv+981kHXZX2J9gtoC2gKLYIEgafNUHIgxi2MnXQoQkJZqUgneuTlWJMQbFaHJdH2Ai3AKi3pIjydIRls36s5M4NixEWzenESGsVQCUSQp/sr9pkWt/DI6uAayLqOLqU9lSVuA8ByQVw613RHUkY1VxtuZzPnfsSoGGWRidVqjAio1LRsPRXzoDLpwKNCPttCEitWUGONJQBKPOANj0zrxelp2XKyVvIwlDNfXoX3XK+ihhP2av34AOTtuZLzTSf/C4mK/xGVCrC1OnnZj9/5xBV7NIBv+xnUOpBMzItUTNXFhY21ubsanP/1p/OM//uN5pnz00Ufx+c9/njidOCot16o4yXkrvPlFmFCnu59jx47h0OtvYHB0CH/zN39DVWEzdu96FXaHnVi6BOKBbOo4lZWVJG4bwcMPP4yPfezjOEj73nffvYot9uhxkn8MheD1h5XaD0X18OKzj+D73/8+yfLy8dX/tRtuAnkf+fxtb51b1qpPIYFkQnGxBsQ7Y3Dq8C/w3988t9M1tYpcbapzm86yM2c0I+t07BQ1QNbpVHYu11loIKs4TCME4gmgNRAQ5h5KVHGSz64JD8ZG3ejrGUE/J5kP0FM92D+KxCQnUtLiyQaWipw8TpzL9wSCXWfDwDWXttT70hZYCAuooANDhn6/gAcipCwPYmCQwcUmysy0utHR4UYWJZ+FmbWyMp5scnbVyM4U6LMQ57TYxxBmUQFLSZZzH1n/lGw1AU120p6Xk5312s3xBF4YVbbJYtf17PH5GmVSQBgTboLamBVUXeOGyAxmMyPohmudBDULiHRhnDF8nfMdHlHShmeaAmgkm6F0am4lK0x2hklRyZ+td7TOxZ6imthDMGtDLzuolNPoYlbibasNWJsLslsaGCSN1trPT700kHV+7DrTvcrgqXcwhJcO+FDdFETHQBiZdFgXEWy5lgzC7BYhifINwiB8tTk+bgK+Gs7U48gbR7Bn1x6E/Bz0WPIBcxrikzNRXJ6LddekYf16si6RkXShQPIusqT2D/ixe98IZTz8SEwwKcbstWtiJ2Up7PJQRmbcD/RzsCaDNgkENBO029nlR3mJFZXldr5LJYnBzPM1IGQIw89pMORFa3gCxwnkGeJnvvqwjbLKa01JSIsRVroV9pKY6c2st1s2FvDS0zHEbN0Tx45zOoaTnIvTJDs3B1Vr16CouFgxsQp4VRwp4uCRaSGKZHYLEKdz7270Hj2K0cYGyhTtRPmffVCxxPLFsRDVuOwxxBZf+tKXGDyz4DOf+YyS+rlwAxnnulwu/PrXv0Y9M9WdtKU4t7Zu3cr+veOtbOtztzPRmyZt+O7du9mv7SPbzDoG6rajvLxcseaeu+5MP2sg60wttzS3awmO4yUysQbY5sYzGHAt275iY5xO4Fial3PJ1ZquQsUQMxloA053AVkMtN26WuYGMA9+RRYZuw4Oh3DolA/dBPqOU6lnx2YbNq8hVe0VirSRIuU33tmBCaqCjTY3YaylBSOc+xnsCPl9iM3MgjM7B04CVp0CWCWjujUxiUGlWBjNFsSw7RJ2VgGwGoV1NQra1Suctv55ASyggawLYGR9CG0BbYEVZwHxB4rPX2JAff1BnKqewIlTlLDNsNAnaMOmDUyyTqaU8gpN7rnSDSFJ7F5vCNXVY5TP7SVbmh1r11JlqSiWfj/S/euyIBbQQNYFMbM+iLbAFS3QPQKcIYj1aFtEJYpeX25AZXYMx9YRxpQiswKkXfHgc7wC6Z0QiITRShBrXXAUR4IDcMCk4jUCaM0xxs7xEfXu5tICYSq7Bb0e1P/mCU6/pt/+LggRRdKqVTBT6WWxi/S/hqjiK+Q3+w5MkLk0hDtvjUdZsY1Kc5OUNgL8FKKP5557jiRA57PJCkBTWFmlvPjii6iqIrnGFEUwP1eznyz6an76s5/ia1/7Gm688Uasr1yHDZs2YP3mjcigIp6UBx98kH2eP+D222/H//7eo/jhD76DRx55RMUTPvyx/0If48x9jIsKxkhCNQ7PdyHtdA79P9/50T6U5Bmxfl2hOrdnnnkORaXr32JYFaxRe2sdbr31yuc2xeletEgDWV++yCZTLdBA1g9/eCq7LOgyvy8AryeAwYFRjAzxpTDk4nwcI8MTCvgqlRFmSRPp/YychJXV7mDW4ZusrfEJk+ytzng7Hyi+RGbI0LWgJ60Ppi0wSwsIY53LHUJ3l0dNXd1eBqkFXkNJabuJWblkak2zIp1TSqowGRsVvfcsD7ssNxcwq9sTQkMj2fc6fGTlo3QecQ7xCUbkUbYnN3tSskdYbqOhSEdKnDHtnQQyt/rQyjpLx0NYZAvJzFpaZFMgLIt5Yeo7NBJGV18Qx2v9ino+NcmIUjKzriomGIwShwshQz7b6+LykkrfbcDx9gjO9FCy0hJRUu0KzOo0UFZ8tkdYOttrIGt0XCthC5ZM2cb2IBra+Hyd8UNe8WlpJuTnWJCfZURhmgFJseJsIBPrVVY7zED2EOW/X/jd8zh9qo59Lhe8rjgmGaUiOasIhSV5HAhlEpAWx4GM/Sr3PrPVPXQwj5PpubnFo9iyJxiYl/h4UaEDBXlW5JEtW85zpvFyNxMARsjE3d4ZQDfZzYdHiAQgOEfA/yUMAuTnWigHcn7yAl+38FG2ZjDiQxNZ6TqY7dsbdoPQPMXQmmd0IttAAKwplu4SMjhf9ZWYma30VtoCC2kBeV8ECHwR8Gp3ZxeZVzuZeNjL53WMCUE+ssMTYJ+dRebmXBQSxJqRlUlFDQJeFgi8eqEtQqzTeDvZYQ8dRNNzzyB13TUoumMn4vILYEtOvnD1Bf9++PBhpa6SSqbaU6dOXQRkFRDrgQMHcP/992OMoNxzi2Rz//a3v6WkZMW5i/leNDDT+mMQlZcLywc+8AF8+9vfnhMwqwayXmjd5fk9zMEGeRpRExjB8752ZMfEqoBALtu6JMMK6hQvz8u75M6qf5zj3kHgGANuLp8BsWSKqcwGyjOFNQZqvLnkTmqWFfZw7CrKKDWNAaWOsm6VBesqLMhIMTLpa3JUEPJ6ISzlwqrqe5Nd1UewqnwPE7AalPabbbsEkWQS5hOj1Qq7sKinp8OelgZbShocnBslKYUAVl20BS5lAQ1kvZRl9HJtAW0BbYHZW0BiQF5fRPnK6hs8ipBDfFUZ6SYU5FOlrcCmGEbN9MHrcr4FJIbS2krWvkPDHFsHFWjj+utTUUg/o1YyPN9W8/VNA1nny7J6v9oC07OAxJdEkbK+N0JVSvKXELyWTJznxkIDcqhOSbjNklWkHIswxhNy4VhgEAOM3Ygvq5RA1nJTAjKNDsRqZtbp3SSLsJaAODv37Ebriy+oo8fl5aP43XerRNpoUHwRzIj4Xfa+Po5GMuNLEpEAWddU2tDT04Ft27apegv5hMRAzi0CcM3Ly1OLHnvsMQU6Pff3s5/b2tquaj/bCfb927/7Wzz11FNK4d0SZjSSapGV6zYit6CUmLksPPH4/49vfvOb2LBhAz71D0/AFONnUpQ8GyaMTVgQIq4kHDao/tDOHTHYeceN6Orqwl133YXP/Y/vISbcheu3z/7czp7j5eYayKqBrJe7P7DQjKyXrcwUP0pAVNhbu7uG0Nk2gPaWfrQ09qC1qRcej5/srmHkF2VwSldTXkGaYmw1k47MxJZYgnkxnARPIJ910RZYzhYQh4YwzNXUjKks09raccV2nJ8fi9Wr49UUH08JZIJ1JhlaZ85kt5ztKJ2nEQKbTp52McvZhZPMdF5b5cQ6sgAKQ2tyEplHiA2NJpZbLztUJ6o9OEVm1tp6r2IUvGl7HJlZTWTvmoRULcQ70E9m1roWZofX+XHopBdryiy4/Xo7kggKs9sm5c6Xwr3TOUyG2T7g5dNKdRG3VxmUhGVm4iRQcCU0JxrIurh3qgy4IxEDRj1A32gEL+z34miNnwxJEawtM+OOHXbkphiQQrbg2RQBpXW0teP73/k+Whq6UFC4Bm6XExMuO0opBX7NxgJcf0MqEhOJJJ3nIu9e/sfgUEABWA8dGceZeg+2borDNWudlE2zKemvmVZD9i2DtN4+7r/VjwOHx9HDz4X5ZLWttGPTerJGWmPUAO5Kx+gmiLUhOIa9/h4lXVNIIOtaUzK2WTNU5q/F8OZ7VwNar2RK/fsSsIA8mwJi9fv9VNCYQG31aRw6+AZOHD2G/r5+lJaXYeOWzbjuhuuRnpHBBKD46Dkr1r3v6BGc/MmPFWNcQnEJCm57B7O7KxZlbChyQQLsraurUwDVxsZGXArIOkjAsLCvTtDmmWTCu++++5QE0DPPPKO2TyYYV7KrzzrFpJ8nDK/f/e53lf3vuOMOtX11dTWefvppBWCVjOyvfOUrF4Fmr/aCaSDr1Vpsaa4vzBZtZCI/4R/EbrZ3Wy1peL+tGEbeazphY2le06Veazf7wR1DBhxqjuBPpyPYUmTAdaVAQSrlzZhvtRJz2aV/K4mkf9ztoSqKAblZJmysNBHMyjEC224BrXr6+yjZV4/hhnoylDeSfbUZY0z0EJZVZ3Y2EkrLkEzW7sSyMsTl5hG0mi7OjkVpJ5f6PbrS66+BrCv9DtDnry2gLbAQFpD4j4/xn9deH8Upxi6GhoMoob/s5h2JZGa1MA4gKig65nPhtXCTCKa/z4tXdvWj+tQY7rknB9dQecpOtadoivFcWO/l8l0DWZfLldTnsRQtwGEhBiaAIy0RpXBS3xPBnWuBHatiEGe7enW/aLSB+K+GCGI95O/H73xtyCUbaxVjNRvNKYqZVSJoV08BE41nuvzqNEGlmMHaWsXMGgr4senv/l8k0TcRTUm0grmorfPgdJ1XkQu9564kHHpjFz7ykY+wDxGD7u5uxV567tURxbTc3FwVT/nWt76l/Prn/n7288svv3xV+7n3vvdj55134OTJk/jsZz8LC8l1Xn15HzLzKpBTuBb5ZZsx2PEU/vmfv6SOf/9/exlNVNFNTSLzcqoRGWlGZJEkKTfTxGDpEB544KMQsg2JV/z+978na/1aXG2dJGZxYRGVuP7+/gsXX/R9hD4rYay9++67sWnTpot+X+4LxNbTKZqRNQoYWae6UArUQNCBx+Nj4NSHiXHP5DTm4XcvA3seymsLk6tPsbkGqa8VpPZYYrITyanxSEtPQFpmIlLT4xV7q9U6/0CMqc5DL9MWWAgLSBAjFBIQph9DBAINDsrcz+8+PkMEhdPRkZlFufdsG2VUyGAcZ4JNSTMvRO2WzjHkvSPMpsOkje/podw0qeP7+2lDb5jAUDIgkhGwrNQOZ6xRZTpHw5nJdR8i+Fbq2tDkxehYiOxoYaxd7aAzi2y8BN9aCdCa7yL1GHORLad7EszqcovjDJQ4ZKZSkYUgMWb5zH81Zn2abh9lA3gekp3YOshnygWsyjJgU6FkKq4MZlYNZJ31bTSjHch7XBhXSYyKhl4CSJgl29oVRC+fbQN/2LTagvJCE4rzzGSiEvapGR3mrY0a6xtRfbIae1/Zg872MViMuXDE5yMxLR/bdxRizdp01W5YrfMrBy7nLVJfLW1kPG12c/LS+W4imzil0gqsyMq0Ij5eZMmvHrgr+5Ykj0E69xuafeiiLfsGgkhMiEFqshk5WWYO4CwK+C/7l3fWlYqLmb7jkSA6KF3TFXKjh8BWYWw1EsBabkxQWb/pRjscOuP3SqbUv0e5BRR4ldL2jfUNaJKJABhZZiUjWxKBlMmpKcjKykY6pWsyCIix2+0wW2b5Yppjm7joTOo7dhTdBw9gpP4MKj70YWRvvwGW+HjFPDfHh7vk7sSx9Zd/+ZcKhNra2vrWepcCsn7hC1/AD3/4QzJEJ+D5559n371AbTM+Pq6kiSRT+kMf+hC+8Y1vqOVDQ0NKxkiuz0c/+lF89atfZXIAX4As3/ve9/DFL35RfT5y5IgCxqovM/yjgawzNNwS2oypJXAjhFd8XZRpG4c5EoN15mSCWdOV838aTeUSOltd1aViAbr74PJDMbOe7qIU4vik1O6mIrLqp1GZJN6gmGWWyvnMRT3lNd/b70d9k4cJpQRo9HqwJqEFqYEWRPqaEXa7ECTzqslmh8nBye6AxUEFAX62xCeottDKdkY+W9kummIdMHOdaXWI5+IE9D6uygKvv/666hO8973vVewqV7Ox9ENaWlpUEkxDQ4NKaikmg/7OnTtRTiCzMMbMtmgg62wtqLfXFtAW0Ba4sgVEnU1ASb19fvq3fGihStsoWUbF71WxyoGyEruKX9jtS8ABf+XTnbM1AgEm+DBW8vrrgzh+bIQyvg4Ul8SisjKeSfMEc+gyrxbQQNZ5Na/eubbAJS0g7UU9CXsEvFpHBUo7XbZFaUAZlU2EiZWccMsiIVRIYXz0YXUzTtNANb1WxmwGQl6UmuMn2VkZr3HEmDXlyCXvlMX7we+aYPJtP2r+6+dKWU0IKERVLXnVqsWr1AVHFrxFGxVxXz/kUkQ8wsra0fI0PvOZzyi/vRBWXDieFiCrjLeFoOLf/u3f8Od//ucX7HXy63/+539e1X7uft+HsW1LFbE/QySr+Cr9Y2tRV99FrIqV/Rkb60NMSOZJ/Pf//nmqeqbhP391GC4qEduJzRDlHplnZ5jxk0d/iH/5l3+Bi3EfAbF++ctfxl/91V+pSl1tnaY6t127dkGmK5WsrCwFBNZA1stbSgNZoxTIernLJkDW8VE3ujoG1dTTOUSn7QgG+scQF+9AQmIsUtLISJiWgGTO5Xus004wlxkWG6WuORfmVrNwqOuiLbDMLCAdtwAdGP0MajQ3E4DQ6EJbm4vAHTPZsmxkb7KzEbMhMYlgKA7WrQIwJMJwOgCeZWaqy56Ohw38+EQIR49PkBmQ4VyCgVNSzKhcFUuAlRnJBEEJONNsjg7n0ATr2tkTIJusmwytbspkW8liaEdxAQEniSZ2VBamnqOUBW+lbPepOsqRNgWwcbUVlaUEjGWIzCHZyBamGpe9tlf6kTkR6B2LoIZg1r31QKoTSr6yhAQ1WWRmtbDpYCxo2RYNZF34S+slgN4TNCgQawcB1Ge6wmhqC6KVGXMZsRGUZcXgjuttyM8ywmyaHuDyUmch7IoROr9ffeVV7N+znzLhgxgZjIHPnYKiitWo2liFG27IoFM3bl7bBQm+ixNe3rP9A3xf1LrQ2eVXUl9rqmKxaQP7b/EmguNm9rCdlf8QEKsA/esa2Hd0hdSAc+NaB1aV2ZGcaJwx0J9CrBgIe3GcbHWN4TG0BMdRZIpHCeVrCsjSmhZjRxzBrOTxnlQIuNQF0cu1BaLEAop9lUAGj0eSBsnuQqfIAFlXG8ni1tLUzHdFF5JSklFGZ9I1G9YrNtZYp5P9oOgCr55rzhBlk/0Ef9Y/+Rs0PP0bFO18J4Gs1yOpogIWZ9y5q87rZ7FtTk7ORceYCsgqYBNhY21ubsanP/1p/OM//uN52z366KP4/Oc/j7i4ONQya13YWIWp9eMf/7i6FrJMQMVni/xeWVnJ5LYRPPzww/jEJz5x9qcZzTWQdUZmW1IbeZisIe3bs2SyGIv4sd2Sodq2nJjzpbKW1Enpyi4bCzDHHf0cp+1vAGq63g7ErcqMIJ6MMjbL8oVah6mmICwlIS/DdD4vgmyv3eMujA2OY98pM041hpGNVqR465A4WgNLTBhGqwXx+QVwUtZO5vH5+Yp51Wi1IiaK2+9lc8PO0YlIcEmYTvbu3Yuvfe1r+Iu/+Itp71m2/fa3v60CVaLIcW6R3z71qU/hc5/73EXBt3PXm85nDWSdjpX0OtoC2gLaAnNngQn6t1pavKg5Q1U5xgKEfKOo0MaEcAGzMuZDEo7l7LueiSVrasZx+vSoIi1JTbFix42pjO9Yoia2M5NzWgrbaCDrUrhKuo7LzQIujpsJocHh1ggaSZbi4zBgVRZwcyUBbRwzC4h1uRVhZhV/1v5AHw4H+slWaVSMrBvNqchgnCbeMAlm1eys0XXlxa/R8NSTGDh1EjEkz8jauhWFd94Fg3RiogS0IsRnrx8iqQ3xF0J6lpd2gP71jxNAakFHR4dSQjvXquKLF5CmlJ/85CcQ5bSpyrPPPouHHnrorf34/fT5EIAu6rfBIP1bJCgrKsxWm/74x48iPf9W/LeP3YKmpiaCVR/GuPHPMe4OIhxww+vqh3ukHWUFTfi3r38dFYx9PPvcC9zHJEGQjP337duHf/iHf4Akt0qRdQRou2HDBvVd/lxYp6BU5JwynXPr6elBb2/vOVtN/XF0dFQxwGog69T2ObtUA1mXIJBV0O0hspP5/UHFyupjK+whjZ7XQybK/lEMDoxx/vZkI3g1jmDWnNwUZOfJlKoYWxOTJYCp5TbOPgx6vnwsIAAhycZVYMyxAEZHA2hrd6O7y8sMBy/Z7QgsJKB1VXmcAraKc8NkmhlYaPlY7fwzkYy1IN8zY+MhgjmCqG90E2TlU1nP4hiqqoxFQb6NIFF2gKMgXhYkI6oAt/r6gypDqLqWLNbuMKpW2VFealPsrDELUFEh8xBQXmPrJJC1tz8Em82Am7bYlNxhLDN/or0IGJzNCwYnDGjoI6C1y4Amzm8oA67JBzISDGCzsmyLBrIu3KWVd7WU9qEI7zHgZAdB1MMRWMNBjAuzNlkWbt5sVczGuRkmyPMz28dYAphejxeP/ecv8PyzL8EQSedgKQdWRx5uvG01br1zFdJS7WSzn19ZUXln+fnOOnbCheoaF8bHg8rZvm5NLDIzrCpZwETQ7kwc72LXLrJqCxBYwP0jo9x3qgUFuWa+C+2UX41RzNpm88ztSTgwxEHiooOkL+JBR9CFM6FR9IY9SDPYUEpQ6yY6SuINZKSm40QXbYFot4CMryQTt52MocePHEMdAZGtzS3IyslGPhlBS8nYlZmdhRQysToJArXbbTAyw1gcGNFaIuzMhelw6SEja8fuV+EZ6KecchYq/+IjlFQmsHQB6z4wMKAY0MRWTzzxhMp2ngrIKqDXfAKN5Ho899xzimn1XPueOXNGsbLKMpHfqaqqwr//+78rYMuNN96Ixx577NzV1ecHH3xQsbDdfvvt+OlPf3rR71ezQANZr8ZaS3PdjhATIcli8QYd/1a2X3db85EZ49Bt2dK8nMuu1uLUl6TDjiGgkX3nowzMSaKkqGeUZgD5KdHbJs3qYrBt8DEhwcVgwHhbK0ZbWzhvw3hXN1yUbRu0F2MorgojjlKypNuxo3wM6VnxiE1JJCMr22tOZjKzxhDYarLaoiooNCu7LOONpX8lwSZhW/+P//gPxbYup3u1QNY9e/bggx/8oLJUdnY25ZTvgdvtVgEq6ZtI+e53vwthep1N0UDW2VhPb6stoC2gLXD1FlD+d6obSWK4xCtq69yMCfhRSCBrOdXkVlc4VOJ2TMwy7RtdvclU4rzExV56qZfKnmHcfEsax96xSCLZiy7zZwENZJ0/2+o9awtcaIGzsaYzZGA93BJBF+NMMl7eVmpAYaoB6YTEyPcFdIdeWMV5+y6xGonrDkaoykcFvYP+PpWknRxjxTWmFGwxp8FIXtaFiJHP20kuwx2L3364vg69h95A8+9/hwxKzK976G+YlGuFkUDRaChK8XEohBOMM+7aN4adN7Xjzz/0flU1UV67kORjbGxMgURlBSGf2Lx585SnsX//fpWwKj/KfkJhI4GyTN7msfoGQ8hJ9+L6bavVto89/lvsqy7DwT9+FAcOHMAnP/lJ3HLX3zPGGSHxVhidbU3Yz9iHL9SDH/3oRyQqugE//MGPmdhERR76gUStTcb9EndIptKeAFo/8pGPMPZ6Pi7owjrN9NymPOELFkqM45e//CU0kPUCw1zwVQNZlyCQ9YJrqL6G6dEW0NmQgFg5DfSNcpL5CALi6SaowUrudJuNgAK7hQANK5xxZMuK50S6ZZk74xx8qK106gqwQQ/yprKzXrb0LBAkk6jfR7ZOglg7OjxoJzurZHSIjHJcnAmJBGKmplKCPsWislBFhl6DWt++ztL5F9nrjk4/JXs8aGK2s9guliCvnGzKXmdxIuhKwJoCulrs4nKHKCsUwvFTbrSzztIRyUg3QSjvM8gkm0BJ7YXorA+OsPPUS4bYM0wwGA4hL9uMolwjygrJik3wWDTY6krXystMxWFXBCfagWNtQKLDgMyECNbmGUCyb8SR9Wc5Fg1knf+rSiJSuCmPOjQeQc8o0DNGACvnw2MEz/P59Y35EW/ioMIRwbYNNlQUm1QG3lwwGk8yLDbhD8++QEbWo8zALUJeQSVWr6/C1m352LA5S7UB89UNCr0FupcECx/frT4FNE0hy3VBvpXO9lhKYUg7dHXvU3FUBPnM/h/23gNKjuu6Ft09nad7cs55kCORSIAAkyjKsjJNylSwnyQHLfvL32tpfenLT99v6Ut+1rKXvUTpf1lLX5aeZEuWFahIKjCJJAiAyMDknKcn93SO03+fOxwYBIHBhJ6EuRerUD1d1VW3zq26de85++w9zeQD12gUwwSyDo9E2H8nFHt2ZYUNFWSoKGVfJI78ZPryBczqnmHggEDWzug0woYZWCnFnG+0q8zfEgKAMg2U+Ei5A9OdV/5x0WdYQQvE6SwKk7V0dGSUywhcw8MYIyBmamKKz05IAS+raqrJ0FyNmro6ZGZncbyz8V5+3oF+TAow97e/RjQQRP173ovs7dsVqHUFzXvLQ3//+9/HX//1X3P8nYuGhoZrAFf5QR+BSUeOHFG/bW9v59z0jSyYAnAtI7OeFAGtCnhVnFdPPfWUyuL+27/9W7Xt+v9ELujJJ59UGda//OUvr9+06M8ayLpok22YH3BoQpdJAmcjY7gQHVf+EGFhPWEtUswVG+ZCdEU3hQWEYWaUzKznujmO5hhacnJrCGTdWmRADtU06NbbkCXBPj5O4GKMiSUhslNEPBxXqrWHDOOy+MjIGkQ0GECM7zNhaVVJGzllCGTUoTlQhZTUdGyvnEF9XTqqajI2pB10pQF5X0ugSZjWBXg6VxYLZP2TP/kTdazKykrIPH+uCLPKwYMHFVPKfffdh+9+97tzm5a01kDWJZlN/0hbQFtAW2DZFhASE1Fpa2wJoKs7yPhogr5/E/1fNsYtLIwJMImF/jUNaAWTRRMKzPrCC6NwuUJU3LMSaJKGHTvTVTvoePCyb8ebHkADWW9qFv2ltkDSLSCxEX84hXLjM2gjkLVlOIEsuhTLsoH9lQaqTjImuwm4NmIkHqG+Ki7HqKIX82AkHkCR0YG661T0TAYSuCS9BfQBl2QB3rdhAj/Hr1xGw//6JpxkMq1629uRWVOD1ILCJR0y2T8SjEiUmJq2ziBOvuZjvNaHtz1yTJ3mpz+dBapeH0s9e/asShSVcUVjYyMxOJnXqiTHkgRtYXYdG+kn4PRute2pn/yUjMK7EAiSxJExTsHwlGc34r3vfbfyz/7m+Su42m7Fy898SsUAjh49iq9+7T8YR6VqsDFBLNwIFcyH8D//4e/VvP8jH/kIHjx+P/YfOoAvf+XLKjlWTiRKL1/4whdIdjc79rlWsdc/XB+XuBkId75ru/FYt/tbA1mfv52J1HYNZL1DgKxzrS2dgDhyuVJBQWFVFDDryNAUertG0N3pQh/XXi8ndgS4VtWyU6wtVEtpRS5Ky/M4uaP0RjLQInOV0mttgTW2gHou+N8sqJWS1d1+Sql40NripdRoFGXldsqOpmPPngw6O0R+RoNtrm8yyVJhnhr8ZDidIEvia+e8uHjZy0ECHUMEXh27J4POD9otde1nAnN1Fbnurt4wnv2dhyCVBOtnxOG7nNixlUwsHEBdP7C6/lqT9VlMJoyLLZ0RNHVEcYWA1upyE95+gjIOZENMtb0x0ydZ5032caTlx71Az/gMfttA4KEfeIASHNvI6C9ZjCttx2Rfz0KOp4GsC7HS8vYRxt8hdwINAwm82s6JCf+2EeC9JTuGlFAM5y8HKQNhxluPURIs24g0R/LutcYrDfj1L3+NjrYhSoUzKJoowV0H9+ADHz2G/MK0Fe//JYNxaiqm+tDnXpxWfWc1gfYH9qWp5ABi75fkYJf+xk/guUwoXzntVYB+AasePezEtno7EzVMsFqEZXZ5bXezXwvwR/V5mIE7EcV5goCuxibRFHNjmykDBy352G7KpIxNqnaS3MyA+rs1s0CAQBm3expnT5/GmVdPo7W5WbF/7d2/DwcOH4KsnZSwtxK8KokxGzWwI3PDqM+HK1//GiaaGpFDEGvhoSMovff4mth+PiDr888/fy0jepjAYgGuXl9MZMEtLS1VDG1f/vKX8eijjyqJoqtXr+LTn/40PvGJT1y/u/r8L//yL/jc5z6nfnfu3Lk3AGdlB2HivRmT65sOxC+EvS0nJwcf+9jHbrZZf7eBLSAeFHH4/yzch+fDg3iLrRR7jdkoMTlhwcYYt29g8+uqL9ICMu4S5/8Uh7KX+xL4xaUECuiH30Wc/95yA0qzV2DAt8g6LmX3OJNLIl4vPD3dcDOZYZLMJO6Odrg7O5Sf08zkhqy6emTW1iKrth7pVVVIr6hUEnyBiAmnL0fRM0RAC+WGD++x4ehdZF/dmKZYivnuqN+IxJ8sN5bFAFll3CZMLJ2dnWp8IOOE68tnPvMZJXUokoIvvPCCYme5fvtiPmsg62KspffVFtAW0BZIngXm4gACaB0di+Klk270D4QVaPPQXWm4+3CGUlyymPV4XqwuPsnOTj+amz24fMlNlrQsvO33ChVpyUb1dyTvblqZI2kg68rYVR9VW+BGC8j8uHeC6k0NM4owRf5+ZHcK9nCObDULM+vmmRgqwhPGaXriPuXfciVCiCTi+D1rGfaZc0DNEhgJZtVlfVhAxjLT3V1o//GPEJ6aJBsrFWbf/vvIv+vmTKZrVWshEBtyhdHeFcU/fOH31Tz7wx/+ML74xS9em0vLWOJTn/oUvv3tbyuVNUlQnR2rzdZaYpjMR8bIOJXxyL765//t/mvHKd3x39HQFkJRHonJSAh25dX/+9pxvv+fP2dsE1Rc+4UisrCQrfYU4zmFBQUqXiPnmJycxO7du9X5vvXNb+GXP/o5PvF//O+49/i96uR/+qd/iv/xP/7HvOaT+I+AZMWHINcmhBYzArRjud21zXvgm2zUQNbnb2KVN3+lgax3GJD1xiaWhzdAuoYAewSPm/Kybj/XlLD1BNT3wtYai8ZmWVv5YwF4ZeemIScvnWtZ0pCdk0bqZTMnNPrFdqN99d8bywIJ0gDGuXgoszw2Tgau0TBfbhFm7kY5kZ8F4kg2akGhFSUldkqrWLQMzXVNLEDgEKWwh4bDGCTb6Qgle/wMEgnwqrTYhmpKVucR0JqetvaAVsnYkYFVN8GsfQMRDLLOeblm1tOCLbU25GSZXnfSXHeBSf4oAcbJ6RkMuGIcgEUQIDOimRjpvdssqK+0UM6c7Dlkt13vJchnwxOclX3vGU/AGzSgLEcyGVOYyZgACb3vqKKBrCvTnFFOUiKxFIKiE+jlIuxRxKzCnJKAk8+CnZlzLjqbQ74Y0h0pnKyY+KxY1QTFQpDrcoswLwqbz8mXTuL7//afmJ4yMXEnXwHV7jq8HYePVpOlm5Idi2RCXWi9pD+YmIxiiJJnza1+vndmFGC1nCypIn1WUDCbDLCYYLuM8eS44qwfdDFw3xdR/Z5wymVlGhULtfR5uQSx2gieX2kGCnGSROgkcTHTdygRQB+dJe44AQn8Lk/YWQlkrSOwNdNAZQCDThhZ6L2j90uuBfwEdIpjo7uzC309vRjo71cAazNfygJazc3LRQmBkkWUn80vLFDyOCJtu9GLgINcr53ByIXzGG+4ioL9d6H+0cdgdjphsq/ui3w+IOt3vvMd5fDKyMhAW1vbTYGs1dXV7EN9CuAiMkDbtm1Tbfp3f/d3+OM//uM3NdU3v/lN/M3f/A3HqHkQwOucA2pux2my/Qnr20KKOLREgkgDWRdirY21zxSZxXv53hI2Vlm/1VqKneZsOPm+0lwVG6stN0ttReEgzDmva9qAZrLNDE4mqKYhrKxAXaEB5ZyvOazLH0Mn255q/CoJFkwikCBNgEzowfEx+MmMHp6aUgyscs4UJi6kSJK92aIk9UyplAhOz4A1i+zory+WjExYyKSRwvd0JGbA8Ggcrd0RXGxiEmkZ5xLbqR7DhFZJitNlY1lAmPFFklCKvHvvu+8+9a5fDJBVfisJLzK/f+tb3woZYwgTqxQZ291F2caBgQF8/OMfx2c/+1n1/VL/00DWpVpO/05bQFtAWyA5FpD8RwGz9g2EFJBV1I/EvyakG1u3pKKs1Eb2LeOG8MMnxyI3P4piZZ2Oor3Dj5d+N8oYmI3ELplM+pQEeDpndUm6BTSQNekm1QfUFniDBQRjFiAwrnkI6BxJoJ/z4rw0A+oKDKjKAwoo0iEY1sXEXN5wgg36h8RpPCQckfhMR9yDLi5pBjOKGZ/Za85FbopVx2fWUduG3W6MNzZg+NSrGHzlZWz/0B+h4i0PQ/wg4htZD0UwNKKIe/YiieIuf4sgzy8qcOePf/xjgj+PsYoJvPjii/jQhz6kFPBk7v7w295PBUnGQWdc+P++Put7/6M//nOcbshSz+Rk77++4Tjl1aLSlkBn6ytvOM7jjz+hGPYjVPDZToIOifOeOHFCEVOIv0Dm+QI8fe6554jtKcGT//wlvPDb51G5pRqf/OQnFSusJK/eqPw2Z1c5hmwTf9WXvvQlBc4V4KpcmyTHyvc3XtsHPvCBuZ8vaa2BrBrIOu+NI6jr+vp6PHGHA1lvZQS/L6TArH3doxjsG2cgd5Q0ztOYGJtGXn4mA7dkzirOQkFRFgqLs5Hq5EvNboXZYmJA16jW8mCvNCjiVvXX32sLJMMCUWahCiNre7sPbe1eBsy9yCQjayEn8TW1aSgqsvEFZyYAyEjQ4awMjb7nhe2ZdPcEtLa0B9HaFkALl2zaqYasgtWVdhQXSX9BSndmO6/lBIFjC0QJvm3rDOH0WR883phiJDy030mJIQvZd9mXrYK8kI8siR19UTS2R3CpOUJ2GAv2MaiWn2OEwy79aDLu5pU9hgRKJ3wJtI8AzzYkmMUIxcq6tSiF8hzyd3Klylf2auY/ugayzm+fxWzlbaPYosJRA6YpCyGMvq3DQNvwDPyRWUmXveVAummG8qAxnLoUUgzKxw/ZUcXgcwGfkWSVgD+A/t5+PPebF/D97/wANmslKqv24N2PH8e+g7UEr6VyMrQyD6MwHgR5/Z2UOevsYr/JvjOH4NID+9NQTrkzkTpbTJG+TZIyZPIojFPdvRFmQobQ2x9m8oUBO7bYsaXOjkr2czLhWot+OJiIYVrYWaNjuBidQIxg1hwDHeQEBZVSqlmArZL9ayKEUOqoi7bASllAHA3xWBwhShEHgyEqVYwSvDqARgIae7q7MeoaQf3WLdi9dy9279uL4tISjvtmGVhXqk5rcVxhZY0QEOI6dxYN3/g6nATr1r3nfcisplRR4epKFc0HZP35z39+LbNawCVzgJM5m0l/UUSZJSnf+ta3FDBFMqW7uroUCEXAKDeWf/qnf8I//uM/UjZxK4TxdTlFMrE1kHU5Flyfv5XxSnfci5NhF3yIgmktuM9ShGrTzaWm1udV6FptVgswNx2BCHCqY1bpIDM1oZQz9lcAzE9fWzAr38EzRJbMkHJDljiDDvFIGLFgEBKoCYy44B0YhG9wQC0hAlljwYCS0Esrr0AmGVczqqqRXlkJW3YOLEw4uVWR970EMTt6Y/jNK0HlvynINWLvVgvKigiK5TBfDzlvZb31/b34nvfs2YMRgp0XC2T9xS9+AWFekXIfwbDvfOc7VVDtBz/4AS5cuKDmIU8//bQ6/nKsoIGsy7Ge/q22gLaAtkByLeAaiTCBPKBiFoNMJt+104n6WrsCszqZOG+1rozvL7lXsbJH6+sL4OWXxpS0r91uxKFD2aiudqhYrx4vJdf2GsiaXHvqo2kLzFlA4iNShIBnlPlvr7TNYHAqgYzUFKqUAHfXGsjCqueAYqaO+DQuRSfRTvU8USM6ailEtTENhQS1msnMqpO31a20pv+Jv0T8JB0/+wku/79fwdb3P4GKh9+q/PcW5639IGtRacFbeL0B/F9/8yHIPFiKMKFKPEXm2OLLf/e7341P//evwEUytAn3DNJMjXjsD96l9v3u936Ck031yM1icun2Gfzt//nEvMcR8gnx98wViR2I/1+IKoQIY9++fWSab1b+AqvVCmGBFcbhi+cu4tWzp/DDH/5w7qe3XJeVleG1115T5wmyHSQhdr5ru7FOtzzwPBs0kHVhMRrNyLpJgaxx8qpHycQapMc7GAirJeALw+cNwj3lw9Skj2xlXMjeKqDXrGynArgWkYavuDQHhSXZcDhtnPgRzaSLtsAGtYAAMqNRAqoIBPJ4YpR7jmB4OMgX3ixTq8gwF5OZVSbyVZUOStEIoFU7O6S5JYPX7ycwbYoMg6ST7+vj0h9S2btFhWbs2kGgEhlQxRmyVmVubOPxxjHljqG5LUigF4NnrLuwFB66y0ngshF2MhWuZBEmWz/ZWLv7o2jqiGLKMwMLAbTHDthQXmzi+dc/CFRsGaHd3AEDMxsJRHQlmOWYwF1VBuwsBRl/DGC+wx1RNJA1ec0ogfVpOhPaeb+0MyO2e8xABt8E8tPJ6psN5DqAVEq7NLeF0dAaRk6miYFmI3bWW5CdQecyEwiSVVxDI/jVL3+D1169gqYrvdiybS8BrAdx30M7UFmdR+Z5CXAn73xS79kJlkH1jQL47+0NqazFuppUAlitdKIL6D9FJUss5jqjZN/y+uLo7KHdmoLwk3VC5HHKCVwtKWIyRp5FMWPLsdfKAR2nPHOUjhF3IozxmRC6Yl4MzvgxEg+iyJiKLWRmrTdm0mFiV3UknHUxJtD7agss2AJhMpF63NNob2tH45Ur6Ovt45hvWoEhS+ikKC0v4xwnnwoU2cr5YSM7qQAm7jSAtQL40Cnm7e1Fz29+BZ+ARAnurSMra/Hd98DAa16tMh+Q9dSpU3jf+96nqtLLuprNb5xrCjubAFKl/OxnP6MU4gG85z3vwZkzZ/AXf/EXinlVbbzuP2FZ+8Y3vqEyqP/zP//zui2L/6iBrIu32Xr/hbhCQ0y+kKSLn4R6UG/KxCFzHsqNnCekLC7RZL1fq67fnWkBSTgUebYxL9A3kcCVfgPcTKQszzVgG3H/e8pnx1hrMSYU4GqMDNq+4WF4BvrUu8c3KMDVQcSjEZgomWcny7ViWeVawKrCtiqAVSOZR8xqccDsIAsJmVlvx0Qic9YpqrL0DcZxhXOLroEYHrw7FTvrzIqV1bRCygt35p21fq5qOUBWuQoBrf7VX/3VTS9I3uvCGHN9YOz6HYUZ9sakmuu3z31ubGykzOEzePzxxxVT/Nz3eq0toC2gLaAtsPoWEDU5H31mwsoqCd/9jFeIy2kLway19MdVVdpWv1Lr7Ixekn0MDARw6ZIbDQ0ePPzWQuzdmwGnY1bBbp1Vd0NXRwNZN3Tz6cqvYwsQ4gKJPV3oTeBir6iVANmOBPZVGFCSReVhp+r61yw2sp5M5yfFyBRV8xpjUyqJe2ImiBrGZu425yMnxUYlojf6XtdT3TdNXejMmCEAdPjMaXQSzGqypyKttAyVb3ubWq8nO/iICxmhQqRrxJqCnVgAAEAASURBVI0vfuFPcO7cuWvVs1gsuP/++/H4H38JVwkul3hreloKtpW0Ecj6DrXfj378C2Tl74KNsV8h5TGSUuBjH/3QTY/zta99jZicN/tm/+M//kMRWvip9DNXSkna8bnPfQ4PP/wwcW1+4twm8cQHP6DIL+b2udVa1N9Onjx5zS8g8QdRgbvZtd2qTrc69q2+10BWDWS91b2hvt/sjKw3M06MbEWRcAwjw1NkJ5rCyNCkYmkdG50mS5kRNjKyOtNsSEtPhTOd67RUpGekwsHvnGl2pDoIbLWZ1b43O77+TltgPVtAwI0Cah0cJKtdr59LgPTkZPC0GpGVZUFOzuySlWXm35S7ZvauDoQQ3Pg6ELi9I4gWZjsHyDoodikptpKZ1YLCAgvSnEakEgS8VmUuKNHRHUYHWQu7e8OUkjMoVtbKcpsCtdo4YFrp9pycnsHAcIxBtQgzkWKUTjdT8nB2YaLQhpA3ksmhl/6/xgHgZPsMmM+gQIk7SwwgiTcyqE68FkHSZN5bGsi6PGtKADlAplBvyKCyYUc8CQwzG3Y6aIA/nEBVfgqqchOooNxpgv1H32CMEqBR9Lti2L/Diq1VJhTlm5IKYvV4yLrd3IH/+M730dk2gljESQDrMdz7wAHUbS1ksk7q8i76hl8rwNgMr5dSGyOjEfT0BNHVwweHJTPDhH17nIq52uEwLvh5EbtK8sU0g/Pjk5zUjkTV4uI6Pc2I/DwzttXbaDtJIFg7AOsNpiCUle9Wglr7CGLtiE6jhRnA8p2DXKwVJidKyM5aSGCrSDfbuOiiLZAMC4jMTCgQxDilikdHRuEigEaYV4XJKxKOqAxhYWGVpbq2ls+MHSbz5rj/ItPTmGxpxuCrJ9H/wvOoe9+jKL//Adjz8ukk40t8Fcp8QNa+vj4cOXJE1WIOqHp9lc6ePYt3vetdCmgsoJHMzEwFYH3qqacoY3RUZVnPjfvkdwJ+ee9736tkhT/ykY/g85///PWHW/RnDWRdtMnW/Q9CibhKtLhKdopXIi7cQ2aKB60lSDVQuYG8FLpoC2wUC8g8TZhZX+ukGsgoP3PcLcmGu8oMKCAzK113SlJxJa5HWL/jTByJUd4t7PUgxmBC2OuFvHOEDTzMBJII/w7zc8zv42cfjFaLAq46ybLtpPSbs6iYTKwFsOXkwihJDEucVIoiS5BJpGcuhXH2aljNt2vKjdhWY6W88NooFayEzTfTMZcDZO3p6VESgx0dHcpkwtgizC1e3o9S0gia/vrXv47jx4+rv2/8T9hahZnldkUYXPr7+zWQ9XaG0tu1BbQFtAVW0QIe+s9c9MldafBhlGtR3JNYRRXV5PJJvpFGX5rEB5Y45FjFK0n+qWKxGQjg9/SpCbz88jh27Ehnwmg6amqclNZduxhO8q907Y+ogaxr3wa6BneWBRgiUYmcU8Sv9TKRs2XYgJ6xWVWS2nxgVzklwi2JTdm3z9fSMwwuqfgMYzOXmcgtTKylTOCuM6YzkTsNDvrASPMy3yH0tlWwgKenG+NXr2CIgNYowZjbP/BBZG/fziRfMgKt4YBFYpPia2FYRbG5j03EcZIquEOuKPZsiyASaCQZhQ22jL2M8xqpjEecCFVcU4m7yM02ksCIS1YKstKNyCTJESFnbyIVmiTw9Pz58ypuc5AERMLwOl+JU/2nqamJsdce7Nq1C5WVlW/YXZJSJ8YnyMx6AS+/+DJxKk6qkRdg556dqKisQCF9USmkbZ6PzGSxdXpDBW7zhwayaiDrvLeIBrK+2TwS9JPOSB5+YWyNc0IjrK2REMESQ1MY7BvDQO8YBvsnMDw4SXZKC6V4M1BVW4hKWaoLkMk0FwG16qItsNEsMBv0NpBtgdKrlIEOEZDpcoXQ1u5FZ4ePTK1hlJUzc7fWiR0708k2SmC3c3OAHuZrS+kzZAlHRLY3gaYWSve0B5R8tjCy7idgq6barkBbazjOUpcgLIYeZmS3doRYxxCaCLzdu8uBI2RmLSD4S+SFVrIIWFoyBZs6ImjpjKKjL0bmRCMePmrjIM4IB8Fn672o9mYl3QFgZDqBF5qBLk4U9zPTcWcpWX+KAfMG93dpIOvS78K5+6OfToQ212xGLIcPKMwwYGuxAbvLgSwG0e1kYZ3h89DeHcOvKf2ZSlZkYWLdu92K0oKUpDqSpW9va+nBudcu4ac/eAo+3rdlZfvxrseO4YFH9jKjL/lMrAI4DdMhLMwPJ191Y2IqRvIHA44cTsf2LUwAolNYkiEW0yeKVGqU76erZGBtag2ijckD6Wkm7NjK91L1LCDfwsmhAPIXc9ylt/bCf8lXBGIEswZBduyZMAQsdD46hjDBQ1kpVhyzFKgs4DxhZ134YfWe2gK3tICb0sTDg0M4Q3bPK5cuc+7Sj4LCQuyiLO3O3bsUeDXV4SATs0UxforDYj6nxS1PtAE3JGSeR6Bv37O/ReP/+iadYTtQsG8/iu85qgBEq3FJ8wFZBawigNTOzk4FPBHgqABOpEgbfepTn8K3v/1t7N+/X0kFSR8vkkJ/9md/pjK0T58+jUK29VyZmJhQ8kayn5z33nvvndu0pLUGsi7JbOv6R+6ZCE5GXeiP+RDnS+iAKRcHLXnqva3fSeu66XTlbrDA3DicgkroGk3gec7TBMzKPHQc30JAK+dqQr6d9PuaJ46T8TvEoIO3rxfurk5METQ43dkBv2sY8VCY4NQcZFRWIr1Clgq1tpGBVUnkGY1kWuViNMHAz2pZxmBW2YH/9Q7OoLkzjJauqFJAeccDqSjMNXGsfIPh9J/r3gJLBbKa2NjC3C5JMnV1dZA4gIwDZEwgbCvC1tLS0oK8vDwFVhUZwhvL1atXVWDsxu9v/FvGKiI9qBlZb7SM/ltbQFtAW2DtLCC+OZKbYXo6xuTyIE6dmaavjonV9MkdvTsDW+tTlW9uFcVJ1s4YN5xZ3oUyKmxt9eLK1WkmAYeVj/Ghhwo4n54fOHLDofSft7GABrLexkB6s7bAIi0giiRBgumu9s/gNw0CiJtBcWYKDtcYSJ4CWJgTmWTRvUXWcP3uLmQj04kIlfM8uBSbwFnGZ+4xF1CVKB/lJBxJ08ysa954MYIv45S2v/iVJzFy8QK2EchaeOCgYmUVX8lalFkfC+AhE+vYZBxDo2S9J2FXdz/JdkZj8PL7zPQURU5UWULFzWIzCnJSkO5MQSoxDykpCaUmKeMtSSCS53MZLp8Fm0DGOjOMg0xNuRXRydM//SVampqJ8ynDwSOHcP9bHiA5o1WRYCz4oEncUQNZn1+QNQ3BYFBGrZuuiAOrvr4eTzzxxKa79sVcsEz4BNjqpTbw1KQXUxNeuCd9mOQ6TIBrJEJwhupxJMOFmS6k50vPTEVObhqXDGTlOBVTq0j2bpYA8WLsq/ddnxaQF7OAuX2UpB8ZDSlA6+hIWIE1BYwoL1thZs3Pt6nJfU7OLEOrfL9Zi9hM+gvJdB4ejhDAFYKXmc+SpSNMgcVFszLaWZQOt1gWB+BKpk0jBLNOkM2wt59gUgJuxaFlIYX91jo7ykrMyMsRVumVbUcZ7A2OxHCVzKwBvoJlQLet1kKG1lkWStMGuI/Y9YOvAFwZIEhwmABhysfnUq5DwKwllIzPS1tZGybznrjxWBrIeqNFbv+3YIzcvAdGyb7aNwGMe3lPkJHVIMybzLorygBKeV+UZhsU0DlCxtbmzoia7PRz0lNTbsbOegsKco1K9vP2Z1zYHpKYECbT/NM/+y1efv4U2lu6UVpWgQcpL7H/UB3qt5cs7ECL2CsYjMPDd0dbexADQ2E6zKNkYTWjpMSKqgobQfMWME7PCdvCnhHps/x+mRwSeDYQxZQ7yndRAnbaVY5VWW5lv2VSrKyLqOaa7BrniyKCGQzPBNBNh4mLMjbiPOFcFvmmVJQZHCg1OZBnsMHIMeXCLLQml6JPus4sIHMVH6WLR10u9PX0YYiSxaNkXxVQgZGZtQ6HE4XFRShntm0xWd9yCKgxEtywmecmE02NGHzlFbg722GgJ6n+fX+ArC1bCSoS7a2VffrmA7LKrfWlL30JX/ziF1X7/PjHP8axY8cU6OTFF19U8r9hsv79wz/8Az7wgQ+oO1EYeLczOz1AJsATJ05A5IUE9CJSwB/+8Ifx3HPPsQ8uwSkCmwXUspyigazLsd76+20wQacr30nPhPvJHp7AXnM2ashGUUZWCl20BTaqBSRxki47UISAgFay4k8ClbmzQb0tRfRjkMhjqYE9kbqLCuuqewohJgoEx8cRnJxAmAkkUb6HZwhovX4AJ+BUI9m+rWTPtpNp1c73r4Ba5bMpNRXGm0jEJcvuHl8CI+MxnLrI8bh3BvVVZi5kYStdm+BPsq5rMx5nqUDW61nen3nmGexhQtP1RUCsDzzwgPpKxhtzjPDX77PQzwJi/elPf6qBrAs1mN5PW0BbQFtglSwg8QpR4JtkgnlXdxCD9K0JO6uoJYlPrb7WjtxcC1VaNk9y6/Wmn5yMYGgoyISOKfpUorj77hxUVTlokzcnd1z/O/154RbQQNaF20rvqS1wOwswzKMIdhoYk+wjkco4RRaq8ujTZD57OdX/CE3R5TYWiBDM6mY8piM2rchGooYZMBKDHaYsVNAXVkCiEYnL6LI2FhC1G1naf/RDuM6eoS8lC/n79qH8wbfAdBuG0mTUeC4JyE/cgvhRpn0zjHXynuESYjKQ4D1kbCWRA6LCGHuNI0hSuMmpKGOYMRw7RCI4Eu/kEFwuKrhCvLPWReIGEku4dP4SWptbMDwwRAVyO+NE5dixawcJT2qY2GRlrGh1fUUayKqBrPM+GxrIOq955t0oHZmg2EddbvSTobWncwQ9XSPo6x5RQcZ0apZVVBWgvCofZRX5yM1Ph5M0ECaTsKyRnpx0feKIXOEY6bzXoDdqCyzGAuLwCAbI6NHiQXOzB60tXmZqGFFUZMe2rU5UVqYiM8uisnjlPk9hZGgz398CvJp2x9DY7Ge2s0fJSIuD6MD+dFSU25BB+ngzBzBrCfz1kplVpLlPk/7+anOALIl2tYgDy0nJQbN5ZQfrfg7u2shG2dgexuWWCA7stOLIXitp9k1kp9w4948vDAVcfPoSgd9hA4OkwN5yYGsRmVkJCCZ+aMMVDWRdWJNxvkKQmEi5ENRMJ0Lf+GzA/EIPGd1nDEizJXCoxoAdZOklWTtsr09aApSVGB2P4/nTIYxPxVGUZ6L8hAW7t1gWduIF7iUZd35/FGNjXnzj//kGXnruJOVE85hpdw8+9LF3kkE+jczyyXPMzk7y6ECZiCoA65nXmPxD0GlNlR27djiwa+csKGYh74Y5ZgRhkZ7tqyJoaGYm5tWAYm8uL7Xi0H4C8wrMZJjamOMpuX86CWZtJDvrmego3xN0OJnSsIdOky2mTEo6M+mBkjbk5Vpgi+vdNpsFBKQq85EIQTNhZisLeLWtpRXnzpylksQQgzBeHDx8GHdRimbnnt3Iys5S7KubzU63ul4BHIUIPLryta9ivOEqtv7hB1BIWwlb3kpneN8OyMpEWzz66KOK2Uzqv3v3biUndOHCBQVOffe7342vfvWrat45d33Cyvrxj39cgZdFNngfnXzNzc0YIaBZnFEiDbxt27a53Ze81kDWJZtuXf5wlAkV4rz/dWQQWQYL/tBeq9by/tFFW2AjW0BkAxMcj1/uT+DFVsDP8Xc6mTDu30ZAax4otTibs3Crcakai/IYAlwVJu+ZOAf79AMKiDU4MQ7fwAC8vb2Y7u2Ghyys/qFhZS4HGbEzqqqRUVODrNo6pJWXw1FQCOMqBFxu1l6S/CVA1vaeKIIMuuyos+DeA1ay9syy097sN/q79WeBpQJZf/jDH+ITn/iEuqBBjhNvTGCS5BZJdIlyLPnkk0+qscdSr14DWZdqOf07bQFtAW2B1bGAgC5kfNPeGcKly1709IaUT/PwwTSlJCeg1rWOVayOJd54FrFLiMiwZ552URXFRxCrE1u2EISyI0O9N281VnzjUfRf81lAA1nns47epi2wMAtI3ED6qwkmbPaMzeDZRiqEUlJnG2OQe8pJUsS1LouzgDcRxWg8iGfpD2uNu7HVmImdTO7eZcpWwFazBrMuzqBJ3nv86hW4zp/D4MsvIauuHrv/9M9hSU+nms3yCBqur6Y8UwrvxTXdPozpClCVjMdU3h0nGZdrjBiKsRhc44znTsTVM5juIGlRvgnFBUaUFJjgIIm7qHufu+jD5cYAHnkwE3t3pl7DgFx/vrX+LIDWoYFB/PqXv0ZbcyvcZGq9/+EHcPT4MeTk5TB27KBSkMRaVyceqYGsGsg67zOhgazzmmfejbNObXZmwTDBfRGyVgbhp36Z1xPgEoTH7Vfrue9NRLFnEsVSWJyF4tIcFJKuLyPTQSCgRQH+5j2Z3qgtsA4sMAdQ8npjcBOYNDkRxhglVyYm5P5ncIf/BNRaVmZXE36RqLER6LpZi9hLwKxuglnHxqPoJzurMLUGCAbOyjIp6Z5SshPm51nWDPArALEQpb/7ByPo6Qujj2tBUlVVWJVMd01l8gBuN7sPBPwnlPu9gzE0tEUgGU6iDHD3XhsqS02KbVGo9td7ifI6lHzlWAKdo0DLkLBuJigjz0zIArK0pq33K3hz/TSQ9c02udk3IQGsk4VV2r3dxWxYv/SEbPN0MoWmg5IuBmQ7EsiwE8RK1mOVpcfZ0dW2KJo6IgSxsj+g5MRdBHEX5XGcwM/JKmoCxn7o4vkevPh8Iy6eeY5s8sM4cPAo7jlxEPc+sI9Zd2RGTSLSWlhYh8jAKkzPHZ0B5JLduajQiupKO+UqLWryttA5UIzM3yFOGNu7gnSuRxQbq82aghwC3UuKLCjkZDEn28z3jMjnrM7EKlltM3ccuVd8dJhMzYQxHA9gcMaP/rhf3UMOwld3m3NQySzgXJUFvDGvce5a9XplLOAnEHNifEJl0raRUUsYWIVNPzcvFwVFhSgsKkJ+QT4VInKZbJSlZOcFCKHLrAUEnCRyRb2//hVGLpxDgn/n7dmLmne9ByZmJQtL60qVOWBJLtumoaFBgU9vPJfH48EHP/hBnDt37tomC5n77r//fnzta19T7Xltw+sfhIn1s5/9LJMY/Nc2lZaWKungRx555Np3y/mggazLsd76++3pyMjrDBQJVKQ4ccJWjNQEk24X+sJef5eka6QtcM0CEpSYYnfomk5QRQMYIGNNGtnGajlHO1RtYJJZgkoJNx9jCbNqhO9Zv2uYIFUmhwwNqnVgfAxxMllI8MSSlg5zWhqsTB5QC4MqZn5n5Xcmh2N2u4MJ7Ta+U9ZIAk/YaYWVtbM3jlOXQkr94eAuzj3yjWoecs1Y+sO6tsBSgaynT5/Ge9/7XnVtJ0+epK+u6g3XOT09fS3J5Re/+AX279//hu2L+UMDWRdjLb2vtoC2gLbA2lhAxkaSLD45GWUsIIRB+vDGxiLKZ7etPhWlTBqXWMVmK6Jm1dbmQ2ubF50dPtTUOPGWtxQowpaVJvrYDLbWQNbN0Mr6GlfaAqIMKYQ6ZzoTjD9SqY6xppKsWXXIPMYf0xl/0mVxFoiSmTWMOLpINNIV96Ij7oGVSd21KekkGclAlSld04sszqRJ3TvsdmOypRlN//YdmOlXqfn9dyKjthbOIrIGJalI4q8vQAVbkg1JrFaUZCenZxRuQVR8hEAnlUBVwbuoNf1JztQUfk9/EtlWU5ksTd5CBYYVEp5LDX71m9JiCw7ucyj2+/XkXhVSlIA/QDKUIXS2daDhSoNS+DNbzLj76N3Ysm0r40mFJGNMHlh4vqbSQFYNZJ3v/oAGss5rnkVvFHCrLNP0lI+QqXWofwKDfWMYHpwkS1JUsbBmEcyak5eOrJw0BpQdSM9wwO6wshO0kRXNAovV/DqT5c2d6YuulP6BtsAKWEAAUsLQOjwcQne3H709AUrVh5GaalKyK4WFNkrWWpCZaUZaOoFGBB8JS+t6emGvgFluekhxEEm/0M0s504CsjqY9RylcyQ/14zycjtKOKDJzjKrAY+ws66FjQKK9j6G1y74MeiKKBbRKkp1b62zsW4mODlIE4TrSmXhTHFg2DMYVWDW/uE4dlBevb7SjLIiE+8dbAiQGh8JxXAj8pWvtCXAJoaTdZdsyKq8WflKPgIbpmgg662bSto2TACrJ2TAhJdynR4GxScTGJ4moNKQAF/x2FFiQFnOLJj1+iP5ZVLkjuNCU0SxIhXkcGLMe33v1tk+4Pp9l/NZ+pxAgKzxo0H87vlz+NmPn0PIN0xgqQ3vfN87se/gLlTVFKrsuuWcR34rfZw4fD2eOOXJwpQpI2h/hAkOvhj27klTEmWFBRzfWBb2AMQozREiY9aESgKIKZD9GIPvArqvKLMqWY7CfLMCxS637uvl9xRLgUja9M6QHZvsrAMEs3pnIqgkO2s5gaylKQ7kGG1IM5jBW0yDi9ZLw61RPUIEXgYIUnSTSXR0ZFQxr/b39nG+MUQQa5zzjFzs3L0LdVu28DmvVkoQGrw6f2NNNDdh7NJF9D33LJwlpdjy2PuRRvCnhcCk9VAmJydx/vx5xch6kIyxttuw+sl90NTUhJ6eHuzatQuVlZVJvQwNZE2qOdfsYLMO+xn8OtyPBr57JHliG9nAa4wE4mnWiTVrF33i5Ftgdj4OXOoDmgZnMDAFZDHRbC/naeU5TJJyzMAQi2AmEkYs4EeUTv2orAlijXimyb46oZYQ1yH2xxGynRuZVGBnIkJaaRmcfF+oNVktrZmZMJpfp3pN/qUs+YiSIDbAefYLZ0KQQE0Wk+72brOiqsyk5v5r4YNY8sVs0h8uBMj6r//6r+jo6CD4pgYf/ehHlaV8vI937NihGFePHj2Kb3/72/Q/k2WFyTpTHEt+8pOfhDC6C5O7AFFvN8aYz/wayDqfdfQ2bQFtAW2B9WUBGR+NkHBDWFkvXvbRr5dQieM11SQpIZhVVOXsduoDbZIQpcS6hLxFGFmffXaEJCQWHDuaSzCHTX1eX6238Wqjgawbr810jdePBSTuGCFDpGsa6B5PoJkkOuMezmcrhIWVscdcJmdSFVKXpVvAT6KREaoVvRJxkaE1pHxiW40Z2GbORE6Kjap5jMks/fD6l0u0gMQ4/UwobvnevyMwNoZUKt2U3nscBXcdWDT5hIx7ohzrRF9nW5VYo7CuBkiu5WXMVgh6pr2Mcfp4TsYmhaQs3ZFC9Vgj8mWh7yifsVwBsVqFsOgmN0TvAJVwiP9o7QgpTMOxI06UkcwsPU3wFeuriG0lltR4tRGXLlyi8ng/autrUVvHZUudIkZJzyCQmxe6UrgQsYgGsmog67xPhgayzmueJW2Uh1+YkKKk6ItxiYSjBGREyYLmxShHGsMD46RtnsDIsFsx7+QS8VJWmY/K2kKUV+UjL59MDgJmTSJD2pIuRP9IW2AeC8h9LpRx8uIP84Xv98fIzBpmwDyI3l4/+vr8KCiwoaLcgW3b01FcYkeak8w+ksKyCYvYK8KAkbCxCjtrR1cADU0BDgASHAhZsH+fU0lv25m9I2DW1S6zwGSyxxKI1tUTxtmLfkqlM8BFp9Whu1JRRyeWiZOhlWo+oewXYGBbVxQtXPqGowyuGfHgPXYyxqTAQbus96IeCT4TfpLaTnCwe7ojgYZBMCvSgPpC4HANr8MiYOD1fiWz9dNA1lu3k7DvjhHAerlfWFgTyokg7Vybn0B1/ix4NZUgZiufGZKxXytyj3QPEDB+OYTRSaJhWe49aENNOcHivMeTSfwn5xoY8OOll1w488qzuHj6KbIrlGHHrp14/EO/h9qtFQxSJodhQfoPn28GFyhL1tERVGwOdbV27NnlRD5lyTL4LJvM0n8s7OaXSePgcARXGoNobgvSeW5EGQH/27akIi9XgPXMcuTxNioL67Ub4roP6p1K84QJZg0xC7gv5mUmsBdXY5OIYgYlRgf2UNJGZG2sKbQn1n+feN3l6Y9JtoA4Gbq7unD29Bn0cD0+No4aOhm2bt+uwKuFxUVwOkX1wabk5FfS2ZDkS1uzw8WCAUzTlk3//h0FYMqhLUvuOYrcXbvXrE7r+cQayLqeW2fhdRM2cBfZwF+IDJMRPID3WCvopM+CnYzgC31nL/xsek9tgbW3gJ9BihGvARd6EugjM6s7AByrN+BgRQwGzxgiI8OY7u6Gu6sTnt4exb4qrN0CWHUWF6tEB0l2cJDt3JadAzPftSaLVYFaDWSrEACrkrhb4Jh3NS0icwNRPxl0xXChMYzXroTxyPFUCDNrmtOgA5+r2RhLPNdCgKyPPfYYXnnlFQhg9Qc/+MG1Mwl49dOf/rT6W5jgDx8+jPHxccX4LskvUp588kk8+uij6vNS/9NA1qVaTv9OW0BbQFtgbSwgSm2SBD8+EUNLqx/nL3lJSkIVpGIrDuxPQzEVliQesA6HNitiMEnSHx0N49VTE0wcjqo41pEj2djO2JYuy7OABrIuz37615vbAqIIOOEDLvYCzzYmqC4yC2DdUgTkOROzoLrNbaJlX72QjIRn4phKRNAUm1KAVjuZWYtSUnHMWoQKEo2QpkuDWZdt6cUfIEy1somGqxg+fQp9L76Are9/Alv+4DGleLNQJTXxh6iEFappjk4w9jgaw9AI1yMx+F5X2BTVzDwCVfMIWs3LSkF2ppHMqozxkpxHYrwCFpf1fGRkgpWR2OZzL3kY34wqUp4tdVbs2pa6+AtfhV9EIhHi16hU19Wj1P5OvXxKJcBu3bENBw4fxP6D+1UC7EoSpGggqwayznurayDrvOZJykYBJ0gHGQyEMTXpw/jINMZG3Aw6e+D3BhEnjbPI+lpI22wlqCSV7KyZ2aSbznJC2FszMp1IJa2fkTJkm2XSmBTD64OsqgUkazcQiMHlCmNwkLTkQ2QdJWOrFMnezcgwk6nVQiCVjYuV9ztf+huJnjJJ1owTHBpkNo+LrKftlN2emIwRBBynfUwcJJGhtYz2IVOrOI1Wu8hgTtpxnNJCkjEkAy2pX0kRmVGZNVRdwcwhAtIsBJCtVBHa/kFXnLLrYVL3JyBslTUVJtRXsX80C8h3pc6cvOPG2d8zh4HyHkDz8Czg0WaGyo6szAVKs2cnPOu9P9dA1v+6J9ikBHaDwe5Z0KowsPJVjkCYLOycvlr4uJZSxqWSzLsF9G2mcYJzY/vKcz/CjNnW7jDv76jK4qsoMWFbLftGToySCRiR53hgIICW5lGcOtmC1oZX0dd1EveeeBDH7juGI8d2I6+AFV5mkZinsEv3M9Owrz/EdYgJPJSxSTehptoGAbPabUYFOr3dqaTOYqMhVxTDZHOVdYhgAxk/zfVBwsZqp3THnQRgvZVd3HSajDILuDXqVtnAwUQM6SkW5BhsqDSmodBoR2YKAwrafXIrE95R30cpbeyh7OuIy4XB/kGuhzExTla4YFBlHztSHaisriL7ag1KSkuQxmzZlXQw3FHGve5ihGmv/6XfYaKxAdM93ah+5PdQ/uBDlC4iaxmZ93T5LwtoIOt/2WKjfpIRTAdl016LjMJNBnAbHfQPWosVC7g453XRFrgTLTATi1FKN8K57hRVUia5TKDKPolquxvmqB8pZGVNkJ4jHiU7K9+9UoxWYV7NQ2pePlLz82Hn2p4jIFanArBuJDspnw3H11daIjh5PoSifCMqS83YWWdhAuvmVM/ZSO0niUkHDhygv20Q//zP/4zHH3/8TdV///vfz0TGl3DixAl873vfu7Zdfvvd734XX/ziFwnQGb32vXzIJIvw5z//ebzvfe9TSkJv2LjIPzSQdZEG07trC2gLaAusAwtIrEKAF/2DYbS0BcjWHVVkHKKsJIDW6iq7UpGzUm1vMxSfL071QR8ZwrxobPTg2LFc7N2bibQ004KVpjaDnRZ7jRrIuliL6f21BWZV8PzhWSbWhkEmZTIe5SXByq5SiTUSxEqVDYr86pIkC8wwQB4jocgglfIa424MxqiYxxhNtSkD1YzHVJvS4TAwgVX7zJJk8YUdJi5gy0mqX3Oe20xm1tLjJ1DxloeRXl4BS/qbE00kljvDsU2Avg8vyXc8xBl4/QIwJQMr47khLnNxTXISqriszWZAZloKMglmzSGANYOf0xxM+GVcfzFx2zlCs4bmINq7QhgZi6Gm0orDB5xkcjUorMzCrnp195p2u+EaduHi2QvoIzOrxJzyCwtQXllOltY6FJE0JdWRqnBqya6ZBrJqIOu895QGss5rnhXbKJ2ZsLa6CWzt6RpBZ+sQOloH0d8zpgCvhcVZiqG1tr4EVXVFkL8F6Gok8E8ckAKQkbUu2gLr0QISIBEQa0uLl7Km02hs8pCZeAbFxTZKmmVg+7Z0grQFkDQbLNmM97OARgWg1U72woYmP65ykcHV3t1ObNuaSinuVMXOOPe8r2Y7q7rxv6tkjH3tgh+jlPROtaXgwRPpqCoXxhZBkwqz6Mr0QSJ12NwRQUN7FJdbwti9xaKYWWUgaWc9Vui0STexsBVPBQx45koC3WMg2DGBQ9UGHKubzd5a76TbGsg6e0vI8yDAZD8nOB0jCZzvBToZ+xMGpz1lBuyhJOnuMoA5KLgVNl+OMTEVx+nLZK0mI+v41AzuO2zDPftmmQ2SycTK3BgEg3G89PIozp/tQEfTKYwOtyPoG8Gf/m8fwSPveAjONDsnYctDhcs1hQg89RGI//Kr07h81QcHZTW21DFL9Z4MsrCaFGvD7R4sOY6MiUTCQ9iqT5/3KVboKXcMe3emcpJH0Ga+6fV+53ZHu7O2zzlPemZ8OB0eQVvcQ1BrAPeYC7GX8s91dJ6k0nkiPbHOB76z2l6uRp4LWWb4UPu8XvR29+AipeVf+d3LCtRqY0rw0ePHse/AfuzavVuxr2rw6vLuAwEtRWjr7l89jYtf/hKq3/4O1L37vUgrL7+pY2x5Z9vYv9ZA1o3dfgJiFbaJVwli/X6wA/vNedjH90oNnfPplEvTRVvgTrCAvEP5IlXL3OdYOIQwHfTCwD3Y2Iq2Cy3wd7UhOtLPpEkTMgrzkb99G3K21COzrh5ZTBCxE7xqJOvqQpk+NoLt+odjaKUKSmN7BMxJw7sedKCihMlnZBjR5c62gDCuNDU1UTa5U40xa2vJ6L91K31z9qRcuAayJsWM+iDaAtoC2gJrYgGJU0hM59wFLy5d8WF4OIwiMrLedyITRQS1ZmbOzhM2il9+qUaU4aPEtc6cmcRTTw1h374M7NmTgcpKBxP39VxpqXbVQNalWk7/brNaQPoiAeT1TQCNBLG+0JxAjhN4cLsBQpZTkKHnbit1b3CKjHhiBq9GR/Bq2EUwawxlJgfeaikluUgq7K/HY1bq/Pq4N7eAMLI2//u/wZqZgUz6akpP3I/0yirubKCHk0U9MxJLoeohY7miiNlPsq7+oRgGyL46NBpXLiIBq5YXm1BWaKQfxExFWKMCsCYrXi/PboDx2fbOEH7y9BRyssy4+xB9LiQxyyXb60rhKm5utYV/KzGoYCCAxquN+NXPn8HgwCDtGMbvvev3cejIIQJb86nwaUs6eYoGsj6/oEYyBIOMoG/CooGsa9foMjmMhKMMTgcx7fbDQ1TMtNsHrycIP3WLhcE1HIqS7SxOMAiprPPTkU8GtQKCWnPz2VGTrVVk2tdrp7d2ltVnXmsLyItaWCndUxGVxTsxEcHERAjT0zHFuBeNzKCgwIriIjvKyu2KrdXhWH0G0vVgp2lPDJNkPR0YDME1GuHnqAJr5uZYUE9AmGQ+W60GZrqs7sREAFRudxzDo1F0kkFyhGsJeleUWrF7u10xszpSlweEu5X9JQvK7eEgcyiqwKxBZk4JA+O+HWbUVVg4WKI9NkASuAyYQ7HZyaYAIFuHE3Cw7kUZCQIfDSgjM6swzK5uy97K6m/+frMDWeU+FBbWXjoLRHq0j2yqweisfESmAyBxumJfzUszKCeCyErwlfymIv1hHydLXf0SLJ59vusrTWQ/MqGYLEiz7/E3/WzJXwwNBckcQHD8lTE0NzSivelpTsQsqKXs+Nve+QD2H97FIDXPu4yHSKTHpO/q7gnhaqOfiTmUsGE/VV1pRynZmwsLLUpyYyHObfc0+xkysHb1kM17OKL6OgHLF+SZKWFmQX6eSbGwWsjIvNmK9LkyOfEmomRnJUt23IcBZgRPkTlPMkELUuwEHaWj3pgBCtnCbNh8NrqT7wk3gTYjzIRtb21FX08vGVjHmdBmgpMMcHkFBNoUFDBBqBg5ebnIITNcilJuuEkndCcbKcnXluCLW7K8x69cRvczTyPG7GMLnWM1v/8u5GzbpiSLknzKDXs4DWTdsE2nKh6YiWE4EcCl6ISSS3vQWoIj5nyCWC2w6HfJxm5cXXtlAenPJTEhNDEOv2uEyzACIy4ExsYQ9ftgJK3GjNGCmMkKT9yKyZgdAyECuXMycXh3JopLMpFN35slLQ1mOyXgmHV2J/nd/FSZmPLEcepiGAOuGGorzFxEBcWyIebZ+jZfvxbQQNb12za6ZtoC2gLaArezgPgvJflndCwC10gUvb0hJuVHVSynqsLGxHUHCvLN9EmsTDzgdvVbre1zdujuDuDixSkV2zJTne6++/JRWmpTfss7aVy4WnbVQNbVsrQ+z51iAXeQioDuBC70AMNkYs1iLKoqD9hebFBqgHbNxLpiTS3xGFlcJBTpi3nRGnPDjSj4BsB2cxb2mnKUqpGZ8RhdVs8C3v4+jF26CNfZs/DTv7Pjj/4bsnfvY8tY4fZSaZZEQhMkEJoitsDDvwXjIDFbiVtaLSmgIDZSScTjZA6n02FUDKlO/m1nzF4UhG8W213K1clYShhfxyZiuHTVzzFVDFPExhw74sTObamsy+rjPRZyHareDIhPTU6iv68fXR1d6O7qVuBWB9XqduzaSXbWWtTU1QjTYtJ8ZBrIqoGs896fGsg6r3lWfWOUMmY+AlkH+ylt2TOKvu4R0jlPIUBga2aWUwFYC4qyGMDOUJ9tqWS15GKjbrWF2sZmLnoiterNpk84jwVk8i9ZrAJm7erykYGUQJz+IBwcKOTlWlFenkqQthXZ2RZ+NyvRIs6BzXQfC6jdR4r7XtrlwiUvAaQxlQG9dYsD4ijKyxXbcEBll2ydeYy9ApsEjNnRHWL2UBiNLQHFirh9ix3lpRYFNJMBnmmFmFumSfXf3R+jDHuYcuwx7N9uwXbKHgr4L3WDyIvL/S+Zk/2TwKmOBIY5+QxEgCO1KdhaKFmUHEQzmTtZg+Rk3gKbEcgqE1Rh0g1FU+BhfpOwrnaPEVQ9aYCLDgOnNYGaAoOSbhHHgZX3/nx40AjZhUWu4mJTBB29USVhIYHiE4coy2Ujg2sSnx1hTQiF4mho8ODy5QkMUAKiv6cBve3PYvferXjbO96JHXtqUVZRuKzbJBCIKxDrwGCE/UIArW1ByozRoV0vTNJ2ZDPD8HYlRuCr2EbkuobEOd4fURJmHm9cSW3U1djpILfBTtmyZLLV3q5e6327m1I2rpmgkoHupxNF3pNVlLXZamKCUwrfo0abcqhoeZv13pI3r59kvUqWq2S+ej1ejv+H0d/bhzYCWQXQKu//yupq7L1r/+uSLsV8Pu4sYM3NLbP63/pdLky2tqDv2d9iqqMd2z/4IRQePAxbdjZSCCbWBdBA1o17F8hYZ4LJEWejY3TI+yDvFgGyHjCT0kMXbYGNZgFOtmYYIYiTaTUeJrtoKMgkhJBaBycmEGISSGBkBD4CWYOjI2RjnUZiJg5HYRHSysqQXlEJX0YZRsyluDyVTQkNO/ZVpqAmHyjJTFBRY/6x/kYz1/X1lXnqGapFNHdGlDKCJNkdu4vjbwni0B+ji7bAUiyggaxLsZr+jbaAtoC2wPqzQIjKegMD9Me3E8x52YfcHDPKSG5RU2VXyesCABHSjdWOU6ympTxM4B8bC+Oll8YwOBjEQw8VoK7OiSz6PYWUQJfFWUADWRdnL7335rWAKGaQ3wwU70XbCJUBSZAjc7fjW4FqxqPy0tn3bl7zrOqVC8VIMBHHFSaBNxPM2km1vArGYvZT0ag4xYEcxmJEK4/e+VWt12Y9Wdjnh29iClf//XvoP3katU98BBm7DyPMtnB76et0z2CSi5u4AuGuTE01ID87BUVUeyzKM6KQhDlpDgG1rs74JUg1y3GCWS9cCeDlU17cc8iJPTtSUVhgJr5h/SvP9nb3orW5BadPnsLE2DhKSkuxZfsWAlp3UHE5G850Jn4zSXy5CoEayKqBrPP2aRrIOq95Vn2jANripIETplZhZA0F6VT2hwhs82OcKJpR1xSXacXYGqfDvqgsB6XleaioLkBhSRbZmTIVsGEzgQBXvZH0CRdtAcnkiJCFVWSoPZ4oFzKQDgQoURPC8FCIYGyy75GhdcuWNFRUOJCWNgtoXfSJNugPZCIijIZCdz9N+/TTUdTVHVQMrZL6tW1LKupqHaissCpHyWo6iaRuQoM/RXbW7r4w2VlD6CRzogy4dm5NJfuihdlLK5N5JsC8YJiTtb4IWih9ODIWV2y19x6worRIBp0rc95k30Y0IUIErwoo8upAApf7ASHYLcoEjtWTVTGdMdN1iIvZjEBWcRRM+QneFgZdF50Fw0A6M/Ty0hN0FBhQmCFMrAY4CUKVrFd5FuebprrG+dwQjH25JYJpgjQP77GhptyEQspVGNnmwqqZrDJFloTuHh8ark6jqXEc7rHX4J1qJdv7OB54+Bg+/LE/hIPphja7dcmnlCzGbjI0t7X7FbDdbmOgv9qOynIbioqsagImiQjzFelT/IEZxe5wUWUkcpwToiOGbMtVXAryLMjKJAsrg+jJZqudr14bYVuUkjYRxOEmI+sQmVnb6DyR9cRMGHstOdhmykSNMR1OLQu9EZrzTXWMRqJM9OlHR2sbLpw/j7GRUQVqraJUTg2zXSsqK5GTm4sMMoTaKP9qtVLmOIl9yJsqtIm/iBNQLGys7U/9CEMnX0EmZXfz9u5D6b3HYXZQx0sXDWTdwPdADEyeI8P3j0LdZF81Yj+ZJGr57ig2kt5DF22BDWaBmWhU9dceMnMIO4e3rw+e3h54Bwcww/eqke9KR2Eh7Hn5cHJty82DnSzmplQHzKl2mGx2xE02+GasaB83o30sBV0MGO4oYeJhdQL5GWTrWPrQeV1bU8bkk9MzSjXid6+FyEaSgsN7Oc+mvF5e1p3NtLauG2aDV04DWTd4A+rqawtoC2gLvG4BiVEKmHVqikoOLvrlW/3oG4igiMpJksy+Z5dTkV2stoLcajZQjE5iiWe98so4Wlt9ioRFgKx79mTQH6PHSottCw1kXazF9P6b1QLTZGLtHk3gCmOIVweAPeWMDxcDFTmzcSpJttRl9SwQZzzGjxiV8gJoik2hn/60iUQY95oLsducjWyDVfnWVq9Gm/NMCqdAgp1xKv9effYsWs60I5q/HdH0EsyY0xSmJJv+m+xMI7JknWGEg0BWYWEVNlYh5LKQf0eUX1eLOEdIwiIkeWvrCOHC5YBiuM9IN+L4PWlUolz/STFUsicWzY/hwSF0tnfi8oWLCASCCrx67333Yte+PYxV5agY1XLuSg1k1UDWee8fDWSd1zzrYqOwtIZI4Tfqcit21pGhKaLfp+HzhmC1mbgQve+wEaBiQ1p6KtIzU5GZ6eTawe8JLOGiA93roil1JWgBBdiMxHkvU8ZuIIi+vgABnORZZxEAa0aGhVm+Fr4ArZTKpTw1GfksHGhsliKOovEJAbOGCEoLY3wyqhhRcnPNKCFQrLCAtskm+zJltlfTWRSm82qSYNb2Tg4UmwNq8JeZYWImthUlHHTlZJtZn5VpJZEEGBqN42prREkDFBcYUV0m0odmlT1l3gCTNxloS+keS6CF4EiRq48QqFudb0ANMyllbab95mP3nD3C6v2/GYCsc+3iIZBy0pfAGDP3ZJn0AT6CqAMElxdnGVCeS+bL3IQCsVoJQL0ddixMtlGvP4F2srBeIYhV3AvZmSk4uMuiMv+E5eh2x1hoS0uf6vPFVF966ZIbkxNeeKYn0dH0K0RCw6iprcPx++/BW95+YkljAbGRLOK8do2G2S+FMDJKxivev6UlNuygHIYwM9xOWkxAsMI8PSnPsyvMY8UwMRlT93x6ugm11VZUlnHMwgmmhf2bLre2QJy29JBBryfuRdeMF91kZ7UTjJRJx0mZ0UkwUiqKUuygOCzMWiL61oZcB1vEISDsq2Ojo2RdHWZyzzDGKXvsmZ4mYzMTNtLSUb9tK6pqqlFcWsLnI3VJz/E6uNQNWYWh06cw8toZTHd3wVFcjNp3vRfOkmINZmVrakbWDXlLE8KagCtOkHZ8Gi+Gh1BC8OrbrGXIJKu3w7AOs6o2ppl1rVfIApJgIEvIPYWIx4MI35VhLhHPNKJkM4/6fGqt9iNDq9lOybaMDDiKipBaUKjWjvwCWPidsGsbroteUD0No5wDdI4C53sSal6WmzYr21hGolZJYjPdgcNTuW6Ruzt5IaxArRLY2bvNim01Zsgc+zoTrVCr6sPeaRbQQNY7rUX19WgLaAtsdguECeQMBmfIzBqkIpNfkZRIrKac/rvyUjuT2sU3v7oxitVuk9YWLxP6fejt8ZNEyIoTx/OQnmFWynmrXZeNfD4NZN3IrafrvhoWIL8ZJhif6mPcsHGQsaXQLGD1rsoEgawpIMxDzVNXoy76HG+2gJdg1gGqGjUTzCrsrPkpNpTSp1ZvzES+0Y40TSzyZqMt4RuJQ0oJMS4bCDGe6J+Bj6Q4fgK8ff44/Pxuqt+FiZ5BTA2OIMVqR86WLSgozUJBEVlyGYMVQGsmFxvHJ+vBpyE+l97+MBqagyQMi+Hgfqci9SnMX/9gViGpCxK8KjGryxcuoZ/J4yPDI8gvLEAxYySVVZWMWRXT9oXEhxhp78U7zjSQVQNZ1UN/q/80kPVWlllf30tnkSDATfpwAboFydI6TZbWrvZhMjcNopO0cVPjXsXiWl1XhJotxajbVqrYWgtLshVgRoNZ11ebbubayGBE7mmSCiPKjJTeXj8zW71oavYQwBFBfr4N9fWzGa55eTYIyGkzFQF8MdFLDWp6+kJ49fS0ApGJas3dhzOwdw+B6mnGVQX4SnsJ96RIf08S0PbiSa9yYtVW27CTQLa9O8n0SHbGlShij1gMaO+JobE9govNEVRR+vCtx2zIyTKRPWZ2UrcS5072MSULS6RBznQlVEZl/8QMdpYa8Pa9ZPnkZNR2GzbLZNdnvuNtFiCrOAmEeUkcBBd7Zx0GBWRe3VFiwL6KWQbWNAavBXgqd9pCAKjTlK/o6IvicnMU5xvCeNsJOw7ttiIzPYVBYTlG8u5ZAZlLQsBVMrG++uoECnIDBJe78fTPfsjaxvCRP/sodu7ZzskF03aXUGTMESVotbHJz77IA/d0jM7aFNx/PBNVlXbVF92OOVW6D8Xm2hvB1aYAGgmG9xDUunu7HTu22rG1nqBL3vu3O84Sqn/H/kR6ZAEkTZOddTQRxEvhYbTFCH6kmM1OUxZOWIuRnWIhMImIBF3WrQXGKcvS1d6BUydP4sK5cxzHh1DIif+RY/dg157dqK2vZ6awMDgTcMN+I5l9x7o1yjqqWNjrgbenBxe+/CUy+0Ww5f1/iNwdOylHXb6Oark2VdFA1rWx+3LPGud747XIqHK6T5FBQpi832IphYlJD8kbmSy3lvr32gI3t0CQiR7+4SFMtrZiqr0N7jYqD5DJPDQ5ASclztIrKsmgXYesujpkVNcglSysljSiUeX9Kc50rpVT/RbjcA554WFwpH8SeKUtQUArcN9WYH8lUJkLpJLB404sInc3yjnp+cYwnnuVsrlHU3HiIBPlOccWyT1dtAUWYwENZF2MtfS+2gLaAtoCG8MC4tMTZtJpKuydfs1DQGtAqU7t3unEvUczIOxiqfYVYrdYByYKUamun2QsP3lqEClkcnvggTyUlTGpnyQsuizcAhrIunBb6T03pwUo0svYlDCxJtDAONUuxgwf3mlATppBgVj1zGxt7wuJxQhCZ5DqeB1UyXuZsRhPIor7LMXYTt9alSld+9WS0ETil5khcc+EewbDJLfqGyYIdIgkPoNRhKl6aqaPojAzjpyUcfhf/C5VdOI4+MS7kFtXTR9QHtsgoWKMUpVbuH6SUMvFHULGUUIK9NsXqaTZGiSZmwlb62w4csCpEogXd7TV31vh03gRcWZCd3d1o+HKVbz0/O8wODDE+NVOHL77MI4eP0YFQRtM5sXHIjWQ9fkFNaqBjDjSD226ooGsG7PJhaU1wpGNe9KPKVLHuWWZ8sJL3nnZFo3GEeNiJG2EjdzZeQWZXDKQV5iJzCynYm8VwIgu2gJraQF5gQtIyuOJEhwZxehICBMTEXi9HJQQnCVMg9nZFuTnkfWzNFUxtDocktVx59+7MjgQGwjYa4DsrCLjIyyIDMMpwGhlJTO+isnuSIZWE9lSVgvcIlT4ETJVdnSH0NNPANVYlOywQFmJBbWUFirlWpon2W0kA1g3pQ8HOXhtaOM9wkwsOceeLWbFzJpqJ6PpGjKzSrbR5z73OYKLLfjUpz7F+5royFuUOC9m2G1QrKxNg7Rn3ICHdpox3fsqXnrpJYySmW/37t245557COiu5yCXKN4bigRhewiueeaZZ9DR0aHOV11djUceeUT9Ji4o8WWWOxXIKoO9cDSBUQ8wODUbrPZwCCjtYOe9nMF7KT8dKCSYla9MCAOrsOUupEizT/E+7eHE6kJjhNMmMAvQiJ11ZpSXGGEl0+gSktJueWphYh0bC+Ps2UnVh6Y7TXANXEJf12tkeZxCWUUJ/vDDj6G8qozg08U5WKV/Dklgm8dvaQuqZ91Dp3UxmaFLS6yoKLeqSZcwL9yqSP8uWZPST3S+zjDtZZ+WQSB+dqaJxzEjn2zTwjKd7D7jVnW6074PJ+IIcumb8aGfWcEjM2Qq499SqkxpyolSkpIKJwGtd/6bc2O0roBXXWRf7WLfLdIskxMTDIYw8EO2VZFjKSRzXDEBOfkF+cjKlmQ03XJr1bIiWR1k+3T/6mm429sxE4ui9PgJlD/0FrL5MWua7bZZiwaybryWj/LdEEAcT4f60U1G7x10tG81Z6HOmM4UCN3PbLwWvTNrnOBgWvreEPve4DiBqyMjCIyNIsD5UYysq/FwGAYmdxiZGSasqkYrHeU2JlRmZcGSmQl7To76bM3KJiOrHSmcmy2myBzBFzagzZVAqwvwEtgqzDe7y4DynNk5wmKOtxH2laS+IFlNWjojOH0pTABrChPjUrBvu1WtU/Q4ZCM047qpowayrpum0BXRFtAW0BZIqgXERyjsrEPDEfT3h9A3ECa4VcAiCWzd4kAFGVpFYU+ke++0IvGpqakIzpyehIuxK/F17tuXib37slYkBnKn2W/uejSQdc4Seq0t8GYLDEwm0D0OtAyRhZJgvcIMA2oLgK1FVK5bRGzqzUfW3yTbAn6CV6eolNcUnUIPVfL8JJIpojreDmOWUsnLIVOrLguzgMRSo3zHekgKNO1NUCWGJFpUhXXzsyTQCCbATIyTuN9NXGxkhHcwduu0J2CJujHx0i+QGO9HZn42ig4fQvHd9yzsxGuwl4yjuhgfbe8kw31nGNlZRhy5y4kCsrIKadlGKdNURRobGWVcq4vsrP2MazETnMXBuFbtljpU19YokhZnmnPBl6SBrM8vyFYayPrEEwsylN5p/Vog4A8TyBpAd6cLPVy6ydbqnvKR3SmC4rIcxc5aUp5LVrZM5OSlU7LdDAsXE98AJgWuYQhLO6nXbwNvgprFmZXi9cbQ0eVDGxlahaXVZjMiK8uMmhonSglmzc21EOxhUmykMoDZLOCnoeEw7RJCQyOBSgS0VpTbKcXNpWaWsdZONlRRkF6tQJPkhBReAABAAElEQVRIpws47dUzPgxSJlzK7h2p2LWNMgppJg4qZ9kVk33b+gk47B2M4TLl2s9djWD/DjP2bLWgpIASzE4OamfJdpJ92tse7/z583jHO97B+zMXDQ0N8wJZ5w7mDgBNQ0BJFvB3n/kz/PznP5/bdG392GOP4Stf+cobwKwCmpXv/v7v/55JC0zVvK7Itr/8y7/EZz7zGQLBlwdmvdOArDFOjCLsY0JRA6YDs86BzpEE2kfIsMT7tYDg1b3lBtTkA1mOhYNX58wf46QrTMmLjt4YWrujaOyIoL7SjAeO2AncTCE7QfKcuQJ0l4lef38QnZ0+nD8/SUB5AncfSsfvnvs5fvv0L7D3rn04dPcBPPS248jO4U22iCJO2hCB9OPjUXR1B3Huolf1tUWFFhzYl4bqKgIDpP+9yZhhNkOPtiYQQOTHXKM8Rk8IjS0hVYMsAlj3705FHfsuCZQbyWagy/ItIBnBkgXcTCfKVUrcXI5OoMLoRK05A1spcSMOFTuMMPNFoQFLy7f3Yo4giQ3SV4cJvgn6A+jp7kYnWVivXr7MZLRJlaCyZ/8+7DtwFxlY6/i85ujx+GIMvML7xkIhuDs7MfTqK+j82U9QeuI+bHns/QosZXYs3CmzwtVc9cNrIOuqm3zZJ5R3xEg8gF+E+zA1E8b7bFWoNWUgle8G7QNYtnn1AZZgAQVaZcLeTDTChWsyX0dDTMz2+RXzqm9wAN6BAfgG+uEl86qwqpqdTmRUVXOpUqyrwsLqKC4isNUCgzgHklSYHw6XG3i+GUxATKCuUIKIwHZKOlpNCRVESdKp1s1hhsfiaOMcprWLCfOeON5yb6qay0gu3GbxuaybxtjAFdFA1g3ceLrq2gLaAtoCC7SAKDV1dgXR0ESJ5ZYggawcM9SloqrCRilfxgQkRnGHufpCoTiGhkKzalinxnH0njzcezyXfs3VVcxbYBOty900kHVdNouu1BpbIEL+miCBq8LCermfRD7+BBkmgYe2A0WUSLcvLi9zja9m85xeVPIm6VcTdbznI0MqNbyScZidpmzUkJnVZiDmhhEYXf7LAkqFNmFQzKTC26RiqcQY+Bk/nCT76sh4XCnFjE3GycYaV4kxWVS3lLh/aaEJRfkpyCX4U+KJQqQV9fvgorrd2MULGL10EeUPPoT6Rx+DkcnMyfQN/dcVLP+TgHOHXFH86rlplRwkxGBb6+zEepAcbBWxHcu/EvZbwSBcQ8M49copNDc0Md7Vg207tmPn7p0K0JqfnwerzcbFyrg1CXbmGRhqIKsGss57T2pG1nnNs6E2xkmlIGysQQJa/b4QAoEwPERKTbv9mBz3EBnvxdSET4GbBMRaXJZLcGsuBNyax9GRM02AKfrluqEa/Q6rrGSlRMn4GQjEFSvr9DQDrqNhxdQ6yrW86wTUWl2dhsrKVPVZQK2boQgzos/PwRxBrMLO2t0b4mAhrhwm4jCSxUm2Wss87IjJtJOA6BTQbSKG7r4wmsnYKBnJaazDgX2zmdgrAWYlez3PK2DWKANtMQyPMejJuhzZZ0V1mRmZlNpYrUCbsKIKcLStrQ0f/vCHCSjsXBSQlaTZzLA04Ml//By++tWvquZ5+OGHceTI3WhqasRPfvITBWD96Ec/ii984QvXwLEvv/wyHn/8cbV/cXEx3vOe9/z/7L0JlFxXdTb6Vddc1VXV8zxP6kGzbNmWLduY2PAINtgYhx8CYUgCfrxFFi9v4IXHnwc/sMKDBX94JIRkAQGCMcbBjsE2P8azLUuyrLHVavU8z2PNc71vn7IUWZZa3a3qVlX3PWvdvtU13HvuPnc4e+9vfx+vGb8Cws7MsHSTTbb3vve9T71e7Z+NBGSVewsJzDE0mwSuDszwDTZhXy11JVDMKlfWdyCHEpo2Eyv6yO67UuLnebfIXURx6ERYVQ421pKluMrA89LAybpOgaxXOxYX/04CqMLGepBsAB0diwrkbzJ44J3vw9HDr+JsZzs+9qk/xW3v3E8mdjoN5pVFPebmo2RZCOHYCY8Csxbkk1G2yoJ6Alhzcoy871yeBVruAyKV0T8UJvg+hEHF0hBHabER5aUmxSQtge1sO53Oy4BhLz5e7f/lWSCS4HOCQKWZBFm8CVbqjboxlQjAzNBJdZYdu40FKDBYYef/Wls/C/i8LPgYGcXZM504dfw45zceCOC7sqqK8/BKMs5XII9MrLlkk7MToCPM3lpLHwvEWRQiLIDTJ46j+7F/J/ufWclXV95+B/K2bEmfjq5zTzQg6zobPAW7OxNdwNHIDBbiYTizjHgH5c9KsqwwSCWc1jQLXAMLhL0ehBYWFEjVMzzE9RABrOMITE/DYLXB7GLxNZ+N1vwCrvOSTKsuF/RkejDZ7VyyoRfpMjKyStR/qcD4Sg8vIsVvUR0G6Fr1sPDt9EgCBU4d2sp1aCxOKjesdJvp/v2AxBtY7HfweBhnyBBSW2FAY40JLfVGmDcgu1q6j0em9k8DsmbqyGn91iygWUCzwPItEGHhup/Ak3ESW4yMhtDP4nWfL4qqSiHcsKKFOYqketzyt5nu35RYp+RmJAb74ovTVA00o7Y2Gy0tDhQVrUwBK92Pda36pwFZ18qy2nYz1QK8rWBsPoHjQ5KzYu7Km8COKmBLKcF75CSxUDlQg2uk5+hKXJ/luFgkM+tQzIezjLedJrFInd6BRhaMtxlykZ9lVuQV6XkE698rIb3xUwlmek5Aq1EFXJ2djyt1S1F8lVyhM1sHF8mqhBQom4BVAa0KxsDKheF4ql0yx8p8osR+4kTDioraxCECKf/tZyjctQv197wfjvIKmKnWk45N5hJegtW7+/xkZqUKZncQN16fjb3EU9h5/EspX6bb8QiJVigYUoys4wS0Dg8OKTDr5NiEAq+WlJagmcDW+sY6lf8SLMXlYnYakFUDsi55fmtA1iXNk/EfBghm9XqCGB2ewfjILMa4XiS4NRyOKOCqM8dGaWA7nDl2uEhB53ASDEdAqyxmzpSMlGxbAiif8fbRDiB9LSAPdVnGJ3j+jgTR3+/FwgLZJzlJzMkxkbHMxKCBicBBi5K3tlr1ir01fY8oNT0ThsO5+Qg6zvgwOhbCIqW+CyjNXV5qQQnZEgv52uWkzOKbE7rU7PXSWxFwoIyRMC7KpEtkheYXoqivsaCGsuOV5SY1AV0LcO0i5cmnWKV19HQIw+NRVZVVSyBrY3USZLfWyTaZeH30ox9VINbBwcHzBloJI6v8aI5sfLt37+Y9OYxPfOITKLrtq8gnwVttIdD+3D/jy1/+str20aNHOb6kAmL7i7/4Czz55JMEc9dAwKbnWpST9+uvvx6TlOC8/fbb8dBDD537aFXrTAeyyvnJug4Io5KAWGcoSTG5CMzytZdOUz4dowoGBZoo0VJAmzuZA19NE9BmiLemnsEkg9Ekwd12axZu3mNFWZGe4G4i8FPUkvdFMkONCxOrD31c5udDlLRyIuAZwot/+B98xs/AyGTzn37yw7iejKwCtl5uk/uLMCsM81oeGAxgmoysIgvW1pLNgDRBqOWXl0YRQLkEshd4D5gkW/P4ZETdG0R6TICrzY0WVJaZUFRIz1Rra2qBEOWjA5SPPh2dw9nIoqoQtmYZUK6zoZzMrGV6zvl0ZDfXsTZYm+StyVhIcYHX48UswTgTExMYHx3FxPgEJvnaTvBNPtm7W7e2oZZyKwJkNVAe+XLO/Jp0UNvoii0gAKvRV1/FLAtNfBPjaLzvAyjdeyNMDgeyJOK2yZoGZM2cAY+RKSIYj+JwdBrPh8bQZMhBo96JVmMuHLrNd+5mzshtjJ5Kgkf894jfp5hWIyzuiAiAlUUdYTdZKChLFuYSWlxAWN7jszMWDsFWWARbcbFKQmSXlyH7zWTEejJh081Vso7DTCq+2h2nX5GUddxaAdTTV8ujLyHJxY3UZLhE+eR0dxhuJlKLC7Jw404zhAlFFGC0plngShbQgKxXspD2uWYBzQKaBTaOBXwkIllkDPHEKS+GhkMy5SOo04Q65gVKipm7yTUoQOt6EU6sh2VHRvw4ccLN2HtQkbHccksBCVdszElpOdQr2V8Dsl7JQtrnm8UCvFWSjZFql24deqbIxsqiSRGsy6NC4PV1OlQXJGDkGyslWdks9kun44ySVERyMJ0Esh6KTCPKnIzkW7Ya81BFUpHiLBZ2sHg8ddnBdDr6y/dFCl4U2zBzsD4/icveXHv5WopnZe3jWgirRHBUgKt5uVkoytOjUC0Sf2D8hcDVpZqQTwjxROdD/6YKnF31zLPccityGhrSNs8iuWS3l3m7MwG89JqHuA4jtjRY0VhnoQ3060bStZRdV/qZyoHNzKL9xClF5LK4sKhyXQVkZS0qKebcsBCuHBecLFa32eyw2qywWpPEioKz0ICsGpB1yXNOA7IuaZ6M/1BAL5I8iJL6L0oqQ2FtdZOhdWZ6EYN9U1wmMTwwBb8vqECsVbVFTKqXoX4LGVrKhBnKQhCMFrDO+BMhQw9Azl2RuJaHu9CuT0+zyrffh+4uD0FWfgJYCeAss2LbdhcqK20oLNz4FbBCwR8nk6eAw6YIIO3u8aOzy68qoFtbbGhttqOFi6LYXydvR8ZI+nOWYNaOswEMDIcVgPW2mx2ormDii1LiqW4CmhP5gaGxqJJAfKOd7FKc8N62lwBaTv7yKb2xlk3OzfLy8rftYqVA1ieeeAKf+cxnFL3+4WOdODhgxuE+HbItCXzw+izc845WAgMX8KUvfQkPPvigmoDfcsstiv31c5/7HL7whS+8pQ9/8zd/g3/9139Fc3Mznn/+eXX/f8sXVvBPJgNZOTwqgNo7lcDZ8WRlq5uAVqnaaylLoLmMTKw5OjhpZxNxnvKYW21g1RcgQJag6teOBSHn4b7dZmzbYkIlJS+onLDq7V5qqORaCxIseuz4Ap5+epxgZhvqGTAtKgA624/gX//lR2jcUo/9d9yC627Yjaqayktt5rLvjY+Hceq0j8B0H8GyIdxwvYv3EwIfS8x0LnR0QC5/XYVCcYyOE2TPe8DhYz6V7C4pNGBbmxU1lWZ1TzKSMdogkRmtrakFJCDG2R8E0CpS0mcpc9MRmcOJyCyqDA5VFbzTmI8yBlP0mzCYsqbGF9vzBjRG4GpPVzflVV5FL1m7I4zKVFMGefd11/EabaIaQqW675sohaw3aLLeaz0mqdh+LBQi+MqLrl89gq7HHkXtu9/D4Nh+5LW0wJTtSMUuMmobGpA1c4YrkIhihpJnL4XHKXk2ig9a6rDPVAI+ATQ21swZxoztaYJOW4LJBffQENwD/Vjs68VCTzfmursVoFWema6aWjjVUqMYrx0s8DAyuG2gDJmOk/QsPYEBUvDBALcs69nEp/AzyTjvB470A891xFFXmIUm1hdKklGK4TZaTZAklkYmonj6RT9ijCfeej2l7soMBLUuvzhuPcdI21d6WUADsqbXeGi90SygWUCzwFpaQOZJkmv0y9xhLIjDR6gKxML2MOdO+25wYdeObMUwthYEF2t5XEttW9TxPFTIevYPkzh+bAHvvLMY27e5FNmK0bi+89Sl+pmOn2lA1nQcFa1P18ICvG0q0pUXziTQN02WyjB9y1rgpoYspRRoIamIlj25FiOz8n1K/oURAfgZd3NT/ehFxt2EmTWbReOtLCJ/h7kM1EFi/mXzjKjMDSSmMLcQw8hkjPn7CEZIRDXvTrK5C1C1rMiAUhIAlTDGUMTF9iZoVcI9wsmjJ65BTLYcs/nGxzB59A0ysx5inKkLO/7yM6i47fZ1jx0t9+wR+whua2wimUft6Q+SpTWOP74zB00NFhipFLqc417u/tbje3HG/eK8sQlZl5cF6kNkZ+0604X2k+2K1MXn86G5pRkNTQ2KnbWsopzELuVk2aWOJMkUNSCrBmRd8jzVgKxLmmdDfhgMhuEjS+vcrAfTkwtki3LDs+inPAbJ0HkDPUfxbLWZiJK3U+7UQeYoJ3LzHUTMM+XFhPtqAT8b0qDaQa2LBSTJ5fPFKHMdYtWrLPKAjyJM8JTgNZ1OI3LzTGSttChAq8Mhct4bO4DgpT1mZyME9ZK1luysAiQzEKgnFc9VlRZUU9LHIpNAgsfWowl74xhZGHv6gmSJjPFeAQVga6xnNRHBrDZKAaS6CVOMgAhPng1hdiF5LjTVsoqpjsy0lCEQ6YG1ajMzM7xn0vNke/TRR/HVr36V7LgFaG9vP//+lfb9ne98B9/85jdx66234gc/fhgTZAxtHwErMgngJmD5+MN/TsDi07jzzjvxk5/8RG3u/vvvV0ys73rXu/Czn/2MQO+oel+YN/fs2YORkREFehXw69W0TAOyitsYkESzT0dZljjGFnRwE2QqwQBxEBy8Fvg4Q3keQawuylUQxGqmY7DaJkPvI6h0kGDqE2fCCAQFtJrA7jbKS1GK024j8DOFoE0BsQor9enTbjoDPgaHQ9i61UmW1CycOXkKp469gSOHX8Ptf3Qr3vfBe1BaVkx2dWbXr9CkUECYWPt5HxEm1pHRIJ2ILAVAb2q0sljAokCo+ksci4DJo6ywFMdrZCxMFlbOL1hRKeEWYV4tJZi3giyscv3L7zPNCbuC6TLi4zArg6fjAcrceNEf88BDYKuw8+XqzArIWm/g/I7srPasDUYpts6jEyVQdW52jqyr4xjsH2ChyRRm+YyQuYs45fn5+SivrCS4vBqFRUWqCnWdu6jt7iotcA6MNXrgVYy88LxiF8wuK0f93ffAzrUArjZT04CsmTPak3wGHAlPYzTuU8UNf2Qux1ZDHmGs8rTWmmaB1FkgxqC1gP4DM9MIUuLN/+Za5N7i/CweFXWV5P4SnJ8YLFYYs7NhzS+AhT6U9c3FkpOrgKtZK1AVSN1RvH1LDJEpNpF+Jhk7xgCGz5Sf1kgwa31RkjHH8Gai5e2/zrx3xAdd9MRx+EQQ49NxglmBbU1G7GwxMb5CKb/Uu/SZZyStx5e1gAZkvaxptA80C2gW0CywYS0g8UoP2cUkPzEySuU0xhatVKrKyzWioc7KXI1RKTVthHyiHGs0GseRI/M4eWKRrGJ6VFfbcd11QggkqkfXbpglDvXyyy8vqwN1dXVU99p1/ruiEiR5gJdeeknFs7Zv3459+/ahqanpfN7h/JdX+UIDsq7ScNrPNowFJJckvpWwsHZPkKBnlkyszJdUk6CksViHWq4FyHct7yMbxtjrfCAs3yUbaxxdJBPp5jLC+BtRNKigMp6oItXqHTCSTGQjcbNKvlXCOwGyrXoIxFx0xwlW5ZqxBFFtDJBtVb6T/FYyT2pi+knIqHIcOqq+GNRrB5mITcRxrDZvGPF54efzr//ppzD0h2dQ/773o/zm/VT1YayerJ/p2gS8OkNsxxsnqLo5GEITGVkbuNTXmInpyNygS4wBpYX5eQJYSaI4NIzpqWnmyGY5vskYtMKf8UYna8mZGXlSBIIBjE6OEdxcghxnzpoM2dbtW9HGJR3bc889t6xu6QIBoh02YdOArJtw0C865AQj8x63n7Knc+jrHidz1BgGyNTqIX1dTq6dCPlCCFNrdV0xWVrzCEZjANsk0iB8FAtDhgraX0Mv7aLj0f7d+BYQwLUwtA4M+Cnt7sWpUwsKxGk269Ha6kB9vR1lZGq128k0RAZBcQg2QrDkciPrp5TP3HwEh173oJcVPD4CfJsabdiz00FgpZEgX4J616mSR2QDRsnqeLozgAOHPQrMtnOrnbJCZhQXGdekHyLFkQSzhvH8wQBBrCaVaKspNxBAp1fJttVOhC9n84vf/+Uvf4nPf/7zKwayfvazn8Vjjz2GT3/60/jbv/1bkDwbs14CWIeA35+Ko3Do/8X/993vquDSrx97kslD4Kknf4u//Mu/VF24/fbbcc899/D8D+FXv/oVjh49qiaFTz31FHbs2HFxN1f0f6YAWSUAIIDKSFyHOQKb+6eBM0wyt1OWxUFcUTFBq3tqsxgMSKCMLKwSELjaJk5YkMDxsak42rvCePlIAG2NZtxMNtaSQj2cBFGnssn+5LoeJBP1M89MqqKTLU0ONPI6Nxk8+PH3f4mO9g5YbHG8/4G78YEP3XfF3cs25V7qJ/B0kuzOBw4tEIgaUaCW3TuzycbqVEDwSxUECDN0TACwBO+63RGcOB0gE6uffYwTvGrC3t12VJKNuSAv9WzMVzww7QuXtECY7KwidfNGZAavh6cwR3Y+FwGs+0zFqGEwpYSBFXKdqQphDdp0SRO+7U0pZBDnPBIhgNvnR19PD06fOoUjBw/zugrATErmm26+GTv37GLFaSOB5ZuPtfNtRtsAbwSmpzDPse74t58iwirjrZ/8cxS0bYW1kDrTm6hpQNb0H2xhhuAUSQXSHwv2w5VlRqs+B1sYRC/jPV9rmgWuxgLnwP1xFtQlKBeSEPYFrwchKkkI8+pCX59iX/UIE+vwEGwFhbCVliK3sRF5jVuU1JsUA1hY6LHqjMXVHMAqfhuhvxGM6PBMewKnWHhooV/WXArs36KDnSoMovKw1j7nKrq9qp9EWCc5NRNlsWgYzx0MYhdBrO+40UrJPx1sBKZoTbPA5SygAVkvZxntfc0CmgU0C2wOC4xR3amT8cET7V6SkUSwi7mJZsYua2osjDFSpekqCAXSyYIjIwGqpXkJaJ0jmNWAu99bSulcM0EZ147B/plnnsGf/dmfLctMH/rQh/Dtb39bfVfAJZJn+M1vfvO23z7wwAP43ve+lxIwqwZkfZt5tTc2kQWYhgF5xOAL6/DCmThODFGZhCQoW0oSuK0lC3ZTUjFwE5lkQx6qAFpnmXN5OTKBrsiCyr/cZC7GjQaSWmSZYNEJvDUzsTQql6jyiczFsqAjkdCx4JekQotUjp2NEYgY5RLD+FSUuRKez0wLVpaScIuLrIV9VdhYJTe7FnGT3t/8B7r//VHGmhpRxLx46b5bYMnLU7nydD7Zjhzz4mRHULG9V5SZISq3Lqde4SjSud/L7ZvH7aFC+Ay6Os+it7sXIwS3jo+OKzIYo0mKpUlQV5CHivpKTI1MYnF2YbmbXtH37vuTDzBnfv+KfrNeX9aArFewtAZkvYKBNsHHwhYVJXoq4A+R9jmgAKxuMrQKuHVh3gcvAa3yvp+fywOmsMiF4tJclFXko4hrYWwVJsCNDBTcBKdBRh2inLNSweallIuAqObnw4qZVNhaFxbCCuQqjKylpVbU1dnJKGzmw9+4JhOkdDCcgPiEjVUCRCLhI5XPs3MRZZ+6WgaLqs2oq7Uim8DetZgkXmgDBYxjxdX0bJQMj2R3JEvjBEFyjW9WE9XXJtkdL/zN1b6WcyHICq8xTpK7ByIYJbjQ7YlhV6sZDdVJGUQT2WPWsq0GyCqBorvuuotA7FP4whe+gM997nPqvA7RAZj2AIMzBGM+9wP8t//2FVRQYvPHjx9BeS7BmeYEfv3vv8Jf/dVfXfKQBFzy0Y9+VDEBXuoLAwMDvE6uPCGcmJjAwYMH8YlPfILV5dWX2tQ1fU+cJ1mmCfwdmaMUC6tZp8iQFOb1IM5/AROthcSNFTqBPFb2ZZOR1cqEcyquAZHHmJqN48BRv5LFyM/JQmONAVtq6ZCSBTiV55t6RvOcOHp0gTILHnVdl5VasGt3DhZmZ1iA0o3fEgwdj0fwznffhj17d6Nla8sVxyYQjHNbZDNmcLmnN6Bc6Nw8I0HnFpSVEoSaLwUrb6+GFJvLbwWw3jcQQndvUDlW2QTvlpWaUFpsQjHZWK1WnQpSX7Ej2hfWxQICPo4S0jSXCGMy5sdw3IsxrmdjIRTqLagjM2uj3olSvV1j6VvmiCwuLmJidAxnOjrQc7YbHo9bzYcLCotY+FWKsvIyxb6al58Hh8OppFKWuWnta2lsgSirhEOsLO777W8w23kGZlcOSm+4ETV3vSs1D5g0PvYLu6YBWS+0Rnq+FjYIYWM9E13AC5Q322Jw4U6ysTpZxGDTaYUm6TlqGdIrzimCvA/6Cez3jo7CO8ZldETdG0OLbpioCGCwZ8PsdPK1Q90nTfL63CLvOV2KyVqfQWzWMgcWv3t4jn7anA4do5xbsQhRiuZ2VOrIorNxGHTEpw+GgP6RKA6dDCkf1WnXYe92M6pZLJoKfypDznatmyu0gAZkXaHBtK9rFtAsoFlgg1lAyDYkJj88klR9Gp8IK9Wn6iozGuttqug9SYqT2QcuZAMzVMp68aVp5lBjqG+wY8sWB2prGYC+Rk1i+Eups8ViMXR2dqreCbHGF7/4Rc7pdPjKV76C73//++p9yVPcdNNNVAM7jccff1wBWD/1qU/ha1/7GueDUia5+qYBWVdvO+2XmW0BuXQk39czCRzuE/XAJDvltgqQjTWBEhf/XyNwX2ZbLvN6z5ABgvEophNB9FEZT+JxQi5iJYD1BmMRag0OZOuMGQdmlfhAjCRC84tUzKUS6/Qc8/9zso6pWIGAU23MvWZTkdXGnGC2Pev8azv/t7MYlnwfKle4VrGEmY7TmDzyOqaPH4OJyj8tH/04XDU1yBJmqDRuM8RRDJHN/vVjPkUctK3VhlriOUTlciO0SDiiSLjcbjexZh5FBhMI+IlHC1BtOcx5BlUOiVXoH+pHZVkFicny1uSwm9ua0dLWuibbvtqNakDWK1hQA7JewUCb9OM4GTV8Psq3j89hdGgGI0RUjY/NKVCrlYysOXnZKCh0KRBrbj4fvtkW2LjYuZgtJjqoEtxeW+DYJh0a7bAvsoCAvKTNzoYxOspq2B4fxsYCiLAqyOUioKrYjMJCWSwEkugJrtKTVXjjJl+83jiGKQ3e2eXHWS5SvVNUaOLkx8LKYBNycw0wm9a+AlqAtR4f2Wo6/Dh60ssJLCuuCgxooVR5STGrbFzJMUjlbUIkCxY9CRxpD+F0dwRF+VkQVtYtdbI/jjsn02vVVgNklQKAlpYWzM3N4etf/zo+/vGPn++eJEWDZMJ55KEf4/9mYKmQTG/ffOgUQawxMicOssL6Y+ghI5w0l8ulgkkeMsNJczA5/C//8i+49dZb1f8X/xHmVglIXakJeHVwcDCtgKxyucfoOAXIhuQmkb47oMMkwavjCwkuBFiSnTeXSdYaBgGaSwlkdeoUK+uVjnW5nwv7q7AOD45G0TMUwdm+iHLK9u4woaLEgILc1FfeC1h/ZiaMw4dnMcZru6raplinhXX5wEtH8eoLh3G28yiZ00vwsT//GCqrKuF0Eb17mSYJ+CBtNzUd5r0ihL7+AKZZBFBXw+1S8qu5yUr5ireD3hXrLY99kQ7rNGUvhkbCisF1kuD56koTGghSr681UzosKaWlzQEuMwBp8HaEgNbRmA89UTeOk6GVpzWcrAquJ5C1Ss/5XRbncwQ5SZWw1t5qAb/Ppxzued63Jwn2HyHT3NDAoJJLsdpsKK+swHZW/dbU16G8olybC7/VfBvmP5HInnjjCKaOvoFJrgt37MSWDz4AE5/HRoK3NkPTgKzpPcrCxhpksPxYdFbJmk3EAthlzFdAViKuM5T/Ib1tvhF7p1hXmXWL+v1qifh9iPB1xOsl8+o8ArOzyWVmhusZxIJBVUjnqKiELNmVnJNWVcFZWaVAq1lkW9gITfwBUdA41BvHEAGt894EtjIJubUii6BWJmlMiZQoQKSDrWYX4ugZjKCTPs/YVAz7rzOjrcEEB/2tjcKolg523kh90ICsG2k0tWPRLKBZQLPA6i3gJrhT2FnfOOZRKnJmsrHW1lgZN7Qgn0X0oqInCnqpzAusvrer+6WAdo+8ToXLfh8CgRja2py4/vo8soutfd5lpT2WGK2AVQW0umvXLgVSFRY0yUns3r2bpDBhFf+X/MS5XNsPfvADfPnLX1a7EgW4kpKSle72Ld/XgKxvMYf2zyaxAFPUIMwCoyRh6RwXFUZRDAQainXYzmJIIWHJ5PvgJhnGFR+m3EcnCWYVIOvZ6DzGSSbSZshDA4lEqpl7ETCrOU3zLir/KsRZZFUNBKXANa7Wfr5e9CTz7wtuEowxDiL5fyrDUw5ej+KCLMW6WkzmVfk/m4zD69lEHUgKrDt+9hMWXU+j5cN/ivytW2Evvrpn11ofg4CE3bTrKwc9ijhI4iytW6zY0UYlTtPGjLvI9SFLMECyECrNdpGo6emnn1Z4hpbmKxM0rWZMsgludjjTUy1RA7JeYUQ1IOsVDLRJP5abiNxAI9QUi4RjRMZHFCOre8FH2uc5jA3PYGxkDovzTGKEoqioKkB1XTGq64uZxC9QjK3iIGmTsE16Al2Dw46yqi0UinEhG+ciWTnHggTh+dDPYIJU+jqdBrS2OlVlbHmZhcxowjS4vpOp9TBLjJPMcDjJSCqsrO0dPsXQKjLgtWRavH6PUwWMBNS7lu3chHeRVdjTZIp9nRT545QXyCGAtaXRoqTHZVImQatUNaluFLDdxHQUw+NxvH4qiDCBd7taWPVNtsyairWrvloNkFXOv5spO91H6U2pmH7wwQfPm0Lg2WLD//6db+Nb3/oWmpubcc//+Sy2k2H2bz5+PYYInmqkNKc8w/fv368mfq+++qoKSEl1tQBfDx8+zKIClrpd1EbJnCQVUFdqso/XXnstrYCskjgO0onqm0rg7ARwejQJbBVpzy2lWajKkypWgvLoKLGeAkae5voUql8mwdJxvHwkCZZuqk0CpZtqyG5mQeoTujwHzpxx49DhebKnEjSbbcS+m/J4Det5nQfx6ENP4MU/vIy8Qiuuv3EH7vuT+1hokqNYIS83vn5/HAODQbSf8eLYcY9ia25sYKUf7w+F+UaCWLMuybDu4+8WFqMEpvvJwspiAY5DcZEBbc1WxcCal8vfko020wPRl7PbRnpf7i9SDexPRDEfD6MrtoB2BlW8ZPWVQMo+St7UEdRanGXVwE4XDLzMjQf7B8i+2oXXDx0msHwUQYJ2Gpoa0drWpsCrRUVFsNntLOoyM9iwMQA7F5hAe/mmBQTcFSaQa+bkCXT8209VpXfp3htRvOc6uOrrN4WdNCBreg9zjPcrdyKCXwf7FCvrNgbMWwy5Kmie3j3XepdOFogxoR1jUNk90M+Fig59vVjs7+PSjywW5BntNmQLYLW8Qi12JrdtZCXX8xloMFugpx+iM5DhX9ZrpR93DQwmPpoUHbqDQBf9kYO99L/pa7vIPnLbFqCuCDDRD0mdl3sNDvLNXUZZWCnKJweOB/E6mVmrywxopAJFW4Nx3RNT184K2p5XYgENyLoSa2nf1SygWUCzwMa1gORpJCa/MB+hmlMQx0lyIfkKG1nZbrzBiYY6G8lGslKaF1hva4q08jxzL6c7FvHss1NoanLg9tsLkZ9vJonK2uZdVnqsXV1duPPOOxnzteCFF16gimGp2sQTTzyBz3zmM0raV/IJVqv1/KYlbyEEHKLqdnHe4vyXVvBCA7KuwFjaVzeEBcRvFBDrEBU9/nA6wdcJqgYyV1mlQ3NZFpUDExtGPnxDDFiKDyJClaQAYiwuX0BndFEVmTtIJHKrsUQxswqRSDo2eXaTKFOpn44xnz8yEcPkbIzqlFE4+GxzObJQRLBqEfOTQiSVzSJXYVwVhUqjyvczRyo52RTm/ZdjpziDF1J0ffaXD2OuswMOFlQXX3c9Km69bTk/v2bfkXwTYViKdKijM4iXCWhtrDdj314HSkhMJuy2G7UJU7yAIM5yjvLII4/gPe95jyq2WYvjzWJMUojF0rFpQNYrjIoGZL2CgbSPz1sgRgRRMBDGzNQipicXMTUxj3lSUbgX/UxkSGUAkxmM2FttZlZVmhVrax7ZWvPynWRrNSPb8Z+O0PmNai80C6TYAvLgD5OVcXY2hImJIFlag2QQDCNEKWwTq38dDiNZSsmcSJZSYWl1uQS49Xb2wRR3a903p4C9DBD19QcxNBzE5FRY8S9JkKi8zIwyUtMXcyIkASQB+q5VS/YjgTNdAQwMhRSTo0gMVFZYUEMWx1Kysxo5yU1lH6RSbJ6V3yc6CWjmZFsScFVlejTXccw5wRYGmVS31QBZpQ/33nsvDh06hHOSPhf3SwJFP/zhD3HLLbfgo//XL9HoGMYdt96ovvbEb59GRf0OOsDJZKm8KUGnO+64Q33+61//GjfemPyuemOFfw4cOIDf//731xTIKg6/LF46/bOs8psi/nbKzWq/oA5ejnMkRpA6Hy0FLKaqyk9Ke7ooVyEA1lQ2AUkHeV8ZGY+ivTtMuQOR02DgodVM1l89JQ9YbZ9i50wq+4Vd+mynhwy6blSTMbWuLhuNlKtamJvFsde78MIf/oDe7jO44137cdP+vdh13S5YrG93gsWGUpwikl5j42EGkQMExtJRYGtsEEYEqwK4y/3hwia/E/DuFMHo45MRjJDB1edPVszl5hhQXmpUbAp2XtMW3l+1llkWiJOxT4Iqws7aG3NjNO6Hm8BWYWIVEKuws5bpbchnYEWfcaI3qRkLqQpdmF9Q7Kujw8Oc/05hlsxzQertCntFTl4u6ghcrK6rIQN8Mee66VnZmRpraFt5iwV4g3QPk5H3D88oUJcwE9bffQ/Kb74FBrLzZhG8tZGbBmRN79GdTYQwFPXgxfAEYrzPv8tSiUq9HS6dBrBP75G7dr0TplVhXg2SlSm4MIfQ/DxZVxfUEmXRhjBRx1jFJODWBJ0royMblpxc2IqKYePzT9bW/HzFTC3VzBuxYPTi0eHUGhP0CbondeibTmCG4hjVBQSyFurQRGyASkym2D+4uA/r8b/4A10DBGlQ8WSKCSw7fa99uy0oLTQo2cD16IO2j8yxgAZkzZyx0nqqWUCzgGaBtbaAzCEkLyCKUL19zNGMB8kAGlVKTqWlZlVQX5BnYh4xM+OJcnwR5l4GBv148cVp5jbAXJMZ27e7UFVlUwQ/6TAnjjOoLbkCAbN+85vfxEc+8pHzQ/+d73xHvSeqbg8//PD598+9+NSnPqVY0gQE+5Of/OTc26taa0DWVZlN+1GGWiDMfGSAJCCnRxPon6bfuJhAPnN4reU6VOfrqOSRoQemdXvFFpiJ8/nHnMvJ8CzmGKuzMe9Sb3Bhi96FnCxiaaiKd61aRBWdsEiXjKBuKr3K4mHuT5hW5bNIhAo9PJclNxrnQ8+ZTbZVh465UD0VULOQz7WZYUYBsaZDk3jVxOFDmD5+DLMdHSjctRvN/+W/QG8yc0nfeKjMJ4T5VvATB494aW+dArDu2m5DdYWJZClCypYOFl6bPpw9exa/+MUvcPfdd2PPnj1rs5M03qoGZL3C4GhA1isYSPt4SQsIsHVhngCIs2PoPjOCrs4RBXQNsNSofksZGprL0ciloqoQxWW5ipVC2DjkppsOjtySB6d9uCEsIJOAkWG/YmY9dnweE5S1EdbOxqZsbN/mUgyt+fkmBaSUc3IjTgh8PgG0BnDspIfMjh5UV1nQRPDa7l3ZKCk2KSDpWl+PUlwzORXBK9x/P9kgZ+ejeOd+Su6wDxKwksluKvsgzLQy4e7oieCpF/xwZLPSsd6EHc0mxSRDeGRK97daIKsAWB977DHFzProo48qZtVzF55UCd13330QQOknP/lJfP4LX8VzTz+Kv/qrz6mvvHRsFNMeSg2UAw5iFwWPbCBwpry8nE5GBN/97ndx//33n9vcitfXGsgqyWEVFKSzNLaow+mRGE4O6+j80/Gnw1RflMB1tTpU5iVlWFZ8gCv4gVQiirTmG+0hPP1SgOeRGXu2EsRZSSCbM/UBVznucQZ4D742SzB+gAy6Edz1rmLs3OlSz9FDr7Tj5z96GsPDp2CyBPA/f/6zuGHfDWSCJHhKIqcXNQkcR3gMB19349RpHyYnw2RiteCd78hBAe9/2ZT0uriJ/eV3EwTBnzwdRMdZP3r7Q9izw4YdW+1obrSyKODt+7p4O9r/mWEBAbUOxrw4TWbWF8PjKjghQNYbTYXYSiY/M4MqLPlQ519mHNHqeykFMdKkKtS9yIrprm4cYcHBqy++rN7Lzc/DLQzy79yzG1vIlm0UDR2tbUoLxEJBJavd+/hjOPGD72PrJ/8cte95L5kJy2C0MUK9gZsGZE3vwe0g48OJCBVUGCwvZDHCe83VyGOAXGuaBZQF+JyTZ5163skzj0uQYHzfxDjmus5inkHkea49IyPwjY/DWVuLnPoG5POZl9PYhDyuLXkErWrFG+fMicN9CRwZYNyBkpGlOTq8dyeTk07AxlzJRogvCCvr7EIMjz8TUOtbr7egkUoh5SXXLummXc3paQENyJqe46L1SrOAZgHNAtfaAjLl7O4J4BSV406e8jB+nYV9NzrJOmZFRTnZ+zM4JzM/L0BdL06ddJNgwo1731+O3XtylWpXKok7VjOGEiP+r//1v+Kf//mfsWXLFghY4sL8y7m8xKc//Wn87d/+7dt28Xd/93cqv7Br1y48+eSTb/t8JW9oQNaVWEv7biZbQO53ot4hhCxPHk9gYCaB3TU67KjUYVtlMoeXycen9X3lFhAikWHmXU5E5/BMaESRh9xoKlZg1mK9dV3oQ5L5Dh0zQGw8SeU89QXInO6OY3AsiqGxGJcIpufJNr4YR0WJHpWlBpVLry4zoqJUD4uSul/58a/XL0RBTVhZxw8dxLHv/nfkU0Fvx4P/C8wkIjE7GKBJ8+Yh8ZCQEB143Yvj7X7cfVcO9uzMJraBJEpku92oTQOyPresodUFArxiN2HTgKybcNBTeMhRaqqFQ1F4yMq6uOCj1IQXiwS2yv8Bfxh+fwghgl311HY2WQwoLctHUWkOSsrzkJvnIOjGsiEC+yk0qbapNbCAz0cwijtMltaIYmqdmwvD44kixCoXEydfIvlSWWlFSQmltVk5m8nBk0uZTwBsMgmanAoRFEdWVLIryv9myoCXlpjR1EjGvTwjJ0RvB7NdanureU/YIINk0JwgmHVwOISegZBKnkoV17ZWGyrLkzT5qQrwyANdjnuGE++ewQgn4VGMT0WVFGJdpQENVcJGu5ojufRvVgtk/c1vfgMJFokE9cGDB3kOlpzfwSwTytu3b1d2ku3vvXE/jh45iA984D71nedffBXPDFajjMlSkbDcwp+GA24l+yNf+O1vf4vdu3ef395KX1wrICuVmZT81NiCDiPzwPBsQjGyinMlyWCXjQys2axyd+q4ToAE4LDyOl6r5iMj6TT7cPhkUDlxwiDcUm9EY42RVYi6lFccijTVyEgQvb0Mgp5aRA6ZT1taXKiutilA9mDfBA6+fAT/48k/wJVnQH1TOe6+9240bmmCwWh4S0BSAOShUEyBxzs6ybZJpmK5FisreM/jUl1p4X0gS4HZL7Sfl+D3Gd4vu/pCisVV7pUCds3n/spKyeZcYECOy6Dunxf+TnuduRaQe6aXMtSzrBIeifswHvNjgotBRyZzyt606HMUm5/I3rAcKXMPdBk9nycb3eTEBM6e6cTQwCDntwuqSMDBgEdxaYlaSijDVlBYAKfLlbayJMs4VO0rV2mBBG+yUYJZJwh0Hvjd04xGU1KprAx1f/xeOKtroEtTyZqrPGz1cw3Imgorpn4bMU6WIokYno+M42B4Cs3GHBUYbzbkkPVBA5yl3uKZtUUJ6sejEQTILB6YmlLAVS+Bqj4+86I+HxlXwzBYrNCT3d/ItYGAfKPdDnNujmJfNfOZZ+JiycmB3sz5AJnJtZa0wBTZWEfoL5wZS2DOR7UiutVtLDbcQdlIYWY1ZXjSgeJMENWT4x0EagxLLCFOtRMjmVnNyo8QCUGtaRYQC2hAVu080CygWUCzgGaBy1lgcTGKGTKy9lMlaoIF9gsLURQVGhXhRm2NlYX2RsY0U0s8cbm+pPJ9ibtKnunIkXm8waW5xYkmEqjU12fDRhnma9mGqSwkam0CYBLZXlF8O9ck/3XXXXcx9nwKX/jCF/C5zyWJM859Lut/+qd/wle+8hVUVFTw+I4wpsxJ4QVNCsBFzW05raenR/XjUvtZzu+172gWyAQLECqBRTJanhnX4eiA+IHJPFZrGVCWSyZL5rQ0zykTRjK1fRQCEV8iigkWm5+NLGCE6nhz8RBaDbloMjLvl0Wyp6y1i69IXlX8+UX68XMk65mZj6m8uYc5QClaFY4OM1k/zcyzWph/tVmYDyL5lMjaq7VNBzsXwnwUIVhqrZO6rcmzTtSEFnq6cfaRXzL+FYWzivlzPvsK2rambkdrtKUwGXAFqniqw48TBLJaqYJZXmJSZGA5LuolblBOIQ3I+tyyzigNyPrhDy/LUNqXNAtcyQJ+srG6CWQd7J/EUP8UBnsnFLA1FIow+Z+LEjKzFpfmIb+I1Om5dsogm9RitojEuEE9CC+sDLzS/rTPNQusxAIipz01FSTDmgc9BIr5+L9Qs1dQ6r68wkZgpwX2bMrkMdBgNusJUNk4LK3Crhim5M2p036cOeultE9UsaE2NdhQXmZS7KzquAkKXMtrUCTKu3qDONMVwByZWdu2iLS5RYFZRdo8lVIEcszBMBMqTLodPBaAlZPw4gI9drYIGE+vJuKpYMlZDpD1Rz/6ESRoU08ZapHmkRbmxLq1tZWgfz9uu+02JeMj1dJRTrI/9rGP4dlnn1UMq6+99poCUnlZUdbGSjJhXL355pvxj//yU/yuw4o9tXqU2xfwf/zv/xsEHOtiklmSSBbL22Xml3u9rCeQNULAZYSOfpCLW+QrWLU6PJcEsQqgVZ+VUJIrrWVZaCgGcmyJNQWvio0kNifszaOTcfQSDH2UrKTivF23lQDQcoM6f5Zry+V+T65PCX6eOLGAgX4WiJCJta3Nif37C1Qwd352EQdeaCc75GEcP/Yqbrh5N265/Sbs2LUDhcVEM7/ZxDkV6Q8BpE5PR9B51od2sh7kEbBeyXvdblbyFRKMajT+p/cjANdwmE41gbvCnjzKCsyuvgB8/jgKCGAVBtZtrVYFgDdd8Ltz+9TWG8MCAmgNEwQ1EGflJ9n8BqJeBXAVEFSt3oFqsrS6CGwVQJTws26E4JsEOYKUTQ4GAvC4PRglA93gwAC6z3ZhenKS14kJDU2N2H39daiprUVRSfGaPiM3xpm0uY7CPTSI2dOnMfz8swgQCN38oQ+jaMdOWAuoMZ2KSUYamlMDsqbhoLBLfgbGZxkMfy48ijfCM3i/pQa7TATd64yKVTs9e631ai0sIED7GP0FCeJH+XwT0L1aE7Dqn5pU4FVhYPVNTMI/OaG6oKff4KyphaumRq2dlZXIrqhUoPysDQzMT5X9/UwAdY6DYFZKSBLQWl8I7KrWoZzqEbn0XQTcmpXBzwQBs07NxtDVH8FLrwcVQ8ste6woys+Cy/GfPkWq7KltJzMtoAFZM3PctF5rFtAsoFlgvSwgCmqSC+ilctxhqkZJLNLFQvm2lmxUVZqp/JTMx2QiWKOdZAQCZhU55rw8E266KU8RplwYe10vO8t+JLfz13/913jooYdwxx134Oc//7kCkp7rg57z+5aWFswxhvH1r38dH//4x899dH794x//GF/84hd5HIUK8HoxkFXyE1/72tfOf3+pF7m5VOtknzQg61JW0j7LVAtIPD1EUp0Fv6gJAu2jceUX3lCnw3YWN1blCRnLRoiiZ+oIpUe/g8y5uBNhHGbh+cHIFIQwpIr5lm3GPJRkWWEH8TFXGTNQeUE+h+RZxFs0Qsz3BSXn6INiX51VIFYBssbU53JfLi3So6SQoMliA/17PYryst7E6aSH3VbaCz/zOROHD2Lq5EkqDnWi+cMfQeXt72AxNpV5MyC2NTQSJn4iQPxEUI3DbfscCjshc6SN2DQgqwZkXfK81hhZlzSP9uEqLBBnhFsY5YJkYg0EQmRmDREYEMD8nBeT43OYnljAFBdxVO3ZBK9VF6KqtohLMfIKkiytqWJlXEX3tZ9scAskwZwxnpsEeXmjBLWGMDFBBrphPwFbRNHR62hscqC+zo7KKhuyCWoVMOtGaHLNyUTWS4ba+XkBqoUxMBgkW2OAoDaTqoBubRYwr1lR1V/lnPmyJhN2Rz/tPzAUQv9QGD0MXrkcBuzabidDJAGmrMZOVRMnUoJkC5RDmGTiTaThZV1CEJ+wyOxuM6tKpqs91uUAWR944AG88sorCoD6q1/96vwhCvD0wQcfVFXNAkAVuZ4zZ85Q/n2SoEEznnrqqfMsq/Kjn/70p6pSWl4XECRzww03YIbMSlIZLZXQ0r773e/i/vvvV69X+2e9gKxyTi4EgIlFoGcigaFZcIkj165DEVlXK5n8Zd0D8pgAdljJasSqQKNKBK/2yJb3u0BQHLwEE7Uh9PI8LS00KBZWYWO1WcjEugYssHIv6u/3EYQ8r0Cle/fmoYZMrMW8JuU52ts1jMcefpYAu9NY9PTjT/70Afzx+98DF5mx5Fw51+ScF0bVXgJRXz9Ciijewgp5XTU1WHmdW+F06CmHrjvvGPPWoEDu45NRtJ/xY5jMzfOUD62tMjOQbKJ0iAm5ZIa1E8irzxKg+7k9aeuNZgE+JXhIOgWGEoZWqRAepPTNWcpUy2dlWTYGV/IVQ6s5i8UeGwDKKoH34aEhdHeexbEjb2BmeoZMxiHUNzagjoUH1bU1yOe91uFywmq1KgbtjTbu2vFcnQUEHBYhOKzr0UcwdfwYXAQ8F+++7s0gWermNFfXy9T+WgOyptaeqdqa3LOPRKYVo3aEbEbvNJWh0eCSUPgGuFunykqbYzsRnxchMoovsjDDPTgADwH3npFRxcJqEpbVnFzYiothKyqCnYoQlrx8vpdDRlYLGVmtMFptyKJihPwvEz9JbmhtaQvIfNofEkWJJDPrICUkFwM63LoF2FqhQ441gUxmLhWfLczk7NhUDIdOhOiLxFRS5ZY9FqVWsbR1tE83iwU0IOtmGWntODULaBbQLLA6C5wD2PiYk5mZjaKr24ez3QFFMlJcRNaxPQ4UFTHuas08sMYCcy3j4wG8+NK0Iim4444i1NbaFah1dda6ul+J0psotUnM6/HHH8fevXvfskGZ3wtJRl9fH770pS+p3MRbvsB/vv3tb+Nb3/oWmpub8dxzbwdaSGH4An2O5TQB0goQVgOyLsda2ncyzQIUrmVuK1nYeKA7ASeVIBtLdGjiUpZDlkuGBoXNUmub2wJx3jOjICNqgsqpEr8LT2OG6njlejvayM66x1igonerBbPKM1aWWeb1BKgqvvu4LCS0Im+S8t/zXFnIz8lirk+PHAfjFMwTmpknZPgnuaYapRBNZXIIKEbCkgCfgf1PP4mOn/0ELR/+U1TdeReyqbBnYKwr3ZvkpReprPnqIRKujIdVXraVZGB7dtjTveur6p8GZH37/OpShtQYWTVG1kudF9p7KbKA3xdUIJyJsTlMjM5jfHSWTJhkBSENn8VK55Ta0NkOggY5w3O57HCRqdVB/WgnF6tNgGZa8iRFQ6Ft5gILCOPiwkJYgVkHBnwErzAhsxghWMsAB4GVuayezc01EizIimCXUYFaxcnP5EncucOPMAk1OxfB0HBIsTUKE6MAdosZLCohXX0ZgXMOVvjY11ACZ04m0xNhnCRDrJuJMGFjrSFwTsBzwgBpI3V+qpowa5KQCCc6CZwdDGPeHUdxvgFNtQayyRjV5F3GdbVj++ijj6pAjABL29vbVWDm4r5/6EMfwksvvaSYV3/xi1+85eOHH35YBY18BMKcayLbI/I97373u8+9pdZyDko19Te+8Q2eu1Nv+SyHCej/58tfRdPe+1DoJHjRkQR9rua41grIKtedMK96CF5d5DJPsKhUqy5SNkGYWINSKcjzU5z8Clb/VbJitYBOFR8F6wLCkP6FWKUoTKxd/WGMcC3sprtazaipYHUiQdCpZgYQGSo/mU87O90EMXsU+Lqg0IQbrid7OUHmRjqPp08M4I1DHXjhDy+yf4soKbfhnvvuwf533Kqkzc8BDNzuZDBYpLrGS3anvgAAQABJREFUJkJKqquk2IyGelZ4ko01n1JdFzYvJUXmKe8lTMkTZGKdnokoh9dszsKWRhabkK25gNdKJifeLzxe7fXKLLDAKuFxBlbaI/OYShCsl4ijkBXCZXobKsjOWsjKYUcGMv0JA6vX48GUVOiOjWOcy8z0NBbm5xVQ1ZnjohxcK2rr61BaXqYArCuznPbtTWcBRgpHXnkZk0dex2J/H3LqG9DwvvfDwnmBKZsP4w3WNCBreg2oyJSFeX/uiM7j9+ERFOgsqNc70WbMRRHv2VrbmBaQxDGdDoTpP0T4TAu5FxFeXESIi/p/cQERqj4I0F7W8XAIcSayzbl5sBPEKgBWe2kZl1KYWEy3Ee9V12LkxZ8ZYz6/fUQSmQmUuISBB2gu0yGfeQfxaTK5ub0J9I9Q8aFPljBu2mnGti1mSEJMEmBa29wW0ICsm3v8taPXLKBZQLPAci0gZBuSmxgkycVZglmnZ6Iq9lpWakYZi+mrqyxUxdJTaSx1uYHl9m2135PYccAfw/MvTJM4xMfjsKKxMRtbtzoZt2Vh4TpOkyRGLDmF73//+6ipqYEovSnf4aKDu/fee3Ho0CF89rOfVcyrF32schU//OEPcQtlmR955JGLP17R///wD/+gCDg0IOuKzKZ9OQMs4A0ROEgfSZQ5hmZZzOgH6ot12F1NEhrmtLIz3P/LgCHIuC5KfsVPSOtRKin1xNyKpbWYsbsmvQuVb+Zb9LqlC9IlHBTjs5QpDnhJGuVjjtVDAisvzz8vn0XkmEOQqjFBgiKDzP0LKY+NrMAFeXoU5uqRn5uFHGeWUizNOANeqcM0TpzI3aHnnkXnL36uYvT5bVtRtu9mFQe70s/T4XOZI53uDJAELEjSoTBqyFp//W4WxxCvYiPZ00ZqGpBVA7IueT5rjKxLmkf7MEUWEEdJHqyyFkc1xhKlhXkfxkdm0dc1hp6uUQz0TiESjiK/yEkWrFI0NlegrqmEEq65ZJozkvI7cxzXFJlN28w6WOAcS6msFxYiZMEMUSplAb29PsVaWlRkVgGHLVtI304mQ6MhSau/Dl1b010kgxc6xcIYJEPqqXYfjp/0kp02RAC5EftucKKulmAlBo/WqkkFmgBo5+aiONnhx3Mvu8nGakITAXe7thMkRQBdKpvcg0RKYWQiiucOBjG3ECcjJXD7DWbsJEhRgHrrGVS6+NiETbWjowMDAwPYtm2bCjRd/J0L/w8TmSvf7+3tZSAojrKqBozFm/BSL1k384HtlTrcWJ8EgAqD6UrbWgBZOQSUtRDnHuidSiZ3uyd0BLAmwJoGtJTrsKUE2MJEr12qAKVa9c15+XqNjZyTbjp+rx0L4ncvB7Cz2cTkLM/LWiNy6dytRT8EQD9MVujDh+cJhF7EXXcVY+euXALpDayAzFJFH//+i5fx/O8PYHKqAzX1xXjnXbdj646tCmh3bmzlHO/uCeDUaS86On2qCOSWfS7U81oWpmVdVuI8C6v8Rr4/MBxGZ5cfR477EQgKC6sF21qtlPUi86SqwJRnb4LHvbEcpHM209ZLW0Cu2RjHPxiPYiDuweusFO6JuzEXC2K/qRQ7yc5aRwkci86w9IbS7NNZslj3dffgtVcP4I3DrysG1tKyUtx0y81o274NdQ0NlADWK7mZLCLXtfM/zQYwTbsT9nowd6YDx//xe9CbLWh8/73Ib22Do6o6TXu8+m5pQNbV224tfilBcCk8eJ3yZI+FBnA7mVj/2FwFexYLUcjnoLWNaYEEQawx+gPe0REs9vVhoacbc5RNm+/qUkDWWDSC3IZGuAisz21sRI68JmO0MFDoSbehk8oszu/Or7W5XkpOFJk7yRx7mEnM7ikdXu2iz0tZvz9qE0YeoDw3s+fUcmwiAnLoZAi/fyWAylI9GqqM2NHCImD6Slrb3BbQgKybe/y1o9csoFlAs8BKLJDMEyYZ39sZxzxNhajOswIANWPfjS4FZi0seGsx/kq2fy2+K0qAvb1UNTrrwXGqbTU3O/G+95XBwNjueir+CfNpU1MTSRP8CqAqQNVLNXn/scceU8ysQtKRzBclvymxsPvuuw+SH/jkJz+Jr371q5faxLLf04CsyzaV9sUMs4AocXSOAwd6ksDCO+n3NRQDpSxoJBZxXYhZMsxkWndpAYkbBBMEW8Z9eDY0iql4ADE623dZKnCdgaQIjOUJmPVyTRQZRTFlfCqu8t0Do1TWm4hhaCyqCKIEpFpZokdVmQFVpQbkkYHVQQVMyYfr+EfW0jZyGGihuxsTrx/G5FEqmYYj2PGZB5FP4pJMOGiJuwjZUl9/CL/9/QIxUjo0N1rRuoXEQ+UbCx2vAVk1IGvybnSZvxqQ9TKG0d5eUwuIUxQi7Z6XlHzzc17MzbgxP+vh/0E6WEmm1mg0rp4nFivZHfIdKCxxobAoh+x0TrK3WtTDVgMWrOkwbbqNBwni8rNaaWoqiOnpMOXaQ6xkIu0+J4QGArpsNgPKyixkLLWguNjCKqb1DUKsxYAkE1EJTPF4x8ZDGBsLE+AZUQDTPILoysvM5wNHBoJ4Uz2xZVxFgecmp6Lo6QtiYjpC+Z0YKjgZq6akeX2NRVUYpSrYI/vz+MkiQ/Be/0iU6ygKhfWz1IhmSsaLrIKByMlUH+dajN2F2wwQfOmllGU/waEj88CMJykQbucEt7ZQh5qCBPLoqFhXgA1OFZD1XN+m3AlMu3WYYt+8BK4Se6scJhMBxHaLDi7KbQqDrFSq5tkpvclxWM/6BbkWRLZhYjqO450hBXQW0O22JiMaqgliXQOWIXE4PZ4IHRIfjh1NSjHl5BA4u82JykobHZQszEwtYqh/Ci8+ewjtx9tZQTmOnde14b4/uQ/FpcVkj3YqBtcZMiz39gYwOhZSrKpSnVdKduW6WgsZVU3nGY5ln1KNOUn21f5Bfnc2AjdZWS08V/Llmid4vaSYTNRkYRV8w2qlTC48P7XXmW0BuZtI4cFigjJpcT8Gox6C5v0IEeIqQZXyLDtqDU7UsGJYAFOGJYIs19ISc5SUmZyYRC8BrONjY5glA6uAdyyUTS4oLEBpWRnKKytRVFyEnNxcPgcyG2hyLW29Wfct1d6+iXEMPvN7xcoacXtQ/a53oeLW2xSwNcuQWYDvpcZRA7IuZZ31/8zD+/OxyAx6Y2Sajvlxg7EI+0zF4JNce46v/3CsyR5joRCigQACfHb5p6fgpyqDn6+DszOIkWVVkJNyj9EZ9NAbjDDYbGqx5ucrBlZrXh4sXMxUb9DpeWawWENra2sB8c1mPXEys4L+GeNfETKz5iewo4osKPR3GNLK2CZ+09BYkpV1cIwlT/z/5t1Uf2CSTJJj2hQqY4f2qjuuAVmv2oTaBjQLaBbQLLDpLCDkIjOzUZWXGBgMYoGqUQGyy1VTsU2YWSupLpVtzwxiETkWISsQ5b9XX5mlCqUBra2Ml9XYVD5pvQb34MGDCoQq+zt58iTVBgsuuevf/OY3+PSnP62UieQ3JVRsONdmGUPbvn27Arf+8pe/xP79+899tKq1BmRdldm0H6WxBTxBHcbo552hCkfPZAI5VCyXosWtFRtDiSONTb9huibqSm7G8/qjbvTHveiJLiJHZ0Jplg3bDHkooSKeWadHnIWkIbJ+L1BlVJa5xQQVFmNYZLxBfHFpkkeVMI/k8O0UZnJm6+FyZHGt45IFK/OvQlqzmZooFnnHx9H16CMs/u5Fw733oWjnLmSXlTMulv4xMZlTzM7FcPpsQCnrjk+FceN1ZHpvtjEnrN8w46kBWTUg65L3JQ3IuqR5tA/XyQLJCkw6emRpHRmaRn/PBBlaJzA2PKMAr/lFLpRV5KOypohAg1wU8H+zxcSFSRpSDRokYbOeiKd1sou2m2tnAZH6XiSgs3/AjzMdboxPEGQdiKGm2sbgg10tTqeB4DBOGExyDkohT2ZPBKVqeJKToR6C4Q6/4VYTZJdLj21t2TxuC1w8XgHWicx5qpvsW5gwDx/14tgpv5JFKC024fpddrK0GpWc0MVskqvtg0zuZekaCOPwSQKWORmUodvH5FtthUEBFjMRzCr2iNCOcz4djg4m0DUBSEXollIdWslwWpFHMCsdFwvPVd4yrwgSXQ2QlXNrUThFmGDJaIyMvwSCuilvISDWUQJsh2eB8YUkyLbYCdQVsUKVC2/ryKWzL+NwLS4jcQqIP8LETAxd/REcOB5CASU2drea1DlRXJB6x0aBuHlPGaTcVGenB0femMP2bS7KNRUiL8+k5LOkgv7MqSG89tJpnD1zClMTQ3DlkzF5/w24/8Mf5H3HxMrLONwEf/cPBPHGUbcK9or0lrAqNzXauR0CggkKlnNeqjQFrD87HyNwnMytHaz05Hg56NjKtVZXY+b5b1BO72qvL+13G98Cc/EQRmJeHAhPYpRVw1aysTYbcrHdmIdcnRl2/i8A12sNgpbrJ8oLOxQMUd7Nj6GhQfR29eDUiRMQRtYEr/vtu3di93XXoaGpkYVSBRn/HN/4Z1/6H2Ek4IdneAQjLz5P+aKHUP/eu1H33ntgKy2BmYUHG6VpQNb0GckoA99TsQCeDA1CAK0NeifaeD+u51prmWcBiYskSHcpTKsJPsPiBKnGImGECYwPLszBOzLKe8wQ18MMyI/BNzkJsyuH8milyKmrU5JpLq7lf2thYeYZYIP1WObZ4gcJQ89zHQkFXpXEZlOJjknOBNUn/pMJJdMOXZROfP44nnoxoApExW8SBQvxp8X3uBY+XabZcCP2VwOybsRR1Y5Js4BmAc0C62MBUYybZbH9yXYvDh7yMDYqBBsmbG3NRimL7u3MwWTKHENIUg4cmCNRCovRSNZz0035aGtzKoDResyRvvGNb+Dv//7vyQjbjOeff16BUS81iqL21traqphbb7vtNjz88MMkNaAyGP2Qj33sY3j22WdRXl6O1157jX2/usJcDch6qRHQ3stEC6icDnMsYws6nBxOoI/EMosBHRU4SIhCX8/FHBexhFrTLLAsCyQzpSCI1Y0jEWJjSCDCdB9uzipBnc4FZ9yMMEmBAgHm7ufimJyJcoljhvm9OYJZC3IMKMon0UixHuVkYK0oofQ884FCWqM14gB4wZ7+1x9hjMUaeVu2oGj3HpTvuxlZolK0Hg/kqxyEiORzWdxz8IgXz7ywiB1bbWhrtioCMAcBylnnqHWvcj/X8ucakPW5ZZlfF5C7wCZsGpB1Ew56mh6ygGwipPcOBsjU6iXbiD8E96JfgVuFrXVWWFvJ3hohMkrAq+UVBSivIri1ugj5RU64crK1YHmajm0mdkuAbWqS4I/C7Y5gbi7MYEoYEwS0ut1ROvhRSt1YUVNrRzXBrflkPDSb9Rl9DgrjXoiMlF6yMwpL48hIEMOjAgCKw2rLYuDIjqpKMtISYJrqOZ5c/8kKo6hiZe3sCrIaO6ImYi1NVuzcZktWjZEFNxVN9uclM+vcQhSnuyMYHI0q8GxNuRF7d5hVlVomTvYFSCrg0cUAMLlI9p+5BIa5zHoJFGX1ellOAi1lAG+ZrBJd2plZDZA1yIm1j+xDw3MErXK/YwSvumlncb5yyc6TZwfBtCD7anL/2VRByBbHyigMrNcGxCrnkzgDUs144BgBehNRiPRGQ7UJrfUEq1vJ2LgGjp/XG1P3k1demVb3mIoKG2WfslFXZ1fg+HgsCg8H8sCL7Xjq8ddYfXcWZmsId7zrduzZuxut29ooh65T4POjx72YJKuyBHSrK81oqLOx2t5IgKqwRss1QwZcVm4ODBGo3h/gElLAVmFdrmRQuJyMxLl0eu28zoVpOtXXdyquWW0b6WOBcCKGAJeZRBCjZP7rZbWwgFsDlMPZbsxHszEHFWRptRHQei2bSKhNjk+g++xZnDh2HAtz8wT7R1FRWYGKqkpUVlURvJqv2Fft2dl8hm8sWZZrafvNvG8BoAmYderoUfQ/9Vv1YLMXl6D2Pe9FDqW9MyFItpzx04Csy7HS+nxnJh5EX8ytpMiys0z4n0yVKNZb4dBllgzn+lgrzfdCByUmBRjz84rdWcCqnpERAleHEZybQ8Tvg9nJgl6yhgvDqvkcyyrfMzkcZGDlHDLbDqM9myzQZrWk+RFv+O7RNSNzCuiLURFkWoduMvV0TwI7KoHWcijlDPGHMrFJAjfK4sX2rjC6B8miNhkliNWIO26iogqL6q4S65CJJtH6TAtoQFbtNNAsoFlAs4BmgdVaQMkkU0Z3bp4gnUnGL1mAP8G1zapX7Kw7d2SrQnyLJfVkA6vt8+V+FyBxwSRzSCdOLuLVV2dw222F2L0rB7mKuGBt+y9A1He/+904fvw4PvGJT+BrX/va5bqp3hdW1gcffJB5mThcLhd27dqFM2fOcAxYMEef4qmnnkJLS8uS21jOhxqQdTlW0r6TCRYQpcGzLFQ8SxIZ8e0IUUBzKaiI+KbKINUHNwC2LBOGYsP0UcCsPuZVFuJhnPTPo9vrhWdOB+OcBfmLLvgJmg74EkpxUdhWXWTjlMXBXGs283l25i+FcdVKP9xMRU6jnIOpSaNvCBtPvH4Yk0ffwNSxowSzNmPbJ/8cRuaCUsXKKrF+n8+HX/3qV+ju7kY2t33TTTdh7969HDPbZYtJLjbuUtuZnNHj9Bkys46EVO729lscqKKqrdNpYuHMAbz00ktUGp5STOr79u1jnrlJFaVcvI8L/xcm9t/97nd43/vep579F3527rV8Z3R09Ny/b1vL/EAKYq6maUBWDci65PmjAVmXNI/24TW0gLCRRCMxeNx0WsfmMEp2VlnmZzysPgnDydImh9MGJzn7c3KzCWS1w8H3sqnRJu+bzUYYTdcWRHENzaftOsUW8PuimBeGVkqAj44GMDYW4MRQz/PQiMJCshgyEJGfJxMHyuk5DEzcyGRxaaBgiruYss0JyFOCRyMEsfb0ksVuOASvj9VdZIIsLTGzEtfMYzXAycmySBWkEvQm+xbm285uJuUHCCocCyu585pqMydmJhQRnGcmqFAAe6losr+ewQi6ByjLPhRRIL5GyshXlxtQVpQE9WUq2bOP8vHE/lPehMfIpGmEDKkksSaIlXKW2Qklaemk4yOLle8LS+uF7XJAVsVeysRlKKpDkIlZAa+KVGaAay/ZV2VZIJB2kQBW3r7Z6ERx+6U5lFfJ48K1SK1YTNfeqZfzPELg7+gEGUo5/n3DZL7iSbGzxYyachZMFKf+GaL2SWRvfz8BgL1edU/J5j3jhr15ZBiwIDfXpJybeaKPO9uH8Mah0zj0ynGCgSdQUpGND5KJtb6xBUazU12jI6NhDNOBEee0iiDWpgYbamssCiwVI7I5xPNgnoBtAaePjUcIeI3AQxBtfp4RTfWUAK0wkfU4eZwbBWB14XmsvV47C4j8jQBYuwhk7SGIaoCVwwUET5VS9qaSQNYSyuAUkKHVmEXWDN4H1qMFg0HFvjo9NU0GYzL7j45hfGwME5SRkQB8DsE/WymNVtdYr4CswiihnffrMTKbbx9uMgBPM3EkwTL/5MSb8kW7FUOiyH9netOArOkxggKSOxmZRUd0HmNxP6r02Xi3uVIxY3OGnh6d1HpxSQsI6D0aDiHmDyDkcSPKoHfI7UbY4yH7qhuhhfnkmlJo8r8ws+p477CXFCO7vAIOLrayMjgoiWawWpFl5GRba2lrgTBVM7wsQDs1DLzWG4ed/myhA2hjgWEZ5SdzmYDKxNCB+NKzC1SGoA/1yhtBlUDbs9WEylJhhbnIuUzb0dE6lkoLaEDWVFpT25ZmAc0CmgU2pwXOAVo7On3o7gmSXCRCgg2CWRnzlJyE5CYErLMWinGpsrjEzsME5Z4kkPW556ZQwj7XVNvRttWlyFDWMmckLKt1VGgQYKqAR++9994rHpYwsX7pS19SQJxzX66oqMBXvvIVBYo9997VrDUg69VYT/ttOlhAfJ85H/NIJG5pH0lgxiMRGRYpVumwu0ZUEEnUwpyw1jQLLNcCQqQluUkfSXZk8ZNv8QxjQl0eL8Z8IQR5vlmCZlgiVCyl/l1lrhFlzOkV0tcuytOjgIuRIWZRF9Xa5S3gJ8BztuM0zjz0b6oofMsDH4KzugaWfKLQr7JJXunQoUOKxdzN2N2FzcGC8//4j/9Q7OgXvn+p18vZjtVei1fIWD82EUEryb9uv8WJ//XzD0IKUi5uDzzwAL73ve9dFsyq1+vxgQ98AK+88gq++c1v4iMf+cjFm1A5szvvvBPt7e1v++zcG1III/OHq2kakFUDsi55/mhA1iXNo314jS0gYFYlDUvQTzQao9Q5JZTJ0jpHMOtA3wSG+qcw2DdJFskIQat61G8pJzihFI1c5xeSpVUyAlrTLJACC4ijEuP5l2RpjSlW1p4eD3p6vBgfD0LHzFM9mRSbm53YQlZFK6uFTebMLXuS440y4SZBl4mpsJItP3rczeMnsyaZG6/b7UTLFrKkstpLQLupbLLvEPc7RcDdGTKzdvcGMUSw3q03ObGtzapAd5YU2lbk1oWN83RPmLLyUYIZI9i73YybdorMulSzZeY4CjuryFmGCTj1sFK0fxromoijYzTJfCqsqG1vSltW5rGij8DSC0HJlwOysr6ArKugs07WV87NJxcTmOB6iouwrwa5vypuT6pRqwqyUOIC8nkrNvE80WfFlWMlidp0SNYGCfJ0k4H41TdCZGMNoKXehGYuLXVkMyWDbKrPbblOggRqe7xRFcg83e5GK6WlmpsdaGx0qPuGAFLl2dfbNYYnHjmA0ZEBXg/TMFto07py3HPfPbBmlxG8GsYbx7xcB9HWYud9x8Z7kFUxyAqrqjQBhU9TbuTUmSCOHPVyG1nK0RWG44pSM1xO3qc47qkChqudan82lQViBLOG4zHMJkIYi/nwenQaw1xnw4BtlLbeZypRr61Z6wPcEwDr0OAgDrz8CjpPd3DOuEjm/irs3L0bTS3NqOJrAbSaTGay+2sg1k11sq7zwYoseIzA6s5fPIThF55D0c5dKL7uepSyIttI1sRMbxqQ9dqPIKd5vAMD/xEcwNHIjLrntuhzsMVAdk6dBiC79iO0dA+iwQDCCwtYGBjAYm8P5nt6sNjfBy/ZV3WsLrPlF8JRUw1XTS0clVUEr5bDVlikWFYF0JrF72QZjFz4fOUEXivKWNre1/pT8W/FNxPVjGkmPF84A/pmCTSVAFsrgF3VZFvJ0OST+JszczEcOhHG+HQUASq87L/egt2t5rf4ltd6DLT9v90Cct8QvzOVTQOyptKa2rY0C2gW0CywOS2QfDQxvhyKY5EFMwJo7emlulSfH9u2ZqucRHkZyURIsJHOTcCsouwnJAanTrnhYyz4vXeXor4+myDc1BKDpMIOMRbadXR0YID+ybZt21BTU5OKzZ7fhgZkPW8K7UUGWkDuS7Ic6k3g+HBSCVFIW97RAhS7dHCYk/k2Tq+1pllgWRaQ88lLJVQpDB0Zj2FoPIphLtOLUfiIhbHlxhHOD2A2dxHbivnsK8xBoyUbRWYLCW0SyRwrYwhyymnn3dIml0JyIZw489DPVdG4q7YO5ftuRiFj9VfbZmdnFfuqlyy6JSUlChxqZbH5E088ga6uLuRRSenpp59GZSVleZZoy9nOU089jam5PJztDpB4LIGp4X/C97//fbXVu+66S/Xj9OnTePzxxxWA9VOf+pRiZReMlTTx/wXAKgUv//iP/4ivf/3r6v3LAVmFAKa2tlYVuezfv1999+I/999/Pz74wQ9e/PaK/teArBqQdckTRgOyLmke7cM0tICAVv3+EOam3ZiaXMAs0VNutx9+oQHkU1tuxllc7GRmdZKlNb/ASVCrAwWFLlZvkhlMY2lNw1HNrC5JZXCICZqp6SBlYkKU9g4qaXCZDwgIzWzWk6WV7KFFFhQXW0glr1fvZdZRJnsrE2qfnyAlsjn2DwZJTx/GwmKM4E4yx7ACrKrSgtJiEydkhpSD4fycyE8RhNc7kGRn1RP56CTwrqHWjDJKoQs7a6qaAGcnZ+MYGImiszeijsWRraO0vBEVJWTZFYn2zMSzKic7ynOTBJ+YWCDTLqtGhSk1QFCyODp6Oj4WY5Kt1UrpCWFPNTMnPth5AKdffwbX3fkJOk5Vink1zApBYXYNE8x6zoGXabBKgPFcIUGvAqyyjoAsQ5RTIfOri2Bnmzmh9pWq8bra7UgwMUAQ69hkXMlhzvGcDoUT2N5sQn2lkSzAZOOlTVLZxF5hGm5oKMAqNkqxz4WRoPF27HTRIbAjJ8eoGI4FMD86NIMz7QTjvXCSDNDddEyGsPem69C6fRdyCpsIhLVicCiILDqr2dkGNJJZVYK4+WSGFlhLmMcyNhHGKBlYZR0kkFmSzMK8WlrM65YsrBLwFRCrBnxI5Shv3m0FEzF4ExH0kJ11hKyAInUtNwlblhG1BgcqdTYUkq3VpiN4NIV3Awm0e1jtOjkxqQCs42RgnaL8mbwvznZObg4qGCiorq1FMVnshJFVO+c373m6nkeefC4mME4JnvHDB+EZHIC9tAwN778P9rJSyn+Tii+DmwZkvfaD5+Y9dzIewEuhMYywgOCPzBVoJog1N8sMjY312o+P9EDdB+gghsm2GibDaoAB7sDMjFqH3WRaJROrBNQTnKSJlJxqjGOYHU5Y+Lwykx3CTvCqsERYcvOS0meaPlzSThn6VwoCRdXi1HAcPVNJ9QxRqmgq0VGKEiwAlLl55h2cMMeMUOGisy+ME51h+lRmbGsyorhAT5bWDDygNB6C5cj/LdV9SVxJYuvw4cNUGRpTibUbbrhBsbXJZ1fbNCDr1VpQ+71mAc0CmgU0C1xogRDBrBOTSSWqPipbRRmTZj0X2U2tqKwQdlYTcy7pBwo9dwx+5lQWFsI48OosBgZ9aGt1oaExm3Fgm4oBn/veZlhrQNbNMMob7xhV/ouHNbkI9NJ/651KkruU5iRQV6RDWzmVCJmOkZyY1jQLXM4Cch75iSfwMSe74OZzgaRKsvjoRwf5vhS9SpPvCasv+TdgtfMzB7EHNg/+f/beM0qyq7wa3pVz55xzT09PDsoJFMhRAkSwSbZ5sV9+ePlbC2OM08vyMssYljGfDZ8DNn4xWBiDAYGEUELSaGY0mhy7p3PO1ZVzffs5rRYzUk9P567qOXfNnaquunXDvufee87z7GfvqCsKC/9ut+ShzuxGOV3wLAbd6OZQW9r/URaSDx9+EVNnTmPy3Fk0vvPdqH3Tm2AWYrAUiK9w+pM/+RP80z/9E3Jzc/HYY4+htrZWrclPZd03vOENasz98MMP4ytf+cqiW1jqej73+b9GL/PCJYUh3H3XQUVK/fjHP65IqfNFqt/85jfx53/+52p7x48fVwRb+ePRRx9VxNeLFy+SYxV6dX+uRWT1ErPt27eT41KKU6dOKdHBV3+0hm80kfWpJaFpCId5x7gBJ01kvQFP+hY8ZO9MEBOjXnRcGKSK3RAuXxxS1uhCXBWF1rqmMjRwLiCp1eW2w8SepYmsNAnUSqJAkxq2YKPYoENSndBQQlXYnj/vY5UN1YJ7Q6iqcqCuzoW2thw+6FklnCMktTnlQ2lv2ZagkuMUm/L+/ijOng/iYgeVkWdi2LndTSVIB5qbXEqddd4+Yy2Pb2o6QUJeDM+9GFDqsNua7djW7MD2VgeJ6RLAWrvk2LSXZNahOF46E0Nnbwy37LFjR4sVNbRHtHFQmu3KlXIeZRrxkqg6BZVE7aZS6xRtKlgMTtLp3OxhwjE2cogKUU/A3vZRhK21kFoBmeNsB0IqLiLRtyQnrRKupSSullB5Vciror4qOfZMUFydO9qr/5eBoSgrj5Ekfa4zjmeORFBXZcb+HXY0VJtRRBLrWk+Ce5zK4rPeOE6c9OKJJ8bQ2urBrl25SolVSOEyyXKRcBRHX7iIc6e60d87SCLrJYxNXMRHPv4J7D14L853kOg6nFDk8ttuyaUSgQe5VEm2UYVVSPZCWp1h5eapsyF0dodJtI+jvs6OA3tcqGWQt6hw5QOztcZFr2/rISC3mGmqs56MTeJMYprzDLab85RS4DZTLoqNDhrhGHl/WDnNSgblQlRNJBK8XsIYpHrdhbPncfTFw5icmFAD+FvvuB37bzqItvZ25OTm8J609tf11jt7+ojWAwGxChe1xdPf/Acko1G0PPR+FO7YAU9NbVaPPzSRdT1ay9LXKffa3oQPJ5PTGEqGFAnybbYaNJiymyC9dAQyb8l58vocMZVOMlQrT1NFQ677EJ9N/oF++Ehon+3ugre7GxGSWmVZd1UlchuakN/cjLwmzrQBtTIAbrazU66nLYtAmEVnQxyPPXaaZNYgizXtwM0NYkspRYHZZw0oYxiZT1+K4bFfhVCQa0JlmUmpspbSoWM97XO3bCNZ4MAkfnk9+78FfvbqR6IS8973vndBa8Bt27bhBz/4AYuV819dfiVvNJF1Jajp32gENAIaAY3A9RAIBCmywTjui0dmcfJMQBXzNzU6sHe3G3m5jIm+4ty2lvmI6+3Tcr4/fHga5yhqIM53dSSx3nVX8SuuXGuX01jO/mzGsprIuhmo622uBgEZ3zDVQnGXuULEpy+Ie2yawi1G3LfdgLritHLVyNT7zmqOXf925QjMjY2lrcy5ZcorQ0PM1yUppJRQwjqDo3wdT1J5PK3EdKqZe66p5FxuQhmLQQvyRFTJAJZvYIJiIc/EhvFyfILF6/kQJ6Y9lkJ4DBZNZl3GaUrRajZK577exx/Dyb//O7Q8+D60vO/9cBQWwexkdfEKJsk33UrntZ6eHnzmM5/B5z73uavW8q1vfQuf//zn4fF4IOTRa/GQlrueGXIYnvvVo/j0p/8XFd4teO6Fsygtodo7Y0kSe5HttLW1sZDGiy984Qtc7tNqv/7mb/4GMr92uhaRVcb2b3vb23DHHXfgkUceee3P1uxvTWTVRNZFG5Mmsi4Kj/4ySxCIRfkQolKrbzZEZa4wyUJBvufsDanPgoGwUmwVEmt+oQeVNUUoryxAaXmBUm41SymnnjQCK0BADWiooiOVU1JhOz0dV0qLorbo88UR8CeUYmIJyaxCbK2spCKd06QsZFawuU39iRAAgwwczZIkN0KVxxGq0UpVtGCQTzXJpiY7mmht7rDL8a1dIEaqr4PhFPoHWIE9FEPfYFQFeyqpyiqk1upKKk9xc2sxaBRVziCVYLsHEuimOuv4JG0cqCi6s8WM2kqqwBZm/71CzpeosQajtLdk4ZWXdTxBElTDJHcmqBAkaqsyuJrsPoTxS0+g8daPIae4RlUDCtlVkqsy28m9nJ8dJBTPv5fv5OyvxflYjwYfDKUxQfvLw6eimJohgcBpRHOdBS31Fr7ncdjWru3O778EKicmSFA9Oq1eBaH29hySWd2K5G4lCVWmIJnCU1Qbf+zHL+H8mUtIG7ysCIyRBA+U192DnILtVI41KvXWhjoHKsutVH+2UFnVSBtPWlaRtNpJu63e/ticqjBVV0WBVZRYS6kS7VTHN7et+X3TrxqBtUSAtxdEqc7qJZl1NEmSKVUChzn7EEOOwYp6kqx2MtiSy2CLg+qsK5lCVLabnprGpQsXcIlBgImxcUVsLaBiXXlFBft35SgpLaMif5GqhrVYLdcMFKxk+/o3GoHlIJCkXU90ehp9T/0S02yzUgFe88Z7UfeWt8BkscKwBupny9mftVpWE1nXCsnlr0e0OxOUdD8Wn8Sj0X40mnIYzM5TcwHVWPW0OQjItR4nSSw0PobA0BACI8MIcg6N8xkVZb+MFXEWlxtWBrBFcdUir3m5/DtHfSafy3uz2wUz5Tey9d6wOehn31bFKUHGYv1TaSqzGnBuMIVCN1BTaFBkVlFmNRroaJGpA6oFIJcx5sR0Cj2DcVUsODWTwN03O9FUa0YuCyCzvSB0gUPekI+kDQiBdan2f9faKXEqePvb366UWK1WKz71qU9hz549OH36NL7+9a+rvrRYAn7ta19jfEd69CubNJF1ZbjpX2kENAIaAY3A4ggkEizcF3VW5iMGh6LKpSrEXIGbhLLWZgqJtDphtxvXNB+x+B4t79uxMbrNdQdx5MgU99mC225j/Kqcecp8qmbcIJMmst4gJ3oLHaa4aUz40jjeBwxOk4jInFJbuQGtnCsL6JJnTSsxly10yPpQ1gAB6m7AF0hiepZuo3QAHWcecmqG/AHmByXrKLlmcS1xMScpuUh573b9+jMHc5MiqCTjwDhjfzGk0Jf0o4vF7N18lZig5FckDtjKWaa1z2aq1W6p/9JkFEvcbuzYS+j4/iOwFxQgt7ERVXfdjRyKTaxkknFzTU2NGkv/9Kc/xb59+65ajRA0RZVVpieeeIL54Parvp//Y7nraWxqwz/8/d9CCKh33XUX3vP+/xctTQ7U19pY3DPHX/jkJz+Jn//857j//vvxb//2b2pTkYg4C/vUeyHP3nPPPeSyTKv1fPjDH57fnVdfpdBVCLof+9jH8OUvf5l57QlFjq2rq1MxChGZWYtJE1k1kXXRdqSJrIvCo7/MUgQk7joz7Se5YRYDveOcJzA8MMEHSooEONovl+SgqDgXRZQQzM13U6XVppRanS47Zdvn7J2zKWmQpadpS+62qC4KGbKnO8BKnKCaRSVR7L/LyhxKnbWA9t+5uRa4XCZWDJuUUmu2gRFgZ3xsPIbTZ4OK0Bpl9VhlpZXWPnZFmBOFSemUiwrtWkxyTYcZoBpiwOqlEyQxMTEmHby2FibHGuy0gjfx2ub21kidVawdhsYTOEqy4wwHHWKL2FRDsm4tz9s6kR3XAqeVrEMIylGSWEMxDrJobxGMGhDg+ew6ewidJ57AHW/9GM9rHW1S2I5lIGWeqxTMVMXVa2GQ4HUYZ996YCSJLhI9O3oSquJxX7sVtRW8PovXnqQsVboyj4xElFLz8eMzSiWgbXsOmhrditg+v7/SnuV51UlF8cPPneM9pItE1jGSV0tQVNYKg6URdmcFioosaG50YtdOEh3Y3iUR7qMlydhkHIPDMaq1xjk4TqCmyooGDl5EvdjDwO5aXYvz+6tfNQLXQyCcTiDA+TjJVh3JWQRScWV53UTSVQUtcEpMDrhJaLUpddbFnxWSvI+EI+zbkQxOUtDw4BD6enuVGquos5bQ4mTX3j1obm1BXX29UmDV/bjrnSH9/UYhkGCgaLanG6NHDqP70Z+i9OBBNL7tHXBXVpHINhd03Kh9WavtaCLrWiG5/PVEWCwwnY7gaHQcj8eG8ICtCndYy1gsIPfTte/LLH8Pt/YvJPgtSg5yXcdDQSRCYSTCIcRIYo16ZxCm0qqorYYnJxGZmUaMig9GksZcfE55qqrhqZa5Bk4WXDhYgGGkeoKebkwEZAwm/fjLY8CLl1kUywJD6Q3trzeigeo+xTkGKvxkrsvFQmctxjGlqMo8TceLcx1xFguaVbFgM8msDpJLsoiXu9Dhbcpny7X/u9ZOPvPMM/jQhz6k+sj/8R//oRJe88uKFaJYGQrZta+vb1UEak1knUdVv2oENAIaAY3AeiAgDluiznryNPMuvWHmB+KoKLPRKc6JMhbyFxZwTER11kwroEkkUsyjRPFLOnQFAglUlNNpjgIHjY0upZ52I6jXayLrelwRep3rgYBS0ORgbXQW6Jkw4EQ/ncE4biulM+G+OpLny+bcCBePZK/Hnul1ZhoCTEkgpvgAzF1zHExDHgoyJUlkTcPLfJ3XL86J8ndK5eY8JKyWl1B1lWJJpcxFFuaZFJH1euNkiQNOUZn1hfgY+pMBFTeQ/IqIhRSb7HCBIh4kuFKLM9Mgyrj98TLnOnr0CKbPn0fM70Prwx9Cye49LD6nMMD1TsRrjqa/vx+33HKL+rSzs5N8D1qVXjFJzqqaMUCZvve97101Br9iMbrgLm89d955F/73//49/PCHP1QFqmW1n2b+14QDe12oqrCq2MuXvvRXqkh17969kJjCaychsu7evRtjY2PXJLIKefUrX/kK6urqKHBGV2wSWWWSuIGotEpuQI5P8tqrmTSR9aklwWcIhylJdgNOmsh6A570G+SQE5QUTLBsKhal9WxECBBRTI77MDo8Q1LrJF+nqejlVwTWyuoi1DeVoa6xDOVVlGXPcawqeHuDQKwPcwEE5JktxDVREY1Ekio4MTbGSuG+EDskQVasxBlYsaO2zkl5d5Kpi6xUZFyZKt0Cm9+wj4ScK530ENVLRZ31MlUg+wYirOBJYHubC60tDpLtqD7rMC23/3fNY5BBZJSVa7McBHR0RXDidJDk9DRyid+tB92orbaRzCrqNavvsAvpMRYz0Oohjo7eOF4+G1OWDm2NFrQ1WtWA45o7mmVfzPczE2y3MihPpTns4Xz08At49ulf4IMf+Rhqa2uV6q2QV8XWYg0g3nCUguzmTXPgeOh4FOc7Y3NJVVFi5SzkZMsaka6vPDBRDIhGk3jm2QlcvOBXhPamJjer8/LgFCK7dY5wIp19mZ978gyeeuwEHHSz8AfG+ZuXYXJsQ3HNW9HcXMTKuly0bXMrMquLys4hDownaUly4kyI11+UA4oUamusaKU6clmJRSkli8KsBHCz8ZxdiaV+n30IyMAqwTrhEMmsk8kIOhJedKVYQRz3ocGcgx0W2uHQEqfUyD7XdQ5vkgPlgb5+vHT4CC53dGJsZJR9tnps296G5pYWqrBWUGHfQwUOO5MWVLLTDf46iOqvNxIBVfXNaObkmdO4/D8/Igkupiq/G9/xLhS279jIXVmzbWki65pBuewVzaRjOB6bQA+VGMZTYbzBWoED1mKwxw3SxJa9Pv2DpSMgfTVlRzYzA/9AP7w9PfD19pCo3oPwxDgSvM7ttOV2V1SSqM6Zr87yMn5WACsD2iYqrUpw3EilcFFkNjL4qztoS8d/Ky4pfaUQE17+CMde3SmcG5ojrjaVGHH3NgNynWJXmT1HnlJjGgM6OX7u7EvgYlcUxQUmvOVuJ/JzjKqIMHuOJjP2dLn2f9fa69/6rd/Cz372s6sUWeaXFVWWP/7jP1b95y9+8YvK+nD+u+W+aiLrchHTy2sENAIaAY3AchBgV0PlXcRNbZROcR2XKRzQH8Y4xTYO7s9hTsJJYitJHMxHZNIk+x1mDLerK4ALjA+fPuXF7XcU4q67S+gMlnnE2/XAThNZ1wNVvc71QIB0Agq9pPHUeeDicBouuwFNJWnc1GCEx5GGg06UOuy8Hshn1zqZSlUurZN0fBydTGNwJIGhMeZA+LeE5jzMN5YWmZXDp4yJ86mU6bTT6ZLtR2axgReTrqUUXjBlS3XWJGZSUXQxFvgiCa2i1pprtOJOFraLMqtZxwSX1IDiQRahM6Z3/v9+G0PPP4/2j30ClbfdDkdJyVyMbklrmVvoqaeewkc+8hFVLDoyMqKUWa/8uRA+q6qqlLvK3/3d3+HBBx+88utX3y93PQ899BAeeOABnDlzBn/4h3+I/LIP4XJ3FLcccFOhXlw8Lfjnf/om/uIv/kJt/9ixY+w7SSv69bQUIuvv/u7v4kc/+tGrPyouLlbHKCquMonTi5Bkr6U0K9uV+XpTbm4uhMz6jne8A/v377/e4lvuezn/S5k0kZWV2XrSCGxVBFTSiQwtH+UGp2nbPDYyg/FRL6YmaXYbjbOzQOsR+mHb7FRLcduRk8tAe4EbeZzzCzwkFVmVUutWxUcf1/ogIIRWIVrOkLw6SkXGoaGwshWXz4UMaKMqSUEBFYILLSSm2ZSdjARaltJ5XZ89Xv5aJRDj8yUwTDKrVEIPj8Rg4LG5SdIroZ15ZbmNVcY2VQ1tYQd9tZNsL0n8Rkgw7WLnbHAkCp8/haICdgqpCCsKlDkeoyLQrnZbcp4oAIhBDkDOXIphltsRtXyxR6yrMqOcVXNbWVnm0KFD+MUvfoGPf/zjisi6Wjw36/dCzhW7qQEOJs93xeGdnVNJ3d1Gm3OexwJWPprXOL45H1gdHg4rVWaxjwoE4oq83kgl1upqx1XXecAfVs+lI89fxEsvXiC5IYhQxMd7xgzKanZj14E3U13AhQYS4MupNCDHNEXSuLT/UV4LARJYJYAiNiR1NTZlI+GmPYmoEOhJI7DZCJCmjSiDLUNJEq5ZNdxJddYkPzPxfl5ucqHC5ESNyU01QSvsr6gJJnmzDVHlboIWzUNUXxUF1snxCZK1A4r0bXfQLqWhAY0tzaisqmS/LVcFDTb7WPX2NQKLIRAYHsbEyRMYO/4yvJc70fjOd6PsppvgLC6Zq/xe7McZ9p0msm7OCYkxUD2YCuLx6CCSfC92Yu0sCKgzezZnh7bwVtNUToiHqLRKhYYIg9xRr1cprsprzB9AMhqhLVmUc5zvKbvByeywk6ReCGdJKecSOHhtu/hqdjqV8qoustjCDWYVh8buEPs2QCeVWTtGaBs4NZcYrS3kuLPUgLoiKDIrQ1ZZMyl3kzEWEJ6IqPGzFIM21phRXZ59BbybDfpy7f8W2l8TM6RtbW3KNvBf//Vf8eY3v1mpqMzw3iZJI5nWyhZQE1kXOgP6M42ARkAjoBFYDwT8dIsbYVy0uzeCnr4IxQKMfK6ZGBe1q9hpKQv8Rek0UwhnosoqOZTz5314/rlJVDE2vG2bh6qszD/m00d6i0+ayLrFT/AWODzJt0QpStLP8dil0TSGyNXiZUsSK9BcZqBrhgi8bIED1YewbASEXyIurCHmimf9SfiDaaWyKjm5CMNBEYpaUVeNbpAc2POfiC3l0iFRXERFdTU/16iUV23WlefHJW4g+ZRx5lfOUyxElFmluL2W8cA6owfNFA0RYiuffMs+vhvpBxLrSybiuPzfP8DAM08jv7kFRbt2o/L222FxuZcFxb//+7/js5/9rBpTd3R0LEhkbWD+KkAHJylQ/eAHP7jg+pe7HiHPzo/v//Iv/xIt2x/CuYth5puZa6M6/f7dLjz60/+Lz3/+8xDyqRBel0tklfilxA1OnTqliKr/+I//iLq6OrX/Tz/9ND7zmc+o+EJ9fT2ee+65BfNyL774Il544YUFj/nKD2Ufe3p6NJH1SlAWeK+JrJrIukCz0B9tZQTkxh2hl/bw4BQuXxrGpfMD6O4cwexMUJFZm7dVoqWtCvJaUp6vVFpl5Mt/nFfe4djKmOpjWxwBCVhIkKXjkh/nzs7iDGchmpUU27FzVy4VFz0oLbVRUW6eVUc7gCxqa2LtMzERx/OHvAwiRVlplMSOdhduvSkHRYVWOEmsW8vrRxJ+Zy+EOIdx5nyIQR8z7r4tR1mqC4l2LZRZ5YzKAEQIrYeOh/Hs0YgaeDRUW3DHfhuKC81bdgC7VYisYQ4kxyZTVNWlhdOhMPa323DTbhtqK81qQLn4Vbuyb4UEHaN68LFjM3j88VEOGGyoq3PRaqIQJSW0qXjNNNA3jpcOdaCvW0h7tE0fvgB/KAqLcxtuu3Mf3v6Og7w3WKk+bFIk1v7BGE6f46D1ElUHeM3t2elC+zY7Z4ciV98IllSvgVD/mSUIiBVOIB3HC7FRvBSfUGqt5SSyiqJgLQlZhUYb0rx+IiQPjY2O4dSJE/jV089ghETWJCOKt991Bw7cchP2sDrTQTKrJOb1pBHIFgRSDJaJmuOl7/0HOr7/nyi75TaU04Ko/KZbYHuFSJItx6KJrBt/piRo7ef980JiBo+Eu1DNAoAP2htVoNpu0OSwVZ8RDiwkOaEmviZIVA3RYmu2txfezg7McPZevozA0KBiHbqrqhnwbkZuUzMKWrchj8FbBwmsZiqD60kjsBIEpPn5OOZ8oSOF88MGDEylcFuzEfe1G+Di8MFuWclaN+83fib1jpwiuWQgoewUb91rx+0cP8sYPYtCHJsH4AJbXopqygI/U3aBYiko0+OPP45vfOMbeJ7qM2INKP3pAwcO4E//9E+xY8eO1yW4FlrfYp9pIuti6OjvNAIaAY2ARmA9EPDSfWuE6qxPPzuj3OJqSRDducOFm/Z7lJVzpgmG9PYGceylGUxMzhXD3XdfKcS9a6v3jzSRdT1av17nWiEgY7FonHbwYQOe7wAeO5PC9goDdlYB++sNKLjaMXytNqvXk8EISJtQESL+J8JKvkAKw+MJ9A8n0TuURP9QHLP8zEXSanmJCQ1VFpVvrCozI49uJKshrS4Gi+yTzCfikyq/MkJiq9tgwdvttagnqdXD95q9shiCc9+NU2Ri9NhLGD91Eh6qpu7+7f8FW2HhsvgYP/nJT/CpT31KKZMODg6+rjhUuB3l5eVqg1JQKiqqC03LXc+b3vQm3E7ibXd3N77whS/gAw//NiRf/PMnvYqr8OZ78/DLx7+BL3/5yyyY2YaFFD+XElvoZTxU1FeFNCtxgyunxx57DJ/4xCfUR0888cQ1VVmv/M213osa63e/+11NZL0WQK98romsmsh6nSaiv95qCEhHRFQHwkEqLXoD8M4ESGIN0fo9gACVW8MkEUXCMcRJxnMyc5BLddbyigKUVuSjjMRWGzMJVluWZRO22knMsuORNifkNq83hpmZOC3Bo2x77PDOxqk8lyQhx4icHDMqKuyUfHcotVYXlU2zZYpzsBeJpKiWGqO9D0nirIoWcqvYq9dSJbK2xoGaajtt3OcIrWtxXNMzCUXk6+6LYXwyRqJwikRWG5rqbaissHLQsHr8hJQYpxLryEQSfUMJ9AzEITb1pUUmpSzT3mRVgTHjFit22wpEVl+A1bOjcRw/P9c2nBxYbmu0UlXXAjffW1dRBXmt9ivtZWIiirNnfRgcDKn3u3bloaVljqh+pb2VFFQE/Vz2VC+eePQEk7wRhGO8fobPUGHShnseeDvad7bwt2XqOvL6kujsimBiis8uqswKsbWQasSV5VYUF1mUuqwEaLd68PNa2OvPMx8BqRwW65uxVAhDMieDmKItTigVR1HKgrK4BaELffB29GNkgIqDJP7JQLmYinYlpSWooFVzSVkpCouKlJJUNhV7ZP7Z0Xu47giwI5jmfX/i9CmMHD2CmUsXYXF70Pq+9yOnrh5WT/aoamoi67q3ltdtQBRYTyamcDExi1GqLjRSceF+WyVsVLI2G7ZYJ/R1R79+HyTZ74oHqYRP0mpoYhzB0VGEqQYempxEikqrBnbwjTabIqia+TwSoqo1J0fNttw8ktDzYM/Lg4XXr4XKqwZdYLF+J+sGWHOMY85Rukf0ThpIZiWhmqouNAfCASZPG0oMtLEUZ5fsACLG2MDoZAKXuuMsKIyjtsKEna1WpcqaSwcVPS0fgaUkmxZa64ULF3Dvvfeqr2pqatDf36/ei9XhvBKr9KkluXb//fcvtArGd0YZw5pZ8LsrP5Tlnn32WXzgAx9QCa8rv9PvNQIaAY2ARkAjsB4IRClgIE5cff0RDA6Jc1VMKbHmMGa6rcVJ1yoH83gGunFlBrXH70/wuRrByy9PU4EshJtuykerxIzL7LBYtm4fSRNZ16P163WuBQKSywnEjOinPfxLPSkEorxf8FJsrxQV1jSKPXTW1DSAtYA649ch+XtxYJdnyjSLJKa8qbl5hs+ZyFzxM4dQSgFciKoOFpx63CbmGUGXUBM8dEt0srZZFMLXMzQkRNapVATDzK1cjHtVjJAC5CpOuN9aDDd1WZ1GXfC+WIMLjY/D23UZlx75nlqs5X0fQD4L1cVdaamTKI4++OCDavG+vj4+w6++Ufh8PkUklQV+/OMfqwLShda9kvW85z3vwZEjR/B7v/d7+IP/53PknCRx/ExQuXeKq+zA5a/hn//5n3HHHXfgkUceed1mVxpbmF+R5Oxqa2tVIezXvvY1PPTQQ/NfLftVE1mfWhJmmsiqiaxLaih6oa2NgKh9BQMRZfHc2zWK3sujGOyfZHA3qYir5VWFisxaXlmA3Hw3lVupnsneio09WTuJrWKprkkVW7uNrNXRyQBJOsZiPd7XH6JKawCTUonLDwm20vsAAEAASURBVCVwUV3tRFmpHQWFNiqZmpRyq5Ud4GwhqM3OJlQA6fzFEC50BFFSZCWx1EZ7dCcJd2Z4PGZ27NYmiCTk4MmpJC52hnHk5SDctG0oL7NgW5NDkVnFYl0GDqtVqRR7kQgHLEdORdDRm1DqurWVFuyjwmdhnpGDFgMTi1uHRJjNRFYhT8c49w4mcbkvjvOXY4rkeetetsMSs3q/Vtfy/HpExUsGukJM7+4O4vDhKfVVCa/jA/vzUV/vet31K8USvd0TePlIL55+4gJC0RCM1hgV+0bR1FyKD/zGB1g4UY5U2kB1gRgGhmK4RCJrMplGEQmsO9ocaGU7dzAgu5WDnfMY69ethUCM6qyXo16cCo7iOW8fjGzXBUkzAsc7ESSZNTwyifqKKhzYdwDbd7Sjtr5O2ZTIQFtPGoFsRiDGQJZvcAAX/v3fEBwZQf1b3ori3XuR39Iitg9ZMZbQRNaNbYEJklijhhQejw7iMomstUY32sz52Gkp0EoLSz0V7KcJaVXNJKgmqbiaoAdcIhhAmOQsIbIGx0YRIgkrODqC6OwsTFaOw2hx5WFwNreunq81VGqohj0/HyYL2YXZMjBbKkZ6uYxBYNwHXBoBzg0DvRMpRWTdzkRqZf4csdWy+lrNDTlWiXl09Sfw9OGIin3k0VLxwA4byawk4DOvtlYOKhtyMBmwkZUmm65MjMlh/P7v/z4+/elPq2Kxc+fO4Xd+53cUubWgoEAlw1yu10tO/exnP8PRo0evi0J1dTUGBgY0kfW6SOkFNAIaAY2ARmAtEZCYrAhsiGvV8ZMBElojmPYm0N7mYtzUSXcsChpQLESc8Ta7Cy/7KjmG55+bxDGSWUuKbGhodENEENxuOsxt0ZCXJrKuZYvX61orBKRwMBwH+iY5/hpN42Q/rblzgb01aTSW0kkzZ622pNeTaQjMOfIYlBunEP8isTSiMkfTmPULgTWJSRJYZZ6ZTSmnOBGVKaO4UWWpSamwFheYIMI5m1UoIbHCS8lZOjd5cSYxjXyDFXstRXS9c6PEwCIOFr2bdOH7gk1PhCbCdCg58y//SOelYcbld6N0/wGU7N235Li8FIjeQqc1mRYiqr700kt417vepdYn4+48FsEvNK1kPUJg/eEPf6iUWf/rv/6L7TaJ4dEEHTwprDSdwk++/zuQ/L6opv6f//PF1/V9rhdbCIfDGGHOwmq1QophRZDpykmuH/lcCK1SEHsttdkrf3Ot95rI+tS1oLnqc01k1UTWqxqE/uPGREBuvkJajUUTSo1VVFlDnKcmfGoeH/ViYsyr3udRobW4NA91jaUkV5SisroQNocoM2ZJVuHGPMUZddRsboiwgxEJ02o5kGDVTByjI6ykGgnT/i0KK6tw8/MtaGZVbjVtcSoqHIqMudkBl6WAKERCUWedpvKsKKV2dUdYbRxlAsuAOlZC79nlopKkhYTW1V8vgmOUZNZZqlWOjsdxsSOCPkrp5+eZUE8l2L27nMjldszm1VVey3bERmLWLyqfCZy+RGVdX0opZYpVYnuzFXZW4VlWuZ2l4LsRy2QzkVUGm6OTSRw+GaGSbgrNtWY0VJupxLp+50ieH2Fey0ePTuPy5SD8/riyhjpwIJ9Kyxa4XFdXQUpid2Y6iJ//+DROnZrGhNeO2elTJFWcxh137cOBm/eibecuDpRtqk0PU1EgzGuqttqKWqoOi+JwDis+ReFYiNq6iGIjrgq9jbVEIMGB7ph3GucHuvH0yaMYsSXhLxa1OxYHmB3YayxAm6cEzYXlvH5cLOqg0l02PADXEiS9ri2JQIoR0gQVIAeeeRrjJ08o8lz5Lbdi2/sfhpHV29mg6KiJrBvbNP1p9qepwvrz6IBSsX6brRqNphzkGa0ksq6uf7uxR7I5W5M+WioeV0Hq4Mgw/CRZ+fr7+NqvPktGY7CRnOqg2reoLzhIXrUXFsHBz8wualk45dnEmYqsJqqzqut0q2aYN+cU6a2+BgFRZg2yxrVzLI2OUWCIQpg0CcIdzUBtsQH5ztf8IEP/lPGzL8ix8whVWc+xIK8njjfeYseOFivyabcoha16WjoC10s2XWtNVxJZRSn1q1/96lWLPvnkk/iN3/gN9dn3v/99lQy7agH+MTQ0RKeRidd+/Lq/J6lm/fzzz2si6+uQ0R9oBDQCGgGNwHojIP0OlR+guMbAYARdPcxFMJaaZI5i3x4PGhvstPil00IGKLPKvoqLV1dXECdPzpAIZcb9D5SilGIIImiyFSdNZN2KZzX7j2k6wH6uF3ihE5hknq+x1ICmUqCZr+KGYdPjlew/ydc4ArkPSw5b8rtjzCMOjVEtm6/yPpUyqDxvQa6JgjhGihiZqLhqoPKqkYJm/I5qrFaKb1rZPjbTHZGHgBDoWJoIo5OE1u6kH90JH26ylmC3pRAVJLO6jFerhF4Djhvy41jAj2Gqqk4wNj917ixqH3gTWiU2P5dsvS4mMj6//fbb+Szvwm/+5m9CYuXzhE/JYX32s5/Ft7/9bezbtw+PPvoouRFyxl4/rWQ9P/nJT/CpT31KEU0PHz7M/kMZc8dJCiHF4XL4cfNNe9T2vvvd/1SqrCLydWVa7Xqxhaeeegof+chH2L5NdB49i9xcMvyvmH71q1/h4YcfVp9IvEHUWVc6aSKrJrIu2nb+7M/+jJa1LfiQJrIuipP+8sZFQFRafbMhTI3PYmRoWs1jIzPqISBW8E5mFDweJ9weO1VaXUqpNTfPBU+OA063nTd6qfTUAfobtwUt7cilDyMkuPHxCIYG51Ra5W8pdJFq3NxcM4mfVqXQmpcnBFAzq4hNV3U+lraljV1KqqEjtPjp6AwphVapjJaElRB0xQ69rNSKokIr1UBo27nKimOlwsntXegIo+NyBD5/kh05I2qqWDVUKcQ/ixpcrAWh1RfgMfVSTZOKnz2DCVWFV1NhRn0VzxMHN/YMqPBe7ZnORiJrnIPPQEiUWOO40BWHnCcZUIpqrpwfSZiux+1Yrt+JiQjVZ0Ls2M+SxJpEVZUDLc0etG2fs4p+7XNgcNCPzo5pPPt0H5UCfCyEoBLlzElEg+fwwNvehdYdBxBL5pDIasDEZFwNij1UGxYF1gpeO8WF5nU5ltW2G/17jcBiCIh9aYyKeFNMhIv16OjQCMZo5TwxO4N4RS6MLZVIFJE0lONCicWJKosHddYcFBsdyDeSPKQpW4vBq7/LIgSEzDrb3Y3xUyfQ+9jPkVNbh9r7HkBeYyOcpYyaZ/ikiawbe4IkGH06PoX+VADWtBFvsVejigoLHAls7I5kwdaEsJqg2mrc50eU6scx3+wrr3zv9yFOEnk8FCSZnOH+cAhpFlUYRXmVBFYXA7/OsjK4ysrV3xY3Mab6gJ40ApuFwISfJIfpNE70McEWNKCEuYMmJlVbStNwsWlKAi3TJ1XgGgOO0tXk5XNRlNOdpb7awiJQC4vyVh8DyPTjX8v9u16y6VrbEoXUm2++WX0tibT77rvvqkXjvG9KXiBKteovfvGLSrXlqgWW8ceJEyfwP//zP5rIugzM9KIaAY2ARkAjsPYITE3HMTQcZX4grIQ1JLciOYjaGjsVUC3MS0hM9WpSx9rvxeJrDAYTyp3vmWcmlLtXa6sHzYwjL+TotfiasuNbTWTNjvN0o+xlhCqsfjovXh5j8SCVWKc51nLZ0nTCMIJ6VWBoWk9bCIEUk3dpklPDPOeBUErN/qC8AoFgEmEWkYqADE17EIunYGNOOZfE1eJ8E10RjSjiq4xdbRx/r0ducbVQR+h6N54M42JyBscZO8xh0Xux0Y4WUy4qTS4UGJhTycQdX+2Br/L34tgkjkyjR46g478eQemBg2h613sYEyyDNWdpcsx/+7d/iy996UuqT/Hf//3fijQqhNVnnnlGFYvKGPuv//qv8eEPf1jt7eDgIP7+7/9evReXFHE0kWm565H82vbt2ynEF8Ldd9+N733ve8rJMBqL4+Mf+yikWLWyshLf+vZTVKS3orzUolTp1cb43/ViC7JeiREIMffBBx/E17/+dfVT6TsNDw/jfe97nyLwSpzhRz/60TVJuvPbW+xVE1k1kXWx9gFNZF0UHv2lRkAhMGcDL7bRc4qtyUQKA73j6O0aRdelYfT1jGF4YArllQWoaShD6/Yq1DeXobq2GDa7Valoaig1AtdDQMhwMgt5WhI+gyS09vQEFDFueiqmrA3at+dge3sOGhtdlKK3KKL09da72d/LQCFFmw6/P4He/ijOnA3g2Ak/qkgubaG9z77d7rmKaCqZrrY/LfgJdkJiPXo8gEsktIpK6652J+682a1UYJ1UsFztxFsBjymN/pEkzlKZ9UJ3HKFwGvfeZse2egsHOKZVE3NXu4+r/X02ElllANo/nMCxM1G8eDKKu2+y4+BOG60+zHCyWnK17WshTOeu2zSOHZuhXcMU21+K7dmOe+4poXWVfUGlIfnNU08N4NlnR6gYS2peahYl+b0kXgxTKSCIPTe/A1bPNhw/FYKdJG8hY+/d4UJTvR1Wm0Gp/q7HsSx0fPozjcBaIiC2JLO0az52+AiOvngYHRcvUS3bjD3792HfzQex6+B+DJtj6DQEcCg+RpKWEfXmHNxsKcZ2cx6sBvkk80kba4mZXtfWRUAIdDOdHbj4n99DdGYaFio/Nr3r3Si7aY5skslHromsG3d22GXA8/FRPBrpR4s5F9vM+Wjn/TCXlmF6ej0C8UAA4alJeC9fnpu7OtWrf2iQyqpU9yZhVQjjufWc+eqpriGBtRRGPotEDdnAyrr5eV06jq/fZf2JRuCaCMiYM8axbd+kAWcG03iuI41aJlbvaTOgpsCAorl6uWv+PlO+kLHPAB1NuvpknBZRhYbvus+JCo7RrFlAxs0UHK+XbLrWford33yC7JFHHlHJtdcu29rayniNH3/1V3+l1GRe+/1S/9ZE1qUipZfTCGgENAIagfVEQPoe4qo2SWGA3r4InjvkRZAxY8lF7Nvjxs52lxIMEIWyzZpkH0MhOr6dmUVHhx8jwxHs35+Pe+8tUYSYrRb31UTWzWppersLISBKrF3jabx4GTg/nMYbtxuwt9aAirw0HByfbOKtYaHd1Z+tEgGm21m0J8qrzB2OMEdNEZzB0STzcklFWi0uZP6t3IxqmctMyM8VoSK2A6aR5V5seqVBZOp9mY8TkKqLmVQMY6kQnogOoSvpw25zgVJm3W0uhMWw+pz4Kk9DRv48xbHyxInjOPMv/wQ7XZkK23dAXNPyGhqXtL+S63rooYcg42CZdu3aRdVeO44fP848cQLvfve78Q//8A+vEj2PHTuGd77znWpZKQA9ePCger/c9ciPRJVVyLBCNhXF1L179+LChQt0+x0jadWG7/zHj3HiXKnKLd9xq4ft+teK70uJLcyTa2VbQordv38/xdjCEAXWAGOvso2f/vSnaG9vl0VWPGkiqyayLtp4NJF1UXj0lxqB1yEgg0x5MIhK6+xMAFOTPsxMBThT9YWlXLFoXBERpTLBYqX0fFEOSsry1FxQmAMXlVvN5l8/MF63Af2BRoAICGlaiJ9eLzufY1FMT0Ux4xUlu6Qiuzoc7FBT1bSi3IGSUptSapX+9GYGYK534mJUS/X5EhgZjaF/IEIyU0JVujnsRkrfW9FY71BEU49nddeHXKOiBDvM7QwOx9HDgFU0lqZ1EG1BGu20ZrcpNUsbVVNXO4ni5+R0ijaJMQyNz52bsiITtjex6o1k1hz35gXEVnts2URkFeXiiZmkIrGeIbE4QeK022ngebCgodpKEit43137cyFtbXo6is7OALq7gww6htHSmoOGBifq6tzKDmp+gDtXCJFm+6ciAJc/fWoC/X0+VFQ6kIiNoPfyCzBb85FT2IDismbkF5SwEMJIpQCzUi8uLbaQvG5SA+f5da72HOvfawQ2AgGpPPXP+tBNm5W+nl709fayn5Rk0oD3SFa3FtLCubqmmtdCBUrKyxAw8r6ajqKHAZfxVIRBmCgcJLAWmOxoMubMVRK/os66Efuvt6ERWE8EItPTmDx7BqMvHcXI0SNoeOvbUHn7nXBVlCvS3XpuezXr1kTW1aC39N+GUlTpSUdwND6BQ7FRvNFWiX2WIhRSTcHG++INO7EDlhSFb6+XpNUphCcnEKLSt7xG+VmCygGKjCrEVA4AjCazUla1ejyw5eXDxuC0s7BQvYrKgpkEV7W87mDdsE0qkw9cxhuzYWCYlpdnSWZl6AmiILSzCmgpA0pyaG2YBW6B4poxOZ1ksWEEUzMp5ZbRwgLQbQ1ZsPMZ0kCWkmxaaFfld5IgE2XWz3zmM/ijP/qjVxNpsrxYEb73ve9VPxU1lZtuummh1SzpM01kXRJMeiGNgEZAI6AR2CAEwuEUvLPMDfRGMDwSU45XbqrqFRWY0driViqtYhO9WfkUEUOYmGBcuSOAI0enUVFhx+7d+SSM2Jn32VqFi5rIukGNXm9mUQRiCWDEmyaJFTg3xHyRic6RrjR2VLFQkAWD4npBg1U9ZTECSYoPiWujL0Cl3dkU3Q5TmPYmMeuneBS/E96GnGOGi1hgScddB6i+auJsVLlceU9tMlXskG0hoiiVWcNI4nx8Bt3Mq0wyr+IxWNBIZdZGs4fOTi51Zin3k8VneO133T/Qj+FDL2Dq/HmExsew7YMfRvnNt8BosahY4fW26KMb1Ec+8hEKHR17dVEr3Z3e8IY34Jvf/CaLd3/9PBeC69vf/na13KOPPqrIp/M/Ws565n8jSqxf+MIXWKwTnP+ITqFV+LM/+3PkFt6p3GvlmthNkaRa5slFmVUmuQ4OHDiAoaEhfPWrX1WOKq+u4Io33/jGN/C1r32NPBUGpK6YhLwqx9bQ0HDFpyt7q4msmsi6aMvRRNZF4dFfagSWhECCrKkoCawDPePooUprdwflyIemFbm1qDQXVTUkadSVoLyqEEUlOXC6qNJnNpLoaiG5SlRfRClQdx6WBPYNupAQQMfGIrh0iXbknX52HOJwuWjLV88OSK2TChtORZoTcqaFHXAJwGRqk5KOk1TAnTkXwvkLQZJNo/C4Sf5sc6GOFj/lZVZF4LOsgULrLJVZ+/pjOHU2iDPnKYffTLt3klmb6m2sQDKzOorX3xpceoNUmOkZSOLQibCq2NzebEVTrUVV8InKjAyKs23KFiKrkJYjJCpfoirupZ44OnsTJK+a8IZbHCgg8dPlWB/shZgqAdGuLj9epBKrtGm5Ju+4s0gpJps4Ip5vW6ISHI2xAMKXpCLxLJ57bhzemTAHzQkc2O9AwD+AX/z8aeSW7EJN892sZiNJvcyGg3tcisQqBFY9aQSyBQGxT5FZLE6ExDo9OYVRWo6cPnkKnZc6SODuI+G7Fbv27lFKrNW1NaqCU5Ls81OKVcQxBl+6aKf9Umxc2WmH+fcuVhK3UImwjpbaToMZNjHW5oW2Plf5/N7oV43A+iEgld+peAy9jz2Gc//2LRTt3IXSvftY/X0LlSNLlULk+m195WvWRNaVY7fUX4qawiSJ/GcT0+hIzGIoGcQ77bXYT4XqG+mel2a1kqgXJ3mdpDnmFuuvJJ8tiUiYFmCjCPL54h8cUHOAFl3xIFl+RCi3tg6eujoqrzYgl4FVUV4VIquZygh60ghkIwLhGAv3/Gm81AM8fT6NtkoD2sqBVs6FtL60WzL/ziCFrcfPxdDBMdv4VAIyZr77oF1ZNK5H0WE2nufF9nkpRNZ/+Zd/wWUqUjdScfqTn/zkq6v77ne/iz/4gz9QfW5RZb311ltVYZkU6X/0ox/FL3/5S9TxnvmrX/1KuSW8+sNlvtFE1mUCphfXCGgENAIagXVHQOJTEjsWZdZjJwIYGZkTvBBl1mY6xZUUW6m8J/mUTepLsWiptzeIJ58a536mkJdrxf4D+SSHuDI6v7PcE6eJrMtFTC+/1ghESWL1BtN0ugA6RoGeiTQONhhxRwuQ50zDqZ0i1hrydV+fFH3KLLm3OHPOrHdWecIwnTPHWUQ5OsmZ4kMTfO/1pZBDsmp5sRlVZUbOZlSUmiiGY1SOIeu+sxu4gUAqjpF0GL+MDmIiGYbbaFVF8bsthXAwlyKF8Zv0xNtAFJa+qXgoiDCL4zv/6/vo/ulPsOO3fhs1991PhdYCVRS/1DVNU6zi5ZdfVoqsUkgqyqwrmZa7HhGMOU8Sbi/FY3bu3KnG9cLBEAfZXz47i76BKPLzzGhrcdC51qHcPk3L4CtEIpFXlV5F+bWpqQnFFKZZq0kTWTWRddG2pImsi8Kjv9QILAkBITRJADgciiIUiFJWO0z1sRB83tCcYiu9Cqap2BqjdIaNchllFfmK2FpZU4TS8nw4nKRiSBmQnjQC10BAAhkxkvV8vjiVTONUgWQVMSt2xzlHwqIEmiap1Y2aGgc7KrTNdJoUofUaq9vUj1Pc13TKgFkey/R0QlVED5HMOkgLnQJWGwuRVUitZawOsll/TQZcyU5LoCoUoW3EGInmQ1T4I6k1EExSydaKlgY7tm9zKKXW1VZeh7mNWVb59Q0JoTWO7sEkaitMaK4zk9BqRQHtKLJtyhYi6ygtQHqJuyixBkksFQJxY7UFtZUmNQhdj6SoXG9CYj11youuyxIEDaOp2cOBQi7Vhe1wu2lPe8VocGYmgcGhCI6fCqCnexojAxOorrIyWGqGNxDCBBWXpX02NVVi1+4a1FTbUUYF1gKqLosygHWzgqnZ1mj1/mYEAjJ4jtBmRAir586cI3n1EsZGRlFUVIRyqq4KcbWENs7FtHfO4eDX6XIyOC/3+l9fNIxBKUucYDqBaRK5hlIseiCJqz8ZUIGWMqMT22mv3WzKgd1oBq+4jDh2vRMageUiIM8TDiIwQ9LJxMkTVGY9QpJeDK0PfxBFtDOy8Rq56oGy3A2s0/KayLpOwL6yWmkX7CqjkwTWn0b64DBa0MT73XYS+atJ5L+RpliAries/A8MDZKsOqRehbwaGBuFxcbiUD5DbAwuiwWYLS9PvVpzcmF1u5XSqpnfW11873AsWU3hRsJXH2v2IKDsEJmgG/Ea0M2k66URIBBJYzsJrdvKDWgsyXz1IEmmiCJO10ACzx+LKGu7Hc1m1FVZUFKoC/eu1xqXQmR9//vfj+effx633347vv/977+6Snmu3Hvvvbh48aLqd992221UesvHyZMnlVKrrPs73/kO7r777ld/s5I3msi6EtT0bzQCGgGNgEZgPRGQZ6AMu0OM405PMz8wyELS/jCmpuIqf9K2TYQ1bKissK3nbiy6bhEwGRgIMs48S7KIjypuJbQnzqVVsCVj8zuLHtACX2oi6wKg6I82DAG5B3SOAReHU+jgq4VDDxlHNZQYUJGbhpWCOjo9v2GnY802JMqr4sQ5PpXC6ERCEVcn6f4hCqziAupxGaiyakSuzDlzgjcieuNgvk1mu42uumsgprRmB7RGK0qkyVWhMutwMoTO5CzOxKbholNRKfMpB+nyVGV0waLJrK+inSIDOhmLou/xx9H9s58in0TNwh07UXnbHcrJ6dUFs+iN3PPiVH0fGk6goytMoa+Q4l3ctI+8ixKLuh4y5XA0kVUTWRdti5rIuig8+kuNwIoRiNOnIBSMYmRoCkMDUxjoHacqGcmsMRkk25BX4EZePudCD4kcTnhyHJydcLltcDhsWqV1xchv/R9KAkgIrVJB3NMTxCiVWr0zcWU5k0/iW1ER1UZJCM3Ls9C22cz2ZmayAqqKN9PQEaLpNPe9tz+q1FkjVLUU9dKqSpsim5aWWFkpJ8ewOiKokA59VGc9cTpIsimVnDjIKWWHrbHOrsiEBflmZSUhOK10kso/P6s6O3vjOHY2qngnHg6SWussqCo3ozCP1d1ZNDDKdCJrJJomeZiJ0L4ElVhjqsIsj1WVN++xqcpKl3N9iG0SAJ1hmx0eDuPkCS8J2QlWy1vQviMHO3bkvnqtyXJS/TlD4vkQ25xcq+cvzGBqwotIYAZ1DXkoLHKg4/IoYkkLikursK01H9tbPaiu5PVLxeAreH0rbZb6dxqBDUFAinkSHPTPTE0zGTCpiKvDtCYZHBjErHdWkVRbt7WimXNb+3aSV11X2apcbyen0ySzJoI4nZjCBG1xUvxBBYMvQugqMzpQZCKBnFY5up74ekjq7zMVgZjfj8j0FDoe+U9MXTivLIxK9u1H8a7dc9XfGfZA0ETW9W1JSfYhptIRnE948QQVFBpNHtxrrUSR2QEXqftbbVKqq/IcCYUgSghxf0Apq8ZojRXzzSI6+8pMQmuMll1yvchyjsJCOIuK4aqshLuCM18d/HueAH5lgcRWw0wfz42LQJiJukDUgEOdaVweS9P2kGPn/DR2VhuVMmsurREzeZIi8GGq4hw6HqW9Y5pjJyoh7bSpAlAp3luOMkgmH+d67Jvc065n//fwww8rVVUhpIoK65VTiPfYz33uc1cRXOX7UhaYiWXgzTfffOXiK3qviawrgk3/SCOgEdAIaAQ2EIGxsRj6ByM4R5c4P62mc3JNqKmy03LXjsJCC9yujXe6S5BsEmWc++jRKbzwwhTFSpxopmBCK2PEOTm0Nl6fEPcGog5oIuuGwq039goCQuYKRMTZAjg3lEbPpBDbDagpBG5pMiCfSqzZ4GyhTyjoJpGGFHeKyqSI2YR5XkWwKBBirpw5Qh/zsvJeBIfECUSEhYoLTCgtMqGEr0UFRqW+faMQltn0ESehtT8VwPE4czWpMCIUDGkz5aHJTBdhsxt2ZlK0OMivry4RmBg+/CJme7oZV8xDy/s+gJyaGphsm1fo8uu9W/47uf8J32JwOI7nXvQr5eJ8On/u3O5ELYuJbTaTymUvf81r+wtNZNVE1kVblCayLgqP/lIjsGIEVLUng/QyEI3HWdFBK0S/j8p7Y7PoJ6m1r3scQ/0T8FG5tagklwplxWjaVom6xlJUVBeR8MaHyI3Sq1oxyjfmD6UDIgkgaVtil+CdjVH5N4bOzgBtckhsHY2QnGmjuqMb27blUN2RSkWsMDObV8HSXCeo5ViSPBaxZY9wkHGpI4yLHVTeozqlnVVz+/Z40NzoUAqVqwnazGMWCKWUAuyxk8RpPE6yeQq33ezGnp0u5Hqo4LkKC5H5bYSjUFV/R09HcaYjhuJ8E1VCzbhlj11VAK6GLLtOp2HB1WY6kXVsipYJnXFc7GY1/UgCdx6wYWerVRGGbTyPq1XZXQgUua9TJpIWETM4dcZHpe2oUmC9+55iFJNA7nCIzblYmnAhTn0DMZw7H8SFS2xvI344TF6kWAkZoTp30lSEaMqOmckeNNQ58M63t6O2Jg8FBXZeqzqJuxD++rPMRSBGq+cgCUfHjx7D8WPHcPrEKT53bGhsasSe/fvQ0raNxRV5rxJYX6vAer0jE1JXgvRVUWjtTfpxJjGDnoQPs1RrPWilUgWtcYTo5TBsPYLX9bDR328NBITIJxXgw4deUKqsU7QEEhLrjk/8FhUnaSlozqy2rYms69vuIukkTsZJbKZywgCVqPdSMeF+WyUDzFSvXt9Nb8raU3H2i6h+4KOSt6+vF7Pd3Zy74OVrIhxS++SproGnplYFkdX7qmpY3FSRcDgpQ8lxs4ydzUzyynvOetIIbFUEOHRWqmJTdAPpmQCeucixNBN1tUUkOdYb0VZBcuhqBs4bAFyYSrKTM0kcORXFs0cjuP92B/bvsKKI42YZx+lpfREQq8IzZ87QSSrAeNE21NXV8Ta6NvdNTWRd33On164R0AhoBDQCq0dAyFCSh5icSqCrJ4yjL/tUrFdcsW4+OJeHsNnmyKyr39rS1qDCzfyvvz+Ei5f8uHTRTyVWA9761nJUVTlVnHhpa8rcpTSRNXPPzVbds7nrak6J9QUWAY7OiqtqGm/cbkQLHS2kAFDS70Y9/MiKJiCiNkGSWPtJyhsYTaKfDo0T00l4fSmSVak2SsJqRYmJLodCXjUqRVZR2pXCScm1iXiSTBk+VF7TcyEZSiGzRqjOejwxiROxSXjTMZRTHOQBexVKDSyW17mUVzGXInpxgzr9/30T4ckJ7PztT6GYyqx2FtFn6yTuuEFyIIQL8TI5EYePBXDf3bnYv8dFN1CJv2w+Z0QTWTWRddHrSxNZF4VHf6kRWFMEYtE4Av4IFfl8JLR6MTE+C5+XSjNUb1XZCPairFZRn6SiZpEHhcU5KCqmjUi+i0qtdqVotqY7pFe2JRCQ4EswROsEKrSOjUfZrqIMyCQVmc5C8qrYnBeX2FFcbEUZbc+tDMZYLJvfQbkSfBlEyuBybDzGCqEoBgep0OKTYwDy88wk5lpoxW4jWdDKSiEJJl3566W/l2BVgB233gGxcuegRwizXJ9UIok6a3mp2LnPKdgufa1XL5ngNqTqr3sgia7+OMYnk2p/K0vNqK82o66SNtjME2W62kymElkF2+ExktmGkorEKso9BVS7bW+i8m3ZXOd7pe3j6jN59V9CTp2hBZUEFS91+JUicjVJ4lIlL4RxIV6LSk48nsLsbJIqwxGSpqMYHo0hEooiGAjz915V+WaymFkd6kM8NksCdQI720tx/wN7WPnv4Xoyi6x0NQr6L43AHAJyPSRJuvNRGU+UV/t7+zDQP8B2ThU9EpLMJN2VUN2pqqYadfX1KKsoVwqsq0mS8ykhPHJMk7w6lAqiN8HrMBVS6qwSdBFl1lozFY2NblhJ9rIYVvig0CdZI7BJCMh1JQGzyXNn0fvYz2FxOlFx620obN+B3PqGTdqrhTeriawL47IWn8Z5V/OlYniMSqwjLH6p432tzZyHdnP+Wqx+U9chbVyUVBNUXA1TgThCMtXcPIUo1VZTyQTSSfb/SexOq7EBEw5UPrC43VRfLVLBY2dxsXq1FxQo4mqmkbw3FWC98RsKAQkhTVN15twQ0D8FjPvSqCOZtbEkTYtMjm/J8c7UJJ0o6UgM4xyLEqX40+kworSQRaztNqWUM59kvKFO6BY5WE1k3SInUh+GRkAjoBHY4ghwWMK4bBITk3F09zCfQpXWGa84blG5j/mTxgYHCgss8FD0YiMnv5/ErIkoDr04RdGSKNrbc9DY6EZdnTPr84KayLqRLUlviyEF+Ck2Iw4W1JNCNwsAi91pVBcasL0SKMkhsZFh40wdL93oZ1Dyf9TMwDRzbLNUzvZy9nEWkaIUFXUllyyz5FctnPNyjLRKp0MJc7y5HpKU6doo32mS8lxLknyKFMmLOEhHfBb0QUKe0YYWxhpbTblwMq9iN2zs8y4T27gU2YsL1IXvfgczHR3Ia2pC6YGDqLzt9kzc3SXvkzjJhqhifIEiYkJmdTD+In2d3e0OlJAELoUzm+lopYmsmsi6aGPWRNZF4dFfagTWFYEkI/hBElv7ukfR1TGCjguDGB6YpHJrGNV1xaipL0FjayUqqdBaVlGgOl8mlomZyIKTB8t6KA6u6wHrla87AkKik05J12U/zp/3oasrQPJ0AlUk3IlCaxsJd3l5FhKjzWxPQqYU8t2679ayNiAdq2lat1/ujuDwER9JuklVGXRgvwctTXYSTYXMunrFyhEGqS73RFXnTSqSdrU70dZiRzODVfZX1r8abITQ6qdSzgu0Tezojan3u7ZZcdteG22KDHAq4uOyoNnQhTORyBrnINZHTI+djeByXwLjUykc2GnFXQftrLJkIQA73esxsXCRg+ckVY/9DCZOq2vKTvXVe+8tQUMDTX4Z+RByhrRdvz+Jnr4IXjwyqwitsj/FRQkqqMVw+mwQkbgJeQUe+CePIh29hAP7G7B33zbs2LOLg4gM9wJdD3D1OrMKAWnnKZKMYhzYh6jAOjQwSAXWl6nAehIXL1xAK5VXd+7ehdvuvIN9l2oWUrjXbSDsTbPoIRHEc/Ex9DEQYyZxdSeJXgctxcg32uFhEIa6fFtSvTCrGo3e2WUjEBgewuUf/jfVKLuUSmvD296B6nveoFRZDetRqbHsPQQ0kXUFoC3xJ/50HKMk6X8/3M2eQwoP2RsUmdVNPdZsmeRZIdVoipCqiKlJ1ZbTHPuGJicRGh2Ft6cLvl6qr9KyKzgyjPD4ONyVVfDU1iK/sQm5jY3I46u7rBy2fJJ4V9Mpzxbg9H5qBJaJgCRooyS0nhlM4xdn5wpDC90G3NUKNBRD2WRmyGNjwSMbp8NGP4tLXzwZVTaQb7vHicZaC8fJkkhZ8Cf6wwxHQBNZM/wE6d3TCGgENAIagasQmBfW6OgM4+TpAEmtYVVAfXCfm3kUJyrLbXNKflTz26hJYt+HDk1RRMGHBN9v2+bBnXcWzZGyspiVpYmsG9WCbuztqFgEBxLUFMGwF3jqfFoV/Mml84Y2I/bXgcRHqrBq7YOMaSivhI+Ua6eMb0WISJRXZ5kDFPXVQaqvDnGemU0gTHJrdZkZNeUm1FZaUFlqRDkVWCU3p8eP1z+l4v50Nj6NU4kpHI9PYrslH3dYylBpciHPYIWJuZWNe9pdf383Y4lklMJEh1/E+PGXMXn2DMpvvRU7PvoJ5f6UKTH5leIixTsDQzG8+FJAXU/335NHLoSNRTyrE/Za6f7M/04TWTWRdb4tLPiqiawLwqI/1AhsCALSSUvEE7T0iiDgC8E3G8LsTBCzVGn1828//xZSq/TCRKm1oroQ5VWFJCUWkQjlViqtG7KjeiNZg4AEYObIdHGS6BKYovX5zAyrikkMlareQCCOEqqzlpXZUVvnUnboHo85ozr6IncvCi1+VtmNswp5ZCSmVC2FoCtExYZ6B+pq7KiptqlB50qrhcIR2QaTZ4MxDAzHMDoWV0q1FRwMNTfaUcf1i+3ESgdBPBVUJkxjjIqsg6MJklnjiHKwJWqse7Zb0VRDQrGD1Z8bGAxbTkPOJCKr3Ctl6iSGgmP/cAIW4tZcZ0FdFe+NtA0R5Z71CEJIAESuHbF1EmJ4f3+YdulutLZ6aO/kQE6OdPQNqnJfKvjPng+w3YoipVENwCMxKrR6IwhzpG23ppDjjrNCNITL54/A7x3Ee973duzZt5P39Hz+JntIKnNnRP9/IyGQYjQpSUJSP4lHXZe7cPHceSpETMJsoZI1LVZKqcBaXlGB0vJSFPO9k2qSFn63XlOMDPMQqEaeCmMoEcAgVVpnaY8TSSVZUZyrZlFopQnbDR+EWa9zoNe7PgjEgwGS+3owfOgQ+n75C1TecSeq7rpbqbLacnPXZ6PLXKsmsi4TsGUsfj4xgzMMLI+lwygw2PBGawWKTQ5YSMzPlilJ6YxkJIIgCavB0ZG5eWTuVYLCMllcVM/2uKm26uF7F9/ncPbAmpMDC19tfLXxMyMVWc12e7Ycut5PjcCGIiBjJBlzTgeBoWngwkgaA1NpCJm1scSAvXWAyzo3/tzQHVvixmQ8LknKF0/E6LYRRxFdNprrzBwr87rn2E5P2YeAJrJm3znTe6wR0AhoBG5kBBTpjQD46Ao3NZ1gjiDCPEQUk1Nx5FCNta7WwTyEHRUktErsd6U5guVgLLmdEbrudXUFceTIFPM4Ntx6axFjbjbk5q5fjG05+7iSZTWRdSWo6d8sF4EEiZCRWBon+oCLI7y2I2mUUKGzvdKAqgKgyD1XI7sR1/Jy9/1GXV7GhIEQCccUrBmfmhOu8QVSCEfTSrhGxIBcTgPcaqb76Cuv8pmLypIibiOTPqfXb0H0P4KXuZOhZBAdyVmM0QXKl4pjn6UQrVRnLTM6b3hlVinID42NYfzkcVz83ndVLL7lwfex8L4S4gyVzVNEOfumcOJ0CD39UZUva6iz4WYW79h4HW1WDEYTWTWRddHrShNZF4VHf6kR2HAEopG4sqAe6J3AQN84+nvG4Z0OIBJJoKgkB4XFObTrzUN+oRv5VPVzOK1wuqkg6bCQ5EdCFRU29aQRmEcgJiS62Th6etg56aF9QE+QnRJaLeRaVQBEgiGFhTZa5ZhJOjKTMG3MGGLlfDBpmETWnr4oK5GDmKa1e2Ehq+0qbAwm2ZFPdVmP26j2W+wiVjIFODAaGY/h2IkgJhm0krVIB66RgariQjMVBU2KNLmawdCUN4VLPSRh9pA0O5LAtgYrGqrNqC43w0N1VgfPSaZNmUJkFQ5riAnOaS8rBjuo1NsnJFEDsTPhlj0M4tEqREit6zV5vXFap4dx4sQMvLyWrFYT9u/Pw44duaoaXq4xP9vQAIOdff1UiqWSsI/EV7m2DIYUycsxjAwHlVXuznaS6qwT8M+cxziJHTCk8d73P4iWtlYGRDOvDawXpnq92YOA3IcTiQT7JazUnJnB9NQU+np6+SwhyW6AXrac6hrq0b5zB5VYd8NFUtJGKwvLPWI6xWsvQeuXpBedfC0l6auSwZcGk4fvnchnVbGQwES1VU8agUxHQIJmKV53I6wAv/Sf34OQV3Pq6lF5510MoNUrq/XNjtBqIuvatyIJKMeojvBcbBRHYuNKhbXJlINdlgK4DJmZsFRtVUirJKfGQkEkQiFFYI35/YjSjisyPYUInxuiwiqv8rfJaiVZNReeKqqv1tTwtRouFkG4yyvmVIfFMkJPGgGNwLIQEEIrBY+ZsE0rddYJP5DnBPbWcsxE+8wi2miaSL4QJaJMm2Tfz3TEOE4WtR06ybCo9M4Ddhb/ZeYYOdPwy7T90UTWTDsjen80AhoBjYBGYKkISJ9ECKy9fYwBnwpQkCBFRzWTIrLWUlCjsMCi7HgtlvVX/hORksHBMJ58ckwJlhQzxrxrZy7q6pyKUJuNLo2ayLrUlqiXWwkCUtwn4yFV4DdDImtvGqOzQEW+AdvKQSVWIWlRiTUDx0MrOd5s/Y3c22IU/olQ7EdIdVLn7Aum6MCYokJkCtOzSebfZJkUJIRfXmxGGRVXK0vNKMo3oiDXSP4DiwqyFYAM2W9G7zBKEquosp6MT6Gaiqx1zKGIMEix0UGXu8yMQW4UfBLrnKbz4Llvf4tuU4ytNDej4rY7ULR9e9YzpqWv00sSa0dXBGcvhOh+a8HBPS6Ul1GoJl9EltJMOWzsFaaJrJrIuui1rYmsi8Kjv9QIbDgCUnUpimcxesTFYglE2avzeUOYnJjFCGU2hvonMDw4zU43q5A8rAptLkd9cxlq60tJbqWKjU3UNTf2QbPhIOkNLhkB6ZgkWIooCqehcJJkpIQKhPQPhDA4EFZWDfnsrDRRYbK52a3UWp3OzEogC1Ewwgo8IbEOsyr6wqWQUr+Ugc/eXW60bXNSWVaCSSvbb15uJBsmST5MoW8ghjPnWIlGpVYjV3frQVoJNdipoDmn+Llk4F+zoOxrmAMzscPo7k+gk2RMOTc37SJhtoaKohyMZdqUCURWwUgCEd0DCRw5GcEUyaxyf5vHTUisImIq98O1noTAR8FHHD/hxblzrFAcjaCi0oHbby9WZGq326yun5HRGE6fDSoS69h4nAUGFg60jVQRjiMepaI2Lc/dtiAqyky4/c4GFiecxQ+++x3s3LMTB2+5CW07tqOouGitd1+vTyOwJghIfyRAQtK5M2dx5uQpHD92DDaq4xUWF6N9xw72QRqVEqubynkup0sV02wGKTvOizUKKmgkI1QxjFDNcAqDrC4WQ5xtljzcbClBgdEG9w0eiFmTRqFXsjEI8Bkkapbey53offznmO7oQPtvfBRlN90MOxWQjZus4K2JrGvfDAJUQZji/evp2AiDyRN4l72eqghF8FBVOhNJ+IrEGo8rgqp/cAC+vj74+nvh6+0jcXUCcRJZHUVFcJWVwVlWDld5uSKrioKBKK+a+CwxWalsRGKrkerdQnAVgrYex65929JrvDEQkHFTkAnBMSb+Xu7luJPKrKyRxoF6A25vNsDOXJTYaGbapPabRBFx3HjyxYjcBtDWaEELnTek6FNP2YWAJrJm1/nSe6sR0AhoBDQCVyMgzmqiDijOdl0UKjhzLkC3tRRFNMy46YBHKbTm5poUmfTqX67tX9I/CjCH09sbxNmzPhw/PoM3vbkMt9xcADvFMMQFLNsmTWTNtjOWXfubYH4vxLHPse40nr0E5NjTisQqBNbyPLpU2DSJdbPPqLqvUaxmaiaBobE5B8vBUearqcaaTFI5t9CE4gITSotMKKRTRx7zfjYbnWrp0En9Lrq+zSlGrkMacLOh2fDtp14ppB9NhjGQDOBYYlIptW6nKmu7OZ9zwQ1PFg6Nj2P82EsY4Txx4jh2/vbvoPaBNzP3xaBKljdCIZGLo+ixkyGMUeBLyOW3HfRgz076GlIwaqMPTxNZNZF10ZugJrIuCo/+UiOQEQiEQ1ESECMYHZ7B2Mi0eg3x73g8SXVAMzt0JPGxNy7EVqXUSkKrqLW6cxzqu2ys0swI4LfYTsyRpGnTMB7FCEl5I0MRVrjFVEBGBgJOJ6tuSMIrKLCiqMhGy3SLUiPNhISykAqjJLN6ZxPo6Y0oQus4SYMOJ9Vlae1eXmZFWakVJcUWtnkTlTKXd/JkIJUkY3KS9hWi/jowFMPEpFjAm7hOM+pYeS1k2XwGq1YzzfrTGOM2zl+OY3QiCV66qCgxoamOmLOqUIiZmTJtNpGVhW+0mkzRZpKBu8EkuvpjHMRKBaYJbU081xzcShXtenSspb1NT9FmYziMCxf8mJiIorjYjsZGF9rbc0iuTSPEQXYfyeBDbCtDw3PtZZbVoyXFNrZBfs97tHdqHL7JEezbV4KWFg9c7iQ6Lp7DL3/+BO57y/249033IS8/b8MVLDOljen9yEwEpP37fX4W0Iyz4GGQisRDmKaannwWo/JecUkJqqii19TCatSqSrhoCW1a7k13nQ49SjXDEKuKL8Vn0ZfitUulVt4pkGOgAjYri6vMLpQYHFQ3ZNHPOu2DXq1GYK0QSITDiFMNufvRn2Dk6BHkVNegaNcuVN5+pyICGjbxutNE1rU6y79ej5DvT1ANYTAVQigdx5tt1cray8S71Wbfr5Kiusr2GJ31cp5FhArdMXn1ziAR5F03wuK4eAyJaAxpklvlOWIiOVWIrI6iYjj43HDKXFwCC58ZZofj1weu32kENAJrhgAvPUVevTyeRtcY0DmWVsqsVQUGtJZR0SbPAJs5ve7ki+UekOz3NBV4Xj4XxRCTmf5AEgd22rGzlfcRJi8lmaKn7EBAE1mz4zzpvdQIaAQ0AhqBayMg/RIhtA6PRtHdHcbIWIzxsCQ8zBGUlVhRU21n3sSCvFwRk7n2elb7jRBohcx65owPzz03ifp6pxIikfhyrtr2Om58tTu/wO81kXUBUPRHq0aAl6tS9xRHigvDVDKmGusYlVi3lRvQVGpAQwkoMLLqzegVLBMByZ1JLjccoeIq82VKdZUiQn6qr4rYjxDn5D4bp/iPuGzKmE/IqwWci/JNisTqcok8xfrk/pZ5OFt28XA6gdlUDCcTU+gloTXCv8vocCfKrFUmN4qMdp4DKnRuelRy40+BOE4Fx0bR/+ST6PzBI2h694OovPsexuarGNd0b/wOrfEWQyHm3Qei6GTRzqXLEdRV29DcaCcPwoa8HFGe37g+hiayaiLros1bE1kXhUd/qRHIOAQkMShy5uOjMxjom8DFswPovDiEnsujitRaVVuMlu1VtKquQm1jKUlSbnYG5yxPNvLhk3HA6R26CgFpRkJsFYJeZ2eA1b2z6OzwU9HXhPJyO3btyqN1jhNV1Y45tUv2WzKp/YxPxKiAGcXhoz5094ZJYrWhvc2lqqM9HhPstrk2f9VBL+MPUWa92BnG4WMBErdS2M1qpJ1tTrQ2OVSQajX9OMF90pvGxa4YnjwUYTUhB9cNFuxps6GB6qyZYnGy2UTWWIxBw/EkfkmMhPxr54D2jv12HNhB5S7yfdezPaZYBXqWKqwvPD9Fdd4EPB4zHnigDDU1Dp4vo1IH7hugatqvvBhlQFO+jyUMKnBitZI050qgPD+AicFedJztxAc+dg+27SjFC88+h97uHkzRXvet73gb7r73nmW0Sr2oRmD9EUiRQS4qrP29vTh94iSeZ5vtuHARJWWl/z977wFkWVZdC67n/XvpvfdZ3reHRtBNI8RHgAABAkmDBolBXzEoQiOFJCREACEFChGfz3yk+X8+aDQxCGEa15gGWt0F3V1d1eWrsrIqvfcvn/dm1j7Z2VSXyqS351Tcui+fuWbd+847Z++118L+gwfw6JveiNr6OhSTnLSVmwQyg3n24+kAq4pn8EJyEu2WQuyjRfcxczGqjCRS0aNo46bkWxktfWxbHYHZK5cVkXXkZz9V6pYHP/af4a6uhtlm37RD10TWtYVe+qyLVJL+RqIfVbT0EgWETi5lDBpvRlPzTe5Y+kh5LITq6MQEAv19SiU40NPDx70Is9jBbLfBVVWtrLYKW9sgi7e+nvdojVJaXc/x2mZgo/epEdguCIwxiSvKrFdGmdD1A287bMDRRgMKHXkq2my9EVAmA4SZTHnpQhJP/iSKR47Z8NARh1LkcTq23vFul/tgo49TE1k3GnG9P42ARkAjoBFYbwR6+yhyQHe4l86EVDHQvj1OHNhHZzvmCNY7Pi3nNjgYw8WLAYxQTEHyEW99ayXq653q8Xqf+1puXxNZ1xJNva1FBLIUQpmLAlfHgO+fz8HHmtmD9QYcrAUaSvQcYhGnjVhLvnmxicJqgII+k7MUqBnLYmAkTaGajHLdtFkNqK82oanWwsX8igLrgnjQanKui/vW6+UhIJdNREF6KAryVGIIUZJZCxmLfNRaiYOWYuZPDMrxbnlb3TnvHvrp07j6lS/D29iEkr37UEsyqzhO7YQm31khsT73Qkg51DrpePv4oz40UXRrI8Y3ixhqIqsmsi7eC7ddayLrbWHRT2oEtjQCklBcVGkNzEcxPxdGwB+h/W8C0WhCvZahWqsM/HwFLpRXFaGiqhDllYVKpdVup3WjbrseAbmPYrEsQqEMiXkpKlAmMR/I8O8U4lTCFJVWsc6pqXGiguTW0lIr7WvW3z5nKRcmHl9Qahmnrfsklzk/rU1p/SOttsamFFQrqNIqx7+SCVCElYJztBEaHk0pi/hZbt/rZuU1VV9bm2yoLLeQOL4ysqwMEBOsSPQHOYnjBG50IoMJEjYry82orzKjpd7M6kOqym6yOOtmEVmlEpOCXrh0PYW+oTQiVD4t9BnR2kBFxQqzshiR67yS6yqfu1uT70QgkFbk7oH+qLJwamn1KCXWhgaXqhKdmEiRPJ3A4HCC35ccYrwXQUJcWZkF1ZVWquqyfw750XX+Cq3WjahrKEb7Xk5uDHF881+/zkmAEcfvP4HOfXvQ2NR4t8PRr2kENgwBIa+Oj41jaGAQPde7qcY6y7FEjCRtUXgvUsqrlVVVCwqsbjd/CzaHXLUcQESdVcis49mYsskRddYoVQ7tVGOtJlGs3eRDmckBj4HVBLppBLYwAgm/H8HBAQz84Ckk5/0qeFZ54j6UHz/B38LNCcxrIuva3TDSV03m4rhMIusv0lM4TLL9I7ZKFBiscLK/2qiWZyGDKKumAkHEqMgdnZxEXNZTU0iFQkpp1WA2w8T+32S1KlVVeWzzeGH1cinwweYrgJ2Lmb8TVi4GiXzqphHQCGwKAlEq3cwwedgzCfROAxkmE0s8JLM2LNhrerbYUE6KPdMks/YNZ3D2SpLzwTwLGYGHjjpQU2GCmUo9m/STtynXb7vuVBNZt+uV08etEdAIaAQ0AndCIKjyJhkMU9BALHhn59LMN5iUKmt7mxPlVGl12I2K5Hqnbazm+TAFFuZmU3jx1CzGxxPYv9+H1lY3amsXLIBXs+2N/Kwmsm4k2rtjX0yFq/nO+SFgbB6wslivvjhPNVaoec9Wm+/s1KsiLpexOBCgcvXsfJY51RxFfLJKjVUcFxlGgpBXZXGxQNHNfJnHzbwzFVd9bqOa861WlGinYrsR5yX50KyBOVEqsw5kwhigw11fJoRig42qrC5FZi0lsdWiBEE2JwbK4nNTAABAAElEQVS9ETjcaR/zLOSfOnsGMxfOI0cHqs7f+hCKOjpVbHSzYvJ3OtaVPC98kPHJNLquxzFK19HqKiuaG2zobLPTRVQ8wta/aSKrJrLe9S7TRNa7wqNf1AhsCwQk6C/E1dlpWukOTGGQPnIjg9OK4GqxsKqJJNbKaiGzFqGkzAePz0kSCol49DW3O6wqCW7cKjKQ2wLxnXeQMmDN0M5BrNSHhuK4fp3k6PkkRBmlpsZOZVYnqqudyrrG6TTTOt2glCk3+74R0qMEdLo50LrRG8UACYZlJNzW11EGv96O8lIL7dxNsFJFc7mWhMrankTfgaEkzpyPQQJXQi7dS2XWliY7yaZmNdESQutKmlSMisXG1Z4kXryQgqiAejh5O9BOmyISWgu8xNgsgbCVbH31n9loIqsQfOV6zodymJ7LMoGZIsE3g5pKExVrrTjUQdIEAxLrlcCU/YfDaYwMx3Dm5Xl1X4m1yf33FzFA6OXkO4uR0SSu3+D3ozfOAT4t1nmvOZwc0HMiJ/dERwur1TjZGx8axTM/PI/mtko88fYTJIwH2Df34fvf/j7VLGvxW7/7QRQWF8HpdK7+QuktaARWiECGHXwyIQUwMYRoF93f249eTs6vd3VRgQ8ksBbi2IkT2Ecl1nIqsjppB70dWzqfQwJZZZNzJe1XhDEPzErtsN7sRiWDMi7wd4KEsU3qbrcjrPqYNxgBIRKOPPsMps6fR3CgX1WAN/3qrykC4WbYtGsi69rcAOxqESbh/lx6Fj2ZIKaycUVifR2VD9YtWMgOPsfihWwqiVwqjWyS4/0ke0l6vqXCIcRmZxGjfZZYaMVIZo1NTyHD1ywcs7hZ0OCpq+dSBy/X7ppaWFnwIMRW3TQCGoGtiYAkdfum8zjTD0Q59zxcD2WzWVcsyV7AwvnOVmoBzgXFlePUhYQq+HzD/Q60072kmBaTm13ouZVw2qrHoomsW/XK6OPSCGgENAIagdUgIOqCIvrRPxDH2fMRBIJptbk9dIdrbKD4RzGLEEnOstEhbq2b5GzEnfHkz2fRdTXEfZgojODE8eNFSnBkufmOtT6+pW5PE1mXipR+370QkAK9VNZA14m8mudcGgYkz3Z/K/MzZYDMc3RbHwRIQ6CTG/FnHpmcPiS5TiTyCFIUyE/y6ow/xyVLAZ+cyi24nAZUl1FQotzE4kSZ0y0QWNfn6PRWV4MArxiy/L3pzgRwikX2c7kkTEzEnrCUocnoQSnFQKzMge42f7tUJAwRmLj8P/47/N3XsOcDH0T50aPKmWonFO+rIQb/O3sxistdcaXMWkZOxf3H3CgtMZN4Lrnv1dxZ9/6sJrJqIutd7xJNZL0rPPpFjcC2QEAmtPKDk2IyMhGnmmaMCyU45v1h+GdDmJoIYHoyoIitNhJXi0o8aGgqRz2X2oYyVlZYYZEshm67GgG5hxIk64myaTTCal9/EtPTSYyNxTFPddJMJofychvVKd20WKdKa4X9FWLhOo9k7nJV5JjTaVHFzPEYM5iZSZN4KtVDSaUoW0kFVbH7Kee6wLe8e1y2LSRxtW1OxPqHEugbSCFI4qwM4I4ccKCu1oaykpWp+antcx9hTvSEvHm1h1VvIxnIhFCUWU8c5DF7jHA61j4IdhdIX31po4msorozT5XaKz1pJi5TnNgaUVVKEmuzBZWlZlZpri+JNZXK4cKFAK53s8/kfS8KrEeOFrKq3oQ4k77nLkQwxOp7P1VYQ1Q3kmrTtmY7WpodaKyzoZAquhZTFs//+wUM9U3wu2HCngP1uP+RDjz7s2dw5cIlKiFlsYdKrI+95XEWEVDRzLRgm/Iq6PqBRmADEQhSdW94aAiXL1zAxfMXWMyQUWTV1rZWEq7rUEOikq+gAG6Pm4Fy27a9XyUQk2OHG6Yaqz+fxHA2gkFWGPdmQyg1OlBPIusBKiCKSutuDMhs4C2nd7UKBKTqO06C4dS5l9HzrW/CWVaO0v0HUPnAA/DR3mijmyayrg3iQrSfohrrt5ODiNG+6yD7onazDw0mz9rs4DZbybGIIR2NIjI2hvDoCCJcwiNcT4wjHQ7DSLkMe3ExHCWlcJSWwsm1ncrcNp8PJgdVfzh+MdsdSn3ATEVWef9OCN7eBir9lEZgRyCQZIJR1Ip6pqjOOgX0U51Vkrv3NwNVTCQWbLG6OilsZFgLpy8mcK0vrZR7xHbyvoM2zos3L+6wI26GDTgJTWTdAJD1LjQCGgGNgEZgwxGQGL7EgeOxnBK6GKJLl4hpTFKh1cG4/Z4OF6147cwT2NeN8DFO8ZGBgShefHEOPq8Fj76hjPkOO7ze5eU7Nhy8V3aoiaybhfzO22+I6p/jAeDlgTy6xvJoLQfaKo1oJolV5jbUb9JtnRAQAmsokqcIDVUcp+juRhGaGSqwppjXsxJ3cZks5lJEd0Uf85qiusqUAhwk+Ysiq5UOoDodtk4XZw02KzmUKGOTAZJYL9E1qi8bRiSXRoPZg4ctFSgy2uA27q4vmMRQcxk6eDIWP33uLGwFdD4+cgT1b3ocxh1S1C9jnCAVlSemUhT0itKxNIMCfo8P7HViP0W9RMxsPcmsmsiqiax37b40kfWu8OgXNQLbFoEcy9DisSTm5sKYGJ3D2MgspkloTTKTIT88TpcdHi8tdb1U2SxwoaDIDS9H+h4P1Xb4/MKPk04UbNsbYA0OPBKhFcRcAsPDVJ9ksEQs10Wh0kUSZ0GhBUVFJO8VkmxZYFFKrRaLadPUQ+V0ZcIUjWZINk2oCmkZfEnJchGPVWx+hMxaUmThPU41l2VYE8pATsjiYxNp2sknFaFVyKdFhWZUVVA9tUa2S6IllV9lf8u1FBCCVT5vwA2SZMVKcWQio6wTq1itWEs10uqKBRKnTPQ2sm0UkVXwDUXzmKEKa98wVVhnspwM59BJAmtLvQV1lWbec+t37rL/ubkkbdXjuHo1TEJ0St3ftbUu1JPMOjGVJoE1iavXYojG8oog7SMpupj3UkMd1X9rbKjlPZCgh8rUuB/PPn2BasZRHD7ewkKBYqpgO/Hk17+F69eu4/j9J7D/0AF07umAicQP3TQCG41ANBJBMEjVv4lJTE5MYGJsggUA01RkDVKBtQhV1dXo3LsH1bW1KC0rXXZ/ttHns9z9pWjhPZtjwoGBmKuZeYilt4nVxJVGFmcYaF1rdqHQZIebiq26aQS2GgJi/R6gavLQMz9FhMTDdDyGhjc/gfLDR2ArLNpQVUxNZF2bu2MyG0M/+6PnUuNwGyx4i70O5STYe/h4tU3ulwzvkQxVt5NU9E1TRUCtqbqaCIb4fBTpGJdX1lkqdMsY1uL2wFVZCVd5BdcVcHIt95eFqtxGnXFY7WXRn9cIbAoCUig5y0K8fiqznh0yqMLJAgfQTtvNxlIDfHy81eqa+0fSuDHIhNFARllPPnTEgfISE7y0odRt6yKgiaxb99roI9MIaAQ0AhqBtUNgfCKJ0bEUenoXHNxEhKKywkY3O5vKQYiYxlq7iiWTWUxNJXHy5IxyEausdKCz00PBEc7TmOuTZSs3TWTdyldnexwbNXYQjAEjfuAaCaxzUQrcMP13vNGA1gqSKJ3M29DNT7e1QSBDbCXfGiGBP0rycCSa5WMKRUTl7wXxHxF/SZPcKrh76TRZVmxCCcVpSosW5m12EljXkwC3Nmeqt3IrAgwfkMQawg06R92gQquosNZQAKTZ5CWp1Qsnne0szKfspjZ19mWKS5zFNJ3SClta0PG+9zNWWqgK/XcCDpIjj/K7fZk58AEKek3NZFBfa0VnmwOV5RYWzZD7sU5fZk1k1UTWu36HNJH1rvDoFzUC2xoBpdTKrIVUjAqxNcPR5+SYH8OD07QOHqFq4BRG+Li8qojqa6Vo21NDK+wqpdYqCq1G7d22ra//ag9e1EhlACNrUWmdnU2htzdCG5sgpmeSnMhkGTDxoaPDoxa32wyrdfMGsMpqh4NqUY4VS4u+wTi6b8Rw/nwYLpeJZEM7jh5yo5n2O3a7VP8tb2JLPoCamImlfHdPHC+djapJWmO9leqsLrRSmdNgyK84cCS2KGESOq/3p3H1RgoXrqWwv92Ko/usaKqzoNC7sdhuFJE1Q9WdXhJ4RZH29KUkKpigfOAQq9irTFS7FQvJ9av4kvtb7puzZ+dx+iU/iapZlJXZ8OijpcjkDIrAeuZcFD19tN3l9VfkVarwHtznRGe7nQRbI+y0dDLy0nRfGcals/3ouzGuigJ+/T0PwWBKY3R4GE995/vwz83hw//bR0gS7FTqlsslPK/2+6w/rxEQBEaGhqk63I1fPHsS/T29tAPKYt/BA7j/oQfQxEl4RVUlv3O0iSFZySg39g5ralzErj9FFcQksrjI6uLzXAYyIXiMVjxAu5wOcwGaGJTRTSOwFRHIxONIkZR4/etfQ++3n0Tdr7wRVQ8+hLIjR2Hzbtx9q4msa3N3nE5N4zJJ9aIYXW9y4zFbNVwksS5vhHr7YxEV3+jkhFJbDfT2INDXh+BAH0nQo4rAKgRVb109FX0b4aWqr6+hgdZYVYrIKr8BorKqlFblN0F+D9YpYHn7o9fPagQ0AmuNgMx7IklgIpDHS/3As9fyON5kwKE6oLNqgcy61vtczfZkbjzNQscfPMuCWrqXtDZYsafFwrUuNloNruv9WU1kXW+E9fY1AhoBjYBGYCsgILkSIW/NU7Wsty+OF04FKR6Tg5PiH488VIAOEj8kF7Hc3MPdzk3GcvF4Bv39MQoxBFUsW+LXj76hlEqHa7uvux3HSl/TRNaVIqc/t4hAlKTJ7gngwhCd84YMOFibx+s7jKjwAR77ynNyi9vX618ioPob5oPn5rMYm85hYDSD4bEMpv1Z5oqZIyswooYCPPXVZtRUWBR51WETQj0WFga1JPelw0i/xHS7PcpSsElilV2MWYo668vpWdxnLsUjtkrlarcWBfjbCZN0NIK5a104/1//C6weL/Z88EMoaGqmkxWloHdIk++9qC73cFzz7PNhJDiucXMs8+hDHrQ20ZFrnfL0msj6zJLuIEM8zhKCXdg0kXUXXnR9yrsWgSzJrLFIAsFAFHMzIczNhuDnkkikkUpmSADMKAKLiZbYJWU+lFUUqKWo2EtrYf5QaWLrrr13hGyYSFChdTapSKxzcyneR7xv0jQc4AhHAjMlxaw6rrCjghXIvgKrIvht1mRFjjcQ5ORqJsUK6STVZFkxyKpBEcH00XKnhhXSVZULVdJyjEs9ThnMyXZmaZ/RRwuhmVlaLQSzKPCRdFlKBdFGG3Ew0/aQBIAVsBBkoOgP5jBKVVZRZ5WKR8bGUEtV1roqs5oc2q1Y00DYnW7q9SSyCo5y30zM5DA0TqVbTobFlsRNu0g5z9ZGqvyyinM97SNl/0LO7uuLMAgYxcREArW1Dnh9NmTzJsz6xSKF15dBSWGUNNY7UF1lVRVolWWcoPM6WyxGpOl9GWW/+uLJLpx5vhv1zeWqKGDfwQbcuH4NP/3R07wXDCgrL8djb3mcSpfVC4SQOwGvn9cIrCECmXQG834/xkZH0Ufi6tTUJAL+eZgtFripuieqqzV1tSxmqafCdgFcbvca7n3rbkqscmQRNcTxXAwj2ahSak3x2UKDFRVUaG2itXeFiYUPBpJ614RWtnXx0Ee2fRDIk3wuBEWpAh9/8QVFVLT5CpQyqwTQxBJ+I5omsq4OZVGHTrC/eTo5iitpP/Zbikmi96GNi4U9znKaKKmKqmp8bhbx2cVlBsn5eWSSSYgyq4FzOEVMlSIFswUWpxNWnw92WmI5qMZt5dpOJQELfwPM4vu2kkHscg5av1cjoBHYFAREsSiWglJm7RoHAlQ0EvGuziqgoQSoK1pIPm7Kwd2yU5kvxlicerUnjf7hNEYm09jfZsPxA7QzpFuHWFPqtvUQ0ETWrXdN9BFpBDQCGgGNwPogIGMVyZX450nwopPXJNVS5xhLltxDgc+CxgY7VVqtKC2xrtn0SsQ7QqEMrl8P4/nnZ+k+Z1eKrO3tXhQXM2GwhZsmsm7hi7MNDm3Un8ew34AuKrHGOZ8ppPpqe6UBbZVGOCy0tde1bqu6ikmlvEpyPvOSfuY651QulflgkoelCUFVxGYsxNlBgSCvx4gCLr5XFiGxWjbYTXJVJ6w/vCQE0oxbirPdYCaMa1RmjefJH2GOZK+lCI3Mm4ij1G5RZs2ROxMZG0XPk99CjPk1cbMScYnK+x9Qud8lAboN3iRjGz/z4QNDSbWMTqRQRy5FA9VZ21pYpMNYzForwGsiqyay3vWroYmsd4VHv6gR2NEIiBJbmtmM4YFpDPZNord7DOOjc5idCaOiskCptNY1laOyWuyxfXA4rZyMm6i6aSaRThTblpdo3dFg7rKTi0aytKNO4Fp3WJEAh4ejDJiIhY5DBVAUmZWEQLvdqFRa16ta516wL6io5tA3EEdXV0yptIq6bFOjAy1UUG3m2klVTRuVZJdj+ZOlQkwylcON3gTOnI+pCmyZ0B056EJTgw2lxRaVXJNtrqRF4zkEQ1TLuZjApetpeFwLBM/De2yseDRxwCiTR5lErmz7Szmm9SKyyjURwm6M9UPX+lK4fCON+RDJwB5WrR+zkchKq4J1toyU6xej+mpvbxgvnfKTRJvhZNuEg4cKYWLE8YWXQpiaJcmEk/WyEgvq62w4dshFVV8rCmkPtcjvEDJswB/BUP8UTv38Gq5eHMQ73vcIDh1v4rXJ42c//gm++v/8f3jTE4/hwUceQmNzIzxez1Lg1+/RCKwYAfltlyWZSCIYDCgV1u4uVoy+fI5B9jj7ZTvuf/BBHDxyBI0tTewD2aHs4pZ5JSjTQ8uc55OTiDEoYyN59ailBK0mH4pNdjgYppHndNMIbBUERJU1NDKMrn/5Z0RIVK999A0oP3oMxXv3kajI3ykZlKxj00TW1YEbyKUwmY/hp4kxDGUjeLejCXupBu0w0BHjNsR5GW+ITYKQmHNZ9losUsgziCp/J4JBJFiwEBkfVfdCZHQE4bExxKanYXG54CgpoeoqFVcbqbzawKWujooBpTBZbet+n6wOJf1pjYBGYL0QEDJrkLaQP7kK9EzmUVFgQEcl57INBjiZCLZtkSSkmrPRxvIy3UqeejaKxhoLju3nfLHSTIII41HrNxVeL+h3/HY1kXXHX2J9ghoBjYBGQCNwCwILU7U8hoaT6LoeYa4kxphzHq0tdrQ0Sf5BnOEWcg8ST16MKd+ymWX9OTQUxblzAUxPS+EiVSmpzNrczKJE5iHWM1ewrIO85c2ayHoLIPrPJSGQolhNMmPAhWEWuI0tuEtUFQCP7TWgnEqsLhIodVseApKbE/cLEQLK0pFQhIoitBT3B0V0JoPJ2Rwmpkna43NCThX3xFrOv0Rop6LUxNyY9Gca9+Whvr3fLcqsU7k4TibGcYkKrVKI32kpxB5zITyMY9q57IYmsfjZy5cxfuoFjD73LNre8160vuOdMNkoAidVLDuk5TiwoZkhLlyJ4eyFqOoLigrNeOiEWxXoOElmVf/WqBvQRFZNZL3rV0cTWe8Kj35RI7CjEZCkqCyxaBLRcIKqgnGqbMYQCsZeVWsVkpZUe9odFloOF6O2QdTbSlBS6iWx1abJrDv6Drnzyck9kWKlXiiUJlEqTdXKNImtSbXIc0YqtFZSnbW+3omGBhcVfc2s1tt4EtBCMAmIUkU1yIrlqWkSB1ghPT5BNVkSUUVJtrPDRUKrnQqbFhVYuvNZ//IV2a5M+kSdVSqUBocXlF9n5tIoKrCgvdWOBpIfK6jcuZIAlUwmxaJoZj6HSaqW9g2llFKr7LOl3oz97TY1aXRRwXS92noQWcV6KU5lnWEqzp7vSimbyMVzksSkTIZFhdWyQgLwUrCQY4iQiH3+/DwG+iOsnE/Dxv7N7rKRkJzjMfG+DmdQUW5DO6vMqkmsrSgjgZUEYoeDxOxXErvSd2YyWfRcG8PT33uZBFgjVVcLcOyBdnh4D/R0X8eFs+cVefCd7/0NPPTowyQgu6iEuXMmNUvBW79n4xEIh8KYmZrC5YuXcL27m7/ns7BxQl1VXa3UV2tqa1AsxKYCUWB1sR/c+L5541G58x5lcp5CVtnlSJWxqLNKpXEgn4KV5FUJzrRykUrjhWn6nbelX9EIbBQCQmAUFc7JM6cxc/E8Zq9eRdmhw2j59XfAXlRMm6P1LZrQRNbVXeluKhn8PDmBjIFq9AYLHrFWoMbI/lh6mdsMHKXyP5vifG1iAhEu0YlxRElWjYyPIRWJ8LUU1VULqLJaoNY2PlaLlwqvVFkVQqtZVFhdTG46Sc0niZUZztvua3Vnpj+tEdAIbAcEaNQDUWcd9QN903lcobIRpzKoKzZifw3Q/Io73m26ow09PZlzszYL40ykXrqeYmI1y2LIHN5wvwPtdPCQedlmH+OGArINdqaJrNvgIulD1AhoBDQCGoE1R0DGLHElSpHBxGQSY+MpDI8mWHRjoDOcCXv3MPfQ5FRKhpKLWG0TcYZZuua99JIfPT0RHDrkQ0eHFzU1DiUostrtr8fnNZF1PVDdudtUxbyMjwzPsahthERxzlsiFEXZUw20VhhRSycJm5lzmN0d0l72DSB9VZREe1FdFRGXqbksc49Z9VyWOTMPHRK9FNTxyppqqx6XkW4YVL0lYVhydkJglTnYOtfOL/u89AfWF4E0WY0pQw4jGTpbZkK4ng1SFiSPJqMHe6xFaDN51QFI3mQnN4nFC5l19ORzuEphicr77kPN6x5FUVv7hjmkbRS+0lcEKT41OUUhqq44pulMK4Jg7SzSOXLQyfy9kTnFtTkaTWTVRNa73kmayHpXePSLGoFdh0A6lUEinsboyAxGhxaWeZJZE4kUPB4nCgrdKCp2w1fkRkGBCy6PAx6fkz9itJJ3UNmHY5XbJWB3HZC76IQXSa2jo3EMDkYh63A4TdIfK/QKrcrapqjIyvuFdvFeCwnQJhJG12iUswycFyZqoiSbRvd1kj+m0pgjiVEUN8vLxTLeihLa/RSQsCgKrcsJLI1RYn9oJMXK67iyFfJSXbS+1o7aam6zyKwGebK95SbaJMkYjeXQ3ZfGwGgGo5MZWnaYUFVmRE0lj5vJRp+HE0ge71or0qw1kVWSjuFoXp3D6GRWnY8QcYW8KjaR1RUmYp5XQb5lXNYlv1WuvwRBpFp9dCyOSxeDGGdwMZM1wE5SvtVuIalVlCzzKOY1a291Ym+HkwRns5q437oj6Ssnx/24cmEQJ392CW2dNbj/kU6UVfgwPz+Dp3/wNAsDAiQQ2vDYWx7H/kMHbt2E/lsjsCYIyH2doLV0lGSm2ZlZTE1OYmxkFBMkOfmp0mdmRWh1TQ32HjiAhqYGRWjVv9P/EXp2EaqPGCWRdSBHy5x0APP5JAqNVlSbXKg3uVFicKi/rdRMNBnWV/HyPx6hfkYj8FoE8mT3RKenMHvpIvq++x1FViw9cBClh4+goLl5XRU3NZH1tddiqX9lGPyNkzh/Nj2DHyVH0WkqwD4qGLRYCuAFC13Yn2eTCWTiCRKVI4qsLITlNPv3VCSMJNVXZUlRbTvJ4GkqEFS7NtqscFdVwVW5sLhZuOCuqFTkVZN1a1tMLhU7/T6NgEZg7RFIZoBpcQHpE3UjIMlCys5qUWc1oIy5KNb5rfkccyVnIcnWGc7TXr6cxNWeFI7us2JPi03Nie02PR5bCabr9RlNZF0vZPV2NQIaAY2ARmA7ICCxZxHTmCDx48rVKGZmUyzCyTI/YEcNrXkrmHsoLLSQLMYSxlXwfUSkQYQhzpzx49KloMoLVJPEeuRIgcq9WCxbb3ykiazb4Q7eGsfI2xuJNDBFhdDeqQUiq6gNF7vyuK/ZoEisVgtz0FvjcLfsUUh/JK6I4jgoebl4coHEGmGuMRTOIkTFVcnVhbkWNF0UcCkpMjLfaFIqrEUFJLGSyKpNWbfsJd7wAxMXu7lsAi9lZigEElH7byKJtZMxzTKjg3HNBVGnnU5onT53Fj3f/AapvFCOVw1PvAWFLa07SpVVLq7qQygGdrU7gd4BFulMJFFO4a7ONoo/VVhRVGiioJnEjFbXG2siqyayqs7kTv9pIuudkNHPawR2JwJCiJElTYmOjCxUHBSF1pnJAAZpny0W2kJwTSXTKKF/Q2NzBVo6qlHfVI5SqhGaWQa3VS1MducVXf+zlgGNtDRtKERFNBbLKGXWgYEo+ql4OTQUI0GURMVqBzo7Pairc6G0dIH0vPDJjftfAj1im0FHVh5jCiNjTIZ1RVkpTbJSgZm2P04cOuAikdGqyKdLPTLZZjyRIzE2g56+BM6cj/K7YKQ6qwn3H3WjqcFO8q6IXy1vUCfYyiKTzrlAFsPjWXT1pnGtL4WmWgtaG8w41El1Vq9B2Qct9XiX8r61JrIKCbdvKIPTTEAmkjkqy1K5lko6bY1WVnJCqbCucsx719OSay+KPi+8MIuzZ+eZqDUgEgNCMSPI02cVoQHtTXY1EN+/10ECK4+LVaZmEpBvV2UaDtFO46cX0d8zoVStTzzUgQdev4d27nFcvnAJX/6//icaGhvwjve+iyTCahQWFd71+PSLGoGVIpBj9HqaCqx9PT148efPY3BgUP194PBB7D94EO2dJFiXl7HYhMoMFgtVgfmF0+2OCNCsG8k81S0YmBnKRfAyCWcBWujI2OgBazkOmYtRRHLrbrHNuSNQ+oUtgYAodcZIZp05f47WRi9i4tQp7PnQb6P+8TdTmbOQ9kZkIa1D00TWlYEazaUxnKMNZHoWv0hN4G22erzeWgm70QyjJCM5UInzekbGRhEcGEBwcAChwUGlxJqgurajrIxk1Up4amvhrqnlug7OUvbvRUUwsm83cTHIXMxk5pqLVl1d2YXSn9II7BIEZBov8+IIk5pXRoGT3Tk17ynl3PLRDgMaSqCUWtdzjrYUqNU8jraXF64luFCRnHNjsbh8lMqsRbS21G3rIKCJrFvnWugj0QhoBDQCGoHNQWAx9yB5guGRBLpvxCj8kaSrWwYH97vR0e5EazPVzF5x/FrpUUq+QFRZh4djeO65GZVzePMTdPpg/sVDZ7yt1jSRdatdka17PDSCxCRrdp+9lqODhAHUXMJDrQYcaQDcDHFZqcS6WuLU1j37tTky6R/EgWyeZODJmQzdEbMYpUPiMF0qGUak8ArdNEvNLAw0cW1EKUVdfFRglX7JZMwrgR/Jick8cLPngmuDiN7KWiAgKqxSoB/MpXAjF1JOUyn+XcA8yaO2KnSYfDBT+IP+T2uxuy27jfj0NOaZh+v7/nfh776GQx/7z6h68EGY7Q4Vh92yB76CA5MxTZLOvBMUBTt3KUan25Qiwr/hYS8O7qXSPIWqliMIdrtD0ETWHUBkFcvPT33qUyRUWPGnf/qnrLaSCom1aZrIujY46q1oBHYyAkmSViPBOJXegrQrDpIgE0CY5NZUKs2BrJC8qGhot8JByY7iEi9KynwoKvHA43XStpjsPd12DQIySRJFyyiDMzMzSUxOJjA1laBaYI6TpBwnQga43Wal1FpaZlOEVq/XrCqHN1ohMMbqw/lAmmTWFAdgSarIZpDnwMxKVZdyWslXVbJSmmsvLYDkHr/XpE1+moWgOUXF135WKE3PpbnNHFy046gotaKxgd+PQk4Kub2VNAmABSO0UhnLKDXTOO1U5F+RTxRaTWiosdDqA7T5WJtk3mqJrOpeICbzQQYdSGKVZZp2JdKKSfBtqjNzomziRHlleCwVw4XjyFOlMqnslrq6SbAeotIZlVhBE18jCR+VFSRaU+G2psqqlqoKi1INvtM1F5VqIfT//GeXaR2VpNJlPdr21KKmvhhXLl5WRNaL5y7iwOED+PV3v5MqxA6lzLrUY9bv0wjcC4E0f3+jsSgmRscwPDRE9dVxzM3NMbGfVveax+tFU3MT6hrqUV5RATdtxje6j73XOWzl14XYkWCVsT+XRH82jPFcDNO5OCx5Azy0Aa+3eFFtcKLKRKtug5iB66YR2DwEMvEYolRinjxzGiP//gycZeXwUZG15uFH4KqqZiBt7cfimsi6/OstSYQp9iM/T05gMjqPTDiCw1Ez2iJGKqsGkAjMK4VVUWTNsi8XiZ08A8I5yvOr+RZjQvaiYjiKi5VllaOkRP1t9XqovOrSffzyL4n+hEZAI0AEZMwjxX4TTBZfn+BcczaPQNyAOtp1NpbmlTqr3SK2nZs/2pmYzmCQc+FL11NKhezYfhvqq8woo2qQblsDAU1k3RrXQR+FRkAjoBHQCGw+AkL+CATp5kV11qHhJKboECZjLpfLpPIOtVRoldyDEMpWSgJJJLJ0BUtRtMFP9dck1dGsSkRkzx7vknIZG4mSJrJuJNrbc1/iTJhiXrFnEuibNmB4Lg8bSav1JRQfqeD8hEV2ohEji26/REByX7JEmSsUpdX5EBVXmUMM0BZcVFhFIEf6I1lk7mencIsorUpOsZBFgYVeKq86Jb/PPP+dkmG/3J1+tMsRkHtIyKwzjG9ezwRZrB/BZDZONzsn3ew8aDP76GZH90vSWXdqS8diSIfD6PnWNzD+wvOofuR1KD96DMV79sJMIZmd2CJUbhYeRf9ggrn1JAqEk0CV+TY65ZQWWziWIX15hX2zJrI+s6RbxhAXRsgWbWfPnsXb3vY2KtqV4MqVK/zB4S/6GjVNZF0jIPVmNAK7BAFRJMtyVhGcj1KddRK918dx49ooJsfmSaDJoLa+FE2tlWhur0JldREJrV6YqExpZvLVRB8CgyIErvAXbZdgvJNOUyZIotTa3x/DjZ4wrl4OKosdsbhpb3ejtc2NulqnqhQ28zkJ3CxXtXS1eMlPqpBYpUJa1Fkvcykn8bSh3oZ9e93K+sdh5z1MC5OlBJYWJ4/XeuK4ci2OazfivP+NOHLAgRYqftbX2rgdUiiXQI693bnJ5DOWoAXkxSSuUZ1Vqiprqyw4wUReVRkrKJnIE8uPpZBvb7f9xedWQ2QVDETdJ87j7B1K4eUrKczSDlKef/0JB5VYzUqtlhzSdW2yPyFQyxDvIq2Wnv7JNAJ0vYinjIrI6naZea0teOC4Gw/d511QYOV1vlNbUKwGetjndV0awsWz/VSi9uE3PvAICos9SJJ88uTXv4We7hsoLSvFkeNH8fCjj9xpc/p5jcCyEFj4/RWl9AwiJEBNkbh24ew5nD71EvxU6rNSefGBhx/CoSNHqMR6ABZKHRtvJye8rL3qN8sEcYJE1huZAE6nZjBEYmsjbXP20A78iKUYHqXOSlI86ax37j00jhqB9Ucg0NuL6fNnMfzMz1RArfODv43Sg4eo2Fkqg4I1JTpqIusSricHIXkho6oly4RMFv2pefxbpAfm+QjunycxfozKOSOTCA8PIzI6isj4GCwsPHCVV6CgqRnehgb4ZF1XTwXWmgXFVRlE6qYR0AhoBNYYAU7b1VztVB/w8kAes5wz1dBQ4rG9BpR5WSxJ9SMZ56w0ObEWhyvHKFaYP3oujhEqCpWXGLGnxYqDHVbGmSSprUdia4HzarahiayrQU9/ViOgEdAIaAR2KgKhEAUe6Ab3wkshTFDNTOhkh/Z7uLhQQNELEaVQebMVDGWSySz6+qLovhbGhYsBHDlciDc9VqZIJZJ/kaJIiSdudtNE1s2+Alt7/zLOj1P1L5Qw4CeX87hOMmuxGzhQAzzcbqAKqyawLl5B+TovEFNFdZW5L5J/MxRsmaGAzDgL/2SeJIIykzMiKpRHAUV16qvNaqmtNKGEduBup/QNi1vUa43A8hGQX5UcCa0XM368lJ7GeDYGl8GMN1mr0Gj2osBAKisn6Tv5Nht8+scY+/lJZFN0e21tQ+s7fwO2goIdp8p6890xNEpOwvUErnbHlajXow950Nxop4CXSTnUrqRf0UTWbUpklcSzKLHeuHEDH/rQhzgY7dNE1pu/LfqxRkAjsGkIyEBZ1Fij4QTCoRhCVGcVYmswEFWP5blImMplFjOVCEmuqylGDUvmKrn2eB3quU07eL3jDUVgcWIViWQQDKYRYJWwXxZ/GqFQGol4VgVWSkpsqK1zorLSzt8626pJmMs5STlGIdsGWaU4RxXV6dk01WRTrGhOQypBRZG1qcGB2hqbUu6Ubd9rQCbbDDJI5Q9kFxRfJ0nknMvA6zZyG1a0t9hRWW7hd2T5k0b5/mVYwS3E0KnZHMamMpj1Z+EP0WKx2IiaCjNaGkgUZUWlzbr87S9itxoiq1R+imLO1Z40FVlJYOWURVRjq8upfsq1TKCl+vNeOC4ey0rXsViWFelpnD4bwo3eOAZZAS/X1G43oaPNiaZ6O6vfrajgtSgroSXvK5Ypd9pfiurUCfrZPPOjc7h4rh8NTRVUYq3BgSONisQ6PjaG737j27x35vHW//RWtO/pIKG/6k6b089rBJaFQISVnvN+P651XUPfjR6MUY3VarNS4boQFbSaLq+sUOqrJaUlDIQXKhKrVmFdFsR3fLPYgYfzaUVoHSOpdTwTBTUTFWGijbY57eYClBrtcDJgo5tGYLMQSIZCSMzNYvTkc5jr6lIJq5L9+9H4xK/C4nbDRLL7WjVNZL07kkJezcTjSHI8EJ+dQWRqCtOTIxibHELf5CBs6SzqGNj1uQvoXuFViqoWl0tdJxuJrBa3B1aurVzLtVOL07kQDF3vwdPdT02/qhHQCOxQBGT+KsmoGc4pxwIGdI3l4I8uFF/uZwL5UJ0RDmselk3k0qt5eyaP/uEMeobS6GJRZ2ONGQ8fs9MK0wDXGjmT7NBLvCGnpYmsGwKz3olGQCOgEdAIbDMEUsw7iDOcxKjFFW6MpNZIhO4bjPE3kQDSyPh0DfMOdhsdf5bJ+hFnPMm79PZG8OKLc3TCs+Cd76zBc8/9AKdPn8b4+DiKiopw33334R3veIfiHNwKn9lspqrrCzh58iSmaZl84MABPEib5La2NlVMf+v7V/K3JrKuBLXd8RlqkJDEClwbz+PsIPN0vKddVmBPtQH1xQaU+/Iq/rrc78ZORE8EeYS46g/kVG5wZp5r5gVnmCcUeQURjXHS6lvI8S6uhbAqaquiwKr+5pq6F7DcRchlJ+Kmz2l9EJD4gbjZTTFX0p0NkswaRSqfRRMFQE5YSuElmdVt5A23Q1twcAD+rqvof+r7kJjunt/6EDz1DbD5fDv0jKn8rFxuOeagI+0wSa3yt/AcDu1zoaTYrPqa5Z68JrI+syTItpQiq5BYP/jBDyoS6xDtQhebVmRdREKvNQIaga2GQII+BUJmHR6cwQiXQaq1RklmzXJCXlZegJIyH8oqCkiuccFb4GLS1g6Hw6pIrSaOsDdahXOr4bdrjoejW7G8mZyiXXN/BMPDtMONZngv0Fanwk5CoR2lpTYGXTjo4eJ0Ul2UE6uNUlfJMDGWTOXQ159AT29MVUtn+Vw5ZfJrqmxUZ7XD6zHx/iURk3L59xI7FMugAAmtQqA8fylGhdKcmii2NNEGkQGqEsruy8RSbIRW0hLJPGb8OXT3p5TFoiQWPZyQNjChV1VmVpVQMkm1c/vLnewvh8iqEp/8T+xKQgzEjbHqc3Qqi4GRNM8XqKNibEezRSUaxZZyuceyVGzkOKTF4zlEollMk5A8QLuDX5wKqkm9iQAV0vagssyCo4dcrBZzoIyKrKK2e68m1etzMyEqUU/h9PPdqp9789uPY++BehQUudFLYuH5l8/h6qUrtHF3430fej+qa2jpbNm5k7V7YaZfXx0Ccs+lWTQSp214YD6AaRKhJhiA7uuh6uLkFGJ8vqGxEQcOHUJbR7siTUsRnCavrg73u306yWCMP5/E5bQffdmQqjauonVOA61zak0ulBkdKkhjZcXxzq45vhtK+rVNRYD9xszlS5g+dxZjtDcSNda6X3kTClpa4K6ugVHUPNfgR1gTWUW5kIMOIaxSjT2XTCGdiCvyajaRUOtUJIJkIIC4fw5R/yx6Z4dYMDWNghAtmGxueAtL4GIRgquqGh5eG1dVFTx8bLLbYbIya6ObRkAjoBHYJASinNNJIlmUkG5wqS8G9lYDtUVURiJhVOacm2XpmWPfm6DrR/9IFj95PgZxTmlrsKCVhZxV5WZ1XGvwM7dJyG//3Woi6/a/hvoMNAIaAY2ARmB9EZiliMbgYJzOcFSYH0uilMIKInohZNZi5gl8PrPKHSzFFe7mI52cTODc2XkcPeYkt+Ddytn15tflcUdHB775zW+qgvjF1ySG+JGPfATf+973Fp96df2e97wHX/ziF9eEzKqJrK/Cqh+8goCEVIS0GowbMOoHrrKQrmvMgJbyPNor6bxAbRCmkndtY1pdkd1TJPlKDjBBxVpxP4zReTAQzinxGD8FZIJ8HI7mFWm10EsRHYrISF6wspQ5TJJYJS+om0ZgPRHIUJm1l3mSbrrZXaZCq4/ude0U/hBHuyrmS+zMk3Cmvp6HsCnbzjD+G6Gw0ZX/+d8Rn5tD7eseRemhwyjes2dTjmejdip998RUGgOK8xBV4lCNdTbU1VhRTdEo4TtYLEvvdzSRdRsSWSUpUl3NKOEtTRNZbwFE/6kR0AhsGQTyohJJmchUKkPFwhTVCanEOBfGzDQrcUbmMDHKZcwPO8mrhfSFaGqpRENLBeoby0j6clBVTpO9tszFXOcDEav3FMmiySTJhqwYnppK0FYniaHBKMmHGWVp2NLsQhOX5mY3XLR/F+XSjWgyCJMlkcgqIqQEl0YZVLrRE1OTRIMhjwN73Whvc5F0a1bKnnc7LtmWVEbLZDMUzqKXBNnrfQmSeTMk6Rpx7KALDfU2VJBYuZImldvpDCuhOIENk0DaO5zG0GgGEzNZqr8a0EmrxZZ6C2orFsjiy0nqLYfIungcg9z3lZ4UhsfZD/CcF8irFqrEcuIshFomGpc+hF0+IoJ3msTjEVaDdfck0NUdxdBIEmFiLwTkumpaTx5wUY3VAZ+XitE8nqWo4sq4TJbL5wfxo++cVv1YRVURTjzUodSmBdcfPfVD/PC7P0BrRxtt3ffj2H3H4GX1nSYVLv866k8sIJBJp6lkHVQk6bNUUejv7cfszCxa2lrR2t6myKvFJKn5Cnz8btlhJfFJ32/re/fQJJw6rHlE8xnM5BIYyURwjUGa4VwEFSSxtjJIc9RSgkIjlTQMZHnophHYBATS0QjCVGwePfksAj03ECMJvvnt70Ddmx6DxeGAcQ0KLDSRlQkFVisJaTU6xeK9iQkGL0cXltFRhFl0kIlGYaGKqqmwAMayYlwo5HiwpACvr9mH+sJKqtMXKcKq2WpTarlGVv4YLbTeWiOy8SbcenqXGgGNwA5BQJKm8RQTyvN5JpPzGJhhMSrVWV/fQXvPWgMKnaLis3knK0pEkrS9MZjG9f60Umh94vVOHN5jgY0Jk+USPzbvTHbenjWRdeddU31GGgGNgEZAI7C2CIgrXJKENL+fOZHpJGPXMeUMR54POttdOHTAQzKrENCWF1OSXIaBcaj3vvfXlRKrxAg/8pHfxyEWv19msasQUrOcw7773e/GF77wBRXnlhjipz71KXzpS19SJ/n444/jgQcewNWrV/Htb39bEVg//OEP4zOf+QwJdRyAraJpIusqwNuhH5U5h8wxrk/m8e9d4vxgQO0rBXRNZUbYzXmlMLpDT/+epyWCO9S3UHk+cWQcpXDMJHN+ImojQjY+jxGlRQaUUQWxtEj6DKqxMtdlowsiRZZhpXCLiLcsJx94z4PSb9AI3AYBfpWRYK5klrmS/lwY19LzuMrlPms5DjNPUm9yw70DXezEjStFd7SRf38G05cuIjYxjvrH3ozWd75Lud3s5Dyd8DvC0Zxyo73Rm8DlazG0UGG+k3l3EfEqKlh6wEgTWbchkVX6gdnZ2VcHh9/4xjfw6U9/mnbLJaqSarWDxpv7mU9+8pPKIuD973//zU/rxxoBjYBGYNUIRCIJqrRGMDUxj+mJACbH55FMpFTfZrGSROawUZHVqhRaC6loKKqGBYUc1Chiq1kTclZ9Bbb+BoTUGgxmaFuTxPhYHLNzVPYNpWlxQetCqrSKKmtRkZW/fxz8cO3xLJBaN2ICJuTMGJU9Z2n7089K6ZmZNAI8ViFjenkcouRZVmpFGUmoQoi0Wu9MtlWEVm5vYjJNyX0SPUm0FGKrw87JJrdTW21DOdeFHOCJyutyz08m/hJPkgnt6EQGw1ykQlPsRAoY/CouMHFCa0Sxj5NcVmYuRRX1XkRWmaDkqDgrScRZ2phMzmQwR1uTQCi3sF+vCW2NrCpnFWgBJ9bLPael3r2iyqOOI8D9SxCQxzEymsAwCazjk0n2OTnU1drQUGtHAyvDhDhcVWWFiUAv9ZiEnD9OMv7lc/049fNr2HeoEYeON6O2oYzbyJKkP45nf/bvOP3CS3jL29+KYyeOo6Kqgkq7a2fjvFQ89Pu2NwKiwJpMJpXy6jgrOsdJRvP7/QiT0CqTXztJaEJkbWxqQm19HZy0LREVVt02HoFojr8J+TR6aJ3TlwkiiRyM7BhLzA5UGZyoY5CmkBY6rh1sobPxqOs9LhWBVDiMQG8PpqjMOn7qRRQ0NrEifC/KDh+mCmiVIrOuJqC2W4isEpTMZTKKlJoMBSG4JhmkTMnjUBjpSBhZymNk2W/n0lyzD5e/8/yMgX2z1evFDAtnRgttCLCQz11cil+p2oNaTxktuu2qX1/qNdXv0whoBDQCG41AOMHEaQDoojprzxTnlQ6ghsnS9gq67vhoUbmJU50Ei2ID4TwuXEvi9IUU2pvMau4pRZyS2NVtcxDQRNbNwV3vVSOgEdAIaAS2HwILAh8iehHH2HgSMxTTsLIgx+ejIARd4cqpqFjKvIPDLs5L9z4/yWOcPPkcJM8vjq9f+cr/Sxe8Nhw9Wqi28y//8mX81V/9FYltZogLrMQDJN545MgRCo6k8Lu/+7v47Gc/qwiusrd/+qd/wt/8zd+oHZ87dw4VFRX3Poi7vEMTWe8Czi58KSqiL1RilXnG0CzzS1QUlXmGuEDIWgrndlPLUAgnnaZQDXGQJRTJUrSGaxLFhMyaIvk9xdflffk8+wm6ZBQy91ZUYFCOjCXM/Vmpk7MU18HdhKs+141FIKGc7CjklA7iEpVZ+esFH3MjbWYf6sxulFMEZH1ljjb2fGVvosoa5m/qxOlT6H/qKVScOIHmt70dzvJy2BgT3slNyPZCZhVH1CvddCnj36LEKlyHqgoLF6tShL5Xv6SJrNuUyHrzzf21r30NH//4x18lskrl1Fo1GYy2traqAe7iNleT1Frchl5rBDQCGoGbERAin5DwhQw23D+Na5eHqDI3rh77CpyoqS9Fx75aqhnWoL65XJFZjfSr0/3RzSju/MfBYFoptF66FMKNG2GMjMRQVm5HW6sbe/d60djoUgqtC2JVS4jirCFkU9Mppe55+kxQrYW82tHmxH3HvcoGyEPFz6Xcr0I4HZ9M0UIogZOnwkoCtprEyhNH3OhsFVVFWlKvIvcmA8YQ1VmvD6Tx4nkGwvxZpdp6qNOKvS0WtDUxCEZLkXvt415E1iwDZFJB3tWbwpUbaVy+QZIvnXCbas04vt+mEokSgLvXflZ7ibLEUxKZ167HcPVaAucvR0loTSOVWAgAVpVb8OY3FWFPB22/STqWfmW5bW4mhBeeu4q+GxOYmw7hsV87gkfeuF9d7+HBYbz4ixfQe70H/jk/3vfb76ca6/Hl7kK/XyOggsXRSBTzDCQ/f/LneOmFF6nC2qcUV088cD+O338fDhw6qJRXTVJarduWQIA64gjnUjiTnsGF9By6MvNoZYDmPksZOs0FykJn+b3Oljg1fRA7AIG5a12qMnzq/DmSLiPY/+H/FZUn7oPF7YZhFT/QO5nIKgrsiy1HZWwhqYaGhxDmEhocRHCgH4GBAUSpwJqYn4eTytju6hr4WGDgbWiEj6RhH9cStBRF1hezs/hxahSVBgeazF4cs5SiiKrNumkENAIage2CgFh99kzl8Ww35120tnwjnfI6KoG6ks0f4Ygi65nLSRZWZpWd5hOvc6CazilLIXxsF/y303FqIut2ulr6WDUCGgGNgEZgKyAg00//fBq9fXGcPR/GpStRtDQ7sLfDiSOHPSgqXLpT3e/93u/hBz/4AR577DGcOPEJCoak8Gu/WoHmFg/j4XH85V/+pYpli2iWx+PBd7/7XfzBH/wBiScWdHd3U1SEVUuvNMlxdHZ2IhAI4BOf+AQ++tGPLr60orUmsq4Ith37ockg0D+Tx0+uAFI8J84Pe6uYVyrb/PnFRoMufYDktoTAOjhGt8WxLAZH01RizWGOc5wqisTUVlnQUGNCfZUZ9dV0oWAOzkK1Vd00AlsRgTCFP2YycfwgNUInu3l0mAuVMutxqrPadqKDHb/EIiJx4b99keIRlSruXnH8BLz1DVvx8qz5MUlhTjSWw8kXwszNxxShvrnRhkfulzHMvRXmNZF1GxNZhfQlCe2nfvAU/viP/1gRWf/bf/k/MTw0fNcbLUtpsgQTLvdqEtgbnRyDx+1Ba2MzB6xWWFi2IVVZZg5erVzkbxnImukbZTbf9DffI/YE8l71GbKKdFL9Xojr1zUCuxsBGZTHogmEgjEEqNQamIuQsBNmP5fg80nauVOtlQqdBpMRotBaXllIVcMilJb74PE6YLWtzH59d6O+vc5eJOnj8SzmGGiZm02SkJhCJJJhBXGG9jeg8iBIRrSjstKO6mqHUmwV5daNaLFYFhFWGIntzzTVWWdZKR3jAE2se8rLpcrIqpQ/iwo5mbTdWe1TfQ+o9Oqfp3rqeAqTU2lML1Zds5KyvYVqftyWKKmuJAEn208SR1FGnZ7LKSLrLJVS49ynKLcKhiUcQFaWmlDBpZAKrbbbkGdvJbLKdrOs+gyxGnSCNibj0xm1lutiMORV4lC2W15ipKUJVVh5LsIZXck53Ot6ynlEWJk6NZ1WGA6PpRCmwq0QWIdH4qz1y7My1YS9nU60k2xcTzXWQgb+nLxXlns8/tkQBvqm8NxPLioVV1Fjbe2sUuT7RDyBi+cv4Btf/TrKK8qx98A+HDpyCNW1Nfc6Bf26RkAhIISpWCxGEvQcizt6MNQ/wHH+kBpji/pqUXGxureqamrYz5SjuKRY2U4vhTSvId4YBHLsb9J59rW0zxnPRTGaJZk+y2pcWuoUk6xWZWI/ZCpAsckO1w600dkYlPVeVopAkkknsbyXgJq/+xosLjeKmIyqff0bYC8sVJb2K9n2TiKyClk1k0wgSVJqnH1xnM44yXm/epzgWmyijCaSojiAMtttVLOlqjsV101WLvzb6vFy8cDqk7VXVdzLOm23YM6YwZnMLH6RnMCjtiocMrNPpwKB3aiLEVZy3+nPaAQ0ApuDAEM1yvbzmigmzeURiJHEWmzAgVoDKnxUat1ExaT5IJ1BZrM4c4mxg0AWB9qtaKYqqyR5lzvv2xx0d9ZeNZF1Z11PfTYaAY2ARkAjsDEICIlNHOsmp1KMcyeZL0szv59nbJDqlNV2tJLYWsh8g9t15xyIuDUJ8VRUVr/85S8zhng/amo8HA9FmD/xKYe5bDbzGoGHz3/+8/jc5z6H173udfjXf/3X/3CyH/7wh/HDH/5QEWP/+Z//+T+8vpwnNJF1OWjt3PdGOK+gRgiujORwY9IAjyOPqkID9lTRtZDihR77zj33xTOT7ztTSsrZUIrxZBFRmkiMaob8ipOGs+BWSREdEY3xuula6eKarhMet5E5OANzVHjNd3lx23qtEdgKCKSozCrOdT10sOvPhlWuhNFUpcraQdGPBhOLK5jB3SlUbMnvifjB2M9/Dv/1bsRmptH5/t+iOut9jB1bVyUksRWu572OQTgDaYpriRut4jswZx9mnyZK8ZVUZm2gW6ootPrIF5AYza15TU1kt2k81wAAQABJREFU3cZEVlFeDQaCePonT79KZP0//vc/wdVLLFO5SzPyV8ziWYbKB28mq0EIrCSvCnGVXyy1ZpJGiKpWlncImXWR1Cqvy/M2rl99np8zMcFjpo/x4tooyR4uQnCV541GLjw2M98na22FepeLqF/SCOwCBISsn0qSDDfux8jANAZ6JzE2PKtIrk4XLVRIZK2sLkJlTTHJO164SWa1c/QuhFarTSzYRblypwx3dsEFX+YpptMLpNaR4TirkiMYGIgiFM5wwGOmNbyDpFEnSV4kfBZYWDFM+wySMS2WOxNIl7n7O75drOyFNDk4lMCN3ji6rkVVIKmoyMzAkpODMzkmM61/ONnkIgOz2yXRuBlahuQwOJLCxSsxjE2kVJCqvcWOxrqFwZ0EqBa2sXJC6DwJrZMknnZTrWZkIqMSfEJeFSKrqNUI+dTFCbDI/ssk2GRaWJ87+yKee/YneNd7fpvBrzo1GE2laTvEBOHoJEm4XKbmsigtkmpQC/a0mBWB1csJ9Xo0mRCIjYqowEZJyp2dy5C0SquK3gRtmBILEx+SyTKpDEqKzWios+OB+3zoaBfr9dtfg7sdpwy0pY/qvjLCZRhXLgygvqkcb/uNB+H1MVtrEIXpMZx+8TS+840n8dDrH8E73/suvuaFkwpsumkE7oSA3Ms5jvFjsTiXKGampzE6Moruq10YHR7B9NQ09uzfq9RX9x04wN/CCvZvnPTeriO5007085uCQILk1QDVWcU+51x6FhK48Rqt2GcuQq2JBTomjmNorCPVx3r0simXaNfudJqKrJMvn8HU2ZdhLyhA/ZvfgsKWFrgqKhVBc7nqrNuNyJrn77kQVnMZLmkWR7HoN5tmAR0tFNPxONLhMOJ+klhnZpAgkTU2O6MeJ4NBpKNROMvKVFW9h8qrrqpquKuquK6Cg2qsZhJaheR6c+MQD7Mkt19J+3E9E8AISe7/yVav1FiNMi68+c36sUZAI6AR2AYISCEh65BxfUKUWRlDpgJQUxmVWekyW09lVodYWb62K9yQs5I5dSYDPHua88L+FOfOBrSSyHp8vzid5HlMusfdkAvxyk40kXUj0db70ghoBDQCGoGdhoBYh4uQhqiy9vTGKOCQopoZ3dUoelFNQmtZqYUiDZL/EAe0145xpqamcPjwYQXJj3/8Y/zjP/4jfvGLX2CGc1xRWj127Bj++q//Gvv27VPxbnnjxz72MTz55JP4/d//ffXarXj+7d/+Lb7whS+o7T5Fy+TVNE1kXQ162/+zDMkgzvt7ImhA93gOvVMLhNbXdxiwr8aAUs/C/GL7n+lrzyBDgpeIwKTSspDsxUUIq4GQEFgXBGjETTFCsZwM3yf5uqoyMyrLJHe3kGsT5dVVGCq99oD0XxqBDUQgwbzIRDaGk6kJTORYDcufrQOmIhywFKOQ+RIHBT+E0LoTWirCuPL0DHq//S0M/PAp7PnQ76D20Tcwnly+YhGJ7YaL5NPjiTx6+hib4XKjJ4HCAhNq6EZbV2Olq60ZdgqACY/DaiUfgX2b5O1v3LiOr371q3jb296Go0ePbrfTXvXxPvPMNiayCoEiziT3977/vVeJrP/3P/0PjJE4cbeWYRRvPhi421teeS2PsclxVnC4+KNYyR/UDH9MqUjC5E6G67RaRAUvy8Ag/+avbVpee+XxwvML75VkjYkMGDfVXT1eL4kcsuZCdRKvT9QUF5/3wickD5cTojSlk/JLuEz6LRqBHYqAkHlkSdICPBFPsb8T9c04gvNRzNLKe2ZynoSeIEKBKGxUNSop9ZFIVsalAtV1JZyEi4q0VjTaobcH8hz4iH19goOfaDStFDjn5pKYmkpwWVi73SRilljRQoscCehUlJMixAHQev62yD0rE9BEgtXSJNYGg1mMjCZYcZRSSq0SUGpscKC5yY56kimtQhC9TQJNkm7SRCk1THXREaqzjo6nMTCcUEqmVZVWdLbShrbeSoVXKRJZeP9y/5dqKPI0FPlT1FSFiCoT5GkuYk+S5GsUFoOHVZ1CQpXF7TRibOg0blx9Bq3734eMsUopsYoirQTKCkiEFTXXciqvFhUYqX66UA1q47maif9aN8FKcB9nVdfwaIrk1ThmWZ0uVJBwOM2inwzvDyYubQY0N9jR2e7Evr0eFDDY53IuX4VVjj+VXOiXnnryJVy/OoK2zhp07K/DngP1HGhbuN8QfvrDn6Cvp1eN1R545EG8/o2PqkIfXaiz1nfAztqejK9jJEbd6L6OyxcvUYn1BsKhMCpJiqprqEdTSzOLN0qUGqvb4+b3kzWrOmK1LW6CRXVWsdDx55IYyIYwmIlQqTWmrMTbzSTXU5211uzeUZXH2+Li7PKDTFJVNDrBwOGpFzDPPic+N0tV1kdR//gTsLrdyw6qbSsiK8cPmUQCoq4qRNXIxDhik5OITk5wmUIyMK/IrIKDjSq19sIi2Iu48LGNpF97QSEsLFAx2uywODjO5Npst8PIAgNZhAR887iTsxtwmIheKg98JzEIp9GCFqOXhPZC1PC7v/ajpF1+c+vT1whoBDYEAZm6SvI1GAeG54CucSopjebRSfWkjkpagdZwHml/ZYK7IUf0y53IXHFsKoO+kQxOnUuw0NKMh4+xMLrEpOapv3ynfnQrAou/XzLXXoumiaxrgaLehkZAI6AR0AjsVgTk5zhDt8IIlczEyW2M6qxDdB4bGk4qEmtNtQ379rj5mCJTzBXcXO9+7do1vPGNb1TQ1dXVYXh4wdVVBKmELyBNfve/8pWvKIVVefz444/j8uXL+LM/+zP80R/9kXrPzf8JGfZTn/oUlV1r8PLLL79KgF18j/ADnnvuucU/77ru6upSn7/dfu76Qf3ijkCAqV8qsOZxjXOIq2N51NLdQQis9cV0DnSDhCYqjO6wYIl8nyNR5uKYO5ycpSCKuBtyCTO/JqRVEZopoiNjoc/AhfMWt0HltkQcx8YcF9NPVGRdEIy5+bu+I24IfRK7AgHJkwiZdZbOdT3ZIC5k5vgM1YVhwUO2CjRSmdVOsY+dQGbN8XdWRBOGf/ZTDPzoB3BSOKJkz17U/cobVYx5V1xwnqTwJmJ03A2w35uhC63wHUbHknwup4pwKsutKBeyPh1uSxi38ZJX0Nd3QxNZl3CDGOLx+NpEbZaws6W+RQJJQir91pPfwsc//nGSdUrw4x/9GCEmotakcftf/dq/kvhTgeNHjy0QV0lWlYFtil84IbUukFdfIbUqImuKr1G5ZJHoqp5LK7KrEG/NotzKZUHRdeHxgpKrEM5E9ZUKr0z4iMqrWvOxnQkhSdLLImqv6jFt+uxMEC0qxAopRCfx1+Sq641oBLY0AtmsEPiTJLEGMDHmp+LhHGamAkq5VcjyLrddKbN6vE6lilhQ5IaH6ohe/i2KrTIJv7UidUufsD64JSOwEMihpf14HGNjcYyMxPjbk1fXXAitPp+ZVcqihmqFjyqtXq+Fvyei2rsQqFnyjpbxRqkyksrKUVrbizro4FBcEW9lv1IxXUxl0NISi3rs44RUqowWk0W37maeBNNxWgh130iQbJohkRco5mCunNXWFWXc1isDu9WcjyQfxbpkapbBsGlOojl5DjI4Jk3ItmJfIhVR/KmGf/IMJoeeRVXLb5K4UaMSlxmSYl0k6paTxFpbQWXccqq5OkiEfWVSfes5rebvheAdq1SjCwPfOX+G5NUMZmbTmCBOgYCMTVjJmmKxDVVY3ZzsV1UsBPSamxyor1+5KqqMv6T/GeiZwPkzvQgHY3j0zYcUmbWw2KNIiGNU0PzON7+NSDiCQ0cPY++BfWjvbF/NKevP7mAEpEAsybG1qK1OUyVhkoQyeTxLNdYUmeY2jnlb29rQ2t6G5tYWjpM5JuZ4WrftiYAisrEfGclGMMjlOoM1EriR4EylwYEqk4uLEwUGqyK57bBY7fa8aFv0qGX+Ozg4qOz8ent7VeKnqakJTzzxBNrYZ0ji6NYm8+0XXngBJ0+exDT7mANUdn7wwQfR0tiIqUsXMXPxAiZOv6TUWIs6OlHMwJqntlaRNW9VFr1124t/bzUia544ZNnPZqmumopGkI5EkaHidYpFA+lIhI9jSPPvDIuEswm+Rx7zvVkSXCXYKOctJFZnSZlSWXUw7iJqq87iEvW8IqvKAGwJLcMB3DTVWLsy83g2NY5mEtjfYK1CiZFzGKoN6KYR0AhoBLYzApJ0jTIR3TWWw8uDHMEwku4mgVXsQOuYiC7zMh7Dpzc62SquHRN0IXnuJc7HaVla5DNiX5sFzVRnXZiDb2fUf3nsp06dwo9+9CO8/e1vf1V17ZevLu+RxNn/7u/+jgooN5QS21qon2gi6/KugX63RkAjoBHQCGgE7oRAkvbjQmYVR7juGzHm7Gk7Tic6UTQrL7Myp7/gCLco4PDiiy/iXe9616ubEz7B7/zOR5g/yVAgZBB/8icfU+TWIhZtnjr1khKb6uzshN/vx2c/+1m+93de/ezigy9/+cv4i7/4C5RybiyEV8n/39yEI/CZz3zm5qfu+LiQ823JiWgi6x0h2pEvSH5nLsqiM/8CiXWWDg9M/2J/DXCwzsB5BPNKOyBMwhQh4/7MazPvFqGqsqiuisoqQ1DqcZyCOELkiiXznCuRpMpzLpW8IZ0OSwoNau7i8yzabu/IW0Gf1C5FQIh3OcZJxyjyIa5Vw8yTBCkA0mj2KCJrk4lOvIyVinvdTmizVy5jkjH3ua6rMFNEsv29vwkf4/EWPt5NTcYsCfZ3QyNJ5Ug7PSO50Zxy0HHSXVcWpkNJ3jdhbrYP519+EvsOPI7augPrAlNVpQW1LAbaim1bK7IuAvq1r33tVSLrpUuXXq2gWnx9NetPf/rTVLJrwW/yyyRJV2mLldg3r29+LMnWhb8Nr75XVFqTCSGWBKiMFuQSoD14gOSPEObn59Vz8lrAz4XrBH/Rc7ksCosKIYPnohJKSRdzLYv8zXWxPMfXC7gI6VUn9NXl0f9pBHY8AjLBkYlxjrOaLNdJluxNkdg61D+FvuvjGOibVCSzklIvaupKFbmsub0KDc3lSqHVvBmedjv+qmyNE5TfHuFsCIFVluHhGPr7Iui+HsLcnBRa5NDc4kZHhxfNzS6UU6FVFELXk9wsxyRxnFQ6x8BQjlXScVy+GlPE1hBtQvZ0urC304k9HS44nFQsJSH7dk3uezXAYxJOKq0vXI6qQV6ApNbDB6kw2uFAa7MdDvtrK65vt607PSf7kCZKt3LMi/sLkcwaDInCLBDg4xAVYucmTmN+4iQ6D78PdXUNSoVVlFiFyMpaFEV8XTyV9UhUyrEKiXVgKIkuknsv0lZJyLaieOulemwslkF/fwwJKjlbzHk8/GABDh3iBKjBDZdLFGxltLKyJgTl089fww+fPI3CEg/qGsvxwOs6UVFZROU1A4YGh3DtCl//3lNUfS3A//IHv8fXKlQhzsr2qD+10xGIkkg1NzuHU8+/gHNnXkY3lQjKKso5QTuAo8ePoa2jg4UaLjXeNZGEdifC+07HaaedX5YdGQ3MIQqtV9PzeDE9pYI1Qmh92FKOPZZCVBqdYK++005dn88aICAEky9+8YsQOz9JEN3c5LU//MM/xJ//+Z+/hswqfcdHPvIRfO9737v57erxe97zHvxX2gL6e3sw+fIZjL/wPPzXu9H5vg+g+pHXwVVZpZRG/8MHb/PEViOyCiFVyKqhkWGER0cQYbFJeGwEYarQhEZHkQoFqTzroaVTGdzV1VxqFHnXU1OrbJ6cTMwZOH8wGBk4JYaLxNXF9W0guONTQlo/nZ7G9XQAc/kkDpuL8SZbjUpW6G/6HWHTL2gENALbBAGZo8mUUlSVAtSDePpynupKCwTWA7XAw20LxZEbragkxyU2dkPjGVy4lsSp8yk89rAdrzsu8+cF27ptAvEdD1N++4WgIjbBn/vc5/CBD3zgju+91wsyXvjWt76lLIXlvV/60pcUOfZen7vX65rIei+E9OsaAY2ARkAjoBFYGgJqzMX/RJQixVzB5SsRdHXH0DcQQ4HPgkMHmf9oc6K+lkwQtlOnfklkfe9734vPf/7zjP3LZ3M4d445++A5fPjDv63e+2//9m945JFH8NBDDzG23o9PfOIT+OhHP6peu/m/f/iHf8Df//3fM8/SgdsRLSQnMsVi/aW0b37zmyp2oYmsS0FrZ7xH3cM8lTP9eZwfBkZm86goMOCxfQZUFtAdkLeuxEjWI6+00QhKsd8s3Q8nZjIYnshheIyughPidkzRGOpU1FaaX1lMirxayKI7M3NXUi8tecvNKATcaIz0/nY3ApIjoXQTLmZmcSE1h75cGEUU+HiLrQ61FPwoNG5NkuFSrprMraMUUvj617+Onp4eCi65cf/99+NQeztCVy+jqHOPikPfa1u3284DDzyAEydOwEmnsAVe3mu3cicxCxG/WFRjf+0nfvnXUopkV3JMi3uQMYj8DogYVShMZV6KVI1NpDAuCx11ZqnYKg6wTusIfPafIZJ+EIlM2+LH13T9ljcW4K2P84dnC7bbja9ud5hbUpF18UBvJrJeuXJFEbwWX1vt+pOf/KRSc3n/+9+/qk2JGkyWv9aiNpVgIinOUhOq3CplVyGtymN5Xh7HmGQS9amklMmz4xLC2gIRSG5qLurmFlot73D+neMi6qwOhwNOl1Ml+uVL62JnoP52udRzLq6F8GoWHXrdNAIagR2DgKi0RsNxkuNJBJoJkwwUIik+wv6ExEUqMUrfI4lmUWwtKfNy8ZEgRJJ8sRu+QpciBMkPrm47BwH1W8GfiFAow2KJFGZnUySyJihZT1VxBndkkGQigdXjsbBqmLaCJLSWlYnyt1FVL68HEvJbpQZlJK9OTacwSdXQGR6XBJvk7nOwyqii3ILqajtKWHHpJtnyVoItN6GOPchtiFrq+CS3M51W2yC3jYEqqqBWWFBXbaXsvlQt3Z4Uu9Tz4+4UIZhC60z85VSVFGtSVHVUd9ep/5+97wCP5KqyPp1barVyzpqg0URPdBznjG1wAkzGeFmv8QLfft/+i3fJLPDvLgss3oBhCcawtsH+DcZpMQ4DDuPx5ByUc1ZL3ercrf7Pfa0ea8YzytIovDdTqlz16lR11Xv3nnsuDu59BTfc/AmUlZbQARgnsFoZ/S2d7On+SSWuXRq13b3xa+/hWKJVBUNRvh0YiDC9UoSRuozo8kdIcPehgCqsy5YmYfVqJ8qpwppGY56QlydbvIMBNDd0Y//uWux+6wTO31qFdRuXoKiE6mzJVmV0+9PL27DjzR08j4kKmstx9fXXwJmaSlymdj8mW2e939xDQNq20ibu6e5BU309yc8NVBhvU8+PZC9wsD2bX1jAKMNSPlvF/F5l8Xky62do7t3KKddIvg0hDKF7yI8WRh+3Rr3ooVpjlMvSaLApMaWglEMhCa0WA9+vmtQ6ZcwXygFee+01iANKSmFhIW677TbVjxaSak9Pj1o+kngibV1J+yfLpEiaQDF4HT58GL/73e+UAeuee+7B17/0JfQ3NqB73z70HDyg+tuiQJqzfgPSly4lwbNU7T/an9kksipDHd+pYbEheNwIDgwoYmqAwbEhTgcZRBse9Kj1gkGcfMp2AH9PaprEH5MExdJWYHGmwp6WBhsHC7/b9vR0mGU5I+Nl26kW/xDbpbEQ/hBq4W8+gCpTGlZa0rGcY100AhoBjcBCQkD6ZuGoAceZIrSui47pXtptGexYxjShlfmgOuuwY3by3bIJw0WBbXiofHSsNoztewLITDcqh/GaFVY6jNnGmu4O7IRrOPEd5LsmBFaxof/Xf/2XUkyTo0yVyNra2oorrrhCOdzkeCPbEzI/2aKJrJNFTu+nEdAIaAQ0AhqBMyMg/WEhw3V1h9BOP0FrWwguZikTW7lkp5NMcBVlTJeGTlx80YXqII888giuueYa5WuXBc3NzEYSDeOqq9YrW6WIW91yy0cYBHsXduzYoQJbRHn19CIE15/+9KfYunUrhPw6lfKf//mfyiaqiaxTQXF+7Cs+Hhk6BmKoJs+5rjuGvkFm0ssAKrKBKmZycFipMDwF/825QkKuS4RhRHG130PVZKbP7h8YgosCMZIhQoRjpMshAitCThVBlmT+PNOZPjuNQ3oqlQhJ4BU/2zzsmpwr2PV5FxACnfSPiG9Estf10m4q4h5Lqcq6ypyBDPpJHMb5laFQ+uvyHf34xz/+rmzqTqcTv/vtb5HU3Iiya69XLwfZ/kxlrOM8/fTTKqhk5L6yz2hiFiKOcTYy63iCZCdTp5H1S0zLezPIoBoJPBY+h/j/PRTT8lBMK0jVVldfLTOjPoOS8qsoerkmsdu0jqsqk7CSw1wsmsg6xl2ZLiLrGKd51+pwKKyIrf1UaxXlVlefi2SkuIqrq7d3eFmfGrup6ipOf3uSncpnGSrtQRqdTmnpaWpQyzidziGJBFfZzkRHlJHGPiGZGOjEkh+lkSQ3NZZ1HM72wnhXZfUCjYBGYE4hIEqtwWAYLY09VGntQPWxVrQ195LU5kJeYSYKi7OooJhLclAWiUKZJC9amKZZyG18JzB3upAH9e9/Tt3SaamM1ytp54OorfGiptrDyB6/6jQXFzM6mQTHsjIHvxMWRkSZVWfSYqE6qnnqpIWzVd5LJ5oQbA8e9qK2zq/IrYUFcdJlRZkQa61UNmUqESsjMM/ScXezQ9xJ2f3d+7yM5AwxKGQI5SVWqrsmIy/HhMwMPts8RiKC82x1mcxySUv84osv4u677yZ2ZZM5xJj7SCNWSMdhGgBEbM7vFwJvGI0tIdQQs+6eiLq+7EwzigutaG1lR6c1gDAbviqdcjSCjRtSmTI5SxGWnc6pBbJESIpvb+3D268fRUtTD9z9XtzwvvOx6cLl6p0hDsRBzyCeePTX2P76dtx4843YdP5mlC0pV4E0Y16w3mBBIyDG5QSBNcAArj62bRvr6nFg714qR9ehiyoFosC6fuMGbNyyiR0zkqMZpKXL4kKgmSl0qiNuvBXqhNcQYfSxDWtorFnJIc1oRRJNOKQ0z0uyxeK6kzN/tZ/+9Kfx3HPPoby8HPJNThQxQm3ZskUpn1xBEsqjjz6qVklKwI0bNyqyi3y7JT2gIoFy7Y9+9CN8/etfV9vt2bMH+fn5SrnUdewYap99Br6uTuSuX4/cDZuQt3ETTOxPm220rp+lzzydRNaYBLXKQO9cjBlbhvgtPjmvgmXDGJIgWJJW/d3d8Pd0w8ex1FnmfV1dCJHIGuN+joICpHBwFBbBSdVVGacUFSI5Jxdmvm8NtAnMZBHyakPUgxcDLWw3AO9PYiCM0YFkpsnSRSOgEdAILEQE+OpFe38MfzoOtDBlaJBk0guXGrChzIBUfkZEgUicuLNZWjoiOFIdRi1T6Uqw5tUXJ2FZmZlO4/nnMJZ2gJBMj/F7LaIQiTJVIutNN90EIZ0miiayJpDQY42ARkAjoBHQCMxdBIRAN0DiXHWtHzt3u+FlCnPp4q5bk4LzNzEj3OoKVXkhnYraasL/Jaqs4g9bvboKHo8H//f//hPWrbsFP/nJl/Bbkmxk2yeffPKk/UAOIv7z22+/XdkiPvWpT0HIr1Mpmsg6FfTmz7509VCMBPBSw+xIK/D6iSFESO7MYHa9K6qAJTnx/sEsdw8mBaD4rcSmJtcjZHIZiw9LyFiivtrVKwqscRXW3v4h5ecTwmpCfbUwz4SsdBOzG4ovelJV0DtpBBYkAkFmsmocGsTBcB/eCHWgiIqs65nNapk5FXkU+rAyk93Mee2nF9Je8tlERGKQ2RjF1i4ZVMTf9/vf/x4nTpxQGcifJQm1kJnAzBRsNFJo4UxlPMd54YUXUFJSonaX7/t4xCy+9a1vKX+l7CT7TCRIdqJ1OtN1jbZMiP8Rcn2OHT3BbDGP49rrbmbbZONou0x6ndilRORsLhZNZB3jrpwrImsibXgoFFSM8CDl4IQgImkTQ5yOyFgcVmp5UC0To12Qiq4BKrn6A1R89cZVX4Oi9MplQhqQlL+i3ppGlZXUBNGVpNfU9FQSmDjm8vSMNG6TpJRbE435MWDSqzUCGoE5hECcLMROgy9IpdYAGwl+DLr9GCDpzNXrITF+UCm2CtlVthUlxaLSbBSX5iAnTwjwDkVsn0OXpKsyDQhEqQoTCEbhZSSPxxNmIEQYfVRr7esLoZ+Rym4uy8qMq7OWliZRHZXKqNlsOLIjORPfAjEuSaSRqIj2uUiyZeR0F0mp3T1hRaRNTzMpJdGSYjvySGo9U4dWFF4lmlPtT6n9Dkrud/I4vX1hqrpaUVRgQSXVSOMKr9PbEBPSzEwTWSU9kpBzm0lcbWwJoplR5XLNQjIW9Vkh+g7w3rl4LweotivzRgONBV0+pUh73vpUYpiiiMrSED0bIXg8j5cQ5EXt+fjhZrz0wl5k56Rh88WVqFiaT4XndPWMNDc2kZR4AIcPHkJfbx9uvfM2rF63RqnCazXW8aC8sLcJs90q2QeOHT2GY4ePoIadVVFllfZnAVNZF1N5NScvj89WNjIYmGW12VTncWGjoq/udAR8sQg8Q2F0xajQygjkxogHg1wmNs21lkxltBHim41GG10WLwLSLhHVk9raWohiyQMPPHAKGP/wD/+Ahx9+WEVjv/rqq6q9K0ayv/qrv+I31KIILyOJ8nK8lStXsj3UfzJtYMRPhVMGjLqqT6D36FG4jh2Bkfsm5eah8KJLkL16NcwMEpVlp5fpJLKK0mqEKZj8JOIGXRz6XcPTLgRkGeeDbrfkaoGFxkClrOpIiY+ZocXKCHcrxxYuE7Kq1NksfX3KXliSkmGy811LUq4EuZ6xsXX6xU1yXuq3K9yNnRwks0whf8eXWvNVeixRGNBFI6AR0AgsRATEwetjRo8udww1VFw62MzMKHzdZjlIaF1mQDGVl6QPN5tvQcno4R6M4a19QVQ3hFFRYsbycguqlkj/cnr7zDN9T7/73e9ChtPLZIms0meVQJcHH3xQpRRuaWlBPbNHaCLr6QjreY2ARkAjoBHQCMw9BKTdJaRUUTFz9TNFb1sQbRzET7CkwoFvfPUGqq8247Of/SxtCP/A7q/0UuMiEm+/vUMRU2X+scf+HxobC2ivPKBsCJLlVFIMCwknUYTAso7B+OJbk4yxl156aWLVpMaayDop2ObdTmGSPZlQE2/XxtDqYrYEkj6rCoBVRUbkpxmQYo/NepDbZEFUvsaQQaXD7iJxtZOCK129Q+in+qooribZmA0yxQinY3iczOtjBsYkZkgXJVaaomBTQjqz2ROa7NXq/TQCs4cApQzgpS9ExABqIgOop+BHG5VaV1syUMmMVsup0DpflFm/8pWvMCjkJ4qT9r//+79KEErEGfppz772hhv4jW7DXXfdhc/feAMyq6rOmgXtTMeROyLBJ1deeeXJ43zve99TN2qiYhay00SDZCdaJ1WxCfyRNo20MY4fP8F2xmO46aZbsGHDzBBZJZiHppA5WRYEkVWiocSBlU3lpkOHDp1kT08H4ueKyDreustDLIPP6yM5yUsiywA8dGQN9LvjY867mU7Q7faoeSHCShHHnQx2NdiHp+PjZDq1bCS7CuHVytaEjUQCaazLvEzbmA/LwnkrnXYmpnnVRSOgEZj7CITDEYQCYbRRTbGVSootTd3o63aTzDhI4moKyezJJLGnID0zBRkcnKnJcDjtSHEm8zcvaq1apXnu3+Xx1zBGlc9AkOk9SGJtafGjqcnHxp5fdTKTk0x8BqyMhuKQYeWzYIEoeSYnG/kNkNTe4z/PeLcMsi4DlM1vaAyiptbHlCMRpUQqRFohseblWkjctCCV6UXsVIoRhdXTy6CXHebuiFIqrW2gt5ANPbvdQGVWC3I5SCohSVEi12G1TF1tZiaIrNI4DVAVR5yLHl6P2x0lLlEa3JiKt59GOOIi+Dt4Dak0BIja7KAngt5eIQEH2fnn951GACGzFpMAfMEFmUqJVVR2p1KExBrg++PAnlqcONKChtpOrD6vHNfevIkY8/1AJWcJrtm/ex9eeOZ5JDMtfAEV3i678nKUVZRN5dR633mOgCgjSiCVZBbooTJgF5UBW2k07mjrUISxVKauXrZiOVauWoUly5aq9qhkGdBlcSPAVyH4FUA7iawnom7Uht2Q1Dq5RjuKzA6UGFPUtKi1WoxMiz6r9I/FfW/m0tXfeeedSv3k+uuvxy9/+cuT6YAkenrTpk1s37TgvvvuU8RUqff3v/99lWr4sssuw+OPP/6uS7nnnnsg0dvXXnstfvGLX6j1YlwLM2p8oK4WLa/9GV4a2MJ8p2VUViKtvAIOOrLsWVmwZ2SSDCqEUH6EWUYjsoqy6hDfjUMRKqmyfR7l91Om1ZhZWYbCIURJ8o9wUGOeL8Ih7PMi4uM0x4rcSoKrWsYAAdlOSKr2zEwkZbI+rFMyo9ntWVS2FnVrLrOQ0CpE1ZkITlIXPcofURNg7fGnYBvJrD1Yb8lSabGWGJ1IMk6tjTLKafUqjYBGQCMwZxCQfl5TbwwHSGRt7jPA7Y9hVSGwLM+AkiwKDrD5yy7VrJY9h4M4XB1SpNYCZjO5YL0NmWlGlcpzVisyhZNJkJybNnApQkK94ooraOPoU9/7j3zkIxM+sqQ9FHU1EX/485//jNtuu00FzWgi64Sh1DtoBDQCGgGNgEbgnCIgba+OTopCUBji2Amfsq9nOv+E//N//lb5uEWVdcOGC9h+GFKE1k984hN46aWXUF5ezqCWp3DkiJfkmEzccssWpfp++eWXKzuCtDfE1ilpkl9++WUUMTB/+/bt9J1NrV+riazn9HGZ8ZPTtYIwRWaEvFrfHcOh1nggW34aFYMpIFiZHycRvdvjNeNVG9cJRBlQBFcCTHPto++Kemrwsj8z6BUfVnxwMxW2LAtRdMaZwkyJJObmZZuQm2VCTqYJKSSyWklc1UUjoBEYHwIBklkHYmHsox11DweHgT5u+kZWMWtdIVVas4w2ekRmNyh2fDWPbyXfS1FjlcBQCSD5+7//+1N2//nPf44vfvGL5B448QbVz0MUasjfvAUGfk8N3DdRJnIcydQidu+JilnIuSYSJDuZOiWuZ6Lj48ePM8DmMbZHblH+jonuP9+3XxBE1pm8CXOdyJq49oSCa1TSDbJVIaQTNeZ8lNOSYljmRbVVCK9CKHBTccbl4tDr4tiFAU4PcJmQYWVbB5VbMjIzSILJQXYuBypkZdERlpObreadzhSSVRznxBmWuG491ghoBMaHgCK9k7wYYa6KEJ3k8l5IqLQ21XcyvXMnmhu6+X4IUAXPwlTgeViyPB9LKguRX5jJ94GdJMd3Gg/jO6veai4jIAYdiZwMhaKqg+nzMVKZpNbmZj/q6gep5MvvBp+TpVT0XLbciSVLHIrcaqVKC9uC01qGWBnpEIfZ0RWCbUdHEA1NARw95lOkTlGtWbs6BStXkCCZbyUZ9d1eviE+35K+hHwQ1j2CusYQaup5LSS1ispNQb4Fa1YmYWm5XXWmRdV0KmUmiKyitiqqtKK8Wl0XQGt7mCTVCNVxzSgpsqGijASZGBV0SPo9fNTLtMkhZGVZVAoWq5m4tVOJ3RfGpZflUIXOqUiscr8komoqJUgSqyg5//ax19DW0ocN5y+j0moZllcVKaV3CZLpZzti20uv4n9+/ivccMt7cOMtNyKX6ppCatVlcSIg3x0/250d7e3YvXMX1Xr3U633IEpKS1DJCMu168/jdCkyszKV+qoES0lH81yQrBbnHZrbVy1kVn6FEOQ7rzPqQ2vMh92hHkYj+5FE6qoQ4bZYcpFqpEKmTks+t2/mDNXu2WefxV/+5V+qowtx5b3vfa9SeX7iiSewZ88e9S55/vnncd5556lt7r//fpUW8N5778VXv/rVd9Xqn/7pn5QC24YNG1QUdmKDIfajhSga5fus99hRdO3dg04OQRJlMlasQPaatchdvxEpdGAJkVTKWYmsfC9GSLqJ8FiBgX6ESL4Jsv8dYv87yHlRWPVT2cXf08Pp+JhRq1R9NcdJqSSo2oSsSoKqnCt5eGxNz6DiKpVWrXyPisGPDScD2+0yNpoYhKTm3912SlzjTI97Y0ES0geU4bWB6bHeZyvjb5jXQGXlqbVQZrrm+vgaAY2ARmD6EBAFJnarsJ9k1sMtQJsrhoJ0A65dQycvndgp8ViI6TvhGEcSZ3NzewQvvu4Hu9I4f50NS0stKMw9d9+LMao86mpxJsk3v7Ozc1JEVkl3KGpqsv/PfvYz3HjjjSfV3zWRdVTo9UqNgEZAI6AR0AjMSQQS2eA8nqhSZ3W7w/jHr9+pMrRIu+Hiiy9WGaH27dunlFpl2f/8z/9w2XoSWd3Yu7efJJx6/PVff0b5yyXQRewFR5mxRdoLYscUm4Nkd5lq0UTWqSI4t/cP0OfDxJn446EYjrUDmczOUFVowJYlBjiYEJHaMdPub5suRGiSUiTWAc8Q2rr4W+qMqj5Ee1eEfrsYswIaFVk1n4FxBTlm5GYalQiLnYqsRiMzC5olXbfY+0VtVluApuu+6OMsfAREmZUuc/QPBekb8eO1cIfKXpdnSsJ55kxcZMmDyUDf7xyFQnyDpfT9CT9NbPgbN56qJnqM39Krrr5a1f73jz+G5MYGLL35vbCQmzYy+9lYxxGip6iySvnjH/+I1cygNhkxi4kEyU6mTqqCk/ijiayvjAs1g9/PL9IiLPOFyDreWyOKaZLGVcisg55BNfZ6h8dc5qXhzkvHWihAZx1JsAa+BIXPb1Tqd3FygTTohRRjsVCV1WaFg2TWFEVqTUYKXzBCgHWkONRyUX01memg0g2U8d4ivZ1GYNYQCIdEKS+E7q4BdHf2o7ujH+4BIbuzV8Viogqrmb/fpGSbUmvNyEpBVk4qMrKcitgqkab6pz1rt2tGTyQkUCGSikJrD5U9O7uCVEukOgsNPPL+lpT0FqqYijJrZiYVTnOTaNQheYjqrUKUnM4ipNZBdoy7e0I0MvH5pNqoKJPy06MIqRkZ7BDniEorn8u0uFLsyPPLtQhBt4vpTDrZoW5pDzHFQAQiSC5Cj6LImsf9c7PNSu1VxNNEoXWiZapEVjECiEEtke6o1xVFnysMrzdO5pVroNCg6uinsM78Kap7JIRjL9Va4/eM941k43AwzCGCVKrW5lLBdvXqNKY7slEtderfX2mU11V34MiBBtQca6UiuwWXXbMWpRV5fC/Q6sIiwTE7t+/A0cNHUVdbh+tvugGXX3UFz08CvFRcl0WDgHRMhdjc09WNluZmqn83o4vGXQmkkiApMwlVxSSylpaXoXxJBZ+hDGX41e3ERfOITOpCvYw+HhgKoTbqYSodkgmjAWWkSWEkcpnZyRTlycg3MtsElR2l56LL4kFASKuf//znz3jBQib92Mc+prKXyDvmuuuuw0GS6R944AGVzeX0nR566CF84xvfoKJ5MXbt2qXeWSO3EUJrX1MTPC3NcFWfwGAHvQ9scwhhVMii5qRkmJLssCQn4/m6BjjZ6Li6uDCuvsr3oqi7xkSJlceRQZ5U+cbKciGryj81Tszz2LLezEwoorYqhjyrM5XKqvGxjYrWalmKkyRWB4zcbmTE+si6n6tpMSBFSEavpbLytlCbMsCmG6y4kCT0CnOq/rWeqxujz6sR0AicUwRaSWBt6gWOtlHRiOk4mQiHKkzAigI6sm0xOrJnpy0TIbG2n/3sXQdDyikdZCredStsOG+lVWX6mGrg52yDPBUiq9i2RFlN0h1KakNxfEnZunXruBRZRfmlsbFxzEuWfpK0MT74wQ9OC+llzBPqDTQCGgGNgEZAI7DIEWCXWtnfJftbSyszn0QC+NUj/wixJYwseRRj+OEPH8LmzedT6CnM778Xu3f3Kdu6zbadwbBfoT3ee3IXsRuI/eAGpkaejqKJrNOB4tw7hqiwBsNG1HYN4ShNSNQJUf7UyjygIgcoyybJc+JuqRm7UJqh1O9FlFUlS+DAIMf000kAnD/AwGxeD008KghOfluisJqaYkAGfXQZVGDNYDZFJ91FslzIq7poBDQCU0cgzCxXDD3F4XAf6ikOIIIfTvpESk0pWG5OQxH9IpZhLtfUzzZ9R2iiDf3CCy9UB6yurlacsZFHj7BvXFpWphb96uGHkbJnF3I3bFSqrJJpLFHGOo74I0tKKG3NIhnYJBPbZMUsEuccy7YwmToljj3RsSayaiLrqM/MQiOyjnqxwyuFaCAKWv1UaO3p7iEBoYtEN6aDlfHwtBAUhJ0uTsEsKrWKamtufq5SapXpnGEF14TKlig5imNNfvyyj1FeqiTDqmlhJ+miEdAInHMExFk+yNDAjtY+1Bxv49CKuhNtVLcMkLyaoohrS5YXYMnSfOQVZijlVgvz3yXI6lNVfTznAOgKnIKAkD97eoKMMnajumYQzU0+RlAaUVRMVVOqtIpCa3a2jQEMJA7xNa7e84yslPf6dBXpEAuhVdIA7T/oRW2dj+cBiovsWL3SwbENeXlWdvjj6VfkGRx5eqXSyojXptYQjlUHcOS4XymeFlHVddkSG1ZXJSMjnalNmO5EjAan7z/adUyGyCok3diQgYEiVI8N81vrp4oqybb1jUEqyAbQQuKumZ387CwzKpcmoZwKrEVUku3vj6CpOYA9+zw0IkSE6oKN56WgIM+CBqrntlOJ1eUKYeslWbjwIiqc2Y2KeDxa/cezTpFk6eH880sHsO3FfSgszsbylUW4YOtKpKXHSaySTqmpoRGPP/IoyYp+rFyzCpvO34SqVVOPRh9PHfU25x4BRcTisx3lsxII+PnNGMTRQ4ex8623cezIEXjcHir4rsGmLVtwwcUXkXCdygAJrdR77u/c/KuBEP26hgI4RMPNvkgvjkRcWGFKx2pLBtaZMplSxw4bFR4lwn/6vkTzD6fFUuOGhgZFOqmpqVGXLOoo0o/1eDxqXlIT/fd//7cyYJnYeBCVFEk3/O1vfxuf/OQn3wVTIqWR9GWF8CrHGln6qZz6b//2byMXnXXaxG+jPRTEkoP7MBQMUYXVH1diZUCpiWQZE4mp9rR02DMyYUtP45AOKwdRWlUD65DMISk7h2RVB8z2pLOeay6viNLD4aO28q5QN37jr8VGqrBebS9GLonnKVpJeS7fOl03jYBGYIYR8DEt54kOYF9TDDvrDVhbDFxSaUBRBpDOZrK0Y0b2a2eqOpLRpK9/CPuOhvCH1/w4r8qKy89PQrYoKfHTM519+5m6hsRxx3I2JbY7fSzX+Mtf/hJ/93d/hzI60l599VUVkCnLx0tkFTW2t99++/RDv2teHGzNDPbTRNZ3QaMXaAQ0AhoBjYBGYFYQEBt7GzPBtbb20F5ZzcxuPvoWlqGwiBmjMmxISxMfgYEZ0kJoaPAx20sfA/X9uPmWfAbit/E73oh169aivLx8WuuriazTCuecOJj4pXwksXYOxPBWTQyvHothfakB68i3WldiUG3+c11RIa6K/y0hmBKJGih0NoQeCq60dkTRQvXVlo6I6i+waYy8bCNKCswoK6RQBcc5GSYKz8SFWM71tejzawQWOgJh2lhbooN4hUIBrVGKFSKMq61F2GzJgYPEVqtSZ507HhFJCf/Rj35U8cLambFRCKcjiwSTSlCICDA++IMfIGfHmzAnO7Dywx9FxvLlKsuYbD+R4/z7v/877rzzzimLWYxlW5hone64446Rl66mxUch2dLHKt3d3Srg9pZbbsGmTZvG2nzBrResx1O0IuuHPzwenBbENkJIiNL5Ji+PAJVZgySsUpGXSq6c51imA/6AUnaVeZlOKL0mtg9yv/Cw4oykFXZSMSadzrn0zHSSXzimw07GaRlpVMdjGkS+sOaTgXRB3Gh9ERqBMyAgKq1+qrR6qMwq6qwD/V64OXg8frVM1FpDVH8Updac/Azk09NSWJxFEjt/01RnVOQR6dXoMu8RCFGRRYa4MmuEY6aPp0qrEFxFETQQiCp10+xsOwoL7TT62KkGalPRltNJavYHJLhiCL19YTX09IaVcqnUQxRh01LNKC2xoYAKpLk5FkXgTDyCiY64pDmRyOsedYyomvYwmnTQF0VONtMnkixaXmIlgZQqsySBJvYf7SZOhsjq5jnlOlqpEtvZxevoZ7piRrLamGrF4SChlsqrojKbZKcKLgmtQlrt7g6pfcIk5DpJuM3MNKt6dnX6GWwSUKq5adynsjKVkWdJvA82/j7Hdw2jXZ+s6+vxKEL7oX31VGVtx9ar1mLN+nLk5gmRnTlvWBrrG0laPIKX//BHBrHk4r13vg8FhQXqG6820H8WPAKiLCSK/tXHT6DmhAw1fK5J4iJRKzc3D3kF+cjnkEt1g2wGOlmpUihELl00AhNFQIisAUYh98dCaGf0cTvVWTuYWkcMN0JgLTWmYLU5HVlMsZMC/YxNFN/5tL30HTdv3gyJgF5O49bXvvY1lQ5Y+rFvvPGGUkYRdTQhpQqxRBTCL7nkEtTV1eHLX/4y7rvvvndd7ve+9z3867/+K6qqqpSR7PQNpA8sKYqkiIrqEPu6UZJVoySnRtn3HeK7cCgSV15tY/84hXW8qqiAaq1UR5dgTsqsGzht4jvQaGEQELObiIqqmdLwkjLJxLHJym+4nWMbFc1Z58Q62W8+Fm8sgoPhXpyIDKCBispbaFzdaitAEn+vop+si0ZAI6ARWKwIiJqRO2BAS58QWg3odNPRTXLr5gojluXFkJdqgHUWmjLSXw4Eh9DUNoRdhwLwMTmPJNS4eKMNS4qpNk512PH0jefCfRzL2XS2OtbX1+Oqq66i+lREpTxcv3692lRs1NJ2qK2tpULbD3Hrrbeq5dLWOL2IQpuIPYxVRIlGVF81kXUspPR6jYBGQCOgEdAIzAwCoVCMypLMBEd7e2cXh27xd0Tgpp8hL9eCIvo4lpTbkUI7fSgUxZEjFPioHlTtIfF/XHB+Jm3e7MdPs4K+JrLOzP0+V0cVgmgfBXzrumLY3QDQ5Yo0BolVFQIV2Qxcoz7IbGVhOBsGkp1BVFbFP9XdFx/6BhgcTvVVqb/dZqSPCnDQX+Wgv8yRTP9VkoG/DQl44zSX26xxRdn50l84GxZ6uUZgPiAgvVCxs7aTxFpHG+uxSL8KgJXMV5utOSimQquIBtACPScuR4JFv/CFLzBAJA0n6DM8E5F1yZIlShRH7PHlx47A3dyEyjvfj9z1G+AoKFT29Ikc57vf/a4iz05VzGIs28JE6/ShD33oXfdk27ZtkGGsUlBQQCGrdmgi6+hIaSLrIiKyjv4ovLM2SKedj8a6vl4Xh164evvQ29OrlG5kPOAa4AvIQ1KRFQkyawpTITpTnUxP7aQCXnzaQZUZcS5axZHHlMUylsHGUB4LnXqyv5FSefLi0EUjoBGYXQREYc87GER7ay+aG7vRVN+JjjYX/N4gUtnjysx2Uo2ZpJHsVGTmpJLYaOPv3Ua1PRt/x2amIZ8F78vsQrIozyZRmZJqsJcKrS0tAUYkD6KtlQkN2HpOTjaRrGYnWcQ2rNBqIinTzOW8/0wjYrFMz7tbOdlInu3oDKOuwU+VWAmsYI+b7fICqrLmc8jLtSqyp5w/KcnIZzCu/J3oTAsZ1OMdogJqQKmg1jYEkcztMjMY/VVoRRbHMi/7Wa0cq/pzWqVDiSu2Jh6AMxFZBY9oZIiBHEy1EjEo1dUQlVfFSBamwULItL19JKf2RuCikcxHgq50+guoECtkWiHiyk9GCMS9JOy2tAXR1h5EKAxlJKhclkSiq4nfTAMOHRxgRLgPjhQLli1zYMuWLC43ToshTe63ENbrazvw5rbDfAcEeB/NuPL69VixupjGO4NSqhPF1te2/RkH9u5Xqu2rqMZ6+wfvUARGHZySeFIW3lict6JUKMFMonwobcCujk401NUrdV7pWOXl52FZZSXWrT8PFUuX8n2QpMmrC+9ROKdXJITWwVgY+6nMKiS5LhJas0x0OJicynCTR8XHVEYjK4XWOWLAOaeALbCTj0zh88ILL+C888475QqFxCqkFClPPfWUSmV02223YceOHSq90Be/+MVTtpcZIbj+9Kc/Veprv/nNb961fqwFYfaLZQgODODHTz6JNPZ3P3zLzScJqkb2c4WoaiTBVYitC72E+BvtpoLyy8FWuGJBZFMxeT0VWVebKTeoi0ZAI6AR0AgoBAaDJLH2x7CrIYYDzTGU07G9NNeAynwDMungplllVkq/m2TW9ij2Hw2itjmMrZvsWLWMgZ4Z8T7xrFRiiicZy9l0tsNLWuCHHnqINmgbrrjiilM2e+2119hn92Ht2rUM3i1UKu933333KdtMZGbv3r14+umnNZF1IqDpbTUCGgGNgEZAIzADCIifQYQ6GunnqKGP4dgJnyLupTI1eqkIRZDUmpVhoX0+QPVWH44f81DUwYjNmzJQXJKsxDzE9p3wOUy1iprIOlUE587+dKmA7lRUd8RQ08mhy4DijBjOX8pMhzSHMPHlrBcRUhHflPiYJIgtSF+VjyRWN0mrIrwiBFYX+wMDnBbRRCGw5mWZUJBrRj5VWHOzzXCSyGqi8Mp0PfOzDoI+oUZggSAghNZmKrMeIZH1OIf+aBBrrVlYSp9ImdkJSgcqddZzfbnPPPMM7r33XvrZreQUtKjA0ZF1km+okDSlPPzznyO/vg7tO3cge/Ua5G3ajPwLLlQCD888++z4j/Pww7j++uunLGYxlm1hQtfGOl133XUjL11Nt7a2KlzeteK0BWKP+NOf/qSJrKfhcvqsJrJqIuvpz8RJEkuYyjMRtoKETR+hEo0oscp8iAo1otTqGWAqZDr0XK5+qjvypSpjDm4u87gH+fIKM81sGjIyM5CVk01Ftxw1zs6myiPns6mkI0RXC51/umgENAKzi4BSaCZZTZRaQxwCVGsVUlu/i+nMW3rRxkHGouIqH/fS8lyUL81DxbIC5OSlUYU5RZHeZrfW+mzTjYA8B2LgiZCgqSKX/SRheiPo6g6ii9HLLS0+PhN8NrispDSZKfmSUVGRQnKrlQrc1mmrjiJYkowaFJVW/5CKmm5nOqCmZj6TjB6NkERaWGDF0iXJKC+zUW1VgiLeUSeVa5COu3TWvVRjlVQpnd3xlEKdXREGX0TZIQcy0i1UPWV6FA6i0ppNFVQhxkqUaaKcTmRN4ONlvaQuvS6mXeHQ6xIFWSGuMpqVBFFJt1JUaENhnhBXzUiloqyowEZIePXw/NU1Pl4PyeO8rqwsK0qKbSij4qzUw2iIURHGi127epXqamamFRs2pDMFA5XPnYy2Y+qj6TAmyO+9o92Fg3vq8NLze7BqbSkuu/Y85Bdm8nvNXJcsSomdqjOP/PQXOHzgELZefik2bN6IyqpKTVhMPCQLdJwgsTY1NpHEvA+HmYJbSKwFdO6WL6lA1apVfFYKkJmVRVJ7Mmxsw0lab01uXqAPxDm6LEn6nkhb3kMSa/OQF8fDNOBEB1BoTMZScyo2mDORb+IzyGjkd97e56jC+rTTisCTJIp+7nOfU8cUw8/p7xdRbC0qKmJASRgPPvigSit0//3347e//a0yZsn+IxXVpA17++23Q77tn/rUp/DNb35zwvUdYl84Njx8j6mMMph95O6PfzxOWuXHWc6hCKzT8aGecO1mf4feoSDqI268EGxWCqw32UpRaHIgzTh97cLZvyp9Ro2ARkAjML0I0NRChaYY2vuZ6aIX2F1PZST2d9eXAisLDVRnnZ0WjCgySR9575EQ9h4OqsDO4nwjLtnEQErn/Ai+GMvZdLY79/Wvfx0/+tGPzrb6lOV33XUXRMF9skUTWSeLnN5PI6AR0AhoBDQC04+A+AiE1CdCE2KTb2j0M+sLiavMpCaiFqUldpSX2pGVacIxElnb2nz0h0Sxfn06LriQ2cqszBt9BcoAAEAASURBVLhCYt90FE1knQ4U58Yx2hikVtcF7KiVjAvA2hJgOYPUJGDNSiVfyywn3BHSW4CkVRfJqu3iB+uKoq2Tviv6qkS4Jpnqqjl8xnPpB8tiEFsmRVQcVI+1Dwu9WMwxWFhvTWKdG8+XroVGQBAIUjzAx+F4xIVq2l6r6Q/JocDHxdZ8lFKZNcdANvo5Ltu3b8cdd9yhatHY2EihpFM5Xm63W2VFkw1+//vfo3gois5du9Cx621krVqNtX/xl7BQEHHHzp0TOo5kcJuqmMVYtoWJXpvUabLl+PHjeOyxxzSRdQwANZFVE1nHeETevVqIDlGSWoUt7iaZVV5KQl5197sVsdU94MYglbwCTMUo/jxx7MmLzEzVN4tZlFhlkFRWZqXulpycTJXHJDU4+PISda/kZIdSe7UxBaNsJy8XXTQCGoGZRSBMoroosnZ19KOzw4VOKrS6+gaZ/j3I3yHVIpOoqmyzIMVpV6S3jEwn0jIcJKs71Tqb/dQGy8zWVh99JhBQBGc63AbcEaa3F9JlAD1UaxUyq5kKrKLCKulHUkiuTEsTMqtFDULatNtNinA5HfVSCqdULm1tC5FUG1L1kc+AEE5FlVXOl5E+PDCK2m6LK63KuePE0yH0DCukitLrgDvKb9IQk1croVdVRUkVlJTE55pqOHJMIaKK0mxdzU4c3L8NF229i895MSNaSZCl8UvUWJlVXY2F+BsmuVbG/BwqwqqTjsACRnXnZFuUGqvs4+oPKwVWIbwKwVa2le9iHsmuJUV2pDEaPBKmQa3BS6NZgOThAErLHCgrTaIaK39faSRpTRMxRn7f7n4fdm4/joaaDgac+LDxguW48NJVJCTyGy25JlnaWlpx4tgJvPnaGwxSGcCt778NK1evYnqltGmrizqR/jMnEFDBSnwwRXm1o6ODKt2t6O7q5m++j+q9IXXPS8vLFZF1GdN8p/I5kCAkXTQCs4FAYIjfIio+Sury41RnZaJ3lUYny2BDgTkZxQaHUmt1UqFVl4WBwFtvvaWIp3I1b7zxBoNnKk65MAmilDRCUp5l5PbGjRsxMlpa9s/Pzz+5Ty+VpdetW6fIrb/+9a9x6aWXnlw3mYl/+Zd/QWZmJv7iL/5iMrvP630Y+qTaUftCvVQHcKFjyI8SElivtRUrlWSzQffX5/UN1pXXCGgEZgQBcXL3eWPY00h1FRJapT9anMn0o/xU5aUbkE5n8jR190atf2NbBDUNYVQ3RFSA55a1NhQXmKjMOsse91FreeaVYzmbzrwXlApKZ2fnGVd/9rOfZR+8AZ/5zGdw4403KlXWhGrMGXcYY6Emso4BkF6tEdAIaAQ0AhqBc4CACE+ICqVkRWsjibWZKq1eZnSTrqsIW4gAhc8bpm87RB9YkApyNlRWOlFenqwy1E2HsIQmsp6DGz/Np/QGY+jxGHCCSqy13RSE4TMlGRY2ljObINvzaWzPz3QRn11cbRVUW2UmK/YvZJAMhX7WL8DANRGpET+WeL8sphj9ZyZkpRs5mEhiNTK7UDwjg6ZazPTd0sfXCEwdgS7aXJuoznog3Asv/SF2ekSWmdOYsS5VZcZyUNzjXJWR2dSEqHo6mXMnCarve9/7lF/x8OHDsDILeO+RwzjxxG9gYZazJe+5CRnLK9FLn+SFF16oLmM8x0mnsMRUxSzGsi1M9NqkTpMtmsj6yrig00RWTWQd14My0Y2E7Opnatquzq44OaK9gypwHNo60MlxgjAhpNbU1FQqfOUjryAf+ZSbzue4gIpfskyUXJOTKJhN4qsuGgGNwOwj4HH70dNFJbQjLTh+uBnHDjVRNTOsSG8rVpegclUxqtaUIDcvQ5FaZ7+G+owzjUDAz87xYATHjw/i+AkPjh51U8k3RvKyEStWOFHFYclSEpozrIroOt2OOCGAdveEUF3tx5GjXjS1UBWcnfKKMjuqKh2M7kpWqqapzrM74XxUUxUyaWNzCHUNAdQ3htDaEWKKlagir6Y4jCTGmtih5zEiB+Fzb2co7c3w+PNoFCAJlqRUidjOooJrLomqknYlN0dIq/H5NBJr5RhSpG59JOHW1Pmx78AgWtqCDPyIYs1qB1avlCFFbSs4dZAofOSIG6+80qWUV9euTWN6wzQazGgNmeYiisuitPz4z19RKszX3LQJy6uKUFicdcqZdrzxFp57+lmS1q0oLCrE9TfdgKKS4lO20TMLB4EgO5IBttd2bH8LO97Yjr27d6tO5qo1q3HRpZdgywUXwMl2miavLpx7Ph+vJBJjMAGG8Ha4G7tD3TjBaORMow0XWfKwiunMl1Clla9UXRYAAoODg1i9erVSXL3kkkvwyCOPMNjEoYIaXS4X/vZv/1YRV9OY9UNII/JuEiXxVVSMliDLyy+/HI8//rjaPkKD2MepnPryyy8rFVeJqpYAyamUxUxkHaLjREKCngo0YCd/ixst2VjL318lDalWw9nbYFPBW++rEdAIaAQWAgISaOkOAEdaY3hmbwwSP1iRbcBFyw2oJKGVyTdmvAiRQ5zdv3/Fh5aOKEpIYl1TacV5VXNfTXssZ5OA97Of/Yzpg2uwdOlS3HPPPWPiec0117AffgQ//OEPlZNtzB3G2EATWccASK/WCGgENAIaAY3AOUZA2kIiOiHZ0vYf8uLYCR9aWwNYUkGV+lSjysLicdNGGogwyCWf9vl0ZhI1Trmdpoms5/jGT8Pp25hhYXd9DAeaY2jpA27eYMDmCoMis86GCqv0JUi3wAD9WK3MPNjYGkFT2xAaWije4hli1kIDCnPNKCsyo6KYWYzyjCpYTcRopttPNw1w6kNoBDQC40RABD06ma1uZ6QbzweaSGJ1Yj1tsWKPLWDWunNVpH8uNvva2lpldxdbuXDCpIgo0xe+8AVlzxfxieeee06JS3hayC159FfwUkjHlp6BsmuuQ/HWrRM+zlTFLMayLUzm2iZ7HzSRVRNZR312vva1rzG6qhIf1kTWUXGa7Eql6sdwNyGz+ulU9Hk5+PxMXS7qjn7Oexn95mPnIUg1ujCV7SLxMRXjxOkoy0QlTIrNZkMKlVpFBSyVTsvUNFGpi0+npaXClmRX20y2rno/jYBG4OwISCrygF+iUj1U6POiv8/LKFUvVZf9ankoGFakOFFrTUt3kJCeoYac/HT+bu1KwfXsR9dr5gMCSn00PIT+/hCHCFxUZ3W7w/B4InyHU2V0ONLTkcJUJbk2qo3akZ1tIzHTxHfz1IkNcn4/1VT7qW7a18eBdfCwk+4nwVYIpmGe3+GIk1Dzcq2sg5XEVvNwGqA4wnIMiVqVdEJuqrMOsO6Dg0PwkuAq+0s7W3XsaRjo7tqN9ubXUbny/fzuFHE5nY1mRqxSDTaZqrN2uyi5StQ2x5yXaZWyiHWUyG6J8O5z8RvGc1ppSHCmxBVkRalViLAZVLEVLNvb/STnenlNQaUMW1zMlNkkBAt2Kdxnuop8j3lZ2LezBof21lNp1428/AxcfMVq5OSlUV03HjYcCATQ29OL17e9hud+9wwuv/pKbLlwCyqWLiGR0Tld1dHHmQMICOlL1Hbr2dmsq6lFQ329kjI2DwcXZefmkMRcxKCiQj4juXz2rVMmf82By9ZVmMcICHlOSHRdQwG0R71oZkSypDd3x8JKCTKf6qyV5nTkG5MgEck01c7jq9VVF/LqAw88oIDIzs7GBSTU9/T0YBfTECX6hw8++CDuvPPOk2CJIeu+++5ThjPpJ27YsIGBN0chSmzSl3z++edPKrme3GkSE4uZyNrD319TZJAkVgaqcvpqWxGqLOlIN1j1b24Sz5LeRSOgEVg8CIjzOcQUt0x2g5ouA+q7407wMsYTLsk1oKoAVHKKTVt2kzMhK3WQFKPVjXFl1pqmiHJ0X3CeLZ5mNHnutp3GcjbJ9X7gAx/A66+/rhxhTzzxxJkgOGWZJrKeAoee0QhoBDQCGgGNwIJHQNpCYr8XwYpeZnHr6Qmjh0IUIt4h/gbJShckidXA8M3y8iSsqEzBurWpKhOdpF6fbNFE1skid273k+eFLlHUdokKqwHVHUNKeVVlVig0IT+NIi9030y3uqnYPiUj4KAvhn43Mw72R+kLi8I1MARfIKZIYiZjjJkFJXMiYKe/KiWZ2RMpsJKaYoTTwXlOS+ZB8xSe23OLvj67RkAjIAhE6Q/xxyJopS+kOuJGC/0hXkRQTkLrUiqzLuOQbDw3fpAf/OAH+Od//mf1TnrqqaewlaRU8UNv27YNH/vYxxT36zvf+Q4+8pGPqJvZ3NSEHz70kJq+m3330P69qLjxJvz3Y49N6DhTFbMYj21hotemLmoSfzSRVRNZR31sNJF1VHhmfKUi1vClNugZJKHHhd7uXpXKtrurh0QaDt3dJNv0YtDtgdFkgiPFodIap1GmOSMzndN0mmVwILk1hVLUSclJJFlYGCUn6ZHNbMSZmS7LrJRcLVxuNEn00eQ7HDMOiD6BRmAeISDpybu7SIKqaUdjbSca6jpIZowyPbkV+UWZKJCBvbrMLKciydm53GIlsdDG3yR/n/qnOI9u9mlVlXe3FCGVippofT0JRc1+EkUCvLeM9sy2Mg1PEsmstpOETIn+tMpgNal7P5X7L6cPkDwrhNpGRlC7aHg6fMyryKg2nqMwn88gh4I8K8mtJJsmxcm0IuptZQdfkjkmvgVivBJyq5BkvTRi+fwyHUX1sZ04cngbrrvhozRclcFBY4CQVi1UZJV9BYMoia+hYRKtOAQHSI7tpQGsrtFPw1eI0dtDSiV2+bJkFdkt9RLDhhBqxUBWXz9IEusgI7/9JNgYmUIhi+dyKCKwAnga/wQCIQaRBPDq/+7D/t21JOiKinIp1m6ooKpuXIFHrklIrIcPHMLut3dhz87d+OjdH8cV117J67bwezp1QvI0XpI+1AQRkPsrUZFBkpUliMjV10eV/HYcP3qMRNYaNDc2kbC8FFWrVmLjlk0oLi09qYA4wVPpzTUCM45AOEYDbiyEE5EBpdDqHaJKPN/NayyZqDA6kWtKQorBgiRJscNnP/HOn/GK6RNMGwJyzx599FFlyOrq6jrluJKy55vf/CbuuOMO9T0euVKUWL/85S/zPec9ubi4uBjf+MY3cMMNN5xcNpWJxUhklZZflKrI1VRCfjPUBR+Npskw4RpbMcpMKVOBU++rEdAIaAQWFQJRUQILA/ubgTeq+W7lfDoJrBcsNaI0y4BUTgtRYqYslzwd+9IxVDeE8OLrAQZpkkS7xILKCgsKqOJEs6nqr8+1myLtAklX2Nraiu9///v44Ac/+K4q3nXXXfjzn/+slNkfozNsrCLtggMHDuDHP/4xbr755rE2H3O9VmQdEyK9gUZAI6AR0AhoBOYUAmGKdgxS8KKm1o+a+gDq6kW0JUqy6xBt/mGIWMYVl2ejpNjOjKIimGFQvo+JXoQmsk4UsXO7Pc2IbBCTSOoHujxUYm2IobmXPiOSWkWF9aLlQDKfhelQYpVziVIwtb04cMx+gviZ/EH63sTX5BpCtyuKHg59JLJKxdKdBuTniOqqmSqsceVVIa5KO14XjYBGYGEiEKJN1kdC6/ZwJ/aEe0CGBYppj91EZdY8UzJSucRomF1ZDxExFIEJ6QdLWbduncqatmfPHiVWeOutt6rsJwk+gYhTvPe971XbPvHIIzC99SZKrroazsoV+NAnPjHu48gBpiJmMR4i60SvTV3UJP5oIqsmso762Ggi66jwzMpKRQai+qqosYbZSgsFQyo1pDDqQ4GgWiYKcd5BqrdycLvd7FwMwjPAMQmwHo8HHiG6kh0kBNasrCxkZnPIykR2TjbHMp9J4msGiUgORWqdlQvTJ9EILHAEwuxdhYIRKmIG4fcybTqHvl4P+no86CHBtbfHjf7eQaolUxkzJxWlFbkoKaPCX0k2nGlCOhdC40y5ZxY4+HPg8uTdLSqmMsi9/Nd//ZZSbHzPe/4Kx44NoLs7SGJnREWGZmZaUVqajJKSZOQX2NQyIbwmihCb33zzTeV0ErKKNHgvvvhipZgu6txnKkajCU8//Tu8/fbbaGtrQ2ZmplJru+aaW/D751zoHxC11SiXW2h0sqC4yI78PAtycqzq/IlHL2EsEFJqNDJEtT+DiszetWs7/vynl/ChD30CZSSyiiFAHIrG4ZyPYlAQomo7lVfbOoJUYA2SWBul2msEBUKizbchl+fKSDdTldZMMq1BnVcMZO3tAezbN0ASsJ/fsTBTIaejokKwsStV2elQsD0ds5bGbhzYU4e6E+38Zvpw1Y0bsGJVifotJgiqgnXNiWo88egTiJHwWLGkAudffAGWrViuvrH693o6qvNrPsr7K+2p+ro6HNp/kATWo4q4LO0lIa0uoepudm6uajulpqaqTqdJBR3o9/T8utOLo7aizhoWAw7JdH3RIJqGBlHPqOS2qE+lN1/ONOdVVGddbk4l1W52jTiL4w7M3lVKn1DS/kqqIiHjL1u2DFVVVfyuxpXEz1QTUWyVfRoaGpgKcC3Ky8vPtNmkly1GImuEijRiMN1BEuvvA43YbM1RQ6kxBU6SxnXRCGgENAIagfEhoPqf/DPgN4BJMrC3MYZGOsaT6Ayvygcd4wbYLTE6xmeuDS59X1F1qqEy6/G6EOpaIrj6IjvWr2J/1E7lJvPMnXt8KM3PrTSRdX7eN11rjYBGQCOgEVi8CEi7TGz1fmZrUxncmL2toyOMJgp2HGcGNTf9C9nMrlZV6WDGl1T6FqxIT5t4BjVNZJ1fz5g8FxGKn+xpBA40M6MC46QzqHK6scyAoowYskkkFV/RsJtoShcnCWkDFFnp6WP68F76jboi6OJ0L4mr4otx0KeUnmpARppJDakkrDqYRUFUWO3MAsgEarBZSGKl/kjC3zWlCumdNQIagTmJgPDrI/SF9DI7VuuQD/vDFAbktN1gwnmWLGyx5EByZVlIZp3NIpytj370oyqDWuK8ktnxyiuvxI9+9CPFGUgsF4JrIoD0//3yl4i89AcYKEJYddeHYC0pHfdxEsebrJjFeIJk5RwTubZEnSY61kRWTWQd9ZnRRNZR4ZkzK6ORqFLVcZO82t/fz9TmLpUOt7+vn2POcwiSADvEVp/dLmnMSZSibr49yU51SA6cl+Wi2KrGdHzKtKxLTk5W28ly2U7IsLpoBDQCE0dAyAWeAT9VlEnQa3OhvbUXnRxL9KoQHZNT7ExNnswhianaGSGU7mAkK8dpyUhyyG/WoomtE4d9Tuyxe/du3HLLLTTsZOO11/agrs5DcmkAXSSzBqlYKh17hyNO6HQ6LSqCOT3dipQUE4MP7PjMZ+5VEVSnX4ykBvyP//gPFb01cp0EM9x+++04dOjQyMVqWsgtjz32JF57M4runhCfPVGBZaffQVXvJHb0ObbZTSrtSjz9Cjv87OxbuE1iXhx3u3Zux6uvvoQ77vwYya8l6jpCNCqEhMDKawpSxcbnj8DHFC9eL8c0eImRQ/YtL7OjtMSuoraTeU4xIgSo8uqhMUzUV1tbA1Sw9Sl117Q0C9auSUNxCb9LSYyam+Z+RoTfz0GPH0f2N+KNVw8pdWRRTL5g60qlmJwgpwrpp721jQTHQ3jhmedRWl6KG295D5WVC1UgyLuA1gvmBQJCThYSWG93D7qYWruzowNdHZ0QwriPaoVCVC2vqMDyFZVYsbIKyQ6HagvNi4vTldQIDCMghpw2ptdpZGqd41SL7B8KKjJrnjEJhUYGCXCcQ4XWZKqzMoRG46YRmDICi5HI6omFmcJqAIcjLhyI9OFqayEusebDzl/VbBtJp3wD9QE0AhoBjcAcQEA5yEkoPdgSA2MN0eKKwUkS6YoCA8qygIJ0ZhNRgZQzU1nJSuIepIP+cAA79gextNSC5eVxZVZxkE93v3RmrmJuHVUTWefW/dC10QhoBDQCGgGNwEQQUG0zKmJ2M9taa1sQ9Q1+RWiVDHTpaRTpoL2/IN+uhCskc5vyNYifgT6FeAa4s59NE1nPjs1cWiP2RQn4olYPmvuA4+0x1UbPIXF1aa4B68vo4yJxlK7OSRUhx4p/yRegP0l8SvQnyXjQxzGzBErWBFkmY9F2SbIbkZlGxdVMI3IyTBybkEISq1VlDJxUFfROGgGNwDxHQMQ9vBQaOEjbbI0S9fAil76PJWYnKkzMUsdpm8h6zDKzvY/ZH4UnIFyrLVu2qPHZoPbTN+mqqUbjS39EP8crPvBB5G3agqScHCpRu8d9HDn+TItZyDkmcm2y/USKJrJqIuuoz4smso4Kz5xaKSQ5UQCMUWZ/iFEHMq+WcV6WS/rIgX6qAHZ2k0jXzXGXImp0tndSGbBHEV7FdZ3idCIvPx/5hfnIK8jjdB5y83LVOD0jgyQ7pybTzak7rysznxCQNBhxleUoO1tRRrRGSZrqR1N9J2pPtKGxrou/zQF27k0oXZJH8lQRllQWUg0wGxlZKeq3lyDWzafrXox1FRVsUfI8ceIEPv7xjyulNCGyHjx4iB3yiFI1lY55V1cQLS0+pubxornJi+6uEAqoPFpChdY1JHA+99y/q/QCguF1112Hiy66CIcPH8bvfvc7RWC955578K1vfUu972UbUW+VqC1RYpXIrnvvvRfr169XKQGF9CoN1/e///3453/5AVW844an5tYQGhv9aO+karBLVGJJak0xMprVjHQqpqammjhtQRojqtMY3ZpCI9ShQzuw/c1XsPWyD/I68xkwEYGLqjW9rjCPEVZqrBKxLUqvhQU0ZpG4WkS1WVFiNZmpoENyrDj/Eh0GUahtaPDi9df5PRoIo7g4mSpxacQgVW0r289E38I7GEBDbQf2vF2N118+iGtu2oSrbtigCK02+zuBG8FgEG9sew0H9h1AGwmtmy/Ygts/cAeMZCHLvdZlfiIgKTAk4GfXWzuwZ9du7N+7j894GpZXreA9Ph9VK1dC2j42u039tuT9q9/B8/NeL/ZaixFHUux4YiHUk9AqqpHtjE72DoWx1ZaP9eYspttxIIlkVl00AlNFYDESWYUs/nywmb+xMLKMdmxm6ipRPdZ6x1N9mvT+GgGNwGJHgF1ndLpjeLsOqOmMoa0fuHqVAZdQmVWIrdYZaroIWUOGhtYIDp0IoaYprAJQb77SgZICk3KQL/Z7M9Hr10TWiSKmt9cIaAQ0AhoBjcDcQkDaRuLfipJwGGbmtjb6FF7d1oPahgC6eyP0IViQnWVDSbGFgx1l9AdkZ1mVb2E0u74mss6t+3y22kR57wMhqrC2GPCHgzH6dWLIpRrqZVUGVGRT+ZTt8qm4SfzM7udyD6G1M4rmtiia2sJKhdXjHUK604jCPBOK880oyDWhIMeEVPqvLHTfmCj9Kuqvcu647f5sV6CXawQ0AosBAfGDRPjBamaGut2hHlRT2KOTWepusJVgI+21mUabEvmYq1jE6MOPMkP30V/9Ek0v/xG5Gzchf8v5yD//fFiYWXsxFU1k1UTWUZ93TWQdFZ55tVIUx4KBoCK0DnoGSWAaZFppDmraS9U8HwL+ADshTIw4TLYTQqwixpIUKxZcIWVZqeQqZNfUtFSmg3YqYmti3kGlMkljabbMkCV5XiGuK6sRGB0BIbQK2dw7yJTrfR709Xjg6h2Eq09+n36m5xhiKveoIr5a6Z0Rtdbs3DTk5KWpcYpTlJNto59Erz0nCAix8WMf+5gisTY2Np6sgxBZRSVV7rsUMfp4vVESN0OMWuJAAmi/K6RUTYUEevnlSbj00vOVYuTdd99NQuzfKzKp02nGr371U3z9619Xx5GUA/kMQJCybds2fPjDH1bkykcffRSXXXaZWi5/fvKTn+ArX/mKIuRJvSRy1e2Jop/EURfP7XZTFXWQjWSmbFHfAdlJHHgyEkuV/FejGFw9+6hguR2lFbcywrqQVoJ4ehaOYKDlwEx1HCGfppP4mpYgxLLeKTQwxImAQuqGOq8QeZuZkqij3U+SqxEZGRaUkshbWJiE3FzbjBkg/L6gUkZ+/ZVD/A0OKvLqhvOXYfV55cSIUXkilcsi38e+nl48/eTv0NLUjNXr1mLdhnUczlPr9Z/5g4D89sLsBPb29KCpoVENrS0tiIQj6jmzU40+Ly+PCsDFDCAoRVZOtlJglfaPLhqB+Y4AX7kIM/25KLI2kczaSuJdB404UXoT7KTbFVCdtYzRyWUktFq1iuR8v93ntP6Licgqv6sepqqqoRrrtlA7MmgMvdiSiyJTCgmtup1+Th9EfXKNgEZgQSAgfUYfA0Db+g0ksg5R+QmwU2UpMwVYV2JAcaYByZYh9n+lJzr9RVRZu3qj2HUwiM6eKCpKzFhWZsGKJRZFbJ3+My7cI2oi68K9t/rKNAIaAY2ARmDxISBtNMmu1kBl1upaL/0gXirF0bdMf4fY9YXUaqR/QHwEosiaxKxsyUkmNRYlzaThackU9/hjP6YvIopP3fPXqk2nmnVs2slYCLCSCVrEMGRa2nwy1mV2EQiEY+gdNKhsCS19MfR7SV6lCuuSHKCcJFYmlVT3azy1kmdHVFWFoNpP4mq/Zwh9FEgZpPqqn2qsUoScKvdZTPJ2G7MJUmk1jX6ltFSjIrCmOuLKqyY+X7poBDQCGoEzIeChMqsID1RH+pWwh4kvlSyDDWssGSik/yOD03O1iD++Y8dbauivr4ezpEQpsybl5MJMVdfFUjSRVRNZR33WNZF1VHgW1MooGU3eQS/6evuUUmt3VzeVIqkOSQlrGXdRwdVPMk+UJJCs7KyTQzZJHplqnuOsTHZQUkn6oPubqoBCBDKwlxEnBJnY+IwTg7R63YJ6dPTFTCMCQySvBgJhqrL2U521EzXHW9FY34V+5uswW0woKctFSTmHsmwSWtORRu+NkFzlNybr5bc1Uw6cabzMBX8oaWQWFRW96zpPJ7KevkGEkcyMOaABaBCNVCcNht7GZz5zHwmhFvz2tztRXy9KpXFyZz5T9WzatJZKqP348pe/TOXVv1Kd+09/+tN4/vnnce211+IXv/jFKadwM+3Al770JW5nwDe/+U0VjDByA+HXhpkiyOeLktQaUSRXNw1SA5z2kOSqpgci8DGFSzR0CIbYLj6DNyMntxgZ6RaSVqngKqqtouLqjCu3nikKVkiyQtT18zhNjT4cPDTACG4/n/0oLrwwCyuqnEqVVoiwM1XEYNLR1osTR1rwx2d38/vlxHtuuwD5RZlIF6/oiNLe1o7a6lo889TTCIfC+MSn78bS5UtJfD11uxG76Mk5hID8HmUQVd1gIECyeD8a2Pk7RHXdE8ePk8zchhWrVmLteeuU0q6o0kuAji4agYWOQDfJd80ktG4PdZLY6oXTYEGVJR3rLVlINzBwjfNWtuO1ouRCfxKm//oWC5FV3CtRBn4eirhwhMOJ8ABWWjPwPlsZyeD87Wjv2vQ/XPqIGgGNwKJGoM0Vw7F2A/Y1xcBENrh4ObCqyICidCpAKTWmmYFHAlB3HgzjSE0IroGoIrJedVGScqrrOP7xY66JrOPHSm+pEdAIaAQ0AhqB+YSA2PcPHR7AcZJZu5htLjOLJBuDSRFbxdchPgcnfQVOEhFTKXQhIh0yn0rxC0eyEa++8jAFlaK4+b1/qXxboi0RJ6xS9ZOERlHajI8NcfVNcRmo/nZM+TniWHFalDZEiWO4L57okitRDdqGZUwr8cl9hg8xPB8nUKpDqMPzWMP7JI4vW5x5n/h5R55H9kmcP7FTvH7vLJf16qzvVPnkPupYaq0c+5191Mws/iEEFNxhYJcHqO8G/nRMEASW5QEbyoyo5PjkdZ6hXrI/XUHDKr4i7GOgXygG9+AQekhe7eiOD+0ce31D6lgFOWalvFqUb0I+lVdzM03kHMRVV89wCr1II6AR0AiMikAbhTxqom68GeqAm9nqNlpysMKUhiUmp1JmtUi0xBwsgb4+9FefwIGf/Fi9aNd84lPIqKxEUg4jCBZJ0URWTWQd9VHXRNZR4VlQK4XkIYpkSrmVZI8AyR4hIX3ItD8+H2AKXp9PBi9JrRx7vVQT9CmCq49j2VaKIyUFGZkZitgq44zMzPg8x0L8caQ42CCNN8AXFIj6YjQCU0RAfodC8gv4Q/x9BaiY7CfBPAB3v49qrR4SsAaZBtuHAY6FuCoqrUWl2WooLs3hvFZpneItmLbde6j4mFBeffLJJxVxdCwi6xDvP/kQfK8ysIDD448/hO985ztKVfVDH/o+1UuDJJiGWUeqziSbsH37N/HCCy8o0up//edPef9tWEVCXh8buA8//DBuuOEGkpzN3M+l0qXLxUVEhvUsRQwLMgihNkJCq2waIuFUSKcyLcuE6Brh/LFjO3Fg/zZcd92HUVRcSrJtPLrayrGZg8XMMdVVz/Sql2vo7Ajg4EE3enqC6pglJUmKpCsE3fR0q4rKPtO+Z6n6hBbHVTmj2PbifhzeXw+73YqllYW44NKVVJe1wzIiP6X8Jl/f9hq2vfyqwrK0rAxXXncVlWIZ+aa9lhPC/VxtHKbFVNo0Qlo9dvgoaqqrVbslLS0d+QUFKCwqRG5+HrLZAZQ2i50RjWbJS6SLRmCBIxCIRcFcDOiK+tE+5ENjZBB9sSA8QyGsZGRypTkN5VSVdJLUqlvtC/xhmObLWyxE1jAbbUHDEJ7xN1KR1Y0VljRUmdKxmr8fI9tTur87zQ+WPpxGQCOw6BHwU5nVEzDgREcMtV1AlxvISI7h/KUks2ZQXWWG4gylj9zjiqKhJYK39gWUqtiKCjOWl1tQlKczUo33wdRE1vEipbfTCGgENAIaAY3A/EJA/Bhi76+lMqsMjU1++gooykJ7f3aOnYRVK33HFHAJRul/FrEB9qVD4nOg74Hjno7fkOw4hIzsDyjSq9jjpf0lBEhhTSZ8JsrRMLwurtKaILwmiK6JMUmPVPJUKeeHibByoJGk2Pi6EdufJMzGiZkjybMyPfJYcZJt4tzDx6UyKA+hzpEg4qrtFAl3+Dxq/chznm05Ka80Ksj+I48lT8VM+UvO9sR56fJ3USl1ew1Q1xVDOpVRS7OAlUzQl5VigHMUYUC5f+QnU3E1it7+IZXdQDId9PRFef+5kng4HfRx8pgpVFh1pnCa42S7AUkckqnca6Ngop2KvnIPZvvaz4aJXq4R0AjMLwT8VGZ1x8KoC7tRP+RBQ9SjlFlXWTKxzJyKfGapm4u+jyg5V77uLtQ+/Tu4GxtgpT+zaOulKLn8ivl1A6ZQW01k1UTWUR8fTWQdFZ5Ft1KRWkkGkRTLrj6XGvp6Od3LaRKlBlwDlP4PKHXIZIcDyY5kppHmONnBFOhJisAq08mctifZYSNZRNRbbWyNCnFE5i1Wi1If1Gl8F93jpS/4LAgIsVVSoPf1uNHc2I32lj6mN+9Wy8RBnp5BCfxMp1KRTON0apqDhHE7f29JSE6x8fdkZgqOuRlRdJZLXnCLf/3rX+Nv/uZvMBaR9fQLv//++6nE+luqrd6L2277PNraAmhvDzBtD5NDC+E58BQefPBBbNiwAV/76q+Qm+fHRRdtVof5wx/+gIceegivv/46uru7SQxNwubNm/HVr34Va9asOUmyPf2c451/88038eKLL+Luu+9GGcmdoxUxPiFmYFStGLUiaG/zo43X0dLso1HGgNwcG6pWOrGkwsFvgJHP68x2G/r7BqnG2ofXXjmItpZebL6wElVrSlG+NP+U34qfwRsD/QN46X9fxLaXtmHr5VuxYfNGLKtcrr5no12zXnduERDCtgTfiGJxb3ePUpVvbWmm+mq7InpL22TJsmVYuWoVKqtWsI2SrNof57bW+uwagXODgChK9tOYc4JpdoSMV0uDTibJq3nGJJSSyCrGnGyTHXaYMFcjlM8NcvqsZ0NgsRBZe4eCaKWq8Z8Y0d/P6ettJVhOMqsoGs9sS+ZsyOvlGgGNgEZgcSAgBNb67hh2NwA+qnwVUpF1WS6wNI9pR20x2BlYOd1F+t89riFs3xdUTngJ8ty4moGkyyxIokKUBHbqMjoCmsg6Oj56rUZAI6AR0AhoBOY7Ap2dATSRxHrw4ADtshFkZdmQR9GKHNr+LVaTIqb6qLopg2dQhDw47Y+iueHXSpE1p+CDJLAaSH6MMTOoCL7ERTfi03Fyq4iACLFV/GJCbIxnQomTIoVIKr4GtcxAIqhsI0RS2ZAlTobketlQiK1qfZyAKp140Wt91/6yXA2yn0zLeYfPz+PE18k54uvUodWxOC/b80zxY8bH8fl4nU6u50FOP7YiwcrGUieO49fEY6jzy7WolaouspXaXiaGt5V9EtMyllm1z/C01CmuOCs7JdbxXGraqDCm1gl6B4FWZkU40mZgQBmwptig1FjLcyhiMuzDUedSRzFQFIVEZSEpRwwIkKzqDzAQjffZ7Y0x6x8z/g3GMMj7L+5KUejNy6LqarYZedkmZKRRsZfLBAtdNAIaAY3AdCIwxHfpANVYGyIevBXugm8oAoeR2enM6VhKZdYsgx1JRrN6B07nead6rLB3EJ179qBz9y507d2D4ksvw7L33QYLM0qayala6EUTWTWRddRnXBNZR4Vn0a2Mq0UypXQ0Gh8iHDOkStKhR0kaCTGETpRZ3QMD6CXZtYfkEReVAXu749OiEhgMBNkpiTEteg4V0HKZkjqX5KvEIIpo2UhNT6XCAR2A77SAFx3W+oI1AiMRUL8x/s7C4WhcOZnj3m43ujr60VTfyc5+FweSFZNtitC6tLIAFcvySdQqgDMtWS0feTw9PbsITIbIKu+/6667joafg3jggQfw6U/fryJYQyF2+Bnh3E0l0507f4N//MdvUMm0GPff/yRWrhzArbdery6utLSUhqMmNS2qrAklVjmuqLVee+21UwJhQkRWvvP5+KKxwYfDRwZQXT2IwcEw1WPTsGxZCsrL+YwmSYqYuJVipt/9B/fW4/WXD9JQFiTxOxlX3bABJWU5NKixozLiu9PR3oEDe/dj3669qKutw10f+xDOv/gCFXhh1BaVKT0/M72zd3CQpO927N25Gwf27ceRQ4dQVFKM5Uy9sWbdWpSVlyMjK3M4oMZGA5moB4upTheNwOJDQLXv+fgHqdDaT4NOz1AAe0I9qGPKHboCVJqdi635yDclI82g1YoX3xMy8SteLETWg5E+vBHsQJhOrEyDDZdbC1DA34lpzpk9J34P9R4aAY2ARmAuIyBOdSaxQXNvDIdbgTeqY3SoG7CxzIDl+UCOc2ZqLwpifQND2HM4iFe2B7B+pRXrV1lRVsT0uA7tcR8LdU1kHQshvV4joBHQCGgENALzGwHJ8hYIUGG1O4jjJzzYu3eAZEcqd2bbsGlTBkpLRUiA5E/+GxLCqiKrxvDILx5S/uZPfvJ+2qHEEkVKqQhjsMhILLbxOZmPr0/sK2TX6DDxVYQ0ZH7kuvg0M83ROZFYp8iyw0TZxProiPXvkGiH68hTxteTXEuF0cRxZDtFrJUxzy31OHlu2edkXeJ1ihKf+LkTdUyM6TtR53hn/1PryO1kAxYhv4oIiAzCRVXjkctkmivUclGllW0T81R5lWnJomdU+wtx953jmckuFSVbIbxGeT2DwRjaB4xoZJs7P8OIfAaPFXDMpJBI4n1MnFu2l9oJLv0kqkp7uadfxvFpszmGVKcJuRkcMjmQvJqeSgVWtp9tPI74hGw0N5qZ4U+OqU306lbrPxoBjcA0IxDlm0qy03VH/NgX7sUb4Q5kU8ij3OzExZZcFJocc86mGyMfK8zs2K1vvI6DP/1vZFatRNm11yGL4+S8vGlGaO4dThNZXxnXTTFQlSveShjX5gtnI01kXTj3cjauRNI1h5jC1+/zk2jlxqDbo8YeGQ9w3jPIaDsfyawBNpAlskoa2zImgUTNixKfCVaqtIp6YIozhWmeRV3ynbEz1XmSeDIb16TPoRGYiwhIh93HvB79rkF0dw6gp4sDx356c8LhCH9H8lsyKjVWIbKmZzqQmZXKIYXT8huyqPVz8doWYp0mQ2SVd+HKlSuVeuS3v/1tfPKTn1TQyL0P0iAkUcvPPvsovvjFLzKqOQf/8R+v0BByDHfd9f6TEIoK7KWXfoTLLXzPtuDzn79PkVszMzOxY8cO9X49ufHwxFNPPYWjR4+evvhd8yUlJairqzurIqvYlMRw43KRdNsdV5Lt6wvBw8hbMw0TqWkWLFniQAGjsiU6ezYMFKJsLOTv/btr8dZrR5UKa9XqUlStLmEARfLJa5RvmSiQSxr6559+DiZa3PILC6jIeimWLl+qCY8nkZo7ExJgE2b7o6uzC60tLWhtblbToqor66StUVxagtLyMpRVlPNdmKUIyZq8Onfuoa7J3EBAyKxi0Klhqp0mptnpIqk1SsM46d4opDJrMQ06RWaqv5PQKmQ9+aeLRuB0BBY6kTXE34kHEbwd7MKfIx1YY8rAKksGlpvTkAKdYvr050HPawQ0AhqBmUBAiAGDTHXa2BPD/iYohSg5z4oCoCInrtI63cqs0scVlanapgh2Hghwmk58pj3dstaG4gKzSoM6G/3amcBzNo6piayzgbI+h0ZAI6AR0AhoBM4tAkJm9FONtbMzSGGIQfo2Qkp1VUQsUlLMSKNPwOk0IzXVouYdDjN+9rMfKqLo5z73OVY+rnY61lXQ7aAEkxRxVKbVfHwsiq1CMFX+CS4XkZjEtPhWZFpIpzKWeamzTMePObxM1nF5/PiJbWVeBpJih9cnjqG2VceL76OOx43Udmrb+LQQUt85F6dpV5NzqHqcfs4R9VLXoECJ03pH2rRV+5P7Jsop7dERK9U+artTMZZNErvL2Bc0YMDHbARUYw1G4tdTkG5AltOAZAuVbIXoyrpRa4djoxqraRoQRY01QAKs3z9ENVYhNtMXRHKstJlTSVwVxVWnA2w3x0msYleMMThYKiD1kDqSKjA8LaTaxLI4cVcIuLIdq6DqIUTc+LSIVMi2cm3xdSO3keMKiVdtw31OTnPbeDbLd/aL7z98fHUsmY4f/9RjyrmH66OIwfF6S505pc6VuCd6rBHQCMwNBESZNcQXdgP9HkeZna4z6kOI741iowMVzEwntl27wUzrLn/8c6QM0b/pOn4Mdc89i2C/C0Y62Jfe8l5krzsPJgud7fLSWqBFE1lfGded1UTWD394XEDpjTQCYyEQIInVO+glwaST6aXb0dXeiU4O7VS+6+zoQF+vSxFdHUz7K6qteYwoUOqtSrU1j6ko8kjEy2BnxzncUI0TYVVDUhqHbElqZbWx7oJev9AQSHTAJV16S2MP/j97bx5lx1Hfj37uPvu+L9KMRvsueZEs2QYMNosBQwBDnBwSwnsQwiPvj5x3spzjE4dftnNCyDkJScjjhUB+IRBjgsEYiMEL3lfZsuTRvs1o9n3uvTN3v+/zqb49M1qsbUbSLFVSTS1dXV396b7d1VWf+nyPHjyNY4d7cPxoDwoKglQ+LkPrqnqsoF/ext9QeREJ4+yMkSw5/ZtZbKjMn/O5EiKrPq53795tyKL3338/vvCFL5xzQl/96lfxla98BWvXriWp9TGucn4Fn/jEx0y5T37ykySq/h9G+bSsLICGhgIsX36UxNPfMtsffPD7uPHGnXxezvgQ5/Pz6aefxsmTJ8451tkZeTRbIMLrZz7zGda7fGqzO0iTTGphQxZHj4Vx+FAYb701zkEBDxrq83HjTRVsczGVt50VwFM7X8WIBoRE+H7jlaM41H4ax4/04KOf2o2dt6/nal+feZ+4h0+RDC4F8eeffg7/8W//jl237cbH7/sECbdV0LvJuvmBgPPc44p1qsOrbyE1+PZ9+/Hqyy/jYPsB09fYuGUTbrjpJtx8y06Sp0uoTj1NWJ4fZ2FbYRGYvwhESdQ7nBzD68lBvJwcQLU3z6iz3hCsNiuV87JcMOOx2pPz9wpev5YtdiLreDZJU1TjeIm/i1fpP5nfxpX7tQjZ38P1u+nskS0CFoEli4BMlo5zsv1XB7N47nAWzRUOmXVHmxdaqxjgxPlcu4gm9odT+OXzMRw+mcB7duVjwyqazqW6FIdYFvM80qygtETWWcFnd7YIWAQsAhYBi8CCQsAleB49GkF7exh7945S9CjF8fWgEbaorQ2hviGfYgNBPPzDb5LImTYW6XSSIkq6zEbO+Jq4IWGK9mkIO2Q95khGSrp5CnVcU0QlctweJ9/Z183j5gXn3HmXVIrj4STEOqRaqc0yTm+UaQ25lHGRaBk3ZRl3y0s1142TG+Xsk9uuuZwYF2p1D1OJdSSL/vEsyvKzaKnMIqg5JOKv+tT/pl6I8dGYBxMJDxd4eZDKeFguQ3XVLEK+DPyeNBfBUwORDRfR11G1Zbmp9rItJl+EWF44XVY6oyLLPrUTOgRUqbVKLZbaPY6ibC5U2qdtvNaO0myuDDcoX31zzX+pLqM4a+JOWeU525hmXIRWHUPltJ+zr1OHoxbLfB7ItItrmHVMt43O/m4bdNc6J+PemzovJ67TdO9jZs64X6fLOPvq79T+plzuhp65vykzBZ0YEk6lqoxuav+pOMvyerhtccror3UWgaWFgAitST6YfpWgVUeqs45k4mijMuudoSZU+fJRaIQK+Fsxv6nrj02Cc59jp07i2I8exqnHf4mt/9eX0PKeuxAoKiKxdfGKKlgiqyWyXvDXZxVZLwiP3XgFCBjVtGTSkFUnqNw6SYXWWCxuQqVjVE9TKNVWKeIZz3hskmoHVFtTWp07P1cZlJWX0pfTl6GsjF4hfWlZKRVdC1hm8T68rwB6u8siR0AfIJMTXOEajWFsNIrx0QmqX06YeCQ8SUVk/Y4S/B0lueK1AJU1pahvrKDSZDlq6sqRly+VVn6hWTfnCFwJkVWN+OhHP2qUU7/4xS8a5dWzGyaC67/+67/i1ltvxXe+8z10dZ3Grl07TbFvfevbJPxvRzQqkh/9ZBrrNxTg7rtvMM/R//W//pwroO/is5PPUvry8pAJi2nmJcDZvosN6jz//PN47LHHpoisGkjRIEg4nER39yQ6OyfR2xujQnCW9XHFLVdZV1eHUFOTh6qqoFl97ZBo3Q/ws89u7tJasTw6EsUREryfemwvCgrzqMbabJRYG5urDJl75se7VMSfeeppo8g6PDSMHbt34l3vucMoeNr3ytxdl9nWJPKqlN4PHzyIY0eO4uTxExyIyfBZls/7rIaLYGpQW1/HBTF1qKquInE6yAEs2y+YLe52/6WDgAZzwqCqNlVZu1NR9GYmMMi4xm8qSWpd5ytDIxVaa2iCxzqLwEwEFjORVWaoTqUjeCzWyV9HFuXeIHYEa7HCy0WW7Dxd/V7NTKRt3CJgEbAIWARcNajTw8DxAaql9lM5ihPwzZXA6jpgfQOfzXw4Gz7EHMGV5AS+1FjfPJjAgWMcp+RkflOdH7u25xmVKTsUeX6gLZH1/LjYXIuARcAiYBGwCCxWBDRfEB5PYniEVrQGEhyfT5h5inic1tA4X6E+lIiVAwM/MmO6ZWX3GGKgVDcDAS8JhSIGOnGT9jOPaTfPiTt5mn9wyjjbRWp0027oVxmRF+lnzgUsFPyFp5xRcGWYJflTNCsTcmM2S3VXhhqZMLxQbVe+0spw9yV5VCmzjfsoFCm2Ywg43JtBx6BzjNV1nNMJphFEBiOjGV5HmuQeTiMaIwGM/eESziOVypdwAVkJVXapthoixj5vFj6prHI/ETo1TsJDmDYId5FajWou89z2OefCNNuZa+rUPmqsyivkf9NWBlPnpE1yzjEU6ryn89y0U4daxDLCJhe62Ag/N88N9SGhupw6FBdWyjD/p9pitk/hKgKpCLQuUdYhv+p7xCXVmnkx3YvMFAnWnSebud0QbbmPCXNlDHGWlUuJ1uTnQhFs3X2NSq3ymWfIuTPLmjyW5W+L0Vwdzr66Nmq3dRaBpYCA+Y3zh9xDRdbOdBSH0ySKkswqguuWQCU2+MtpkS5oRAvmAx5pcqNS5FOd+J+f4eT//BwVFLeq3rIVDTt3IUR+1GJ1lsj6xCVdWqvIahVZL+lGsYVmj4CIrnESW8e4umBocAhDA4MYGsqFTA/2Dxjiq8h4xSXFVFgrNuqsIq8WUaW1pKSE+UUmHqJiYICEV5FXgiF6hibNuJ9kFkvam/31sjXMXwT0QSUzJwN9Y+jpGkLniQGc7hxEX9cwP1S8JHwXoqq2lGqtpaisLjGm1QtJ8MsvCJEIxg5anoitMplhv15me5WvlMgqAusPf/hDo8z60EMPmQ9lty1Snv61X/s1iFD6O7/zO/jzP/9zEknTaG5uNkUefPBB7Nixi4qsaWPCZ6A/hmXLC/Gud20h2TSMv/zLv+JzdpchmJZwoMEx6ROkiqsPoZAGgKR27XxcK+5jYuYH8p49L+GZZx7HPff8BgmqjRx0ghmIGufgVB8JrL00HzQ4GDfk2IYGEkfXlFBRO8+k3XO4FqFIrHHOZB56qxMH9nfgwL4OrNnQjPffcxMKivJITg2e0Qwtruju6sYPH/xvDq6NYsPmjdh6wzas27DujHI2ce0R0IBQmjfaJBe2jI+PYZh9gv6+fhw7ehSnOzoxODBAUn4t1qxbi01bNmN5S4tRYNX73jqLgEXgyhFIcYQ5yWEcmds5SC/TO+oZLPMVo4UrlZtpeqeUZD4uIaPaAt8VV34ou+ciQWCxElk1mDnMQU39Fn4e7zT3/jtCDaj3FaCMg5vWWQQsAhYBi8D1QyDByXSu3cXzR2DIrAkusmyr8WDrMppBLQJKuO5GfZS5HN7o6U/jxOkUXtob41ijBzu3hLCswY9qKrPa/tC594Ilsp6Lic2xCFgELAIWAYvAUkBA81Sy3hYOpzjXmzBzBoMktg4NJzBCcmsk8hPOe0gp9P2GWKc5CJH7zJyEIbOK1Mo0ya0i74mYqnkLl8iqPJfg6ihpOvuqnNnG7VLnNORWo9LppKeJhk65c4iBUuicSQJkPepLLqb5MpE0J0kopi4O2ruy2NfB+cSxLPL9WdzU4kER1VUT8TRGqc46MkZC63jazAN5SVatrfKhrsqPumofaip8qCjLXZsr7AirLbpXpM4qwZQsFV5FsE1xfkehFF2NiqzmPaXqyrwMy6QZUXnH5+rIpU0Z1qttRrU2V7f2E4lapFqzLVfGPbaOY47htuks9Vqp3ZrjqS2mHTp+ri7mcTdDFNU9xtuI95FLNGWCW0WmFpF0Kl/llJcrp1D3mjM/5+w7c5tzX2rulqRhs4/Ks97c/i6B1UlP7z9VXkTWGccycXNv8/7WsdV+hnI6lpz5jlKbzI+Ax2JoolPh9LfW9L6qi2TmXJ1nh2CbzzmWewweU8fWMfg3FypunUVgbhGI0CrdgcQwDqRHzZhvK8UK1gfKOfdRhEpPCAXegLlP5/aoV1Zb36uvoOu5ZxE+3Ym8igqs/ti9KCYnwE9xn8XoLJH1iUu6rJbIaomsl3Sj2EKzR8BZ0aSOZxpJklXT6ZRRkEyRvKJ0KpU0JJZoJEqlyVGMDI8Y0qsJmR4bGaM54YhpiIiuVdXVqKqpJtHKCWtqq0naqzLk14JCa2J49lfM1jCfEdDvKZngbycpRc4EFVvjVDwmwZDk1t6eEfR2D5PoOorIeIyk8Hw0La/G8hW1aG6poVprJYl+IefDZD6f5AJo25USWR955BF8/vOfNyT8F198EXV1lJTJORH8N2/ebMitqv+2227jh50XN9GMemdnJ770pS/hj/7oj/kMzfC5qcGiLPbvfxUf+9ivmRp+8IMfMr8No6NJDhjFTajBpGg0ZQZ18vJ8VLb2oqDAj/w8LwmBfifOPBFdO069jkOHn0Nb2wdJLqzi/gljHkgf4RUVQTTSNFADfWVOfVV1BWmDRgNG19LFYlztPRTBo//9IrpI5F67cRnWb15uyKx+jmzp43mmO3HsOAmvB/DU40+imKbo773vXjSnwoJTAABAAElEQVQ2N6GIJhqsu74IqF8Q4fu948RJvLFnDw62HzAE1uZly9Da1obV69agpraWJqn47CrIN8qs+k0spsHF63sF7NGXKgIafNUQ7CTNgY2nE+imMusJklnfSo3QRBif+d4QbgpUY6WPi8lIaPXPm6GdpXrFrv95L1Yia4ymDt9IDuJQagxdXK2/OVCBdwUbEPKSxG3v++t/49kWWAQsAksaAc4XG9OkmoQ/MZjFK8eBSDyLPBJMb1sjZVYgSOLCWZ9/s8JMKmKa0H91fxxdfRxz4fFu3sx+0eagmfidy2PNqqHzZGdLZJ0nF8I2wyJgEbAIWAQsAtcBAZEURRwUoVWCGAqdeAYPPfSvZj744x//PxmqHJVaTTmHACvCoBRA3fIK3XJuPUnWzalklhHRUkqv7r65Y5k8EiIZijAY0nxHvuY/fGbOI49pzYOcHTp5HhTk+ymW5OF2MgDpFsN4s66JxvxO0qrBS0ezONmTwuBwBoXeNPycU4pxnoiG+5DP866q8KOyzIsq+vJSL9VYvcgLirhKLKXCynKKz7b/67TJaZiJq4GmlTllVJPkKKWKOMVMxI0b2iQTZjeN0+Ti2q5MbTFlz0o721RcG7Sf+W/SJku7Ky+XcOLTae2jbaZaQ2RlmqEhyZ5FlhXxVXN2UoA1ZFiRbJXH8s42l5TrNMJ854iY69aj8tykOhwSreIuoZa/L7e+qTxu4+/KJQmfsQ/LmH1ZnwijIo66BHL9TqZI44xPk8Ud0q0Ukw1B3GwTGdwhl2s/xc3+EsjJ7TsdOtvM9pzyso4bUFlDNJ/e1+ujtcdcHQ6hVTeAdRaBuUVA1rcmOebbwzmPIxLySI5iKBvHzZzv2MCx32XeIgS1wmIeuPjICMKdHWj/39/GxOAg1tz7SVRt2ozipuZ50Lq5b4Ilsj5xSaBaIqslsl7SjWILXRsEkskkSXlUZKNq69jYuCG0jo+Ok0g1avJkFjqRSJjG+Hz8wAgG2OFyvF8h06FQiMSsfJqYLuRHSD4KiwqNcpvIrYrn5dRcRYKxziKwWBDQx0oqxRWUwxEM9I+hn2RWKbYOD46bDxl9pARDAeQXhqjMSbN4pVSYqigy6q2l5fytUK1V2627PAQuhcj6zW9+E0epLNlGQt5nP/tZcwA9x9avX0/y8QTe8Y534Hvf+54hq4rY/+lPfxqPP/44Ghsb8cILL/BD0lGd/O53v4s/+IM/MM84qbLecsst/BhN8/pm8Fu/9Vv45S9/iZaWFvziF0/xmUlS0njKkFjHxhJmVXQkkjL3ggZjtLJWKyul4KtHoT4u3ZWagwP70NP7EhVg7+YztoYDRfpY5mpdDv5UV4dQV5+P+vo8o/DqDvBcHmqzK20GDvgBfuJoj1FjPdx+2pzHbe/ehOWtNaioKjnjAMJIuD7z5NN45cVXuC2LlatX4a4PvNeof9t3wRlwXbNESu97ms3o7+ujsnQ3erq7jRKr3vcZjVjy/mxdsQIrVrYZX0xVdqmvW2cRsAhcHQTSHJQNU59VJD6R+QYzk5jgQE851Sirfflo9BagjuqU1d48DuHqn3VLEYHFSGSN8z4f5iDmE7Eu9PK+X+YvwjpfGTZyQNM6i4BFwCJgEZg/CGhSdzAMHOjmZDwJrV0jQEs1vxmqgBU1QHmBh4TWuWuvyKunulM4cjKJ/YeTaG32Y+OqAJrq/DS1ascTZyJtiawz0bBxi4BFwCJgEbAIWARcBP7xH//RzF/8/u//viHVOUTUabKqCLCGBJsjq5o0RTucPBHxHJKsSefyVYcIehL3cOvTdpXVHIaxPEfWpVGoNHMf7ryHG4rUp7jmRBzlS6VF5hO5z/FMc74kEPQx7eZPh0YB1pR1iH+uSqV73tcjFMmRWlEIT3BBVjiDwdEsTvSm0d6ZwWQswwXrQENZFqV5DsmSxk1RXOhFZTkVV0sd1dWSIh8K84Xd9TiDhXFMEV11n8kbsipJqA5x1SWfilyq7Q4J1SWxSp/UIaXmCKbc31WNFZHVrc8pd5l18Xhql1P/jLpIqFW92ibnCL84SqlGQZXXWXNtun/NJecfXXtHmZVx7WP+KHTvC2deURu1ydz72pYr65Yz+ykvV0ZU4Kk8Zs48hgR0tE0KtArPSTNfc3qawzTbmVaWaXeuvJs2eZr75A9cirH6nTv7TFupVBudfaV6y3Is45Rz6nXKO3OmirvnxEZYt0ARiGSTGEjHsD81jKOpcQoXUG3ak49V/hI0+gpRSTEP5y6+fieYkegfLa4eeuhBDLW/hfyqatTddDOW3fFu3qO6TxfXGIQlsloi6wV/bQ888ABWr16N+yyR9YI42Y3XDwF3BZTbAqXTJOpFImEM9g+S9NJjfF9PrzEX3cuw53Q3V/CluLrHh/qG+mnfSNOQTNfR19TVoKiwiOYq5nCE222kDS0C8wAB97ejD/jJiQROnxrA0YOncfjAaZw83kd14wjNzhdg1bom+ka0rWlEQ1MlSX35plM+D05hwTThUois9957L5599lns3r0b3//+96fOTaqsX/jCF/gxmUFpaSm2bduGAwcOoI/EPhHyf/rTn2Ldummz97qu7373u3Hw4EHzIbZr1y6Ul5fjjTfeMEqt+jj7zne+Y4ixOoj7gerEnQ/kWCxNZVbHRyJJEmkzfKYq1LOVxEIOaoTH38Lo2KtYu+7DaG1ZblRYKypEgNbiAX0sOh+MUydyjSPuQMETP38dj/3kVbS01WHN+mbctGs1ysrPVVcVaXgiOoFv/3/fwrNPPYOP//onsHP3Tt7zjWYhxDVuvj1cDoFoNIpRrjJ88bnn8fILL+IQVViDvO+333QjdtyyE9tuvMEsQhF5VfecdRYBi8C1QUBjm1qtfJRk1r3JYbyaHIAGezaR1LfVV4EbgtUIcIRPw4HWLT0EFiORdTgTR0c6gh/HToIW6PDr+SvR7OUiL4/9Vlx6d7g9Y4uARWC+I6B+iiaF20lmff5IFh1DUmMFPrjVg1W1HhTT6t5c9lD0TS0i6y+fn4RUWkuKvHjnjny0LbPviJn3iiWyzkTDxi0CFgGLgEXAImARcBGYSWR1884XuvNZl9qTmy4/XZvmDBKJjLFKJ8t0mu+IRugVMu3MiTCk2IeZCzF5jhU7zYmIBCghD82BFJHQWVwUoFiSz4kXBzin7KdQkrb5uW06Lgt3IsFe7/FrLcKKksR6vCuFw6dSeJ0LsXoHaB2V80HVZT401viwvNGHlqYAltX7qL5K1do8Ie70nu3w+/S9NJexc+/VuftaOafuGVW7UX3PiOTtkm4d9WNXBZlzhhwIc/POVjsm1cJRTJ4imms/isaINE1CueMdZWQ3bRSUDQE9l0/CeSJHNJdgjgjoidy+SqtdIpIGcoqtIokbUjnTrlKsG6qM4kYBVgTzGWVd1VgR0d3yJjRqsrk6tY37GcVZkmK13alT26k66+7LbU6+q2LrEN/n8r6wdV17BESm1hjwqVQEP413YCSbwGp/qbFGtzVQaZ6E7vPw2rfOOWKG4j9DB9rR8+ILOP7oT9C4aze2fen/hpdzpN6c4NX1attcH9cSWS2R9YL3lCWyXhAeu3GeIiDCl1Rb47EYSVdRfnRESdSb4EdI1BCVTHqSA8xUeZMCXypJz2VoiUTSkGDT6nmxByeyjMxJl5aV0JcZEllpeSnJfSVUqiyl2eI8dlzswPQ8vQ1ssy4RAbOKz5C/YxijUuvIcJgqxxOGyDoRjSMRT3I1ZsKsEAyGqCpSVoia+nKSvcuMLyzKo4KxVUC8ENwPPfQQtKK4qqoK+/fvN6TUs8t/6lOfwtNPP20IplJVnemkxHr//febZ5ib39TUhC9/+ct43/ve52ZNhVJw/eM//uMzCLHaWEuz61//+texY8eOqbIzI+5H7fRHac70Ts6Uj/uRqu2HDr2KvXufxvvf/+toIZFVqquhkLP6WIu+rvegzODAOA63d+Lg/k6aou/DztvXY8OWFpqeL6PpoHNVhU/SXP1rL7+Ko4eOUJk2gg995ENYv2mDUei2aqwz75KrH49GIhgeGsaxI0fQcfIUOk518F3rM+/k8opyVFXXoIELT7TopKq62ryHfRqFsM4iYBG4pgiIJDKWSWCA6pSnqdDaS/M7GtwReTWPGg5rOMjT4itGOVcr53nsb/SaXpzrfLDFRGTVfa7+0WvJQexJDYK69ain6vCtgXpUeIPw8463ziJgEbAIWATmHwKajB2OAj1jWRzqAbpHpKTjwfKqLLYv94Drc1FIM6lz5UbGMzhFQkD70QQ6e9LYtCaANa1BKrPyO5kLPa0DLJHV3gUWAYuARcAiYBGwCJwPgUslsp5v38vN0/e9SHFJkeMMYU5zyVJ8BeeHZbHNIe+9/fyIQ2ZVX9MV0pDZdkdR01HgNPk8hhZWmXIsK+VXEepCnEMRETZIYmuePNMKlS+yq0kzLqEQxa9ULETHnYxlMR7NYGSUnn3V4bEMxg1pl2qsk8B4zIM42y7Nj9UNVFstBkq5IEuLsooVUok1KEKfnQK/3NtsQZbXfeve107o3NciS0g9Vnkz73MpzJq55dw25/egU1c+fyfu/W9+C/w9zPjNuPWbek1597fj/GZchVrTJtZj6uZO2o88Q/5XhN9Yipu0E+roJm0Kms3mj373Tr5KqMzZaRVzKjLlTBlT1JTVJrWBP0hTj9Lm8Arpp9rDmMjeUnHWHCkDo+qquNRd5R2rl6YqU2ZmnmMd0y3r1GNUo7Uv6z2jrPJIpnXyp/dxjjOdnmll0+yv/Ux7pstc6XPGQWjx/Y3RKtc45zyOZsZxiqIGskxXRmt0zVRlXUvrXI3+Qs58XD/5jix/X3GK//S/uRdHf/AQQuQv1e/ciapNm1GyvGVRXRBLZH3ikq6nZ3JyUo+jJecskXXJXfIlc8JS3ouQLDPQ14/+/n6j3trPuFRcBwcGSOQbM52CQhJZy8rLjK+orKSZ9TIqD5ZDZJqCwkJ+TOQb1dYAe/P+QMAQaqTiGvAHcua42SOwziKwwBBI8ysjGo6ht2cYp4710Tx7L7o6BxGbjPOeD6KuqQL1jfKVxkS7VFpDoQA/wP0Mg6aj7pigWGAnPo+bm+aSyPb2dpw8eRKbNm0iebTloq0dHh7Gvn37zLNu7dq1Zp+5Ivw9//zzeOyxx/CZz3wGy5cvv2hbrlUBfVDGSbw+drgHzzz+Ju/ZBFWEC3D7nZuxam2jGfyZ2RZ9VGtRw55XXsOPHnqYxMgqtLatwC237kLTsqaZRW38KiFgBjZ4f8cmY1zpHsVA/wC6O0+jnaRvkVj7qT68dsN6bNqyGZu2bqFyegOfQzRbrlEB6ywCFoHrjoA+kqMZKjhkJ/FqYsAM8PST3LreX25WLDd5C1Dpy0c+yawcgr+OwzzXHaol04DFRGRNcPBygvrDTyS68UKijyvwq7DRX4FWkrTzrRrrkrmn7YlaBCwCCxcBzTce7s3iQDewt4OT8wXA9hZgWQVQVyqlVk4mzsGwnb5DuT4YL70Rx4tvxFBW4kMzVay2bwgx7pAAFi6Kc9NyS2SdGxxtLRYBi4BFwCJgEVhsCFxLIutssBMxVfNmk5NpCidxrIDhRE7VVXGpuU5MOEquUnNVXOWiDNVXFInMIap6UVDgN4TWvDwvQz/znTA/X2RWbmdekIuuJO4gRUhDisuR4wwZTQQ29mEdAhqJg4aY580pY4qUS9JqNIuxcAYDw2kMjmTQO5jGAEmtw2GSall/QbEUWL3Y0OrHznV+cArFKEzOBiO7r0XgaiAg4ql+fyKaG9VYkcfppewqIrmj8MptKkM11xQjrsKs9tG+IqdrXynFisSubzft6yjHkswuwq1bp8rrWKacE7r7OmWYx2M4dakOtoP7SKlTyrFaQOkSVs8Jc0RS5WsO/Yyy3FfkVLON5Hcff+RO2iXF5giyud+/81zIPR+YcOqkQqzqYN0eL587ufh0WWfbdFrkW9XhzLVpyk1pkXOV4zxjpq+qs905VxVQWs4EJs3jKmSe5gzcuOpxCqlep4w2TmWbI7rlnXynDbkyqlDlGahmtz4nW395NAYqoTpn6zKsL84x4ePpMJ5O9GCUxFZVezOt0K32lVLcIA8hznT45uJgV9jYsZMncIKKrJHuLmRocXTFh+5B/Y6d8JKr5NEFXgTOElmfuKSraIms9913SUDZQhaBhYKASGFSY03EE+zUT/t4jAqUTEvNVcqtESrzjY+P04x2mJ5hOIwI4yLBypRxQWEBiXyVqKYqXCXDSpKgTEjSa3FpiTFJbdX8FspdYdvpIqAPgxR78okY1VhJBJyciPP3EKNaKxVbh8Ike49jaGCM8YhRt5Sp9ubl1WhurSH5rxpFxXk09x1yq7PhIkRgvhJZ41QQFvn6rb0n8crzh7B2YzN2v3OjUREW4fpsJ/XazlOdeOXFl/HzR36K97zvTtxx13tIaK00ixXOLm/Tc4+AiMRjY2M4fPAg9u99E6eojqv3r1RXm0mSbmltNe9WLSApKi42JNa5ImTP/dnYGi0CSxOBNAd3YpkUxrIktFKZVQqtpzJUV07HUOvNxyqqs24hAbCIxD+rzrr475HFRGQVKftgahQH6HvTE3hvqAkbAxUo4L18/dbeL/57yJ6hRcAiYBGYSwSicQ8GOIl/pBc4PgCcGgS2tQBbl3nQUOahMqum2GbnpNwj10eCQEd3Gi+/GTMTmzu35qGF5lnrqq2UlSWyOveI/WsRsAhYBCwCFgGLwJkILBQiq6PimFObFAGOJDr1AR1inebTHFVJ5StPipVuXCS6JMmlCZLsYpRBjccZV5phPOak40wrP87tpjzL5kuxlcTWwqIACa9eWhB1CLBFhSSiFmobhWXoqT+D8EQWgySqDo5m0T+UNm0Ql6mcC6wKqa7qpUn0rnEP9nV7sKzaSxVWD9Y2etBc5QWNMDqE2TkggJ15dW3KIjA3COi35v4GndBNk5CqbzF6EbpFZFQIKcaa0Ml3tmuf6f0uVF+Wlapa/VGYJVFV+8oZdVYTzqxbv3ltc7arjNrlqNnqueE8H6Q2O11uuqzqP3ObU94te4ZKrTmOyLROXXrWiFjrquTqWKYu05YZx9B+uX2n22lOyRBZ9bxwCa6uEqzIsfJeEen5fDBxlpsKmTm1D/NFop1JnnW2uQRcl+TrpL004HZmnW45h2zrHkNlDEE41xY3fyYJ2Gm72ipCr3NOs/mrq6/7R+IGg5zfOJAawcH0KC11ZVHDuY7dgVpa7Co0cx2zOc5s9k2QrzTeQYuWj/8SR3/0MNb++n1oueu9KKBFS3/+uXPhsznW9drXElmfuCToLZHVElkv6UaxhRYPAqlkkivmJqnMOorRkVES+EYYyjvxEcYz7BhosUWIynBSh8vniyGUR/Op+Urnc1VdgYkrP7+APhfmMXTK5/GF7piHWDzI2TNZrAjofo9QpXWQBNbe7mH0dA2jr3uEH9tJs/qpsCjPKF8WkSxYQpmTYnoTMi1FzEDQbzqRixWfpXZe85HIGqMS6/BgGK88d5Dk1AHz8bb95lXYces6DsTwI+gsqR0taJAK9zNPPY3jR4+ZZ/x73n8Xbnvn7bxXaRxCXz/WXRUEtGCE1g7Q39tnFFf7entNODhAs818/+o9uXrtGrStWoWV9KFQyKifX5XG2EotAhaBOUUgTDJrf3oS7ST+dXDVcpKm2Is9AdRRmbWBAzwitsocT77Xb1Yyz+nBbWXzAoHFQGTVyvskR5GPpMfxK66811xOFVfb7whUYznVWK2zCFgELAIWgYWFANfokswKKrNmsedkFsV5HtSWerC6DmgsB8oKpHijp/3sXCIhE65ZPPPqJLr70igq9GBNaxCb1gRpmnVpq1xZIuvs7i27t0XAImARsAhYBBYrAguFyDob/FMksiboYzEqupK4akIptlLJVeRVKbcqX+lYbrsIrlJJ1LyGz6iyis1Fmp7mLUQqC0itlXNuVG2Nsw86EctidIyLzMNphKMZ9j09KCaBtbLCj6LSAFIsO57yYiTuw7omKrEu86KViqxlVGK1ziJgEZgdAiKcyotQKpKoQ0oVwTRHYGXoxJ1thkhqtoloOmM/5Zl6ckRVkVIN+VRluC23z8x6HXJqbnvu2IbMmiurfVTeIbw6BE2lnTpEbuUBOPLpEEZFBdajxlE9dZVanZAKryLFOI8iwwswU6jcX+qyZj9OqTqhm3bCqf1z39zaz1V7zVXp1JGrW1fDFGXaPea5adatdrrHZkXmOMwz+6gO7eSmc+1UA022OdaMdrrl3HwTisicNcqsh0lk7adFOj8bvy5QjiZ/Iap9eQiSZRvQs/ms/Zxz1nk652rOWdi67TXhjPa7aZaXc/c3GDNv5jnpvLO819LxGDqe+CUO/dd3Ub56Lao306LlzltQWFvrHNipasH+tURWS2S94M37wAMPYPXq1bjPElkviJPduDgRkLljsyJHHQXqxZs085yVMzTNQAU5EVz7+/rRKxJObz9NIvejv6cPw0PDhqRTUlKCqppq1NXX0Qx7vQlrGa+pq6WKaxXNQ5Ccww8I6ywCCwEB994XqdWYTqBq60DvGLo6B3HiaK/xp070cYVniAqKJWhb3YCVaxqwgqFIrValdSFc5Utr43wkskop+PiRbvz0v18ygzkf/NhOLG+tpWp2sfkoOvvMYlTePnb4GL759W+QaB3EXXe/F6vXrEZjc9N5y5+9v01fOQJaGNLdRTPNzz6HfW/sJfG4Aw1NjdiybSs207e2rTCLQYJBh8BqTIVc+eHsnhYBi8A1REAEQA2AxWh+Zzgbx97kEEmtIzhMQuA6fxm2BiqxwV9uCK1W0fIaXphreKjFQGQViXUsm8CryUH8MHYCOwM1uItqrOXekFFjvYZw2kNZBCwCFgGLwBwgoLk5TfCNTgA9Y8CvDmZxuDeLTU3AFiqzbmqiqVcSTWfrdByZmOwZSKP9aBJPvjCB1a0hvHtXHqrKfSgqyM1KzfZAC3B/S2RdgBfNNtkiYBGwCFgELALXAIGlQGTVPDNZRc58M6NKGcVHRRRnqLk3N6605t8momlEoymEIykMDafQO5BC/0gGQ1RdHZvwkLxK1de0FxlaH0U6CW8miZA/A+rKoLSYJNVSHzKcf57IBtER9pv0ptYA1rcE0NZIq0lBD62KWjEPA7z9YxGYAwTc37qqEgHSoUnqN67ft/MMcA+TyxKv0jwDpvNnlDWfj/xjCqvE+etQ/Wce66yyZFM6bVANzjb9VZ5LhDWEV/Fh+D1LSowh4xqlaT2PjNK0nkviyziK1IaMa0i4LG/207ewuAN8nplyyieZl/vqG9klzxp1WZVRPeZYuW2qQ/VR3dpRoHWIwIpPHd/EVa/TPh3LbMu1wyHnEguer1kAwJM1iwGo0uoquBp1Vz72pOxqBJBIIJWKqwijKmMUZWeUV7mMl8f0ZjDqiWMUcYzQl/lDWB4sQnkgiBJ/wNlfirSsZ0qZ1lWRnXkMoxrLY+baIGVaHcMcm8fxc4Pa6NcChly+sz3XxlydhuDK6zdy5Ah6X30ZvS+9ZN4FW3/vi6hYuw7eRcA9skTWJ8yv9WJ/rCKrJbJe7B6x25cYAnq5iwQVm4whPB5GJBIx4UTUCSPhCImsNCWWSvLlzDcoy2sf0yngG9asNOGLq6CA0uPFRRDhtaikCKWlpQyLTbqgkIquVHq1BJ4ldnMtoNMVuXsiGsc4Z4OGSCIcHqKnIubERJwmUZLmfjf3Ps+plPZJyiuKSCoUubuERNdSKhgH2BljL826BYfAfCKypkioTiZSeO3Fw9j3+knzzG1orsTud2xAWWUR1TzPnZHUs7h931vY+/pevLlnL5qWNeGDv/ZhVFXR9DWfydbNLQJSv43wXalFHx0nT5LE2oU+qrHKBQIBFBcXc6FHPZqXL0N9QwMqKiv4oUm1Ri1XtM4iYBFYkAiI0DqZTaGPptlP0yT7KaqzRplmrxgV3iDqqdC6gsqWFVS5LKSZdusWDwILnciqgeYIjUW9mhjEsdQYhjIx3Egl1luCtQjCC79GE62zCFgELAIWgQWJQJxz/ByuwMGeLI70UbWKBIDCYBYraz1oqQKaK3OKLLP4DOGnJhW1gI6eJF55M2ZMvYaCwA0bQ1i5LGDUscyk04JE8MobbYmsV46d3dMiYBGwCFgELAKLGYGlQGS91OsnclY8kUF0kv3U8SwGSV6VHxhKYTxC9VYquhryFdVWQ0Ev54+9KMj3wefRHDQJZEmOu4nUShaa+ryjJMKqvzs+QRIW6WtFIZrFppGZ4nzOTbMPLBJXKORF0NTlM/UpHQop7jPbQjxGHtMqI9KrHa6/1Ktpy1kEFgYC+n413BWFfJSIlKo8BiZfeUoblVlt17ZcGe0n8qhTB8vk4jpzldEzzS1r9hNxlYXd8jPLiGI7VffUMSU457TLHD8XN/u59eTapHJOfYzoQaWMKed84Ku9Z7uZWRoTduck3Xx3aEDtnqRwR5jCB4OZOCJcPJBAGtW0PldJ4YMSWqQLipWqQ5idzn9Mtz63/pntmW5frlQumM5X6akajEprfHQEk/09GDt+FNlkHA07bkFRXT38HITQELag0B4ixSruKL06FmmMOqy2K59/VJ7UJZZxyLSKy2n8wtTDP9Nx5StNrzr4x6lnOk76NPOm91G90/vPyGcZt61unTr00aOH8N///V9473vvxuYt201b5vpPkO+1AN+p89E98cQTl9QsS2S1RNZLulFsIYuAi4AIfnESXYcGhzDQN0DCjswmU7m1R8qtfTTPPmjUXGU+uby8zKi2VlGhtaq6OhevRBnzRe7xk+Qj1VY94I25a67G8PtI8OFLQWnrLALzBQF1prSStKd7mCqtQzhxuBsnj/Xi5PE+5OcHUUYi6zIqZC5rqUFzSzVVWgtRQPVWmT/RR7NIrU5nZ352GuYLzvOhHfOFyKp7TmRqEal/8ehr2P/6Cdx+52Zs3r7C3GeB4LnkKJEqkzRf/+jDj+CN194wCwg2b9uMd955BwdkOMNo3ZwgoPdgmiTjRCLOazTB918Pjhw6RMz3mPjExCS233gDtt6wHZu3biHZvcwo487JwW0lFgGLwLxCYDLDAXckSQwcwN7UEAd8Uqj0hLCN6qwtfhLZSWoNcEiFvV0zaDKvGm8bc9kILHQia4KDkr2ZCTwS70Qkm6SCcBnWU0V4ha/ksrGwO1gELAIWAYvA/ERgIgH0jAK/fCuD3jGaXc0Dti33GJ/PSX19Rs52VCIczaKTZNbX9sexpz2Jd9+Sh+3rg6goIymA6lea5FlKzhJZl9LVtudqEbAIWAQsAhaBS0dgKRJZRWCSN0qDOWVC6SHF4w6JdWg0jb6hNPrpB4YzGByhxVCWK8j3or7Gh/pqHxoY1lZ6UV1JkimJOJonicXSGBuneiv3P9aVQvvJBIZHU0hyNVddQRoBjnEkYlR4Daco0sQK2SENsF9aXOSn6BKtBxQFcuF0urDQh0JuzyexVeRWTUn7pBjIvqz8GQQmJkRCmpl/6XeCLWkRsAhYBGaPgJ6FDoHWfcbm0iTROs9cpqeeu1kK0oksS/VXchuMwqvK8YGsOlwVWRPPpeMsNJZK4GQygsOJcRRmqHaNEGqQh2KqXweyfEiyfkcdNhfqeW/qdYi/7rFEvNUxFYow7CrXusd2lW1NmRl1aLu4GCKJugRQPuiRiU8iNRFBID+EwspKw73wkXsh3sVMdVePh0RW8xzPTj2zjYqseYa7BFX3Wc8yet6TzKp9HKKpQ26d3sclpTr1uWW08MIlporAKu8e11GgnT7W9D6aH3LeL11dx/DE4w/hll3vowX5rbO/Oc5TQ1mZH+X089FZIutFrsoDDzzAG2M17rNE1osgZTdbBM5EwLwo+WaJx6lMGU8Y9VYRW6XgGovFGU5iYnICkyTyiOAjH41GTTg5ofgEX1xpPtB9VLGsMOp05RXlJhTZtbyizJB+pNpqyaxnYm9T1xcB88E8meC9nUAkPEEv1eIJo9o6OhKBfJR5kcgkiawFqK4to0nxStTLN1QivzBoCK3X9yzs0S+GwHwgsjofJFTSOdCFZ5/YRxXsOPILQthx6zqsWFVvyNNedqzPdqMjo0YR9NGHH8Xpzk68/4MfwIbNG3kfNtjn6dlgzSItZfKhwUEcbG/H4YOH0MeFHHJVNdVoaGxEfWMDqvk+q+AHVUlZqSERa8GGdRYBi8DiQyDNAaQkyYHDWrGcjaEzHUF3Kop+xit9eWj2FmIdyYINngKEvFystfggWFJntNCJrCdTYRxJj2NPcpCr6f24K68ZtVxdX8SV9dZZBCwCFgGLwOJAgHNV4LAFukeAY/201tGdpRlWD6qpUHVDqwfLKmk5gvNPmkC5UicxrAmqZh04lsTeAwlDVqgs92LX9jzUkHCw1IzTWCLrld5Jdj+LgEXAImARsAgsbgSWGpHVIbCynziZwchYmiTVDImnGRJOabY6TAuI7D+KHFRI0mpBPtVTSSQt4KKrwgIv8zwklEohlaRWhlocJeV/EYDkkjTJ3ct63jiRwfG+DLpJgt3QkEVbNS0mUo01IPPYJGjJXHgymTHlE3FZu8sgoXRS+VkKU+TSuVBlRPwSkUlqrflsW2GhyK4O4VWhm5dPhVhty5PSK73btsV9F9uzswhYBOYTAnrOyhmCKEORPk0W/yhPTmUUJRXUbFP6jHImQ2W4r3bJlZcVuiSZpKOZBAbSMexPDKM7HUUhZTokgrDNX408D0n/Km+O5Tyf3baApFnVqfr43znmzHiubZr/do47XX6qLW77p87Fg0Q4jLFTJ3HysZ8hUFyC5nfdiVB5JQJFJVPHc47r1OfiYMJcm3RMUk+nztk0k21z22uOz7EUOffczHnl2nq+8kLYydf5KC5isc5cdZjASeeO45bRPol4B6Ljj6Gw+FYE89Y6hef4746bSrDz5vkpXmGJrBe52JbIehGA7GaLwBUiYJTqSHQdHxs3yqxSbh0ZGjYKrooPDw8jGonwAyJJxcoCrngrMmGxCQtp+rrQ5OXzSyafqq6hvDx+QAS5Io6hiYeQl59nSFmWGHSFF8nuNicIqEOi+32Yipm9PSPo6hhE9+kh9FG11UPSWn4BlVrLi1BOE/DllSUoKclHcUkBCopoargwz2z3cwbJlfOfk0bZSmaNwHwgssZjSSpej2IfVViffXK/Ia9u2NKC1euaUFHFGciznNNBzpBUeRgvv/ASTp04SdJ0AB/75MewYmUbVx9bgspZkF12cpKLNPTuGub7rL+vD73dPeg6fZrXqZ8rGmlmo7oG6zaux6o1a7C8tcW+oy4bYbuDRWDhI5Dk8uKuTBTHSBTclxymAfcs8kkWXO4rRCMJrTLHU+bjqmHw3c9/1i08BBYqkdUQrmls7+XkgLk3pSDS6ivG7cE6FPAetffjwrsXbYstAhYBi8CFENDUiZRNOoay2HMKVGYFwjTjuqERWFnnRWM5CQMkBsyWcNrTn8bxzhT2H0kYwsLNm/OwotmPOipp6V2zVJwlsi6VK23P0yJgEbAIWAQsApeHwGImsoqkkyAxNJ6gWmrc8YpPxOjZ74xMZBxPJX/FVUaupMhLFX+qrVb4UFUu7yWh1SGunq//qOOQh4q+sSz7th7s76IJbC7akpWBHSuAdQ0e5HHqY6bmh0hCUoCVims0mqJISBoTE2kTRiIpto/pXL62q5z6zlLYC4pAS0KrzDEHg7Q2INJqkJ7KsCGqtjpxqb3KZLMsjbKcQrbHscxIq0xUCQxwIZnfbHfqVTk7D3h5vx9b2iJgEbg+CCQ5hkwNVLyc6MfB1CgimSSqvHlGrKOR8xw1nOMIkBTqO99Dew6a7JJD9fwXDyNJ4bzho0dx4LvfoaXMFKo3b0f5xq0obVudI5Jy/CNXVoqwDmGU+1Ip1uFxOPWIY2rSJl/7OIRaHe+McqxL287Yn4WkLKuyZlvueGqjs79Th7NNxxWR193mtMNto8rHJk8hPPoYikpuRSj/ahFZS3HzjefyCebgEs26CktkvQiElsh6EYDsZovALBAwpCqtfkunjPllmbuWT/EFo1BqrVJpHRoYnCK4iuQqhbthho5qawaVVZWoqatBTW0tamsZ1jGUr68zZNZQiMvzrLMIXEcEdK+naGI8TdmTZFJKxUl2QOJUaBxBd8cQTncMkPAmIvc4SdoFaKQ6aysVNVtW1KJpeTU7KflWpfU6Xr/zHXo+EFmHB8N47sl9OHmsDyNU+r3tjk24adcaPvfOr+qr52oikcDj//NL/Mc3/zd27N6JG3fchI1UYy0rL7ODJOe70JeRp995d1cXjh0+ipdfegkdJAoPkMy6Zv06rNuwAWsZ6r1UWFjE1dhBDmgFLeaXga8tahFYLAhwDMKos8Y40BPmyuUj6TG0c7BHK5f9lHbY6q/E+kA5VnIFs7gdljy48K78QiWyxqgaPE7V4J/EOrAvNYz3hpqw0V+BOh/7oRx4tM4iYBGwCFgEFh8C6pckpJzKif79p7N4sxPgZyYqioA71oHKrCQN5KnUlTspY9EwE557bRJHTqYMeXVdWwC335THcQ5N1l953QtpT0tkXUhXy7bVImARsAhYBCwC1w6BxUpklXIdpyKotJrGAJVRewfT6B1Io38ojSEqsYq8U1rsdYiqhrDqRSXJq+UlJIOGSPAkqVNETxkwc8O36zeqPzs+CTx1MIvDvTRVze7repJXd7Z5QKOIKCCJVfuevb+IQg4xySEQKS3z126+G4qoJJPXUmqNUTHWEF0nUoiI6EoCbjSaJOmVhFgSYUWGjZIIq7LqRefxXIqKAygu8jOkL2KcoZP2oYTbtF1KrlJ1tUTWa/fbs0eyCFgErhwBPd/4tEQ0m0JPegKvUhihg1bohjJx7ArUYmewBuVeis5RnfVqOj2n5bJkhU6SP9T13LMYeHMvhg8dxJpPfBKtH/ywefh7OO+iOVzNtpiQLwSFGo6YqsPZnMvIlTtPedUhp/2EgZPIBVNJpzLnGGceUyW179SxGZnZNnfbiRNH8JOfPIg77qBV1Q3bnAPM8d88KYwXXN1rdKVNtkTWiyBniawXAchutghcRQRSyRQJf3GMj4/TLPsYwpQFHx+THzN50UiUZEB+nfBl46X3+RzVSi9DxaXEKrVWKboWFRcZX1xcTCXXQn4oFDO/kB9EIcj0tv04uIoX0lZ9DgL6OBapcHx0gqTsMAb7RzFIxdaRobAhuarf49OKzICfKziDvHfzqNZaTJXNEpRzRqmYxFblW7Mk50B7zTKuN5FVir4njvXilecPqaeMlWsbsXZjM1pX1r8tBmOjozh04BD2vPIaFVlfxt33fBC7bt9N0/YV5ln4tjvaDW+LgN5RoyOjVFum8mpnJ/p7+4yieDKZ5KSsBqaKSEhvxbKWFjQ0NZq03k/WWQQsAhYBDWdz2B596Ul0UqG1Ix3GUDpuBtVLPUHUkjzY7C0iiZAq7VTDlB6mdQsDgYVIZNWgWyfJ1G8mh9DB+zFOUut7go1o85eANi7Mt9bCQN+20iJgEbAIWASuBAFNlHSPAicHwcn/jCEClNB0a1sNsKbeY8isBVSeulKn+o91pHD0VAKHTiRRVuLDptUBNNf7jdLWlda7kPazRNaFdLVsWy0CFgGLgEXAInDtEFjoRFYpysVJ2qRuC8KRNJVVSWyiD0czRnk1QQVWarw4hFH2CY36HOENsW8p5VWRWZ2QfU6qrhayD+ook178GlAzBjRahxMDwJE+jrHRwoD6nc2VWayihYFV7Mt6Pdk5mUfTnF6KC7SSVJiVOqu8FF0nJzWPTWVCKc7GpNzKuHwizbIZZzSP3WjNYXu8znJ1hfxvWEwKTZoRqbQGpfJKhdc8KrtK8VXKr67iq0KlpQgrpVd56ywCFgGLwPVEQIsWJj1pnEiN4xj9CZJZQySvVniDWOUrRZOvCBWc65CAx9V2yckJRDpPo/uF53D8J4+g8dbb0PyuO1Da0opgScnVPvyc13/o0CF897vfxYc+9CHccMMNc17/fK/QElkvcoUskfUiANnNFoHriICUBUVmFXGou6vb+L6ePvTQlHNPVw/6enuN6l0hCav1DfWooxJebb2j1Kp4dU0NSstK2ekPGBPvIr7qM0Khvi5Mmh8X1lkErgUCGX7xx2jvpKeLBMWjvTh6sAunjvfx/h4laTWAZa01aFvdgJaVdWhsrqKCZpFRafVyZerUR7C9X6/FpTLHuF5EVg2YaGXWnpcO4809J6jG2ouVaxrx0V+/leT8kLknzgeC7q9TVAj96Y8eNQrXUgO96+73YftN289X3OZdAAFh6XqRWE8cP443XttDcvCLfCdFSDQvxi237sbW7duxYdNGmhAS6fzqf6RdoMl2k0XAIjDPEdCAz3A2jiPJMTyb7MVAJoYUR/ZvDdVjS4CWB2iWJ59kQh8HfGzPdJ5fTDZvoRFZOcdj7jetnP9x/BSWcYBxtb8Mm/3lqKYZKOssAhYBi4BFYOkgIDWrQ1Sx2ktl1hePZNFSDdy22oPllR5Uc97HTLRfYWdE37Jd/Wn88jma/BvLoKjAix1bgti0hgvMWediH86wRNal8zuyZ2oRsAhYBCwCFoHLQWChEFlFEJVz5iekreExceq1YHScKqtUXu0dzKCPyqs9AymGVC6lWmkRianVlX7UV3vRWMuwxo+6ap8hrfqp93AlfUC1RX4i6UE/+5XPHWXf9WiWi7A82NAI3Ewl1jIqsV5ht9U50Vn+lbJrIk51Viq1hsMpijMlMe6G4ynmMc08ZxuVXUmIFVG2qJBqrVRsLSmhUmtOxVXxYqm6FhM3qbnSFxT4jYqrRJpcDBWatNqe619PizjxirkFZ3ludneLgEXAInA+BPoykzhKMusLyT4T3hiowlbObayl9bn8rNfMbZxvv7nO637+Oez/9r8hr7wcZW0rsfzd70Fp64ore+HMdeMuoz5LZH3iktDyTE5O5rool1R+0RSyRNZFcyntiSxCBKRomUpxtVssxo+BCZpwkJ+k6Qb6aJQd/5iTR9XWJEmvMZaTT1BBL5FIcoVcnCYp+DFA0lG5XmY0rS1fUVnpxElyFSFJXwG2g78Ib6B5dkoiJ6bTXMFJm37hsSjCtIUyPhrF2NgE4xOYiMRpsmSS9zuXmNKJtFhbX47ahnKStMuNWmthUZ69V6/Rdb1eRNYx3hN93SN4/qm3cLpjgCqsy7B2QzNWrW8yCr7nU+nVs3KwfxBvvbkfjzz8iCH133HXHWhpbUF1LZclW3fJCOh3OkTzFFowcaj9ADo7Oowiq9S9y/geqamrQW1tLcM6VFWLcF5uF0VcMrq2oEVg6SKgD+04zfCMZ5Loy04aczynuXo5QlVMDTwv8xZiha8Ybb4Ss6L5WqxgXrpXY/ZnvtCIrFHed6ezE3gzMYSXUwPY5a/BjlANV8vnXXXzT7NH29ZgEbAIWAQsAnOJALmmRo1V6qyHe0hEGPdgMJwlIcCD1VRmXV4JcCjiipwhG8SyONWVpCprCvsPJ7B+ZZA+gKY6TsgXstMzT5zGAB3TfnPXIEtknTssbU0WAYuARcAiYBFYTAgsFCLrJBVHJ0gVGR3PYHg0hVH2EUdIIh2PSHFVJElQTRTIl2ooFUOp7YCCPCmsSl1UcQ8KSGpVXh77k1IePd9cxqVcWym8DvD4x/qB109xDx67OJQ1lgSWcQFWVVEWIdZ/PZ36viKzplIZpKjimqA6a4LKtVJp5bQ242mTdlVeldY2Z3sWGZ6jtpntqoNe9UkRVqH6qloMlpfvc0itNA2dTxXXfKanvddsE+lV6q7BoBXbuJ73hD22RWCxIzCZ4fwGklRnDeNUJsI5jqhRYm2h1TmJJmh+QzIdEue6mi58uhOD+95E9/PPI9LdhbWfug91N95kVFk9C8hipiWyWiLrBX8nlsh6QXjsRovAvEZAHfnxsXFDMhLxaKB/gL4fQwNDNOM+iOGhYSRTSXbq87mCrdios5aUlqK0tITxMpJYZcKdhAESlIKhIDv58k48EAiYPJmItkp78/o2WNCNy4jYSpXWoYExnD41SD+A052DEJmRS15RSUmU6ppSVNFXVBWTNFfED9eg46niGsoLwkdzJJaIPfe3wbUmskoBNBFPGbXet/aeNGq9Gh1674duRCtVekVsPt911nNQBP69r72BfXvfxH6SWbffdAM+cd+9HFAK8f6wZu4vdneICBzjgggpgI+NjVH9uwudpzpw/NgxvkeG4Pf50bZqJbZs24bWthUkmNeZa3G+63GxY9ntFgGLgEVApNa+9AROpsM08z6MbhIMSzw0vUuVTBFZq6jOWu4NGXPvgWtgksdekctHYCERWdPsUEoB+MU4rVrwXouQUP3OYD1uDFRrHsg6i4BFwCJgEViiCHAYwhBY3+igutWxLGpKPGiqgCG01pUCJSQjaO7pcuefNKGf4OR7+9EknnxxkmQGL2oqvdi2LkR1LplJdcyuXgnsL774In7+85/jnnvuwTZ+m12O07dbP8cLVYcIp319fWhra8PGjRvxgQ98gMQBsg1m6SyRdZYA2t0tAhYBi4BFwCKwSBGYT0RWTkEYUqohWhrypQiY8lQ/nZTCahZjYSqMkrw6Rj/KeJR5IqUWFUh51Yeqch+qy70MvSgrcUitPloVnCsX5cKo0UkPjpPEeqQvY8isK2uBrcsdKwIVhXN1pGtbj0NSzVCoKU1Bm5QJowyj0RQiVHU1YSTJ/IyJixSbIvE1RPJqnsjBCklizSORWPEQw4J8v8lT3PG09sRrIR6Xz0d1RIZ+v9JeE4pY7KRFMlZff+6u27VF0x7NImARuJ4IhLNJ9FKd9flErxHsCJC+utpfivVUZq3g3AbtzRqC69V6wqQ4J56i4N2B//wPdD3zNJZRkbWWRNbK9RvgJydooThLZLVE1gveq5bIekF47EaLwLxHIM2leSKrJvmlpYHnZDJh4slkkqSwBJVbJzAyOoKxkTFDeB0ZHjbh6MiIUXmVamslFVqraqqpXFiNmpoa1FDBsJpp5RUVFxmC67wHwjZwQSIgEqJ8gvb9kiQxxmJUFuaM0jhVWocHw+jrGTbqnP19o4bkKOJqM23/LW+twbLWWt6zpYbcKiaC/eic21vgWhNZJyfiJOKP4dXnD+Hxn+7BzbvXYtMNK7BiZT1KSgvg5WDD+VwqmTLky+/9+3/i2NHj2LJ9CzZvo9+62ZDw7X1xPtSm81wi8MnjJ9C+/y28/tprJJKPGdtFq9euIf5taFnRivKKCpr6KebAUB5XNwfs720aQhuzCFgErgCBBJVY48hgJBNHL0mth9Ik0XMF80g2gQ00976RvtXPhVeeoCUbXgG+V3uXhUJkZS8TE0jjaHIMP46dQpE3gFuDdVQALkKtb+EM6l3t62nrtwhYBCwCSxEBKbMmqAA1HAF6qM762sksevgZxCEGbKQ6602tHgQ48a0J7stx+r7i6ARGqOTVO5DGi2/E0Nmbxs4tQaxdEaS5WZ+ZPL+cOlVWi8w/9rGP4dlnn8Xf/M3f4Dd+4zcuuQp9Ez/33HP4zd/8TbMI9Owdd+/ejW984xso44L32ThLZJ0NenZfi4BFwCJgEbAIzB4BLVjpokDB27l169Zh/fr1Z2z2+/3QPMDTTz9tFr1s3rwZu3btwurVq+dkoYsONp+IrJNxEimpujownMEg/cBwCoMjGfQPSy2UCqAkOoqcWlbskFRNvMRnSKx5IfYP/aCn8meAxEhf1vTrxIWcKz6kupJH+oD2rgw9CZjsi25elsWKai268iLoz5o+6hkXcYEkTDeZbZXVRupqGNVVEYsz7JiL5DrTK08qr3GquE5Ovr2fmNCcosixKc4zyvIoOIfhN75QYaHiPgo9BVBIRVcTmu1aYOblPMdldvYXCNa2mRYBi8DVRUDCCTGqs45k4zhGsY7Xk0OYJLk1SELrbo49ryOhtTBHZr0aLcny4Znlg7TruWfR89ILiHZ3o3RFG9b/5qcRohVNz+UOZFyNRl5CnZbIaomsF7xNLJH1gvDYjRaBBY2AFA5jkzGEw+EceXWUBKVRE1cYHg8bBT4/v778/gACtIshglJIyqxUaFU8v6CAPh+FhYVURCxAYVEhFV6dsID5UnH18WPXOovAXCGgj9Q4Ca0is/b1jKCffqBvzKi0ivAakhJrKMBVl0EUFIWoKlyAkrICTroUMdR9GqLPm7PBg7k6r4VWz7UishoiJcnLvd0jVFU9hu7TQxgdCuPWOzZh07ZWkunz+Wx6+2dMV+dpHDl0BM8+9QwJ0Ql84J67jXqoyPjWnR8BYR6NRDAyPILe3l5i341BKnoPMx2NhM1zv4ILHKTCKhJrXX09f3PnV8Q9/xFsrkXAImARuDQEkiSzagXzsdQ4OtIRdNIkTwAcWKZCa703H/W+QjR42e/0+BHyWIXtS0P16pdaKERWDunhQGoUh+gPJkex3F+Mu0KNvL+o7m/vp6t/o9gjWAQsAhaBBYCAyKyTSQ/e7MziaC8wNglwHSXaaqR4BdSR26n57cudB0qyXq4tx8tvxnDoOCe0WElTHZVZ14dQUiRzsxfXZhEBVQRWfef+0z/9E/7yL//SIHq5RNb9+/fjgx/8oKlnxYoV+PCHP2y+7x566CEcoxUOufe///341re+RQIBWQVX6CyR9QqBs7tZBCwCFgGLgEVgDhBQv+HOO++E3vtv577whS/g/vvvn9qsfT73uc/hkUcemcpzI/feey++9rWvzQmZ9VoSWUWWlKl6TiMZhdVJqptOxrnIlWqrnCqlZ8j0TEVW9duolUFiKs3Ys4/mkFh9KC32oNSQWqn+SVV9EVivhlObtRRqhEYKu0ayRoH19LDT/2xgX3RLM60HlJJMG1KppeMMsZXXJhbLEVl17SZThthq8qjsKhKriK4T9GmWTaUyFERRH5qKq/RGfZXkZKX9uTwTp5VHTWsHuHItGCRBmX31UMglt5KoTJKr6wNU4w0GablU+1+dW2DpXFR7phaBRYSAnsjpLBdCZGM4wHFnzW30ZyZQyzmNJlqeW+ErRhWFFGSJ7mq5cGcHhg604+TPfgYfOT4rPnQPytpWopBzugvBWSKrJbJe8D594IEHzMqq++6774Ll7EaLgEVg4SLgKEI47Z8Z12B4PEYlrO4empLuNr5nRjg0MIR0Js1VasVoaGqkb0B9o+MbGDY01pttIrtaZxGYawSce9VjFFsVHx+Nktg6iiMHu3DscDeOHepGJDxhVhbJ9PzKNQ1oW9OIpmVVqGuoMIqRWoFp3ZUhcK2IrBmuwB2i+u7+N07g4f96js+YCrz7A9tJoJTi7sUVYZ791TN46hdPmgm35a3L8YEP342aOtrase68COi3JH+aBOB2Dmy+8Myz2P/mPg7c+A1xdfdtt2LthvXEf0XuN6SVzPaHdF4wbaZFwCIwJwhINVPKZeNUY+2nCfjnaJJnT3KQhFYvVlCV9R00A9/oLUS5l7MG1s0LBBYKkVVE6R9RifWt5DBaOHi4gavhtwWqSJW277V5cSPZRlgELAIWgXmCgMgDSfI3u0kceOJAFqcGgTBJD+/Z4MEtq7wkDXCS+wrX00jh63hHEj9/ZgIhToLfdVs+ljUEUFl2cfWnRx99FP/8z/+MgwcPUmVqYgqtyyWy/tVf/RX+4R/+AW1tbYaoMlN59Stf+Qq++tWvmrqfeeYZU2bqQJcZsUTWywTMFrcIWAQsAhYBi8AcIqCx3dbWVlphjOK22247b80f//jH8YlPfMJs03jvl7/8ZdPXUMZdd92FW265BW+99RYefvhhQ2D97Gc/i7/4i7+gYiZlM2fhrjWRVYTVodEU+gbT6BvKMMzFByn8QxKrRqHqq730PtTX+FHHsI7pMimv5jtj4SrFmDnrqz00Tl0X0PAm2ruBJ9upppFmQAAAQABJREFUFBvJUnnVi7s2AusbgeI8S6B05wrd21Bp57o410jpRCJDq44ZjI5RJGc8hfEw/ViS1vySTNMrzjASTps87eMnziWlAZTSl5T4jS8rDZo8pUvLGC9mPrcbFd6rRGZ2z8uGFgGLwMJDQO8LvVeOUKhjb2oIryYGaB8si3cGG7DeX4Y2zm9cNcfn2ERfH/b9279CpNZSzus23Xo76nfectUOOZcVWyKrJbJe8H6yRNYLwmM3WgQWNQJSWhCJTAPiUueLhOkjUfOxq/REdAKTE5M0qZHkh2uSYcqEKX5VpbhkMcP9pcgqpdaSUpl4L2NIM7A0R6aB8eLSYqPkKgUJS4Ra1LfSVT858yEa12rLBEao1jlGUquIrQqjkTg/UpP8SOU9SlMjWhkZDPlRVV1KX2LIkOWVxSirKMqZmr/qzV0UB7gWRNYYlXfDVN598ZkDOHms1zwnREi+YecaKrHmURmUM4Zv4yY4KDc4OIRfPf6UUWPddftubLthmyFjSjnaumkE9PvRs77r9Gl0njqF48eOY3BgwDzjQ1xOXlyi30mNUV5taGyE1Fj1LLfOImARsAhcSwQSWSoskHjYnY6iKxNFb3qC5NYkVzZnUcfVy80ks4qMWOnNg9/jtVTEa3lxzjrWQiCyDpIU3cV76YVEH0ZJkn5HqMGshK/hqnhLYz3rgtqkRcAiYBGwCJCgAUSpoNo5lMVJElmP9WdpypUqXFy3vbnJg2aqs5bkUxnrMl8iUgEbHkvjjXZaISGZIkETqRtXB7GVyqw0MnNBZa+//du/hfzZ7nKIrBqL+8hHPoKXXnrJKLBJiW2mE9ll1apVJkskk49+9KMzN19W3BJZLwsuW9giYBGwCFgELAJzisAoLTCuX78etbW12Lt370XJp8PDw9i+fbtRbP/MZz5jlN81hiz3L//yL/izP/szE9+zZw/q6upM/Er/zCWRVU0UGVV9rHA0jSjV9CMTGUSiWSdkPJHgWDjLSXmTU5NGaVVqnPI0Qon8kJdm5j0oJGm1sIDxXEgxuwv2za70/C+0X4x9w8EI8NZp9kOHs1Rl9aCxHGit9qClOovKQraZyqGX2QW90CEX7TZZepQqa1yE1pyXcmuSGDskV/bFme9uTyYzLA/eK7xftG9aIdNunOk040rrCpArTtVWPy1F0rpCng8FBbQeRQXf/Hw/57F8VPP1Mk71Xm2nuquXHw5XmwS9aC+mPTGLwAJEQOPPA5lJHEmOoZvKrLJCV+nJQ1ugBK2c06jzcEyaD3N3kcRcnWKCVjb7+a7u2/MaBt54HQ233oaVH/4IghSp8+dzEGMeO0tktUTWC96elsh6QXjsRovAkkZARFeRWYeHhjFAs9P9XNUx0NdPU9ROODgwyE58xpBZyyvKUVlVSTJrOabjJLOSIJWXn8cPxAA/uPzwM9TqUD+/vvw+J7Qk1yV9m83q5KORGIYGxnG6YwAdJ/qNHxkOIzaRoCpnGWrqy406q+LVNaUI5Qf5ccnVk/zg9BuzIQGn42i/KM+5DleTyKoBJz1fBvrGeM368Mzj+0ikn8Tud27A6vXNWE411gs5PXd6e3qxf+8+vPHa6zh29Dju+/R92LF7p3keeS/X7uOFDrZAt2ngMcXFB7HYpHmOh8fDJLAexZFDh3DowEGzMEELDrbesB2btm5B87JlfF4XL9Cztc22CFgEFhMCWsMcI6n1SHoc7ckRs5K5gBqa9b5CrKOi5jISWku9JH8wL0hCq3XXHoH5TGTV9ILMOh1Kj+G1xCCGs3EUefx4f14zGjwF7PfZ6Z9rf8fYI1oELAIWgYWDgL5Vu0dIJujOYj8JBYPhLLYt92AV+RvLKz0oCGaNsurlnJHIFD0Dabx1JIHn9sSxptWPGzfnoZEKYCVFbz/BHYvFqB41bg6lb9x3vvOdEOnkcois2lnqbPF4HD/4wQ+M0trMtstSU0tLi8n6+7//e0ip7UqdJbJeKXJ2P4uARcAiYBGwCMweAb2H7777btx666148MEHL1rhj3/8Y/zu7/6umbeT+nv+DLKLvpvXrVsHkWPvv/9+nL0Q5qKVn1XgUoms6ofJp3KEQk4fkEioeQSOc4tUyLSUS6OTGURJWB2LZKi6SU8F07DiJLOOR1iATgTVilIvKst9qKaXGn5luRelxVTb57br7XQ+qYwHfezqyRrAy8dIwCQJs7bUgxtbPdhAJVYfm3m5i6iu93ktpOPH42laLM3w3klSLCfNMIVwmIqtjEcYj1DRVdvcNLvjnHtyyKoFJK4WFgYMgbWA5NWCQnqFzBfBNT/fa9ReRabWfj5ezJlx5Tn52u74hYSdbatFwCJwfgQynNeQuMJRzms8E++FhDsqfCFs8Vdila8Uxd4AQrRC55vDOY0sX44JitN1P/8s9n3j/0Xlho1oee/7UL5qNfJraub1WLglsloi6/l/SblcS2S9IDx2o0VgSSMgIlSaX4bJZIIr1ZJm4Dsei5tQg90aCI9KwZVKruFwGCJKaZA9wnCMYWxy0uwvZT+RW6trqlFBsmtVVRWVMquo+ldh1FsDXOpoJ5WX9K12xScvdeBkgmQ9KrVOkryqcHyMaq3jJGDTXL3UWxVOROOG1FfbUGGIrfVNTlhHM/bBoN98SF5xIxbpjleTyKprpmvy0rMHaNq+3ajnLmutwdYb21BJFd2Cwry3RVXPpUQ8gTff2Ivv/+eDfLZUYM26Ndh+03Y0L1/GD3+q9HGwbak7qWaPDI8Y4mr7/rfQvm8/B098VMouwbLlLWhqboLUV0uppF3MlXkarNRCA+ssAhYBi8B8QEBExCiN8Ixl4lzJHMOpTASnUmFMcvCn1BvEJn+FWcncRHKrddcegflMZE3yHtG98xwHCx+Ln8ZNgWpsCVZiBc04FYLyGdZZBCwCFgGLgEXgIgjEkkCYJmmPU5X1BIkFCguptrRlmQdtVMZqJqH1cpxUnKQcdro3jX2HEhgcySBJjsU7bg5h5XKqOnFC/GKfsPrO3bJlC/q4wPxyiaxjY2Omufrum7noU/FvfOMbhqCiAk8++STWrFlzOad2RllLZD0DDpuwCFgELAIWAYvANUVAC1a+9KUv4bd/+7fxla98BQO0xiUiagsXrMhiosaKZ7q/+7u/M32K22+/Hd/73vdmbjLxz372s/jZz36GO++8E9/+9rfP2X45GZdCZBWBVcKX6jOJlBqO0kT8eNohqZKgOkZz8CKqhkla9XpkEh4kDnrppaxKciGnExSKwJonlUyqY2qoWyqrwYAHIfa3/L4s8xReTuuvTtkxKsn2k8T6EgmsJwayqCr2oKUKWFsPVHKhUxHPx0NClJ3nuDr4q1b10aXAmkpRmVUkaYYpkomddJbz4hmzXYquIlOL+CpF1xjJr1J6deOTkyljdSHOvFgunuI+UmaVQmtRoR+FRSK+MjR+Ol5UJNIr1VxZVs5ebwOD/WMRWDAI6DcrKyff//73ceTIERQVFZnFozfefDM6gwkcpEjHgdQoAiSvVtPK3M5QLTSfUcAx6pmjCm9Xz82sp6CggIs8+II8y0k0TvP4Tz/9NPr7+7F582bs3LEDJWOjOPhf38Waez+Fmu03GNa86j9f+V27dmH16tV87p3ZR9ChXnzxRXR1dZ111OmkFrxICX42zhJZLZH1gvePJbJeEB670SJgEbgAAnpxSrFVJNbRkVEqtw4Z4pTIU4qPj4lAGOXHoUwshNhxz6M6az475gwZz+fLN79AaXrFlZ/brrTKaD+pt1pnEbhUBGSufiISR1/vCPoopSI/TELr2GiE91nI+CKOBBTSF9NOoAlLnFDxwuJ8S24l2FeDyKpnRoozdgN9ozh6qBuH208bNd3tO1Zj/eZlaFpWzWcA7StewIlAf/L4SaPE+tQvniD5dTvufP+dJMrXLGlFUWGb4YiLFhMMDQ5SQbvfqGj3U0Fb6dGREVTTtFQjCazr+HGhsJKLCmZOZF4AdrvJImARsAhcFwTSHLTXyuWT6QgOU2FTpuInMklUcOCnzleAJm8Bqhgvp0JryEOzXWcMAV2XJi+Jg85nIusIyc+HOUD4Fr3umfcGm3BDsBoFVGU9c4hwSVwqe5IWAYuARcAiMAsEhmjm9fRIFntOgmZes1RjhTHz2lbrQW0JyRKhy1PJGqNiWHdfCm8eSuJYRxIbV4ewqsWPZQ1+FOS9vTKrTmE2RNbzQSCrSd/61rfwJ3/yJ5ykTxqSyr//+7+fd4JMYwPt7e3nq+aMPE3aSdHtk5/8pFFxO2OjTVgELAIWAYuARcAicFUREHn1q1/9KlpIXBWpRkRWORFXpNKq7/jm5uapd/0Xv/hF/PCHP8TnP/95/Omf/uk5bfvrv/5rSK1927Zt+OHDPzFKqSKaGi5N1kOlVOrO5dJufoZkv6m4u40ZD33v6yyfxkc+/kWjsCqioAiEMtsuAqFUV7NUJ00yP0kiIbsmDjHQmIQngZChkweGJAiyT5bPvlNJMUUbChkWeVFS6EUxCaAlJAzmsY/mpxImeTvzzsXJFRqNUoV1KItj/SKz0i4R8VxPBdaV7GOKzGpVWOfdZTP3ulFwJZF1IprCpFEFlsAOF+IzHZ1QnAurGXeJrlJalQqrIU9zijsY9PH3yLSfJGsSqwOKi1hNorWzDSateIB58n6WlQqsvFOP8qyC6/y7Q2yLliICIoe+9NJL+PSnPz1lScXFQYtIf/SjH8Gzsg770iPoTU0gTuGFZb4iWpsrQou/GMWegBmvvpR61q5d61ZtQu3zuc99Do888sgZ+Urce++9+H/u+TDCfb2o33kLiuob4Cff5kLlv/a1r51BZlX9Wsiyf//+c+p3M6TWLtX22ThLZLVE1gveP5bIekF47EaLgEXgIggY8hS/OjP82sxQPUsmv02coUyHT1KVdbB/wPg+EqqkHjHQN2BIViK8Ril3XsQXel19HU3B15pQ8bqGehMvLSvl9iK7Eu0i18FunkZA92RWgyBmICRNVeAMTYTQPAhN13d2DOD0yQGcojn7XhJcB3pHUV1XhoamSixvq8Wylhq0tNWREClyNUc8lrC7GkRWPR8i45PY98YJPPLgCyivKsaaDc3YcsMKNBN7mVhRB/lCbowryX/+k59TafQInzdp7LptN9757nfBy32XMikzzRVzUso+2H4Ae2lK6tWXXsYAV+HVkLy6YfMm3HDTjahvaKASdiUHSoIGK63Gt84iYBGwCMx3BDj3wWEevsvZz+wmkfVIagyvpAapzpri6mUfbgnWYnOgEmWeoCGzzvfzWQztm69EVt0rJzJhPDJ5ihRooMGbb0isrb5iULDlon2MxXBt7DlYBCwCFgGLwNwhwCEFEieAQSp/tVOI5MkDDplViqy7V3mwosYx+XrhL9jp9ojsITOyUmXdeyCBodEMqit8uOu2fJq8lfnRt69proisqufYsWP4wz/8Qzz77LOmcRs2bDAmiMvLy6cbOyP2i1/8Anv27JmRc/5ofX09jh8/boms54fH5loELAIWAYuAReCqIvB7v/d7ePjhh6eOUV1dbebnhoeHTV6Q48GPPvoo9N7X+Ptdd92Fffv24Y/+6I/w+7//+1P7uZGvf/3r+PKXv4ympiY8/ewrmCBJTyRTR7GSRFNaymvf9wrH5x1VS0NGZV9HypXqQ3EaIBf3oL/rdeZlUb/qs4gnpGwpcqqjvhqLc7wnwT4XCYIShBN5r4jk1PISL70PpVQqLWNYVsp0sRelzA+xjFRWNY0gL+KnrDQr/v+z9yZgdlz1lfh5W7/3et83datb+2bJlmQbrziGxCyBBLCdOGwJZGYIYZjl+3/zkXxAhkkIEwYIA9ngmxCyzEwgDGGxMWBjY2PwKsuWLdnapV6k3vfuty//c271k9q21G5LrVYvvyvdvmvVqzp1q+rWveeeX2CaBar4YnRaKLW/O499XcBzXXnXp9zVBqxm/5L6KiBv0dwiRUB9eTm1eTcHybTylC7ksxV67Z55juA6laUQVJo+g0n6ccYnpS6scNLLk7qr7qtSkrDLykIU3wmynRcxHkR5eQgVFcwjadvFmY5QwVXEVnOGgCFweREYoqDb9ddfz3t5Eo2Njbj99tudcNv3v/99HD58GNW0JnrvD+9F9aom7M+M0A/jBYa1vghuCjdiPa2HNftLMJf9SCFdi1Hk9A7X+/lv/uZvXFrvcx3HgQMHXD9A6qpSVX//dr7vQ0Voe+Mv48++9KVXrf+nf/qnfJ7x5U2nRTBr1qxxC2Nuvvlml/fyP3fccQfuvPPOl2e/prQRWY3IOmuDMSLrrPBYoSFgCFwEAnrh6YXpVFupEqiX+cT4hAsnx714LBZzH9R51tXHrD4A1Pv3Apr6oO2PCJdQlpWXs6Ne5kiv5TSNLfKrwuKSYnbaPVLWRRyqbbrMEchwYEXm7EdHpjA6PEHl4EmG9COTjuiaFRHbddBosIWNr5SjBuVUa62sLqVqZbkLnVorFVtXiptvIqvIxGNcbvzsU0dx8lgvnwVxrN3QhB0ksdY3Vjny8KthK/J7x4kOElnvdST56268Hpu2bMLa9etebdNlWe6er3yGnursQmdHJ30HB0ImnKKOlLBLS7VIoIlKt63O67kpBWxzhoAhYAgsRQSo9YFJklcHswl05ibRm41hKJcgldXnVi+vDpbSNA89B4BCzAtoFsPcJUFgMRJZMyQ69+TiOJQdxWPJXtcWbuCgYIMvikr/7GrvlwQk26khYAgYAobAskBAY1NxKn/1jvlwpDcProfFKE3BSpG1tRrY1OxDBT+xwq/BkFD/UBZdPVJmpTWZeB7tLUFsaAthfbt6MB4J4+XgzQeRVcqrf/Inf4Kvf/3rbhxOk1O/93u/h//yX/4LSSO0u3uR7hkuqJTqjCmyXiSQtrkhYAgYAobAikfAkeTYK9B0hYihHjm0QJBjXiFfIQlwcv/ud9+Offv2OaLqF//nV5EPtbg5tr7OX+A//+ePQoRWkVK+/d2HMDYZwO1v3+Hy/vRPP4O6tt/w9jm9XxHzpvq+hU984uMQIfYv/vYpnOpNOfKMd3FEXs3g8N7/6SVf5W8oXMGz8WH9lf+WNXm8Ypl6h+0IqF4WVSaZze6JU1uNhn1eSOXV4qifKqteOlJERUpqM0jpcqk4XS9OTeHEQB7H6TuHPBKuiKubG+EU/6mrgpBpTiyVSzrrcer7QU4EVSkIS8lV8RRJ3ArlkyRwp+gTLFN+OiWbVCTFuo11f3hz5G5H/FMgziotlVYtgAuHqT4c4b1BYmskzDCidID5hTiVXBkPOvGYwp4sNAQMgflC4I/+6I/wt3/7tySbV+BHP/oR2tra3K5lxfjWW2/F6dOncdddd+ELVEvv55i1LM1JoGM4n6QFuhw0l9FGddbv/smX57Qfqa7L6X2+a9cuJ2z0gQ98AJ/5zGfcM0JlX/3qV/Hf/tt/UxSPP/wQuv7pH7Hp9/89rr7uuletr8WrIuTKjVJQaistezZQKEl9iwLB1RXO4x8jsj44JzR9VA2cfrXMqf6yqWRE1mVzKe1EDIElh4AUW2UmfHhwiMqBA+jroWKrVFt7e9FzqsfFU6mkO6+6unrU1teipq7GfTzXNdS7sLK6EiUlJCyIzMoOecAfcKqOfioNKq48rU55NZXHJQeeHfBFIyDyajqVxqmuIXR3DKCTKq2dVGvtoi8q4mpHEllXra5FU0s1mlvrUFtXjqqaMn4kem1M6qEBfjTORUX0og/2Muxgvois+shWJ3d4cBIdx3vxk3v30sxKClddvR7brmrHhs20m/MqzvtQz+PQiwexb+8+PPXYE07B+f2/+9uoq6+j+ZWLn3R7lUNYNMWFBQJpqq9qccDgwCAVbvfhBZp4eOH5A8SjHmvWr8W1119Hku9mttu6eZmUXDQA2IEYAobAikeAQ7kOg04O/hyk+fhn0oMkMMbQSgLr5lAltgerUeEPI0qKa4hkVvYEVzxm8w3AYiOyiuQc5yTa3swQDrFN9GXj2FVUizeFW9zV14SZOUPAEDAEDAFD4GIQEJEkTdO3ezuAp47nMDQlAmseN2/yOUJrDU3Zik9BwdM5uRjNkD6+L4XDJ7jgk6pM2zeFcfPVEUfS4JrEV7iLJbJqguiDH/wgTpw44fYtM4GaExChZb6cEVnnC0nbjyFgCBgChsBSQ0DcMzdSMR3KWpzSjpM2HRZUG7267DQU6roNvboFsho353i6CKzsfzgVVKq6qy9CUpzU3bk2xYWunHkiSoZ93RwrHkFJxUb0DAY95VRun2J5feTnNCn8uw7Wu39wH558sQ3/56/f4pTUP/GJT6Jz6jfd72SzPoYUp+F2Gyv/EV/4wuchc8bXvvnbjmDnmUX3FOmDgTx8uR7OjZBYx06QSKhn4v68yxPZVP7U8R8LBdx464dIspOaKhChoqTId5zWg0irYRJUNcSvfS1WNVUH4Gv4U2gDMU5xUl8Fjx3Lc2EUFWgzPmxv9eENW30o4flHVs7UxmtAb+VUFVE9naYlQyq0TkxSrXWcCq70Xsg8KbkqzVBxWaD08YaTgmtpaYjz41JyDTo119ISipswXqy86bJQyM97S/PkHodc3yvenLn37aLvDJUV8lcO8namhsCFI6D7Riqo+r7+6Ec/ij/8wz98yc60ePTjH/8478syHDx40N1zIq8O5RN4Nj2EnyZPo8QXxA2RJnzql+48s58/4H54O55x59qPFF+1IFWLUbXvmeJFure3bNniiKif/MQn0PboI0jfeRc+/OEPv3r9T37S1dOP69v+V3/1V3HTTTc56y1nDmieI0ZkNSLrrE3KiKyzwmOFhoAhcAkR0Ie5yKwp2g4RoTWRSJDgFmeYpCn4BOKxOKTYKq94XPGpmJMyj6lsasoR5MJhKbaWUTmzlmazq1FVXeWFNVWoqqrmirQIyYfnmAm4hOdmu178CGjQSKbpE/E0piYTiNFPTSX4wUg/HsP4WIzqlnH6BONT7DxqlWMIdY0VaGiqoq9GXUMFqmtJbuUojT4el5ObLyJrknaChO0TP6fJ+73H2XEnQbi1ximx1tZXzkmJNcPRuRSJmz/43j147JHHsH7jemzdsQ27r7kaJaUl/Mie42zhEr9Ael7qGXmq+xSOHDyEw5yM7OGqvmKS+Wtqapz6an1jg1s1V810KZ+Lej6uFHyW+OW1wzcEDIHXgICmhGJ5mufKp0lajKGXRNZuElvHmU4xf0OwAhsDFWjlyuZyn9TNltc7+jVAdUmqLjYia4xKvUO5JH6Y7HIqvVeFatz1Xxsss2t/SVqA7dQQMAQMgZWHgCOdcAxhJAb0jQGH+zx1VhoawfoGYFe7D3VlQNkcjbiIhDIwnMXxrgz2PJ9EMdWTWpsCuGJjCC2Nrxy/0jfdlVdeib6+Pnzuc5/De97znjlfhF4uFhdxVSYLpar2+c9/3qXnvIM5VjQi6xyBsmqGgCFgCBgCywoB9REcEY2E0zQJik6BkeRREUhprBDJFMU0GCpd8CKiKn4mX4qMrCMSKXU3HKlN5FSRXTXsLTKoQj/nH1yaRBUv7eX5fHkuqOHIx3Rdl3ZxLu7lcMhVWwK4+fp1bi7tS1/6Msoa3oqvfvE9eOKJJ/CRj3wEN/3K/+ftj3ULv3f3tz6Nr33ta47E8oef+ieP6KbfmK6jUIQZ7d/FdXyMKO6mSXhMCnXM3/7mV0i2zeJ9v/3vvXNhviO5sszny1GQZvq8eJ5y2sdycFJhjaWA57uBfZ28xiQIl0fy2NTkR0t1Hk2VVJfVdaI3t3IR8OYp9bzwvEitM71HWFce2xDLVE8qr4pL2VVpqbu6Zw0bmRReUyxLTdeRcms0SnIrlY1LShkWB+iDJMB6cRFhFXfqrvwmkTNhqJXbHu3M54aA+C2rV692HJd77rnHKaTO3FIEzVtvvdVl3X///U4tXUIMSc5baAz7dG4KxzMT0Bj2r6zZ7vbzvXvuxtZdV6IEZ8cDzrWfL37xi25M4PWvfz2+8Y1vzPxZF//d3/1d/PCHP3Tf/B9a04YnKqrO1P/n//t/2Vd46UtnZv1/+Id/cPv49re/7Qi6v/M7v+PGDwYGBhw5tr29ne/vAJ87fMHNgzMiqxFZZ21GRmSdFR4rNAQMgcuMANWyHXl1iKqtUm4dHhp2sulSIVR8ihLtWp0ajoS50qyUHfFSrjRTWOK88qLFxSSzRtkRj3CFZ8iFLs5tirjkU6tWjOh1mS/0Ivn5gvLn6PAUlS7H0Ht6GL2n6BmK0Jrm6ENlVQnKK0tQQV8Ii0uo/FYcJqHQCyORIqqEesqti+TUXvNhXCyRVfdliiNvA72jOHG0j2qhJ6m6PIKdVGLdsn012tY20rTJ2Q75bAeoe72rsxMP/vgBHD54GL92+6/jqt073SRc8FxyNbPtbImV6YNAfmxkFCM0GdHPicue0z1UEu5mGx1wCwDWrFuLjZs3YesVVzgSv56D5gwBQ8AQWCkIaABohANAB2lS/lhmHN0ktVb7itAYKEaLvxgN9NX+CKI+mteiN3fxCCwmIqtIzV3ONNO4U+eVCu9bI61YRYXeYq5sN2cIGAKGgCFgCMw3AiIhHB8ADvXksZ/EhJIwJ7FqfDQLC7RU+SDTsDTy8qqOn8zo6c/g6f1p9A5kEE/kcc2OMDatDaGcCq8hmgwtuIshsoqg8p3vfIeKTaV45JFHnHnAwn7nMzQi63yiafsyBAwBQ8AQuNQIFMhjeh+LiJrL+zjPVIhLAMOLZ1nBi8vsN7mlyqfXohR58jNJQPVUUZUW6cwRz5THeCHvbMg8lkn1VPv2SGraXnEvX7+n4xMJlMbhKNLiKZVKEVXpgvKp+gqK79zM48j0UdW0CP3jDZicyjrT41I3VfnG9iC2b2vn/rP4u7/7OjZf8UZ87r//R9c/uPHGG/G1r/+LR0CdVlINFwVwxx3vguYHpOj+6U9/+qIux1/91V+53/4P/+E/XNR+lsrGun7xtA+DExyvGIZTYe0a8WFVZR4bGv3Y3gLQGKBH+F0qJ2XHuWgQEKE1RYL81FSGIlBZzltSqEchFV1jsYzLn+IzQOUJWoEQIz5IRVYRWsNUQZYvoiKy0kVUQlY6EglynpzqwMwLkl0tBddgiM8bPXOY9kKpJnPOk88j79njKbkuGmDsQAyBBUSgk/PV1113nfvFI0eOOMvBM39e79vW1laXJbKpSKcFl2VHIo0cXqBVsejpcbzx+ptc0SOHnsNkhO+KQAlKKcwR4TzGufZT+L7/0Ic+hP/6X/9rYbdnwj/7sz/Dl7/8ZezcuRNf/O334UsPP+Le96r/B//pPyFcUXGmriIz6//gBz9wZVr8+ud//ucQcXWKonIisspJNE4qrZob0PmJU3ExzoisD84JPh/JUheH9Jx+ZvFVMiLr4rsmdkSGgCFwFgGZ0ZbXyzrLr3uFBWKX4lJuHR8bd6RWR3YV0ZUqEwWi68jwCFebRWgmvhy1NLnd0FjvTJHXNzRQUbMB9cyTaqEIrbbK7CzuKz2WYVuTl5mONJdDZzhTJYXW0ZHJM8RWEVxHhidp1iNGJcxqNDZXoaWtzvOttWxXUUduXapYXiyRVaTf4aEJPPvUMdx39x60clZv8xWrsXV7G+qbKnnPiUB+dmJuNpz273seP7z7XqfKqnv5V95yG1VZN7iVX8v9vpUi9cT4OPY+tQf7nnkWh1540ZHv29a0E8srHIG1qrqaSrfljqQf4GimEfNna01WZggYAssNgRwHTLIclE1RxWMok0B/Po796REczY45RRIRGq8tqieptQS1JLSau3gEFguRtTCA83CqBz9L9pC0HMWGUAV2hWpRDvYzlouMy8VfMtuDIWAIGAKGwDwioPcPDY9glOqsnUM5PNcFPNuRx7YWP7Y2AztoKraS5IS5vIaSVEwan8w5VdZH9yaxZnUQG9pC2L6pCJVlZ5VS5kJk/bu/+zscPXoU69atg1RV5DTRdAUXPPb39+MP/uAPHBnFFZzjTzEXgV/Mt6QRWc8BqmUZAoaAIWAILEoEPBIrVVE59k9jgVQ1zCNBr/d7QsqGivMdnZAvlE2Xx1me4OKTGAliMYZxmo2XE2FUegthkr/CJIkFgxRfYVxEsSKGKlMo0lihnohjIpQVsa4jlolUxjqOuEoCmcbONXpe6FModKPpCqfjCvc8+RDe9773urHy557bj1B42jrJdL09Tz6Cu+66yx3no48+hubm1fjxj++BSC2aF3vsscc4T9bo/Q63kZjCjh07HEHlm9/8Jm6++Wa37YX+WWlE1iSJyt3DPiqx5vHoEaC2NI+NjcDWVX6s4qKncNBToS1c1wvF1bZbmQjo+SXymIRkRJrOiUDPeN6R8Qv5HjFeZfEEn1UkuIroeob8Oh0vEF5VJpVXTrmjlAqtpWUhzjcF6bnArlyh58vLlU/PPBHeQ3xemTMEViICDz74IN773ve67+eenh7HXZmJg77DW1pa3Jz2X/zFX+D2228/UyxRBjemQHGOR3/6MN733ve5/fxTxx48lxjETqq0bgpWop7j3KGX7eeOO+7Abbfdhueff959359rgchXvvIV/PEf/7H7/Ye++x288wMf9Op/7GN49y+/EbXbrjhzLIrMrL9nzx7Hyfn93/99fPe73z1TT5ZdxMkZZv9ATn0HkV63bdt2ps7MyLPPPot9+/bNzDpnXGMQBw4cwNvf/nbs3r37nHWWc6ba0VycEVnf/e654GR1DAFDwBBYVAhkSDKUausElVknSGgdJ+FrYnwCY6Njjvw1NjbmCLAiw/ppo0OS5xqYV+j5IFUhi0h2jU4runKli1N0LT2TVllhu0V18nYwC4pAIpFCfCpFZeBxmuSbcOHYyBTb2qQzW+vaF9uWU2LlKsViKrSWcWlteYWUW4tRwbBAbnUDTYt8pOJiiKxTkwmqrw7jwL4OnO4eonJyApu2tWLblW2oa6ikWvLciESpVMqR0p9+cg9+fM8PqTi6DTuv2YVNWzY75dEFbQAL9GMahBB5dWx0lNidcr7n9Gn3nBMeGr6sqa3B6vY2+nY0r2p2z6+ARjjNGQKGgCGwwhFIcABoimbmT2Yn0EE/lKOaOoeGwvCjjoM/TfSrgqVUbA07dVYbbr2wBrNYiKwT+TT6cnE8merHi1TkvT5Uj62BKjRRjdfUdy/s2tpWhoAhYAgYAnNHQCSFiYQPR3pyeLGHylspkVQ8ddb2WkA+JCW0s3zUV+ycc86cEMrjeFcG+w+nMTSSdRPCV20JobUpiJrKgCOVzIXI+hu/8Rv4+c9/Dimrfetb33K/1d3djWuvvfYVv3uujL/8y7/Eu971rnMVzSnPiKxzgskqGQKGgCFgCFwgAlrEKqJWhuTTTNbnCFeesinNbdPCreJSSpU6qstnKBX1XE7beOqpXplX11Ng9cgkeZHAOOYqgpjYJUopfsYrzX2rWH8UqkxEMoWBaeVTqRSKrOqRWj31VBG9CsqpCqWoWsgrqK0qX3lSUHXljsR6lsCqn53NaSx548aNjnwisoze6XISgDjNceU777wTx44dw+te9zpHTNH4s8aZt27d6sahb7nlFmeeWP0Nici8//3vxwMPPIBVq1Y5kqsIORfjVgKR1bUVgtQ3JhKrp95Po3+uTbbV5rGp0YemSh/K5jYtcjFw27aGwFkE+HxKkKCaIik/HpcFCIlD5VxchP14PHsmnmRZKp3jk5COf7Q4nEaPHKHekepn5GlqU+qsem55iq6MS+WVPhLxlF4VFlRfRdTX80jbmTMElgMC//RP/4SPkRhaQXXTw4cPn5PIunbtWhLIJ/GFL3wBv/Vbv3XO0565n7/f/wj2JPp4+/nQSlXWtmAZtoarsXXdxjP7EXl2y5YtjlD6mc98Br/zO7/ziv1+/etfx8c//nFn0fTZJ5/EdhJERUD9U6qr31xTjZabbkaorAwBklHlZtYXQVZ9hDe/+c2OiCqi6v/6X/8L7e3tru5Pf/pTfPSjH3X7W7NmjbP4cq7FsLIE87Of/cxtM9ufxsZGdHV1GZF1NpBYZkRWI7K+ShOxYkPAEFhqCOhlKy9V1qHBQfSc6kFvTy/Ncp8mya7Xxfv7BpDistvyijL3Um9oboRenA2NVGulYmvdtIprKCRT8cHpzra6EfynFbGu8+2FSw0fO96LRyBF1VEpj3ae7EfXiX6cPNaLro4BdJygKZ+wViYWo7W93vmW1bVoWlWN2oYKDmZ5ZGp9uHkfhIuvDV0IkdUN2HBUr5sYHDzQjQd/uJeE8Ch+6bYrsXZjM5pbauYMuu5dKZE+98xzePqpp7Hn8SfxrrvuwNve8fZlRywvPKvyJNyn0mmSdwdw4uhxPPnY4zh08CBOHDuOK3ftxK5rduOa112LVVzJV1xS4p4/cwbUKhoChoAhsMIQEKn1WHYc+9JDeDzdTzJrwCl2Sp11Y7AcFb4ij8zKQd3lru4935d+MRBZednQmZnA05khdOemEM+l8bZIG7YGq9hLN2cIGAKGgCFgCCwcAlJvm6Ai209eAPZ3q1+Rd8qsb9jikRUiVFfTu0nf/+dzmlyejOVxz09jJLWmsWltEbatD2Hr+iIuys6TDOvH1VdfjVOnTuGLX/wifvM3f/MVu5LSmiaLREb553/+Z1d+9913O7W1V1Q+R8ZXv/pVN4F0jqI5ZRmRdU4wWSVDwBAwBFYcAhr35FvQkT/1KjyTVj5fji6tKirzAuZ59fQG5QwPc0VcpdIgiaxSF3TqqVRClTqq0kmacU8on+qqXrnqkMAlRVW+o6Wu6pRUp9VXVUf70mKTSNiHKH34TAgUR0jGYlrv8AjN/EbI9YgyTz4SZnmUIhbMLy1mGCX5lDzPwBwtj02f4rwHX/rSl/DZz37W7VcEVCmbSQBGaqsi0oTDYdxzzz0vUU9TP+HDH/6wI8CKjCMzxC+++CL6+jS3Eca9997rCDMXe7DLnciq9srmSYI1sLeD/mQOJ2mFubYMuG27D221FKYouVgUbXtD4NIioGdsmkTW8YkM5+UyGB1N0Upl2qVHxxTPUEgq7eWzXC4Y8qOcaq0VFUVnlFsVl4JrRUUIFVRwLS0LOBVXfs44Uqy203eR922kedFXplXHnCGwmBEofGdLmVSLR7UIZKbTXENTU5PL+vu//3unojqzvBCfuZ9DXSdw71QHfpHqRcQXxGqSWe8qXo/NzW1n9vOmN73JLVw9fvw4PvnJT7p3eGFfhfDP//zP8fnPfx6bN2/GA/ffj5s5PqD6nyC59dr4JNp++TaUr12HcHm522Rm/YJC6MmTJx1ZVaRZib3NdD/60Y/OWHq5n/s/nyrrzG3OFz906JAbuzBF1vMh5OUbkdWIrLO3ECs1BAyBJYmABkKSySTJqkmuLo0jNsWJ7njCC5mOc7Wq8hMJKnZxFWqSIxxajeq2YZhOpV0HRCqt5ZUVqKCvrKqir4DMecvMeTlf9pFoxJHrliRIdtAXjIBWa2copy8FUqmOTk7EZ/gE21eS7U3tKoUEQ63SFnG1uq6cqpplqKmvYFjuVErD4SBXLV7c6uYLPpFzbHghRNax0SkM9I1i7xNH0UkybzXPbc26Rmzevpr3SvGclVh1OFpJ3tXRie9/+3vEMc79rMWua3djy7Yt/LhdfMTfc0A45ywNKo5TRfo4V8YfPXwEp/jho2dTCZ871TU1qOazprG5yRHs6xoaOEAa5SABbU+ZMwQMAUPAEDgvAllOdkmxczCbQG8uhn4qd/Zl40giB/basIarmtsDpfRl4FIlBCQzYG5OCFxuIqu7tiSuvpAdwf2JbjT7i7EtVE2CcgVq/SZvMqeLaJUMAUPAEDAE5g0Bp/7Gid9TIz50DgHH+kmqoTqr+Cw7VoMKXEBFsczInv8n3cQx574On0w7ddaT3RnU1/hxzfYw6ms5EVzKnS1yZ0TWRX6B7PAMAUPAELgMCOj9RgFVzq/AkUnTaSqB0kspVXERTBVKUfVMfLpcaVfXpT0lVpnRljKgCFEioXoqgRpv91RRvXyv3CNNkWjl6ospxYUhVDwt1NH2Uk6VCqrLd+VeOkhFVKeyOv07qqf6Z/KZLnJ1lDd9HJcB35f/pMwDf/nLXybRbPQlRSKZaMGK1OFe7r7xjW84MswU580KTuaQZZZYimzz4ZYzkZXTPSRSA11UYX2+G+gfJ2mabbe91o/VNQppql1kaBvKn4+mZPu4hAiIkK35S5FZU6mcezYrTKWyM+LK98pdHaldM+19yzA+I81pU6+M+9R+pdAa4WKAkpIgiXEBWrRUKMuWAYZBF6rMKVaTIGvOEFjMCGiRiBTQ5To6OthuX/qQl/VgEUnlvv/977tFqS7xsj8z93Oi4yRO+5JOsEGW5oZzSdyWrsUbtu5yW32P+7mGi1vf+c534oknnsBHPvIRp7z6sl26d/rXvvY13HTTTfgm3/Hv4nEW6r9+cgwRclzWv/N2VLSvgZ/HLUJsof6//Mu/vHx3r0hneXO3tbW5RTDqc9xxxx2vqDPXDCOyPjgnqIzIakTWOTUUq2QIGALLCwG9cBMktsqM99DgEAb7BzBI9dbBgSEMDQxieGgYoyOjjqgqBcSKShJXuTpVK1TLqOLqwvIydr5LoJU3ReEi12EpxIPBkEuHikKOfLe80LOzORcChVXkoyOTbEfj6D01TDVg+SGMDk860mtlVSkqq0lSJJm1qpq+phSl5VF+rIXZhkJOzTXM0Q0RW4uoBEx+zYK3n9dCZE1z9FFk3u6Ofhw5eIpqor1OqfamN2zHhk3NqCVh16/Rvjk6YdhxsgMvPH8A9937YzQ2NeKdd76LirbNjjw+x90s6moiy4tAPznOD5KhIacQfYKr4jpOnHRKtMUlJOVs307i7lZspo+EI04VelGflB2cIWAIGAKLEAGpt2T5XjmZm8Sh9CgOZccwlk+hjoTH1f5SrCWhVeqslf6wI7gGtVhCL15z50XgchJZOa6OeD6D41Rj3Z8Zxt70AK4vasQbw6sQJUE5ZITk8143KzAEDAFDwBC4tAiIyDAWpyprVx4He/I42gdsJIl1UxNNA1YDNSSj8pPfkW3OdSSaPI7TxGfHqTQeeiLJRbN5rG4OYvOaEFav4tgAhwZEqlmszoisi/XK2HEZAoaAIfDaEBDhKM9vYoWeJ7mJ6qUeyckjOolQmmOGFnO4uKvrleWn6+o9prI0w7QIqySrSrHSkVNJdkqL8MQ8hVImd+msCKskuJK8KhPXNFzltlG9LH9D3+qyhMupFpqwJjkw7D8TV1q+iKaunZKqylj3bP5L4yJLOUtpi/fV+tou3HRtjTcXVFU1d7V+/XpniXC2nWmO7IUXXoAU2LZzPLq9vX226q+5bLkSWWmoD1NU+e0dy+Mw+37PdVGtl22uodKH69b50ML+XxGV9dXOzBkCyw2BZJJz61S3npzMOD9BJdepKS8+OaX5Qiq7TqQpKpVx9UJFfs57UtmaJNYCqVXxKAmu0Wkyq4iuqhMOB9xCA1m21AICLUAIBmXl0sf5dr9TcS0sLNDtZZa2llvrWvzn09nZieuuu84d6LmIqk899RR+/dd/3bXNAwcOoLKy8pwn9fL97Lp6N5K5LA5QvOEg5zDWPTeE29/xTrefJ/Y/iyh5KX/00f8P3/nOd5wy6//7f/9vWune272fN8u73vUuaH7/gx/8ID796U87wmuh/seuvRqDLxzA5t+8C3VX7URpYxNuJxF1Zn0JL/X09DjOy+rVq9mXY2duhtP8vfLVd/j7vz+/2uyMTc4bNSLrg+fFZmaBEVmNyDqzPVjcEDAEVggCeuHqJSzZ94L6qpRZ0xwlkYnvdDLlFFrHxsaomDjuVrOOUTlRxNdRhlJRlHJkgMtyK6sqUVtXS183Hdairr6OiorVTsVVRD51IsytDARE7lSbUphKZpwqq9RZpdo6RIKr/PDgBMMxEhknnFqpVEsbV9WQuFmFhuYq1DdWkuhayo+z4Gsigs4Hwuq43nffffjABz7gVlfNts8RHv+B5zrw4vOd9B3Y9boN2HZlO1rb6pwSqwi5c/2YLNyT93znbux96mniUoItV2zFLW/4JRLGixHQMvdl4Hr5ISDS6r69zzglVhHnG2hqYu36dWhfuwbNNAGlZ0pJSSlEatWzY64YLgN47BQMAUPAEJhXBDTBlshnEUMGI/kkTmWncDQz7lRax3IpbKea55ZgJdZR0VOkVptimB3+y0lkzeZzGOSK9B8muxjG0UwzS+76BSrBN6VNEM1+6azUEDAEDAFD4BIjIIW5KZoy7qEQ2vF+khpIZh2ezGNHqw9bmn3Y0JBHmMSZ8zkRgqZiXIDTTeXxoyk8+2IK110Vxq5tRairpmoRFb0WqzMi62K9MnZchoAhYAjMHYECKdUjkgKJZI5KqZ5aanJGPMGFF1JMlRKlV0dp1nN1vHiC5VLpc8QjEpEkVia9BhFNi0hEcqp7StMrrvxCuVd2Nq0yDQlLPVVrFzXFIhVWhSIxSZk1QO/FC2Ve2kelVa9uoVzfjSTFsrLqm7v0CCxXImv/uKfE/9hRn1NhrSvzYesqH9Y3ANQsQSTItqfGZ84QWIYIcKiVc+takKD5dS6AYNqpcDPu5XvvAK+c74p4BvEEx2Zj8ozHc2fCuMrizCcBlrtx743SkgDKykOcHwyijL60EJaFUFrm5ZWwjt4xdp8twwa2yE9J87U33ngjjtHK5vvf/35orLxA+FT/4mMf+xj+8R//Ebt27cIPfvCDl5BNZ57ay/fz2c9+loIcOUxRxGGccxZ/8fE/ObOfd33rC2j1lyB+31783od+zxFNH3/8cTQ2cvXstBuiaNKOHTvc733zm9/EzTffjLvvvhsf+tCHXP1f/OxnOPT5/4Fi8lgaqe5adu11r6j/4IMP4r3vfa/jvezfv98JuhX2r/Bn3Mddd93lsqQoK3XWC3VGZDUi66xt51Of+hQ2btyIdxuRdVacrNAQMARWJgLqeIhYN0HVRBFYx0lolUKriK0uZN7k5KQjLAaD6jRTJeNlqqxFHKUJcfmvVFujxVTdZChiWnEhXlzMFWZh1jHV1uXeyjxSa/oMkXVo8CyZVe1MTqTP8LQqaxFtD0aiYUdyjVK6paQ0wjbkhYpLvVXt7lIMur0akTXNZfQi6J7qGkTXyX6cPNZHsm7aDQLuvm4DNm1rZTuPcCCStpZeg5MK8ulTp/HAj3+Cro4u3HDzDdi24wqs27CO58oRyyXodG1Fjh8dHqHi8wD6enrR39fv1J8naWIiy9lKndvq9jas27gBrVzNVlNb4/KMvLoEL7gdsiFgCCxaBPSmTZLQOkIi5PHsOLpIaD2ViyHqC6DUF0S9P4oGmqlvZFjm48Co/6VmgRbtiS3wgV1OIutpXrMTVNd9PNWHMK/bDaEGrA6UopYKu+YMAUPAEDAEDIHFgsBEAhiYyONAdx4nBmSO2IeaMmANzcu2VPtQX+6ZKD4Xt0ETwVNxqroeT+OJZxMoKfajviaA7ZuK0FAjhaLFuXDDiKyLpfXZcRgChsBKQ0BDyhp7lNqpSETZnM+FUjilWJZT+PZClXtpZ/5ZdZnOsX6aRKSzdbQPj4jk1FW5YHBmuqDS6uXxtwl4gQBL7oUXZyZ34RYaimzqEVQLhFUq7FGl0iO0iuAqwmqeodRVPUIrh7vPxM+QWEmGVb65pYfAciKy6n4bVz+PJNbjA3l0D+cxGgOqqby/scGH9to8mqjIeinma5belbcjNgT0ftJ7gQscuNDBkVVfQmL1iK0JElzjjuCadaRYvcukuKqFCwXlVSmyirBaSFNbinEpb2thhEKqclPJVWmFmkosxN17xi2g4A7NGQLzhMCXvvQliHiqOdx//dd/xU033eT6Yw899BDe9773sc0n8bnPfQ7vec973C92d3fjr//6r138wx/+MFpbW118Lvv57Of+B8besdNZIrvFV4+3bX+dE1m75ZZb8I1vfIP3ht8JtolU+8ADD2AVhZJEMtW8c4ribVu3bj1T/x++8hUc+9530P62t+Pf/cf/9Ir6Em8Td1D8mNtvvx1/+Zd/6Y5T53n69GnceeedjsD7ute9Dt/97nfdObsKF/DHiKxGZJ212XzKiKyz4mOFhoAhYAgIgQLJ8BUhO+CpdMoRXUVM6zvd60yE95zuYUjPcITkNRFfpc5aV1+PxuYmNNHLXLrChuZG1NbWckVZCVU3bTRmJbQ4tSN9wOmPVOLybEcDfaNsMyPo7hhAd+egC/sp4zI2OklSY4VTZ21qqUHTqmo00y5hE5Vbq2vKES0JX5IVh69GZJ2aTFBJdhw//dGzOLi/0w1a7rx6Pd741t0oLqV55siFEbMPPH8AP3/oEXTQlJEI3ne9791Yv3G9W/21VNuGOvwiw79IExJ7n9qDx3/xGFeXTvHaFePa66/Drt27cAVXyUVJag9yZFcfBEZgXapX247bEDAElgIC3is4j/F8GgNU9XyUpMgXaLJnIpdGW6AMNxQ1YB1DqX2aeyUCl5PIqmv1TGYQMRKS1/IavSnSihLw3fnKw7QcQ8AQMAQMAUPgsiHgvvf5chqPA10kOPxkP6jSmkMpFVVv2ODD9etE1OHk63nmUrX9yFgWpweyeOiJBDpPp/HWW4qxdX0Raqq4iPo82122E+YPG5H1cqJvv20IGAIrGQERhKTonaAiqhTu4jT1nKA6eEyh8hJ5l6cwRi81VcW9UPW9tOqn0h65NUxCUIQLJyIyAx0GTUFPhzT7HJXpZ5pPL2bo1fGxnJ715bWt6hfznScCq4hHZ0h97gX5cjPQnjqqrqG+1fWXW7iY9+ds+YxMiy4hBJYTkZW3G471A3tPAs9zwVKM99gbtgDbVnmLldS3O9Pel9A1skM1BBYCgelXgJtv1/zX2fl279eVTqX47uL7aHwsg9GxFMbH05xfT0+HGcblNSefxsRkhu+kAAV1glSNDKGiPEgrh0Uop5JrRYWXV1nppcuo5Kp3k92fC3GlV8ZvxONx3HHHHe47WGcsJdRIJIK9e/c6Uuk73vEO/M3f/M2Zdr5nzx782q/9mgPne9/7Hq655hoXn8t+/uyvvoQHE93Ylx6itbkUbnl4AB/9/Y84smlFRQV27tyJF198EX19FH7gvPq9996LLVv4cpp2UmUVeVZz1XOpXyDXanORYnfv3s0+ZtyRYyXupt+45557sG3btsJPXFBoRFYjss7acIzIOis8VmgIGAKGwKsikOVyZa1oicfimJqccgS1KZLUzsZjzItxVTNNzWfSyFDJMpPJuHSGKo1SY1TnWS/+isoKmksonxGWu3RZWZkzsW4Et1e9HEuygj7QYrQ/GI8l+QEWwyTlWybGFMap+Btnm+FKRPo0l9Zn6TMuzJH4zMFDKrSWlVE5rqKYbSXKj7RilE7HpdoaIDn6QkxrnIvIqoFRHd8pEm2PH+lBJ5VY1SZLSKZtbq1F21qqorXXk4wpdeLXNrOWSJAYOzhEkufjuO+H91GFdRu279iOHTuvJGG3ekldV30MZHmPDwwMULG2GyePn0APV6rFuZJNN3s0GuU51aCugcT2JpLZGxtQXV1jqsxL6irbwRoChsByQCBFuZg4TfX0UJVVvo+kVpntiZMkWeErcgqta4NlaAwUo5wKrTJdbw7OXFJ1dTX+zb/5NwsGxyRJx0PZBH6e7sPRzBh2BGuwJVSFdbw+ujLmDAFDwBAwBAyBxYhAimp4k0kfVVnz6BoiqXWEanQ0f1kRzTvCQ2sNTc+S6HOuz2eZao5RmfW5Q2kc7Uxz0okEicYArr6CY0dlIhEtrn6JEVkXYwu0YzIEDIHFioDIPHquZ6g6x6kCWnJSKMEMLy3FVMULadVx8ek8qa96ZTLr7O1L48saA/bUvkn+nI5r3sHPPwqlbqe3h+p4aa++8lVHJFKVSfFO6qcKQ/RO+U5pvsM8NTyprHrvL3tk6HMAAEAASURBVJUpfqYu91XIkxqr2+1ivRB2XAuCwFInsup+5dQMhiapmN/rY58uj74xoI5q+02VwIZGn4uXhHX/6D4yZwgYAheKgNRYM1QJT6U8Umsyqfl3j9yqUMquXujlOyVybuPUwnmfFhTEle/y+K5V6M2ta2FGwPmIFmZEaRHThS/Pk6Kr91670POw7VYGAuO0uPne974XIqkWXBEt9N5666346le/SlVgrvyZdiK4vu1tb3OpH/zgB458WiibbT9f4X58nHPvnrYs15GdcPMXFXc/h0998o8gPkrBtbS04I//+I/x5je/uZB1JpRy6yc/+clX1P8U8954880IUmgpMON4v0Ll1i9/+csYHR09sw9FRF7Vua1du/Yl+ReSMCKrEVlnbTdGZJ0VHis0BAwBQ+CiERDxUGbFhwYHSWwbxGD/APp7+x3JbUDmxQeGMDEx7gaRKququGKsEpXVlY7oVlVIMyyvLKdiR4hktyJHTgwxLpJigKNKhbjk480tHwRyJDknk2m2kTEM9o3THP0I284oBnrGMNA/yg5ngtc+6AisldVlbDsl9KWoqiklGbqEbaaE7SXIOgH3oSZyqdqIn4OOARd67cXL58ClyjnYooHORx99DPfffx/e/VvvRWNjM9KpDFdCpqgcO4Zjh047ImvPqSFs37kW265sw5btbSgti7jfea1XQCTvkaFh7H9uPxVLn8aTjz+J33r/e3DrL9+K4mmV0te6z4WuL/KqrpdWpUltdXJyAl0dnThy+AiOHDrk7vuKykps2LgBV1GBdc36dY7Eqg9oc4aAIWAIGAKXH4EEyasyW/9iZhRPpweR9eURzvuxlWTJdip/NgaiKCW5lTroCPDZvZJJrQupyCpFnhwnU7szk+7aHMqOucG6X4+0Y1OwAkU+9nEuf/OxIzAEDAFDwBAwBM6LgCMr8YUmZdZnO4GjfTJHm8fuNT5savTUu0R8iNCc8rnc6f4Mjndm8NizSUdeve6qIrQ1h1Bb5ZnXXCyflEZkPdfVszxDwBBYbgjoma5vFBeKHMOICDKFZz3yPuZNlzPMcrzwbN2Z+SybJrEmScwRYUdkVQ4DeyQdR1hlnPkqd2UuLnKrR2LVNknW037yOSp9c4GDlFKjVFEVD6GgnOqpq3IBBJXAI1w8IZVVF5fiqtRVme/V9dRUpaIqt1jeL97R2N+ljMBSJrKKbJ7K+jBMEmvHkA9PHc9jiqrGYfbbblifx/ZWkuGksm+GFpdyE7VjX4II6N0qNzWV4Vyc5ycmMpxrl6eCK/3URNaFk8zTIsF0KuvUW4uLqeJaHKRAT5BhwIXRYj9KmOflB/ge1bvU+97SIpEA51Q1/a65VB/HjL10IX+G8rh3WPZ3hSEwPDyMp59+2imySmlVyqwX4l5tP1MU5DhBIuv+zDCeTPZjg78cm4/HMNBxCjupCNvW1ka7Zd48/7l+X3PxB/bvx/GjR7GWYktH/8d/x6rXvx7tt70ZlWvXoYjqrjPnrCVAVVB6lZLr+vXrUVdXd65dX1CeEVmNyDprwzEi66zwWKEhYAgYAheNgFZDi+Qm1VYRWlO07ZNMJl06lUy5eDyeoILrpFsJIxPkkmafnA6VVn0puYrkKnXKmlqZla/xQhevJpmxzCk9Gpn1oi/ZotmB2k6eo58is+ojK6n2kki7tMJEPMU2k2TbEXkywTZDBVequU5NJlxa24U5GllcEqGib4TqrUUuXgiLqebq8qmoqngxQym8FnGbR3/xKB548Ce49Za3IJsMo/f0MERc1W9GIkVobqlxCqwNzVWoqSsniTXKVYqvfcTGU6ON4dALB/Gv//JtqrmGsHnLJuy8ehfWbVjviNozO86L5uK87EBEYNU9++KBFxxx9RDNOGggu7SsFC2rV2NVyyoqrza6+1bKy1ESdC/0Y+ZlP21JQ8AQMAQMgXlAQGRJKbFOUflzhKqsp3JT3krn7CT37kODP4rNJLVuDPCdR3XWCAmUK9UtJJE1I9VcZB25+MeJLqwhqVhKrJsCFaj1R0ztZKU2QjtvQ8AQMASWGAKaZ42TcETDKyRBACcHGA7mHelh2yofNlLJaw3ng85FGpKJ6FESX58/lERXbxbDYzmnynrNjiJESFqSWtBicEZkXQxXwY7BEDAELjUCnP93KqoikzqSKYkxjnwqUinjyo+T5KYyKaZ6RNSzIacHkJgmpua4L5FigiSOSuk0RGKchlYLoRf3U+10Rh3GQ7Rdrm08FVRvW9UtkGy0L6e4yn070g1fExI1cL/FAoUufzp+hpCjeszTu+hc76NLja3tf/kisJSJrKPsu/VSffWJY3mcHsmjPOpDW00eW5r9qC4FOCXilPUXR29s+bYhOzND4FwIeHPvfC9TxVyLOqTkKoXz88VTnGPVIpBEIkvvqbsmEhLw0dwr39XKpwKs3ud6pwb5Xi4tDaGUhNeSEo/wWlrqkV8VziTCqr69O891lSxvPhHIcv4iRjLrIK2WybrcEVotk1JrmT+EtkAprg7VoYpCHMVMn8/lyVfJkKA6tP95dDxwP5IjIwhEoth052+gestW+CigtlBz8kZkNSLr+dqpyzci66zwWKEhYAgYApccAXW2RVKNx2MYGRnFKDsNI8MjGB1WfBTDQ0MkJ3okV8nQh7mSJxoVKTGKCE2UR8IRhtNpV+blR4sj03WVZjxMgiK3VwdkoTohlxy8FfwDajcpqqSKtDrO2bDR4UmMjU65cJyh8ibGY+5aB6nIKuVWKbN6Cr4yjeGlpdgqAqpXxwuV7uw+jKMn92Nd627KC0RJ0oyRHJt0Cq8NjZVYv3kVNmxuceRY7eNCnM5B5O5DLxzCc8/soxLrE1i/cQPe8ra3oL6xHuVc4bVYncjpCZJXZfJB9+gAlZaltjw4MODSY2NjVMWtJIG1BRs3b0LbmnZHYtV9aM4QMAQMAUNg8SLAJSTu4HqyMXSSxHokO46hXIJ5PjcQVE9lVpFa60iirKYP0wajVjqvJLdQRFZdiUkSiw9zUO6FzAj2p4dxU1Ejri2qRwUH5VYymXgltTc7V0PAEDAElhsCQ1wjc4pECKmzSpm1mIp4LVXAugYunCkHKopfSYiQGt/p/hwOHUth36E0mur92Ly2CO2rgqipCniEpcvMoDAi63JrqXY+hsDyQYDDj85JWVFEVA7pUSnVI6SK/KK0ylz+NFFV5SLCFIirZ7dhvggz3KcLC9tSiXVm2m2rMtbNs+wMyYb798wee2RRLUYoIlFGQ6tSVHWqqkyLpColVSmrujLVoTKc8qgB4NQgtZ3iqitvBJrl02aX25ksNSKrnhkxkt1GYz50DuWcEmvvqEyTAxsa6Bv9WF/vXSW775Zba7XzWa4IeORWihjEs5znzCDGUGquSk9NZadDpmM5TMXSrk8gLLS4pIjzqkEpL3Mhid7FyguFGKcPKmSe3ueubpHmYr1yL6+wzfQiFM3RGul1uTazBTsvtlAKcmSwPzUMWS8bzac4RxFAi78YrRSBaGZY4Z997DzW24uhQwfR/bOHMXrsKNa8+a1o2H01yqnqGlAHdAGcEVkfnBPKPippTX/OzKn+sqlkRNZlcyntRAwBQ2AJIyBCn/McFZPJIZHktComy1Ezj7CY4qowrpAZIGGORLmBvn5HmBvoY9yR5wYRi8XYcQ5RpbUWDU0NjggoBUjnma6dVm71ccm1qbYu4cYy49C9NsOBVrYfmbVXKAVXxdV20ml9hFGh1am0SrU1Oa3Y6im3OhVXqblOStWViq6MJ2JUDKbaa+0qoKaFNq1iTWhqXoVVrbVobq1BXUMllYFLSIwu4gcZl/u7VfoXNmMmMwZSIv7m//4mXtz/An9jFXZdsxs3/9LrqRSwuNupCLh9PT04fPAQ9jz5FI4ePkzF2h5HWt1yxVbs2HkVcWtGdXU1P2ZDjjis+85I5DMasEUNAUPAEFjECGiFc5oKrUkqgvbm4o5I+SLJlCdJbm33l2JLURWuClSjPlCMEt+FLehYxKc/66EtFJE1y35NF/G+O9nJ1eZptAZLsTNY61Rx/SQQX1jvY9ZTs0JDwBAwBAwBQ+CSI8BPdnBNKoan8jja58PPDmaRzvlRFsnj9ZuAbc009cx5o4Dk9KYdX4mOUNXVm8FzB9PoOM1FrbE8brs5gq3rPWXWy02kMCJr4WpZaAgYAosNAVlM4jAplVDpqcAWT5DIQuW1xLSPKR2nMhvLp0hoUTizjpSxC3kiwvj4fNZzWqTTaNhPkQkSS7koIUIiS5Sh1rBHmF9E0ks04tURH0Aq2tEI609vKyKqlFH1/Nb3jRZVKq6nf+GZXkh7469emYsX6rj6RmJdbG3OjuelCCxFIutpElef7czjwCmq6A/kcf0GP3a0gmqsPtConVNPfulZWsoQMAQWOwL6pvLm4hVqYYs3L8+peOeU1ptWc6xSZo3FMpwzzWFiIu385GSGwjZp5mWYzrq8WMwjxEajAVq9DKCioghlZUHnKypCKKNyaznDinLlU9V1WtHVE5xa7IjZ8S1WBNRS5ZKcuxgniXU/5ywO0L+QHsGGYAWuoTLrJob1FOM4n8tzfj7Lee6j3/sOuh/6KUKlpai78iqs+7V3IFzOFbYL4IzIakTWWZuZEVlnhccKDQFDwBBYFAiI8JfNqEM85dRZJ0n+m6ASpEKptU7QpHkinqBCZ8oRYNWJcYNfCl3vnN1vjoxJabOktITmEMrYeS5nvBRl5WVMe6FUXqUYaWS7RXHZL+ogdN1FaJVqayqZoTmMNAmqKS/NPJFVlZd+eRnzZIJjdKIb/SPHceXWm9DGFViVVWwjlcVsK1L6LXKmpi7qALnxieMncPDAi9j71F6nzHrzra/Hxk0b0drGUaFF5kQu1702ONCPU92n6LsxNDjEFZoxd49J7Vj3U/OqZqfC2tyyivdWOSJUSTZnCBgChoAhsDQRcIObnBicyKXRn0+gOzOJ0zTboxXPMnlfxMnGOg4IrSKZtTlQghoqtNL4DvVZNfW4fN1CEFm5lAvHsxM4lB51SqzC9rpwPVeUl1AJl7NG5gwBQ8AQMAQMgSWMgMZsZG56kOqsx/p9TqG1j+qs5fx8bKjwYXOTD/WcOypjukBm0ulOkPzaN5jBgSNpHO/KoKkugPaWILasp8lLmrqVus/lckZkvVzI2+8aAssXAQ1pOwU1qpimqWwqc8EcHkdKIRcEuDzlKz5d5uWxDpWsVVdpT1V1Jk6F6X/mMfqScXD3GCWhdMY3nWq7ZzEjes5y7T0tXlGljev7Q1Rno9Erp4haCKWOWogH/HlPmW1aqS3I7YMB5jFtimwzr4nFlzMCS4XISk0QUO8DR3q5qHbYB5FZi3i/Vpf6qcSaR2s1UE5OUOgy9reWczuxczMEFhMCmiNVXyKZpOeCFhFbXVxp+kQi67ziqqf+ipybj3ehS3p/XEfibFqLWCKRAOfiubglEqSn4jrj4XBgOp+LY5ivRTJFVHiVsqs5Q+B8CKRIZpUIR1d2Csdo1SzmI5+EnWipsrZyvmJtsBxlvhBC57EoN3hgPwaefQZ9e54imbUMbbe9CVUbNqCksel8Pzlv+UZkNSLrrI3JiKyzwmOFhoAhYAgsCQTUOU4mk47QOtDfT6XIPqfU2kdp+P7efudHRkYc8bWqqpKqrTWoqavzQsbr6uuo2FqLquoqR3QNcLRNJui1GtzPVeb+gMwdMM0etqlKLokmccEH6Ug7/LB67LFHcf/99+MDH/iAI7Je8A7PsaGI2VI0/cXPfoGHfvKga2dta9rxq7/+NqcmfI5NFjzLw0GD5CT7kiAuknjv6R4cP3YMB557ngqsR6jWEEcd76OdV+/GFVfuwKYtW/hxGaYC68pS5lvwi2M/aAgYAobAZUIgTfKqTN0/nxl2K50PkmRZFghhjb8MW4NVWEPTPaX+EMKkswanpz5fMil6mY57vn/2UhNZpYabyGXwcLoXL2ZGwblfbAtV4dZw83kH3eb7HG1/hoAhYAgYAobAQiAgkpaEfw6TMPFMB4kTfTJvDVy7No9NTX6sqiKBQuQnkqVmuheOpvDcoTS6qMxaXubHG6+PopGk1hKSWWcSX2duc6njRmS91Ajb/g2BpYWAnm+FMUbRQgtxnYWUz1jsFM8UijSqZ6G2kfMU0rx0UiQSEv9TaaqpOgVVpamYyniK+Ql5xj3FVK+uVy7SierwuSoyK3/TqaY6tVSppJIkQtJIMRVTaXTKKatGoySRKD6tmhphWbHirm5BhZXE1Zc9k72jtr+GgCFwPgQWO5FVzyRx0MbiwOmRPB47ShIrQ5HOr1njoxornxkhr092vnO0fEPAEFiZCLjvOXZipMzqKbd6qq0TE1JtZXyMaq5OwTWDsTFZXvVIsCUl/HYrCVI4KECl1hBKqOZaRtXWYuaXlXKRIpVbVRaNitA6PU/vVNxFas1znp5q7vyjbz/N4btQRfTLcSx6Zbau13bWEt4YyaXwZLqffgAh8juafVFcW1SPFlo5K+eouvJeLsCR4xz45OlT2P93X3NhzdZtaLruejTsvhp+ckUkknapnBFZH5wTtD6SEaY/k+ZUf9lUMiLrsrmUdiKGgCGwwhEokANFaE0mEiTZJZCkTzCeSCSp2Eqz8YzHpqgkRhXJ+Jk4811ZkgN7aa4SD6G8ssKRWqtJbK2qqkZltczJV9FXOiXXAqF1hUO+bE9fg8uPPnrpiKzDQ8M4cvAw9jzxFPY/fwC33HoLyaC7sLq9FdHi4kWBqwisuo+OHzuO40eP4uihI/zQHOVgeg7VNbWO/N3Q1OgI4NXVukeqUF5e4cyL6f4wZwgYAoaAIbD8EMjx/ZgBVctpsmc4l8RALoF+rnjWquc4iZdFvgDWBcuwNlCO9kApikhoDVwuNsklhP9SE1mF6cnMBJ7ODGKUOF8XanBmkbSS3L8M8byEl8p2bQgYAoaAIbAEENCExASJE0OTeZwc9KFzKI/esTxoEIXqXz6sbwAVwDQrOa0IyHBsIo/+oQyefTGFgeGsM129bUMRrtpSRNKFZ6rabbCAf4zIuoBg208ZAoscARFRpWzIoTUSTKlUplAKZgxFPvWIqQyn89MZ33S5VyaFVa9ezpExNMwm8qgUTAthIV5I69lHDQaqpYp8Nh13CwH80/kkerDclWl/UkRl6O3be256SqtevhfntqxT8NreCT54j+RFfhXs8AyBxYPAYieyTiSA/nHguS4tLsqhmOT1Birjr6v3obkSqC3jc4D3vQ35L542ZUdiCCwmBERmlYKrFs7Ip9O5aT8jzf5QmnW8MtZx/SNPzVXbFJRdC+Up7YN15PTsEek1GvXIr2dDv5dPEmxJcRDFDItC7LuYgutiah4LdiwShpA66yDnK3qzMZygpbM+xuMU5WjjfMUVwWpalCtGle+lls7ynPNO0frv4HP70L/3aZx+8nE0X3cD2t/0FhQ3NCBMy6OXyhmR1Yiss7YtI7LOCo8VGgKGgCGwbBDIUtYjTaLqyPCI8zKLrvjo8LAzka74xPgEV8DzY51kQvmS0hLPl5TOiJcgEqV5eSpPhmhOXabTw5GwlyYJVvGCeuuyAW8FnoiIrPfdd9+8KrKKBCoi9fGjx/Hzhx/BMNsgGSl469vfSkXT7Y5EfblWC4q8KxK4SN5jo2O8N4adP33qNHp7eqhy3MsBbz9JrDXYuGkTNtC3tq12xO7LdcwrsFnaKRsChoAhsGgQyLC/lEQWndlJSJm1KzeFMa56rg1QEc0fdeZ7agIRVPnDKCGhVaTW5ULCvFRE1oIS68HsKPamBxEjvhVE7g1UYm2mKSSp3JozBAwBQ8AQMASWKwJSIxwYF5kVePokMEUlwVKqAW4gkXVNnc+RKIqpFEgr1k5xR0SwA0dSONKRQcepNFY3h3Dl5iI01AZQSZVWrf1YyPUfRmRdri3TzmslISBifY6yhLm8z5nIzfLBlMtRLZUhjStR1VRphfSs9/JyPceUn5EnGZV8DReKuKF0Ou0po7q4iB7KY1k263PEDylSi7ihUL+n33WEVRo+ihRJOZUmdkNUVnVxTz3VxalUdjaf9c7UYZxlMpwUIqljIZ+JK6nd2LkaAq+GwGIksop4luIzyKmwjnr9r05OVYzF8tjS7MPGRi4oaqQSM58f9ux4tSts5YaAITBXBNS3EXE1Hs9icirD+Uha/5pMc97US0vZdYr5ClWeTnG0lH2xIhLsi4rY9wlzjFn9IIbq43h5Xn6Y5SF65WnBTpAfjupHhUJe/Gwe+0UivLKsoOY61+O3eosfAQlxiNB6ODuGI9lxHEqPIOIPYhXH1tv8pS6s9kcQoSBHYHqsPc+Od2piAr1PPYmD//INFNOCb+22K9BwzbWoaF+DALkgl+JlaERWI7LOekcZkXVWeKzQEDAEDIFlg4BnwokDhhwNzGQzLszlGGfakVzTKUfkm5qccgRXqWaK3Do85BFeFR8bG0OM5VJmra6tQS3Nqtc31KG2nmF9PUN2bupqSXotdWRWI/gt3eZzKYisIop2nuzE00/uwY/u/iF27NyB2371zVjVssq1qcvZXqRoPNg/gJMnTmD/vudw6MWDOHbkKFa1tqCtvR2btmx2xFWpsEaiUX4kkshN4naQphXMGQKGgCFgCKw8BDTJm59e6ZwgqXU4n6QyawwvcHDoVJZ9Kaq2bgpWYFuoGhup0FpLcisFfDg8tPTJmJeKyDrFFeJ92TieoAmkh1O9jsB6dVEdGmgGqdhnNNaVd5fZGRsChoAhsPIQkIJhggqFUmc92JPHnhOeae2aUj9u3JDH2no/SsM00s3uhAhj8XgOXT1ZPLEvgZFxMsbofunaKLZSnVXErYUkXhiRdeW1Vzvj5YeACKgim6bSPkewSKT4nCGpPkE1VRr7cqHSSeXz+ZMgoT6eUDk94wnG46wrYirXrSM4g1AqommEhAtHPCWhwpFSOSf+knxHVFWZyKqsy22kKqYFgT6f9+zTfn0zTOjqOecWDLLclTHDq+M9A922WgCw/C6XnZEhsGQQWIxEVhHxR6Z82Nvh9blODgBbVwE7Wn1oqQKqSvgs4jNIzxNzhoAhYAjMFwKap1evRIRWtziIq4MUz3MRkZenfK9MYUrKrfQit06R7FoguRZCkV1Fgo3FvHKpt4rMWlYapA+htExh0AvLQjPiQafmKpKrCK3mlhcCOc5ZJElmlehGD+crDmRG8Gx6CDVUY20LluO6cD2afMWOzKqr7/gjnCOf6u3B0P7n0f3IzzB04AC2/vYH0HLz6xGuqICf8+Hz7YzIakTWWduUEVlnhccKDQFDwBBYMQiooyJCa4Lm1CcpIz8xNo7xcXqGE1yJI7XWyYlJTLFMTqRDmVB36qu03RSgWmWANpaCnC0pKgqjuOSliq5Kl04rvEajxRyIpDKZ2WNZtO1rvomsUjod6B/ELx7+OTpOnuSgdha7r70aN95yk1P1FSl0IZ3UYUXaFlG7v6+Pqqu9VIgddG0+xRF5KROzr08i6yo0t7Rg9erVJGrXo6y8zLX9hTxW+y1DwBAwBAyBxY9AQoNDJK92UKH1VGYKfXnaCKYLwY9yfxHquNK5iWTWWoZV9BokWqrDhPNNZNUQbjKfwWkOrO2hEqtMIKWRww3BemwlEXjmCnFhas4QMAQMAUPAEFjOCLgJSxJaT4/QvG0f0DMKjLNbUVnM71MSK9bWycStD+VRD4WxiRyOdabpMzjZTbOBq0JobwliQ5smKmWGe2F6HEZkXc6t0s5tMSPg+BA8wDTVvaTwlaVql8zSStXUy6O6KYe4RFAt5Cmfw3IzVFBVpjyfm8gWsUJOzyP11QuEC8UdAUNkC/6wfvul3quvp06Q48Qa6tP6b6mhFpEoIbKESPYuzjynlMo8L/3SesFAnvkLry6tszVnCBgC84vAYiKypvj8S2b9ON6XQwdV8E9TjTXH0ZlSEug3SIW1wYcy9rHCpl0xv43A9mYIGAIXhIBTuudzK5HIeouMGCYSXEykkIuH4iSwJrXgaDpPfUH130TC9/M70JvH9+bzC4t/vHyvnNP0Tt21oOxaUH2V4qv6cRGnAEuVV6cIqzl9U7i/oAt5mTZKc557ChmcyIzjcGbMzV1k2Luv8BVxnqIY7cFS1HCeQmm5dGwKcc6Tdz/8kCOzSo21Zus2NN9wIyLV1fDPs7CTEVmNyDrrrWFE1lnhsUJDwBAwBAyBGQiIfJih/af+3j6S//ppbr0PfYyLBFgwvz4yNOJIgJVVVaiTUmtjPVVbG9DY2OjidVRwVbqIUvQhLrtXR9r90yin4jP8jJ+26AIjMJ9EVg1y9/f248ihw/jW//2mu853/tad2LB5IxrYLhbK6ThEYJVPp1LoI4FVyqv79j6D/c89z5WLUygvL8fOq3fjyl07cRV9QX11oY7RfscQMAQMAUNg6SMwRVLmcC6JvSRlPkvfl4uTzBrCzlAttgarsM5fjpCPC4DYA3LqQUvslOebyEojWRghXs+nh/H9RAdWcxDtV8ItztRR1fRA2hKDyA7XEDAEDAFDwBCYFwREENt/Ko99nXk80wEUU63wdevgTN621XoqYRpKkdt/JIUn9yUxMJxDcdSH226KorUpiOLIwkw2GpHVuw721xB4rQjoPpdToPvZEUUZcyHHSAtpxxidrsegkHShSKkJqnVJEVXKqVJFlVJqQS01Nq2UOjPt1c0jJuKDtmEooiv5p4jyueF5v3uGFOLRCJ9DUT+iJDPo2eLyGY8yLxJmWYT1GRcxVcQIHr45Q8AQMASwGIisetbKj/N5Nzzpw0/2Z536vZRXt1OF9ZZNJLPyGReSKR1zhoAhYAgsUQTiIrhSNX9sLEWfpkgVhRcYHx/PeF7xCcVVlqYwlfpwAc6Lhpwvk4IrfYVLe3Gn6uryZaFSAlfe96U3l+/1XQtxheq7FtJLFMZld9hagCYC6570APZlhnCAFuWq/GFczbmKLZyrWBMsg58L1ZwlA5790IH96HnicZz6+SMI0ELpjn/7IVSuX4+i0rJ5xcaIrEZknbVBGZF1Vnis0BAwBAwBQ2AGAuqAigSYiCe4+ivO1V7yMcaZZhijl6KrypJUtUzTlLzULWVSPkXiYDqddj6VSk+rs5aiorLC+crKyjPxCsajxVFHdlWH19zCIzBfRFZdc7WJhx94CHue2INiXtc169bi+puuR01tDa8zZWUWwKn9qX12nuxAx4mTDE9idHTUfVRJIbi8ohzVNdU8plpHtFa8uqbGKQ5LddicIWAIGAKGgCEwVwS02pna3hjIxjFAddF+ElmH80mMU7FVM9RhXwDraMZndaD0jBmfpURonU8ia2Fl+C+SvTiRnXADnZsCFdhdVItiBB1Wc8Xd6hkChoAhYAgYAssRgZEpYICGcU7056kaBgxOSJE1j7YaHzY2+dBQLuJZHmMTefQOZPHC0RR6B7OOaLaeqqw7t4URocCKFBEvpTMi66VE1/a9XBFIZ4AU1VM5dMaQ5mPpXV6KcZXJnCzLpKaaVDnz0ySbKkyyLEMFVU9p1SMMyPCVFLhkIpY0AhcqT2kvn+WMuDzVnVG/UK66UnIWUUHPFi8tZVUvX0NkIqkW8l066Af/c39596xRmQ3nLtdWa+dlCLx2BBYDkXWKBNZT7Ecd7smTwErCPpUGK0uANXU+rKrMo7GSKtHTz8XXfoa2hSFgCBgCiwOBTCbnVPfVP0ylsq4vKaV+l04yrb5mIc2+pFPxp4qrQinye9t7aanBZlkm1f6c4lR6lVJrERdXRqMB54ujQRdGuJCpuFhxLniazguH/a7faX3Cy982tGBOdhMK8xRdmUn0ct5iOJ9AGS3J1dOK3OZgJZoDxSjzhZAeHcPkqW503H8fxjs7UEJBqobd16Dlll+i0i8/BObpohqR1Yiss94dRmSdFR4rNAQMAUPAEHgNCIjoKtVWEVlHh0cxNDjkzLUPMhwcGGSc6aFhjAwP0xQBJ1MilKwnkbVcZFYSCcvKykgorEAZ46VlpezwRmi+IETvqbcqHg4XcfA06PL8lAnwa9TV3LwjcLFE1gLpWde842QnHvnpwzh88DDecNsbqXR6FdrWtjui8rwf+PQO9fsi0CbpJycnMT42xvY4iM6OTnTRn+4+5UisdQ312LBpI7Zs3YrWttWoknkEa1OX6rLYfg0BQ8AQWHEIZEholdpoR3YSBzIjHCSK0YxPGqv9JU55tNVf6lZAl3PQKAyqF1GpVdPOi9nNF5FVg2hDJPp2Zafw81QPJonL7lAdNpDIqpXg5gwBQ8AQMAQMAUPAQyDNicOxmA+H+4BHj3BykpOMpVRD3NrsI6E1T2KrDxESMsgdozJrEodO0HxgVwZ11X4SWYvQXBdEdSWJZpeQXGZEVmutKwUBKRrlqVgks62a8Hch08w+m1a+xkgL5QzPlntxkQFo9MoRVEUu8EitXp7IrSKyzsyfGRcJQdt6oUcskApquEiqWnweyJNkEKanQazpPJYx7uWdrVOor3wOt5K8aiTUldKW7TwNgYVC4HIRWfXcJacLEwmgb4wk1t4cOod86BoCrmrL44oWH9aSyColVnOGgCFgCKw0BNSPTZLcGqeC6+Rkmj7j/NRUFlNTGUwxrVD5sVgWsXjGLWQqKgpwnt4jrkYYisQq8mqEyvwiuEYiFCZQXzQS4Dw+LZLxG7Sw8En9zIAWS7k8b3FVkKuhCgutFJq7tAhIVGKUYhtHMmNOoXUiR2VezolrPL6NohsNJLVWcJ4ilEij79FHMbD3aQwdfBG123dg7dt+DSX19SiiZdP5cEZkfXBOMPpIutE8yopzRmRdcZfcTtgQMAQMgUuKQIHMmuGIapqyASK2yoy7lDlT8lRozaRTmBgnuXB8nATDcZo2GMPYyKiXHmUe87Wd1DtFLJRyZ01dLWrpa6iSWe3SNSwvZoeYtqvMzTsCF0tklXKvlHifeWovvvft7zqScmtbK15343Voa29DmCTmS0UYLZBouzu7cOL4cRw88ALJtCfRc+o06hsb0NLaivY1a9C0qtm1pfKycn5sRfhhFUWoiLN/5gwBQ8AQMAQMgXlCQIMMIrMm8hwEzGcwSOKmyKzHs+NUak0gw8GjFpJat3LV8xqqtDYEoo7GupjJrPNBZM1xFXiWs0pPZgbweKqPBN4Amv3FuJZE1jo/38k+zqKbMwQMAUPAEDAEDAGHgOtPUIVRamJDVGc9RDWxI715TDBdU+rDtWuB1VRorS0FzYTn0TeQwYGjaXT3ZjA8msV1OyPYtTWMkmKS2kh2uxTOiKyXAlXb52JEIMN7MSnFVPqEU0ZlmJTnOBgNMMgnSArwQi8/lfG5ctXjEKnbXoqqmqznGn2nbCVz1lK40j0qBWUNT4UYV1r5KhdR1ZUXylgvxG6z6mk/Pl/+DBGgQEh1qqv8HYVenldHTwJXxkihjsSV5klgaTFeOjsmQ8AQuEwIXC4ia5KE/wn2i546DhzhYqDRGJz66rZVPjRVSuHej3Aw5xb6XCZo7GcNAUPAELisCIjMmuXKK6e+yrhTXuUiSimzarEWp+m9MqZdH9gRX7MUERIBliFJsHEXz7i0y0swj2XapxRcRW4tLQ2ipMQLFZcvZrqsNOTll1DEikRYU/W/9M2hMCYf44zFWC6FztwkjmfGcZIqrdJtbQuUcZ6iigqtFcDIOCYOHcLxe76PDOf7i0liXfOmt6Duyqvm5aPBiKxGZJ21xRuRdVZ4rNAQMAQMAUNgnhEQyVAyBBMTk/QTGKNE/RhNvCt0pNbptEiQmqwJUQ7AKbByBLeIMgJSclWovGg0StP09IWQxFapuMpcfUlJ8Zm6l4owOc/QLKrdXQyRVSRWXduDBw7iwHP78dwz+7Bj55XYfc0utK9bQxVejhTNo1ObEmk6FptyqqtSAh4cGHDKv6NsW1OTUyRPZ9js8mhZ3eqUV9vWtKO+vgElpSUcsOdovjlDwBAwBAwBQ2ABEOAbCcPZJE6QyNpNJdIhqrUGOFtcjCBq/GHU+MJoCJagyleECpry8bNssZFaL5bIqvexVn53UqV2P1Vqj3EF+BWhamwimXctB8uiRmJdgJZoP2EIGAKGgCGwFBHgXKJTeOykktjRvjw6BvOI0ex4ZZTEjGofWunrKGoeIpntVG8axzszOHg8hdqqAFY1BLG+LYT6GqnkeGbG5xMDI7LOJ5q2r/lEgF1P52QW1TON6nMKfZlpU6maZJe6qSbypdx3Np9xlmkCXxP3boLfxZXnqbFq1zmVMZLXZD+31350r55VbPXiKpOSq5RYdUxcz+bUqQIBTvJPE1RFUuVwJ8JUr6JRKqeeKqJqEcsVql4omHfE1iKRWFnfEVkZlzMSqoPB/hgChsAiQ2ChiawJqlaLtHp6FFRf5QIfqrGK1Foe9WF9gw/bVgFRKVTzuWrOEDAEDAFDYG4IqG8rBdckF2aJqOp5j8CaIHk1VsiLeXlpLvjysXPqp/qqpmCD7K8WlFi9OC2GMM8r8+JSe3X9Wy3kUn+YfV+RYVXP9YeZX0h723p94LmdgdV6OQL6lpHgRjfH6I9wrmKE4/VyFZyXqOY8RRPVWaN9I0g9uReTLx7CBIWjVt/6BjRcfQ3KKBgVKuFK2otwRmR9cE7omSLru989J6CskiFgCBgChoAhMB8IOEIrd6SwENdIrgZzRYRMJBMYHhrGQN8A+np60d/Xj77eXvQy3tfTx3QfO8ABp8raQJXNxqZGKGxoom9sdGmpuFZUlCOo0V9zrwmBiyGySo2348RJfPN/f4PE0iG0kjx64y03Yfe1V7sPF328zKdTe5kkMfpUVxee3fsM9sk/8wxJqqVsB024avcuXLFjOzZv2+pIzyJB6xgKfj6PxfZlCBgChoAhYAjMhgB7Oiym6VH+m6JKa29uypE596QHMJZNUYk0gN1UJd3Glc+buPI55KN5JafROtteF7bsoomsPNzD2VH8ONGNOFVqS0nYfUN4lTtf9RAWG3F3YdG1XzMEDAFDwBAwBF4dAZHkZIa8YxjY3wU8fDDnCBlr6oDr1/uxsZEThZws7B/M4PDJNPbsT2FgKIs33lCMreuDaKzjZCAnFOfTGZF1PtG0fc0nAjmNNeaoiMrJ9LibZGeoCXiq9Ekh1eXNiCeodCxlY03GK+7qcU5X9eQ1lqQJ9ghNpkZpJCpKk6pRksOjSjN0+VSUKiZhKkIlVZdHs9WqV8x8GihiHifluQ+ZWZVKqveNICLq9H3JYz4Td98PXpn7klAVRaZdYZNC2kJDwBAwBBYbAgtNZHXq9b3AE8dy2NcJbG0GdrT6sKvdh6qSPPtImhdYbCjZ8RgChoAhsDQQ0By+51zP9Mz8fiFfoeb8s1w0FotlMT6RphXWDMWPCmGGacbHUixTPj3TaS5CEEm1rCyIsvIgystDnN8PubCsLMCw6Ey8oqLILc4M0WSBPc8L1+PCQl3FLFfYJWlRTqITe1IDOJgdc+TWHRSe2O6vxLZcKSYeeAhH/vf/QVlLC6q3bsXat/wqSle1XNiPTm9lRFYjss7agD71qU9h48aNeLcRWWfFyQoNAUPAEDAEFg4Br5OrFV1x52NTU4hNxTA5OYkpxuOxOFU2J7nyK+WUOLMkTmYokZCjV6h0VpIJdCKxlpLQWFZexk5uOUpdWObSZUxLuTVCRVdT5Xzp9b0QIquum0ilz+zZi/37nkfHyQ7U1dXh2hteh9Vtq1FPovF8OP2Orr9Isqe6u0lg7SbJuY/tY4KTAAGn2Bumcm9NbS19DcnNjajlcVTX1Lhyu9bzcRVsH4aAIWAIGAIXi0CaA0QxEjkHcwkSWmPoz8TdyucU8/0cRZIyaSvVWVsCpWjgCugSKbRe7I/Ow/YXQ2QVcfUozRVplfdBqrF65ooq0R4sdyq083B4tgtDwBAwBAwBQ2BFICDVx/EEMDABnBjIY2Dch+GpHCIkx1WX+rCBn98V4RwCrHjkZAYnT6WdOXOps27bUOTIrFXl89ezMCLrimh2C3aS3gS4CNueWmqKocjb6VTOC6fTqXQOKU56Z7M+hl5ZioRVKagqn8ODrO+ZQnWcJf5xFg9cIu/FeRsU8nxUMxaB1E+Sk9iiCnwiPDHF9WWuLy7VKBFQpQIVIiFcIddLu7yZacW9ei+tKwVWEcnlNfFuk+8L1qzshwwBQ+AyIbAQRNYEFerH41Ss78+jmwt9+sapXs3nrFRY22qpXF+ZR0MFlfz4vLbn7mVqCPazhoAhsKIQkIKryKkp9t8LXoquyksksi5PceWlkqrDOX5aL9B2sn4gawf6JihYM8jSvIFLq4wR9del0hoh+TXsFovJiivjWmTGMBKR1yIy5WkhmqfsuqIuwhxPtkBmncin0ZdPoIdW5Hqo1DrFcfwMSa5Bjj0UnTyFsheOIbT/CMriOaz6/9m7DwA5yvKP48/e7fVecunJpZKQhBAIoUpRVARpAoo0/4qKoGABAaUrIr0TpFcFCSABIkEQQboBQiekt7vU673/n+fdm81e37u95O5y38G9qTsz+9mLt/vOb553/wMke9p0SZsw0RUdC/NQLTYjyEqQtcUvROsZgqytRZhHAAEEEBgoAmWlZXrnVqls3bxVH1tcd/JbbGxdy+u4tKRUP/zWSnJKsnZnnyYZmZmSnpGuY3tkumXp2s19UlKSBl79LvTq11bmaG2BjvbrOEo/2NryaK3gqR+KB1MAsidB1oryCmf+4oKF8tknn8rwEcNl5h67y1cOOdCFS3v6e2Xh2CZ9VFdX65eaGhdutmq9VoF15YqVskofBVu36hcR7SpRb86ZOm2aTJsx3YVXLcDMgAACCCCAQH8XsCpMWxprZG19mXyiAc88rdRaqPPj/CkyPjpFcvWR5YuTxCi/xIretKFX0t0Fdfdzx766ngZZq7Xxy17j27UbJU8bxHz6GubEDpG9/UM0JNDf6s7uWFOOhgACCCCAQE8FrLtyC/kt1cpji9eIrNUudBu0+uRU7TZ3vFZozc326Y2gWgV+c728/UG16zZ90rhYmTTWL7mjYlzFSAvhRToQZI1UcOd4vl0E1WudehE6cOE5MG1VmQLLND6kF6cD8+5maF3u1rVaZhevG/VRpwHVGg2m2sOCqRZS9aYt2FqjF71rNLy0bTqwTW29Ps8uiOtzLAzbpBfFtclI4lyFVK2Gql1KW+VUm7exVU61C9zxujxBL3bHunFgeayGw62qqq23Kqo2Twhq5/h95VUggMCOEdheQVb7m+P+/1//Hmwta5KNJT75eJ2N7aYEkRmjRPYaF6VVWEWStII2AwIIIIBA/xSw7wX1+pm9SgOS5eV1+mhoHtdrb5w6X2Hz9tB596hz29uNYQkJGmBNtN5bo12ANSnJ32I6IUF7RUj0u4CrBV+j9TkWgrWb0wJju/ks8Pk+dLn9HbH5wThUNNZJidTKh7UF8qVWZ7V2/IzGaBlXHye1TzwrsYs/l+HDx8rIWbNlzEEHS4wWE4uO7f4fWoKsr4T16+XTqm/2mWfQDQRZB91bzgtGAAEEdhqBBi2xUFtnVVlr9Y6tWhdytOCqe+h8VVW1Vm+tbK7mWqbVXLWqq3ZBb1VdLXRpj/o6bfHW8EhqWtq2sGtz0DVdw6+B4GumfhBO0Du3tP+vQTJ0J8hqXzLsysNnn3wmb7z2ugaKCyQmNka+ctBXZNIukyRrSLZ+4NdvBT0cLLxqFVhXrVwly5culZXLVkhhQYHrSS1b9z1MA7NDhwWqrqY1v4/JKSl6QSLWhZN7eFiehgACCCCAwA4VqGnSavSiXS411kqBBj43653P+Y1VGv60pY2SERUnk/zpMk5DrSOjEiVGw599Ef/saZB1aX2JfKEh3eVajTVZ/BpizZHRWm02Kyq+D+K4O/St5WAIIIAAAghsNwG7oGFVaypqoqRIK7LmF/tkXWGTBloDh8xIbJLJWp11mN7jWVRYL+vy61yF1mHZUTJhTIxMmRAr2Rn6iSLCa3QEWbfbWzxgdmzhVauM6ioruepKFjq1KqmBUGm1C6IGKqV6YdRASFUDqc1BVRdM1el6249ezLZqp9HanGRhawuQBiqZWvVTrbTnj3LLY1xFVFsXqHxq29p2MW570QBroDKq7ccuUkcHL1xbJdbAsijtDsFbHhzbRW53AdsuYm9bbxVbI/33MmDeVE4UAQQQ6AWB7RFktc8/Vn17Y7HezLNJK7Fu1ACrVqfPSfXJ8PRGGac38gzRzz4WYo1t/lvSCy+FXSCAAAIIbCcBuwGuXu/StECr3fhWb70q6HRgbNNanVVvdLNHnfXKEFLp1Sq6VruqrnqTm1Z4dTe02Vi/V1RX1+v2dtL6eV6/LwSCrhp2TYqWJA24WgA2OTlGQ7BRbmzz9rDQqz0G49CgVnX6hpQ2Ba5RbLEqrfXlsr62TApXLJOmz5fKuNc/lXGZo2TcgQdL9tRpkpY7rttUBFkJsnb6S0OQtVMeViKAAAIIDGCBBv1kW11d46q2lhQXS3GhPopLpLioSEp0bMss2GpByVgNPVp39HHxcRKfEK+PQHDVW5ag825at7H1sTq251i4NU5LOdjzbFmMtphbRdeBPoQbZLVqqeUaMs1ft14+WvyRLHpnkYweO0YmTpooe+2zlwwZmqMN/OFfEXMVOXSfZWVlUqYVdYv1PSoqLHTBVRsXFRa5h/mmaTXdsbljZdzE8TJqzBjJ1Cq7MTEx3TreQH+fOH8EEEAAgZ1TwN35rI1FKxrKZLU+tjZWuxs40n2xkqmB1uzoBMnQ6TR9pEfp5xBftMS4zk63v0d3g6z2Wor1tXxUX+hCrHF6nuO10uw+MUMlyefvkzDu9lfiCAgggAACCOx4AQt1FFWI5BeJfLq+SbaWa0BQL9oNTRMZktwkKVokpby4XlavrnEXAK0a5eTcGBk93C85WValMlCdpidnTpC1J2p9/xy7L9m662zUKr7WXad152kXjK3Sr11AtgvF9fpo1LCQLbNt3djm7UJy8zbe9t62Nm7Qbdy8e17g+cEL026993xbFzi+9xyroGrBWAuvWhVUbepxv582HxujF5V13q3T31lbF9hOx3qx2e9v0sqqduE5sG2MzluY1YZuNE/1/ZvDGSCAAAI7iUBvB1nLqkVKKkU2lVr1VZENRXpDT61FlPRzzTCRCTk+GZvV5P5+hH9VYifB5mUggAACg0TAvldYaLWqqkGLV9W7aq6VVZoJ0KqulZW6vLJex7q8OjBfp8FYu/7svkvEWs+s1mNDlLv5LUa/X9hNcG5sN8vZdw7dxi71B9bZevueoTfPtVrmLXc3zOmNcDvbUKuFN8qlXtZoL3LL60tlS3WJlGpvqTELX5PsrWUyLD5Dhs2ZI0N230MysnI0P5Gof43DcyDI+kpYvy5UZD3ppLCg2AgBBBBAAIGBJGBBS9c1vasMofcR6bw1ztsH1ia9o6jGKrdWVrmgpHVXX7C1wAUnbeymdZktb9DWdAtJZmZnSZY+bJydna3d12cHpocElidrCX0LwXYnvNkfPcMNstZrWHjl8pWy8LkFsiF/g17waJBvHXm4zNl3jt7BltDtUK/tzx7Lly6TpUu+lM8/+UTWrFotGzdslLHjcrXC62SZMm1XDbDmSo6GZC1c7Nf3JVpvpbPHQHfvj78LnBMCCCCAwI4X0E8q7uJ9vVZirdbHloYqWdNQLl80FMt67c6nRIOhk6JTZZfoNJnqz5AcDbam+PQq/g4YuhtkXafn/bGGWL/UiqxlWm32m/Gj9ZzTXVXWaK0qy4AAAggggAACvSegOUPtjl2rXmoVzLUFjfJFvshneRpqLbNgh8jEISKThzTJ50tr5PNltS7kMXakXw7YM04y0y0g2LO/zQRZe+893FF70mYx61zHVSpy1YpqtGKRVi2qqtaxq2okOt42XaXLanS+qvmh94S77Wy53kPuKrFam4xd3LVgaXxc4KH3fut0lIZL7YJw87Sus+C0LbPt4vRjrNtGp20bF1jVda4iqqVP7X+BkX5KtqjStq4+veVuG13u5vWJto1N2+CNA3P8RAABBBDYkQK9GWS1v1srNot+vmmS91aLVOnfrexkkZljfLLrCJH0JP174290YaPmPwE78qVyLAQQQACBHSRgfw/sFga7+S5wvd/nxtZbia2zsQ2B9dYrRGNzuFWDr+X1UqbhVxuXu4eGNcvrtHdXGweW2U17Pv1OkZLsl5RUv1Zr1bE+UlNjJKl5nJKiy1Ki9aFFr7Sia3ycXaN2h91pfpiiff+q14dVad1cXynrqgrl4/xlUqY9tCY99aKk77GHDNv/ANlt9ldk6PDR+j0sPASCrAM0yGpf+q3r43nz5smyZcv0H0ey7LvvvjJHE82JiYnuH2Jv/Au4/PLLZfLkyXISQdbe4GQfCCCAAAIDTMACqnXar4CFWa37+oryCvf3141tXv8WV1RUSq22ytfW6q29zYP7CKyfxewDcuhHMr+22MfFxUtCYoJ2UZCo3RMkuenExCT9+52g84FlVsHVQpgWvuyPQ1dBVrOoVJePP/xYln+5TNbrHVhWEXXy1F1kyq5TtELqaO16rfMLYGbXoMHXQq20WrB1q2zetEm2bN4sWzdvce9JXV292mpXchpUtXCwBVeHDR/uHplZWfplIanLY/RHW84JAQQQQACB7ghYqLVSGqSgQbvxaayUzQ2VUtColdR0uQ3aGbCkalXWTF+cDNVAa3ZUvFjl1lit0hr6GaU7x+xs23CDrJVN9ZKv57tMA6yf1xe5SrIjo5JkenPw1s4u3Iatzs6HdQgggAACCAwGgXfeeUcWLlwoRx99tMyaNavLl2zX7UqrtFqZVirbrCHWaUMr5blntl1n2GeffWXGzL3kH6/ohnqzb3pqlIwb5ZdJuXoRTiu3WpCwOwNB1u5o9XxbuyjrqqK6aqeB8Gid63JTp7XKUEODT8d6kVG73gwst4qqge6XrQtOm66rs0qoge2skpHt0y5OekOLG4S3LdbVgZkW670nNY+ticuvlYj8NrZqRVbpyKoXNc/b2MLStp39jkVHabVUHdt29jybjo7WZTptVY12tgvBrbiYRQABBAaFQKRB1lr9W1VW7ZP84ia9SadJq8/7pFxvoLDrBhlJPhmuledHZYoMT9e/I/r3JbrzSxKDwpwXiQACCCDQUsC+99j3odrawKPG3aSnN+RV1+vNerZMb+CrbnBVXm26trZBv1vZ95/W34sD358CywPfj+xad7T+8bHvL3F6A5/1EmHj+Hi/TgeWxWnINTAdresC07adfbcaSN95yrXntRK9RpFfqT3gLl0iNW8vkvJNG/Rm2jpJ00Br/JQpEjs+V5JjEyQtOk5StfBGsj7iRYtRtXqhBFkHYJDVfmHfffddOe2001x3yKH/zFJSUmT+/PkyRX8JemMgyNobiuwDAQQQQGBnF6iqrJTysnJXnXXLli0avAx0d791y1YpdNVbdVxQpB9ya7QKabSkpaVJRka6ZGi4My09TdIzMvSR7h62LDU1VYOYiRKjpSbsA65PQ58W5rDwp93lZWP3sA+xtszGrT7kbU/zjoKsVt3WwqclxcWuAuvCBQtl7ao1MnL0SK3Curcc9LWDA6+hnXN11XH1AlldfZ3uI1B51cKw69auldWrVsnKZctlzerVsm71WhkxaqSMyc2VaTOmaTh2qoyfOKFfB3+353vBvhFAAAEEEAgVsIBoqVZk/by+WKucFssSDYradRoLsk70p8q46BQZ5U/WhqJY8Wu3rDFa9dQaigL/he6pZ9NdBVktCFGrd2hvaayW9+u2yMqGMtmogdZD40bJfn6tpq4BWz+VWHuGz7MQQAABBAalgN0Ae9xxx8kbb7wh1113nZx88slhO3R1neGZZ+bLi++PlPwN9TJlvF/2mxUv2RnRkpocCBe289W+3WMTZG2XJbgwEBbVKKgmjN08XTzMAABAAElEQVTlTv2MZlNWIcgGb72ttPU232K6eZltb4FVu7hao4HUQMVU/exV53PVUd1F2LptlVStMq+rruouxgYqqNrzrJqqVSWq1ek4DZbGNVdITYgPVEoNjnW5q6war9vENEmCjbViamJ8tFZTFX1eoJKqLY/VqqoWSA33d0ZfEgMCCCCAwCAQ6EmQ1W7IsYfdmFFWLZJX1CRfbBD5cI0WvdCwqlVh3XuCT6vN+yQnxap0DwJIXiICCCCAwA4TsMCr3QBYWlqn2QBtiy/TsVVy1Wl7uGldV9ZcwdW+h9kNh0kJ0a5ia1JStCQn+XU6Wotc6VinraprYqKt16quiVHaq6m2kfstCxD4DmVjC8V68/a9yr7P27x9OQws7z/ft8qqymRz8VZZOe9xWfXqK7J5bLbU7KZB1gP2kZysoTIsPs31IpftT5AMvW5hRTei9PX41Mle1wotkvXU43+Xw448QnbXEOz2GKyQhl0b6Y/DK68MwCBrQUGBq75arpXghg0b5hqqrHveZ599VpYuXeoqnr3wwgsyevToiM0JskZMyA4QQAABBAaBgAUv6/RRW1OrjxoXWK2xaa1MWl1d7Sq2WojVHjbvpqt0eW1dYN5bppVdbV297ss+qFnlVqu6npKaEhinpWo3BCkt5m19QoLer6TlLOw5O2LoKMhaVlomG/LyZfH7i+WjDz50Id1hI4bLrtN3ldFjx8jQYUPbPUd7veayccMG2bA+X/Ly1rv9bN64ST+o6x1o8Vo9ToO+aekW9s3QELAGfzMzNBCcLqlqkqQGdvFuR73+HWHMMRBAAAEEEOiJQL2GROukUcOsegd0Y60UaXXWYg22FjbV6HyNVGjQVZuEXAXUUdFJYlVQh0Xp5w29+7k3Gm46C7I2amNbvZ7bJ/WFslQDtnlaPTZdq8VO9afLmKhkGe7Xaup6McoarRgQQAABBBBAoGMB++5r34GtzWHu3Lly1VVXuY27G2RtfZ3hOxqITYhPkOee23ad4Zln/ylPvJElfr3xNFo/Z+wyLlYmjImWsSNjJUGDiuH82SbI2vF7aWu0ScSFRi1UWqNB05oaDZ/aMr1AasFS7ShI1zeHSy106qZt3LxOKwhZeNWqrFrI1QI7VsHUjZurmfp8Fu6xKqeBaqhWEchbb8vcQ5cFn2fTWjXVrou22K75eYH96IVV3a+ttyqq0bqxO0bztE8/2Lnt9IdtY78r4fy+dK7FWgQQQACBnUmgJ0HWilqfFJY3ytKNPleFtaBcb6bQqnYWYB2W5pOhaU2SpTfdJMc1SbxW8+Zvz870G8NrQQABBPpeoFHDlu4mQuvVQr+DeRVdraqrPbSzVze26W3r7Dtbg9TbNsHnBCrBes+zcKzdmFivYwutxsZahVar3qrBVg282g2GiQl+nY92NxHaMpt26zX4attajxf2Xa+vBytaVVNfKyXLlsqWzz+TFYvflcLqUqkfMVRqZ02Txj2mSblfHfW7ovZPK8lRMZIi+tBrBck+v5QuXy+fzlsoUw4/UEbsPnW7vJwx0cmSq0U/+uMwIIOsl156qdx7772umpt1GTR27FhnW1ZWJocccojk5+fLiSeeKDfeeGPE5gRZIyZkBwgggAACCAQFXJBVA6wlxSVSVloqxTou1UdJiY6bHyXFpVJRUSF1emXCqrfG60WkxKQEF+ZMTEzU0GqCe8QnxuvdWYm6Ps6ti9XqrX6/hlBi/OLXR1RUdGBal9l+YvQKhD9Gp/XqgoVDLfhq0/bo7hAaZB05YqQLoRYXFbkqrKtWrJJVK1ZqEHWD7Ln3bJk+c4ZMmjxJklO0JUmHer0CYxfbKrWKrVVctXGF3pxTqh6FerNOYUGhVrTdKrY/q3KbmZUpw4cPl7Hjx2kV1rEyRj/3xKuBvV4GBBBAAAEEEOhYwIKjDXpHdoFWP83XqqerG8p1XCHFDTUaWo2WrKg4yY6Kd6HWdL3zOUXDrIlRege4NhwlaAOSBV672+zVXpDVzsPCtRaq3azn8nm9fmbQ87Hqq5OiU2Xf2KGuwao3grQda7AGAQQQQACBnUdgwYIFcuedd8qSJUvcd2rvlXU3yNr6OsPQEWOkosYnBUWlctKxXw1eZxj/tWv1+36NbNpQJxNHRsnEUdEyfrRfhmZFS3qqdn3YXG3TO4/W450pyGpBUXfh0o1tuvmhK4LTuqy++eJmYJl+JtP5Jq206m3ToBPetAVZ7WKmdY9s1eXsAqZd8NTssJsPXBzVfWr3lW5aL4xqZziBi6K6nS1vaLB9W/WaQOXTOA30WPeU9t7EaYjHdWNp094y7apSm4h03qqpWvVUndcLifFuefPzdFsbCAC1/o1mHgEEEECgtwTCCbLqnzep1ps4qmpFSqu0jaNcZEuZVWIVKaoI/O0bk+WTXUf4ZHi69kiTxN+u3np/2A8CCCCAQOQCLsyqAdWqygb9/q6PKn1U1EtVVaPO1wWW6fIqXV7hlje474R2o6Bdwo+N0+/c+n0tVkOqMfbdTgOuMe57nS6zdTZty/RGxBgd+/VmRguz2tgqtdq07cd6gPWWe9O23NsmUNU18tcbuod6LWJVtXWLrH75X7Llyy+0em2xbJ4wTAqmj5OykdlSl5Umfi1mFafXI5L0ukSiaDhXg6y1K/Jl01OvSc5h+0jqzImhu+y16RkxGTLTn9Vr++vNHQ24IKt1I7zvvvvKqlWr5Oyzz5bf/e53LTweeOABueiii1y1NmvIirQyGUHWFrzMIIAAAgggEJGA3UHVoLdiNerVChs36JWHJq1oUq/jRp2vt2X6sBCrVSitKK9wgVe7WaW0pNQFOwPjMhd+tQqo5fqwCyCx2mdbUnKSq9zqqpQmJQUqt2qAtEUVV63uahVMrcprvFZyjdcPiN39vBAaZM1Iz9BKqhtl0TvvytIvlrqqqlOn7Sp77TtHRo8ZI0Nyst25eYFZC+xu1aDq2lWrZY0+Vq9cpRfH8qRIg6vZQ4ZIztCh7nmjRo2SEaNG6nkGKq7GaWDXr+HbOH2d9nmou+cc0RvHkxFAAAEEEBigAnq9R+qbGqTWKrVqxazKxjqt0FqnQdIKWavB1vUNFVKoAVMLsQ6LSpTx/hR9pLoKqTGijVvdTC60F2St0eOXaFXYxXUF8kbtRknSxqgRWgl2z9hsGalVYVP12D0JzQ7Qt4TTRgABBBBAIGKBG264QezReuhOkLW96wwWFLGHVQV94m/brjM8/+oXMvfFBikqbpQU/Zue4muQJO1mftIYv+w5XW+MyYyStGQtudnBsLMEWQMhVq2MqhchrSqqdsSjbTeB6WqrnmqVVG25Vlatbq6cWqPjKtum3ieu4qq33KqvNk/b5zWrXJqgFXasmk6c3rcbqxco3UMvRtqFSQuY2v28sXox0o1tvS63kGogsGrVUAMhVq/6aWCsFy81j2ptKFaV1T7a2bStc11QuuWBqqu2JLBt4GKmbcuAAAIIIIDA9hQIJ8hqVcrzi5tk9VaRJfkim0oDgdbJw3wyYajI+CE+SUsQSdS/kxbi0Z6YGRBAAAEEEOg3AvY90oYGvQExUM01MA7c6Bi6LHDTpG1Xb9859ftlVbUFXAOhVwu6Vtt8c+jV5t3DbdPgvofacSzAmpgY7R4JNtZqrUlJWrjCTWtYVMcJuszbJslVdrVQbODae69+D7RchBa3qtViVgVLv5T1b74uW1Yt17aFrTLqyG9L+t5zpGnoEKnRAG6l9uVWodcuqvU6RtGyNbLx6ddkyGF7S8p2CrLu5s+U3WMIstrvTMSDBWDGaCjEQi7PP/+87LHHHi32+eWXX7qqrLbwpZdekmnTprVY390ZgqzdFWN7BBBAAAEEIhewoGu9luGoqqpy1VkrtUKrq14arGBa0bw8UM3UKpzaZ4TAxQj9oKlXJOzOqSifjQPzdneVTduy4Hq91cq677XqrK5Ka3RgbNVct1VttTu0tHqrXhHx69in+125aqUs0Q+cu0ycrJ+8m6RMK6eWa1VVG5KSEmXsuFzJnZDrjmUVWC2Ia9VVy8osjFumH7KrtKpInQvs2utsbGxw55CVna1h1mzJGTZMcnJyxOYtaGsVZhkQQAABBBBAIHIBq9Ba2VQvBQ3VsrmpSiukVmnF1hqxsKmu0kqt2l2R3v0crxVZLdxqXfkk6djCp0l6Z7RVa9VbSnStfp5o53S8IOuPfny61Gmjk+0/X8Oy+XosO2aFHtu67RkTlSwTY9LcMbjG1A4kixBAAAEEEOhEwG58tV5NbLDv+QcffLAUFhZKd4Ks3bnOsOCFl2RJxVQp1OpnRYV12suMXmAqb3Dd9o4f6pMhGmQdmu2X4UOiJEMrtCZoyNUCkd7Qm0FWuwho1wEb7SKgTgQuBmo1Um/aG2s1U6uCqpdRtM3BnuNz27rtm7exiqe2zh62rdvOW2fP8/bljW1brapq52AV522w59gJ2ZxdlDRXuyBpgz3fVti2tnngYQtD9qGzXlUcVz3VKqJqZdQYvfhoj1id90d78xZqtTaaQFDHW+9CO67CjgViLbBqR2dAAAEEEECg/wu0DrLa39UaDa6W1YgUV4gUljdJUaXOV4tU6g0kNVq13IKqiXrzxxjNnozUCqxD00Rv+Oh+jzL9X4czRAABBBAYjALe98ZavVmyTm9+rK6u15sg7cbJ5ocGV0PnbTsLuNbUWLEs+94ZuIHRq7Dq3cjobm502YHmmxv1e6Nd87fv7m5b/fsaqPqq30H1hskYrQBroVj7DupN27w9AvOB5fb91J4X5Sq/tv9ltEn/wFdt2SKFmi0o/OILKVm1QqITkyQ6PVWihmZrOfV0acxIdWPRQlyb1m+UD/7xL5l+2EEyevep2+XXYKQ/WUbpoz8OA64i69q1a2WfffZxlsuWLdOwSJI2kFg3NI3uIpJrgNIud214/LHHZP/993fTPf3xxyuvlEkTJ8qJJ57Y013wPAQQQAABBBDYTgJ2+cP+9tfW1Liga4lWO7WKre6hF7XK9GHTVrm1pFjX2XxxIExq27pAqQZNY7Wch1U8tdCoVTyN1fIfNg5dFmfrdBurrFrXWC9N+sF01RcrZOumLfqBNsZVYJ09Z7bsvufu+kFZ75bSi2gb8vIkb12e5LvxOlm/fp0Lr9pxxk2YIBMmTZKJkydJ7vhxMmr0KFe51aquMiCAAAIIIIDAjhHQWIXe5dwgeY2VsrK+VJY1lOi4zIVPs6PiJScqQYZGJ2q11gT3sOmsaK2S3mRh1kDDlDWCWTLDxjdce51kZGbKyaf/n1ToXdQf1m6Vz+uLZEldsUzQ4Op+sTkyITpNhur+GBBAAAEEEEAgcgELss6cOVM2bdrUrSBre9cZQs/GCmmMHj3aLXr88cdlt9kHymbNzn60rkm+WNcga/O028OiGomqqJWMlGgZOSxa9pkRKxO1SqtVaPVbiVH9nGGfDz76cLE899x8Of6E78mUKdsuQll7RudD4LNG6Hb2FAu5aMc2Wv3UKqA2uW4X6+p1rMEX96jTC346vW2dLQ+s3/YcXWbP1eW2rL75ubW2nbdft4/Avmw7O6YFU+2lxWu1mngN7MZr9TebtvCuBVETtKJqvFVWtSqqVl01pskts2qrcW65bRPtqq7a86z6qgVS7eIfAwIIIIAAAoNN4M65d+jNJA1y1s/Pce0KdY0+KalskvVFIss3NelDJE+nY/SmjpGZPpkxSmSX4VGSq5kXF7xpPy8z2Bh5vQgggAACCLgbJ2trA5VZK8r15tOKBimvaB6X10mlVnIt1+VuXFYnFZWNOl/nKrxWatXXev3OmxCvFVuTrIprlI512qq5Jse4sVV03VbJVQth6PddW2/L7BEXF61FqwI3Vra+udJdP3DvUZOUa2ag8MsvZOlTT0qRhlrjtGfW1NxcyZyyi2RMmixpY3MlX4tnPamFPb/19a/L7rvttl3eXb9mI6I1C9EfhwEXZLUTPuWUU9yd1hs2bHBVzQoLCmXN6tVSXVUt4ydOkIO/eohYZbZbb7lVMtP0VqQIhv++9YZkZmTI9KmRVXaN4BR4KgIIIIAAAgh0IdBo3QVr/3V1dVqeX/u2s88B9XoVxpuu07CqTds4MF3jxlYN1S5OeYN9kHQfJl0DUKAVyGcVXN1ybyvtlkCv1MQnJ8imtflSUlQsDXqsFL1DKlkfKcnJroKqVW/161UcF4iNi3fhWAvMJiUn6bapkpKSImlpWonNHjptlVytMuy2D7PbjscUAggggAACCGwfAQuyNmgipFIapLSxVkqb6qS4qUaKGmqk1qd3eWvItVY/Z9Tq2Cqs1muXtPZfrFZkjdcqrQk+bagSbbjSsVVzfevmhyUmPUWyTvmalGv11VhdlqjbpftiZUR0klZj1c8Boo1fWtmVAQEEEEAAAQQiF+hpkLX1dYbQtgE7K7vJdNSoUa594bbbbpNvH32cVNdZZTSRgjK9ebW0SbYWNcjmggbZUtToLpKlJ/gkKdYufjVXEtUqLhbqLC/4RPKW/lNGTz1GUrJ2cUFUC4R63SpahdLAtGZYrDKqpVWbK5+6dXqz7LbqpoHnWduB28x9MrEzDszbfTa23C6cWRVWF4J12wYW2rxO6XLdwG1jc7qd+xkY25O97UL3G9hpk16b2VZF1UKtrqKqBlEDy9VOK9HYtI3tYSHVwLw3DlSx8baxc20+sp4FAwIIIIAAAoNDwKqcv/n8XHd9YuLBZ0uVVmGt0spzFma1kGq83QyiN4Yk6k0faYki6frISvZJmt4Xmxzv/oy7P82DQ4tXiQACCCCAQNcCdtNnQ71mBvTmTgumuhs6m6dt3i2ra2geN7oKrsFtdTt7rn33toJVjfr32Ho0se/oNnY9mrjlgfVuXtfpJYPAdvYNXL/cWi8h0Vo+PUqvI3i9j0TpF2f7XmzzjdWVUldaLOWrl0t9Yb7ENlRKfHStxPu18FaUPbS9QXuJ/VzzBpOrKmV4rX5A2A5D7jcPk3GHfWs77DnyXQ64IOsjjzwiF1xwgQt+fPnll1JcWCTrtErr+4sWuS57Z+89R075wWmue1/rSqhkS0EbpWoNt5RWBrr/bbOynQWx/hhJT05pZw2LEEAAAQQQQGAgC7gLM/qp1i5YWfC1Uj8MWpfD4Q5FWo21sqxcb6apkrKyMlfxtVznExISJF1vhBk9ZrSMGjNGRmq1Vau4OlKrueQMG+o+xxBYDVeZ7RBAAAEEENixAhZarZZG2dBQIRsaq2Rt4SZZ+Zdnwj6JxuHpkve9PaRMg7FTYzNkhj9TZsdkyxBfvCQRYA3bkQ0RQAABBBAIR6CnQdbQ6wxLly517QKhx7Mg6/jx4911hhtuuEG+//3vB1fbBSsLtd5z11y9PrE5uLyjCWt7sDaA2pQjpc4/0QVZLbxiF8nsope72OYuftnFMr0QpvfbBi6c6R51O1vmuki0bS2Iqg+7AOZ1XWiBUOsK0bswFtV8gcyv3RtG68qoKA2fWpi0OVQarRfR3HN0mXWLaN0pes+1/QYege0D+7ULcc1dLup60QtyDAgggAACCCDQvkBTY52sePnP7a9sZ6kvLlMqxv9CK7GKVDRnVYamiUwe5pNJQ0XG5/hkSHKTJOmNMgwIIIAAAggg0PsC+hVbC2Y1SFW13aSqVVwr9VGuvbBoVddKm24eWzXXSl1fWWXL9WFjm9eHhWbtu32MfQ/X79qxMVr4Qm9utY5YY3Tar9OxsV9o28DnYb+AtDf+KwlLwt8+7B3rhnv+6jey13nnd+cpO2zbARdkfe655+SMM85wXQCvX7/ehU5CtaxBaPjw4W7Rgw8+KN/4xjdCV7vpVatWyZNPPtlmeXsLRo4cKfY46KCD2lvNMgQQQAABBBDYiQTefPNNWbNmTdiv6NBDD5WcnJywt2dDBBBAAAEEEBh4ApWVlfLMM+EHWbOzs9ttixh4r5wzRgABBBBAoP8L9DTI2hvXGebNmyertae4roakpCRJT0+XAw880FV57Wp71iOAAAIIIIDAwBWwghlPPPFE2C/Aems78sgjw96eDRFAAAEEEEBgYAp8+umn8vHHH4d98nPmzJGJEyeGvf3OsuGAC7K+/fbbctxxxzl/C5rExLTsjq+0tFSmTJni1j/77LMye/bsneW94nUggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIBAs0BPg6xcZ+BXCAEEEEAAAQQQQAABBBBAAAEEEOhfAgMuyLp27VrZZ599nGJ7QdVFixbJ0Ucf7brq+eyzz9ydzv2LnLNBAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQACBSAV6GmTlOkOk8jwfAQQQQAABBBBAAAEEEEAAAQQQ6F2BARdktYap/fffX1asWCGnnXaaXHvttdLY2OhUfD6fXHDBBfLwww/LHnvsIQsWLJCmpqbeFWNvCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggg0OcCPQ2ycp2hz986TgABBBBAAAEEEEAAAQQQQAABBBBoITDggqx29rfccotcc801rurq008/LQcccIALrL766qty6qmnSk1NjVx33XVy8sknt3ixzCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggMDOIRBOkPX++++X5cuXy4QJE+T0008PvnCuMwQpmEAAAQQQQAABBBBAAAEEEEAAAQT6XGBABlmrqqrk+OOPl8WLFzvA3XbbTeLj4+WDDz6Q+vp6OeaYY+TOO++kGmuf/3pxAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIbB+BcIKs3/3ud+WNN95wPb3NmzcveCJcZwhSMIEAAggggAACCCCAAAIIIIAAAgj0ucCADLKaWmlpqZxyyiny3nvvBRFjY2PlkEMOkbvuuktsmgEBBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQR2TgGfzyezZ8+WvLw8uemmm+R73/temxd64oknyn//+1856KCD5LHHHmuxnusMLTiYQQABBBBAAAEEEEAAAQQQQAABBPpMYMAGWT2xwsJCef/9911F1r322suNvXWMEUAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAIHOBLjO0JkO6xBAAAEEEEAAAQQQQAABBBBAAIHtLzDgg6zbn4gjIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAghsDwGCrNtDlX0igAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCHQpEHaQ9b333mvqcm9sgAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAQJgCmzZtCmtLH0HWsJzYCAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAgTAGCrGFCsRkCCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAQO8KEGTtXU/2hgACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCAQpgBB1jCh2AwBBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAoHcFCLL2rid7QwABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBAIU4Aga5hQbIYAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggg0LsCYQdZq6qqmnr30OwtEoGmpiapqKqW6po6fdRKVXWt1Dc0RLLLQfdcf3S0JMTHSnycPWIkKSFefD7foHPgBSOAAAIIIIAAAggggAACCCCAAAIIIIDA9hWorauXwpIyqayqEZu29l0GBBBAoL8I2LWR2Bi/JCbESWZaipvuL+fGeSCAAAIIIIAAAggggAACCAwOgVdeeSWsF+ojyBqW0w7ZqKyiSjYXFLsGzx1ywEFyEGukyclKl5SkhEHyinmZCCCAAAIIIIAAAggggAACCCCAAAIIILC9Baw9N39zgTQ2El7d3tbsHwEEIheIivLJiJwsrpVETskeEEAAAQQQQAABBBBAAAEEuiFAkLUbWP1h041bi6SopNydilUTjdPwpU+aJDpKxCqM2l2zVBVt+055FQ5s3NjYKFFRURITG6uPeK2CUC0lZeWuqq09MyMtWYZlZ7TdCUsQQAABBBBAAAEEEEAAAQQQQAABBBBAAIFuCNTV18vKdZtcm2RCfJxkZ6RJZnqqtk/SM1Q3GNkUAQS2s4AF7QuLS2VrUYleK6lx11DGjx4qMX7/dj4yu0cAAQQQQAABBBBAAAEEEEAgIECQdQD9JmwuLJGColKJ0rBqalK8NNRVu9CqXxsSojXEag8LaDJ0LGAh1oaGBveo10ZkC7amp6dLdna2bNaQ8AarjKDLsjJSJSczreMdsQYBBBBAAAEEEEAAAQQQQAABBBBAAAEEEOhCYMOWQikurZDU5ESZMHZkF1uzGgEEEOh7gRVr8qS0vFLSU5Nk+JDMvj8hzgABBBBAAAEEEEAAAQQQQGBQCBBkHSBvc4VWDV2bv8UFV1MTY6S6skK8AKs3Jsja9ZvZOshqoVYLtKakpMjo0aOlrKJSVqzJdwHXMSOGSFJCfNc7ZQsEEEAAAQQQQAABBBBAAAEEEEAAAQQQQKAdgaWr8/Sm+kaZMmGMWEVWBgQQQKC/C1hF1iUr1mrxlCiZnEsAv7+/X5wfAggggAACCCCAAAIIILCzCBBkHQDvpFUNXbluo9TW1UtCbLTUVbcMsRJkDf9NbB1ktRBraJg1NzdXNmll1vxNWyU2xi/jRw9z4eHwj8CWCCCAAAIIIIAAAggggAACCCCAAAIIIIBAQOCLFevcxKxpkyBBAAEEBozA4s+WuXOdOmH0gDlnThQBBBBAAAEEEEAAAQQQQGBgCxBkHQDvn3XhkrepQPx692t9VaneBRvtqrF6AVZvTEXWrt/M1kFWL8TqBVpHjhwpQ4YMcXcbV9fUysihWa7br673zBYIIIAAAggggAACCCCAAAIIIIAAAggggEBLAYKsLT2YQwCBgSFAkHVgvE+cJQIIIIAAAggggAACCCCwMwkQZB0A7+b6jVu1y/sq8TXUijTWBYOsrQOtBFm7fjNbB1m9AKs39vl8MnPmTNlaWCLrNmyWlKQEGTUsu+sdswUCCCCAAAIIIIAAAggggAACCCCAAAIIINBKgCBrKxBmEUBgQAgQZB0QbxMniQACCCCAAAIIIIAAAgjsVAIEWQfA27l0dZ40NDRKU025REX5CLJG8J51FWS1Cq2jRo2SjIxM+WzZarWOksm5IyM4Ik9FAAEEEEAAAQQQQAABBBBAAAEEEEAAgcEqQJB1sL7zvG4EBrYAQdaB/f5x9ggggAACCCCAAAIIIIDAQBQgyDoA3jWvsbOxutSFWL1KrN7Y7/cHl0dFRQ2AV9R3pxhOkDU5OVkmT54sH36+3J3o1Amj++6EOTICCCCAAAIIIIAAAggggAACCCCAAAIIDFgBr2131rRJA/Y1cOIIIDD4BAiyDr73nFeMAAIIIIAAAggggAACCPS1AEHWvn4Hwji+19jZVFOmFVmjxIKrXnjVm/aWE2TtHNSCrPX19eKNbdqqsNrYW+7z+WTWrFlCQ03nlqxFAAEEEEAAAQQQQAABBBBAAAEEEEAAgc4FvLZdgqydO7EWAQT6lwDXR/rX+8HZIIAAAggggAACCCCAAAKDQYAg6wB4l73GTiqyRv5mhVOR1QKte++9N0HWyLnZAwIIIIAAAggggAACCCCAAAIIIIAAAoNawGvbJcg6qH8NePEIDDgBgqwD7i3jhBFAAAEEEEAAAQQQQACBAS/QL4OsNTU1EhcX1ynumjVrZP78+W6b3XffXQ488MBOtx/IK73GTiqyRv4uepVYvXF7FVlt2Zw5cwiyRs7NHhBAAAEEEEAAAQQQQAABBBBAAAEEEBjUAl7bLkHWQf1rwItHYMAJEGQdcG8ZJ4wAAggggAACCCCAAAIIDHiBfhFkraiokKeeeko++eQTWbdunZSUlEhsbKxkZWW5x7Rp0+Sggw6ScePGBcHfeecdueKKK9z8EUccIb/4xS+C63a2Ca+xkyBr5O+sF2D1xgRZ25q+/vrr8thjj7kVo0aNkt///vdtN2IJAggggAACCCCAAAIIIIAAAggggAACCHQp4LXtEmTtkooNEECgHwkQZO1HbwanggACCCCAAAIIIIAAAggMEoE+D7JaaO6OO+5w4dWuzPfff3+5+OKL3WaDMcgqteUSFRUlfr/fPaKjo4PT3nIbM3Qs4AVYvXFHQda99tprQFVkvemmm+Tll192L/yaa66R6dOnd4zQxRqrdPyXv/zFbZWbmyt33nlnF89gNQIIIIAAAggggAACCCCAAAIIIIBAfxMIp9er/nbOkZ5Pf+zFiyBrpO8qz0cAgb4QIMjaF+ocEwEEEEAAAQQQQAABBBAY3AJ9GmT98MMPXTC1oaHBvQs+n08mTJggOTk5smnTJrGGRwsaesPUqVPlxhtvdLMEWf1CkNX7zWg5rq2tlRdfflWOPPwbLVfonBdg9cY7S5D1uuuuE+8f89VXXy0zZ85s89rDXUCQNVwptkMAAQQQQAABBBBAAAEEEEAAAQT6j0BPer3qP2ffO2fSH9uMCbL2znvLXhBAYMcKEGTdsd4cDQEEEEAAAQQQQAABBBBAQILZt64sfFVVVU1dbdSd9RYkPPXUU6WwsNA9zQKs5557rowbNy64GwskLlu2TB599FGx0CtB1r6ryFpvYeOmJlcBNvgG9dOJJ56eLwsWviwXn/9rmTRxfIuz9AKs3pggawseN2MXPbZu3eqm4+PjZejQoW03YgkCCCCAAAIIIIAAAggggAACCCCAQL8R6GmvV/3mBfTSiRBk7SVIdoMAAoNegCDroP8VAAABBBBAAAEEEEAAAQQQ2OECXhHHrg7c60HWzz//3AVX7cBxcXFy//33S2ZmZofn8e9//1s+/fRT+eUvf+m26apRsklDl1bhtbtDT5/X3eN0Z3vvrn2pjTzIagHOq667WRoaGuWM00+TYUNzOjwVs3j+hZfkw48/ldVr1oolmceOGSW7Tpksxx51hPijozt8bl+tWLc+Xy678hqx4O2oEcPlD5de2OI8vQCrN94RQdZIf6fsXKOiojol7c2KrJ0eqJ2Vkb6+dnbJIgQQQAABBBBAAAEEEEAAAQQQQACBMAUi6fUqzEMMmM26ajPuixfite3OmjapLw7PMRFAAIEeCRBk7REbT0IAAQQQQAABBBBAAAEEEIhAoM+CrP/4xz/k7rvvdqc+ceJEue2227r1Mlo3Sv785z+XhQsXyv/+9z/57LPPxKq5jh07Vg4++GA55phjOgy1FhcXy5NPPinLly+XFStWSF1dnXueVYg94ogjxMbesGXLFnn88cfdbFZWlpx00knequB46dKl8uKLL7r5o446yu0ruLJ54q677nLn5/f75cwzz2y9us2819hpQdZoDY/a8+wROm1BR1vWVeBx0fuL5dY773XH+OMlF0ju2DFtjmcLGjQIevf9j8hb7y5qd/2smTPknDN/vMMqtFqY87EnnpI9dt9Npk7Zpd1zskDlH6++UZatWBlc/93vHCVHHv7N4LwXYPXGrYOs9rrtMXv2bImkoWbJkiXy8ssvu4rCa9asce/V6NGjZcqUKXLyySdLSkpK8JxsYt68ebJx40a37Cc/+YkUFBTI/Pnz3e/y6tWrJTs7WyZNmiQ/+tGPZMSIEcHner9vH3zwQfD5e+21lwwZMiS4jfd71voYVm01Ly/PVTu2Y8yYMUMOPPBAtx/b1gargnzooYcG9+VNdPf1ec9bvHixPP/887JhwwbZtGmTJCUlSU5OTvDf6vTp0zv8t+rtgzECCCCAAAIIIIAAAggggAACCCCAQEDA2rgi6fVqZ3Ns3Wb8i1/8os9fote2S5C1z98KTgABBLohEMn1kW4chk0RQAABBBBAAAEEEEAAAQQQCAr0WZDVQqe33HKLO5HY2FgXEE1ISAieWFcToY2SFtyrqamRjz/+uN2n7bfffnLJJZe0WWfhP6tkaWHW9gYLAJ5++ukuCGvrrcv1E044QSwwGRMTI0899ZQbhz739ttvlwULFrhFtq0FD0MH67LdGpdtGDNmjFiotavBa+zsaZB17bo8+eLLpVpVdZ28u+h9qauvd4fsLMi68KVX5K9/f8ptN2XyRDn0qwdJjHq8+vpbsvijT9zyo474ppxw7FFdnX7E68377/OelncWLdJziJEzf/IjGT9+XJv9/vvV1+XBRwNBY2+lvU9X/+FiyRmS7RZ5AVZv3NtBVtuvhUAfeeQRF4j1ziN0nJGRIRdccIHMnDkzuNga1S1IbYMFXe13q7q6Orjem0hMTJQ//OEPMm3aNLfopZdekhtvvNFb3e7Yws32Oxl6jIceekiefvppefbZZ93vsz3xG9/4hvz617+WTz75RM4//3y3LwuC27l6Q09fnz3vT3/6k7z11lvertodH3/88e7fXLsrWYgAAggggAACCCCAAAIIIIAAAggg0EIg0l6vWuwsZGag9sAT2mZsRQpaB1n74nV5bbsEWUN+wZhEAIF+L0CQtd+/RZwgAggggAACCCCAAAIIILDTCfRZkPWLL76Q3/zmN0HQ0047TU488cSwqzGGNkoGd6ITFj4dNmyYbN682VU99dZdfvnlsvfee3uzYsc/99xzgyE+Cxda9UmrUvnll1+6SpXexj/96U/l2GOPdbNnn322q95qMxYgtOd4gzWEnnLKKVJYWOgWjRo1Su655x5vtRu/+eabcuWVV7rpb3/722KVZLsavMZOX11FsApraDVWrxKrN269v2eee0GefOa51ovlyksv7LAi68V/+LMLvmZnZcpVV1wkic0hY6tYe/mfrpM169ZLVmaG3HztlWG/Z21OIMwF/5j/vLzy2n+DW8fHx8nZZ54hY0aPCi4rLimV8y++Qiorq4LLvIkZ06bKBb852816AVZvbEHW0DCrV5F1zz337FFFVgsmP/PMM+5Y9n7Y75xVBi4tLRULTufn57t1mZmZ7nfDgqk2hIZM3YLmH7adz+dzFVq95VaZ9dZbb3Wzb7/9ttuP/c5ZmNuG9PR0CQ2FW5jXziv0GLZf7/fUPUl/hBNk7enre/DBB+Xvf/+7dygZOXKk7LLLLi5EvnLlymCY3Konn3HGGcHtmEAAAQQQQAABBBBAAAEEEEAAAQQQ6Fgg0l6vQvfc3R54rA3V2jqtbcfambz2qbi4ONdb0D777CNHHnmkpKamhh7GTYfbc5D3RGuz+9e//uXadO141tOP9UhkPRfNmjVL7GZs6/kntM3Ygqw97cXrscceEytIYIP1smRtVj0dvLZdgqw9FeR5CCDQFwIEWftCnWMigAACCCCAAAIIIIAAAoNboM+CrBa6sy7Ut2zZEnwHJkyY4KpR7rbbbq7hMbiinYnQRklbnZaWJj/72c/EGkgtjGr7t8qVFh60wYKJXoDU5i1Ea2FWG+w5v/3tb8ULFVog1SpWesG75ORkeeCBB8TG9913nzz55JPueVat1SpIesOyZcvknHPO8Wbd2IJ/VnnVG0Kff9FFF8kBBxzgrepw7DV29jTIatVYP/ks8FrX522QDz4MVK7tKMhq21x46R/d+Rx/7JFyzLe/1eLcXnntDbn/4b+5ZRed/yuZusvkFut7c+afL/5LFrzwrza7TE5Mkl+dc5YMHzbUrbv9rvvknf+932Y7b8FZP/mh7LfPXuIFWL1xbwZZ165dK2eddZarxGoN6ZdddpnY77Q3WIXVa665xjWo27LQir2hIVNbd9BBB7l/C9ZQbsMirUZrv892vjbcdNNNMmXKFDdtP6yysPeP+eqrr25R7dXbqPUxLAxtDf22Hwu2Zmdni1U37qgiaySvz15reXm5C+VeddVVsvvuu3un5cYWyLV/G3Z8gqwtaJhBAAEEEEAAAQQQQAABBBBAAAEEOhSItNcr27G1k/Wkh6EbbrhBXn755Q7PzVZYqPXPf/5zi2IAtjy0naqznoNsW2uTuv7668XaXjsa7Di2H2vvveKKK9xmPe3Fy55shQ3WrVvn9jNjxgy59tpr3XRPfnhtuwRZe6LHcxBAoK8ECLL2lTzHRQABBBBAAAEEEEAAAQQGr4CXfetKwFdVVdXU1UbdXf+///1PrFKqBUdDB+sKfeLEiWKB1jlz5og1FrYeQoOsFsSzBsrWd/dbV+3WKGqDVWm1MKoNoc+1AKx1A29VK1sPv//972Xx4sVusVWL/cEPfuAChZdeeqlbtu+++4o3bQtsP3/7WyDg6TbQH//3f/8n3/ve97xZF5j99NNPXaDv8ccfb3POwQ1DJrzGzp4GWUN2JYveXyy3zA1Uie0oyPr6W+/IXfc97J5mlUytomnosG59nvzusj+5Rd897mg56vBvhq7uten/vPpfeeKpf3S4v3R978791dmSt2GjXHfzHR1uZytSU1Pkuisv00ql8S4Muj2CrPa7/O6777rzsLCmhURbD1Yp2ALQFkgdN26czJ07120S2nh//vnnyyGHHNL6qe533H53bTjvvPPka1/7WnCb7gZZLSBr4W2r7tp66CjI2tPXZxUy7N+BDRaY/etf/+qmW/8wk5KSEsnKymq9inkEEEAAAQQQQAABBBBAAAEEEEAAgXYELLgZSa9Xtsue9sATGmS1tlfrncp6CSooKBCr7mrtbzbYzdN33nmnKxLgFuiP0LawznoOsnYlu+nZ64nIei7Kzc2V4cOHu6qs1v7rDY8++qgLu3pBVm+5jcPtxct7DkFWT4IxAggMVgGCrIP1ned1I4AAAggggAACCCCAAAJ9J9CnQVZ72R999JG7o711N+ehJNY4+cMf/tCFWr3loWFU6ybKC6x6621sjaXW7VNdXZ1rrJw/f75YSPb+++93VQZsm5NPPllOOeUUm2wzWNDWqmraMHPmTLFKlxrodZU0rTsrC8FaGNUbrBrnqlWrXDVN61pr48aNMnnyZLnlllvcJnY+xx13nFhlztAQo/f8jsZekDWqvlKsiqY1vHpjm7aHvS5v3NF+bLkFWW++4263iQVZx+WObbP58wtfkseeeNotv+2GP0tmRnqLbey1n/aTQED4W9/4qpxy4gkt1vfGzJtvvysPP/pYl7uy0GNaeroUawCyq+HA/feVbx56SJdBVgtUWgXf7jTUWBjbftdqa2tdd2N33x0wbu+czjzzTFm9erWrSGHdv1kDfGjjvXVdlq6vqfVgFYIffPBBt/jUU0+Vk046KbhJd4OsFrq2iwjtDe0FWSN5fZWVlWJBcK+a7I033timCkd758EyBBBAAAEEEEAAAQQQQAABBBBAAIHOBSLt9SqSHnheeOEFqaiokP33398FS0PP1NpF7WZtrzeuSy65RPbbb7/gJqFtYbawo56D/vjHP8pbb73lnmftgFZUwNpbvSEvL08swPrqq6+6sVVtDQ2ydrcXL2+/BFk9CcYIIDBYBbpzfWSwGvG6EUAAAQQQQAABBBBAAAEEelegz4Os9nIs4GZdp7/++uuuW/OtW7e2eZUW9vv1r38tX//61926cIKstqEF6KzKow3PPvusq7z6pz/9Sd544w23zLprt26m2huKi4vl+9//vluVk5PjuqeyGatyYNUObLBQrFcBwKs6aZVcbb0XUrTQoDW0rly5Un7+85+75x199NHys5/9zE139WNHB1n/piHWBRpmteGe22+QxMTENqf4f2ec4wLC++8zR8766Q/brI9kwfsffCh33ftAsGpDV/sy/wvO+6UkJyV1tanbp/2+dVaRtSdBVqu0ahV7bUjS89hjjz06PJf3339fLNxpgzW02+9GaON9R0HW559/Xu64I1B51qr8er9vtp/uBlk7Oobtq70ga6Sv7+KLLxZ73TZY6PqAAw5wge9dd9213dCu25AfCCCAAAIIIIAAAggggAACCCCAAAJdCkTS61VPe+Dp8qR0g6efflruuSfQM9Rpp50WbGe154a2hXXUc1BotVlrG/7LX/4iY8aMaffQ7733nuvd64MPPggGWbvbi1fojh9++GHx2qjtmMcff3zo6m5Ne227s6a17RmpWztiYwQQQGAHChBk3YHYHAoBBBBAAAEEEEAAAQQQQMAJ9Isga+v3Ij8/Xz788EN55plnZN26dcHVFhB86KGHXFAw3CCrhf2sCyobvCBraEOpBQPHjx8fPEbohFWhPOqoo1zQ1hpL7flW9dTOwavE6nXxbtVerTE1JibGrbOKm+eee67bnVVqPfLII8WqFNx6661uWesqBKHHbT3tNXZGN1QFK7H2tCLr/977IFiR9U+X/a7diqx33feQvPbG2+40Hr7ndveaW5/TGWefK2XlFTJj2lT5nYZIe3NYvWZtsHpnuPvN0i7rM1pVjm3vuV6A1RtbaNUeVmU2dGxB1O401Njv6+9+97v2DtnpMuu6zRrDQ38nOwqZvvzyy2Jdttmwo4Oskb6+1157zVU0bg9jxIgR8pWvfMX9W7Ou5BgQQAABBBBAAAEEEEAAAQQQQAABBLon0JNeryLpgcfaSlsPtj8rDFBQUCBFRUWuJ66nnnrKbXbYYYfJL3+5rQ0xtC2so56DnnzySbnvvvvc8w866CC58MILWx+yzXw4bcbWLtheL15tdtZLC7y2XYKsvQTKbhBAYIcIdOf6yA45IQ6CAAIIIIAAAggggAACCCCw0wv0yyCrp27BwieeeEKsMdMbvOBoOI2S9pwf/vCHYl1Z2eAFWU8//XSxsKwN9957r4wcOdJNt/fDAqh2HtY4axVW4+LiXMjWCy0efvjhcvbZZ7sQo4X9rLqrVXm1BtGTTz7ZNd7OmjVLrrrqKrnpppvkX//6l9uXdROfkpLS3iHbLPMaO6W2PBhktUBtaJjVqlzaMht3Nix6f7Hceue9bpM/XnKB5I5tW8Vg7j0PyNvvvue2sSBrew3TZ/3qAg2ylsv0XafIBb85u7ND9qt1XoDVG4eGV71pC7XOnj27W0FWqyZs77ENGRkZnVZkDQX58Y9/7CqShjbedxRk/fe//y3XX3+9e/qODrJG+vrspK2LN6tmsWHDhlCC4HR6erpYteSOguXBDZlAAAEEEEAAAQQQQAABBBBAAAEEEGgjYG1b3en1KtIeeOwErNehl156Sd566y1Zvnx5sBei1if3zW9+U371q18FF4fTFua1pdqTvDbh4A46mAi3zbi9Xrw62GXEi722XYKsEVOyAwQQ2IECBFl3IDaHQgABBBBAAAEEEEAAAQQQcAL9OshqZ2iBw5NOOklKSkrcCdv0qaeeKuE2SrYXZL3ooovEupmy4ZprrnHdTrmZVj+qq6vl2GOPdUuTk5Nl3rx5brqmpkZOOOEEqaurk3Hjxrlu3a3x0xqLrbKAVRiwwaqvWhVWC5xaBVdrcF2zZo0L6nldxLsNu/jhNXb66iqC4dXQEKsXYPXGne3Ogqy3zA106XXlpRe2G2R95LF58uLL/3G7uW/uzRrejW2zyx+d+Supra2VvWfvIWef+eM26/vrAi/A6o3tPfMCrN7Ygqx77rlnt4KsK1ascFVV7XXPmDFDrr322m4RhNN435dB1khfn4dh7kuWLJFPPvlEPv/8c1m8eLH7d+Stnz59uvv35M0zRgABBBBAAAEEEEAAAQQQQAABBBDomUBXvV4tW7Ysoh6GVq5c6W7szsvL6/IEexJktd6urP3Ihuuuu06s3airIdw24/Z68epq3z1d77XtEmTtqSDPQwCBvhAgyNoX6hwTAQQQQAABBBBAAAEEEBjcAv0+yGpvj1U4ffvtQFf3p5xyiqt0Gm6jZHtB1ttvv10WLFjg3nmrBGANqe0Nq1atkrPOOsutmjRpkgumetudf/75Loxn1Up//vOfi+3Tpv/2t7+5Cpu23XvvvSeXXHKJe4ptM3fuXLEutiwc+9Of/tTbVZdjr7Ezqr6yyyCrBVw7G/733gdy8x13u03+dNnvZFzu2DabP/P8C/LEU/Pd8rtuvV4rxya32MZewymnn+Vey9e/epD88NTvt1gf6cz6vHxp1DBpOIOdyyOPPyklpaXOprPnHLj/vvLNQw9xwdXOgqwWaO1ukNWqTxx33HHu8FZZ9K9//WuX1XFDz7U3g6xW1XSPPfYI3b2bDucYtqGFTO3324aDDz5YLrjgAldNI5LX53bWzg8LqNu/GauWbIP9G5o/f77ExMS0szWLEEAAAQQQQAABBBBAAAEEEEAAAQS6K2BtXe31ehUbG9vjHoYqKipcu6nd6G6Dtensv//+suuuu8rYsWNl6NChsnr1arnyyivd+p4EWc8880y3D9uBtb1OmDDB7auzH5G0GXe230jWeW27BFkjUeS5CCCwowUIsu5ocY6HAAIIIIAAAggggAACCCDQZ0HWu+8OhClPO+00iY+P7/CdsMDhGWecIevXr3fbXH755bL33ntHVJH1mWeekbvuusvtb8qUKWLdVLU32Da2rQ1eoM/bzsJ3jzzyiJu1aq3l5eUybdq0YNfvtsIqtlqlVgs5JiUliTXw2nDZZZfJPvvs46bD+eE1dkY3VPVKkPWm2wOv/arLf99ukPWV116Xex541J3aVVdcJOPGjmlxmgWFRfKL31zolh13zLfl+GOObLE+0pmX/v0fufm2QOg3nH3l5AyRmrrGTjdNS0uVG666Qn/X4sIKsloQtLsNNVYpeOvWre48LDR6xBFHdHpOdhHBqujaEE7ItLOKrLfccossXLjQ7evSSy+Vfffd102H/gjnGLZ9e0FWW97T12cVbu21xsXF2W7aDFb52P6dWKVjGx599FHJyspqsx0LEEAAAQQQQAABBBBAAAEEEEAAAQR6JmBtrK17vdpvv/163MNQaPvqsGHD5OKLL24TNLUesaxnLBt6EmQNLW7QUXtXaw2CrK1FmEcAAQR6JtDd6yM9OwrPQgABBBBAAAEEEEAAAQQQQGCbQJ8FWW+++WZ58cUXxRo6zznnHJk1a9a2s2qesgbWBx98UObNm+eWWBDu4YcfltTU1IiCrBY6tUqtNrbBqk8ecsghbtr7YV1jnXfeeVJVVeUW3XDDDa6igLf+008/ld/+9rferBv/5Cc/ke985zstll1zzTXy6quvBpdZdQJ7PRZsDXfY0UHWJV8ukyv+fL07Pau2+o2vHdziVN9Z9L7c0lzV9RdnnC777zunxfremHn2uX/K3fc/1OWuMjMz5Nqr/iBPPD1f3n73vQ63987TC1V2VZG1J0FWqyT6l7/8xZ1DSkqKWAN7e12eWaUKq0D60ksvBQPV4YRMOwuyPvbYY+7fhh38mGOOceHv1hjhHMOe01GQtaevz/6tWFjcjt/ev3MLeFuQ1cKuFgq3CiH274QBAQQQQAABBBBAAAEEEEAAAQQQQKD3BEKDodbrlfUa1dMeeEL3ZT1P2b5aD5EGWe+991556qmn3G5/8IMfuPaj1sdoPU+QtbUI8wgggEDPBAiy9syNZyGAAAIIIIAAAggggAACCPRcoM+DrN6pW6B1l112cQ8LAW7evFlee+01Wbt2rbeJ/OxnP5Ojjz7azUfaKPnkk0/Kfffd5/ZloTnb7+zZs12FzGXLlrnuzr0Qq1UnuOSSS4LnYRNWbfWEE04IVpG0ZQ888IAL5tq0N7z++uvBLrps2cSJE+W2227zVoc19oKs/sZqV5E1OjranadV8/QeUVFRbtrWdTb8770P5MbbAmHLP1u11dyxbTZvamqSn//6QiksKpKpUybLpRee0GHprgAAQABJREFU2yJYeNPtf5F3F30g1v3Y3bffIPEdVNpss+NuLnh83tPyt8ef6PBZqfp78ucrL5fRo0ZKUXGJnPu7S7X6bSB4HPqk3abvKr//7a/coo6CrBaitHXeegtcdrehxsKxZ599tlgI2gb7vfrqV7/qKvVad2qlpaXy2Wefif1OlJSUSE5Ojjz0UCCsG07ItLMg69tvvy12AcE7rl08mDRpkhQWFsrHH38sVsk4nGPY8zsKsvb09YXub+rUqS40Pn78eFeJedWqVfL000+LjW1oXfnYLeQHAggggAACCCCAAAIIIIAAAggggEC7ApH2etXTHnjshn6vB60rrrhC5sxpe6P7+++/7yq12on3pCLrCy+8ILfeeqt73ZmZma7gQUxMTLsO1lZr6yJtM/Z2vnr1arFehGywG69HjRrlrer22GvbnTVtUrefyxMQQACBvhLo7vWRvjpPjosAAggggAACCCCAAAIIILDzCPRZkPWee+5xAbZwKQ899FD5zW9+EwxURtooaVUxr732WnnzzTc7PYVx48a5EKCFDlsP1jWWVRawwbabO3du601cRVerNmnHs8GqHPz4xz9us11nC7zGzpimmnaDrBZe9cKt7QVZ6zWg6R1/0fuLZe7dD7jDWUB13LhAkDUhPj5oaysfffxJee6fL7rtjj3qcDnyW990QdmX//Nfefhvf3fLrRLrOWf+xE1vrx8PPPyozNfqrK2HxMQE+cOlF8nECeODq/7171flvof+Gpy3CQvbXn/V5TI0Z4hb7gVVQ0OrFmJtHWTdfffdux1ktQNY8Nqq8HphVnfQDn70ZpDVQqZW2XjFihVtjmYh5wULFkQcZLUd9+T1hQZZ25xcyIIhQ4bIHXfcIRZkZ0AAAQQQQAABBBBAAAEEEEAAAQQQ6Fog0l6vetoDj4VXrX3Whq997WuuZ6vQs7Wbua2NbMuWLW5xT4Ks1pvW6aef7m4Ot50cccQRctZZZ4m1dYUOb731liscYO1KS5cuFTs3G2x7u7G7vcF669q4caNbZT0ntQ7IWpXZdevWufUzZsxw7cjt7SecZV7bLkHWcLTYBgEE+osAQdb+8k5wHggggAACCCCAAAIIIIDA4BHosyCrEVvD4sKFC12FSmuYbG8YM2aM6ybdunoPHRYtWuS6brdlRx55pGvEDF3vTVtjZ35+vgtpWqOkVTANHayx9uGHH9ZKnpWhi9123/rWt1zo1MKQ7Q3WBbpVYbXhpJNOEqtg0N4Q2rBrVTP32muv9jbrcJnX2Bkrta6h1qvC6o27CrI+Nf95+fuTz3S4f1tx4bnnyB677xbcpqSkVK748/WyPi/fLbMG4iitMGqhWBsyMzLkst+fJ8OHDXXz2+uHVYede9d98vJ/Xg0eIk7fj0t/f77sOnVKcJlN2LaX/OFqWbp8W5jzpO9+R4458vDgdp0FWS3MaoFQG8+cObNHQVY7kB3Dqoz+4x//kCKtatt6sKDmAQccIIcddphMnjzZrf7lL3/p/j3YzN///ndJTU1t/TT5z3/+E2w0//73vy+nnXZai22sirFV+33vvfdaLE9MTHTdsIVzDHuiXWg477zz3D7auxDR3ddnIepXX33V/VtfsmSJe59CT9B+tw4//HCxLu3S0tJCVzGNAAIIIIAAAggggAACCCCAAAIIINCJgBdk9Tbpbq9XPe2Bx9q+rFCBDda2Y21pVpXV2tXspmZru7W2Om/oSZDVnhtaldXmp02bJl/5ylfEej+yHn6sJ6IPP/zQVsmjjz4q1tMWQVbHwQ8EEEAgIgGCrBHx8WQEEEAAAQQQQAABBBBAAIEeCPRpkDX0fLdu3eqqPVr363HaVb1VZxw5cqQkJCSEbrZdpq1R1cKuVkXTQnqjR48WC9C2vhN/uxw8jJ16QdY4X12Pg6yPz/tHp0f6/W9/JbNmzmixTWlZmVx/8x2yZOnyFg3PuWPHyHm/PCtY5bTFk7bDjDWo33TbXHn77f9JdEy0XHDur1uEbkMPuWbternwkj+4wO3okSPkWq3G6teKtd4QbpB1t91263GQ1TuWjSsqKtzvtQVaLXhsVVjHjh3bovpt6Pa9MV1cXOx+n61LtfT0dPf73LpSRW8cx/bR3ddnXbJt2LBBNm3a5E7BPIYPH75D/p331mtmPwgggAACCCCAAAIIIIAAAggggEB/EYi01yt7HT3pgcfanc4880zJy8vrkMLawizYakNPg6zWLmhh3ZdeeqnD43grCLJ6EowRQACByAUIskZuyB4QQAABBBBAAAEEEEAAAQS6J9BvgqzdO+3BtXVokNWqr3qVWL1xVxVZI9WqqqqWZStWuobnSRPHS0pycqS77PbzrdH7+ptvlwO/sp/st/ecTp//6OPzZP7zC+WPl1woU3aZ1GLbroKstt4e1mUYDTUt6JhBAAEEEEAAAQQQQAABBBBAAAEEEOiHApH0euW9HGsP624PQ3aj8k033SQfffSRtxs3TkpKkuOPP14mTZokF198sVtmvfGcffbZwe3C7TnIe4L1QHT33XfL+vXrW9xwb+snTJgg1rOW9X70wQcf9EovXhbSXb16tTu8VZu9+uqr3XRPfnhtu7OmtWyn7Mm+eA4CCCCwowS4PrKjpDkOAggggAACCCCAAAIIIICAJ0CQ1ZPox2OvsdMqsvZFkLUf07R7ajU1NbJg4cvynaOPaLOeIGsbEhYggAACCCCAAAIIIIAAAggggAACCOwkAr3R61V3euCxnq7WrFnjqrpam1xWVpbsuuuuEh8fv11Eq6qqZN26dVJYWCixsbGSm5srmZmZ2+VYvbVTr22XIGtvibIfBBDYEQIEWXeEMsdAAAEEEEAAAQQQQAABBBAIFSDIGqrRT6e9xs74qHqCrBG+R+EEWa36KxVZI4Tm6QgggAACCCCAAAIIIIAAAggggAACCCAgXtsuQVZ+GRBAYCAJEGQdSO8W54oAAggggAACCCCAAAII7BwCBFkHwPvoNXYmRDe0CbJ6FVpDxwPgJfXZKYYGWS2w6s3bdOj89OnThYaaPnubODACCCCAAAIIIIAAAggggAACCCCAAAI7hYDXtkuQdad4O3kRCAwaAa6PDJq3mheKAAIIIIAAAggggAACCPQbAYKs/eat6PhEvMbORH8jQdaOmcJa4wVXW49bB1mnTZtGkDUsUTZCAAEEEEAAAQQQQAABBBBAAAEEEEAAgY4EvLZdgqwdCbEcAQT6owBB1v74rnBOCCCAAAIIIIAAAggggMDOLUCQdQC8v15jJ0HWyN+s1gFWb54ga+S27AEBBBBAAAEEEEAAAQQQQAABBBBAAAEEWgp4bbsEWVu6MIcAAv1bgCBr/35/ODsEEEAAAQQQQAABBBBAYGcUIMg6AN5Vr7EzKaapRUXW6Oho8fv97uFN25ihYwEvuOqNLcDaetrn88mkSZOoyNoxI2sQQAABBBBAAAEEEEAAAQQQQAABBBBAIAwBr22XIGsYWGyCAAL9RoAga795KzgRBBBAAAEEEEAAAQQQQGDQCBBkHQBvtdfYmRwrwSCrF1wlyNq9N9ALrXrj1pVYbXlCQoKMGjWKIGv3aNkaAQQQQAABBBBAAAEEEEAAAQQQQAABBFoJeG27BFlbwTCLAAL9WoAga79+ezg5BBBAAAEEEEAAAQQQQGCnFCDIOgDeVq+xMyXO54KsrUOsFmb1lkVFRYlVFGVoK9DU1CSNjY3SugpraJjVgqzZ2dmSlpYmH36+3O1k6oTRbXfGEgQQQAABBBBAAAEEEEAAAQQQQAABBBBAoAsBr22XIGsXUKxGAIF+JUCQtV+9HZwMAggggAACCCCAAAIIIDAoBAiyDoC3eenqPGloaJS0BL+GVEW8KqyhY4KsXb+RXQVZLdBqIeDc3Fypra2Tz5at1oBwlEzOHdn1ztkCAQQQQAABBBBAAAEEEEAAAQQQQAABBBBoJUCQtRUIswggMCAECLIOiLeJk0QAAQQQQAABBBBAAAEEdioBgqwD4O1cv3GrlFVUyZCMVKmvreoyyGoviaqsLd9YC7Ha0FlFVguyZmVlSUpKimwtLJF1GzZLSlKCjBqW3XJnzCGAAAIIIIAAAggggAACCCCAAAIIIIAAAmEIEGQNA4lNEECg3wkQZO13bwknhAACCCCAAAIIIIAAAgjs9AIEWQfAW1xaXil5mwokPi5WhqQnSXV1dZswa2hFVu8lEWYNSHghVpvrLMiakJDggqy2/ZIVa6W6plZGDs2S1OREj5QxAggggAACCCCAAAIIIIAAAggggAACCCAQtgBB1rCp2BABBPqRAEHWfvRmcCoIIIAAAggggAACCCCAwCARIMg6AN5oC1auXLdRauvqZcTQbImPiWoTZm0vyGovbbCHWUNDrObRUZA1Pj5e0tLSbBPZtLVI8jdtldgYv4wfPWzQGzoUfiCAAAIIIIAAAggggAACCCCAAAIIIIBAtwUIsnabjCcggEA/ECDI2g/eBE4BAQQQQAABBBBAAAEEEBhkAgRZB8gbXlFVLWvzt7hQ5YSxIyQmOhBmjYqKctVZOwqyDpCXt8NOs3WQ1eYtxGoPG8oqKmXFmnyxAOyYEUMkKSGwfIedIAdCAAEEEEAAAQQQQAABBBBAAAEEEEAAgZ1GYOnqPGloaJQpE8ZIQnzcTvO6eCEIILDzClRV17he66L1OtTk3JE77wvllSGAAAIIIIAAAggggAACCPQrAYKs/ert6PxkNheWSEFRqUT5fDI8J0tysjOkrq7OhS6t8qqFWS3YytCxgAVXGxoagmYxMTHBjTdrJdYNmwukUUOsWRmpkpMZqNAa3IAJBBBAAAEEEEAAAQQQQAABBBBAAAEEEECgGwIbthRKcWmFpCYnyoSxBMK6QcemCCDQRwIr1uRJaXmlpKcmyfAhmX10FhwWAQQQQAABBBBAAAEEEEBgsAkQZB1g7/hGDVsWlZS7s06Ij5W0lGRJ1KqhiQlxEuP3D7BX07enW1dfL5VVNfqolpKycqmqrnUnlJGWLMM0JMyAAAIIIIAAAggggAACCCCAAAIIIIAAAghEImBtkCvXbRK7wd4qsmZnpElmeqoWJPBFslueiwACCPSqQGNjkxQWl8rWohK9VlLjiqaMHz2U6069qszOEEAAAQQQQAABBBBAAAEEOhMgyNqZTj9dV1ZRJZsLiqW2rr6fnuHAPK3YGL/kZKVLSlLCwHwBnDUCCCCAAAIIIIAAAggggAACCCCAAAII9DsBa8/Nt56gNCjGgAACCPR3AQvaj9BeAblW0t/fKc4PAQQQQAABBBBAAAEEENi5BAiyDtD3s6mpSSq0kmh1TZ0+al010fqGhgH6avrmtP3R0VoFIVbi4+wRI0la2dbnoxJC37wbHBUBBBBAAAEEEEAAAQQQQAABBBBAAIGdV8CKEhSWlLkeomza2ncZEEAAgf4iYNdGrNiH9f6XmZbipvvLuXEeCCCAAAIIIIAAAggggAACg0OAIOvgeJ95lQgggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggEC/EyDI2u/eEk4IAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQGBwCBFkHx/vMq0QAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQQQQAABBBBAAAEEEEAAAQT6nQBB1n73lnBCCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAwOAQIMg6ON5nXiUCCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCCAAAIIIIAAAggggAACCCDQ7wTeeOMNqa2t7fK8fFVVVU1dbsUGCCCAAAL/z95ZwF1Sm307QPGySFkoi7tri9sCi2vR4iwUeCnu7l5atLjzFpdixUsLFBZZ3Ir7iyywyxaX9tt/aM6XM8+cmYwcmWeu/H7Pc+bMmckkVzJ3Msl/7kAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABAIJPPHEE2bUqFGpRyNkTUXEARCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAJZCLz22mvmrbfeSj0FIWsqIg6AAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQyELg//7v/8wHH3yQ6pUVIWsWqhwLAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgkEpAQlaFd99913z++ectj0fI2hINP0AAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQjkIeCErDo3yTMrQtY8dDkHAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAoCUBX8iqg7766ivz2WefmS+//NJ8++239rzxxhvPIGRtiZAfIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABPIQiApZW8WBkLUVGfZDAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEI5CKAkDUXNk6CAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQKEoAIWtRgpwPAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgkIsAQtZc2DgJAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAoCgBhKxFCXI+BCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAQC4CCFlzYeMkCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAgaIEELIWJcj5EIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAArkIIGTNhY2TIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABIoSQMhalCDnQwACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCOQigJA1FzZOggAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEChKACFrUYKcDwEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIJCLQNeErO+PGJkrwZwEAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAoOoEphk4edWzQPohAAEIQAACEIAABCAAAQiUQgAhaykYiQQCEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIBAOAGErOGsOBICEIAABCAAAQhAAAIQ6N8EELL27/IldxCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAQA8SQMjag4VCkiAAAQhAAAIQgAAEIACBrhBAyNoV7FwUAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCoMwGErHUuffIOAQhAAAIQgAAEIAABCPgEui5krcoD2vsjRlpuVUmvX8hV2IZvFUqJNPoEqLM+DbYhAIFOEMDudIIy14BAdwhwf3eHO1eFAAQg0IoAdrkVGfZDAAL9hQB2rr+UJPmAAASqTABbXOXSI+0QgAAEIAABCEAAAhCAQDsIIGQNpMoDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFF2I0HynPPPdd88803TSlcaaWVzLzzztu0L+nL6NGjzSWXXNJ0yAQTTGB22GEH88knn5hPP/3UzD777E2/+19GjRpl0zD22GObgQMH+j+Vup2X7xtvvGGGDx9u3n//fTNixAjzn//8xyh/P/vZz8w666xjpp122lLTSWTJBNpdZ7/99lvz3XffmYknnrhlQnq9zrZMOD+UTuCqq64yH330UVO866+/vpluuuma9vEFAmkEPvvsMzNgwAAz1lhjxR4qu6T2VGGSSSYxE000UexxRXfmbSuLXrdXzk+7p5988knzwAMPNCVX7cV2223XtK9Xv6ge3X///eatt96y/ZovvvjCjDfeeLZOzTnnnGattdbq1aSnpquM/kHqRXIcQL8iB7Q2nPL666+bW2+9tSlm9eE32GCDxr5erUONBLLRVgK9/swXUofbCqgfRY5dbk9hdrKP1B/tdVoftD2l1r1Y+5NN69X62Cu2rr89X3bK1nXqOp20Av3pvm8Ht/5Y5u3gVLU4GeurWomRXghAAAIQgAAEIAABCECgLgQQsgaWdDcG99Zdd12jwU0/7LzzzpmEDO+8844VrfpxSOh5wQUXmP32288Kb44++mgz33zz+Yc0tv/5z38aCQMlZF1sscUa+8veyMpXYo+zzz7b3HHHHVa8Gpeeww47zCy55JJxP7GvTQTaWWevvvpq8+KLL1ph9dxzz22FPXHZ6NU6G5dW9rWXwP/8z/9YQZh/lWOOOcb84he/8HexDYFEAuoovf322/YFidlmmy1WzPr555+b5557zsYzwwwzmEGDBiXGmffHrG1l3uv06nlp9/S1115rLrrooqbkTzrppEbiAxfUf4i+JDT++OObcccd1x3Slc+nn37anHbaaVbAGpeAWWaZxZx55plxP1ViXxn9g7Izqj42/YqyqeaL7x//+Ic59thjm06ea665zCmnnNLYF1KHJP7WS20u6OWDpJef3HF89i6BqjzzhdTh3qXcOymrsl3u1f6FK92QPpI7tuhniL0ueo1On5/WB+1kejrR1vUnm9aL9bGXbF3W50ts3Y93eydtaqfsS3+679vBrD+WeTs4lRFnp+wMY31llBZxQAACEIAABCAAAQhAAAIQaA8BhKyBXLMO7gVGm3hYGQOucUJWCTbksdQVvoStrcSsvSoK/N///V9zxRVXJPJDyJqIpy0/tqvOqo4eccQR5quvvrLplrC6lZi1V+tsW4ATaSKBXppwTEwoP/YsATew7RKotjNOzIqQ1RFq72faPR0yuXThhRea6667rimh6623ntlxxx2b9nXyi14Y2n777Y3qUauAkLUVmXz7nYCAfkU+fmWfFTJxntbH/Prrr82vfvWrPknT/Y6YtQ+WyuyoyjNfSB2uDPQuJbTqdrkX+xd+UYb0kfzji2yn2esicXfr3LQ+aKfS1am2rj/ZtF6rj71m67KOdWPrfrzbO2lTO2Vf+tN93w5m/bHM28GpjDg7YWcY6yujpIgDAhCAAAQgAAEIQAACEIBA+wg4LWPaFcYaM9H7/93bpB0d8HvWwbKAKNt6SDfSW8aAa5yQVd6JfG9FAtdKzNqLokAt+7LFFluY77//PrHMEbIm4mnLj+2qs1pa+cADD2xKcysxay/W2aaE86VjBHplwrFjGeZCpRKIDmy7yOPErAhZHZ32fqbd0yGTS/JIf/311zclVG2X4u5W0JKnN954Y+LlEbIm4sn0Y1RA4E6mX+FIdP4zZOI8rY/ZStwju/DTn/6085niioUJVOmZL6QOFwbSjyPoD3a5F/sXfpUJ6SP5xxfZTrPXReLu1rlpfdBOpatTbV1/smm9VB970dZlHevG1v14t3fSpnbKvvSn+74dzPpjmbeDUxlxttvOMNZXRikRBwQgAAEIQAACEIAABCAAgfYSQMgayDfr4F5gtImH3XTTTUbLqfhBS2LPPPPM/q7E7Tgha6sT4sSsvSgKfOaZZ8z+++/flI2JJprIHHTQQdZLp5YMfvXVV83ss89uJptssqbj+NJeAu2qs1ryWeUbDXGik16ss9F0870zBHplwrEzueUqZRJoNbDtrhEVsyJkdWTa+5l2T6vtf+qpp5oSMeGEE5o111yzsa/dkyKNC2XY2Hfffc1zzz3XdMbgwYPN0KFDzSSTTGLef/99869//cssuOCCTcdU6UsZ/YMy8ttKQODipl/hSHT2M2TiPK0OdUrc01ky9b5alZ75QupwvUuzde77i13uxf6FTz2kj+QfX2Q7zV4Xibtb56b1QTuVrk61df3JpvVKfexVW5d1rBtb9+Pd3kmb2in70p/u+3Yw649l3g5OZcTZTjvDWF8ZJUQcEIAABCAAAQhAAAIQgAAE2k8AIWsg46yDe4HRln7YDz/8YMUOWkJT4r8sQlYlJipmdaLAccYZxyy66KKlp9dFmIXv7bffbk4//XR3qv1cddVVzR577NG0r8wvo0ePNpo0GDhwoJFH26JB3mQ1kC0Bbqsgr7kSR0nE0p9DSJ1tJWQVl6jopBfrbH8uv17OW94JR92fH3/8sZl00kmNRHB5wpdffmn+/e9/Z/YCp3Nkb+Q97ic/+UmeS3NOQQJpA9suel/MWhUhq+ztF198YQYMGOCy0bVPV9eVgND6nvee9jPZzkkR/zpZtjfeeGPbd/PP0XLaU045pb8rcVt2Q304eTDvdMhr79qdTvWjPvnkE2tL9WJTmoDApaeq/QrZofHHH9/2/11euvWpPrNsjdrQpL6uS18ZE+edEve4NJf1qftH7X037t1oHnrt+aSsZ75O2Mc8dThPOxgts7K+6/4ZOXKkbXf03NXu4NoN1fsXX3zRjFn9J/GSVbDLne5fdKv+dMpm5R0L0Yvgqs9lj6GE9EHV7qkvprGz0JC1vSyzrUuyjSE2LW8ZhbIJOc7Zkl7zvB61qb3cB80yFqsy6bSty3qPhNSbkGM6ZevyXkcvOaqfXeaYUch934pdtM63Oi5uf7fK2E9LJ+1ZnjJvV9vmM2jndtYyLsPORMcClL/+PNbXzvIjbghAAAIQgAAEIAABCEAAAt0ggJA1kHqWwb3f//73fSZjdtpppyZBgiZsrrvuuqara9nYzTffvLHv/PPPNx988EHjuza22GKLPh5Z9XB+yy23mIceesi89NJLduBekz1zzjmnWWihhcyVV17ZFEfaF1/M2kuiQHkr+/Of/2zFuRLo+mGaaaZp4uI4JTFUGdx3333mvffeM9NOO23TssIaaFb5PPnkk/Z6WtpSQWymm246M9tss9myihOZvPzyy+bqq6/2k2dmmGEGs/XWWxtNyOqa4qpryGvsYostZjbddFMryNRJyucdd9xhnnjiCTuhqEH5hRde2Pz2t79tm4fZXq+zSUJWMfMnN3upzipthO4RCJlwdKnTfaulwt5++207uCkxh0TrusdnnHFGs+yyy5pVVlnFHd7nc9SoUXZpcHmDlN12NkOiIsUh+77ccsvZFwK0zw+PPfaYue2226yt+fDDD427toS0U001lbURur7sCKG9BEIHtl0qnJhVE9fOo6bKadCgQe6QUj+z9EXcheP6CBKWqY+w8sorG01Y+UETYvvss09j16OPPmruvPPOxndtzDvvvGb99ddv2nfOOeeYESNGNO3bZpttzPTTT2/3PfLII+bBBx80r732mhUXavJcaXNBadJ9Is/za621VqwIPO2eTmp/XR/i9ddf79O3mnrqqc2ss87qkmLbZ32JCstc36Jx4JgNTSr97ne/s8J1f/9WW21lbYe/L7p91llnWRbqv0XDkksu2XhxRgzF0g/Kq/pEslny2OpEQLIbOn755Ze3f2ULOZSGPPYuqT8msalYZA177713H5HkRx99ZPu9Kmf1FR0XveA1xRRTmLnmmsssscQSjT5Xq2tWpV+hPqz6nC+88ILtz6rdUn1W+av+6n7zg178Ur9Toax7WxPpN954o+3byoZKDKfVEVzQBLts5XzzzWdWWmkl26d1v7nPkInzpDqk+iP78/DDD7soG596ES9NmBd3jymCe++919qtRmRjNmaaaSaz5ZZb+rtabrdKs14muOqqq2y78dZbb9l7Xc8iq6++ullvvfUa974iLquckuxjrz2fOHutezj0mc8vhG7Yx5A6nLcdlM0944wz/Cza7SJtktpfte1qf9SOyHZqn2yfbIhWgIlrx5LqkfpC99xzj7VHEtbr2XeOOeawaW3VbshOqZ3SNWUj9GzcSpTTq3bZ1deQ/oVg6JleNrGVfRD7uHGKvPXHFsCYf0ll545plaYsNktxtYrHrSyUlBbZ3b///e+2HqlOaSxk7rnnNhpP05hPXFBfTDb18ccfNyoHfVe7rzEb9XWj/axoXzcuzui+Vn1QveisZ0iVmdpkPefpukOGDDGrrbZaUzRF28ssbZ3up1/96ldN189iG5NsWp4yakpIgS+tbEnSM3dSfSyrD5pkU/U8r3tefTPVl7TQaVsX+nyZx9aJb6ux0bg2Q/d40T5lkn1x7FvViSy2rlPXcWnWp8Y6ZW90bb14rbqi+rXMMsvYsWrZPz/4/X5/f6vtpPs+ek5SnU/qRxS1g0pHEvu4eqVzWtXDLPYs6bq6hkIZdevHmH4cZ2h32+aulfTZKk+t+itFyjiPnZF9dSFpLED3itrnkLEAxad4dbzqlNKl0GtjfTZR/IMABCAAAQhAAAIQgAAEINBPCSBkDSzY0ME9RacBY71t6oczzzzTCjTcvr/97W9W+OC+61ODzSeddFJjV6vBcok8XNADtUSIcRO37hgNMPleRDWZu8kmm5g//elP9pAVV1zRLL300u5w+6mBJ4k6ekkUePfdd5uTTz65KZ2tvhx11FFWMBbHcP/997fCHQlqXFBe//jHP9qvzz//vDn11FPNu+++636O/ZToZrvttrOTzj7fuME/DZhowGP48OGxca277rpmhx12sBMwKheVWTRIgHHuuefGinuix2b93mt1Npp+TUzoHnKT2ZoAEA8/aCJUE1a9VGf99LHdeQJx9/8xxxxjhXIuNbLVl112mdGSg/JslBQWWWQRs/vuu9vJAv+4G264wcbhC3f83/3t7bffviEA1MTO4Ycf3kdo5B/vtjXhqusQ2ktAAuRoPZDAQ2I4TRRJYBEN8vTYq4PbIX2EaH70woYEki5cf/311vOO+65PiSwPO+wwf5dtD6OdyhNOOMEsuOCC9rgjjzwysa/iRyZbLnGohK1+SLun49pfCRdPOeUUk6UPoWtq4kL3qB8k3tU97AeJzHQf+0Ftll4i0n2bFCTy0WRLWpAQ6LTTTrOHSbSqyaRhw4alnWaFjLJtZYa89i6p7N544w0r7MmaziuuuMJMPvnk9jTdt3qp69JLL22IV1vFJyHizjvvbM+tcr9CdUDPAPLqExp+85vfmA022MAeXta9LbHsLrvsEpoE+1LInnvu2XR80r3rDkyqQ6H3kuLShKSWBvWDhHO6Z6Me3XbbbTfzyiuv+IeazTbbLFjIGpdmiXklSJPQLy7od/9lgrLKKY5xrz6fZLHX7plPLLtpH+P4uvbHlXPedlDPhUOHDjV62ckPedsktdVqU5555hk/uj7bui/0sqXqvAut8rnRRhvZ52eJF1xQ2yixQJZ2Qx7KJVpUqMrzXpb6qnydffbZVhAfZx+Sxiny1h9dU6FV2amP5EJcmrLaLMUVF4//DBaXFid8ajWupbEXjZVF+4YSjx5//PFBz1Mun9G+rtuf9BmXJz0bStyiF5TjwoYbbmi23Xbbxlhc0fYyS1un8b1DDjnEJiuPbSyzjOLY5NmXxZb4z9xxZefqYxl90Cw2VS+ryHar79YrfdDQse48tk5jqscee2xTcattbNVmyO53q0+Z1dbF3SPRdj+u7mW9juCpHyABq8attMJKaPD7/SHnhORJ8WSp89F+RFE7qOu3SmereqUXxaP1ME+b0+q67WhHO9W2iWdaiKvHSf2VImWcx87o2T7PWIBeIqzyWF9aufE7BCAAAQhAAAIQgAAEIACBqhOIag5a5WesMSKOvsq6VkcH7A8dLAuIqiOHZElvJ0WBhx56aEtxZCswGrg/7rjjzF577WUP0eC6BnziQi+JArMMaLhJzbgBl7h8OiGrBrJ33XXXTIODEqD63i7iBrfirhndJ0+vaeLZuAnLaDx5vlehzmqZ5ZC3oHupzuYpC84pj0Dc/e8mrdxVZAsfeOAB9zX1U+I2icicQE0eHPwXENIicJNqEkZKqBL1mtHqfISsrci0f7+zKRKyOk+G0atKkBRin6LnZf2epS+iuPP2EbotZFXaJbDSCya+R9G0ezqu/XUTiln6ELr+GmusYT0la9sFTa5qAtEPEgPJi7of9ILQvvvu6++K3Q4VJDghqya91UcJ7ryPNVafPMQmJHBnXnun6JPKrgwRQdzyg0nZUr9P9l+eTBWSvKs4G6ClguXds10hy/2tNKkfH/fiU1L6/AntsgSSWScrlT4/HfqedO/qd4WkOhR6LykeCevkPT360qHEtb7ndXm6ivO8euGFFwZ73Y5Ls9KQFmRXnCfLssopjnFaOvR7N55Psthr98zXbfsYx9e1P45zFiGizvHbQT0HSbzvhzxtkl7Q2HHHHe0LOH5cSdvqSyy11FL2kLh8tjpXQlaVS5Z+srzAOq+dVbHLWeqrWCUJWeNYunGKIvVH8caVXbSOlmGzdK24ePxnsLi06Ly0oDZY97wLEifJU2vaGIo73n2WJWR18SV96sUvvQCmULS9zNLWOSFrXttYVhklscnyW6/2QfPa1AUWWCDo2bETfdDQ/mceWxcnZG1V7mozsgpZFVdZfcpW6fL3+/2zuHukXTb1r3/9q315zU9LyHaUTdo5IXnKW+ddP6KoHVQe4tLZKm+qV3FC1lbH+/ujbU7cddtR5p1s2/z8ttqOa9PjjnX9lSJlnMfOSMiaZyzg9NNPt9595em7imN9cWXAPghAAAIQgAAEIAABCEAAAv2JQPBcOELWkbbcpxn4o+enpErQKVGglp4/+OCDY5Mib2DyKhT1JqaDqypklRfbP/zhDy1FphIYuHD00UfbpUuzDLhoyUYJT+SR1Q/ytqqBZjGVUEmTAX6QdxAJ25yH0LjBLf/4ItsS0TlPukXiiZ5bhTqLkDVaanxPIxB3//uTqK1sqO4zLbv+wQcfxApN5c1OkwISEMm7te99SmmS8G7++ee3EzHynvX00083PAQ6Iau8JGop9miQcEXe4jR4LS9wEngpIGSNkurcdzeBWLXB7Vb1W+TS+gjtFrJq2UgJVNRP0TLkanfjPBpHhWVp93Rc++sml7L0IcRI/Qj1saJCQXlsl31QkOcPeaqTJ18/SCC58MIL+7tit2UP5CWrlWcd16+RdzoJgU488US73G40Mnna1wSOPJO/+eabDYGS+i+33XZb9PBc34vYO10wqezyCFmVNy0RKXsb9xKS6rg8oQ0aNMguDS/PubKrfpCY6+c//7ndVRXBlEu/RKxaxjguqA2TN+aoUFPH+hPaZQkk/clKPWOoLuoeF2+VTZzAKCrAS7p3XR6T6pDuJXkuit6vOld1RfbbhWWXXdbo3pIowA+//OUv7X3v9t18881WcOa+63OeeeaxzyL+vqTtuDQnHe9+k5BeonWFssopjrG7XtHPsp9Psthr98zXTfsofnF8Xfvj+PpCxKztoPqkevk0WseztklxL3BpVRgtga4+qwQEupYfZCfPO+88o7YmLp/+sf62BHzyUpaln1xFIWuW+io+ErJOP/30se2iz89tO2FIkfqjuOLKLlpHy7BZulZcPP4zWFxadF5I8L2xt3qeUjx6dlI/Uy8lRO+bTgpZ9UyoVQYUiraXWds6eczLaxvLKiOb8YL/erkPmtemaqWpl156yZLpdh80VMiax9a99dZbfTxhtqoOUSFrp/uUrdLl7/f7Z3H3SDtsqvrz6r/Hje2rj6s+mMaoo+PUSrff7/fz0Wo7JE9567zrRxS1g0p7XDpb5amIkFVx+m1O3HXbUeadbNtacfP3x7Xp/u9u2/VXipRxHjujZ86oQ5KQsQCttqXnVoSsrgT5hAAEIAABCEAAAhCAAAQg0FsEELIGlkfo4J6i65QoUEsuaYDAD3pYl/BDk7SatJXwMuoVLCpk3W677exkvx+P2w4R8Lhji3xm4XvdddcZeUPyw+DBg40G6qMhy4CLBGkalIuGgw46yPLUfk2Si6eEN35YddVVzR577GF3xQ1u6Qd5gJKXNg2yaBBPgyXRIAGb6o/KSEucRpc+1UClJta11GOZoQp1NquQNUl0Vga7LHW2jOsRR3YCcfe/P4kqEZOWkvKDBGMSRWhpc02a6c1+LWPoB91/Eq9rUkFegKJBXiQ1iOuCBHq33367FaFL9CbPykrHgw8+6A6xn1GPD9opj60XXXSR9RoYTUfTyXxpGwHXDiZ5Y/Q9ss4444xWxNWOBGWxO0X6CO0QsqrtlrhuhRVWsCJWn4/2H3DAAX3avHXWWafpHku7p+Pa3+jkUpy3jnXXXdeKLvw0aVvtvfO0635TeylP7AoS4PpLgGvflFNOaZe394Vz2p8UtMxoVMirdGq5OxfkQfLAAw90XxufEiBJcDvZZJPZfYpHQqSLL77YCujLErJKIJvX3ilhSWX33XffNSbzGxkbsyEbLAFG3MSteylAx6sMoi8haZ+W7nRBdVp9Lz/oxQEtd6kQIiLolX6Fll2WoCkatMSx6qzqgvqaOmb48OFNh/kT2mUJJD/66CNzySWXWI9z8lqtZxE/tPIidc011zQ8Lofcu0l1SNdTm6z7Mxq0FKvETH7QCyayOX6QjVff23mB1v2m+84Pu+22m1l99dX9XYnbcWlWWpRO1T+JfPVMo/Lyg8rSLYFaVjnFMdY1e/n5JPSZr9v2URzj+Ebbn6LtYNE2KY6TBLWqg3rGVNCLFb/+9a+N+jV+UH1UvYzLp3+cv602Q6LNaEjqJ+tlsSweWXvFLiuPWfoXOj7OPmh/NDhhSNH6E1d20Toal6asNkvpj4vHfwaLS4vOUx3TuIpE0xLyyFZHgwSAel5TUF2Nvkyk9O69995m8cUXt/Va/XiNj/mhLCGrriHP3er7a2BVL12//PLL/qXstuvTldFeZmnr4u55JSik71hWGfWBkWNHr/ZB4/iG2tRDDjnEvlQjHN3ug2Z5vlR6s9i6VvVI8USDBIezzDJL1/qUWW1dXN7aYVNvvfVWc+aZZ0ZxGXldlhBP/Va9XHnEEUeYxx57rOk4v9/f9EOLL2l5KlLnXT+iDDsYl84WWTJJQtasbU7cddtR5p1s21px8/fHten+727b9VfKKOMsdibvWID6EhrX0dxM1cb6HHM+IQABCEAAAhCAAAQgAAEI9GcCCFkDSzfL4F4nRIEawJYYKupdIrrM/TvvvNMQXLis1l3IKrGYJkg0gey8VmmZb4nENGHiBw3yR5dDlAcwTdj7QWITDbQoxA1u6VpahsqFv/zlL3bJZPddn5qwufHGGxteozQJooHJaNC1p5566ujuQt+rUGcRshYq4lqeHDfg6iZRNUG/0UYb9eFywgknmAUXXLCxX7ZWE5TRCX0J5+WFOU5Ar6WJ11prLStm9cVso0ePthOqmmzYb7/9zLPPPtu4jjZkj4YOHWqXrh4wYEDTb7Ll8t5E6DyBKgpZi/YR2iFkjZacJtwkUBwxYoSdPJD3DbWffoiKu5PuaZ0X1/5GJ5eyTIrELW0nT5KXXnqpvZclaI8KzDfeeGN7H/v5SNsOEbLG9T0kuFefQBOv0SCB3J133mn0slIZ4Zlnnslt73T9tLKLS6PypnxHg+8NKa6uy1P+5Zdfbl8KcufqgSfKQrZYnk0Vui0iUBpCnzX0coPEmX6YdNJJzWWXXWa98rr9xx9/vLn//vvdV/vpT2iXJZBsusB/v0icrntb97hERvLKGBVrlrE8q2vTdVnVhVAhq56f1N7KA6Uf9FKanhHU5msS2feWLI/H8sqk+y40xNV7LYst2+bCueeea/v/7rs+/eeKssopzj72+vNJqJC12/ZRZRbHN9r+6Dg/ZG0Hi7ZJEqyKqR+0VLnquh/kPVJtsh9++9vfmrXXXjs2n2qDNC4hIbvqrl74kohBdvfQQw/1o7HbSf1k2Q558FOokl1WerP0L3R8nH1oNU4x1VRT6ZSmkLX+hNTRuDRltVlKZFw8vr2OS0vUHskOq08VHe/Ss5deYv7000/N5ptv3sREX6Le/FuNh/l93T6RxOxIy5NO0UvPetEmmma9WKL7Iy5kbS+ztHVFbGMZZRSX3zz7erUPWsSmqk863XTTWRzdtnWh/U9XdllsXVw9atVmaGxFY9XRkPUeibtmtD2Ou5+z2rpOXUfLn+ulaD/IU7rKQeI7F9L6/e64pM+0PBWp864fEXf9Mso4qV7pxT73gpi7ftY2R+el8dExRetWp9s2pTktxOUpS39F8Wct41A7U2QsQGOuap8RsqbVAH6HAAQgAAEIQAACEIAABCDQHQIIWQO5Zxnc64QoUF76dt5556bUy5OKJrb9CdZWA/fyPOom7+vmkdWfRPEByivC448/7u8y22yzjV063N8Zx14DiBKhauIuZHDrhRdesJ5C/Hg1Qe4LaeVVTeKWaJBwxg16R3/L+70KddYXsiZ5PHSis17y0JO3XDivGIG4AVd3/8d559H9K4/HziuVu7omNYYNG+a+2k9NnErsoiVQWwVNxGiAfKGFFjLyLOnbZol67rrrrlan2uWutRSlvFeGLFHeMiJ+KEwgxKZo2VznETLJPhVNTGhfJK6dytJH8Cf3yxJRKe+aJLjnnnvMQw89ZL0NR72QRvlEl/pOuqd1bkj7Gzopovj0kou8KGuCxA/OG5iWeX7//ff9n4xEaZqQzhJChKxxyzjqPHmW7kSQKDGvvVP60soumgfZR9nJaJDnHNlkN3HrL13oHyt7Hg1RIaV+l1dOeRBNum9DbED0Wnm+h97fcW2SvBhKpOqHtAntMu9tXfeJJ54w8r4qL8YSsaUFf0n0kHs3rQ5lEfcobX/605+s4NlPp+qXJrrjvMhqtQut0pAlpKVZcd177719XpqTaE2CeYWyyimEca89n4QKWbttH1VOIXx1XJF2sGibpMl6eXSOhqi9jLOVrr0JzaeukafdkHjReUKvkl1WfrP0L3R8iH3QcX4oUn9Cyi4kTWk2S+lNiyckLYonrp+lMayVV17ZxIkbVZfVh/XrdKvxML+vq2ulhbQ8ufPjVvzQksd6CceFIu1llrauiG0so4xcfot+5rEl/jVDy86dE9oHLWJTVR/cSy3dtnWh/U/HJ4utC61HLm73WeQeCblmSJ1Is3Wduk7cC9BbbLFFHyF/Wr/fsU36TMtTkTrv+hHu+u0uY3cdfablyx2b1OaExlO0bnW6bXN5T/oMyVPc+UXKONTOFB0LUDupMamk+YNeG+uLY80+CEAAAhCAAAQgAAEIQAAC/ZEAQtbAUs0yuNcJUeADDzxg9MDtB73BLg9Ufmg1cK9zEbL6pIwVrUY9M2lZuiFDhjQdKM9SUc81OsAJTEMGyeJERlEhq+KMW77UXUe/lxWqUGcRspZV2vWJJ2nAVWI6Lf/oB3k6lgfAaNBSblrSzQ/LL7+8FUBJBBW37KV/rLYnn3xyO6m73HLL2Z/kjVWTEiFB19KkqOIgdJ5AiIit1wa3i/YR/Mn9skRUr776ql3aT15GQkO3haxKp+yE7IUfNBEnj3LyLOOHqGcX/7ekbcUXFfVq8kae7VyQhy95WfVD1mXO/XPzbOe1d7pWkj2OpkUTeAcffHAfD56a6Fd5+C8FyGugvAfmDXopbMopp6yUkDVOJBNXF9ImtMu6t+W19JxzzunTTqaVSbeFrB988IEVSfme8ySQvvLKK43SJsG9H6KeuvzfWm2H1PtHH33U2kY/jm4JWXvt+SRUyNoL9jHk+a+MdrBIm6SXV0MHf/z6qG31Xw888MBgMYg7P2u7ITE5QtZfOHxNn0XrT0gdLcNmKdFp8YSkRfGobXvllVe02QhOyCoPhfJU6Ad5Kbz44ov9XabVeJjf1206ocWXtDy50+LqvFb30ItRZQ/VOfgAAEAASURBVLSXWYSsRWxjGWXkmJTxGcc1Lt7oM7eOCS07HZulD1rEpi611FJWkK1rImQVhR9DGfdISN0NqRNp/bNOXUcvUEefn7WU+korreSw2c+0fn/TwS2+pOWpSJ13/YhOlbGfxbR8uWOT2hwdExJP0brV6bbN5T3pMyRP/vlllHGokLXoWIDaFr3UipDVL0G2IQABCEAAAhCAAAQgAAEI9AaB0LmMscZ4APlPmUnOIgwt87p548qS3jhR4BlnnGFmm222xuXjHrajy9gnDRbcdtttRnH6QctOn3feef6ulgP3vpDVX2a06eQxX0IEPNFz8nzPwjd0UlPpSGIYTafEqRKp+kGel+SByQ9ffvmlkeeraDj77LPNTDPNFDS49eabb5qddtqpKYo4Ieuaa65ptGygHzolZO21OouQ1a8FbIcQSLr/JUyVQNUP8qIob4rRcNZZZ5lbbrmlaffSSy9t5MVZjaiWTQ1tTDWhqOVXFeK8wTVdxPuiSTkt5TbhhBN6e9nsBIGQdrDXhKxF+wj+5H6c2G3xxRc3RxxxRBP+uImtE044wSy44ILm5ZdftsLtqFjTRaB6LY+xal/90AtC1jivKBI+rrbaavYe9tObtGSif1x0O0TIGtdHccvrRuNr1/ci9i7JHvvplVhXywLLK58fJptsMqOl6KPLK8s2y0bnDVUUskoMM3LkyKYsS2DmXpRwP6RNaJdxb+ta8mCqid24oPta7Vd0Al7HdlvIqjTEeblSXdVLLb4nZtU/vSyoSc4sIaTeP/XUU1Yg6MebJmTNaoMVd8jke689n4Q+8/WCfUzjW1Y7WKRN2mSTTczo0aP9qha87QQoafmMRpi13ZDn75lnntlG021xlxKRZYwiVHThGIXYB3dsGfUnpOxC0pRms5TmtHhC0qJ4JNZyKx7ou4ITssaNpw0aNMg+L/145I//Oy1k3XfffRtibJcO1etNN920lPYyi5C1iG0so4xc/sv4zGpL/GfutPro0pe1D1rEpiJk7bvqgsqhV/qUSkuarQu5R0LqXtp14p6x1X/Vyj1+SOv3+8e22k7LU5E67/oRnSpjP49p+XLHJrU5OiYknqJl3um2zeU96TMkT/75ZZRxaJ+q6FgAQla/5NiGAAQgAAEIQAACEIAABCDQWwRCtTcIWUf8OGE8zcB0j3hxQtbf//73Zt55522UftzgRBYh6yOPPNJHRDLJJJOYa665pnENbbQauEfI2tfTiSZFXnzxxSZ+GrBZd911m/bpptFgYjRoslVewkIGt9566y07wePHESdkXWuttaznDv+4TglZe63OImT1awHbIQSSBly1zJU8/vnhpz/9qbn22mv9XXZb3v5ks/0gO7/DDjvYXV988YX1RCfxYNpyyhLDyNubC/LMesMNN5jhw4f38T7ojnGfu+yyi5G4ndBZAlUUshbtI6QJWRdaaCGjyTI/xE2yOSGrRNhqI/2g9nKbbbYxiy22mBUnxi3l3QtCVnlr1DKD8t6YFLSM7RVXXGHUF8saQoSscYI78dOEYidDXnuXZI9d+iUI32OPPfq8GCAvKbLD8ngbDU8++WSf5d5VBlGhdfQ8fZdwWuJqeeGskmBKSxTLM58f9HLUOuus4++y9+j999/ftM9/eS1OyJr13hbDjTbaqM9LVxJabrjhhrbM1L8dOnRon3uoU0JWPRu1ui/vvvtuc/LJJzcxivvit/lxv7faF1Lv5dVdk6h+SBOyZi0nxV3F55NQIWsv2Mc0vmW1g0XaJK008sILL/hVzd6nSy65ZNO+uC8SpE8zzTRB9Sh6fpZ2Y9JJJ7XtgOKokl1WekNFFzpWIcQ+/HikseLMov2otDoamqY0mxUST0haFE+cKNQJWeW5V7/7YYIJJjBXX321UbvjQqvxML+v645N+gwtrzgvqHrxSP3dMtrLVkLWuLauiG0so4ySeOb5LYst8Z+5Q8ouTx+0iE1VHf34448thm7buiyCfSU4i60LrUeKt5f6lEpPmq0LyVtI3Uu7Tpw3YuflWel0oRNC1iJ1Xv0ItfFl2MEQ9o6LPkOPT2pzQuMpWuadbtt8Tq22Q/Lkzi3rPg61M0XGApRmOQ7RC7R4ZHUlyCcEIAABCEAAAhCAAAQgAIHeIYCQNbAssgzuyVunHt79oIn5VVddtbGrqJD1jTfe6LOkrSKXR1Z5ZnWh1cB9nJBVy0lGvaVpsPj777+30WnQyQ960JeXWQkAioYsfEMnNZWmLAMup5xyirnrrruasqIyU9n5QUuNHn300f4uM8UUU1hPTdoZMkjWa0LWKtTZOCFrVepsU2XhS8cIJN3/EpxuvfXWfdJy2WWXmYEDBzbtl5dF2Vw/aNmxwYMHW5upiTIXJHaTIF4DqrIFY7yZu58anxLLarB06qmntl4o9YNsr7wt6VwJj1577bXG8W5DonrlidBZAlEhq8pObasf1E6qvVSQ6E4T6X6QB89ovfJ/D90ObSuL9hH8yX1tR729Kz+yyX5IErLuvvvutn77x0eXQu+mkHX11Ve3y9f66fO35YlRHpSTgjwryTuzH2QPol6eVT+iorUQIauWbr/pppv86K1IUGJAeb2MBk3KvDnG+/sss8wS/SnXd9ky2ak89k4vCSTZYyXou+++s4JUt6S0S6TyJu/4yyyzjNvV9CnPpPJQ6gedI1uuetoqiI88b7kHISciqEK/Qn3Q6LL3zsuRn9+0Ce0y7u3HHnvMHHbYYf5lzc9+9rM+90s3hay6d5WmuKB6rSVb49pq/3h5/XVeIt3+q666yrz00kvuq/3Uc8MSSyzR2JdW73VgmoChjHLSdar4fBL6zNdt+xjCt6x2UNfK2yZptQ29dOWHtPZPx0rgNe6449q+TUg9cvHnbTck+lM/qkp2WXmOE10k8Q2xD45lGfUnpOxC0pRms5TmtHhC0qJ4kkRFrZ7loi/+6ZlK+/yg+uX3dcuy52+//bbNuwTnfpBHea38U0Z72UrIGtfWFbGNZZSRz6DIdl5bomfudvZBi9hU9andS0ndtnWhz5euDLPYutB6pLh7qU+p9KTZupC8pdnCkOvohSu9eOUHvVii1YX81XqOPPJI8/DDD/uHGf8FtpDn0rQ8Fanz6kfoJe4y7GBaOpsgjPkSenxSm6M4Q+IpWuZltm1RDnm/h+TJxV3WfRxqZ4qMBejcESNGmFGjRjWErFUY63Os+YQABCAAAQhAAAIQgAAEINDfCbj527R84pE1g0fWOC8MEhJoeRWJQSVW0kN5dLI+i0dWCWb0JnN0kFweVbS8qAaJ9NuNN97YR4CigXtfyOqW3dKguLy0fPvtt2n1wT7kyzOWL2hIPSnhgCyDp6GTmrpclgGXuIliCU7kQcdNgP/www92GdKoN5tFFlnElq+uGTK41WtC1irU2Tgha1XqrOoFofMEku5/2UfZUCc+dKmLikXlKTUqTtOxmlDQZMAf//hH62lOE9VRUX+c6F0CK9kwedTTBMSOO+7Y9PKBS0eceFaCc01GEDpLwAlZVb6LLrqovbgmqkM7UGon1V5mXZI6LpehbWXRPoI/uX/fffcZeVaNBglRJdrS5PLtt99uha3R/oPzyBrnqV51XwJOF+La9nZ4ZJXX1KgId6aZZrKTga3KSPe6vLJG+1wu7frUpFzUq536exKf+EH9CvXN/BAiZL3zzjvtUuz+edqWgFieL/0g0ZFslDzzRkVL/nFZtvUCVl57N9FEE6X2x+QFXmLmaBB32eqkELd07uyzz249ksrzbzTohQF5t9dEoRO3OBFBFfoVSrs8eftB/X49Z8w///x2t/KmOqn+ph/8Ce0y7u04r6561pGgRl6KFcRUL45ElzQv2yOrxMlqw90LeC7fei6S0LdViBMI+MfqGU5igWgQX03W+iF6Pyb1Q9x5aUKJMspJ16ri80lcu6CXiCR09EO37WMI37LaQV0rb5t066239qnL6pfKw9pKK63kI7Xbat/VXsnDpfqlq6yySlA9chHlbTdUvmorq2SXlees/YsQ++BYllF/QmxASJrSbJbSnBZPSFoUT5KoSOMyepEl2raoL6cVLPTyge4V9VHVL/JDVMhahj3Xi+zHHHOMfZnRv5aEZmoTlQ6NAfohT3uZpa0rYhvLKCM/r0W289oStSHt7IMWsanq38r7ukK3bV3o86Urwyy2LrQeKe5e6lMqPWm2LiRvabYw5Dpqh6MvRuo82Ti13epvqz/6+OOPa3dT8Pv9Ic+laXkqUufVj5AtLsMOpqWzCcKYL6HHJ7U5ijMknqJlXmbbFuWQ93tInlzcZd3HWexM3rEAecXWC7MSslZprM+x5hMCEIAABCAAAQhAAAIQgEB/JxCqw0DImkHIesghh8QOIqkyaQmpqNDDVbIsQladc9RRR5lhw4a50xuf8g6qwdD33nsvdplrDdxrsluTVgpOyKrtkAl8TQ6UKWLVdbMMnoZOaireLAMuEv5oqfBPP/1UpzaCRKwSkGkSQiKLqABZB5500klG5acQMrjVa0LWKtRZeVd7/vnnLWM32K8vVaizNtH86ziBtPs/bpBViVxxxRXNwgsvbIWKOiZqsxdccEEr7PM9a8tOrLDCCmbOOee0Lyy8//77dvI/6sl11llntWIw571S9lTXkgBOwlYJcGRj5EEmGg4//PAmT2/R3/neHgJxQlZdKUTMWqaIVdfM0lbGeW1UHCF9BF/IqvzvueeeOrVP0MSZJltaCTydkDVOmC0PtWuvvbadxH3qqaeMJtuj8bRDyPr3v//dnHjiiX3yoqW6f/GLX1iPWfKorHbx5z//eeM4CWueeeaZxnd/Y8CAAdZDnhPuud9CJgx1bIiQVQIJiS5lW6JB4kXZEfXv1L944IEH7MoAEiiVKWT93e9+Zy+d1d7ppCR7fMcddxh5K4sLykOr8Ic//MHMPffcVhxy+umn9zlM/bZll13WviwgoafEnZrkdeJO5SMqZFUkvd6vkNfYnXfeuU9+NQGnNkb18JVXXrFebqMH+RPaZdzbcS9s6JqDx4gNdf/Kq83NN98cK/wvW8iq6yp/ev7xg8TMEt3LQ688Qem+Vn/fBe3T8sutgo6ViCwayhA+Kc40oUQZ5aTrVPH5JPSZr9v2MYRvWe2grqWQp02SbZPNi94jik+rrOhlHfVbxFN2RsIYnaOgfkAeIWvWdkMvlrgVE6r2vJe1f5HULlro3r8y6k+IDQhJU5rNUrLT4glJi+JJExVdc8015uKLL9ahmUJZQlYJyTQGpLZObYlbKt5PjMS2Wga8rPZScYe2dVtssUXuvmNZZeSzyLtd5Jlb10yqj0X6oCr/vDZ1p5126iNkVVq70QfN8nypNGaxdfI6q7FnP8w111xGq2FFQ1n3SEjdTaoTLl1ptq5T19FLJdtss00f0b5LZ9Kn3+8PeS5Ny1PRfoQ8JEdXN1P62/Hc4HNJy5c7Nq3NCYmnjLpVVtvm8lX0MyRP7hpl3cdZ7IzGbvKMBWg8Kk7Iqrz0+lif480nBCAAAQhAAAIQgAAEIACB/kwAIWtg6WYZ3Gsljkq7VFYhq7yCOjFqWtz+71Eha3SCNmnwtB0iVqUtC9/QSU3Fm2XARce3GizRb62CxGv+BHjI4FavCVmrUGd9IasmOX2BUa/X2VZ1h/3tJZB2/0uAJzGQEzWFpEYCIXlmm2GGGYw/qRZyro5xQgAnZA09T9eT0Ev2m9BZAq2ErEpF0gB32SJWXS9LWymvk3vttZdOyxSik/uyr5o805KoWYMTsuqekQeXrKEdQlaVmWxDVDQbTdvZZ59t1Na4cM899xgJJ+PCOuusYzQhHQ0hE4Y6J0TIquO0jLn6fbJdIaFdQtaQa+sYZ++0nWSP5SFXXleyBv8lIgn9H3300UxR+ELWqvUrDj74YPPEE09kyq8O9ie0y7i3P/nkE2sfol5QQxLWDiGrbI48mCaFpZde2grV3TGyBfKMJs990SBxsDzpyZ5HQ6eErGWUk9JexeeTLM983bSPIXzLagddPczTJulc9WnUjsirY5bg7HlIPXLx5ukn++KuqtnlrP2LpHbRMXSfZdSfkLILSVOauEtpTosnJC2KJ01UJIHX0KFDM/dRo33dvPZcaUwKetFJQlt5BS2rvdT1srR1eW1jWWWUxCf0tzy2xNksXSOpPhbtg+a1qb1k67I8X4pnFlv37rvvBgtZy7pHQupuUp1QHhXSbF2nrqO0xPWHtD8t+P3+kOfSkDzlrfO6J/XSqMYVOvHc4LMJyZeOT2tzQuIpo26V1bb5DIpsh+TJxV/WfZzFzqi/mGcsIEnIqvwoDa0mTbs91ud48wkBCEAAAhCAAAQgAAEIQKA/E2j1TBbNMx5ZM3hk/eabb+xSr3qAbxUmn3xyM3LkyKafswpZdfIZZ5yR6G1LHqi+++67puukCVl1sAZOJILxPRG2S8Sq62UZPI0bxNMb3NFlJhVvlgEXHa+gyQZdI2SCb5FFFrEiVi0L50LI4FavCVmrUGeThKxi38t11tUNPjtLIOT+l8dUTQZqkDItaBJSHpHc8qtZJ9U23nhjO9mq62QRssqDppY+nnrqqdOSyO9tIJAkZNXlZM+jXjLbMbCta2VpK3V8HuFDdHJf8dx0003mnHPO0WZsUB2NejPXgU7IqmUE5f09SQwr0WVUXNoOIavSFcIlKmSVmExetdTWRIM8gGgp+2gImTDUOaFCVh171113mfPOO8/Ii3xa6KaQ1bd3SmeSPS4qIlD8WhJQfWJ5gQkNSUJWxdHL/Qq1XQceeGDiPRXHwZ/Q1u9F723FceWVVxr10VoFLRGufmY0tEPI+uGHH5odd9wx9nru+lEhq/ZffvnlVrDqjnGfiy22mDnyyCPd16bPvMInLT2tiXwX0oQSOq6Mcqri80mWZz5x6pZ91LXT+JbVDupaCnnapB/PNObee+81559/vrWbbl/apxOFpeXTjydPP3nDDTdsrMARFbIq7l62y0pflv5FUruouPxQRv0JKbuQNIXYrLR4QtKi/KeJinSM7P5xxx1n1OeKBvWD5G1YXsr9oLE4/wWavPbcjzO6rb7xoYceauR90oUy2kvFlbWty2Mbyywjl/+8n3lsiQTOLiTVxzL6oHlsapKQVenupK3L+nyp9IXauixCVsVbxj0SUneT6oTSoZBm6zp1nR9TY+xqPxdeeGGsCFSCPNUZeYf2w6677mrWWGMNuyvkuTQkT4osT513/YhOlbHPITRfaW1OSDxl1C2lvYy2zWdQZDskT378ZZSx4gu1M+ov5hkLSBOyKg29PNan9BEgAAEIQAACEIAABCAAAQj0ZwIIWQNLN+vgnpbs01J60QF1DWjLA6DeQD7++OObru6Wq3Y745aQ0yC9lo/1gwZftfSM/1azRKdaRlODVhq88oOW2DzqqKMa3lyjHlndsf7gaTtFrLpeFr5a8lgiDj9IWLbPPvv4u+x2KMPoiZrs0AS7llWMC1oSSaIcLbEYDXFL6cwzzzxNntzeeeedpmVNFUeceEhe3qJCZA1eDho0KHrZwt97vc5KYPz888/bfPpLTfoZ79U666eR7c4RCL3/dY9pMlOeiaP3m1KrSVAttypbqqWJXdBgqZbt1uSaJmlaBQlWNt10UzPvvPM2DpHnQE0qatlW/4WBxgFjNuTFZ/311zdrrbWWkd0mdIdAmpBVqfIHuNslYtV1srSVOl5BAq2rrrqqqY+gOr3ccsvZPkL0JZC4tkgvdtxwww3m0ksvbYpHfYNlllnGLqspD29q2/zge8yUWFweTaP9ItVtiR7VP4p6PF188cXNEUcc0Ygy7Z4OaX8VmUR1mmCRl9g4Qag8L0vIOt100zWurY0DDjjATmr6O+Ut+dxzz/V3NbZfe+01y6axY8yGBPGyNX7YYIMN7FLO/j61eb7ncf83TVJeffXVNv0SM8UFLXeqfuC6664b93PmfUXsnS6WVHayv+rLZg2qL+pf+UH9BLHTfdvKc63KQH3p5Zdf3uiFL4Uq9iskoNf9EX0RQ/eS+qjDhg0z999/v4+nySOrfijj3lYcEhzKc2m0DZ1//vlt2Uu8GV3OXMJjCYwUQu7dpDpkI/nvP72Ip+cEeaGLiuN1yJAhQxrPQO685557zgqm3Hf3qeUml112Wfe16VMC14cffrhpX/SZKiTNWo7aX9lBEereVz12oYxyCmHca88nWZ75HKtu2EddO4RvGe2gy6c+s7ZJ/rl6ZtJ9e8sttxiJJFuFWWaZxUj8veaaaxq9uBmSTxdXnnZDaany816W/kWIfXAs9Vm0/oSUXUiaQmxWWjwhaVGe1Ud95plntNkIGvNxLxW6nRoHk8BI/S5xUv9UdVcvI6geqq30Q3TcLa8911jQ8OHDm17m0ssbCyywgNl9992NXpjxQxntpYsva1uX1TaWXUYu3Xk+89gS/zpJ9bGsPmhWm6o+qHtu6nYfNM/zZait0/0YXUo+Ojbql1UZ90hI3U2qEy49abauU9dx6dHnm2++aVdk0Di1XiLVi856mXLFFVe0/dhXX33VP9z4z+Ihz6UheXIXyFrnXT+iU2Xs0qnP0HyltTkh8ZRRt1zai7ZtLp6inyF58q9RRhkrvlA744/ZZBkLWH311e04q9oYrcKhMd+40MtjfXHpZR8EIAABCEAAAhCAAAQgAIH+QgAha2BJ5hnc08O7HnjdYPqss87aFgGisqAHfIlDNKmtCXoJpuRpolXw38aOTrr652hwSmIACSLiltX0jy2ynYdvkeuFnqvJNJWf/sRYAyQSrejNXQmB+lvo5TorsZEGkxVaDfbrt7rXWTEg5CMg0ZNsqO53fcrm6X6ffvrprdA8KVZ52B4xYoT9U12V2F0TC1NNNZWZZJJJWp4qEetHH31kz3MeLSWW1bmyMxpQJXSXgMRQKt+kwW2lUO297M8cc8xhJ9Dbkeq8baXfR9AE+9xzz23rZqhoyeVl9OjRViQgj/Oq25o4m3DCCd3PqZ+ujdEknLYluFN/Zbzxxks9tx0HKA1ioPxI9CABq+7Xaaed1m7715QAYPPNN+8jPNeS5BtttJF/aMe2JdKT3ZC9+vjjj23aJICXONAX3ZedoLz2rux0JMUney6brAcdpVesJJrWi0Cy6Srv/tKv+OCDD6y3Odkf3ZcSj8pe6YW5NCGrY1j03lY8ikMT6PIgJMGb+mq6l7oVdM/K1jhxrcpffOKeZy666CJz7bXXNiVVx0vw7sTOTT926UsZ5dSlpHf8st2yj2kZLasdLLNNUlyyI2pL1F9Qndd9IiFgUh82La/+76HtRn+xy1n6Fz6ntO2y6k/adar0u2y8+m+txmYkopP4yA96yUce5soI7vlR95DaPo2bKT1Jocz2MktbpzT1qm1M4uX/FmpL/HM6vR1iU3vJ1uV9vhTXdtm6Mu+RTpd/O66n+1aixlZ9Uglbd9lllz4vcKlvq3GpdoeQOh9NA2UcJdL8vdttW3Nq8n0rq4zz2JmQsQDlqj+M9eUrHc6CAAQgAAEIQAACEIAABCDQ+wQQsgaWUZHBvcBL1Pow+GYrfnmAkmChaJBQbr755isaTS3Pp87WstjJNAS6SqBsu5NVyNrVzHf54vJad9ZZZzWlQqIJeRKNetxqOqjLX+gvdLkAMly+7Ps7i5A1QzL73aGa6Nxyyy2t4NnPXNyqFv7vbPcloBdznDfNvr9m2yNPihITtytUKa1xDKraJsXlpZf3lW2XezmvVU2bPMVJFCjPwfKEqhePJQDSSxVaOUOrX0SDvKWuttpq0d18L5FA1W1siSh6PirsXM8XkRXja3W2RRZZxHqNnHPOOa1AVS80ykmFXrySmNQPej7VagmEahIo0rZhf6tZ5tjiapYbqYYABCAAAQhAAAIQgAAE2kcAIWsgWx4oA0HlPAy+2cBttdVW1tNYtrP6Hq2lc4466qi+P7AnlQB1NhURB0AAAiUTKNvuIGQNLyB5udGSjH7QZOKxxx7r7+q5bfoLPVckLRNU9v2NkLUl6qYfJPbWstLRcPLJJ1vv1dH9fG9N4K677jKnnHJK6wMy/HLaaadZD+cZTsl0aJXSGpexqrZJcXnp5X1l2+VezmtV07bTTjtZ79uh6ddqG6effrrRCgWE9hGouo1tH5neixk713tlEk3Rgw8+aI455pjo7sTve++9txkyZEjiMfzYuwSKtG3Y394t16SUYYuT6PAbBCAAAQhAAAIQgAAEIFBHAghZA0udB8pAUDkPg282cAhTsvFqx9HU2XZQJU4IQCCJQNl2ByFrEu3//5sErBINRcN+++1nVlhhhejunvpOf6GniiMxMWXf3whZE3E3fpSIVWJWPwwaNMhceOGF/i62AwhUaeK8SmmNoq9ymxTNS69/L9su93p+q5i+LGIfLcstkfzMM89cxaxWKs1VtrGVAl1CYrFzJUBscxRZhayDBw82+++/f5tTRfTtJFCkbcP+trNk2hc3trh9bIkZAhCAAAQgAAEIQAACEKgmAYSsgeXGA2UgqJyHwTcbOHk70jJSRcPcc89tNttss6LR1PJ86mwti51MQ6CrBMq2OwhZw4rzzDPPNLfeemvTwRNNNJG5/PLLzQQTTNC0v9e+0F/otRJpnZ6y72+ErK1Zu1/Ul5bY+4cffnC77OeWW25J/7iJSNiXp59+2lx33XVhB6ccpSVVp5lmmpSj8v9cpbRGc1nlNimal17/XrZd7vX8VjF9oWKfueaay9r7hRdeuIrZrFyaq2xjKwe7YIKxcwUBduD0UCGrnk9XXXVVo37shBNO2IGUcYl2ESjStmF/21Uq7Y0XW9xevsQOAQhAAAIQgAAEIAABCFSPAELWwDLjgTIQVM7D4JsTHKd1jQB1tmvouTAEakugbLszatQoc8EFFzTxlDAzzvto00E1+3LJJZeYjz/+uCnXs802m1lvvfWa9vEFAkUIlH1/33777eb5559vStKKK65oFllkkaZ9df7yyiuvmJtuuqkPAolbp5pqqj772QGBXiBAm9S5UijbLncu5fW50ptvvmlefPFF89Zbb5nPPvvMfP755+aLL74wAwYMMAMHDjRTTjmlWWCBBYxe4CVAAAJ9CWDn+jLptT1ffvmlefbZZ408sn/44YfWzv3rX/8y//nPf6yNk63TagLLLrusmXjiiXst+aQnBwHathzQKn4KtrjiBUjyIQABCEAAAhCAAAQgAIHSCSBkDUTKA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPAGErIFFyANlIKich8E3JzhO6xoB6mzX0HNhCNSWAHantkVPxmtAgPu7BoVMFiEAgUoRwC5XqrhILAQgkIMAdi4HNE6BAAQgUDIBbHHJQIkOAhCAAAQgAAEIQAACEKg8AYSsgUXIA2UgqJyHwTcnOE7rGgHqbNfQc2EI1JYAdqe2RU/Ga0CA+7sGhUwWIQCBShHALlequEgsBCCQgwB2Lgc0ToEABCBQMgFscclAiQ4CEIAABCAAAQhAAAIQqDwBhKyBRcgDZSConIfBNyc4TusaAeps19BzYQjUlgB2p7ZFT8ZrQID7uwaFTBYhAIFKEcAuV6q4SCwEIJCDAHYuBzROgQAEIFAyAWxxyUCJDgIQgAAEIAABCEAAAhCoPIGuC1krT5AMQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEMhIYJqBk2c8g8MhAAEIQAACEIAABCAAAQj0TwIIWftnuZIrCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCECghwkgZO3hwiFpEIAABCAAAQhAAAIQgEBHCSBk7ShuLgYBCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEDAGISs1AIIQAACEIAABCAAAQhAAAI/EkDISk2AAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQg0GECCFk7DJzLQQACEIAABCAAAQhAAAI9SwAha88WDQmDAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAT6KwGErP21ZMkXBCAAAQhAAAIQgAAEIJCVQNeFrD+d4CdZ09yV4z//+nt73aqktyuQClwUvgXgcWpXCFBnu4Kdi0Kg1gSwO7UufjLfzwlwf/fzAiZ7EIBA5QhglytXZCQYAhDISAA7lxEYh0MAAhBoAwFnixGytgEuUUIAAhCAAAQgAAEIQAAClSSAkDWw2NwDJULWQGAZD4NvRmAc3nUC1NmuFwEJgEDtCGB3alfkZLhGBLi/a1TYZBUCEKgEAexyJYqJREIAAgUIYOcKwONUCEAAAiURcLYYIWtJQIkGAhCAAAQgAAEIQAACEKg8AYSsgUXoHigRsgYCy3gYfDMC4/CuE6DOdr0ISAAEakcAu1O7IifDNSLA/V2jwiarEIBAJQhglytRTCQSAhAoQAA7VwAep0IAAhAoiYCzxQhZSwJKNBCAAAQgAAEIQAACEIBA5QkgZA0sQvdAiZA1EFjGw+CbERiHd50AdbbrRUACIFA7Atid2hU5Ga4RAe7vGhU2WYUABCpBALtciWIikRCAQAEC2LkC8DgVAhCAQEkEnC1GyFoSUKKBAAQgAAEIQAACEIAABCpPACFrYBG6B0qErIHAMh4G34zAOLzrBKizXS8CEgCB2hHA7tSuyMlwjQhwf9eosMkqBCBQCQLY5UoUE4mEAAQKEMDOFYDHqRCAAARKIuBsMULWkoASDQQgAAEIQAACEIAABCBQeQIIWQOL0D1QImQNBJbxMPhmBMbhXSdAne16EZAACNSOAHandkVOhmtEgPu7RoVNViEAgUoQwC5XophIJAQgUIAAdq4APE6FAAQgUBIBZ4sRspYElGggAAEIQAACEIAABCAAgcoTQMgaWITugRIhayCwjIfBNyMwDu86Aeps14uABECgdgSwO7UrcjJcIwLc3zUqbLIKAQhUggB2uRLFRCIhAIECBLBzBeBxKgQgAIGSCDhbjJC1JKBEAwEIQAACEIAABCAAAQhUngBC1sAidA+UCFkDgWU8DL4ZgXF41wlQZ7teBCQAArUjgN2pXZGT4RoR4P6uUWGTVQhAoBIEsMuVKCYSCQEIFCCAnSsAj1MhAAEIlETA2WKErCUBJRoIQAACEIAABCAAAQhAoPIEELIGFqF7oETIGggs42HwzQiMw7tOgDrb9SIgARCoHQHsTu2KnAzXiAD3d40Km6xCAAKVIIBdrkQxkUgIQKAAAexcAXicCgEIQKAkAs4WI2QtCSjRQAACEIAABCAAAQhAAAKVJ4CQNbAI3QMlQtZAYBkPg29GYBzedQLU2a4XAQmAQO0IYHdqV+RkuEYEuL9rVNhkFQIQqAQB7HIliolEQgACBQhg5wrA41QIQAACJRFwthgha0lAiQYCEIAABCAAAQhAAAIQqDwBhKyBRegeKBGyBgLLeBh8MwLj8K4ToM52vQhIAARqRwC7U7siJ8M1IsD9XaPCJqsQgEAlCGCXK1FMJBICEChAADtXAB6nQgACECiJgLPFCFlLAko0EIAABCAAAQhAAAIQgEDlCSBkDSxC90CJkDUQWMbD4JsRGId3nQB1tutFQAIgUDsC2J3aFTkZrhEB7u8aFTZZhQAEKkEAu1yJYiKREIBAAQLYuQLwOBUCEIBASQScLUbIWhJQooEABCAAAQhAAAIQgAAEKk8AIWtgEboHSoSsgcAyHgbfjMA4vOsEqLNdLwISAIHaEcDu1K7IyXCNCHB/16iwySoEIFAJAtjlShQTiYQABAoQwM4VgMepEIAABEoi4GwxQtaSgBINBCAAAQhAAAIQgAAEIFB5AghZA4vQPVAiZA0ElvEw+GYExuFdJ0Cd7XoRkAAI1I4Adqd2RU6Ga0SA+7tGhU1WIQCBShDALleimEgkBCBQgAB2rgA8ToUABCBQEgFnixGylgSUaCAAAQhAAAIQgAAEIACByhNAyBpYhO6BEiFrILCMh8E3IzAO7zoB6mzXi4AEQKB2BLA7tStyMlwjAtzfNSpssgoBCFSCAHa5EsVEIiEAgQIEsHMF4HEqBCAAgZIIOFuMkLUkoEQDAQhAAAIQgAAEIAABCFSeAELWwCJ0D5R5hazff/+90d8EE0wQeMV6HVaUb6doffTRR+bGG2+0l5tzzjnN8ssv37j0bbfdZt599137fbPNNjM//elPG7+x0f8I9Hqd7ZbN+eabb8x3331Xufr/r3/9y3z77bdmiimmMGONNVamCvvDDz+YTz/91EwyySQdt/Fff/21+clPfmL/MiU6cvC///1vo7jGH398M84440R+jf/6xRdfmIkmmigzr/jY6rVX94mCeGcJvW53kvJSVduQlCd+g0CZBIrc3//5z3/M6NGjzdhjj23bojLTRVwQgAAE6kqgiF0uykzPJepr6/lCfX0CBCAAgXYQKMPOtXvsqci4Q5G0lTXWkrXcumn/u/nMnpe3ew7SGHzoWJZfJkXG84ryKjIO2a164njnfe4skueivP1y77VtZ4sRsvZayZAeCEAAAhCAAAQgAAEIQKBbBBCyBpJ3D5RZhKx6OL/pppvMSy+9ZF5//XUrZJ1++umNBJBDhgwxM888c+DV+/9hefh2g8oLL7xgjjjiCHvpZZZZxuy2226NZBx55JHm+eeft99PO+00M8000zR+Y6P/EShaZ//xj3+Ye+65x4oADzjggMyCtjiiZducV199tSHcnmqqqcxWW23V57JvvfWWefjhh43ujQ8++MCMHDnSHqNB5EGDBpk111zTLLnkkn3O+9Of/mSP7/NDwg7ZzYUWWsi88cYb5vrrr084su9PE044odl5552bfpDw/IorrjAvv/yyFQDpx3HHHdfeu6uvvrpZYYUVrCio6aT/ftGEyB133GHuvfdemw99V5h88snNPPPMY37961+bqaee+r9Hh32E8FZMEtRfe+21RserEdcA8rTTTmvblk022cQMGDAg9YISrj7yyCNG9VDxfPbZZ0b7JOJVee2xxx6xcTz22GPmoYcesu3axx9/bAXLs88+u5lvvvlsWSstISGk/pdVznHp0eC76uCHH35of15vvfXMbLPN1nSo7qdzzz23aV/Sl7XXXtuWQdwxKrO//e1vRvy0rUkahYknntgcfPDBfa4dF4f2FbU7yvfxxx9vRdtLLbWUWWWVVVpdKnZ/SLm5E/PaBnc+nxCoG4Es97cm8R599FEzfPhw884771i7oslMBdmVOeaYw8gmyTYTIAABCEAgH4EsdjnuCln7TcOGDbPPVOqfjho1yqjfpr61nsOWW245s+qqqwa9rFC0vxeXF/ZBAAL9k0BeO1f22FOUbpFxhyJpK2OsRXnJYof13FyW/de1s7Y9ecbzdJ0777zTPPvss9pMDXphfNttt+1zXB7eGnt78sknLTOxU5up5yCJWNVeajxO42KTTTZZn+u5HXnH88oY48g7Dll2PREL1dO0cbEynjuL5Dlv/XRlXZVPZ4sRslalxEgnBCAAAQhAAAIQgAAEINBuAghZAwm7B8pQIasmHo4++mg7uRx3CYmqJF7RRDOhuDinUwwRsnaKdO9fJ6tNiObomGOOMc8884zdfdFFFxX2YFq2zRkxYoQ56KCDrMBRiZxuuunMySef3JQNifQPPfTQpn1xXxZccEEjsa7vHWG//fYzb775ZtzhLfdts802Zo011rDCnd/97nctj4v7QcKeiy++uPHTzTffbK688koj7wutwiyzzGIOP/xwI3vtB3lflX1/7733/N1N2/KctMMOO5jBgwc37W/1JYS3zv3rX/9qLr300oYQMhqfRKy77rqrEfNWQQPREttLABUX9LKF8hcNt99+u7nkkkvsYHf0N32XMFLX9ss57jjtC6n/Sl/Rcm51fQ3Wqw64sNdee5kllljCfbWfmlTZZZddmvYlfVHel1122T6HaJLl1FNPNV999VWf37RD99D8888f+1t0Z1G7I9H2IYccYqOVWHvo0KHRSyR+Dyk3RVDENiQmgB8h0I8JZLm/9VKV+qRpYZ111jFbbLFF2mH8DgEIQAACMQSy2OWY04P6uzpPL8Pqpdi0oH6+XkgaOHBg4qFF+3uJkfMjBCDQrwjksXNljz1FgRYZdyiStjLGWlxeQu1w2fZf1+/UM/sf//hHc//997ssJ37qJe8zzjij6Zi8vP38NUXofdEYnl7OXnjhhb29P27mHc8rY4wj7zhkO+qJaISMixV97syb5zJ49yn8Ht7hbDFC1h4uJJIGAQhAAAIQgAAEIAABCHSUAELWQNzugTJEyKpltffZZx/z/vvv29glaJp33nmtUE3CNb0drjDBBBOYY4891shLa91DFr7dZIWQtZv0e+vaeeqsPF7Ka+ltt91m7rrrrkaGigpZy7Y5n3/+uTnssMOM3pp3IU7I6t8POm6GGWawnkGVnn/+859G8biw0UYbGf25sP/++1vPqu57yGdZQlYJJE866SQryJQHUnlXlhdSeWPVYKkGWp1nu6WXXtrsvvvujeQpbxK3youpwpRTTmkkFBIfTZrIS6smLRQUn2z8TDPNZL+3+hfK+7nnnjNHHXVUIxq1HWpblCZ5V3W85Q1XkwQS70bDJ598Yk488cQmEfGkk05qZpxxRjPeeOMZeXmQt4yokFXeRM8+++xGdM7TherIa6+91hC3Lr/88n0837qTstb/dglZ7777bnP++ee7ZNnPMoSs8tCtuuQH3euXXXaZ9Xar/eoPyHvuz3/+c+sF+JVXXjEHHnhg24WsEi8//fTTVogsT7oKoULWrOWmuIvYBp1PgEAdCWTpV0iQ7toaTdTKM7Zsv5Ze1USn8xIujnG2qY58yTMEIACBrASy2GUXd55+k8aIJMxxQX18re6il8O0so9bQUC/65lDzzFxL44V6e+5a/MJAQjUi0BWO1f22FOUdpFxhyJpK2OsRXnJaofLsv952p6iz+xZhKxq0/QytQtFePurobnnIL3oobFWN06n62ifXsbXpwtFxvOK8ioyDllWPXEc9Bk6LlbkubNInovy9vNahW1nixGyVqG0SCMEIAABCEAAAhCAAAQg0AkCPS9kXXL+vm/PZgUz7Nkns57S53j3QBkiZNUSSJpcUBh//PGtRzm3zLwmluV9TcIfBS0Pt91229ntOv/LwrebnPyBFAmWJA5wwR9M0wCdK3P3O5/9i0DWOnv55ZebW265pSFo82kUFbKWaXM0sHvcccdZIYyfxlZCVgkehwwZYpcwlrjRhS+//NKcfvrp5oknnrC7JOCTJ1GJOxV0HS1jlRbkkVODtgq/+c1v7FLoOk/npwVN/EqQq6DB6wsuuMBuSzjobLCWHNtggw3sfvfvxRdfNEeM8Xbn0nfmmWc2PB8pPyeccII9dPLJJ7f2XUJQFzSBIH4uzSussILZaaed3M99PkN5q+3Ye++9Gy9IrLzyynZpNjeJLYGqPDS9/fbb9hpaUnrLLbdsup68z0qUK0+jCj/72c+s6DS69PRnn31m/Dzp2H333deKXLWt8pa3WRe0vPXvf/97+1XLn55zzjl9lnHLU/+LlrNLn/8p76gS8qqc/JAmZJX4VOclBdVx5d+F6CScuG299da2X+COkehM/QSdGxKy2h2Jm1X/NKEWDSFC1jzlpuuorcxrG6Lp5DsE6kIgy/2tCUXZjw033NAsvvjiTTZEYnW99KDJXIVf/vKXRl7QCRCAAAQgkI1AFrusmPP2m/TcoH78iiuuaJ+p9MKTC+oP6xlSXtNc0POR/6Jc0f6ei5dPCECgfgSy2rkyx57iaBcZd8ibtjLGWvLa4aL2Xwzztj1Fn9l9IatWp9EzSaugF8jdWGBR3hp715iVXpTXc46LV9fWeI/mY3QNBY31aczPhSLjeUV5FRmHLKOeOAb6zDIuVuS5s0iei/L281uFbWeLEbJWobRIIwQgAAEIQAACEIAABCDQCQIIWQMpuwfKECGrBD0S9ig44ZV/GXlq1RI3mpSYZJJJzHnnnRfrUcM/p79vZ+GbxELiJF9IlHRsnt80kCKBmwJCVouhtv+y1lkta68l0uJCUSFrmTZHnjwfeOABm8y55prLelbVlzghq7xLawBZv8UF/b7jjjs2BpElBJx55pnjDo3dJ28KBx10kP1NnhYkKJXHudCgCWEN0Cr86le/Mptuuqn1WqqXB2R/NZgub5kSEkaDREDyEqEgD9uLLbaY3fbLsdWSzRLCymurgrzUOpGn3RH5F8rb904qAa0mDfwBe0Xre7WQMFJCYnmMdeEf//iH3afvEtrLW2wIT4ljxUBBS5nKq0WUmZ8P5znXnvDffz43f7+2i9b/uHKOXkPf33jjDVsuX3/9tU2/RALyQKuQJmSNq//2xBb/VL/23HNP4zpZ2267rVlttdVaHB2+O6vd0T3Y6mWZECFr3nJrt20IJ8aREKgOgSz3t9qZ2WabrU874HI7bNgwc8opp9ivajPOPfdc9xOfEIAABCAQSCCLXVaUeftNep7Sn54bWgX1Vd1qGXqhTC9IuVC0v+fi4RMCEKgfgax2rsyxpyjtouMOedNWxlhLXjtc1P6LYd62p+gzuy9kjRtPiZav+16Ut1almGWWWZpe5HNx61Mv0P/lL3+xu6Iv9Pmsso7nFeEloXORccgy6oljlHVcLO9zZ9E8F+Ht8lqlT2eLEbJWqdRIKwQgAAEIQAACEIAABCDQTgJOY5F2jbG++uqrdNd5abF4v78/YqT9liYMrZpHVnkhlHjVvf2riWNNIEeDPOu98847drfeUF144eKeZ6PXqNJ398CeVh+Up5tuuqnhUXCrrbYyn376qV2qXUuCa+BTy2LPOuusZvPNN7fLN0c5XHHFFdaLlYReQ4cOjf5sv+ttZy3VrbDssssaCfoUELJaDPwbQyBLnRUwCdhHjBjRYHfqqac2loIvIuQr0+Zcc8015rrrrrNpnHvuuc3//M//WA+e2pFVyOcy6k+6yhvo0ksv7X5K/ZRHx2effdYeF/WkkHay7IG8XytIBKtBdr04oDLYeeedG6dfeOGFdn9jx383JLp9/PHH7bdddtnFLLfccnZbYtr77rvPbkuYKIFiNGhgeP/997e75aVW144LWXirXHS8wpprrmk9e8bFKQ+0//znP+1Pv/3tb83gwYMbhylNSpvCAQccYBZZZJHGb0kbspk33nijPSTqjdWdJ3v5hz/8wX6VuEpeaf3Qrvrfqpz9a2tbHgoPPvhgM3LkSPuygzy96IUTeU1ViJt4kedalb1C1vrvT86Ih0TDEk4XDVntjl7ucIJsXVseSG677TabjBAha7vKTQkoYhtsBvgHgX5GIOv9nZR9TfDKe44CQtYkUvwGAQhAoDWBrHa5nf2mY445prHiQ1TIWrS/15oAv0AAAv2dQBY7V+bYUxzXIuMORdJWxlhLO+1wkv0Xx3a2PUnP7HmFrGXwjqs/bp//Qt+gQYOMxl5dKHM8z8Xpf7biVXQc0r9Gq+20eqLz8oyLtbqe29/qubMTeW7F26WtSp/OFiNkrVKpkVYIQAACEIAABCAAAQhAoJ0EELIG0nUPlGlCS1/AJE94Z511VuwV5IX1nnvusb/JS6C8BdY5hPIVI1+MpaWEbr755thlkyVek0jYiVAdXwmNR48ebb3gXnnllW530+ef//xn437zveoiZG3CVOsvWepsHCiJDDWIqFBEyFqWzfGXQZe3Tg2CynOlE31mFfK5PO+2226N5Y3lXXWhhRZyPyV+Pv/880ZLhilMNNFEVgwa4j3URapzFYeCll7eeOON3U92qfVPPvnEfm/lKVOiW00ISHx4zjnnNF5IuPfee+13nSzvpBJvTjDBBI24teF7Pl155ZXN9ttv3/S7vmTlLc96GpBXiPN4an8Y88/3MLHKKqvYFyv0m89TNlEeZ0ODli+VMFNBy9SvsMIKfU7VCwUSPivoJQFNQiWFsup/Ujm762tSSwJfveig4Mr87LPPbpuQVZ671V4o6NrzzTef3S76r6jd8etdiJA1mt6yyk3x5rUN0TTxHQL9hUDR+9vnoL6xW4ZaLy3o5QUCBCAAAQhkI1DULpfVb/rmm2/sM5nGMBS0GoFe3G0Vivb3WsXLfghAoP8RyGLnyhp7akWxyLhDkbQVHWuJy09Zdjir/Vdaymp7FFfSM3teIWs7eCutLmiFKa0YpBB9ybqs8Tx3rehnEi+NpeUdh4xeJ/o9pJ7kHReLXiv6Pem5s515VjqSeEfT2evfnS1GyNrrJUX6IAABCEAAAhCAAAQgAIFOEUDIGkjaPVCmCVnlyVMCMAUJttyy2NHLaJkbLXejkORdL3pef/0eylf594WsPg95nJLoTIIqFzTBo4kePyBk9WmwnZdAljobd42yBpfLsDnyeqr7RJ6k5bVU3iO17Lr/Bn0eIasmW3fccUfzww8/WATyhCCPCCFB3lTlbVNBgnX9hQblR95cFSaeeGIjrwsSw7ogYaoGsBVkM7beemuzxhpruJ+NPAro+loeXkuWnXDCCY3fNPCswVgXZpxxRmuT9OKCgjxxyJvrk08+ab/LXv3iF7+w2+5fHt4SzDov0VtssYXRMmhxwR9EXnTRRY08jypcddVV5oYbbrDbenFCL1Boqa733nvPCvtlP6eddtomTvbgMf/k1U9MFORpVZMBcUECWw2OK1xyySWxcbnzyqj/aeWsa6nuqW7rPlHw29t2CVm/++47ozJS/RlnnHFsW6/PDz/80KjTJaHv1FNPbSQYzxqK2p2iE2pllJvyXMQ2ZGXG8RCoCoGi97fLp9ofLa0qW6Q2Tm16K7vtzuETAhCAAAT6Eihql8voN2lpXvVZH3vsMZtAreSjl3WTQtH+XlLc/AYBCPQvAlnsXBljT0n0iow7FElb0bGWuDyVYYfz2H+lpYy2R/GkPbPnFbK2g7fS64L/crdWhNJL6i6UMZ7n4op+pvEqMg4ZvZb/PaSeFBkX868V3U577mxXnpWONN7RtPb6d2eLEbL2ekmRPghAAAIQgAAEIAABCECgUwQQsgaSdg+UaUJW/83fJZZYwi6dG3eJv/71r+bcc8+1P2np+l133TXusNrsC+UrIFEhqwam5HFRIiwFDaScdNJJVpSn75rAn3322bVpA0JWR4LPIgSy1Nm465Q1uFzU5rzzzjtWtCkBogR2hx9+uJlzzjltkosKWbUcvfPMKaGnBrrHHnvsOBxN+3QPOwG6vLDqPF+I2nRwzBe9QPDqq6/aX+SJVfbBDx988IEVZOrThZlnntmKQyVMFQOJPHVtebGbY4453GH289prrzX6c2G88cYzQ4YMMauuuqq5++6WNsmMAABAAElEQVS7za233mp/Wm655azoVSJGF/LylodoeYpWkEdUX0zr4tbnfffdZ4W72pYXUHkDVfAnGeSp9fXXX28wsgeM+ad8KA/rrbeeFTS7/WqfJMJUOPnkk41EzXFBHlndiwSnn366FUPHHad9ZdT/tHLWdfyB81/+8pdmn332adTBLEJWxSXPuxKGjTvuuNZDrzzbSlDs2h4do/DRRx+ZXXbZxW6r3i+11FLmjjvuMN9++63d5/5JJC1B8YILLuh2pX4WtTtFJ9TKKDdlMq9tSAXEARCoMIG897cmL2+//XYzatQoI29Urv2TzZKoXjafAAEIQAAC2QnktcvuSnn7TY8++qh55ZVXbJ/yqaeeMl999ZWNUs9oe++9t5lsssncJWI/i/b3YiNlJwQg0C8JZLFzRcee0gAWGXcokraiYy1x+cprh4vaf6Ulb9sTzUfaM7s/xqRxPjfWp7E7vbQ7ePBgs/zyy9txRj/udvB28cszqcbK9HykoBfrV1ppJfez/SwyntcUUeRLGq+i45D+5bLWkyLjYv51sz53lplnPx3aTuMdPb7XvztbjJC110uK9EEAAhCAAAQgAAEIQAACnSKAkDWQtHugTBOySsB02WWX2VglYnJiluhlHnzwQXPaaafZ3QsssID1eBc9pk7fQ/mKiS9k1UCnhMDR4C9JpTJQWbiAkNWR4LMIgSx1Nu46ZQ0uF7E5I0eONAcffLD5+OOPrdc2eSqQ6M6FIkJWxSnRoPPQKcGePIGmBXmxlHhUYhyFX//612b99ddPO63x+/Dhw43ufwUJUeWNdcIJJ2z87jYkVJVY1gl+3H73OcUUU1i73Eq0ef/991txqDs++rn22mtbAZG84blQhPewYcOMlmBTUH7kJTbOo6cGtOWJT0ECXOch/KijjjLPPfec3Z/2T8L/I488sjHhII+1bgJdkxVTTTVVbBR77LGH9TiqH3XdqADYP6lo/Q8pZ3mglSdaBXnnPuKII8z444/fSEZWIWvjRG9D5Svhr+q3Cy+++KIVQ7vvSZ86X15zJbINCUXtTt4JNZe2ouWmePLaBpcGPiHQXwnkvb/ffvtt2976XOT9XG2pvKsTIAABCEAgH4G8dtldLW+/SX159en9kOWZqGh/z78u2xCAQP8mkMXOFRl7CqFYZNyhSNqKjrXE5S2vHS5q/5WWvG2Pn4+QZ3ZfyOqf62/rxV6Nw/hjSO3g7a6p+RjVBQUJauVAxB8DcsflGc9z58Z9hvDSeUXHId21s9STouNi7pr6zPPcWVae/XSE8vbP6fVtZ4sRsvZ6SZE+CEAAAhCAAAQgAAEIQKBTBBCyBpJ2D5RpQtarr77aXH/99TbWlVde2Wy//faxV/BFOL7YKPbgGuwM5SsUvpD1/PPPN5NOOmkfQvJcqLe8FaIeGRGy9sHFjhwEstTZuOjLGFxWvHltjgaTJWJ1gtE4oWleIeu///1vK2R0wkkJaeQlOW4AOcrmkUceMVpqTGGSSSaxQlR5lQsJEsFKFKjBVYXNNtvMigzjzn3//fetV1bnaTR6jESw8mS34oorRn+y36+55hpz3XXXxf6mnYsuuqgZOnSo0cC9wvfff1+Itzzt7bXXXg3PEhLYbrvttmaeeeax8cvTwUMPPWS98mmgWGGxxRZriJt87yb6TV5AtTSpJhS+/vpre67aJRfkmXW77bYzWoLMF2m2srk6b7/99jNvvvmmjULLAuoljVahSP0PKWdNjpx66qlGx6oMjjvuuD7eq0KFrBI1Dxw40NZH1W3dF/Ks6wflRx5HFHxvMPo+YMAA+5u8/UqErHOd90T9rgmWE0880Uw99dT6mhiK2p28E2ouUUXKTXEUsQ0uDXxCoL8SyHt/x00oipHszeabb45H1v5aYcgXBCDQdgJ57bJLWN5+U5xARXFqtQXF6Z4v3HWin0X7e9H4+A4BCPRfAlnsXN6xJ/dybRLFouMORdJWdKwlLl957XBR+6+05G17XD5Cn9klZNUYlF6gk6dwjdtpLErjHc4jquKcfvrp7UppblyvHbx1HY0/Hn300XYMSN932GEHu3KStqMh63he9Hz/eygvnVN0HNJdN7SelDEu5q6pzzzPnWXl2aUjC293ThU+nS1GyFqF0iKNEIAABCAAAQhAAAIQgEAnCCBkDaTsHijThKz+0iZavkbL2MQF/w3kueee23q/izuuLvtC+YpHiJD1rrvuMhdccIHFJy+QvhALIWtdalV785mlzsalpOjgsoszr82RsFFpUJBXyDivpxqE1r2kIGGnxI0Ksm1JE6gXX3yxFerp2J/85CdGotkk75w6TkEDkvLi+u6779rvEpJq6fbQ4Hu6lnhQ3ljjxLPymClhrQbXJ554Ypu+L774wqZZ3o8kfnRhjTXWMNtss437agWpEkBKrKiwwgorWMHr3//+d3u+PAO4oMH8ww47zEh0qv1FeT/55JPWE6ufvnHGGceWn4Sy0bDmmmsaeTVRkKjXHXP44YebeeedN3q4ufTSS81f/vKXxv4LL7zQijf9c7UkmYSdcUFCW1d2yrcm21uFIvU/pJx9kaoEvZo8iQaVtROkSng8wwwzWO+FWv7OBXkUltA0GuTJVyycaHq88cYzl1xyia3v/j250EIL2Tqt3/2g+iDRteqdwuqrr26Fz/4xcdtF7U7eCTWXliLlpjjy2gZ3fT4h0J8J5L2/1SbI47eW0vzkk0/shLLaJGfzoysT9GeG5A0CEIBAmQTy2mWXhrz9JvU/9adnsddee83cdtttjT62niu0+oSesVqFov29VvGyHwIQ6H8Estg5/zm3HePdRcYdiqatyFhLXK3Ia4eL2n+lJW/b4/IR+syuF6I1zjH22GO7U+2nnkluueUWI7GoC5tssonZYIMN3FdTNm+92H3QQQc1BLRa8UYvWkeDno/yjOdF4/G/h/IqMg7pX0/bofWkrHExd/2sz51l5tmlIZS3O74qn84WI2StSomRTghAAAIQgAAEIAABCECg3QQQsgYSdg+UaULWe++914pbFO0yyyxjdtttt9graIL5rLPOsr8tscQS1tNe7IE12RnKVzhChKz33XefFbHpeISsokAom0CWOht37aKDyy7OvDZnq622aggrXVyhn62EkDrfF5HrexYBje/JMkmIqnijQSLYPffc03o40G9bbrmlWXvttaOHma+++srstNNOduBXAl55bPBFthJiyjZLqOiCBsDd0u/ywuoG5OXRVPbIDdzLi4iEoFrO3gmIZpllFis+9YWsLt7QT5/3PffcY6644orGAL0fh0S5mtT+7LPP7G6V8VprrWW3/UmhVl5Vv/vuO7PzzjsbechQOGKMAFkeX8VL4iiF0047zUwzzTR2O/rPr9Mnn3yyFfBGj3Hf/WMvuugiK5R2vyV9hpazP2CfFF/0N+VX+Q4J8ua79957m2+//dYeLq8YEsP6HsFXWWUVo5cn4oK8smoQXkHCYpVzWihqd/JOqLl05S03nV/ENrjr8wmB/kyg6P3ts7nzzjuNXkZQ0IsoernLtVX+cWxDAAIQgEBrAkXtcpF+k58qvfgkgY68mv0/9s4C3I7i/MNDg5dAggSXBHfX4lJCaCBAcA/uaYHiUNxdgxV3irtrKBR39wdNCBQI1v7//Kad07l795wzu7Pnnrt33+957j0ro+/Mfufst99+I/F/4/vp3Hbs7z1XDp8QgEDPJ5BFz+W1PemF1xCJsTsU0ba8tpa0vhWlh7Pqf7Ul5runyHv2c88914ipxF8tyB749V9RvPWCulYEcg+4tBLOYYcdZlencHW5z7z2PJc/+RnKK9YOmaw3uV9vnnSFXazefWcr+hzKO8mnDPtOF+PIWobRoo0QgAAEIAABCEAAAhCAQFcQcPf5zeoa59cb0P9rlijL+U+++Momb+YYuvT8C2cpNjXtyBefTT2e5aC7oWzWXi3NrAgZkjRDjavzzjvvNHLekTRydHHpe/pnKF9xCHFkffjhh42WOZLgyGox8K9gAlnmbFrVMcZlv7y8OkcRWHfccUe/qOBtGYXnmmuuTum1rJgcHV3EUEVC1vUXInL8lCOqnAMlzR7QJsv0HxRMNtlk9vpPi8YqY7kM6hI5Hcr5MCly6DzooIPMO++8Y08pqqYeHksUZVuR7ySKHis9n5QnnnjCyJHTiZa1VxTTongr+oKikirqhJxO+/bta51GFVVUjkuPPvqordpvn4tErROnn3563WXstezfCy+8YPNvvfXWNlKor3Ods6ZNkPg3bNiwmoNtPWdZlyXv/A8dZ/+hiasz5FNRZBVNNlQ0L5zTs6IcL7fcch0cNrWv42nyxhtv2AcuOidHM/ebIC2tOxard3x+oVFgXd36zDtuMbrBr59tCPRkArHXt89G38P6HlVEJEmzlwv8vGxDAAIQgMB/CMTq5by/m9L433zzzeayyy6zp5Zeeml735SWTsdif+/VK5fjEIBAzyOQRc/ltT3Ve7EzSTPG7lBU2/LYWpL90H6RejiL/lfdeb97ir5nf+6554xsYZJpppnGnHbaaXbb/xfLW86SsmG9+eabtth+/fpZJ9Z6qwjltefNNttsfrPtdhZesXbITpWnHEibJ11hF6t331l0n7PwTsHT7Q85XYwja7cfKhoIAQhAAAIQgAAEIAABCHQRARxZA0G7G8pmjqwynhxwwAG21FlnndUcffTRqTVcfvnl5qabbrLnhg4dajbYYIPUdFU5GMpXPHzjZj1nqRBHVkVjVOREfSbFj6gno6ucjSWvvPJKLVpfMuLuoYceal5++WWbrlHUQpuAf6UnkGXOpnU2r3E5WVYrdc4XX3xhI3SqTi1j6TtnJtuhBwcnnniiUVRSiXSadFuo+EZOOWbK2TK5HHu9suR4usceexhFPZVsueWWZs0110xN7i9D1eglAt8ILGO4HOO1vOc222xTK7ee/lHUUDmByqguCY1Km4V3rRGJDTkDf/zxx/aor4cUBUXRZiX1HJF17pRTTrHLUmtbUVyHDBlijjzySPP888/rkNl3333NIossYrf9f3KWEnf1XTr1yiuvbBj9L8/8zzLOftvqbfvRKcRH0dGzyvHHH2+eeuopm22rrbYygwYNMiNHjjQnn3yyPdbIMVZRtTRvJeONN551Tkj7PrIJ/vsvVu/EPlDLM26xusHvP9sQ6MkEYq/vJJu9997bvP/++/awokcvueSSySTsQwACEIBAAwKxejnP76Z6zdHvTf3ulMw444z2vqte2tjfe/XK5TgEINDzCGTRc620PYlsjN2h1W1T++rZWnQuKUXq4Sz6X+3I893Tint23YfofkSi1YPcajT2QMC/Zry1Mo4cZWWnl0w11VTWXq/PNCnSnpeVV4wdMq0vaceyzhNXRhF2sbT7ziL7nJW361uZPp0uxpG1TKNGWyEAAQhAAAIQgAAEIACBVhLAkTWQrruhbObIOnr06FrUPS3xfNFFF6U6Y/lOj3ojeJVVVglsSc9MFspXvY91ZN1+++1rS2dfeumlJi1qI46sPXOeFdmrLHM2rd48xuW0clqpc0IdK5955hkb2VRRVSVZnfPloLj77rvXlq93kUDT+pt2zF/KSk6wcjqVY2Ca+Ebatdde22y66aZpyYwMpS66du/evW2kUznKatwkcjiU/qjnbOvrKTm/rr766qn1+AdDeft5/G1FUlU0CsmCCy5Ye6lC+4p+4SK1br755mbw4ME63EkOP/xw8+KLL9rjenCgiE9+FIf11lvPbLjhhp3y+U7+in5xzjnndErjH8gz/7OMs19XvW1/LuR1ZPXHWcZ7RcX1HVT1wEZRctOW9H799ddt5F+1r5mjuOtDrN6JfaCWddxidYPrN58QqAKB2Os7ycj/vatI03KsRyAAAQhAIJxArF7O+rupUcvuueceo5foJHPPPbeRPamexP7eq1cuxyEAgZ5HIIuea6XtSWRj7A6tblsjW0varChSD2fR/2pL1u+eVt2z+za1mWeeufYyRhqv5LFmvOXEKnudW01oyimntN+L9ZxYVX5R9rw8vHzbU1Y7ZJJNvf2s88SV47ctr10s7b7TLzemz3l4u76V6dPpYhxZyzRqtBUCEIAABCAAAQhAAAIQaCUBHFkD6bobymaOrCrOX2o47cGxDC5ybFIEOzm3jBgxwmgp7CpLFr6+41C9iIiNIrLut99+5u2337a4FdVEBrWkXHPNNea6666zh4nImqTDvghkmbNpxLIYl0eNGmVkmJfIgTK5rFWrdE6IY+Xf//53o8ifzol1/fXXN/rLIrfddpu5+OKLbZYpppjCRmPViwAhIn2qpdu/+uorm7yZ0+itt95qLrnkEpu2UbRMP0LsAgssUFsCXlE3tfyZRA+Q9SA5Tfwly+RcOsccc6Ql63AshHeHDN6OIqHKkfLDDz+0Rw888ECjdjvxjdqKMKvIq0nGP/zwg33o8e2339psSjPddNMZf0m4ueaay0Z0deW6T+lL6U3JwIEDzbBhw9yp1M8s818FZB3n1EoTB33Deh6D/eeff26GDx9em/tyFtaSeRLfkL/jjjualVdeOVG7Mf4LE7/73e9q0Vk7JfQOxOqd2AdqWcatCN3gdZ1NCPR4AqHXt/S9JM1B3kHyIyDp2IUXXmgmmWQSd5pPCEAAAhAIIBCql+sVFfq7SSta9OrVq14x9ri/CkCz39qxv/caNoSTEIBAjyKQVc/F2J60BLlssfqUyPbjLwEfa3eIaVujQW1ma0nLG6qHi9b/akvod4/StvKe3be3LLfcctZupzqbSTPeslsdc8wxtUissm/p2Ys+m0msPS8vr1g7ZCvmiWPlj1PSLhZz3xnbZ7UvL2/XtzJ9Ol2MI2uZRo22QgACEIAABCAAAQhAAAKtJIAjayBdd0MZ4sh655132gfGKlrLvh177LEdHIbOP/98c/fdd9uaF154YSPHyqpLFr6xjqxyunvssccs8j/84Q9miy22qOGXM97f/vY362DklkjHkbWGhw2PQJY562WrbWYxLiuy8+23317Le8UVV3TQKa3SOc0cKx9//HEb6dMZN3Ut6ZrKInLo32WXXcw333xjs/nXW0g5t9xyi42MqrSKwqDru140VqV59dVXzSGHHKJNK/vuu69ZZJFF3K79VIRY6ZmPPvrI7m+00UZm3XXXtduHHXaYeemll+y2HIrlpJp0JvId6RWxVUtqNWqTLezXf814u3TJTznxnn766bV2pS03qj5pGXtFoZCkjdWVV15pdZ/OTzvttObkk0+2fdP4yjH366+/1in7AEIPIpzIoVNOtGPHjrWHtLxb0tnapXWfWea/8mQdZ1dPo89GBnvlk5PqoEGDzAorrNApcrcenpxwwgm1CCDTTz+9XeLVzQV9x+u7XqJ5KecDRWd1MmbMGKOHBM5peNdddzXLL7+8O133M1bvhD5Qq9eA0HErQjfUawPHIdBTCYRe30888YTR7wC9NCIneKd3HBctm6mlWd955x17KDTis8vPJwQgAAEI/IdAqF6uxyv0d5N+Rw8YMMDqdf1uTMqDDz5ozjrrrNrhpKNJ7cR/N2J/7yXLYx8CEOi5BLLquRjb03fffWe0+o6TIUOGmE022cTtmli7Q0zbao1IbITYWhJZ7G6oHi5a/6vy0O+emHv2O+64w9qfdD8yyyyz2D77/+SULGdTZyvUCkzLLrusnyR1uxlv2Q9lk3vzzTdtft3n6CVu3yE6teD/Hoyx58XwirVDtmKeOE6N7GIx952xfY7h7fpWpk+ni3FkLdOo0VYIQAACEIAABCAAAQhAoJUEcGQNpOtuKEMcWeWQpQhsLkLhPPPMYw02E044oTX03H///bVa5Vikh9BVlyx8Yx1Z/UiL4i6HrP79+xtdDDK2OUcvNya+Y52/fLaMcDLGOVF0xpdfftnuyplOjmBIzyWQZc6KwltvvWXefffdGpDLLrus5vinpd6lHySaN8nlf5s5srZK5zRzrDzxxBPtG/JqtyLFLrXUUtpsKJtuummHSAl+VMoQR1S/cDlOygnWOQNut912ZrXVVvOTpG4fffTR5tlnn7Xn5Ggq/rqeJ5poIvPBBx9Yx1MZXSWK6qAlyyaeeGK7/8Ybb9jl4F0UEUVkVRRYGdDVHj1ovuqqq2zEbWXQg5o11ljD5m32rxlv5f/LX/5i5p13XqMl01Sfou499dRTRo5LkkknndTIOTfNkfSRRx6xDq824a//Vl99dbP00ksbObnqnBxwnSSjiSuKrSIqSMRp1VVXtfNUzr733Xef1Z86J4dOOcAmJWb+5x3nZBuS+40M9kqruSo2ckCVs7PGunfv3ubTTz81+h757LPPakUmeelFiL322st8/PHHNo3Ga+ONN7YRW9977z0bvVbOrBKNp+9cbQ/W+ZdV7+h3iOakm6+vvfaaHWsVr/74D5P0W8TNc1d93nErQje4NvAJgaoQCL2+R44cWdOz+o6ac8457e/YPn36WF2sh/jue1HfzfreqBc9vCps6ScEIACBPARC9bIrO+/vJjmm6je1VkvQ6gdyatWqMfoN/PTTT9fuW1SPv1KEqzf2954rh08IQKB6BLLquRjbUzNHVtGPsTvEtE116zdzXltLXj0cq//V7rzfPTH37DfddJO5/PLLVb2ZddZZrb1EtiCtpCO7+UMPPVSzQeiZiNgmJQ9vrUC055571oqS7VQ2mkai9q211lo2SYw9L4aXKo+xQxYxT+oxamQXi73vjOlzLO96/e2ux50uxpG1u44Q7YIABCAAAQhAAAIQgAAEupoAjqyBxN0NZYgjq4qUQ6SitcmIU08GDx5sHajqna/S8Sx8Yx1Z5WCkt5ldtMUkZz30lyFMRlAJjqxJQuyLQJY5q/SKyqmoBc1kiSWWsA5wfrpmjqxK2wqd08yx0jcs+u1ttO1H69SDjN12263mcKPl2OUgGSr+cvZyFJQDuR4AN5PRo0fbSNiK9uCL8roXEHRcTn2K7pB0Cr3mmmuM6vYlmVfnks7ufvq07Wa8lUfOkC5adLIMOdMqwrdYpImcGWVI1lxpJMnIKEorh059pzkH4LT8WhrwoIMOMtNNN12n0zHzP+84d2pE4kAjg72SOkfWRLYOu/q+WGeddYyi9iblxRdftBHZG/0OkPO2mIW++JBV78jBWY7WIaLxnWmmmTokzTtusbqhQyPYgUBFCIRe3/4DxUZopJ8UJWno0KGNknEOAhCAAATqEAjVyy573t9NzkHFlVPvc+qpp7bLJyd/68f+3qtXH8chAIGeTyCrnhORvLanEEfWWLtD3rapXzG2lrx6OFb/q915v3ti7tl9R1a1oZ5MM8001kaVZu/IwzvpyFqvXv/4QgstZPbff//aobz2vBheqjzGDlnEPKkBSGw0sovF3nfG9DmWd6Kb3X7X6WIcWbv9UNFACEAAAhCAAAQgAAEIQKCLCHR7R9Yu4tC0GndDGerIqgK1/PQ555xjtOyyL5NMMomRE6ucX5D/EMjCVwYovXEuueCCC1LfvvYjD6633npmww03/E9F//0vhzEtz+ciqLqTimylaLpvv/127e1yP8qjotkp8p5Ey0BrOWgn/hJFZ5xxRoeoky4Nnz2HQJY5q15ffPHF5rbbbmsKQBEy//jHP3ZI50elkGOKormmLVVftM6R0VHXg0QObnJ08+WUU04xWu4pi8iRUhERJDfffLPti7Z17ckRtVevXtptKnI4lZP5999/b9OqnSuvvHLTfC6B8l199dXmrrvuqi135s7pc5llljFbbrml6du3r3+4ti0nRS0d/8knn9SOuQ1Fxdtiiy06RLt05xp9NuOtvGnGfkVIVTRctTcZUTNZn5Z20zxU1Fg9JPJFfRXHhRde2D9c21Z6faf9/e9/7/CShuakxlTzNvlg3WXOO/9jx9nVn/Y5YsQIG01W5xQ9VU7kvtx9993m0UcfNa+//notmoh/Xg9j5HytqC31RPND3wdu6TuXTswUDXzYsGFNx8zl0WdWvaOHharDRWT1y0pun3TSSTaysH8877jF6ga/DWxDoCoEQq9vRVvV6g7ST4rwnCZ6oUD6XJH9EAhAAAIQyEcgVC+70vP+btI9nCLoa5UFRWFNiu6PBg4caF+cmmCCCZKnTezvvU4FcgACEKgMgax6zoHJY3uSDUYr1rh70zRbrcqPsTsof562KV+MrSWvHo7V/2p33u+emHt2rTxz++23Gy0971YHUluc6EVv2ee0+lHa95bS5eGtepP2UldnvU+trqNVi3zJY8+L4eXqzmuHLGKeuDYkPxvZxYq478zb5yJ4J/vanfedLsaRtTuPEm2DAAQgAAEIQAACEIAABLqSAI6sgbTdDWUWR1ZX9Ndff220fI2iss0yyyw2Wp2cWJD/EYjh+79Ssm3JeKq3ubWUuB4OyRFLznQIBEIItGPOhrRLadA5oaSMdYRVdGYZxBXpVBEjZpxxRjPZZJM1LUROoXpRQfnlhKol6JVXDo5pjsZNCwxI8M4779ilo/V9opci5Hyq75Ws9clBVPpP/Zb+Uxnqe8h3kzjJeUp55bSriLXNHGgDutZtkyg6t8Z51KhRdr4o8qyWew2ZI65Tiv4rZipL3zPiLQfkrNKd9U7WvpAeAhDoSCDP9a3ve72cpb8ff/zRKMqzlvWs9xJGxxrZgwAEIACBRgTy6OVG5TU7J+ct6fMvv/zSjBkzxv5G172FXk4IWXWiWfmchwAEIJAkEKvnWml7irU7ZG1bUbaWJOOQ/bLqf43Rp59+am0lsnnouyr0e6udvDUm7bDnubkg5848dsh2zpPY+868fXbMevqn08U4svb0kaZ/EIAABCAAAQhAAAIQgEAoARxZA0m5G8o8jqyBVVQ6GXwrPfyl7DxztpTDRqMhUGoC6J1SDx+Nh0BDAlzfDfFwEgIQgECXE0AvdzlyKoQABLqYAHqui4FTHQQgAIEUAk4X48iaAodDEIAABCAAAQhAAAIQgEAlCeDIGjjs7oYSR9ZAYBmTwTcjMJK3nQBztu1DQAMgUDkC6J3KDTkdrhABru8KDTZdhQAESkEAvVyKYaKREIBABAH0XAQ8skIAAhAoiIDTxTiyFgSUYiAAAQhAAAIQgAAEIACB0hPAkTVwCN0NJY6sgcAyJoNvRmAkbzsB5mzbh4AGQKByBNA7lRtyOlwhAlzfFRpsugoBCJSCAHq5FMNEIyEAgQgC6LkIeGSFAAQgUBABp4txZC0IKMVAAAIQgAAEIAABCEAAAqUngCNr4BC6G0ocWQOBZUwG34zASN52AszZtg8BDYBA5Qigdyo35HS4QgS4vis02HQVAhAoBQH0cimGiUZCAAIRBNBzEfDICgEIQKAgAk4X48haEFCKgQAEIAABCEAAAhCAAARKTwBH1sAhdDeUOLIGAsuYDL4ZgZG87QSYs20fAhoAgcoRQO9UbsjpcIUIcH1XaLDpKgQgUAoC6OVSDBONhAAEIgig5yLgkRUCEIBAQQScLsaRtSCgFAMBCEAAAhCAAAQgAAEIlJ4AjqyBQ+huKHFkDQSWMRl8MwIjedsJMGfbPgQ0AAKVI4DeqdyQ0+EKEeD6rtBg01UIQKAUBNDLpRgmGgkBCEQQQM9FwCMrBCAAgYIIOF2MI2tBQCkGAhCAAAQgAAEIQAACECg9ARxZA4fQ3VDiyBoILGMy+GYERvK2E2DOtn0IaAAEKkcAvVO5IafDFSLA9V2hwaarEIBAKQigl0sxTDQSAhCIIICei4BHVghAAAIFEXC6GEfWgoBSDAQgAAEIQAACEIAABCBQegI4sgYOobuhxJE1EFjGZPDNCIzkbSfAnG37ENAACFSOAHqnckNOhytEgOu7QoNNVyEAgVIQQC+XYphoJAQgEEEAPRcBj6wQgAAECiLgdDGOrAUBpRgIQAACEIAABCAAAQhAoPQEcGQNHEJ3Q4kjayCwjMngmxEYydtOgDnb9iGgARCoHAH0TuWGnA5XiADXd4UGm65CAAKlIIBeLsUw0UgIQCCCAHouAh5ZIQABCBREwOliHFkLAkoxEIAABCAAAQhAAAIQgEDpCeDIGjiE7oYSR9ZAYBmTwTcjMJK3nQBztu1DQAMgUDkC6J3KDTkdrhABru8KDTZdhQAESkEAvVyKYaKREIBABAH0XAQ8skIAAhAoiIDTxTiyFgSUYiAAAQhAAAIQgAAEIACB0hPAkTVwCN0NJY6sgcAyJoNvRmAkbzsB5mzbh4AGQKByBNA7lRtyOlwhAlzfFRpsugoBCJSCAHq5FMNEIyEAgQgC6LkIeGSFAAQgUBABp4txZC0IKMVAAAIQgAAEIAABCEAAAqUngCNr4BC6G0ocWQOBZUwG34zASN52AszZtg8BDYBA5Qigdyo35HS4QgS4vis02HQVAhAoBQH0cimGiUZCAAIRBNBzEfDICgEIQKAgAk4X48haEFCKgQAEIAABCEAAAhCAAARKTwBH1sAhdDeUOLIGAsuYDL4ZgZG87QSYs20fAhoAgcoRQO9UbsjpcIUIcH1XaLDpKgQgUAoC6OVSDBONhAAEIgig5yLgkRUCEIBAQQScLsaRtSCgFAMBCEAAAhCAAAQgAAEIlJ5A2x1ZS0+QDkAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhDISABH1ozASA4BCEAAAhCAAAQgAAEI9FgCOLL22KGlYxCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAQHclgCNrdx0Z2gUBCEAAAhCAAAQgAAEIdDWBtjuyluUG7ZMvvrJjU5b2dvVEiq0PvrEEyd/VBJizXU2c+iAAAfQOcwACPZcA13fPHVt6BgEIlJMAermc40arIQCBcALouXBWpIQABCDQKgLo4laRpVwIQAACEIAABCAAAQhAoKwEcGQNHDluKANB5UwG35zgyNY2AszZtqGnYghUlgB6p7JDT8crQIDruwKDTBchAIFSEUAvl2q4aCwEIJCDAHouBzSyQAACECiYALq4YKAUBwEIQAACEIAABCAAAQiUngCOrIFDyA1lIKicyeCbExzZ2kaAOds29FQMgcoSQO9UdujpeAUIcH1XYJDpIgQgUCoC6OVSDReNhQAEchBAz+WARhYIQAACBRNAFxcMlOIgAAEIQAACEIAABCAAgdITwJE1cAi5oQwElTMZfHOCI1vbCDBn24aeiiFQWQLoncoOPR2vAAGu7woMMl2EAARKRQC9XKrhorEQgEAOAui5HNDIAgEIQKBgAujigoFSHAQgAAEIQAACEIAABCBQegI4sgYOITeUgaByJoNvTnBkaxsB5mzb0FMxBCpLAL1T2aGn4xUgwPVdgUGmixCAQKkIoJdLNVw0FgIQyEEAPZcDGlkgAAEIFEwAXVwwUIqDAAQgAAEIQAACEIAABEpPAEfWwCHkhjIQVM5k8M0JjmxtI8CcbRt6KoZAZQmgdyo79HS8AgS4viswyHQRAhAoFQH0cqmGi8ZCAAI5CKDnckAjCwQgAIGCCaCLCwZKcRCAAAQgAAEIQAACEIBA6QngyBo4hNxQBoLKmQy+OcGRrW0EmLNtQ0/FEKgsAfROZYeejleAANd3BQaZLkIAAqUigF4u1XDRWAhAIAcB9FwOaGSBAAQgUDABdHHBQCkOAhCAAAQgAAEIQAACECg9ARxZA4eQG8pAUDmTwTcnOLK1jQBztm3oqRgClSWA3qns0NPxChDg+q7AINNFCECgVATQy6UaLhoLAQjkIICeywGNLBCAAAQKJoAuLhgoxUEAAhCAAAQgAAEIQAACpSeAI2vgEHJDGQgqZzL45gRHtrYRYM62DT0VQ6CyBNA7lR16Ol4BAlzfFRhkuggBCJSKAHq5VMNFYyEAgRwE0HM5oJEFAhCAQMEE0MUFA6U4CEAAAhCAAAQgAAEIQKD0BHBkDRxCbigDQeVMBt+c4MjWNgLM2bahp2IIVJYAeqeyQ0/HK0CA67sCg0wXIQCBUhFAL5dquGgsBCCQgwB6Lgc0skAAAhAomAC6uGCgFAcBCEAAAhCAAAQgAAEIlJ4AjqyBQ8gNZSConMngmxMc2dpGgDnbNvRUDIHKEkDvVHbo6XgFCHB9V2CQ6SIEIFAqAujlUg0XjYUABHIQQM/lgEYWCEAAAgUTQBcXDJTiIAABCEAAAhCAAAQgAIHSE8CRNXAIuaEMBJUzGXxzgiNb2wgwZ9uGnoohUFkC6J3KDj0drwABru8KDDJdhAAESkUAvVyq4aKxEIBADgLouRzQyAIBCECgYALo4oKBUhwEIAABCEAAAhCAAAQgUHoCOLIGDiE3lIGgciaDb05wZGsbAeZs29BTMQQqSwC9U9mhp+MVIMD1XYFBposQgECpCKCXSzVcNBYCEMhBAD2XAxpZIAABCBRMAF1cMFCKgwAEIAABCEAAAhCAAARKTwBH1sAh5IYyEFTOZPDNCY5sbSPAnG0beiqGQGUJoHcqO/R0vAIEuL4rMMh0EQIQKBUB9HKphovGQgACOQig53JAIwsEIACBggmgiwsGSnEQgAAEIAABCEAAAhCAQOkJ4MgaOITcUAaCypmsLHw//fRTc80119hezjPPPGbVVVet9fjGG280H3zwgd3feuutTe/evWvn2Oh5BLr7nP3ll1/Mzz//bCaaaKIuhf/jjz+a7777zkw66aRm3HHHzVT3Dz/8YNTuSSaZJFM+lzhvn//v//7PfP311/aa7dWrlysu+FP51ee87R47dqxlNd544wXXmZZQ/CQTTjhh2ulOx2J5dyow8IDjLdZ59GRRvP79738blSVeecY9sLs2WWyfXV2xeqddY672t7Nux49PCHRnArHXd3fuG22DAAQgUEYC3UUvd+Vv1jKOE22GAATyEyhCz+W1w4S2WraWiSee2IwzzjihWWrpWt22WkXdaCOmz7G2rbxjVZS9pBsNQ5c0JS/v2MbFzDG/7q60YcbYqv02t2q7CF3cqrZRLgQgAAEIQAACEIAABCAAgXYQwJE1kHrsDeWDDz5obr/9dmt4O/TQQ4MdjQKbV/pksXy7CsCLL75o/vznP9vqVlxxRbPPPvvUqtb2Cy+8YPfPP/98M/3009fOsdHzCMTO2VbohH/+85/W0fqVV14xb731lnVknWWWWczcc89tBg0aZGadddZMA/HGG2+Yq6++2uaZeuqpzfbbb98p/zvvvGMeeeQRo2vjk08+MV999ZWREfo3v/mNmWaaacwqq6xiBg8enOqwqLyPPvqozasvo9GjR9vy5RA644wzmnXWWccst9xyner0D+Tpsxx8//GPf5iHH37YvPfee7bdMmrKmVFtnn/++c0WW2xh+vbt61fVYVt9lE5X38VaBuTJJpvMDBgwwAwcONAsv/zyHdInd+QUf/nll5vXX3/dfPTRR5bXTDPNZMdKdausZqIy7r77bvPEE08YbcspU/Lb3/7WHHnkkWbOOefsUEQM71tuucU899xzHcqrtzPllFOanXbaqXZaxunHH3/ctvP99983n332mRFvidqqlwLWW289s+CCC9byJDeK4CUngMcee8w88MADlvuYMWOMjumBmObZfvvtV6v27bffNldccUVtP2RDD9f23HNPm7SIPqfVmVXvxIz5N998Y0499dS0ZqQe0xhqLJ3E1O3K4BMCVSKQ9fquxybku7teXo5DAAIQgMD/CMTq5bz3e1l+s15wwQUm1KjnerbGGmuYxRZbzO3yCQEIVJhAXj2Xxw6TBfPIkSPNQw89ZF599VXz+eef25eGZdeSzUB2Itmb6klRbQvV4UXrYdmaDj74YGszkV3pD3/4Q72u1o7H9DnWtpVnrFplL8lzH5SHtwMfk1dlhM4xV58+8/COsee5umPmmCujK22YskfltVW79nblZ15d3JVtpC4IQAACEIAABCAAAQhAAAJdSSDU5j3Orw4y/1dkw8p2gxbb3gMOOMA888wzFuG1116bO3JfkWPQncqK5dtVfcGRtatId/96Yuds0TpBDqT777+/dcxMoycnuyOOOMI6SqadTx6Ts+Hw4cONnP0kM888sznnnHM6JJPjtu/M3eGktyOnTDnEyRnWiZxtndOfO5b2ueiiixo5/6dFzMzbZ599Wp06Jl777ruvWXzxxTslGTVqlDn++OPN888/3+mcO7DCCitYfmnRUe+8805z7rnn1hxPXR73KV577723Ud/ryVNPPWWOOeYY8/3336cmOeqoo8zCCy9cOxfL+4QTTjD33XdfrbxGG9NOO6258MILa0nk/C/d2UyGDh1qttlmm07JiuClByXHHnusdabtVMGvB+SAeeKJJ9ZO6eHAYYcdVtsP2ZBT7nXXXWeTxva5Xn1Z9E7smOshg6KLh4rm7Morr2yTx9YdWifpINCTCGS5vuv1O+S7u15ejkMAAhCAQEcCsXrZv+cItQFl/c26yy67GDlrZJEddtjBDBkyJEsW0kIAAj2UQB49l9cOE4rwpptuMiNGjLAvSKflkXOn7reLtBGl1ROqw4vWw3Le/dOf/mSbtPbaa5sdd9wxrXm1YzHjEWvbyjtWrbCX5L0Pysq7Bv7XjZi8Kid0jrk68/KOseep7pg55trelTbMGFu1a29Xf+bRxV3dRuqDAAQgAAEIQAACEIAABCDQlQRwZA2kneeGUpE0BFiGhltvvbVWU+hDjFqGCmzk4dsOLDiytoN696wzz5xtlU5QhFFFwPz4448tLC1Rv8ACC1iH+WeffdYosqJkookmMieddJJRlNZG8u2331on0w8++KCWLM2RVc75Mrw6UbnTTTedfaCgKKWK0OpE0UbPOuus2sMG/1pSmv79+5sZZpjBRpF96aWXjNrgZNNNNzWbbbaZ27WfMX32oyfLYXWuueYyk046qdXXiuDgRA6leoDiR0dVxAXld46Z448/vllyySVNv379zJtvvlmLyqwyNt98c7PJJpu44uynnF/lIOtEzDRWP/30k40WqigHEkWlveiii2zEUpfWfd54443mvPPOs9FEdWzcccc14isH0q+//tq89tpr1gnTd2SN5Z3F8K1o1IpK7UQPYWTglzje6p+i2IqHliVzIraKdu2kCF5ffvmlOeSQQzo85O/Tp4+Nnqvxe/fdd80UU0zRwZFVUW7lQJ1FfEfWmD43qjOL3okd86yOrP7YxdbdiAHnINBTCWS5vtMYhH53p+XlGAQgAAEIdCaQRy/H3O/l+c266667Gq0kkEVwZM1Ci7QQ6NkEsuq5GDtMCEmtOHPyySfXkroVc2Sbkq1G9hjJqquu2unF6CLalkeHF6WH9SKDbGx6gfyLL76w/WzmyBrT51jbVsxYFW0vyXMflIe3HZRf/8XkzTPHVG8M7xh7Xswcc7y62oYZY6t2be7qz6y6uKvbR30QgAAEIAABCEAAAhCAAAS6mkC3d2RdoP+80UxeePfl6DKy3lAqGt31119fczTyG4Ajq0/jP9tZ+XYuoWuO+M45craS444TbeutX4mcuOTMhfRcAlnnbCt1gh89UhFAzzjjjNr8k5OgjMRyspQMHjzY7LzzznUHRkbKAw88sDaXXcJ6jqxa8mzgwIFm3XXXtU6sLr2M4tKBWmbNyZlnnmmdB7Wva0lLuQ8aNMjm1QMKJ3JwPO6448yTTz5pD8lRU2XJ6dBJTJ91rSrSrJxjl1pqKSPHXyeKEqBInM65cuONNzZbbLGFO93BeCwH1yOPPNLMOuustfN6ccFFrpXjsPrft29fez5pAF5zzTWtA7KLJKKH1+Ipx0qJmG633XZ22/1LGq+1NOj2229v/Miv4idWfr9iefuGb0XPWGaZZVyTOn1qmT+/bs0/PViQQ7Ly+ef0gEaOve7HyNJLL20ZqNAieP3rX/8y2267rZFTpmTKKac0e+21l12S0B747z/NBzm3OtH8lXNxM5HDtsqTaD5cddVVdjtvn23mBv+y6J3YMfcdWWeccUZz+umnN2iZsePqlniMrbthRZyEQA8lkOX6TiLI8t2dzMs+BCAAAQikE8iql2Pu9/L+ZpX+l1NMM9H9jVshSNEDQ5aqblYm5yEAgfITyKrnYuwwIbT86Kaydey+++61bI8//rg5/PDD7b7uOy+77LKarUUHY9uWV4fH6mHZSvQStJwjk9LMkTWmz75tKattS+2MGasi7SVZ74NieMfkFbO8cyyWd4w9L2aOqd3+PNN+V9gw9Xsnr61abWyHZNXF7WgjdUIAAhCAAAQgAAEIQAACEOhKAs53pFmd44wdO/Y/rz03Sxl4PvQGrayOrHJkkkNTmuDI2plK6HzonLPjET3EcY40Hc8UsyfnHDlxSXBkLYZpWUvJOmdbqRNkzJdRX5L2YFKRWuUQKec8RR694oorapFRk/yPP/54c//999vD8847r3n55f+8CJDmyCrnPy0xpWiq9UQRf1xkVz2EkNFSosijo0ePNio3TRRFVo6PzqFUzrm+w2hMnxUddPbZZ7eRTNPqVhRWRQyQyNFV0Tyd+MZ6LfGmBwtJ0RLriior0UNi5ZH4BuDJJ5/c/PWvf+3gnKs0fgRSOfDK0D3VVFPplB0/Oa1+9NFHdl9ReNdaay273exfLG/f8K0ovMsuu2yzKmvnxWLOOefs4MBaO/nrxiOPPGKOOuooe0hcLr/8crsdy0uFPPjgg+bYY4+15enlglNOOcVGu7UHCvgn47icnyUbbrih2Wqrrex23j7bzA3+ZdE7sWPuO7KmXf8Nmhl9fTcqm3MQ6KkEslzfSQZZvruTedmHAAQgAIF0Aln1csz9Xit/s77++utm+PDhtpNaHUGrPvTu3Tu90xyFAAQqRSCrnouxwzQDqxd63UvXU089tX1B2H9hV/n937zJ6NKxbYvR4c361kgP6759gw02SC2imSNrTJ9jbFuxY1WkvcSfE81smIIcwzsmr+rOO8diecfY82LmmGzQ7bBhxtiqNU7tkKy6uB1tpE4IQAACEIAABCAAAQhAAAJdSQBH1kDaWW8o5Tj22Wef1Uo/+uija0tl48haw1LbyMJX/Fx0PTnnjRo1yjoNy+HuvffesxH35KQ2bNiwDhEiXWVyHtNb1IoKKEe0NNHbu4899pg9tfLKKxsZwyQ4sloM/PuVQJY5K2Ct0gmKvqmooYpCIJEToJwBkyKnR10fEkXkWXzxxe22/+/SSy+1Tq46Nt9889kHnopmKcnqyGYz/fpPTo8u+o/vyOrON/r0nWAVtXOFFVawyYvsc1r9vmPlDDPMYM477zybTJGS1llnnRrr6667zmg5+aQ899xzNtqsjvfr189cfPHFNokciMVYMmTIEKP+pYkifDoHYkWqWG211Wwyf7n7OeaYwzpljjPOOGlF5DpWj7cKizF8N2uMHIvVT4nvyBrLS+X5y/wdeuihZoklltDhQuSVV16pLWeY1SmgXp+bNSyr3mlWXqMxj3FkbVavzjeqOyQ/aSDQ0wjkvb5b8d3d09jSHwhAAAJ5CGTVyzH3e638zbr//vubZ5991iJIrjaRhwt5IACBnkMgi55rtR1GttprrrnGwk1GY3XEZac94ogj7K5sIqeeeqrdLqJtMTrcta/eZyM9rIAMsiE50Yuy7sXqRo6sMX2OtW3FjJXrZ6PPUHtJnvugvLzV3pi8yp93jsXyzmvPi5lj6m87bZiqv5HE2KoblZv3XBZdnLcO8kEAAhCAAAQgAAEIQAACECgTARxZA0cr9oZSS1NrCWUJjqydoWfh6z/kUcRGLTmetgSTHIvksOecUF2tG220kfn6669tRMpbb73VHe7wefXVV9tIJTroR7jEkbUDpkrvZJmzaaCK0glvv/22ddZTHYrceckll6RVZ0477TRzxx132HOKGqnokb74yz0pcuXJJ59sfo3EbbbcckubLI8jq65L1aXrTaI2yMk8VLbZZpvakvOKArDYYovZrEX1uV47HnjgAXPcccfZ04okqiieEkWWdc6ncmCVI2uaJKM0aLl5LdWmqKNykpWoHDmzpokfpcGP6Kpo0NJBEr0csdBCC6Vlz32sHm8VmNfwHdIYcbzgggtsUjmayuFUEsvrhRdeMPvss48tS98D6kORorJVh2STTTaxywGGll+vz83yx+qdZPmNxrzVjqyN6k62k30IVIFAnuu7Fd/dVWBNHyEAAQiEEMijl/1yQ+/3Wvmb1S9b9y+KxjrJJJP4zWQbAhCoMIEseq7VdhjZAeT4JvnjH/9ofv/733caGQUy2GyzzexxrWBzyy232O1WtC1Uh3dqZOJAVj3s/75v5Mga0+dY21bMWCXwpO6G2Et8TjE2TL+cRrzTGhqTV+WFzrFY3nnteTFzTP1rpw1T9deTWFt1vXJjjmfRxTH1kBcCEIAABCAAAQhAAAIQgEBZCODIGjhSsTeUocaJwOb0uGRZ+PqOrD4IRfJTdEIZNp3IaU7Oc77gyOrTYDsvgSxzNq2OonSCop3qTXKJHD3l8JkmiugwYsQIeyoZDVQRerRE+i+//GImnXRS68Q63XTTmc8//zy3I6uiHp900klGy8NLFAFWjuWhIudXOaorUoREUVEVHVVSRJ9tQXX++Y6kigKraLASRbRVZFuJlri74YYb7HbaPzH+8ccf7akzzzzTDBgwwEYOcZGe5cQ3dOjQtKzWQdY5di699NJ2bBRxV0Z1Lc3Vq1cv68CvBzeffPKJ+eijj4y2p512WiMDfh5pxFvl5TV8N2uLoo0oospPP/1k9bccqOU8LNHxvLyUX5Fw5UQskeO2nKrlZKyHNuqvvjNmnHHG1Ki6NlODf7pmFFVFIqcA1ZUWnTetiEZ9TkvvH4vVO35Zzca8lY6szer228k2BKpCIOv13Yrv7qqwpp8QgAAEQghk1cvJMkPv91r5m3XPPfc0WkVAIucv3V8hEIAABByBLHqu1XYYrdKiSJwSvUzs7AKure5TdhRFipTI4VH34a1oW6gOd+2q95lVD4c6R8b0Oda2FTNW9Ti54yH2kiLvg0J5u/b5nzF5VU7oHIvlndeeFzPH2m3D9MfJ3461VftlFbmdRRcXWS9lQQACEIAABCAAAQhAAAIQ6K4EcGQNHJnYG8pQ40Rgc3pcsix8k46scjTTAxk5JElk9JLDnJzyJHKMmmuuuey2/uHIWkPBRgSBLHM2rZqidML9999vjj/+eFvFsssuW3NqTdZ555131pZdW2mlleyb8UojA7aWsteDgPHGG88cc8wxZp555rHZszqyPv744+a1114zcoB7+umnzffff2/LUXkHHnig6du3r90P+acl5bR8lkSRZhU96De/+Y3dj+2zLaTOP72Zv/nmmxsZNyV77LGHGThwoN2Ws+U666xjlxPTAUW/VdvSRE6Tn332mT2l8ZlvvvlsHxTtWaLoIooykib33nuvOfHEE+2pBRdc0I6J71SoOqX3FH3EOcu6cmabbTbrsLnooou6Q0GfjXirAN/wrXHQn14cUORrOc+uttpqZtVVV7UOtY0qlCPpzTffbEaPHm3eeust88Ybb9jkE000kRk2bJhRBFonGvO8vFSG32aVq7pcfa6OCSaYwNYpR9fevXu7w00/NS9cWZovishaT7L0uV4Z7nis3nHl6LPZmPtzTuk1RroGxh9/fOsErCi3eojovnuVJlSa1R1aDukg0JMIZLm+i/zu7kkM6QsEIACBIglk0ctp9Ybe77XqN6vsInpZUaIorPptHfriVVp/OAYBCPQ8Aln0XCvtMCIre4Be1JXo5WKtCpQmcsp3AQz0ArBewm5F20J1eFob3bE8ejjUOTKmz7G2rZixcmzcZ1Z7SdH3QaG8XXv9z5i8Kid0jsXy9n9nZLHnxcwx357UDhumP05F2qr9covczqKLi6yXsiAAAQhAAAIQgAAEIAABCHRXAjiyBo5M7A1lqHEisDk9LlkWvr4jq5apkVNeUvxld+Skt8oqq9SSwClfawAAQABJREFU4MhaQ8FGBIEsczatmqJ0gqKCnnvuubYKzXPN9zR56KGHrEOkzi2yyCLmyCOPtM6Ew4cPN1988YV1SlTk0eWXX76WPasjq6LBykDoy5Zbbmmdx/1jzbbVHkU+dVE25BQqR0MnMX12ZdT7FEsXaVUPei+77DIbfdWl32GHHWxET+0PGjTI7Lbbbu5Uh8+dd97ZvPvuu/aYWIv5I488Yo466ih7TA6gihadFkFVDF1k3bnnnttGtn3ppZfM3nvv3aGOejtyMNVD66WWWqpekg7Hm/FWYt/w3SGzt9OvXz9z7LHHmmmmmcY72nFTTMTGF0Xalc7WAyhfYnipHM3n559/3i+y7rZedpDDsSLbNhMtd6j2SuQUoChaGs96kqXP9cpwx2P1jisnZMz9Bw8uX/JTc22DDTawztPJc/X2Q+qul5fjEOjJBEKvb70IUOR3d09mSt8gAAEIxBAI1cv16gi932vFb1at4qD7FC0LLMlzT1avXxyHAAR6DoEseq6VdhgRXW+99WovQ+ul5np2he22286uSqM8WgVINpNWtC1Uh6sdaZJXD4c6R8b2Oca2FTNWSVZZ7CWtuA8K5Z1st/Zj8ip/6ByL5Z3Xnhczx9ptwxRfJ0XZql15rfjMootbUT9lQgACEIAABCAAAQhAAAIQ6G4EcGQNHJHYG8pQ40Rgc3pcsix8fUfWK6+80vTp06cTD0XxU8QRSTJaHo6sFgv/IglkmbNpVRWlExQVVNeBZM011zS6PtJk5MiRNlKxzsnQL4dDRQR1DzeTzqJKV4Qjq8pZaKGFbF1ydGwm//73v21U2eeee84mlXPjmWee2cGZNG+f9ZCjkcjpcb/99jN64CDZfffdzRprrNEhix6oKJqkEznYrrvuumbSSSe1y9YrIu2NN95ol7Zzac466yzTv39/89VXX5ntt9++Fu11pplmsk6d888/v02qL+SHH37Y3HTTTeabb76xx5ZZZhlz0EEHdYgwohOTTTaZjYI6YMAAGynz/ffft/lUh0ROuKeffrqZdtpp7X69fyG8lVeGb7VNTqeKrDvhhBPaNioahoteq3SzzDKLfZik6J1pkvaQQunkCLr11lt3iMgaw0tl+lErtK8otYsttph9IKbIu3LullOqk8GDB3dysnXn3Kfmxi677FJzUlab5cjZSLL0uVE5Oherd1RG6Jg7R9YpppjCTD311HaOK6/0gsbdFy11p6i8zSS07mblcB4CPZFAyPWtJRqL/u7uiSzpEwQgAIEiCITo5Ub1hN7vteI362OPPWaOOOII2zzdp8g2Uu/3eaM+cA4CEOjZBLLouVbZYUT4X//6VwdbQD1br9Lqfvydd97Rpn1BWy8Nt6JtoTrcNiTlX149HOocGdvnvLYt2bH8lXSyjlUSVai9pFX3QaG8k+3Wfkxe5Q+ZY7HXhurJa8+LmWN+NFe1oattmKrTSZojq85lsVW7slr1mUUXt6oNlAsBCEAAAhCAAAQgAAEIQKA7EcCRNXA0Ym8oQ4wTgU3pkcmy8A1xZL311lut85tgydFMTnpOcGR1JPiMIZBlzqbVU5RO8JfoHjhwoNGS52niR7fUMveKZqw2SBRVUddFUrTEl64liSJPytFPIudOLQ2VFEVQ/f77762Do5Zdl0OmHCwlMnafccYZZrzxxktm67CvJeSUT6LomMcdd5x1vPUT5e2zIm7WE30ZKsKd+ixRNNNDDjmkU3IZkRU1SdEFfNES9T/++KN/qLZ93XXX1Zbx1NJyKtc5yypRr1697Bj88ssvtTxuY8iQIUaRMvw+yxnzwAMPNKrTFzkYKtqpi2S79tprmx133NFP0mk7hLcyjR071tanZch8kUPo3/72N3PppZfWDmtebbzxxrV9f0P9VhQN5fvyyy+tM+k999xjXN+TEbTz8lKda621ltHDDokctxdYYAG77f8bMWKEdTx2x8S5d+/ebrfTpx/ZWIZ4OQXIqbeRZO1zo7Ji9Y7KDh1zpdVcSluCVtf3KaecUnPo1VzUPG8W0TZL3aofgUCVCIRc34poXPR3d5UY01cIQAACWQiE6OVG5YXe7xX9m1UvDml1iw8++MA2b5tttjFDhw5t1FTOQQACFSWQRc/5NokstqdGdhgfu68LtTKOXqhMEz+S6DHHHGMWXHDBDvaSotoWqsPT2hijh0OdI2PHI8a2FTNWSV6h9pJW3QeF8k62W/sxeZU/dI7F8s5rz4uZY37edtgwxddJEbZqV1arPrPo4la1gXIhAAEIQAACEIAABCAAAQh0JwI4sgaORuwNZahxIrA5PS5ZFr4hjqz33nuvOfHEEy0nHFl73HTpFh3KMmfTGlyUTrjrrrusQ5nqWHHFFc0+++yTVp2Rs6CLSLrsssvayKBqQx6p5xSYLEvGQjnWfvzxx/aUopGus846yWS1fd8BXQeTTo0uYd4+H3DAAa6IDp+KKKoIdx999JE9riinethSb7l4RQpVRINnnnmmQzluRw6TL7zwgt1VGddff707ZT/vuOMOc+GFF3aIZOoSyGlQzr5jxoyxhxwzP8q0ol8oCkmayAlYzoIStUNjVU9CedfL7x8/7bTTjPolcVFk/fONtm+55RajqLUSOUyrr77DbB5eKkuO185Btl6UEDm6aqlVF8lWjtMuQq7K8EUPozQebj5vu+22dvlDP03odrM+1ysnVu8UOeaffPKJdZJwDtwu8nC9thdZd706OA6BMhMIub79B7hZ+xr63Z21XNJDAAIQ6KkEQvRyo76H3u8V/ZvVj4IW+uJVo35wDgIQ6LkEsui5ou0wSapaTUsvu0rOP/98M/300yeT2H3dv+slXolsHzPPPLNpRdtCdbhtSOJfjB4OdY4sos95bVsxY5VAlbqbZi8ZNWpU7YW+1EwNDja6DwrlnVZ8TF6VFzrHWs27nj0vZo51ZxtmVlt12tgXfSyLLi66bsqDAAQgAAEIQAACEIAABCDQHQngyBo4KrE3lKHGicDm9LhkWfiGOLLed9991tFMoHBk7XHTpVt0KMucTWtwUTpBS6MfeuihtopGDoQ333yzOfvss206OUIqAutmm22W1rSmx+TEOe+88zZNpwSK0njBBRfYtMstt5zZf//9U/Np2XpF03CRShVFWddumuTtc5rzpyLIysH1tddes1VNM800VnfUi/7ht+eVV14xzz33nJFjkdo944wzmnnmmccuwS4nR0n//v1rTpp+XhlOH3zwQaMvYT08UH2KWqsxVORanZMcdNBB9pjvBLjyyiubvffe255P/nv11VeNlnmXyCn02muvTSax+1l4pxaQOPiPf/zDtlWHp5tuutqYJ5Kl7orduuuua6O0KoGipIqFL1l5Ka+Lvq1tOQ5PO+202uwkGn/nlKwItopkmyb+Q4o+ffoYLcXXLBprWjk6FtLntLwxeqfoMVf7FMX49ddft01VlOeVVloprdmmFXWnVsRBCJSYQMj1rQe4XfHdXWKMNB0CEIBAYQRC9HKjykLv94r8zaqXuPTilV44kriX4hq1k3MQgEB1CWTRc0XaYdKI+7beRi9JbrDBBrWVdNwLq61oW6gOT/YlVg/7dodGq+wU2eestq2YsUrySttPs5fope9W3AeF8k5rZ0xelRc6x1rNu549L2aOdXcbZqitOm3cW3Esiy5uRf2UCQEIQAACEIAABCAAAQhAoLsRwJE1cERibyhDjROBzelxybLw9Q04zmiZBBLiyKrl1G+77Ta7pHcyv//msJzf5PgnefHFF+2S7NpORr9UJEwXhbFR9ADlRcpPIMucTettUTpBDpiKJiqZffbZjd6kTxM58jmnxk022cTojf5moigXinYhUZQLF+mzWT7//MiRI81hhx1mD80yyyw1Z9pkmiOPPNJoaTOJ2qY21pOi+qxIknIU1XUtmXrqqY0icvbr169e1UHH5bR39NFH27Ry7JODXxbRA+cPP/zQZnG65JFHHjFHHXWUPbbQQgvVyk+Wq2ihzol2/PHHNzfeeGMnHacxycI7WUfa/jvvvFOLEqsHDDIKZxHpWZUhOfDAA83vfve74OxpvJTZX3KwkfO1xkpjJtl6662NHowlRZFbxdVFflHZQ4YMSSbLtJ+nz3n1TivGXJ3Vta2yJfWYtKpuWyn/INCDCOS9vpMIivjuTpbJPgQgAIEqEojVy6H3e0X+ZtVKBu5+cPLJJ7cvc00wwQRVHD76DAEIBBDIoueKssPUa5bsAE8//bQ9rZe1l1hiiU5Jf/jhB7sqilZLkU1XznJazaUVbQvV4clGxurhUOfIVvQ52Zd6tq2YsUrWUW8/j70kz31QKO+0dsbkVXmhc6zVvOvZ82LmWHe3YcpO1cxWnTbmrTqWRRe3qg2UCwEIQAACEIAABCAAAQhAoDsRwJE1cDRibyhDjROBzelxybLwjXVklYOcW0b6hhtuSI2ohyNrj5tihXcoy5xNq7woneBHZxt33HGtA2Haw0rf0XqPPfYwAwcOTGtWh2N5jMAdCvh15/bbbzenn366PTzffPOZ448/vkOSJ5980hx++OG1JeBDnGyL6LOcWGW0dJE4p5pqKts2ObPGiiKiKjKq5OSTTzZzzTVXcJFqjyKEShZddFFzxBFH2G3fQVWOotdcc419YGNPev8USWPPPfe0RxTVVNFNfcnD289fb9uP1DBgwABz5pln1kuaetzXy4rMu+CCC6amSx6sx0vptHyci2y73Xbb2aivyfzaV5TgZ5991p7StiIHJ8Vf2k5OAYrGKkfhGMnT5zx6p1Vjrr7738cHH3ywWXrppTsgaWXdHSpiBwI9gECe6zut20V8d6eVyzEIQAACVSMQq5dD7/eK+s36008/mW222aa2NHejlQaqNpb0FwIQSCeQRc8VYYdJb8V/jvrLm2+88capy8j7wQW0qs1ll11mM7eibaE63O9TEXo41DmyFX32+6LteratmLFK1lFvP4+9JM99UCjvtHbG5FV5oXOs1bzr2fNi5lh3t2E2s1WnjXcrj2XRxa1sB2VDAAIQgAAEIAABCEAAAhDoLgRwZA0cidgbylDjRGBzelyyLHx9x5k8EVl333138+abb1qGcraS01VSLr30UnPFFVfYw0RkTdJhXwSyzNk0Yll0wpdffll7IKloE3PMMUeHIv3lvRVdUhE7fZHTppasVPQK5b/88suNlkZvJs2MwIqg2qtXr4bF+BEb11prLbPTTjvV0j/22GNGTotaek2iZcI23XTT2vlGGzF9Hjt2rDnkkENqkVinmWYaG+FUn7HiRx2Ye+65zUknnRRcpKKKSN+89957No+ipi6yyCK1/L4hX/1fffXVa+fchu+Ev8IKK5h9993XnTIxvGuF1NmQw66M+BI/Cq36JNG8qyd+9AelkZNu79696yWvHW/GSxG3zzjjDJteY3veeecZOXv7ormga/Hbb7+1h5Vmhhlm8JMYXT/Dhg0zo0ePtsd33nlnM3jw4A5p/J1W9jmr3mnlmH/66adGDsLu+r3gggvMdNNNV0PRyrprlbABgR5EIOv1Xa/rzb676+XjOAQgAAEIdCQQq5dD7/eK+s2qlRjcS2xTTjmljcY63njjdewUexCAAAQ8Aln1XIwdRsvFv/HGG0afEr1MLGdUJ/7y5vPOO6/RqipJkZ1W9lpJ0r4U07ZkPdoP1eF+3iL0cBbnyKL77PelkW0rZqxaaS/Jcx+UhbfPR9sxeZU/dI7F8FY9zaSePU/5YuZYu2yYsbbqZrxacT6rLm5FGygTAhCAAAQgAAEIQAACEIBAdyKAI2vgaMTeUIYaJwKb0+OSZeEb68gqx7mHHnrIMlxnnXWMlqV2IoccOcfKGcwtc44jq6PDp08gy5z187ntLDpBDyRlEHdy8803G/+hpPbPPvtse3qWWWaxy0n65+WwrSXXJIsvvnht+SR7oMG/ZkZgXRuzzTabdT7t169fp5LuueeeDo6cijS67LLL2nRaokzRh5wRW9ehrsdQydtnOfPut99+duk51aWopUcddVSHByihbUimkxFb46A6JH5/k2mT+3KSPO6448zzzz9vT2kc3Zi6tBpDF+lUD310XtFZnSjStDg6p8y99trLrLLKKvZ0DO+bbrrJtkuOxmmO/zKqyzHYjaWi/6644oq23kcffdRGL1VeOdYmHVq/+eYby+mtt96y6WeeeWZzzjnn2O1G/0J4KRrKtttua7744gtbVNocu+iii6y+V4Lpp5/enHvuuZ3aeP3115vzzz/fliHuctj0ry97wvvXqj6riix6J2bMVZecVNdee22z6qqrdopcLgdgRQt2EY1nnHFGO25ufGPrVv0IBKpGIMv13YhNs+/uRnk5BwEIQAAC/yMQq5dD7/eK+M2q+4+tttrKfP3117YDvg3jfz1iCwIQgEBHAln1XF47jGr97rvvzNChQ2sN2GCDDczWW29d25c9QS82jxkzxh7785//bF+SdQn0IqV02/fff28PnXrqqR1e8o5pm6vD/wzV4S5PUXo4i3Nk0X12fWlm24oZq1baS/LcB2Xh7fi4z5i8KiN0jsXwjrHnqY0xc6xdNswYW7X63A7Jqovb0UbqhAAEIAABCEAAAhCAAAQg0JUEcGQNpJ31hvL11183b7/9dq10Ob44Y5ucQyaccEJ7To4zoUso1wrrgRtZ+MY6st5xxx3W0c9hXHnlla0z3ocffmjkkOWcntx5/yGQv4yVHLXksOXEX7pdTk8aW6TnEsgyZ0UhRic0c2TVA8vNN9/c/Pzzzxb4/PPPbw3+E000kXnuuefMXXfdVRsIReiUQ2GINDMC77DDDuaDDz6wUS4VMWP22Wc3/fv3t7pOS4o/9dRTtWoUWVQRRp3ICU4RGyXjjDNOzcHVnU/7VFRMFzU1b58V7dSPCiv9O+mkk6ZVVzumCLj+AxcZq7UUvTgrwqe+SF999VXzwgsv1PIMHDjQ7Lbbbp2cIpVAD2RUr5x/9b3w7rvvmpEjRxo5dUomm2wy62ycjLwr53q1XbpKMvXUU9sH1tNOO61RVFNFJpEzq2SBBRawjsJ259d/MbyvvfZaG9FJZWmMl1xySSPHRUUqlU689957a1FVxEQOuU78KB4au3nmmcfq2759+9p+3HLLLeaf//ynTa55oLzzzTefy24/8/JS5gceeKBDexRJdbnlljNyGNC5++67r1aXXnJIfh9rfOQU4NqoMR00aFAtT9pGEX1OK1fHsuidmDFXXXJiFSc5Sy+xxBJ2vuta0XzX9+gnn3yiZFaS7GLrduXyCYEqEchyfTfi0uy7u1FezkEAAhCAwP8IZNXLMfd7sb9Z/VUZdI8he0SjF6/+10u2IACBKhPIqufy2mHEuJkjq9LoxdIbbrhBm2biiSc2a6yxhr1Hlw1E96AfffSRPSd7hNL6EtM2lROjw5U/rx5WQAW9BO4i1b700kvWVqEyZRvRijdOZMvzX2aO7XOMbSvvWLXSXhJyHxTDOyavxjBmjuXlHWPPU5tj5li7bJgxtmr1uR2SVRe3o43UCQEIQAACEIAABCAAAQhAoCsJ4MgaSDvrDaUiyumt12ayzDLLmIMOOqhZsh5/PgvfWEdWGVK0NLQc8NJEzlRy1pGxRoIjaxoljmWZs6IVoxOaObKqfDlhy3lMzoX1ZL311rMRKuudTx5vZgR2xsFkvuS+HC2PPvpo63jpzvmObu5Ys89TTjnFzDnnnLVkefqcdGStFdZgY7HFFjOHH354LcVVV11lLr744tq+vyH9oagi66+/vn+4w/Yf/vCHWsTnDid+3VGE2MMOO6wDKz+NHGgPPfTQhuOsqKHi7TvTx/D2Dd9+W5LbWlZebffr9R9SJNP7++KmqK1aeiwpMbz0MOjggw+210eyXH8/GQ3GnfOXLpTjsJwC5LzcSIroc73ys+idmDFX/c6RtV5bdFzjtuGGG5ott9yyQ7LYujsUxg4EKkIgy/XdCEmz7+5GeTkHAQhAAAL/I5BVL8fc78X8ZpVzmF68cqsy7L777tb56389YQsCEIBAOoGsek6l5LHDKF+II6tepNS9pP9StPL6MuWUU1p7xwwzzOAfttt526bMMTo8Rg/rpVnZI0LkrLPOsi+P+2lj+hxj28o7Vq20l4TcB8XwjsmrMYuZY3l5x9jz3DyLmWPtsGHG2Kpdn7v6M48u7uo2Uh8EIAABCEAAAhCAAAQgAIGuJNDtHVm7EkajurLeUCYdz+qVrchw+++/f73TlTmehe8ee+xh3njjDctGb7ynRVP0I5psvPHGdrkeH+Znn31mlzz3IyjqvCIGDh8+3JZ/4YUX2ix+BL6XX37ZaLluiZbsdtva13Llin4p+etf/1qLHGkP8K/HEcgyZ9X5GJ3gv3kvxzE5yadF2NGy9HL21JJrvkwyySQ2oqgczrLIqFGjrHOh8ijSqozmvmi+Kxqnoom6iNP++V69ehlFwJSTm4tC7c7L0VLLj2eR0047zUYE9fNk7bMieWiJ+SyiaJRyHnVSz9g/66yzWkdMvaDQSNIcMxVtZNlll7Vt8yNspJXz8ccfmxNOOMG89tprHU5rbijCtKK2JsuI4S1mmnN64OCixvoVy7FTEWi32WabTuMsQ78iAksnK2psmugBlPSuovqmSSwvLcN24403WudjGf99mXzyyW3diy++uH/YbivaxkYbbWQfuOmA2rj66qt3Spc8UESfk2W6/Sx6J2bMVZ+WgXvwwQfNK6+8UosO49qhTzksy1FC0X+TElt3sjz2IVAFAlmu70Y8mn13N8rLOQhAAAIQ+B+BrHo55n5Pteb9zXrdddcZrQAkkT1DL17pPgyBAAQg0IxAVj3nystqh1E+OXvqhV8XeTTNVqt0WmlIdi2t4OO/qC17h1aIkQ1dL5nWkzxtU1kxOjxGDye51OuXa6Nefk5K3j7H2rbyjFUr7SUh90ExvGPyuvGTbaqZ1HtWlId3jD3Pb2feOaYyutqGGWOr9vvcldt5dXFXtpG6IAABCEAAAhCAAAQgAAEIdCUBHFkDaXNDGQgqZ7J28JXxVNEZ33//ffugRwZRt2x5zm6QrUIE2jFnQ/GOGTPGLnUvp70BAwYYOQrK6N8qkTFVzuGKfqCl7eXYKOO66k1zuG1FO7qyzzK8v/rqqzZqsx4S9+nTxygaaaj+eOutt+ySeHoo07t3byNnSo3T+OOPnwnN6NGjzdtvv23bobpVhhxiWyWKZq0fDV988YVR3RpbjbOW9WsWpVRt0hhpjmiu/PDDD0aRY5Vf/W8kRfHSPFUkbhnyNW7ipXFr5bWRt8/1eLRD7yg6uZzjv/zyS/vwURFwxE7zHoEABIoj0I7ru7jWUxIEIACBnkegXXq5Hb9Ze97o0SMIQCCEQKyea6UdRvYHvQyre/i+ffva1XmSL+w26mMr29ao3naey9rnWNuW62vesSraXuLa09M/8/COtec5plnnmMunz662YXYHW7Xf/0bbsbq4UdmcgwAEIAABCEAAAhCAAAQgUEYCOLIGjho3lIGgciaDb05wZGsbAeZs29BTMQQqSwC9U9mhp+MVIMD1XYFBposQgECpCKCXSzVcNBYCEMhBAD2XAxpZIAABCBRMAF1cMFCKgwAEIAABCEAAAhCAAARKTwBH1sAh5IYyEFTOZPDNCY5sbSPAnG0beiqGQGUJoHcqO/R0vAIEuL4rMMh0EQIQKBUB9HKphovGQgACOQig53JAIwsEIACBggmgiwsGSnEQgAAEIAABCEAAAhCAQOkJ4MgaOITcUAaCypkMvjnBka1tBJizbUNPxRCoLAH0TmWHno5XgADXdwUGmS5CAAKlIoBeLtVw0VgIQCAHAfRcDmhkgQAEIFAwAXRxwUApDgIQgAAEIAABCEAAAhAoPQEcWQOHkBvKQFA5k8E3JziytY0Ac7Zt6KkYApUlgN6p7NDT8QoQ4PquwCDTRQhAoFQE0MulGi4aCwEI5CCAnssBjSwQgAAECiaALi4YKMVBAAIQgAAEIAABCEAAAqUngCNr4BByQxkIKmcy+OYER7a2EWDOtg09FUOgsgTQO5UdejpeAQJc3xUYZLoIAQiUigB6uVTDRWMhAIEcBNBzOaCRBQIQgEDBBNDFBQOlOAhAAAIQgAAEIAABCECg9ARwZA0cQm4oA0HlTAbfnODI1jYCzNm2oadiCFSWAHqnskNPxytAgOu7AoNMFyEAgVIRQC+XarhoLAQgkIMAei4HNLJAAAIQKJgAurhgoBQHAQhAAAIQgAAEIAABCJSeAI6sgUPIDWUgqJzJ4JsTHNnaRoA52zb0VAyByhJA71R26Ol4BQhwfVdgkOkiBCBQKgLo5VINF42FAARyEEDP5YBGFghAAAIFE0AXFwyU4iAAAQhAAAIQgAAEIACB0hPAkTVwCLmhDASVMxl8c4IjW9sIMGfbhp6KIVBZAuidyg49Ha8AAa7vCgwyXYQABEpFAL1cquGisRCAQA4C6Lkc0MgCAQhAoGAC6OKCgVIcBCAAAQhAAAIQgAAEIFB6AjiyBg4hN5SBoHImg29OcGRrGwHmbNvQUzEEKksAvVPZoafjFSDA9V2BQaaLEIBAqQigl0s1XDQWAhDIQQA9lwMaWSAAAQgUTABdXDBQioMABCAAAQhAAAIQgAAESk8AR9bAIeSGMhBUzmTwzQmObG0jwJxtG3oqhkBlCaB3Kjv0dLwCBLi+KzDIdBECECgVAfRyqYaLxkIAAjkIoOdyQCMLBCAAgYIJoIsLBkpxEIAABCAAAQhAAAIQgEDpCeDIGjiE3FAGgsqZDL45wZGtbQSYs21DT8UQqCwB9E5lh56OV4AA13cFBpkuQgACpSKAXi7VcNFYCEAgBwH0XA5oZIEABCBQMAF0ccFAKQ4CEIAABCAAAQhAAAIQKD0BHFkDh5AbykBQOZPBNyc4srWNAHO2beipGAKVJYDeqezQ0/EKEOD6rsAg00UIQKBUBNDLpRouGgsBCOQggJ7LAY0sEIAABAomgC4uGCjFQQACEIAABCAAAQhAAAKlJ4Aja+AQckMZCCpnMvjmBEe2thFgzrYNPRVDoLIE0DuVHXo6XgECXN8VGGS6CAEIlIoAerlUw0VjIQCBHATQczmgkQUCEIBAwQTQxQUDpTgIQAACEIAABCAAAQhAoPQE2u7IWnqCdAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIBARgLTTtU3Yw6SQwACEIAABCAAAQhAAAIQ6JkEcGTtmeNKryAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAgW5MAEfWbjw4NA0CEIAABCAAAQhAAAIQ6FICbXdknWTCcbu0w3kr+/aHX2zWsrQ3bz/blQ++7SJPvXkJMGfzkiMfBCCQlwB6Jy858kGg+xPg+u7+Y0QLIQCBahFAL1drvOktBKpIAD1XxVGnzxCAQHcj4HQxjqzdbWRoDwQgAAEIQAACEIAABCDQLgI4sgaSdzeUOLIGAsuYDL4ZgZG87QSYs20fAhoAgcoRQO9UbsjpcIUIcH1XaLDpKgQgUAoC6OVSDBONhAAEIgig5yLgkRUCEIBAQQScLsaRtSCgFAMBCEAAAhCAAAQgAAEIlJ4AjqyBQ+huKHFkDQSWMRl8MwIjedsJMGfbPgQ0AAKVI4DeqdyQ0+EKEeD6rtBg01UIQKAUBNDLpRgmGgkBCEQQQM9FwCMrBCAAgYIIOF2MI2tBQCkGAhCAAAQgAAEIQAACECg9ARxZA4fQ3VDiyBoILGMy+GYERvK2E2DOtn0IaAAEKkcAvVO5IafDFSLA9V2hwaarEIBAKQigl0sxTDQSAhCIIICei4BHVghAAAIFEXC6GEfWgoBSDAQgAAEIQAACEIAABCBQegI4sgYOobuhxJE1EFjGZPDNCIzkbSfAnG37ENAACFSOAHqnckNOhytEgOu7QoNNVyEAgVIQQC+XYphoJAQgEEEAPRcBj6wQgAAECiLgdDGOrAUBpRgIQAACEIAABCAAAQhAoPQEcGQNHEJ3Q4kjayCwjMngmxEYydtOgDnb9iGgARCoHAH0TuWGnA5XiADXd4UGm65CAAKlIIBeLsUw0UgIQCCCAHouAh5ZIQABCBREwOliHFkLAkoxEIAABCAAAQhAAAIQgEDpCeDIGjiE7oYSR9ZAYBmTwTcjMJK3nQBztu1DQAMgUDkC6J3KDTkdrhABru8KDTZdhQAESkEAvVyKYaKREIBABAH0XAQ8skIAAhAoiIDTxTiyFgSUYiAAAQhAAAIQgAAEIACB0hPAkTVwCN0NJY6sgcAyJoNvRmAkbzsB5mzbh4AGQKByBNA7lRtyOlwhAlzfFRpsugoBCJSCAHq5FMNEIyEAgQgC6LkIeGSFAAQgUBABp4txZC0IKMVAAAIQgAAEIAABCEAAAqUngCNr4BC6G0ocWQOBZUwG34zASN52AszZtg8BDYBA5Qigdyo35HS4QgS4vis02HQVAhAoBQH0cimGiUZCAAIRBNBzEfDICgEIQKAgAk4X48haEFCKgQAEIAABCEAAAhCAAARKTwBH1sAhdDeUOLIGAsuYDL4ZgZG87QSYs20fAhoAgcoRQO9UbsjpcIUIcH1XaLDpKgQgUAoC6OVSDBONhAAEIgig5yLgkRUCEIBAQQScLsaRtSCgFAMBCEAAAhCAAAQgAAEIlJ4AjqyBQ+huKHFkDQSWMRl8MwIjedsJMGfbPgQ0AAKVI4DeqdyQ0+EKEeD6rtBg01UIQKAUBNDLpRgmGgkBCEQQQM9FwCMrBCAAgYIIOF2MI2tBQCkGAhCAAAQgAAEIQAACECg9ARxZA4fQ3VDiyBoILGMy+GYERvK2E2DOtn0IaAAEKkcAvVO5IafDFSLA9V2hwaarEIBAKQigl0sxTDQSAhCIIICei4BHVghAAAIFEXC6GEfWgoBSDAQgAAEIQAACEIAABCBQegI4sgYOobuhxJE1EFjGZPDNCIzkbSfAnG37ENAACFSOAHqnckNOhytEgOu7QoNNVyEAgVIQQC+XYphoJAQgEEEAPRcBj6wQgAAECiLgdDGOrAUBpRgIQAACEIAABCAAAQhAoPQEcGQNHEJ3Q4kjayCwjMngmxEYydtOgDnb9iGgARCoHAH0TuWGnA5XiADXd4UGm65CAAKlIIBeLsUw0UgIQCCCAHouAh5ZIQABCBREwOliHFkLAkoxEIAABCAAAQhAAAIQgEDpCeDIGjiE7oYyjyPr//3f/5lvvvnGTDLJJKZXr16BNVYrWQzfriT1+eefmxtvvNFWOeecc5oVVlihVv3tt99uPvroI7u/ySab2PGunWSjxxHo7nP2l19+MfqbcMIJu5S99N13331Xqfnfzj63a5yLnFQ//vijLW6CCSZoWmyR36f//ve/zQ8//GBUb1d/N2fpsw8lVu+o3p9//jnX9RnL/l//+pcZPXq06d27d5frJZ8h2xDorgRir+/u2i/aBQEIQKCsBNqtl3VPNfHEE5txxhknM8KYvJkrIwMEIFBaAkXouVbbJGL0Wd62uXvf3/zmN/b+NWaAs9odYu7Z1c5//vOf5qeffjKTTz555u+PWNtWzFjFMJZdZ9xxx7V/WcuJ6bM4q8+ycaj+rBLT7qx1+elj55hfVtbtvNdk1noapc96TTYqq6hzThfjyFoUUcqBAAQgAAEIQAACEIAABMpOAEfWwBF0N5Qhjqy6KX/22WfNyJEjzfvvv28+++wza0SSo0y/fv3MPPPMYzbccEPTp0+fwNp7frIsfNtJ45VXXjF/+ctfbBOWXXZZs/vuu9eac+ihh5qXX37Z7p966qlm2mmnrZ1jo+cRiJ2zjz76qLn33nutYXnfffe1znSxlGSwvummm8zrr79u3nnnHevIOuOMMxo5Xa+66qqmf//+map46623ao7b0l1bbLFFan4ZftUX6TzV+/3335tJJ53UzDzzzGaVVVYxyyyzTGq+5EGVc/TRR1t9qTy///3vk0lq++rriBEjavvNNgYPHmw5KF1MXldP3j4XUXfecb7rrrvMiy++6LrQ8FMPPYYNG9YwjU6Kw2WXXWa/57Q/ZMgQM9tss2mzruiFgAceeMA89dRTRtsy3kt++9vfmgMOOKBD/iK/T2Ws/vvf/2507Wluf/3110bH5Byw9NJLm+HDh9dtc/JE6LXh8mXps8uT9plV7+g3yBNPPGH03fXpp5+ar776yharF2umm246s+aaa9q+p9VVBHuVceedd5r777/f1q99Sd++fe1voY022shMPfXUadVzDAKVI5Dl+i7iu6RygOkwBCAAgYwEsujltKLz3O/p9/Hjjz9u7+e+/PJL+/LR7LPPbuabbz77u01OVfUkJm+9MjkOAQj0bAJ59Vxem0QozRh9lqdtcux78sknzT/+8Q/z4YcfWjuFnBQlslPMMcccRjYl6eJmktXuEHPP7tqioApXXHGFeeONN2wgDR0fb7zxrF16jTXWMCuttJKp9/2R17bl6s4zVkXcy8jGcu2111rbjh5uqX/TTz+9tfvpmYtskvUkb581VrJ7yr6iZz1jxoyxNjHVLZvp8ssvb1ZfffWGzs952i2bm+w5WUQ24IUWWshmiZljRYxVnmsyts8+q6zXpJ+3q7adLsaRtauIUw8EIAABCEAAAhCAAAQg0N0J4MgaOELuhjLEkfWII44wL7zwQsOSJ5poIus0s/DCCzdMV5WTWfi2kwmOrO2k373qjp2zvp648MILc0VI9InIgHr44Ydbo7t/3G1L58hJUAb4EPniiy/M/vvvb539lH6GGWYwJ510UqesirB4xhlnmJdeeqnTOXfgd7/7ndlxxx2bOuvK6H7ggQfabDK2b7311q6ITp8y/u66666djtc7sNtuu5nlllvOno7JqwJi+hxbd8w4a5wefvjheog6HJdz4emnn97hWNqOjMs333xz7dSf/vQns9RSS9X2kxt6yeOUU04xY8eOTZ6y+wcddJCZf/75a+f866R2MLER8n2qB1N6wUAPptJEzt66fkIk9NpwZWXts8uX9plF78ihXTybyYILLmjkTJ+MShvLXteJmH788cd1m6CoJdtvv71ZccUV66bhBASqQiDL9R37XVIVpvQTAhCAQAyBLHo5rR7/t1TI/d4dd9xhLrroIusUk1aeXvTTPU3yN5vSxuRNq4tjEIBANQjk0XMxNokQqjH6LG/bFLBA9t5mstZaa5nNNtusbrKsdofYe3Y1RPaYK6+80mgFlHoyYMAAc8ghhxjZTnyJsW2pnLxjFXsvc99995mLL7649lK03ydty4lV35eydSQlb58VuEIBLJqJ6tYL+lNNNVWnpHnb/ec//9m89957ncprdGCrrbYygwYNsi/GxNiFYscq7zUZ02efS9Zr0s/bldtOF+PI2pXUqQsCEIAABCAAAQhAAAIQ6M4EcGQNHB13QxniyOpH5pSRSBE0ZMjQ27OK4uZEx+QYps+qSxa+7WSFI2s76XevuvPMWb0FLj1w++23m7vvvrvWoZAHm7XEKRtaKnyvvfYyn3zyiT0r57B5553XOsfKqV5vv0smnHBCc+SRRxpFaW0k3377rTn44IONojo4SXNkVRQD6Ttn8FfEh8UWW8xMOeWUNjKri1CsMjbYYAMzdOhQV1yHTxkWn3/+efvgVpGHJEU7sip6sqIoS7IaYv28sX2OqTt2nLM4siqitBw/G8k999xjzjvvvA5JGjmyat5fcsklNgqqMmmeKmLGNNNMY6OGvPnmm2a//fbr4MhaxPfpqFGjzLHHHtvB8D/ZZJPZiMHjjz++jZyuCLQhjqyh14aDkqfPLm/aZxa9439fqayZZprJ8tY8eu2114z64mT99dc3+vMlhr3q0IMy95tHOkEP/aRH9CBDUVrluC6R3pBemmWWWew+/yBQVQJZru+Y75Kq8qXfEIAABLISyKKXXdl57/e0WsHZZ5/tiqmt5KP7sbfffrvm3LrCCiuYXXbZpZZOGzF5OxTEDgQgUDkCWfVcrE2iGeAYfRbTNr1Q7e5PnR1fq5ho2XjZtdzKImq/bx/y+5PH7hB7z64XdY8//nj7HaGVZmTz0mozuseWk6ycXF1kWb1gvscee9SaHGvbihmrmHsZvUR/2GGH1foh+6bsnxp/rcDj7BwaP72crYi6TmL6LNuqXlBxonplN9PLJVqZShFancjuoXHxXzyJafc+++xj3n33XVd80KdzZI2dYzFjFXNNxvTZAcpzTbq8Xf3pdDGOrF1NnvogAAEIQAACEIAABCAAge5KoNs7sq63UliEtEaAr3+geUSyRvl1zt1QhjqyasliOYXIqUsGJCeKzCZjhjOCrbfeekZL3lRdsvBtJyvfACQDoQyYTnynHzmAyaCF9FwCWefs5Zdfbm655ZaaE59PJtaRVUt5Sa9IJphgAnPcccfV5p90jd6+1wNQiZa52mabbex22j8ZGo866ihrrPfPpzmy+oZrOeQr4mv//v1r2RSd4a9//avdlxPtaaedZvr06VM7LwPzTjvtZOTImpQsjqxyhpSjYiOR06RbSs03xGbNG9vnmLpjx9l3ZFV0iiWXXLIuMj0E8b+7kgn1XSbmeljvSz1HVp+b0muZsy233LJDlF49JNL81Vg5kV6N+T5VVBI9rBF3yRRTTGEf/ieXBFQdcm5tJFmuDZWTt8+N2pBF7+j7Ss65Yq1lELXUnZPvv//eXo/PPPOMPSTmimjij3kMe5V7zDHH2LL79u1rdZLPV/NGesZFr9dSh9IFCASqTCDL9R3zXVJlxvQdAhCAQBYCWfSyyo2539t7773ty1UqR7/dFLHeiZa7PuGEE+yu7mfOOeecDvdUMXldHXxCAALVJJBVz8XaJJpRjtFnMW2TI6vsEXr5WnYS3yahl63lOOmWdpedX9Eifclrd4i9Z9eLwM7Wp2cLesbgy6uvvmr+8mu0WTlwSs4888xapFDfXpHHnhczVnnvZWTf3HPPPWsv8a+22mpm2LBhNYdROS4qGuoHH3xg+ys7yOabb2639S+mz7JdqOyVV17Z2lf0QrYT8ZW9VysWOZFd1r2sG9tu2aLcGLry0z5Vp7OxbLvttub3v/+9DTwQYxfKO1ZqX8w1GdNn1Z33mlTedojTxTiytoM+dUIAAhCAAAQgAAEIQAAC3ZEAjqyBo+JuKEMcWfUWt5bt8Q1ffjVyFrntttvsoTQDmJ+2KttZ+DZiIucY56zWKF3ecziy5iXX8/JlnbNy6JRjZ5rEOrLqwaYecEqcsdKvR5Fahw8fbg2fvXv3Nueee27N0Oun07YiFjzyyCP28FxzzWUjN2onzZHVX+pp6623tlFUbUbvn6IyyngukRFV7XOiSLH1nGqzOLKmtc3VkfbpG2Kz5o3tc0zdsePsO7LWczhN45U8pkgQGtcffvjBOp7KgP/+++/bZGnlyuD+xz/+0bgfHHrQMHDgwGSxqfux36ePPvqoddhU4Xq5QJE/FZkjj2S5NmL63KhtWfSOri856GqOp4nO77DDDrUXa+SY7Duix7D39V295RelFzSPJIoW6xw00trKMQhUgUCW6zvmu6QKLOkjBCAAgSIIZNHLqs///ZOsv9H9nhxutLqGREsRa9Uevdzli/871EVZ0/mYvH75bEMAAtUkkFXPxdokGlGO1WcxbdO96WyzzdbhxU6/rSNHjjQnn3yyPaQXNUeMGOGfNnntDjH37HoxXPY02R70IrJWv0l+d6iRcsJVNFCJvmuWWGIJux1j24odq7z3MopAK2dNicZBNi7/ZVwd9yOf6rmMXqjXCjGSmD7LtqI/2S7qiexhbmUrvZCiF1Mkse2uV59/XKvh7L///vaQogrLaVm2r5g5psLyjpXyxlyTyt9M6vVZ+fJek83qbNV5p4txZG0VYcqFAAQgAAEIQAACEIAABMpGwPmVNGv3OGPHjv3P67vNUgae/+SLr2zKZo6hZYzI2gyBbwCbbrrpzCmnnNIsS48/727Ym80Hgbjppptq0fW22GILM3r0aLtUu5ZNkjFNS0TPOuusZtNNN7VLVifhXXHFFfZNexm05HyXJnqDWUsSSZZbbjkjhz4JjqwWA/9+JZBlzgqYnEm/+OKLGjtd927Jq0YPNmsZ6mwosqKcQ12UZxnUZdBNiqIWfPjhh/awojYsvPDCySTmmmuuMdddd509Pvfcc5sdd9yxtvRY0uFTb7crsoGr96KLLjITTzxxpzJ9I7KMx2eddVYtjRzPnUFdBxXFUUuxS7qjI2sRfc5rBC5inItwZFU0EkXe/eqrr+xLA4rCISdqRbaQpDmy+kZ7PRySM6ketBQhzb5P/eXI9t13X7PIIovkqjbLtaEKWtXnrHqnWWf9By2KXKvlBkOlEXs9NHnooYdsUXJalvNyUuQQrfGRKFqs5icCgSoTyHJ95/0uqTJf+g4BCEAgK4Eselll573fk33ixhtvtM1LRmN1bZZt4sQTT7S7+j2tyPaSmLy2AP5BAAKVJpBFzxVhk2gEO0aftbpteslTUVslaY6sRdkd0vjUu2eXfXGXXXapZbnggguMXlxPil5Yffrpp+3hXXfd1Sy//PI2WmWMPS9mrNSQvPcyslfKNiNZc8017So/difx7+CDD669lL/zzjubFVdcMbrPiSpSd4844ohaRFTfkTWm3akVpRxU1NUXX3zRnsm6+l+9OabC8o5Vq69Jta1Rn1t5TaruosXpYhxZiyZLeRCAAAQgAAEIQAACEIBAWQngyBo4cu6GMsTRslmRinaoiBoS/yFEs3w9+XwWvr4xYv311zc333xz6tLkegNZDnvOCdXxk9PfN998YyNSXnnlle5wh88bbrjBuHN+hEscWTtgqvROljmbBkrGVDkFSmIcWX1nsKSjqF+vorDee++99tDGG29s1llnHf90hyW2FLlSBlhF3HSG8aQjq6IMyNgp+e1vf2sjEHUo8L87evvfj7p6/vnnGy1blib+Ml/d0ZG1iD7nNQIXMc6xjqwyROuBgF4YkLjIqmeffXZDR1YtZSfdKVH++eabz24X8a/R9+nLL79sDj30UFuNvgcUiSSP+PMy5NpQHa3qc6zeSfZ/9913ry2RqOgdCy20UDJJ3f1G7O+//3677K0yK7KYHC8mnHDCDmX5ETK0JOB2223X4Tw7EKgagSzXd97vkqoxpb8QgAAEYghk0ctp9YTe7ym6nF6Ckuy0005mpZVW6lScXt7VS4YSvZArJyJJTF5bAP8gAIFKE8ii54qwSTSCHaPPWt022Z3dsvF6OVYvyTopyu7gykt+Nrpn13fGqFGjbBZnn0nm1wuretFCLxOfc8451hE31rYVM1ZqX957GUXF1Qu1Ej86uT3g/fMjpLuVoWL77BWfuvnjjz9a+6meN0iOPvpoG2RD2zHtVv5m4s9BBRiQ7S/LSkSN5ljesWr1Ndmoz/65GFtgM+5Fnne6GEfWIqlSFgQgAAEIQAACEIAABCBQZgI4sgaOnruhLMKR1TeoKPqZjEpVlyx8fUdWn5veipdhTg95nCgyq4xHvuDI6tNgOy+BLHM2rY7QB5tpef1jih4sp1OJnNDcUlJ+Gm3fdttt5uKLL7aHk5EL9Na+rhNFV1UEB0XM1HLxfoSHpCOrorsqyqtEy5ddeumldjvt32abbWZ++ukne+r44483M888c1qyDs603dGRtYg+5zUCFzHOMY6sikarOaJ2SPw51MiR9eeffzYafy1316tXLzsH9fnZZ58Z/QDRg/ipp57ayEE0jzT6Pr3qqqvM3/72N1usHLflwC3H6o8//ti+zKDvjOmnnz41krBrS55ro5V9jtU7rl/61AOWHXbYwUYm0b6iRCtKfKg0Yq+HaXqo5kTXvL673ZJ+isasyDDPPvusTaJziy66qEvOJwQqSSDL9Z33u6SSYOk0BCAAgZwEsujltCpC7/cU5U/R/iSKtKqXndNETjt6sUziVsOIyZtWB8cgAIFqEcii54qwSTSiG6PPWtk23bNqiXTd58vmLHuZr6eLsDvU49Lsnl2OqXqJVKK2bbnllmbQoEG14vTdctBBB1l7zIABA8wxxxxjz8XatmLGSg3Iey+jF2Td6mmyM6211lq1vvobvuPx4osvbrSSUGyf/fKT21ptS3axp556yp7SClgKrOEkpt2ujEafGmOtUidRwA/9hUqzOZZ3rFp5TapvjfrcymsylGvWdE4X48ialRzpIQABCEAAAhCAAAQgAIGeSgBH1sCRdTeUsY6sekNXzh1uSXE5kayyyiqBrei5ybLwTTqyyhl46NCh1iFJhGRklLOcW/JcRsbZZ5+9Bg9H1hoKNiIIZJmzadWEPthMy+sf86MiLrXUUrUoqX4abd93331mxIgR9vByyy1ndtttN7stY64MgHooKqfCQw45xMw555z2XCNHVhnxtRSZHNIkZ511Vs1JzR7w/imqq8qSKELm3HPP7Z3936Yf+TKLI6tKULRHtWm88cazESb01r2M2nJUTIpviM2St4g+5607dpzVT9+R9Te/+Y3Rn0QRG+RIquXWVlhhBTsP7Anvn/+AZLHFFjN77bVXLX8jR1a/v3JiXGaZZcydd95Zc2x2VeihihxNF1xwQXeo6Wez71O/v4rC8c4775i33nqrQ7njjz++WX311c2QIUM6LcOX99poZZ9j9Y7feS1h66J5aWzEy80JP13adjP2ynPttdfaP5dfrLVcrnjfc8895tZbb7WntLShfhfJwRmBQJUJZLm+fT0jZlm+A6vMmL5DAAIQyEIgi15OKzf0fk/3ZXrJS3LSSScZvUCYJorI6l7aPe200+yLhzF50+rgGAQgUC0CWfRcETaJRnRj9FmRbZO9/o477jBjxowxiirpbAj6vS3nSdkWfIm1O/hlJbeb3bN/+umn9gUIfTrp37+/tYXpZVLZ9/Qyr6JzKorsHHPMYZPF2rZixkoNyHsvo5XTtIKaRNHL/Zdn7cH//nvooYfMmWeeafe0IpBWBorts1++tp988knz5ptv2r4899xzZuzYsTaJ7Kl66b9Pnz61LDHtrhVSZ0PPQFwAD42z5qNsfKHSbI7lHasir8lkX5r1uZXXZLItRe07XYwja1FEKQcCEIAABCAAAQhAAAIQKDsBHFkDR9DdUMY6sl5yySU15w0ZFuRYpmiGVZcsfH1HVhnP5JSXFH+Zo1133dXIUcYJjqyOBJ8xBLLM2bR6Qh9spuX1j8kZTHpFonmu+Z4mjz32mDn11FPtqQUWWMAogsJXX31lDjjgAPPll1/a6A2KDi1HQyeNHFmV5k9/+pPR8lySRkuDy+nRLUevelV/msQ4sqaVp4gUclCUg6QvSUOsf85t18sb2+e8dceMs+uTb8x1x5Kfcmj8y1/+Yvr161c7paimimggUZRrnfe/txo5sr766qv24UmtsAYbYq5IGXKUDZFm36eHHXaYeemll0KKsi87yMlaztySmGujlX2O1TsOhq55XZcuqpeuEUWtDZVm7F05Dz/8sH2Q4vaTn4MHD7YPAzX2CASqTiDL9Z33u6TqjOk/BCAAgSwEsujltHJD7/cUQc85wOj3uv873C93+PDhdkUDHdOKHHJIisnrl802BCBQTQJZ9FwRNolGlGP0WZFtk+1K98q+aOUSOYJq5aKkxNgdkmX5+6H37HJUlSOjc7j1y9D25JNPbu1/yZckYmxbMWOlNuW9lxk5cqQ5+eSTVYSZaKKJbITZtNV95GSqKLoSfVe6Vaxi+mwL8/6pfNXjy0YbbWTWXXdd/5Ddjm13pwL/e0ArH2leyuFaUq/+/ybv9BEyx/KOVZHXpN/wkD636pr021H0ttPFOLIWTZbyIAABCEAAAhCAAAQgAIGyEsCRNXDk3A1ljCOrHGoOP/xwu6SPqt1+++1tdLLAJvToZFn4+o6s5513nplsssk6sdEb2nrjWbnfb9kAAEAASURBVLLBBhvYiK0uEY6sjgSfMQSyzNm0ekIfbKbl9Y9dffXV5vrrr7eHGjmT/n97ZwFvR3H+76Fp8AQnWJDgTilePEBxadAgKVAgQAlQ+FHcneJSoGiRYm1xK+5Fg7YEt3+QBBIoBOef74Q5zD3Zc87szN57snefySd39+yOPu/se86+++47Tz75pJGDt5IMuXJGlBOrM3hmObK1cmRVNEe9ve+SHOHWX399G9lSxnQZ0m+55ZbacvTKJ2Pv7LPP7op02MY4ssooP8MMM9g2FR1WfVYkTT+JtaKNuuQMsTFlU8cc23asnJ3BXmPXg/FHHnnELh+v6BCKKCI5iZeLEq58ffv2tcvl6bwM7lpyXsZiOblquVM/soTyN3Nk9aMwKG/v3r2tLBQdRA8e1LaLdqLzesFDS8736dNHHxumkO9TP0qIKlK0Vy3xJueAL7/80rLQdeGSIoXuuOOONpp3yrXRWWNWP1P1jurQdaJ54Zx89TBOUcx952Tla5RC2Luy11xzjbnuuuvcx/G2WuZv++23bxjNebwCHIBANyaQ5/qO/S7pxvgYGgQgAIHCCeTRy1mNh9zvfffddx1eumtk31D9++23n3nzzTdtU3o5cOGFF44u2+jFQls5fyAAgcoQyKPnirBJNAKbogulz4rsW5Yjq/ot+8XWW289XkTWWLtDIxY6nueeffjw4dZO4yJ719erKJ2KJLv66qt3OBVr29KqR/7L4nm+t9x3T+y9jKLkyhnV2a/knLvDDjuYhRZayI5NkWll85KNSbYupWWWWabmmBw75iwbZpYjq9pTBFh9/8t+5lJqv1099dt///vf5uSTT7aHe/XqZaPQyo4XkkLnWKysirwm/fGEjLkzrkm/D52x73QxjqydQZc6IQABCEAAAhCAAAQgAIEyEsCRNVBq7oYy1pFVxpQDDzywZmxRxDk9iCCNI5CHb4gj65133mkuuOACW7mc63wjG46szLoiCOSZs1nthTzYzCpXf8xfBqp///5ml112qc9iP/sRABZccEEjw576oKRoiFlRA2T41bWkJOO3HP2U1I6MsnrYoDfdFYHST1pC/Ouvv/YP1fYvueSShstc5XFkVYWKJpm1ZJYcaM8999xaFFj1R+26aJspZYsYc0y/Y+WsKKMuyXlTLOqXj9cy8TfddJOR06FLW2yxhRkwYEAHJ1U9AJCTa31SFArnPCzHRBn55Ry5yiqrWEdnPSxQWmKJJewDBPXBT4oCoUisn3/+uT28zjrrWOdGP4+/H/p9OnDgQOuUqrJaUk8P++vTpZdeap2t3fELL7zQiEfKtfHQQw+Zosfs+peqd1TPxRdfbB/saF/XhJza3RKDOtYshbL/9ttv7dyRU6+Slv3Tw7P77rvPti2ZuyTHaC31Vx8hxp1nC4GqEMh7fcd8l1SFJeOEAAQgUASBvHq5vs3Q+z3/N6vuYfSyXVbyI8npt5OcZVLKZrXBMQhAoFoE8ui5ImwSzeim6LMi+6aXeLVCi+wCI0eOtI6Ruo/VPa5S/apffr/z2B3keNgohd6zyxanl1Ll2DnFFFPYe3vZVeTIKTuNxuLSuuuua37729+6j0n2PH/Meb+3XAdi72W0rPzxxx/fYWw9evSwdk0nI9eGtuutt56NXq79Iux5qkdJ/dd/2U1fe+01c+utt9ZWrJJtQ4EEfBtkSr/HtdjxrxxRFTnYrZIle8uGG27YMVOTT6FzTFXEyKrIa9INI3TM/vws6pp0feisrdPFOLJ2FmHqhQAEIAABCEAAAhCAAATKRgBH1kCJuRvKGEdWGZQUMcPBViQ6OX/pbW7SOAJ5+IY4st5///32TWTVjiMrs6wzCOSZs1nthz7YzCrrH7vnnnus06aOrbjiimbIkCH+6dq+DO/nnHOO/bzccsuZ7bbbruasV8sUuOMbAhVZQJE+n3vuuczSch588cUX7TnpPDkONkp5HVkb1aPjikaxzz771Bxqm0WCra+nVdkixxzadqyc9cA7NJ1//vnmrrvustld1Ao/2mpoPcqniBhykPSjY6+11lpGLxJkJT1okSFdSXNGcywr5fk+9Y3XjaKEfPPNN2b33Xc3kqmS+qyIrc6RNasPzY6p38OGDatFBC9izH57qXrHf8lD9dY/hPPbqt/Pw15RWJ1jtKLg6nvbOVDr4ZEiNV911VW1h4H9+vWzD6Pq2+QzBKpEIPX69lm1+h7z87IPAQhAAALZBFL1cuj93q677mqdpdSL008/3WQtk6xzfn2nnHKKfQkopazqJEEAAtUmkEfPdbZNIkWfdXbf7rjjDqOXXpX0krcCJ7j721i7g4siWj8DQ+/Zx4wZY8RMToZ6OV0rwPkvqMrBUTZAvejtkgJqKLCGS7G2rRRZubabbVvdy8hupZeHZaOoT3LolQPp6NGj7SnZPrVylEuxY3blG23lQKwAJoqQq1Tfro6l9Fvl/eSvBKSVj84+++zgVXZC55jfXqP9RrLqjGsydMxFX5ONxl7kcaeLcWQtkip1QQACEIAABCAAAQhAAAJlJuB8K1uNYaKxBpKfXuNtlTvg/PCPPrG5WjmGDljtqIDammf5+72HNM8QcNbdULbqb31VMixpCd9XXnnFnpKDjJxYG0XZqC9flc95+IY4sj7wwAPWuU78cGStyizq2nHmmbNZPfMfRF500UXWGJ6Vr9UxLY2uN/2VnPNhVpnbb7/dqB0lOdcpAuvgwYOzsrY8Jh22wAILdMj38ssvm+eff94+hFXUBy03Nv/88xtFmdhzzz1tXkXqlENpo1SkI6vakBHZGe0VgXallVZq1PR4x0PKFjHm8Rpu0O9YOTdyHM1qd+jQoXZJOp1TRNUzzjjD+M6tWWUaHVOEKEWK8g3k4i85ZCU5f+qFDyU9GHJz1c+b9/vURd9WHWeeeabp06ePX11tX9/RzhFby9wvu+yySdeGliJ0EcFTx1zr5I87KXpHS+zJOcJFZVGkcn0/hqS87BUZWlFslBQlRLqpPj322GNGThguHXvssWaeeeZxH9lCoHIEUq7vLFgh32NZ5TgGAQhAAALjCKTq5dD7Pd++0ezlOy2f7Jx23EtaKWWRMwQgAIE8eq6zbRIp+qyz+6Z7aDkmKkqrknuZQPuxdgetRFOf8tyzyylS9hqlRrY2vbh7yCGHmNdff93m0yo5ukeoT3ltWymyqm+70edW9zJy4H344YeNVo2Rc+o000xjX/DQKkFyOtZKOUqN7BF5x9yon/7xG2+80Vx++eX20PLLL2/23ntv/7TdT+23KlHkWdUtJ1KlLKdZeyLjT545llE881CWrIq+JvOMuchrMnPAnXDQ6WIcWTsBLlVCAAIQgAAEIAABCEAAAqUkgCNroNjcDWUeR1YtrS3HjJdeesm2MsMMM9hob9qSOhLIw9c3mLkHOB1rMybEkVVvrCsinLb1yY8iKAOIHP+UJEtF7FOqj36pJbxd5MlmkVRsYf6UnkCeOZs12NAHm1ll/WNykj/ooIPsobnnntscd9xx/una/hVXXGFuuOEG+3nTTTc1m2++ee1co52PPvrIRqvUeS2N5TudNSpTf1xG0tNOO80ebubUpwxFO7JqibUnnnjCtq0l1LSUWmhKKZtnzFn9yWq7M+Xs+vDWW2+Z//u//7MfFcXCRUh15xtt/aitigCriL8uPfroo+bUU0+1H51zqzvnbxW1wjk89+zZ0xr/fd0c833qL7+a5Xzt2tf8lMyUFLlh4403dqcabptdG0WNOavxWL2jhwgnn3yyXUpP9er6lx4ISXnZa2m9HXfcsVZ1o+9pLQsnx2E5ySrliQ5bq5wdCHQjArHXdyMEWd8ljfJyHAIQgAAExieQqpdD7/eOOeYY8+yzz9oO7L///mbJJZccrzNynho0aJDR7yf9Rv7b3/5mowGmlB2vEQ5AAAKVI5BHz3W2TSJFn3V23zQxZCuRzURJq//oBVilouwOee/Z/aXhm60E4ztXKriGVlQKTY1sWymyCm075V5GTp7vvfeebSqvfb7RmEP6Lfuj+q3Ut29fa4MJKefyhPbbd2KWA69e3J544oldNQ23eedYw4rqTmTJquhrMs+Yi7om64bZqR+dLsaRtVMxUzkEIAABCEAAAhCAAAQgUCICOLIGCsvdUIY6ssrxQ1ESXZS36aef3sjRESfWbOB5+KY6su688861ZaQvu+yyzKV3cGTNlhNHfyKQZ87+VOqnvdAHmz+VyN77+OOPa9EjtXzWJZdckmnA9B2tFS2xf//+2RV6R5s563nZmu4qyqaibSrJ2D3vvPM2zF+0I6uvK/TQQZEZQlNK2TxjzupPVtudKWfXBz9iwhxzzFEzwLvzjbbNHFl9B1U5xyoyhluCz69P0TAUKUSp3mk69vtUEWVdFI5tt93WbLDBBn6TtX0twadowkp6cKDIGa1Ss2ujiDE3aj9G7zz99NM2ErIiWCiFOrIrbwz7ESNG2KVvVV6OFvqebfRQxZ/rcn799a9/rWIkCFSSQMz13QyUf33l/Q5sVi/nIAABCFSFQKpeDr3f81dAGDBggNliiy3GQ+y/UKvVfc4991ybJ6XseI1wAAIQqByBPHqus20SKfqss/umieHbkrX6jF7UVSrC7hBzz+7bYTbaaCOz9dZb2/7U//HtPFoxSTaZ0NTItpUiq9C2Y+9l9BxGq+4oLb744rUX/0PbbTTmkPL/+te/jF7kVVpwwQXtc6CQcsoT2m9F2R0yZIhdDUvl9HJwVnRfnfNTzBzzyzfbz5JVkddk3jEXcU02G29nnHO6GEfWzqBLnRCAAAQgAAEIQAACEIBAGQngyBooNXdDGeLI+uWXX5rjjz++FolVbzzLyKUtKZtAHr6+gaRRpLdmEVkPOOAA89prr9mO6K1hOWzVp2uuucZcd9119jARWevp8FkE8szZLGKhDzZVduTIkUZGQCU5htUvv+0v4+Qb1G2BsX/kjCYnMUXykRPheeedZ6aaaip3uuG2mbNew0LeCT8y5XzzzVczJntZOuwW6cj64Ycfmr322ssuuaVGZMicaaaZOrTX6ENK2bxjru9Ds7Y7S86uD/6DkFbRc10Zbf1y9RFZdd5/4DN48GCz+uqr63CH5L888Ktf/aoWnTXl+9R/iKDvX0VelbO3n1S/rkW3TKvyzDLLLH6WzP1W10bKmDMb/PFgXr3z73//2ygCiXNi3WyzzYz+h6QU9oqArCXzlOREr4c4WUlO9Z988ok9pYdN0hMkCFSVQN7ruxmnZt8lzcpxDgIQgAAEfiKQqpdD7/eGDh1qV/JRywsssIDRSgL1SbYJ2SiU1l57bbPDDjvY/ZSytgL+QAAClSaQV8+l2CR++OEHa4vVVmm66aYzcsx3KVWfxfZNka6Vsl64dX3zV6/RsYsuushMOeWU9nSq3SH2nv3mm282f/3rX20fmq1+40eyXGyxxYwcNUNSM9tWqqxatR97LyNZ6gW+d955xzahsWrMoanZmL/77jvTo0ePplX5kUn97+qmhcaezNPvW265xVx66aW2Sl1DisZab+eqby92jtXXk/W5maxir8n6dvKOOfWarG+/Kz47XYwja1fQpg0IQAACEIAABCAAAQhAoAwEcGQNlJK7oWzlyCpHMT140BIqSoosJ8OJb5wLbLJS2UL5CkqqI6uceh5++GHLd/311zfbbbddjbWcff7xj38YOVXJSKWEI2sNDzsegTxz1itW2w19sKkCirJ666231speeeWVHQyVt99+uzWkK4OWrzrhhBM6nL/gggvMnXfeacv/4he/MHLmDkmtnPWa1SGnVBn3pROVshwc68vncWSVk+q6665rVllllfGiKssB709/+lMtIvass85ql/RyDyZSytb32f8cMuaUtlPkfNttt5kXXnjBOjHOOeecfrftvh5E6AUM9xBHER5WXHHF8fJlHWjlyKq5pzmopOjkMu4rOqtLo0aNsvPDOZO6JeZTv08VtWHPPfc0ihCqJF0vne8nLcsqfa8088wzm1NPPbXpAyxXttW1ETtmV3+jbR69oyXx5MDtZJo1/kbtpLLX7yDNNyU53stJ1V1/rk3/hRNFbNXSiD179nSn2UKgcgTyXN8p3yWVA8uAIQABCEQSyKOXs5oIvd/TbzW93DN69GhbzR577GH0UplLchKRY86YMWPsoWOPPbb2YmNKWVc/WwhAoLoE8uq5FJvE559/bqNHOtobb7yxGThwoPto71tjdaEqie3bY489ZmRj0wufeqm2/r71s88+s6sLvf7667av9SvIpNgdUu7Z//Of/5jDDjusxm///fc3Sy65ZO2zdtQ32dDfffdde3zLLbc0v/nNbzrkyfrQyraV+t3TGfcyekFWTp3ODiHb6Mknn5w1vMxjrcas7+F+/frZeSK7Vn267777zDnnnFM7HGIDVeY8/ZadZvfddzeffvqpbcd/XlFruG4nZY6pqhRZxV6T/hBixpxyTfptd+W+08U4snYlddqCAAQgAAEIQAACEIAABCZkAjiyBkrH3VC2cmTVW7/77LNPrVa9Fa2le5qlueee22y44YbNsnT7c6F8BSLVkdV/G1316SHRXHPNZXQxyJnLOT3pnJJvGPKX9JOTl5y9XPKXbpezrJyiSN2XQJ45KwqvvvqqeeONN2pALr/88trDSC17Pumkk9pzmjduiTKXuZUjq4yYinTpoi4utNBC1glRdcqIe88997iqrGOfjPMhqZWznuqQsVfLsivioqIAvP/++2bYsGHmxRdfrDXRv39/s9NOO433QED9lbHXReT473//ax588EFbTvX5jpTq8+STT16rU8umyTgph0gZ65Vfulbt6xr/4IMPannro9SmlFWlKWNOaTtFzjfccIO54oorLBN954iZHHwVrVd67f7776/JQfPn8MMPt3lD/rRyZNVLAfvuu6957733bHUzzDCD2WqrrWyE3DfffNNGl5Izq9LCCy9cexhTxPep5pMeZrikpeuXX355O3d0Ts6ULtXPE3c8a9vq2ogdc1Zb/rE8ekcPbRR5Q0mRnJdbbjm/qsx9zU9Fr01lLx1wyCGH1OaUrk9FhdZDPzlh6Lq/6qqrao7uocvhZXaagxDoJgTyXN8p3yXdBBfDgAAEINDpBPLoZXUm5X5PUfUUXU9psskmM2ussYa9J5Tz0d13321tFTqn3+968cpPKWX9etiHAASqRyCvnkuxSbRyZBX9FH0W2zc/Cqfuheeff35rI5566qmt7pUznnvpVvfVspXo/tZPsXaHlHt2tX/ccceZZ555xnZFL4fKtig7mr5H3n77bfuyqBxelTS2E088sYNdLcW2lSKr1HsZyUC2I9mWZF9QxNwnnnjCyOlYqXfv3kaOvfWrWelc7JjlmKrvZNk9FT1dTq1a4U3tP/XUUzU5qI1GkW9T+q16/ZWM5EyrZw+tXgZOnWMpsoq9JjVWl2LGrLKx16Rrt6u3ThfjyNrV5GkPAhCAAAQgAAEIQAACEJhQCeDIGigZd0OZ15E1pPollljCaLmVKqdQvmKU6sgqByO9Se3eSK/nLsOkHOJkcFHCkbWeEJ9FIM+cVX5FG1RUzFZpmWWWsU5/fr5WjqzKKydsRSGVY2KjtMEGG1jDdqPz9cdbOespvyIYyyEtK+laUoSNjTbaKOu0NTLLuS0kaWyzzz57LaszptYOZOyo/U022cQo6oSfUsqqnpQxp7YdK2ffkdVnUb8/00wz2Yi9eRzxWzmyqg05OytScLP5KUO8nB9d2/XOlPV9zfpc/30qJ2k93BG3Zqk+GkyzvDoXcm3EjLlVu3n0jv/AolW97ryL8FUEey1/q2Vw/aSHPs7h3h2vfynEHWcLgaoRyHN9p36XVI0t44UABCAQQyCPXlb9Kfd7ekFP9zvOISmrv1pCWL+VZ5lllg6nU8p2qIgPEIBA5Qjk1XMCFGuTCHFkTdVnMX3zHVmbTQDZlxS1ddNNNx0vW6zdIeWeXZ34+OOPrf1GUT39VH/frZfCtVpcvWNnim0rRVap9zJ6MdqtouaPW/t6eVarUMnJNSvFjtk5smbV6R/r06eP0UvSWe2n9FvXjyK2O6fqnXfe2b704redtZ86x1JlFXNNunHEjlnlY69J13ZXb50uxpG1q8nTHgQgAAEIQAACEIAABCAwoRKY4B1ZJxRw7oaylSOrIs7tvffeubqtyHh6U7jKKZSvGMnpV9FOlC688MLMiLf+m7cDBgwwW2yxhc3v/sgJSUv++FEjdU5vqCuy5WuvvVaLXqhIkmuuuaYtqoiRMkgprbzyykZLYLvkL6V81lln2brcObbdj0CeOavRX3rppeaWW25pCULRIut1iB/pQMZzRXPNeute0VfPPfdco+Un/TTllFMaObHKqTNPklFc14OSnEj1cLU+NTICK8qxrj055jZKMkrusMMOtaiNjfLp+CmnnGIN0i6Plm5/6KGHzMsvv5xZXs6QMuwqSkN9SimrulLGnNq22o+Rs76bbr31VqNl81yUCtXlkh50rL766tbReZJJJnGHg7bnnXeejRSlzIq82kjmw4cPN9KNr7zySod6NacVGVtzwY+6W9T3qZa907Unh2s9bPHTNNNMY+f4L37xC/9wy/2Qa0OV5B1zq4bz6J3TTjvNaBm5PElOv4rYWxR7OfNecMEFlkN9PxThZrvttusQebk+D58hUCUCea7vIr5LqsSWsUIAAhCIIZBHL6v+lPs9ldfvVN3LKaK+//KXfivr95nuEbMcY1LLqjwJAhCoJoG8es5RirFJfPHFF0YrcbgVebJstao/RReqfN6+yTFQqxjJvqQVY7KSXiCQbUyROBulGLtDyj2764e4Xn311eaOO+4w6kN9WmGFFcygQYOMbB/1KcW2pbpiZZV6L5PlEKootFqFRmP17UpFjVnzSivLKPKrorDWpx49epi1117bvkjfyKaW0u8bb7zR2oLVrp5dKBqr2myVUudYqqzUv7zXpBtT7Jhd+Zhr0pXt6q3TxTiydjV52oMABCAAAQhAAAIQgAAEJlQCOLIGSsbdULZyZA2sjmx1BNrBV8ZTRZ3Tcksy/ujhkIxBJAiEEGjHnA3pl/KMHj3aaGlvPQCdc845bdQePQDtjCSjv9pSBGNdR1NNNZVdMr6rriW1K8fdkSNHGhnwFalIy3upH61SbNkixhzbtj+mGDkrasX7779veSlqhxxY+/bta+eI9rsiqV09IBIDzRPNUT106OykSKDS+XLS1FxVu4pA21nXhj+eosY8Iesdf7z+vh4e6BpVFHQ5AE8xxRR2zsnZPMsh3y/LPgSqRCDm+i7iu6RKjBkrBCAAgTwEYvRynvob5dXvdf1W1m9WvfijCHrNnHL8elLK+vWwDwEIVINAqp6LsUmEkk3VZzF9UxkFPtD/r776ymjVmFlnnTXTCbTRONpld5A9TPfc+u4QO9k6ZOtpZhsrwrYlDrGyir2Xef31140eaMnmqRf35aQr+06IfSF1zHLe1fwYMWKEGTVqlLUthdrUUvrdaL511fFYWfn9i7km/fKx++26JvP01+liHFnzUCMvBCAAAQhAAAIQgAAEINCdCeDIGihdd0OJI2sgsJzZ4JsTGNnbToA523YR0AEIVI4AeqdyImfAFSLA9V0hYTNUCECgFATQy6UQE52EAAQSCKDnEuBRFAIQgEBBBJwuxpG1IKBUAwEIQAACEIAABCAAAQiUngCOrIEidDeUOLIGAsuZDb45gZG97QSYs20XAR2AQOUIoHcqJ3IGXCECXN8VEjZDhQAESkEAvVwKMdFJCEAggQB6LgEeRSEAAQgURMDpYhxZCwJKNRCAAAQgAAEIQAACEIBA6QngyBooQndDiSNrILCc2eCbExjZ206AOdt2EdABCFSOAHqnciJnwBUiwPVdIWEzVAhAoBQE0MulEBOdhAAEEgig5xLgURQCEIBAQQScLsaRtSCgVAMBCEAAAhCAAAQgAAEIlJ4AjqyBInQ3lDiyBgLLmQ2+OYGRve0EmLNtFwEdgEDlCKB3KidyBlwhAlzfFRI2Q4UABEpBAL1cCjHRSQhAIIEAei4BHkUhAAEIFETA6WIcWQsCSjUQgAAEIAABCEAAAhCAQOkJ4MgaKEJ3Q4kjayCwnNngmxMY2dtOgDnbdhHQAQhUjgB6p3IiZ8AVIsD1XSFhM1QIQKAUBNDLpRATnYQABBIIoOcS4FEUAhCAQEEEnC7GkbUgoFQDAQhAAAIQgAAEIAABCJSeAI6sgSJ0N5Q4sgYCy5kNvjmBkb3tBJizbRcBHYBA5QigdyoncgZcIQJc3xUSNkOFAARKQQC9XAox0UkIQCCBAHouAR5FIQABCBREwOliHFkLAko1EIAABCAAAQhAAAIQgEDpCeDIGihCd0OJI2sgsJzZ4JsTGNnbToA523YR0AEIVI4AeqdyImfAFSLA9V0hYTNUCECgFATQy6UQE52EAAQSCKDnEuBRFAIQgEBBBJwuxpG1IKBUAwEIQAACEIAABCAAAQiUngCOrIEidDeUOLIGAsuZDb45gZG97QSYs20XAR2AQOUIoHcqJ3IGXCECXN8VEjZDhQAESkEAvVwKMdFJCEAggQB6LgEeRSEAAQgURMDpYhxZCwJKNRCAAAQgAAEIQAACEIBA6QngyBooQndDiSNrILCc2eCbExjZ206AOdt2EdABCFSOAHqnciJnwBUiwPVdIWEzVAhAoBQE0MulEBOdhAAEEgig5xLgURQCEIBAQQScLsaRtSCgVAMBCEAAAhCAAAQgAAEIlJ4AjqyBInQ3lDiyBgLLmQ2+OYGRve0EmLNtFwEdgEDlCKB3KidyBlwhAlzfFRI2Q4UABEpBAL1cCjHRSQhAIIEAei4BHkUhAAEIFETA6WIcWQsCSjUQgAAEIAABCEAAAhCAQOkJ4MgaKEJ3Q4kjayCwnNngmxMY2dtOgDnbdhHQAQhUjgB6p3IiZ8AVIsD1XSFhM1QIQKAUBNDLpRATnYQABBIIoOcS4FEUAhCAQEEEnC7GkbUgoFQDAQhAAAIQgAAEIAABCJSeAI6sgSJ0N5Q4sgYCy5kNvjmBkb3tBJizbRcBHYBA5QigdyoncgZcIQJc3xUSNkOFAARKQQC9XAox0UkIQCCBAHouAR5FIQABCBREwOliHFkLAko1EIAABCAAAQhAAAIQgEDpCeDIGihCd0OJI2sgsJzZ4JsTGNnbToA523YR0AEIVI4AeqdyImfAFSLA9V0hYTNUCECgFATQy6UQE52EAAQSCKDnEuBRFAIQgEBBBJwuxpG1IKBUAwEIQAACEIAABCAAAQiUnkDbHVlLT5ABQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhCAAAQgAAEIQAACEMhJAEfWnMDIDgEIQAACEIAABCAAAQh0WwI4snZb0TIwCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEBgQiWAI+uEKhn6BQEIQAACEIAABCAAAQh0NYG2O7KW5QZt+EefWNmUpb9dPZFS24NvKkHKdzUB5mxXE6c9CEAAvcMcgED3JcD13X1ly8ggAIFyEkAvl1Nu9BoCEAgngJ4LZ0VOCEAAAp1FAF3cWWSpFwIQgAAEIAABCEAAAhAoKwEcWQMlxw1lIKjIbPCNBEexthFgzrYNPQ1DoLIE0DuVFT0DrwABru8KCJkhQgACpSKAXi6VuOgsBCAQQQA9FwGNIhCAAAQKJoAuLhgo1UEAAhCAAAQgAAEIQAACpSeAI2ugCLmhDAQVmQ2+keAo1jYCzNm2oadhCFSWAHqnsqJn4BUgwPVdASEzRAhAoFQE0MulEhedhQAEIgig5yKgUQQCEIBAwQTQxQUDpToIQAACEIAABCAAAQhAoPQEcGQNFCE3lIGgIrPBNxIcxdpGgDnbNvQ0DIHKEkDvVFb0DLwCBLi+KyBkhggBCJSKAHq5VOKisxCAQAQB9FwENIpAAAIQKJgAurhgoFQHAQhAAAIQgAAEIAABCJSeAI6sgSLkhjIQVGQ2+EaCo1jbCDBn24aehiFQWQLoncqKnoFXgADXdwWEzBAhAIFSEUAvl0pcdBYCEIgggJ6LgEYRCEAAAgUTQBcXDJTqIAABCEAAAhCAAAQgAIHSE8CRNVCE3FAGgorMBt9IcBRrGwHmbNvQ0zAEKksAvVNZ0TPwChDg+q6AkBkiBCBQKgLo5VKJi85CAAIRBNBzEdAoAgEIQKBgAujigoFSHQQgAAEIQAACEIAABCBQegI4sgaKkBvKQFCR2eAbCY5ibSPAnG0behqGQGUJoHcqK3oGXgECXN8VEDJDhAAESkUAvVwqcdFZCEAgggB6LgIaRSAAAQgUTABdXDBQqoMABCAAAQhAAAIQgAAESk8AR9ZAEXJDGQgqMht8I8FRrG0EmLNtQ0/DEKgsAfROZUXPwCtAgOu7AkJmiBCAQKkIoJdLJS46CwEIRBBAz0VAowgEIACBggmgiwsGSnUQgAAEIAABCEAAAhCAQOkJ4MgaKEJuKANBRWaDbyQ4irWNAHO2behpGAKVJYDeqazoGXgFCHB9V0DIDBECECgVAfRyqcRFZyEAgQgC6LkIaBSBAAQgUDABdHHBQKkOAhCAAAQgAAEIQAACECg9ARxZA0XIDWUgqMhs8I0ER7G2EWDOtg09DUOgsgTQO5UVPQOvAAGu7woImSFCAAKlIoBeLpW46CwEIBBBAD0XAY0iEIAABAomgC4uGCjVQQACEIAABCAAAQhAAAKlJ4Aja6AIuaEMBBWZDb6R4CjWNgLM2bahp2EIVJYAeqeyomfgFSDA9V0BITNECECgVATQy6USF52FAAQiCKDnIqBRBAIQgEDBBNDFBQOlOghAAAIQgAAEIAABCECg9ARwZA0UITeUgaAis8E3EhzF2kaAOds29DQMgcoSQO9UVvQMvAIEuL4rIGSGCAEIlIoAerlU4qKzEIBABAH0XAQ0ikAAAhAomAC6uGCgVAcBCEAAAhCAAAQgAAEIlJ4AjqyBIuSGMhBUZDb4RoKjWNsIMGfbhp6GIVBZAuidyoqegVeAANd3BYTMECEAgVIRQC+XSlx0FgIQiCCAnouARhEIQAACBRNAFxcMlOogAAEIQAACEIAABCAAgdITwJE1UITcUAaCiswG30hwFGsbAeZs29DTMAQqSwC9U1nRM/AKEOD6roCQGSIEIFAqAujlUomLzkIAAhEE0HMR0CgCAQhAoGAC6OKCgVIdBCAAAQhAAAIQgAAEIFB6AjiyBoow5Ybyhx9+MKNHjzY9evQwvXr1CmyxWtlS+HYlqffff99cc801tsmFFlrIrLHGGrXmr7/+evP222/bz9tvvz2yrpHpnjsT+pz99ttvzTfffGMmm2yyLhXAd999Z0aMGGF69+6du+2Ushpku8bsA/7+++/NmDFjzKSTTmp1vn8ua7+d3w9ffvmlZTbllFNmda3psa+++sp8/vnnVs4///nPm+atP5kyZldW36X6Ti1Lcv1O/R3Qbr2juS159+zZsyzo6ScESkOg3dd3aUDRUQhAAAJdRAC93EWgaQYCEGgbgSL0XGfbYWR3mHzyyc1EE02Um1NK31LK5u4oBZIIpMgq1Q6Z0vF22Vdkn9J1FWML1HhTeKfwUtkUfZDadmeWL0IXd2b/qBsCEIAABCAAAQhAAAIQgEBXE8CRNZB4nhtKOQc98sgj5rHHHjNvvfWW+eCDD4ycfpSmmGIKIwfIAQMGmMUXXzyw9e6fLQ/fdtJ4/vnnzX777We7sOqqq5o//vGPte5o/7nnnrOfL7jgAjPrrLPWzrHT/Qikztn77rvP3HrrrdYYf8QRR1jHx1RKn332mXW0fumll8yrr75qHVnnnHNOs+CCC5p1113XzD333OM18emnn5rTTz99vOONDkh3SYf5SUbMm266ydx+++1GXyr6rDTttNOaRRdd1AwaNMjMPPPMfpHafkpZVRIz5lrjGTvDhg0zV199tT3Tp08fs/POO2fk+umQHFcffvhhc++995qXX37ZjBo1yuiYHrKstNJK5oADDvgp89i9or8f8syj119/3Tz00ENGekxy+vjjj23fZLzu27ev2WSTTWyfO3T4xw8q++CDD9qyw4cPN5988omR8ftnP/uZmWmmmUz//v3NBhtskOnAnzJmOWM/+eST5oEHHjBvvvmmUdv6PpVDqNrV/Npuu+3MNNNMk9Xt8Y6pz4ceeqitY+WVVzbrr7/+eHncgZRrI2XMrv2sbareyTN+175e4Ljiiivs/H733XetzGeffXarV8R+qqmmclmDturDhRdeaGWpAltssYWZb775gsqSCQLdmUCe6ztFP3VnhowNAhCAQJEEulIv615q6NChQd2ffvrpza677hqUl0wQgAAEmhHIo+f8eoq2w/h1a//RRx81999/v/nPf/5jPvzwQ+twJ7uW7OiyW8gO0Sil9C2lrN+fmPtuVz6lrOrIYyNybbptatuqJ/Z+P2+/U2SVaodM4dUu+4rkIhu07HqyF8shVLacfv36mbXXXtvIPtYspfD2680rZ5WN0Qdl+10Vq4t9tuxDAAIQgAAEIAABCEAAAhDoTgRwZA2UZp4bSjk6ylGoVdp0003Njjvu2CpbJc7n4dtOIDiytpP+hNV26pw96KCDzNNPP20Hde2110a/Ce+oyLHwwAMPtM5+7pi/VQSLo48+2jqf+cdlRFUE4dD0f//3f2b11VevZR85cqR11nznnXdqx+p3FMFxyJAhZs011+xwKqWsKoodc4dOeB/00sFee+1lnVF1eI455jDnnnuul6PjrpwVTzjhBPvSQscz4z7J4ffkk0/ucKro74fQeSTn5n322adDX7I+/PKXvzRyrPajncpB33fazyqnYzKCyylaDsB+ShmzPz6/Tn9fc3v//fc3Sy+9tH84c18Pwv7whz/YcxtttJEZPHhwZj4dTLk2UsbcsENjT6TqnTzjVz/knH7++efbKMNZ/ZLMpRM0b0KTnFivu+66WnbJeMUVV6x9ZgcCVSWQ5/pO0U9V5cu4IQABCOQl0JV6+U9/+pO5++67g7qoFwQvuuiioLxkggAEINCMQB495+op2g7j6nXbG264wZx33nnWIdId87dyuNP9tm+zcOdT+pZS1rXvtnnvu105bVPKqrxvQ8lra0xtW+3H3u/n6XeKrFLtkBqjS3l5tcu+ojGfdNJJ5tlnn3VdH2+7yiqrWHuoVpeqTym86+vKI2eVjdUHZftdFaOL69nyGQIQgAAEIAABCEAAAhCAQHcigCNroDTz3FDKSUbGDCU52CywwALWSU1vu8po4KIV6rycgxTZs+opD992ssKRtZ30J6y2Y+asInVK6coQd/PNN9cGlNe4XCv4446iVioqz3vvvWePaNnvxRZbzOqdZ555xihym9Jkk01mTjnlFKMorS7ldYbxdZbalRObIpEqzTDDDEYO+nIAlaHzxhtvrOnCiSee2Jx66qn2bX/lTSnryseOWeXr0//+9z/r6Pn222/XTjVzZB0xYoQ57LDDjCKVujT11FPb8Wmsb7zxhpluuunGc2Qt4vshZh75ukv9nWuuucxss81m5fDCCy8Yjd+lrbfe2myzzTbuo3W4lrHZJc2fWWaZxT44UiQHRUl1SZE6zznnnA4PlVLG7Ee6dt+nvXv3tteRoue6JIdKPezSNivJ6ViO43JM/uijj2yWoh1Z/WsjZcxZ/XfHYvSOysaMX79X5CDskuQuvfL111/bKMSKyKGkiL6XXHKJjTjv8jba3nLLLeass87qcFpzC0fWDkj4UFECea7vlO/uiuJl2BCAAARyE+hKvZzH4UIrv2gFGBIEIACBVAJ59JzaSrE9hfT1zjvvtHYjl9etwiI7je7/FVVSaY011hjvRd2UvqWUdX3VNua+25VPKRtjI3Ltpvbbryfv/X5Mv1NkpbKxNkx/nDGyapd9RdeMbFUu4Irslcsuu6yZccYZzSuvvFJbWU7j23bbbc3AgQP9oRZyzcfIWZ1I0Qdl+12VVxd3EBIfIAABCEAAAhCAAAQgAAEIdEMCE7wj62abPpqM/drrlk+uI88NpRxY5BQkZ6AVVljByKnMJTnQyDHEgV9++eXtMsfufFW3efi2k5HvDCYHZBmDXPIdrvRgSQ+YSN2XQN45q6g5f//73+2y8/VUUh1ZtczSkUceaavV2/NyFHPzT47z0kkyUCpp+ffddtvN7uuP7wyj5eXPPPPM2rmsHekzt4zb448/bp05lW/aaac1Z599tpEzp0syVh5yyCG1yLNrrbWW2Xvvve3plLKqIGXMrn9uK2P2wQcf3MGAq3ONHFm/++4787vf/c6yUz4t77nvvvvaZe702aVRo0Z14KHjqd8PsfNIuuuAAw4w6667rvnNb35j9EDIJb1kceKJJxrJREkRdDVXZeBWkgPooYceapcbU1k5sboko7jyKuqGS5oHWp7MpZQxS6+Koxxrl1tuuQ7fp0888YSd9+7lkK222spoqXs/6btYxng9aKhPeRxZ814bKWOu76f/Oa/eiR1//cOh9dZbzzrLu6g3cuTWnJDDtpLmxU477eR3dbx9yevwww8fTwfiyDoeKg5UlECe6zvlu7uieBk2BCAAgdwEulIv+w4XijQoO1KjpHsx38bUKB/HIQABCLQikEfPqa4i7TBZfdt9991rLwuvs846dmUfl++RRx4xRx11lP0oPXj55ZebaaaZxp1O6lvquGLvu9X5lLIqH2sjKqJt1eFS3vv92H6nyCrVDhkrq3baV3xnUL34fcwxx5i5557bic0GWnArUSn4gWx7RV1XaiRWziqbog/K9rsqry4WHxIEIAABCEAAAhCAAAQgAIHuTMD5U7Ya40RjxowZ99pzq5yB50Nv0MroyKrodvPPP3/DhwsPPvigOfbYYy0pOX9dccUVgdS6b7bQ+dCKgBznnJNdq7wx53FkjaHWPcvknbMyDCoSa1ZKdWSVMV9GfSUZ+tZff/0OzShSq5zM5HSoaJZXXnllLWKm7wzTyHGzQ2XeB39MisS64447emfH7UofKuKBkqKAKlqnUkpZlU8Zs8r7SUts3XPPPfbQwgsvbF588UW734jHfffdZ0444QSbRw7Dp512mo1K6dfZaD/1+8HnVt9Gs3mk6Jkff/yxdc6tL6fPitqrly+cU6icoZ1xW46kirAr+TVKu+yyi3HRbIcMGWL00MmllDEruvm8885rnWtdff5WUVivv/56e0iOroqS6yeNe/PNN/cP1fbzOLI2mgu1yup2UsZcV1WHj3n1Tuz4/YdD+p1y8cUX1xybXYf8iCJyftYDCkVlzkqvvfaa1QNjf0saOdvLGdpFM8aRNYsYx6pIIM/1nfLdXUW2jBkCEIBADIGu1Mu+wwW/jWKkRRkIQCCGQB49p/qLtMPU91cvSbqXrvv06WNtRvXLnPu2G9kgNt5441o1KX1LKasOxN53p5ZV+VgbURFtqw6lmPv92H6nyMpvM68NU+OMlXM77Su+M+jgwYON7GD1STZb2bCUZE9WGZdSeKsOn7mr022b2TBT9UHZflfl1cWOIVsIQAACEIAABCAAAQhAAALdlQCOrIGSLfKGUo45itamhCPrOAHk4StDhx7gK8k5b+TIkdZBUM5nb775po2OKMenHXbYoUPkwHEtGeuQo7eoFcVERpyspAiEDz/8sD21+uqrGzm3KeHIajHwZyyBPHNWwORM+sEHH9TYHXfccbXl3JsZ72oFGuwomqYiUeoNfyU5xkuv1Kddd93VXh86ruitSy+9tM2S4gxz8sknm7vuusvWs+GGG9qIjfaD90cG7d///vf2iKKAyiFOKaVs6phtB378c9lll1nHXn1cZJFFzF577WWjrepzI+dFjUfjUjriiCPMMsssY/eL+NPq+6Gz5pH67jujKnL4KqusEjwkPXCX3lSqd2RtVUmrMTcr778YMttss5m//OUvHbLr5YahQ4fWjilKiHN87UxH1lqDDXZix5xX78SOX87uujaU9HBQcyMrKRKxc/zW75o111xzvGyKRK/rSo7UetFEkVzleK/IIEo4a4yHjAMVJZDn+k757q4oXoYNAQhAIDeBrtTLZXO4yA2TAhCAwARJII+eK9IOkwVDtqJrrrnGnqqPxuryy0579NFH24/zzTefOf300+1+St9Syrp+xd53q3xKWZVPsRGltq32Y+/3Y/qdKqsUO6TGGsurXfYVrSa1ySab1OzF1113nZliiik0lA5JNjOt4KQ044wzmksvvdTup/JWJTFyVrkUfaDyZftdlUcXa3wkCEAAAhCAAAQgAAEIQAAC3Z0AjqyBEi7yhlKGA7cMsxyg5AhV9ZSHr+9EpgiCWtY6a9noySef3DrsOSdUx3jLLbc0o0ePthEpb775Zne4w/bqq682l1xyiT3mR7jEkbUDpkp/yDNns0BpCXQZfJVSHFl9R1FFQ/zrX/+a1Zw544wzzG233WbP/fa3vzVbbLGF3U9xhrnjjjtsNFJVpIgZf/7zn42WovKTH71Uy5M7p9aUsqljdv3zl9hSZNVTTz3VKGLkoEGDbJYsR9bnnnvOaLl7JekWGUeLTHm/H4qaRxqDIuq6HwWKurDUUksFDU36V3NKelVJc00vE4SmvGP267333nvNiSeeaA8pErqi4zZLvszb6cgaO+ZUvRM6fkWNl5OwUn2kG5+vH12jPnKH8unBh6J7KJqGkhzq5fSuaw1HVouEPxCoEchzfad8d9caZAcCEIAABJoS6Eq9XDaHi6bgOAkBCJSGQB49V5QdphEc2cYfe+wxe3rvvfc2a6211nhZFchgm222sce1KshNN91k91P6llJ2vA7+eCD0vjurfEpZ1ZdiI8rbdpH3+yH9TpVVih0yRVbtsq9o1ST3UrIcWGWHykr1kWavuuoqM9VUU9kX+J0NN8benNVWiJxVLkUfqHzZflfl0cUaHwkCEIAABCAAAQhAAAIQgEB3J+B8VlqNc6Kxzj0/tMqU53zoDdpmmz6ap9rMvNdet3zm8TwHQ/vbqk5Fg9Pb419//bWZaKKJrDOHnG+qnvLw9R1ZfW6KQimmMmy6JGcqOVX5CUdWnwb7sQTyzNmsNkKNd1ll/WOKgqmIhkpyPJQDYlZSFEotw67kR1hMcYYZMWKE2XbbbWvN9evXzxx++OG15cUVrUCfpfeUtL/sssva/ZSyqWNWB5555hkbGfLbb781vXv3trpYy51/+OGHTR1ZFZlARl0lOQPLgVNGXxmI5cgpPdS3b9/MKAe2UJM/Md8PRc0j9V0vBihig5IimyrCaauk6NannHKK0VJpSor0q4i/oSlmzH7dviOlIsgqkmyzlOfBTMq10awPKWNO1Tuh49fvFBeVXA7OWnYvK/kOucsvv7y9plw+zSVFX3WRen29gyOro8QWAj8RyHN9d5Z++qk37EEAAhCAQFfq5bI5XDA7IACB7kEgj54rwg7TjJpW+NDKJUp6QbWRrVz3pnKgVNL9qBz0UvqWUtZ2IuNP6H13RlH7wqful5VavXybVT7FRpSn30Xf74f0O1VWKXbILNahvNplX9GqdXqZWGnSSSc1//znP7OGYY/JXvPVV1/Z/bPPPtvIvpvKO6uxEDmrXIo+UPmy/a7Ko4s1PhIEIAABCEAAAhCAAAQgAIHuTgBH1kAJx95QysHpxhtvtEvqvvrqq2bYsGG2RUUt3GGHHYwimJHyLdNe78gq5yU5YMl5TElOQnKkkoOakgyACyywgN3XHxxZayjYSSAQqxNck6HGO5e/0faee+4xJ510kj294oor1pxa6/PffvvttWXXVlttNbPffvvZLL4zjA5IN8nRfuKJJ7ZOmYo6qgcF7vqqr/fyyy83V1xxRe3wJJNMYrQMnHTbLbfcUjOU9u/f3yiqRo8ePWp5Y8umjlnGXC2JrocfPXv2NMcff7xZaKGFbL9aObL6xlCNUTrd6XU3MDHQOTm69urVyx0eb1vE90NR80hL+GnpLiVFWlBEai0Dn5W0LPx///tfo7nz1FNPmS+++MJmE8ODDz7YTDPNNFnF7LEixuwqVyRYOVLLmVZpzz33NGuvvbY7nbkNfdCgwqnXhutAkWNO1Tuh45f8FZlcSZFwdO1mpbvuustoeT6lxRdf3F5LLp8ePiriiZKcXDU33JzCkdVRYguBnwjkub6L0k8/tc4eBCAAAQjUE+hKvezfY+j3kv7rJV2tMqOVI9Zcc02zxhprGEUgJEEAAhAoikAePZdqh2nVZ9nIhw8fbrPphVWtkJOVFJHVBTDQamd6ITmlbylls/qnY6H33VnlU8qqvhQbUZ62i77fD+l3EbKKtUOmyKpd9hXZdjfZZBOjIANKWsFL9r6spJf0P/jgA3tKNuZFFlkk6brKakPHQuSsfCn6QOXL9rsqjy7W+EgQgAAEIAABCEAAAhCAAAS6OwEcWQMlHHtDqeV0d9tttw6tKMqdlkiRsY00jkAevr4jq5zx5JRXn/wlaOSwJic6l3BkdSTYphDIM2ez2gk13mWV9Y/pjfrzzz/fHtI813zPSvfff3/NyWzJJZc0xxxzjM1W7wyTVVYPUTfffHMbfTTr/N13322NhFnndGzAgAF22XrVU59iyqaM+eOPPzZ77bWX+eijj+zDYUXwXHnllWvdauXIqvzPPvtsLX+zHTnQywDc6IFzEd8PRcwjsVCUBhfVRAZsOeE2Sor6K2dWPw0aNMi+JOAfy9ovYsyuXs17F1FCUVj0QEJRJpqlPA9mirg21Jcix5yqd0LH/+CDDxotf6ckBwpFNpcTRX3SPHBRoBdccEEbnVd5FLVY0YuVFBn9xBNP7CAbHFktGv5AoAOBPNd3UfqpQwf4AAEIQAACHQh0pV72HS46dML7MOOMM5oTTjjBzDTTTN5RdiEAAQjEE8ij51LsMCE9lN3IvSSrl2wb6bqddtrJvPvuu7ZKrQ6j+9CUvqWUbTSu0PvurPIpZVVfio0otO3OuN8P6XdRsoqxQ6bIqp32lV122cWuIKX+r7vuumaPPfbIGop9diXblZLsxbIbF8XbbzBEzsqfog9Uvmy/q/LoYo2PBAEIQAACEIAABCAAAQhAoLsTwJE1UMKxN5RZDixqUo4h22+/PRFZf+Sfh6/vyPq3v/3NTD311ONJUZHk9MazkiL2DRw40O7rD46sNRTsJBDIM2ezmgk13mWV9Y/pjXpdB0rrrbee0fWRlbT0u1vy3Xc4c84w0003nenTp4/p3bu3fVtfDp2KXOonLe2kaED16bLLLjNXXnll/eHaZ0VjHDx4sNHD1/oUUzZ2zHrwq8iSr732mu1GlsNmK0dWPyqAKvnlL39pllpqKfuQRRFC5TD82GOP1Ya5wQYbjPcygztZxPdD6jxSZIaDDjrIDB061HZLL1hoGbFmDqFZjqwqvMQSS1i+WXIucsyqS87EBxxwgPnhhx9s1UOGDLGRgF07jbahD2ZUvohrQ/UUIWfVo5Sqd0LH/8knn5idd965Fu129tlnt/N40UUXtf3Qj8cHHnjA3HDDDebTTz+1x1ZYYQVzyCGHGD2kOe6446xsFO3j9NNPHy9KL46sFhl/INCBQJ7ruyj91KEDfIAABCAAgQ4EulIvy+FCv6300rNWN9Bvcf3G0v2YW31AnZtzzjnti0NaRYMEAQhAIJVAHj0Xa4eRs2mrpGXq/RXLGtl6Vc/uu+9uXn/9dVulc7hL6VtK2UbjCr3vziqfUlb1pdiIQtrurPv9kH4XJasYO2SKrNppX5FTuFZgckkvrf/mN7+xtl+tHqTVlq6//nrz9NNPuyzmnHPOMXPNNZeN4Jpib65V6O2EyDlVH6i5sv2uyqOLPZzsQgACEIAABCAAAQhAAAIQ6LYEcGQNFG3sDaWcbBQBUA5OI0aMsE5O//rXv2rL3tdHCw3sTrfLlodviCPrzTcLYEecAAAxW0lEQVTfbJ2xBEpGGjmsuYQjqyPBNoVAnjmb1U6I8S6rXP0xf0l4Lauu5dWzkh8BQEtEKVKoS4rEqYiW9WnYsGFGy4W5t/InmWQSc91119UijH7zzTdGDmn33nuvLaolyHfccUcjHScHN0X6dEkPZI8//ngjhzillLKxY1YEZ3FXUnRY6YL6JEOu9IfSlFNOaeSIqrTOOuvYJbg23HBD23cdk2PsYostpt0O6bzzzrOGYHdQ/e3Vq5f7WNsW8f2QOo+0ZJ9kpaTIsYqcKUfnZknzRZFS9HBdc0Tl33rrLVtE8j3rrLNMz549M6soYsz64aKoupKV0nLLLWcOO+ywzPbqD4Y8mPHLxF4bfh1FjNnVl6p38oz/iSeesFzVf5d69Ohhr51vv/3WHaptN954Y6NoH76Tqpxbs5aElGO9HDOU5Ogupww5UWvJXBIEqkog7/VdhH6qKmvGDQEIQCCEQFfq5TFjxhjda/3sZz/r0DXZkf7xj38YOd24pN//W221lfvIFgIQgEA0gTx6LtYO49uemnXUt7VotRW9bJ2V/AiTsjEtvvji1lFPDntKee1inTGuPPfd9WNMKau6UmxEIW131v1+SL9TZZVih6yXkz6H8HLl2mVfkVOoVpZ64YUXXFfsVr85vvrqqw7H3AfZfWUjTuXt6vO3IXJW/hR9oPJl+12VRxdrfCQIQAACEIAABCAAAQhAAALdnQCOrIESLvKG8qabbrJvt6ppOUopemj9A4vAbnWbbHn4hjiy3nXXXebkk0+2fHBk7TbTZIIaSJ45m9XxUONdVln/2B133GGdTXVs1VVXNX/84x/907V9OZe6SBgrrriijcJZO9lkZ/jw4XbZeWfgdG/mq4iisLqHqksvvbQ5/PDDa7pMxlItQ6WICTIWK80zzzzmzDPPtPspZWPHrAiT4h6TnNOqHFudE1+jKCEa76BBg4yiLijJOdRFsmzVdt7vh5R55Dv8q1+xL1bImUoO1O+9954dnjhvsskmrYZaO59nzIpIpai6binBfv36WadsRTkPSXkeNLSqr9m10apsnjH7daXqnbzjv+2228xFF13UIRKY648ebMhhedSoUfaQk7v/YMvlDdnqGtG1QoJAVQmkXt8+txT95NfDPgQgAIEqE5iQ9PIZZ5xh9LtMyUXBr7JsGDsEIFAMgTx6LtYOoxVgQpJW01IACKULLrjAzDrrrJnFZGvRSjpKejFXL06m9C2lbGYHxx7Me9/t15NSVvWk2IhC2u6s+/2QfqfKKsUO6cvI7Yfwcnm1bZd9RbZJRSj1o676/dIL+s8995w9JNva3//+d7ufyttvw+2HyFl5U/SBa6vZdkL7XZVHFzcbF+cgAAEIQAACEIAABCAAAQh0FwI4sgZKssgbSkU30zIuiq6hpOh9LkphYHe6XbY8fEMcWe+++25rpBEoHFm73XSZIAaUZ85mdTjUeJdV1j+mZeyPOOIIe6jZQ80bb7zR/PnPf7b5tGSblmMLTYp++fLLL9vsimq62mqr2f2tt97aRpzWBy0prvbr00MPPWS03JtLivA6//zzm5SysWNWBNZtttnGdSXXVkbfhRde2EZxHT16tC0rB7+ZZ545sx49rHFG4sGDB5uNNtooM1/9wbzfD7HzSEuXKnqJi7apqNXSlbFJERsuvPBCW3yllVYyBx54YHBVoWNWFFhx1dJnSjPNNJPV840itWR1IO+Dhqw6/GONrg0/T9Z+6Jjry6bqnZjxy1H5vvvuM/rBqAcg4q3fLLreFX1X55ScDvAfCNgTgX+WWGIJc9xxxwXmJhsEuh+B1Ou7nkisfqqvh88QgAAEqkpgQtLLTz75pP2tJVkoir373V1V2TBuCECgGAJ59FysHSbU9uTbev0XqOtHuvnmm9dWZ3EvF6f0LaVsfd/c55j77iLKqo5YG5HKhvS7s+73Q/qdKqsUO6T41KcQXvVl2mlfeemll8zQoUPt6lmySfXt29cstNBCpnfv3uZ3v/ud7epcc81VC76Syrt+7PocImflS9EHKt8qTWi/q/Lo4lZj4zwEIAABCEAAAhCAAAQgAIHuQABH1kApFn1DKUPe66+/bls/+OCDza9+9avAnnTPbHn4+sYMZ7SspxLiyKqlxW+55Ra7THJ9eUXJveSSS+xhyUqOf0rPP/+8kSOfUn30S0XCdG8wN4seYAvzp/QE8szZrMGGGu+yyvrH5NSnCJVK8847r5FROSvJ6fLaa6+1pwYOHGjfbs/Kl3XsyCOPNFoKXEnLuGkJcS3rrgcILjW6Fr///nuz2Wab2aXolVdRP5dZZpnosv3797eOjJ01ZkX2UIQPJUX2UIQPP/nL2DnnVv+825dDnpxFlbbffvsO43V5Gm3zfD/EzCPJUs7FipqrpEgHmhMpSXVqnihpmXjnNB1aZ6sxKyKwHCWlg5X69Oljo3fOOOOMoU3YfDEPGpo1kHVtNMvvn2s1Zj+v20/VO0WPX1FY33nnHdu9PN97fhQXOScrSjQJAlUnkHp91/NL0U/1dfEZAhCAQBUJTEh6WbYj/XZUUlR8vURGggAEIJBKII+e62zbk2zjTz31lB2SXtaW3ag+KSDEgAEDjOxMsulqlRmtcJbSt5Sy9f1zn1Puu1PKqv0YG1ER/XZ1aBtzvx/S7xRZpdgwZYfMSqmyqq+zXfYV2S7dS8UKXOCee6Twrh+b+xwiZ+VN0QeurWbbCe13VR5d3GxcnIMABCAAAQhAAAIQgAAEINBdCODIGijJom8o5TTklp1WVLzFF188sCfdM1sevqmOrD57LX0+6aSTjgcVR9bxkHCgjkCeOVtX1H4MNd5llfWPjRw5shZl9Oc//7l9qDnJJJP4Wey+72itZeDXXnvt8fI0OuBfc4ceeqhZfvnl7Rv8GoOSHiDoWspqV+f98rvttptZbrnlrHE9puwGG2xgOnPMrRxZTzjhhFoEyp122slG19Y46pMikj7zzDP2sPYVpTQ0+Tqq1fdD3nn0+OOPm6OOOsp8++23tjtqS46sqenWW281Z555pq1mkUUWMSeddFKuKpuNWU6scshyEW5nmGEGW7+cWfOmoh80+HPbXRuhfWo25kZ1pOqdIscvebhlIn/5y1+ao48+ulG3xzse82BrvEo4AIFuRiD1+q7HkaKf6uviMwQgAIEqEpiQ9LIfFa1fv37m7LPPrqJIGDMEIFAwgTx6rjPtMBqWH+lzq622qtmM/CH7wQW0Usjll19uT6f0LaWs3zd/P+W+O6Ws+pDXRlRUv/16Yu73Q/qdIquPPvqoNqfy2jBlh8xKqbLy62ynfeUPf/iD+c9//mO7I9ktsMACdj+Ftz82fz9Ezsqfog/89hrtT2i/q/Lo4kZj4jgEIAABCEAAAhCAAAQgAIHuRABH1kBpht5Q6q1wJb0R3ij5b30qzzXXXGN69erVKHsljofyFQz/wXyjKJDNIrIOGTLEvPLKK5arHgDpQVB9uuyyy8yVV15pDyvyCRFZ6wnxOc+czaIVarxT2REjRtj/2pdumW+++bRbS/7ywXqLXkt0+0mOgFtuuaVR9AqVv+KKK8zUU0/tZ2m4//777xs5bDrHRy1jqeUslTbddFOjZbGU5LgoB8as5C/fdcopp5gFF1wwqaza6Kwxt3JkVRRnLaeupKXt//KXvxg5EPtpzJgx1kD+v//9zx5Wntlmm81GDdGBIr8f8syjhx9+2Mgx1slym222MZJNq6TIrT169GiazY/8t+GGG5pdd93V5k/9ThTLww47rBaJVcw1x7WNSUU+aGh0baSOudm4UvVOUePXGPXd+Oabb9ruKsLvkksu2azrHc7FPNjqUAEfINANCaRe3z6SRvrJz8M+BCAAAQg0JzAh6WX/t5MfLa35CDgLAQhAoDmBvHouxQ6jpcyHDRtmtFXSC6pyRnXJX+p74YUXNloBpz7JTit7rZJvd9DnlL6llFXb9SnlvjulrPqRx0ZUZL/9uvzvrNAVWEL7nSKrFBumPz63nyorV0877SsPPvigOfbYY21XZKuVzdZPKbz9etx+qJxT9YFrr9HWn6MTwu+qvLq40bg4DgEIQAACEIAABCAAAQhAoLsQwJE1UJKhN5QPPfSQufjii22ExFVWWWU8h6VPP/3URjB79dVXbctZS1cHdqlbZQvlq0GnOrLKkev++++3/DbZZBOjpXtckoOXnGMVkdUtu40jq6PD1ieQZ8765dx+qPFO+c877zxz/fXXu6LmxhtvND179uzw2S3lrmXd9ea6f14O21pyTWnppZeuLQGvz3JS3Wijjcwaa6wxXnRiOREqyqKLhNm3b19z7rnn1vTa/vvvb5599llVY+aff35r8Kx30vSdyhWx9dprr7V9Symr9sQgdswq3yi1cmT9+uuvze9+9zsbkVZ1SH9Ij/jpkksusTpEx2addVZz/vnnW2ad8f0QOo+0VJiiyTony6x++2Pw96UD55lnHuv0OuOMM/qn7P6//vWvDsZu/0FFypjleH3AAQfYZQLV0Oyzz24N7P7DrvE60+JAngcNsddGyphbdN+k6p0842/Ul48//ticeOKJtWtfOsddi43K1B/3Hxr486U+H58hUCUCea7vWP1UJZ6MFQIQgEAqga7SyzfccIP9XaWXzLJespUzh17scr/jtdLGqquumjo8ykMAAhDIfX+ZYofRS9ByJHRp8803N9tvv737aHWcXrQdNWqUPablzeVg5pJe1JJt4osvvrCHTj/99A4veaf0LaWs65+/TbnvTimrPoTaiPz+uv3Utl09Mff7of1OkVWqHdKNz22L4NVO+4r6L1uObG9KWbaZFN6Ok78NlbN+88TqgzL+rsrzm9PnyT4EIAABCEAAAhCAAAQgAIHuSgBH1kDJht5Q+m+yKmLcQgstZB2ApplmGvPOO++Ym266yXz22We2VS1lI2eQRlEMA7vWLbKF8tVgUx1Zb7vtNuvo58CtvvrqVkaSjx4SabkhP+HI6tNg3xHIM2dV5uWXXzavvfaaK24U2dQZ4OWQMumkk9pzcnxcfPHFa/m008qRdfTo0XZ5+G+++caWW3TRRa3Bf7LJJjNDhw41d9xxR60+GW7lZO+SnFjlnDnFFFOYZZZZxqhs7969jb4cdK0MHz7cZbXRPP2+aempffbZpxZRQ7pst912M3LQlxOsHBwvvfTSmlF08ODB1mlWFaaUVfmUMat8o9TKkVXl7r33Xqu7XR1aZmyllVayHHVOzrsuyXHeMSvi+yF2HskhWRFZlfTds+KKK7ouNtzusMMONvLpLrvsYt5++20beVaRUeadd14z11xz2fn7+OOPmyeeeKJWh6JyKjqnSyljVrRPF9lV9Ymj5mazpGjF/sMxvZygeeiivrzwwgtWfqpD89V/MKbrQteBS7HXRsqYXduNtnn1Tsr41Qc9PBR3OTBLX73xxhvm0UcfNXopR2mqqaayjvH1UaLtySZ/Yh5sNamOUxDoFgTyXN+x+qlbgGIQEIAABLqIQFfpZb3od9FFF9lR6Xf2sssua/QCoVbV0DLad911V+23rO7VZEMiQQACECiCQB49p/ZS7DCtHFlVv14C/uc//6ldM/nkk5t11lnH3o/KXiv71LvvvmvPSUcqr59S+pZSVn1Iue9OKau2Y21Eqf1W+UYp5H4/tt8pskq1Q6bKql32FTmsPvPMM9beqxWlZO8Vi+eee64mwrXXXtvssccetcAF7kQKb9URK2eVjdUHZfxdlVcXiw8JAhCAAAQgAAEIQAACEIBAdyaAI2ugdENvKH0HlmZVy5FIETcGDhzYLFtlzoXyFZBUR1ZFWpWznRyzspJkI2cpGWuUcGTNosSxPHNWtBTJVG+Ft0orrLCCOeSQQzpka+XIqsxywpazoh54NkoDBgyw0UT9884Zxj9Wv69rYosttjCDBg2qP2WXddPybn6SYVQGXj8papCiB/lJS8LFllU9sWP2+1C/H+LIKqfIQw891LZfX97/XB9hpIjvh9h55Duy+n1stn/aaafZSLvOkbVZXp2beeaZzXHHHWf69OlTy5oy5npH1lqlTXaWWmopc9RRR9Vy6MURySEknXPOOdZB1+WNvTZSxuzabrTNq3dSxq8+rL/++rXo5PV9UoTcI488soO86/M0+hzyYKtRWY5DoLsSyHN9x+qn7sqOcUEAAhDoDAJdpZd9h4tm45hlllnsby+9+EiCAAQgUASBPHrOtRdrhwlxZNVL1rJd+C/Lunbddvrpp7d2h9lmm80dqm1j+6YKUsqm3HenlFW/Y21EKpvaturISiH3+yn9TpFVih0ylVe77CtXXXWVDTKQJSvZexUZebPNNss6bY+l8E6Rc6w+KOPvqhhd3FBgnIAABCAAAQhAAAIQgAAEINANCEzwjqwTCuPQG0oZNRT9UFH5Xn/99czuy9i21157GUW2I40jEMpXuffcc08zbNgwW/Dqq6/OjNDnR0zcaqut7NJK41oa9/eDDz6wS2H7bx/rjKLoSjaq30VF0RvJ6667ri344osvmn333dfu9+/fv7avA1oCW9EvlS6++GJbl/3An25JIM+cFYB6Z9RGUBTZ88ADD+xw2n8LXUZGOcT27NmzQx59ePbZZ42cD7Xkmp+mnHJKG6VSzqj16eabbzb33Xefeemll2qRfvw8elA6ZMgQs9hii/mHO+zrzf6zzz7bvPfeex2O64OiUWsZ+0bLX6aUVf0xY1a5RmnkyJH2JQOdV9RROTdmJS1zdf3111tjsIyrfpp22mmtHll66aX9w/YhQer3Q+w8koPpAw880KE/rT6cccYZNvqq9JoiQSkSp4si7Jft0aOHUVRaOTq7yMLufMp3oqKuaO7kSYoqfMQRR9SK6GGZDPIuImvtRMaO2Mo506XYayNlzK7tRtu8eidl/OpD1oMWRcZRRF/Jxo9g26jPWce1DOTtt99uT8lxXw78JAhUnUCe6ztWP1WdMeOHAAQgkIdAV+ll/ebV/Z1ehnJR7/1+6iVBRUrbcccdx/ut7edjHwIQgEBeAnn0nF93jB2m/t40y1arNrTSkOxaWlHGf1FbtjBFrZa9zH951u+X9mP65uqILVs/Nldf1rbe7pBSVvXH2ohUNrVt1ZGVQu73U/qtNmNlpbKxdshUXu2yrzRyZJ177rltgJUQe0ws71Q5x+iDMv6uitXFms8kCEAAAhCAAAQgAAEIQAAC3ZEAjqyBUo25oRw1apRRdD85TX755ZdmhhlmsE4ycnIidSQQw7djDfk/ybFJEf/eeustI0csGUTlyEqCQAiBdszZkH4pj3SPlomSg2W/fv2MnOdl9G+WFIFYDrAjRoywxmxFuVDZqaeeulmx2jk5dqq8Ih2rjl69ell9p7aznG5rBcfupJR19cSM2ZVN2cqoqjHLUCo9ImaKltSKdxm/HzRWfZ/pe+2TTz4xeqgux88QGYtxGcesfqdcG0WPuav1zquvvmqXb9QDRF3T+v2iOT7xxBMLDQkCECiQQMz1naKfCuw6VUEAAhDolgS6Wi9r5RgZ6D766CPz8ccf23so/dbWEtr63U2CAAQgUDSBGD3n96Ez7TDSiQoQIXuLXpCef/75c71ImdK3lLI+H/Y7n0CsrIqwQ+YdXbvsK3rZWjZi3TvKbik7r+yWMc9AYnnnZVWfP0YflOl3VaourufFZwhAAAIQgAAEIAABCEAAAmUngCNroAS5oQwEFZkNvpHgKNY2AszZtqGnYQhUlgB6p7KiZ+AVIMD1XQEhM0QIQKBUBNDLpRIXnYUABCIIoOcioFEEAhCAQMEE0MUFA6U6CEAAAhCAAAQgAAEIQKD0BHBkDRQhN5SBoCKzwTcSHMXaRoA52zb0NAyByhJA71RW9Ay8AgS4visgZIYIAQiUigB6uVTiorMQgEAEAfRcBDSKQAACECiYALq4YKBUBwEIQAACEIAABCAAAQiUngCOrIEi5IYyEFRkNvhGgqNY2wgwZ9uGnoYhUFkC6J3Kip6BV4AA13cFhMwQIQCBUhFAL5dKXHQWAhCIIICei4BGEQhAAAIFE0AXFwyU6iAAAQhAAAIQgAAEIACB0hPAkTVQhNxQBoKKzAbfSHAUaxsB5mzb0NMwBCpLAL1TWdEz8AoQ4PqugJAZIgQgUCoC6OVSiYvOQgACEQTQcxHQKAIBCECgYALo4oKBUh0EIAABCEAAAhCAAAQgUHoCOLIGipAbykBQkdngGwmOYm0jwJxtG3oahkBlCaB3Kit6Bl4BAlzfFRAyQ4QABEpFAL1cKnHRWQhAIIIAei4CGkUgAAEIFEwAXVwwUKqDAAQgAAEIQAACEIAABEpPAEfWQBFyQxkIKjIbfCPBUaxtBJizbUNPwxCoLAH0TmVFz8ArQIDruwJCZogQgECpCKCXSyUuOgsBCEQQQM9FQKMIBCAAgYIJoIsLBkp1EIAABCAAAQhAAAIQgEDpCeDIGihCbigDQUVmg28kOIq1jQBztm3oaRgClSWA3qms6Bl4BQhwfVdAyAwRAhAoFQH0cqnERWchAIEIAui5CGgUgQAEIFAwAXRxwUCpDgIQgAAEIAABCEAAAhAoPQEcWQNFyA1lIKjIbPCNBEexthFgzrYNPQ1DoLIE0DuVFT0DrwABru8KCJkhQgACpSKAXi6VuOgsBCAQQQA9FwGNIhCAAAQKJoAuLhgo1UEAAhCAAAQgAAEIQAACpSeAI2ugCLmhDAQVmQ2+keAo1jYCzNm2oadhCFSWAHqnsqJn4BUgwPVdASEzRAhAoFQE0MulEhedhQAEIgig5yKgUQQCEIBAwQTQxQUDpToIQAACEIAABCAAAQhAoPQEcGQNFCE3lIGgIrPBNxIcxdpGgDnbNvQ0DIHKEkDvVFb0DLwCBLi+KyBkhggBCJSKAHq5VOKisxCAQAQB9FwENIpAAAIQKJgAurhgoFQHAQhAAAIQgAAEIAABCJSeAI6sgSLkhjIQVGQ2+EaCo1jbCDBn24aehiFQWQLoncqKnoFXgADXdwWEzBAhAIFSEUAvl0pcdBYCEIgggJ6LgEYRCEAAAgUTQBcXDJTqIAABCEAAAhCAAAQgAIHSE8CRNVCE3FAGgorMBt9IcBRrGwHmbNvQ0zAEKksAvVNZ0TPwChDg+q6AkBkiBCBQKgLo5VKJi85CAAIRBNBzEdAoAgEIQKBgAujigoFSHQQgAAEIQAACEIAABCBQegI4sgaKkBvKQFCR2eAbCY5ibSPAnG0behqGQGUJoHcqK3oGXgECXN8VEDJDhAAESkUAvVwqcdFZCEAgggB6LgIaRSAAAQgUTABdXDBQqoMABCAAAQhAAAIQgAAESk8AR9ZAEXJDGQgqMht8I8FRrG0EmLNtQ0/DEKgsAfROZUXPwCtAgOu7AkJmiBCAQKkIoJdLJS46CwEIRBBAz0VAowgEIACBggmgiwsGSnUQgAAEIAABCEAAAhCAQOkJtN2RtfQEGQAEIAABCEAAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIACBnARmnmGanCXIDgEIQAACEIAABCAAAQhAoHsSwJG1e8qVUUEAAhCAAAQgAAEIQAACEIAABCAAAQhAAAIQgAAEIAABCEAAAhMwARxZJ2Dh0DUIQAACEIAABCAAAQhAoEsJtN2RdcpJf96lA45t7H9ffmuLlqW/seNsVzn4tos87cYSYM7GkqMcBCAQSwC9E0uOchCY8AlwfU/4MqKHEIBAtQigl6slb0YLgSoSQM9VUeqMGQIQmNAIOF2MI+uEJhn6AwEIQAACEIAABCAAAQi0iwCOrIHk3Q0ljqyBwHJmg29OYGRvOwHmbNtFQAcgUDkC6J3KiZwBV4gA13eFhM1QIQCBUhBAL5dCTHQSAhBIIICeS4BHUQhAAAIFEXC6GEfWgoBSDQQgAAEIQAACEIAABCBQegI4sgaK0N1Q4sgaCCxnNvjmBEb2thNgzrZdBHQAApUjgN6pnMgZcIUIcH1XSNgMFQIQKAUB9HIpxEQnIQCBBALouQR4FIUABCBQEAGni3FkLQgo1UAAAhCAAAQgAAEIQAACpSeAI2ugCN0NJY6sgcByZoNvTmBkbzsB5mzbRUAHIFA5AuidyomcAVeIANd3hYTNUCEAgVIQQC+XQkx0EgIQSCCAnkuAR1EIQAACBRFwuhhH1oKAUg0EIAABCEAAAhCAAAQgUHoCOLIGitDdUOLIGggsZzb45gRG9rYTYM62XQR0AAKVI4DeqZzIGXCFCHB9V0jYDBUCECgFAfRyKcREJyEAgQQC6LkEeBSFAAQgUBABp4txZC0IKNVAAAIQgAAEIAABCEAAAqUngCNroAjdDSWOrIHAcmaDb05gZG87AeZs20VAByBQOQLoncqJnAFXiADXd4WEzVAhAIFSEEAvl0JMdBICEEgggJ5LgEdRCEAAAgURcLoYR9aCgFINBCAAAQhAAAIQgAAEIFB6AjiyBorQ3VDiyBoILGc2+OYERva2E2DOtl0EdAAClSOA3qmcyBlwhQhwfVdI2AwVAhAoBQH0cinERCchAIEEAui5BHgUhQAEIFAQAaeLcWQtCCjVQAACEIAABCAAAQhAAAKlJ4Aja6AI3Q0ljqyBwHJmg29OYGRvOwHmbNtFQAcgUDkC6J3KiZwBV4gA13eFhM1QIQCBUhBAL5dCTHQSAhBIIICeS4BHUQhAAAIFEXC6GEfWgoBSDQQgAAEIQAACEIAABCBQegI4sgaK0N1Q4sgaCCxnNvjmBEb2thNgzrZdBHQAApUjgN6pnMgZcIUIcH1XSNgMFQIQKAUB9HIpxEQnIQCBBALouQR4FIUABCBQEAGni3FkLQgo1UAAAhCAAAQgAAEIQAACpSeAI2ugCN0NJY6sgcByZoNvTmBkbzsB5mzbRUAHIFA5AuidyomcAVeIANd3hYTNUCEAgVIQQC+XQkx0EgIQSCCAnkuAR1EIQAACBRFwuhhH1oKAUg0EIAABCEAAAhCAAAQgUHoCOLIGitDdUOLIGggsZzb45gRG9rYTYM62XQR0AAKVI4DeqZzIGXCFCHB9V0jYDBUCECgFAfRyKcREJyEAgQQC6LkEeBSFAAQgUBABp4txZC0IKNVAAAIQgAAEIAABCEAAAqUngCNroAjdDSWOrIHAcmaDb05gZG87AeZs20VAByBQOQLoncqJnAFXiADXd4WEzVAhAIFSEEAvl0JMdBICEEgggJ5LgEdRCEAAAgURcLoYR9aCgFINBCAAAQhAAAIQgAAEIFB6AjiyBorQ3VDiyBoILGc2+OYERva2E2DOtl0EdAAClSOA3qmcyBlwhQhwfVdI2AwVAhAoBQH0cinERCchAIEEAui5BHgUhQAEIFAQAaeLcWQtCCjVQAACEIAABCAAAQhAAAKlJ/Dhhx+ab7/9tuU4JhozZswPLXPlyDD8o09s7rI4hrobyrL0N4coJois8J0gxEAnchBgzuaARVYIQKAQAuidQjBSCQQmSAJc3xOkWOgUBCBQYQLo5QoLn6FDoCIE0HMVETTDhAAEJmgCThfjyDpBi4nOQQACEIAABCAAAQhAAAJdSGDUqFHmiy++aNkijqxfjvP2xZG15VyJyuBu2Cd0vvL8vv766+0Y559/frPKKqvUxnvrrbead999134eOHCgmXLKKWvn2Ol+BCb0Oas3FPR/0kknTYL/1Vdf2fKTTDJJUj1dXbgr+/3DDz+Yzz//vLLX/Pfff2++/PJLoznSo0eP3KLOIyux/vTTT83PfvYz06tXr6i2vvnmm2hZpVxXn332mfn666/NtNNOayaaaKLcfVeBCUnv5JGbG6yuk8knnzx6/K4ethDojgRSru9U3dgdeTImCEAAAqkEUvRyatt++dTf2n5d7EMAAhDwCRSh51Lukf2+NNpPuYdM6VtKWX8seXV4qn1Jtpmf//zn9r/fj87e/+6778zHH39s7TRls0PGzjHZd1RWtikxz5Pc/ZueHcTY0VLnSZ6+dlbeGJuS60ve68qV0zalrF9PkftOF+PIWiRV6oIABCAAAQhAAAIQgAAEykxA99wjRoxoOQQcWQtyZH311VdrjpAzzjij2W677VrCr0IGd8M+oTuyvvTSS+bwww+3IllxxRXNkCFDauI54ogjzIsvvmg/n3766WbmmWeunWOn+xFInbMPPfSQueuuu6xD1/7772+dAFMpyVHuhhtuMC+//LJ5/fXXrSNr3759jZyu11hjDTPXXHO1bELO2vfee6954oknjPZlBFeaYoopzEEHHWTmmWeepnXImHrcccdZh70VVljBrLXWWk3z+ydTyqb22/UjVEerr5Lfo48+alnrjZDevXubOeaYw/Tv399o7PXpjTfeMH//+9/rDzf9PNlkk5ndd9/d5pF8zzvvvKb5/ZMbbLCBlb1/zN+P5S2j77///W+jOSxeo0ePtoZgOWcuv/zyZq+99vKbGW8/j6xk2H788cfNk08+ad555x07J/XDRUlzcr755jMa5yKLLDJeOzrw1ltvmccee8xId7///vvmk09+jAY/9mHBLLPMYtZbbz3b58zCPx5Mua70csOVV15phg0bZh1wVWXPnj3t98M666xjVlttNeuU26x9/1yq3omVufqQR25+n6VLHnnkEauX9INTD2rmnXdeKzPxl1MyCQIQyOeonqob4Q0BCEAAAq0J5PndVeTv9NTf2q1HRg4IQAAC4wjk0XM+s5R7ZL+eRvsp95ApfUsp68YSo8Nj7EuuPW11r37ttdda+8z/+3//z95jzzrrrNYetMUWW1hblZ9f+5dffrm1kdQfb/ZZdsUllliilkXOvrfffru55557bF36rDTNNNOYhRZayGy55ZamT58+tfyNdkJtDak2Nb/9mDkm+5JsgLIvffDBB0bRYSQ72TT0jGfllVc2v/71rzNfuhabZ555xpZXPSov25acWFVWvCSrqaee2u9mh/3UeeIqS7ELqY5Ye3aonF0//W3MdeXKp5R1dXT21uliHFk7mzT1QwACEIAABCAAAQhAAAJlIhASlXWisc5MY+9zfyhsXMM/+tGZZNJ8b6wW1oGcFbkbyhRHy48++sgceOCB1ulHzc8222zmlFNOydmT7pm9CL5dQQZH1q6gXI42Uufs0UcfbZ577jk72Isuuig6QqSjJUV+1FFHWWc/d8zfyiFSjqhy/GuUZFQ97bTTzJgxYzKzHHLIIWbRRRfNPOcOymHv4IMPth/lqLf99tu7Uy23sWWL6Lc6F6qjFWXirLPOMi+88ELDMf3qV78ygwcP7uCgLGfME088sWGZrBNy1rz44ovtKRl9f//732dlyzy2xx57mJVWWinznA7G8JbzlBz1NZasJKdpzcNGKa+s9OKA9G6rtOGGG5ptttmmQzY5dGvOtkqLL764kTN5VhSMlOvqxhtvNH/729+MIpM0Sv369TOHHXaY0fUZklL1TozM1a+8cnNjue2228wll1xiH+64Y/5WDt+ap1ns/XzsQ6AKBPJc3ym6sQosGSMEIACBIgjk0ctF/U5P/a1dxLipAwIQqA6BPHrOUUm5R3Z1NNum3EOm9C2lrBtPjA6PtS+5Nu+++25z6aWX1l5Cd8fdVi9c655bdg8/7bfffubNN9/0D7Xc/+1vf2vWXXddm0/9lu3nvffea1hOUUp33nlns+qqqzbMk8fWkGpTc52ImWMKXKEAFq2SeOvl/hlmmKFDVt8G3OGE90F2Ib0Y/otf/MI7Om43dZ74FcbahVwd/lhC7dl55OzacduY66qIsq6Ortg6XYwja1fQpg0IQAACEIAABCAAAQhAoEwERo4caXRf2CjZiKx6w9Q5ZGg/xbG1ao6s//vf/8yhhx5aW3peoHFk/Wm6uRv2FEfhn2rrvD0cWTuPbdlqjpmzegtcUSFvvfVWc+edd9aGHGr4qxWo29FS6fvuu68ZPny4PSNj8cILL2ydY+Usq6gSSlre65hjjjGK0lqf1Ke//vWvNrKmzqkORXCYaaaZbCTJV155xRxwwAENHVn1BfLss89apzUX5jvUkTWlbGq/HYdQHa3vPRmvnXOlomsutdRSZvrpp7eRWV1UZtW7+eabm0033dQ1YZ0/u9KRVRGjFTm6PsXy1g+FE044ocPDjqmmmspGoZ144olt9NNpp522oSNrjKzkFC0ju5KM+orkqYieWr5NrF3ED52vH6+vr3V+9tlnt3Na18t///tfI5m7tNlmmxn991PKdaUHLCeddJL9naRItZKDotVqvsjBVk6uLrKsnJ733HNPv+mG+zF6R5XFylxlY+Smcors/Oc//1m7NrkoI4pS+9prr9V+Q66yyiq1qMMuL1sIVJFAnus7RTdWkS1jhgAEIBBDII9ezuvIWv+7Vf1L/a0dM0bKQAAC1SaQR8+JVMo9cgjplHvIlL6llHXjitHhKfYltauXq4888kjXBWvrky1Q49EqOs7mIRvKmWeeaVe1cZn/+Mc/GkU4zZOcI6vq1wu5WqFHSfYwvVys5xxyCFaUVmfHkQ1Edsg555zT5vX/5LU1FOHIGjvHZFuVA6dLsqtqJTa9lKsVsRRh1SVxkD3If2HXX8XN2bbk9CobseOo8jqmoCfaupQ6T1w9KXahFHt2Xjm7/mobc1258illXR1dtXW6GEfWriJOOxCAAAQgAAEIQAACEIBAmQjI1qDVkbPSRGONED9MN910Rv9loJAhQjfS7qZcjq1yKJHDhm5u3Tnn/Oq2yq9z748YNTbv2KWBJxkXkVXHVNZttS+n2X0PfH/sse/Gnhu39OwPZmw+M9aJ1nxvxp4Ye7zHuP7asmPzjf33ww9jz41NtszYcicfO5Nd5kX1ufZdO+MKq6rs9pVf5cZ8M67OySfuYevyx6g6mo1fhgIZjOQ4o3EpqT0ta3z42Ghz7nPW+F37qt/l036e9tX/ev5uvLbSsX/cZ7d1/Luqfd2wC434qu2ubt+N220btS8HJBmUlG+ZZZYxO+20k0UovnJQk6FO52SgkkHLcXfb2Pmn8kqqW/vdTf6Ou9s24j8hjV9ztkePn1kdJpm00n/XXXedXYreyU5jdOnkk0+2znmx45cDqSKEqk7pZkVedfNPznIyoMpArfOrrrqqXd7Lb//hhx+2TqyufS2HNWDAAOs46PSHvhzkrKj63Rg0n+VQqGiWY6N22/pVh5Lq79+/v3UObDT/XVnpSOV37au8+jlw4ECrfxvNfy0Zr8gTSiqrfstxVH1U31ROTrxy4FX9ja4/GeEb6Wi9gOC3r2XELhkbYVJJhmU5IM4555w1+SsaxtVXX23bU7t6qKClwRxHteWPU/W4z2779ttvW4dR9VkPHDQ/lBQxVs5LyicHY/VNSflUv7a+bNz3tOMvGelhheNtC4/9o/okKzneqg5Xn3i5fmur6KYyBCu/lorbYYcdzAILLGD5uPk/evRo22fH35V/8MEHzWWXXWabVHnJSu1pTumz2tR8mGSSSaz8VE51KJKFIgSvv/76NiqFP//UlvSxHAdUh5a4UxRc7ausHgaIndrSEnhypNQ5/ReLCy+80Dz//PP2sxy3FWlW9bvx69zZZ59tP6ufYi/uYqzx/ulPf6o59coZU/PV8ZfDr5aLU1sbb7yxWXvttTvMP9c31x+NU07AjfgLnPLqt8j33/8w9rvyZ7Y+HZd8HX/XvuP/6aefWgd0X+aqR+2svvrqduk699lt3fhVR73cNE7/GlP7Yqm8Yui37yJEqz458m633XZ2DGpn6NCh5txzz1Vx2xd9f/bq1avl+DVWvw2VbzZ+N//cfFLbbpwqq+Q+u60/flfe5aN9+Hfm/Pvi63F6fNKfj/u+ajb/9L2u72U9MFZ0Jf/6k2489dRT7cNUzefFFlvMRvNm/nP9Oz1nlR/6D/3/4+8BNy/4/hv3e1q/aZz+/fyrb8fOE2N6Tdbx/kfXUP3vD73I51YC0O9F7Tf7/aHyasvx1/eLfmu639r6XfjbsZHvtNqB//tDv5d1D1LfvupRfTru+t+sfdeu2yL/8eUvOYuPz1+MleDf+P6D+Tfh21/dda9tnt+fmv+6jzvnnHPstaF7d9meFHlS56THjj/++Np98GqrrWa22mqrmp6zF8/YP3770j2+/pEt1UX41Ooy2267be3+T46E7kVJldE9pOwlqk/t67xvF5O9xNkANC+V392jq29a9t61//TTT9v7U9WlcUmHa1y61mXDcWU1BpXVEvAq6+4NdFztyWaj47IByV4iHe7GqzyyT6nPyqPjjzzySM0WJ92uyKlzzDGHstrz9913n13lRZ9lX5IjpWwxuv/XmMRLDpSqT/fqsrHIpqFzsgWcccYZNqCGzq+55pr2Xt71R+NS0jnlF0NtNWYl5dO+mOolYeXbeuut7fgVXVO2EuXRy80au7auvOrWeZVTHr28O2jQoFq9qsvZIV1b6r/skBqnOyZbg8ajfqh/qktt6L/qcPx1zn1WXjmWOjuab1NTvbLRaY6pLtmKNMdUn+p46qmnzHnnnWfbV33OTqG8eh4gu6HmpexnmluufbV51113mWuvvdb2Q/nFRA6t2lddsl1JJrJtyXbl+qxzsumqXXHT5/XWW89ssMEGdtxqQ6ycPU12E70Moxe1Xfv333+/tUOqLWeH1DzRZ/3XfaPstrIPu/64rexCeqlb/XHyc/w1LrXxj3/8o2bPdufUT9UhzuqT8rryjqfO+3JWWfFz81R16L+uCzn3al/1uDZUXr+N9BtL5zSmHXfc0cwzzzz2sxu/xufPP7WvpOvYXZMq+9sff1epLjd+ta2VsJqNX3l1Xkn9a2R/yxq/a8cWHvvHfXZb9UXlvvxWc/t74xxZdd7x135nt9/u8dN+4+sP+TP/uf47V/+if9A/7vtb39V8//L7g99fPP9z9xh8/06437/yGdG9s+wFumb1//8DcdvATAxHcWsAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"execution_count": 29,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from IPython.display import Image\n",
"Image(filename='./images/parallel_coordinates_plot.png')"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.12"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: examples/insurance_lite/config.yaml
================================================
input_features:
- name: image_path
type: image
preprocessing:
height: 224
width: 224
in_memory: true
num_channels: 3
encoder: vit
img_height: 224
in_channels: 3
use_pretrained: true
hidden_size: 768
num_hidden_layers: 12
num_attention_heads: 12
intermediate_size: 3072
- name: insurance_company
type: category
preprocessing:
missing_value_strategy: fill_with_const
fill_value: UNKNOWN
- name: cost_of_vehicle
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: expiry_date
type: date
preprocessing:
missing_value_strategy: fill_with_const
fill_value: ""
datetime_format: "%Y-%m-%d"
- name: min_coverage
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: max_coverage
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: condition
type: category
preprocessing:
missing_value_strategy: fill_with_const
fill_value: UNKNOWN
combiner:
type: concat
num_fc_layers: 3
output_size: 256
output_features:
- name: amount
type: number
preprocessing:
normalization: zscore
trainer:
epochs: 10
early_stop: 0
batch_size: 8
preprocessing:
split:
type: random
probabilities: [0.7, 0.1, 0.2]
================================================
FILE: examples/insurance_lite/train.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example on multi-modal data.
# Import required libraries
import logging
import os
import shutil
from ludwig.api import LudwigModel
from ludwig.datasets import insurance_lite
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
# Download and prepare the dataset
dataset = insurance_lite.load()
# Define Ludwig model object that drive model training
model = LudwigModel(config="./config.yaml", logging_level=logging.INFO, backend="local")
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(dataset=dataset, experiment_name="simple_experiment", model_name="simple_model")
# list contents of output directory
print("contents of output directory:", output_directory)
for item in os.listdir(output_directory):
print("\t", item)
================================================
FILE: examples/kfold_cv/README.md
================================================
# K-Ffold Cross Validation Example
This directory contains two examples of performing a k-fold cross validation analysis with Ludwig.
## Classification Example
This example illustrates running the k-fold cv with the `ludwig experiment` cli.
To run this example execute this bash script:
```
./k-fold_cv_classification.sh
```
This bash script performs these steps:
- Download and prepare data for training and create a Ludwig config file
- Execute `ludwig experiment` to run the 5-fold cross validation
- Display results from the 5-fold cross validation analysis
Sample output:
```
Cleaning out old results
Downloading data set
Preparing data for training
Saving training and test data sets
Preparing Ludwig config
Completed data preparation
Training: 100%|████████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 23.14it/s]
Evaluation train: 100%|████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 98.62it/s]
Evaluation test : 100%|█████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 321.03it/s]
Training: 100%|███████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 190.18it/s]
Evaluation train: 100%|███████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 331.68it/s]
Evaluation test : 100%|█████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 298.08it/s]
<<<< DELETED LINES >>>>>
Training: 100%|███████████████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 248.00it/s]
Evaluation train: 100%|███████████████████████████████████████████████████████████████████████| 12/12 [00:00<00:00, 400.31it/s]
Evaluation test : 100%|█████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 340.35it/s]
Evaluation: 100%|████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 27.87it/s]
retrieving results from results
#
# K-fold Cross Validation Results
#
{'combined': {'accuracy_mean': 0.9736263736263737,
'accuracy_std': 0.011206636293610508,
'loss_mean': 0.06359774886251807,
'loss_std': 0.011785678840394689},
'diagnosis': {'accuracy_mean': 0.9736263736263737,
'accuracy_std': 0.011206636293610508,
'average_precision_macro_mean': 0.995842104045726,
'average_precision_macro_std': 0.002339014329647542,
'average_precision_micro_mean': 0.995842104045726,
'average_precision_micro_std': 0.002339014329647542,
'average_precision_samples_mean': 0.995842104045726,
'average_precision_samples_std': 0.002339014329647542,
'loss_mean': 0.06359774886251807,
'loss_std': 0.011785678840394689,
'roc_auc_macro_mean': 0.9973999160508542,
'roc_auc_macro_std': 0.0011259319854886507,
'roc_auc_micro_mean': 0.9973999160508542,
'roc_auc_micro_std': 0.0011259319854886507}}
```
## Regression Example
This illustrates using the Ludwig API to run the K-fold cross validation analysis. To run the example, open the jupyter notebook `regression_example.ipynb`. Following steps are performed:
- Download and prepare data for training and create a Ludwig config data structure from a pandas dataframe structure
- Use `ludwig.api.kfold_cross_validate()` function to run the 5-fold cross validation
- Display results from the 5-fold cross validation analysis
Expected output from running the example:

================================================
FILE: examples/kfold_cv/display_kfold_cv_results.py
================================================
#!/usr/bin/env python
import argparse
import os.path
import pprint
import sys
from ludwig.utils.data_utils import load_json
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Display K-fold cross validation results",
prog="display_kfold_cv_results",
usage="%(prog)s [options]",
)
# ----------------------------
# Experiment naming parameters
# ----------------------------
parser.add_argument(
"--results_directory", type=str, default="results", help="directory that contains the K-fold cv results"
)
args = parser.parse_args(sys.argv[1:])
results_directory = args.results_directory
print("Retrieving results from ", results_directory)
kfold_cv_stats = load_json(os.path.join(results_directory, "kfold_training_statistics.json"))
print("#\n# K-fold Cross Validation Results\n#")
pprint.pprint(kfold_cv_stats["overall"])
================================================
FILE: examples/kfold_cv/k-fold_cv_classification.sh
================================================
#!/bin/bash
#
# Download and prepare training data
#
python prepare_classification_data_set.py
#
# Run 5-fold cross validation
#
ludwig experiment \
--config config.yaml \
--dataset data/train.csv \
--output_directory results \
--logging_level 'error' \
-kf 5
#
# Display results from K-fold cv
#
python display_kfold_cv_results.py --results_directory results
================================================
FILE: examples/kfold_cv/prepare_classification_data_set.py
================================================
#!/usr/bin/env python
# Download and prepare training data set
# Create Ludwig config file
#
# Based on the
# [UCI Wisconsin Breast Cancer data set](https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(original))
#
import os.path
import shutil
import pandas as pd
import requests
import yaml
from sklearn.model_selection import train_test_split
from ludwig.constants import TRAINER
# Constants
DATA_SET_URL = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data"
DATA_SET = "wdbc.data"
DATA_DIR = "./data"
RESULTS_DIR = "results"
# Clean out previous results
print("Cleaning out old results")
if os.path.isfile(DATA_SET):
os.remove(DATA_SET)
if os.path.isfile("config.yaml"):
os.remove("config.yaml")
shutil.rmtree(RESULTS_DIR, ignore_errors=True)
shutil.rmtree(DATA_DIR, ignore_errors=True)
# Retrieve data from UCI Machine Learning Repository
# Download required data
print("Downloading data set")
r = requests.get(DATA_SET_URL)
if r.status_code == 200:
with open(DATA_SET, "w") as f:
f.write(r.content.decode("utf-8"))
# create pandas dataframe from downloaded data
print("Preparing data for training")
raw_df = pd.read_csv(DATA_SET, header=None, sep=",", skipinitialspace=True)
raw_df.columns = ["ID", "diagnosis"] + ["X" + str(i) for i in range(1, 31)]
# convert diagnosis attribute to binary format
raw_df["diagnosis"] = raw_df["diagnosis"].map({"M": 1, "B": 0})
# Create train/test split
print("Saving training and test data sets")
train_df, test_df = train_test_split(raw_df, train_size=0.8, random_state=17)
os.mkdir(DATA_DIR)
train_df.to_csv(os.path.join(DATA_DIR, "train.csv"), index=False)
test_df.to_csv(os.path.join(DATA_DIR, "test.csv"), index=False)
print("Preparing Ludwig config")
# Create ludwig input_features
num_features = ["X" + str(i) for i in range(1, 31)]
input_features = []
# setup input features for number variables
for p in num_features:
a_feature = {
"name": p,
"type": "number",
"preprocessing": {"missing_value_strategy": "fill_with_mean", "normalization": "zscore"},
}
input_features.append(a_feature)
# Create ludwig output features
output_features = [{"name": "diagnosis", "type": "binary", "num_fc_layers": 2, "output_size": 64}]
# setup ludwig config
config = {
"input_features": input_features,
"output_features": output_features,
TRAINER: {"epochs": 20, "batch_size": 32},
}
with open("config.yaml", "w") as f:
yaml.dump(config, f)
print("Completed data preparation")
================================================
FILE: examples/kfold_cv/regression_example.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# K-fold cross validation - Regression Model\n",
"Based on the [Ludwig regression example](https://ludwig-ai.github.io/ludwig-docs/examples/#simple-regression-fuel-efficiency-prediction) \n",
"\n",
"[Data set](https://archive.ics.uci.edu/ml/datasets/auto+mpg)\n",
"\n",
"This example demonstrates teh following:\n",
"\n",
"- Download a data set and create a pandas dataframe\n",
"- Create a training and hold-out test data sets\n",
"- Create a Ludwig config data structure from the pandas dataframe\n",
"- Run a 5-fold cross validation analysis with the training data\n",
"- Use Ludwig APIs to train and assess model performance on hold-out test data set"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import logging\n",
"import os\n",
"import os.path\n",
"import shutil\n",
"import tempfile\n",
"\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import pandas as pd\n",
"import requests\n",
"import scipy.stats as stats\n",
"import seaborn as sns\n",
"from sklearn.model_selection import train_test_split\n",
"\n",
"from ludwig.api import kfold_cross_validate, LudwigModel"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Contstants"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"DATA_SET_URL = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'\n",
"DATA_SET = 'auto_mpg.data'\n",
"RESULTS_DIR = 'results'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Clean out previous results"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"if os.path.isfile(DATA_SET):\n",
" os.remove(DATA_SET)\n",
" \n",
"shutil.rmtree(RESULTS_DIR, ignore_errors=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Retrieve data from UCI Machine Learning Repository"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Download required data"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"r = requests.get(DATA_SET_URL)\n",
"if r.status_code == 200:\n",
" with open(DATA_SET,'w') as f:\n",
" f.write(r.content.decode(\"utf-8\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Pandas DataFrame from downloaded data"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(398, 8)"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"raw_df = pd.read_csv(DATA_SET,\n",
" header=None,\n",
" na_values = \"?\", comment='\\t',\n",
" sep=\" \", skipinitialspace=True)\n",
"\n",
"\n",
"raw_df.columns = ['MPG','Cylinders','Displacement','Horsepower','Weight',\n",
" 'Acceleration', 'ModelYear', 'Origin']\n",
"raw_df.shape"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" MPG Cylinders Displacement Horsepower Weight Acceleration ModelYear \\\n",
"0 18.0 8 307.0 130.0 3504.0 12.0 70 \n",
"1 15.0 8 350.0 165.0 3693.0 11.5 70 \n",
"2 18.0 8 318.0 150.0 3436.0 11.0 70 \n",
"3 16.0 8 304.0 150.0 3433.0 12.0 70 \n",
"4 17.0 8 302.0 140.0 3449.0 10.5 70 \n",
"\n",
" Origin \n",
"0 1 \n",
"1 1 \n",
"2 1 \n",
"3 1 \n",
"4 1 "
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"raw_df.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create train/test split"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(318, 8)\n",
"(80, 8)\n"
]
}
],
"source": [
"train_df, test_df = train_test_split(raw_df, train_size=0.8, random_state=17)\n",
"print(train_df.shape)\n",
"print(test_df.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Setup Ludwig config"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"num_features = ['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'ModelYear']\n",
"cat_features = ['Origin']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Ludwig input_features"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"input_features = []\n",
"# setup input features for number variables\n",
"for p in num_features:\n",
" a_feature = {'name': p, 'type': 'number', \n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean', 'normalization': 'zscore'}}\n",
" input_features.append(a_feature)\n",
"\n",
"# setkup input features for categorical variables\n",
"for p in cat_features:\n",
" a_feature = {'name': p, 'type': 'category'}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Ludwig output features"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"output_features =[\n",
" {\n",
" 'name': 'MPG',\n",
" 'type': 'number',\n",
" 'num_fc_layers': 2,\n",
" 'fc_size': 64\n",
" }\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'input_features': [{'name': 'Cylinders',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'Displacement',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'Horsepower',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'Weight',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'Acceleration',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}},\n",
" {'name': 'ModelYear',\n",
" 'type': 'number',\n",
" 'preprocessing': {'missing_value_strategy': 'fill_with_mean',\n",
" 'normalization': 'zscore'}}],\n",
" 'output_features': [{'name': 'MPG',\n",
" 'type': 'number',\n",
" 'num_fc_layers': 2,\n",
" 'fc_size': 64}],\n",
" 'training': {'epochs': 100, 'batch_size': 32}}"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"config = {\n",
" 'input_features' : input_features,\n",
" 'output_features': output_features,\n",
" 'trainer': {\n",
" 'epochs': 100,\n",
" 'batch_size': 32\n",
" }\n",
"}\n",
"config"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Perform K-fold Cross Validation analysis"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"starting 5-fold cross validation\n",
"training on fold 1\n",
"CPU times: user 40.7 s, sys: 5.38 s, total: 46 s\n",
"Wall time: 40.6 s\n"
]
}
],
"source": [
"%%time\n",
"with tempfile.TemporaryDirectory() as tmpdir:\n",
" data_csv_fp = os.path.join(tmpdir,'train.csv')\n",
" train_df.to_csv(data_csv_fp, index=False)\n",
"\n",
" (\n",
" kfold_cv_stats, \n",
" kfold_split_indices \n",
" ) = kfold_cross_validate(\n",
" num_folds=5,\n",
" config=config,\n",
" dataset=data_csv_fp,\n",
" output_directory=tmpdir,\n",
" logging_level=logging.ERROR\n",
" )\n"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'loss_mean': 8.111681,\n",
" 'loss_std': 2.4598064,\n",
" 'error_mean': 0.0380627,\n",
" 'error_std': 0.5965346,\n",
" 'mean_squared_error_mean': 8.111682,\n",
" 'mean_squared_error_std': 2.4598064,\n",
" 'mean_absolute_error_mean': 2.0598435,\n",
" 'mean_absolute_error_std': 0.2779836,\n",
" 'r2_mean': 0.8666786,\n",
" 'r2_std': 0.03552912}"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"kfold_cv_stats['overall']['MPG']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Train model and assess model performance"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
"model = LudwigModel(\n",
" config=config,\n",
" logging_level=logging.ERROR\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"CPU times: user 8.34 s, sys: 1.78 s, total: 10.1 s\n",
"Wall time: 15 s\n"
]
}
],
"source": [
"%%time\n",
"training_stats = model.train(\n",
" training_set=train_df,\n",
" output_directory=RESULTS_DIR,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"/opt/project/ludwig/data/preprocessing.py:1045: SettingWithCopyWarning: \n",
"A value is trying to be set on a copy of a slice from a DataFrame.\n",
"Try using .loc[row_indexer,col_indexer] = value instead\n",
"\n",
"See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n",
" computed_fill_value,\n"
]
}
],
"source": [
"test_stats, mpg_hat_df, _ = model.evaluate(dataset=test_df, collect_predictions=True, collect_overall_stats=True)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'MPG': {'loss': 8.303831,\n",
" 'error': -0.45136052,\n",
" 'mean_squared_error': 8.303831,\n",
" 'mean_absolute_error': 2.2274728,\n",
" 'r2': 0.8558148},\n",
" 'combined': {'loss': 8.303831}}"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_stats"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"/usr/local/lib/python3.6/dist-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n",
" FutureWarning\n"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAQ8AAAEKCAYAAAAM4tCNAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO2deXyV5Zn3v1cCkSVAIAkQNlnCBFFWEVCsgzqtYq1axe21o2Ndal9nxplWW+lMO52ZzttW/LR2fK0Oii86dbdYLVQZi4CliIgoO1ES1kDIQkLIRrbr/eM853hycnK25OzX9/PJ55znfrbrwHN+576v+7quW1QVwzCMcMmItwGGYSQnJh6GYUSEiYdhGBFh4mEYRkSYeBiGEREmHoZhRESfaF5cRA4Cp4F2oE1V54jIMOAVYDxwELhJVWuiaYdhGL1PLHoel6rqTFWd42w/DKxV1cnAWmfbMIwkIx7DlmuB55z3zwHXxcEGwzB6iEQzwlREDgA1gAL/parLRKRWVXOc/QLUuLd9zr0XuBdg4MCB50+ZMiVqdhpGutLWrpRW1XP66GdVqpofzrlR9XkAF6tqmYgMB94VkX3eO1VVRcSveqnqMmAZwJw5c3Tr1q1RNtUw0ouKumZueXozLaea2fvviw6Fe35Uhy2qWua8VgBvAHOBEyJSAOC8VkTTBsMwuuIWjvJTzay4c25E14iaeIjIQBEZ5H4PfAXYBbwF3OEcdgfwZrRsMAyjK77CMXfCsIiuE81hywjgDZdbgz7Ai6r6joh8BLwqIncBh4CbomiDYRhe9JZwQBTFQ1VLgRl+2quBy6N1X8Mw/NObwgEWYWoYaUFvCweYeBhGyhMN4QATD8NIaaIlHGDiYRgpSzSFA0w8DCMlibZwgImHYaQcsRAOMPEwjJQiVsIBJh6GkTLEUjjAxMMwUoJYCweYeBhG0hMP4QATD8NIauIlHGDiYRhJSzyFA0w8DCMpibdwgImHYSQdiSAcYOJhGElFoggHmHgYRtKQSMIBJh6GkRQkmnCAiYdhJDyJKBxg4mEYCU2iCgeYeBhGwpLIwgEmHoaRkCS6cICJh2EkHMkgHGDiYRgJRbIIB5h4GEbCkEzCASYehpEQJJtwgImHYcSdZBQOMPEwjLiSrMIBJh6GETeSWTjAxMMw4kKyCweYeBhGzEkF4QATD8OIKakiHGDiYRgxI5WEA0w8DCMmpJpwgImHYUSdVBQOMPEwjKiSqsIBMRAPEckUkU9EZJWzPUFEPhSR/SLyiohkRdsGw4gHqSwcEJuexwPAXq/tnwO/VNVCoAa4KwY2GEZMSXXhgCiLh4iMAb4KPONsC3AZ8LpzyHPAddG0wTBiTToIB0S/5/EY8D2gw9nOBWpVtc3ZPgqM9neiiNwrIltFZGtlZWWUzTSM3iFdhAOiKB4icjVQoaofR3K+qi5T1TmqOic/P7+XrTOM3iedhAOgTxSvvQC4RkSuAvoBg4FfATki0sfpfYwByqJog2HEhHQTDohiz0NVl6jqGFUdD9wCvKeqtwHrgMXOYXcAb0bLBsOIBekoHBCfOI/vA98Rkf24fCDL42CDYfSItnaXGy9dhQOiO2zxoKrrgfXO+1Jgbizuaxi9TWllPW/vKufP+6uYMTaHVduPUd3QknbCATESD8NIBUor67nxqQ+obmgBYFNJNQCP3Twj7YQDLDzdMELm7V3lHuHwpqy2OQ7WxB8TDyMpcPsY4nWvtvYO/ry/yu/xm0qqaI+hfYmCDVuMhMbbx7CgMI9F541kYn52zO/VJzODGWNz+OjgSTo6YPqYIeRmZ3GgqpGLJuWRmZl+v8MmHkbC4s/H8OzGA7x234W9LiDB7lVR18zvtx9DFc4pGMRFhblMLRhMcflpFhalZxBj+smlkTT48zFUN7Tw9q7ymN6roq6ZG57cxNGaJto6lF3H6nhiXQk/enM3BTn9uX35Fkor63vdpkTHxMNISHriYwjXPxLoXuuLK7hl2WbK67o6RasbWthfUU/OgKyoCFqiY+JhJCR9MjNYUJjnd193PobSynqeWLef25/dwhPr9ofcGwh0r5LKBsrrmikaMcjv/n3ldYzPG5CWTlMTDyNhWXTeSHIHdq4VlTswi0XnjexyrNtnsXRNMZtKqlm6ppgbn/ogZAHxd68MgcaWNlbcOZdF0wr8njdl5GAOpqnTNL0+rZFUTMzP5rX7LuShK4pYUJjLQ1cUdess7al/xPteF4wfyrCBWWT1yeD5b85j7oRh3QpZ4fBsahtb/ApaqiOqGm8bgjJnzhzdunVrvM0w4kh7e0e3v+xt7R3c/uwWT8SnNwsKc3n+zrkh9woq6po9Pg7fkHP3VO6mkipmjRvK1IJBHD/VzKVFw6M2fRwrRORjVZ0Tzjk2VWskBYG+/G6fhT/xCGc44Uly8yMc4Oqd3H9pIfddMpHMzIyAgpYOpO8nN1KKcPwj/mZjwsmOdQtGOgsHWM/DSBHcPgv3sOKiSV2jUbuLIE3ntPqeYD4PI+XwHk60tXfQJzOjSwQpuHomT31jNt9fuTPthcN8Hkba4y0Wm0urKattYnROf8YNG0CHzw9ldUML3/rNNppb29NaOCLFxMNICbyHJAuL8pkxJocDVQ3sPlZHc2sHWZkZ/PPVU/nuq9s7nVfb2MKLd88z4YiAgOIhIv8ZwjXqVPWfe8kewwgb3yHJ12aM4n+/sK1TklvuwCwevXEGk/KzKfEKHLv5grHMn+Q/utQITLCex7XAj4Ic8zBg4mHEDe8AscLh2eyvqPcbMPbhgWpmjB3iEY/B/fpwz5cmxtxe99Aq2QkmHr9U1ecCHSAiQ3vRHsMIC9+ktvG5A9h7vM7vsR8fquHIySYyxNXjuOdLE2Ma3BXL2iSxIKB4qOpjwS4QyjGGES18A8QOVDWysCjfb8DY/op6zrR18OLd82I+VIllbZJYEbDvJCLnisg1Xtu/FJFnnb/Z0TfPMILjHSBWUlnPlJGD/Ca5NTmzKvHwccSyNkmsCDbw+hngXejgCmA1roWbgvlCDCMm+CbQjR3anyWLpnDXxRO4YPxQhvTvS5+MDB65YVpcZlVStf5pMPEoUNVNXtt1qvpbVf1vwFzURkwJVOTHnXfy/J1z+fhwLQ++voM/7jnB7mN11DW10tLewZGa+FQ5j6Q2STIQzOpOFVBUdb7X5vDeN8cwuhJOkR8Fz6/8oZONNLa04w4Ni+evfDi5N8lCsNmWYyIyT1U/9G4UkfnAseiZZRguQnU0uqc/3VXOe5ph29uEknuTbAQTj+8Dr4jICmCb03Y+rgWqb46iXYYBfOFonJSfzYS8ARyoaqTEmfK8/9LCLtOfc8cPZdWOrr9rifAr75vSn+wEm6rdIiLzgL8F/sZp3g3MV9UTUbbNSHPOtLaz40gtP71+Gvsr6tl7vI6FRfnc/aUJrC+uoKTiNDf91+ZOvZIMgaw+GTx28wzKapsT8lc+FYQDQsttGQXsAF5S1b1RtscwPEltTa1t3H3JRO7774+7hJovu/183vz0WJfpzw6Fr88azXWzxgCkzK98IhIszuNHwKvADcBqEbknJlYZacvBqnq2HaqhpLKBtXsr2VBcyYNXFDF0QF/PMdUNLRyubmTroRoAzh42gAFZmYiz//DJRo9j1IQjegTredwMzFTVRhHJBd4Bno6+WUa6crSmiZ++va9LT+N7V05hycqdnuM2lVYxb0Iuf/kX+fx6fQnNre1cNa2Aiyfn0djSZqIRA4L9C59R1UYAVa0O4XjDiJi29g427q/yG4m5v6KeSV4+i8H9spgyMpufv7OPU02tdCis3nmcR9cUM39ibqxNT0uC9TwmishbznsBJnlto6rX+D/NMCJjx9FTftvdiyuVVNaTOzCLSfkD+d5vd9LhUwivuqGF9cWVnDtqSAysTW9CScn35tFoGWIYfTIzmD8x12+MxqyxQzlxuomHrihi+pgh3P/CNurPtPm9zqaSKnOUxoBgU7UbIr2wiPQD3gfOcu7zuqr+i4hMAF4GcoGPgb9W1Zbur2SkAqHWsLh6egHPbTrYpdbo9bNHc/awAVQ3tHDL05tpbe/gulmjWbmtrMs1kjnkO5kIVklsR6D9qjo9wO4zwGWqWi8ifYGNIvI28B1cdUJeFpGngLuAJ8O020gSwq1hESgS07vK+XPfnEdedhYbiiu7CE28g8HShYDV00XkU1zpAi8CvweavPer6qGQbiIyANgIfBtXVu5IVW0TkQuBH6vqFYHOt+rpyUl3FctDrWHhXQW9u+URymoa2fBZJat3Ho9qMFiqVP/qjl6vnq6qM0VkCnArLgHZ47z+j6r6H3B2NigT19CkEHgCKAFqvc49Cozu5tx7gXsBxo0bF9KHMRKLQDUs7r+0MOj5gYTDt0fzb9ecy6Th/ley7wmpVv2rNwlr3RYRuRmXCPxcVZeGcV4O8AbwQ2CFqhY67WOBt1X1vEDnW88j+eit9WO9hWP5HXO4cFJej3s0oRKr+yQCkfQ8gv7vichoEfmuiGwEvgH8I2H6KFS1FlcBoQuBHBFx93jGAF09XkbS0xs1LNzCcay2iWtnjuLx9/bz4oeHWLXjeEyqcqVi9a/eJFh4+gZcvo6+wJ24smlXA1kiErAkk4jkOz0ORKQ/8GVgLy4RWewcdgfwZk8+gJG49KSGhbdwZGVm8NKWI2wqqea9fRVsLu3am4HerdeRqtW/epNgcR5n43KYfgvH/+AgTnuguvUFwHOO3yMDeFVVV4nIHuBlEfkJ8AmwPFLjjcTAnzOxrb0j4hoW3kOVr88azUtbjnj2BSpw3JtTtL6FlaN1n2QmmMN0fKQXVtUdwCw/7aXA3EivayQO/pyJGQKrd3ZuC6eGha+P4/H39nfaX1JZz91fmkDuwKyoT9EuOm8kz248YFPB3RBsqnakqgYc4IVyTE8xh2ni0Z0zccmiKTz4+o5ObaE6GP3Nqjyxbj9L1xR3KgZ0suEMj986i+1HT0W9XodbIBOxLkhvEo2Frv8ABFtiIZRjjBSirb2DzaXVfp2Je8tPd1rSMdSp2e7iOL46bSQjBp3F3vLTnmJA54wcxJih/bl4cn7Uw9BTrfpXbxJMPGaIiP/lt1wIEGi/kUJ4D1OmjxnCT6+fxiPv7KOmsdVzjHcCm5tguSbdCQe4ivv4S9F/7b4LgdjV6zDh6Eown0dmrAwxEhO3M9RfIWJ/dTamjBzM+uLKTtcI5GAMJBzQ80AzI3qYnBp+8V7uIFBshXedjdyBWZwzclCnXkcgB2Mw4bDp0sQmlBqmRprh28sYkJVJY0u732P3ldex6LwR9M8a7ZlteeiKoqAOxmDCATZdmuiYeBhd8B0qBIutuO+SiSh4Yj2CORhDEQ43Nl2auIQkHiIyCTiqqmdEZCEwHXjeCTs3Ugh/Q4VAsRULi/J56v3SLolj3QUAhCMckJqLJaUKISXGOan5c4DxuKZm3wTOVdWromqdg8V5xBZ3bIU3Qwf07RJbsbAon79/8RNKqho8x+UOzOJXt8zk1+tLumShhiscvnin6Bu9S1QS4xw6nDT6rwOPq+pDuMLPjRTEX05Khgijcvp7FpO+/9JC1hdXdhIOcDlR1xVXcqLuDEvXFHPjUx9QWlkfknAEWsgabLo00QjV59EqIrfiSmT7mtPWN8DxRhITbKiQmZkRcCbEO9ajuqGF1z4+yprd5d0Kh9XMSE5CHbZMBe4DPlDVl5w6pDep6s+jbSDYsKW3iKQaVqChgr/hDcBdF09w9UqcKdv+fTMQkW6FI11qZiQyURu2qOoeVf17VX3J2T4QK+Eweo53zMYT6/ZT6hWHEQy3cPgbUnSXcl84PLtTrEdbh3Y7VLGaGclLqLMtC4Af40rR74OTkq+qgVLyjTjh3cPwFxn67MYDIf+yBxpS+A5v5k3IZdSQfvzHHzovabx08fRufRyBgsAsnySxCdXnsRxXBbGPAf/RQkbc8f2iXzOjoEfh3aEIj2/iWGllPbfMHceKPx+grUNZuni6Z9FpXywILLkJVTxOqerbUbXE6BH+vuifnzhNxekzfo8P5Zc9HOFxXyf7rD6s2V2OiPDC3fOCTsdaEFjyEqp4rBORpcBKXOuxAKCq26JilRE2/r7oO8vqWDRtZES/7OEMKdzDpEjiOCwILHkJVTzmOa/e3lgFLutdc4xI6O6LXlJZz9SCQRFV3QplSOE9TJoxNodV249R3dASdgCY1cxITkISD1W9NNqGGJET6It+/FRzxL/sgYYU/oZJAI/dPCPsyFE3JhzJRaizLUOAfwEucZo2AP+mqv6XNDdiTndf9EuLhgOu8PKZY3IYOqBrbF938R8T87N55VvzWbP7RBfheWLd/i7DJICy2uZe/FRGIhPqsOVZYBdwk7P918D/A66PhlFG+HTnO8gQuOFJ/0FYQLfTsN5DkqunF7D0humMGjoAsClWw0Wo4jFJVW/w2v5XJ1nOSCD8+Q789RCqG1pYteM4Gz6r5ONDNUDnaVjAb9Uw9xRtn8wMZozNsSnWNCfU/+UmEbnYveEEjTUFON6II96zIN31ED48UE2OzxCmuqGFzaXVQaM+K+qaWbX9WJdr2hRrehFqz+PbuBZwGoIruvQk8DfRMsroHQI5UqeNHsK7eyq6tB+rbWLbYf9lWjaVVHH9zFHc9uwWqhtaeOzmGZTVNtsUa5oS6mzLp7gqqQ92tq1iepLQnSP14sI8ntpQ2uX4UTn96Z/Vx6/gTB+Tw23PbukSx2E+jvQkoHiIyDdU9Tci8h2fdgBU9RdRtM3oBQI5Uv3Ff8yfmAvQRXCG9u/bbRyHP+GIJIPXSC6C9TwGOq+D/OwLnstvJATdBWEFiv/w3jd9TOAAMN9EPKvNkR6EWs9jgar+OVhbtLB6HtElUM2O4zWNfocq0FUouitLaLU5Ep9oliF8PMQ2IwkJVOU8kHDc+NQHLF1TzKaSapauKeb25Vu4+5LOVRqsNkfqEszncSFwEZDv4/cYDNhqcilMpCu5uReBCme5SSM5Cfa/mQVk4xKZQV5/dcDi6Jpm9JRgBYW7oycrubnrl3pjgWOpSbC1ajcAG0RkhaoeipFNRoR4ryvrz2kZygxIT1dym1owmPf2fbFWrQWOpS6hBok9IyI3uhd5EpGhwMuqekX0TDNCxVss5k90lQJ85k+l1DS2svd4HSMGncWqHcfZXFodcAakN1Zyu27WaHIGZFngWBoQ6mzLJ6o6K1hbtLDZlu7jJrqrPv7gFUUsWbmTn14/jUfXFAetTh5uIZ+DVfVsPVjD3vLT7CuvY8rIwZwzchBzxg9lfF62LdCUZER10ScRGed1o7OxOI+YEKzyeSDH5WVFw9lfUR+0OnkkFcBW7yznwdd3sL64kn59M1lfXMmDr+9g9U7XdU04Up9Q/4f/CdgoIv8tIr8B3geWBDpBRMaKyDoR2SMiu0XkAad9mIi8KyKfO69De/YRUhd/06HuFdgguONyxrgh7D3uP5NgU0kV7e0dEQmH931LKutZu7fCM7vivq6R+oS6bss7wGzgFeBl4HxVXRPktDbgu6o6FZgP3O8sHvUwsFZVJwNrnW3DD8GyW92OS39MGTmYTw+f4pyCwX73XzQpj+qGFo9wLL9jTlgVwK6e7n+1UZtZSR8C/i+LyBTndTYwDjjm/I1z2rpFVY+7CySr6mlgLzAauBZ4zjnsOeC6nnyAVCVYwR33r3t3Cy9dXJhHS3s7Fxfm+d0/d/xQbnl6M8dqm7h25igef29/0AWhvIdQVfUtPLp4eqfKZDazkl4EdJiKyNOqeo+IrPOzW1U1pALIIjIe11DnPOCwquY47QLUuLd9zrkXuBdg3Lhx5x86lH4zxd0t5/jQFUWdlj5wz7ZsKqli2ughnJ07kFe3HmHYwCxONrRw05yxHKpuYGfZKaaNHsK5owbzyJpiKk+fISszg7rmNs+1ugsn784x+6tbZvLkhhKbWUlyInGYhjTb0hNEJBtXzdP/UNWVIlLrLRYiUqOqAf0e6TrbEu46ru3tHby45TA/fHN3l30PLyriSHUTG/dXcehkIxkCi88fw6tbj3Y51lecILCQWfRo8hOJeAQLTw9Yo1RVVwY5vy/wW+AFr2NPiEiBqh4XkQKga0UaAwh/TRPFFaTlL9V+SP8sfrbliy//rHE5HK3xXwzOO5zcHaUarGapkX4ECxL7mvM6HFeOy3vO9qXAJlyLQPnFGZIsB/b61P14C7gD+Jnz+mb4ZqcPoaxp4rt+yhO3zWbj51V8cqSGaaNzmDZ6MD94Y6fn+OyzMvnmggnsOV7HppJqJuVnMyFvAAeqGimprOeiSXkcO9XEW9uPewogz5+YazVLjU4EC0+/E0BE/geYqqrHne0CYEWQay/AVWV9p1ex5B/gEo1XReQu4BBfVGQ3AhBIOHyLFb/60RF+ePVU9pbXUVx+mlNNLZxq+sKv8U9fncqP3tzND756Do8uns7e8tPsPV7HwqJ8vv2XEzlvzBCue2JTp2s+unh6RItHGalLqOHpY93C4XAC1+xLt6jqRlz1Tv1xeYj3NYLQ3XTuzrJTHHR6EvmDzvLsKxye7Qkc6+hQfvb2vi5V0h+/dVaXa/7HH/by+K2z2H70lIWeG0Do4rFWRNYALznbNwN/jI5JRqgECxL72oyRPP/BYU43t3qKFTe1tLHtcC2Fw7PZV37ar/C8/3lll7T6msZWntxQwvN3zjUHqQGEXgD5b0Xk63yxYtwyVX0jemYZoRAou3Vi3kB+s/kwjS1tPP/NL1arb2/v4Kn3S/nkcE230ac7y04xPm9AJ/EA828YnQnnSdgGrFbVfwTWiIi/uqZGjFlYlN8lCGxo/768s+sEVfUtZGVmkJf9xf7MzAwWnTeSmsbWbqNP503IpbaxtVOb+TcMX0Jdq/YeXAFbw4BJuCJFn8J8F1Ej1Orjm0urefCKIg5UNbD72CnGDRvAH/dUUFl/BoC65jbe3lXeKW5jYn42//BXk2lrV373SVkXJ+jV0wu4enpBRItjG+lDqD6P+4G5wIcAqvq5iAyPmlVpTDjVx9vaO1i7t4JNJdX89fxxTM7P5oUth2lt7xz451sGsKymkSfXl9DU2s5Pvn4enxyuZfexU0wZOZjzz87h7GEDyMzMCDpFbKQ3oYrHGVVtca/XIiJ9sJT8XsfftKt7/Vh/AuLt83j/sypqm1q7CAd09VVs+KyScwoGs3zjAb79m21Mys9mfN4A1hdXMmxgVqdjTTiM7gj1ydggIj8A+ovIl4HXgN9Hz6z0JFgWrT8WnTeSof37cuhkI00t7Qzu1/n3wNdX0dbewaodxykcnu3xlbjT6msbW7jy3BG9+ImMVCbUnsf3gbuBncC3gD8Az0TLqHQkWBat7/DB7RPJPqsP2f36UN/SxgN/Vch5o3P4oKSKnWWnmDdhGFdPH9Wp1+LurTzyzj6+d+UU9lfUeyqBXVqUz6Th5gc3QiOoeIhIJrBbVacAT0ffpPQk0LSr97DDNxTdvZLb0sXT+fdVe6luaPEMQzZ8VsXsca6cQ28BcdcfXbJyp+fYT4/Uctu8gHF/htGJoOKhqu0iUiwi41T1cCyMSle6KyrsHnb484kAngAwd3tJZb0nRmNdcSWfHqll6eLpHgHxTbibPW6ozaYYYRPqsGUosFtEtgCetQRV9ZqoWJWmBMuiXbXjONUNLZw9bACV9WdoamlHgcMnGzl8stHvNfeV15EzoK/f6VqbTTF6Qqji8cOoWmF46O5L3dbewe6yUyxZNIVfry+hubWdq6YVcPHkPNYXV3DD7DG8/nFZl+tNGTmY9cWVNLe2+xUKEw4jUoLV8+gH3AcU4nKWLlfVtkDnGL2Dvy/1VdNG8o+vbqfDmY1dvdO1FssvbppBzoAsv1mvhcOzWb7xANfPHm1CYfQqwXoezwGtwJ+ARcBU4IFoG5VuhBJNerKhhR//fo9HONxUN7TwyZFapo8ewhO3zWZzSTUfHTrJlJGDKRyezSPv7LPQciMqBBOPqao6DUBElgNbom9S+hBqNGlFXTM3L9vMqaZWP1eBjw6e5NqZo1j85AecnTuAv7tsMvvK61i14xh3XjSeq2eMMmeo0esEEw/P06qqbe4IU6PnhBpN+mFpFd9+4RNONbVy3azRrNzW1a9x0aQ8PiipprqhheqGFu5c8ZFnCjZv0FkmHEZUCDYIniEidc7faWC6+72I+M/nNkLCPXPiTXVDC6t2uGouldU08vbO49z69IecbGihvUO5YPwwv8soXHHuCM95btxRo6t3HrdFmIyoEKwMYWasDEkn2to72FzaNRgM4MMD1fxxzyB+9+kxNu6v6uTjcEeFltU28cnhmk5TuaEEmBlGb2JPVZyYPmaI3/Zpo4fwh13lvLevgjofH0dNYytLVu7kRF0T910yibOH9ffs627xJ3OUGtEi1DgPoxfpk5nBxYV5vLb1aJep1aIRg1i+8QBt7cpV0wpYvfN4l/OHD+rHm9vLGNI/i+bWDjIk/GUaDKOnmHjEiTFD+7Nk0RT2lp/2JKaNHtKP//P2Pk9a/cKifDaXVncRmDFDB/DEuhLP9q9umcn4vGyLGjViiolHDwm14pcv4/Oy6VDo1zeDqQWDaG5t5/+uK6Hy9BnPMRkZ0klgZo7NYczQATzyzj7PMdUNLWzcX8WFE3M9gmHCYcQCE48ICafily/egnPoZBPr9lVQWtVAY0sbo4b049ipZgqHZ7PnWB3LNx5gUn4218wo4EhNo6fH4c3OslO9+tkMIxRMPCIg3Ipf3ue5BWf+xFxGDenHsvdLPAsyDe7Xh6fvmMP64krPEgngmnZ9a/txFhbl+73uBeOHWW/DiDkmHhEQqOKX7wLRbvwJztD+fcnKzARc4lHX3MbavRX8/eWTPUskuKdfSyrruftLE/zmr0wZOYj29g4TECOm2NMWJsEqfnUXkOVPcGqaWqlpbGHUkC+mXD88UO0RAt/p10fe2ceSRVN44PJCFhTmcu8lE3nwiiLKaptMOIyYYz2PMAm14pc3gQRnSsEgRgzux7FTrhXrp4/J8ezznX6dNyEXgD99XsXQgVmeuqOv3Xdhb3w0wwgLE48ICFbxy5dAgjNvQi7riys91/jK1BGdBMh3+rW0sp4Tp5IjfPAAAApVSURBVM+wqaSK62ePtlgOI26IauKvoDBnzhzdunVrvM3ohNv5GWpAVmllPTf8ehM1XlGjuQOzePTGGTyzsdSTQn+6uZV7L5kU9P7m4zB6ExH5WFXnhHOO9TwiJNyALO8q50UjB3FxYR5n5w7kP9/7nGEDs1hfXMnyjQdYUJjLXQsmBL2mCYcRb0w8ekgoX+KKumZueXoz1Q0tvHD3fM4fl8MrW4+wZOXOLsdaIpuRLNhTGmXcwlF+qpkVd85l7gRXTMb8ibmWyGYkNdbziCL+hMONJbIZyY45TKNEIOHwxZyfRryJxGEatSdWRJ4VkQoR2eXVNkxE3hWRz53XodG6fzwJRzjAnJ9GchLNp3YFcKVP28PAWlWdDKx1tlOKcIXDMJKVqImHqr4PnPRpvhbXcg44r9dF6/7xwITDSCdi3V8eoaru0ljlwIjuDhSRe0Vkq4hsraysjI11PcCEw0g34jbYVpentltvraouU9U5qjonP99/KnqiYMJhpCOxFo8TIlIA4LxWxPj+vY4Jh5GuxFo83gLucN7fAbwZ4/v3KiYcRjoTzanal4APgCIROSoidwE/A74sIp8Df+VsJyUmHEa6E7UIU1W9tZtdl0frnrHChMMwLLclbEw4DMOFiUcYmHAYxheYeISICYdhdMbEIwRMOAyjKyYeQTDhMAz/mHgEwITDMLrHxKMbTDgMIzAmHn4w4TCM4Jh4+GDCYRihYeLhhQmHYYSOiYeDCYdhhIeJByYchhEJaS8eJhyGERlpLR4mHIYROWkrHiYchtEz0lI8TDgMo+eknXiYcBhG75BW4mHCYRi9R9qIhwmHYfQuaSEeJhyG0fukvHiYcBhGdEhp8TDhMIzokbLiYcJhGNElJcXDhMMwok/KiYcJh2HEhpQSDxMOw4gdKSMeJhyGEVtSQjxMOAwj9iS9eJhwGEZ8SGrxMOEwjPiRtOJhwmEY8SUpxcOEwzDiT9KJhwmHYSQGSSUeJhyGkTgkjXiYcBhGYhEX8RCRK0WkWET2i8jDwY5va1cTDsNIMGIuHiKSCTwBLAKmAreKyNRA55RW1ZtwGEaCEY+ex1xgv6qWqmoL8DJwbaATWtvVhMMwEow+cbjnaOCI1/ZRYJ7vQSJyL3Cvs3lm3sTcXTGwrTfIA6ribUQYJJO9yWQrJJe9ReGeEA/xCAlVXQYsAxCRrao6J84mhUQy2QrJZW8y2QrJZa+IbA33nHgMW8qAsV7bY5w2wzCSiHiIx0fAZBGZICJZwC3AW3GwwzCMHhDzYYuqtonI3wJrgEzgWVXdHeS0ZdG3rNdIJlshuexNJlshuewN21ZR1WgYYhhGipM0EaaGYSQWJh6GYUREQotHuGHssUZEnhWRChHZ5dU2TETeFZHPndeh8bTRjYiMFZF1IrJHRHaLyANOe6La209EtojIdsfef3XaJ4jIh84z8YrjdE8IRCRTRD4RkVXOdiLbelBEdorIp+5p2nCfhYQVj0jC2OPACuBKn7aHgbWqOhlY62wnAm3Ad1V1KjAfuN/590xUe88Al6nqDGAmcKWIzAd+DvxSVQuBGuCuONroywPAXq/tRLYV4FJVnekVixLes6CqCfkHXAis8dpeAiyJt11+7BwP7PLaLgYKnPcFQHG8bezG7jeBLyeDvcAAYBuuSOQqoI+/ZyTONo5xvnCXAasASVRbHXsOAnk+bWE9Cwnb88B/GPvoONkSDiNU9bjzvhwYEU9j/CEi44FZwIcksL3OMOBToAJ4FygBalW1zTkkkZ6Jx4DvAR3Odi6JayuAAv8jIh87qSAQ5rOQsOHpqYCqqogk1Fy4iGQDvwX+QVXrRMSzL9HsVdV2YKaI5ABvAFPibJJfRORqoEJVPxaRhfG2J0QuVtUyERkOvCsi+7x3hvIsJHLPI1nD2E+ISAGA81oRZ3s8iEhfXMLxgqqudJoT1l43qloLrMPV9c8REfePXqI8EwuAa0TkIK4s8cuAX5GYtgKgqmXOawUuYZ5LmM9CIotHsoaxvwXc4by/A5dvIe6Iq4uxHNirqr/w2pWo9uY7PQ5EpD8u/8xeXCKy2DksIexV1SWqOkZVx+N6Tt9T1dtIQFsBRGSgiAxyvwe+Auwi3Gch3o6bIE6dq4DPcI11/yne9vix7yXgONCKa0x7F66x7lrgc+CPwLB42+nYejGuce4O4FPn76oEtnc68Ilj7y7gR077RGALsB94DTgr3rb62L0QWJXItjp2bXf+dru/W+E+CxaebhhGRCTysMUwjATGxMMwjIgw8TAMIyJMPAzDiAgTD8MwIsLEwzCMiDDxSHBEJNdJm/5URMpFpMxru8cp3iLyLyLyU5+2mSKyN8A5PxaRB3t67wDXd6eLz3G214vIYfGKpReR34lIvfN+vIg0Of8me0TkKRHJcPZNFpFVIlLi5HGsE5FLnH03O+nyq6L1WVIZE48ER1Wr1ZU2PRN4CleK90znr8Ur/DlSXgJu9mm7xWmPJ5eqqvdyALW4wsBxIk8LfI4vcf6NpuMq4XCdiPQDVgPLVHWSqp4P/B2uIClU9RXg7uh+jNTFxCMJEZEVzq/rh8Ajvj0BEdnlZM4iIt9wiup8KiL/5dRJ8aCqnwE1IuK98NZNwEsico+IfOQU5PmtiAzwY8t6rx5CnpPf4c6IXeqcv0NEvuW0F4jI+449u0TkSyF+7JdxiRrA9cBKfwepK4t1E1AI3AZ8oKpvee3fpaorQrynEQATj+RlDHCRqn6nuwNE5BxcvYoFzq9yO64vlC8v4XwxnYI7J1X1c2Clql6groI8ewmvmM1dwClVvQC4ALhHRCYA/wtXXYuZwAxcYfKhsBa4xBG/W4BX/B3kCNzlwE7gXFx1QIwoYCn5yctr6kpZD8TlwPnAR467oD/+MyVfATaJyHfpPGQ5T0R+AuQA2biWywiVrwDTRcSdGDYEmIwr4fFZJ8P3d6oaqni0Axsd+/qr6kHvcgLAJKf2hwJvqurbIvJl7wNE5A3Hhs9U9fowPovhBxOP5KXB630bnXuR/ZxXAZ5T1SWBLqSqR0TkAPCXwA24Ut/BVWbxOlXdLiJ/gyvpyxfve/fzahfg71S1i+A4DsuvAitE5Beq+nwg+7x4GVf6+I/97HP7PLzZDVzi3lDVrztDrEdDvJ8RABu2pAYHgdkAIjIbmOC0rwUWOwVf3AVuz+7mGi8BvwRKVfWo0zYIOO70EvwNd9z3Pt95v9irfQ3wbedcROQvnFTws4ETqvo08Izb7hD5E/BTQnfmvggsEJFrvNq6+G2MyLCeR2rwW+B2EdmNq7TgZwCqukdE/hlXubkMXKUD7gcO+bnGa8B/4pqNcPND53qVzusgP+c9CrwqrlJ2q73an8FV33WbM8VaCVyHq/fykIi0AvXA7aF+SHWlgIfca1DVJnFV+fqFiDwGnABOAz8J9RpG91hKvpFwODM2c1S1Kgb3Wgg8qKpXR/teqYYNW4xEpBJY654CjhYicjPwa1zLIhhhYj0PwzAiwnoehmFEhImHYRgRYeJhGEZEmHgYhhER/x89paLFxrVANQAAAABJRU5ErkJggg==",
"text/plain": [
"| \n", " | MPG | \n", "Cylinders | \n", "Displacement | \n", "Horsepower | \n", "Weight | \n", "Acceleration | \n", "ModelYear | \n", "Origin | \n", "
|---|---|---|---|---|---|---|---|---|
| 0 | \n", "18.0 | \n", "8 | \n", "307.0 | \n", "130.0 | \n", "3504.0 | \n", "12.0 | \n", "70 | \n", "1 | \n", "
| 1 | \n", "15.0 | \n", "8 | \n", "350.0 | \n", "165.0 | \n", "3693.0 | \n", "11.5 | \n", "70 | \n", "1 | \n", "
| 2 | \n", "18.0 | \n", "8 | \n", "318.0 | \n", "150.0 | \n", "3436.0 | \n", "11.0 | \n", "70 | \n", "1 | \n", "
| 3 | \n", "16.0 | \n", "8 | \n", "304.0 | \n", "150.0 | \n", "3433.0 | \n", "12.0 | \n", "70 | \n", "1 | \n", "
| 4 | \n", "17.0 | \n", "8 | \n", "302.0 | \n", "140.0 | \n", "3449.0 | \n", "10.5 | \n", "70 | \n", "1 | \n", "
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
}
],
"source": [
"a = plt.axes(aspect='equal')\n",
"sns.scatterplot(test_df['MPG'].values, mpg_hat_df['MPG_predictions'].values,\n",
" s=50)\n",
"plt.xlabel('True Values [MPG]')\n",
"plt.ylabel('Predictions [MPG]')\n",
"lims = [0, 50]\n",
"plt.xlim(lims)\n",
"plt.ylim(lims)\n",
"_ = plt.plot(lims, lims)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Compare K-fold Cross Validation metrics against hold-out test metrics"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Hold-out Test Metrics"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'loss': 8.303831,\n",
" 'error': -0.45136052,\n",
" 'mean_squared_error': 8.303831,\n",
" 'mean_absolute_error': 2.2274728,\n",
" 'r2': 0.8558148}"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_stats['MPG']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### K-fold Cross Validation Metrics"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'loss_mean': 8.111681,\n",
" 'loss_std': 2.4598064,\n",
" 'error_mean': 0.0380627,\n",
" 'error_std': 0.5965346,\n",
" 'mean_squared_error_mean': 8.111682,\n",
" 'mean_squared_error_std': 2.4598064,\n",
" 'mean_absolute_error_mean': 2.0598435,\n",
" 'mean_absolute_error_std': 0.2779836,\n",
" 'r2_mean': 0.8666786,\n",
" 'r2_std': 0.03552912}"
]
},
"execution_count": 20,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"kfold_cv_stats['overall']['MPG']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: examples/lbfgs/config.yaml
================================================
input_features:
- name: RESOURCE
type: category
- name: MGR_ID
type: category
- name: ROLE_ROLLUP_1
type: category
- name: ROLE_ROLLUP_2
type: category
- name: ROLE_DEPTNAME
type: category
- name: ROLE_TITLE
type: category
- name: ROLE_FAMILY_DESC
type: category
- name: ROLE_FAMILY
type: category
- name: ROLE_CODE
type: category
output_features:
- name: ACTION
type: binary
preprocessing:
split:
type: fixed
defaults:
category:
encoder:
type: sparse
trainer:
batch_size: 32769 # entire training set
train_steps: 1
steps_per_checkpoint: 1
learning_rate: 1
regularization_lambda: 0.0000057
optimizer:
type: lbfgs
max_iter: 100
tolerance_grad: 0.0001
history_size: 10
================================================
FILE: examples/lbfgs/model.py
================================================
import logging
import pandas as pd
from ludwig.api import LudwigModel
from ludwig.datasets import amazon_employee_access_challenge
df = amazon_employee_access_challenge.load()
model = LudwigModel(config="config.yaml", logging_level=logging.INFO)
training_statistics, preprocessed_data, output_directory = model.train(
df,
skip_save_processed_input=True,
skip_save_log=True,
skip_save_progress=True,
skip_save_training_description=True,
skip_save_training_statistics=True,
)
# Predict on unlabeled test
config = model.config
config["preprocessing"] = {}
model.config = config
unlabeled_test = df[df.split == 2].reset_index(drop=True)
preds, _ = model.predict(unlabeled_test)
# Save predictions to csv
action = preds.ACTION_probabilities_True
submission = pd.merge(unlabeled_test.reset_index(drop=True).id.astype(int), action, left_index=True, right_index=True)
submission.rename(columns={"ACTION_probabilities_True": "Action", "id": "Id"}, inplace=True)
submission.to_csv("submission.csv", index=False)
================================================
FILE: examples/llama2_7b_finetuning_4bit/README.md
================================================
# Llama2-7b Fine-Tuning 4bit (QLoRA)
[](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
This example shows how to fine-tune [Llama2-7b](https://huggingface.co/meta-llama/Llama-2-7b-hf) to follow instructions.
Instruction tuning is the first step in adapting a general purpose Large Language Model into a chatbot.
This example uses no distributed training or big data functionality. It is designed to run locally on any machine
with GPU availability.
## Prerequisites
- [HuggingFace API Token](https://huggingface.co/docs/hub/security-tokens)
- Access approval to [Llama2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf)
- GPU with at least 12 GiB of VRAM (in our tests, we used an Nvidia T4)
## Running
### Command Line
Set your token environment variable from the terminal, then run the API script:
```bash
export HUGGING_FACE_HUB_TOKEN=""
./run_train.sh
```
### Python API
Set your token environment variable from the terminal, then run the API script:
```bash
export HUGGING_FACE_HUB_TOKEN=""
python train_alpaca.py
```
## Upload to HuggingFace
You can upload to the HuggingFace Hub from the command line:
```bash
ludwig upload hf_hub -r / -m
```
================================================
FILE: examples/llama2_7b_finetuning_4bit/llama2_7b_4bit.yaml
================================================
model_type: llm
base_model: meta-llama/Llama-2-7b-hf
quantization:
bits: 4
adapter:
type: lora
input_features:
- name: instruction
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0003
batch_size: 2
gradient_accumulation_steps: 8
epochs: 3
learning_rate_scheduler:
warmup_fraction: 0.01
backend:
type: local
================================================
FILE: examples/llama2_7b_finetuning_4bit/run_train.sh
================================================
#!/usr/bin/env bash
# Fail fast if an error occurs
set -e
# Get the directory of this script, which contains the config file
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
# Train
ludwig train --config ${SCRIPT_DIR}/llama2_7b_4bit.yaml --dataset ludwig://alpaca
================================================
FILE: examples/llama2_7b_finetuning_4bit/train_alpaca.py
================================================
import logging
import os
import yaml
from ludwig.api import LudwigModel
config = yaml.safe_load("""
model_type: llm
base_model: meta-llama/Llama-2-7b-hf
quantization:
bits: 4
adapter:
type: lora
input_features:
- name: instruction
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0003
batch_size: 2
gradient_accumulation_steps: 8
epochs: 3
learning_rate_scheduler:
warmup_fraction: 0.01
backend:
type: local
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset="ludwig://alpaca",
experiment_name="alpaca_instruct_4bit",
model_name="llama2_7b",
)
# list contents of output directory
print("contents of output directory:", output_directory)
for item in os.listdir(output_directory):
print("\t", item)
================================================
FILE: examples/llm_base_model_dequantization/README.md
================================================
# Convert quantized base model to fp16
Ludwig has utility functions to convert nf4 quantized bitsandbytes base models back to fp16
for more efficient inference. This is desireable since inference with bitsandbytes is slow because
every forward pass through the model requires dequantizing the model weights from nf4 to fp16 layer
by layer and then quantizing it back to nf4 to keep memory usage constant.
By dequantizing the base model in fp16 upfront, you can get the same effect of the quantized weights
without sacrificing on inference performance.
## Visual Illustration
### Without dequantization upfront
| **Request 1:** | **Request 2:** | **Request 3:** |
| ------------------------------------------ | ------------------------------------------ | ------------------------------------------ |
| - Quantized bitsandbytes model | - Quantized bitsandbytes model | - Quantized bitsandbytes model |
| - Dequantization of layer 1 (nf4 to fp16) | - Dequantization of layer 1 (nf4 to fp16) | - Dequantization of layer 1 (nf4 to fp16) |
| - Forward Pass (using dequantized weights) | - Forward Pass (using dequantized weights) | - Forward Pass (using dequantized weights) |
| - Quantization of layer 1 (fp16 to nf4) | - Quantization of layer 1 (fp16 to nf4) | - Quantization of layer 1 (fp16 to nf4) |
| - Dequantization of layer 2 (nf4 to fp16) | - Dequantization of layer 2 (nf4 to fp16) | - Dequantization of layer 2 (nf4 to fp16) |
| - Forward Pass (using dequantized weights) | - Forward Pass (using dequantized weights) | - Forward Pass (using dequantized weights) |
| - Quantization of layer 2 (fp16 to nf4) | - Quantization of layer 2 (fp16 to nf4) | - Quantization of layer 2 (fp16 to nf4) |
| - ... | - ... | - ... |
| - Final Output | - Final Output | - Final Output |
### With dequantization upfront
| **Request 1:** | **Request 2:** | **Request 3:** |
| -------------------------------- | -------------------------------- | -------------------------------- |
| - Dequantized base model in fp16 | - Dequantized base model in fp16 | - Dequantized base model in fp16 |
| - Forward pass through layer 1 | - Forward pass through layer 1 | - Forward pass through layer 1 |
| - Forward pass through layer 2 | - Forward pass through layer 2 | - Forward pass through layer 2 |
| - ... | - ... | - ... |
| - Final Output | - Final Output | - Final Output |
## Running the example script
The example `phi_2_dequantization.py` shows how you how you can quantize and then dequantized Phi-2. This process
can be repeated for any other base model supported by Ludwig that is quantized using 4 bits nf4 bitsandbytes quantization. You will need a GPU to run the script successfully.
Beneath the surface, this script:
1. Loads the base model in 4 bit nf4 quantization
1. Dequantizes the model layer by layer back into fp16 in-place.
1. Write the new dequantized weights to disk at `save_path`
1. Write the tokenizer to disk at `save_path`
Make sure you update the paths at the top of the file for base model, save path, and huggingface repo ID!
## Bonus
If desired, you can also use Ludwig to push the new dequantized model weights straight to HuggingFace hub!
```python
from ludwig.utils.hf_utils import upload_folder_to_hfhub
upload_folder_to_hfhub(repo_id=hfhub_repo_id, folder_path=save_path)
```
### Dequantized base models already on huggingface hub
- [CodeLlama 7b Instruct](https://huggingface.co/arnavgrg/codallama-7b-instruct-nf4-fp16-upscaled)
- [CodeLlama 13b Instruct](https://huggingface.co/arnavgrg/codellama-13b-instruct-nf4-fp16-upscaled)
- [CodeLlama 70b Instruct](https://huggingface.co/arnavgrg/codellama-70b-instruct-nf4-fp16-upscaled)
- [Llama 2 7b](https://huggingface.co/arnavgrg/llama-2-7b-nf4-fp16-upscaled)
- [Llama 2 7b Chat](https://huggingface.co/arnavgrg/llama-2-7b-chat-nf4-fp16-upscaled)
- [Llama 2 13b Chat](https://huggingface.co/arnavgrg/llama-2-13b-chat-nf4-fp16-upscaled)
- [Llama 2 70b Chat](https://huggingface.co/arnavgrg/llama-2-70b-chat-nf4-fp16-upscaled)
- [Mistral 7b](https://huggingface.co/arnavgrg/mistral-7b-nf4-fp16-upscaled)
- [Mistral 7b Instruct](https://huggingface.co/arnavgrg/mistral-7b-instruct-nf4-fp16-upscaled)
- [NousMistral Yarn 7b 128K](https://huggingface.co/arnavgrg/NousResearch-Yarn-Mistral-7b-128k-nf4-fp16-upscaled)
- [Microsoft Phi-2](https://huggingface.co/arnavgrg/phi-2-nf4-fp16-upscaled)
- [Zephyr 7b Beta](https://huggingface.co/arnavgrg/zephyr-7b-beta-nf4-fp16-upscaled)
================================================
FILE: examples/llm_base_model_dequantization/phi_2_dequantization.py
================================================
import logging
import os
import yaml
from huggingface_hub import whoami
from ludwig.api import LudwigModel
from ludwig.utils.hf_utils import upload_folder_to_hfhub
hf_username = whoami().get("name")
base_model_name = "microsoft/phi-2"
dequantized_path = "microsoft-phi-2-dequantized"
save_path = "/home/ray/" + dequantized_path
hfhub_repo_id = os.path.join(hf_username, dequantized_path)
config = yaml.safe_load(f"""
model_type: llm
base_model: {base_model_name}
quantization:
bits: 4
input_features:
- name: instruction
type: text
output_features:
- name: output
type: text
trainer:
type: none
backend:
type: local
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
model.save_dequantized_base_model(save_path=save_path)
# Optional: Upload to Huggingface Hub
upload_folder_to_hfhub(repo_id=hfhub_repo_id, folder_path=save_path)
================================================
FILE: examples/llm_few_shot_learning/simple_model_training.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example
#
# This is a simple example of how to use the LLM model type to train
# a zero shot classification model. It uses the facebook/opt-350m model
# as the base LLM model.
# Import required libraries
import logging
import shutil
import pandas as pd
import yaml
from ludwig.api import LudwigModel
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
review_label_pairs = [
{"review": "I loved this movie!", "label": "positive"},
{"review": "The food was okay, but the service was terrible.", "label": "negative"},
{"review": "I can't believe how rude the staff was.", "label": "negative"},
{"review": "This book was a real page-turner.", "label": "positive"},
{"review": "The hotel room was dirty and smelled bad.", "label": "negative"},
{"review": "I had a great experience at this restaurant.", "label": "positive"},
{"review": "The concert was amazing!", "label": "positive"},
{"review": "The traffic was terrible on my way to work this morning.", "label": "negative"},
{"review": "The customer service was excellent.", "label": "positive"},
{"review": "I was disappointed with the quality of the product.", "label": "negative"},
{"review": "The scenery on the hike was breathtaking.", "label": "positive"},
{"review": "I had a terrible experience at this hotel.", "label": "negative"},
{"review": "The coffee at this cafe was delicious.", "label": "positive"},
{"review": "The weather was perfect for a day at the beach.", "label": "positive"},
{"review": "I would definitely recommend this product.", "label": "positive"},
{"review": "The wait time at the doctor's office was ridiculous.", "label": "negative"},
{"review": "The museum was a bit underwhelming.", "label": "neutral"},
{"review": "I had a fantastic time at the amusement park.", "label": "positive"},
{"review": "The staff at this store was extremely helpful.", "label": "positive"},
{"review": "The airline lost my luggage and was very unhelpful.", "label": "negative"},
{"review": "This album is a must-listen for any music fan.", "label": "positive"},
{"review": "The food at this restaurant was just okay.", "label": "neutral"},
{"review": "I was pleasantly surprised by how great this movie was.", "label": "positive"},
{"review": "The car rental process was quick and easy.", "label": "positive"},
{"review": "The service at this hotel was top-notch.", "label": "positive"},
]
df = pd.DataFrame(review_label_pairs)
df["split"] = [0] * 15 + [2] * 10
config = yaml.safe_load("""
model_type: llm
base_model: facebook/opt-350m
generation:
temperature: 0.1
top_p: 0.75
top_k: 40
num_beams: 4
max_new_tokens: 64
prompt:
task: "Classify the sample input as either negative, neutral, or positive."
retrieval:
type: semantic
k: 3
model_name: paraphrase-MiniLM-L3-v2
input_features:
-
name: review
type: text
output_features:
-
name: label
type: category
preprocessing:
fallback_label: "neutral"
decoder:
type: category_extractor
match:
"negative":
type: contains
value: "positive"
"neural":
type: contains
value: "neutral"
"positive":
type: contains
value: "positive"
preprocessing:
split:
type: fixed
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset=df, experiment_name="simple_experiment", model_name="simple_model", skip_save_processed_input=True
)
training_set, val_set, test_set, _ = preprocessed_data
# batch prediction
preds, _ = model.predict(test_set, skip_save_predictions=False)
print(preds)
================================================
FILE: examples/llm_finetuning/README.md
================================================
# LLM Fine-tuning
These examples show you how to fine-tune Large Language Models by taking advantage of model parallelism
with [DeepSpeed](https://www.deepspeed.ai/), allowing Ludwig to scale to very large models with billions of
parameters.
The task here will be to fine-tune a large billion+ LLM to classify the sentiment of [IMDB movie reviews](https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews). As such, we'll be taking a pretrained LLM, attaching a classification head,
and fine-tuning the weights to improve performance of the LLM on the task. Ludwig will do this for you without no machine learning
code, just configuration.
## Prerequisites
- Installed Ludwig with `ludwig[distributed]` dependencies
- Have a CUDA-enabled version of PyTorch installed
- Have access to a machine or cluster of machines with multiple GPUs
- The IMDB dataset used in these examples comes from Kaggle, so make sure you have your credentials set (e.g., `$HOME/.kaggle.kaggle.json`)
## Running DeepSpeed on Ray
This is the recommended way to use DeepSpeed, which supports auto-batch size tuning and distributed data processing.
There is some overhead from using Ray with small datasets (\<100MB), but in most cases performance should be comparable
to using native DeepSpeed.
From the head node of your Ray cluster:
```bash
./run_train_dsz3_ray.sh
```
### Python API
If you want to run Ludwig programatically (from a notebook or as part of a larger workflow), you can run the following
Python script using the Ray cluster launcher from your local machine.
```bash
ray submit cluster.yaml train_imdb_ray.py
```
If running directly on the Ray head node, you can omit the `ray submit` portion and run like an ordinary Python script:
```bash
python train_imdb_ray.py
```
## Running DeepSpeed Native
This mode is suitable for datasets small enough to fit in memory on a single machine, as it doesn't make use of
distributed data processing (requires use of the Ray backend).
The following example assumes you have 4 GPUs available, but can easily be modified to support your preferred
setup.
From a terminal on your machine:
```bash
./run_train_dsz3.sh
```
================================================
FILE: examples/llm_finetuning/imdb_deepspeed_zero3.yaml
================================================
input_features:
- name: review
type: text
encoder:
type: auto_transformer
pretrained_model_name_or_path: bigscience/bloom-3b
trainable: true
adapter: lora
output_features:
- name: sentiment
type: category
trainer:
batch_size: 4
epochs: 3
gradient_accumulation_steps: 8
backend:
type: deepspeed
zero_optimization:
stage: 3
offload_optimizer:
device: cpu
pin_memory: true
================================================
FILE: examples/llm_finetuning/imdb_deepspeed_zero3_ray.yaml
================================================
input_features:
- name: review
type: text
encoder:
type: auto_transformer
pretrained_model_name_or_path: bigscience/bloom-3b
trainable: true
adapter: lora
output_features:
- name: sentiment
type: category
trainer:
batch_size: 4
epochs: 3
gradient_accumulation_steps: 8
backend:
type: ray
trainer:
use_gpu: true
strategy:
type: deepspeed
zero_optimization:
stage: 3
offload_optimizer:
device: cpu
pin_memory: true
================================================
FILE: examples/llm_finetuning/run_train_dsz3.sh
================================================
#!/usr/bin/env bash
# Fail fast if an error occurs
set -e
# Get the directory of this script, which contains the config file
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
# Train
deepspeed --no_python --no_local_rank --num_gpus 4 ludwig train --config ${SCRIPT_DIR}/imdb_deepspeed_zero3.yaml --dataset ludwig://imdb
================================================
FILE: examples/llm_finetuning/run_train_dsz3_ray.sh
================================================
#!/usr/bin/env bash
# Fail fast if an error occurs
set -e
# Get the directory of this script, which contains the config file
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
# Train
ludwig train --config ${SCRIPT_DIR}/imdb_deepspeed_zero3_ray.yaml --dataset ludwig://imdb
================================================
FILE: examples/llm_finetuning/train_imdb_ray.py
================================================
import logging
import os
import yaml
from ludwig.api import LudwigModel
config = yaml.safe_load("""
input_features:
- name: review
type: text
encoder:
type: auto_transformer
pretrained_model_name_or_path: bigscience/bloom-3b
trainable: true
adapter:
type: lora
output_features:
- name: sentiment
type: category
trainer:
batch_size: 4
epochs: 3
backend:
type: ray
trainer:
use_gpu: true
strategy:
type: deepspeed
zero_optimization:
stage: 3
offload_optimizer:
device: cpu
pin_memory: true
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset="ludwig://imdb",
experiment_name="imdb_sentiment",
model_name="bloom3b",
)
# list contents of output directory
print("contents of output directory:", output_directory)
for item in os.listdir(output_directory):
print("\t", item)
================================================
FILE: examples/llm_instruction_tuning/train_alpaca_ray.py
================================================
import logging
import os
import yaml
from ludwig.api import LudwigModel
config = yaml.safe_load("""
model_type: llm
base_model: bigscience/bloomz-3b
adapter:
type: lora
input_features:
- name: instruction
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
batch_size: 4
epochs: 3
backend:
type: ray
trainer:
use_gpu: true
strategy:
type: deepspeed
zero_optimization:
stage: 3
offload_optimizer:
device: cpu
pin_memory: true
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset="ludwig://alpaca",
experiment_name="alpaca_instruct",
model_name="bloom560m",
)
# list contents of output directory
print("contents of output directory:", output_directory)
for item in os.listdir(output_directory):
print("\t", item)
================================================
FILE: examples/llm_text_generation/simple_model_training.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example
#
# This is a simple example of how to use the LLM model type to train
# a model on a simple question and answer dataset. It uses the
# facebook/opt-350m model as the base LLM model.
# Import required libraries
import logging
import shutil
import pandas as pd
import yaml
from ludwig.api import LudwigModel
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
qa_pairs = [
{"Question": "What is the capital of Uzbekistan?", "Answer": "Tashkent"},
{"Question": "Who is the founder of Microsoft?", "Answer": "Bill Gates"},
{"Question": "What is the tallest building in the world?", "Answer": "Burj Khalifa"},
{"Question": "What is the currency of Brazil?", "Answer": "Real"},
{"Question": "What is the boiling point of mercury in Celsius?", "Answer": "-38.83"},
{"Question": "What is the most commonly spoken language in the world?", "Answer": "Mandarin"},
{"Question": "What is the diameter of the Earth?", "Answer": "12,742 km"},
{"Question": 'Who wrote the novel "1984"?', "Answer": "George Orwell"},
{"Question": "What is the name of the largest moon of Neptune?", "Answer": "Triton"},
{"Question": "What is the speed of light in meters per second?", "Answer": "299,792,458 m/s"},
{"Question": "What is the smallest country in Africa by land area?", "Answer": "Seychelles"},
{"Question": "What is the largest organ in the human body?", "Answer": "Skin"},
{"Question": 'Who directed the film "The Godfather"?', "Answer": "Francis Ford Coppola"},
{"Question": "What is the name of the smallest planet in our solar system?", "Answer": "Mercury"},
{"Question": "What is the largest lake in Africa?", "Answer": "Lake Victoria"},
{"Question": "What is the smallest country in Asia by land area?", "Answer": "Maldives"},
{"Question": "Who is the current president of Russia?", "Answer": "Vladimir Putin"},
{"Question": "What is the chemical symbol for gold?", "Answer": "Au"},
{"Question": "What is the name of the famous Swiss mountain known for skiing?", "Answer": "The Matterhorn"},
{"Question": "What is the largest flower in the world?", "Answer": "Rafflesia arnoldii"},
]
df = pd.DataFrame(qa_pairs)
config = yaml.safe_load("""
input_features:
- name: Question
type: text
output_features:
- name: Answer
type: text
model_type: llm
generation:
temperature: 0.1
top_p: 0.75
top_k: 40
num_beams: 4
max_new_tokens: 5
base_model: facebook/opt-350m
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset=df, experiment_name="simple_experiment", model_name="simple_model", skip_save_processed_input=True
)
training_set, val_set, test_set, _ = preprocessed_data
# batch prediction
preds, _ = model.predict(test_set, skip_save_predictions=False)
print(preds)
================================================
FILE: examples/llm_zero_shot_learning/simple_model_training.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example
#
# This is a simple example of how to use the LLM model type to train
# a zero shot classification model. It uses the facebook/opt-350m model
# as the base LLM model.
# Import required libraries
import logging
import shutil
import pandas as pd
import yaml
from ludwig.api import LudwigModel
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
review_label_pairs = [
{"review": "I loved this movie!", "label": "positive"},
{"review": "The food was okay, but the service was terrible.", "label": "negative"},
{"review": "I can't believe how rude the staff was.", "label": "negative"},
{"review": "This book was a real page-turner.", "label": "positive"},
{"review": "The hotel room was dirty and smelled bad.", "label": "negative"},
{"review": "I had a great experience at this restaurant.", "label": "positive"},
{"review": "The concert was amazing!", "label": "positive"},
{"review": "The traffic was terrible on my way to work this morning.", "label": "negative"},
{"review": "The customer service was excellent.", "label": "positive"},
{"review": "I was disappointed with the quality of the product.", "label": "negative"},
{"review": "The scenery on the hike was breathtaking.", "label": "positive"},
{"review": "I had a terrible experience at this hotel.", "label": "negative"},
{"review": "The coffee at this cafe was delicious.", "label": "positive"},
{"review": "The weather was perfect for a day at the beach.", "label": "positive"},
{"review": "I would definitely recommend this product.", "label": "positive"},
{"review": "The wait time at the doctor's office was ridiculous.", "label": "negative"},
{"review": "The museum was a bit underwhelming.", "label": "neutral"},
{"review": "I had a fantastic time at the amusement park.", "label": "positive"},
{"review": "The staff at this store was extremely helpful.", "label": "positive"},
{"review": "The airline lost my luggage and was very unhelpful.", "label": "negative"},
{"review": "This album is a must-listen for any music fan.", "label": "positive"},
{"review": "The food at this restaurant was just okay.", "label": "neutral"},
{"review": "I was pleasantly surprised by how great this movie was.", "label": "positive"},
{"review": "The car rental process was quick and easy.", "label": "positive"},
{"review": "The service at this hotel was top-notch.", "label": "positive"},
]
df = pd.DataFrame(review_label_pairs)
config = yaml.safe_load("""
model_type: llm
base_model: facebook/opt-350m
generation:
temperature: 0.1
top_p: 0.75
top_k: 40
num_beams: 4
max_new_tokens: 64
prompt:
task: "Classify the sample input as either negative, neutral, or positive."
input_features:
-
name: review
type: text
output_features:
-
name: label
type: category
preprocessing:
fallback_label: "neutral"
decoder:
type: category_extractor
match:
"negative":
type: contains
value: "positive"
"neutral":
type: contains
value: "neutral"
"positive":
type: contains
value: "positive"
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset=df, experiment_name="simple_experiment", model_name="simple_model", skip_save_processed_input=True
)
training_set, val_set, test_set, _ = preprocessed_data
# batch prediction
preds, _ = model.predict(test_set, skip_save_predictions=False)
print(preds)
================================================
FILE: examples/mnist/README.md
================================================
# MNIST Hand-written Digit Classification
This API example is based on [Ludwig's MNIST Hand-written Digit image classification example](https://ludwig-ai.github.io/ludwig-docs/examples/#image-classification-mnist).
### Examples
| File | Description |
| ---------------------------------- | -------------------------------------------------------------------------------------------------------------------------- |
| simple_model_training.py | Demonstrates using Ludwig api for training a model. |
| advance_model_training.py | Demonstrates a method to assess alternative model architectures. |
| assess_model_performance.py | Assess model performance on hold-out test data set. This shows how to load a previously trained model to make predictions. |
| visualize_model_test_results.ipynb | Example for extracting training statistics and generate custom visualizations. |
================================================
FILE: examples/mnist/advanced_model_training.py
================================================
#!/usr/bin/env python
# # Multiple Model Training Example
#
# This example trains multiple models and extracts training statistics
import glob
import logging
import os
import shutil
from collections import namedtuple
import yaml
# ## Import required libraries
from ludwig.api import LudwigModel
from ludwig.constants import TRAINER
from ludwig.datasets import mnist
from ludwig.visualize import learning_curves
# clean out old results
shutil.rmtree("./results", ignore_errors=True)
shutil.rmtree("./visualizations", ignore_errors=True)
file_list = glob.glob("./data/*.json")
file_list += glob.glob("./data/*.hdf5")
for f in file_list:
try:
os.remove(f)
except FileNotFoundError:
pass
# read in base config
with open("./config.yaml") as f:
base_model = yaml.safe_load(f.read())
# Specify named tuple to keep track of training results
TrainingResult = namedtuple("TrainingResult", ["name", "train_stats"])
# specify alternative architectures to test
FullyConnectedLayers = namedtuple("FullyConnectedLayers", ["name", "fc_layers"])
list_of_fc_layers = [
FullyConnectedLayers(name="Option1", fc_layers=[{"output_size": 64}]),
FullyConnectedLayers(name="Option2", fc_layers=[{"output_size": 128}, {"output_size": 64}]),
FullyConnectedLayers(name="Option3", fc_layers=[{"output_size": 128}]),
]
#
list_of_train_stats = []
# load and split MNIST dataset
training_set, test_set, _ = mnist.load(split=True)
# ## Train models
for model_option in list_of_fc_layers:
print(">>>> training: ", model_option.name)
# set up Python dictionary to hold model training parameters
config = base_model.copy()
config["input_features"][0]["fc_layers"] = model_option.fc_layers
config[TRAINER]["epochs"] = 5
# Define Ludwig model object that drive model training
model = LudwigModel(config, logging_level=logging.INFO)
# initiate model training
train_stats, _, _ = model.train(
training_set=training_set,
test_set=test_set,
experiment_name="multiple_experiment",
model_name=model_option.name,
)
# save training stats for later use
list_of_train_stats.append(TrainingResult(name=model_option.name, train_stats=train_stats))
print(">>>>>>> completed: ", model_option.name, "\n")
# generating learning curves from training
option_names = [trs.name for trs in list_of_train_stats]
train_stats = [trs.train_stats for trs in list_of_train_stats]
learning_curves(
train_stats, "Survived", model_names=option_names, output_directory="./visualizations", file_format="png"
)
================================================
FILE: examples/mnist/assess_model_performance.py
================================================
#!/usr/bin/env python
#
# Load a previously saved model and make predictions on the test data set
#
import os.path
# ## Import required libraries
import pandas as pd
from sklearn.metrics import accuracy_score
from ludwig.api import LudwigModel
from ludwig.datasets import mnist
# create data set for predictions
test_data = {"image_path": [], "label": []}
dataset = mnist.Mnist()
test_dir = os.path.join(dataset.processed_dataset_path, "testing")
for label in os.listdir(test_dir):
files = os.listdir(os.path.join(test_dir, label))
test_data["image_path"] += [os.path.join(test_dir, label, f) for f in files]
test_data["label"] += len(files) * [label]
# collect data into a data frame
test_df = pd.DataFrame(test_data)
print(test_df.head())
# retrieve a trained model
model = LudwigModel.load("./results/multiple_experiment_Option3/model")
# make predictions
pred_df, _ = model.predict(dataset=test_df)
print(pred_df.head())
# print accuracy on test data set
print("predicted accuracy", accuracy_score(test_df["label"], pred_df["label_predictions"]))
================================================
FILE: examples/mnist/config.yaml
================================================
input_features:
- name: image_path
type: image
preprocessing:
num_processes: 4
encoder: stacked_cnn
conv_layers:
- num_filters: 32
filter_size: 3
pool_size: 2
pool_stride: 2
- num_filters: 64
filter_size: 3
pool_size: 2
pool_stride: 2
dropout: 0.4
fc_layers:
- output_size: 128
dropout: 0.4
output_features:
- name: label
type: category
trainer:
epochs: 5
================================================
FILE: examples/mnist/simple_model_training.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example
#
# This example is the API example for this Ludwig command line example
# (https://ludwig-ai.github.io/ludwig-docs/latest/examples/mnist/).
import logging
import shutil
import yaml
from ludwig.api import LudwigModel
from ludwig.datasets import mnist
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
# set up Python dictionary to hold model training parameters
with open("./config.yaml") as f:
config = yaml.safe_load(f.read())
# Define Ludwig model object that drive model training
model = LudwigModel(config, logging_level=logging.INFO)
# load and split MNIST dataset
training_set, test_set, _ = mnist.load(split=True)
# initiate model training
train_stats, _, output_directory = model.train( # training statistics # location for training results saved to disk
training_set=training_set,
test_set=test_set,
experiment_name="simple_image_experiment",
model_name="single_model",
skip_save_processed_input=True,
)
================================================
FILE: examples/mnist/visualize_model_test_results.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Ludwig Visualization Demonstration"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"import warnings\n",
"warnings.simplefilter('ignore')\n",
"from ludwig.api import LudwigModel\n",
"from ludwig.datasets import mnist\n",
"from ludwig.visualize import compare_performance, compare_classifiers_performance_from_pred, \\\n",
" confusion_matrix\n",
"from ludwig.utils.data_utils import load_json\n",
"import pandas as pd\n",
"import os\n",
"import os.path\n",
"import shutil\n",
"\n",
"shutil.rmtree('./viz2', ignore_errors=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare test data set for use"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" image_path label\n",
"0 /opt/project/examples/mnist/data/mnist_png/tes... 0\n",
"1 /opt/project/examples/mnist/data/mnist_png/tes... 0\n",
"2 /opt/project/examples/mnist/data/mnist_png/tes... 0\n",
"3 /opt/project/examples/mnist/data/mnist_png/tes... 0\n",
"4 /opt/project/examples/mnist/data/mnist_png/tes... 0\n"
]
}
],
"source": [
"# create test dataframe\n",
"test_data = {'image_path': [], 'label': []}\n",
"dataset = mnist.Mnist()\n",
"test_dir = os.path.join(dataset.processed_dataset_path, 'testing')\n",
"for label in os.listdir(test_dir):\n",
" files = os.listdir(os.path.join(test_dir, label))\n",
" test_data['image_path'] += [os.path.join(test_dir, label, f) for f in files]\n",
" test_data['label'] += len(files) * [label]\n",
"\n",
"# collect data into a data frame\n",
"test_df = pd.DataFrame(test_data)\n",
"print(test_df.head())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generate predictions the test data set for the different neural network options"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"# get list of models to visualize results\n",
"models_list = ['Option1', 'Option2', 'Option3']\n",
"test_stats_list = []\n",
"preds_list = []\n",
"\n",
"for m in models_list:\n",
" # retrieve a trained model\n",
" model = LudwigModel.load('./results/multiple_experiment_'+ m + '/model')\n",
"\n",
" # make predictions\n",
" test_stats, pred_df, _ = model.evaluate(dataset=test_df, collect_predictions=True, collect_overall_stats=True)\n",
" \n",
" # collect test statsitics\n",
" preds_list.append(pred_df['label_predictions'].astype('int'))\n",
" test_stats_list.append(test_stats)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Show model performance on test data set"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVwV1f/H8dflApcrIJuCCC647wluuOKC4oZ7pSn6TSszNU3NzF+laZYtSrlWZllpaqVZ6Df3LXFJEHPDDUFBNgWR9e7z+4Ovt0jNNbnq5/l4+IA7Z5Yz5/qYNzNz5oxKURQFIYQQwsbYlXYFhBBCiBuRgBJCCGGTJKCEEELYJAkoIYQQNkkCSgghhE2SgBJCCGGTJKAecpcvX2bw4MEEBgYye/bs0q6OuImYmBjCwsJKuxp3rXbt2pw/f/6W86WkpFC7dm1MJtMdb+NelhWPJvvSrsDjqGPHjly+fBm1Wo1Wq6Vdu3a8+eabODs73/G6Vq9ejYeHB4cOHUKlUv0LtRX3Q9OmTdm0aVNpV0OIh4qcQZWSTz/9lLi4OH766SeOHTvG4sWL72h5RVGwWCykpqZSvXr1uwon+Uv1wZB2FuLuSECVMh8fH9q2bcuZM2cAOHz4MAMHDqRp06b06tWLAwcOWOeNiIggMjKSgQMH8sQTTzB58mTWrVvH0qVLCQwMZO/evRgMBmbNmkWbNm1o06YNs2bNwmAwAHDgwAHatWvH559/TuvWrXn99deZP38+L7/8MpMmTSIwMJDw8HASExP57LPPaNmyJSEhIezZs8dahzVr1tCtWzcCAwPp1KkTq1atspZdW/+XX35Jy5YtadOmDWvWrLGW63Q6Zs+eTYcOHWjSpAmDBg1Cp9Pdcr//Li0tjTFjxhAcHEyLFi2YMWMGABaLhUWLFtGhQwdatmzJ5MmTycvLA/68fLRmzRpCQkJo1qwZK1eu5MiRI4SHh9O0aVPregDWrl3LwIEDmTFjBk2aNKFr167s27fvjtrhr+18bdo1n3/+OW3btiUwMJCwsDDrum/n+7tZ+/5dRkYGL774Is2bN6dz5858//331rL58+czbtw4Jk+eTGBgID169ODo0aM3Xddf7dy5kz59+hAUFERISAjz58+/bp41a9ZY92Hp0qXW6RaLhc8//5zQ0FBatGjBuHHjyMnJua3tiseQIh64Dh06KNHR0YqiKEpqaqrSvXt3JTIyUklPT1eaN2+u7Ny5UzGbzcqePXuU5s2bK1lZWYqiKMqQIUOUkJAQ5fTp04rRaFQMBoPy2muvKXPnzrWu++OPP1aefPJJ5fLly0pWVpby9NNPK5GRkYqiKMr+/fuVunXrKh988IGi1+uVoqIiZd68eUqDBg2U3bt3K0ajUXn11VeVDh06KIsWLVIMBoOyevVqpUOHDtb179ixQzl//rxisViUAwcOKI0aNVKOHTtWYv0ff/yxYjAYlJ07dyqNGjVScnJyFEVRlOnTpytDhgxR0tPTFZPJpMTGxip6vf6W+/1XJpNJCQ8PV2bNmqUUFBQoOp1OOXjwoKIoivLDDz8ooaGhyoULF5T8/Hxl9OjRyqRJkxRFUZTk5GSlVq1ayptvvqnodDrlt99+Uxo0aKCMGjVKuXz5spKenq4EBwcrBw4cUBRFUdasWaPUrVtX+eqrrxSDwaBs2LBBCQoKUq5cuXLb7fDXdt6/f7/Stm1bRVEUJSEhQWnXrp2Snp5urdv58+dv+/u7Wfv+3TPPPKNMmzZN0el0yokTJ5QWLVooe/fuVRRFsX7vO3fuVEwmk/LRRx8pTz755E3/z9aqVUtJSkqy1uPkyZOK2WxW4uPjlZYtWypbtmwp0c6vvPKKUlBQoJw8eVJp0aKF9f/7smXLlCeffFJJS0tT9Hq98uabbyqvvPJKiWWNRuNN6yEeLxJQpaBDhw5K48aNlSZNmijt27dXpk2bphQVFSmfffaZ9YB6zfDhw5W1a9cqilIcUB9//HGJ8r8HVKdOnZSdO3daP+/evdsaMPv371fq16+v6HQ6a/m8efOU//znP9bP27ZtUxo3bqyYTCZFURQlLy9PqVWrlnL16tUb7suoUaOUZcuWWdffsGHDEgeY4OBgJS4uTjGbzUrDhg2V+Pj469Zxq/3+q0OHDiktWrS44UFs6NChyvLly62fExISlHr16ilGo9F68LsWCoqiKM2bN1c2bNhg/TxmzBjlq6++UhSlOKBat26tWCwWa3n//v2Vn3766bba4e/t/NeASkpKUoKDg5Xo6GjFYDCUWM+tvr+bte/fpaamKnXq1FHy8vKs0z766CPltddeUxSl+HsfNmyYtezMmTNKw4YNb7hvilIyoP7unXfeUWbNmqUoyp8hc/bsWWv5+++/r7z++uuKoihK165drSGpKIqSkZFx3XckASWukU4SpWThwoW0atWqxLTU1FQ2btzIjh07rNNMJhMtWrSwfvb19f3H9WZmZlKxYkXr54oVK5KZmWn97OHhgUajKbGMl5eX9XcnJyc8PDxQq9XWzwCFhYWULVuWXbt2sXDhQpKSkrBYLOh0OmrVqmVd3t3dHXv7P/9babVaCgsLuXLlCnq9nkqVKl1X59vZ72vS0tKoWLFiiW38dd/9/Pysn/38/DCZTGRlZd1wXzUazXWfCwsLrZ99fHxK3Nv7a1veqh1u1M7XVKlShalTpzJ//nzOnj1LmzZtmDJlCj4+Prf8/m7WvjdqCzc3N1xcXEqs69ixY9bP5cqVs/7u5OSEXq/HZDLdsG3/6o8//uCjjz7izJkzGI1GDAYDXbt2LTHPX/+f+vn5cfr0aaD4ux49ejR2dn/eXbCzsyvxHQlxjdyDsiG+vr707t2bmJgY67/Dhw/zwgsvWOe5VWcIb29vUlNTrZ/T0tLw9va+7eX/icFg4OWXX2b48OFER0cTExNDu3btUG5jQPxrB+zk5OTrym5nv/86b1pa2g07Hnh7e3Px4kXr59TUVOzt7UuE0J3IyMgosW/X2vJ22uFW7RweHs7KlSvZsWMHKpWKjz76yLoP//T93S5vb2+uXr1Kfn5+iXX5+Pjc8br+buLEiXTq1Ildu3YRGxvLwIEDr/s/kJaWZv09NTXVug8VKlRgyZIlJb7ro0eP3pd6iUePBJQN6dWrFzt27OC3337DbDaj1+s5cOAA6enpt72OHj16sHjxYrKzs8nOzmbhwoWEh4ffl/oZDAYMBgOenp7Y29uza9cuoqOjb2tZOzs7+vfvz3vvvUdGRgZms5m4uDgMBsMd7XejRo0oX748c+bMobCwEL1eT2xsLAA9e/bk66+/Jjk5mYKCAiIjI+nWrdstzwhuJjs7m2+++Qaj0civv/5KQkICISEh99QOAOfOnWPfvn0YDAYcHR3RaDTWM4r79f35+voSGBjI3Llz0ev1nDx5kh9//JFevXrd8br+rqCgADc3NzQaDUeOHGH9+vXXzbNo0SKKioo4c+YMa9eupXv37gAMGjSIjz/+2PqHRHZ2Nlu3br3nOolHk1zisyG+vr4sWrSIDz/8kIkTJ2JnZ0ejRo2YPn36ba/jpZdeoqCgwHog6tq1Ky+99NJ9qZ+LiwtvvPEG48ePx2Aw0KFDBzp27Hjby7/22mvMmTOHAQMGUFhYSJ06dVi6dOkd7bdarebTTz/lnXfeoUOHDkDx2UiTJk3o378/GRkZDBkyBL1eT5s2bXjzzTfven8bNWrE+fPnCQ4Oply5csybNw8PDw+Ae2oHg8HAnDlzSEhIwMHBgcDAQGsPwvv5/c2dO5dp06bRtm1bypYty9ixY6+7rHw3pk2bxvvvv8+MGTNo3rw53bp1Izc3t8Q813oOKorC8OHDadOmDQBDhw61TsvMzMTLy4vu3bsTGhp6z/USjx6VcjvXZ4R4zKxdu5YffviBlStXlnZVhHhsySU+IYQQNkkCSgghhE2SS3xCCCFskpxBCSGEsEmPbC++Q4cOodVq73g5s9lsfUj1dhmNRhwcHB7ItmR7trG9R3nfZHs3ptfrady48R1vS9y9Rzag1Go1devWvePlLl26RPny5e9omfPnz1OlSpUHsi3Znm1s71HeN9nejcXHx9/xdsS9kUt8QgghbJIElBBCCJskASWEEMImSUAJIYSwSRJQQgghbJIElBBCCJskASWEEMImSUAJIYSwSRJQQgghbNIjO1js8eMnqF+/XmlXQwjxiIiPj7+r0WnE3Xtkhzqys1NRdcqG0q6GEOIR8euwaqVdhceOXOITQghhkySghBBC2CQJKCGEEDZJAkoIIYRNkoASQghhkySghBBC2CQJKCGEEDbpkX0OSgjxcDFkniMv7ldMVy5i51QW57rt0NZsgcpOXWI+xWwk/8gWdMnHsBTl4VC+Cq6Nu+Hg6YdiMpD3xyb0KSew6PJx9A7AJbA7Du4VsBh15B/eiP5iPBZDEY4+1XEN7IZ9WW8Us4nCU3soPLUXi74Ah3KVcQ3sjoNXpVJqDQGP8EgS8fHxdPv6XGlXQwhxG3J//4krO5bi4uLCE088wfnz50lJScEpoAne/d9EpS7+W9qsyydj5esYMxOpWrUqPj4+HD58GL3RhEf7Z8n/YxPGrGSqV6+Ol5cXcXFxGC0KHh1GkBf7C6YradSsWRN3d3fi4uIwY4dXjwnkxfyC/uIJqlatSsWKFYmLi6NIp8er6xhcGnUBih/UlZEkHiy5xCeEKFXG7Itc2fkVAwYMICUlhT179pCUlMSCBQvQJcaSF/df67w5O7+CKyn88ssvJCYm8ttvv3HhwgU6hLTjyvYvUBdcYvPmzZw9e5Y9e/Zw/vx5WrVozpWtn6Ex5LJz505Onz5NdHQ0586dI7BRAy7/PBtDajzffvstiYmJREdHc+HCBcK6dCZ7y6eY86+UYus83iSghBClKu/QerROGhYuXMjly5fx9/fnm2++YfTo0bRr14682CgAFEWh8FQ0ERERhIeH88orr+Dh4YHZbGbx4sXY2dnx3HPP0blzZ1544QXKly+PRlO8XoAxY8YQEhLCkCFD8PX1xdPTk/nz5wPQt29fhgwZQmRkJAEBAZjNZhYtWoSdYibvj42l1jaPOwkoIUSpMlw6T2BgIN7e3mzdupWLFy+ydu1aAMLCwjDlpGEx6sBiwqLLp0qVKgAkJCRQUKQjIyOD2rVrU7lyZapWrWotu5qbR1ZWFo0bN6Z8+fLWsrNnz5KVlUVOTg6tWrXC2dmZsLAwAH744QeSkpL47bffqFatGjVq1MB4KelBN4n4HwkoIUSpshTmUKFCBQByc3NL/Lw2vejMAQzpZ1G7eLJlyxYAZs2axaeLFtK4cWMAfH192bx5MwAffvghXyz5nJo1a1rLNm3aBMAnn3zCsmXL8PPzs27jn7ZvLsj5F/de/BMJKCFEqbIr40ZmZiYArq6uJX5em3456kPSl7+KOT+bPXv20L17d44cOUKZMmXYt28fAMnJyWzevJk+ffpw8uRJ1Go1sbGxWCwWLl68yLp163jqqadITEzEZDJx9OhRDAYDGRkZ/7h9dRm3B9cYogQJKCFEqXIsV5m4uDiysrLo0KEDZcuWpUePHgBs27YNgKVLl7Jy5UoAHBwciI+PZ8iQIbz//vvUqVOH/fv3k5KSglar5dChQwwePJh58+ZRu3ZtduzYQVZWFi4uLkRHRzNo0CC++OILatSowaZNm8jPz7duJzw8HC8vL1q3bs2FCxc4e/YsDuUql07DCHkOSghRulwadyft0H+ZMGECn376KVevXgXg66+/ZuvWrQC0adOGsmXLFs/v4kJiYiL5+fm4uLhw+vRpRowYAYCXlxcXLlywlh0/fpwXX3wRAD8/P06ePGktO3z4MGPHjgXg+++/Z+DAgUydOpWpU6eSl5dHREQERouCyxNdH3STiP+RgBJClCrH8lVwa/MM33zzDRs2bKBZs2YkJiZy6tQpVPaOKCYD3bt3R60ufmD3ypUr1KlTh2rVqnHlyhUOHDgADlq0NVqQcvYA9erVIyAggEuXLnHw4EHsnFzQVm/G6dMxNGjQgCpVqpCRkUFsbCx2ZdzwGfQeV7Z/QZ8+fWjQoAF+fn7s27eP3NxcPEJHYl+2XCm30ONLHtQVQtgEXcoJ8uP+i/HKRey0xSNJONcNIf/YNnRJh0FR0FSqj0rtQNG5GMx5WagcNDhVbYzrE2HYacuSf3gjRYmHMOdnoXIsgzYgEJdGXbDTOJMXtwFd0mHMBVew05RBW60pzg07o9a6opgM5B/bTuGp6D9HkgjqiaZCDWv95EHdB08CSgghboME1IMnnSSEEELYJAkoIYQQNkkCSgghhE2SgBJCCGGTJKCEEELYJAkoIYQQNum2Aio9PZ1Ro0bRpUsXQkNDeeeddzAYDDedPzc3lxUrVlg/Z2Rk8PLLL991JSMjIwkJCSEwMPCu1yGEEOLhcsuAUhSFMWPGEBoayubNm9m0aROFhYVERkbedJnc3FzruFkAPj4+zJs3764r2aFDB3744Ye7Xl4IIcTD55ZDHe3fvx+NRkP//v0BUKvVTJ06lU6dOuHv78+ePXvIz88nIyODXr16MWbMGObMmcOFCxfo3bs3rVq1YvDgwbz44ousX78evV7P9OnTOXbsGGq1milTphAcHMzatWvZvn07RUVFJCcnExoayuTJkwGsw+kLIYR4fNwyoM6cOUP9+vVLTHNxccHX1xez2czRo0eJiopCq9UyYMAAQkJCmDhxImfOnOHnn38GICUlxbrstUt/UVFRJCQkMGLECOt7WuLj41m3bh2Ojo507dqViIgIfH1972rHFMVC0uwed7WsEEIAYNSBgxNQfHwSD9Y9DxbbqlUrPDw8AOjcuTOxsbGEhobedP7Y2FiGDBkCQPXq1alYsSKJiYkAtGzZ0voelurVq3Px4sW7DiiVyg6my3tchBD3YPrV0q7BY+2W96Bq1KjB8ePHS0zLz88nLS0NtVqNSqUqUfb3z3fC0dHR+rtarcZsNt/1uoQQQjzcbhlQLVu2pKioiHXr1gFgNpuZPXs2ffv2RavVEh0dTU5ODjqdjq1btxIUFISzszMFBQU3XF/Tpk2JiooCIDExkbS0NKpVq3Yfd0kIIcSj4JYBpVKpWLhwIRs3bqRLly6EhYWh0WiYMGECAI0aNWLs2LH06tWLsLAwGjZsiIeHB0FBQfTs2ZP333+/xPqeeeYZFEUhPDycV155hffee6/EmdONfPDBB7Rr146ioiLatWvH/Pnz72GXhRBCPAzu6XUba9eu5dixY7z11lv3s073RXx8PHVXB5d2NYQQD7O/3IOKj4+X1208YDKShBBCCJt0T734+vXrR79+/e5XXYQQQggrOYMSQghhk+75OSghhLgbiqLw+0UzMakWtA7Qpbo9/mVv/DfzlSKF3edNpOQqVHFX0aW6PY7q4kda0vIs7Dpv5lKBgocW2lS2p6r7n+s5ednMngtm9Cao6q6ibRV7HOzgwEUzp7MsGMwQ4K6iQ4A9ZRzu/jEZcf9JQAkhHriLuRYGriliz4U/n3W0t4PRzRyZ00WD2u7PoFh22MC4jTpy9X8u7+eq4qveWn6/aGb6Lj0my59lKmB0Mwdeb6th+M9FbEq4vecpvZ1VfNNHS1gNOSzaCrnEJ4R4oBRF4akfiziS48yiRYtIT0/n5MmTPD9yFJ8cMBC5/883Jfx23sTwn3U0bd2R6Oho0tPT2bBhA14BDemyvJA3duh58ulBHD58mEuXLnHixAnGjB3LgoNG/ObmE52hZfbs2SQmJpKRkcG2bdsA8PPzY/369SQnJ5ORkcHWrVupWPMJ+n9fyMVcy82qLh4wCSghxAO1PdHM3mQzH374IaNGjWLhwoXEx8ezaNEiunXrxvvRBvSm4qdf5v1uoKKfH1FRUTg4OPDcc89Rp04dfvnlFxwcHHBzc+Pbb79Fq9UyZMgQrl69yrx586zdwVesWMGECRP46quvGDVqFAcOHADA29sbe3t7ZsyYwZdffkmnTp344YcfKDDCupOmUmsbUZIElBDigdqZZEKtVjNs2DDi4+OZOXMmU6ZMAWD48OFcLlQ4can4LCb+koVmzZpRpkwZ1q1bx6b/rmfLli1UqVKFjh07oigKBoOBtLQ0du7YRlJSEgAGgwE/Pz969erF6tWr2b9/P5cvX7Y+s3n48GG6du3KkiVLeP3110lLS6NKlSqoVCouFcoZlK2QgBJCPFDJuQq+vr5oNBrS0tIArD8DAgIAuHC1OCR8XFScO3cOgG7dutGyTTvat28PQNWqVcnNzeX555+nTZs2FBbpGThwIBMnTiQhIYFmzZoBMGjQIFatWsWuXbs4cOAAZcqUQVEUfF1U1nJfX1+WLFmCoii08FM/sLYQ/0wCSgjxQDnZQ1FREQD29vYlfhYWFgLQZ3UR3h/msT3RzJEjR5gwYQJ16tRhy5Yt1vUUFRXh4+PDwoULiYmJITQ0lP/+97+8++671KtXzzoe6JEjRyhXrhwzZswgKCiIvn37ApCWrzB69GiWL1/OypUrGTduHC6OSCcJGyIBJYR4oKp72JGVlUVqaiq1a9fG3t7e+s65o0ePAsWv7hkw7EXKlCkDQGRkJOXLl8fJyYm4uDgAtmzZQsOGDXFzc2PLli0Unt5NVFQUGo2GZs2aER8fj8ViITMzE2d7i/Uszd7eHpVKxfvvv8+CBQuYM2cOgwcPxmQykW+AH0/IPShbcU9j8dkyGYtPCNt07oqFWvPzeX7kiyxevJiYmBgqVqyIm5sbTzzxBAkJCaxcuZKBAwdSsWJF0tLS2LVrFykpKQQEBNCyZUvmzp3LxIkT8fT05OTJkzg4OPDjjz/SvXt33N3dadiwIefOnWPp0qUMHTqU7777jk6dOqFSqWjUqBHVqlXj999/ByA9Pd1atwYNGvB0QC4Le2iLJ8hYfKVKzmWFEA9UNQ87Xm7hSOSnn3L69Gn69etHTk4OS5cutb68dPXq1Rw5coS8vDwAli1bRrNmzTh48CBTp05l586d1PS048LVbJo0acLQoUPx8/Pjiy++YOXKldb7ViNHjmTbtm20adOGhQsX8sUXX5CVlYVGo2Hq1KnX1a2oqIiyGnlY11bIGZQQ4oEzWxTm/25g7j4DybnFh6DWldTM7KAh6rSJz2MNGMxQw9MOb2cVMalmCozFywa4qxjdzJGXWzgSm2bm9W16diWZuXYga1rRjpkdnGhVSc2MXXqWHDKQqwe1CjoEqHmyngMf7TWQlHN9b70G3nasHqClptf/OkrIGVSpkoASQpQaRVHIKFDQ2qtwc7r5mYvZonCpUEGtgnJlVNe9udtoVrhcqOChVeFkf+MyrzIq6/BIt00CqlTJJT4hRKlRqVRUcLl1aKjt/nk+B7UKX9cbl/9TmbBt0otPCCGETZKAEkIIYZMkoIQQQtgkCSghhBA2SQJKCCGETZKAEkIIYZMkoIQQQtgkCSghhBA2SQJKCCGETXpkR5JQLJYSw5QIIcQdM+rAwam0a/HYemTPoIymu3uny6VLl+54mfPnzz+wbcn2bGN7j/K+yfb+QsKpVD2yASWEEOLhJgElhBDCJklACSGEsEkSUEIIIWySBJQQQgibJAElhBDCJklACSGEsEkSUEIIIWySBJQQQgibJAElhBDCJklACSGEsEkSUEIIIWySBJQQQgibpFIURSntSvwbjh8/Qf369Uq7GkKIR0R8fDx169Yt7Wo8Vh7Z90HZ2amoOmVDaVdDCPGI+HVYtdKuwmNHLvEJIYSwSRJQQgghbJIElBBCCJskASWEEMImSUAJIYSwSRJQQgghbJIElBBCCJv0yD4HJYR4eCgWM/lHtpAX919M2Rex07riXKctZYMHoC7jVmJeU24mOb99hy75KJaiXBzKVaZsk3DK1A3BlJPO1T0r0KWcwKLLx7F8VVyb9qJM7daYsi+Ss2cF+osnsegLcPSpRtlmfXD0rkb21s8wZqeU2I7KXkPZ5n1xqd/hQTaF+AsJKCFEqcv6dR4Fx7bRtGlT2g/tR2JiIj///DMFp6LxHRZpDSnjlVTSv5mAk52Fp3r3xsfHh82bN3Mi6iOcjm5Dn3oKF42agb16Ua5cOTZu3Mipn2ejrdYUXfJR3Jy19O8TjoeHBxs2bCBh7TsAODs7MyA8vESdTp48yR+bF+Ncpy0qtRwqS4O0uhCiVOlSTlBwbBtvvPEGM2fOJDk5GV9fXw4fPkxwcDC5+3/Eo+MIAK5s/wI3rQMxMTF4enqSkJBAZGQko0ePZtGiRXh7exMbG4tWq+XChQt8/PHHPPvssyxbtgx/f39iYmJQqVSkp6cTGRnJoEGD+P777ylXrhwrV64sUa+PPvqIw6++imI2SkCVErkHJYQoVQVHt+Lp6cnrr79ObGwsVapUYdq0aTRt2pSnn36a/CObURQFRVHQnT9CREQE1apVY8yYMTRt2pT4+HhmzpyJk5MTI0aMwN/fn+eee46goCCSkpJ47733sLe3Z+TIkfj4+BAREUFgYCCXL1/mgw8+KFGXF154Aa1Wi1ar5fXXXwdA5aApjWYRyBmUEKKUGbMvEtSgAWXKlOH3339HURQOHDgAQPPmzfnuu++wFOVi5+SCYjbi7OwMgEqlsv709PSkWrVqJcqu/atQoQL+/v7XlQFUqVKF8uXLW+vy4Ycf8u677xIbG8v48eM5efIklqK86+6DWetuNJKSkoJOp/t3Gucx4OTkhL+/Pw4ODteVSUAJIUqVxVCIu3t1AOuB/tpPd3d3AK5Gf4e9WwUAVq1axWuvvcaCBQuYOHEiderUAcDT05MVK1Ywfvx4li5dyttvv02VKlUA8PDw4Ntvv2XUqFEsX76cjIwMvL29rWVXr17lww8/JC4ujsaNGzN58mRWr17NE088QeGpaFwDu9+w7ikpKbi6ulK1alVr6InbpygKWVlZpKSkEBAQcF25BJQQolTZu3iRnJwMQLly5Ur8TEkp7lmXd+jPNxMkJiZSv359evfuDUB4eDidO3cmPj6erKws6tevT3h4OEajkYEDB9KyZUvOnj1LXl4eDRo0oEePHhQVFTF8+HDq16/P+fPn0ev1TJ48GYCVK1fSr18/GjVqhEajwZSTftO663Q6Cad7oFKp8PLy4tKlSzzgE1AAACAASURBVDcsl3tQQohS5ehbiz/++INTp07RrVs3wsLCGDlyJADff/89AAcPHuTcuXNA8SWhkJAQdu/eTVFREZ06dWL9+vVkZWVRtmxZgoOD2blzJwBt27ZlzZo15OXl4eXlRePGjdm+fTtarZbg4GBWrVqFXq+nb9++TJo0iZYtWzJy5EgCAgI4c+YMer0eddnyN6z3NRJO9+af2k/OoIQQpco1qAe5B38iIiKCzz77jI0bN3Lp0iXGjh3LkSNHrptfrVYzf/58PD09MRgMrF69mnHjxgHg6OjIp59+iru7Ozqdjm+++YZXXnkFAK1Wy5dffknZsmUpLCzks88+Y+LEiQAUFhYybtw4PvzwQwBiYmJ44YUXUDlqKVOr1QNqCfF3ElBCiFKlLuNGufBXiYn6iKCgINzc3MjPz8dsNqOtGUzRmQM0a9bMOn9BQQFeXl54eHhQWFiIXq/HwTsAj479uLz9Czw9PXF3d6egoACDwYBjhZq4B/YlZecy3N3dcXd3Jz8/H6PRiMavLq61q7Fp0wYqVaqEq6srBoMBvV6PnZML5XtPwd7V67b3RWc04+Sgvm9tc7/X97CRgBJClLoyNZrj/9JXFBzfiTE7BRcnV5zrtsXBqxKGS0nokg6DoqCp1ACV2p6ic7GY8i6jcXDCrcoTOFV9ApXKDk2lBuiS4jDlZeHkqMWjaiCayg1RqVQ4VWqI7vwfmPKz0WrK4BkQhMa/PiqVCtfAnhSdP4zpShoaewdcPP0oU7s1dhrnO9oPJwf1fX2Td9LsHrecJyUlhRdffJH169eXmP7JJ5/QrFkzWrVqxbJly3j66afRarX3pV5bt26latWq1KhR46bzREREMHnyZBo2bHjX25GAEkLYBDuNM65B1x+QHctXxbF81ZLTvK/v8QWgqVADTYUbHzQ1FWujqVj7hmUO5SrhUK7SnVXYxl277AnwzTff0KtXr/saUO3bt//HgLofJKCEEOIhZzabeeONN4iLi8PHx4dFixYxffp02rdvT2ZmJpmZmQwbNgx3d3eWLVvG//3f/3Hs2DFUKhX9+/fnP//5zw3X+/3337N69WqMRiNVqlThgw8+ID4+nu3bt/P777+zePFi5s+fT+XKlW9aN4vFwtSpU/Hx8bHeD7xdElBCCPGQO3/+PHPnzuWdd95h3LhxbNq0yVo2dOhQli1bxtdff42npyfHjh0jIyPDekkwNzf3puvt3LkzTz31FACRkZH8+OOPRERE0LFjR9q3b0/Xrl3/sV5ms5lJkyZRs2ZNRo0adcf7Jd3MhRDiIefv70/dunUBqF+/PhcvXrzpvJUqVSI5OZmZM2eye/duXFxcbjrvmTNneOaZZwgPDycqKoozZ87cUb3eeuutuw4nkIASQoiHnqOjo/V3tVqN2Wy+6bxubm78/PPPNG/enFWrVvF///d/N513ypQpvPXWW0RFRTFmzBgMBsMd1SswMJADBw6g1+vvaLlr5BKfEELcJzqj+bZ63t3J+u5HN3NnZ2cKCgrw9PQkOzsbR0dHwsLCCAgI4NVXX73pcgUFBZQvXx6j0UhUVBQ+Pj4l1ncrAwYMICYmhnHjxrFgwQLs7e8scuQMSggh7pP7/czS/VrfU089xXPPPUdERASZmZlERETQu3dvXn31VSZMmHDT5caNG8eTTz7JoEGDqFatmnV69+7dWbp0KX369OHChQv/uO1nn32WevXqMXnyZCwWyx3VW6UoinKrmdLT03n77bdJSEjAYrHQvn17Jk+eXOK08q9yc3OJiopi8ODBAGRkZDBr1izmzZt3R5UDKCoqYty4cVy4cAG1Wk2HDh2YNGnSLZeLj4+n29fn7nh7QghxI78Oq2a9z3NNfHz8ddPEnbtZO97yDEpRFMaMGUNoaCibN29m06ZNFBYWEhkZedNlcnNzS7z8y8fH567C6Zrhw4ezceNGfvrpJw4dOsSuXbvuel1CCCEeDre8ILh//340Gg39+/cHim/ATZ06lU6dOuHv78+ePXvIz88nIyODXr16MWbMGObMmcOFCxfo3bs3rVq1YvDgwdYnnfV6PdOnT+fYsWOo1WqmTJlCcHAwa9euZfv27RQVFZGcnExoaCiTJ0+2DuoIxTcC69WrR0ZGxr/bKkII8Rh5++23OXToUIlpQ4cOtR73/61lb+WWAXXmzBnq169fYpqLiwu+vr6YzWaOHj1KVFQUWq2WAQMGEBISwsSJEzlz5gw///wz8OeQ+QArVqwAICoqioSEBEaMGGHtsx8fH8+6detwdHSka9euRERE4Ovra102NzeXHTt2MGzYsFvumKJY7uvNSiHEY8ioAwcnoPj49KiaNm1aqSx7K/fci69Vq1Z4eHgAxQ91xcbGEhoaetP5Y2NjGTJkCADVq1enYsWKJCYmAtCyZUtcXV2tZRcvXrQGlMlkYsKECURERFCp0q2HJFGp7GD6jd+CKYQQt2X61dKuwWPtlvegatSowfHjx0tMy8/PJy0tDbVafd27PO7l3Sj/1Jf/zTffpGrVqjcdkkMIIcSj5ZYB1bJlS4qKili3bh1QPHTF7Nmz6du3L1qtlujoaHJyctDpdGzdupWgoKB/7CPftGlToqKigOI3Y6alpZXovngjkZGR5OfnM3Xq1DvdPyGEEA+pWwaUSqVi4cKFbNy4kS5duhAWFoZGo7H2nW/UqBFjx46lV69ehIWF0bBhQzw8PAgKCqJnz568//77Jdb3zDPPoCgK4eHhvPLKK7z33ns37a4OxV3cP/30U86ePUvfvn3p3bs3P/zwwz3uthBC/AuMOtte30Pmtp6Dupm1a9dy7Ngx3nrrrftZp/siPj6euquDS7saQoiH2V/uQd3oWZ0bPr9zP+9929A9MJPJdMcjQdyumz0HJUMdCSHEQ+6ll14iPT0dvV7P0KFDefrpp9m9ezeRkZGYzWY8PDz4+uuvKSgo4J133uHYsWMAjBkzhrCwMAIDA4mLiwNg48aN7Ny5k9mzZzNlyhQcHR2Jj48nKCiIHj16MGvWLPR6PU5OTrz77rtUq1YNs9nMRx99xG+//YZKpeKpp56iRo0afPvttyxatAiA6OhovvvuOxYuXHjb+3VPAdWvXz/69et3L6sQQghxj959913c3d3R6XQMGDCATp068eabb7J8+XIqVapETk4OAIsWLcLFxcXaD+Dq1VufoWVkZLBq1SrUajX5+fmsWLECe3t79u7dS2RkJPPnz2f16tVcvHiRdevWYW9vT05ODm5ubrz99ttkZ2fj6enJ2rVr7/jZKDmDEkKIh9y3337Lli1bAEhLS2P16tU0bdrU+kiOu7s7APv27WPu3LnW5dzcbn05smvXrqjVxWMC5uXl8dprr3H+/HlUKhVGo9G63oEDB1ovAV7bXu/evfnll1/o168fcXFx1/VJuBUJKCFEqTl40cyKo0YyCyxU87BjRKAjAR7X990qMCgsP2LkUJoZowVCqqh5uoEDTvYqMvItLD9iJP6yBYMZqrqrGNTAgbrl1aTmFZedumzBpECAu4pnGjpQqawdUadN7E8xk5ZvoayjiiBfNUMaOeDsePePypSGAwcOsHfvXlavXo1WqyUiIoK6dety7tzdjUX691dj/PU18Z988gktWrRg4cKFpKSkMHTo0H9cV79+/Rg1apR18IU7vYclASWEeOAUReGlDTo+jTXi7OxMxYoV+XF/ErP35LOguxMvNv2zZ++py2a6LC/kwlWFcuXKYW9vz1eH05mxW8/MDk6M2lBEnkGFr68vjo6OrIq/yKzfChjUwIGfTxkpMKrw8/NDrVbz3fGLvLO7APP/uoZptVr8/auQk5HD54cu8e4ePTuHOd8wJG1VXl4ebm5uaLVaEhISOHz4MHq9npiYGJKTk62X+Nzd3WnVqhUrVqywvgPq6tWruLm5Ua5cORISEggICGDr1q04OzvfdFvXXrnx008/Wae3atWK1atX06JFC+slPnd3d3x8fPD29mbx4sUsW7bsjvdNAkoI8cD9cMLEp7FGJk2axLRp03BxcSE1NZUXX3yRMeuj6BigppaXGkVReGZtEXonb/ZsWEPr1q0B2LJlCwMHDmTw2mxq1KjBwQ0bqFWrFgCXL19m2LBhrPjvf6lXrx5RUVHWZy0zMjIYPHgw27ZtY/bs2UyaNMl6+WrPnj306tWLF9bnsiXixgfoWzLq7m/Pu78MtXQz7dq1Y9WqVXTr1o2AgAAaN26Mp6cnM2bMYOzYsVgsFry8vPjqq68YNWoUM2bMoGfPntjZ2TFmzBi6dOnCxIkTGTlyJJ6enjRo0IDCwsIbbuu5555jypQpLF68mJCQEOv0J598kqSkJHr16oW9vT1PPfWUdcSg8PBwsrOzqV69+h3v/j11M7dl0s1cCNvV4ot8CtzrcuzYMX799VemTp3Kjz/+iKurKwEBAfynnpGFPbScuGSm/qICPv/8c55//nlCQ0Oxs7Nj8+bNfPLJJ4wfP57Zs2fz2muvERERwcGDBzl58iS7d+8mJCSE+fPnM2bMGPr168e5c+c4fPgwv/76K927d2f8+PEkJSVx4sQJ3n77bQYOHMibb77Je7PeIX+qK072qrvrZi5KmDFjBnXr1uXJJ5+86Tx3/boNIYS4nyyKwuF0Cz179gSKB5A+fPgwUVFReHt7ExwcTFx68YvtUnKL/36uU6cOUHwzft++fUDxX+aAdSi26tWrWwe2vtaN+trPmjVrXlf28ccfs27dOk6fPs2vv/4KgL29PWYFLI/kn+0PXr9+/Th16hS9e/e+q+XlEp8Q4oHKLlIwmMHPzw+AK1eulPjp5+fHpgMWzl2xoP3fESo6Opq2bduyaNEi63if15Zfu3Ytzz//PNOnTwfgwoUL1p5qq1atYvjw4dbeYwkJCcyfPx+A5wId+CLOSEBAANOnTyc5OZlFixYRUkVNGYeHq6OErVq7du09LS9nUEKIB8pNo8JOVXyvCKBMmTIA1hvzly9fJrNAofq8fNotK74XMn36dGbOnEn16tXRaDRkZWWRnp4OwIcffkjbtm3p0KEDFStWxNXV1Toc2rx582jevDnNmzenSpUqVKhQge+++w6AL+KMNGnShH379mE2m2nXrh2ZmZk809DhjvbnEb1L8sD8U/tJQAkhHigHtYpqHnZER0cD0L59e1QqFW3btkWn0xEbG4u7uztff/01L730EgBOTk7MmDGDtm3b8sUXX+Dl5WV939y1M6mkpCQyMzMpLCykYsWK15Wlp6ej0+msZV26dGHnzp3k5eUxaNAgFKW4l+CrW3QUGG4vdJycnMjKypKQukuKopCVlYWT0407gsglPiHEAzeyiQOvbtnGmjVrGD16NMOGDcPFxYX/+7//IzMzE19fX4YOHYqjoyOLFi2iY8eOLFu2jOzsbKpWrcqhQ4eYOXMmAEuWLKFbt27ExMSQn5+Pn5+f9XLf559/TkhICMePH0en0+Hl5WW93Dd8+HBcXFyKewEePAjA8uXLiYiIIC1foYbnrS/z+fv7k5KSwqVLl/6dhnoMODk54e/vf8My6cUnhHjgiowKIcsKOJhqoWXLltSqVYv9+/dz6tQpoPjdcK1atSIzM5MTJ07g7OxM+/bt8fHx4ezZs+zevRs/VxVP1Xcgcr8BPz8/goOD0Wg0/PHHHyXeYVe5cmWaN2+Og4MDcXFxnDx5EoB69erh7e1dol4ZGRkknoknbaIr7k637sUn/l0SUEKIUlFkVPgs1vC/kSQUqnnYMbKJIx0D1EzboefEZQuOauhWw54zWRb2ppjJLlLwdlYxoK4DI5s64qlVse2ciQUHDZy8bMFgVghwt2NwQweGNXZg01kTi2OMnM6yYLIUb2PoE8X3mL7+w4jBXLJOGjUMD3RkYIP/3YeSgCpVElBCCHEzElClSjpJCCGEsEkSUEIIIWySBJQQQgibJAElhBDCJklACSGEsEkSUEIIIWySBJQQQgibJAElhBDCJklACSGEsEmP7GCxisVyf1+9LIR4/NzGK9fFv+eRPYMymkx3tdzdjEp8/vz5B7Yt2Z5tbO9R3jfZ3l9IOJWqRzaghBBCPNwkoIQQQtgkCSghhBA2SQJKCCGETZKAEkIIYZMkoIQQQtgkCSghhBA2SQJKCCGETZKAEkIIYZMkoIQQQtgkCSghhBA2SQJKCCGETZKAEkIIYZMkoIQQQtgklaIoSmlX4t9w/PgJ6tevV9rVEEI8IuLj46lbt25pV+Ox8si+sNDOTkXVKRtKuxpCiEfEr8OqlXYVHjtyiU8IIYRNkoASQghhkySghBBC2CQJKCGEEDZJAkoIIYRNkoASQghhkx7ZbuZCiIePxVCE6WoGdpoyqF3Lo1KpbjifoihYinIxF+RgX7Y8dpoyJcsKczAX5mLv5oOdo1PJsoIczEW52Lv7YOfwZ5lFl48p7zKo7LB3LVdinaJ0SEAJIUqdRV9Izu6vyT+yFcWkB8CxQg3c2z+LtsoTJebVJR8je+tnGDMTiyeo7XGp3xH39s9iyEjgyrbPMV6+AIDK3hHnBp3waP8f9CnxZG9fgin7YnGZgwaXRl1wbtCJ7E0LMKSf/ctWVGirN8Wz8yjs3bz/9f0XN/bIjiQRHx9Pt6/PlXY1hBC3oCgKmd+/hSnlKP/5z38ICwsjNTWVBQsWcCbhHBUGf4CmYm0A9OlnSf92EtUDqvDSSy/h7+/P7t27Wbp0KTqdDlBRu3YtRo0aRYUKFdi+fTtfffUVRqMRUNGgQX1eeOEFvL292bRpE99++y0mk4myZcsydepUqlevjslk4vjx4yxcuJA8VRkqDl+ASu3Ar8OqyUgSD5jcgxJClCrd+T/QJcUxd+5clixZgoODA/379ycmJoYK3uXJ+W25dd6rvy2nYgVvYmJiCA8PJzU1lcjISJYsWQJAQEBVYmJi6Ny5M5mZmSxatIj58+cDUKdObQ4ePEi7du24fPkyX375JR988AEAXl5etGvXjpycHAICApg5cyZffvklpuyL6JKPP+gmEf8jASWEKFWFp/fh5ubGyJEj+f333+nTpw9jx46lbNmyjBw5El1SHBZ9IQD69DP07NkTd3d3Zs+ezYTJr7Njxw6GDBmCv78/ffr0wcXFhRkzZjBu4mT279/PiBEjKFeuHAMGDMDJyYk33niDsa9MJC4ujpdeeglXV1cSExNp1aoVzz//PN27dwegatWqQPG9KVE6JKCEEKXKdDWdGjVq4OjoyOnTpwE4e7b4flC9esUDPptyMwFQ2dlTWFgcVjVr1sTRTqFy5coA1KlTp0SZ1sEOPz8/7O3tqVmzZokyZ40Dvr6+aDQaqlUrHmOvatWqrFixgl27dnHp0iXGjx8PYL28KB48CSghROmyWHBwcACK70f99ee16ZfWzebSutmY87P48ccf2bt3L1OmTKGgoMB6puPg4MDy5cuJiYlh5syZ5ObmUqFCBQAcHR358ssvOXr0KHPnziUnJwd3d/cS2zCbzeTk5JCdnU358uUZNmwYAPrUUw+mHcR1JKCEEKXKvmx5zp0r7tDk7+8PgJ+fHwAJCQnF08vaU8UuCwCdTkfbtm0JDAykZcuW/PLLL5hMJn7//XcKCgoIDg4mKCiIFi1asHXrVvR6PbGxseTk5BAUFETTpk1p2rQpe/fuJS8vj6NHjwKQnJzM6NGjCQkJITU1lWHDhqFWq//sLSgeOOlmLoQoVU5VA8k8spk1a9bQp08fZs2aRVhYGGaz2dr5Yfny5QQHB2NvX3zIWrBgAYcOHaJhw4Y89dRTfPPNN2RlZeHo6EhkZCRxcXEEBQXRs2dPFi9eTH5+PmXLlmXmzJkcPXqU4OBgOnbsyJw5c9Dr9Tz77LM0b96ckydPUrduXSpWrMjhw4cxm82oy5YvzeZ5rElACSFKVZnarXAoX5Xnn3+eCxcu0LdvX1JTU+nWrZv1ntTvv/9Obm6udRlfX18mTpxIfn4+kyZNYt68eQBYLBYqV65Mp06duHr1KuPHj2fBggUAmEwmatasSVhYGFeuXOGll17is88+AyApKYnBgwfTsWNHrl69yuLFi3nvvfewK+NGmdqtH3CLiGvkOSghRKkz5WZyecPH6C8csU6zc3LFrfUgcg+uw/y/ThI3ZKfGuW47XAN7cGndu5jzs/9SZo9z/Q64NArl0k/vYim8+meZ2gGXhqHYu3kXd2W3mEus1tGnOl7dx+HoXdyJQp6DevAkoIQQNsNwKQnjpfPYaZzRVG6AnYMTitmEISMBFAsO5SqjUjuiTz+DOfcSKrUDGr+6qF08AFBMBvRppzHnXUZlrykucy7uDGEx6jCkny0uc3BC418PtbZscZkuH31GAub8bOw0ZbB3q1C8rb8MtSQB9eDJJT4hhM1wLF8Vx/JVS0xTqe2v6+rt5F/vhsur7B1xqtTghmV2Dk43L3NyuW5IJVH6pBefEEIImyQBJYQQwiZJQAkhhLBJElBCCCFskgSUEEIImyQBJYQQwibdVkClp6czatQounTpQmhoKO+88w4Gg+Gm8+fm5rJixQrr54yMDF5++eW7ruSIESPo1asXPXr04K233sJsNt96ISGEEA+1WwaUoiiMGTOG0NBQNm/ezKZNmygsLCQyMvKmy+Tm5rJy5UrrZx8fH+tQJHfjk08+4ZdffmH9+vVcuXKFjRs33vW6hBBCPBxu+aDu/v370Wg09O/fHwC1Ws3UqVPp1KkT/v7+7Nmzh/z8fDIyMujVqxdjxoxhzpw5XLhwgd69e9OqVSsGDx7Miy++yPr169Hr9UyfPp1jx46hVquZMmUKwcHBrF27lu3bt1NUVERycjKhoaFMnjwZABcXF6B4LC2j0Vji6W4hhBCPplsG1JkzZ6hfv36JaS4uLvj6+mI2mzl69ChRUVFotVoGDBhASEgIEydO5MyZM/z8888ApKSkWJe9dukvKiqKhIQERowYwaZNm4Di4YnWrVuHo6MjXbt2JSIiAl9fX6D4Mt+RI0do164dYWFht9wxRbGQNLvHbTaDEELchFEHDk7Ex8eXdk0eO/c81FGrVq3w8CgeB6tz587ExsYSGhp60/ljY2MZMmQIANWrV6dixYokJha/b6Vly5a4urpayy5evGgNqKVLl6LX65k0aRL79++ndet/HmFYpbKD6W73untCiMfd9Ku3nkf8K255D6pGjRocP368xLT8/HzS0tJQq9XXXW67l8tvjo6O1t/VavV1nSE0Gg2dOnVi27Ztd70NIYQQD4dbBlTLli0pKipi3bp1QPFrkWfPnk3fvn3RarVER0eTk5ODTqdj69atBAUF4ezsTEFBwQ3X17RpU6KiogBITEwkLS2NatWq3XT7BQUFZGYWD7VvMpnYuXPnP84vhBDi0XDLgFKpVCxcuJCNGzfSpUsXwsLC0Gg0TJgwAYBGjRoxduxYevXqRVhYGA0bNsTDw8P6Nsv333+/xPqeeeYZFEUhPDycV155hffee6/EmdPfFRUVMWrUKMLDw+nTpw9eXl4MHDjwHndbCCGErbun90GtXbuWY8eO8dZbb93POt0X8fHx1F0dXNrVEEI87P53Dyo+Pl7eB/WAyUgSQgghbNI99eLr168f/fr1u191EUIIIazkDEoIIYRNkle+CyFKzf4UE5H7DcSmmtE6qOhZ057xwY74uJT821lnUph/wMD6MyYu5lqo6m7Hc0GOPFXfnitFCnP2GdiWaOJSgYKnVkW7KvZMauWIq6OKufsMbD5nIrNAoaanHS82daBbDXsWHjSw4YyJxCsWAPzL2tGnjj2jmjqisZfRamzBPXWSsGXSSUII2/bFIQPPR+nw8vKiS5cuXLlyhS1btlDOyUL0cGeqexaHVJFRIWRZAQdTLbRo0YJq1aoRGxvL6dOn6VbDntNZZpJy7WjXrh1+fn5kZmayc+dO7CwG7O2gwKiidevWVKpUib1793L+/HmcHaDACE2aNKFWrVqoVCpOnTpFbGwsnQLUbI4og921Zzqlk0SpkTMoIcQDl12k8MomHV26dOGnn37Czs4OJycnjh8/TuvWrZmyrYAfniwDwEd7DcSkKfzwww/069ePc+fOUaNGDd5++22mT5+OnZ0d0dF7CA4OJj4+ntq1a3Pq1CmaNGmCzmhk69ZNtG3bluTkZKpUqcL48eNZsGABWq2WmJgYsrKycHV1xdHRkSVLlvDCCy+wJcFMWA05PJY2uQclhHjgvjtqJN8Ac+bMwWQy4efnx5AhQ6hfvz5jxozhxxMmMguKL739etZEmzZtGDBgAJ988gk1a9Zkw4YNTJ06lUqVKuHv709wcDA//fQTv4wNZOnSpdStW5e6devSu3dvOnbsyLRp06hevToxMTG8++67uLm5odfrqVy5MuXKlcPf3x+dTmcdFPvEJXmljy2QgPr/9u4+KKp6DwP4s7yJXkHFF3CCYKbx6nAlF8vCVFReJFl2gVHMEmWKtJobFpNZNtjVqXFqrBmVRhT/8I6KzSCBjQplK23YhQm7I6JoLXYFAeXFi7YIusLu9/7BsOnNal08cLDn8w+we5bnnLO759mz5+z+iGjA/XDFhtGjR2Pq1Kk4deoU2tvb8fXXXwMAZs+eDQAw/7e3oH62CsaNGwcA6OjoANA7pI+npydmzJiBxsZGfPtt7x5U67S/Izo6GtXV1Th79qzjdhaLBUDv17T5+PggLCwMdrsdbW1tWLx4MV5++WV4e3tj3759AIDJ47hpVAPuwxLRgGu/8UvpdHV13fGz7/Id33ej/prAXQOYTCY0NzcjMzMT06ZNg06nc0xrt9thMpnw5JNPYsWKFQgMDMTOnTvR3d2N4uJiWCwWbNy4EU8//TSio6MBAOPHjwcAjBo1Clu2bMG4ceNw/fp1mM1mAEA3d6BUgS8TiGjATRzphkuXLgGAYzSEvp99l+ed7kZq0Q2cbrXj6tWreOyxx/Dhhx/ixx9/dAyIajabMWvWLGRlZSE7OxuPT9diQ63ACAAACfRJREFUw4YNyMjIgE6nQ0NDA8LDw5GdnY3q6moUFRU5bgf0jvYdGBiICRMmoLW1FVu3boWfnx++/KlnQNcH3R0LiogGXPhEN3R1dcFoNEKr1WLu3LlIT08HAMc4ctnZ2TCbzfDz8wMAhIaGYteuXSgqKsK8efPQ0NCA48ePo+9E5KCgIAwb/hcEBwcDgOPySZMmYfv27TAajYiMjER1dTVqamowffp0GAwGhISEQKvVwtfXFyICq9UKb55mrgp8i4+IBlxKqCfWHbNi9erVyM/Ph8lkgs1mw969e7Fnzx4AQEBAACZNmgR3d3cAwM6dOx0jGZw8eRIrV66EzWZDRUUFdu3ahfT0dKSkpAAADhw4gJKSEgBAQUGBY1Tu8vJyPP/88wCAhx56CIWFhY7/f+XKFaxatQqdnZ3QTRoxcCuDfhM/B0VEg6KsvgeGT7vws7V3gFKLxYK2tjY86u+G6hY7vLy84Obmhps3bwIAPD09ERISgu7ubtTV1cF3GPDPxOHYVnkLpjobfH194e/vj7a2Nly7ds2R4+3tjYcffhhdXV1obGzE+BEaBPpqcLLZjhEjRiAoKAidnZ1obm5GT08P/jHXCxvmef8yo/wc1KBhQRHRoGm/Idh98ha+v2zDCA8NEv7qAcNkD5xptePA2W5024CpE9wwZZw7in7oxn+u2uHhpkFEoDtSH/XEaG8NbHbBIXMPSi/Y0Nppx9jhGsx+2AOLQz3w78s2FJ7rQf3Pdgxz1yAy2B1Lp3pihCdQdK4H/2qwoanDjuEeGoSM1mDJ3zwROt79zplkQQ0aFhQR0e9hQQ0aniRBRESqxIIiIiJVYkEREZEqsaCIiEiVWFBERKRKLCgiIlIlFhQREakSC4qIiFSJBUVERKr0wH5ZrNjtjk+AExG5rPsm4On9x9PRfffA7kF197g2nktbW9s936a+vn7AspinjrwHedmY939YToPmgS0oIiIa2lhQRESkSiwoIiJSJRYUERGpEguKiIhUiQVFRESqxIIiIiJVYkEREZEqsaCIiEiVNCIigz0TSqiqqsKwYcMGezaI6AFhtVqh1WoHezb+VB7YgiIioqGNb/EREZEqsaCIiEiVWFBERKRKLCgiIlIlFhQREakSC4qIiFRpSBdUWVkZ4uLiEBsbi9zc3F9df+vWLbz++uuIjY1FSkoKGhsbFc07ceIEkpOTERoaii+++KJfWc7k7d69G/Hx8dDr9UhLS0NTU5OieZ9++in0ej0SExPx7LPP4vz584rm9fnyyy8xefJknD59WrGswsJCREREIDExEYmJiThw4IDLWc7kAUBxcTHi4+Oh0+nwxhtvKJq3adMmx7LFxcXh8ccfVzTv0qVLWL58OZKSkqDX6/HNN98oltXU1IS0tDTo9XosX74czc3NLmcBwLp16zBz5kwkJCTc9XoRwfvvv4/Y2Fjo9XrU1NT0K49+hwxRPT09Eh0dLRcvXhSr1Sp6vV5qa2vvmGbfvn2yfv16ERE5fPiwvPbaa4rmNTQ0yLlz5+TNN9+UkpISl7OczauoqJCuri4REcnLy1N8+To6Ohy/G41GeeGFFxTN68t87rnnJCUlRaqrqxXL+uyzz2Tjxo0u/X9X8i5cuCCJiYly7do1ERG5cuWKonm327Nnj7z99tuK5mVlZUleXp6IiNTW1sr8+fMVy8rIyJDCwkIRESkvL5c1a9a4lNWnsrJSzpw5Izqd7q7Xm0wmSU9PF7vdLidPnpTFixf3K49+25Ddg6qurkZwcDCCgoLg5eUFnU6HY8eO3TFNaWkpkpOTAQBxcXGoqKiAuPi5ZGfyAgMDMWXKFLi59X+1OpMXERGB4cOHAwC0Wm2/Xjk6kzdy5EjH7zdu3IBGo1E0DwC2bt2KlStX9utbQZzNul+cycvPz8eyZcswatQoAMDYsWMVzbvdkSNHfnPv4H7laTQaXL9+HQDQ0dGBCRMmKJb1008/ISIiAkDvc6K/9+2MGTMc98vdHDt2DElJSdBoNNBqtbBYLGhtbe1XJt3dkC2olpYWBAQEOP729/dHS0vLr6aZOHEiAMDDwwM+Pj64evWqYnn3073mFRQUIDIyUvG8vLw8xMTEYPPmzcjKylI0r6amBs3NzZg3b57LOc5mAcDRo0eh1+uxevVqXL58WdG8uro6XLhwAUuXLsWSJUtQVlamaF6fpqYmNDY2OjboSuW9+uqrOHToECIjI7Fq1SqXHyvOZE2ZMgVHjx4FAHz11Vfo7Ox0+XnuyjwFBAQoui34MxuyBUW/+Pzzz3HmzBm8+OKLimctW7YMRqMRa9asQU5OjmI5drsdH3zwAd566y3FMm43f/58lJaW4tChQ3jqqacUz7XZbKivr8fevXvx8ccfY/369bBYLIpmAr17T3FxcXB3d1c8Jzk5GWVlZcjNzcXatWtht9sVyVq7di1OnDiBpKQkVFZWwt/fX/Hlo4ExZAvK39//jre0Wlpa4O/v/6tp+l4J9/T0oKOjA2PGjFEs735yNq+8vBw7duxATk4OvLy8FM/ro9PpYDQaFcvr7OyE2WzGihUrEBUVhaqqKrzyyisunSjhzLKNGTPGsf5SUlL6deDb2cdmVFQUPD09ERQUhJCQENTV1SmW16e4uBg6nc6lnHvJKygowMKFCwEA4eHhsFqtLu3VOLsuP/nkExw8eBCZmZkAAF9f33vOcnWempubFd0W/JkN2YIKCwtDXV0dGhoacOvWLRw5cgRRUVF3TBMVFYWioiIAvWeCRUREuHzcxJm8+8mZvLNnz+Ldd99FTk5Ov45hOJt3+wbUZDIhODhYsTwfHx989913KC0tRWlpKbRaLXJychAWFqbIst1+DKG0tBSPPPKIYssGADExMaisrAQAtLe3o66uDkFBQYrlAb3HaiwWC8LDw13KuZe8iRMnoqKiwpFrtVrh5+enSFZ7e7tj7yw3NxeLFi1yccmcExUVhYMHD0JEUFVVBR8fH5ePsdEfGOyzNPrDZDLJggULJDo6WrZv3y4iIlu2bBGj0SgiIjdv3pSMjAyJiYmRRYsWycWLFxXNO3XqlMyZM0emTZsmTzzxhMTHxyual5aWJjNnzhSDwSAGg0FeeuklRfPee+89iY+PF4PBIKmpqWI2mxXNu11qaqrLZ/E5k/XRRx9JfHy86PV6SU1NlfPnz7uc5Uye3W6XTZs2ycKFCyUhIUEOHz6saJ6IyLZt22Tz5s39ynE2r7a2Vp555hnR6/ViMBjk+PHjimWVlJRIbGysLFiwQN555x2xWq39WrbMzEyZNWuWhIaGypw5cyQ/P1/2798v+/fvF5He+27Dhg0SHR0tCQkJ/Xpc0u/jcBtERKRKQ/YtPiIierCxoIiISJVYUEREpEosKCIiUiUWFBERqRILioiIVIkFRUREqvQ/iOUlr4XY7mYAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# overall model performance\n",
"compare_performance(\n",
" test_stats_list,\n",
" 'label',\n",
" model_names=models_list,\n",
" output_directory='./viz2',\n",
" file_format='png'\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeXxMd/fA8c8smcm+SUSQEPsWFLVFUUtRe7RUiWqpR1vaWtpHq7S1a4vfQ9XTatUuaJWiVYqisceeBBGSSGTft9nn90eYNkWtTxJ63q9XXyP3zr33e29frznzvXPuOQqr1WpFCCGEKGeUZT0AIYQQ4lYkQAkhhCiXJEAJIYQolyRACSGEKJckQAkhhCiX1GU9gP+VEydO4ODgcM/bmc1mVCrVPW1jNBqxs7MrlWPJ8crH8R7nc5Pj3Zper6dp06b3fCxx/x7bAKVSqahfv/49b5eWloa3t/c9bRMXF0e1atVK5VhyvPJxvMf53OR4txYVFXXPxxEPRm7xCSGEKJckQAkhhCiXJEAJIYQolyRACSGEKJckQAkhhCiXJEAJIYQolyRACSGEKJckQAkhhCiXJEAJIYQolyRACSGEKJcUj2tH3YiISBo2bFDWwxBCPMJ0RjP2dsU1+6Kiou6rfJq4f49tLT6lUkH1SdvLehhCiL9htVqx6gtAZYfSTntX71VoHVEoSt78sVrMWPSFKLWOKJQ3F4G1GHVgMaPQOKJQKP5YbtCBxYRC61Ri+Q2xc3re55mJh+GxDVBCiPLLarWQf2oHucd+wJSVBCiwrxaIW7uh2FcteefDlJtG1m/LKYo5itVQhFLrhFNgF9yCBmPOSSVr33J0cafBYgaFEm2Verg/FYLWrxEFEXvJC/8RQ/IlAJRaJ7T+gSjUWvRXz2HOzwBAoXXCqf5TuLcfhsrBtbQvh7gNCVBCiFKXvW8FuUe+JygoiODgiWRnZ/Ptt9+SsO49fF6Yib1fIwDMhTkkr5qAvVXPayNfpkaNGpw4cYKNGzdScG4PVpOBSt6eDJ0wnipVqpCWlsa6deu4vGEK2sr10F89R2BgIAPfmI6joyORkZF88803ODg4MLBfP5o0aYJGo+Hs2bOsXbuW1KRoKoV8hkJ17y08xMMnSRJCiFJlykkh99hmRowYwe+//07Xrl0ZM2YMERERBFTzJ2vvMm78NJ5zaANqYwEHDx5k1qxZVKlShWXLlrF+/XosujxUmDly5Agff/wxFSpUYMKECYSHh1PB3Q391XOMHTuWM2fO8NxzzxEQEMD7778PQL169Vi+fDmtW7emV69eLFu2jHXr1mFIiaEw+khZXh7xJxKghBClquB8GFjMfPTRR6SmptK8eXMGDRqEq6sr48aNw5B0EVN2MgD6hEjat29P48aNWbRoES8OG8769evp378/TZo0wdvbGz8/P3766Scm7khi1apVuLu7U7NmTezt7Zk1axZhYWE0bNiQ4OBgateuDUB8fDzVq1enY8eOBAYGkpmZSe/evVEoFBjT4sry8og/kQAlhChVpuwkPD09qVq1KhcuXMBoNHL27FkAmjRpcv09ydffbbUlL3h6emI16vH09AQgMDCQpKQkFixYQLdu3VjQsyrDhg1jzZo1HD9+nHbt2uHs7EyFChVISUnh6tWrvPPOOwBkZGSQnJkLgI+PD05OTpw6dQqr1YrKpUIpXg3xdyRACSFKldWkx8nJCShu2f7n1xvLM3/9kszdSzFmXmPv3r0cOnSI119/natXr9KrVy8AXFxcUKvV1K5dG7PZTGFhIUVFRVSvXh0nJyfbvjw9PXn55Zc5d+4cc+bMoUOHDsUDMRupXbs2e/bsIT09ncGDB6N0dMOpXrvSvBzib0iAEkKUKpWLN9euXcNgMFCpUiUA22tcXPHtNbuiDLiwB4xFGI1G2rdvT7du3ZgwYQILFy4E4NixYzz11FP06tWLzz//nNenzGX69OkEBQXRt29f274OHz7M9h072bBhA4DtWaZWLZpx8OBBDAYDQUFBXLp0CUthDqa89FK9HuL2JEAJIUqVvV9DzGYza9asoUGDBkycOJHp06cDsHz5cgCWLVtGbm6uLXCNHTsWlUqFl5cXw4cP5+TJkxw/fpykpCQAOnfuTJs6lXn22WcBuHbtGqdPn+bs2bO0bNmSLk93IDg4GIvFwqFDh6hZsyZ79uzBy8uLgwcPMmbMGD799FOcnJwoOLen9C+KuCVJMxdClCr76k+g8a3DhAkTsFqtTJ48mZycHMaNG8fWrVsBSEhIICIiApPJBEDHjh356KOPMJlMbNiwgSlTpgBw/vx5Ro0aZds2NTWV999/nz17ioPMoEGDmDdvHt9//z1Xr14lJCSE06dPExgYyOXLlwFo3bq1bWyzZs3CZNKX5uUQf+OxLXUUFRVFjxWXy3oYQohbMOWkkrZ5Nobk6D8WKpQ4B3ahKPYk5ty0v91e41MTr14TyT+7i9xjm8FqKbHeqVFnnAM7k75tPuY/37JTqlHaO2MpzL7tvr0HTMGxViugZCUJKXVU+mQGJYQodWq3ilQaNh99QgSGpIso1FrsazTHzr0SFkMRurjTWM0m7Cr4oXb1Qhd7GmN2MgqlEo1vXbRV6qFQKPB4+hVcmvVCd/Uc5oJsVA7OaKvUx66CHwBV/rWUopjjGLOSUDl7YO/XCJWLF4bkaEw5qTeNy87LH42Xf2lfDnEbEqCEEGVCoVBg79fIVjXiBqXGAcfarUssc6zb9rb7UbtVxNmt062PobLDsU6bm5Zrfeug9a1zH6MWpUmSJIQQQpRLEqCEEEKUS4/vLT6rRUrlCyEeiNWoQ2FnX9bD+Md6fAOUQgkfuZX1KIQQjzDFRzllPYR/tMc3QAkhyi2L1cras0a+PmEkNttCJWclIY3tGNnMDq26ZOPAa3kWZh3Qc/CqmTwDNPNV8nYrDW381JxNMTPvkIHwJDP5BitVXJT0q6dmTEsNWhVsvWhi6QkjkWlm7JQKGngrGdNSQ47Oyq+XTUSmWzBZwMdJwdQOWhr73NzsUJQdCVBCiFJltVoZsqmI0HMm6tevT8eOLYmMjGTMz8cIjTCye5gjGlVxkIpMM9NuWQFF2NOxY2fquruza9cuNizL4OWmdqw5a8TB2Y2nn34aFxcXoqOjeWfXYbZdNOHroiD0nAk/Pz/aP9sevV7P0aNH6bwyHgBXV1cCAwPRarXsP3uWf/+ayc9DnMry0oi/kAAlhChVv8SYCT1nYtq0aUyZMoWCggKcnJxYtWoVw4YNY9lJI6NbaAB4bbsOO9eKHDt4EB8fH7Kzs6lQoQL9+vXj2507qV69OuHh4Tg4OJCYmEitWrX45ptvGDlyJADTp0/nvffeIzc3F71ez7Fjx+jTpw+1a9fm4sWLtjENGDCAi79vLpPrIW5PsviEEKXqv8cN+Pn5MWnSJPbu3YuLiwvLli0jJCSENm3asOS4AYB8g5X9cWbGjBlDzZo1GTRoELVq1UKv1zN//nwAOnXqhKenJxMnTmTuwAZcvnyZAQMGAPDEE0/wwQcfsHbtWry9vfH19eXVV18FICUlhXbt2jF16tSyuQjirkiAEkKUqvPpFlq1aoWdnR379u3DarWyb98+AIKCgriYYcFqtZJvKK7CdqP/U35+PgaDAYPBQMOGDXFzc2PPnj0kJyfz4osvUrHHO1StWpV169YB0K9fPwC0Wi27d+9mxYoVuLi4AOCtyiMsLIyCgoLSPn1xDyRACSFKVWaRFS8vLwAKCwtLvHp5eaEzwVfhRnZfNgOwYcMGLBYLy5cvZ9++fVSsWNH23pycHMLDw2ncuDGDBw9Gp9Nx9OhRoLgRIRQ3Qdy9ezfBwcHs3LkTlUpFSGMNzppSPW1xHyRACSFKla+LgsTERAA8PDxKvF67dg2A0dt1DP2hCID9+/fTunVr1q5dy44dOwgPD6egoIDExETGjh1Lz549GTRoEIGBgRw9epSlS5fi5uZm29fixYv5dPZ0duzYQUBAAP7+/ny0T0++oeS4zqVaGLdDR6Hxsayf/UiSACWEKFXNfFXs37+f7Oxs+vbtS+PGjXnhhRcwmUxs27YNgBMnTtj+7eHhgb29PQsXLiQuLo6mTZuyadMmdDodFktxFfNatWrh6elJxYoVUSqVmEwmtm/fDkDTpk1xdPWkbt265Ofnc+3aNbRaLV26dKFu3bpA8SyrS5cu/N8RA+vPGcvgqohbkSw+IUSpGtdaw4pTObz66qt8/vnnnD59mpycHMaPH2/r0RQQEIBKVfxMkqenJ3v37kWlUmE2m9m8eTNvvfUWAEuWLOHZZ59l4cKFLFy4kMLCQt555x0KCgoIDw9n6tSpTJo0iVdeeYXMzExCQkLQ6/VUrVqVXbt22cY0depUzGYzarWahFyZQZUXj3U/qPrrW9/5jUKIUjf/kJ53dulR22moVq0aiYmJFBYW8kQlJSeTLWg0GqxWK0Zj8WzG2dmZKlWqkJ6eTkZGBg28lSzsbs/wLUUk5Bb/puXm5kZiYiI6nY7Rze0oMMKqM0ZcXFzw9vYmPj4eq9lETU8lFzOKj/FXBoOBbYMd6FnHrnjBnypJSD+o0icBSghRJqIzzCw7aSQ2x0IlJyUhTex4opKS7dEmwuLNKBTQvZaaXL2VXTFmkgssuGkVPFtbTa86atRKBfkGK6vPGDmdbCb3eiWJvnXVBPmrsVqtHLxqJvSckUydlZoeSl5oZEctTyWh54xEpVluGlOrqir61FWjVFyvZiEBqkzdVYBKTk7m448/JiYmBovFQseOHXn33Xdv+Q0EIDc3l61btzJkyBCg+JmDmTNnsnDhwvsa5IIFC9i8eTO5ubmcPHnyrraRACWEeGASoMrUHZMkrFYrY8aMoUuXLuzcuZNffvmFwsJCFixYcNttcnNzbc8iQHG65/0GJ4Cnn36ajRs33vf2QgghHj13TJI4fPgwWq3W9nS2SqXi/fffp3PnzlStWpXff/+d/Px8UlJS6NOnD2PGjGHevHnEx8fTt29f2rZty5AhQxg9ejTbtm1Dr9fz0Ucfce7cOVQqFZMmTaJ169Zs2rSJPXv2UFRUxNWrV+nSpQvvvvsuUJyFI4QQ4p/ljgEqOjqahg0blljm7OyMr68vZrOZs2fPsnXrVhwcHHjuuefo0KEDEyZMIDo6mi1btgCQkJBg23bNmjUAbN26lZiYGEaMGMEvv/wCFE+hN2/ejEajoXv37oSEhODr63tfJ2axWkpMz4UQ4l7pTTqSE1PKehj/WA+cZt62bVvbQ3Zdu3YlPDycLl263Pb94eHhDB06FICaNWtSuXJlrly5AkCbNm1spUhq1qxJYmLifQcopUJJ4IrA+9pWCCEAzr50lmrVqgHFX6BF6bpjgKpVq5ZthnNDfn4+SUlJqFQqFIqSvVv++ve9+HPSxY1nHoQQjyddgo6sA1kY042o3dS4t3XHsZbjTe+zmCzkHMyh8FIhZp0Zh2oOeLT3QO2ixlxgJissC12cDovOgtpDjWszV5zqO6FQKDCkGcj6PQt9oh6FWoG2shb3IHesZisFUQXor+nBAmo3dfE+XeXR0PLkjv832rRpw2effcbmzZvp168fZrOZOXPm0L9/fxwcHAgLCyM7Oxt7e3t+/fVXZs2ahZOT022LMLZo0YKtW7fSpk0brly5QlJSEjVq1CAyMvKhn5wQonxK3ZpK6vepODg4UKtWLeKOx3F5z2U8O3niG+Jr+6JryjVx5ZMr6BP0VKxYEW93by4evUjatjR8B/uSsikFU7YJf39/XFxciD8ST+yvsXh28cTO046UjSmolCrq1KmDXq8n9mgsqZtSbeNwdHREo9GQW5CLLlGH37/8yuqSiFu4YxafQqFg8eLF7Nixg2eeeYZu3bqh1WoZP348AI0bN2bs2LH06dOHbt26ERgYiIeHB82aNaNXr17MnTu3xP5efPFFrFYrvXv3Zty4ccyePfu26eo3fPLJJ7Rv356ioiLat2/PokWLHuCUhRBlqSi2iNTvUxkyZAgJCQmcOXOGa9euMX78eDL3ZJJ3Ms/23murr6FIV7Bt2zZSUlK4cOECkZGR1AuoR+KyRFyVrhw7doy4uDjOnTtHWloa48aNI/PXTFI2pDBo4CDi4uKIjIwkJiaG9evXA+Dv78/FixcpKCggKyuLXr16obuqK6tLIm7jgR7U3bRpE+fOnSuXPVWioqIYeHRgWQ9DCPEXV7+8ivK8kri4OGJjY3n++edZuHAhnTt3pl69elxTXaPGezWwGC1Ejo5kwtsT+Oyzz3j11VfZuXMn58+f59ChQ3Tu3Jnhw4fz7bff8uGHH7Jo6SIiwiOws7PD29ubgIAALly4wMGDBxkxYgQFBQXUqFGDgwcPUrFiRQYOHEhgYCCjRo0iODiYn479RO0ZtUuM9exLZ23/luegSp8UixVClCrdVR3t27fHxcWFLVu2cOHCBb777jtUKhXdu3dHF188kzHlmsAMderUAeDUqVPEX40nMzOTTp06YW9vz7lz5zAajdSpU4fWTVvj5OTEiRMnAHj++eexs7Pj8OHDvPHGGwwcOJDTp08DkJqayueff050dHTZXARxVx4oQAUHB5fL2ZMQovwy5ZioXLkyANnZ2SVeK1eujKXIQtGVIixFFhQaBb/99hsAc+fOZeF/FlKlShUAfH19OXXqFKGhoQwZMsRW/Xz27NlAcYIXwKuvvkpAQADz58+3JXxVGlwJhd39J3SJ0iEzKCFEqVI5qUhLSwPAycmpxOuN5TEfx3Dpg0tYDVbWrVvHqFGj0Ov1+Pr6EhUVhdFoJD09nTFjxhASEsKIESNwcnIiJiaGLVu24ODgQHp6OgCzZs0ieGAwO3bsICgoiKpVq5K8LhnrX/o+6RP0ZIVlYbU8luVJH0kSoIQQpUpbWcvhw4cxGo106tQJpVJJ586dAThw4AAAy5cv55NPPgGKM+02bNjAs88+y8cff4y/vz+7d+8mLy/P1jU3NTUVnU5HXl4erq6u2NvbExYWBoCrqytWoxVXV1fMZjNZWVkolUo8PT1tgdHFxQVPT08SlyaSdzrvr0MWZUQClBCiVHk+7UlCQgLTp0/nqaeeoqioiKFDh7J06VKOHz8OQL9+/XjmmWeA4oy79PR0EhMTOX36NElJSbz55psArFy5kszMTDZu3EhsbCzt27dn5cqVZGVlsX37djZv3szkyZOJjY0lKCiIyZMnU1BQQJUqVcjIyOCjjz4CYMWKFSQnJwNINl85Ik+lCSFKlXMjZ9zbujN9+nTWrVtH8+bNiYyM5OzZPzLmunbtil6vB4rLrXXs2BF/f3+Sk5PZt28faKHigIqc33KeatWqERQUhKurKxcvXuT06dM41HDAarTSv39/WrRoQbVq1Thz5owtKSIlJYU2bdqUGNeNhGaN198/9iJKz2PdD0rSzIUon6xWK7nHc8nal4Uh3WCrJOHexp30n9MpjC4EwKmBE1ajlfyIfEw5JpQOSlwau+DZyRM7dzt0iToydmagu6rDUmRB7anGtakrHh09wApZ+7LIPpKNpcCCpqIG9yB3nOo7kfZjGvok/U3jcqjhgHcvb5Sa4ptLkmZetiRACSHEbUiAKlvyG5QQQohySQKUEEKIcumxTZKwWiwlpudCCHGvLDodSnv7sh7GP9ZjG6AUSiVR9eR+sRDi/tU/Lz2gytJjG6CEEOVbocXCr3l5JBqNeKvVdHVxwU2luuV7I3U6ThcVkW+x0NDentaOjigVCqxWK+FFRUTpdRRYLPio1Tzl5IyXuvijzWC1sj8/n8sGA2oF1NRoaePoiEKhIFqvJ8agx2wFL7WKNo5OqB6gn514+CRACSFK3a95eXyQnESuxWJbNjs1hfcq+vCcu7ttmd5i4YPkZLbn5ZbYvq5Wy8xKvsxKTeFEUVGJdXYKBVN9fPBSqZmSnET6LRqfuqtUZP9l+UseHvy7os/DOD3xkEiShBCiVCUaDUxMukaDli0JCwvDaDRy6tQp2j/zDB+mJHNO90fA+b/0NH7Kz2PatGkkJCSQn5/P6tWryXBx4bm4WM6ZzXz11Vekp6ej1+s5e/Ysnbt1Y0pyMq8lJuDfpAk//fQTRUVF5OTk2PrTab28CA0NJSoqisuXL9O1a1cOFxaW1SURtyEBSghRqpZnZqHQaPj+++/x9/dn2LBhqFQqvvvuOzwrVGBpRgYAJquVDdnZDB8+nClTprBu3TpCQkJ44YUXmD9/PgDPPfccr776Klu2bOGZZ57Bz8+Pr776CgBvb292795N7dq1GTZsGIMHD7ZVq7C3t6ewsJDLly8TEBCAo+PNreZF2ZMAJYQoVeFFhXTq1InKlSuzdu1a1q1bx9KlS3F2dqZ///62W3YpJhNFVitt27YFYM2aNWz94QeSkpIYPHgwKpWKrKwsABITEzl//jx6vd62bMCAAbi7u7Nw4UK0Wi25ubmsXr0agLi4OF555RVbKw9RPkmAEkKUqhSTiWrVqgHFVcj//FqtWjUyzGYMFgteKhUqIDIyEoDRo0cT8vLLVK5cGbVaTeXKlfn5559Zvnw5U6ZMITk5Ga1Wy8iRIwFo3rw5APPnz2fGjBkcOHCApUuXAvBahQqlecriPkmAEkKUKgeFgoKCAgDs7OxKvObn5wPQIvoirS5FYwYWL17Ml19+Sb9+/fjggw9ISEgAoKCggCFDhjB8+HDmzp1LmzZtyM7OJjQ0FJVKRV5ecduMmTNnUr16dcLCwhg5ciTe3t78mpd/07gu6PVE62+uzyfKjgQoIUSp8tdoOHnyJABNmzYt8Xpj+ZvjxzNk+HAATCYTo0ePplKlSrRo0QJ7e3uOHDlCZmYmzZo1A2Dbtm0UnjpFREQENWrUwN3d3dbePScnB3uFgtzc4kxAs9lMtOHWgahv7BVO/yUrUJSdx7pYLP2Dy3oYQoi/+CEnm8nJyYSGhjJo0CCOHj1Ks2bNOHToEO3btwcgNzeXS5cu0axZMxo0aMCmTZuIjo7mySefxNXVlR49erBv3z46duzI7t27iY2N5cyZM/Tp04fDhw8TFBSERqPh9OnTeHt7c+DAAfr06cPatWsJCQmhatWq/P7777i5ueHu7k5aWho5OTnUrl2bt7y8+FcFL6Dkg7pSLLb0yXNQQohS1cvVjdDsbIYMGcJ3333Hk08+yeLFi1m/fr3tPRMmTCAnJweA+Ph4Fi9ejL+/P7/99htr1qwhJTmZVo6O/PbbbzzxxBP07NkTFxcXfvzxR9avX4+9QoHVaOTJJ59kyJAh+Pv7s2bNGr7//nugeFZ1o2PvDZbrz2Td7mFhUfpkBiWEKHX5ZjNfZWbwfU4OWWYzzkolfVxdCfHw5NO0VE4WFaGk+IFcrULJ4cICiqxW1EA7Jyde8axAC0dHduTl8k1GJhf0OkyAm1JJJ2cX3vL2wmi1sjg9gx15ueisViqq1fRxdaWHiyszU1O4YjDcNK4m9vbM9q1sC1IygypbEqCEEGXGarVSZLXioFCg+JsyQ1arlUKrBXuF8pbliCxWKwarFXvlzT+r/926O5EAVbbkFp8QoswoFAoc76L+nUKhwElx+1tvSoUC+9vs5+/WifJNsviEEEKUSxKghBBClEuP7S0+q8VCA+nlIoR4ABa9HqVWW9bD+Md6bGdQRpPpvrZLS0u7523i4uJK7VhyvPJxvMf53OR4f5DgVLYe2wAlhBDi0SYBSgghRLkkAUoIIUS5JAFKCCFEuSQBSgghRLkkAUoIIUS5JAFKCCFEuSQBSgghRLkkAUoIIUS5JAFKCCFEuSQBSgghRLkkAUoIIUS5JAFKCCFEuSQBSgghRLmksFqt1rIexP9CREQkDRs2KOthCCEeYTqjGXu74lbzUVFR1K9fv4xH9M/y2DYsVCoVVJ+0vayHIYS4A4tRj0VfgMrBFYXq7z+SLIYisJhR2juXWG61WrEaCrGaTSgdXFAolCXX6QuwWswoHVxRKBR/rDObMBfmoNQ6otQ43HS82Dk9/3Y8RqORhIQEdDrd3ZyquAV7e3uqVq2KnZ3dTese2wAlhCjfjNnJZO9bQeHFg2Axo9A44Nz4GdzbvYhS62R7n9VqpSBiDzkH12PKugaAnXd13NoMxLFuELlHvifvxDbM+ZkAKDQOODXogPtTIeSd2E7eyZ+wFGZfX+eIc6NOaHxrk3diO4aUGLCYAVB7VsGtzSCcG3W663NISEjAxcWF6tWrlwh84u5YrVYyMjJISEggICDgpvUSoIQQpc6cn0Xy6om4qK28/eZY6taty8GDBwkNDSUl8TyVhn6CQll8ay3v+Bay9nxN69at6dt3LCqVijVr1nD6x09Q2rtg0eXRq1cvOnbsiEaj4fTp06xevZqEUzsA6N+/P0899RQqlYoTJ06wdu1a8k5sIzAwkF7D36VatWpkZWWxZcsWDm+fj9VkwKVp97s6D51OJ8HpASgUCipUqHDbDseSJCGEKHU5R75Dqc/n4MGDzJw5k7p167Jy5UqWL1+OIekCBVH7AbDoC8nev4r+/ftz6NAhgoKCaNOmDSdOnKBz585YdHkMHTqUrVu30r59e6pXr87XX3/NvHnzAPjXv/7Fpk2baNWqFXXq1GH58uXMnDkTgHfffZeRI0dStWpVxo4dy6FDh+jUqRM5YWu5l5/mJTg9mL+7fhKghBClrvD8AQYMGECDBg2YNWsWnTp1YvPmzbz44ovUqlWLwvMHADCkXsZq0vOvf/0LgD59+tC3b1+USiWTJ08GoEmTJgC8/fbbvPTBghLLGjduDMBb4yfy8r9nlVg2ffp0atWqRa9evRg3bhwAPXr0wJyfidVQWBqXQdyB3OITQpQqi1GPOT/TFijOnTsHQEREBP369aNRo0bE/X6i+M3Xv13fmNFUrFgRpbL4e3VgYCAAS5YsoXv37nz99dekp6eTkpLCtGnTAFi0aBGdOnVi2dIvycvLIzExkVmzigNVzLV0237r1q0LwLFjx1BonVDcImHibvw56+9heNj7exAmkwm1unRDhgQoIUSpspqNADg6OgJgNhcnKZhMJttyY3o8GTuXwPX3fvrpp7Rv354TJ06gUCgwm804Oxdn8lWvXp0qVapw5swZkpKSaNWqFfXr12fXrl3UqFGDypUrcxjhBqsAACAASURBVOzYMbKzs2nWrBl169Zl//79cP03rsmTJzNhwgT+85//sGHDBtzaDi6RBXgv7O1UDzV7+E5ZhDe8/vrrJCcno9frGTZsGIMGDWL//v0sWLAAs9mMh4cHK1asoKCggBkzZti+FIwZM4Zu3brxxBNPcPLkSQB27NjBb7/9xpw5c5g0aRIajYaoqCiaNWtGz549mTlzJnq9Hnt7e2bNmkWNGjUwm8189tlnHDhwAIVCwcCBA6lVqxarVq3iiy++ACAsLIy1a9eyePHiuz5/CVBCiFKl1DqhsLPnypUrAPj6+pZ4vXLlCkqlEvurR9Dr9QDs2bOHWrVq0apVK9LS0ti6dStnzpwBYPz48Xh4eBAcHEy2zsz55s2ZOnUqCxcu5J133sHV1ZWePXtisCpJuHKJDz74gKVLl0JBJl9++SWjRo1iypQpzJgxAwBj9rXSviQPbNasWbi7u6PT6Xjuuefo3LkzU6ZMYfXq1fj5+ZGdXZzF+MUXX+Ds7MzWrVsByMnJueO+U1JSCA0NRaVSkZ+fz5o1a1Cr1Rw8eJAFCxawaNEi1q9fT2JiIps3b0atVpOdnY2bmxsff/wxmZmZeHp6smnTJgYMGHBP5yUBSghRqhQKBfZ+jQgNDWX27Nm8+eabKJVKnnvuOSIjIzly5Ag+Pj5cu3aN0NBQBg8eTIsWLXjyySdJSUlhwoQJeHh48OWXXwIQHx8PwOjRo4mJicHf35/IyMgS615//XVSU1OpWLEihw8fBopnZaNGjSImJoaKFSuycOFCjh8/zsqVKzF1fBm1i1cZXJ37s2rVKnbt2gVAUlIS69evp0WLFvj5+QHg7u4OwKFDh5g/f75tOzc3tzvuu3v37qhU1zMq8/L497//TVxcHAqFAqPRaNvvCy+8YLsFeON4ffv25ccffyQ4OJiTJ08yd+7cezovCVBCiFLn2mYQKWveoU+fPkyfPp2ZM2cSFhbGu+++i8ViwWQycfLkSWJjYwFQq9W89dZb+Pj4cOnSJYYOHcq6desA+OCDD3BxcWHUqFFotVp+++03Jk6cCBRn6mk0Gt5++23s7OzYuXMn48ePB8BgMNhua7Vr1w6A3NxcoPgB3kfFkSNHOHjwIOvXr8fBwYGQkBDq16/P5cuX72t/N2atNzg4/PF73H/+8x9atWrF4sWLSUhIYNiwYX+7r+DgYF577TU0Gg3du3e/59+wJEAJIUqdfdX6VOjxJnt2f83utm1ty1Wu3ri2DCbt6CaaNWtmW3748GHq1atn+1uh1uLWZhBOjbuS9sMsQkJCSuxf5eSBZ7c3yDy+lcGDB5dc5+wJwKRJk5g0adJNY7Or4I/areJDOc/SkJeXh5ubGw4ODsTExHDq1Cn0ej3Hjx/n6tWrtlt87u7utG3bljVr1tgyIHNycnBzc8PLy4uYmBgCAgL49ddfcXJyuu2xfHx8APjhhx9sy9u2bcv69etp1aqV7Rafu7s7Pj4+VKxYkSVLlrB8+fJ7PjcJUEKIMuHc+Bkc67ajKOYY5sJs1O6+ONRojkKpwrlJN4wZV1Eo1Wj9AzHnpaO/dh5LUR5KRzccaj6J6nq5I9/h/4c+MQpjRgKYTajdfLCv1hiFWoNzk27or0ZgzEwEq8W2zmqxoI8/i9VScqakUNlh7x9430kSZaF9+/aEhobSo0cPAgICaNq0KZ6enkybNo2xY8disVioUKEC3377La+99hrTpk2jV69eKJVKxowZwzPPPMOECRP417/+haenJ40aNaKw8NZp9iNHjmTSpEksWbKEDh062JY///zzxMbG0qdPH9RqNQMHDmTo0KEA9O7dm8zMTGrWrHnP5/bYFouNioqix4r7m+IKIQSUzKK7VbHYvy57nNPM79e0adOoX78+zz///G3fc7tCvI/O1wQhhCjnHnYwedSDU3BwMBcuXKBv3773tb3c4hNCCPE/sWnTpgfa/vENUFbLXT/kJoQQt2I16lDY2Zf1MP6xHt8ApVDCR3fO8RdCiNtRfHTnB1nF/87jG6CEEOVabLaFzw7q+fmSCb0JWlZRMaGNhiD/kh9LVquVjZEmvj5h4EKGBWeNguB6at5urcHNXsF/jxtZd85IfI4FjQoaVVTxdisNQf4qFh81sCHSxNUcC/ZqaOyjYnwbDTU8lHxzwsixa2aS8y0APF1dzazOWlRKqU5eXkiAEkKUurMpZp76tgAdWnr3HoCzszPbt2/nh2/TWN7XnpeaamzvnbhTz/zDBurVq0fHvi1JTU1l1s6drDxjpIaHkt9izbRo0YKuXQLR6/Xs27ePTisTbdu3bt2abs80oKioiL179/LUt8kAKJVK6tWrR7Um1dDpdHyydy8dq6voUfvmzq6ibEiAEkKUunG/6LB39+H0kSNUrlwZvV7PkiVLePbZZ3n7l730r2+Hq1bBsUQz8w8beOONN1i4cCHR0dH4+fkRFRVFUFAQ8bF6pk+fzgcffEB0dDQVKlTA2dmZDh06cPjwYebPn8+4ceO4cOECPj4+aLVa2rZty6lTp1i0aBGvv/46UNwZ18/Pj8S8x/Kpm3t29uxZtmzZwgcffHDL9SkpKcycOZOFCxf+T8chaeZCiFJ1OcvC7itmJkyYQLVq1QgODqZ69epYrVY++eQTsnXwXWRxjbedMSYUCgWzZ8/mwoUL1K9fn7feeovmzZszfPhwoLjeW0FBARP7NeGll15Co9HQrVs327qMjAw+HtiE0aNH4+DgQNeuXQFYvHgx/v7+JCQkPLyTM+oe3r4e4v5uVIy/W4GBgbcNTgA+Pj7/8+AEMoMSQpSyC+nFH5ZBQUEA7N+/n9zcXKKiomjRogVarZYL6cW/C+UZrGg0GhwdHdHr9agUVnS64g/t1q1b8+WXX7JixQo++eQT2r8yncDAQLKysvjxxx8BWLFiBVOnTqXJix/bKqFv27YNwFZQ1mq1PryuuHb2Dzc56y6SNBISEhg5ciQNGzYkMjKS2rVrM3fuXHr27EmPHj04ePAgI0eOxM3NjUWLFmEwGPDz82P27Nk4OTlx5swZZs2aRWFhIRqNhuXLlxMREcGyZcv48ssvOXr0qK0LsUKhYPXq1WRnZzN69Gi2bduGXq/no48+4ty5c6hUKiZNmkTr1q3ZtGkTe/bsoaioiKtXr9KlSxfefffdezp9CVBCiFKVdX1S4OlZXBOvqKioxKuHhwfLT6dQp4KSxDwrer2BjRs38sILL/Drnt9o0KABAF5exdXGr1y5QkZGBt27d8fLy4uLFy+SlZUFQHR0NDk5OfTo0QNfX18uXLhgKwi7tLc9r259yDOeMnLlyhVmzpxJ8+bNee+991i7di1QXFX8hx9+IDMzk7Fjx/Ltt9/i6OjIV199xbfffsuoUaMYN24cCxYsoHHjxuTn52NvXzKtftmyZUydOpXmzZtTUFCAVqstsX7NmjUAbN26lZiYGEaMGMEvv/wCFFeI2Lx5s61YbEhIiK2tyt2QW3xCiFJV2aV4tpKYWJzI4OHhARQHLKPRSGpqKqkFVkZu1bH6TPGtvqFDhzJs2DDCwsL45JNPADh//jwA33zzDenp6TRq1Iinn36aVq1aMWXKFNRqNd988w1XrlyhSZMmPPvss7Rr145///vfALcMTq9u1fH99duLjxJfX1+aN28OQJ8+fQgPDwfg2WefBeD06dNcunSJwYMH07dvXzZv3sy1a9e4cuUK3t7etu7Gzs7ON1Ucb9asGXPmzGHlypXk5eXdtD48PJw+ffoAULNmTSpXrmzr9dWmTRtcXFzQarXUrFnT9v/8bkmAEkKUqsCKSuyUf1TDHjNmDL1796Zu3bps2bIFi8XC888/T3x8PAMHDgSgVatWHDt2jNWrV9O5c2csFottlmAymfD09CQgIMD2QWswGLBYLJjNZry9vfH397e1iL/Rw6h+/fr07NkTBwcHHBwc6NmzJ/Xr1+fVrUUYzY9WssRfb1He+PtGqwyr1UpQUBBbtmxhy5Yt/PTTT8yaNeuu9j1q1ChmzJiBTqdj8ODBxMTE3PW4NJo/sjFVKtU9/xYmAUoIUaoqOCp5uakdS5cuZcWKFbz//vv8+OOPHD582NbHydHRET8/P1vbh+DgYKKiooiMjKRhw4a8/PLLtl5Ob7zxBiqVisuXLxMaGsqpU6eYM2cOFouFN954AxcXF+Li4li2bBnHjh1j3rx5ALzyyits27YNLy8vKlSowLZt2xgxYgRZOtA9Ou2gALh27Zrtemzbts02m7qhadOmnDhxgri4OAAKCwu5cuUKAQEBpKWl2boT5+fnYzKVPPn4+Hjq1q3LqFGjCAwMtM2ObmjRooWtQ++VK1dISkqiRo0aD+W8JEAJIUrdnC72NKtoZvjw4Xh5eVGlShWCgoLQZ8RT00PBihUrUCgUfPvttwBMnDgRb29vqlevTkBAAKtXreSjDlrmPaNlw4YNVKpUiSpVquDp6ckTTzxBQVo8/eqpWblyJd7e3lStWhUPDw9atmyJOScJgHfeeQeFQlHiv4kTJ1LPS4mz5u9GX/4EBASwZs0aevToQW5u7k09sDw9PZk9ezbjx4+nd+/eDBo0iMuXL6PRaFiwYAEzZsygT58+vPLKKzc1LFyxYgW9evWid+/eqNVq2rdvX2L9iy++iNVqpXfv3owbN47Zs2eXmDk9iMe63Ub99a3LehhCiNuwWK1sv2gqUUliaGM79GZYc8ZIeqEFL0clPeuo+TnaxJkUMzoz1PZUEtLYjmruxd+vo9LMfBdpIja7uFpEA28VQxrb4W6v4GyKmU1RJuJzLDjYQWBFFS8G2pGlsxJ6zkiBoeTHn6OdgsGBdvi7Xf/u/qcsurtpt4FRV5zJ97Dcxf4SEhJsGXWPqtu127irLL7k5GQ+/vhjYmJisFgsdOzY0dZK+VZyc3PZunUrQ4YMAR7soa6ioiLeeust4uPjUalUPP3007bbAEKIR5dSoaB3XTt61y1ZucEJGNuq5GfLGy1v/428vreKKR1u3ZYi0EdFoM/N61y0Ct4N0t5iiwf0sAvL/sML1d7xFp/VamXMmDF06dKFnTt38ssvv1BYWMiCBQtuu01ubi7r1q2z/f2gD3W98sor7Nixgx9++IETJ06wb9+++96XEEI8TqpWrfpIz57+zh1nUIcPH0ar1TJgwACgOBPj/fffp3PnzlStWpXff/+d/Px8UlJS6NOnD2PGjGHevHnEx8fTt29f2rZty5AhQ+77oS4HBwdaty6+VafRaGjQoAEpKSn/26sihBCizN0xQEVHR9OwYcMSy5ydnfH19cVsNnP27Fm2bt2Kg4MDzz33HB06dGDChAlER0ezZcsWgBKlRB7koa7c3Fz27t3LSy+9dMcTs1gtd/UUthBC3I7epCM5Ub4Ql5UHriTRtm1b24N2Xbt2JTw8nC5dutz2/eHh4QwdOhS4/UNdN9YlJibaApTJZGL8+PGEhITg5+d3x3EpFUoCVwQ+0LkJIf7Zzr50lmrVqgHFX6BF6bpjgKpVq5ZthnNDfn4+SUlJqFSq2z4gdj/+7qGuKVOmUL16dVuBSCHEo81qtVIQUUD24WxMuSY0FTV4dvDE3u/mxABTvomsfVno4nRYzVac6jnh3s4dlYMKQ5qBrP1Z6JP0WM1WNF4a3Nq44VjDEX2KnqwDWRiSDFgtVjQVNbi3dUfjrSHnaA6FMYWYckyo7FXYV7fHs4MnKqdbJ1yI0nfHJIk2bdpQVFTE5s2bgeKquHPmzKF///44ODgQFhZGdnY2Op2OX3/9lWbNmuHk5ERBQcEt93c/D3UtWLCA/Px83n///Xs9PyFEOWS1WElYkkDsZ7Goz6upa1cX3UEdl6ZcIv3n9BLvLYorIvq9aNK+T8MrwwvffF+S1iQR/V40GbsziJ4cTdbPWVQpqEINSw10B3VcnnaZK59e4dLkS+T8kkPVoqpUN1Wn6EARMR/GEPV6FNeWX8PuvB31NPXwzvQmdWMq0e9Fo7+mv82o/zk2bdrEtGnTAFi0aBHffPNNmYzjjgFKoVCwePFiduzYwTPPPEO3bt3QarWMHz8egMaNGzN27Fj69OlDt27dCAwMxMPDg2bNmtGrVy/mzp1bYn/3+lBXcnIy//3vf7l06RL9+/enb9++bNy48QFPWwhRlrLDssk5msO0adNITEzk+PHjJCQkMHDgQJI3JKNLLK6TZ7VYSfgygcrulTl16hSXLl3i/PnzHDp0CE+NJ0mrkmhYpyGxsbFERkZy4sQJkpOTGTBgAAURBTzR+AmuXr1KREQEp06dIikpyVafbuHChaSmpnLs2DGio6M5efIknvaeJK64t3pxf6Y3P9zgdq/7s1qtWCyWhzqGsnRXv0H5+vry3//+95brKlWqxBdffHHT8hvlRG64kQap1WqZPXv2Te8PDg4mODjY9veXX35p+/eFCxfuZphCiEdExs4MnnjiCaZMmcKmTZuYOHEiP//8M1988QU//fQTGbsyqDK8CvpEPfpremasmEFgYCBPPvkkGo2GsLAwPvzwQ9544w2GDx9OlSpV6NevH+Hh4Vy9epWxY8fy/fffM3LkSHx8fOjatStxcXFcvHiRN954g59++omIiAg6depEZGQks2fP5uWXX2b06NFMmz4Ni9GC0u7eC+1oVdqH+tv32ZfO3vE9CQkJjBgxgiZNmhAREUGPHj3Yu3cvBoOBrl278uabbwKwefNmvvnmGxQKBXXr1uXTTz9lz549LFmyBKPRiLu7O5999pmtSnx5IO02hBClymq2okvU8eyw4pnMhg0buHLlCj///DNvv/02LVu25FDcIQCM2cWFXWvWrAkU93Cysyt+sLd79+4AHD16FCjuL1WhQoUSy44ePcprr71G+/btSU5OLrHuz1+Cw8LCePnll/+oQ/eI1deJi4tj7ty55Ofn88svv/Ddd99htVp57bXXOHbsGO7u7ixZsoR169bh6elJdnY2AM2bN2fDhg0oFAo2btzI119/zaRJk8r4bP7wQAHqr7MeIYS4E3OBGSzYMnRzcnJKvPr6+qI/pKcorgiu363avXs3QUFBrFy5EpVKZXsfwK5du/j999+ZMGECZrPZVhgWYPv27Rw7dozJkydjsVi4dOkSq1evBsCjvQdZ+7No0KAB06dPJzo6miVLluDcyBml5tEqU1q5cmWaNm3K3LlzCQsLo1+/fkBxUdjY2Fh0Oh3du3e39eByd3cHin9CGTduHGlpaRgMBqpWrVpm53ArMoMSQpQqlaMKFJCWlgYUP1f559e0tDQsRRZiPvyjrcOMGTPIy8ujY8eOJCQkkJGRYWtKOG/ePNq1a0fz5s25fPkyly5dYv369TRp0oRFixbx5JNPUq9ePTIzM4mJiWHVqlW0bduWrP1ZtG/fns2bN3P16lW6d+9OVlYWvr3uvqFeeeHo6AgU/wY1atQoXnjhhRLrV61adcvtZsyYwfDhw+ncuTNHjhzh888//5+P9V48Wl8ThBCPPIVagcZHw969ewFsiVdPP/00+fn5HD9+nAoVKrB582ZbMpabmxtffPEFvXr1YufOnVSoUIFNmzYB2G7r5ebmotPpMJlMtmU3XvPy8igsLMRsNtuW9e/fn507d5Kens6YMWPw9vbGz8+PlI0pmHX31reovGjXrh3ff/+9LYs6JSWFjIwMWrduzY4dO2xB/cYtvry8PHx8fABsmdrlicyghBClrkLnCuxfs5/ly5czcuRIXn75ZSwWC+PHjyczM5MqVarQt29f2wdthw4dWLduHXl5eXh6erJ3715mzpwJwOeff06XLl04deoUOp0ODw8P3nnnHaA4U69du3acP38eo9GIs7Mz7733HgAvvPACWq2W2rVrs3//fgBWrlzJSy+9hDnXjMr+0Xseql27dsTExNhmUI6Ojnz66afUrl2b0aNHExISglKppEGDBsyZM4cxY8bw1ltv4ebmRqtWrUpU/SkPHut2GwOPDizrYQghbsFitBD7WSyFFwpp2LAhtWvX5tixY7aW4HZ2dgQGBpKVlcWVK1fQaDS0bNkSHx8foqOjOXPmDBofDe5B7qT+kIqnhyfNmjVDq9Vy9uxZ4uPjQQWYwcvLi2bNmqFSqThz5oztGAEBAbYqODdkZmYSnxRP3f+ri8pBVSKL7m7abejNerSqh1cl/WHvr7x6oHYbQgjxMCntlAS8E0D2oWxiD8Zy6fglND4aqg2qhmNNR9K2pxGdGI3CU0GVLsXp5icuncB82YzaTY3vMF88gjxQapU4N3Qmc08mYZfDiitJeGvw6+OHa3NXCqMLydybyYFLB4rX+Wrwf94fzJBxMIN0U8mHghVeCvz6+aFyuL/Z08MOJv+E4PR3JEAJIcqEQq3A4ykPPJ7yuGldpYGV7no/jjUdcazpeMt1TnWccKrjdMt1rs1d7/oYomxIkoQQQohySQKUEEKIcumxvcVntVjuqkyIEELcjkWnQ2n/z267XpYe2wClUCqJqndzVogQQtyt+uelB1RZemwDlBCi/IvS6ThQUIDBaiHQ3oGnnJxQ3qKnXIHFwv78fGINBhyVSjo5O+N3vQtClsnEnoJ8koxGNAoltbUa2jk5Y6dQkG4y8Vt+PkkmI/YKJXW0WoKcnFArFKSajJzT6Ug3FT+U+6SjAwGaRzNrbuXKlaxbt45atWqRmppKREQE48aNY8SIEWU9tAciAUoIUep0FguTkpLYmZ8HgFKpxGLJoLZGy+dVqtiCD8DxwkImXLtGmtlkW/ZJWipDPTxo5uDAe0lJ6KzW6/soLt4XoNHQ19WNLzLSMfxlXW2NlqoaO/bm5980rp8CalD9b9r/3IlFr0epfXhB7m73t3btWpYvX46dnR2JiYns3r37oY2hLEmShBCi1C3OSOfXwgJmzJhBVlYWOp2O0NBQMl2cmZh0jRv1A7JMJt68lohXneJqD3q9noSEBF5/4w1WZWUx7to1WgQFcfr0aQwGA4WFhWzZsoUsR0f+Lz2Ndk8/TUREBAaDgYKCAjZu3EjS9eA0dOhQDh48SGJiIseOHQMgvLDwgc5LqdUSVa/+Q/vvboLT1KlTSUhI4NVXX2Xr1q00btwYtfrxmHtIgBJClKp8s5m1WVm8+OKLTJ48mQ0bNvD2228zaNAg5s6dy1mdjsPXA8Uv+Xlkm82EhobSqFEjunTpwq5du/j8889p3bo1UFwstkGDBnTr1o158+bRp08fRo0aBcB//vMfAgIC6NSpE0uWLOG5557jpZdeAorLAO3atQsHBwdbPbpH0bRp06hYsSIrVqxg+PDhZT2ch0oClBCiVJ3X6ymyWhk6dChQ/AH7xRdfEB0dzZAhQ1AoFJwqKgIg3mDE3t6exo0bExERwdHff2fLli1AcXduKK5+bjabSUxMJD29uDJEamrqTesyMjJsywC++uorPvzwQ1u9P1H+PB7zQCHEIyPlelNAf39/oGQwqV27Nt7e3iTrDQD42qnRZem4dOkSTzzxBM8PGcLAgQNLbP/2229z4MABoqKKM+5+/vlnVqxYAcDYsWPZt28fly5dAmDTpk1s2LABgBAPD1Zdr+4tyieZQQkhSpWTsvhjJy+vOEFCcz0p4cZrfn4+G3OyaXDhPLOvB6/nn3+e8PBw5s2bh5ubW4ntQ0ND0Wg0tGnThrFjx9KjRw/effddADZu3IjRaKRly5a8++67BAcHM3bsWKA4+eKvtuTmkGt+NFttPI4kQAkhSpX/9Zbt4eHhQHHbcScnJ+rWrcv58+cpLCykSZMmTJ06laZNmwJw7tw5OnTogI+PD9999x0AP/30EwqFgsDAQK5evUpSeDg7/r+9Ow+IqtwfP/6eGZhhGxBUFgV3UVAUtxLNJfcN1NSyXLLUb1pW2mKWWS7VTbv3p3lLvta1xSwr90xFEyJXNPmKopKCoiwism8Dwyzn9wdJcV0yDBjt8/oHnPOc+TznAefDc86zREQA0LFjR3Q6HW3atOHChQvknTjB7t27AejQoQMACUbjdXU7VlrKE6kp3K2bPGRlZdG7d28+/fRTwsPD6d27N8U3GK14t5BbfEKIWtVcqyXIwYH33nuPRx99lK1bt5Kfn49er+f1118HIDg4mEWLFpGamkpcXBzLly+nU6dOqFQqevToQVRUFBs2bEBRFDZv3sz48eP5JCKCxo0bAxW38oxGIzt27CA0NJRV339PixYtANiyZQsAb775JjNmzMDT0xOAjIwMwsPDWbx4MQZFwfkG87H+iNVo/Esn997uMPOoqKjK76/tbXUvkAQlhKhVKpWKuQ09efLiRfz9/ZkwYQJ6vZ5NmzZx5swZAA4dOsS0adM4ePAgAGvWrGHIkCE4OTmxZMkSdu/eTVM7e9RaLRMnTuTbb78lKCiI0tJSoqKiKntnY8aMYdSoUQQEBLBnzx5++OEHTpw4AUBERMR1G/TFx8fjpFJjX43kBPylc6Bq4v3uNvf0hoWMfqiuqyGEuIlTZaWE5+RwoKQEs6LQ3sGBKe4euGjU/L+sLPItFuppNLRzcOB0WRnnjUbMQCM7O0a71WOyuzsqIDwnh4iiQjLNZuxUKlpqtUx296CviwurcrL5oaiITLMZrUpFa52OKe4eFFutfJqbQ9l/ffw5qFQ86VGfcfXqAVWXOrqdDQtF9ciGhUIIm9LewZEPG/tiVRQUQPO7XksvZ5frylsVBQtc17t52dOTlz09sSgKaip6aNe86unFq55eNzz28K9JSNguSVBCiDp1o7X3blbuVqO6NLd4n1sdu1OKolRJfOLPudVNPBnFJ4QQ1eTg4EBOTs5dO+qvrimKQk5ODg432dLknu1BKVYrgbJUvhDiDvzRKDpfX1/S0tIqV6cQf56DgwO+vr43PHbPJiiT2fzHhW4gKyuLhg0b/qlzLl26RNOmTWsllsSzjXj38rVJvN/80Sg6e3t7mjdv/qfji9sjt/iEEELYJElQQgghbJIkKCGEEDZJEpQQQgibJAlKRwhRJAAAIABJREFUCCGETZIEJYQQwiZJghJCCGGTJEEJIYSwSZKghBBC2CRJUEIIIWySJCghhBA2SRKUEEIImyQJSgghhE2SBCWEEMImSYISQghhk1TKPboV5OnTZ2jXLrCuqyGEuMuVmSw42GtISEggICCgrqvzt3LPblioVqtoNm9HXVdDCPEHFKsFS3EuKjstGie3W5e1mLCU5KNxckNlp61yzFpehrW0ELWDC2qdU9XzzOVYDIVonN1Qaeyviw2gca5X5dg1F98dXt1LE3fonk1QQgjbplgtFB7dTOGxbVhL8gHQ+rShXu9JODYLrlLWlJtOXuTHlCb/HyhWVHY6nNs9SL3ekyqO/biG8stnK8vbe7bAvc/jaJzdyY36GGPKKUBBpXXEpcMg9J1HkBf1H0qTY8Hy6+7bag2OLbri3n869vW8a6sZxC3cs7f4EhISGPr5hbquhhDiJnL2rKL4+E6GDh3K6NGjycvL4+OPPybp/AU8H1mCY9OOAJgLs8n47DncHDQ89dRTNG/enNjYWNauXUuZyQxWKy2aN2PKlCk0btyYq1ev8sUXX3DmzBkAvL29mT59On5+fuzfv5/169djNpvRaDTMmTMHf39/VCoVZ8+e5ZNPPqHApKHRtFWotY7Abz0oucVX+2SQhBCi1ply0ig+vovZs2ezc+dO2rdvz2OPPUZcXBwtWzQnP/ozrv3tXHD4GxzVFo4ePcqLL76ISqVixYoVbNiwASxmdFp7Dh8+zPPPP09ZWRlTp04lJiaGBg0a0KBBA44fP8706dPRaDR88sknrF69GgCtVsuMGTNwd3enU6dOvPfee2zZsgVLURalSUfrsnnEryRBCSFqneHcIVQqeO2110hPT+eBBx7gsccew9nZmdmzZ1N+JRFzQSYAxstn6dOnD61atWLlypU8Net5Nm7cyIgRI+jYsSMNGjTA09OTiIgIFu3PZ8OGDej1enx9fRkxYgTe3t68/fbbTHv6OSIjI5kyZQq+vr6UlpbSqlUrxo0bx/33309paWllD8liyK/L5hG/kgQlhKh15vwreHl50bBhQ86ePYvVauWXX34BoH379pVlAFQqFRaLBYBGjRqBqaziK9CuXTvS09N5++23CQ0NZc2EDkyePJlVq1YRFxdXeV7jxo1Rm8vw8vJCrVbTtm1bANzc3Pjwww/Zs2cPZrOZ2bNnA6Dz8a+9xhA3JQlKCFHrFIsJBwcHgMokcu2ro2PFs5+cXSvJ2bWS8qyLREZGEh0dzYwZM8jLy6NPnz4AODk5odPp6N27N8XFxSQlJZGXl0dISAhubm5s2rSJ48ePs2DBAnJzcyuTn7OzM1CR/FxdXXF0dESv1xMWFgZA+dXk2msMcVOSoIQQtU7j2pD09HRMJlNlb8jHxweACxcqBje52ZlxzT6FGgWz2Uz//v3p2bMn48ePJzw8HICYmBj69OlDr169+PDDD3ll2SqWLl1Kp06dGD58OAaDgfvuu48+ffowduxYvvnmGwCOHq14xpSfn8+kSZPo0aMHJ06c4JFHHsHb25vyK0m13STiBmSYuRCi1jk06UDh4W/5/PPPmTZtGgsXLqRbt24ArFmzBoDVq1czduxYPD09ycrKYv78+Zw7d44WLVowbdo0Dhw4wKlTpzCZTACMGDGC2NhYxowZA0ByckUvaPHixRw/fpz27dvzyCOPsGXLFjIyMhgyZAiDBw/m5MmTNGnShICAALKzs8nKysKlhUcdtIr4b5KghBC1zqFpR3SNA3jhhRcoLS1l6tSp5OXl8eSTTxIZGQlAYmIiMTExmM0V85TatWvHU089hclkIjw8nLfeeguAs2fPMnHiRJ5//nlWr17N1atXeeaZZzh8+DAA3bp1Y8qUKZSUlLB06VLeeecdAPLy8rj//vsZP348JSUl7Nixg8WLF2NBjXNg39pvFHEdmQclhKgT5qJssrf/E2Pqqd9e1Njh2iUMQ9IRzLnptzxf1ySIBsNmUxy/l4KYDb9NuAVQqXFo3onyK0lYDQVVznNs2Q1do7bkH/gSFGuVYxqX+tQf+hyOLbpUvibzoOqOJCghRJ0yXkmi/EoSKnsdjk2D0bi4o5hNlKWdBqsF+/p+qJ1cMaYlYC64AioNukb+aBs2q3wPS0kexvQELIYC1A56dI3aYufaAKvRgDHtDObCq6g09uh8A7H3aPzrOfkYM85iKcpBZafFzs0LnW8gKrWmSv0kQdUducUnhKhTOu9W6LxbVXlNZWd/3XJHjs073fQ9NM7uOPn3uO51tc4Jx5Zdb3JOPZxa3V+NGovaIqP4hBBC2CRJUEIIIWzSvXuLT7HKMvlCiDtjKqvcD0rUvns3QanUsPDWe8sIIcQtLSzAoa7r8Dd27yYoIYTN25loYkVMOf+XYcVZC2H+dsztqcPPrerTh4IyhXcPGNmRaCajWKGFu4rpnbU8EWxPepHCO/uN/HjRQlaJlQZOavo20/BaLx3O9vDWvnL2JpvJKlFo00DN0121jGxrx/87XM6e82YSc62YrdDCXcWEIHue7qbFTq2qoxYRv3dPDzMP+KZ7XVdDCHETSw8YmRdppGnTpgwbNozs7Gy2bduGXmMiZpozrTwqklRBmcL9/ykhMQ8GDRpEs2bNiImJIS4ujgeaaEjMsVJodWDo0KH4+PiQmZnJzp07MRgMANjb2zN06FAaNWrETz/9REJCAgAajYauXbvSoUMHNBoNcXFxxMTEMDbQjm/HOqJSqWDhb3OoZJh57ZMelBCi1qUXWnkj2sjDDz/MV199RUFBAXq9nkuXLtG1a1dejSxhw7iKbduX7DNyvkBNZOQP9OjRg1OnThEeHs4777zD/Pnzsbe358SJWPz9/Tl69CjdunUjOTmZDh06oFarOXjwIP7+/iQlJREeHs4LL7zA8uXLCQkJYf/+/aSlpeHu7o6zszPLli3jlVde4UCKhV5N5eOxrskoPiFErVt30oTJqmLZsmXk5OTg5+fHE088QatWrXjmmWfYdMZMbmnFzZ29F8wMHDiQvn378u6779KlSxd27drFyy+/TOPGjWnevDkBAQGsX7+e8+/1Y926dbRu3ZqWLVsyduxYgoODmTt3Lh07duTYsWMsWrQIV1dXUlNT6dq1K35+frRu3Rqj0cj06dMBOJpuqcvmEb+SBCWEqHXncqz4+PjQtGlT4uLiMBgMHDp0CIDu3bujAOdzK5YhKjGBq6srQOW6fGazGXt7ezp16sT58+eJjIxk4MCBnO84j8GDBxMdHc3Zs2dveJ5erycgIIBLly4RGxtb5XhKSgoA9RzkGZQtkAQlhKh1eWUK7u7uAJSWlgJQVlYGgIdHxUriSw8aWfVzOeUWhT179pCens68efOIjo4mNDQUgPr166MoCufOncPV1ZW+fftSr149zp07h6IobNu2jfz8fJYuXcqBAwfo3r17lRgejiq8vLyIiIjAYDDwxBNPUM8BRrWV23u2QH4KQoha11iv4sfEisVg69evD/yWNNLS0gDYlGBmU8K1BWDz6NSpE+PHj8fFxYVLly4xefJkzpw5w4ABA5g5cyaLFi3i0+WLmPTsfJYsWcK2bdvYuXMnQUFBjBs3Djs7O7Kyshg1ahRnzpwBoIFfayIiItBqtfTt25eTJ08CUC53+GyC9KCEELWuayMN+fn5REZG0q1bN4YNG8YzzzwDwMaNGwFYt24dmZmZuLi4ANC7d2927drFiRMnGDZsGAkJCfz888+VPbB27dphcvahXbt2wG89sx49evDdd99x4cIFBg4cyP79+7l06RItWrTg0KFDNGnShM8++4yQkBCeeuop7Ozs+PyEqbabRNyA9KCEELVufHt7Fvxo5Omnn2bt2rXs2LGDsrIyli9fzqZNm4CKbdnr1atXMdwbWLp0KS1btgQgMjKSp59+GoD9+/ezcuVKZsyYwdixYzGZTKxatYro6GgAPvroI9zc3LBarezcuZMZM2YA0KRJE/R6PRaLhZdffrmybmvXriW3VLpQtkDmQQkh6sThVDNhX5eSbVBo2LAhJSUlGAwG+jTVcCjVgqnqVk2oVCo8PT0xGo3k5+fj46LiqzGOLD1oJCLJgp2dHR4eHuTm5mI2m7FTg9kKarUaT09PDAYDhYWFtHBX0dpDze7zN09CG8c5MibQXuZB1THpQQkh6kSInx3Jz7vw5UkTx6/k42yvIqyNE72bajiXY2XbWTNmK3T0UtPCXc22s2aS83Kx10APP0ceCrDDwU5Fn6YaIpMtRF80k1WSRwN/Nb2bOjGopYaTmVa2nzOTUpCDg52Kvs0cCfW3w2yFjWdMpBZe//d5J281g1vJR6MtuK0e1JUrV1i0aBHnz5/HarXSt29f5s6di1arvWH5wsJCtm/fzoQJEwDIzMzk7bffZuXKldWq5NSpU8nKysJisdClSxfefPNNNJpbL94oPSghxB2THlSd+sNBEoqiMGvWLAYMGMCePXvYvXs3BoOB5cuX3/ScwsJC1q9fX/lvLy+vaicngPfff5/vvvuO77//nry8PCIiIqr9XkIIIe4Of9iPjYmJQafTMWbMGKBi/arXXnuN/v374+vry4EDByguLiYzM5OwsDBmzZrFv/71L1JSUhg5ciQ9evRgwoQJzJgxg++//x6j0cjChQs5deoUGo2GefPm0b17dzZv3kxUVBSlpaWkpqYyYMAA5s6dC1A5isdsNmMymSofmgohhLh3/WGCSkxMrBy2eY2Liws+Pj5YLBbi4+PZvn07jo6OjB07lj59+vDiiy+SmJjItm3bgN/mNQB8+eWXAGzfvp3z588zdepUdu/eDVR0obdu3YpWq2XIkCFMmjQJHx8foOI238mTJ+nduzeDBw/+wwuzKtYq3XMhhKgOQ7mBrIysuq7G39IdPwns0aNH5YzwgQMHEhsby4ABA25aPjY2lokTJwLQsmVLGjVqRHJyMgAhISHo9frKY+np6ZUJas2aNRiNRl566SViYmLo2bPnLeulVqkJ+jzoTi9PCPE3F/94PE2bNq1cBV3Unj9MUK1atars4VxTXFxMRkYGGo3mutttd3L77feDLjQaDRZL1WGgOp2O/v37ExkZ+YcJSghh+8pzysn9MZfS5FLUWjX6YD31Quqh1lZ9PK4oCoWxhRSdKMKcZ8a+gT3uvd1xauGE1WSl4HABxWeKMReZ0ThrcPZ3xr2XOyp7FQUxBRSfKsZcaEbrpcWjrwc6Xx1FJ4ooiivClF0xKdfO3Q7Xzq7og/XyGMFG/OEgiZCQEEpLS9m6dSsAFouFd999l9GjR+Po6MjBgwfJz8+nrKyMvXv30rlzZ5ydnSkpKbnh+3Xt2pXt27cDkJycTEZGBi1atLhp/JKSEq5evQpUPIOKjo6+ZXkhxN2h6EQRifMSyY/Ip51zO7yLvbn86WXOLzqPudBcWU6xKqR+kErqB6loz2oJdArE8n8WLiy+QMb6DC4uvUj6J+m4XXajg2sHGuY0JGNdBklvJHF+4XnSPkrD6aITgU6BlB0uI+mNJJLfTiZlRQqcgECnQNo5t8MuwY6U91NIX5POPTo99K7zhwlKpVLx4YcfEhERwaBBgxg8eDA6nY4XXngBgA4dOvDss88SFhbG4MGDCQoKwt3dnc6dOzNixAiWLl1a5f0ee+wxFEUhNDSUOXPm8I9//OOmw9WhYrmSmTNnEhoayqhRo6hfvz7jx4+/w8sWQtQlq9FK2po0OgVVrEZ+5MgRzp07x44dO1DlqMjcmFlZNjcql8LYQpYuXUpGRgYHDx4kPT2dqVOnkrM7B0OSga+//ppLly4RFRVFUlISu3fvxppjpSyljP/85z+kp6dz8OBB0tLSGPPQGAxJBhwcHMjNzeXIkSPExMRw5coVXn/9dfIP5GNIMtRh64hr7mglic2bN3Pq1CneeOONv7JOf4mEhAQePvpwXVdDCHEDefvySP8knQMHDtClSxfuu+8+hgwZwrJly3j22Wf5IPwDAlYGoHHWcOEfFwhwCeDYsWN89tlnTJs2jaioKDp37kzz5s1xcHAgNTWVH374gTEvjmH1q6t59NFH6dy5M97e3uzcuZNly5axYMECYmNj8fT0pHnz5hiNRnr16sXx48dp0aIFMTExFBYW0rBhQ7wf86bBoAZAxTMokHlQdUEWixVC1LqytDJcXFzo2bMnx48fJz4+nm+++QaAIUOGgAWMV4wAWAotNGvWDICkpCSsKivJycm4uLgQEhLC1atXSUxMpFmzZvRv2Z+2bduSkZHBhQsXqpxnUkykpKTg6elJhw4dsFgsHDhwgJYtWxIQEIBGo2H//v0A2Lvb13qbiOvd0Si+hx56iIceeuivqosQ4m/CXGDG29sbqJjY//uv114vOlEECmhcNRw+fJiioiKefvppPDw8Kudl+vj4UF5ezsqVK1mxYgVr165Fr9fz5ptvUlBQQHR0NOXl5bzyyiu0b9++coTxtdHBDRo0qNy0sKioiC+++AIAjfOtV6oRtUN6UEKIWmfnalc5+Ona1JJrE/KvvZ71XRYX3rqA4ayBy5cv06dPH3bv3k2TJk2IiooCKuZYBgcH8+9//5vPP/8cV1dXli1bxqJFixgwYAAJCQn079+fQ4cO4eXlxb59+wBITU0FKpZx0+l0tGvXjuLiYr766iv0ej1Fx4tqtT3EjUmCEkLUOl1jHYWFhRw7doyOHTvi5+dXuUvuteQzf/58du3ahZubG1AxveXJJ59k1qxZNG/evHI/qWvHy8vLq3y99npmZiaTJ09m7ty5tG7dunKr99atW1fsIWUyUVBQgNlsxsHBAbVajWKVUXy2QJbsFULUOrf73cjckMns2bPZtm0bKSkpABw6dIjw8HAAgoODGTJkSOUo36ioKOrVq4eLiwtZWVlMmDABo9HIoUOHiIyMZMaMGTz00EN4enpy7Nixyvmbp06dwmg0otfrSU9P55FHHkFRFDp37szXX3+NxWJBo9FgNptZvHgxBQUFNAlsUjcNI6q4p/eDklF8QtiugqMFpK5OxVHrSK9evcjLy+Pnn39G7aTGarDi5+eHq6srv/zyCxaLhSZNmhAYGIjJZGL//v2Um8vxGutF/v58jBlGOnToQKNGjbh69SrHjx+vnMvUsmVL/P39MRgMHDx4EAsWUAArBAQE0KxZM0pKSvjll1/IzMykXo96NJ7WGJW6YrKujOKrO5KghBB1puxyGbl7K1aSUGlVuAa74t7XHcNZA/mH81EsCrrGOnTeOgqPF2LKMoEanFo64fGgBzofHZZSC3k/5VGSUIK50IzGRYNTayc8+nlQfKqYwp8LKc8pR22nxqmNEx59PbBztSMnMgdDogFTngm1Vo19fXvc7ndD37HqShKSoOqOJCghhLgFSVB1RwZJCCGEsEmSoIQQQtike3YUn2K1VnbNhRCiOqxGI0aLEZ1GV9dV+Vu6ZxOUSq0moa3cLxZCVF/ALwlIaqo792yCEkLYvnJFIbKoiARjGY4qNX1dXAhwcLhh2eRyIwdLSsgyW/C1t2eIXo9eU7Ek0emyMmIMJeSZLbhrNHR1cqKDgwMqlYqzZWXEGAzkWiw012oZpNfjpFZzxWTiiMHAxfJyLCj42mvp7+JCfTv5WLQV8pMQQtSJX8rKmJWexmWzGa1Wi8lk4t852QzXu/K2jw/aX4d6K4rCBznZrM7JwQrY2dlhNptZlnWVJd7e7CsuZuuv6/jpdDqMxopFZofo9bipNXxTkA//dd4AFxe2FhRg/vV1tVpNeXk5S6+qeMvbh6GurnXRJOK/yCAJIUStMykKsy+no/HxYdeuXRiNRnJzc3nzzTfZUVTIJ7k5lWV3FxcRnpPD5ClTSEtLw2QyERsbS3BICC9cvszWwkLmz59PTk4OZWVl5OXlsXjxYiKKivimIJ/Zs2dz9epVTCYTBw4coEm7dmwsKKBlmzbEx8dTVlaG0Wjk9OnTdH3gAV69ksFlk6kOW0dcIwlKCFHr9hYVkWIy8cEHH9C/f38mTZrEd999x8KFCxkxYgSf5+ZS/usUzQ35+QQGBrJmzRri4uLo1KkTLi4urF+/Hq1Wi6+vL2+99RaJiYm0a9eO+Ph4FixYQOvWrXnggQdYvnw5u3fvplu3brRo0YJ169ahUqlwc3PjwIEDjBgxgjlz5hAYGMgnn3xCuaKwv6S4jltIgCQoIUQdOFFWiouLC2FhYcTGxrJu3TqWLVsGVOy6XWC1kvLroq+pJhPBwcGo1Wr27t3LmRMnOHLkCH5+fvTs2ZPi4mKKi4sxmUwUFRVRXl5OaWkp+fn5dO3aFYCIiAhOxcZy8uRJgoKCCAwM5OjRo8ycOZOIiAjef/99CgsLqV+/PgAlVmvdNIyoQp5BCSFq3RWTGV9fXwCys7OrfG3SpGKh1nSTiSZaLd52dsTHx2O1WpkwYQLZ2dkMHDiwsuyPP/7I888/z8cff1y56OzMmTPJysoiLi4OgKlTp2Jvb09ISEjleadPn6a+RkOOxcL8+fNxdXVl3rx5ANzn5FRLLSFuRXpQQoha56xWV25QqNNVDOR2+HX0XkFBAQAz09MIPneWY6WlxMfHM2XKFLRaLYsWLSItLQ2A/Px8/P39Wb16NTt37qR169Zs2rSJDz74gPbt2xMdHc1zzz2Hp6cnr776KsnJyVVi5CkKK1asYMmSJSxZsoSlS5fiplYToLvxSEJRuyRBCSFqXVOtloyMDNLS0ggKCkKn09GlSxcAjh07BsCkSZN4++23KxPXN998Q8eOHWnTpg3FxcWUlZURGRlJ69atsbOz49ixY1hTUjh27BgajYY2bdoAsHr1atq3b0/Hjh1RqVRkZ2dz5MgRHBwc+Pbbb5k1axbPPPMMixYtQqPRUGC1srtINiy0Bff0YrGMlu3ohbBF6aZyhl64wGOTJ/P5559z6dIlGjRoQEFBAR07diQ7O5tt27YRFhZGvXr1KCgoIDExkcuXL9OsWTOaNGnCrFmz+PDDD3F3dyc+Ph4PDw+io6Pp3bs3xcXFBAUFkZWVRU5ODvHx8fj7+9OwYUMmTZrE119/Td++ffnxxx+vq5uLiwvjtDrmenoS8EtC5euyWGztk2dQQoha19hey/T69Qlfu5bY2FjCwsLIzs7m66+/pujX3suKFSvYuHEjBoMBgDlz5tChQweMRiNbtmzhwoULPOjswtGCAtq3b8/o0aPx8fFh06ZNbNmyhdzcXKDieZS/vz9btmxh48aNpKenAxUJZ/LkydfVzWg04uEoz6BsgfSghBB1QlEUdhUV8XleLmfKynBUq3nQxYUZ9euzu6iI7woKMaPQUqvF086OGIOByyYTGpWKYAdHJrq709/FhQvl5YTnZHP019Ui3DUaujg68aSHB7uKCvmhqIgrZjNalYquTk487u6Bu0bDu1czuWI2X1evtjodb3p5U9/OTnpQdUwSlBCizimKUmWTwFuVA26r7F9xniSouiW3+IQQde52E8efTTB3ep6oWzKKTwghhE26Z3tQitVK4O+650II8WdZjUbUOtlwo67csz0o0w0eft6OrKysP33OpUuXai2WxLONePfytUm830hyqlv3bIISQghxd5MEJYQQwiZJghJCCGGTJEEJIYSwSZKghBBC2CRJUEIIIWySJCghhBA2SRKUEEIImyQJSgghhE2SBCWEEMIm3bPbbcTFxaGTZUqEEH8Ro9FIcHBwXVfjb+WeTVBCCCHubnKLTwghhE2SBCWEEMImSYISQghhkyRBCSGEsEmSoIQQQtgkSVBCCCFs0l2doPbt28fgwYMZOHAgH3300XXHy8vLmT17NgMHDmTcuHGkpaXVaLyff/6Z0aNHExgYSERExB3Fup14n376KcOGDSM0NJTHH3+c9PT0Go23fv16QkNDGTlyJI8++ihJSUk1Gu+a3bt306ZNG+Lj42ss1ubNm+nevTsjR45k5MiRbNiwodqxbicewM6dOxk2bBjDhw/nxRdfrNF477zzTuW1DR48mK5du9ZovMuXLzNp0iRGjRpFaGgoP/30U43FSk9P5/HHHyc0NJRJkyZx5cqVascCePXVVwkJCWHEiBE3PK4oCm+99RYDBw4kNDSU06dP31E8cQvKXcpsNiv9+/dXUlJSFKPRqISGhiqJiYlVyqxbt05ZsGCBoiiK8v333yvPP/98jcZLTU1VEhISlJdfflnZtWtXtWPdbrzDhw8rBoNBURRF+fLLL2v8+oqKiiq/37t3r/Lkk0/WaLxrMR977DFl3LhxysmTJ2ss1qZNm5RFixZV6/2rEy85OVkZOXKkkp+fryiKomRnZ9dovN9bu3atMm/evBqN9/rrrytffvmloiiKkpiYqDz44IM1FuvZZ59VNm/erCiKohw6dEh56aWXqhXrmqNHjyqnTp1Shg8ffsPj0dHRytSpUxWr1aocP35cGTt27B3FEzd31/agTp48SdOmTfHz80Or1TJ8+HAiIyOrlImKimL06NEADB48mMOHD6NUc17y7cTz9fWlbdu2qNV33qy3E6979+44OjoCEBwcfEd/Od5OPBcXl8rvS0tLUalUNRoP4P3332f69Ol3tCrI7cb6q9xOvG+//ZYJEybg5uYGQP369Ws03u/t2LHjpr2DvyqeSqWiuLgYgKKiIjw9PWss1vnz5+nevTtQ8X/iTn+23bp1q/y53EhkZCSjRo1CpVIRHBxMYWEhV69evaOY4sbu2gSVmZmJt7d35b+9vLzIzMy8royPjw8AdnZ26PV68vLyaizeX+nPxtu4cSO9e/eu8XhffvklAwYM4L333uP111+v0XinT5/mypUr9O3bt9pxbjcWwJ49ewgNDeW5554jIyOjRuNdvHiR5ORkxo8fz8MPP8y+fftqNN416enppKWlVX6g11S8WbNmsX37dnr37s3//M//VPt35XZitW3blj179gDwww8/UFJSUu3/59Wpk7e3d41+Fvyd3bUJSvxm27ZtnDp1imlslNdMAAADgUlEQVTTptV4rAkTJrB3715eeuklwsPDayyO1Wrl3Xff5ZVXXqmxGL/34IMPEhUVxfbt2+nRo0eNx7VYLFy6dIkvvviCf/3rXyxYsIDCwsIajQkVvafBgwej0WhqPM7o0aPZt28fH330EXPnzsVqtdZIrLlz5/Lzzz8zatQojh49ipeXV41fn6gdd22C8vLyqnJLKzMzEy8vr+vKXPtL2Gw2U1RUhLu7e43F+yvdbrxDhw7xv//7v4SHh6PVams83jXDhw9n7969NRavpKSEc+fOMXnyZPr160dcXBwzZ86s1kCJ27k2d3f3yvYbN27cHT34vt3fzX79+mFvb4+fnx/NmjXj4sWLNRbvmp07dzJ8+PBqxfkz8TZu3MjQoUMB6NSpE0ajsVq9mtttyw8++ICtW7cyZ84cAFxdXf90rOrW6cqVKzX6WfB3dtcmqKCgIC5evEhqairl5eXs2LGDfv36VSnTr18/tmzZAlSMBOvevXu1n5vcTry/0u3EO3PmDG+88Qbh4eF39AzjduP9/gM0Ojqapk2b1lg8vV7PkSNHiIqKIioqiuDgYMLDwwkKCqqRa/v9M4SoqChatmxZY9cGMGDAAI4ePQpAbm4uFy9exM/Pr8biQcWzmsLCQjp16lStOH8mno+PD4cPH66MazQa8fDwqJFYubm5lb2zjz76iDFjxlTzym5Pv3792Lp1K4qiEBcXh16vr/YzNvEH6nqUxp2Ijo5WBg0apPTv319ZtWqVoiiKsmLFCmXv3r2KoihKWVmZ8uyzzyoDBgxQxowZo6SkpNRovBMnTii9evVSOnbsqNx3333KsGHDajTe448/roSEhChhYWFKWFiY8tRTT9VovCVLlijDhg1TwsLClIkTJyrnzp2r0Xi/N3HixGqP4rudWP/85z+VYcOGKaGhocrEiROVpKSkase6nXhWq1V55513lKFDhyojRoxQvv/++xqNpyiKsnLlSuW99967ozi3Gy8xMVF55JFHlNDQUCUsLEzZv39/jcXatWuXMnDgQGXQoEHKa6+9phiNxju6tjlz5ig9e/ZUAgMDlV69einffvut8tVXXylfffWVoigVP7uFCxcq/fv3V0aMGHFHv5fi1mS7DSGEEDbprr3FJ4QQ4t4mCUoIIYRNkgQlhBDCJkmCEkIIYZMkQQkhhLBJkqCEEELYJElQQgghbNL/B54HaTLIbbgHAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Classifiction performance metrics by model\n",
"train_metadata_json = load_json('./results/multiple_experiment_Option1/model/training_set_metadata.json')\n",
"compare_classifiers_performance_from_pred(\n",
" preds_list,\n",
" test_df['label'].to_numpy().astype('int'),\n",
" train_metadata_json,\n",
" 'label',\n",
" 10,\n",
" model_names=models_list,\n",
" output_directory='./viz2',\n",
" file_format='png'\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVyU5fr48c+jKKKAisqgZv4Cw0xN+2apiRsGorgnUsdMLLOjJalpWppLLnROWma2kWVanUxcwNTcMCX3XSvTErE0YThfRECRbeb+/cFhvnlUZhhmmGG43q/X83o12z3XEFzecz33c92aUkohhBDCpqo5OgAhhHBFklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKruEmrVq0YOHAg/fr1Izo6mhs3blg91rRp09iyZQsA06dP59y5c3d87sGDBzl27FiZ3yM4OJgrV65YfP9fPfjgg2V6r/fee49PP/20TK8RVZckV3GTWrVqkZCQwMaNG6lRowarVq266fGioiKrxp0/fz4tWrS44+OHDh3i+PHjVo0thDNyc3QAwnl16NCBs2fPcvDgQd599128vb1JSUlh8+bNLFy4kEOHDlFQUMDw4cN54oknUEoxd+5c9u7dS+PGjalRo4ZprBEjRvDKK6/Qtm1bkpKSeOeddzAYDNSvX5/58+ezatUqqlWrxoYNG3j99dfx9/dn1qxZXL58GYDXXnuNhx56iMzMTF5++WX0ej3t27fHkmtgxo0bR1paGvn5+Tz99NNERkaaHluwYAF79+6lYcOGvPPOO/j4+PDHH38wZ84cMjMzqVWrFnPnziUgIMD2P2Dh2pQQf9G+fXullFKFhYXq73//u/rqq6/UgQMHVLt27dQff/yhlFJq1apV6v3331dKKZWfn68GDx6s/vjjD7V161YVFRWlioqKVFpamnrooYfUd999p5RS6qmnnlKnTp1SGRkZqlu3bqaxMjMzlVJKLVmyRC1btswUx6RJk9Thw4eVUkr9+eefKiwsTCml1Ny5c9V7772nlFLq+++/V4GBgSojI+OWz9GzZ0/T/SXvcePGDRUeHq6uXLmilFIqMDBQJSQkKKWUeu+999ScOXOUUko9/fTTKiUlRSml1IkTJ9SIESNuG6MQpZGZq7hJXl4eAwcOBIpnrkOHDuX48eO0bduWZs2aAbB3717Onj3L1q1bAcjJyeH333/n8OHDhIeHU716dXQ6HZ06dbpl/BMnTtChQwfTWPXq1bttHPv27bupRnvt2jWuX7/O4cOHWbp0KQA9evSgbt26Zj/TF198wfbt2wFITU3l999/p379+lSrVo2+ffsCMHDgQF588UWuX7/O8ePHeemll0yvLygoMPseQvw3Sa7iJiU11/9Wu3Zt038rpZgxYwZdu3a96Tm7d++2WRxGo5HVq1fj7u5ernEOHjzIvn37+Oabb/Dw8GDEiBHk5+ff9rmapqGUwtvb+7Y/AyHKQk5oiTILCgri66+/prCwEICUlBRyc3N5+OGH+e677zAYDKSnp3Pw4MFbXtu+fXuOHDnCxYsXAbh69SoAderU4fr16ze9xxdffGG6/csvvwDw8MMP8+233wLFyTwrK6vUWHNycqhbty4eHh4kJydz4sQJ02NGo9E0+/7222956KGH8PT05K677uK7774Div8hOXPmTNl+QEIgyVVYISIighYtWjBkyBD69evHzJkzMRgMhISE0Lx5c/r27cvUqVNp3779La/18fHhjTfeYPz48QwYMICJEycC0LNnT7Zv387AgQM5cuQI06dP56effqJ///707duXr7/+GoAXXniBI0eOEB4ezvbt22nSpEmpsXbr1o2ioiL69OnDokWLboqpdu3anDp1in79+nHgwAFeeOEFAN566y3WrFnDgAEDCA8PZ8eOHbb60YkqRFNKWg4KIYStycxVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhyFUIIO5Dk6iRkubEQrkWSqwP9NaFqmsa1a9c4c+YMc+bMYefOnQ6MTAhRXpJcHUjTNADS0tI4efIkY8eOZfPmzWzfvh03N+mpI0RlJn/BDnD58mV0Oh3Vq1fniy++ICkpCV9fX4YNG8Zdd93FDz/8gL+/v6PDFEKUg/QWqEBKKVJTUxk5ciRfffUVtWvXZvPmzbRr1w5fX1/q16/PW2+9xT333MPQoUMdHa4Qohxk5lqBNE3D09OTRo0a4evrC8DQoUOpVq24OnP9+nXS0tLo06ePI8MUQtiA1FwryIULF4DiZtTVq1e/aaO/ki8Pb7/9NgBt2rSp8PiEELYlM1c7U0pRWFjI+PHjefTRRxk7diyZmZnk5OSYthopERQUxH333Wd6XckJLyFE5SM1VzvT6/XodDpSU1MZO3YsDz74IMnJyfTo0QMfHx9q1qyJj48P+fn5eHt788ADD1C9enVHhy2EKCdJrnailCIrK4vhw4czcuRIhg0bhl6vZ/LkyRw+fJjnnnuOP/74g/z8fDRN48qVKyxZsgSdTufo0IUQNiDJ1c527drFu+++y4gRIxgyZAhXrlxhzJgxhIWFMXr0aNPz8vPzy70ZnxDCeUjN1Q5+/fVXGjRogKenJz169MDDw4N58+ZhMBiIiIjg/fff5+9//zsXL15kzpw5ANSoUcPBUQshbElmrjaWmppKaGgojRo1IjAwkOHDhxMQEEBWVhavvPIKY8eOpW/fvqSlpTFp0iSWLl2Kj4+Po8MWQthY9dmzZ892dBCuIjs7m4YNG1K7dm1TrwB3d3feffddvLy8yMnJYcuWLbi7u9OxY0cGDRpEnTp1HB22EMIOZJ2rjej1eiZNmsThw4d5+umn6dy5My1atKBly5Z8/vnn+Pj40Lx5c9LS0li0aBFZWVk3LcMSQrgWKQvYyNWrV9m0aRN79uxhzJgxtG3bljVr1nDixAnCw8Pp2rUrAMnJyXh7e9OoUSMHRyyEsCcpC9hIrVq1aN68OQaDgdWrV3P33XcTHBzMlStXOHjwIDk5ObRs2RIfHx8pBQhRBcj30nI4fPgwCQkJptt169ald+/ePPbYY3z88cf89ttvDBgwgBYtWvDjjz9y7do1B0YrhKhIshSrHIqKioiJiaFatWr0798fKE6woaGh5OXlsX37dsaPH09YWBi1atXC09PTwRELISqKzFytoJRCKUXnzp1ZsmQJixcvZsOGDabH6tWrR0BAACkpKRiNRnx9ffH29q7wOP/973/L9jFOLjc319EhlIn8PllOkqsVNE1D0zTOnDnDI488wrx583j33XfZuHGjqdlKbm4u+fn5Fv/xGAwGm8b4ww8/8OKLL5KammqzMX/77TcOHTpEZmamzcb8/fff+fHHHykoKLDZmBcuXODHH3/EaDTa7Od6/vx5jh8/TmFhoc3G3LFjBwsXLiQjI8Mm4wGcOHGC+Ph4Tpw4YbOf6ZEjR4iPjweKf/clwVpGTmhZac2aNbz//vuEh4fj7+9Py5Ytef/997lw4QK7d+8mISGBGTNm0Lhx41LHSUlJMXXHMhgMNlmetWfPHhYuXEhmZiZXr16lW7du5R5z9+7dzJo1i5SUFLZt20anTp3KfWLu+++/5/XXX+fo0aPs37+fwMBA6tevX64xd+zYwezZs0lOTubEiRNcunSJFi1alOsKuG3btjFjxgx++uknDh48iF6vJyAggJo1a1o95qFDh5g/fz5RUVG0bNnS6nH+KjExkZiYGPLz8zl8+DBt2rShXr16Vo9nNBrJzc3lhRde4OjRo1SrVo22bduiaRpGo1G6tpmjRJkYDAallFIffvih2rFjx02PnT17Vm3atEmtWLFCXbhwwexYO3fuVA888ICaNGmS6b6ioqJyxbd371712GOPqV9//VUVFBSoUaNGqUOHDpVrzAMHDqjQ0FB18uRJpZRS48aNU3v37i3XmEePHlVhYWHq559/VkopNWvWLDVt2rRyjXnlyhX17LPPqt9++00ppVRcXJwaMmSIWrp0qcrJybFqzIKCAvXSSy+pI0eOKKWU2rJli3rzzTfV22+/bfWYSin12WefqWXLlimllEpLS1N79uxRJ06cUNnZ2VaNd+XKFfXMM8+os2fPKqWUmjZtmtq8ebP63//9X5WXl2d1nEopFRsbqz799FM1ZcoUtXz58nKNVZVIWaCMqlWrxsWLF9m7d+9NHax+//13AgMD6du3L08//TTNmzcvdZzc3Fy+/PJLXnvtNWrUqMHkyZMBqF69erm+dhoMBv7xj39w7733cuPGDe655x5+++03wPp6WcOGDZkzZw4PPPAA//73vzl58iRffvklM2fOZMuWLVaP+9xzz3H//fcDEB0dTVZWVrm+yrq5uZGbm8u///1voHiXh6ZNm5KZmcmuXbusHvfatWv8/vvvAISEhNCzZ08KCwv59ttvrf7sf20r+dJLL7F27Vq+/PJL5syZQ1ZWVpnHc3NzIy8vj/Pnz3Pt2jUOHTpEQkICCxYs4IMPPihXbdfNzY3U1FQGDx7MqVOniImJYdGiRSilMBqNVo/r6qQsUAZKKYqKili8eDHBwcF06dKF5ORkpk+fzvnz57n33nvx9PS06OtSjRo16NSpE23atKFTp04kJiaSmJhIaGhouUoDzZs3p3HjxhiNRmrVqoWmacTExBAUFETDhg2tGtPHx4e77roLgJUrV9K2bVtmz55NZmYmO3fu5JFHHsHDw6NMY/r6+tK8eXNq1qyJwWAgJyeHr7/+mj59+uDh4UFmZmaZx3R3d6egoIDExERyc3P57rvvyM3NpU2bNhw5coRevXqVaTwoToINGjRg/fr1+Pn50bRpU/z8/Lh69Sr79+8nNDTUqq/HtWrVYuHChRw7dow+ffowceJEWrVqxY8//oinp6fZf5z/m7u7O3Xq1CE2NpZvv/2WPn368MYbb+Dt7c3Ro0e55557rP7/36BBA1JTUxk0aBB//vknn376KQEBAfTo0UNKA6WQmWsZaJpGjRo1uH79Ounp6URFRbFu3Truu+8+Jk+ejJ+fX5l+2XQ6HXXq1MHHx4c5c+aQn59vmsH+/PPPJCcnWx1rSYLu1q0bw4YNY9euXTaZaYwdO5Zx48YBMGTIEK5du2bVSbPq1aublqYppfDy8qJu3br4+PiwYcMGFi9eTF5eXpnH7devH926dePgwYPk5eWxcOFCnnjiCTIyMqxeZ9yhQweCgoJISEjg8OHDVK9enf79+5Oens6ZM2esGrNly5ZMnTqVkydPcunSJQCaNWuG0WjkypUrVo0ZFhbG8uXLeeihh0zfCDp37sz169f5888/rRoTihN3SkoKq1evZtWqVTz33HOkpqayatUqq8esCmSdaxmdP3/e9FV49OjRPProozZpF1i/fn3mzJnDW2+9RVhYGEajkZUrV9ogYrjvvvv4/PPPGT16dLl2OVD/tfXM1q1bycjIMG22aC03Nzfc3Nxo3LgxixYtYu/evcTExFCrVq0yj+Xl5cWAAQPo16+f6R+Y+Pj4cvVycHd3p3///miaxscff8z58+epWbMmGRkZ5bqMuVu3bkRHR/Pee+/RpEkTAE6fPs2YMWOsHrNu3bp06tSJLVu2UKNGDfLz87l06VK5TprpdDr8/Pz44IMPmDlzJsHBwRw4cKDMs+sqx2HV3kosJydH5ebm3nSf0Wi0ydjLly9Xjz76qDpz5oxNxisRHR2tLl68aJOx8vPz1erVq1Xfvn1NJ1DKw2g0qvz8fNWrVy/VvXt3lZKSUv4g/yMuLk716dPHJj/P/Px8tX//fjVhwgQ1depU08m48vrpp5/UokWLVExMjE3izMrKUitWrFDDhw9XzzzzjPrll1/KPebly5fVjz/+aLpdcmJX3Jk0bnEiWVlZTJgwgalTp5o2KiwvZYeNDgsLC9m3bx/NmjXD39/fZuOuW7eOtm3bcu+999pszD///JOioiKbzrIMBgOapjl9V7OSMogtrwy0x++Tq5Lk6mSq8nYv8ocrXIkkVyGEsAPn/l4jhBCVlCRXIYTTy8/PJzs729FhlEmVXoqVlPgDmZfLfjWMEOJm9ZvUpVuvrnYb/1JyLLkFLbi/bWi5lhNWpCqdXDMvZ7F05ApHhyFEpffiipF2G/vGjRsUGb3QeX2LPnkXTQL/Ybf3siUpCwghnNrllGX4ea3Hp/YuruY9YvP2nPYiyVUI4bRKZq1e7r9QTSuiYZ1E9MmvOTosi0hyFUI4rZJZa4nKNHuV5CqEcEp/nbWWqEyzV0muQgin9N+z1hKVZfbqsOQaHBx8U2u1gwcP8vzzzwOY2vj9tZ1bv379TK3Z/vran376ieDgYE6fPl2B0Qsh7Ol2s9YSlWX2WqHJtaCgwOKO6H5+fnz00UelPufMmTNER0ezePFi7r//fnJycqQzuhAu4E6z1hKVYfZaIck1OTmZN998k7CwMC5cuGDRa3r06MG5c+c4f/78bR8/f/48L7zwAv/85z954IEHADh69ChhYWG89957XL582VbhCyEqUF5eHkVG79vOWktU04poUDvRtKWPM7Jbcs3NzWXt2rU8+eSTzJgxg4CAADZs2GDqkG42sGrVGD16NB9//PFtHx83bhwzZ86kQ4cOpvt69OjBqlWr8PLyYuzYsTz77LN89913Nt22WQhhXwUFBdSukWL2ebVrnic/P78CIrKO3a7QCgoKomXLlsybN4+AgACLXvPf7eb69evHhx9+yMWLF295bufOnYmLiyMoKOimy+F8fHyIiooiKiqK48eP89prr/HBBx/w7bfflu8DCSEqjEJhpPQSn8K5G/rZbea6ZMkSdDod48ePZ+nSpbfs4VOvXr2bGjFkZWXdsme9m5sbzzzzDJ988skt48+cOROAOXPm3PLYuXPn+Mc//sHUqVP5n//5H+bNm2eLjySEqCBKgUEZzR7OzG7JNSgoiMWLF/PVV1/h5eXFuHHjiIqKMp3x79ixIwkJCUBxZ/cNGzbQsWPHW8YZPHgw+/fvv2XTNk3TWLRoEefPn+fdd98Fijf1GzZsGDNmzMDf35/169czf/582rVrZ6+PKYSwAyNGijCUehjMzGwdze6NW+rXr8/IkSMZOXIkp06dMn2FHzduHLNnz2bAgAEopejatSsDBgy45fU1a9ZkxIgRzJ8//5bH3N3d+fDDD3nqqado2LAhnTp1IiYmxuIyhBDCORkBg5k+/kalwIk3rqjSOxEkfLFRumIJYQMvrhjJwBH9bDJWdnY26Zf/SUPv0v828wpakK997rS70FbploNCCOekAIOZE1ZGJz+hJclVCOF0jEpRaOaEVZEkVyGEKBsFZk9XGXHqkqskVyGE81Eoi8oCzrzhiyRXG9t6+YTNx+zdpL3NxxTCmRWvFjDzHAXVnXjqKslVCOF0jGgUmvnSb0CjRgXFYw1JrkIIp6MonpmWxtzjjibJVQjhdIqXYpU+c3Xu67MkuQohnJBBaaBKvzpfmXnc0SS5CiGcjkIzO3NVTr0QS5KrEMIJKTSMZvtKSXIVQogyKT6hZSZ5mnvcwZy7aFEOr776Kp07d6ZfP9s0kxBCVByD0ihQ1Us9ipz6EgIXTq5Dhgxh2bJljg5DCGGFkrJA6YfMXB3i4Ycfpm7duo4OQwhhhZITWqUdliTX232DvXr1KqNGjSI0NJRRo0aRlZVV/J5KMW/ePEJCQujfvz8///yz6TXr168nNDSU0NBQ1q+/8660f+WyyVUIUXkZ0ChU1Us9iixYinW7b7CxsbF07tyZbdu20blzZ2JjYwFISkriwoULbNu2jblz5zJ79mygOBkvXbqU1atXExcXx9KlS00JuTSSXIUQTqd45lrN7GHO7b7BJiYmMmjQIAAGDRrEjh07brpf0zTat29f3LQ7PZ09e/bQpUsX6tWrR926denSpQs//PCD2feW1QJCCKejlIbBzMy0mqpGcnIyEydONN0XGRlJZGRkqa/LyMjA19cXgEaNGpGRkQGAXq/Hz8/P9Dw/Pz/0ev0t9+t0OvR6vdnPIMlVCOF0LFnnakQjICCAdevWWf0+mqahafY5MeayZYFJkybxxBNPkJKSQrdu3YiLi3N0SEIICxmwYCmWlZe/NmjQgPT0dADS09Px8fEBimekaWlppuelpaWh0+luuV+v16PT6cy+j8sm17fffps9e/bw888/k5SUREREhKNDEkJYSCkNo6pm9rBGcHAw8fHxAMTHx9OrV6+b7ldKceLECby8vPD19SUoKIg9e/aQlZVFVlYWe/bsISgoyOz7SFlACOF0Sk5olcb85bHF32APHTpEZmYm3bp1Y/z48YwZM4YJEyawZs0amjRpwuLFiwHo3r07u3fvJiQkBA8PDxYsWABAvXr1GDduHEOHDgXghRdeoF69embfW5KrEMLpGNGKO2OVwmDBOG+//fZt71+x4tZtuzVNY9asWbd9/tChQ03J1VKSXIUQTseoNApV6enJzczjjubc0QkhqiRlwRVYTr4RgSRXW7PHZoKvJP9o8zEB/hnQ1vaD2mNZi3L2PyNhawrz61zNPe5oklyFEE7H+J/LX0tj7VKsiiLJVQjhdIw2Wi3gSJJchRBOp2Sda2msXedaUSS5CiGcjuz+KoQQdmCkmvmaq5PvRCDJVQjhdCwrCzj3TgSSXIUQTsdowVIsqbk6yPnz52/q83jx4kWio6OJiopyXFBCCIsoMHsRgbPvoeWyydXf35+EhAQADAYD3bp1IyQkxMFRCSEsYVQahcbSa6oGo8xcHW7//v00a9aMpk2bOjoUIYQFLOmKZck2L45UJZLrpk2bbtr9UQjh3IpPaFXu3gLOnfptoKCggJ07dxIWFuboUIQQFjJatPurLMVyqKSkJFq3bk3Dhg0dHYoQwkKWzFxlKZaDbdq0ifDwcEeHIYQoA0XlX+fq0mWB3Nxc9u3bR2hoqKNDEUKUgZHiy19LO2QplgPVrl2bgwcPOjoMIUQZKaWZranKagEhhCgjS3YikJmrEEKUkRHMblAoyVUIIcrIosYtUhYQQoiyUWhmt3Ex1+/V0SS5CiGcjkVXaNljM0wbkuRaCdhll1Yg+twZm4+5pMV9Nh9TVD0K8y0FpeYqhBBlZFSWlAWcu+bq3NEJIaqk4iu0zB+W+PzzzwkPD6dfv35MmjSJ/Px8Ll68SEREBCEhIUyYMIGCggKguBfJhAkTCAkJISIigkuXLln9GSS5CiGcjlKYTazKguSq1+tZuXIla9euZePGjRgMBjZt2sTChQuJiopi+/bteHt7s2bNGgDi4uLw9vZm+/btREVFsXDhQqs/gyRXIYTTsWjmauFYBoOBvLw8ioqKyMvLo1GjRhw4cIDevXsDMHjwYBITEwHYuXMngwcPBqB3797s378fpaxrbig1VyGE07Go5mrBHlo6nY5nnnmGnj174u7uTpcuXWjdujXe3t64uRWnPz8/P/R6PVA8023cuDEAbm5ueHl5kZmZiY+PT5k/gyRXIYTTKV4tYL7lYHJy8k175UVGRhIZGWm6nZWVRWJiIomJiXh5efHSSy/xww8/2Cvsm7hscs3Pz2f48OEUFBRgMBjo3bs30dHRjg5LCGGBkrJAqc9RGgEBAaxbt+6Oz9m3bx933XWXaeYZGhrKsWPHyM7OpqioCDc3N9LS0tDpdEDxTDc1NRU/Pz+KiorIycmhfv36Vn0Gl6251qxZkxUrVrBhwwbi4+P54YcfOHHihKPDEkJYwoITWkYLSqFNmjTh5MmT3LhxA6UU+/fvp0WLFnTs2JGtW7cCsH79eoKDgwEIDg5m/fr1AGzdupVOnTqhWXmxgsvOXDVNo06dOgAUFRVRVFRk9Q9JCFGxjEozu7urUTM/N2zXrh29e/dm8ODBuLm50apVKyIjI+nRowcTJ05k8eLFtGrVioiICACGDh3KlClTCAkJoW7durzzzjtWfwaXTa5QfJZwyJAh/PHHH/ztb3+jXbt2jg5JCGEBhfkrsCy9Qis6OvqWkmCzZs1My6/+yt3dnSVLllgcZ2lctiwAUL16dRISEti9ezenTp3i119/dXRIQggLWLIUy5J1ro7k0sm1hLe3Nx07dqyws4RCiPJR/ykLlH5IcnWIK1eukJ2dDUBeXh779u3D39/fwVEJISyiihNsqYc0bnGM9PR0pk2bhsFgQClFWFgYPXv2dHRYQggLWLoUy5m5bHK97777iI+Pd3QYQggrKFV8mHuOM7tjcn3wwQdNS5dKrq3VNA2lFJqmcezYsYqJUAhR5Sg0s5e3WtoVy1HumFyPHz9ekXEIIYSJpZe/OjOLTmgdOXKEtWvXAsUnii5evGjXoIQQVVtJWaDUw9FBmmE2uS5dupRly5YRGxsLQGFhIVOmTLF7YEKIqs3cagEq+8x1+/btfPjhh3h4eADFjQ2uX79u98CEEFWXK6xzNbtaoEaNGmiaZjq5lZuba/egxH+xU08Ee2wm+GryKZuPGRPwgM3HFM7NotUCFROK1cwm1z59+jBz5kyys7NZvXo1a9euZdiwYRURmxCiyrLg8lYnLwuYTa7PPvsse/fupU6dOqSkpBAdHU2XLl0qIjYhRBVVsodWaZx9tYBFFxEEBgaSl5eHpmkEBgbaOyYhRBWnLJi5OvsVWmZPaMXFxREREcH27dvZunUrkZGRt23VJYQQNqMsPJyY2ZnrsmXLWL9+vWmrg8zMTJ544gmGDh1q9+CEEFWX2ZlrZW/cUr9+fVNHf4A6depYvaeMEEJYQikNo5mlVsrSvbUd5I7Jdfny5QDcfffdDBs2jF69eqFpGomJibRs2bLCAhRCVFGuulqg5EKBu+++m7vvvtt0f69evewfVTmlpqbyyiuvkJGRgaZpDBs2jJEjRzo6LCGEpVy5K9aLL75YkXHYVPXq1Zk2bRqtW7fm2rVrPP7443Tp0oUWLVo4OjQhhKWcPHmaY7bmeuXKFT755BPOnTtHfn6+6f6VK1faNbDy8PX1xdfXFwBPT0/8/f3R6/WSXIWoJJTSUGZrrs5dFjC7FGvy5Mn4+/tz6dIlXnzxRZo2bUrbtm0rIjabuHTpEr/88ovs/CpEZWLJNi9OXnM1m1yvXr1KREQEbm5uPPLII8TExHDgwIGKiK3crl0WQkcAABE5SURBVF+/TnR0NK+99hqenp6ODkcIURauvs7Vza34Kb6+vuzatQtfX1+ysrLsHlh5FRYWEh0dTf/+/QkNDXV0OEKIslBYsBrAuWeuZpPr2LFjycnJYerUqcydO5fr16/z6quvVkRsVlNKMX36dPz9/Rk1apSjwxFCWMPczLSyz1xLdkz18vLiiy++sHtAtnD06FESEhIIDAxk4MCBAEyaNInu3bs7ODIhhGUsaIZdWZPr3LlzTT1cb2fGjBl2CcgWOnTowNmzZx0dhhDCSpb0c620ybVNmzYVGYcQQvwfBZhbamXhaoHs7GxmzJjBr7/+iqZpLFiwgHvuuYeJEyfy559/0rRpUxYvXkzdunVRSjF//nx2795NrVq1ePPNN2ndurVVH+GOyXXw4MFWDSiEEOWlAZqNZq7z58+na9euLFmyhIKCAvLy8vjoo4/o3LkzY8aMITY2ltjYWKZMmUJSUhIXLlxg27ZtnDx5ktmzZxMXF2fVZ7Bo91chhKhQNmo5mJOTw+HDh01d/GrWrIm3tzeJiYkMGjQIgEGDBrFjxw4A0/2aptG+fXuys7NJT0+36iNY1CxbCCEqliUntDSSk5OZOHGi6a7IyEgiIyNNty9duoSPjw+vvvoqZ86coXXr1kyfPp2MjAzTVZyNGjUiIyMDAL1ej5+fn+n1fn5+6PV603PLQpKrsCl7bCY45tfzNh8zNtDf5mMKG1KAuZaCCgICAli3bt0dn1JUVMTp06d5/fXXadeuHfPmzSM2Nvam5/x1A1ZbcsnVAkKISs6Sr/0WlAX8/Pzw8/MzXf4eFhZGbGwsDRo0ID09HV9fX9LT0/Hx8QFAp9ORlpZmen1aWho6nc6qjyCrBYQQzskG/VwbNWqEn58f58+fx9/fn/379xMQEEBAQADx8fGMGTOG+Ph4UyvV4OBgvvzyS8LDwzl58iReXl5WlQRAVgsIIZyRAs1MWcDsaoL/eP3115k8eTKFhYU0a9aMmJgYjEYjEyZMYM2aNTRp0oTFixcD0L17d3bv3k1ISAgeHh4sWLDA6o/gki0HhRCiRKtWrW5bl12xYsUt92maxqxZs2zyvi7fclAIUfmUrHM1dzgzl245KISopJRm2eHEXLbloBCiErNkKVZl3f21RGVsOQjF9ZS4uDiUUkRERBAVFeXokIQQZWDua79zz1tdtOXgr7/+SlxcHHFxcdSoUYPRo0fTs2dPmjdv7ujQhBCWsNE6V0cym1zvNEuNiYmxeTC2kpyczAMPPICHhwcADz/8MNu2beO5555zcGRCCIu5enLt0aOH6b/z8/PZsWOH1YtqK0pgYCCLFy8mMzOTWrVqkZSUJBdFCFGZKNDMtBw0tw7W0cwm1969e990u1+/fvztb3+zW0C2EBAQwOjRo3n22Wfx8PDgvvvuo1o1aQAmRKVRCTYgNKfMjVsuXLhg6iDjzCIiIoiIiADg7bfftvr6YCFExbNlP1dHMZtcH3zwwZsauDRq1IjJkyfbNShbyMjIoEGDBly+fJlt27axevVqR4ckhLCUJZe/VvaywPHjxysiDpsbP348V69exc3NjVmzZuHt7e3okIQQZeHqM9eRI0fecg3u7e5zNv/6178cHYIQwlquXHPNz8/nxo0bZGZmkpWVhfrPVozXrl1Dr9dXWIBCiKrHkpqrs/cWuGNyXbVqFStWrCA9PZ0hQ4aYkqunpydPPfVUhQUohKiCXPkigpEjRzJy5Ei++OILRowYUZExCSFEpZ+5ml38Wa1aNbKzs023s7Ky+Oqrr+walBCiirPR7q+OZPaE1urVqxk+fLjpdt26dYmLi7vpPmFnysl/i+zMHpsJPn32os3HXNmymc3HrNIq+a+92eRqNBpRSpnWuhoMBgoLC+0emBCi6tKqwjrXoKAgJkyYwBNPPAEUn+jq2rWr3QMTQlRtLn+F1pQpU/jmm2/4+uuvAXj00UcZNmyY3QMTQlRhlaCmao5FJ7SefPJJlixZwpIlS2jRogVz586tiNiEEFVUSVnA3OHMLGrccvr0aTZu3MiWLVto2rQpoaGh9o5LCFHVuWpZICUlhU2bNrFx40bq169P3759UUpVmt0IhBCVmCtfRNCnTx86dOjAxx9/bNoe5fPPP6+ouIQQVVxl30PrjjXXpUuX0qhRI55++mlmzJjB/v37TZfAVgZJSUn07t2bkJAQYmNjHR2OEKIMXLrm+thjj/HYY4+Rm5tLYmIiK1as4MqVK8yaNYuQkBCCgoIqMs4yMRgMvPHGGyxfvhydTsfQoUMJDg6mRYsWjg5NCGEJFygLmF0tULt2bfr3789HH33E7t27uf/++/nkk08qIjarnTp1iubNm9OsWTNq1qxJeHg4iYmJjg5LCFEWNrz81WAwMGjQIJ5//nkALl68SEREBCEhIUyYMIGCggIACgoKmDBhAiEhIURERHDp0iWrwy/TxlJ169YlMjLS6Xu56vV6/Pz8TLd1Op20SRSiktGUmaMMY61cuZKAgADT7YULFxIVFcX27dvx9vZmzZo1AMTFxeHt7c327duJiopi4cKFVscvu/YJIZyPucRahplrWloau3btYujQocVDK8WBAwdMm68OHjzY9M12586dDB48GCjenLU855pcMrnqdDrS0tJMt/V6vWxQKERlY6OywIIFC5gyZYppB+jMzEy8vb1xcys+5eTn52f6ZqvX62ncuDEAbm5ueHl5kZmZaVX4Lplc27Zty4ULF7h48SIFBQVs2rSJ4OBgR4clhLCUhS0Hk5OTGTJkiOn45ptvbhrm+++/x8fHhzZt2lRs/FixtXZl4ObmxsyZMxk9ejQGg4HHH3+ce++919FhCSEsZFFXLAUBAQGsW7fujs85duwYO3fuJCkpifz8fK5du8b8+fPJzs6mqKgINzc30tLSTN9sdTodqamp+Pn5UVRURE5ODvXr17fqM7hkcgXo3r073bt3d3QYQggr2WIngpdffpmXX34ZgIMHD/LZZ5+xaNEioqOj2bp1K+Hh4axfv970zTY4OJj169fz4IMPsnXrVjp16mRqt1pWLlkWEEJUcnbeiWDKlCksX76ckJAQrl69SkREBABDhw7l6tWrhISEsHz5ciZPnmz1e7jszFUIUXnZY/fXjh070rFjRwCaNWtmWn71V+7u7ixZsqRsA9+BJFchhPNRgLnLW538Ci1JrkIIp+TyOxEI4YpW3ne3zcfs87N16yHN+a51PbuM69RcoLeAJFchhNMpXopVevYsa821oklyFUI4JVuf0KpoklyFEM5HygJCCGF79liKVdEkuQohnI+Fl786M0muQgjnI2UBIYSwPUvKAs6eXF22t0B2djbR0dGEhYXRp08fjh8/7uiQhBAWU6AsOJyYy85c58+fT9euXVmyZAkFBQXk5eU5OiQhhKVcoObqkjPXnJwcDh8+bNrWoWbNmnh7ezs4KiGExVxga22XTK6XLl3Cx8eHV199lUGDBjF9+nRyc3MdHZYQwlJ2bjlYEVwyuRYVFXH69GmefPJJ4uPj8fDwIDY21tFhCSEsVHL5a6mHk9dcXTK5+vn54efnR7t27QAICwvj9OnTDo5KCFEWZrfWdu7c6prJtVGjRvj5+XH+/HkA9u/ff9Oe5UIIJ+cCZQGXXS3w+uuvM3nyZAoLC2nWrBkxMTGODkkIYSFXWOfqssm1VatWpe4KKYRwYkpZ0HLQubOryyZXIUQlJzNXIYSwLUtOWDn7CS1JrkII56MAM2UBs487mCRXIYTzcYHLXyW5CiGckAWNWSS5CqelabYf0x5ncO0Rpx3Ya5fWAaczbD7mhvsb2HxMW5KaqxBC2IMFu79Ky0EhhLCGua5X0hVLCCHKprgsoMwe5qSmpjJixAj69u1LeHg4K1asAODq1auMGjWK0NBQRo0aRVZWFgBKKebNm0dISAj9+/fn559/tvozSHIVQjgnG/QVqF69OtOmTWPz5s188803/Otf/+LcuXPExsbSuXNntm3bRufOnU1d85KSkrhw4QLbtm1j7ty5zJ492+rwJbkKIZyPMtNu0Gj+8lgAX19fWrduDYCnpyf+/v7o9XoSExMZNGgQAIMGDWLHjh0Apvs1TaN9+/ZkZ2eTnp5u1UeQmqsQwvkoLFiKpUhOTmbixImmuyIjI4mMjLzt0y9dusQvv/xCu3btyMjIwNfXFyjuopeRUbwiQ6/X4+fnZ3qNn58fer3e9NyycNnk+vnnnxMXF4emaQQGBhITE4O7u7ujwxJCWMLCiwgCAgIsatB0/fp1oqOjee211/D09Lx5HE1Ds8NyP5csC+j1elauXMnatWvZuHEjBoOBTZs2OTosIYTFLNn91bKRCgsLiY6Opn///oSGhgLQoEED09f99PR0fHx8ANDpdKSlpZlem5aWhk6ns+oTuGRyBTAYDOTl5VFUVEReXp5V03ohhGNYtM2LBTVXpRTTp0/H39+fUaNGme4PDg4mPj4egPj4eHr16nXT/UopTpw4gZeXl9W5wyXLAjqdjmeeeYaePXvi7u5Oly5dCAoKcnRYQgiLWXL5q/nkevToURISEggMDGTgwIEATJo0iTFjxjBhwgTWrFlDkyZNWLx4MQDdu3dn9+7dhISE4OHhwYIFC6z+BC6ZXLOyskhMTCQxMREvLy9eeuklEhISTD9cIYSTU5i/SMCCskCHDh04e/bsbR8rWfP6V5qmMWvWLPMDW8AlywL79u3jrrvuwsfHhxo1ahAaGsrx48cdHZYQwlJKoRmNpR4YnfsSLZdMrk2aNOHkyZPcuHEDpZRsUChEZVOyFMsGJ7QcxSXLAu3ataN3794MHjwYNzc3WrVqdce1b0IIJ2SjsoAjuWRyBYiOjiY6OtrRYQghrKBhvneAbFAohBBlpTBfU1XOXXOV5CqEcEKyE4EQQtieJTVX5564SnIVQjghZb6mKjVXIYQoK6XAYGZq6uTrXCW5VmVO/i+/iWaH5dhGg+3HtBN7bCY4/Mwlm47nc73QpuOZ1rKae44Tk+QqhHBOckJLCCFsTMoCQghhB0qZX8cq61yFEMIKUhYQQggbUwrMNcOWE1pCCFFGSpmvqTp5zdUlWw6WMBgMDBo0iOeff97RoQghysKiloPOPXN16eS6cuVK6eMqRGVUMnMt7ZDk6hhpaWns2rWLoUOHOjoUIUSZWbL7q3MnV5etuS5YsIApU6Zw/fp1R4cihCgrF1jn6pIz1++//x4fHx/atGnj6FCEENZQoJTRzCEz1wp37Ngxdu7cSVJSEvn5+Vy7do3JkyezcOFCR4cmhLCEJUuxzD3uYC6ZXF9++WVefvllAA4ePMhnn30miVWIykQpMJhpruPkZQGXTK5CiEpOumI5v44dO9KxY0dHhyGEKAOlFMrMzFRJbwEhhLCC9BYQQggbs6Tmau5xB3PJpVhCiEpOKZSx9MPSmmtSUhK9e/cmJCSE2NhYOwf+fyS5CiGcT0k/11IP88nVYDDwxhtvsGzZMjZt2sTGjRs5d+5cBXwAKQsIIZyMpmnc2/H/4V7HvdTnefrURtO0Up9z6tQpmjdvTrNmzQAIDw8nMTGRFi1a2CzeO6nSybV527tY8vMbjg5DiIpn43JlvpZvs7E8PT0JHtAd1d/8zHTz5s1MmDDBdDsyMpLIyEjTbb1ej5+fn+m2Tqfj1KlTNou1NFU6ubZv397RIQgh/oumadSuXdui50ZERBAREWHniKwjNVchhMvS6XSkpaWZbuv1enQ6XYW8tyRXIYTLatu2LRcuXODixYsUFBSwadMmgoODK+S9q3RZQAjh2tzc3Jg5cyajR4/GYDDw+OOPc++991bIe2vK2ft2CSFEJSRlASGEsANJrkIIYQeSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIezg/wOdcPs8eDN9egAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVxUVf/A8c+s7Dui4L6DIIqC4C5qrqTmlktqmo+Va6aW5c+ex3LLLMwWTTOX8iklNTVNLfdccckVN1SQHdkZhlnv7w9yEsGlHpQRz/v18oVz7rnnfucyzPcu554jkyRJQhAEQRCsjLy8AxAEQRCE0ogEJQiCIFglkaAEQRAEqyQSlCAIgmCVRIISBEEQrJJIUIIgCIJVEgnqCfnss8+YOnVqeYfxRCUkJNCwYUOMRuP/3FbHjh05fPhwqcumT59OZGTk/7yNZ0lkZCShoaG0bt36iW/75MmTdOnShaCgIH777bd/3M7o0aPZtGlTGUb25CUlJREUFITJZCrvUKySSFBlaOvWrfTt25egoCDatGnD6NGjOXHiRHmHJTwhDRs2JC4urrzDeKikpCRWrlzJ9u3bOXToUKl18vPzmTNnDh06dCAoKIjOnTszZ84cMjMz/+ftL168mKFDh3L69Gk6d+78j9v5+uuveeGFF/7neO41ffp0GjZsWCJ5zp07l4YNG7Jx48ZHaudBB1V3+Pj4cPr0aRQKxT+OtyITCaqMrFy5krlz5/Laa69x6NAh9u7dy5AhQ9i9e3d5h/aPlcWZj/AXa9mfSUlJuLq64uHhUepyvV7PiBEjuHbtGl9//TUnT55k3bp1uLq6cu7cuTLZfv369f/ndh6nWrVqsXnzZstro9HIL7/8Qo0aNcpsG2X5eZAkCbPZXGbtWQuRoMpAXl4eixcv5r333qNLly7Y29ujUqno2LEjb7/9dqnrTJw4kdatW9O8eXOGDh3K1atXLcv2799Pjx49CAoKom3btqxYsQKAzMxMXn31VYKDg2nRogVDhgyxfChTU1OZMGECYWFhdOzYkTVr1ljaO3v2LH379qVZs2a0atWKefPmlRrTsWPHaNeuHcuWLaN169a888475OTk8OqrrxIWFkZISAivvvoqKSkplnWGDRvGokWLGDRoEEFBQYwaNeq+R9k7d+6kY8eOXLlyBbPZzLJly+jcuTOhoaFMmjSJ7OxsS92ffvqJ8PBwQkNDWbJkyUN/B1lZWYwcOZKgoCBeeuklEhMTAZg1axbz588vVve1115j1apVpbYTGxvLyJEjadGiBV27dmX79u2WZdOnT2fWrFmMGTOGoKAgBgwYQHx8PABDhw4FoHfv3gQFBbF9+/ZS96der2fOnDm0adOGNm3aMGfOHPR6fbH9v3TpUkJDQ+nYsSNbtmwBin6HrVq1KnYpaNeuXfTq1avU95GXl8dbb71FWFgY4eHhfPnll5jNZg4fPsyoUaNIS0sjKCiI6dOnl1h38+bNJCcn8/nnn1OvXj3kcjkeHh6MGzeO9u3bW/bTsGHDCA4OpmfPnsUOxB60nzp37sytW7d47bXXCAoKQq/XlzjTuPtyuE6nY+rUqYSGhhIcHEy/fv24ffs2UPTZi4qKAsBsNvPll18SHh5Oy5Yteeutt8jLywP+utS8adMmOnTo8EifqY4dO3Ly5ElycnIAOHjwIA0bNsTT09NSJz4+nuHDhxMaGkpoaChTpkwhNzcXgGnTppGUlGR5n8uXL7fEERUVRYcOHRgxYkSxy+DZ2dm0a9eOPXv2AKDRaHjuuef46aefSo1x2LBhREZGMmjQIJo0acKtW7c4deoU/fr1o3nz5vTr149Tp04BcPToUZ5//nnLuiNHjqRfv36W10OGDPmfLrc+NpLwP9u/f7/k5+cnGQyG+9ZZvHixNGXKFMvrqKgoKS8vT9LpdNLs2bOlXr16WZa1bt1aio6OliRJkrKzs6Xz589LkiRJCxculGbOnCnp9XpJr9dL0dHRktlslkwmk/TCCy9In332maTT6aT4+HipY8eO0oEDByRJkqSBAwdKmzZtkiRJkvLz86XTp0+XGuPRo0clPz8/acGCBZJOp5O0Wq2UmZkp7dixQyooKJDy8vKkCRMmSK+//rplnZdeeknq1KmTdP36dUmr1UovvfSS9NFHH0mSJEm3bt2SGjRoIBkMBunHH3+UOnfuLN28eVOSJElatWqVNGDAACk5OVnS6XTSzJkzpcmTJ0uSJElXr16VmjZtKh0/flzS6XTS3LlzJT8/P+nQoUOlxv32228Xq//BBx9IgwYNkiRJks6cOSO1bt1aMplMkiRJUkZGhhQYGCilp6eXaEej0Ujt2rWTfvzxR8lgMEgXLlyQWrRoIV29etWynRYtWkhnzpyRDAaD9Oabb0pvvPGGZf0GDRpY3t/99ueiRYukAQMGSLdv35YyMjKkF198UYqMjCxWf+7cuZJOp5OOHTsmNWnSRIqNjZUkSZK6d+8u7du3z9L+2LFjpRUrVpS6T6ZNmya99tprUl5ennTr1i2pS5cu0vr16y3badu2banrSZIkvfHGG9Jbb7113+V6vV7q3LmztGTJEkmn00mHDx+WmjZtaonzYfspPDy82O/y3td3/618//330quvvioVFBRIRqNROnfunJSXlydJUtFn7857ioqKkjp37izFx8dL+fn50rhx46SpU6dKkvTX53DGjBmSVquVYmJiJH9/f+natWulvr+3335b+uSTT6T/+7//k9auXStJkiRNnDhR2rp1qzRo0CBpw4YNkiRJ0s2bN6Xff/9d0ul0UkZGhjRkyBBp9uzZ931fd+KYNm2apNFoJK1WW+xvRJIk6eDBg1KrVq2k27dvSzNmzJAmTJhw39/DSy+9JLVv3166cuWKZDAYpPT0dCk4OFjatGmTZDAYpK1bt0rBwcFSZmampNVqpYCAACkjI0PS6/VSy5YtpTZt2kh5eXmSVquVGjduLGVmZt53W+VFnEGVgezsbNzc3FAqlY+8Tv/+/XF0dEStVjNhwgQuXbpkOeJTKpVcu3aN/Px8XFxc8Pf3t5Snp6eTlJSESqUiODgYmUzGuXPnyMzMZPz48ajVaqpXr87AgQMtR/9KpZL4+HgyMzNxcHCgadOm941LLpczceJE1Go1tra2uLm50bVrV+zs7HB0dOT1118nOjq62Dp9+/aldu3a2Nra0q1bN2JiYootX716NStWrODbb7+lZs2aAPzwww9MnjyZKlWqoFarGT9+PDt37sRoNLJjxw46dOhASEgIarWaSZMmIZc/+KN6d/3Jkyfzxx9/kJycTGBgIE5OThw5cgSA7du306JFi2JHwnfs27ePqlWr0q9fP5RKJY0aNaJr167s2LHDUqdz584EBgaiVCrp1atXiff6sP25detWxo0bh4eHB+7u7owbN85ylnTHpEmTUKvVtGjRgvbt2/PLL78A0KdPH0vd7Oxsfv/9dyIiIkps02QysX37dqZMmYKjoyPVqlVj5MiRJbZzP9nZ2VSqVOm+y8+cOUNBQQFjxoxBrVbTsmVLwsPD2bZt2z/eT/ejVCrJzs4mLi4OhUJBQEAAjo6OJept3bqVl19+merVq+Pg4MCbb77J9u3bi11GGz9+PLa2tvj6+uLr68ulS5ceuO3evXuzefNmcnNziY6OLnG/rGbNmrRu3Rq1Wo27uzsjR44s8bdRmgkTJmBvb4+trW2JZW3atKFbt268/PLL7N+/n1mzZj2wrRdeeIH69eujVCr5/fffqVmzJn369EGpVBIREUGdOnXYu3cvtra2NG7cmBMnTnDhwgV8fX1p1qwZp06d4o8//qBmzZq4ubk9NPYn7dG/UYX7cnV1JSsrC6PR+EhJymQyERkZyY4dO8jMzLR8+WZlZeHk5MTixYtZsmQJH3/8MQ0bNmTKlCkEBQXxyiuv8PnnnzNq1CgAXnzxRcaMGUNiYiJpaWkEBwcX28ad13PmzGHx4sV0796datWqMX78eMLDw0uNzc3NDRsbG8trrVbLvHnzOHjwoOVyh0ajwWQyWW7s3v1lZmdnR0FBQbE2V6xYwbhx46hSpYqlLCkpiXHjxhVLPHK5nIyMDNLS0orVtbe3x9XV9YH79O76Dg4OuLi4kJaWhre3Ny+88AJbtmyhdevWbNmyheHDh5faRmJiImfPni2xH+++jHZ3YrO1tS3xXu917/5MS0vDx8fH8trHx4e0tDTLa2dnZ+zt7Utd3rt3b7p3705BQQG//PILwcHBeHl5ldhmVlYWBoOhxHZSU1MfGOsdrq6upKen33f5nd/P3b+7e9v/u/vpfnr37k1KSgpvvvkmubm59OrVi8mTJ6NSqUrEVLVqVcvrqlWrYjQaycjIKDWm0j6n9woODiYzM5MlS5bQoUOHEgnl9u3bzJkzhxMnTqDRaJAkCWdn54e+p7s/q6UZOHAg3333Ha+99tpDk4a3t7fl//d+tqD47yUkJITjx49TuXJlQkJCcHZ2Jjo62nIwZI1EgioDQUFBqNVqfvvtN7p16/bQ+lu3bmX37t2sXLmSatWqkZeXR0hICNKfA8sHBgayZMkSDAYDa9eu5Y033mD//v04Ojoyffp0pk+fzpUrVxgxYgSNGzfG29ubatWqsWvXrlK3V6tWLT755BPMZjO7du1i4sSJHDt2rNgX4R0ymazY62+++YYbN26wfv16KlWqRExMDH369LHE+ii++eYbRo8ejaenJ127dgWK/kjnzp1L8+bNS9T38vIiNjbW8lqr1Ra7P1Wau++LaTQacnJyLF/evXr1IiIigkuXLhEbG3vfnmPe3t6EhISwcuXKR35vD3Pv/vTy8irWSSA5OblYksnNzaWgoMDyu0lOTrbUrVy5MkFBQezatYvNmzczePDgUrfp5uaGSqUiKSmJevXqWdqpXLnyI8XcqlUrFi1aVCyOe99DSkoKZrPZkqSSk5OpVavWI7V/Lzs7O7RareX13clRpVIxfvx4xo8fT0JCAmPGjKF27doMGDCgREx37jtC0QGQUqnEw8Oj2Gfj7+rVqxdffPFFsXu6d3zyySfIZDK2bt2Kq6srv/32G++///5D27z3M3E3k8nEe++9R58+ffjvf/9L3759LVcdHtbWnc/W3ZKTk2nbti0ALVq0YP78+fj4+PCvf/0LFxcXZs6ciUqlstxDtTbiEl8ZcHJyYuLEibz//vv89ttvaLVaDAYD+/fvZ8GCBSXqazQa1Go1bm5uaLVaPvnkE8syvV7Pli1byMvLQ6VS4eDgYPkS2Lt3L3FxcUiShJOTEwqFAplMRmBgIA4ODixbtozCwkJMJhNXrlzh7NmzQNFN7ztnaneO8B52yezuWG1sbHB2diY7O5vPP//8b++fevXq8fXXX/P+++9bbqYPHjyYRYsWWb5UMjMzLTdpu3btyr59+zhx4gR6vZ7Fixc/tIfS/v37LfU//fRTmjRpYjm6rFKlCo0bN2batGl06dKl1EsrUHSZ8ObNm/z0008YDAYMBgNnz54tliwfxNPTk1u3bj2wTs+ePVmyZAmZmZlkZmbyxRdfFLt5DUWdBPR6PSdOnGDfvn3FDnp69+7NihUruHLlCl26dCl1GwqFgm7duhEZGUl+fj6JiYmsXLnyvh0q7tW7d2+qVKnChAkTiI2NxWw2k5WVxdKlS9m/fz+BgYHY2try9ddfYzAYOHbsGHv27KFHjx6P1P69fH192b59OwaDgXPnzrFz507LsqNHj3L58mVMJhOOjo4olcpSP7sRERGsXr2aW7duodFoiIyMpHv37n/rsntphg0bxsqVKwkJCSmxTKPRYG9vj5OTE6mpqXz99dfFlj/K5+FeS5cuRSaTMXfuXF555RXefvvtR35Gqn379ty8eZOtW7diNBrZvn07165do0OHDkDRgfSNGzc4e/YsgYGB1K9f33LVoLT3Zw1Egiojo0aNYvr06Xz55Ze0bNmSDh06sHbt2lKP1vv06YOPjw9t27alZ8+eJe4Jbd68mY4dO9KsWTN++OEHPvroIwDi4uIsPdVefPFFBg8eTFhYGAqFgqVLl3Lp0iU6depEWFgY//d//0d+fj5Q1AOpZ8+eBAUFMWfOHCIjI+/7JX2vESNGoNPpCAsL48UXX7Qcjf1dvr6+LF26lJkzZ7J//36GDx9Ox44dGTVqFEFBQQwcONCSUOvXr897773H1KlTadu2Lc7Ozg+9LBIREcEXX3xBaGgoFy5csOyzO/r06cOVK1fo3bv3fdtwdHRkxYoVbN++nbZt29KmTRsWLlxo6WX3MOPHj2f69OkEBwcX6/13t7FjxxIQEECvXr3o1asX/v7+jB071rLc09MTZ2dn2rZty9SpU/nPf/5D3bp1Lcufe+45EhMTee6557Czs7tvLDNnzsTOzo7OnTszZMgQIiIiivXaehC1Ws2qVauoU6cOo0aNonnz5gwYMICsrCwCAwNRq9UsXbqUAwcOEBYWxqxZs1iwYEGxOP+ON954g/j4eFq0aMFnn31WLGHfvn2biRMn0rx5c3r06EGLFi1K/R3269ePXr168dJLL9GpUyfUajUzZ878R/HczdXVlZYtW5Z61jN+/HguXrxIcHAwY8aMKXHAMGbMGJYsWUJwcLClJ+6DnD9/nlWrVvHhhx+iUCj417/+BcCyZcseKVY3NzeWLl3KypUrCQ0N5euvv2bp0qW4u7sDRZfK/f39qVevHmq1GihKWj4+Pvd95KC8yaS/c61GEJ5S0dHRTJs2jb179z7wEkt5OnbsGNOmTePAgQMPrNe5c2fef/99WrVq9YQiE4TyIc6ghArPYDCwZs0a+vfvb7XJ6VHt3LkTmUxGWFhYeYciCI+d6CQhVGixsbH069cPX1/f+z6g/LQYNmwY165dY8GCBY98D1EQnmbiEp8gCIJglcRhmCAIgmCVKtwlvlOnTj2wd5M1MBgMJR40tDYixrIhYiwbIsayYa0x6nS6Uke4qXAJSqFQ4OfnV95hPFBcXNwDH76zBiLGsiFiLBsixrJhrTHebygscYlPEARBsEoiQQmCIAhWSSQoQRAEwSqJBCUIgiBYJZGgBEEQBKskEpQgCIJglUSCEgRBEKySSFCCIAiCVRIJShAEQbBKFW6w2AsXLuLv36i8wxAEQajwCg0mbFWK/7mdmJiYUkcAqnBDHcnlMmpN31beYQiCIFR4N+f3fKztV7gEJQiCUFEYc9Mx5qahcHBD5eZz33qSJGHWZCOZDMjUtijsnIstN2nzMGYmglyOyr0qchuHovWMBgxZiUgGHSrPmsjVtkX187OQTIYS21E4eyKTPbk7QyJBCYIgWBlDVjKZvy6l8MZJS5napyHunV/Dxru+pcxcmE/mnq/RxkZjLsgpKpTJcWk5ENe2L2HMyyBr3zcUXDoEZuOfa8lw8O+A2qs22YfXIek0RaVqO5ya9cSYmUTBlcOlxqV09cZ7RCRyW8fH8r5LbO+JbEUQBEF4JGa9ltQf3sVVZeb/Zs8mNDSUixcv8vHHH3Prh3fxeeULlM5eAOSf303B+d28/PLLNGvWDAcHB9avX8+ufdtwCulD6n/fxtaYzxsTx9OlSxeMRiM///wzy5YtQ3NhL7169WLw4ME4ODiwbt061q5dC8DIkSNp27ZtsbgyMzOZOnUqBbHROPqHP5F9YfUJatWqVURFRSGTyWjQoAHz5s3DxsamvMMSBEF4LPJO/4IpN50thw7RvHlz1qxZw0svvUTv3r1p0KABOUd/xKPLWABMmixUKhVz5swhPT2dwMBALly4wM7d+8g9vgnyb/PrwYMEBQWxevVqsrOzCQgIAKBv375s2LCBLVu2kJKSwnfffYe7uzufffYZXl5e1KtXDwB7e3uaN2/OH3/8AfBEL/FZdTfz1NRU1qxZw4YNG/j5558xmUxs2yY6QAiCUHFpY48TGhpKq1atWLNmDWPGjOGjjz6iZs2a9O3bF+2145a6Kvfq6PV6fHx8mDVrVrF2Ci7/Tnh4OGFhYbz33nu8//77vPfee0ycOBGAAQMGADBp0iReffVVtFotkydPBuDDDz+kXbt2tGvXju+++w6AL7/8EplSjW2tkhMLPi5WnaAATCYThYWFGI1GCgsL8fLyKu+QBEEQHhtjTioNGzYE4Pr16wDcuHEDgIYNG2LKy7B0YHAI6Ijn89NKtCEZdBgzEwkPL7oUN2XKFBISEsjJyWHChAkA5ObmAtC8eXP8/f2xs7Ojdu3a2NjYYFOtEbZ1mqNUKpk8ebLlZMEhoBMKe5fHuwPuYtUJqnLlyowaNYrw8HDatGmDo6Mjbdq0Ke+wBEEQHh9JQi4v/au5qFwidf2/SV3/b/JObsW+YWtkKtt7G7mrPhw+fJhatWoRExNDZGQkXl5ezJ8/n9jYWH788UfOnTuHRqOxrKPyqI4u4SIDBgygRo0afPbZZ+h0epxD+jyud10qq74HlZOTw+7du9m9ezdOTk5MmjSJzZs307t37/IOTRAE4bFQOntx9epVAMv07DVq1ACwlDf2UqPX6zm7exlZu5fdt6079Y8ePUpcQiKnT5+madOmeHh4WB6ObdCgAQUFBfz+++9cvHgRrVaLKukykl7LtGnT0Gg0LFmyBPsGLVG5Vy2xjbi4uDJ9/3ez6gR1+PBhqlWrhru7OwBdunTh9OnTIkEJglBh2dVpzqGD33Lq1CmGDRtGXl4ew4YNIzk5mQ0bNgCwa9cuEhISCAwMBOCbb76hdu3aAAwePJjGjRvz5ptvsn79eubPn8+IESPQaDRERERw6dIlrl69StOmTRk1ahRxcXFERETg4+PDlClTABnG7GQ6depEUFAQixcvJjMzkyo9+pYa750k+r+IiYkptdyqL/H5+Phw5swZtFotkiRx5MgR6tatW95hCYIgPDZOzXoid3AlIiKClStX0r59e3bu3El4eDharRaAzZs3s2vXLss69vb2pKenExUVxfXr17G3t0cmk5GXl0f79u05ceIEQ4YM4aeffrJ0N8/JyaFmzZoMHjyYrKwsunbtyg8//IBd/VAkg45GjRoRFRVFZGQkNlUbYVPV94nvC6sfi2/x4sVs374dpVKJn58fc+bMQa1W37d+TEwM3Vdff4IRCoIglC19+k0yd3yOLumSpUzlUQOXVgPJ3L38r4dyAZlSjWTUl2hDprLFObg3msu/F40icacdrzo4NGpHzpEoy0O6AAoHN5zD+uPYuDPJqyZhzE75c4GKyoNmY1vNv8Q2ymqoo/uNxWf1CervEglKEISKQp8eZxnqSF25LjKZ7M/hiZJAJkPlXhXJZPwrmdxF6VwJuY09kmRGn3INc0EuStfKKN2rIZPJMBt0GNJuYNLmILd1wsa7ATJF0V0fyWzCkJkIkmRppzSPO0FZ9T0oQRCEZ5m6Uk3UlYrf45EpVcXKZHJFiTrF6svk2Hg3KFEuV9nc97KdTK5A7VnjH0Zddqz6HpQgCILw7BIJShAEQbBKFe4Sn9ksPfY5SgRBEISym7DwfircGZTRWHIOE2vzOB9sKysixrIhYiwbIsayUdYxPs7kBBUwQQmCIAgVg0hQgiAIglUSCUoQBEGwShUuQSmVqvIO4aHKYuyqx03EWDYqYoyFBtNjikQQiqtwvfjkchm1potJDQXhcRG9ZIUnpcIlKEF4WpkNhRTEHECfGotMZYtdvRbYVG2ETCYrVk8ym9CnXEOfGotZpwGZAvv6oZapEIx5t9Fc2IsxNx2lowcO/uEonCuhS7iALvGeUaNlcuzrtsCoyUSffOWeZcXbFYQnTSQoQbACuuQrpG/4AJMmCzc3N7RaLbnHNmBXrwWVek9HpiwaINls0JHy7RQM6TeLrZ9zZB3Vxq5Gc/43Mnd/jRwz7u7uZGZmkv37Wuzrh1Fw5XCp287et/K+cd1pV66+d0I8QXj8Ktw9KEF42kgmA+mbP6RmZTcOHDhAZmYmGRkZfPTRRxTGRpNzZL2lri4xBkP6TRYuXEh8fDxarZYff/wRSaeh4NJBMn/9il4RPYiNjSU9PZ24uDgGDuhvSU4pKSlotVrLv+3bt1vazsvLK7bsTruGzIQnvk8EAZ6CM6jVq1cTFRWFJEkMGDCAl19+ubxDEoQyVXD5EKacVD7/fjuhoaH07duXrl27MnXqVI4ePcrGrVtwaTmw6Czqz8kHUlJS+PTTT1m4cCEqVVHHoNzjm3BxcWbNmjUkJiYSHh7Oxx9/zMqVK9m7dy/p6enY2Nhw5MgRoqKiAEhI+Cv52NjYsHv3brZs2QLAzZs3AZDbOj7BvSEIf7HqM6grV64QFRVFVFQUmzdvZt++fU/F09qC8Hfokq7g6OhI9+7dOXXqFJs2beLTTz8FYODAgUj6gqLpFQAbn4YoXb1ZuHAhq1evLtaOISOeLl264OLiwrp169i3bx9r167F3t6enj3/6thgb29P/fr1MZvN/Pbbb8XacHJyol69ehgMBvbs2QOAwt7lcb59Qbgvq05QsbGxBAYGYmdnh1KpJCQkpNgskoJQEZjyM6lWrRoAt2/fBiAjIwPAUm7ISMBUmI9MZYPPK19i36BVqW09rJ3c3FwKCgp47rnnWLp0Kfv27UOhKBquJjs7G51OR/fu3Vm+fDk7d+5EJpOR/8eOx/G2BeGhrPoSX4MGDVi0aBFZWVnY2tpy4MABAgICyjssQShTcht7stOyAbCzswPA1raoU0J2dlH57c3zAVA4V8It/BUKrhzG3tOzRFt36t+vnTtnRwD79u2jffv2BAQEcObMGapWrYrBYEAmk3Hs2DHat29P3bp1Sbq3dx9Pfty5/Px8q796ImIse1adoOrWrcvo0aN55ZVXsLOzw9fXF7ncqk/6BOFvU7pXJfXcr9y8eZPAwEDs7e1p2bIlAMeOHQNg9OjRBAQE8M4771iSVWnu1A8LCwMo1o63tzcuLi5cunQJlUqFg4MDAIWFhVSvXh0bGxuuXbuGjY0N9vb2lmUyl5JfE0/6AeS4uDirf+hZxPjPxcTElFpu9d/2AwYMYOPGjaxduxYXFxdq1apV3iEJQplyaNQeSa7g7bffxsPDgxs3brB69Wpu3rzJZ599BkBERASTJk3CxsYGgJ07d5KUVHRfqlevXuh0OgYNGsTFixdZsWIF/fv3J+FGL8QAACAASURBVD4+nhEjRrBu3Tqio6OpVasWMTExXL9+naSkJIKDg/nvf//L5cuXadCgAVevXiU2NpbExET8/f1ZsWIFCQkJ2NZoXG77Rni2WfUZFBRdQ/fw8CApKYldu3axfv36h68kCE8RpZMnrm2Gsn79aqKjo4mIiCAjI4ONGzdSWFgIwPz581m9ejUajQaADz74gKVLlxZr58SJE0DR2daaNWto1qwZ586dY/fu3QAcPXqUsLAwmjVrhkKh4OzZsxw4cACAPXv20KpVK4KCgpDJZJw+fZrDhw9jW7MpDgGdntSuEIRiZJL0Z79VKzVkyBCys7NRKpW88847lksW9xMTE0P31defUHSCUHYKrh0jN3oz+tRY5Cob7Oq1wCVsAAVXjqK5sAfJbEJdqRZyB1cK486CZC62vsLeGZeWg9CnxpJ/7leMuekoHD1wbNwJp6bdyTuzA+3V40XPNUlmlK5VsPdti2OTruSf2oY2NhpDZiIASrcqOPh1wCmoB7J7xrcsj6GOrPXS1N1EjP9cTEwMfn5+JcqtPkH9XSJBCcLjJRJU6USM/9z9EpTV34MSBEEQnk0iQQmCIAhWSSQoQRAEwSpZfS++v8tslsR8NYLwGBUaTNiqFOUdhvAMqHBnUEajobxDeKin4UluEWPZqIgxiuQkPCkVLkEJgiAIFYNIUIIgCIJVqnAJSnnPQ4XWyBqfQ7iXiLFsPCjGQoPpCUYiCE+fCtdJQi6XUWv6tvIOQxAeSnTmEYQHq3BnUIIgCELFUOHOoAShMO4succ3oku+gkyhxLZ2c1zC+qNyr1qsniSZ0ZzbTd4fv2DMTERu74yDX3ucQ/ogmQzkHIlCe+MU5oJs5DYO2FT1wzmsP4U3TqG5fAhjdgqYTSgc3LGrG4xzWH+MmYloLu5HnxqLWa9FplDiGNgFp6Ae5bQ3BOHpJRKUUKHkndlF5o7FeHt702v4YDQaDRs3biT50kEqD5mPTZV6lroZ2z9Fc343gYGBtOs3kuvXr7Njx3ryzuwAkwmlWUePbt2oUaMGGRkZbN++neRv9gHQunVrAgI6oFQquXHjBr/+upXc4xsBcHR0JLRZMzw8PLh16xYnfvsKe982KOycy2OXCMJTSyQoocIwF+aTtXcFnTt3Ztu2bWg0Guzs7FiwYAHBwcFk7F5G5SEfIpPJKLx1Hs353cyYMYPZs2eTmppKpUqV+P333+nQoQOSJLH/yBHCwsI4evQoTZs2JSsri4CAADIzM9m6dSvZ2dm4uLjg7u7O3r176dixI1A0OWCjRo0AWLt2LS+99BJmbZ5IUILwN1n9Pajr16/Tu3dvy79mzZqxatWq8g5LsEIFVw4j6TTMnz8fs9lMvXr1eP755/H29mbatGnoEi5izCqa5C//7K94eHgwY8YMjh8/jre3N3PnzqVdu3b06dMHNzc3wsLC2LVrFz3/8x2LFxedlTVp0gSA+vXrU6dOHby9vUlMTCQ8PBy1Wg3A0KFDCQwMLLf9IAgVhdWfQdWpU4fNmzcDYDKZaNeuHc8991w5RyVYI0NmEmq1mubNm/PHH3+QmZnJkSNHgL+mQDdkJqJyr4oxM5EmTZpgZ2fH0aNHkSSJw4cPW+pu2rSJdevW0b17d95sG03//v05deoUx48fB4om0hw9ejQ1a9bEy8uLZcuWodfrkant+OOPP6hdu3b57ARBqECsPkHd7ciRI1SvXp2qVas+vLLwzDHr8nFxcQFAq9UCWGakdXd3ByD3+EZMuWnoki7h1tL/gXVv3LiBSqWiTZs2VKpUiejoaMzmvyYJnDhxIj4+PgCWmW5dWw9Gn3YDCm4+zrcqCM+EpypBbdu2jYiIiPIOQ7BSCkcPbt++jU6nw9PTE/gr2SQkJACgu3Ue3a3zxco8PDyK/UxISCAoKIjp06ezZMkSJr77AaMGPs9XX33Fzp07WblyJQCBgYEoFAoOHDjA5MmTWbFiBRf2flMUzD1nUKnrZlKpzzvYeNcvVm4NY/Xl5+dbRRwPImIsG09DjHd7ahKUXq9nz549TJkypbxDEayUTZX6SJLEhg0bGDJkCC+++KLlnlFUVBQAn376KYMHDyY0NJSTJ09y8+ZNevbsSfv27Rk1ahQAGzZswGg0AuDr64u3k9LSTkFBAX5+frRt25bo6GgqVapEjRo1AMjOzgagY8eO+Pr6AlCjRg369evH4cOHyfr9OyoPmFUsZmsYDcNaZ1m9m4ixbFhrjDExMaWWPzUJ6sCBA/j7+1uOjAXhXrZ1mqGqVItp06bh5eXFDz/8gMFgYPny5axYsaKojq0tzs7OyOVyjEYjw4cP56uvvmLfvn1kZmYyadIkzp8vOsP697//zdtvv018fDwmk4m1a9eyceNGAgMDWbBggeVyYnJyMmPGjCExMRGADz74gObNm6PT6WjRogVr166lX79+/HriUvnsGEF4SskkSZLKO4hHMXnyZNq0aUO/fv0eWC8mJobuq68/oagEa6NPjyMt6j+Y8tJxd3dHp9Oh0WiwqeqHPv0mkl5rqWtTPQB98lUw6alUqRLZ2dno9XqcmvXEpM2nIGY/crkcDw8PsrOzMRj+mspFJpPh6emJXq8nJycHAIeAzmgu7gVz6WPsOQb1wKPLWMtraxnqyFqPqu8mYiwb1hpjTEwMfn5+JcqfijOogoICDh8+zPvvv1/eoQhWTl2pJlXHfIXm0kF0SZeRK1R41WmOba0gTHnpFFw6hGQyoHKvhl39UMyF+WjO76YgMwnbus54+LVDXakWAIXNIii8eQqtJgu7uk64+vhiVzcYffIVCuPPoc1NQ6ZQ4epUCfv6oajcq+Ic0hvt9ZMgmYvFpXB0x75hm3LYI4Lw9HoqEpS9vT3Hjh0r7zCEp4RMqcYxoBOOAZ2KlSudvXBu8UKxMoW9C84t+pbajm01P2yrlTyqs6nqh03VkuUAaq/aqL1EF3NBKAtW/6CuIAiC8GwSCUoQBEGwSiJBCYIgCFbpqbgH9XeYzZLV9I4ShAcpNJiwVSnKOwxBsFoV7gzKaDQ8vFI5exqe5BYxlo0HxSiSkyA8WIVLUIIgCELFIBKUIAiCYJUqXIJSKlXlHcJDWeOT3PcSMZaN0mIsNJQ+0oQgCMVVuE4ScrmMWtO3lXcYgnBfohOPIDyaCpegBMGYdxtDehwytT023vWQKUo/q5YkCUPGLUw5aSicPFBVqoVMJitaZtSjT4/DrM1FbueMulItZH+enRtzb2PISgSzCaVLZZRuPshkMsyGQozZqcW2IVMoLcsFQfh7RIISKgyTNpfMXUsouHzIMhaewtEd13YjcGxcfNgjfdp1MnZ+gT7psqVMXbku7l3Gok+7Qfb+VZgL8y3L5HbOODRqT2HcGQy344u1pfauj3OLfmTu+AyzTlMiLtuagXi9OEckKUH4m0SCEioESZJI3zQXWfo13pn+Nj179iQtLY3IyEgObo9EbueIfb1QoCiRpf7wf3i7O/HO55/TrFkzzp8/z7x587jxbdF8Y8899xyvvfYaVapUISUlhc8//5y9e7fi5eXFjE8/pXHjxqhUKs6cOcPcuXNJ2jwfuVzO+vXri8V1+PBhFi1ahDE7BZWb9xPfL4LwNLPqThLJyckMGzaMHj160LNnT1avXl3eIQlWqjDuDLpb54mMjGTu3LlcvHiRevXqsWfPHho2bEj2we+4M7NM3oktoMtnx44dDB8+nCNHjtC3b1/27NmDSqWicuXKbNu2jaZNm/L9998THBzML7/8gpubG3Xq1KFLly5ER0dz+/Ztxo0bZ0lKMpmMAQMG0LRpUxwdHXF0dMTW1vbPCJ+KWW0EwapY9RmUQqFg+vTp+Pv7k5+fT79+/WjdujX16tUr79AEK6ONjcbBwYFRo0Zx8uRJxowZQ4cOHdi7dy+vv/46b7zxBqb8TJROHmhjowkPDycgIIDIyEimTJlCTk4Os2bN4vnnn+fMmTOoVCoOHTrE6iNxtDt2jAEDBuDg4MCZM2fw9/fHbDYjk8nIyMigefPmxWLZvXs369at49KlS6SkpACgdBVnT4Lwd1n1GZSXlxf+/v4AODo6UqdOHVJTUx+ylvAsMuWmU6tWLdRqtWX0hjs/GzRo8GedNACMuemWsjt14uPjLXVjY2N56623GDp0KKfXRdK3b18mTpxIQkICWq0WbJ0ACA8Px83NjU2bNhWL5bXXXmPv3r3cunWLadOmAVB4/eTjfPuCUCFZdYK6W0JCAjExMTRp0qS8QxGs1L2TQ1t65P1ZnvL9O6R89xZmbW6June3UaVKFSZPnsz58+dZsGABly9f5q233sLDwwMAc0EOvXv35ueff2bfvn2MGTOmqNxsJjw8HHt7e/z8/MjIyGDevHk4OzujvR79uN62IFRYVn2J7w6NRsPEiRN59913cXR0LO9wBCukcPHi5oU/0Ol01KlTB4DatYsmDrx8uainXlBgY9zd3dmbfMlSdqfO3XXbtWuHt7c3H374ISt/+hU3Nzfmz59P69at2bJlC2PHjuWzzz4jKiqKESNGoNPpALC1tWXfvn0AXLp0idjYWCpXroybmxu3dQXF4rWmcQTz8/OtKp7SiBjLxtMQ492sPkEZDAYmTpzI888/T5cuXco7HMFK2ddtQWr0TyxbtowJEyawZs0aQkJC0Ov1fPnllwDMnz+fLl26WBLJH3/8wejRo1GpVAwZMoRr167x888/U7duXQwGA6+//joqlYp//etf6HQ6zp07R0hICF988QVms5mqVauya9cuALp3706nTp2YPXs2u3fvpnr16rRq1YqTJ08SHx+Pa4fi3dytaRSMuLg4q4qnNCLGsmGtMcbExJRabtUJSpIkZsyYQZ06dRg5cmR5hyNYMZsajbGtFcTUqVOJjY0lIiKCU6dOMXz4cK5duwbAr7/+SlJSEiaTCUmS6NatG1OmTKF58+asXr2ahQsXYjQauXz5Ml27duWVV16hW7duHDlyhGXLlnHjxg1UKhWrVq0qsX2z2czJkyfZsWMHTZo0wWw2M2fOHCIjI5E7eeIQKA6uBOHvkkn3uxhvBU6cOMHQoUNp0KABcnnR7bI333yT9u3b33edmJgYuq++/qRCFKyIuTCfzN1fo7m4F8xF490pXSrj2m44eae3oUu4CIDcwRWP58aSe+pndPFnLevbVPXD/bnX0KXEkn1wDWZNtmWZwtEdtXcDCm+eRjLoSg9AoQSTsViRba0g3Lu8jsrNx1JmbUMdWetR9d1EjGXDWmOMiYnBz8+vRLlVn0EFBwdb7hUIwsPIbR3x7PkGbuEjMWTcQqayRe1VG5lcgb1fO0x5t0Eyo3B0R6ZQYd+wFYbsFEy56Sgc3VG5VwWKRpRwDOiIISsJc0EOcnsXVO5VkckVmHUFmAvzSmxb4eCOTKnCpMnGkJUEyFC5VUHh4PaE94IgVBxWnaAE4Z9Q2LugsHcpViaTyVA6VypRV+VaBZVrlRLlMoUStWeNEuVyG3vkNvb337aDKwoH138QtSAI93pqupkLgiAIzxaRoARBEASrVOEu8ZnNktXdhBaEuxUaTNiqFOUdhiBYvQp3BmU0Gso7hId6Gh6UEzGWjdJiFMlJEB5NhUtQgiAIQsUgEpQgCIJglUSCEgRBEKxShUtQSqWqvEN4KGt8kvteIsayUamymAdKEP6pCteLTy6XUWv6tvIOQxAA6xvWSBCeJhUuQQnPBkmS0MWfo+DqEcy6AtSVauLQuDMKO+eSdU0GCi4fojCuaNw9m+oBOPi2RZd8mcIbp0tMxi5TKLFv2BqFrROai3sxZCYiU6qxqxeKbc0mFN44ReGf4/rdTa5UY9+ofakjUwiC8PeJBCU8dSSjgfTN89FeO4aTkxMebm7En99N9qHvqdR7OnZ1/pqC3ZibRuq69zBmJuDl5QVA2tldZGz7BACFomSXb0mSyPl9LciVYDbi5eWFVqsl7eRWZDYOSDrNfdfLP/crPmOWIZNVuKvngvDEib8i4amTe+IntNeOsXDhQtLS0oiLi+P8+fMEBfhxe+tCzHdNDpix4wscTHls3bqV1NRUUlNT+eWXX3B3dwfg3LlzGI3GYv++++47AJoHNeHKlSukpqaSnp7Op59+CvqitlNSUkqsFxkZiTE7BXOh5snvFEGogKw+QeXm5jJx4kS6detG9+7dOX36dHmHJJQjyWwiN3ozPXr0YMqUKaxdu5b27dtTvXp1li1bhrkwj/xzvwKgT4+j8MZJ3nnnHSIiIhg7dqxljqcZM2YAMH36dIYPH87w4cOJiooCIDq6aHr2lStX4unpSb169Zg/fz4TJ06kb9++AIwbN86y3s6dOy3rydQPHkxWEIRHZ/WX+ObMmUPbtm1ZvHgxer2ewsLC8g5JKEemvAzMBdmWRLF8+XKOHTvGwYMH6dmzJzVq1CAjNRYA/Z8/+/bti1ar5auvvkKSJCIjI+nbty9Tpkxhy5YtyJQ2YNLz7rvvkp2dzfLly5HJZPj5+XHhwgVib8Zz6NAhAHr37s2GDRtYv349KJTYKBUsWLCAW7du8cMPP+AYFIFMLkaKEISyYNVnUHl5eURHR9O/f38A1Go1zs4lb4ILzw5TfgYAPj5FEwBmZmYCkJWVBUDVqlUxZCZizE3HkH7TUjcnJwez2YwkSWRnZ1O1atHcT85hA5CpbIiIiMDX15elS5eSn5+PJEkcPXqUgIAAZr47nXfffReAatWqAeDZ5x1kMgVDhw6lSpUqLFq0CKPJjHNwrye2LwShorPqM6iEhATc3d155513uHTpEv7+/syYMQN7e3EJ5Vklt3UE/kpMdz4Ld35mZGSgT7pC4pKRlnUyMzNxcflrfih7e3syMooSnfbacczaXKZOnYper2fx4sXY+PiiS7rEoEGDmD17Nr169eLKlSsApKWlAaC5sBdMeqZOnUpOTg7Lly/Hwa8dSmevEjFb+5iB+fn5IsYyIGIse1adoIxGIxcvXmTmzJk0adKE2bNns2zZMt54443yDk0oJ0qXyqBQcujQIYYOHUq7du24fPkyISEhJCcnc+PGDRo0aMBbb73Fzz//zE8//cShQ4cYNGgQTZo0QafT4enpycaNGwEw3I6jRYsWtGvXjpUrV5KcnIxX/1dJ+/E/aDQaRo4sSnTTp08HYPPmzchUthTGn6NHjx74+fnx4YcfkpeXh3eLvqXGbO0PFFvrNOB3EzGWDWuNMSYmptRyq77EV6VKFapUqUKTJk0A6NatGxcvlnz+RHh2yJRqHAM6sXLlSk6fPs2iRYtISUnB29ubt99+G4PBQJUqVXjllVdo1qwZALNmzSIjI4OjR49y6tQpsrKy+Pe//21pc9q0aQAsXLgQlVcdbKo1AmDGjBkkJCQQFxfHvHnziIqKYt26dcjkCiSdhmnTpqHX6/n000+xrdkUdeU6T36HCEIFZtVnUJUqVaJKlSpcv36dOnXqcOTIEerWrVveYQnlzKX1EFKunyI4OJiuXbvi4+PDr7/+Snx8PFDUdbxLly5cv34dgEtXrlGrVi2ef/555HI5W7ZsIU+jxa5+GNqrR1m6dCmLFy/m4sWLeERMQaayQW7nTGRkJKdOncLR0ZHjx49z5swZ1N4Nsa3WiPyTm5kzZw65ublFZ10DXy/PXSIIFZJVJyiAmTNnMnXqVAwGA9WrV2fevHnlHZJQzpROHni/vIjcE5v57fgRzLpjqCrVwqv/SJRuPmQf/I4DF24hUzvj1f8/KFy8yD22kfXb94AkYVszBO8WfVG6VCZr93J+j4kHmQyXli/i0Kg9MpkcrwH/IevIeqJ+2Ytk1KN0qYx71/E4BnTCrC/AVJDNgQu3QCbHtcNIbGsFlfduEYQKRyZJ0r0jvTzVYmJi6L76enmHIQjA0zEWn7Xel7ibiLFsWGuMMTEx+Pn5lSi36ntQgiAIwrNLJChBEATBKokEJQiCIFglq+8k8XeZzdJTcd1feDYUFOqxt1WXdxiC8FSqcGdQRqOhvEN4qKfhSW4RY9lIT00u7xAE4alV4RKUIAiCUDGIBCUIgiBYpQqXoJRKVXmH8FDW+BzCvUSMj6bQYCrvEAShwqpwnSTkchm1pm8r7zCEZ4TokCMIj0+FO4MSBEEQKoYKdwYlVBy6pMvkHFlPYfxZkMzYVPPHJaw/tjUCi9WTJImCmAPkntiCPi0WucoWu3phODbpQu7xjZaJC+8mt3HApc0QlM6VyD2+Ce31k5h1BSgc3bCt2QSlsxeFcWcwpN/EbChE4eiOXZ1gXFoPRuno/oT2gCA820SCEqySNvYEaRvex6uSJ6+MeQWlUklUVBSJ37+L5/PTcGjU3lI3++B35B5ZR6NGjYgY9ia3b99m3bp1pJ7/DZVKxaAXXyzR/okTJ7i04QOQK3F2tGfEoH5UqVKFmzdvsmnTJjSFhYSEhBDSawQuLi7cuHGDTZs2kXL9JN4vL0JhJ2Z2FoTHTSQowepIZhOZu78iwL8RR44cwWAwYDQamT9/PuHh4Rzf8zV29cOQq2wwZKeQezSKESNGsGrVKhISEvDw8OA///kPTZo0wWQy8e2335bYxtixY7l06RIhzYPYtWsXcrmc8+fPU7duXc6ePcuFCxc4fvy4ZQqPGjVqcPLkScLCwsg7+TOubYY86d0iCM+cp+IelMlkok+fPrz66qvlHYrwBOgSYzBmJTNz5kwcHR1p27YtQUFBqFQq3n//fUyaLApvngZAc3EfchnMnTuXpKQk6tWrx8iRI6levTrjx48nNzcXlUpl+Xf06FF0Oh2bNm0C4OOPP0aSJPz8/GjdujVVq1bl6tWrAHTu3JmaNWtSu3ZtTpw4QfPmzfH19UWfGltu+0YQniVPRYJas2aNmKjwGWLMSgIgJCSEgoICLly4QGJiIklJSQQHBxerY8xKwsfHBx8fH86cOYNOp+P48eMAlrrKqo0wmsyEhIQQFhbGt99+S0pKCq6urrRu3ZqsrCw2btzIuXPn+Pe//43RaARgz8EjAMjlcuzs7CgoKCApKQmFvcsT3R+C8Kyy+gSVkpLCvn376N+/f3mHIjwhZp0WAFdXV3Q6naVcp9Ph5OSEXC4n59gGco7+iOb8HlxdXS3L7/55p1zp5gOS2TK1+8cffwyAi4sLcrmcOnXq8OOPP3Lu3DlmzpzJ6NGjAVDYOWFra8u6deto2LAhI0aMIDMzC8fA557AXhAEwervQc2dO5dp06ah0WjKOxThCVE4eQAQHx+Pv78/arUag8GAp6cnSUlJmM1mKMghe/8qAG7dugWAp6cnAJUqVSpWrrl4gPr169O7d2+2bNnCpUuXULhUtrSVlJTEwo8/oWmTQAYPHkxwcDDLli3DRWlk87bfaNq0KS+88AI///wzANI94z0+aEzA/Px8qx8zUMRYNkSMZc+qE9TevXtxd3cnICCAY8eOlXc4whNi410fkPHDDz8wb9483nnnHXJzc3FxceGrr74C4M0332T27Nn07duXHTt28Msvv9CpUycGDhxIz55FD89+//33AEj6At58803kcjkLFy5E4eyFW/uXub3lQ3766Seef/552rVtQ9u2bQE4deoUcrmcQ4cO0bBhQ9avX4+vry++vr78+OOPpBz7Eduaf3V1f9CIFtY6g+ndRIxlQ8T4z8XExJRabtUJ6tSpU+zZs4cDBw6g0+nIz89n6tSpLFy4sLxDEx4jpUtl7P3asWjRIurVq8e7776LXC7n+++/Z/bs2QAYjUYKCgowmYqGGho7dizLly9n3bp15OTkMGvWLLZtKxpRxNXVlYiICPbs2cPBgwdx6/Qv7Bu2QulejUmTJmFvb8/+/fspKCjgiy++YPny5SgUCjw9PcnIyKBTp0506tQJgJMnT5J0Oal8dowgPGNkkiRJ5R3Eozh27BjffPON5Qj6fmJiYui++voTikp4XEzaXNI3fIAuMQaVSoVcLken06HyqgMmI4aMeEtdm+oBGLNTMOXdxs7ODr1ej8lkwt6vPQpHN/Kif7LUVTh64POvpcjVdujTb5L24/uYctOwtbVFp9PxKH8Ozi364hY+Cnj4UEfWesR6NxFj2RAx/nMxMTH4+fmVKLfqMyjh2aWwc6by0AUUxp2hMO4MSBLO1f2xq9McSV9IwdUjf4784I59vRYggeby7xjSbqBW2WBXLxSbKvWQjAZsfHwxabKQKZTY1WmOXG0HgLpSLaqO+YqCK0fQp1zDxsYeGx9fbGs2QZd4CX3qtRJxKZ08sKvb4knvDkF4Jj01CSo0NJTQ0NDyDkN4gmQyGXa1mmJXq2nxcht7HAM6lajv6B8O/uHF6ypVOPi2uf82FCoc/Nrh4NeuWLltNT9sq5U8ohME4cmx+m7mgiAIwrNJJChBEATBKokEJQiCIFilp+Ye1KMymyUxiZzwxBQaTNiqFOUdhiBUSBXuDMp4z1P+1uhpeJJbxPhoRHIShMenwiUoQRAEoWIQCUoQBEGwShUuQSmVqvIO4aGs8Unuez1KjIUG0xOIRBCEZ1WF6yQhl8uoNX1beYfxTBCdUQRBeJwqXIKqKCTJjD7pCsa82yidPFD7NEQmK/2E12zQoUu4iFlfgNqzJiqPasWWm7R5lgn+FE6eKP+czgLAVJCDMTsFAKWLFwoHN4y5aZjys4q1IbdzQuXmU5ZvURAE4YFEgrJChQkxZO5YjCHjlqVM5VEd924TsK3WqFjdvDO7yN6/CrM211JmWysIjx6TUDp5ok+9Tsp/30bSF00CiOz/27vz+BrP/P/jr3OyryJUEluIXdW+FGmKyIq20a+aTg1Ga2lRahmqZbTKg7Y6ppRWVX+GVrVVaxhKBgmxlkQjKoIsNNEkksh+cs71+yPjTDKYKic9d+LzfDw8knNf933u97kl+Zz73Nd9XXrqD5mBS7sASq+eJ3PTGyjDvycF1Nvg6NuJksungdsHTXXvPZy6AX+y+OsVQog7qXXXoGq68ptZXP9mHs08HfnHvpO1zgAAIABJREFUP/5BfHw869evp5mnI9e/+Svl+VnmdYuST5Dzzw/p17s7u3fvJi4ujiVLlmCfk8wvmxegysvIivwAn/p12blzJ7t27aJlCz8KEw9hMpSQFfkBvo182LVrF7t27aJxQx9KLv9A9+7dzMtu/QsODqbw3AHrHRghxENH82dQpaWlvPDCC+YpFEJCQnj11VetHava5B/fgq0qZ8+ePbi5ubFy5Upefvll/P39ad26NfnHv8Nz4DgA8qI30Lp1a/bs2cOPP/7I3r17mTFjBk2aNOGPf/wjP/+/qRiyU1m9cydhYWHo9Xrc3d25mmck99B6jLk/s3bzfp588kn0ej0uLi5Axcy0YWFhREVFkZ2dDVTMv6Sz2lERQjyMNH8GZW9vz7p169i+fTtbt24lOjqaM2fOWDtWtSm5fJrQ0FCaN2/O6tWr+etf/8rHH39Ms2bNCAsLo/jyD0DFtaOyzGTGjRuHra0ts2bNYubMmcTExDB8+HDq1auHITuV0aNH07VrV7766qv/7CP9HDdPbuOVV17Bz8+PLVu23DHLtm3b+PTTT5kwYQJRUVGg1/yPixCiFtH8XxydTmd+Z19eXl7xTl5Xe9/Ll+dfp2XLlgCkpVVcg0pPTwegZcuWGG/+8u/1fjEvq7xuWloaer2e5s2b07hxY5YtW8a4cePIyckx70OVFuLn58fixYsZM2YM+fn/uX5V2dKlS9m7dy9XrlwhKCgI480cjEV51fCqhRDidpovUABGo5Gnn36aPn360KdPHzp16mTtSNVHp6e8vLzi238XYv2/z1zKy8tRhlKufT6ZjH9MMy+rvE7ldZctW2Y+43RzcwPA29sbe3t7PvroI3bt2sWFCxfMbwB8fHyws7PjzJkzNG/eHDs7O0JDQ3Fzc+Odd95BlZdSmp7wOx0IIcTDTvPXoABsbGzYtm0b+fn5TJw4kQsXLtC6dWtrx6oWth5eJCYmAv85O2rRogUA58+fByC8d0eysxsRExNTZd2EhARatmxJWVkZly5dws/Pjy5dujB48GDz80dGRvLEE0/g5+dH69atee6558xt//rXv+jatSvJyclkZFR0PT969CgAHh4eAJjKSqrkteZ4eAUFBZoYj+9/kYyWIRktoyZkrKxGFKhb3N3d6dWrF9HR0bW2QDm3fJz9+7/i9OnTTJgwgfr16/N///d/nDlzhu+//x7AfC0uICCAjz/+mKlTp/Lhhx8yYsQIevTowYoVK8jPz2fs2LG4uroCMGXKFCIiIhg/fjxnz57lT3/6E05OFVOfz549m9DQUEaOHElSUhKLFi2ia9euxMfH4+9fMRvtrWtY9l4tquS15qgYKSkpmh+VQzJahmS0DK1mvPVG+79pvkDl5ORga2uLu7s7JSUlHDlyhLFjx1o7VrVx6/4UBfF7CAoK4tVXX6Vz584sXbqUDz/8EKUq7k1asWIFycnJAFy9epWePXsyefJkGjZsyIQJE1i7di0AP/5ShkpPpywzmQYNGnD16lV2795NXl4ep85fQWdrT3lOOo0bN+bixYvs3buXgoICPv/8c8rLy2nRogWnT59myZIlbNy4Eef2T2L/iPZ+uIUQtZNO3fqrp1Hnz59n9uzZGI1GlFKEhoYyadKku66fmJhI2LpLv2NCyzPkXOXG/k8pvnTSvMzRrxvu3Z8mZ+9K88gPjr4dce8xlBsH/x+GX65UrGhjh+tjA6nb78/oHZwByPl+FTd/2AUo9E7u1H/qLzg16wxA1q5lFJ7dB4DeuQ4u7ftRfOkU5Tnp5n3r7Bxx6zoID/8R6CqNdWjtoY60+m6wMsloGZLRMrSaMTExkXbt2t22XPNnUG3btmXr1q3WjvG7svNsRINh8ykvyMFYkIONqye2rp4ANBy3GlPxTdDpsXGq6Pjg6NeN8tyfMZUWYVfXB72DS5Xn8wx6GY+AUSijAb2DMzqb/xSZ+uFT8QwcizKWo3dwQWdjC4FjMRbeoDw/C72DM7Z1GlTZRgghfg+aL1APM9tKhekWnU6PjXOd/1qm+9Vx8m6dTd25zeW2ZTYudbFxqfsb0gohhGXViG7mQgghHj5SoIQQQmhSrfuIz2RSVr94/7AoMRhxtLOxdgwhRC1V686gyssN1o7wq2rCjXL3klGKkxCiOtW6AiWEEKJ2kAIlhBBCk6RACSGE0KRaV6BsbbV/Q6kW7+T+b76+vpQYjNaOIYR4iNW6Xnx6vY5msyOtHaNWkN6QQghrqnUFqiZQJiNFF2IpTj6OMpRi79UC147B2Lh43LauqbSIgh/3U5p+DvR6nHw74dK+Hzpbe3N7/qntmIoqJh109O2Ic6vHMRbfpCB+L2U/J6GztcPJrzvObfpiLMqjMOFfGLJSMJUVY+Pkjn3Dtri0D0Bv5/i7HgchhPhfpED9zkylhWRumkfZzz/h7e1N3bp1OR99hLyj3/BIxBvmQVwByn65QuamNzEV5prneUrdfZC8o9/i9YeF2LjV55dtizGkxuHq6opSil9Obadu4DjyYr7AVFpImzZtuHnjJtd2/Au7I19hyLmKDkWTJk2oU6cO1zMvkxm/l/zj3+H9x8V3LJJCCGENte4alNblRn+B6ZdkNmzYwNWrVzl37hyJiYl0aNOS7J1LMRlKAVBKkR35N3w8XDh27BhJSUmkpKSwZ88eXEyF5Oz7hIK4PZRc/oEPP/yQ3Nxczp49C8CN/atp6duIs2fPcv78ea5evcq3336LvuA6KBNffPEFKSkpxMfHk5GRwZ49e7ArziYvdpM1D40QQlSh+QJ16NAhQkJCCAoKYvXq1daO80BMZcUUxP2TP/3pT7zwwgssXryYPn364Ovry4oVKzAW3qAo8RAApWlnKctMZuHChfTs2ZOnn36aCRMmEBwczIwZMyhOOkrOnhUEBgYycuRICgsLq+zrb3/7G23btqVfv3688cYbPPvss4wbNw6A1atX065dO1q1asXhw4cJDg7G39+f0mvnf/djIoQQd6PpAmU0Gnn77bdZs2YNkZGR7Ny5k4sXL1o71n0z5FxFlZcxZMgQANauXUtsbCw//PADAQEBuLm5UXa9Yi6rssyKr0OGDOHatWts376dtWvXYjKZzFO4u7m58dlnnzFr1ixyc3PN+7GzsyM0NJSEhAQOHjxonsDw1nYHDhwgLy8PV1dX7OzsKCgo4MKFC+jt7z7iuRBC/N40XaDi4+Px9fWlSZMm2NvbM2jQIPbv32/tWPfNWHgDgIYNK6bGyMvLAzAXl4YNG1L2yxUMWWmUZSbj4OCAp6eneT2DwUBRUZF5+/fff5/k5GRWrVpVZT9eXl7o9Xrz81Z+/ls2bNjA6dOn6dmzJ+vWrSMtLQ1j8c3qeulCCPGbabqTRGZmJt7e3ubHXl5exMfHWzHRg7FxrJhgMCsrCwBn54ozFhcXF/Py0uxsrn32snmbgoIC83o6nQ4nJydSU1Np2LAh48aN46OPPmLGjBm4ublhMpmYNGkSn332WZXndXV1rbJfgIiICOrXr8/777/PxIkTiY2NZeN3O27LrOVxAwsKCjSdDySjpUhGy6gJGSvTdIGqbWw9G4FOz6FDhxg0aBADBw5k27ZtdO7cmXPnzpGdnU337t2ZMWMG69evJzIykkOHDhEeHk6rVq1o3LgxNjY2HDp0CBsbG65du0ZERASAuRffhAkTWLFiBSdOnKBDhw54e3sTEBAAVFzPA/D39+fw4cMUFBSQnl4xtbuHhwfKWH5bZi3fVKzV6asrk4yWIRktQ6sZExMT77hc0wXKy8uLjIwM8+PMzEy8vLysmOjB2Di54dz2CVauXMnzzz/PZ599xqpVqzAYDLz22msANGrUiOHDh3Ps2DEiIyN5/fXX6dmzJ+fOnUOv15OSksLChQtJT0+nUaNG5udOT0/HaDTSoUMHAKZPn05kZCQpKSnY29tz7tw5li1bBsDBgwcpLS3FZDLh4uLCjz/+yKZNm3Bs2uH3PyhCCHEXmi5Qjz32GFeuXCEtLQ0vLy8iIyNZunSptWM9kLpPjiJjw4907dqV/v37U69ePfbt28eNGxXXp6Kjo+nTpw9XrlwBIP7Hc/j6+hISEkJZWRl79+6lXGdL3QFj0dk5UHL5B4ouHOHpp58278OhUXuiYw7TuHFjgoODyc/PZ//+/RiNFUMXtWnTho4dO2JnZ0dqairHjh0DR3e8I1783Y+HEELcjaYLlK2tLfPmzeOll17CaDTy7LPP0qpVK2vHeiC2dRrgM2Y5N0/tICbhOCbDBey9O+I9+Cn0Ds7kHf2G0z/fQO/eAu+BM9A7OJN/Yhs7D50CvR7HTuG493gaW/cGALh2Cib/6LckpFbcA+Xx5Cjcez2L4fpl8k9uY2vUUXS29rj0GIp796coSYnj6vkYUg6dRJmM2LjUxa33H3DrEi436QohNEWnlFLWDmFJiYmJhK27ZO0YtYLWx+LT6ufplUlGy5CMlqHVjImJibRr1+625ZruZi6EEOLhJQVKCCGEJkmBEkIIoUma7iRxP0wmpflrJzVFicGIo52NtWMIIR5Ste4MqrzcYO0Iv6om3MmdkpIixUkIYVW1rkAJIYSoHaRACSGE0KRaV6Bsbe2sHeFXWeI+hBKD0QJJhBBCu2pdJwm9Xkez2ZHWjlHtpCOIEKK2q3VnUA87k8mEwXBvHUXKy8vN4/NVppSipKSEuw0yYjAYMJlMd9x3SUnJbwsshBB3IQWqljh9+jTPPPMMjo6O2Nvb07lzZ9avX3/HIvPdd9/Rq1cv7OzscHBwIDQ0lMOHD7Nx40aefPJJ3N3dadu2LW5uboSEhHDs2DHy8/OZPn06jRo1wt7eHgcHBzp37sy6detYvXo1HTt2xNHREScnJ1xdXQkODiYmJsYKR0IIUVvUuo/4HkbHjh3jySefxM3NjUmTJuHh4cGWLVsYOXIkFy9e5K233jKvu2LFCiZPnkzbtm2ZN28eJSUlbNiwAX9/fwA6duzImDFj8Pb2JjMzk2+++QZ/f39sbGwwmUw888wzdOjQgZKSEr7//ntGjx4NwOOPP8706dNxd3cnMzOTLVu2MGDAAKKjo+nVq5c1DosQooaTwWJrqMrXoAICArh8+TJxcXHo9XqysrJo2bIlI0eOZNOmTSQnJ9O4cWNu3LhBs2bN8Pf3Z8eOHaSlpeHs7IyzszM9evQgMTGR48eP4+3tTUZGBj169CA3N5dOnTqRmprKJ598wrhx44iKiqJp06a0bNmSoKAg9u3bx5YtW2jatClKKbp160ZeXh7t2rUjICCAr776qlqOgVYHvqxMMlqGZLQMrWassYPFvv766/Tu3ZvBgwdbO4ompaSkEB0dzbRp0/D09GT48OF06NCBrKwsFixYQFlZGV9//TUAO3bsID8/n7fffhuDwUCnTp0ICQnBxcWF2bNnAzBp0iR8fX3p2bMny5cvx8PDg6CgIAD69OnDzZs3iYyMZMqUKQD07t0bgD/84Q9069aN7t27s2nTJurUqUO7du1IS0uzwlERQtQGmi9QQ4cOZc2aNdaOoVkXL14EoGvXrgD88MMPlJaWkpiYiK+vL56eniQnJwOQnJyMjY0NnTp14tKlS+Tl5XHmzJkq2x8/ftx83apBg4o5p86dOwfAu+++i06n4/HHH2fhwoX89NNPbNiwAYDS0lJGjhzJe++9R0hICDt37iQmJgZ3d/ff6UgIIWobzV+D6tGjB+np6daOoVkFBQUAuLm5AVBWVlblq5ubGytXrsTT05N33nkHFxcXbG1tze1KKQwGg3l7AJ1Ox3vvvcfw4cN54403iI2NBcDDwwOdToezszO2trbY2dnh6upq3q5Lly707dsXd3d3GjVqhLu7u3mmYCGE+K00X6DE3aWkpGBjY2P+vmvXrnh5eZGfn0+DBg0wGo1cu3YNnU7HokWL0Ol0FBYWkp2dbT478vDwME/9DuDg4MC6desYNmwYkyZN4qOPPgIqita7777LuXPnGDNmDO7u7iQlJTFz5kxGjhwJwGuvvQbA22+/zdy5cxk+fDjr16+vtrEHCwoKND+uoWS0DMloGTUhY2VSoGowX19fGjRoQJ06ddiwYQMRERG8+eabxMbG8uijj7Jx40YMBgPPPfccmzZtYuLEiaxcuZINGzYwZcoUZsyYQdOmTQFYv349AF988QXPPvssR48e5ZFHHmH+/PlERUVx6NAhsrOzad68Oe3ataNHjx4AXL9+HRsbG/7+97+zb98+AMLCwgBIS0vjkUceqbaLslq94FuZZLQMyWgZWs2YmJh4x+VSoGo4Jycnpk2bxvz583nzzTeZOnUqzz//PJs3b2batGkAFBUVkZKSYv44cN68eXh4eLBgwQJKS0t59913Wbt2LQDOzs6kpKTg4+Nj7kKenZ3NoUOHGDFiBH/729/Yu3cvpaWlbN26lUWLFqGUolevXrz00kvY2NiQlpbG66+/zvbt25k7d65VjosQouaTAlULzJ49m6SkJBYuXMjChQvR6XQopWjXrh2dOnVi586d7Ny5EwB/f3+Ki4sZPXq0uQBBxX1MR48eJTw8/K77OX78OF26dLlj260zqlv7Bhg5cqQUKCHEfdN8gZo2bRrHjx/nxo0bBAQEMHnyZIYNG2btWJpib2/P+vXrmT17Nrt27aKoqIju3bsTGhqKUoq9e/eSmZmJp6cnYWFh2NnZERUVxZEjR7CzsyMoKIhu3bqRlpbG/v37UUqRlZVF/fr1AXB3dyc8PJyioiIiIyMr5opydOTRRx8lODiY3Nxc9u/fT1JSEkajER8fH/r370+rVq2sfGSEEDWZ3KhbQ1X3YLFa/ay6MsloGZLRMiTj/auxN+oKIYR4OEmBEkIIoUlSoIQQQmiS5jtJ/FYmk3ooJvMrMRhxtLOxdgwhhKg2te4Mqrz83ibrsyZL3MktxUkIUdvVugIlhBCidpACJYQQQpNqXYG6NXiqEEKImk0KlBBCCE2qdb347iQ9PZ3o6GhMJhN9+/alWbNmd103Pj6e06dP4+rqSmBgIB4eHua2H374gbNnz+Lu7k5gYKB5Mj6lFCdPniQhIYG6desSGBhonidJKcWxY8c4f/489erVIzAwsFpfqxBC1Bqqljl37pz5+9LSUjV+/HhlY2OjAAUonU6nRowYoQoKCqpsl56ergYMGGBeD1AuLi5q0aJF6vLly8rf379Km5ubm/rggw/UhQsXVM+ePau0eXh4qFWrVqmEhATVpUuXKm316tVT77333u99WH6zK1euWDvCr5KMliEZLUMy3r/Kf7crq3Uf8VU2Z84cVq9ezcSJE4mLiyMhIYFZs2axceNGJk+ebF5PKcXQoUM5efIkH3zwAUlJScTGxhIaGsqcOXNo3rw5CQkJLF++nIsXLxITE0O/fv2YNm0arVu35vLly6xatYrk5GQOHDhAr169ePnll3n00UfJyMhgzZo1JCcns3//fjp27MjMmTM5cOCA9Q6MEELUBA9a+fr376+ys7PNj48eParGjRunlFJq8+bNqk2bNioxMdHcPmjQIJWWlnbbtmfPnlX9+/dXCQkJD5TnViW+fv26cnR0VH/+85+VUkpt3LhRrVmzRiml1PTp05Ver1eXLl1SSikVGRmpAPX5558rpZRauHChOnDggFJKmc+Ovv76a1VeXq7mz5+vjhw5ooxGo+rQoYMCVGRkpCorK1Nz585VJ06cUAaDQbVo0UIB6uDBg6q4uFjNmTNHxcXFqZKSEtW4cWPVv3//B3qd1U2r77Qqk4yWIRktQzLeP4ueQZWVlVFUVHRP63p7e/Pxxx//z3XOnz/Pq6++yrJly2jfvj03b97EZDLdTzSzI0eOUFJSwvjx4zGZTIwdO5bx48dTWFjIuHHjMJlMHDx4EIB9+/bh7OzMiBEjOHnyJG+88QZ/+ctfABg7diz16tVj2LBhHD58mPnz5/PGG2+g1+t56aWXaNy4MeHh4ezbt48FCxYwf/58bG1tGTNmDG3atCEgIICdO3eyaNEiFi5ciIODA6NGjeLgwYMYDNq/qVgIIazlNxWo5ORkFi9eTGhoKFeuXLmnbfr168fFixe5dOnOU2BcunSJiRMn8u6779KxY0cATp06RWhoKMuXL+fatWu/JaJZamoqAH5+fuTn51NQUIDRaCQzM5PmzZuj1+vN66SmptK0aVNsbW3N+7t69SoALVq0MHequLWscpufn1+VZbe2/7U2k8lkXi6EEOJ2v1qgioqK2Lx5M88//zxvvvkmLVq0YPv27bRv3/7edvDvM41PPvnkju2vvPIK8+bNo3v37uZl/fr146uvvsLNzY2XX36ZF198kd27d1NWVnaPLwvs7OyAirO9yl3PbW1tMRgMmEwm/vrXv9KyZUs2b95sfm69Xm9eD6C0tNTcdut5/lfbra+/1lY5oxBCiNv9ajdzf39/2rRpwzvvvEOLFi3u6Ul1Ol2Vx4MHD2bVqlWkpaXdtm7v3r355ptv8Pf3r1JIPD09zdOSnz59mjlz5rBy5Up27Njxq/tPSUnBxcUFgISEBIKDg/Hx8eHmzZv4+Phw5swZANq3b0+XLl0oLi4mLS2N/Px82rRpA2D+mpCQwKVLlyguLjYva926tbntwoULGAyGO26XmJiIyWS6Y5u9vT1lZWUWGZevOhQUFGg22y2S0TIko2VIxmrwaxevoqOj1ZQpU1RYWJhavny5Sk9Pr9IeERGhLl++bH68Z88eNXv2bKVURSeJt956Syml1FdffaXmzp17WyeJrKwsNXHiRDV37tzb9p2UlKQWL16sgoKC1Jw5c9SZM2fu+WJbYWGheuSRR9SAAQOU0WhU8fHx6sSJE0oppYYOHaoA9Ze//EUppVR4eLgC1Lx585RSSn3//fcqNTVVFRQUKF9fXwWoJUuWKKWU2r17t7p69arKzc1V3t7eClArVqxQSim1c+dOlZmZqbKyslTdunWrdLzYtm2bysrKUteuXVOurq7q+eef/9XXYk1avZhamWS0DMloGZLx/t13Jwl/f3+WLVvGF198gZubG6+88gqjR48mPT0dgF69erFt2zYAjEYj27dvp1evXrc9T0REBLGxseTk5FRZrtPpWLp0KZcuXeLvf/87UHGG8dxzz/Hmm2/i5+fHli1bWLhwIZ06dbrnwuvs7MyCBQuIioqib9++xMbGEh8fT//+/fnuu+8AOHbsGIsXLyY5ORmABQsWMHz4cDIyMvj222/p0qUL6enp1K1blzlz5vDCCy+QnZ3Nl19+SdeuXcnOzsbd3Z2pU6cyatQocnNz+fzzz+natSuFhYW4ubkxfvx4xo4dS0FBAR9//DHdu3fHZDIxf/78e34tQgjxULqfahcXF6euXbumlFIqPz9fTZs2TQ0ZMkQNHjxYLVmyRBmNRqVU1TMopZRat26dat269R27mefn56unnnpKbdiwQV28eFFdvHjxfqLdVok///xz5efnZ75RtnHjxmrFihVq6dKlytnZWQGqfv366uuvv1Zz5sxRderUMa/bvXt3tXfvXlVYWKhmzJih3NzczG2PP/64OnDggMrPz1evvvqq+bkAFRAQoI4cOaJu3LihXn75ZeXk5GRuGzBggNqxY8d9vbbfk1bfaVUmGS1DMlqGZLx/dzuD0imllJVqY7VITEykXbt2VZaZTCZSUlIwmUzmHnwABoMBo9GInZ1dlQ4MKSkpuLq60rBhwyrPU1JSQkpKCu7u7vj4+FRpKy4uJjU1FQ8PD7y8vKq0FRUVkZqaSr169XjkkUdISUnB19fX0i/doiSjZUhGy5CMlqHVjHf6uw0PyVh8er2e5s2b37bczs7utp50Dg4O5k4Q/83R0dHc0eG/OTk53bXN2dmZtm3b/sbUQgjxcKvVQx0JIYSouaRACSGE0KRaV6CMRqO1IwghhLAAKVBCCCE0qdYVKCGEELWDFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmiSFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmhSrZtu48yZMzg4OFg7hhBCiHtUWlpK586db1te6wqUEEKI2kE+4hNCCKFJUqCEEEJokhQoIYQQmiQFSgghhCZJgRJCCKFJUqCEEEJoUo0qUIcOHSIkJISgoCBWr159W3tZWRlTp04lKCiIYcOGkZ6ebm775JNPCAoKIiQkhOjoaM1lPHz4MEOHDmXIkCEMHTqU2NhYzWW85dq1a3Tp0oXPPvtMkxnPnz/P8OHDGTRoEEOGDKG0tFRTGQ0GA7NmzWLIkCGEhYXxySefVEu+e8l44sQJIiIiaN++Pf/85z+rtG3ZsoXg4GCCg4PZsmWL5jImJiZW+X/etWuX5jLeUlBQQEBAAG+//bYmM167do0xY8YQFhZGeHj4bb/zVqNqiPLychUYGKhSU1NVaWmpGjJkiEpKSqqyzoYNG9TcuXOVUkrt3LlTTZkyRSmlVFJSkhoyZIgqLS1VqampKjAwUJWXl2sqY0JCgsrIyFBKKfXTTz8pf39/i+d70Iy3TJ48WU2ePFmtWbNGcxkNBoMaPHiwSkxMVEoplZOTo7n/6+3bt6upU6cqpZQqKipS/fv3V2lpaVbJmJaWphITE9XMmTPV7t27zctv3LihBgwYoG7cuKFyc3PVgAEDVG5urqYyXrp0SV2+fFkppVRGRobq27evysvL01TGWxYsWKCmTZum3nrrLYvns0TGESNGqJiYGKWUUgUFBaqoqKhacv5WNeYMKj4+Hl9fX5o0aYK9vT2DBg1i//79VdaJiooiIiICgJCQEGJjY1FKsX//fgYNGoS9vT1NmjTB19eX+Ph4TWVs3749Xl5eALRq1YrS0lLKyso0lRFg3759NGrUiFatWlk8myUyHj58mDZt2tC2bVsA6tati42NjaYy6nQ6iouLKS8vp6SkBDs7O1xdXa2SsXHjxrRt2xa9vuqfgpiYGPr27YuHhwd16tShb9++1fLJw4NkbN68Oc2nnwnjAAAEXklEQVSaNQPAy8sLT09PcnJyNJUR4McffyQ7O5u+fftaPJslMl68eJHy8nJzPhcXF5ycnKot629RYwpUZmYm3t7e5sdeXl5kZmbeto6Pjw8Atra2uLm5cePGjXva1toZK9uzZw/t27fH3t5eUxkLCwv59NNPmTRpksVzWSrj5cuX0el0vPjii0RERPDpp59qLmNISAhOTk74+/vTv39/xowZg4eHh1UyVse2v1fGyuLj4zEYDDRt2tSS8YAHy2gymViyZAmzZs2yeK7KHiTjlStXcHd3Z9KkSTzzzDMsWbIEo9FYXVF/E1trBxBVJSUl8f7777N27VprR7nNihUrGDVqFC4uLtaOcldGo5FTp07x7bff4uTkxOjRo+nQoQO9e/e2djSz+Ph49Ho90dHR5Ofn88c//pE+ffrQpEkTa0erka5fv87MmTNZsmTJHc9grOnLL78kICCgSvHQmvLyck6ePMnWrVvx8fHhtdde47vvvmPYsGHWjlZzCpSXlxcZGRnmx5mZmeaPxCqv8/PPP+Pt7U15eTk3b96kbt2697SttTMCZGRkMGnSJJYsWVIt7wQfNGNcXBx79uzh/fffJz8/H71ej4ODAyNGjNBMRm9vb3r06IGnpycAAQEBJCQkWLxAPUjG5cuX88QTT2BnZ0e9evXo2rUrZ8+etXiBepCfey8vL44fP15l2549e1o034NmhIrOB+PHj+e1116742CjlvAgGU+fPs2pU6fYuHEjhYWFGAwGnJ2dmTFjhmYyent7065dO/PPX2BgIHFxcRbNd7+09Xbjf3jssce4cuUKaWlplJWVERkZyYABA6qsM2DAAHNvoz179vD444+j0+kYMGAAkZGRlJWVkZaWxpUrV+jYsaOmMubn5zNu3DimT59Ot27dLJ7NEhm//PJLoqKiiIqKYtSoUYwfP97ixelBM/r7+3PhwgXzNZ4TJ07QsmVLTWX08fHh2LFjABQVFREXF4efn59VMt6Nv78/MTEx5OXlkZeXR0xMDP7+/prKWFZWxsSJE3n66acJDQ21eDZLZFy6dCkHDhwgKiqKWbNm8cwzz1i8OD1oxscee4z8/Hzz9btjx45Vy+/MfbFqF43f6MCBAyo4OFgFBgaqlStXKqWUWrZsmdq3b59SSqmSkhI1efJkNXDgQPXss8+q1NRU87YrV65UgYGBKjg4WB04cEBzGT/66CPVqVMn9dRTT5n/ZWVlaSpjZR9++GG19eJ70Ixbt25V4eHhatCgQWrJkiWay1hQUKAmT56swsPDVVhYmPr000+tljEuLk498cQTqlOnTqpnz54qPDzcvO0333yjBg4cqAYOHKi+/fZbzWXcunWrat++fZXfmXPnzmkqY2WbN2+utl58D5oxJiZGDR48WA0ePFjNmjVLlZaWVlvO30Km2xBCCKFJNeYjPiGEEA8XKVBCCCE0SQqUEEIITZICJYQQQpOkQAkhhNAkKVBCCCE0SQqUEEIITfr/i/Xml8HpT94AAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVyU5fr48c+jKKKAisqgZv4Cw0xN+2apiRsGorgnUsdMLLOjJalpWppLLnROWma2kWVanUxcwNTcMCX3XSvTErE0YThfRECRbeb+/cFhvnlUZhhmmGG43q/X83o12z3XEFzecz33c92aUkohhBDCpqo5OgAhhHBFklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKruEmrVq0YOHAg/fr1Izo6mhs3blg91rRp09iyZQsA06dP59y5c3d87sGDBzl27FiZ3yM4OJgrV65YfP9fPfjgg2V6r/fee49PP/20TK8RVZckV3GTWrVqkZCQwMaNG6lRowarVq266fGioiKrxp0/fz4tWrS44+OHDh3i+PHjVo0thDNyc3QAwnl16NCBs2fPcvDgQd599128vb1JSUlh8+bNLFy4kEOHDlFQUMDw4cN54oknUEoxd+5c9u7dS+PGjalRo4ZprBEjRvDKK6/Qtm1bkpKSeOeddzAYDNSvX5/58+ezatUqqlWrxoYNG3j99dfx9/dn1qxZXL58GYDXXnuNhx56iMzMTF5++WX0ej3t27fHkmtgxo0bR1paGvn5+Tz99NNERkaaHluwYAF79+6lYcOGvPPOO/j4+PDHH38wZ84cMjMzqVWrFnPnziUgIMD2P2Dh2pQQf9G+fXullFKFhYXq73//u/rqq6/UgQMHVLt27dQff/yhlFJq1apV6v3331dKKZWfn68GDx6s/vjjD7V161YVFRWlioqKVFpamnrooYfUd999p5RS6qmnnlKnTp1SGRkZqlu3bqaxMjMzlVJKLVmyRC1btswUx6RJk9Thw4eVUkr9+eefKiwsTCml1Ny5c9V7772nlFLq+++/V4GBgSojI+OWz9GzZ0/T/SXvcePGDRUeHq6uXLmilFIqMDBQJSQkKKWUeu+999ScOXOUUko9/fTTKiUlRSml1IkTJ9SIESNuG6MQpZGZq7hJXl4eAwcOBIpnrkOHDuX48eO0bduWZs2aAbB3717Onj3L1q1bAcjJyeH333/n8OHDhIeHU716dXQ6HZ06dbpl/BMnTtChQwfTWPXq1bttHPv27bupRnvt2jWuX7/O4cOHWbp0KQA9evSgbt26Zj/TF198wfbt2wFITU3l999/p379+lSrVo2+ffsCMHDgQF588UWuX7/O8ePHeemll0yvLygoMPseQvw3Sa7iJiU11/9Wu3Zt038rpZgxYwZdu3a96Tm7d++2WRxGo5HVq1fj7u5ernEOHjzIvn37+Oabb/Dw8GDEiBHk5+ff9rmapqGUwtvb+7Y/AyHKQk5oiTILCgri66+/prCwEICUlBRyc3N5+OGH+e677zAYDKSnp3Pw4MFbXtu+fXuOHDnCxYsXAbh69SoAderU4fr16ze9xxdffGG6/csvvwDw8MMP8+233wLFyTwrK6vUWHNycqhbty4eHh4kJydz4sQJ02NGo9E0+/7222956KGH8PT05K677uK7774Div8hOXPmTNl+QEIgyVVYISIighYtWjBkyBD69evHzJkzMRgMhISE0Lx5c/r27cvUqVNp3779La/18fHhjTfeYPz48QwYMICJEycC0LNnT7Zv387AgQM5cuQI06dP56effqJ///707duXr7/+GoAXXniBI0eOEB4ezvbt22nSpEmpsXbr1o2ioiL69OnDokWLboqpdu3anDp1in79+nHgwAFeeOEFAN566y3WrFnDgAEDCA8PZ8eOHbb60YkqRFNKWg4KIYStycxVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhyFUIIO5Dk6iRkubEQrkWSqwP9NaFqmsa1a9c4c+YMc+bMYefOnQ6MTAhRXpJcHUjTNADS0tI4efIkY8eOZfPmzWzfvh03N+mpI0RlJn/BDnD58mV0Oh3Vq1fniy++ICkpCV9fX4YNG8Zdd93FDz/8gL+/v6PDFEKUg/QWqEBKKVJTUxk5ciRfffUVtWvXZvPmzbRr1w5fX1/q16/PW2+9xT333MPQoUMdHa4Qohxk5lqBNE3D09OTRo0a4evrC8DQoUOpVq24OnP9+nXS0tLo06ePI8MUQtiA1FwryIULF4DiZtTVq1e/aaO/ki8Pb7/9NgBt2rSp8PiEELYlM1c7U0pRWFjI+PHjefTRRxk7diyZmZnk5OSYthopERQUxH333Wd6XckJLyFE5SM1VzvT6/XodDpSU1MZO3YsDz74IMnJyfTo0QMfHx9q1qyJj48P+fn5eHt788ADD1C9enVHhy2EKCdJrnailCIrK4vhw4czcuRIhg0bhl6vZ/LkyRw+fJjnnnuOP/74g/z8fDRN48qVKyxZsgSdTufo0IUQNiDJ1c527drFu+++y4gRIxgyZAhXrlxhzJgxhIWFMXr0aNPz8vPzy70ZnxDCeUjN1Q5+/fVXGjRogKenJz169MDDw4N58+ZhMBiIiIjg/fff5+9//zsXL15kzpw5ANSoUcPBUQshbElmrjaWmppKaGgojRo1IjAwkOHDhxMQEEBWVhavvPIKY8eOpW/fvqSlpTFp0iSWLl2Kj4+Po8MWQthY9dmzZ892dBCuIjs7m4YNG1K7dm1TrwB3d3feffddvLy8yMnJYcuWLbi7u9OxY0cGDRpEnTp1HB22EMIOZJ2rjej1eiZNmsThw4d5+umn6dy5My1atKBly5Z8/vnn+Pj40Lx5c9LS0li0aBFZWVk3LcMSQrgWKQvYyNWrV9m0aRN79uxhzJgxtG3bljVr1nDixAnCw8Pp2rUrAMnJyXh7e9OoUSMHRyyEsCcpC9hIrVq1aN68OQaDgdWrV3P33XcTHBzMlStXOHjwIDk5ObRs2RIfHx8pBQhRBcj30nI4fPgwCQkJptt169ald+/ePPbYY3z88cf89ttvDBgwgBYtWvDjjz9y7do1B0YrhKhIshSrHIqKioiJiaFatWr0798fKE6woaGh5OXlsX37dsaPH09YWBi1atXC09PTwRELISqKzFytoJRCKUXnzp1ZsmQJixcvZsOGDabH6tWrR0BAACkpKRiNRnx9ffH29q7wOP/973/L9jFOLjc319EhlIn8PllOkqsVNE1D0zTOnDnDI488wrx583j33XfZuHGjqdlKbm4u+fn5Fv/xGAwGm8b4ww8/8OKLL5KammqzMX/77TcOHTpEZmamzcb8/fff+fHHHykoKLDZmBcuXODHH3/EaDTa7Od6/vx5jh8/TmFhoc3G3LFjBwsXLiQjI8Mm4wGcOHGC+Ph4Tpw4YbOf6ZEjR4iPjweKf/clwVpGTmhZac2aNbz//vuEh4fj7+9Py5Ytef/997lw4QK7d+8mISGBGTNm0Lhx41LHSUlJMXXHMhgMNlmetWfPHhYuXEhmZiZXr16lW7du5R5z9+7dzJo1i5SUFLZt20anTp3KfWLu+++/5/XXX+fo0aPs37+fwMBA6tevX64xd+zYwezZs0lOTubEiRNcunSJFi1alOsKuG3btjFjxgx++uknDh48iF6vJyAggJo1a1o95qFDh5g/fz5RUVG0bNnS6nH+KjExkZiYGPLz8zl8+DBt2rShXr16Vo9nNBrJzc3lhRde4OjRo1SrVo22bduiaRpGo1G6tpmjRJkYDAallFIffvih2rFjx02PnT17Vm3atEmtWLFCXbhwwexYO3fuVA888ICaNGmS6b6ioqJyxbd371712GOPqV9//VUVFBSoUaNGqUOHDpVrzAMHDqjQ0FB18uRJpZRS48aNU3v37i3XmEePHlVhYWHq559/VkopNWvWLDVt2rRyjXnlyhX17LPPqt9++00ppVRcXJwaMmSIWrp0qcrJybFqzIKCAvXSSy+pI0eOKKWU2rJli3rzzTfV22+/bfWYSin12WefqWXLlimllEpLS1N79uxRJ06cUNnZ2VaNd+XKFfXMM8+os2fPKqWUmjZtmtq8ebP63//9X5WXl2d1nEopFRsbqz799FM1ZcoUtXz58nKNVZVIWaCMqlWrxsWLF9m7d+9NHax+//13AgMD6du3L08//TTNmzcvdZzc3Fy+/PJLXnvtNWrUqMHkyZMBqF69erm+dhoMBv7xj39w7733cuPGDe655x5+++03wPp6WcOGDZkzZw4PPPAA//73vzl58iRffvklM2fOZMuWLVaP+9xzz3H//fcDEB0dTVZWVrm+yrq5uZGbm8u///1voHiXh6ZNm5KZmcmuXbusHvfatWv8/vvvAISEhNCzZ08KCwv59ttvrf7sf20r+dJLL7F27Vq+/PJL5syZQ1ZWVpnHc3NzIy8vj/Pnz3Pt2jUOHTpEQkICCxYs4IMPPihXbdfNzY3U1FQGDx7MqVOniImJYdGiRSilMBqNVo/r6qQsUAZKKYqKili8eDHBwcF06dKF5ORkpk+fzvnz57n33nvx9PS06OtSjRo16NSpE23atKFTp04kJiaSmJhIaGhouUoDzZs3p3HjxhiNRmrVqoWmacTExBAUFETDhg2tGtPHx4e77roLgJUrV9K2bVtmz55NZmYmO3fu5JFHHsHDw6NMY/r6+tK8eXNq1qyJwWAgJyeHr7/+mj59+uDh4UFmZmaZx3R3d6egoIDExERyc3P57rvvyM3NpU2bNhw5coRevXqVaTwoToINGjRg/fr1+Pn50bRpU/z8/Lh69Sr79+8nNDTUqq/HtWrVYuHChRw7dow+ffowceJEWrVqxY8//oinp6fZf5z/m7u7O3Xq1CE2NpZvv/2WPn368MYbb+Dt7c3Ro0e55557rP7/36BBA1JTUxk0aBB//vknn376KQEBAfTo0UNKA6WQmWsZaJpGjRo1uH79Ounp6URFRbFu3Truu+8+Jk+ejJ+fX5l+2XQ6HXXq1MHHx4c5c+aQn59vmsH+/PPPJCcnWx1rSYLu1q0bw4YNY9euXTaZaYwdO5Zx48YBMGTIEK5du2bVSbPq1aublqYppfDy8qJu3br4+PiwYcMGFi9eTF5eXpnH7devH926dePgwYPk5eWxcOFCnnjiCTIyMqxeZ9yhQweCgoJISEjg8OHDVK9enf79+5Oens6ZM2esGrNly5ZMnTqVkydPcunSJQCaNWuG0WjkypUrVo0ZFhbG8uXLeeihh0zfCDp37sz169f5888/rRoTihN3SkoKq1evZtWqVTz33HOkpqayatUqq8esCmSdaxmdP3/e9FV49OjRPProozZpF1i/fn3mzJnDW2+9RVhYGEajkZUrV9ogYrjvvvv4/PPPGT16dLl2OVD/tfXM1q1bycjIMG22aC03Nzfc3Nxo3LgxixYtYu/evcTExFCrVq0yj+Xl5cWAAQPo16+f6R+Y+Pj4cvVycHd3p3///miaxscff8z58+epWbMmGRkZ5bqMuVu3bkRHR/Pee+/RpEkTAE6fPs2YMWOsHrNu3bp06tSJLVu2UKNGDfLz87l06VK5TprpdDr8/Pz44IMPmDlzJsHBwRw4cKDMs+sqx2HV3kosJydH5ebm3nSf0Wi0ydjLly9Xjz76qDpz5oxNxisRHR2tLl68aJOx8vPz1erVq1Xfvn1NJ1DKw2g0qvz8fNWrVy/VvXt3lZKSUv4g/yMuLk716dPHJj/P/Px8tX//fjVhwgQ1depU08m48vrpp5/UokWLVExMjE3izMrKUitWrFDDhw9XzzzzjPrll1/KPebly5fVjz/+aLpdcmJX3Jk0bnEiWVlZTJgwgalTp5o2KiwvZYeNDgsLC9m3bx/NmjXD39/fZuOuW7eOtm3bcu+999pszD///JOioiKbzrIMBgOapjl9V7OSMogtrwy0x++Tq5Lk6mSq8nYv8ocrXIkkVyGEsAPn/l4jhBCVlCRXIYTTy8/PJzs729FhlEmVXoqVlPgDmZfLfjWMEOJm9ZvUpVuvrnYb/1JyLLkFLbi/bWi5lhNWpCqdXDMvZ7F05ApHhyFEpffiipF2G/vGjRsUGb3QeX2LPnkXTQL/Ybf3siUpCwghnNrllGX4ea3Hp/YuruY9YvP2nPYiyVUI4bRKZq1e7r9QTSuiYZ1E9MmvOTosi0hyFUI4rZJZa4nKNHuV5CqEcEp/nbWWqEyzV0muQgin9N+z1hKVZfbqsOQaHBx8U2u1gwcP8vzzzwOY2vj9tZ1bv379TK3Z/vran376ieDgYE6fPl2B0Qsh7Ol2s9YSlWX2WqHJtaCgwOKO6H5+fnz00UelPufMmTNER0ezePFi7r//fnJycqQzuhAu4E6z1hKVYfZaIck1OTmZN998k7CwMC5cuGDRa3r06MG5c+c4f/78bR8/f/48L7zwAv/85z954IEHADh69ChhYWG89957XL582VbhCyEqUF5eHkVG79vOWktU04poUDvRtKWPM7Jbcs3NzWXt2rU8+eSTzJgxg4CAADZs2GDqkG42sGrVGD16NB9//PFtHx83bhwzZ86kQ4cOpvt69OjBqlWr8PLyYuzYsTz77LN89913Nt22WQhhXwUFBdSukWL2ebVrnic/P78CIrKO3a7QCgoKomXLlsybN4+AgACLXvPf7eb69evHhx9+yMWLF295bufOnYmLiyMoKOimy+F8fHyIiooiKiqK48eP89prr/HBBx/w7bfflu8DCSEqjEJhpPQSn8K5G/rZbea6ZMkSdDod48ePZ+nSpbfs4VOvXr2bGjFkZWXdsme9m5sbzzzzDJ988skt48+cOROAOXPm3PLYuXPn+Mc//sHUqVP5n//5H+bNm2eLjySEqCBKgUEZzR7OzG7JNSgoiMWLF/PVV1/h5eXFuHHjiIqKMp3x79ixIwkJCUBxZ/cNGzbQsWPHW8YZPHgw+/fvv2XTNk3TWLRoEefPn+fdd98Fijf1GzZsGDNmzMDf35/169czf/582rVrZ6+PKYSwAyNGijCUehjMzGwdze6NW+rXr8/IkSMZOXIkp06dMn2FHzduHLNnz2bAgAEopejatSsDBgy45fU1a9ZkxIgRzJ8//5bH3N3d+fDDD3nqqado2LAhnTp1IiYmxuIyhBDCORkBg5k+/kalwIk3rqjSOxEkfLFRumIJYQMvrhjJwBH9bDJWdnY26Zf/SUPv0v828wpakK997rS70FbploNCCOekAIOZE1ZGJz+hJclVCOF0jEpRaOaEVZEkVyGEKBsFZk9XGXHqkqskVyGE81Eoi8oCzrzhiyRXG9t6+YTNx+zdpL3NxxTCmRWvFjDzHAXVnXjqKslVCOF0jGgUmvnSb0CjRgXFYw1JrkIIp6MonpmWxtzjjibJVQjhdIqXYpU+c3Xu67MkuQohnJBBaaBKvzpfmXnc0SS5CiGcjkIzO3NVTr0QS5KrEMIJKTSMZvtKSXIVQogyKT6hZSZ5mnvcwZy7aFEOr776Kp07d6ZfP9s0kxBCVByD0ihQ1Us9ipz6EgIXTq5Dhgxh2bJljg5DCGGFkrJA6YfMXB3i4Ycfpm7duo4OQwhhhZITWqUdliTX232DvXr1KqNGjSI0NJRRo0aRlZVV/J5KMW/ePEJCQujfvz8///yz6TXr168nNDSU0NBQ1q+/8660f+WyyVUIUXkZ0ChU1Us9iixYinW7b7CxsbF07tyZbdu20blzZ2JjYwFISkriwoULbNu2jblz5zJ79mygOBkvXbqU1atXExcXx9KlS00JuTSSXIUQTqd45lrN7GHO7b7BJiYmMmjQIAAGDRrEjh07brpf0zTat29f3LQ7PZ09e/bQpUsX6tWrR926denSpQs//PCD2feW1QJCCKejlIbBzMy0mqpGcnIyEydONN0XGRlJZGRkqa/LyMjA19cXgEaNGpGRkQGAXq/Hz8/P9Dw/Pz/0ev0t9+t0OvR6vdnPIMlVCOF0LFnnakQjICCAdevWWf0+mqahafY5MeayZYFJkybxxBNPkJKSQrdu3YiLi3N0SEIICxmwYCmWlZe/NmjQgPT0dADS09Px8fEBimekaWlppuelpaWh0+luuV+v16PT6cy+j8sm17fffps9e/bw888/k5SUREREhKNDEkJYSCkNo6pm9rBGcHAw8fHxAMTHx9OrV6+b7ldKceLECby8vPD19SUoKIg9e/aQlZVFVlYWe/bsISgoyOz7SFlACOF0Sk5olcb85bHF32APHTpEZmYm3bp1Y/z48YwZM4YJEyawZs0amjRpwuLFiwHo3r07u3fvJiQkBA8PDxYsWABAvXr1GDduHEOHDgXghRdeoF69embfW5KrEMLpGNGKO2OVwmDBOG+//fZt71+x4tZtuzVNY9asWbd9/tChQ03J1VKSXIUQTseoNApV6enJzczjjubc0QkhqiRlwRVYTr4RgSRXW7PHZoKvJP9o8zEB/hnQ1vaD2mNZi3L2PyNhawrz61zNPe5oklyFEE7H+J/LX0tj7VKsiiLJVQjhdIw2Wi3gSJJchRBOp2Sda2msXedaUSS5CiGcjuz+KoQQdmCkmvmaq5PvRCDJVQjhdCwrCzj3TgSSXIUQTsdowVIsqbk6yPnz52/q83jx4kWio6OJiopyXFBCCIsoMHsRgbPvoeWyydXf35+EhAQADAYD3bp1IyQkxMFRCSEsYVQahcbSa6oGo8xcHW7//v00a9aMpk2bOjoUIYQFLOmKZck2L45UJZLrpk2bbtr9UQjh3IpPaFXu3gLOnfptoKCggJ07dxIWFuboUIQQFjJatPurLMVyqKSkJFq3bk3Dhg0dHYoQwkKWzFxlKZaDbdq0ifDwcEeHIYQoA0XlX+fq0mWB3Nxc9u3bR2hoqKNDEUKUgZHiy19LO2QplgPVrl2bgwcPOjoMIUQZKaWZranKagEhhCgjS3YikJmrEEKUkRHMblAoyVUIIcrIosYtUhYQQoiyUWhmt3Ex1+/V0SS5CiGcjkVXaNljM0wbkuRaCdhll1Yg+twZm4+5pMV9Nh9TVD0K8y0FpeYqhBBlZFSWlAWcu+bq3NEJIaqk4iu0zB+W+PzzzwkPD6dfv35MmjSJ/Px8Ll68SEREBCEhIUyYMIGCggKguBfJhAkTCAkJISIigkuXLln9GSS5CiGcjlKYTazKguSq1+tZuXIla9euZePGjRgMBjZt2sTChQuJiopi+/bteHt7s2bNGgDi4uLw9vZm+/btREVFsXDhQqs/gyRXIYTTsWjmauFYBoOBvLw8ioqKyMvLo1GjRhw4cIDevXsDMHjwYBITEwHYuXMngwcPBqB3797s378fpaxrbig1VyGE07Go5mrBHlo6nY5nnnmGnj174u7uTpcuXWjdujXe3t64uRWnPz8/P/R6PVA8023cuDEAbm5ueHl5kZmZiY+PT5k/gyRXIYTTKV4tYL7lYHJy8k175UVGRhIZGWm6nZWVRWJiIomJiXh5efHSSy/xww8/2Cvsm7hscs3Pz2f48OEUFBRgMBjo3bs30dHRjg5LCGGBkrJAqc9RGgEBAaxbt+6Oz9m3bx933XWXaeYZGhrKsWPHyM7OpqioCDc3N9LS0tDpdEDxTDc1NRU/Pz+KiorIycmhfv36Vn0Gl6251qxZkxUrVrBhwwbi4+P54YcfOHHihKPDEkJYwoITWkYLSqFNmjTh5MmT3LhxA6UU+/fvp0WLFnTs2JGtW7cCsH79eoKDgwEIDg5m/fr1AGzdupVOnTqhWXmxgsvOXDVNo06dOgAUFRVRVFRk9Q9JCFGxjEozu7urUTM/N2zXrh29e/dm8ODBuLm50apVKyIjI+nRowcTJ05k8eLFtGrVioiICACGDh3KlClTCAkJoW7durzzzjtWfwaXTa5QfJZwyJAh/PHHH/ztb3+jXbt2jg5JCGEBhfkrsCy9Qis6OvqWkmCzZs1My6/+yt3dnSVLllgcZ2lctiwAUL16dRISEti9ezenTp3i119/dXRIQggLWLIUy5J1ro7k0sm1hLe3Nx07dqyws4RCiPJR/ykLlH5IcnWIK1eukJ2dDUBeXh779u3D39/fwVEJISyiihNsqYc0bnGM9PR0pk2bhsFgQClFWFgYPXv2dHRYQggLWLoUy5m5bHK97777iI+Pd3QYQggrKFV8mHuOM7tjcn3wwQdNS5dKrq3VNA2lFJqmcezYsYqJUAhR5Sg0s5e3WtoVy1HumFyPHz9ekXEIIYSJpZe/OjOLTmgdOXKEtWvXAsUnii5evGjXoIQQVVtJWaDUw9FBmmE2uS5dupRly5YRGxsLQGFhIVOmTLF7YEKIqs3cagEq+8x1+/btfPjhh3h4eADFjQ2uX79u98CEEFWXK6xzNbtaoEaNGmiaZjq5lZuba/egxH+xU08Ee2wm+GryKZuPGRPwgM3HFM7NotUCFROK1cwm1z59+jBz5kyys7NZvXo1a9euZdiwYRURmxCiyrLg8lYnLwuYTa7PPvsse/fupU6dOqSkpBAdHU2XLl0qIjYhRBVVsodWaZx9tYBFFxEEBgaSl5eHpmkEBgbaOyYhRBWnLJi5OvsVWmZPaMXFxREREcH27dvZunUrkZGRt23VJYQQNqMsPJyY2ZnrsmXLWL9+vWmrg8zMTJ544gmGDh1q9+CEEFWX2ZlrZW/cUr9+fVNHf4A6depYvaeMEEJYQikNo5mlVsrSvbUd5I7Jdfny5QDcfffdDBs2jF69eqFpGomJibRs2bLCAhRCVFGuulqg5EKBu+++m7vvvtt0f69evewfVTmlpqbyyiuvkJGRgaZpDBs2jJEjRzo6LCGEpVy5K9aLL75YkXHYVPXq1Zk2bRqtW7fm2rVrPP7443Tp0oUWLVo4OjQhhKWcPHmaY7bmeuXKFT755BPOnTtHfn6+6f6VK1faNbDy8PX1xdfXFwBPT0/8/f3R6/WSXIWoJJTSUGZrrs5dFjC7FGvy5Mn4+/tz6dIlXnzxRZo2bUrbtm0rIjabuHTpEr/88ovs/CpEZWLJNi9OXnM1m1yvXr1KREQEbm5uPPLII8TExHDgwIGKiK3crl0WQkcAABE5SURBVF+/TnR0NK+99hqenp6ODkcIURauvs7Vza34Kb6+vuzatQtfX1+ysrLsHlh5FRYWEh0dTf/+/QkNDXV0OEKIslBYsBrAuWeuZpPr2LFjycnJYerUqcydO5fr16/z6quvVkRsVlNKMX36dPz9/Rk1apSjwxFCWMPczLSyz1xLdkz18vLiiy++sHtAtnD06FESEhIIDAxk4MCBAEyaNInu3bs7ODIhhGUsaIZdWZPr3LlzTT1cb2fGjBl2CcgWOnTowNmzZx0dhhDCSpb0c620ybVNmzYVGYcQQvwfBZhbamXhaoHs7GxmzJjBr7/+iqZpLFiwgHvuuYeJEyfy559/0rRpUxYvXkzdunVRSjF//nx2795NrVq1ePPNN2ndurVVH+GOyXXw4MFWDSiEEOWlAZqNZq7z58+na9euLFmyhIKCAvLy8vjoo4/o3LkzY8aMITY2ltjYWKZMmUJSUhIXLlxg27ZtnDx5ktmzZxMXF2fVZ7Bo91chhKhQNmo5mJOTw+HDh01d/GrWrIm3tzeJiYkMGjQIgEGDBrFjxw4A0/2aptG+fXuys7NJT0+36iNY1CxbCCEqliUntDSSk5OZOHGi6a7IyEgiIyNNty9duoSPjw+vvvoqZ86coXXr1kyfPp2MjAzTVZyNGjUiIyMDAL1ej5+fn+n1fn5+6PV603PLQpKrsCl7bCY45tfzNh8zNtDf5mMKG1KAuZaCCgICAli3bt0dn1JUVMTp06d5/fXXadeuHfPmzSM2Nvam5/x1A1ZbcsnVAkKISs6Sr/0WlAX8/Pzw8/MzXf4eFhZGbGwsDRo0ID09HV9fX9LT0/Hx8QFAp9ORlpZmen1aWho6nc6qjyCrBYQQzskG/VwbNWqEn58f58+fx9/fn/379xMQEEBAQADx8fGMGTOG+Ph4UyvV4OBgvvzyS8LDwzl58iReXl5WlQRAVgsIIZyRAs1MWcDsaoL/eP3115k8eTKFhYU0a9aMmJgYjEYjEyZMYM2aNTRp0oTFixcD0L17d3bv3k1ISAgeHh4sWLDA6o/gki0HhRCiRKtWrW5bl12xYsUt92maxqxZs2zyvi7fclAIUfmUrHM1dzgzl245KISopJRm2eHEXLbloBCiErNkKVZl3f21RGVsOQjF9ZS4uDiUUkRERBAVFeXokIQQZWDua79zz1tdtOXgr7/+SlxcHHFxcdSoUYPRo0fTs2dPmjdv7ujQhBCWsNE6V0cym1zvNEuNiYmxeTC2kpyczAMPPICHhwcADz/8MNu2beO5555zcGRCCIu5enLt0aOH6b/z8/PZsWOH1YtqK0pgYCCLFy8mMzOTWrVqkZSUJBdFCFGZKNDMtBw0tw7W0cwm1969e990u1+/fvztb3+zW0C2EBAQwOjRo3n22Wfx8PDgvvvuo1o1aQAmRKVRCTYgNKfMjVsuXLhg6iDjzCIiIoiIiADg7bfftvr6YCFExbNlP1dHMZtcH3zwwZsauDRq1IjJkyfbNShbyMjIoEGDBly+fJlt27axevVqR4ckhLCUJZe/VvaywPHjxysiDpsbP348V69exc3NjVmzZuHt7e3okIQQZeHqM9eRI0fecg3u7e5zNv/6178cHYIQwlquXHPNz8/nxo0bZGZmkpWVhfrPVozXrl1Dr9dXWIBCiKrHkpqrs/cWuGNyXbVqFStWrCA9PZ0hQ4aYkqunpydPPfVUhQUohKiCXPkigpEjRzJy5Ei++OILRowYUZExCSFEpZ+5ml38Wa1aNbKzs023s7Ky+Oqrr+walBCiirPR7q+OZPaE1urVqxk+fLjpdt26dYmLi7vpPmFnysl/i+zMHpsJPn32os3HXNmymc3HrNIq+a+92eRqNBpRSpnWuhoMBgoLC+0emBCi6tKqwjrXoKAgJkyYwBNPPAEUn+jq2rWr3QMTQlRtLn+F1pQpU/jmm2/4+uuvAXj00UcZNmyY3QMTQlRhlaCmao5FJ7SefPJJlixZwpIlS2jRogVz586tiNiEEFVUSVnA3OHMLGrccvr0aTZu3MiWLVto2rQpoaGh9o5LCFHVuWpZICUlhU2bNrFx40bq169P3759UUpVmt0IhBCVmCtfRNCnTx86dOjAxx9/bNoe5fPPP6+ouIQQVVxl30PrjjXXpUuX0qhRI55++mlmzJjB/v37TZfAVgZJSUn07t2bkJAQYmNjHR2OEKIMXLrm+thjj/HYY4+Rm5tLYmIiK1as4MqVK8yaNYuQkBCCgoIqMs4yMRgMvPHGGyxfvhydTsfQoUMJDg6mRYsWjg5NCGEJFygLmF0tULt2bfr3789HH33E7t27uf/++/nkk08qIjarnTp1iubNm9OsWTNq1qxJeHg4iYmJjg5LCFEWNrz81WAwMGjQIJ5//nkALl68SEREBCEhIUyYMIGCggIACgoKmDBhAiEhIURERHDp0iWrwy/TxlJ169YlMjLS6Xu56vV6/Pz8TLd1Op20SRSiktGUmaMMY61cuZKAgADT7YULFxIVFcX27dvx9vZmzZo1AMTFxeHt7c327duJiopi4cKFVscvu/YJIZyPucRahplrWloau3btYujQocVDK8WBAwdMm68OHjzY9M12586dDB48GCjenLU855pcMrnqdDrS0tJMt/V6vWxQKERlY6OywIIFC5gyZYppB+jMzEy8vb1xcys+5eTn52f6ZqvX62ncuDEAbm5ueHl5kZmZaVX4Lplc27Zty4ULF7h48SIFBQVs2rSJ4OBgR4clhLCUhS0Hk5OTGTJkiOn45ptvbhrm+++/x8fHhzZt2lRs/FixtXZl4ObmxsyZMxk9ejQGg4HHH3+ce++919FhCSEsZFFXLAUBAQGsW7fujs85duwYO3fuJCkpifz8fK5du8b8+fPJzs6mqKgINzc30tLSTN9sdTodqamp+Pn5UVRURE5ODvXr17fqM7hkcgXo3r073bt3d3QYQggr2WIngpdffpmXX34ZgIMHD/LZZ5+xaNEioqOj2bp1K+Hh4axfv970zTY4OJj169fz4IMPsnXrVjp16mRqt1pWLlkWEEJUcnbeiWDKlCksX76ckJAQrl69SkREBABDhw7l6tWrhISEsHz5ciZPnmz1e7jszFUIUXnZY/fXjh070rFjRwCaNWtmWn71V+7u7ixZsqRsA9+BJFchhPNRgLnLW538Ci1JrkIIp+TyOxEI4YpW3ne3zcfs87N16yHN+a51PbuM69RcoLeAJFchhNMpXopVevYsa821oklyFUI4JVuf0KpoklyFEM5HygJCCGF79liKVdEkuQohnI+Fl786M0muQgjnI2UBIYSwPUvKAs6eXF22t0B2djbR0dGEhYXRp08fjh8/7uiQhBAWU6AsOJyYy85c58+fT9euXVmyZAkFBQXk5eU5OiQhhKVcoObqkjPXnJwcDh8+bNrWoWbNmnh7ezs4KiGExVxga22XTK6XLl3Cx8eHV199lUGDBjF9+nRyc3MdHZYQwlJ2bjlYEVwyuRYVFXH69GmefPJJ4uPj8fDwIDY21tFhCSEsVHL5a6mHk9dcXTK5+vn54efnR7t27QAICwvj9OnTDo5KCFEWZrfWdu7c6prJtVGjRvj5+XH+/HkA9u/ff9Oe5UIIJ+cCZQGXXS3w+uuvM3nyZAoLC2nWrBkxMTGODkkIYSFXWOfqssm1VatWpe4KKYRwYkpZ0HLQubOryyZXIUQlJzNXIYSwLUtOWDn7CS1JrkII56MAM2UBs487mCRXIYTzcYHLXyW5CiGckAWNWSS5CqelabYf0x5ncO0Rpx3Ya5fWAaczbD7mhvsb2HxMW5KaqxBC2IMFu79Ky0EhhLCGua5X0hVLCCHKprgsoMwe5qSmpjJixAj69u1LeHg4K1asAODq1auMGjWK0NBQRo0aRVZWFgBKKebNm0dISAj9+/fn559/tvozSHIVQjgnG/QVqF69OtOmTWPz5s188803/Otf/+LcuXPExsbSuXNntm3bRufOnU1d85KSkrhw4QLbtm1j7ty5zJ492+rwJbkKIZyPMtNu0Gj+8lgAX19fWrduDYCnpyf+/v7o9XoSExMZNGgQAIMGDWLHjh0Apvs1TaN9+/ZkZ2eTnp5u1UeQmqsQwvkoLFiKpUhOTmbixImmuyIjI4mMjLzt0y9dusQvv/xCu3btyMjIwNfXFyjuopeRUbwiQ6/X4+fnZ3qNn58fer3e9NyycNnk+vnnnxMXF4emaQQGBhITE4O7u7ujwxJCWMLCiwgCAgIsatB0/fp1oqOjee211/D09Lx5HE1Ds8NyP5csC+j1elauXMnatWvZuHEjBoOBTZs2OTosIYTFLNn91bKRCgsLiY6Opn///oSGhgLQoEED09f99PR0fHx8ANDpdKSlpZlem5aWhk6ns+oTuGRyBTAYDOTl5VFUVEReXp5V03ohhGNYtM2LBTVXpRTTp0/H39+fUaNGme4PDg4mPj4egPj4eHr16nXT/UopTpw4gZeXl9W5wyXLAjqdjmeeeYaePXvi7u5Oly5dCAoKcnRYQgiLWXL5q/nkevToURISEggMDGTgwIEATJo0iTFjxjBhwgTWrFlDkyZNWLx4MQDdu3dn9+7dhISE4OHhwYIFC6z+BC6ZXLOyskhMTCQxMREvLy9eeuklEhISTD9cIYSTU5i/SMCCskCHDh04e/bsbR8rWfP6V5qmMWvWLPMDW8AlywL79u3jrrvuwsfHhxo1ahAaGsrx48cdHZYQwlJKoRmNpR4YnfsSLZdMrk2aNOHkyZPcuHEDpZRsUChEZVOyFMsGJ7QcxSXLAu3ataN3794MHjwYNzc3WrVqdce1b0IIJ2SjsoAjuWRyBYiOjiY6OtrRYQghrKBhvneAbFAohBBlpTBfU1XOXXOV5CqEcEKyE4EQQtieJTVX5564SnIVQjghZb6mKjVXIYQoK6XAYGZq6uTrXCW5VmVO/i+/iWaH5dhGg+3HtBN7bCY4/Mwlm47nc73QpuOZ1rKae44Tk+QqhHBOckJLCCFsTMoCQghhB0qZX8cq61yFEMIKUhYQQggbUwrMNcOWE1pCCFFGSpmvqTp5zdUlWw6WMBgMDBo0iOeff97RoQghysKiloPOPXN16eS6cuVK6eMqRGVUMnMt7ZDk6hhpaWns2rWLoUOHOjoUIUSZWbL7q3MnV5etuS5YsIApU6Zw/fp1R4cihCgrF1jn6pIz1++//x4fHx/atGnj6FCEENZQoJTRzCEz1wp37Ngxdu7cSVJSEvn5+Vy7do3JkyezcOFCR4cmhLCEJUuxzD3uYC6ZXF9++WVefvllAA4ePMhnn30miVWIykQpMJhpruPkZQGXTK5CiEpOumI5v44dO9KxY0dHhyGEKAOlFMrMzFRJbwEhhLCC9BYQQggbs6Tmau5xB3PJpVhCiEpOKZSx9MPSmmtSUhK9e/cmJCSE2NhYOwf+fyS5CiGcT0k/11IP88nVYDDwxhtvsGzZMjZt2sTGjRs5d+5cBXwAKQsIIZyMpmnc2/H/4V7HvdTnefrURtO0Up9z6tQpmjdvTrNmzQAIDw8nMTGRFi1a2CzeO6nSybV527tY8vMbjg5DiIpn43JlvpZvs7E8PT0JHtAd1d/8zHTz5s1MmDDBdDsyMpLIyEjTbb1ej5+fn+m2Tqfj1KlTNou1NFU6ubZv397RIQgh/oumadSuXdui50ZERBAREWHniKwjNVchhMvS6XSkpaWZbuv1enQ6XYW8tyRXIYTLatu2LRcuXODixYsUFBSwadMmgoODK+S9q3RZQAjh2tzc3Jg5cyajR4/GYDDw+OOPc++991bIe2vK2ft2CSFEJSRlASGEsANJrkIIYQeSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIezg/wOdcPs8eDN9egAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVxUVf/A8c+s7Dui4L6DIIqC4C5qrqTmlktqmo+Va6aW5c+ex3LLLMwWTTOX8iklNTVNLfdccckVN1SQHdkZhlnv7w9yEsGlHpQRz/v18oVz7rnnfucyzPcu554jkyRJQhAEQRCsjLy8AxAEQRCE0ogEJQiCIFglkaAEQRAEqyQSlCAIgmCVRIISBEEQrJJIUIIgCIJVEgnqCfnss8+YOnVqeYfxRCUkJNCwYUOMRuP/3FbHjh05fPhwqcumT59OZGTk/7yNZ0lkZCShoaG0bt36iW/75MmTdOnShaCgIH777bd/3M7o0aPZtGlTGUb25CUlJREUFITJZCrvUKySSFBlaOvWrfTt25egoCDatGnD6NGjOXHiRHmHJTwhDRs2JC4urrzDeKikpCRWrlzJ9u3bOXToUKl18vPzmTNnDh06dCAoKIjOnTszZ84cMjMz/+ftL168mKFDh3L69Gk6d+78j9v5+uuveeGFF/7neO41ffp0GjZsWCJ5zp07l4YNG7Jx48ZHaudBB1V3+Pj4cPr0aRQKxT+OtyITCaqMrFy5krlz5/Laa69x6NAh9u7dy5AhQ9i9e3d5h/aPlcWZj/AXa9mfSUlJuLq64uHhUepyvV7PiBEjuHbtGl9//TUnT55k3bp1uLq6cu7cuTLZfv369f/ndh6nWrVqsXnzZstro9HIL7/8Qo0aNcpsG2X5eZAkCbPZXGbtWQuRoMpAXl4eixcv5r333qNLly7Y29ujUqno2LEjb7/9dqnrTJw4kdatW9O8eXOGDh3K1atXLcv2799Pjx49CAoKom3btqxYsQKAzMxMXn31VYKDg2nRogVDhgyxfChTU1OZMGECYWFhdOzYkTVr1ljaO3v2LH379qVZs2a0atWKefPmlRrTsWPHaNeuHcuWLaN169a888475OTk8OqrrxIWFkZISAivvvoqKSkplnWGDRvGokWLGDRoEEFBQYwaNeq+R9k7d+6kY8eOXLlyBbPZzLJly+jcuTOhoaFMmjSJ7OxsS92ffvqJ8PBwQkNDWbJkyUN/B1lZWYwcOZKgoCBeeuklEhMTAZg1axbz588vVve1115j1apVpbYTGxvLyJEjadGiBV27dmX79u2WZdOnT2fWrFmMGTOGoKAgBgwYQHx8PABDhw4FoHfv3gQFBbF9+/ZS96der2fOnDm0adOGNm3aMGfOHPR6fbH9v3TpUkJDQ+nYsSNbtmwBin6HrVq1KnYpaNeuXfTq1avU95GXl8dbb71FWFgY4eHhfPnll5jNZg4fPsyoUaNIS0sjKCiI6dOnl1h38+bNJCcn8/nnn1OvXj3kcjkeHh6MGzeO9u3bW/bTsGHDCA4OpmfPnsUOxB60nzp37sytW7d47bXXCAoKQq/XlzjTuPtyuE6nY+rUqYSGhhIcHEy/fv24ffs2UPTZi4qKAsBsNvPll18SHh5Oy5Yteeutt8jLywP+utS8adMmOnTo8EifqY4dO3Ly5ElycnIAOHjwIA0bNsTT09NSJz4+nuHDhxMaGkpoaChTpkwhNzcXgGnTppGUlGR5n8uXL7fEERUVRYcOHRgxYkSxy+DZ2dm0a9eOPXv2AKDRaHjuuef46aefSo1x2LBhREZGMmjQIJo0acKtW7c4deoU/fr1o3nz5vTr149Tp04BcPToUZ5//nnLuiNHjqRfv36W10OGDPmfLrc+NpLwP9u/f7/k5+cnGQyG+9ZZvHixNGXKFMvrqKgoKS8vT9LpdNLs2bOlXr16WZa1bt1aio6OliRJkrKzs6Xz589LkiRJCxculGbOnCnp9XpJr9dL0dHRktlslkwmk/TCCy9In332maTT6aT4+HipY8eO0oEDByRJkqSBAwdKmzZtkiRJkvLz86XTp0+XGuPRo0clPz8/acGCBZJOp5O0Wq2UmZkp7dixQyooKJDy8vKkCRMmSK+//rplnZdeeknq1KmTdP36dUmr1UovvfSS9NFHH0mSJEm3bt2SGjRoIBkMBunHH3+UOnfuLN28eVOSJElatWqVNGDAACk5OVnS6XTSzJkzpcmTJ0uSJElXr16VmjZtKh0/flzS6XTS3LlzJT8/P+nQoUOlxv32228Xq//BBx9IgwYNkiRJks6cOSO1bt1aMplMkiRJUkZGhhQYGCilp6eXaEej0Ujt2rWTfvzxR8lgMEgXLlyQWrRoIV29etWynRYtWkhnzpyRDAaD9Oabb0pvvPGGZf0GDRpY3t/99ueiRYukAQMGSLdv35YyMjKkF198UYqMjCxWf+7cuZJOp5OOHTsmNWnSRIqNjZUkSZK6d+8u7du3z9L+2LFjpRUrVpS6T6ZNmya99tprUl5ennTr1i2pS5cu0vr16y3badu2banrSZIkvfHGG9Jbb7113+V6vV7q3LmztGTJEkmn00mHDx+WmjZtaonzYfspPDy82O/y3td3/618//330quvvioVFBRIRqNROnfunJSXlydJUtFn7857ioqKkjp37izFx8dL+fn50rhx46SpU6dKkvTX53DGjBmSVquVYmJiJH9/f+natWulvr+3335b+uSTT6T/+7//k9auXStJkiRNnDhR2rp1qzRo0CBpw4YNkiRJ0s2bN6Xff/9d0ul0UkZGhjRkyBBp9uzZ931fd+KYNm2apNFoJK1WW+xvRJIk6eDBg1KrVq2k27dvSzNmzJAmTJhw39/DSy+9JLVv3166cuWKZDAYpPT0dCk4OFjatGmTZDAYpK1bt0rBwcFSZmampNVqpYCAACkjI0PS6/VSy5YtpTZt2kh5eXmSVquVGjduLGVmZt53W+VFnEGVgezsbNzc3FAqlY+8Tv/+/XF0dEStVjNhwgQuXbpkOeJTKpVcu3aN/Px8XFxc8Pf3t5Snp6eTlJSESqUiODgYmUzGuXPnyMzMZPz48ajVaqpXr87AgQMtR/9KpZL4+HgyMzNxcHCgadOm941LLpczceJE1Go1tra2uLm50bVrV+zs7HB0dOT1118nOjq62Dp9+/aldu3a2Nra0q1bN2JiYootX716NStWrODbb7+lZs2aAPzwww9MnjyZKlWqoFarGT9+PDt37sRoNLJjxw46dOhASEgIarWaSZMmIZc/+KN6d/3Jkyfzxx9/kJycTGBgIE5OThw5cgSA7du306JFi2JHwnfs27ePqlWr0q9fP5RKJY0aNaJr167s2LHDUqdz584EBgaiVCrp1atXiff6sP25detWxo0bh4eHB+7u7owbN85ylnTHpEmTUKvVtGjRgvbt2/PLL78A0KdPH0vd7Oxsfv/9dyIiIkps02QysX37dqZMmYKjoyPVqlVj5MiRJbZzP9nZ2VSqVOm+y8+cOUNBQQFjxoxBrVbTsmVLwsPD2bZt2z/eT/ejVCrJzs4mLi4OhUJBQEAAjo6OJept3bqVl19+merVq+Pg4MCbb77J9u3bi11GGz9+PLa2tvj6+uLr68ulS5ceuO3evXuzefNmcnNziY6OLnG/rGbNmrRu3Rq1Wo27uzsjR44s8bdRmgkTJmBvb4+trW2JZW3atKFbt268/PLL7N+/n1mzZj2wrRdeeIH69eujVCr5/fffqVmzJn369EGpVBIREUGdOnXYu3cvtra2NG7cmBMnTnDhwgV8fX1p1qwZp06d4o8//qBmzZq4ubk9NPYn7dG/UYX7cnV1JSsrC6PR+EhJymQyERkZyY4dO8jMzLR8+WZlZeHk5MTixYtZsmQJH3/8MQ0bNmTKlCkEBQXxyiuv8PnnnzNq1CgAXnzxRcaMGUNiYiJpaWkEBwcX28ad13PmzGHx4sV0796datWqMX78eMLDw0uNzc3NDRsbG8trrVbLvHnzOHjwoOVyh0ajwWQyWW7s3v1lZmdnR0FBQbE2V6xYwbhx46hSpYqlLCkpiXHjxhVLPHK5nIyMDNLS0orVtbe3x9XV9YH79O76Dg4OuLi4kJaWhre3Ny+88AJbtmyhdevWbNmyheHDh5faRmJiImfPni2xH+++jHZ3YrO1tS3xXu917/5MS0vDx8fH8trHx4e0tDTLa2dnZ+zt7Utd3rt3b7p3705BQQG//PILwcHBeHl5ldhmVlYWBoOhxHZSU1MfGOsdrq6upKen33f5nd/P3b+7e9v/u/vpfnr37k1KSgpvvvkmubm59OrVi8mTJ6NSqUrEVLVqVcvrqlWrYjQaycjIKDWm0j6n9woODiYzM5MlS5bQoUOHEgnl9u3bzJkzhxMnTqDRaJAkCWdn54e+p7s/q6UZOHAg3333Ha+99tpDk4a3t7fl//d+tqD47yUkJITjx49TuXJlQkJCcHZ2Jjo62nIwZI1EgioDQUFBqNVqfvvtN7p16/bQ+lu3bmX37t2sXLmSatWqkZeXR0hICNKfA8sHBgayZMkSDAYDa9eu5Y033mD//v04Ojoyffp0pk+fzpUrVxgxYgSNGzfG29ubatWqsWvXrlK3V6tWLT755BPMZjO7du1i4sSJHDt2rNgX4R0ymazY62+++YYbN26wfv16KlWqRExMDH369LHE+ii++eYbRo8ejaenJ127dgWK/kjnzp1L8+bNS9T38vIiNjbW8lqr1Ra7P1Wau++LaTQacnJyLF/evXr1IiIigkuXLhEbG3vfnmPe3t6EhISwcuXKR35vD3Pv/vTy8irWSSA5OblYksnNzaWgoMDyu0lOTrbUrVy5MkFBQezatYvNmzczePDgUrfp5uaGSqUiKSmJevXqWdqpXLnyI8XcqlUrFi1aVCyOe99DSkoKZrPZkqSSk5OpVavWI7V/Lzs7O7RareX13clRpVIxfvx4xo8fT0JCAmPGjKF27doMGDCgREx37jtC0QGQUqnEw8Oj2Gfj7+rVqxdffPFFsXu6d3zyySfIZDK2bt2Kq6srv/32G++///5D27z3M3E3k8nEe++9R58+ffjvf/9L3759LVcdHtbWnc/W3ZKTk2nbti0ALVq0YP78+fj4+PCvf/0LFxcXZs6ciUqlstxDtTbiEl8ZcHJyYuLEibz//vv89ttvaLVaDAYD+/fvZ8GCBSXqazQa1Go1bm5uaLVaPvnkE8syvV7Pli1byMvLQ6VS4eDgYPkS2Lt3L3FxcUiShJOTEwqFAplMRmBgIA4ODixbtozCwkJMJhNXrlzh7NmzQNFN7ztnaneO8B52yezuWG1sbHB2diY7O5vPP//8b++fevXq8fXXX/P+++9bbqYPHjyYRYsWWb5UMjMzLTdpu3btyr59+zhx4gR6vZ7Fixc/tIfS/v37LfU//fRTmjRpYjm6rFKlCo0bN2batGl06dKl1EsrUHSZ8ObNm/z0008YDAYMBgNnz54tliwfxNPTk1u3bj2wTs+ePVmyZAmZmZlkZmbyxRdfFLt5DUWdBPR6PSdOnGDfvn3FDnp69+7NihUruHLlCl26dCl1GwqFgm7duhEZGUl+fj6JiYmsXLnyvh0q7tW7d2+qVKnChAkTiI2NxWw2k5WVxdKlS9m/fz+BgYHY2try9ddfYzAYOHbsGHv27KFHjx6P1P69fH192b59OwaDgXPnzrFz507LsqNHj3L58mVMJhOOjo4olcpSP7sRERGsXr2aW7duodFoiIyMpHv37n/rsntphg0bxsqVKwkJCSmxTKPRYG9vj5OTE6mpqXz99dfFlj/K5+FeS5cuRSaTMXfuXF555RXefvvtR35Gqn379ty8eZOtW7diNBrZvn07165do0OHDkDRgfSNGzc4e/YsgYGB1K9f33LVoLT3Zw1Egiojo0aNYvr06Xz55Ze0bNmSDh06sHbt2lKP1vv06YOPjw9t27alZ8+eJe4Jbd68mY4dO9KsWTN++OEHPvroIwDi4uIsPdVefPFFBg8eTFhYGAqFgqVLl3Lp0iU6depEWFgY//d//0d+fj5Q1AOpZ8+eBAUFMWfOHCIjI+/7JX2vESNGoNPpCAsL48UXX7Qcjf1dvr6+LF26lJkzZ7J//36GDx9Ox44dGTVqFEFBQQwcONCSUOvXr897773H1KlTadu2Lc7Ozg+9LBIREcEXX3xBaGgoFy5csOyzO/r06cOVK1fo3bv3fdtwdHRkxYoVbN++nbZt29KmTRsWLlxo6WX3MOPHj2f69OkEBwcX6/13t7FjxxIQEECvXr3o1asX/v7+jB071rLc09MTZ2dn2rZty9SpU/nPf/5D3bp1Lcufe+45EhMTee6557Czs7tvLDNnzsTOzo7OnTszZMgQIiIiivXaehC1Ws2qVauoU6cOo0aNonnz5gwYMICsrCwCAwNRq9UsXbqUAwcOEBYWxqxZs1iwYEGxOP+ON954g/j4eFq0aMFnn31WLGHfvn2biRMn0rx5c3r06EGLFi1K/R3269ePXr168dJLL9GpUyfUajUzZ878R/HczdXVlZYtW5Z61jN+/HguXrxIcHAwY8aMKXHAMGbMGJYsWUJwcLClJ+6DnD9/nlWrVvHhhx+iUCj417/+BcCyZcseKVY3NzeWLl3KypUrCQ0N5euvv2bp0qW4u7sDRZfK/f39qVevHmq1GihKWj4+Pvd95KC8yaS/c61GEJ5S0dHRTJs2jb179z7wEkt5OnbsGNOmTePAgQMPrNe5c2fef/99WrVq9YQiE4TyIc6ghArPYDCwZs0a+vfvb7XJ6VHt3LkTmUxGWFhYeYciCI+d6CQhVGixsbH069cPX1/f+z6g/LQYNmwY165dY8GCBY98D1EQnmbiEp8gCIJglcRhmCAIgmCVKtwlvlOnTj2wd5M1MBgMJR40tDYixrIhYiwbIsayYa0x6nS6Uke4qXAJSqFQ4OfnV95hPFBcXNwDH76zBiLGsiFiLBsixrJhrTHebygscYlPEARBsEoiQQmCIAhWSSQoQRAEwSqJBCUIgiBYJZGgBEEQBKskEpQgCIJglUSCEgRBEKySSFCCIAiCVRIJShAEQbBKFW6w2AsXLuLv36i8wxAEQajwCg0mbFWK/7mdmJiYUkcAqnBDHcnlMmpN31beYQiCIFR4N+f3fKztV7gEJQiCUFEYc9Mx5qahcHBD5eZz33qSJGHWZCOZDMjUtijsnIstN2nzMGYmglyOyr0qchuHovWMBgxZiUgGHSrPmsjVtkX187OQTIYS21E4eyKTPbk7QyJBCYIgWBlDVjKZvy6l8MZJS5napyHunV/Dxru+pcxcmE/mnq/RxkZjLsgpKpTJcWk5ENe2L2HMyyBr3zcUXDoEZuOfa8lw8O+A2qs22YfXIek0RaVqO5ya9cSYmUTBlcOlxqV09cZ7RCRyW8fH8r5LbO+JbEUQBEF4JGa9ltQf3sVVZeb/Zs8mNDSUixcv8vHHH3Prh3fxeeULlM5eAOSf303B+d28/PLLNGvWDAcHB9avX8+ufdtwCulD6n/fxtaYzxsTx9OlSxeMRiM///wzy5YtQ3NhL7169WLw4ME4ODiwbt061q5dC8DIkSNp27ZtsbgyMzOZOnUqBbHROPqHP5F9YfUJatWqVURFRSGTyWjQoAHz5s3DxsamvMMSBEF4LPJO/4IpN50thw7RvHlz1qxZw0svvUTv3r1p0KABOUd/xKPLWABMmixUKhVz5swhPT2dwMBALly4wM7d+8g9vgnyb/PrwYMEBQWxevVqsrOzCQgIAKBv375s2LCBLVu2kJKSwnfffYe7uzufffYZXl5e1KtXDwB7e3uaN2/OH3/8AfBEL/FZdTfz1NRU1qxZw4YNG/j5558xmUxs2yY6QAiCUHFpY48TGhpKq1atWLNmDWPGjOGjjz6iZs2a9O3bF+2145a6Kvfq6PV6fHx8mDVrVrF2Ci7/Tnh4OGFhYbz33nu8//77vPfee0ycOBGAAQMGADBp0iReffVVtFotkydPBuDDDz+kXbt2tGvXju+++w6AL7/8EplSjW2tkhMLPi5WnaAATCYThYWFGI1GCgsL8fLyKu+QBEEQHhtjTioNGzYE4Pr16wDcuHEDgIYNG2LKy7B0YHAI6Ijn89NKtCEZdBgzEwkPL7oUN2XKFBISEsjJyWHChAkA5ObmAtC8eXP8/f2xs7Ojdu3a2NjYYFOtEbZ1mqNUKpk8ebLlZMEhoBMKe5fHuwPuYtUJqnLlyowaNYrw8HDatGmDo6Mjbdq0Ke+wBEEQHh9JQi4v/au5qFwidf2/SV3/b/JObsW+YWtkKtt7G7mrPhw+fJhatWoRExNDZGQkXl5ezJ8/n9jYWH788UfOnTuHRqOxrKPyqI4u4SIDBgygRo0afPbZZ+h0epxD+jyud10qq74HlZOTw+7du9m9ezdOTk5MmjSJzZs307t37/IOTRAE4bFQOntx9epVAMv07DVq1ACwlDf2UqPX6zm7exlZu5fdt6079Y8ePUpcQiKnT5+madOmeHh4WB6ObdCgAQUFBfz+++9cvHgRrVaLKukykl7LtGnT0Gg0LFmyBPsGLVG5Vy2xjbi4uDJ9/3ez6gR1+PBhqlWrhru7OwBdunTh9OnTIkEJglBh2dVpzqGD33Lq1CmGDRtGXl4ew4YNIzk5mQ0bNgCwa9cuEhISCAwMBOCbb76hdu3aAAwePJjGjRvz5ptvsn79eubPn8+IESPQaDRERERw6dIlrl69StOmTRk1ahRxcXFERETg4+PDlClTABnG7GQ6depEUFAQixcvJjMzkyo9+pYa750k+r+IiYkptdyqL/H5+Phw5swZtFotkiRx5MgR6tatW95hCYIgPDZOzXoid3AlIiKClStX0r59e3bu3El4eDharRaAzZs3s2vXLss69vb2pKenExUVxfXr17G3t0cmk5GXl0f79u05ceIEQ4YM4aeffrJ0N8/JyaFmzZoMHjyYrKwsunbtyg8//IBd/VAkg45GjRoRFRVFZGQkNlUbYVPV94nvC6sfi2/x4sVs374dpVKJn58fc+bMQa1W37d+TEwM3Vdff4IRCoIglC19+k0yd3yOLumSpUzlUQOXVgPJ3L38r4dyAZlSjWTUl2hDprLFObg3msu/F40icacdrzo4NGpHzpEoy0O6AAoHN5zD+uPYuDPJqyZhzE75c4GKyoNmY1vNv8Q2ymqoo/uNxWf1CervEglKEISKQp8eZxnqSF25LjKZ7M/hiZJAJkPlXhXJZPwrmdxF6VwJuY09kmRGn3INc0EuStfKKN2rIZPJMBt0GNJuYNLmILd1wsa7ATJF0V0fyWzCkJkIkmRppzSPO0FZ9T0oQRCEZ5m6Uk3UlYrf45EpVcXKZHJFiTrF6svk2Hg3KFEuV9nc97KdTK5A7VnjH0Zddqz6HpQgCILw7BIJShAEQbBKFe4Sn9ksPfY5SgRBEISym7DwfircGZTRWHIOE2vzOB9sKysixrIhYiwbIsayUdYxPs7kBBUwQQmCIAgVg0hQgiAIglUSCUoQBEGwShUuQSmVqvIO4aHKYuyqx03EWDYqYoyFBtNjikQQiqtwvfjkchm1potJDQXhcRG9ZIUnpcIlKEF4WpkNhRTEHECfGotMZYtdvRbYVG2ETCYrVk8ym9CnXEOfGotZpwGZAvv6oZapEIx5t9Fc2IsxNx2lowcO/uEonCuhS7iALvGeUaNlcuzrtsCoyUSffOWeZcXbFYQnTSQoQbACuuQrpG/4AJMmCzc3N7RaLbnHNmBXrwWVek9HpiwaINls0JHy7RQM6TeLrZ9zZB3Vxq5Gc/43Mnd/jRwz7u7uZGZmkv37Wuzrh1Fw5XCp287et/K+cd1pV66+d0I8QXj8Ktw9KEF42kgmA+mbP6RmZTcOHDhAZmYmGRkZfPTRRxTGRpNzZL2lri4xBkP6TRYuXEh8fDxarZYff/wRSaeh4NJBMn/9il4RPYiNjSU9PZ24uDgGDuhvSU4pKSlotVrLv+3bt1vazsvLK7bsTruGzIQnvk8EAZ6CM6jVq1cTFRWFJEkMGDCAl19+ubxDEoQyVXD5EKacVD7/fjuhoaH07duXrl27MnXqVI4ePcrGrVtwaTmw6Czqz8kHUlJS+PTTT1m4cCEqVVHHoNzjm3BxcWbNmjUkJiYSHh7Oxx9/zMqVK9m7dy/p6enY2Nhw5MgRoqKiAEhI+Cv52NjYsHv3brZs2QLAzZs3AZDbOj7BvSEIf7HqM6grV64QFRVFVFQUmzdvZt++fU/F09qC8Hfokq7g6OhI9+7dOXXqFJs2beLTTz8FYODAgUj6gqLpFQAbn4YoXb1ZuHAhq1evLtaOISOeLl264OLiwrp169i3bx9r167F3t6enj3/6thgb29P/fr1MZvN/Pbbb8XacHJyol69ehgMBvbs2QOAwt7lcb59Qbgvq05QsbGxBAYGYmdnh1KpJCQkpNgskoJQEZjyM6lWrRoAt2/fBiAjIwPAUm7ISMBUmI9MZYPPK19i36BVqW09rJ3c3FwKCgp47rnnWLp0Kfv27UOhKBquJjs7G51OR/fu3Vm+fDk7d+5EJpOR/8eOx/G2BeGhrPoSX4MGDVi0aBFZWVnY2tpy4MABAgICyjssQShTcht7stOyAbCzswPA1raoU0J2dlH57c3zAVA4V8It/BUKrhzG3tOzRFt36t+vnTtnRwD79u2jffv2BAQEcObMGapWrYrBYEAmk3Hs2DHat29P3bp1Sbq3dx9Pfty5/Px8q796ImIse1adoOrWrcvo0aN55ZVXsLOzw9fXF7ncqk/6BOFvU7pXJfXcr9y8eZPAwEDs7e1p2bIlAMeOHQNg9OjRBAQE8M4771iSVWnu1A8LCwMo1o63tzcuLi5cunQJlUqFg4MDAIWFhVSvXh0bGxuuXbuGjY0N9vb2lmUyl5JfE0/6AeS4uDirf+hZxPjPxcTElFpu9d/2AwYMYOPGjaxduxYXFxdq1apV3iEJQplyaNQeSa7g7bffxsPDgxs3brB69Wpu3rzJZ599BkBERASTJk3CxsYGgJ07d5KUVHRfqlevXuh0OgYNGsTFixdZsWIF/fv3J+FGL8QAACAASURBVD4+nhEjRrBu3Tqio6OpVasWMTExXL9+naSkJIKDg/nvf//L5cuXadCgAVevXiU2NpbExET8/f1ZsWIFCQkJ2NZoXG77Rni2WfUZFBRdQ/fw8CApKYldu3axfv36h68kCE8RpZMnrm2Gsn79aqKjo4mIiCAjI4ONGzdSWFgIwPz581m9ejUajQaADz74gKVLlxZr58SJE0DR2daaNWto1qwZ586dY/fu3QAcPXqUsLAwmjVrhkKh4OzZsxw4cACAPXv20KpVK4KCgpDJZJw+fZrDhw9jW7MpDgGdntSuEIRiZJL0Z79VKzVkyBCys7NRKpW88847lksW9xMTE0P31defUHSCUHYKrh0jN3oz+tRY5Cob7Oq1wCVsAAVXjqK5sAfJbEJdqRZyB1cK486CZC62vsLeGZeWg9CnxpJ/7leMuekoHD1wbNwJp6bdyTuzA+3V40XPNUlmlK5VsPdti2OTruSf2oY2NhpDZiIASrcqOPh1wCmoB7J7xrcsj6GOrPXS1N1EjP9cTEwMfn5+JcqtPkH9XSJBCcLjJRJU6USM/9z9EpTV34MSBEEQnk0iQQmCIAhWSSQoQRAEwSpZfS++v8tslsR8NYLwGBUaTNiqFOUdhvAMqHBnUEajobxDeKin4UluEWPZqIgxiuQkPCkVLkEJgiAIFYNIUIIgCIJVqnAJSnnPQ4XWyBqfQ7iXiLFsPCjGQoPpCUYiCE+fCtdJQi6XUWv6tvIOQxAeSnTmEYQHq3BnUIIgCELFUOHOoAShMO4succ3oku+gkyhxLZ2c1zC+qNyr1qsniSZ0ZzbTd4fv2DMTERu74yDX3ucQ/ogmQzkHIlCe+MU5oJs5DYO2FT1wzmsP4U3TqG5fAhjdgqYTSgc3LGrG4xzWH+MmYloLu5HnxqLWa9FplDiGNgFp6Ae5bQ3BOHpJRKUUKHkndlF5o7FeHt702v4YDQaDRs3biT50kEqD5mPTZV6lroZ2z9Fc343gYGBtOs3kuvXr7Njx3ryzuwAkwmlWUePbt2oUaMGGRkZbN++neRv9gHQunVrAgI6oFQquXHjBr/+upXc4xsBcHR0JLRZMzw8PLh16xYnfvsKe982KOycy2OXCMJTSyQoocIwF+aTtXcFnTt3Ztu2bWg0Guzs7FiwYAHBwcFk7F5G5SEfIpPJKLx1Hs353cyYMYPZs2eTmppKpUqV+P333+nQoQOSJLH/yBHCwsI4evQoTZs2JSsri4CAADIzM9m6dSvZ2dm4uLjg7u7O3r176dixI1A0OWCjRo0AWLt2LS+99BJmbZ5IUILwN1n9Pajr16/Tu3dvy79mzZqxatWq8g5LsEIFVw4j6TTMnz8fs9lMvXr1eP755/H29mbatGnoEi5izCqa5C//7K94eHgwY8YMjh8/jre3N3PnzqVdu3b06dMHNzc3wsLC2LVrFz3/8x2LFxedlTVp0gSA+vXrU6dOHby9vUlMTCQ8PBy1Wg3A0KFDCQwMLLf9IAgVhdWfQdWpU4fNmzcDYDKZaNeuHc8991w5RyVYI0NmEmq1mubNm/PHH3+QmZnJkSNHgL+mQDdkJqJyr4oxM5EmTZpgZ2fH0aNHkSSJw4cPW+pu2rSJdevW0b17d95sG03//v05deoUx48fB4om0hw9ejQ1a9bEy8uLZcuWodfrkant+OOPP6hdu3b57ARBqECsPkHd7ciRI1SvXp2qVas+vLLwzDHr8nFxcQFAq9UCWGakdXd3ByD3+EZMuWnoki7h1tL/gXVv3LiBSqWiTZs2VKpUiejoaMzmvyYJnDhxIj4+PgCWmW5dWw9Gn3YDCm4+zrcqCM+EpypBbdu2jYiIiPIOQ7BSCkcPbt++jU6nw9PTE/gr2SQkJACgu3Ue3a3zxco8PDyK/UxISCAoKIjp06ezZMkSJr77AaMGPs9XX33Fzp07WblyJQCBgYEoFAoOHDjA5MmTWbFiBRf2flMUzD1nUKnrZlKpzzvYeNcvVm4NY/Xl5+dbRRwPImIsG09DjHd7ahKUXq9nz549TJkypbxDEayUTZX6SJLEhg0bGDJkCC+++KLlnlFUVBQAn376KYMHDyY0NJSTJ09y8+ZNevbsSfv27Rk1ahQAGzZswGg0AuDr64u3k9LSTkFBAX5+frRt25bo6GgqVapEjRo1AMjOzgagY8eO+Pr6AlCjRg369evH4cOHyfr9OyoPmFUsZmsYDcNaZ1m9m4ixbFhrjDExMaWWPzUJ6sCBA/j7+1uOjAXhXrZ1mqGqVItp06bh5eXFDz/8gMFgYPny5axYsaKojq0tzs7OyOVyjEYjw4cP56uvvmLfvn1kZmYyadIkzp8vOsP697//zdtvv018fDwmk4m1a9eyceNGAgMDWbBggeVyYnJyMmPGjCExMRGADz74gObNm6PT6WjRogVr166lX79+/HriUvnsGEF4SskkSZLKO4hHMXnyZNq0aUO/fv0eWC8mJobuq68/oagEa6NPjyMt6j+Y8tJxd3dHp9Oh0WiwqeqHPv0mkl5rqWtTPQB98lUw6alUqRLZ2dno9XqcmvXEpM2nIGY/crkcDw8PsrOzMRj+mspFJpPh6emJXq8nJycHAIeAzmgu7gVz6WPsOQb1wKPLWMtraxnqyFqPqu8mYiwb1hpjTEwMfn5+JcqfijOogoICDh8+zPvvv1/eoQhWTl2pJlXHfIXm0kF0SZeRK1R41WmOba0gTHnpFFw6hGQyoHKvhl39UMyF+WjO76YgMwnbus54+LVDXakWAIXNIii8eQqtJgu7uk64+vhiVzcYffIVCuPPoc1NQ6ZQ4epUCfv6oajcq+Ic0hvt9ZMgmYvFpXB0x75hm3LYI4Lw9HoqEpS9vT3Hjh0r7zCEp4RMqcYxoBOOAZ2KlSudvXBu8UKxMoW9C84t+pbajm01P2yrlTyqs6nqh03VkuUAaq/aqL1EF3NBKAtW/6CuIAiC8GwSCUoQBEGwSiJBCYIgCFbpqbgH9XeYzZLV9I4ShAcpNJiwVSnKOwxBsFoV7gzKaDQ8vFI5exqe5BYxlo0HxSiSkyA8WIVLUIIgCELFIBKUIAiCYJUqXIJSKlXlHcJDWeOT3PcSMZaN0mIsNJQ+0oQgCMVVuE4ScrmMWtO3lXcYgnBfohOPIDyaCpegBMGYdxtDehwytT023vWQKUo/q5YkCUPGLUw5aSicPFBVqoVMJitaZtSjT4/DrM1FbueMulItZH+enRtzb2PISgSzCaVLZZRuPshkMsyGQozZqcW2IVMoLcsFQfh7RIISKgyTNpfMXUsouHzIMhaewtEd13YjcGxcfNgjfdp1MnZ+gT7psqVMXbku7l3Gok+7Qfb+VZgL8y3L5HbOODRqT2HcGQy344u1pfauj3OLfmTu+AyzTlMiLtuagXi9OEckKUH4m0SCEioESZJI3zQXWfo13pn+Nj179iQtLY3IyEgObo9EbueIfb1QoCiRpf7wf3i7O/HO55/TrFkzzp8/z7x587jxbdF8Y8899xyvvfYaVapUISUlhc8//5y9e7fi5eXFjE8/pXHjxqhUKs6cOcPcuXNJ2jwfuVzO+vXri8V1+PBhFi1ahDE7BZWb9xPfL4LwNLPqThLJyckMGzaMHj160LNnT1avXl3eIQlWqjDuDLpb54mMjGTu3LlcvHiRevXqsWfPHho2bEj2we+4M7NM3oktoMtnx44dDB8+nCNHjtC3b1/27NmDSqWicuXKbNu2jaZNm/L9998THBzML7/8gpubG3Xq1KFLly5ER0dz+/Ztxo0bZ0lKMpmMAQMG0LRpUxwdHXF0dMTW1vbPCJ+KWW0EwapY9RmUQqFg+vTp+Pv7k5+fT79+/WjdujX16tUr79AEK6ONjcbBwYFRo0Zx8uRJxowZQ4cOHdi7dy+vv/46b7zxBqb8TJROHmhjowkPDycgIIDIyEimTJlCTk4Os2bN4vnnn+fMmTOoVCoOHTrE6iNxtDt2jAEDBuDg4MCZM2fw9/fHbDYjk8nIyMigefPmxWLZvXs369at49KlS6SkpACgdBVnT4Lwd1n1GZSXlxf+/v4AODo6UqdOHVJTUx+ylvAsMuWmU6tWLdRqtWX0hjs/GzRo8GedNACMuemWsjt14uPjLXVjY2N56623GDp0KKfXRdK3b18mTpxIQkICWq0WbJ0ACA8Px83NjU2bNhWL5bXXXmPv3r3cunWLadOmAVB4/eTjfPuCUCFZdYK6W0JCAjExMTRp0qS8QxGs1L2TQ1t65P1ZnvL9O6R89xZmbW6June3UaVKFSZPnsz58+dZsGABly9f5q233sLDwwMAc0EOvXv35ueff2bfvn2MGTOmqNxsJjw8HHt7e/z8/MjIyGDevHk4OzujvR79uN62IFRYVn2J7w6NRsPEiRN59913cXR0LO9wBCukcPHi5oU/0Ol01KlTB4DatYsmDrx8uainXlBgY9zd3dmbfMlSdqfO3XXbtWuHt7c3H374ISt/+hU3Nzfmz59P69at2bJlC2PHjuWzzz4jKiqKESNGoNPpALC1tWXfvn0AXLp0idjYWCpXroybmxu3dQXF4rWmcQTz8/OtKp7SiBjLxtMQ492sPkEZDAYmTpzI888/T5cuXco7HMFK2ddtQWr0TyxbtowJEyawZs0aQkJC0Ov1fPnllwDMnz+fLl26WBLJH3/8wejRo1GpVAwZMoRr167x888/U7duXQwGA6+//joqlYp//etf6HQ6zp07R0hICF988QVms5mqVauya9cuALp3706nTp2YPXs2u3fvpnr16rRq1YqTJ08SHx+Pa4fi3dytaRSMuLg4q4qnNCLGsmGtMcbExJRabtUJSpIkZsyYQZ06dRg5cmR5hyNYMZsajbGtFcTUqVOJjY0lIiKCU6dOMXz4cK5duwbAr7/+SlJSEiaTCUmS6NatG1OmTKF58+asXr2ahQsXYjQauXz5Ml27duWVV16hW7duHDlyhGXLlnHjxg1UKhWrVq0qsX2z2czJkyfZsWMHTZo0wWw2M2fOHCIjI5E7eeIQKA6uBOHvkkn3uxhvBU6cOMHQoUNp0KABcnnR7bI333yT9u3b33edmJgYuq++/qRCFKyIuTCfzN1fo7m4F8xF490pXSrj2m44eae3oUu4CIDcwRWP58aSe+pndPFnLevbVPXD/bnX0KXEkn1wDWZNtmWZwtEdtXcDCm+eRjLoSg9AoQSTsViRba0g3Lu8jsrNx1JmbUMdWetR9d1EjGXDWmOMiYnBz8+vRLlVn0EFBwdb7hUIwsPIbR3x7PkGbuEjMWTcQqayRe1VG5lcgb1fO0x5t0Eyo3B0R6ZQYd+wFYbsFEy56Sgc3VG5VwWKRpRwDOiIISsJc0EOcnsXVO5VkckVmHUFmAvzSmxb4eCOTKnCpMnGkJUEyFC5VUHh4PaE94IgVBxWnaAE4Z9Q2LugsHcpViaTyVA6VypRV+VaBZVrlRLlMoUStWeNEuVyG3vkNvb337aDKwoH138QtSAI93pqupkLgiAIzxaRoARBEASrVOEu8ZnNktXdhBaEuxUaTNiqFOUdhiBYvQp3BmU0Gso7hId6Gh6UEzGWjdJiFMlJEB5NhUtQgiAIQsUgEpQgCIJglUSCEgRBEKxShUtQSqWqvEN4KGt8kvteIsayUamymAdKEP6pCteLTy6XUWv6tvIOQxAA6xvWSBCeJhUuQQnPBkmS0MWfo+DqEcy6AtSVauLQuDMKO+eSdU0GCi4fojCuaNw9m+oBOPi2RZd8mcIbp0tMxi5TKLFv2BqFrROai3sxZCYiU6qxqxeKbc0mFN44ReGf4/rdTa5UY9+ofakjUwiC8PeJBCU8dSSjgfTN89FeO4aTkxMebm7En99N9qHvqdR7OnZ1/pqC3ZibRuq69zBmJuDl5QVA2tldZGz7BACFomSXb0mSyPl9LciVYDbi5eWFVqsl7eRWZDYOSDrNfdfLP/crPmOWIZNVuKvngvDEib8i4amTe+IntNeOsXDhQtLS0oiLi+P8+fMEBfhxe+tCzHdNDpix4wscTHls3bqV1NRUUlNT+eWXX3B3dwfg3LlzGI3GYv++++47AJoHNeHKlSukpqaSnp7Op59+CvqitlNSUkqsFxkZiTE7BXOh5snvFEGogKw+QeXm5jJx4kS6detG9+7dOX36dHmHJJQjyWwiN3ozPXr0YMqUKaxdu5b27dtTvXp1li1bhrkwj/xzvwKgT4+j8MZJ3nnnHSIiIhg7dqxljqcZM2YAMH36dIYPH87w4cOJiooCIDq6aHr2lStX4unpSb169Zg/fz4TJ06kb9++AIwbN86y3s6dOy3rydQPHkxWEIRHZ/WX+ObMmUPbtm1ZvHgxer2ewsLC8g5JKEemvAzMBdmWRLF8+XKOHTvGwYMH6dmzJzVq1CAjNRYA/Z8/+/bti1ar5auvvkKSJCIjI+nbty9Tpkxhy5YtyJQ2YNLz7rvvkp2dzfLly5HJZPj5+XHhwgVib8Zz6NAhAHr37s2GDRtYv349KJTYKBUsWLCAW7du8cMPP+AYFIFMLkaKEISyYNVnUHl5eURHR9O/f38A1Go1zs4lb4ILzw5TfgYAPj5FEwBmZmYCkJWVBUDVqlUxZCZizE3HkH7TUjcnJwez2YwkSWRnZ1O1atHcT85hA5CpbIiIiMDX15elS5eSn5+PJEkcPXqUgIAAZr47nXfffReAatWqAeDZ5x1kMgVDhw6lSpUqLFq0CKPJjHNwrye2LwShorPqM6iEhATc3d155513uHTpEv7+/syYMQN7e3EJ5Vklt3UE/kpMdz4Ld35mZGSgT7pC4pKRlnUyMzNxcflrfih7e3syMooSnfbacczaXKZOnYper2fx4sXY+PiiS7rEoEGDmD17Nr169eLKlSsApKWlAaC5sBdMeqZOnUpOTg7Lly/Hwa8dSmevEjFb+5iB+fn5IsYyIGIse1adoIxGIxcvXmTmzJk0adKE2bNns2zZMt54443yDk0oJ0qXyqBQcujQIYYOHUq7du24fPkyISEhJCcnc+PGDRo0aMBbb73Fzz//zE8//cShQ4cYNGgQTZo0QafT4enpycaNGwEw3I6jRYsWtGvXjpUrV5KcnIxX/1dJ+/E/aDQaRo4sSnTTp08HYPPmzchUthTGn6NHjx74+fnx4YcfkpeXh3eLvqXGbO0PFFvrNOB3EzGWDWuNMSYmptRyq77EV6VKFapUqUKTJk0A6NatGxcvlnz+RHh2yJRqHAM6sXLlSk6fPs2iRYtISUnB29ubt99+G4PBQJUqVXjllVdo1qwZALNmzSIjI4OjR49y6tQpsrKy+Pe//21pc9q0aQAsXLgQlVcdbKo1AmDGjBkkJCQQFxfHvHnziIqKYt26dcjkCiSdhmnTpqHX6/n000+xrdkUdeU6T36HCEIFZtVnUJUqVaJKlSpcv36dOnXqcOTIEerWrVveYQnlzKX1EFKunyI4OJiuXbvi4+PDr7/+Snx8PFDUdbxLly5cv34dgEtXrlGrVi2ef/555HI5W7ZsIU+jxa5+GNqrR1m6dCmLFy/m4sWLeERMQaayQW7nTGRkJKdOncLR0ZHjx49z5swZ1N4Nsa3WiPyTm5kzZw65ublFZ10DXy/PXSIIFZJVJyiAmTNnMnXqVAwGA9WrV2fevHnlHZJQzpROHni/vIjcE5v57fgRzLpjqCrVwqv/SJRuPmQf/I4DF24hUzvj1f8/KFy8yD22kfXb94AkYVszBO8WfVG6VCZr93J+j4kHmQyXli/i0Kg9MpkcrwH/IevIeqJ+2Ytk1KN0qYx71/E4BnTCrC/AVJDNgQu3QCbHtcNIbGsFlfduEYQKRyZJ0r0jvTzVYmJi6L76enmHIQjA0zEWn7Xel7ibiLFsWGuMMTEx+Pn5lSi36ntQgiAIwrNLJChBEATBKokEJQiCIFglq+8k8XeZzdJTcd1feDYUFOqxt1WXdxiC8FSqcGdQRqOhvEN4qKfhSW4RY9lIT00u7xAE4alV4RKUIAiCUDGIBCUIgiBYpQqXoJRKVXmH8FDW+BzCvUSMj6bQYCrvEAShwqpwnSTkchm1pm8r7zCEZ4TokCMIj0+FO4MSBEEQKoYKdwYlVBy6pMvkHFlPYfxZkMzYVPPHJaw/tjUCi9WTJImCmAPkntiCPi0WucoWu3phODbpQu7xjZaJC+8mt3HApc0QlM6VyD2+Ce31k5h1BSgc3bCt2QSlsxeFcWcwpN/EbChE4eiOXZ1gXFoPRuno/oT2gCA820SCEqySNvYEaRvex6uSJ6+MeQWlUklUVBSJ37+L5/PTcGjU3lI3++B35B5ZR6NGjYgY9ia3b99m3bp1pJ7/DZVKxaAXXyzR/okTJ7i04QOQK3F2tGfEoH5UqVKFmzdvsmnTJjSFhYSEhBDSawQuLi7cuHGDTZs2kXL9JN4vL0JhJ2Z2FoTHTSQowepIZhOZu78iwL8RR44cwWAwYDQamT9/PuHh4Rzf8zV29cOQq2wwZKeQezSKESNGsGrVKhISEvDw8OA///kPTZo0wWQy8e2335bYxtixY7l06RIhzYPYtWsXcrmc8+fPU7duXc6ePcuFCxc4fvy4ZQqPGjVqcPLkScLCwsg7+TOubYY86d0iCM+cp+IelMlkok+fPrz66qvlHYrwBOgSYzBmJTNz5kwcHR1p27YtQUFBqFQq3n//fUyaLApvngZAc3EfchnMnTuXpKQk6tWrx8iRI6levTrjx48nNzcXlUpl+Xf06FF0Oh2bNm0C4OOPP0aSJPz8/GjdujVVq1bl6tWrAHTu3JmaNWtSu3ZtTpw4QfPmzfH19UWfGltu+0YQniVPRYJas2aNmKjwGWLMSgIgJCSEgoICLly4QGJiIklJSQQHBxerY8xKwsfHBx8fH86cOYNOp+P48eMAlrrKqo0wmsyEhIQQFhbGt99+S0pKCq6urrRu3ZqsrCw2btzIuXPn+Pe//43RaARgz8EjAMjlcuzs7CgoKCApKQmFvcsT3R+C8Kyy+gSVkpLCvn376N+/f3mHIjwhZp0WAFdXV3Q6naVcp9Ph5OSEXC4n59gGco7+iOb8HlxdXS3L7/55p1zp5gOS2TK1+8cffwyAi4sLcrmcOnXq8OOPP3Lu3DlmzpzJ6NGjAVDYOWFra8u6deto2LAhI0aMIDMzC8fA557AXhAEwervQc2dO5dp06ah0WjKOxThCVE4eQAQHx+Pv78/arUag8GAp6cnSUlJmM1mKMghe/8qAG7dugWAp6cnAJUqVSpWrrl4gPr169O7d2+2bNnCpUuXULhUtrSVlJTEwo8/oWmTQAYPHkxwcDDLli3DRWlk87bfaNq0KS+88AI///wzANI94z0+aEzA/Px8qx8zUMRYNkSMZc+qE9TevXtxd3cnICCAY8eOlXc4whNi410fkPHDDz8wb9483nnnHXJzc3FxceGrr74C4M0332T27Nn07duXHTt28Msvv9CpUycGDhxIz55FD89+//33AEj6At58803kcjkLFy5E4eyFW/uXub3lQ3766Seef/552rVtQ9u2bQE4deoUcrmcQ4cO0bBhQ9avX4+vry++vr78+OOPpBz7Eduaf3V1f9CIFtY6g+ndRIxlQ8T4z8XExJRabtUJ6tSpU+zZs4cDBw6g0+nIz89n6tSpLFy4sLxDEx4jpUtl7P3asWjRIurVq8e7776LXC7n+++/Z/bs2QAYjUYKCgowmYqGGho7dizLly9n3bp15OTkMGvWLLZtKxpRxNXVlYiICPbs2cPBgwdx6/Qv7Bu2QulejUmTJmFvb8/+/fspKCjgiy++YPny5SgUCjw9PcnIyKBTp0506tQJgJMnT5J0Oal8dowgPGNkkiRJ5R3Eozh27BjffPON5Qj6fmJiYui++voTikp4XEzaXNI3fIAuMQaVSoVcLken06HyqgMmI4aMeEtdm+oBGLNTMOXdxs7ODr1ej8lkwt6vPQpHN/Kif7LUVTh64POvpcjVdujTb5L24/uYctOwtbVFp9PxKH8Ozi364hY+Cnj4UEfWesR6NxFj2RAx/nMxMTH4+fmVKLfqMyjh2aWwc6by0AUUxp2hMO4MSBLO1f2xq9McSV9IwdUjf4784I59vRYggeby7xjSbqBW2WBXLxSbKvWQjAZsfHwxabKQKZTY1WmOXG0HgLpSLaqO+YqCK0fQp1zDxsYeGx9fbGs2QZd4CX3qtRJxKZ08sKvb4knvDkF4Jj01CSo0NJTQ0NDyDkN4gmQyGXa1mmJXq2nxcht7HAM6lajv6B8O/uHF6ypVOPi2uf82FCoc/Nrh4NeuWLltNT9sq5U8ohME4cmx+m7mgiAIwrNJJChBEATBKokEJQiCIFilp+Ye1KMymyUxiZzwxBQaTNiqFOUdhiBUSBXuDMp4z1P+1uhpeJJbxPhoRHIShMenwiUoQRAEoWIQCUoQBEGwShUuQSmVqvIO4aGs8Unuez1KjIUG0xOIRBCEZ1WF6yQhl8uoNX1beYfxTBCdUQRBeJwqXIKqKCTJjD7pCsa82yidPFD7NEQmK/2E12zQoUu4iFlfgNqzJiqPasWWm7R5lgn+FE6eKP+czgLAVJCDMTsFAKWLFwoHN4y5aZjys4q1IbdzQuXmU5ZvURAE4YFEgrJChQkxZO5YjCHjlqVM5VEd924TsK3WqFjdvDO7yN6/CrM211JmWysIjx6TUDp5ok+9Tsp/30bSF00CiOz/27vz+BrP/P/jr3OyryJUEluIXdW+FGmKyIq20a+aTg1Ga2lRahmqZbTKg7Y6ppRWVX+GVrVVaxhKBgmxlkQjKoIsNNEkksh+cs71+yPjTDKYKic9d+LzfDw8knNf933u97kl+Zz73Nd9XXrqD5mBS7sASq+eJ3PTGyjDvycF1Nvg6NuJksungdsHTXXvPZy6AX+y+OsVQog7qXXXoGq68ptZXP9mHs08HfnHvpO1zgAAIABJREFUP/5BfHw869evp5mnI9e/+Svl+VnmdYuST5Dzzw/p17s7u3fvJi4ujiVLlmCfk8wvmxegysvIivwAn/p12blzJ7t27aJlCz8KEw9hMpSQFfkBvo182LVrF7t27aJxQx9KLv9A9+7dzMtu/QsODqbw3AHrHRghxENH82dQpaWlvPDCC+YpFEJCQnj11VetHava5B/fgq0qZ8+ePbi5ubFy5Upefvll/P39ad26NfnHv8Nz4DgA8qI30Lp1a/bs2cOPP/7I3r17mTFjBk2aNOGPf/wjP/+/qRiyU1m9cydhYWHo9Xrc3d25mmck99B6jLk/s3bzfp588kn0ej0uLi5Axcy0YWFhREVFkZ2dDVTMv6Sz2lERQjyMNH8GZW9vz7p169i+fTtbt24lOjqaM2fOWDtWtSm5fJrQ0FCaN2/O6tWr+etf/8rHH39Ms2bNCAsLo/jyD0DFtaOyzGTGjRuHra0ts2bNYubMmcTExDB8+HDq1auHITuV0aNH07VrV7766qv/7CP9HDdPbuOVV17Bz8+PLVu23DHLtm3b+PTTT5kwYQJRUVGg1/yPixCiFtH8XxydTmd+Z19eXl7xTl5Xe9/Ll+dfp2XLlgCkpVVcg0pPTwegZcuWGG/+8u/1fjEvq7xuWloaer2e5s2b07hxY5YtW8a4cePIyckx70OVFuLn58fixYsZM2YM+fn/uX5V2dKlS9m7dy9XrlwhKCgI480cjEV51fCqhRDidpovUABGo5Gnn36aPn360KdPHzp16mTtSNVHp6e8vLzi238XYv2/z1zKy8tRhlKufT6ZjH9MMy+rvE7ldZctW2Y+43RzcwPA29sbe3t7PvroI3bt2sWFCxfMbwB8fHyws7PjzJkzNG/eHDs7O0JDQ3Fzc+Odd95BlZdSmp7wOx0IIcTDTvPXoABsbGzYtm0b+fn5TJw4kQsXLtC6dWtrx6oWth5eJCYmAv85O2rRogUA58+fByC8d0eysxsRExNTZd2EhARatmxJWVkZly5dws/Pjy5dujB48GDz80dGRvLEE0/g5+dH69atee6558xt//rXv+jatSvJyclkZFR0PT969CgAHh4eAJjKSqrkteZ4eAUFBZoYj+9/kYyWIRktoyZkrKxGFKhb3N3d6dWrF9HR0bW2QDm3fJz9+7/i9OnTTJgwgfr16/N///d/nDlzhu+//x7AfC0uICCAjz/+mKlTp/Lhhx8yYsQIevTowYoVK8jPz2fs2LG4uroCMGXKFCIiIhg/fjxnz57lT3/6E05OFVOfz549m9DQUEaOHElSUhKLFi2ia9euxMfH4+9fMRvtrWtY9l4tquS15qgYKSkpmh+VQzJahmS0DK1mvPVG+79pvkDl5ORga2uLu7s7JSUlHDlyhLFjx1o7VrVx6/4UBfF7CAoK4tVXX6Vz584sXbqUDz/8EKUq7k1asWIFycnJAFy9epWePXsyefJkGjZsyIQJE1i7di0AP/5ShkpPpywzmQYNGnD16lV2795NXl4ep85fQWdrT3lOOo0bN+bixYvs3buXgoICPv/8c8rLy2nRogWnT59myZIlbNy4Eef2T2L/iPZ+uIUQtZNO3fqrp1Hnz59n9uzZGI1GlFKEhoYyadKku66fmJhI2LpLv2NCyzPkXOXG/k8pvnTSvMzRrxvu3Z8mZ+9K88gPjr4dce8xlBsH/x+GX65UrGhjh+tjA6nb78/oHZwByPl+FTd/2AUo9E7u1H/qLzg16wxA1q5lFJ7dB4DeuQ4u7ftRfOkU5Tnp5n3r7Bxx6zoID/8R6CqNdWjtoY60+m6wMsloGZLRMrSaMTExkXbt2t22XPNnUG3btmXr1q3WjvG7svNsRINh8ykvyMFYkIONqye2rp4ANBy3GlPxTdDpsXGq6Pjg6NeN8tyfMZUWYVfXB72DS5Xn8wx6GY+AUSijAb2DMzqb/xSZ+uFT8QwcizKWo3dwQWdjC4FjMRbeoDw/C72DM7Z1GlTZRgghfg+aL1APM9tKhekWnU6PjXOd/1qm+9Vx8m6dTd25zeW2ZTYudbFxqfsb0gohhGXViG7mQgghHj5SoIQQQmhSrfuIz2RSVr94/7AoMRhxtLOxdgwhRC1V686gyssN1o7wq2rCjXL3klGKkxCiOtW6AiWEEKJ2kAIlhBBCk6RACSGE0KRaV6BsbbV/Q6kW7+T+b76+vpQYjNaOIYR4iNW6Xnx6vY5msyOtHaNWkN6QQghrqnUFqiZQJiNFF2IpTj6OMpRi79UC147B2Lh43LauqbSIgh/3U5p+DvR6nHw74dK+Hzpbe3N7/qntmIoqJh109O2Ic6vHMRbfpCB+L2U/J6GztcPJrzvObfpiLMqjMOFfGLJSMJUVY+Pkjn3Dtri0D0Bv5/i7HgchhPhfpED9zkylhWRumkfZzz/h7e1N3bp1OR99hLyj3/BIxBvmQVwByn65QuamNzEV5prneUrdfZC8o9/i9YeF2LjV55dtizGkxuHq6opSil9Obadu4DjyYr7AVFpImzZtuHnjJtd2/Au7I19hyLmKDkWTJk2oU6cO1zMvkxm/l/zj3+H9x8V3LJJCCGENte4alNblRn+B6ZdkNmzYwNWrVzl37hyJiYl0aNOS7J1LMRlKAVBKkR35N3w8XDh27BhJSUmkpKSwZ88eXEyF5Oz7hIK4PZRc/oEPP/yQ3Nxczp49C8CN/atp6duIs2fPcv78ea5evcq3336LvuA6KBNffPEFKSkpxMfHk5GRwZ49e7ArziYvdpM1D40QQlSh+QJ16NAhQkJCCAoKYvXq1daO80BMZcUUxP2TP/3pT7zwwgssXryYPn364Ovry4oVKzAW3qAo8RAApWlnKctMZuHChfTs2ZOnn36aCRMmEBwczIwZMyhOOkrOnhUEBgYycuRICgsLq+zrb3/7G23btqVfv3688cYbPPvss4wbNw6A1atX065dO1q1asXhw4cJDg7G39+f0mvnf/djIoQQd6PpAmU0Gnn77bdZs2YNkZGR7Ny5k4sXL1o71n0z5FxFlZcxZMgQANauXUtsbCw//PADAQEBuLm5UXa9Yi6rssyKr0OGDOHatWts376dtWvXYjKZzFO4u7m58dlnnzFr1ixyc3PN+7GzsyM0NJSEhAQOHjxonsDw1nYHDhwgLy8PV1dX7OzsKCgo4MKFC+jt7z7iuRBC/N40XaDi4+Px9fWlSZMm2NvbM2jQIPbv32/tWPfNWHgDgIYNK6bGyMvLAzAXl4YNG1L2yxUMWWmUZSbj4OCAp6eneT2DwUBRUZF5+/fff5/k5GRWrVpVZT9eXl7o9Xrz81Z+/ls2bNjA6dOn6dmzJ+vWrSMtLQ1j8c3qeulCCPGbabqTRGZmJt7e3ubHXl5exMfHWzHRg7FxrJhgMCsrCwBn54ozFhcXF/Py0uxsrn32snmbgoIC83o6nQ4nJydSU1Np2LAh48aN46OPPmLGjBm4ublhMpmYNGkSn332WZXndXV1rbJfgIiICOrXr8/777/PxIkTiY2NZeN3O27LrOVxAwsKCjSdDySjpUhGy6gJGSvTdIGqbWw9G4FOz6FDhxg0aBADBw5k27ZtdO7cmXPnzpGdnU337t2ZMWMG69evJzIykkOHDhEeHk6rVq1o3LgxNjY2HDp0CBsbG65du0ZERASAuRffhAkTWLFiBSdOnKBDhw54e3sTEBAAVFzPA/D39+fw4cMUFBSQnl4xtbuHhwfKWH5bZi3fVKzV6asrk4yWIRktQ6sZExMT77hc0wXKy8uLjIwM8+PMzEy8vLysmOjB2Di54dz2CVauXMnzzz/PZ599xqpVqzAYDLz22msANGrUiOHDh3Ps2DEiIyN5/fXX6dmzJ+fOnUOv15OSksLChQtJT0+nUaNG5udOT0/HaDTSoUMHAKZPn05kZCQpKSnY29tz7tw5li1bBsDBgwcpLS3FZDLh4uLCjz/+yKZNm3Bs2uH3PyhCCHEXmi5Qjz32GFeuXCEtLQ0vLy8iIyNZunSptWM9kLpPjiJjw4907dqV/v37U69ePfbt28eNGxXXp6Kjo+nTpw9XrlwBIP7Hc/j6+hISEkJZWRl79+6lXGdL3QFj0dk5UHL5B4ouHOHpp58278OhUXuiYw7TuHFjgoODyc/PZ//+/RiNFUMXtWnTho4dO2JnZ0dqairHjh0DR3e8I1783Y+HEELcjaYLlK2tLfPmzeOll17CaDTy7LPP0qpVK2vHeiC2dRrgM2Y5N0/tICbhOCbDBey9O+I9+Cn0Ds7kHf2G0z/fQO/eAu+BM9A7OJN/Yhs7D50CvR7HTuG493gaW/cGALh2Cib/6LckpFbcA+Xx5Cjcez2L4fpl8k9uY2vUUXS29rj0GIp796coSYnj6vkYUg6dRJmM2LjUxa33H3DrEi436QohNEWnlFLWDmFJiYmJhK27ZO0YtYLWx+LT6ufplUlGy5CMlqHVjImJibRr1+625ZruZi6EEOLhJQVKCCGEJkmBEkIIoUma7iRxP0wmpflrJzVFicGIo52NtWMIIR5Ste4MqrzcYO0Iv6om3MmdkpIixUkIYVW1rkAJIYSoHaRACSGE0KRaV6Bsbe2sHeFXWeI+hBKD0QJJhBBCu2pdJwm9Xkez2ZHWjlHtpCOIEKK2q3VnUA87k8mEwXBvHUXKy8vN4/NVppSipKSEuw0yYjAYMJlMd9x3SUnJbwsshBB3IQWqljh9+jTPPPMMjo6O2Nvb07lzZ9avX3/HIvPdd9/Rq1cv7OzscHBwIDQ0lMOHD7Nx40aefPJJ3N3dadu2LW5uboSEhHDs2DHy8/OZPn06jRo1wt7eHgcHBzp37sy6detYvXo1HTt2xNHREScnJ1xdXQkODiYmJsYKR0IIUVvUuo/4HkbHjh3jySefxM3NjUmTJuHh4cGWLVsYOXIkFy9e5K233jKvu2LFCiZPnkzbtm2ZN28eJSUlbNiwAX9/fwA6duzImDFj8Pb2JjMzk2+++QZ/f39sbGwwmUw888wzdOjQgZKSEr7//ntGjx4NwOOPP8706dNxd3cnMzOTLVu2MGDAAKKjo+nVq5c1DosQooaTwWJrqMrXoAICArh8+TJxcXHo9XqysrJo2bIlI0eOZNOmTSQnJ9O4cWNu3LhBs2bN8Pf3Z8eOHaSlpeHs7IyzszM9evQgMTGR48eP4+3tTUZGBj169CA3N5dOnTqRmprKJ598wrhx44iKiqJp06a0bNmSoKAg9u3bx5YtW2jatClKKbp160ZeXh7t2rUjICCAr776qlqOgVYHvqxMMlqGZLQMrWassYPFvv766/Tu3ZvBgwdbO4ompaSkEB0dzbRp0/D09GT48OF06NCBrKwsFixYQFlZGV9//TUAO3bsID8/n7fffhuDwUCnTp0ICQnBxcWF2bNnAzBp0iR8fX3p2bMny5cvx8PDg6CgIAD69OnDzZs3iYyMZMqUKQD07t0bgD/84Q9069aN7t27s2nTJurUqUO7du1IS0uzwlERQtQGmi9QQ4cOZc2aNdaOoVkXL14EoGvXrgD88MMPlJaWkpiYiK+vL56eniQnJwOQnJyMjY0NnTp14tKlS+Tl5XHmzJkq2x8/ftx83apBg4o5p86dOwfAu+++i06n4/HHH2fhwoX89NNPbNiwAYDS0lJGjhzJe++9R0hICDt37iQmJgZ3d/ff6UgIIWobzV+D6tGjB+np6daOoVkFBQUAuLm5AVBWVlblq5ubGytXrsTT05N33nkHFxcXbG1tze1KKQwGg3l7AJ1Ox3vvvcfw4cN54403iI2NBcDDwwOdToezszO2trbY2dnh6upq3q5Lly707dsXd3d3GjVqhLu7u3mmYCGE+K00X6DE3aWkpGBjY2P+vmvXrnh5eZGfn0+DBg0wGo1cu3YNnU7HokWL0Ol0FBYWkp2dbT478vDwME/9DuDg4MC6desYNmwYkyZN4qOPPgIqita7777LuXPnGDNmDO7u7iQlJTFz5kxGjhwJwGuvvQbA22+/zdy5cxk+fDjr16+vtrEHCwoKND+uoWS0DMloGTUhY2VSoGowX19fGjRoQJ06ddiwYQMRERG8+eabxMbG8uijj7Jx40YMBgPPPfccmzZtYuLEiaxcuZINGzYwZcoUZsyYQdOmTQFYv349AF988QXPPvssR48e5ZFHHmH+/PlERUVx6NAhsrOzad68Oe3ataNHjx4AXL9+HRsbG/7+97+zb98+AMLCwgBIS0vjkUceqbaLslq94FuZZLQMyWgZWs2YmJh4x+VSoGo4Jycnpk2bxvz583nzzTeZOnUqzz//PJs3b2batGkAFBUVkZKSYv44cN68eXh4eLBgwQJKS0t59913Wbt2LQDOzs6kpKTg4+Nj7kKenZ3NoUOHGDFiBH/729/Yu3cvpaWlbN26lUWLFqGUolevXrz00kvY2NiQlpbG66+/zvbt25k7d65VjosQouaTAlULzJ49m6SkJBYuXMjChQvR6XQopWjXrh2dOnVi586d7Ny5EwB/f3+Ki4sZPXq0uQBBxX1MR48eJTw8/K77OX78OF26dLlj260zqlv7Bhg5cqQUKCHEfdN8gZo2bRrHjx/nxo0bBAQEMHnyZIYNG2btWJpib2/P+vXrmT17Nrt27aKoqIju3bsTGhqKUoq9e/eSmZmJp6cnYWFh2NnZERUVxZEjR7CzsyMoKIhu3bqRlpbG/v37UUqRlZVF/fr1AXB3dyc8PJyioiIiIyMr5opydOTRRx8lODiY3Nxc9u/fT1JSEkajER8fH/r370+rVq2sfGSEEDWZ3KhbQ1X3YLFa/ay6MsloGZLRMiTj/auxN+oKIYR4OEmBEkIIoUlSoIQQQmiS5jtJ/FYmk3ooJvMrMRhxtLOxdgwhhKg2te4Mqrz83ibrsyZL3MktxUkIUdvVugIlhBCidpACJYQQQpNqXYG6NXiqEEKImk0KlBBCCE2qdb347iQ9PZ3o6GhMJhN9+/alWbNmd103Pj6e06dP4+rqSmBgIB4eHua2H374gbNnz+Lu7k5gYKB5Mj6lFCdPniQhIYG6desSGBhonidJKcWxY8c4f/489erVIzAwsFpfqxBC1Bqqljl37pz5+9LSUjV+/HhlY2OjAAUonU6nRowYoQoKCqpsl56ergYMGGBeD1AuLi5q0aJF6vLly8rf379Km5ubm/rggw/UhQsXVM+ePau0eXh4qFWrVqmEhATVpUuXKm316tVT77333u99WH6zK1euWDvCr5KMliEZLUMy3r/Kf7crq3Uf8VU2Z84cVq9ezcSJE4mLiyMhIYFZs2axceNGJk+ebF5PKcXQoUM5efIkH3zwAUlJScTGxhIaGsqcOXNo3rw5CQkJLF++nIsXLxITE0O/fv2YNm0arVu35vLly6xatYrk5GQOHDhAr169ePnll3n00UfJyMhgzZo1JCcns3//fjp27MjMmTM5cOCA9Q6MEELUBA9a+fr376+ys7PNj48eParGjRunlFJq8+bNqk2bNioxMdHcPmjQIJWWlnbbtmfPnlX9+/dXCQkJD5TnViW+fv26cnR0VH/+85+VUkpt3LhRrVmzRiml1PTp05Ver1eXLl1SSikVGRmpAPX5558rpZRauHChOnDggFJKmc+Ovv76a1VeXq7mz5+vjhw5ooxGo+rQoYMCVGRkpCorK1Nz585VJ06cUAaDQbVo0UIB6uDBg6q4uFjNmTNHxcXFqZKSEtW4cWPVv3//B3qd1U2r77Qqk4yWIRktQzLeP4ueQZWVlVFUVHRP63p7e/Pxxx//z3XOnz/Pq6++yrJly2jfvj03b97EZDLdTzSzI0eOUFJSwvjx4zGZTIwdO5bx48dTWFjIuHHjMJlMHDx4EIB9+/bh7OzMiBEjOHnyJG+88QZ/+ctfABg7diz16tVj2LBhHD58mPnz5/PGG2+g1+t56aWXaNy4MeHh4ezbt48FCxYwf/58bG1tGTNmDG3atCEgIICdO3eyaNEiFi5ciIODA6NGjeLgwYMYDNq/qVgIIazlNxWo5ORkFi9eTGhoKFeuXLmnbfr168fFixe5dOnOU2BcunSJiRMn8u6779KxY0cATp06RWhoKMuXL+fatWu/JaJZamoqAH5+fuTn51NQUIDRaCQzM5PmzZuj1+vN66SmptK0aVNsbW3N+7t69SoALVq0MHequLWscpufn1+VZbe2/7U2k8lkXi6EEOJ2v1qgioqK2Lx5M88//zxvvvkmLVq0YPv27bRv3/7edvDvM41PPvnkju2vvPIK8+bNo3v37uZl/fr146uvvsLNzY2XX36ZF198kd27d1NWVnaPLwvs7OyAirO9yl3PbW1tMRgMmEwm/vrXv9KyZUs2b95sfm69Xm9eD6C0tNTcdut5/lfbra+/1lY5oxBCiNv9ajdzf39/2rRpwzvvvEOLFi3u6Ul1Ol2Vx4MHD2bVqlWkpaXdtm7v3r355ptv8Pf3r1JIPD09zdOSnz59mjlz5rBy5Up27Njxq/tPSUnBxcUFgISEBIKDg/Hx8eHmzZv4+Phw5swZANq3b0+XLl0oLi4mLS2N/Px82rRpA2D+mpCQwKVLlyguLjYva926tbntwoULGAyGO26XmJiIyWS6Y5u9vT1lZWUWGZevOhQUFGg22y2S0TIko2VIxmrwaxevoqOj1ZQpU1RYWJhavny5Sk9Pr9IeERGhLl++bH68Z88eNXv2bKVURSeJt956Syml1FdffaXmzp17WyeJrKwsNXHiRDV37tzb9p2UlKQWL16sgoKC1Jw5c9SZM2fu+WJbYWGheuSRR9SAAQOU0WhU8fHx6sSJE0oppYYOHaoA9Ze//EUppVR4eLgC1Lx585RSSn3//fcqNTVVFRQUKF9fXwWoJUuWKKWU2r17t7p69arKzc1V3t7eClArVqxQSim1c+dOlZmZqbKyslTdunWrdLzYtm2bysrKUteuXVOurq7q+eef/9XXYk1avZhamWS0DMloGZLx/t13Jwl/f3+WLVvGF198gZubG6+88gqjR48mPT0dgF69erFt2zYAjEYj27dvp1evXrc9T0REBLGxseTk5FRZrtPpWLp0KZcuXeLvf/87UHGG8dxzz/Hmm2/i5+fHli1bWLhwIZ06dbrnwuvs7MyCBQuIioqib9++xMbGEh8fT//+/fnuu+8AOHbsGIsXLyY5ORmABQsWMHz4cDIyMvj222/p0qUL6enp1K1blzlz5vDCCy+QnZ3Nl19+SdeuXcnOzsbd3Z2pU6cyatQocnNz+fzzz+natSuFhYW4ubkxfvx4xo4dS0FBAR9//DHdu3fHZDIxf/78e34tQgjxULqfahcXF6euXbumlFIqPz9fTZs2TQ0ZMkQNHjxYLVmyRBmNRqVU1TMopZRat26dat269R27mefn56unnnpKbdiwQV28eFFdvHjxfqLdVok///xz5efnZ75RtnHjxmrFihVq6dKlytnZWQGqfv366uuvv1Zz5sxRderUMa/bvXt3tXfvXlVYWKhmzJih3NzczG2PP/64OnDggMrPz1evvvqq+bkAFRAQoI4cOaJu3LihXn75ZeXk5GRuGzBggNqxY8d9vbbfk1bfaVUmGS1DMlqGZLx/dzuD0imllJVqY7VITEykXbt2VZaZTCZSUlIwmUzmHnwABoMBo9GInZ1dlQ4MKSkpuLq60rBhwyrPU1JSQkpKCu7u7vj4+FRpKy4uJjU1FQ8PD7y8vKq0FRUVkZqaSr169XjkkUdISUnB19fX0i/doiSjZUhGy5CMlqHVjHf6uw0PyVh8er2e5s2b37bczs7utp50Dg4O5k4Q/83R0dHc0eG/OTk53bXN2dmZtm3b/sbUQgjxcKvVQx0JIYSouaRACSGE0KRaV6CMRqO1IwghhLAAKVBCCCE0qdYVKCGEELWDFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmiSFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmhSrZtu48yZMzg4OFg7hhBCiHtUWlpK586db1te6wqUEEKI2kE+4hNCCKFJUqCEEEJokhQoIYQQmiQFSgghhCZJgRJCCKFJUqCEEEJoUo0qUIcOHSIkJISgoCBWr159W3tZWRlTp04lKCiIYcOGkZ6ebm775JNPCAoKIiQkhOjoaM1lPHz4MEOHDmXIkCEMHTqU2NhYzWW85dq1a3Tp0oXPPvtMkxnPnz/P8OHDGTRoEEOGDKG0tFRTGQ0GA7NmzWLIkCGEhYXxySefVEu+e8l44sQJIiIiaN++Pf/85z+rtG3ZsoXg4GCCg4PZsmWL5jImJiZW+X/etWuX5jLeUlBQQEBAAG+//bYmM167do0xY8YQFhZGeHj4bb/zVqNqiPLychUYGKhSU1NVaWmpGjJkiEpKSqqyzoYNG9TcuXOVUkrt3LlTTZkyRSmlVFJSkhoyZIgqLS1VqampKjAwUJWXl2sqY0JCgsrIyFBKKfXTTz8pf39/i+d70Iy3TJ48WU2ePFmtWbNGcxkNBoMaPHiwSkxMVEoplZOTo7n/6+3bt6upU6cqpZQqKipS/fv3V2lpaVbJmJaWphITE9XMmTPV7t27zctv3LihBgwYoG7cuKFyc3PVgAEDVG5urqYyXrp0SV2+fFkppVRGRobq27evysvL01TGWxYsWKCmTZum3nrrLYvns0TGESNGqJiYGKWUUgUFBaqoqKhacv5WNeYMKj4+Hl9fX5o0aYK9vT2DBg1i//79VdaJiooiIiICgJCQEGJjY1FKsX//fgYNGoS9vT1NmjTB19eX+Ph4TWVs3749Xl5eALRq1YrS0lLKyso0lRFg3759NGrUiFatWlk8myUyHj58mDZt2tC2bVsA6tati42NjaYy6nQ6iouLKS8vp6SkBDs7O1xdXa2SsXHjxrRt2xa9vuqfgpiYGPr27YuHhwd16tShb9++1fLJw4NkbN68Oc2nnwnjAAAEXklEQVSaNQPAy8sLT09PcnJyNJUR4McffyQ7O5u+fftaPJslMl68eJHy8nJzPhcXF5ycnKot629RYwpUZmYm3t7e5sdeXl5kZmbeto6Pjw8Atra2uLm5cePGjXva1toZK9uzZw/t27fH3t5eUxkLCwv59NNPmTRpksVzWSrj5cuX0el0vPjii0RERPDpp59qLmNISAhOTk74+/vTv39/xowZg4eHh1UyVse2v1fGyuLj4zEYDDRt2tSS8YAHy2gymViyZAmzZs2yeK7KHiTjlStXcHd3Z9KkSTzzzDMsWbIEo9FYXVF/E1trBxBVJSUl8f7777N27VprR7nNihUrGDVqFC4uLtaOcldGo5FTp07x7bff4uTkxOjRo+nQoQO9e/e2djSz+Ph49Ho90dHR5Ofn88c//pE+ffrQpEkTa0erka5fv87MmTNZsmTJHc9grOnLL78kICCgSvHQmvLyck6ePMnWrVvx8fHhtdde47vvvmPYsGHWjlZzCpSXlxcZGRnmx5mZmeaPxCqv8/PPP+Pt7U15eTk3b96kbt2697SttTMCZGRkMGnSJJYsWVIt7wQfNGNcXBx79uzh/fffJz8/H71ej4ODAyNGjNBMRm9vb3r06IGnpycAAQEBJCQkWLxAPUjG5cuX88QTT2BnZ0e9evXo2rUrZ8+etXiBepCfey8vL44fP15l2549e1o034NmhIrOB+PHj+e1116742CjlvAgGU+fPs2pU6fYuHEjhYWFGAwGnJ2dmTFjhmYyent7065dO/PPX2BgIHFxcRbNd7+09Xbjf3jssce4cuUKaWlplJWVERkZyYABA6qsM2DAAHNvoz179vD444+j0+kYMGAAkZGRlJWVkZaWxpUrV+jYsaOmMubn5zNu3DimT59Ot27dLJ7NEhm//PJLoqKiiIqKYtSoUYwfP97ixelBM/r7+3PhwgXzNZ4TJ07QsmVLTWX08fHh2LFjABQVFREXF4efn59VMt6Nv78/MTEx5OXlkZeXR0xMDP7+/prKWFZWxsSJE3n66acJDQ21eDZLZFy6dCkHDhwgKiqKWbNm8cwzz1i8OD1oxscee4z8/Hzz9btjx45Vy+/MfbFqF43f6MCBAyo4OFgFBgaqlStXKqWUWrZsmdq3b59SSqmSkhI1efJkNXDgQPXss8+q1NRU87YrV65UgYGBKjg4WB04cEBzGT/66CPVqVMn9dRTT5n/ZWVlaSpjZR9++GG19eJ70Ixbt25V4eHhatCgQWrJkiWay1hQUKAmT56swsPDVVhYmPr000+tljEuLk498cQTqlOnTqpnz54qPDzcvO0333yjBg4cqAYOHKi+/fZbzWXcunWrat++fZXfmXPnzmkqY2WbN2+utl58D5oxJiZGDR48WA0ePFjNmjVLlZaWVlvO30Km2xBCCKFJNeYjPiGEEA8XKVBCCCE0SQqUEEIITZICJYQQQpOkQAkhhNAkKVBCCCE0SQqUEEIITfr/i/Xml8HpT94AAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVyU5fr48c+jKKKAisqgZv4Cw0xN+2apiRsGorgnUsdMLLOjJalpWppLLnROWma2kWVanUxcwNTcMCX3XSvTErE0YThfRECRbeb+/cFhvnlUZhhmmGG43q/X83o12z3XEFzecz33c92aUkohhBDCpqo5OgAhhHBFklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKruEmrVq0YOHAg/fr1Izo6mhs3blg91rRp09iyZQsA06dP59y5c3d87sGDBzl27FiZ3yM4OJgrV65YfP9fPfjgg2V6r/fee49PP/20TK8RVZckV3GTWrVqkZCQwMaNG6lRowarVq266fGioiKrxp0/fz4tWrS44+OHDh3i+PHjVo0thDNyc3QAwnl16NCBs2fPcvDgQd599128vb1JSUlh8+bNLFy4kEOHDlFQUMDw4cN54oknUEoxd+5c9u7dS+PGjalRo4ZprBEjRvDKK6/Qtm1bkpKSeOeddzAYDNSvX5/58+ezatUqqlWrxoYNG3j99dfx9/dn1qxZXL58GYDXXnuNhx56iMzMTF5++WX0ej3t27fHkmtgxo0bR1paGvn5+Tz99NNERkaaHluwYAF79+6lYcOGvPPOO/j4+PDHH38wZ84cMjMzqVWrFnPnziUgIMD2P2Dh2pQQf9G+fXullFKFhYXq73//u/rqq6/UgQMHVLt27dQff/yhlFJq1apV6v3331dKKZWfn68GDx6s/vjjD7V161YVFRWlioqKVFpamnrooYfUd999p5RS6qmnnlKnTp1SGRkZqlu3bqaxMjMzlVJKLVmyRC1btswUx6RJk9Thw4eVUkr9+eefKiwsTCml1Ny5c9V7772nlFLq+++/V4GBgSojI+OWz9GzZ0/T/SXvcePGDRUeHq6uXLmilFIqMDBQJSQkKKWUeu+999ScOXOUUko9/fTTKiUlRSml1IkTJ9SIESNuG6MQpZGZq7hJXl4eAwcOBIpnrkOHDuX48eO0bduWZs2aAbB3717Onj3L1q1bAcjJyeH333/n8OHDhIeHU716dXQ6HZ06dbpl/BMnTtChQwfTWPXq1bttHPv27bupRnvt2jWuX7/O4cOHWbp0KQA9evSgbt26Zj/TF198wfbt2wFITU3l999/p379+lSrVo2+ffsCMHDgQF588UWuX7/O8ePHeemll0yvLygoMPseQvw3Sa7iJiU11/9Wu3Zt038rpZgxYwZdu3a96Tm7d++2WRxGo5HVq1fj7u5ernEOHjzIvn37+Oabb/Dw8GDEiBHk5+ff9rmapqGUwtvb+7Y/AyHKQk5oiTILCgri66+/prCwEICUlBRyc3N5+OGH+e677zAYDKSnp3Pw4MFbXtu+fXuOHDnCxYsXAbh69SoAderU4fr16ze9xxdffGG6/csvvwDw8MMP8+233wLFyTwrK6vUWHNycqhbty4eHh4kJydz4sQJ02NGo9E0+/7222956KGH8PT05K677uK7774Div8hOXPmTNl+QEIgyVVYISIighYtWjBkyBD69evHzJkzMRgMhISE0Lx5c/r27cvUqVNp3779La/18fHhjTfeYPz48QwYMICJEycC0LNnT7Zv387AgQM5cuQI06dP56effqJ///707duXr7/+GoAXXniBI0eOEB4ezvbt22nSpEmpsXbr1o2ioiL69OnDokWLboqpdu3anDp1in79+nHgwAFeeOEFAN566y3WrFnDgAEDCA8PZ8eOHbb60YkqRFNKWg4KIYStycxVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhyFUIIO5Dk6iRkubEQrkWSqwP9NaFqmsa1a9c4c+YMc+bMYefOnQ6MTAhRXpJcHUjTNADS0tI4efIkY8eOZfPmzWzfvh03N+mpI0RlJn/BDnD58mV0Oh3Vq1fniy++ICkpCV9fX4YNG8Zdd93FDz/8gL+/v6PDFEKUg/QWqEBKKVJTUxk5ciRfffUVtWvXZvPmzbRr1w5fX1/q16/PW2+9xT333MPQoUMdHa4Qohxk5lqBNE3D09OTRo0a4evrC8DQoUOpVq24OnP9+nXS0tLo06ePI8MUQtiA1FwryIULF4DiZtTVq1e/aaO/ki8Pb7/9NgBt2rSp8PiEELYlM1c7U0pRWFjI+PHjefTRRxk7diyZmZnk5OSYthopERQUxH333Wd6XckJLyFE5SM1VzvT6/XodDpSU1MZO3YsDz74IMnJyfTo0QMfHx9q1qyJj48P+fn5eHt788ADD1C9enVHhy2EKCdJrnailCIrK4vhw4czcuRIhg0bhl6vZ/LkyRw+fJjnnnuOP/74g/z8fDRN48qVKyxZsgSdTufo0IUQNiDJ1c527drFu+++y4gRIxgyZAhXrlxhzJgxhIWFMXr0aNPz8vPzy70ZnxDCeUjN1Q5+/fVXGjRogKenJz169MDDw4N58+ZhMBiIiIjg/fff5+9//zsXL15kzpw5ANSoUcPBUQshbElmrjaWmppKaGgojRo1IjAwkOHDhxMQEEBWVhavvPIKY8eOpW/fvqSlpTFp0iSWLl2Kj4+Po8MWQthY9dmzZ892dBCuIjs7m4YNG1K7dm1TrwB3d3feffddvLy8yMnJYcuWLbi7u9OxY0cGDRpEnTp1HB22EMIOZJ2rjej1eiZNmsThw4d5+umn6dy5My1atKBly5Z8/vnn+Pj40Lx5c9LS0li0aBFZWVk3LcMSQrgWKQvYyNWrV9m0aRN79uxhzJgxtG3bljVr1nDixAnCw8Pp2rUrAMnJyXh7e9OoUSMHRyyEsCcpC9hIrVq1aN68OQaDgdWrV3P33XcTHBzMlStXOHjwIDk5ObRs2RIfHx8pBQhRBcj30nI4fPgwCQkJptt169ald+/ePPbYY3z88cf89ttvDBgwgBYtWvDjjz9y7do1B0YrhKhIshSrHIqKioiJiaFatWr0798fKE6woaGh5OXlsX37dsaPH09YWBi1atXC09PTwRELISqKzFytoJRCKUXnzp1ZsmQJixcvZsOGDabH6tWrR0BAACkpKRiNRnx9ffH29q7wOP/973/L9jFOLjc319EhlIn8PllOkqsVNE1D0zTOnDnDI488wrx583j33XfZuHGjqdlKbm4u+fn5Fv/xGAwGm8b4ww8/8OKLL5KammqzMX/77TcOHTpEZmamzcb8/fff+fHHHykoKLDZmBcuXODHH3/EaDTa7Od6/vx5jh8/TmFhoc3G3LFjBwsXLiQjI8Mm4wGcOHGC+Ph4Tpw4YbOf6ZEjR4iPjweKf/clwVpGTmhZac2aNbz//vuEh4fj7+9Py5Ytef/997lw4QK7d+8mISGBGTNm0Lhx41LHSUlJMXXHMhgMNlmetWfPHhYuXEhmZiZXr16lW7du5R5z9+7dzJo1i5SUFLZt20anTp3KfWLu+++/5/XXX+fo0aPs37+fwMBA6tevX64xd+zYwezZs0lOTubEiRNcunSJFi1alOsKuG3btjFjxgx++uknDh48iF6vJyAggJo1a1o95qFDh5g/fz5RUVG0bNnS6nH+KjExkZiYGPLz8zl8+DBt2rShXr16Vo9nNBrJzc3lhRde4OjRo1SrVo22bduiaRpGo1G6tpmjRJkYDAallFIffvih2rFjx02PnT17Vm3atEmtWLFCXbhwwexYO3fuVA888ICaNGmS6b6ioqJyxbd371712GOPqV9//VUVFBSoUaNGqUOHDpVrzAMHDqjQ0FB18uRJpZRS48aNU3v37i3XmEePHlVhYWHq559/VkopNWvWLDVt2rRyjXnlyhX17LPPqt9++00ppVRcXJwaMmSIWrp0qcrJybFqzIKCAvXSSy+pI0eOKKWU2rJli3rzzTfV22+/bfWYSin12WefqWXLlimllEpLS1N79uxRJ06cUNnZ2VaNd+XKFfXMM8+os2fPKqWUmjZtmtq8ebP63//9X5WXl2d1nEopFRsbqz799FM1ZcoUtXz58nKNVZVIWaCMqlWrxsWLF9m7d+9NHax+//13AgMD6du3L08//TTNmzcvdZzc3Fy+/PJLXnvtNWrUqMHkyZMBqF69erm+dhoMBv7xj39w7733cuPGDe655x5+++03wPp6WcOGDZkzZw4PPPAA//73vzl58iRffvklM2fOZMuWLVaP+9xzz3H//fcDEB0dTVZWVrm+yrq5uZGbm8u///1voHiXh6ZNm5KZmcmuXbusHvfatWv8/vvvAISEhNCzZ08KCwv59ttvrf7sf20r+dJLL7F27Vq+/PJL5syZQ1ZWVpnHc3NzIy8vj/Pnz3Pt2jUOHTpEQkICCxYs4IMPPihXbdfNzY3U1FQGDx7MqVOniImJYdGiRSilMBqNVo/r6qQsUAZKKYqKili8eDHBwcF06dKF5ORkpk+fzvnz57n33nvx9PS06OtSjRo16NSpE23atKFTp04kJiaSmJhIaGhouUoDzZs3p3HjxhiNRmrVqoWmacTExBAUFETDhg2tGtPHx4e77roLgJUrV9K2bVtmz55NZmYmO3fu5JFHHsHDw6NMY/r6+tK8eXNq1qyJwWAgJyeHr7/+mj59+uDh4UFmZmaZx3R3d6egoIDExERyc3P57rvvyM3NpU2bNhw5coRevXqVaTwoToINGjRg/fr1+Pn50bRpU/z8/Lh69Sr79+8nNDTUqq/HtWrVYuHChRw7dow+ffowceJEWrVqxY8//oinp6fZf5z/m7u7O3Xq1CE2NpZvv/2WPn368MYbb+Dt7c3Ro0e55557rP7/36BBA1JTUxk0aBB//vknn376KQEBAfTo0UNKA6WQmWsZaJpGjRo1uH79Ounp6URFRbFu3Truu+8+Jk+ejJ+fX5l+2XQ6HXXq1MHHx4c5c+aQn59vmsH+/PPPJCcnWx1rSYLu1q0bw4YNY9euXTaZaYwdO5Zx48YBMGTIEK5du2bVSbPq1aublqYppfDy8qJu3br4+PiwYcMGFi9eTF5eXpnH7devH926dePgwYPk5eWxcOFCnnjiCTIyMqxeZ9yhQweCgoJISEjg8OHDVK9enf79+5Oens6ZM2esGrNly5ZMnTqVkydPcunSJQCaNWuG0WjkypUrVo0ZFhbG8uXLeeihh0zfCDp37sz169f5888/rRoTihN3SkoKq1evZtWqVTz33HOkpqayatUqq8esCmSdaxmdP3/e9FV49OjRPProozZpF1i/fn3mzJnDW2+9RVhYGEajkZUrV9ogYrjvvvv4/PPPGT16dLl2OVD/tfXM1q1bycjIMG22aC03Nzfc3Nxo3LgxixYtYu/evcTExFCrVq0yj+Xl5cWAAQPo16+f6R+Y+Pj4cvVycHd3p3///miaxscff8z58+epWbMmGRkZ5bqMuVu3bkRHR/Pee+/RpEkTAE6fPs2YMWOsHrNu3bp06tSJLVu2UKNGDfLz87l06VK5TprpdDr8/Pz44IMPmDlzJsHBwRw4cKDMs+sqx2HV3kosJydH5ebm3nSf0Wi0ydjLly9Xjz76qDpz5oxNxisRHR2tLl68aJOx8vPz1erVq1Xfvn1NJ1DKw2g0qvz8fNWrVy/VvXt3lZKSUv4g/yMuLk716dPHJj/P/Px8tX//fjVhwgQ1depU08m48vrpp5/UokWLVExMjE3izMrKUitWrFDDhw9XzzzzjPrll1/KPebly5fVjz/+aLpdcmJX3Jk0bnEiWVlZTJgwgalTp5o2KiwvZYeNDgsLC9m3bx/NmjXD39/fZuOuW7eOtm3bcu+999pszD///JOioiKbzrIMBgOapjl9V7OSMogtrwy0x++Tq5Lk6mSq8nYv8ocrXIkkVyGEsAPn/l4jhBCVlCRXIYTTy8/PJzs729FhlEmVXoqVlPgDmZfLfjWMEOJm9ZvUpVuvrnYb/1JyLLkFLbi/bWi5lhNWpCqdXDMvZ7F05ApHhyFEpffiipF2G/vGjRsUGb3QeX2LPnkXTQL/Ybf3siUpCwghnNrllGX4ea3Hp/YuruY9YvP2nPYiyVUI4bRKZq1e7r9QTSuiYZ1E9MmvOTosi0hyFUI4rZJZa4nKNHuV5CqEcEp/nbWWqEyzV0muQgin9N+z1hKVZfbqsOQaHBx8U2u1gwcP8vzzzwOY2vj9tZ1bv379TK3Z/vran376ieDgYE6fPl2B0Qsh7Ol2s9YSlWX2WqHJtaCgwOKO6H5+fnz00UelPufMmTNER0ezePFi7r//fnJycqQzuhAu4E6z1hKVYfZaIck1OTmZN998k7CwMC5cuGDRa3r06MG5c+c4f/78bR8/f/48L7zwAv/85z954IEHADh69ChhYWG89957XL582VbhCyEqUF5eHkVG79vOWktU04poUDvRtKWPM7Jbcs3NzWXt2rU8+eSTzJgxg4CAADZs2GDqkG42sGrVGD16NB9//PFtHx83bhwzZ86kQ4cOpvt69OjBqlWr8PLyYuzYsTz77LN89913Nt22WQhhXwUFBdSukWL2ebVrnic/P78CIrKO3a7QCgoKomXLlsybN4+AgACLXvPf7eb69evHhx9+yMWLF295bufOnYmLiyMoKOimy+F8fHyIiooiKiqK48eP89prr/HBBx/w7bfflu8DCSEqjEJhpPQSn8K5G/rZbea6ZMkSdDod48ePZ+nSpbfs4VOvXr2bGjFkZWXdsme9m5sbzzzzDJ988skt48+cOROAOXPm3PLYuXPn+Mc//sHUqVP5n//5H+bNm2eLjySEqCBKgUEZzR7OzG7JNSgoiMWLF/PVV1/h5eXFuHHjiIqKMp3x79ixIwkJCUBxZ/cNGzbQsWPHW8YZPHgw+/fvv2XTNk3TWLRoEefPn+fdd98Fijf1GzZsGDNmzMDf35/169czf/582rVrZ6+PKYSwAyNGijCUehjMzGwdze6NW+rXr8/IkSMZOXIkp06dMn2FHzduHLNnz2bAgAEopejatSsDBgy45fU1a9ZkxIgRzJ8//5bH3N3d+fDDD3nqqado2LAhnTp1IiYmxuIyhBDCORkBg5k+/kalwIk3rqjSOxEkfLFRumIJYQMvrhjJwBH9bDJWdnY26Zf/SUPv0v828wpakK997rS70FbploNCCOekAIOZE1ZGJz+hJclVCOF0jEpRaOaEVZEkVyGEKBsFZk9XGXHqkqskVyGE81Eoi8oCzrzhiyRXG9t6+YTNx+zdpL3NxxTCmRWvFjDzHAXVnXjqKslVCOF0jGgUmvnSb0CjRgXFYw1JrkIIp6MonpmWxtzjjibJVQjhdIqXYpU+c3Xu67MkuQohnJBBaaBKvzpfmXnc0SS5CiGcjkIzO3NVTr0QS5KrEMIJKTSMZvtKSXIVQogyKT6hZSZ5mnvcwZy7aFEOr776Kp07d6ZfP9s0kxBCVByD0ihQ1Us9ipz6EgIXTq5Dhgxh2bJljg5DCGGFkrJA6YfMXB3i4Ycfpm7duo4OQwhhhZITWqUdliTX232DvXr1KqNGjSI0NJRRo0aRlZVV/J5KMW/ePEJCQujfvz8///yz6TXr168nNDSU0NBQ1q+/8660f+WyyVUIUXkZ0ChU1Us9iixYinW7b7CxsbF07tyZbdu20blzZ2JjYwFISkriwoULbNu2jblz5zJ79mygOBkvXbqU1atXExcXx9KlS00JuTSSXIUQTqd45lrN7GHO7b7BJiYmMmjQIAAGDRrEjh07brpf0zTat29f3LQ7PZ09e/bQpUsX6tWrR926denSpQs//PCD2feW1QJCCKejlIbBzMy0mqpGcnIyEydONN0XGRlJZGRkqa/LyMjA19cXgEaNGpGRkQGAXq/Hz8/P9Dw/Pz/0ev0t9+t0OvR6vdnPIMlVCOF0LFnnakQjICCAdevWWf0+mqahafY5MeayZYFJkybxxBNPkJKSQrdu3YiLi3N0SEIICxmwYCmWlZe/NmjQgPT0dADS09Px8fEBimekaWlppuelpaWh0+luuV+v16PT6cy+j8sm17fffps9e/bw888/k5SUREREhKNDEkJYSCkNo6pm9rBGcHAw8fHxAMTHx9OrV6+b7ldKceLECby8vPD19SUoKIg9e/aQlZVFVlYWe/bsISgoyOz7SFlACOF0Sk5olcb85bHF32APHTpEZmYm3bp1Y/z48YwZM4YJEyawZs0amjRpwuLFiwHo3r07u3fvJiQkBA8PDxYsWABAvXr1GDduHEOHDgXghRdeoF69embfW5KrEMLpGNGKO2OVwmDBOG+//fZt71+x4tZtuzVNY9asWbd9/tChQ03J1VKSXIUQTseoNApV6enJzczjjubc0QkhqiRlwRVYTr4RgSRXW7PHZoKvJP9o8zEB/hnQ1vaD2mNZi3L2PyNhawrz61zNPe5oklyFEE7H+J/LX0tj7VKsiiLJVQjhdIw2Wi3gSJJchRBOp2Sda2msXedaUSS5CiGcjuz+KoQQdmCkmvmaq5PvRCDJVQjhdCwrCzj3TgSSXIUQTsdowVIsqbk6yPnz52/q83jx4kWio6OJiopyXFBCCIsoMHsRgbPvoeWyydXf35+EhAQADAYD3bp1IyQkxMFRCSEsYVQahcbSa6oGo8xcHW7//v00a9aMpk2bOjoUIYQFLOmKZck2L45UJZLrpk2bbtr9UQjh3IpPaFXu3gLOnfptoKCggJ07dxIWFuboUIQQFjJatPurLMVyqKSkJFq3bk3Dhg0dHYoQwkKWzFxlKZaDbdq0ifDwcEeHIYQoA0XlX+fq0mWB3Nxc9u3bR2hoqKNDEUKUgZHiy19LO2QplgPVrl2bgwcPOjoMIUQZKaWZranKagEhhCgjS3YikJmrEEKUkRHMblAoyVUIIcrIosYtUhYQQoiyUWhmt3Ex1+/V0SS5CiGcjkVXaNljM0wbkuRaCdhll1Yg+twZm4+5pMV9Nh9TVD0K8y0FpeYqhBBlZFSWlAWcu+bq3NEJIaqk4iu0zB+W+PzzzwkPD6dfv35MmjSJ/Px8Ll68SEREBCEhIUyYMIGCggKguBfJhAkTCAkJISIigkuXLln9GSS5CiGcjlKYTazKguSq1+tZuXIla9euZePGjRgMBjZt2sTChQuJiopi+/bteHt7s2bNGgDi4uLw9vZm+/btREVFsXDhQqs/gyRXIYTTsWjmauFYBoOBvLw8ioqKyMvLo1GjRhw4cIDevXsDMHjwYBITEwHYuXMngwcPBqB3797s378fpaxrbig1VyGE07Go5mrBHlo6nY5nnnmGnj174u7uTpcuXWjdujXe3t64uRWnPz8/P/R6PVA8023cuDEAbm5ueHl5kZmZiY+PT5k/gyRXIYTTKV4tYL7lYHJy8k175UVGRhIZGWm6nZWVRWJiIomJiXh5efHSSy/xww8/2Cvsm7hscs3Pz2f48OEUFBRgMBjo3bs30dHRjg5LCGGBkrJAqc9RGgEBAaxbt+6Oz9m3bx933XWXaeYZGhrKsWPHyM7OpqioCDc3N9LS0tDpdEDxTDc1NRU/Pz+KiorIycmhfv36Vn0Gl6251qxZkxUrVrBhwwbi4+P54YcfOHHihKPDEkJYwoITWkYLSqFNmjTh5MmT3LhxA6UU+/fvp0WLFnTs2JGtW7cCsH79eoKDgwEIDg5m/fr1AGzdupVOnTqhWXmxgsvOXDVNo06dOgAUFRVRVFRk9Q9JCFGxjEozu7urUTM/N2zXrh29e/dm8ODBuLm50apVKyIjI+nRowcTJ05k8eLFtGrVioiICACGDh3KlClTCAkJoW7durzzzjtWfwaXTa5QfJZwyJAh/PHHH/ztb3+jXbt2jg5JCGEBhfkrsCy9Qis6OvqWkmCzZs1My6/+yt3dnSVLllgcZ2lctiwAUL16dRISEti9ezenTp3i119/dXRIQggLWLIUy5J1ro7k0sm1hLe3Nx07dqyws4RCiPJR/ykLlH5IcnWIK1eukJ2dDUBeXh779u3D39/fwVEJISyiihNsqYc0bnGM9PR0pk2bhsFgQClFWFgYPXv2dHRYQggLWLoUy5m5bHK97777iI+Pd3QYQggrKFV8mHuOM7tjcn3wwQdNS5dKrq3VNA2lFJqmcezYsYqJUAhR5Sg0s5e3WtoVy1HumFyPHz9ekXEIIYSJpZe/OjOLTmgdOXKEtWvXAsUnii5evGjXoIQQVVtJWaDUw9FBmmE2uS5dupRly5YRGxsLQGFhIVOmTLF7YEKIqs3cagEq+8x1+/btfPjhh3h4eADFjQ2uX79u98CEEFWXK6xzNbtaoEaNGmiaZjq5lZuba/egxH+xU08Ee2wm+GryKZuPGRPwgM3HFM7NotUCFROK1cwm1z59+jBz5kyys7NZvXo1a9euZdiwYRURmxCiyrLg8lYnLwuYTa7PPvsse/fupU6dOqSkpBAdHU2XLl0qIjYhRBVVsodWaZx9tYBFFxEEBgaSl5eHpmkEBgbaOyYhRBWnLJi5OvsVWmZPaMXFxREREcH27dvZunUrkZGRt23VJYQQNqMsPJyY2ZnrsmXLWL9+vWmrg8zMTJ544gmGDh1q9+CEEFWX2ZlrZW/cUr9+fVNHf4A6depYvaeMEEJYQikNo5mlVsrSvbUd5I7Jdfny5QDcfffdDBs2jF69eqFpGomJibRs2bLCAhRCVFGuulqg5EKBu+++m7vvvtt0f69evewfVTmlpqbyyiuvkJGRgaZpDBs2jJEjRzo6LCGEpVy5K9aLL75YkXHYVPXq1Zk2bRqtW7fm2rVrPP7443Tp0oUWLVo4OjQhhKWcPHmaY7bmeuXKFT755BPOnTtHfn6+6f6VK1faNbDy8PX1xdfXFwBPT0/8/f3R6/WSXIWoJJTSUGZrrs5dFjC7FGvy5Mn4+/tz6dIlXnzxRZo2bUrbtm0rIjabuHTpEr/88ovs/CpEZWLJNi9OXnM1m1yvXr1KREQEbm5uPPLII8TExHDgwIGKiK3crl0WQkcAABE5SURBVF+/TnR0NK+99hqenp6ODkcIURauvs7Vza34Kb6+vuzatQtfX1+ysrLsHlh5FRYWEh0dTf/+/QkNDXV0OEKIslBYsBrAuWeuZpPr2LFjycnJYerUqcydO5fr16/z6quvVkRsVlNKMX36dPz9/Rk1apSjwxFCWMPczLSyz1xLdkz18vLiiy++sHtAtnD06FESEhIIDAxk4MCBAEyaNInu3bs7ODIhhGUsaIZdWZPr3LlzTT1cb2fGjBl2CcgWOnTowNmzZx0dhhDCSpb0c620ybVNmzYVGYcQQvwfBZhbamXhaoHs7GxmzJjBr7/+iqZpLFiwgHvuuYeJEyfy559/0rRpUxYvXkzdunVRSjF//nx2795NrVq1ePPNN2ndurVVH+GOyXXw4MFWDSiEEOWlAZqNZq7z58+na9euLFmyhIKCAvLy8vjoo4/o3LkzY8aMITY2ltjYWKZMmUJSUhIXLlxg27ZtnDx5ktmzZxMXF2fVZ7Bo91chhKhQNmo5mJOTw+HDh01d/GrWrIm3tzeJiYkMGjQIgEGDBrFjxw4A0/2aptG+fXuys7NJT0+36iNY1CxbCCEqliUntDSSk5OZOHGi6a7IyEgiIyNNty9duoSPjw+vvvoqZ86coXXr1kyfPp2MjAzTVZyNGjUiIyMDAL1ej5+fn+n1fn5+6PV603PLQpKrsCl7bCY45tfzNh8zNtDf5mMKG1KAuZaCCgICAli3bt0dn1JUVMTp06d5/fXXadeuHfPmzSM2Nvam5/x1A1ZbcsnVAkKISs6Sr/0WlAX8/Pzw8/MzXf4eFhZGbGwsDRo0ID09HV9fX9LT0/Hx8QFAp9ORlpZmen1aWho6nc6qjyCrBYQQzskG/VwbNWqEn58f58+fx9/fn/379xMQEEBAQADx8fGMGTOG+Ph4UyvV4OBgvvzyS8LDwzl58iReXl5WlQRAVgsIIZyRAs1MWcDsaoL/eP3115k8eTKFhYU0a9aMmJgYjEYjEyZMYM2aNTRp0oTFixcD0L17d3bv3k1ISAgeHh4sWLDA6o/gki0HhRCiRKtWrW5bl12xYsUt92maxqxZs2zyvi7fclAIUfmUrHM1dzgzl245KISopJRm2eHEXLbloBCiErNkKVZl3f21RGVsOQjF9ZS4uDiUUkRERBAVFeXokIQQZWDua79zz1tdtOXgr7/+SlxcHHFxcdSoUYPRo0fTs2dPmjdv7ujQhBCWsNE6V0cym1zvNEuNiYmxeTC2kpyczAMPPICHhwcADz/8MNu2beO5555zcGRCCIu5enLt0aOH6b/z8/PZsWOH1YtqK0pgYCCLFy8mMzOTWrVqkZSUJBdFCFGZKNDMtBw0tw7W0cwm1969e990u1+/fvztb3+zW0C2EBAQwOjRo3n22Wfx8PDgvvvuo1o1aQAmRKVRCTYgNKfMjVsuXLhg6iDjzCIiIoiIiADg7bfftvr6YCFExbNlP1dHMZtcH3zwwZsauDRq1IjJkyfbNShbyMjIoEGDBly+fJlt27axevVqR4ckhLCUJZe/VvaywPHjxysiDpsbP348V69exc3NjVmzZuHt7e3okIQQZeHqM9eRI0fecg3u7e5zNv/6178cHYIQwlquXHPNz8/nxo0bZGZmkpWVhfrPVozXrl1Dr9dXWIBCiKrHkpqrs/cWuGNyXbVqFStWrCA9PZ0hQ4aYkqunpydPPfVUhQUohKiCXPkigpEjRzJy5Ei++OILRowYUZExCSFEpZ+5ml38Wa1aNbKzs023s7Ky+Oqrr+walBCiirPR7q+OZPaE1urVqxk+fLjpdt26dYmLi7vpPmFnysl/i+zMHpsJPn32os3HXNmymc3HrNIq+a+92eRqNBpRSpnWuhoMBgoLC+0emBCi6tKqwjrXoKAgJkyYwBNPPAEUn+jq2rWr3QMTQlRtLn+F1pQpU/jmm2/4+uuvAXj00UcZNmyY3QMTQlRhlaCmao5FJ7SefPJJlixZwpIlS2jRogVz586tiNiEEFVUSVnA3OHMLGrccvr0aTZu3MiWLVto2rQpoaGh9o5LCFHVuWpZICUlhU2bNrFx40bq169P3759UUpVmt0IhBCVmCtfRNCnTx86dOjAxx9/bNoe5fPPP6+ouIQQVVxl30PrjjXXpUuX0qhRI55++mlmzJjB/v37TZfAVgZJSUn07t2bkJAQYmNjHR2OEKIMXLrm+thjj/HYY4+Rm5tLYmIiK1as4MqVK8yaNYuQkBCCgoIqMs4yMRgMvPHGGyxfvhydTsfQoUMJDg6mRYsWjg5NCGEJFygLmF0tULt2bfr3789HH33E7t27uf/++/nkk08qIjarnTp1iubNm9OsWTNq1qxJeHg4iYmJjg5LCFEWNrz81WAwMGjQIJ5//nkALl68SEREBCEhIUyYMIGCggIACgoKmDBhAiEhIURERHDp0iWrwy/TxlJ169YlMjLS6Xu56vV6/Pz8TLd1Op20SRSiktGUmaMMY61cuZKAgADT7YULFxIVFcX27dvx9vZmzZo1AMTFxeHt7c327duJiopi4cKFVscvu/YJIZyPucRahplrWloau3btYujQocVDK8WBAwdMm68OHjzY9M12586dDB48GCjenLU855pcMrnqdDrS0tJMt/V6vWxQKERlY6OywIIFC5gyZYppB+jMzEy8vb1xcys+5eTn52f6ZqvX62ncuDEAbm5ueHl5kZmZaVX4Lplc27Zty4ULF7h48SIFBQVs2rSJ4OBgR4clhLCUhS0Hk5OTGTJkiOn45ptvbhrm+++/x8fHhzZt2lRs/FixtXZl4ObmxsyZMxk9ejQGg4HHH3+ce++919FhCSEsZFFXLAUBAQGsW7fujs85duwYO3fuJCkpifz8fK5du8b8+fPJzs6mqKgINzc30tLSTN9sdTodqamp+Pn5UVRURE5ODvXr17fqM7hkcgXo3r073bt3d3QYQggr2WIngpdffpmXX34ZgIMHD/LZZ5+xaNEioqOj2bp1K+Hh4axfv970zTY4OJj169fz4IMPsnXrVjp16mRqt1pWLlkWEEJUcnbeiWDKlCksX76ckJAQrl69SkREBABDhw7l6tWrhISEsHz5ciZPnmz1e7jszFUIUXnZY/fXjh070rFjRwCaNWtmWn71V+7u7ixZsqRsA9+BJFchhPNRgLnLW538Ci1JrkIIp+TyOxEI4YpW3ne3zcfs87N16yHN+a51PbuM69RcoLeAJFchhNMpXopVevYsa821oklyFUI4JVuf0KpoklyFEM5HygJCCGF79liKVdEkuQohnI+Fl786M0muQgjnI2UBIYSwPUvKAs6eXF22t0B2djbR0dGEhYXRp08fjh8/7uiQhBAWU6AsOJyYy85c58+fT9euXVmyZAkFBQXk5eU5OiQhhKVcoObqkjPXnJwcDh8+bNrWoWbNmnh7ezs4KiGExVxga22XTK6XLl3Cx8eHV199lUGDBjF9+nRyc3MdHZYQwlJ2bjlYEVwyuRYVFXH69GmefPJJ4uPj8fDwIDY21tFhCSEsVHL5a6mHk9dcXTK5+vn54efnR7t27QAICwvj9OnTDo5KCFEWZrfWdu7c6prJtVGjRvj5+XH+/HkA9u/ff9Oe5UIIJ+cCZQGXXS3w+uuvM3nyZAoLC2nWrBkxMTGODkkIYSFXWOfqssm1VatWpe4KKYRwYkpZ0HLQubOryyZXIUQlJzNXIYSwLUtOWDn7CS1JrkII56MAM2UBs487mCRXIYTzcYHLXyW5CiGckAWNWSS5CqelabYf0x5ncO0Rpx3Ya5fWAaczbD7mhvsb2HxMW5KaqxBC2IMFu79Ky0EhhLCGua5X0hVLCCHKprgsoMwe5qSmpjJixAj69u1LeHg4K1asAODq1auMGjWK0NBQRo0aRVZWFgBKKebNm0dISAj9+/fn559/tvozSHIVQjgnG/QVqF69OtOmTWPz5s188803/Otf/+LcuXPExsbSuXNntm3bRufOnU1d85KSkrhw4QLbtm1j7ty5zJ492+rwJbkKIZyPMtNu0Gj+8lgAX19fWrduDYCnpyf+/v7o9XoSExMZNGgQAIMGDWLHjh0Apvs1TaN9+/ZkZ2eTnp5u1UeQmqsQwvkoLFiKpUhOTmbixImmuyIjI4mMjLzt0y9dusQvv/xCu3btyMjIwNfXFyjuopeRUbwiQ6/X4+fnZ3qNn58fer3e9NyycNnk+vnnnxMXF4emaQQGBhITE4O7u7ujwxJCWMLCiwgCAgIsatB0/fp1oqOjee211/D09Lx5HE1Ds8NyP5csC+j1elauXMnatWvZuHEjBoOBTZs2OTosIYTFLNn91bKRCgsLiY6Opn///oSGhgLQoEED09f99PR0fHx8ANDpdKSlpZlem5aWhk6ns+oTuGRyBTAYDOTl5VFUVEReXp5V03ohhGNYtM2LBTVXpRTTp0/H39+fUaNGme4PDg4mPj4egPj4eHr16nXT/UopTpw4gZeXl9W5wyXLAjqdjmeeeYaePXvi7u5Oly5dCAoKcnRYQgiLWXL5q/nkevToURISEggMDGTgwIEATJo0iTFjxjBhwgTWrFlDkyZNWLx4MQDdu3dn9+7dhISE4OHhwYIFC6z+BC6ZXLOyskhMTCQxMREvLy9eeuklEhISTD9cIYSTU5i/SMCCskCHDh04e/bsbR8rWfP6V5qmMWvWLPMDW8AlywL79u3jrrvuwsfHhxo1ahAaGsrx48cdHZYQwlJKoRmNpR4YnfsSLZdMrk2aNOHkyZPcuHEDpZRsUChEZVOyFMsGJ7QcxSXLAu3ataN3794MHjwYNzc3WrVqdce1b0IIJ2SjsoAjuWRyBYiOjiY6OtrRYQghrKBhvneAbFAohBBlpTBfU1XOXXOV5CqEcEKyE4EQQtieJTVX5564SnIVQjghZb6mKjVXIYQoK6XAYGZq6uTrXCW5VmVO/i+/iWaH5dhGg+3HtBN7bCY4/Mwlm47nc73QpuOZ1rKae44Tk+QqhHBOckJLCCFsTMoCQghhB0qZX8cq61yFEMIKUhYQQggbUwrMNcOWE1pCCFFGSpmvqTp5zdUlWw6WMBgMDBo0iOeff97RoQghysKiloPOPXN16eS6cuVK6eMqRGVUMnMt7ZDk6hhpaWns2rWLoUOHOjoUIUSZWbL7q3MnV5etuS5YsIApU6Zw/fp1R4cihCgrF1jn6pIz1++//x4fHx/atGnj6FCEENZQoJTRzCEz1wp37Ngxdu7cSVJSEvn5+Vy7do3JkyezcOFCR4cmhLCEJUuxzD3uYC6ZXF9++WVefvllAA4ePMhnn30miVWIykQpMJhpruPkZQGXTK5CiEpOumI5v44dO9KxY0dHhyGEKAOlFMrMzFRJbwEhhLCC9BYQQggbs6Tmau5xB3PJpVhCiEpOKZSx9MPSmmtSUhK9e/cmJCSE2NhYOwf+fyS5CiGcT0k/11IP88nVYDDwxhtvsGzZMjZt2sTGjRs5d+5cBXwAKQsIIZyMpmnc2/H/4V7HvdTnefrURtO0Up9z6tQpmjdvTrNmzQAIDw8nMTGRFi1a2CzeO6nSybV527tY8vMbjg5DiIpn43JlvpZvs7E8PT0JHtAd1d/8zHTz5s1MmDDBdDsyMpLIyEjTbb1ej5+fn+m2Tqfj1KlTNou1NFU6ubZv397RIQgh/oumadSuXdui50ZERBAREWHniKwjNVchhMvS6XSkpaWZbuv1enQ6XYW8tyRXIYTLatu2LRcuXODixYsUFBSwadMmgoODK+S9q3RZQAjh2tzc3Jg5cyajR4/GYDDw+OOPc++991bIe2vK2ft2CSFEJSRlASGEsANJrkIIYQeSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIezg/wOdcPs8eDN9egAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVxUVf/A8c+s7Dui4L6DIIqC4C5qrqTmlktqmo+Va6aW5c+ex3LLLMwWTTOX8iklNTVNLfdccckVN1SQHdkZhlnv7w9yEsGlHpQRz/v18oVz7rnnfucyzPcu554jkyRJQhAEQRCsjLy8AxAEQRCE0ogEJQiCIFglkaAEQRAEqyQSlCAIgmCVRIISBEEQrJJIUIIgCIJVEgnqCfnss8+YOnVqeYfxRCUkJNCwYUOMRuP/3FbHjh05fPhwqcumT59OZGTk/7yNZ0lkZCShoaG0bt36iW/75MmTdOnShaCgIH777bd/3M7o0aPZtGlTGUb25CUlJREUFITJZCrvUKySSFBlaOvWrfTt25egoCDatGnD6NGjOXHiRHmHJTwhDRs2JC4urrzDeKikpCRWrlzJ9u3bOXToUKl18vPzmTNnDh06dCAoKIjOnTszZ84cMjMz/+ftL168mKFDh3L69Gk6d+78j9v5+uuveeGFF/7neO41ffp0GjZsWCJ5zp07l4YNG7Jx48ZHaudBB1V3+Pj4cPr0aRQKxT+OtyITCaqMrFy5krlz5/Laa69x6NAh9u7dy5AhQ9i9e3d5h/aPlcWZj/AXa9mfSUlJuLq64uHhUepyvV7PiBEjuHbtGl9//TUnT55k3bp1uLq6cu7cuTLZfv369f/ndh6nWrVqsXnzZstro9HIL7/8Qo0aNcpsG2X5eZAkCbPZXGbtWQuRoMpAXl4eixcv5r333qNLly7Y29ujUqno2LEjb7/9dqnrTJw4kdatW9O8eXOGDh3K1atXLcv2799Pjx49CAoKom3btqxYsQKAzMxMXn31VYKDg2nRogVDhgyxfChTU1OZMGECYWFhdOzYkTVr1ljaO3v2LH379qVZs2a0atWKefPmlRrTsWPHaNeuHcuWLaN169a888475OTk8OqrrxIWFkZISAivvvoqKSkplnWGDRvGokWLGDRoEEFBQYwaNeq+R9k7d+6kY8eOXLlyBbPZzLJly+jcuTOhoaFMmjSJ7OxsS92ffvqJ8PBwQkNDWbJkyUN/B1lZWYwcOZKgoCBeeuklEhMTAZg1axbz588vVve1115j1apVpbYTGxvLyJEjadGiBV27dmX79u2WZdOnT2fWrFmMGTOGoKAgBgwYQHx8PABDhw4FoHfv3gQFBbF9+/ZS96der2fOnDm0adOGNm3aMGfOHPR6fbH9v3TpUkJDQ+nYsSNbtmwBin6HrVq1KnYpaNeuXfTq1avU95GXl8dbb71FWFgY4eHhfPnll5jNZg4fPsyoUaNIS0sjKCiI6dOnl1h38+bNJCcn8/nnn1OvXj3kcjkeHh6MGzeO9u3bW/bTsGHDCA4OpmfPnsUOxB60nzp37sytW7d47bXXCAoKQq/XlzjTuPtyuE6nY+rUqYSGhhIcHEy/fv24ffs2UPTZi4qKAsBsNvPll18SHh5Oy5Yteeutt8jLywP+utS8adMmOnTo8EifqY4dO3Ly5ElycnIAOHjwIA0bNsTT09NSJz4+nuHDhxMaGkpoaChTpkwhNzcXgGnTppGUlGR5n8uXL7fEERUVRYcOHRgxYkSxy+DZ2dm0a9eOPXv2AKDRaHjuuef46aefSo1x2LBhREZGMmjQIJo0acKtW7c4deoU/fr1o3nz5vTr149Tp04BcPToUZ5//nnLuiNHjqRfv36W10OGDPmfLrc+NpLwP9u/f7/k5+cnGQyG+9ZZvHixNGXKFMvrqKgoKS8vT9LpdNLs2bOlXr16WZa1bt1aio6OliRJkrKzs6Xz589LkiRJCxculGbOnCnp9XpJr9dL0dHRktlslkwmk/TCCy9In332maTT6aT4+HipY8eO0oEDByRJkqSBAwdKmzZtkiRJkvLz86XTp0+XGuPRo0clPz8/acGCBZJOp5O0Wq2UmZkp7dixQyooKJDy8vKkCRMmSK+//rplnZdeeknq1KmTdP36dUmr1UovvfSS9NFHH0mSJEm3bt2SGjRoIBkMBunHH3+UOnfuLN28eVOSJElatWqVNGDAACk5OVnS6XTSzJkzpcmTJ0uSJElXr16VmjZtKh0/flzS6XTS3LlzJT8/P+nQoUOlxv32228Xq//BBx9IgwYNkiRJks6cOSO1bt1aMplMkiRJUkZGhhQYGCilp6eXaEej0Ujt2rWTfvzxR8lgMEgXLlyQWrRoIV29etWynRYtWkhnzpyRDAaD9Oabb0pvvPGGZf0GDRpY3t/99ueiRYukAQMGSLdv35YyMjKkF198UYqMjCxWf+7cuZJOp5OOHTsmNWnSRIqNjZUkSZK6d+8u7du3z9L+2LFjpRUrVpS6T6ZNmya99tprUl5ennTr1i2pS5cu0vr16y3badu2banrSZIkvfHGG9Jbb7113+V6vV7q3LmztGTJEkmn00mHDx+WmjZtaonzYfspPDy82O/y3td3/618//330quvvioVFBRIRqNROnfunJSXlydJUtFn7857ioqKkjp37izFx8dL+fn50rhx46SpU6dKkvTX53DGjBmSVquVYmJiJH9/f+natWulvr+3335b+uSTT6T/+7//k9auXStJkiRNnDhR2rp1qzRo0CBpw4YNkiRJ0s2bN6Xff/9d0ul0UkZGhjRkyBBp9uzZ931fd+KYNm2apNFoJK1WW+xvRJIk6eDBg1KrVq2k27dvSzNmzJAmTJhw39/DSy+9JLVv3166cuWKZDAYpPT0dCk4OFjatGmTZDAYpK1bt0rBwcFSZmampNVqpYCAACkjI0PS6/VSy5YtpTZt2kh5eXmSVquVGjduLGVmZt53W+VFnEGVgezsbNzc3FAqlY+8Tv/+/XF0dEStVjNhwgQuXbpkOeJTKpVcu3aN/Px8XFxc8Pf3t5Snp6eTlJSESqUiODgYmUzGuXPnyMzMZPz48ajVaqpXr87AgQMtR/9KpZL4+HgyMzNxcHCgadOm941LLpczceJE1Go1tra2uLm50bVrV+zs7HB0dOT1118nOjq62Dp9+/aldu3a2Nra0q1bN2JiYootX716NStWrODbb7+lZs2aAPzwww9MnjyZKlWqoFarGT9+PDt37sRoNLJjxw46dOhASEgIarWaSZMmIZc/+KN6d/3Jkyfzxx9/kJycTGBgIE5OThw5cgSA7du306JFi2JHwnfs27ePqlWr0q9fP5RKJY0aNaJr167s2LHDUqdz584EBgaiVCrp1atXiff6sP25detWxo0bh4eHB+7u7owbN85ylnTHpEmTUKvVtGjRgvbt2/PLL78A0KdPH0vd7Oxsfv/9dyIiIkps02QysX37dqZMmYKjoyPVqlVj5MiRJbZzP9nZ2VSqVOm+y8+cOUNBQQFjxoxBrVbTsmVLwsPD2bZt2z/eT/ejVCrJzs4mLi4OhUJBQEAAjo6OJept3bqVl19+merVq+Pg4MCbb77J9u3bi11GGz9+PLa2tvj6+uLr68ulS5ceuO3evXuzefNmcnNziY6OLnG/rGbNmrRu3Rq1Wo27uzsjR44s8bdRmgkTJmBvb4+trW2JZW3atKFbt268/PLL7N+/n1mzZj2wrRdeeIH69eujVCr5/fffqVmzJn369EGpVBIREUGdOnXYu3cvtra2NG7cmBMnTnDhwgV8fX1p1qwZp06d4o8//qBmzZq4ubk9NPYn7dG/UYX7cnV1JSsrC6PR+EhJymQyERkZyY4dO8jMzLR8+WZlZeHk5MTixYtZsmQJH3/8MQ0bNmTKlCkEBQXxyiuv8PnnnzNq1CgAXnzxRcaMGUNiYiJpaWkEBwcX28ad13PmzGHx4sV0796datWqMX78eMLDw0uNzc3NDRsbG8trrVbLvHnzOHjwoOVyh0ajwWQyWW7s3v1lZmdnR0FBQbE2V6xYwbhx46hSpYqlLCkpiXHjxhVLPHK5nIyMDNLS0orVtbe3x9XV9YH79O76Dg4OuLi4kJaWhre3Ny+88AJbtmyhdevWbNmyheHDh5faRmJiImfPni2xH+++jHZ3YrO1tS3xXu917/5MS0vDx8fH8trHx4e0tDTLa2dnZ+zt7Utd3rt3b7p3705BQQG//PILwcHBeHl5ldhmVlYWBoOhxHZSU1MfGOsdrq6upKen33f5nd/P3b+7e9v/u/vpfnr37k1KSgpvvvkmubm59OrVi8mTJ6NSqUrEVLVqVcvrqlWrYjQaycjIKDWm0j6n9woODiYzM5MlS5bQoUOHEgnl9u3bzJkzhxMnTqDRaJAkCWdn54e+p7s/q6UZOHAg3333Ha+99tpDk4a3t7fl//d+tqD47yUkJITjx49TuXJlQkJCcHZ2Jjo62nIwZI1EgioDQUFBqNVqfvvtN7p16/bQ+lu3bmX37t2sXLmSatWqkZeXR0hICNKfA8sHBgayZMkSDAYDa9eu5Y033mD//v04Ojoyffp0pk+fzpUrVxgxYgSNGzfG29ubatWqsWvXrlK3V6tWLT755BPMZjO7du1i4sSJHDt2rNgX4R0ymazY62+++YYbN26wfv16KlWqRExMDH369LHE+ii++eYbRo8ejaenJ127dgWK/kjnzp1L8+bNS9T38vIiNjbW8lqr1Ra7P1Wau++LaTQacnJyLF/evXr1IiIigkuXLhEbG3vfnmPe3t6EhISwcuXKR35vD3Pv/vTy8irWSSA5OblYksnNzaWgoMDyu0lOTrbUrVy5MkFBQezatYvNmzczePDgUrfp5uaGSqUiKSmJevXqWdqpXLnyI8XcqlUrFi1aVCyOe99DSkoKZrPZkqSSk5OpVavWI7V/Lzs7O7RareX13clRpVIxfvx4xo8fT0JCAmPGjKF27doMGDCgREx37jtC0QGQUqnEw8Oj2Gfj7+rVqxdffPFFsXu6d3zyySfIZDK2bt2Kq6srv/32G++///5D27z3M3E3k8nEe++9R58+ffjvf/9L3759LVcdHtbWnc/W3ZKTk2nbti0ALVq0YP78+fj4+PCvf/0LFxcXZs6ciUqlstxDtTbiEl8ZcHJyYuLEibz//vv89ttvaLVaDAYD+/fvZ8GCBSXqazQa1Go1bm5uaLVaPvnkE8syvV7Pli1byMvLQ6VS4eDgYPkS2Lt3L3FxcUiShJOTEwqFAplMRmBgIA4ODixbtozCwkJMJhNXrlzh7NmzQNFN7ztnaneO8B52yezuWG1sbHB2diY7O5vPP//8b++fevXq8fXXX/P+++9bbqYPHjyYRYsWWb5UMjMzLTdpu3btyr59+zhx4gR6vZ7Fixc/tIfS/v37LfU//fRTmjRpYjm6rFKlCo0bN2batGl06dKl1EsrUHSZ8ObNm/z0008YDAYMBgNnz54tliwfxNPTk1u3bj2wTs+ePVmyZAmZmZlkZmbyxRdfFLt5DUWdBPR6PSdOnGDfvn3FDnp69+7NihUruHLlCl26dCl1GwqFgm7duhEZGUl+fj6JiYmsXLnyvh0q7tW7d2+qVKnChAkTiI2NxWw2k5WVxdKlS9m/fz+BgYHY2try9ddfYzAYOHbsGHv27KFHjx6P1P69fH192b59OwaDgXPnzrFz507LsqNHj3L58mVMJhOOjo4olcpSP7sRERGsXr2aW7duodFoiIyMpHv37n/rsntphg0bxsqVKwkJCSmxTKPRYG9vj5OTE6mpqXz99dfFlj/K5+FeS5cuRSaTMXfuXF555RXefvvtR35Gqn379ty8eZOtW7diNBrZvn07165do0OHDkDRgfSNGzc4e/YsgYGB1K9f33LVoLT3Zw1Egiojo0aNYvr06Xz55Ze0bNmSDh06sHbt2lKP1vv06YOPjw9t27alZ8+eJe4Jbd68mY4dO9KsWTN++OEHPvroIwDi4uIsPdVefPFFBg8eTFhYGAqFgqVLl3Lp0iU6depEWFgY//d//0d+fj5Q1AOpZ8+eBAUFMWfOHCIjI+/7JX2vESNGoNPpCAsL48UXX7Qcjf1dvr6+LF26lJkzZ7J//36GDx9Ox44dGTVqFEFBQQwcONCSUOvXr897773H1KlTadu2Lc7Ozg+9LBIREcEXX3xBaGgoFy5csOyzO/r06cOVK1fo3bv3fdtwdHRkxYoVbN++nbZt29KmTRsWLlxo6WX3MOPHj2f69OkEBwcX6/13t7FjxxIQEECvXr3o1asX/v7+jB071rLc09MTZ2dn2rZty9SpU/nPf/5D3bp1Lcufe+45EhMTee6557Czs7tvLDNnzsTOzo7OnTszZMgQIiIiivXaehC1Ws2qVauoU6cOo0aNonnz5gwYMICsrCwCAwNRq9UsXbqUAwcOEBYWxqxZs1iwYEGxOP+ON954g/j4eFq0aMFnn31WLGHfvn2biRMn0rx5c3r06EGLFi1K/R3269ePXr168dJLL9GpUyfUajUzZ878R/HczdXVlZYtW5Z61jN+/HguXrxIcHAwY8aMKXHAMGbMGJYsWUJwcLClJ+6DnD9/nlWrVvHhhx+iUCj417/+BcCyZcseKVY3NzeWLl3KypUrCQ0N5euvv2bp0qW4u7sDRZfK/f39qVevHmq1GihKWj4+Pvd95KC8yaS/c61GEJ5S0dHRTJs2jb179z7wEkt5OnbsGNOmTePAgQMPrNe5c2fef/99WrVq9YQiE4TyIc6ghArPYDCwZs0a+vfvb7XJ6VHt3LkTmUxGWFhYeYciCI+d6CQhVGixsbH069cPX1/f+z6g/LQYNmwY165dY8GCBY98D1EQnmbiEp8gCIJglcRhmCAIgmCVKtwlvlOnTj2wd5M1MBgMJR40tDYixrIhYiwbIsayYa0x6nS6Uke4qXAJSqFQ4OfnV95hPFBcXNwDH76zBiLGsiFiLBsixrJhrTHebygscYlPEARBsEoiQQmCIAhWSSQoQRAEwSqJBCUIgiBYJZGgBEEQBKskEpQgCIJglUSCEgRBEKySSFCCIAiCVRIJShAEQbBKFW6w2AsXLuLv36i8wxAEQajwCg0mbFWK/7mdmJiYUkcAqnBDHcnlMmpN31beYQiCIFR4N+f3fKztV7gEJQiCUFEYc9Mx5qahcHBD5eZz33qSJGHWZCOZDMjUtijsnIstN2nzMGYmglyOyr0qchuHovWMBgxZiUgGHSrPmsjVtkX187OQTIYS21E4eyKTPbk7QyJBCYIgWBlDVjKZvy6l8MZJS5napyHunV/Dxru+pcxcmE/mnq/RxkZjLsgpKpTJcWk5ENe2L2HMyyBr3zcUXDoEZuOfa8lw8O+A2qs22YfXIek0RaVqO5ya9cSYmUTBlcOlxqV09cZ7RCRyW8fH8r5LbO+JbEUQBEF4JGa9ltQf3sVVZeb/Zs8mNDSUixcv8vHHH3Prh3fxeeULlM5eAOSf303B+d28/PLLNGvWDAcHB9avX8+ufdtwCulD6n/fxtaYzxsTx9OlSxeMRiM///wzy5YtQ3NhL7169WLw4ME4ODiwbt061q5dC8DIkSNp27ZtsbgyMzOZOnUqBbHROPqHP5F9YfUJatWqVURFRSGTyWjQoAHz5s3DxsamvMMSBEF4LPJO/4IpN50thw7RvHlz1qxZw0svvUTv3r1p0KABOUd/xKPLWABMmixUKhVz5swhPT2dwMBALly4wM7d+8g9vgnyb/PrwYMEBQWxevVqsrOzCQgIAKBv375s2LCBLVu2kJKSwnfffYe7uzufffYZXl5e1KtXDwB7e3uaN2/OH3/8AfBEL/FZdTfz1NRU1qxZw4YNG/j5558xmUxs2yY6QAiCUHFpY48TGhpKq1atWLNmDWPGjOGjjz6iZs2a9O3bF+2145a6Kvfq6PV6fHx8mDVrVrF2Ci7/Tnh4OGFhYbz33nu8//77vPfee0ycOBGAAQMGADBp0iReffVVtFotkydPBuDDDz+kXbt2tGvXju+++w6AL7/8EplSjW2tkhMLPi5WnaAATCYThYWFGI1GCgsL8fLyKu+QBEEQHhtjTioNGzYE4Pr16wDcuHEDgIYNG2LKy7B0YHAI6Ijn89NKtCEZdBgzEwkPL7oUN2XKFBISEsjJyWHChAkA5ObmAtC8eXP8/f2xs7Ojdu3a2NjYYFOtEbZ1mqNUKpk8ebLlZMEhoBMKe5fHuwPuYtUJqnLlyowaNYrw8HDatGmDo6Mjbdq0Ke+wBEEQHh9JQi4v/au5qFwidf2/SV3/b/JObsW+YWtkKtt7G7mrPhw+fJhatWoRExNDZGQkXl5ezJ8/n9jYWH788UfOnTuHRqOxrKPyqI4u4SIDBgygRo0afPbZZ+h0epxD+jyud10qq74HlZOTw+7du9m9ezdOTk5MmjSJzZs307t37/IOTRAE4bFQOntx9epVAMv07DVq1ACwlDf2UqPX6zm7exlZu5fdt6079Y8ePUpcQiKnT5+madOmeHh4WB6ObdCgAQUFBfz+++9cvHgRrVaLKukykl7LtGnT0Gg0LFmyBPsGLVG5Vy2xjbi4uDJ9/3ez6gR1+PBhqlWrhru7OwBdunTh9OnTIkEJglBh2dVpzqGD33Lq1CmGDRtGXl4ew4YNIzk5mQ0bNgCwa9cuEhISCAwMBOCbb76hdu3aAAwePJjGjRvz5ptvsn79eubPn8+IESPQaDRERERw6dIlrl69StOmTRk1ahRxcXFERETg4+PDlClTABnG7GQ6depEUFAQixcvJjMzkyo9+pYa750k+r+IiYkptdyqL/H5+Phw5swZtFotkiRx5MgR6tatW95hCYIgPDZOzXoid3AlIiKClStX0r59e3bu3El4eDharRaAzZs3s2vXLss69vb2pKenExUVxfXr17G3t0cmk5GXl0f79u05ceIEQ4YM4aeffrJ0N8/JyaFmzZoMHjyYrKwsunbtyg8//IBd/VAkg45GjRoRFRVFZGQkNlUbYVPV94nvC6sfi2/x4sVs374dpVKJn58fc+bMQa1W37d+TEwM3Vdff4IRCoIglC19+k0yd3yOLumSpUzlUQOXVgPJ3L38r4dyAZlSjWTUl2hDprLFObg3msu/F40icacdrzo4NGpHzpEoy0O6AAoHN5zD+uPYuDPJqyZhzE75c4GKyoNmY1vNv8Q2ymqoo/uNxWf1CervEglKEISKQp8eZxnqSF25LjKZ7M/hiZJAJkPlXhXJZPwrmdxF6VwJuY09kmRGn3INc0EuStfKKN2rIZPJMBt0GNJuYNLmILd1wsa7ATJF0V0fyWzCkJkIkmRppzSPO0FZ9T0oQRCEZ5m6Uk3UlYrf45EpVcXKZHJFiTrF6svk2Hg3KFEuV9nc97KdTK5A7VnjH0Zddqz6HpQgCILw7BIJShAEQbBKFe4Sn9ksPfY5SgRBEISym7DwfircGZTRWHIOE2vzOB9sKysixrIhYiwbIsayUdYxPs7kBBUwQQmCIAgVg0hQgiAIglUSCUoQBEGwShUuQSmVqvIO4aHKYuyqx03EWDYqYoyFBtNjikQQiqtwvfjkchm1potJDQXhcRG9ZIUnpcIlKEF4WpkNhRTEHECfGotMZYtdvRbYVG2ETCYrVk8ym9CnXEOfGotZpwGZAvv6oZapEIx5t9Fc2IsxNx2lowcO/uEonCuhS7iALvGeUaNlcuzrtsCoyUSffOWeZcXbFYQnTSQoQbACuuQrpG/4AJMmCzc3N7RaLbnHNmBXrwWVek9HpiwaINls0JHy7RQM6TeLrZ9zZB3Vxq5Gc/43Mnd/jRwz7u7uZGZmkv37Wuzrh1Fw5XCp287et/K+cd1pV66+d0I8QXj8Ktw9KEF42kgmA+mbP6RmZTcOHDhAZmYmGRkZfPTRRxTGRpNzZL2lri4xBkP6TRYuXEh8fDxarZYff/wRSaeh4NJBMn/9il4RPYiNjSU9PZ24uDgGDuhvSU4pKSlotVrLv+3bt1vazsvLK7bsTruGzIQnvk8EAZ6CM6jVq1cTFRWFJEkMGDCAl19+ubxDEoQyVXD5EKacVD7/fjuhoaH07duXrl27MnXqVI4ePcrGrVtwaTmw6Czqz8kHUlJS+PTTT1m4cCEqVVHHoNzjm3BxcWbNmjUkJiYSHh7Oxx9/zMqVK9m7dy/p6enY2Nhw5MgRoqKiAEhI+Cv52NjYsHv3brZs2QLAzZs3AZDbOj7BvSEIf7HqM6grV64QFRVFVFQUmzdvZt++fU/F09qC8Hfokq7g6OhI9+7dOXXqFJs2beLTTz8FYODAgUj6gqLpFQAbn4YoXb1ZuHAhq1evLtaOISOeLl264OLiwrp169i3bx9r167F3t6enj3/6thgb29P/fr1MZvN/Pbbb8XacHJyol69ehgMBvbs2QOAwt7lcb59Qbgvq05QsbGxBAYGYmdnh1KpJCQkpNgskoJQEZjyM6lWrRoAt2/fBiAjIwPAUm7ISMBUmI9MZYPPK19i36BVqW09rJ3c3FwKCgp47rnnWLp0Kfv27UOhKBquJjs7G51OR/fu3Vm+fDk7d+5EJpOR/8eOx/G2BeGhrPoSX4MGDVi0aBFZWVnY2tpy4MABAgICyjssQShTcht7stOyAbCzswPA1raoU0J2dlH57c3zAVA4V8It/BUKrhzG3tOzRFt36t+vnTtnRwD79u2jffv2BAQEcObMGapWrYrBYEAmk3Hs2DHat29P3bp1Sbq3dx9Pfty5/Px8q796ImIse1adoOrWrcvo0aN55ZVXsLOzw9fXF7ncqk/6BOFvU7pXJfXcr9y8eZPAwEDs7e1p2bIlAMeOHQNg9OjRBAQE8M4771iSVWnu1A8LCwMo1o63tzcuLi5cunQJlUqFg4MDAIWFhVSvXh0bGxuuXbuGjY0N9vb2lmUyl5JfE0/6AeS4uDirf+hZxPjPxcTElFpu9d/2AwYMYOPGjaxduxYXFxdq1apV3iEJQplyaNQeSa7g7bffxsPDgxs3brB69Wpu3rzJZ599BkBERASTJk3CxsYGgJ07d5KUVHRfqlevXuh0OgYNGsTFixdZsWIF/fv3J+FGL8QAACAASURBVD4+nhEjRrBu3Tqio6OpVasWMTExXL9+naSkJIKDg/nvf//L5cuXadCgAVevXiU2NpbExET8/f1ZsWIFCQkJ2NZoXG77Rni2WfUZFBRdQ/fw8CApKYldu3axfv36h68kCE8RpZMnrm2Gsn79aqKjo4mIiCAjI4ONGzdSWFgIwPz581m9ejUajQaADz74gKVLlxZr58SJE0DR2daaNWto1qwZ586dY/fu3QAcPXqUsLAwmjVrhkKh4OzZsxw4cACAPXv20KpVK4KCgpDJZJw+fZrDhw9jW7MpDgGdntSuEIRiZJL0Z79VKzVkyBCys7NRKpW88847lksW9xMTE0P31defUHSCUHYKrh0jN3oz+tRY5Cob7Oq1wCVsAAVXjqK5sAfJbEJdqRZyB1cK486CZC62vsLeGZeWg9CnxpJ/7leMuekoHD1wbNwJp6bdyTuzA+3V40XPNUlmlK5VsPdti2OTruSf2oY2NhpDZiIASrcqOPh1wCmoB7J7xrcsj6GOrPXS1N1EjP9cTEwMfn5+JcqtPkH9XSJBCcLjJRJU6USM/9z9EpTV34MSBEEQnk0iQQmCIAhWSSQoQRAEwSpZfS++v8tslsR8NYLwGBUaTNiqFOUdhvAMqHBnUEajobxDeKin4UluEWPZqIgxiuQkPCkVLkEJgiAIFYNIUIIgCIJVqnAJSnnPQ4XWyBqfQ7iXiLFsPCjGQoPpCUYiCE+fCtdJQi6XUWv6tvIOQxAeSnTmEYQHq3BnUIIgCELFUOHOoAShMO4succ3oku+gkyhxLZ2c1zC+qNyr1qsniSZ0ZzbTd4fv2DMTERu74yDX3ucQ/ogmQzkHIlCe+MU5oJs5DYO2FT1wzmsP4U3TqG5fAhjdgqYTSgc3LGrG4xzWH+MmYloLu5HnxqLWa9FplDiGNgFp6Ae5bQ3BOHpJRKUUKHkndlF5o7FeHt702v4YDQaDRs3biT50kEqD5mPTZV6lroZ2z9Fc343gYGBtOs3kuvXr7Njx3ryzuwAkwmlWUePbt2oUaMGGRkZbN++neRv9gHQunVrAgI6oFQquXHjBr/+upXc4xsBcHR0JLRZMzw8PLh16xYnfvsKe982KOycy2OXCMJTSyQoocIwF+aTtXcFnTt3Ztu2bWg0Guzs7FiwYAHBwcFk7F5G5SEfIpPJKLx1Hs353cyYMYPZs2eTmppKpUqV+P333+nQoQOSJLH/yBHCwsI4evQoTZs2JSsri4CAADIzM9m6dSvZ2dm4uLjg7u7O3r176dixI1A0OWCjRo0AWLt2LS+99BJmbZ5IUILwN1n9Pajr16/Tu3dvy79mzZqxatWq8g5LsEIFVw4j6TTMnz8fs9lMvXr1eP755/H29mbatGnoEi5izCqa5C//7K94eHgwY8YMjh8/jre3N3PnzqVdu3b06dMHNzc3wsLC2LVrFz3/8x2LFxedlTVp0gSA+vXrU6dOHby9vUlMTCQ8PBy1Wg3A0KFDCQwMLLf9IAgVhdWfQdWpU4fNmzcDYDKZaNeuHc8991w5RyVYI0NmEmq1mubNm/PHH3+QmZnJkSNHgL+mQDdkJqJyr4oxM5EmTZpgZ2fH0aNHkSSJw4cPW+pu2rSJdevW0b17d95sG03//v05deoUx48fB4om0hw9ejQ1a9bEy8uLZcuWodfrkant+OOPP6hdu3b57ARBqECsPkHd7ciRI1SvXp2qVas+vLLwzDHr8nFxcQFAq9UCWGakdXd3ByD3+EZMuWnoki7h1tL/gXVv3LiBSqWiTZs2VKpUiejoaMzmvyYJnDhxIj4+PgCWmW5dWw9Gn3YDCm4+zrcqCM+EpypBbdu2jYiIiPIOQ7BSCkcPbt++jU6nw9PTE/gr2SQkJACgu3Ue3a3zxco8PDyK/UxISCAoKIjp06ezZMkSJr77AaMGPs9XX33Fzp07WblyJQCBgYEoFAoOHDjA5MmTWbFiBRf2flMUzD1nUKnrZlKpzzvYeNcvVm4NY/Xl5+dbRRwPImIsG09DjHd7ahKUXq9nz549TJkypbxDEayUTZX6SJLEhg0bGDJkCC+++KLlnlFUVBQAn376KYMHDyY0NJSTJ09y8+ZNevbsSfv27Rk1ahQAGzZswGg0AuDr64u3k9LSTkFBAX5+frRt25bo6GgqVapEjRo1AMjOzgagY8eO+Pr6AlCjRg369evH4cOHyfr9OyoPmFUsZmsYDcNaZ1m9m4ixbFhrjDExMaWWPzUJ6sCBA/j7+1uOjAXhXrZ1mqGqVItp06bh5eXFDz/8gMFgYPny5axYsaKojq0tzs7OyOVyjEYjw4cP56uvvmLfvn1kZmYyadIkzp8vOsP697//zdtvv018fDwmk4m1a9eyceNGAgMDWbBggeVyYnJyMmPGjCExMRGADz74gObNm6PT6WjRogVr166lX79+/HriUvnsGEF4SskkSZLKO4hHMXnyZNq0aUO/fv0eWC8mJobuq68/oagEa6NPjyMt6j+Y8tJxd3dHp9Oh0WiwqeqHPv0mkl5rqWtTPQB98lUw6alUqRLZ2dno9XqcmvXEpM2nIGY/crkcDw8PsrOzMRj+mspFJpPh6emJXq8nJycHAIeAzmgu7gVz6WPsOQb1wKPLWMtraxnqyFqPqu8mYiwb1hpjTEwMfn5+JcqfijOogoICDh8+zPvvv1/eoQhWTl2pJlXHfIXm0kF0SZeRK1R41WmOba0gTHnpFFw6hGQyoHKvhl39UMyF+WjO76YgMwnbus54+LVDXakWAIXNIii8eQqtJgu7uk64+vhiVzcYffIVCuPPoc1NQ6ZQ4epUCfv6oajcq+Ic0hvt9ZMgmYvFpXB0x75hm3LYI4Lw9HoqEpS9vT3Hjh0r7zCEp4RMqcYxoBOOAZ2KlSudvXBu8UKxMoW9C84t+pbajm01P2yrlTyqs6nqh03VkuUAaq/aqL1EF3NBKAtW/6CuIAiC8GwSCUoQBEGwSiJBCYIgCFbpqbgH9XeYzZLV9I4ShAcpNJiwVSnKOwxBsFoV7gzKaDQ8vFI5exqe5BYxlo0HxSiSkyA8WIVLUIIgCELFIBKUIAiCYJUqXIJSKlXlHcJDWeOT3PcSMZaN0mIsNJQ+0oQgCMVVuE4ScrmMWtO3lXcYgnBfohOPIDyaCpegBMGYdxtDehwytT023vWQKUo/q5YkCUPGLUw5aSicPFBVqoVMJitaZtSjT4/DrM1FbueMulItZH+enRtzb2PISgSzCaVLZZRuPshkMsyGQozZqcW2IVMoLcsFQfh7RIISKgyTNpfMXUsouHzIMhaewtEd13YjcGxcfNgjfdp1MnZ+gT7psqVMXbku7l3Gok+7Qfb+VZgL8y3L5HbOODRqT2HcGQy344u1pfauj3OLfmTu+AyzTlMiLtuagXi9OEckKUH4m0SCEioESZJI3zQXWfo13pn+Nj179iQtLY3IyEgObo9EbueIfb1QoCiRpf7wf3i7O/HO55/TrFkzzp8/z7x587jxbdF8Y8899xyvvfYaVapUISUlhc8//5y9e7fi5eXFjE8/pXHjxqhUKs6cOcPcuXNJ2jwfuVzO+vXri8V1+PBhFi1ahDE7BZWb9xPfL4LwNLPqThLJyckMGzaMHj160LNnT1avXl3eIQlWqjDuDLpb54mMjGTu3LlcvHiRevXqsWfPHho2bEj2we+4M7NM3oktoMtnx44dDB8+nCNHjtC3b1/27NmDSqWicuXKbNu2jaZNm/L9998THBzML7/8gpubG3Xq1KFLly5ER0dz+/Ztxo0bZ0lKMpmMAQMG0LRpUxwdHXF0dMTW1vbPCJ+KWW0EwapY9RmUQqFg+vTp+Pv7k5+fT79+/WjdujX16tUr79AEK6ONjcbBwYFRo0Zx8uRJxowZQ4cOHdi7dy+vv/46b7zxBqb8TJROHmhjowkPDycgIIDIyEimTJlCTk4Os2bN4vnnn+fMmTOoVCoOHTrE6iNxtDt2jAEDBuDg4MCZM2fw9/fHbDYjk8nIyMigefPmxWLZvXs369at49KlS6SkpACgdBVnT4Lwd1n1GZSXlxf+/v4AODo6UqdOHVJTUx+ylvAsMuWmU6tWLdRqtWX0hjs/GzRo8GedNACMuemWsjt14uPjLXVjY2N56623GDp0KKfXRdK3b18mTpxIQkICWq0WbJ0ACA8Px83NjU2bNhWL5bXXXmPv3r3cunWLadOmAVB4/eTjfPuCUCFZdYK6W0JCAjExMTRp0qS8QxGs1L2TQ1t65P1ZnvL9O6R89xZmbW6June3UaVKFSZPnsz58+dZsGABly9f5q233sLDwwMAc0EOvXv35ueff2bfvn2MGTOmqNxsJjw8HHt7e/z8/MjIyGDevHk4OzujvR79uN62IFRYVn2J7w6NRsPEiRN59913cXR0LO9wBCukcPHi5oU/0Ol01KlTB4DatYsmDrx8uainXlBgY9zd3dmbfMlSdqfO3XXbtWuHt7c3H374ISt/+hU3Nzfmz59P69at2bJlC2PHjuWzzz4jKiqKESNGoNPpALC1tWXfvn0AXLp0idjYWCpXroybmxu3dQXF4rWmcQTz8/OtKp7SiBjLxtMQ492sPkEZDAYmTpzI888/T5cuXco7HMFK2ddtQWr0TyxbtowJEyawZs0aQkJC0Ov1fPnllwDMnz+fLl26WBLJH3/8wejRo1GpVAwZMoRr167x888/U7duXQwGA6+//joqlYp//etf6HQ6zp07R0hICF988QVms5mqVauya9cuALp3706nTp2YPXs2u3fvpnr16rRq1YqTJ08SHx+Pa4fi3dytaRSMuLg4q4qnNCLGsmGtMcbExJRabtUJSpIkZsyYQZ06dRg5cmR5hyNYMZsajbGtFcTUqVOJjY0lIiKCU6dOMXz4cK5duwbAr7/+SlJSEiaTCUmS6NatG1OmTKF58+asXr2ahQsXYjQauXz5Ml27duWVV16hW7duHDlyhGXLlnHjxg1UKhWrVq0qsX2z2czJkyfZsWMHTZo0wWw2M2fOHCIjI5E7eeIQKA6uBOHvkkn3uxhvBU6cOMHQoUNp0KABcnnR7bI333yT9u3b33edmJgYuq++/qRCFKyIuTCfzN1fo7m4F8xF490pXSrj2m44eae3oUu4CIDcwRWP58aSe+pndPFnLevbVPXD/bnX0KXEkn1wDWZNtmWZwtEdtXcDCm+eRjLoSg9AoQSTsViRba0g3Lu8jsrNx1JmbUMdWetR9d1EjGXDWmOMiYnBz8+vRLlVn0EFBwdb7hUIwsPIbR3x7PkGbuEjMWTcQqayRe1VG5lcgb1fO0x5t0Eyo3B0R6ZQYd+wFYbsFEy56Sgc3VG5VwWKRpRwDOiIISsJc0EOcnsXVO5VkckVmHUFmAvzSmxb4eCOTKnCpMnGkJUEyFC5VUHh4PaE94IgVBxWnaAE4Z9Q2LugsHcpViaTyVA6VypRV+VaBZVrlRLlMoUStWeNEuVyG3vkNvb337aDKwoH138QtSAI93pqupkLgiAIzxaRoARBEASrVOEu8ZnNktXdhBaEuxUaTNiqFOUdhiBYvQp3BmU0Gso7hId6Gh6UEzGWjdJiFMlJEB5NhUtQgiAIQsUgEpQgCIJglUSCEgRBEKxShUtQSqWqvEN4KGt8kvteIsayUamymAdKEP6pCteLTy6XUWv6tvIOQxAA6xvWSBCeJhUuQQnPBkmS0MWfo+DqEcy6AtSVauLQuDMKO+eSdU0GCi4fojCuaNw9m+oBOPi2RZd8mcIbp0tMxi5TKLFv2BqFrROai3sxZCYiU6qxqxeKbc0mFN44ReGf4/rdTa5UY9+ofakjUwiC8PeJBCU8dSSjgfTN89FeO4aTkxMebm7En99N9qHvqdR7OnZ1/pqC3ZibRuq69zBmJuDl5QVA2tldZGz7BACFomSXb0mSyPl9LciVYDbi5eWFVqsl7eRWZDYOSDrNfdfLP/crPmOWIZNVuKvngvDEib8i4amTe+IntNeOsXDhQtLS0oiLi+P8+fMEBfhxe+tCzHdNDpix4wscTHls3bqV1NRUUlNT+eWXX3B3dwfg3LlzGI3GYv++++47AJoHNeHKlSukpqaSnp7Op59+CvqitlNSUkqsFxkZiTE7BXOh5snvFEGogKw+QeXm5jJx4kS6detG9+7dOX36dHmHJJQjyWwiN3ozPXr0YMqUKaxdu5b27dtTvXp1li1bhrkwj/xzvwKgT4+j8MZJ3nnnHSIiIhg7dqxljqcZM2YAMH36dIYPH87w4cOJiooCIDq6aHr2lStX4unpSb169Zg/fz4TJ06kb9++AIwbN86y3s6dOy3rydQPHkxWEIRHZ/WX+ObMmUPbtm1ZvHgxer2ewsLC8g5JKEemvAzMBdmWRLF8+XKOHTvGwYMH6dmzJzVq1CAjNRYA/Z8/+/bti1ar5auvvkKSJCIjI+nbty9Tpkxhy5YtyJQ2YNLz7rvvkp2dzfLly5HJZPj5+XHhwgVib8Zz6NAhAHr37s2GDRtYv349KJTYKBUsWLCAW7du8cMPP+AYFIFMLkaKEISyYNVnUHl5eURHR9O/f38A1Go1zs4lb4ILzw5TfgYAPj5FEwBmZmYCkJWVBUDVqlUxZCZizE3HkH7TUjcnJwez2YwkSWRnZ1O1atHcT85hA5CpbIiIiMDX15elS5eSn5+PJEkcPXqUgIAAZr47nXfffReAatWqAeDZ5x1kMgVDhw6lSpUqLFq0CKPJjHNwrye2LwShorPqM6iEhATc3d155513uHTpEv7+/syYMQN7e3EJ5Vklt3UE/kpMdz4Ld35mZGSgT7pC4pKRlnUyMzNxcflrfih7e3syMooSnfbacczaXKZOnYper2fx4sXY+PiiS7rEoEGDmD17Nr169eLKlSsApKWlAaC5sBdMeqZOnUpOTg7Lly/Hwa8dSmevEjFb+5iB+fn5IsYyIGIse1adoIxGIxcvXmTmzJk0adKE2bNns2zZMt54443yDk0oJ0qXyqBQcujQIYYOHUq7du24fPkyISEhJCcnc+PGDRo0aMBbb73Fzz//zE8//cShQ4cYNGgQTZo0QafT4enpycaNGwEw3I6jRYsWtGvXjpUrV5KcnIxX/1dJ+/E/aDQaRo4sSnTTp08HYPPmzchUthTGn6NHjx74+fnx4YcfkpeXh3eLvqXGbO0PFFvrNOB3EzGWDWuNMSYmptRyq77EV6VKFapUqUKTJk0A6NatGxcvlnz+RHh2yJRqHAM6sXLlSk6fPs2iRYtISUnB29ubt99+G4PBQJUqVXjllVdo1qwZALNmzSIjI4OjR49y6tQpsrKy+Pe//21pc9q0aQAsXLgQlVcdbKo1AmDGjBkkJCQQFxfHvHnziIqKYt26dcjkCiSdhmnTpqHX6/n000+xrdkUdeU6T36HCEIFZtVnUJUqVaJKlSpcv36dOnXqcOTIEerWrVveYQnlzKX1EFKunyI4OJiuXbvi4+PDr7/+Snx8PFDUdbxLly5cv34dgEtXrlGrVi2ef/555HI5W7ZsIU+jxa5+GNqrR1m6dCmLFy/m4sWLeERMQaayQW7nTGRkJKdOncLR0ZHjx49z5swZ1N4Nsa3WiPyTm5kzZw65ublFZ10DXy/PXSIIFZJVJyiAmTNnMnXqVAwGA9WrV2fevHnlHZJQzpROHni/vIjcE5v57fgRzLpjqCrVwqv/SJRuPmQf/I4DF24hUzvj1f8/KFy8yD22kfXb94AkYVszBO8WfVG6VCZr93J+j4kHmQyXli/i0Kg9MpkcrwH/IevIeqJ+2Ytk1KN0qYx71/E4BnTCrC/AVJDNgQu3QCbHtcNIbGsFlfduEYQKRyZJ0r0jvTzVYmJi6L76enmHIQjA0zEWn7Xel7ibiLFsWGuMMTEx+Pn5lSi36ntQgiAIwrNLJChBEATBKokEJQiCIFglq+8k8XeZzdJTcd1feDYUFOqxt1WXdxiC8FSqcGdQRqOhvEN4qKfhSW4RY9lIT00u7xAE4alV4RKUIAiCUDGIBCUIgiBYpQqXoJRKVXmH8FDW+BzCvUSMj6bQYCrvEAShwqpwnSTkchm1pm8r7zCEZ4TokCMIj0+FO4MSBEEQKoYKdwYlVBy6pMvkHFlPYfxZkMzYVPPHJaw/tjUCi9WTJImCmAPkntiCPi0WucoWu3phODbpQu7xjZaJC+8mt3HApc0QlM6VyD2+Ce31k5h1BSgc3bCt2QSlsxeFcWcwpN/EbChE4eiOXZ1gXFoPRuno/oT2gCA820SCEqySNvYEaRvex6uSJ6+MeQWlUklUVBSJ37+L5/PTcGjU3lI3++B35B5ZR6NGjYgY9ia3b99m3bp1pJ7/DZVKxaAXXyzR/okTJ7i04QOQK3F2tGfEoH5UqVKFmzdvsmnTJjSFhYSEhBDSawQuLi7cuHGDTZs2kXL9JN4vL0JhJ2Z2FoTHTSQowepIZhOZu78iwL8RR44cwWAwYDQamT9/PuHh4Rzf8zV29cOQq2wwZKeQezSKESNGsGrVKhISEvDw8OA///kPTZo0wWQy8e2335bYxtixY7l06RIhzYPYtWsXcrmc8+fPU7duXc6ePcuFCxc4fvy4ZQqPGjVqcPLkScLCwsg7+TOubYY86d0iCM+cp+IelMlkok+fPrz66qvlHYrwBOgSYzBmJTNz5kwcHR1p27YtQUFBqFQq3n//fUyaLApvngZAc3EfchnMnTuXpKQk6tWrx8iRI6levTrjx48nNzcXlUpl+Xf06FF0Oh2bNm0C4OOPP0aSJPz8/GjdujVVq1bl6tWrAHTu3JmaNWtSu3ZtTpw4QfPmzfH19UWfGltu+0YQniVPRYJas2aNmKjwGWLMSgIgJCSEgoICLly4QGJiIklJSQQHBxerY8xKwsfHBx8fH86cOYNOp+P48eMAlrrKqo0wmsyEhIQQFhbGt99+S0pKCq6urrRu3ZqsrCw2btzIuXPn+Pe//43RaARgz8EjAMjlcuzs7CgoKCApKQmFvcsT3R+C8Kyy+gSVkpLCvn376N+/f3mHIjwhZp0WAFdXV3Q6naVcp9Ph5OSEXC4n59gGco7+iOb8HlxdXS3L7/55p1zp5gOS2TK1+8cffwyAi4sLcrmcOnXq8OOPP3Lu3DlmzpzJ6NGjAVDYOWFra8u6deto2LAhI0aMIDMzC8fA557AXhAEwervQc2dO5dp06ah0WjKOxThCVE4eQAQHx+Pv78/arUag8GAp6cnSUlJmM1mKMghe/8qAG7dugWAp6cnAJUqVSpWrrl4gPr169O7d2+2bNnCpUuXULhUtrSVlJTEwo8/oWmTQAYPHkxwcDDLli3DRWlk87bfaNq0KS+88AI///wzANI94z0+aEzA/Px8qx8zUMRYNkSMZc+qE9TevXtxd3cnICCAY8eOlXc4whNi410fkPHDDz8wb9483nnnHXJzc3FxceGrr74C4M0332T27Nn07duXHTt28Msvv9CpUycGDhxIz55FD89+//33AEj6At58803kcjkLFy5E4eyFW/uXub3lQ3766Seef/552rVtQ9u2bQE4deoUcrmcQ4cO0bBhQ9avX4+vry++vr78+OOPpBz7Eduaf3V1f9CIFtY6g+ndRIxlQ8T4z8XExJRabtUJ6tSpU+zZs4cDBw6g0+nIz89n6tSpLFy4sLxDEx4jpUtl7P3asWjRIurVq8e7776LXC7n+++/Z/bs2QAYjUYKCgowmYqGGho7dizLly9n3bp15OTkMGvWLLZtKxpRxNXVlYiICPbs2cPBgwdx6/Qv7Bu2QulejUmTJmFvb8/+/fspKCjgiy++YPny5SgUCjw9PcnIyKBTp0506tQJgJMnT5J0Oal8dowgPGNkkiRJ5R3Eozh27BjffPON5Qj6fmJiYui++voTikp4XEzaXNI3fIAuMQaVSoVcLken06HyqgMmI4aMeEtdm+oBGLNTMOXdxs7ODr1ej8lkwt6vPQpHN/Kif7LUVTh64POvpcjVdujTb5L24/uYctOwtbVFp9PxKH8Ozi364hY+Cnj4UEfWesR6NxFj2RAx/nMxMTH4+fmVKLfqMyjh2aWwc6by0AUUxp2hMO4MSBLO1f2xq9McSV9IwdUjf4784I59vRYggeby7xjSbqBW2WBXLxSbKvWQjAZsfHwxabKQKZTY1WmOXG0HgLpSLaqO+YqCK0fQp1zDxsYeGx9fbGs2QZd4CX3qtRJxKZ08sKvb4knvDkF4Jj01CSo0NJTQ0NDyDkN4gmQyGXa1mmJXq2nxcht7HAM6lajv6B8O/uHF6ypVOPi2uf82FCoc/Nrh4NeuWLltNT9sq5U8ohME4cmx+m7mgiAIwrNJJChBEATBKokEJQiCIFilp+Ye1KMymyUxiZzwxBQaTNiqFOUdhiBUSBXuDMp4z1P+1uhpeJJbxPhoRHIShMenwiUoQRAEoWIQCUoQBEGwShUuQSmVqvIO4aGs8Unuez1KjIUG0xOIRBCEZ1WF6yQhl8uoNX1beYfxTBCdUQRBeJwqXIKqKCTJjD7pCsa82yidPFD7NEQmK/2E12zQoUu4iFlfgNqzJiqPasWWm7R5lgn+FE6eKP+czgLAVJCDMTsFAKWLFwoHN4y5aZjys4q1IbdzQuXmU5ZvURAE4YFEgrJChQkxZO5YjCHjlqVM5VEd924TsK3WqFjdvDO7yN6/CrM211JmWysIjx6TUDp5ok+9Tsp/30bSF00CiOz/27vz+BrP/P/jr3OyryJUEluIXdW+FGmKyIq20a+aTg1Ga2lRahmqZbTKg7Y6ppRWVX+GVrVVaxhKBgmxlkQjKoIsNNEkksh+cs71+yPjTDKYKic9d+LzfDw8knNf933u97kl+Zz73Nd9XXrqD5mBS7sASq+eJ3PTGyjDvycF1Nvg6NuJksungdsHTXXvPZy6AX+y+OsVQog7qXXXoGq68ptZXP9mHs08HfnHvpO1zgAAIABJREFUP/5BfHw869evp5mnI9e/+Svl+VnmdYuST5Dzzw/p17s7u3fvJi4ujiVLlmCfk8wvmxegysvIivwAn/p12blzJ7t27aJlCz8KEw9hMpSQFfkBvo182LVrF7t27aJxQx9KLv9A9+7dzMtu/QsODqbw3AHrHRghxENH82dQpaWlvPDCC+YpFEJCQnj11VetHava5B/fgq0qZ8+ePbi5ubFy5Upefvll/P39ad26NfnHv8Nz4DgA8qI30Lp1a/bs2cOPP/7I3r17mTFjBk2aNOGPf/wjP/+/qRiyU1m9cydhYWHo9Xrc3d25mmck99B6jLk/s3bzfp588kn0ej0uLi5Axcy0YWFhREVFkZ2dDVTMv6Sz2lERQjyMNH8GZW9vz7p169i+fTtbt24lOjqaM2fOWDtWtSm5fJrQ0FCaN2/O6tWr+etf/8rHH39Ms2bNCAsLo/jyD0DFtaOyzGTGjRuHra0ts2bNYubMmcTExDB8+HDq1auHITuV0aNH07VrV7766qv/7CP9HDdPbuOVV17Bz8+PLVu23DHLtm3b+PTTT5kwYQJRUVGg1/yPixCiFtH8XxydTmd+Z19eXl7xTl5Xe9/Ll+dfp2XLlgCkpVVcg0pPTwegZcuWGG/+8u/1fjEvq7xuWloaer2e5s2b07hxY5YtW8a4cePIyckx70OVFuLn58fixYsZM2YM+fn/uX5V2dKlS9m7dy9XrlwhKCgI480cjEV51fCqhRDidpovUABGo5Gnn36aPn360KdPHzp16mTtSNVHp6e8vLzi238XYv2/z1zKy8tRhlKufT6ZjH9MMy+rvE7ldZctW2Y+43RzcwPA29sbe3t7PvroI3bt2sWFCxfMbwB8fHyws7PjzJkzNG/eHDs7O0JDQ3Fzc+Odd95BlZdSmp7wOx0IIcTDTvPXoABsbGzYtm0b+fn5TJw4kQsXLtC6dWtrx6oWth5eJCYmAv85O2rRogUA58+fByC8d0eysxsRExNTZd2EhARatmxJWVkZly5dws/Pjy5dujB48GDz80dGRvLEE0/g5+dH69atee6558xt//rXv+jatSvJyclkZFR0PT969CgAHh4eAJjKSqrkteZ4eAUFBZoYj+9/kYyWIRktoyZkrKxGFKhb3N3d6dWrF9HR0bW2QDm3fJz9+7/i9OnTTJgwgfr16/N///d/nDlzhu+//x7AfC0uICCAjz/+mKlTp/Lhhx8yYsQIevTowYoVK8jPz2fs2LG4uroCMGXKFCIiIhg/fjxnz57lT3/6E05OFVOfz549m9DQUEaOHElSUhKLFi2ia9euxMfH4+9fMRvtrWtY9l4tquS15qgYKSkpmh+VQzJahmS0DK1mvPVG+79pvkDl5ORga2uLu7s7JSUlHDlyhLFjx1o7VrVx6/4UBfF7CAoK4tVXX6Vz584sXbqUDz/8EKUq7k1asWIFycnJAFy9epWePXsyefJkGjZsyIQJE1i7di0AP/5ShkpPpywzmQYNGnD16lV2795NXl4ep85fQWdrT3lOOo0bN+bixYvs3buXgoICPv/8c8rLy2nRogWnT59myZIlbNy4Eef2T2L/iPZ+uIUQtZNO3fqrp1Hnz59n9uzZGI1GlFKEhoYyadKku66fmJhI2LpLv2NCyzPkXOXG/k8pvnTSvMzRrxvu3Z8mZ+9K88gPjr4dce8xlBsH/x+GX65UrGhjh+tjA6nb78/oHZwByPl+FTd/2AUo9E7u1H/qLzg16wxA1q5lFJ7dB4DeuQ4u7ftRfOkU5Tnp5n3r7Bxx6zoID/8R6CqNdWjtoY60+m6wMsloGZLRMrSaMTExkXbt2t22XPNnUG3btmXr1q3WjvG7svNsRINh8ykvyMFYkIONqye2rp4ANBy3GlPxTdDpsXGq6Pjg6NeN8tyfMZUWYVfXB72DS5Xn8wx6GY+AUSijAb2DMzqb/xSZ+uFT8QwcizKWo3dwQWdjC4FjMRbeoDw/C72DM7Z1GlTZRgghfg+aL1APM9tKhekWnU6PjXOd/1qm+9Vx8m6dTd25zeW2ZTYudbFxqfsb0gohhGXViG7mQgghHj5SoIQQQmhSrfuIz2RSVr94/7AoMRhxtLOxdgwhRC1V686gyssN1o7wq2rCjXL3klGKkxCiOtW6AiWEEKJ2kAIlhBBCk6RACSGE0KRaV6BsbbV/Q6kW7+T+b76+vpQYjNaOIYR4iNW6Xnx6vY5msyOtHaNWkN6QQghrqnUFqiZQJiNFF2IpTj6OMpRi79UC147B2Lh43LauqbSIgh/3U5p+DvR6nHw74dK+Hzpbe3N7/qntmIoqJh109O2Ic6vHMRbfpCB+L2U/J6GztcPJrzvObfpiLMqjMOFfGLJSMJUVY+Pkjn3Dtri0D0Bv5/i7HgchhPhfpED9zkylhWRumkfZzz/h7e1N3bp1OR99hLyj3/BIxBvmQVwByn65QuamNzEV5prneUrdfZC8o9/i9YeF2LjV55dtizGkxuHq6opSil9Obadu4DjyYr7AVFpImzZtuHnjJtd2/Au7I19hyLmKDkWTJk2oU6cO1zMvkxm/l/zj3+H9x8V3LJJCCGENte4alNblRn+B6ZdkNmzYwNWrVzl37hyJiYl0aNOS7J1LMRlKAVBKkR35N3w8XDh27BhJSUmkpKSwZ88eXEyF5Oz7hIK4PZRc/oEPP/yQ3Nxczp49C8CN/atp6duIs2fPcv78ea5evcq3336LvuA6KBNffPEFKSkpxMfHk5GRwZ49e7ArziYvdpM1D40QQlSh+QJ16NAhQkJCCAoKYvXq1daO80BMZcUUxP2TP/3pT7zwwgssXryYPn364Ovry4oVKzAW3qAo8RAApWlnKctMZuHChfTs2ZOnn36aCRMmEBwczIwZMyhOOkrOnhUEBgYycuRICgsLq+zrb3/7G23btqVfv3688cYbPPvss4wbNw6A1atX065dO1q1asXhw4cJDg7G39+f0mvnf/djIoQQd6PpAmU0Gnn77bdZs2YNkZGR7Ny5k4sXL1o71n0z5FxFlZcxZMgQANauXUtsbCw//PADAQEBuLm5UXa9Yi6rssyKr0OGDOHatWts376dtWvXYjKZzFO4u7m58dlnnzFr1ixyc3PN+7GzsyM0NJSEhAQOHjxonsDw1nYHDhwgLy8PV1dX7OzsKCgo4MKFC+jt7z7iuRBC/N40XaDi4+Px9fWlSZMm2NvbM2jQIPbv32/tWPfNWHgDgIYNK6bGyMvLAzAXl4YNG1L2yxUMWWmUZSbj4OCAp6eneT2DwUBRUZF5+/fff5/k5GRWrVpVZT9eXl7o9Xrz81Z+/ls2bNjA6dOn6dmzJ+vWrSMtLQ1j8c3qeulCCPGbabqTRGZmJt7e3ubHXl5exMfHWzHRg7FxrJhgMCsrCwBn54ozFhcXF/Py0uxsrn32snmbgoIC83o6nQ4nJydSU1Np2LAh48aN46OPPmLGjBm4ublhMpmYNGkSn332WZXndXV1rbJfgIiICOrXr8/777/PxIkTiY2NZeN3O27LrOVxAwsKCjSdDySjpUhGy6gJGSvTdIGqbWw9G4FOz6FDhxg0aBADBw5k27ZtdO7cmXPnzpGdnU337t2ZMWMG69evJzIykkOHDhEeHk6rVq1o3LgxNjY2HDp0CBsbG65du0ZERASAuRffhAkTWLFiBSdOnKBDhw54e3sTEBAAVFzPA/D39+fw4cMUFBSQnl4xtbuHhwfKWH5bZi3fVKzV6asrk4yWIRktQ6sZExMT77hc0wXKy8uLjIwM8+PMzEy8vLysmOjB2Di54dz2CVauXMnzzz/PZ599xqpVqzAYDLz22msANGrUiOHDh3Ps2DEiIyN5/fXX6dmzJ+fOnUOv15OSksLChQtJT0+nUaNG5udOT0/HaDTSoUMHAKZPn05kZCQpKSnY29tz7tw5li1bBsDBgwcpLS3FZDLh4uLCjz/+yKZNm3Bs2uH3PyhCCHEXmi5Qjz32GFeuXCEtLQ0vLy8iIyNZunSptWM9kLpPjiJjw4907dqV/v37U69ePfbt28eNGxXXp6Kjo+nTpw9XrlwBIP7Hc/j6+hISEkJZWRl79+6lXGdL3QFj0dk5UHL5B4ouHOHpp58278OhUXuiYw7TuHFjgoODyc/PZ//+/RiNFUMXtWnTho4dO2JnZ0dqairHjh0DR3e8I1783Y+HEELcjaYLlK2tLfPmzeOll17CaDTy7LPP0qpVK2vHeiC2dRrgM2Y5N0/tICbhOCbDBey9O+I9+Cn0Ds7kHf2G0z/fQO/eAu+BM9A7OJN/Yhs7D50CvR7HTuG493gaW/cGALh2Cib/6LckpFbcA+Xx5Cjcez2L4fpl8k9uY2vUUXS29rj0GIp796coSYnj6vkYUg6dRJmM2LjUxa33H3DrEi436QohNEWnlFLWDmFJiYmJhK27ZO0YtYLWx+LT6ufplUlGy5CMlqHVjImJibRr1+625ZruZi6EEOLhJQVKCCGEJkmBEkIIoUma7iRxP0wmpflrJzVFicGIo52NtWMIIR5Ste4MqrzcYO0Iv6om3MmdkpIixUkIYVW1rkAJIYSoHaRACSGE0KRaV6Bsbe2sHeFXWeI+hBKD0QJJhBBCu2pdJwm9Xkez2ZHWjlHtpCOIEKK2q3VnUA87k8mEwXBvHUXKy8vN4/NVppSipKSEuw0yYjAYMJlMd9x3SUnJbwsshBB3IQWqljh9+jTPPPMMjo6O2Nvb07lzZ9avX3/HIvPdd9/Rq1cv7OzscHBwIDQ0lMOHD7Nx40aefPJJ3N3dadu2LW5uboSEhHDs2DHy8/OZPn06jRo1wt7eHgcHBzp37sy6detYvXo1HTt2xNHREScnJ1xdXQkODiYmJsYKR0IIUVvUuo/4HkbHjh3jySefxM3NjUmTJuHh4cGWLVsYOXIkFy9e5K233jKvu2LFCiZPnkzbtm2ZN28eJSUlbNiwAX9/fwA6duzImDFj8Pb2JjMzk2+++QZ/f39sbGwwmUw888wzdOjQgZKSEr7//ntGjx4NwOOPP8706dNxd3cnMzOTLVu2MGDAAKKjo+nVq5c1DosQooaTwWJrqMrXoAICArh8+TJxcXHo9XqysrJo2bIlI0eOZNOmTSQnJ9O4cWNu3LhBs2bN8Pf3Z8eOHaSlpeHs7IyzszM9evQgMTGR48eP4+3tTUZGBj169CA3N5dOnTqRmprKJ598wrhx44iKiqJp06a0bNmSoKAg9u3bx5YtW2jatClKKbp160ZeXh7t2rUjICCAr776qlqOgVYHvqxMMlqGZLQMrWassYPFvv766/Tu3ZvBgwdbO4ompaSkEB0dzbRp0/D09GT48OF06NCBrKwsFixYQFlZGV9//TUAO3bsID8/n7fffhuDwUCnTp0ICQnBxcWF2bNnAzBp0iR8fX3p2bMny5cvx8PDg6CgIAD69OnDzZs3iYyMZMqUKQD07t0bgD/84Q9069aN7t27s2nTJurUqUO7du1IS0uzwlERQtQGmi9QQ4cOZc2aNdaOoVkXL14EoGvXrgD88MMPlJaWkpiYiK+vL56eniQnJwOQnJyMjY0NnTp14tKlS+Tl5XHmzJkq2x8/ftx83apBg4o5p86dOwfAu+++i06n4/HHH2fhwoX89NNPbNiwAYDS0lJGjhzJe++9R0hICDt37iQmJgZ3d/ff6UgIIWobzV+D6tGjB+np6daOoVkFBQUAuLm5AVBWVlblq5ubGytXrsTT05N33nkHFxcXbG1tze1KKQwGg3l7AJ1Ox3vvvcfw4cN54403iI2NBcDDwwOdToezszO2trbY2dnh6upq3q5Lly707dsXd3d3GjVqhLu7u3mmYCGE+K00X6DE3aWkpGBjY2P+vmvXrnh5eZGfn0+DBg0wGo1cu3YNnU7HokWL0Ol0FBYWkp2dbT478vDwME/9DuDg4MC6desYNmwYkyZN4qOPPgIqita7777LuXPnGDNmDO7u7iQlJTFz5kxGjhwJwGuvvQbA22+/zdy5cxk+fDjr16+vtrEHCwoKND+uoWS0DMloGTUhY2VSoGowX19fGjRoQJ06ddiwYQMRERG8+eabxMbG8uijj7Jx40YMBgPPPfccmzZtYuLEiaxcuZINGzYwZcoUZsyYQdOmTQFYv349AF988QXPPvssR48e5ZFHHmH+/PlERUVx6NAhsrOzad68Oe3ataNHjx4AXL9+HRsbG/7+97+zb98+AMLCwgBIS0vjkUceqbaLslq94FuZZLQMyWgZWs2YmJh4x+VSoGo4Jycnpk2bxvz583nzzTeZOnUqzz//PJs3b2batGkAFBUVkZKSYv44cN68eXh4eLBgwQJKS0t59913Wbt2LQDOzs6kpKTg4+Nj7kKenZ3NoUOHGDFiBH/729/Yu3cvpaWlbN26lUWLFqGUolevXrz00kvY2NiQlpbG66+/zvbt25k7d65VjosQouaTAlULzJ49m6SkJBYuXMjChQvR6XQopWjXrh2dOnVi586d7Ny5EwB/f3+Ki4sZPXq0uQBBxX1MR48eJTw8/K77OX78OF26dLlj260zqlv7Bhg5cqQUKCHEfdN8gZo2bRrHjx/nxo0bBAQEMHnyZIYNG2btWJpib2/P+vXrmT17Nrt27aKoqIju3bsTGhqKUoq9e/eSmZmJp6cnYWFh2NnZERUVxZEjR7CzsyMoKIhu3bqRlpbG/v37UUqRlZVF/fr1AXB3dyc8PJyioiIiIyMr5opydOTRRx8lODiY3Nxc9u/fT1JSEkajER8fH/r370+rVq2sfGSEEDWZ3KhbQ1X3YLFa/ay6MsloGZLRMiTj/auxN+oKIYR4OEmBEkIIoUlSoIQQQmiS5jtJ/FYmk3ooJvMrMRhxtLOxdgwhhKg2te4Mqrz83ibrsyZL3MktxUkIUdvVugIlhBCidpACJYQQQpNqXYG6NXiqEEKImk0KlBBCCE2qdb347iQ9PZ3o6GhMJhN9+/alWbNmd103Pj6e06dP4+rqSmBgIB4eHua2H374gbNnz+Lu7k5gYKB5Mj6lFCdPniQhIYG6desSGBhonidJKcWxY8c4f/489erVIzAwsFpfqxBC1Bqqljl37pz5+9LSUjV+/HhlY2OjAAUonU6nRowYoQoKCqpsl56ergYMGGBeD1AuLi5q0aJF6vLly8rf379Km5ubm/rggw/UhQsXVM+ePau0eXh4qFWrVqmEhATVpUuXKm316tVT77333u99WH6zK1euWDvCr5KMliEZLUMy3r/Kf7crq3Uf8VU2Z84cVq9ezcSJE4mLiyMhIYFZs2axceNGJk+ebF5PKcXQoUM5efIkH3zwAUlJScTGxhIaGsqcOXNo3rw5CQkJLF++nIsXLxITE0O/fv2YNm0arVu35vLly6xatYrk5GQOHDhAr169ePnll3n00UfJyMhgzZo1JCcns3//fjp27MjMmTM5cOCA9Q6MEELUBA9a+fr376+ys7PNj48eParGjRunlFJq8+bNqk2bNioxMdHcPmjQIJWWlnbbtmfPnlX9+/dXCQkJD5TnViW+fv26cnR0VH/+85+VUkpt3LhRrVmzRiml1PTp05Ver1eXLl1SSikVGRmpAPX5558rpZRauHChOnDggFJKmc+Ovv76a1VeXq7mz5+vjhw5ooxGo+rQoYMCVGRkpCorK1Nz585VJ06cUAaDQbVo0UIB6uDBg6q4uFjNmTNHxcXFqZKSEtW4cWPVv3//B3qd1U2r77Qqk4yWIRktQzLeP4ueQZWVlVFUVHRP63p7e/Pxxx//z3XOnz/Pq6++yrJly2jfvj03b97EZDLdTzSzI0eOUFJSwvjx4zGZTIwdO5bx48dTWFjIuHHjMJlMHDx4EIB9+/bh7OzMiBEjOHnyJG+88QZ/+ctfABg7diz16tVj2LBhHD58mPnz5/PGG2+g1+t56aWXaNy4MeHh4ezbt48FCxYwf/58bG1tGTNmDG3atCEgIICdO3eyaNEiFi5ciIODA6NGjeLgwYMYDNq/qVgIIazlNxWo5ORkFi9eTGhoKFeuXLmnbfr168fFixe5dOnOU2BcunSJiRMn8u6779KxY0cATp06RWhoKMuXL+fatWu/JaJZamoqAH5+fuTn51NQUIDRaCQzM5PmzZuj1+vN66SmptK0aVNsbW3N+7t69SoALVq0MHequLWscpufn1+VZbe2/7U2k8lkXi6EEOJ2v1qgioqK2Lx5M88//zxvvvkmLVq0YPv27bRv3/7edvDvM41PPvnkju2vvPIK8+bNo3v37uZl/fr146uvvsLNzY2XX36ZF198kd27d1NWVnaPLwvs7OyAirO9yl3PbW1tMRgMmEwm/vrXv9KyZUs2b95sfm69Xm9eD6C0tNTcdut5/lfbra+/1lY5oxBCiNv9ajdzf39/2rRpwzvvvEOLFi3u6Ul1Ol2Vx4MHD2bVqlWkpaXdtm7v3r355ptv8Pf3r1JIPD09zdOSnz59mjlz5rBy5Up27Njxq/tPSUnBxcUFgISEBIKDg/Hx8eHmzZv4+Phw5swZANq3b0+XLl0oLi4mLS2N/Px82rRpA2D+mpCQwKVLlyguLjYva926tbntwoULGAyGO26XmJiIyWS6Y5u9vT1lZWUWGZevOhQUFGg22y2S0TIko2VIxmrwaxevoqOj1ZQpU1RYWJhavny5Sk9Pr9IeERGhLl++bH68Z88eNXv2bKVURSeJt956Syml1FdffaXmzp17WyeJrKwsNXHiRDV37tzb9p2UlKQWL16sgoKC1Jw5c9SZM2fu+WJbYWGheuSRR9SAAQOU0WhU8fHx6sSJE0oppYYOHaoA9Ze//EUppVR4eLgC1Lx585RSSn3//fcqNTVVFRQUKF9fXwWoJUuWKKWU2r17t7p69arKzc1V3t7eClArVqxQSim1c+dOlZmZqbKyslTdunWrdLzYtm2bysrKUteuXVOurq7q+eef/9XXYk1avZhamWS0DMloGZLx/t13Jwl/f3+WLVvGF198gZubG6+88gqjR48mPT0dgF69erFt2zYAjEYj27dvp1evXrc9T0REBLGxseTk5FRZrtPpWLp0KZcuXeLvf/87UHGG8dxzz/Hmm2/i5+fHli1bWLhwIZ06dbrnwuvs7MyCBQuIioqib9++xMbGEh8fT//+/fnuu+8AOHbsGIsXLyY5ORmABQsWMHz4cDIyMvj222/p0qUL6enp1K1blzlz5vDCCy+QnZ3Nl19+SdeuXcnOzsbd3Z2pU6cyatQocnNz+fzzz+natSuFhYW4ubkxfvx4xo4dS0FBAR9//DHdu3fHZDIxf/78e34tQgjxULqfahcXF6euXbumlFIqPz9fTZs2TQ0ZMkQNHjxYLVmyRBmNRqVU1TMopZRat26dat269R27mefn56unnnpKbdiwQV28eFFdvHjxfqLdVok///xz5efnZ75RtnHjxmrFihVq6dKlytnZWQGqfv366uuvv1Zz5sxRderUMa/bvXt3tXfvXlVYWKhmzJih3NzczG2PP/64OnDggMrPz1evvvqq+bkAFRAQoI4cOaJu3LihXn75ZeXk5GRuGzBggNqxY8d9vbbfk1bfaVUmGS1DMlqGZLx/dzuD0imllJVqY7VITEykXbt2VZaZTCZSUlIwmUzmHnwABoMBo9GInZ1dlQ4MKSkpuLq60rBhwyrPU1JSQkpKCu7u7vj4+FRpKy4uJjU1FQ8PD7y8vKq0FRUVkZqaSr169XjkkUdISUnB19fX0i/doiSjZUhGy5CMlqHVjHf6uw0PyVh8er2e5s2b37bczs7utp50Dg4O5k4Q/83R0dHc0eG/OTk53bXN2dmZtm3b/sbUQgjxcKvVQx0JIYSouaRACSGE0KRaV6CMRqO1IwghhLAAKVBCCCE0qdYVKCGEELWDFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmiSFCghhBCaJAVKCCGEJkmBEkIIoUlSoIQQQmhSrZtu48yZMzg4OFg7hhBCiHtUWlpK586db1te6wqUEEKI2kE+4hNCCKFJUqCEEEJokhQoIYQQmiQFSgghhCZJgRJCCKFJUqCEEEJoUo0qUIcOHSIkJISgoCBWr159W3tZWRlTp04lKCiIYcOGkZ6ebm775JNPCAoKIiQkhOjoaM1lPHz4MEOHDmXIkCEMHTqU2NhYzWW85dq1a3Tp0oXPPvtMkxnPnz/P8OHDGTRoEEOGDKG0tFRTGQ0GA7NmzWLIkCGEhYXxySefVEu+e8l44sQJIiIiaN++Pf/85z+rtG3ZsoXg4GCCg4PZsmWL5jImJiZW+X/etWuX5jLeUlBQQEBAAG+//bYmM167do0xY8YQFhZGeHj4bb/zVqNqiPLychUYGKhSU1NVaWmpGjJkiEpKSqqyzoYNG9TcuXOVUkrt3LlTTZkyRSmlVFJSkhoyZIgqLS1VqampKjAwUJWXl2sqY0JCgsrIyFBKKfXTTz8pf39/i+d70Iy3TJ48WU2ePFmtWbNGcxkNBoMaPHiwSkxMVEoplZOTo7n/6+3bt6upU6cqpZQqKipS/fv3V2lpaVbJmJaWphITE9XMmTPV7t27zctv3LihBgwYoG7cuKFyc3PVgAEDVG5urqYyXrp0SV2+fFkppVRGRobq27evysvL01TGWxYsWKCmTZum3nrrLYvns0TGESNGqJiYGKWUUgUFBaqoqKhacv5WNeYMKj4+Hl9fX5o0aYK9vT2DBg1i//79VdaJiooiIiICgJCQEGJjY1FKsX//fgYNGoS9vT1NmjTB19eX+Ph4TWVs3749Xl5eALRq1YrS0lLKyso0lRFg3759NGrUiFatWlk8myUyHj58mDZt2tC2bVsA6tati42NjaYy6nQ6iouLKS8vp6SkBDs7O1xdXa2SsXHjxrRt2xa9vuqfgpiYGPr27YuHhwd16tShb9++1fLJw4NkbN68Oc2nnwnjAAAEXklEQVSaNQPAy8sLT09PcnJyNJUR4McffyQ7O5u+fftaPJslMl68eJHy8nJzPhcXF5ycnKot629RYwpUZmYm3t7e5sdeXl5kZmbeto6Pjw8Atra2uLm5cePGjXva1toZK9uzZw/t27fH3t5eUxkLCwv59NNPmTRpksVzWSrj5cuX0el0vPjii0RERPDpp59qLmNISAhOTk74+/vTv39/xowZg4eHh1UyVse2v1fGyuLj4zEYDDRt2tSS8YAHy2gymViyZAmzZs2yeK7KHiTjlStXcHd3Z9KkSTzzzDMsWbIEo9FYXVF/E1trBxBVJSUl8f7777N27VprR7nNihUrGDVqFC4uLtaOcldGo5FTp07x7bff4uTkxOjRo+nQoQO9e/e2djSz+Ph49Ho90dHR5Ofn88c//pE+ffrQpEkTa0erka5fv87MmTNZsmTJHc9grOnLL78kICCgSvHQmvLyck6ePMnWrVvx8fHhtdde47vvvmPYsGHWjlZzCpSXlxcZGRnmx5mZmeaPxCqv8/PPP+Pt7U15eTk3b96kbt2697SttTMCZGRkMGnSJJYsWVIt7wQfNGNcXBx79uzh/fffJz8/H71ej4ODAyNGjNBMRm9vb3r06IGnpycAAQEBJCQkWLxAPUjG5cuX88QTT2BnZ0e9evXo2rUrZ8+etXiBepCfey8vL44fP15l2549e1o034NmhIrOB+PHj+e1116742CjlvAgGU+fPs2pU6fYuHEjhYWFGAwGnJ2dmTFjhmYyent7065dO/PPX2BgIHFxcRbNd7+09Xbjf3jssce4cuUKaWlplJWVERkZyYABA6qsM2DAAHNvoz179vD444+j0+kYMGAAkZGRlJWVkZaWxpUrV+jYsaOmMubn5zNu3DimT59Ot27dLJ7NEhm//PJLoqKiiIqKYtSoUYwfP97ixelBM/r7+3PhwgXzNZ4TJ07QsmVLTWX08fHh2LFjABQVFREXF4efn59VMt6Nv78/MTEx5OXlkZeXR0xMDP7+/prKWFZWxsSJE3n66acJDQ21eDZLZFy6dCkHDhwgKiqKWbNm8cwzz1i8OD1oxscee4z8/Hzz9btjx45Vy+/MfbFqF43f6MCBAyo4OFgFBgaqlStXKqWUWrZsmdq3b59SSqmSkhI1efJkNXDgQPXss8+q1NRU87YrV65UgYGBKjg4WB04cEBzGT/66CPVqVMn9dRTT5n/ZWVlaSpjZR9++GG19eJ70Ixbt25V4eHhatCgQWrJkiWay1hQUKAmT56swsPDVVhYmPr000+tljEuLk498cQTqlOnTqpnz54qPDzcvO0333yjBg4cqAYOHKi+/fZbzWXcunWrat++fZXfmXPnzmkqY2WbN2+utl58D5oxJiZGDR48WA0ePFjNmjVLlZaWVlvO30Km2xBCCKFJNeYjPiGEEA8XKVBCCCE0SQqUEEIITZICJYQQQpOkQAkhhNAkKVBCCCE0SQqUEEIITfr/i/Xml8HpT94AAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVzU5dr48c8XUUQBFZVBzfwFhpWa9mS54YaBKO6J1DETy+yoSWqaluaSC50n9ZjZRnZMq5OJG6Xmhim571qZloilCUMPIqDINnP//uBhnjwqMwwzzDBc79fr+3qdmfnOPdd49Oqe63t/r1tTSimEEELYlJujAxBCCFckyVUIIexAkqsQQtiBJFchhLADSa5CCGEHklyFEMIOJLmKWzz44IMMGDCAvn37EhMTw82bN60ea9q0aWzduhWA6dOnc/78+buee+jQIY4fP17mzwgJCeHq1asWP/9XjzzySJk+69133+WTTz4p03tE1SXJVdyiZs2aJCQksGnTJqpXr87q1atveb2oqMiqcefPn0/z5s3v+vrhw4c5ceKEVWML4YzcHR2AcF7t2rXj3LlzHDp0iHfeeQcfHx9SUlLYsmULCxcu5PDhwxQUFDBs2DCeeuoplFLMnTuXffv20ahRI6pXr24aa/jw4bz66qu0bt2apKQk/vnPf2IwGKhXrx7z589n9erVuLm58fXXX/PGG28QEBDArFmzuHLlCgCvv/46jz76KJmZmbzyyivo9Xratm2LJffAjB07lrS0NPLz83n22WeJiooyvbZgwQL27dtHgwYN+Oc//4mvry+///47c+bMITMzk5o1azJ37lwCAwNt/wcsXJsS4i/atm2rlFKqsLBQ/f3vf1dffPGFOnjwoGrTpo36/ffflVJKrV69Wr333ntKKaXy8/PVoEGD1O+//662bdumoqOjVVFRkUpLS1OPPvqo+vbbb5VSSj3zzDPq9OnTKiMjQ3Xt2tU0VmZmplJKqaVLl6rly5eb4pg0aZI6cuSIUkqpP/74Q4WHhyullJo7d6569913lVJKfffddyooKEhlZGTc9j169Ohher7kM27evKkiIiLU1atXlVJKBQUFqYSEBKWUUu+++66aM2eOUkqpZ599VqWkpCillDp58qQaPnz4HWMUojQycxW3yMvLY8CAAUDxzHXIkCGcOHGC1q1b07RpUwD27dvHuXPn2LZtGwA5OTn89ttvHDlyhIiICKpVq4ZOp6NDhw63jX/y5EnatWtnGqtu3bp3jGP//v231GivX7/OjRs3OHLkCMuWLQOge/fu1KlTx+x3+uyzz9ixYwcAqamp/Pbbb9SrVw83Nzf69OkDwIABA3jppZe4ceMGJ06c4OWXXza9v6CgwOxnCPGfJLmKW5TUXP9TrVq1TP9bKcWMGTPo0qXLLefs2bPHZnEYjUbWrFmDh4dHucY5dOgQ+/fv56uvvsLT05Phw4eTn59/x3M1TUMphY+Pzx3/DIQoC7mgJcosODiYL7/8ksLCQgBSUlLIzc3lscce49tvv8VgMJCens6hQ4due2/btm05evQoly5dAuDatWsA1K5dmxs3btzyGZ999pnp8c8//wzAY489xjfffAMUJ/OsrKxSY83JyaFOnTp4enqSnJzMyZMnTa8ZjUbT7Pubb77h0UcfxcvLi3vuuYdvv/0WKP4PydmzZ8v2ByQEklyFFSIjI2nevDmDBw+mb9++zJw5E4PBQGhoKM2aNaNPnz5MnTqVtm3b3vZeX19f3nzzTcaPH0///v2ZOHEiAD169GDHjh0MGDCAo0ePMn36dH788Uf69etHnz59+PLLLwEYN24cR48eJSIigh07dtC4ceNSY+3atStFRUX07t2bRYsW3RJTrVq1OH36NH379uXgwYOMGzcOgLfffpu1a9fSv39/IiIi2Llzp63+6EQVoiklLQeFEMLWZOYqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhydRKy3FgI1yLJ1YH+mlA1TeP69eucPXuWOXPmsGvXLgdGJoQoL0muDqRpGgBpaWmcOnWKMWPGsGXLFnbs2IG7u/TUEaIyk3/BDnDlyhV0Oh3VqlXjs88+IykpCT8/P4YOHco999zD999/T0BAgKPDFEKUg/QWqEBKKVJTUxkxYgRffPEFtWrVYsuWLbRp0wY/Pz/q1avH22+/zX333ceQIUMcHa4Qohxk5lqBNE3Dy8uLhg0b4ufnB8CQIUNwcyuuzty4cYO0tDR69+7tyDCFEDYgNdcKcvHiRaC4GXW1atVu2eiv5MfD4sWLAWjVqlWFxyeEsC2ZudqZUorCwkLGjx9Pp06dGDNmDJmZmeTk5Ji2GikRHBzMAw88YHpfyQUvIUTlIzVXO9Pr9eh0OlJTUxkzZgyPPPIIycnJdO/eHV9fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri2HDhjFixAiGDh2KXq9n8uTJHDlyhBdeeIHff/+d/Px8NE3j6tWrLF26FJ1O5+jQhRA2IMnVznbv3s0777zD8OHDGTx4MFevXmX06NGEh4czatQo03n5+fnl3oxPCOE8pOZqB7/88gv169fHy8uL7t274+npybx58zAYDERGRvLee+/x97//nUuXLjFnzhwAqlev7uCohRC2JDNXG0tNTSUsLIyGDRsSFBTEsGHDCAwMJCsri1dffZUxY8bQp08f0tLSmDRpEsuWLcPX19fRYQshbKza7NmzZzs6CFeRnZ1NgwYNqFWrlqlXgIeHB++88w7e3t7k5OSwdetWPDw8aN++PQMHDqR27dqODlsIYQeyztVG9Ho9kyZN4siRIzz77LN07NiR5s2b06JFCz799FN8fX1p1qwZaWlpLFq0iKysrFuWYQkhXIuUBWzk2rVrbN68mb179zJ69Ghat27N2rVrOXnyJBEREXTp0gWA5ORkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HAmjVruPfeewkJCeHq1ascOnSInJwcWrRoga+vr5QChKgC5HdpORw5coSEhATT4zp16tCrVy+eeOIJPvroI3799Vf69+9P8+bN+eGHH7h+/boDoxVCVCRZilUORUVFxMbG4ubmRr9+/YDiBBsWFkZeXh47duxg/PjxhIeHU7NmTby8vBwcsRCiosjM1QpKKZRSdOzYkaVLl7JkyRK+/vpr02t169YlMDCQlJQUjEYjfn5++Pj4VHicf/75p2wf4+Ryc3MdHUKZyN8ny0lytYKmaWiaxtmzZ3n88ceZN28e77zzDps2bTI1W8nNzSU/P9/ifzwGg8GmMX7//fe89NJLpKam2mzMX3/9lcOHD5OZmWmzMX/77Td++OEHCgoKbDbmxYsX+eGHHzAajTb7c71w4QInTpygsLDQZmPu3LmThQsXkpGRYZPxAE6ePMnGjRs5efKkzf5Mjx49ysaNG4Hiv/uSYC0jF7SstHbtWt577z0iIiIICAigRYsWvPfee1y8eJE9e/aQkJDAjBkzaNSoUanjpKSkmLpjGQwGmyzP2rt3LwsXLiQzM5Nr167RtWvXco+5Z88eZs2aRUpKCtu3b6dDhw7lvjD33Xff8cYbb3Ds2DEOHDhAUFAQ9erVK9eYO3fuZPbs2SQnJ3Py5EkuX75M8+bNy3UH3Pbt25kxYwY//vgjhw4dQq/XExgYSI0aNawe8/Dhw8yfP5/o6GhatGhh9Th/lZiYSGxsLPn5+Rw5coRWrVpRt25dq8czGo3k5uYybtw4jh07hpubG61bt0bTNIxGo3RtM0eJMjEYDEoppT744AO1c+fOW147d+6c2rx5s1q5cqW6ePGi2bF27dqlHn74YTVp0iTTc0VFReWKb9++feqJJ55Qv/zyiyooKFAjR45Uhw8fLteYBw8eVGFhYerUqVNKKaXGjh2r9u3bV64xjx07psLDw9VPP/2klFJq1qxZatq0aeUa8+rVq+r5559Xv/76q1JKqfj4eDV48GC1bNkylZOTY9WYBQUF6uWXX1ZHjx5VSim1detW9dZbb6nFixdbPaZSSv3rX/9Sy5cvV0oplZaWpvbu3atOnjypsrOzrRrv6tWr6rnnnlPnzp1TSik1bdo0tWXLFvU///M/Ki8vz+o4lVIqLi5OffLJJ2rKlClqxYoV5RqrKpGyQBm5ublx6dIl9u3bd0sHq99++42goCD69OnDs88+S7NmzUodJzc3l88//5zXX3+d6tWrM3nyZACqVatWrp+dBoOBf/zjH9x///3cvHmT++67j19//RWwvl7WoEED5syZw8MPP8yff/7JqVOn+Pzzz5k5cyZbt261etwXXniBhx56CICYmBiysrLK9VPW3d2d3Nxc/vzzT6B4l4cmTZqQmZnJ7t27rR73+vXr/PbbbwCEhobSo0cPCgsL+eabb6z+7n9tK/nyyy+zbt06Pv/8c+bMmUNWVlaZx3N3dycvL48LFy5w/fp1Dh8+TEJCAgsWLOD9998vV23X3d2d1NRUBg0axOnTp4mNjWXRokUopTAajVaP6+qkLFAGSimKiopYsmQJISEhdO7cmeTkZKZPn86FCxe4//778fLysujnUvXq1enQoQOtWrWiQ4cOJCYmkpiYSFhYWLlKA82aNaNRo0YYjUZq1qyJpmnExsYSHBxMgwYNrBrT19eXe+65B4BVq1bRunVrZs+eTWZmJrt27eLxxx/H09OzTGP6+fnRrFkzatSogcFgICcnhy+//JLevXvj6elJZmZmmcf08PCgoKCAxMREcnNz+fbbb8nNzaVVq1YcPXqUnj17lmk8KE6C9evXZ8OGDfj7+9OkSRP8/f25du0aBw4cICwszKqfxzVr1mThwoUcP36c3r17M3HiRB588EF++OEHvLy8zP7H+T95eHhQu3Zt4uLi+Oabb+jduzdvvvkmPj4+HDt2jPvuu8/q///r169PamoqAwcO5I8//uCTTz4hMDCQ7t27S2mgFDJzLQNN06hevTo3btwgPT2d6Oho1q9fzwMPPMDkyZPx9/cv0182nU5H7dq18fX1Zc6cOeTn55tmsD/99BPJyclWx1qSoLt27crQoUPZvXu3TWYaY8aMYezYsQAMHjyY69evW3XRrFq1aqalaUopvL29qVOnDr6+vnz99dcsWbKEvLy8Mo/bt29funbtyqFDh8jLy2PhwoU89dRTZGRkWL3OuF27dgQHB5OQkMCRI0eoVq0a/fr1Iz09nbNnz1o1ZosWLZg6dSqnTp3i8uXLADRt2hSj0cjVq1etGjM8PJwVK1bw6KOPmn4RdOzYkRs3bvDHH39YNSYUJ+6UlBTWrFnD6tWreeGFF0hNTWX16tVWj1kVyDrXMrpw4YLpp/CoUaPo1KmTTdoF1qtXjzlz5vD2228THh6O0Whk1apVNogYHnjgAT799FNGjRpVrl0O1H9sPbNt2zYyMjJMmy1ay93dHXd3dxo1asSiRYvYt28fsbGx1KxZs8xjeXt7079/f/r27Wv6D8zGjRvL1cvBw8ODfv36oWkaH330ERcuXKBGjRpkZGSU6zbmrl27EhMTw7vvvkvjxo0BOHPmDKNHj7Z6zDp16tChQwe2bt1K9erVyc/P5/Lly+W6aKbT6fD39+f9999n5syZhISEcPDgwTLPrqsch1V7K7GcnByVm5t7y3NGo9EmY69YsUJ16tRJnT171ibjlYiJiVGXLl2yyVj5+flqzZo1qk+fPqYLKOVhNBpVfn6+6tmzp+rWrZtKSUkpf5D/Kz4+XvXu3dsmf575+fnqwIEDasKECWrq1Kmmi3Hl9eOPP6pFixap2NhYm8SZlZWlVq5cqYYNG6aee+459fPPP5d7zCtXrqgffvjB9Ljkwq64O2nc4kSysrKYMGECU6dONW1UWF7KDhsdFhYWsn//fpo2bUpAQIDNxl2/fj2tW7fm/vvvt9mYf/zxB0VFRTadZRkMBjRNc/quZiVlEFveGWiPv0+uSpKrk6nK273IP1zhSiS5CiGEHTj37xohhKikJLkKIZxefn4+2dnZjg6jTKr0UqykxO/JvFL2u2GEELeq17gOXXt2sdv4l5PjyC1ozkOtw8q1nLAiVenkmnkli2UjVjo6DCEqvZdWjrDb2Ddv3qTI6I3O+xv0ybtpHPQPu32WLUlZQAjh1K6kLMffewO+tXZzLe9xm7fntBdJrkIIp1Uya/X2+Bk3rYgGtRPRJ7/u6LAsIslVCOG0SmatJSrT7FWSqxDCKf111lqiMs1eJbkKIZzSf85aS1SW2avDkmtISMgtrdUOHTrEiy++CGBq4/fXdm59+/Y1tWb763t//PFHQkJCOHPmTAVGL4SwpzvNWktUltlrhSbXgoICizui+/v78+GHH5Z6ztmzZ4mJiWHJkiU89NBD5OTkSGd0IVzA3WatJSrD7LVCkmtycjJvvfUW4eHhXLx40aL3dO/enfPnz3PhwoU7vn7hwgXGjRvHf//3f/Pwww8DcOzYMcLDw3n33Xe5cuWKrcIXQlSgvLw8iow+d5y1lnDTiqhfK9G0pY8zsltyzc3NZd26dTz99NPMmDGDwMBAvv76a1OHdLOBubkxatQoPvroozu+PnbsWGbOnEm7du1Mz3Xv3p3Vq1fj7e3NmDFjeP755/n2229tum2zEMK+CgoKqFU9xex5tWpcID8/vwIiso7d7tAKDg6mRYsWzJs3j8DAQIve85/t5vr27csHH3zApUuXbju3Y8eOxMfHExwcfMvtcL6+vkRHRxMdHc2JEyd4/fXXef/99/nmm2/K94WEEBVGoTBSeolP4dwN/ew2c126dCk6nY7x48ezbNmy2/bwqVu37i2NGLKysm7bs97d3Z3nnnuOjz/++LbxZ86cCcCcOXNue+38+fP84x//YOrUqfzXf/0X8+bNs8VXEkJUEKXAoIxmD2dmt+QaHBzMkiVL+OKLL/D29mbs2LFER0ebrvi3b9+ehIQEoLiz+9dff0379u1vG2fQoEEcOHDgtk3bNE1j0aJFXLhwgXfeeQco3tRv6NChzJgxg4CAADZs2MD8+fNp06aNvb6mEMIOjBgpwlDqYTAzs3U0uzduqVevHiNGjGDEiBGcPn3a9BN+7NixzJ49m/79+6OUokuXLvTv3/+299eoUYPhw4czf/78217z8PDggw8+4JlnnqFBgwZ06NCB2NhYi8sQQgjnZAQMZvr4G5UCJ964okrvRJDw2SbpiiWEDby0cgQDhve1yVjZ2dmkX/lvGviU/m8zr6A5+dqnTrsLbZVuOSiEcE4KMJi5YGV08gtaklyFEE7HqBSFZi5YFUlyFUKIslFg9nKVEacuuUpyFUI4H4WyqCzgzBu+SHK1sW1XTtp8zF6N29p8TCGcWfFqATPnKKjmxFNXSa5CCKdjRKPQzI9+AxrVKygea0hyFUI4HUXxzLQ05l53NEmuQginU7wUq/SZq3PfnyXJVQjhhAxKA1X63fnKzOuOJslVCOF0FJrZmaty6oVYklyFEE5IoWE021dKkqsQQpRJ8QUtM8nT3OsO5txFi3J47bXX6NixI3372qaZhBCi4hiURoGqVupR5NS3ELhwch08eDDLly93dBhCCCuUlAVKP2Tm6hCPPfYYderUcXQYQggrlFzQKu2wJLne6RfstWvXGDlyJGFhYYwcOZKsrKziz1SKefPmERoaSr9+/fjpp59M79mwYQNhYWGEhYWxYcPdd6X9K5dNrkKIysuARqGqVupRZMFSrDv9go2Li6Njx45s376djh07EhcXB0BSUhIXL15k+/btzJ07l9mzZwPFyXjZsmWsWbOG+Ph4li1bZkrIpZHkKoRwOsUzVzezhzl3+gWbmJjIwIEDARg4cCA7d+685XlN02jbtm1x0+70dPbu3Uvnzp2pW7cuderUoXPnznz//fdmP1tWCwghnI5SGgYzM1M35UZycjITJ040PRcVFUVUVFSp78vIyMDPzw+Ahg0bkpGRAYBer8ff3990nr+/P3q9/rbndToder3e7HeQ5CqEcDqWrHM1ohEYGMj69eut/hxN09A0+1wYc9mywKRJk3jqqadISUmha9euxMfHOzokIYSFDFiwFMvK21/r169Peno6AOnp6fj6+gLFM9K0tDTTeWlpaeh0utue1+v16HQ6s5/jssl18eLF7N27l59++omkpCQiIyMdHZIQwkJKaRiVm9nDGiEhIWzcuBGAjRs30rNnz1ueV0px8uRJvL298fPzIzg4mL1795KVlUVWVhZ79+4lODjY7OdIWUAI4XRKLmiVxvztscW/YA8fPkxmZiZdu3Zl/PjxjB49mgkTJrB27VoaN27MkiVLAOjWrRt79uwhNDQUT09PFixYAEDdunUZO3YsQ4YMAWDcuHHUrVvX7GdLchVCOB0jWnFnrFIYLBhn8eLFd3x+5crbt+3WNI1Zs2bd8fwhQ4aYkqulJLkKIZyOUWkUqtLTk7uZ1x3NuaMTQlRJyoI7sJx8IwJJrrZmj80EJ57/2eZjAvyz+YO2H9TNDs00jJb8ABSuRGF+nau51x1NkqsQwukY//f219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXDhwi19Hi9dukRMTAzR0dGOC0oIYREFZm8icPY9tFw2uQYEBJCQkACAwWCga9euhIaGOjgqIYQljEqj0Fh6TdVglJmrwx04cICmTZvSpEkTR4cihLCAJV2xLNnmxZGqRHLdvHnzLbs/CiGcW/EFrcrdW8C5U78NFBQUsGvXLsLDwx0dihDCQkaLdn+VpVgOlZSURMuWLWnQoIGjQxFCWMiSmassxXKwzZs3ExER4egwhBBloKj861xduiyQm5vL/v37CQsLc3QoQogyMFJ8+2tphyzFcqBatWpx6NAhR4chhCgjpTSzNVVZLSCEEGVkyU4EMnMVQogyMoLZDQoluQohRBlZ1LhFygJCCFE2Cs3sNi7m+r06miRXIYTTsegOLU2Sqygnu+zSCoz79Rebj/leUAubjymqHoX5loJScxVCiDIyKkvKAlJzFUKIMim+Q6tyrxZw7tQvhKiSlCqevZZ2KAtvf/3000+JiIigb9++TJo0ifz8fC5dukRkZCShoaFMmDCBgoICoLjR04QJEwgNDSUyMpLLly9b/R0kuQohnE7JzLXUw4Jx9Ho9q1atYt26dWzatAmDwcDmzZtZuHAh0dHR7NixAx8fH9auXQtAfHw8Pj4+7Nixg+joaBYuXGj1d5DkKoRwOiU119IOc3tslTAYDOTl5VFUVEReXh4NGzbk4MGD9OrVC4BBgwaRmJgIwK5duxg0aBAAvXr14sCBAyhlXedYqbkKIZxO8WoB8y0Hk5OTb9krLyoqiqioKNNjnU7Hc889R48ePfDw8KBz5860bNkSHx8f3N2L05+/vz96vR4onuk2atQIAHd3d7y9vcnMzMTX17fM38Flk2t+fj7Dhg2joKAAg8FAr169iImJcXRYQggLWHJBSymNwMBA1q9ff9dzsrKySExMJDExEW9vb15++WW+//57W4d7Ry6bXGvUqMHKlSupXbs2hYWF/O1vf6Nr1660bdvW0aEJIcxRlsxczQ+zf/9+7rnnHtPMMywsjOPHj5OdnU1RURHu7u6kpaWh0+mA4pluamoq/v7+FBUVkZOTQ7169az6Ci5bc9U0jdq1awNQVFREUVERmpPf0SGEKGZUGgajW6mHuZsMABo3bsypU6e4efMmSikOHDhA8+bNad++Pdu2bQNgw4YNhISEABASEsKGDRsA2LZtGx06dLA6b7hscoXiQvaAAQPo1KkTnTp1ok2bNo4OSQhhAUXxOlZzhzlt2rShV69eDBo0iH79+mE0GomKimLKlCmsWLGC0NBQrl27RmRkJABDhgzh2rVrhIaGsmLFCiZPnmz1d3DZsgBAtWrVSEhIIDs7m3HjxvHLL78QFBTk6LCEEGZYWnO1RExMzG3XW5o2bWpafvVXHh4eLF261PJAS+HSM9cSPj4+tG/fvsIK2UKI8lEWlAUMRucu87lscr169SrZ2dkA5OXlsX//fgICAhwclRDCIqo4wZZ6OPntry5bFkhPT2fatGkYDAaUUoSHh9OjRw9HhyWEsIAtywKO4rLJ9YEHHmDjxo2ODkMIYQWlig9z5zizuybXRx55xLQEoeT2L03TUEqhaRrHjx+vmAiFEFWOQjN7e6u5ma2j3TW5njhxoiLjEEIIE0tvf3VmFl3QOnr0KOvWrQOKLxRdunTJrkEJIaq2krJAqYejgzTDbHJdtmwZy5cvJy4uDoDCwkKmTJli98CEEFWbudUCVPaZ644dO/jggw/w9PQEiu+9vXHjht0DE0JUXa6wztXsaoHq1aujaZrp4lZubq7dgxIV4737bX+32vQLtq/Vzw+QZjtVjUWrBSomFKuZTa69e/dm5syZZGdns2bNGtatW8fQoUMrIjYhRJVlwTYuTl4WMJtcn3/+efbt20ft2rVJSUkhJiaGzp07V0RsQogqSlnUcrCSJ1eAoKAg8vLy0DRNGp8IIexOWTBzdfY7tMxe0IqPjycyMpIdO3awbds2oqKi7thNRgghbEZZeDgxszPX5cuXs2HDBlM37szMTJ566imGDBli9+CEEFWX2ZlrZW/cUq9ePVNHf4DatWtbve2BEEJYQikNo5mlVsqSvbUd6K7JdcWKFQDce++9DB06lJ49e6JpGomJibRo0aLCAhRCVFGuulqg5EaBe++9l3vvvdf0fM+ePe0fVTmlpqby6quvkpGRgaZpDB06lBEjRjg6LCGEpVy5K9ZLL71UkXHYVLVq1Zg2bRotW7bk+vXrPPnkk3Tu3JnmzZs7OjQhhKWcPHmaY7bmevXqVT7++GPOnz9Pfn6+6flVq1bZNbDy8PPzw8/PDwAvLy8CAgLQ6/WSXIWoJJTSUGZrrs5dFjC7FGvy5MkEBARw+fJlXnrpJZo0aULr1q0rIjabuHz5Mj///LPs/CpEZWLJNi9OXnM1m1xLtp11d3fn8ccfJzY2loMHD1ZEbOV248YNYmJieNQNBFwAABE0SURBVP311/Hy8nJ0OEKIsnD1da7u7sWn+Pn5sXv3bvz8/MjKyrJ7YOVVWFhITEwM/fr1IywszNHhCCHKQmHBagDnnrmaTa5jxowhJyeHqVOnMnfuXG7cuMFrr71WEbFZTSnF9OnTCQgIYOTIkY4ORwhhDXMz08o+cy3ZMdXb25vPPvvM7gHZwrFjx0hISCAoKIgBAwYAMGnSJLp16+bgyIQQlrGgGXZlTa5z58419XC9kxkzZtglIFto164d586dc3QYQggrWdLPtdIm11atWlVkHEII8X8UYG6plYWrBbKzs5kxYwa//PILmqaxYMEC7rvvPiZOnMgff/xBkyZNWLJkCXXq1EEpxfz589mzZw81a9bkrbfeomXLllZ9hbsm10GDBlk1oBBClJcGaDaauc6fP58uXbqwdOlSCgoKyMvL48MPP6Rjx46MHj2auLg44uLimDJlCklJSVy8eJHt27dz6tQpZs+eTXx8vFXfwaLdX4UQokLZqOVgTk4OR44cMXXxq1GjBj4+PiQmJjJw4EAABg4cyM6dOwFMz2uaRtu2bcnOziY9Pd2qr2BRs2whhKhYllzQ0khOTmbixImmp6KiooiKijI9vnz5Mr6+vrz22mucPXuWli1bMn36dDIyMkx3cTZs2JCMjAwA9Ho9/v7+pvf7+/uj1+tN55aFJFdhU/bYTHDkud9sPuaKFs1sPmalUsrFauvGs+1wxTVX8+cEBgayfv36u55SVFTEmTNneOONN2jTpg3z5s0jLi7ulnP+ugGrLbnkagEhRCVnyc9+C8oC/v7++Pv7m25/Dw8PJy4ujvr165Oeno6fnx/p6en4+voCoNPpSEtLM70/LS0NnU5n1VeQ1QJCCOdkg36uDRs2xN/fnwsXLhAQEMCBAwcIDAwkMDCQjRs3Mnr0aDZu3GhqpRoSEsLnn39OREQEp06dwtvb26qSAMhqASGEM1KgmSkLmF1N8L/eeOMNJk+eTGFhIU2bNiU2Nhaj0ciECRNYu3YtjRs3ZsmSJQB069aNPXv2EBoaiqenJwsWLLD6K7hky0EhhCjx4IMP3rEuu3Llytue0zSNWbNm2eRzXb7loBCi8ilZ52rucGYu3XJQCFFJKc2yw4m5bMtBIUQlZslSrMq6+2uJythyEIrrKfHx8SiliIyMJDo62tEhCSHKwNzPfueet7poy8FffvmF+Ph44uPjqV69OqNGjaJHjx40a1bFF44LUVnYaJ2rI5lNrnebpcbGxto8GFtJTk7m4YcfxtPTE4DHHnuM7du388ILLzg4MiGExVw9uXbv3t30v/Pz89m5c6fVi2orSlBQEEuWLCEzM5OaNWuSlJQkN0UIUZko0My0HDS3DtbRzCbXXr163fK4b9++/O1vf7NbQLYQGBjIqFGjeP755/H09OSBBx7AzU0agAlRaVSCDQjNKXPjlosXL5o6yDizyMhIIiMjAVi8eLHV9wcLISqeLfu5OorZ5PrII4/c0sClYcOGTJ482a5B2UJGRgb169fnypUrbN++nTVr1jg6JCGEpSy5/bWylwVOnDhREXHY3Pjx47l27Rru7u7MmjULHx8fR4ckhCgLV5+5jhgx4rZ7cO/0nLP597//7egQhBDWcuWaa35+Pjdv3iQzM5OsrCzU/27FeP36dfR6fYUFKISoeiypuTp7b4G7JtfVq1ezcuVK0tPTGTx4sCm5enl58cwzz1RYgEKIKsiVbyIYMWIEI0aM4LPPPmP48OEVGZMQQlT6mavZxZ9ubm5kZ2ebHmdlZfHFF1/YNSghRBVno91fHcnsBa01a9YwbNgw0+M6deoQHx9/y3NC2JM9NhMcdvayzcf84oF7bD6m3SgbZyZ7JDonT57mmE2uRqMRpZRpravBYKCwsNDugQkhqi6tKqxzDQ4OZsKECTz11FNA8YWuLl262D0wIUTV5vJ3aE2ZMoWvvvqKL7/8EoBOnToxdOhQuwcmhKjCKkFN1RyLLmg9/fTTLF26lKVLl9K8eXPmzp1bEbEJIaqokrKAucOZWdS45cyZM2zatImtW7fSpEkTwsLC7B2XEKKqc9WyQEpKCps3b2bTpk3Uq1ePPn36oJSqNLsRCCEqMVe+iaB37960a9eOjz76yLQ9yqefflpRcQkhqrjKvofWXWuuy5Yto2HDhjz77LPMmDGDAwcOmG6BrQySkpLo1asXoaGhxMXFOTocIUQZuHTN9YknnuCJJ54gNzeXxMREVq5cydWrV5k1axahoaEEBwdXZJxlYjAYePPNN1mxYgU6nY4hQ4YQEhJC8+bNHR2aEMISLlAWMLtaoFatWvTr148PP/yQPXv28NBDD/Hxxx9XRGxWO336NM2aNaNp06bUqFGDiIgIEhMTHR2WEKIsKvntr2XaWKpOnTpERUU5fS9XvV6Pv7+/6bFOp5M2iUJUMpoyc5RhLIPBwMCBA3nxxRcBuHTpEpGRkYSGhjJhwgQKCgoAKCgoYMKECYSGhhIZGcnly9bfJi279gkhnI+5xFrGmeuqVasIDAw0PV64cCHR0dHs2LEDHx8f1q5dC0B8fDw+Pj7s2LGD6OhoFi5caPVXcMnkqtPpSEtLMz3W6/WyQaEQlY2NygJpaWns3r2bIUOGFA+rFAcPHjTtbD1o0CBT2XDXrl0MGjQIKN75ujwX8l0yubZu3ZqLFy9y6dIlCgoK2Lx5MyEhIY4OSwhhKQtbDiYnJzN48GDT8dVXX9021IIFC5gyZQpubsXpLjMzEx8fH9zdi6/n+/v7m8qGer2eRo0aAeDu7o63tzeZmZlWfYUyb61dGbi7uzNz5kxGjRqFwWDgySef5P7773d0WEIIC1nUFUtBYGAg69evv+s53333Hb6+vrRq1YpDhw7ZOMrSuWRyBejWrRvdunVzdBhCCCvZYieC48ePs2vXLpKSksjPz+f69evMnz+f7OxsioqKcHd3Jy0tzVQ21Ol0pKam4u/vT1FRETk5OdSrV8+q+F2yLCCEqORstBPBK6+8QlJSErt27WLx4sV06NCBRYsW0b59e7Zt2wbAhg0bTGXDkJAQNmzYAMC2bdvo0KGDqZd1WUlyFUI4nZLdX82uGLDSlClTWLFiBaGhoVy7do3IyEgAhgwZwrVr1wgNDWXFihVMnjzZ6s9w2bKAEKISU4C521vLmFzbt29P+/btAWjatKlp+dVfeXh4sHTp0rINfBeSXIUQTsnldyIQwhXZYzPB/mcybD4mwNcP1bfLuE7NBXoLSHIVQjid4qVYpWfP8tRcK4IkVyGEU7LFUixHkuQqhHA+UhYQQgjbK1mKVeo5klyFEKKMLLz91ZlJchVCOB8pCwghhO1ZUhZw9uTqsre/ZmdnExMTQ3h4OL179+bEiROODkkIYTEFyoLDibnszHX+/Pl06dKFpUuXUlBQQF5enqNDEkJYygVqri45c83JyeHIkSOmzuM1atTAx8fHwVEJISzmAltru2RyvXz5Mr6+vrz22msMHDiQ6dOnk5ub6+iwhBCWslHLQUdyyeRaVFTEmTNnePrpp9m4cSOenp7ExcU5OiwhhIVKbn8t9XDymqtLJld/f3/8/f1p06YNAOHh4Zw5c8bBUQkhysKe/Vwrgksm14YNG+Lv78+FCxcAOHDgwC3b6gohnJwLlAVcdrXAG2+8weTJkyksLKRp06bExsY6OiQhhIVcYZ2ryybXBx98sNRdIYUQTkwpC1oOOnd2ddnkKoSo5GTmKoQQtmXJBStnv6AlyVUI4XwUYKYsYPZ1B5PkKoRwPi5w+6skVyGEE7KgMYskVyHKSdNsP6YdrjTba5fWJ39Ot/mY6x70s/mYtiQ1VyGEsAcLdn+VloNCCGENc12vpCuWEEKUTXFZQJk9zElNTWX48OH06dOHiIgIVq5cCcC1a9cYOXIkYWFhjBw5kqysLACUUsybN4/Q0FD69evHTz/9ZPV3kOQqhHBONugrUK1aNaZNm8aWLVv46quv+Pe//8358+eJi4ujY8eObN++nY4dO5q65iUlJXHx4kW2b9/O3LlzmT17ttXhS3IVQjgfZabdoNH87bEAfn5+tGzZEgAvLy8CAgLQ6/UkJiYycOBAAAYOHMjOnTsBTM9rmkbbtm3Jzs4mPd26C4pScxVCOB+FBUuxFMnJyUycONH0VFRUFFFRUXc8/fLly/z888+0adOGjIwM/PyKV0w0bNiQjIwMAPR6Pf7+/qb3+Pv7o9frTeeWhcsm108//ZT4+Hg0TSMoKIjY2Fg8PDwcHZYQwhIW3kQQGBhoUYOmGzduEBMTw+uvv46Xl9et42gamh2W+7lkWUCv17Nq1SrWrVvHpk2bMBgMbN682dFhCSEsZsnur5aNVFhYSExMDP369SMsLAyA+vXrm37up6en4+vrC4BOpyMtLc303rS0NHQ6nVXfwCWTK4DBYCAvL4+ioiLy8vKsmtYLIRzDom1eLKi5KqWYPn06AQEBjBw50vR8SEgIGzduBGDjxo307NnzlueVUpw8eRJvb2+rc4dLlgV0Oh3PPfccPXr0wMPDg86dOxMcHOzosIQQFrPk9lfzyfXYsWMkJCQQFBTEgAEDAJg0aRKjR49mwoQJrF27lsaNG7NkyRIAunXrxp49ewgNDcXT05MFCxZY/Q1cMrlmZWWRmJhIYmIi3t7evPzyyyQkJJj+cIUQTk5h/iYBC8oC7dq149y5c3d8rWTN619pmsasWbPMD2wBlywL7N+/n3vuuQdfX1+qV69OWFgYJ06ccHRYQghLKYVmNJZ6YHTuW7RcMrk2btyYU6dOcfPmTZRSskGhEJVNyVIsG1zQchSXLAu0adOGXr16MWjQINzd3XnwwQfvuvZNCOGEbFQWcCSXTK4AMTExxMTEODoMIYQVNMz3DpANCoUQoqwU5muqyrlrrpJchRBOSHYiEEII27Ok5urcE1dJrkIIJ6TM11Sl5iqEEGWlFBjMTE2dfJ2rJFfh/Jx8hmJv9thMcNjZyzYdz/dGoU3HM61lNXeOE5PkKoRwTnJBSwghbEzKAkIIYQdKmV/HKutchRDCClIWEEIIG1MKzDXDlgtaQghRRkqZr6k6ec3VJVsOljAYDAwcOJAXX3zR0aEIIcrCopaDzj1zdenkumrVKunjKkRlVDJzLe2Q5OoYaWlp7N69myFDhjg6FCFEmVmy+6tzJ1eXrbkuWLCAKVOmcOPGDUeHIoQoKxdY5+qSM9fvvvsOX19fWrVq5ehQhBDWUKCU0cwhM9cKd/z4cXbt2kVSUhL5+flcv36dyZMns3DhQkeHJoSwhCVLscy97mAumVxfeeUVXnnlFQAOHTrEv/71L0msQlQmSoHBUPo5Tl4WcMnkKoSo5KQrlvNr37497du3d3QYQogyUEqhzMxMlfQWEEIIK0hvASGEsDFLaq7mXncwl1yKJYSo5JRCGUs/LK25JiUl0atXL0JDQ4mLi7Nz4P9HkqsQwvmU9HMt9TCfXA0GA2+++SbLly9n8+bNbNq0ifPnz1fAF5CygBDCyWiaxv3t/x8etT1KPc/LtxaappV6zunTp2nWrBlNmzYFICIigsTERJo3b26zeO+mSifXZq3vYelPbzo6DCEqno3Llflavs3G8vLyIqR/N1Q/8zPTLVu2MGHCBNPjqKgooqKiTI/1ej3+/v6mxzqdjtOnT9ss1tJU6eTatm1bR4cghPgPmqZRq1Yti86NjIwkMjLSzhFZR2quQgiXpdPpSEtLMz3W6/XodLoK+WxJrkIIl9W6dWsuXrzIpUuXKCgoYPPmzYSEhFTIZ1fpsoAQwrW5u7szc+ZMRo0ahcFg4Mknn+T++++vkM/WlLP37RJCiEpIygJCCGEHklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKrEELYwf8H9PD+fFw0J7IAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdd3gU1f748ffW9B5ICL0nlEAgIaGEEjFUCUVAmhFUVKpUUdSv+AP0IhAvSBFBihdRoiIgoVxaAOmhBCQQSqhppLfNZsv8/ojsJSYR1EA2y3k9D0/YmTNnPmey2c/OmTNnZJIkSQiCIAiCmZFXdgCCIAiCUBaRoARBEASzJBKUIAiCYJZEghIEQRDMkkhQgiAIglkSCUoQBEEwSyJBPSVLly5l+vTplR3GU3X37l2aNm2KXq//x3WFhIRw9OjRMtfNmjWLiIiIf7yPZ0lERASBgYF07Njxqe87JiaG0NBQ/Pz82Lt379+u57XXXmPLli0VGNnTl5iYiJ+fHwaDobJDMUsiQVWg7du3M3DgQPz8/OjUqROvvfYap0+fruywhKekadOm3Lp1q7LDeKTExETWrl1LVFQUv/76a5ll8vLymDdvHl27dsXPz4/u3bszb948MjIy/vH+lyxZwogRIzh79izdu3f/2/WsXr2aAQMG/ON4/mjWrFk0bdq0VPKcP38+TZs25aeffnqsev7sS9UDXl5enD17FoVC8bfjtWQiQVWQtWvXMn/+fN58801+/fVXDhw4wPDhw9m3b19lh/a3VcSZj/A/5nI8ExMTcXZ2xs3Nrcz1RUVFhIeHc+3aNVavXk1MTAzff/89zs7OXLhwoUL237hx439cz5NUr149tm7danqt1+vZuXMnderUqbB9VOT7QZIkjEZjhdVnLkSCqgC5ubksWbKEDz/8kNDQUGxtbVGpVISEhPDOO++Uuc2kSZPo2LEjbdu2ZcSIEVy9etW0Ljo6mt69e+Pn50dwcDBr1qwBICMjgzfeeAN/f3/atWvH8OHDTW/KlJQUJk6cSFBQECEhIWzYsMFUX2xsLAMHDqRNmzZ06NCBTz75pMyYTpw4QefOnVm1ahUdO3bk3XffJTs7mzfeeIOgoCACAgJ44403SE5ONm0zatQoPv/8c1566SX8/PwYM2ZMud+yd+/eTUhICPHx8RiNRlatWkX37t0JDAxk8uTJZGVlmcr+/PPPdOvWjcDAQFasWPHI30FmZiajR4/Gz8+PkSNHcu/ePQDmzJnDp59+WqLsm2++ybp168qs5/r164wePZp27drRo0cPoqKiTOtmzZrFnDlzGDt2LH5+fgwePJjbt28DMGLECADCwsLw8/MjKiqqzONZVFTEvHnz6NSpE506dWLevHkUFRWVOP4rV64kMDCQkJAQtm3bBhT/Djt06FCiK2jPnj3069evzHbk5uYyc+ZMgoKC6NatG8uXL8doNHL06FHGjBlDamoqfn5+zJo1q9S2W7duJSkpiS+++IJGjRohl8txc3Nj/PjxdOnSxXScRo0ahb+/P3369CnxRezPjlP37t25c+cOb775Jn5+fhQVFZU603i4O1yr1TJ9+nQCAwPx9/dn0KBBpKWlAcXvvcjISACMRiPLly+nW7dutG/fnpkzZ5Kbmwv8r6t5y5YtdO3a9bHeUyEhIcTExJCdnQ3A4cOHadq0Ke7u7qYyt2/f5uWXXyYwMJDAwECmTZtGTk4OADNmzCAxMdHUzq+++soUR2RkJF27diU8PLxEN3hWVhadO3dm//79AOTn5/P888/z888/lxnjqFGjiIiI4KWXXqJVq1bcuXOHM2fOMGjQINq2bcugQYM4c+YMAMePH+eFF14wbTt69GgGDRpkej18+PB/1N36xEjCPxYdHS35+PhIOp2u3DJLliyRpk2bZnodGRkp5ebmSlqtVpo7d67Ur18/07qOHTtKp06dkiRJkrKysqSLFy9KkiRJCxculD744AOpqKhIKioqkk6dOiUZjUbJYDBIAwYMkJYuXSpptVrp9u3bUkhIiHTo0CFJkiRpyJAh0pYtWyRJkqS8vDzp7NmzZcZ4/PhxycfHR1qwYIGk1WoljUYjZWRkSLt27ZIKCgqk3NxcaeLEidJbb71l2mbkyJHSc889J924cUPSaDTSyJEjpc8++0ySJEm6c+eO1KRJE0mn00k//PCD1L17d+nmzZuSJEnSunXrpMGDB0tJSUmSVquVPvjgA2nKlCmSJEnS1atXpdatW0snT56UtFqtNH/+fMnHx0f69ddfy4z7nXfeKVH+//2//ye99NJLkiRJ0vnz56WOHTtKBoNBkiRJSk9Pl3x9faX79++Xqic/P1/q3Lmz9MMPP0g6nU767bffpHbt2klXr1417addu3bS+fPnJZ1OJ02dOlV6++23Tds3adLE1L7yjufnn38uDR48WEpLS5PS09OloUOHShERESXKz58/X9JqtdKJEyekVq1aSdevX5ckSZJ69eolHTx40FT/uHHjpDVr1pR5TGbMmCG9+eabUm5urnTnzh0pNDRU2rx5s2k/wcHBZW4nSZL09ttvSzNnzix3fVFRkdS9e3dpxYoVklarlY4ePSq1bt3aFOejjlO3bt1K/C7/+Prhv5VNmzZJb7zxhlRQUCDp9XrpwoULUm5uriRJxe+9B22KjIyUunfvLt2+fVvKy8uTxo8fL02fPl2SpP+9D2fPni1pNBopLi5Oat68uXTt2rUy2/fOO+9Iixcvlt5//31p48aNkiRJ0qRJk6Tt27dLL730kvTjjz9KkiRJN2/elI4cOSJptVopPT1dGj58uDR37txy2/UgjhkzZkj5+fmSRqMp8TciSZJ0+PBhqUOHDlJaWpo0e/ZsaeLEieX+HkaOHCl16dJFio+Pl3Q6nXT//n3J399f2rJli6TT6aTt27dL/v7+UkZGhqTRaKQWLVpI6enpUlFRkdS+fXupU6dOUm5urqTRaKSWLVtKGRkZ5e6rsogzqAqQlZWFi4sLSqXysbd58cUXsbe3R61WM3HiRC5fvmz6xqdUKrl27Rp5eXk4OTnRvHlz0/L79++TmJiISqXC398fmUzGhQsXyMjIYMKECajVamrXrs2QIUNM3/6VSiW3b98mIyMDOzs7WrduXW5ccrmcSZMmoVarsba2xsXFhR49emBjY4O9vT1vvfUWp06dKrHNwIEDqV+/PtbW1vTs2ZO4uLgS69evX8+aNWv45ptvqFu3LgDfffcdU6ZMwdPTE7VazYQJE9i9ezd6vZ5du3bRtWtXAgICUKvVTJ48Gbn8z9+qD5efMmUK586dIykpCV9fXxwcHDh27BgAUVFRtGvXrsQ34QcOHjxIzZo1GTRoEEqlkmbNmtGjRw927dplKtO9e3d8fX1RKpX069evVFsfdTy3b9/O+PHjcXNzw9XVlfHjx5vOkh6YPHkyarWadu3a0aVLF3bu3AlA//79TWWzsrI4cuQIffv2LbVPg8FAVFQU06ZNw97enlq1ajF69OhS+ylPVlYW1apVK3f9+fPnKSgoYOzYsajVatq3b0+3bt3YsWPH3z5O5VEqlWRlZXHr1i0UCgUtWrTA3t6+VLnt27fzyiuvULt2bezs7Jg6dSpRUVElutEmTJiAtbU13t7eeHt7c/ny5T/dd1hYGFu3biUnJ4dTp06Vul5Wt25dOnbsiFqtxtXVldGjR5f62yjLxIkTsbW1xdrautS6Tp060bNnT1555RWio6OZM2fOn9Y1YMAAGjdujFKp5MiRI9StW5f+/fujVCrp27cvDRo04MCBA1hbW9OyZUtOnz7Nb7/9hre3N23atOHMmTOcO3eOunXr4uLi8sjYn7bH/0QVyuXs7ExmZiZ6vf6xkpTBYCAiIoJdu3aRkZFh+vDNzMzEwcGBJUuWsGLFChYtWkTTpk2ZNm0afn5+vPrqq3zxxReMGTMGgKFDhzJ27Fju3btHamoq/v7+Jfbx4PW8efNYsmQJvXr1olatWkyYMIFu3bqVGZuLiwtWVlam1xqNhk8++YTDhw+bujvy8/MxGAymC7sPf5jZ2NhQUFBQos41a9Ywfvx4PD09TcsSExMZP358icQjl8tJT08nNTW1RFlbW1ucnZ3/9Jg+XN7Ozg4nJydSU1OpUaMGAwYMYNu2bXTs2JFt27bx8ssvl1nHvXv3iI2NLXUcH+5GezixWVtbl2rrH/3xeKampuLl5WV67eXlRWpqqum1o6Mjtra2Za4PCwujV69eFBQUsHPnTvz9/alevXqpfWZmZqLT6UrtJyUl5U9jfcDZ2Zn79++Xu/7B7+fh390f6/+rx6k8YWFhJCcnM3XqVHJycujXrx9TpkxBpVKViqlmzZqm1zVr1kSv15Oenl5mTGW9T//I39+fjIwMVqxYQdeuXUsllLS0NObNm8fp06fJz89HkiQcHR0f2aaH36tlGTJkCP/5z3948803H5k0atSoYfr/H99bUPL3EhAQwMmTJ/Hw8CAgIABHR0dOnTpl+jJkjkSCqgB+fn6o1Wr27t1Lz549H1l++/bt7Nu3j7Vr11KrVi1yc3MJCAhA+n1ieV9fX1asWIFOp2Pjxo28/fbbREdHY29vz6xZs5g1axbx8fGEh4fTsmVLatSoQa1atdizZ0+Z+6tXrx6LFy/GaDSyZ88eJk2axIkTJ0p8ED4gk8lKvP76669JSEhg8+bNVKtWjbi4OPr372+K9XF8/fXXvPbaa7i7u9OjRw+g+I90/vz5tG3btlT56tWrc/36ddNrjUZT4vpUWR6+Lpafn092drbpw7tfv3707duXy5cvc/369XJHjtWoUYOAgADWrl372G17lD8ez+rVq5cYJJCUlFQiyeTk5FBQUGD63SQlJZnKenh44Ofnx549e9i6dSvDhg0rc58uLi6oVCoSExNp1KiRqR4PD4/HirlDhw58/vnnJeL4YxuSk5MxGo2mJJWUlES9evUeq/4/srGxQaPRmF4/nBxVKhUTJkxgwoQJ3L17l7Fjx1K/fn0GDx5cKqYH1x2h+AuQUqnEzc2txHvjr+rXrx/Lli0rcU33gcWLFyOTydi+fTvOzs7s3buXjz/++JF1/vE98TCDwcCHH35I//79+fbbbxk4cKCp1+FRdT14bz0sKSmJ4OBgANq1a8enn36Kl5cXr7/+Ok5OTnzwwQeoVCrTNVRzI7r4KoCDgwOTJk3i448/Zu/evWg0GnQ6HdHR0SxYsKBU+fz8fNRqNS4uLmg0GhYvXmxaV1RUxLZt28jNzUWlUmFnZ2f6EDhw4AC3bt1CkiQcHBxQKBTIZDJ8fX2xs7Nj1apVFBYWYjAYiI+PJzY2Fii+6P3gTO3BN7xHdZk9HKuVlRWOjo5kZWXxxRdf/OXj06hRI1avXs3HH39supg+bNgwPv/8c9OHSkZGhukibY8ePTh48CCnT5+mqKiIJUuWPHKEUnR0tKn8v//9b1q1amX6dunp6UnLli2ZMWMGoaGhZXatQHE34c2bN/n555/R6XTodDpiY2NLJMs/4+7uzp07d/60TJ8+fVixYgUZGRlkZGSwbNmyEhevoXiQQFFREadPn+bgwYMlvvSEhYWxZs0a4uPjCQ0NLXMfCoWCnj17EhERQV5eHvfu3WPt2rXlDqj4o7CwMDw9PZk4cSLXr1/HaDSSmZnJypUriY6OxtfXF2tra1avXo1Op+PEiRPs37+f3r17P1b9f+Tt7U1UVBQ6nY4LFy6we/du07rjx49z5coVDAYD9vb2KJXKMt+7ffv2Zf369dy5c4f8/HwiIiLo1avXX+p2L8uoUaNYu3YtAQEBpdbl5+dja2uLg4MDKSkprF69usT6x3k//NHKlSuRyWTMnz+fV199lXfeeeex75Hq0qULN2/eZPv27ej1eqKiorh27Rpdu3YFir9IJyQkEBsbi6+vL40bNzb1GpTVPnMgElQFGTNmDLNmzWL58uW0b9+erl27snHjxjK/rffv3x8vLy+Cg4Pp06dPqWtCW7duJSQkhDZt2vDdd9/x2WefAXDr1i3TSLWhQ4cybNgwgoKCUCgUrFy5ksuXL/Pcc88RFBTE+++/T15eHlA8AqlPnz74+fkxb948IiIiyv2Q/qPw8HC0Wi1BQUEMHTrU9G3sr/L29mblypV88MEHREdH8/LLLxMSEsKYMWPw8/NjyJAhpoTauHFjPvzwQ6ZPn05wcDCOjo6P7Bbp27cvy5YtIzAwkN9++810zB7o378/8fHxhIWFlVuHvb09a9asISoqiuDgYDp16sTChQtNo+weZcKECcyaNQt/f/8So/8eNm7cOFq0aEG/fv3o168fzZs3Z9y4cab17u7uODo6EhwczPTp0/noo49o2LChaf3zzz/PvXv3eP7557GxsSk3lg8++AAbGxu6d+/O8OHD6du3b4lRW39GrVazbt06GjRowJgxY2jbti2DBw8mMzMTX19f1Go1K1eu5NChQwQFBTFnzhwWLFhQIs6/4u233+b27du0a9eOpUuXlkjYaWlpTJo0ibZt29K7d2/atWtX5u9w0KBB9OvXj5EjR/Lcc8+hVqv54IMP/lY8D3N2dqZ9+/ZlnvVMmDCBS5cu4e/vz9ixY0t9YRg7diwrVqzA39/fNBL3z1y8eJF169bxr3/9C4VCweuvvw7AqlWrHitWFxcXVq5cydq1awkMDGT16tWsXLkSV1dXoLirvHnz5jRq1Ai1Wg0UJy0vL69ybzmobDLpr/TVCEIVderUKWbMmMGBAwf+tIulMp04cYIZM2Zw6NChPy3XvXt3Pv74Yzp06PCUIhOEyiHOoASLp9Pp2LBhAy+++KLZJqfHtXv3bmQyGUFBQZUdiiA8cWKQhGDRrl+/zqBBg/D29i73BuWqYtSoUVy7do0FCxY89jVEQajKRBefIAiCYJbE1zBBEATBLFlcF9+ZM2f+dHRTVaTT6UrdmFiVWVp7wPLaZGntAdEmc6bVasuc4cbiEpRCocDHx6eyw6hQt27d+tOb9aoaS2sPWF6bLK09INpkzsqbCkt08QmCIAhmSSQoQRAEwSyJBCUIgiCYJZGgBEEQBLMkEpQgCIJglkSCEgRBEMySSFCCIAiCWRIJShAEQTBLIkEJgiAIZsniJov97bdLNG/erLLDEARBsHiFOgPWKsU/ricuLq7MGYAsbqojuVxGvVk7KjsMQRAEi3fz0z5PtH6LS1CCIAiWQpeZiCEvA6VTdZSO1cstJ0lGDHkZYDQit7ZDbmVXvNxoQJ+VjCE/E5nKGqWzJwpr+9+3kTDkpKLPTUOmtELlWhO5uuRE20adFmNBNgAKOxdkyqc7Ma1IUIIgCGZGm3yNzP+uRJt42bTMup4frqFvoXLxMi3T56SRuW8VmlvnkbT5xQsVSly7v4nCzoX0nf/GqMn5X8UyObZNO2Ll5U3OyR+Lk9oDChUOfr1x6fIKMqWKwjsXSY38CElXCIDc1gmPoXNRV6//RNv+MJGgBEEQzIg+5z4pm96jlocb0z7/nObNm3Py5EkWL15Myqb38Hp1OXIrWwByTm1Bdu88b4weRatWrbCysmL58uXEntsJcjne9Wsxc+ZMatWqRX5+PkePHiUiIoKCy4dp37494eHhNGjQgLy8PHbt2sVXX30FRj3OncNJ+2URTRrU5Z133gFg3Lhx5MdFiwT1sPXr1xMZGYkkSQwePJhXXnmlskMSBEF4YnJO/IAKPYcOHcLJyYnIyEimTp1Kt27d6NChA7nnonAKfBEAQ34mtWrW5J133kGr1dK0aVN27NjB+ZupSDoj9es3wdbWlvPnzxMaGkq/fv2wsbHho48+4sUXX6RZs2bExMTQr18/BgwYgFKpZPnKLzFqCyA/g/XrtxMYGAjA5MmTkfS6p3oszHqYeXx8PJGRkURGRrJ161YOHjzIrVu3KjssQRCEJ6bg2kkGDBhAvXr1WLhwIW+88Qbr16+nffv2BAUFobl20lRW5VqL+Ph46tevz6pVq0rUY+XZiB07djBkyBCmTZvGjBkzAPDw8ABg7ty5dO7cmSlTpvDWW28BEBQUBEYD+b8dYNq0abi4uHDkyJGn1PLSzDpBXb9+HV9fX2xsbFAqlQQEBLBnz57KDksQBOGJkAx6DLnpNG3aFIAbN24AkJCQAEDTpk3RZ6eayju1H4Jrz4ll1vVgeY8ePdixYwfffPMNFy5cYO7cuQBonP/XVdejRw8AoqKiAPDx8eH//u//CA8Pp6CgwFQuPy4ayaCvkLY+DrNOUE2aNCEmJobMzEw0Gg2HDh0iOTm5ssMSBEF4ciQJubzsj2a5XI4hN42UzR+S+sMcCq4cwa5Z11Ll9Nkp6DPuApCRkcHFixe5efMmLVu2ZNiwYQDoUhOQyWQsXLiQqVOnMnfuXL777jsAvv76a1auXMnp06dNsahUKoz5WeRd2PsEGl02s74G1bBhQ1577TVeffVVbGxs8Pb2LvcXJwiCUNXJFEoU9q5cvXoVwPQ49zp16gBw9epVFAoFraqryMrK4sr2hWXWI+m0JK2bDMCpU6c4deoUXl5e3Lt3j6FDh7Jw4UKU+gLWb9rE4MGDmThxIl988YVp+5YtWxIUFMTUqVNNy9LT0/H09CQ/5VqJfT3Jyy5mnaAABg8ezODBgwFYvHixqf9UEATBEtk0aMuPP/7IggULmDJlCq6uroSHh3Pu3Dl+/fVXHBwcOH78ONu3b6dfv364uLgQERFB8+bNAZg4cSJ9+/Zl9OjRREREYG1tTWJiIiEhIQAcP34cgI8++oihQ4eSkpJCr1696NWrF2fPnuX9998nPDwchaJ4hojZs2fj6+vL6NGjyc7OxqqhS4l4HyTRfyIuLq7M5WafoNLT03FzcyMxMZE9e/awefPmyg5JEAThiXFsP4SkS9F069aNd999l65du7Ju3Trmz5+PJEno9XoiIyOJiYkBQCaTYWtrS0JCgulalY1N8Q23p06dYtSoUfj7+5Oens6MGTNYunQpUHw2FhkZWWLfhYXF9zz9+OOPpmVNmjThypUrfP/99xQWFuLWuucTPwYPmP1cfMOHDycrKwulUsm7775L+/bt/7R8XFwcvdbfeErRCYIgVLzCOxfJ2LMcXdpt0zK1V1McWvciY+8qpKL/DVyQqayQdNrHq1iuwM47GENBNoU3z5ZZRO3REM+XFwOQvGEqRSnXi/ejtsVj2HysPBuZylbUVEflzcVn9gnqrxIJShAESyBJEkUp1zHkZ6J0rI66WnFXmrFIgz47FZlcgdK1JlKRBn3O/VLbK509wain6P5NjIV5yK0dUbnVRGHjCIAuK7lUYpPJ5ShdayGTyUwx6DPuIhmNKJ2ql5oK6UknKLPv4hMEQXgWyWSyEmcrD8jVNqZkBSCzsi3xuiQrrGs1L3ONytnzsWJQudV+rHifBDEkThAEQTBLIkEJgiAIZsniuviMRumJP6NEEARBqLgHFpbH4s6g9E95MsOnwdLmH7S09oDltcnS2gOiTU/Ck0xOYIEJShAEQbAMIkEJgiAIZkkkKEEQBMEsWVyCUipVlR1ChauIua7MiaW1ByyvTZbWHqjabSrUGSo7hEphcaP45HIZ9WbtqOwwBEEQKsyzOjLZ4hKUIAjC45IMOgquHEWbeBnkCmzqt8G6np9pqh9TOcmILjUBbdJVjIW5IJNhU78t6ur1kYwGilITKEq+9vs6OTYNA1A516Ag/ij6nNRS+5VbOwAUl/8DpWN1bJt0QGaBvUF/lUhQgiA8k3Tpd0n94SP0Wck4Ojqi1+tJPfUzVrWaUX3Qh8it7YHi5JSy6T20dy6W2D7r0DfUfGMN93+eT1FSfIl12Uc2YtfyefLO/r3eHKeOw3DuNOLvNcyCWNw1KEEQhEeRJIm0XxbhqjYSFRVFdnY2mZmZfPXVV0ip18g88LWprC79Lto7F3n33Xe5fv06Go2GI0eOgNFAXuxuipLimTNnDgkJCWg0Gnbv3o2kLyLv/C7at2+PRqMp9a9r164899xzZa5r164d2sQrlXh0zIfZn0HduHGDKVOmmF7fuXOHSZMm8corr1ReUIIgVGmFt2MpSr7KJ2vW0KtXL8LDw2nSpAmzZ8/m/PnzfLF8Bc6dR6GwcwHJCBQ/On3hwoV88cUXqNXq4op+fxhEWloaixYtYunSpaZ1cmt7EhISSjyVds6cOTg5OXH58mWUSqVpnUwmY/78+SiVSq5du4bCq81TPBrmy+wTVIMGDdi6dSsABoOBzp078/zzz1dyVIIgVGUPuuQGDx7MzZs32bBhA87OzsyePZshQ4bwxRdfUJSagE19F1RutVFVb8CXX34JwJIlS0z1qKs3QOVWx5SYHjwMEMCx3UAyLh/hy3UbMWpyCAoKolq1anz99dckJycD8OXa/2AszCUkJAQnJyeWLl1KRkYGHr16PMWjYb6qVBffsWPHqF27NjVr1qzsUARBqMIMeRk4OTnh4OBAeno6AFlZWRgMBmrVqgWALuMehsI8kCRqvLwYe78yRtIpVdQY/W/sWjxXapVVjcbUCI/ArccEAKZPnw7AwoULUVVvQJ2Z23F57nXTOoPBQEREBFY1fbCuVfrZSM8isz+DetiOHTvo27dvZYchCEIVJ1fbkpeXh16vx9raGgCVSoVCoSArKwuAzL1fkrn3S+S2zrh0G0P+pYOl6sk98wsKa3vyfzuAWlXy4zT37E5U1RuQffJHGjZsyIABA/jll1+Ii4vD/YXiZJVz8idatGhBr1692Lx5MwkJCVQbMLvMmMuady8vL6/S5+N7kqpMgioqKmL//v1MmzatskMRBKGKU7rWxGAwcPr0adq0aYO7uzvNmjUD4MSJEwAMGTKEDh068Mknn5CyY3GZ9RTeiCH5RkyZ6wouH6bw5jmMhblMXbYMuVzOwoULUThUw7ZpJwoTzqC7f5NpC9YC8Nlnn6F0rYlN48Ay6yvrRuNbt25V6RuQH4iLiytzeZXp4jt06BDNmzfH3d29skMRBKGKs20chNzagffeew+Ay5cvs3PnTu7fv8+nn34KQLdu3Zg8eTKurq4ArF+/Hq1Wi1KpJCAgAK1WaxrAFRkZSV5eHgBdu3ZFq9UyduxYjIW5uLu7M3r0aE6dOkV0dDSOAWHIFEpyTm/Dy8uL4cOHEx0dzaHowbkAACAASURBVOnTp3EMGIBMVmU+lp+4KnMGtWPHDvr0eTbvphYEoWLJrWxxCXmVA1GfU69ePQYMGEBBQQE//vgjubnFN89++eWX7Nmzh7t37wKwdOlSfv755xL1XLxYfG/UokWL+Pbbb0usO3fuHABWVlaMGDGCuLg4ZFZ22PuGAqDPTETlpOall17iwoULyG2dsW8R8kTbXdXIJOn3cZJmrKCggG7durF3714cHBz+tGxcXBy91t94SpEJglCVFd6OJefET7/PJKHEpr4fjkGDKUq6Su7ZX5D0OlQuXihdvCi8dQ7JoC+xvdzKFpnKBmNBFpKx5Hx5cmt7rGp6o717CaO2ALnKGqcOQ7FpGABAwbWT5ByPxFikQa62xanTcGzqtS4zzvKmOrKkLj4fn9IDQ6rEGZStra2pX1gQBKGiWNfxxbqOb6nlavc62LcsPTKvItk2aodto3ZPdB9VnejsFARBEMySSFCCIAiCWRIJShAEQTBLVeIa1F9hNErP7LNTBEGwTIU6A9YqRWWH8dRZ3BmUXq+r7BAqnKXdKW5p7QHLa5OltQeqdpuexeQEFpigBEEQBMsgEpQgCIJgliwuQSkt8DHJlnAj3sMsrT1geW2ytPZA+W0q1BnKXC5UPosbJCGXy6g36+89ZlkQhGePGFRlvizuDEoQBEGwDBZ3BiUIgnkovH2BnJM/oU28gkyhxLp+G5yCBqNyLfnA0aK02+TH/hdtyjWMmlyQybBt3B7nTsORjAbyYv9L3vld6DOTkNs5Y9esKw5tXyD/twNorh5Hl34HSV+EwsEd2ybtcWw3EN39W+RfOkhRynWMRRpkCiX2vqE4+PWupKMh/B0iQQmCUOHyYv9L+s5/4+npSdjLw8jPz2fLli0kXT6Mx7BPsarRGACjtoDkDVOwUsjwa92aGjUakZmZycGD32LbOIjs45EUXD5MmzZt6PBiT65evcqePd+SfWQjAK1bt6bNc/2xsbHhypUr7Nv3Hbkxv2AszMXe3p7ANm1wc3Pj7t27nNr7JbZNO6KwdarMQyP8BSJBCYJQoYzaAjL3ryYkJISoqCg0Gg3W1tZ89tlnBAQEcH/fKjxGLEAmk6HLTETSadn84zZeeOEFAI4fP0779u3J+20/BZcPM3fuXGbPnk1ycjKenp7s2bOHHj16UKNGDc6ePUtKSgpqtRoXFxd++uknBg0aBMCxY8do0aIFAJs2bWL48OEYNbkiQVUhZn8Nat26dfTp04e+ffsydepUtFptZYckCMKfKIg/hlGbb3rwX6NGjejTpw+enp7MnDkT7b049BnFz1iSW9sDMGvWLNODAR/Ii/0vNWrUYMaMGRw+fJgaNWqwcOFCQkND6dWrF/n5+Tz33HN4enpSq1Yt7ty5w8CBA031jBo1ypSghKrJrBNUSkoKGzZs4Mcff+SXX37BYDCwY4cYoScI5kyXcReVSkXbtm25cuUK6enpHD16FICgoKDfyyQCoHL2xCl4JJcuXSIzM7NEPZI2nzZt2qBWq03bP1xPTk4O+/fvB8BoNCKXy0lPTzc92fbcuXOmhw8KVZPZd/EZDAYKCwtRKpUUFhZSvXr1yg5JEIQ/YdTm4+joiFwup7CwEMDU8/Hg7Cbn1BYMufdRutTEqf0QMBrJ/vXbUnW5uLgAmOp58PNBPTKVNbZqBZGRkbi7uzNgwACK9Aa8Xl1B9okfISf+yTZWeKLMOkF5eHgwZswYunXrhpWVFR07dqRTp06VHZYgCH9Cae9Geno6Go0GNzc34H8J5cHj07V3LqK9U/y4dJV7XXRpZc+T96D8g3oe/HywvLqrEzt27KBx48b06dOHffv2AZB5eAOa+GO41alTor6U79+n2oD3sKrRpMTyqjpPX15eXpWN/XGYdYLKzs5m37597Nu3DwcHByZPnszWrVsJCwur7NAEQSiH+vcRej/++CMjR47kpZdeMl0LioyMBCAiIoIRI0YQFBTEjRs3CAwMpFatWkBxEho0aBCxsbEcO3aMxMREwsLC2Lx5M6+88goGg4EtW7bg6OjIsWPHqF+/PitWrKBx48Y0btyYzZs3kxF/jG7dutG0aVMA6tSpw6BBgzh27BgZh77BY+j/KxFzVZ05w5Ie+V4Ws05QR48epVatWqZvX6GhoZw9e1YkKEEwY9b1/FBVb8DMmTPx8PBg06ZN6HQ61qxZw1dffVVcxtra1A0IMGHCBAYPHoxWq6VOnTps3LiRGTNmsHTpUkaNGsXKlSs5dOgQaWlpTJgwgfj4eOrUqYOXlxdarZYxY8aY9n/48GEyMjL4+OOPCQgIQKvV4u/vz8aNGxkyZAg7j8VWynER/jqzTlBeXl6cP3/eNEz14WGjgiCYJ5lMhvsL00mN/D9CQ0NxcXGhqKiI/Px81F5NkaXd4a233uKtt94ybTNq1ChGjRpVZn37ow/TtGlTqlWrRmZmJjqdDpnahtu3b2NtbV1uHMHBwWUut2/V8581UHhqzDpBtWrVih49ejBgwACUSiU+Pj4MHTq0ssMSBOER1O51qPn6l+RfPoI28TJyhYrq9dtgXb8Nhtz7FFw5iqQvQulaE3W1emiunUAy6EvUIbe2x9Y7GAx68n7bR0FmMrYNnbBr1hWlqxeaayfRpd8ptW+lixdKZ08Kb54DyVhincLOpbhOoUqQSZIkVXYQFSkuLo5e629UdhiCIFQRVXmyWEu6BuXj41NquVnfByUIgiA8u0SCEgRBEMySSFCCIAiCWTLrQRJ/h9EoVek+ZUEQnq5CnQFrlaKywxDKYHFnUHq9rrJDqHCWdqe4pbUHLK9NltYeKL9NIjmZL4tLUIIgCIJlEAlKEARBMEsWl6CUSlVlh1DhLOE+h4dZWnugarWpUGeo7BAE4bFY3CAJuVxGvVnimVGCUB4xiEioKiwuQQlCZdPn3EeXdhu5lR1qz0bIFGX/mUmShC7tFoacNBSO7qjc6yKTydDnZWDUlH7QntLRHbmVHQAGTQ5FqQkgSahcaqBwrI6kK0SfnVpiG5lShdK5BjKZrOIbKghPmEhQglBBDPmZpO9Zjib+OFA8g5jCoRou3UZj59O5RFlt0lUy9iyjKPmaaZm6RmOUzl4UxB0ybf8wmcoKt95T0Fw/Sf6lQ2DUP7TOGkmnLXM7m4YBVH/x/yqkjYLwNIkEJQgVQJKMpP74/1Dl3OPDDz+gR48eJCYmsmjRIo5vW4DcxhGbeq0B0OdlkPL9+9TxdOfdlSvx9fXl3LlzfPLJJ9yJi6Zz585MmDCh1D4mTJhA6tZPsba2ZvLE8YSFhaFQKDh8+DDvv/8+NjY2rF+/vsQ2Bw4cYMWKFejzMlDauz6VYyEIFaVKDJIwGAz079+fN954o7JDEYQyaa6doigpnhUrVjBnzhzOnz9P8+bNOXjwIPXq1SP7yEZT2ZyTP6EwaNm7dy9Dhgzh2LFjDB8+nD179iCXy1Eqldjb25v+9e/fn7CwMPT64jOmH374gYULFxIfH8/u3bupXr06AEqlksGDB9OyZUvTtlZWVsU7taw5oYVnRJU4g9qwYQMNGzYkLy+vskMRhDJprp/Czc2N4cOHc/jwYcaNG0fv3r3ZsWMHY8eO5b333sNYmIfc2h7N9dP07t2bRo0aMW/ePN5//310Oh3vvPMOzz//PLt372b//v0AtGvXjl69erFu3ToyMjLw8fGhT58+LFmyhC+++IKsrCzu379fIpbdu3ezZcsW4uLiSE0tvialdHB76sdEEP4psz+DSk5O5uDBg7z44ouVHYoglEufk0rDhg1RKBSmGQtu374NQJMmTUxlAAw5903Lbt68WWZZpw7DAJg+fToAixYtAqBLly4AhIeHEx8fT2pqKsuWLSsRy+TJkzl48CB37941dRUW3r5QwS0WhCfP7BPU/PnzmTFjhunR0IJgrsp7tNqD5cnfvkvyf2Yi6bWlyj4YZSdJEjK1LYW3ztGgQQMGDhzIzp07uXjxIgBGY/ED+C5evIi7uztbt25l3LhxtGvXjsLCQjp37oyNjQ2+vr7k5eWxaNEirKys0Fw/9aSaLQhPjFl38R04cABXV1datGjBiRMnKjscQSiX0qk616+fRK/XU79+fQDTzytXrgDQtqUPTk5O7Lt3ybSsQYMGANSrV89UVioqQHsvjilLl6JQKPjss89QOLijsHUiPj4egAsXLpCemc25c+cICwvD1dUVpVLJ4cOHTetv375Nq1atcHR0RKMtKBHvo+bay8vLs7j5+ESbqh6zTlBnzpxh//79HDp0CK1WS15eHtOnT2fhwoWVHZoglGDTKJD753axYcMGxowZw9dff01wcDAajYYvv/wSgM8//5ygoCCUSiU7d+7k8uXLjB8/HicnJ15++WUuXLjAvn37AHBzc2PMmDHExMRw4MABXLqNwVikITr6O86fP8+gQYO4efMm4eHhJCYmcuzYMfr168fMmTM5ePAgDRs2pFWrVhw+fJj79+/j6tegRLyPmvnCUp7U+jDRJvMVFxdX5nKz7jebNm0ahw4dYv/+/SxevJigoCCRnASzZNPAH6uazRg/fjwzZsygTp06HDt2jI4dO3Lnzh0Adu7cyYYNG4DikanPPfcca9aswdvbmy+//JLQ0FCwdgCgZcuWbN68mVmzZiFT22LfqicO/mHIbJzo2bMnGzZsMA2oCA4OJjs7m6NHj3LgwAFatGiBSqVizpw59OvXD6VLDeyada2sQyMIf5tMKq/j3MycOHGCr7/+2vRttDxxcXH0Wn/jKUUlCP9j0OSQuXcV+XGHQCq+VqR0qYFzl1fIOf4DRclXAVDYu+L6/FvknNqC9u4l0/ZWtVsULz/5E/kXi8+kkMlx7T4WhzZ9AShKu03GnuVo71w0badyr4t9q1DyLuxFl5pQIiabhgG4Pv8WSqfqpmWPM9WRpXwzf5hok/mKi4vDx8en1PIqk6Ael0hQQmUz5Geiy7iHXG2Lqno9ZDI5kiRhyL0PkoTC3s00/ZEuMxFDbjoKB3dULjX+V0deJpKhCJmVHQpr+1L70GUlY8i5j8KxGkonD9MgC0NeJrqsRGQyOUoXLxS2TqW2FQnKclhKm8pLUGZ9DUoQqiKFnQsKO5cSy2QyGUrH6qXKqly8ULl4la7D3qXUshLbOXuicvYsc7tHbSsIVYVZX4MSBEEQnl0iQQmCIAhmyeK6+IxGSTzvRhD+RKHOgLVKUdlhCMIjWdwZlF6vq+wQKpyl3Yhnae2BqtUmkZyEqsLiEpQgCIJgGUSCEgRBEMySSFCCIAiCWbK4BKVUqio7hApnCTfiPayqtqdQZ6jsEAThmWJxo/jkchn1Zu2o7DAECyRGhwrC02VxCUqomgyaXPIv7KXo/k3kVrbYNA7Cuo6vaQqfh+ky7pF3cT+GnFQUDu7YtwhB6VqLwhunKbx3uURZmUyOVa1m6NJuY9DklKpL5eqFTK6kKO12ye0USuyadkLlXrtiGyoIwmMTCUqodJqEM9z/+VOkogLq1KlDVlYWqTHbsWkYQLX+7yF7qNs2+3gkWdEbUKtVeHl5kXj1V3KOR2JVxxft7VgUipJDqCVJIttoRCaTlfnQS4OhuNuurO1yY7ZTa9z6EvsXBOHpsbhrUELVYtQWkLZ9Ia2aNeHChQvcunWL1NRUFi9ejOb6KXJObTGV1SZeISt6PcOGvcTt27dJSEjg7t27vPzyy2hvxwKQmZmJXq83/du5cydQ/Ij0h5c/+FerVi2srKxKLV+/fj1GTQ763PuVclwEQTDzM6ikpCRmzpxJeno6MpmMIUOGEB4eXtlhCRUo7+I+jJocvvzyS+rWrUvXrl0ZPnw4U6ZMYf/+/UTt+xnHwEHI5ApyTm7B3d2dr776iqtXr9K3b1+WLVvGypUr2bNnD8nJyQDs2rWLb7/9Fih+DwEcPnyYl19+GQBra2uWL19OUlISycnJprOnzZs388svvwCQkFD82Aq5ld1TPR6CIPyPWZ9BKRQKZs2aRVRUFN9//z3ffvst165dq+ywhApUlHydmjVr0q5dO3799Veio6P56quvABg4cGDxWUxO8VlMUco1QkNDsbOzY/PmzZw+fZrvv/8eGxsbevbsaaqzWrVqBAcHU61aNU6ePAnArfQCvt2yg2+++Qaj0YhSqeTzzz9Hr9ebtqtZsyYdO3bEycmJmJgYAGQqq6d1KARB+AOzTlDVq1enefPmANjb29OgQQNSUlIqOSqhIhny0vHyKn7cRGZmZomfNWvWBKAo+Rr6nPvoc+6bymZkZJRZNjU1lcTERHx9fVm0aBHR0dEolUrsWoRg37oXMpmMadOmkZ2dbUqEAPfu3SMtLY3AwECWLl1qOpPKv7j/SR8CQRDKYdZdfA+7e/cucXFxtGrVqrJDESqQ3NqejIxEAGxsbEr8TE9PByBt66em8g8Sk62tbYmfD8o2adIEo7H4abYHDhyga9euNGvWjPg7v1F0P4E+ffrg4+PDv/71L3Jzc5Fb2aHV5lO7dm0kSUImk3H+/HlCQkLw9PQkL7nkGXt5c+7l5eVVqfn4HsXS2gOiTVVRlUhQ+fn5TJo0iffeew97+9JPFxWqLpVbLW6dOMa9e/cICAjAxsaGzp07A3D06FEApk+fjre3N2PHjuXYsWMAdO7cmYiICIKDgwE4duwYtWvXplq1apw5cwZbW1vc3NyA4j/iwls3THUVFRXx73//G+t6fhg1OdRzUqBQKIiLi8PJyQknp+Kn0BYUFJQawVfeTcaW8mTTByytPSDaZM7i4uLKXG7WXXwAOp2OSZMm8cILLxAaGlrZ4QgVzL5ld/RGiZkzZ+Lh4UFSUhJLly7l/PnzrFmzBoBevXrx6quvIpPJiIuLY9myZfTv35+MjAyGDh3K6tWrOX/+PLVr1yYmJoaUlBRSUlJo2bIlK1eu5MaN4uQUEBBAly5d2LhxI0lJSTi2G4BkNNCsWTMuXbpEUlISiYmJ1KlTh7lz55KTk4N1Pb/KPDyC8Ewz6zMoSZKYPXs2DRo0YPTo0ZUdjvAEKJ08cOo4jG+//Q+HDx8mNDSUpKQkdu/ebbpHaebMmbi6upq67iZMmMDatWvx8/MjNjbWNBDi6NGjtGjRgjZt2iCXy4mNjeXs2bNY1/Oj8M5F0tPTCQ0NJTY2FlX1+ljX80Pt0Yiff/6ZNm3a4Ovri9Fo5MyZM/z222/YNuuCTaPASjs2gvCsk0mSJFV2EOU5ffo0I0aMoEmTJqabLKdOnUqXLl3K3SYuLo5e6288rRCFCqK5EUPO6W3o7icgU9ti26Q9jgH9yb8UTcGVI2A0ovZshFPwSAouHyYv9r8YctNQ2Lth3/I57Fp2J//CXgqunUSXfhckCaWzB3Y+nbH3DaXg6nFyz0aBvgi5rSPOnV9GXa0ekr6InJhfKEw4jS4jCWQyVC41sGsRgl2zrsjk/7uB98+mOrKUrpYHLK09INpkzuLi4vDx8Sm13KwT1N8hEpTwpIgEVbWJNpmv8hKU2V+DEgRBEJ5NIkEJgiAIZkkkKEEQBMEsmfUovr/DaJTEc3uEJ6JQZ8BapXh0QUEQKoTFnUHp9brKDqHCWdqd4lW1PSI5CcLTZXEJShAEQbAMIkEJgiAIZsniEpTSAp9+agn3OTzsabSnUGd44vsQBOHJsrhBEnK5jHqzdlR2GEIlEwNlBKHqs7gzKEEQBMEyWNwZlPDkFVw9Qc7Jn9AmxSNTqrFp0Ban9kNQV6tXopxk0JN7Noq8czvRZSahsHXErllXHAMHobAtfqRFTsx2cs/sAKMemdIKx4AwbBoGkHXkWzQJZzDkZaByroF96544+PVCplCZ5u3T3ruEZNCjdPLAzjsYpw5DkCksr4tXEJ5VIkEJf0nOqZ/J3L+ahg0bMmDKZHJycvj+++9J3nACj2HzsfJqChTPRH9/66dorh6nU6dOBAeP5OrVq/z8888UxB/DMzyCopTrZO79kk6dOlGvXj3i4uKI2bkEua0zSn0Bg/r3p27duhw9epRf962i8HYs6uoNyP71W2rVqsWAN17DxsaGixcvEhW1CZVbLeyalT+RsCAIVYtIUMJjM+RnkXX4G8LCwvjpp59ISUnBwcGBuXPn4ufnR9r+NXiM+BcymYzChDNorh5nwYIFzJgxgxs3blC3bl1OnjxJp06dyD6ykYJrJ2nSpAl79uzBxsaGiIgIYmJiUBk0/Hr0KN7e3pw+fZoFCxawcOFCZsyYgebqccLDw1mzZg2pqakkJCQwdepUPD090eemVfYhEgShApn9NahDhw7Ro0cPnn/+eVatWlXZ4TzTCuKPIum0zJ8/n/z8fJo0acLAgQOpVq0a06dPR3vvEvqsZADyLuylRo0avP3220RHR9OwYUM++eQT2rdvT1hYGLkx25Fy77N27VrOnTtXYj+9e/embdu2zJ07l65du7Jr1y4mT56Ml5cXVlZWLF26lDNnzlC/fn06duxI/fr1AVA6uD/1YyIIwpNj1gnKYDDw8ccfs3r1anbs2MEvv/zCtWvXKjusZ5Yu4x52dnY0a9aMuLg48vLyTA8L9Pf3B0CfmWj62apVK1QqlanMH8tOmTKFatWqMXv27BL7sbGxAUCpVJp+qlQqfH196dy5Mw4ODshkMmJiYjh16hQvvvgiAEad9kk2XxCEp8ysE1RsbCx169aldu3aqNVq+vTpw759+yo7rGeWVKTByal4cINWqy3x09nZGYDsXzeRffwHilKum5aVVdbb25s5c+bwyiuvUFBQUGI/UVFR3Lp1i/fff58zZ87QvXt3AFxcXHBxcQGgQYMGREREYDAY2LBhA23atCEvdveTbL4gCE+ZWV+DSklJwdPT0/Taw8OD2NjYSozo2aawdyP5YjI6nQ539+LutGrVqgFw584dALSJl9EmXgbg9u3bAGWW7d27NwD/+te/cHR0BGDo0KEkJSXx2Wef0bp1awYMGICtrS0BAQGEh4dz4cIFHBwcADhw4ABfr/8GpVJJYGAgfn5+nP/upxLxPs05//Ly8qrsHINlsbT2gGhTVWTWCUowL1ZeTck2Gtm8eTMjRowgPDzc1F23adMmANasWcOwYcNo2rQpJ0+eJCEhgf79+7Nt2zZef/11DAYDkZGR1K9fn//85z9A8RcPX19f0tPTSUws7iLs378/586dw9vbmwEDBhATE8PFixdRqVQkJCTg5+dHC5+mhISEAHD27FmUzp4l4n2aM3BYypNNH7C09oBokzmLi4src7lZJygPDw+Sk5NNr1NSUvDw8KjEiJ5t1g3aoKpen+nTp+Pk5MS6devIz89n0aJFbNy4ESjuxisoKECSJPR6PSNGjGD58uVERUWRmJjIa6+9xvXr17l+/Tp79+4FoG3btgQHB7Nt2zZTPTNnzsTHxwe9Xs+2bduYPHkyADqdjpEjR7Js2TJiY2NJS0tjwoQJnDlzBrdekyvnwAiC8ESYdYJq2bIlN2/e5M6dO3h4eLBjxw4WLVpU2WE9s2QyOdX6zST1h4954YUXsLa2Rq/Xo9frsa7flqKkeMaNG8e4ceMAsGnUjuMx5/Dz88PW1haNRoOEDKcOL+HYbgBGnZbso98TE7PD1A0IIFNa0axZM2xtbdHr9RQVFaF0qUGN0UvRZyZxLCoCPz8/bGxs0Gg0ADj4h2HXsnulHBdBEJ4Ms05QSqWSDz/8kNdeew2DwcCgQYNo3LhxZYf1TFO51cbrtRUUXD1OUVI8Vr/PJGFV0wdDXiYF104gGXSo3GpjXdcXSVtAftwhdJmJONk6YesdjOr3rji5lR2u3cdi06AN+uxUZEorbJu0RyoqoODaSQzZqSgVCpxqNsOmQVtkcgXq6vWpVdeX/LhD6DOTsLZ3wbqeH+rq9Sv5yAiCUNHMOkEBdOnShS5dxOwA5kSmUGLn3Qk7704llivsXXBo3bNkWWt7HPx6l1+XXIFto8CSC20ccGz7QrnbyB9RpyAIlsGsh5kLgiAIzy6RoARBEASzJBKUIAiCYJbM/hrUX2U0SuJhdQKFOgPWKkVlhyEIwj9gcWdQer2uskOocJZ2p/jTaI9IToJQ9VlcghIEQRAsg0hQgiAIglmyuASlVFreI78tYa4tKL4uJAiC8LgsbpCEXC6j3qwdlR2GUAYxeEUQhL/C4hLUs8yoLUB79zckgw61ZyOUjtXLLavPuU9R8lVQqLCu6YPc2v735Wno0m5h1BYgt3FA7dEAhU3x4zAkSUKXdgt9VjJyKzusavogUyiLJ4bNTkGffgejTovCxhG1ZyPkVrZPpd2CIFgmkaAsgCRJ5BzbTPaJH5CKNL8vlWHrE4xbj/HIrexMZY3aAjL+u4L8S9EgGYtLqqxxbDcQXeY9Ci5Fl6xcrsShTR/sfZ8nfUcERSnXTasUDu64hLxGXuweChPOlNhMprTCMehFnDq8hEwmeyLtFgTBslncNahnUd7ZHWQd/oZB/fpw8OBBYmJieO+9d9FdO0bajogSZdN3LkF75TDvzJxBTEwMhw4dYuig/mT/+i0Fl6J5/fXXOXz4MBcvXmT//v28/upock9vJenrCbgrNKxatYrTp0+zZcsW2vo0IG3rpxQmnGH69OkcPXqUCxcusGfPHoa+OIDsIxvJv3Swcg6KIAhVntknKK1Wy4svvki/fv3o06cPS5YsqeyQzIpk0JF19DtCQkKIjIzEaDRy+vRp5s2bx0cffYTm6nG0ydcAKLp/k4IrR3j//ff59NNPOXv2LFqtlk2bNtGjRw8AXF1dOXDgAJs2bcLb25tVq1bRoUMHALZv386QIUNYvXo1Xl5e7N+/3/R8LhcXF3bv3s0PP/yAv7///2/v3uOirNP/j79mOMlRFBEwBU+Jmmmah1Q0Bc+K/rTMat3NsmzzkFlmhbHZZm2W+fWrrmVa6ldLVy3PtVYeCpMMTaVwPKKABzQVHEFgmJnr94cxK4GrhjHDdD0fDx7I/bnvmet9i1ze9/3hvlm2bBlNmjThA7nqcQAAIABJREFU8oHtztkxSqkqz+VP8Xl7e7N48WL8/f0pLi7m4YcfpmvXrtx1113OLs0lWM4ex56f63gG01//+lcOHTpEnz59GD16NJMnT6bw+B58whs7TsONHj2a7OxsHn/8cerXr8+xY8cYPXo0mzZtYtq0aY7XbtCgASNHjqRatWpERETQpk0b1qxZw7wFH2K1Wpk/fz5/+ctfePvtt5k8ebJju7vvvpv4+Hi8vb2RfGvl7hCllNtw+SMog8GAv/+VayglD8fTaxr/YTWfBaBx48YAZGVlAXDixAmCg4MJCQnBav75l3V/JigoiNDQUMd6JZ9LtgeYMWMG+/fvZ+TIkcydO5ctW7aQm5tLYWEhLVu2JLpxQ7p16wZAo0aNHNstWrSIQ4cOER8fz6uvvspPP/2EwQ2n/SulKofLNygAm83GoEGD6NSpE506daJVq1bOLsllGAxX/gqtVusvX19p3kbjf5bn7fmMUwvHcWn3emw2W6lxDw+PUtsDbN26laVLl3L06FFGjRpFTEwMBQUFjBo1itq1a2MymYiNjQWuTNAo8dlnn7F06VJOnTrFpEmTuOOOO7DlXfg94yul3JjLn+KDKz9E165di9lsZsyYMRw6dIgmTZo4uyyX4Bl85RqQyWTi7rvvpnHjxvz44480aNCA7OxsLl68SL169WjTpiV799rJyMggMzOTBg0aYDQaHUdABw4cAK40rvXr17N+/XpycnKYO3cu3bp1Y/v27SxZsoSPP/6Y0NBQBg0axHvvvcfmzZsdTXHFihXAlSY5ZcoUOnfujGnJ8lL1ZmRkkJeX53b3F3S3TO6WBzRTVVQlGlSJoKAgOnToQFJSkjaoX3jVisIzOJyZM2fy4IMP8vHHH5OVlUVYWBjPPfccAN26deP//u//ePzxx/nggw+YPn06s2bN4t///jfh4eHYbDZmzJgBXGl0ycnJFBcXM2TIEGw2G1u2bAFg2rRpVKtWDT8/P/70pz+xd+9e1q9fj5+fH6mpqWzbtg2j0ch9991HYWEhSUlJeIXULVVvVFQUGRkZbnN3jBLulsnd8oBmcmUmk6nc5S5/iu/ChQuYzWYACgsL2bFjBw0bNnRyVa7DYPQguOtf2L17NzExMaSkpHD58mUefvhhR9M5ePAgc+bMYf/+/QDMnj2bYcOGYTab2bNnD126dGHnzp0AfPjhh/j5+REaGsqyZcuIiYlhx44dAPzwww9ERERQu3ZtXnrpJbp27UpRURFFRUUsWbKE6tWrExwczAcffMA999yDyXSAoHuGOmfHKKWqPJc/gjp79iwvvvgiNpsNEaFPnz50797d2WW5FP9mXRG7jd3bP+LRRx8FwODtR9A9Q/EMDCFl60K+//57DJ7e1Igbhb3AzMq16x2n5Dyqh1Ej7gkKM39k2ltvO36BF8CzRgQh/Z/FcuYo/1r5Cf/617+uDBg98YvuTHi7QeR+s4QpU14F/nM9yqtWJKGDE/Br1K7S9oNSyr24fINq2rQpa9ascXYZLi/gju74N+uK9cIpxGbBs+ZtGL2qAeB/Zw+kuAiDl49jWdA9Q7FeOAkennjVvA2D0YOgtoOwWwqxXsxGbFY8/GvgEVDzyjWmFrEEd/0z1pzTiN2GV3C44/ZIYcNew150GevFbBDBI6AmRr9gnW2plKoQl29Q6sYZjB541apXZrnRqxr80pj+s8wH77Cyp0qN3tXwDq1f7usbvarhXbtB+WM+fnjX1lOvSqlbx+WvQSmllPpj0gallFLKJbndKT67XfS5Qy6qsNhGNS8PZ5ehlKoi3O4IymotdnYJt5y7/CKeNiel1M1wuwallFLKPWiDUkop5ZK0QSmllHJJbtegPN3w8Q5V9V5bhcU2Z5eglKrC3G4Wn9FooP6LG51dhgKdTamUqhC3a1B/FGK1kL9/GwUZ+8Bux6ducwJaxGH08Suzri0/l7zUL7CcOYrBywffRu3xa9IR26Xz5O/fRvH5LOyWAjz8quNTtzl+t99DvimJ4nOZZV7L4OUNBg/EUlBmzOgXREDLXngG1PxdMiul/li0QVVBVvNZziyfjDXnNFFRUXh5eXHkqyTMySuoPey1UrcqKji+l59Xvw7FhTRt2pScczlk/7QFr1qRFJ/LxGAwEBUVRWBgINmnjvLzvk2c58oznYKCgsq8d0FBAVarlcDAwDJjly9fxpJ9hNpDXv4d0yul/ijc7hrUH8GFL9/D336ZTZs2cfz4cQ4fPsx3331HeLAf5z+b6XjKrb24kHMbpnNn09sxmUzs37+fkydPsmTJEiT3FADr1q3j2LFjpKamcvbsWdauXYuXlxe1atUiNze3zMdjjz1GZGRkuWMPPvggxWePOXPXKKXciMs3KLPZzNNPP02fPn3o27cve/bscXZJTlV84SQFR77n+eefp1evXvz1r39l0KBBdOjQgalTp2LJPkJR1k8A5O//Bnt+LnPmzCEyMpJOnTrx5ptvMnz4cIYPHw7AzJkziY6OJjo6mh9++IGBAwdy9913YzabGTJkiOMjNTUVgB07dnD27NlSYwcPHsRut5OcnIxH9TCn7RullHtx+VN8r7/+Ol26dGHWrFlYLBYKCwudXZJTWX45QomPj8dms/HBBx9gtVrJzs5mwIABv6yTTrXIOyk+m0716tXp0qUL27dvJzk5mXPnzpGQkMCAAQNYtGgRmzdvpk6dOkRERODl5UVubi7p6ekUFRWxYfsein/OoH79KO644w42bdrkaFQbkn6g+FwGzZo1Izo6mk8//ZQjR45Qa9CLTts3Sin34tJHUJcuXSIlJYX7778fAG9v73Kvi/yR2PJzAKhTpw75+flYrVYAcnNzqVWrFt7e3liyj1B8LgvLz8epU6eOY/zqzyXLAdasWcOuXbu48847ef/99/n555+p1qANIb3HAsKECRPw8PDg7bffxiOgJpETV1Mj7gkAx2Pl3377bTyDw/Fr0rFS9oNSyv259BHUiRMnqFmzJi+99BIHDhzgjjvuYPLkyfj5lZ2p9kfh4XtlcsK5c+do3LgxBoMBEcHf3x+z2YzFYsGStpX8tK1X1gsNBcDf37/U53Pnzjles2fPnoSGhjJ79mwmTZrEt99+y2df78T8/afUrFmTkSNHsmfPHjZv3kxwtxEYPLwwf7+a8PBwhg8fzrfffst3331HzZ5/xWAsfb+98u4jmJeX5zb3FyzhbpncLQ9opqrIpRuU1Wpl//79JCYm0qpVK6ZOncr777/PM8884+zSnMYr5MoDCb/55huaNm3Kvffey6lTp6hXrx4bNmwAoH///vz5z39m+vTp7Nq1C5PJROvWralZsyZxcXGO7T09PWnbti07d+4kLy+P06dPAxAcHIz14hmsF8/wTEIC/v7+TJ8+HYO3L4F39cXy83EKj+1m3Ouv4+Pjw9tvv43RNwj/O3uUqbe8XzLOyMiosr98fC3ulsnd8oBmcmUmk6nc5S59ii88PJzw8HBatWoFQJ8+fdi/f7+Tq3Iur9oN8Y6IZurUqWRkZLB582bS0tIc15YAoqOjGTZsmOM03oQJE/D29ub06dMsWLCAPXv28N577+Ht7U1ycjKXLl3CbDbz6KOPsnv3btauXQuAj48P48aNIzMzkxUrVhDYqg9GH38u7d5AQEAATz31FAcPHmTdunUEtu7neJy8UkrdCi59BBUaGkp4eDjp6ek0bNiQ5ORkGjVq5OyynMpgMFCz11OcWPYSt99+O7169cLb25tNmzZxucgCwPLly0lOTubAgQMAbNq0ibp169KjRw/Onz/P1q1bHVPRmzZtSosWLfDw8OD48eOkpKRgDAjB57ZmeF3MYsiQIZw9exarHQLbDgTAln8BL6OR/v37k52dDR7eBLYZ4JwdopRyWy7doAASExOZOHEixcXF1KtXj3/84x/OLsnpfMIbU2fkPzGnrOWL73+5k8TtXanTbhD2wnxyU9Zw4XQ+Hre1ps59Q7EXXca8ax2rNydj9PIhqNODBLYZQMGR78k8nEz6thRE7HgE1KR6lz8TcFcf7IV5XPx2GXtO52LwqEnooAfxDLpyPavGvY+Sm7ycPafNGDxDCf1/j+DhH+zkvaKUcjcGKfmvtJswmUz0XZzu7DIU174Xn7ucN7+au2VytzygmVyZyWSiWbNmZZa79DUopZRSf1zaoJRSSrkkbVBKKaVckstPkrhZdrvoc4hcRGGxjWpeHtdfUSmlyuF2R1BWa7GzS7jlqupvimtzUkpVhNs1KKWUUu5BG5RSSimX5HYNytPTy9kllFFYbHN2CUopVeW43SQJo9FA/Rc3OruMUnTShlJK3Ty3O4KqSkQEi8VyQ+vabDbHs59u1XsXFhbiZjcSUUq5EW1QTnD48GGGDx+Ov78/Pj4+NGnShDlz5mCzlT0VuHnzZh566CG8vb3x9vamS5cufP7552RnZzNx4kQ6depEeHg4YWFhdOvWjaNHjzq23bVrFy1btiQsLIywsDDuv/9+Fi9eTLdu3ahevTq+vr4EBATQs2dPkpOTK3MXKKXUdbndKT5Xd/jwYdq3b4/dbmfEiBHUqVOHTZs2MW7cOPbt28f8+fMd665atYqhQ4cSFRXFCy+8gNFoZPny5fTr1w8AX19f2rZty6BBgzAajSxZsoR58+bx1ltvcenSJe6//34MBgNDhgyhsLCQRYsW8cknn9CiRQtGjBhBREQEZ8+eZdWqVXTt2pWtW7cSExPjrF2jlFKlaIOqZImJidhsNn766SdCQkLIzMzk5Zdf5oUXXuCtt95i9OjRtG7dGovFwnPPPUe7du1ISkoiJycHm83GK6+8QlxcHElJSQwdOpSFCxdisVioVq0a69ev58KFCwBMmjSJrKwstm/fTseOHfn5559ZtGgRAPPmzSMyMpLTp0/Trl07Xn31Ve666y5eeeUVNm/e7MS9o5RS/+Hyp/heeuklOnbsyIABVf95Q5cvX2bVqlWMGjWKyMhIxo4dS4sWLTCZTCQkJODr68tHH30EQFJSEpmZmSQmJuLj40Pnzp1p27YtXl5evPLKKwCsX7+e6tWrs379+lLv8+WXX/Lee+/x7LPPUqtWLU6ePFlqfMKECURGRtK+fXtmzJhBUFAQvXv3Zu/evZWzI5RS6ga4fIMaMmQICxYscHYZt0RGRgY2m402bdoAsGfPHux2O6mpqVSvXp1GjRo5riEdOXIEgDZt2mA2m0lPTyc7O5vTp087ts/JySEvL6/Ue5jNZkaOHEnTpk2ZMmUKI0aMoKCgoNQ6WVlZjskRtWvXBiAtLY2IiIjfL7xSSt0kl29Q7dq1o3r16s4u45YoaSaBgYEAjhl8JZ8DAwNZs2YNiYmJJCYmOpZdPdPPYrEQEBCAwWDggQceKPMeK1eu5OTJkyxatIh3332XHTt2lFnHarViMBj4xz/+wfDhw5kyZQpJSUmMHj361gZWSqkK0GtQleTq++mV/Ll27dqYTCbHUUxmZiYAb7zxhuMIJyMjg6ZNm+Lt7Y3VaiUkJMRxBLRixYpy36tWrVp06NCBoKAgevToQWRkJB4eHiQnJ9OxY0cuXrzIkiVLeOihh5gwYQIzZ84E4MSJE5Vy37+8vLwqe3/Ba3G3TO6WBzRTVaQNqpJERUURGRlJgwYN+Oijjxg7diwTJ04kMjLSMYPu5MmTdO7cme3bt/PGG28wefJkli5dyrRp0/j73/9OQUEBAQEBvPPOOwA0atSI3r1707hxYwBGjBiByWTiiy++cKwDUL9+fXx8fNi6dSsAixcv5sEHHyQlJYXg4GCmTJnC119/zaxZs5g6dSpG4+97YO0uTwG9mrtlcrc8oJlcmclkKne5NqhKZDAYSEhI4IknnmDMmDEkJCTQt29fvvjiC8aOHQtAUVERGRkZ5ObmAjBz5kxuu+02xowZg9FoZN68eUybNg2AJk2aMGnSJODKN+oTTzzB7t27+fTTT5k4caLjfdu1a0dgYCAJCQkA+Pv7k5GRQe3atRkxYgRw5dpVSQNTSilXoA2qkj322GOkpaUxa9Ys5s6di8FgQESIjIxk8ODBrF69mvr16wPQokULwsLCGD9+POPHj3e8RkxMDPXq1WPZsmWOda/m6+vLoUOHuHjxIi1atODee+8tNT5w4MBya+vWrdvvfvSklFI3yuUb1LPPPsv3339PTk4OXbt2Zdy4cQwdOtTZZf1mRqOR//mf/2HcuHGsXbvW0UQGDhyIp6cn27ZtIyMjg4CAAPr164efnx+rV6/mwIED2O127r33XmJiYrDZbAwfPpwzZ86Uef1evXoRERFB3bp1SU9P5+uvv0ZEiImJwc/Pj6+++gq73V5qu8DAQMcvACullCswiJvdjM1kMtF3cbqzyyilojeLdZfzzCXcLQ+4XyZ3ywOayZWZTCaaNWtWZrmez1FKKeWStEEppZRySdqglFJKuSSXnyRxs+x2cbkHBBYW26jm5eHsMpRSqkpxuyMoq7XY2SWUoc1JKaVunts1KKWUUu5BG5RSSimX5HYNysNDT6cppZQ70AallFLKJbndLL7ynDhxgqSkJOx2O507dy73/nUlUlNT2bNnDwEBAcTFxREcHOwY++GHH/jxxx8JCgoiLi6OoKAgAESEXbt2kZaWRo0aNYiLiyMgIMAxtnPnTg4cOEBISAhxcXH4+fn9rnmVUsotiJvZv3+/489FRUXy5JNPioeHhwACiMFgkOHDh0teXl6p7U6cOCGxsbGO9QDx9/eXN954Q44dOyYxMTGlxgIDA2XGjBly6NAhad++famx4OBgeffddyUtLU1at25daiwkJEQWLlx4U5mOHz9+K3aNy3C3PCLul8nd8ohoJld29c/tq7l1g3ruuefEYDDI008/Lfv27ZO0tDR58cUXxcPDQx599FHHena7Xdq3by9BQUEyY8YMOXz4sCQnJ8t9993naCw1atSQ2bNny5EjR2T79u0SHx/vGAsNDZV3331Xjh49Ktu2bZPevXs7xiIiImTBggVy9OhR2bx5s3Tv3l0A2bp16w1ncpdvwhLulkfE/TK5Wx4RzeTKfrcG1b17dzl//rzj6++++05GjRolIiKffPKJREdHi8lkcoz3799fsrKyymz7448/Svfu3SUtLa1C9ZQEPXv2rFSrVs3RiJYtWyYLFiwQkSuNy2g0Snp6uoiIbNy4UQDHkc3rr78u27ZtExFxHB2tWLFCrFarTJkyRXbs2CE2m01atGghgGzcuFEsFoskJiZKSkqKFBcXS6NGjQSQr7/+WgoKCiQhIUH27dsnhYWFUrduXenevfsNZ3KXb8IS7pZHxP0yuVseEc3kym5pgyoqKpL8/HwRuX6Duvfee2X8+PGO8fIalMlkku7du8u+fftERMRsNovNZvstpTmCrlmzRgD57rvvxGazSUBAgHh4eEheXp4cPHiwVEOaMGGC+Pn5SXFxsaSkpAgg7du3FxGR+fPnS0hIiIiIfP311wI4msvMmTOlbt26IiLy2WefCSD9+/cXkStNLjo6WkREVq5cKYA88MADIiIyefJkMRqNYrFYbiiTu3wTlnC3PCLul8nd8ohoJld2rQZ1U7P4jh49yptvvkmfPn04fvz4DW3TrVs3jhw5Qnp6+Y/ASE9PZ8yYMbz11lu0bNkSgN27d9OnTx9mz57NqVOnbqZEh8zMTAAaNmyI2WwmLy8Pm83GmTNnaNCgAUaj0bFOZmYmkZGReHp6Ot7v5MmTwJXHqpdMqihZdvVYw4YNSy0r2f56Y3a73bFcKaVUWddtUJcvX+aTTz7hoYce4uWXX6ZRo0asW7eO5s2b39gbGI08/vjjzJs3r9zx0aNH87e//Y22bds6lnXr1o3ly5cTGBjIU089xciRI/n888+xWCw3GAu8vLwAsFgspaaee3p6UlxcjN1u55VXXqFx48Z88sknjtcueaKsp+eVCY5FRUWOsZLX+W9jJZ+vN3Z1jUoppcq67jTzmJgYoqOjmTp1Ko0aNbqhFzUYDKW+HjBgAO+++y5ZWVll1u3YsSMrV64kJiamVCOpWbMmI0aMYMSIEezZs4eEhATmzp3L+vXrr/v+GRkZ+Pv7A5CWluZ4wuylS5eIiIhg7969ADRv3pzWrVtTUFBAVlYWZrOZ6OhoAMfntLQ00tPTKSgocCxr0qSJY+zQoUMUFxeXu53JZMJut5c75u3tjcViISMj47p58vLybmi9qsLd8oD7ZXK3PKCZqqTrnRtMSkqS8ePHS9++fWX27Nly4sSJUuODBw+WY8eOOb7etGmTvPjiiyJy5RrUq6++KiIiy5cvl8TExDLXoM6dOydjxoyRxMTEMu99+PBhefPNN6Vnz56SkJAge/fuveFzmfn5+RIaGiqxsbFis9kkNTVVUlJSRERkyJAhAsikSZNERKRfv34CyN/+9jcREfnyyy8lMzNT8vLyJCoqSgCZNm2aiIh8/vnncvLkScnNzZXw8HABZM6cOSIismHDBjlz5oycO3dOatSoUeo619q1a+XcuXNy6tQpCQgIkIceeui6WUq4y3nmEu6WR8T9MrlbHhHN5Mp+8zWomJgYZs6cyUcffURgYCCjR49mxIgRnDhxAoAOHTqwdu1aAGw2G+vWraNDhw5lXmfw4MEkJydz4cKFUssNBgPvvPMO6enp/O///i9w5QjjgQce4OWXX6Zhw4asXr2a119/nVatWt1w4/Xz8+O1115jy5YtdO7cmeTkZFJTU+nevTuffvopADt37uTNN9/k6NGjALz22msMGzaM7OxsVq1aRevWrTlx4gQ1atQgISGBP/3pT5w/f56PP/6YNm3acP78eYKCgnjmmWd45JFHyM3NZeHChbRp04b8/HwCAwN58skneeKJJ8jLy+O9996jbdu2iAhTpky54SxKKfWH9Fu63b59++TUqVMicmXG3bPPPivx8fEyYMAAmTZtmmMG3tVHUCIiixcvliZNmpQ7zdxsNsvAgQNl6dKlcuTIETly5MhvKa1MJ164cKE0bNjQ8XtJdevWlTlz5sg777wjfn5+AkitWrVkxYoVkpCQINWrV3es27ZtW/niiy8kPz9fJk6cKIGBgY6xe+65R7Zt2yZms1mefvppx2sB0rVrV9mxY4fk5OTIU089Jb6+vo6x2NhY2bVr101lcpf/JZVwtzwi7pfJ3fKIaCZXdq0jKIOIiJN64+/CZDLRrFmzUsvsdjsZGRnY7XbHDD6A4uJibDYbXl5epSYwZGRkEBAQQJ06dUq9TmFhIRkZGQQFBREREVFqrKCggMzMTIKDgwkLCys1dvnyZTIzMwkJCSE0NPSmM2VkZBAVFXXT27kqd8sD7pfJ3fKAZnJl5f3chj/IvfiMRiMNGjQos9zLy6vMTDofHx/HJIhfq1atmmOiw6/5+vpec8zPz4+mTZveZNVKKfXH5nZ3M1dKKeUetEEppZRySW7XoGw2m7NLUEopdQtog1JKKeWS3K5BKaWUcg/aoJRSSrkkbVBKKaVckjYopZRSLkkblFJKKZekDUoppZRL0gallFLKJWmDUkop5ZK0QSmllHJJbve4jb179+Lj4+PsMpRSSt2goqIi7rrrrjLL3a5BKaWUcg96ik8ppZRL0gallFLKJWmDUkop5ZK0QSmllHJJ2qCUUkq5JG1QSimlXFKValDffPMNvXv3pmfPnrz//vtlxi0WC8888ww9e/Zk6NChnDhxwjE2b948evbsSe/evUlKSqrMsq/pt+b59ttvGTJkCPHx8QwZMoTk5OTKLv2aKvJ3BHDq1Clat27NBx98UFkl/1cVyXPgwAGGDRtG//79iY+Pp6ioqDJLv6bfmqm4uJgXXniB+Ph4+vbty7x58yq79Gu6XqaUlBQGDx5M8+bN+fe//11qbPXq1fTq1YtevXqxevXqyir5v/qteUwmU6nvuc8++6wyy771pIqwWq0SFxcnmZmZUlRUJPHx8XL48OFS6yxdulQSExNFRGTDhg0yfvx4ERE5fPiwxMfHS1FRkWRmZkpcXJxYrdZKz3C1iuRJS0uT7OxsERE5ePCgxMTEVG7x11CRTCXGjRsn48aNkwULFlRa3ddSkTzFxcUyYMAAMZlMIiJy4cIFp3/PiVQs07p16+SZZ54REZHLly9L9+7dJSsrq3IDlONGMmVlZYnJZJLnn39ePv/8c8fynJwciY2NlZycHMnNzZXY2FjJzc2t7AilVCRPenq6HDt2TEREsrOzpXPnznLx4sXKLP+WqjJHUKmpqURFRVGvXj28vb3p378/mzdvLrXOli1bGDx4MAC9e/cmOTkZEWHz5s30798fb29v6tWrR1RUFKmpqc6I4VCRPM2bNycsLAyA22+/naKiIiwWS6Vn+LWKZAL46quvuO2227j99tsrvfbyVCTPt99+S3R0NE2bNgWgRo0aeHh4VHqGX6tIJoPBQEFBAVarlcLCQry8vAgICHBGjFJuJFPdunVp2rQpRmPpH3nbt2+nc+fOBAcHU716dTp37uz0MywVydOgQQPq168PQFhYGDVr1uTChQuVVfotV2Ua1JkzZwgPD3d8HRYWxpkzZ8qsExERAYCnpyeBgYHk5OTc0LaVrSJ5rrZp0yaaN2+Ot7f371/0dVQkU35+PvPnz2fs2LGVWvN/U5E8x44dw2AwMHLkSAYPHsz8+fMrtfZrqUim3r174+vrS0xMDN27d+exxx4jODi4UusvT0X+fVfVnw03IjU1leLiYiIjI29leZXK09kFqN/u8OHDTJ8+nQ8//NDZpVTYnDlzeOSRR/D393d2KbeEzWZj9+7drFq1Cl9fX0aMGEGLFi3o2LGjs0v7zVJTUzEajSQlJWE2m3n44Yfp1KkT9erVc3Zp6lfOnj3L888/z7Rp08ocZVUlVabysLAwsrOzHV+fOXPGcZrr6nVOnz4NgNVq5dKlS9SoUeOGtq1sFckDkJ2dzdixY5k2bZrL/A+pIpn27dvH9OnTiY2NZfHixcyCxGInAAACSUlEQVSbN4+lS5dWav2/VpE84eHhtGvXjpo1a+Lr60vXrl1JS0ur1PrLU5FMGzZsoEuXLnh5eRESEkKbNm348ccfK7X+8lTk33dV/dnw3+Tl5fHkk08yYcKEcm/AWpVUmQZ15513cvz4cbKysrBYLGzcuJHY2NhS68TGxjpm4WzatIl77rkHg8FAbGwsGzduxGKxkJWVxfHjx2nZsqUzYjhUJI/ZbGbUqFE899xz3H333c4ov1wVyfTxxx+zZcsWtmzZwiOPPMKTTz7J8OHDnRHDoSJ5YmJiOHTokOOaTUpKCo0bN3ZGjFIqkikiIoKdO3cCcPnyZfbt20fDhg0rPcOv3Uima4mJiWH79u1cvHiRixcvsn37dmJiYn7niv+7iuSxWCyMGTOGQYMG0adPn9+50krg1CkaN2nbtm3Sq1cviYuLk7lz54qIyMyZM+Wrr74SEZHCwkIZN26c9OjRQ+677z7JzMx0bDt37lyJi4uTXr16ybZt25xS/6/91jz//Oc/pVWrVjJw4EDHx7lz55yW42oV+TsqMWvWLJeYxSdSsTxr1qyRfv36Sf/+/WXatGlOqb88vzVTXl6ejBs3Tvr16yd9+/aV+fPnOy3Dr10v0759+6RLly7SqlUrad++vfTr18+x7cqVK6VHjx7So0cPWbVqlVPq/7XfmmfNmjXSvHnzUj8b9u/f77QcFaWP21BKKeWSqswpPqWUUn8s2qCUUkq5JG1QSimlXJI2KKWUUi5JG5RSSimXpA1KKaWUS9IGpZRSyiX9f9tDKZx9eth+AAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVzU5dr48c8XUUQBFZVBzfwFhpWa9mS54YaBKO6J1DETy+yoSWqaluaSC50n9ZjZRnZMq5OJG6Xmhim571qZloilCUMPIqDINnP//uBhnjwqMwwzzDBc79fr+3qdmfnOPdd49Oqe63t/r1tTSimEEELYlJujAxBCCFckyVUIIexAkqsQQtiBJFchhLADSa5CCGEHklyFEMIOJLmKWzz44IMMGDCAvn37EhMTw82bN60ea9q0aWzduhWA6dOnc/78+buee+jQIY4fP17mzwgJCeHq1asWP/9XjzzySJk+69133+WTTz4p03tE1SXJVdyiZs2aJCQksGnTJqpXr87q1atveb2oqMiqcefPn0/z5s3v+vrhw4c5ceKEVWML4YzcHR2AcF7t2rXj3LlzHDp0iHfeeQcfHx9SUlLYsmULCxcu5PDhwxQUFDBs2DCeeuoplFLMnTuXffv20ahRI6pXr24aa/jw4bz66qu0bt2apKQk/vnPf2IwGKhXrx7z589n9erVuLm58fXXX/PGG28QEBDArFmzuHLlCgCvv/46jz76KJmZmbzyyivo9Xratm2LJffAjB07lrS0NPLz83n22WeJiooyvbZgwQL27dtHgwYN+Oc//4mvry+///47c+bMITMzk5o1azJ37lwCAwNt/wcsXJsS4i/atm2rlFKqsLBQ/f3vf1dffPGFOnjwoGrTpo36/ffflVJKrV69Wr333ntKKaXy8/PVoEGD1O+//662bdumoqOjVVFRkUpLS1OPPvqo+vbbb5VSSj3zzDPq9OnTKiMjQ3Xt2tU0VmZmplJKqaVLl6rly5eb4pg0aZI6cuSIUkqpP/74Q4WHhyullJo7d6569913lVJKfffddyooKEhlZGTc9j169Ohher7kM27evKkiIiLU1atXlVJKBQUFqYSEBKWUUu+++66aM2eOUkqpZ599VqWkpCillDp58qQaPnz4HWMUojQycxW3yMvLY8CAAUDxzHXIkCGcOHGC1q1b07RpUwD27dvHuXPn2LZtGwA5OTn89ttvHDlyhIiICKpVq4ZOp6NDhw63jX/y5EnatWtnGqtu3bp3jGP//v231GivX7/OjRs3OHLkCMuWLQOge/fu1KlTx+x3+uyzz9ixYwcAqamp/Pbbb9SrVw83Nzf69OkDwIABA3jppZe4ceMGJ06c4OWXXza9v6CgwOxnCPGfJLmKW5TUXP9TrVq1TP9bKcWMGTPo0qXLLefs2bPHZnEYjUbWrFmDh4dHucY5dOgQ+/fv56uvvsLT05Phw4eTn59/x3M1TUMphY+Pzx3/DIQoC7mgJcosODiYL7/8ksLCQgBSUlLIzc3lscce49tvv8VgMJCens6hQ4due2/btm05evQoly5dAuDatWsA1K5dmxs3btzyGZ999pnp8c8//wzAY489xjfffAMUJ/OsrKxSY83JyaFOnTp4enqSnJzMyZMnTa8ZjUbT7Pubb77h0UcfxcvLi3vuuYdvv/0WKP4PydmzZ8v2ByQEklyFFSIjI2nevDmDBw+mb9++zJw5E4PBQGhoKM2aNaNPnz5MnTqVtm3b3vZeX19f3nzzTcaPH0///v2ZOHEiAD169GDHjh0MGDCAo0ePMn36dH788Uf69etHnz59+PLLLwEYN24cR48eJSIigh07dtC4ceNSY+3atStFRUX07t2bRYsW3RJTrVq1OH36NH379uXgwYOMGzcOgLfffpu1a9fSv39/IiIi2Llzp63+6EQVoiklLQeFEMLWZOYqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhydRKy3FgI1yLJ1YH+mlA1TeP69eucPXuWOXPmsGvXLgdGJoQoL0muDqRpGgBpaWmcOnWKMWPGsGXLFnbs2IG7u/TUEaIyk3/BDnDlyhV0Oh3VqlXjs88+IykpCT8/P4YOHco999zD999/T0BAgKPDFEKUg/QWqEBKKVJTUxkxYgRffPEFtWrVYsuWLbRp0wY/Pz/q1avH22+/zX333ceQIUMcHa4Qohxk5lqBNE3Dy8uLhg0b4ufnB8CQIUNwcyuuzty4cYO0tDR69+7tyDCFEDYgNdcKcvHiRaC4GXW1atVu2eiv5MfD4sWLAWjVqlWFxyeEsC2ZudqZUorCwkLGjx9Pp06dGDNmDJmZmeTk5Ji2GikRHBzMAw88YHpfyQUvIUTlIzVXO9Pr9eh0OlJTUxkzZgyPPPIIycnJdO/eHV9fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri2HDhjFixAiGDh2KXq9n8uTJHDlyhBdeeIHff/+d/Px8NE3j6tWrLF26FJ1O5+jQhRA2IMnVznbv3s0777zD8OHDGTx4MFevXmX06NGEh4czatQo03n5+fnl3oxPCOE8pOZqB7/88gv169fHy8uL7t274+npybx58zAYDERGRvLee+/x97//nUuXLjFnzhwAqlev7uCohRC2JDNXG0tNTSUsLIyGDRsSFBTEsGHDCAwMJCsri1dffZUxY8bQp08f0tLSmDRpEsuWLcPX19fRYQshbKza7NmzZzs6CFeRnZ1NgwYNqFWrlqlXgIeHB++88w7e3t7k5OSwdetWPDw8aN++PQMHDqR27dqODlsIYQeyztVG9Ho9kyZN4siRIzz77LN07NiR5s2b06JFCz799FN8fX1p1qwZaWlpLFq0iKysrFuWYQkhXIuUBWzk2rVrbN68mb179zJ69Ghat27N2rVrOXnyJBEREXTp0gWA5ORkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HAmjVruPfeewkJCeHq1ascOnSInJwcWrRoga+vr5QChKgC5HdpORw5coSEhATT4zp16tCrVy+eeOIJPvroI3799Vf69+9P8+bN+eGHH7h+/boDoxVCVCRZilUORUVFxMbG4ubmRr9+/YDiBBsWFkZeXh47duxg/PjxhIeHU7NmTby8vBwcsRCiosjM1QpKKZRSdOzYkaVLl7JkyRK+/vpr02t169YlMDCQlJQUjEYjfn5++Pj4VHicf/75p2wf4+Ryc3MdHUKZyN8ny0lytYKmaWiaxtmzZ3n88ceZN28e77zzDps2bTI1W8nNzSU/P9/ifzwGg8GmMX7//fe89NJLpKam2mzMX3/9lcOHD5OZmWmzMX/77Td++OEHCgoKbDbmxYsX+eGHHzAajTb7c71w4QInTpygsLDQZmPu3LmThQsXkpGRYZPxAE6ePMnGjRs5efKkzf5Mjx49ysaNG4Hiv/uSYC0jF7SstHbtWt577z0iIiIICAigRYsWvPfee1y8eJE9e/aQkJDAjBkzaNSoUanjpKSkmLpjGQwGmyzP2rt3LwsXLiQzM5Nr167RtWvXco+5Z88eZs2aRUpKCtu3b6dDhw7lvjD33Xff8cYbb3Ds2DEOHDhAUFAQ9erVK9eYO3fuZPbs2SQnJ3Py5EkuX75M8+bNy3UH3Pbt25kxYwY//vgjhw4dQq/XExgYSI0aNawe8/Dhw8yfP5/o6GhatGhh9Th/lZiYSGxsLPn5+Rw5coRWrVpRt25dq8czGo3k5uYybtw4jh07hpubG61bt0bTNIxGo3RtM0eJMjEYDEoppT744AO1c+fOW147d+6c2rx5s1q5cqW6ePGi2bF27dqlHn74YTVp0iTTc0VFReWKb9++feqJJ55Qv/zyiyooKFAjR45Uhw8fLteYBw8eVGFhYerUqVNKKaXGjh2r9u3bV64xjx07psLDw9VPP/2klFJq1qxZatq0aeUa8+rVq+r5559Xv/76q1JKqfj4eDV48GC1bNkylZOTY9WYBQUF6uWXX1ZHjx5VSim1detW9dZbb6nFixdbPaZSSv3rX/9Sy5cvV0oplZaWpvbu3atOnjypsrOzrRrv6tWr6rnnnlPnzp1TSik1bdo0tWXLFvU///M/Ki8vz+o4lVIqLi5OffLJJ2rKlClqxYoV5RqrKpGyQBm5ublx6dIl9u3bd0sHq99++42goCD69OnDs88+S7NmzUodJzc3l88//5zXX3+d6tWrM3nyZACqVatWrp+dBoOBf/zjH9x///3cvHmT++67j19//RWwvl7WoEED5syZw8MPP8yff/7JqVOn+Pzzz5k5cyZbt261etwXXniBhx56CICYmBiysrLK9VPW3d2d3Nxc/vzzT6B4l4cmTZqQmZnJ7t27rR73+vXr/PbbbwCEhobSo0cPCgsL+eabb6z+7n9tK/nyyy+zbt06Pv/8c+bMmUNWVlaZx3N3dycvL48LFy5w/fp1Dh8+TEJCAgsWLOD9998vV23X3d2d1NRUBg0axOnTp4mNjWXRokUopTAajVaP6+qkLFAGSimKiopYsmQJISEhdO7cmeTkZKZPn86FCxe4//778fLysujnUvXq1enQoQOtWrWiQ4cOJCYmkpiYSFhYWLlKA82aNaNRo0YYjUZq1qyJpmnExsYSHBxMgwYNrBrT19eXe+65B4BVq1bRunVrZs+eTWZmJrt27eLxxx/H09OzTGP6+fnRrFkzatSogcFgICcnhy+//JLevXvj6elJZmZmmcf08PCgoKCAxMREcnNz+fbbb8nNzaVVq1YcPXqUnj17lmk8KE6C9evXZ8OGDfj7+9OkSRP8/f25du0aBw4cICwszKqfxzVr1mThwoUcP36c3r17M3HiRB588EF++OEHvLy8zP7H+T95eHhQu3Zt4uLi+Oabb+jduzdvvvkmPj4+HDt2jPvuu8/q///r169PamoqAwcO5I8//uCTTz4hMDCQ7t27S2mgFDJzLQNN06hevTo3btwgPT2d6Oho1q9fzwMPPMDkyZPx9/cv0182nU5H7dq18fX1Zc6cOeTn55tmsD/99BPJyclWx1qSoLt27crQoUPZvXu3TWYaY8aMYezYsQAMHjyY69evW3XRrFq1aqalaUopvL29qVOnDr6+vnz99dcsWbKEvLy8Mo/bt29funbtyqFDh8jLy2PhwoU89dRTZGRkWL3OuF27dgQHB5OQkMCRI0eoVq0a/fr1Iz09nbNnz1o1ZosWLZg6dSqnTp3i8uXLADRt2hSj0cjVq1etGjM8PJwVK1bw6KOPmn4RdOzYkRs3bvDHH39YNSYUJ+6UlBTWrFnD6tWreeGFF0hNTWX16tVWj1kVyDrXMrpw4YLpp/CoUaPo1KmTTdoF1qtXjzlz5vD2228THh6O0Whk1apVNogYHnjgAT799FNGjRpVrl0O1H9sPbNt2zYyMjJMmy1ay93dHXd3dxo1asSiRYvYt28fsbGx1KxZs8xjeXt7079/f/r27Wv6D8zGjRvL1cvBw8ODfv36oWkaH330ERcuXKBGjRpkZGSU6zbmrl27EhMTw7vvvkvjxo0BOHPmDKNHj7Z6zDp16tChQwe2bt1K9erVyc/P5/Lly+W6aKbT6fD39+f9999n5syZhISEcPDgwTLPrqsch1V7K7GcnByVm5t7y3NGo9EmY69YsUJ16tRJnT171ibjlYiJiVGXLl2yyVj5+flqzZo1qk+fPqYLKOVhNBpVfn6+6tmzp+rWrZtKSUkpf5D/Kz4+XvXu3dsmf575+fnqwIEDasKECWrq1Kmmi3Hl9eOPP6pFixap2NhYm8SZlZWlVq5cqYYNG6aee+459fPPP5d7zCtXrqgffvjB9Ljkwq64O2nc4kSysrKYMGECU6dONW1UWF7KDhsdFhYWsn//fpo2bUpAQIDNxl2/fj2tW7fm/vvvt9mYf/zxB0VFRTadZRkMBjRNc/quZiVlEFveGWiPv0+uSpKrk6nK273IP1zhSiS5CiGEHTj37xohhKikJLkKIZxefn4+2dnZjg6jTKr0UqykxO/JvFL2u2GEELeq17gOXXt2sdv4l5PjyC1ozkOtw8q1nLAiVenkmnkli2UjVjo6DCEqvZdWjrDb2Ddv3qTI6I3O+xv0ybtpHPQPu32WLUlZQAjh1K6kLMffewO+tXZzLe9xm7fntBdJrkIIp1Uya/X2+Bk3rYgGtRPRJ7/u6LAsIslVCOG0SmatJSrT7FWSqxDCKf111lqiMs1eJbkKIZzSf85aS1SW2avDkmtISMgtrdUOHTrEiy++CGBq4/fXdm59+/Y1tWb763t//PFHQkJCOHPmTAVGL4SwpzvNWktUltlrhSbXgoICizui+/v78+GHH5Z6ztmzZ4mJiWHJkiU89NBD5OTkSGd0IVzA3WatJSrD7LVCkmtycjJvvfUW4eHhXLx40aL3dO/enfPnz3PhwoU7vn7hwgXGjRvHf//3f/Pwww8DcOzYMcLDw3n33Xe5cuWKrcIXQlSgvLw8iow+d5y1lnDTiqhfK9G0pY8zsltyzc3NZd26dTz99NPMmDGDwMBAvv76a1OHdLOBubkxatQoPvroozu+PnbsWGbOnEm7du1Mz3Xv3p3Vq1fj7e3NmDFjeP755/n2229tum2zEMK+CgoKqFU9xex5tWpcID8/vwIiso7d7tAKDg6mRYsWzJs3j8DAQIve85/t5vr27csHH3zApUuXbju3Y8eOxMfHExwcfMvtcL6+vkRHRxMdHc2JEyd4/fXXef/99/nmm2/K94WEEBVGoTBSeolP4dwN/ew2c126dCk6nY7x48ezbNmy2/bwqVu37i2NGLKysm7bs97d3Z3nnnuOjz/++LbxZ86cCcCcOXNue+38+fP84x//YOrUqfzXf/0X8+bNs8VXEkJUEKXAoIxmD2dmt+QaHBzMkiVL+OKLL/D29mbs2LFER0ebrvi3b9+ehIQEoLiz+9dff0379u1vG2fQoEEcOHDgtk3bNE1j0aJFXLhwgXfeeQco3tRv6NChzJgxg4CAADZs2MD8+fNp06aNvb6mEMIOjBgpwlDqYTAzs3U0uzduqVevHiNGjGDEiBGcPn3a9BN+7NixzJ49m/79+6OUokuXLvTv3/+299eoUYPhw4czf/78217z8PDggw8+4JlnnqFBgwZ06NCB2NhYi8sQQgjnZAQMZvr4G5UCJ964okrvRJDw2SbpiiWEDby0cgQDhve1yVjZ2dmkX/lvGviU/m8zr6A5+dqnTrsLbZVuOSiEcE4KMJi5YGV08gtaklyFEE7HqBSFZi5YFUlyFUKIslFg9nKVEacuuUpyFUI4H4WyqCzgzBu+SHK1sW1XTtp8zF6N29p8TCGcWfFqATPnKKjmxFNXSa5CCKdjRKPQzI9+AxrVKygea0hyFUI4HUXxzLQ05l53NEmuQginU7wUq/SZq3PfnyXJVQjhhAxKA1X63fnKzOuOJslVCOF0FJrZmaty6oVYklyFEE5IoWE021dKkqsQQpRJ8QUtM8nT3OsO5txFi3J47bXX6NixI3372qaZhBCi4hiURoGqVupR5NS3ELhwch08eDDLly93dBhCCCuUlAVKP2Tm6hCPPfYYderUcXQYQggrlFzQKu2wJLne6RfstWvXGDlyJGFhYYwcOZKsrKziz1SKefPmERoaSr9+/fjpp59M79mwYQNhYWGEhYWxYcPdd6X9K5dNrkKIysuARqGqVupRZMFSrDv9go2Li6Njx45s376djh07EhcXB0BSUhIXL15k+/btzJ07l9mzZwPFyXjZsmWsWbOG+Ph4li1bZkrIpZHkKoRwOsUzVzezhzl3+gWbmJjIwIEDARg4cCA7d+685XlN02jbtm1x0+70dPbu3Uvnzp2pW7cuderUoXPnznz//fdmP1tWCwghnI5SGgYzM1M35UZycjITJ040PRcVFUVUVFSp78vIyMDPzw+Ahg0bkpGRAYBer8ff3990nr+/P3q9/rbndToder3e7HeQ5CqEcDqWrHM1ohEYGMj69eut/hxN09A0+1wYc9mywKRJk3jqqadISUmha9euxMfHOzokIYSFDFiwFMvK21/r169Peno6AOnp6fj6+gLFM9K0tDTTeWlpaeh0utue1+v16HQ6s5/jssl18eLF7N27l59++omkpCQiIyMdHZIQwkJKaRiVm9nDGiEhIWzcuBGAjRs30rNnz1ueV0px8uRJvL298fPzIzg4mL1795KVlUVWVhZ79+4lODjY7OdIWUAI4XRKLmiVxvztscW/YA8fPkxmZiZdu3Zl/PjxjB49mgkTJrB27VoaN27MkiVLAOjWrRt79uwhNDQUT09PFixYAEDdunUZO3YsQ4YMAWDcuHHUrVvX7GdLchVCOB0jWnFnrFIYLBhn8eLFd3x+5crbt+3WNI1Zs2bd8fwhQ4aYkqulJLkKIZyOUWkUqtLTk7uZ1x3NuaMTQlRJyoI7sJx8IwJJrrZmj80EJ57/2eZjAvyz+YO2H9TNDs00jJb8ABSuRGF+nau51x1NkqsQwukY//f219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXDhwi19Hi9dukRMTAzR0dGOC0oIYREFZm8icPY9tFw2uQYEBJCQkACAwWCga9euhIaGOjgqIYQljEqj0Fh6TdVglJmrwx04cICmTZvSpEkTR4cihLCAJV2xLNnmxZGqRHLdvHnzLbs/CiGcW/EFrcrdW8C5U78NFBQUsGvXLsLDwx0dihDCQkaLdn+VpVgOlZSURMuWLWnQoIGjQxFCWMiSmassxXKwzZs3ExER4egwhBBloKj861xduiyQm5vL/v37CQsLc3QoQogyMFJ8+2tphyzFcqBatWpx6NAhR4chhCgjpTSzNVVZLSCEEGVkyU4EMnMVQogyMoLZDQoluQohRBlZ1LhFygJCCFE2Cs3sNi7m+r06miRXIYTTsegOLU2Sqygnu+zSCoz79Rebj/leUAubjymqHoX5loJScxVCiDIyKkvKAlJzFUKIMim+Q6tyrxZw7tQvhKiSlCqevZZ2KAtvf/3000+JiIigb9++TJo0ifz8fC5dukRkZCShoaFMmDCBgoICoLjR04QJEwgNDSUyMpLLly9b/R0kuQohnE7JzLXUw4Jx9Ho9q1atYt26dWzatAmDwcDmzZtZuHAh0dHR7NixAx8fH9auXQtAfHw8Pj4+7Nixg+joaBYuXGj1d5DkKoRwOiU119IOc3tslTAYDOTl5VFUVEReXh4NGzbk4MGD9OrVC4BBgwaRmJgIwK5duxg0aBAAvXr14sCBAyhlXedYqbkKIZxO8WoB8y0Hk5OTb9krLyoqiqioKNNjnU7Hc889R48ePfDw8KBz5860bNkSHx8f3N2L05+/vz96vR4onuk2atQIAHd3d7y9vcnMzMTX17fM38Flk2t+fj7Dhg2joKAAg8FAr169iImJcXRYQggLWHJBSymNwMBA1q9ff9dzsrKySExMJDExEW9vb15++WW+//57W4d7Ry6bXGvUqMHKlSupXbs2hYWF/O1vf6Nr1660bdvW0aEJIcxRlsxczQ+zf/9+7rnnHtPMMywsjOPHj5OdnU1RURHu7u6kpaWh0+mA4pluamoq/v7+FBUVkZOTQ7169az6Ci5bc9U0jdq1awNQVFREUVERmpPf0SGEKGZUGgajW6mHuZsMABo3bsypU6e4efMmSikOHDhA8+bNad++Pdu2bQNgw4YNhISEABASEsKGDRsA2LZtGx06dLA6b7hscoXiQvaAAQPo1KkTnTp1ok2bNo4OSQhhAUXxOlZzhzlt2rShV69eDBo0iH79+mE0GomKimLKlCmsWLGC0NBQrl27RmRkJABDhgzh2rVrhIaGsmLFCiZPnmz1d3DZsgBAtWrVSEhIIDs7m3HjxvHLL78QFBTk6LCEEGZYWnO1RExMzG3XW5o2bWpafvVXHh4eLF261PJAS+HSM9cSPj4+tG/fvsIK2UKI8lEWlAUMRucu87lscr169SrZ2dkA5OXlsX//fgICAhwclRDCIqo4wZZ6OPntry5bFkhPT2fatGkYDAaUUoSHh9OjRw9HhyWEsIAtywKO4rLJ9YEHHmDjxo2ODkMIYQWlig9z5zizuybXRx55xLQEoeT2L03TUEqhaRrHjx+vmAiFEFWOQjN7e6u5ma2j3TW5njhxoiLjEEIIE0tvf3VmFl3QOnr0KOvWrQOKLxRdunTJrkEJIaq2krJAqYejgzTDbHJdtmwZy5cvJy4uDoDCwkKmTJli98CEEFWbudUCVPaZ644dO/jggw/w9PQEiu+9vXHjht0DE0JUXa6wztXsaoHq1aujaZrp4lZubq7dgxIV4737bX+32vQLtq/Vzw+QZjtVjUWrBSomFKuZTa69e/dm5syZZGdns2bNGtatW8fQoUMrIjYhRJVlwTYuTl4WMJtcn3/+efbt20ft2rVJSUkhJiaGzp07V0RsQogqSlnUcrCSJ1eAoKAg8vLy0DRNGp8IIexOWTBzdfY7tMxe0IqPjycyMpIdO3awbds2oqKi7thNRgghbEZZeDgxszPX5cuXs2HDBlM37szMTJ566imGDBli9+CEEFWX2ZlrZW/cUq9ePVNHf4DatWtbve2BEEJYQikNo5mlVsqSvbUd6K7JdcWKFQDce++9DB06lJ49e6JpGomJibRo0aLCAhRCVFGuulqg5EaBe++9l3vvvdf0fM+ePe0fVTmlpqby6quvkpGRgaZpDB06lBEjRjg6LCGEpVy5K9ZLL71UkXHYVLVq1Zg2bRotW7bk+vXrPPnkk3Tu3JnmzZs7OjQhhKWcPHmaY7bmevXqVT7++GPOnz9Pfn6+6flVq1bZNbDy8PPzw8/PDwAvLy8CAgLQ6/WSXIWoJJTSUGZrrs5dFjC7FGvy5MkEBARw+fJlXnrpJZo0aULr1q0rIjabuHz5Mj///LPs/CpEZWLJNi9OXnM1m1xLtp11d3fn8ccfJzY2loMHD1ZEbOV248YNYmJieNQNBFwAABE0SURBVP311/Hy8nJ0OEKIsnD1da7u7sWn+Pn5sXv3bvz8/MjKyrJ7YOVVWFhITEwM/fr1IywszNHhCCHKQmHBagDnnrmaTa5jxowhJyeHqVOnMnfuXG7cuMFrr71WEbFZTSnF9OnTCQgIYOTIkY4ORwhhDXMz08o+cy3ZMdXb25vPPvvM7gHZwrFjx0hISCAoKIgBAwYAMGnSJLp16+bgyIQQlrGgGXZlTa5z58419XC9kxkzZtglIFto164d586dc3QYQggrWdLPtdIm11atWlVkHEII8X8UYG6plYWrBbKzs5kxYwa//PILmqaxYMEC7rvvPiZOnMgff/xBkyZNWLJkCXXq1EEpxfz589mzZw81a9bkrbfeomXLllZ9hbsm10GDBlk1oBBClJcGaDaauc6fP58uXbqwdOlSCgoKyMvL48MPP6Rjx46MHj2auLg44uLimDJlCklJSVy8eJHt27dz6tQpZs+eTXx8vFXfwaLdX4UQokLZqOVgTk4OR44cMXXxq1GjBj4+PiQmJjJw4EAABg4cyM6dOwFMz2uaRtu2bcnOziY9Pd2qr2BRs2whhKhYllzQ0khOTmbixImmp6KiooiKijI9vnz5Mr6+vrz22mucPXuWli1bMn36dDIyMkx3cTZs2JCMjAwA9Ho9/v7+pvf7+/uj1+tN55aFJFdhU/bYTHDkud9sPuaKFs1sPmalUsrFauvGs+1wxTVX8+cEBgayfv36u55SVFTEmTNneOONN2jTpg3z5s0jLi7ulnP+ugGrLbnkagEhRCVnyc9+C8oC/v7++Pv7m25/Dw8PJy4ujvr165Oeno6fnx/p6en4+voCoNPpSEtLM70/LS0NnU5n1VeQ1QJCCOdkg36uDRs2xN/fnwsXLhAQEMCBAwcIDAwkMDCQjRs3Mnr0aDZu3GhqpRoSEsLnn39OREQEp06dwtvb26qSAMhqASGEM1KgmSkLmF1N8L/eeOMNJk+eTGFhIU2bNiU2Nhaj0ciECRNYu3YtjRs3ZsmSJQB069aNPXv2EBoaiqenJwsWLLD6K7hky0EhhCjx4IMP3rEuu3Llytue0zSNWbNm2eRzXb7loBCi8ilZ52rucGYu3XJQCFFJKc2yw4m5bMtBIUQlZslSrMq6+2uJythyEIrrKfHx8SiliIyMJDo62tEhCSHKwNzPfueet7poy8FffvmF+Ph44uPjqV69OqNGjaJHjx40a1bFF44LUVnYaJ2rI5lNrnebpcbGxto8GFtJTk7m4YcfxtPTE4DHHnuM7du388ILLzg4MiGExVw9uXbv3t30v/Pz89m5c6fVi2orSlBQEEuWLCEzM5OaNWuSlJQkN0UIUZko0My0HDS3DtbRzCbXXr163fK4b9++/O1vf7NbQLYQGBjIqFGjeP755/H09OSBBx7AzU0agAlRaVSCDQjNKXPjlosXL5o6yDizyMhIIiMjAVi8eLHV9wcLISqeLfu5OorZ5PrII4/c0sClYcOGTJ482a5B2UJGRgb169fnypUrbN++nTVr1jg6JCGEpSy5/bWylwVOnDhREXHY3Pjx47l27Rru7u7MmjULHx8fR4ckhCgLV5+5jhgx4rZ7cO/0nLP597//7egQhBDWcuWaa35+Pjdv3iQzM5OsrCzU/27FeP36dfR6fYUFKISoeiypuTp7b4G7JtfVq1ezcuVK0tPTGTx4sCm5enl58cwzz1RYgEKIKsiVbyIYMWIEI0aM4LPPPmP48OEVGZMQQlT6mavZxZ9ubm5kZ2ebHmdlZfHFF1/YNSghRBVno91fHcnsBa01a9YwbNgw0+M6deoQHx9/y3NC2JM9NhMcdvayzcf84oF7bD6m3SgbZyZ7JDonT57mmE2uRqMRpZRpravBYKCwsNDugQkhqi6tKqxzDQ4OZsKECTz11FNA8YWuLl262D0wIUTV5vJ3aE2ZMoWvvvqKL7/8EoBOnToxdOhQuwcmhKjCKkFN1RyLLmg9/fTTLF26lKVLl9K8eXPmzp1bEbEJIaqokrKAucOZWdS45cyZM2zatImtW7fSpEkTwsLC7B2XEKKqc9WyQEpKCps3b2bTpk3Uq1ePPn36oJSqNLsRCCEqMVe+iaB37960a9eOjz76yLQ9yqefflpRcQkhqrjKvofWXWuuy5Yto2HDhjz77LPMmDGDAwcOmG6BrQySkpLo1asXoaGhxMXFOTocIUQZuHTN9YknnuCJJ54gNzeXxMREVq5cydWrV5k1axahoaEEBwdXZJxlYjAYePPNN1mxYgU6nY4hQ4YQEhJC8+bNHR2aEMISLlAWMLtaoFatWvTr148PP/yQPXv28NBDD/Hxxx9XRGxWO336NM2aNaNp06bUqFGDiIgIEhMTHR2WEKIsKvntr2XaWKpOnTpERUU5fS9XvV6Pv7+/6bFOp5M2iUJUMpoyc5RhLIPBwMCBA3nxxRcBuHTpEpGRkYSGhjJhwgQKCgoAKCgoYMKECYSGhhIZGcnly9bfJi279gkhnI+5xFrGmeuqVasIDAw0PV64cCHR0dHs2LEDHx8f1q5dC0B8fDw+Pj7s2LGD6OhoFi5caPVXcMnkqtPpSEtLMz3W6/WyQaEQlY2NygJpaWns3r2bIUOGFA+rFAcPHjTtbD1o0CBT2XDXrl0MGjQIKN75ujwX8l0yubZu3ZqLFy9y6dIlCgoK2Lx5MyEhIY4OSwhhKQtbDiYnJzN48GDT8dVXX9021IIFC5gyZQpubsXpLjMzEx8fH9zdi6/n+/v7m8qGer2eRo0aAeDu7o63tzeZmZlWfYUyb61dGbi7uzNz5kxGjRqFwWDgySef5P7773d0WEIIC1nUFUtBYGAg69evv+s53333Hb6+vrRq1YpDhw7ZOMrSuWRyBejWrRvdunVzdBhCCCvZYieC48ePs2vXLpKSksjPz+f69evMnz+f7OxsioqKcHd3Jy0tzVQ21Ol0pKam4u/vT1FRETk5OdSrV8+q+F2yLCCEqORstBPBK6+8QlJSErt27WLx4sV06NCBRYsW0b59e7Zt2wbAhg0bTGXDkJAQNmzYAMC2bdvo0KGDqZd1WUlyFUI4nZLdX82uGLDSlClTWLFiBaGhoVy7do3IyEgAhgwZwrVr1wgNDWXFihVMnjzZ6s9w2bKAEKISU4C521vLmFzbt29P+/btAWjatKlp+dVfeXh4sHTp0rINfBeSXIUQTsnldyIQwhXZYzPB/mcybD4mwNcP1bfLuE7NBXoLSHIVQjid4qVYpWfP8tRcK4IkVyGEU7LFUixHkuQqhHA+UhYQQgjbK1mKVeo5klyFEKKMLLz91ZlJchVCOB8pCwghhO1ZUhZw9uTqsre/ZmdnExMTQ3h4OL179+bEiROODkkIYTEFyoLDibnszHX+/Pl06dKFpUuXUlBQQF5enqNDEkJYygVqri45c83JyeHIkSOmzuM1atTAx8fHwVEJISzmAltru2RyvXz5Mr6+vrz22msMHDiQ6dOnk5ub6+iwhBCWslHLQUdyyeRaVFTEmTNnePrpp9m4cSOenp7ExcU5OiwhhIVKbn8t9XDymqtLJld/f3/8/f1p06YNAOHh4Zw5c8bBUQkhysKe/Vwrgksm14YNG+Lv78+FCxcAOHDgwC3b6gohnJwLlAVcdrXAG2+8weTJkyksLKRp06bExsY6OiQhhIVcYZ2ryybXBx98sNRdIYUQTkwpC1oOOnd2ddnkKoSo5GTmKoQQtmXJBStnv6AlyVUI4XwUYKYsYPZ1B5PkKoRwPi5w+6skVyGEE7KgMYskVyHKSdNsP6YdrjTba5fWJ39Ot/mY6x70s/mYtiQ1VyGEsAcLdn+VloNCCGENc12vpCuWEEKUTXFZQJk9zElNTWX48OH06dOHiIgIVq5cCcC1a9cYOXIkYWFhjBw5kqysLACUUsybN4/Q0FD69evHTz/9ZPV3kOQqhHBONugrUK1aNaZNm8aWLVv46quv+Pe//8358+eJi4ujY8eObN++nY4dO5q65iUlJXHx4kW2b9/O3LlzmT17ttXhS3IVQjgfZabdoNH87bEAfn5+tGzZEgAvLy8CAgLQ6/UkJiYycOBAAAYOHMjOnTsBTM9rmkbbtm3Jzs4mPd26C4pScxVCOB+FBUuxFMnJyUycONH0VFRUFFFRUXc8/fLly/z888+0adOGjIwM/PyKV0w0bNiQjIwMAPR6Pf7+/qb3+Pv7o9frTeeWhcsm108//ZT4+Hg0TSMoKIjY2Fg8PDwcHZYQwhIW3kQQGBhoUYOmGzduEBMTw+uvv46Xl9et42gamh2W+7lkWUCv17Nq1SrWrVvHpk2bMBgMbN682dFhCSEsZsnur5aNVFhYSExMDP369SMsLAyA+vXrm37up6en4+vrC4BOpyMtLc303rS0NHQ6nVXfwCWTK4DBYCAvL4+ioiLy8vKsmtYLIRzDom1eLKi5KqWYPn06AQEBjBw50vR8SEgIGzduBGDjxo307NnzlueVUpw8eRJvb2+rc4dLlgV0Oh3PPfccPXr0wMPDg86dOxMcHOzosIQQFrPk9lfzyfXYsWMkJCQQFBTEgAEDAJg0aRKjR49mwoQJrF27lsaNG7NkyRIAunXrxp49ewgNDcXT05MFCxZY/Q1cMrlmZWWRmJhIYmIi3t7evPzyyyQkJJj+cIUQTk5h/iYBC8oC7dq149y5c3d8rWTN619pmsasWbPMD2wBlywL7N+/n3vuuQdfX1+qV69OWFgYJ06ccHRYQghLKYVmNJZ6YHTuW7RcMrk2btyYU6dOcfPmTZRSskGhEJVNyVIsG1zQchSXLAu0adOGXr16MWjQINzd3XnwwQfvuvZNCOGEbFQWcCSXTK4AMTExxMTEODoMIYQVNMz3DpANCoUQoqwU5muqyrlrrpJchRBOSHYiEEII27Ok5urcE1dJrkIIJ6TM11Sl5iqEEGWlFBjMTE2dfJ2rJFfh/Jx8hmJv9thMcNjZyzYdz/dGoU3HM61lNXeOE5PkKoRwTnJBSwghbEzKAkIIYQdKmV/HKutchRDCClIWEEIIG1MKzDXDlgtaQghRRkqZr6k6ec3VJVsOljAYDAwcOJAXX3zR0aEIIcrCopaDzj1zdenkumrVKunjKkRlVDJzLe2Q5OoYaWlp7N69myFDhjg6FCFEmVmy+6tzJ1eXrbkuWLCAKVOmcOPGDUeHIoQoKxdY5+qSM9fvvvsOX19fWrVq5ehQhBDWUKCU0cwhM9cKd/z4cXbt2kVSUhL5+flcv36dyZMns3DhQkeHJoSwhCVLscy97mAumVxfeeUVXnnlFQAOHTrEv/71L0msQlQmSoHBUPo5Tl4WcMnkKoSo5KQrlvNr37497du3d3QYQogyUEqhzMxMlfQWEEIIK0hvASGEsDFLaq7mXncwl1yKJYSo5JRCGUs/LK25JiUl0atXL0JDQ4mLi7Nz4P9HkqsQwvmU9HMt9TCfXA0GA2+++SbLly9n8+bNbNq0ifPnz1fAF5CygBDCyWiaxv3t/x8etT1KPc/LtxaappV6zunTp2nWrBlNmzYFICIigsTERJo3b26zeO+mSifXZq3vYelPbzo6DCEqno3Llflavs3G8vLyIqR/N1Q/8zPTLVu2MGHCBNPjqKgooqKiTI/1ej3+/v6mxzqdjtOnT9ss1tJU6eTatm1bR4cghPgPmqZRq1Yti86NjIwkMjLSzhFZR2quQgiXpdPpSEtLMz3W6/XodLoK+WxJrkIIl9W6dWsuXrzIpUuXKCgoYPPmzYSEhFTIZ1fpsoAQwrW5u7szc+ZMRo0ahcFg4Mknn+T++++vkM/WlLP37RJCiEpIygJCCGEHklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKrEELYwf8H9PD+fFw0J7IAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdd3gU1f748ffW9B5ICL0nlEAgIaGEEjFUCUVAmhFUVKpUUdSv+AP0IhAvSBFBihdRoiIgoVxaAOmhBCQQSqhppLfNZsv8/ojsJSYR1EA2y3k9D0/YmTNnPmey2c/OmTNnZJIkSQiCIAiCmZFXdgCCIAiCUBaRoARBEASzJBKUIAiCYJZEghIEQRDMkkhQgiAIglkSCUoQBEEwSyJBPSVLly5l+vTplR3GU3X37l2aNm2KXq//x3WFhIRw9OjRMtfNmjWLiIiIf7yPZ0lERASBgYF07Njxqe87JiaG0NBQ/Pz82Lt379+u57XXXmPLli0VGNnTl5iYiJ+fHwaDobJDMUsiQVWg7du3M3DgQPz8/OjUqROvvfYap0+fruywhKekadOm3Lp1q7LDeKTExETWrl1LVFQUv/76a5ll8vLymDdvHl27dsXPz4/u3bszb948MjIy/vH+lyxZwogRIzh79izdu3f/2/WsXr2aAQMG/ON4/mjWrFk0bdq0VPKcP38+TZs25aeffnqsev7sS9UDXl5enD17FoVC8bfjtWQiQVWQtWvXMn/+fN58801+/fVXDhw4wPDhw9m3b19lh/a3VcSZj/A/5nI8ExMTcXZ2xs3Nrcz1RUVFhIeHc+3aNVavXk1MTAzff/89zs7OXLhwoUL237hx439cz5NUr149tm7danqt1+vZuXMnderUqbB9VOT7QZIkjEZjhdVnLkSCqgC5ubksWbKEDz/8kNDQUGxtbVGpVISEhPDOO++Uuc2kSZPo2LEjbdu2ZcSIEVy9etW0Ljo6mt69e+Pn50dwcDBr1qwBICMjgzfeeAN/f3/atWvH8OHDTW/KlJQUJk6cSFBQECEhIWzYsMFUX2xsLAMHDqRNmzZ06NCBTz75pMyYTpw4QefOnVm1ahUdO3bk3XffJTs7mzfeeIOgoCACAgJ44403SE5ONm0zatQoPv/8c1566SX8/PwYM2ZMud+yd+/eTUhICPHx8RiNRlatWkX37t0JDAxk8uTJZGVlmcr+/PPPdOvWjcDAQFasWPHI30FmZiajR4/Gz8+PkSNHcu/ePQDmzJnDp59+WqLsm2++ybp168qs5/r164wePZp27drRo0cPoqKiTOtmzZrFnDlzGDt2LH5+fgwePJjbt28DMGLECADCwsLw8/MjKiqqzONZVFTEvHnz6NSpE506dWLevHkUFRWVOP4rV64kMDCQkJAQtm3bBhT/Djt06FCiK2jPnj3069evzHbk5uYyc+ZMgoKC6NatG8uXL8doNHL06FHGjBlDamoqfn5+zJo1q9S2W7duJSkpiS+++IJGjRohl8txc3Nj/PjxdOnSxXScRo0ahb+/P3369CnxRezPjlP37t25c+cOb775Jn5+fhQVFZU603i4O1yr1TJ9+nQCAwPx9/dn0KBBpKWlAcXvvcjISACMRiPLly+nW7dutG/fnpkzZ5Kbmwv8r6t5y5YtdO3a9bHeUyEhIcTExJCdnQ3A4cOHadq0Ke7u7qYyt2/f5uWXXyYwMJDAwECmTZtGTk4OADNmzCAxMdHUzq+++soUR2RkJF27diU8PLxEN3hWVhadO3dm//79AOTn5/P888/z888/lxnjqFGjiIiI4KWXXqJVq1bcuXOHM2fOMGjQINq2bcugQYM4c+YMAMePH+eFF14wbTt69GgGDRpkej18+PB/1N36xEjCPxYdHS35+PhIOp2u3DJLliyRpk2bZnodGRkp5ebmSlqtVpo7d67Ur18/07qOHTtKp06dkiRJkrKysqSLFy9KkiRJCxculD744AOpqKhIKioqkk6dOiUZjUbJYDBIAwYMkJYuXSpptVrp9u3bUkhIiHTo0CFJkiRpyJAh0pYtWyRJkqS8vDzp7NmzZcZ4/PhxycfHR1qwYIGk1WoljUYjZWRkSLt27ZIKCgqk3NxcaeLEidJbb71l2mbkyJHSc889J924cUPSaDTSyJEjpc8++0ySJEm6c+eO1KRJE0mn00k//PCD1L17d+nmzZuSJEnSunXrpMGDB0tJSUmSVquVPvjgA2nKlCmSJEnS1atXpdatW0snT56UtFqtNH/+fMnHx0f69ddfy4z7nXfeKVH+//2//ye99NJLkiRJ0vnz56WOHTtKBoNBkiRJSk9Pl3x9faX79++Xqic/P1/q3Lmz9MMPP0g6nU767bffpHbt2klXr1417addu3bS+fPnJZ1OJ02dOlV6++23Tds3adLE1L7yjufnn38uDR48WEpLS5PS09OloUOHShERESXKz58/X9JqtdKJEyekVq1aSdevX5ckSZJ69eolHTx40FT/uHHjpDVr1pR5TGbMmCG9+eabUm5urnTnzh0pNDRU2rx5s2k/wcHBZW4nSZL09ttvSzNnzix3fVFRkdS9e3dpxYoVklarlY4ePSq1bt3aFOejjlO3bt1K/C7/+Prhv5VNmzZJb7zxhlRQUCDp9XrpwoULUm5uriRJxe+9B22KjIyUunfvLt2+fVvKy8uTxo8fL02fPl2SpP+9D2fPni1pNBopLi5Oat68uXTt2rUy2/fOO+9Iixcvlt5//31p48aNkiRJ0qRJk6Tt27dLL730kvTjjz9KkiRJN2/elI4cOSJptVopPT1dGj58uDR37txy2/UgjhkzZkj5+fmSRqMp8TciSZJ0+PBhqUOHDlJaWpo0e/ZsaeLEieX+HkaOHCl16dJFio+Pl3Q6nXT//n3J399f2rJli6TT6aTt27dL/v7+UkZGhqTRaKQWLVpI6enpUlFRkdS+fXupU6dOUm5urqTRaKSWLVtKGRkZ5e6rsogzqAqQlZWFi4sLSqXysbd58cUXsbe3R61WM3HiRC5fvmz6xqdUKrl27Rp5eXk4OTnRvHlz0/L79++TmJiISqXC398fmUzGhQsXyMjIYMKECajVamrXrs2QIUNM3/6VSiW3b98mIyMDOzs7WrduXW5ccrmcSZMmoVarsba2xsXFhR49emBjY4O9vT1vvfUWp06dKrHNwIEDqV+/PtbW1vTs2ZO4uLgS69evX8+aNWv45ptvqFu3LgDfffcdU6ZMwdPTE7VazYQJE9i9ezd6vZ5du3bRtWtXAgICUKvVTJ48Gbn8z9+qD5efMmUK586dIykpCV9fXxwcHDh27BgAUVFRtGvXrsQ34QcOHjxIzZo1GTRoEEqlkmbNmtGjRw927dplKtO9e3d8fX1RKpX069evVFsfdTy3b9/O+PHjcXNzw9XVlfHjx5vOkh6YPHkyarWadu3a0aVLF3bu3AlA//79TWWzsrI4cuQIffv2LbVPg8FAVFQU06ZNw97enlq1ajF69OhS+ylPVlYW1apVK3f9+fPnKSgoYOzYsajVatq3b0+3bt3YsWPH3z5O5VEqlWRlZXHr1i0UCgUtWrTA3t6+VLnt27fzyiuvULt2bezs7Jg6dSpRUVElutEmTJiAtbU13t7eeHt7c/ny5T/dd1hYGFu3biUnJ4dTp06Vul5Wt25dOnbsiFqtxtXVldGjR5f62yjLxIkTsbW1xdrautS6Tp060bNnT1555RWio6OZM2fOn9Y1YMAAGjdujFKp5MiRI9StW5f+/fujVCrp27cvDRo04MCBA1hbW9OyZUtOnz7Nb7/9hre3N23atOHMmTOcO3eOunXr4uLi8sjYn7bH/0QVyuXs7ExmZiZ6vf6xkpTBYCAiIoJdu3aRkZFh+vDNzMzEwcGBJUuWsGLFChYtWkTTpk2ZNm0afn5+vPrqq3zxxReMGTMGgKFDhzJ27Fju3btHamoq/v7+Jfbx4PW8efNYsmQJvXr1olatWkyYMIFu3bqVGZuLiwtWVlam1xqNhk8++YTDhw+bujvy8/MxGAymC7sPf5jZ2NhQUFBQos41a9Ywfvx4PD09TcsSExMZP358icQjl8tJT08nNTW1RFlbW1ucnZ3/9Jg+XN7Ozg4nJydSU1OpUaMGAwYMYNu2bXTs2JFt27bx8ssvl1nHvXv3iI2NLXUcH+5GezixWVtbl2rrH/3xeKampuLl5WV67eXlRWpqqum1o6Mjtra2Za4PCwujV69eFBQUsHPnTvz9/alevXqpfWZmZqLT6UrtJyUl5U9jfcDZ2Zn79++Xu/7B7+fh390f6/+rx6k8YWFhJCcnM3XqVHJycujXrx9TpkxBpVKViqlmzZqm1zVr1kSv15Oenl5mTGW9T//I39+fjIwMVqxYQdeuXUsllLS0NObNm8fp06fJz89HkiQcHR0f2aaH36tlGTJkCP/5z3948803H5k0atSoYfr/H99bUPL3EhAQwMmTJ/Hw8CAgIABHR0dOnTpl+jJkjkSCqgB+fn6o1Wr27t1Lz549H1l++/bt7Nu3j7Vr11KrVi1yc3MJCAhA+n1ieV9fX1asWIFOp2Pjxo28/fbbREdHY29vz6xZs5g1axbx8fGEh4fTsmVLatSoQa1atdizZ0+Z+6tXrx6LFy/GaDSyZ88eJk2axIkTJ0p8ED4gk8lKvP76669JSEhg8+bNVKtWjbi4OPr372+K9XF8/fXXvPbaa7i7u9OjRw+g+I90/vz5tG3btlT56tWrc/36ddNrjUZT4vpUWR6+Lpafn092drbpw7tfv3707duXy5cvc/369XJHjtWoUYOAgADWrl372G17lD8ez+rVq5cYJJCUlFQiyeTk5FBQUGD63SQlJZnKenh44Ofnx549e9i6dSvDhg0rc58uLi6oVCoSExNp1KiRqR4PD4/HirlDhw58/vnnJeL4YxuSk5MxGo2mJJWUlES9evUeq/4/srGxQaPRmF4/nBxVKhUTJkxgwoQJ3L17l7Fjx1K/fn0GDx5cKqYH1x2h+AuQUqnEzc2txHvjr+rXrx/Lli0rcU33gcWLFyOTydi+fTvOzs7s3buXjz/++JF1/vE98TCDwcCHH35I//79+fbbbxk4cKCp1+FRdT14bz0sKSmJ4OBgANq1a8enn36Kl5cXr7/+Ok5OTnzwwQeoVCrTNVRzI7r4KoCDgwOTJk3i448/Zu/evWg0GnQ6HdHR0SxYsKBU+fz8fNRqNS4uLmg0GhYvXmxaV1RUxLZt28jNzUWlUmFnZ2f6EDhw4AC3bt1CkiQcHBxQKBTIZDJ8fX2xs7Nj1apVFBYWYjAYiI+PJzY2Fii+6P3gTO3BN7xHdZk9HKuVlRWOjo5kZWXxxRdf/OXj06hRI1avXs3HH39supg+bNgwPv/8c9OHSkZGhukibY8ePTh48CCnT5+mqKiIJUuWPHKEUnR0tKn8v//9b1q1amX6dunp6UnLli2ZMWMGoaGhZXatQHE34c2bN/n555/R6XTodDpiY2NLJMs/4+7uzp07d/60TJ8+fVixYgUZGRlkZGSwbNmyEhevoXiQQFFREadPn+bgwYMlvvSEhYWxZs0a4uPjCQ0NLXMfCoWCnj17EhERQV5eHvfu3WPt2rXlDqj4o7CwMDw9PZk4cSLXr1/HaDSSmZnJypUriY6OxtfXF2tra1avXo1Op+PEiRPs37+f3r17P1b9f+Tt7U1UVBQ6nY4LFy6we/du07rjx49z5coVDAYD9vb2KJXKMt+7ffv2Zf369dy5c4f8/HwiIiLo1avXX+p2L8uoUaNYu3YtAQEBpdbl5+dja2uLg4MDKSkprF69usT6x3k//NHKlSuRyWTMnz+fV199lXfeeeex75Hq0qULN2/eZPv27ej1eqKiorh27Rpdu3YFir9IJyQkEBsbi6+vL40bNzb1GpTVPnMgElQFGTNmDLNmzWL58uW0b9+erl27snHjxjK/rffv3x8vLy+Cg4Pp06dPqWtCW7duJSQkhDZt2vDdd9/x2WefAXDr1i3TSLWhQ4cybNgwgoKCUCgUrFy5ksuXL/Pcc88RFBTE+++/T15eHlA8AqlPnz74+fkxb948IiIiyv2Q/qPw8HC0Wi1BQUEMHTrU9G3sr/L29mblypV88MEHREdH8/LLLxMSEsKYMWPw8/NjyJAhpoTauHFjPvzwQ6ZPn05wcDCOjo6P7Bbp27cvy5YtIzAwkN9++810zB7o378/8fHxhIWFlVuHvb09a9asISoqiuDgYDp16sTChQtNo+weZcKECcyaNQt/f/8So/8eNm7cOFq0aEG/fv3o168fzZs3Z9y4cab17u7uODo6EhwczPTp0/noo49o2LChaf3zzz/PvXv3eP7557GxsSk3lg8++AAbGxu6d+/O8OHD6du3b4lRW39GrVazbt06GjRowJgxY2jbti2DBw8mMzMTX19f1Go1K1eu5NChQwQFBTFnzhwWLFhQIs6/4u233+b27du0a9eOpUuXlkjYaWlpTJo0ibZt29K7d2/atWtX5u9w0KBB9OvXj5EjR/Lcc8+hVqv54IMP/lY8D3N2dqZ9+/ZlnvVMmDCBS5cu4e/vz9ixY0t9YRg7diwrVqzA39/fNBL3z1y8eJF169bxr3/9C4VCweuvvw7AqlWrHitWFxcXVq5cydq1awkMDGT16tWsXLkSV1dXoLirvHnz5jRq1Ai1Wg0UJy0vL69ybzmobDLpr/TVCEIVderUKWbMmMGBAwf+tIulMp04cYIZM2Zw6NChPy3XvXt3Pv74Yzp06PCUIhOEyiHOoASLp9Pp2LBhAy+++KLZJqfHtXv3bmQyGUFBQZUdiiA8cWKQhGDRrl+/zqBBg/D29i73BuWqYtSoUVy7do0FCxY89jVEQajKRBefIAiCYJbE1zBBEATBLFlcF9+ZM2f+dHRTVaTT6UrdmFiVWVp7wPLaZGntAdEmc6bVasuc4cbiEpRCocDHx6eyw6hQt27d+tOb9aoaS2sPWF6bLK09INpkzsqbCkt08QmCIAhmSSQoQRAEwSyJBCUIgiCYJZGgBEEQBLMkEpQgCIJglkSCEgRBEMySSFCCIAiCWRIJShAEQTBLIkEJgiAIZsniJov97bdLNG/erLLDEARBsHiFOgPWKsU/ricuLq7MGYAsbqojuVxGvVk7KjsMQRAEi3fz0z5PtH6LS1CCIAiWQpeZiCEvA6VTdZSO1cstJ0lGDHkZYDQit7ZDbmVXvNxoQJ+VjCE/E5nKGqWzJwpr+9+3kTDkpKLPTUOmtELlWhO5uuRE20adFmNBNgAKOxdkyqc7Ma1IUIIgCGZGm3yNzP+uRJt42bTMup4frqFvoXLxMi3T56SRuW8VmlvnkbT5xQsVSly7v4nCzoX0nf/GqMn5X8UyObZNO2Ll5U3OyR+Lk9oDChUOfr1x6fIKMqWKwjsXSY38CElXCIDc1gmPoXNRV6//RNv+MJGgBEEQzIg+5z4pm96jlocb0z7/nObNm3Py5EkWL15Myqb38Hp1OXIrWwByTm1Bdu88b4weRatWrbCysmL58uXEntsJcjne9Wsxc+ZMatWqRX5+PkePHiUiIoKCy4dp37494eHhNGjQgLy8PHbt2sVXX30FRj3OncNJ+2URTRrU5Z133gFg3Lhx5MdFiwT1sPXr1xMZGYkkSQwePJhXXnmlskMSBEF4YnJO/IAKPYcOHcLJyYnIyEimTp1Kt27d6NChA7nnonAKfBEAQ34mtWrW5J133kGr1dK0aVN27NjB+ZupSDoj9es3wdbWlvPnzxMaGkq/fv2wsbHho48+4sUXX6RZs2bExMTQr18/BgwYgFKpZPnKLzFqCyA/g/XrtxMYGAjA5MmTkfS6p3oszHqYeXx8PJGRkURGRrJ161YOHjzIrVu3KjssQRCEJ6bg2kkGDBhAvXr1WLhwIW+88Qbr16+nffv2BAUFobl20lRW5VqL+Ph46tevz6pVq0rUY+XZiB07djBkyBCmTZvGjBkzAPDw8ABg7ty5dO7cmSlTpvDWW28BEBQUBEYD+b8dYNq0abi4uHDkyJGn1PLSzDpBXb9+HV9fX2xsbFAqlQQEBLBnz57KDksQBOGJkAx6DLnpNG3aFIAbN24AkJCQAEDTpk3RZ6eayju1H4Jrz4ll1vVgeY8ePdixYwfffPMNFy5cYO7cuQBonP/XVdejRw8AoqKiAPDx8eH//u//CA8Pp6CgwFQuPy4ayaCvkLY+DrNOUE2aNCEmJobMzEw0Gg2HDh0iOTm5ssMSBEF4ciQJubzsj2a5XI4hN42UzR+S+sMcCq4cwa5Z11Ll9Nkp6DPuApCRkcHFixe5efMmLVu2ZNiwYQDoUhOQyWQsXLiQqVOnMnfuXL777jsAvv76a1auXMnp06dNsahUKoz5WeRd2PsEGl02s74G1bBhQ1577TVeffVVbGxs8Pb2LvcXJwiCUNXJFEoU9q5cvXoVwPQ49zp16gBw9epVFAoFraqryMrK4sr2hWXWI+m0JK2bDMCpU6c4deoUXl5e3Lt3j6FDh7Jw4UKU+gLWb9rE4MGDmThxIl988YVp+5YtWxIUFMTUqVNNy9LT0/H09CQ/5VqJfT3Jyy5mnaAABg8ezODBgwFYvHixqf9UEATBEtk0aMuPP/7IggULmDJlCq6uroSHh3Pu3Dl+/fVXHBwcOH78ONu3b6dfv364uLgQERFB8+bNAZg4cSJ9+/Zl9OjRREREYG1tTWJiIiEhIQAcP34cgI8++oihQ4eSkpJCr1696NWrF2fPnuX9998nPDwchaJ4hojZs2fj6+vL6NGjyc7OxqqhS4l4HyTRfyIuLq7M5WafoNLT03FzcyMxMZE9e/awefPmyg5JEAThiXFsP4SkS9F069aNd999l65du7Ju3Trmz5+PJEno9XoiIyOJiYkBQCaTYWtrS0JCgulalY1N8Q23p06dYtSoUfj7+5Oens6MGTNYunQpUHw2FhkZWWLfhYXF9zz9+OOPpmVNmjThypUrfP/99xQWFuLWuucTPwYPmP1cfMOHDycrKwulUsm7775L+/bt/7R8XFwcvdbfeErRCYIgVLzCOxfJ2LMcXdpt0zK1V1McWvciY+8qpKL/DVyQqayQdNrHq1iuwM47GENBNoU3z5ZZRO3REM+XFwOQvGEqRSnXi/ejtsVj2HysPBuZylbUVEflzcVn9gnqrxIJShAESyBJEkUp1zHkZ6J0rI66WnFXmrFIgz47FZlcgdK1JlKRBn3O/VLbK509wain6P5NjIV5yK0dUbnVRGHjCIAuK7lUYpPJ5ShdayGTyUwx6DPuIhmNKJ2ql5oK6UknKLPv4hMEQXgWyWSyEmcrD8jVNqZkBSCzsi3xuiQrrGs1L3ONytnzsWJQudV+rHifBDEkThAEQTBLIkEJgiAIZsniuviMRumJP6NEEARBqLgHFpbH4s6g9E95MsOnwdLmH7S09oDltcnS2gOiTU/Ck0xOYIEJShAEQbAMIkEJgiAIZkkkKEEQBMEsWVyCUipVlR1ChauIua7MiaW1ByyvTZbWHqjabSrUGSo7hEphcaP45HIZ9WbtqOwwBEEQKsyzOjLZ4hKUIAjC45IMOgquHEWbeBnkCmzqt8G6np9pqh9TOcmILjUBbdJVjIW5IJNhU78t6ur1kYwGilITKEq+9vs6OTYNA1A516Ag/ij6nNRS+5VbOwAUl/8DpWN1bJt0QGaBvUF/lUhQgiA8k3Tpd0n94SP0Wck4Ojqi1+tJPfUzVrWaUX3Qh8it7YHi5JSy6T20dy6W2D7r0DfUfGMN93+eT1FSfIl12Uc2YtfyefLO/r3eHKeOw3DuNOLvNcyCWNw1KEEQhEeRJIm0XxbhqjYSFRVFdnY2mZmZfPXVV0ip18g88LWprC79Lto7F3n33Xe5fv06Go2GI0eOgNFAXuxuipLimTNnDgkJCWg0Gnbv3o2kLyLv/C7at2+PRqMp9a9r164899xzZa5r164d2sQrlXh0zIfZn0HduHGDKVOmmF7fuXOHSZMm8corr1ReUIIgVGmFt2MpSr7KJ2vW0KtXL8LDw2nSpAmzZ8/m/PnzfLF8Bc6dR6GwcwHJCBQ/On3hwoV88cUXqNXq4op+fxhEWloaixYtYunSpaZ1cmt7EhISSjyVds6cOTg5OXH58mWUSqVpnUwmY/78+SiVSq5du4bCq81TPBrmy+wTVIMGDdi6dSsABoOBzp078/zzz1dyVIIgVGUPuuQGDx7MzZs32bBhA87OzsyePZshQ4bwxRdfUJSagE19F1RutVFVb8CXX34JwJIlS0z1qKs3QOVWx5SYHjwMEMCx3UAyLh/hy3UbMWpyCAoKolq1anz99dckJycD8OXa/2AszCUkJAQnJyeWLl1KRkYGHr16PMWjYb6qVBffsWPHqF27NjVr1qzsUARBqMIMeRk4OTnh4OBAeno6AFlZWRgMBmrVqgWALuMehsI8kCRqvLwYe78yRtIpVdQY/W/sWjxXapVVjcbUCI/ArccEAKZPnw7AwoULUVVvQJ2Z23F57nXTOoPBQEREBFY1fbCuVfrZSM8isz+DetiOHTvo27dvZYchCEIVJ1fbkpeXh16vx9raGgCVSoVCoSArKwuAzL1fkrn3S+S2zrh0G0P+pYOl6sk98wsKa3vyfzuAWlXy4zT37E5U1RuQffJHGjZsyIABA/jll1+Ii4vD/YXiZJVz8idatGhBr1692Lx5MwkJCVQbMLvMmMuady8vL6/S5+N7kqpMgioqKmL//v1MmzatskMRBKGKU7rWxGAwcPr0adq0aYO7uzvNmjUD4MSJEwAMGTKEDh068Mknn5CyY3GZ9RTeiCH5RkyZ6wouH6bw5jmMhblMXbYMuVzOwoULUThUw7ZpJwoTzqC7f5NpC9YC8Nlnn6F0rYlN48Ay6yvrRuNbt25V6RuQH4iLiytzeZXp4jt06BDNmzfH3d29skMRBKGKs20chNzagffeew+Ay5cvs3PnTu7fv8+nn34KQLdu3Zg8eTKurq4ArF+/Hq1Wi1KpJCAgAK1WaxrAFRkZSV5eHgBdu3ZFq9UyduxYjIW5uLu7M3r0aE6dOkV0dDSOAWHIFEpyTm/Dy8uL4cOHEx0dzaHowbkAACAASURBVOnTp3EMGIBMVmU+lp+4KnMGtWPHDvr0eTbvphYEoWLJrWxxCXmVA1GfU69ePQYMGEBBQQE//vgjubnFN89++eWX7Nmzh7t37wKwdOlSfv755xL1XLxYfG/UokWL+Pbbb0usO3fuHABWVlaMGDGCuLg4ZFZ22PuGAqDPTETlpOall17iwoULyG2dsW8R8kTbXdXIJOn3cZJmrKCggG7durF3714cHBz+tGxcXBy91t94SpEJglCVFd6OJefET7/PJKHEpr4fjkGDKUq6Su7ZX5D0OlQuXihdvCi8dQ7JoC+xvdzKFpnKBmNBFpKx5Hx5cmt7rGp6o717CaO2ALnKGqcOQ7FpGABAwbWT5ByPxFikQa62xanTcGzqtS4zzvKmOrKkLj4fn9IDQ6rEGZStra2pX1gQBKGiWNfxxbqOb6nlavc62LcsPTKvItk2aodto3ZPdB9VnejsFARBEMySSFCCIAiCWRIJShAEQTBLVeIa1F9hNErP7LNTBEGwTIU6A9YqRWWH8dRZ3BmUXq+r7BAqnKXdKW5p7QHLa5OltQeqdpuexeQEFpigBEEQBMsgEpQgCIJgliwuQSkt8DHJlnAj3sMsrT1geW2ytPZA+W0q1BnKXC5UPosbJCGXy6g36+89ZlkQhGePGFRlvizuDEoQBEGwDBZ3BiUIgnkovH2BnJM/oU28gkyhxLp+G5yCBqNyLfnA0aK02+TH/hdtyjWMmlyQybBt3B7nTsORjAbyYv9L3vld6DOTkNs5Y9esKw5tXyD/twNorh5Hl34HSV+EwsEd2ybtcWw3EN39W+RfOkhRynWMRRpkCiX2vqE4+PWupKMh/B0iQQmCUOHyYv9L+s5/4+npSdjLw8jPz2fLli0kXT6Mx7BPsarRGACjtoDkDVOwUsjwa92aGjUakZmZycGD32LbOIjs45EUXD5MmzZt6PBiT65evcqePd+SfWQjAK1bt6bNc/2xsbHhypUr7Nv3Hbkxv2AszMXe3p7ANm1wc3Pj7t27nNr7JbZNO6KwdarMQyP8BSJBCYJQoYzaAjL3ryYkJISoqCg0Gg3W1tZ89tlnBAQEcH/fKjxGLEAmk6HLTETSadn84zZeeOEFAI4fP0779u3J+20/BZcPM3fuXGbPnk1ycjKenp7s2bOHHj16UKNGDc6ePUtKSgpqtRoXFxd++uknBg0aBMCxY8do0aIFAJs2bWL48OEYNbkiQVUhZn8Nat26dfTp04e+ffsydepUtFptZYckCMKfKIg/hlGbb3rwX6NGjejTpw+enp7MnDkT7b049BnFz1iSW9sDMGvWLNODAR/Ii/0vNWrUYMaMGRw+fJgaNWqwcOFCQkND6dWrF/n5+Tz33HN4enpSq1Yt7ty5w8CBA031jBo1ypSghKrJrBNUSkoKGzZs4Mcff+SXX37BYDCwY4cYoScI5kyXcReVSkXbtm25cuUK6enpHD16FICgoKDfyyQCoHL2xCl4JJcuXSIzM7NEPZI2nzZt2qBWq03bP1xPTk4O+/fvB8BoNCKXy0lPTzc92fbcuXOmhw8KVZPZd/EZDAYKCwtRKpUUFhZSvXr1yg5JEIQ/YdTm4+joiFwup7CwEMDU8/Hg7Cbn1BYMufdRutTEqf0QMBrJ/vXbUnW5uLgAmOp58PNBPTKVNbZqBZGRkbi7uzNgwACK9Aa8Xl1B9okfISf+yTZWeKLMOkF5eHgwZswYunXrhpWVFR07dqRTp06VHZYgCH9Cae9Geno6Go0GNzc34H8J5cHj07V3LqK9U/y4dJV7XXRpZc+T96D8g3oe/HywvLqrEzt27KBx48b06dOHffv2AZB5eAOa+GO41alTor6U79+n2oD3sKrRpMTyqjpPX15eXpWN/XGYdYLKzs5m37597Nu3DwcHByZPnszWrVsJCwur7NAEQSiH+vcRej/++CMjR47kpZdeMl0LioyMBCAiIoIRI0YQFBTEjRs3CAwMpFatWkBxEho0aBCxsbEcO3aMxMREwsLC2Lx5M6+88goGg4EtW7bg6OjIsWPHqF+/PitWrKBx48Y0btyYzZs3kxF/jG7dutG0aVMA6tSpw6BBgzh27BgZh77BY+j/KxFzVZ05w5Ie+V4Ws05QR48epVatWqZvX6GhoZw9e1YkKEEwY9b1/FBVb8DMmTPx8PBg06ZN6HQ61qxZw1dffVVcxtra1A0IMGHCBAYPHoxWq6VOnTps3LiRGTNmsHTpUkaNGsXKlSs5dOgQaWlpTJgwgfj4eOrUqYOXlxdarZYxY8aY9n/48GEyMjL4+OOPCQgIQKvV4u/vz8aNGxkyZAg7j8VWynER/jqzTlBeXl6cP3/eNEz14WGjgiCYJ5lMhvsL00mN/D9CQ0NxcXGhqKiI/Px81F5NkaXd4a233uKtt94ybTNq1ChGjRpVZn37ow/TtGlTqlWrRmZmJjqdDpnahtu3b2NtbV1uHMHBwWUut2/V8581UHhqzDpBtWrVih49ejBgwACUSiU+Pj4MHTq0ssMSBOER1O51qPn6l+RfPoI28TJyhYrq9dtgXb8Nhtz7FFw5iqQvQulaE3W1emiunUAy6EvUIbe2x9Y7GAx68n7bR0FmMrYNnbBr1hWlqxeaayfRpd8ptW+lixdKZ08Kb54DyVhincLOpbhOoUqQSZIkVXYQFSkuLo5e629UdhiCIFQRVXmyWEu6BuXj41NquVnfByUIgiA8u0SCEgRBEMySSFCCIAiCWTLrQRJ/h9EoVek+ZUEQnq5CnQFrlaKywxDKYHFnUHq9rrJDqHCWdqe4pbUHLK9NltYeKL9NIjmZL4tLUIIgCIJlEAlKEARBMEsWl6CUSlVlh1DhLOE+h4dZWnugarWpUGeo7BAE4bFY3CAJuVxGvVnimVGCUB4xiEioKiwuQQlCZdPn3EeXdhu5lR1qz0bIFGX/mUmShC7tFoacNBSO7qjc6yKTydDnZWDUlH7QntLRHbmVHQAGTQ5FqQkgSahcaqBwrI6kK0SfnVpiG5lShdK5BjKZrOIbKghPmEhQglBBDPmZpO9Zjib+OFA8g5jCoRou3UZj59O5RFlt0lUy9iyjKPmaaZm6RmOUzl4UxB0ybf8wmcoKt95T0Fw/Sf6lQ2DUP7TOGkmnLXM7m4YBVH/x/yqkjYLwNIkEJQgVQJKMpP74/1Dl3OPDDz+gR48eJCYmsmjRIo5vW4DcxhGbeq0B0OdlkPL9+9TxdOfdlSvx9fXl3LlzfPLJJ9yJi6Zz585MmDCh1D4mTJhA6tZPsba2ZvLE8YSFhaFQKDh8+DDvv/8+NjY2rF+/vsQ2Bw4cYMWKFejzMlDauz6VYyEIFaVKDJIwGAz079+fN954o7JDEYQyaa6doigpnhUrVjBnzhzOnz9P8+bNOXjwIPXq1SP7yEZT2ZyTP6EwaNm7dy9Dhgzh2LFjDB8+nD179iCXy1Eqldjb25v+9e/fn7CwMPT64jOmH374gYULFxIfH8/u3bupXr06AEqlksGDB9OyZUvTtlZWVsU7taw5oYVnRJU4g9qwYQMNGzYkLy+vskMRhDJprp/Czc2N4cOHc/jwYcaNG0fv3r3ZsWMHY8eO5b333sNYmIfc2h7N9dP07t2bRo0aMW/ePN5//310Oh3vvPMOzz//PLt372b//v0AtGvXjl69erFu3ToyMjLw8fGhT58+LFmyhC+++IKsrCzu379fIpbdu3ezZcsW4uLiSE0tvialdHB76sdEEP4psz+DSk5O5uDBg7z44ouVHYoglEufk0rDhg1RKBSmGQtu374NQJMmTUxlAAw5903Lbt68WWZZpw7DAJg+fToAixYtAqBLly4AhIeHEx8fT2pqKsuWLSsRy+TJkzl48CB37941dRUW3r5QwS0WhCfP7BPU/PnzmTFjhunR0IJgrsp7tNqD5cnfvkvyf2Yi6bWlyj4YZSdJEjK1LYW3ztGgQQMGDhzIzp07uXjxIgBGY/ED+C5evIi7uztbt25l3LhxtGvXjsLCQjp37oyNjQ2+vr7k5eWxaNEirKys0Fw/9aSaLQhPjFl38R04cABXV1datGjBiRMnKjscQSiX0qk616+fRK/XU79+fQDTzytXrgDQtqUPTk5O7Lt3ybSsQYMGANSrV89UVioqQHsvjilLl6JQKPjss89QOLijsHUiPj4egAsXLpCemc25c+cICwvD1dUVpVLJ4cOHTetv375Nq1atcHR0RKMtKBHvo+bay8vLs7j5+ESbqh6zTlBnzpxh//79HDp0CK1WS15eHtOnT2fhwoWVHZoglGDTKJD753axYcMGxowZw9dff01wcDAajYYvv/wSgM8//5ygoCCUSiU7d+7k8uXLjB8/HicnJ15++WUuXLjAvn37AHBzc2PMmDHExMRw4MABXLqNwVikITr6O86fP8+gQYO4efMm4eHhJCYmcuzYMfr168fMmTM5ePAgDRs2pFWrVhw+fJj79+/j6tegRLyPmvnCUp7U+jDRJvMVFxdX5nKz7jebNm0ahw4dYv/+/SxevJigoCCRnASzZNPAH6uazRg/fjwzZsygTp06HDt2jI4dO3Lnzh0Adu7cyYYNG4DikanPPfcca9aswdvbmy+//JLQ0FCwdgCgZcuWbN68mVmzZiFT22LfqicO/mHIbJzo2bMnGzZsMA2oCA4OJjs7m6NHj3LgwAFatGiBSqVizpw59OvXD6VLDeyada2sQyMIf5tMKq/j3MycOHGCr7/+2vRttDxxcXH0Wn/jKUUlCP9j0OSQuXcV+XGHQCq+VqR0qYFzl1fIOf4DRclXAVDYu+L6/FvknNqC9u4l0/ZWtVsULz/5E/kXi8+kkMlx7T4WhzZ9AShKu03GnuVo71w0badyr4t9q1DyLuxFl5pQIiabhgG4Pv8WSqfqpmWPM9WRpXwzf5hok/mKi4vDx8en1PIqk6Ael0hQQmUz5Geiy7iHXG2Lqno9ZDI5kiRhyL0PkoTC3s00/ZEuMxFDbjoKB3dULjX+V0deJpKhCJmVHQpr+1L70GUlY8i5j8KxGkonD9MgC0NeJrqsRGQyOUoXLxS2TqW2FQnKclhKm8pLUGZ9DUoQqiKFnQsKO5cSy2QyGUrH6qXKqly8ULl4la7D3qXUshLbOXuicvYsc7tHbSsIVYVZX4MSBEEQnl0iQQmCIAhmyeK6+IxGSTzvRhD+RKHOgLVKUdlhCMIjWdwZlF6vq+wQKpyl3Yhnae2BqtUmkZyEqsLiEpQgCIJgGUSCEgRBEMySSFCCIAiCWbK4BKVUqio7hApnCTfiPayqtqdQZ6jsEAThmWJxo/jkchn1Zu2o7DAECyRGhwrC02VxCUqomgyaXPIv7KXo/k3kVrbYNA7Cuo6vaQqfh+ky7pF3cT+GnFQUDu7YtwhB6VqLwhunKbx3uURZmUyOVa1m6NJuY9DklKpL5eqFTK6kKO12ye0USuyadkLlXrtiGyoIwmMTCUqodJqEM9z/+VOkogLq1KlDVlYWqTHbsWkYQLX+7yF7qNs2+3gkWdEbUKtVeHl5kXj1V3KOR2JVxxft7VgUipJDqCVJIttoRCaTlfnQS4OhuNuurO1yY7ZTa9z6EvsXBOHpsbhrUELVYtQWkLZ9Ia2aNeHChQvcunWL1NRUFi9ejOb6KXJObTGV1SZeISt6PcOGvcTt27dJSEjg7t27vPzyy2hvxwKQmZmJXq83/du5cydQ/Ij0h5c/+FerVi2srKxKLV+/fj1GTQ763PuVclwEQTDzM6ikpCRmzpxJeno6MpmMIUOGEB4eXtlhCRUo7+I+jJocvvzyS+rWrUvXrl0ZPnw4U6ZMYf/+/UTt+xnHwEHI5ApyTm7B3d2dr776iqtXr9K3b1+WLVvGypUr2bNnD8nJyQDs2rWLb7/9Fih+DwEcPnyYl19+GQBra2uWL19OUlISycnJprOnzZs388svvwCQkFD82Aq5ld1TPR6CIPyPWZ9BKRQKZs2aRVRUFN9//z3ffvst165dq+ywhApUlHydmjVr0q5dO3799Veio6P56quvABg4cGDxWUxO8VlMUco1QkNDsbOzY/PmzZw+fZrvv/8eGxsbevbsaaqzWrVqBAcHU61aNU6ePAnArfQCvt2yg2+++Qaj0YhSqeTzzz9Hr9ebtqtZsyYdO3bEycmJmJgYAGQqq6d1KARB+AOzTlDVq1enefPmANjb29OgQQNSUlIqOSqhIhny0vHyKn7cRGZmZomfNWvWBKAo+Rr6nPvoc+6bymZkZJRZNjU1lcTERHx9fVm0aBHR0dEolUrsWoRg37oXMpmMadOmkZ2dbUqEAPfu3SMtLY3AwECWLl1qOpPKv7j/SR8CQRDKYdZdfA+7e/cucXFxtGrVqrJDESqQ3NqejIxEAGxsbEr8TE9PByBt66em8g8Sk62tbYmfD8o2adIEo7H4abYHDhyga9euNGvWjPg7v1F0P4E+ffrg4+PDv/71L3Jzc5Fb2aHV5lO7dm0kSUImk3H+/HlCQkLw9PQkL7nkGXt5c+7l5eVVqfn4HsXS2gOiTVVRlUhQ+fn5TJo0iffeew97+9JPFxWqLpVbLW6dOMa9e/cICAjAxsaGzp07A3D06FEApk+fjre3N2PHjuXYsWMAdO7cmYiICIKDgwE4duwYtWvXplq1apw5cwZbW1vc3NyA4j/iwls3THUVFRXx73//G+t6fhg1OdRzUqBQKIiLi8PJyQknp+Kn0BYUFJQawVfeTcaW8mTTByytPSDaZM7i4uLKXG7WXXwAOp2OSZMm8cILLxAaGlrZ4QgVzL5ld/RGiZkzZ+Lh4UFSUhJLly7l/PnzrFmzBoBevXrx6quvIpPJiIuLY9myZfTv35+MjAyGDh3K6tWrOX/+PLVr1yYmJoaUlBRSUlJo2bIlK1eu5MaN4uQUEBBAly5d2LhxI0lJSTi2G4BkNNCsWTMuXbpEUlISiYmJ1KlTh7lz55KTk4N1Pb/KPDyC8Ewz6zMoSZKYPXs2DRo0YPTo0ZUdjvAEKJ08cOo4jG+//Q+HDx8mNDSUpKQkdu/ebbpHaebMmbi6upq67iZMmMDatWvx8/MjNjbWNBDi6NGjtGjRgjZt2iCXy4mNjeXs2bNY1/Oj8M5F0tPTCQ0NJTY2FlX1+ljX80Pt0Yiff/6ZNm3a4Ovri9Fo5MyZM/z222/YNuuCTaPASjs2gvCsk0mSJFV2EOU5ffo0I0aMoEmTJqabLKdOnUqXLl3K3SYuLo5e6288rRCFCqK5EUPO6W3o7icgU9ti26Q9jgH9yb8UTcGVI2A0ovZshFPwSAouHyYv9r8YctNQ2Lth3/I57Fp2J//CXgqunUSXfhckCaWzB3Y+nbH3DaXg6nFyz0aBvgi5rSPOnV9GXa0ekr6InJhfKEw4jS4jCWQyVC41sGsRgl2zrsjk/7uB98+mOrKUrpYHLK09INpkzuLi4vDx8Sm13KwT1N8hEpTwpIgEVbWJNpmv8hKU2V+DEgRBEJ5NIkEJgiAIZkkkKEEQBMEsmfUovr/DaJTEc3uEJ6JQZ8BapXh0QUEQKoTFnUHp9brKDqHCWdqd4lW1PSI5CcLTZXEJShAEQbAMIkEJgiAIZsniEpTSAp9+agn3OTzsabSnUGd44vsQBOHJsrhBEnK5jHqzdlR2GEIlEwNlBKHqs7gzKEEQBMEyWNwZlPDkFVw9Qc7Jn9AmxSNTqrFp0Ban9kNQV6tXopxk0JN7Noq8czvRZSahsHXErllXHAMHobAtfqRFTsx2cs/sAKMemdIKx4AwbBoGkHXkWzQJZzDkZaByroF96544+PVCplCZ5u3T3ruEZNCjdPLAzjsYpw5DkCksr4tXEJ5VIkEJf0nOqZ/J3L+ahg0bMmDKZHJycvj+++9J3nACj2HzsfJqChTPRH9/66dorh6nU6dOBAeP5OrVq/z8888UxB/DMzyCopTrZO79kk6dOlGvXj3i4uKI2bkEua0zSn0Bg/r3p27duhw9epRf962i8HYs6uoNyP71W2rVqsWAN17DxsaGixcvEhW1CZVbLeyalT+RsCAIVYtIUMJjM+RnkXX4G8LCwvjpp59ISUnBwcGBuXPn4ufnR9r+NXiM+BcymYzChDNorh5nwYIFzJgxgxs3blC3bl1OnjxJp06dyD6ykYJrJ2nSpAl79uzBxsaGiIgIYmJiUBk0/Hr0KN7e3pw+fZoFCxawcOFCZsyYgebqccLDw1mzZg2pqakkJCQwdepUPD090eemVfYhEgShApn9NahDhw7Ro0cPnn/+eVatWlXZ4TzTCuKPIum0zJ8/n/z8fJo0acLAgQOpVq0a06dPR3vvEvqsZADyLuylRo0avP3220RHR9OwYUM++eQT2rdvT1hYGLkx25Fy77N27VrOnTtXYj+9e/embdu2zJ07l65du7Jr1y4mT56Ml5cXVlZWLF26lDNnzlC/fn06duxI/fr1AVA6uD/1YyIIwpNj1gnKYDDw8ccfs3r1anbs2MEvv/zCtWvXKjusZ5Yu4x52dnY0a9aMuLg48vLyTA8L9Pf3B0CfmWj62apVK1QqlanMH8tOmTKFatWqMXv27BL7sbGxAUCpVJp+qlQqfH196dy5Mw4ODshkMmJiYjh16hQvvvgiAEad9kk2XxCEp8ysE1RsbCx169aldu3aqNVq+vTpw759+yo7rGeWVKTByal4cINWqy3x09nZGYDsXzeRffwHilKum5aVVdbb25s5c+bwyiuvUFBQUGI/UVFR3Lp1i/fff58zZ87QvXt3AFxcXHBxcQGgQYMGREREYDAY2LBhA23atCEvdveTbL4gCE+ZWV+DSklJwdPT0/Taw8OD2NjYSozo2aawdyP5YjI6nQ539+LutGrVqgFw584dALSJl9EmXgbg9u3bAGWW7d27NwD/+te/cHR0BGDo0KEkJSXx2Wef0bp1awYMGICtrS0BAQGEh4dz4cIFHBwcADhw4ABfr/8GpVJJYGAgfn5+nP/upxLxPs05//Ly8qrsHINlsbT2gGhTVWTWCUowL1ZeTck2Gtm8eTMjRowgPDzc1F23adMmANasWcOwYcNo2rQpJ0+eJCEhgf79+7Nt2zZef/11DAYDkZGR1K9fn//85z9A8RcPX19f0tPTSUws7iLs378/586dw9vbmwEDBhATE8PFixdRqVQkJCTg5+dHC5+mhISEAHD27FmUzp4l4n2aM3BYypNNH7C09oBokzmLi4src7lZJygPDw+Sk5NNr1NSUvDw8KjEiJ5t1g3aoKpen+nTp+Pk5MS6devIz89n0aJFbNy4ESjuxisoKECSJPR6PSNGjGD58uVERUWRmJjIa6+9xvXr17l+/Tp79+4FoG3btgQHB7Nt2zZTPTNnzsTHxwe9Xs+2bduYPHkyADqdjpEjR7Js2TJiY2NJS0tjwoQJnDlzBrdekyvnwAiC8ESYdYJq2bIlN2/e5M6dO3h4eLBjxw4WLVpU2WE9s2QyOdX6zST1h4954YUXsLa2Rq/Xo9frsa7flqKkeMaNG8e4ceMAsGnUjuMx5/Dz88PW1haNRoOEDKcOL+HYbgBGnZbso98TE7PD1A0IIFNa0axZM2xtbdHr9RQVFaF0qUGN0UvRZyZxLCoCPz8/bGxs0Gg0ADj4h2HXsnulHBdBEJ4Ms05QSqWSDz/8kNdeew2DwcCgQYNo3LhxZYf1TFO51cbrtRUUXD1OUVI8Vr/PJGFV0wdDXiYF104gGXSo3GpjXdcXSVtAftwhdJmJONk6YesdjOr3rji5lR2u3cdi06AN+uxUZEorbJu0RyoqoODaSQzZqSgVCpxqNsOmQVtkcgXq6vWpVdeX/LhD6DOTsLZ3wbqeH+rq9Sv5yAiCUNHMOkEBdOnShS5dxOwA5kSmUGLn3Qk7704llivsXXBo3bNkWWt7HPx6l1+XXIFto8CSC20ccGz7QrnbyB9RpyAIlsGsh5kLgiAIzy6RoARBEASzJBKUIAiCYJbM/hrUX2U0SuJhdQKFOgPWKkVlhyEIwj9gcWdQer2uskOocJZ2p/jTaI9IToJQ9VlcghIEQRAsg0hQgiAIglmyuASlVFreI78tYa4tKL4uJAiC8LgsbpCEXC6j3qwdlR2GUAYxeEUQhL/C4hLUs8yoLUB79zckgw61ZyOUjtXLLavPuU9R8lVQqLCu6YPc2v735Wno0m5h1BYgt3FA7dEAhU3x4zAkSUKXdgt9VjJyKzusavogUyiLJ4bNTkGffgejTovCxhG1ZyPkVrZPpd2CIFgmkaAsgCRJ5BzbTPaJH5CKNL8vlWHrE4xbj/HIrexMZY3aAjL+u4L8S9EgGYtLqqxxbDcQXeY9Ci5Fl6xcrsShTR/sfZ8nfUcERSnXTasUDu64hLxGXuweChPOlNhMprTCMehFnDq8hEwmeyLtFgTBslncNahnUd7ZHWQd/oZB/fpw8OBBYmJieO+9d9FdO0bajogSZdN3LkF75TDvzJxBTEwMhw4dYuig/mT/+i0Fl6J5/fXXOXz4MBcvXmT//v28/upock9vJenrCbgrNKxatYrTp0+zZcsW2vo0IG3rpxQmnGH69OkcPXqUCxcusGfPHoa+OIDsIxvJv3Swcg6KIAhVntknKK1Wy4svvki/fv3o06cPS5YsqeyQzIpk0JF19DtCQkKIjIzEaDRy+vRp5s2bx0cffYTm6nG0ydcAKLp/k4IrR3j//ff59NNPOXv2LFqtlk2bNtGjRw8AXF1dOXDgAJs2bcLb25tVq1bRoUMHALZv386QIUNYvXo1Xl5e7N+/3/R8LhcXF3bv3s0PP/yAv7///2/v3uOirNP/j79mOMlRFBEwBU+Jmmmah1Q0Bc+K/rTMat3NsmzzkFlmhbHZZm2W+fWrrmVa6ldLVy3PtVYeCpMMTaVwPKKABzQVHEFgmJnr94cxK4GrhjHDdD0fDx7I/bnvmet9i1ze9/3hvlm2bBlNmjThA7nqcQAAIABJREFU8oHtztkxSqkqz+VP8Xl7e7N48WL8/f0pLi7m4YcfpmvXrtx1113OLs0lWM4ex56f63gG01//+lcOHTpEnz59GD16NJMnT6bw+B58whs7TsONHj2a7OxsHn/8cerXr8+xY8cYPXo0mzZtYtq0aY7XbtCgASNHjqRatWpERETQpk0b1qxZw7wFH2K1Wpk/fz5/+ctfePvtt5k8ebJju7vvvpv4+Hi8vb2RfGvl7hCllNtw+SMog8GAv/+VayglD8fTaxr/YTWfBaBx48YAZGVlAXDixAmCg4MJCQnBav75l3V/JigoiNDQUMd6JZ9LtgeYMWMG+/fvZ+TIkcydO5ctW7aQm5tLYWEhLVu2JLpxQ7p16wZAo0aNHNstWrSIQ4cOER8fz6uvvspPP/2EwQ2n/SulKofLNygAm83GoEGD6NSpE506daJVq1bOLsllGAxX/gqtVusvX19p3kbjf5bn7fmMUwvHcWn3emw2W6lxDw+PUtsDbN26laVLl3L06FFGjRpFTEwMBQUFjBo1itq1a2MymYiNjQWuTNAo8dlnn7F06VJOnTrFpEmTuOOOO7DlXfg94yul3JjLn+KDKz9E165di9lsZsyYMRw6dIgmTZo4uyyX4Bl85RqQyWTi7rvvpnHjxvz44480aNCA7OxsLl68SL169WjTpiV799rJyMggMzOTBg0aYDQaHUdABw4cAK40rvXr17N+/XpycnKYO3cu3bp1Y/v27SxZsoSPP/6Y0NBQBg0axHvvvcfmzZsdTXHFihXAlSY5ZcoUOnfujGnJ8lL1ZmRkkJeX53b3F3S3TO6WBzRTVVQlGlSJoKAgOnToQFJSkjaoX3jVisIzOJyZM2fy4IMP8vHHH5OVlUVYWBjPPfccAN26deP//u//ePzxx/nggw+YPn06s2bN4t///jfh4eHYbDZmzJgBXGl0ycnJFBcXM2TIEGw2G1u2bAFg2rRpVKtWDT8/P/70pz+xd+9e1q9fj5+fH6mpqWzbtg2j0ch9991HYWEhSUlJeIXULVVvVFQUGRkZbnN3jBLulsnd8oBmcmUmk6nc5S5/iu/ChQuYzWYACgsL2bFjBw0bNnRyVa7DYPQguOtf2L17NzExMaSkpHD58mUefvhhR9M5ePAgc+bMYf/+/QDMnj2bYcOGYTab2bNnD126dGHnzp0AfPjhh/j5+REaGsqyZcuIiYlhx44dAPzwww9ERERQu3ZtXnrpJbp27UpRURFFRUUsWbKE6tWrExwczAcffMA999yDyXSAoHuGOmfHKKWqPJc/gjp79iwvvvgiNpsNEaFPnz50797d2WW5FP9mXRG7jd3bP+LRRx8FwODtR9A9Q/EMDCFl60K+//57DJ7e1Igbhb3AzMq16x2n5Dyqh1Ej7gkKM39k2ltvO36BF8CzRgQh/Z/FcuYo/1r5Cf/617+uDBg98YvuTHi7QeR+s4QpU14F/nM9yqtWJKGDE/Br1K7S9oNSyr24fINq2rQpa9ascXYZLi/gju74N+uK9cIpxGbBs+ZtGL2qAeB/Zw+kuAiDl49jWdA9Q7FeOAkennjVvA2D0YOgtoOwWwqxXsxGbFY8/GvgEVDzyjWmFrEEd/0z1pzTiN2GV3C44/ZIYcNew150GevFbBDBI6AmRr9gnW2plKoQl29Q6sYZjB541apXZrnRqxr80pj+s8wH77Cyp0qN3tXwDq1f7usbvarhXbtB+WM+fnjX1lOvSqlbx+WvQSmllPpj0gallFLKJbndKT67XfS5Qy6qsNhGNS8PZ5ehlKoi3O4IymotdnYJt5y7/CKeNiel1M1wuwallFLKPWiDUkop5ZK0QSmllHJJbtegPN3w8Q5V9V5bhcU2Z5eglKrC3G4Wn9FooP6LG51dhgKdTamUqhC3a1B/FGK1kL9/GwUZ+8Bux6ducwJaxGH08Suzri0/l7zUL7CcOYrBywffRu3xa9IR26Xz5O/fRvH5LOyWAjz8quNTtzl+t99DvimJ4nOZZV7L4OUNBg/EUlBmzOgXREDLXngG1PxdMiul/li0QVVBVvNZziyfjDXnNFFRUXh5eXHkqyTMySuoPey1UrcqKji+l59Xvw7FhTRt2pScczlk/7QFr1qRFJ/LxGAwEBUVRWBgINmnjvLzvk2c58oznYKCgsq8d0FBAVarlcDAwDJjly9fxpJ9hNpDXv4d0yul/ijc7hrUH8GFL9/D336ZTZs2cfz4cQ4fPsx3331HeLAf5z+b6XjKrb24kHMbpnNn09sxmUzs37+fkydPsmTJEiT3FADr1q3j2LFjpKamcvbsWdauXYuXlxe1atUiNze3zMdjjz1GZGRkuWMPPvggxWePOXPXKKXciMs3KLPZzNNPP02fPn3o27cve/bscXZJTlV84SQFR77n+eefp1evXvz1r39l0KBBdOjQgalTp2LJPkJR1k8A5O//Bnt+LnPmzCEyMpJOnTrx5ptvMnz4cIYPHw7AzJkziY6OJjo6mh9++IGBAwdy9913YzabGTJkiOMjNTUVgB07dnD27NlSYwcPHsRut5OcnIxH9TCn7RullHtx+VN8r7/+Ol26dGHWrFlYLBYKCwudXZJTWX45QomPj8dms/HBBx9gtVrJzs5mwIABv6yTTrXIOyk+m0716tXp0qUL27dvJzk5mXPnzpGQkMCAAQNYtGgRmzdvpk6dOkRERODl5UVubi7p6ekUFRWxYfsein/OoH79KO644w42bdrkaFQbkn6g+FwGzZo1Izo6mk8//ZQjR45Qa9CLTts3Sin34tJHUJcuXSIlJYX7778fAG9v73Kvi/yR2PJzAKhTpw75+flYrVYAcnNzqVWrFt7e3liyj1B8LgvLz8epU6eOY/zqzyXLAdasWcOuXbu48847ef/99/n555+p1qANIb3HAsKECRPw8PDg7bffxiOgJpETV1Mj7gkAx2Pl3377bTyDw/Fr0rFS9oNSyv259BHUiRMnqFmzJi+99BIHDhzgjjvuYPLkyfj5lZ2p9kfh4XtlcsK5c+do3LgxBoMBEcHf3x+z2YzFYsGStpX8tK1X1gsNBcDf37/U53Pnzjles2fPnoSGhjJ79mwmTZrEt99+y2df78T8/afUrFmTkSNHsmfPHjZv3kxwtxEYPLwwf7+a8PBwhg8fzrfffst3331HzZ5/xWAsfb+98u4jmJeX5zb3FyzhbpncLQ9opqrIpRuU1Wpl//79JCYm0qpVK6ZOncr777/PM8884+zSnMYr5MoDCb/55huaNm3Kvffey6lTp6hXrx4bNmwAoH///vz5z39m+vTp7Nq1C5PJROvWralZsyZxcXGO7T09PWnbti07d+4kLy+P06dPAxAcHIz14hmsF8/wTEIC/v7+TJ8+HYO3L4F39cXy83EKj+1m3Ouv4+Pjw9tvv43RNwj/O3uUqbe8XzLOyMiosr98fC3ulsnd8oBmcmUmk6nc5S59ii88PJzw8HBatWoFQJ8+fdi/f7+Tq3Iur9oN8Y6IZurUqWRkZLB582bS0tIc15YAoqOjGTZsmOM03oQJE/D29ub06dMsWLCAPXv28N577+Ht7U1ycjKXLl3CbDbz6KOPsnv3btauXQuAj48P48aNIzMzkxUrVhDYqg9GH38u7d5AQEAATz31FAcPHmTdunUEtu7neJy8UkrdCi59BBUaGkp4eDjp6ek0bNiQ5ORkGjVq5OyynMpgMFCz11OcWPYSt99+O7169cLb25tNmzZxucgCwPLly0lOTubAgQMAbNq0ibp169KjRw/Onz/P1q1bHVPRmzZtSosWLfDw8OD48eOkpKRgDAjB57ZmeF3MYsiQIZw9exarHQLbDgTAln8BL6OR/v37k52dDR7eBLYZ4JwdopRyWy7doAASExOZOHEixcXF1KtXj3/84x/OLsnpfMIbU2fkPzGnrOWL73+5k8TtXanTbhD2wnxyU9Zw4XQ+Hre1ps59Q7EXXca8ax2rNydj9PIhqNODBLYZQMGR78k8nEz6thRE7HgE1KR6lz8TcFcf7IV5XPx2GXtO52LwqEnooAfxDLpyPavGvY+Sm7ycPafNGDxDCf1/j+DhH+zkvaKUcjcGKfmvtJswmUz0XZzu7DIU174Xn7ucN7+au2VytzygmVyZyWSiWbNmZZa79DUopZRSf1zaoJRSSrkkbVBKKaVckstPkrhZdrvoc4hcRGGxjWpeHtdfUSmlyuF2R1BWa7GzS7jlqupvimtzUkpVhNs1KKWUUu5BG5RSSimX5HYNytPTy9kllFFYbHN2CUopVeW43SQJo9FA/Rc3OruMUnTShlJK3Ty3O4KqSkQEi8VyQ+vabDbHs59u1XsXFhbiZjcSUUq5EW1QTnD48GGGDx+Ov78/Pj4+NGnShDlz5mCzlT0VuHnzZh566CG8vb3x9vamS5cufP7552RnZzNx4kQ6depEeHg4YWFhdOvWjaNHjzq23bVrFy1btiQsLIywsDDuv/9+Fi9eTLdu3ahevTq+vr4EBATQs2dPkpOTK3MXKKXUdbndKT5Xd/jwYdq3b4/dbmfEiBHUqVOHTZs2MW7cOPbt28f8+fMd665atYqhQ4cSFRXFCy+8gNFoZPny5fTr1w8AX19f2rZty6BBgzAajSxZsoR58+bx1ltvcenSJe6//34MBgNDhgyhsLCQRYsW8cknn9CiRQtGjBhBREQEZ8+eZdWqVXTt2pWtW7cSExPjrF2jlFKlaIOqZImJidhsNn766SdCQkLIzMzk5Zdf5oUXXuCtt95i9OjRtG7dGovFwnPPPUe7du1ISkoiJycHm83GK6+8QlxcHElJSQwdOpSFCxdisVioVq0a69ev58KFCwBMmjSJrKwstm/fTseOHfn5559ZtGgRAPPmzSMyMpLTp0/Trl07Xn31Ve666y5eeeUVNm/e7MS9o5RS/+Hyp/heeuklOnbsyIABVf95Q5cvX2bVqlWMGjWKyMhIxo4dS4sWLTCZTCQkJODr68tHH30EQFJSEpmZmSQmJuLj40Pnzp1p27YtXl5evPLKKwCsX7+e6tWrs379+lLv8+WXX/Lee+/x7LPPUqtWLU6ePFlqfMKECURGRtK+fXtmzJhBUFAQvXv3Zu/evZWzI5RS6ga4fIMaMmQICxYscHYZt0RGRgY2m402bdoAsGfPHux2O6mpqVSvXp1GjRo5riEdOXIEgDZt2mA2m0lPTyc7O5vTp087ts/JySEvL6/Ue5jNZkaOHEnTpk2ZMmUKI0aMoKCgoNQ6WVlZjskRtWvXBiAtLY2IiIjfL7xSSt0kl29Q7dq1o3r16s4u45YoaSaBgYEAjhl8JZ8DAwNZs2YNiYmJJCYmOpZdPdPPYrEQEBCAwWDggQceKPMeK1eu5OTJkyxatIh3332XHTt2lFnHarViMBj4xz/+wfDhw5kyZQpJSUmMHj361gZWSqkK0GtQleTq++mV/Ll27dqYTCbHUUxmZiYAb7zxhuMIJyMjg6ZNm+Lt7Y3VaiUkJMRxBLRixYpy36tWrVp06NCBoKAgevToQWRkJB4eHiQnJ9OxY0cuXrzIkiVLeOihh5gwYQIzZ84E4MSJE5Vy37+8vLwqe3/Ba3G3TO6WBzRTVaQNqpJERUURGRlJgwYN+Oijjxg7diwTJ04kMjLSMYPu5MmTdO7cme3bt/PGG28wefJkli5dyrRp0/j73/9OQUEBAQEBvPPOOwA0atSI3r1707hxYwBGjBiByWTiiy++cKwDUL9+fXx8fNi6dSsAixcv5sEHHyQlJYXg4GCmTJnC119/zaxZs5g6dSpG4+97YO0uTwG9mrtlcrc8oJlcmclkKne5NqhKZDAYSEhI4IknnmDMmDEkJCTQt29fvvjiC8aOHQtAUVERGRkZ5ObmAjBz5kxuu+02xowZg9FoZN68eUybNg2AJk2aMGnSJODKN+oTTzzB7t27+fTTT5k4caLjfdu1a0dgYCAJCQkA+Pv7k5GRQe3atRkxYgRw5dpVSQNTSilXoA2qkj322GOkpaUxa9Ys5s6di8FgQESIjIxk8ODBrF69mvr16wPQokULwsLCGD9+POPHj3e8RkxMDPXq1WPZsmWOda/m6+vLoUOHuHjxIi1atODee+8tNT5w4MBya+vWrdvvfvSklFI3yuUb1LPPPsv3339PTk4OXbt2Zdy4cQwdOtTZZf1mRqOR//mf/2HcuHGsXbvW0UQGDhyIp6cn27ZtIyMjg4CAAPr164efnx+rV6/mwIED2O127r33XmJiYrDZbAwfPpwzZ86Uef1evXoRERFB3bp1SU9P5+uvv0ZEiImJwc/Pj6+++gq73V5qu8DAQMcvACullCswiJvdjM1kMtF3cbqzyyilojeLdZfzzCXcLQ+4XyZ3ywOayZWZTCaaNWtWZrmez1FKKeWStEEppZRySdqglFJKuSSXnyRxs+x2cbkHBBYW26jm5eHsMpRSqkpxuyMoq7XY2SWUoc1JKaVunts1KKWUUu5BG5RSSimX5HYNysNDT6cppZQ70AallFLKJbndLL7ynDhxgqSkJOx2O507dy73/nUlUlNT2bNnDwEBAcTFxREcHOwY++GHH/jxxx8JCgoiLi6OoKAgAESEXbt2kZaWRo0aNYiLiyMgIMAxtnPnTg4cOEBISAhxcXH4+fn9rnmVUsotiJvZv3+/489FRUXy5JNPioeHhwACiMFgkOHDh0teXl6p7U6cOCGxsbGO9QDx9/eXN954Q44dOyYxMTGlxgIDA2XGjBly6NAhad++famx4OBgeffddyUtLU1at25daiwkJEQWLlx4U5mOHz9+K3aNy3C3PCLul8nd8ohoJld29c/tq7l1g3ruuefEYDDI008/Lfv27ZO0tDR58cUXxcPDQx599FHHena7Xdq3by9BQUEyY8YMOXz4sCQnJ8t9993naCw1atSQ2bNny5EjR2T79u0SHx/vGAsNDZV3331Xjh49Ktu2bZPevXs7xiIiImTBggVy9OhR2bx5s3Tv3l0A2bp16w1ncpdvwhLulkfE/TK5Wx4RzeTKfrcG1b17dzl//rzj6++++05GjRolIiKffPKJREdHi8lkcoz3799fsrKyymz7448/Svfu3SUtLa1C9ZQEPXv2rFSrVs3RiJYtWyYLFiwQkSuNy2g0Snp6uoiIbNy4UQDHkc3rr78u27ZtExFxHB2tWLFCrFarTJkyRXbs2CE2m01atGghgGzcuFEsFoskJiZKSkqKFBcXS6NGjQSQr7/+WgoKCiQhIUH27dsnhYWFUrduXenevfsNZ3KXb8IS7pZHxP0yuVseEc3kym5pgyoqKpL8/HwRuX6Duvfee2X8+PGO8fIalMlkku7du8u+fftERMRsNovNZvstpTmCrlmzRgD57rvvxGazSUBAgHh4eEheXp4cPHiwVEOaMGGC+Pn5SXFxsaSkpAgg7du3FxGR+fPnS0hIiIiIfP311wI4msvMmTOlbt26IiLy2WefCSD9+/cXkStNLjo6WkREVq5cKYA88MADIiIyefJkMRqNYrFYbiiTu3wTlnC3PCLul8nd8ohoJld2rQZ1U7P4jh49yptvvkmfPn04fvz4DW3TrVs3jhw5Qnp6+Y/ASE9PZ8yYMbz11lu0bNkSgN27d9OnTx9mz57NqVOnbqZEh8zMTAAaNmyI2WwmLy8Pm83GmTNnaNCgAUaj0bFOZmYmkZGReHp6Ot7v5MmTwJXHqpdMqihZdvVYw4YNSy0r2f56Y3a73bFcKaVUWddtUJcvX+aTTz7hoYce4uWXX6ZRo0asW7eO5s2b39gbGI08/vjjzJs3r9zx0aNH87e//Y22bds6lnXr1o3ly5cTGBjIU089xciRI/n888+xWCw3GAu8vLwAsFgspaaee3p6UlxcjN1u55VXXqFx48Z88sknjtcueaKsp+eVCY5FRUWOsZLX+W9jJZ+vN3Z1jUoppcq67jTzmJgYoqOjmTp1Ko0aNbqhFzUYDKW+HjBgAO+++y5ZWVll1u3YsSMrV64kJiamVCOpWbMmI0aMYMSIEezZs4eEhATmzp3L+vXrr/v+GRkZ+Pv7A5CWluZ4wuylS5eIiIhg7969ADRv3pzWrVtTUFBAVlYWZrOZ6OhoAMfntLQ00tPTKSgocCxr0qSJY+zQoUMUFxeXu53JZMJut5c75u3tjcViISMj47p58vLybmi9qsLd8oD7ZXK3PKCZqqTrnRtMSkqS8ePHS9++fWX27Nly4sSJUuODBw+WY8eOOb7etGmTvPjiiyJy5RrUq6++KiIiy5cvl8TExDLXoM6dOydjxoyRxMTEMu99+PBhefPNN6Vnz56SkJAge/fuveFzmfn5+RIaGiqxsbFis9kkNTVVUlJSRERkyJAhAsikSZNERKRfv34CyN/+9jcREfnyyy8lMzNT8vLyJCoqSgCZNm2aiIh8/vnncvLkScnNzZXw8HABZM6cOSIismHDBjlz5oycO3dOatSoUeo619q1a+XcuXNy6tQpCQgIkIceeui6WUq4y3nmEu6WR8T9MrlbHhHN5Mp+8zWomJgYZs6cyUcffURgYCCjR49mxIgRnDhxAoAOHTqwdu1aAGw2G+vWraNDhw5lXmfw4MEkJydz4cKFUssNBgPvvPMO6enp/O///i9w5QjjgQce4OWXX6Zhw4asXr2a119/nVatWt1w4/Xz8+O1115jy5YtdO7cmeTkZFJTU+nevTuffvopADt37uTNN9/k6NGjALz22msMGzaM7OxsVq1aRevWrTlx4gQ1atQgISGBP/3pT5w/f56PP/6YNm3acP78eYKCgnjmmWd45JFHyM3NZeHChbRp04b8/HwCAwN58skneeKJJ8jLy+O9996jbdu2iAhTpky54SxKKfWH9Fu63b59++TUqVMicmXG3bPPPivx8fEyYMAAmTZtmmMG3tVHUCIiixcvliZNmpQ7zdxsNsvAgQNl6dKlcuTIETly5MhvKa1MJ164cKE0bNjQ8XtJdevWlTlz5sg777wjfn5+AkitWrVkxYoVkpCQINWrV3es27ZtW/niiy8kPz9fJk6cKIGBgY6xe+65R7Zt2yZms1mefvppx2sB0rVrV9mxY4fk5OTIU089Jb6+vo6x2NhY2bVr101lcpf/JZVwtzwi7pfJ3fKIaCZXdq0jKIOIiJN64+/CZDLRrFmzUsvsdjsZGRnY7XbHDD6A4uJibDYbXl5epSYwZGRkEBAQQJ06dUq9TmFhIRkZGQQFBREREVFqrKCggMzMTIKDgwkLCys1dvnyZTIzMwkJCSE0NPSmM2VkZBAVFXXT27kqd8sD7pfJ3fKAZnJl5f3chj/IvfiMRiMNGjQos9zLy6vMTDofHx/HJIhfq1atmmOiw6/5+vpec8zPz4+mTZveZNVKKfXH5nZ3M1dKKeUetEEppZRySW7XoGw2m7NLUEopdQtog1JKKeWS3K5BKaWUcg/aoJRSSrkkbVBKKaVckjYopZRSLkkblFJKKZekDUoppZRL0gallFLKJWmDUkop5ZK0QSmllHJJbve4jb179+Lj4+PsMpRSSt2goqIi7rrrrjLL3a5BKaWUcg96ik8ppZRL0gallFLKJWmDUkop5ZK0QSmllHJJ2qCUUkq5JG1QSimlXFKValDffPMNvXv3pmfPnrz//vtlxi0WC8888ww9e/Zk6NChnDhxwjE2b948evbsSe/evUlKSqrMsq/pt+b59ttvGTJkCPHx8QwZMoTk5OTKLv2aKvJ3BHDq1Clat27NBx98UFkl/1cVyXPgwAGGDRtG//79iY+Pp6ioqDJLv6bfmqm4uJgXXniB+Ph4+vbty7x58yq79Gu6XqaUlBQGDx5M8+bN+fe//11qbPXq1fTq1YtevXqxevXqyir5v/qteUwmU6nvuc8++6wyy771pIqwWq0SFxcnmZmZUlRUJPHx8XL48OFS6yxdulQSExNFRGTDhg0yfvx4ERE5fPiwxMfHS1FRkWRmZkpcXJxYrdZKz3C1iuRJS0uT7OxsERE5ePCgxMTEVG7x11CRTCXGjRsn48aNkwULFlRa3ddSkTzFxcUyYMAAMZlMIiJy4cIFp3/PiVQs07p16+SZZ54REZHLly9L9+7dJSsrq3IDlONGMmVlZYnJZJLnn39ePv/8c8fynJwciY2NlZycHMnNzZXY2FjJzc2t7AilVCRPenq6HDt2TEREsrOzpXPnznLx4sXKLP+WqjJHUKmpqURFRVGvXj28vb3p378/mzdvLrXOli1bGDx4MAC9e/cmOTkZEWHz5s30798fb29v6tWrR1RUFKmpqc6I4VCRPM2bNycsLAyA22+/naKiIiwWS6Vn+LWKZAL46quvuO2227j99tsrvfbyVCTPt99+S3R0NE2bNgWgRo0aeHh4VHqGX6tIJoPBQEFBAVarlcLCQry8vAgICHBGjFJuJFPdunVp2rQpRmPpH3nbt2+nc+fOBAcHU716dTp37uz0MywVydOgQQPq168PQFhYGDVr1uTChQuVVfotV2Ua1JkzZwgPD3d8HRYWxpkzZ8qsExERAYCnpyeBgYHk5OTc0LaVrSJ5rrZp0yaaN2+Ot7f371/0dVQkU35+PvPnz2fs2LGVWvN/U5E8x44dw2AwMHLkSAYPHsz8+fMrtfZrqUim3r174+vrS0xMDN27d+exxx4jODi4UusvT0X+fVfVnw03IjU1leLiYiIjI29leZXK09kFqN/u8OHDTJ8+nQ8//NDZpVTYnDlzeOSRR/D393d2KbeEzWZj9+7drFq1Cl9fX0aMGEGLFi3o2LGjs0v7zVJTUzEajSQlJWE2m3n44Yfp1KkT9erVc3Zp6lfOnj3L888/z7Rp08ocZVUlVabysLAwsrOzHV+fOXPGcZrr6nVOnz4NgNVq5dKlS9SoUeOGtq1sFckDkJ2dzdixY5k2bZrL/A+pIpn27dvH9OnTiY2NZfHixcyCxGInAAACSUlEQVSbN4+lS5dWav2/VpE84eHhtGvXjpo1a+Lr60vXrl1JS0ur1PrLU5FMGzZsoEuXLnh5eRESEkKbNm348ccfK7X+8lTk33dV/dnw3+Tl5fHkk08yYcKEcm/AWpVUmQZ15513cvz4cbKysrBYLGzcuJHY2NhS68TGxjpm4WzatIl77rkHg8FAbGwsGzduxGKxkJWVxfHjx2nZsqUzYjhUJI/ZbGbUqFE899xz3H333c4ov1wVyfTxxx+zZcsWtmzZwiOPPMKTTz7J8OHDnRHDoSJ5YmJiOHTokOOaTUpKCo0bN3ZGjFIqkikiIoKdO3cCcPnyZfbt20fDhg0rPcOv3Uima4mJiWH79u1cvHiRixcvsn37dmJiYn7niv+7iuSxWCyMGTOGQYMG0adPn9+50krg1CkaN2nbtm3Sq1cviYuLk7lz54qIyMyZM+Wrr74SEZHCwkIZN26c9OjRQ+677z7JzMx0bDt37lyJi4uTXr16ybZt25xS/6/91jz//Oc/pVWrVjJw4EDHx7lz55yW42oV+TsqMWvWLJeYxSdSsTxr1qyRfv36Sf/+/WXatGlOqb88vzVTXl6ejBs3Tvr16yd9+/aV+fPnOy3Dr10v0759+6RLly7SqlUrad++vfTr18+x7cqVK6VHjx7So0cPWbVqlVPq/7XfmmfNmjXSvHnzUj8b9u/f77QcFaWP21BKKeWSqswpPqWUUn8s2qCUUkq5JG1QSimlXJI2KKWUUi5JG5RSSimXpA1KKaWUS9IGpZRSyiX9f9tDKZx9eth+AAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3deVzU5dr48c8XUUQBFZVBzfwFhpWa9mS54YaBKO6J1DETy+yoSWqaluaSC50n9ZjZRnZMq5OJG6Xmhim571qZloilCUMPIqDINnP//uBhnjwqMwwzzDBc79fr+3qdmfnOPdd49Oqe63t/r1tTSimEEELYlJujAxBCCFckyVUIIexAkqsQQtiBJFchhLADSa5CCGEHklyFEMIOJLmKWzz44IMMGDCAvn37EhMTw82bN60ea9q0aWzduhWA6dOnc/78+buee+jQIY4fP17mzwgJCeHq1asWP/9XjzzySJk+69133+WTTz4p03tE1SXJVdyiZs2aJCQksGnTJqpXr87q1atveb2oqMiqcefPn0/z5s3v+vrhw4c5ceKEVWML4YzcHR2AcF7t2rXj3LlzHDp0iHfeeQcfHx9SUlLYsmULCxcu5PDhwxQUFDBs2DCeeuoplFLMnTuXffv20ahRI6pXr24aa/jw4bz66qu0bt2apKQk/vnPf2IwGKhXrx7z589n9erVuLm58fXXX/PGG28QEBDArFmzuHLlCgCvv/46jz76KJmZmbzyyivo9Xratm2LJffAjB07lrS0NPLz83n22WeJiooyvbZgwQL27dtHgwYN+Oc//4mvry+///47c+bMITMzk5o1azJ37lwCAwNt/wcsXJsS4i/atm2rlFKqsLBQ/f3vf1dffPGFOnjwoGrTpo36/ffflVJKrV69Wr333ntKKaXy8/PVoEGD1O+//662bdumoqOjVVFRkUpLS1OPPvqo+vbbb5VSSj3zzDPq9OnTKiMjQ3Xt2tU0VmZmplJKqaVLl6rly5eb4pg0aZI6cuSIUkqpP/74Q4WHhyullJo7d6569913lVJKfffddyooKEhlZGTc9j169Ohher7kM27evKkiIiLU1atXlVJKBQUFqYSEBKWUUu+++66aM2eOUkqpZ599VqWkpCillDp58qQaPnz4HWMUojQycxW3yMvLY8CAAUDxzHXIkCGcOHGC1q1b07RpUwD27dvHuXPn2LZtGwA5OTn89ttvHDlyhIiICKpVq4ZOp6NDhw63jX/y5EnatWtnGqtu3bp3jGP//v231GivX7/OjRs3OHLkCMuWLQOge/fu1KlTx+x3+uyzz9ixYwcAqamp/Pbbb9SrVw83Nzf69OkDwIABA3jppZe4ceMGJ06c4OWXXza9v6CgwOxnCPGfJLmKW5TUXP9TrVq1TP9bKcWMGTPo0qXLLefs2bPHZnEYjUbWrFmDh4dHucY5dOgQ+/fv56uvvsLT05Phw4eTn59/x3M1TUMphY+Pzx3/DIQoC7mgJcosODiYL7/8ksLCQgBSUlLIzc3lscce49tvv8VgMJCens6hQ4due2/btm05evQoly5dAuDatWsA1K5dmxs3btzyGZ999pnp8c8//wzAY489xjfffAMUJ/OsrKxSY83JyaFOnTp4enqSnJzMyZMnTa8ZjUbT7Pubb77h0UcfxcvLi3vuuYdvv/0WKP4PydmzZ8v2ByQEklyFFSIjI2nevDmDBw+mb9++zJw5E4PBQGhoKM2aNaNPnz5MnTqVtm3b3vZeX19f3nzzTcaPH0///v2ZOHEiAD169GDHjh0MGDCAo0ePMn36dH788Uf69etHnz59+PLLLwEYN24cR48eJSIigh07dtC4ceNSY+3atStFRUX07t2bRYsW3RJTrVq1OH36NH379uXgwYOMGzcOgLfffpu1a9fSv39/IiIi2Llzp63+6EQVoiklLQeFEMLWZOYqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5CiGEHUhydRKy3FgI1yLJ1YH+mlA1TeP69eucPXuWOXPmsGvXLgdGJoQoL0muDqRpGgBpaWmcOnWKMWPGsGXLFnbs2IG7u/TUEaIyk3/BDnDlyhV0Oh3VqlXjs88+IykpCT8/P4YOHco999zD999/T0BAgKPDFEKUg/QWqEBKKVJTUxkxYgRffPEFtWrVYsuWLbRp0wY/Pz/q1avH22+/zX333ceQIUMcHa4Qohxk5lqBNE3Dy8uLhg0b4ufnB8CQIUNwcyuuzty4cYO0tDR69+7tyDCFEDYgNdcKcvHiRaC4GXW1atVu2eiv5MfD4sWLAWjVqlWFxyeEsC2ZudqZUorCwkLGjx9Pp06dGDNmDJmZmeTk5Ji2GikRHBzMAw88YHpfyQUvIUTlIzVXO9Pr9eh0OlJTUxkzZgyPPPIIycnJdO/eHV9fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri2HDhjFixAiGDh2KXq9n8uTJHDlyhBdeeIHff/+d/Px8NE3j6tWrLF26FJ1O5+jQhRA2IMnVznbv3s0777zD8OHDGTx4MFevXmX06NGEh4czatQo03n5+fnl3oxPCOE8pOZqB7/88gv169fHy8uL7t274+npybx58zAYDERGRvLee+/x97//nUuXLjFnzhwAqlev7uCohRC2JDNXG0tNTSUsLIyGDRsSFBTEsGHDCAwMJCsri1dffZUxY8bQp08f0tLSmDRpEsuWLcPX19fRYQshbKza7NmzZzs6CFeRnZ1NgwYNqFWrlqlXgIeHB++88w7e3t7k5OSwdetWPDw8aN++PQMHDqR27dqODlsIYQeyztVG9Ho9kyZN4siRIzz77LN07NiR5s2b06JFCz799FN8fX1p1qwZaWlpLFq0iKysrFuWYQkhXIuUBWzk2rVrbN68mb179zJ69Ghat27N2rVrOXnyJBEREXTp0gWA5ORkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HAmjVruPfeewkJCeHq1ascOnSInJwcWrRoga+vr5QChKgC5HdpORw5coSEhATT4zp16tCrVy+eeOIJPvroI3799Vf69+9P8+bN+eGHH7h+/boDoxVCVCRZilUORUVFxMbG4ubmRr9+/YDiBBsWFkZeXh47duxg/PjxhIeHU7NmTby8vBwcsRCiosjM1QpKKZRSdOzYkaVLl7JkyRK+/vpr02t169YlMDCQlJQUjEYjfn5++Pj4VHicf/75p2wf4+Ryc3MdHUKZyN8ny0lytYKmaWiaxtmzZ3n88ceZN28e77zzDps2bTI1W8nNzSU/P9/ifzwGg8GmMX7//fe89NJLpKam2mzMX3/9lcOHD5OZmWmzMX/77Td++OEHCgoKbDbmxYsX+eGHHzAajTb7c71w4QInTpygsLDQZmPu3LmThQsXkpGRYZPxAE6ePMnGjRs5efKkzf5Mjx49ysaNG4Hiv/uSYC0jF7SstHbtWt577z0iIiIICAigRYsWvPfee1y8eJE9e/aQkJDAjBkzaNSoUanjpKSkmLpjGQwGmyzP2rt3LwsXLiQzM5Nr167RtWvXco+5Z88eZs2aRUpKCtu3b6dDhw7lvjD33Xff8cYbb3Ds2DEOHDhAUFAQ9erVK9eYO3fuZPbs2SQnJ3Py5EkuX75M8+bNy3UH3Pbt25kxYwY//vgjhw4dQq/XExgYSI0aNawe8/Dhw8yfP5/o6GhatGhh9Th/lZiYSGxsLPn5+Rw5coRWrVpRt25dq8czGo3k5uYybtw4jh07hpubG61bt0bTNIxGo3RtM0eJMjEYDEoppT744AO1c+fOW147d+6c2rx5s1q5cqW6ePGi2bF27dqlHn74YTVp0iTTc0VFReWKb9++feqJJ55Qv/zyiyooKFAjR45Uhw8fLteYBw8eVGFhYerUqVNKKaXGjh2r9u3bV64xjx07psLDw9VPP/2klFJq1qxZatq0aeUa8+rVq+r5559Xv/76q1JKqfj4eDV48GC1bNkylZOTY9WYBQUF6uWXX1ZHjx5VSim1detW9dZbb6nFixdbPaZSSv3rX/9Sy5cvV0oplZaWpvbu3atOnjypsrOzrRrv6tWr6rnnnlPnzp1TSik1bdo0tWXLFvU///M/Ki8vz+o4lVIqLi5OffLJJ2rKlClqxYoV5RqrKpGyQBm5ublx6dIl9u3bd0sHq99++42goCD69OnDs88+S7NmzUodJzc3l88//5zXX3+d6tWrM3nyZACqVatWrp+dBoOBf/zjH9x///3cvHmT++67j19//RWwvl7WoEED5syZw8MPP8yff/7JqVOn+Pzzz5k5cyZbt261etwXXniBhx56CICYmBiysrLK9VPW3d2d3Nxc/vzzT6B4l4cmTZqQmZnJ7t27rR73+vXr/PbbbwCEhobSo0cPCgsL+eabb6z+7n9tK/nyyy+zbt06Pv/8c+bMmUNWVlaZx3N3dycvL48LFy5w/fp1Dh8+TEJCAgsWLOD9998vV23X3d2d1NRUBg0axOnTp4mNjWXRokUopTAajVaP6+qkLFAGSimKiopYsmQJISEhdO7cmeTkZKZPn86FCxe4//778fLysujnUvXq1enQoQOtWrWiQ4cOJCYmkpiYSFhYWLlKA82aNaNRo0YYjUZq1qyJpmnExsYSHBxMgwYNrBrT19eXe+65B4BVq1bRunVrZs+eTWZmJrt27eLxxx/H09OzTGP6+fnRrFkzatSogcFgICcnhy+//JLevXvj6elJZmZmmcf08PCgoKCAxMREcnNz+fbbb8nNzaVVq1YcPXqUnj17lmk8KE6C9evXZ8OGDfj7+9OkSRP8/f25du0aBw4cICwszKqfxzVr1mThwoUcP36c3r17M3HiRB588EF++OEHvLy8zP7H+T95eHhQu3Zt4uLi+Oabb+jduzdvvvkmPj4+HDt2jPvuu8/q///r169PamoqAwcO5I8//uCTTz4hMDCQ7t27S2mgFDJzLQNN06hevTo3btwgPT2d6Oho1q9fzwMPPMDkyZPx9/cv0182nU5H7dq18fX1Zc6cOeTn55tmsD/99BPJyclWx1qSoLt27crQoUPZvXu3TWYaY8aMYezYsQAMHjyY69evW3XRrFq1aqalaUopvL29qVOnDr6+vnz99dcsWbKEvLy8Mo/bt29funbtyqFDh8jLy2PhwoU89dRTZGRkWL3OuF27dgQHB5OQkMCRI0eoVq0a/fr1Iz09nbNnz1o1ZosWLZg6dSqnTp3i8uXLADRt2hSj0cjVq1etGjM8PJwVK1bw6KOPmn4RdOzYkRs3bvDHH39YNSYUJ+6UlBTWrFnD6tWreeGFF0hNTWX16tVWj1kVyDrXMrpw4YLpp/CoUaPo1KmTTdoF1qtXjzlz5vD2228THh6O0Whk1apVNogYHnjgAT799FNGjRpVrl0O1H9sPbNt2zYyMjJMmy1ay93dHXd3dxo1asSiRYvYt28fsbGx1KxZs8xjeXt7079/f/r27Wv6D8zGjRvL1cvBw8ODfv36oWkaH330ERcuXKBGjRpkZGSU6zbmrl27EhMTw7vvvkvjxo0BOHPmDKNHj7Z6zDp16tChQwe2bt1K9erVyc/P5/Lly+W6aKbT6fD39+f9999n5syZhISEcPDgwTLPrqsch1V7K7GcnByVm5t7y3NGo9EmY69YsUJ16tRJnT171ibjlYiJiVGXLl2yyVj5+flqzZo1qk+fPqYLKOVhNBpVfn6+6tmzp+rWrZtKSUkpf5D/Kz4+XvXu3dsmf575+fnqwIEDasKECWrq1Kmmi3Hl9eOPP6pFixap2NhYm8SZlZWlVq5cqYYNG6aee+459fPPP5d7zCtXrqgffvjB9Ljkwq64O2nc4kSysrKYMGECU6dONW1UWF7KDhsdFhYWsn//fpo2bUpAQIDNxl2/fj2tW7fm/vvvt9mYf/zxB0VFRTadZRkMBjRNc/quZiVlEFveGWiPv0+uSpKrk6nK273IP1zhSiS5CiGEHTj37xohhKikJLkKIZxefn4+2dnZjg6jTKr0UqykxO/JvFL2u2GEELeq17gOXXt2sdv4l5PjyC1ozkOtw8q1nLAiVenkmnkli2UjVjo6DCEqvZdWjrDb2Ddv3qTI6I3O+xv0ybtpHPQPu32WLUlZQAjh1K6kLMffewO+tXZzLe9xm7fntBdJrkIIp1Uya/X2+Bk3rYgGtRPRJ7/u6LAsIslVCOG0SmatJSrT7FWSqxDCKf111lqiMs1eJbkKIZzSf85aS1SW2avDkmtISMgtrdUOHTrEiy++CGBq4/fXdm59+/Y1tWb763t//PFHQkJCOHPmTAVGL4SwpzvNWktUltlrhSbXgoICizui+/v78+GHH5Z6ztmzZ4mJiWHJkiU89NBD5OTkSGd0IVzA3WatJSrD7LVCkmtycjJvvfUW4eHhXLx40aL3dO/enfPnz3PhwoU7vn7hwgXGjRvHf//3f/Pwww8DcOzYMcLDw3n33Xe5cuWKrcIXQlSgvLw8iow+d5y1lnDTiqhfK9G0pY8zsltyzc3NZd26dTz99NPMmDGDwMBAvv76a1OHdLOBubkxatQoPvroozu+PnbsWGbOnEm7du1Mz3Xv3p3Vq1fj7e3NmDFjeP755/n2229tum2zEMK+CgoKqFU9xex5tWpcID8/vwIiso7d7tAKDg6mRYsWzJs3j8DAQIve85/t5vr27csHH3zApUuXbju3Y8eOxMfHExwcfMvtcL6+vkRHRxMdHc2JEyd4/fXXef/99/nmm2/K94WEEBVGoTBSeolP4dwN/ew2c126dCk6nY7x48ezbNmy2/bwqVu37i2NGLKysm7bs97d3Z3nnnuOjz/++LbxZ86cCcCcOXNue+38+fP84x//YOrUqfzXf/0X8+bNs8VXEkJUEKXAoIxmD2dmt+QaHBzMkiVL+OKLL/D29mbs2LFER0ebrvi3b9+ehIQEoLiz+9dff0379u1vG2fQoEEcOHDgtk3bNE1j0aJFXLhwgXfeeQco3tRv6NChzJgxg4CAADZs2MD8+fNp06aNvb6mEMIOjBgpwlDqYTAzs3U0uzduqVevHiNGjGDEiBGcPn3a9BN+7NixzJ49m/79+6OUokuXLvTv3/+299eoUYPhw4czf/78217z8PDggw8+4JlnnqFBgwZ06NCB2NhYi8sQQgjnZAQMZvr4G5UCJ964okrvRJDw2SbpiiWEDby0cgQDhve1yVjZ2dmkX/lvGviU/m8zr6A5+dqnTrsLbZVuOSiEcE4KMJi5YGV08gtaklyFEE7HqBSFZi5YFUlyFUKIslFg9nKVEacuuUpyFUI4H4WyqCzgzBu+SHK1sW1XTtp8zF6N29p8TCGcWfFqATPnKKjmxFNXSa5CCKdjRKPQzI9+AxrVKygea0hyFUI4HUXxzLQ05l53NEmuQginU7wUq/SZq3PfnyXJVQjhhAxKA1X63fnKzOuOJslVCOF0FJrZmaty6oVYklyFEE5IoWE021dKkqsQQpRJ8QUtM8nT3OsO5txFi3J47bXX6NixI3372qaZhBCi4hiURoGqVupR5NS3ELhwch08eDDLly93dBhCCCuUlAVKP2Tm6hCPPfYYderUcXQYQggrlFzQKu2wJLne6RfstWvXGDlyJGFhYYwcOZKsrKziz1SKefPmERoaSr9+/fjpp59M79mwYQNhYWGEhYWxYcPdd6X9K5dNrkKIysuARqGqVupRZMFSrDv9go2Li6Njx45s376djh07EhcXB0BSUhIXL15k+/btzJ07l9mzZwPFyXjZsmWsWbOG+Ph4li1bZkrIpZHkKoRwOsUzVzezhzl3+gWbmJjIwIEDARg4cCA7d+685XlN02jbtm1x0+70dPbu3Uvnzp2pW7cuderUoXPnznz//fdmP1tWCwghnI5SGgYzM1M35UZycjITJ040PRcVFUVUVFSp78vIyMDPzw+Ahg0bkpGRAYBer8ff3990nr+/P3q9/rbndToder3e7HeQ5CqEcDqWrHM1ohEYGMj69eut/hxN09A0+1wYc9mywKRJk3jqqadISUmha9euxMfHOzokIYSFDFiwFMvK21/r169Peno6AOnp6fj6+gLFM9K0tDTTeWlpaeh0utue1+v16HQ6s5/jssl18eLF7N27l59++omkpCQiIyMdHZIQwkJKaRiVm9nDGiEhIWzcuBGAjRs30rNnz1ueV0px8uRJvL298fPzIzg4mL1795KVlUVWVhZ79+4lODjY7OdIWUAI4XRKLmiVxvztscW/YA8fPkxmZiZdu3Zl/PjxjB49mgkTJrB27VoaN27MkiVLAOjWrRt79uwhNDQUT09PFixYAEDdunUZO3YsQ4YMAWDcuHHUrVvX7GdLchVCOB0jWnFnrFIYLBhn8eLFd3x+5crbt+3WNI1Zs2bd8fwhQ4aYkqulJLkKIZyOUWkUqtLTk7uZ1x3NuaMTQlRJyoI7sJx8IwJJrrZmj80EJ57/2eZjAvyz+YO2H9TNDs00jJb8ABSuRGF+nau51x1NkqsQwukY//f219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXDhwi19Hi9dukRMTAzR0dGOC0oIYREFZm8icPY9tFw2uQYEBJCQkACAwWCga9euhIaGOjgqIYQljEqj0Fh6TdVglJmrwx04cICmTZvSpEkTR4cihLCAJV2xLNnmxZGqRHLdvHnzLbs/CiGcW/EFrcrdW8C5U78NFBQUsGvXLsLDwx0dihDCQkaLdn+VpVgOlZSURMuWLWnQoIGjQxFCWMiSmassxXKwzZs3ExER4egwhBBloKj861xduiyQm5vL/v37CQsLc3QoQogyMFJ8+2tphyzFcqBatWpx6NAhR4chhCgjpTSzNVVZLSCEEGVkyU4EMnMVQogyMoLZDQoluQohRBlZ1LhFygJCCFE2Cs3sNi7m+r06miRXIYTTsegOLU2Sqygnu+zSCoz79Rebj/leUAubjymqHoX5loJScxVCiDIyKkvKAlJzFUKIMim+Q6tyrxZw7tQvhKiSlCqevZZ2KAtvf/3000+JiIigb9++TJo0ifz8fC5dukRkZCShoaFMmDCBgoICoLjR04QJEwgNDSUyMpLLly9b/R0kuQohnE7JzLXUw4Jx9Ho9q1atYt26dWzatAmDwcDmzZtZuHAh0dHR7NixAx8fH9auXQtAfHw8Pj4+7Nixg+joaBYuXGj1d5DkKoRwOiU119IOc3tslTAYDOTl5VFUVEReXh4NGzbk4MGD9OrVC4BBgwaRmJgIwK5duxg0aBAAvXr14sCBAyhlXedYqbkKIZxO8WoB8y0Hk5OTb9krLyoqiqioKNNjnU7Hc889R48ePfDw8KBz5860bNkSHx8f3N2L05+/vz96vR4onuk2atQIAHd3d7y9vcnMzMTX17fM38Flk2t+fj7Dhg2joKAAg8FAr169iImJcXRYQggLWHJBSymNwMBA1q9ff9dzsrKySExMJDExEW9vb15++WW+//57W4d7Ry6bXGvUqMHKlSupXbs2hYWF/O1vf6Nr1660bdvW0aEJIcxRlsxczQ+zf/9+7rnnHtPMMywsjOPHj5OdnU1RURHu7u6kpaWh0+mA4pluamoq/v7+FBUVkZOTQ7169az6Ci5bc9U0jdq1awNQVFREUVERmpPf0SGEKGZUGgajW6mHuZsMABo3bsypU6e4efMmSikOHDhA8+bNad++Pdu2bQNgw4YNhISEABASEsKGDRsA2LZtGx06dLA6b7hscoXiQvaAAQPo1KkTnTp1ok2bNo4OSQhhAUXxOlZzhzlt2rShV69eDBo0iH79+mE0GomKimLKlCmsWLGC0NBQrl27RmRkJABDhgzh2rVrhIaGsmLFCiZPnmz1d3DZsgBAtWrVSEhIIDs7m3HjxvHLL78QFBTk6LCEEGZYWnO1RExMzG3XW5o2bWpafvVXHh4eLF261PJAS+HSM9cSPj4+tG/fvsIK2UKI8lEWlAUMRucu87lscr169SrZ2dkA5OXlsX//fgICAhwclRDCIqo4wZZ6OPntry5bFkhPT2fatGkYDAaUUoSHh9OjRw9HhyWEsIAtywKO4rLJ9YEHHmDjxo2ODkMIYQWlig9z5zizuybXRx55xLQEoeT2L03TUEqhaRrHjx+vmAiFEFWOQjN7e6u5ma2j3TW5njhxoiLjEEIIE0tvf3VmFl3QOnr0KOvWrQOKLxRdunTJrkEJIaq2krJAqYejgzTDbHJdtmwZy5cvJy4uDoDCwkKmTJli98CEEFWbudUCVPaZ644dO/jggw/w9PQEiu+9vXHjht0DE0JUXa6wztXsaoHq1aujaZrp4lZubq7dgxIV4737bX+32vQLtq/Vzw+QZjtVjUWrBSomFKuZTa69e/dm5syZZGdns2bNGtatW8fQoUMrIjYhRJVlwTYuTl4WMJtcn3/+efbt20ft2rVJSUkhJiaGzp07V0RsQogqSlnUcrCSJ1eAoKAg8vLy0DRNGp8IIexOWTBzdfY7tMxe0IqPjycyMpIdO3awbds2oqKi7thNRgghbEZZeDgxszPX5cuXs2HDBlM37szMTJ566imGDBli9+CEEFWX2ZlrZW/cUq9ePVNHf4DatWtbve2BEEJYQikNo5mlVsqSvbUd6K7JdcWKFQDce++9DB06lJ49e6JpGomJibRo0aLCAhRCVFGuulqg5EaBe++9l3vvvdf0fM+ePe0fVTmlpqby6quvkpGRgaZpDB06lBEjRjg6LCGEpVy5K9ZLL71UkXHYVLVq1Zg2bRotW7bk+vXrPPnkk3Tu3JnmzZs7OjQhhKWcPHmaY7bmevXqVT7++GPOnz9Pfn6+6flVq1bZNbDy8PPzw8/PDwAvLy8CAgLQ6/WSXIWoJJTSUGZrrs5dFjC7FGvy5MkEBARw+fJlXnrpJZo0aULr1q0rIjabuHz5Mj///LPs/CpEZWLJNi9OXnM1m1xLtp11d3fn8ccfJzY2loMHD1ZEbOV248YNYmJieNQNBFwAABE0SURBVP311/Hy8nJ0OEKIsnD1da7u7sWn+Pn5sXv3bvz8/MjKyrJ7YOVVWFhITEwM/fr1IywszNHhCCHKQmHBagDnnrmaTa5jxowhJyeHqVOnMnfuXG7cuMFrr71WEbFZTSnF9OnTCQgIYOTIkY4ORwhhDXMz08o+cy3ZMdXb25vPPvvM7gHZwrFjx0hISCAoKIgBAwYAMGnSJLp16+bgyIQQlrGgGXZlTa5z58419XC9kxkzZtglIFto164d586dc3QYQggrWdLPtdIm11atWlVkHEII8X8UYG6plYWrBbKzs5kxYwa//PILmqaxYMEC7rvvPiZOnMgff/xBkyZNWLJkCXXq1EEpxfz589mzZw81a9bkrbfeomXLllZ9hbsm10GDBlk1oBBClJcGaDaauc6fP58uXbqwdOlSCgoKyMvL48MPP6Rjx46MHj2auLg44uLimDJlCklJSVy8eJHt27dz6tQpZs+eTXx8vFXfwaLdX4UQokLZqOVgTk4OR44cMXXxq1GjBj4+PiQmJjJw4EAABg4cyM6dOwFMz2uaRtu2bcnOziY9Pd2qr2BRs2whhKhYllzQ0khOTmbixImmp6KiooiKijI9vnz5Mr6+vrz22mucPXuWli1bMn36dDIyMkx3cTZs2JCMjAwA9Ho9/v7+pvf7+/uj1+tN55aFJFdhU/bYTHDkud9sPuaKFs1sPmalUsrFauvGs+1wxTVX8+cEBgayfv36u55SVFTEmTNneOONN2jTpg3z5s0jLi7ulnP+ugGrLbnkagEhRCVnyc9+C8oC/v7++Pv7m25/Dw8PJy4ujvr165Oeno6fnx/p6en4+voCoNPpSEtLM70/LS0NnU5n1VeQ1QJCCOdkg36uDRs2xN/fnwsXLhAQEMCBAwcIDAwkMDCQjRs3Mnr0aDZu3GhqpRoSEsLnn39OREQEp06dwtvb26qSAMhqASGEM1KgmSkLmF1N8L/eeOMNJk+eTGFhIU2bNiU2Nhaj0ciECRNYu3YtjRs3ZsmSJQB069aNPXv2EBoaiqenJwsWLLD6K7hky0EhhCjx4IMP3rEuu3Llytue0zSNWbNm2eRzXb7loBCi8ilZ52rucGYu3XJQCFFJKc2yw4m5bMtBIUQlZslSrMq6+2uJythyEIrrKfHx8SiliIyMJDo62tEhCSHKwNzPfueet7poy8FffvmF+Ph44uPjqV69OqNGjaJHjx40a1bFF44LUVnYaJ2rI5lNrnebpcbGxto8GFtJTk7m4YcfxtPTE4DHHnuM7du388ILLzg4MiGExVw9uXbv3t30v/Pz89m5c6fVi2orSlBQEEuWLCEzM5OaNWuSlJQkN0UIUZko0My0HDS3DtbRzCbXXr163fK4b9++/O1vf7NbQLYQGBjIqFGjeP755/H09OSBBx7AzU0agAlRaVSCDQjNKXPjlosXL5o6yDizyMhIIiMjAVi8eLHV9wcLISqeLfu5OorZ5PrII4/c0sClYcOGTJ482a5B2UJGRgb169fnypUrbN++nTVr1jg6JCGEpSy5/bWylwVOnDhREXHY3Pjx47l27Rru7u7MmjULHx8fR4ckhCgLV5+5jhgx4rZ7cO/0nLP597//7egQhBDWcuWaa35+Pjdv3iQzM5OsrCzU/27FeP36dfR6fYUFKISoeiypuTp7b4G7JtfVq1ezcuVK0tPTGTx4sCm5enl58cwzz1RYgEKIKsiVbyIYMWIEI0aM4LPPPmP48OEVGZMQQlT6mavZxZ9ubm5kZ2ebHmdlZfHFF1/YNSghRBVno91fHcnsBa01a9YwbNgw0+M6deoQHx9/y3NC2JM9NhMcdvayzcf84oF7bD6m3SgbZyZ7JDonT57mmE2uRqMRpZRpravBYKCwsNDugQkhqi6tKqxzDQ4OZsKECTz11FNA8YWuLl262D0wIUTV5vJ3aE2ZMoWvvvqKL7/8EoBOnToxdOhQuwcmhKjCKkFN1RyLLmg9/fTTLF26lKVLl9K8eXPmzp1bEbEJIaqokrKAucOZWdS45cyZM2zatImtW7fSpEkTwsLC7B2XEKKqc9WyQEpKCps3b2bTpk3Uq1ePPn36oJSqNLsRCCEqMVe+iaB37960a9eOjz76yLQ9yqefflpRcQkhqrjKvofWXWuuy5Yto2HDhjz77LPMmDGDAwcOmG6BrQySkpLo1asXoaGhxMXFOTocIUQZuHTN9YknnuCJJ54gNzeXxMREVq5cydWrV5k1axahoaEEBwdXZJxlYjAYePPNN1mxYgU6nY4hQ4YQEhJC8+bNHR2aEMISLlAWMLtaoFatWvTr148PP/yQPXv28NBDD/Hxxx9XRGxWO336NM2aNaNp06bUqFGDiIgIEhMTHR2WEKIsKvntr2XaWKpOnTpERUU5fS9XvV6Pv7+/6bFOp5M2iUJUMpoyc5RhLIPBwMCBA3nxxRcBuHTpEpGRkYSGhjJhwgQKCgoAKCgoYMKECYSGhhIZGcnly9bfJi279gkhnI+5xFrGmeuqVasIDAw0PV64cCHR0dHs2LEDHx8f1q5dC0B8fDw+Pj7s2LGD6OhoFi5caPVXcMnkqtPpSEtLMz3W6/WyQaEQlY2NygJpaWns3r2bIUOGFA+rFAcPHjTtbD1o0CBT2XDXrl0MGjQIKN75ujwX8l0yubZu3ZqLFy9y6dIlCgoK2Lx5MyEhIY4OSwhhKQtbDiYnJzN48GDT8dVXX9021IIFC5gyZQpubsXpLjMzEx8fH9zdi6/n+/v7m8qGer2eRo0aAeDu7o63tzeZmZlWfYUyb61dGbi7uzNz5kxGjRqFwWDgySef5P7773d0WEIIC1nUFUtBYGAg69evv+s53333Hb6+vrRq1YpDhw7ZOMrSuWRyBejWrRvdunVzdBhCCCvZYieC48ePs2vXLpKSksjPz+f69evMnz+f7OxsioqKcHd3Jy0tzVQ21Ol0pKam4u/vT1FRETk5OdSrV8+q+F2yLCCEqORstBPBK6+8QlJSErt27WLx4sV06NCBRYsW0b59e7Zt2wbAhg0bTGXDkJAQNmzYAMC2bdvo0KGDqZd1WUlyFUI4nZLdX82uGLDSlClTWLFiBaGhoVy7do3IyEgAhgwZwrVr1wgNDWXFihVMnjzZ6s9w2bKAEKISU4C521vLmFzbt29P+/btAWjatKlp+dVfeXh4sHTp0rINfBeSXIUQTsnldyIQwhXZYzPB/mcybD4mwNcP1bfLuE7NBXoLSHIVQjid4qVYpWfP8tRcK4IkVyGEU7LFUixHkuQqhHA+UhYQQgjbK1mKVeo5klyFEKKMLLz91ZlJchVCOB8pCwghhO1ZUhZw9uTqsre/ZmdnExMTQ3h4OL179+bEiROODkkIYTEFyoLDibnszHX+/Pl06dKFpUuXUlBQQF5enqNDEkJYygVqri45c83JyeHIkSOmzuM1atTAx8fHwVEJISzmAltru2RyvXz5Mr6+vrz22msMHDiQ6dOnk5ub6+iwhBCWslHLQUdyyeRaVFTEmTNnePrpp9m4cSOenp7ExcU5OiwhhIVKbn8t9XDymqtLJld/f3/8/f1p06YNAOHh4Zw5c8bBUQkhysKe/Vwrgksm14YNG+Lv78+FCxcAOHDgwC3b6gohnJwLlAVcdrXAG2+8weTJkyksLKRp06bExsY6OiQhhIVcYZ2ryybXBx98sNRdIYUQTkwpC1oOOnd2ddnkKoSo5GTmKoQQtmXJBStnv6AlyVUI4XwUYKYsYPZ1B5PkKoRwPi5w+6skVyGEE7KgMYskVyHKSdNsP6YdrjTba5fWJ39Ot/mY6x70s/mYtiQ1VyGEsAcLdn+VloNCCGENc12vpCuWEEKUTXFZQJk9zElNTWX48OH06dOHiIgIVq5cCcC1a9cYOXIkYWFhjBw5kqysLACUUsybN4/Q0FD69evHTz/9ZPV3kOQqhHBONugrUK1aNaZNm8aWLVv46quv+Pe//8358+eJi4ujY8eObN++nY4dO5q65iUlJXHx4kW2b9/O3LlzmT17ttXhS3IVQjgfZabdoNH87bEAfn5+tGzZEgAvLy8CAgLQ6/UkJiYycOBAAAYOHMjOnTsBTM9rmkbbtm3Jzs4mPd26C4pScxVCOB+FBUuxFMnJyUycONH0VFRUFFFRUXc8/fLly/z888+0adOGjIwM/PyKV0w0bNiQjIwMAPR6Pf7+/qb3+Pv7o9frTeeWhcsm108//ZT4+Hg0TSMoKIjY2Fg8PDwcHZYQwhIW3kQQGBhoUYOmGzduEBMTw+uvv46Xl9et42gamh2W+7lkWUCv17Nq1SrWrVvHpk2bMBgMbN682dFhCSEsZsnur5aNVFhYSExMDP369SMsLAyA+vXrm37up6en4+vrC4BOpyMtLc303rS0NHQ6nVXfwCWTK4DBYCAvL4+ioiLy8vKsmtYLIRzDom1eLKi5KqWYPn06AQEBjBw50vR8SEgIGzduBGDjxo307NnzlueVUpw8eRJvb2+rc4dLlgV0Oh3PPfccPXr0wMPDg86dOxMcHOzosIQQFrPk9lfzyfXYsWMkJCQQFBTEgAEDAJg0aRKjR49mwoQJrF27lsaNG7NkyRIAunXrxp49ewgNDcXT05MFCxZY/Q1cMrlmZWWRmJhIYmIi3t7evPzyyyQkJJj+cIUQTk5h/iYBC8oC7dq149y5c3d8rWTN619pmsasWbPMD2wBlywL7N+/n3vuuQdfX1+qV69OWFgYJ06ccHRYQghLKYVmNJZ6YHTuW7RcMrk2btyYU6dOcfPmTZRSskGhEJVNyVIsG1zQchSXLAu0adOGXr16MWjQINzd3XnwwQfvuvZNCOGEbFQWcCSXTK4AMTExxMTEODoMIYQVNMz3DpANCoUQoqwU5muqyrlrrpJchRBOSHYiEEII27Ok5urcE1dJrkIIJ6TM11Sl5iqEEGWlFBjMTE2dfJ2rJFfh/Jx8hmJv9thMcNjZyzYdz/dGoU3HM61lNXeOE5PkKoRwTnJBSwghbEzKAkIIYQdKmV/HKutchRDCClIWEEIIG1MKzDXDlgtaQghRRkqZr6k6ec3VJVsOljAYDAwcOJAXX3zR0aEIIcrCopaDzj1zdenkumrVKunjKkRlVDJzLe2Q5OoYaWlp7N69myFDhjg6FCFEmVmy+6tzJ1eXrbkuWLCAKVOmcOPGDUeHIoQoKxdY5+qSM9fvvvsOX19fWrVq5ehQhBDWUKCU0cwhM9cKd/z4cXbt2kVSUhL5+flcv36dyZMns3DhQkeHJoSwhCVLscy97mAumVxfeeUVXnnlFQAOHTrEv/71L0msQlQmSoHBUPo5Tl4WcMnkKoSo5KQrlvNr37497du3d3QYQogyUEqhzMxMlfQWEEIIK0hvASGEsDFLaq7mXncwl1yKJYSo5JRCGUs/LK25JiUl0atXL0JDQ4mLi7Nz4P9HkqsQwvmU9HMt9TCfXA0GA2+++SbLly9n8+bNbNq0ifPnz1fAF5CygBDCyWiaxv3t/x8etT1KPc/LtxaappV6zunTp2nWrBlNmzYFICIigsTERJo3b26zeO+mSifXZq3vYelPbzo6DCEqno3Llflavs3G8vLyIqR/N1Q/8zPTLVu2MGHCBNPjqKgooqKiTI/1ej3+/v6mxzqdjtOnT9ss1tJU6eTatm1bR4cghPgPmqZRq1Yti86NjIwkMjLSzhFZR2quQgiXpdPpSEtLMz3W6/XodLoK+WxJrkIIl9W6dWsuXrzIpUuXKCgoYPPmzYSEhFTIZ1fpsoAQwrW5u7szc+ZMRo0ahcFg4Mknn+T++++vkM/WlLP37RJCiEpIygJCCGEHklyFEMIOJLkKIYQdSHIVQgg7kOQqhBB2IMlVCCHsQJKrEELYwf8H9PD+fFw0J7IAAAAASUVORK5CYII=\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdd3gU1f748ffW9B5ICL0nlEAgIaGEEjFUCUVAmhFUVKpUUdSv+AP0IhAvSBFBihdRoiIgoVxaAOmhBCQQSqhppLfNZsv8/ojsJSYR1EA2y3k9D0/YmTNnPmey2c/OmTNnZJIkSQiCIAiCmZFXdgCCIAiCUBaRoARBEASzJBKUIAiCYJZEghIEQRDMkkhQgiAIglkSCUoQBEEwSyJBPSVLly5l+vTplR3GU3X37l2aNm2KXq//x3WFhIRw9OjRMtfNmjWLiIiIf7yPZ0lERASBgYF07Njxqe87JiaG0NBQ/Pz82Lt379+u57XXXmPLli0VGNnTl5iYiJ+fHwaDobJDMUsiQVWg7du3M3DgQPz8/OjUqROvvfYap0+fruywhKekadOm3Lp1q7LDeKTExETWrl1LVFQUv/76a5ll8vLymDdvHl27dsXPz4/u3bszb948MjIy/vH+lyxZwogRIzh79izdu3f/2/WsXr2aAQMG/ON4/mjWrFk0bdq0VPKcP38+TZs25aeffnqsev7sS9UDXl5enD17FoVC8bfjtWQiQVWQtWvXMn/+fN58801+/fVXDhw4wPDhw9m3b19lh/a3VcSZj/A/5nI8ExMTcXZ2xs3Nrcz1RUVFhIeHc+3aNVavXk1MTAzff/89zs7OXLhwoUL237hx439cz5NUr149tm7danqt1+vZuXMnderUqbB9VOT7QZIkjEZjhdVnLkSCqgC5ubksWbKEDz/8kNDQUGxtbVGpVISEhPDOO++Uuc2kSZPo2LEjbdu2ZcSIEVy9etW0Ljo6mt69e+Pn50dwcDBr1qwBICMjgzfeeAN/f3/atWvH8OHDTW/KlJQUJk6cSFBQECEhIWzYsMFUX2xsLAMHDqRNmzZ06NCBTz75pMyYTpw4QefOnVm1ahUdO3bk3XffJTs7mzfeeIOgoCACAgJ44403SE5ONm0zatQoPv/8c1566SX8/PwYM2ZMud+yd+/eTUhICPHx8RiNRlatWkX37t0JDAxk8uTJZGVlmcr+/PPPdOvWjcDAQFasWPHI30FmZiajR4/Gz8+PkSNHcu/ePQDmzJnDp59+WqLsm2++ybp168qs5/r164wePZp27drRo0cPoqKiTOtmzZrFnDlzGDt2LH5+fgwePJjbt28DMGLECADCwsLw8/MjKiqqzONZVFTEvHnz6NSpE506dWLevHkUFRWVOP4rV64kMDCQkJAQtm3bBhT/Djt06FCiK2jPnj3069evzHbk5uYyc+ZMgoKC6NatG8uXL8doNHL06FHGjBlDamoqfn5+zJo1q9S2W7duJSkpiS+++IJGjRohl8txc3Nj/PjxdOnSxXScRo0ahb+/P3369CnxRezPjlP37t25c+cOb775Jn5+fhQVFZU603i4O1yr1TJ9+nQCAwPx9/dn0KBBpKWlAcXvvcjISACMRiPLly+nW7dutG/fnpkzZ5Kbmwv8r6t5y5YtdO3a9bHeUyEhIcTExJCdnQ3A4cOHadq0Ke7u7qYyt2/f5uWXXyYwMJDAwECmTZtGTk4OADNmzCAxMdHUzq+++soUR2RkJF27diU8PLxEN3hWVhadO3dm//79AOTn5/P888/z888/lxnjqFGjiIiI4KWXXqJVq1bcuXOHM2fOMGjQINq2bcugQYM4c+YMAMePH+eFF14wbTt69GgGDRpkej18+PB/1N36xEjCPxYdHS35+PhIOp2u3DJLliyRpk2bZnodGRkp5ebmSlqtVpo7d67Ur18/07qOHTtKp06dkiRJkrKysqSLFy9KkiRJCxculD744AOpqKhIKioqkk6dOiUZjUbJYDBIAwYMkJYuXSpptVrp9u3bUkhIiHTo0CFJkiRpyJAh0pYtWyRJkqS8vDzp7NmzZcZ4/PhxycfHR1qwYIGk1WoljUYjZWRkSLt27ZIKCgqk3NxcaeLEidJbb71l2mbkyJHSc889J924cUPSaDTSyJEjpc8++0ySJEm6c+eO1KRJE0mn00k//PCD1L17d+nmzZuSJEnSunXrpMGDB0tJSUmSVquVPvjgA2nKlCmSJEnS1atXpdatW0snT56UtFqtNH/+fMnHx0f69ddfy4z7nXfeKVH+//2//ye99NJLkiRJ0vnz56WOHTtKBoNBkiRJSk9Pl3x9faX79++Xqic/P1/q3Lmz9MMPP0g6nU767bffpHbt2klXr1417addu3bS+fPnJZ1OJ02dOlV6++23Tds3adLE1L7yjufnn38uDR48WEpLS5PS09OloUOHShERESXKz58/X9JqtdKJEyekVq1aSdevX5ckSZJ69eolHTx40FT/uHHjpDVr1pR5TGbMmCG9+eabUm5urnTnzh0pNDRU2rx5s2k/wcHBZW4nSZL09ttvSzNnzix3fVFRkdS9e3dpxYoVklarlY4ePSq1bt3aFOejjlO3bt1K/C7/+Prhv5VNmzZJb7zxhlRQUCDp9XrpwoULUm5uriRJxe+9B22KjIyUunfvLt2+fVvKy8uTxo8fL02fPl2SpP+9D2fPni1pNBopLi5Oat68uXTt2rUy2/fOO+9Iixcvlt5//31p48aNkiRJ0qRJk6Tt27dLL730kvTjjz9KkiRJN2/elI4cOSJptVopPT1dGj58uDR37txy2/UgjhkzZkj5+fmSRqMp8TciSZJ0+PBhqUOHDlJaWpo0e/ZsaeLEieX+HkaOHCl16dJFio+Pl3Q6nXT//n3J399f2rJli6TT6aTt27dL/v7+UkZGhqTRaKQWLVpI6enpUlFRkdS+fXupU6dOUm5urqTRaKSWLVtKGRkZ5e6rsogzqAqQlZWFi4sLSqXysbd58cUXsbe3R61WM3HiRC5fvmz6xqdUKrl27Rp5eXk4OTnRvHlz0/L79++TmJiISqXC398fmUzGhQsXyMjIYMKECajVamrXrs2QIUNM3/6VSiW3b98mIyMDOzs7WrduXW5ccrmcSZMmoVarsba2xsXFhR49emBjY4O9vT1vvfUWp06dKrHNwIEDqV+/PtbW1vTs2ZO4uLgS69evX8+aNWv45ptvqFu3LgDfffcdU6ZMwdPTE7VazYQJE9i9ezd6vZ5du3bRtWtXAgICUKvVTJ48Gbn8z9+qD5efMmUK586dIykpCV9fXxwcHDh27BgAUVFRtGvXrsQ34QcOHjxIzZo1GTRoEEqlkmbNmtGjRw927dplKtO9e3d8fX1RKpX069evVFsfdTy3b9/O+PHjcXNzw9XVlfHjx5vOkh6YPHkyarWadu3a0aVLF3bu3AlA//79TWWzsrI4cuQIffv2LbVPg8FAVFQU06ZNw97enlq1ajF69OhS+ylPVlYW1apVK3f9+fPnKSgoYOzYsajVatq3b0+3bt3YsWPH3z5O5VEqlWRlZXHr1i0UCgUtWrTA3t6+VLnt27fzyiuvULt2bezs7Jg6dSpRUVElutEmTJiAtbU13t7eeHt7c/ny5T/dd1hYGFu3biUnJ4dTp06Vul5Wt25dOnbsiFqtxtXVldGjR5f62yjLxIkTsbW1xdrautS6Tp060bNnT1555RWio6OZM2fOn9Y1YMAAGjdujFKp5MiRI9StW5f+/fujVCrp27cvDRo04MCBA1hbW9OyZUtOnz7Nb7/9hre3N23atOHMmTOcO3eOunXr4uLi8sjYn7bH/0QVyuXs7ExmZiZ6vf6xkpTBYCAiIoJdu3aRkZFh+vDNzMzEwcGBJUuWsGLFChYtWkTTpk2ZNm0afn5+vPrqq3zxxReMGTMGgKFDhzJ27Fju3btHamoq/v7+Jfbx4PW8efNYsmQJvXr1olatWkyYMIFu3bqVGZuLiwtWVlam1xqNhk8++YTDhw+bujvy8/MxGAymC7sPf5jZ2NhQUFBQos41a9Ywfvx4PD09TcsSExMZP358icQjl8tJT08nNTW1RFlbW1ucnZ3/9Jg+XN7Ozg4nJydSU1OpUaMGAwYMYNu2bXTs2JFt27bx8ssvl1nHvXv3iI2NLXUcH+5GezixWVtbl2rrH/3xeKampuLl5WV67eXlRWpqqum1o6Mjtra2Za4PCwujV69eFBQUsHPnTvz9/alevXqpfWZmZqLT6UrtJyUl5U9jfcDZ2Zn79++Xu/7B7+fh390f6/+rx6k8YWFhJCcnM3XqVHJycujXrx9TpkxBpVKViqlmzZqm1zVr1kSv15Oenl5mTGW9T//I39+fjIwMVqxYQdeuXUsllLS0NObNm8fp06fJz89HkiQcHR0f2aaH36tlGTJkCP/5z3948803H5k0atSoYfr/H99bUPL3EhAQwMmTJ/Hw8CAgIABHR0dOnTpl+jJkjkSCqgB+fn6o1Wr27t1Lz549H1l++/bt7Nu3j7Vr11KrVi1yc3MJCAhA+n1ieV9fX1asWIFOp2Pjxo28/fbbREdHY29vz6xZs5g1axbx8fGEh4fTsmVLatSoQa1atdizZ0+Z+6tXrx6LFy/GaDSyZ88eJk2axIkTJ0p8ED4gk8lKvP76669JSEhg8+bNVKtWjbi4OPr372+K9XF8/fXXvPbaa7i7u9OjRw+g+I90/vz5tG3btlT56tWrc/36ddNrjUZT4vpUWR6+Lpafn092drbpw7tfv3707duXy5cvc/369XJHjtWoUYOAgADWrl372G17lD8ez+rVq5cYJJCUlFQiyeTk5FBQUGD63SQlJZnKenh44Ofnx549e9i6dSvDhg0rc58uLi6oVCoSExNp1KiRqR4PD4/HirlDhw58/vnnJeL4YxuSk5MxGo2mJJWUlES9evUeq/4/srGxQaPRmF4/nBxVKhUTJkxgwoQJ3L17l7Fjx1K/fn0GDx5cKqYH1x2h+AuQUqnEzc2txHvjr+rXrx/Lli0rcU33gcWLFyOTydi+fTvOzs7s3buXjz/++JF1/vE98TCDwcCHH35I//79+fbbbxk4cKCp1+FRdT14bz0sKSmJ4OBgANq1a8enn36Kl5cXr7/+Ok5OTnzwwQeoVCrTNVRzI7r4KoCDgwOTJk3i448/Zu/evWg0GnQ6HdHR0SxYsKBU+fz8fNRqNS4uLmg0GhYvXmxaV1RUxLZt28jNzUWlUmFnZ2f6EDhw4AC3bt1CkiQcHBxQKBTIZDJ8fX2xs7Nj1apVFBYWYjAYiI+PJzY2Fii+6P3gTO3BN7xHdZk9HKuVlRWOjo5kZWXxxRdf/OXj06hRI1avXs3HH39supg+bNgwPv/8c9OHSkZGhukibY8ePTh48CCnT5+mqKiIJUuWPHKEUnR0tKn8v//9b1q1amX6dunp6UnLli2ZMWMGoaGhZXatQHE34c2bN/n555/R6XTodDpiY2NLJMs/4+7uzp07d/60TJ8+fVixYgUZGRlkZGSwbNmyEhevoXiQQFFREadPn+bgwYMlvvSEhYWxZs0a4uPjCQ0NLXMfCoWCnj17EhERQV5eHvfu3WPt2rXlDqj4o7CwMDw9PZk4cSLXr1/HaDSSmZnJypUriY6OxtfXF2tra1avXo1Op+PEiRPs37+f3r17P1b9f+Tt7U1UVBQ6nY4LFy6we/du07rjx49z5coVDAYD9vb2KJXKMt+7ffv2Zf369dy5c4f8/HwiIiLo1avXX+p2L8uoUaNYu3YtAQEBpdbl5+dja2uLg4MDKSkprF69usT6x3k//NHKlSuRyWTMnz+fV199lXfeeeex75Hq0qULN2/eZPv27ej1eqKiorh27Rpdu3YFir9IJyQkEBsbi6+vL40bNzb1GpTVPnMgElQFGTNmDLNmzWL58uW0b9+erl27snHjxjK/rffv3x8vLy+Cg4Pp06dPqWtCW7duJSQkhDZt2vDdd9/x2WefAXDr1i3TSLWhQ4cybNgwgoKCUCgUrFy5ksuXL/Pcc88RFBTE+++/T15eHlA8AqlPnz74+fkxb948IiIiyv2Q/qPw8HC0Wi1BQUEMHTrU9G3sr/L29mblypV88MEHREdH8/LLLxMSEsKYMWPw8/NjyJAhpoTauHFjPvzwQ6ZPn05wcDCOjo6P7Bbp27cvy5YtIzAwkN9++810zB7o378/8fHxhIWFlVuHvb09a9asISoqiuDgYDp16sTChQtNo+weZcKECcyaNQt/f/8So/8eNm7cOFq0aEG/fv3o168fzZs3Z9y4cab17u7uODo6EhwczPTp0/noo49o2LChaf3zzz/PvXv3eP7557GxsSk3lg8++AAbGxu6d+/O8OHD6du3b4lRW39GrVazbt06GjRowJgxY2jbti2DBw8mMzMTX19f1Go1K1eu5NChQwQFBTFnzhwWLFhQIs6/4u233+b27du0a9eOpUuXlkjYaWlpTJo0ibZt29K7d2/atWtX5u9w0KBB9OvXj5EjR/Lcc8+hVqv54IMP/lY8D3N2dqZ9+/ZlnvVMmDCBS5cu4e/vz9ixY0t9YRg7diwrVqzA39/fNBL3z1y8eJF169bxr3/9C4VCweuvvw7AqlWrHitWFxcXVq5cydq1awkMDGT16tWsXLkSV1dXoLirvHnz5jRq1Ai1Wg0UJy0vL69ybzmobDLpr/TVCEIVderUKWbMmMGBAwf+tIulMp04cYIZM2Zw6NChPy3XvXt3Pv74Yzp06PCUIhOEyiHOoASLp9Pp2LBhAy+++KLZJqfHtXv3bmQyGUFBQZUdiiA8cWKQhGDRrl+/zqBBg/D29i73BuWqYtSoUVy7do0FCxY89jVEQajKRBefIAiCYJbE1zBBEATBLFlcF9+ZM2f+dHRTVaTT6UrdmFiVWVp7wPLaZGntAdEmc6bVasuc4cbiEpRCocDHx6eyw6hQt27d+tOb9aoaS2sPWF6bLK09INpkzsqbCkt08QmCIAhmSSQoQRAEwSyJBCUIgiCYJZGgBEEQBLMkEpQgCIJglkSCEgRBEMySSFCCIAiCWRIJShAEQTBLIkEJgiAIZsniJov97bdLNG/erLLDEARBsHiFOgPWKsU/ricuLq7MGYAsbqojuVxGvVk7KjsMQRAEi3fz0z5PtH6LS1CCIAiWQpeZiCEvA6VTdZSO1cstJ0lGDHkZYDQit7ZDbmVXvNxoQJ+VjCE/E5nKGqWzJwpr+9+3kTDkpKLPTUOmtELlWhO5uuRE20adFmNBNgAKOxdkyqc7Ma1IUIIgCGZGm3yNzP+uRJt42bTMup4frqFvoXLxMi3T56SRuW8VmlvnkbT5xQsVSly7v4nCzoX0nf/GqMn5X8UyObZNO2Ll5U3OyR+Lk9oDChUOfr1x6fIKMqWKwjsXSY38CElXCIDc1gmPoXNRV6//RNv+MJGgBEEQzIg+5z4pm96jlocb0z7/nObNm3Py5EkWL15Myqb38Hp1OXIrWwByTm1Bdu88b4weRatWrbCysmL58uXEntsJcjne9Wsxc+ZMatWqRX5+PkePHiUiIoKCy4dp37494eHhNGjQgLy8PHbt2sVXX30FRj3OncNJ+2URTRrU5Z133gFg3Lhx5MdFiwT1sPXr1xMZGYkkSQwePJhXXnmlskMSBEF4YnJO/IAKPYcOHcLJyYnIyEimTp1Kt27d6NChA7nnonAKfBEAQ34mtWrW5J133kGr1dK0aVN27NjB+ZupSDoj9es3wdbWlvPnzxMaGkq/fv2wsbHho48+4sUXX6RZs2bExMTQr18/BgwYgFKpZPnKLzFqCyA/g/XrtxMYGAjA5MmTkfS6p3oszHqYeXx8PJGRkURGRrJ161YOHjzIrVu3KjssQRCEJ6bg2kkGDBhAvXr1WLhwIW+88Qbr16+nffv2BAUFobl20lRW5VqL+Ph46tevz6pVq0rUY+XZiB07djBkyBCmTZvGjBkzAPDw8ABg7ty5dO7cmSlTpvDWW28BEBQUBEYD+b8dYNq0abi4uHDkyJGn1PLSzDpBXb9+HV9fX2xsbFAqlQQEBLBnz57KDksQBOGJkAx6DLnpNG3aFIAbN24AkJCQAEDTpk3RZ6eayju1H4Jrz4ll1vVgeY8ePdixYwfffPMNFy5cYO7cuQBonP/XVdejRw8AoqKiAPDx8eH//u//CA8Pp6CgwFQuPy4ayaCvkLY+DrNOUE2aNCEmJobMzEw0Gg2HDh0iOTm5ssMSBEF4ciQJubzsj2a5XI4hN42UzR+S+sMcCq4cwa5Z11Ll9Nkp6DPuApCRkcHFixe5efMmLVu2ZNiwYQDoUhOQyWQsXLiQqVOnMnfuXL777jsAvv76a1auXMnp06dNsahUKoz5WeRd2PsEGl02s74G1bBhQ1577TVeffVVbGxs8Pb2LvcXJwiCUNXJFEoU9q5cvXoVwPQ49zp16gBw9epVFAoFraqryMrK4sr2hWXWI+m0JK2bDMCpU6c4deoUXl5e3Lt3j6FDh7Jw4UKU+gLWb9rE4MGDmThxIl988YVp+5YtWxIUFMTUqVNNy9LT0/H09CQ/5VqJfT3Jyy5mnaAABg8ezODBgwFYvHixqf9UEATBEtk0aMuPP/7IggULmDJlCq6uroSHh3Pu3Dl+/fVXHBwcOH78ONu3b6dfv364uLgQERFB8+bNAZg4cSJ9+/Zl9OjRREREYG1tTWJiIiEhIQAcP34cgI8++oihQ4eSkpJCr1696NWrF2fPnuX9998nPDwchaJ4hojZs2fj6+vL6NGjyc7OxqqhS4l4HyTRfyIuLq7M5WafoNLT03FzcyMxMZE9e/awefPmyg5JEAThiXFsP4SkS9F069aNd999l65du7Ju3Trmz5+PJEno9XoiIyOJiYkBQCaTYWtrS0JCgulalY1N8Q23p06dYtSoUfj7+5Oens6MGTNYunQpUHw2FhkZWWLfhYXF9zz9+OOPpmVNmjThypUrfP/99xQWFuLWuucTPwYPmP1cfMOHDycrKwulUsm7775L+/bt/7R8XFwcvdbfeErRCYIgVLzCOxfJ2LMcXdpt0zK1V1McWvciY+8qpKL/DVyQqayQdNrHq1iuwM47GENBNoU3z5ZZRO3REM+XFwOQvGEqRSnXi/ejtsVj2HysPBuZylbUVEflzcVn9gnqrxIJShAESyBJEkUp1zHkZ6J0rI66WnFXmrFIgz47FZlcgdK1JlKRBn3O/VLbK509wain6P5NjIV5yK0dUbnVRGHjCIAuK7lUYpPJ5ShdayGTyUwx6DPuIhmNKJ2ql5oK6UknKLPv4hMEQXgWyWSyEmcrD8jVNqZkBSCzsi3xuiQrrGs1L3ONytnzsWJQudV+rHifBDEkThAEQTBLIkEJgiAIZsniuviMRumJP6NEEARBqLgHFpbH4s6g9E95MsOnwdLmH7S09oDltcnS2gOiTU/Ck0xOYIEJShAEQbAMIkEJgiAIZkkkKEEQBMEsWVyCUipVlR1ChauIua7MiaW1ByyvTZbWHqjabSrUGSo7hEphcaP45HIZ9WbtqOwwBEEQKsyzOjLZ4hKUIAjC45IMOgquHEWbeBnkCmzqt8G6np9pqh9TOcmILjUBbdJVjIW5IJNhU78t6ur1kYwGilITKEq+9vs6OTYNA1A516Ag/ij6nNRS+5VbOwAUl/8DpWN1bJt0QGaBvUF/lUhQgiA8k3Tpd0n94SP0Wck4Ojqi1+tJPfUzVrWaUX3Qh8it7YHi5JSy6T20dy6W2D7r0DfUfGMN93+eT1FSfIl12Uc2YtfyefLO/r3eHKeOw3DuNOLvNcyCWNw1KEEQhEeRJIm0XxbhqjYSFRVFdnY2mZmZfPXVV0ip18g88LWprC79Lto7F3n33Xe5fv06Go2GI0eOgNFAXuxuipLimTNnDgkJCWg0Gnbv3o2kLyLv/C7at2+PRqMp9a9r164899xzZa5r164d2sQrlXh0zIfZn0HduHGDKVOmmF7fuXOHSZMm8corr1ReUIIgVGmFt2MpSr7KJ2vW0KtXL8LDw2nSpAmzZ8/m/PnzfLF8Bc6dR6GwcwHJCBQ/On3hwoV88cUXqNXq4op+fxhEWloaixYtYunSpaZ1cmt7EhISSjyVds6cOTg5OXH58mWUSqVpnUwmY/78+SiVSq5du4bCq81TPBrmy+wTVIMGDdi6dSsABoOBzp078/zzz1dyVIIgVGUPuuQGDx7MzZs32bBhA87OzsyePZshQ4bwxRdfUJSagE19F1RutVFVb8CXX34JwJIlS0z1qKs3QOVWx5SYHjwMEMCx3UAyLh/hy3UbMWpyCAoKolq1anz99dckJycD8OXa/2AszCUkJAQnJyeWLl1KRkYGHr16PMWjYb6qVBffsWPHqF27NjVr1qzsUARBqMIMeRk4OTnh4OBAeno6AFlZWRgMBmrVqgWALuMehsI8kCRqvLwYe78yRtIpVdQY/W/sWjxXapVVjcbUCI/ArccEAKZPnw7AwoULUVVvQJ2Z23F57nXTOoPBQEREBFY1fbCuVfrZSM8isz+DetiOHTvo27dvZYchCEIVJ1fbkpeXh16vx9raGgCVSoVCoSArKwuAzL1fkrn3S+S2zrh0G0P+pYOl6sk98wsKa3vyfzuAWlXy4zT37E5U1RuQffJHGjZsyIABA/jll1+Ii4vD/YXiZJVz8idatGhBr1692Lx5MwkJCVQbMLvMmMuady8vL6/S5+N7kqpMgioqKmL//v1MmzatskMRBKGKU7rWxGAwcPr0adq0aYO7uzvNmjUD4MSJEwAMGTKEDh068Mknn5CyY3GZ9RTeiCH5RkyZ6wouH6bw5jmMhblMXbYMuVzOwoULUThUw7ZpJwoTzqC7f5NpC9YC8Nlnn6F0rYlN48Ay6yvrRuNbt25V6RuQH4iLiytzeZXp4jt06BDNmzfH3d29skMRBKGKs20chNzagffeew+Ay5cvs3PnTu7fv8+nn34KQLdu3Zg8eTKurq4ArF+/Hq1Wi1KpJCAgAK1WaxrAFRkZSV5eHgBdu3ZFq9UyduxYjIW5uLu7M3r0aE6dOkV0dDSOAWHIFEpyTm/Dy8uL4cOHEx0dzaHowbkAACAASURBVOnTp3EMGIBMVmU+lp+4KnMGtWPHDvr0eTbvphYEoWLJrWxxCXmVA1GfU69ePQYMGEBBQQE//vgjubnFN89++eWX7Nmzh7t37wKwdOlSfv755xL1XLxYfG/UokWL+Pbbb0usO3fuHABWVlaMGDGCuLg4ZFZ22PuGAqDPTETlpOall17iwoULyG2dsW8R8kTbXdXIJOn3cZJmrKCggG7durF3714cHBz+tGxcXBy91t94SpEJglCVFd6OJefET7/PJKHEpr4fjkGDKUq6Su7ZX5D0OlQuXihdvCi8dQ7JoC+xvdzKFpnKBmNBFpKx5Hx5cmt7rGp6o717CaO2ALnKGqcOQ7FpGABAwbWT5ByPxFikQa62xanTcGzqtS4zzvKmOrKkLj4fn9IDQ6rEGZStra2pX1gQBKGiWNfxxbqOb6nlavc62LcsPTKvItk2aodto3ZPdB9VnejsFARBEMySSFCCIAiCWRIJShAEQTBLVeIa1F9hNErP7LNTBEGwTIU6A9YqRWWH8dRZ3BmUXq+r7BAqnKXdKW5p7QHLa5OltQeqdpuexeQEFpigBEEQBMsgEpQgCIJgliwuQSkt8DHJlnAj3sMsrT1geW2ytPZA+W0q1BnKXC5UPosbJCGXy6g36+89ZlkQhGePGFRlvizuDEoQBEGwDBZ3BiUIgnkovH2BnJM/oU28gkyhxLp+G5yCBqNyLfnA0aK02+TH/hdtyjWMmlyQybBt3B7nTsORjAbyYv9L3vld6DOTkNs5Y9esKw5tXyD/twNorh5Hl34HSV+EwsEd2ybtcWw3EN39W+RfOkhRynWMRRpkCiX2vqE4+PWupKMh/B0iQQmCUOHyYv9L+s5/4+npSdjLw8jPz2fLli0kXT6Mx7BPsarRGACjtoDkDVOwUsjwa92aGjUakZmZycGD32LbOIjs45EUXD5MmzZt6PBiT65evcqePd+SfWQjAK1bt6bNc/2xsbHhypUr7Nv3Hbkxv2AszMXe3p7ANm1wc3Pj7t27nNr7JbZNO6KwdarMQyP8BSJBCYJQoYzaAjL3ryYkJISoqCg0Gg3W1tZ89tlnBAQEcH/fKjxGLEAmk6HLTETSadn84zZeeOEFAI4fP0779u3J+20/BZcPM3fuXGbPnk1ycjKenp7s2bOHHj16UKNGDc6ePUtKSgpqtRoXFxd++uknBg0aBMCxY8do0aIFAJs2bWL48OEYNbkiQVUhZn8Nat26dfTp04e+ffsydepUtFptZYckCMKfKIg/hlGbb3rwX6NGjejTpw+enp7MnDkT7b049BnFz1iSW9sDMGvWLNODAR/Ii/0vNWrUYMaMGRw+fJgaNWqwcOFCQkND6dWrF/n5+Tz33HN4enpSq1Yt7ty5w8CBA031jBo1ypSghKrJrBNUSkoKGzZs4Mcff+SXX37BYDCwY4cYoScI5kyXcReVSkXbtm25cuUK6enpHD16FICgoKDfyyQCoHL2xCl4JJcuXSIzM7NEPZI2nzZt2qBWq03bP1xPTk4O+/fvB8BoNCKXy0lPTzc92fbcuXOmhw8KVZPZd/EZDAYKCwtRKpUUFhZSvXr1yg5JEIQ/YdTm4+joiFwup7CwEMDU8/Hg7Cbn1BYMufdRutTEqf0QMBrJ/vXbUnW5uLgAmOp58PNBPTKVNbZqBZGRkbi7uzNgwACK9Aa8Xl1B9okfISf+yTZWeKLMOkF5eHgwZswYunXrhpWVFR07dqRTp06VHZYgCH9Cae9Geno6Go0GNzc34H8J5cHj07V3LqK9U/y4dJV7XXRpZc+T96D8g3oe/HywvLqrEzt27KBx48b06dOHffv2AZB5eAOa+GO41alTor6U79+n2oD3sKrRpMTyqjpPX15eXpWN/XGYdYLKzs5m37597Nu3DwcHByZPnszWrVsJCwur7NAEQSiH+vcRej/++CMjR47kpZdeMl0LioyMBCAiIoIRI0YQFBTEjRs3CAwMpFatWkBxEho0aBCxsbEcO3aMxMREwsLC2Lx5M6+88goGg4EtW7bg6OjIsWPHqF+/PitWrKBx48Y0btyYzZs3kxF/jG7dutG0aVMA6tSpw6BBgzh27BgZh77BY+j/KxFzVZ05w5Ie+V4Ws05QR48epVatWqZvX6GhoZw9e1YkKEEwY9b1/FBVb8DMmTPx8PBg06ZN6HQ61qxZw1dffVVcxtra1A0IMGHCBAYPHoxWq6VOnTps3LiRGTNmsHTpUkaNGsXKlSs5dOgQaWlpTJgwgfj4eOrUqYOXlxdarZYxY8aY9n/48GEyMjL4+OOPCQgIQKvV4u/vz8aNGxkyZAg7j8VWynER/jqzTlBeXl6cP3/eNEz14WGjgiCYJ5lMhvsL00mN/D9CQ0NxcXGhqKiI/Px81F5NkaXd4a233uKtt94ybTNq1ChGjRpVZn37ow/TtGlTqlWrRmZmJjqdDpnahtu3b2NtbV1uHMHBwWUut2/V8581UHhqzDpBtWrVih49ejBgwACUSiU+Pj4MHTq0ssMSBOER1O51qPn6l+RfPoI28TJyhYrq9dtgXb8Nhtz7FFw5iqQvQulaE3W1emiunUAy6EvUIbe2x9Y7GAx68n7bR0FmMrYNnbBr1hWlqxeaayfRpd8ptW+lixdKZ08Kb54DyVhincLOpbhOoUqQSZIkVXYQFSkuLo5e629UdhiCIFQRVXmyWEu6BuXj41NquVnfByUIgiA8u0SCEgRBEMySSFCCIAiCWTLrQRJ/h9EoVek+ZUEQnq5CnQFrlaKywxDKYHFnUHq9rrJDqHCWdqe4pbUHLK9NltYeKL9NIjmZL4tLUIIgCIJlEAlKEARBMEsWl6CUSlVlh1DhLOE+h4dZWnugarWpUGeo7BAE4bFY3CAJuVxGvVnimVGCUB4xiEioKiwuQQlCZdPn3EeXdhu5lR1qz0bIFGX/mUmShC7tFoacNBSO7qjc6yKTydDnZWDUlH7QntLRHbmVHQAGTQ5FqQkgSahcaqBwrI6kK0SfnVpiG5lShdK5BjKZrOIbKghPmEhQglBBDPmZpO9Zjib+OFA8g5jCoRou3UZj59O5RFlt0lUy9iyjKPmaaZm6RmOUzl4UxB0ybf8wmcoKt95T0Fw/Sf6lQ2DUP7TOGkmnLXM7m4YBVH/x/yqkjYLwNIkEJQgVQJKMpP74/1Dl3OPDDz+gR48eJCYmsmjRIo5vW4DcxhGbeq0B0OdlkPL9+9TxdOfdlSvx9fXl3LlzfPLJJ9yJi6Zz585MmDCh1D4mTJhA6tZPsba2ZvLE8YSFhaFQKDh8+DDvv/8+NjY2rF+/vsQ2Bw4cYMWKFejzMlDauz6VYyEIFaVKDJIwGAz079+fN954o7JDEYQyaa6doigpnhUrVjBnzhzOnz9P8+bNOXjwIPXq1SP7yEZT2ZyTP6EwaNm7dy9Dhgzh2LFjDB8+nD179iCXy1Eqldjb25v+9e/fn7CwMPT64jOmH374gYULFxIfH8/u3bupXr06AEqlksGDB9OyZUvTtlZWVsU7taw5oYVnRJU4g9qwYQMNGzYkLy+vskMRhDJprp/Czc2N4cOHc/jwYcaNG0fv3r3ZsWMHY8eO5b333sNYmIfc2h7N9dP07t2bRo0aMW/ePN5//310Oh3vvPMOzz//PLt372b//v0AtGvXjl69erFu3ToyMjLw8fGhT58+LFmyhC+++IKsrCzu379fIpbdu3ezZcsW4uLiSE0tvialdHB76sdEEP4psz+DSk5O5uDBg7z44ouVHYoglEufk0rDhg1RKBSmGQtu374NQJMmTUxlAAw5903Lbt68WWZZpw7DAJg+fToAixYtAqBLly4AhIeHEx8fT2pqKsuWLSsRy+TJkzl48CB37941dRUW3r5QwS0WhCfP7BPU/PnzmTFjhunR0IJgrsp7tNqD5cnfvkvyf2Yi6bWlyj4YZSdJEjK1LYW3ztGgQQMGDhzIzp07uXjxIgBGY/ED+C5evIi7uztbt25l3LhxtGvXjsLCQjp37oyNjQ2+vr7k5eWxaNEirKys0Fw/9aSaLQhPjFl38R04cABXV1datGjBiRMnKjscQSiX0qk616+fRK/XU79+fQDTzytXrgDQtqUPTk5O7Lt3ybSsQYMGANSrV89UVioqQHsvjilLl6JQKPjss89QOLijsHUiPj4egAsXLpCemc25c+cICwvD1dUVpVLJ4cOHTetv375Nq1atcHR0RKMtKBHvo+bay8vLs7j5+ESbqh6zTlBnzpxh//79HDp0CK1WS15eHtOnT2fhwoWVHZoglGDTKJD753axYcMGxowZw9dff01wcDAajYYvv/wSgM8//5ygoCCUSiU7d+7k8uXLjB8/HicnJ15++WUuXLjAvn37AHBzc2PMmDHExMRw4MABXLqNwVikITr6O86fP8+gQYO4efMm4eHhJCYmcuzYMfr168fMmTM5ePAgDRs2pFWrVhw+fJj79+/j6tegRLyPmvnCUp7U+jDRJvMVFxdX5nKz7jebNm0ahw4dYv/+/SxevJigoCCRnASzZNPAH6uazRg/fjwzZsygTp06HDt2jI4dO3Lnzh0Adu7cyYYNG4DikanPPfcca9aswdvbmy+//JLQ0FCwdgCgZcuWbN68mVmzZiFT22LfqicO/mHIbJzo2bMnGzZsMA2oCA4OJjs7m6NHj3LgwAFatGiBSqVizpw59OvXD6VLDeyada2sQyMIf5tMKq/j3MycOHGCr7/+2vRttDxxcXH0Wn/jKUUlCP9j0OSQuXcV+XGHQCq+VqR0qYFzl1fIOf4DRclXAVDYu+L6/FvknNqC9u4l0/ZWtVsULz/5E/kXi8+kkMlx7T4WhzZ9AShKu03GnuVo71w0badyr4t9q1DyLuxFl5pQIiabhgG4Pv8WSqfqpmWPM9WRpXwzf5hok/mKi4vDx8en1PIqk6Ael0hQQmUz5Geiy7iHXG2Lqno9ZDI5kiRhyL0PkoTC3s00/ZEuMxFDbjoKB3dULjX+V0deJpKhCJmVHQpr+1L70GUlY8i5j8KxGkonD9MgC0NeJrqsRGQyOUoXLxS2TqW2FQnKclhKm8pLUGZ9DUoQqiKFnQsKO5cSy2QyGUrH6qXKqly8ULl4la7D3qXUshLbOXuicvYsc7tHbSsIVYVZX4MSBEEQnl0iQQmCIAhmyeK6+IxGSTzvRhD+RKHOgLVKUdlhCMIjWdwZlF6vq+wQKpyl3Yhnae2BqtUmkZyEqsLiEpQgCIJgGUSCEgRBEMySSFCCIAiCWbK4BKVUqio7hApnCTfiPayqtqdQZ6jsEAThmWJxo/jkchn1Zu2o7DAECyRGhwrC02VxCUqomgyaXPIv7KXo/k3kVrbYNA7Cuo6vaQqfh+ky7pF3cT+GnFQUDu7YtwhB6VqLwhunKbx3uURZmUyOVa1m6NJuY9DklKpL5eqFTK6kKO12ye0USuyadkLlXrtiGyoIwmMTCUqodJqEM9z/+VOkogLq1KlDVlYWqTHbsWkYQLX+7yF7qNs2+3gkWdEbUKtVeHl5kXj1V3KOR2JVxxft7VgUipJDqCVJIttoRCaTlfnQS4OhuNuurO1yY7ZTa9z6EvsXBOHpsbhrUELVYtQWkLZ9Ia2aNeHChQvcunWL1NRUFi9ejOb6KXJObTGV1SZeISt6PcOGvcTt27dJSEjg7t27vPzyy2hvxwKQmZmJXq83/du5cydQ/Ij0h5c/+FerVi2srKxKLV+/fj1GTQ763PuVclwEQTDzM6ikpCRmzpxJeno6MpmMIUOGEB4eXtlhCRUo7+I+jJocvvzyS+rWrUvXrl0ZPnw4U6ZMYf/+/UTt+xnHwEHI5ApyTm7B3d2dr776iqtXr9K3b1+WLVvGypUr2bNnD8nJyQDs2rWLb7/9Fih+DwEcPnyYl19+GQBra2uWL19OUlISycnJprOnzZs388svvwCQkFD82Aq5ld1TPR6CIPyPWZ9BKRQKZs2aRVRUFN9//z3ffvst165dq+ywhApUlHydmjVr0q5dO3799Veio6P56quvABg4cGDxWUxO8VlMUco1QkNDsbOzY/PmzZw+fZrvv/8eGxsbevbsaaqzWrVqBAcHU61aNU6ePAnArfQCvt2yg2+++Qaj0YhSqeTzzz9Hr9ebtqtZsyYdO3bEycmJmJgYAGQqq6d1KARB+AOzTlDVq1enefPmANjb29OgQQNSUlIqOSqhIhny0vHyKn7cRGZmZomfNWvWBKAo+Rr6nPvoc+6bymZkZJRZNjU1lcTERHx9fVm0aBHR0dEolUrsWoRg37oXMpmMadOmkZ2dbUqEAPfu3SMtLY3AwECWLl1qOpPKv7j/SR8CQRDKYdZdfA+7e/cucXFxtGrVqrJDESqQ3NqejIxEAGxsbEr8TE9PByBt66em8g8Sk62tbYmfD8o2adIEo7H4abYHDhyga9euNGvWjPg7v1F0P4E+ffrg4+PDv/71L3Jzc5Fb2aHV5lO7dm0kSUImk3H+/HlCQkLw9PQkL7nkGXt5c+7l5eVVqfn4HsXS2gOiTVVRlUhQ+fn5TJo0iffeew97+9JPFxWqLpVbLW6dOMa9e/cICAjAxsaGzp07A3D06FEApk+fjre3N2PHjuXYsWMAdO7cmYiICIKDgwE4duwYtWvXplq1apw5cwZbW1vc3NyA4j/iwls3THUVFRXx73//G+t6fhg1OdRzUqBQKIiLi8PJyQknp+Kn0BYUFJQawVfeTcaW8mTTByytPSDaZM7i4uLKXG7WXXwAOp2OSZMm8cILLxAaGlrZ4QgVzL5ld/RGiZkzZ+Lh4UFSUhJLly7l/PnzrFmzBoBevXrx6quvIpPJiIuLY9myZfTv35+MjAyGDh3K6tWrOX/+PLVr1yYmJoaUlBRSUlJo2bIlK1eu5MaN4uQUEBBAly5d2LhxI0lJSTi2G4BkNNCsWTMuXbpEUlISiYmJ1KlTh7lz55KTk4N1Pb/KPDyC8Ewz6zMoSZKYPXs2DRo0YPTo0ZUdjvAEKJ08cOo4jG+//Q+HDx8mNDSUpKQkdu/ebbpHaebMmbi6upq67iZMmMDatWvx8/MjNjbWNBDi6NGjtGjRgjZt2iCXy4mNjeXs2bNY1/Oj8M5F0tPTCQ0NJTY2FlX1+ljX80Pt0Yiff/6ZNm3a4Ovri9Fo5MyZM/z222/YNuuCTaPASjs2gvCsk0mSJFV2EOU5ffo0I0aMoEmTJqabLKdOnUqXLl3K3SYuLo5e6288rRCFCqK5EUPO6W3o7icgU9ti26Q9jgH9yb8UTcGVI2A0ovZshFPwSAouHyYv9r8YctNQ2Lth3/I57Fp2J//CXgqunUSXfhckCaWzB3Y+nbH3DaXg6nFyz0aBvgi5rSPOnV9GXa0ekr6InJhfKEw4jS4jCWQyVC41sGsRgl2zrsjk/7uB98+mOrKUrpYHLK09INpkzuLi4vDx8Sm13KwT1N8hEpTwpIgEVbWJNpmv8hKU2V+DEgRBEJ5NIkEJgiAIZkkkKEEQBMEsmfUovr/DaJTEc3uEJ6JQZ8BapXh0QUEQKoTFnUHp9brKDqHCWdqd4lW1PSI5CcLTZXEJShAEQbAMIkEJgiAIZsniEpTSAp9+agn3OTzsabSnUGd44vsQBOHJsrhBEnK5jHqzdlR2GEIlEwNlBKHqs7gzKEEQBMEyWNwZlPDkFVw9Qc7Jn9AmxSNTqrFp0Ban9kNQV6tXopxk0JN7Noq8czvRZSahsHXErllXHAMHobAtfqRFTsx2cs/sAKMemdIKx4AwbBoGkHXkWzQJZzDkZaByroF96544+PVCplCZ5u3T3ruEZNCjdPLAzjsYpw5DkCksr4tXEJ5VIkEJf0nOqZ/J3L+ahg0bMmDKZHJycvj+++9J3nACj2HzsfJqChTPRH9/66dorh6nU6dOBAeP5OrVq/z8888UxB/DMzyCopTrZO79kk6dOlGvXj3i4uKI2bkEua0zSn0Bg/r3p27duhw9epRf962i8HYs6uoNyP71W2rVqsWAN17DxsaGixcvEhW1CZVbLeyalT+RsCAIVYtIUMJjM+RnkXX4G8LCwvjpp59ISUnBwcGBuXPn4ufnR9r+NXiM+BcymYzChDNorh5nwYIFzJgxgxs3blC3bl1OnjxJp06dyD6ykYJrJ2nSpAl79uzBxsaGiIgIYmJiUBk0/Hr0KN7e3pw+fZoFCxawcOFCZsyYgebqccLDw1mzZg2pqakkJCQwdepUPD090eemVfYhEgShApn9NahDhw7Ro0cPnn/+eVatWlXZ4TzTCuKPIum0zJ8/n/z8fJo0acLAgQOpVq0a06dPR3vvEvqsZADyLuylRo0avP3220RHR9OwYUM++eQT2rdvT1hYGLkx25Fy77N27VrOnTtXYj+9e/embdu2zJ07l65du7Jr1y4mT56Ml5cXVlZWLF26lDNnzlC/fn06duxI/fr1AVA6uD/1YyIIwpNj1gnKYDDw8ccfs3r1anbs2MEvv/zCtWvXKjusZ5Yu4x52dnY0a9aMuLg48vLyTA8L9Pf3B0CfmWj62apVK1QqlanMH8tOmTKFatWqMXv27BL7sbGxAUCpVJp+qlQqfH196dy5Mw4ODshkMmJiYjh16hQvvvgiAEad9kk2XxCEp8ysE1RsbCx169aldu3aqNVq+vTpw759+yo7rGeWVKTByal4cINWqy3x09nZGYDsXzeRffwHilKum5aVVdbb25s5c+bwyiuvUFBQUGI/UVFR3Lp1i/fff58zZ87QvXt3AFxcXHBxcQGgQYMGREREYDAY2LBhA23atCEvdveTbL4gCE+ZWV+DSklJwdPT0/Taw8OD2NjYSozo2aawdyP5YjI6nQ539+LutGrVqgFw584dALSJl9EmXgbg9u3bAGWW7d27NwD/+te/cHR0BGDo0KEkJSXx2Wef0bp1awYMGICtrS0BAQGEh4dz4cIFHBwcADhw4ABfr/8GpVJJYGAgfn5+nP/upxLxPs05//Ly8qrsHINlsbT2gGhTVWTWCUowL1ZeTck2Gtm8eTMjRowgPDzc1F23adMmANasWcOwYcNo2rQpJ0+eJCEhgf79+7Nt2zZef/11DAYDkZGR1K9fn//85z9A8RcPX19f0tPTSUws7iLs378/586dw9vbmwEDBhATE8PFixdRqVQkJCTg5+dHC5+mhISEAHD27FmUzp4l4n2aM3BYypNNH7C09oBokzmLi4src7lZJygPDw+Sk5NNr1NSUvDw8KjEiJ5t1g3aoKpen+nTp+Pk5MS6devIz89n0aJFbNy4ESjuxisoKECSJPR6PSNGjGD58uVERUWRmJjIa6+9xvXr17l+/Tp79+4FoG3btgQHB7Nt2zZTPTNnzsTHxwe9Xs+2bduYPHkyADqdjpEjR7Js2TJiY2NJS0tjwoQJnDlzBrdekyvnwAiC8ESYdYJq2bIlN2/e5M6dO3h4eLBjxw4WLVpU2WE9s2QyOdX6zST1h4954YUXsLa2Rq/Xo9frsa7flqKkeMaNG8e4ceMAsGnUjuMx5/Dz88PW1haNRoOEDKcOL+HYbgBGnZbso98TE7PD1A0IIFNa0axZM2xtbdHr9RQVFaF0qUGN0UvRZyZxLCoCPz8/bGxs0Gg0ADj4h2HXsnulHBdBEJ4Ms05QSqWSDz/8kNdeew2DwcCgQYNo3LhxZYf1TFO51cbrtRUUXD1OUVI8Vr/PJGFV0wdDXiYF104gGXSo3GpjXdcXSVtAftwhdJmJONk6YesdjOr3rji5lR2u3cdi06AN+uxUZEorbJu0RyoqoODaSQzZqSgVCpxqNsOmQVtkcgXq6vWpVdeX/LhD6DOTsLZ3wbqeH+rq9Sv5yAiCUNHMOkEBdOnShS5dxOwA5kSmUGLn3Qk7704llivsXXBo3bNkWWt7HPx6l1+XXIFto8CSC20ccGz7QrnbyB9RpyAIlsGsh5kLgiAIzy6RoARBEASzJBKUIAiCYJbM/hrUX2U0SuJhdQKFOgPWKkVlhyEIwj9gcWdQer2uskOocJZ2p/jTaI9IToJQ9VlcghIEQRAsg0hQgiAIglmyuASlVFreI78tYa4tKL4uJAiC8LgsbpCEXC6j3qwdlR2GUAYxeEUQhL/C4hLUs8yoLUB79zckgw61ZyOUjtXLLavPuU9R8lVQqLCu6YPc2v735Wno0m5h1BYgt3FA7dEAhU3x4zAkSUKXdgt9VjJyKzusavogUyiLJ4bNTkGffgejTovCxhG1ZyPkVrZPpd2CIFgmkaAsgCRJ5BzbTPaJH5CKNL8vlWHrE4xbj/HIrexMZY3aAjL+u4L8S9EgGYtLqqxxbDcQXeY9Ci5Fl6xcrsShTR/sfZ8nfUcERSnXTasUDu64hLxGXuweChPOlNhMprTCMehFnDq8hEwmeyLtFgTBslncNahnUd7ZHWQd/oZB/fpw8OBBYmJieO+9d9FdO0bajogSZdN3LkF75TDvzJxBTEwMhw4dYuig/mT/+i0Fl6J5/fXXOXz4MBcvXmT//v28/upock9vJenrCbgrNKxatYrTp0+zZcsW2vo0IG3rpxQmnGH69OkcPXqUCxcusGfPHoa+OIDsIxvJv3Swcg6KIAhVntknKK1Wy4svvki/fv3o06cPS5YsqeyQzIpk0JF19DtCQkKIjIzEaDRy+vRp5s2bx0cffYTm6nG0ydcAKLp/k4IrR3j//ff59NNPOXv2LFqtlk2bNtGjRw8AXF1dOXDgAJs2bcLb25tVq1bRoUMHALZv386QIUNYvXo1Xl5e7N+/3/R8LhcXF3bv3s0PP/yAv7///2/v3uOirNP/j79mOMlRFBEwBU+Jmmmah1Q0Bc+K/rTMat3NsmzzkFlmhbHZZm2W+fWrrmVa6ldLVy3PtVYeCpMMTaVwPKKABzQVHEFgmJnr94cxK4GrhjHDdD0fDx7I/bnvmet9i1ze9/3hvlm2bBlNmjThA7nqcQAAIABJREFU8oHtztkxSqkqz+VP8Xl7e7N48WL8/f0pLi7m4YcfpmvXrtx1113OLs0lWM4ex56f63gG01//+lcOHTpEnz59GD16NJMnT6bw+B58whs7TsONHj2a7OxsHn/8cerXr8+xY8cYPXo0mzZtYtq0aY7XbtCgASNHjqRatWpERETQpk0b1qxZw7wFH2K1Wpk/fz5/+ctfePvtt5k8ebJju7vvvpv4+Hi8vb2RfGvl7hCllNtw+SMog8GAv/+VayglD8fTaxr/YTWfBaBx48YAZGVlAXDixAmCg4MJCQnBav75l3V/JigoiNDQUMd6JZ9LtgeYMWMG+/fvZ+TIkcydO5ctW7aQm5tLYWEhLVu2JLpxQ7p16wZAo0aNHNstWrSIQ4cOER8fz6uvvspPP/2EwQ2n/SulKofLNygAm83GoEGD6NSpE506daJVq1bOLsllGAxX/gqtVusvX19p3kbjf5bn7fmMUwvHcWn3emw2W6lxDw+PUtsDbN26laVLl3L06FFGjRpFTEwMBQUFjBo1itq1a2MymYiNjQWuTNAo8dlnn7F06VJOnTrFpEmTuOOOO7DlXfg94yul3JjLn+KDKz9E165di9lsZsyYMRw6dIgmTZo4uyyX4Bl85RqQyWTi7rvvpnHjxvz44480aNCA7OxsLl68SL169WjTpiV799rJyMggMzOTBg0aYDQaHUdABw4cAK40rvXr17N+/XpycnKYO3cu3bp1Y/v27SxZsoSPP/6Y0NBQBg0axHvvvcfmzZsdTXHFihXAlSY5ZcoUOnfujGnJ8lL1ZmRkkJeX53b3F3S3TO6WBzRTVVQlGlSJoKAgOnToQFJSkjaoX3jVisIzOJyZM2fy4IMP8vHHH5OVlUVYWBjPPfccAN26deP//u//ePzxx/nggw+YPn06s2bN4t///jfh4eHYbDZmzJgBXGl0ycnJFBcXM2TIEGw2G1u2bAFg2rRpVKtWDT8/P/70pz+xd+9e1q9fj5+fH6mpqWzbtg2j0ch9991HYWEhSUlJeIXULVVvVFQUGRkZbnN3jBLulsnd8oBmcmUmk6nc5S5/iu/ChQuYzWYACgsL2bFjBw0bNnRyVa7DYPQguOtf2L17NzExMaSkpHD58mUefvhhR9M5ePAgc+bMYf/+/QDMnj2bYcOGYTab2bNnD126dGHnzp0AfPjhh/j5+REaGsqyZcuIiYlhx44dAPzwww9ERERQu3ZtXnrpJbp27UpRURFFRUUsWbKE6tWrExwczAcffMA999yDyXSAoHuGOmfHKKWqPJc/gjp79iwvvvgiNpsNEaFPnz50797d2WW5FP9mXRG7jd3bP+LRRx8FwODtR9A9Q/EMDCFl60K+//57DJ7e1Igbhb3AzMq16x2n5Dyqh1Ej7gkKM39k2ltvO36BF8CzRgQh/Z/FcuYo/1r5Cf/617+uDBg98YvuTHi7QeR+s4QpU14F/nM9yqtWJKGDE/Br1K7S9oNSyr24fINq2rQpa9ascXYZLi/gju74N+uK9cIpxGbBs+ZtGL2qAeB/Zw+kuAiDl49jWdA9Q7FeOAkennjVvA2D0YOgtoOwWwqxXsxGbFY8/GvgEVDzyjWmFrEEd/0z1pzTiN2GV3C44/ZIYcNew150GevFbBDBI6AmRr9gnW2plKoQl29Q6sYZjB541apXZrnRqxr80pj+s8wH77Cyp0qN3tXwDq1f7usbvarhXbtB+WM+fnjX1lOvSqlbx+WvQSmllPpj0gallFLKJbndKT67XfS5Qy6qsNhGNS8PZ5ehlKoi3O4IymotdnYJt5y7/CKeNiel1M1wuwallFLKPWiDUkop5ZK0QSmllHJJbtegPN3w8Q5V9V5bhcU2Z5eglKrC3G4Wn9FooP6LG51dhgKdTamUqhC3a1B/FGK1kL9/GwUZ+8Bux6ducwJaxGH08Suzri0/l7zUL7CcOYrBywffRu3xa9IR26Xz5O/fRvH5LOyWAjz8quNTtzl+t99DvimJ4nOZZV7L4OUNBg/EUlBmzOgXREDLXngG1PxdMiul/li0QVVBVvNZziyfjDXnNFFRUXh5eXHkqyTMySuoPey1UrcqKji+l59Xvw7FhTRt2pScczlk/7QFr1qRFJ/LxGAwEBUVRWBgINmnjvLzvk2c58oznYKCgsq8d0FBAVarlcDAwDJjly9fxpJ9hNpDXv4d0yul/ijc7hrUH8GFL9/D336ZTZs2cfz4cQ4fPsx3331HeLAf5z+b6XjKrb24kHMbpnNn09sxmUzs37+fkydPsmTJEiT3FADr1q3j2LFjpKamcvbsWdauXYuXlxe1atUiNze3zMdjjz1GZGRkuWMPPvggxWePOXPXKKXciMs3KLPZzNNPP02fPn3o27cve/bscXZJTlV84SQFR77n+eefp1evXvz1r39l0KBBdOjQgalTp2LJPkJR1k8A5O//Bnt+LnPmzCEyMpJOnTrx5ptvMnz4cIYPHw7AzJkziY6OJjo6mh9++IGBAwdy9913YzabGTJkiOMjNTUVgB07dnD27NlSYwcPHsRut5OcnIxH9TCn7RullHtx+VN8r7/+Ol26dGHWrFlYLBYKCwudXZJTWX45QomPj8dms/HBBx9gtVrJzs5mwIABv6yTTrXIOyk+m0716tXp0qUL27dvJzk5mXPnzpGQkMCAAQNYtGgRmzdvpk6dOkRERODl5UVubi7p6ekUFRWxYfsein/OoH79KO644w42bdrkaFQbkn6g+FwGzZo1Izo6mk8//ZQjR45Qa9CLTts3Sin34tJHUJcuXSIlJYX7778fAG9v73Kvi/yR2PJzAKhTpw75+flYrVYAcnNzqVWrFt7e3liyj1B8LgvLz8epU6eOY/zqzyXLAdasWcOuXbu48847ef/99/n555+p1qANIb3HAsKECRPw8PDg7bffxiOgJpETV1Mj7gkAx2Pl3377bTyDw/Fr0rFS9oNSyv259BHUiRMnqFmzJi+99BIHDhzgjjvuYPLkyfj5lZ2p9kfh4XtlcsK5c+do3LgxBoMBEcHf3x+z2YzFYsGStpX8tK1X1gsNBcDf37/U53Pnzjles2fPnoSGhjJ79mwmTZrEt99+y2df78T8/afUrFmTkSNHsmfPHjZv3kxwtxEYPLwwf7+a8PBwhg8fzrfffst3331HzZ5/xWAsfb+98u4jmJeX5zb3FyzhbpncLQ9opqrIpRuU1Wpl//79JCYm0qpVK6ZOncr777/PM8884+zSnMYr5MoDCb/55huaNm3Kvffey6lTp6hXrx4bNmwAoH///vz5z39m+vTp7Nq1C5PJROvWralZsyZxcXGO7T09PWnbti07d+4kLy+P06dPAxAcHIz14hmsF8/wTEIC/v7+TJ8+HYO3L4F39cXy83EKj+1m3Ouv4+Pjw9tvv43RNwj/O3uUqbe8XzLOyMiosr98fC3ulsnd8oBmcmUmk6nc5S59ii88PJzw8HBatWoFQJ8+fdi/f7+Tq3Iur9oN8Y6IZurUqWRkZLB582bS0tIc15YAoqOjGTZsmOM03oQJE/D29ub06dMsWLCAPXv28N577+Ht7U1ycjKXLl3CbDbz6KOPsnv3btauXQuAj48P48aNIzMzkxUrVhDYqg9GH38u7d5AQEAATz31FAcPHmTdunUEtu7neJy8UkrdCi59BBUaGkp4eDjp6ek0bNiQ5ORkGjVq5OyynMpgMFCz11OcWPYSt99+O7169cLb25tNmzZxucgCwPLly0lOTubAgQMAbNq0ibp169KjRw/Onz/P1q1bHVPRmzZtSosWLfDw8OD48eOkpKRgDAjB57ZmeF3MYsiQIZw9exarHQLbDgTAln8BL6OR/v37k52dDR7eBLYZ4JwdopRyWy7doAASExOZOHEixcXF1KtXj3/84x/OLsnpfMIbU2fkPzGnrOWL73+5k8TtXanTbhD2wnxyU9Zw4XQ+Hre1ps59Q7EXXca8ax2rNydj9PIhqNODBLYZQMGR78k8nEz6thRE7HgE1KR6lz8TcFcf7IV5XPx2GXtO52LwqEnooAfxDLpyPavGvY+Sm7ycPafNGDxDCf1/j+DhH+zkvaKUcjcGKfmvtJswmUz0XZzu7DIU174Xn7ucN7+au2VytzygmVyZyWSiWbNmZZa79DUopZRSf1zaoJRSSrkkbVBKKaVckstPkrhZdrvoc4hcRGGxjWpeHtdfUSmlyuF2R1BWa7GzS7jlqupvimtzUkpVhNs1KKWUUu5BG5RSSimX5HYNytPTy9kllFFYbHN2CUopVeW43SQJo9FA/Rc3OruMUnTShlJK3Ty3O4KqSkQEi8VyQ+vabDbHs59u1XsXFhbiZjcSUUq5EW1QTnD48GGGDx+Ov78/Pj4+NGnShDlz5mCzlT0VuHnzZh566CG8vb3x9vamS5cufP7552RnZzNx4kQ6depEeHg4YWFhdOvWjaNHjzq23bVrFy1btiQsLIywsDDuv/9+Fi9eTLdu3ahevTq+vr4EBATQs2dPkpOTK3MXKKXUdbndKT5Xd/jwYdq3b4/dbmfEiBHUqVOHTZs2MW7cOPbt28f8+fMd665atYqhQ4cSFRXFCy+8gNFoZPny5fTr1w8AX19f2rZty6BBgzAajSxZsoR58+bx1ltvcenSJe6//34MBgNDhgyhsLCQRYsW8cknn9CiRQtGjBhBREQEZ8+eZdWqVXTt2pWtW7cSExPjrF2jlFKlaIOqZImJidhsNn766SdCQkLIzMzk5Zdf5oUXXuCtt95i9OjRtG7dGovFwnPPPUe7du1ISkoiJycHm83GK6+8QlxcHElJSQwdOpSFCxdisVioVq0a69ev58KFCwBMmjSJrKwstm/fTseOHfn5559ZtGgRAPPmzSMyMpLTp0/Trl07Xn31Ve666y5eeeUVNm/e7MS9o5RS/+Hyp/heeuklOnbsyIABVf95Q5cvX2bVqlWMGjWKyMhIxo4dS4sWLTCZTCQkJODr68tHH30EQFJSEpmZmSQmJuLj40Pnzp1p27YtXl5evPLKKwCsX7+e6tWrs379+lLv8+WXX/Lee+/x7LPPUqtWLU6ePFlqfMKECURGRtK+fXtmzJhBUFAQvXv3Zu/evZWzI5RS6ga4fIMaMmQICxYscHYZt0RGRgY2m402bdoAsGfPHux2O6mpqVSvXp1GjRo5riEdOXIEgDZt2mA2m0lPTyc7O5vTp087ts/JySEvL6/Ue5jNZkaOHEnTpk2ZMmUKI0aMoKCgoNQ6WVlZjskRtWvXBiAtLY2IiIjfL7xSSt0kl29Q7dq1o3r16s4u45YoaSaBgYEAjhl8JZ8DAwNZs2YNiYmJJCYmOpZdPdPPYrEQEBCAwWDggQceKPMeK1eu5OTJkyxatIh3332XHTt2lFnHarViMBj4xz/+wfDhw5kyZQpJSUmMHj361gZWSqkK0GtQleTq++mV/Ll27dqYTCbHUUxmZiYAb7zxhuMIJyMjg6ZNm+Lt7Y3VaiUkJMRxBLRixYpy36tWrVp06NCBoKAgevToQWRkJB4eHiQnJ9OxY0cuXrzIkiVLeOihh5gwYQIzZ84E4MSJE5Vy37+8vLwqe3/Ba3G3TO6WBzRTVaQNqpJERUURGRlJgwYN+Oijjxg7diwTJ04kMjLSMYPu5MmTdO7cme3bt/PGG28wefJkli5dyrRp0/j73/9OQUEBAQEBvPPOOwA0atSI3r1707hxYwBGjBiByWTiiy++cKwDUL9+fXx8fNi6dSsAixcv5sEHHyQlJYXg4GCmTJnC119/zaxZs5g6dSpG4+97YO0uTwG9mrtlcrc8oJlcmclkKne5NqhKZDAYSEhI4IknnmDMmDEkJCTQt29fvvjiC8aOHQtAUVERGRkZ5ObmAjBz5kxuu+02xowZg9FoZN68eUybNg2AJk2aMGnSJODKN+oTTzzB7t27+fTTT5k4caLjfdu1a0dgYCAJCQkA+Pv7k5GRQe3atRkxYgRw5dpVSQNTSilXoA2qkj322GOkpaUxa9Ys5s6di8FgQESIjIxk8ODBrF69mvr16wPQokULwsLCGD9+POPHj3e8RkxMDPXq1WPZsmWOda/m6+vLoUOHuHjxIi1atODee+8tNT5w4MBya+vWrdvvfvSklFI3yuUb1LPPPsv3339PTk4OXbt2Zdy4cQwdOtTZZf1mRqOR//mf/2HcuHGsXbvW0UQGDhyIp6cn27ZtIyMjg4CAAPr164efnx+rV6/mwIED2O127r33XmJiYrDZbAwfPpwzZ86Uef1evXoRERFB3bp1SU9P5+uvv0ZEiImJwc/Pj6+++gq73V5qu8DAQMcvACullCswiJvdjM1kMtF3cbqzyyilojeLdZfzzCXcLQ+4XyZ3ywOayZWZTCaaNWtWZrmez1FKKeWStEEppZRySdqglFJKuSSXnyRxs+x2cbkHBBYW26jm5eHsMpRSqkpxuyMoq7XY2SWUoc1JKaVunts1KKWUUu5BG5RSSimX5HYNysNDT6cppZQ70AallFLKJbndLL7ynDhxgqSkJOx2O507dy73/nUlUlNT2bNnDwEBAcTFxREcHOwY++GHH/jxxx8JCgoiLi6OoKAgAESEXbt2kZaWRo0aNYiLiyMgIMAxtnPnTg4cOEBISAhxcXH4+fn9rnmVUsotiJvZv3+/489FRUXy5JNPioeHhwACiMFgkOHDh0teXl6p7U6cOCGxsbGO9QDx9/eXN954Q44dOyYxMTGlxgIDA2XGjBly6NAhad++famx4OBgeffddyUtLU1at25daiwkJEQWLlx4U5mOHz9+K3aNy3C3PCLul8nd8ohoJld29c/tq7l1g3ruuefEYDDI008/Lfv27ZO0tDR58cUXxcPDQx599FHHena7Xdq3by9BQUEyY8YMOXz4sCQnJ8t9993naCw1atSQ2bNny5EjR2T79u0SHx/vGAsNDZV3331Xjh49Ktu2bZPevXs7xiIiImTBggVy9OhR2bx5s3Tv3l0A2bp16w1ncpdvwhLulkfE/TK5Wx4RzeTKfrcG1b17dzl//rzj6++++05GjRolIiKffPKJREdHi8lkcoz3799fsrKyymz7448/Svfu3SUtLa1C9ZQEPXv2rFSrVs3RiJYtWyYLFiwQkSuNy2g0Snp6uoiIbNy4UQDHkc3rr78u27ZtExFxHB2tWLFCrFarTJkyRXbs2CE2m01atGghgGzcuFEsFoskJiZKSkqKFBcXS6NGjQSQr7/+WgoKCiQhIUH27dsnhYWFUrduXenevfsNZ3KXb8IS7pZHxP0yuVseEc3kym5pgyoqKpL8/HwRuX6Duvfee2X8+PGO8fIalMlkku7du8u+fftERMRsNovNZvstpTmCrlmzRgD57rvvxGazSUBAgHh4eEheXp4cPHiwVEOaMGGC+Pn5SXFxsaSkpAgg7du3FxGR+fPnS0hIiIiIfP311wI4msvMmTOlbt26IiLy2WefCSD9+/cXkStNLjo6WkREVq5cKYA88MADIiIyefJkMRqNYrFYbiiTu3wTlnC3PCLul8nd8ohoJld2rQZ1U7P4jh49yptvvkmfPn04fvz4DW3TrVs3jhw5Qnp6+Y/ASE9PZ8yYMbz11lu0bNkSgN27d9OnTx9mz57NqVOnbqZEh8zMTAAaNmyI2WwmLy8Pm83GmTNnaNCgAUaj0bFOZmYmkZGReHp6Ot7v5MmTwJXHqpdMqihZdvVYw4YNSy0r2f56Y3a73bFcKaVUWddtUJcvX+aTTz7hoYce4uWXX6ZRo0asW7eO5s2b39gbGI08/vjjzJs3r9zx0aNH87e//Y22bds6lnXr1o3ly5cTGBjIU089xciRI/n888+xWCw3GAu8vLwAsFgspaaee3p6UlxcjN1u55VXXqFx48Z88sknjtcueaKsp+eVCY5FRUWOsZLX+W9jJZ+vN3Z1jUoppcq67jTzmJgYoqOjmTp1Ko0aNbqhFzUYDKW+HjBgAO+++y5ZWVll1u3YsSMrV64kJiamVCOpWbMmI0aMYMSIEezZs4eEhATmzp3L+vXrr/v+GRkZ+Pv7A5CWluZ4wuylS5eIiIhg7969ADRv3pzWrVtTUFBAVlYWZrOZ6OhoAMfntLQ00tPTKSgocCxr0qSJY+zQoUMUFxeXu53JZMJut5c75u3tjcViISMj47p58vLybmi9qsLd8oD7ZXK3PKCZqqTrnRtMSkqS8ePHS9++fWX27Nly4sSJUuODBw+WY8eOOb7etGmTvPjiiyJy5RrUq6++KiIiy5cvl8TExDLXoM6dOydjxoyRxMTEMu99+PBhefPNN6Vnz56SkJAge/fuveFzmfn5+RIaGiqxsbFis9kkNTVVUlJSRERkyJAhAsikSZNERKRfv34CyN/+9jcREfnyyy8lMzNT8vLyJCoqSgCZNm2aiIh8/vnncvLkScnNzZXw8HABZM6cOSIismHDBjlz5oycO3dOatSoUeo619q1a+XcuXNy6tQpCQgIkIceeui6WUq4y3nmEu6WR8T9MrlbHhHN5Mp+8zWomJgYZs6cyUcffURgYCCjR49mxIgRnDhxAoAOHTqwdu1aAGw2G+vWraNDhw5lXmfw4MEkJydz4cKFUssNBgPvvPMO6enp/O///i9w5QjjgQce4OWXX6Zhw4asXr2a119/nVatWt1w4/Xz8+O1115jy5YtdO7cmeTkZFJTU+nevTuffvopADt37uTNN9/k6NGjALz22msMGzaM7OxsVq1aRevWrTlx4gQ1atQgISGBP/3pT5w/f56PP/6YNm3acP78eYKCgnjmmWd45JFHyM3NZeHChbRp04b8/HwCAwN58skneeKJJ8jLy+O9996jbdu2iAhTpky54SxKKfWH9Fu63b59++TUqVMicmXG3bPPPivx8fEyYMAAmTZtmmMG3tVHUCIiixcvliZNmpQ7zdxsNsvAgQNl6dKlcuTIETly5MhvKa1MJ164cKE0bNjQ8XtJdevWlTlz5sg777wjfn5+AkitWrVkxYoVkpCQINWrV3es27ZtW/niiy8kPz9fJk6cKIGBgY6xe+65R7Zt2yZms1mefvppx2sB0rVrV9mxY4fk5OTIU089Jb6+vo6x2NhY2bVr101lcpf/JZVwtzwi7pfJ3fKIaCZXdq0jKIOIiJN64+/CZDLRrFmzUsvsdjsZGRnY7XbHDD6A4uJibDYbXl5epSYwZGRkEBAQQJ06dUq9TmFhIRkZGQQFBREREVFqrKCggMzMTIKDgwkLCys1dvnyZTIzMwkJCSE0NPSmM2VkZBAVFXXT27kqd8sD7pfJ3fKAZnJl5f3chj/IvfiMRiMNGjQos9zLy6vMTDofHx/HJIhfq1atmmOiw6/5+vpec8zPz4+mTZveZNVKKfXH5nZ3M1dKKeUetEEppZRySW7XoGw2m7NLUEopdQtog1JKKeWS3K5BKaWUcg/aoJRSSrkkbVBKKaVckjYopZRSLkkblFJKKZekDUoppZRL0gallFLKJWmDUkop5ZK0QSmllHJJbve4jb179+Lj4+PsMpRSSt2goqIi7rrrrjLL3a5BKaWUcg96ik8ppZRL0gallFLKJWmDUkop5ZK0QSmllHJJ2qCUUkq5JG1QSimlXFKValDffPMNvXv3pmfPnrz//vtlxi0WC8888ww9e/Zk6NChnDhxwjE2b948evbsSe/evUlKSqrMsq/pt+b59ttvGTJkCPHx8QwZMoTk5OTKLv2aKvJ3BHDq1Clat27NBx98UFkl/1cVyXPgwAGGDRtG//79iY+Pp6ioqDJLv6bfmqm4uJgXXniB+Ph4+vbty7x58yq79Gu6XqaUlBQGDx5M8+bN+fe//11qbPXq1fTq1YtevXqxevXqyir5v/qteUwmU6nvuc8++6wyy771pIqwWq0SFxcnmZmZUlRUJPHx8XL48OFS6yxdulQSExNFRGTDhg0yfvx4ERE5fPiwxMfHS1FRkWRmZkpcXJxYrdZKz3C1iuRJS0uT7OxsERE5ePCgxMTEVG7x11CRTCXGjRsn48aNkwULFlRa3ddSkTzFxcUyYMAAMZlMIiJy4cIFp3/PiVQs07p16+SZZ54REZHLly9L9+7dJSsrq3IDlONGMmVlZYnJZJLnn39ePv/8c8fynJwciY2NlZycHMnNzZXY2FjJzc2t7AilVCRPenq6HDt2TEREsrOzpXPnznLx4sXKLP+WqjJHUKmpqURFRVGvXj28vb3p378/mzdvLrXOli1bGDx4MAC9e/cmOTkZEWHz5s30798fb29v6tWrR1RUFKmpqc6I4VCRPM2bNycsLAyA22+/naKiIiwWS6Vn+LWKZAL46quvuO2227j99tsrvfbyVCTPt99+S3R0NE2bNgWgRo0aeHh4VHqGX6tIJoPBQEFBAVarlcLCQry8vAgICHBGjFJuJFPdunVp2rQpRmPpH3nbt2+nc+fOBAcHU716dTp37uz0MywVydOgQQPq168PQFhYGDVr1uTChQuVVfotV2Ua1JkzZwgPD3d8HRYWxpkzZ8qsExERAYCnpyeBgYHk5OTc0LaVrSJ5rrZp0yaaN2+Ot7f371/0dVQkU35+PvPnz2fs2LGVWvN/U5E8x44dw2AwMHLkSAYPHsz8+fMrtfZrqUim3r174+vrS0xMDN27d+exxx4jODi4UusvT0X+fVfVnw03IjU1leLiYiIjI29leZXK09kFqN/u8OHDTJ8+nQ8//NDZpVTYnDlzeOSRR/D393d2KbeEzWZj9+7drFq1Cl9fX0aMGEGLFi3o2LGjs0v7zVJTUzEajSQlJWE2m3n44Yfp1KkT9erVc3Zp6lfOnj3L888/z7Rp08ocZVUlVabysLAwsrOzHV+fOXPGcZrr6nVOnz4NgNVq5dKlS9SoUeOGtq1sFckDkJ2dzdixY5k2bZrL/A+pIpn27dvH9OnTiY2NZfHixcyCxGInAAACSUlEQVSbN4+lS5dWav2/VpE84eHhtGvXjpo1a+Lr60vXrl1JS0ur1PrLU5FMGzZsoEuXLnh5eRESEkKbNm348ccfK7X+8lTk33dV/dnw3+Tl5fHkk08yYcKEcm/AWpVUmQZ15513cvz4cbKysrBYLGzcuJHY2NhS68TGxjpm4WzatIl77rkHg8FAbGwsGzduxGKxkJWVxfHjx2nZsqUzYjhUJI/ZbGbUqFE899xz3H333c4ov1wVyfTxxx+zZcsWtmzZwiOPPMKTTz7J8OHDnRHDoSJ5YmJiOHTokOOaTUpKCo0bN3ZGjFIqkikiIoKdO3cCcPnyZfbt20fDhg0rPcOv3Uima4mJiWH79u1cvHiRixcvsn37dmJiYn7niv+7iuSxWCyMGTOGQYMG0adPn9+50krg1CkaN2nbtm3Sq1cviYuLk7lz54qIyMyZM+Wrr74SEZHCwkIZN26c9OjRQ+677z7JzMx0bDt37lyJi4uTXr16ybZt25xS/6/91jz//Oc/pVWrVjJw4EDHx7lz55yW42oV+TsqMWvWLJeYxSdSsTxr1qyRfv36Sf/+/WXatGlOqb88vzVTXl6ejBs3Tvr16yd9+/aV+fPnOy3Dr10v0759+6RLly7SqlUrad++vfTr18+x7cqVK6VHjx7So0cPWbVqlVPq/7XfmmfNmjXSvHnzUj8b9u/f77QcFaWP21BKKeWSqswpPqWUUn8s2qCUUkq5JG1QSimlXJI2KKWUUi5JG5RSSimXpA1KKaWUS9IGpZRSyiX9f9tDKZx9eth+AAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3de1yUZfr48c+DKKKAisqgZv4C00pN+2Z5whMGonhOpNZMLHNXTVLTtDQPeaDd1DWzE9maVpuJJ0rNE6bk+ayVaYlYmDD0RQQUOc3cvz/4MpurMsMwwwzD9X69ntdrZ+bhnmtYvLrneu7nujWllEIIIYRNuTk6ACGEcEWSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIexAkqu4xYMPPsjAgQPp168f0dHR3Lx50+qxpk+fzrZt2wCYMWMGFy5cuOu5hw8f5sSJE2V+j+DgYK5evWrx83/2yCOPlOm93nnnHT7++OMy/YyouiS5ilvUrFmT+Ph4Nm/eTPXq1VmzZs0trxcVFVk17oIFC2jevPldXz9y5AgnT560amwhnJG7owMQzqt9+/acP3+ew4cP8/bbb+Pj40NycjJbt25l0aJFHDlyhIKCAoYPH85TTz2FUop58+axf/9+GjVqRPXq1U1jjRgxgldeeYU2bdqQmJjIP//5TwwGA/Xq1WPBggWsWbMGNzc3vvrqK15//XUCAgKYPXs2V65cAeC1117j0UcfJTMzk5dffhm9Xk+7du2w5B6YcePGkZaWRn5+Ps8++yyRkZGm1xYuXMj+/ftp0KAB//znP/H19eW3335j7ty5ZGZmUrNmTebNm0dgYKDtf8HCtSkh/qRdu3ZKKaUKCwvV3/72N/X555+rQ4cOqbZt26rffvtNKaXUmjVr1LvvvquUUio/P18NHjxY/fbbb2r79u0qKipKFRUVqbS0NPXoo4+qb775Riml1DPPPKPOnDmjMjIyVLdu3UxjZWZmKqWUWrZsmVqxYoUpjsmTJ6ujR48qpZT6/fffVVhYmFJKqXnz5ql33nlHKaXUt99+q1q0aKEyMjJu+xw9e/Y0PV/yHjdv3lTh4eHq6tWrSimlWrRooeLj45VSSr3zzjtq7ty5Simlnn32WZWcnKyUUurUqVNqxIgRd4xRiNLIzFXcIi8vj4EDBwLFM9ehQ4dy8uRJ2rRpQ9OmTQHYv38/58+fZ/v27QDk5OTw66+/cvToUcLDw6lWrRo6nY6OHTveNv6pU6do3769aay6deveMY4DBw7cUqO9fv06N27c4OjRoyxfvhyAHj16UKdOHbOf6dNPP2Xnzp0ApKam8uuvv1KvXj3c3Nzo27cvAAMHDuTFF1/kxo0bnDx5kpdeesn08wUFBWbfQ4j/JslV3KKk5vrfatWqZfrfSilmzpxJ165dbzln7969NovDaDSydu1aPDw8yjXO4cOHOXDgAF9++SWenp6MGDGC/Pz8O56raRpKKXx8fO74OxCiLOSCliizoKAgvvjiCwoLCwFITk4mNzeXxx57jG+++QaDwUB6ejqHDx++7WfbtWvHsWPHSElJAeDatWsA1K5dmxs3btzyHp9++qnp8U8//QTAY489xtdffw0UJ/OsrKxSY83JyaFOnTp4enqSlJTEqVOnTK8ZjUbT7Pvrr7/m0UcfxcvLi3vuuYdvvvkGKP4Pyblz58r2CxICSa7CChERETRv3pwhQ4bQr18/Zs2ahcFgICQkhGbNmtG3b1+mTZtGu3btbvtZX19f3njjDSZMmMCAAQOYNGkSAD179mTnzp0MHDiQY8eOMWPGDH744Qf69+9P3759+eKLLwAYP348x44dIzw8nJ07d9K4ceNSY+3WrRtFRUX06dOHxYsX3xJTrVq1OHPmDP369ePQoUOMHz8egLfeeot169YxYMAAwsPD2bVrl61+daIK0ZSSloNCCGFrMnMVQgg7kOQqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5OglZbiyEa5Hk6kB/TqiapnH9+nXOnTvH3Llz2b17twMjE0KUlyRXB9I0DYC0tDROnz7N2LFj2bp1Kzt37sTdXXrqCFGZyb9gB7hy5Qo6nY5q1arx6aefkpiYiJ+fH8OGDeOee+7hu+++IyAgwNFhCiHKQXoLVCClFKmpqYwcOZLPP/+cWrVqsXXrVtq2bYufnx/16tXjrbfe4r777mPo0KGODlcIUQ4yc61Amqbh5eVFw4YN8fPzA2Do0KG4uRVXZ27cuEFaWhp9+vRxZJhCCBuQmmsFuXTpElDcjLpatWq3bPRX8uVhyZIlALRu3brC4xNC2JbMXO1MKUVhYSETJkygc+fOjB07lszMTHJyckxbjZQICgrigQceMP1cyQUvIUTlIzVXO9Pr9eh0OlJTUxk7diyPPPIISUlJ9OjRA19fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri+HDhzNy5EiGDRuGXq9nypQpHD16lBdeeIHffvuN/Px8NE3j6tWrLFu2DJ1O5+jQhRA2IMnVzvbs2cPbb7/NiBEjGDJkCFevXmXMmDGEhYUxevRo03n5+fnl3oxPCOE8pOZqBz///DP169fHy8uLHj164Onpyfz58zEYDERERPDuu+/yt7/9jZSUFObOnQtA9erVHRy1EMKWZOZqY6mpqYSGhtKwYUNatGjB8OHDCQwMJCsri1deeYWxY8fSt29f0tLSmDx5MsuXL8fX19fRYQshbKzanDlz5jg6CFeRnZ1NgwYNqFWrlqlXgIeHB2+//Tbe3t7k5OSwbds2PDw86NChA4MGDaJ27dqODlsIYQeyztVG9Ho9kydP5ujRozz77LN06tSJ5s2b07JlSz755BN8fX1p1qwZaWlpLF68mKysrFuWYQkhXIuUBWzk2rVrbNmyhX379jFmzBjatGnDunXrOHXqFOHh4XTt2hWApKQkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HA2rVruffeewkODubq1ascPnyYnJwcWrZsia+vr5QChKgC5HtpORw9epT4+HjT4zp16tC7d2+eeOIJPvzwQ3755RcGDBhA8+bN+f7777l+/boDoxVCVCRZilUORUVFxMTE4ObmRv/+/YHiBBsaGkpeXh47d+5kwoQJhIWFUbNmTby8vBwcsRCiosjM1QpKKZRSdOrUiWXLlrF06VK++uor02t169YlMDCQ5ORkjEYjfn5++Pj4VHicf/zxh2wf4+Ryc3MdHUKZyN+T5SS5WkHTNDRN49y5czz++OPMnz+ft99+m82bN5uareTm5pKfn2/xPx6DwWDTGL/77jtefPFFUlNTbTbmL7/8wpEjR8jMzLTZmL/++ivff/89BQUFNhvz0qVLfP/99xiNRpv9Xi9evMjJkycpLCy02Zi7du1i0aJFZGRk2GQ8gFOnTrFp0yZOnTpls9/psWPH2LRpE1D8ty8J1jJyQctK69at49133yU8PJyAgABatmzJu+++y6VLl9i7dy/x8fHMnDmTRo0alTpOcnKyqTuWwWCwyfKsffv2sWjRIjIzM7l27RrdunUr95h79+5l9uzZJCcns2PHDjp27FjuC3Pffvstr7/+OsePH+fgwYO0aNGCevXqlWvMXbt2MWfOHJKSkjh16hSXL1+mefPm5boDbseOHcycOZMffviBw4cPo9frCQwMpEaNGlaPeeTIERYsWEBUVBQtW7a0epw/S0hIICYmhvz8fI4ePUrr1q2pW7eu1eMZjUZyc3MZP348x48fx83NjTZt2qBpGkajUbq2maNEmRgMBqWUUu+//77atWvXLa+dP39ebdmyRa1atUpdunTJ7Fi7d+9WDz/8sJo8ebLpuaKionLFt3//fvXEE0+on3/+WRUUFKhRo0apI0eOlGvMQ4cOqdDQUHX69GmllFLjxo1T+/fvL9eYx48fV2FhYerHH39USik1e/ZsNX369HKNefXqVfX888+rX375RSmlVFxcnBoyZIhavny5ysnJsWrMgoIC9dJLL6ljx44ppZTatm2bevPNN9WSJUusHlMppf71r3+pFStWKKWUSktLU/v27VOnTp1S2dnZVo139epV9dxzz6nz588rpZSaPn262rp1q/rf//1flZeXZ3WcSikVGxurPv74YzV16lS1cuXKco1VlUhZoIzc3NxISUlh//79t3Sw+vXXX2nRogV9+/bl2WefpVmzZqWOk5uby2effcZrr71G9erVmTJlCgDVqlUr19dOg8HA3//+d+6//35u3rzJfffdxy+//AJYXy9r0KABc+fO5eGHH+aPP/7g9OnTfPbZZ8yaNYtt27ZZPe4LL7zAQw89BEB0dDRZWVnl+irr7u5Obm4uf/zxB1C8y0OTJk3IzMxkz549Vo97/fp1fv31VwBCQkLo2bMnhYWFfP3111Z/9j+3lXzppZdYv349n332GXPnziUrK6vM47m7u5OXl8fFixe5fv06R44cIT4+noULF/Lee++Vq7br7u5OamoqgwcP5syZM8TExLB48WKUUhiNRqvHdXVSFigDpRRFRUUsXbqU4OBgunTpQlJSEjNmzODixYvcf//9eHl5WfR1qXr16nTs2JHWrVvTsWNHEhISSEhIIDQ0tFylgWbNmtGoUSOMRiM1a9ZE0zRiYmIICgqiQYMGVo3p6+vLPffcA8Dq1atp06YNc+bMITMzk927d/P444/j6elZpjH9/Pxo1qwZNWrUwGAwkJOTwxdffEGfPn3w9PQkMzOzzGN6eHhQUFBAQkICubm5fPPNN+Tm5tK6dWuOHTtGr169yjQeFCfB+vXrs3HjRvz9/WnSpAn+/v5cu3aNgwcPEhoaatXX45o1a7Jo0SJOnDhBnz59mDRpEg8++CDff/89Xl5eZv/j/N88PDyoXbs2sbGxfP311/Tp04c33ngDHx8fjh8/zn333Wf1///169cnNTWVQYMG8fvvv/Pxxx8TGBhIjx49pDRQCpm5loGmaVSvXp0bN26Qnp5OVFQUGzZs4IEHHmDKlCn4+/uX6Y9Np9NRu3ZtfH19mTt3Lvn5+aYZ7I8//khSUpLVsZYk6G7dujFs2DD27Nljk5nG2LFjGTduHABDhgzh+vXrVl00q1atmmlpmlIKb29v6tSpg6+vL1999RVLly4lLy+vzOP269ePbt26cfjwYfLy8li0aBFPPfUUGRkZVq8zbt++PUFBQcTHx3P06FGqVatG//79SU9P59y5c1aN2bJlS6ZNm8bp06e5fPkyAE2bNsVoNHL16lWrxgwLC2PlypU8+uijpm8EnTp14saNG/z+++9WjQnFiTs5OZm1a9eyZs0aXnjhBVJTU1mzZo3VY1YFss61jC5evGj6Kjx69Gg6d+5sk3aB9erVY+7cubz11luEhYVhNBpZvXq1DSKGBx54gE8++YTRo0eXa5cD9V9bz2zfvp2MjAzTZovWcnd3x93dnUaNGrF48WL2799PTEwMNWvWLPNY3t7eDBgwgH79+pn+A7Np06Zy9XLw8PCgf//+aJrGhx9+yMWLF6lRowYZGRnluo25W7duREdH884779C4cWMAzp49y5gxY6wes06dOnTs2JFt27ZRvXp18vPzuXz5crkumul0Ovz9/XnvvfeYNWsWwcHBHDp0qMyz6yrHYdXeSiwnJ0fl5ube8pzRaLTJ2CtXrlSdO3dW586ds8l4JaKjo1VKSopNxsrPz1dr165Vffv2NV1AKQ+j0ajy8/NVr169VPfu3VVycnL5g/w/cXFxqk+fPjb5febn56uDBw+qiRMnqmnTppkuxpXXDz/8oBYvXqxiYmJsEmdWVpZatWqVGj58uHruuefUTz/9VO4xr1y5or7//nvT45ILu+LupHGLE8nKymLixIlMmzbNtFFheSk7bHRYWFjIgQMHaNq0KQEBATYbd8OGDbRp04b777/fZmP+/vvvFBUV2XSWZTAY0DTN6bualZRBbHlnoD3+nlyVJFcnU5W3e5F/uMKVSHIVQgg7cO7vNUIIUUlJchVCOL38/Hyys7MdHUaZVOmlWIkJ35F5pex3wwghblWvcR269epqt/EvJ8WSW9Cch9qElms5YUWq0sk180oWy0eucnQYQlR6L64aabexb968SZHRG5331+iT9tC4xd/t9l62JGUBIYRTu5K8An/vjfjW2sO1vMdt3p7TXiS5CiGcVsms1dvjJ9y0IhrUTkCf9Jqjw7KIJFchhNMqmbWWqEyzV0muQgin9OdZa4nKNHuV5CqEcEr/PWstUVlmrw5LrsHBwbe0Vjt8+DB//etfAUxt/P7czq1fv36m1mx//tkffviB4OBgzp49W4HRCyHs6U6z1hKVZfZaocm1oKDA4o7o/v7+fPDBB6Wec+7cOaKjo1m6dCkPPfQQOTk50hldCBdwt1lricowe62Q5JqUlMSbb75JWFgYly5dsuhnevTowYULF7h48eIdX7948SLjx4/nH//4Bw8//DAAx48fJywsjHfeeYcrV67YKnwhRAXKy8ujyOhzx1lrCTetiPq1Ekxb+jgjuyXX3Nxc1q9fz9NPP83MmTMJDAzkq6++MnVINxuYmxujR4/mww8/vOPr48aNY9asWbRv3970XI8ePVizZg3e3t6MHTuW559/nm+++cam2zYLIeyroKCAWtWTzZ5Xq8ZF8vPzKyAi69jtDq2goCBatmzJ/PnzCQwMtOhn/rvdXL9+/Xj//fdJSUm57dxOnToRFxdHUFDQLbfD+fr6EhUVRVRUFCdPnuS1117jvffe4+uvvy7fBxJCVBiFwkjpJT6Fczf0s9vMddmyZeh0OiZMmMDy5ctv28Onbt26tzRiyMrKum3Pend3d5577jk++uij28afNWsWAHPnzr3ttQsXLvD3v/+dadOm8T//8z/Mnz/fFh9JCFFBlAKDMpo9nJndkmtQUBBLly7l888/x9vbm3HjxhEVFWW64t+hQwfi4+OB4s7uX331FR06dLhtnMGDB3Pw4MHbNm3TNI3Fixdz8eJF3n77baB4U79hw4Yxc+ZMAgIC2LhxIwsWLKBt27b2+phCCDswYqQIQ6mHwczM1tHs3rilXr16jBw5kpEjR3LmzBnTV/hx48YxZ84cBgwYgFKKrl27MmDAgNt+vkaNGowYMYIFCxbc9pqHhwfvv/8+zzzzDA0aNKBjx47ExMRYXIYQQjgnI2Aw08ffqBQ48cYVVXongvhPN0tXLCFs4MVVIxk4op9NxsrOzib9yj9o4FP6v828gubka5847S60VbrloBDCOSnAYOaCldHJL2hJchVCOB2jUhSauWBVJMlVCCHKRoHZy1VGnLrkKslVCOF8FMqisoAzb/giydXGtl85ZfMxezduZ/MxhXBmxasFzJyjoJoTT10luQohnI4RjUIzX/oNaFSvoHisIclVCOF0FMUz09KYe93RJLkKIZxO8VKs0meuzn1/liRXIYQTMigNVOl35yszrzuaJFchhNNRaGZnrsqpF2JJchVCOCGFhtFsXylJrkIIUSbFF7TMJE9zrzuYcxctyuHVV1+lU6dO9Otnm2YSQoiKY1AaBapaqUeRU99C4MLJdciQIaxYscLRYQghrFBSFij9kJmrQzz22GPUqVPH0WEIIaxQckGrtMOS5Hqnb7DXrl1j1KhRhIaGMmrUKLKysorfUynmz59PSEgI/fv358cffzT9zMaNGwkNDSU0NJSNG+++K+2fuWxyFUJUXgY0ClW1Uo8iC5Zi3ekbbGxsLJ06dWLHjh106tSJ2NhYABITE7l06RI7duxg3rx5zJkzByhOxsuXL2ft2rXExcWxfPlyU0IujSRXIYTTKZ65upk9zLnTN9iEhAQGDRoEwKBBg9i1a9ctz2uaRrt27Yqbdqens2/fPrp06ULdunWpU6cOXbp04bvvvjP73rJaQAjhdJTSMJiZmbopN5KSkpg0aZLpucjISCIjI0v9uYyMDPz8/ABo2LAhGRkZAOj1evz9/U3n+fv7o9frb3tep9Oh1+vNfgZJrkIIp2PJOlcjGoGBgWzYsMHq99E0DU2zz4Uxly0LTJ48maeeeork5GS6detGXFyco0MSQljIgAVLsay8/bV+/fqkp6cDkJ6ejq+vL1A8I01LSzOdl5aWhk6nu+15vV6PTqcz+z4um1yXLFnCvn37+PHHH0lMTCQiIsLRIQkhLKSUhlG5mT2sERwczKZNmwDYtGkTvXr1uuV5pRSnTp3C29sbPz8/goKC2LdvH1lZWWRlZbFv3z6CgoLMvo+UBYQQTqfkglZpzN8eW/wN9siRI2RmZtKtWzcmTJjAmDFjmDhxIuvWraNx48YsXboUgO7du7N3715CQkLw9PRk4cKFANStW5dx48YxdOhQAMaPH0/dunXNvrckVyGE0zGiFXfGKoXBgnGWLFlyx+dXrbp9225N05g9e/Ydzx86dKgpuVpKkqsQwukYlUahKj09uZt53dGcOzohRJWkLLgDy8k3IpDkamv22EzwlaTvbT4mwD8C29hlXCHKS2F+nau51x1NkqsQwukY/+/219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXjx4i19HlNSUoiOjiYqKspxQQkhLKLA7E0Ezr6Hlssm14CAAOLj4wEwGAx069aNkJAQB0clhLCEUWkUGkuvqRqMMnN1uIMHD9K0aVOaNGni6FCEEBawpCuWJdu8OFKVSK5btmy5ZfdHIYRzK76gVbl7Czh36reBgoICdu/eTVhYmKNDEUJYyGjR7q+yFMuhEhMTadWqFQ0aNHB0KEIIC1kyc5WlWA62ZcsWwsPDHR2GEKIMFJV/natLlwVyc3M5cOAAoaGhjg5FCFEGRopvfy3tkKVYDlSrVi0OHz7s6DCEEGWklGa2piqrBYQQoows2YlAZq5CCFFGRjC7QaEkVyGEKCOLGrdIWUAIIcpGoZndxsVcv1dHk+QqhHA6Ft2hpUlyFeVkr11ax//ys83HfPf+FjYfU1Q9CvMtBaXmKoQQZWRUlpQFpOYqhBBlUnyHVuVeLeDcqV8IUSUpVTx7Le1QFt7++sknnxAeHk6/fv2YPHky+fn5pKSkEBERQUhICBMnTqSgoAAobvQ0ceJEQkJCiIiI4PLly1Z/BkmuQginUzJzLfWwYBy9Xs/q1atZv349mzdvxmAwsGXLFhYtWkRUVBQ7d+7Ex8eHdevWARAXF4ePjw87d+4kKiqKRYsWWf0ZJLkKIZxOSc21tMPcHlslDAYDeXl5FBUVkZeXR8OGDTl06BC9e/cGYPDgwSQkJACwe/duBg8eDEDv3r05ePAgSlnXOVZqrkIIp1O8WsB8y8GkpKRb9sqLjIwkMjLS9Fin0/Hcc8/Rs2dPPDw86NKlC61atcLHxwd39+L05+/vj16vB4pnuo0aNQLA3d0db29vMjMz8fX1LfNncNnkmp+fz/DhwykoKMBgMNC7d2+io6MdHZYQwgKWXNBSSiMwMJANGzbc9ZysrCwSEhJISEjA29ubl156ie+++87W4d6RyybXGjVqsGrVKmrXrk1hYSF/+ctf6NatG+3atXN0aEIIc5QlM1fzwxw4cIB77rnHNPMMDQ3lxIkTZGdnU1RUhLu7O2lpaeh0OqB4ppuamoq/vz9FRUXk5ORQr149qz6Cy9ZcNU2jdu3aABQVFVFUVITm5Hd0CCGKGZWGwehW6mHuJgOAxo0bc/r0aW7evIlSioMHD9K8eXM6dOjA9u3bAdi4cSPBwcEABAcHs3HjRgC2b99Ox44drc4bLptcobiQPXDgQDp37kznzp1p27ato0MSQlhAUbyO1dxhTtu2benduzeDBw+mf//+GI1GIiMjmTp1KitXriQkJIRr164REREBwNChQ7l27RohISGsXLmSKVOmWP0ZXLYsAFCtWjXi4+PJzs5m/Pjx/Pzzz7RoIbdnCuHsLK25WiI6Ovq26y1NmzY1Lb/6Mw8PD5YtW2Z5oKVw6ZlrCR8fHzp06FBhhWwhRPkoC8oCBqNzl/lcNrlevXqV7OxsAPLy8jhw4AABAQEOjkoIYRFVnGBLPZz89leXLQukp6czffp0DAYDSinCwsLo2bOno8MSQljAlmUBR3HZ5PrAAw+wadMmR4chhLCCUsWHuXOc2V2T6yOPPGJaglBy+5emaSil0DSNEydOVEyEQogqR6GZvb3V3MzW0e6aXE+ePFmRcQghhImlt786M4suaB07doz169cDxReKUlJS7BqUEKJqKykLlHo4OkgzzCbX5cuXs2LFCmJjYwEoLCxk6tSpdg9MCFG1mVstQGWfue7cuZP3338fT09PoPje2xs3btg9MCFE1eUK61zNrhaoXr06mqaZLm7l5ubaPSjxX+zUE8Eemwm+mnTG5mPGBD5s8zGFc7NotUDFhGI1s8m1T58+zJo1i+zsbNauXcv69esZNmxYRcQmhKiyLNjGxcnLAmaT6/PPP8/+/fupXbs2ycnJREdH06VLl4qITQhRRSmLWg5W8uQK0KJFC/Ly8tA0TRqfCCHsTlkwc3X2O7TMXtCKi4sjIiKCnTt3sn37diIjI+/YTUYIIWxGWXg4MbMz1xUrVrBx40ZTN+7MzEyeeuophg4davfghBBVl9mZa2Vv3FKvXj1TR3+A2rVrW73tgRBCWEIpDaOZpVbKkr21HeiuyXXlypUA3HvvvQwbNoxevXqhaRoJCQm0bNmywgIUQlRRrrpaoORGgXvvvZd7773X9HyvXr3sH1U5paam8sorr5CRkYGmaQwbNoyRI0c6OiwhhKVcuSvWiy++WJFx2FS1atWYPn06rVq14vr16zz55JN06dKF5s2bOzo0IYSlnDx5mmO25nr16lU++ugjLly4QH5+vun51atX2zWw8vDz88PPzw8ALy8vAgIC0Ov1klyFqCSU0lBma67OXRYwuxRrypQpBAQEcPnyZV588UWaNGlCmzZtKiI2m7h8+TI//fST7PwqRGViyTYvTl5zNZtcS7addXd35/HHHycmJoZDhw5VRGzlduPGDaKjo3nttdfw8vJydMKnu6EAABEsSURBVDhCiLJw9XWu7u7Fp/j5+bFnzx78/PzIysqye2DlVVhYSHR0NP379yc0NNTR4QghykJhwWoA5565mk2uY8eOJScnh2nTpjFv3jxu3LjBq6++WhGxWU0pxYwZMwgICGDUqFGODkcIYQ1zM9PKPnMt2THV29ubTz/91O4B2cLx48eJj4+nRYsWDBw4EIDJkyfTvXt3B0cmhLCMBc2wK2tynTdvnqmH653MnDnTLgHZQvv27Tl//ryjwxBCWMmSfq6VNrm2bt26IuMQQoj/UIC5pVYWrhbIzs5m5syZ/Pzzz2iaxsKFC7nvvvuYNGkSv//+O02aNGHp0qXUqVMHpRQLFixg79691KxZkzfffJNWrVpZ9RHumlwHDx5s1YBCCFFeGqDZaOa6YMECunbtyrJlyygoKCAvL48PPviATp06MWbMGGJjY4mNjWXq1KkkJiZy6dIlduzYwenTp5kzZw5xcXFWfQaLdn8VQogKZaOWgzk5ORw9etTUxa9GjRr4+PiQkJDAoEGDABg0aBC7du0CMD2vaRrt2rUjOzub9PR0qz6CRc2yhRCiYllyQUsjKSmJSZMmmZ6KjIwkMjLS9Pjy5cv4+vry6quvcu7cOVq1asWMGTPIyMgw3cXZsGFDMjIyANDr9fj7+5t+3t/fH71ebzq3LCS52pqdNhOsLOyxmeCz51NsPubqlk1tPmalYuu/U1v/2SvAXEtBBYGBgWzYsOGupxQVFXH27Flef/112rZty/z584mNjb3lnD9vwGpLLrlaQAhRyVnytd+CsoC/vz/+/v6m29/DwsKIjY2lfv36pKen4+fnR3p6Or6+vgDodDrS0tJMP5+WloZOp7PqI8hqASGEc7JBP9eGDRvi7+/PxYsXCQgI4ODBgwQGBhIYGMimTZsYM2YMmzZtMrVSDQ4O5rPPPiM8PJzTp0/j7e1tVUkAZLWAEMIZKdDMlAXMrib4P6+//jpTpkyhsLCQpk2bEhMTg9FoZOLEiaxbt47GjRuzdOlSALp3787evXsJCQnB09OThQsXWv0RXLLloBBClHjwwQfvWJddtWrVbc9pmsbs2bNt8r4u33JQCFH5lKxzNXc4M5duOSiEqKSUZtnhxFy25aAQohKzZClWZd39tURlbDkIxfWUuLg4lFJEREQQFRXl6JCEEGVg7mu/c89bXbTl4M8//0xcXBxxcXFUr16d0aNH07NnT5o1a+bo0IQQlrDROldHMptc7zZLjYmJsXkwtpKUlMTDDz+Mp6cnAI899hg7duzghRdecHBkQgiLuXpy7dGjh+l/5+fns2vXLqsX1VaUFi1asHTpUjIzM6lZsyaJiYlyU4QQlYkCzUzLQXPrYB3NbHLt3bv3LY/79evHX/7yF7sFZAuBgYGMHj2a559/Hk9PTx544AHc3KQBmBCVRiXYgNCcMjduuXTpkqmDjDOLiIggIiICgCVLllh9f7AQouLZsp+ro5hNro888sgtDVwaNmzIlClT7BqULWRkZFC/fn2uXLnCjh07WLt2raNDEkJYypLbXyt7WeDkyZMVEYfNTZgwgWvXruHu7s7s2bPx8fFxdEhCiLJw9ZnryJEjb7sH907POZt///vfjg5BCGEtV6655ufnc/PmTTIzM8nKykL931aM169fR6/XV1iAQoiqx5Kaq7P3Frhrcl2zZg2rVq0iPT2dIUOGmJKrl5cXzzzzTIUFKISoglz5JoKRI0cycuRIPv30U0aMGFGRMQkhRKWfuZpd/Onm5kZ2drbpcVZWFp9//rldgxJCVHE22v3Vkcxe0Fq7di3Dhw83Pa5Tpw5xcXG3PCf+RDn5/+OVkD02Exx+7rLNx/z8gXtsPqbd2Prv1B5/9pX8n5LZ5Go0GlFKmda6GgwGCgsL7R6YEKLq0qrCOtegoCAmTpzIU089BRRf6OratavdAxNCVG0uf4fW1KlT+fLLL/niiy8A6Ny5M8OGDbN7YEKIKqwS1FTNseiC1tNPP82yZctYtmwZzZs3Z968eRURmxCiiiopC5g7nJlFjVvOnj3L5s2b2bZtG02aNCE0NNTecQkhqjpXLQskJyezZcsWNm/eTL169ejbty9KqUqzG4EQohJz5ZsI+vTpQ/v27fnwww9N26N88sknFRWXEKKKq+x7aN215rp8+XIaNmzIs88+y8yZMzl48KDpFtjKIDExkd69exMSEkJsbKyjwxFClIFL11yfeOIJnnjiCXJzc0lISGDVqlVcvXqV2bNnExISQlBQUEXGWSYGg4E33niDlStXotPpGDp0KMHBwTRv3tzRoQkhLOECZQGzqwVq1apF//79+eCDD9i7dy8PPfQQH330UUXEZrUzZ87QrFkzmjZtSo0aNQgPDychIcHRYQkhyqKS3/5apo2l6tSpQ2RkpNP3ctXr9fj7+5se63Q6aZMoRCWjKTNHGcYyGAwMGjSIv/71rwCkpKQQERFBSEgIEydOpKCgAICCggImTpxISEgIERERXL5s/W3SsmufEML5mEusZZy5rl69msDAQNPjRYsWERUVxc6dO/Hx8WHdunUAxMXF4ePjw86dO4mKimLRokVWfwSXTK46nY60tDTTY71eLxsUClHZ2KgskJaWxp49exg6dGjxsEpx6NAh087WgwcPNpUNd+/ezeDBg4Hina/LcyHfJZNrmzZtuHTpEikpKRQUFLBlyxaCg4MdHZYQwlIWthxMSkpiyJAhpuPLL7+8baiFCxcydepU3NyK011mZiY+Pj64uxdfz/f39zeVDfV6PY0aNQLA3d0db29vMjMzrfoIZd5auzJwd3dn1qxZjB49GoPBwJNPPsn999/v6LCEEBayqCuWgsDAQDZs2HDXc7799lt8fX1p3bo1hw8ftnGUpXPJ5ArQvXt3unfv7ugwhBBWssVOBCdOnGD37t0kJiaSn5/P9evXWbBgAdnZ2RQVFeHu7k5aWpqpbKjT6UhNTcXf35+ioiJycnKoV6+eVfG7ZFlACFHJ2WgngpdffpnExER2797NkiVL6NixI4sXL6ZDhw5s374dgI0bN5rKhsHBwWzcuBGA7du307FjR1Mv67KS5CqEcDolu7+aXTFgpalTp7Jy5UpCQkK4du0aERERAAwdOpRr164REhLCypUrmTJlitXv4bJlASFEJaYAc7e3ljG5dujQgQ4dOgDQtGlT0/KrP/Pw8GDZsmVlG/guJLkKIZySy+9EIIQrssdmgoPP/mHzMQE2PtTQLuM6NRfoLSDJVQjhdIqXYpWePctTc60IklyFEE7JFkuxHEmSqxDC+UhZQAghbK9kKVap50hyFUKIMrLw9ldnJslVCOF8pCwghBC2Z0lZwNmTq8ve/pqdnU10dDRhYWH06dOHkydPOjokIYTFFCgLDifmsjPXBQsW0LVrV5YtW0ZBQQF5eXmODkkIYSkXqLm65Mw1JyeHo0ePmjqP16hRAx8fHwdHJYSwmAtsre2SyfXy5cv4+vry6quvMmjQIGbMmEFubq6jwxJCWMpGLQcdySWTa1FREWfPnuXpp59m06ZNeHp6Ehsb6+iwhBAWKrn9tdTDyWuuLplc/f398ff3p23btgCEhYVx9uxZB0clhCgLe/ZzrQgumVwbNmyIv78/Fy9eBODgwYO3bKsrhHByLlAWcNnVAq+//jpTpkyhsLCQpk2bEhMT4+iQhBAWcoV1ri6bXB988MFSd4UUQjgxpSxoOejc2dVlk6sQopKTmasQQtiWJResnP2CliRXIYTzUYCZsoDZ1x1MkqsQwvm4wO2vklyFEE7IgsYsklyFqBrstUvrsJ/SbD7m2gf9bT6mLUnNVQgh7MGC3V+l5aAQQljDXNcr6YolhBBlU1wWUGYPc1JTUxkxYgR9+/YlPDycVatWAXDt2jVGjRpFaGgoo0aNIisrCwClFPPnzyckJIT+/fvz448/Wv0ZJLkKIZyTDfoKVKtWjenTp7N161a+/PJL/v3vf3PhwgViY2Pp1KkTO3bsoFOnTqaueYmJiVy6dIkdO3Ywb9485syZY3X4klyFEM5HmWk3aDR/eyyAn58frVq1AsDLy4uAgAD0ej0JCQkMGjQIgEGDBrFr1y4A0/OaptGuXTuys7NJT0+36iNIzVUI4XwUFizFUiQlJTFp0iTTU5GRkURGRt7x9MuXL/PTTz/Rtm1bMjIy8PPzA4q76GVkZACg1+vx9//PSgp/f3/0er3p3LJw2eT6ySefEBcXh6ZptGjRgpiYGDw8PBwdlhDCEhbeRBAYGGhRg6YbN24QHR3Na6+9hpeX163jaBqappUn2jtyybKAXq9n9erVrF+/ns2bN2MwGNiyZYujwxJCWMyS3V8tG6mwsJDo6Gj69+9PaGgoAPXr1zd93U9PT8fX1xcAnU5HWtp/1hWnpaWh0+ms+gQumVwBDAYDeXl5FBUVkZeXZ9W0XgjhGBZt82JBzVUpxYwZMwgICGDUqFGm54ODg9m0aRMAmzZtolevXrc8r5Ti1KlTeHt7W507XLIsoNPpeO655+jZsyceHh506dKFoKAgR4clhLCYJbe/mk+ux48fJz4+nhYtWjBw4EAAJk+ezJgxY5g4cSLr1q2jcePGLF26FIDu3buzd+9eQkJC8PT0ZOHChVZ/ApdMrllZWSQkJJCQkIC3tzcvvfQS8fHxpl+uEMLJKczfJGBBWaB9+/acP3/+jq+VrHn9M03TmD17tvmBLeCSZYEDBw5wzz334OvrS/Xq1QkNDeXkyZOODksIYSml0IzGUg+Mzn2Llksm18aNG3P69Glu3ryJUko2KBSisilZimWDC1qO4pJlgbZt29K7d28GDx6Mu7s7Dz744F3XvgkhnJCNygKO5JLJFSA6Opro6GhHhyGEsIKG+d4BskGhEEKUlcJ8TVU5d81VkqsQwgnJTgRCCGF7ltRcnXviKslVCOGElPmaqtRchRCirJQCg5mpqZOvc5XkKoSTs8dmgs+eT7HpePWvF9h0PNNaVnPnODFJrkII5yQXtIQQwsakLCCEEHaglPl1rLLOVQghrCBlASGEsDGlwFwzbLmgJYQQZaSU+Zqqk9dcXbLlYAmDwcCgQYP461//6uhQhBBlYVHLQeeeubp0cl29erX0cRWiMiqZuZZ2SHJ1jLS0NPbs2cPQoUMdHYoQosws2f3VuZOry9ZcFy5cyNSpU7lx44ajQxFClJULrHN1yZnrt99+i6+vL61bt3Z0KEIIayhQymjmkJlrhTtx4gS7d+8mMTGR/Px8rl+/zpQpU1i0aJGjQxNCWMKSpVjmXncwl0yuL7/8Mi+//DIAhw8f5l//+pckViEqE6XAYCj9HCcvC7hkchVCVHLSFcv5dejQgQ4dOjg6DCFEGSilUGZmpkp6CwghhBWkt4AQQtiYJTVXc687mEsuxRJCVHJKoYylH5bWXBMTE+nduzchISHExsbaOfD/kOQqhHA+Jf1cSz3MJ1eDwcAbb7zBihUr2LJlC5s3b+bChQsV8AGkLCCEcDKapnF/h/+HR22PUs/z8q2FpmmlnnPmzBmaNWtG06ZNAQgPDychIYHmzZvbLN67qdLJtVmbe1j24xuODkOIildk2+HytXybjeXl5UXwgO6o/uZnplu3bmXixImmx5GRkURGRpoe6/V6/P3/s8GjTqfjzJkzNou1NFU6ubZr187RIQgh/oumadSqVcuicyMiIoiIiLBzRNaRmqsQwmXpdDrS0tJMj/V6PTqdrkLeW5KrEMJltWnThkuXLpGSkkJBQQFbtmwhODi4Qt67SpcFhBCuzd3dnVmzZjF69GgMBgNPPvkk999/f4W8t6acvW+XEEJUQlIWEEIIO5DkKoQQdiDJVQgh7ECSqxBC2IEkVyGEsANJrkIIYQeSXIUQwg7+P3JG+n7HvBQZAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVwVVf/A8c9duayyiqC5K+6FgqC44lZC7rtZueeeW9Jj9Txa+pSWpJWaaaI9mmWlZppaLuC+4ZbiLiigsst2uev8/uDnTQTTUrkXPO/Xy5femTMz3zlc+c6cOXOOTJIkCUEQBEGwMXJrByAIgiAIJREJShAEQbBJIkEJgiAINkkkKEEQBMEmiQQlCIIg2CSRoARBEASbJBJUKfnss8+YNm2atcMoVYmJifj5+WE0Gh97X6GhoRw4cKDEdREREURGRj72MZ4lkZGRBAUFERISUurHPn78OJ07d8bf35/ff//9H+9nxIgRbNiw4QlGVvqSk5Px9/fHZDJZOxSbJBLUE7R582Z69eqFv78/rVq1YsSIERw7dszaYQmlxM/Pj4SEBGuH8VDJycmsXLmSrVu3sn///hLL5ObmMmfOHNq1a4e/vz8dO3Zkzpw5ZGRkPPbxFy1axODBgzlx4gQdO3b8x/tZvnw5PXv2fOx47hcREYGfn1+x5Dl37lz8/Pz46aefHmk/f3VRdZevry8nTpxAoVD843jLM5GgnpCVK1cyd+5c3njjDfbv38/u3bsZNGgQO3futHZo/9iTuPMR/mQr9ZmcnIyrqyseHh4lrtfr9bz22mtcvnyZ5cuXc/z4cb777jtcXV05c+bMEzl+nTp1Hns/T1P16tXZtGmT5bPRaOTXX3+latWqT+wYT/L7IEkSZrP5ie3PVogE9QTk5OSwaNEi3nvvPTp37oyDgwMqlYrQ0FBmzJhR4jYTJ04kJCSEZs2aMXjwYC5dumRZFx0dTdeuXfH396d169asWLECgIyMDEaPHk1AQADNmzdn0KBBli/l7du3mTBhAsHBwYSGhrJ69WrL/k6fPk2vXr1o2rQpLVu25L///W+JMR0+fJg2bdqwbNkyQkJCePvtt7lz5w6jR48mODiYwMBARo8eza1btyzbDBkyhE8//ZQBAwbg7+/PsGHDHniVvX37dkJDQ7l48SJms5lly5bRsWNHgoKCmDRpEllZWZayGzdupH379gQFBbFkyZKH/gwyMzMZOnQo/v7+vPLKKyQlJQEwa9YsPvzwwyJl33jjDaKiokrcz5UrVxg6dCjNmzenS5cubN261bIuIiKCWbNmMWrUKPz9/enbty/Xr18HYPDgwQB0794df39/tm7dWmJ96vV65syZQ6tWrWjVqhVz5sxBr9cXqf+lS5cSFBREaGgoP//8M1D4M2zZsmWRpqAdO3bQrVu3Es8jJyeHt956i+DgYNq3b8/ixYsxm80cOHCAYcOGkZKSgr+/PxEREcW23bRpEzdv3uTzzz+ndu3ayOVyPDw8GDduHG3btrXU05AhQwgICCAsLKzIhdhf1VPHjh25ceMGb7zxBv7+/uj1+mJ3Gvc2h+t0OqZNm0ZQUBABAQH07t2btLQ0oPC7t379egDMZjOLFy+mffv2tGjRgrfeeoucnBzgz6bmDRs20K5du0f6ToWGhnL8+HHu3LkDwN69e/Hz88PT09NS5vr167z66qsEBQURFBTE1KlTyc7OBmD69OkkJydbzvOrr76yxLF+/XratWvHa6+9VqQZPCsrizZt2rBr1y4A8vLy6NSpExs3biwxxiFDhhAZGcmAAQN4/vnnuXHjBrGxsfTu3ZtmzZrRu3dvYmNjATh06BAvv/yyZduhQ4fSu3dvy+dBgwY9VnPrUyMJjy06OlqqX7++ZDAYHlhm0aJF0tSpUy2f169fL+Xk5Eg6nU764IMPpG7dulnWhYSESEePHpUkSZKysrKkP/74Q5IkSfr444+ld999V9Lr9ZJer5eOHj0qmc1myWQyST179pQ+++wzSafTSdevX5dCQ0OlmJgYSZIkqV+/ftKGDRskSZKk3Nxc6cSJEyXGeOjQIal+/frSvHnzJJ1OJ2m1WikjI0Patm2blJ+fL+Xk5EgTJkyQxowZY9nmlVdekTp06CBdvXpV0mq10iuvvCLNnz9fkiRJunHjhlS3bl3JYDBIP/zwg9SxY0cpPj5ekiRJioqKkvr27SvdvHlT0ul00rvvvitNnjxZkiRJunTpkvTCCy9IR44ckXQ6nTR37lypfv360v79+0uMe8aMGUXKv//++9KAAQMkSZKkU6dOSSEhIZLJZJIkSZLS09OlJk2aSKmpqcX2k5eXJ7Vp00b64YcfJIPBIJ09e1Zq3ry5dOnSJctxmjdvLp06dUoyGAzSlClTpDfffNOyfd26dS3n96D6/PTTT6W+fftKaWlpUnp6utS/f38pMjKySPm5c+dKOp1OOnz4sPT8889LV65ckSRJkl566SVpz549lv2PHTtWWrFiRYl1Mn36dOmNN96QcnJypBs3bkidO3eWvv/+e8txWrduXeJ2kiRJb775pvTWW289cL1er5c6duwoLVmyRNLpdNKBAwekF154wRLnw+qpffv2RX6W93++9//Kt99+K40ePVrKz8+XjEajdObMGSknJ0eSpMLv3t1zWr9+vdSxY0fp+vXrUm5urjRu3Dhp2rRpkiT9+T2cOXOmpNVqpbi4OKlhw4bS5cuXSzy/GTNmSAsWLJDeeecdac2aNZIkSdLEiROlzZs3SwMGDJB+/PFHSZIkKT4+Xtq3b5+k0+mk9PR0adCgQdIHH3zwwPO6G8f06dOlvLw8SavVFvk/IkmStHfvXqlly5ZSWlqaNHPmTGnChAkP/Dm88sorUtu2baWLFy9KBoNBSk1NlQICAqQNGzZIBoNB2rx5sxQQECBlZGRIWq1WatSokZSeni7p9XqpRYsWUqtWraScnBxJq9VKjRs3ljIyMh54LGsRd1BPQFZWFm5ubiiVykfepk+fPjg5OaFWq5kwYQLnz5+3XPEplUouX75Mbm4uFSpUoGHDhpblqampJCcno1KpCAgIQCaTcebMGTIyMhg/fjxqtZrnnnuOfv36Wa7+lUol169fJyMjA0dHR1544YUHxiWXy5k4cSJqtRqNRoObmxtdunTB3t4eJycnxowZw9GjR4ts06tXL2rUqIFGo+HFF18kLi6uyPpVq1axYsUKvvnmG6pVqwbAunXrmDx5MpUqVUKtVjN+/Hi2b9+O0Whk27ZttGvXjsDAQNRqNZMmTUIu/+uv6r3lJ0+ezMmTJ7l58yZNmjTB2dmZgwcPArB161aaN29e5Er4rj179lC5cmV69+6NUqmkQYMGdOnShW3btlnKdOzYkSZNmqBUKunWrVuxc31YfW7evJlx48bh4eGBu7s748aNs9wl3TVp0iTUajXNmzenbdu2/PrrrwD06NHDUjYrK4t9+/YRHh5e7Jgmk4mtW7cydepUnJycqFKlCkOHDi12nAfJysrCy8vrgetPnTpFfn4+o0aNQq1W06JFC9q3b8+WLVv+cT09iFKpJCsri4SEBBQKBY0aNcLJyalYuc2bN/P666/z3HPP4ejoyJQpU9i6dWuRZrTx48ej0WioV68e9erV4/z583957O7du7Np0yays7M5evRosedl1apVIyQkBLVajbu7O0OHDi32f6MkEyZMwMHBAY1GU2xdq1atePHFF3n99deJjo5m1qxZf7mvnj17UqdOHZRKJfv27aNatWr06NEDpVJJeHg4NWvWZPfu3Wg0Gho3bsyxY8c4e/Ys9erVo2nTpsTGxnLy5EmqVauGm5vbQ2MvbY/+G1V4IFdXVzIzMzEajY+UpEwmE5GRkWzbto2MjAzLL9/MzEycnZ1ZtGgRS5Ys4ZNPPsHPz4+pU6fi7+/P8OHD+fzzzxk2bBgA/fv3Z9SoUSQlJZGSkkJAQECRY9z9PGfOHBYtWsRLL71ElSpVGD9+PO3bty8xNjc3N+zs7CyftVot//3vf9m7d6+luSMvLw+TyWR5sHvvLzN7e3vy8/OL7HPFihWMGzeOSpUqWZYlJyczbty4IolHLpeTnp5OSkpKkbIODg64urr+ZZ3eW97R0ZEKFSqQkpKCj48PPXv25OeffyYkJISff/6ZV199tcR9JCUlcfr06WL1eG8z2r2JTaPRFDvX+91fnykpKfj6+lo++/r6kpKSYvns4uKCg4NDieu7d+/OSy+9RH5+Pr/++isBAQFUrFix2DEzMzMxGAzFjnP79u2/jPUuV1dXUlNTH7j+7s/n3p/d/fv/u/X0IN27d+fWrVtMmTKF7OxsunXrxuTJk1GpVMViqly5suVz5cqVMRqNpKenlxhTSd/T+wUEBJCRkcGSJUto165dsYSSlpbGnDlzOHbsGHl5eUiShIuLy0PP6d7vakn69evH//73P954442HJg0fHx/Lv+//bkHRn0tgYCBHjhzB29ubwMBAXFxcOHr0qOViyBaJBPUE+Pv7o1ar+f3333nxxRcfWn7z5s3s3LmTlStXUqVKFXJycggMDET6/4HlmzRpwpIlSzAYDKxZs4Y333yT6OhonJyciIiIICIigosXL/Laa6/RuHFjfHx8qFKlCjt27CjxeNWrV2fBggWYzWZ27NjBxIkTOXz4cJFfhHfJZLIin7/++muuXbvG999/j5eXF3FxcfTo0cMS66P4+uuvGTFiBJ6ennTp0gUo/E86d+5cmjVrVqx8xYoVuXLliuWzVqst8nyqJPc+F8vLy+POnTuWX97dunUjPDyc8+fPc+XKlQf2HPPx8SEwMJCVK1c+8rk9zP31WbFixSKdBG7evFkkyWRnZ5Ofn2/52dy8edNS1tvbG39/f3bs2MGmTZsYOHBgicd0c3NDpVKRnJxM7dq1Lfvx9vZ+pJhbtmzJp59+WiSO+8/h1q1bmM1mS5K6efMm1atXf6T938/e3h6tVmv5fG9yVKlUjB8/nvHjx5OYmMioUaOoUaMGffv2LRbT3eeOUHgBpFQq8fDwKPLd+Lu6devGF198UeSZ7l0LFixAJpOxefNmXF1d+f3335k9e/ZD93n/d+JeJpOJ9957jx49erB27Vp69eplaXV42L7ufrfudfPmTVq3bg1A8+bN+fDDD/H19WXkyJFUqFCBd999F5VKZXmGamtEE98T4OzszMSJE5k9eza///47Wq0Wg8FAdHQ08+bNK1Y+Ly8PtVqNm5sbWq2WBQsWWNbp9Xp+/vlncnJyUKlUODo6Wn4J7N69m4SEBCRJwtnZGYVCgUwmo0mTJjg6OrJs2TIKCgowmUxcvHiR06dPA4UPve/eqd29wntYk9m9sdrZ2eHi4kJWVhaff/75366f2rVrs3z5cmbPnm15mD5w4EA+/fRTyy+VjIwMy0PaLl26sGfPHo4dO4Zer2fRokUP7aEUHR1tKb9w4UKef/55y9VlpUqVaNy4MdOnT6dz584lNq1AYTNhfHw8GzduxGAwYDAYOH36dJFk+Vc8PT25cePGX5YJCwtjyZIlZGRkkJGRwRdffFHk4TUUdhLQ6/UcO3aMPXv2FLno6d69OytWrODixYt07ty5xGMoFApefPFFIiMjyc3NJSkpiZUrVz6wQ8X9unfvTqVKlZgwYQJXrlzBbDaTmZnJ0qVLiY6OpkmTJmg0GpYvX47BYODw4cPs2rWLrl27PtL+71evXj22bt2KwWDgzJkzbN++3bLu0KFDXLhwAZPJhJOTE0qlssTvbnh4OKtWreLGjRvk5eURGRnJSy+99Lea3UsyZMgQVq5cSWBgYLF1eXl5ODg44OzszO3bt1m+fHmR9Y/yfbjf0qVLkclkzJ07l+HDhzNjxoxHfkeqbdu2xMfHs3nzZoxGI1u3buXy5cu0a9cOKLyQvnbtGqdPn6ZJkybUqVPH0mpQ0vnZApGgnpBhw4YRERHB4sWLadGiBe3atWPNmjUlXq336NEDX19fWrduTVhYWLFnQps2bSI0NJSmTZuybt065s+fD0BCQoKlp1r//v0ZOHAgwcHBKBQKli5dyvnz5+nQoQPBwcG888475ObmAoU9kMLCwvD392fOnDlERkY+8Jf0/V577TV0Oh3BwcH079/fcjX2d9WrV4+lS5fy7rvvEh0dzauvvkpoaCjDhg3D39+ffv36WRJqnTp1eO+995g2bRqtW7fGxcXloc0i4eHhfPHFFwQFBXH27FlLnd3Vo0cPLl68SPfu3R+4DycnJ1asWMHWrVtp3bo1rVq14uOPP7b0snuY8ePHExERQUBAQJHef/caO3YsjRo1olu3bnTr1o2GDRsyduxYy3pPT09cXFxo3bo106ZN4z//+Q+1atWyrO/UqRNJSUl06tQJe3v7B8by7rvvYm9vT8eOHRk0aBDh4eFFem39FbVaTVRUFDVr1mTYsGE0a9aMvn37kpmZSZMmTVCr1SxdupSYmBiCg4OZNWsW8+bNKxLn3/Hmm29y/fp1mjdvzmeffVYkYaelpTFx4kSaNWtG165dad68eYk/w969e9OtWzdeeeUVOnTogFqt5t133/1H8dzL1dWVFi1alHjXM378eM6dO0dAQACjRo0qdsEwatQolixZQkBAgKUn7l/5448/iIqK4qOPPkKhUDBy5EgAli1b9kixurm5sXTpUlauXElQUBDLly9n6dKluLu7A4VN5Q0bNqR27dqo1WqgMGn5+vo+8JUDa5NJf6etRhDKqKNHjzJ9+nR27979l00s1nT48GGmT59OTEzMX5br2LEjs2fPpmXLlqUUmSBYh7iDEso9g8HA6tWr6dOnj80mp0e1fft2ZDIZwcHB1g5FEJ460UlCKNeuXLlC7969qVev3gNfUC4rhgwZwuXLl5k3b94jP0MUhLJMNPEJgiAINklchgmCIAg2qdw18cXGxv5l7yZbZzAYir2EWNaU9XMQ8VuXiN/6SvscdDpdiSPclLsEpVAoqF+/vrXD+McSEhL+8sW8sqCsn4OI37pE/NZX2ufwoKGwRBOfIAiCYJNEghIEQRBskkhQgiAIgk0SCUoQBEGwSSJBCYIgCDZJJChBEATBJokEJQiCINgkkaAEQRAEmyQSlCAIgmCTyt1gsWfPnqNhwwbWDkMQBKHcKzCY0KgUj72fuLi4EkcAKndDHcnlMqpHbLF2GIIgCOVe/IdhT3X/5S5BCYIglAdmfQGGtASQyVF7VUemfPDgrWa9FrM2B2SgcPYqNjGnKS8LyagHhRKlk/t96zKRjAZkShUKRzfLckmSMOVlgsmITKlG4ej6ZE/wEYgEJQiCYEMks4msfWvJOf4zkl4LgNyhAhWC++Ic0L1I8sk5tZ2coxsxpCcChU9rVB5VqfTaAuQqDZIkkbHtM3JP77Bs41C3JV49/4UkSaT98jH556It6xwbtsczfCqSZCZ1w1y0lw5Z1jm98CIeXcY/5bMvSiQoQRAEG5K5ZyU5RzcyYMAABg8ejF6v56uvvmLbtuUgk+ES0B0AkzabjO1fEBzUnK6TRlKlShWSkpJ49913KUg4hUPtIPLjYsg9vYMxY8YQGBjIwYMH+eqrrzBmp6G9Fkv+uWjefPNNmjRpwp49e1i9ejVuHUaRd3Y32kuHeOutt6hXrx47duxg3Xff4xY6ArlKU2p1YfO9+FatWkV4eDhhYWFERUVZOxxBEISnxpiTRs7xXxg5ciTffvstarUaHx8ffv31V7p06cKdA99h1hcAYM7PBsnMyJEj6dChA0OGDKFHjx4ASEYDptxMMn5bSnBwMJ999hlDhw6ldevWhcfJTCZz11e0b9+eyMhIhg4dSosWLQAwpCWQFR1FWFgYH330EUOHDiUwMBAkM5jNpVofNp2gLl68yPr161m/fj2bNm1iz549JCQkWDssQRCEp6Lg2gkwG5kyZQp5eXmEh4fTq1cvACZPnoxZm40u+TwACmdPZCo7hg8fTkhICFqttsi+0nd8gRoDUVFRxS7u07ctwlGt4Ouvv2bFihVF121dSAUnB5YtW1ZsXWmz6QR15coVmjRpgr29PUqlksDAQHbs2PHwDQVBEMog450UFAoFtWvXJjExEYPBwK1btygoKMDPz89SBkCu1lBp8HwU93V6AMg7twftpUO8//77ZGVlMX/+/KLHybrFvHnziI+P5/PPP79v3U0WLlzIyZMn+frrr4usM2QmP8nTfSibTlB169bl+PHjZGZmotVqiYmJ4datW9YOSxAE4emQzMhksmK98ADk8sJf1xnbFnH7+/dI3/4FcgcXHOq3KVZWe+kQAQEBjB07lpEjR1r2J5fLUSgUtG7dmiFDhjB69GgUisL3mBQKBQqFgi5dutC9e3fGjh1bZJ1cLidl3Uwks+lpnX0xNt1JolatWowYMYLhw4djb29PvXr1LD8kQRCE8kZRoSJGo5Fr165RuXJlFAoF7u7uaDQaLl26BEC1atWoVFHFH3/EkHTy1wfuq0GDBjg4OHD69GnLssGDB6PRaNi5cydOTk5cuHDBsm7kyJHY2dlx5swZKlSoQHx8vGXdpEmTsLOzY8yYMZjzs1E4/dkd/Wk+drHpBAXQt29f+vbtC8CCBQvw9va2ckSCIAhPh331F0Am57PPPmPhwoWsW7eOChUqAFia4iZNmsTkyZNp1qwZsbGxDBs2jDZt2mBvb0+VKlWIiorip59+IiYmhv79+wNQqVIlFi5cyN69e1mwYAEpKSmWddWrV+ejjz7i999/Z/HixWRlZXH9+nUA/Pz8mD17Nlu2bGH58uUAyNT2RWKuVq3aY593XFxcicttPkGlp6fj4eFBcnIyO3bs4Pvvv7d2SIIgCE+FsoI3Ts934bPPPkOn01m6mffv35+NGzcCcOrUKdavX09WVhYAarUaBwcHNmzYAICDgwMqlYr4+HgSs40YMxKpVKkSrVq1IiYmhgMHDgAQn1GAMSORatWqERAQwG+//cbhw4cBuJKahzEjkbp169K4cWN++eUXjh8/jlvH0cjVpdfN3ObH4hs0aBBZWVkolUrefvttS1fIB4mLi+OlVVdLKTpBEIQnSzIayNy9gpxT28FkAArvWlwCe2DISCY/7v9frFWoLOtL4tw0HPdOb6C9doLUnz5AMuoA0FT3x7v/+wDkXz5M6sYPLfuxr9uCij1nApAXF0PalgVgMgJ/vsR7ryc11NGDxuKz+QT1d4kEJQhCeWDSZqO/dRlkcux86iK3cwDAkHULyaBD4eSOXOOEMetW4TBG95Db2aN0qWj5bNblYcxOQ6ZUoXT1KdIJw1SQiyknHZlSjcrNp1gMptxMZCo7VK6VisX4tBOUzTfxCYIgPIsU9i7Y12habPn9ieL+pFISuZ0jai/Hko+jcUKhcXpgDAp7l0eI9ukQXeIEQRAEmyQSlCAIgmCTyl0Tn9ksPfU5SgRBEIQnN2Hhg5S7Oyij8cG9WsqC8jDWYFk/BxG/dYn4re9Rz+FpJicohwlKEARBKB9EghIEQRBskkhQgiAIgk0qdwlKqVRZO4TH8iTGtbK2sn4O5Sn+AkPpjTwtCE9auevFJ5fLqB6xxdphCIJNED1ahbKs3CUoQSgtxuwU8s7uwZiThtLZE8eGoShdPEssq7t5kfyLB5D0WlRe1XGs3xa5nQNmg478iwcwpFxDMupRuHjiULclKjdfTPl30CVfwJB+AyQzCid3HPxCkCnVaK8eR3/zIqa8LORqe5TuVXD0a4n8ASMCCEJZJBKUIPwD2Uc2kLlnJXIZuLu7k5GRQda+Nbi1H45LQDdLOclkJG3LAvLjYrCzs8PR0ZGM2C1kxXyDW/vhZO1fi+nObTQaDfb29mRmZpIVvRpNDX901/+wDPB5l/7WZSSzidwTWy1zBeXm5pKt1ZIVHUXFPv/GztevtKtDEJ6KcvcMShCeNl3yBTJ3r6BP717Ex8eTmprK1atX6dHtZTJ3LkN367KlbPaxn8mPi2HWrFmkpaWRnp7OoUOHqFejCulbI6mgMLBz5060Wi0ZGRkkJyfTo3s3Cq4e5zlfb2JiYrhz5w5arZYXX3wRXdJ5tFeO0bNnT3Jzc0lJSSE/P59jx45Rw9eL9K2fWrFmBOHJsvkEFRUVRVhYGOHh4UyZMgWdTvfwjQThKco+/COenp5ERUWRnp5O+/btyc7OZtWqVbi5uZF9pHBeHslsIvvoT3Tu3Jn33nuPjRs3Eh4eTqNGjVi2bBkAQ4YMITQ0lH//+980btyYChUqMHfuXMuxYmJi2LFjBxqNxjKbtEyhJCEhgQEDBhAYGMiXX35Js2bNmDBhAob0G5jy75R+pQjCU2DTCer27dusXr2aH3/8kV9++QWTycSWLaIDhGBdupuX6Nq1K46Ojqxdu5Y9e/awbt06XFxc6NKlC/qbFwEw5aRhzsuiX79+QOGMqFu2bGH//v2EhITg4+PDtWvXALCzs8PBwQGZTMbVq4XTxVy/fp133nmHkydPFjm+s38YsbGxbNmyhYsXL5KcnAxg2U6mtCuVehCEp82mExSAyWSioKAAo9FIQUEBFStWfPhGgvAUmXLTqVKlCgBpaWkAZGRkAFClShWMOamYCnIxpCdalt1bNj093bL8l19+YcOGDfzrX//i8OHD5OXlERERAUCl10purnMJ7I5MpWH8+PHcuXOHWbNmERsbS1RUFAAylfopnLUglD6b7iTh7e3NsGHDaN++PXZ2doSEhNCqVStrhyU84+R2jpbptu3t7QHQaAqnwc7KygKTkcSFAyzl/6rsW2+9Rc+ePRk1ahQ7d+4kOjqaTZs2UatWLTJ+W1Ls2Ppbl7i1NgLJUMA333xDdHQ0vXv3ZubMmSxatIjXX38d/e2r2FWqbdmmrI0Nl5ubW+ZivldZjx9s5xxsOkHduXOHnTt3snPnTpydnZk0aRKbNm2ie/fu1g5NeIYp3X05dOgQAC1atGDx4sUEBwcDcPjwYWQyGZGRkVy+fJnPP/+cQ4cO0b9/f4KDg7l48SJNmzbl9u3bxMfHU6tWLQCOHTtG/M00bt26xQsvvIBKpUKffKHE4+tu/EGtWrW4evUq6enpqNVqZs6cablTM+vyipQvay8eJyQklLmY71XW44fSP4e4uLgSl9t0E9+BAweoUqUK7u7uqFQqOpSWZZoAACAASURBVHfuzIkTJ6wdlvCMc2rSmdjYWNauXcsrr7zC9evX6d+/P6tWreLMmTPIZDImTZpEr169APjqq6+4cOECixcvtvzHnzlzJgaDgbVr12I0Gtm6dStH9u4iICCA77//HoPBQO3atdHpdMyaNQuATZs2WZoSP/nkE1JTU4mLi2Pv3r0YjUYWL14MChVq71pWqxtBeJJs+g7K19eXU6dOodVq0Wg0HDx4kEaNGlk7LOEZ59SoA3lndjJ48GCWL1/O888/z4kTJ4iOjgbAbDbTq1cvyzOnvLw8mjRpQo8ePfDx8WHbtm1cuHABhaMbu3fvpk6dOoSGhuLo6MiMGTPYtWsXADdv3mTAgAFFjm0yFQ5dNHXqVFq1aoWHhwepqans2rWLpKQk3EJHPHD6bkEoa2SSJEnWDuKvLFq0iK1bt6JUKqlfvz5z5sxBrX7wQ+C4uDheWnW1FCMUnkVmg46c2M3kndn5/yNJeOHYuCNOjdqTuWcV+tuXQSbHsV4rHBuFkn34R/IvHsSsy0ddsTrOzbrh4BdCwbVYso9uxJB2HclQgMLFCwe/EBz9WpG19xsMmcnFji3ptSgqeGPMSMSsy0du71K4T/8w7Gs2K1K2LA51VNabyMp6/GCdJr769esXW27zCervEglKEP4kElTpK+vxg+0kKJt+BiUIgiA8u0SCEgRBEGySSFCCIAiCTbLpXnz/hNkslcl2d0F4GgoMJjQqhbXDEIR/pNzdQRmNBmuH8Fhs4e3tx1XWz6E8xS+Sk1CWlbsEJQiCIJQPIkEJgiAINqncJSilUmXtEB5LWX9/Asr+Odha/AUGk7VDEASrKHedJORyGdUjxJxRQvkhOv0Iz6pydwclCIIglA/l7g5KEB6VZNSTE/sLuWd+x5iTjtLFC6fGnXD274rsvqZiY0462Ud+Iv/iQSR9Piqv6rgEdMNckEfOya1IJfQeVTi4gEyBKS+zyHK5xokKIQNROnty59APFFw7jmQyYufrh0vznmiqNnmq5y0IZYVIUMIzSTIZuf3du+gSz9KmTRuef747J06cYN+ur8i/fBjv/u8jkxd20TZmp3Bz9RQU+jx6dOtGpUqV2L59O5c3zAXA39+f6tWrF9m/Vqtl27ZteHl5FZtk8+TJk1xbNxOZSoO9Ss7AXr1wdHTk559/5ua3/8L9xQk4P9+lVOpBEGyZSFDCMyn3j53oEs+yevVqhgwZws2bN/Hx8WHFihWMGDGCvHPRODUKBSAr5hs0kp6jJ09St25dMjMzWbRoEcOHDycqKooxY8YwcuTIIvuPj4+nRo0aNGrUiJ9++qnIurFjx7JkyRJ8K3pw5MgR3N3d0Wq1LFq0iLCwMHbu/hrHeq2Q2zmWWn0Igi2y+WdQV69epXv37pY/TZs2JSoqytphCWVc7ukd+Pv7M2TIENasWYOvry/r169n+PDhNGzYkNzTOwAw6wvIi4th5MiRNGjQgHHjxvHcc8+RmJjIf//7X1QqFZMmTcLV1RVXV1cGDx4MwPfff1/keGFhYZYyK1asAGD69On4+vrSvXt3ateujclk4sMPP0TS5ZF/YX/pVogg2CCbT1A1a9Zk06ZNbNq0iZ9++gl7e3s6depk7bCEMs6YkWyZpv3AgQNF/g4KCsL4//MwGe/cArPJUnb//v3odDqOHz9OpUqVqFatGlqtFq29F3fu3GHUqFEYDAYWLVpU5HgrV67k1KlTfP7557i6ugIU2WdGRgYXLlygWbNmqNVqDBnF54EShGdNmWriO3jwIM899xyVK1e2dihCGWfW5eHm5gYUPi8CKCgoAMDd3R1TbgY5sb+gS74AYCl7t8y9ZTXV/THeuU1gYCBt27Zl1apVJCUlAZCZmcmHH37IhQsX6NixI6+88gr29vb06dPngcd3dXUlX5f71OtAEGxdmUpQW7ZsITw83NphCOWAwsmDxMREADw8PIr8fXd5xm9LLeXvLXvlypUiZfWZuZi12UybFgnAxx9/jMqrOobUeE6ePMnJkycBWL16Nf369bPcOSUmJlK3bl08PT1JSUnB3d0dnU5HamoqLnU9isT7d8YHzM3NLdPjCYr4rc9WzqHMJCi9Xs+uXbuYOnWqtUMRygG1T21+/fVX8vPzGThwIIcOHaJ///7k5OSwfft25HI5t27dYv/+/fTs2ZMffviB4cOHM3bsWNzc3AgJCeHAgQMkJxc2xdWoUYPevXvz66+/8scff+DeeSwZOxYzfPhwzGYzJ0+epFOnTqhUKs6dOwfADz/8QGhoKJMnT+bEiRPUrVuXtWvXIkkSdpXqFIn374xuUdZndBXxW581ZtQtic0/g7orJiaGhg0b4unpae1QhHKgQvNepKamMmzYMLy9vdm7dy+urq68/vrrZGYWvrfk4uKCg4MDANu2bWPOnDn06dOHbdu2ERcXx6hRoyz7GzduHEajkfnz56Nw8sCxQTsA5HI5kZGRxMbG8tFHH7F//37GjBkDwPLly/nqq6+YOnUq3333HTt37mT69OmovKqjqdm0dCtEEGyQTJIkydpBPIrJkyfTqlUrevfu/Zfl4uLieGnV1VKKSijL7hz+kazoVSjkMjw8PEhPT8dkltBUbUxBwqk/C8oVaJ5rTEHCSTQaDc7OzqSmpiLXOOMWOpz0bZ+D2Wgp7t7pDZybhpO6eT7556KRyWRUrFiR7OxstFotCkc3PMKncmf/t+gSz+Lo6IidnR0ZGRkonL2o2Pc/qL3+vHr9u0MdlfUreBG/9VnjDqp+/frFlpeJJr78/HwOHDjA7NmzrR2KUI5UCOqNg18IeWd3k5+TjpOfJ06NQlE4e1EQfxL9rUsgl+NQKwiV53PokuLIv3gQrT4fd/+aODZoh9zOAZVnVQoSToNkRunmi4NfCACe4dPQ+Yehu36GvOxUVFXtcfCsikO91sjVGjTVnqfgWizaa7HoTQY8WvjhWK81MqXayjUjCLahTCQoBwcHDh8+bO0whHJI5VoJ15CBxZbb1/DHvoZ/kWV2letjV7n4VZ6dT13sfOoWWy6TydBUaYCmSoMSjy2TybCv2Qz7ms3+YfSCUL6VmWdQgiAIwrNFJChBEATBJokEJQiCINikMvEM6u8wmyUxwZtQrhQYTGhUCmuHIQilrtzdQRlLmJenLLGFt7cfV1k/B1uLXyQn4VlV7hKUIAiCUD6IBCUIgiDYpHKXoJT3TdVd1pT1N9Ch7J+DNeIvMJhK/ZiCYOvKXScJuVxG9Ygt1g5DEP4W0bFHEIordwlKEEpi1uWjv3UZCQk771rINU4PLGvMScOQmoBM7YCdT21kChVmXT7G7NRiZeUaR5TOnpgKcjGkXUfS5aNwckflWRWZovC/l0mbgyEtAUlfgMLZo3CdXHR8EISHEQlKKNcks4msfWvJObYJyVA4IaBMZYdz03Bc27xaJFGYtNlk7FhSON26ZAZA4eSOfZ1g8s7uRtJr/+JIMuDPcZcVzp5UaNmf/PP7KUg4WaSkwqUiHp3HYl8r4ImdpyCURyJBCeXanf3fkn3wOwYNGsTQoUORy+WsXr2aVatWgSTh1n4YAJIkkbphLrLUy7wdMYOwsDBSUlKIjIxk796tODs7s+J/3xfb//Lly9mxYwf//vd7BAUF4erqSkJCAp988gnHtn+BTCbjgw8+ICAgABcXF65evcr8+fM5tWEOPq9FovaqXso1Ighlh013krh58yZDhgyha9euhIWFFf5SEYRHZNJmk310AwMHDmTNmjWYTCby8/OJiori9ddfJ/v4Zkx5hXM/FSScQnfjDyIjI5k7dy7nzp2jdu3a7Nq1Cz8/P2QyGU5OTpY/ISEh9O3bFxcXFwBGjx7NtWvXOH78OH369GHnzp24ubmhUCgYMWIEFy9e5NSpUwwcOJCdO3fiYKci99QOa1aPINg8m76DUigURERE0LBhQ3Jzc+nduzchISHUrl3b2qEJZYDuxlkkg46JEydiMpno168fer2eO3fuMHHiRKKioihIOI1jg7ZorxzF0dGRYcOGcfz4cUaNGkW7du3YvXs3Y8aM4c0336Rr164AqNVq4uPjSUxMZOPGjQDUrVuX3NxcAKpWrUq3bt2oXbs2x44do1atWuTl5QFQp04dOnToQPXq1bmWU/yZliAIf7LpO6iKFSvSsGFDAJycnKhZsya3b9+2clRCWWHMTgEKk0dmZibZ2dkUFBSQkpJC3bp1i5QxZqdQvXp11Gq1ZSSJ69evW7YHqNCiPyBj8ODB+Pj48Omnn2I0GnGo1xq9ozcAvr6+BAcHc/XqVU6dOoUkSegdvIDC7utNmzYlLi6OCxcuoPYs293xBeFps+kEda/ExETi4uJ4/vnnrR2KUMbcP2m0TCazLMuKXsWt/72F9uLBYuXu315/+woyGUybNo07d+6wbNkyHBq0xcEvBH3aderVq8f+/fvR6/W89NJL6PV6XNu8iiH9Bo0bN2b//v1kZmbStWtXTCYTzk1F13JB+Cs23cR3V15eHhMnTuRf//oXTk4P7h4sCPdSVii8q7lw4QLBwcG4urqi1+upWLEip0+fBqB69erUquXDCe0t4uPj0el01KhRA8Dy94ULFwDQXj1G165dadCgAfPnzycnJwc3n7qkbfqIkJCW/PzzzyQlJdG1a1cSExMByIpZTWhoKBs2bODSpUuEhYVZWgHyzu/DpdnLlnif1BiAubm5Njee4N8h4rc+WzkHm09QBoOBiRMn8vLLL9O5c2drhyOUIXbPNUKmticyMpL169ezYcMGDAYDKpWKTz/9FIDBgwfzwQcf0LlzZ3777TeWLVvGhAkTWL16NYGBgej1ehYvXmzZ5/Tp0zEYDCxcuBBNtecxF+QBEr///jsajYYbN26wZs0aAN5++21iY2PZtm0bKpUKmUzG998X9gScPHkyZy8eKJKgntQIFgkJCWV6NA8Rv/WV9jnExcWVuNymE5QkScycOZOaNWsydOhQa4cjlDEKjRMuQb354Yf/0atXL0s38379+rF+/XoATp8+TVRUFMnJyUBh892VK1cIDw8nNjaWV199lcuXLyNT2+PmZE98fDybN28mKSmJin1Hob99BYB169YVO35+fj5ms9mSsO6l1WqRyeye4tkLQtknkx7U8G4Djh07xuDBg6lbty5yeeHjsilTptC2bdsHbhMXF8dLq66WVoiCjZMkM9kH15N9dAPmgsJedjI7R1wCuiEZdGQf2QBIyJRq3EJHoEu+SN653WAuHBtPWcEb17avI5kMpP+6CMxGAOzrBOPVcybGrJvcXhuBKTfjb8UlU9rh0fVNHOu3Bp7sUEdl/QpexG991riDql+/frHlNn0HFRAQYGn/F4R/QiaTU6Flf5wDu2NIuYYkgbpiDeRqDQAuQb2RDAXINc7I7Rxw9u+KW/uhGNJvIFNpUFesYRltwqFOMOaCHJArUTp7AKBy86XyG19jyk0vdmy5xgmZQo0pr3jyuns8QRAezKYTlCA8KXKVBrvKxa/QFA4VgArFlhUuv28fdg4lJhWZQmnpkFGSv1onCMKDlZlu5oIgCMKzRSQoQRAEwSaVuyY+s1kSc+sIZU6BwYRGJabgEIR7lbs7KKPRYO0QHostvBz3uMr6OVgjfpGcBKG4cpegBEEQhPJBJChBEATBJokEJQiCINikcpeglEqVtUN4LGX9DXSw7XMoMJisHYIgCI+o3PXik8tlVI/YYu0wBBslengKQtlR7hKUYB2SZEZ75SjaK8eQTAbsfOri2LA9crV9sbJmfQF55/agSz6PTKHEvkZT7GsHYcxOJf9cNGajvkh5tedzOPiFgFyJLvEs+RcPYi7IQWFfAbvnGmHn64f2yhH0KdcwF+SicHBFU+15NDWbIZPJSqsKBEF4wkSCEh6buSCXlPX/QZd8Hjc3NxwcHEg68ztZ+9ZSse9/sKtU21JWn3KVlPX/wZSbga+vLwUFBaSe3IbauxaGrFvIDNpiSSXbZMI1O5WC+BMUJJzGwcEBLy8vbl++TfbRDZZyLi4uVPTw4NbVW2Qf3YB9zQC8es1Epijbzb6C8Kwqd8+ghNKXGb0KKe0qUVFRpKamkpiYyMGDB6la0ZW0zfOR/n9kcEkyk7b5E3xcHdi3bx9JSUmkpKSwZs0a5HeSkHR5LFiwAKPRWOSPr68vWdGrMN88zxdffEFaWhrx8fHk5OTQqlUrAGJiYrhz5w5Xr14lOzubTz/9FO3VY2Qf22TNqhEE4THYfIKKiYmhS5cudOrUiWXLllk7HOE+Jm0Ouad/Y9iwYbz22mt8+OGHhIeHExgYyCeffIIxIwnt5SMAFFyNxZCWwLx58wgJCaFnz57MmjWLQYMGMXr0aMs+8/PzefXVVy1/MjMzAZg5cyZjx45l9uzZ1KhRgw4dOlhmrj158iShoaE0b96cK1euMGnSJIKDg9FeOVb6lSIIwhNh0wnKZDIxe/Zsli9fzpYtW/jll1+4fPmytcMS7mFISwCzkV69egHwxRdfsGXLFs6dO0e3bt1QKBSWSf10ty8jk8no2bMnly5dYuPGjXz++ecAlu0B5HI5ISEhNGzYkDNnzqDVagEYMmQI169fJysriyFDhqDT6YiPjwdg4sSJ7N69m6NHj3Lo0CEA1Go1mIylVRWCIDxhNp2gTp8+TbVq1XjuuedQq9WEhYWxc+dOa4cl3OPuRH2+vr4AZGQUfs7MzESpVOLt7Y0h/QbG7FQM6Tdwc3NDo9FY7oqysrIAqFy5MgAGg4EjR47g4+PDhAkTOHbsGEFBQdjZ2VGjRg2qVq3K2LFjGTJkCIcOHaJnz54A2FVpAECnTp0YMGAA27dvZ9++fWhqNiu9yhAE4Ymy6U4St2/fplKlSpbP3t7enD592ooRCfeTa5yAPxOTg4MDOp0OBwcHy/KC5GTyL+wHQK9UYjKZsLcv7N2n0RROHJieXjjh34wZMzCbzUDhHdPq1asZMGAAhw8fJi8vD3t7e1q2bIm3tzeXL1/m1VdfZcOGDegSzzFkyBBWrFjBb7/9Rp8+fTCbzYW9/+7zsLH2cnNzy/R4giJ+6yrr8YPtnINNJyjB9qncqwCwf/9+WrduTevWrdm/fz8NGjQgNjaWgoICWrRowfDhw1m1ahV79+7l8OHDBAQE4O3tzQsvvADAgQMHAOjcuTO7du1Cr9dbXvjNzS2cqv3QoUN06NABtVqNnZ0d8Ocd2Ntvv83cuXPZvHkz48ePx83NDZlMRuauFXj3m1Uk5oe9SFzWp+wW8VtXWY8frDPle0lsuonP29ubW7duWT7fvn0bb28xO6ktUVaoiKa6PwsWLODatWv8+OOPxMfHI5fLeeuttwCoVasWw4cPx8/PD4CIiAiMRiOXL19m8+bN3Lhxg3nz5gGwcOFCsrKyuHnzJu+//z7x8fEsXrwYgH/961/k5uZy6tQpdu/eTXp6umW7KVOmAPDyyy+TkJBAUlIS/fr1w5B+vbSrRBCEJ8Sm76AaN25MfHw8N27cwNvbmy1btvDJJ59YOyzhPm6hI7i95i3q1atHeHg4Li4ubNmyhdTUVAB27txJ586dOXfuHAB79+6jatWqhIeHk5eXx+bNm9HpdAC0bNmSVq1aUbFiRZKSkti5cyd6lFQIGcSRA+ss2+Xn57Nr1y7Ls6y+ffuiUhV93+ns2bMonT1LsSYEQXiSbDpBKZVK3nvvPUaMGIHJZKJ3797UqVPH2mEJ91F7VcNn2GdkH9nAz7sPIhkLR5Lw7jwdmUJJ1oHviDl7A7m9L5VemQwyGdlHNvC/n7YgU6jQNOiIR/OemHIzyT21ja37TmAuyEHu6IamYUc8g/qgdPHCvlYg2Uc3sHbjNmQqNWqfJvj06E3euWgOXjxbLC65QxXcWvS3Qo0IgvAk2HSCAmjbti1t27a1dhjCQyhdKuLecTQwuti6ir3fLbbMq0dEsWUq10poqtR/4DHsfOrg1e2tYsvVFWv+vWAFQSgTbPoZlCAIgvDsEglKEARBsEkiQQmCIAg2yeafQf1dZrMk5vwRHqjAYEKjUlg7DEEQHkG5u4MyGg3WDuGx2MLb24/Lls9BJCdBKDvKXYISBEEQygeRoARBEASbVO4SlFJZtmdPLatjeBUYTNYOQRCEcqbcdZKQy2VUj9hi7TCeOaJjiiAIT1q5u4MSBEEQyodydwdV3uhTE7hz8Hu0V48hGfXY+dTFpXkvHOoEFSurvXKMO0d+RJ98AeRK7Gs0pULLfhizbpF9dCOGtOuYdfnI7Z0L9xPcF3XFmtw5tJ7883sxZqciU6pRe1XHsVEoBVePo0+5Wuw4cjtHKrQcgEPdFqVRBYIgPKNEgrJhupsXub32bVwcNbzy2mBcXFzYuHEjl396H7f2w3Fp3tNSNufEVjJ2LKZGjRr0mjSBvLw8vvvuO26unAhAw4YNadvtVdzc3EhJSWHLli0kr40AmRyFTOLFF1+kYcOGaLVafvvtN85v+wyFQsHAgQOLxRUbG8uFXctFghIE4akSCcpGSZJE5s6vqFzJi9jYWOzt7cnOzuajjz6iV69e/Lz1fzg2CkXhUAFTQS6Ze1by4osv8ssvv5CamoqjoyNz5syhWbNmxMfH8/bbbxMcHIxOp6NBgwZkZ2fTpEkTEhISWPzll4waNYqDBw9StWpVIiMjadOmDSdPnuSbb74pFtukSZOIW/qVFWpFEIRnSZl4BmUymejRowejRxcfKbu8MmbdQpcUx9SpU/Hy8qJXr174+fmRm5vL3LlzkQw68s/vA0B78SCSXsucOXPQ6/XUr1+fsLAw3N3dmTFjBgBvvPEGtWvXpmHDhixfvhwXFxeaNm0KQPv27cnIyKDLxI+YMGECCoWC1q1bk5+fj0qlsvzZu3cvBoOBH3/8ETvfelarG0EQng1lIkGtXr2aWrVqWTuMUmXMTAYgMDAQgCNHjpCbm8v58+dp0KABDg4OGP6/jCEzGZVKxQsvvMClS5fIysriyJEjAAQEBACF06Z369aNd955h65du3Lo0CF27doFFM5i6+TkROQbL/P2229z7do11q9fD4BDQA+MZgl/f39at27N2rVrSUpKwiWwR6nWhyAIzx6bT1C3bt1iz5499OnTx9qhlCqzLh8AV1dXAMuMs3f/rlChAjnHfubOoR/IProRZ2dn5HK5Zb1ery+yPUCbNm3o378/vr6+KJVK7O3tgcI71IKCAmrWrImHhwc5OTnI5YVfDTufumA2MW3aNAA+/vhjVF7V0dRo+rSrQBCEZ5zNP4OaO3cu06dPJy8vz9qhlCqFswcA169fp2HDhnh6epKYmIinpyd6vZ7bt28DElnRUQBkZGSQl5eHp2fhFOd3/75x44Zln9OmTWPatGnMmDGDDz/8kKFDhzJ//nwWLlzIyZMn6Rjek4a1qnL69GmmT5/O6NGjyfh9GTVq1KB37978+uuv/PHHH3iETUEmkxWL+e4YfLm5uTY9Ht/DiPitS8RvfbZyDjadoHbv3o27uzuNGjXi8OHD1g6nVKm9qiNT2rFu3TpeeuklIiIiOHr0KPXr1+d///sfZrOZgQMHsmLFCsaNG8fKlStZt24dw4cPZ8SIEdSvXzgz7bfffgvAnDlziImJwWAw0LFjR6Dw7tRoNJKTk0PVqlV5oV4t2rRpA0BWVhYAppw0psz9NwqFgo8//hiFsyeO9duUGPPdUTASEhLK7IgYIOK3NhG/9ZX2OcTFxZW43KYTVGxsLLt27SImJgadTkdubi7Tpk3j448/tnZoT53czgFn/66sWbOGxo0bM2bMGMaNG8cvv/zC9OnTgcKmufz8fIxGIwARERF4eHjw5ZdfotPpWLRoEStXrgSgS5cuREREIJfLycjIIDIyktWrVwPw+uuvs3DhQo4fP47RaGT79u3MmzcPABcXF7p3787evXvZtWsXbu2HIVPY9NdGEIRyQiZJkmTtIB7F4cOH+frrr/nyyy//slxcXBwvrSr+cmlZZDYUkLbpI7RXjqJUKlEqlRQUFKB09UFu74z+5kVLWXWlOpj1WowZiWg0GoxGI0ajEYWzJ6acdECy9MbLzy98vqWp0RT76i+QGb0KzCbs7OwwGAyYzWaUrpVQ+9QlPy7GcgyFkzu+I5Yit3MoFuu9Qx2V9StIEb91ifitzxp3UHdbfe4lLoVtmFyloWKff6NLikN79TiSUY+TT10c6gQjmU1oLx3CpM1GYe+MfZ1gZAoV2suH0SWdR61QYV+zKXaVG2DOy0J77TiGjCQwGXFzcsPuuUaoK9VBJpPhUK812suHMWanolGqUXlWs4xUke8Xgik3A5lcgX3NgBKTkyAIwtNQZhJUUFAQQUHFh/d5FthVro9d5aJXFzKFEscGbYuVdajbEoe6LYssUzi54dS44wP3r3TxwrlpeInrHP1C/kHEgiAIj8/mu5kLgiAIzyaRoARBEASbJBKUIAiCYJPKzDOoR2U2S2LyPCsoMJjQqBTWDkMQhHKk3N1BGY0Ga4fwWGzh7e1/QiQnQRCetHKXoARBEITyQSQoQRAEwSaVuwSlVKqsHcJjedjb2wUGUylFIgiCYF3lrpOEXC6jesQWa4fx1IgOIIIgPCvKXYJ6FmVmZnLgwAEMBgOBgYFUrlz5gWXj4+MtU8i3atUKZ2dnAFJTUzl16hSZmZl4eXnRrFkznJ2dkSSJa9euERcXR35+Pp6envxfe3ceV1W1/3/8dQ4IMiYqAuY8oJI5DynkAA4I6k2cbl1v2qBcNc0UM1HMOcdyykopsxyvQ4455qVQLIdQCBFEZFJQQZBB5rN+f/jzfOVqVxPlHPDzfDx8CHutfc577YwPe+919mrbti22trYAJCcnEx4ezu3bt3FycqJt27ZlMmYhRMUnBaoc0+l0BAQEsGzZMv0DYE1MTPjnP//J559/jqXl/z03Lz09nVGjRrFjxw7uPR/Y1taWDz74gLNnz7Jv374Sr21jY8OsWbM4cOAAR44cKdFmUxgpwgAAIABJREFUaWmJr68voaGhBAUFlWirVq0a/v7+TJw48RmMWAjxPJECVY4tXLiQ+fPnM2zYMP71r39hbn53/ahly5ah0+lYv369vu8bb7zBf/7zH6ZPn86AAQPIyMhg+fLlzJo1C4CpU6fSs2dP7O3tuXr1KqtWrdIXmQ8//JDXXnsNGxsbkpOTCQwM5LPPPgPgk08+wdXVFTs7O+Li4li6dCl+fn60a9dOv7aUEEI8CaOfJJGZmcn48ePx9PSkT58+hIaGGjqSUcjOzmbRokW89tprfP/992RlZREREcGSJUuYPHky33//PdHRd5fjCAkJ4eDBg3zyySfMnj2bkydPYmpqyq5du+jc+e6DZX18fAgLC2PHjh106tSJXbt20aRJEwDs7Ow4dOgQO3bsoH379mzdupWGDRsCMHDgQH799Vf27t1Ljx49+PHHH6lRowaBgYGGOTBCiArD6M+g5s2bx6uvvsqKFSsoKCggLy/P0JGMwqlTp8jIyGDMmDEAvPXWW1y/fp1+/foxZswYFixYwJEjR3B2dubw4cNotVp8fX25dOkSY8eO5eWXXyYsLIzRo0cTEhKCm5sb+fn5ANjb2zNmzBiaNWtGVFQUU6dO1b9v+/bt8fLywtzcHICXX35Zv1+jRo0YPHgwjRo1IikpqYyPiBCiojHqM6isrCxOnz7NoEGDADAzM9PfnH/e3XviRKNGjSgsLCQlJQWlFNeuXaN27dpUrlyZhIQEfd+aNWtiaWlJYmIigL6ANGrUCEBfZKpXr46npycpKSkl7i999913XLp0CS8vLz7++GMuXLgAQMuWLQGoXbs2Xbt2JSYmhjNnzui3CyHEkzLqApWUlETVqlWZOnUqr732GtOmTdNPBnjemZjcfbRQUVERWu3//WfUarXodDqKi4tZtGgRrVq14ttvv9UvC6/RaPT97u1/T/369Tlx4gTW1tZ4enqSkZGhX+Xyxx9/5Pvvvyc5OZkpU6bot4eGhtK8eXNCQkLIzc3F09OT/Px8mSQhhCg1o77EV1RUxIULFwgICKBly5bMnTuXNWvWMGHCBENHM6j4+HgsLCyAu0slN27cmPr165OUlETt2rW5fPkyhYWF1K9fn3r16nHz5k2Sk5NJT0/XnzHdu4d08eJFANq2bcv+/fu5ffs2nTp1IjY2Vt+u0WjYsmULAKampgQEBODq6kpkZCRubm788MMPxMbG4u3tTXJyMgCLFi3Cz8+vTI/L05KdnV1un4kIkt/Qynt+MJ4xGHWBcnR0xNHRUX+5yNPTkzVr1hg4leHVrVsXR0dHnJyc+PTTT+nbty87duwgPT0dGxsbJk2aBICXlxerVq1iyJAhbNu2jaVLlzJ37lz27dtHw4YNKSwsZPny5QBs374dBwcHcnJy2LZtGwDz58/nyJEj/P777wQFBWFqasrAgQPJzc0lODgYgL1792JlZYWVlZV+qrqfnx/BwcGsXLnSAEen9OLj4x/5RA9jJvkNq7znh7IfQ2Rk5EO3G3WBsre3x9HRkdjYWBo0aMDJkyf1v/k/78zNzZk9ezYjR46kW7dujBw5EgsLCwYOHMjOnTsBCA8PZ9WqVcTExAB3C058fDw+Pj6EhIQwbNgw/vjjDwA2btzICy+8UOI9rl+/Tm5uLhs3buSll17CxMSEwMBA1q1bR1RUFACBgYH6y4333Lp1Sz+JQgghnpRRFyiAgIAA/Pz8KCwspHbt2nzyySeGjmQ03n33XQBmz57Nm2++CdydEj5r1iwsLS2ZPn06v/zyC1ZWVnz11VfExMTwxRdfsGHDBuDuBIk1a9awYsUKpk+f/qfvM3PmTP2He+HuzL3PP/+czz777KGXW62srPjyyy+f5lCFEM8hjbr/J08FEBkZSZ/1sYaO8cw87Fl8xcXFXLx4kaKiIpo0aULlypUByMnJITc3FysrK/09q5ycHKKjo7GwsMDZ2RmtVotSirS0tAde19LSEktLSzIzM7ly5Qo6nY6aNWtSo0YNNBoNOp2OW7duPbBfWlqa/jNU5VF5v0Qj+Q2rvOcHw1ziuzfx6n5GfwYlHs3ExISXXnrpge337g3997bWrVuX2KbRaKhevfqfvr6tre1Dp41rtdqH7peTk/O40YUQ4k8Z9TRzIYQQzy8pUEIIIYxShbvEp9OpCr1mUl5hMZUrmTy6oxBClHMV7gyqqKjQ0BFK5VEfjpPiJIR4XlS4AiWEEKJikAIlhBDCKEmBEkIIYZQqXIEyNa1k6Ail8mcfjssrLC7jJEIIYVgVbhafVquh3kf7DR3jqavIMxOFEOJhKlyBel6kp6ezbt06fv31V8zMzPD09GTIkCGYmZk90Dc2Npa1a9cSHR1NtWrV+Pvf/0737t2JjIxkz549REREcOfOHV588UX+9re/4e7uTnh4OPv27ePChQvk5uZSu3ZtfHx86NKlC7/99hu7du0iNjaW4uJiatasSd++fenZs6d+vSkhhCgtKVDl0KlTp+jTpw+3bt3C2dmZO3fusHHjRhYuXMjRo0dxcHDQ9127di2jR4/GxMSExo0bc+3aNdauXYudnR3p6eloNBrq1KmDtbU1R44cYeXKlVSrVk3/jL26detiaWnJ4cOHWb58OS1atCAsLAwzMzPq16+PiYkJhw8fZuXKlbz55pt8++23BjoqQoiKpsLdg6roiouL+ec//0mVKlUIDQ0lKiqKxMREdu/eTWxsbIlFAuPi4hgzZgy9evUiLi6OP/74g+TkZObOnUt6ejrW1tbcuHFD35aamspHH31EWloa1atXJzU1lStXrhAREcHNmzeZMGECYWFhAKSmpnLx4kUiIiJITU1lxowZfPfddxw5csRQh0YIUcEYfYHKz89n0KBB9O/fH29vb1asWGHoSAa1f/9+oqOjWbx4Ma1ataJnz574+fnRv39/xo4dy6ZNm/Sr2q5atQoTExPWrl1LYWEhzZs3Z9euXUybNo2OHTui0Wj4+uuvad68OR07diQrK4tPPvmEqlWrArB69WpcXFxwdXWloKCAJUuWYGlpCcDw4cOpV68enTt3pqCgAH9/fzQaDSdPnjTYsRFCVCxGX6DMzMxYv349e/bsYdeuXQQHB3Pu3DlDxzKYc+fOodFo8Pb2JioqiqNHj/L1118D0LdvX3Q6HeHh4fq+rVu35sUXX+TQoUNERESwadMmfd+srCw++ugjIiIiOHXqFHFxceh0OrRaLTdv3iQgIIDIyEhCQkK4evUqOp1Ovzjhrl27MDExwdraGq1WS2hoKEqpEpcXhRCiNIy+QGk0Gv2SEUVFRRQVFT3XN+JTUlKoVq0a5ubmZGRkAHD79m0AatasCUBISAiRkZFER0frt93re+/ve9ttbW0BmDRpEm3btmXRokWkpqbi5+dH06ZNgbuLRjZr1ozZs2eTlZVFq1atqFy5MpcvX+bw4cNotVqWLl0K8D+X7RBCiL+iXEySKC4uxsfHh4SEBN54442Hrk30PIiPj8fU1JSMjAyKi4v1hfveZbfU1FQAZs2axaxZswCoX78+gL6vtbV1ib5ZWVksXbqUiRMnsmDBAqZOnQrA5s2bSUlJYfXq1YwePZoZM2Ywd+5cAP0ZrL29PXXr1mXnzp1s2rSJn3/+ma1bt9KsWbNHPlPQmGVnZ0t+A5L8hmcsYygXBcrExITdu3eTmZnJ2LFjiY6OxtnZ2dCxylzdunXp2LEjK1euJCQkhFdeeYVatWrRpk0bAH755RcARo0ahbu7Ox988AHnzp0jMzOTLl26UKlSJdzd3fV9TUxM2LRpE0OGDGHFihWsW7cOZ2dnEhISuHnzJjt37qR///4sXLiQrVu34uzsTFxcHDVq1MDMzIzY2Fjy8vLIzMykTp06WFlZUalSJaytrcv1iqLlfUVUyW9Y5T0/GGZF3Ycx+kt897O1taVjx44EBwcbOorBDBgwgBo1ajB58mRycnKIjY1l9+7dXLp0iSVLlgDQvn17hg4dirW1NZmZmUydOpWmTZuSlZXFpEmT2L17N/v378fOzo4hQ4YAMH78eKKiooiKiqJFixY4OTnRv39/AKZMmaJvc3Z25uWXX+by5cukp6dz69Ytmjdvzrp164iLi6Nr164GOzZCiIrF6M+gbt26hampKba2tuTl5RESEsLIkSMNHctgLC0tWb16NUOHDqVOnTr06tWLnJwcjhw5QqVKdx/ztGDBAr755hsSExOBu7Px9u7di6urK7GxsZw6dQq4ez+qc+fOD7zHhQsXKCwsfGhbbGwskZGRdOjQgYYNG5KXl8eFCxeIjo7Gw8ODt956Sz+LUAghSsPoz6Bu3LjBm2++Sb9+/Rg0aBCdO3eme/fuho5lUAMHDuT3339n4MCBREREkJyczKRJk/RnUy4uLlhbW/POO++QkpLC/v37adGiBWfPnsXExITly5dz9epVxo0bh7W19QN/evbsSZ8+fR7aNmjQIEaNGoWNjQ1nz54lJiaGxo0b880333DgwIGHPslCCCGehEYppQwd4mmKjIykz/pYQ8d46srTs/jK+zV4yW9Ykt/wDHEPqlmzZg9sN/ozKCGEEM8nKVBCCCGMkhQoIYQQRsnoZ/H9VTqdKlf3ax5XXmExlSuZGDqGEEKUmQp3BlVUVGjoCKXyZ5/eluIkhHjeVLgCJYQQomKQAiWEEMIoVbgCZWpaydARgLv3jIQQQjy5CjdJQqvVUO+j/YaOUSEnagghRFmqcGdQxk6n01FY+HgTOYqKiigufnpnYkop8vLyqGAPDxFCVFBSoMpIeHg4gwYNwtLSEjMzM5o3b87XX3+NTqd7oO++fftwdXXFzMwMMzMzPDw8CAoKIiEhgffff58OHTrg4OCAg4MDvXr1KvFw1qCgIJo1a4aDgwOOjo4MGzaMwMBA3NzcsLa2xsLCAltbW7y9vQkNDS3LQyCEEH9JhbvEZ4zOnTuHq6srlStXxtfXl+rVq7Nnzx7effddLl68yOLFi/V9t27dypQpU2jcuDHTpk2jqKiIjRs34u7ujlIKKysrOnTowIABA9BoNAQGBvLtt98ydepUUlNTGTp0KHZ2dvj4+HD79m02btzIxo0bad26NaNGjaJGjRokJyezdetWOnfuzMmTJ2nVqpUBj44QQjycFKgyMGXKFKytrQkPD6dy5cqkpKQQEBDAqFGj+Oyzz/jXv/5Fw4YNyc7OZsGCBbi7u3Po0CGSk5MxMzNjxowZdO7cmXPnzvHuu++ydOlSioqKMDc357vvvuPWrVsAvPfee2RkZPDTTz/RvHlzoqOj2bx5MwAbNmzAysqKtLQ02rRpQ0BAAC1atGDu3Lls377dkIdHCCEeyugv8U2dOpVOnTrRt29fQ0d5Ijdu3ODw4cOMHz+eGjVq8Oabb9K8eXOuXr3K7NmzUUqxZcsWAA4ePEh6ejozZ85Eo9HQtm1bunXrhoWFBdOmTQPuFhobGxv96rn3bNu2ja1bt/Lxxx9TWFjI7du3S7S//fbb1KtXj7Zt27Ju3Trs7e3p2rWrfvl2IYQwNkZfoHx8fAgMDDR0jCd2+fJlAP2y7KGhoRQWFvLHH3/g6OiIk5OTvk9MTIy+b1JSEjdv3uTixYvk5eXp909LSyM3N7fEe9y4cYMxY8bQrl07JkyYwPDhwykqKirRJyEhQf91jRo10Ol0REZG4uTk9GwGLoQQpWT0l/jat29PUlKSoWM8sezsbABsbGwAKCgoANDP5LOxsWHdunW8+OKLLF68GBMTEywsLPT97u1zb/+hQ4eydevWEu/x3XffYW5uzvr165k3bx7h4eEP5FBKYWJiwooVK/D29mbChAmEhYWxadOmpz9oIYR4Coy+QJVn8fHxaLVa/ddubm7UqFGDlJQUatSoAaBfln3+/PkopVBKcfXqVapXr45Go6Fy5cpYW1tz6dIlgAeK0z316tXDxcWF119/ncGDB1OlShWsra05dOgQvXv3JjMzk507d+Ll5cU777zDN998A8CVK1f+9Pl/Tyo7O/upv2ZZkvyGJfkNz1jGIAXqGapbty41a9akevXqbNiwgX/84x/4+/tz5MgR2rRpw86dO8nJyaFv377s3buXyZMns2TJEjZs2MDUqVPx9/fHzs4OrVbL999/D4CLiwvdunWjdu3aAPj6+hIdHc3p06dZunSp/r2bNm1Kbm4ux48fB2Dnzp307t2b4OBg6tSpw8yZMzl48CCrV6/G39//qY67vK8oKvkNS/IbniFW1H0YKVDPWKVKlfjwww/1fyZNmsTAgQPZt28f48aNAyA3N5f4+HgyMzMBmDdvHvb29vpp5p999hmrV68GoEWLFnz44YfA3X9E77//Pv/5z3/Yv38/fn5++vft0aMH6enpzJkzBwALCwvi4+OpU6cOI0aMAO6evV24cKGsDoUQQvwlUqDKwAcffEBUVBSLFy9m8eLFaDQalFI0btyYPn36cODAAerVqwdAy5YtsbS0ZOTIkYwcOVL/Gr1798bc3JwtW7boZ/3dz87OjqioKGJiYujcufMDn23q2rXrQ7MNGDDg6Q1UCCGeIqMvUBMnTuTUqVOkp6fTpUsXxo0bx+DBgw0d6y8xNTUlMDAQPz8/9u3bR05ODq1bt8bLywuNRsORI0dITk7mhRde4KWXXsLZ2ZlffvmF4OBgtFotHh4edOzYkYKCAg4ePEhaWtoDr+/p6Ym9vT329vZERUVx4sQJNBoN3bp1A+4+YeK/H3FUpUoVvLy8yuowCCHEX2L0BerTTz81dISnpmnTpjRt2vSB7Z6envqv4+Pj0Wg0dO3a9YGzHjMzM/r37//I93F2dsbZ2bnEtnuX9YQQorww+s9BCSGEeD5JgRJCCGGUpEAJIYQwSkZ/D+qv0umUUSwWmFdYTOVKJoaOIYQQ5VaFO4MqKnq8xQCfNSlOQghROhWuQAkhhKgYpEAJIYQwShWuQJmYyKU1IYSoCKRACSGEMEoVbhbfwyQlJREcHIxOp8PV1VX/3LuHCQsLIzQ0FGtrazw8PKhSpYq+7ffffyc8PBxbW1s8PDywtbUF7q61dObMGSIiIrCzs8PDwwNra2t922+//cbFixepVq0aHh4eWFpaPtPxCiFEhaAqmAsXLui/zs/PV76+vsrExEQBClAajUYNGzZMZWdnl9gvKSlJubu76/sBysrKSs2fP19duXJFubm5lWizsbFRn376qYqOjlYdOnQo0ValShX1xRdfqIiICNW6desSbdWqVVPr1q370/xxcXHP6tCUmfI+BslvWJLf8Mp6DPf/3L5fhbvEdz9/f3/WrFnD2LFjOX/+PBEREUyZMoXNmzfrl7qAu2c5Pj4+nDlzhk8//ZRLly5x8uRJPD098ff3p379+kRERLBy5UpiYmI4fvw43bp1Y+LEiTg7O3PlyhW++OILLl++TFBQEB07dmT06NG89NJLpKSkEBgYyOXLl/npp59o0aIFb731FkFBQYY7MEIIUR6UtvJ1795dpaWl6b//9ddf1ahRo5RSSu3YsUM1adJERUZG6tu9vb1VYmLiA/uGh4er7t27q4iIiFLluVeJb9y4oSpXrqzeeustpZRSmzdvVoGBgUoppSZNmqS0Wq2KjY1VSim1f/9+BejPbObNm6eCgoKUUkp/dvTvf/9bFRUVqZkzZ6qQkBBVXFysmjdvrgC1f/9+VVBQoAICAtTp06dVYWGhatiwoQLUzz//rHJzc5W/v786f/68ysvLU7Vq1VLdu3d/aH757cvwJL9hSX7DK9dnUAUFBdy5c+ex+jo6OvLll1/+zz4XL15k/PjxLFu2DBcXF7KystDpdE8STS8kJIS8vDx8fX3R6XSMHDkSX19fcnJyGDVqFDqdjp9//hmAo0ePYmlpybBhwzhz5gzTpk3TLwo4cuRIqlWrxuDBgzlx4gQzZ85k2rRpaLVa3n33XWrVqoWXlxdHjx5lzpw5zJw5E1NTU95++22aNGlCly5d2LdvH/Pnz2fevHmYm5szfPhwfv75ZwoLjeNDxUIIYYz+UoG6fPkyCxYswNPTk7i4uMfap1u3bsTExBAbG/vQ9tjYWMaOHcuiRYto0aIFAGfPnsXT05OVK1dy7dq1vxJRLyEhAYAGDRqQmZlJdnY2xcXFXL9+nfr166PVavV9EhISqFOnDqampvr3u3r1KgANGzbUT6q4t+3+tgYNGpTYdm//R7XpdDr9diGEEA96ZIG6c+cOO3bs4PXXX2f69Ok0bNiQPXv24OLi8nhv8P/PNL766quHto8ZM4YZM2bQrl07/bZu3bqxZcsWbGxsGD16NO+88w4HDhygoKDgMYd1d6l1uHu2d//Uc1NTUwoLC9HpdHz88cc0atSIHTt26F9bq9Xq+wHk5+fr2+69zv9qu/f3o9ruzyiEEOJBj5xm7ubmRpMmTZg7dy4NGzZ8rBfVaDQlvu/bty9ffPEFiYmJD/Tt1KkT27Ztw83NrUQhqVq1KiNGjGDEiBGEhobi7+/P6tWr2bt37yPfPz4+HisrKwAiIiLo1asXTk5OZGVl4eTkxLlz5wBwcXGhdevW5ObmkpiYSGZmJk2aNAHQ/x0REUFsbCy5ubn6bfcWA4yIiCA6OprCwsKH7hcZGYlOp3tom5mZGQUFBcTHx5fInp2d/cC28qa8j0HyG5bkNzyjGcOjbl4FBwer999/X/Xp00etXLlSJSUllWgfMGCAunLliv77Q4cOqY8++kgpdXeSxKxZs5RSSm3ZskUFBAQ8MEkiNTVVjR07VgUEBDzw3pcuXVILFixQPXv2VP7+/urcuXOPfbMtJydH2dvbK3d3d1VcXKzCwsLU6dOnlVJK+fj4KEB9+OGHSimlvLy8FKBmzJihlFLqyJEjKiEhQWVnZ6u6desqQC1cuFAppdSBAwfU1atXVUZGhnJ0dFSAWrVqlVJKqX379qnr16+r1NRUZWdnV2Lixe7du1Vqaqq6du2asra2Vq+//vpD88sNVsOT/IYl+Q2v3EyScHNzY9myZWzcuBEbGxvGjBnDiBEjSEpKAqBjx47s3r0bgOLiYvbs2UPHjh0feJ0BAwZw8uRJbt26VWK7RqNh6dKlxMbGsnz5cuDuGcaQIUOYPn06DRo04IcffmDevHm0bNnysQuvpaUlc+bM4dixY7i6unLy5EnCwsLo3r07O3fuBOC3335jwYIFXL58GYA5c+YwdOhQUlJS2L59O61btyYpKQk7Ozv8/f35xz/+QVpaGps2baJNmzakpaVha2vLhAkTGD58OBkZGaxbt442bdqQk5ODjY0Nvr6+jBw5kuzsbL788kvatWuHUoqZM2c+9liEEOK59CTV7vz58+ratWtKKaUyMzPVxIkTVb9+/VTfvn3VwoULVXFxsVKq5BmUUkqtX79eOTs7P3SaeWZmpurfv7/asGGDiomJUTExMU8S7YFKvG7dOtWgQQP9B2Vr1aqlVq1apZYuXaosLS0VoKpXr67+/e9/K39/f/XCCy/o+7Zr104dPnxY5eTkKD8/P2VjY6Nve+WVV1RQUJDKzMxU48eP178WoLp06aJCQkJUenq6Gj16tLKwsNC3ubu7qzNnzvxpfvnty/Akv2FJfsMzljMojVJKGag2PhORkZE0a9asxDadTkd8fDw6nU4/gw+gsLCQ4uJiKlWqVGICQ3x8PNbW1tSsWbPE6+Tl5REfH4+trS1OTk4l2nJzc0lISKBKlSo4ODiUaLtz5w4JCQlUq1YNe3v7/5k/Pj6eunXrPtHYjUV5H4PkNyzJb3hlPYaH/dyG5+RZfFqtlvr16z+wvVKlSg/MpDM3N9dPgvhvlStX1k90+G8WFhZ/2mZpaUnTpk3/YmohhHi+VehHHQkhhCi/pEAJIYQwShWuQBUXFxs6ghBCiKdACpQQQgijVOEKlBBCiIpBCpQQQgijJAVKCCGEUZICJYQQwihJgRJCCGGUpEAJIYQwSlKghBBCGCUpUEIIIYySFCghhBBGqcItt3Hu3DnMzc0NHUMIIcRjys/Pp1WrVg9sr3AFSgghRMUgl/iEEEIYJSlQQgghjJIUKCGEEEZJCpQQQgijJAVKCCGEUZICJYQQwiiVqwL1yy+/0Lt3b3r27MmaNWseaC8oKGDChAn07NmTwYMHk5SUpG/76quv6NmzJ7179yY4OLgsY+s9af4TJ07g4+NDv3798PHx4eTJk2UdHSjd8Qe4du0arVu35uuvvy6ryCWUJv/FixcZOnQo3t7e9OvXj/z8/LKMrvekYygsLGTKlCn069ePPn368NVXX5V1dODR+U+fPs2AAQNwcXHh4MGDJdp++OEHevXqRa9evfjhhx/KKnIJT5o/MjKyxL+fH3/8sSxj65Xm+ANkZ2fTpUsXZs+eXRZxQZUTRUVFysPDQyUkJKj8/HzVr18/denSpRJ9NmzYoAICApRSSu3bt0+9//77SimlLl26pPr166fy8/NVQkKC8vDwUEVFReUmf0REhEpJSVFKKRUVFaXc3NzKNLtSpct/z7hx49S4ceNUYGBgmeW+pzT5CwsLVd++fVVkZKRSSqlbt26V+b8fpUo3hj179qgJEyYopZS6c+eO6t69u0pMTDS6/ImJiSoyMlJNnjxZHThwQL89PT1dubu7q/T0dJWRkaHc3d1VRkZGuckfGxurrly5opRSKiUlRbm6uqrbt2+XZfxS5b9nzpw5auLEiWrWrFllkrncnEGFhYVRt25dateujZmZGd7e3vz0008l+hw7dowBAwYA0Lt3b06ePIlSip9++glvb2/MzMyoXbs2devWJSwsrNzkd3FxwcHBAYDGjRuTn59PQUFBuckPcPToUV588UUaN25cprnvKU3+EydO0KRJE5o2bQqAnZ0dJiYm5WoMGo2G3NxcioqKyMvLo1KlSlhbWxtd/lq1atG0aVO02pI/mo4fP46rqytVqlThhRdewNXVtcyvhJQmf/369alXrx4ADg4OVK1alVu3bpVVdKB0+QH++OMRun6BAAAD60lEQVQP0tLScHV1LavI5ecS3/Xr13F0dNR/7+DgwPXr1x/o4+TkBICpqSk2Njakp6c/1r7PWmny3+/QoUO4uLhgZmb27EP/V7YnzZ+Tk8PatWt57733yjTzf2d70vxXrlxBo9HwzjvvMGDAANauXVum2e/P96Rj6N27NxYWFri5udG9e3fefvttqlSpYnT5n8W+T8vTyhAWFkZhYSF16tR5mvEeqTT5dTodCxcuZMqUKc8q3kOZlum7iVK5dOkSS5Ys4ZtvvjF0lL9k1apVDB8+HCsrK0NHeSLFxcWcPXuW7du3Y2FhwYgRI2jevDmdOnUydLTHFhYWhlarJTg4mMzMTN544w06d+5M7dq1DR3tuXLjxg0mT57MwoULH3qWYqw2bdpEly5dShS4slBuCpSDgwMpKSn6769fv66/7HV/n+TkZBwdHSkqKiIrKws7O7vH2vdZK01+gJSUFN577z0WLlxY5r953cv2pPnPnz/PoUOHWLJkCZmZmWi1WszNzRk2bFi5yO/o6Ej79u2pWrUqAF26dCEiIqLMC1RpxrBy5UpeffVVKlWqRLVq1WjTpg3h4eFlWqBK8/+hg4MDp06dKrFvhw4dnnrGR2Uozc+R7OxsfH19+eCDDx76YNRnrTT5Q0NDOXv2LJs3byYnJ4fCwkIsLS3x8/N7VnGBcnSJ7+WXXyYuLo7ExEQKCgrYv38/7u7uJfq4u7vrZ/ccOnSIV155BY1Gg7u7O/v376egoIDExETi4uJo0aJFucmfmZnJqFGjmDRpEm3bti3T3PeUJv+mTZs4duwYx44dY/jw4fj6+pZpcSptfjc3N6Kjo/X3cE6fPk2jRo3KNH9px+Dk5MRvv/0GwJ07dzh//jwNGjQwuvx/xs3NjePHj3P79m1u377N8ePHcXNze8aJSypN/oKCAsaOHcvf/vY3PD09n3HShytN/qVLlxIUFMSxY8eYMmUKr7322jMvTkD5mcWnlFJBQUGqV69eysPDQ61evVoppdSyZcvU0aNHlVJK5eXlqXHjxqkePXqogQMHqoSEBP2+q1evVh4eHqpXr14qKCioXOX//PPPVcuWLVX//v31f1JTU8tN/vutWLHCILP4lCpd/l27dikvLy/l7e2tFi5caJD8Sj35GLKzs9W4ceOUl5eX6tOnj1q7dq1R5j9//rx69dVXVcuWLVWHDh2Ul5eXft9t27apHj16qB49eqjt27eXq/y7du1SLi4uJf4fvnDhQrnJf78dO3aU2Sw+WW5DCCGEUSo3l/iEEEI8X6RACSGEMEpSoIQQQhglKVBCCCGMkhQoIYQQRkkKlBBCCKMkBUoIIYRR+n9de09aYys0bgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3de1yUZfr48c+DKKKAisqgZv4C00pN+2Z5whMGonhOpNZMLHNXTVLTtDQPeaDd1DWzE9maVpuJJ0rNE6bk+ayVaYlYmDD0RQQUOc3cvz/4MpurMsMwwwzD9X69ntdrZ+bhnmtYvLrneu7nujWllEIIIYRNuTk6ACGEcEWSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIexAkqu4xYMPPsjAgQPp168f0dHR3Lx50+qxpk+fzrZt2wCYMWMGFy5cuOu5hw8f5sSJE2V+j+DgYK5evWrx83/2yCOPlOm93nnnHT7++OMy/YyouiS5ilvUrFmT+Ph4Nm/eTPXq1VmzZs0trxcVFVk17oIFC2jevPldXz9y5AgnT560amwhnJG7owMQzqt9+/acP3+ew4cP8/bbb+Pj40NycjJbt25l0aJFHDlyhIKCAoYPH85TTz2FUop58+axf/9+GjVqRPXq1U1jjRgxgldeeYU2bdqQmJjIP//5TwwGA/Xq1WPBggWsWbMGNzc3vvrqK15//XUCAgKYPXs2V65cAeC1117j0UcfJTMzk5dffhm9Xk+7du2w5B6YcePGkZaWRn5+Ps8++yyRkZGm1xYuXMj+/ftp0KAB//znP/H19eW3335j7ty5ZGZmUrNmTebNm0dgYKDtf8HCtSkh/qRdu3ZKKaUKCwvV3/72N/X555+rQ4cOqbZt26rffvtNKaXUmjVr1LvvvquUUio/P18NHjxY/fbbb2r79u0qKipKFRUVqbS0NPXoo4+qb775Riml1DPPPKPOnDmjMjIyVLdu3UxjZWZmKqWUWrZsmVqxYoUpjsmTJ6ujR48qpZT6/fffVVhYmFJKqXnz5ql33nlHKaXUt99+q1q0aKEyMjJu+xw9e/Y0PV/yHjdv3lTh4eHq6tWrSimlWrRooeLj45VSSr3zzjtq7ty5Simlnn32WZWcnKyUUurUqVNqxIgRd4xRiNLIzFXcIi8vj4EDBwLFM9ehQ4dy8uRJ2rRpQ9OmTQHYv38/58+fZ/v27QDk5OTw66+/cvToUcLDw6lWrRo6nY6OHTveNv6pU6do3769aay6deveMY4DBw7cUqO9fv06N27c4OjRoyxfvhyAHj16UKdOHbOf6dNPP2Xnzp0ApKam8uuvv1KvXj3c3Nzo27cvAAMHDuTFF1/kxo0bnDx5kpdeesn08wUFBWbfQ4j/JslV3KKk5vrfatWqZfrfSilmzpxJ165dbzln7969NovDaDSydu1aPDw8yjXO4cOHOXDgAF9++SWenp6MGDGC/Pz8O56raRpKKXx8fO74OxCiLOSCliizoKAgvvjiCwoLCwFITk4mNzeXxx57jG+++QaDwUB6ejqHDx++7WfbtWvHsWPHSElJAeDatWsA1K5dmxs3btzyHp9++qnp8U8//QTAY489xtdffw0UJ/OsrKxSY83JyaFOnTp4enqSlJTEqVOnTK8ZjUbT7Pvrr7/m0UcfxcvLi3vuuYdvvvkGKP4Pyblz58r2CxICSa7CChERETRv3pwhQ4bQr18/Zs2ahcFgICQkhGbNmtG3b1+mTZtGu3btbvtZX19f3njjDSZMmMCAAQOYNGkSAD179mTnzp0MHDiQY8eOMWPGDH744Qf69+9P3759+eKLLwAYP348x44dIzw8nJ07d9K4ceNSY+3WrRtFRUX06dOHxYsX3xJTrVq1OHPmDP369ePQoUOMHz8egLfeeot169YxYMAAwsPD2bVrl61+daIK0ZSSloNCCGFrMnMVQgg7kOQqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5OglZbiyEa5Hk6kB/TqiapnH9+nXOnTvH3Llz2b17twMjE0KUlyRXB9I0DYC0tDROnz7N2LFj2bp1Kzt37sTdXXrqCFGZyb9gB7hy5Qo6nY5q1arx6aefkpiYiJ+fH8OGDeOee+7hu+++IyAgwNFhCiHKQXoLVCClFKmpqYwcOZLPP/+cWrVqsXXrVtq2bYufnx/16tXjrbfe4r777mPo0KGODlcIUQ4yc61Amqbh5eVFw4YN8fPzA2Do0KG4uRVXZ27cuEFaWhp9+vRxZJhCCBuQmmsFuXTpElDcjLpatWq3bPRX8uVhyZIlALRu3brC4xNC2JbMXO1MKUVhYSETJkygc+fOjB07lszMTHJyckxbjZQICgrigQceMP1cyQUvIUTlIzVXO9Pr9eh0OlJTUxk7diyPPPIISUlJ9OjRA19fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri+HDhzNy5EiGDRuGXq9nypQpHD16lBdeeIHffvuN/Px8NE3j6tWrLFu2DJ1O5+jQhRA2IMnVzvbs2cPbb7/NiBEjGDJkCFevXmXMmDGEhYUxevRo03n5+fnl3oxPCOE8pOZqBz///DP169fHy8uLHj164Onpyfz58zEYDERERPDuu+/yt7/9jZSUFObOnQtA9erVHRy1EMKWZOZqY6mpqYSGhtKwYUNatGjB8OHDCQwMJCsri1deeYWxY8fSt29f0tLSmDx5MsuXL8fX19fRYQshbKzanDlz5jg6CFeRnZ1NgwYNqFWrlqlXgIeHB2+//Tbe3t7k5OSwbds2PDw86NChA4MGDaJ27dqODlsIYQeyztVG9Ho9kydP5ujRozz77LN06tSJ5s2b07JlSz755BN8fX1p1qwZaWlpLF68mKysrFuWYQkhXIuUBWzk2rVrbNmyhX379jFmzBjatGnDunXrOHXqFOHh4XTt2hWApKQkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HA2rVruffeewkODubq1ascPnyYnJwcWrZsia+vr5QChKgC5HtpORw9epT4+HjT4zp16tC7d2+eeOIJPvzwQ3755RcGDBhA8+bN+f7777l+/boDoxVCVCRZilUORUVFxMTE4ObmRv/+/YHiBBsaGkpeXh47d+5kwoQJhIWFUbNmTby8vBwcsRCiosjM1QpKKZRSdOrUiWXLlrF06VK++uor02t169YlMDCQ5ORkjEYjfn5++Pj4VHicf/zxh2wf4+Ryc3MdHUKZyN+T5SS5WkHTNDRN49y5czz++OPMnz+ft99+m82bN5uareTm5pKfn2/xPx6DwWDTGL/77jtefPFFUlNTbTbmL7/8wpEjR8jMzLTZmL/++ivff/89BQUFNhvz0qVLfP/99xiNRpv9Xi9evMjJkycpLCy02Zi7du1i0aJFZGRk2GQ8gFOnTrFp0yZOnTpls9/psWPH2LRpE1D8ty8J1jJyQctK69at49133yU8PJyAgABatmzJu+++y6VLl9i7dy/x8fHMnDmTRo0alTpOcnKyqTuWwWCwyfKsffv2sWjRIjIzM7l27RrdunUr95h79+5l9uzZJCcns2PHDjp27FjuC3Pffvstr7/+OsePH+fgwYO0aNGCevXqlWvMXbt2MWfOHJKSkjh16hSXL1+mefPm5boDbseOHcycOZMffviBw4cPo9frCQwMpEaNGlaPeeTIERYsWEBUVBQtW7a0epw/S0hIICYmhvz8fI4ePUrr1q2pW7eu1eMZjUZyc3MZP348x48fx83NjTZt2qBpGkajUbq2maNEmRgMBqWUUu+//77atWvXLa+dP39ebdmyRa1atUpdunTJ7Fi7d+9WDz/8sJo8ebLpuaKionLFt3//fvXEE0+on3/+WRUUFKhRo0apI0eOlGvMQ4cOqdDQUHX69GmllFLjxo1T+/fvL9eYx48fV2FhYerHH39USik1e/ZsNX369HKNefXqVfX888+rX375RSmlVFxcnBoyZIhavny5ysnJsWrMgoIC9dJLL6ljx44ppZTatm2bevPNN9WSJUusHlMppf71r3+pFStWKKWUSktLU/v27VOnTp1S2dnZVo139epV9dxzz6nz588rpZSaPn262rp1q/rf//1flZeXZ3WcSikVGxurPv74YzV16lS1cuXKco1VlUhZoIzc3NxISUlh//79t3Sw+vXXX2nRogV9+/bl2WefpVmzZqWOk5uby2effcZrr71G9erVmTJlCgDVqlUr19dOg8HA3//+d+6//35u3rzJfffdxy+//AJYXy9r0KABc+fO5eGHH+aPP/7g9OnTfPbZZ8yaNYtt27ZZPe4LL7zAQw89BEB0dDRZWVnl+irr7u5Obm4uf/zxB1C8y0OTJk3IzMxkz549Vo97/fp1fv31VwBCQkLo2bMnhYWFfP3111Z/9j+3lXzppZdYv349n332GXPnziUrK6vM47m7u5OXl8fFixe5fv06R44cIT4+noULF/Lee++Vq7br7u5OamoqgwcP5syZM8TExLB48WKUUhiNRqvHdXVSFigDpRRFRUUsXbqU4OBgunTpQlJSEjNmzODixYvcf//9eHl5WfR1qXr16nTs2JHWrVvTsWNHEhISSEhIIDQ0tFylgWbNmtGoUSOMRiM1a9ZE0zRiYmIICgqiQYMGVo3p6+vLPffcA8Dq1atp06YNc+bMITMzk927d/P444/j6elZpjH9/Pxo1qwZNWrUwGAwkJOTwxdffEGfPn3w9PQkMzOzzGN6eHhQUFBAQkICubm5fPPNN+Tm5tK6dWuOHTtGr169yjQeFCfB+vXrs3HjRvz9/WnSpAn+/v5cu3aNgwcPEhoaatXX45o1a7Jo0SJOnDhBnz59mDRpEg8++CDff/89Xl5eZv/j/N88PDyoXbs2sbGxfP311/Tp04c33ngDHx8fjh8/zn333Wf1///169cnNTWVQYMG8fvvv/Pxxx8TGBhIjx49pDRQCpm5loGmaVSvXp0bN26Qnp5OVFQUGzZs4IEHHmDKlCn4+/uX6Y9Np9NRu3ZtfH19mTt3Lvn5+aYZ7I8//khSUpLVsZYk6G7dujFs2DD27Nljk5nG2LFjGTduHABDhgzh+vXrVl00q1atmmlpmlIKb29v6tSpg6+vL1999RVLly4lLy+vzOP269ePbt26cfjwYfLy8li0aBFPPfUUGRkZVq8zbt++PUFBQcTHx3P06FGqVatG//79SU9P59y5c1aN2bJlS6ZNm8bp06e5fPkyAE2bNsVoNHL16lWrxgwLC2PlypU8+uijpm8EnTp14saNG/z+++9WjQnFiTs5OZm1a9eyZs0aXnjhBVJTU1mzZo3VY1YFss61jC5evGj6Kjx69Gg6d+5sk3aB9erVY+7cubz11luEhYVhNBpZvXq1DSKGBx54gE8++YTRo0eXa5cD9V9bz2zfvp2MjAzTZovWcnd3x93dnUaNGrF48WL2799PTEwMNWvWLPNY3t7eDBgwgH79+pn+A7Np06Zy9XLw8PCgf//+aJrGhx9+yMWLF6lRowYZGRnluo25W7duREdH884779C4cWMAzp49y5gxY6wes06dOnTs2JFt27ZRvXp18vPzuXz5crkumul0Ovz9/XnvvfeYNWsWwcHBHDp0qMyz6yrHYdXeSiwnJ0fl5ube8pzRaLTJ2CtXrlSdO3dW586ds8l4JaKjo1VKSopNxsrPz1dr165Vffv2NV1AKQ+j0ajy8/NVr169VPfu3VVycnL5g/w/cXFxqk+fPjb5febn56uDBw+qiRMnqmnTppkuxpXXDz/8oBYvXqxiYmJsEmdWVpZatWqVGj58uHruuefUTz/9VO4xr1y5or7//nvT45ILu+LupHGLE8nKymLixIlMmzbNtFFheSk7bHRYWFjIgQMHaNq0KQEBATYbd8OGDbRp04b777/fZmP+/vvvFBUV2XSWZTAY0DTN6bualZRBbHlnoD3+nlyVJFcnU5W3e5F/uMKVSHIVQgg7cO7vNUIIUUlJchVCOL38/Hyys7MdHUaZVOmlWIkJ35F5pex3wwghblWvcR269epqt/EvJ8WSW9Cch9qElms5YUWq0sk180oWy0eucnQYQlR6L64aabexb968SZHRG5331+iT9tC4xd/t9l62JGUBIYRTu5K8An/vjfjW2sO1vMdt3p7TXiS5CiGcVsms1dvjJ9y0IhrUTkCf9Jqjw7KIJFchhNMqmbWWqEyzV0muQgin9OdZa4nKNHuV5CqEcEr/PWstUVlmrw5LrsHBwbe0Vjt8+DB//etfAUxt/P7czq1fv36m1mx//tkffviB4OBgzp49W4HRCyHs6U6z1hKVZfZaocm1oKDA4o7o/v7+fPDBB6Wec+7cOaKjo1m6dCkPPfQQOTk50hldCBdwt1lricowe62Q5JqUlMSbb75JWFgYly5dsuhnevTowYULF7h48eIdX7948SLjx4/nH//4Bw8//DAAx48fJywsjHfeeYcrV67YKnwhRAXKy8ujyOhzx1lrCTetiPq1Ekxb+jgjuyXX3Nxc1q9fz9NPP83MmTMJDAzkq6++MnVINxuYmxujR4/mww8/vOPr48aNY9asWbRv3970XI8ePVizZg3e3t6MHTuW559/nm+++cam2zYLIeyroKCAWtWTzZ5Xq8ZF8vPzKyAi69jtDq2goCBatmzJ/PnzCQwMtOhn/rvdXL9+/Xj//fdJSUm57dxOnToRFxdHUFDQLbfD+fr6EhUVRVRUFCdPnuS1117jvffe4+uvvy7fBxJCVBiFwkjpJT6Fczf0s9vMddmyZeh0OiZMmMDy5ctv28Onbt26tzRiyMrKum3Pend3d5577jk++uij28afNWsWAHPnzr3ttQsXLvD3v/+dadOm8T//8z/Mnz/fFh9JCFFBlAKDMpo9nJndkmtQUBBLly7l888/x9vbm3HjxhEVFWW64t+hQwfi4+OB4s7uX331FR06dLhtnMGDB3Pw4MHbNm3TNI3Fixdz8eJF3n77baB4U79hw4Yxc+ZMAgIC2LhxIwsWLKBt27b2+phCCDswYqQIQ6mHwczM1tHs3rilXr16jBw5kpEjR3LmzBnTV/hx48YxZ84cBgwYgFKKrl27MmDAgNt+vkaNGowYMYIFCxbc9pqHhwfvv/8+zzzzDA0aNKBjx47ExMRYXIYQQjgnI2Aw08ffqBQ48cYVVXongvhPN0tXLCFs4MVVIxk4op9NxsrOzib9yj9o4FP6v828gubka5847S60VbrloBDCOSnAYOaCldHJL2hJchVCOB2jUhSauWBVJMlVCCHKRoHZy1VGnLrkKslVCOF8FMqisoAzb/giydXGtl85ZfMxezduZ/MxhXBmxasFzJyjoJoTT10luQohnI4RjUIzX/oNaFSvoHisIclVCOF0FMUz09KYe93RJLkKIZxO8VKs0meuzn1/liRXIYQTMigNVOl35yszrzuaJFchhNNRaGZnrsqpF2JJchVCOCGFhtFsXylJrkIIUSbFF7TMJE9zrzuYcxctyuHVV1+lU6dO9Otnm2YSQoiKY1AaBapaqUeRU99C4MLJdciQIaxYscLRYQghrFBSFij9kJmrQzz22GPUqVPH0WEIIaxQckGrtMOS5Hqnb7DXrl1j1KhRhIaGMmrUKLKysorfUynmz59PSEgI/fv358cffzT9zMaNGwkNDSU0NJSNG+++K+2fuWxyFUJUXgY0ClW1Uo8iC5Zi3ekbbGxsLJ06dWLHjh106tSJ2NhYABITE7l06RI7duxg3rx5zJkzByhOxsuXL2ft2rXExcWxfPlyU0IujSRXIYTTKZ65upk9zLnTN9iEhAQGDRoEwKBBg9i1a9ctz2uaRrt27Yqbdqens2/fPrp06ULdunWpU6cOXbp04bvvvjP73rJaQAjhdJTSMJiZmbopN5KSkpg0aZLpucjISCIjI0v9uYyMDPz8/ABo2LAhGRkZAOj1evz9/U3n+fv7o9frb3tep9Oh1+vNfgZJrkIIp2PJOlcjGoGBgWzYsMHq99E0DU2zz4Uxly0LTJ48maeeeork5GS6detGXFyco0MSQljIgAVLsay8/bV+/fqkp6cDkJ6ejq+vL1A8I01LSzOdl5aWhk6nu+15vV6PTqcz+z4um1yXLFnCvn37+PHHH0lMTCQiIsLRIQkhLKSUhlG5mT2sERwczKZNmwDYtGkTvXr1uuV5pRSnTp3C29sbPz8/goKC2LdvH1lZWWRlZbFv3z6CgoLMvo+UBYQQTqfkglZpzN8eW/wN9siRI2RmZtKtWzcmTJjAmDFjmDhxIuvWraNx48YsXboUgO7du7N3715CQkLw9PRk4cKFANStW5dx48YxdOhQAMaPH0/dunXNvrckVyGE0zGiFXfGKoXBgnGWLFlyx+dXrbp9225N05g9e/Ydzx86dKgpuVpKkqsQwukYlUahKj09uZt53dGcOzohRJWkLLgDy8k3IpDkamv22EzwlaTvbT4mwD8C29hlXCHKS2F+nau51x1NkqsQwukY/+/219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXjx4i19HlNSUoiOjiYqKspxQQkhLKLA7E0Ezr6Hlssm14CAAOLj4wEwGAx069aNkJAQB0clhLCEUWkUGkuvqRqMMnN1uIMHD9K0aVOaNGni6FCEEBawpCuWJdu8OFKVSK5btmy5ZfdHIYRzK76gVbl7Czh36reBgoICdu/eTVhYmKNDEUJYyGjR7q+yFMuhEhMTadWqFQ0aNHB0KEIIC1kyc5WlWA62ZcsWwsPDHR2GEKIMFJV/natLlwVyc3M5cOAAoaGhjg5FCFEGRopvfy3tkKVYDlSrVi0OHz7s6DCEEGWklGa2piqrBYQQoows2YlAZq5CCFFGRjC7QaEkVyGEKCOLGrdIWUAIIcpGoZndxsVcv1dHk+QqhHA6Ft2hpUlyFeVkr11ax//ys83HfPf+FjYfU1Q9CvMtBaXmKoQQZWRUlpQFpOYqhBBlUnyHVuVeLeDcqV8IUSUpVTx7Le1QFt7++sknnxAeHk6/fv2YPHky+fn5pKSkEBERQUhICBMnTqSgoAAobvQ0ceJEQkJCiIiI4PLly1Z/BkmuQginUzJzLfWwYBy9Xs/q1atZv349mzdvxmAwsGXLFhYtWkRUVBQ7d+7Ex8eHdevWARAXF4ePjw87d+4kKiqKRYsWWf0ZJLkKIZxOSc21tMPcHlslDAYDeXl5FBUVkZeXR8OGDTl06BC9e/cGYPDgwSQkJACwe/duBg8eDEDv3r05ePAgSlnXOVZqrkIIp1O8WsB8y8GkpKRb9sqLjIwkMjLS9Fin0/Hcc8/Rs2dPPDw86NKlC61atcLHxwd39+L05+/vj16vB4pnuo0aNQLA3d0db29vMjMz8fX1LfNncNnkmp+fz/DhwykoKMBgMNC7d2+io6MdHZYQwgKWXNBSSiMwMJANGzbc9ZysrCwSEhJISEjA29ubl156ie+++87W4d6RyybXGjVqsGrVKmrXrk1hYSF/+ctf6NatG+3atXN0aEIIc5QlM1fzwxw4cIB77rnHNPMMDQ3lxIkTZGdnU1RUhLu7O2lpaeh0OqB4ppuamoq/vz9FRUXk5ORQr149qz6Cy9ZcNU2jdu3aABQVFVFUVITm5Hd0CCGKGZWGwehW6mHuJgOAxo0bc/r0aW7evIlSioMHD9K8eXM6dOjA9u3bAdi4cSPBwcEABAcHs3HjRgC2b99Ox44drc4bLptcobiQPXDgQDp37kznzp1p27ato0MSQlhAUbyO1dxhTtu2benduzeDBw+mf//+GI1GIiMjmTp1KitXriQkJIRr164REREBwNChQ7l27RohISGsXLmSKVOmWP0ZXLYsAFCtWjXi4+PJzs5m/Pjx/Pzzz7RoIbdnCuHsLK25WiI6Ovq26y1NmzY1Lb/6Mw8PD5YtW2Z5oKVw6ZlrCR8fHzp06FBhhWwhRPkoC8oCBqNzl/lcNrlevXqV7OxsAPLy8jhw4AABAQEOjkoIYRFVnGBLPZz89leXLQukp6czffp0DAYDSinCwsLo2bOno8MSQljAlmUBR3HZ5PrAAw+wadMmR4chhLCCUsWHuXOc2V2T6yOPPGJaglBy+5emaSil0DSNEydOVEyEQogqR6GZvb3V3MzW0e6aXE+ePFmRcQghhImlt786M4suaB07doz169cDxReKUlJS7BqUEKJqKykLlHo4OkgzzCbX5cuXs2LFCmJjYwEoLCxk6tSpdg9MCFG1mVstQGWfue7cuZP3338fT09PoPje2xs3btg9MCFE1eUK61zNrhaoXr06mqaZLm7l5ubaPSjxX+zUE8Eemwm+mnTG5mPGBD5s8zGFc7NotUDFhGI1s8m1T58+zJo1i+zsbNauXcv69esZNmxYRcQmhKiyLNjGxcnLAmaT6/PPP8/+/fupXbs2ycnJREdH06VLl4qITQhRRSmLWg5W8uQK0KJFC/Ly8tA0TRqfCCHsTlkwc3X2O7TMXtCKi4sjIiKCnTt3sn37diIjI+/YTUYIIWxGWXg4MbMz1xUrVrBx40ZTN+7MzEyeeuophg4davfghBBVl9mZa2Vv3FKvXj1TR3+A2rVrW73tgRBCWEIpDaOZpVbKkr21HeiuyXXlypUA3HvvvQwbNoxevXqhaRoJCQm0bNmywgIUQlRRrrpaoORGgXvvvZd7773X9HyvXr3sH1U5paam8sorr5CRkYGmaQwbNoyRI0c6OiwhhKVcuSvWiy++WJFx2FS1atWYPn06rVq14vr16zz55JN06dKF5s2bOzo0IYSlnDx5mmO25nr16lU++ugjLly4QH5+vun51atX2zWw8vDz88PPzw8ALy8vAgIC0Ov1klyFqCSU0lBma67OXRYwuxRrypQpBAQEcPnyZV588UWaNGlCmzZtKiI2m7h8+TI//fST7PwqRGViyTYvTl5zNZtcS7addXd35/HHHycmJoZDhw5VRGzlduPGDaKjo3nttdfw8vJydMKnu6EAABEsSURBVDhCiLJw9XWu7u7Fp/j5+bFnzx78/PzIysqye2DlVVhYSHR0NP379yc0NNTR4QghykJhwWoA5565mk2uY8eOJScnh2nTpjFv3jxu3LjBq6++WhGxWU0pxYwZMwgICGDUqFGODkcIYQ1zM9PKPnMt2THV29ubTz/91O4B2cLx48eJj4+nRYsWDBw4EIDJkyfTvXt3B0cmhLCMBc2wK2tynTdvnqmH653MnDnTLgHZQvv27Tl//ryjwxBCWMmSfq6VNrm2bt26IuMQQoj/UIC5pVYWrhbIzs5m5syZ/Pzzz2iaxsKFC7nvvvuYNGkSv//+O02aNGHp0qXUqVMHpRQLFixg79691KxZkzfffJNWrVpZ9RHumlwHDx5s1YBCCFFeGqDZaOa6YMECunbtyrJlyygoKCAvL48PPviATp06MWbMGGJjY4mNjWXq1KkkJiZy6dIlduzYwenTp5kzZw5xcXFWfQaLdn8VQogKZaOWgzk5ORw9etTUxa9GjRr4+PiQkJDAoEGDABg0aBC7du0CMD2vaRrt2rUjOzub9PR0qz6CRc2yhRCiYllyQUsjKSmJSZMmmZ6KjIwkMjLS9Pjy5cv4+vry6quvcu7cOVq1asWMGTPIyMgw3cXZsGFDMjIyANDr9fj7+5t+3t/fH71ebzq3LCS52pqdNhOsLOyxmeCz51NsPubqlk1tPmalYuu/U1v/2SvAXEtBBYGBgWzYsOGupxQVFXH27Flef/112rZty/z584mNjb3lnD9vwGpLLrlaQAhRyVnytd+CsoC/vz/+/v6m29/DwsKIjY2lfv36pKen4+fnR3p6Or6+vgDodDrS0tJMP5+WloZOp7PqI8hqASGEc7JBP9eGDRvi7+/PxYsXCQgI4ODBgwQGBhIYGMimTZsYM2YMmzZtMrVSDQ4O5rPPPiM8PJzTp0/j7e1tVUkAZLWAEMIZKdDMlAXMrib4P6+//jpTpkyhsLCQpk2bEhMTg9FoZOLEiaxbt47GjRuzdOlSALp3787evXsJCQnB09OThQsXWv0RXLLloBBClHjwwQfvWJddtWrVbc9pmsbs2bNt8r4u33JQCFH5lKxzNXc4M5duOSiEqKSUZtnhxFy25aAQohKzZClWZd39tURlbDkIxfWUuLg4lFJEREQQFRXl6JCEEGVg7mu/c89bXbTl4M8//0xcXBxxcXFUr16d0aNH07NnT5o1a+bo0IQQlrDROldHMptc7zZLjYmJsXkwtpKUlMTDDz+Mp6cnAI899hg7duzghRdecHBkQgiLuXpy7dGjh+l/5+fns2vXLqsX1VaUFi1asHTpUjIzM6lZsyaJiYlyU4QQlYkCzUzLQXPrYB3NbHLt3bv3LY/79evHX/7yF7sFZAuBgYGMHj2a559/Hk9PTx544AHc3KQBmBCVRiXYgNCcMjduuXTpkqmDjDOLiIggIiICgCVLllh9f7AQouLZsp+ro5hNro888sgtDVwaNmzIlClT7BqULWRkZFC/fn2uXLnCjh07WLt2raNDEkJYypLbXyt7WeDkyZMVEYfNTZgwgWvXruHu7s7s2bPx8fFxdEhCiLJw9ZnryJEjb7sH907POZt///vfjg5BCGEtV6655ufnc/PmTTIzM8nKykL931aM169fR6/XV1iAQoiqx5Kaq7P3Frhrcl2zZg2rVq0iPT2dIUOGmJKrl5cXzzzzTIUFKISoglz5JoKRI0cycuRIPv30U0aMGFGRMQkhRKWfuZpd/Onm5kZ2drbpcVZWFp9//rldgxJCVHE22v3Vkcxe0Fq7di3Dhw83Pa5Tpw5xcXG3PCf+RDn5/+OVkD02Exx+7rLNx/z8gXtsPqbd2Prv1B5/9pX8n5LZ5Go0GlFKmda6GgwGCgsL7R6YEKLq0qrCOtegoCAmTpzIU089BRRf6OratavdAxNCVG0uf4fW1KlT+fLLL/niiy8A6Ny5M8OGDbN7YEKIKqwS1FTNseiC1tNPP82yZctYtmwZzZs3Z968eRURmxCiiiopC5g7nJlFjVvOnj3L5s2b2bZtG02aNCE0NNTecQkhqjpXLQskJyezZcsWNm/eTL169ejbty9KqUqzG4EQohJz5ZsI+vTpQ/v27fnwww9N26N88sknFRWXEKKKq+x7aN215rp8+XIaNmzIs88+y8yZMzl48KDpFtjKIDExkd69exMSEkJsbKyjwxFClIFL11yfeOIJnnjiCXJzc0lISGDVqlVcvXqV2bNnExISQlBQUEXGWSYGg4E33niDlStXotPpGDp0KMHBwTRv3tzRoQkhLOECZQGzqwVq1apF//79+eCDD9i7dy8PPfQQH330UUXEZrUzZ87QrFkzmjZtSo0aNQgPDychIcHRYQkhyqKS3/5apo2l6tSpQ2RkpNP3ctXr9fj7+5se63Q6aZMoRCWjKTNHGcYyGAwMGjSIv/71rwCkpKQQERFBSEgIEydOpKCgAICCggImTpxISEgIERERXL5s/W3SsmufEML5mEusZZy5rl69msDAQNPjRYsWERUVxc6dO/Hx8WHdunUAxMXF4ePjw86dO4mKimLRokVWfwSXTK46nY60tDTTY71eLxsUClHZ2KgskJaWxp49exg6dGjxsEpx6NAh087WgwcPNpUNd+/ezeDBg4Hina/LcyHfJZNrmzZtuHTpEikpKRQUFLBlyxaCg4MdHZYQwlIWthxMSkpiyJAhpuPLL7+8baiFCxcydepU3NyK011mZiY+Pj64uxdfz/f39zeVDfV6PY0aNQLA3d0db29vMjMzrfoIZd5auzJwd3dn1qxZjB49GoPBwJNPPsn999/v6LCEEBayqCuWgsDAQDZs2HDXc7799lt8fX1p3bo1hw8ftnGUpXPJ5ArQvXt3unfv7ugwhBBWssVOBCdOnGD37t0kJiaSn5/P9evXWbBgAdnZ2RQVFeHu7k5aWpqpbKjT6UhNTcXf35+ioiJycnKoV6+eVfG7ZFlACFHJ2WgngpdffpnExER2797NkiVL6NixI4sXL6ZDhw5s374dgI0bN5rKhsHBwWzcuBGA7du307FjR1Mv67KS5CqEcDolu7+aXTFgpalTp7Jy5UpCQkK4du0aERERAAwdOpRr164REhLCypUrmTJlitXv4bJlASFEJaYAc7e3ljG5dujQgQ4dOgDQtGlT0/KrP/Pw8GDZsmVlG/guJLkKIZySy+9EIIQrssdmgoPP/mHzMQE2PtTQLuM6NRfoLSDJVQjhdIqXYpWePctTc60IklyFEE7JFkuxHEmSqxDC+UhZQAghbK9kKVap50hyFUKIMrLw9ldnJslVCOF8pCwghBC2Z0lZwNmTq8ve/pqdnU10dDRhYWH06dOHkydPOjokIYTFFCgLDifmsjPXBQsW0LVrV5YtW0ZBQQF5eXmODkkIYSkXqLm65Mw1JyeHo0ePmjqP16hRAx8fHwdHJYSwmAtsre2SyfXy5cv4+vry6quvMmjQIGbMmEFubq6jwxJCWMpGLQcdySWTa1FREWfPnuXpp59m06ZNeHp6Ehsb6+iwhBAWKrn9tdTDyWuuLplc/f398ff3p23btgCEhYVx9uxZB0clhCgLe/ZzrQgumVwbNmyIv78/Fy9eBODgwYO3bKsrhHByLlAWcNnVAq+//jpTpkyhsLCQpk2bEhMT4+iQhBAWcoV1ri6bXB988MFSd4UUQjgxpSxoOejc2dVlk6sQopKTmasQQtiWJResnP2CliRXIYTzUYCZsoDZ1x1MkqsQwvm4wO2vklyFEE7IgsYsklyFqBrstUvrsJ/SbD7m2gf9bT6mLUnNVQgh7MGC3V+l5aAQQljDXNcr6YolhBBlU1wWUGYPc1JTUxkxYgR9+/YlPDycVatWAXDt2jVGjRpFaGgoo0aNIisrCwClFPPnzyckJIT+/fvz448/Wv0ZJLkKIZyTDfoKVKtWjenTp7N161a+/PJL/v3vf3PhwgViY2Pp1KkTO3bsoFOnTqaueYmJiVy6dIkdO3Ywb9485syZY3X4klyFEM5HmWk3aDR/eyyAn58frVq1AsDLy4uAgAD0ej0JCQkMGjQIgEGDBrFr1y4A0/OaptGuXTuys7NJT0+36iNIzVUI4XwUFizFUiQlJTFp0iTTU5GRkURGRt7x9MuXL/PTTz/Rtm1bMjIy8PPzA4q76GVkZACg1+vx9//PSgp/f3/0er3p3LJw2eT6ySefEBcXh6ZptGjRgpiYGDw8PBwdlhDCEhbeRBAYGGhRg6YbN24QHR3Na6+9hpeX163jaBqappUn2jtyybKAXq9n9erVrF+/ns2bN2MwGNiyZYujwxJCWMyS3V8tG6mwsJDo6Gj69+9PaGgoAPXr1zd93U9PT8fX1xcAnU5HWtp/1hWnpaWh0+ms+gQumVwBDAYDeXl5FBUVkZeXZ9W0XgjhGBZt82JBzVUpxYwZMwgICGDUqFGm54ODg9m0aRMAmzZtolevXrc8r5Ti1KlTeHt7W507XLIsoNPpeO655+jZsyceHh506dKFoKAgR4clhLCYJbe/mk+ux48fJz4+nhYtWjBw4EAAJk+ezJgxY5g4cSLr1q2jcePGLF26FIDu3buzd+9eQkJC8PT0ZOHChVZ/ApdMrllZWSQkJJCQkIC3tzcvvfQS8fHxpl+uEMLJKczfJGBBWaB9+/acP3/+jq+VrHn9M03TmD17tvmBLeCSZYEDBw5wzz334OvrS/Xq1QkNDeXkyZOODksIYSml0IzGUg+Mzn2Llksm18aNG3P69Glu3ryJUko2KBSisilZimWDC1qO4pJlgbZt29K7d28GDx6Mu7s7Dz744F3XvgkhnJCNygKO5JLJFSA6Opro6GhHhyGEsIKG+d4BskGhEEKUlcJ8TVU5d81VkqsQwgnJTgRCCGF7ltRcnXviKslVCOGElPmaqtRchRCirJQCg5mpqZOvc5XkKoSTs8dmgs+eT7HpePWvF9h0PNNaVnPnODFJrkII5yQXtIQQwsakLCCEEHaglPl1rLLOVQghrCBlASGEsDGlwFwzbLmgJYQQZaSU+Zqqk9dcXbLlYAmDwcCgQYP461//6uhQhBBlYVHLQeeeubp0cl29erX0cRWiMiqZuZZ2SHJ1jLS0NPbs2cPQoUMdHYoQosws2f3VuZOry9ZcFy5cyNSpU7lx44ajQxFClJULrHN1yZnrt99+i6+vL61bt3Z0KEIIayhQymjmkJlrhTtx4gS7d+8mMTGR/Px8rl+/zpQpU1i0aJGjQxNCWMKSpVjmXncwl0yuL7/8Mi+//DIAhw8f5l//+pckViEqE6XAYCj9HCcvC7hkchVCVHLSFcv5dejQgQ4dOjg6DCFEGSilUGZmpkp6CwghhBWkt4AQQtiYJTVXc687mEsuxRJCVHJKoYylH5bWXBMTE+nduzchISHExsbaOfD/kOQqhHA+Jf1cSz3MJ1eDwcAbb7zBihUr2LJlC5s3b+bChQsV8AGkLCCEcDKapnF/h/+HR22PUs/z8q2FpmmlnnPmzBmaNWtG06ZNAQgPDychIYHmzZvbLN67qdLJtVmbe1j24xuODkOIildk2+HytXybjeXl5UXwgO6o/uZnplu3bmXixImmx5GRkURGRpoe6/V6/P3/s8GjTqfjzJkzNou1NFU6ubZr187RIQgh/oumadSqVcuicyMiIoiIiLBzRNaRmqsQwmXpdDrS0tJMj/V6PTqdrkLeW5KrEMJltWnThkuXLpGSkkJBQQFbtmwhODi4Qt67SpcFhBCuzd3dnVmzZjF69GgMBgNPPvkk999/f4W8t6acvW+XEEJUQlIWEEIIO5DkKoQQdiDJVQgh7ECSqxBC2IEkVyGEsANJrkIIYQeSXIUQwg7+P3JG+n7HvBQZAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVwVVf/A8c9duayyiqC5K+6FgqC44lZC7rtZueeeW9Jj9Txa+pSWpJWaaaI9mmWlZppaLuC+4ZbiLiigsst2uev8/uDnTQTTUrkXPO/Xy5femTMz3zlc+c6cOXOOTJIkCUEQBEGwMXJrByAIgiAIJREJShAEQbBJIkEJgiAINkkkKEEQBMEmiQQlCIIg2CSRoARBEASbJBJUKfnss8+YNm2atcMoVYmJifj5+WE0Gh97X6GhoRw4cKDEdREREURGRj72MZ4lkZGRBAUFERISUurHPn78OJ07d8bf35/ff//9H+9nxIgRbNiw4QlGVvqSk5Px9/fHZDJZOxSbJBLUE7R582Z69eqFv78/rVq1YsSIERw7dszaYQmlxM/Pj4SEBGuH8VDJycmsXLmSrVu3sn///hLL5ObmMmfOHNq1a4e/vz8dO3Zkzpw5ZGRkPPbxFy1axODBgzlx4gQdO3b8x/tZvnw5PXv2fOx47hcREYGfn1+x5Dl37lz8/Pz46aefHmk/f3VRdZevry8nTpxAoVD843jLM5GgnpCVK1cyd+5c3njjDfbv38/u3bsZNGgQO3futHZo/9iTuPMR/mQr9ZmcnIyrqyseHh4lrtfr9bz22mtcvnyZ5cuXc/z4cb777jtcXV05c+bMEzl+nTp1Hns/T1P16tXZtGmT5bPRaOTXX3+latWqT+wYT/L7IEkSZrP5ie3PVogE9QTk5OSwaNEi3nvvPTp37oyDgwMqlYrQ0FBmzJhR4jYTJ04kJCSEZs2aMXjwYC5dumRZFx0dTdeuXfH396d169asWLECgIyMDEaPHk1AQADNmzdn0KBBli/l7du3mTBhAsHBwYSGhrJ69WrL/k6fPk2vXr1o2rQpLVu25L///W+JMR0+fJg2bdqwbNkyQkJCePvtt7lz5w6jR48mODiYwMBARo8eza1btyzbDBkyhE8//ZQBAwbg7+/PsGHDHniVvX37dkJDQ7l48SJms5lly5bRsWNHgoKCmDRpEllZWZayGzdupH379gQFBbFkyZKH/gwyMzMZOnQo/v7+vPLKKyQlJQEwa9YsPvzwwyJl33jjDaKiokrcz5UrVxg6dCjNmzenS5cubN261bIuIiKCWbNmMWrUKPz9/enbty/Xr18HYPDgwQB0794df39/tm7dWmJ96vV65syZQ6tWrWjVqhVz5sxBr9cXqf+lS5cSFBREaGgoP//8M1D4M2zZsmWRpqAdO3bQrVu3Es8jJyeHt956i+DgYNq3b8/ixYsxm80cOHCAYcOGkZKSgr+/PxEREcW23bRpEzdv3uTzzz+ndu3ayOVyPDw8GDduHG3btrXU05AhQwgICCAsLKzIhdhf1VPHjh25ceMGb7zxBv7+/uj1+mJ3Gvc2h+t0OqZNm0ZQUBABAQH07t2btLQ0oPC7t379egDMZjOLFy+mffv2tGjRgrfeeoucnBzgz6bmDRs20K5du0f6ToWGhnL8+HHu3LkDwN69e/Hz88PT09NS5vr167z66qsEBQURFBTE1KlTyc7OBmD69OkkJydbzvOrr76yxLF+/XratWvHa6+9VqQZPCsrizZt2rBr1y4A8vLy6NSpExs3biwxxiFDhhAZGcmAAQN4/vnnuXHjBrGxsfTu3ZtmzZrRu3dvYmNjATh06BAvv/yyZduhQ4fSu3dvy+dBgwY9VnPrUyMJjy06OlqqX7++ZDAYHlhm0aJF0tSpUy2f169fL+Xk5Eg6nU764IMPpG7dulnWhYSESEePHpUkSZKysrKkP/74Q5IkSfr444+ld999V9Lr9ZJer5eOHj0qmc1myWQyST179pQ+++wzSafTSdevX5dCQ0OlmJgYSZIkqV+/ftKGDRskSZKk3Nxc6cSJEyXGeOjQIal+/frSvHnzJJ1OJ2m1WikjI0Patm2blJ+fL+Xk5EgTJkyQxowZY9nmlVdekTp06CBdvXpV0mq10iuvvCLNnz9fkiRJunHjhlS3bl3JYDBIP/zwg9SxY0cpPj5ekiRJioqKkvr27SvdvHlT0ul00rvvvitNnjxZkiRJunTpkvTCCy9IR44ckXQ6nTR37lypfv360v79+0uMe8aMGUXKv//++9KAAQMkSZKkU6dOSSEhIZLJZJIkSZLS09OlJk2aSKmpqcX2k5eXJ7Vp00b64YcfJIPBIJ09e1Zq3ry5dOnSJctxmjdvLp06dUoyGAzSlClTpDfffNOyfd26dS3n96D6/PTTT6W+fftKaWlpUnp6utS/f38pMjKySPm5c+dKOp1OOnz4sPT8889LV65ckSRJkl566SVpz549lv2PHTtWWrFiRYl1Mn36dOmNN96QcnJypBs3bkidO3eWvv/+e8txWrduXeJ2kiRJb775pvTWW289cL1er5c6duwoLVmyRNLpdNKBAwekF154wRLnw+qpffv2RX6W93++9//Kt99+K40ePVrKz8+XjEajdObMGSknJ0eSpMLv3t1zWr9+vdSxY0fp+vXrUm5urjRu3Dhp2rRpkiT9+T2cOXOmpNVqpbi4OKlhw4bS5cuXSzy/GTNmSAsWLJDeeecdac2aNZIkSdLEiROlzZs3SwMGDJB+/PFHSZIkKT4+Xtq3b5+k0+mk9PR0adCgQdIHH3zwwPO6G8f06dOlvLw8SavVFvk/IkmStHfvXqlly5ZSWlqaNHPmTGnChAkP/Dm88sorUtu2baWLFy9KBoNBSk1NlQICAqQNGzZIBoNB2rx5sxQQECBlZGRIWq1WatSokZSeni7p9XqpRYsWUqtWraScnBxJq9VKjRs3ljIyMh54LGsRd1BPQFZWFm5ubiiVykfepk+fPjg5OaFWq5kwYQLnz5+3XPEplUouX75Mbm4uFSpUoGHDhpblqampJCcno1KpCAgIQCaTcebMGTIyMhg/fjxqtZrnnnuOfv36Wa7+lUol169fJyMjA0dHR1544YUHxiWXy5k4cSJqtRqNRoObmxtdunTB3t4eJycnxowZw9GjR4ts06tXL2rUqIFGo+HFF18kLi6uyPpVq1axYsUKvvnmG6pVqwbAunXrmDx5MpUqVUKtVjN+/Hi2b9+O0Whk27ZttGvXjsDAQNRqNZMmTUIu/+uv6r3lJ0+ezMmTJ7l58yZNmjTB2dmZgwcPArB161aaN29e5Er4rj179lC5cmV69+6NUqmkQYMGdOnShW3btlnKdOzYkSZNmqBUKunWrVuxc31YfW7evJlx48bh4eGBu7s748aNs9wl3TVp0iTUajXNmzenbdu2/PrrrwD06NHDUjYrK4t9+/YRHh5e7Jgmk4mtW7cydepUnJycqFKlCkOHDi12nAfJysrCy8vrgetPnTpFfn4+o0aNQq1W06JFC9q3b8+WLVv+cT09iFKpJCsri4SEBBQKBY0aNcLJyalYuc2bN/P666/z3HPP4ejoyJQpU9i6dWuRZrTx48ej0WioV68e9erV4/z583957O7du7Np0yays7M5evRosedl1apVIyQkBLVajbu7O0OHDi32f6MkEyZMwMHBAY1GU2xdq1atePHFF3n99deJjo5m1qxZf7mvnj17UqdOHZRKJfv27aNatWr06NEDpVJJeHg4NWvWZPfu3Wg0Gho3bsyxY8c4e/Ys9erVo2nTpsTGxnLy5EmqVauGm5vbQ2MvbY/+G1V4IFdXVzIzMzEajY+UpEwmE5GRkWzbto2MjAzLL9/MzEycnZ1ZtGgRS5Ys4ZNPPsHPz4+pU6fi7+/P8OHD+fzzzxk2bBgA/fv3Z9SoUSQlJZGSkkJAQECRY9z9PGfOHBYtWsRLL71ElSpVGD9+PO3bty8xNjc3N+zs7CyftVot//3vf9m7d6+luSMvLw+TyWR5sHvvLzN7e3vy8/OL7HPFihWMGzeOSpUqWZYlJyczbty4IolHLpeTnp5OSkpKkbIODg64urr+ZZ3eW97R0ZEKFSqQkpKCj48PPXv25OeffyYkJISff/6ZV199tcR9JCUlcfr06WL1eG8z2r2JTaPRFDvX+91fnykpKfj6+lo++/r6kpKSYvns4uKCg4NDieu7d+/OSy+9RH5+Pr/++isBAQFUrFix2DEzMzMxGAzFjnP79u2/jPUuV1dXUlNTH7j+7s/n3p/d/fv/u/X0IN27d+fWrVtMmTKF7OxsunXrxuTJk1GpVMViqly5suVz5cqVMRqNpKenlxhTSd/T+wUEBJCRkcGSJUto165dsYSSlpbGnDlzOHbsGHl5eUiShIuLy0PP6d7vakn69evH//73P954442HJg0fHx/Lv+//bkHRn0tgYCBHjhzB29ubwMBAXFxcOHr0qOViyBaJBPUE+Pv7o1ar+f3333nxxRcfWn7z5s3s3LmTlStXUqVKFXJycggMDET6/4HlmzRpwpIlSzAYDKxZs4Y333yT6OhonJyciIiIICIigosXL/Laa6/RuHFjfHx8qFKlCjt27CjxeNWrV2fBggWYzWZ27NjBxIkTOXz4cJFfhHfJZLIin7/++muuXbvG999/j5eXF3FxcfTo0cMS66P4+uuvGTFiBJ6ennTp0gUo/E86d+5cmjVrVqx8xYoVuXLliuWzVqst8nyqJPc+F8vLy+POnTuWX97dunUjPDyc8+fPc+XKlQf2HPPx8SEwMJCVK1c+8rk9zP31WbFixSKdBG7evFkkyWRnZ5Ofn2/52dy8edNS1tvbG39/f3bs2MGmTZsYOHBgicd0c3NDpVKRnJxM7dq1Lfvx9vZ+pJhbtmzJp59+WiSO+8/h1q1bmM1mS5K6efMm1atXf6T938/e3h6tVmv5fG9yVKlUjB8/nvHjx5OYmMioUaOoUaMGffv2LRbT3eeOUHgBpFQq8fDwKPLd+Lu6devGF198UeSZ7l0LFixAJpOxefNmXF1d+f3335k9e/ZD93n/d+JeJpOJ9957jx49erB27Vp69eplaXV42L7ufrfudfPmTVq3bg1A8+bN+fDDD/H19WXkyJFUqFCBd999F5VKZXmGamtEE98T4OzszMSJE5k9eza///47Wq0Wg8FAdHQ08+bNK1Y+Ly8PtVqNm5sbWq2WBQsWWNbp9Xp+/vlncnJyUKlUODo6Wn4J7N69m4SEBCRJwtnZGYVCgUwmo0mTJjg6OrJs2TIKCgowmUxcvHiR06dPA4UPve/eqd29wntYk9m9sdrZ2eHi4kJWVhaff/75366f2rVrs3z5cmbPnm15mD5w4EA+/fRTyy+VjIwMy0PaLl26sGfPHo4dO4Zer2fRokUP7aEUHR1tKb9w4UKef/55y9VlpUqVaNy4MdOnT6dz584lNq1AYTNhfHw8GzduxGAwYDAYOH36dJFk+Vc8PT25cePGX5YJCwtjyZIlZGRkkJGRwRdffFHk4TUUdhLQ6/UcO3aMPXv2FLno6d69OytWrODixYt07ty5xGMoFApefPFFIiMjyc3NJSkpiZUrVz6wQ8X9unfvTqVKlZgwYQJXrlzBbDaTmZnJ0qVLiY6OpkmTJmg0GpYvX47BYODw4cPs2rWLrl27PtL+71evXj22bt2KwWDgzJkzbN++3bLu0KFDXLhwAZPJhJOTE0qlssTvbnh4OKtWreLGjRvk5eURGRnJSy+99Lea3UsyZMgQVq5cSWBgYLF1eXl5ODg44OzszO3bt1m+fHmR9Y/yfbjf0qVLkclkzJ07l+HDhzNjxoxHfkeqbdu2xMfHs3nzZoxGI1u3buXy5cu0a9cOKLyQvnbtGqdPn6ZJkybUqVPH0mpQ0vnZApGgnpBhw4YRERHB4sWLadGiBe3atWPNmjUlXq336NEDX19fWrduTVhYWLFnQps2bSI0NJSmTZuybt065s+fD0BCQoKlp1r//v0ZOHAgwcHBKBQKli5dyvnz5+nQoQPBwcG888475ObmAoU9kMLCwvD392fOnDlERkY+8Jf0/V577TV0Oh3BwcH079/fcjX2d9WrV4+lS5fy7rvvEh0dzauvvkpoaCjDhg3D39+ffv36WRJqnTp1eO+995g2bRqtW7fGxcXloc0i4eHhfPHFFwQFBXH27FlLnd3Vo0cPLl68SPfu3R+4DycnJ1asWMHWrVtp3bo1rVq14uOPP7b0snuY8ePHExERQUBAQJHef/caO3YsjRo1olu3bnTr1o2GDRsyduxYy3pPT09cXFxo3bo106ZN4z//+Q+1atWyrO/UqRNJSUl06tQJe3v7B8by7rvvYm9vT8eOHRk0aBDh4eFFem39FbVaTVRUFDVr1mTYsGE0a9aMvn37kpmZSZMmTVCr1SxdupSYmBiCg4OZNWsW8+bNKxLn3/Hmm29y/fp1mjdvzmeffVYkYaelpTFx4kSaNWtG165dad68eYk/w969e9OtWzdeeeUVOnTogFqt5t133/1H8dzL1dWVFi1alHjXM378eM6dO0dAQACjRo0qdsEwatQolixZQkBAgKUn7l/5448/iIqK4qOPPkKhUDBy5EgAli1b9kixurm5sXTpUlauXElQUBDLly9n6dKluLu7A4VN5Q0bNqR27dqo1WqgMGn5+vo+8JUDa5NJf6etRhDKqKNHjzJ9+nR27979l00s1nT48GGmT59OTEzMX5br2LEjs2fPpmXLlqUUmSBYh7iDEso9g8HA6tWr6dOnj80mp0e1fft2ZDIZwcHB1g5FEJ460UlCKNeuXLlC7969qVev3gNfUC4rhgwZwuXLl5k3b94jP0MUhLJMNPEJgiAINklchgmCIAg2qdw18cXGxv5l7yZbZzAYir2EWNaU9XMQ8VuXiN/6SvscdDpdiSPclLsEpVAoqF+/vrXD+McSEhL+8sW8sqCsn4OI37pE/NZX2ufwoKGwRBOfIAiCYJNEghIEQRBskkhQgiAIgk0SCUoQBEGwSSJBCYIgCDZJJChBEATBJokEJQiCINgkkaAEQRAEmyQSlCAIgmCTyt1gsWfPnqNhwwbWDkMQBKHcKzCY0KgUj72fuLi4EkcAKndDHcnlMqpHbLF2GIIgCOVe/IdhT3X/5S5BCYIglAdmfQGGtASQyVF7VUemfPDgrWa9FrM2B2SgcPYqNjGnKS8LyagHhRKlk/t96zKRjAZkShUKRzfLckmSMOVlgsmITKlG4ej6ZE/wEYgEJQiCYEMks4msfWvJOf4zkl4LgNyhAhWC++Ic0L1I8sk5tZ2coxsxpCcChU9rVB5VqfTaAuQqDZIkkbHtM3JP77Bs41C3JV49/4UkSaT98jH556It6xwbtsczfCqSZCZ1w1y0lw5Z1jm98CIeXcY/5bMvSiQoQRAEG5K5ZyU5RzcyYMAABg8ejF6v56uvvmLbtuUgk+ES0B0AkzabjO1fEBzUnK6TRlKlShWSkpJ49913KUg4hUPtIPLjYsg9vYMxY8YQGBjIwYMH+eqrrzBmp6G9Fkv+uWjefPNNmjRpwp49e1i9ejVuHUaRd3Y32kuHeOutt6hXrx47duxg3Xff4xY6ArlKU2p1YfO9+FatWkV4eDhhYWFERUVZOxxBEISnxpiTRs7xXxg5ciTffvstarUaHx8ffv31V7p06cKdA99h1hcAYM7PBsnMyJEj6dChA0OGDKFHjx4ASEYDptxMMn5bSnBwMJ999hlDhw6ldevWhcfJTCZz11e0b9+eyMhIhg4dSosWLQAwpCWQFR1FWFgYH330EUOHDiUwMBAkM5jNpVofNp2gLl68yPr161m/fj2bNm1iz549JCQkWDssQRCEp6Lg2gkwG5kyZQp5eXmEh4fTq1cvACZPnoxZm40u+TwACmdPZCo7hg8fTkhICFqttsi+0nd8gRoDUVFRxS7u07ctwlGt4Ouvv2bFihVF121dSAUnB5YtW1ZsXWmz6QR15coVmjRpgr29PUqlksDAQHbs2PHwDQVBEMog450UFAoFtWvXJjExEYPBwK1btygoKMDPz89SBkCu1lBp8HwU93V6AMg7twftpUO8//77ZGVlMX/+/KLHybrFvHnziI+P5/PPP79v3U0WLlzIyZMn+frrr4usM2QmP8nTfSibTlB169bl+PHjZGZmotVqiYmJ4datW9YOSxAE4emQzMhksmK98ADk8sJf1xnbFnH7+/dI3/4FcgcXHOq3KVZWe+kQAQEBjB07lpEjR1r2J5fLUSgUtG7dmiFDhjB69GgUisL3mBQKBQqFgi5dutC9e3fGjh1bZJ1cLidl3Uwks+lpnX0xNt1JolatWowYMYLhw4djb29PvXr1LD8kQRCE8kZRoSJGo5Fr165RuXJlFAoF7u7uaDQaLl26BEC1atWoVFHFH3/EkHTy1wfuq0GDBjg4OHD69GnLssGDB6PRaNi5cydOTk5cuHDBsm7kyJHY2dlx5swZKlSoQHx8vGXdpEmTsLOzY8yYMZjzs1E4/dkd/Wk+drHpBAXQt29f+vbtC8CCBQvw9va2ckSCIAhPh331F0Am57PPPmPhwoWsW7eOChUqAFia4iZNmsTkyZNp1qwZsbGxDBs2jDZt2mBvb0+VKlWIiorip59+IiYmhv79+wNQqVIlFi5cyN69e1mwYAEpKSmWddWrV+ejjz7i999/Z/HixWRlZXH9+nUA/Pz8mD17Nlu2bGH58uUAyNT2RWKuVq3aY593XFxcicttPkGlp6fj4eFBcnIyO3bs4Pvvv7d2SIIgCE+FsoI3Ts934bPPPkOn01m6mffv35+NGzcCcOrUKdavX09WVhYAarUaBwcHNmzYAICDgwMqlYr4+HgSs40YMxKpVKkSrVq1IiYmhgMHDgAQn1GAMSORatWqERAQwG+//cbhw4cBuJKahzEjkbp169K4cWN++eUXjh8/jlvH0cjVpdfN3ObH4hs0aBBZWVkolUrefvttS1fIB4mLi+OlVVdLKTpBEIQnSzIayNy9gpxT28FkAArvWlwCe2DISCY/7v9frFWoLOtL4tw0HPdOb6C9doLUnz5AMuoA0FT3x7v/+wDkXz5M6sYPLfuxr9uCij1nApAXF0PalgVgMgJ/vsR7ryc11NGDxuKz+QT1d4kEJQhCeWDSZqO/dRlkcux86iK3cwDAkHULyaBD4eSOXOOEMetW4TBG95Db2aN0qWj5bNblYcxOQ6ZUoXT1KdIJw1SQiyknHZlSjcrNp1gMptxMZCo7VK6VisX4tBOUzTfxCYIgPIsU9i7Y12habPn9ieL+pFISuZ0jai/Hko+jcUKhcXpgDAp7l0eI9ukQXeIEQRAEmyQSlCAIgmCTyl0Tn9ksPfU5SgRBEIQnN2Hhg5S7Oyij8cG9WsqC8jDWYFk/BxG/dYn4re9Rz+FpJicohwlKEARBKB9EghIEQRBskkhQgiAIgk0qdwlKqVRZO4TH8iTGtbK2sn4O5Sn+AkPpjTwtCE9auevFJ5fLqB6xxdphCIJNED1ahbKs3CUoQSgtxuwU8s7uwZiThtLZE8eGoShdPEssq7t5kfyLB5D0WlRe1XGs3xa5nQNmg478iwcwpFxDMupRuHjiULclKjdfTPl30CVfwJB+AyQzCid3HPxCkCnVaK8eR3/zIqa8LORqe5TuVXD0a4n8ASMCCEJZJBKUIPwD2Uc2kLlnJXIZuLu7k5GRQda+Nbi1H45LQDdLOclkJG3LAvLjYrCzs8PR0ZGM2C1kxXyDW/vhZO1fi+nObTQaDfb29mRmZpIVvRpNDX901/+wDPB5l/7WZSSzidwTWy1zBeXm5pKt1ZIVHUXFPv/GztevtKtDEJ6KcvcMShCeNl3yBTJ3r6BP717Ex8eTmprK1atX6dHtZTJ3LkN367KlbPaxn8mPi2HWrFmkpaWRnp7OoUOHqFejCulbI6mgMLBz5060Wi0ZGRkkJyfTo3s3Cq4e5zlfb2JiYrhz5w5arZYXX3wRXdJ5tFeO0bNnT3Jzc0lJSSE/P59jx45Rw9eL9K2fWrFmBOHJsvkEFRUVRVhYGOHh4UyZMgWdTvfwjQThKco+/COenp5ERUWRnp5O+/btyc7OZtWqVbi5uZF9pHBeHslsIvvoT3Tu3Jn33nuPjRs3Eh4eTqNGjVi2bBkAQ4YMITQ0lH//+980btyYChUqMHfuXMuxYmJi2LFjBxqNxjKbtEyhJCEhgQEDBhAYGMiXX35Js2bNmDBhAob0G5jy75R+pQjCU2DTCer27dusXr2aH3/8kV9++QWTycSWLaIDhGBdupuX6Nq1K46Ojqxdu5Y9e/awbt06XFxc6NKlC/qbFwEw5aRhzsuiX79+QOGMqFu2bGH//v2EhITg4+PDtWvXALCzs8PBwQGZTMbVq4XTxVy/fp133nmHkydPFjm+s38YsbGxbNmyhYsXL5KcnAxg2U6mtCuVehCEp82mExSAyWSioKAAo9FIQUEBFStWfPhGgvAUmXLTqVKlCgBpaWkAZGRkAFClShWMOamYCnIxpCdalt1bNj093bL8l19+YcOGDfzrX//i8OHD5OXlERERAUCl10purnMJ7I5MpWH8+PHcuXOHWbNmERsbS1RUFAAylfopnLUglD6b7iTh7e3NsGHDaN++PXZ2doSEhNCqVStrhyU84+R2jpbptu3t7QHQaAqnwc7KygKTkcSFAyzl/6rsW2+9Rc+ePRk1ahQ7d+4kOjqaTZs2UatWLTJ+W1Ls2Ppbl7i1NgLJUMA333xDdHQ0vXv3ZubMmSxatIjXX38d/e2r2FWqbdmmrI0Nl5ubW+ZivldZjx9s5xxsOkHduXOHnTt3snPnTpydnZk0aRKbNm2ie/fu1g5NeIYp3X05dOgQAC1atGDx4sUEBwcDcPjwYWQyGZGRkVy+fJnPP/+cQ4cO0b9/f4KDg7l48SJNmzbl9u3bxMfHU6tWLQCOHTtG/M00bt26xQsvvIBKpUKffKHE4+tu/EGtWrW4evUq6enpqNVqZs6cablTM+vyipQvay8eJyQklLmY71XW44fSP4e4uLgSl9t0E9+BAweoUqUK7u7uqFQqOpSWZZoAACAASURBVHfuzIkTJ6wdlvCMc2rSmdjYWNauXcsrr7zC9evX6d+/P6tWreLMmTPIZDImTZpEr169APjqq6+4cOECixcvtvzHnzlzJgaDgbVr12I0Gtm6dStH9u4iICCA77//HoPBQO3atdHpdMyaNQuATZs2WZoSP/nkE1JTU4mLi2Pv3r0YjUYWL14MChVq71pWqxtBeJJs+g7K19eXU6dOodVq0Wg0HDx4kEaNGlk7LOEZ59SoA3lndjJ48GCWL1/O888/z4kTJ4iOjgbAbDbTq1cvyzOnvLw8mjRpQo8ePfDx8WHbtm1cuHABhaMbu3fvpk6dOoSGhuLo6MiMGTPYtWsXADdv3mTAgAFFjm0yFQ5dNHXqVFq1aoWHhwepqans2rWLpKQk3EJHPHD6bkEoa2SSJEnWDuKvLFq0iK1bt6JUKqlfvz5z5sxBrX7wQ+C4uDheWnW1FCMUnkVmg46c2M3kndn5/yNJeOHYuCNOjdqTuWcV+tuXQSbHsV4rHBuFkn34R/IvHsSsy0ddsTrOzbrh4BdCwbVYso9uxJB2HclQgMLFCwe/EBz9WpG19xsMmcnFji3ptSgqeGPMSMSsy0du71K4T/8w7Gs2K1K2LA51VNabyMp6/GCdJr769esXW27zCervEglKEP4kElTpK+vxg+0kKJt+BiUIgiA8u0SCEgRBEGySSFCCIAiCTbLpXnz/hNkslcl2d0F4GgoMJjQqhbXDEIR/pNzdQRmNBmuH8Fhs4e3tx1XWz6E8xS+Sk1CWlbsEJQiCIJQPIkEJgiAINqncJSilUmXtEB5LWX9/Asr+Odha/AUGk7VDEASrKHedJORyGdUjxJxRQvkhOv0Iz6pydwclCIIglA/l7g5KEB6VZNSTE/sLuWd+x5iTjtLFC6fGnXD274rsvqZiY0462Ud+Iv/iQSR9Piqv6rgEdMNckEfOya1IJfQeVTi4gEyBKS+zyHK5xokKIQNROnty59APFFw7jmQyYufrh0vznmiqNnmq5y0IZYVIUMIzSTIZuf3du+gSz9KmTRuef747J06cYN+ur8i/fBjv/u8jkxd20TZmp3Bz9RQU+jx6dOtGpUqV2L59O5c3zAXA39+f6tWrF9m/Vqtl27ZteHl5FZtk8+TJk1xbNxOZSoO9Ss7AXr1wdHTk559/5ua3/8L9xQk4P9+lVOpBEGyZSFDCMyn3j53oEs+yevVqhgwZws2bN/Hx8WHFihWMGDGCvHPRODUKBSAr5hs0kp6jJ09St25dMjMzWbRoEcOHDycqKooxY8YwcuTIIvuPj4+nRo0aNGrUiJ9++qnIurFjx7JkyRJ8K3pw5MgR3N3d0Wq1LFq0iLCwMHbu/hrHeq2Q2zmWWn0Igi2y+WdQV69epXv37pY/TZs2JSoqytphCWVc7ukd+Pv7M2TIENasWYOvry/r169n+PDhNGzYkNzTOwAw6wvIi4th5MiRNGjQgHHjxvHcc8+RmJjIf//7X1QqFZMmTcLV1RVXV1cGDx4MwPfff1/keGFhYZYyK1asAGD69On4+vrSvXt3ateujclk4sMPP0TS5ZF/YX/pVogg2CCbT1A1a9Zk06ZNbNq0iZ9++gl7e3s6depk7bCEMs6YkWyZpv3AgQNF/g4KCsL4//MwGe/cArPJUnb//v3odDqOHz9OpUqVqFatGlqtFq29F3fu3GHUqFEYDAYWLVpU5HgrV67k1KlTfP7557i6ugIU2WdGRgYXLlygWbNmqNVqDBnF54EShGdNmWriO3jwIM899xyVK1e2dihCGWfW5eHm5gYUPi8CKCgoAMDd3R1TbgY5sb+gS74AYCl7t8y9ZTXV/THeuU1gYCBt27Zl1apVJCUlAZCZmcmHH37IhQsX6NixI6+88gr29vb06dPngcd3dXUlX5f71OtAEGxdmUpQW7ZsITw83NphCOWAwsmDxMREADw8PIr8fXd5xm9LLeXvLXvlypUiZfWZuZi12UybFgnAxx9/jMqrOobUeE6ePMnJkycBWL16Nf369bPcOSUmJlK3bl08PT1JSUnB3d0dnU5HamoqLnU9isT7d8YHzM3NLdPjCYr4rc9WzqHMJCi9Xs+uXbuYOnWqtUMRygG1T21+/fVX8vPzGThwIIcOHaJ///7k5OSwfft25HI5t27dYv/+/fTs2ZMffviB4cOHM3bsWNzc3AgJCeHAgQMkJxc2xdWoUYPevXvz66+/8scff+DeeSwZOxYzfPhwzGYzJ0+epFOnTqhUKs6dOwfADz/8QGhoKJMnT+bEiRPUrVuXtWvXIkkSdpXqFIn374xuUdZndBXxW581ZtQtic0/g7orJiaGhg0b4unpae1QhHKgQvNepKamMmzYMLy9vdm7dy+urq68/vrrZGYWvrfk4uKCg4MDANu2bWPOnDn06dOHbdu2ERcXx6hRoyz7GzduHEajkfnz56Nw8sCxQTsA5HI5kZGRxMbG8tFHH7F//37GjBkDwPLly/nqq6+YOnUq3333HTt37mT69OmovKqjqdm0dCtEEGyQTJIkydpBPIrJkyfTqlUrevfu/Zfl4uLieGnV1VKKSijL7hz+kazoVSjkMjw8PEhPT8dkltBUbUxBwqk/C8oVaJ5rTEHCSTQaDc7OzqSmpiLXOOMWOpz0bZ+D2Wgp7t7pDZybhpO6eT7556KRyWRUrFiR7OxstFotCkc3PMKncmf/t+gSz+Lo6IidnR0ZGRkonL2o2Pc/qL3+vHr9u0MdlfUreBG/9VnjDqp+/frFlpeJJr78/HwOHDjA7NmzrR2KUI5UCOqNg18IeWd3k5+TjpOfJ06NQlE4e1EQfxL9rUsgl+NQKwiV53PokuLIv3gQrT4fd/+aODZoh9zOAZVnVQoSToNkRunmi4NfCACe4dPQ+Yehu36GvOxUVFXtcfCsikO91sjVGjTVnqfgWizaa7HoTQY8WvjhWK81MqXayjUjCLahTCQoBwcHDh8+bO0whHJI5VoJ15CBxZbb1/DHvoZ/kWV2letjV7n4VZ6dT13sfOoWWy6TydBUaYCmSoMSjy2TybCv2Qz7ms3+YfSCUL6VmWdQgiAIwrNFJChBEATBJokEJQiCINikMvEM6u8wmyUxwZtQrhQYTGhUCmuHIQilrtzdQRlLmJenLLGFt7cfV1k/B1uLXyQn4VlV7hKUIAiCUD6IBCUIgiDYpHKXoJT3TdVd1pT1N9Ch7J+DNeIvMJhK/ZiCYOvKXScJuVxG9Ygt1g5DEP4W0bFHEIordwlKEEpi1uWjv3UZCQk771rINU4PLGvMScOQmoBM7YCdT21kChVmXT7G7NRiZeUaR5TOnpgKcjGkXUfS5aNwckflWRWZovC/l0mbgyEtAUlfgMLZo3CdXHR8EISHEQlKKNcks4msfWvJObYJyVA4IaBMZYdz03Bc27xaJFGYtNlk7FhSON26ZAZA4eSOfZ1g8s7uRtJr/+JIMuDPcZcVzp5UaNmf/PP7KUg4WaSkwqUiHp3HYl8r4ImdpyCURyJBCeXanf3fkn3wOwYNGsTQoUORy+WsXr2aVatWgSTh1n4YAJIkkbphLrLUy7wdMYOwsDBSUlKIjIxk796tODs7s+J/3xfb//Lly9mxYwf//vd7BAUF4erqSkJCAp988gnHtn+BTCbjgw8+ICAgABcXF65evcr8+fM5tWEOPq9FovaqXso1Ighlh013krh58yZDhgyha9euhIWFFf5SEYRHZNJmk310AwMHDmTNmjWYTCby8/OJiori9ddfJ/v4Zkx5hXM/FSScQnfjDyIjI5k7dy7nzp2jdu3a7Nq1Cz8/P2QyGU5OTpY/ISEh9O3bFxcXFwBGjx7NtWvXOH78OH369GHnzp24ubmhUCgYMWIEFy9e5NSpUwwcOJCdO3fiYKci99QOa1aPINg8m76DUigURERE0LBhQ3Jzc+nduzchISHUrl3b2qEJZYDuxlkkg46JEydiMpno168fer2eO3fuMHHiRKKioihIOI1jg7ZorxzF0dGRYcOGcfz4cUaNGkW7du3YvXs3Y8aM4c0336Rr164AqNVq4uPjSUxMZOPGjQDUrVuX3NxcAKpWrUq3bt2oXbs2x44do1atWuTl5QFQp04dOnToQPXq1bmWU/yZliAIf7LpO6iKFSvSsGFDAJycnKhZsya3b9+2clRCWWHMTgEKk0dmZibZ2dkUFBSQkpJC3bp1i5QxZqdQvXp11Gq1ZSSJ69evW7YHqNCiPyBj8ODB+Pj48Omnn2I0GnGo1xq9ozcAvr6+BAcHc/XqVU6dOoUkSegdvIDC7utNmzYlLi6OCxcuoPYs293xBeFps+kEda/ExETi4uJ4/vnnrR2KUMbcP2m0TCazLMuKXsWt/72F9uLBYuXu315/+woyGUybNo07d+6wbNkyHBq0xcEvBH3aderVq8f+/fvR6/W89NJL6PV6XNu8iiH9Bo0bN2b//v1kZmbStWtXTCYTzk1F13JB+Cs23cR3V15eHhMnTuRf//oXTk4P7h4sCPdSVii8q7lw4QLBwcG4urqi1+upWLEip0+fBqB69erUquXDCe0t4uPj0el01KhRA8Dy94ULFwDQXj1G165dadCgAfPnzycnJwc3n7qkbfqIkJCW/PzzzyQlJdG1a1cSExMByIpZTWhoKBs2bODSpUuEhYVZWgHyzu/DpdnLlnif1BiAubm5Njee4N8h4rc+WzkHm09QBoOBiRMn8vLLL9O5c2drhyOUIXbPNUKmticyMpL169ezYcMGDAYDKpWKTz/9FIDBgwfzwQcf0LlzZ3777TeWLVvGhAkTWL16NYGBgej1ehYvXmzZ5/Tp0zEYDCxcuBBNtecxF+QBEr///jsajYYbN26wZs0aAN5++21iY2PZtm0bKpUKmUzG998X9gScPHkyZy8eKJKgntQIFgkJCWV6NA8Rv/WV9jnExcWVuNymE5QkScycOZOaNWsydOhQa4cjlDEKjRMuQb354Yf/0atXL0s38379+rF+/XoATp8+TVRUFMnJyUBh892VK1cIDw8nNjaWV199lcuXLyNT2+PmZE98fDybN28mKSmJin1Hob99BYB169YVO35+fj5ms9mSsO6l1WqRyeye4tkLQtknkx7U8G4Djh07xuDBg6lbty5yeeHjsilTptC2bdsHbhMXF8dLq66WVoiCjZMkM9kH15N9dAPmgsJedjI7R1wCuiEZdGQf2QBIyJRq3EJHoEu+SN653WAuHBtPWcEb17avI5kMpP+6CMxGAOzrBOPVcybGrJvcXhuBKTfjb8UlU9rh0fVNHOu3Bp7sUEdl/QpexG991riDql+/frHlNn0HFRAQYGn/F4R/QiaTU6Flf5wDu2NIuYYkgbpiDeRqDQAuQb2RDAXINc7I7Rxw9u+KW/uhGNJvIFNpUFesYRltwqFOMOaCHJArUTp7AKBy86XyG19jyk0vdmy5xgmZQo0pr3jyuns8QRAezKYTlCA8KXKVBrvKxa/QFA4VgArFlhUuv28fdg4lJhWZQmnpkFGSv1onCMKDlZlu5oIgCMKzRSQoQRAEwSaVuyY+s1kSc+sIZU6BwYRGJabgEIR7lbs7KKPRYO0QHostvBz3uMr6OVgjfpGcBKG4cpegBEEQhPJBJChBEATBJokEJQiCINikcpeglEqVtUN4LGX9DXSw7XMoMJisHYIgCI+o3PXik8tlVI/YYu0wBBslengKQtlR7hKUYB2SZEZ75SjaK8eQTAbsfOri2LA9crV9sbJmfQF55/agSz6PTKHEvkZT7GsHYcxOJf9cNGajvkh5tedzOPiFgFyJLvEs+RcPYi7IQWFfAbvnGmHn64f2yhH0KdcwF+SicHBFU+15NDWbIZPJSqsKBEF4wkSCEh6buSCXlPX/QZd8Hjc3NxwcHEg68ztZ+9ZSse9/sKtU21JWn3KVlPX/wZSbga+vLwUFBaSe3IbauxaGrFvIDNpiSSXbZMI1O5WC+BMUJJzGwcEBLy8vbl++TfbRDZZyLi4uVPTw4NbVW2Qf3YB9zQC8es1Epijbzb6C8Kwqd8+ghNKXGb0KKe0qUVFRpKamkpiYyMGDB6la0ZW0zfOR/n9kcEkyk7b5E3xcHdi3bx9JSUmkpKSwZs0a5HeSkHR5LFiwAKPRWOSPr68vWdGrMN88zxdffEFaWhrx8fHk5OTQqlUrAGJiYrhz5w5Xr14lOzubTz/9FO3VY2Qf22TNqhEE4THYfIKKiYmhS5cudOrUiWXLllk7HOE+Jm0Ouad/Y9iwYbz22mt8+OGHhIeHExgYyCeffIIxIwnt5SMAFFyNxZCWwLx58wgJCaFnz57MmjWLQYMGMXr0aMs+8/PzefXVVy1/MjMzAZg5cyZjx45l9uzZ1KhRgw4dOlhmrj158iShoaE0b96cK1euMGnSJIKDg9FeOVb6lSIIwhNh0wnKZDIxe/Zsli9fzpYtW/jll1+4fPmytcMS7mFISwCzkV69egHwxRdfsGXLFs6dO0e3bt1QKBSWSf10ty8jk8no2bMnly5dYuPGjXz++ecAlu0B5HI5ISEhNGzYkDNnzqDVagEYMmQI169fJysriyFDhqDT6YiPjwdg4sSJ7N69m6NHj3Lo0CEA1Go1mIylVRWCIDxhNp2gTp8+TbVq1XjuuedQq9WEhYWxc+dOa4cl3OPuRH2+vr4AZGQUfs7MzESpVOLt7Y0h/QbG7FQM6Tdwc3NDo9FY7oqysrIAqFy5MgAGg4EjR47g4+PDhAkTOHbsGEFBQdjZ2VGjRg2qVq3K2LFjGTJkCIcOHaJnz54A2FVpAECnTp0YMGAA27dvZ9++fWhqNiu9yhAE4Ymy6U4St2/fplKlSpbP3t7enD592ooRCfeTa5yAPxOTg4MDOp0OBwcHy/KC5GTyL+wHQK9UYjKZsLcv7N2n0RROHJieXjjh34wZMzCbzUDhHdPq1asZMGAAhw8fJi8vD3t7e1q2bIm3tzeXL1/m1VdfZcOGDegSzzFkyBBWrFjBb7/9Rp8+fTCbzYW9/+7zsLH2cnNzy/R4giJ+6yrr8YPtnINNJyjB9qncqwCwf/9+WrduTevWrdm/fz8NGjQgNjaWgoICWrRowfDhw1m1ahV79+7l8OHDBAQE4O3tzQsvvADAgQMHAOjcuTO7du1Cr9dbXvjNzS2cqv3QoUN06NABtVqNnZ0d8Ocd2Ntvv83cuXPZvHkz48ePx83NDZlMRuauFXj3m1Uk5oe9SFzWp+wW8VtXWY8frDPle0lsuonP29ubW7duWT7fvn0bb28xO6ktUVaoiKa6PwsWLODatWv8+OOPxMfHI5fLeeuttwCoVasWw4cPx8/PD4CIiAiMRiOXL19m8+bN3Lhxg3nz5gGwcOFCsrKyuHnzJu+//z7x8fEsXrwYgH/961/k5uZy6tQpdu/eTXp6umW7KVOmAPDyyy+TkJBAUlIS/fr1w5B+vbSrRBCEJ8Sm76AaN25MfHw8N27cwNvbmy1btvDJJ59YOyzhPm6hI7i95i3q1atHeHg4Li4ubNmyhdTUVAB27txJ586dOXfuHAB79+6jatWqhIeHk5eXx+bNm9HpdAC0bNmSVq1aUbFiRZKSkti5cyd6lFQIGcSRA+ss2+Xn57Nr1y7Ls6y+ffuiUhV93+ns2bMonT1LsSYEQXiSbDpBKZVK3nvvPUaMGIHJZKJ3797UqVPH2mEJ91F7VcNn2GdkH9nAz7sPIhkLR5Lw7jwdmUJJ1oHviDl7A7m9L5VemQwyGdlHNvC/n7YgU6jQNOiIR/OemHIzyT21ja37TmAuyEHu6IamYUc8g/qgdPHCvlYg2Uc3sHbjNmQqNWqfJvj06E3euWgOXjxbLC65QxXcWvS3Qo0IgvAk2HSCAmjbti1t27a1dhjCQyhdKuLecTQwuti6ir3fLbbMq0dEsWUq10poqtR/4DHsfOrg1e2tYsvVFWv+vWAFQSgTbPoZlCAIgvDsEglKEARBsEkiQQmCIAg2yeafQf1dZrMk5vwRHqjAYEKjUlg7DEEQHkG5u4MyGg3WDuGx2MLb24/Lls9BJCdBKDvKXYISBEEQygeRoARBEASbVO4SlFJZtmdPLatjeBUYTNYOQRCEcqbcdZKQy2VUj9hi7TCeOaJjiiAIT1q5u4MSBEEQyodydwdV3uhTE7hz8Hu0V48hGfXY+dTFpXkvHOoEFSurvXKMO0d+RJ98AeRK7Gs0pULLfhizbpF9dCOGtOuYdfnI7Z0L9xPcF3XFmtw5tJ7883sxZqciU6pRe1XHsVEoBVePo0+5Wuw4cjtHKrQcgEPdFqVRBYIgPKNEgrJhupsXub32bVwcNbzy2mBcXFzYuHEjl396H7f2w3Fp3tNSNufEVjJ2LKZGjRr0mjSBvLw8vvvuO26unAhAw4YNadvtVdzc3EhJSWHLli0kr40AmRyFTOLFF1+kYcOGaLVafvvtN85v+wyFQsHAgQOLxRUbG8uFXctFghIE4akSCcpGSZJE5s6vqFzJi9jYWOzt7cnOzuajjz6iV69e/Lz1fzg2CkXhUAFTQS6Ze1by4osv8ssvv5CamoqjoyNz5syhWbNmxMfH8/bbbxMcHIxOp6NBgwZkZ2fTpEkTEhISWPzll4waNYqDBw9StWpVIiMjadOmDSdPnuSbb74pFtukSZOIW/qVFWpFEIRnSZl4BmUymejRowejRxcfKbu8MmbdQpcUx9SpU/Hy8qJXr174+fmRm5vL3LlzkQw68s/vA0B78SCSXsucOXPQ6/XUr1+fsLAw3N3dmTFjBgBvvPEGtWvXpmHDhixfvhwXFxeaNm0KQPv27cnIyKDLxI+YMGECCoWC1q1bk5+fj0qlsvzZu3cvBoOBH3/8ETvfelarG0EQng1lIkGtXr2aWrVqWTuMUmXMTAYgMDAQgCNHjpCbm8v58+dp0KABDg4OGP6/jCEzGZVKxQsvvMClS5fIysriyJEjAAQEBACF06Z369aNd955h65du3Lo0CF27doFFM5i6+TkROQbL/P2229z7do11q9fD4BDQA+MZgl/f39at27N2rVrSUpKwiWwR6nWhyAIzx6bT1C3bt1iz5499OnTx9qhlCqzLh8AV1dXAMuMs3f/rlChAjnHfubOoR/IProRZ2dn5HK5Zb1ery+yPUCbNm3o378/vr6+KJVK7O3tgcI71IKCAmrWrImHhwc5OTnI5YVfDTufumA2MW3aNAA+/vhjVF7V0dRo+rSrQBCEZ5zNP4OaO3cu06dPJy8vz9qhlCqFswcA169fp2HDhnh6epKYmIinpyd6vZ7bt28DElnRUQBkZGSQl5eHp2fhFOd3/75x44Zln9OmTWPatGnMmDGDDz/8kKFDhzJ//nwWLlzIyZMn6Rjek4a1qnL69GmmT5/O6NGjyfh9GTVq1KB37978+uuv/PHHH3iETUEmkxWL+e4YfLm5uTY9Ht/DiPitS8RvfbZyDjadoHbv3o27uzuNGjXi8OHD1g6nVKm9qiNT2rFu3TpeeuklIiIiOHr0KPXr1+d///sfZrOZgQMHsmLFCsaNG8fKlStZt24dw4cPZ8SIEdSvXzgz7bfffgvAnDlziImJwWAw0LFjR6Dw7tRoNJKTk0PVqlV5oV4t2rRpA0BWVhYAppw0psz9NwqFgo8//hiFsyeO9duUGPPdUTASEhLK7IgYIOK3NhG/9ZX2OcTFxZW43KYTVGxsLLt27SImJgadTkdubi7Tpk3j448/tnZoT53czgFn/66sWbOGxo0bM2bMGMaNG8cvv/zC9OnTgcKmufz8fIxGIwARERF4eHjw5ZdfotPpWLRoEStXrgSgS5cuREREIJfLycjIIDIyktWrVwPw+uuvs3DhQo4fP47RaGT79u3MmzcPABcXF7p3787evXvZtWsXbu2HIVPY9NdGEIRyQiZJkmTtIB7F4cOH+frrr/nyyy//slxcXBwvrSr+cmlZZDYUkLbpI7RXjqJUKlEqlRQUFKB09UFu74z+5kVLWXWlOpj1WowZiWg0GoxGI0ajEYWzJ6acdECy9MbLzy98vqWp0RT76i+QGb0KzCbs7OwwGAyYzWaUrpVQ+9QlPy7GcgyFkzu+I5Yit3MoFuu9Qx2V9StIEb91ifitzxp3UHdbfe4lLoVtmFyloWKff6NLikN79TiSUY+TT10c6gQjmU1oLx3CpM1GYe+MfZ1gZAoV2suH0SWdR61QYV+zKXaVG2DOy0J77TiGjCQwGXFzcsPuuUaoK9VBJpPhUK812suHMWanolGqUXlWs4xUke8Xgik3A5lcgX3NgBKTkyAIwtNQZhJUUFAQQUHFh/d5FthVro9d5aJXFzKFEscGbYuVdajbEoe6LYssUzi54dS44wP3r3TxwrlpeInrHP1C/kHEgiAIj8/mu5kLgiAIzyaRoARBEASbJBKUIAiCYJPKzDOoR2U2S2LyPCsoMJjQqBTWDkMQhHKk3N1BGY0Ga4fwWGzh7e1/QiQnQRCetHKXoARBEITyQSQoQRAEwSaVuwSlVKqsHcJjedjb2wUGUylFIgiCYF3lrpOEXC6jesQWa4fx1IgOIIIgPCvKXYJ6FmVmZnLgwAEMBgOBgYFUrlz5gWXj4+MtU8i3atUKZ2dnAFJTUzl16hSZmZl4eXnRrFkznJ2dkSSJa9euERcXR35+Pp6envxfe3ceV1W1/3/8dQ4IMiYqAuY8oJI5DynkAA4I6k2cbl1v2qBcNc0UM1HMOcdyykopsxyvQ4455qVQLIdQCBFEZFJQQZBB5rN+f/jzfOVqVxPlHPDzfDx8CHutfc577YwPe+919mrbti22trYAJCcnEx4ezu3bt3FycqJt27ZlMmYhRMUnBaoc0+l0BAQEsGzZMv0DYE1MTPjnP//J559/jqXl/z03Lz09nVGjRrFjxw7uPR/Y1taWDz74gLNnz7Jv374Sr21jY8OsWbM4cOAAR44cKdFmUxgpwgAAIABJREFUaWmJr68voaGhBAUFlWirVq0a/v7+TJw48RmMWAjxPJECVY4tXLiQ+fPnM2zYMP71r39hbn53/ahly5ah0+lYv369vu8bb7zBf/7zH6ZPn86AAQPIyMhg+fLlzJo1C4CpU6fSs2dP7O3tuXr1KqtWrdIXmQ8//JDXXnsNGxsbkpOTCQwM5LPPPgPgk08+wdXVFTs7O+Li4li6dCl+fn60a9dOv7aUEEI8CaOfJJGZmcn48ePx9PSkT58+hIaGGjqSUcjOzmbRokW89tprfP/992RlZREREcGSJUuYPHky33//PdHRd5fjCAkJ4eDBg3zyySfMnj2bkydPYmpqyq5du+jc+e6DZX18fAgLC2PHjh106tSJXbt20aRJEwDs7Ow4dOgQO3bsoH379mzdupWGDRsCMHDgQH799Vf27t1Ljx49+PHHH6lRowaBgYGGOTBCiArD6M+g5s2bx6uvvsqKFSsoKCggLy/P0JGMwqlTp8jIyGDMmDEAvPXWW1y/fp1+/foxZswYFixYwJEjR3B2dubw4cNotVp8fX25dOkSY8eO5eWXXyYsLIzRo0cTEhKCm5sb+fn5ANjb2zNmzBiaNWtGVFQUU6dO1b9v+/bt8fLywtzcHICXX35Zv1+jRo0YPHgwjRo1IikpqYyPiBCiojHqM6isrCxOnz7NoEGDADAzM9PfnH/e3XviRKNGjSgsLCQlJQWlFNeuXaN27dpUrlyZhIQEfd+aNWtiaWlJYmIigL6ANGrUCEBfZKpXr46npycpKSkl7i999913XLp0CS8vLz7++GMuXLgAQMuWLQGoXbs2Xbt2JSYmhjNnzui3CyHEkzLqApWUlETVqlWZOnUqr732GtOmTdNPBnjemZjcfbRQUVERWu3//WfUarXodDqKi4tZtGgRrVq14ttvv9UvC6/RaPT97u1/T/369Tlx4gTW1tZ4enqSkZGhX+Xyxx9/5Pvvvyc5OZkpU6bot4eGhtK8eXNCQkLIzc3F09OT/Px8mSQhhCg1o77EV1RUxIULFwgICKBly5bMnTuXNWvWMGHCBENHM6j4+HgsLCyAu0slN27cmPr165OUlETt2rW5fPkyhYWF1K9fn3r16nHz5k2Sk5NJT0/XnzHdu4d08eJFANq2bcv+/fu5ffs2nTp1IjY2Vt+u0WjYsmULAKampgQEBODq6kpkZCRubm788MMPxMbG4u3tTXJyMgCLFi3Cz8+vTI/L05KdnV1un4kIkt/Qynt+MJ4xGHWBcnR0xNHRUX+5yNPTkzVr1hg4leHVrVsXR0dHnJyc+PTTT+nbty87duwgPT0dGxsbJk2aBICXlxerVq1iyJAhbNu2jaVLlzJ37lz27dtHw4YNKSwsZPny5QBs374dBwcHcnJy2LZtGwDz58/nyJEj/P777wQFBWFqasrAgQPJzc0lODgYgL1792JlZYWVlZV+qrqfnx/BwcGsXLnSAEen9OLj4x/5RA9jJvkNq7znh7IfQ2Rk5EO3G3WBsre3x9HRkdjYWBo0aMDJkyf1v/k/78zNzZk9ezYjR46kW7dujBw5EgsLCwYOHMjOnTsBCA8PZ9WqVcTExAB3C058fDw+Pj6EhIQwbNgw/vjjDwA2btzICy+8UOI9rl+/Tm5uLhs3buSll17CxMSEwMBA1q1bR1RUFACBgYH6y4333Lp1Sz+JQgghnpRRFyiAgIAA/Pz8KCwspHbt2nzyySeGjmQ03n33XQBmz57Nm2++CdydEj5r1iwsLS2ZPn06v/zyC1ZWVnz11VfExMTwxRdfsGHDBuDuBIk1a9awYsUKpk+f/qfvM3PmTP2He+HuzL3PP/+czz777KGXW62srPjyyy+f5lCFEM8hjbr/J08FEBkZSZ/1sYaO8cw87Fl8xcXFXLx4kaKiIpo0aULlypUByMnJITc3FysrK/09q5ycHKKjo7GwsMDZ2RmtVotSirS0tAde19LSEktLSzIzM7ly5Qo6nY6aNWtSo0YNNBoNOp2OW7duPbBfWlqa/jNU5VF5v0Qj+Q2rvOcHw1ziuzfx6n5GfwYlHs3ExISXXnrpge337g3997bWrVuX2KbRaKhevfqfvr6tre1Dp41rtdqH7peTk/O40YUQ4k8Z9TRzIYQQzy8pUEIIIYxShbvEp9OpCr1mUl5hMZUrmTy6oxBClHMV7gyqqKjQ0BFK5VEfjpPiJIR4XlS4AiWEEKJikAIlhBDCKEmBEkIIYZQqXIEyNa1k6Ail8mcfjssrLC7jJEIIYVgVbhafVquh3kf7DR3jqavIMxOFEOJhKlyBel6kp6ezbt06fv31V8zMzPD09GTIkCGYmZk90Dc2Npa1a9cSHR1NtWrV+Pvf/0737t2JjIxkz549REREcOfOHV588UX+9re/4e7uTnh4OPv27ePChQvk5uZSu3ZtfHx86NKlC7/99hu7du0iNjaW4uJiatasSd++fenZs6d+vSkhhCgtKVDl0KlTp+jTpw+3bt3C2dmZO3fusHHjRhYuXMjRo0dxcHDQ9127di2jR4/GxMSExo0bc+3aNdauXYudnR3p6eloNBrq1KmDtbU1R44cYeXKlVSrVk3/jL26detiaWnJ4cOHWb58OS1atCAsLAwzMzPq16+PiYkJhw8fZuXKlbz55pt8++23BjoqQoiKpsLdg6roiouL+ec//0mVKlUIDQ0lKiqKxMREdu/eTWxsbIlFAuPi4hgzZgy9evUiLi6OP/74g+TkZObOnUt6ejrW1tbcuHFD35aamspHH31EWloa1atXJzU1lStXrhAREcHNmzeZMGECYWFhAKSmpnLx4kUiIiJITU1lxowZfPfddxw5csRQh0YIUcEYfYHKz89n0KBB9O/fH29vb1asWGHoSAa1f/9+oqOjWbx4Ma1ataJnz574+fnRv39/xo4dy6ZNm/Sr2q5atQoTExPWrl1LYWEhzZs3Z9euXUybNo2OHTui0Wj4+uuvad68OR07diQrK4tPPvmEqlWrArB69WpcXFxwdXWloKCAJUuWYGlpCcDw4cOpV68enTt3pqCgAH9/fzQaDSdPnjTYsRFCVCxGX6DMzMxYv349e/bsYdeuXQQHB3Pu3DlDxzKYc+fOodFo8Pb2JioqiqNHj/L1118D0LdvX3Q6HeHh4fq+rVu35sUXX+TQoUNERESwadMmfd+srCw++ugjIiIiOHXqFHFxceh0OrRaLTdv3iQgIIDIyEhCQkK4evUqOp1Ovzjhrl27MDExwdraGq1WS2hoKEqpEpcXhRCiNIy+QGk0Gv2SEUVFRRQVFT3XN+JTUlKoVq0a5ubmZGRkAHD79m0AatasCUBISAiRkZFER0frt93re+/ve9ttbW0BmDRpEm3btmXRokWkpqbi5+dH06ZNgbuLRjZr1ozZs2eTlZVFq1atqFy5MpcvX+bw4cNotVqWLl0K8D+X7RBCiL+iXEySKC4uxsfHh4SEBN54442Hrk30PIiPj8fU1JSMjAyKi4v1hfveZbfU1FQAZs2axaxZswCoX78+gL6vtbV1ib5ZWVksXbqUiRMnsmDBAqZOnQrA5s2bSUlJYfXq1YwePZoZM2Ywd+5cAP0ZrL29PXXr1mXnzp1s2rSJn3/+ma1bt9KsWbNHPlPQmGVnZ0t+A5L8hmcsYygXBcrExITdu3eTmZnJ2LFjiY6OxtnZ2dCxylzdunXp2LEjK1euJCQkhFdeeYVatWrRpk0bAH755RcARo0ahbu7Ox988AHnzp0jMzOTLl26UKlSJdzd3fV9TUxM2LRpE0OGDGHFihWsW7cOZ2dnEhISuHnzJjt37qR///4sXLiQrVu34uzsTFxcHDVq1MDMzIzY2Fjy8vLIzMykTp06WFlZUalSJaytrcv1iqLlfUVUyW9Y5T0/GGZF3Ycx+kt897O1taVjx44EBwcbOorBDBgwgBo1ajB58mRycnKIjY1l9+7dXLp0iSVLlgDQvn17hg4dirW1NZmZmUydOpWmTZuSlZXFpEmT2L17N/v378fOzo4hQ4YAMH78eKKiooiKiqJFixY4OTnRv39/AKZMmaJvc3Z25uWXX+by5cukp6dz69Ytmjdvzrp164iLi6Nr164GOzZCiIrF6M+gbt26hampKba2tuTl5RESEsLIkSMNHctgLC0tWb16NUOHDqVOnTr06tWLnJwcjhw5QqVKdx/ztGDBAr755hsSExOBu7Px9u7di6urK7GxsZw6dQq4ez+qc+fOD7zHhQsXKCwsfGhbbGwskZGRdOjQgYYNG5KXl8eFCxeIjo7Gw8ODt956Sz+LUAghSsPoz6Bu3LjBm2++Sb9+/Rg0aBCdO3eme/fuho5lUAMHDuT3339n4MCBREREkJyczKRJk/RnUy4uLlhbW/POO++QkpLC/v37adGiBWfPnsXExITly5dz9epVxo0bh7W19QN/evbsSZ8+fR7aNmjQIEaNGoWNjQ1nz54lJiaGxo0b880333DgwIGHPslCCCGehEYppQwd4mmKjIykz/pYQ8d46srTs/jK+zV4yW9Ykt/wDHEPqlmzZg9sN/ozKCGEEM8nKVBCCCGMkhQoIYQQRsnoZ/H9VTqdKlf3ax5XXmExlSuZGDqGEEKUmQp3BlVUVGjoCKXyZ5/eluIkhHjeVLgCJYQQomKQAiWEEMIoVbgCZWpaydARgLv3jIQQQjy5CjdJQqvVUO+j/YaOUSEnagghRFmqcGdQxk6n01FY+HgTOYqKiigufnpnYkop8vLyqGAPDxFCVFBSoMpIeHg4gwYNwtLSEjMzM5o3b87XX3+NTqd7oO++fftwdXXFzMwMMzMzPDw8CAoKIiEhgffff58OHTrg4OCAg4MDvXr1KvFw1qCgIJo1a4aDgwOOjo4MGzaMwMBA3NzcsLa2xsLCAltbW7y9vQkNDS3LQyCEEH9JhbvEZ4zOnTuHq6srlStXxtfXl+rVq7Nnzx7effddLl68yOLFi/V9t27dypQpU2jcuDHTpk2jqKiIjRs34u7ujlIKKysrOnTowIABA9BoNAQGBvLtt98ydepUUlNTGTp0KHZ2dvj4+HD79m02btzIxo0bad26NaNGjaJGjRokJyezdetWOnfuzMmTJ2nVqpUBj44QQjycFKgyMGXKFKytrQkPD6dy5cqkpKQQEBDAqFGj+Oyzz/jXv/5Fw4YNyc7OZsGCBbi7u3Po0CGSk5MxMzNjxowZdO7cmXPnzvHuu++ydOlSioqKMDc357vvvuPWrVsAvPfee2RkZPDTTz/RvHlzoqOj2bx5MwAbNmzAysqKtLQ02rRpQ0BAAC1atGDu3Lls377dkIdHCCEeyugv8U2dOpVOnTrRt29fQ0d5Ijdu3ODw4cOMHz+eGjVq8Oabb9K8eXOuXr3K7NmzUUqxZcsWAA4ePEh6ejozZ85Eo9HQtm1bunXrhoWFBdOmTQPuFhobGxv96rn3bNu2ja1bt/Lxxx9TWFjI7du3S7S//fbb1KtXj7Zt27Ju3Trs7e3p2rWrfvl2IYQwNkZfoHx8fAgMDDR0jCd2+fJlAP2y7KGhoRQWFvLHH3/g6OiIk5OTvk9MTIy+b1JSEjdv3uTixYvk5eXp909LSyM3N7fEe9y4cYMxY8bQrl07JkyYwPDhwykqKirRJyEhQf91jRo10Ol0REZG4uTk9GwGLoQQpWT0l/jat29PUlKSoWM8sezsbABsbGwAKCgoANDP5LOxsWHdunW8+OKLLF68GBMTEywsLPT97u1zb/+hQ4eydevWEu/x3XffYW5uzvr165k3bx7h4eEP5FBKYWJiwooVK/D29mbChAmEhYWxadOmpz9oIYR4Coy+QJVn8fHxaLVa/ddubm7UqFGDlJQUatSoAaBfln3+/PkopVBKcfXqVapXr45Go6Fy5cpYW1tz6dIlgAeK0z316tXDxcWF119/ncGDB1OlShWsra05dOgQvXv3JjMzk507d+Ll5cU777zDN998A8CVK1f+9Pl/Tyo7O/upv2ZZkvyGJfkNz1jGIAXqGapbty41a9akevXqbNiwgX/84x/4+/tz5MgR2rRpw86dO8nJyaFv377s3buXyZMns2TJEjZs2MDUqVPx9/fHzs4OrVbL999/D4CLiwvdunWjdu3aAPj6+hIdHc3p06dZunSp/r2bNm1Kbm4ux48fB2Dnzp307t2b4OBg6tSpw8yZMzl48CCrV6/G39//qY67vK8oKvkNS/IbniFW1H0YKVDPWKVKlfjwww/1fyZNmsTAgQPZt28f48aNAyA3N5f4+HgyMzMBmDdvHvb29vpp5p999hmrV68GoEWLFnz44YfA3X9E77//Pv/5z3/Yv38/fn5++vft0aMH6enpzJkzBwALCwvi4+OpU6cOI0aMAO6evV24cKGsDoUQQvwlUqDKwAcffEBUVBSLFy9m8eLFaDQalFI0btyYPn36cODAAerVqwdAy5YtsbS0ZOTIkYwcOVL/Gr1798bc3JwtW7boZ/3dz87OjqioKGJiYujcufMDn23q2rXrQ7MNGDDg6Q1UCCGeIqMvUBMnTuTUqVOkp6fTpUsXxo0bx+DBgw0d6y8xNTUlMDAQPz8/9u3bR05ODq1bt8bLywuNRsORI0dITk7mhRde4KWXXsLZ2ZlffvmF4OBgtFotHh4edOzYkYKCAg4ePEhaWtoDr+/p6Ym9vT329vZERUVx4sQJNBoN3bp1A+4+YeK/H3FUpUoVvLy8yuowCCHEX2L0BerTTz81dISnpmnTpjRt2vSB7Z6envqv4+Pj0Wg0dO3a9YGzHjMzM/r37//I93F2dsbZ2bnEtnuX9YQQorww+s9BCSGEeD5JgRJCCGGUpEAJIYQwSkZ/D+qv0umUUSwWmFdYTOVKJoaOIYQQ5VaFO4MqKnq8xQCfNSlOQghROhWuQAkhhKgYpEAJIYQwShWuQJmYyKU1IYSoCKRACSGEMEoVbhbfwyQlJREcHIxOp8PV1VX/3LuHCQsLIzQ0FGtrazw8PKhSpYq+7ffffyc8PBxbW1s8PDywtbUF7q61dObMGSIiIrCzs8PDwwNra2t922+//cbFixepVq0aHh4eWFpaPtPxCiFEhaAqmAsXLui/zs/PV76+vsrExEQBClAajUYNGzZMZWdnl9gvKSlJubu76/sBysrKSs2fP19duXJFubm5lWizsbFRn376qYqOjlYdOnQo0ValShX1xRdfqIiICNW6desSbdWqVVPr1q370/xxcXHP6tCUmfI+BslvWJLf8Mp6DPf/3L5fhbvEdz9/f3/WrFnD2LFjOX/+PBEREUyZMoXNmzfrl7qAu2c5Pj4+nDlzhk8//ZRLly5x8uRJPD098ff3p379+kRERLBy5UpiYmI4fvw43bp1Y+LEiTg7O3PlyhW++OILLl++TFBQEB07dmT06NG89NJLpKSkEBgYyOXLl/npp59o0aIFb731FkFBQYY7MEIIUR6UtvJ1795dpaWl6b//9ddf1ahRo5RSSu3YsUM1adJERUZG6tu9vb1VYmLiA/uGh4er7t27q4iIiFLluVeJb9y4oSpXrqzeeustpZRSmzdvVoGBgUoppSZNmqS0Wq2KjY1VSim1f/9+BejPbObNm6eCgoKUUkp/dvTvf/9bFRUVqZkzZ6qQkBBVXFysmjdvrgC1f/9+VVBQoAICAtTp06dVYWGhatiwoQLUzz//rHJzc5W/v786f/68ysvLU7Vq1VLdu3d/aH757cvwJL9hSX7DK9dnUAUFBdy5c+ex+jo6OvLll1/+zz4XL15k/PjxLFu2DBcXF7KystDpdE8STS8kJIS8vDx8fX3R6XSMHDkSX19fcnJyGDVqFDqdjp9//hmAo0ePYmlpybBhwzhz5gzTpk3TLwo4cuRIqlWrxuDBgzlx4gQzZ85k2rRpaLVa3n33XWrVqoWXlxdHjx5lzpw5zJw5E1NTU95++22aNGlCly5d2LdvH/Pnz2fevHmYm5szfPhwfv75ZwoLjeNDxUIIYYz+UoG6fPkyCxYswNPTk7i4uMfap1u3bsTExBAbG/vQ9tjYWMaOHcuiRYto0aIFAGfPnsXT05OVK1dy7dq1vxJRLyEhAYAGDRqQmZlJdnY2xcXFXL9+nfr166PVavV9EhISqFOnDqampvr3u3r1KgANGzbUT6q4t+3+tgYNGpTYdm//R7XpdDr9diGEEA96ZIG6c+cOO3bs4PXXX2f69Ok0bNiQPXv24OLi8nhv8P/PNL766quHto8ZM4YZM2bQrl07/bZu3bqxZcsWbGxsGD16NO+88w4HDhygoKDgMYd1d6l1uHu2d//Uc1NTUwoLC9HpdHz88cc0atSIHTt26F9bq9Xq+wHk5+fr2+69zv9qu/f3o9ruzyiEEOJBj5xm7ubmRpMmTZg7dy4NGzZ8rBfVaDQlvu/bty9ffPEFiYmJD/Tt1KkT27Ztw83NrUQhqVq1KiNGjGDEiBGEhobi7+/P6tWr2bt37yPfPz4+HisrKwAiIiLo1asXTk5OZGVl4eTkxLlz5wBwcXGhdevW5ObmkpiYSGZmJk2aNAHQ/x0REUFsbCy5ubn6bfcWA4yIiCA6OprCwsKH7hcZGYlOp3tom5mZGQUFBcTHx5fInp2d/cC28qa8j0HyG5bkNzyjGcOjbl4FBwer999/X/Xp00etXLlSJSUllWgfMGCAunLliv77Q4cOqY8++kgpdXeSxKxZs5RSSm3ZskUFBAQ8MEkiNTVVjR07VgUEBDzw3pcuXVILFixQPXv2VP7+/urcuXOPfbMtJydH2dvbK3d3d1VcXKzCwsLU6dOnlVJK+fj4KEB9+OGHSimlvLy8FKBmzJihlFLqyJEjKiEhQWVnZ6u6desqQC1cuFAppdSBAwfU1atXVUZGhnJ0dFSAWrVqlVJKqX379qnr16+r1NRUZWdnV2Lixe7du1Vqaqq6du2asra2Vq+//vpD88sNVsOT/IYl+Q2v3EyScHNzY9myZWzcuBEbGxvGjBnDiBEjSEpKAqBjx47s3r0bgOLiYvbs2UPHjh0feJ0BAwZw8uRJbt26VWK7RqNh6dKlxMbGsnz5cuDuGcaQIUOYPn06DRo04IcffmDevHm0bNnysQuvpaUlc+bM4dixY7i6unLy5EnCwsLo3r07O3fuBOC3335jwYIFXL58GYA5c+YwdOhQUlJS2L59O61btyYpKQk7Ozv8/f35xz/+QVpaGps2baJNmzakpaVha2vLhAkTGD58OBkZGaxbt442bdqQk5ODjY0Nvr6+jBw5kuzsbL788kvatWuHUoqZM2c+9liEEOK59CTV7vz58+ratWtKKaUyMzPVxIkTVb9+/VTfvn3VwoULVXFxsVKq5BmUUkqtX79eOTs7P3SaeWZmpurfv7/asGGDiomJUTExMU8S7YFKvG7dOtWgQQP9B2Vr1aqlVq1apZYuXaosLS0VoKpXr67+/e9/K39/f/XCCy/o+7Zr104dPnxY5eTkKD8/P2VjY6Nve+WVV1RQUJDKzMxU48eP178WoLp06aJCQkJUenq6Gj16tLKwsNC3ubu7qzNnzvxpfvnty/Akv2FJfsMzljMojVJKGag2PhORkZE0a9asxDadTkd8fDw6nU4/gw+gsLCQ4uJiKlWqVGICQ3x8PNbW1tSsWbPE6+Tl5REfH4+trS1OTk4l2nJzc0lISKBKlSo4ODiUaLtz5w4JCQlUq1YNe3v7/5k/Pj6eunXrPtHYjUV5H4PkNyzJb3hlPYaH/dyG5+RZfFqtlvr16z+wvVKlSg/MpDM3N9dPgvhvlStX1k90+G8WFhZ/2mZpaUnTpk3/YmohhHi+VehHHQkhhCi/pEAJIYQwShWuQBUXFxs6ghBCiKdACpQQQgijVOEKlBBCiIpBCpQQQgijJAVKCCGEUZICJYQQwihJgRJCCGGUpEAJIYQwSlKghBBCGCUpUEIIIYySFCghhBBGqcItt3Hu3DnMzc0NHUMIIcRjys/Pp1WrVg9sr3AFSgghRMUgl/iEEEIYJSlQQgghjJIUKCGEEEZJCpQQQgijJAVKCCGEUZICJYQQwiiVqwL1yy+/0Lt3b3r27MmaNWseaC8oKGDChAn07NmTwYMHk5SUpG/76quv6NmzJ7179yY4OLgsY+s9af4TJ07g4+NDv3798PHx4eTJk2UdHSjd8Qe4du0arVu35uuvvy6ryCWUJv/FixcZOnQo3t7e9OvXj/z8/LKMrvekYygsLGTKlCn069ePPn368NVXX5V1dODR+U+fPs2AAQNwcXHh4MGDJdp++OEHevXqRa9evfjhhx/KKnIJT5o/MjKyxL+fH3/8sSxj65Xm+ANkZ2fTpUsXZs+eXRZxQZUTRUVFysPDQyUkJKj8/HzVr18/denSpRJ9NmzYoAICApRSSu3bt0+9//77SimlLl26pPr166fy8/NVQkKC8vDwUEVFReUmf0REhEpJSVFKKRUVFaXc3NzKNLtSpct/z7hx49S4ceNUYGBgmeW+pzT5CwsLVd++fVVkZKRSSqlbt26V+b8fpUo3hj179qgJEyYopZS6c+eO6t69u0pMTDS6/ImJiSoyMlJNnjxZHThwQL89PT1dubu7q/T0dJWRkaHc3d1VRkZGuckfGxurrly5opRSKiUlRbm6uqrbt2+XZfxS5b9nzpw5auLEiWrWrFllkrncnEGFhYVRt25dateujZmZGd7e3vz0008l+hw7dowBAwYA0Lt3b06ePIlSip9++glvb2/MzMyoXbs2devWJSwsrNzkd3FxwcHBAYDGjRuTn59PQUFBuckPcPToUV588UUaN25cprnvKU3+EydO0KRJE5o2bQqAnZ0dJiYm5WoMGo2G3NxcioqKyMvLo1KlSlhbWxtd/lq1atG0aVO02pI/mo4fP46rqytVqlThhRdewNXVtcyvhJQmf/369alXrx4ADg4OVK1alVu3bpVVdKB0+QH++OMRun6BAAAD60lEQVQP0tLScHV1LavI5ecS3/Xr13F0dNR/7+DgwPXr1x/o4+TkBICpqSk2Njakp6c/1r7PWmny3+/QoUO4uLhgZmb27EP/V7YnzZ+Tk8PatWt57733yjTzf2d70vxXrlxBo9HwzjvvMGDAANauXVum2e/P96Rj6N27NxYWFri5udG9e3fefvttqlSpYnT5n8W+T8vTyhAWFkZhYSF16tR5mvEeqTT5dTodCxcuZMqUKc8q3kOZlum7iVK5dOkSS5Ys4ZtvvjF0lL9k1apVDB8+HCsrK0NHeSLFxcWcPXuW7du3Y2FhwYgRI2jevDmdOnUydLTHFhYWhlarJTg4mMzMTN544w06d+5M7dq1DR3tuXLjxg0mT57MwoULH3qWYqw2bdpEly5dShS4slBuCpSDgwMpKSn6769fv66/7HV/n+TkZBwdHSkqKiIrKws7O7vH2vdZK01+gJSUFN577z0WLlxY5r953cv2pPnPnz/PoUOHWLJkCZmZmWi1WszNzRk2bFi5yO/o6Ej79u2pWrUqAF26dCEiIqLMC1RpxrBy5UpeffVVKlWqRLVq1WjTpg3h4eFlWqBK8/+hg4MDp06dKrFvhw4dnnrGR2Uozc+R7OxsfH19+eCDDx76YNRnrTT5Q0NDOXv2LJs3byYnJ4fCwkIsLS3x8/N7VnGBcnSJ7+WXXyYuLo7ExEQKCgrYv38/7u7uJfq4u7vrZ/ccOnSIV155BY1Gg7u7O/v376egoIDExETi4uJo0aJFucmfmZnJqFGjmDRpEm3bti3T3PeUJv+mTZs4duwYx44dY/jw4fj6+pZpcSptfjc3N6Kjo/X3cE6fPk2jRo3KNH9px+Dk5MRvv/0GwJ07dzh//jwNGjQwuvx/xs3NjePHj3P79m1u377N8ePHcXNze8aJSypN/oKCAsaOHcvf/vY3PD09n3HShytN/qVLlxIUFMSxY8eYMmUKr7322jMvTkD5mcWnlFJBQUGqV69eysPDQ61evVoppdSyZcvU0aNHlVJK5eXlqXHjxqkePXqogQMHqoSEBP2+q1evVh4eHqpXr14qKCioXOX//PPPVcuWLVX//v31f1JTU8tN/vutWLHCILP4lCpd/l27dikvLy/l7e2tFi5caJD8Sj35GLKzs9W4ceOUl5eX6tOnj1q7dq1R5j9//rx69dVXVcuWLVWHDh2Ul5eXft9t27apHj16qB49eqjt27eXq/y7du1SLi4uJf4fvnDhQrnJf78dO3aU2Sw+WW5DCCGEUSo3l/iEEEI8X6RACSGEMEpSoIQQQhglKVBCCCGMkhQoIYQQRkkKlBBCCKMkBUoIIYRR+n9de09aYys0bgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAVcAAAEYCAYAAADoP7WhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO3de1yUZfr48c+DKKKAisqgZv4C00pN+2Z5whMGonhOpNZMLHNXTVLTtDQPeaDd1DWzE9maVpuJJ0rNE6bk+ayVaYlYmDD0RQQUOc3cvz/4MpurMsMwwwzD9X69ntdrZ+bhnmtYvLrneu7nujWllEIIIYRNuTk6ACGEcEWSXIUQwg4kuQohhB1IchVCCDuQ5CqEEHYgyVUIIexAkqu4xYMPPsjAgQPp168f0dHR3Lx50+qxpk+fzrZt2wCYMWMGFy5cuOu5hw8f5sSJE2V+j+DgYK5evWrx83/2yCOPlOm93nnnHT7++OMy/YyouiS5ilvUrFmT+Ph4Nm/eTPXq1VmzZs0trxcVFVk17oIFC2jevPldXz9y5AgnT560amwhnJG7owMQzqt9+/acP3+ew4cP8/bbb+Pj40NycjJbt25l0aJFHDlyhIKCAoYPH85TTz2FUop58+axf/9+GjVqRPXq1U1jjRgxgldeeYU2bdqQmJjIP//5TwwGA/Xq1WPBggWsWbMGNzc3vvrqK15//XUCAgKYPXs2V65cAeC1117j0UcfJTMzk5dffhm9Xk+7du2w5B6YcePGkZaWRn5+Ps8++yyRkZGm1xYuXMj+/ftp0KAB//znP/H19eW3335j7ty5ZGZmUrNmTebNm0dgYKDtf8HCtSkh/qRdu3ZKKaUKCwvV3/72N/X555+rQ4cOqbZt26rffvtNKaXUmjVr1LvvvquUUio/P18NHjxY/fbbb2r79u0qKipKFRUVqbS0NPXoo4+qb775Riml1DPPPKPOnDmjMjIyVLdu3UxjZWZmKqWUWrZsmVqxYoUpjsmTJ6ujR48qpZT6/fffVVhYmFJKqXnz5ql33nlHKaXUt99+q1q0aKEyMjJu+xw9e/Y0PV/yHjdv3lTh4eHq6tWrSimlWrRooeLj45VSSr3zzjtq7ty5Simlnn32WZWcnKyUUurUqVNqxIgRd4xRiNLIzFXcIi8vj4EDBwLFM9ehQ4dy8uRJ2rRpQ9OmTQHYv38/58+fZ/v27QDk5OTw66+/cvToUcLDw6lWrRo6nY6OHTveNv6pU6do3769aay6deveMY4DBw7cUqO9fv06N27c4OjRoyxfvhyAHj16UKdOHbOf6dNPP2Xnzp0ApKam8uuvv1KvXj3c3Nzo27cvAAMHDuTFF1/kxo0bnDx5kpdeesn08wUFBWbfQ4j/JslV3KKk5vrfatWqZfrfSilmzpxJ165dbzln7969NovDaDSydu1aPDw8yjXO4cOHOXDgAF9++SWenp6MGDGC/Pz8O56raRpKKXx8fO74OxCiLOSCliizoKAgvvjiCwoLCwFITk4mNzeXxx57jG+++QaDwUB6ejqHDx++7WfbtWvHsWPHSElJAeDatWsA1K5dmxs3btzyHp9++qnp8U8//QTAY489xtdffw0UJ/OsrKxSY83JyaFOnTp4enqSlJTEqVOnTK8ZjUbT7Pvrr7/m0UcfxcvLi3vuuYdvvvkGKP4Pyblz58r2CxICSa7CChERETRv3pwhQ4bQr18/Zs2ahcFgICQkhGbNmtG3b1+mTZtGu3btbvtZX19f3njjDSZMmMCAAQOYNGkSAD179mTnzp0MHDiQY8eOMWPGDH744Qf69+9P3759+eKLLwAYP348x44dIzw8nJ07d9K4ceNSY+3WrRtFRUX06dOHxYsX3xJTrVq1OHPmDP369ePQoUOMHz8egLfeeot169YxYMAAwsPD2bVrl61+daIK0ZSSloNCCGFrMnMVQgg7kOQqhBB2IMlVCCHsQJKrEELYgSRXIYSwA0muQghhB5JchRDCDiS5OglZbiyEa5Hk6kB/TqiapnH9+nXOnTvH3Llz2b17twMjE0KUlyRXB9I0DYC0tDROnz7N2LFj2bp1Kzt37sTdXXrqCFGZyb9gB7hy5Qo6nY5q1arx6aefkpiYiJ+fH8OGDeOee+7hu+++IyAgwNFhCiHKQXoLVCClFKmpqYwcOZLPP/+cWrVqsXXrVtq2bYufnx/16tXjrbfe4r777mPo0KGODlcIUQ4yc61Amqbh5eVFw4YN8fPzA2Do0KG4uRVXZ27cuEFaWhp9+vRxZJhCCBuQmmsFuXTpElDcjLpatWq3bPRX8uVhyZIlALRu3brC4xNC2JbMXO1MKUVhYSETJkygc+fOjB07lszMTHJyckxbjZQICgrigQceMP1cyQUvIUTlIzVXO9Pr9eh0OlJTUxk7diyPPPIISUlJ9OjRA19fX2rUqIGvry/5+fn4+Pjw8MMPU61aNUeHLYQoJ0mudqKUIisri+HDhzNy5EiGDRuGXq9nypQpHD16lBdeeIHffvuN/Px8NE3j6tWrLFu2DJ1O5+jQhRA2IMnVzvbs2cPbb7/NiBEjGDJkCFevXmXMmDGEhYUxevRo03n5+fnl3oxPCOE8pOZqBz///DP169fHy8uLHj164Onpyfz58zEYDERERPDuu+/yt7/9jZSUFObOnQtA9erVHRy1EMKWZOZqY6mpqYSGhtKwYUNatGjB8OHDCQwMJCsri1deeYWxY8fSt29f0tLSmDx5MsuXL8fX19fRYQshbKzanDlz5jg6CFeRnZ1NgwYNqFWrlqlXgIeHB2+//Tbe3t7k5OSwbds2PDw86NChA4MGDaJ27dqODlsIYQeyztVG9Ho9kydP5ujRozz77LN06tSJ5s2b07JlSz755BN8fX1p1qwZaWlpLF68mKysrFuWYQkhXIuUBWzk2rVrbNmyhX379jFmzBjatGnDunXrOHXqFOHh4XTt2hWApKQkfHx8aNiwoYMjFkLYk5QFbKRmzZo0a9YMg8HA2rVruffeewkODubq1ascPnyYnJwcWrZsia+vr5QChKgC5HtpORw9epT4+HjT4zp16tC7d2+eeOIJPvzwQ3755RcGDBhA8+bN+f7777l+/boDoxVCVCRZilUORUVFxMTE4ObmRv/+/YHiBBsaGkpeXh47d+5kwoQJhIWFUbNmTby8vBwcsRCiosjM1QpKKZRSdOrUiWXLlrF06VK++uor02t169YlMDCQ5ORkjEYjfn5++Pj4VHicf/zxh2wf4+Ryc3MdHUKZyN+T5SS5WkHTNDRN49y5czz++OPMnz+ft99+m82bN5uareTm5pKfn2/xPx6DwWDTGL/77jtefPFFUlNTbTbmL7/8wpEjR8jMzLTZmL/++ivff/89BQUFNhvz0qVLfP/99xiNRpv9Xi9evMjJkycpLCy02Zi7du1i0aJFZGRk2GQ8gFOnTrFp0yZOnTpls9/psWPH2LRpE1D8ty8J1jJyQctK69at49133yU8PJyAgABatmzJu+++y6VLl9i7dy/x8fHMnDmTRo0alTpOcnKyqTuWwWCwyfKsffv2sWjRIjIzM7l27RrdunUr95h79+5l9uzZJCcns2PHDjp27FjuC3Pffvstr7/+OsePH+fgwYO0aNGCevXqlWvMXbt2MWfOHJKSkjh16hSXL1+mefPm5boDbseOHcycOZMffviBw4cPo9frCQwMpEaNGlaPeeTIERYsWEBUVBQtW7a0epw/S0hIICYmhvz8fI4ePUrr1q2pW7eu1eMZjUZyc3MZP348x48fx83NjTZt2qBpGkajUbq2maNEmRgMBqWUUu+//77atWvXLa+dP39ebdmyRa1atUpdunTJ7Fi7d+9WDz/8sJo8ebLpuaKionLFt3//fvXEE0+on3/+WRUUFKhRo0apI0eOlGvMQ4cOqdDQUHX69GmllFLjxo1T+/fvL9eYx48fV2FhYerHH39USik1e/ZsNX369HKNefXqVfX888+rX375RSmlVFxcnBoyZIhavny5ysnJsWrMgoIC9dJLL6ljx44ppZTatm2bevPNN9WSJUusHlMppf71r3+pFStWKKWUSktLU/v27VOnTp1S2dnZVo139epV9dxzz6nz588rpZSaPn262rp1q/rf//1flZeXZ3WcSikVGxurPv74YzV16lS1cuXKco1VlUhZoIzc3NxISUlh//79t3Sw+vXXX2nRogV9+/bl2WefpVmzZqWOk5uby2effcZrr71G9erVmTJlCgDVqlUr19dOg8HA3//+d+6//35u3rzJfffdxy+//AJYXy9r0KABc+fO5eGHH+aPP/7g9OnTfPbZZ8yaNYtt27ZZPe4LL7zAQw89BEB0dDRZWVnl+irr7u5Obm4uf/zxB1C8y0OTJk3IzMxkz549Vo97/fp1fv31VwBCQkLo2bMnhYWFfP3111Z/9j+3lXzppZdYv349n332GXPnziUrK6vM47m7u5OXl8fFixe5fv06R44cIT4+noULF/Lee++Vq7br7u5OamoqgwcP5syZM8TExLB48WKUUhiNRqvHdXVSFigDpRRFRUUsXbqU4OBgunTpQlJSEjNmzODixYvcf//9eHl5WfR1qXr16nTs2JHWrVvTsWNHEhISSEhIIDQ0tFylgWbNmtGoUSOMRiM1a9ZE0zRiYmIICgqiQYMGVo3p6+vLPffcA8Dq1atp06YNc+bMITMzk927d/P444/j6elZpjH9/Pxo1qwZNWrUwGAwkJOTwxdffEGfPn3w9PQkMzOzzGN6eHhQUFBAQkICubm5fPPNN+Tm5tK6dWuOHTtGr169yjQeFCfB+vXrs3HjRvz9/WnSpAn+/v5cu3aNgwcPEhoaatXX45o1a7Jo0SJOnDhBnz59mDRpEg8++CDff/89Xl5eZv/j/N88PDyoXbs2sbGxfP311/Tp04c33ngDHx8fjh8/zn333Wf1///169cnNTWVQYMG8fvvv/Pxxx8TGBhIjx49pDRQCpm5loGmaVSvXp0bN26Qnp5OVFQUGzZs4IEHHmDKlCn4+/uX6Y9Np9NRu3ZtfH19mTt3Lvn5+aYZ7I8//khSUpLVsZYk6G7dujFs2DD27Nljk5nG2LFjGTduHABDhgzh+vXrVl00q1atmmlpmlIKb29v6tSpg6+vL1999RVLly4lLy+vzOP269ePbt26cfjwYfLy8li0aBFPPfUUGRkZVq8zbt++PUFBQcTHx3P06FGqVatG//79SU9P59y5c1aN2bJlS6ZNm8bp06e5fPkyAE2bNsVoNHL16lWrxgwLC2PlypU8+uijpm8EnTp14saNG/z+++9WjQnFiTs5OZm1a9eyZs0aXnjhBVJTU1mzZo3VY1YFss61jC5evGj6Kjx69Gg6d+5sk3aB9erVY+7cubz11luEhYVhNBpZvXq1DSKGBx54gE8++YTRo0eXa5cD9V9bz2zfvp2MjAzTZovWcnd3x93dnUaNGrF48WL2799PTEwMNWvWLPNY3t7eDBgwgH79+pn+A7Np06Zy9XLw8PCgf//+aJrGhx9+yMWLF6lRowYZGRnluo25W7duREdH884779C4cWMAzp49y5gxY6wes06dOnTs2JFt27ZRvXp18vPzuXz5crkumul0Ovz9/XnvvfeYNWsWwcHBHDp0qMyz6yrHYdXeSiwnJ0fl5ube8pzRaLTJ2CtXrlSdO3dW586ds8l4JaKjo1VKSopNxsrPz1dr165Vffv2NV1AKQ+j0ajy8/NVr169VPfu3VVycnL5g/w/cXFxqk+fPjb5febn56uDBw+qiRMnqmnTppkuxpXXDz/8oBYvXqxiYmJsEmdWVpZatWqVGj58uHruuefUTz/9VO4xr1y5or7//nvT45ILu+LupHGLE8nKymLixIlMmzbNtFFheSk7bHRYWFjIgQMHaNq0KQEBATYbd8OGDbRp04b777/fZmP+/vvvFBUV2XSWZTAY0DTN6bualZRBbHlnoD3+nlyVJFcnU5W3e5F/uMKVSHIVQgg7cO7vNUIIUUlJchVCOL38/Hyys7MdHUaZVOmlWIkJ35F5pex3wwghblWvcR269epqt/EvJ8WSW9Cch9qElms5YUWq0sk180oWy0eucnQYQlR6L64aabexb968SZHRG5331+iT9tC4xd/t9l62JGUBIYRTu5K8An/vjfjW2sO1vMdt3p7TXiS5CiGcVsms1dvjJ9y0IhrUTkCf9Jqjw7KIJFchhNMqmbWWqEyzV0muQgin9OdZa4nKNHuV5CqEcEr/PWstUVlmrw5LrsHBwbe0Vjt8+DB//etfAUxt/P7czq1fv36m1mx//tkffviB4OBgzp49W4HRCyHs6U6z1hKVZfZaocm1oKDA4o7o/v7+fPDBB6Wec+7cOaKjo1m6dCkPPfQQOTk50hldCBdwt1lricowe62Q5JqUlMSbb75JWFgYly5dsuhnevTowYULF7h48eIdX7948SLjx4/nH//4Bw8//DAAx48fJywsjHfeeYcrV67YKnwhRAXKy8ujyOhzx1lrCTetiPq1Ekxb+jgjuyXX3Nxc1q9fz9NPP83MmTMJDAzkq6++MnVINxuYmxujR4/mww8/vOPr48aNY9asWbRv3970XI8ePVizZg3e3t6MHTuW559/nm+++cam2zYLIeyroKCAWtWTzZ5Xq8ZF8vPzKyAi69jtDq2goCBatmzJ/PnzCQwMtOhn/rvdXL9+/Xj//fdJSUm57dxOnToRFxdHUFDQLbfD+fr6EhUVRVRUFCdPnuS1117jvffe4+uvvy7fBxJCVBiFwkjpJT6Fczf0s9vMddmyZeh0OiZMmMDy5ctv28Onbt26tzRiyMrKum3Pend3d5577jk++uij28afNWsWAHPnzr3ttQsXLvD3v/+dadOm8T//8z/Mnz/fFh9JCFFBlAKDMpo9nJndkmtQUBBLly7l888/x9vbm3HjxhEVFWW64t+hQwfi4+OB4s7uX331FR06dLhtnMGDB3Pw4MHbNm3TNI3Fixdz8eJF3n77baB4U79hw4Yxc+ZMAgIC2LhxIwsWLKBt27b2+phCCDswYqQIQ6mHwczM1tHs3rilXr16jBw5kpEjR3LmzBnTV/hx48YxZ84cBgwYgFKKrl27MmDAgNt+vkaNGowYMYIFCxbc9pqHhwfvv/8+zzzzDA0aNKBjx47ExMRYXIYQQjgnI2Aw08ffqBQ48cYVVXongvhPN0tXLCFs4MVVIxk4op9NxsrOzib9yj9o4FP6v828gubka5847S60VbrloBDCOSnAYOaCldHJL2hJchVCOB2jUhSauWBVJMlVCCHKRoHZy1VGnLrkKslVCOF8FMqisoAzb/giydXGtl85ZfMxezduZ/MxhXBmxasFzJyjoJoTT10luQohnI4RjUIzX/oNaFSvoHisIclVCOF0FMUz09KYe93RJLkKIZxO8VKs0meuzn1/liRXIYQTMigNVOl35yszrzuaJFchhNNRaGZnrsqpF2JJchVCOCGFhtFsXylJrkIIUSbFF7TMJE9zrzuYcxctyuHVV1+lU6dO9Otnm2YSQoiKY1AaBapaqUeRU99C4MLJdciQIaxYscLRYQghrFBSFij9kJmrQzz22GPUqVPH0WEIIaxQckGrtMOS5Hqnb7DXrl1j1KhRhIaGMmrUKLKysorfUynmz59PSEgI/fv358cffzT9zMaNGwkNDSU0NJSNG+++K+2fuWxyFUJUXgY0ClW1Uo8iC5Zi3ekbbGxsLJ06dWLHjh106tSJ2NhYABITE7l06RI7duxg3rx5zJkzByhOxsuXL2ft2rXExcWxfPlyU0IujSRXIYTTKZ65upk9zLnTN9iEhAQGDRoEwKBBg9i1a9ctz2uaRrt27Yqbdqens2/fPrp06ULdunWpU6cOXbp04bvvvjP73rJaQAjhdJTSMJiZmbopN5KSkpg0aZLpucjISCIjI0v9uYyMDPz8/ABo2LAhGRkZAOj1evz9/U3n+fv7o9frb3tep9Oh1+vNfgZJrkIIp2PJOlcjGoGBgWzYsMHq99E0DU2zz4Uxly0LTJ48maeeeork5GS6detGXFyco0MSQljIgAVLsay8/bV+/fqkp6cDkJ6ejq+vL1A8I01LSzOdl5aWhk6nu+15vV6PTqcz+z4um1yXLFnCvn37+PHHH0lMTCQiIsLRIQkhLKSUhlG5mT2sERwczKZNmwDYtGkTvXr1uuV5pRSnTp3C29sbPz8/goKC2LdvH1lZWWRlZbFv3z6CgoLMvo+UBYQQTqfkglZpzN8eW/wN9siRI2RmZtKtWzcmTJjAmDFjmDhxIuvWraNx48YsXboUgO7du7N3715CQkLw9PRk4cKFANStW5dx48YxdOhQAMaPH0/dunXNvrckVyGE0zGiFXfGKoXBgnGWLFlyx+dXrbp9225N05g9e/Ydzx86dKgpuVpKkqsQwukYlUahKj09uZt53dGcOzohRJWkLLgDy8k3IpDkamv22EzwlaTvbT4mwD8C29hlXCHKS2F+nau51x1NkqsQwukY/+/219JYuxSrokhyFUI4HaONVgs4kiRXIYTTKVnnWhpr17lWFEmuQginI7u/CiGEHRhxM19zdfKdCCS5CiGcjmVlAefeiUCSqxDC6RgtWIolNVcHuXjx4i19HlNSUoiOjiYqKspxQQkhLKLA7E0Ezr6Hlssm14CAAOLj4wEwGAx069aNkJAQB0clhLCEUWkUGkuvqRqMMnN1uIMHD9K0aVOaNGni6FCEEBawpCuWJdu8OFKVSK5btmy5ZfdHIYRzK76gVbl7Czh36reBgoICdu/eTVhYmKNDEUJYyGjR7q+yFMuhEhMTadWqFQ0aNHB0KEIIC1kyc5WlWA62ZcsWwsPDHR2GEKIMFJV/natLlwVyc3M5cOAAoaGhjg5FCFEGRopvfy3tkKVYDlSrVi0OHz7s6DCEEGWklGa2piqrBYQQoows2YlAZq5CCFFGRjC7QaEkVyGEKCOLGrdIWUAIIcpGoZndxsVcv1dHk+QqhHA6Ft2hpUlyFeVkr11ax//ys83HfPf+FjYfU1Q9CvMtBaXmKoQQZWRUlpQFpOYqhBBlUnyHVuVeLeDcqV8IUSUpVTx7Le1QFt7++sknnxAeHk6/fv2YPHky+fn5pKSkEBERQUhICBMnTqSgoAAobvQ0ceJEQkJCiIiI4PLly1Z/BkmuQginUzJzLfWwYBy9Xs/q1atZv349mzdvxmAwsGXLFhYtWkRUVBQ7d+7Ex8eHdevWARAXF4ePjw87d+4kKiqKRYsWWf0ZJLkKIZxOSc21tMPcHlslDAYDeXl5FBUVkZeXR8OGDTl06BC9e/cGYPDgwSQkJACwe/duBg8eDEDv3r05ePAgSlnXOVZqrkIIp1O8WsB8y8GkpKRb9sqLjIwkMjLS9Fin0/Hcc8/Rs2dPPDw86NKlC61atcLHxwd39+L05+/vj16vB4pnuo0aNQLA3d0db29vMjMz8fX1LfNncNnkmp+fz/DhwykoKMBgMNC7d2+io6MdHZYQwgKWXNBSSiMwMJANGzbc9ZysrCwSEhJISEjA29ubl156ie+++87W4d6RyybXGjVqsGrVKmrXrk1hYSF/+ctf6NatG+3atXN0aEIIc5QlM1fzwxw4cIB77rnHNPMMDQ3lxIkTZGdnU1RUhLu7O2lpaeh0OqB4ppuamoq/vz9FRUXk5ORQr149qz6Cy9ZcNU2jdu3aABQVFVFUVITm5Hd0CCGKGZWGwehW6mHuJgOAxo0bc/r0aW7evIlSioMHD9K8eXM6dOjA9u3bAdi4cSPBwcEABAcHs3HjRgC2b99Ox44drc4bLptcobiQPXDgQDp37kznzp1p27ato0MSQlhAUbyO1dxhTtu2benduzeDBw+mf//+GI1GIiMjmTp1KitXriQkJIRr164REREBwNChQ7l27RohISGsXLmSKVOmWP0ZXLYsAFCtWjXi4+PJzs5m/Pjx/Pzzz7RoIbdnCuHsLK25WiI6Ovq26y1NmzY1Lb/6Mw8PD5YtW2Z5oKVw6ZlrCR8fHzp06FBhhWwhRPkoC8oCBqNzl/lcNrlevXqV7OxsAPLy8jhw4AABAQEOjkoIYRFVnGBLPZz89leXLQukp6czffp0DAYDSinCwsLo2bOno8MSQljAlmUBR3HZ5PrAAw+wadMmR4chhLCCUsWHuXOc2V2T6yOPPGJaglBy+5emaSil0DSNEydOVEyEQogqR6GZvb3V3MzW0e6aXE+ePFmRcQghhImlt786M4suaB07doz169cDxReKUlJS7BqUEKJqKykLlHo4OkgzzCbX5cuXs2LFCmJjYwEoLCxk6tSpdg9MCFG1mVstQGWfue7cuZP3338fT09PoPje2xs3btg9MCFE1eUK61zNrhaoXr06mqaZLm7l5ubaPSjxX+zUE8Eemwm+mnTG5mPGBD5s8zGFc7NotUDFhGI1s8m1T58+zJo1i+zsbNauXcv69esZNmxYRcQmhKiyLNjGxcnLAmaT6/PPP8/+/fupXbs2ycnJREdH06VLl4qITQhRRSmLWg5W8uQK0KJFC/Ly8tA0TRqfCCHsTlkwc3X2O7TMXtCKi4sjIiKCnTt3sn37diIjI+/YTUYIIWxGWXg4MbMz1xUrVrBx40ZTN+7MzEyeeuophg4davfghBBVl9mZa2Vv3FKvXj1TR3+A2rVrW73tgRBCWEIpDaOZpVbKkr21HeiuyXXlypUA3HvvvQwbNoxevXqhaRoJCQm0bNmywgIUQlRRrrpaoORGgXvvvZd7773X9HyvXr3sH1U5paam8sorr5CRkYGmaQwbNoyRI0c6OiwhhKVcuSvWiy++WJFx2FS1atWYPn06rVq14vr16zz55JN06dKF5s2bOzo0IYSlnDx5mmO25nr16lU++ugjLly4QH5+vun51atX2zWw8vDz88PPzw8ALy8vAgIC0Ov1klyFqCSU0lBma67OXRYwuxRrypQpBAQEcPnyZV588UWaNGlCmzZtKiI2m7h8+TI//fST7PwqRGViyTYvTl5zNZtcS7addXd35/HHHycmJoZDhw5VRGzlduPGDaKjo3nttdfw8vJydMKnu6EAABEsSURBVDhCiLJw9XWu7u7Fp/j5+bFnzx78/PzIysqye2DlVVhYSHR0NP379yc0NNTR4QghykJhwWoA5565mk2uY8eOJScnh2nTpjFv3jxu3LjBq6++WhGxWU0pxYwZMwgICGDUqFGODkcIYQ1zM9PKPnMt2THV29ubTz/91O4B2cLx48eJj4+nRYsWDBw4EIDJkyfTvXt3B0cmhLCMBc2wK2tynTdvnqmH653MnDnTLgHZQvv27Tl//ryjwxBCWMmSfq6VNrm2bt26IuMQQoj/UIC5pVYWrhbIzs5m5syZ/Pzzz2iaxsKFC7nvvvuYNGkSv//+O02aNGHp0qXUqVMHpRQLFixg79691KxZkzfffJNWrVpZ9RHumlwHDx5s1YBCCFFeGqDZaOa6YMECunbtyrJlyygoKCAvL48PPviATp06MWbMGGJjY4mNjWXq1KkkJiZy6dIlduzYwenTp5kzZw5xcXFWfQaLdn8VQogKZaOWgzk5ORw9etTUxa9GjRr4+PiQkJDAoEGDABg0aBC7du0CMD2vaRrt2rUjOzub9PR0qz6CRc2yhRCiYllyQUsjKSmJSZMmmZ6KjIwkMjLS9Pjy5cv4+vry6quvcu7cOVq1asWMGTPIyMgw3cXZsGFDMjIyANDr9fj7+5t+3t/fH71ebzq3LCS52pqdNhOsLOyxmeCz51NsPubqlk1tPmalYuu/U1v/2SvAXEtBBYGBgWzYsOGupxQVFXH27Flef/112rZty/z584mNjb3lnD9vwGpLLrlaQAhRyVnytd+CsoC/vz/+/v6m29/DwsKIjY2lfv36pKen4+fnR3p6Or6+vgDodDrS0tJMP5+WloZOp7PqI8hqASGEc7JBP9eGDRvi7+/PxYsXCQgI4ODBgwQGBhIYGMimTZsYM2YMmzZtMrVSDQ4O5rPPPiM8PJzTp0/j7e1tVUkAZLWAEMIZKdDMlAXMrib4P6+//jpTpkyhsLCQpk2bEhMTg9FoZOLEiaxbt47GjRuzdOlSALp3787evXsJCQnB09OThQsXWv0RXLLloBBClHjwwQfvWJddtWrVbc9pmsbs2bNt8r4u33JQCFH5lKxzNXc4M5duOSiEqKSUZtnhxFy25aAQohKzZClWZd39tURlbDkIxfWUuLg4lFJEREQQFRXl6JCEEGVg7mu/c89bXbTl4M8//0xcXBxxcXFUr16d0aNH07NnT5o1a+bo0IQQlrDROldHMptc7zZLjYmJsXkwtpKUlMTDDz+Mp6cnAI899hg7duzghRdecHBkQgiLuXpy7dGjh+l/5+fns2vXLqsX1VaUFi1asHTpUjIzM6lZsyaJiYlyU4QQlYkCzUzLQXPrYB3NbHLt3bv3LY/79evHX/7yF7sFZAuBgYGMHj2a559/Hk9PTx544AHc3KQBmBCVRiXYgNCcMjduuXTpkqmDjDOLiIggIiICgCVLllh9f7AQouLZsp+ro5hNro888sgtDVwaNmzIlClT7BqULWRkZFC/fn2uXLnCjh07WLt2raNDEkJYypLbXyt7WeDkyZMVEYfNTZgwgWvXruHu7s7s2bPx8fFxdEhCiLJw9ZnryJEjb7sH907POZt///vfjg5BCGEtV6655ufnc/PmTTIzM8nKykL931aM169fR6/XV1iAQoiqx5Kaq7P3Frhrcl2zZg2rVq0iPT2dIUOGmJKrl5cXzzzzTIUFKISoglz5JoKRI0cycuRIPv30U0aMGFGRMQkhRKWfuZpd/Onm5kZ2drbpcVZWFp9//rldgxJCVHE22v3Vkcxe0Fq7di3Dhw83Pa5Tpw5xcXG3PCf+RDn5/+OVkD02Exx+7rLNx/z8gXtsPqbd2Prv1B5/9pX8n5LZ5Go0GlFKmda6GgwGCgsL7R6YEKLq0qrCOtegoCAmTpzIU089BRRf6OratavdAxNCVG0uf4fW1KlT+fLLL/niiy8A6Ny5M8OGDbN7YEKIKqwS1FTNseiC1tNPP82yZctYtmwZzZs3Z968eRURmxCiiiopC5g7nJlFjVvOnj3L5s2b2bZtG02aNCE0NNTecQkhqjpXLQskJyezZcsWNm/eTL169ejbty9KqUqzG4EQohJz5ZsI+vTpQ/v27fnwww9N26N88sknFRWXEKKKq+x7aN215rp8+XIaNmzIs88+y8yZMzl48KDpFtjKIDExkd69exMSEkJsbKyjwxFClIFL11yfeOIJnnjiCXJzc0lISGDVqlVcvXqV2bNnExISQlBQUEXGWSYGg4E33niDlStXotPpGDp0KMHBwTRv3tzRoQkhLOECZQGzqwVq1apF//79+eCDD9i7dy8PPfQQH330UUXEZrUzZ87QrFkzmjZtSo0aNQgPDychIcHRYQkhyqKS3/5apo2l6tSpQ2RkpNP3ctXr9fj7+5se63Q6aZMoRCWjKTNHGcYyGAwMGjSIv/71rwCkpKQQERFBSEgIEydOpKCgAICCggImTpxISEgIERERXL5s/W3SsmufEML5mEusZZy5rl69msDAQNPjRYsWERUVxc6dO/Hx8WHdunUAxMXF4ePjw86dO4mKimLRokVWfwSXTK46nY60tDTTY71eLxsUClHZ2KgskJaWxp49exg6dGjxsEpx6NAh087WgwcPNpUNd+/ezeDBg4Hina/LcyHfJZNrmzZtuHTpEikpKRQUFLBlyxaCg4MdHZYQwlIWthxMSkpiyJAhpuPLL7+8baiFCxcydepU3NyK011mZiY+Pj64uxdfz/f39zeVDfV6PY0aNQLA3d0db29vMjMzrfoIZd5auzJwd3dn1qxZjB49GoPBwJNPPsn999/v6LCEEBayqCuWgsDAQDZs2HDXc7799lt8fX1p3bo1hw8ftnGUpXPJ5ArQvXt3unfv7ugwhBBWssVOBCdOnGD37t0kJiaSn5/P9evXWbBgAdnZ2RQVFeHu7k5aWpqpbKjT6UhNTcXf35+ioiJycnKoV6+eVfG7ZFlACFHJ2WgngpdffpnExER2797NkiVL6NixI4sXL6ZDhw5s374dgI0bN5rKhsHBwWzcuBGA7du307FjR1Mv67KS5CqEcDolu7+aXTFgpalTp7Jy5UpCQkK4du0aERERAAwdOpRr164REhLCypUrmTJlitXv4bJlASFEJaYAc7e3ljG5dujQgQ4dOgDQtGlT0/KrP/Pw8GDZsmVlG/guJLkKIZySy+9EIIQrssdmgoPP/mHzMQE2PtTQLuM6NRfoLSDJVQjhdIqXYpWePctTc60IklyFEE7JFkuxHEmSqxDC+UhZQAghbK9kKVap50hyFUKIMrLw9ldnJslVCOF8pCwghBC2Z0lZwNmTq8ve/pqdnU10dDRhYWH06dOHkydPOjokIYTFFCgLDifmsjPXBQsW0LVrV5YtW0ZBQQF5eXmODkkIYSkXqLm65Mw1JyeHo0ePmjqP16hRAx8fHwdHJYSwmAtsre2SyfXy5cv4+vry6quvMmjQIGbMmEFubq6jwxJCWMpGLQcdySWTa1FREWfPnuXpp59m06ZNeHp6Ehsb6+iwhBAWKrn9tdTDyWuuLplc/f398ff3p23btgCEhYVx9uxZB0clhCgLe/ZzrQgumVwbNmyIv78/Fy9eBODgwYO3bKsrhHByLlAWcNnVAq+//jpTpkyhsLCQpk2bEhMT4+iQhBAWcoV1ri6bXB988MFSd4UUQjgxpSxoOejc2dVlk6sQopKTmasQQtiWJResnP2CliRXIYTzUYCZsoDZ1x1MkqsQwvm4wO2vklyFEE7IgsYsklyFqBrstUvrsJ/SbD7m2gf9bT6mLUnNVQgh7MGC3V+l5aAQQljDXNcr6YolhBBlU1wWUGYPc1JTUxkxYgR9+/YlPDycVatWAXDt2jVGjRpFaGgoo0aNIisrCwClFPPnzyckJIT+/fvz448/Wv0ZJLkKIZyTDfoKVKtWjenTp7N161a+/PJL/v3vf3PhwgViY2Pp1KkTO3bsoFOnTqaueYmJiVy6dIkdO3Ywb9485syZY3X4klyFEM5HmWk3aDR/eyyAn58frVq1AsDLy4uAgAD0ej0JCQkMGjQIgEGDBrFr1y4A0/OaptGuXTuys7NJT0+36iNIzVUI4XwUFizFUiQlJTFp0iTTU5GRkURGRt7x9MuXL/PTTz/Rtm1bMjIy8PPzA4q76GVkZACg1+vx9//PSgp/f3/0er3p3LJw2eT6ySefEBcXh6ZptGjRgpiYGDw8PBwdlhDCEhbeRBAYGGhRg6YbN24QHR3Na6+9hpeX163jaBqappUn2jtyybKAXq9n9erVrF+/ns2bN2MwGNiyZYujwxJCWMyS3V8tG6mwsJDo6Gj69+9PaGgoAPXr1zd93U9PT8fX1xcAnU5HWtp/1hWnpaWh0+ms+gQumVwBDAYDeXl5FBUVkZeXZ9W0XgjhGBZt82JBzVUpxYwZMwgICGDUqFGm54ODg9m0aRMAmzZtolevXrc8r5Ti1KlTeHt7W507XLIsoNPpeO655+jZsyceHh506dKFoKAgR4clhLCYJbe/mk+ux48fJz4+nhYtWjBw4EAAJk+ezJgxY5g4cSLr1q2jcePGLF26FIDu3buzd+9eQkJC8PT0ZOHChVZ/ApdMrllZWSQkJJCQkIC3tzcvvfQS8fHxpl+uEMLJKczfJGBBWaB9+/acP3/+jq+VrHn9M03TmD17tvmBLeCSZYEDBw5wzz334OvrS/Xq1QkNDeXkyZOODksIYSml0IzGUg+Mzn2Llksm18aNG3P69Glu3ryJUko2KBSisilZimWDC1qO4pJlgbZt29K7d28GDx6Mu7s7Dz744F3XvgkhnJCNygKO5JLJFSA6Opro6GhHhyGEsIKG+d4BskGhEEKUlcJ8TVU5d81VkqsQwgnJTgRCCGF7ltRcnXviKslVCOGElPmaqtRchRCirJQCg5mpqZOvc5XkKoSTs8dmgs+eT7HpePWvF9h0PNNaVnPnODFJrkII5yQXtIQQwsakLCCEEHaglPl1rLLOVQghrCBlASGEsDGlwFwzbLmgJYQQZaSU+Zqqk9dcXbLlYAmDwcCgQYP461//6uhQhBBlYVHLQeeeubp0cl29erX0cRWiMiqZuZZ2SHJ1jLS0NPbs2cPQoUMdHYoQosws2f3VuZOry9ZcFy5cyNSpU7lx44ajQxFClJULrHN1yZnrt99+i6+vL61bt3Z0KEIIayhQymjmkJlrhTtx4gS7d+8mMTGR/Px8rl+/zpQpU1i0aJGjQxNCWMKSpVjmXncwl0yuL7/8Mi+//DIAhw8f5l//+pckViEqE6XAYCj9HCcvC7hkchVCVHLSFcv5dejQgQ4dOjg6DCFEGSilUGZmpkp6CwghhBWkt4AQQtiYJTVXc687mEsuxRJCVHJKoYylH5bWXBMTE+nduzchISHExsbaOfD/kOQqhHA+Jf1cSz3MJ1eDwcAbb7zBihUr2LJlC5s3b+bChQsV8AGkLCCEcDKapnF/h/+HR22PUs/z8q2FpmmlnnPmzBmaNWtG06ZNAQgPDychIYHmzZvbLN67qdLJtVmbe1j24xuODkOIildk2+HytXybjeXl5UXwgO6o/uZnplu3bmXixImmx5GRkURGRpoe6/V6/P3/s8GjTqfjzJkzNou1NFU6ubZr187RIQgh/oumadSqVcuicyMiIoiIiLBzRNaRmqsQwmXpdDrS0tJMj/V6PTqdrkLeW5KrEMJltWnThkuXLpGSkkJBQQFbtmwhODi4Qt67SpcFhBCuzd3dnVmzZjF69GgMBgNPPvkk999/f4W8t6acvW+XEEJUQlIWEEIIO5DkKoQQdiDJVQgh7ECSqxBC2IEkVyGEsANJrkIIYQeSXIUQwg7+P3JG+n7HvBQZAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeVwVVf/A8c9duayyiqC5K+6FgqC44lZC7rtZueeeW9Jj9Txa+pSWpJWaaaI9mmWlZppaLuC+4ZbiLiigsst2uev8/uDnTQTTUrkXPO/Xy5femTMz3zlc+c6cOXOOTJIkCUEQBEGwMXJrByAIgiAIJREJShAEQbBJIkEJgiAINkkkKEEQBMEmiQQlCIIg2CSRoARBEASbJBJUKfnss8+YNm2atcMoVYmJifj5+WE0Gh97X6GhoRw4cKDEdREREURGRj72MZ4lkZGRBAUFERISUurHPn78OJ07d8bf35/ff//9H+9nxIgRbNiw4QlGVvqSk5Px9/fHZDJZOxSbJBLUE7R582Z69eqFv78/rVq1YsSIERw7dszaYQmlxM/Pj4SEBGuH8VDJycmsXLmSrVu3sn///hLL5ObmMmfOHNq1a4e/vz8dO3Zkzpw5ZGRkPPbxFy1axODBgzlx4gQdO3b8x/tZvnw5PXv2fOx47hcREYGfn1+x5Dl37lz8/Pz46aefHmk/f3VRdZevry8nTpxAoVD843jLM5GgnpCVK1cyd+5c3njjDfbv38/u3bsZNGgQO3futHZo/9iTuPMR/mQr9ZmcnIyrqyseHh4lrtfr9bz22mtcvnyZ5cuXc/z4cb777jtcXV05c+bMEzl+nTp1Hns/T1P16tXZtGmT5bPRaOTXX3+latWqT+wYT/L7IEkSZrP5ie3PVogE9QTk5OSwaNEi3nvvPTp37oyDgwMqlYrQ0FBmzJhR4jYTJ04kJCSEZs2aMXjwYC5dumRZFx0dTdeuXfH396d169asWLECgIyMDEaPHk1AQADNmzdn0KBBli/l7du3mTBhAsHBwYSGhrJ69WrL/k6fPk2vXr1o2rQpLVu25L///W+JMR0+fJg2bdqwbNkyQkJCePvtt7lz5w6jR48mODiYwMBARo8eza1btyzbDBkyhE8//ZQBAwbg7+/PsGHDHniVvX37dkJDQ7l48SJms5lly5bRsWNHgoKCmDRpEllZWZayGzdupH379gQFBbFkyZKH/gwyMzMZOnQo/v7+vPLKKyQlJQEwa9YsPvzwwyJl33jjDaKiokrcz5UrVxg6dCjNmzenS5cubN261bIuIiKCWbNmMWrUKPz9/enbty/Xr18HYPDgwQB0794df39/tm7dWmJ96vV65syZQ6tWrWjVqhVz5sxBr9cXqf+lS5cSFBREaGgoP//8M1D4M2zZsmWRpqAdO3bQrVu3Es8jJyeHt956i+DgYNq3b8/ixYsxm80cOHCAYcOGkZKSgr+/PxEREcW23bRpEzdv3uTzzz+ndu3ayOVyPDw8GDduHG3btrXU05AhQwgICCAsLKzIhdhf1VPHjh25ceMGb7zxBv7+/uj1+mJ3Gvc2h+t0OqZNm0ZQUBABAQH07t2btLQ0oPC7t379egDMZjOLFy+mffv2tGjRgrfeeoucnBzgz6bmDRs20K5du0f6ToWGhnL8+HHu3LkDwN69e/Hz88PT09NS5vr167z66qsEBQURFBTE1KlTyc7OBmD69OkkJydbzvOrr76yxLF+/XratWvHa6+9VqQZPCsrizZt2rBr1y4A8vLy6NSpExs3biwxxiFDhhAZGcmAAQN4/vnnuXHjBrGxsfTu3ZtmzZrRu3dvYmNjATh06BAvv/yyZduhQ4fSu3dvy+dBgwY9VnPrUyMJjy06OlqqX7++ZDAYHlhm0aJF0tSpUy2f169fL+Xk5Eg6nU764IMPpG7dulnWhYSESEePHpUkSZKysrKkP/74Q5IkSfr444+ld999V9Lr9ZJer5eOHj0qmc1myWQyST179pQ+++wzSafTSdevX5dCQ0OlmJgYSZIkqV+/ftKGDRskSZKk3Nxc6cSJEyXGeOjQIal+/frSvHnzJJ1OJ2m1WikjI0Patm2blJ+fL+Xk5EgTJkyQxowZY9nmlVdekTp06CBdvXpV0mq10iuvvCLNnz9fkiRJunHjhlS3bl3JYDBIP/zwg9SxY0cpPj5ekiRJioqKkvr27SvdvHlT0ul00rvvvitNnjxZkiRJunTpkvTCCy9IR44ckXQ6nTR37lypfv360v79+0uMe8aMGUXKv//++9KAAQMkSZKkU6dOSSEhIZLJZJIkSZLS09OlJk2aSKmpqcX2k5eXJ7Vp00b64YcfJIPBIJ09e1Zq3ry5dOnSJctxmjdvLp06dUoyGAzSlClTpDfffNOyfd26dS3n96D6/PTTT6W+fftKaWlpUnp6utS/f38pMjKySPm5c+dKOp1OOnz4sPT8889LV65ckSRJkl566SVpz549lv2PHTtWWrFiRYl1Mn36dOmNN96QcnJypBs3bkidO3eWvv/+e8txWrduXeJ2kiRJb775pvTWW289cL1er5c6duwoLVmyRNLpdNKBAwekF154wRLnw+qpffv2RX6W93++9//Kt99+K40ePVrKz8+XjEajdObMGSknJ0eSpMLv3t1zWr9+vdSxY0fp+vXrUm5urjRu3Dhp2rRpkiT9+T2cOXOmpNVqpbi4OKlhw4bS5cuXSzy/GTNmSAsWLJDeeecdac2aNZIkSdLEiROlzZs3SwMGDJB+/PFHSZIkKT4+Xtq3b5+k0+mk9PR0adCgQdIHH3zwwPO6G8f06dOlvLw8SavVFvk/IkmStHfvXqlly5ZSWlqaNHPmTGnChAkP/Dm88sorUtu2baWLFy9KBoNBSk1NlQICAqQNGzZIBoNB2rx5sxQQECBlZGRIWq1WatSokZSeni7p9XqpRYsWUqtWraScnBxJq9VKjRs3ljIyMh54LGsRd1BPQFZWFm5ubiiVykfepk+fPjg5OaFWq5kwYQLnz5+3XPEplUouX75Mbm4uFSpUoGHDhpblqampJCcno1KpCAgIQCaTcebMGTIyMhg/fjxqtZrnnnuOfv36Wa7+lUol169fJyMjA0dHR1544YUHxiWXy5k4cSJqtRqNRoObmxtdunTB3t4eJycnxowZw9GjR4ts06tXL2rUqIFGo+HFF18kLi6uyPpVq1axYsUKvvnmG6pVqwbAunXrmDx5MpUqVUKtVjN+/Hi2b9+O0Whk27ZttGvXjsDAQNRqNZMmTUIu/+uv6r3lJ0+ezMmTJ7l58yZNmjTB2dmZgwcPArB161aaN29e5Er4rj179lC5cmV69+6NUqmkQYMGdOnShW3btlnKdOzYkSZNmqBUKunWrVuxc31YfW7evJlx48bh4eGBu7s748aNs9wl3TVp0iTUajXNmzenbdu2/PrrrwD06NHDUjYrK4t9+/YRHh5e7Jgmk4mtW7cydepUnJycqFKlCkOHDi12nAfJysrCy8vrgetPnTpFfn4+o0aNQq1W06JFC9q3b8+WLVv+cT09iFKpJCsri4SEBBQKBY0aNcLJyalYuc2bN/P666/z3HPP4ejoyJQpU9i6dWuRZrTx48ej0WioV68e9erV4/z583957O7du7Np0yays7M5evRosedl1apVIyQkBLVajbu7O0OHDi32f6MkEyZMwMHBAY1GU2xdq1atePHFF3n99deJjo5m1qxZf7mvnj17UqdOHZRKJfv27aNatWr06NEDpVJJeHg4NWvWZPfu3Wg0Gho3bsyxY8c4e/Ys9erVo2nTpsTGxnLy5EmqVauGm5vbQ2MvbY/+G1V4IFdXVzIzMzEajY+UpEwmE5GRkWzbto2MjAzLL9/MzEycnZ1ZtGgRS5Ys4ZNPPsHPz4+pU6fi7+/P8OHD+fzzzxk2bBgA/fv3Z9SoUSQlJZGSkkJAQECRY9z9PGfOHBYtWsRLL71ElSpVGD9+PO3bty8xNjc3N+zs7CyftVot//3vf9m7d6+luSMvLw+TyWR5sHvvLzN7e3vy8/OL7HPFihWMGzeOSpUqWZYlJyczbty4IolHLpeTnp5OSkpKkbIODg64urr+ZZ3eW97R0ZEKFSqQkpKCj48PPXv25OeffyYkJISff/6ZV199tcR9JCUlcfr06WL1eG8z2r2JTaPRFDvX+91fnykpKfj6+lo++/r6kpKSYvns4uKCg4NDieu7d+/OSy+9RH5+Pr/++isBAQFUrFix2DEzMzMxGAzFjnP79u2/jPUuV1dXUlNTH7j+7s/n3p/d/fv/u/X0IN27d+fWrVtMmTKF7OxsunXrxuTJk1GpVMViqly5suVz5cqVMRqNpKenlxhTSd/T+wUEBJCRkcGSJUto165dsYSSlpbGnDlzOHbsGHl5eUiShIuLy0PP6d7vakn69evH//73P954442HJg0fHx/Lv+//bkHRn0tgYCBHjhzB29ubwMBAXFxcOHr0qOViyBaJBPUE+Pv7o1ar+f3333nxxRcfWn7z5s3s3LmTlStXUqVKFXJycggMDET6/4HlmzRpwpIlSzAYDKxZs4Y333yT6OhonJyciIiIICIigosXL/Laa6/RuHFjfHx8qFKlCjt27CjxeNWrV2fBggWYzWZ27NjBxIkTOXz4cJFfhHfJZLIin7/++muuXbvG999/j5eXF3FxcfTo0cMS66P4+uuvGTFiBJ6ennTp0gUo/E86d+5cmjVrVqx8xYoVuXLliuWzVqst8nyqJPc+F8vLy+POnTuWX97dunUjPDyc8+fPc+XKlQf2HPPx8SEwMJCVK1c+8rk9zP31WbFixSKdBG7evFkkyWRnZ5Ofn2/52dy8edNS1tvbG39/f3bs2MGmTZsYOHBgicd0c3NDpVKRnJxM7dq1Lfvx9vZ+pJhbtmzJp59+WiSO+8/h1q1bmM1mS5K6efMm1atXf6T938/e3h6tVmv5fG9yVKlUjB8/nvHjx5OYmMioUaOoUaMGffv2LRbT3eeOUHgBpFQq8fDwKPLd+Lu6devGF198UeSZ7l0LFixAJpOxefNmXF1d+f3335k9e/ZD93n/d+JeJpOJ9957jx49erB27Vp69eplaXV42L7ufrfudfPmTVq3bg1A8+bN+fDDD/H19WXkyJFUqFCBd999F5VKZXmGamtEE98T4OzszMSJE5k9eza///47Wq0Wg8FAdHQ08+bNK1Y+Ly8PtVqNm5sbWq2WBQsWWNbp9Xp+/vlncnJyUKlUODo6Wn4J7N69m4SEBCRJwtnZGYVCgUwmo0mTJjg6OrJs2TIKCgowmUxcvHiR06dPA4UPve/eqd29wntYk9m9sdrZ2eHi4kJWVhaff/75366f2rVrs3z5cmbPnm15mD5w4EA+/fRTyy+VjIwMy0PaLl26sGfPHo4dO4Zer2fRokUP7aEUHR1tKb9w4UKef/55y9VlpUqVaNy4MdOnT6dz584lNq1AYTNhfHw8GzduxGAwYDAYOH36dJFk+Vc8PT25cePGX5YJCwtjyZIlZGRkkJGRwRdffFHk4TUUdhLQ6/UcO3aMPXv2FLno6d69OytWrODixYt07ty5xGMoFApefPFFIiMjyc3NJSkpiZUrVz6wQ8X9unfvTqVKlZgwYQJXrlzBbDaTmZnJ0qVLiY6OpkmTJmg0GpYvX47BYODw4cPs2rWLrl27PtL+71evXj22bt2KwWDgzJkzbN++3bLu0KFDXLhwAZPJhJOTE0qlssTvbnh4OKtWreLGjRvk5eURGRnJSy+99Lea3UsyZMgQVq5cSWBgYLF1eXl5ODg44OzszO3bt1m+fHmR9Y/yfbjf0qVLkclkzJ07l+HDhzNjxoxHfkeqbdu2xMfHs3nzZoxGI1u3buXy5cu0a9cOKLyQvnbtGqdPn6ZJkybUqVPH0mpQ0vnZApGgnpBhw4YRERHB4sWLadGiBe3atWPNmjUlXq336NEDX19fWrduTVhYWLFnQps2bSI0NJSmTZuybt065s+fD0BCQoKlp1r//v0ZOHAgwcHBKBQKli5dyvnz5+nQoQPBwcG888475ObmAoU9kMLCwvD392fOnDlERkY+8Jf0/V577TV0Oh3BwcH079/fcjX2d9WrV4+lS5fy7rvvEh0dzauvvkpoaCjDhg3D39+ffv36WRJqnTp1eO+995g2bRqtW7fGxcXloc0i4eHhfPHFFwQFBXH27FlLnd3Vo0cPLl68SPfu3R+4DycnJ1asWMHWrVtp3bo1rVq14uOPP7b0snuY8ePHExERQUBAQJHef/caO3YsjRo1olu3bnTr1o2GDRsyduxYy3pPT09cXFxo3bo106ZN4z//+Q+1atWyrO/UqRNJSUl06tQJe3v7B8by7rvvYm9vT8eOHRk0aBDh4eFFem39FbVaTVRUFDVr1mTYsGE0a9aMvn37kpmZSZMmTVCr1SxdupSYmBiCg4OZNWsW8+bNKxLn3/Hmm29y/fp1mjdvzmeffVYkYaelpTFx4kSaNWtG165dad68eYk/w969e9OtWzdeeeUVOnTogFqt5t133/1H8dzL1dWVFi1alHjXM378eM6dO0dAQACjRo0qdsEwatQolixZQkBAgKUn7l/5448/iIqK4qOPPkKhUDBy5EgAli1b9kixurm5sXTpUlauXElQUBDLly9n6dKluLu7A4VN5Q0bNqR27dqo1WqgMGn5+vo+8JUDa5NJf6etRhDKqKNHjzJ9+nR27979l00s1nT48GGmT59OTEzMX5br2LEjs2fPpmXLlqUUmSBYh7iDEso9g8HA6tWr6dOnj80mp0e1fft2ZDIZwcHB1g5FEJ460UlCKNeuXLlC7969qVev3gNfUC4rhgwZwuXLl5k3b94jP0MUhLJMNPEJgiAINklchgmCIAg2qdw18cXGxv5l7yZbZzAYir2EWNaU9XMQ8VuXiN/6SvscdDpdiSPclLsEpVAoqF+/vrXD+McSEhL+8sW8sqCsn4OI37pE/NZX2ufwoKGwRBOfIAiCYJNEghIEQRBskkhQgiAIgk0SCUoQBEGwSSJBCYIgCDZJJChBEATBJokEJQiCINgkkaAEQRAEmyQSlCAIgmCTyt1gsWfPnqNhwwbWDkMQBKHcKzCY0KgUj72fuLi4EkcAKndDHcnlMqpHbLF2GIIgCOVe/IdhT3X/5S5BCYIglAdmfQGGtASQyVF7VUemfPDgrWa9FrM2B2SgcPYqNjGnKS8LyagHhRKlk/t96zKRjAZkShUKRzfLckmSMOVlgsmITKlG4ej6ZE/wEYgEJQiCYEMks4msfWvJOf4zkl4LgNyhAhWC++Ic0L1I8sk5tZ2coxsxpCcChU9rVB5VqfTaAuQqDZIkkbHtM3JP77Bs41C3JV49/4UkSaT98jH556It6xwbtsczfCqSZCZ1w1y0lw5Z1jm98CIeXcY/5bMvSiQoQRAEG5K5ZyU5RzcyYMAABg8ejF6v56uvvmLbtuUgk+ES0B0AkzabjO1fEBzUnK6TRlKlShWSkpJ49913KUg4hUPtIPLjYsg9vYMxY8YQGBjIwYMH+eqrrzBmp6G9Fkv+uWjefPNNmjRpwp49e1i9ejVuHUaRd3Y32kuHeOutt6hXrx47duxg3Xff4xY6ArlKU2p1YfO9+FatWkV4eDhhYWFERUVZOxxBEISnxpiTRs7xXxg5ciTffvstarUaHx8ffv31V7p06cKdA99h1hcAYM7PBsnMyJEj6dChA0OGDKFHjx4ASEYDptxMMn5bSnBwMJ999hlDhw6ldevWhcfJTCZz11e0b9+eyMhIhg4dSosWLQAwpCWQFR1FWFgYH330EUOHDiUwMBAkM5jNpVofNp2gLl68yPr161m/fj2bNm1iz549JCQkWDssQRCEp6Lg2gkwG5kyZQp5eXmEh4fTq1cvACZPnoxZm40u+TwACmdPZCo7hg8fTkhICFqttsi+0nd8gRoDUVFRxS7u07ctwlGt4Ouvv2bFihVF121dSAUnB5YtW1ZsXWmz6QR15coVmjRpgr29PUqlksDAQHbs2PHwDQVBEMog450UFAoFtWvXJjExEYPBwK1btygoKMDPz89SBkCu1lBp8HwU93V6AMg7twftpUO8//77ZGVlMX/+/KLHybrFvHnziI+P5/PPP79v3U0WLlzIyZMn+frrr4usM2QmP8nTfSibTlB169bl+PHjZGZmotVqiYmJ4datW9YOSxAE4emQzMhksmK98ADk8sJf1xnbFnH7+/dI3/4FcgcXHOq3KVZWe+kQAQEBjB07lpEjR1r2J5fLUSgUtG7dmiFDhjB69GgUisL3mBQKBQqFgi5dutC9e3fGjh1bZJ1cLidl3Uwks+lpnX0xNt1JolatWowYMYLhw4djb29PvXr1LD8kQRCE8kZRoSJGo5Fr165RuXJlFAoF7u7uaDQaLl26BEC1atWoVFHFH3/EkHTy1wfuq0GDBjg4OHD69GnLssGDB6PRaNi5cydOTk5cuHDBsm7kyJHY2dlx5swZKlSoQHx8vGXdpEmTsLOzY8yYMZjzs1E4/dkd/Wk+drHpBAXQt29f+vbtC8CCBQvw9va2ckSCIAhPh331F0Am57PPPmPhwoWsW7eOChUqAFia4iZNmsTkyZNp1qwZsbGxDBs2jDZt2mBvb0+VKlWIiorip59+IiYmhv79+wNQqVIlFi5cyN69e1mwYAEpKSmWddWrV+ejjz7i999/Z/HixWRlZXH9+nUA/Pz8mD17Nlu2bGH58uUAyNT2RWKuVq3aY593XFxcicttPkGlp6fj4eFBcnIyO3bs4Pvvv7d2SIIgCE+FsoI3Ts934bPPPkOn01m6mffv35+NGzcCcOrUKdavX09WVhYAarUaBwcHNmzYAICDgwMqlYr4+HgSs40YMxKpVKkSrVq1IiYmhgMHDgAQn1GAMSORatWqERAQwG+//cbhw4cBuJKahzEjkbp169K4cWN++eUXjh8/jlvH0cjVpdfN3ObH4hs0aBBZWVkolUrefvttS1fIB4mLi+OlVVdLKTpBEIQnSzIayNy9gpxT28FkAArvWlwCe2DISCY/7v9frFWoLOtL4tw0HPdOb6C9doLUnz5AMuoA0FT3x7v/+wDkXz5M6sYPLfuxr9uCij1nApAXF0PalgVgMgJ/vsR7ryc11NGDxuKz+QT1d4kEJQhCeWDSZqO/dRlkcux86iK3cwDAkHULyaBD4eSOXOOEMetW4TBG95Db2aN0qWj5bNblYcxOQ6ZUoXT1KdIJw1SQiyknHZlSjcrNp1gMptxMZCo7VK6VisX4tBOUzTfxCYIgPIsU9i7Y12habPn9ieL+pFISuZ0jai/Hko+jcUKhcXpgDAp7l0eI9ukQXeIEQRAEmyQSlCAIgmCTyl0Tn9ksPfU5SgRBEIQnN2Hhg5S7Oyij8cG9WsqC8jDWYFk/BxG/dYn4re9Rz+FpJicohwlKEARBKB9EghIEQRBskkhQgiAIgk0qdwlKqVRZO4TH8iTGtbK2sn4O5Sn+AkPpjTwtCE9auevFJ5fLqB6xxdphCIJNED1ahbKs3CUoQSgtxuwU8s7uwZiThtLZE8eGoShdPEssq7t5kfyLB5D0WlRe1XGs3xa5nQNmg478iwcwpFxDMupRuHjiULclKjdfTPl30CVfwJB+AyQzCid3HPxCkCnVaK8eR3/zIqa8LORqe5TuVXD0a4n8ASMCCEJZJBKUIPwD2Uc2kLlnJXIZuLu7k5GRQda+Nbi1H45LQDdLOclkJG3LAvLjYrCzs8PR0ZGM2C1kxXyDW/vhZO1fi+nObTQaDfb29mRmZpIVvRpNDX901/+wDPB5l/7WZSSzidwTWy1zBeXm5pKt1ZIVHUXFPv/GztevtKtDEJ6KcvcMShCeNl3yBTJ3r6BP717Ex8eTmprK1atX6dHtZTJ3LkN367KlbPaxn8mPi2HWrFmkpaWRnp7OoUOHqFejCulbI6mgMLBz5060Wi0ZGRkkJyfTo3s3Cq4e5zlfb2JiYrhz5w5arZYXX3wRXdJ5tFeO0bNnT3Jzc0lJSSE/P59jx45Rw9eL9K2fWrFmBOHJsvkEFRUVRVhYGOHh4UyZMgWdTvfwjQThKco+/COenp5ERUWRnp5O+/btyc7OZtWqVbi5uZF9pHBeHslsIvvoT3Tu3Jn33nuPjRs3Eh4eTqNGjVi2bBkAQ4YMITQ0lH//+980btyYChUqMHfuXMuxYmJi2LFjBxqNxjKbtEyhJCEhgQEDBhAYGMiXX35Js2bNmDBhAob0G5jy75R+pQjCU2DTCer27dusXr2aH3/8kV9++QWTycSWLaIDhGBdupuX6Nq1K46Ojqxdu5Y9e/awbt06XFxc6NKlC/qbFwEw5aRhzsuiX79+QOGMqFu2bGH//v2EhITg4+PDtWvXALCzs8PBwQGZTMbVq4XTxVy/fp133nmHkydPFjm+s38YsbGxbNmyhYsXL5KcnAxg2U6mtCuVehCEp82mExSAyWSioKAAo9FIQUEBFStWfPhGgvAUmXLTqVKlCgBpaWkAZGRkAFClShWMOamYCnIxpCdalt1bNj093bL8l19+YcOGDfzrX//i8OHD5OXlERERAUCl10purnMJ7I5MpWH8+PHcuXOHWbNmERsbS1RUFAAylfopnLUglD6b7iTh7e3NsGHDaN++PXZ2doSEhNCqVStrhyU84+R2jpbptu3t7QHQaAqnwc7KygKTkcSFAyzl/6rsW2+9Rc+ePRk1ahQ7d+4kOjqaTZs2UatWLTJ+W1Ls2Ppbl7i1NgLJUMA333xDdHQ0vXv3ZubMmSxatIjXX38d/e2r2FWqbdmmrI0Nl5ubW+ZivldZjx9s5xxsOkHduXOHnTt3snPnTpydnZk0aRKbNm2ie/fu1g5NeIYp3X05dOgQAC1atGDx4sUEBwcDcPjwYWQyGZGRkVy+fJnPP/+cQ4cO0b9/f4KDg7l48SJNmzbl9u3bxMfHU6tWLQCOHTtG/M00bt26xQsvvIBKpUKffKHE4+tu/EGtWrW4evUq6enpqNVqZs6cablTM+vyipQvay8eJyQklLmY71XW44fSP4e4uLgSl9t0E9+BAweoUqUK7u7uqFQqOpSWZZoAACAASURBVHfuzIkTJ6wdlvCMc2rSmdjYWNauXcsrr7zC9evX6d+/P6tWreLMmTPIZDImTZpEr169APjqq6+4cOECixcvtvzHnzlzJgaDgbVr12I0Gtm6dStH9u4iICCA77//HoPBQO3atdHpdMyaNQuATZs2WZoSP/nkE1JTU4mLi2Pv3r0YjUYWL14MChVq71pWqxtBeJJs+g7K19eXU6dOodVq0Wg0HDx4kEaNGlk7LOEZ59SoA3lndjJ48GCWL1/O888/z4kTJ4iOjgbAbDbTq1cvyzOnvLw8mjRpQo8ePfDx8WHbtm1cuHABhaMbu3fvpk6dOoSGhuLo6MiMGTPYtWsXADdv3mTAgAFFjm0yFQ5dNHXqVFq1aoWHhwepqans2rWLpKQk3EJHPHD6bkEoa2SSJEnWDuKvLFq0iK1bt6JUKqlfvz5z5sxBrX7wQ+C4uDheWnW1FCMUnkVmg46c2M3kndn5/yNJeOHYuCNOjdqTuWcV+tuXQSbHsV4rHBuFkn34R/IvHsSsy0ddsTrOzbrh4BdCwbVYso9uxJB2HclQgMLFCwe/EBz9WpG19xsMmcnFji3ptSgqeGPMSMSsy0du71K4T/8w7Gs2K1K2LA51VNabyMp6/GCdJr769esXW27zCervEglKEP4kElTpK+vxg+0kKJt+BiUIgiA8u0SCEgRBEGySSFCCIAiCTbLpXnz/hNkslcl2d0F4GgoMJjQqhbXDEIR/pNzdQRmNBmuH8Fhs4e3tx1XWz6E8xS+Sk1CWlbsEJQiCIJQPIkEJgiAINqncJSilUmXtEB5LWX9/Asr+Odha/AUGk7VDEASrKHedJORyGdUjxJxRQvkhOv0Iz6pydwclCIIglA/l7g5KEB6VZNSTE/sLuWd+x5iTjtLFC6fGnXD274rsvqZiY0462Ud+Iv/iQSR9Piqv6rgEdMNckEfOya1IJfQeVTi4gEyBKS+zyHK5xokKIQNROnty59APFFw7jmQyYufrh0vznmiqNnmq5y0IZYVIUMIzSTIZuf3du+gSz9KmTRuef747J06cYN+ur8i/fBjv/u8jkxd20TZmp3Bz9RQU+jx6dOtGpUqV2L59O5c3zAXA39+f6tWrF9m/Vqtl27ZteHl5FZtk8+TJk1xbNxOZSoO9Ss7AXr1wdHTk559/5ua3/8L9xQk4P9+lVOpBEGyZSFDCMyn3j53oEs+yevVqhgwZws2bN/Hx8WHFihWMGDGCvHPRODUKBSAr5hs0kp6jJ09St25dMjMzWbRoEcOHDycqKooxY8YwcuTIIvuPj4+nRo0aNGrUiJ9++qnIurFjx7JkyRJ8K3pw5MgR3N3d0Wq1LFq0iLCwMHbu/hrHeq2Q2zmWWn0Igi2y+WdQV69epXv37pY/TZs2JSoqytphCWVc7ukd+Pv7M2TIENasWYOvry/r169n+PDhNGzYkNzTOwAw6wvIi4th5MiRNGjQgHHjxvHcc8+RmJjIf//7X1QqFZMmTcLV1RVXV1cGDx4MwPfff1/keGFhYZYyK1asAGD69On4+vrSvXt3ateujclk4sMPP0TS5ZF/YX/pVogg2CCbT1A1a9Zk06ZNbNq0iZ9++gl7e3s6depk7bCEMs6YkWyZpv3AgQNF/g4KCsL4//MwGe/cArPJUnb//v3odDqOHz9OpUqVqFatGlqtFq29F3fu3GHUqFEYDAYWLVpU5HgrV67k1KlTfP7557i6ugIU2WdGRgYXLlygWbNmqNVqDBnF54EShGdNmWriO3jwIM899xyVK1e2dihCGWfW5eHm5gYUPi8CKCgoAMDd3R1TbgY5sb+gS74AYCl7t8y9ZTXV/THeuU1gYCBt27Zl1apVJCUlAZCZmcmHH37IhQsX6NixI6+88gr29vb06dPngcd3dXUlX5f71OtAEGxdmUpQW7ZsITw83NphCOWAwsmDxMREADw8PIr8fXd5xm9LLeXvLXvlypUiZfWZuZi12UybFgnAxx9/jMqrOobUeE6ePMnJkycBWL16Nf369bPcOSUmJlK3bl08PT1JSUnB3d0dnU5HamoqLnU9isT7d8YHzM3NLdPjCYr4rc9WzqHMJCi9Xs+uXbuYOnWqtUMRygG1T21+/fVX8vPzGThwIIcOHaJ///7k5OSwfft25HI5t27dYv/+/fTs2ZMffviB4cOHM3bsWNzc3AgJCeHAgQMkJxc2xdWoUYPevXvz66+/8scff+DeeSwZOxYzfPhwzGYzJ0+epFOnTqhUKs6dOwfADz/8QGhoKJMnT+bEiRPUrVuXtWvXIkkSdpXqFIn374xuUdZndBXxW581ZtQtic0/g7orJiaGhg0b4unpae1QhHKgQvNepKamMmzYMLy9vdm7dy+urq68/vrrZGYWvrfk4uKCg4MDANu2bWPOnDn06dOHbdu2ERcXx6hRoyz7GzduHEajkfnz56Nw8sCxQTsA5HI5kZGRxMbG8tFHH7F//37GjBkDwPLly/nqq6+YOnUq3333HTt37mT69OmovKqjqdm0dCtEEGyQTJIkydpBPIrJkyfTqlUrevfu/Zfl4uLieGnV1VKKSijL7hz+kazoVSjkMjw8PEhPT8dkltBUbUxBwqk/C8oVaJ5rTEHCSTQaDc7OzqSmpiLXOOMWOpz0bZ+D2Wgp7t7pDZybhpO6eT7556KRyWRUrFiR7OxstFotCkc3PMKncmf/t+gSz+Lo6IidnR0ZGRkonL2o2Pc/qL3+vHr9u0MdlfUreBG/9VnjDqp+/frFlpeJJr78/HwOHDjA7NmzrR2KUI5UCOqNg18IeWd3k5+TjpOfJ06NQlE4e1EQfxL9rUsgl+NQKwiV53PokuLIv3gQrT4fd/+aODZoh9zOAZVnVQoSToNkRunmi4NfCACe4dPQ+Yehu36GvOxUVFXtcfCsikO91sjVGjTVnqfgWizaa7HoTQY8WvjhWK81MqXayjUjCLahTCQoBwcHDh8+bO0whHJI5VoJ15CBxZbb1/DHvoZ/kWV2letjV7n4VZ6dT13sfOoWWy6TydBUaYCmSoMSjy2TybCv2Qz7ms3+YfSCUL6VmWdQgiAIwrNFJChBEATBJokEJQiCINikMvEM6u8wmyUxwZtQrhQYTGhUCmuHIQilrtzdQRlLmJenLLGFt7cfV1k/B1uLXyQn4VlV7hKUIAiCUD6IBCUIgiDYpHKXoJT3TdVd1pT1N9Ch7J+DNeIvMJhK/ZiCYOvKXScJuVxG9Ygt1g5DEP4W0bFHEIordwlKEEpi1uWjv3UZCQk771rINU4PLGvMScOQmoBM7YCdT21kChVmXT7G7NRiZeUaR5TOnpgKcjGkXUfS5aNwckflWRWZovC/l0mbgyEtAUlfgMLZo3CdXHR8EISHEQlKKNcks4msfWvJObYJyVA4IaBMZYdz03Bc27xaJFGYtNlk7FhSON26ZAZA4eSOfZ1g8s7uRtJr/+JIMuDPcZcVzp5UaNmf/PP7KUg4WaSkwqUiHp3HYl8r4ImdpyCURyJBCeXanf3fkn3wOwYNGsTQoUORy+WsXr2aVatWgSTh1n4YAJIkkbphLrLUy7wdMYOwsDBSUlKIjIxk796tODs7s+J/3xfb//Lly9mxYwf//vd7BAUF4erqSkJCAp988gnHtn+BTCbjgw8+ICAgABcXF65evcr8+fM5tWEOPq9FovaqXso1Ighlh013krh58yZDhgyha9euhIWFFf5SEYRHZNJmk310AwMHDmTNmjWYTCby8/OJiori9ddfJ/v4Zkx5hXM/FSScQnfjDyIjI5k7dy7nzp2jdu3a7Nq1Cz8/P2QyGU5OTpY/ISEh9O3bFxcXFwBGjx7NtWvXOH78OH369GHnzp24ubmhUCgYMWIEFy9e5NSpUwwcOJCdO3fiYKci99QOa1aPINg8m76DUigURERE0LBhQ3Jzc+nduzchISHUrl3b2qEJZYDuxlkkg46JEydiMpno168fer2eO3fuMHHiRKKioihIOI1jg7ZorxzF0dGRYcOGcfz4cUaNGkW7du3YvXs3Y8aM4c0336Rr164AqNVq4uPjSUxMZOPGjQDUrVuX3NxcAKpWrUq3bt2oXbs2x44do1atWuTl5QFQp04dOnToQPXq1bmWU/yZliAIf7LpO6iKFSvSsGFDAJycnKhZsya3b9+2clRCWWHMTgEKk0dmZibZ2dkUFBSQkpJC3bp1i5QxZqdQvXp11Gq1ZSSJ69evW7YHqNCiPyBj8ODB+Pj48Omnn2I0GnGo1xq9ozcAvr6+BAcHc/XqVU6dOoUkSegdvIDC7utNmzYlLi6OCxcuoPYs293xBeFps+kEda/ExETi4uJ4/vnnrR2KUMbcP2m0TCazLMuKXsWt/72F9uLBYuXu315/+woyGUybNo07d+6wbNkyHBq0xcEvBH3aderVq8f+/fvR6/W89NJL6PV6XNu8iiH9Bo0bN2b//v1kZmbStWtXTCYTzk1F13JB+Cs23cR3V15eHhMnTuRf//oXTk4P7h4sCPdSVii8q7lw4QLBwcG4urqi1+upWLEip0+fBqB69erUquXDCe0t4uPj0el01KhRA8Dy94ULFwDQXj1G165dadCgAfPnzycnJwc3n7qkbfqIkJCW/PzzzyQlJdG1a1cSExMByIpZTWhoKBs2bODSpUuEhYVZWgHyzu/DpdnLlnif1BiAubm5Njee4N8h4rc+WzkHm09QBoOBiRMn8vLLL9O5c2drhyOUIXbPNUKmticyMpL169ezYcMGDAYDKpWKTz/9FIDBgwfzwQcf0LlzZ3777TeWLVvGhAkTWL16NYGBgej1ehYvXmzZ5/Tp0zEYDCxcuBBNtecxF+QBEr///jsajYYbN26wZs0aAN5++21iY2PZtm0bKpUKmUzG998X9gScPHkyZy8eKJKgntQIFgkJCWV6NA8Rv/WV9jnExcWVuNymE5QkScycOZOaNWsydOhQa4cjlDEKjRMuQb354Yf/0atXL0s38379+rF+/XoATp8+TVRUFMnJyUBh892VK1cIDw8nNjaWV199lcuXLyNT2+PmZE98fDybN28mKSmJin1Hob99BYB169YVO35+fj5ms9mSsO6l1WqRyeye4tkLQtknkx7U8G4Djh07xuDBg6lbty5yeeHjsilTptC2bdsHbhMXF8dLq66WVoiCjZMkM9kH15N9dAPmgsJedjI7R1wCuiEZdGQf2QBIyJRq3EJHoEu+SN653WAuHBtPWcEb17avI5kMpP+6CMxGAOzrBOPVcybGrJvcXhuBKTfjb8UlU9rh0fVNHOu3Bp7sUEdl/QpexG991riDql+/frHlNn0HFRAQYGn/F4R/QiaTU6Flf5wDu2NIuYYkgbpiDeRqDQAuQb2RDAXINc7I7Rxw9u+KW/uhGNJvIFNpUFesYRltwqFOMOaCHJArUTp7AKBy86XyG19jyk0vdmy5xgmZQo0pr3jyuns8QRAezKYTlCA8KXKVBrvKxa/QFA4VgArFlhUuv28fdg4lJhWZQmnpkFGSv1onCMKDlZlu5oIgCMKzRSQoQRAEwSaVuyY+s1kSc+sIZU6BwYRGJabgEIR7lbs7KKPRYO0QHostvBz3uMr6OVgjfpGcBKG4cpegBEEQhPJBJChBEATBJokEJQiCINikcpeglEqVtUN4LGX9DXSw7XMoMJisHYIgCI+o3PXik8tlVI/YYu0wBBslengKQtlR7hKUYB2SZEZ75SjaK8eQTAbsfOri2LA9crV9sbJmfQF55/agSz6PTKHEvkZT7GsHYcxOJf9cNGajvkh5tedzOPiFgFyJLvEs+RcPYi7IQWFfAbvnGmHn64f2yhH0KdcwF+SicHBFU+15NDWbIZPJSqsKBEF4wkSCEh6buSCXlPX/QZd8Hjc3NxwcHEg68ztZ+9ZSse9/sKtU21JWn3KVlPX/wZSbga+vLwUFBaSe3IbauxaGrFvIDNpiSSXbZMI1O5WC+BMUJJzGwcEBLy8vbl++TfbRDZZyLi4uVPTw4NbVW2Qf3YB9zQC8es1Epijbzb6C8Kwqd8+ghNKXGb0KKe0qUVFRpKamkpiYyMGDB6la0ZW0zfOR/n9kcEkyk7b5E3xcHdi3bx9JSUmkpKSwZs0a5HeSkHR5LFiwAKPRWOSPr68vWdGrMN88zxdffEFaWhrx8fHk5OTQqlUrAGJiYrhz5w5Xr14lOzubTz/9FO3VY2Qf22TNqhEE4THYfIKKiYmhS5cudOrUiWXLllk7HOE+Jm0Ouad/Y9iwYbz22mt8+OGHhIeHExgYyCeffIIxIwnt5SMAFFyNxZCWwLx58wgJCaFnz57MmjWLQYMGMXr0aMs+8/PzefXVVy1/MjMzAZg5cyZjx45l9uzZ1KhRgw4dOlhmrj158iShoaE0b96cK1euMGnSJIKDg9FeOVb6lSIIwhNh0wnKZDIxe/Zsli9fzpYtW/jll1+4fPmytcMS7mFISwCzkV69egHwxRdfsGXLFs6dO0e3bt1QKBSWSf10ty8jk8no2bMnly5dYuPGjXz++ecAlu0B5HI5ISEhNGzYkDNnzqDVagEYMmQI169fJysriyFDhqDT6YiPjwdg4sSJ7N69m6NHj3Lo0CEA1Go1mIylVRWCIDxhNp2gTp8+TbVq1XjuuedQq9WEhYWxc+dOa4cl3OPuRH2+vr4AZGQUfs7MzESpVOLt7Y0h/QbG7FQM6Tdwc3NDo9FY7oqysrIAqFy5MgAGg4EjR47g4+PDhAkTOHbsGEFBQdjZ2VGjRg2qVq3K2LFjGTJkCIcOHaJnz54A2FVpAECnTp0YMGAA27dvZ9++fWhqNiu9yhAE4Ymy6U4St2/fplKlSpbP3t7enD592ooRCfeTa5yAPxOTg4MDOp0OBwcHy/KC5GTyL+wHQK9UYjKZsLcv7N2n0RROHJieXjjh34wZMzCbzUDhHdPq1asZMGAAhw8fJi8vD3t7e1q2bIm3tzeXL1/m1VdfZcOGDegSzzFkyBBWrFjBb7/9Rp8+fTCbzYW9/+7zsLH2cnNzy/R4giJ+6yrr8YPtnINNJyjB9qncqwCwf/9+WrduTevWrdm/fz8NGjQgNjaWgoICWrRowfDhw1m1ahV79+7l8OHDBAQE4O3tzQsvvADAgQMHAOjcuTO7du1Cr9dbXvjNzS2cqv3QoUN06NABtVqNnZ0d8Ocd2Ntvv83cuXPZvHkz48ePx83NDZlMRuauFXj3m1Uk5oe9SFzWp+wW8VtXWY8frDPle0lsuonP29ubW7duWT7fvn0bb28xO6ktUVaoiKa6PwsWLODatWv8+OOPxMfHI5fLeeuttwCoVasWw4cPx8/PD4CIiAiMRiOXL19m8+bN3Lhxg3nz5gGwcOFCsrKyuHnzJu+//z7x8fEsXrwYgH/961/k5uZy6tQpdu/eTXp6umW7KVOmAPDyyy+TkJBAUlIS/fr1w5B+vbSrRBCEJ8Sm76AaN25MfHw8N27cwNvbmy1btvDJJ59YOyzhPm6hI7i95i3q1atHeHg4Li4ubNmyhdTUVAB27txJ586dOXfuHAB79+6jatWqhIeHk5eXx+bNm9HpdAC0bNmSVq1aUbFiRZKSkti5cyd6lFQIGcSRA+ss2+Xn57Nr1y7Ls6y+ffuiUhV93+ns2bMonT1LsSYEQXiSbDpBKZVK3nvvPUaMGIHJZKJ3797UqVPH2mEJ91F7VcNn2GdkH9nAz7sPIhkLR5Lw7jwdmUJJ1oHviDl7A7m9L5VemQwyGdlHNvC/n7YgU6jQNOiIR/OemHIzyT21ja37TmAuyEHu6IamYUc8g/qgdPHCvlYg2Uc3sHbjNmQqNWqfJvj06E3euWgOXjxbLC65QxXcWvS3Qo0IgvAk2HSCAmjbti1t27a1dhjCQyhdKuLecTQwuti6ir3fLbbMq0dEsWUq10poqtR/4DHsfOrg1e2tYsvVFWv+vWAFQSgTbPoZlCAIgvDsEglKEARBsEkiQQmCIAg2yeafQf1dZrMk5vwRHqjAYEKjUlg7DEEQHkG5u4MyGg3WDuGx2MLb24/Lls9BJCdBKDvKXYISBEEQygeRoARBEASbVO4SlFJZtmdPLatjeBUYTNYOQRCEcqbcdZKQy2VUj9hi7TCeOaJjiiAIT1q5u4MSBEEQyodydwdV3uhTE7hz8Hu0V48hGfXY+dTFpXkvHOoEFSurvXKMO0d+RJ98AeRK7Gs0pULLfhizbpF9dCOGtOuYdfnI7Z0L9xPcF3XFmtw5tJ7883sxZqciU6pRe1XHsVEoBVePo0+5Wuw4cjtHKrQcgEPdFqVRBYIgPKNEgrJhupsXub32bVwcNbzy2mBcXFzYuHEjl396H7f2w3Fp3tNSNufEVjJ2LKZGjRr0mjSBvLw8vvvuO26unAhAw4YNadvtVdzc3EhJSWHLli0kr40AmRyFTOLFF1+kYcOGaLVafvvtN85v+wyFQsHAgQOLxRUbG8uFXctFghIE4akSCcpGSZJE5s6vqFzJi9jYWOzt7cnOzuajjz6iV69e/Lz1fzg2CkXhUAFTQS6Ze1by4osv8ssvv5CamoqjoyNz5syhWbNmxMfH8/bbbxMcHIxOp6NBgwZkZ2fTpEkTEhISWPzll4waNYqDBw9StWpVIiMjadOmDSdPnuSbb74pFtukSZOIW/qVFWpFEIRnSZl4BmUymejRowejRxcfKbu8MmbdQpcUx9SpU/Hy8qJXr174+fmRm5vL3LlzkQw68s/vA0B78SCSXsucOXPQ6/XUr1+fsLAw3N3dmTFjBgBvvPEGtWvXpmHDhixfvhwXFxeaNm0KQPv27cnIyKDLxI+YMGECCoWC1q1bk5+fj0qlsvzZu3cvBoOBH3/8ETvfelarG0EQng1lIkGtXr2aWrVqWTuMUmXMTAYgMDAQgCNHjpCbm8v58+dp0KABDg4OGP6/jCEzGZVKxQsvvMClS5fIysriyJEjAAQEBACF06Z369aNd955h65du3Lo0CF27doFFM5i6+TkROQbL/P2229z7do11q9fD4BDQA+MZgl/f39at27N2rVrSUpKwiWwR6nWhyAIzx6bT1C3bt1iz5499OnTx9qhlCqzLh8AV1dXAMuMs3f/rlChAjnHfubOoR/IProRZ2dn5HK5Zb1ery+yPUCbNm3o378/vr6+KJVK7O3tgcI71IKCAmrWrImHhwc5OTnI5YVfDTufumA2MW3aNAA+/vhjVF7V0dRo+rSrQBCEZ5zNP4OaO3cu06dPJy8vz9qhlCqFswcA169fp2HDhnh6epKYmIinpyd6vZ7bt28DElnRUQBkZGSQl5eHp2fhFOd3/75x44Zln9OmTWPatGnMmDGDDz/8kKFDhzJ//nwWLlzIyZMn6Rjek4a1qnL69GmmT5/O6NGjyfh9GTVq1KB37978+uuv/PHHH3iETUEmkxWL+e4YfLm5uTY9Ht/DiPitS8RvfbZyDjadoHbv3o27uzuNGjXi8OHD1g6nVKm9qiNT2rFu3TpeeuklIiIiOHr0KPXr1+d///sfZrOZgQMHsmLFCsaNG8fKlStZt24dw4cPZ8SIEdSvXzgz7bfffgvAnDlziImJwWAw0LFjR6Dw7tRoNJKTk0PVqlV5oV4t2rRpA0BWVhYAppw0psz9NwqFgo8//hiFsyeO9duUGPPdUTASEhLK7IgYIOK3NhG/9ZX2OcTFxZW43KYTVGxsLLt27SImJgadTkdubi7Tpk3j448/tnZoT53czgFn/66sWbOGxo0bM2bMGMaNG8cvv/zC9OnTgcKmufz8fIxGIwARERF4eHjw5ZdfotPpWLRoEStXrgSgS5cuREREIJfLycjIIDIyktWrVwPw+uuvs3DhQo4fP47RaGT79u3MmzcPABcXF7p3787evXvZtWsXbu2HIVPY9NdGEIRyQiZJkmTtIB7F4cOH+frrr/nyyy//slxcXBwvrSr+cmlZZDYUkLbpI7RXjqJUKlEqlRQUFKB09UFu74z+5kVLWXWlOpj1WowZiWg0GoxGI0ajEYWzJ6acdECy9MbLzy98vqWp0RT76i+QGb0KzCbs7OwwGAyYzWaUrpVQ+9QlPy7GcgyFkzu+I5Yit3MoFuu9Qx2V9StIEb91ifitzxp3UHdbfe4lLoVtmFyloWKff6NLikN79TiSUY+TT10c6gQjmU1oLx3CpM1GYe+MfZ1gZAoV2suH0SWdR61QYV+zKXaVG2DOy0J77TiGjCQwGXFzcsPuuUaoK9VBJpPhUK812suHMWanolGqUXlWs4xUke8Xgik3A5lcgX3NgBKTkyAIwtNQZhJUUFAQQUHFh/d5FthVro9d5aJXFzKFEscGbYuVdajbEoe6LYssUzi54dS44wP3r3TxwrlpeInrHP1C/kHEgiAIj8/mu5kLgiAIzyaRoARBEASbJBKUIAiCYJPKzDOoR2U2S2LyPCsoMJjQqBTWDkMQhHKk3N1BGY0Ga4fwWGzh7e1/QiQnQRCetHKXoARBEITyQSQoQRAEwSaVuwSlVKqsHcJjedjb2wUGUylFIgiCYF3lrpOEXC6jesQWa4fx1IgOIIIgPCvKXYJ6FmVmZnLgwAEMBgOBgYFUrlz5gWXj4+MtU8i3atUKZ2dnAFJTUzl16hSZmZl4eXnRrFkznJ2dkSSJa9euERcXR35+Pp6envxfe3ceV1W1/3/8dQ4IMiYqAuY8oJI5DynkAA4I6k2cbl1v2qBcNc0UM1HMOcdyykopsxyvQ4455qVQLIdQCBFEZFJQQZBB5rN+f/jzfOVqVxPlHPDzfDx8CHutfc577YwPe+919mrbti22trYAJCcnEx4ezu3bt3FycqJt27ZlMmYhRMUnBaoc0+l0BAQEsGzZMv0DYE1MTPjnP//J559/jqXl/z03Lz09nVGjRrFjxw7uPR/Y1taWDz74gLNnz7Jv374Sr21jY8OsWbM4cOAAR44cKdFmUxgpwgAAIABJREFUaWmJr68voaGhBAUFlWirVq0a/v7+TJw48RmMWAjxPJECVY4tXLiQ+fPnM2zYMP71r39hbn53/ahly5ah0+lYv369vu8bb7zBf/7zH6ZPn86AAQPIyMhg+fLlzJo1C4CpU6fSs2dP7O3tuXr1KqtWrdIXmQ8//JDXXnsNGxsbkpOTCQwM5LPPPgPgk08+wdXVFTs7O+Li4li6dCl+fn60a9dOv7aUEEI8CaOfJJGZmcn48ePx9PSkT58+hIaGGjqSUcjOzmbRokW89tprfP/992RlZREREcGSJUuYPHky33//PdHRd5fjCAkJ4eDBg3zyySfMnj2bkydPYmpqyq5du+jc+e6DZX18fAgLC2PHjh106tSJXbt20aRJEwDs7Ow4dOgQO3bsoH379mzdupWGDRsCMHDgQH799Vf27t1Ljx49+PHHH6lRowaBgYGGOTBCiArD6M+g5s2bx6uvvsqKFSsoKCggLy/P0JGMwqlTp8jIyGDMmDEAvPXWW1y/fp1+/foxZswYFixYwJEjR3B2dubw4cNotVp8fX25dOkSY8eO5eWXXyYsLIzRo0cTEhKCm5sb+fn5ANjb2zNmzBiaNWtGVFQUU6dO1b9v+/bt8fLywtzcHICXX35Zv1+jRo0YPHgwjRo1IikpqYyPiBCiojHqM6isrCxOnz7NoEGDADAzM9PfnH/e3XviRKNGjSgsLCQlJQWlFNeuXaN27dpUrlyZhIQEfd+aNWtiaWlJYmIigL6ANGrUCEBfZKpXr46npycpKSkl7i999913XLp0CS8vLz7++GMuXLgAQMuWLQGoXbs2Xbt2JSYmhjNnzui3CyHEkzLqApWUlETVqlWZOnUqr732GtOmTdNPBnjemZjcfbRQUVERWu3//WfUarXodDqKi4tZtGgRrVq14ttvv9UvC6/RaPT97u1/T/369Tlx4gTW1tZ4enqSkZGhX+Xyxx9/5Pvvvyc5OZkpU6bot4eGhtK8eXNCQkLIzc3F09OT/Px8mSQhhCg1o77EV1RUxIULFwgICKBly5bMnTuXNWvWMGHCBENHM6j4+HgsLCyAu0slN27cmPr165OUlETt2rW5fPkyhYWF1K9fn3r16nHz5k2Sk5NJT0/XnzHdu4d08eJFANq2bcv+/fu5ffs2nTp1IjY2Vt+u0WjYsmULAKampgQEBODq6kpkZCRubm788MMPxMbG4u3tTXJyMgCLFi3Cz8+vTI/L05KdnV1un4kIkt/Qynt+MJ4xGHWBcnR0xNHRUX+5yNPTkzVr1hg4leHVrVsXR0dHnJyc+PTTT+nbty87duwgPT0dGxsbJk2aBICXlxerVq1iyJAhbNu2jaVLlzJ37lz27dtHw4YNKSwsZPny5QBs374dBwcHcnJy2LZtGwDz58/nyJEj/P777wQFBWFqasrAgQPJzc0lODgYgL1792JlZYWVlZV+qrqfnx/BwcGsXLnSAEen9OLj4x/5RA9jJvkNq7znh7IfQ2Rk5EO3G3WBsre3x9HRkdjYWBo0aMDJkyf1v/k/78zNzZk9ezYjR46kW7dujBw5EgsLCwYOHMjOnTsBCA8PZ9WqVcTExAB3C058fDw+Pj6EhIQwbNgw/vjjDwA2btzICy+8UOI9rl+/Tm5uLhs3buSll17CxMSEwMBA1q1bR1RUFACBgYH6y4333Lp1Sz+JQgghnpRRFyiAgIAA/Pz8KCwspHbt2nzyySeGjmQ03n33XQBmz57Nm2++CdydEj5r1iwsLS2ZPn06v/zyC1ZWVnz11VfExMTwxRdfsGHDBuDuBIk1a9awYsUKpk+f/qfvM3PmTP2He+HuzL3PP/+czz777KGXW62srPjyyy+f5lCFEM8hjbr/J08FEBkZSZ/1sYaO8cw87Fl8xcXFXLx4kaKiIpo0aULlypUByMnJITc3FysrK/09q5ycHKKjo7GwsMDZ2RmtVotSirS0tAde19LSEktLSzIzM7ly5Qo6nY6aNWtSo0YNNBoNOp2OW7duPbBfWlqa/jNU5VF5v0Qj+Q2rvOcHw1ziuzfx6n5GfwYlHs3ExISXXnrpge337g3997bWrVuX2KbRaKhevfqfvr6tre1Dp41rtdqH7peTk/O40YUQ4k8Z9TRzIYQQzy8pUEIIIYxShbvEp9OpCr1mUl5hMZUrmTy6oxBClHMV7gyqqKjQ0BFK5VEfjpPiJIR4XlS4AiWEEKJikAIlhBDCKEmBEkIIYZQqXIEyNa1k6Ail8mcfjssrLC7jJEIIYVgVbhafVquh3kf7DR3jqavIMxOFEOJhKlyBel6kp6ezbt06fv31V8zMzPD09GTIkCGYmZk90Dc2Npa1a9cSHR1NtWrV+Pvf/0737t2JjIxkz549REREcOfOHV588UX+9re/4e7uTnh4OPv27ePChQvk5uZSu3ZtfHx86NKlC7/99hu7du0iNjaW4uJiatasSd++fenZs6d+vSkhhCgtKVDl0KlTp+jTpw+3bt3C2dmZO3fusHHjRhYuXMjRo0dxcHDQ9127di2jR4/GxMSExo0bc+3aNdauXYudnR3p6eloNBrq1KmDtbU1R44cYeXKlVSrVk3/jL26detiaWnJ4cOHWb58OS1atCAsLAwzMzPq16+PiYkJhw8fZuXKlbz55pt8++23BjoqQoiKpsLdg6roiouL+ec//0mVKlUIDQ0lKiqKxMREdu/eTWxsbIlFAuPi4hgzZgy9evUiLi6OP/74g+TkZObOnUt6ejrW1tbcuHFD35aamspHH31EWloa1atXJzU1lStXrhAREcHNmzeZMGECYWFhAKSmpnLx4kUiIiJITU1lxowZfPfddxw5csRQh0YIUcEYfYHKz89n0KBB9O/fH29vb1asWGHoSAa1f/9+oqOjWbx4Ma1ataJnz574+fnRv39/xo4dy6ZNm/Sr2q5atQoTExPWrl1LYWEhzZs3Z9euXUybNo2OHTui0Wj4+uuvad68OR07diQrK4tPPvmEqlWrArB69WpcXFxwdXWloKCAJUuWYGlpCcDw4cOpV68enTt3pqCgAH9/fzQaDSdPnjTYsRFCVCxGX6DMzMxYv349e/bsYdeuXQQHB3Pu3DlDxzKYc+fOodFo8Pb2JioqiqNHj/L1118D0LdvX3Q6HeHh4fq+rVu35sUXX+TQoUNERESwadMmfd+srCw++ugjIiIiOHXqFHFxceh0OrRaLTdv3iQgIIDIyEhCQkK4evUqOp1Ovzjhrl27MDExwdraGq1WS2hoKEqpEpcXhRCiNIy+QGk0Gv2SEUVFRRQVFT3XN+JTUlKoVq0a5ubmZGRkAHD79m0AatasCUBISAiRkZFER0frt93re+/ve9ttbW0BmDRpEm3btmXRokWkpqbi5+dH06ZNgbuLRjZr1ozZs2eTlZVFq1atqFy5MpcvX+bw4cNotVqWLl0K8D+X7RBCiL+iXEySKC4uxsfHh4SEBN54442Hrk30PIiPj8fU1JSMjAyKi4v1hfveZbfU1FQAZs2axaxZswCoX78+gL6vtbV1ib5ZWVksXbqUiRMnsmDBAqZOnQrA5s2bSUlJYfXq1YwePZoZM2Ywd+5cAP0ZrL29PXXr1mXnzp1s2rSJn3/+ma1bt9KsWbNHPlPQmGVnZ0t+A5L8hmcsYygXBcrExITdu3eTmZnJ2LFjiY6OxtnZ2dCxylzdunXp2LEjK1euJCQkhFdeeYVatWrRpk0bAH755RcARo0ahbu7Ox988AHnzp0jMzOTLl26UKlSJdzd3fV9TUxM2LRpE0OGDGHFihWsW7cOZ2dnEhISuHnzJjt37qR///4sXLiQrVu34uzsTFxcHDVq1MDMzIzY2Fjy8vLIzMykTp06WFlZUalSJaytrcv1iqLlfUVUyW9Y5T0/GGZF3Ycx+kt897O1taVjx44EBwcbOorBDBgwgBo1ajB58mRycnKIjY1l9+7dXLp0iSVLlgDQvn17hg4dirW1NZmZmUydOpWmTZuSlZXFpEmT2L17N/v378fOzo4hQ4YAMH78eKKiooiKiqJFixY4OTnRv39/AKZMmaJvc3Z25uWXX+by5cukp6dz69Ytmjdvzrp164iLi6Nr164GOzZCiIrF6M+gbt26hampKba2tuTl5RESEsLIkSMNHctgLC0tWb16NUOHDqVOnTr06tWLnJwcjhw5QqVKdx/ztGDBAr755hsSExOBu7Px9u7di6urK7GxsZw6dQq4ez+qc+fOD7zHhQsXKCwsfGhbbGwskZGRdOjQgYYNG5KXl8eFCxeIjo7Gw8ODt956Sz+LUAghSsPoz6Bu3LjBm2++Sb9+/Rg0aBCdO3eme/fuho5lUAMHDuT3339n4MCBREREkJyczKRJk/RnUy4uLlhbW/POO++QkpLC/v37adGiBWfPnsXExITly5dz9epVxo0bh7W19QN/evbsSZ8+fR7aNmjQIEaNGoWNjQ1nz54lJiaGxo0b880333DgwIGHPslCCCGehEYppQwd4mmKjIykz/pYQ8d46srTs/jK+zV4yW9Ykt/wDHEPqlmzZg9sN/ozKCGEEM8nKVBCCCGMkhQoIYQQRsnoZ/H9VTqdKlf3ax5XXmExlSuZGDqGEEKUmQp3BlVUVGjoCKXyZ5/eluIkhHjeVLgCJYQQomKQAiWEEMIoVbgCZWpaydARgLv3jIQQQjy5CjdJQqvVUO+j/YaOUSEnagghRFmqcGdQxk6n01FY+HgTOYqKiigufnpnYkop8vLyqGAPDxFCVFBSoMpIeHg4gwYNwtLSEjMzM5o3b87XX3+NTqd7oO++fftwdXXFzMwMMzMzPDw8CAoKIiEhgffff58OHTrg4OCAg4MDvXr1KvFw1qCgIJo1a4aDgwOOjo4MGzaMwMBA3NzcsLa2xsLCAltbW7y9vQkNDS3LQyCEEH9JhbvEZ4zOnTuHq6srlStXxtfXl+rVq7Nnzx7effddLl68yOLFi/V9t27dypQpU2jcuDHTpk2jqKiIjRs34u7ujlIKKysrOnTowIABA9BoNAQGBvLtt98ydepUUlNTGTp0KHZ2dvj4+HD79m02btzIxo0bad26NaNGjaJGjRokJyezdetWOnfuzMmTJ2nVqpUBj44QQjycFKgyMGXKFKytrQkPD6dy5cqkpKQQEBDAqFGj+Oyzz/jXv/5Fw4YNyc7OZsGCBbi7u3Po0CGSk5MxMzNjxowZdO7cmXPnzvHuu++ydOlSioqKMDc357vvvuPWrVsAvPfee2RkZPDTTz/RvHlzoqOj2bx5MwAbNmzAysqKtLQ02rRpQ0BAAC1atGDu3Lls377dkIdHCCEeyugv8U2dOpVOnTrRt29fQ0d5Ijdu3ODw4cOMHz+eGjVq8Oabb9K8eXOuXr3K7NmzUUqxZcsWAA4ePEh6ejozZ85Eo9HQtm1bunXrhoWFBdOmTQPuFhobGxv96rn3bNu2ja1bt/Lxxx9TWFjI7du3S7S//fbb1KtXj7Zt27Ju3Trs7e3p2rWrfvl2IYQwNkZfoHx8fAgMDDR0jCd2+fJlAP2y7KGhoRQWFvLHH3/g6OiIk5OTvk9MTIy+b1JSEjdv3uTixYvk5eXp909LSyM3N7fEe9y4cYMxY8bQrl07JkyYwPDhwykqKirRJyEhQf91jRo10Ol0REZG4uTk9GwGLoQQpWT0l/jat29PUlKSoWM8sezsbABsbGwAKCgoANDP5LOxsWHdunW8+OKLLF68GBMTEywsLPT97u1zb/+hQ4eydevWEu/x3XffYW5uzvr165k3bx7h4eEP5FBKYWJiwooVK/D29mbChAmEhYWxadOmpz9oIYR4Coy+QJVn8fHxaLVa/ddubm7UqFGDlJQUatSoAaBfln3+/PkopVBKcfXqVapXr45Go6Fy5cpYW1tz6dIlgAeK0z316tXDxcWF119/ncGDB1OlShWsra05dOgQvXv3JjMzk507d+Ll5cU777zDN998A8CVK1f+9Pl/Tyo7O/upv2ZZkvyGJfkNz1jGIAXqGapbty41a9akevXqbNiwgX/84x/4+/tz5MgR2rRpw86dO8nJyaFv377s3buXyZMns2TJEjZs2MDUqVPx9/fHzs4OrVbL999/D4CLiwvdunWjdu3aAPj6+hIdHc3p06dZunSp/r2bNm1Kbm4ux48fB2Dnzp307t2b4OBg6tSpw8yZMzl48CCrV6/G39//qY67vK8oKvkNS/IbniFW1H0YKVDPWKVKlfjwww/1fyZNmsTAgQPZt28f48aNAyA3N5f4+HgyMzMBmDdvHvb29vpp5p999hmrV68GoEWLFnz44YfA3X9E77//Pv/5z3/Yv38/fn5++vft0aMH6enpzJkzBwALCwvi4+OpU6cOI0aMAO6evV24cKGsDoUQQvwlUqDKwAcffEBUVBSLFy9m8eLFaDQalFI0btyYPn36cODAAerVqwdAy5YtsbS0ZOTIkYwcOVL/Gr1798bc3JwtW7boZ/3dz87OjqioKGJiYujcufMDn23q2rXrQ7MNGDDg6Q1UCCGeIqMvUBMnTuTUqVOkp6fTpUsXxo0bx+DBgw0d6y8xNTUlMDAQPz8/9u3bR05ODq1bt8bLywuNRsORI0dITk7mhRde4KWXXsLZ2ZlffvmF4OBgtFotHh4edOzYkYKCAg4ePEhaWtoDr+/p6Ym9vT329vZERUVx4sQJNBoN3bp1A+4+YeK/H3FUpUoVvLy8yuowCCHEX2L0BerTTz81dISnpmnTpjRt2vSB7Z6envqv4+Pj0Wg0dO3a9YGzHjMzM/r37//I93F2dsbZ2bnEtnuX9YQQorww+s9BCSGEeD5JgRJCCGGUpEAJIYQwSkZ/D+qv0umUUSwWmFdYTOVKJoaOIYQQ5VaFO4MqKnq8xQCfNSlOQghROhWuQAkhhKgYpEAJIYQwShWuQJmYyKU1IYSoCKRACSGEMEoVbhbfwyQlJREcHIxOp8PV1VX/3LuHCQsLIzQ0FGtrazw8PKhSpYq+7ffffyc8PBxbW1s8PDywtbUF7q61dObMGSIiIrCzs8PDwwNra2t922+//cbFixepVq0aHh4eWFpaPtPxCiFEhaAqmAsXLui/zs/PV76+vsrExEQBClAajUYNGzZMZWdnl9gvKSlJubu76/sBysrKSs2fP19duXJFubm5lWizsbFRn376qYqOjlYdOnQo0ValShX1xRdfqIiICNW6desSbdWqVVPr1q370/xxcXHP6tCUmfI+BslvWJLf8Mp6DPf/3L5fhbvEdz9/f3/WrFnD2LFjOX/+PBEREUyZMoXNmzfrl7qAu2c5Pj4+nDlzhk8//ZRLly5x8uRJPD098ff3p379+kRERLBy5UpiYmI4fvw43bp1Y+LEiTg7O3PlyhW++OILLl++TFBQEB07dmT06NG89NJLpKSkEBgYyOXLl/npp59o0aIFb731FkFBQYY7MEIIUR6UtvJ1795dpaWl6b//9ddf1ahRo5RSSu3YsUM1adJERUZG6tu9vb1VYmLiA/uGh4er7t27q4iIiFLluVeJb9y4oSpXrqzeeustpZRSmzdvVoGBgUoppSZNmqS0Wq2KjY1VSim1f/9+BejPbObNm6eCgoKUUkp/dvTvf/9bFRUVqZkzZ6qQkBBVXFysmjdvrgC1f/9+VVBQoAICAtTp06dVYWGhatiwoQLUzz//rHJzc5W/v786f/68ysvLU7Vq1VLdu3d/aH757cvwJL9hSX7DK9dnUAUFBdy5c+ex+jo6OvLll1/+zz4XL15k/PjxLFu2DBcXF7KystDpdE8STS8kJIS8vDx8fX3R6XSMHDkSX19fcnJyGDVqFDqdjp9//hmAo0ePYmlpybBhwzhz5gzTpk3TLwo4cuRIqlWrxuDBgzlx4gQzZ85k2rRpaLVa3n33XWrVqoWXlxdHjx5lzpw5zJw5E1NTU95++22aNGlCly5d2LdvH/Pnz2fevHmYm5szfPhwfv75ZwoLjeNDxUIIYYz+UoG6fPkyCxYswNPTk7i4uMfap1u3bsTExBAbG/vQ9tjYWMaOHcuiRYto0aIFAGfPnsXT05OVK1dy7dq1vxJRLyEhAYAGDRqQmZlJdnY2xcXFXL9+nfr166PVavV9EhISqFOnDqampvr3u3r1KgANGzbUT6q4t+3+tgYNGpTYdm//R7XpdDr9diGEEA96ZIG6c+cOO3bs4PXXX2f69Ok0bNiQPXv24OLi8nhv8P/PNL766quHto8ZM4YZM2bQrl07/bZu3bqxZcsWbGxsGD16NO+88w4HDhygoKDgMYd1d6l1uHu2d//Uc1NTUwoLC9HpdHz88cc0atSIHTt26F9bq9Xq+wHk5+fr2+69zv9qu/f3o9ruzyiEEOJBj5xm7ubmRpMmTZg7dy4NGzZ8rBfVaDQlvu/bty9ffPEFiYmJD/Tt1KkT27Ztw83NrUQhqVq1KiNGjGDEiBGEhobi7+/P6tWr2bt37yPfPz4+HisrKwAiIiLo1asXTk5OZGVl4eTkxLlz5wBwcXGhdevW5ObmkpiYSGZmJk2aNAHQ/x0REUFsbCy5ubn6bfcWA4yIiCA6OprCwsKH7hcZGYlOp3tom5mZGQUFBcTHx5fInp2d/cC28qa8j0HyG5bkNzyjGcOjbl4FBwer999/X/Xp00etXLlSJSUllWgfMGCAunLliv77Q4cOqY8++kgpdXeSxKxZs5RSSm3ZskUFBAQ8MEkiNTVVjR07VgUEBDzw3pcuXVILFixQPXv2VP7+/urcuXOPfbMtJydH2dvbK3d3d1VcXKzCwsLU6dOnlVJK+fj4KEB9+OGHSimlvLy8FKBmzJihlFLqyJEjKiEhQWVnZ6u6desqQC1cuFAppdSBAwfU1atXVUZGhnJ0dFSAWrVqlVJKqX379qnr16+r1NRUZWdnV2Lixe7du1Vqaqq6du2asra2Vq+//vpD88sNVsOT/IYl+Q2v3EyScHNzY9myZWzcuBEbGxvGjBnDiBEjSEpKAqBjx47s3r0bgOLiYvbs2UPHjh0feJ0BAwZw8uRJbt26VWK7RqNh6dKlxMbGsnz5cuDuGcaQIUOYPn06DRo04IcffmDevHm0bNnysQuvpaUlc+bM4dixY7i6unLy5EnCwsLo3r07O3fuBOC3335jwYIFXL58GYA5c+YwdOhQUlJS2L59O61btyYpKQk7Ozv8/f35xz/+QVpaGps2baJNmzakpaVha2vLhAkTGD58OBkZGaxbt442bdqQk5ODjY0Nvr6+jBw5kuzsbL788kvatWuHUoqZM2c+9liEEOK59CTV7vz58+ratWtKKaUyMzPVxIkTVb9+/VTfvn3VwoULVXFxsVKq5BmUUkqtX79eOTs7P3SaeWZmpurfv7/asGGDiomJUTExMU8S7YFKvG7dOtWgQQP9B2Vr1aqlVq1apZYuXaosLS0VoKpXr67+/e9/K39/f/XCCy/o+7Zr104dPnxY5eTkKD8/P2VjY6Nve+WVV1RQUJDKzMxU48eP178WoLp06aJCQkJUenq6Gj16tLKwsNC3ubu7qzNnzvxpfvnty/Akv2FJfsMzljMojVJKGag2PhORkZE0a9asxDadTkd8fDw6nU4/gw+gsLCQ4uJiKlWqVGICQ3x8PNbW1tSsWbPE6+Tl5REfH4+trS1OTk4l2nJzc0lISKBKlSo4ODiUaLtz5w4JCQlUq1YNe3v7/5k/Pj6eunXrPtHYjUV5H4PkNyzJb3hlPYaH/dyG5+RZfFqtlvr16z+wvVKlSg/MpDM3N9dPgvhvlStX1k90+G8WFhZ/2mZpaUnTpk3/YmohhHi+VehHHQkhhCi/pEAJIYQwShWuQBUXFxs6ghBCiKdACpQQQgijVOEKlBBCiIpBCpQQQgijJAVKCCGEUZICJYQQwihJgRJCCGGUpEAJIYQwSlKghBBCGCUpUEIIIYySFCghhBBGqcItt3Hu3DnMzc0NHUMIIcRjys/Pp1WrVg9sr3AFSgghRMUgl/iEEEIYJSlQQgghjJIUKCGEEEZJCpQQQgijJAVKCCGEUZICJYQQwiiVqwL1yy+/0Lt3b3r27MmaNWseaC8oKGDChAn07NmTwYMHk5SUpG/76quv6NmzJ7179yY4OLgsY+s9af4TJ07g4+NDv3798PHx4eTJk2UdHSjd8Qe4du0arVu35uuvvy6ryCWUJv/FixcZOnQo3t7e9OvXj/z8/LKMrvekYygsLGTKlCn069ePPn368NVXX5V1dODR+U+fPs2AAQNwcXHh4MGDJdp++OEHevXqRa9evfjhhx/KKnIJT5o/MjKyxL+fH3/8sSxj65Xm+ANkZ2fTpUsXZs+eXRZxQZUTRUVFysPDQyUkJKj8/HzVr18/denSpRJ9NmzYoAICApRSSu3bt0+9//77SimlLl26pPr166fy8/NVQkKC8vDwUEVFReUmf0REhEpJSVFKKRUVFaXc3NzKNLtSpct/z7hx49S4ceNUYGBgmeW+pzT5CwsLVd++fVVkZKRSSqlbt26V+b8fpUo3hj179qgJEyYopZS6c+eO6t69u0pMTDS6/ImJiSoyMlJNnjxZHThwQL89PT1dubu7q/T0dJWRkaHc3d1VRkZGuckfGxurrly5opRSKiUlRbm6uqrbt2+XZfxS5b9nzpw5auLEiWrWrFllkrncnEGFhYVRt25dateujZmZGd7e3vz0008l+hw7dowBAwYA0Lt3b06ePIlSip9++glvb2/MzMyoXbs2devWJSwsrNzkd3FxwcHBAYDGjRuTn59PQUFBuckPcPToUV588UUaN25cprnvKU3+EydO0KRJE5o2bQqAnZ0dJiYm5WoMGo2G3NxcioqKyMvLo1KlSlhbWxtd/lq1atG0aVO02pI/mo4fP46rqytVqlThhRdewNXVtcyvhJQmf/369alXrx4ADg4OVK1alVu3bpVVdKB0+QH++OMRun6BAAAD60lEQVQP0tLScHV1LavI5ecS3/Xr13F0dNR/7+DgwPXr1x/o4+TkBICpqSk2Njakp6c/1r7PWmny3+/QoUO4uLhgZmb27EP/V7YnzZ+Tk8PatWt57733yjTzf2d70vxXrlxBo9HwzjvvMGDAANauXVum2e/P96Rj6N27NxYWFri5udG9e3fefvttqlSpYnT5n8W+T8vTyhAWFkZhYSF16tR5mvEeqTT5dTodCxcuZMqUKc8q3kOZlum7iVK5dOkSS5Ys4ZtvvjF0lL9k1apVDB8+HCsrK0NHeSLFxcWcPXuW7du3Y2FhwYgRI2jevDmdOnUydLTHFhYWhlarJTg4mMzMTN544w06d+5M7dq1DR3tuXLjxg0mT57MwoULH3qWYqw2bdpEly5dShS4slBuCpSDgwMpKSn6769fv66/7HV/n+TkZBwdHSkqKiIrKws7O7vH2vdZK01+gJSUFN577z0WLlxY5r953cv2pPnPnz/PoUOHWLJkCZmZmWi1WszNzRk2bFi5yO/o6Ej79u2pWrUqAF26dCEiIqLMC1RpxrBy5UpeffVVKlWqRLVq1WjTpg3h4eFlWqBK8/+hg4MDp06dKrFvhw4dnnrGR2Uozc+R7OxsfH19+eCDDx76YNRnrTT5Q0NDOXv2LJs3byYnJ4fCwkIsLS3x8/N7VnGBcnSJ7+WXXyYuLo7ExEQKCgrYv38/7u7uJfq4u7vrZ/ccOnSIV155BY1Gg7u7O/v376egoIDExETi4uJo0aJFucmfmZnJqFGjmDRpEm3bti3T3PeUJv+mTZs4duwYx44dY/jw4fj6+pZpcSptfjc3N6Kjo/X3cE6fPk2jRo3KNH9px+Dk5MRvv/0GwJ07dzh//jwNGjQwuvx/xs3NjePHj3P79m1u377N8ePHcXNze8aJSypN/oKCAsaOHcvf/vY3PD09n3HShytN/qVLlxIUFMSxY8eYMmUKr7322jMvTkD5mcWnlFJBQUGqV69eysPDQ61evVoppdSyZcvU0aNHlVJK5eXlqXHjxqkePXqogQMHqoSEBP2+q1evVh4eHqpXr14qKCioXOX//PPPVcuWLVX//v31f1JTU8tN/vutWLHCILP4lCpd/l27dikvLy/l7e2tFi5caJD8Sj35GLKzs9W4ceOUl5eX6tOnj1q7dq1R5j9//rx69dVXVcuWLVWHDh2Ul5eXft9t27apHj16qB49eqjt27eXq/y7du1SLi4uJf4fvnDhQrnJf78dO3aU2Sw+WW5DCCGEUSo3l/iEEEI8X6RACSGEMEpSoIQQQhglKVBCCCGMkhQoIYQQRkkKlBBCCKMkBUoIIYRR+n9de09aYys0bgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Confustion matrix by model\n",
"confusion_matrix(\n",
" test_stats_list,\n",
" train_metadata_json,\n",
" 'label',\n",
" [10,10,10],\n",
" False,\n",
" model_names=models_list,\n",
" output_directory='./viz2',\n",
" file_format='png'\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.8"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: examples/ray/kubernetes/README.md
================================================
## Running on Kubernetes
### Connect to k8s cluster with a Ray operator
You should now be pointing to your cluster with `kubectl`. Check the nodes to make sure you're connected correctly:
```
kubectl get nodes
```
We recommend using the [Kuberay](https://github.com/ray-project/kuberay) implementation of the Ray Operator to launch Ray clusters.
### Configure the Ray cluster
First choose your preferred cluster template from `clusters`, for example:
```
export CLUSTER_NAME=ludwig-ray-cpu-cluster
```
### Start the cluster
```
./utils/ray_up.sh $CLUSTER_NAME
```
### Submit a script for execution
```
./utils/submit.sh $CLUSTER_NAME scripts/train.py
```
### SSH into the head node
```
./utils/attach.sh $CLUSTER_NAME
```
### Run the Ray Dashboard
```
./utils/dashboard.sh $CLUSTER_NAME
```
Navigate to http://localhost:8267
### (For Ludwig Developers) Sync local Ludwig repo
```
./utils/rsync_up.sh $CLUSTER_NAME ~/repos/ludwig
```
### Shutdown the cluster
```
./utils/ray_down.sh $CLUSTER_NAME
```
### Connecting to remote filesystems (S3, GCS, etc.)
Build a custom Docker image deriving from `ludwig-ray` or `ludwig-ray-gpu` containing the library needed for your
data:
- `s3fs`
- `adlfs`
- `gcsfs`
Set environment variables into the cluster YAML definition with your credentials. For example, you can connect to S3 using the environment variables described in the [boto3 documentation](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/configuration.html#using-environment-variables).
You could also include the credentials directly into the Docker image if they don't need to be configured at runtime.
================================================
FILE: examples/ray/kubernetes/clusters/ludwig-ray-cpu-cluster.yaml
================================================
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: ludwig-ray-cpu-cluster
spec:
rayVersion: "2.3.1"
headGroupSpec:
serviceType: ClusterIP
replicas: 1
rayStartParams:
port: "6379"
metrics-export-port: "8080"
node-manager-port: "22346"
object-manager-port: "22345"
object-store-memory: "200000000"
redis-password: "LetMeInRay"
dashboard-host: "0.0.0.0"
node-ip-address: $MY_POD_IP
block: "true"
template:
metadata:
labels:
rayCluster: ludwig-ray-cpu-cluster
rayNodeType: head
groupName: headgroup
annotations:
key: value
spec:
volumes:
- emptyDir:
medium: Memory
name: dshm
containers:
- name: ray-head
image: ludwigai/ludwig-ray:master
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- ray stop
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- containerPort: 6379
name: redis
protocol: TCP
- containerPort: 10001
name: client
protocol: TCP
- containerPort: 8265
name: dashboard
protocol: TCP
- containerPort: 8000
name: ray-serve
protocol: TCP
- containerPort: 8080
name: metrics
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16Gi
requests:
cpu: "4"
memory: 8Gi
securityContext:
capabilities:
add:
- SYS_PTRACE
workerGroupSpecs:
- replicas: 1
minReplicas: 1
maxReplicas: 1
groupName: worker-cpu
rayStartParams:
redis-password: "LetMeInRay"
node-ip-address: $MY_POD_IP
block: "true"
template:
metadata:
labels:
rayCluster: ludwig-ray-cpu-cluster
rayNodeType: worker
groupName: worker-cpu
annotations:
key: value
spec:
volumes:
- emptyDir:
medium: Memory
name: dshm
initContainers:
- name: init-myservice
image: busybox:1.28
command:
[
"sh",
"-c",
"until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done",
]
containers:
- name: machine-learning
image: ludwigai/ludwig-ray:master
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- ray stop
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16Gi
requests:
cpu: "4"
memory: 8Gi
================================================
FILE: examples/ray/kubernetes/clusters/ludwig-ray-gpu-cluster.yaml
================================================
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: ludwig-ray-gpu-cluster
spec:
rayVersion: "2.3.1"
headGroupSpec:
serviceType: ClusterIP
replicas: 1
rayStartParams:
port: "6379"
metrics-export-port: "8080"
node-manager-port: "22346"
object-manager-port: "22345"
object-store-memory: "200000000"
redis-password: "LetMeInRay"
dashboard-host: "0.0.0.0"
node-ip-address: $MY_POD_IP
block: "true"
template:
metadata:
labels:
rayCluster: ludwig-ray-gpu-cluster
rayNodeType: head
groupName: headgroup
annotations:
key: value
spec:
volumes:
- emptyDir:
medium: Memory
name: dshm
containers:
- name: ray-head
image: ludwigai/ludwig-ray-gpu:master
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- ray stop
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- containerPort: 6379
name: redis
protocol: TCP
- containerPort: 10001
name: client
protocol: TCP
- containerPort: 8265
name: dashboard
protocol: TCP
- containerPort: 8000
name: ray-serve
protocol: TCP
- containerPort: 8080
name: metrics
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16Gi
nvidia.com/gpu: "1"
requests:
cpu: "4"
memory: 8Gi
securityContext:
capabilities:
add:
- SYS_PTRACE
workerGroupSpecs:
- replicas: 1
minReplicas: 1
maxReplicas: 1
groupName: worker-gpu
rayStartParams:
redis-password: "LetMeInRay"
node-ip-address: $MY_POD_IP
block: "true"
template:
metadata:
labels:
rayCluster: ludwig-ray-gpu-cluster
rayNodeType: worker
groupName: worker-gpu
annotations:
key: value
spec:
volumes:
- emptyDir:
medium: Memory
name: dshm
initContainers:
- name: init-myservice
image: busybox:1.28
command:
[
"sh",
"-c",
"until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done",
]
containers:
- name: machine-learning
image: ludwigai/ludwig-ray-gpu:master
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- ray stop
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16Gi
nvidia.com/gpu: "1"
requests:
cpu: "4"
memory: 8Gi
================================================
FILE: examples/ray/kubernetes/utils/attach.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
head_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)
kubectl exec -it $head_pod -- /bin/bash
================================================
FILE: examples/ray/kubernetes/utils/dashboard.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
head_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)
kubectl port-forward ${head_pod} 8267:8265
================================================
FILE: examples/ray/kubernetes/utils/krsync.sh
================================================
#!/bin/bash
# https://serverfault.com/a/887402
if [ -z "$KRSYNC_STARTED" ]; then
export KRSYNC_STARTED=true
exec rsync --blocking-io --rsh "$0" $@
fi
# Running as --rsh
namespace=''
pod=$1
shift
# If use uses pod@namespace rsync passes as: {us} -l pod namespace ...
if [ "X$pod" = "X-l" ]; then
pod=$1
shift
namespace="-n $1"
shift
fi
exec kubectl $namespace exec -i $pod -- "$@"
================================================
FILE: examples/ray/kubernetes/utils/ray_down.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
kubectl delete -f clusters/$cluster_name.yaml
================================================
FILE: examples/ray/kubernetes/utils/ray_up.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
kubectl apply -f clusters/$cluster_name.yaml
================================================
FILE: examples/ray/kubernetes/utils/rsync_up.sh
================================================
#!/bin/bash
# Example: ./rsync_up.sh cluster-name ~/repos/ludwig
cluster_name="${1:-$CLUSTER_NAME}"
ludwig_local_dir=$2
pods=$(kubectl get pods --no-headers -o custom-columns=":metadata.name" | grep ${cluster_name}-)
script_full_path=$(dirname "$0")
echo "Rsync to head and workers..."
for pod in $pods
do
echo "Rsync to pod: $pod"
${script_full_path}/krsync.sh -a --progress --stats ${ludwig_local_dir}/ludwig/ ${pod}:/home/ray/anaconda3/lib/python3.7/site-packages/ludwig
done
================================================
FILE: examples/ray/kubernetes/utils/submit.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
py_script=$2
head_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)
fname=$(basename $py_script)
kubectl cp $py_script $head_pod:/home/ray/. && kubectl exec -it $head_pod -- python /home/ray/$fname
================================================
FILE: examples/ray/kubernetes/utils/upload.sh
================================================
#!/bin/bash
cluster_name="${1:-$CLUSTER_NAME}"
py_script=$2
head_pod=$(kubectl get pods | grep $cluster_name-head | cut -d' ' -f1)
fname=$(basename $py_script)
kubectl cp $py_script $head_pod:/home/ray/.
echo /home/ray/$fname
================================================
FILE: examples/regex_freezing/ecd_freezing_with_regex_training.py
================================================
import logging
import os
import shutil
import pandas as pd
import yaml
from datasets import load_dataset
from ludwig.api import LudwigModel
"""
To inspect model layers in the terminal, type: "ludwig collect_summary -pm resnet18"
For some models, a HuggingFace Token will be necessary.
Once you obtain one, use "export HUGGING_FACE_HUB_TOKEN=""" in the terminal.
"""
dataset = load_dataset("beans")
train_df = pd.DataFrame(
{"image_path": [f"train_{i}.jpg" for i in range(len(dataset["train"]))], "label": dataset["train"]["labels"]}
)
test_df = pd.DataFrame(
{"image_path": [f"test_{i}.jpg" for i in range(len(dataset["test"]))], "label": dataset["test"]["labels"]}
)
os.makedirs("train_images", exist_ok=True)
os.makedirs("test_images", exist_ok=True)
for i, img in enumerate(dataset["train"]["image"]):
img.save(f"train_images/train_{i}.jpg")
for i, img in enumerate(dataset["test"]["image"]):
img.save(f"test_images/test_{i}.jpg")
train_df["image_path"] = train_df["image_path"].apply(lambda x: os.path.join("train_images", x))
test_df["image_path"] = test_df["image_path"].apply(lambda x: os.path.join("test_images", x))
train_df.to_csv("beans_train.csv", index=False)
test_df.to_csv("beans_test.csv", index=False)
config = yaml.safe_load(r"""
input_features:
- name: image_path
type: image
encoder:
type: resnet
use_pretrained: true
trainable: true
output_features:
- name: label
type: category
trainer:
epochs: 1
batch_size: 5
layers_to_freeze_regex: '(layer1\.0\.*|layer2\.0\.*)'
""")
model = LudwigModel(config, logging_level=logging.INFO)
train_stats = model.train(dataset="beans_train.csv", skip_save_model=True)
eval_stats, predictions, output_directory = model.evaluate(dataset="beans_test.csv")
print("Training Statistics: ", train_stats)
print("Evaluation Statistics: ", eval_stats)
shutil.rmtree("train_images")
shutil.rmtree("test_images")
os.remove("beans_train.csv")
os.remove("beans_test.csv")
================================================
FILE: examples/regex_freezing/llm_freezing_with_regex_training.py
================================================
import logging
import yaml
from ludwig.api import LudwigModel
"""
To inspect model layers in the terminal, type: "ludwig collect_summary -pm resnet18"
For some models, a HuggingFace Token will be necessary.
Once you obtain one, use "export HUGGING_FACE_HUB_TOKEN=""" in the terminal.
"""
config_str = yaml.safe_load(r"""
model_type: llm
base_model: facebook/opt-350m
adapter:
type: lora
prompt:
template: |
### Instruction:
Generate a concise summary of the following text, capturing the main points and conclusions.
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
preprocessing:
max_sequence_length: 256
output_features:
- name: output
type: text
preprocessing:
max_sequence_length: 256
trainer:
type: finetune
layers_to_freeze_regex: (decoder\.layers\.22\.final_layer_norm\.*)
learning_rate: 0.0001
batch_size: 5
gradient_accumulation_steps: 16
epochs: 1
learning_rate_scheduler:
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
generation:
pad_token_id : 0
""")
model = LudwigModel(config=config_str, logging_level=logging.INFO)
results = model.train(dataset="ludwig://alpaca")
================================================
FILE: examples/semantic_segmentation/camseq.py
================================================
import logging
import os
import shutil
import pandas as pd
import torch
import yaml
from torchvision.utils import save_image
from ludwig.api import LudwigModel
from ludwig.datasets import camseq
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
# set up Python dictionary to hold model training parameters
with open("./config_camseq.yaml") as f:
config = yaml.safe_load(f.read())
# Define Ludwig model object that drive model training
model = LudwigModel(config, logging_level=logging.INFO)
# load Camseq dataset
df = camseq.load(split=False)
pred_set = df[0:1] # prediction hold-out 1 image
data_set = df[1:] # train,test,validate on remaining images
# initiate model training
train_stats, _, output_directory = model.train( # training statistics # location for training results saved to disk
dataset=data_set,
experiment_name="simple_image_experiment",
model_name="single_model",
skip_save_processed_input=True,
)
# print("{}".format(model.model))
# predict
pred_set.reset_index(inplace=True)
pred_out_df, results = model.predict(pred_set)
if not isinstance(pred_out_df, pd.DataFrame):
pred_out_df = pred_out_df.compute()
pred_out_df["image_path"] = pred_set["image_path"]
pred_out_df["mask_path"] = pred_set["mask_path"]
for index, row in pred_out_df.iterrows():
pred_mask = torch.from_numpy(row["mask_path_predictions"])
pred_mask_path = os.path.dirname(os.path.realpath(__file__)) + "/predicted_" + os.path.basename(row["mask_path"])
print(f"\nSaving predicted mask to {pred_mask_path}")
if torch.any(pred_mask.gt(1)):
pred_mask = pred_mask.float() / 255
save_image(pred_mask, pred_mask_path)
print("Input image_path: {}".format(row["image_path"]))
print("Label mask_path: {}".format(row["mask_path"]))
print(f"Predicted mask_path: {pred_mask_path}")
================================================
FILE: examples/semantic_segmentation/config_camseq.yaml
================================================
input_features:
- name: image_path
type: image
preprocessing:
num_processes: 6
infer_image_max_height: 1024
infer_image_max_width: 1024
encoder: unet
output_features:
- name: mask_path
type: image
preprocessing:
num_processes: 6
infer_image_max_height: 1024
infer_image_max_width: 1024
infer_image_num_classes: true
num_classes: 32
decoder:
type: unet
num_fc_layers: 0
loss:
type: softmax_cross_entropy
combiner:
type: concat
num_fc_layers: 0
trainer:
epochs: 100
early_stop: -1
batch_size: 1
max_batch_size: 1
================================================
FILE: examples/serve/README.md
================================================
# Ludwig Model Serve Example
This example shows Ludwig's http model serving capability, which is able to load a pre-trained Ludwig model and respond to REST APIs for predictions.
A simple client program illustrates how to invoke the REST API to retrieve predictions for provided input features. The two REST APIs covered by this example:
| REST API | Description |
| ---------------- | ------------------------------- |
| `/predict` | Single record prediction |
| `/batch_predict` | Prediction for batch of records |
### Preparatory Steps
- Run the `simple_model_training.py` example in `examples/titanic`. This should result the following file structures:
```
examples/
titantic/
results/
simple_experiment_simple_model/
model/
description.json
training_statistics.json
```
### Run Model Server Example
- Open two terminal windows
- In first terminal window:
- Ensure current working directory is `examples/serve`
- Start ludwig model server with the `titanic` trained model. The following command uses the default host address (`0.0.0.0`) and port number (`8000`).
```
ludwig serve --model_path ../titanic/results/simple_experiment_simple_model/model
```
Sample start up messages for ludwig model server
```
███████████████████████
█ █ █ █ ▜█ █ █ █ █ █
█ █ █ █ █ █ █ █ █ █ ███
█ █ █ █ █ █ █ █ █ ▌ █
█ █████ █ █ █ █ █ █ █ █
█ █ ▟█ █ █ █
███████████████████████
ludwig v0.3 - Serve
INFO: Started server process [4429]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
```
- In the second terminal window:
- Ensure current working director is `examples/serve`
- Run the sample client program
```
python client_program.py
```
Output should look like this
````
retrieved 1309 records for predictions
single record for prediction:
{'PassengerId': 1, 'Survived': 0.0, 'Pclass': 3, 'Name': 'Braund, Mr. Owen Harris', 'Sex': 'male', 'Age': 22.0, 'SibSp': 1, 'Parch': 0, 'Ticket': 'A/5 21171', 'Fare': 7.25, 'Cabin': nan, 'Embarked': 'S', 'split': 0}
invoking REST API /predict for single record...
Received 1 predictions
Sample predictions:
Survived_predictions Survived_probabilities_False Survived_probabilities_True Survived_probability
0 False 0.906132 0.093868 0.906132
invoking REST API /batch_predict for entire dataframe...
Received 1309 predictions
Sample predictions:
Survived_predictions Survived_probabilities_False Survived_probabilities_True Survived_probability
0 False 0.906132 0.093868 0.906132
1 True 0.165714 0.834286 0.834286
2 True 0.441169 0.558831 0.558831
3 True 0.228311 0.771689 0.771689
4 False 0.878072 0.121928 0.878072```
````
================================================
FILE: examples/serve/client_program.py
================================================
import sys
import pandas as pd
import requests
from ludwig.datasets import titanic
# Ludwig model server default values
LUDWIG_HOST = "0.0.0.0"
LUDWIG_PORT = "8000"
#
# retrieve data to make predictions
#
test_df = titanic.load()
print(f"retrieved {test_df.shape[0]:d} records for predictions")
#
# execute REST API /predict for a single record
#
# get a single record from dataframe and convert to list of dictionaries
prediction_request_dict_list = test_df.head(1).to_dict(orient="records")
# extract dictionary for the single record only
prediction_request_dict = prediction_request_dict_list[0]
print("single record for prediction:\n", prediction_request_dict)
# construct URL
predict_url = "".join(["http://", LUDWIG_HOST, ":", LUDWIG_PORT, "/predict"])
print("\ninvoking REST API /predict for single record...")
# connect using the default host address and port number
try:
response = requests.post(predict_url, data=prediction_request_dict)
except requests.exceptions.ConnectionError as e:
print(e)
print("REST API /predict failed")
sys.exit(1)
# check if REST API worked
if response.status_code == 200:
# REST API successful
# convert JSON response to panda dataframe
pred_df = pd.read_json("[" + response.text + "]", orient="records")
print(f"\nReceived {pred_df.shape[0]:d} predictions")
print("Sample predictions:")
print(pred_df.head())
else:
# Error encountered during REST API processing
print("\nError during predictions, error code: ", response.status_code, "reason code: ", response.text)
#
# execute REST API /batch_predict on a pandas dataframe
#
# create json representation of dataset for REST API
prediction_request_json = test_df.to_json(orient="split")
print("\ninvoking REST API /batch_predict for entire dataframe...")
# construct URL
batch_predict_url = "".join(["http://", LUDWIG_HOST, ":", LUDWIG_PORT, "/batch_predict"])
# connect using the default host address and port number
response = requests.post(batch_predict_url, data={"dataset": prediction_request_json})
try:
response = requests.post(batch_predict_url, data={"dataset": prediction_request_json})
except requests.exceptions.ConnectionError as e:
print(e)
print("REST API /batch_predict failed")
sys.exit(1)
# check if REST API worked
if response.status_code == 200:
# REST API successful
# convert JSON response to panda dataframe
pred_df = pd.read_json(response.text, orient="split")
print(f"\nReceived {pred_df.shape[0]:d} predictions")
print("Sample predictions:")
print(pred_df.head())
else:
# Error encountered during REST API processing
print("\nError during predictions, error code: ", response.status_code, "reason code: ", response.text)
================================================
FILE: examples/synthetic/train.py
================================================
"""Train a model from entirely synthetic data."""
import logging
import tempfile
import yaml
from ludwig.api import LudwigModel
from ludwig.data.dataset_synthesizer import build_synthetic_dataset_df
config = yaml.safe_load("""
input_features:
- name: Pclass (new)
type: category
output_features:
- name: Survived
type: binary
""")
df = build_synthetic_dataset_df(120, config)
model = LudwigModel(config, logging_level=logging.INFO)
with tempfile.TemporaryDirectory() as tmpdir:
model.train(dataset=df, output_directory=tmpdir)
================================================
FILE: examples/tabnet/higgs/medium_config.yaml
================================================
input_features:
- name: lepton_pT
type: number
- name: lepton_eta
type: number
- name: lepton_phi
type: number
- name: missing_energy_magnitude
type: number
- name: missing_energy_phi
type: number
- name: jet_1_pt
type: number
- name: jet_1_eta
type: number
- name: jet_1_phi
type: number
- name: jet_1_b-tag
type: number
- name: jet_2_pt
type: number
- name: jet_2_eta
type: number
- name: jet_2_phi
type: number
- name: jet_2_b-tag
type: number
- name: jet_3_pt
type: number
- name: jet_3_eta
type: number
- name: jet_3_phi
type: number
- name: jet_3_b-tag
type: number
- name: jet_4_pt
type: number
- name: jet_4_eta
type: number
- name: jet_4_phi
type: number
- name: jet_4_b-tag
type: number
- name: m_jj
type: number
- name: m_jjj
type: number
- name: m_lv
type: number
- name: m_jlv
type: number
- name: m_bb
type: number
- name: m_wbb
type: number
- name: m_wwbb
type: number
output_features:
- name: label
type: binary
weight_regularization: null
combiner:
type: tabnet
size: 32 # N_a
output_size: 96 # N_d
sparsity: 0.000001 # lambda_sparse
bn_virtual_divider: 32 # factor to divide batch_size B to get B_v from the paper
bn_momentum: 0.1 # m_B
num_steps: 8 # N_steps
relaxation_factor: 2 # gamma
bn_virtual_bs: 256 # B_v
trainer:
batch_size: 8192 # B
eval_batch_size: 500000 # 65536 131072 262144 524288
epochs: 1000
early_stop: 20
learning_rate: 0.025
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 10000
decay_rate: 0.9
staircase: true
validation_field: label
================================================
FILE: examples/tabnet/higgs/small_config.yaml
================================================
input_features:
- name: lepton_pT
type: number
- name: lepton_eta
type: number
- name: lepton_phi
type: number
- name: missing_energy_magnitude
type: number
- name: missing_energy_phi
type: number
- name: jet_1_pt
type: number
- name: jet_1_eta
type: number
- name: jet_1_phi
type: number
- name: jet_1_b-tag
type: number
- name: jet_2_pt
type: number
- name: jet_2_eta
type: number
- name: jet_2_phi
type: number
- name: jet_2_b-tag
type: number
- name: jet_3_pt
type: number
- name: jet_3_eta
type: number
- name: jet_3_phi
type: number
- name: jet_3_b-tag
type: number
- name: jet_4_pt
type: number
- name: jet_4_eta
type: number
- name: jet_4_phi
type: number
- name: jet_4_b-tag
type: number
- name: m_jj
type: number
- name: m_jjj
type: number
- name: m_lv
type: number
- name: m_jlv
type: number
- name: m_bb
type: number
- name: m_wbb
type: number
- name: m_wwbb
type: number
output_features:
- name: label
type: binary
weight_regularization: null
combiner:
type: tabnet
size: 24 # N_a
output_size: 26 # N_d
sparsity: 0.000001 # lambda_sparse
bn_virtual_divider: 32 # factor to divide batch_size B to get B_v from the paper
bn_momentum: 0.4 # m_B
num_steps: 5 # N_steps
relaxation_factor: 1.5 # gamma
bn_virtual_bs: 512 # B_v
trainer:
batch_size: 16384 # B
eval_batch_size: 500000 # 65536 131072 262144 524288
epochs: 1000
early_stop: 20
learning_rate: 0.02
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.9
staircase: true
validation_field: label
================================================
FILE: examples/tabnet/higgs/train_higgs_medium.py
================================================
import logging
from ludwig.api import LudwigModel
from ludwig.datasets import higgs
model = LudwigModel(
config="medium_config.yaml",
logging_level=logging.INFO,
)
higgs_df = higgs.load()
model.train(dataset=higgs_df, experiment_name="higgs_medium", model_name="higgs_tabnet_medium")
================================================
FILE: examples/tabnet/higgs/train_higgs_small.py
================================================
import logging
from ludwig.api import LudwigModel
from ludwig.datasets import higgs
model = LudwigModel(
config="small_config.yaml",
logging_level=logging.INFO,
)
higgs_df = higgs.load()
model.train(dataset=higgs_df, experiment_name="higgs_small", model_name="higgs_tabnet_small")
================================================
FILE: examples/titanic/README.md
================================================
# Kaggle Titanic Survivor Prediction
This API example is based on [Ludwig's Kaggle Titanic example](https://ludwig-ai.github.io/ludwig-docs/examples/#kaggles-titanic-predicting-survivors) for predicting probability of surviving.
### Preparatory Steps
Create and download your [Kaggle API Credentials](https://github.com/Kaggle/kaggle-api#api-credentials).
The Titanic dataset is hosted by Kaggle, and as such Ludwig will need to authenticate you through the Kaggle API to download the dataset. You will also need to join [the competition](https://www.kaggle.com/c/titanic) to enable downloading of the data.
### Examples
| File | Description |
| ---------------------------- | ------------------------------------------------------------------------------ |
| simple_model_training.py | Demonstrates using Ludwig api for training a model. |
| multiple_model_training.py | Trains two models and generates a visualization for results of training. |
| model_training_results.ipynb | Example for extracting training statistics and generate custom visualizations. |
Enter `python simple_model_training.py` will train a single model. Results of model training will be stored in this location.
```
./results/
simple_experiment_simple_model/
```
Enter `python multiple_model_training.py` will train two models and generate standard Ludwig visualizations comparing the
two models. Results will in the following directories:
```
./results/
multiple_model_experiment_model1/
multiple_model_experiment_model2/
./visualizations/
learning_curves_Survived_accuracy.png
learning_curves_Survived_loss.png
```
This is the standard Ludwig learning curve plot from training the two models

This is the custom visualization created by the Jupyter notebook `model_training_results.ipynb`.

================================================
FILE: examples/titanic/model1_config.yaml
================================================
input_features:
- name: Pclass
type: category
- name: Sex
type: category
- name: Age
type: number
preprocessing:
missing_value_strategy: fill_with_mean
- name: SibSp
type: number
- name: Parch
type: number
- name: Fare
type: number
preprocessing:
missing_value_strategy: fill_with_mean
- name: Embarked
type: category
output_features:
- name: Survived
type: binary
================================================
FILE: examples/titanic/model2_config.yaml
================================================
input_features:
- name: Pclass
type: category
- name: Sex
type: category
- name: Age
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: SibSp
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: Parch
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: Fare
type: number
preprocessing:
missing_value_strategy: fill_with_mean
normalization: zscore
- name: Embarked
type: category
output_features:
- name: Survived
type: binary
fc_layers: [{ output_size: 50 }]
================================================
FILE: examples/titanic/model_training_results.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Custom Analysis of Training Results\n",
"\n",
"Notebook demonstrates two methods for plotting training results. First method uses Ludwig's visualization api. Second method illustrates converting Ludwig training statistics into a pandas dataframe and plotting data with seaborn package.\n",
"\n",
"This notebook is dependent on running the multiple model training example beforehand. To run the mulitple model training example, enter this command:\n",
"``` \n",
"python multiple_model_training.py\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Import required libraries"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"pycharm": {
"is_executing": false
}
},
"outputs": [],
"source": [
"from ludwig.utils.data_utils import load_json\n",
"from ludwig.visualize import learning_curves\n",
"import pandas as pd\n",
"import numpy as np\n",
"import os.path\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generate Annotated Learning Curves Using Ludwig Visualization API"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdeXxU1d348c+ZLTsJhJ0AIezIqlDRuiBiiywi4to+tq64UXBpK60/bB8fxaVWC1hpre1T20ctakFFsFXcLQoSiAoGBMKWsCUhezL7+f1x7ywJk5CETJbJ9/1yXjNz77n3njnB+c459yxKa40QQgjR3ljaOgNCCCFEJBKghBBCtEsSoIQQQrRLEqCEEEK0SxKghBBCtEsSoIQQQrRLEqBEzFJKna+U2tXW+eislFJvK6V+HIXz/lUp9XBLn1e0PxKgRFQopfYrpaa1ZR601p9orYdH6/xKqe8rpT5WSlUopQqVUh8ppS6L1vVaglJqjlIqRylVrpQqUkq9r5QaFI1raa0v1Vq/EI1zi85BApTosJRS1ja89pXAq8DfgAygF/AgMLsZ51JKqaj/v6iUGoKR3/uAVGAQ8HvA14xz2Vo2d0KcTAKUaFVKKYtSarFSaq9Sqlgp9YpSqlvY/leVUkeVUmVm7eSMsH1/VUqtVEqtV0pVAReZNbWfKqW+Mo9ZpZSKN9NPUUrlhx1fb1pz/8+VUkeUUoeVUrcopbT5pV73MyjgKeB/tNbPa63LtNZ+rfVHWutbzTS/Vkr9X9gxmeb5bOb7D5VSjyil/gNUAz9TSm2pc517lFJvmq/jlFJPKqUOKqWOKaX+oJRKMPd1V0q9pZQqVUqdUEp9Uk/AGw/s01q/pw0VWut/aq0PhpXvw2HXj1R+9yulvgKqzNev1cnzMqXU8rDPeIuZ91Kl1OiwdD2UUjVKqZ7m+1lmza5UKbVRKTU2LO0EpdRWs6a6CohHdAoSoERr+wlwOXAh0BcowfgVH/A2MBToCWwFXqxz/A+AR4AU4FNz29XAdIwawVjghgauHzGtUmo6cC8wDRgCTGngHMOB/sBrDaRpjOuB+Rif5Q/AcKXU0LD9PwBeMl8/BgzDCDJDgH4YNTYwakT5QA+MmtwvgUhzmG0FRiilnlZKXaSUSm5Gnq8DZgJpwD+AGUqpFAjWaK8OyzMAWmsXsNo8NuBq4COt9XGl1ATgL8BtQDrwR+BNM7A5gNeBvwPdMGqt85qRb9EBSYASre124AGtdb75xfVr4MpAzUJr/Rfzl31g3zilVGrY8W9orf9j1lic5rblWuvDWusTwFqML/H61Jf2auB/tdY7tNbV5rXrk24+H2nsh67HX83rebXWZcAbmF/iZqAagfFFrTAC2T1a6xNa6wpgKXCteR4P0AcYqLX2mPfeTgpQWus8jMDbD3gFKDJrTU0JVMu11oe01jVa6wMYQW+uuW8qUK21/jzCcS+F5RdqB9/5wB+11pu01j7zvpULmGw+7MDvzM/2GvBFE/IrOjAJUKK1DQTWmE05pUAuxj2QXkopq1LqMbP5rxzYbx7TPez4QxHOeTTsdTXQ0BdufWn71jl3pOsEFJvPfRpI0xh1r/ESoVrGD4DXzWDZA0gEssPK7V/mdoDfAHuAd5RSeUqpxfVdUGv9udb6aq11D+B84ALggRbM80tE9gGQqJQ6WymVifHDYI25byBwX+CzmZ+vP8bfpC9QUCfgHmhCfkUHJgFKtLZDwKVa67SwR7zWugDjC24ORjNbKpBpHqPCjo/W9PtHMDo7BPRvIO0ujM/RUFNTFUZQCegdIU3dz/Iu0EMpNR7jSz/wZV8E1ABnhJVZqtY6GcCscd6ntc4CLgPuVUpd3EDeMI/7AqPpLXBvqDl5fhWYopTKwKhJRQxQWmsfRq3tOvPxllkTBKMsH6nzbyJRa/0yxt+ln1mLDBhwqs8mYoMEKBFNdqVUfNjDhnGv5RGl1EAI3iyfY6ZPwWjaKcb4olzainl9BbhRKTVSKZUILKkvoflr/l5giVLqRqVUF2V0/jhPKfWcmSwHuEApNcBsovzFqTKgtfZgfOH/BuN+y7vmdj/wJ+DpsE4F/ZRS3zdfz1JKDTG/xMswaqT+uuc383dr2DlGYAS0QJNcDsY9pW5Kqd7A3Y3IcyHwIfC/GB0wchtI/hJwDfBDageyPwG3m7UrpZRKUkrNNO9tfQZ4gYVKKbtS6grgO6fKl4gNEqBENK3H+OUfePwaWAa8idEcVYHx5Xi2mf5vGM03BcA3hL44o05r/TawHKMpak/YtV31pH8N48v2JuAwcAx4GOM+Elrrd4FVwFdANvBWI7PyEkYN8lWttTds+/2BfJnNnxswOmuA0alkA1CJ8YX+rNb6gwjnLsUISF8rpSoxmgnXAE+Y+/8OfInRtPqOmf+m5Lm+5j0AtNabMGppfTE6wwS2bwFuBZ7B6DSzB7PzitbaDVxhvj+BUearG5kv0cEpWbBQiJMppUYC24G4OoFCCNFKpAYlhEkpNdfs2twVeBxYK8FJiLYjAUqIkNuA48BejPs4d7RtdoTo3KSJTwghRLskNSghhBDtUrua8LF79+46MzOzScfU1NSQkJAQnQx1cFI2kUm51E/KJjIpl8haqlyys7OLzMHjtbSrAJWZmcmWLVtOnTBMTk4O48c3NLNN5yVlE5mUS/2kbCKTcomspcpFKRVxdhBp4hNCCNEuSYASQgjRLkmAEkII0S61q3tQQojOw+PxkJ+fj9PpPHXiNqaUIje3oWkGO6emlkt8fDwZGRnY7fZGpZcAJYRoE/n5+aSkpJCZmUntycrbn+rqahITE0+dsJNpSrlorSkuLiY/P59BgwY16hhp4hNCtAmn00l6enq7D06iZSilSE9Pb1KNObYClM8D+qRVBoQQ7ZQEp86lqX/v2GniqzoO2c8DGibdCQld2zpHQgghTkPs1KAKc8FdAe5KOJLd1rkRQnQyU6dO5cSJE41O84tf/IJzzjmHWbNm1Zt+w4YN7Nmzp8l5ee+993juuecaTHPs2DEWLlzY5HO3ptgJUFZH6LWrov50QgjRDlxxxRU8//zzDaZpKEB5vfWvBHPxxRczf/78Bs/dq1cvli9ffuqMtqHYaeJzpIReS4ASQpxCfn4+t9xyC+PHj2fbtm2MHj2aefPmsXz5ck6cOMGTTz7J2LFjKS0t5f777+fw4cMkJCTw0EMPMWLECEpKSrjvvvs4duwY48ePJ3xliDfeeIO///3veDwexo0bx69+9SusVmut60+aNIn8/Px687d161bef/99Nm/ezMqVK1mxYgUPPPAAI0aMIDs7m1mzZpGZmcnKlSvxeDykpaXx5JNP0r17d1avXs327dt58MEHWbx4McnJyWzfvp3CwkJ+9rOfMX36dPLz87n99tt56623WL16Ne+//z41NTUcOnSIadOm8fOf/xyAV199leeff56UlBRGjBiBw+HgwQcfjM4fpY7YCVBxyaHX7sq2y4cQosn+9HEev9vwLVVuX4udM8lh5e5pw7j1gqx60xw8eJBly5axdOlSrrzyStauXcvLL7/Me++9xx/+8AeeffZZVqxYwYgRI/jjH//IZ599xv33388bb7zB73//e84880wWLFjAhx9+yGuvvQbA3r17efvtt3n55Zex2+38+te/Zu3atVx++eVNyv+ZZ57J1KlTmTJlCtOnTw9u93g8rF5trHpfVlbGK6+8glIqGEgWL1580rmOHz/OSy+9RF5eHnfccUet8wXk5uby+uuv43A4mD59Otdffz0Wi4WVK1eyevVqkpKS+PGPf8yIESOa9DlOR9QClFJqOLAqbFMW8KDW+nfRuF6RM47u5mtPTTmNGwYmhGgP/vRJXosGJ4Aqt48/fZLXYIDKyMhg+PDhAAwZMoRzzjkHpRTDhw+noKAAgOzsbJ544gkAzjnnHEpLS6msrOSLL77gmWeeAWDKlCmkpqYC8Nlnn7F9+3auvPJKINSdvqXMmDEj+Pro0aPcc889FBYW4na7ycjIiHjMtGnTsFgsDBkyhKKioohpzjnnHFJSjJaowYMHU1BQQGlpKZMmTSItLQ2A6dOns3///hb7LKcStQCltd4FjAdQSlmBAmBNtK7nUknB1xZPJaWVbtKSHQ0cIYRoL249PysqNahbz68/OAE4HKHvCIvFEnyvlMLna15etNbMnTuX++67r1nHn0r48hYPP/wwN9xwAxdffDGbNm0KBsy6wj9nfcLTWK3WZn/+ltRaTXwXA3u11hGnVG8JvXuk4FV2bNqDFR9bdx3n/HF9sdtipx+IELHq1guyGqzptKWJEyeyfv16hg0bxqZNm+jatSvJyclMmjSJtWvXcuedd/LRRx9RVlYGGDWRO++8kxtuuIH09HRKS0upqqqiX79+Tb52UlISVVVV9e6vqKigV69eALz++uvN+4ANGDNmDEuXLqWsrIykpCTeeecdhg0b1uLXqU9rBahrgZcj7VBKzQfmA/Tp04ecnJwmnbi4uDh4zAgVh017APC5Kvhg60F62EvprGMBw8tGhEi51K81y0YpRXV1datcKxKn04nf7w/mwev14nK5qK6urrXv5ptv5le/+hWzZs0iPj6eX//611RXV3PTTTfxi1/8grVr1zJu3Dh69+5NTU0Nffv25Y477uCGG25Aa43NZmPx4sV07doVv99PTU0N1dXVLF68mOzsbEpLSzn//PO5/fbbmTt3bq08XnzxxTz00EO88MIL/OY3v8Hn8+F0OoN5vvXWW1m4cCFdunRh0qRJ+Hw+qqurcbvdeL1eqqura30uMGp4dT9jeHoAn8+Hy+UiJSWFG2+8kXnz5pGamkpmZibx8fG1yqypf0O3293of2MqvOdJNCilHMBh4Ayt9bGG0k6cOFGf1oKFX/wByoxK2ifx8yiy9WdcZgpZvTvnHFqyyFpkUi71a82yyc3NZeTIka1yrdPVmefiq6qqIikpCa/Xy4IFC5g3bx6XXHIJ0LxyifR3V0pla60n1k3bGjWoS4GtpwpOLaHMH0+q+TpOG1F9+8EKeqXFkRRvrf9AIYQQET3zzDNs3LgRl8vFeeedx7Rp01rt2q0RoK6jnua9lrRxTxG7vynnx/2N92l2JwWAzw85+8o5d0SazPslhBBNdP/997fZtaPag0AplQRcAqyO5nUAissqGODZF3yfYgu1ix4vc1NQ7Ip2FoQQQrSgqAYorXWV1jpda10WzesAfN+yiYt8nwXfb91ziIz0uOD7rw5U4PbKTOdCCNFRxEwfbEfVEfCEak1J1PDnz/cQbzc+osvjZ8dBmWFCCCE6ipgJUCT3BndN8G2PODf/2nGMI2FjCPYfr6G4wt0WuRNCCNFEsROgUnqBO1SD6uEwAtHSf31DckLoY27LK8fvj27XeiFE5xON5TaaasWKFfz5z38GYNmyZWzcuPGkNJs2beK2225r8Dy5ubl89NFHwfeNWb4jGmInQCX3qtXEl+7wYkHj9Wv+d1MeVovRg6+ixsfuI203OFAIIaBxy22cjkWLFnHuuec269i6Aaoxy3dEQ+zMZp7c21ju3eMEezxWpekZ7+Oo08bGvCJmnNGXJHPNqJ35lfRLjyM5PnY+vhCiadr7chsVFRVcdtllvPfee1gsFqqrq7n00kvZsGEDa9asYdWqVXg8HgYOHMgTTzxRa44+gMWLFwdnQv/4449ZunQpCQkJnHXWWcE0X331FY888ggul4v4+HiWLl1KRkYGy5cvx+l0kp2dzW233YbT6Qwu35Gfn88vf/lLSkpKSEtL4/HHH6dv3771LutxOmLnGzqhK1hsRjOfPR6An5zXmwc2GDP3PvrvHTw19yyqXX78Gr7cVyFjo4RoJ3YfrmJnfhXeFmx+t1kUIzKSGNo3qd407Xm5jcD6S5s3b2by5Ml8+OGHnHfeedjtdi655BKuvvpqAJ5++mlee+01rr/++ojncblcLFmyhBdeeIGBAwdy9913B/dlZWXx4osvYrPZ2LhxI08//TQrVqxg4cKFwYAEBJf3AGOC2rlz5zJ37lxeeuklHn74YZ599lmgcct6NEXsNPFZLCc18109No3hvYzp46vcPt76JvRr5XiZm/xiZ6tnUwhxsj1Hqls0OAF4/Zo9p2jODyy3EViKor7lNmbOnAmcvNzGnDlzgPqX25gzZw6fffYZhw4datZnmDFjBuvXrwdg3bp1waU2du/ezQ9+8ANmz57N2rVr2b17d73nyMvLIyMjg8zMTJRSXHbZZcF9FRUVLFq0iFmzZvHoo482eJ6Abdu2Be+bzZw5k+zs7OC+xizr0RSxE6DACFBhHSXs3ioemzcmOFns2q8P47eEppD/ar+MjRKiPRjSJxGbpWVbM2wWxZA+Dc8TF83lNt544w3eeOMN/v3vf/OTn/ykWeeaOnUqn376KaWlpezYsYPJkycDRvPdgw8+yNq1a1mwYAFud/N6Jy9btoyzzz6bt956i5UrVzb7PAGNWdajKWKniQ/MGlTYmGB3BRMyu3LjuYP4y3+MWSYef/cbfvX9sbi9GrdXs+NgJROyurRRhoUQAEP7NtwU15baermN0aNH88gjjzBlypTgfayqqip69OiBx+Nh7dq1wSU3IsnKyqKgoICDBw8yYMAA1q1bF9wXvlzHmjWh5foaWuZjwoQJrFu3jssvv5y3336biRNPmuO1xcRWDapOV3PcFQD89PvDyOhq3EA8XuFiS0FxMMn+4zUUlcvYKCFEZAsWLCA3N5fZs2fz29/+lsceewyAu+66iy1btjBz5kzeffdd+vbtCxgr8959993cdNNNzJ49m5tuuonCwsKTznvvvfdy7bXXsm/fPi644AJeffXViNefMWMGb775Zq2VdBctWsRVV13FddddR1ZWw+toxcXF8dBDDzF//nzmzp1Lt27dgvtuueUWnnrqKS6//HK8Xm9w+9lnn82ePXuYM2dOsIkxYMmSJaxevZrZs2ezbt06HnjggVOUYPNFfbmNpjjt5TY+WAq5r8Owi433vcfB6GsB+PjbQn70l83B41ZcOZHA3yMlwcrUMelYWriJoa3JshKRSbnUT5bbiKwzL7fRkGgvtxFbNag696BwhaY2umBYD644M1TFXvHxLqzmpzfGRtW/aqUQQojWF1sBKqV3xCa+gCUzR5GeZNzE+/Z4BftLQwFsZ34VlTVehBBCtA+xFaDqdDOvG6C6Jjl4cPao4PvffbATu81o1vNryNlfQXtq8hRCiM4sBgOU05hRAsBTA/7ataLLxvXlouE9ACMovZidF9xXKGOjhBCi3YixANUT0EZgCnDXXmJDKcXDc8eQ5DC6a362r5gyd2gxQxkbJYQQ7UNsBShbnDHlUa2OEhUnJeuXlsDPp48Ivn9ywzfYrEZTn9ur2X7g5GOEEEK0rtgKUGCuCxV+HyryIoX/NXkgZw5IA6DS7eOdXQXBfQcKnTI2SgjRJE1ZbuPIkSNcf/31zJgxg5kzZ/LCCy9ETL9hwwb27NnT5Lw0ZnmMY8eOsXDhwiafuzXFYIDqWaejROQAZbUoHp83FrtZc1q7/TBuHbpftS2vHJ+sGyWEiAKr1crixYtZv349q1at4qWXXooYiBoKUOEDa+tqzPIYvXr1Yvny5U3LeCuLramOwOhqXnYg9D5CE1/A0F4p3HXREH63wZgg8en3d/KLS0bj90Ol08fuw1WMyEiOdo6FEG2gLZfb6NmzJz179gQgOTmZrKwsjh07xpAhQ4Jptm7dyvvvv8/mzZtZuXIlK1as4IEHHmDEiBFkZ2cza9YsMjMzWblyJR6Ph7S0NJ588km6d+/O6tWrg7OR17cMRn5+PrfffjtvvfUWq1ev5v3336empoZDhw4xbdo0fv7znwPw6quv8vzzzwdnV3c4HMFZzqMtqgFKKZUGPA+MBjRwk9b6s2hek+ReUJQbeu9u+H7SHVMGs+6rI+w+XsnRCic5h08wtrcxFciugir6pceTkhB7cVyIdmXjCvjwsXpbPJrFkQxTFsO59U/U2h6W28jPzyc3N5dx48bV2n7mmWcyderU4JpOAR6PJ7j8RVlZGa+88gpKqWAgWbx48UnXaMwyGLm5ubz++us4HA6mT5/O9ddfj8ViYeXKlaxevZqkpCR+/OMfM2LEiJOOjZZoN/EtA/6ltR4BjANyT5H+9NWdTeIU/+DjbFYemzc2OOP5Xz/PA2X8EgqsGyVjo4SIso3PtGxwAuN8G59pMElbL7dRVVXFwoUL+eUvf0lycuNaa8Ln5Dt69Cg333wzs2fP5vnnn693uYzGLINxzjnnkJKSQlxcHIMHD6agoICvv/6aSZMmkZaWht1uP+31nZoqagFKKZUKXAD8GUBr7dZal0brekEpvWvfg2qgiS/grIFd+fE5mYBRzfvTZ6E/cmG5m0NFMjZKiKg6d4FR42lJjmTjvA0lacPlNjweDwsXLmT27Nl873vfa/T5w1fOffjhh/nhD3/I2rVreeihh+pdLqMxy2CEp7Farc3+/C0pmm1Xg4BC4H+VUuOAbGCR1rrWpHdKqfnAfIA+ffqQk5PTpIsUFxfXOia5sJwhYTUoV0UxuY045/f7+Hkr0UpRtY9vjpaz53gRQ3p2B2Db3hIK87/FqjpWTapu2QiDlEv9WrNslFJUV5v/r46/2XhEQ3XkRQudTid+vz+YB6/Xi8vlorq6uta+cePG8dZbb3H77bezZcsWUlNTsVgsjB8/ntWrV3Prrbfy6aefUlZWRk1NDePHj+eee+7hmmuuoVu3bpSVlVFVVUXfvn3x+/3U1NRQVVXFkiVLGDBgANdcc02oHOpwOByUlJQE9/t8PpxOZ/B9WVkZqampVFdX89prr+Hz+aiursbtduP1eqmurq71ucAIoHU/Y3j6wHVcLhdDhgzh4Ycf5ujRoyQmJvL2228zdOjQWmVWX97r43a7G/1vLJoBygacCfxEa71JKbUMWAwsCU+ktX4OeA6M2cybOpPySbMvFybC56ECi1PuRs/O/JuU49z41y8A+NOmg/xmTnf8fvBjhS6ZjB+c2qS8tTWZtTsyKZf6tfZs5m05Q3h8fDwWiyWYB5vNRlxcHImJibX23XPPPdx///1cc801JCQk8MQTT5CYmMjdd9/Nfffdx1VXXcWECRPo27cvCQkJjBkzhnvvvZe77roLv9+P3W7nwQcfJDExEYvFQkJCArm5uaxbt45hw4Zx3XXXAcbyGxdeeGGtPM6ZM4clS5awatUqli9fjtVqJT4+PpjnhQsXcv/995OamsrZZ58dDCQOhwObzUZiYmKtzwXGD4O6nzE8PRg1qLi4ODIzM7njjjv40Y9+RGpqKllZWXTt2jWYrjmzmTscjkbPYh+15TaUUr2Bz7XWmeb784HFWuuZ9R1z2sttADjL4LEBcO5tYDF7zVz032Bt3EqPi/6xjTdyDgNw/uAeXDFmYHDf+aO60r1Ly64YGU3yRRyZlEv9ZLmNyDrzchtVVVUkJSXh9XpZsGAB8+bN45JLLgE68HIbWuujwCGl1HBz08XAN9G6XlBcF7DF157uyNP4KuiDs0bRNdEOwCd7Cyl1haZBkrFRQojO5plnnmHOnDnMmjWLjIwMpk2b1mrXjnb/6Z8ALyqlHEAecGOUrwdKGT35vE6IM2+6uqsgPq1Rh6cnx7Fk1ijufeVLAJZ9uJNfTx+H1sbYqG8PVzFSxkYJITqJ+++/v82uHdVu5lrrHK31RK31WK315VrrkmheLyi5V50aVNMWI5w7oR8XDDNmPC+t8fDR3qPBfd8WVFEh60YJIUTUxd5URwAp5rIbAU1o4gPjJuLSuaNJNGc8f/2rfFxml0u/hpx95TI2Sgghoiw2A1Ry79oByt305dwzuiby0+8Zt8808Oynu4L7iso9HJSxUUIIEVUxGqDMe1ABTWziC/jxuZmM72/cuzpYUs2OY6EWyu0HKnB5ZN0oIYSIltgMUCl17kG5m9bEFxCY8dxmMeZB+tvmffjN1XrdXs32g7JulBDCEI3lNppqxYoV/PnPfwZg2bJlbNy48aQ0mzZt4rbbbmvwPLm5uXz00UfB941ZviMaYjNAJde9B9W8GhTA8N4p3DllMABun5//27IvuO9goZPCMlk3SgjRNI1dbuN0LFq0iHPPPbdZx9YNUI1ZviMaYnOa7rq9+JpxDyrcXVOHsO7rI+wtrGJbQQnThlfRt0sSYHSYmDo2HatZyxJCdAztfbmNiooKLrvsMt577z0sFgvV1dVceumlbNiwgTVr1rBq1So8Hg8DBw7kiSeeqDVHH8DixYuDM6F//PHHLF26lISEBM4666xgmq+++opHHnkEl8tFfHw8S5cuJSMjg+XLl+N0OsnOzua2227D6XQGl+/Iz8/nl7/8JSUlJaSlpfH444/Tt2/fepf1OB2xGaBSete5B9W8Jr6AOJuVx+eN5co/GCuF/HHjHv57+lhAGWOjCqoY2V/GRgnRbAc+gbwN4GvBFgmrA7KmwcDz603SnpfbCKy/tHnzZiZPnsyHH37Ieeedh91u55JLLuHqq68G4Omnn+a1117j+uuvj3h+l8vFkiVLeOGFFxg4cCB33313cF9WVhYvvvgiNpuNjRs38vTTT7NixQoWLlwYDEhAcHkPMCaonTt3LnPnzuWll17i4Ycf5tlnnwUat6xHU8RmE19id/CEZoA4nSa+gImZ3bh+sjHtUbnTw9u5h4P7vj0sY6OEOC0HPmnZ4ATG+Q580mCS9r7cxowZM1i/fj0A69atCy61sXv3bn7wgx8we/Zs1q5dW+8yGwB5eXlkZGSQmZmJUorLLrssuK+iooJFixYxa9YsHn300QbPE7Bt2zZmzZoFwMyZM8nOzg7ua8yyHk0RmzUoq82Y7ijAXQVaE1z0qZl+Pn04G3KPcaTMybu7jnBeVg9S4hzBsVHnjeyKOs1rCNEpDTw/OjWoBmpPEN3lNu67774G0zVmuY2pU6fy9NNPU1payo4dO5g8eTJgNN89++yzjBgxgtWrV7N58+Zm5XXZsmWcffbZ/P73vyc/P58f/ehHzTpPQGOW9WiK2AxQAIndwOsGmwPQRpOfPeGUhzUkJd7Ow5eP5uYXtqCBP2zczc8uOgMwxkYdKnIyoMfpXUOITlI3LAAAACAASURBVGng+acMJm1l4sSJrF+/nmHDhrFp0ya6du1KcnIykyZNYu3atdx555189NFHlJWVAUYt68477+SGG24gPT2d0tJSqqqq6NevX/CcWmseeOABsrKyuPHG+meAS0pKYvTo0TzyyCNMmTIleB+rqqqKHj164PF4WLt2Lb169ar3HFlZWRQUFHDw4EEGDBjAunXrgvsqKiqCx65Zs6bWdauqIrc8TZgwgXXr1nH55Zfz9ttvM3HiSXO8tpjYbOIDo5nP2/zpjupz8chezBrbB4DDZTV8cShUjf1axkYJEXMWLFhAbm4us2fP5re//S2PPfYYAHfddRdbtmxh5syZvPvuu/Tt2xeAIUOGcPfdd3PTTTcxe/ZsbrrpJgoLC2udMzs7mzfeeIPPP/+cOXPmMGfOnFq95sLNmDGDN998s9ZKuosWLeKqq67iuuuuIysrq8H8x8XF8dBDDzF//nzmzp1Lt27dgvtuueUWnnrqKS6//HK83tBtirPPPps9e/YwZ86cYBNjwJIlS1i9ejWzZ89m3bp1PPDAA40oxeaJ2nIbzdEiy20ErPovcDiMMVEAE2+HtIEnp2uGwgoX0576iLIaDw6rhf+ZMQ6H+ctmQI94zmon60bJshKRSbnUT5bbiKwzL7fRkA673EabS+x+WvPxNaRHShz/b6ZRwG6fn799kRfcJ2OjhBCiZcRugErq3qJjoeq68qwMzhtiLAm/42gZecWhWSVy9sm6UUIIcbpiN0Aldm+R+fjqY8x4PoZ4u1GEf/siD7/ZXFrp9LH7cMteT4hY1J5uMYjoa+rfO3YDVFL0mvgCBqQnct8lxoznZU4Pb+7ID+7bJetGCdGg+Ph4iouLJUh1ElpriouLiY+PP3ViUwx3M0+PahNfwI3fzeTNLw/zdUEZH+85xvlZPUhPjJexUUKcQkZGBvn5+Sf1cGuP3G53i4/xiQVNLZf4+HgyMjIanT52A9RJNajoBCib1cJj88Zw2TP/wefX/GXTXn560SgUKrhu1EAZGyXESex2O4MGDWrrbDRKTk5Oh+lx2JqiXS6x28QXpXFQkZzRN5X5FxhjEQ6X1bBxX+gXoawbJYQQzRPDASq9zqq6LX8PKtyii4cyqLsxw/mb2/Op8Rj3n2TdKCGEaJ7YDVA2Byh76L27MqqXi7dbefSKMcalIqwbVVQuY6OEEKIpohqglFL7lVJfK6VylFJNmyKiJcSngLkCLj4X+Js3+WNjTc5K57rv9Afgm2Nl7DxeFty3LU/GRgkhRFO0Rg3qIq31+EjTWERdYnfwhi+7Ed1mPoDFl46kZ0ocAP/Yuh+f3wiQMjZKCCGaJnab+ODk+1BR7CgRkJpg56E5owFjbNTrX4fWgZGxUUII0XhRnSxWKbUPKAE08Eet9XMR0swH5gP06dPnrLoz555KcXEx6enpEff13/o46akOSDVmGd7T5SIqHT2bdP7meuzTYj7Pd6KAn100kj6pRgeKeIuL3vYTp7s0VaM0VDadmZRL/aRsIpNyiaylymXChAkRJ4uNdoDqp7UuUEr1BN4FfqK1/ri+9C06mznAu7+C4p3Q3ZyOfswPoNeYJp2/uY6VO5n21EdUOL30TU3gp1NGBQfsnjW4S6usGyWzdkcm5VI/KZvIpFwia6lyaZPZzLXWBebzcWAN8J1oXu8kSa03FqquXl3i+eUMYwDb4bIaPtp7LLhP1o0SQohTi1qAUkolKaVSAq+B7wHbo3W9iOouuRGl6Y7qc83E/pw9yFgc7O3cw1S6PEY2vJodMjZKCCEaFM0aVC/gU6XUl8BmYJ3W+l9RvN7J6i650Qq9+MJZLIrH5o3FYbPg9vl5eev+4L4DMjZKCCEaFLUApbXO01qPMx9naK0fida16nXSbBKt3817UPck7p42FDDGRn19pCS4T8ZGCSFE/WK7m3lSdNeEaqxbz89iZJ8uAPzzy4N4fDI2SgghTiW2A1QUl31vCrvVwuPzxmBR5rpR22VslBBCnEpsByhHojECKyDK8/E1ZGxGGjefZywt8J99hRSUGcEysG6ULNomhBC1xXaAAnAkhV67q6ANA8G9lwxnQLdENPDS1n3BJeKLyj0cKnI2fLAQQnQysR+gEtLAbzahaR/4PW2XFYeVpXONgcKHy2r4aI+MjRJCiPrEfoBq47FQdZ03tDtXnmUsefyvnYcpcxpdzWXdKCGEqC32A9RJS7+3TUeJcP9v5ki6J8fh9vl5ZduB4PaDhU4Ky2RslBBCQGcIUInptQfrtmFHiYC0RAf/fdkZgDE2KqfgRHBfzj4ZGyWEENAZAtRJY6HavgYFMGNMby4Z1QuANV8fwu01FlOsdPr4VsZGCSFEJwhQiXWnO2ofX/5KKf5nzmhS4myUOz28uSM/uO9bGRslhBCdIUC1/XRH9emdGs/iGSMA2LivkIMlRt5kbJQQQnSGAHXShLHtJ0ABXDdpAN8Z1A0NrMrZX2ts1MFCGRslhOi8Yj9AteMaFJgznl8xBofNwuGyGj4MGxu1/aCMjRJCdF6xH6BOWrSwfXSSCJfVI5lFFxsznv9752FKql2AOTbqgIyNEkJ0TrEfoOK6gDesw4GrfX7hz7/AmPHc7fPz6pcHg9sPFsnYKCFE5xT7AUopY9LYgHYwDiqS8BnPc+uMjdomY6OEEJ1Q7AcoAEdK6LXPBX5f2+WlAeEznq/56hBOj5HPKqePXQXt696ZEEJEW+cIUEnp7W66o/oEZjwvd3lYGz426nAV5TI2SgjRiXSOANVOB+tGkuCw8ugVxoznn+0vZP8Jo0lSa8jJk7FRQojOo3MEqLpjodpZV/O6vjukO1dPzEADr+QcCN5/Kq7wcEDGRgkhOomoByillFUptU0p9Va0r1Wvk5Z+b98BCuCBGaPokRLHkfIaPtxzNLh9u6wbJYToJFqjBrUIyG2F69Svg9WgAFIT7Txkznj+711HKK4yxkZ5fJqvZWyUEKITaFSAUkotUkp1UYY/K6W2KqW+14jjMoCZwPOnm9HTktSjw9yDCnfpmD58/4xeeHx+XvsytG7UoSInx0tdbZgzIYSIPlsj092ktV6mlPo+0BW4Hvg78M4pjvsd8HMgpb4ESqn5wHyAPn36kJOT08gsGYqLi095TGJxKcPCltwoPHyAgvKmXaetXDNE8cm3ip3Hy9maX8yZGekAbNpVRD9HIRZV/7GNKZvOSMqlflI2kUm5RBbtcmlsgAp8Dc4A/q613qGUauCrEZRSs4DjWutspdSU+tJprZ8DngOYOHGiHj9+fCOzZMjJyeGUxxSnwM7fBd/2SE2gx5imXactLbEe5Berv2bN14cY0TOVRIcNr7YRlz6YMwbUG/sbVzadkJRL/aRsIpNyiSza5dLYe1DZSql3MALUv5VSKcCp7tR/F7hMKbUf+AcwVSn1f83O6elI6tGuJ4w9lWsn9WdyVjcqXd5aY6N2H6mmrNrThjkTQojoaWyAuhlYDEzSWlcDduDGhg7QWv9Ca52htc4ErgXe11r/1+lkttniUsDX/ufjq49SiseuGEuczcKmA0XkFRn5N8ZGVcjYKCFETGpsgDoH2KW1LlVK/Rfw/4Cy6GWrhXWQ+fgaktk9iXsvGWaMjfryAF6/UYE9Uelh//Gahg8WQogOqLEBaiVQrZQaB9wH7AX+1tiLaK0/1FrPakb+Wk74fHxeJ+iON5bo5vMGMaZfKscqnLy/OzQ2asfBSpzu9jm/oBBCNFdjA5RXG+1Ic4BntNa/p4Geee1SUnfwBpat0ODteN20bVYLj88bi82ieHfXEY5XGvfVPD7NV/s7VrOlEEKcSmMDVIVS6hcY3cvXKaUsGPehOo66Y6E6YDMfwKi+Xbj9wsF4/ZpXc0JjowpOuDha0vGCrhBC1KexAeoawIUxHuookAH8Jmq5ioa6s0l0kMG6kSyYOoSsHknsKapg88Gi4PacfeV4fR2v6VIIISJpVIAyg9KLQKo5vsmptW70Pah2IamHce8poIN1NQ8Xb7fyxLyxKAVvbs+n0mV0Na9x+/nmUMf9XEIIEa6xUx1dDWwGrgKuBjYppa6MZsZaXAdacqMxJmZ240eTB1Ll9vLG9kPB7XuPVlNSKWOjhBAdX2Ob+B7AGAP1Y631j4DvAEuil60o6OCDdSP52fQR9EtLYMuhE+w6Xh7cvi2vHL+MjRJCdHCNDVAWrfXxsPfFTTi2feiAM5qfSnKcjUfmjgbgtS8P4DbvP5VVe9l7tP2uGiyEEI3R2CDzL6XUv5VSNyilbgDWAeujl60o6KAzmp/KlOE9uWJCP4qqXLyz83Bwe+6hSjx+axvmTAghTk9jO0n8DGNC17Hm4zmt9f3RzFiLS+oec018AUtmjaJ7soMP9hzjcJlRc/L5odjbRaZBEkJ0WI1uptNa/1Nrfa/5WBPNTEWFPYHQpOyAq7zepB1N1yQH/33ZaPxasyrnQPD+U40/nvxiWSJeCNExNRiglFIVSqnyCI8KpVTH+4a3d+z5+BoyY0xvvjeqFwdLqvg0L3S78OsDlbi9MjZKCNHxNBigtNYpWusuER4pWusurZXJFhMXPh9fjTEdeIxQSvE/l48mJd7G+twCSqqNaZ1cHr8sES+E6JA6Vk+805WYHlp2Q/vB5244fQfTq0s8S2aOwuX188+vQtMgHSx0UlgWW59VCBH7OleASupeezaJGOnJF+6qiRmcN6Q7O46WkVNwIrh9275yfP7YqTEKIWJfJwtQdSeMjb0ApZTi0SvGkOiwsuarQ9R4jBpjldPHzvzYuu8mhIhtnTtAxWANCqB/t0R+/v3hlLs8rN1eZ4n4KpkGSQjRMXTCABWbY6Hq+tE5mYzs7uDzA0XsDVsiflteuYyNEkJ0CJ0rQCWmd4oaFIDFoljwnTTsNgurcvYHl+EoqZJpkIQQHUPnClCd4B5UuH5d7Nx7yTAKK138e9eR4PZvDlVS5ZQl4oUQ7ZsEqBh3y3mDGJeRyge7j9aaBilnnzT1CSHat6gFKKVUvFJqs1LqS6XUDqXUf0frWo2WmF7nHlTs92qzWS08ceU4LBZqTYN0vMzNoSKZBkkI0X5FswblAqZqrccB44HpSqnJUbzeqVltYLGH3rvK2i4vrWh47xQWTh3KwZIqPqk1DVIFLo9MgySEaJ+iFqC0IVBFsZuPtm9TiuH5+Bpy+5TBnNG3C+u/KeBEtQsAt1fz1X6ZBkkI0T5F9R6UUsqqlMoBjgPvaq03RfN6jRKfGnrt6TxNXHarhd9cOQ6/1ryaE5oGKb/YydESVxvmTAghIrNF8+Raax8wXimVBqxRSo3WWm8PT6OUmg/MB+jTpw85OTlNukZxcXGTjsl0QZrfBxYraC9fbtuCVlEthjYTqWzmjUxm1Y5ythwqZmL/dAA27yomI64Qi2r7Cm5raOq/mc5EyiYyKZfIol0urfLNrLUuVUp9AEwHttfZ9xzGYohMnDhRjx8/vknnzsnJoUnHFAwFVyUkGDWpcUP7Q3KvJl2zo4hUNqNG+/nymU95/etDjOjZheQ4Oz6sWNMGMW5Qx5ugvjma/G+mE5GyiUzKJbJol0s0e/H1MGtOKKUSgEuAndG6XqMl9YCa0tD76qK2y0sbcNgsPHnVOJxeH2u+PhTcnneshqJymfFcCNF+RPMeVB/gA6XUV8AXGPeg3ori9RonqTs4w3rvdbIABTC6Xyp3ThnM1vwT7DgaCtbb8mTGcyFE+xG1Jj6t9VfAhGidv9k6eQ0qYMHUIbyz4xivfXmAwekpxNutVJoznp8xIOXUJxBCiCjrXDNJgBmgOncNCiDOZuU3V42lwuVl7Y6wGc8PV1MqM54LIdqBThqgpAYFMDYjjTsuHMxn+wvZE5jxHNi6txy/NPUJIdpY5wtQielGLz6/OVmqu7L2KrudzE8uHsLw3ims2rYftznjeVm1l91HZMZzIUTb6nwBKj7NGAMlzXyA0dT35FXjKKlx86/cguD2nfmVlNd42zBnQojOrvMFKIsFUvuDU5r5Akb3S+Wui4bw0d5jHCgxZnj3a6OpT2Y8F0K0lc4XoAC6Zcl9qDoWXDSE4b278I+t+/D6zcUNKz3skcUNhRBtpBMHKGniC+ewWfjtVeMornbxTvjihgcrqZSmPiFEG+jEAUpqUHWN6tuFRRcP5b1vj5JfatSc/Bq25klTnxCi9UmAAqguBvkCBuD2Cwczpl8X/rFtX3BWieIKD3nHak5xpBBCtKzOG6A8NeA1557zOsET+8u/N4bNauG3V4+nqMrFe7tDTX07DlZQ6ZSmPiFE6+mcAarrQEBJT756DOmZzM++P5x3dh7hcJnR1OfzS68+IUTr6pwByhZndDUP7yhRJQEq3E3fHcRZmV15eet+aeoTQrSJzhmgALoNqn0fqkYCVDiLRfHbq8ZRUiNNfUKIttGJA1SdjhJSgzpJ/26J/Gr2GbyzS5r6hBCtr5MHKBkLdSpXTczgouE9T2rqkwG8QohokwAVUFMM2t92+WmnlFI8Nm8MNV4v735bewCvzNUnhIimzh2gfC5wmzUBv7f2SrsiqHtyHI9eMYZ3dx0hvzRsrr49ZfilqU8IESWdN0B1zTSeay3/XtwmWekIvndGb66emMFLW/fjNZflKKny8m2BjB8TQkRH5w1QjkRI6VtnRonCtstPB7Bk1igcdsW/dh4ObttZUCUr8AohoqLzBig4+T5U+aG2y0sHkBRn4+lrxvNx3jH2n6gEjBmituwpC3agEEKIltLJA9QgKM0PvT/+jXEvStTrzAFdueuiIbyYvQ+X11iVuKLGx46DlW2cMyFErIlagFJK9VdKfaCU+kYptUMptSha12q2bllQeTxUi/K5oOjbts1TB7DgoiEMSE/gje2hGufeo9UUlrnbMFdCiFgTzRqUF7hPaz0KmAzcpZQaFcXrNV23LOO5aE9o27Ev2yYvHYjNamHZtRP4+kgp3xwN3cPL3luG2ytd9YUQLSNqAUprfURrvdV8XQHkAv2idb1mCQSowt2hbYW54JOawKn075bII3NHs2rbASpdRieJGrefL/dVtHHOhBCxQrXGlDVKqUzgY2C01rq8zr75wHyAPn36nLV+/fomnbu4uJj09PRm5cviqWbsuksB0Gdeh0rsCsD+lHMojRvQrHO2J6dTNo217PMTFLniuOnsIcFtPeylJFvb76SyrVEuHZWUTWRSLpG1VLlMmDAhW2s9se72qAcopVQy8BHwiNZ6dUNpJ06cqLds2dKk8+fk5DB+/PjmZ/A3Q6CqEPqfBQPPNrb1GAXjrm/+OduJ0y6bRqh0eZm5/BMmD+jB5IE9ALBZFFPHppMUb43qtZurNcqlo5KyiUzKJbKWKhelVMQAFdVefEopO/BP4MVTBac2E2zmC7sPVbTLWMRQnFJynI3l107grR35FFYaZeb1a7bILBNCiNMUzV58CvgzkKu1fipa1zltgQDlLANrnPFa++D4jrbLUwczrn8a91wyjL9vycPnNzpJnKj0sCtfZpkQQjRfNGtQ3wWuB6YqpXLMx4woXq95AgEKwBX2hXrsq9bPSwd283mDGNY7+aRZJorKpcOJEKJ5otmL71OttdJaj9VajzcfTesB0Rr6nx16/e2G0OsTe6SZrwmUUjx51Ti+OVbKnqJQT74vdpfh8kjXcyFE03XumSQABn4XEs1eKCfyIC7VeK39ULq/zbLVEXVNcrDsugm8vHVfsOu50+Nna16ZLHAohGgyCVBWG4ycHXpfHTZ5bEle6+eng5uU2Y1bL8ji5a37g9uOlrjJO9p+u50LIdonCVAAo+aEXh/cFHpdsq/18xIDbr8wi77d4vloz7Hgtq8PVFBSKbOeCyEaTwIUQOb5kGAM0uXo9tD28gK5D9UMSil+e/U4vjxygkPmAoca2PRtqUyFJIRoNAlQAFY7jJhlvPa5jW9TADSUHmirXHVoqQl2VvxgAi9v3U+Nx5ghvsbtJ3uP3I8SQjSOBKiAUZeHXheH3XuSZr5mG90vlXsuGVr7flSpm91HqtsuU0KIDkMCVEDWhRCfZrw+viu0XTpKnJarJ/Vn3MAufLDnaHDbjoOVMj5KCHFKEqACrHYYMdN4XX441MxXUQBeV5tlKxY8OOsMjlZWsa84tKjhZ7tKqXH72jBXQoj2TgJUuEAzn9cFTnPSde2HMrkPdTocNgu//+FZrM/Np8IcH+X1aTbuLJGl4oUQ9ZIAFS5rSmigbsn+0Ha5D3XaeqTE8dS143hp675gUCqv9rF1r3SaEEJEJgEqnM0RauYrC80pJwGqZYzNSOOOi7JqLRWfX+xi71HpNCGEOJkEqLrOmGs8hweo8kOyym4LmTO+H2dlpbLpQFFw21f7KzheJvf5hBC1SYCqK2uK0ZvP64SqYmOb9kPpwbbMVUxZdPFQXLg5cMLoNKGU4j+5JZRXe9s4Z0KI9kQCVF02B4w0B+2G16JKpbt5S1FK8egVY9lyuIjSmkDNVPHh9mKc0rNPCGGSABVJoJmv/EhoW1l+2+QlRsXbrSy7djzrd+bj8hpByeeHD7YXS88+IQQgASqyQRcac/NVHA9tq8gH6W3WotKT43jqmnG8uf1QcHl4p1vz8TfF0rNPCCEBKiKr3ViCw1UOHnOyWE8NOEvaNl8xqH+3RB68fCRv5xYEt5VW+vjPzhIJUkJ0chKg6nPGFcZzZWFoW7k080XDiN5duG3qID7JCy3PUVjmYdPu0gaOEkLEOglQ9ck831hptzKsma+8oP704rRMyuzGrDN7kX2oOLjtyAk3W/ZKkBKis5IAVR+rDUZeJjWoVjR1RC+mjk5nx9FQUDpU6CI7T4KUEJ1R1AKUUuovSqnjSqntp07dTo2cXbujRHmBMSZKRM3Ukb2YPCyNvUUVwW0Hj7v4z67iBo4SQsSiaNag/gpMj+L5oy/zPCMguc2peHwuqJYvymibNqoX47NSggN5AY6XeHlve2EDRwkhYk3UApTW+mPgRLTO3ypsccbMEuHNfBVyH6o1TBvVi4lDu7AvLEiVV/pZm31UevcJ0UmoaP7PrpTKBN7SWo9uIM18YD5Anz59zlq/fn2TrlFcXEx6evpp5LJh6fvfpP+Jj2HAJACOxw/jcPKEqF2vJUW7bFpDXomHfVVpZHXvEtx2vLyMs9KrsFlVs84ZC+USLVI2kUm5RNZS5TJhwoRsrfXEutttp33m06S1fg54DmDixIl6/PjxTTo+JyeHph7TJIO6wwuvBd/2dNTQM5rXa0FRL5tWMB44UFTF6s1HyOyWAkDPLqlsK43j8km96NElvsnnjIVyiRYpm8ikXCKLdrlIL75TSc2AuG6h9xXSUaK1DeyexI8u6M++E6GOE92T4lmbfZzP9sg9QSFilQSoxsi6EFzmvRDthyq5Wd/a0pPjWPj9LAprqoPTInVNiOPQMTe/fzePKnOlXiFE7IhmN/OXgc+A4UqpfKXUzdG6VtQN/V6dAbsyHqot2KwW5l80iPgEcPuMWqzdaqFvShJ/2HCAD3Yelw4UQsSQaPbiu05r3UdrbddaZ2it/xyta0Vd/+9ATah5iWNft11eBDPH9+asISmUOkOLSGalp1Bw3MODq7/hP3ukhitELJAmvsaw2o17UQEn9rZdXgQAQ3olc/35/fCr0PpRSQ4bZ/brTu6BGn76j69YtfkgJVWyErIQHVWb9+LrMAZ8F0p2Gq/9btjxTxj8PYhPadt8dWI2q4V5Z/dl5+EKtuWVE28z/jmnJ8Xx3aReVNR4+J83duLVPob2TiarRzKDuidR5fbj92ssluZ1UxdCtA4JUI01/FL44HNISANlgSNbjCB19BuoKQOfG/xe6DYYMiYazYIDzoH0wW2d85g3om8Kw3ons21/GXlHa7BZjIaBlDg752f1AqDG42XXoWo+/qaYoirNs9u+wK81SgEKrBaF3apIjLPSNdFB10Q7aYkOUhPspMTbSIk3npPibCQ5rCTG2UiwW7FKkBMiaiRANVZyT6guA4sN4pKNbd0GGg9PDbirwFUF1Sfg4H/gmzXgLIc+42D8D2H0lZAkA/2ixWJRnJWVxpgBXcjZV8ahIicWFWrBTrDbGJSezKD05AbP4/X7qXB6KHd5KSh0s8tVRZXbG3w4vT6cHh81Hh8urx+tNcoCVqWw2yzE2y3E263E26zEBV7brcTbAq+N5zibhbhAGvM5uM1mMd8brx3mduPZeG+zKJSS4ChimwSoppizEnJehhO7wB4HgS8Ie4LxSOpuBKwAjxPKD8OXL8J/nobU/tClL6T0hZQ+kNzLeKT0htR+ECfNhafLYbPwnaFdmTREU1juZmdBFUXlbhSN+zK3WSx0TYyja2Jck6/t1xq314/H58fj9xuv/eZ7n8bj8+N2+qmq8uL1G++9fo3Xb+z3+v14g9t02OuwZzOdXxtNlBbAalVYlMJmMYJkeCCLs1lxWI3XwYc1tN9uDW1z2CwcO1zFfl1Qa1vdNHarCr63h6WxWyVoipYlAaop4lNh8u3G67JDsGut2eW8nq7N9nhIzzIeddUcMR7HfOB1QU0JVJcCFuM6Sb2MWltyL0jqYQS/xHTjWQLZKSml6JkaR8/UOLTWOD1+Kmq8lFf7OJh/hK7pPXB5fDg9fpwePx6vH6/v1OdtiEWpYI2prfi1Edx8gaBmBjRfIOiZ231ejdPtp9Lvw+v34gum6cKhHcXGMYFz+TReHTqHL/Awt4VvV0qjUCiLUR4WpbBaFBaLxqoUFovCZrFgsyozqFlw2EKvA4HObjXSOKwWbBYLdlvgtRGE7eY5bFYLDmvonA6rBVudc9gsxnub1YLdYjzbrCp0DqmNtlsSoJortT98505ztvNKY3n4mhKoOGwsy1GRbzT9nYrFCo5E45HaL7Td64bS3XAsxzi/u9poRnRXAwocSRCfZgSzuC7GIz7VuEcWnwYJaSQVHYMCH9iTjPPHp4IjBSydq/OmUooEh5UEh5WeqVB5rILxHVL9iAAAC3ZJREFUWZHvDXp9GpfHj9MMXm6PH7fXqBm5PaGakNenQw/zS7w9jMCyKIXDqsDavv/GPjOI+nR4wDPK0h8IeFrj8/hx+TXVfj8+7auV1ufX+HXt95G2NSaNQoMCC8poGDFrp0oZzbcut4uEjRuxYPzvY1FGOpvVgtViBDlbWMCzmcE0ECADaULPobTWOtutFoz9YfsC+y2BdKruPgsWC+a1MGvUxjZrnfSBc9T6AaFol0FaAtTpUpZQgOiSAb3GGNu1hupCKNkPpfugdL9RU/L7jM4U2vy5Xt8/CpsDbN0gsVvk/XX5feA8BpUHjet4XQz1uuDIauO9zwU+r3Fti914WG1gjTOaJ20J4Eg2Ap/DDGiOZLAnmvvjwBZvvHYkhfbZ4kP7rPb6P08HYfwqt5IU3/RakD+8duHX+PzUea/x+8GntZnWOMb4sjRqP36/xqdD5zK2Yb4OTx++3djXkcYoG1+WbVfTbEl1A17g7xj4uwT/3oF9XuNv7NYav/aH/qZaozWhv695fOC9pva/geA+8/zavJbWtffXfR2eTge3A+ha//sqFOZ/xvvAazM4KwXxuHi8XyVZPRq+t9tcEqCiRSlI6mk8Mr5TfzqfBzxVUHoQCr8xApmrnHqbDetjsYLFvBd2OrQfvGXgKjJqcYHeiYHA6veGAp3fZwRav998Dg+6CpTNzJf5rCzGM1bjZ6jVYQZKu/HaFmdus4Kyho61xRmB1BZnvLeaAdYSlkZZw4Kj+X+PMq9jsZkP45iE0r1wzB52jbDrKQuE368KnEdZjHMF9ivzdeCzARavC4vXid3nNjrIOEvBWWb8QEjqbjTVpvQ0gnuUArmuE+yCX0z+sC+6QAA09+mwoHnoUD59+/XD58f8oqvzheiv/ax17WuE11ACwTjwJag7WBBtLKtFYUXRhi27babG4+WfWwr42aXDo3J+CVBtzWoHaxr0ToPeY41tWoOn2ghUzlJwVxivXRXGw11pbPPU1K6NtQRlMWtEcdD0fgItxAfaAz4/eDW4NOAn+A2n/WGPwLeeDuU/0HvP7wPtNQJoWMAfroFP14aOj0SHn0+Fzqn95nlrnxNlNcrMHm/UJlWdJrZAAA8G+kBwNz9b4JzBwGoNBd1AwEfX+czBn7RmHkBpsCkLDJsJZ8xtcsmXHalmSJ+kJh/XFHV/ues6QbTe92EBNXRshGc/Eff56wTL2sE5rLYR4fwejwer1WYUPbEZaJsjwW5jZM+0qJ1fAlR7pFSoqS2lz6nTa23WbFxG0PLWgKeG/Xt2ktmvJ3idxsPnNn7Ne8x7Wd7q0PbAF357ER5oRNPt29CsANUalNlEZGlkz8r2oL5lJQLBVhOqVUJ4jbF2ENZhr8PTBYJh8DcYEbZT+xzh28OvEzg2mIaT0wfOS9g+f4Q8RspL6BjA5+SCkX2jVu4SoGKBUmZNzG40H5lK82ugfxPWatHa+FXv85iBy2XeN/MY24LP3tD7QM0g/LhgQPQaafyesJ+cCvCH7fOG1YDkZ2mLie/a1jnoFALBFuiUg7ZzcnLokjggaueXACVCVOC+ke3072WdjrrNeNR5H3j4fWH7dKgpLtjE5w09wuzevZuhgwebxzXUPKrN81nDmvjCmunCKWV2KDEflsD/WmbTXHhefB6jpuupMn4ABJoRAzUK7TN/wvrC7udZwn4MmOfRgWY/M7AHyio+Dfqd1byyF6IdkQAl2p/AfRiic9e5yl4K3SKMTRNCtCvSyC+EEKJdkgAlhBD/v717jZWrKsM4/n9srVhKqAUk2iJtpUGLgYKkqRZIA34AbQQNXkEIkfCFhIsaBWPiJZpIQgSNBDEULbFBTLk1xhC1kqofKBRaubQaCCocUmiNUEXC/fHDWidMjjMYes5h75n9/JKTc/aa3b3XvHln3u61Z9aKVkqBioiIVkqBioiIVkqBioiIVkqBioiIVkqBioiIVpLdnm/vS9oN/P11/rMDgX9MQ3dGQWLTX+IyWGLTX+LS31TF5VDbB01sbFWB2huSttg+tul+tFFi01/iMlhi01/i0t90xyVDfBER0UopUBER0UqjUKB+3HQHWiyx6S9xGSyx6S9x6W9a4zL096AiImI0jcIVVEREjKAUqIiIaKWhLlCSTpb0F0kPS7qk6f40RdIhku6QtF3Sg5IurO3zJP1G0kP1dyeXWZU0Q9JWSb+s24skba55c6OkWU33sQmS5kpaL+nPknZI+kByBiRdXF9HD0i6QdI+Xc0ZSddJ2iXpgZ62vjmi4gc1RvdJOmay5x/aAiVpBnAVcAqwFPiMpKXN9qoxLwFftL0UWAGcX2NxCbDR9hJgY93uoguBHT3blwFX2D4MeAr4fCO9at73gdttvwc4ihKjTueMpPnABcCxtt9HWTXz03Q3Z34KnDyhbVCOnAIsqT/nAVdP9uRDW6CA5cDDth+x/QLwc+DUhvvUCNs7bd9b//435Y1mPiUea+tua4HTmulhcyQtAD4CXFu3BZwIrK+7dDUu+wMnAGsAbL9g+2mSM1BWGn+rpJnAbGAnHc0Z278H/jmheVCOnApc7+JOYK6kd0zm/MNcoOYDj/Vsj9W2TpO0EDga2AwcbHtnfegJ4OCGutWkK4EvA6/U7QOAp22/VLe7mjeLgN3AT+rw57WS9qXjOWP7ceBy4FFKYdoD3ENyptegHJny9+RhLlAxgaQ5wE3ARbb/1fuYy/cJOvWdAkmrgV2272m6Ly00EzgGuNr20cB/mDCc19GceRvlSmAR8E5gX/53iCuq6c6RYS5QjwOH9GwvqG2dJOnNlOK0zvbNtfnJ8Uvs+ntXU/1ryErgo5L+RhkCPpFy32VuHb6B7ubNGDBme3PdXk8pWF3PmQ8Bf7W92/aLwM2UPErOvGpQjkz5e/IwF6i7gSX10zWzKDcyNzTcp0bU+yprgB22v9fz0Abg7Pr32cBtb3TfmmT7UtsLbC+k5MfvbJ8B3AGcXnfrXFwAbD8BPCbp8Np0ErCdjucMZWhvhaTZ9XU1HpfO50yPQTmyATirfppvBbCnZyhwrwz1TBKSPky5xzADuM72dxruUiMkHQf8AbifV++1fJVyH+oXwLsoy5h80vbEG56dIGkV8CXbqyUtplxRzQO2Amfafr7J/jVB0jLKh0dmAY8A51D+09rpnJH0TeBTlE/HbgXOpdxL6VzOSLoBWEVZVuNJ4OvArfTJkVrQf0gZEn0WOMf2lkmdf5gLVEREjK5hHuKLiIgRlgIVERGtlAIVERGtlAIVERGtlAIVERGtlAIV0WKSVo3Pwh7RNSlQERHRSilQEVNA0pmS7pK0TdI1dQ2qZyRdUdcW2ijpoLrvMkl31jVzbulZT+cwSb+V9CdJ90p6dz38nJ51m9bVL0Qi6bsqa4DdJ+nyhp56xLRJgYqYJEnvpcw8sNL2MuBl4AzKRKNbbB8BbKJ8Cx/geuArto+kzP4x3r4OuMr2UcAHKbNpQ5md/iLKumeLgZWSDgA+BhxRj/Pt6X2WEW+8FKiIyTsJeD9wt6RtdXsxZdqpG+s+PwOOq+swzbW9qbavBU6QtB8w3/YtALafs/1s3ecu22O2XwG2AQspy0A8B6yR9HHK1DIRIyUFKmLyBKy1vaz+HG77G33229t5xXrnfHsZmFnXJlpOmYV8NXD7Xh47orVSoCImbyNwuqS3A0iaJ+lQyutrfAbszwJ/tL0HeErS8bX9c8CmuhLymKTT6jHeImn2oBPWtb/2t/0r4GLKku0RI2Xm/98lIl6L7e2Svgb8WtKbgBeB8ymLAC6vj+2i3KeCskTBj2oBGp9FHEqxukbSt+oxPvEap90PuE3SPpQruC9M8dOKaFxmM4+YJpKesT2n6X5EDKsM8UVERCvlCioiIlopV1AREdFKKVAREdFKKVAREdFKKVAREdFKKVAREdFK/wW79SlUUoo9XAAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {
"needs_background": "light"
},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAagAAAEYCAYAAAAJeGK1AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOydd3xUVfr/31NTJz2ZJBATIKGH3kTpIF0ExYLiroquXVdXBX/fZffLrmVdy7LWVfbLLuiqoFgIogiosBYQRUIJJYSEhJBC6kzK1Pv74yZT0khCJpNJzvv1yotbzr1zOFM+93nOc55HIUmShEAgEAgEXQyltzsgEAgEAkFTCIESCAQCQZdECJRAIBAIuiRCoAQCgUDQJRECJRAIBIIuiRAogUAgEHRJhEAJehQHDhxg9uzZ3u5Gj2XFihV89NFHHX7flStX8tJLL3X4fQXeRQiUoNOYPn063333nVf7MGbMGL744guP3X/v3r3cfPPNjBw5kgkTJnDLLbewa9cuj71eR7Bz504WLVrEqFGjGD9+PLfeeiu5ubkeea1169axePFij9xb0P1Qe7sDAkFHYrPZUKlUXnntzz//nCeffJJVq1bxxhtvEBQUxIEDB/j000+ZMWNGm+4lSRKSJKFUevYZMicnhyeeeIJXXnmFCRMmUFVVxbffftuuMbRarajV4idF0HEIC0rgdex2O2+++SYzZ85k/PjxPPTQQ5SXlzvOP/jgg1xxxRWMHj2am2++mVOnTjnOrVy5kj/84Q/ceeedjBgxgn379jF9+nT++c9/snDhQkaPHs3DDz+MyWQCYN++fUyePNlxfUttAd566y2uvPJKrrzySjZv3syAAQPIyclp9H+QJIlnn32We++9l6VLl6LT6VAqlYwbN44///nPALz88sv87ne/c1yTl5fHgAEDsFqtACxfvpyXXnqJG2+8keHDh7Nu3TqWLFni9jr/+te/uPvuuwEwm8385S9/YerUqUycOJHVq1dTW1sLQGlpKb/5zW8YM2YM48aNY9myZdjt9kb9zsjIoHfv3lx++eUoFAqCg4OZPXs28fHxjvF1dZ01NX5vvvkmCxcuZMSIEbz55ps8+OCDbq/x5z//2TEGy5cvZ/PmzZjNZsaMGcPJkycd7UpLSxk2bBglJSUAfPXVVyxatIgxY8Zw4403cvz4cUfbY8eOsXjxYkaOHNnoPRN0H4RACbzOxo0b2blzJ2+//TZ79+4lNDSUNWvWOM5PnjyZL774gu+//57Bgwe7/cgDpKWlcffdd/Pzzz8zevRoALZv3866devYtWsXJ06cYMuWLc2+fnNt9+zZw7/+9S/Wr1/Pl19+yb59+5q9R1ZWFufPn7/k+a1PPvmEP/3pT/z888/cdNNNnDlzhuzsbMf5rVu3snDhQgCef/55zpw5w8cff8yOHTsoKiri1VdfBWD9+vXo9Xq+//57vv32Wx555BEUCkWj1xsyZAhZWVk8/fTT/PDDD1RVVbW5z9u2bePNN9/kwIEDzJ8/n2+++Qaj0QjIFu3nn3/OggUL3K7RarXMmjWLbdu2OY5t376dsWPHEhkZybFjx3jyySdZs2YN+/bt44YbbuDee+/FbDZjNpu57777WLRoEfv372fOnDns2LGjzf0WdH2EQAm8znvvvcdvf/tbYmNj0Wq13H///XzxxRcOy+K6664jODgYrVbLAw88wPHjxzEYDI7rZ8yYwejRo1Eqlfj5+QHyk7perycsLIxp06aRkZHR7Os313b79u0sWbKElJQUAgICeOCBB5q9R73FFxMTc0ljsXjxYlJSUlCr1eh0OmbMmEFaWhoA2dnZZGVlMX36dCRJYtOmTTz55JOEhYURHBzMb37zG8cPvlqtpri4mPz8fDQaDWPGjGlSoBISEti4cSOFhYU8/PDDTJgwgZUrV7ZJqJYvX05cXBz+/v706tWLwYMHs3PnTgB++OEH/P39GTFiRKPrFi5c6CZQruL7/vvvc8MNNzB8+HBUKhWLFy9Go9Hwyy+/cOjQISwWC7/61a/QaDTMmTOH1NTU1g+ywGcQDmOB18nPz+e+++5zm29RKpWUlJQQFRXFSy+9xOeff05paamjTVlZGTqdDoC4uLhG94yOjnZsBwQEUFRU1OzrN9e2qKiIoUOHOs419Tr1hIWFOa5JSEho8f/bEg1fY+HChTz77LPcf//9pKWlMXPmTAICAigpKaGmpsbNBShJksONd8cdd/DKK69w++23A3DDDTdw1113NfmaI0aMYO3atQCkp6fz29/+ljfeeINHH320XX1esGABaWlpXHPNNaSlpTWynuoZP348tbW1HDp0iMjISI4fP87MmTMB+TPx8ccf8/bbbzvaWywWioqKUCgU6PV6N8Gtd0kKuhdCoAReJzY2lqefftrhnnPl448/ZteuXaxfv57evXtjMBgYO3YsnZGEPyYmhsLCQsf++fPnm23bt29f4uLi2LFjB3fccUeTbQICAhxzRAAXLlxo1KahlTNx4kRKS0vJyMggLS2NVatWARAeHo6/vz/btm1Dr9c3uk9wcDArV65k5cqVnDx5kl/96lekpqZy+eWXt/h/HjZsGFdddZVjnq89fZ47dy5/+ctfKCgo4Msvv+T9999v8rVUKhVz5swhLS2NqKgopk6dSnBwMCCL3t13380999zT6Lr9+/dTWFiIJEmO187Pz7+kBwNB10S4+ASdisViwWQyOf6sVis33XQTf/vb3zh37hwgT5bXu4iqqqrQarWEh4dTU1PDiy++2Gl9nTNnDlu2bOH06dPU1NTw2muvNdtWoVCwcuVKXnvtNT788EOMRiN2u50DBw7w+9//HoBBgwbx448/kp+fj8Fg4B//+MdF+1DvwnruueeoqKjgiiuuAGQLc+nSpTz99NOOoILCwkL27t0LyAEGOTk5SJKETqdDpVI16eI7cOAAmzZtctzj9OnT7N69m+HDhzv6/M0331BeXk5xcTH//ve/L9rniIgIxo0bx6pVq+jduzf9+vVrtu3ChQvZvn07W7dudbO0li5dynvvvcehQ4eQJInq6mq+/vprjEYjI0aMQK1Ws2HDBiwWCzt27ODw4cMX7ZfA9xACJehU7rrrLoYNG+b4e/nll7n11luZPn06t99+OyNHjuT6668nPT0dgGuuuYb4+HgmTZrE/Pnzm5zL8BRTpkxh+fLl3HrrrcyaNcvxo63VaptsP2fOHF566SU+/PBDJk2axMSJE1m7dq0jxPyKK65g3rx5XH311SxZsoRp06a1qh8LFy7ku+++Y86cOW5h3I899hiJiYlcf/31jBo1il//+tecOXMGkMPHb7vtNkaOHMkNN9zATTfdxIQJExrdOyQkhN27d7Nw4UJGjhzJnXfeycyZM1mxYgUAixYtYuDAgY73Z968ea3q84IFC/juu++ade/VM3z4cIdb1TU6MDU1lT/96U+sWbOGsWPHctVVVzmCV7RaLS+//DIfffQR48aN47PPPmPWrFmt6pfAt1CIgoUCQes4ffo0CxYs4PDhw2K9j0DQCQgLSiBogS+//BKz2UxFRQV//etfmTZtmhAngaCTEAIlELTAe++9x+WXX86sWbNQqVT88Y9/9HaXBIIeg3DxCQQCgaBLIiwogUAgEHRJfM6Z/ssvvziyBbQFi8WCRqPxQI98EzEejRFj4o4Yj8aIMWlMR4yJyWRqMkLX5wTKz8+PQYMGtfm6nJwcEhMTPdAj30SMR2PEmLgjxqMxYkwa0xFj0lwqMuHiEwgEAkGXRAiUQCAQCLokQqAEAoFA0CURAiUQCASCLokQKIFAIBB0SYRACQQCgaBLIgRKIOgMLDUgkrYIBG3C59ZBCQTtwm6HgxtB7QfDboAmaiN5jKMfw8f3QEgvWPElBIQ7z1VdkPulUEL0QIgeAKGXgVI8OwoEQqAEPYPdf4L/1hU7NBth7ArnObsNjn2MtkYDbVlwuPdF+O7vMPIWuOrPTbcpy4FP7gNLNZScgoNvw8QHnOc/uQ9Ofu5+TVAM3PgOJIxrfL/SLDj2KWR8Chcy4cqHYdIjzvMmA2y+DfJ+hKQrYfAi6D8b/ENb//8SCLoIHn1M27NnD7Nnz2bWrFm8+eabjc7n5+ezfPlyrrnmGhYuXMg333zjye4IugKSXf6xrv+zmjrmvuW58P2r8K8FsH4+FB13nivKkIWknm+ek11u9Wx/Aj64nbhty2H3n2Vr62Kc2gm7/hdqyuC7l+H4Z43b2O2yAJmNQJ3FlrHVed5QACe/kK0nV6qKYNsj7i5BQ6H8f/v7SNj5Bzj3E5gq5D78uE5uY7PC5l9D5pdQWw7H02DLnfDXZNi1RrgYBT6Hxywom83GmjVrWL9+PXq9nuuuu47p06eTnJzsaPP6668zd+5cli1bRmZmJnfddRe7d+/2VJcE3qaqGA7+n/zj6UrsCBiytPEPtSuGAtAGg1+w+/H8g/DZY7LF4MrGxbBiJ4TEw7ZHwW51njMWwoH/g8vvg9wf4ce3nOf2/BUKj8GSf4CfDszVcvuwy0CpktvUlMGn97u/3vYnoO8U0AY5j+1/E7L3QmhvGDQHTJWQ/pH8f9HFwrFPIKY/9JsC1aVQXgC5+8BugYLDspgNvloWlk/vl+/VFJ89JrsPT2yHzJ2Nz9vMsPcFmHAvBEU1P8YCQRfDYxZUeno6iYmJJCQkoNVqmT9/Prt27XJro1AoMBqNABgMBmJiYjzVHYG3sZog/e3G4gRQ8Auc+Upu05T18uM6eGEgvDxKtobqKc+FjUsaixOAIR/+c718bc63jc//9yWorYBtv2187sQ2eO1yWDscno6Hv4+Al4Y4raTtT4DhvPs1FWdlcavnQibs/KO83WciqLWyOESnOK2oI1vgsnGgUoMuBuY9CxPudt7j62fk8TieBqd21B1UQP85sOhViB8pH5Ls8N7N8PO/nddOuBdmrIa44XV9mAx+IY3/rwJBF8Zj9aA+//xz9u7dy1NPPQXAxx9/THp6OqtXr3a0KSoq4o477qCiooKamhrWr1/P0KFDW7xveno6oaFt96cbjUaCg4Mv3rCH0KnjIUlEFewkyHha3kWBXalFIdlQSta6JhIc+wybqYaima9giRwIgKbsFHGf3ojCbgHAGhRLwYK3sfmFE7v91/gVH5avV6ipjR+HKXo4oYfeQiFZG3WjctAyAs/uRl1VAIApchB+JbLg2VX+VFw2i/AzWxtd50pt7Fj8C5yCWNV3LkFZ2x19OL9oE+qKbMJ/WoumMgeCo2HEUucNijOpqayg5Mo/0XvrdTDmFsepmsDeXIicSK/Nc1FaZRfkhSv+l7CDr6GuLgTAMPB6Si//HwCUNSXEpd2M2pjv1kdjvwWUTHrKGQhit4Ky7c4S8Z1pjBiTxnTEmFRXVzeZBNyrQRLbtm1j8eLF3H777Rw8eJDHH3+ctLQ0lC1EMGk0mnZlzhVZiN3p1PHI2Qt14gSgGHwtKv9wWHcV9J0IYb1QKBTQfwbqXz4gfveDsntOFwvbb5FdXnWoqwro/c0j0Gs01IkTChWKX6cRkHg5AQCJQ+W5H1dCehNyzV/h8GZIexjAIU4AyqmPU3nZdYQPnwdbH5LdYiC7HdX+8nwZuIkTw24k6JrXYf1cyP0BhWQlfutNYHOZV4tt8MAV1ouAk7voXbADwhLcTgVU55EwMhEm3OMI6Ij67n9lCwkgMArdoufQOaIAEyHyY/jnVU7LNGkSwTetJ1itbfbtaC3iO9MYMSaN8WQ2c48JlF6vp6CgwLFfWFiIXq93a/PBBx+wbp08wTty5EhMJhNlZWVERkZ6qluClpDscGa3HEDQ7yo5JPtSObwZCn5yPs33Hg+hSfDPWVBdDCd2yBaGXzBo/CH1aqgug6//BEGREJEg/ykU7pP8NUUweL68HdUfSk/If/Vc+SCUOkWRuOFw7ANQSjD8OvcgCW0QBIUTUvozjLgREsZD0TGI6CvPe2V/DYWHobLOUjFXwYVsmPusHA4+/wX4x2SQbO7ipNVB7BDAxW2pCYDAMPj2b9B/euPxyj8gR/ntfwvMBqc4qTQw8R44/omzrUoDl10BN2+WgypCE2DRa1BwECpyoc9UCOzYOSdJkjhTWENhuYmeGHJhN6uJt9nRqJwP0SaLnaO5RmrNtmav04f60Tc2QH4QE7QajwlUamoq2dnZ5Obmotfr2bZtGy+88IJbm7i4OL7//nuWLFnC6dOnMZlMREREeKpLgotReBiy6uYJVVpInn1p90t/H/K+B22AvF9dCmjgvWVO8bDbIWoIGHPlH2P/EPmvnohWPJnZTVByovFx12tN5fIfyPM9DSk9RThAlg76zYTIfnJQw75XZKFQa9zvl3SlHEQBspU04R74/hV5XxME41ZAv2mQtaPhK0FYb6gqgdBejc/l/wR9Zsj32/Oc8/iI66G2RP5zpeQUjLsP7v6vvJ+3D45/LG+XnYZx97sHblwi2UU1HMo2dNj9fA81BzIrmNA/DIVCgd0u8f2JcsqMlhavKiw3o1BA39jATupn98BjQRJqtZrVq1ezYsUK5s2bx9y5c0lJSWHt2rWOYImVK1eyadMmrr76ah555BGeffZZ8YThTcrOOLcvHG++XWtI3wSnv3CKk7kajmyVxSn3h7pGCrj2LRh/Nwy85tJer6M4swuKM+R5m/T/yOLUFLWlcHKbc3/WGpj7V5j9DDx8WN53cSESHOvcDu0tB0xo6sZGEyRbaiCLYslJOcKwfu3SZWMhoJl5V1td8InVJAdqnHCZQ6sthyPvOa2wS6TUaCG9R4uTTEGZmRPnqgBIzzFcVJzqSc8xUGIwe7Jr3Q6PzkFNmTKFKVOmuB176KGHHNvJycm89957nuyCoC0Yzjm3jQXy+h1tGyc/JUlejHpsc517izrX4Q+ya8yV2U/JC0kBeo2VXVS15XDkQzj0vnxc7Qdzn4OQOOf9j6fJC2BTr5PnqdqDzSbPK/nXWUE5/5UtDoCjmyByAFTk1DVWwMBFsmCUnYGcPfLhvB/kPseNkkPQx9/lvL+xQHazAShUMGgx/Pi6vB8aD+GXOdtG9AP/MOd9z/0II26Fmz+UI/OCdM62vcZC9GDZRZmxRRbSqiI48r78/kkN3EylmXD6y0u2hk0WO/tPlmOv8+uFBqoZlBBMT3qcPF9mIrtIdg1n5FVRY7Y79gH6xwcSqWs895eRZ6S8yookwf6TFUxLjcBfq+q0fvsyIpOEQMZuk39UXSk9DbHDnfuG83I0WFB04+slSc6I8M1zYK12n19JmgqX/w62PwZHP5KPjb9bDoV2JThW/pvyJKgC4MRnMPlx6DvNvV1042ifSyakN9bv1qK2GsFaC4WHnOeSZ8tzZyALV00pFB2R9zM+kkVC1WC+rv48yIISehn4h0NtmTx3FD/MeT4iGcKSnAJVckJ29alUEBoDdRF9hPeFAYuc67EkuzyvBnDBxVrTBEBMKpzbL+9nfw0hvSFmSLuGxi5J7D9VTo1ZtsQ0KgXj+4cS5N+zfj5iwrRcKDdiNMvj7ypOvSL9GJwQ3KQHKCRQzVeHSzBbJWotdvadqqCf3juuvkA/FRE6TavbS5JEUYUZi7XpGUelEmwdY6A3Sc/6hAmap6rIfTEruAtU4WE4/B9AAak3gT7V2S7ne9j+OBSky+I1fLHzXOQASJ4jBzks/RdMfFC2zJImNZ8PT6GQ0/e4pvDxNNpgiuOuIu7cp+7jEDMUEie7923wdfJ41Y9Zxkct37vXWPnfiGTIr4sC1Lr8QEX0g4AICOsD5WfchacevxB53JUuT97xo6EyT7bknB2EoTfKr1VbLrsLAY59CFED3a9vJUfPGrlQ6XRjjUnueeIEoFQo6BNm4VS5hlqz81dZF6BiVN+QZqcnAv1UjE0O5dvj8hxoqcFCqaGiU/rcFMOSdPRrxVyYJEn8nFXJ2eLaFtv5qbT0SZI8Mj0jMlIKZAz5jY+VZcr/1hrg0Dt1ByVIfwdy94PJKGcxWD9XFie1Hwya7VxzExgl/6i6fnB7jZIXjXbBuUazfwwMuNp5IDBaFqOGfVX7wbBbGltNTREQKQsQOP91Ox8uixNA7wlN30OhgmE3N+1u7T9fts7q6TcLIvvL4fFDb3AmprWZnZZYGzhXUkvm+WrH/qDeQcSGd0B0p4+iUcH4lDCUdR8JtUrB+P5hqFUt/5TGhMkWVlfgcI6BC5UXnws7U1hzUXECsNgVDtdvR9PzHoMETeM6/1RPTRkc3yZnNEie5DyuUMAv6+HEV2Csz6iggIFznBF4Kj8Y8auOCVXvTHqNla2MynxInNR8/4OiYdTtctRcQ8uzHrUfJFzhTOHUlECFO1N/oU+VgzIqzjqPKVTyHJerCLmiVMvjnP2NPI9V74oE0ATC6N9A7neyC7GN84k1FgUnT1c69mPDtAzo1XERgb5KhE7DFYPCybtQS5I+AF1A635G+8cHolYpvBYoUVFlxVhrk+fCTslzYQHNzIWVGMyk5zgDYsKDNQT6NRZhpUKBv70SldIzD5xCoAQylS4WlMrPuZ7nqz9BcBNh2QFhkDAcMuoEasQNEOyyRGDo9R2+BqfTiBsl/12M0MuaF46m0AbLc2yuc32uoqVQyOuauKL19wRZiFLmNn3OP7T5cy1gsdrJKtNgq3s0DvJTMTo5VETZ1hEVoiUqpG2LoRUKBf1iA1vlXvME1SabYy5MDnqpYNLgcJQNxKXWbGP/yQrHssOwIDWTBoc3K0I5OU2kL+sghEAJ5DkPVxdfr3Fwti4xaUSS+3qdsL5QniVvR/aFK+5unOS1zzQ5MEDQmPB+zQtUK5EkiV/OGDhbXOOxxbLyj5P8vqqUMH5AKFq1mBHwZQL9VIxLCeO/GWWAvGzg0/1FNAzFdF0Pr1XLLkxPWUgXQ3ziBFB9wZlOSKuDuBHOc5F95ESnIM/JjF5R95RfR0NxikyBvjM9219fJtLFpRcc2/YwfuBkfhXZRTXYJfnHxBN/rozsG0JoYOsjvwRdl+hQLUMuc37mJFp+78cmhxLo17Qb0GS1UVRZi4fSuQLCghIAVLrMP4XEyz+cdlvjiK9eY2Q3VPJcqK2sC6V2+XCGJsgRZC2VzejpRPaHqEHyPFO/q9p8eWG5iWO5VRdv2AEokBjQO5iEqIBOeT1B+6i12MgsMpJZZORUkYEqk41+0UEkx+hI0QcTFew+j5oSF0h1rY3souYtcKUCAgMVfHY0n6wLVZgszqjFsmozmUVGckqrsdklxiUE8/69iR5x/wqBErgHSOh6ydF5pTkQ1dd5vH6yHmThGrZMFjFX2hHC3ONQKOVFuJLU5kjGqlobP55yhidHhWiYODDcY4tlz549S1Lvdi6EFnicnJIqXvvqNB8dPIe5hcVIIxLCeHBGMtMGxKBQKFAoFIzoG0K/+AB2Hy9mx9HzfH2imBoXEZIkqdXu44PnqjBZ7fhrOv77LwRK4B4goesl1x4qP+suUNGDGrujhCC1nybEqT4Ra3lV06lzSgwWLDb5Z8Nfq2RcimfnBkQ8RNckq9jIq1+d5uNfzjmCWFril9xybv/XAYb2CuGqwbHklFSTWWQgo8CA2Xppq2wTIgK4ITXcI+IEQqAEDQMkQuLh62ehPM+9Xf1iU4HHOHGuioy8i7vvFAoYnxKKn0a4UnsSpwoNvPJVJlsP5Tdad5QUGUh/vezSC/JTc7qoisxiIxn5lQ7r6si5So6cq2zizjIBGpXjoUSjUtInKoiUmGCSY4IJDXDOQQZoVfSLDqZvdBCBWjU5OTnN3PHSEQLV0zn3szOkXBMESi2c+lLOU1dZACGxEBwnZyYQeIyCMlOrxAlgeJKOiCZyvgm6H7UWG3tOFvPRwXN8frSgURDDFcmRPDA9hQl9my5RVFhZyz++yeI/+3OotTS2lgbG6piXGsfcobGk6HVN3MG7CIHqydSUwxcrIbHOOrKaIesrR3E+zmfAlY9BeJIIfPAgVbVWDmQ655YidRoui246MEEXoGoyIanA95EkiWKDiVNFRk4VGvjpbDm7MwqpaqLO1OT+0Tw4PZkxSS2XJ9KH+LN64WDumdqPTQdyKTaY6BsdRHJMMCkxOqJ1XXshvRCoroi1Vi5PEeih2ljmKvyq8+HL5yHApfbS2R/gkEsOuIHzIEasZ2oOSZKorLaiC1A3WuzYWqw2iX0nK9zmlsb3DxPuu26IyWrju8wSigy1JEUGkaLXERqgYf+ZUrYfOc8XRwsorDS1eI+Zg2K4f3oKIxLC2vTa0To/7pvme14QIVBdjaoi+OktOaHqwEXN52e7lPsf+AexlmoIDIbAAc5zxmL3kPNBCzv2tbsR9YXqiirMhAepuXJwBGpV20RKXnBbSUW1nCpJqZDzvAlx6h7Y7BLnymo4kl/BF0cL2JVRhNHknhZLq1ZeNFChT1QQc4fGcvWIeAbGhrTYtrshBKorYa2FQ2/L4gRyddv4sR0XLWc1yYleLdWNz0kSGAqd+6EJ7gt2BW4cOWukqELOqVZWZeVgViVjkpvPaN0UZwpryL3gTMY5LEnXplIIAu8jSRI/ZJXy9r4cig1O68dYayXrgrHJeR9XGopTkFZFil5HSkwwKfpgJqVEMzBW12NTTAmB6ipIEhz9AKqLncfMRrmybTvr+DS6/7EPZAsKwGYFY6Fc2r3XGIgbCYWZkPmlfH7otSLOuBlyL9RwusBd5PNKagkP1pAc17o8aw2TcV4W7U9SjFgQ2xWRJIlfcsvZmVHI+QtljMyXSI7RUWu18fpXp9mfXdrqeyVGBpLaK7Qu1NtIjcVGtM6PuUNjmTM0lnFJERfNjN6TEALVVcjZA8VHGx8/92PHCFTOXvcieplfQ/FJWLYZ+tdlNLjxHfj+FaitgClPXPprdkMqqiwczHKG6mrVCsx1xdyOnDUQFqS+aBLRppJxjujTNutL4HkuGE28/vVpth8+T36F09Ldcrj1ghQV7EdyTBBjkyKYOzSOQXFOa8hulyivsRAWoGn3HGZ3RwiUJ8n/SS6DYGtFen2Ty/qEmFQoOixvl5yUC8/5h8kl049udk82qlRBwkT3/HgNKT0NmZ+79OuwLE6pS53iBHJ5iEmPtu7/1gOx2uzsO1nhqCAa7K9i8pAIvj9eRlldSQvz7HkAACAASURBVO9vM8ouOodktUmOoAiNWuHxBbeCtlNRY+Ha178jp6QJd3gD1EoFS8f0ZsGweMf7qFUr6RMZRHhQ8w8rSqWCiBbOC4RAeQ67DU5sda4xai1hSXKhuV9qoDQTkCD/ACRNgyPvymLTkJNp4BcK+qGNz9WWw+F3ceTMM16AM9/K26NubVvfejh5JSaqTHLIr1qpYPwAOaBhXP8wRxkDu4SjNHprGJscSpC/yMjRlZAkicc2H3ITp7BADVcN1hOqslBiUZNZZKS82sLk/lHcPaUfvcO9U0KjuyMEylNYa9ouToGRzrLe8WPrBAo4d0C2wpoSp3qObZbrNgW51G6yWeqCIuoWgKq0cCwNJDvWgCjUiW2sO9TDKTM6UxClxAcSUleoLtBPxfj+YXx/vBxrG0qLpiYGow/r2utQeiLr9p5hxzFnwNAzS1K5bnRvNColOTk5JCYmerF3PQshUJ7C7JIVICACRt95kQsU4KdzLoiNGSwXorNUg6lCnkOqJ2ka9B4nC9Av/4KaUlnADr0N4+5zVoE9uRUq61IWKZRQXSmvrwKqk2YRInLptYkKlxx5EcHu0XZRIVrmjYl2y/rcEhqVAo2or9Tl+DG7lGc/P+7Yv+2KJG4a14ailIIORQiUp3AN5dbq5DmktqBUy5F1Z791Px41APrNdArZsFvgx9flek7VxXBog1zl1WyUXYP19JsN7//KsVvdZzY9a0XFpWG3S471SgChQY3DwVVKRbO1cwRdC0mSyK+olUtUFBrqSlUYOZZf6UjAOvKyMFbNHeTlnvZshEB5CouLBaVpp386fqy7QAVEwJAb3NMO6eJg0GI4ukneL8uS/1yJHQ4Wk2xpAejiMcWINU5twVBjdSToDNAqxWLaLkBplZlvMy9wqtAgpwcqMlJZ47RyNSol4/tEMDc1jkkpUVSbbew4WsBnRwr4Kbu0yRRC9YQHanh12ShRRdjLCIHyFGZXCyqoffcI1ssF7kpOglIjW0uaJtbKxI2UXXm53zVxj1gYtAS2/tZ5bMhikVuvjZRXOa2nsCasJ0HnUGI08dmRAj4/cp4fskovWm5iy8FzbDl4jkCtCpPV3qryFAkRAbx4/Qjiw8S6NG8jBMpTuFlQ7RQokCvUFh2VE7YGRjXfrv98COktR+3Vo9JC7Ag5gO/4VufxIYvh0srA9DhcazSFBYmvTWdjt0v8+/ts/vrFCapbsHyao6lrwgI1jnISKXXVZ1NidOhD/MSatC6CR79pe/bs4amnnsJut7N06VLuuusut/NPP/00+/btA6C2tpaSkhIOHDjQ1K18D1eB0l5CCKomQM70cDEUStmScsVqggun4OR2efEtyPNTvcfA2bPt71MPRFhQ3uN0sZEnPkjnQE5Zo3OjE8MZmxThSA0Uo/N3JEApqKjli6MFfHb4PNl1IeNjEsOZMzSW2UNi6R0eIISoi+MxgbLZbKxZs4b169ej1+u57rrrmD59OsnJzoy6Tz75pGN748aNHDt2zFPd6XxcXXyXYkG1h9pK2PYoHPkQpAZPjkOuESmM2ogkSVRUCwvKG3zwUx5PfnTYLWddSkwwt0xIZPaQWGJD/Zu9Vh/iz/CEMB6bPYC8shoCtCqigkVYvy/hsW9aeno6iYmJJCQkADB//nx27drlJlCubNu2jQceeMBT3el8OiJIoj2UnIZ3b4ILJxqfU6phxLLO60s3wVBjc2SP8Nco8deKSL3O4D/7zvLkR4cd+2qlgnunJXPftH74qVv/HigUChIixEJaX8RjAlVYWEhsbKxjX6/Xk56e3mTbc+fOkZeXx4QJHVxawpu4ufg6yYI6vRs23+Y+DxWeBNEDIXoADJgPMSJstq2I+afOZ8P32az+xJmbcmCsjhevH8HgeLE4oifRJb5t27ZtY/bs2ahUF38qslgs5OTktPk1jEZju65rL72qKx2De66oHGt56zMMtAWV4RyBOTsJyv4Sv2LnA4Ck0lJyxf9S1W++s7EE1I1BZ4+HL9DcmORVqnF8VazV5ORUNmrTHenMz4jFZievwkx2mYn081VuCVkHRAfw/LzeBFnKyGliHqozEd+bxnhyTDwmUHq9noICZ1LTwsJC9Hp9k20/++wzVq9e3ar7ajSadqUa6fQUJVnONEe9klKaDg9vLyWnIeNTOPYJ5B9sfF4Xh+LGd4jqNZrm4v56esqWs8U1nCutJSUuyJF9vLkxyTlaCshWVFJ8JHERzc97dCc8/Rkx1FrYfbyIzw6f55uTxU3WThqREMa/bx9HaEDXCEzp6d+bpuiIMcnIyGjyuMcEKjU1lezsbHJzc9Hr9Wzbto0XXnihUbvTp09TWVnJyJEjm7iLj2KzODOYK5SgbsMPWm0FfPogFB2DPlNg8CJInAglmXCsTpQKDzd9rUIF/efAghdBF9t0GwE1Zhs/Z1UiSVBcYWbKkIgmM0NAfYCEiODrKCqqLezMKGT7kfPsOXWhxWqyoxPD+ddtY9H5izHvqXhMoNRqNatXr2bFihXYbDauvfZaUlJSWLt2LUOHDmXGjBmAbD3Nmzeve4V7uqY50gS2PmquphzeXgLnfpL3L5yEH99y5uRrCqUG+k6VhWzgfAiMuJSe9wiKKsyOWkw2O+w7WcHU1KbHrarWhrWuNIZWrcBfKxY4t0RBRS2/5JaTWSRnd8gpqXYsjrXZJU4VGRylRhoSH+pP/1i5muzQXqHMHRonMjn0cDw6BzVlyhSmTJniduyhhx5y2+9WkXv1WFoRYi5Jcg0ovxBZwKpLYeM1cP5Qy/cDUPlB8gxZlPrPgYA25vnr4RRXuNfnqjLZ+CmzgrgmDF3X9U/hQZru9SDVQeSWVrP9yHm2Hyng4Nnyi1/gwuC4EOalxjJnaBzJMcEe6qHAV+kSQRLdjpYi+GwWSH8f9r4ApVlyItno/lBTJu/XM2UlVJfIc03GQlAHQMosWZRSrgJ/Ec3UHiRJaiRQAAXlZhTBKpIaHHeN4GvODdhTOZRbzsu7T7Ezo6hN1w3vHcqcoXHMHRpLUlQnrxEU+BRCoDyBuYGLD+QChgc3ysJU7pLFwWxwuvQAUMDVf3cWE5z7HFTkQlBU54Wrd2OMtTbHZLxGpSAxJoDM8/L7dd6opqDMRGy4vJjTbpcochEzEWIu81NOGS/vPsXXJ4obnVMpFYxNCmdQXAgpMTr6RgcR6LJuLEbn3+LiWoHAFfGN8wQN8/AVZcAn98uFB11RKEFynSRWwDWvuS+mVSohXEQNdRSu1lNUiJYhlwVTXmXhQqUFUHAgU56PCvZXc+Ss0REgoVBApK5nW1D7skp4eXcm/8284HZcoYAp/aOZlxrHrEH6FsucCwRtQQiUJ3AtVnj+EGxeIddrqicgAibeD2PvBEsNFB+X3Xuxw6D36M7vbw/C1SKKDtWiVCgYlyKXbK8x27HYJPadrKBfbACnC5yW8KDewT0yg0RplZkvjxXw4U/n2J9d6nZOoYCFw+K5f3oy/fU6L/VQ0J0RAuUJXC2ozJ1OcVJpYdKjcPn94Fc3IewfAjo99J3S+D6CDkWSJC5UughU3fonP42Scf3D2HOkBAkFldVWDmYZHO3iwv3oH+/bqXIkSeJkoZEdRwsoqTLTJyqIlJhg+sUE46+pE14JCg21nCo0cqrIwN7j+fySf7RRiQqlAhaN6MV905JFYIPAowiB8gSuUXeWGvnfXqNh0asi1ZAXKa+yOkKc/TVKdAFOiygiWENCqJWzFe5uvGB/FaP7hfhE9F5ZlZnMYiOnCo0UVNY6jleZrHx1oois4qoWrr44aqWCJaN6ce/UZBHcIOgUhEB5AlcLylIrl7i440tQ9jwXUVeiuIF7r6HoRAXaUGh15BTLP+4qpYLx/cPQdOG1OFUmK2//kMOG73M4V17jkdcYdVkY81LjmJcaJ4r4CToVIVCewDWKz1IrW01CnLxOcRPuvYYM7xOCzS6Hlw9L0hES2DW/IhXVFt7el8O6vVmUuZQCaYlArYrpA2MYFBdC9oWquoW0VVhdXHihAZq62ko6wlUmrpkwgLhQIUoC79A1v32+jqsFZa2BsMu81xcBIGcxKDG4W1BNoVIqGJsS2lndahP1AQufHS7g28wLbsIC4KdW1lWHDSYhIhCVUrYQFSgYGKdjSv9o53xTK8jJyRHiJPAqQqA6GklqMAdV5+ITeJVSg8VR0ynIX0Wgn29YtMUGE18cLWD7kfP8kFXaKGABoHd4APdOTeba0b3aVCdJIOjqCIHqaGxmsNelx7FZ5O2wBO/2qYcjSRKnzjut2ubce5dCebWZXRlFHMmvILPISGaRkSKDiYTwAJJjdCTHBBPhkomissZKZpEcLXe2tJqwQC0pMcEkxwQToFHVnTOSW1btyBvYkGG9Q7llfCKLR/VCo+q682QCQXsRAtXRNLSeQLj4vMzxc1UUljvdewlRHZPJoMZs4+NfzvHZ4fN8f7qkkcsNILukmuySanZmFLZ4r2KDiWKDie9Ol7TYrj5gYc7QWHqH+3bou0BwMYRAdTRu8091AhUqLChvUVBm4nie8z1JiQ901H+6FIoNJm5Zt48ThYaLN74ElAoYkxjhSKgq0gQJehJCoDoac4MQc4USQuK9158ejLHWyoHMCsd+dIiWwQmXvrC0qLKWm976gdMN1hWNvCyMqf1jGBCrI0UfjD7En7Ml1ZwqMnC6yEiNxeZo66dW0Tc6iJQYHUlRgZRWmesWyBoxWW30iw4mRR9MUmRQmwIbBILuhBCojsZtDVQN6OJB1bNzuHmLX7KctYcCtErGpoSivMQFt+cralj21j7OXJDfZ5VSwSOz+rN4ZK8m1wgNjg9hcPzFM8/r/DUkRgYxc3DTVacFgp6IEKiOxnUNlLVWzD95CUmS3NY9je8fhp+mfYEEkiRx7Hwl2w8XsPmnXAorTYCcWWHtjSOZPyyuQ/osEAjcEQLV0TTMIhHez3t96cFYXaq2qpQKwoOdVmyN2carX2XyY3Ypt13RhzlDYxtdL0kS6XkVfHbkPJ8fKSCnxL1opEal4OWbRjV5rUAg6BiEQHU0DfPwiQAJr+BaVlyjdrr1vjt9gZUfHuZsqfw+7c8u5S9LhnH9WPl9qrXY+Mc3WWw6kNts6qDQAA0vXj+cGYOEO04g8CRCoDqahkESwsXnFSw2Z50tjUqBzS7xx0+PsvGHHLd2kgSPf5iO1S4RSjW3f7C3UfADQLCfmpmDYpibGtfmjAwCgaB9CIHqaFwtKGuNWKTrJSxWFwtKpeTf32W7iVOIv5qYEH8yi4wAPPnRYRSA60qmEH81Vw2JZe7QWK5IjhKiJBB0MkKgOpqmMpkLOp2GLr609HzH/vSBMTyzJBV/tYrl/7eP9Dw5FL3+iiCtipVzB3LD2MvQduFM5gJBd0d8+zqahi6+0N7e60sPxuri4pMkiYO55YC88PXF64ejD/EnNFDDxjvGMyIhzNF2cv9odjwyheWXJwlxEgi8jLCgOhLJ7u7i8w8BjVj57w1cXXxFBpMjn92oy8IJC3RmkggN0PDunRPYcjAPlcnADZOG+ERxQoGgJyAEqiOx1uJwFFlNECKsJ2/h6uLLKXVatdMGxjRqG6BVcfP4RHJycoQ4CQRdCOHD6EhEBF+XwWJ1uvhO1QVCAEwb0FigBAJB10QIVEdiaZhFQkTweQtXC6qsWs4oERviz6A4nbe6JBAI2ogQqI6kUQSfEChv4WpB1SdpnTYwWrjwBAIfwqMCtWfPHmbPns2sWbN48803m2zz2WefMW/ePObPn8+jjz7qye54HnODLBJhid7rSw/H1YKqtcoCNVW49wQCn8JjQRI2m401a9awfv169Ho91113HdOnTyc5OdnRJjs7mzfffJN3332X0NBQSkpaLtbW5bEYXbaFi8+buApUjcWKRqXgiuQoL/ZIIBC0FY9ZUOnp6SQmJpKQkIBWq2X+/Pns2rXLrc2mTZu4+eabCQ0NBSAyMtJT3ekcaiud25Yq4eLzIq4uvlqLjfF9Ign2E0GrAoEv4bFvbGFhIbGxzkzPer2e9PR0tzbZ2dkA3Hjjjdjtdu6//34mT57c4n0tFgs5OTkttmkKo9HYruvaQvSFs9QX4bbbIbegBOiaVmFnjIc3qTX7AfJ8U43FxvAY9UX/v919TNqKGI/GiDFpjCfHxKuPlDabjZycHDZu3EhBQQG33HILW7duJSSk+QJvGo2GxMS2z+3k5OS067o2kefMfq30D/X8610CnTIeXuRQYaFju8ZiY8nlA0iMbrmabncfk7YixqMxYkwa0xFjkpGR0eRxj7n49Ho9BQUFjv3CwkL0en2jNtOnT0ej0ZCQkEBSUpLDqvJJzC5zUIER3utHD8dul6jPdGSzS6iUCvpGBXm3UwKBoM14TKBSU1PJzs4mNzcXs9nMtm3bmD59ulubmTNnsn//fgBKS0vJzs4mIcFH520kCWzOCq7o4r3Xlx5Owwi+2FB/EV4uEPggHnPxqdVqVq9ezYoVK7DZbFx77bWkpKSwdu1ahg4dyowZM5g0aRLffvst8+bNQ6VS8fjjjxMeHu6pLnkWm8ll2wKhopKut3CtBVVjsaIP8fNibwQCQXtplUDdf//9XHfddUyePBmlsvVG15QpU5gyZYrbsYceesixrVAoWLVqFatWrWr1PbssJpcIPnM1hAs/tbdwTRRba7ERGyIS9goEvkir1GbZsmVs3bqVq666iueff56srCxP98v3MBmc2+YqsQbKi7hbUDb0oUKgBAJfpFUW1MSJE5k4cSIGg4G0tDRuu+024uLiWLp0KVdffTUajcbT/ez6NLSgxBoor+FqQdVYbFwWIQRKIPBFWu2vKysrY8uWLWzevJlBgwZx6623cuzYMW6//XZP9s93MJx3btutEBDWfFuBR2kUJCFcfAKBT9IqC+q+++7jzJkzLFq0iDfeeIOYGDmn2bx581iyZIlHO+gzGJwh9ajEpLw3ES4+gaB70CqBWr58ORMmTGjy3JYtWzq0Qz5LjUvGCL/mFxoLPI9VBEkIBN2CVrn4Tp8+TWWlc46loqKCd955x2Od8knMLkESgT6eU9DHqbW4W1DROmHRCgS+SKsEatOmTW7ph0JDQ9m8ebPHOuWTWF3WQQXHNt9O4HEMtRbHtlqlQKMSZc8EAl+kVd9cu92OJDndJjabDYvF0sIVPRHn+Ig6UN6l2mRzbAdohTgJBL5Kq+agrrzySh5++GFuvPFGAN577z0mTZrk0Y75FDYzKFXytt0GEX29258ejuzik1MbBYkSGwKBz9Kqb+9jjz3Ge++9x7vvvgvI66KWLl3q0Y75FK51oMxVEHaZ9/oiwGKTUNfl3gsNEAIlEPgqrfr2KpVKli1bxrJlyzzdH9+k4qxz22oSa6C8jN0uQZ1BGx4kFpELBL5KqwQqOzubF198kczMTEwmZzBAwwq5PZZyF4FCZM32NgqX9yAqWETwCQS+SqtmkFetWsVNN92ESqViw4YNXHPNNVx99dWe7pvvYMh3botFul5FkuT6T/XoQ8X7IRD4Kq0SKJPJxOWXXw5Ar169eOCBB/jmm2882jGfotplka625aqtAs9itUso6+afzFYbcaEBXu6RQCBoL61y8Wm1Wux2O4mJibz99tvo9Xqqqqo83TffwWwAVd2kR4CopOtNLBaR5kgg6C60yoJ68sknqamp4X/+5384evQon376KX/5y1883TffwXWRri7Oe/0QUFbtXJ9nstnRiTBzgcBnuei312azsX37dp544gmCgoJ45plnOqNfPobzqZ1QEWLuTYoqnQ8LNrtdlHoXCHyYi1pQKpWKn376qTP64ptIEihddD4y2Xt9EXDBaHbuCG0SCHyaVvk/Bg0axN13382cOXMIDAx0HL/qqqs81jGfwVAAmrp5DskOIcLF503Kqyyo6z7WrtF8AoHA92iVQJnNZsLDw9m3b5/bcSFQwIVTzm2bBRQi95s3MdRaCK+bd9KqxXshEPgyrRIoMe/UAuXZzm2p2VaCTqLKZCO8bulTgEYIlEDgy7RKoFatWtXkcSFcNFikq/VePwSAXKCwniB/lRd7IhAILpVWCdTUqVMd2yaTiZ07dzrKvvd4qi+Api7fm1ik63UsNqcZGxIg8vAJBL5MqwRq9uzZbvsLFiwQiWPrMRlAU7c4NyDcu30RYHeJ+I8IEhatQODLtMtJn52dTUlJycUb9gSstc5tUUnXq5itdkeaI4AIkclcIPBpWmVBjRw50m3BY3R0NL/73e881imfwnUhqMgi4VWKDLX4q53zTn4aMQclEPgyrRKogwcPtuvme/bs4amnnsJut7N06VLuuusut/NbtmzhueeeQ6/XA3DLLbf4ViFESQK1y1O6sKC8SmFlLQEuoqRRi3VQAoEv0yoX35dffonBYHDsV1ZWsnPnzhavsdlsrFmzhnXr1rFt2zbS0tLIzMxs1G7evHl88sknfPLJJ74lTgBmI6hdkpGKOSivcuZCNf6uAqUSYeYCgS/Tqm/wK6+8gk6nc+yHhITwyiuvtHhNeno6iYmJJCQkoNVqmT9/fvcrcFhTDioXI1Qtag95iyJDLX/5/Li7BaUSFpRA4Mu0ysVndw2NqsNmszXR0klhYSGxsU6Xl16vJz09vVG7HTt28OOPP9KnTx9WrVpFXFzL8zgWi4WcnJzWdNsNo9HYrutaQlN6gnil08WXc64AFL4x7+GJ8fAWVrvE77ZmU2I04+eYg5I4l5dLW3LFdqcx6QjEeDRGjEljPDkmrRKooUOH8swzz3DzzTcD8M477zBkyJBLfvFp06axYMECtFot7733Hk888QQbNmxo8RqNRkNiYmKbXysnJ6dd17WILRtK6n4QJYnEpL4de38P4pHx8BJ//eI4B/OrCNI6P84alZKkpLb9/7rTmHQEYjwaI8akMR0xJhkZGU0eb5WL7/e//z0ajYaHH36Y3/72t/j5+bF69eoWr9Hr9RQUFDj2CwsLHcEQ9YSHh6PVymtVli5dytGjR1vTna5DjUuovdTYyhR4nq9OFPHqV6cB3CL4RICEQOD7tMqCCgwMbHNYeWpqKtnZ2eTm5qLX69m2bRsvvPCCW5uioiJHRordu3fTr1+/Nr2G16kuc9kRP4jeYO1OZ7Leif0iHdsiQEIg8H1a9S2+7bbbqKysdOxXVFRwxx13tHiNWq1m9erVrFixgnnz5jF37lxSUlJYu3atI1hi48aNzJ8/n6uvvpoNGzb4Xm6/2nLntshi3ulYbXaOnXd+Lh+YnuLYFgESAoHv0yoLqqysjJCQEMd+aGhoqzJJTJkyhSlTprgde+ihhxzbjz76KI8++mhr+9r1MDlD730lOKI7kVNajdkqu1ZjQ/wJcinvrhalNgQCn6dV32KlUkl+vjNrd15eniilDWB2ESiVSKvT2ZwqdI5/ij6YMoPFsS8sKIHA92mVBfXwww+zbNkyxo4diyRJ/PTTT6xZs8bTfev6mKugLshDlNrofE4UGB3bo3tHcOp8tWM/UiceGAQCX6dVAjV58mQ+/PBD3n//fQYPHszMmTPx9/e/+IXdHUs1UJc9Qi3Go7M5WSRbUJGBflwW6lxIHhWiITEmwFvdEggEHUSrBGrz5s1s2LCBgoICBg4cyKFDhxgxYsRF1yx1e6wm57ZG/CB2NicLDGhUSm4b3w9FXRRlgFbJuJQwt6zmAoHAN2nVHNSGDRv44IMPiI+PZ+PGjXz00UduQRM9FpurQAV5rx89ELPVzpkLVcwf1IteoYEAKBUwrn8YfqLUu0DQLWjVN1mr1eLnJ+eZM5vN9OvXjzNnzni0Yz6Bzerc9tM1307Q4Zy5UIXVLjEsPsxxbFiSjohgMfckEHQXWuXii42NpbKykpkzZ3LbbbcREhJCfHy8p/vWtbHbQRIC5S1OFhrQqpSEB8oPTgoFJEYLN6tA0J1olUC9+uqrADzwwAOMHz8eg8HApEmTPNqxLo/ZAErXTObix7EzOVloICbYGZgS5KdCqRTzTgJBd6JVAuXKuHHjPNEP36Om3H3tk1qEmXcmJwsNxOicAqULaPNHWSAQdHHEbHJ7qW0gUCpRC6ozOVloRO8mUCKTh0DQ3RAC1V4aWlBioW6nUWuxkVNShT5YWFACQXdGCFR7qS0HpRAob5BZZMQuQYzOOe8XLARKIOh2CIFqLzVl7uXehYuv0zhVZECpgOgg55jr/IWLTyDobgiBai+NXHxi/U1ncaLASESgH+q6mk/+GiUakb1cIOh2iG91e2kYJKEWFlRncarQ0CBAQrj3BILuiBCo9lIj5qC8xYkGa6CCRQSfQNAtEQLVXhqFmQuB6gyqTFbyymrEGiiBoAcgBKq91JbL+XVALvcuSr53CifqihTqg50RfCJAQiDonohf1fZichbLc0t5JPAoe09eABAWlEDQAxAC1V7MLgIl3HudxlcnigjWqgnSyqKkUirw14qPsUDQHRHf7PZiqXFuq0Q13c6gxGjiUF55A+tJhUIUJxQIuiVCoNqD3Q7WWue+qKbbKXxzshhJQqQ4Egh6CEKg2oOpQqyB8gJfnSgGQO+a4kgESAgE3RYhUO1BJIrtdKw2O9+cKAJEgIRA0FMQAtUeasvdI/eEQHmcg7nlVNbKFYzjQlxCzIVACQTdFiFQ7UFYUJ3O7uOy9aRRKQn1d459kHDxCQTdFvH42R5EscJO56s6gdIH+zui9oL8VahEmXefxWKxkJeXR21t7cUbdxGsVisZGRne7kaXoi1j4u/vT+/evdFoWpdc26MCtWfPHp566insdjtLly7lrrvuarLdF198wYMPPsgHH3xAamqqJ7vUMdSUCQuqE8kvr+F4gZxBYnRChON4WKB4vvJl8vLy0Ol0JCUl+cxSAZPJhJ+feCB1pbVjIkkSJSUl5OXl0adPn1bd22MuPpvNxpo1a1i3bh3btm0jLS2NzMzMRu2MRiMbNmxg+PDhnupKx9PQxacWAuUp1qLw4QAAIABJREFU7HaJ93/MBUCpUDAhKdpxLiFahPf7MrW1tURGRvqMOAkuDYVCQWRkZJssZo8JVHp6OomJiSQkJKDVapk/fz67du1q1G7t2rXceeedvvVU0qiarg/13UNIktSh97PZJbYeymfO2j2s3XUKgCGxofir5Tknf40SfZh4MPB1hDj1LNr6fnvMR1JYWEhsbKxjX6/Xk56e7tbm6NGjFBQUMHXqVP75z3+26r4Wi4WcnJw298doNLbruqaIKM5D52JBXSirpMrWMffuLDpyPMprleSUawjQSPQLN6Nq52OPzS5xpKCab7IqiAgKJyU6lN4hwZwslNNKTerrtJ7C/Mzknj3bEd130JFj0h3w9HhYrVZMJpPH7u8J7Ha7z/XZ07R1TKxWa6s/V15z4tvtdp599lmeeeaZNl2n0WhITExs8+vl5OSQmJjIqV/2UpKx13HcqgogN3oKJm14q+81tbwCXaRz6NLLVJyttLe5T96ktMxERHggID/VxIX6k6LXcVlE4EUDD+x2iYO55ew7U8L50lqG6SNRqxQYzQryTcFcOTCyzf05XlDJXRt+4mxpNYtTExgcK78fC4f0xmiyMK5vOP3CQh3thyXHdngEX/1nRCDj6fHIyMjwLc8JLc+3TJ8+nQ8++ICIiIgmzzdss2rVKr7++msiIyNJS0trsv3OnTtJSkoiOTm5Tf3ctWsXp0+fbnbeH2Qj4qmnnuLvf/97m+7dkLbOy6nV6kafq+aCLDwmUHq9noKCAsd+YWEher3esV9VVcXJkye59dZbASguLuaee+7h9ddf91igxMmfv6b/p4tIaXD8ghTCPeaH+VEa2Kr7vKM5T1JMX8f+//2Qz39La1q4oqtyvtERrVpJ36ggUvQ6UmKC6Rsd5HCrWe0SP2SV8PmRAgoqawnQqHhk6iBH6XWA9LMGfsi5wAMzkvFTt05AKqot3LnhALmlNYzqHcHkfnq38zeP6UN8uD95JbLvOiZUK8LLBT7PkiVLuOWWW3jiiSeabbNz506mTp3apEBZrVbU6qZ/wmfMmMGMGTNafH29Xn/J4uRpPCZQqampZGdnk5ubi16vZ9u2bbzwwguO8zqdjn379jn2ly9fzuOPP+7RKD6TsazJ41GKSt7RPsVq6228b5vKSEUmc1Q/0ktRzGvWRRyV3CNOQhVVbnNQ1bbu82Nptto5XmBwRM01hwK4ZXQfooLcE+XGhQTwt2+y+ezweaYOiCFFH0xKTDDDE8LQNOH7kySJRzcfIre0hriQAG4YmdSojd2OQ5wAEmNEcER34609Wfxt50mqzLYOu2eQVsXDM/tz5+S+TZ7Py8tjxYoVjBgxgoMHDzJ06FCuvfZa/v73v1NaWsrzzz/PsGHDKC8v58knnyQ3Nxc/Pz/+/Oc/M3DgQMrKynj00UcpLCxkxIgRbvOwn3zyCRs3bsRisTB8+HD+8Ic/oFK5/06MHTuWvLy8Zvv/888/s3v3bvbv38/rr7/Oyy+/zP/7f/+PgQMH8tNPP7FgwQKSkpJ4/fXXsVgshIWF8fzzzxMVFcWWLVs4cuQIq1evZuXKlQQHB3PkyBGKi4t57LHHmDNnDnl5edx9992kpaWxZcsWdu/eTU1NDbm5ucycOZPHH38cgM2bN7Nu3Tp0Oh0DBw5Eq9WyevXqDniHLo7HBEqtVrN69WpWrFiBzWbj2muvJSUlhbVr1zJ06NCLqrsnGDRhHrmG3xNqdVoOQaZCVHYLWuBZ8vhT7T/Q5HwLkuyyGxdWTdrod93uk/iDxS2K79YJA1moaLtby5u4Pn1JSFSbbBhNVkzW1rkqQ/w1JEUEO/a1GgVmi/wFnZAYxfu/5JB14YzjfK+wAJ5Zksrk/tFu93lzTxY7Mwrx16i4bVw/tHUiFuyvYlS/EL7NKMPm0iWtWkFcuG+5hQQX5629WR0qTgBVZhtv7c1qVqAAzp49y9q1a3n66ae57rrr2Lp1K++++y67du3ijTfe4LXXXuPll19m8ODBvPbaa+zZs4cnnniCTz75hFdffZVRo0Zx//338/XXX/PBBx8AcPr0abZv3867776LRqPhj3/8I1u3buWaa65pU/9HjRrF9OnTmTp1KnPmzHEct1gsbNmyBYCKigo2bdqEQqFwCMnKlSsb3auoqIj//Oc/ZGVlcc8997jdr56MjAw+/vhjtFotc+bMYfny5SiVSl5//XW2bNlCUFAQv/rVrxg4sHWepo7Ao3NQU6ZMYcqUKW7HHnrooSbbbty40ZNdAaAy7zgJfiXg5xL9FZTg1kYDoJQg678ARBoziNBI2F1KavhZK90EKsAviP/f3v1HRVXnjx9/zgwzgPwMRVjFVCR/rJqpGbJLZfzwB4hg6jlrnjrqabMfhqZlhqttrtJm5u+0/LjbVlutZQgSWCZu4nclUbL1o/FpdU0TUjQEggGHmWG+f4xcGWH4JcMgvB7neM7cO3fufd/LdV7zft/3+/2yqG+3L03b8t5xCxlD7urVjV/d4Ur2KWsNdWSQH6knL9gEu8LSKh77ay7TRwfxwoRBXCk3cPxCKWu++B4V8Ojo/vhfn6Vco1YROtAX724ujAz25tiZX5T93OnvLoNzO6Hf3x/skBrU7++3H5wAgoKCGDRoEAAhISGEhYWhUqkYNGgQhYWFAOTl5bF582YAQkNDKS0tpaKigqNHj7JlyxYAxo0bh4+P9RlpTk4OJ0+eZPr06cCN7vRtJSYmRnl96dIlnnvuOa5cuUJ1dTVBQUENfiYqKgq1Wk1ISAg///xzg9uEhYXh5eUFwIABAygsLKS0tJQxY8bg6+sLwMSJEzl37lybnUtTutRIR513D2pQoaaJLtG97sZUWYbLpf9FbTHjU/49Jb7Xx2lZzOhM5TYBykTzRkV3Rj19dPy6jycqrLmZyqvMuLpoeGPaPfxwtYLTlyvIPn2F0kojALvyCtiVZ9usMWHQr/h1oK+yPHqAN97XB+H26eFOmd7E6YuVaDUqggO6tdu5ifbz+weCG63pOIpOd+PHqlqtVpZVKhVmc+uCpcViYerUqSxevLhNyngzd/cbTdyrVq1i9uzZREZGcuTIESVg3qzuedpTdxuNRtPq829LXSpAefboTdV9z1N5paEujhY8C/+Ja7X114VmQDiU/wT6Yu5x+y/6gQ8AoK66at28zjOokQN7YFHfXkHqyuUr+Pf0b3rDRrioVfh761BfH9vQ19+dkz9au4R7uuh4NtLaHeVKuYE/7jlFxv/W75QxJMCHCYN7Kct3/aobvbvbVueG9fUiqIcbrlo17rrO87xP3B7uvfde9uzZwzPPPMPRo0e544478PT0ZMyYMaSnp/P0009z8OBBysrKAGtN5Omnn2b27Nl0796d0tJS9Ho9vXv3bvGxPTw80Ov1dt8vLy9XOp+lpqa27gQbMXz4cJKTkykrK8PDw4N9+/YxcODANj+OPV0qQAG4e/vh7m2nG2jfX0PuVqi8Yh1QNngifLsL37JT+Ppd/9IsrgJUoKm9dCp6dfeE22zAoam8ht5+bZsJ+E5/d767UEGNBUr0Jn4oqsRVa32mtGzSr4kZ2ouU44VcKb+Gv5cbvX3duTvwDmXwXg9vLb++07PBfft63F4/AETnMX/+fJKSkoiLi8PV1ZU///nPADzzzDMsXryY2NhYRo4cSa9e1h9aISEhLFy4kLlz51JTU4NWq2XFihX1AtSiRYvIzc2lpKSEBx54gGeffZYZM2bYbBMTE8Py5ct5//33G+xxN3/+fBYsWICPjw+hoaGNdrpojYCAAObNm8eMGTPw8fEhODhYaQZsDypLW08B4GD5+fkMGTKkxZ9r9pgO/WXIfRPM1dblS99BxVV48vrYqcI8+OtECHvcuqxxhYf+2OLyOJujxrgcPV1KQXHLBzK669Q8NLy7EtCcQcZB2WqPcVCt+b/sTF1xLj69Xo+Hhwcmk4n58+czbdo0oqOjlfdbek0a+rvbuxck3cbNPHrCkGk3ln2D4HI+mK5/6eqLZaLYRvRvxTMitQruG+jr1OAkhGjYli1biI+PZ/LkyQQFBREVFdVux+5yTXzN0r3OUF4XN6gxwuXvoNdIOJctyQob0cNbx8hgL4pKq2lO3Vytso5r8vOUJjwhOqLGBhI7mgSohri4gUptHQvlogOVBn761hqgvt8rNagm9OvZjX49pbedEOLWSJtKQ1Qq0HrcWNa6wcV/w8+nofjMTak2ulZ7tBBCtBcJUPZo69QAagPU/2VYl6UGJYQQDidNfPboPKB2+IGLOxSdutGVXAKUEEI4nNSg7Lm5BmU2WLuYg21QkmSFQgisqTSuXr3a7G1eeuklwsLCmDx5cpuVYfPmzUpuvY0bN3L48OF62xw5coR58+Y1up/8/HwOHjyoLGdlZbF9+/Y2K2dzSYCy5+ZnUHV1rzP1vUZ6nwkhWu7hhx9mx44dDtv/ggUL+M1vftOqz94coCIjIxvNLeUo0sRnj65uDeqm9A49h4DJOqWP1KCEuHWnf9LzfwV6TDVtN2+Ai1rF4CAP7url0eD7HT3dRnl5OVOmTCErKwu1Wk1lZSWTJk1i//797N69m507d2I0Gunbty9r1qyxmaMPYOnSpcpM6NnZ2SQnJ+Pu7s7o0aOVbU6cOMHq1asxGAy4ubmRnJxMUFAQmzZt4tq1a+Tl5TFv3jyuXbumpO8oKCggKSmJkpIS/Pz8eOWVV+jXr5/dtB63QmpQ9tStQbncXIOqM6mlPIMS4paduVjZpsEJrAk2z1ysbHSbH3/8kTlz5rB3715++OEHJd3GkiVLeOuttwCUdBvp6ekkJiYq44Jq021kZGQQHR3NTz/9BNim20hLS0OtVpOent7i8tfmX8rNzQXgq6++Ijw8HK1WS3R0NJ9++il79uwhODhYSfXREIPBwPLly3nrrbdISUnhypUrynvBwcF88MEHpKamkpiYyPr169HpdCQmJhITE0NaWprN7OlgnaB26tSppKenExcXp0z9BDfSerz99ts2+f9aS2pQ9ujsNPF1vwt0deaLc5EAJcStCvlVN4fUoEJ+1fh4vI6ebiMmJobMzEzGjh1LRkYGjzzyCACnT59mw4YNlJeXo9frCQ8Pt7uPs2fPEhQURL9+/QCYMmUKH3/8MWCtpb344oucP38elUqF0WhsskzHjx9Xrkd8fDyvv/668l5z0nq0hAQoe+p2knC7kQqCQZNuzNMH0sQnRBu4q5f9pjhH6ujpNiIiIli/fj2lpaWcOnWKsWPHAtbmu61btzJ48GBSUlKUWlZLbdy4kdDQUN58800KCgp47LHHbqm8zUnr0RLSxGdP3Sa+bnfceD00wdqjr5Y08QnRqdWm2wAaTLcB1Eu38cUXX1BcXAxAaWmpUhtrKQ8PD4YNG8bq1asZN26c8hxLr9fj7++P0WhssvkwODiYwsJCfvzxRwAyMjKU9+qm69i9e7fNce2l+Rg5cqSyj/T0dEaNGtWqc2sOCVD21G3ic/OB3zwLD/8P9B59Uw1KApQQndn8+fM5deoUcXFxbNiwwSbdxrFjx4iNjeXLL79sMN1GXFwcc+fOtXnuU2vRokX87ne/44cffuCBBx7gk08+afD4MTEx7Nmzx+ZZ0IIFC5gxYwYzZ84kOLjxRI+urq6sXLmSJ554gqlTp+LndyPd0OOPP866detISEjAZDIp60NDQzlz5gzx8fFkZmba7G/58uWkpKQQFxdHWlqaQ+fqk3Qb9pir4Z8vW1+rNBDxpxsDdY9th9IfrK9HPQ5+A1pcHmeT1BL1yTWxJek26uuK6TaaIuk2nEGju5E112K2rTVJDUoIIRxOAlRj6naUMNZpj60boGSyWCGEcAgJUI2p+xyqum6Akk4SQgjhaBKgGmNTg6oz4E+6mQshhMNJgGpM3RpUbROfxXJTgJK5+IQQwhEkQDWm7lio6us1KIvZmmkXrL371DLWWQghHEECVGMa6iRhkudPQoj6WpJu4+LFizz66KPExMQQGxvLu+++2+D2+/fv58yZMy0uS3PSYxQVFZGYmNjifbcnhwao7OxsJkyYQHR0dIMX66OPPiIuLo74+HhmzpzZqj+EQ9k08V2vQUkXcyHELdJoNCxdupTMzEx27tzJhx9+2OD3X2MBqu7A2ps1Jz1GQEAAmzZtalnB25nD2qfMZjMrV67knXfeISAggOnTpxMREUFIyI1cSnFxccycOROwRvxXX31VSbbVIWgb6MUnXcyFaHuHN8NXf4bqirbbp84Txi21zgLTAGem2+jZsyc9e/YEwNPTk+DgYIqKimy+H7/55hsOHDhAbm4u27ZtY/PmzSxbtozBgweTl5fH5MmT6devH9u2bcNoNOLr68vatWvp0aMHKSkpSnoMe2kwCgoKePLJJ/nss89ISUnhwIEDVFVVceHCBaKioliyZAkAn3zyCTt27FBmV9fpdKxYsaLt/k6NcFgN6sSJE/Tt25c+ffqg0+mIjY0lKyvLZhtPzxuzgldVVaGqnamho2ioic+mi7l0kBCiTRze0rbBCaz7O7yl0U06QrqNgoIC8vPzGTFihM36UaNGERERwZIlS0hLS+POO+8EwGg0kpKSwty5cxk9ejQff/wxqampxMbG2k2A2Jw0GPn5+WzYsIH09HT27t3LxYsXKSoqYtu2bezcuZOPPvqIs2fPNno925rDalBFRUUEBgYqywEBAZw4caLedh988AHvvPMORqPRbjtsXUajkfPnz7e4PBUVFS3+nNZQRq/rr6sry7h4/jxulYUEXF93zWihqBVl6Qhacz06O7kmthx9PUwmEwaD9Qef5r4n0fy/11FVNzxBaWtYdB6Y73sSs8HQ4PvV1dX07t2bfv36YTQa6d+/P2PGjKG6upr+/ftTUFCAwWDg2LFjrFu3DoPBwJgxYygpKaG4uJjc3FzWr1+PwWAgLCwMb29vqqurOXToECdPnmTatGmANd2Gj48PBoMBi8VCdXW1ct6VlZXMnz+fF154Aa1Wq6yvZTabMRqNyvqamhqio6OV5R9//JE33niDK1euYDQa6d27NwaDAZPJhNlsxmAwYDabGTduHEajkT59+vDzzz9jMBiorq6mpqZG2f6+++5TZiPv378/586do7S0lFGjRuHu7k5NTQ1RUVGcP3/eppy1+2guk8nU7PvK6V3QZs2axaxZs0hPT2fbtm289tprjW6v1WpbNT9Yq+YVM9wB1gmA0VmqrZ+/eBWuT0zs5ul7287dJvPO1SfXxFZ7zMWnzOH2wHPWf21IhfULzt6XnE6nw9XVVSmDVqulW7duyrqamhpcXV1RqVTKtgaDAZVKVW89oCxrNBq76TbqfsZoNPL8888THx9PbGxsg2XUaDRotVrlGGq1Gm9vb2V5zZo1zJ49m8jISI4cOcKWLVtwdXXFxcUFjUaDq6srGo1GOa9arq6u6HQ61Gq1sr27u7vNtVCr1Wi1WmU/gM1+a7V0Lj4XF5d691V+fn6D2zqsiS8gIIBLly4py0VFRcq07g2JjY1l//79jipO62hv6iRhqYHyn26s8wys/xkhRKfiiHQbFouFZcuWERwczJw5c+weu7G0F2CbLiM1NbX1J2nH8OHDOXr0KGVlZZhMJvbt29fmx2iMwwLU8OHDOXfuHBcuXKC6upqMjAwiIiJstjl37pzy+quvvup4v17Vmjrp3i1gumYboLx6NfgxIUTn4Yh0G3l5eaSlpfH1118THx9PfHw8Bw8erHfsmJgY/vKXv5CQkKDkc7q5bAsWLODhhx/G19e33vu3KiAggHnz5impPXr37o2Xl1ebH8ceh6bbOHjwIMnJyZjNZqZNm8ZTTz3Fxo0bGTZsGJGRkaxatYqcnBxcXFzw9vZmxYoV3HXXXY3us93SbdT61+tQdX1sQ9hzkLv1RkeJ8Bdts+3eRqQ5qz65JrYk3UZ9XTHdhl6vx8PDA5PJxPz585k2bRrR0dHK+45Mt+HQZ1APPvggDz74oM26BQsWKK//8Ic/OPLwbUPrcSNAlRXcCE7abuDq47xyCSFEO9iyZQuHDx/GYDAQHh5OVFRUux3b6Z0kOjxdna7mV0/feO3V+0YCQyGE6KQcmTG3KTLVUVPqdpQorhOgvOX5kxBCOJIEqKZoG5jRHKw1KCGEEA4jAaopdZv46pIAJYQQDiUBqil1a1C1XNzA/Y72L4sQQnQhEqCa0lCA8uolHSSEEDYckW6jpTZv3qxMuL1x40YOHz5cb5sjR44wb968RveTn59vMy6rOek7HEF68TWloSY+b2neE0K0Xm26jaFDh1JRUcG0adP47W9/azOb+a2qO6SnpfLz8zl58qQyTCgyMpLIyMi2KlqzSYBqir0alBCi7Zw/BGf326azuVUaHQRHQd/7G3y7o6fbKC8vZ8qUKWRlZaFWq6msrGTSpEns37+f3bt3s3PnToxGI3379mXNmjW4u7vbnN/SpUsZN24cEydOJDs7m+TkZNzd3Rk9erSyzYkTJ1i9ejUGgwE3NzeSk5MJCgpi06ZNXLt2jby8PObNm8e1a9eU9B0FBQUkJSVRUlKCn58fr7zyCv369bOb1uNWSBNfU7QN1KCkg4QQbev8obYNTmDd3/lDjW7SkdNt1OZfys3NBazTwYWHh6PVaomOjubTTz9lz549BAcHs2vXLrv7NxgMLF++nLfeeouUlBSbaZeCg4P54IMPSE1NJTExkfXr16PT6UhMTCQmJoa0tDRiYmJs9rdq1SqmTp1Keno6cXFxytRP0Ly0Hi0hNaimaN2xzot8/deRRgfdujuzREJ0Pn3vd0wNyk7tqVZQUBCDBg0CrHPohYWFoVKpGDRokDLBa15eHps3bwYgNDSU0tJSKioqOHr0KFu2WPNNjRs3Dh8f68wyOTk5nDx5kunTpwPWdBvduzf8naHX60lMTCQpKckmP16tmJgYMjMzGTt2LBkZGTzyyCMAnD59mg0bNlBeXo5eryc8PNzuOZ49e5agoCD69esHwJQpU/j4448Bay3txRdf5Pz586hUKoxGY6PXC+D48ePK9YiPj+f1119X3ouKikKtVhMSEsLPP//c5L6aIgGqKSq1tRZVOwbKq5d1nRCi7fS9v8lg4gi1+Y/AmsqidlmlUmE2m1u1T4vFYjfdRl1Go5HExETi4uIYP358g9tERESwfv16SktLOXXqFGPHjgWszXdbt25l8ODBpKSkKLWsltq4cSOhoaG8+eabFBQU8Nhjj7VqP7XqXs+2IN+0zVG3mU+ePwnRpTg73cawYcNYvXo148aNU55j6fV6/P39MRqNjTYfgrUZr7CwUJkNPSMjQ3mvbrqO3bt32xzXXpqPkSNHKvtIT09n1KhRjR7/VkiAag5dnY4S8vxJiC7Fmek2wNrMt2fPHptnQQsWLFBSYAQHBzdafldXV1auXMkTTzzB1KlT8fPzU957/PHHWbduHQkJCZhMJmV9aGgoZ86cIT4+nszMTJv9LV++nJSUFOLi4khLS3PoXH0OTbfhCO2ebgPgXDac2Wt9HhW22DZg3aYktUR9ck1sSbqN+rpiuo2m3LbpNjqNvvfDHf2ts0d0guAkhBC3AwlQzaFSgU8fZ5dCCCG6FHkGJYRwmtvsCYO4RS39e0uAEkI4hZubG8XFxRKkugiLxUJxcTFubm7N/ow08QkhnCIoKIiCgoJ6Pdw6MpPJhIuLfG3W1ZJr4ubmRlBQULP3LVdaCOEUWq2W/v37O7sYLSI9Petz5DWRJj4hhBAdkgQoIYQQHZIEKCGEEB3SbTeTxLfffisjuYUQohMxGAzcc8899dbfdgFKCCFE1yBNfEIIITokCVBCCCE6JAlQQgghOiQJUEIIITokCVBCCCE6JAlQQgghOqROH6Cys7OZMGEC0dHRbN++3dnFcYqLFy/y6KOPEhMTQ2xsLO+++y4ApaWlzJkzh/HjxzNnzhzKysqcXNL2ZTabSUhIYN68eQBcuHCBGTNmEB0dzcKFC6murnZyCdvXL7/8QmJiIhMnTmTSpEkcP368S98jf/vb34iNjWXy5MksWrQIg8HQ5e6Rl156ibCwMCZPnqyss3dPWCwWVq1aRXR0NHFxcZw6deqWj9+pA5TZbGblypXs2LGDjIwMPvvsM86cOePsYrU7jUbD0qVLyczMZOfOnXz44YecOXOG7du3ExYWxr59+wgLC+tyAfy9995jwIAByvLatWuZPXs2X375Jd7e3uzatcuJpWt/q1ev5v777+fzzz8nLS2NAQMGdNl7pKioiPfee49PP/2Uzz77DLPZTEZGRpe7Rx5++GF27Nhhs87ePZGdnc25c+fYt28ff/rTn/jjH/94y8fv1AHqxIkT9O3blz59+qDT6YiNjSUrK8vZxWp3PXv2ZOjQoQB4enoSHBxMUVERWVlZJCQkAJCQkMD+/fudWcx2denSJb766iumT58OWH/9ff3110yYMAGAqVOndql7pby8nKNHjyrXQ6fT4e3t3aXvEbPZzLVr1zCZTFy7dg1/f/8ud4+MGTMGHx8fm3X27ona9SqVinvuuYdffvmFy5cv39LxO3WAKioqIjAwUFkOCAigqKjIiSVyvoKCAvLz8xkxYgTFxcX07NkTAH9/f4qLi51cuvaTnJzMCy+8gFpt/S9QUlKCt7e3ktcmMDCwS90rBQUF+Pn58dJLL5GQkMCyZcuorKzssvdIQEAAc+fO5aGHHiI8PBxPT0+GDh3ape+RWvbuiZu/b9vi+nTqACVs6fV6EhMTSUpKwtPT0+Y9lUqFSqVyUsna1z//+U/8/PwYNmyYs4vSYZhMJr777jtmzpxJamoq7u7u9ZrzutI9UlZWRlZWFllZWRw6dIiqqioOHTrk7GJ1OI6+Jzp1wsKAgAAuXbqkLBcVFREQEODEEjmP0WgkMTGRuLg4xo8fD0D37t25fPkyPXv25PLly/j5+Tm5lO3jm2++4cCBA2RnZ2MwGKioqGD16tX88ssvSnawtf31AAAElUlEQVTQS5cudal7JTAwkMDAQEaMGAHAxIkT2b59e5e9Rw4fPkxQUJByvuPHj+ebb77p0vdILXv3xM3ft21xfTp1DWr48OGcO3eOCxcuUF1dTUZGBhEREc4uVruzWCwsW7aM4OBg5syZo6yPiIggNTUVgNTUVCIjI51VxHa1ePFisrOzOXDgAOvWrWPs2LG88cYbhIaG8sUXXwCwe/fuLnWv+Pv7ExgYyNmzZwHIyclhwIABXfYe6dWrF//+97+pqqrCYrGQk5NDSEhIl75Hatm7J2rXWywWvv32W7y8vJSmwNbq9LOZHzx4kOTkZMxmM9OmTeOpp55ydpHa3bFjx5g1axYDBw5UnrksWrSIu+++m4ULF3Lx4kV69erFhg0b8PX1dXJp29eRI0f461//yttvv82FCxd47rnnKCsrY8iQIaxduxadTufsIrab/Px8li1bhtFopE+fPrz66qvU1NR02Xtk06ZNZGZm4uLiwpAhQ1i9ejVFRUVd6h5ZtGgRubm5lJSU0L17d5599lmioqIavCcsFgsrV67k0KFDuLu7k5yczPDhw2/p+J0+QAkhhLg9deomPiGEELcvCVBCCCE6JAlQQgghOiQJUEIIITokCVBCCCE6JAlQQtxmjhw5oszALkRnJgFKCCFEh9SppzoSwpnS0tJ4//33MRqNjBgxgpdffpl7772XGTNm8K9//YsePXqwfv16/Pz8yM/P5+WXX6aqqoo777yT5ORkfHx8OH/+PC+//DJXr15Fo9GwceNGACorK0lMTOQ///kPQ4cOZe3atahUKtauXcuBAwfQaDSEh4fz4osvOvkqCNF6UoMSwgH++9//snfvXj766CPS0tJQq9Wkp6dTWVnJsGHDyMjIYMyYMWzZsgWAJUuW8Pzzz5Oens7AgQOV9c8//zyzZs1iz549/OMf/8Df3x+A7777jqSkJDIzMykoKCAvL4+SkhK+/PJLMjIySE9P75KzpojORQKUEA6Qk5PDyZMnmT59OvHx8eTk5HDhwgXUajUxMTEAxMfHk5eXR3l5OeXl5dx3332ANc/QsWPHqKiooKioiOjoaABcXV1xd3cH4O677yYwMBC1Ws3gwYMpLCzEy8sLV1dXkpKS2LdvH25ubs45eSHaiDTxCeEAFouFqVOnsnjxYpv1W7dutVlubaqCuvO/aTQazGYzLi4u7Nq1i5ycHD7//HP+/ve/895777Vq/0J0BFKDEsIBwsLC+OKLL5RkbqWlpRQWFlJTU6PMhp2ens7o0aPx8vLC29ubY8eOAdZnV2PGjMHT05PAwEAlY2l1dTVVVVV2j6nX6ykvL+fBBx8kKSmJ77//3sFnKYRjSQ1KCAcICQlh4cKFzJ07l5qaGrRaLStWrKBbt26cOHGCbdu24efnx4YNGwB47bXXlE4StTOJA6xZs4YVK1awceNGtFqt0kmiIXq9nqeffhqDwQDA0qVLHX+iQjiQzGYuRDsaOXIkx48fd3YxhLgtSBOfEEKIDklqUEIIITokqUEJIYTokCRACSGE6JAkQAkhhOiQJEAJIYTokCRACSGE6JD+PxtzubQWLUATAAAAAElFTkSuQmCC\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# retrieve training statistics\n",
"list_of_stats = []\n",
"list_of_models = []\n",
"\n",
"for model in ['model1', 'model2']:\n",
" experiment_model_dir = './results/multiple_experiment_' + model \n",
" train_stats = load_json(os.path.join(experiment_model_dir,'training_statistics.json'))\n",
" list_of_stats.append(train_stats)\n",
" list_of_models.append(model)\n",
" \n",
"\n",
"# generating learning curves from training\n",
"learning_curves(list_of_stats, 'Survived',\n",
" model_names=list_of_models,\n",
" output_directory='./visualizations',\n",
" file_format='png')\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generate Annotated Learning Curves Using seaborn package\n",
"\n",
"### Helper function to collect training statistics"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"# function to generate pandas data frame from training statistcs\n",
"# Parameter:\n",
"# experiment_model_dir: directory containing the training statistics for a specific model training experiment\n",
"#\n",
"# Returns: pandas dataframe containing the performance metric and loss\n",
"#\n",
"\n",
"def extract_training_stats(experiment_model_dir):\n",
" list_of_splits = ['training', 'validation', 'test']\n",
" list_of_df = []\n",
" for split in list_of_splits:\n",
" train_stats = load_json(os.path.join(experiment_model_dir,'training_statistics.json'))\n",
" df = pd.DataFrame(train_stats[split]['combined'])\n",
" df.columns = [split + '_' + c for c in df.columns]\n",
" list_of_df.append(df)\n",
" \n",
" df = pd.concat(list_of_df, axis=1)\n",
" df['epoch'] = df.index + 1\n",
" \n",
" return df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Retrieve training results"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"pycharm": {
"is_executing": false
}
},
"outputs": [],
"source": [
"model1 = extract_training_stats('./results/multiple_experiment_model1')\n",
"model1.name = 'model1'\n",
"model2 = extract_training_stats('./results/multiple_experiment_model2')\n",
"model2.name = 'model2'"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" training_loss validation_loss test_loss epoch\n",
"0 6.646716 7.069627 7.541213 1\n",
"1 6.495552 6.909096 7.370474 2\n",
"2 6.315707 6.718051 7.167351 3\n",
"3 6.135415 6.526596 6.963694 4\n",
"4 5.954975 6.334948 6.759850 5"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"model1.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Helper function to generate plot ready data"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"# create pandas dataframe suitable for plotting learning curves\n",
"# Parameters\n",
"# train_df_list: list of pandas datatframe containing training statistics\n",
"#\n",
"# Returns: plot ready pandas dataframe\n",
"\n",
"def create_plot_ready_data(list_of_train_stats_df):\n",
" # holding ready for plot ready data\n",
" plot_ready_list = []\n",
" \n",
" # consolidate the multiple training statistics dataframes\n",
" for df in list_of_train_stats_df:\n",
" for col in ['training', 'validation']:\n",
" df2 = df[['epoch', col + '_loss']].copy()\n",
" df2.columns = ['epoch', 'loss']\n",
" df2['type'] = col\n",
" df2['model'] = df.name\n",
" plot_ready_list.append(df2)\n",
"\n",
" return pd.concat(plot_ready_list, axis=0, ignore_index=True)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Plot learning curves"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"# create plot ready data\n",
"learning_curves = create_plot_ready_data([model1, model2])"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Text(0.5, 1.0, 'Learning Curves')"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAlcAAAGFCAYAAADQJdY9AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzdd3RVVdrH8e+5Jb2QBqGTRg9FpIqglACOgI5BHRAFFRHFCgMqqCgi9plRR2UsYAXLywgjKr0pCEgRVCR0CEkggYQkpN973z8ikZBCkNzclN9nLde6nL3P2c+9zFo8s/c+zzYcDocDEREREakUJlcHICIiIlKbKLkSERERqURKrkREREQqkZIrERERkUqk5EpERESkEim5EhEREalESq5EarmFCxfSqlUrDh8+7OpQKuxszPHx8S4ZPyEhgaeffpqYmBiio6Pp3LkzN9xwA2+++SYZGRkuiUlEag6LqwMQETnfVVddxaeffkr9+vWrfOwtW7YwYcIEgoKCGD16NFFRURQUFLBjxw4+/vhjUlNTeeyxx6o8LhGpOZRciYjT5efnY7FYMAyjQv0DAwMJDAx0clQlnT59mvvvv5+IiAjmzp2Ll5dXUVvv3r25/fbb2b59+yWP43A4yM/Px83N7ZKfJSLVj5YFRQSATz/9lGHDhhEdHU337t157LHHSEtLK9bno48+4qabbqJbt25cfvnl3HjjjaxZs6ZYn/j4eFq1asXHH3/MCy+8QO/evYmOjiY9PZ1HHnmEPn368OuvvzJy5Eg6duxITEwM8+fPL/aM0pYF+/Xrx+TJk1myZAlDhgyhU6dO/PWvf+XHH38s8V3mzZtHv379iI6OJjY2lm3bttGvXz8eeeSRcn+Dzz//nFOnTjF9+vRiidVZXl5eXHHFFQBs2rSJVq1asWnTpgrH/sUXXzB48GDat2/PihUr6NatG7Nnzy4xztdff02rVq349ddfi65t3ryZ2267jc6dO9OpUyfuuOMO4uLiit23fv16br75Zrp06ULnzp0ZNGgQr7/+ernfWUQqn2auRISXXnqJuXPnMnr0aKZMmcLx48f55z//yd69e1mwYAFmsxmAY8eOERsbS5MmTSgoKGD16tWMHz+et99+mz59+hR75ltvvUV0dDQzZ87EZrPh7u4OQGZmJpMmTeK2227j3nvvZeHChcyYMYOwsDB69OhRbpxbt27l4MGDPPDAA7i7u/Ovf/2Lu+++m1WrVuHn5wcUJkizZ88mNjaWwYMHc+TIESZPnkx6evoFf4cNGzYQEhJCdHT0n/kZy7Vp0yZ+++03Jk6cSFBQEI0bN2bw4MEsWbKEKVOmFP3GAIsXL6Zly5a0bdsWgDVr1nDPPffQt29fXnzxRQDeeecdRo0axeLFi2nYsCFHjx5lwoQJDBo0iHvuuQer1crhw4c5evRopX8XESmfkiuROi4+Pp53332Xe++9l4kTJxZdb9GiBSNHjmT16tUMGDAAgKlTpxa12+12evbsyaFDh5g/f36J5Co4OJh///vfJZYCz5w5w5NPPlmUSHXt2pXvvvuOJUuWXDC5yszM5Msvv8Tf379ojNjYWNauXcvQoUOx2+28/vrr9OnTh1mzZhXdFxISwn333XfB3yIxMZHGjRtfsN+fkZ6ezsKFCwkJCSm6Nnz4cD799FM2bNjAlVdeCcCpU6dYv349Dz74YFG/WbNm0bVrV958882iaz169KB///689957TJs2jV9++YX8/HyeeuopfHx8AOjZs6dTvouIlE/LgiJ13IYNG7Db7QwbNoyCgoKi/zp27Ii3tzdbtmwp6vvzzz8zfvx4evXqRdu2bWnXrh3ff/89Bw8eLPHc/v37l7rHytPTs1gS5ebmRosWLUhISLhgrJ06dSpKrABatWoFFCZFAElJSSQlJTF48OASsVgsrv3/kh07diyWWAF06dKFZs2asWjRoqJrS5YsKfr7ADh06BBHjhxh6NChxf5+PDw86Ny5c9GyaJs2bbBarTz00EN8++23nDx5suq+nIgUo5krkTru7D/CAwcOLLX97L6rxMRExowZQ2RkJNOnT6dRo0aYzWb+9a9/ceDAgRL3lfWm39nlu3O5ubmRl5d3wVjPTazO3geQm5sLQHJyMgBBQUHF+pnNZgICAi74/IYNG5bYx1RZzk+szho2bBjvvfceWVlZeHl5sWjRInr06EGDBg2AP/5+pk2bxrRp00rc36hRIwCaN2/OO++8w9tvv82UKVPIy8ujQ4cOTJ48mW7dujnlO4lI6ZRcidRx9erVA+C9994rNfE5275+/XoyMjL45z//SWhoaFF7Tk5Oqc+t6JuBlelsAnP+rI3NZiM1NfWC9/fs2ZPvv/+en3/+mfbt25fb9+wesvz8/GLXz38J4Kyyfo/hw4fz+uuvs2zZMjp27MiuXbt4/vnni9rP/v6TJk0qdZnParUWfe7Rowc9evQgLy+PrVu38uqrrzJ+/HhWrlzpkrcvReoqLQuK1HFXXHEFJpOJhIQEoqOjS/zXtGlTALKzswGKLa8dPHiQbdu2uSTu0oSGhhIaGsq3335b7PqKFSsoKCi44P0jRowgICCAmTNnkpWVVaI9OzubDRs2AH/MGO3du7dYn/PfnryQZs2a0blzZxYvXsyiRYvw8vIqNosYHh5O48aN2bt3b6l/P61bty7xTDc3N3r27Mmdd95JVlaWy4qxitRVmrkSqSPWr1/P7t27i13z9fXliiuuYNy4ccycOZODBw/SrVs33N3dSUxM5Pvvv2fEiBH06NGDXr16YbFYmDp1KmPHjiU5OZnXXnuNhg0b4nA4XPStijOZTEycOJHp06czbdo0Bg8ezNGjR3n77bfx9fW94GxavXr1eO2115gwYQLXX399sSKiO3fuZMGCBQwaNIhevXpRv359unXrxpw5cwgICCAwMJDFixf/qURm+PDhPP3008TFxTFgwAC8vb2L2gzD4Mknn+See+4hPz+fIUOGEBAQQEpKCtu3b6dRo0aMHTuW+fPn8+OPP9KnTx8aNmxIamoqc+bMoX79+rRs2fKiYxKRP0/JlUgdMXPmzBLXoqKi+Oqrr3j44YcJDw/nk08+4ZNPPsEwDEJDQ+nZsyctWrQo6vviiy/y6quvMmHCBJo1a8akSZNYv349mzdvruJvU7YRI0Zw5swZ3n//fRYvXlwU94QJE/D19b3g/V27dmXRokW8++67zJs3j6SkJKxWK+Hh4YwaNYqRI0cW9X3xxReZMWMGzzzzDO7u7txwww10796d6dOnX1TM11xzDbNmzSI5OZnhw4eXaO/bty8fffQRb731FtOnTycnJ4eQkBA6duzINddcA0Dr1q1Zt24dr7zyCidPnqRevXpcdtllvPTSS3h4eFxUPCJyaQxHdfm/nCIiTrJr1y5iY2N5/vnnue6661wdjojUckquRKRWOXr0KJ988gldunTBx8eH/fv3M2fOHKxWK1999RWenp6uDlFEajktC4pIreLh4UFcXBxffvkl6enp+Pn50atXLyZNmqTESkSqhGauRERERCqRSjGIiIiIVCIlVyIiIiKVqFrtubLb7dhsWqUUERGR6s9qNZd6vVolVzabg7S0klWRRURERKqbkJDSa+dpWVBERESkEim5EhEREalESq5EREREKlG12nMlIiIil8ZmKyA1NZmCgjxXh1JrWCxuBASEYDZXLG1SciUiIlKLpKYm4+Hhhbd3KIZhuDqcGs/hcHDmTDqpqckEBzes0D1aFhQREalFCgry8Pb2U2JVSQzDwNvb76JmApVciYiI1DJKrCrXxf6eSq5ERESk0sTGDiUtLe2S+9RkSq5EREREKpE2tIuIiNRxiYkJTJp0H+3aRbNr107atGnLNdcM5b335pCamsoTT8ykSZOmzJ79NAkJx3B392DKlGlERkZx+nQaM2ZMIzk5mfbto3E4/jjGbunSr/niiwXk5xfQtm07Jk16BLO59CNjahPNXImIiAjHjsVz88238MknX3D48CGWL/+WN954l3vvfYAPP5zLu+/OISqqFe+/v4Dx4+/lmWeeBGDu3Lfp0KETH330GX36XM3x40kAHDp0kJUrl/Pmm+8xb94nmExmli37xpVfscpo5kpERERo2LARERGRAISFhXP55d0wDIPw8EgSExNJSkrkmWdeAKBLl66kp5/mzJlMduzYzqxZhdd79eqNr68fAFu3bmbPnt3ceeetAOTm5hAQEOCCb1b16lRy5fHLR+Cwk9P+VleHIiIiUq1YrdaizyaTqejPJpMJm60Ai+XiUgaHw8GQIddy990TKzXOmqBOLQu67/8Gj92fuToMERGRGqdjx84sX/4tANu2/Yi/vz/e3j506vTH9Y0bvycjIx2ALl26sWbNSlJTTwGQnn6apKRE1wRfxerUzJXdKxhr2n5XhyEiIlLj3H77Xcye/TS33XYz7u4eTJv2FABjx45jxoxp3HLLjURHd6BBg1CgcGlx3LgJPPTQRBwOO2azhYcfnkpoaMWqnNdkhuPcbf0ulp9vIy0ty2nP997wDJ4755Iyfh+owJqIiNRCSUmHCQ1t7uowap3SfteQEN9S+9apZUG7ZwiGLRcjL8PVoYiIiEgtVbeSK68QAEzZKS6ORERERGqrOpVcFTToRGbvGdjd/V0dioiIiNRSTkuuDhw4wPDhw4v+u+yyy5g3b56zhquQ7VnB3B7XjTPmei6NQ0RERGovp70tGB4ezqJFiwCw2Wz06dOHgQMHOmu4CinIz8M/fiUffpvI+GGDXBqLiIiI1E5Vsiy4ceNGmjZtSuPGjatiuDJd1jSAOW7/xP/g//hm93GXxiIiIiK1U5UkV0uWLOHaa6+tiqHKZzLj8AqitXcWzy3fx9HUbFdHJCIiIuWIjR1KWlpahfs8++xTXHvtQEaPvrEqwiuV05OrvLw8Vq1axeDBg509VIXYvULoHpyPxWwwbclu7NWnzJeIiIhcomuuGcrLL7/m0hicXqF93bp1tGvXjuDgYGcPVSEOr2A8c07x5OBWAJhUTFRERKRSJSYmMGnSfbRrF82uXTtp06Yt11wzlPfem0NqaipPPDGTJk2aMnv20yQkHMPd3YMpU6YRGRnF6dNpzJgxjeTkZNq3j+bcWudLl37NF18sID+/gLZt2zFp0iOYzeZiY3fqdBmJiQlV/ZWLcXpytWTJEv7yl784e5gKs3vVx3pqL30igoDCgyWTM/Oo7+vu4shEREQq15JfjrP456RKfeaw9qH8pV2DC/Y7diyemTOf59FHw7nzzltZvvxb3njjXb77bi0ffjiX+vUbEBXVitmzX2br1i0888yTzJv3CXPnvk2HDp0YO3YcGzZ8x1dfFb4cd+jQQVauXM6bb76HxWLhpZeeY9mybxgypBpsOzqPU5cFs7Ky2LBhAzExMc4c5qLkN+xOXrO+RX+es+Ewoz/aRmZugQujEhERqV0aNmxEREQkJpOJsLBwLr+8G4ZhEB4eSWJiIjt37mDQoGsA6NKlK+nppzlzJpMdO7YTEzMEgF69euPr6wfA1q2b2bNnN3feeStjxoxk69bNJCQcc9n3K49TZ668vLzYtGmTM4e4aDltb4a2Nxf9uW9kEHM3HeHN7w7x9/6RLoxMRESkcv2lXYMKzTI5g9VqLfpsMpmK/mwymbDZCrBYLi4FcTgcDBlyLXffPbFS43SGOlWh3ZSRgJGZiCkjAQoK3xRs08CX2I6N+HxHAr8m6cxBERGRqtCxY2eWL/8WgG3bfsTf3x9vbx86dfrj+saN35ORkQ5Aly7dWLNmJamppwBITz9NUlKia4K/gDqVXPmufBC/5fcR9EE3rMe3F12f0LsFgd5uPLdiLza73h4UERFxtttvv4s9e3Zz220389ZbrzNt2lMAjB07jp9+2s4tt9zIunWradAgFICwsHDGjZvAQw9N5LbbbubBB+8lJaXkWcFPPvkYd989liNHDnP99dfw1VdfVun3AjAcjupTiyA/30ZaWpbTnu//v1swMhOwnoojPeYNcqOGFbUt3X2C6V//xvSYKIZHN3RaDCIiIs6UlHSY0NDmrg6j1intdw0J8S21r9PfFqxO7F71sZ7cDYApK7lYW0zrEHIKbAxqXd8VoYmIiEgtUaeWBe1eIZiyTuIwzCWSK8MwGB7dEA+rmbSsfBdFKCIiIjVdnUuuDEcBds9AjOzkUvv8dOw0Q9/exKbDqVUcnYiIiNQGdSy5Klzys/s2BXPpRUNbN/AlxMeNF1buI7fAXpXhiYiISC1Qx5KrEADO9JhKZt9nS+3jbjExpX8kR1Kz+WDL0aoMT0RERGqBOpZcFc5cmbJOlNuvR4tABrYKYd6mIxxNza6K0ERERKSWqFPJ1Qe/5gLgvvd/BM7tAuVUoXjoqnCsZhP/WLO/qsITERGR88TGDiUtLa1CfY4fT+K++8Zzyy0juOWWG/nss/lVFGVxdaoUQ7rdgxyHlbS0U4RmHcfITcPhEVBq3xAfd54a0ormgV5VHKWIiIj8GWazhYkTH6JVq9ZkZZ3h9ttH07Vrd8LCwqs0jjqVXI3r1YLTPwdy7FQGoSYwZaVgKyO5AugbGQxAvs2Oze7Aw2quqlBFRERqrMTEBCZNuo927aLZtWsnbdq05ZprhvLee3NITU3liSdm0qRJU2bPfpqEhGO4u3swZco0IiOjOH06jRkzppGcnEz79tGcW+t86dKv+eKLBeTnF9C2bTsmTXoEs/mPf5uDg4MJDi78t9vLy5sWLVqQknJCyZUzWcwmvIMa4ZlcOL2Yl56IOTCq3HtyC+zc9vE2ujUL4OGrI6oiTBERkUrh/tsXeOxeUKnPzGlzM7mtYy/Y79ixeGbOfJ5HHw3nzjtvZfnyb3njjXf57ru1fPjhXOrXb0BUVCtmz36ZrVu38MwzTzJv3ifMnfs2HTp0YuzYcWzY8B1ffbUIgEOHDrJy5XLefPM9LBYLL730HMuWfcOQIdeWOn5iYgJxcXto27Z9pX7/iqhTe64AzD71ae5lA2DRD7u40Ok/7hYTnRr78+n2Y+w5kVkVIYqIiNR4DRs2IiIiEpPJRFhYOJdf3g3DMAgPjyQxMZGdO3cwaNA1AHTp0pX09NOcOZPJjh3biYkZAkCvXr3x9fUDYOvWzezZs5s777yVMWNGsnXrZhISjpU6dlZWFtOmTeGBBybh7e1TNV/4HHVq5goK3xj0tG0C4HhSPJ9sPcaoy5uUe889vVuwem8Kz6/Yyzt/64TJMKoiVBERkUuS2zq2QrNMzmC1Wos+m0ymoj+bTCZstgIslotLQRwOB0OGXMvdd08st19BQQHTp08hJmYwffv2u/jAK0Gdm7mye4Vgyk0jZdT3HA27mdfWHWBbfPlvIfh5WHmgbzi7EjP4cldSFUUqIiJSe3Xs2Jnly78FYNu2H/H398fb24dOnf64vnHj92RkpAPQpUs31qxZSWrqKQDS00+TlJRY7JkOh4PZs5+mefMwbr75lir8NsXVweSqsNaVYXHjscHtaFLPk8eX/EZmbkG59w1pU58uTf359/qDnM7W2YMiIiKX4vbb72LPnt3cdtvNvPXW60yb9hQAY8eO46eftnPLLTeybt1qGjQIBSAsLJxx4ybw0EMTue22m3nwwXtJSUkp9sydO39i6dKv2bZtC2PGjGTMmJFs3PhdlX83w3GhTUdVKD/fRlpallPHcDuwFP9v7iC77UjsXiFsaX43t3+ynWHtQ5kW07Lcew+ezCLuRCYxrUMwtDQoIiLVUFLSYUJDm7s6jFqntN81JMS31L51cOaq8AgcS/IvuB1eRbtQX0Z1acKXu5LYcqT8w5rDgrwY1KY+hmGQnW+rinBFRESkhql7yZV3g8IPZjdMWckA3NWrOc0CPHlm2d4KJU3/Xn+QMR9vp8Cmg51FRESkuLqXXHkVFhdzGCZM2SngsONhNTM9piUJp3N487tDF3xGdCM/DpzM4pOtpb8CKiIiInVXnUuuMLtjd/cHHBj2Aozc0wB0buLPiE6NWLDtGD8dO13uI/pEBNE3Ioi3Nx4mMT2nCoIWERGRmqLuJVcUvjFo2Arf+DOdOVF0/d4rW9DA151nlsWRW1D+kt/kfoXV2l9epYOdRURE5A91NLkKARycvmYudt9GRde93SxMi4ni0Kls3v3hcLnPCPXzYFzP5qzdf5L1+086OWIRERGpKepscmXkppEXNhCHW/HXKHu0COTadg34YPNR9hwv/7ibkV0ac/cVzencxN+Z4YqIiDhNRkYGCxd+7uowapU6mlzVx3TmBJ473saSsLlE+0NXhVPPy42nl+4p941Ai9nEHT2a4+NuueAyooiISHWUmZnBf/+r5Koy1bmzBeH3I3AKsvDe+CzZncZR0KhbsXY/DytT+0cyZfGvfPhjPGO7Nyv3eT8eSWPakt28MaIDEcHezgxdRESkUr311mscO3aMMWNG0qRJU2JihtCnz1UAPPXUdPr1G0BGRgbr1q0mMzOTlJRkYmKGcPvtdwGwdOnXfPHFAvLzC2jbth2TJj2C2Wx24TdyvTo7cwVg9wjAlJVSap+ro4Lp3zKYdzYe5tDJ8qvGRwR7UWB38PzKfVSjgvciIiIXdPfd99G4cWPmzfuEG264kW+++R8AmZmZ/PzzTnr27A3A7t2/MGvWC7z//nxWr17Bb7/9yqFDB1m5cjlvvvke8+Z9gslkZtmyb1z5daqFOppcFVZpd7j5Yco6UWa/v/eLxNNqZuayOGz2spOmAC837r0yjO3xp/n617KfJyIiUp117tyFo0ePkpqayooV39K3bz8slsJFrssv746/fz3c3T3o27cfO3fuYOvWzezZs5s777yVMWNGsnXrZhISVAOyzi4LAjisnhhlzFwBBHm78fDVETz5zR4+35HAzZc1LrPvddGhfPVzEv9ae4De4YH4e1orPW4RERFnGzz4GpYt+5oVK5bx2GNPFl0veaaugcPhYMiQa7n77olVG2Q1V0dnrgqXBR1mN0zZyeX2HdKmPr3CAvj3+oMknC67YKjJMJg6IIrTOfm8UYEq7yIiItWBl5cXWVl/bH+55pqhfPbZfADCwsKLrm/Zson09NPk5uawfv0aOnToSJcu3VizZiWpqacASE8/TVJSYtV+gWqoTs5cOTwCcBhm7D6NyG/ev9y+hmHw6IAobpq3lVnL4ng9NrqU7L1Qq/o+TLo6guhGfs4IW0REpNL5+9cjOrojo0ffSI8eV3DvvQ/QvHkYffr0Ldavbdt2TJs2heTkE8TEDKF167YAjBs3gYcemojDYcdstvDww1MJDW3oiq9SbdTJ5AqTGbtnMA43H7Iuv/+C3UP9PLivTxjPr9zH/34+zrDo0DL73ti5cOnQ7nDgcIDZVHoiJiIiUl3MmDGr6HNOTg7x8UcYMGBwsT4hIfWZPfvlEvf27x9D//4xTo+xJqmTy4LwezmGzESsxzYUnS9Ynr92bEjnJv78Y+1+kjNzy+2bmVvAHfN38NmOhMoKV0RExOm2bNnEqFGxxMbehI+Pj6vDqbEMRzWqHZCfbyMtrfyyB5XF73+jMacfwZK2n7RhC8hv2vuC9xxJzWbkB1vp2SKAF4a1LXN50OFw8MDCn9mZkM7nYy8nxMe9ssMXEREpVVLSYUJDm7s6jFqntN81JMS31L5OnblKT0/n/vvvZ/DgwQwZMoTt27c7c7iLYveqXzRjdaFN7Wc1C/BkfK/mrNl3khVxZb9laBgGU/pHUmB38MrqA5USr4iIiNQMTk2uZs2axZVXXsm3337LokWLiIiIcOZwF8XhFYIpJxUAU1bFkiuAv3VpQpsGPry4ch9p2fll9mtSz5Mx3ZqyIi6ZHw6duuR4RUREpGZwWnKVkZHBli1biI2NBcDNzQ0/v+rzFp3dKwTDYcNhsl5UcmUxGTw+qCXpuQW8snp/uX1v7dqUZgGePL9yn84eFBERqSOcllzFx8cTGBjIo48+ynXXXce0adOK1dFwtWJH4GSXvcRXmqgQH8Z2a8o3u0/w/YGyZ6XcLCYeHRDFqC5NsOitQRERkTrBaclVQUEBv/76K3/729/48ssv8fT05D//+Y+zhrtodu/CKu0FwW2x+Ta96PvHdm9GWJAXzy6PIzO3oMx+lzerR2ynRphNRrlH6IiIiNQGGRkZLFz4+UXfN3ny/WRkZJTb55133mLLlk1/NrQq47TkKjQ0lNDQUDp27AjA4MGD+fXXX5013EU7O3OV2/J6sro9fNH3u1lMPDGoJSln8nh9/cEL9n/zu4M89N+fdbCziIjUapmZGfz3vyWTq4KCsiciAF566VV8fUt/++6sO++8m65du19SfFXBaUVEQ0JCCA0N5cCBA4SHh7Nx48ZqtaH9bHJlOnMC8s6Am/dFP6N9Qz9uvqwxn2w9xsBWIXRpWq/MvkHebmw8lMryPcnEtK7/p+MWERGpzt566zWOHTvGmDEjsVgsuLm54evry+HDh1mwYCGPPjqJ48ePk5eXx4gRNzN8+F8BiI0dyjvvfEh2dhaTJ99Phw6d2LVrJyEhITz33Mu4u3swa9YMevXqzdVXDyA2dihDhlzL99+vo6CggJkzn6d58xakpqby1FPTSElJoX37aLZs2cS7735EvXpl/xtd2Zxaof3xxx9n8uTJ5Ofn07RpU2bPnu3M4S6Kw+qNw+KJ+/4leG9+iZTx+6CMulXlmXBFC9buO8kzy+KYf2sXPKzmUvvd0LERX/1ynH+sOUCvsEB83OtmcXwREak6K1YsZdmybyr1mTExQxgwYFCZ7XfffR8HDuxn3rxP2LbtR6ZMeZAPPviURo0KTzB59NEn8PPzJzc3hzvvvJWrruqHv3/xxCc+/igzZsxi6tTpPP74I6xZs4pBg64pMZa/vz/vvfcxCxd+zvz5H/LII48zd+5/6NKlK6NHj+WHHzbw1VeLKvX7V4RTSzG0adOGhQsX8r///Y833ngDf39/Zw53cQyjcPbKno9hy4WC7D/1GA+rmekxLYlPy2HOhsNl9jObDB4ZEMXJM3m89f2hPxm0iIhIzdKmTbuixArg888XcNttf+Ouu8Zy4sRxjh49WuKehg0bERXVCoBWrVqTmFj6iSd9+/b7vU8bEhMLD4zeufOnouN4ektjteIAACAASURBVPToha9v1VcqqNPTJ3avEIzcNABM2aewW73+1HMub1aP6zuE8snWeAa0CqFdaOlrxm1DfbmhY0M+35HAte0a0LpB+WvLIiIil2LAgEHlzjJVBU9Pz6LP27b9yI8/bmbOnLl4eHgwceJd5OWVPFLOarUWfTaZzNhspR87Z7W6AWA2m7DZyt/TVZXq7NmC8HtylV9YHsKUm3pJz7q/TzjB3m7MXLqHfFvZNa3u6R3GDR0bUd9XR+KIiEjt4+XlVWbppTNnMvH19cPDw4PDhw/x668/V/r40dEdWbVqOQCbN/9ARkZ6pY9xIXU8uaqPkVf42qeRfWlV1H3cLTwyIIr9KVnM3XSkzH6+Hham9I8k0MsNu94cFBGRWsbfvx7R0R0ZPfpG3njj1WJt3bv3wmazMWpULG+99Rpt27av9PFvv30cW7ZsYvToG1m9egVBQUF4ef25lak/q84e3AzgteWfeG9+CYfJjfSY18mLKLlZ7mJNX7KbFXEpfHTLZUSGlP0G4pYjqby4cj9v3tiBIG+3Sx5XREQEdHBzXl4eJpMJi8XCzz/v5KWXnmPevE8u+bkXc3Bznd9zBXDqlvXYfRtfoHfFTL46ks2H03h66R7eG9m5zMrsIT7uxJ/O5l9rD/D0Na0rZWwREZG67vjxJJ544hHsdgdWq5WpU6dVeQx1PLn6vdZVdkqlJVf1vKxM7hfBtCW/MX9rPKO7ll79vUWgF6O7NuW9H44wPDq03BpZIiIiUjFNmzZj7txLn6m6FHV8z1XhzJXPmkfx2vxKpT13YKsQ+kYEMWfDYY6kll3iYWy3pjTy9+D5FfvK3QQvIiIiNUcdT67OVmlPxHwqrtKeaxgGUwdEYjUbPLMsrsyN6x5WM1P6RXLwVBYf/RhfaeOLiIiI69Tx5Cqo8IPJDVPOpZViOF+IjzsP9g1ne/xpFv6UWGa/K8IDueXyJnRoVPVFzkRERKTy1enkCrM7dvd6YDJhyrm0UgylGdY+lG7N6vHauoMkpeeU2e+BvuF0aVoPh8Ohg51FRERquLqdXPH70qDDgeGE5MowDB6LicLucPDs8r3lJk6pWXlM/GIXa/edrPQ4REREqquBA68EICUlmenTp5TaZ+LEu/jtt1/Lfc5nn31CTs4fExmTJ99PRkZG5QV6EZRceYWAvQBTdio4Ydaosb8n914ZxsZDqXz964ky+/m6WziZlcdLq/eTnW+r9DhERESqs+DgEJ555oU/ff9nn80vlly99NKr+Pq65pi5Ol2KAcDuFYwp/TCpN1buqeHnurFzI5bvSeaVNfvp0SKg1KKhFrOJR/pHMe7Tn3hn42Hu6xPutHhERESc5c03X6N+/QbccMONALz77hzMZjPbt28lIyOdgoICxo2bwJVXXlXsvsTEBKZMeZAPP/yM3Nwcnn32Kfbt20uzZi3Izf3jbMGXXprN7t2/kpuby9VX9+eOO8bz+ecLSElJ5v77x+PvX4/XXptDbOxQ3nnnQ+rVq8eCBR+xZMliAIYOvY4bbxxJYmICkyffT4cOndi1aychISE899zLuLt7XPJvoOTKIxBTXga2oFZOG8NkGDwe05JRH27lxVX7eG5o21L7dWriz9B2Dfh46zGuaduAiOCyK7yLiIhUxJQpD5Z6/YUX/gnAW2+9zoED+0q0jx8/kYiISJYv/5bly78tcV9Z+vcfyKuvvlKUXK1evYKXX36NESNuxtvbh7S0NMaPH0Pv3n0xjNILbf/3v1/g7u7Bxx9/wb59e7njjluK2u666x78/Pyx2Ww88MAE9u3by4gRN/Pppx/z6qtzqFeveN3I337bzddf/4///Od9HA4Hd901hk6dLsPX14/4+KPMmDGLqVOn8/jjj7BmzSoGDbr001rq/LKgwzMQU+5pfNY8iun0IaeN0yLIizt7NmdlXAqr9qaU2e/+PuH4uJl5fuU+bW4XEZEap2XL1qSmniIlJZm9e+Pw9fUlKCiYOXP+zW233cyDD95DcnIyp06Vvcf4p5+2FyU5kZFRREREFrWtWrWc228fxe23j+LQoQMcOnSg3Hh27txBnz5X4+npiZeXF337Xs1PP+0AoGHDRkRFFU6utGrVmsTEhEv9+oBmrrB7FpZj8PzlQ3LDYrD7t3DaWKMvb8LKuBSeX7GXLk388fe0luhTz8vKg1eFk5yZh80BltKTehERkQq50EzT3XdPLLd94MDBDBw4+KLGvPrqAaxevZJTp07Sr18My5Z9Q1paGu+++xEWi4XY2KHk5eVd1DMBEhKOMX/+R7z99gf4+fkxa9aMP/Wcs6zWP/4dNpnM2Gy55fSuuDo/c2X3CCz67IxyDOeymE08HtOS09n5/GNt2Zn2te1CGdu9WZnnEoqIiFRn/foNZOXKZaxevZKrrx5AZmYmAQEBWCwWtm37kaSksus/AnTs2LloKfLAgX3s31+4bHnmzBk8PDzx8fHh1KmT/PDDhqJ7vLy8yMo6U+qz1q9fQ05ODtnZ2axbt5qOHTtV4rctqc7PXDk8z02uKreQaGlaNfDh1m5NmbvpKINah9CzRWCZfd/eeJj0nAImXR3h9LhEREQqS3h4BFlZZwgJCSE4OJiYmCFMnfoQt956E61bt6V58xbl3n/99bE8++xTjBoVS/PmYbRs2RqAqKiWtGzZipEjY2nQoAHR0R2L7hk27HomTbqP4OAQXnttTtH1Vq1aM2TItYwbdytQuKG9ZcvKWwIsjeGoRht78vNtpKVlVemY5pO/EbhgAA4MsrrcR1aP0mtsVKbcAju3fLiVnHw7C8Z0wdut9Bz3H2v2M3/rMeaO7ES7hqrgLiIiF5aUdJjQ0OauDqPWKe13DQkpvdSDlgV/33PlsHo5fVnwLHeLiccHteJ4Ri7/Xn+ozH539WpOsI8bs1fso8BebXJgERERKUedT64c7oWvbOY36U1u1PAqG7dDIz9uuqwxn+9IYHv86VL7eLtZePiqCPacyOSLHc6bvhQREZHKU+eTK8xW7O7+2H0akt+4Z5UOfU/vFjTyc+eZZXHklFGVvX/LYHo0D+Ct7w+Rklk5bzGIiIiI8yi54vdCoqn7cdv/dZWO62k181hMS46kZvP2xiOl9jEMgyn9I+nWPACtDIqISEVUo+3UtcLF/p5KrgCHZxCW1Dh81k2v8rG7Nw9gePtQPv7xKLuPl37AZNMAT14Y1pb6vu5VHJ2IiNQ0FosbZ86kK8GqJA6HgzNn0rFYSh5dV5Y6X4oBCmeuzGkHMfLSCw9vLqMcv7M80Dec7w+eYubSOD4Y1RmLufScd+vRNN7ffJQXh7fD3aK8WERESgoICCE1NZnMzDRXh1JrWCxuBASEVLy/E2OpMeyegWDPxbDnY+Rn4nCr2lO0fT0sPDIgksmLfuX9LUe5o0fpr9Dm2+xsPJTKB1uOMq6nXrMVEZGSzGYLwcENXR1GnabpDwoLiRr52QAY2VVTjuF8fSODGdgqhHd/OMKBkyUrzAL0aBHIgJYhzNt0hPi07CqOUERERCpCyRVg9wjCcBS+rVdVta5KM7lfBF5WM88sjcNWxu71h68Ox2o28YIOdhYREamWlFzx+7IgkNsiBofV22VxBHq5MalfBLsSM/h0+7FS+4T4uDP+ihZsPJTKqr0pVRyhiIiIXIiSK8Dx++HNWV0mYgts6dJYBreuzxVhgbz53aEyl/5GdGpEn4ggvNzMVRydiIiIXIiSK/6YuTKn7XfZnquzDMPgkQGRmE0Gzy7fW+rSn8Vk8PJ17co99FlERERcQ8kVf5wv6LtqEl47/uPiaCDUz4P7+oSx5Ugai39OKrPfqaw8Hv3fbuJOZFZhdCIiIlIeJVf8sSzosHhiuHBD+7mu79CQy5r488+1B0gu49gbs2Gw9Wgaz63Yh12b20VERKoFJVeAw+qNw+wOZjdMOamuDgcAk2EwLaYl+TYHz60o/c1Af08r9/cNY1diOot3lT3DJSIiIlXHqUVE+/Xrh7e3NyaTCbPZzMKFC5053J9nGNg9AsBuqzYzVwDNAjwZ36s5r647yPI9ycS0rl+iz1/aNmDxriReX3+QqyKDqedldUGkIiIicpbTZ67ef/99Fi1aVH0Tq9/ZPYPAMDBlV4+Zq7P+1qUJbUN9eXHVftKy8ku0G4bB1AFRZObZeG39ARdEKCIiIufSsuDvivZdedRzcSTFWUwGj8e0JDO3gJfX7C+1T0SwN7d1bUKAl5sKi4qIiLiY088WvOOOOzAMg5tuuombbrrJ2cP9aXbPQExWL9L+Wv1m2CJDvBnbvSlvbzzCoNYh9A4PKtFnQu8wF0QmIiIi53NqcjV//nwaNGjAyZMnGTt2LOHh4XTt2tWZQ/5pdo9ATC6ucVWesd2bsTIuhdnL9/LpGH983Ev+1dkdDuZvPYbVbOLGzo1cEKWIiIg4dVmwQYMGAAQFBTFw4EB27tzpzOEuicMzCFNeOkHvdcKUdtDV4ZRgNZt4YlBLUs7k8eq60vdWmX4vzfD6+gMkpedUcYQiIiICTkyusrKyyMzMLPr8/fffExUV5azhLtnZKu2m7BSXHt5cnnYN/fjbZU34784kfjySVmqfyf0isTvglTXa3C4iIuIKTkuuTp48yciRIxk2bBgjRoygb9++9OnTx1nDXTK7xx9HyVSXWlelufuK5jSt58Ezy+LIybeVaG/k78EdPZqxem8K3x+onkmiiIhIbWY4qtHrZfn5NtLSslwytvXYBup9eSMA6f1eIbfNjS6JoyK2Hk3j7s92MrJLYx66KqJEe77NzsgPtpJnc/DpbV3wsOqAZxERkcoWEuJb6nWVYvid3eOPN/Cq88wVQJem9fhrh4Ys2HaMnxPTS7RbzSam9o+iga876TkFLohQRESk7lJy9buze64chrna7rk61319wgj2duPppXHkFdhLtF/erB5zbuxAfV93F0QnIiJSdym5+p3DIwCA7A53cKbrQy6O5sJ83C08OjCKgyezmLvpSKl9DMNgZ0I6L6ws/WxCERERqXxKrs4yWbC7+2PYc8Hi4epoKqR3eBCD29Rn7uaj7E3OLLXPnhOZfL4jgWW/JVdxdCIiInWTkqtz2D2DsCRsxvv7ma4OpcImXRWBn7uFmUvjKLCXnJ36a4eGtGngwz/WHiAzV/uvREREnE3J1TkcHoGYsk7gdnilq0OpsHpeVv7eP5LdxzOZvzW+RLvZZPDowChSs/J487tDVR+giIhIHaPk6hx2zyAMu61aH4NTmgEtg7kqMog5Gw5z+FTJUhZtGvgS27ERX/yUwO7jGS6IUEREpO5QcnUOu0cA2PIxctPAXrJAZ3VlGAZT+kdiNRvMWr4Xeymb1yf0bkFEsDenzuS7IEIREZG6Q8nVORyeQRi2bAyHHSOvZP2o6izEx52H+kawPf40C39KLNHu427h49GXcUV4YCl3i4iISGVRcnUOu0cghqOwZlRNWxoEGNq+Ad2a1eO1dQdLPbjZMAzSsvN5YeU+Us7kuSBCERGR2k/J1TnsnoVV2tP7zsbuXd/F0Vw8wzB4LCYKu8PB7BV7S61tdTo7ny93JfLPNftdEKGIiEjtp+TqHGcLidqC2+JwK/28oOqusb8n914ZxoaDqXyz+0SJ9uaBXtzatSlLf0tm8+HqfcyPiIhITaTk6hxnZ648di/AcmKni6P580Z0akSHRn68sno/J0tZ/hvTrSlN6nnw/Mp9pR6dIyIiIn+ekqtznD1f0PPX+Vjjv3NxNH+e2WQwPaYlWfk2Xlq1r0S7h9XM3/tFciQ1mw9/POqCCEVERGovJVfnsHsUzlwVHt5cs5fMwoK8GNezOSviUli9N6VEe6+wQAa0DCEtW1XbRUREKpPF1QFUK1YvHGZ3HCYLRk7Ne1vwfKMvb8KKPck8v3IfXZr64+dhLdb+zF9aYzYZLopORESkdtLM1bkMo3Bp0GTFlF2zZ64ALGYTTwxqRVpWHv9Yc6BEu9lkYHc4WLwrifX7T7ogQhERkdpHydV57B6BYJgw1YKZK4BWDXwY3bUpX/1ynI2HSn4nuwMWbD/Gcyv2kpVXc6rSi4iIVFdKrs7j8AzC7uZDTtQwV4dSae7s2ZwWgZ48u2wvZ/KK77GymAweGRDFicw8/rPhsIsiFBERqT2UXJ3H7hGAgUFOh9tdHUqlcbeYeHxQK45n5PL6uoMl2js08uO66FAWbItnb3KmCyIUERGpPZRcncfuGYSRfRJrwg816vDmC+nQyI+bLmvMFz8lsi0+rUT7xCvD8PWw8tyKfaUe/CwiIiIVo+TqPA6PQEz5mdT7byxGDS/HcL57eregkb8HzyyNIye/eOLo72nlvj5h5BbYScvOd1GEIiIiNZ+Sq/OcrdIO1JpN7Wd5Ws1MGxjF0bQc5pSyv2pouwbMG9WZQC83F0QnIiJSOyi5Oo/99/MFofYlVwDdmgdwXXQon2yN55fE9GJthmFgMRnsSz7Dh1tUuV1EROTPUHJ1Hsc5M1dGdu2s/fRA33CCvd2YuSyOfFvJswW/2X2cV9cdZEf8aRdEJyIiUrMpuTqP3SOw6HNtKCRaGh93C48MiGJ/ShZzNx0p0X5nz+aE+rrz3Mq9FJSSfImIiEjZlFyd5+zhzTbfJjjcfV0cjfNcGRHEoNYhvLfpKPuSzxRr87Samdwvgv0pWczfdsxFEYqIiNRMSq7O4/h9z1VO6xHkRg13cTTONfnqSPzcLTy9dA8F9uLlF/pGBnNleCD/2XCYpPQcF0UoIiJS8yi5Op/Jgt3dH1P2SbDluToap6rnZWVyvwh2H89k/tb4Eu1/7x+Jt7uFfSlnSrlbRERESqPkqhR2zyDc932F/5Kxrg7F6Qa2CqFvRBBzNhzm8KmsYm0N/TxYfGc3eocHlXG3iIiInE/JVSkcHoHgcNTatwXPZRgGUwdE4mY2MWtZXInq7G4WE1l5Nt7eeLhE4VEREREpSclVKQoLidpqZZ2r0oT4uPPgVeFsP5bO//2UWKI97kQm/9lwmHd/KPlmoYiIiBSn5KoUdo8AsBUU7ruqI+fsDW3XgB7NA3h93UESz9vA3qmJP39p14CPfozn4MmsMp4gIiIioOSqVA7PIAxbDoYtFwqyXR1OlTAMg0cHRuHAwbPL9+I4L6l8oE8YXm5mnltRsk1ERET+oOSqFHbPYAyHHYfJgiknzdXhVJlG/h5MvDKMHw6lsuTX48XaArzcuPfKMLbFn+brX0+4KEIREZHqz+nJlc1m47rrrmP8+PHOHqrSnC0kmnrzSuy+jVwcTdWK7dSITo39eGX1AVIyc4u1XRcdSnRDP35JynBRdCIiItWf05OrDz74gIiICGcPU6nsnsFA7T1bsDwmw2B6TEvybHaeX7mv2BKgyTB4Y0Q0U/pHujBCERGR6s2pyVVSUhJr1qwhNjbWmcNUurOHN/uu/jtuB5e5OJqq1zzQi7t6NmfNvpOsjEsp1uZhNeNwOFi1N4VfEtNdFKGIiEj15dTk6tlnn+Xvf/87JlPN2tp1dlnQkrYf8+nDLo7GNUZe3oQ2DXx4cdU+0rLyi7XlFth5edU+Zi3fW+LYHBERkbquQlnP+++/T2ZmJg6Hg8cee4zrr7+e7777rtx7Vq9eTWBgIO3bt6+UQKuS/feZK4dhKizHUAdZTAZPDGpFek4BL6/ZX6zNw2pmUr9I9iaf4bPtOthZRETkXBVKrv7v//4PHx8fvvvuO9LT03nhhRd4+eWXy71n27ZtrFq1in79+vHwww/zww8/MHny5EoJ2unM7tjdfMHsjlFHComWJjLEm7Hdm/Lt7hOs3188ybw6MogrwgKZ8/1hjmfklvEEERGRuqdCydXZTc1r165l+PDhREVFXbDW0aRJk1i3bh2rVq3ilVdeoUePHrz00kuXHnEVsXsGFZZiqKMzV2eN7d6MiGAvnluxl8zcgqLrhmHw9/4R2BwOXlm9v5wniIiI1C0VSq7at2/P7bffzrp16+jduzeZmZk1bh/VxXJ4BoFhwpST6upQXMpqNvH4oFaknMnjX2sPFGtr7O/JHT2asS/lDOk5+WU8QUREpG4xHBUot22329m9ezdNmzbFz8+PtLQ0kpKSaN26daUGk59vIy2tehyv4rfkdsyp+0i/dh62euGuDsflXlt3gA+2xPN6bDTdmwcUXc+32bE7wN1Su5NtERGR84WE+JZ6vUL/Im7fvp2wsDD8/PxYtGgRb775Jr6+pT+wtrB7BWHkZyqx+t24ns1pFuDJs8viyMqzFV23mk24W0zEp2Xz9XlV3UVEROqiCiVXM2bMwNPTk99++425c+fSrFkzpk6d6uzYXMrhEYQpOwWfddPBXnDhG2o5D6uZx2NakpieyxvfHSzRPm/TUWYujdPBziIiUudVKLmyWCwYhsGKFSsYNWoUo0aN4syZM86OzaXsXoXnC3rumoeRe9rV4VQLnZr4M6JTIz7bnsCO+OK/yT1XttDBziIiIlQwufL29mbOnDksXryYq666CrvdTkFB7Z7NsXsEFn2u628MnuveK8No6OfOzGVx5OT/sTwY6OXGRB3sLCIiUrHk6h//+Adubm48++yzhISEkJSUxB133OHs2FzqbCFRAFMdrnV1Pi83M4/FtORIajZvbzxSrG347wc7/3PtAU5n6+1BERGpmyqUXIWEhDB06FAyMjJYvXo17u7uXHfddc6OzaXOHt4MdfMA5/J0bx7A8OhQPvrxKL8kZRRdNxkGjw6MJLfAxi6dOygiInVUhZKrr7/+mhEjRvDtt9/yzTffFH2uzRye5y4L1u1aV6V5sG84Qd5uzFy6h3ybveh6VIgPS+7qQe/woHLuFhERqb0sFen01ltv8cUXXxAUVPgP5qlTpxgzZgyDBw92anCudHZZMLdpX/JDL3NxNNWPj7uFRwdE8fCXvzB30xHu6tWiqM3Xw0JegZ0vdyXx1w6hWMyqgSUiInVHhY+/OZtYAdSrV6/2vxFmdsPu5oetXji24LaujqZaujIiiMFt6vPepqPsTc4s1rblSBovrtrHgu0JLopORETENSqUXPXu3Zs77riDhQsXsnDhQu666y769Onj7Nhczu4ZiOVUHNaEH1wdSrU16eoI/D0sPP1tHAX2PxLuXmEBXBkeyJzvD5GUnuPCCEVERKqWecaMGTMu1Kl37954eHjw888/c/LkSWJiYhg9enSlB2O3O8ipRmfUeexdjCXlF8zpR8ltdYOrw6mWPKxmGvl7sGB7Au4WE52b+AOFBzt3aOzH5zsSOJKaTUzr+i6OVEREpHJ5e7uXer1Ce64ABg0axKBBgyotoJrA7hmEGQeGSjGUq3/LEPpFJfPOxsNcFRlMWJAXAA39PBjXszmvrT/I2n0p9I0MvsCTREREar5yk6vOnTtjGEaJ6w6HA8Mw2LZtm9MCqw7snkFgt6mIaAVM6R/J1qNpzFy6h7dv7oTZVPi/m5FdGvP17uOsP3BKyZWIiNQJ5SZX27dvr6o4qiW7ZxCGLVczVxUQ5O3GpH4RPPH1Hj7dfoyRXZoAYDGbeOvGjvh7VHiSVEREpEbTO/LlcHgGYeDAKMiB/GxXh1PtDW5dn97hgbzx3SGOpv7xe9XztGIYBpsPp7IvuXafSSkiIqLkqhxFta6aD8Cw57k4murPMAweHRCF1Wwwc1kc9nPKdWTn25i+5DeeXV78uoiISG2j5KocZ5Or7Msm4HD3d3E0NUN9X3ce6hvB9vjT/N9PiUXXPa1mHugbzq7EDL7cmVjOE0RERGo2JVflOHu+oCl1P+RpOauihrZvQI/mAby27gAJp/+ocXVN2/pc3tSf19cf4uQZzQSKiEjtpOSqHGfPF/RbMwX3g7X7LMXKZBgGj8VEYWAwa1lcUTV/wzCYOiCKnAIb/1iz38VRioiIOIeSq3LYPc49vFlvDF6Mhn4e3NcnjM1H0vhyV1LR9RaBXtzWtSnb409zOrv6FIwVERGpLEquyvP7+YIODJVj+BP+2rEhlzf1519rDxQ7AmdM92Z8NvZy/D2tLoxORETEOZRcXYDdMwjMbiok+ieYDINpMS2x2R08u3xv0fKgu8WEt5uFlMxcVuxJdnGUIiIilUvJ1QU4vIJxGGYlV39Sk3qeTLwyjI2HUvnql+PF2v6z8TCPf/0bB09muSg6ERGRyqfk6gLsHoFgmHBYPFwdSo01onMjOjf24x9rDpCcmVt0/e4rWuDlZmb2ij9mtURERGo6JVcXYPcMBosnGTH/dnUoNZbJMJg+qBV5Nnux5cFALzfuuzKM7fGn+d95s1oiIiI1lZKrC7B7BhVuZnfYXR1KjdYswJN7erfguwOn+Gb3iaLrw6JD6djIj1fXHiA1S7WvRESk5lNydQEOz0AMh43AeZeD3ebqcGq0mzo3JrqhHy+v3k/K70VETYbBowOjyCmws+VImosjFBERuXRKri7gbJV2c9YJjNzTLo6mZjObDJ4Y3JKcfBvPnbM8GBHszf/GdSOmdX0XRygiInLplFxdwNnzBQG9MVgJWgR6cfcVLVi7/yTLfvujDEOAlxs2u4NFuxLJLdASrIiI1FxKri6gWHKlQqKVYmSXJkQ39OXFVfuKlgcBfk5M55lle5m76YgLoxMREbk0Sq4uwHFOcmVo5qpSmE0GTwxqRXa+jefPKcPQsbE/Q9rU5/3NR1X7SkREaiwlVxeg8wWdo0VQ4fLgmn0nWX5OlfYHrwrH283M7OVx2FX7SkREaiAlVxditmJ38yOnVSw5bUa4OppaZWSXJrRv6MsLK/dx8vflwUAvN+7vE872Y+n87+ekCzxBRESk+lFyVQF2r2Cw5YLZ3dWh1CrnLg8+d87y4ND2DejcxJ+1+7QMKyIiNY+SqwpweAZjTdqK5/a3XB1KrRMW5MVdvYovDxqGwYvD2vLSde1cHJ2IiMjFc1pylZubS2xsLMOGDeMvf/kLr776qrOGcjq7ZyCm7FO4xa93dSi10qjLm9AutHB58Ozbg/6eNatzQgAAIABJREFUVkyGwS+J6WyPV30xERGpOZyWXLm5ufH++++zePFivvzyS9avX8+OHTucNZxT2T2CwGHD0IZ2p7CYDJ4cXPLtQbvDwVNL45jx7R5y8lUdX0REaganJVeGYeDt7Q1AQUEBBQUFGIbhrOGcyu4VDPZ8vS3oRGHnvD249PfioibDYGr/SBJO5/D2xsMujlBERKRinLrnymazMXz4cHr16kWvXr3o2LGjM4dzGodHIAZgytEGa2cqVlw0MxeALk3rMbx9KB//GE/ciUwXRygiInJhTk2uzGYzixYtYu3atezcuZO4uDhnDuc0dq/C8wWNghzIV3FLZyk8e7AVuQV2nj3n7MH7+oTh72ll1vK92OyqfSUiItVblbwt6OfnR/fu3Vm/vmZuCLd7FFZpz+wxFUxmF0dTu7UI9GLCFS1Yf+AU3+w+ARRubn/oqv9v787jq6jv/Y+/vjNnzXKykVXCkoRNNgVRcd/YRFxQ7621WrW/x/X2tqUuba9Kq9YF2161antt67XW5VZrtRVlUVBQsAoCsiprWBMISSB7crZZfn/MSQDRXsAkk+XzfDzyODlzzpn55BwmvPP5znynmL11YfbUhl2uUAghhPjnOixc1dTU0NDQAEAkEuHjjz+mqKioozbXoaygM0u7mTZQ5rrqBN8YcxKjC0I8ung71YnhwUlDs/n7d8YxMCvJ5eqEEEKIf67DwlVVVRU33ngj06ZN45prruGss87iwgsv7KjNdSgr6AwL+rfPxVv2D5er6flahwdjpsXDC53hQaUUoYCXhkicv67Z1zZkKIQQQnQ1no5a8dChQ5k9e3ZHrb5T2YEMAPy7FmH7UokXnuNuQb1Av4wg3zt3II+/v505n1dy+Yg8AOZvrOKx97eTlezl4sHZLlcphBBCHE1maD8WuhfLn47lS0Gv2+l2Nb3Gv55awJi+aTz+/nb2N0QAuOaUAobkpPBfi7fTEIm7XKEQQghxNAlXx8gKZoHuR6+XcNVZNKX42aTBWLbNQwu3Yts2Hk0xc+Igalti/GapfBZCCCG6HglXx8gK9sFWCr25UqZj6ER904P88PwiPtldxxvrKwAYlpvKdWP6MnvDfj4tq3O5QiGEEOJIEq6OkR3MRJkGAHr9LneL6WWmj8rn9H7pPLFkB3vrnakYbj27PyelBeS6g0IIIbocCVfHyApmoYwIzeNux/anuV1Or6ISw4OaUjzwzlYs2ybo1fnzjWP4f+P7u12eEEIIcQQJV8fICmahYvW0jLsdK/Ukt8vpdfJCAe64oJjV5fX8dc0+AJJ9HmzbZu7n+yk90OxyhUIIIYRDwtUxspJyULaFd89SPBUr3S6nV5o2IpdzijL57Yc72VXjHPfWGDV44oMdzFq4VS6NI4QQokuQcHWMrFAhAMnLZ5Gy7BGXq+mdlFLMnDAIv0fj5+9swbBsQgEvd1xYzIaKRl5bu8/tEoUQQggJV8fKDPUDwPaFZK4rF/VJ8fOfF5fwWUUjL60sA2DKsBzOGpjB0//YSUViPiwhhBDCLRKujpGZ2tf5RvOihatRsUZ3C+rFJg7N4ZLB2Tzz8W62VjWhlOKuSwYBMOvdbXJpHCGEEK6ScHWsPAHM5DxsywRkOga3/eclJYQCHu5/ZwsxwyI/FOB75wzkYHOM+ojhdnlCCCF6MQlXx8EK9UOLOx0rGRp0V3rQy08nDmZbdTP/s2w34Fwa58XrTyU96HW5OiGEEL2ZhKvjYIb6obVUEx0wEStxMWfhnnOLs7h8RC4vrixjw74GdE3h0TV2HmzhueV73C5PCCFELyXh6jiYoX5ozZU0TP498cJz3S5HALdfUExOip/73t5MOO4M2b63tZrffbSLf+w46HJ1QggheiMJV8fBDPVDYaPXbkOTYcEuIcXv4f4pQyiri/DUkh0A3HR6IUVZSTzy7jaaonL8lRBCiM4l4eo4tE7HkLzsF2T87QqXqxGtxham882xJ/H6ugqW7arBq2v8bNJgDjTH+M1SCcFCCCE6l4Sr42ClJea68gTQIjWoqFw0uKv4j3MGMjAriQfe2Up9OM6I/BDXjenL39dX8GlZndvlCSGE6EUkXB0HKykHW/ejbAuQMwa7Er9H48EpQ6kNx/nlolIA/v3s/gzOTqayMepydUIIIXoTCVfHQ2mYoUKU4VzXTq+XcNWVDMlN4d/G9+fdLdUs2FRFwKvz4rfGcOnJuW6XJoQQoheRcHWczFA/VLgGGyWdqy7oxtMLGZmfyi8XlVLZGEXXFJG4yZNLdrBhX4Pb5QkhhOgFJFwdJytUiN5YjpE3Flv3uV2O+AKPprh/ylDipsWDC7Zg2TaGZfPulmoeXLCVmGG5XaIQQogeTsLVcTJD/dGi9dRPfZ7w2O+7XY74Ev0ygtx+QRGf7K7jr2v2keL3cPeEQeysaeGPn8jkokIIITqWhKvj1Dodg96wByyZQ6mrumpUPucUZfKbpTvYfqCZswdmMvXkHF74ZA+bK+Wi20IIITqOhKvj1Bqu/Btfoc8fSlCRWpcrEl9GKcVPJw4m2efhZ/M3EzMs7riwmIwkHw8s2ErclOFBIYQQHUPC1XGyQoUAKCOCsgz0uh0uVyS+Slayj59Oci7u/IePdxEKeLl7wiD6ZQSJxCVcCSGE6BgetwvobmxfKlYgE2VGAGc6BiNvrMtVia9yXnEWV43K46WV5Zw1MJPzirM4rzjL7bKEEEL0YNK5OgFmqBAtUoetNJmOoRu4/YJiCjOC3P/2FhojznFyy3fVcNvfP8OQ4UEhhBDtTMLVCTBD/dEay7BS+6LX73K7HPF/CHp1HpgyhOqmKL9ctA2AqGHx0c4a/rSizOXqhBBC9DQSrk6AFeqH3rgXM20AWku12+WIYzA8P8T/G9+fBZureXtTJeeX9GHS0Gz+uHwPW6ua3C5PCCFEDyLh6gSYoUKUFafxvIeov/KvbpcjjtFNZ/RjdEGIX75XSnldmB9dVEJawMPP39kiZw8KIYRoNxKuToAZ6g+A3rzf5UrE8fBoigenDkUpuHf+Fmdy0UsGsbW6meeWy+SiQggh2oeEqxNgpjlzXXn3rSL9r1Pw7XrP5YrEscoPBbj7kkFsqGjgj8t2c8GgPtw4rpAxhWlulyaEEKKHkKkYToCVUoCtdDBa0BvL8W99g9iAS9wuSxyjiUNz+HhnDc99socz+mfwg/MGAmDbNqZl49Hlbw4hhBAnTv4XORGaByv1JPTGcqJFU/DvfBeMsNtViePw44tLyA8FuPftzTRGDAzT4vY3Pufpf+xyuzQhhBDdXIeFq4qKCm644QYuvfRSpk6dygsvvNBRm3KFGeqH3rCHaMnlKKMF3+733S5JHIdkn4eHpg6lqjHKI+9tQ9cUual+/ndVOev21rtdnhBCiG6sw8KVruvcddddzJ8/n1dffZWXX36Z0tLSjtpcpzNDhegNZcRPOhMrmIW/dI7bJYnjNCI/xL+dNYB3t1Qz57NKZpw/kPy0APe/s4Vw3HS7PCGEEN1Uh4WrnJwchg8fDkBKSgpFRUVUVlZ21OY6nRnqjxauBjNGtOhSZzJRW07n726+fXohp/VL578Wl1LVGOPeSYPZWxfhqSVyzUghhBAnplOOuSovL2fTpk2MHj26MzbXKayQc8ag3rCHpnPuo+7a+aDkELbuRtcUD0wZQsCrM3PeJobnpfKNMSfx+roKVpfXuV2eEEKIbqjD00BzczMzZszgnnvuISUlpaM312nMUCEAekMZeAKgFCpS63JV4kRkp/i5f/IQtlU38+SSHfzHOQO4/YIiRuWH3C5NCCFEN9Sh4SoejzNjxgymTZvGxIkTO3JTna5tItGG3QAEVz9N1gvjINbsZlniBJ1dlMn1Y/vy+roKPt5VyzfH9sWja1Q0RLBt2+3yhBBCdCMdFq5s22bmzJkUFRVx8803d9RmXGMHMrC8KWgNzszeRt5YlBHBv1smFO2uvnfuAIblpvDQgq1UNET4vKKBq59bydubqtwuTQghRDfSYeHq008/5c0332T58uVcccUVXHHFFSxZsqSjNtf5lMJKnDEIEM8fh5mUi3/bWy4XJk6UV9eYddkwLNtm5tzNlPRJ5uTcVH61qJSKhojb5QkhhOgmlN2FxjzicZO6uha3yzhmofnfQa/fRe11iwBI/vBegp//mYO3rMX2pbpcnThRCzdXMXPeZm44rS9Xn5LPN19YzdDcFJ6+dhS6ptwuTwghRBeRnf3l/9fL6W1fgxnqj96wBxL5NFpyOcqM4tv5rsuVia9j4tAcrh6dz0urytl+oIU7LypmdXk9L39a7nZpQgghugEJV1+DGSpEGWFU+AAARt4Y4vmngy0TUHZ3t19QzJCcFH7+zhbG9k3jgpIsXlhRRktMPlshhBD/nAwLfg3e8o9If/Nfqb/0OWIDe9bZkALK68J866XVDMhM4r+uOJmoYdE3Peh2WUIIIboIGRbsAPH8cVi+EL4dC45YrjVVoDXIEFJ31zc9yL2Th/D5/kZeXFlO3/QgkbjJAjl7UAghxD8h4err0H3EBlyMf9dCsAxnmWWS8fKFJK152tXSRPu4aFAfvjHmJP6yei+Lt1bz2tp9/HT+ZhZvO+B2aUIIIbooCVdfU3TgJLRILd6Klc4CTcfIPw3v3uXuFibazYzzBjI8L5UHFmzlrIGZDMtN4eGFW6lsjLpdmhBCiC5IwtXXFOt3Ibbux7fjnUPLCs7EU7sVFT7oYmWivXh1jUemDcOjKWbO28RPJw0mblrcO38zptVlDlkUQgjRRUi4+rp8ycQKz8W/c0HblAzxgjMA8FascLMy0Y7yQwEenjqMnQdbeHFFGT++qITV5fW8uLLM7dKEEEJ0MRKu2kFs4GT0xnI8Bz4HwMgZha378e77xOXKRHs6Y0AG/372ABZsrqYxajBxSDa7alrk2oNCCCGOIOGqHUQHTsBW2qGhQd1PZMh0rKQcdwsT7e7bpxdyfnEWTy3dyZUj87h/8hCUklnbhRBCHCLzXLWTtDeuRovWU/sNuXBzT9cUNfj2n9fQFDX43xvGsLmyife2VnPf5CFoErSEEKLXkHmuOlhs4GQ8Bzej1e9qW6Y1VaA173evKNEhUvwefnX5yYTjJnfN2UR5XZj5G6v48yqZ20wIIYSEq3YTLZoEgL91QlEjTOZLZxFc/ycXqxIdpbhPMj+bNIT1+xrYcbCZiwZl8d8f7mTd3nq3SxNCCOEyCVftxAr1w8g62TlrEMATxMgZJQe192AThmTz7dMLmb2hkpEFIfJCAWbO20xdOO52aUIIIVwk4aodRYsm46lYiWqpBpwpGTxV6yAedrky0VG+e/YAzinK5LdLd3LDuL7UtMR4eOFWt8sSQgjhIglX7ShaNBmFjX/XuwDEC85EWXG8lavdLUx0GF1TPHjpUPplJvG7f+ziu2cP4Fun9XW7LCGEEC6ScNWOzKxhmKF+bVMyxPNOw1Ya3n1yKZyeLMXv4fErhwMw5/NKivskY1o2u2u655mvQgghvh4JV+1JKaIDJ+Mr+wcq1ojtDxEtnortT3e7MtHB+qYHeWTaMPbUtPCz+Zt5/P3tfOeVteyrj7hdmhBCiE4m4aqdxYomoawYvt2LAWic9DvCo7/jclWiM4zrl8EdF5bwjx01RAwT07b5yVsbicRNt0sTQgjRiSRctbN43mmYSbn4S+e0LdOaK+Uizr3Etafkc+0pBbz1WSUTh+awpaqJX7y3TS6RI4QQvYiEq/am6URLpuLb/T4q1oiK1JL1/FgCG19xuzLRCZRS3HlhMecWZTJ7fQUTh2Qzb2MVr6+rcLs0IYQQnUTCVQeIllyOMqP4di7EDmRgZAyW+a56EV1TPHzZMIbkpLCk9ACjC0J8sO0AlnSvhBCiV5Bw1QGMvDGYKfn4S+cCznxX3oqVYBkuVyY6S9Cr8/hVI8hM9lFWF+auCSVy3UEhhOglJFx1BKURLZ6Gb88HqGg98YIz0OJNeA5sdLsy0Yn6JPv49VUjiJkWd87eyNryen749w00RSVkCyFETybhqoNEB01DWXF8OxYQLzgDAG/FCperEp2tuE8yv7r8ZMpqw/zivW18squWmfM2YVgyRCiEED2VhKsOYuScgplaSKD0LayUfGJ9z8X2BN0uS7hgXL8Mfj5lCDsOttA/M4mPd9by5JIdbpclhBCig3jcLqDHUopoyWUE1/0PKlJL/RVytmBvNnFoDk0xk0fe3Ua/jCB/Wb2XgZlBpo8ucLs0IYQQ7Uw6Vx0oOuhylGXg3/E2AKq5CsyYy1UJt0wflc/3zx3Intoweal+frV4u8zgLoQQPZCEqw5k9BmBkTYA/7Y5ePd8QJ/nx+CpXOt2WcJF3z69kBvHFbK/Mcr5xVkUpAXcLkkIIUQ7k3DVkZQiWnI53r0fYSbnAeCtXu9yUcJt3z93ANNH5bN42wGe/2QPb6yvoKw27HZZQggh2okcc9XBoiWXkfzpU/gqVmIm5+Kp3uB2ScJlSil+cnEJzTGD//7HLgIejaxkH89edwp9kn1ulyeEEOJrks5VBzOzhmFklOAvfQsjexSeKulcCWcW9/unDGXKsBwihkVlY5QZf5M5sIQQoieQcNXRlCJaMg3v3uWY6UXotaUQa3a7KtEFeDTFfZOHcNnwXAzLpvRAM3fO/pyoYbldmhBCiK9BwlUniJZcjsIGI4yZORi9pdLtkkQXoWuKn00azBUj87BtWF1ez2OLS90uSwghxNcgx1x1AjNzEEbaQDwNe6i9bpHb5YguRlOKeyYMwqMp/raugrhlY9m2XItQCCG6qQ4LV3fffTcffPABWVlZzJ07t6M2023EBlxM8LOXIN4CKPDKbO3iEE0p/vPiEry6xl9W7yUcMxmQmcR3xvfDq0uDWQghupMO+609ffp0nn322Y5afbcT638JyoySNu8WMl6b6nY5ogtSSnHHBUXMOG8gi7Yd4I+f7OHO2Z8Tk2OwhBCiW+mwcDVu3DjS0tI6avXdTrzgdCxvCipaj167TQ5qF19KKcUN4wp56NKhaAqW7arlh3/fIAFLCCG6ERlv6Cy6j3jhuWhN5ShsPAc+d7si0YVNGpbD09eOwu9RrCqr57uvraclZrpdlhBCiGMg4aoTxfpfjB6pBWSmdvF/G1uYzgvXjyHk97B+XwP3vr3Z7ZKEEEIcAwlXnSja/yIALG+yzNQujklxn2RevWksg7KTWVJ6kEfe3SYTjQohRBcn4aoT2ck5xHNGg+ZBRercLkd0E31S/Lz4rTHcOK6Qv6+vYMLTy3hnk8yVJoQQXVWHhas77riDb3zjG+zcuZPzzjuP1157raM21a3E+l+EitbTePGv3S5FdCMeTfGD8wZyz4RBmLbNz+Zv4dfvb3e7LCGEEF9C2bZtu11Eq3jcpK6uxe0yOpSnci0Zr19GwyVPEh08HWSiSHGcNlc2cuur62mJm/TLCPLba0aSHwq4XZYQQvQ62dmpX7pchgU7mZEzCiuQRcoHdxPY8Ce3yxHd0NDcVObfegaj8lPZUxvmqmdX8NaGCrrQ30lCCNGrSbjqbEojOuASlBHGW7nW7WpEN5Xs9/DHb57KXZeUcFJ6gAcXbuO7f13H7pqe3fkVQojuQIYFXeDbPo+0d27FTC2k5sZlbpcjujnLtpm9YT+PLi7FsGwmD83m384aQN90ucSSEEJ0JBkW7ELihedho6E1lieuNSjEidOUYvqofK4fexLY8Pamaqb/cSV3vbWRbdVNbpcnhBC9jnSuXJL+lwl4D26idvpsjPzT3C5H9BC7a1p47P3tLNtViwJs4OyBmUwals34AZmkB71ulyiEED3GV3WuPJ1ch0iIDZyM9+AmvBUrJFyJdtM/M4mnrh7Jyj21PLZ4O7qm2FTZyEc7a1DAqIIQZxdlck5RJgMzk/Do0rwWQoj2Jp0rl+i128l8+Xwig64kPPRazOyR2MFMt8sSPYhp2UQMk6BX538+3s2LK8tI8urURZwZ3hWQneIjN9VPbmqA3FQ/KX4dr67h1RUezblN9umEAh5CAS+hgIf0oJdkn46SaUSEEL3cV3WuJFy5KPW9H+Lf+gbKtrBRxPPGEjn5m5gZxdD2sTi3diADM70IlHQaxPHbVNnIX1bvZfHWA0QMi4wkL32SfOSk+omaFpUNEfY3RIhbx7Y+j6bISvaRlewjM8nrfJ/kJS3oJSPJS3rQ+UpLBDIJY0KInkjCVRelIrUEPvszSWt/jxb955fEsbwpGDkjMXJGE885BSNvLFZKfidVKnqClpjJ4m3VvLulmq1Vzdw9YRDnFWfx1zX7+O2HO8hM8pHk1Qn6dIJejbMHZjJ+QCbldWE+2lmDpsBGYVgW4bhFfTjOgeYYB5tj1IXjWF/x20RXkJoIWqGAhySvTpLP+Qp6dWebXp2AVyN42PcBj47foxHwavg9Gv7E/dYvn66haxLahBDukHDV1Zlxgmv/QPLKx1FmDCuQQcOE3wKQ9OlvwIyDpqNFatDrdqPsOADx/NOJDLqcaPFl2El93PwJRDdk2zZKKdaW17No2wHqwnGaowYtcZPmqMmUk3P45ti+rC6v49ZX1x/1+jF90/jDv47Gtm3unb8Zr+4EIY+m0JSGbdv0SfHRGDU40ByjJWrSHDNpiZu0JG7DiduocYxtsy/waKotaPk9Gr7DgpfPo+FP3DqPq7bv2x7/wmsDniMf83/Ffb/H+TmlIydE7yXhqpvQmirwVG8AM0as5DIAQvO/g6dqLXqzc7FeW+mYoX5ESy7Hv/MdPDVbsJVGvO85RIsmY6YNwEopwEwpAG+Smz+O6CEMy6a2JUZNS5yaFqdTdaApRnrQy5Wj8onETa5/aTX14TgNEYPWXyoeTfHxbeeglOKWl9eyoaIBn64SnSmnY/XQ1KEMzklh7mf7WbL9IB5N4dEUeuJrcE4KfdODVDVE2FzlTC1h286AuWXb6Joi4NGJGiYNEQPTsombNnHLwrBsYoZF1LCIma23zrLW+1+HgkNhzaPh1xXew8Kc77D73sR93xH3E4Hv8NckAqG39VZ3wqNH1/BqznM9ifV6E+vzaM596eIJ0bkkXPUAWvN+PJXr8FStw1O3nYZJvwelyHjlIrTmKrAMtPiR8xpZ/nRsfxqWLxUrqQ9Wcj5m6kmYaQMwMwdjhvqDL9mln0j0RIZl0xiJUxc2aIoajCwIAbBwcxV76yM0RgzCcZOwYRGJm3z/3IH0TQ/yv6vKeWvDfiKGSSRuEU50s2acX8S3TuvL0u0HuXP250dt75yiTH591QhaYibn/+ajIx7z6opQwMs7/34mAD95ayN7alvaOlfeREj53jkDyErxs3hrNWv3NqArhVKHLv1ZlJVMTqqPA40xth1oxsbp+lm2c6triiSfTjRuUtNiYNk2hmVjWhaGBXHTCXpx88hwFzMt4mb7/QrWFG2hzXtYkGsNrJ62IKbwak5IO/x9OBTWNHyexDJNJdbR+rzW1xy5Ha/Hee6hEyK+sE5dQ1dIp0/0KDIVQw9gJecRK8ojVjTpiOWRk7+Jt/wjvBUrjljePOYHaNE6fDsX4G3Y/dXrDWRiphRgZgzCSi3ASsrBTM7FSsrBSs7BCmY7HTD5pSiOgUdTZCT5yEjyHbF84tCcf/q6b53Wl2+d1veIZa0BBuD0fun87ZZxiU6USSTRkUoLeNq2e9clJUQTy1uDzOH/agvTA9i209mKmhZxw6I5Fifg1emT7KOmJc6qPXWJ0OO8HuD2C4qYMiyX97cd4KkPdx5V+/nFWTw0dRiNEYOL/vvjox5P9ul88IOzAfjOK2vZXdNC0KuTFvDgTQSeeycPJjc1wOwNFSzfVYumFJoicas4pW+IoqxkyuvCrCmvb1u3s1sqUvw6eal+InGL3bUtmIn3zrJsTCcNEvDqGJZNS8ykyTIwTZu4ZWPaNnHDIm7Zbd2+uGnRjrnPqRXagtzxhr1DIe1QZ7MtNGpaW6ez7UspPBptjznbU0eERK926MxYXVd4D3uO5wuvcdYp4VAcG+lc9SSWiZYYOkSBlZQLmo4KH0RrrkSL1qMiNeiN+9Drd2JkDEbFm/BvexPvwU3YSgPbRnH0Pwlb82EF+zjdr2AWdlJ2IoTlJEJYLnYwK9EpC4EmuV10f3aiA6UAj64RiZscaI5hmHZbAIubNikBDyV9kokZFh+UHmgLKDHT6VZpmuK6MScB8OKKMvY3Rp0AYzmvj5sWd1xYTH4owJ9XlfPuluq2dccti5hhcetZA7h8ZB6Ltx3gnrmbML9w9sBFg/rwy8tPpq4lzoTfHX1ZrbSAh/e+dxYA33hhFdsPHP279uUbxzAoO4Unl+xgzmf7DwslTtj4l1MLOHtgJuv2NvDqmr3o2qEAqJSiX3qQ0/un0xIzWbilmkTuaz3pGV1TDMpOxrBsdh1sIWpabd0/KxEGk7w6lm3TFDWJGCaWDYZpYdg2hmm3hUXDtDASncHO/E/s8FB3+PdfnMLki+HxiJD3hRDYFqIT953nccRz9MO257zvh91XRwdL/QuvbwuhusKjnNB4+Pr0xLLWkKtJiDwmMiwovpJWtxNf+Yd4K1ahN+xBa9yL1lJFeORNGNkj8O1ZQmDbbGwU6D5spaNsE6w4yv7yY1YsPYjtT8UO9sEKpGH7Qm1DlLY/hO0JYnuD2J4kbE8AvEnO44F0rEAGtj9Npp0Q4p+wEh24uGlhmDaaBqGAty24tIayuGljWBYKxRkDMgBYUnqQ+nDceY5pYySGKKePyicjycd7W6pZU15PLDGcaVjOc6aNyOOsgZms2lPHMx/vIm4dqiFuWpw5IJOfXFxCTUuMq59bmdi23RYEM5O8LPjueACu/dNKdtWEj/q5Xr1pLEVZyfzivW38bV3FUY//5OISrj2lgHe3VHPP3E0AifDrBIXzirPaavj+65+hK44II6l+Dz88v4i4ZfHiinLqwnEUJIaBFQo4rziLoE9n4/5G9taHAXX9l61TAAAP8UlEQVREBzQ/5Cct6KW2JU5FQ8Q5BrC1U4iNV3NO7IiZFvVh5zhAKxEgTcv57JRSmJbz2Vi2s8xKvFdtz2vHfy/Hq3WIuXWIXNec90BL3G/trOqJkzpau3q6Umia87jnsPe9LRx+RRD8Yqe2dR2twfHQekhs49D6DwV8pwYNGJSTzJi+6R3+Pkm4EsfHMsE2Qfeh1+3AW7YUrbkSvXk/WtN+VKSGeL8LaDnl3/Ds/5T0+bccvQpvMvGTzkZF6/FWrnbWyZd3xr7IRmF7k50g5kt1Qpg/FdubhO1LxfKmOMt9iVtvkvPlOXSLN4it+7F1H+h+bI8fNJ8MbwrRyaxE18m0bYJeHYDqpmhi+NZuOybNsGwGZycT8OqUVjeztz6cCHaJExRMm1EnOcOjOw+2sKT0QNtQppEIkYOyk7lseB6NEYPH3i89LBw660j2eZh12TAA/vOtjZTXhTHt1tc7X7//l1H0TQ/y6OJS3tywv215q7svKWH66AIWbKrip/M3H/XzThySzcOXDeNAU5Qpf/jkqMcPD5lXP7eSPbVHh8zXbj6N/hlBfrGolLmfVR7qRCVCxrdPL+SCkj6s2F3L8yvKjugiakpxcl4KU4fnUh+O8/yKMrREPGwdRg56NSYNzcGwbZaUHqAlZgKJLqANNjZDslPwejT21kWoC8ePqjEjyUuy30NTxKA2HAMUtm0njkkEr6YI+HTipkVj1MBOdB1bg6ZtOz+TadlETdt57Rceb+1oGqblDHUfY+g8OS+VF64/9Rie+fVIuBIdxzJRkRq0aAPKaEHFm1GxZmxNJ97vAgCSVjyeGJqsQ0Xq0KK1qEg99VP+B3QvKUt/hm/f8qNWHSs4EzuQjl5bil6747BulgW2xfHGJBuV6JolOeHNl4LtTXGCmCeArQewvUEnjOl+0LzYuvfQ9x4/6AFsT+JxTwBb84Huxda8TmdP8zr3lQ5KB03H1jzOcz1BGTIVopsyEyFLV84wcdSwaIjE28Jb6+NJPp2CtAAxw2JDRUNb9671Vk902MA50aMxarQ93hpCp4/KJy3oZfG2A3y2rwHTPnIdU07OYUzfdNaW1/Pqmr1tAdBMfI0tTOeWM/tR0xLjtr9/5ixPhBPDskgPennum074uOnPayirCx/WNXNC0F9vOo1+GUEeWriVNzfsP+r9uGfCIK4alc/8jZXc9/aWox6fNDSbh6YOo6oxytRnjg6ZfZJ9vJ042WT6H1dQVhc56jmv33wa/TOTvrQGTcGPLizm0uG5LN56gMfe394WMJ+YPoIR+aHj/5CPk4Qr0bXFmtHijah4C8TDbSHNyDoZOzkHT8VK/DveQUXqUEYYZUZRRphovwuIDbocT9UGUt//sRPsjEN/BZopJ9Ey9nsoI0ry8kdQZuzoTeeNRVkGeu12VLwJjohs9nEHuP+LrfRDHTXl/BWPnuioWQYozXm8NYx5As5wqifQNnO/rXtA+UDTQSls5Ul8r7V92a3fo5zHNC/On6St6/AmQmTAqcXjdwIhJP68TZwup3TQPE5o1DxOUEwcn9e6PoWdGDb2OiH08ICJfWj4OHFrJ9Z5aH3O87BMFBaq5SBa+ABa+CAqXIMWOYgWPgiWiR1IxwxmYQcyMUP9sNIGYCVlO9v+0jfcBivmfPa27bynX/VcIcRRDNM52eHwcGfZNil+D0GvTlPUoLoplghvhwJaKOClMCNI1LBYt7e+LSC2Do16dcU5RU7I/GDbAZpihhP+DlvPlGG5pAY8fLyzhi1VTdg2h7aDczLJyXmpbNzfyNubqhLH5NncOK6QgrRAh783Eq5E72FbqFgTymgB226bxd67bzkq1gxmBGVEnJBmRAiPvAk0D/4tr+Op2QpmPBHeIhBvITzmPzCyhhLY9CrB9X9CmVEwo85/1lac2MBJRIZcjV6zjeSVjwE4jxkRFDZmaiEtp96KMmMkfzwLZRtHlRwZPB1b8+IrW4LefPRfiGZKAbYngBau+dKZ/G3dh60HwIyhmUf/9ddTWL6Q89mY0aMes8EJa7rzC7X18//SEzRawxyJEHnYc6yUk7A1Da2lOrGd1qAJoDCTcsCbhIrWo0Xq2pa3rsFKyqZxwm8w8sa2288thOiaJFwJ0dls2wlYZhQ74BxYqR/c3NadaT2uTVkG8fxxoDQ8+1ejtVQ7x7vZltPxsS3iJ52JlZyHp/ozPPtXoSzD6XLZJsqyiOeNId73bLSmfQQ2vpLoHiWGJW0bK6kP0UFXApC8bJYTHG3Leb1tgmXScup3QSkCm19Dr9vp1GAZia6TRXTQVZihQjz7luPbe/R0A/HcsRgFZ6Ca9hEonXPY++Cs3w72IZqYGDe45veJbVu0dr9sbxKRwdPB40evKQUzmjgBIs050cEfIp5/BnYwE0/ZR/j2foTWUo0WPuB0PK0YVnI+VkoBqqUKb9VaDgUjp/9oJWUTLzwPjDD+0rmJGuy2x20URs4poECv2YoWa0y8T1Zb183MHILtS3FO/Gjad/gH3hbmGy96HDN7eHv+axJCdEESroQQQggh2tFXhSs5110IIYQQoh1JuBJCCCGEaEcSroQQQggh2pGEKyGEEEKIdiThSgghhBCiHUm4EkIIIYRoRxKuhBBCCCHakYQrIYQQQoh2JOFKCCGEEKIdSbgSQgghhGhHEq6EEEIIIdqRhCshhBBCiHYk4UoIIYQQoh0p27Ztt4sQQgghhOgppHMlhBBCCNGOJFwJIYQQQrQjCVdCCCGEEO1IwpUQQgghRDuScCWEEEII0Y4kXAkhhBBCtKMeGa6WLl3KpEmTmDBhAs8884zb5fRqFRUV3HDDDVx66aVMnTqVF154AYC6ujpuvvlmJk6cyM0330x9fb3LlfZOpmly5ZVXcuuttwJQVlbGtddey4QJE7jtttuIxWIuV9g7NTQ0MGPGDCZPnsyUKVNYs2aN7DNdwPPPP8/UqVO57LLLuOOOO4hGo7LPuOTuu+9m/PjxXHbZZW3LvmofsW2bhx56iAkTJjBt2jQ+//zzDq+vx4Ur0zR54IEHePbZZ5k3bx5z586ltLTU7bJ6LV3Xueuuu5g/fz6vvvoqL7/8MqWlpTzzzDOMHz+ehQsXMn78eAnBLnnxxRcpLi5uu//oo49y00038e677xIKhXj99dddrK73evjhhzn33HN55513ePPNNykuLpZ9xmWVlZW8+OKL/O1vf2Pu3LmYpsm8efNkn3HJ9OnTefbZZ49Y9lX7yNKlS9m1axcLFy7kwQcf5P777+/w+npcuFq/fj39+/ensLAQn8/H1KlTWbRokdtl9Vo5OTkMHz4cgJSUFIqKiqisrGTRokVceeWVAFx55ZW89957bpbZK+3fv58PPviAa665BnD+ulu+fDmTJk0C4KqrrpJ9xwWNjY2sXLmy7XPx+XyEQiHZZ7oA0zSJRCIYhkEkEiE7O1v2GZeMGzeOtLS0I5Z91T7SulwpxSmnnEJDQwNVVVUdWl+PC1eVlZXk5eW13c/NzaWystLFikSr8vJyNm3axOjRozl48CA5OTkAZGdnc/DgQZer631mzZrFj3/8YzTN+TVQW1tLKBTC4/EAkJeXJ/uOC8rLy8nMzOTuu+/myiuvZObMmbS0tMg+47Lc3FxuueUWLrzwQs455xxSUlIYPny47DNdyFftI1/MBZ3xOfW4cCW6pubmZmbMmME999xDSkrKEY8ppVBKuVRZ7/T++++TmZnJiBEj3C5FfIFhGGzcuJHrrruO2bNnEwwGjxoClH2m89XX17No0SIWLVrEhx9+SDgc5sMPP3S7LPEV3N5HPK5tuYPk5uayf//+tvuVlZXk5ua6WJGIx+PMmDGDadOmMXHiRACysrKoqqoiJyeHqqoqMjMzXa6yd1m9ejWLFy9m6dKlRKNRmpqaePjhh2loaMAwDDweD/v375d9xwV5eXnk5eUxevRoACZPnswzzzwj+4zLPv74Y/r27dv2vk+cOJHVq1fLPtOFfNU+8sVc0BmfU4/rXI0cOZJdu3ZRVlZGLBZj3rx5XHTRRW6X1WvZts3MmTMpKiri5ptvblt+0UUXMXv2bABmz57NxRdf7FaJvdKdd97J0qVLWbx4MY8//jhnnnkmjz32GGeccQYLFiwA4I033pB9xwXZ2dnk5eWxY8cOAJYtW0ZxcbHsMy4rKChg3bp1hMNhbNtm2bJllJSUyD7ThXzVPtK63LZt1q5dS2pqatvwYUdRtm3bHboFFyxZsoRZs2ZhmiZXX3013/3ud90uqddatWoV119/PYMHD247tueOO+5g1KhR3HbbbVRUVFBQUMATTzxBenq6y9X2Tp988gnPPfccf/jDHygrK+P222+nvr6eYcOG8eijj+Lz+dwusdfZtGkTM2fOJB6PU1hYyCOPPIJlWbLPuOypp55i/vz5eDwehg0bxsMPP0xlZaXsMy644447WLFiBbW1tWRlZfGDH/yASy655Ev3Edu2eeCBB/jwww8JBoPMmjWLkSNHdmh9PTJcCSGEEEK4pccNCwohhBBCuEnClRBCCCFEO5JwJYQQQgjRjiRcCSGEEEK0IwlXQgghhBDtSMKVEKLX++STT7j11lvdLkMI0UNIuBJCCCGEaEc97vI3Qoie68033+Sll14iHo8zevRo7rvvPk477TSuvfZaPvroI/r06cOvf/1rMjMz2bRpE/fddx/hcJh+/foxa9Ys0tLS2L17N/fddx81NTXous6TTz4JQEtLCzNmzGDr1q0MHz6cRx99VK7fJ4Q4IdK5EkJ0C9u3b+ftt9/mlVde4c0330TTNObMmUNLSwsjRoxg3rx5jBs3jt/+9rcA/OQnP+FHP/oRc+bMYfDgwW3Lf/SjH3H99dfz1ltv8Ze//IXs7GwANm7cyD333MP8+fMpLy/n008/de1nFUJ0bxKuhBDdwrJly/jss8+45ppruOKKK1i2bBllZWVomsall14KwBVXXMGnn35KY2MjjY2NnH766QBcddVVrFq1iqamJiorK5kwYQIAfr+fYDAIwKhRo8jLy0PTNIYOHcrevXvd+UGFEN2eDAsKIboF27a56qqruPPOO49Y/vTTTx9x/0SH8g6/Hpyu65imeULrEUII6VwJIbqF8ePHs2DBAg4ePAhAXV0de/fuxbIsFixYAMCcOXMYO3YsqamphEIhVq1aBTjHao0bN46UlBTy8vJ47733AIjFYoTDYXd+ICFEjyWdKyFEt1BSUsJtt93GLbfcgmVZeL1e7r33XpKSkli/fj2/+93vyMzM5IknngDgl7/8ZdsB7YWFhTzyyCMA/OpXv+Lee+/lySefxOv1th3QLoQQ7UXZtm27XYQQQpyoU089lTVr1rhdhhBCtJFhQSGEEEKIdiSdKyGEEEKIdiSdKyGEEEKIdiThSgghhBCiHUm4EkIIIYRoRxKuhBBCCCHakYQrIYQQQoh2JOFKCCGEEKId/X+04OdTs0QDvAAAAABJRU5ErkJggg==\n",
"text/plain": [
"| \n", " | training_loss | \n", "validation_loss | \n", "test_loss | \n", "epoch | \n", "
|---|---|---|---|---|
| 0 | \n", "6.646716 | \n", "7.069627 | \n", "7.541213 | \n", "1 | \n", "
| 1 | \n", "6.495552 | \n", "6.909096 | \n", "7.370474 | \n", "2 | \n", "
| 2 | \n", "6.315707 | \n", "6.718051 | \n", "7.167351 | \n", "3 | \n", "
| 3 | \n", "6.135415 | \n", "6.526596 | \n", "6.963694 | \n", "4 | \n", "
| 4 | \n", "5.954975 | \n", "6.334948 | \n", "6.759850 | \n", "5 | \n", "
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Plot learning curves for the different models\n",
"fig = plt.figure(figsize=(10,6))\n",
"sns.set_style(style='dark')\n",
"ax = sns.lineplot(x='epoch', y='loss',\n",
" style='type',\n",
" hue='model',\n",
" data=learning_curves)\n",
"ax.set_title('Learning Curves', fontdict={'fontsize': 16})"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"fig.savefig('./visualizations/custom_learning_curve.png')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.7"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: examples/titanic/multiple_model_training.py
================================================
#!/usr/bin/env python
# # Multiple Model Training Example
#
# This example trains multiple models and extracts training statistics
import logging
import shutil
# ## Import required libraries
from ludwig.api import LudwigModel
from ludwig.datasets import titanic
from ludwig.visualize import learning_curves
# clean out old results
shutil.rmtree("./results", ignore_errors=True)
shutil.rmtree("./visualizations", ignore_errors=True)
# list models to train
list_of_model_ids = ["model1", "model2"]
list_of_train_stats = []
training_set, _, _ = titanic.load(split=True)
# ## Train models
for model_id in list_of_model_ids:
print(">>>> training: ", model_id)
# Define Ludwig model object that drive model training
model = LudwigModel(config="./" + model_id + "_config.yaml", logging_level=logging.WARN)
# initiate model training
train_stats, _, _ = model.train(
dataset=training_set, experiment_name="multiple_model_experiment", model_name=model_id
)
# save training stats for later use
list_of_train_stats.append(train_stats)
print(">>>>>>> completed: ", model_id, "\n")
# generating learning curves from training
learning_curves(
list_of_train_stats,
"Survived",
model_names=list_of_model_ids,
output_directory="./visualizations",
file_format="png",
)
================================================
FILE: examples/titanic/simple_model_training.py
================================================
#!/usr/bin/env python
# # Simple Model Training Example
#
# This example is the API example for this Ludwig command line example
# (https://ludwig-ai.github.io/ludwig-docs/latest/examples/titanic/).
# Import required libraries
import logging
import os
import shutil
import yaml
from ludwig.api import LudwigModel
from ludwig.datasets import titanic
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
# Download and prepare the dataset
training_set, test_set, _ = titanic.load(split=True)
config = yaml.safe_load("""
input_features:
- name: Pclass
type: category
- name: Sex
type: category
- name: Age
type: number
preprocessing:
missing_value_strategy: fill_with_mean
- name: SibSp
type: number
- name: Parch
type: number
- name: Fare
type: number
preprocessing:
missing_value_strategy: fill_with_mean
- name: Embarked
type: category
output_features:
- name: Survived
type: binary
""")
# Define Ludwig model object that drive model training
model = LudwigModel(config=config, logging_level=logging.INFO)
# initiate model training
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(
dataset=training_set, experiment_name="simple_experiment", model_name="simple_model", skip_save_processed_input=True
)
# list contents of output directory
print("contents of output directory:", output_directory)
for item in os.listdir(output_directory):
print("\t", item)
# batch prediction
model.predict(test_set, skip_save_predictions=False)
================================================
FILE: examples/twitter_bots/README.md
================================================
# Twitter Bots Example
We'll be using the twitter human-bots dataset which is composed of 37438 rows each corresponding to a Twitter user
account. Each row contains 20 feature columns collected via the Twitter API. These features contain multiple data
modalities, including the account description and the profile image.
The target column account_type has two unique values: bot or human. 25013 user accounts were annotated as human
accounts, the remaining 12425 are bots.
### Preparatory Steps
Create and download your [Kaggle API Credentials](https://github.com/Kaggle/kaggle-api#api-credentials).
The Twitter Bots dataset is hosted by Kaggle, Ludwig will need to authenticate you through the Kaggle API to download
the dataset.
### Examples
Run `python train_twitter_bots.py` to train a single model.
For a faster, more lightweight model run `python train_twitter_bots_text_only.py`, which does not use image features.
This will download the Twitter Bots dataset into the current
directory, train a model, and write results into the following directories:
```
./outputs/results/
api_experiment_run/
./outputs/visualizations/
confusion_matrix__account_type_top2.png
confusion_matrix_entropy__account_type_top2.png
learning_curves_account_type_accuracy.png
learning_curves_account_type_loss.png
```
After training, the script will generate the following plots:



================================================
FILE: examples/twitter_bots/train_twitter_bots.py
================================================
#!/usr/bin/env python
"""Trains model on Twitter Bots dataset using default settings."""
import logging
import os
import shutil
import yaml
from ludwig import datasets
from ludwig.api import LudwigModel
from ludwig.utils.fs_utils import rename
from ludwig.visualize import confusion_matrix, learning_curves
if __name__ == "__main__":
# Cleans out prior results
results_dir = os.path.join("outputs", "results")
visualizations_dir = os.path.join("outputs", "visualizations")
shutil.rmtree(results_dir, ignore_errors=True)
shutil.rmtree(visualizations_dir, ignore_errors=True)
# Loads the dataset
twitter_bots_dataset = datasets.get_dataset("twitter_bots", cache_dir="downloads")
training_set, val_set, test_set = twitter_bots_dataset.load(split=True)
# Moves profile images into local directory, so relative paths in the dataset will be resolved.
if not os.path.exists("profile_images"):
rename(os.path.join(twitter_bots_dataset.processed_dataset_dir, "profile_images"), "profile_images")
config = yaml.safe_load("""
input_features:
- name: default_profile
type: binary
- name: default_profile_image
type: binary
- name: description
type: text
- name: favourites_count
type: number
- name: followers_count
type: number
- name: friends_count
type: number
- name: geo_enabled
type: binary
- name: lang
type: category
- name: location
type: category
- name: profile_background_image_path
type: category
- name: profile_image_path
type: image
preprocessing:
num_channels: 3
- name: statuses_count
type: number
- name: verified
type: binary
- name: average_tweets_per_day
type: number
- name: account_age_days
type: number
output_features:
- name: account_type
type: binary
""")
model = LudwigModel(config, logging_level=logging.INFO)
train_stats, preprocessed_data, output_directory = model.train(dataset=training_set, output_directory=results_dir)
# Generates predictions and performance statistics for the test set.
test_stats, predictions, output_directory = model.evaluate(
test_set, collect_predictions=True, collect_overall_stats=True, output_directory=results_dir
)
confusion_matrix(
[test_stats],
model.training_set_metadata,
"account_type",
top_n_classes=[2],
model_names=[""],
normalize=True,
output_directory=visualizations_dir,
file_format="png",
)
# Visualizes learning curves, which show how performance metrics changed over time during training.
learning_curves(
train_stats, output_feature_name="account_type", output_directory=visualizations_dir, file_format="png"
)
================================================
FILE: examples/twitter_bots/train_twitter_bots_text_only.py
================================================
#!/usr/bin/env python
"""Trains twitter bots using tabular and text features only, no images."""
import logging
import os
import shutil
import yaml
from ludwig.api import LudwigModel
from ludwig.datasets import twitter_bots
from ludwig.visualize import confusion_matrix, learning_curves
if __name__ == "__main__":
# Cleans out prior results
results_dir = os.path.join("outputs", "results")
visualizations_dir = os.path.join("outputs", "visualizations")
shutil.rmtree(results_dir, ignore_errors=True)
shutil.rmtree(visualizations_dir, ignore_errors=True)
# Loads the dataset
training_set, val_set, test_set = twitter_bots.load(split=True)
config = yaml.safe_load("""
input_features:
- name: created_at
type: date
column: created_at
- name: default_profile
type: binary
column: default_profile
- name: description
type: text
column: description
- name: favourites_count
type: number
column: favourites_count
- name: followers_count
type: number
column: followers_count
- name: friends_count
type: number
column: friends_count
- name: geo_enabled
type: binary
column: geo_enabled
- name: lang
type: category
column: lang
- name: location
type: text
column: location
- name: screen_name
type: text
column: screen_name
- name: statuses_count
type: number
column: statuses_count
- name: verified
type: binary
column: verified
- name: average_tweets_per_day
type: number
column: average_tweets_per_day
- name: account_age_days
type: number
column: account_age_days
output_features:
- name: account_type
type: category
column: account_type
trainer:
batch_size: 16
defaults:
text:
preprocessing:
tokenizer: space_punct
max_sequence_length: 16
model_type: ecd
""")
model = LudwigModel(config, logging_level=logging.INFO)
train_stats, preprocessed_data, output_directory = model.train(dataset=training_set, output_directory=results_dir)
# Generates predictions and performance statistics for the test set.
test_stats, predictions, output_directory = model.evaluate(
test_set, collect_predictions=True, collect_overall_stats=True, output_directory=results_dir
)
confusion_matrix(
[test_stats],
model.training_set_metadata,
"account_type",
top_n_classes=[2],
model_names=[""],
normalize=True,
output_directory=visualizations_dir,
file_format="png",
)
# Visualizes learning curves, which show how performance metrics changed over time during training.
learning_curves(
train_stats, output_feature_name="account_type", output_directory=visualizations_dir, file_format="png"
)
================================================
FILE: examples/wine_quality/README.md
================================================
# Ludwig Defaults Config Section Example
Demonstrates how to use Ludwig's defaults section introduced in v0.6.
### Preparatory Steps
- Create `data` directory
- Download [Kaggle wine quality data set](https://www.kaggle.com/rajyellow46/wine-quality) into the `data` directory. Directory should
appear as follows:
```
wine_quality/
data/
winequalityN.csv
```
### Description
Jupyter notebook `model_defaults_example.ipynb` demonstrates how to use the defaults section of Ludwig.
Key features demonstrated in the notebook:
- Training data is prepared for use
- Programmatically create Ludwig config dictionary from the training data dataframe
- How to define preprocessing, encoder, decoder and loss sub-sections under the defaults section
================================================
FILE: examples/wine_quality/model_defaults_example.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd \n",
"import numpy as np\n",
"\n",
"import os\n",
"\n",
"import shutil\n",
"from pprint import pprint\n",
"import logging\n",
"\n",
"from ludwig.api import LudwigModel"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Receive data for training"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_df = pd.read_csv('./data/winequalityN.csv')\n",
"train_df['quality'] = train_df['quality'].apply(str)\n",
"train_df.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Replace white space in column names with underscore\n",
"new_col = []\n",
"for i in range(len(train_df.columns)):\n",
" new_col.append(train_df.columns[i].replace(' ', '_'))\n",
" \n",
"train_df.columns = new_col"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_df.describe().T"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_df.dtypes"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_df['quality'].value_counts().sort_index()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cols = list(set(train_df.columns) - set(['quality']))\n",
"features = train_df[cols]\n",
"\n",
"#extract categorical features\n",
"categorical_features = []\n",
"for p in features:\n",
" if train_df[p].dtype == 'object':\n",
" categorical_features.append(p)\n",
" \n",
"print(\"categorical features:\", categorical_features, '\\n')\n",
"\n",
"# get numerical features\n",
"numerical_features = list(set(features) - set(categorical_features))\n",
"\n",
"print(\"numerical features:\", numerical_features, \"\\n\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for feature in categorical_features:\n",
" print(f\"# of distinct values in categorical feature '{feature}' : {train_df[feature].nunique()}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Ludwig Config"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# template for config\n",
"config = {'input_features':[], 'output_features': [], 'trainer':{}}\n",
"\n",
"# setup input features for categorical features\n",
"for p in categorical_features:\n",
" a_feature = {\n",
" 'name': p.replace(' ','_'), \n",
" 'type': 'category'\n",
" }\n",
" config['input_features'].append(a_feature)\n",
"\n",
"# setup input features for numerical features\n",
"for p in numerical_features:\n",
" a_feature = {\n",
" 'name': p.replace(' ', '_'), \n",
" 'type': 'number'\n",
" }\n",
" config['input_features'].append(a_feature)\n",
"\n",
"# set up output variable\n",
"config['output_features'].append({'name': 'quality', 'type':'category'})\n",
"\n",
"# set default preprocessing and encoder for numerical features\n",
"config['defaults'] = {\n",
" 'number': {\n",
" 'preprocessing': {\n",
" 'missing_value_strategy': 'fill_with_mean', \n",
" 'normalization': 'zscore'\n",
" },\n",
" 'encoder': {\n",
" 'type': 'dense',\n",
" 'num_layers': 2\n",
" },\n",
" },\n",
" 'category': {\n",
" 'encoder': {\n",
" 'type': 'sparse'\n",
" },\n",
" 'decoder': {\n",
" 'top_k': 2\n",
" },\n",
" 'loss': {\n",
" 'confidence_penalty': 0.1 \n",
" }\n",
" }\n",
"}\n",
"\n",
"# set up trainer\n",
"config['trainer'] = {'epochs': 5}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pprint(config, indent=2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Initialize and Train LudwigModel"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model = LudwigModel(config, backend = 'local', logging_level = logging.INFO)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Inspecting Config After Model Initialization"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pprint(model.config['input_features'], indent=2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pprint(model.config['output_features'], indent=2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"eval_stats, train_stats, _, _ = model.experiment(\n",
" dataset = train_df,\n",
" experiment_name = 'wine_quality'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Cleanup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" shutil.rmtree('./results')\n",
" items = os.listdir('./')\n",
" for item in items:\n",
" if item.endswith(\".hdf5\") or item.endswith(\".json\") or item == '.lock_preprocessing':\n",
" os.remove(os.path.join('./', item))\n",
"except Exception as e:\n",
" pass "
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.8.13 64-bit",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.13"
},
"orig_nbformat": 4,
"vscode": {
"interpreter": {
"hash": "949777d72b0d2535278d3dc13498b2535136f6dfe0678499012e853ee9abcab1"
}
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: examples/wmt15/config_large.yaml
================================================
input_features:
- name: en
type: text
encoder: bert
pretrained_model_name_or_path: bert-base-uncased
output_features:
- name: fr
type: text
tokenizer: french_tokenize
================================================
FILE: examples/wmt15/config_small.yaml
================================================
input_features:
- name: en
type: text
encoder: embed
output_features:
- name: fr
type: text
================================================
FILE: examples/wmt15/train_nmt.py
================================================
"""Sample ludwig training code for training an NMT model (en -> fr) on WMT15 (https://www.statmt.org/wmt15/).
The dataset is rather large (8GB), which can take several minutes to preprocess.
"""
import logging
import shutil
from ludwig.api import LudwigModel
from ludwig.datasets import wmt15
# clean out prior results
shutil.rmtree("./results", ignore_errors=True)
# Download and prepare the dataset
training_set = wmt15.load()
model = LudwigModel(config="./config_small.yaml", logging_level=logging.INFO)
(
train_stats, # dictionary containing training statistics
preprocessed_data, # tuple Ludwig Dataset objects of pre-processed training data
output_directory, # location of training results stored on disk
) = model.train(dataset=training_set, experiment_name="simple_experiment", model_name="simple_model")
================================================
FILE: ludwig/__init__.py
================================================
# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import logging
import sys
from ludwig.globals import LUDWIG_VERSION as __version__ # noqa
logging.basicConfig(level=logging.INFO, stream=sys.stdout, format="%(message)s")
# Disable annoying message about NUMEXPR_MAX_THREADS
logging.getLogger("numexpr").setLevel(logging.WARNING)
================================================
FILE: ludwig/accounting/__init__.py
================================================
================================================
FILE: ludwig/accounting/used_tokens.py
================================================
import torch
def get_used_tokens_for_ecd(inputs: dict[str, torch.Tensor], targets: dict[str, torch.Tensor]) -> int:
"""Returns the number of used tokens for an ECD model.
The number of used tokens is the total size of the input and output tensors, which corresponds to 1 token for
binary, category, and number features, and variable number of tokens for text features, for each example in the
batch.
Args:
inputs: The input tensors for one forward pass through ecd.
targets: The target tensors for one forward pass through ecd.
"""
used_tokens = 0
for input_feature_tensor in inputs.values():
used_tokens += torch.flatten(input_feature_tensor).shape[0]
if targets is not None:
# targets may be None for evaluation.
for output_feature_tensor in targets.values():
used_tokens += torch.flatten(output_feature_tensor).shape[0]
return used_tokens
def get_used_tokens_for_llm(model_inputs: torch.Tensor, tokenizer) -> int:
"""Returns the number of used tokens for an LLM model.
Args:
model_inputs: torch.Tensor with the merged input and target IDs.
tokenizer: The tokenizer used to encode the inputs.
Returns:
The total number of non-pad tokens, for all examples in the batch.
"""
return torch.sum(model_inputs != tokenizer.pad_token_id).item()
================================================
FILE: ludwig/api.py
================================================
# !/usr/bin/env python
# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""
File name: LudwigModel.py
Author: Piero Molino
Date created: 5/21/2019
Python Version: 3+
"""
import copy
import dataclasses
import logging
import os
import sys
import tempfile
import time
import traceback
from collections import OrderedDict
from dataclasses import dataclass
from pprint import pformat
from typing import Any, ClassVar
import numpy as np
import pandas as pd
import torch
from tabulate import tabulate
from ludwig.api_annotations import PublicAPI
from ludwig.backend import Backend, initialize_backend, provision_preprocessing_workers
from ludwig.callbacks import Callback
from ludwig.constants import (
AUTO,
BATCH_SIZE,
EVAL_BATCH_SIZE,
FALLBACK_BATCH_SIZE,
FULL,
HYPEROPT,
HYPEROPT_WARNING,
MIN_DATASET_SPLIT_ROWS,
MODEL_ECD,
MODEL_LLM,
TEST,
TIMESERIES,
TRAINING,
VALIDATION,
)
from ludwig.data.cache.types import CacheableDataset
from ludwig.data.dataset.base import Dataset
from ludwig.data.postprocessing import convert_predictions, postprocess
from ludwig.data.preprocessing import load_metadata, preprocess_for_prediction, preprocess_for_training
from ludwig.datasets import load_dataset_uris
from ludwig.features.feature_registries import update_config_with_metadata, update_config_with_model
from ludwig.globals import (
LUDWIG_VERSION,
MODEL_FILE_NAME,
MODEL_HYPERPARAMETERS_FILE_NAME,
MODEL_WEIGHTS_FILE_NAME,
set_disable_progressbar,
TRAIN_SET_METADATA_FILE_NAME,
TRAINING_CHECKPOINTS_DIR_PATH,
)
from ludwig.models.base import BaseModel
from ludwig.models.calibrator import Calibrator
from ludwig.models.inference import InferenceModule, save_ludwig_model_for_inference
from ludwig.models.predictor import (
calculate_overall_stats,
print_evaluation_stats,
save_evaluation_stats,
save_prediction_outputs,
)
from ludwig.models.registry import model_type_registry
from ludwig.schema.model_config import ModelConfig
from ludwig.types import ModelConfigDict, TrainingSetMetadataDict
from ludwig.upload import get_upload_registry
from ludwig.utils import metric_utils
from ludwig.utils.backward_compatibility import upgrade_config_dict_to_latest_version
from ludwig.utils.config_utils import get_preprocessing_params
from ludwig.utils.data_utils import (
figure_data_format,
generate_kfold_splits,
load_dataset,
load_json,
load_yaml,
save_json,
)
from ludwig.utils.dataset_utils import generate_dataset_statistics
from ludwig.utils.defaults import default_random_seed
from ludwig.utils.fs_utils import makedirs, path_exists, upload_output_directory
from ludwig.utils.heuristics import get_auto_learning_rate
from ludwig.utils.llm_utils import create_text_streamer, TextStreamer
from ludwig.utils.misc_utils import (
get_commit_hash,
get_file_names,
get_from_registry,
get_output_directory,
set_saved_weights_in_checkpoint_flag,
)
from ludwig.utils.print_utils import print_boxed
from ludwig.utils.tokenizers import HFTokenizer
from ludwig.utils.torch_utils import DEVICE
from ludwig.utils.trainer_utils import get_training_report
from ludwig.utils.types import DataFrame, TorchDevice
from ludwig.utils.upload_utils import HuggingFaceHub
logger = logging.getLogger(__name__)
@PublicAPI
@dataclass
class EvaluationFrequency: # noqa F821
"""Represents the frequency of periodic evaluation of a metric during training. For example:
"every epoch"
frequency: 1, period: EPOCH
"every 50 steps".
frequency: 50, period: STEP
"""
frequency: float = 1.0
period: str = "epoch" # One of "epoch" or "step".
EPOCH: ClassVar[str] = "epoch" # One epoch is a single pass through the training set.
STEP: ClassVar[str] = "step" # One step is training on one mini-batch.
@PublicAPI
@dataclass
class TrainingStats: # noqa F821
"""Training stats were previously represented as a tuple or a dict.
This class replaces those while preserving dict and tuple-like behavior (unpacking, [] access).
"""
training: dict[str, Any]
validation: dict[str, Any]
test: dict[str, Any]
evaluation_frequency: EvaluationFrequency = dataclasses.field(default_factory=EvaluationFrequency)
# TODO(daniel): deprecate multiple return value unpacking and dictionary-style element access
def __iter__(self):
return iter((self.training, self.test, self.validation))
def __contains__(self, key):
return (
(key == TRAINING and self.training)
or (key == VALIDATION and self.validation)
or (key == TEST and self.test)
)
def __getitem__(self, key):
# Supports dict-style [] element access for compatibility.
return {TRAINING: self.training, VALIDATION: self.validation, TEST: self.test}[key]
@PublicAPI
@dataclass
class PreprocessedDataset: # noqa F821
training_set: Dataset
validation_set: Dataset
test_set: Dataset
training_set_metadata: TrainingSetMetadataDict
# TODO(daniel): deprecate multiple return value unpacking and indexed access
def __iter__(self):
return iter((self.training_set, self.validation_set, self.test_set, self.training_set_metadata))
def __getitem__(self, index):
return (self.training_set, self.validation_set, self.test_set, self.training_set_metadata)[index]
@PublicAPI
@dataclass
class TrainingResults: # noqa F821
train_stats: TrainingStats
preprocessed_data: PreprocessedDataset
output_directory: str
def __iter__(self):
"""Supports tuple-style return value unpacking ex.
train_stats, training_set, output_dir = model.train(...)
"""
return iter((self.train_stats, self.preprocessed_data, self.output_directory))
def __getitem__(self, index):
"""Provides indexed getter ex.
train_stats = model.train(...)[0]
"""
return (self.train_stats, self.preprocessed_data, self.output_directory)[index]
@PublicAPI
class LudwigModel:
"""Class that allows access to high level Ludwig functionalities.
# Inputs
:param config: (Union[str, dict]) in-memory representation of
config or string path to a YAML config file.
:param logging_level: (int) Log level that will be sent to stderr.
:param backend: (Union[Backend, str]) `Backend` or string name
of backend to use to execute preprocessing / training steps.
:param gpus: (Union[str, int, List[int]], default: `None`) GPUs
to use (it uses the same syntax of CUDA_VISIBLE_DEVICES)
:param gpu_memory_limit: (float: default: `None`) maximum memory fraction
[0, 1] allowed to allocate per GPU device.
:param allow_parallel_threads: (bool, default: `True`) allow Torch
to use multithreading parallelism to improve performance at the
cost of determinism.
# Example usage:
```python
from ludwig.api import LudwigModel
```
Train a model:
```python
config = {...}
ludwig_model = LudwigModel(config)
train_stats, _, _ = ludwig_model.train(dataset=file_path)
```
or
```python
train_stats, _, _ = ludwig_model.train(dataset=dataframe)
```
If you have already trained a model you can load it and use it to predict
```python
ludwig_model = LudwigModel.load(model_dir)
```
Predict:
```python
predictions, _ = ludwig_model.predict(dataset=file_path)
```
or
```python
predictions, _ = ludwig_model.predict(dataset=dataframe)
```
Evaluation:
```python
eval_stats, _, _ = ludwig_model.evaluate(dataset=file_path)
```
or
```python
eval_stats, _, _ = ludwig_model.evaluate(dataset=dataframe)
```
"""
def __init__(
self,
config: str | dict,
logging_level: int = logging.ERROR,
backend: Backend | str | None = None,
gpus: str | int | list[int] | None = None,
gpu_memory_limit: float | None = None,
allow_parallel_threads: bool = True,
callbacks: list[Callback] | None = None,
) -> None:
"""Constructor for the Ludwig Model class.
# Inputs
:param config: (Union[str, dict]) in-memory representation of
config or string path to a YAML config file.
:param logging_level: (int) Log level that will be sent to stderr.
:param backend: (Union[Backend, str]) `Backend` or string name
of backend to use to execute preprocessing / training steps.
:param gpus: (Union[str, int, List[int]], default: `None`) GPUs
to use (it uses the same syntax of CUDA_VISIBLE_DEVICES)
:param gpu_memory_limit: (float: default: `None`) maximum memory fraction
[0, 1] allowed to allocate per GPU device.
:param allow_parallel_threads: (bool, default: `True`) allow Torch
to use multithreading parallelism to improve performance at the
cost of determinism.
:param callbacks: (list, default: `None`) a list of
`ludwig.callbacks.Callback` objects that provide hooks into the
Ludwig pipeline.
# Return
:return: (None) `None`
"""
# check if config is a path or a dict
if isinstance(config, str): # assume path
config_dict = load_yaml(config)
self.config_fp = config
else:
config_dict = copy.deepcopy(config)
self.config_fp = None # type: ignore [assignment]
self._user_config = upgrade_config_dict_to_latest_version(config_dict)
# Initialize the config object
self.config_obj = ModelConfig.from_dict(self._user_config)
# setup logging
self.set_logging_level(logging_level)
# setup Backend
self.backend = initialize_backend(backend or self._user_config.get("backend"))
self.callbacks = callbacks if callbacks is not None else []
# setup PyTorch env (GPU allocation, etc.)
self.backend.initialize_pytorch(
gpus=gpus, gpu_memory_limit=gpu_memory_limit, allow_parallel_threads=allow_parallel_threads
)
# setup model
self.model = None
self.training_set_metadata: dict[str, dict] | None = None
# online training state
self._online_trainer = None
# Zero-shot LLM usage.
if (
self.config_obj.model_type == MODEL_LLM
and self.config_obj.trainer.type == "none"
# Category output features require a vocabulary. The LLM LudwigModel should be initialized with
# model.train(dataset).
and self.config_obj.output_features[0].type == "text"
):
self._initialize_llm()
def _initialize_llm(self, random_seed: int = default_random_seed):
"""Initialize the LLM model.
Should only be used in a zero-shot (NoneTrainer) setting.
"""
self.model = LudwigModel.create_model(self.config_obj, random_seed=random_seed)
if self.model.model.device.type == "cpu" and torch.cuda.is_available():
logger.warning(f"LLM was initialized on {self.model.model.device}. Moving to GPU for inference.")
self.model.model.to(torch.device("cuda"))
def train(
self,
dataset: str | dict | pd.DataFrame | None = None,
training_set: str | dict | pd.DataFrame | Dataset | None = None,
validation_set: str | dict | pd.DataFrame | Dataset | None = None,
test_set: str | dict | pd.DataFrame | Dataset | None = None,
training_set_metadata: str | dict | None = None,
data_format: str | None = None,
experiment_name: str = "api_experiment",
model_name: str = "run",
model_resume_path: str | None = None,
skip_save_training_description: bool = False,
skip_save_training_statistics: bool = False,
skip_save_model: bool = False,
skip_save_progress: bool = False,
skip_save_log: bool = False,
skip_save_processed_input: bool = False,
output_directory: str | None = "results",
random_seed: int = default_random_seed,
**kwargs,
) -> TrainingResults:
"""This function is used to perform a full training of the model on the specified dataset.
During training if the skip parameters are False
the model and statistics will be saved in a directory
`[output_dir]/[experiment_name]_[model_name]_n` where all variables are
resolved to user specified ones and `n` is an increasing number
starting from 0 used to differentiate among repeated runs.
# Inputs
:param dataset: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing the entire dataset to be used in the experiment.
If it has a split column, it will be used for splitting
(0 for train, 1 for validation, 2 for test),
otherwise the dataset will be randomly split.
:param training_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing training data.
:param validation_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing validation data.
:param test_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing test data.
:param training_set_metadata: (Union[str, dict], default: `None`)
metadata JSON file or loaded metadata. Intermediate preprocessed
structure containing the mappings of the input dataset created the
first time an input file is used in the same directory with the
same name and a '.meta.json' extension.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`,
`'feather'`, `'fwf'`,
`'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``),
`'json'`, `'jsonl'`, `'parquet'`,
`'pickle'` (pickled Pandas DataFrame),
`'sas'`, `'spss'`, `'stata'`, `'tsv'`.
:param experiment_name: (str, default: `'experiment'`) name for
the experiment.
:param model_name: (str, default: `'run'`) name of the model that is
being used.
:param model_resume_path: (str, default: `None`) resumes training of
the model from the path specified. The config is restored.
In addition to config, training statistics, loss for each
epoch and the state of the optimizer are restored such that
training can be effectively continued from a previously interrupted
training process.
:param skip_save_training_description: (bool, default: `False`)
disables saving the description JSON file.
:param skip_save_training_statistics: (bool, default: `False`)
disables saving training statistics JSON file.
:param skip_save_model: (bool, default: `False`) disables
saving model weights and hyperparameters each time the model
improves. By default Ludwig saves model weights after each epoch
the validation metric improves, but if the model is really big
that can be time consuming. If you do not want to keep
the weights and just find out what performance a model can get
with a set of hyperparameters, use this parameter to skip it,
but the model will not be loadable later on and the returned model
will have the weights obtained at the end of training, instead of
the weights of the epoch with the best validation performance.
:param skip_save_progress: (bool, default: `False`) disables saving
progress each epoch. By default Ludwig saves weights and stats
after each epoch for enabling resuming of training, but if
the model is really big that can be time consuming and will uses
twice as much space, use this parameter to skip it, but training
cannot be resumed later on.
:param skip_save_log: (bool, default: `False`) disables saving
TensorBoard logs. By default Ludwig saves logs for the TensorBoard,
but if it is not needed turning it off can slightly increase the
overall speed.
:param skip_save_processed_input: (bool, default: `False`) if input
dataset is provided it is preprocessed and cached by saving an HDF5
and JSON files to avoid running the preprocessing again. If this
parameter is `False`, the HDF5 and JSON file are not saved.
:param output_directory: (str, default: `'results'`) the directory that
will contain the training statistics, TensorBoard logs, the saved
model and the training progress files.
:param random_seed: (int, default: `42`) a random seed that will be
used anywhere there is a call to a random number generator: data
splitting, parameter initialization and training set shuffling
:param kwargs: (dict, default: {}) a dictionary of optional parameters.
# Return
:return: (Tuple[Dict, Union[Dict, pd.DataFrame], str]) tuple containing
`(training_statistics, preprocessed_data, output_directory)`.
`training_statistics` is a nested dictionary of dataset -> feature_name -> metric_name -> List of metrics.
Each metric corresponds to each training checkpoint.
`preprocessed_data` is the tuple containing these three data sets
`(training_set, validation_set, test_set)`.
`output_directory` filepath to where training results are stored.
"""
# Only reset the metadata if the model has not been trained before
if self.training_set_metadata:
logger.warning(
"This model has been trained before. Its architecture has been defined by the original training set "
"(for example, the number of possible categorical outputs). The current training data will be mapped "
"to this architecture. If you want to change the architecture of the model, please concatenate your "
"new training data with the original and train a new model from scratch."
)
training_set_metadata = self.training_set_metadata
if self._user_config.get(HYPEROPT):
print_boxed("WARNING")
logger.warning(HYPEROPT_WARNING)
# setup directories and file names
if model_resume_path is not None:
if path_exists(model_resume_path):
output_directory = model_resume_path
if self.backend.is_coordinator():
logger.info(f"Model resume path '{model_resume_path}' exists, trying to resume training.")
else:
if self.backend.is_coordinator():
logger.info(
f"Model resume path '{model_resume_path}' does not exist, starting training from scratch"
)
model_resume_path = None
if model_resume_path is None:
if self.backend.is_coordinator():
output_directory = get_output_directory(output_directory, experiment_name, model_name)
else:
output_directory = None
# if we are skipping all saving,
# there is no need to create a directory that will remain empty
should_create_output_directory = not (
skip_save_training_description
and skip_save_training_statistics
and skip_save_model
and skip_save_progress
and skip_save_log
and skip_save_processed_input
)
output_url = output_directory
with upload_output_directory(output_directory) as (output_directory, upload_fn):
train_callbacks = self.callbacks
if upload_fn is not None:
# Upload output files (checkpoints, etc.) to remote storage at the end of
# each epoch and evaluation, in case of failure in the middle of training.
class UploadOnEpochEndCallback(Callback):
def on_eval_end(self, trainer, progress_tracker, save_path):
upload_fn()
def on_epoch_end(self, trainer, progress_tracker, save_path):
upload_fn()
train_callbacks = train_callbacks + [UploadOnEpochEndCallback()]
description_fn = training_stats_fn = model_dir = None
if self.backend.is_coordinator():
if should_create_output_directory:
makedirs(output_directory, exist_ok=True)
description_fn, training_stats_fn, model_dir = get_file_names(output_directory)
if isinstance(training_set, Dataset) and training_set_metadata is not None:
preprocessed_data = (training_set, validation_set, test_set, training_set_metadata)
else:
# save description
if self.backend.is_coordinator():
description = get_experiment_description(
self.config_obj.to_dict(),
dataset=dataset,
training_set=training_set,
validation_set=validation_set,
test_set=test_set,
training_set_metadata=training_set_metadata,
data_format=data_format,
backend=self.backend,
random_seed=random_seed,
)
if not skip_save_training_description:
save_json(description_fn, description)
# print description
experiment_description = [
["Experiment name", experiment_name],
["Model name", model_name],
["Output directory", output_directory],
]
for key, value in description.items():
if key != "config": # Config is printed separately.
experiment_description.append([key, pformat(value, indent=4)])
if self.backend.is_coordinator():
print_boxed("EXPERIMENT DESCRIPTION")
logger.info(tabulate(experiment_description, tablefmt="fancy_grid"))
print_boxed("LUDWIG CONFIG")
logger.info("User-specified config (with upgrades):\n")
logger.info(pformat(self._user_config, indent=4))
logger.info(
"\nFull config saved to:\n"
f"{output_directory}/{experiment_name}/model/model_hyperparameters.json"
)
preprocessed_data = self.preprocess( # type: ignore[assignment]
dataset=dataset,
training_set=training_set,
validation_set=validation_set,
test_set=test_set,
training_set_metadata=training_set_metadata,
data_format=data_format,
experiment_name=experiment_name,
model_name=model_name,
model_resume_path=model_resume_path,
skip_save_training_description=skip_save_training_description,
skip_save_training_statistics=skip_save_training_statistics,
skip_save_model=skip_save_model,
skip_save_progress=skip_save_progress,
skip_save_log=skip_save_log,
skip_save_processed_input=skip_save_processed_input,
output_directory=output_directory,
random_seed=random_seed,
**kwargs,
)
training_set, validation_set, test_set, training_set_metadata = preprocessed_data
self.training_set_metadata = training_set_metadata
if self.backend.is_coordinator():
dataset_statistics = generate_dataset_statistics(training_set, validation_set, test_set)
if not skip_save_model:
# save train set metadata
os.makedirs(model_dir, exist_ok=True) # type: ignore[arg-type]
save_json( # type: ignore[arg-type]
os.path.join(model_dir, TRAIN_SET_METADATA_FILE_NAME), training_set_metadata
)
logger.info("\nDataset Statistics")
logger.info(tabulate(dataset_statistics, headers="firstrow", tablefmt="fancy_grid"))
for callback in self.callbacks:
callback.on_train_init(
base_config=self._user_config,
experiment_directory=output_directory,
experiment_name=experiment_name,
model_name=model_name,
output_directory=output_directory,
resume_directory=model_resume_path,
)
# Build model if not provided
# if it was provided it means it was already loaded
if not self.model:
if self.backend.is_coordinator():
print_boxed("MODEL")
# update model config with metadata properties derived from training set
update_config_with_metadata(self.config_obj, training_set_metadata)
logger.info("Warnings and other logs:")
self.model = LudwigModel.create_model(self.config_obj, random_seed=random_seed)
# update config with properties determined during model instantiation
update_config_with_model(self.config_obj, self.model)
set_saved_weights_in_checkpoint_flag(self.config_obj)
# auto tune learning rate
if hasattr(self.config_obj.trainer, "learning_rate") and self.config_obj.trainer.learning_rate == AUTO:
detected_learning_rate = get_auto_learning_rate(self.config_obj)
self.config_obj.trainer.learning_rate = detected_learning_rate
with self.backend.create_trainer(
model=self.model,
config=self.config_obj.trainer,
resume=model_resume_path is not None,
skip_save_model=skip_save_model,
skip_save_progress=skip_save_progress,
skip_save_log=skip_save_log,
callbacks=train_callbacks,
random_seed=random_seed,
) as trainer:
# auto tune batch size
self._tune_batch_size(trainer, training_set, random_seed=random_seed)
if (
self.config_obj.model_type == "LLM"
and trainer.config.type == "none"
and self.config_obj.adapter is not None
and self.config_obj.adapter.pretrained_adapter_weights is not None
):
trainer.model.initialize_adapter() # Load pre-trained adapter weights for inference only
# train model
if self.backend.is_coordinator():
print_boxed("TRAINING")
if not skip_save_model:
self.save_config(model_dir)
for callback in self.callbacks:
callback.on_train_start(
model=self.model,
config=self.config_obj.to_dict(),
config_fp=self.config_fp,
)
try:
train_stats = trainer.train(
training_set,
validation_set=validation_set,
test_set=test_set,
save_path=model_dir,
)
self.model, train_trainset_stats, train_valiset_stats, train_testset_stats = train_stats
# Calibrates output feature probabilities on validation set if calibration is enabled.
# Must be done after training, and before final model parameters are saved.
if self.backend.is_coordinator():
calibrator = Calibrator(
self.model,
self.backend,
batch_size=trainer.eval_batch_size,
)
if calibrator.calibration_enabled():
if validation_set is None:
logger.warning(
"Calibration uses validation set, but no validation split specified."
"Will use training set for calibration."
"Recommend providing a validation set when using calibration."
)
calibrator.train_calibration(training_set, TRAINING)
elif len(validation_set) < MIN_DATASET_SPLIT_ROWS:
logger.warning(
f"Validation set size ({len(validation_set)} rows) is too small for calibration."
"Will use training set for calibration."
f"Validation set much have at least {MIN_DATASET_SPLIT_ROWS} rows."
)
calibrator.train_calibration(training_set, TRAINING)
else:
calibrator.train_calibration(validation_set, VALIDATION)
if not skip_save_model:
self.model.save(model_dir)
# Evaluation Frequency
if self.config_obj.model_type == MODEL_ECD and self.config_obj.trainer.steps_per_checkpoint:
evaluation_frequency = EvaluationFrequency(
self.config_obj.trainer.steps_per_checkpoint, EvaluationFrequency.STEP
)
elif self.config_obj.model_type == MODEL_ECD and self.config_obj.trainer.checkpoints_per_epoch:
evaluation_frequency = EvaluationFrequency(
1.0 / self.config_obj.trainer.checkpoints_per_epoch, EvaluationFrequency.EPOCH
)
else:
evaluation_frequency = EvaluationFrequency(1, EvaluationFrequency.EPOCH)
# Unpack train()'s return.
# The statistics are all nested dictionaries of TrainerMetrics: feature_name -> metric_name ->
# List[TrainerMetric], with one entry per training checkpoint, according to steps_per_checkpoint.
# We reduce the dictionary of TrainerMetrics to a simple list of floats for interfacing with Ray
# Tune.
train_stats = TrainingStats(
metric_utils.reduce_trainer_metrics_dict(train_trainset_stats),
metric_utils.reduce_trainer_metrics_dict(train_valiset_stats),
metric_utils.reduce_trainer_metrics_dict(train_testset_stats),
evaluation_frequency,
)
# save training statistics
if self.backend.is_coordinator():
if not skip_save_training_statistics:
save_json(training_stats_fn, train_stats)
# results of the model with highest validation test performance
if (
self.backend.is_coordinator()
and validation_set is not None
and not self.config_obj.trainer.skip_all_evaluation
):
print_boxed("TRAINING REPORT")
training_report = get_training_report(
trainer.validation_field,
trainer.validation_metric,
test_set is not None,
train_valiset_stats,
train_testset_stats,
)
logger.info(tabulate(training_report, tablefmt="fancy_grid"))
logger.info(f"\nFinished: {experiment_name}_{model_name}")
logger.info(f"Saved to: {output_directory}")
finally:
for callback in self.callbacks:
callback.on_train_end(output_directory)
self.training_set_metadata = training_set_metadata
if self.is_merge_and_unload_set():
# For an LLM model trained with a LoRA adapter, merge first, then save the full model.
self.model.merge_and_unload(progressbar=self.config_obj.adapter.postprocessor.progressbar)
if self.backend.is_coordinator() and not skip_save_model:
self.model.save_base_model(model_dir)
elif self.backend.is_coordinator() and not skip_save_model:
self.model.save(model_dir)
# Synchronize model weights between workers
self.backend.sync_model(self.model)
print_boxed("FINISHED")
return TrainingResults(train_stats, preprocessed_data, output_url)
def train_online(
self,
dataset: str | dict | pd.DataFrame,
training_set_metadata: str | dict | None = None,
data_format: str = "auto",
random_seed: int = default_random_seed,
) -> None:
"""Performs one epoch of training of the model on `dataset`.
# Inputs
:param dataset: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing the entire dataset to be used in the experiment.
If it has a split column, it will be used for splitting (0 for train,
1 for validation, 2 for test), otherwise the dataset will be
randomly split.
:param training_set_metadata: (Union[str, dict], default: `None`)
metadata JSON file or loaded metadata. Intermediate preprocessed
structure containing the mappings of the input
dataset created the first time an input file is used in the same
directory with the same name and a '.meta.json' extension.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`, `'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``), `'json'`, `'jsonl'`,
`'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`, `'spss'`,
`'stata'`, `'tsv'`.
:param random_seed: (int, default: `42`) a random seed that is going to be
used anywhere there is a call to a random number generator: data
splitting, parameter initialization and training set shuffling
# Return
:return: (None) `None`
"""
training_set_metadata = training_set_metadata or self.training_set_metadata
preprocessing_params = get_preprocessing_params(self.config_obj)
with provision_preprocessing_workers(self.backend):
# TODO (Connor): Refactor to use self.config_obj
training_dataset, _, _, training_set_metadata = preprocess_for_training(
self.config_obj.to_dict(),
training_set=dataset,
training_set_metadata=training_set_metadata,
data_format=data_format,
skip_save_processed_input=True,
preprocessing_params=preprocessing_params,
backend=self.backend,
random_seed=random_seed,
callbacks=self.callbacks,
)
if not self.training_set_metadata:
self.training_set_metadata = training_set_metadata
if not self.model:
update_config_with_metadata(self.config_obj, training_set_metadata)
self.model = LudwigModel.create_model(self.config_obj, random_seed=random_seed)
# update config with properties determined during model instantiation
update_config_with_model(self.config_obj, self.model)
set_saved_weights_in_checkpoint_flag(self.config_obj)
if not self._online_trainer:
self._online_trainer = self.backend.create_trainer(
config=self.config_obj.trainer, model=self.model, random_seed=random_seed
)
self._tune_batch_size(self._online_trainer, dataset, random_seed=random_seed)
self.model = self._online_trainer.train_online(training_dataset)
def _tune_batch_size(self, trainer, dataset, random_seed: int = default_random_seed):
"""Sets AUTO batch-size-related parameters based on the trainer, backend type, and number of workers.
Batch-size related parameters that are set:
- trainer.batch_size
- trainer.eval_batch_size
- trainer.gradient_accumulation_steps
- trainer.effective_batch_size
The final batch size selected may be non-deterministic even with a fixed random seed since throughput-based
heuristics may be affected by resources used by other processes running on the machine.
"""
if not self.config_obj.trainer.can_tune_batch_size():
# Some model types don't have batch sizes to be tuned
return
# Render the batch size and gradient accumulation steps prior to batch size tuning. This is needed in the event
# the effective_batch_size and gradient_accumulation_steps are set explicitly, but batch_size is AUTO. In this
# case, we can infer the batch_size directly without tuning.
num_workers = self.backend.num_training_workers
self.config_obj.trainer.update_batch_size_grad_accum(num_workers)
# TODO (ASN): add support for substitute_with_max parameter
# TODO(travis): detect train and eval batch sizes separately (enable / disable gradients)
if self.config_obj.trainer.batch_size == AUTO:
if self.backend.supports_batch_size_tuning():
tuned_batch_size = trainer.tune_batch_size(
self.config_obj.to_dict(), dataset, random_seed=random_seed, tune_for_training=True
)
else:
logger.warning(
f"Backend {self.backend.BACKEND_TYPE} does not support batch size tuning, "
f"using fallback training batch size {FALLBACK_BATCH_SIZE}."
)
tuned_batch_size = FALLBACK_BATCH_SIZE
# TODO(travis): pass these in as args to trainer when we call train,
# to avoid setting state on possibly remote trainer
self.config_obj.trainer.batch_size = tuned_batch_size
# Re-render the gradient_accumulation_steps to account for the explicit batch size.
self.config_obj.trainer.update_batch_size_grad_accum(num_workers)
if self.config_obj.trainer.eval_batch_size in {AUTO, None}:
if self.backend.supports_batch_size_tuning():
tuned_batch_size = trainer.tune_batch_size(
self.config_obj.to_dict(), dataset, random_seed=random_seed, tune_for_training=False
)
else:
logger.warning(
f"Backend {self.backend.BACKEND_TYPE} does not support batch size tuning, "
f"using fallback eval batch size {FALLBACK_BATCH_SIZE}."
)
tuned_batch_size = FALLBACK_BATCH_SIZE
self.config_obj.trainer.eval_batch_size = tuned_batch_size
# Update trainer params separate to config params for backends with stateful trainers
trainer.batch_size = self.config_obj.trainer.batch_size
trainer.eval_batch_size = self.config_obj.trainer.eval_batch_size
trainer.gradient_accumulation_steps = self.config_obj.trainer.gradient_accumulation_steps
def save_dequantized_base_model(self, save_path: str) -> None:
"""Upscales quantized weights of a model to fp16 and saves the result in a specified folder.
Args:
save_path (str): The path to the folder where the upscaled model weights will be saved.
Raises:
ValueError:
If the model type is not 'llm' or if quantization is not enabled or the number of bits is not 4 or 8.
RuntimeError:
If no GPU is available, as GPU is required for quantized models.
Returns:
None
"""
if self.config_obj.model_type != MODEL_LLM:
raise ValueError(
f"Model type {self.config_obj.model_type} is not supported by this method. Only `llm` model type is "
"supported."
)
if not self.config_obj.quantization:
raise ValueError(
"Quantization is not enabled in your Ludwig model config. "
"To enable quantization, set `quantization` to `{'bits': 4}` or `{'bits': 8}` in your model config."
)
if self.config_obj.quantization.bits != 4:
raise ValueError(
"This method only works with quantized models with 4 bits. "
"Support for 8-bit quantized models will be added in a future release."
)
if not torch.cuda.is_available():
raise RuntimeError("GPU is required for quantized models but no GPU found.")
# Create the LLM model class instance with the loaded LLM if it hasn't been initialized yet.
if not self.model:
self.model = LudwigModel.create_model(self.config_obj)
self.model.save_dequantized_base_model(save_path)
logger.info(
"If you want to upload this model to huggingface.co, run the following Python commands: \n"
"from ludwig.utils.hf_utils import upload_folder_to_hfhub; \n"
f"upload_folder_to_hfhub(repo_id='desired/huggingface/repo/name', folder_path='{save_path}')"
)
def generate(
self,
input_strings: str | list[str],
generation_config: dict | None = None,
streaming: bool | None = False,
) -> str | list[str]:
"""A simple generate() method that directly uses the underlying transformers library to generate text.
Args:
input_strings (Union[str, List[str]]): Input text or list of texts to generate from.
generation_config (Optional[dict]): Configuration for text generation.
streaming (Optional[bool]): If True, enable streaming output.
Returns:
Union[str, List[str]]: Generated text or list of generated texts.
"""
if self.config_obj.model_type != MODEL_LLM:
raise ValueError(
f"Model type {self.config_obj.model_type} is not supported by this method. Only `llm` model type is "
"supported."
)
if not torch.cuda.is_available():
# GPU is generally well-advised for working with LLMs and is required for loading quantized models, see
# https://github.com/ludwig-ai/ludwig/issues/3695.
raise ValueError("GPU is not available.")
# TODO(Justin): Decide if it's worth folding padding_side handling into llm.py's tokenizer initialization.
# For batch inference with models like facebook/opt-350m, if the tokenizer padding side is off, HF prints a
# warning, e.g.:
# "A decoder-only architecture is being used, but right-padding was detected! For correct generation results, "
# "please set `padding_side='left'` when initializing the tokenizer.
padding_side = "left" if not self.model.model.config.is_encoder_decoder else "right"
tokenizer = HFTokenizer(self.config_obj.base_model, padding_side=padding_side)
with self.model.use_generation_config(generation_config):
start_time = time.time()
tokenized_inputs = tokenizer.tokenizer(input_strings, return_tensors="pt", padding=True)
input_ids = tokenized_inputs["input_ids"].to("cuda")
attention_mask = tokenized_inputs["attention_mask"].to("cuda")
if streaming:
streamer = create_text_streamer(tokenizer.tokenizer)
outputs = self._generate_streaming_outputs(input_strings, input_ids, attention_mask, streamer)
else:
outputs = self._generate_non_streaming_outputs(input_strings, input_ids, attention_mask)
decoded_outputs = tokenizer.tokenizer.batch_decode(outputs, skip_special_tokens=True)
logger.info(f"Finished generating in: {(time.time() - start_time):.2f}s.")
return decoded_outputs[0] if len(decoded_outputs) == 1 else decoded_outputs
def _generate_streaming_outputs(
self,
input_strings: str | list[str],
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
streamer: TextStreamer,
) -> torch.Tensor:
"""Generate streaming outputs for the given input.
Args:
input_strings (Union[str, List[str]]): Input text or list of texts to generate from.
input_ids (torch.Tensor): Tensor containing input IDs.
attention_mask (torch.Tensor): Tensor containing attention masks.
streamer (Union[TextStreamer, None]): Text streamer instance for streaming output.
Returns:
torch.Tensor: Concatenated tensor of generated outputs.
"""
outputs = []
input_strings = input_strings if isinstance(input_strings, list) else [input_strings]
for i in range(len(input_ids)):
with torch.no_grad():
logger.info(f"Input: {input_strings[i]}\n")
# NOTE: self.model.model.generation_config is not used here because it is the default
# generation config that the CausalLM was initialized with, rather than the one set within the
# context manager.
generated_output = self.model.model.generate(
input_ids=input_ids[i].unsqueeze(0),
attention_mask=attention_mask[i].unsqueeze(0),
generation_config=self.model.generation,
streamer=streamer,
)
logger.info("----------------------")
outputs.append(generated_output)
return torch.cat(outputs, dim=0)
def _generate_non_streaming_outputs(
self,
_input_strings: str | list[str],
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
) -> torch.Tensor:
"""Generate non-streaming outputs for the given input.
Args:
_input_strings (Union[str, List[str]]): Unused input parameter.
input_ids (torch.Tensor): Tensor containing input IDs.
attention_mask (torch.Tensor): Tensor containing attention masks.
streamer (Union[TextStreamer, None]): Text streamer instance for streaming output.
Returns:
torch.Tensor: Tensor of generated outputs.
"""
with torch.no_grad():
# NOTE: self.model.model.generation_config is not used here because it is the default
# generation config that the CausalLM was initialized with, rather than the one set within the
# context manager.
return self.model.model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
generation_config=self.model.generation,
)
def predict(
self,
dataset: str | dict | pd.DataFrame | None = None,
data_format: str = None,
split: str = FULL,
batch_size: int = 128,
generation_config: dict | None = None,
skip_save_unprocessed_output: bool = True,
skip_save_predictions: bool = True,
output_directory: str = "results",
return_type: str | dict | pd.DataFrame = pd.DataFrame,
callbacks: list[Callback] | None = None,
**kwargs,
) -> tuple[dict | pd.DataFrame, str]:
"""Using a trained model, make predictions from the provided dataset.
# Inputs
:param dataset: (Union[str, dict, pandas.DataFrame]): source containing the entire dataset to be evaluated.
:param data_format: (str, default: `None`) format to interpret data sources. Will be inferred automatically
if not specified. Valid formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`, `'hdf5'` (cache file produced during previous training), `'html'` (file containing a single
HTML ``), `'json'`, `'jsonl'`, `'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`,
`'spss'`, `'stata'`, `'tsv'`.
:param split: (str, default= `'full'`): if the input dataset contains a split column, this parameter
indicates which split of the data to use. Possible values are `'full'`, `'training'`, `'validation'`,
`'test'`.
:param batch_size: (int, default: 128) size of batch to use when making predictions.
:param generation_config: (Dict, default: `None`) config for the generation of the
predictions. If `None`, the config that was used during model training is
used. This is only used if the model type is LLM. Otherwise, this parameter is
ignored. See
[Large Language Models](https://ludwig.ai/latest/configuration/large_language_model/#generation) under
"Generation" for an example generation config.
:param skip_save_unprocessed_output: (bool, default: `True`) if this parameter is `False`, predictions and
their probabilities are saved in both raw unprocessed numpy files containing tensors and as
postprocessed CSV files (one for each output feature). If this parameter is `True`, only the CSV ones
are saved and the numpy ones are skipped.
:param skip_save_predictions: (bool, default: `True`) skips saving test predictions CSV files.
:param output_directory: (str, default: `'results'`) the directory that will contain the training
statistics, TensorBoard logs, the saved model and the training progress files.
:param return_type: (Union[str, dict, pandas.DataFrame], default: pd.DataFrame) indicates the format of the
returned predictions.
:param callbacks: (Optional[List[Callback]], default: None) optional list of callbacks to use during this
predict operation. Any callbacks already registered to the model will be preserved.
# Return
:return `(predictions, output_directory)`: (Tuple[Union[dict, pd.DataFrame], str])
`predictions` predictions from the provided dataset,
`output_directory` filepath string to where data was stored.
"""
self._check_initialization()
# preprocessing
start_time = time.time()
logger.debug("Preprocessing")
dataset, _ = preprocess_for_prediction( # TODO (Connor): Refactor to use self.config_obj
self.config_obj.to_dict(),
dataset=dataset,
training_set_metadata=self.training_set_metadata,
data_format=data_format,
split=split,
include_outputs=False,
backend=self.backend,
callbacks=self.callbacks + (callbacks or []),
)
logger.debug("Predicting")
with self.backend.create_predictor(self.model, batch_size=batch_size) as predictor:
with self.model.use_generation_config(generation_config):
predictions = predictor.batch_predict(
dataset,
)
if self.backend.is_coordinator():
# if we are skipping all saving,
# there is no need to create a directory that will remain empty
should_create_exp_dir = not (skip_save_unprocessed_output and skip_save_predictions)
if should_create_exp_dir:
makedirs(output_directory, exist_ok=True)
logger.debug("Postprocessing")
postproc_predictions = postprocess(
predictions,
self.model.output_features,
self.training_set_metadata,
output_directory=output_directory,
backend=self.backend,
skip_save_unprocessed_output=skip_save_unprocessed_output or not self.backend.is_coordinator(),
)
converted_postproc_predictions = convert_predictions(
postproc_predictions, self.model.output_features, return_type=return_type, backend=self.backend
)
if self.backend.is_coordinator():
if not skip_save_predictions:
save_prediction_outputs(
postproc_predictions, self.model.output_features, output_directory, self.backend
)
logger.info(f"Saved to: {output_directory}")
logger.info(f"Finished predicting in: {(time.time() - start_time):.2f}s.")
return converted_postproc_predictions, output_directory
def evaluate(
self,
dataset: str | dict | pd.DataFrame | None = None,
data_format: str | None = None,
split: str = FULL,
batch_size: int | None = None,
skip_save_unprocessed_output: bool = True,
skip_save_predictions: bool = True,
skip_save_eval_stats: bool = True,
collect_predictions: bool = False,
collect_overall_stats: bool = False,
output_directory: str = "results",
return_type: str | dict | pd.DataFrame = pd.DataFrame,
**kwargs,
) -> tuple[dict, dict | pd.DataFrame, str]:
"""This function is used to predict the output variables given the input variables using the trained model
and compute test statistics like performance measures, confusion matrices and the like.
# Inputs
:param dataset: (Union[str, dict, pandas.DataFrame]) source containing
the entire dataset to be evaluated.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`, `'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``), `'json'`, `'jsonl'`,
`'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`, `'spss'`,
`'stata'`, `'tsv'`.
:param split: (str, default=`'full'`): if the input dataset contains
a split column, this parameter indicates which split of the data
to use. Possible values are `'full'`, `'training'`, `'validation'`, `'test'`.
:param batch_size: (int, default: None) size of batch to use when making
predictions. Defaults to model config eval_batch_size
:param skip_save_unprocessed_output: (bool, default: `True`) if this
parameter is `False`, predictions and their probabilities are saved
in both raw unprocessed numpy files containing tensors and as
postprocessed CSV files (one for each output feature).
If this parameter is `True`, only the CSV ones are saved and the
numpy ones are skipped.
:param skip_save_predictions: (bool, default: `True`) skips saving
test predictions CSV files.
:param skip_save_eval_stats: (bool, default: `True`) skips saving
test statistics JSON file.
:param collect_predictions: (bool, default: `False`) if `True`
collects post-processed predictions during eval.
:param collect_overall_stats: (bool, default: False) if `True`
collects overall stats during eval.
:param output_directory: (str, default: `'results'`) the directory that
will contain the training statistics, TensorBoard logs, the saved
model and the training progress files.
:param return_type: (Union[str, dict, pd.DataFrame], default: pandas.DataFrame) indicates
the format to of the returned predictions.
# Return
:return: (`evaluation_statistics`, `predictions`, `output_directory`)
`evaluation_statistics` dictionary containing evaluation performance
statistics,
`postprocess_predictions` contains predicted values,
`output_directory` is location where results are stored.
"""
self._check_initialization()
for callback in self.callbacks:
callback.on_evaluation_start()
# preprocessing
logger.debug("Preprocessing")
dataset, training_set_metadata = preprocess_for_prediction( # TODO (Connor): Refactor to use self.config_obj
self.config_obj.to_dict(),
dataset=dataset,
training_set_metadata=self.training_set_metadata,
data_format=data_format,
split=split,
include_outputs=True,
backend=self.backend,
callbacks=self.callbacks,
)
# Fallback to use eval_batch_size or batch_size if not provided
if batch_size is None:
# Requires dictionary getter since some trainer configs may not have a batch_size param
batch_size = self.config_obj.trainer.to_dict().get(
EVAL_BATCH_SIZE, None
) or self.config_obj.trainer.to_dict().get(BATCH_SIZE, None)
logger.debug("Predicting")
with self.backend.create_predictor(self.model, batch_size=batch_size) as predictor:
eval_stats, predictions = predictor.batch_evaluation(
dataset,
collect_predictions=collect_predictions or collect_overall_stats,
)
# calculate the overall metrics
if collect_overall_stats:
dataset = dataset.to_df()
overall_stats = calculate_overall_stats(
self.model.output_features, predictions, dataset, training_set_metadata
)
eval_stats = {
of_name: (
{**eval_stats[of_name], **overall_stats[of_name]}
# account for presence of 'combined' key
if of_name in overall_stats
else {**eval_stats[of_name]}
)
for of_name in eval_stats
}
if self.backend.is_coordinator():
# if we are skipping all saving,
# there is no need to create a directory that will remain empty
should_create_exp_dir = not (
skip_save_unprocessed_output and skip_save_predictions and skip_save_eval_stats
)
if should_create_exp_dir:
makedirs(output_directory, exist_ok=True)
if collect_predictions:
logger.debug("Postprocessing")
postproc_predictions = postprocess(
predictions,
self.model.output_features,
self.training_set_metadata,
output_directory=output_directory,
backend=self.backend,
skip_save_unprocessed_output=skip_save_unprocessed_output or not self.backend.is_coordinator(),
)
else:
postproc_predictions = predictions # = {}
if self.backend.is_coordinator():
should_save_predictions = (
collect_predictions and postproc_predictions is not None and not skip_save_predictions
)
if should_save_predictions:
save_prediction_outputs(
postproc_predictions, self.model.output_features, output_directory, self.backend
)
print_evaluation_stats(eval_stats)
if not skip_save_eval_stats:
save_evaluation_stats(eval_stats, output_directory)
if should_save_predictions or not skip_save_eval_stats:
logger.info(f"Saved to: {output_directory}")
if collect_predictions:
postproc_predictions = convert_predictions(
postproc_predictions, self.model.output_features, return_type=return_type, backend=self.backend
)
for callback in self.callbacks:
callback.on_evaluation_end()
return eval_stats, postproc_predictions, output_directory
def forecast(
self,
dataset: DataFrame,
data_format: str | None = None,
horizon: int = 1,
output_directory: str | None = None,
output_format: str = "parquet",
) -> DataFrame:
# TODO(travis): WIP
dataset, _, _, _ = load_dataset_uris(dataset, None, None, None, self.backend)
if isinstance(dataset, CacheableDataset):
dataset = dataset.unwrap()
dataset = load_dataset(dataset, data_format=data_format, df_lib=self.backend.df_engine.df_lib)
window_sizes = [
feature.preprocessing.window_size
for feature in self.config_obj.input_features
if feature.type == TIMESERIES
]
if not window_sizes:
raise ValueError("Forecasting requires at least one input feature of type `timeseries`.")
# TODO(travis): there's a lot of redundancy in this approach, since we are preprocessing the same DataFrame
# multiple times with only a small number of features (the horizon) being appended each time.
# A much better approach would be to only preprocess a single row, but incorporating the row-level embedding
# over the window_size of rows precending it, then performing the model forward pass on only that row of
# data.
max_lookback_window_size = max(window_sizes)
total_forecasted = 0
while total_forecasted < horizon:
# We only need the last `window_size` worth of rows to forecast the next value
dataset = dataset.tail(max_lookback_window_size)
# Run through preprocessing and prediction to obtain row-wise next values
# TODO(travis): can optimize the preprocessing part here, since we only need to preprocess / predict
# the last row, not the last `window_size` rows.
preds, _ = self.predict(dataset, skip_save_predictions=True, skip_save_unprocessed_output=True)
next_series = {}
for feature in self.config_obj.output_features:
if feature.type == TIMESERIES:
key = f"{feature.name}_predictions"
next_series[feature.column] = pd.Series(preds[key].iloc[-1])
next_preds = pd.DataFrame(next_series)
dataset = pd.concat([dataset, next_preds], axis=0).reset_index(drop=True)
total_forecasted += len(next_preds)
horizon_df = dataset.tail(total_forecasted).head(horizon)
return_cols = [feature.column for feature in self.config_obj.output_features if feature.type == TIMESERIES]
results_df = horizon_df[return_cols]
if output_directory is not None:
if self.backend.is_coordinator():
# TODO(travis): generalize this to support any pandas output format
if output_format == "parquet":
output_path = os.path.join(output_directory, "forecast.parquet")
results_df.to_parquet(output_path)
elif output_format == "csv":
output_path = os.path.join(output_directory, "forecast.csv")
results_df.to_csv(output_path)
else:
raise ValueError(f"`output_format` {output_format} not supported. Must be one of [parquet, csv]")
logger.info(f"Saved to: {output_path}")
return results_df
def experiment(
self,
dataset: str | dict | pd.DataFrame | None = None,
training_set: str | dict | pd.DataFrame | None = None,
validation_set: str | dict | pd.DataFrame | None = None,
test_set: str | dict | pd.DataFrame | None = None,
training_set_metadata: str | dict | None = None,
data_format: str | None = None,
experiment_name: str = "experiment",
model_name: str = "run",
model_resume_path: str | None = None,
eval_split: str = TEST,
skip_save_training_description: bool = False,
skip_save_training_statistics: bool = False,
skip_save_model: bool = False,
skip_save_progress: bool = False,
skip_save_log: bool = False,
skip_save_processed_input: bool = False,
skip_save_unprocessed_output: bool = False,
skip_save_predictions: bool = False,
skip_save_eval_stats: bool = False,
skip_collect_predictions: bool = False,
skip_collect_overall_stats: bool = False,
output_directory: str = "results",
random_seed: int = default_random_seed,
**kwargs,
) -> tuple[dict | None, TrainingStats, PreprocessedDataset, str]:
"""Trains a model on a dataset's training and validation splits and uses it to predict on the test split.
It saves the trained model and the statistics of training and testing.
# Inputs
:param dataset: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing the entire dataset to be used in the experiment.
If it has a split column, it will be used for splitting (0 for train,
1 for validation, 2 for test), otherwise the dataset will be
randomly split.
:param training_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing training data.
:param validation_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing validation data.
:param test_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing test data.
:param training_set_metadata: (Union[str, dict], default: `None`)
metadata JSON file or loaded metadata. Intermediate preprocessed
structure containing the mappings of the input
dataset created the first time an input file is used in the same
directory with the same name and a '.meta.json' extension.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`, `'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``), `'json'`, `'jsonl'`,
`'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`, `'spss'`,
`'stata'`, `'tsv'`.
:param experiment_name: (str, default: `'experiment'`) name for
the experiment.
:param model_name: (str, default: `'run'`) name of the model that is
being used.
:param model_resume_path: (str, default: `None`) resumes training of
the model from the path specified. The config is restored.
In addition to config, training statistics and loss for
epoch and the state of the optimizer are restored such that
training can be effectively continued from a previously interrupted
training process.
:param eval_split: (str, default: `test`) split on which
to perform evaluation. Valid values are `training`, `validation`
and `test`.
:param skip_save_training_description: (bool, default: `False`) disables
saving the description JSON file.
:param skip_save_training_statistics: (bool, default: `False`) disables
saving training statistics JSON file.
:param skip_save_model: (bool, default: `False`) disables
saving model weights and hyperparameters each time the model
improves. By default Ludwig saves model weights after each epoch
the validation metric improves, but if the model is really big
that can be time consuming. If you do not want to keep
the weights and just find out what performance a model can get
with a set of hyperparameters, use this parameter to skip it,
but the model will not be loadable later on and the returned model
will have the weights obtained at the end of training, instead of
the weights of the epoch with the best validation performance.
:param skip_save_progress: (bool, default: `False`) disables saving
progress each epoch. By default Ludwig saves weights and stats
after each epoch for enabling resuming of training, but if
the model is really big that can be time consuming and will uses
twice as much space, use this parameter to skip it, but training
cannot be resumed later on.
:param skip_save_log: (bool, default: `False`) disables saving
TensorBoard logs. By default Ludwig saves logs for the TensorBoard,
but if it is not needed turning it off can slightly increase the
overall speed.
:param skip_save_processed_input: (bool, default: `False`) if input
dataset is provided it is preprocessed and cached by saving an HDF5
and JSON files to avoid running the preprocessing again. If this
parameter is `False`, the HDF5 and JSON file are not saved.
:param skip_save_unprocessed_output: (bool, default: `False`) by default
predictions and their probabilities are saved in both raw
unprocessed numpy files containing tensors and as postprocessed
CSV files (one for each output feature). If this parameter is True,
only the CSV ones are saved and the numpy ones are skipped.
:param skip_save_predictions: (bool, default: `False`) skips saving test
predictions CSV files
:param skip_save_eval_stats: (bool, default: `False`) skips saving test
statistics JSON file
:param skip_collect_predictions: (bool, default: `False`) skips
collecting post-processed predictions during eval.
:param skip_collect_overall_stats: (bool, default: `False`) skips
collecting overall stats during eval.
:param output_directory: (str, default: `'results'`) the directory that
will contain the training statistics, TensorBoard logs, the saved
model and the training progress files.
:param random_seed: (int: default: 42) random seed used for weights
initialization, splits and any other random function.
# Return
:return: (Tuple[dict, dict, tuple, str))
`(evaluation_statistics, training_statistics, preprocessed_data, output_directory)`
`evaluation_statistics` dictionary with evaluation performance
statistics on the test_set,
`training_statistics` is a nested dictionary of dataset -> feature_name -> metric_name -> List of metrics.
Each metric corresponds to each training checkpoint.
`preprocessed_data` tuple containing preprocessed
`(training_set, validation_set, test_set)`, `output_directory`
filepath string to where results are stored.
"""
if self._user_config.get(HYPEROPT):
print_boxed("WARNING")
logger.warning(HYPEROPT_WARNING)
train_stats, preprocessed_data, output_directory = self.train(
dataset=dataset,
training_set=training_set,
validation_set=validation_set,
test_set=test_set,
training_set_metadata=training_set_metadata,
data_format=data_format,
experiment_name=experiment_name,
model_name=model_name,
model_resume_path=model_resume_path,
skip_save_training_description=skip_save_training_description,
skip_save_training_statistics=skip_save_training_statistics,
skip_save_model=skip_save_model,
skip_save_progress=skip_save_progress,
skip_save_log=skip_save_log,
skip_save_processed_input=skip_save_processed_input,
skip_save_unprocessed_output=skip_save_unprocessed_output,
output_directory=output_directory,
random_seed=random_seed,
)
training_set, validation_set, test_set, training_set_metadata = preprocessed_data
eval_set = validation_set
if eval_split == TRAINING:
eval_set = training_set
elif eval_split == VALIDATION:
eval_set = validation_set
elif eval_split == TEST:
eval_set = test_set
else:
logger.warning(f"Eval split {eval_split} not supported. " f"Using validation set instead")
if eval_set is not None:
trainer_dict = self.config_obj.trainer.to_dict()
batch_size = trainer_dict.get(EVAL_BATCH_SIZE, trainer_dict.get(BATCH_SIZE, None))
# predict
try:
eval_stats, _, _ = self.evaluate(
eval_set,
data_format=data_format,
batch_size=batch_size,
output_directory=output_directory,
skip_save_unprocessed_output=skip_save_unprocessed_output,
skip_save_predictions=skip_save_predictions,
skip_save_eval_stats=skip_save_eval_stats,
collect_predictions=not skip_collect_predictions,
collect_overall_stats=not skip_collect_overall_stats,
return_type="dict",
)
except NotImplementedError:
logger.warning(
"Skipping evaluation as the necessary methods are not "
"supported. Full exception below:\n"
f"{traceback.format_exc()}"
)
eval_stats = None
else:
logger.warning(f"The evaluation set {eval_set} was not provided. " f"Skipping evaluation")
eval_stats = None
return eval_stats, train_stats, preprocessed_data, output_directory
def collect_weights(self, tensor_names: list[str] = None, **kwargs) -> list:
"""Load a pre-trained model and collect the tensors with a specific name.
# Inputs
:param tensor_names: (list, default: `None`) List of tensor names to collect
weights
# Return
:return: (list) List of tensors
"""
self._check_initialization()
collected_tensors = self.model.collect_weights(tensor_names)
return collected_tensors
def collect_activations(
self,
layer_names: list[str],
dataset: str | dict[str, list] | pd.DataFrame,
data_format: str | None = None,
split: str = FULL,
batch_size: int = 128,
**kwargs,
) -> list:
"""Loads a pre-trained model model and input data to collect the values of the activations contained in the
tensors.
# Inputs
:param layer_names: (list) list of strings for layer names in the model
to collect activations.
:param dataset: (Union[str, Dict[str, list], pandas.DataFrame]) source
containing the data to make predictions.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`, `'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``), `'json'`, `'jsonl'`,
`'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`, `'spss'`,
`'stata'`, `'tsv'`.
:param split: (str, default= `'full'`): if the input dataset contains
a split column, this parameter indicates which split of the data
to use. Possible values are `'full'`, `'training'`, `'validation'`, `'test'`.
:param batch_size: (int, default: 128) size of batch to use when making
predictions.
# Return
:return: (list) list of collected tensors.
"""
self._check_initialization()
# preprocessing
logger.debug("Preprocessing")
dataset, training_set_metadata = preprocess_for_prediction( # TODO (Connor): Refactor to use self.config_obj
self.config_obj.to_dict(),
dataset=dataset,
training_set_metadata=self.training_set_metadata,
data_format=data_format,
split=split,
include_outputs=False,
)
logger.debug("Predicting")
with self.backend.create_predictor(self.model, batch_size=batch_size) as predictor:
activations = predictor.batch_collect_activations(
layer_names,
dataset,
)
return activations
def preprocess(
self,
dataset: str | dict | pd.DataFrame | None = None,
training_set: str | dict | pd.DataFrame | None = None,
validation_set: str | dict | pd.DataFrame | None = None,
test_set: str | dict | pd.DataFrame | None = None,
training_set_metadata: str | dict | None = None,
data_format: str | None = None,
skip_save_processed_input: bool = True,
random_seed: int = default_random_seed,
**kwargs,
) -> PreprocessedDataset:
"""This function is used to preprocess data.
# Args:
:param dataset: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing the entire dataset to be used in the experiment.
If it has a split column, it will be used for splitting
(0 for train, 1 for validation, 2 for test),
otherwise the dataset will be randomly split.
:param training_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing training data.
:param validation_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing validation data.
:param test_set: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing test data.
:param training_set_metadata: (Union[str, dict], default: `None`)
metadata JSON file or loaded metadata. Intermediate preprocessed
structure containing the mappings of the input
dataset created the first time an input file is used in the same
directory with the same name and a '.meta.json' extension.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`,
`'feather'`, `'fwf'`,
`'hdf5'` (cache file produced during previous training),
`'html'` (file containing a single HTML ``),
`'json'`, `'jsonl'`, `'parquet'`,
`'pickle'` (pickled Pandas DataFrame),
`'sas'`, `'spss'`, `'stata'`, `'tsv'`.
:param skip_save_processed_input: (bool, default: `False`) if input
dataset is provided it is preprocessed and cached by saving an HDF5
and JSON files to avoid running the preprocessing again. If this
parameter is `False`, the HDF5 and JSON file are not saved.
:param random_seed: (int, default: `42`) a random seed that will be
used anywhere there is a call to a random number generator: data
splitting, parameter initialization and training set shuffling
# Returns:
:return: (PreprocessedDataset) data structure containing
`(proc_training_set, proc_validation_set, proc_test_set, training_set_metadata)`.
# Raises:
RuntimeError: An error occurred while preprocessing the data. Examples include training dataset
being empty after preprocessing, lazy loading not being supported with RayBackend, etc.
"""
print_boxed("PREPROCESSING")
for callback in self.callbacks:
callback.on_preprocess_start(self.config_obj.to_dict())
preprocessing_params = get_preprocessing_params(self.config_obj)
proc_training_set = proc_validation_set = proc_test_set = None
try:
with provision_preprocessing_workers(self.backend):
# TODO (Connor): Refactor to use self.config_obj
preprocessed_data = preprocess_for_training(
self.config_obj.to_dict(),
dataset=dataset,
training_set=training_set,
validation_set=validation_set,
test_set=test_set,
training_set_metadata=training_set_metadata,
data_format=data_format,
skip_save_processed_input=skip_save_processed_input,
preprocessing_params=preprocessing_params,
backend=self.backend,
random_seed=random_seed,
callbacks=self.callbacks,
)
proc_training_set, proc_validation_set, proc_test_set, training_set_metadata = preprocessed_data
return PreprocessedDataset(proc_training_set, proc_validation_set, proc_test_set, training_set_metadata)
except Exception as e:
raise RuntimeError(f"Caught exception during model preprocessing: {str(e)}") from e
finally:
for callback in self.callbacks:
callback.on_preprocess_end(proc_training_set, proc_validation_set, proc_test_set, training_set_metadata)
@staticmethod
def load(
model_dir: str,
logging_level: int = logging.ERROR,
backend: Backend | str | None = None,
gpus: str | int | list[int] | None = None,
gpu_memory_limit: float | None = None,
allow_parallel_threads: bool = True,
callbacks: list[Callback] = None,
from_checkpoint: bool = False,
) -> "LudwigModel": # return is an instance of ludwig.api.LudwigModel class
"""This function allows for loading pretrained models.
# Inputs
:param model_dir: (str) path to the directory containing the model.
If the model was trained by the `train` or `experiment` command,
the model is in `results_dir/experiment_dir/model`.
:param logging_level: (int, default: 40) log level that will be sent to
stderr.
:param backend: (Union[Backend, str]) `Backend` or string name
of backend to use to execute preprocessing / training steps.
:param gpus: (Union[str, int, List[int]], default: `None`) GPUs
to use (it uses the same syntax of CUDA_VISIBLE_DEVICES)
:param gpu_memory_limit: (float: default: `None`) maximum memory fraction
[0, 1] allowed to allocate per GPU device.
:param allow_parallel_threads: (bool, default: `True`) allow Torch
to use
multithreading parallelism to improve performance at the cost of
determinism.
:param callbacks: (list, default: `None`) a list of
`ludwig.callbacks.Callback` objects that provide hooks into the
Ludwig pipeline.
:param from_checkpoint: (bool, default: `False`) if `True`, the model
will be loaded from the latest checkpoint (training_checkpoints/)
instead of the final model weights.
# Return
:return: (LudwigModel) a LudwigModel object
# Example usage
```python
ludwig_model = LudwigModel.load(model_dir)
```
"""
# Initialize PyTorch before calling `broadcast()` to prevent initializing
# Torch with default parameters
backend_param = backend
backend = initialize_backend(backend)
backend.initialize_pytorch(
gpus=gpus, gpu_memory_limit=gpu_memory_limit, allow_parallel_threads=allow_parallel_threads
)
config = backend.broadcast_return(lambda: load_json(os.path.join(model_dir, MODEL_HYPERPARAMETERS_FILE_NAME)))
# Upgrades deprecated fields and adds new required fields in case the config loaded from disk is old.
config_obj = ModelConfig.from_dict(config)
# Ensure that the original backend is used if it was specified in the config and user requests it
if backend_param is None and "backend" in config:
# Reset backend from config
backend = initialize_backend(config.get("backend"))
# initialize model
ludwig_model = LudwigModel(
config_obj.to_dict(),
logging_level=logging_level,
backend=backend,
gpus=gpus,
gpu_memory_limit=gpu_memory_limit,
allow_parallel_threads=allow_parallel_threads,
callbacks=callbacks,
)
# generate model from config
set_saved_weights_in_checkpoint_flag(config_obj)
ludwig_model.model = LudwigModel.create_model(config_obj)
# load model weights
ludwig_model.load_weights(model_dir, from_checkpoint)
# If merge_and_unload was NOT performed before saving (i.e., adapter weights exist),
# we need to merge them now for inference.
if ludwig_model.is_merge_and_unload_set():
weights_save_path = os.path.join(model_dir, MODEL_WEIGHTS_FILE_NAME)
adapter_config_path = os.path.join(weights_save_path, "adapter_config.json")
if os.path.exists(adapter_config_path):
ludwig_model.model.merge_and_unload(progressbar=config_obj.adapter.postprocessor.progressbar)
# load train set metadata
ludwig_model.training_set_metadata = backend.broadcast_return(
lambda: load_metadata(os.path.join(model_dir, TRAIN_SET_METADATA_FILE_NAME))
)
return ludwig_model
def load_weights(
self,
model_dir: str,
from_checkpoint: bool = False,
) -> None:
"""Loads weights from a pre-trained model.
# Inputs
:param model_dir: (str) filepath string to location of a pre-trained
model
:param from_checkpoint: (bool, default: `False`) if `True`, the model
will be loaded from the latest checkpoint (training_checkpoints/)
instead of the final model weights.
# Return
:return: `None`
# Example usage
```python
ludwig_model.load_weights(model_dir)
```
"""
if self.backend.is_coordinator():
if from_checkpoint:
with self.backend.create_trainer(
model=self.model,
config=self.config_obj.trainer,
) as trainer:
checkpoint = trainer.create_checkpoint_handle()
training_checkpoints_path = os.path.join(model_dir, TRAINING_CHECKPOINTS_DIR_PATH)
trainer.resume_weights_and_optimizer(training_checkpoints_path, checkpoint)
else:
self.model.load(model_dir)
self.backend.sync_model(self.model)
def save(self, save_path: str) -> None:
"""This function allows to save models on disk.
# Inputs
:param save_path: (str) path to the directory where the model is
going to be saved. Both a JSON file containing the model
architecture hyperparameters and checkpoints files containing
model weights will be saved.
# Return
:return: (None) `None`
# Example usage
```python
ludwig_model.save(save_path)
```
"""
self._check_initialization()
# save config
self.save_config(save_path)
# save model weights
self.model.save(save_path)
# save training set metadata
training_set_metadata_path = os.path.join(save_path, TRAIN_SET_METADATA_FILE_NAME)
save_json(training_set_metadata_path, self.training_set_metadata)
@staticmethod
def upload_to_hf_hub(
repo_id: str,
model_path: str,
repo_type: str = "model",
private: bool = False,
commit_message: str = "Upload trained [Ludwig](https://ludwig.ai/latest/) model weights",
commit_description: str | None = None,
) -> bool:
"""Uploads trained model artifacts to the HuggingFace Hub.
# Inputs
:param repo_id: (`str`)
A namespace (user or an organization) and a repo name separated
by a `/`.
:param model_path: (`str`)
The path of the saved model. This is either (a) the folder where
the 'model_weights' folder and the 'model_hyperparameters.json' file
are stored, or (b) the parent of that folder.
:param private: (`bool`, *optional*, defaults to `False`)
Whether the model repo should be private.
:param repo_type: (`str`, *optional*)
Set to `"dataset"` or `"space"` if uploading to a dataset or
space, `None` or `"model"` if uploading to a model. Default is
`None`.
:param commit_message: (`str`, *optional*)
The summary / title / first line of the generated commit. Defaults to:
`f"Upload {path_in_repo} with huggingface_hub"`
:param commit_description: (`str` *optional*)
The description of the generated commit
# Returns
:return: (bool) True for success, False for failure.
"""
if os.path.exists(os.path.join(model_path, MODEL_FILE_NAME, MODEL_WEIGHTS_FILE_NAME)) and os.path.exists(
os.path.join(model_path, MODEL_FILE_NAME, MODEL_HYPERPARAMETERS_FILE_NAME)
):
experiment_path = model_path
elif os.path.exists(os.path.join(model_path, MODEL_WEIGHTS_FILE_NAME)) and os.path.exists(
os.path.join(model_path, MODEL_HYPERPARAMETERS_FILE_NAME)
):
experiment_path = os.path.dirname(model_path)
else:
raise ValueError(
f"Can't find 'model_weights' and '{MODEL_HYPERPARAMETERS_FILE_NAME}' either at "
f"'{model_path}' or at '{model_path}/model'"
)
model_service = get_upload_registry()["hf_hub"]
hub: HuggingFaceHub = model_service()
hub.login()
upload_status: bool = hub.upload(
repo_id=repo_id,
model_path=experiment_path,
repo_type=repo_type,
private=private,
commit_message=commit_message,
commit_description=commit_description,
)
return upload_status
def save_config(self, save_path: str) -> None:
"""Save config to specified location.
# Inputs
:param save_path: (str) filepath string to save config as a
JSON file.
# Return
:return: `None`
"""
os.makedirs(save_path, exist_ok=True)
model_hyperparameters_path = os.path.join(save_path, MODEL_HYPERPARAMETERS_FILE_NAME)
save_json(model_hyperparameters_path, self.config_obj.to_dict())
def to_torchscript(
self,
model_only: bool = False,
device: TorchDevice | None = None,
):
"""Converts the trained model to Torchscript.
# Inputs
:param model_only (bool, optional): If True, only the ECD model will be converted to Torchscript. Else,
preprocessing and postprocessing steps will also be converted to Torchscript. :param device (TorchDevice,
optional): If None, the model will be converted to Torchscript on the same device to ensure maximum model
parity.
# Returns
:return: A torch.jit.ScriptModule that can be used to predict on a dictionary of inputs.
"""
if device is None:
device = DEVICE
self._check_initialization()
if model_only:
return self.model.to_torchscript(device)
else:
inference_module = InferenceModule.from_ludwig_model(
self.model, self.config_obj.to_dict(), self.training_set_metadata, device=device
)
return torch.jit.script(inference_module)
def save_torchscript(
self,
save_path: str,
model_only: bool = False,
device: TorchDevice | None = None,
):
"""Saves the Torchscript model to disk.
# Inputs
:param save_path (str): The path to the directory where the model will be saved.
:param model_only (bool, optional): If True, only the ECD model will be converted to Torchscript. Else, the
preprocessing and postprocessing steps will also be converted to Torchscript.
:param device (TorchDevice, optional): If None, the model will be converted to Torchscript on the same device to
ensure maximum model parity.
# Return
:return: `None`
"""
if device is None:
device = DEVICE
save_ludwig_model_for_inference(
save_path,
self.model,
self.config_obj.to_dict(),
self.training_set_metadata,
model_only=model_only,
device=device,
)
def _check_initialization(self):
if self.model is None or self._user_config is None or self.training_set_metadata is None:
raise ValueError("Model has not been trained or loaded")
def free_gpu_memory(self):
"""Manually moves the model to CPU to force GPU memory to be freed.
For more context: https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/35
"""
if torch.cuda.is_available():
self.model.model.to(torch.device("cpu"))
torch.cuda.empty_cache()
@staticmethod
def create_model(config_obj: ModelConfig | dict, random_seed: int = default_random_seed) -> BaseModel:
"""Instantiates BaseModel object.
# Inputs
:param config_obj: (Union[Config, dict]) Ludwig config object
:param random_seed: (int, default: ludwig default random seed) Random seed used for weights initialization,
splits and any other random function. # Return
:return: (ludwig.models.BaseModel) Instance of the Ludwig model object.
"""
if isinstance(config_obj, dict):
config_obj = ModelConfig.from_dict(config_obj)
model_type = get_from_registry(config_obj.model_type, model_type_registry)
return model_type(config_obj, random_seed=random_seed)
@staticmethod
def set_logging_level(logging_level: int) -> None:
"""Sets level for log messages.
# Inputs
:param logging_level: (int) Set/Update the logging level. Use logging
constants like `logging.DEBUG` , `logging.INFO` and `logging.ERROR`.
# Return
:return: `None`
"""
logging.getLogger("ludwig").setLevel(logging_level)
if logging_level in {logging.WARNING, logging.ERROR, logging.CRITICAL}:
set_disable_progressbar(True)
else:
set_disable_progressbar(False)
@property
def config(self) -> ModelConfigDict:
"""Returns the fully-rendered config of this model including default values."""
return self.config_obj.to_dict()
@config.setter
def config(self, user_config: ModelConfigDict):
"""Updates the config of this model.
WARNING: this can have unexpected results on an already trained model.
"""
self._user_config = user_config
self.config_obj = ModelConfig.from_dict(self._user_config)
def is_merge_and_unload_set(self) -> bool:
"""Check whether the encapsulated model is of type LLM and is configured to merge_and_unload QLoRA weights.
# Return
:return (bool): whether merge_and_unload should be done.
"""
# TODO: In the future, it may be possible to move up the model type check into the BaseModel class.
return self.config_obj.model_type == MODEL_LLM and self.model.is_merge_and_unload_set()
@PublicAPI
def kfold_cross_validate(
num_folds: int,
config: dict | str,
dataset: str = None,
data_format: str = None,
skip_save_training_description: bool = False,
skip_save_training_statistics: bool = False,
skip_save_model: bool = False,
skip_save_progress: bool = False,
skip_save_log: bool = False,
skip_save_processed_input: bool = False,
skip_save_predictions: bool = False,
skip_save_eval_stats: bool = False,
skip_collect_predictions: bool = False,
skip_collect_overall_stats: bool = False,
output_directory: str = "results",
random_seed: int = default_random_seed,
gpus: str | int | list[int] | None = None,
gpu_memory_limit: float | None = None,
allow_parallel_threads: bool = True,
backend: Backend | str | None = None,
logging_level: int = logging.INFO,
**kwargs,
) -> tuple[dict, dict]:
"""Performs k-fold cross validation and returns result data structures.
# Inputs
:param num_folds: (int) number of folds to create for the cross-validation
:param config: (Union[dict, str]) model specification
required to build a model. Parameter may be a dictionary or string
specifying the file path to a yaml configuration file. Refer to the
[User Guide](http://ludwig.ai/user_guide/#model-config)
for details.
:param dataset: (Union[str, dict, pandas.DataFrame], default: `None`)
source containing the entire dataset to be used for k_fold processing.
:param data_format: (str, default: `None`) format to interpret data
sources. Will be inferred automatically if not specified. Valid
formats are `'auto'`, `'csv'`, `'df'`, `'dict'`, `'excel'`, `'feather'`,
`'fwf'`,
`'html'` (file containing a single HTML ``), `'json'`, `'jsonl'`,
`'parquet'`, `'pickle'` (pickled Pandas DataFrame), `'sas'`, `'spss'`,
`'stata'`, `'tsv'`. Currently `hdf5` format is not supported for
k_fold cross validation.
:param skip_save_training_description: (bool, default: `False`) disables
saving the description JSON file.
:param skip_save_training_statistics: (bool, default: `False`) disables
saving training statistics JSON file.
:param skip_save_model: (bool, default: `False`) disables
saving model weights and hyperparameters each time the model
improves. By default Ludwig saves model weights after each epoch
the validation metric improves, but if the model is really big
that can be time consuming. If you do not want to keep
the weights and just find out what performance a model can get
with a set of hyperparameters, use this parameter to skip it,
but the model will not be loadable later on and the returned model
will have the weights obtained at the end of training, instead of
the weights of the epoch with the best validation performance.
:param skip_save_progress: (bool, default: `False`) disables saving
progress each epoch. By default Ludwig saves weights and stats
after each epoch for enabling resuming of training, but if
the model is really big that can be time consuming and will uses
twice as much space, use this parameter to skip it, but training
cannot be resumed later on.
:param skip_save_log: (bool, default: `False`) disables saving TensorBoard
logs. By default Ludwig saves logs for the TensorBoard, but if it
is not needed turning it off can slightly increase the
overall speed.
:param skip_save_processed_input: (bool, default: `False`) if input
dataset is provided it is preprocessed and cached by saving an HDF5
and JSON files to avoid running the preprocessing again. If this
parameter is `False`, the HDF5 and JSON file are not saved.
:param skip_save_predictions: (bool, default: `False`) skips saving test
predictions CSV files.
:param skip_save_eval_stats: (bool, default: `False`) skips saving test
statistics JSON file.
:param skip_collect_predictions: (bool, default: `False`) skips collecting
post-processed predictions during eval.
:param skip_collect_overall_stats: (bool, default: `False`) skips collecting
overall stats during eval.
:param output_directory: (str, default: `'results'`) the directory that
will contain the training statistics, TensorBoard logs, the saved
model and the training progress files.
:param random_seed: (int, default: `42`) Random seed
used for weights initialization,
splits and any other random function.
:param gpus: (list, default: `None`) list of GPUs that are available
for training.
:param gpu_memory_limit: (float: default: `None`) maximum memory fraction
[0, 1] allowed to allocate per GPU device.
:param allow_parallel_threads: (bool, default: `True`) allow Torch to
use multithreading parallelism
to improve performance at the cost of determinism.
:param backend: (Union[Backend, str]) `Backend` or string name
of backend to use to execute preprocessing / training steps.
:param logging_level: (int, default: INFO) log level to send to stderr.
# Return
:return: (tuple(kfold_cv_statistics, kfold_split_indices), dict) a tuple of
dictionaries `kfold_cv_statistics`: contains metrics from cv run.
`kfold_split_indices`: indices to split training data into
training fold and test fold.
"""
# if config is a path, convert to dictionary
if isinstance(config, str): # assume path
config = load_yaml(config)
backend = initialize_backend(backend or config.get("backend"))
# check for k_fold
if num_folds is None:
raise ValueError("k_fold parameter must be specified")
logger.info(f"starting {num_folds:d}-fold cross validation")
# create output_directory if not available
if not os.path.isdir(output_directory):
os.mkdir(output_directory)
# prepare data for k-fold processing
# use Ludwig's utility to facilitate creating a dataframe
# that is used as the basis for creating folds
dataset, _, _, _ = load_dataset_uris(dataset, None, None, None, backend)
# determine data format of provided dataset
if not data_format or data_format == "auto":
data_format = figure_data_format(dataset)
data_df = load_dataset(dataset, data_format=data_format, df_lib=backend.df_engine.df_lib)
kfold_cv_stats = {}
kfold_split_indices = {}
for train_indices, test_indices, fold_num in generate_kfold_splits(data_df, num_folds, random_seed):
with tempfile.TemporaryDirectory() as temp_dir_name:
curr_train_df = data_df.iloc[train_indices]
curr_test_df = data_df.iloc[test_indices]
kfold_split_indices["fold_" + str(fold_num)] = {
"training_indices": train_indices,
"test_indices": test_indices,
}
# train and validate model on this fold
logger.info(f"training on fold {fold_num:d}")
model = LudwigModel(
config=config,
logging_level=logging_level,
backend=backend,
gpus=gpus,
gpu_memory_limit=gpu_memory_limit,
allow_parallel_threads=allow_parallel_threads,
)
eval_stats, train_stats, preprocessed_data, output_directory = model.experiment(
training_set=curr_train_df,
test_set=curr_test_df,
experiment_name="cross_validation",
model_name="fold_" + str(fold_num),
skip_save_training_description=skip_save_training_description,
skip_save_training_statistics=skip_save_training_statistics,
skip_save_model=skip_save_model,
skip_save_progress=skip_save_progress,
skip_save_log=skip_save_log,
skip_save_processed_input=skip_save_processed_input,
skip_save_predictions=skip_save_predictions,
skip_save_eval_stats=skip_save_eval_stats,
skip_collect_predictions=skip_collect_predictions,
skip_collect_overall_stats=skip_collect_overall_stats,
output_directory=os.path.join(temp_dir_name, "results"),
random_seed=random_seed,
)
# augment the training statistics with scoring metric from
# the hold out fold
if dataclasses.is_dataclass(train_stats):
train_stats_dict = dataclasses.asdict(train_stats)
elif hasattr(train_stats, "to_dict"):
train_stats_dict = train_stats.to_dict()
else:
train_stats_dict = vars(train_stats)
train_stats_dict["fold_eval_stats"] = eval_stats
# collect training statistics for this fold
kfold_cv_stats["fold_" + str(fold_num)] = train_stats_dict
# consolidate raw fold metrics across all folds
raw_kfold_stats = {}
for fold_name in kfold_cv_stats:
curr_fold_eval_stats = kfold_cv_stats[fold_name]["fold_eval_stats"]
for of_name in curr_fold_eval_stats:
if of_name not in raw_kfold_stats:
raw_kfold_stats[of_name] = {}
fold_eval_stats_of = curr_fold_eval_stats[of_name]
for metric in fold_eval_stats_of:
if metric not in {
"predictions",
"probabilities",
"confusion_matrix",
"overall_stats",
"per_class_stats",
"roc_curve",
"precision_recall_curve",
}:
if metric not in raw_kfold_stats[of_name]:
raw_kfold_stats[of_name][metric] = []
raw_kfold_stats[of_name][metric].append(fold_eval_stats_of[metric])
# calculate overall kfold statistics
overall_kfold_stats = {}
for of_name in raw_kfold_stats:
overall_kfold_stats[of_name] = {}
for metric in raw_kfold_stats[of_name]:
mean = np.mean(raw_kfold_stats[of_name][metric])
std = np.std(raw_kfold_stats[of_name][metric])
overall_kfold_stats[of_name][metric + "_mean"] = mean
overall_kfold_stats[of_name][metric + "_std"] = std
kfold_cv_stats["overall"] = overall_kfold_stats
logger.info(f"completed {num_folds:d}-fold cross validation")
return kfold_cv_stats, kfold_split_indices
def _get_compute_description(backend) -> dict:
"""Returns the compute description for the backend."""
compute_description = {"num_nodes": backend.num_nodes}
if torch.cuda.is_available():
# Assumption: All nodes are of the same instance type.
# TODO: fix for Ray where workers may be of different skus
compute_description.update(
{
"gpus_per_node": torch.cuda.device_count(),
"arch_list": torch.cuda.get_arch_list(),
"gencode_flags": torch.cuda.get_gencode_flags(),
"devices": {},
}
)
for i in range(torch.cuda.device_count()):
compute_description["devices"][i] = {
"gpu_type": torch.cuda.get_device_name(i),
"device_capability": torch.cuda.get_device_capability(i),
"device_properties": str(torch.cuda.get_device_properties(i)),
}
return compute_description
@PublicAPI
def get_experiment_description(
config,
dataset=None,
training_set=None,
validation_set=None,
test_set=None,
training_set_metadata=None,
data_format=None,
backend=None,
random_seed=None,
):
description = OrderedDict()
description["ludwig_version"] = LUDWIG_VERSION
description["command"] = " ".join(sys.argv)
commit_hash = get_commit_hash()
if commit_hash is not None:
description["commit_hash"] = commit_hash[:12]
if random_seed is not None:
description["random_seed"] = random_seed
if isinstance(dataset, str):
description["dataset"] = dataset
if isinstance(training_set, str):
description["training_set"] = training_set
if isinstance(validation_set, str):
description["validation_set"] = validation_set
if isinstance(test_set, str):
description["test_set"] = test_set
if training_set_metadata is not None:
description["training_set_metadata"] = training_set_metadata
# determine data format if not provided or auto
if not data_format or data_format == "auto":
data_format = figure_data_format(dataset, training_set, validation_set, test_set)
if data_format:
description["data_format"] = str(data_format)
description["config"] = config
description["torch_version"] = torch.__version__
description["compute"] = _get_compute_description(backend)
return description
================================================
FILE: ludwig/api_annotations.py
================================================
def PublicAPI(*args, **kwargs):
"""Annotation for documenting public APIs. Public APIs are classes and methods exposed to end users of Ludwig.
If stability="stable", the APIs will remain backwards compatible across minor Ludwig releases
(e.g., Ludwig 0.6 -> Ludwig 0.7).
If stability="experimental", the APIs can be used by advanced users who are tolerant to and expect
breaking changes. This will likely be seen in the case of incremental new feature development.
Args:
stability: One of {"stable", "experimental"}
Examples:
>>> from api_annotations import PublicAPI
>>> @PublicAPI
... def func1(x):
... return x
>>> @PublicAPI(stability="experimental")
... def func2(y):
... return y
"""
if len(args) == 1 and len(kwargs) == 0 and callable(args[0]):
return PublicAPI(stability="stable")(args[0])
if "stability" in kwargs:
stability = kwargs["stability"]
assert stability in ["stable", "experimental"], stability
elif kwargs:
raise ValueError(f"Unknown kwargs: {kwargs.keys()}")
else:
stability = "stable"
def wrap(obj):
if stability == "experimental":
message = f"PublicAPI ({stability}): This API is {stability} and may change before becoming stable."
else:
message = "PublicAPI: This API is stable across Ludwig releases."
_append_doc(obj, message=message)
_mark_annotated(obj)
return obj
return wrap
def DeveloperAPI(*args, **kwargs):
"""Annotation for documenting developer APIs. Developer APIs are lower-level methods explicitly exposed to
advanced Ludwig users and library developers. Their interfaces may change across minor Ludwig releases (for
e.g., Ludwig 0.6.1 and Ludwig 0.6.2).
Examples:
>>> from api_annotations import DeveloperAPI
>>> @DeveloperAPI
... def func(x):
... return x
"""
if len(args) == 1 and len(kwargs) == 0 and callable(args[0]):
return DeveloperAPI()(args[0])
def wrap(obj):
_append_doc(obj, message="DeveloperAPI: This API may change across minor Ludwig releases.")
_mark_annotated(obj)
return obj
return wrap
def Deprecated(*args, **kwargs):
"""Annotation for documenting a deprecated API. Deprecated APIs may be removed in future releases of Ludwig
(e.g., Ludwig 0.7 to Ludwig 0.8).
Args:
message: A message to help users understand the reason for the deprecation, and provide a migration path.
Examples:
>>> from api_annotations import Deprecated
>>> @Deprecated
... def func(x):
... return x
>>> @Deprecated(message="g() is deprecated because the API is error prone. Please call h() instead.")
... def g(y):
... return y
"""
if len(args) == 1 and len(kwargs) == 0 and callable(args[0]):
return Deprecated()(args[0])
message = "**DEPRECATED:** This API is deprecated and may be removed in a future Ludwig release."
if "message" in kwargs:
message += " " + kwargs["message"]
del kwargs["message"]
if kwargs:
raise ValueError(f"Unknown kwargs: {kwargs.keys()}")
def inner(obj):
_append_doc(obj, message=message, directive="warning")
_mark_annotated(obj)
return obj
return inner
def _append_doc(obj, message: str, directive: str | None = None) -> str:
"""
Args:
message: An additional message to append to the end of docstring for a class
or method that uses one of the API annotations
directive: A shorter message that provides contexts for the message and indents it.
For example, this could be something like 'warning' or 'info'.
"""
if not obj.__doc__:
obj.__doc__ = ""
obj.__doc__ = obj.__doc__.rstrip()
indent = _get_indent(obj.__doc__)
obj.__doc__ += "\n\n"
if directive is not None:
obj.__doc__ += f"{' ' * indent}.. {directive}::\n"
obj.__doc__ += f"{' ' * (indent + 4)}{message}"
else:
obj.__doc__ += f"{' ' * indent}{message}"
obj.__doc__ += f"\n{' ' * indent}"
def _mark_annotated(obj) -> None:
# Set magic token for check_api_annotations linter.
if hasattr(obj, "__name__"):
obj._annotated = obj.__name__
def _is_annotated(obj) -> bool:
# Check the magic token exists and applies to this class (not a subclass).
return hasattr(obj, "_annotated") and obj._annotated == obj.__name__
def _get_indent(docstring: str) -> int:
"""
Example:
>>> def f():
... '''Docstring summary.'''
>>> f.__doc__
'Docstring summary.'
>>> _get_indent(f.__doc__)
0
>>> def g(foo):
... '''Docstring summary.
...
... Args:
... foo: Does bar.
... '''
>>> g.__doc__
'Docstring summary.\\n\\n Args:\\n foo: Does bar.\\n '
>>> _get_indent(g.__doc__)
4
>>> class A:
... def h():
... '''Docstring summary.
...
... Returns:
... None.
... '''
>>> A.h.__doc__
'Docstring summary.\\n\\n Returns:\\n None.\\n '
>>> _get_indent(A.h.__doc__)
8
"""
if not docstring:
return 0
non_empty_lines = list(filter(bool, docstring.splitlines()))
if len(non_empty_lines) == 1:
# Docstring contains summary only.
return 0
# The docstring summary isn't indented, so check the indentation of the second non-empty line.
return len(non_empty_lines[1]) - len(non_empty_lines[1].lstrip())
================================================
FILE: ludwig/automl/__init__.py
================================================
from ludwig.automl.automl import auto_train # noqa
from ludwig.automl.automl import cli_init_config # noqa
from ludwig.automl.automl import create_auto_config # noqa
from ludwig.automl.automl import train_with_config # noqa; noqa
================================================
FILE: ludwig/automl/auto_tune_config.py
================================================
import copy
import logging
import math
from collections import OrderedDict
import psutil
try:
import GPUtil
except ImportError:
raise ImportError("GPUtil is not installed. In order to use auto_train please run pip install ludwig[ray]")
from ludwig.api import LudwigModel
from ludwig.backend import initialize_backend
from ludwig.constants import (
AUTO,
AUTOML_DEFAULT_TEXT_ENCODER,
AUTOML_LARGE_TEXT_DATASET,
AUTOML_MAX_ROWS_PER_CHECKPOINT,
AUTOML_SMALLER_TEXT_ENCODER,
AUTOML_SMALLER_TEXT_LENGTH,
AUTOML_TEXT_ENCODER_MAX_TOKEN_LEN,
HYPEROPT,
MINIMUM_BATCH_SIZE,
PREPROCESSING,
SPACE,
TEXT,
TRAINER,
)
from ludwig.data.preprocessing import preprocess_for_training
from ludwig.features.feature_registries import update_config_with_metadata
from ludwig.schema.model_config import ModelConfig
from ludwig.utils.automl.utils import get_model_type
from ludwig.utils.torch_utils import initialize_pytorch
logger = logging.getLogger(__name__)
# maps variable search space that can be modified to minimum permissible value for the range
RANKED_MODIFIABLE_PARAM_LIST = {
"tabnet": OrderedDict(
{
"trainer.batch_size": 32,
"combiner.size": 8,
"combiner.output_size": 8,
}
),
"concat": OrderedDict(
{
"trainer.batch_size": 32,
"combiner.output_size": 64,
"combiner.num_fc_layers": 1,
}
),
"tabtransformer": OrderedDict(
{
"trainer.batch_size": 32,
"combiner.num_heads:": 4,
"combiner.output_size": 8,
"combiner.num_layers": 4,
"combiner.num_fc_layers": 1,
}
),
"text": OrderedDict( # for single input feature text models e.g. bert and its variants
{
"trainer.batch_size": 16,
}
),
}
BYTES_PER_MiB = 1048576
BYTES_PER_WEIGHT = 4 # assumes 32-bit precision = 4 bytes
BYTES_OPTIMIZER_PER_WEIGHT = 8 # for optimizer m and v vectors
def get_trainingset_metadata(config, dataset, backend):
_, _, _, training_set_metadata = preprocess_for_training(
config, dataset=dataset, preprocessing_params=config[PREPROCESSING], backend=backend
)
return training_set_metadata
# Note: if run in Ray Cluster, this method is run remote with gpu resources requested if available
def _get_machine_memory():
if GPUtil.getGPUs():
machine_mem = GPUtil.getGPUs()[0].memoryTotal * BYTES_PER_MiB
else:
machine_mem = psutil.virtual_memory().total
return machine_mem
def _get_text_feature_max_length(config, training_set_metadata) -> int:
"""Returns max sequence length over text features, subject to preprocessing limit."""
max_length = 0
for feature in config["input_features"]:
if feature["type"] == TEXT:
feature_max_len = training_set_metadata[feature["name"]]["max_sequence_length"]
if feature_max_len > max_length:
max_length = feature_max_len
if (
("preprocessing" in config)
and (TEXT in config["preprocessing"])
and ("max_sequence_length" in config["preprocessing"][TEXT])
):
limit = config["preprocessing"][TEXT]["max_sequence_length"]
else:
limit = 256 # Preprocessing default max_sequence_length = 256
if max_length > limit + 2: # For start and stop symbols.
max_length = limit + 2
return max_length
def _get_text_model_memory_usage(config, training_set_metadata, memory_usage) -> int:
max_feature_token_length = _get_text_feature_max_length(config, training_set_metadata)
memory_usage = (memory_usage / AUTOML_TEXT_ENCODER_MAX_TOKEN_LEN) * max_feature_token_length
return memory_usage
def compute_memory_usage(config_obj, training_set_metadata, model_category) -> int:
update_config_with_metadata(config_obj, training_set_metadata)
lm = LudwigModel.create_model(config_obj)
model_size = lm.get_model_size() # number of parameters in model
batch_size = config_obj.trainer.batch_size
if batch_size == AUTO:
# Smallest valid batch size that will allow training to complete
batch_size = MINIMUM_BATCH_SIZE
memory_usage = model_size * (BYTES_PER_WEIGHT + BYTES_OPTIMIZER_PER_WEIGHT) * batch_size
if model_category == TEXT:
return _get_text_model_memory_usage(config_obj.to_dict(), training_set_metadata, memory_usage)
else:
return memory_usage
def sub_new_params(config: dict, new_param_vals: dict):
new_config = copy.deepcopy(config)
for param, val in new_param_vals.items():
config_section = param.split(".")[0]
param_name = param.split(".")[1]
new_config[config_section][param_name] = val
return new_config
def get_new_params(current_param_values, hyperparam_search_space, params_to_modify):
for param, _ in params_to_modify.items():
if param in hyperparam_search_space:
if hyperparam_search_space[param][SPACE] == "choice":
current_param_values[param] = hyperparam_search_space[param]["categories"][-1]
else:
current_param_values[param] = hyperparam_search_space[param]["upper"]
return current_param_values
def _update_text_encoder(input_features: list, old_text_encoder: str, new_text_encoder: str) -> None:
for feature in input_features:
if feature["type"] == TEXT and feature["encoder"] == old_text_encoder:
feature["encoder"] = new_text_encoder
def _get_text_feature_min_usable_length(input_features: list, training_set_metadata) -> int:
"""Returns min of AUTOML_SMALLER_TEXT_LENGTH and lowest 99th percentile sequence length over text features."""
min_usable_length = AUTOML_SMALLER_TEXT_LENGTH
for feature in input_features:
if feature["type"] == TEXT:
feature_99ptile_len = training_set_metadata[feature["name"]]["max_sequence_length_99ptile"]
if feature_99ptile_len < min_usable_length:
min_usable_length = feature_99ptile_len
return round(min_usable_length)
def reduce_text_feature_max_length(config, training_set_metadata) -> bool:
"""Reduce max sequence length, when viable, to control its quadratic impact."""
input_features = config["input_features"]
min_usable_length = _get_text_feature_min_usable_length(input_features, training_set_metadata)
seq_len_limit = {"max_sequence_length": min_usable_length}
if "preprocessing" not in config:
config["preprocessing"] = {TEXT: seq_len_limit}
elif (
(TEXT not in config["preprocessing"])
or ("max_sequence_length" not in config["preprocessing"][TEXT])
or (min_usable_length < float(config["preprocessing"][TEXT]["max_sequence_length"]))
):
config["preprocessing"][TEXT] = seq_len_limit
else:
return False
return True
# For hyperparam_search_space comprised solely of choice spaces, compute maximum number of
# combinations and return that value if it is less than num_samples; else return num_samples.
def _update_num_samples(num_samples, hyperparam_search_space):
max_num_samples = 1
for param in hyperparam_search_space.keys():
if hyperparam_search_space[param][SPACE] == "choice":
max_num_samples *= len(hyperparam_search_space[param]["categories"])
else:
return num_samples
if max_num_samples < num_samples:
return max_num_samples
return num_samples
# Note: if run in Ray Cluster, this method is run remote with gpu resources requested if available
def memory_tune_config(config, dataset, model_category, row_count, backend):
backend = initialize_backend(backend)
fits_in_memory = False
tried_reduce_seq_len = False
config_obj = ModelConfig.from_dict(config)
raw_config = config_obj.to_dict()
training_set_metadata = get_trainingset_metadata(raw_config, dataset, backend)
modified_hyperparam_search_space = copy.deepcopy(raw_config[HYPEROPT]["parameters"])
current_param_values = {}
param_list = []
model_type = get_model_type(raw_config)
if model_type in RANKED_MODIFIABLE_PARAM_LIST:
params_to_modify = RANKED_MODIFIABLE_PARAM_LIST[model_type]
if len(params_to_modify.keys()) > 0:
param_list = list(params_to_modify.keys())
max_memory = _get_machine_memory()
initialize_pytorch()
while param_list:
# compute memory utilization
current_param_values = get_new_params(current_param_values, modified_hyperparam_search_space, params_to_modify)
temp_config = sub_new_params(raw_config, current_param_values)
config_obj = ModelConfig.from_dict(temp_config)
mem_use = compute_memory_usage(config_obj, training_set_metadata, model_category)
if mem_use > max_memory and model_category == TEXT and not tried_reduce_seq_len:
tried_reduce_seq_len = True
if reduce_text_feature_max_length(config, training_set_metadata):
reduce_text_feature_max_length(temp_config, training_set_metadata)
config_obj = ModelConfig.from_dict(temp_config)
mem_use = compute_memory_usage(config_obj, training_set_metadata, model_category)
logger.info(f"Checking model estimated mem use {mem_use} against memory size {max_memory}")
if mem_use <= max_memory:
fits_in_memory = True
break
# check if we have exhausted tuning of current param (e.g. we can no longer reduce the param value)
param, min_value = param_list[0], params_to_modify[param_list[0]]
if param in modified_hyperparam_search_space.keys():
param_space = modified_hyperparam_search_space[param]["space"]
if param_space == "choice":
if (
len(modified_hyperparam_search_space[param]["categories"]) >= 2
and modified_hyperparam_search_space[param]["categories"][-2] >= min_value
):
modified_hyperparam_search_space[param]["categories"] = modified_hyperparam_search_space[param][
"categories"
][:-1]
else:
param_list.pop(0) # exhausted reduction of this parameter
else:
# reduce by 10%
upper_bound, lower_bound = (
modified_hyperparam_search_space[param]["upper"],
modified_hyperparam_search_space[param]["lower"],
)
reduction_val = (upper_bound - lower_bound) * 0.1
new_upper_bound = upper_bound - reduction_val
if (new_upper_bound) > lower_bound and new_upper_bound > min_value:
modified_hyperparam_search_space[param]["upper"] = new_upper_bound
else:
param_list.pop(0) # exhausted reduction of this parameter
else:
param_list.pop(0) # param not in hyperopt search space
if model_category == TEXT and row_count > AUTOML_LARGE_TEXT_DATASET:
if "checkpoints_per_epoch" not in config[TRAINER] and "steps_per_checkpoint" not in config[TRAINER]:
checkpoints_per_epoch = max(2, math.floor(row_count / AUTOML_MAX_ROWS_PER_CHECKPOINT))
config[TRAINER][
"checkpoints_per_epoch"
] = checkpoints_per_epoch # decrease latency to get model accuracy signal
if "evaluate_training_set" not in config[TRAINER]:
config[TRAINER]["evaluate_training_set"] = False # reduce overhead for increased evaluation frequency
if not fits_in_memory:
# Switch to smaller pre-trained model encoder for large datasets.
_update_text_encoder(config["input_features"], AUTOML_DEFAULT_TEXT_ENCODER, AUTOML_SMALLER_TEXT_ENCODER)
modified_config = copy.deepcopy(config)
modified_config[HYPEROPT]["parameters"] = modified_hyperparam_search_space
modified_config[HYPEROPT]["executor"]["num_samples"] = _update_num_samples(
modified_config[HYPEROPT]["executor"]["num_samples"], modified_hyperparam_search_space
)
return modified_config, fits_in_memory
================================================
FILE: ludwig/automl/automl.py
================================================
"""automl.py.
Driver script which:
(1) Builds a base config by performing type inference and populating config
w/default combiner parameters, training parameters, and hyperopt search space
(2) Tunes config based on resource constraints
(3) Runs hyperparameter optimization experiment
"""
import argparse
import copy
import logging
import os
import warnings
from typing import Any
import numpy as np
import pandas as pd
import yaml
from ludwig.api import LudwigModel
from ludwig.api_annotations import PublicAPI
from ludwig.automl.base_config import (
create_default_config,
DatasetInfo,
get_dataset_info,
get_features_config,
get_reference_configs,
)
from ludwig.backend import Backend, initialize_backend
from ludwig.constants import (
AUTO,
AUTOML_DEFAULT_IMAGE_ENCODER,
AUTOML_DEFAULT_TABULAR_MODEL,
AUTOML_DEFAULT_TEXT_ENCODER,
BINARY,
CATEGORY,
ENCODER,
HYPEROPT,
IMAGE,
INPUT_FEATURES,
NAME,
NUMBER,
OUTPUT_FEATURES,
TABULAR,
TEXT,
TRAINER,
TYPE,
)
from ludwig.contrib import add_contrib_callback_args
from ludwig.data.cache.types import CacheableDataset
from ludwig.datasets import load_dataset_uris
from ludwig.globals import LUDWIG_VERSION, MODEL_FILE_NAME
from ludwig.hyperopt.run import hyperopt
from ludwig.schema.model_config import ModelConfig
from ludwig.types import ModelConfigDict
from ludwig.utils.automl.ray_utils import _ray_init
from ludwig.utils.automl.utils import _add_transfer_config, get_model_type, set_output_feature_metric
from ludwig.utils.data_utils import load_dataset, use_credentials
from ludwig.utils.defaults import default_random_seed
from ludwig.utils.fs_utils import open_file
from ludwig.utils.heuristics import get_auto_learning_rate
from ludwig.utils.misc_utils import merge_dict
from ludwig.utils.print_utils import print_ludwig
try:
import dask.dataframe as dd
from ray.tune import ExperimentAnalysis
except ImportError as e:
raise RuntimeError("ray is not installed. In order to use auto_train please run pip install ludwig[ray]") from e
logger = logging.getLogger(__name__)
OUTPUT_DIR = "."
TABULAR_TYPES = {CATEGORY, NUMBER, BINARY}
class AutoTrainResults:
def __init__(self, experiment_analysis: ExperimentAnalysis, creds: dict[str, Any] = None):
self._experiment_analysis = experiment_analysis
self._creds = creds
@property
def experiment_analysis(self):
return self._experiment_analysis
@property
def best_trial_id(self) -> str:
return self._experiment_analysis.best_trial.trial_id
@property
def best_model(self) -> LudwigModel | None:
checkpoint = self._experiment_analysis.best_checkpoint
if checkpoint is None:
logger.warning("No best model found")
return None
# Use credentials context for remote checkpoints that may need custom auth
with use_credentials(self._creds):
with checkpoint.as_directory() as ckpt_path:
model_dir = os.path.join(ckpt_path, MODEL_FILE_NAME)
if not os.path.isdir(model_dir):
logger.warning(
f"Best checkpoint does not contain model files at {model_dir}. "
"The trial may not have completed a full training epoch."
)
return None
# Ray Tune checkpoints contain training_checkpoints/ (from
# mid-training saves) but not model_weights (only saved after
# training completes). Load from the training checkpoint.
return LudwigModel.load(model_dir, from_checkpoint=True)
@PublicAPI
def auto_train(
dataset: str | pd.DataFrame | dd.DataFrame,
target: str,
time_limit_s: int | float,
output_directory: str = OUTPUT_DIR,
tune_for_memory: bool = False,
user_config: dict = None,
random_seed: int = default_random_seed,
use_reference_config: bool = False,
**kwargs,
) -> AutoTrainResults:
"""Main auto train API that first builds configs for each model type (e.g. concat, tabnet, transformer). Then
selects model based on dataset attributes. And finally runs a hyperparameter optimization experiment.
All batch and learning rate tuning is done @ training time.
# Inputs
:param dataset: (str, pd.DataFrame, dd.DataFrame) data source to train over.
:param target: (str) name of target feature
:param time_limit_s: (int, float) total time allocated to auto_train. acts
as the stopping parameter
:param output_directory: (str) directory into which to write results, defaults to
current working directory.
:param tune_for_memory: (bool) refine hyperopt search space for available
host / GPU memory
:param user_config: (dict) override automatic selection of specified config items
:param random_seed: (int, default: `42`) a random seed that will be used anywhere
there is a call to a random number generator, including
hyperparameter search sampling, as well as data splitting,
parameter initialization and training set shuffling
:param use_reference_config: (bool) refine hyperopt search space by setting first
search point from reference model config, if any
:param kwargs: additional keyword args passed down to `ludwig.hyperopt.run.hyperopt`.
# Returns
:return: (AutoTrainResults) results containing hyperopt experiments and best model
"""
config = create_auto_config(
dataset,
target,
time_limit_s,
tune_for_memory,
user_config,
random_seed,
use_reference_config=use_reference_config,
)
return train_with_config(dataset, config, output_directory=output_directory, random_seed=random_seed, **kwargs)
@PublicAPI
def create_auto_config(
dataset: str | pd.DataFrame | dd.DataFrame | DatasetInfo,
target: str | list[str],
time_limit_s: int | float,
tune_for_memory: bool = False,
user_config: dict = None,
random_seed: int = default_random_seed,
imbalance_threshold: float = 0.9,
use_reference_config: bool = False,
backend: Backend | str = None,
) -> ModelConfigDict:
"""Returns an auto-generated Ludwig config with the intent of training the best model on given given dataset /
target in the given time limit.
# Inputs
:param dataset: (str, pd.DataFrame, dd.DataFrame, DatasetInfo) data source to train over.
:param target: (str, List[str]) name of target feature
:param time_limit_s: (int, float) total time allocated to auto_train. acts
as the stopping parameter
:param tune_for_memory: (bool) DEPRECATED refine hyperopt search space for available
host / GPU memory
:param user_config: (dict) override automatic selection of specified config items
:param random_seed: (int, default: `42`) a random seed that will be used anywhere
there is a call to a random number generator, including
hyperparameter search sampling, as well as data splitting,
parameter initialization and training set shuffling
:param imbalance_threshold: (float) maximum imbalance ratio (minority / majority) to perform stratified sampling
:param use_reference_config: (bool) refine hyperopt search space by setting first
search point from reference model config, if any
# Return
:return: (dict) selected model configuration
"""
backend = initialize_backend(backend)
if not isinstance(dataset, DatasetInfo):
# preload ludwig datasets
dataset, _, _, _ = load_dataset_uris(dataset, None, None, None, backend)
if isinstance(dataset, CacheableDataset):
dataset = dataset.unwrap()
dataset = load_dataset(dataset, df_lib=backend.df_engine.df_lib)
dataset_info = get_dataset_info(dataset) if not isinstance(dataset, DatasetInfo) else dataset
features_config = create_features_config(dataset_info, target)
return create_automl_config_for_features(
features_config,
dataset_info,
target,
time_limit_s=time_limit_s,
user_config=user_config,
random_seed=random_seed,
imbalance_threshold=imbalance_threshold,
use_reference_config=use_reference_config,
backend=backend,
)
@PublicAPI
def create_automl_config_for_features(
features_config: ModelConfigDict,
dataset_info: DatasetInfo,
target: str | list[str],
time_limit_s: int | float,
tune_for_memory: bool = False,
user_config: dict = None,
random_seed: int = default_random_seed,
imbalance_threshold: float = 0.9,
use_reference_config: bool = False,
backend: Backend | str = None,
) -> ModelConfigDict:
default_configs = create_default_config(
features_config, dataset_info, target, time_limit_s, random_seed, imbalance_threshold, backend
)
model_config, _, _ = _model_select(dataset_info, default_configs, user_config, use_reference_config)
if tune_for_memory:
warnings.warn("`tune_for_memory=True` is deprecated, `batch_size=auto` will be used instead")
return model_config
@PublicAPI
def create_features_config(
dataset_info: DatasetInfo,
target_name: str | list[str] = None,
) -> ModelConfigDict:
return get_features_config(dataset_info.fields, dataset_info.row_count, target_name)
@PublicAPI
def train_with_config(
dataset: str | pd.DataFrame | dd.DataFrame,
config: dict,
output_directory: str = OUTPUT_DIR,
random_seed: int = default_random_seed,
**kwargs,
) -> AutoTrainResults:
"""Performs hyperparameter optimization with respect to the given config and selects the best model.
# Inputs
:param dataset: (str) filepath to dataset.
:param config: (dict) optional Ludwig configuration to use for training, defaults
to `create_auto_config`.
:param output_directory: (str) directory into which to write results, defaults to
current working directory.
:param random_seed: (int, default: `42`) a random seed that will be used anywhere
there is a call to a random number generator, including
hyperparameter search sampling, as well as data splitting,
parameter initialization and training set shuffling
:param kwargs: additional keyword args passed down to `ludwig.hyperopt.run.hyperopt`.
# Returns
:return: (AutoTrainResults) results containing hyperopt experiments and best model
"""
_ray_init()
model_type = get_model_type(config)
hyperopt_results = _train(
config, dataset, output_directory=output_directory, model_name=model_type, random_seed=random_seed, **kwargs
)
# catch edge case where metric_score is nan
# TODO (ASN): Decide how we want to proceed if at least one trial has
# completed
for trial in hyperopt_results.ordered_trials:
if isinstance(trial.metric_score, str) or np.isnan(trial.metric_score):
warnings.warn(
"There was an error running the experiment. "
"A trial failed to start. "
"Consider increasing the time budget for experiment. "
)
# Extract credentials needed to pull artifacts, if provided
creds = None
backend: Backend = initialize_backend(kwargs.get("backend"))
if backend is not None:
creds = backend.storage.artifacts.credentials
experiment_analysis = hyperopt_results.experiment_analysis
return AutoTrainResults(experiment_analysis, creds)
def _model_select(
dataset_info: DatasetInfo,
default_configs,
user_config,
use_reference_config: bool,
):
"""Performs model selection based on dataset or user specified model.
Note: Current implementation returns tabnet by default for tabular datasets.
"""
fields = dataset_info.fields
base_config = copy.deepcopy(default_configs["base_config"])
model_category = None
input_features = default_configs["base_config"]["input_features"]
# tabular dataset heuristics
if len(fields) > 3 and all(f[TYPE] in TABULAR_TYPES for f in input_features):
model_category = TABULAR
base_config = merge_dict(base_config, default_configs["combiner"][AUTOML_DEFAULT_TABULAR_MODEL])
# override combiner heuristic if explicitly provided by user
if user_config is not None:
if "combiner" in user_config.keys():
model_type = user_config["combiner"]["type"]
base_config = merge_dict(base_config, default_configs["combiner"][model_type])
else:
# text heuristics
for i, input_feature in enumerate(input_features):
base_config_input_feature = base_config["input_features"][i]
# default text encoder is bert
if input_feature[TYPE] == TEXT:
model_category = TEXT
if ENCODER in input_feature:
base_config_input_feature[ENCODER][TYPE] = AUTOML_DEFAULT_TEXT_ENCODER
else:
base_config_input_feature[ENCODER] = {TYPE: AUTOML_DEFAULT_TEXT_ENCODER}
# TODO(shreya): Should this hyperopt config param be set here?
base_config[HYPEROPT]["executor"]["num_samples"] = 5 # set for small hyperparameter search space
base_config = merge_dict(base_config, default_configs[TEXT][AUTOML_DEFAULT_TEXT_ENCODER])
# TODO (ASN): add image heuristics
if input_feature[TYPE] == IMAGE:
model_category = IMAGE
if ENCODER in input_feature:
base_config_input_feature[ENCODER][TYPE] = AUTOML_DEFAULT_IMAGE_ENCODER
else:
base_config_input_feature[ENCODER] = {TYPE: AUTOML_DEFAULT_IMAGE_ENCODER}
# Merge combiner config
base_config = merge_dict(base_config, default_configs["combiner"]["concat"])
# Adjust learning rate based on other config settings
if base_config[TRAINER]["learning_rate"] == AUTO:
# Add a fake output feature to ensure we can load the ModelConfig, as we expect there to be at least
# one output feature in all cases
# TODO(travis): less hacky way to do this, we should probably allow ModelConfig to be created without output
# features
load_config = copy.deepcopy(base_config)
if not load_config.get(OUTPUT_FEATURES):
load_config[OUTPUT_FEATURES] = [{"name": "fake", "type": "binary"}]
base_config[TRAINER]["learning_rate"] = get_auto_learning_rate(ModelConfig.from_dict(load_config))
# override and constrain automl config based on user specified values
if user_config is not None:
base_config = merge_dict(base_config, user_config)
# remove all parameters from hyperparameter search that user has
# provided explicit values for
hyperopt_params = copy.deepcopy(base_config["hyperopt"]["parameters"])
for hyperopt_params in hyperopt_params.keys():
config_section, param = hyperopt_params.split(".")[0], hyperopt_params.split(".")[1]
if config_section in user_config.keys():
if param in user_config[config_section]:
del base_config["hyperopt"]["parameters"][hyperopt_params]
# if single output feature, set relevant metric and goal if not already set
base_config = set_output_feature_metric(base_config)
# add as initial trial in the automl search the hyperparameter settings from
# the best model for a similar dataset and matching model type, if any.
if use_reference_config:
ref_configs = get_reference_configs()
base_config = _add_transfer_config(base_config, ref_configs)
return base_config, model_category, dataset_info.row_count
def _train(
config: dict,
dataset: str | pd.DataFrame | dd.DataFrame,
output_directory: str,
model_name: str,
random_seed: int,
**kwargs,
):
hyperopt_results = hyperopt(
config,
dataset=dataset,
output_directory=output_directory,
model_name=model_name,
random_seed=random_seed,
skip_save_log=True, # avoid per-step log overhead by default
**kwargs,
)
return hyperopt_results
def init_config(
dataset: str,
target: str | list[str],
time_limit_s: int | float,
tune_for_memory: bool = False,
suggested: bool = False,
hyperopt: bool = False,
output: str = None,
random_seed: int = default_random_seed,
use_reference_config: bool = False,
**kwargs,
):
config = create_auto_config(
dataset=dataset,
target=target,
time_limit_s=time_limit_s,
random_seed=random_seed,
use_reference_config=use_reference_config,
tune_for_memory=tune_for_memory,
)
if HYPEROPT in config and not hyperopt:
del config[HYPEROPT]
if not suggested:
# Only use inputs and outputs
minimal_config = {
INPUT_FEATURES: [{"name": f[NAME], "type": f[TYPE]} for f in config[INPUT_FEATURES]],
OUTPUT_FEATURES: [{"name": f[NAME], "type": f[TYPE]} for f in config[OUTPUT_FEATURES]],
}
if hyperopt:
minimal_config[HYPEROPT] = config[HYPEROPT]
config = minimal_config
if output is None:
print(yaml.safe_dump(config, None, sort_keys=False))
else:
with open_file(output, "w") as f:
yaml.safe_dump(config, f, sort_keys=False)
def cli_init_config(sys_argv):
parser = argparse.ArgumentParser(
description="This script initializes a valid config from a dataset.",
prog="ludwig init_config",
usage="%(prog)s [options]",
)
parser.add_argument(
"-d",
"--dataset",
type=str,
help="input data file path",
)
parser.add_argument(
"-t",
"--target",
type=str,
help="target(s) to predict as output features of the model",
action="append",
required=False,
)
parser.add_argument(
"--time_limit_s",
type=int,
help="time limit to train the model in seconds when using hyperopt",
required=False,
)
parser.add_argument(
"--suggested",
type=bool,
help="use suggested config from automl, otherwise only use inferred types and return a minimal config",
default=False,
required=False,
)
parser.add_argument(
"--hyperopt",
type=bool,
help="include automl hyperopt config",
default=False,
required=False,
)
parser.add_argument(
"--random_seed",
type=int,
help="seed for random number generators used in hyperopt to improve repeatability",
required=False,
)
parser.add_argument(
"--use_reference_config",
type=bool,
help="refine hyperopt search space by setting first search point from stored reference model config",
default=False,
required=False,
)
parser.add_argument(
"-o",
"--output",
type=str,
help="output initialized YAML config path",
required=False,
)
add_contrib_callback_args(parser)
args = parser.parse_args(sys_argv)
args.callbacks = args.callbacks or []
for callback in args.callbacks:
callback.on_cmdline("init_config", *sys_argv)
print_ludwig("Init Config", LUDWIG_VERSION)
init_config(**vars(args))
================================================
FILE: ludwig/automl/base_config.py
================================================
"""Uses heuristics to build ludwig configuration file:
(1) infer types based on dataset
(2) populate with
- default combiner parameters,
- preprocessing parameters,
- combiner specific default training parameters,
- combiner specific hyperopt space
- feature parameters
(3) add machineresources
(base implementation -- # CPU, # GPU)
"""
import logging
import os
from dataclasses import dataclass
from typing import Any
import dask.dataframe as dd
import numpy as np
import pandas as pd
import yaml
from dataclasses_json import dataclass_json, LetterCase
from tqdm import tqdm
from ludwig.api_annotations import DeveloperAPI
from ludwig.backend import Backend
from ludwig.constants import (
COLUMN,
COMBINER,
ENCODER,
EXECUTOR,
HYPEROPT,
INPUT_FEATURES,
PREPROCESSING,
SCHEDULER,
SEARCH_ALG,
SPLIT,
TEXT,
TYPE,
)
from ludwig.types import ModelConfigDict
from ludwig.utils.automl.data_source import DataSource, wrap_data_source
from ludwig.utils.automl.field_info import FieldConfig, FieldInfo, FieldMetadata
from ludwig.utils.automl.type_inference import infer_type, should_exclude
from ludwig.utils.data_utils import load_yaml
from ludwig.utils.misc_utils import merge_dict
from ludwig.utils.system_utils import Resources
logger = logging.getLogger(__name__)
PATH_HERE = os.path.abspath(os.path.dirname(__file__))
CONFIG_DIR = os.path.join(PATH_HERE, "defaults")
BASE_AUTOML_CONFIG = os.path.join(CONFIG_DIR, "base_automl_config.yaml")
REFERENCE_CONFIGS = os.path.join(CONFIG_DIR, "reference_configs.yaml")
combiner_defaults = {
"concat": os.path.join(CONFIG_DIR, "combiner/concat_config.yaml"),
"tabnet": os.path.join(CONFIG_DIR, "combiner/tabnet_config.yaml"),
"transformer": os.path.join(CONFIG_DIR, "combiner/transformer_config.yaml"),
}
encoder_defaults = {"text": {"bert": os.path.join(CONFIG_DIR, "text/bert_config.yaml")}}
# Cap for number of distinct values to return.
MAX_DISTINCT_VALUES_TO_RETURN = 10
@DeveloperAPI
@dataclass_json(letter_case=LetterCase.CAMEL)
@dataclass
class DatasetInfo:
fields: list[FieldInfo]
row_count: int
size_bytes: int = -1
def allocate_experiment_resources(resources: Resources) -> dict:
"""Allocates ray trial resources based on available resources.
# Inputs :param resources (dict) specifies all available GPUs, CPUs and associated metadata of the machines
(i.e. memory)
# Return
:return: (dict) gpu and cpu resources per trial
"""
# TODO (ASN):
# (1) expand logic to support multiple GPUs per trial (multi-gpu training)
# (2) add support for kubernetes namespace (if applicable)
# (3) add support for smarter allocation based on size of GPU memory
experiment_resources = {"cpu_resources_per_trial": 1}
gpu_count, cpu_count = resources.gpus, resources.cpus
if gpu_count > 0:
experiment_resources.update({"gpu_resources_per_trial": 1})
if cpu_count > 1:
cpus_per_trial = max(int(cpu_count / gpu_count), 1)
experiment_resources["cpu_resources_per_trial"] = cpus_per_trial
return experiment_resources
def get_resource_aware_hyperopt_config(
experiment_resources: dict[str, Any], time_limit_s: int | float, random_seed: int
) -> dict[str, Any]:
"""Returns a Ludwig config with the hyperopt section populated with appropriate parameters.
Hyperopt parameters are intended to be appropriate for the given resources and time limit.
"""
executor = experiment_resources
executor.update({"time_budget_s": time_limit_s})
if time_limit_s is not None:
executor.update({SCHEDULER: {"max_t": time_limit_s}})
return {
HYPEROPT: {
SEARCH_ALG: {"random_state_seed": random_seed},
EXECUTOR: executor,
},
}
def _get_stratify_split_config(field_meta: FieldMetadata) -> dict:
return {
PREPROCESSING: {
SPLIT: {
TYPE: "stratify",
COLUMN: field_meta.name,
}
}
}
def get_default_automl_hyperopt() -> dict[str, Any]:
"""Returns general, default settings for hyperopt.
For example:
- We set a random_state_seed for sample sequence repeatability
- We use an increased reduction_factor to get more pruning/exploration.
TODO: If settings seem reasonable, consider building this into the hyperopt schema, directly.
"""
return yaml.safe_load("""
search_alg:
type: variant_generator
executor:
type: ray
num_samples: 10
time_budget_s: 3600
scheduler:
type: async_hyperband
time_attr: time_total_s
max_t: 3600
grace_period: 72
reduction_factor: 5
""")
def create_default_config(
features_config: ModelConfigDict,
dataset_info: DatasetInfo,
target_name: str | list[str],
time_limit_s: int | float,
random_seed: int,
imbalance_threshold: float = 0.9,
backend: Backend = None,
) -> dict:
"""Returns auto_train configs for three available combiner models. Coordinates the following tasks:
- extracts fields and generates list of FieldInfo objects
- gets field metadata (i.e avg. words, total non-null entries)
- builds input_features and output_features section of config
- for imbalanced datasets, a preprocessing section is added to perform stratified sampling if the imbalance ratio
is smaller than imbalance_threshold
- for each combiner, adds default training, hyperopt
- infers resource constraints and adds gpu and cpu resource allocation per
trial
# Inputs
:param dataset_info: (str) filepath Dataset Info object.
:param target_name: (str, List[str]) name of target feature
:param time_limit_s: (int, float) total time allocated to auto_train. acts
as the stopping parameter
:param random_seed: (int, default: `42`) a random seed that will be used anywhere
there is a call to a random number generator, including
hyperparameter search sampling, as well as data splitting,
parameter initialization and training set shuffling
:param imbalance_threshold: (float) maximum imbalance ratio (minority / majority) to perform stratified sampling
:param backend: (Backend) backend to use for training.
# Return
:return: (dict) dictionaries contain auto train config files for all available
combiner types
"""
base_automl_config = load_yaml(BASE_AUTOML_CONFIG)
base_automl_config.update(features_config)
targets = convert_targets(target_name)
features_metadata = get_field_metadata(dataset_info.fields, dataset_info.row_count, targets)
# Handle expensive features for CPU
resources = backend.get_available_resources()
for ifeature in base_automl_config[INPUT_FEATURES]:
if resources.gpus == 0:
if ifeature[TYPE] == TEXT:
# When no GPUs are available, default to the embed encoder, which is fast enough for CPU
ifeature[ENCODER] = {"type": "embed"}
# create set of all feature types appearing in the dataset
feature_types = [[feat[TYPE] for feat in features] for features in features_config.values()]
feature_types = set(sum(feature_types, []))
model_configs = {}
# update hyperopt config
experiment_resources = allocate_experiment_resources(resources)
base_automl_config = merge_dict(
base_automl_config, get_resource_aware_hyperopt_config(experiment_resources, time_limit_s, random_seed)
)
# add preprocessing section if single output feature is imbalanced
outputs_metadata = [f for f in features_metadata if f.mode == "output"]
if len(outputs_metadata) == 1:
of_meta = outputs_metadata[0]
is_categorical = of_meta.config.type in ["category", "binary"]
is_imbalanced = of_meta.imbalance_ratio < imbalance_threshold
if is_categorical and is_imbalanced:
base_automl_config.update(_get_stratify_split_config(of_meta))
model_configs["base_config"] = base_automl_config
# read in all encoder configs
for feat_type, default_configs in encoder_defaults.items():
if feat_type in feature_types:
if feat_type not in model_configs.keys():
model_configs[feat_type] = {}
for encoder_name, encoder_config_path in default_configs.items():
model_configs[feat_type][encoder_name] = load_yaml(encoder_config_path)
# read in all combiner configs
model_configs[COMBINER] = {}
for combiner_type, default_config in combiner_defaults.items():
combiner_config = load_yaml(default_config)
model_configs[COMBINER][combiner_type] = combiner_config
return model_configs
# Read in the score and configuration of a reference model trained by Ludwig for each dataset in a list.
def get_reference_configs() -> dict:
reference_configs = load_yaml(REFERENCE_CONFIGS)
return reference_configs
def get_dataset_info(df: pd.DataFrame | dd.DataFrame) -> DatasetInfo:
"""Constructs FieldInfo objects for each feature in dataset. These objects are used for downstream type
inference.
# Inputs
:param df: (Union[pd.DataFrame, dd.DataFrame]) Pandas or Dask dataframe. # Return
:return: (DatasetInfo) Structure containing list of FieldInfo objects.
"""
source = wrap_data_source(df)
return get_dataset_info_from_source(source)
def is_field_boolean(source: DataSource, field: str) -> bool:
"""Returns a boolean indicating whether the object field should have a bool dtype.
Columns with object dtype that have 3 distinct values of which one is Nan/None is a bool type column.
"""
unique_values = source.df[field].unique()
if len(unique_values) <= 3:
for entry in unique_values:
try:
if np.isnan(entry):
continue
except TypeError:
# For some field types such as object arrays, np.isnan throws a TypeError
# In this case, do nothing and proceed to checking if the entry is a bool object
pass
if isinstance(entry, bool):
continue
return False
return True
return False
@DeveloperAPI
def get_dataset_info_from_source(source: DataSource) -> DatasetInfo:
"""Constructs FieldInfo objects for each feature in dataset. These objects are used for downstream type
inference.
# Inputs
:param source: (DataSource) A wrapper around a data source, which may represent a pandas or Dask dataframe. # Return
:return: (DatasetInfo) Structure containing list of FieldInfo objects.
"""
row_count = len(source)
fields = []
for field in tqdm(source.columns, desc="Analyzing fields", total=len(source.columns)):
logger.info(f"Analyzing field: {field}")
dtype = source.get_dtype(field)
num_distinct_values, distinct_values, distinct_values_balance = source.get_distinct_values(
field, MAX_DISTINCT_VALUES_TO_RETURN
)
nonnull_values = source.get_nonnull_values(field)
image_values = source.get_image_values(field)
audio_values = source.get_audio_values(field)
if dtype == "object":
# Check if it is a nullboolean field. We do this since if you read a csv with
# pandas that has a column of booleans and some missing values, the column is
# interpreted as object dtype instead of bool
if is_field_boolean(source, field):
dtype = "bool"
avg_words = None
if source.is_string_type(dtype):
try:
avg_words = source.get_avg_num_tokens(field)
except AttributeError:
# Series is not actually a string type despite being an object, e.g., Decimal, Datetime, etc.
avg_words = None
fields.append(
FieldInfo(
name=field,
dtype=dtype,
distinct_values=distinct_values,
num_distinct_values=num_distinct_values,
distinct_values_balance=distinct_values_balance,
nonnull_values=nonnull_values,
image_values=image_values,
audio_values=audio_values,
avg_words=avg_words,
)
)
return DatasetInfo(fields=fields, row_count=row_count, size_bytes=source.size_bytes())
def get_features_config(
fields: list[FieldInfo],
row_count: int,
target_name: str | list[str] = None,
) -> dict:
"""Constructs FieldInfo objects for each feature in dataset. These objects are used for downstream type
inference.
# Inputs
:param fields: (List[FieldInfo]) FieldInfo objects for all fields in dataset
:param row_count: (int) total number of entries in original dataset :param target_name (str, List[str]) name of
target feature # Return
:return: (dict) section of auto_train config for input_features and output_features
"""
targets = convert_targets(target_name)
metadata = get_field_metadata(fields, row_count, targets)
return get_config_from_metadata(metadata, targets)
def convert_targets(target_name: str | list[str] = None) -> set[str]:
targets = target_name
if isinstance(targets, str):
targets = [targets]
if targets is None:
targets = []
return set(targets)
def get_config_from_metadata(metadata: list[FieldMetadata], targets: set[str] = None) -> dict:
"""Builds input/output feature sections of auto-train config using field metadata.
# Inputs
:param metadata: (List[FieldMetadata]) field descriptions :param targets (Set[str]) names of target features #
Return
:return: (dict) section of auto_train config for input_features and output_features
"""
config = {
"input_features": [],
"output_features": [],
}
for field_meta in metadata:
if field_meta.name in targets:
config["output_features"].append(field_meta.config.to_dict())
elif not field_meta.excluded and field_meta.mode == "input":
config["input_features"].append(field_meta.config.to_dict())
return config
@DeveloperAPI
def get_field_metadata(fields: list[FieldInfo], row_count: int, targets: set[str] = None) -> list[FieldMetadata]:
"""Computes metadata for each field in dataset.
# Inputs
:param fields: (List[FieldInfo]) FieldInfo objects for all fields in dataset
:param row_count: (int) total number of entries in original dataset :param targets (Set[str]) names of target
features # Return
:return: (List[FieldMetadata]) list of objects containing metadata for each field
"""
metadata = []
column_count = len(fields)
for idx, field in enumerate(fields):
missing_value_percent = 1 - float(field.nonnull_values) / row_count
dtype = infer_type(field, missing_value_percent, row_count)
metadata.append(
FieldMetadata(
name=field.name,
config=FieldConfig(
name=field.name,
column=field.name,
type=dtype,
),
excluded=should_exclude(idx, field, dtype, column_count, row_count, targets),
mode=infer_mode(field, targets),
missing_values=missing_value_percent,
imbalance_ratio=field.distinct_values_balance,
)
)
return metadata
def infer_mode(field: FieldInfo, targets: set[str] = None) -> str:
if field.name in targets:
return "output"
if field.name.lower() == "split":
return "split"
return "input"
================================================
FILE: ludwig/automl/defaults/base_automl_config.yaml
================================================
trainer:
batch_size: auto #256
learning_rate: auto #.001
# validation_metric: accuracy
hyperopt:
search_alg:
# Gives results like default + supports random_state_seed for sample sequence repeatability
type: variant_generator
executor:
type: ray
num_samples: 10
time_budget_s: 7200
scheduler:
type: async_hyperband
time_attr: time_total_s
max_t: 7200
grace_period: 72
# Increased over default to get more pruning/exploration
reduction_factor: 5
================================================
FILE: ludwig/automl/defaults/combiner/concat_config.yaml
================================================
combiner:
type: concat
hyperopt:
# goal: maximize
parameters:
combiner.num_fc_layers:
space: randint
lower: 1
upper: 4
combiner.output_size:
space: choice
categories: [128, 256]
combiner.dropout:
space: uniform
lower: 0.0
upper: 0.1
# This needs to be loguniform due to invalid schemas created by merging with a choice parameter space. See the
# comment in ludwig/automl/defaults/text/bert_config.yaml for more information.
trainer.learning_rate:
space: loguniform
lower: 0.00002
upper: 0.001
trainer.batch_size:
space: choice
categories: [64, 128, 256, 512, 1024]
================================================
FILE: ludwig/automl/defaults/combiner/tabnet_config.yaml
================================================
combiner:
type: tabnet
trainer:
batch_size: auto
learning_rate_scaling: sqrt
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.8
optimizer:
type: adam
hyperopt:
parameters:
trainer.learning_rate:
space: loguniform
lower: 0.00002
upper: 0.001
trainer.learning_rate_scheduler.decay_rate:
space: choice
categories: [0.8, 0.9, 0.95]
trainer.learning_rate_scheduler.decay_steps:
space: choice
categories: [500, 2000, 8000, 10000, 20000]
combiner.size:
space: choice
categories: [8, 16, 24, 32, 64]
combiner.output_size:
space: choice
categories: [8, 16, 24, 32, 64, 128]
combiner.num_steps:
space: choice
categories: [3, 4, 5, 6, 7, 8, 9, 10]
combiner.relaxation_factor:
space: choice
categories: [1.0, 1.2, 1.5, 2.0]
combiner.sparsity:
space: choice
categories: [0.0, 0.000001, 0.0001, 0.001, 0.01, 0.1]
combiner.bn_virtual_bs:
space: choice
categories: [256, 512, 1024, 2048, 4096]
combiner.bn_momentum:
space: choice
categories: [0.4, 0.3, 0.2, 0.1, 0.05, 0.02]
================================================
FILE: ludwig/automl/defaults/combiner/transformer_config.yaml
================================================
combiner:
type: transformer
trainer:
batch_size: auto #256
learning_rate: auto #0.0001
# validation_metric: accuracy
hyperopt:
# goal: maximize
parameters:
trainer.learning_rate:
space: loguniform
lower: 0.00002
upper: 0.001
trainer.batch_size:
space: choice
categories: [64, 128, 256]
combiner.num_heads:
space: choice
categories: [4]
combiner.dropout:
space: uniform
lower: 0.1
upper: 0.3
combiner.num_layers:
space: randint
lower: 3
upper: 4
combiner.num_fc_layers:
space: choice
categories: [1, 2]
combiner.fc_dropout:
space: uniform
lower: 0.1
upper: 0.5
================================================
FILE: ludwig/automl/defaults/reference_configs.yaml
================================================
# Record the score and configuration of a reference model trained by Ludwig for specified datasets.
# This information is useful for Ludwig AutoML hyperparameter transfer learning or for manual experimentation.
datasets:
- name: adult_census_income
goal: maximize
metric: accuracy
validation_metric_score: 0.8682432174682617
training_rows: 29305
test_rows: 16281
validation_rows: 3256
config:
output_features:
- name: income
type: category
input_features:
- name: age
type: number
- name: workclass
type: category
- name: fnlwgt
type: number
- name: education
type: category
- name: education-num
type: number
- name: marital-status
type: category
- name: occupation
type: category
- name: relationship
type: category
- name: race
type: category
- name: sex
type: category
- name: capital-gain
type: number
- name: capital-loss
type: number
- name: hours-per-week
type: number
- name: native-country
type: category
combiner:
type: tabnet
size: 8 # N_a
output_size: 128 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.4 # m_B
num_steps: 3 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 4096 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 500
decay_rate: 0.95
validation_metric: accuracy
- name: allstate_claims_severity
goal: minimize
metric: root_mean_squared_error
validation_metric_score: 1915.5531005859375
training_rows: 131726
test_rows: 37750
validation_rows: 18842
config:
output_features:
- name: loss
type: number
input_features:
- column: cat1
name: cat1
type: category
- column: cat2
name: cat2
type: category
- column: cat3
name: cat3
type: category
- column: cat4
name: cat4
type: category
- column: cat5
name: cat5
type: category
- column: cat6
name: cat6
type: category
- column: cat7
name: cat7
type: category
- column: cat8
name: cat8
type: category
- column: cat9
name: cat9
type: category
- column: cat10
name: cat10
type: category
- column: cat11
name: cat11
type: category
- column: cat12
name: cat12
type: category
- column: cat13
name: cat13
type: category
- column: cat14
name: cat14
type: category
- column: cat15
name: cat15
type: category
- column: cat16
name: cat16
type: category
- column: cat17
name: cat17
type: category
- column: cat18
name: cat18
type: category
- column: cat19
name: cat19
type: category
- column: cat20
name: cat20
type: category
- column: cat21
name: cat21
type: category
- column: cat22
name: cat22
type: category
- column: cat23
name: cat23
type: category
- column: cat24
name: cat24
type: category
- column: cat25
name: cat25
type: category
- column: cat26
name: cat26
type: category
- column: cat27
name: cat27
type: category
- column: cat28
name: cat28
type: category
- column: cat29
name: cat29
type: category
- column: cat30
name: cat30
type: category
- column: cat31
name: cat31
type: category
- column: cat32
name: cat32
type: category
- column: cat33
name: cat33
type: category
- column: cat34
name: cat34
type: category
- column: cat35
name: cat35
type: category
- column: cat36
name: cat36
type: category
- column: cat37
name: cat37
type: category
- column: cat38
name: cat38
type: category
- column: cat39
name: cat39
type: category
- column: cat40
name: cat40
type: category
- column: cat41
name: cat41
type: category
- column: cat42
name: cat42
type: category
- column: cat43
name: cat43
type: category
- column: cat44
name: cat44
type: category
- column: cat45
name: cat45
type: category
- column: cat46
name: cat46
type: category
- column: cat47
name: cat47
type: category
- column: cat48
name: cat48
type: category
- column: cat49
name: cat49
type: category
- column: cat50
name: cat50
type: category
- column: cat51
name: cat51
type: category
- column: cat52
name: cat52
type: category
- column: cat53
name: cat53
type: category
- column: cat54
name: cat54
type: category
- column: cat55
name: cat55
type: category
- column: cat56
name: cat56
type: category
- column: cat57
name: cat57
type: category
- column: cat58
name: cat58
type: category
- column: cat59
name: cat59
type: category
- column: cat60
name: cat60
type: category
- column: cat61
name: cat61
type: category
- column: cat62
name: cat62
type: category
- column: cat63
name: cat63
type: category
- column: cat64
name: cat64
type: category
- column: cat65
name: cat65
type: category
- column: cat66
name: cat66
type: category
- column: cat67
name: cat67
type: category
- column: cat68
name: cat68
type: category
- column: cat69
name: cat69
type: category
- column: cat70
name: cat70
type: category
- column: cat71
name: cat71
type: category
- column: cat72
name: cat72
type: category
- column: cat73
name: cat73
type: category
- column: cat74
name: cat74
type: category
- column: cat75
name: cat75
type: category
- column: cat76
name: cat76
type: category
- column: cat77
name: cat77
type: category
- column: cat78
name: cat78
type: category
- column: cat79
name: cat79
type: category
- column: cat80
name: cat80
type: category
- column: cat81
name: cat81
type: category
- column: cat82
name: cat82
type: category
- column: cat83
name: cat83
type: category
- column: cat84
name: cat84
type: category
- column: cat85
name: cat85
type: category
- column: cat86
name: cat86
type: category
- column: cat87
name: cat87
type: category
- column: cat88
name: cat88
type: category
- column: cat89
name: cat89
type: category
- column: cat90
name: cat90
type: category
- column: cat91
name: cat91
type: category
- column: cat92
name: cat92
type: category
- column: cat93
name: cat93
type: category
- column: cat94
name: cat94
type: category
- column: cat95
name: cat95
type: category
- column: cat96
name: cat96
type: category
- column: cat97
name: cat97
type: category
- column: cat98
name: cat98
type: category
- column: cat99
name: cat99
type: category
- column: cat100
name: cat100
type: category
- column: cat101
name: cat101
type: category
- column: cat102
name: cat102
type: category
- column: cat103
name: cat103
type: category
- column: cat104
name: cat104
type: category
- column: cat105
name: cat105
type: category
- column: cat106
name: cat106
type: category
- column: cat107
name: cat107
type: category
- column: cat108
name: cat108
type: category
- column: cat109
name: cat109
type: category
- column: cat110
name: cat110
type: category
- column: cat111
name: cat111
type: category
- column: cat112
name: cat112
type: category
- column: cat113
name: cat113
type: category
- column: cat114
name: cat114
type: category
- column: cat115
name: cat115
type: category
- column: cat116
name: cat116
type: category
- column: cont1
name: cont1
type: number
- column: cont2
name: cont2
type: number
- column: cont3
name: cont3
type: number
- column: cont4
name: cont4
type: number
- column: cont5
name: cont5
type: number
- column: cont6
name: cont6
type: number
- column: cont7
name: cont7
type: number
- column: cont8
name: cont8
type: number
- column: cont9
name: cont9
type: number
- column: cont10
name: cont10
type: number
- column: cont11
name: cont11
type: number
- column: cont12
name: cont12
type: number
- column: cont13
name: cont13
type: number
- column: cont14
name: cont14
type: number
combiner:
type: tabnet
size: 128 # N_a
output_size: 8 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.02 # m_B
num_steps: 10 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 4096 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 10000
decay_rate: 0.9
validation_metric: root_mean_squared_error
- name: bnp_claims_management
goal: maximize
metric: accuracy
validation_metric_score: 0.7761691808700562
training_rows: 80101
test_rows: 22823
validation_rows: 11397
config:
output_features:
- name: target
type: binary
input_features:
- name: v1
type: number
- name: v2
type: number
- name: v3
type: category
- name: v4
type: number
- name: v5
type: number
- name: v6
type: number
- name: v7
type: number
- name: v8
type: number
- name: v9
type: number
- name: v10
type: number
- name: v11
type: number
- name: v12
type: number
- name: v13
type: number
- name: v14
type: number
- name: v15
type: number
- name: v16
type: number
- name: v17
type: number
- name: v18
type: number
- name: v19
type: number
- name: v20
type: number
- name: v21
type: number
- name: v22
type: category
- name: v23
type: number
- name: v24
type: category
- name: v25
type: number
- name: v26
type: number
- name: v27
type: number
- name: v28
type: number
- name: v29
type: number
- name: v30
type: category
- name: v31
type: category
- name: v32
type: number
- name: v33
type: number
- name: v34
type: number
- name: v35
type: number
- name: v36
type: number
- name: v37
type: number
- name: v38
type: number
- name: v39
type: number
- name: v40
type: number
- name: v41
type: number
- name: v42
type: number
- name: v43
type: number
- name: v44
type: number
- name: v45
type: number
- name: v46
type: number
- name: v47
type: category
- name: v48
type: number
- name: v49
type: number
- name: v50
type: number
- name: v51
type: number
- name: v52
type: category
- name: v53
type: number
- name: v54
type: number
- name: v55
type: number
- name: v56
type: category
- name: v57
type: number
- name: v58
type: number
- name: v59
type: number
- name: v60
type: number
- name: v61
type: number
- name: v62
type: category
- name: v63
type: number
- name: v64
type: number
- name: v65
type: number
- name: v66
type: category
- name: v67
type: number
- name: v68
type: number
- name: v69
type: number
- name: v70
type: number
- name: v71
type: category
- name: v72
type: category
- name: v73
type: number
- name: v74
type: category
- name: v75
type: category
- name: v76
type: number
- name: v77
type: number
- name: v78
type: number
- name: v79
type: category
- name: v80
type: number
- name: v81
type: number
- name: v82
type: number
- name: v83
type: number
- name: v84
type: number
- name: v85
type: number
- name: v86
type: number
- name: v87
type: number
- name: v88
type: number
- name: v89
type: number
- name: v90
type: number
- name: v91
type: category
- name: v92
type: number
- name: v93
type: number
- name: v94
type: number
- name: v95
type: number
- name: v96
type: number
- name: v97
type: number
- name: v98
type: number
- name: v99
type: number
- name: v100
type: number
- name: v101
type: number
- name: v102
type: number
- name: v103
type: number
- name: v104
type: number
- name: v105
type: number
- name: v106
type: number
- name: v107
type: category
- name: v108
type: number
- name: v109
type: number
- name: v110
type: category
- name: v111
type: number
- name: v112
type: category
- name: v113
type: category
- name: v114
type: number
- name: v115
type: number
- name: v116
type: number
- name: v117
type: number
- name: v118
type: number
- name: v119
type: number
- name: v120
type: number
- name: v121
type: number
- name: v122
type: number
- name: v123
type: number
- name: v124
type: number
- name: v125
type: category
- name: v126
type: number
- name: v127
type: number
- name: v128
type: number
- name: v129
type: number
- name: v130
type: number
- name: v131
type: number
combiner:
type: tabnet
size: 32 # N_a
output_size: 8 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.02 # m_B
num_steps: 3 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 256 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 2000
decay_rate: 0.4
validation_metric: accuracy
- name: ieee_fraud
goal: maximize
metric: accuracy
validation_metric_score: 0.9836957454681396
training_rows: 413498
test_rows: 118039
validation_rows: 59003
config:
output_features:
- name: isFraud
type: binary
input_features:
- name: TransactionDT
type: number
- name: TransactionAmt
type: number
- name: ProductCD
type: category
- name: card1
type: number
- name: card2
type: number
- name: card3
type: number
- name: card4
type: category
- name: card5
type: number
- name: card6
type: category
- name: addr1
type: number
- name: addr2
type: number
- name: dist1
type: number
- name: dist2
type: number
- name: P_emaildomain
type: category
- name: R_emaildomain
type: category
- name: C1
type: number
- name: C2
type: number
- name: C3
type: number
- name: C4
type: number
- name: C5
type: number
- name: C6
type: number
- name: C7
type: number
- name: C8
type: number
- name: C9
type: number
- name: C10
type: number
- name: C11
type: number
- name: C12
type: number
- name: C13
type: number
- name: C14
type: number
- name: D1
type: number
- name: D2
type: number
- name: D3
type: number
- name: D4
type: number
- name: D5
type: number
- name: D6
type: number
- name: D7
type: number
- name: D8
type: number
- name: D9
type: number
- name: D10
type: number
- name: D11
type: number
- name: D12
type: number
- name: D13
type: number
- name: D14
type: number
- name: D15
type: number
- name: M1
type: category
- name: M2
type: category
- name: M3
type: category
- name: M4
type: category
- name: M5
type: category
- name: M6
type: category
- name: M7
type: category
- name: M8
type: category
- name: M9
type: category
- name: V1
type: number
- name: V2
type: number
- name: V3
type: number
- name: V4
type: number
- name: V5
type: number
- name: V6
type: number
- name: V7
type: number
- name: V8
type: number
- name: V9
type: number
- name: V10
type: number
- name: V11
type: number
- name: V12
type: number
- name: V13
type: number
- name: V14
type: number
- name: V15
type: number
- name: V16
type: number
- name: V17
type: number
- name: V18
type: number
- name: V19
type: number
- name: V20
type: number
- name: V21
type: number
- name: V22
type: number
- name: V23
type: number
- name: V24
type: number
- name: V25
type: number
- name: V26
type: number
- name: V27
type: number
- name: V28
type: number
- name: V29
type: number
- name: V30
type: number
- name: V31
type: number
- name: V32
type: number
- name: V33
type: number
- name: V34
type: number
- name: V35
type: number
- name: V36
type: number
- name: V37
type: number
- name: V38
type: number
- name: V39
type: number
- name: V40
type: number
- name: V41
type: number
- name: V42
type: number
- name: V43
type: number
- name: V44
type: number
- name: V45
type: number
- name: V46
type: number
- name: V47
type: number
- name: V48
type: number
- name: V49
type: number
- name: V50
type: number
- name: V51
type: number
- name: V52
type: number
- name: V53
type: number
- name: V54
type: number
- name: V55
type: number
- name: V56
type: number
- name: V57
type: number
- name: V58
type: number
- name: V59
type: number
- name: V60
type: number
- name: V61
type: number
- name: V62
type: number
- name: V63
type: number
- name: V64
type: number
- name: V65
type: number
- name: V66
type: number
- name: V67
type: number
- name: V68
type: number
- name: V69
type: number
- name: V70
type: number
- name: V71
type: number
- name: V72
type: number
- name: V73
type: number
- name: V74
type: number
- name: V75
type: number
- name: V76
type: number
- name: V77
type: number
- name: V78
type: number
- name: V79
type: number
- name: V80
type: number
- name: V81
type: number
- name: V82
type: number
- name: V83
type: number
- name: V84
type: number
- name: V85
type: number
- name: V86
type: number
- name: V87
type: number
- name: V88
type: number
- name: V89
type: number
- name: V90
type: number
- name: V91
type: number
- name: V92
type: number
- name: V93
type: number
- name: V94
type: number
- name: V95
type: number
- name: V96
type: number
- name: V97
type: number
- name: V98
type: number
- name: V99
type: number
- name: V100
type: number
- name: V101
type: number
- name: V102
type: number
- name: V103
type: number
- name: V104
type: number
- name: V105
type: number
- name: V106
type: number
- name: V107
type: number
- name: V108
type: number
- name: V109
type: number
- name: V110
type: number
- name: V111
type: number
- name: V112
type: number
- name: V113
type: number
- name: V114
type: number
- name: V115
type: number
- name: V116
type: number
- name: V117
type: number
- name: V118
type: number
- name: V119
type: number
- name: V120
type: number
- name: V121
type: number
- name: V122
type: number
- name: V123
type: number
- name: V124
type: number
- name: V125
type: number
- name: V126
type: number
- name: V127
type: number
- name: V128
type: number
- name: V129
type: number
- name: V130
type: number
- name: V131
type: number
- name: V132
type: number
- name: V133
type: number
- name: V134
type: number
- name: V135
type: number
- name: V136
type: number
- name: V137
type: number
- name: V138
type: number
- name: V139
type: number
- name: V140
type: number
- name: V141
type: number
- name: V142
type: number
- name: V143
type: number
- name: V144
type: number
- name: V145
type: number
- name: V146
type: number
- name: V147
type: number
- name: V148
type: number
- name: V149
type: number
- name: V150
type: number
- name: V151
type: number
- name: V152
type: number
- name: V153
type: number
- name: V154
type: number
- name: V155
type: number
- name: V156
type: number
- name: V157
type: number
- name: V158
type: number
- name: V159
type: number
- name: V160
type: number
- name: V161
type: number
- name: V162
type: number
- name: V163
type: number
- name: V164
type: number
- name: V165
type: number
- name: V166
type: number
- name: V167
type: number
- name: V168
type: number
- name: V169
type: number
- name: V170
type: number
- name: V171
type: number
- name: V172
type: number
- name: V173
type: number
- name: V174
type: number
- name: V175
type: number
- name: V176
type: number
- name: V177
type: number
- name: V178
type: number
- name: V179
type: number
- name: V180
type: number
- name: V181
type: number
- name: V182
type: number
- name: V183
type: number
- name: V184
type: number
- name: V185
type: number
- name: V186
type: number
- name: V187
type: number
- name: V188
type: number
- name: V189
type: number
- name: V190
type: number
- name: V191
type: number
- name: V192
type: number
- name: V193
type: number
- name: V194
type: number
- name: V195
type: number
- name: V196
type: number
- name: V197
type: number
- name: V198
type: number
- name: V199
type: number
- name: V200
type: number
- name: V201
type: number
- name: V202
type: number
- name: V203
type: number
- name: V204
type: number
- name: V205
type: number
- name: V206
type: number
- name: V207
type: number
- name: V208
type: number
- name: V209
type: number
- name: V210
type: number
- name: V211
type: number
- name: V212
type: number
- name: V213
type: number
- name: V214
type: number
- name: V215
type: number
- name: V216
type: number
- name: V217
type: number
- name: V218
type: number
- name: V219
type: number
- name: V220
type: number
- name: V221
type: number
- name: V222
type: number
- name: V223
type: number
- name: V224
type: number
- name: V225
type: number
- name: V226
type: number
- name: V227
type: number
- name: V228
type: number
- name: V229
type: number
- name: V230
type: number
- name: V231
type: number
- name: V232
type: number
- name: V233
type: number
- name: V234
type: number
- name: V235
type: number
- name: V236
type: number
- name: V237
type: number
- name: V238
type: number
- name: V239
type: number
- name: V240
type: number
- name: V241
type: number
- name: V242
type: number
- name: V243
type: number
- name: V244
type: number
- name: V245
type: number
- name: V246
type: number
- name: V247
type: number
- name: V248
type: number
- name: V249
type: number
- name: V250
type: number
- name: V251
type: number
- name: V252
type: number
- name: V253
type: number
- name: V254
type: number
- name: V255
type: number
- name: V256
type: number
- name: V257
type: number
- name: V258
type: number
- name: V259
type: number
- name: V260
type: number
- name: V261
type: number
- name: V262
type: number
- name: V263
type: number
- name: V264
type: number
- name: V265
type: number
- name: V266
type: number
- name: V267
type: number
- name: V268
type: number
- name: V269
type: number
- name: V270
type: number
- name: V271
type: number
- name: V272
type: number
- name: V273
type: number
- name: V274
type: number
- name: V275
type: number
- name: V276
type: number
- name: V277
type: number
- name: V278
type: number
- name: V279
type: number
- name: V280
type: number
- name: V281
type: number
- name: V282
type: number
- name: V283
type: number
- name: V284
type: number
- name: V285
type: number
- name: V286
type: number
- name: V287
type: number
- name: V288
type: number
- name: V289
type: number
- name: V290
type: number
- name: V291
type: number
- name: V292
type: number
- name: V293
type: number
- name: V294
type: number
- name: V295
type: number
- name: V296
type: number
- name: V297
type: number
- name: V298
type: number
- name: V299
type: number
- name: V300
type: number
- name: V301
type: number
- name: V302
type: number
- name: V303
type: number
- name: V304
type: number
- name: V305
type: number
- name: V306
type: number
- name: V307
type: number
- name: V308
type: number
- name: V309
type: number
- name: V310
type: number
- name: V311
type: number
- name: V312
type: number
- name: V313
type: number
- name: V314
type: number
- name: V315
type: number
- name: V316
type: number
- name: V317
type: number
- name: V318
type: number
- name: V319
type: number
- name: V320
type: number
- name: V321
type: number
- name: V322
type: number
- name: V323
type: number
- name: V324
type: number
- name: V325
type: number
- name: V326
type: number
- name: V327
type: number
- name: V328
type: number
- name: V329
type: number
- name: V330
type: number
- name: V331
type: number
- name: V332
type: number
- name: V333
type: number
- name: V334
type: number
- name: V335
type: number
- name: V336
type: number
- name: V337
type: number
- name: V338
type: number
- name: V339
type: number
- name: id_01
type: number
- name: id_02
type: number
- name: id_03
type: number
- name: id_04
type: number
- name: id_05
type: number
- name: id_06
type: number
- name: id_07
type: number
- name: id_08
type: number
- name: id_09
type: number
- name: id_10
type: number
- name: id_11
type: number
- name: id_12
type: category
- name: id_13
type: number
- name: id_14
type: number
- name: id_15
type: category
- name: id_16
type: category
- name: id_17
type: number
- name: id_18
type: number
- name: id_19
type: number
- name: id_20
type: number
- name: id_21
type: number
- name: id_22
type: number
- name: id_23
type: category
- name: id_24
type: number
- name: id_25
type: number
- name: id_26
type: number
- name: id_27
type: category
- name: id_28
type: category
- name: id_29
type: category
- name: id_30
type: category
- name: id_31
type: text
- name: id_32
type: number
- name: id_33
type: category
- name: id_34
type: category
- name: id_35
type: category
- name: id_36
type: category
- name: id_37
type: category
- name: id_38
type: category
- name: DeviceType
type: category
- name: DeviceInfo
type: category
combiner:
type: tabnet
size: 128 # N_a
output_size: 24 # N_d
sparsity: 0.000001 # lambda_sparse
bn_momentum: 0.02 # m_B
num_steps: 10 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 2048 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 10000
decay_rate: 0.95
validation_metric: accuracy
- name: mercedes_benz_greener
goal: minimize
metric: root_mean_squared_error
validation_metric_score: 7.685836315155029
training_rows: 2969
test_rows: 840
validation_rows: 400
config:
output_features:
- name: y
type: number
input_features:
- name: X0
type: category
- name: X1
type: category
- name: X2
type: category
- name: X3
type: category
- name: X4
type: category
- name: X5
type: category
- name: X6
type: category
- name: X8
type: category
- name: X10
type: binary
- name: X11
type: binary
- name: X12
type: binary
- name: X13
type: binary
- name: X14
type: binary
- name: X15
type: binary
- name: X16
type: binary
- name: X17
type: binary
- name: X18
type: binary
- name: X19
type: binary
- name: X20
type: binary
- name: X21
type: binary
- name: X22
type: binary
- name: X23
type: binary
- name: X24
type: binary
- name: X26
type: binary
- name: X27
type: binary
- name: X28
type: binary
- name: X29
type: binary
- name: X30
type: binary
- name: X31
type: binary
- name: X32
type: binary
- name: X33
type: binary
- name: X34
type: binary
- name: X35
type: binary
- name: X36
type: binary
- name: X37
type: binary
- name: X38
type: binary
- name: X39
type: binary
- name: X40
type: binary
- name: X41
type: binary
- name: X42
type: binary
- name: X43
type: binary
- name: X44
type: binary
- name: X45
type: binary
- name: X46
type: binary
- name: X47
type: binary
- name: X48
type: binary
- name: X49
type: binary
- name: X50
type: binary
- name: X51
type: binary
- name: X52
type: binary
- name: X53
type: binary
- name: X54
type: binary
- name: X55
type: binary
- name: X56
type: binary
- name: X57
type: binary
- name: X58
type: binary
- name: X59
type: binary
- name: X60
type: binary
- name: X61
type: binary
- name: X62
type: binary
- name: X63
type: binary
- name: X64
type: binary
- name: X65
type: binary
- name: X66
type: binary
- name: X67
type: binary
- name: X68
type: binary
- name: X69
type: binary
- name: X70
type: binary
- name: X71
type: binary
- name: X73
type: binary
- name: X74
type: binary
- name: X75
type: binary
- name: X76
type: binary
- name: X77
type: binary
- name: X78
type: binary
- name: X79
type: binary
- name: X80
type: binary
- name: X81
type: binary
- name: X82
type: binary
- name: X83
type: binary
- name: X84
type: binary
- name: X85
type: binary
- name: X86
type: binary
- name: X87
type: binary
- name: X88
type: binary
- name: X89
type: binary
- name: X90
type: binary
- name: X91
type: binary
- name: X92
type: binary
- name: X93
type: binary
- name: X94
type: binary
- name: X95
type: binary
- name: X96
type: binary
- name: X97
type: binary
- name: X98
type: binary
- name: X99
type: binary
- name: X100
type: binary
- name: X101
type: binary
- name: X102
type: binary
- name: X103
type: binary
- name: X104
type: binary
- name: X105
type: binary
- name: X106
type: binary
- name: X107
type: binary
- name: X108
type: binary
- name: X109
type: binary
- name: X110
type: binary
- name: X111
type: binary
- name: X112
type: binary
- name: X113
type: binary
- name: X114
type: binary
- name: X115
type: binary
- name: X116
type: binary
- name: X117
type: binary
- name: X118
type: binary
- name: X119
type: binary
- name: X120
type: binary
- name: X122
type: binary
- name: X123
type: binary
- name: X124
type: binary
- name: X125
type: binary
- name: X126
type: binary
- name: X127
type: binary
- name: X128
type: binary
- name: X129
type: binary
- name: X130
type: binary
- name: X131
type: binary
- name: X132
type: binary
- name: X133
type: binary
- name: X134
type: binary
- name: X135
type: binary
- name: X136
type: binary
- name: X137
type: binary
- name: X138
type: binary
- name: X139
type: binary
- name: X140
type: binary
- name: X141
type: binary
- name: X142
type: binary
- name: X143
type: binary
- name: X144
type: binary
- name: X145
type: binary
- name: X146
type: binary
- name: X147
type: binary
- name: X148
type: binary
- name: X150
type: binary
- name: X151
type: binary
- name: X152
type: binary
- name: X153
type: binary
- name: X154
type: binary
- name: X155
type: binary
- name: X156
type: binary
- name: X157
type: binary
- name: X158
type: binary
- name: X159
type: binary
- name: X160
type: binary
- name: X161
type: binary
- name: X162
type: binary
- name: X163
type: binary
- name: X164
type: binary
- name: X165
type: binary
- name: X166
type: binary
- name: X167
type: binary
- name: X168
type: binary
- name: X169
type: binary
- name: X170
type: binary
- name: X171
type: binary
- name: X172
type: binary
- name: X173
type: binary
- name: X174
type: binary
- name: X175
type: binary
- name: X176
type: binary
- name: X177
type: binary
- name: X178
type: binary
- name: X179
type: binary
- name: X180
type: binary
- name: X181
type: binary
- name: X182
type: binary
- name: X183
type: binary
- name: X184
type: binary
- name: X185
type: binary
- name: X186
type: binary
- name: X187
type: binary
- name: X189
type: binary
- name: X190
type: binary
- name: X191
type: binary
- name: X192
type: binary
- name: X194
type: binary
- name: X195
type: binary
- name: X196
type: binary
- name: X197
type: binary
- name: X198
type: binary
- name: X199
type: binary
- name: X200
type: binary
- name: X201
type: binary
- name: X202
type: binary
- name: X203
type: binary
- name: X204
type: binary
- name: X205
type: binary
- name: X206
type: binary
- name: X207
type: binary
- name: X208
type: binary
- name: X209
type: binary
- name: X210
type: binary
- name: X211
type: binary
- name: X212
type: binary
- name: X213
type: binary
- name: X214
type: binary
- name: X215
type: binary
- name: X216
type: binary
- name: X217
type: binary
- name: X218
type: binary
- name: X219
type: binary
- name: X220
type: binary
- name: X221
type: binary
- name: X222
type: binary
- name: X223
type: binary
- name: X224
type: binary
- name: X225
type: binary
- name: X226
type: binary
- name: X227
type: binary
- name: X228
type: binary
- name: X229
type: binary
- name: X230
type: binary
- name: X231
type: binary
- name: X232
type: binary
- name: X233
type: binary
- name: X234
type: binary
- name: X235
type: binary
- name: X236
type: binary
- name: X237
type: binary
- name: X238
type: binary
- name: X239
type: binary
- name: X240
type: binary
- name: X241
type: binary
- name: X242
type: binary
- name: X243
type: binary
- name: X244
type: binary
- name: X245
type: binary
- name: X246
type: binary
- name: X247
type: binary
- name: X248
type: binary
- name: X249
type: binary
- name: X250
type: binary
- name: X251
type: binary
- name: X252
type: binary
- name: X253
type: binary
- name: X254
type: binary
- name: X255
type: binary
- name: X256
type: binary
- name: X257
type: binary
- name: X258
type: binary
- name: X259
type: binary
- name: X260
type: binary
- name: X261
type: binary
- name: X262
type: binary
- name: X263
type: binary
- name: X264
type: binary
- name: X265
type: binary
- name: X266
type: binary
- name: X267
type: binary
- name: X268
type: binary
- name: X269
type: binary
- name: X270
type: binary
- name: X271
type: binary
- name: X272
type: binary
- name: X273
type: binary
- name: X274
type: binary
- name: X275
type: binary
- name: X276
type: binary
- name: X277
type: binary
- name: X278
type: binary
- name: X279
type: binary
- name: X280
type: binary
- name: X281
type: binary
- name: X282
type: binary
- name: X283
type: binary
- name: X284
type: binary
- name: X285
type: binary
- name: X286
type: binary
- name: X287
type: binary
- name: X288
type: binary
- name: X289
type: binary
- name: X290
type: binary
- name: X291
type: binary
- name: X292
type: binary
- name: X293
type: binary
- name: X294
type: binary
- name: X295
type: binary
- name: X296
type: binary
- name: X297
type: binary
- name: X298
type: binary
- name: X299
type: binary
- name: X300
type: binary
- name: X301
type: binary
- name: X302
type: binary
- name: X304
type: binary
- name: X305
type: binary
- name: X306
type: binary
- name: X307
type: binary
- name: X308
type: binary
- name: X309
type: binary
- name: X310
type: binary
- name: X311
type: binary
- name: X312
type: binary
- name: X313
type: binary
- name: X314
type: binary
- name: X315
type: binary
- name: X316
type: binary
- name: X317
type: binary
- name: X318
type: binary
- name: X319
type: binary
- name: X320
type: binary
- name: X321
type: binary
- name: X322
type: binary
- name: X323
type: binary
- name: X324
type: binary
- name: X325
type: binary
- name: X326
type: binary
- name: X327
type: binary
- name: X328
type: binary
- name: X329
type: binary
- name: X330
type: binary
- name: X331
type: binary
- name: X332
type: binary
- name: X333
type: binary
- name: X334
type: binary
- name: X335
type: binary
- name: X336
type: binary
- name: X337
type: binary
- name: X338
type: binary
- name: X339
type: binary
- name: X340
type: binary
- name: X341
type: binary
- name: X342
type: binary
- name: X343
type: binary
- name: X344
type: binary
- name: X345
type: binary
- name: X346
type: binary
- name: X347
type: binary
- name: X348
type: binary
- name: X349
type: binary
- name: X350
type: binary
- name: X351
type: binary
- name: X352
type: binary
- name: X353
type: binary
- name: X354
type: binary
- name: X355
type: binary
- name: X356
type: binary
- name: X357
type: binary
- name: X358
type: binary
- name: X359
type: binary
- name: X360
type: binary
- name: X361
type: binary
- name: X362
type: binary
- name: X363
type: binary
- name: X364
type: binary
- name: X365
type: binary
- name: X366
type: binary
- name: X367
type: binary
- name: X368
type: binary
- name: X369
type: binary
- name: X370
type: binary
- name: X371
type: binary
- name: X372
type: binary
- name: X373
type: binary
- name: X374
type: binary
- name: X375
type: binary
- name: X376
type: binary
- name: X377
type: binary
- name: X378
type: binary
- name: X379
type: binary
- name: X380
type: binary
- name: X382
type: binary
- name: X383
type: binary
- name: X384
type: binary
- name: X385
type: binary
combiner:
type: tabnet
size: 128 # N_a
output_size: 8 # N_d
sparsity: 0.1 # lambda_sparse
bn_momentum: 0.1 # m_B
num_steps: 9 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 256 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 500
decay_rate: 0.95
validation_metric: root_mean_squared_error
- name: otto_group_product
goal: maximize
metric: accuracy
validation_metric_score: 0.7956883907318115
training_rows: 43459
test_rows: 12296
validation_rows: 6123
config:
output_features:
- name: target
type: category
input_features:
- name: feat_1
type: number
- name: feat_2
type: number
- name: feat_3
type: number
- name: feat_4
type: number
- name: feat_5
type: number
- name: feat_6
type: number
- name: feat_7
type: number
- name: feat_8
type: number
- name: feat_9
type: number
- name: feat_10
type: number
- name: feat_11
type: number
- name: feat_12
type: number
- name: feat_13
type: number
- name: feat_14
type: number
- name: feat_15
type: number
- name: feat_16
type: number
- name: feat_17
type: number
- name: feat_18
type: number
- name: feat_19
type: number
- name: feat_20
type: number
- name: feat_21
type: category
- name: feat_22
type: number
- name: feat_23
type: number
- name: feat_24
type: number
- name: feat_25
type: number
- name: feat_26
type: number
- name: feat_27
type: number
- name: feat_28
type: number
- name: feat_29
type: number
- name: feat_30
type: number
- name: feat_31
type: number
- name: feat_32
type: number
- name: feat_33
type: number
- name: feat_34
type: number
- name: feat_35
type: number
- name: feat_36
type: number
- name: feat_37
type: number
- name: feat_38
type: number
- name: feat_39
type: number
- name: feat_40
type: number
- name: feat_41
type: number
- name: feat_42
type: number
- name: feat_43
type: number
- name: feat_44
type: number
- name: feat_45
type: number
- name: feat_46
type: number
- name: feat_47
type: number
- name: feat_48
type: number
- name: feat_49
type: number
- name: feat_50
type: number
- name: feat_51
type: number
- name: feat_52
type: number
- name: feat_53
type: number
- name: feat_54
type: number
- name: feat_55
type: number
- name: feat_56
type: number
- name: feat_57
type: number
- name: feat_58
type: number
- name: feat_59
type: number
- name: feat_60
type: number
- name: feat_61
type: number
- name: feat_62
type: number
- name: feat_63
type: number
- name: feat_64
type: number
- name: feat_65
type: number
- name: feat_66
type: number
- name: feat_67
type: number
- name: feat_68
type: number
- name: feat_69
type: number
- name: feat_70
type: number
- name: feat_71
type: number
- name: feat_72
type: number
- name: feat_73
type: number
- name: feat_74
type: number
- name: feat_75
type: number
- name: feat_76
type: number
- name: feat_77
type: number
- name: feat_78
type: number
- name: feat_79
type: number
- name: feat_80
type: number
- name: feat_81
type: number
- name: feat_82
type: number
- name: feat_83
type: number
- name: feat_84
type: number
- name: feat_85
type: number
- name: feat_86
type: number
- name: feat_87
type: number
- name: feat_88
type: number
- name: feat_89
type: number
- name: feat_90
type: number
- name: feat_91
type: number
- name: feat_92
type: number
- name: feat_93
type: number
combiner:
type: tabnet
size: 128 # N_a
output_size: 128 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.2 # m_B
num_steps: 3 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 512 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.4
validation_metric: accuracy
- name: poker_hand
goal: maximize
metric: accuracy
validation_metric_score: 0.9804078340530396
training_rows: 22509
test_rows: 0
validation_rows: 2501
config:
output_features:
- name: hand
type: category
input_features:
- name: S1
type: number
- name: C1
type: number
- name: S2
type: number
- name: C2
type: number
- name: S3
type: number
- name: C3
type: number
- name: S4
type: number
- name: C4
type: number
- name: S5
type: number
- name: C5
type: number
combiner:
type: tabnet
size: 16 # N_a
output_size: 128 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.02 # m_B
num_steps: 6 # N_steps
relaxation_factor: 1.0 # gamma
bn_virtual_bs: 512 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 8000
decay_rate: 0.8
validation_metric: accuracy
- name: porto_seguro_safe_driver
goal: maximize
metric: accuracy
validation_metric_score: 0.9630663394927979
training_rows: 416779
test_rows: 118948
validation_rows: 59485
config:
output_features:
- name: target
type: binary
input_features:
- name: ps_ind_01
type: category
- name: ps_ind_02_cat
type: number
- name: ps_ind_03
type: category
- name: ps_ind_04_cat
type: category
- name: ps_ind_05_cat
type: category
- name: ps_ind_06_bin
type: binary
- name: ps_ind_07_bin
type: binary
- name: ps_ind_08_bin
type: binary
- name: ps_ind_09_bin
type: binary
- name: ps_ind_10_bin
type: binary
- name: ps_ind_11_bin
type: binary
- name: ps_ind_12_bin
type: binary
- name: ps_ind_13_bin
type: binary
- name: ps_ind_14
type: category
- name: ps_ind_15
type: category
- name: ps_ind_16_bin
type: binary
- name: ps_ind_17_bin
type: binary
- name: ps_ind_18_bin
type: binary
- name: ps_reg_01
type: number
- name: ps_reg_02
type: number
- name: ps_reg_03
type: number
- name: ps_car_01_cat
type: category
- name: ps_car_02_cat
type: category
- name: ps_car_03_cat
type: category
- name: ps_car_04_cat
type: category
- name: ps_car_05_cat
type: category
- name: ps_car_06_cat
type: category
- name: ps_car_07_cat
type: category
- name: ps_car_08_cat
type: binary
- name: ps_car_09_cat
type: category
- name: ps_car_10_cat
type: category
- name: ps_car_11_cat
type: number
- name: ps_car_11
type: category
- name: ps_car_12
type: number
- name: ps_car_13
type: number
- name: ps_car_14
type: number
- name: ps_car_15
type: number
- name: ps_calc_01
type: number
- name: ps_calc_02
type: number
- name: ps_calc_03
type: number
- name: ps_calc_04
type: category
- name: ps_calc_05
type: category
- name: ps_calc_06
type: category
- name: ps_calc_07
type: category
- name: ps_calc_08
type: category
- name: ps_calc_09
type: category
- name: ps_calc_10
type: number
- name: ps_calc_11
type: number
- name: ps_calc_12
type: category
- name: ps_calc_13
type: category
- name: ps_calc_14
type: number
- name: ps_calc_15_bin
type: binary
- name: ps_calc_16_bin
type: binary
- name: ps_calc_17_bin
type: binary
- name: ps_calc_18_bin
type: binary
- name: ps_calc_19_bin
type: binary
- name: ps_calc_20_bin
type: binary
combiner:
type: tabnet
size: 32 # N_a
output_size: 32 # N_d
sparsity: 0.0001 # lambda_sparse
bn_momentum: 0.4 # m_B
num_steps: 5 # N_steps
relaxation_factor: 1.2 # gamma
bn_virtual_bs: 1024 # B_v
trainer:
batch_size: 1024 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 10000
decay_rate: 0.9
validation_metric: accuracy
- name: santander_customer_satisfaction
goal: maximize
metric: accuracy
validation_metric_score: 0.9611535668373108
training_rows: 53298
test_rows: 15128
validation_rows: 7594
config:
output_features:
- name: TARGET
type: binary
input_features:
- name: var3
type: number
- name: var15
type: number
- name: imp_ent_var16_ult1
type: number
- name: imp_op_var39_comer_ult1
type: number
- name: imp_op_var39_comer_ult3
type: number
- name: imp_op_var40_comer_ult1
type: number
- name: imp_op_var40_comer_ult3
type: number
- name: imp_op_var40_efect_ult1
type: number
- name: imp_op_var40_efect_ult3
type: number
- name: imp_op_var40_ult1
type: number
- name: imp_op_var41_comer_ult1
type: number
- name: imp_op_var41_comer_ult3
type: number
- name: imp_op_var41_efect_ult1
type: number
- name: imp_op_var41_efect_ult3
type: number
- name: imp_op_var41_ult1
type: number
- name: imp_op_var39_efect_ult1
type: number
- name: imp_op_var39_efect_ult3
type: number
- name: imp_op_var39_ult1
type: number
- name: imp_sal_var16_ult1
type: number
- name: ind_var1_0
type: binary
- name: ind_var1
type: binary
- name: ind_var2_0
type: binary
- name: ind_var2
type: binary
- name: ind_var5_0
type: binary
- name: ind_var5
type: binary
- name: ind_var6_0
type: binary
- name: ind_var6
type: binary
- name: ind_var8_0
type: binary
- name: ind_var8
type: binary
- name: ind_var12_0
type: binary
- name: ind_var12
type: binary
- name: ind_var13_0
type: binary
- name: ind_var13_corto_0
type: binary
- name: ind_var13_corto
type: binary
- name: ind_var13_largo_0
type: binary
- name: ind_var13_largo
type: binary
- name: ind_var13_medio_0
type: binary
- name: ind_var13_medio
type: binary
- name: ind_var13
type: binary
- name: ind_var14_0
type: binary
- name: ind_var14
type: binary
- name: ind_var17_0
type: binary
- name: ind_var17
type: binary
- name: ind_var18_0
type: binary
- name: ind_var18
type: binary
- name: ind_var19
type: binary
- name: ind_var20_0
type: binary
- name: ind_var20
type: binary
- name: ind_var24_0
type: binary
- name: ind_var24
type: binary
- name: ind_var25_cte
type: binary
- name: ind_var26_0
type: binary
- name: ind_var26_cte
type: binary
- name: ind_var26
type: binary
- name: ind_var25_0
type: binary
- name: ind_var25
type: binary
- name: ind_var27_0
type: binary
- name: ind_var28_0
type: binary
- name: ind_var28
type: binary
- name: ind_var27
type: binary
- name: ind_var29_0
type: binary
- name: ind_var29
type: binary
- name: ind_var30_0
type: binary
- name: ind_var30
type: binary
- name: ind_var31_0
type: binary
- name: ind_var31
type: binary
- name: ind_var32_cte
type: binary
- name: ind_var32_0
type: binary
- name: ind_var32
type: binary
- name: ind_var33_0
type: binary
- name: ind_var33
type: binary
- name: ind_var34_0
type: binary
- name: ind_var34
type: binary
- name: ind_var37_cte
type: binary
- name: ind_var37_0
type: binary
- name: ind_var37
type: binary
- name: ind_var39_0
type: binary
- name: ind_var40_0
type: binary
- name: ind_var40
type: binary
- name: ind_var41_0
type: binary
- name: ind_var41
type: binary
- name: ind_var39
type: binary
- name: ind_var44_0
type: binary
- name: ind_var44
type: binary
- name: ind_var46_0
type: binary
- name: ind_var46
type: binary
- name: num_var1_0
type: number
- name: num_var1
type: number
- name: num_var4
type: category
- name: num_var5_0
type: number
- name: num_var5
type: number
- name: num_var6_0
type: number
- name: num_var6
type: number
- name: num_var8_0
type: number
- name: num_var8
type: number
- name: num_var12_0
type: number
- name: num_var12
type: number
- name: num_var13_0
type: number
- name: num_var13_corto_0
type: number
- name: num_var13_corto
type: number
- name: num_var13_largo_0
type: number
- name: num_var13_largo
type: number
- name: num_var13_medio_0
type: number
- name: num_var13_medio
type: number
- name: num_var13
type: number
- name: num_var14_0
type: number
- name: num_var14
type: number
- name: num_var17_0
type: number
- name: num_var17
type: number
- name: num_var18_0
type: number
- name: num_var18
type: number
- name: num_var20_0
type: number
- name: num_var20
type: number
- name: num_var24_0
type: number
- name: num_var24
type: number
- name: num_var26_0
type: number
- name: num_var26
type: number
- name: num_var25_0
type: number
- name: num_var25
type: number
- name: num_op_var40_hace2
type: number
- name: num_op_var40_hace3
type: number
- name: num_op_var40_ult1
type: number
- name: num_op_var40_ult3
type: number
- name: num_op_var41_hace2
type: number
- name: num_op_var41_hace3
type: number
- name: num_op_var41_ult1
type: number
- name: num_op_var41_ult3
type: number
- name: num_op_var39_hace2
type: number
- name: num_op_var39_hace3
type: number
- name: num_op_var39_ult1
type: number
- name: num_op_var39_ult3
type: number
- name: num_var27_0
type: binary
- name: num_var28_0
type: binary
- name: num_var28
type: binary
- name: num_var27
type: binary
- name: num_var29_0
type: number
- name: num_var29
type: number
- name: num_var30_0
type: number
- name: num_var30
type: number
- name: num_var31_0
type: number
- name: num_var31
type: number
- name: num_var32_0
type: number
- name: num_var32
type: number
- name: num_var33_0
type: number
- name: num_var33
type: number
- name: num_var34_0
type: number
- name: num_var34
type: number
- name: num_var35
type: number
- name: num_var37_med_ult2
type: number
- name: num_var37_0
type: number
- name: num_var37
type: number
- name: num_var39_0
type: number
- name: num_var40_0
type: number
- name: num_var40
type: number
- name: num_var41_0
type: number
- name: num_var41
type: binary
- name: num_var39
type: number
- name: num_var42_0
type: number
- name: num_var42
type: number
- name: num_var44_0
type: number
- name: num_var44
type: number
- name: num_var46_0
type: binary
- name: num_var46
type: binary
- name: saldo_var1
type: number
- name: saldo_var5
type: number
- name: saldo_var6
type: number
- name: saldo_var8
type: number
- name: saldo_var12
type: number
- name: saldo_var13_corto
type: number
- name: saldo_var13_largo
type: number
- name: saldo_var13_medio
type: number
- name: saldo_var13
type: number
- name: saldo_var14
type: number
- name: saldo_var17
type: number
- name: saldo_var18
type: number
- name: saldo_var20
type: number
- name: saldo_var24
type: number
- name: saldo_var26
type: number
- name: saldo_var25
type: number
- name: saldo_var28
type: binary
- name: saldo_var27
type: binary
- name: saldo_var29
type: number
- name: saldo_var30
type: number
- name: saldo_var31
type: number
- name: saldo_var32
type: number
- name: saldo_var33
type: number
- name: saldo_var34
type: number
- name: saldo_var37
type: number
- name: saldo_var40
type: number
- name: saldo_var41
type: binary
- name: saldo_var42
type: number
- name: saldo_var44
type: number
- name: saldo_var46
type: binary
- name: var36
type: number
- name: delta_imp_amort_var18_1y3
type: number
- name: delta_imp_amort_var34_1y3
type: number
- name: delta_imp_aport_var13_1y3
type: number
- name: delta_imp_aport_var17_1y3
type: number
- name: delta_imp_aport_var33_1y3
type: number
- name: delta_imp_compra_var44_1y3
type: number
- name: delta_imp_reemb_var13_1y3
type: number
- name: delta_imp_reemb_var17_1y3
type: number
- name: delta_imp_reemb_var33_1y3
type: number
- name: delta_imp_trasp_var17_in_1y3
type: number
- name: delta_imp_trasp_var17_out_1y3
type: number
- name: delta_imp_trasp_var33_in_1y3
type: number
- name: delta_imp_trasp_var33_out_1y3
type: number
- name: delta_imp_venta_var44_1y3
type: number
- name: delta_num_aport_var13_1y3
type: number
- name: delta_num_aport_var17_1y3
type: number
- name: delta_num_aport_var33_1y3
type: number
- name: delta_num_compra_var44_1y3
type: number
- name: delta_num_reemb_var13_1y3
type: number
- name: delta_num_reemb_var17_1y3
type: number
- name: delta_num_reemb_var33_1y3
type: number
- name: delta_num_trasp_var17_in_1y3
type: number
- name: delta_num_trasp_var17_out_1y3
type: number
- name: delta_num_trasp_var33_in_1y3
type: number
- name: delta_num_trasp_var33_out_1y3
type: number
- name: delta_num_venta_var44_1y3
type: number
- name: imp_amort_var18_hace3
type: binary
- name: imp_amort_var18_ult1
type: number
- name: imp_amort_var34_hace3
type: binary
- name: imp_amort_var34_ult1
type: number
- name: imp_aport_var13_hace3
type: number
- name: imp_aport_var13_ult1
type: number
- name: imp_aport_var17_hace3
type: number
- name: imp_aport_var17_ult1
type: number
- name: imp_aport_var33_hace3
type: number
- name: imp_aport_var33_ult1
type: number
- name: imp_var7_emit_ult1
type: number
- name: imp_var7_recib_ult1
type: number
- name: imp_compra_var44_hace3
type: number
- name: imp_compra_var44_ult1
type: number
- name: imp_reemb_var13_hace3
type: binary
- name: imp_reemb_var13_ult1
type: number
- name: imp_reemb_var17_hace3
type: number
- name: imp_reemb_var17_ult1
type: number
- name: imp_reemb_var33_hace3
type: binary
- name: imp_reemb_var33_ult1
type: number
- name: imp_var43_emit_ult1
type: number
- name: imp_trans_var37_ult1
type: number
- name: imp_trasp_var17_in_hace3
type: number
- name: imp_trasp_var17_in_ult1
type: number
- name: imp_trasp_var17_out_hace3
type: binary
- name: imp_trasp_var17_out_ult1
type: number
- name: imp_trasp_var33_in_hace3
type: number
- name: imp_trasp_var33_in_ult1
type: number
- name: imp_trasp_var33_out_hace3
type: binary
- name: imp_trasp_var33_out_ult1
type: number
- name: imp_venta_var44_hace3
type: number
- name: imp_venta_var44_ult1
type: number
- name: ind_var7_emit_ult1
type: binary
- name: ind_var7_recib_ult1
type: binary
- name: ind_var10_ult1
type: binary
- name: ind_var10cte_ult1
type: binary
- name: ind_var9_cte_ult1
type: binary
- name: ind_var9_ult1
type: binary
- name: ind_var43_emit_ult1
type: binary
- name: ind_var43_recib_ult1
type: binary
- name: var21
type: number
- name: num_var2_0_ult1
type: binary
- name: num_var2_ult1
type: binary
- name: num_aport_var13_hace3
type: number
- name: num_aport_var13_ult1
type: number
- name: num_aport_var17_hace3
type: number
- name: num_aport_var17_ult1
type: number
- name: num_aport_var33_hace3
type: number
- name: num_aport_var33_ult1
type: number
- name: num_var7_emit_ult1
type: number
- name: num_var7_recib_ult1
type: number
- name: num_compra_var44_hace3
type: number
- name: num_compra_var44_ult1
type: number
- name: num_ent_var16_ult1
type: number
- name: num_var22_hace2
type: number
- name: num_var22_hace3
type: number
- name: num_var22_ult1
type: number
- name: num_var22_ult3
type: number
- name: num_med_var22_ult3
type: number
- name: num_med_var45_ult3
type: number
- name: num_meses_var5_ult3
type: category
- name: num_meses_var8_ult3
type: category
- name: num_meses_var12_ult3
type: category
- name: num_meses_var13_corto_ult3
type: category
- name: num_meses_var13_largo_ult3
type: category
- name: num_meses_var13_medio_ult3
type: number
- name: num_meses_var17_ult3
type: category
- name: num_meses_var29_ult3
type: category
- name: num_meses_var33_ult3
type: category
- name: num_meses_var39_vig_ult3
type: category
- name: num_meses_var44_ult3
type: category
- name: num_op_var39_comer_ult1
type: number
- name: num_op_var39_comer_ult3
type: number
- name: num_op_var40_comer_ult1
type: number
- name: num_op_var40_comer_ult3
type: number
- name: num_op_var40_efect_ult1
type: number
- name: num_op_var40_efect_ult3
type: number
- name: num_op_var41_comer_ult1
type: number
- name: num_op_var41_comer_ult3
type: number
- name: num_op_var41_efect_ult1
type: number
- name: num_op_var41_efect_ult3
type: number
- name: num_op_var39_efect_ult1
type: number
- name: num_op_var39_efect_ult3
type: number
- name: num_reemb_var13_hace3
type: binary
- name: num_reemb_var13_ult1
type: number
- name: num_reemb_var17_hace3
type: number
- name: num_reemb_var17_ult1
type: number
- name: num_reemb_var33_hace3
type: binary
- name: num_reemb_var33_ult1
type: number
- name: num_sal_var16_ult1
type: number
- name: num_var43_emit_ult1
type: number
- name: num_var43_recib_ult1
type: number
- name: num_trasp_var11_ult1
type: number
- name: num_trasp_var17_in_hace3
type: number
- name: num_trasp_var17_in_ult1
type: number
- name: num_trasp_var17_out_hace3
type: binary
- name: num_trasp_var17_out_ult1
type: number
- name: num_trasp_var33_in_hace3
type: number
- name: num_trasp_var33_in_ult1
type: number
- name: num_trasp_var33_out_hace3
type: binary
- name: num_trasp_var33_out_ult1
type: number
- name: num_venta_var44_hace3
type: number
- name: num_venta_var44_ult1
type: number
- name: num_var45_hace2
type: number
- name: num_var45_hace3
type: number
- name: num_var45_ult1
type: number
- name: num_var45_ult3
type: number
- name: saldo_var2_ult1
type: binary
- name: saldo_medio_var5_hace2
type: number
- name: saldo_medio_var5_hace3
type: number
- name: saldo_medio_var5_ult1
type: number
- name: saldo_medio_var5_ult3
type: number
- name: saldo_medio_var8_hace2
type: number
- name: saldo_medio_var8_hace3
type: number
- name: saldo_medio_var8_ult1
type: number
- name: saldo_medio_var8_ult3
type: number
- name: saldo_medio_var12_hace2
type: number
- name: saldo_medio_var12_hace3
type: number
- name: saldo_medio_var12_ult1
type: number
- name: saldo_medio_var12_ult3
type: number
- name: saldo_medio_var13_corto_hace2
type: number
- name: saldo_medio_var13_corto_hace3
type: number
- name: saldo_medio_var13_corto_ult1
type: number
- name: saldo_medio_var13_corto_ult3
type: number
- name: saldo_medio_var13_largo_hace2
type: number
- name: saldo_medio_var13_largo_hace3
type: number
- name: saldo_medio_var13_largo_ult1
type: number
- name: saldo_medio_var13_largo_ult3
type: number
- name: saldo_medio_var13_medio_hace2
type: number
- name: saldo_medio_var13_medio_hace3
type: binary
- name: saldo_medio_var13_medio_ult1
type: number
- name: saldo_medio_var13_medio_ult3
type: number
- name: saldo_medio_var17_hace2
type: number
- name: saldo_medio_var17_hace3
type: number
- name: saldo_medio_var17_ult1
type: number
- name: saldo_medio_var17_ult3
type: number
- name: saldo_medio_var29_hace2
type: number
- name: saldo_medio_var29_hace3
type: number
- name: saldo_medio_var29_ult1
type: number
- name: saldo_medio_var29_ult3
type: number
- name: saldo_medio_var33_hace2
type: number
- name: saldo_medio_var33_hace3
type: number
- name: saldo_medio_var33_ult1
type: number
- name: saldo_medio_var33_ult3
type: number
- name: saldo_medio_var44_hace2
type: number
- name: saldo_medio_var44_hace3
type: number
- name: saldo_medio_var44_ult1
type: number
- name: saldo_medio_var44_ult3
type: number
- name: var38
type: number
combiner:
type: tabnet
size: 24 # N_a
output_size: 128 # N_d
sparsity: 0.001 # lambda_sparse
bn_momentum: 0.2 # m_B
num_steps: 7 # N_steps
relaxation_factor: 1.2 # gamma
bn_virtual_bs: 256 # B_v
trainer:
batch_size: 4096 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 10000
decay_rate: 0.8
validation_metric: accuracy
- name: santander_customer_transaction
goal: maximize
metric: accuracy
validation_metric_score: 0.9150915145874023
training_rows: 139904
test_rows: 40098
validation_rows: 19998
config:
output_features:
- name: target
type: binary
input_features:
- name: var_0
type: number
- name: var_1
type: number
- name: var_2
type: number
- name: var_3
type: number
- name: var_4
type: number
- name: var_5
type: number
- name: var_6
type: number
- name: var_7
type: number
- name: var_8
type: number
- name: var_9
type: number
- name: var_10
type: number
- name: var_11
type: number
- name: var_12
type: number
- name: var_13
type: number
- name: var_14
type: number
- name: var_15
type: number
- name: var_16
type: number
- name: var_17
type: number
- name: var_18
type: number
- name: var_19
type: number
- name: var_20
type: number
- name: var_21
type: number
- name: var_22
type: number
- name: var_23
type: number
- name: var_24
type: number
- name: var_25
type: number
- name: var_26
type: number
- name: var_27
type: number
- name: var_28
type: number
- name: var_29
type: number
- name: var_30
type: number
- name: var_31
type: number
- name: var_32
type: number
- name: var_33
type: number
- name: var_34
type: number
- name: var_35
type: number
- name: var_36
type: number
- name: var_37
type: number
- name: var_38
type: number
- name: var_39
type: number
- name: var_40
type: number
- name: var_41
type: number
- name: var_42
type: number
- name: var_43
type: number
- name: var_44
type: number
- name: var_45
type: number
- name: var_46
type: number
- name: var_47
type: number
- name: var_48
type: number
- name: var_49
type: number
- name: var_50
type: number
- name: var_51
type: number
- name: var_52
type: number
- name: var_53
type: number
- name: var_54
type: number
- name: var_55
type: number
- name: var_56
type: number
- name: var_57
type: number
- name: var_58
type: number
- name: var_59
type: number
- name: var_60
type: number
- name: var_61
type: number
- name: var_62
type: number
- name: var_63
type: number
- name: var_64
type: number
- name: var_65
type: number
- name: var_66
type: number
- name: var_67
type: number
- name: var_68
type: number
- name: var_69
type: number
- name: var_70
type: number
- name: var_71
type: number
- name: var_72
type: number
- name: var_73
type: number
- name: var_74
type: number
- name: var_75
type: number
- name: var_76
type: number
- name: var_77
type: number
- name: var_78
type: number
- name: var_79
type: number
- name: var_80
type: number
- name: var_81
type: number
- name: var_82
type: number
- name: var_83
type: number
- name: var_84
type: number
- name: var_85
type: number
- name: var_86
type: number
- name: var_87
type: number
- name: var_88
type: number
- name: var_89
type: number
- name: var_90
type: number
- name: var_91
type: number
- name: var_92
type: number
- name: var_93
type: number
- name: var_94
type: number
- name: var_95
type: number
- name: var_96
type: number
- name: var_97
type: number
- name: var_98
type: number
- name: var_99
type: number
- name: var_100
type: number
- name: var_101
type: number
- name: var_102
type: number
- name: var_103
type: number
- name: var_104
type: number
- name: var_105
type: number
- name: var_106
type: number
- name: var_107
type: number
- name: var_108
type: number
- name: var_109
type: number
- name: var_110
type: number
- name: var_111
type: number
- name: var_112
type: number
- name: var_113
type: number
- name: var_114
type: number
- name: var_115
type: number
- name: var_116
type: number
- name: var_117
type: number
- name: var_118
type: number
- name: var_119
type: number
- name: var_120
type: number
- name: var_121
type: number
- name: var_122
type: number
- name: var_123
type: number
- name: var_124
type: number
- name: var_125
type: number
- name: var_126
type: number
- name: var_127
type: number
- name: var_128
type: number
- name: var_129
type: number
- name: var_130
type: number
- name: var_131
type: number
- name: var_132
type: number
- name: var_133
type: number
- name: var_134
type: number
- name: var_135
type: number
- name: var_136
type: number
- name: var_137
type: number
- name: var_138
type: number
- name: var_139
type: number
- name: var_140
type: number
- name: var_141
type: number
- name: var_142
type: number
- name: var_143
type: number
- name: var_144
type: number
- name: var_145
type: number
- name: var_146
type: number
- name: var_147
type: number
- name: var_148
type: number
- name: var_149
type: number
- name: var_150
type: number
- name: var_151
type: number
- name: var_152
type: number
- name: var_153
type: number
- name: var_154
type: number
- name: var_155
type: number
- name: var_156
type: number
- name: var_157
type: number
- name: var_158
type: number
- name: var_159
type: number
- name: var_160
type: number
- name: var_161
type: number
- name: var_162
type: number
- name: var_163
type: number
- name: var_164
type: number
- name: var_165
type: number
- name: var_166
type: number
- name: var_167
type: number
- name: var_168
type: number
- name: var_169
type: number
- name: var_170
type: number
- name: var_171
type: number
- name: var_172
type: number
- name: var_173
type: number
- name: var_174
type: number
- name: var_175
type: number
- name: var_176
type: number
- name: var_177
type: number
- name: var_178
type: number
- name: var_179
type: number
- name: var_180
type: number
- name: var_181
type: number
- name: var_182
type: number
- name: var_183
type: number
- name: var_184
type: number
- name: var_185
type: number
- name: var_186
type: number
- name: var_187
type: number
- name: var_188
type: number
- name: var_189
type: number
- name: var_190
type: number
- name: var_191
type: number
- name: var_192
type: number
- name: var_193
type: number
- name: var_194
type: number
- name: var_195
type: number
- name: var_196
type: number
- name: var_197
type: number
- name: var_198
type: number
- name: var_199
type: number
combiner:
type: tabnet
size: 8 # N_a
output_size: 8 # N_d
sparsity: 0.0 # lambda_sparse
bn_momentum: 0.4 # m_B
num_steps: 3 # N_steps
relaxation_factor: 2.0 # gamma
bn_virtual_bs: 256 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.95
validation_metric: accuracy
- name: sarcos
goal: minimize
metric: root_mean_squared_error
validation_metric_score: 2.0124664306640625
training_rows: 40036
test_rows: 0
validation_rows: 4448
config:
output_features:
- name: torque_1
type: number
input_features:
- name: position_1
type: number
- name: position_2
type: number
- name: position_3
type: number
- name: position_4
type: number
- name: position_5
type: number
- name: position_6
type: number
- name: position_7
type: number
- name: velocity_1
type: number
- name: velocity_2
type: number
- name: velocity_3
type: number
- name: velocity_4
type: number
- name: velocity_5
type: number
- name: velocity_6
type: number
- name: velocity_7
type: number
- name: acceleration_1
type: number
- name: acceleration_2
type: number
- name: acceleration_3
type: number
- name: acceleration_4
type: number
- name: acceleration_5
type: number
- name: acceleration_6
type: number
- name: acceleration_7
type: number
combiner:
type: tabnet
size: 128 # N_a
output_size: 8 # N_d
sparsity: 0.000001 # lambda_sparse
bn_momentum: 0.02 # m_B
num_steps: 4 # N_steps
relaxation_factor: 1.2 # gamma
bn_virtual_bs: 4096 # B_v
trainer:
batch_size: 256 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.005
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.4
validation_metric: root_mean_squared_error
- name: walmart_recruiting
goal: maximize
metric: accuracy
validation_metric_score: 0.31689465045928955
training_rows: 453154
test_rows: 129276
validation_rows: 64624
config:
output_features:
- name: TripType
type: category
input_features:
- name: VisitNumber
type: number
- name: Weekday
type: category
- name: Upc
type: number
- name: ScanCount
type: number
- name: FinelineNumber
type: number
combiner:
type: tabnet
size: 32 # N_a
output_size: 128 # N_d
sparsity: 0.000001 # lambda_sparse
bn_momentum: 0.4 # m_B
num_steps: 4 # N_steps
relaxation_factor: 1.2 # gamma
bn_virtual_bs: 4096 # B_v
trainer:
batch_size: 8192 # B
eval_batch_size: null # 65536 131072 262144 524288
epochs: 300
early_stop: 30
learning_rate: 0.01
optimizer:
type: adam
learning_rate_scheduler:
decay: exponential
decay_steps: 20000
decay_rate: 0.9
validation_metric: accuracy
================================================
FILE: ludwig/automl/defaults/text/bert_config.yaml
================================================
trainer:
epochs: 10
learning_rate_scheduler:
warmup_fraction: 0.1
decay: linear
optimizer:
type: adamw
use_mixed_precision: true
defaults:
text:
encoder:
type: bert
trainable: true
hyperopt:
# goal: maximize
parameters:
# This parameter space was updated to be loguniform because of issues merging with the trainer.learning_rate
# parameter space in ludwig/automl/defaults/combiner/concat_config.yaml. Doing automl on a text feature would
# create an invalid combination of loguniform and choice paramters.
# TODO(jeffkinnison): Add a second pass `merge_dicts` to handle parameter spaces
trainer.learning_rate:
space: loguniform
lower: 0.00002
upper: 0.00003
trainer.batch_size:
space: choice
categories: [16, 32, 64, 128]
================================================
FILE: ludwig/backend/__init__.py
================================================
#! /usr/bin/env python
# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import contextlib
import logging
import os
from ludwig.api_annotations import DeveloperAPI
from ludwig.backend.base import Backend, LocalBackend
logger = logging.getLogger(__name__)
# TODO: remove LOCAL_BACKEND as a global constant, replace with singleton LocalBackend.shared_instance().
LOCAL_BACKEND = LocalBackend.shared_instance()
LOCAL = "local"
DASK = "dask"
DEEPSPEED = "deepspeed"
RAY = "ray"
ALL_BACKENDS = [LOCAL, DASK, DEEPSPEED, RAY]
def _has_ray():
# Temporary workaround to prevent tests from automatically using the Ray backend. Taken from
# https://stackoverflow.com/questions/25188119/test-if-code-is-executed-from-within-a-py-test-session
if "PYTEST_CURRENT_TEST" in os.environ:
return False
try:
import ray
except ImportError:
return False
if ray.is_initialized():
return True
try:
ray.init("auto", ignore_reinit_error=True)
return True
except Exception:
return False
def get_local_backend(**kwargs):
return LocalBackend(**kwargs)
def create_deepspeed_backend(**kwargs):
from ludwig.backend.deepspeed import DeepSpeedBackend
return DeepSpeedBackend(**kwargs)
def create_ray_backend(**kwargs):
from ludwig.backend.ray import RayBackend
return RayBackend(**kwargs)
backend_registry = {
LOCAL: get_local_backend,
DEEPSPEED: create_deepspeed_backend,
RAY: create_ray_backend,
None: get_local_backend,
}
@DeveloperAPI
def create_backend(type, **kwargs):
if isinstance(type, Backend):
return type
if type is None and _has_ray():
type = RAY
return backend_registry[type](**kwargs)
@DeveloperAPI
def initialize_backend(backend):
if isinstance(backend, dict):
backend = create_backend(**backend)
else:
backend = create_backend(backend)
backend.initialize()
return backend
@contextlib.contextmanager
def provision_preprocessing_workers(backend):
if backend.BACKEND_TYPE == RAY:
with backend.provision_preprocessing_workers():
yield
else:
yield
================================================
FILE: ludwig/backend/base.py
================================================
#! /usr/bin/env python
# Copyright (c) 2023 Predibase, Inc., 2020 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
from __future__ import annotations
import time
from abc import ABC, abstractmethod
from collections.abc import Callable, Generator
from concurrent.futures import ThreadPoolExecutor
from contextlib import contextmanager
from typing import Any, TYPE_CHECKING
import numpy as np
import pandas as pd
import psutil
import torch
from tqdm import tqdm
from ludwig.api_annotations import DeveloperAPI
from ludwig.backend.utils.storage import StorageManager
from ludwig.constants import MODEL_LLM
from ludwig.data.cache.manager import CacheManager
from ludwig.data.dataframe.base import DataFrameEngine
from ludwig.data.dataframe.pandas import PANDAS
from ludwig.data.dataset.base import DatasetManager
from ludwig.data.dataset.pandas import PandasDatasetManager
from ludwig.distributed import init_dist_strategy
from ludwig.distributed.base import DistributedStrategy
from ludwig.models.base import BaseModel
from ludwig.schema.trainer import BaseTrainerConfig
from ludwig.types import HyperoptConfigDict
from ludwig.utils.audio_utils import read_audio_from_path
from ludwig.utils.batch_size_tuner import BatchSizeEvaluator
from ludwig.utils.dataframe_utils import from_batches, to_batches
from ludwig.utils.fs_utils import get_bytes_obj_from_path
from ludwig.utils.misc_utils import get_from_registry
from ludwig.utils.system_utils import Resources
from ludwig.utils.torch_utils import initialize_pytorch
from ludwig.utils.types import DataFrame, Series
if TYPE_CHECKING:
from ludwig.trainers.base import BaseTrainer
@DeveloperAPI
class Backend(ABC):
def __init__(
self,
dataset_manager: DatasetManager,
cache_dir: str | None = None,
credentials: dict[str, dict[str, Any]] | None = None,
):
credentials = credentials or {}
self._dataset_manager = dataset_manager
self._storage_manager = StorageManager(**credentials)
self._cache_manager = CacheManager(self._dataset_manager, cache_dir)
@property
def storage(self) -> StorageManager:
return self._storage_manager
@property
def cache(self) -> CacheManager:
return self._cache_manager
@property
def dataset_manager(self) -> DatasetManager:
return self._dataset_manager
@abstractmethod
def initialize(self):
raise NotImplementedError()
@abstractmethod
def initialize_pytorch(self, *args, **kwargs):
raise NotImplementedError()
@contextmanager
@abstractmethod
def create_trainer(self, config: BaseTrainerConfig, model: BaseModel, **kwargs) -> Generator:
raise NotImplementedError()
@abstractmethod
def sync_model(self, model):
raise NotImplementedError()
@abstractmethod
def broadcast_return(self, fn):
raise NotImplementedError()
@abstractmethod
def is_coordinator(self):
raise NotImplementedError()
@property
@abstractmethod
def df_engine(self) -> DataFrameEngine:
raise NotImplementedError()
@property
@abstractmethod
def supports_multiprocessing(self):
raise NotImplementedError()
@abstractmethod
def read_binary_files(self, column: Series, map_fn: Callable | None = None) -> Series:
raise NotImplementedError()
@property
@abstractmethod
def num_nodes(self) -> int:
raise NotImplementedError()
@property
@abstractmethod
def num_training_workers(self) -> int:
raise NotImplementedError()
@abstractmethod
def get_available_resources(self) -> Resources:
raise NotImplementedError()
@abstractmethod
def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -> int | None:
raise NotImplementedError()
@abstractmethod
def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dataset_len: int) -> int:
"""Returns best batch size (measured in samples / s) on the given evaluator.
The evaluator class will need to be instantiated on each worker in the backend cluster, then call
`evaluator.select_best_batch_size(dataset_len)`.
"""
raise NotImplementedError()
@abstractmethod
def batch_transform(
self, df: DataFrame, batch_size: int, transform_fn: Callable, name: str | None = None
) -> DataFrame:
"""Applies `transform_fn` to every `batch_size` length batch of `df` and returns the result."""
raise NotImplementedError()
def supports_batch_size_tuning(self) -> bool:
return True
class LocalPreprocessingMixin:
@property
def df_engine(self):
return PANDAS
@property
def supports_multiprocessing(self):
return True
@staticmethod
def read_binary_files(column: pd.Series, map_fn: Callable | None = None, file_size: int | None = None) -> pd.Series:
column = column.fillna(np.nan).replace([np.nan], [None]) # normalize NaNs to None
sample_fname = column.head(1).values[0]
with ThreadPoolExecutor() as executor: # number of threads is inferred
if isinstance(sample_fname, str):
if map_fn is read_audio_from_path: # bypass torchaudio issue that no longer takes in file-like objects
result = executor.map( # type: ignore[misc]
lambda path: map_fn(path) if path is not None else path, column.values
)
else:
result = executor.map(
lambda path: get_bytes_obj_from_path(path) if path is not None else path, column.values
)
else:
# If the sample path is not a string, assume the paths has already been read in
result = column.values
if map_fn is not None and map_fn is not read_audio_from_path:
result = executor.map(map_fn, result)
return pd.Series(result, index=column.index, name=column.name)
@staticmethod
def batch_transform(df: DataFrame, batch_size: int, transform_fn: Callable, name: str | None = None) -> DataFrame:
name = name or "Batch Transform"
batches = to_batches(df, batch_size)
transform = transform_fn()
out_batches = [transform(batch.reset_index(drop=True)) for batch in tqdm(batches, desc=name)]
out_df = from_batches(out_batches).reset_index(drop=True)
return out_df
class LocalTrainingMixin:
@staticmethod
def initialize():
init_dist_strategy("local")
@staticmethod
def initialize_pytorch(*args, **kwargs):
initialize_pytorch(*args, **kwargs)
@staticmethod
def create_predictor(model: BaseModel, **kwargs):
from ludwig.models.predictor import get_predictor_cls
return get_predictor_cls(model.type())(model, **kwargs) # type: ignore[call-arg]
def sync_model(self, model):
pass
@staticmethod
def broadcast_return(fn):
return fn()
@staticmethod
def is_coordinator() -> bool:
return True
@staticmethod
def tune_batch_size(evaluator_cls: type[BatchSizeEvaluator], dataset_len: int) -> int:
evaluator = evaluator_cls()
return evaluator.select_best_batch_size(dataset_len)
class RemoteTrainingMixin:
def sync_model(self, model):
pass
@staticmethod
def broadcast_return(fn):
return fn()
@staticmethod
def is_coordinator() -> bool:
return True
@DeveloperAPI
class LocalBackend(LocalPreprocessingMixin, LocalTrainingMixin, Backend):
BACKEND_TYPE = "local"
_shared_instance: LocalBackend
@classmethod
def shared_instance(cls) -> LocalBackend:
"""Returns a shared singleton LocalBackend instance."""
if not hasattr(cls, "_shared_instance"):
cls._shared_instance = cls()
return cls._shared_instance
def __init__(self, **kwargs) -> None:
super().__init__(dataset_manager=PandasDatasetManager(self), **kwargs)
@property
def num_nodes(self) -> int:
return 1
@property
def num_training_workers(self) -> int:
return 1
def get_available_resources(self) -> Resources:
return Resources(cpus=psutil.cpu_count(), gpus=torch.cuda.device_count())
def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -> int | None:
# Every trial will be run with Pandas and NO Ray Datasets. Allow Ray Tune to use all the
# trial resources it wants, because there is no Ray Datasets process to compete with it for CPUs.
return None
def create_trainer(
self,
config: BaseTrainerConfig,
model: BaseModel,
**kwargs,
) -> BaseTrainer: # type: ignore[override]
from ludwig.trainers.registry import get_llm_trainers_registry, get_trainers_registry
trainer_cls: type
if model.type() == MODEL_LLM:
trainer_cls = get_from_registry(config.type, get_llm_trainers_registry())
else:
trainer_cls = get_from_registry(model.type(), get_trainers_registry())
return trainer_cls(config=config, model=model, **kwargs)
@DeveloperAPI
class DataParallelBackend(LocalPreprocessingMixin, Backend, ABC):
BACKEND_TYPE = "deepspeed"
def __init__(self, **kwargs):
super().__init__(dataset_manager=PandasDatasetManager(self), **kwargs)
self._distributed: DistributedStrategy | None = None
@abstractmethod
def initialize(self):
pass
def initialize_pytorch(self, *args, **kwargs):
initialize_pytorch(
*args, local_rank=self._distributed.local_rank(), local_size=self._distributed.local_size(), **kwargs
)
def create_trainer(
self,
config: BaseTrainerConfig,
model: BaseModel,
**kwargs,
) -> BaseTrainer: # type: ignore[override]
from ludwig.trainers.trainer import Trainer
return Trainer(config, model, distributed=self._distributed, **kwargs)
def create_predictor(self, model: BaseModel, **kwargs):
from ludwig.models.predictor import get_predictor_cls
return get_predictor_cls(model.type())(model, distributed=self._distributed, **kwargs) # type: ignore[call-arg]
def sync_model(self, model):
# Model weights are only saved on the coordinator, so broadcast
# to all other ranks
self._distributed.sync_model(model)
def broadcast_return(self, fn):
"""Returns the result of calling `fn` on coordinator, broadcast to all other ranks.
Specifically, `fn` is only executed on coordinator, but its result is returned by every rank by broadcasting the
return value from coordinator.
"""
result = fn() if self.is_coordinator() else None
if self._distributed:
name = f"broadcast_return_{int(time.time())}"
result = self._distributed.broadcast_object(result, name=name)
return result
def is_coordinator(self):
return self._distributed.rank() == 0
@property
def num_nodes(self) -> int:
return self._distributed.size() // self._distributed.local_size()
@property
def num_training_workers(self) -> int:
return self._distributed.size()
def get_available_resources(self) -> Resources:
# TODO(travis): this double-counts on the same device, it should use a cross-communicator instead
cpus = torch.as_tensor([psutil.cpu_count()], dtype=torch.int)
cpus = self._distributed.allreduce(cpus).item()
gpus = torch.as_tensor([torch.cuda.device_count()], dtype=torch.int)
gpus = self._distributed.allreduce(gpus).item()
return Resources(cpus=cpus, gpus=gpus)
def max_concurrent_trials(self, hyperopt_config: HyperoptConfigDict) -> int | None:
# Return None since there is no Ray component
return None
def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dataset_len: int) -> int:
evaluator = evaluator_cls()
return evaluator.select_best_batch_size(dataset_len)
================================================
FILE: ludwig/backend/datasource.py
================================================
"""Custom Ray datasource utilities for reading binary files with None handling."""
import logging
from typing import Optional, TYPE_CHECKING
import pandas as pd
import ray
import urllib3
from ludwig.utils.fs_utils import get_bytes_obj_from_http_path, is_http
if TYPE_CHECKING:
import pyarrow
logger = logging.getLogger(__name__)
def read_binary_files_with_index(
paths_and_idxs: list[tuple[str | None, int]],
filesystem: Optional["pyarrow.fs.FileSystem"] = None,
) -> "ray.data.Dataset":
"""Read binary files into a Ray Dataset, handling None paths and HTTP URLs.
Each row in the resulting dataset has columns:
- "data": the raw bytes of the file (or None if path was None/failed)
- "idx": the original index for reordering
Args:
paths_and_idxs: List of (path, index) tuples. Path can be None.
filesystem: PyArrow filesystem for reading non-HTTP files.
Returns:
A ray.data.Dataset with "data" and "idx" columns.
"""
def _read_file(path: str | None, idx: int) -> dict:
if path is None:
return {"data": None, "idx": idx}
elif is_http(path):
try:
data = get_bytes_obj_from_http_path(path)
except urllib3.exceptions.HTTPError as e:
logger.warning(e)
data = None
return {"data": data, "idx": idx}
else:
try:
with filesystem.open_input_stream(path) as f:
data = f.read()
except Exception as e:
logger.warning(f"Failed to read file {path}: {e}")
data = None
return {"data": data, "idx": idx}
# Create a dataset from the paths and indices, then map to read files
records = [{"path": p, "idx": i} for p, i in paths_and_idxs]
ds = ray.data.from_items(records)
def read_batch(batch: pd.DataFrame) -> pd.DataFrame:
results = []
for _, row in batch.iterrows():
result = _read_file(row["path"], row["idx"])
results.append(result)
return pd.DataFrame(results)
ds = ds.map_batches(read_batch, batch_format="pandas")
return ds
================================================
FILE: ludwig/backend/deepspeed.py
================================================
from typing import Any
import deepspeed
from ludwig.backend.base import DataParallelBackend
from ludwig.constants import FALLBACK_BATCH_SIZE
from ludwig.distributed import init_dist_strategy
from ludwig.utils.batch_size_tuner import BatchSizeEvaluator
class DeepSpeedBackend(DataParallelBackend):
BACKEND_TYPE = "deepspeed"
def __init__(
self,
zero_optimization: dict[str, Any] | None = None,
fp16: dict[str, Any] | None = None,
bf16: dict[str, Any] | None = None,
compression_training: dict[str, Any] | None = None,
**kwargs
):
super().__init__(**kwargs)
self.zero_optimization = zero_optimization
self.fp16 = fp16
self.bf16 = bf16
self.compression_training = compression_training
def initialize(self):
# Unlike when we use the Ray backend, we need to initialize the `torch.distributed` context so we can
# broadcast, allgather, etc. before preparing the model within the trainer.
deepspeed.init_distributed()
self._distributed = init_dist_strategy(
self.BACKEND_TYPE,
zero_optimization=self.zero_optimization,
fp16=self.fp16,
bf16=self.bf16,
compression_training=self.compression_training,
)
def supports_batch_size_tuning(self) -> bool:
# TODO(travis): need to fix checkpoint saving/loading for DeepSpeed to enable tuning
return False
def tune_batch_size(self, evaluator_cls: type[BatchSizeEvaluator], dataset_len: int) -> int:
return FALLBACK_BATCH_SIZE
================================================
FILE: ludwig/backend/ray.py
================================================
#! /usr/bin/env python
# Copyright (c) 2020 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import contextlib
import copy
import logging
import os
import tempfile
from collections.abc import Callable
from functools import partial
from typing import Any, TYPE_CHECKING
import dask
import numpy as np
import pandas as pd
import ray
import ray.train as rt
import torch
import tqdm
from fsspec.config import conf
from pyarrow.fs import FSSpecHandler, PyFileSystem
from ray import ObjectRef
from ray.train import Checkpoint, RunConfig, ScalingConfig
from ray.train.constants import TRAIN_ENABLE_WORKER_SPREAD_ENV
from ray.train.torch import TorchConfig, TorchTrainer
from ray.util.dask import ray_dask_get
from ray.util.placement_group import placement_group, remove_placement_group
if TYPE_CHECKING:
from ludwig.api import LudwigModel
from ludwig.backend.base import Backend, RemoteTrainingMixin
from ludwig.backend.datasource import read_binary_files_with_index
from ludwig.constants import MODEL_ECD, MODEL_LLM, NAME, PREPROCESSING, PROC_COLUMN, TYPE
from ludwig.data.dataframe.base import DataFrameEngine
try:
from ludwig.data.dataset.ray import (
_SCALAR_TYPES,
cast_as_tensor_dtype,
RayDataset,
RayDatasetManager,
RayDatasetShard,
)
except (ImportError, AttributeError):
_SCALAR_TYPES = cast_as_tensor_dtype = RayDataset = RayDatasetManager = RayDatasetShard = None
from ludwig.models.base import BaseModel
from ludwig.models.ecd import ECD
from ludwig.models.predictor import BasePredictor, get_output_columns, get_predictor_cls
from ludwig.schema.trainer import ECDTrainerConfig
from ludwig.trainers.registry import get_ray_trainers_registry, register_ray_trainer
from ludwig.trainers.trainer import BaseTrainer, RemoteTrainer
from ludwig.utils.data_utils import use_credentials
from ludwig.utils.fs_utils import get_fs_and_path
from ludwig.utils.misc_utils import get_from_registry
from ludwig.utils.system_utils import Resources
from ludwig.utils.torch_utils import get_torch_device, initialize_pytorch
from ludwig.utils.types import Series
logger = logging.getLogger(__name__)
FIFTEEN_MINS_IN_S = 15 * 60
def _num_nodes() -> int:
node_resources = [node["Resources"] for node in ray.nodes()]
return len(node_resources)
def get_trainer_kwargs(**kwargs) -> dict[str, Any]:
kwargs = copy.deepcopy(kwargs)
# Our goal is to have a worker per resource used for training.
# The priority is GPUs, but can fall back to CPUs if there are no
# GPUs available.
use_gpu = kwargs.get("use_gpu", int(ray.cluster_resources().get("GPU", 0)) > 0)
if use_gpu:
num_workers = int(ray.cluster_resources().get("GPU", 0))
else:
num_workers = _num_nodes()
# Remove nics if present (legacy option)
kwargs.pop("nics", None)
defaults = dict(
backend=TorchConfig(),
num_workers=num_workers,
use_gpu=use_gpu,
resources_per_worker={
"CPU": 0 if use_gpu else 1,
"GPU": 1 if use_gpu else 0,
},
)
return {**defaults, **kwargs}
def _create_dask_engine(**kwargs):
from ludwig.data.dataframe.dask import DaskEngine
return DaskEngine(**kwargs)
def _create_modin_engine(**kwargs):
from ludwig.data.dataframe.modin import ModinEngine
return ModinEngine(**kwargs)
def _create_pandas_engine(**kwargs):
from ludwig.data.dataframe.pandas import PandasEngine
return PandasEngine(**kwargs)
_engine_registry = {
"dask": _create_dask_engine,
"modin": _create_modin_engine,
"pandas": _create_pandas_engine,
}
def _get_df_engine(processor):
logger.info(f"Ray processor params: {processor}")
if processor is None:
# TODO ray: find an informed way to set the parallelism, in practice
# it looks like Dask handles this well on its own most of the time
return _create_dask_engine()
processor_kwargs = processor.copy()
dtype = processor_kwargs.pop("type", "dask")
engine_cls = _engine_registry.get(dtype)
return engine_cls(**processor_kwargs)
def _make_picklable(obj):
"""Recursively convert defaultdicts (which contain unpicklable lambdas) to regular dicts."""
from collections import defaultdict
if isinstance(obj, defaultdict):
return {k: _make_picklable(v) for k, v in obj.items()}
elif isinstance(obj, dict):
return {k: _make_picklable(v) for k, v in obj.items()}
elif isinstance(obj, tuple) and hasattr(obj, "_fields"):
# NamedTuple: reconstruct with the same field names
return type(obj)(**{f: _make_picklable(getattr(obj, f)) for f in obj._fields})
elif isinstance(obj, list):
return [_make_picklable(item) for item in obj]
elif isinstance(obj, tuple):
return tuple(_make_picklable(item) for item in obj)
return obj
def train_fn(
executable_kwargs: dict[str, Any] = None,
model_ref: ObjectRef = None, # noqa: F821
training_set_metadata: dict[str, Any] = None,
features: dict[str, dict] = None,
**kwargs,
):
"""Ray Train worker function for distributed training.
Runs inside each Ray worker process. Loads the model from an object ref, wraps dataset shards, trains, and saves
results to a Ray checkpoint so the driver can retrieve them (Ray Train 2.x requires a checkpoint for metrics).
"""
# Pin GPU before loading the model to prevent memory leaking onto other devices
initialize_pytorch()
# Initialize a local distributed strategy so metric modules can sync.
from ludwig.distributed import init_dist_strategy
init_dist_strategy("local")
train_shard = RayDatasetShard(
rt.get_dataset_shard("train"),
features,
training_set_metadata,
)
try:
val_shard = rt.get_dataset_shard("val")
except KeyError:
val_shard = None
if val_shard is not None:
val_shard = RayDatasetShard(
val_shard,
features,
training_set_metadata,
)
try:
test_shard = rt.get_dataset_shard("test")
except KeyError:
test_shard = None
if test_shard is not None:
test_shard = RayDatasetShard(
test_shard,
features,
training_set_metadata,
)
model = ray.get(model_ref)
# Use Ray Train's device assignment which respects use_gpu setting,
# rather than get_torch_device() which always picks CUDA if available.
from ray.train.torch import get_device as ray_get_device
device = ray_get_device()
model = model.to(device)
trainer = RemoteTrainer(model=model, report_tqdm_to_ray=True, **executable_kwargs)
results = trainer.train(train_shard, val_shard, test_shard, **kwargs)
if results is not None:
# only return the model state dict back to the head node.
trained_model, *args = results
results = (trained_model.cpu().state_dict(), *args)
torch.cuda.empty_cache()
# Save results to a checkpoint so the driver can retrieve them.
# In Ray Train 2.x, result.metrics is only populated when a checkpoint is provided.
train_results = results, trainer.validation_field, trainer.validation_metric
# Convert defaultdicts to regular dicts so they can be pickled by torch.save.
train_results = _make_picklable(train_results)
with tempfile.TemporaryDirectory() as tmpdir:
torch.save(train_results, os.path.join(tmpdir, "train_results.pt"))
rt.report(metrics={}, checkpoint=Checkpoint.from_directory(tmpdir))
@ray.remote
def tune_batch_size_fn(
dataset: RayDataset = None,
data_loader_kwargs: dict[str, Any] = None,
executable_kwargs: dict[str, Any] = None,
model: ECD = None, # noqa: F821
ludwig_config: dict[str, Any] = None,
training_set_metadata: dict[str, Any] = None,
features: dict[str, dict] = None,
**kwargs,
) -> int:
# Pin GPU before loading the model to prevent memory leaking onto other devices
initialize_pytorch()
try:
ds = dataset.to_ray_dataset(shuffle=False)
train_shard = RayDatasetShard(
ds,
features,
training_set_metadata,
)
device = get_torch_device()
model = model.to(device)
trainer = RemoteTrainer(model=model, **executable_kwargs)
return trainer.tune_batch_size(ludwig_config, train_shard, **kwargs)
finally:
torch.cuda.empty_cache()
@ray.remote
def tune_learning_rate_fn(
dataset: RayDataset,
config: dict[str, Any],
data_loader_kwargs: dict[str, Any] = None,
executable_kwargs: dict[str, Any] = None,
model: ECD = None, # noqa: F821
training_set_metadata: dict[str, Any] = None,
features: dict[str, dict] = None,
**kwargs,
) -> float:
# Pin GPU before loading the model to prevent memory leaking onto other devices
initialize_pytorch()
try:
ds = dataset.to_ray_dataset(shuffle=False)
train_shard = RayDatasetShard(
ds,
features,
training_set_metadata,
)
device = get_torch_device()
model = model.to(device)
trainer = RemoteTrainer(model=model, **executable_kwargs)
return trainer.tune_learning_rate(config, train_shard, **kwargs)
finally:
torch.cuda.empty_cache()
class TqdmCallback(rt.UserCallback):
"""Class for a custom ray callback that updates tqdm progress bars in the driver process."""
def __init__(self) -> None:
"""Constructor for TqdmCallback."""
super().__init__()
self.progess_bars = {}
def after_report(self, run_context, metrics: list[dict], checkpoint=None) -> None:
"""Called every time ray.train.report is called from subprocesses.
In Ray 2.x, metrics is a list of metric dicts (one per worker). We look for progress_bar data from the
coordinator worker.
"""
for result in metrics:
progress_bar_opts = result.get("progress_bar")
if not progress_bar_opts:
continue
# Skip commands received by non-coordinators
if not progress_bar_opts["is_coordinator"]:
continue
_id = progress_bar_opts["id"]
action = progress_bar_opts.get("action")
if action == "create":
progress_bar_config = progress_bar_opts.get("config")
self.progess_bars[_id] = tqdm.tqdm(**progress_bar_config)
elif action == "close":
if _id in self.progess_bars:
self.progess_bars[_id].close()
elif action == "update":
update_by = progress_bar_opts.get("update_by", 1)
if _id in self.progess_bars:
self.progess_bars[_id].update(update_by)
@contextlib.contextmanager
def spread_env(use_gpu: bool = False, num_workers: int = 1, **kwargs):
if TRAIN_ENABLE_WORKER_SPREAD_ENV in os.environ:
# User set this explicitly, so honor their selection
yield
return
try:
if not use_gpu and num_workers > 1:
# When doing CPU-only training, default to a SPREAD policy to avoid
# packing too many workers on a single machine
os.environ[TRAIN_ENABLE_WORKER_SPREAD_ENV] = "1"
yield
finally:
if TRAIN_ENABLE_WORKER_SPREAD_ENV in os.environ:
del os.environ[TRAIN_ENABLE_WORKER_SPREAD_ENV]
def _build_scaling_config(trainer_kwargs: dict[str, Any]) -> ScalingConfig:
"""Convert legacy trainer kwargs to a Ray ScalingConfig."""
return ScalingConfig(
num_workers=trainer_kwargs.get("num_workers", 1),
use_gpu=trainer_kwargs.get("use_gpu", False),
resources_per_worker=trainer_kwargs.get("resources_per_worker"),
)
def run_train_remote(train_loop, trainer_kwargs: dict[str, Any], callbacks=None, datasets=None, train_loop_config=None):
"""Run a distributed training function using Ray TorchTrainer."""
resolved_kwargs = get_trainer_kwargs(**trainer_kwargs)
scaling_config = _build_scaling_config(resolved_kwargs)
torch_config = resolved_kwargs.get("backend", TorchConfig())
run_config_kwargs = {}
if callbacks:
run_config_kwargs["callbacks"] = callbacks
with spread_env(**resolved_kwargs):
torch_trainer = TorchTrainer(
train_loop_per_worker=train_loop,
train_loop_config=train_loop_config,
torch_config=torch_config,
scaling_config=scaling_config,
run_config=RunConfig(**run_config_kwargs),
datasets=datasets,
)
result = torch_trainer.fit()
return result
@register_ray_trainer(MODEL_ECD, default=True)
class RayTrainerV2(BaseTrainer):
def __init__(
self,
model: BaseModel,
trainer_kwargs: dict[str, Any],
data_loader_kwargs: dict[str, Any],
executable_kwargs: dict[str, Any],
**kwargs,
):
self.model = model.cpu()
self.data_loader_kwargs = data_loader_kwargs
self.executable_kwargs = executable_kwargs
self.trainer_kwargs = trainer_kwargs
self._validation_field = None
self._validation_metric = None
@staticmethod
def get_schema_cls():
return ECDTrainerConfig
def train(
self,
training_set: RayDataset,
validation_set: RayDataset | None = None,
test_set: RayDataset | None = None,
**kwargs,
):
executable_kwargs = self.executable_kwargs
kwargs = {
"training_set_metadata": training_set.training_set_metadata,
"features": training_set.features,
**kwargs,
}
dataset = {"train": training_set.to_ray_dataset(shuffle=True)}
if validation_set is not None:
dataset["val"] = validation_set.to_ray_dataset(shuffle=False)
if test_set is not None:
dataset["test"] = test_set.to_ray_dataset(shuffle=False)
train_loop_config = {"executable_kwargs": executable_kwargs, "model_ref": ray.put(self.model), **kwargs}
def _train_loop(config):
train_fn(**config)
result = run_train_remote(
_train_loop,
trainer_kwargs=self.trainer_kwargs,
callbacks=[TqdmCallback()],
datasets=dataset,
train_loop_config=train_loop_config,
)
# Load training results from the checkpoint saved by train_fn
with result.checkpoint.as_directory() as tmpdir:
train_results = torch.load(os.path.join(tmpdir, "train_results.pt"), weights_only=False)
results, self._validation_field, self._validation_metric = train_results
# load state dict back into the model
state_dict, *args = results
self.model.load_state_dict(state_dict)
results = (self.model, *args)
return results
def train_online(self, *args, **kwargs):
# TODO: When this is implemented we also need to update the
# Tqdm flow to report back the callback
raise NotImplementedError()
def tune_batch_size(
self,
config: dict[str, Any],
training_set: RayDataset,
**kwargs,
) -> int:
return ray.get(
tune_batch_size_fn.options(num_cpus=self.num_cpus, num_gpus=self.num_gpus).remote(
dataset=training_set,
data_loader_kwargs=self.data_loader_kwargs,
executable_kwargs=self.executable_kwargs,
model=ray.put(self.model),
ludwig_config=config,
training_set_metadata=training_set.training_set_metadata,
features=training_set.features,
**kwargs,
)
)
def tune_learning_rate(self, config, training_set: RayDataset, **kwargs) -> float:
return ray.get(
tune_learning_rate_fn.options(num_cpus=self.num_cpus, num_gpus=self.num_gpus).remote(
dataset=training_set,
config=config,
data_loader_kwargs=self.data_loader_kwargs,
executable_kwargs=self.executable_kwargs,
model=ray.put(self.model),
training_set_metadata=training_set.training_set_metadata,
features=training_set.features,
**kwargs,
)
)
@property
def validation_field(self):
return self._validation_field
@property
def validation_metric(self):
return self._validation_metric
@property
def config(self) -> ECDTrainerConfig:
return self.executable_kwargs["config"]
@property
def batch_size(self) -> int:
return self.config.batch_size
@batch_size.setter
def batch_size(self, value: int):
self.config.batch_size = value
@property
def eval_batch_size(self) -> int:
return self.config.eval_batch_size if self.config.eval_batch_size is not None else self.config.batch_size
@eval_batch_size.setter
def eval_batch_size(self, value: int):
self.config.eval_batch_size = value
@property
def resources_per_worker(self) -> dict[str, Any]:
trainer_kwargs = get_trainer_kwargs(**self.trainer_kwargs)
return trainer_kwargs.get("resources_per_worker", {})
@property
def num_cpus(self) -> int:
return self.resources_per_worker.get("CPU", 1)
@property
def num_gpus(self) -> int:
return self.resources_per_worker.get("GPU", 0)
def set_base_learning_rate(self, learning_rate: float):
self.config.learning_rate = learning_rate
def shutdown(self):
pass
def eval_fn(
predictor_kwargs: dict[str, Any] = None,
model_ref: ObjectRef = None, # noqa: F821
training_set_metadata: dict[str, Any] = None,
features: dict[str, dict] = None,
**kwargs,
):
"""Ray Train worker function for distributed evaluation.
Runs inside each Ray worker process. Loads the model from an object ref, wraps the eval dataset shard, runs
prediction and evaluation, and saves results to a Ray checkpoint for driver retrieval.
"""
# Pin GPU before loading the model to prevent memory leaking onto other devices
initialize_pytorch()
# Initialize a local distributed strategy so metric modules can sync.
from ludwig.distributed import init_dist_strategy
init_dist_strategy("local")
try:
eval_shard = RayDatasetShard(
rt.get_dataset_shard("eval"),
features,
training_set_metadata,
)
model = ray.get(model_ref)
# Use Ray Train's device assignment which respects use_gpu setting
from ray.train.torch import get_device as ray_get_device
device = ray_get_device()
model = model.to(device)
predictor_cls = get_predictor_cls(model.type())
predictor = predictor_cls(dist_model=model, model=model, report_tqdm_to_ray=True, **predictor_kwargs)
eval_results = predictor.batch_evaluation(eval_shard, **kwargs)
# Save results to a checkpoint so the driver can retrieve them.
# In Ray Train 2.x, result.metrics is only populated when a checkpoint is provided.
eval_results = _make_picklable(eval_results)
with tempfile.TemporaryDirectory() as tmpdir:
torch.save(eval_results, os.path.join(tmpdir, "eval_results.pt"))
rt.report(metrics={}, checkpoint=Checkpoint.from_directory(tmpdir))
finally:
torch.cuda.empty_cache()
class RayPredictor(BasePredictor):
def __init__(
self, model: BaseModel, df_engine: DataFrameEngine, trainer_kwargs, data_loader_kwargs, **predictor_kwargs
):
self.batch_size = predictor_kwargs["batch_size"]
self.trainer_kwargs = trainer_kwargs
self.data_loader_kwargs = data_loader_kwargs
self.predictor_kwargs = predictor_kwargs
self.actor_handles = []
self.model = model.cpu()
self.df_engine = df_engine
def get_trainer_kwargs(self) -> dict[str, Any]:
return get_trainer_kwargs(**self.trainer_kwargs)
def get_resources_per_worker(self) -> tuple[int, int]:
trainer_kwargs = self.get_trainer_kwargs()
resources_per_worker = trainer_kwargs.get("resources_per_worker", {})
num_gpus = resources_per_worker.get("GPU", 0)
num_cpus = resources_per_worker.get("CPU", (1 if num_gpus == 0 else 0))
return num_cpus, num_gpus
def batch_predict(self, dataset: RayDataset, *args, collect_logits: bool = False, **kwargs):
self._check_dataset(dataset)
predictor_kwargs = self.predictor_kwargs
output_columns = get_output_columns(self.model.output_features, include_logits=collect_logits)
batch_predictor = self.get_batch_infer_model(
self.model,
predictor_kwargs,
output_columns,
dataset.features,
dataset.training_set_metadata,
*args,
collect_logits=collect_logits,
**kwargs,
)
columns = [f.proc_column for f in self.model.input_features.values()]
def to_tensors(df: pd.DataFrame) -> pd.DataFrame:
for c in columns:
df[c] = cast_as_tensor_dtype(df[c])
return df
num_cpus, num_gpus = self.get_resources_per_worker()
predictions = dataset.ds.map_batches(to_tensors, batch_format="pandas").map_batches(
batch_predictor,
batch_size=self.batch_size,
compute=ray.data.ActorPoolStrategy(),
batch_format="pandas",
num_cpus=num_cpus,
num_gpus=num_gpus,
)
predictions = self.df_engine.from_ray_dataset(predictions)
return predictions
def predict_single(self, batch):
raise NotImplementedError("predict_single can only be called on a local predictor")
def batch_evaluation(
self,
dataset: RayDataset,
collect_predictions: bool = False,
collect_logits=False,
**kwargs,
):
# We need to be in a distributed context to collect the aggregated metrics, since it relies on collective
# communication ops. However, distributed training is not suitable for transforming one big dataset to another.
# For that we will use Ray Datasets. Therefore, we break this up into two separate steps, and two passes over
# the dataset. In the future, we can explore ways to combine these into a single step to reduce IO.
# Collect eval metrics by distributing work across nodes / gpus
datasets = {"eval": dataset.to_ray_dataset(shuffle=False)}
predictor_kwargs = {
**self.predictor_kwargs,
"collect_predictions": False,
}
eval_loop_config = {
"predictor_kwargs": predictor_kwargs,
"model_ref": ray.put(self.model),
"training_set_metadata": dataset.training_set_metadata,
"features": dataset.features,
**kwargs,
}
def _eval_loop(config):
eval_fn(**config)
result = run_train_remote(
_eval_loop,
trainer_kwargs=self.trainer_kwargs,
datasets=datasets,
train_loop_config=eval_loop_config,
)
# Load eval results from the checkpoint saved by eval_fn
with result.checkpoint.as_directory() as tmpdir:
eval_stats, _ = torch.load(os.path.join(tmpdir, "eval_results.pt"), weights_only=False)
predictions = None
if collect_predictions:
# Collect eval predictions by using Ray Datasets to transform partitions of the data in parallel
predictions = self.batch_predict(dataset, collect_logits=collect_logits)
return eval_stats, predictions
def batch_collect_activations(self, model, *args, **kwargs):
raise NotImplementedError("Ray backend does not support collecting activations at this time.")
def _check_dataset(self, dataset):
if not isinstance(dataset, RayDataset):
raise RuntimeError(f"Ray backend requires RayDataset for inference, " f"found: {type(dataset)}")
def shutdown(self):
for handle in self.actor_handles:
ray.kill(handle)
self.actor_handles.clear()
def get_batch_infer_model(
self,
model: "LudwigModel", # noqa: F821
predictor_kwargs: dict[str, Any],
output_columns: list[str],
features: dict[str, dict],
training_set_metadata: dict[str, Any],
*args,
**kwargs,
):
model_ref = ray.put(model)
_, num_gpus = self.get_resources_per_worker()
class BatchInferModel:
def __init__(self):
model = ray.get(model_ref)
# Respect the GPU setting from resources_per_worker.
# When num_gpus=0, force CPU even if CUDA is available on the machine,
# to avoid device mismatches between model outputs and targets.
if num_gpus > 0:
device = get_torch_device()
else:
device = "cpu"
self.model = model.to(device)
self.output_columns = output_columns
self.features = features
self.training_set_metadata = training_set_metadata
self.reshape_map = {
f[PROC_COLUMN]: training_set_metadata[f[NAME]].get("reshape") for f in features.values()
}
predictor_cls = get_predictor_cls(self.model.type())
predictor = predictor_cls(dist_model=self.model, model=self.model, **predictor_kwargs)
self.predict = partial(predictor.predict_single, *args, **kwargs)
def __call__(self, df: pd.DataFrame) -> pd.DataFrame:
dataset = self._prepare_batch(df)
predictions = self.predict(batch=dataset).set_index(df.index)
ordered_predictions = predictions[self.output_columns]
return ordered_predictions
def _prepare_batch(self, batch: pd.DataFrame) -> dict[str, np.ndarray]:
res = {}
for c in self.features.keys():
if self.features[c][TYPE] not in _SCALAR_TYPES:
# Ensure columns stacked instead of turned into np.array([np.array, ...], dtype=object) objects
res[c] = np.stack(batch[c].values)
else:
res[c] = batch[c].to_numpy()
for c in self.features.keys():
reshape = self.reshape_map.get(c)
if reshape is not None:
res[c] = res[c].reshape((-1, *reshape))
return res
return BatchInferModel
class RayBackend(RemoteTrainingMixin, Backend):
BACKEND_TYPE = "ray"
def __init__(self, processor=None, trainer=None, loader=None, preprocessor_kwargs=None, **kwargs):
super().__init__(dataset_manager=RayDatasetManager(self), **kwargs)
self._preprocessor_kwargs = preprocessor_kwargs or {}
self._df_engine = _get_df_engine(processor)
self._distributed_kwargs = trainer or {}
self._pytorch_kwargs = {}
self._data_loader_kwargs = loader or {}
self._preprocessor_pg = None
def initialize(self):
initialize_ray()
dask.config.set(scheduler=ray_dask_get)
# Disable placement groups on dask
dask.config.set(annotations={"ray_remote_args": {"placement_group": None}})
# Prevent Dask from converting object-dtype columns to PyArrow strings,
# which corrupts binary data, numpy arrays, and complex Python objects.
dask.config.set({"dataframe.convert-string": False})
def generate_bundles(self, num_cpu):
# Ray requires that each bundle be scheduleable on a single node.
# So a bundle of 320 cpus would never get scheduled. For now a simple heuristic
# to be used is to just request 1 cpu at a time.
return [{"CPU": 1} for _ in range(int(num_cpu))]
@contextlib.contextmanager
def provision_preprocessing_workers(self):
num_cpu = self._preprocessor_kwargs.get("num_cpu")
if not num_cpu:
logger.info(
"Backend config has num_cpu not set." " provision_preprocessing_workers() is a no-op in this case."
)
yield
else:
bundles = self.generate_bundles(num_cpu)
logger.info("Requesting bundles of %s for preprocessing", bundles)
self._preprocessor_pg = placement_group(bundles)
ready = self._preprocessor_pg.wait(FIFTEEN_MINS_IN_S)
if not ready:
remove_placement_group(self._preprocessor_pg)
raise TimeoutError(
"Ray timed out in provisioning the placement group for preprocessing."
f" {num_cpu} CPUs were requested but were unable to be provisioned."
)
logger.info("%s CPUs were requested and successfully provisioned", num_cpu)
try:
with dask.config.set(annotations={"ray_remote_args": {"placement_group": self._preprocessor_pg}}):
yield
finally:
self._release_preprocessing_workers()
def _release_preprocessing_workers(self):
if self._preprocessor_pg is not None:
remove_placement_group(self._preprocessor_pg)
self._preprocessor_pg = None
def initialize_pytorch(self, **kwargs):
# Make sure we don't claim any GPU resources on the head node
initialize_pytorch(gpus=-1)
self._pytorch_kwargs = kwargs
def create_trainer(self, model: BaseModel, **kwargs) -> "BaseTrainer": # noqa: F821
executable_kwargs = {**kwargs, **self._pytorch_kwargs}
if model.type() == MODEL_LLM:
from ludwig.trainers.registry import get_llm_ray_trainers_registry
trainer_config = kwargs.get("config")
trainer_type = trainer_config.type if trainer_config else None
trainer_cls = get_from_registry(trainer_type, get_llm_ray_trainers_registry())
else:
trainer_cls = get_from_registry(model.type(), get_ray_trainers_registry())
# Deep copy to workaround https://github.com/ray-project/ray/issues/24139
all_kwargs = {
"model": model,
"trainer_kwargs": copy.deepcopy(self._distributed_kwargs),
"data_loader_kwargs": self._data_loader_kwargs,
"executable_kwargs": executable_kwargs,
}
all_kwargs.update(kwargs)
return trainer_cls(**all_kwargs)
def create_predictor(self, model: BaseModel, **kwargs):
executable_kwargs = {**kwargs, **self._pytorch_kwargs}
return RayPredictor(
model,
self.df_engine,
copy.deepcopy(self._distributed_kwargs),
self._data_loader_kwargs,
**executable_kwargs,
)
def set_distributed_kwargs(self, **kwargs):
self._distributed_kwargs = kwargs
@property
def df_engine(self):
return self._df_engine
@property
def supports_multiprocessing(self):
return False
def check_lazy_load_supported(self, feature):
if not feature[PREPROCESSING]["in_memory"]:
raise ValueError(
f"RayBackend does not support lazy loading of data files at train time. "
f"Set preprocessing config `in_memory: True` for feature {feature[NAME]}"
)
def read_binary_files(self, column: Series, map_fn: Callable | None = None, file_size: int | None = None) -> Series:
column = column.fillna(np.nan).replace([np.nan], [None]) # normalize NaNs to None
# Assume that the list of filenames is small enough to fit in memory. Should be true unless there
# are literally billions of filenames.
# TODO(travis): determine if there is a performance penalty to passing in individual files instead of
# a directory. If so, we can do some preprocessing to determine if it makes sense to read the full directory
# then filter out files as a postprocessing step (depending on the ratio of included to excluded files in
# the directory). Based on a preliminary look at how Ray handles directory expansion to files, it looks like
# there should not be any difference between providing a directory versus a list of files.
pd_column = self.df_engine.compute(column)
fnames = pd_column.values.tolist()
idxs = pd_column.index.tolist()
# Sample a filename to extract the filesystem info
sample_fname = fnames[0]
if isinstance(sample_fname, str):
fs, _ = get_fs_and_path(sample_fname)
filesystem = PyFileSystem(FSSpecHandler(fs))
paths_and_idxs = list(zip(fnames, idxs))
ds = read_binary_files_with_index(paths_and_idxs, filesystem=filesystem)
# Rename "data" column to "value" for downstream compatibility
ds = ds.rename_columns({"data": "value"})
else:
# Assume the path has already been read in, so just convert directly to a dataset
# Name the column "value" to match the behavior of the above
column_df = column.to_frame(name="value")
column_df["idx"] = column_df.index
ds = self.df_engine.to_ray_dataset(column_df)
# Collect the Ray Dataset to pandas to avoid Arrow's string coercion
# for binary/object columns (to_dask() converts bytes to string[pyarrow],
# corrupting binary data and complex Python objects).
pdf = ds.to_pandas()
if map_fn is not None:
with use_credentials(conf):
pdf["value"] = pdf["value"].map(map_fn)
pdf = pdf.rename(columns={"value": column.name})
if "idx" in pdf.columns:
pdf = pdf.set_index("idx", drop=True)
pdf.index.name = column.index.name
# Convert to Dask for downstream compatibility.
# Note: dataframe.convert-string is disabled globally in RayBackend.initialize()
# to prevent object-dtype columns from being coerced to PyArrow strings.
df = self.df_engine.from_pandas(pdf)
return df[column.name]
@property
def num_nodes(self) -> int:
if not ray.is_initialized():
return 1
return len(ray.nodes())
@property
def num_training_workers(self) -> int:
return self._distributed_kwargs.get("num_workers", 1)
def max_concurrent_trials(self, hyperopt_config) -> int | None:
# Limit concurrency based on available resources to avoid deadlocks between
# Ray Tune trials and the Ray Datasets used internally for distributed training.
resources = self.get_available_resources()
num_cpus_per_trial = self._distributed_kwargs.get("resources_per_worker", {}).get("CPU", 1)
num_workers = self._distributed_kwargs.get("num_workers", 1)
cpus_per_trial = num_cpus_per_trial * num_workers
if cpus_per_trial > 0 and resources.cpus > 0:
return max(1, int(resources.cpus // cpus_per_trial))
return None
def tune_batch_size(self, evaluator_cls, dataset_len: int) -> int:
evaluator = evaluator_cls()
return evaluator.select_best_batch_size(dataset_len)
def batch_transform(self, df, batch_size: int, transform_fn, name: str | None = None):
name = name or "Batch Transform"
import dask.dataframe as dd
from ludwig.utils.dataframe_utils import from_batches, to_batches
# Compute Dask DataFrame to pandas before batching, as Dask-expr
# doesn't support row slicing via integer indexing (df[i:j]).
npartitions = df.npartitions if hasattr(df, "npartitions") else 1
df = self.df_engine.compute(df)
batches = to_batches(df, batch_size)
transform = transform_fn()
out_batches = [transform(batch.reset_index(drop=True)) for batch in batches]
out_df = from_batches(out_batches).reset_index(drop=True)
# Convert back to Dask so downstream code (split, etc.) still works
return dd.from_pandas(out_df, npartitions=max(1, npartitions))
def get_available_resources(self) -> Resources:
resources = ray.cluster_resources()
return Resources(cpus=resources.get("CPU", 0), gpus=resources.get("GPU", 0))
def initialize_ray():
if not ray.is_initialized():
try:
ray.init("auto", ignore_reinit_error=True)
except ConnectionError:
init_ray_local()
def init_ray_local():
logger.info("Initializing new Ray cluster...")
ray.init(ignore_reinit_error=True)
================================================
FILE: ludwig/backend/utils/__init__.py
================================================
================================================
FILE: ludwig/backend/utils/storage.py
================================================
import contextlib
from typing import Any, Optional, Union
from ludwig.utils import data_utils
CredInputs = Optional[Union[str, dict[str, Any]]]
DEFAULTS = "defaults"
ARTIFACTS = "artifacts"
DATASETS = "datasets"
CACHE = "cache"
class Storage:
def __init__(self, creds: dict[str, Any] | None):
self._creds = creds
@contextlib.contextmanager
def use_credentials(self):
with data_utils.use_credentials(self._creds):
yield
@property
def credentials(self) -> dict[str, Any] | None:
return self._creds
class StorageManager:
def __init__(
self,
defaults: CredInputs = None,
artifacts: CredInputs = None,
datasets: CredInputs = None,
cache: CredInputs = None,
):
defaults = load_creds(defaults)
cred_inputs = {
DEFAULTS: defaults,
ARTIFACTS: load_creds(artifacts),
DATASETS: load_creds(datasets),
CACHE: load_creds(cache),
}
self.storages = {k: Storage(v if v is not None else defaults) for k, v in cred_inputs.items()}
@property
def defaults(self) -> Storage:
return self.storages[DEFAULTS]
@property
def artifacts(self) -> Storage:
"""TODO(travis): Currently used for hyperopt, but should be used for all outputs."""
return self.storages[ARTIFACTS]
@property
def datasets(self) -> Storage:
"""TODO(travis): Should be used to read in datasets."""
return self.storages[DATASETS]
@property
def cache(self) -> Storage:
return self.storages[CACHE]
def load_creds(cred: CredInputs) -> dict[str, Any]:
if isinstance(cred, str):
cred = data_utils.load_json(cred)
return cred
================================================
FILE: ludwig/benchmarking/README.md
================================================
# Ludwig Benchmarking
### Some use cases
- Regression testing for ML experiments across releases and PRs.
- Model performance testing for experimenting with new features and hyperparameters.
- Resource usage tracking for the full ML pipeline.
## Ludwig benchmarking CLI and API
To run benchmarks, run the following command from the command line
```
ludwig benchmark --benchmarking_config path/to/benchmarking/config.yaml
```
To use the API
```
from ludwig.benchmarking.benchmark import benchmark
benchmarking_config_path = "path/to/benchmarking/config.yaml"
benchmark(benchmarking_config_path)
```
In what follows, we describe what the benchmarking config looks for
multiple use cases.
## The benchmarking config
The benchmarking config is where you can specify
1. The datasets you want to run the benchmarks on and their configs.
1. Whether these experiments are hyperopt or regular train and eval experiments.
1. The name of the experiment.
1. A python script to edit the specified Ludwig configs programmatically/on the fly.
1. The export path of these experiment's artifacts. (remotely or locally)
1. Whether to use `LudwigProfiler` to track resource
usage for preprocessing, training, and evaluation of the experiment.
You can find an example of a benchmarking config in the `examples/` directory.
## Basic Usage
Say you implemented a new feature and would like to test it on several datasets.
In this case, this is what the benchmarking config could look like
```
experiment_name: SMOTE_test
hyperopt: false
export:
export_artifacts: true
export_base_path: s3://benchmarking.us-west-2.ludwig.com/bench/ # include the slash at the end.
experiments:
- dataset_name: ames_housing
config_path: /home/ray/configs/ames_housing_SMOTE.yaml
experiment_name: SMOTE_test_with_hyperopt
hyperopt: true
- dataset_name: protein
- ...
...
- dataset_name: mercedes_benz_greener
config_path: /home/ray/configs/mercedes_benz_greener_SMOTE.yaml
```
For each experiment:
- `dataset_name`: name of the dataset in `ludwig.datasets` to run the benchmark on.
- `config_path` (optional): path to Ludwig config. If not specified, this will load
the config corresponding to the dataset only containing `input_features` and
`output_features`.
This will run `LudwigModel.experiment` on the datasets with their specified configs.
If these configs contain a hyperopt section and you'd like to run hyperopt, change
to `hyperopt: true`.
You can specify the same dataset multiple times with different configs.
**Exporting artifacts**
By specifying `export_artifacts: true`, this will export the experiment artifacts
to the `export_base_path`. Once the model is trained and the artifacts are pushed
to the specified path, you will get a similar message to the following:
```
Uploaded metrics report and experiment config to
s3://benchmarking.us-west-2.ludwig.com/bench/ames_housing/SMOTE_test
```
This is the directory structure of the exported artifacts for one of the experiments.
```
s3://benchmarking.us-west-2.ludwig.com/bench/
└── ames_housing
└── SMOTE_test
├── config.yaml
└── experiment_run
├── description.json
├── model
│ ├── logs
│ │ ├── test
│ │ │ └── events.out.tfevents.1663320893.macbook-pro.lan.8043.2
│ │ ├── training
│ │ │ └── events.out.tfevents.1663320893.macbook-pro.lan.8043.0
│ │ └── validation
│ │ └── events.out.tfevents.1663320893.macbook-pro.lan.8043.1
│ ├── model_hyperparameters.json
│ ├── training_progress.json
│ └── training_set_metadata.json
├── test_statistics.json
└── training_statistics.json
```
Note that model checkpoints are not exported. Any other experiments on
the `ames_housing` dataset will also live under
`s3://benchmarking.us-west-2.ludwig.com/bench/ames_housing/`
**Overriding parameters**
The benchmarking config's global parameters `experiment_name` and `hyperopt` can be overridden
if specified within an experiment.
## Programmatically editing Ludwig configs
To apply some changes to multiple Ludwig configs, you can specify a path to a python script
that does this without the need to do manual modifications across many configs. Example:
```
experiment_name: logistic_regression_hyperopt
hyperopt: true
process_config_file_path: /home/ray/process_config.py
export:
export_artifacts: true
export_base_path: s3://benchmarking.us-west-2.ludwig.com/bench/ # include the slash at the end.
experiments:
- dataset_name: ames_housing
config_path: /home/ray/configs/ames_housing_SMOTE.yaml
...
```
In `/home/ray/process_config.py`, define the following function and add custom code to modify
ludwig configs
```
def process_config(ludwig_config: dict, experiment_dict: dict) -> dict:
"""Modify a Ludwig config.
:param ludwig_config: a Ludwig config.
:param experiment_dict: a benchmarking config experiment dictionary.
returns: a modified Ludwig config.
"""
# code to modify the Ludwig config.
return ludwig_config
```
View the `examples/` folder for an example `process_config.py`.
## Benchmarking the resource usage with `LudwigProfiler`
To benchmark the resource usage of the preprocessing, training, and evaluation
steps of `LudwigModel.experiment`, you can specify in the benchmarking config
global parameters
```
profiler:
enable: true
use_torch_profiler: false
logging_interval: 0.1
```
- `enable: true` will run benchmarking with `LudwigProfiler`.
- `use_torch_profiler: false` will skip using the torch profiler.
- `logging_interval: 0.1` will instruct `LudwigProfiler` to collect
resource usage information every 0.1 seconds.
Note that profiling is only enabled in the case where `hyperopt: false`.
`LudwigProfiler` is passed in to `LudwigModel` callbacks. The specific
callbacks that will be called are:
- `on_preprocess_(start/end)`
- `on_train_(start/end)`
- `on_evaluation_(start/end)`
This is an example directory output when using the profiler:
```
full_bench_with_profiler_with_torch
├── config.yaml
├── experiment_run
├── system_resource_usage
│ ├── evaluation
│ │ └── run_0.json
│ ├── preprocessing
│ │ └── run_0.json
│ └── training
│ └── run_0.json
└── torch_ops_resource_usage
├── evaluation
│ └── run_0.json
├── preprocessing
│ └── run_0.json
└── training
└── run_0.json
```
The only difference is the `system_resource_usage` and `torch_ops_resource_usage`.
The difference between these two outputs can be found in the `LudwigProfiler` README.
## Parameters and defaults
Each of these parameters can also be specified in the experiments section to override the global value.
If not specified, the value of the global parameter will be propagated to the experiments.
- `experiment_name` (required): name of the benchmarking run.
- `export` (required): dictionary specifying whether to export the experiment artifacts and the export path.
- `hyperopt` (optional): whether this is a hyperopt run or `LudwigModel.experiment`.
- `process_config_file_path` (optional): path to python script that will modify configs.
- `profiler` (optional): dictionary specifying whether to use the profiler and its parameters.
## Comparing experiments
You can summarize the exported artifacts of two experiments on multiple datasets.
For example, if you ran two experiments on the datasets `ames_housing` called
`small_batch_size` and `big_batch_size` where you varied the batch size,
you can create a diff summary of the model performance and resource usage of the two
experiments. This is how:
```
from ludwig.benchmarking.summarize import summarize_metrics
dataset_list, metric_diffs, resource_usage_diffs = summarize_metrics(
bench_config_path = "path/to/benchmarking_config.yaml",
base_experiment = "small_batch_size",
experimental_experiment = "big_batch_size",
download_base_path = "s3://benchmarking.us-west-2.ludwig.com/bench/")
```
This will print
```
Model performance metrics for *small_batch_size* vs. *big_batch_size* on dataset *ames_housing*
Output Feature Name Metric Name small_batch_size big_batch_size Diff Diff Percentage
SalePrice mean_absolute_error 180551.609 180425.109 -126.5 -0.07
SalePrice mean_squared_error 38668763136.0 38618021888.0 -50741248.0 -0.131
SalePrice r2 -5.399 -5.391 0.008 -0.156
SalePrice root_mean_squared_error 196643.75 196514.688 -129.062 -0.066
SalePrice root_mean_squared_percentage_error 1.001 1.001 -0.001 -0.07
Exported a CSV report to summarize_output/performance_metrics/ames_housing/small_batch_size-big_batch_size.csv
Resource usage for *small_batch_size* vs. *big_batch_size* on *training* of dataset *ames_housing*
Metric Name small_batch_size big_batch_size Diff Diff Percentage
average_cpu_memory_usage 106.96 Mb 109.43 Mb 2.48 Mb 2.315
average_cpu_utilization 1.2966666666666666 1.345 0.04833333333333334 3.728
average_global_cpu_memory_available 3.46 Gb 3.46 Gb -1.10 Mb -0.031
average_global_cpu_utilization 37.43333333333334 40.49 3.056666666666665 8.166
disk_footprint 372736 413696 40960 10.989
max_cpu_memory_usage 107.50 Mb 111.93 Mb 4.43 Mb 4.117
max_cpu_utilization 1.44 1.67 0.22999999999999998 15.972
max_global_cpu_utilization 54.1 60.9 6.799999999999997 12.569
min_global_cpu_memory_available 3.46 Gb 3.46 Gb -712.00 Kb -0.02
num_cpu 10 10 0 0.0
num_oom_events 0 0 0 inf
num_runs 1 1 0 0.0
torch_cpu_average_memory_used 81.44 Kb 381.15 Kb 299.70 Kb 367.992
torch_cpu_max_memory_used 334.26 Kb 2.65 Mb 2.32 Mb 711.877
torch_cpu_time 57.400ms 130.199ms 72.799ms 126.828
torch_cuda_time 0.000us 0.000us 0.000us inf
total_cpu_memory_size 32.00 Gb 32.00 Gb 0 b 0.0
total_execution_time 334.502ms 1.114s 779.024ms 232.891
Exported a CSV report to summarize_output/resource_usage_metrics/ames_housing/training-small_batch_size-big_batch_size.csv
Resource usage for *small_batch_size* vs. *big_batch_size* on *evaluation* of dataset *ames_housing*
...
Resource usage for *small_batch_size* vs. *big_batch_size* on *preprocessing* of dataset *ames_housing*
...
```
================================================
FILE: ludwig/benchmarking/__init__.py
================================================
================================================
FILE: ludwig/benchmarking/artifacts.py
================================================
import os
from dataclasses import dataclass
from typing import Any
from ludwig.globals import MODEL_FILE_NAME
from ludwig.types import ModelConfigDict, TrainingSetMetadataDict
from ludwig.utils.data_utils import load_json, load_yaml
@dataclass
class BenchmarkingResult:
# The Ludwig benchmarking config.
benchmarking_config: dict[str, Any]
# The config for one experiment.
experiment_config: dict[str, Any]
# The Ludwig config used to run the experiment.
ludwig_config: ModelConfigDict
# The python script that is used to process the config before being used.
process_config_file: str
# Loaded `description.json` file.
description: dict[str, Any]
# Loaded `test_statistics.json` file.
test_statistics: dict[str, Any]
# Loaded `training_statistics.json` file.
training_statistics: dict[str, Any]
# Loaded `model_hyperparameters.json` file.
model_hyperparameters: dict[str, Any]
# Loaded `training_progress.json` file.
training_progress: dict[str, Any]
# Loaded `training_set_metadata.json` file.
training_set_metadata: TrainingSetMetadataDict
def build_benchmarking_result(benchmarking_config: dict, experiment_idx: int):
experiment_config = benchmarking_config["experiments"][experiment_idx]
process_config_file = ""
if experiment_config["process_config_file_path"]:
with open(experiment_config["process_config_file_path"]) as f:
process_config_file = "".join(f.readlines())
experiment_run_path = os.path.join(experiment_config["experiment_name"], "experiment_run")
return BenchmarkingResult(
benchmarking_config=benchmarking_config,
experiment_config=experiment_config,
ludwig_config=load_yaml(experiment_config["config_path"]),
process_config_file=process_config_file,
description=load_json(os.path.join(experiment_run_path, "description.json")),
test_statistics=load_json(os.path.join(experiment_run_path, "test_statistics.json")),
training_statistics=load_json(os.path.join(experiment_run_path, "training_statistics.json")),
model_hyperparameters=load_json(
os.path.join(experiment_run_path, MODEL_FILE_NAME, "model_hyperparameters.json")
),
training_progress=load_json(os.path.join(experiment_run_path, MODEL_FILE_NAME, "training_progress.json")),
training_set_metadata=load_json(
os.path.join(experiment_run_path, MODEL_FILE_NAME, "training_set_metadata.json")
),
)
================================================
FILE: ludwig/benchmarking/benchmark.py
================================================
import argparse
import importlib
import logging
import os
import shutil
from typing import Any
import ludwig.datasets
from ludwig.api import LudwigModel
from ludwig.benchmarking.artifacts import BenchmarkingResult, build_benchmarking_result
from ludwig.benchmarking.profiler_callbacks import LudwigProfilerCallback
from ludwig.benchmarking.utils import (
create_default_config,
delete_hyperopt_outputs,
delete_model_checkpoints,
export_artifacts,
load_from_module,
populate_benchmarking_config_with_defaults,
propagate_global_parameters,
save_yaml,
validate_benchmarking_config,
)
from ludwig.contrib import add_contrib_callback_args
from ludwig.hyperopt.run import hyperopt
from ludwig.utils.data_utils import load_yaml
logger = logging.getLogger()
def setup_experiment(experiment: dict[str, str]) -> dict[Any, Any]:
"""Set up the backend and load the Ludwig config.
Args:
experiment: dictionary containing the dataset name, config path, and experiment name.
Returns a Ludwig config.
"""
shutil.rmtree(os.path.join(experiment["experiment_name"]), ignore_errors=True)
if "config_path" not in experiment:
experiment["config_path"] = create_default_config(experiment)
model_config = load_yaml(experiment["config_path"])
if experiment["process_config_file_path"]:
process_config_spec = importlib.util.spec_from_file_location(
"process_config_file_path.py", experiment["process_config_file_path"]
)
process_module = importlib.util.module_from_spec(process_config_spec)
process_config_spec.loader.exec_module(process_module)
model_config = process_module.process_config(model_config, experiment)
experiment["config_path"] = experiment["config_path"].replace(
".yaml", "-" + experiment["experiment_name"] + "-modified.yaml"
)
save_yaml(experiment["config_path"], model_config)
return model_config
def benchmark_one(experiment: dict[str, str | dict[str, str]]) -> None:
"""Run a Ludwig exepriment and track metrics given a dataset name.
Args:
experiment: dictionary containing the dataset name, config path, and experiment name.
"""
logger.info(f"\nRunning experiment *{experiment['experiment_name']}* on dataset *{experiment['dataset_name']}*")
# configuring backend and paths
model_config = setup_experiment(experiment)
# loading dataset
# dataset_module = importlib.import_module(f"ludwig.datasets.{experiment['dataset_name']}")
dataset_module = ludwig.datasets.get_dataset(experiment["dataset_name"])
dataset = load_from_module(dataset_module, model_config["output_features"][0])
if experiment["hyperopt"]:
# run hyperopt
hyperopt(
config=model_config,
dataset=dataset,
output_directory=experiment["experiment_name"],
skip_save_model=True,
skip_save_training_statistics=True,
skip_save_progress=True,
skip_save_log=True,
skip_save_processed_input=True,
skip_save_unprocessed_output=True,
skip_save_predictions=True,
skip_save_training_description=True,
hyperopt_log_verbosity=0,
)
delete_hyperopt_outputs(experiment["experiment_name"])
else:
backend = None
ludwig_profiler_callbacks = None
if experiment["profiler"]["enable"]:
ludwig_profiler_callbacks = [LudwigProfilerCallback(experiment)]
# Currently, only local backend is supported with LudwigProfiler.
backend = "local"
logger.info("Currently, only local backend is supported with LudwigProfiler.")
# run model and capture metrics
model = LudwigModel(
config=model_config, callbacks=ludwig_profiler_callbacks, logging_level=logging.ERROR, backend=backend
)
model.experiment(
dataset=dataset,
output_directory=experiment["experiment_name"],
skip_save_processed_input=True,
skip_save_unprocessed_output=True,
skip_save_predictions=True,
skip_collect_predictions=True,
)
delete_model_checkpoints(experiment["experiment_name"])
def benchmark(benchmarking_config: dict[str, Any] | str) -> dict[str, tuple[BenchmarkingResult, Exception]]:
"""Launch benchmarking suite from a benchmarking config.
Args:
benchmarking_config: config or config path for the benchmarking tool. Specifies datasets and their
corresponding Ludwig configs, as well as export options.
"""
if isinstance(benchmarking_config, str):
benchmarking_config = load_yaml(benchmarking_config)
validate_benchmarking_config(benchmarking_config)
benchmarking_config = populate_benchmarking_config_with_defaults(benchmarking_config)
benchmarking_config = propagate_global_parameters(benchmarking_config)
experiment_artifacts = {}
for experiment_idx, experiment in enumerate(benchmarking_config["experiments"]):
dataset_name = experiment["dataset_name"]
try:
benchmark_one(experiment)
experiment_artifacts[dataset_name] = (build_benchmarking_result(benchmarking_config, experiment_idx), None)
except Exception as e:
logger.exception(
f"Experiment *{experiment['experiment_name']}* on dataset *{experiment['dataset_name']}* failed"
)
experiment_artifacts[dataset_name] = (None, e)
finally:
if benchmarking_config["export"]["export_artifacts"]:
export_base_path = benchmarking_config["export"]["export_base_path"]
export_artifacts(experiment, experiment["experiment_name"], export_base_path)
return experiment_artifacts
def cli(sys_argv):
parser = argparse.ArgumentParser(
description="This script runs a ludwig experiment on datasets specified in the benchmark config and exports "
"the experiment artifact for each of the datasets following the export parameters specified in"
"the benchmarking config.",
prog="ludwig benchmark",
usage="%(prog)s [options]",
)
parser.add_argument("--benchmarking_config", type=str, help="The benchmarking config.")
add_contrib_callback_args(parser)
args = parser.parse_args(sys_argv)
benchmark(args.benchmarking_config)
================================================
FILE: ludwig/benchmarking/examples/benchmarking_config.yaml
================================================
experiment_name: example_benchmarking_run
hyperopt: false
process_config_file_path: /home/ray/process_config.py
profiler:
enable: true
use_torch_profiler: false
logging_interval: 0.1
export:
export_artifacts: true
export_base_path: s3://benchmarking.us-west-2.ludwig.com/bench/ # include the slash at the end.
experiments:
- dataset_name: ames_housing
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/ames_housing.yaml
- dataset_name: protein
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/protein.yaml
- dataset_name: mercedes_benz_greener
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/mercedes_benz_greener.yaml
- dataset_name: santander_customer_satisfaction
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/santander_customer_satisfaction.yaml
- dataset_name: connect4
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/connect4.yaml
- dataset_name: otto_group_product
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/otto_group_product.yaml
- dataset_name: bnp_claims_management
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/bnp_claims_management.yaml
- dataset_name: santander_customer_transaction
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/santander_customer_transaction.yaml
- dataset_name: allstate_claims_severity
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/allstate_claims_severity.yaml
- dataset_name: naval
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/naval.yaml
- dataset_name: sarcos
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/sarcos.yaml
- dataset_name: walmart_recruiting
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/walmart_recruiting.yaml
- dataset_name: numerai28pt6
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/numerai28pt6.yaml
- dataset_name: adult_census_income
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/adult_census_income.yaml
- dataset_name: amazon_employee_access_challenge
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/amazon_employee_access_challenge.yaml
- dataset_name: forest_cover
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/forest_cover.yaml
- dataset_name: mushroom_edibility
config_path: /home/ray/anaconda3/lib/python3.12/site-packages/ludwig/benchmarking/configs/mushroom_edibility.yaml
================================================
FILE: ludwig/benchmarking/examples/process_config.py
================================================
"""This function will take in a Ludwig config, strip away all its parameters except input and output featuresand
add some other parameters to run logistic regression hyperopt."""
def process_config(ludwig_config: dict, experiment_dict: dict) -> dict:
"""Modify a Ludwig config by programmatically adding elements to the config dictionary.
The purpose is to apply changes for all datasets that are the same or are based on the
attributes of `experiment_dict` (e.g. dataset_name) removing the need to manually apply
small changes to configs on many datasets.
:param ludwig_config: a Ludwig config.
:param experiment_dict: a benchmarking config experiment dictionary.
Returns: a modified Ludwig config.
"""
# only keep input_features and output_features
main_config_keys = list(ludwig_config.keys())
for key in main_config_keys:
if key not in ["input_features", "output_features"]:
del ludwig_config[key]
temp = {
"preprocessing": {"split": {"type": "fixed"}},
"trainer": {"epochs": 1024, "early_stop": 7, "eval_batch_size": 16384, "evaluate_training_set": False},
"hyperopt": {
"goal": "maximize",
"output_feature": None,
"metric": None,
"split": "validation",
"parameters": {
"defaults.number.preprocessing.normalization": {"space": "choice", "categories": ["zscore", None]},
"defaults.number.preprocessing.missing_value_strategy": {
"space": "choice",
"categories": ["fill_with_const", "fill_with_mean"],
},
"combiner.type": {"space": "choice", "categories": ["tabnet", "concat"]},
"trainer.learning_rate_scheduler.decay": {"space": "choice", "categories": [True, False]},
"trainer.learning_rate": {"space": "loguniform", "lower": 0.0001, "upper": 0.1},
"trainer.learning_rate_scheduler.decay_rate": {"space": "uniform", "lower": 0.4, "upper": 0.96},
"trainer.batch_size": {"space": "randint", "lower": 32, "upper": 2048},
},
"search_alg": {"type": "variant_generator"},
"executor": {"type": "ray", "num_samples": 1000},
"scheduler": {"type": "bohb", "reduction_factor": 2},
},
}
# add config parameters from temp
for key, value in temp.items():
ludwig_config[key] = value
dataset_name_to_metric = {
"ames_housing": "r2",
"mercedes_benz_greener": "r2",
"mushroom_edibility": "accuracy",
"amazon_employee_access_challenge": "roc_auc",
"naval": "r2",
"sarcos": "r2",
"protein": "r2",
"adult_census_income": "accuracy",
"otto_group_product": "accuracy",
"santander_customer_satisfaction": "accuracy",
"amazon_employee_access": "roc_auc",
"numerai28pt6": "accuracy",
"bnp_claims_management": "accuracy",
"allstate_claims_severity": "r2",
"santander_customer_transaction": "accuracy",
"connect4": "accuracy",
"forest_cover": "accuracy",
"ieee_fraud": "accuracy",
"porto_seguro_safe_driver": "accuracy",
"walmart_recruiting": "accuracy",
"poker_hand": "accuracy",
"higgs": "accuracy",
}
# add hyperopt output feature and metric.
dataset_name = experiment_dict["dataset_name"]
ludwig_config["hyperopt"]["metric"] = dataset_name_to_metric[dataset_name]
ludwig_config["hyperopt"]["output_feature"] = ludwig_config["output_features"][0]["name"]
# use sparse encoder for categorical features to mimic logistic regression.
for i, feature in enumerate(ludwig_config["input_features"]):
if feature["type"] == "category":
ludwig_config["input_features"][i]["encoder"] = "sparse"
for i, feature in enumerate(ludwig_config["output_features"]):
if feature["type"] == "category":
ludwig_config["output_features"][i]["encoder"] = "sparse"
# make sure to return the ludwig_config
return ludwig_config
================================================
FILE: ludwig/benchmarking/profiler.py
================================================
import contextlib
import glob
import logging
import os
import shutil
import threading
import time
from queue import Empty as EmptyQueueException
from queue import Queue
from subprocess import PIPE, Popen
from typing import Any
from xml.etree.ElementTree import fromstring
import psutil
import torch
from cpuinfo import get_cpu_info
from gpustat.core import GPUStatCollection
from ludwig.benchmarking.profiler_dataclasses import profiler_dataclass_to_flat_dict, TorchProfilerMetrics
from ludwig.benchmarking.reporting import get_metrics_from_system_usage_profiler, get_metrics_from_torch_profiler
from ludwig.constants import LUDWIG_TAG
from ludwig.globals import LUDWIG_VERSION
from ludwig.utils.data_utils import save_json
STOP_MESSAGE = "stop"
logger = logging.getLogger()
def get_gpu_info():
"""Gathers general hardware information about an nvidia GPU.
This function was copied from `experiment_impact_tracker` to get around a Pandas 2.0 breaking change impacting the
package. https://github.com/Breakend/experiment-impact-
tracker/blob/master/experiment_impact_tracker/gpu/nvidia.py#L48-L73
"""
p = Popen(["nvidia-smi", "-q", "-x"], stdout=PIPE)
outs, errors = p.communicate()
xml = fromstring(outs)
data = []
driver_version = xml.findall("driver_version")[0].text
cuda_version = xml.findall("cuda_version")[0].text
for gpu_id, gpu in enumerate(xml.getiterator("gpu")):
gpu_data = {}
name = [x for x in gpu.getiterator("product_name")][0].text
memory_usage = gpu.findall("fb_memory_usage")[0]
total_memory = memory_usage.findall("total")[0].text
gpu_data["name"] = name
gpu_data["total_memory"] = total_memory
gpu_data["driver_version"] = driver_version
gpu_data["cuda_version"] = cuda_version
data.append(gpu_data)
return data
def monitor(queue: Queue, info: dict[str, Any], logging_interval: int, cuda_is_available: bool) -> None:
"""Monitors hardware resource use.
Collects system specific metrics (CPU/CUDA, CPU/CUDA memory) at a `logging_interval` interval and pushes
results back to the parent process.
Args:
queue: queue from which we can push and retrieve messages sent to the function targeted by the thread.
info: dictionary containing system resource usage information about the running process.
logging_interval: time interval at which we will poll the system for usage metrics.
cuda_is_available: stores torch.cuda.is_available().
"""
info["global_cpu_memory_available"] = [psutil.virtual_memory().available]
info["global_cpu_utilization"] = [psutil.cpu_percent()]
# get the pid of the parent process.
tracked_process = psutil.Process(os.getpid())
# will return a meaningless 0 value on the first call because `interval` arg is set to None.
tracked_process.cpu_percent(interval=logging_interval)
with tracked_process.oneshot():
info["cpu_utilization"] = [tracked_process.cpu_percent() / info["num_cpu"]]
info["cpu_memory_usage"] = [tracked_process.memory_full_info().uss]
try:
info["num_accessible_cpus"] = len(tracked_process.cpu_affinity())
except Exception:
pass
while True:
try:
message = queue.get(block=False)
if isinstance(message, str):
if message == STOP_MESSAGE:
# synchronize CUDA to get accurate timing for jobs running on GPU.
if cuda_is_available:
torch.cuda.synchronize()
queue.put(info)
return
else:
queue.put(message)
except EmptyQueueException:
pass
if cuda_is_available:
gpu_infos = GPUStatCollection.new_query()
for i, gpu_info in enumerate(gpu_infos):
gpu_key = f"cuda_{i}"
info[f"{gpu_key}_memory_used"].append(gpu_info.memory_used)
with tracked_process.oneshot():
info["cpu_utilization"].append(tracked_process.cpu_percent() / info["num_cpu"])
info["cpu_memory_usage"].append(tracked_process.memory_full_info().uss)
info["global_cpu_memory_available"].append(psutil.virtual_memory().available)
info["global_cpu_utilization"].append(psutil.cpu_percent())
time.sleep(logging_interval)
class LudwigProfiler(contextlib.ContextDecorator):
"""Track system resource (hardware and software) usage.
Warning: If `use_torch_profiler=True` while profiling on CUDA, it's not possible to benchmark DataLoaders
with `num_workers > 0` due to CUDA multiprocessing limitations. See warning under `profile` class
definition: https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler.py
Attributes:
tag: a string tag describing the code block/function that we're tracking.
(e.g trainer.train, preprocessing, etc.)
output_dir: path where metrics are saved.
logging_interval: time interval in seconds at which system is polled for resource usage.
"""
def __init__(self, tag: str, use_torch_profiler: bool, output_dir: str, logging_interval: float = 0.1) -> None:
self.tag = tag
self._tag = LUDWIG_TAG + self.tag
self.use_torch_profiler = use_torch_profiler
self.output_dir = output_dir
self.logging_interval = logging_interval
self.cuda_is_available = torch.cuda.is_available()
self.launched = False
if self.use_torch_profiler:
self.profiler_activities = [torch.profiler.ProfilerActivity.CPU]
if self.cuda_is_available:
self.profiler_activities.append(torch.profiler.ProfilerActivity.CUDA)
os.makedirs(os.path.join(self.output_dir), exist_ok=True)
def _init_tracker_info(self):
"""Initialize new self.info, self.torch_profiler, and self.torch_record_function instances.
Important to call this in __enter__ if the user decides not to create a new class instance and therefore
__init__ wouldn't be called.
"""
self.info = {"code_block_tag": self.tag}
if self.use_torch_profiler:
self.torch_profiler = torch.profiler.profile(activities=self.profiler_activities, profile_memory=True)
self.torch_record_function = torch.profiler.record_function(self._tag)
def _populate_static_information(self) -> None:
"""Populate the report with static software and hardware information."""
self.info["ludwig_version"] = LUDWIG_VERSION
self.info["start_disk_usage"] = shutil.disk_usage(os.path.expanduser("~")).used
# CPU information
cpu_info = get_cpu_info()
self.info["cpu_architecture"] = cpu_info["arch"]
self.info["num_cpu"] = psutil.cpu_count()
self.info["cpu_name"] = cpu_info.get("brand_raw", "unknown")
self.info["total_cpu_memory_size"] = psutil.virtual_memory().total
# GPU information
if self.cuda_is_available:
gpu_infos = get_gpu_info()
gpu_usage = GPUStatCollection.new_query()
for i, gpu_info in enumerate(gpu_infos):
gpu_key = f"cuda_{i}"
self.info[f"{gpu_key}_memory_used"] = [gpu_usage[i].memory_used]
self.info[f"{gpu_key}_name"] = gpu_info["name"]
self.info[f"{gpu_key}_total_memory"] = gpu_info["total_memory"]
self.info[f"{gpu_key}_driver_version"] = gpu_info["driver_version"]
self.info[f"{gpu_key}_cuda_version"] = gpu_info["cuda_version"]
# recording in microseconds to be in line with torch profiler time recording.
self.info["start_time"] = time.perf_counter_ns() / 1000
def __enter__(self):
"""Populate static information and monitors resource usage."""
if self.launched:
raise RuntimeError("LudwigProfiler already launched. You can't use the same instance.")
self._init_tracker_info()
self._populate_static_information()
if self.use_torch_profiler:
# contextlib.ExitStack gracefully handles situations where __enter__ or __exit__ calls throw exceptions.
with contextlib.ExitStack() as ctx_exit_stack:
try:
# Launch torch.profiler to track PyTorch operators.
ctx_exit_stack.enter_context(self.torch_profiler)
except RuntimeError:
# PyTorch profiler is already enabled on this thread.
# Using the running PyTorch profiler to track events.
self.torch_profiler = None
ctx_exit_stack.enter_context(self.torch_record_function)
self._ctx_exit_stack = ctx_exit_stack.pop_all()
try:
# Starting thread to monitor system resource usage.
self.queue = Queue()
self.t = threading.Thread(
target=monitor,
args=(
self.queue,
self.info,
self.logging_interval,
self.cuda_is_available,
),
)
self.t.start()
self.launched = True
except Exception:
self.launched = False
logger.exception("Encountered exception when launching tracker thread.")
return self
def __exit__(self, exc_type, exc_val, exc_tb) -> None:
"""Stop profiling, postprocess and export resource usage metrics."""
try:
self.queue.put(STOP_MESSAGE)
self.t.join()
result = self.queue.get()
# If monitor thread crashed, result may be a string instead of dict
if isinstance(result, dict):
self.info = result
# recording in microseconds to be in line with torch profiler time recording.
self.info["end_time"] = time.perf_counter_ns() / 1000
self.info["end_disk_usage"] = shutil.disk_usage(os.path.expanduser("~")).used
self.launched = False
except Exception:
logger.exception("Encountered exception when joining tracker thread.")
finally:
if self.use_torch_profiler:
self._ctx_exit_stack.close()
self._export_torch_metrics()
self._export_system_usage_metrics()
def _export_system_usage_metrics(self):
"""Export system resource usage metrics (no torch operators)."""
system_usage_metrics = get_metrics_from_system_usage_profiler(self.info)
output_subdir = os.path.join(self.output_dir, "system_resource_usage", system_usage_metrics.code_block_tag)
os.makedirs(output_subdir, exist_ok=True)
num_prev_runs = len(glob.glob(os.path.join(output_subdir, "run_*.json")))
file_name = os.path.join(output_subdir, f"run_{num_prev_runs}.json")
save_json(file_name, profiler_dataclass_to_flat_dict(system_usage_metrics))
def _reformat_torch_usage_metrics_tags(
self, torch_usage_metrics: dict[str, Any]
) -> dict[str, list[TorchProfilerMetrics]]:
reformatted_dict = {}
for key, value in torch_usage_metrics.items():
assert key.startswith(LUDWIG_TAG)
reformatted_key = key[len(LUDWIG_TAG) :]
reformatted_dict[reformatted_key] = value
return reformatted_dict
def _export_torch_metrics(self):
"""Export resource usage metrics of torch operators."""
if self.torch_profiler:
torch_usage_metrics = get_metrics_from_torch_profiler(self.torch_profiler)
torch_usage_metrics = self._reformat_torch_usage_metrics_tags(torch_usage_metrics)
for tag, runs in torch_usage_metrics.items():
temp_dir = os.path.join(self.output_dir, "torch_ops_resource_usage", tag)
os.makedirs(temp_dir, exist_ok=True)
for run in runs:
num_prev_runs = len(glob.glob(os.path.join(temp_dir, "run_*.json")))
save_json(os.path.join(temp_dir, f"run_{num_prev_runs}.json"), profiler_dataclass_to_flat_dict(run))
================================================
FILE: ludwig/benchmarking/profiler_callbacks.py
================================================
from typing import Any
from ludwig.api_annotations import DeveloperAPI
from ludwig.benchmarking.profiler import LudwigProfiler
from ludwig.callbacks import Callback
from ludwig.constants import EVALUATION, PREPROCESSING, TRAINING
# TODO: Change annotation to PublicAPI once Ludwig 0.7 is released
@DeveloperAPI
class LudwigProfilerCallback(Callback):
"""Class that defines the methods necessary to hook into process."""
def __init__(self, experiment: dict[str, Any]):
self.experiment_name = experiment["experiment_name"]
self.use_torch_profiler = experiment["profiler"]["use_torch_profiler"]
self.logging_interval = experiment["profiler"]["logging_interval"]
self.preprocess_profiler = None
self.train_profiler = None
self.evaluation_profiler = None
def on_preprocess_start(self, *args, **kwargs):
self.preprocess_profiler = LudwigProfiler(
tag=PREPROCESSING,
output_dir=self.experiment_name,
use_torch_profiler=self.use_torch_profiler,
logging_interval=self.logging_interval,
)
self.preprocess_profiler.__enter__()
def on_preprocess_end(self, *args, **kwargs):
self.preprocess_profiler.__exit__(None, None, None)
del self.preprocess_profiler
def on_train_start(self, *args, **kwargs):
self.train_profiler = LudwigProfiler(
tag=TRAINING,
output_dir=self.experiment_name,
use_torch_profiler=self.use_torch_profiler,
logging_interval=self.logging_interval,
)
self.train_profiler.__enter__()
def on_train_end(self, *args, **kwargs):
self.train_profiler.__exit__(None, None, None)
del self.train_profiler
def on_evaluation_start(self):
self.evaluation_profiler = LudwigProfiler(
tag=EVALUATION,
output_dir=self.experiment_name,
use_torch_profiler=self.use_torch_profiler,
logging_interval=self.logging_interval,
)
self.evaluation_profiler.__enter__()
def on_evaluation_end(self):
self.evaluation_profiler.__exit__(None, None, None)
del self.evaluation_profiler
================================================
FILE: ludwig/benchmarking/profiler_dataclasses.py
================================================
import dataclasses
from dataclasses import dataclass
from ludwig.utils.data_utils import flatten_dict
@dataclass
class DeviceUsageMetrics:
# Max CUDA memory utilization of the code block.
max_memory_used: float
# Average CUDA memory utilization of the code block.
average_memory_used: float
@dataclass
class SystemResourceMetrics:
# Name of the code block/function to be profiled.
code_block_tag: str
# Name of the CPU that the code ran on.
cpu_name: str
# CPU architecture that the code ran on.
cpu_architecture: str
# Number of CPUs on the machine.
num_cpu: int
# Total CPU memory size.
total_cpu_memory_size: float
# Ludwig version in the environment.
ludwig_version: str
# Total execution time of the code block.
total_execution_time: float
# The change in disk memory before and after the code block ran.
disk_footprint: float
# Max CPU utilization of the code block.
max_cpu_utilization: float
# Max CPU memory (RAM) utilization of the code block.
max_cpu_memory_usage: float
# Min system-wide CPU memory available (how much physical memory is left).
min_global_cpu_memory_available: float
# Max system-wide CPU utilization.
max_global_cpu_utilization: float
# Average CPU utilization of the code block.
average_cpu_utilization: float
# Average CPU memory (RAM) utilization of the code block.
average_cpu_memory_usage: float
# Average system-wide CPU memory available (how much physical memory is left).
average_global_cpu_memory_available: float
# Average system-wide CPU utilization.
average_global_cpu_utilization: float
# Per device usage. Dictionary containing max and average memory used per device.
device_usage: dict[str, DeviceUsageMetrics]
@dataclass
class TorchProfilerMetrics:
# Time taken by torch ops to execute on the CPU.
torch_cpu_time: float
# Time taken by torch ops to execute on CUDA devices.
torch_cuda_time: float
# Number of out of memory events.
num_oom_events: int
# Per device usage by torch ops. Dictionary containing max and average memory used per device.
device_usage: dict[str, DeviceUsageMetrics]
def profiler_dataclass_to_flat_dict(data: SystemResourceMetrics | TorchProfilerMetrics) -> dict:
"""Returns a flat dictionary representation, with the device_usage key removed."""
nested_dict = dataclasses.asdict(data)
nested_dict[""] = nested_dict.pop("device_usage")
return flatten_dict(nested_dict, sep="")
================================================
FILE: ludwig/benchmarking/reporting.py
================================================
from collections import Counter, defaultdict
from statistics import mean
from typing import Any
import torch
from torch._C._autograd import _KinetoEvent
from torch.autograd import DeviceType, profiler_util
from ludwig.benchmarking.profiler_dataclasses import DeviceUsageMetrics, SystemResourceMetrics, TorchProfilerMetrics
from ludwig.constants import LUDWIG_TAG
def initialize_stats_dict(main_function_events: list[profiler_util.FunctionEvent]) -> dict[str, list]:
"""Initialize dictionary which stores resource usage information per tagged code block.
:param main_function_events: list of main function events.
"""
info = {}
for event_name in [evt.name for evt in main_function_events]:
info[event_name] = []
return info
def get_memory_details(kineto_event: _KinetoEvent) -> tuple[str, int]:
"""Get device name and number of bytes (de)allocated during an event.
:param kineto_event: a Kineto event instance.
"""
if kineto_event.device_type() in [DeviceType.CPU, DeviceType.MKLDNN, DeviceType.IDEEP]:
return "cpu", kineto_event.nbytes()
elif kineto_event.device_type() in [DeviceType.CUDA, DeviceType.HIP]:
return f"cuda_{kineto_event.device_index()}", kineto_event.nbytes()
else:
raise ValueError(f"Device {kineto_event.device_type()} is not valid.")
def get_device_memory_usage(
kineto_event: _KinetoEvent, memory_events: list[list[_KinetoEvent | bool]]
) -> dict[str, DeviceUsageMetrics]:
"""Get CPU and CUDA memory usage for an event.
:param kineto_event: a Kineto event instance.
:param memory_events: list of memory events.
"""
mem_records_acc = profiler_util.MemRecordsAcc(memory_events)
start_us = kineto_event.start_ns() / 1000
end_us = start_us + kineto_event.duration_ns() / 1000
records_in_interval = mem_records_acc.in_interval(start_us, end_us)
memory_so_far = defaultdict(int)
count_so_far = defaultdict(int)
average_so_far = defaultdict(float)
max_so_far = defaultdict(int)
for mem_record in records_in_interval:
device, nbytes = get_memory_details(mem_record[0])
memory_so_far[device] += nbytes
max_so_far[device] = max(max_so_far[device], memory_so_far[device])
average_so_far[device] = (memory_so_far[device] + (average_so_far[device] * count_so_far[device])) / (
count_so_far[device] + 1
)
count_so_far[device] += 1
memory_info_per_device = {}
for device in count_so_far:
memory_info_per_device[f"torch_{device}_"] = DeviceUsageMetrics(
max_memory_used=max_so_far[device], average_memory_used=average_so_far[device]
)
return memory_info_per_device
def get_torch_op_time(events: list[profiler_util.FunctionEvent], attr: str) -> int | float:
"""Get time torch operators spent executing for a list of events.
:param events: list of events.
:param attr: a FunctionEvent attribute. Expecting one of "cpu_time_total", "device_time_total".
"""
if attr not in ["cpu_time_total", "device_time_total"]:
return -1
total = 0
for e in events:
# Possible trace_names are torch ops, or tagged code blocks by LudwigProfiler (which are
# prepended with LUDWIG_TAG).
if LUDWIG_TAG not in e.trace_name:
total += getattr(e, attr)
else:
total += get_torch_op_time(e.cpu_children, attr)
return total
def get_device_run_durations(function_event: profiler_util.FunctionEvent) -> tuple[float, float]:
"""Get CPU and device run durations for an event.
:param function_event: a function event instance.
"""
torch_cpu_time = get_torch_op_time(function_event.cpu_children, "cpu_time_total")
torch_device_time = get_torch_op_time(function_event.cpu_children, "device_time_total")
return torch_cpu_time, torch_device_time
def get_num_oom_events(kineto_event: _KinetoEvent, out_of_memory_events: list[list[_KinetoEvent | bool]]) -> int:
oom_records_acc = profiler_util.MemRecordsAcc(out_of_memory_events)
start_us = kineto_event.start_ns() / 1000
end_us = start_us + kineto_event.duration_ns() / 1000
records_in_interval = oom_records_acc.in_interval(start_us, end_us)
return len(list(records_in_interval))
def get_resource_usage_report(
main_kineto_events: list[_KinetoEvent],
main_function_events: list[profiler_util.FunctionEvent],
memory_events: list[list[_KinetoEvent | bool]],
out_of_memory_events: list[list[_KinetoEvent | bool]],
info: dict[str, Any],
) -> dict[str, list[TorchProfilerMetrics]]:
"""Get relevant information from Kineto events and function events exported by the profiler.
:param main_kineto_events: list of main Kineto events.
:param main_function_events: list of main function events.
:param memory_events: list of memory events.
:param out_of_memory_events: list of out of memory events.
:param info: dictionary used to record resource usage metrics.
"""
main_kineto_events = sorted(
(evt for evt in main_kineto_events if LUDWIG_TAG in evt.name()), key=lambda x: x.correlation_id()
)
main_function_events = sorted((evt for evt in main_function_events if LUDWIG_TAG in evt.name), key=lambda x: x.id)
for kineto_event, function_event in zip(main_kineto_events, main_function_events):
# Two different instances of `function_event` can have the same name if a the same
# tagged code block/function was executed more than once.
memory_info_per_device = get_device_memory_usage(kineto_event, memory_events)
torch_cpu_time, torch_cuda_time = get_device_run_durations(function_event)
num_oom_events = get_num_oom_events(kineto_event, out_of_memory_events)
torch_profiler_metrics = TorchProfilerMetrics(
torch_cpu_time=torch_cpu_time,
torch_cuda_time=torch_cuda_time,
num_oom_events=num_oom_events,
device_usage=memory_info_per_device,
)
info[function_event.name].append(torch_profiler_metrics)
return info
def get_all_events(kineto_events: list[_KinetoEvent], function_events: profiler_util.EventList) -> tuple[
list[_KinetoEvent],
list[profiler_util.FunctionEvent],
list[list[_KinetoEvent | bool]],
list[list[_KinetoEvent | bool]],
]:
"""Return main Kineto and function events, memory and OOM events for functions/code blocks tagged in
LudwigProfiler.
:param kineto_events: list of Kineto Events.
:param function_events: list of function events.
"""
# LUDWIG_TAG is prepended to LudwigProfiler tags. This edited tag is passed in to `torch.profiler.record_function`
# so we can easily retrieve events for code blocks wrapped with LudwigProfiler.
main_function_events = [evt for evt in function_events if LUDWIG_TAG in evt.name]
main_kineto_events = [event for event in kineto_events if LUDWIG_TAG in event.name()]
memory_events = [[event, False] for event in kineto_events if profiler_util.MEMORY_EVENT_NAME in event.name()]
# profiler_util.OUT_OF_MEMORY_EVENT_NAME seems to only be in newer versions of torch.
out_of_memory_events = [[event, False] for event in kineto_events if "[OutOfMemory]" in event.name()]
return main_kineto_events, main_function_events, memory_events, out_of_memory_events
def get_metrics_from_torch_profiler(profile: torch.profiler.profiler.profile) -> dict[str, list[TorchProfilerMetrics]]:
"""Export time and resource usage metrics (CPU and CUDA) from a PyTorch profiler.
The profiler keeps track of *torch operations* being executed in C++. It keeps track
of what device they're executed on, their execution time, and memory usage.
We only track the aforementioned metrics, but the torch profiler can keep track of
the stack trace, FLOPs, and torch modules. Tracking each additional item adds overhead.
The torch profiler surfaces these metrics that are tracked under the hood by `libkineto`.
More on the Kineto project: https://github.com/pytorch/kineto
:param profile: profiler object that contains all the events that
were registered during the execution of the wrapped code block.
"""
# events in both of these lists are in chronological order.
kineto_events = profile.profiler.kineto_results.events()
function_events = profile.profiler.function_events
main_kineto_events, main_function_events, memory_events, out_of_memory_events = get_all_events(
kineto_events, function_events
)
assert Counter([event.name for event in main_function_events]) == Counter(
[event.name() for event in main_kineto_events]
)
info = initialize_stats_dict(main_function_events)
info = get_resource_usage_report(
main_kineto_events, main_function_events, memory_events, out_of_memory_events, info
)
return info
def get_metrics_from_system_usage_profiler(system_usage_info: dict) -> SystemResourceMetrics:
"""Package system resource usage metrics (no torch operators) in a dataclass.
:param system_usage_info: dictionary containing resource usage information.
"""
device_usage_dict: dict[str, DeviceUsageMetrics] = {}
for key in system_usage_info:
if "cuda_" in key and "_memory_used" in key:
cuda_device_name = "_".join(key.split("_")[:2]) + "_"
max_memory_used = max(system_usage_info[key], default=0)
average_memory_used = mean(system_usage_info.get(key, [0]))
device_usage_dict[cuda_device_name] = DeviceUsageMetrics(
max_memory_used=max_memory_used, average_memory_used=average_memory_used
)
return SystemResourceMetrics(
code_block_tag=system_usage_info["code_block_tag"],
cpu_name=system_usage_info.get("cpu_name", "unknown"),
cpu_architecture=system_usage_info["cpu_architecture"],
num_cpu=system_usage_info["num_cpu"],
total_cpu_memory_size=system_usage_info["total_cpu_memory_size"],
ludwig_version=system_usage_info["ludwig_version"],
total_execution_time=system_usage_info["end_time"] - system_usage_info["start_time"],
disk_footprint=system_usage_info["end_disk_usage"] - system_usage_info["start_disk_usage"],
max_cpu_utilization=max(system_usage_info["cpu_utilization"], default=0),
max_cpu_memory_usage=max(system_usage_info["cpu_memory_usage"], default=0),
min_global_cpu_memory_available=min(system_usage_info["global_cpu_memory_available"], default=0),
max_global_cpu_utilization=max(system_usage_info["global_cpu_utilization"], default=0),
average_cpu_utilization=mean(system_usage_info.get("cpu_utilization", [0])),
average_cpu_memory_usage=mean(system_usage_info.get("cpu_memory_usage", [0])),
average_global_cpu_memory_available=mean(system_usage_info.get("global_cpu_memory_available", [0])),
average_global_cpu_utilization=mean(system_usage_info.get("global_cpu_utilization", [0])),
device_usage=device_usage_dict,
)
================================================
FILE: ludwig/benchmarking/summarize.py
================================================
import argparse
import logging
import os
import shutil
from ludwig.benchmarking.summary_dataclasses import (
build_metrics_diff,
build_resource_usage_diff,
export_metrics_diff_to_csv,
export_resource_usage_diff_to_csv,
MetricsDiff,
ResourceUsageDiff,
)
from ludwig.benchmarking.utils import download_artifacts
logger = logging.getLogger()
def summarize_metrics(
bench_config_path: str, base_experiment: str, experimental_experiment: str, download_base_path: str
) -> tuple[list[str], list[MetricsDiff], list[list[ResourceUsageDiff]]]:
"""Build metric and resource usage diffs from experiment artifacts.
bench_config_path: bench config file path. Can be the same one that was used to run
these experiments.
base_experiment: name of the experiment we're comparing against.
experimental_experiment: name of the experiment we're comparing.
download_base_path: base path under which live the stored artifacts of
the benchmarking experiments.
"""
local_dir, dataset_list = download_artifacts(
bench_config_path, base_experiment, experimental_experiment, download_base_path
)
metric_diffs, resource_usage_diffs = [], []
for dataset_name in dataset_list:
try:
metric_diff = build_metrics_diff(dataset_name, base_experiment, experimental_experiment, local_dir)
metric_diffs.append(metric_diff)
base_path = os.path.join(local_dir, dataset_name, base_experiment)
experimental_path = os.path.join(local_dir, dataset_name, experimental_experiment)
resource_usage_diff = build_resource_usage_diff(
base_path, experimental_path, base_experiment, experimental_experiment
)
resource_usage_diffs.append(resource_usage_diff)
except Exception:
logger.exception(f"Exception encountered while creating diff summary for {dataset_name}.")
shutil.rmtree(local_dir, ignore_errors=True)
export_and_print(dataset_list, metric_diffs, resource_usage_diffs)
return dataset_list, metric_diffs, resource_usage_diffs
def export_and_print(
dataset_list: list[str], metric_diffs: list[MetricsDiff], resource_usage_diffs: list[list[ResourceUsageDiff]]
) -> None:
"""Export to CSV and print a diff of performance and resource usage metrics of two experiments.
:param dataset_list: list of datasets for which to print the diffs.
:param metric_diffs: Diffs for the performance metrics by dataset.
:param resource_usage_diffs: Diffs for the resource usage metrics per dataset per LudwigProfiler tag.
"""
for dataset_name, experiment_metric_diff in zip(dataset_list, metric_diffs):
output_path = os.path.join("summarize_output", "performance_metrics", dataset_name)
os.makedirs(output_path, exist_ok=True)
logger.info(
"Model performance metrics for *{}* vs. *{}* on dataset *{}*".format(
experiment_metric_diff.base_experiment_name,
experiment_metric_diff.experimental_experiment_name,
experiment_metric_diff.dataset_name,
)
)
logger.info(experiment_metric_diff.to_string())
filename = (
"-".join([experiment_metric_diff.base_experiment_name, experiment_metric_diff.experimental_experiment_name])
+ ".csv"
)
export_metrics_diff_to_csv(experiment_metric_diff, os.path.join(output_path, filename))
for dataset_name, experiment_resource_diff in zip(dataset_list, resource_usage_diffs):
output_path = os.path.join("summarize_output", "resource_usage_metrics", dataset_name)
os.makedirs(output_path, exist_ok=True)
for tag_diff in experiment_resource_diff:
logger.info(
"Resource usage for *{}* vs. *{}* on *{}* of dataset *{}*".format(
tag_diff.base_experiment_name,
tag_diff.experimental_experiment_name,
tag_diff.code_block_tag,
dataset_name,
)
)
logger.info(tag_diff.to_string())
filename = (
"-".join(
[tag_diff.code_block_tag, tag_diff.base_experiment_name, tag_diff.experimental_experiment_name]
)
+ ".csv"
)
export_resource_usage_diff_to_csv(tag_diff, os.path.join(output_path, filename))
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Summarize the model performance metrics and resource usage metrics of two experiments.",
prog="python summarize.py",
usage="%(prog)s [options]",
)
parser.add_argument("--benchmarking_config", type=str, help="The benchmarking config.")
parser.add_argument("--base_experiment", type=str, help="The name of the first experiment.")
parser.add_argument("--experimental_experiment", type=str, help="The name of the second experiment.")
parser.add_argument("--download_base_path", type=str, help="The base path to download experiment artifacts from.")
args = parser.parse_args()
summarize_metrics(
args.benchmarking_config, args.base_experiment, args.experimental_experiment, args.download_base_path
)
================================================
FILE: ludwig/benchmarking/summary_dataclasses.py
================================================
import csv
import logging
import os
from dataclasses import dataclass
from statistics import mean
import ludwig.modules.metric_modules # noqa: F401
from ludwig.benchmarking.utils import format_memory, format_time
from ludwig.globals import MODEL_FILE_NAME, MODEL_HYPERPARAMETERS_FILE_NAME
from ludwig.modules.metric_registry import get_metric_classes, metric_feature_type_registry # noqa: F401
from ludwig.types import ModelConfigDict
from ludwig.utils.data_utils import load_json
logger = logging.getLogger()
@dataclass
class MetricDiff:
"""Diffs for a metric."""
# Name of the metric.
name: str
# Value of the metric in base experiment (the one we benchmark against).
base_value: float
# Value of the metric in the experimental experiment.
experimental_value: float
# experimental_value - base_value.
diff: float
# Percentage of change the metric with respect to base_value.
diff_percentage: float | str
def __post_init__(self):
"""Add human-readable string representations to the field."""
if "memory" in self.name:
self.base_value_str = format_memory(self.base_value)
self.experimental_value_str = format_memory(self.experimental_value)
self.diff_str = format_memory(self.diff)
elif "time" in self.name:
self.base_value_str = format_time(self.base_value)
self.experimental_value_str = format_time(self.experimental_value)
self.diff_str = format_time(self.diff)
else:
self.base_value_str = str(self.base_value)
self.experimental_value_str = str(self.experimental_value)
self.diff_str = str(self.diff)
def build_diff(name: str, base_value: float, experimental_value: float) -> MetricDiff:
"""Build a diff between any type of metric.
:param name: name assigned to the metric to be diff-ed.
:param base_value: base value of the metric.
:param experimental_value: experimental value of the metric.
"""
diff = experimental_value - base_value
diff_percentage = 100 * diff / base_value if base_value != 0 else "inf"
return MetricDiff(
name=name,
base_value=base_value,
experimental_value=experimental_value,
diff=diff,
diff_percentage=diff_percentage,
)
##############################
# Resource Usage Dataclasses #
##############################
@dataclass
class MetricsSummary:
"""Summary of metrics from one experiment."""
# Path containing the artifacts for the experiment.
experiment_local_directory: str
# Full Ludwig config.
config: ModelConfigDict
# LudwigModel output feature type.
output_feature_type: str
# LudwigModel output feature name.
output_feature_name: str
# Dictionary that maps from metric name to their values.
metric_to_values: dict[str, float | int]
# Names of metrics for the output feature.
metric_names: set[str]
@dataclass
class MetricsDiff:
"""Store diffs for two experiments."""
# Dataset the two experiments are being compared on.
dataset_name: str
# Name of the base experiment (the one we benchmark against).
base_experiment_name: str
# Name of the experimental experiment.
experimental_experiment_name: str
# Path under which all artifacts live on the local machine.
local_directory: str
# `MetricsSummary` of the base_experiment.
base_summary: MetricsSummary
# `MetricsSummary` of the experimental_experiment.
experimental_summary: MetricsSummary
# `List[MetricDiff]` containing diffs for metric of the two experiments.
metrics: list[MetricDiff]
def to_string(self):
ret = []
spacing_str = "{:<20} {:<33} {:<13} {:<13} {:<13} {:<5}"
ret.append(
spacing_str.format(
"Output Feature Name",
"Metric Name",
self.base_experiment_name,
self.experimental_experiment_name,
"Diff",
"Diff Percentage",
)
)
for metric in sorted(self.metrics, key=lambda m: m.name):
output_feature_name = self.base_summary.output_feature_name
metric_name = metric.name
experiment1_val = round(metric.base_value, 3)
experiment2_val = round(metric.experimental_value, 3)
diff = round(metric.diff, 3)
diff_percentage = metric.diff_percentage
if isinstance(diff_percentage, float):
diff_percentage = round(metric.diff_percentage, 3)
ret.append(
spacing_str.format(
output_feature_name,
metric_name,
experiment1_val,
experiment2_val,
diff,
diff_percentage,
)
)
return "\n".join(ret)
def export_metrics_diff_to_csv(metrics_diff: MetricsDiff, path: str):
"""Export metrics report to .csv.
:param metrics_diff: MetricsDiff object containing the diff for two experiments on a dataset.
:param path: file name of the exported csv.
"""
with open(path, "w", newline="") as f:
writer = csv.DictWriter(
f,
fieldnames=[
"Dataset Name",
"Output Feature Name",
"Metric Name",
metrics_diff.base_experiment_name,
metrics_diff.experimental_experiment_name,
"Diff",
"Diff Percentage",
],
)
writer.writeheader()
for metric in sorted(metrics_diff.metrics, key=lambda m: m.name):
output_feature_name = metrics_diff.base_summary.output_feature_name
metric_name = metric.name
experiment1_val = round(metric.base_value, 3)
experiment2_val = round(metric.experimental_value, 3)
diff = round(metric.diff, 3)
diff_percentage = metric.diff_percentage
if isinstance(diff_percentage, float):
diff_percentage = round(metric.diff_percentage, 3)
writer.writerow(
{
"Dataset Name": metrics_diff.dataset_name,
"Output Feature Name": output_feature_name,
"Metric Name": metric_name,
metrics_diff.base_experiment_name: experiment1_val,
metrics_diff.experimental_experiment_name: experiment2_val,
"Diff": diff,
"Diff Percentage": diff_percentage,
}
)
logger.info(f"Exported a CSV report to {path}\n")
def build_metrics_summary(experiment_local_directory: str) -> MetricsSummary:
"""Build a metrics summary for an experiment.
:param experiment_local_directory: directory where the experiment artifacts live.
e.g. local_experiment_repo/ames_housing/some_experiment/
"""
config = load_json(
os.path.join(experiment_local_directory, "experiment_run", MODEL_FILE_NAME, MODEL_HYPERPARAMETERS_FILE_NAME)
)
report = load_json(os.path.join(experiment_local_directory, "experiment_run", "test_statistics.json"))
output_feature_type: str = config["output_features"][0]["type"]
output_feature_name: str = config["output_features"][0]["name"]
metric_dict = report[output_feature_name]
full_metric_names = get_metric_classes(output_feature_type)
metric_to_values: dict[str, float | int] = {
metric_name: metric_dict[metric_name] for metric_name in full_metric_names if metric_name in metric_dict
}
metric_names: set[str] = set(metric_to_values)
return MetricsSummary(
experiment_local_directory=experiment_local_directory,
config=config,
output_feature_name=output_feature_name,
output_feature_type=output_feature_type,
metric_to_values=metric_to_values,
metric_names=metric_names,
)
def build_metrics_diff(
dataset_name: str, base_experiment_name: str, experimental_experiment_name: str, local_directory: str
) -> MetricsDiff:
"""Build a MetricsDiff object between two experiments on a dataset.
:param dataset_name: the name of the Ludwig dataset.
:param base_experiment_name: the name of the base experiment.
:param experimental_experiment_name: the name of the experimental experiment.
:param local_directory: the local directory where the experiment artifacts are downloaded.
"""
base_summary: MetricsSummary = build_metrics_summary(
os.path.join(local_directory, dataset_name, base_experiment_name)
)
experimental_summary: MetricsSummary = build_metrics_summary(
os.path.join(local_directory, dataset_name, experimental_experiment_name)
)
metrics_in_common = set(base_summary.metric_names).intersection(set(experimental_summary.metric_names))
metrics: list[MetricDiff] = [
build_diff(name, base_summary.metric_to_values[name], experimental_summary.metric_to_values[name])
for name in metrics_in_common
]
return MetricsDiff(
dataset_name=dataset_name,
base_experiment_name=base_experiment_name,
experimental_experiment_name=experimental_experiment_name,
local_directory=local_directory,
base_summary=base_summary,
experimental_summary=experimental_summary,
metrics=metrics,
)
##############################
# Resource Usage Dataclasses #
##############################
@dataclass
class ResourceUsageSummary:
"""Summary of resource usage metrics from one experiment."""
# The tag with which the code block/function is labeled.
code_block_tag: str
# Dictionary that maps from metric name to their values.
metric_to_values: dict[str, float | int]
# Names of metrics for the output feature.
metric_names: set[str]
@dataclass
class ResourceUsageDiff:
"""Store resource usage diffs for two experiments."""
# The tag with which the code block/function is labeled.
code_block_tag: str
# Name of the base experiment (the one we benchmark against).
base_experiment_name: str
# Name of the experimental experiment.
experimental_experiment_name: str
# `List[Diff]` containing diffs for metric of the two experiments.
metrics: list[MetricDiff]
def to_string(self):
ret = []
spacing_str = "{:<36} {:<20} {:<20} {:<20} {:<5}"
ret.append(
spacing_str.format(
"Metric Name",
self.base_experiment_name,
self.experimental_experiment_name,
"Diff",
"Diff Percentage",
)
)
for metric in sorted(self.metrics, key=lambda m: m.name):
diff_percentage = metric.diff_percentage
if isinstance(metric.diff_percentage, float):
diff_percentage = round(metric.diff_percentage, 3)
ret.append(
spacing_str.format(
metric.name,
metric.base_value_str,
metric.experimental_value_str,
metric.diff_str,
diff_percentage,
)
)
return "\n".join(ret)
def export_resource_usage_diff_to_csv(resource_usage_diff: ResourceUsageDiff, path: str):
"""Export resource usage metrics report to .csv.
:param resource_usage_diff: ResourceUsageDiff object containing the diff for two experiments on a dataset.
:param path: file name of the exported csv.
"""
with open(path, "w", newline="") as f:
writer = csv.DictWriter(
f,
fieldnames=[
"Code Block Tag",
"Metric Name",
resource_usage_diff.base_experiment_name,
resource_usage_diff.experimental_experiment_name,
"Diff",
"Diff Percentage",
],
)
writer.writeheader()
for metric in sorted(resource_usage_diff.metrics, key=lambda m: m.name):
diff_percentage = metric.diff_percentage
if isinstance(metric.diff_percentage, float):
diff_percentage = round(metric.diff_percentage, 3)
writer.writerow(
{
"Code Block Tag": resource_usage_diff.code_block_tag,
"Metric Name": metric.name,
resource_usage_diff.base_experiment_name: metric.base_value_str,
resource_usage_diff.experimental_experiment_name: metric.experimental_value_str,
"Diff": metric.diff_str,
"Diff Percentage": diff_percentage,
}
)
logger.info(f"Exported a CSV report to {path}\n")
def average_runs(path_to_runs_dir: str) -> dict[str, int | float]:
"""Return average metrics from code blocks/function that ran more than once.
Metrics for code blocks/functions that were executed exactly once will be returned as is.
:param path_to_runs_dir: path to where metrics specific to a tag are stored.
e.g. resource_usage_out_dir/torch_ops_resource_usage/LudwigModel.evaluate/
This directory will contain JSON files with the following pattern run_*.json
"""
runs = [load_json(os.path.join(path_to_runs_dir, run)) for run in os.listdir(path_to_runs_dir)]
# asserting that keys to each of the dictionaries are consistent throughout the runs.
assert len(runs) == 1 or all(runs[i].keys() == runs[i + 1].keys() for i in range(len(runs) - 1))
runs_average = {"num_runs": len(runs)}
for key in runs[0]:
if isinstance(runs[0][key], (int, float)):
runs_average[key] = mean([run[key] for run in runs])
return runs_average
def summarize_resource_usage(path: str, tags: list[str] | None = None) -> list[ResourceUsageSummary]:
"""Create resource usage summaries for each code block/function that was decorated with ResourceUsageTracker.
Each entry of the list corresponds to the metrics collected from a code block/function run.
Important: code blocks that ran more than once are averaged.
:param path: corresponds to the `output_dir` argument in a ResourceUsageTracker run.
:param tags: (optional) list of tags to create summary for. If None, metrics from all tags will be summarized.
"""
summary = dict()
# metric types: system_resource_usage, torch_ops_resource_usage.
all_metric_types = {"system_resource_usage", "torch_ops_resource_usage"}
for metric_type in all_metric_types.intersection(os.listdir(path)):
metric_type_path = os.path.join(path, metric_type)
# code block tags correspond to the `tag` argument in ResourceUsageTracker.
for code_block_tag in os.listdir(metric_type_path):
if tags and code_block_tag not in tags:
continue
if code_block_tag not in summary:
summary[code_block_tag] = {}
run_path = os.path.join(metric_type_path, code_block_tag)
# Metrics from code blocks/functions that ran more than once are averaged.
summary[code_block_tag][metric_type] = average_runs(run_path)
summary_list = []
for code_block_tag, metric_type_dicts in summary.items():
merged_summary: dict[str, float | int] = {}
for metrics in metric_type_dicts.values():
assert "num_runs" in metrics
assert "num_runs" not in merged_summary or metrics["num_runs"] == merged_summary["num_runs"]
merged_summary.update(metrics)
summary_list.append(
ResourceUsageSummary(
code_block_tag=code_block_tag, metric_to_values=merged_summary, metric_names=set(merged_summary)
)
)
return summary_list
def build_resource_usage_diff(
base_path: str,
experimental_path: str,
base_experiment_name: str | None = None,
experimental_experiment_name: str | None = None,
) -> list[ResourceUsageDiff]:
"""Build and return a ResourceUsageDiff object to diff resource usage metrics between two experiments.
:param base_path: corresponds to the `output_dir` argument in the base ResourceUsageTracker run.
:param experimental_path: corresponds to the `output_dir` argument in the experimental ResourceUsageTracker run.
"""
base_summary_list = summarize_resource_usage(base_path)
experimental_summary_list = summarize_resource_usage(experimental_path)
summaries_list = []
for base_summary in base_summary_list:
for experimental_summary in experimental_summary_list:
if base_summary.code_block_tag == experimental_summary.code_block_tag:
summaries_list.append((base_summary, experimental_summary))
diffs = []
for base_summary, experimental_summary in summaries_list:
metrics_in_common = set(base_summary.metric_names).intersection(set(experimental_summary.metric_names))
metrics: list[MetricDiff] = [
build_diff(name, base_summary.metric_to_values[name], experimental_summary.metric_to_values[name])
for name in metrics_in_common
]
diff = ResourceUsageDiff(
code_block_tag=base_summary.code_block_tag,
base_experiment_name=base_experiment_name if base_experiment_name else "experiment_1",
experimental_experiment_name=(
experimental_experiment_name if experimental_experiment_name else "experiment_2"
),
metrics=metrics,
)
diffs.append(diff)
return diffs
================================================
FILE: ludwig/benchmarking/utils.py
================================================
import asyncio
import functools
import logging
import os
import shutil
import uuid
from concurrent.futures import ThreadPoolExecutor
from types import ModuleType
from typing import Any
import fsspec
import pandas as pd
import yaml
from ludwig.api_annotations import DeveloperAPI
from ludwig.constants import BINARY, CATEGORY
from ludwig.datasets import model_configs_for_dataset
from ludwig.datasets.loaders.dataset_loader import DatasetLoader
from ludwig.globals import CONFIG_YAML, MODEL_FILE_NAME, MODEL_WEIGHTS_FILE_NAME
from ludwig.utils.data_utils import load_yaml
from ludwig.utils.dataset_utils import get_repeatable_train_val_test_split
from ludwig.utils.defaults import default_random_seed
from ludwig.utils.fs_utils import get_fs_and_path
HYPEROPT_OUTDIR_RETAINED_FILES = [
"hyperopt_statistics.json",
"params.json",
"stderr",
"stdout",
"result.json",
"error.txt",
]
logger = logging.getLogger()
def load_from_module(
dataset_module: DatasetLoader | ModuleType, output_feature: dict[str, str], subsample_frac: float = 1
) -> pd.DataFrame:
"""Load the ludwig dataset, optionally subsamples it, and returns a repeatable split. A stratified split is
used for classification datasets.
Args:
dataset_module: ludwig datasets module (e.g. ludwig.datasets.sst2, ludwig.datasets.ames_housing, etc.)
subsample_frac: percentage of the total dataset to load.
"""
dataset = dataset_module.load(split=False)
if subsample_frac < 1:
dataset = dataset.sample(frac=subsample_frac, replace=False, random_state=default_random_seed)
if output_feature["type"] in [CATEGORY, BINARY]:
return get_repeatable_train_val_test_split(
dataset,
stratify_colname=output_feature["name"],
random_seed=default_random_seed,
)
else:
return get_repeatable_train_val_test_split(dataset, random_seed=default_random_seed)
def export_artifacts(experiment: dict[str, str], experiment_output_directory: str, export_base_path: str):
"""Save the experiment artifacts to the `bench_export_directory`.
Args:
experiment: experiment dict that contains "dataset_name" (e.g. ames_housing),
"experiment_name" (specified by user), and "config_path" (path to experiment config.
Relative to ludwig/benchmarks/configs).
experiment_output_directory: path where the model, data, and logs of the experiment are saved.
export_base_path: remote or local path (directory) where artifacts are
exported. (e.g. s3://benchmarking.us-west-2.ludwig.com/bench/ or your/local/bench/)
"""
protocol, _ = fsspec.core.split_protocol(export_base_path)
fs, _ = get_fs_and_path(export_base_path)
try:
export_full_path = os.path.join(export_base_path, experiment["dataset_name"], experiment["experiment_name"])
# override previous experiment with the same name
if fs.exists(export_full_path):
fs.rm(export_full_path, recursive=True)
fs.put(experiment_output_directory, export_full_path, recursive=True)
fs.put(
os.path.join(experiment["config_path"]),
os.path.join(export_full_path, CONFIG_YAML),
)
logger.info(f"Uploaded experiment artifact to\n\t{export_full_path}")
except Exception:
logger.exception(
f"Failed to upload experiment artifacts for experiment *{experiment['experiment_name']}* on "
f"dataset {experiment['dataset_name']}"
)
def download_artifacts(
bench_config_path: str,
base_experiment: str,
experimental_experiment: str,
download_base_path: str,
local_dir: str = "benchmarking_summaries",
) -> tuple[str, list[str]]:
"""Download benchmarking artifacts for two experiments.
Args:
bench_config_path: bench config file path. Can be the same one that was used to run
these experiments.
base_experiment: name of the experiment we're comparing against.
experimental_experiment: name of the experiment we're comparing.
download_base_path: base path under which live the stored artifacts of
the benchmarking experiments.
"""
bench_config = load_yaml(bench_config_path)
protocol, _ = fsspec.core.split_protocol(download_base_path)
fs, _ = get_fs_and_path(download_base_path)
os.makedirs(local_dir, exist_ok=True)
coroutines = []
for experiment in bench_config["experiments"]:
dataset_name = experiment["dataset_name"]
for experiment_name in [base_experiment, experimental_experiment]:
coroutines.append(download_one(fs, download_base_path, dataset_name, experiment_name, local_dir))
downloaded_names = asyncio.run(asyncio.gather(*coroutines, return_exceptions=True))
dataset_names = [experiment_tuple[0] for experiment_tuple in set(downloaded_names) if experiment_tuple[0]]
assert (
len({experiment_tuple[1] for experiment_tuple in downloaded_names}) == 1 and downloaded_names[0][1] == local_dir
), "Experiments not downloaded to the same path"
return local_dir, dataset_names
@DeveloperAPI
async def download_one(
fs, download_base_path: str, dataset_name: str, experiment_name: str, local_dir: str
) -> tuple[str, str]:
"""Download `config.yaml` and `report.json` for an experiment.
Args:
fs: filesystem to use to download.
download_base_path: base path under which live the stored artifacts of
the benchmarking experiments.
dataset_name: name of the dataset we ran the experiments on.
experiment_name: name of the experiment (e.g. `v0.5.3_with_bert`)
local_dir: local directory under which the artifacts will be downloaded.
"""
loop = asyncio.get_running_loop()
local_experiment_dir = os.path.join(local_dir, dataset_name, experiment_name)
remote_experiment_directory = os.path.join(download_base_path, dataset_name, experiment_name)
os.makedirs(local_experiment_dir, exist_ok=True)
try:
with ThreadPoolExecutor() as pool:
func = functools.partial(
fs.get,
remote_experiment_directory,
local_experiment_dir,
recursive=True,
)
await loop.run_in_executor(pool, func)
except Exception:
logger.exception(f"Couldn't download experiment *{experiment_name}* of dataset *{dataset_name}*.")
return "", local_dir
return dataset_name, local_dir
def validate_benchmarking_config(benchmarking_config: dict[str, Any]) -> None:
"""Validates the parameters of the benchmarking config.
Args:
benchmarking_config: benchmarking config dictionary.
Raises:
ValueError if any of the expected parameters is not there.
"""
if "experiment_name" not in benchmarking_config and not all(
"experiment_name" in experiment for experiment in benchmarking_config["experiments"]
):
raise ValueError("You must either specify a global experiment name or an experiment name for each experiment.")
if "export" not in benchmarking_config:
raise ValueError("""You must specify export parameters. Example:
export:
export_artifacts: true
export_base_path: s3://benchmarking.us-west-2.ludwig.com/bench/ # include the slash at the end.
""")
if "experiments" not in benchmarking_config:
raise ValueError("You must specify a list of experiments.")
for experiment in benchmarking_config["experiments"]:
if "dataset_name" not in experiment:
raise ValueError("A Ludwig dataset must be specified.")
def populate_benchmarking_config_with_defaults(benchmarking_config: dict[str, Any]) -> dict[str, Any]:
"""Populates the parameters of the benchmarking config with defaults.
Args:
benchmarking_config: benchmarking config dictionary.
"""
if "hyperopt" not in benchmarking_config:
benchmarking_config["hyperopt"] = False
if "process_config_file_path" not in benchmarking_config:
benchmarking_config["process_config_file_path"] = None
if "profiler" not in benchmarking_config:
benchmarking_config["profiler"] = {"enable": False, "use_torch_profiler": False, "logging_interval": None}
return benchmarking_config
def propagate_global_parameters(benchmarking_config: dict[str, Any]) -> dict[str, Any]:
"""Propagate the global parameters of the benchmarking config to local experiments.
Args:
benchmarking_config: benchmarking config dictionary.
"""
for experiment in benchmarking_config["experiments"]:
if "experiment_name" not in experiment:
experiment["experiment_name"] = benchmarking_config["experiment_name"]
if "export" not in experiment:
experiment["export"] = benchmarking_config["export"]
if "hyperopt" not in experiment:
experiment["hyperopt"] = benchmarking_config["hyperopt"]
if "process_config_file_path" not in experiment:
experiment["process_config_file_path"] = benchmarking_config["process_config_file_path"]
if "profiler" not in experiment:
experiment["profiler"] = benchmarking_config["profiler"]
return benchmarking_config
def create_default_config(experiment: dict[str, Any]) -> str:
"""Create a Ludwig config that only contains input and output features.
Args:
experiment: experiment dictionary.
Returns:
path where the default config is saved.
"""
model_config = model_configs_for_dataset(experiment["dataset_name"])["default"]
# only keep input_features and output_features
main_config_keys = list(model_config.keys())
for key in main_config_keys:
if key not in ["input_features", "output_features"]:
del model_config[key]
config_path = f"{experiment['dataset_name']}-{uuid.uuid4().hex}.yaml"
save_yaml(config_path, model_config)
return config_path
def delete_model_checkpoints(output_directory: str):
"""Deletes outputs of the experiment run that we don't want to save with the artifacts.
Args:
output_directory: output directory of the hyperopt run.
"""
shutil.rmtree(os.path.join(output_directory, MODEL_FILE_NAME, "training_checkpoints"), ignore_errors=True)
if os.path.isfile(os.path.join(output_directory, MODEL_FILE_NAME, MODEL_WEIGHTS_FILE_NAME)):
os.remove(os.path.join(output_directory, MODEL_FILE_NAME, MODEL_WEIGHTS_FILE_NAME))
def delete_hyperopt_outputs(output_directory: str):
"""Deletes outputs of the hyperopt run that we don't want to save with the artifacts.
Args:
output_directory: output directory of the hyperopt run.
"""
for path, currentDirectory, files in os.walk(output_directory):
for file in files:
filename = os.path.join(path, file)
if file not in HYPEROPT_OUTDIR_RETAINED_FILES:
os.remove(filename)
def save_yaml(filename, dictionary):
with open(filename, "w") as f:
yaml.dump(dictionary, f, default_flow_style=False)
def format_time(time_us):
"""Defines how to format time in FunctionEvent.
from https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler_util.py
"""
US_IN_SECOND = 1000.0 * 1000.0
US_IN_MS = 1000.0
if time_us >= US_IN_SECOND:
return f"{time_us / US_IN_SECOND:.3f}s"
if time_us >= US_IN_MS:
return f"{time_us / US_IN_MS:.3f}ms"
return f"{time_us:.3f}us"
def format_memory(nbytes):
"""Returns a formatted memory size string.
from https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler_util.py
"""
KB = 1024
MB = 1024 * KB
GB = 1024 * MB
if abs(nbytes) >= GB:
return f"{nbytes * 1.0 / GB:.2f} Gb"
elif abs(nbytes) >= MB:
return f"{nbytes * 1.0 / MB:.2f} Mb"
elif abs(nbytes) >= KB:
return f"{nbytes * 1.0 / KB:.2f} Kb"
else:
return str(nbytes) + " b"
================================================
FILE: ludwig/callbacks.py
================================================
# !/usr/bin/env python
# Copyright (c) 2021 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
from abc import ABC
from collections.abc import Callable
from typing import Any
from ludwig.api_annotations import PublicAPI
from ludwig.types import HyperoptConfigDict, ModelConfigDict, TrainingSetMetadataDict
@PublicAPI
class Callback(ABC):
def on_cmdline(self, cmd: str, *args: list[str]):
"""Called when Ludwig is run on the command line with the callback enabled.
:param cmd: The Ludwig subcommand being run, ex. "train", "evaluate", "predict", ...
:param args: The full list of command-line arguments (sys.argv).
"""
def on_preprocess_start(self, config: ModelConfigDict, **kwargs):
"""Called before preprocessing starts.
:param config: The config dictionary.
"""
def on_preprocess_end(
self,
training_set,
validation_set,
test_set,
training_set_metadata: TrainingSetMetadataDict,
**kwargs,
):
"""Called after preprocessing ends.
:param training_set: The training set.
:type training_set: ludwig.dataset.base.Dataset
:param validation_set: The validation set.
:type validation_set: ludwig.dataset.base.Dataset
:param test_set: The test set.
:type test_set: ludwig.dataset.base.Dataset
:param training_set_metadata: Values inferred from the training set, including preprocessing settings,
vocabularies, feature statistics, etc. Same as training_set_metadata.json.
"""
def on_hyperopt_init(self, experiment_name: str, **kwargs):
"""Called to initialize state before hyperparameter optimization begins.
:param experiment_name: The name of the current experiment.
"""
def on_hyperopt_preprocessing_start(self, experiment_name: str, **kwargs):
"""Called before data preprocessing for hyperparameter optimization begins.
:param experiment_name: The name of the current experiment.
"""
def on_hyperopt_preprocessing_end(self, experiment_name: str, **kwargs):
"""Called after data preprocessing for hyperparameter optimization is completed.
:param experiment_name: The name of the current experiment.
"""
def on_hyperopt_start(self, experiment_name: str, **kwargs):
"""Called before any hyperparameter optimization trials are started.
:param experiment_name: The name of the current experiment.
"""
def on_hyperopt_end(self, experiment_name: str, **kwargs):
"""Called after all hyperparameter optimization trials are completed.
:param experiment_name: The name of the current experiment.
"""
def on_hyperopt_finish(self, experiment_name: str, **kwargs):
"""Deprecated.
Use on_hyperopt_end instead.
"""
# TODO(travis): remove in favor of on_hyperopt_end for naming consistency
def on_hyperopt_trial_start(self, parameters: HyperoptConfigDict, **kwargs):
"""Called before the start of each hyperparameter optimization trial.
:param parameters: The complete dictionary of parameters for this hyperparameter optimization experiment.
"""
def on_hyperopt_trial_end(self, parameters: HyperoptConfigDict, **kwargs):
"""Called after the end of each hyperparameter optimization trial.
:param parameters: The complete dictionary of parameters for this hyperparameter optimization experiment.
"""
def should_stop_hyperopt(self):
"""Returns true if the entire hyperopt run (all trials) should be stopped.
See: https://docs.ray.io/en/latest/tune/api_docs/stoppers.html#ray.tune.Stopper
"""
return False
def on_resume_training(self, is_coordinator: bool, **kwargs):
pass
def on_train_init(
self,
base_config: ModelConfigDict,
experiment_directory: str,
experiment_name: str,
model_name: str,
output_directory: str,
resume_directory: str | None,
**kwargs,
):
"""Called after preprocessing, but before the creation of the model and trainer objects.
:param base_config: The user-specified config, before the insertion of defaults or inferred values.
:param experiment_directory: The experiment directory, same as output_directory if no experiment specified.
:param experiment_name: The experiment name.
:param model_name: The model name.
:param output_directory: file path to where training results are stored.
:param resume_directory: model directory to resume training from, or None.
"""
def on_train_start(
self,
model,
config: ModelConfigDict,
config_fp: str | None,
**kwargs,
):
"""Called after creation of trainer, before the start of training.
:param model: The ludwig model.
:type model: ludwig.utils.torch_utils.LudwigModule
:param config: The config dictionary.
:param config_fp: The file path to the config, or none if config was passed to stdin.
"""
def on_train_end(self, output_directory: str, **kwargs):
"""Called at the end of training, before the model is saved.
:param output_directory: file path to where training results are stored.
"""
def on_trainer_train_setup(self, trainer, save_path: str, is_coordinator: bool, **kwargs):
"""Called in every trainer (distributed or local) before training starts.
:param trainer: The trainer instance.
:type trainer: trainer: ludwig.models.Trainer
:param save_path: The path to the directory model is saved in.
:param is_coordinator: Is this trainer the coordinator.
"""
def on_trainer_train_teardown(self, trainer, progress_tracker, save_path: str, is_coordinator: bool, **kwargs):
"""Called in every trainer (distributed or local) after training completes.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
:param is_coordinator: Is this trainer the coordinator.
"""
def on_batch_start(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator only before each batch.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_batch_end(self, trainer, progress_tracker, save_path: str, sync_step: bool = True, **kwargs):
"""Called on coordinator only after each batch.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
:param sync_step: Whether the model params were updated and synced in this step.
"""
def on_eval_start(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator at the start of evaluation.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_eval_end(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator at the end of evaluation.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_epoch_start(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator only before the start of each epoch.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_epoch_end(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator only after the end of each epoch.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_validation_start(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator before validation starts.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_validation_end(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator after validation is complete.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_test_start(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator before testing starts.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def on_test_end(self, trainer, progress_tracker, save_path: str, **kwargs):
"""Called on coordinator after testing ends.
:param trainer: The trainer instance.
:type trainer: ludwig.models.trainer.Trainer
:param progress_tracker: An object which tracks training progress.
:type progress_tracker: ludwig.utils.trainer_utils.ProgressTracker
:param save_path: The path to the directory model is saved in.
"""
def should_early_stop(self, trainer, progress_tracker, is_coordinator, **kwargs):
# Triggers early stopping if any callback on any worker returns True
return False
def on_checkpoint(self, trainer, progress_tracker, **kwargs):
"""Called after each checkpoint is passed, regardless of whether the model was evaluated or saved at that
checkpoint."""
def on_save_best_checkpoint(self, trainer, progress_tracker, save_path, **kwargs):
"""Called on every worker immediately after a new best model is checkpointed."""
def on_build_metadata_start(self, df, mode: str, **kwargs):
"""Called before building metadata for dataset.
:param df: The dataset.
:type df: pd.DataFrame
:param mode: "prediction", "training", or None.
"""
def on_build_metadata_end(self, df, mode, **kwargs):
"""Called after building dataset metadata.
:param df: The dataset.
:type df: pd.DataFrame
:param mode: "prediction", "training", or None.
"""
def on_build_data_start(self, df, mode, **kwargs):
"""Called before build_data, which does preprocessing, handling missing values, adding metadata to
training_set_metadata.
:param df: The dataset.
:type df: pd.DataFrame
:param mode: "prediction", "training", or None.
"""
def on_build_data_end(self, df, mode, **kwargs):
"""Called after build_data completes.
:param df: The dataset.
:type df: pd.DataFrame
:param mode: "prediction", "training", or None.
"""
def on_evaluation_start(self, **kwargs):
"""Called before preprocessing for evaluation."""
def on_evaluation_end(self, **kwargs):
"""Called after evaluation is complete."""
def on_visualize_figure(self, fig, **kwargs):
"""Called after a visualization is generated.
:param fig: The figure.
:type fig: matplotlib.figure.Figure
"""
def on_ludwig_end(self, **kwargs):
"""Convenience method for any cleanup.
Not yet implemented.
"""
def prepare_ray_tune(
self,
train_fn: Callable,
tune_config: dict[str, Any],
tune_callbacks: list[Callable],
**kwargs,
):
"""Configures Ray Tune callback and config.
:param train_fn: The function which runs the experiment trial.
:param tune_config: The ray tune configuration dictionary.
:param tune_callbacks: List of callbacks (not used yet).
:returns: Tuple[Callable, Dict] The train_fn and tune_config, which will be passed to ray tune.
"""
return train_fn, tune_config
================================================
FILE: ludwig/check.py
================================================
import argparse
import logging
import tempfile
from ludwig.api import LudwigModel
from ludwig.api_annotations import DeveloperAPI
from ludwig.constants import INPUT_FEATURES, OUTPUT_FEATURES, TRAINER
from ludwig.data.dataset_synthesizer import build_synthetic_dataset_df
from ludwig.globals import LUDWIG_VERSION
from ludwig.utils.print_utils import get_logging_level_registry, print_ludwig
NUM_EXAMPLES = 100
@DeveloperAPI
def check_install(logging_level: int = logging.INFO, **kwargs):
config = {
INPUT_FEATURES: [
{"name": "in1", "type": "text"},
{"name": "in2", "type": "category"},
{"name": "in3", "type": "number"},
],
OUTPUT_FEATURES: [{"name": "out1", "type": "binary"}],
TRAINER: {"epochs": 2, "batch_size": 8},
}
try:
df = build_synthetic_dataset_df(NUM_EXAMPLES, config)
model = LudwigModel(config, logging_level=logging_level)
with tempfile.TemporaryDirectory() as tmpdir:
model.train(dataset=df, output_directory=tmpdir)
except Exception:
print("=== CHECK INSTALL COMPLETE... FAILURE ===")
raise
print("=== CHECK INSTALL COMPLETE... SUCCESS ===")
@DeveloperAPI
def cli(sys_argv):
parser = argparse.ArgumentParser(
description="This command checks Ludwig installation on a synthetic dataset.",
prog="ludwig check_install",
usage="%(prog)s [options]",
)
parser.add_argument(
"-l",
"--logging_level",
default="warning",
help="the level of logging to use",
choices=["critical", "error", "warning", "info", "debug", "notset"],
)
args = parser.parse_args(sys_argv)
args.logging_level = get_logging_level_registry()[args.logging_level]
logging.getLogger("ludwig").setLevel(args.logging_level)
global logger
logger = logging.getLogger("ludwig.check")
print_ludwig("Check Install", LUDWIG_VERSION)
check_install(**vars(args))
================================================
FILE: ludwig/cli.py
================================================
#! /usr/bin/env python
# Copyright (c) 2023 Predibase, Inc., 2019 Uber Technologies, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
import argparse
import sys
import ludwig.contrib
from ludwig.globals import LUDWIG_VERSION
from ludwig.utils.print_utils import get_logo
class CLI:
"""CLI describes a command line interface for interacting with Ludwig.
Functions are described below.
"""
def __init__(self):
parser = argparse.ArgumentParser(
description="ludwig cli runner",
usage=f"""\n{get_logo("ludwig cli", LUDWIG_VERSION)}
ludwig