Repository: metabrainz/picard-plugins
Branch: 2.0
Commit: 1ad24cca7804
Files: 157
Total size: 2.3 MB
Directory structure:
gitextract_xqnp2_8g/
├── .github/
│ └── workflows/
│ └── test.yml
├── .gitignore
├── .prospector.yml
├── .pylintrc
├── README.md
├── build_ui.py
├── generate.py
├── get_plugin_data.py
├── plugins/
│ ├── abbreviate_artistsort/
│ │ └── abbreviate_artistsort.py
│ ├── acousticbrainz/
│ │ ├── __init__.py
│ │ ├── ui_options_acousticbrainz_tags.py
│ │ └── ui_options_acousticbrainz_tags.ui
│ ├── acousticbrainz_tonal-rhythm/
│ │ └── acousticbrainz_tonal-rhythm.py
│ ├── add_to_collection/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── manifest.py
│ │ ├── options.py
│ │ ├── override_module.py
│ │ ├── post_save_processor.py
│ │ ├── settings.py
│ │ └── ui_add_to_collection_options.py
│ ├── additional_artists_details/
│ │ ├── __init__.py
│ │ ├── docs/
│ │ │ └── README.md
│ │ ├── options_additional_artists_details.ui
│ │ └── ui_options_additional_artists_details.py
│ ├── additional_artists_variables/
│ │ └── additional_artists_variables.py
│ ├── addrelease/
│ │ └── addrelease.py
│ ├── albumartist_website/
│ │ └── albumartist_website.py
│ ├── albumartistextension/
│ │ └── albumartistextension.py
│ ├── amazon/
│ │ └── amazon.py
│ ├── bpm/
│ │ ├── __init__.py
│ │ ├── ui_options_bpm.py
│ │ └── ui_options_bpm.ui
│ ├── classical_extras/
│ │ ├── Readme.md
│ │ ├── __init__.py
│ │ ├── const.py
│ │ ├── options_classical_extras.ui
│ │ ├── suffixtree.py
│ │ └── ui_options_classical_extras.py
│ ├── classicdiscnumber/
│ │ └── classicdiscnumber.py
│ ├── collect_artists/
│ │ └── collect_artists.py
│ ├── compatible_TXXX/
│ │ └── compatible_TXXX.py
│ ├── critiquebrainz/
│ │ └── critiquebrainz.py
│ ├── cuesheet/
│ │ └── cuesheet.py
│ ├── decade/
│ │ └── __init__.py
│ ├── decode_cyrillic/
│ │ └── decode_cyrillic.py
│ ├── decode_greek_cyrillic/
│ │ └── decode_greek1253.py
│ ├── deezerart/
│ │ ├── __init__.py
│ │ ├── deezer/
│ │ │ ├── __init__.py
│ │ │ ├── client.py
│ │ │ └── obj.py
│ │ ├── options.py
│ │ └── options.ui
│ ├── discnumber/
│ │ └── discnumber.py
│ ├── enhanced_titles/
│ │ ├── __init__.py
│ │ ├── options_enhanced_titles.ui
│ │ └── ui_options_enhanced_titles.py
│ ├── fanarttv/
│ │ ├── __init__.py
│ │ ├── ui_options_fanarttv.py
│ │ └── ui_options_fanarttv.ui
│ ├── featartist/
│ │ └── featartist.py
│ ├── featartistsintitles/
│ │ └── featartistsintitles.py
│ ├── fix_tracknums/
│ │ └── fix_tracknums.py
│ ├── format_performer_tags/
│ │ ├── __init__.py
│ │ ├── docs/
│ │ │ ├── HISTORY.md
│ │ │ └── README.md
│ │ ├── ui_options_format_performer_tags.py
│ │ └── ui_options_format_performer_tags.ui
│ ├── genre_mapper/
│ │ ├── __init__.py
│ │ ├── options_genre_mapper.ui
│ │ └── ui_options_genre_mapper.py
│ ├── haikuattrs/
│ │ └── haikuattrs.py
│ ├── happidev_lyrics/
│ │ └── happidev_lyrics.py
│ ├── hyphen_unicode/
│ │ └── hyphen_unicode.py
│ ├── instruments/
│ │ └── instruments.py
│ ├── keep/
│ │ └── keep.py
│ ├── key_wheel_converter/
│ │ └── key_wheel_converter.py
│ ├── lastfm/
│ │ ├── __init__.py
│ │ ├── ui_options_lastfm.py
│ │ └── ui_options_lastfm.ui
│ ├── loadasnat/
│ │ └── loadasnat.py
│ ├── losslessfuncs/
│ │ └── __init__.py
│ ├── lrclib_lyrics/
│ │ ├── __init__.py
│ │ ├── option_lrclib_lyrics.py
│ │ └── option_lrclib_lyrics.ui
│ ├── matroska_tagger/
│ │ └── matroska_tagger.py
│ ├── mod/
│ │ └── __init__.py
│ ├── moodbars/
│ │ ├── __init__.py
│ │ ├── ui_options_moodbar.py
│ │ └── ui_options_moodbar.ui
│ ├── musixmatch/
│ │ ├── README
│ │ ├── __init__.py
│ │ └── ui_options_musixmatch.py
│ ├── no_release/
│ │ └── no_release.py
│ ├── non_ascii_equivalents/
│ │ └── non_ascii_equivalents.py
│ ├── padded/
│ │ └── padded.py
│ ├── papercdcase/
│ │ └── papercdcase.py
│ ├── performer_tag_replace/
│ │ ├── __init__.py
│ │ ├── options_performer_tag_replace.ui
│ │ └── ui_options_performer_tag_replace.py
│ ├── persistent_variables/
│ │ ├── __init__.py
│ │ └── ui_variables_dialog.py
│ ├── playlist/
│ │ └── playlist.py
│ ├── post_tagging_actions/
│ │ ├── __init__.py
│ │ ├── actions_status.py
│ │ ├── actions_status.ui
│ │ ├── docs/
│ │ │ └── guide.md
│ │ ├── options_post_tagging_actions.py
│ │ └── options_post_tagging_actions.ui
│ ├── release_type/
│ │ └── release_type.py
│ ├── releasetag_aggregations/
│ │ └── releasetag_aggregations.py
│ ├── remove_perfect_albums/
│ │ └── remove_perfect_albums.py
│ ├── reorder_sides/
│ │ └── reorder_sides.py
│ ├── replace_forbidden_symbols/
│ │ └── replace_forbidden_symbols.py
│ ├── replaygain2/
│ │ ├── __init__.py
│ │ ├── ui_options_replaygain2.py
│ │ └── ui_options_replaygain2.ui
│ ├── save_and_rewrite_header/
│ │ └── save_and_rewrite_header.py
│ ├── script_logger/
│ │ └── __init__.py
│ ├── search_engine_lookup/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── ui_options_search_engine_editor.py
│ │ ├── ui_options_search_engine_editor.ui
│ │ ├── ui_options_search_engine_lookup.py
│ │ └── ui_options_search_engine_lookup.ui
│ ├── smart_title_case/
│ │ └── smart_title_case.py
│ ├── sort_multivalue_tags/
│ │ └── sort_multivalue_tags.py
│ ├── soundtrack/
│ │ └── soundtrack.py
│ ├── standardise_feat/
│ │ └── standardise_feat.py
│ ├── standardise_performers/
│ │ └── standardise_performers.py
│ ├── submit_folksonomy_tags/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ └── ui_config.py
│ ├── submit_isrc/
│ │ ├── README.md
│ │ └── __init__.py
│ ├── tangoinfo/
│ │ ├── README.md
│ │ └── __init__.py
│ ├── theaudiodb/
│ │ ├── __init__.py
│ │ ├── ui_options_theaudiodb.py
│ │ └── ui_options_theaudiodb.ui
│ ├── titlecase/
│ │ └── titlecase.py
│ ├── tracks2clipboard/
│ │ └── tracks2clipboard.py
│ ├── viewvariables/
│ │ ├── __init__.py
│ │ ├── ui_variables_dialog.py
│ │ └── ui_variables_dialog.ui
│ ├── wikidata/
│ │ ├── __init__.py
│ │ ├── ui_options_wikidata.py
│ │ └── ui_options_wikidata.ui
│ └── workandmovement/
│ ├── __init__.py
│ └── roman.py
├── setup.cfg
└── test/
├── __init__.py
├── plugin_test_case.py
├── test_add_to_collection.py
├── test_doctest.py
├── test_generate.py
└── test_keep.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/test.yml
================================================
name: Test
on: [push, pull_request]
jobs:
unittest:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: ['3.10', '3.11', '3.12', '3.13', '3.14']
steps:
- uses: actions/checkout@v1
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v1
with:
python-version: ${{ matrix.python-version }}
- name: Install gettext
run: sudo apt-get install gettext
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install picard
- name: Test plugins
run: python -m unittest discover -v
================================================
FILE: .gitignore
================================================
# Generated by the script
plugins.json
plugins/*.zip
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
# Distribution / packaging / development
.venv/
.vscode/
.Python
env/
build/
================================================
FILE: .prospector.yml
================================================
# Configuration for prospector, mainly used by Codacy.
pep8:
# Please see comments in setup.cfg as to why we disable the below checks.
disable:
- E127
- E128
- E129
- E226
- E241
- E501
- W503
pyflakes:
disable:
# Undefined name. Ignore this since it otherwise detects the gettext
# helpers (_, ngettext, N_) as undefined. There seems to be no clean way
# to specify additional builtins for pyflakes with prospector.
# We also test for this with flake8 in a saner way.
- F821
# F401: Module imported but unused
# F841: Unused variables
# We have some valid cases for both, but PyFlakes does not allow to ignore
# them case by case. flake8 also checks this, so this is redundant.
- F401
- F841
# Ignore syntax errors as reported by PyFlakes since on Codacy this does
# not support Python 3 syntax.
# - F999
================================================
FILE: .pylintrc
================================================
[MASTER]
# A comma-separated list of package or module names from where C extensions may
# be loaded. Extensions are loading into the active Python interpreter and may
# run arbitrary code.
extension-pkg-whitelist=
# Add files or directories to the ignore list. They should be base names, not
# paths.
ignore=CVS
# Add files or directories matching the regex patterns to the ignore list. The
# regex matches against base names, not paths.
ignore-patterns=ui_.*\.py
# Python code to execute, usually for sys.path manipulation such as
# pygtk.require().
#init-hook=
# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
# number of processors available to use.
jobs=0
# Control the amount of potential inferred values when inferring a single
# object. This can help the performance when dealing with large functions or
# complex, nested conditions.
limit-inference-results=100
# List of plugins (as comma separated values of python modules names) to load,
# usually to register additional checkers.
load-plugins=
# Pickle collected data for later comparisons.
persistent=yes
# Specify a configuration file.
#rcfile=
# When enabled, pylint would attempt to guess common misconfiguration and emit
# user-friendly hints instead of false-positive error messages.
suggestion-mode=yes
# Allow loading of arbitrary C extensions. Extensions are imported into the
# active Python interpreter and may run arbitrary code.
unsafe-load-any-extension=no
[MESSAGES CONTROL]
# Only show warnings with the listed confidence levels. Leave empty to show
# all. Valid levels: HIGH, INFERENCE, INFERENCE_FAILURE, UNDEFINED.
confidence=
# Disable the message, report, category or checker with the given id(s). You
# can either give multiple identifiers separated by comma (,) or put this
# option multiple times (only on the command line, not in the configuration
# file where it should appear only once). You can also use "--disable=all" to
# disable everything first and then reenable specific checks. For example, if
# you want to run only the similarities checker, you can use "--disable=all
# --enable=similarities". If you want to run only the classes checker, but have
# no Warning level messages displayed, use "--disable=all --enable=classes
# --disable=W".
disable=all
# Enable the message, report, category or checker with the given id(s). You can
# either give multiple identifier separated by comma (,) or put this option
# multiple time (only on the command line, not in the configuration file where
# it should appear only once). See also the "--disable" option for examples.
enable=consider-using-enumerate,
format-combined-specification,
return-in-init,
catching-non-exception,
bad-except-order,
unexpected-special-method-signature,
# Enforce list comprehensions
# Newline at EOF
raising-bad-type,
raising-non-exception,
format-needs-mapping,
invalid-all-object,
bad-super-call,
nonexistent-operator,
missing-kwoa,
missing-format-argument-key,
init-is-generator,
access-member-before-definition,
used-before-assignment,
redundant-keyword-arg,
assert-on-tuple,
assignment-from-no-return,
expression-not-assigned,
misplaced-bare-raise,
redefined-argument-from-local,
not-in-loop,
bad-exception-context,
unidiomatic-typecheck,
no-staticmethod-decorator,
nonlocal-and-global,
confusing-with-statement,
global-variable-undefined,
global-variable-not-assigned,
inconsistent-mro,
no-classmethod-decorator,
nonlocal-without-binding,
duplicate-bases,
duplicate-argument-name,
duplicate-key,
useless-else-on-loop,
arguments-differ,
logging-too-many-args,
too-few-format-args,
bad-format-string-key,
invalid-sequence-index,
inherit-non-class,
bad-format-string,
invalid-format-index,
invalid-star-assignment-target,
no-method-argument,
no-value-for-parameter,
missing-format-attribute,
logging-too-few-args,
too-few-format-args,
mixed-format-string,
# Old style class
logging-format-truncated,
truncated-format-string,
notimplemented-raised,
# Builtin redefined
function-redefined,
reimported,
repeated-keyword,
lost-exception,
return-outside-function,
return-arg-in-generator,
non-iterator-returned,
method-hidden,
too-many-star-expressions,
trailing-whitespace,
unexpected-keyword-arg,
missing-format-string-key,
unnecessary-lambda,
unnecessary-pass,
unreachable,
logging-unsupported-format,
bad-format-character,
unused-import,
exec-used,
pointless-statement,
pointless-string-statement,
undefined-all-variable,
misplaced-future,
continue-in-finally,
invalid-slots,
invalid-slice-index,
invalid-slots-object,
star-needs-assignment-target,
global-at-module-level,
yield-outside-function,
mixed-indentation,
non-parent-init-called,
bare-except,
#no-self-use,
dangerous-default-value,
arguments-differ,
signature-differs,
duplicate-except,
abstract-class-instantiated,
binary-op-exception,
undefined-variable
[REPORTS]
# Python expression which should return a note less than 10 (10 is the highest
# note). You have access to the variables errors warning, statement which
# respectively contain the number of errors / warnings messages and the total
# number of statements analyzed. This is used by the global evaluation report
# (RP0004).
evaluation=10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)
# Template used to display messages. This is a python new-style format string
# used to format the message information. See doc for all details.
#msg-template=
# Set the output format. Available formats are text, parseable, colorized, json
# and msvs (visual studio). You can also give a reporter class, e.g.
# mypackage.mymodule.MyReporterClass.
output-format=text
# Tells whether to display a full report or only the messages.
reports=no
# Activate the evaluation score.
score=yes
[REFACTORING]
# Maximum number of nested blocks for function / method body
max-nested-blocks=5
# Complete name of functions that never returns. When checking for
# inconsistent-return-statements if a never returning function is called then
# it will be considered as an explicit return statement and no message will be
# printed.
never-returning-functions=sys.exit
[FORMAT]
# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
expected-line-ending-format=
# Regexp for a line that is allowed to be longer than the limit.
ignore-long-lines=^\s*(# )??$
# Number of spaces of indent required inside a hanging or continued line.
indent-after-paren=4
# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
# tab).
indent-string=' '
# Maximum number of characters on a single line.
max-line-length=100
# Maximum number of lines in a module.
max-module-lines=1000
# List of optional constructs for which whitespace checking is disabled. `dict-
# separator` is used to allow tabulation in dicts, etc.: {1 : 1,\n222: 2}.
# `trailing-comma` allows a space between comma and closing bracket: (a, ).
# `empty-line` allows space-only lines.
no-space-check=trailing-comma,
dict-separator
# Allow the body of a class to be on the same line as the declaration if body
# contains single statement.
single-line-class-stmt=no
# Allow the body of an if to be on the same line as the test if there is no
# else.
single-line-if-stmt=no
[SPELLING]
# Limits count of emitted suggestions for spelling mistakes.
max-spelling-suggestions=4
# Spelling dictionary name. Available dictionaries: none. To make it working
# install python-enchant package..
spelling-dict=
# List of comma separated words that should not be checked.
spelling-ignore-words=
# A path to a file that contains private dictionary; one word per line.
spelling-private-dict-file=
# Tells whether to store unknown words to indicated private dictionary in
# --spelling-private-dict-file option instead of raising a message.
spelling-store-unknown-words=no
[SIMILARITIES]
# Ignore comments when computing similarities.
ignore-comments=yes
# Ignore docstrings when computing similarities.
ignore-docstrings=yes
# Ignore imports when computing similarities.
ignore-imports=no
# Minimum lines number of a similarity.
min-similarity-lines=4
[VARIABLES]
# List of additional names supposed to be defined in builtins. Remember that
# you should avoid defining new builtins when possible.
additional-builtins=_, N_, ngettext, gettext_countries,
gettext_attributes, pgettext_attributes
# Tells whether unused global variables should be treated as a violation.
allow-global-unused-variables=yes
# List of strings which can identify a callback function by name. A callback
# name must start or end with one of those strings.
callbacks=cb_,
_cb
# A regular expression matching the name of dummy variables (i.e. expected to
# not be used).
dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
# Argument names that match this expression will be ignored. Default to name
# with leading underscore.
ignored-argument-names=_.*|^ignored_|^unused_
# Tells whether we should check for unused import in __init__ files.
init-import=no
# List of qualified module names which can have objects that can redefine
# builtins.
redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
[MISCELLANEOUS]
# List of note tags to take in consideration, separated by a comma.
notes=FIXME,
XXX,
TODO
[LOGGING]
# Format style used to check logging format string. `old` means using %
# formatting, while `new` is for `{}` formatting.
logging-format-style=old
# Logging modules to check that the string format arguments are in logging
# function parameter format.
logging-modules=logging
[BASIC]
# Naming style matching correct argument names.
argument-naming-style=snake_case
# Regular expression matching correct argument names. Overrides argument-
# naming-style.
#argument-rgx=
# Naming style matching correct attribute names.
attr-naming-style=snake_case
# Regular expression matching correct attribute names. Overrides attr-naming-
# style.
#attr-rgx=
# Bad variable names which should always be refused, separated by a comma.
bad-names=foo,
bar,
baz,
toto,
tutu,
tata
# Naming style matching correct class attribute names.
class-attribute-naming-style=any
# Regular expression matching correct class attribute names. Overrides class-
# attribute-naming-style.
#class-attribute-rgx=
# Naming style matching correct class names.
class-naming-style=PascalCase
# Regular expression matching correct class names. Overrides class-naming-
# style.
#class-rgx=
# Naming style matching correct constant names.
const-naming-style=UPPER_CASE
# Regular expression matching correct constant names. Overrides const-naming-
# style.
#const-rgx=
# Minimum line length for functions/classes that require docstrings, shorter
# ones are exempt.
docstring-min-length=-1
# Naming style matching correct function names.
function-naming-style=snake_case
# Regular expression matching correct function names. Overrides function-
# naming-style.
#function-rgx=
# Good variable names which should always be accepted, separated by a comma.
good-names=i,
j,
k,
ex,
Run,
_
# Include a hint for the correct naming format with invalid-name.
include-naming-hint=no
# Naming style matching correct inline iteration names.
inlinevar-naming-style=any
# Regular expression matching correct inline iteration names. Overrides
# inlinevar-naming-style.
#inlinevar-rgx=
# Naming style matching correct method names.
method-naming-style=snake_case
# Regular expression matching correct method names. Overrides method-naming-
# style.
#method-rgx=
# Naming style matching correct module names.
module-naming-style=snake_case
# Regular expression matching correct module names. Overrides module-naming-
# style.
#module-rgx=
# Colon-delimited sets of names that determine each other's naming style when
# the name regexes allow several styles.
name-group=
# Regular expression which should only match function or class names that do
# not require a docstring.
no-docstring-rgx=^_
# List of decorators that produce properties, such as abc.abstractproperty. Add
# to this list to register other decorators that produce valid properties.
# These decorators are taken in consideration only for invalid-name.
property-classes=abc.abstractproperty
# Naming style matching correct variable names.
variable-naming-style=snake_case
# Regular expression matching correct variable names. Overrides variable-
# naming-style.
#variable-rgx=
[TYPECHECK]
# List of decorators that produce context managers, such as
# contextlib.contextmanager. Add to this list to register other decorators that
# produce valid context managers.
contextmanager-decorators=contextlib.contextmanager
# List of members which are set dynamically and missed by pylint inference
# system, and so shouldn't trigger E1101 when accessed. Python regular
# expressions are accepted.
generated-members=
# Tells whether missing members accessed in mixin class should be ignored. A
# mixin class is detected if its name ends with "mixin" (case insensitive).
ignore-mixin-members=yes
# Tells whether to warn about missing members when the owner of the attribute
# is inferred to be None.
ignore-none=yes
# This flag controls whether pylint should warn about no-member and similar
# checks whenever an opaque object is returned when inferring. The inference
# can return multiple potential results while evaluating a Python object, but
# some branches might not be evaluated, which results in partial inference. In
# that case, it might be useful to still emit no-member and other checks for
# the rest of the inferred objects.
ignore-on-opaque-inference=yes
# List of class names for which member attributes should not be checked (useful
# for classes with dynamically set attributes). This supports the use of
# qualified names.
ignored-classes=optparse.Values,thread._local,_thread._local
# List of module names for which member attributes should not be checked
# (useful for modules/projects where namespaces are manipulated during runtime
# and thus existing member attributes cannot be deduced by static analysis. It
# supports qualified module names, as well as Unix pattern matching.
ignored-modules=
# Show a hint with possible names when a member name was not found. The aspect
# of finding the hint is based on edit distance.
missing-member-hint=yes
# The minimum edit distance a name should have in order to be considered a
# similar match for a missing member name.
missing-member-hint-distance=1
# The total number of similar names that should be taken in consideration when
# showing a hint for a missing member.
missing-member-max-choices=1
[CLASSES]
# List of method names used to declare (i.e. assign) instance attributes.
defining-attr-methods=__init__,
__new__,
setUp
# List of member names, which should be excluded from the protected access
# warning.
exclude-protected=_asdict,
_fields,
_replace,
_source,
_make
# List of valid names for the first argument in a class method.
valid-classmethod-first-arg=cls
# List of valid names for the first argument in a metaclass class method.
valid-metaclass-classmethod-first-arg=cls
[IMPORTS]
# Allow wildcard imports from modules that define __all__.
allow-wildcard-with-all=no
# Analyse import fallback blocks. This can be used to support both Python 2 and
# 3 compatible code, which means that the block might have code that exists
# only in one or another interpreter, leading to false positives when analysed.
analyse-fallback-blocks=no
# Deprecated modules which should not be used, separated by a comma.
deprecated-modules=optparse,tkinter.tix
# Create a graph of external dependencies in the given file (report RP0402 must
# not be disabled).
ext-import-graph=
# Create a graph of every (i.e. internal and external) dependencies in the
# given file (report RP0402 must not be disabled).
import-graph=
# Create a graph of internal dependencies in the given file (report RP0402 must
# not be disabled).
int-import-graph=
# Force import order to recognize a module as part of the standard
# compatibility libraries.
known-standard-library=
# Force import order to recognize a module as part of a third party library.
known-third-party=enchant
[DESIGN]
# Maximum number of arguments for function / method.
max-args=5
# Maximum number of attributes for a class (see R0902).
max-attributes=7
# Maximum number of boolean expressions in an if statement.
max-bool-expr=5
# Maximum number of branch for function / method body.
max-branches=12
# Maximum number of locals for function / method body.
max-locals=15
# Maximum number of parents for a class (see R0901).
max-parents=7
# Maximum number of public methods for a class (see R0904).
max-public-methods=20
# Maximum number of return / yield for function / method body.
max-returns=6
# Maximum number of statements in function / method body.
max-statements=50
# Minimum number of public methods for a class (see R0903).
min-public-methods=2
[EXCEPTIONS]
# Exceptions that will emit a warning when being caught. Defaults to
# "Exception".
overgeneral-exceptions=Exception
================================================
FILE: README.md
================================================
# MusicBrainz Picard Plugins
This repository hosts plugins for [MusicBrainz Picard](https://picard.musicbrainz.org/). If you're a plugin author and would like to include your plugin here, simply open a pull request.
> [!NOTE]
> This repository is for Picard v1 and v2 plugins only. Plugins for Picard v3 are managed through the [Picard Plugins Registry](https://github.com/metabrainz/picard-plugins-registry).
Note that new plugins being added to the repository should be under the GNU General Public License version 2 ("GPL") or a license compatible with it. See https://www.gnu.org/licenses/license-list.html for a list of compatible licenses.
## Development Notes
The script `generate.py` will generate a file called `plugins.json`, which contains metadata about all the plugins in this repository. `plugins.json` is used by [picard-website](https://github.com/musicbrainz/picard-website) and Picard itself to display information about downloadable plugins.
================================================
FILE: build_ui.py
================================================
#!/usr/bin/env python3
import glob
import os
from PyQt5 import uic
os.chdir(os.path.dirname(__file__))
plugin_dir = os.path.relpath('plugins')
def compile_ui(uifile, pyfile):
if newer(uifile, pyfile):
print("compiling %s -> %s" % (uifile, pyfile))
with open(pyfile, "w") as out:
uic.compileUi(uifile, out)
else:
print("skipping %s -> %s: up to date" % (uifile, pyfile))
def newer(file1, file2):
"""Returns True, if file1 has been modified after file2
"""
if not os.path.exists(file2):
return True
return os.path.getmtime(file1) > os.path.getmtime(file2)
if __name__ == '__main__':
for uifile in glob.glob(os.path.join(plugin_dir, '*/*.ui')):
pyfile = os.path.splitext(os.path.basename(uifile))[0] + '.py'
pyfile = os.path.join(os.path.dirname(uifile), pyfile)
compile_ui(uifile, pyfile)
================================================
FILE: generate.py
================================================
#!/usr/bin/env python3
from __future__ import print_function
import argparse
import os
import json
import zipfile
from hashlib import md5
from subprocess import check_call
from get_plugin_data import get_plugin_data
VERSION_TO_BRANCH = {
None: '2.0',
'1.0': '1.0',
'2.0': '2.0',
}
def build_json(dest_dir):
"""
Traverse the plugins directory to generate json data.
"""
plugins = {}
# All top level directories in plugin_dir are plugins
for dirname in next(os.walk(plugin_dir))[1]:
files = {}
data = {}
if dirname in [".git"]:
continue
dirpath = os.path.join(plugin_dir, dirname)
for root, dirs, filenames in os.walk(dirpath):
for filename in filenames:
ext = os.path.splitext(filename)[1]
if ext not in [".pyc"]:
file_path = os.path.join(root, filename)
with open(file_path, "rb") as md5file:
md5Hash = md5(md5file.read()).hexdigest()
files[file_path.split(os.path.join(dirpath, ''))[1]] = md5Hash
if ext in ['.py'] and not data:
data = get_plugin_data(os.path.join(plugin_dir, dirname, filename))
if files and data:
print("Added: " + dirname)
data['files'] = files
plugins[dirname] = data
out_path = os.path.join(dest_dir, plugin_file)
with open(out_path, "w") as out_file:
json.dump({"plugins": plugins}, out_file, sort_keys=True, indent=2)
def zip_files(dest_dir):
"""
Zip up plugin folders
"""
for dirname in next(os.walk(plugin_dir))[1]:
archive_path = os.path.join(dest_dir, dirname)
archive = zipfile.ZipFile(archive_path + ".zip", "w")
dirpath = os.path.join(plugin_dir, dirname)
plugin_files = []
for root, dirs, filenames in os.walk(dirpath):
for filename in filenames:
file_path = os.path.join(root, filename)
plugin_files.append(file_path)
if (len(plugin_files) == 1
and os.path.basename(plugin_files[0]) != '__init__.py'):
# There's only one file, put it directly into the zipfile
archive.write(plugin_files[0],
os.path.basename(plugin_files[0]),
compress_type=zipfile.ZIP_DEFLATED)
else:
for filename in plugin_files:
# Preserve the folder structure relative to plugin_dir
# in the zip file
name_in_zip = os.path.join(os.path.relpath(filename,
plugin_dir))
archive.write(filename,
name_in_zip,
compress_type=zipfile.ZIP_DEFLATED)
print("Created: " + dirname + ".zip")
# The file that contains json data
plugin_file = "plugins.json"
# The directory which contains plugin files
plugin_dir = "plugins"
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Generate plugin files for Picard website.')
parser.add_argument('version', nargs='?', help="Build output files for the specified version")
parser.add_argument('--build_dir', default="build", help="Path for the build output. DEFAULT = %(default)s")
parser.add_argument('--pull', action='store_true', dest='pull', help="Pulls the remote origin and updates the files before building")
parser.add_argument('--no-zip', action='store_false', dest='zip', help="Do not generate the zip files in the build output")
parser.add_argument('--no-json', action='store_false', dest='json', help="Do not generate the json file in the build output")
args = parser.parse_args()
check_call(["git", "checkout", "-q", VERSION_TO_BRANCH[args.version], '--', 'plugins'])
dest_dir = os.path.abspath(os.path.join(args.build_dir, args.version or ''))
if not os.path.exists(dest_dir):
os.makedirs(dest_dir)
if args.pull:
check_call(["git", "pull", "-q"])
if args.json:
build_json(dest_dir)
if args.zip:
zip_files(dest_dir)
================================================
FILE: get_plugin_data.py
================================================
# -*- coding: utf-8 -*-
from __future__ import print_function
import ast
KNOWN_DATA = [
'PLUGIN_NAME',
'PLUGIN_AUTHOR',
'PLUGIN_VERSION',
'PLUGIN_API_VERSIONS',
'PLUGIN_LICENSE',
'PLUGIN_LICENSE_URL',
'PLUGIN_DESCRIPTION',
]
def get_plugin_data(filepath):
"""Parse a python file and return a dict with plugin metadata"""
data = {}
with open(filepath, 'r', encoding='utf-8') as plugin_file:
source = plugin_file.read()
try:
root = ast.parse(source, filepath)
except:
print("Cannot parse " + filepath)
raise
for node in ast.iter_child_nodes(root):
if isinstance(node, ast.Assign) and len(node.targets) == 1:
target = node.targets[0]
if (isinstance(target, ast.Name)
and isinstance(target.ctx, ast.Store)
and target.id in KNOWN_DATA):
name = target.id.replace('PLUGIN_', '', 1).lower()
if name not in data:
try:
data[name] = ast.literal_eval(node.value)
except ValueError:
print('Cannot evaluate value in '
+ filepath + ':' +
ast.dump(node))
return data
================================================
FILE: plugins/abbreviate_artistsort/abbreviate_artistsort.py
================================================
# -*- coding: utf-8 -*-
# This is the Sort Multivalue Tags plugin for MusicBrainz Picard.
# Copyright (C) 2013 Sophist
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Abbreviate artist-sort"
PLUGIN_AUTHOR = "Sophist"
PLUGIN_DESCRIPTION = '''Abbreviate Artist-Sort and Album-Artist-Sort Tags.
e.g. "Vivaldi, Antonio" becomes "Vivaldi, A."
This is particularly useful for classical albums that can have a long list of artists.
%artistsort% is abbreviated into %_artistsort_abbrev% and
%albumartistsort% is abbreviated into %_albumartistsort_abbrev%.'''
PLUGIN_VERSION = "0.4.1"
PLUGIN_API_VERSIONS = ["1.0", "2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import log
from picard.metadata import register_track_metadata_processor
# NOTE: This plugin will not work consistently if you have not enabled the 'Standardize Artist Names' option!
# The algorithm for this is complicated because the tags can contain multiple names separated by various characters
# As an example from http://musicbrainz.org/release/6c0cfb20-2606-46c1-9306-ee5e7cb5bfdf
# Sorted: Vivaldi, Antonio, Caldara, Antonio; Queyras, Jean-Guihen, Kallweit, Georg, Akademie für Alte Musik Berlin
# Unsorted: Antonio Vivaldi, Antonio Caldara; Jean-Guihen Queyras, Georg Kallweit, Akademie für Alte Musik Berlin
# As you can see, in unsorted, names are separated by ',' as well as ';' but could be e.g. 'feat:'
# The only known is that in sorted, surname is separated from forename(s) by a ','
# It is further complicated by non-latin (e.g. japanese) script artist names
# where unsorted is in local script, but sorted can be in latin, and names can be in local locale or general.
# If the names are just reversed, and we shift Unsorted to the right by one character (for the ',' in sorted),
# then the punctuation should start to match up:
# Sorted: Vivaldi, Antonio, Caldara, Antonio; Queyras, Jean-Guihen, Kallweit, Georg, Akademie für Alte Musik Berlin
# Unsorted: Antonio Vivaldi, Antonio Caldara; Jean-Guihen Queyras, Georg Kallweit, Akademie für Alte Musik Berlin
# ^
# Of course if we have non-latin or locale names, alignment could be way off:
# Sorted: Verdi, Giuseppe, Vivaldi, Antonio
# Unsorted: Joe Green, Antonio Vivaldi
# In the absence of an array version of the tags (PR pending)
# we need to process the tag and sorted tag together in a special way as follows:
#
# 1. Look for the first ',' in sorted and tentatively set surname to the string up to that point.
# Case a. Sorted: Stuff, ...
# Unsorted: Stuff, ...
# Case b. Sorted: Surname, Forename(s)...
# Unsorted: Forename(s) Surname...
# Special case: Sorted: Major, Major...
# Unsorted: Major Major...
# Case c. Sorted: Stuff; Surname, Forename(s)...
# Unsorted: Stuff; Forename(s) Surname...
# Case d. Sorted: Latin Surname, Latin Forename(s)...
# Unsorted: Foreign...
# Case e. Sorted: Beatles, The...
# Unsorted: The Beatles...
# 2. Locate surname in unsorted:
# Case a. unsorted starts with surname - move both to new strings
# Case b. surname can be found in unsorted - forename(s) are what is before and match beginning of rest
# Case c. If first word is same in sorted and unsorted, move words that match to new strings, then treat as b.
# Case d. Try to handle without abbreviating and get to next name which might not be foreign
_abbreviate_tags = [
('albumartistsort', 'albumartist', '~albumartistsort_abbrev'),
('artistsort', 'artist', '~artistsort_abbrev'),
]
_prefixes = ["A", "The"]
_split = ", "
_abbreviate_cache = {}
def abbreviate_artistsort(tagger, metadata, track, release):
for sortTag, unsortTag, sortTagNew in _abbreviate_tags:
if not (sortTag in metadata and unsortTag in metadata):
continue
sorts = list(metadata.getall(sortTag))
unsorts = list(metadata.getall(unsortTag))
for i in range(0, min(len(sorts), len(unsorts))):
sort = sorts[i]
log.debug("%s: Trying to abbreviate '%s'." % (PLUGIN_NAME, sort))
if sort in _abbreviate_cache:
log.debug(" Using abbreviation found in cache: '%s'." % (_abbreviate_cache[sort]))
sorts[i] = _abbreviate_cache[sort]
continue
unsort = unsorts[i]
new_sort = ""
new_unsort = ""
while len(sort) > 0 and len(unsort) > 0:
if not _split in sort:
log.debug(" Ending without separator '%s' - moving '%s'." % (_split, sort))
new_sort += sort
new_unsort += unsort
sort = unsort = ""
continue
surname, rest = sort.split(_split, 1)
if rest == "":
log.debug(" Ending with separator '%s' - moving '%s'." % (_split, surname))
new_sort += sort
new_unsort += unsort
sort = unsort = ""
continue
# Move leading whitespace
new_unsort += unsort[0:len(unsort) - len(unsort.lstrip())]
unsort = unsort.lstrip()
# Sorted: Stuff, ...
# Unsorted: Stuff, ...
temp = surname + _split
l = len(temp)
if unsort[:l] == temp:
log.debug(" No forename - moving '%s'." % (surname))
new_sort += temp
new_unsort += temp
sort = sort[l:]
unsort = unsort[l:]
continue
# Sorted: Stuff; Surname, Forename(s)...
# Unsorted: Stuff; Forename(s) Surname...
# Move matching words plus white-space one by one
if unsort.find(' ' + surname) == -1:
while surname.split(None, 1)[0] == unsort.split(None, 1)[0]:
x = unsort.split(None, 1)[0]
log.debug(" Moving matching word '%s'." % (x))
new_sort += x
new_unsort += x
surname = surname[len(x):]
unsort = unsort[len(x):]
new_sort += surname[0:len(surname) - len(surname.lstrip())]
surname = surname.lstrip()
new_unsort += unsort[0:len(unsort) - len(unsort.lstrip())]
unsort = unsort.lstrip()
# If we still can't find surname then we are up a creek...
pos = unsort.find(' ' + surname)
if pos == -1:
log.debug(
_("%s: Track %s: Unable to abbreviate surname '%s' - not matched in unsorted %s: '%s'."),
PLUGIN_NAME,
metadata['tracknumber'],
surname,
unsortTag,
unsort[i],
)
log.warning(" Could not match surname '%s' in remaining unsorted: %s" % (surname, unsort))
break
# Sorted: Surname, Forename(s)...
# Unsorted: Forename(s) Surname...
forename = unsort[:pos]
if rest[:len(forename)] != forename:
log.debug(
_("%s: Track %s: Unable to abbreviate surname (%s) - forename (%s) not matched in unsorted %s: '%s'."),
PLUGIN_NAME,
metadata['tracknumber'],
surname,
forename,
unsortTag,
unsort[i],
)
log.warning(" Could not match forename (%s) for surname (%s) in remaining unsorted (%s):" % (forename, surname, unsort))
break
inits = ' '.join([x[0] + '.' for x in forename.split()])
# Sorted: Beatles, The...
# Unsorted: The Beatles...
if forename in _prefixes:
inits = forename
new_sort += surname + _split + inits
sort = rest[len(forename):]
new_sort += sort[0:len(sort) - len(sort[1:].lstrip())]
sort = sort[1:].lstrip()
new_unsort += forename
unsort = unsort[len(forename):]
new_unsort += unsort[0:len(unsort) - len(unsort.lstrip())]
unsort = unsort.lstrip()
new_unsort += surname
unsort = unsort[len(surname):]
new_unsort += unsort[0:len(unsort) - len(unsort[1:].lstrip())]
unsort = unsort[1:].lstrip()
if forename != inits:
log.debug(
_("%s: Abbreviated surname (%s, %s) to (%s, %s) in '%s'."),
PLUGIN_NAME,
surname,
forename,
surname,
inits,
sortTag,
)
log.debug("Abbreviated (%s, %s) to (%s, %s)." % (surname, forename, surname, inits))
else: # while loop ended without a break i.e. no errors
if unsorts[i] != new_unsort:
log.error(
_("%s: Track %s: Logic error - mangled %s from '%s' to '%s'."),
PLUGIN_NAME,
metadata['tracknumber'],
unsortTag,
unsorts[i],
new_unsort,
)
log.warning("Error: Unsorted text for %s has changed from '%s' to '%s'!" % (unsortTag, unsorts[i], new_unsort))
_abbreviate_cache[sorts[i]] = new_sort
log.debug(" Abbreviated and cached (%s) as (%s)." % (sorts[i], new_sort))
if sorts[i] != new_sort:
log.debug(_("%s: Abbreviated tag '%s' to '%s'."),
PLUGIN_NAME,
sorts[i],
new_sort,
)
sorts[i] = new_sort
metadata[sortTagNew] = sorts
register_track_metadata_processor(abbreviate_artistsort)
================================================
FILE: plugins/acousticbrainz/__init__.py
================================================
# -*- coding: utf-8 -*-
# AcousticBrainz plugin for Picard
#
# Copyright (C) 2021 Wargreen
# Copyright (C) 2021 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License version 2 as
# published by the Free Software Foundation.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License along
# with this program; if not, write to the Free Software Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
#
# Plugin metadata
# =============================================================================
PLUGIN_NAME = 'AcousticBrainz Tags'
PLUGIN_AUTHOR = ('Wargreen , '
'Hugo Geoffroy "pistache" , '
'Philipp Wolfer , '
'Regorxxx ')
PLUGIN_DESCRIPTION = '''
Tag files with tags from the AcousticBrainz database, all highlevel classifiers
and tonal/rhythm data.
By default, only simple mood and genre information is saved, but the plugin can
be configured to include all highlevel data.
Based on code from Andrew Cook, Sambhav Kothari
WARNING: Experimental plugin. All guarantees voided by use.'''
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
PLUGIN_VERSION = "2.2.3"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3", "2.4", "2.5", "2.6", "2.7"]
# Plugin configuration
# =============================================================================
ACOUSTICBRAINZ_HOST = "acousticbrainz.org"
ACOUSTICBRAINZ_PORT = 80
# Subset of the low level data to add as tags.
# Represent the data as nested dicts.
SUBLOWLEVEL_SUBSET = {"rhythm": {"bpm": None},
"tonal": {"chords_changes_rate": None,
"chords_key": None,
"chords_scale": None,
"key_key": None,
"key_scale": None}}
# Imports
# =============================================================================
from functools import partial
from json import dumps as dump_json
from picard import (
config,
log,
)
from picard.metadata import (
register_album_metadata_processor,
register_track_metadata_processor,
)
from picard.ui.options import (
OptionsPage,
register_options_page,
)
from picard.webservice import ratecontrol
from picard.plugins.acousticbrainz.ui_options_acousticbrainz_tags import Ui_AcousticBrainzOptionsPage
ratecontrol.set_minimum_delay((ACOUSTICBRAINZ_HOST, ACOUSTICBRAINZ_PORT), 1000)
# Constants
# =============================================================================
LOWLEVEL = "lowlevel"
HIGHLEVEL = "highlevel"
# Logging utilities
# -------------------------------------------------------------------------
def log_msg(logger, text, *args):
logger("%s: " + text, PLUGIN_NAME, *args)
def debug(*args):
log_msg(log.debug, *args)
def warning(*args):
log_msg(log.warning, *args)
def error(*args):
log_msg(log.error, *args)
# TrackDataProcessor class
# =============================================================================
# (used to apply AcousticBrainz data to Track metadata)
class TrackDataProcessor:
def __init__(self, recording_id, metadata, level, data, files=None):
self.recording_id = recording_id
self.metadata = metadata
self.level = level
self.data = self._extract_data(data)
self.files = files
self.do_simplemood = config.setting["acousticbrainz_add_simplemood"]
self.simplemood_tagname = config.setting["acousticbrainz_simplemood_tagname"]
self.do_simplegenre = config.setting["acousticbrainz_add_simplegenre"]
self.simplegenre_tagname = config.setting["acousticbrainz_simplegenre_tagname"]
self.do_keybpm = config.setting["acousticbrainz_add_keybpm"]
self.do_fullhighlevel = config.setting["acousticbrainz_add_fullhighlevel"]
self.do_sublowlevel = config.setting["acousticbrainz_add_sublowlevel"]
# Logging utilities
# -------------------------------------------------------------------------
def log(self, logger, text, *args):
log_msg(logger, "[%s: %s] " + text, self.shortid, self.title, *args)
def debug(self, *args):
self.log(log.debug, *args)
def warning(self, *args):
self.log(log.warning, *args)
def error(self, *args):
self.log(log.error, *args)
# Read-only properties
# -------------------------------------------------------------------------
@property
def shortid(self):
return self.recording_id[:8]
@property
def title(self):
return self.metadata["title"]
# Callback
# -------------------------------------------------------------------------
def process(self):
if not self.data:
self.warning('No %s data for track %s', self.level, self.recording_id)
if self.level == HIGHLEVEL:
if self.do_simplemood:
self.process_simplemood()
if self.do_simplegenre:
self.process_simplegenre()
if self.do_fullhighlevel:
self.process_fullhighlevel()
if self.level == LOWLEVEL:
if self.do_keybpm:
self.process_keybpm()
if self.do_sublowlevel:
self.process_sublowlevel()
# Processing helper methods
# -------------------------------------------------------------------------
def _extract_data(self, data):
if not self.recording_id in data:
return {}
if self.level == LOWLEVEL:
return data[self.recording_id]["0"]
elif self.level == HIGHLEVEL:
return data[self.recording_id]["0"]["highlevel"]
def filter_data(self, data, subset):
result = {}
for key, value in subset.items():
if key in data:
if isinstance(value, dict):
self.debug("filter_data : traversing %s", key)
result[key] = self.filter_data(data[key], value)
else:
self.debug("filter_data : adding result %s", key)
result[key] = data[key]
else:
self.debug("filter_data : Subset key %s not found in data", key)
continue
self.debug("filter_data : result : %s", result)
return result
def update_metadata(self, name, values):
self.metadata[name] = values
if self.files:
for file in self.files:
file.metadata[name] = values
# Processing methods
# -------------------------------------------------------------------------
# (fill metadata with fetched data)
def process_simplemood(self):
self.debug("processing simplemood data")
mood_tagname = self.simplemood_tagname;
moods = []
for classifier, data in self.data.items():
if "value" in data:
value = data["value"]
inverted = value.startswith("not_")
if classifier.startswith("mood_") and not inverted:
moods.append(value)
self.update_metadata(mood_tagname, moods)
def process_simplegenre(self):
self.debug("processing simplegenre data")
genre_tagname = self.simplegenre_tagname;
genres = []
for classifier, data in self.data.items():
if "value" in data:
value = data["value"]
inverted = value.startswith("not_")
if classifier.startswith("genre_") and not inverted:
genres.append(value)
self.update_metadata(genre_tagname, genres)
def process_fullhighlevel(self):
self.debug("processing fullhighlevel data")
f_count, c_count = 0, 0
for classifier, data in self.data.items():
classifier = classifier.lower()
if "all" in data:
c_count += 1
for feature, proba in data["all"].items():
feature = feature.lower()
f_count += 1
self.update_metadata("ab:hi:{}:{}".format(classifier, feature), dump_json(proba))
else:
self.warning("fullhighlevel : ignored invalid classifier data (%s)", classifier)
self.debug("fullhighlevel : parsed %d features from %d classifiers", f_count, c_count)
def process_keybpm(self):
self.debug("processing keybpm data")
if "tonal" in self.data:
tonal_data = self.data["tonal"]
if "key_key" in tonal_data:
key = tonal_data["key_key"]
if "key_scale" in tonal_data:
if tonal_data["key_scale"] == "minor":
key += "m"
self.update_metadata('key', key)
self.debug("track '%s' is in key %s", self.title, key)
if "rhythm" in self.data:
rhythm_data = self.data["rhythm"]
if "bpm" in rhythm_data:
bpm = int(rhythm_data["bpm"] + 0.5)
self.update_metadata('bpm', bpm)
self.debug("keybpm : Track '%s' has %s bpm", self.title, bpm)
def process_sublowlevel(self):
self.debug("processing sublowlevel data")
subset = SUBLOWLEVEL_SUBSET
filtered_data = self.filter_data(self.data, subset)
f_count, c_count = 0, 0
for classifier, data in filtered_data.items():
classifier = classifier.lower()
c_count += 1
for feature, proba in data.items():
feature = feature.lower()
f_count += 1
self.update_metadata("ab:lo:{}:{}".format(classifier, feature), proba)
self.debug("sublowlevel : parsed %d features from %d classifiers", f_count, c_count)
class AcousticBrainzRequest:
MAX_BATCH_SIZE = 25
def __init__(self, webservice, recording_ids):
self.webservice = webservice
self.recording_ids = recording_ids
def request_highlevel(self, callback):
self._batch('high-level', self.recording_ids, callback, {})
def request_lowlevel(self, callback):
self._batch('low-level', self.recording_ids, callback, {})
def _batch(self, action, recording_ids, callback, result, response=None, reply=None, error=None):
if response and not error:
self._merge_results(result, response)
if not recording_ids or error:
callback(result, error)
return
batch = recording_ids[:self.MAX_BATCH_SIZE]
recording_ids = recording_ids[self.MAX_BATCH_SIZE:]
self._do_request(action, batch,
callback=partial(self._batch, action, recording_ids, callback, result))
def _do_request(self, action, recording_ids, callback):
self.webservice.get(
ACOUSTICBRAINZ_HOST,
ACOUSTICBRAINZ_PORT,
'/api/v1/%s' % action,
callback,
priority=True,
parse_response_type='json',
queryargs=self._get_query_args(action, recording_ids)
)
def _get_query_args(self, action, recording_ids):
queryargs = {
'recording_ids': ';'.join(recording_ids),
}
if action == 'high-level':
queryargs['map_classes'] = 'true'
return queryargs
def _merge_results(self, full, new):
mapping = new.get('mbid_mapping', {})
new = {mapping.get(k, k): v for (k, v) in new.items() if k != 'mbid_mapping'}
full.update(new)
# Plugin class
# =============================================================================
# (provides track processing callback)
class AcousticBrainzPlugin:
result_cache = {
LOWLEVEL: {},
HIGHLEVEL: {},
}
def process_album(self, album, metadata, release):
debug('Processing album %s', album.id)
recording_ids = self.get_recording_ids(release)
self.run_requests(album, recording_ids, self.album_callback)
def process_track(self, album, metadata, track_node, release_node):
# Run requests for standalone recordings
if not release_node and 'id' in track_node:
recording_id = track_node['id']
debug('Processing recording %s', recording_id)
self.run_requests(album, [recording_id], partial(self.nat_callback, recording_id))
# Apply metadata changes for already loaded results for album tracks
elif 'recording' in track_node:
recording_id = track_node['recording']['id']
for level in (LOWLEVEL, HIGHLEVEL):
result = self.result_cache[level].get(album.id)
if result:
self.apply_result(recording_id, metadata, level, result)
def run_requests(self, album, recording_ids, callback):
request = AcousticBrainzRequest(album.tagger.webservice, recording_ids)
if self.do_highlevel:
album._requests += 1
request.request_highlevel(partial(callback, HIGHLEVEL, album))
if self.do_lowlevel:
album._requests += 1
request.request_lowlevel(partial(callback, LOWLEVEL, album))
@property
def do_highlevel(self):
return (config.setting["acousticbrainz_add_simplemood"]
or config.setting["acousticbrainz_add_simplegenre"]
or config.setting["acousticbrainz_add_fullhighlevel"])
@property
def do_lowlevel(self):
return (config.setting["acousticbrainz_add_keybpm"]
or config.setting["acousticbrainz_add_sublowlevel"])
def get_recording_ids(self, release):
return [track['recording']['id'] for track in self.iter_tracks(release)]
@staticmethod
def iter_tracks(release):
for media in release['media']:
if 'pregap' in media:
yield media['pregap']
if 'tracks' in media:
yield from media['tracks']
if 'data-tracks' in media:
yield from media['data-tracks']
def album_callback(self, level, album, result=None, error=None):
if not error:
# Store the result, the actual processing will be done by the
# track metadata processor.
self.result_cache[level][album.id] = result
album.run_when_loaded(partial(self.clear_cache, level, album))
album._requests -= 1
album._finalize_loading(error)
def nat_callback(self, recording_id, level, album, result=None, error=None):
for track in album.tracks:
if track.id == recording_id:
self.apply_result(track.id, track.metadata, level, result, files=track.files)
def apply_result(self, recording_id, metadata, level, result, files=None):
debug('Updating recording %s with %s results', recording_id, level)
processor = TrackDataProcessor(recording_id, metadata, level, result, files=files)
processor.process()
def clear_cache(self, level, album):
try:
del self.result_cache[level][album.id]
except KeyError:
pass
# Plugin options page
# =============================================================================
# (define plugin options and link with user interface)
class AcousticBrainzOptionsPage(OptionsPage):
NAME = "acousticbrainz_tags"
TITLE = "AcousticBrainz tags"
PARENT = "plugins"
options = [
config.BoolOption("setting", "acousticbrainz_add_simplemood", True),
config.TextOption("setting", "acousticbrainz_simplemood_tagname", "ab:mood"),
config.BoolOption("setting", "acousticbrainz_add_simplegenre", True),
config.TextOption("setting", "acousticbrainz_simplegenre_tagname", "ab:genre"),
config.BoolOption("setting", "acousticbrainz_add_keybpm", False),
config.BoolOption("setting", "acousticbrainz_add_fullhighlevel", False),
config.BoolOption("setting", "acousticbrainz_add_sublowlevel", False)
]
def __init__(self, parent=None):
super(AcousticBrainzOptionsPage, self).__init__(parent)
self.ui = Ui_AcousticBrainzOptionsPage()
self.ui.setupUi(self)
def load(self):
setting = config.setting
self.ui.add_simplemood.setChecked(setting["acousticbrainz_add_simplemood"])
self.ui.simplemood_tagname.setText(setting["acousticbrainz_simplemood_tagname"])
self.ui.add_simplegenre.setChecked(setting["acousticbrainz_add_simplegenre"])
self.ui.simplegenre_tagname.setText(setting["acousticbrainz_simplegenre_tagname"])
self.ui.add_fullhighlevel.setChecked(setting["acousticbrainz_add_fullhighlevel"])
self.ui.add_keybpm.setChecked(setting["acousticbrainz_add_keybpm"])
self.ui.add_sublowlevel.setChecked(setting["acousticbrainz_add_sublowlevel"])
def save(self):
setting = config.setting
setting["acousticbrainz_add_simplemood"] = self.ui.add_simplemood.isChecked()
setting["acousticbrainz_simplemood_tagname"] = str(self.ui.simplemood_tagname.text())
setting["acousticbrainz_add_simplegenre"] = self.ui.add_simplegenre.isChecked()
setting["acousticbrainz_simplegenre_tagname"] = str(self.ui.simplegenre_tagname.text())
setting["acousticbrainz_add_keybpm"] = self.ui.add_keybpm.isChecked()
setting["acousticbrainz_add_fullhighlevel"] = self.ui.add_fullhighlevel.isChecked()
setting["acousticbrainz_add_sublowlevel"] = self.ui.add_sublowlevel.isChecked()
plugin = AcousticBrainzPlugin()
register_album_metadata_processor(plugin.process_album)
register_track_metadata_processor(plugin.process_track)
register_options_page(AcousticBrainzOptionsPage)
================================================
FILE: plugins/acousticbrainz/ui_options_acousticbrainz_tags.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/acousticbrainz/ui_options_acousticbrainz_tags.ui'
#
# Created by: PyQt5 UI code generator 5.15.7
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_AcousticBrainzOptionsPage(object):
def setupUi(self, AcousticBrainzOptionsPage):
AcousticBrainzOptionsPage.setObjectName("AcousticBrainzOptionsPage")
AcousticBrainzOptionsPage.setEnabled(True)
AcousticBrainzOptionsPage.resize(527, 443)
AcousticBrainzOptionsPage.setWindowTitle("")
self.verticalLayout = QtWidgets.QVBoxLayout(AcousticBrainzOptionsPage)
self.verticalLayout.setObjectName("verticalLayout")
self.acousticbrainzTags_groupBox = QtWidgets.QGroupBox(AcousticBrainzOptionsPage)
self.acousticbrainzTags_groupBox.setObjectName("acousticbrainzTags_groupBox")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.acousticbrainzTags_groupBox)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.add_simplemood = QtWidgets.QCheckBox(self.acousticbrainzTags_groupBox)
self.add_simplemood.setObjectName("add_simplemood")
self.verticalLayout_2.addWidget(self.add_simplemood)
self.simplemood_tagname_label = QtWidgets.QLabel(self.acousticbrainzTags_groupBox)
self.simplemood_tagname_label.setObjectName("simplemood_tagname_label")
self.verticalLayout_2.addWidget(self.simplemood_tagname_label)
self.simplemood_tagname = QtWidgets.QLineEdit(self.acousticbrainzTags_groupBox)
self.simplemood_tagname.setObjectName("simplemood_tagname")
self.verticalLayout_2.addWidget(self.simplemood_tagname)
self.add_simplegenre = QtWidgets.QCheckBox(self.acousticbrainzTags_groupBox)
self.add_simplegenre.setObjectName("add_simplegenre")
self.verticalLayout_2.addWidget(self.add_simplegenre)
self.simplegenre_tagname_label = QtWidgets.QLabel(self.acousticbrainzTags_groupBox)
self.simplegenre_tagname_label.setObjectName("simplegenre_tagname_label")
self.verticalLayout_2.addWidget(self.simplegenre_tagname_label)
self.simplegenre_tagname = QtWidgets.QLineEdit(self.acousticbrainzTags_groupBox)
self.simplegenre_tagname.setObjectName("simplegenre_tagname")
self.verticalLayout_2.addWidget(self.simplegenre_tagname)
self.add_keybpm = QtWidgets.QCheckBox(self.acousticbrainzTags_groupBox)
self.add_keybpm.setObjectName("add_keybpm")
self.verticalLayout_2.addWidget(self.add_keybpm)
self.add_fullhighlevel = QtWidgets.QCheckBox(self.acousticbrainzTags_groupBox)
self.add_fullhighlevel.setObjectName("add_fullhighlevel")
self.verticalLayout_2.addWidget(self.add_fullhighlevel)
self.add_sublowlevel = QtWidgets.QCheckBox(self.acousticbrainzTags_groupBox)
self.add_sublowlevel.setObjectName("add_sublowlevel")
self.verticalLayout_2.addWidget(self.add_sublowlevel)
spacerItem = QtWidgets.QSpacerItem(20, 20, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Preferred)
self.verticalLayout_2.addItem(spacerItem)
self.sublowlevel_descr = QtWidgets.QLabel(self.acousticbrainzTags_groupBox)
self.sublowlevel_descr.setTextFormat(QtCore.Qt.RichText)
self.sublowlevel_descr.setObjectName("sublowlevel_descr")
self.verticalLayout_2.addWidget(self.sublowlevel_descr)
spacerItem1 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem1)
self.verticalLayout.addWidget(self.acousticbrainzTags_groupBox)
self.retranslateUi(AcousticBrainzOptionsPage)
QtCore.QMetaObject.connectSlotsByName(AcousticBrainzOptionsPage)
def retranslateUi(self, AcousticBrainzOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.acousticbrainzTags_groupBox.setTitle(_translate("AcousticBrainzOptionsPage", "AcousticBrainz Tags"))
self.add_simplemood.setText(_translate("AcousticBrainzOptionsPage", "Add simple Mood tags"))
self.simplemood_tagname_label.setText(_translate("AcousticBrainzOptionsPage", "Mood tag name:"))
self.add_simplegenre.setText(_translate("AcousticBrainzOptionsPage", "Add simple Genre tags"))
self.simplegenre_tagname_label.setText(_translate("AcousticBrainzOptionsPage", "Genre tag name:"))
self.add_keybpm.setText(_translate("AcousticBrainzOptionsPage", "Add simple BPM and Key tags"))
self.add_fullhighlevel.setText(_translate("AcousticBrainzOptionsPage", "Add all highlevel AcousticBrainz tags"))
self.add_sublowlevel.setText(_translate("AcousticBrainzOptionsPage", "Add a subset of the lowlevel AcousticBrainz tags"))
self.sublowlevel_descr.setText(_translate("AcousticBrainzOptionsPage", "The low level subset include:
- rhythm:bpm
- tonal:chords_change_rate
- tonal:chords_key
- tonal:chords_scale
- tonal:key_key
- tonal:key_scale
"))
================================================
FILE: plugins/acousticbrainz/ui_options_acousticbrainz_tags.ui
================================================
AcousticBrainzOptionsPage
true
0
0
527
443
-
AcousticBrainz Tags
-
Add simple Mood tags
-
Mood tag name:
-
-
Add simple Genre tags
-
Genre tag name:
-
-
Add simple BPM and Key tags
-
Add all highlevel AcousticBrainz tags
-
Add a subset of the lowlevel AcousticBrainz tags
-
Qt::Vertical
QSizePolicy::Preferred
20
20
-
<html><head/><body><p>The low level subset include:</p><ul style="margin-top: 0px; margin-bottom: 0px; margin-left: 0px; margin-right: 0px; -qt-list-indent: 1;"><li style=" margin-top:12px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">rhythm:bpm</li><li style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">tonal:chords_change_rate</li><li style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">tonal:chords_key</li><li style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">tonal:chords_scale</li><li style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">tonal:key_key</li><li style=" margin-top:0px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">tonal:key_scale</li></ul></body></html>
Qt::RichText
-
Qt::Vertical
20
40
================================================
FILE: plugins/acousticbrainz_tonal-rhythm/acousticbrainz_tonal-rhythm.py
================================================
# -*- coding: utf-8 -*-
# Acousticbrainz Tonal/Rhythm plugin for Picard
# Copyright (C) 2015 Sophist
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License version 2 as
# published by the Free Software Foundation.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License along
# with this program; if not, write to the Free Software Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
#
PLUGIN_NAME = 'AcousticBrainz Tonal-Rhythm'
PLUGIN_AUTHOR = 'Sophist, Sambhav Kothari'
PLUGIN_DESCRIPTION = '''Add's the following tags:
- Key (in ID3v2.3 format)
- Beats Per Minute (BPM)
from the AcousticBrainz database.
This plugin is deprecated, please consider using the AcousticBrainz Tags
plugin instead.
'''
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
PLUGIN_VERSION = '1.1.6'
PLUGIN_API_VERSIONS = ["2.0"] # Requires support for TKEY which is in 1.4
from json import JSONDecodeError
from picard import log
from picard.metadata import register_track_metadata_processor
from functools import partial
from picard.webservice import ratecontrol
from picard.util import load_json
ACOUSTICBRAINZ_HOST = "acousticbrainz.org"
ACOUSTICBRAINZ_PORT = 80
ratecontrol.set_minimum_delay((ACOUSTICBRAINZ_HOST, ACOUSTICBRAINZ_PORT), 1000)
class AcousticBrainz_Key:
def get_data(self, album, track_metadata, track_node, release_node):
if "musicbrainz_recordingid" not in track_metadata:
log.error("%s: Error parsing response. No MusicBrainz recording id found.",
PLUGIN_NAME)
return
recordingId = track_metadata['musicbrainz_recordingid']
if recordingId:
log.debug("%s: Add AcousticBrainz request for %s (%s)",
PLUGIN_NAME, track_metadata['title'], recordingId)
self.album_add_request(album)
path = "/%s/low-level" % recordingId
return album.tagger.webservice.get(
ACOUSTICBRAINZ_HOST,
ACOUSTICBRAINZ_PORT,
path,
partial(self.process_data, album, track_metadata),
priority=True,
important=False,
parse_response_type=None)
def process_data(self, album, track_metadata, response, reply, error):
if error:
log.error("%s: Network error retrieving acousticBrainz data for recordingId %s",
PLUGIN_NAME, track_metadata['musicbrainz_recordingid'])
self.album_remove_request(album)
return
try:
data = load_json(response)
except JSONDecodeError:
log.error("%s: Network error retrieving AcousticBrainz data for recordingId %s",
PLUGIN_NAME, track_metadata['musicbrainz_recordingid'])
self.album_remove_request(album)
return
if "tonal" in data:
if "key_key" in data["tonal"]:
key = data["tonal"]["key_key"]
if "key_scale" in data["tonal"]:
scale = data["tonal"]["key_scale"]
if scale == "minor":
key += "m"
track_metadata["key"] = key
log.debug("%s: Track '%s' is in key %s", PLUGIN_NAME, track_metadata["title"], key)
if "rhythm" in data:
if "bpm" in data["rhythm"]:
bpm = int(data["rhythm"]["bpm"] + 0.5)
track_metadata["bpm"] = bpm
log.debug("%s: Track '%s' has %s bpm", PLUGIN_NAME, track_metadata["title"], bpm)
self.album_remove_request(album)
def album_add_request(self, album):
album._requests += 1
def album_remove_request(self, album):
album._requests -= 1
if album._requests == 0:
album._finalize_loading(None)
register_track_metadata_processor(AcousticBrainz_Key().get_data)
================================================
FILE: plugins/add_to_collection/README.md
================================================
# Add to Collection
This plugin allows you to add any saved release to one of your user release [collections](https://musicbrainz.org/doc/Collections).
Download [here](https://picard.musicbrainz.org/api/v2/download?id=add_to_collection).
---
The plugin adds a settings page under the "Plugins" section under "Options..." from Picard's main menu that lets you choose
the collection you want to add the releases to

================================================
FILE: plugins/add_to_collection/__init__.py
================================================
from picard.plugins.add_to_collection.manifest import *
from picard.plugins.add_to_collection import options, post_save_processor
options.register_options()
post_save_processor.register_processor()
================================================
FILE: plugins/add_to_collection/manifest.py
================================================
PLUGIN_NAME = "Add to Collection"
PLUGIN_AUTHOR = "Dvir Yitzchaki (dvirtz@gmail.com)"
PLUGIN_DESCRIPTION = "Adds any saved release to one of your user collections"
PLUGIN_VERSION = "0.1.2"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = ("MIT",)
PLUGIN_LICENSE_URL = "https://spdx.org/licenses/MIT.html"
PLUGIN_USER_GUIDE_URL = (
"https://github.com/metabrainz/picard-plugins/blob/2.0/plugins/add_to_collection/README.md"
)
================================================
FILE: plugins/add_to_collection/options.py
================================================
from picard.collection import Collection, user_collections
from picard.ui.options import OptionsPage, register_options_page
from picard.plugins.add_to_collection import settings
from picard.plugins.add_to_collection.manifest import PLUGIN_NAME
from picard.plugins.add_to_collection.ui_add_to_collection_options import (
Ui_AddToCollectionOptions,
)
from picard.plugins.add_to_collection.override_module import override_module
class AddToCollectionOptionsPage(OptionsPage):
NAME = "add-to-collection"
TITLE = PLUGIN_NAME
PARENT = "plugins"
options = [settings.collection_id_option()]
def __init__(self, parent=None) -> None:
super().__init__(parent)
self.ui = Ui_AddToCollectionOptions()
self.ui.setupUi(self)
def load(self) -> None:
self.set_collection_name(settings.collection_id())
def save(self) -> None:
settings.set_collection_id(self.ui.collection_name.currentData())
def set_collection_name(self, value: str) -> None:
self.ui.collection_name.clear()
collection: Collection
for collection in sorted(user_collections.values(), key=lambda c: c.name.lower()):
self.ui.collection_name.addItem(collection.name, collection.id)
idx = self.ui.collection_name.findData(value)
if idx != -1:
self.ui.collection_name.setCurrentIndex(idx)
def register_options() -> None:
with override_module(AddToCollectionOptionsPage):
register_options_page(AddToCollectionOptionsPage)
================================================
FILE: plugins/add_to_collection/override_module.py
================================================
from contextlib import contextmanager
from typing import Generator
@contextmanager
def override_module(obj: object) -> Generator[None, None, None]:
# picard expects hooks to be defined at module level
module = obj.__module__
obj.__module__ = ".".join(module.split(".")[:-1])
yield
obj.__module__ = module
================================================
FILE: plugins/add_to_collection/post_save_processor.py
================================================
from picard import log
from picard.collection import Collection, user_collections
from picard.file import File, register_file_post_save_processor
from picard.plugins.add_to_collection import settings
from picard.plugins.add_to_collection.override_module import override_module
def post_save_processor(file: File) -> None:
collection_id = settings.collection_id()
if not collection_id:
log.error("cannot find collection ID setting")
return
collection: Collection = user_collections.get(collection_id)
if not collection:
log.error(f"cannot find collection with id {collection_id}")
return
release_id = file.metadata["musicbrainz_albumid"]
if release_id and release_id not in collection.releases:
log.debug("Adding release %r to %r", release_id, collection.name)
collection.add_releases(set([release_id]), callback=lambda: None)
def register_processor() -> None:
with override_module(post_save_processor):
register_file_post_save_processor(post_save_processor)
================================================
FILE: plugins/add_to_collection/settings.py
================================================
from picard.config import TextOption, get_config
from typing import Optional
COLLECTION_ID = "add_to_collection_id"
def collection_id_option() -> TextOption:
return TextOption(section="setting", name=COLLECTION_ID, default=None)
def collection_id() -> Optional[str]:
config = get_config()
if COLLECTION_ID in config.setting:
return config.setting[COLLECTION_ID]
return None
def set_collection_id(value: str) -> None:
config = get_config()
config.setting[COLLECTION_ID] = value
================================================
FILE: plugins/add_to_collection/ui_add_to_collection_options.py
================================================
from PyQt5 import QtCore, QtWidgets
class Ui_AddToCollectionOptions(object):
def setupUi(self, AddToCollectionOptions):
AddToCollectionOptions.setObjectName("AddToCollectionOptions")
AddToCollectionOptions.resize(472, 215)
self.verticalLayout = QtWidgets.QVBoxLayout(AddToCollectionOptions)
self.verticalLayout.setObjectName("verticalLayout")
self.collection_label = QtWidgets.QLabel(AddToCollectionOptions)
self.collection_label.setObjectName("collection_label")
self.verticalLayout.addWidget(self.collection_label)
sizePolicy = QtWidgets.QSizePolicy(
QtWidgets.QSizePolicy.MinimumExpanding, QtWidgets.QSizePolicy.Fixed
)
self.collection_name = QtWidgets.QComboBox(AddToCollectionOptions)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(
self.collection_name.sizePolicy().hasHeightForWidth()
)
self.collection_name.setSizePolicy(sizePolicy)
self.collection_name.setEditable(False)
self.collection_name.setObjectName("collection_name")
self.verticalLayout.addWidget(self.collection_name)
spacerItem = QtWidgets.QSpacerItem(
20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding
)
self.verticalLayout.addItem(spacerItem)
self.retranslateUi(AddToCollectionOptions)
QtCore.QMetaObject.connectSlotsByName(AddToCollectionOptions)
def retranslateUi(self, AddToCollectionOptions):
_translate = QtCore.QCoreApplication.translate
AddToCollectionOptions.setWindowTitle(_("Form"))
self.collection_label.setText(_("Collection to add releases to:"))
================================================
FILE: plugins/additional_artists_details/__init__.py
================================================
# -*- coding: utf-8 -*-
"""Additional Artists Details
"""
# Copyright (C) 2023-2024 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
# pylint: disable=line-too-long
# pylint: disable=import-error
# pylint: disable=too-many-arguments
# pylint: disable=too-many-locals
from collections import namedtuple
from functools import partial
from picard import (
config,
log,
)
from picard.album import register_album_post_removal_processor
from picard.metadata import (
register_album_metadata_processor,
register_track_metadata_processor,
)
from picard.plugin import PluginPriority
from picard.plugins.additional_artists_details.ui_options_additional_artists_details import (
Ui_AdditionalArtistsDetailsOptionsPage,
)
from picard.webservice.api_helpers import MBAPIHelper
from picard.ui.options import (
OptionsPage,
register_options_page,
)
PLUGIN_NAME = 'Additional Artists Details'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides specialized album and track variables with artist details for use in tagging and naming scripts. Note that this creates
additional calls to the MusicBrainz API for the artist and area information, and this will slow down processing. This will be particularly
noticable when there are many different album or track artists, such as on a [Various Artists] release. There is an option to disable track
artist processing, which can significantly increase the processing speed if you are only interested in album artist details.
Please see the user
guide on GitHub for more information.
'''
PLUGIN_VERSION = '0.4'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.7', '2.8', '2.11']
PLUGIN_LICENSE = 'GPL-2.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-2.0.html'
PLUGIN_USER_GUIDE_URL = 'https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/additional_artists_details/docs/README.md'
# Named tuples for code clarity
Area = namedtuple('Area', ['parent', 'name', 'country', 'type', 'type_text'])
MetadataPair = namedtuple('MetadataPair', ['artists', 'target'])
# MusicBrainz ID codes for relationship types
RELATIONSHIP_TYPE_PART_OF = 'de7cc874-8b1b-3a05-8272-f3834c968fb7'
# MusicBrainz ID codes for area types
AREA_TYPE_COUNTRY = '06dd0ae4-8c74-30bb-b43d-95dcedf961de'
AREA_TYPE_COUNTY = 'bcecec27-8bdb-3e00-8254-d948dda502fa'
AREA_TYPE_MUNICIPALITY = '17246454-5ac4-36a1-b81a-4753eb2dab20'
# Area types to exclude from the location string
EXCLUDE_AREA_TYPES = {AREA_TYPE_MUNICIPALITY, AREA_TYPE_COUNTY}
# Standard text for arguments
ALBUM_ARTISTS = 'album_artists'
ARTIST = 'artist'
ARTIST_REQUESTS = 'artist_requests'
AREA = 'area'
AREA_REQUESTS = 'area_requests'
ISO_CODES_1 = 'iso-3166-1-codes'
ISO_CODES_2 = 'iso-3166-2-codes'
OPT_AREA_DETAILS = 'aad_area_details'
OPT_PROCESS_TRACKS = 'aad_process_tracks'
TRACKS = 'tracks'
def log_helper(text, *args):
"""Logging helper to prepend the plugin name to the text.
Args:
text (str): Text to log.
args (list): List of text replacement arguments.
Returns:
list: updated text and replacement arguments.
"""
retval = ["%s: " + text, PLUGIN_NAME]
retval.extend(args)
return retval
class CustomHelper(MBAPIHelper):
"""Custom MusicBrainz API helper to retrieve artist and area information.
"""
def get_artist_by_id(self, _id, handler, inc=None, priority=False, important=False,
mblogin=False, refresh=False):
"""Get information for the specified artist MBID.
Args:
_id (str): Artist MBID to retrieve.
handler (object): Callback used to process the returned information.
inc (list, optional): List of includes to add to the API call. Defaults to None.
priority (bool, optional): Process the request at a high priority. Defaults to False.
important (bool, optional): Identify the request as important. Defaults to False.
mblogin (bool, optional): Request requires logging into MusicBrainz. Defaults to False.
refresh (bool, optional): Request triggers a refresh. Defaults to False.
Returns:
RequestTask: Requested task object.
"""
return self._get_by_id(ARTIST, _id, handler, inc, priority=priority, important=important, mblogin=mblogin, refresh=refresh)
def get_area_by_id(self, _id, handler, inc=None, priority=False, important=False, mblogin=False, refresh=False):
"""Get information for the specified area MBID.
Args:
_id (str): Area MBID to retrieve.
handler (object): Callback used to process the returned information.
inc (list, optional): List of includes to add to the API call. Defaults to None.
priority (bool, optional): Process the request at a high priority. Defaults to False.
important (bool, optional): Identify the request as important. Defaults to False.
mblogin (bool, optional): Request requires logging into MusicBrainz. Defaults to False.
refresh (bool, optional): Request triggers a refresh. Defaults to False.
Returns:
RequestTask: Requested task object.
"""
if inc is None:
inc = ['area-rels']
return self._get_by_id(AREA, _id, handler, inc, priority=priority, important=important, mblogin=mblogin, refresh=refresh)
class ArtistDetailsPlugin:
"""Plugin to retrieve artist details, including area and country information.
"""
result_cache = {
ARTIST: {},
ARTIST_REQUESTS: set(),
AREA: {},
AREA_REQUESTS: set(),
}
album_processing_count = {}
albums = {}
def _make_empty_target(self, album_id):
"""Create an empty album target node if it doesn't exist.
Args:
album_id (str): MBID of the album.
"""
if album_id not in self.albums:
self.albums[album_id] = {ALBUM_ARTISTS: set(), TRACKS: []}
def _add_target(self, album_id, artists, target_metadata):
"""Add a metadata target to update for an album.
Args:
album_id (str): MBID of the album.
artists (set): Set of artists to include.
target_metadata (Metadata): Target metadata to update.
"""
self._make_empty_target(album_id)
self.albums[album_id][TRACKS].append(MetadataPair(artists, target_metadata))
def _remove_album(self, album_id):
"""Removes an album from the metadata processing dictionary.
Args:
album_id (str): MBID of the album to remove.
"""
log.debug(*log_helper("Removing album '%s'", album_id))
self.albums.pop(album_id, None)
self.album_processing_count.pop(album_id, None)
def _album_add_request(self, album):
"""Increment the number of pending requests for an album.
Args:
album (Album): The Album object to use for the processing.
"""
if album.id not in self.album_processing_count:
self.album_processing_count[album.id] = 0
self.album_processing_count[album.id] += 1
album._requests += 1
def _album_remove_request(self, album):
"""Decrement the number of pending requests for an album.
Args:
album (Album): The Album object to use for the processing.
"""
if album.id not in self.album_processing_count:
self.album_processing_count[album.id] = 1
self.album_processing_count[album.id] -= 1
album._requests -= 1
album._finalize_loading(None) # pylint: disable=protected-access
def remove_album(self, album):
"""Remove the album from the albums processing dictionary.
Args:
album (Album): The album object to remove.
"""
self._remove_album(album.id)
def make_album_vars(self, album, album_metadata, _release_metadata):
"""Process album artists.
Args:
album (Album): The Album object to use for the processing.
album_metadata (Metadata): Metadata object for the album.
_release_metadata (dict): Dictionary of release data from MusicBrainz api.
"""
artists = set(artist.id for artist in album.get_album_artists())
self._make_empty_target(album.id)
self.albums[album.id][ALBUM_ARTISTS] = artists
if not config.setting[OPT_PROCESS_TRACKS]:
log.info(*log_helper("Track artist processing is disabled."))
self._artist_processing(artists, album, album_metadata, 'Album')
def make_track_vars(self, album, album_metadata, track_metadata, _release_metadata):
"""Process track artists.
Args:
album (Album): The Album object to use for the processing.
album_metadata (Metadata): Metadata object for the album.
track_metadata (dict): Dictionary of track data from MusicBrainz api.
_release_metadata (dict): Dictionary of release data from MusicBrainz api.
"""
artists = set()
source_type = 'track'
# Test for valid metadata node.
# The 'artist-credit' key should always be there.
# This check is to avoid a runtime error if it doesn't exist for some reason.
if config.setting[OPT_PROCESS_TRACKS]:
if 'artist-credit' in track_metadata:
for artist_credit in track_metadata['artist-credit']:
if 'artist' in artist_credit:
if 'id' in artist_credit['artist']:
artists.add(artist_credit['artist']['id'])
else:
# No 'artist' specified. Log as an error.
self._metadata_error(album.id, 'artist-credit.artist', source_type)
else:
# No valid metadata found. Log as error.
self._metadata_error(album.id, 'artist-credit', source_type)
self._artist_processing(artists, album, album_metadata, 'Track')
def _artist_processing(self, artists, album, destination_metadata, source_type):
"""Retrieves the information for each artist not already processed.
Args:
artists (set): Set of artist MBIDs to process.
album (Album): Album object to use for the processing.
destination_metadata (Metadata): Metadata object to update with the new variables.
source_type (str): Source type (album or track) for logging messages.
"""
for temp_id in artists:
if temp_id not in self.result_cache[ARTIST_REQUESTS]:
self.result_cache[ARTIST_REQUESTS].add(temp_id)
log.debug(*log_helper('Retrieving artist ID %s information from MusicBrainz.', temp_id))
self._get_artist_info(temp_id, album)
else:
log.debug(*log_helper('%s artist ID %s information available from cache.', source_type, temp_id))
self._add_target(album.id, artists, destination_metadata)
self._save_artist_metadata(album.id)
def _save_artist_metadata(self, album_id):
"""Saves the new artist details variables to the metadata targets for the specified album.
Args:
album_id (str): MBID of the album to process.
"""
if album_id in self.album_processing_count and self.album_processing_count[album_id]:
return
if album_id not in self.albums or not self.albums[album_id][TRACKS]:
log.error(*log_helper("No metadata targets found for album '%s'", album_id))
return
for item in self.albums[album_id][TRACKS]:
# Add album artists to track so they are available in the metadata
artists = self.albums[album_id][ALBUM_ARTISTS].copy().union(item.artists)
destination_metadata = item.target
for artist in artists:
if artist in self.result_cache[ARTIST]:
self._set_artist_metadata(destination_metadata, artist, self.result_cache[ARTIST][artist])
def _set_artist_metadata(self, destination_metadata, artist_id, artist_info):
"""Adds the artist information to the destination metadata.
Args:
destination_metadata (Metadata): Metadata object to update with new variables.
artist_id (str): MBID of the artist to update.
artist_info (dict): Dictionary of information for the artist.
"""
def _set_item(key, value):
destination_metadata[f"~artist_{artist_id}_{key.replace('-', '_')}"] = value
for item in artist_info.keys():
if item in {'area', 'begin-area', 'end-area'}:
country, location = self._drill_area(artist_info[item])
if country:
_set_item(item.replace('area', 'country'), country)
if location:
_set_item(item.replace('area', 'location'), location)
else:
_set_item(item, artist_info[item])
def _get_artist_info(self, artist_id, album):
"""Gets the artist information from the MusicBrainz website.
Args:
artist_id (str): MBID of the artist to retrieve.
album (Album): The Album object to use for the processing.
"""
self._album_add_request(album)
helper = CustomHelper(album.tagger.webservice)
handler = partial(
self._artist_submission_handler,
artist=artist_id,
album=album,
)
return helper.get_artist_by_id(artist_id, handler)
def _artist_submission_handler(self, document, _reply, error, artist=None, album=None):
"""Handles the response from the webservice requests for artist information.
"""
try:
if error:
log.error(*log_helper("Artist '%s' information retrieval error.", artist))
return
artist_info = {}
for item in ['type', 'gender', 'name', 'sort-name', 'disambiguation']:
if item in document and document[item]:
artist_info[item] = document[item]
if 'life-span' in document:
for item in ['begin', 'end']:
if item in document['life-span'] and document['life-span'][item]:
artist_info[item] = document['life-span'][item]
for item in ['area', 'begin-area', 'end-area']:
if item in document and document[item] and 'id' in document[item] and document[item]['id']:
area_id = document[item]['id']
artist_info[item] = area_id
if area_id not in self.result_cache[AREA_REQUESTS]:
self._get_area_info(area_id, album)
self.result_cache[ARTIST][artist] = artist_info
finally:
self._album_remove_request(album)
self._save_artist_metadata(album.id)
def _get_area_info(self, area_id, album):
"""Gets the area information from the MusicBrainz website.
Args:
area_id (str): MBID of the area to retrieve.
album (Album): The Album object to use for the processing.
"""
self.result_cache[AREA_REQUESTS].add(area_id)
self._album_add_request(album)
log.debug(*log_helper('Retrieving area ID %s from MusicBrainz.', area_id))
helper = CustomHelper(album.tagger.webservice)
handler = partial(
self._area_submission_handler,
area=area_id,
album=album,
)
return helper.get_area_by_id(area_id, handler)
def _area_submission_handler(self, document, _reply, error, area=None, album=None):
"""Handles the response from the webservice requests for area information.
"""
try:
if error:
log.error(*log_helper("Area '%s' information retrieval error.", area))
return
(_id, name, country, _type, type_text) = self._parse_area(document)
if _type == AREA_TYPE_COUNTRY and _id not in self.result_cache[AREA]:
self._area_logger(_id, f"{name} ({country})", type_text)
self.result_cache[AREA][_id] = Area('', name, country, _type, type_text)
if 'relations' in document:
for rel in document['relations']:
self._parse_area_relation(_id, rel, album, name, _type, type_text)
finally:
self._album_remove_request(album)
self._save_artist_metadata(album.id)
@staticmethod
def _area_logger(area_id, area_name, area_type):
"""Adds a log entry for the area retrieved.
Args:
area_id (str): MBID of the area added.
area_name (str): Name of the area added.
area_type (str): Type of area added.
"""
log.debug(*log_helper("Adding area: %s => %s of type '%s'", area_id, area_name, area_type))
def _parse_area_relation(self, area_id, area_relation, album, area_name, area_type, area_type_text):
"""Parse an area relation to extract the area information.
Args:
area_id (str): MBID of the area providing the relationship.
area_relation (dict): Dictionary of the area relationship.
album (Album): The Album object to use for the processing.
area_name (str): Name of the area providing the relationship.
area_type (str): MBID of the type of area providing the relationship.
area_type_text (str): Text description of the area providing the relationship.
"""
if 'type-id' not in area_relation or 'area' not in area_relation or area_relation['type-id'] != RELATIONSHIP_TYPE_PART_OF:
return
(_id, name, country, _type, type_text) = self._parse_area(area_relation['area'])
if not _id:
return
if 'direction' in area_relation and area_relation['direction'] == 'backward':
if area_id not in self.result_cache[AREA]:
self._area_logger(area_id, area_name, area_type_text)
self.result_cache[AREA][area_id] = Area(_id, area_name, '', area_type, type_text)
self.result_cache[AREA_REQUESTS].add(area_id)
if _type == AREA_TYPE_COUNTRY:
if _id not in self.result_cache[AREA]:
self._area_logger(_id, f"{name} ({country})", type_text)
self.result_cache[AREA][_id] = Area('', name, country, _type, type_text)
self.result_cache[AREA_REQUESTS].add(_id)
else:
if _id not in self.result_cache[AREA] and _id not in self.result_cache[AREA_REQUESTS]:
self._get_area_info(_id, album)
else:
self._area_logger(_id, name, type_text)
self.result_cache[AREA_REQUESTS].add(_id)
self.result_cache[AREA][_id] = Area(area_id, name, '', _type, type_text)
@staticmethod
def _parse_area(area_info):
"""Parse a dictionary of area information to return selected elements.
Args:
area_info (dict): Area information to parse.
Returns:
tuple: Selected information for the area (id, name, country code, type code, type text).
"""
if 'id' not in area_info:
return ('', '', '', '', '')
area_id = area_info['id']
area_name = area_info['name'] if 'name' in area_info else 'Unknown Name'
area_type = area_info['type-id'] if 'type-id' in area_info else ''
area_type_text = area_info['type'] if 'type' in area_info else 'Unknown Area Type'
country = ''
if area_type == AREA_TYPE_COUNTRY:
if ISO_CODES_1 in area_info and area_info[ISO_CODES_1]:
country = area_info[ISO_CODES_1][0]
elif ISO_CODES_2 in area_info and area_info[ISO_CODES_2]:
country = area_info[ISO_CODES_2][0][:2]
return (area_id, area_name, country, area_type, area_type_text)
@staticmethod
def _metadata_error(album_id, metadata_element, metadata_group):
"""Logs metadata-related errors.
Args:
album_id (str): MBID of the album being processed.
metadata_element (str): Metadata element initiating the error.
metadata_group (str): Metadata group initiating the error.
"""
log.error(*log_helper("Album '%s' missing '%s' in %s metadata.", album_id, metadata_element, metadata_group))
def _drill_area(self, area_id):
"""Drills up from the specified area to determine the two-character
country code and the full location description for the area.
Args:
area_id (str): MBID of the area to process.
Returns:
tuple: The two-character country code and full location description for the area.
"""
country = ''
location = []
i = 7 # Counter to avoid potential runaway processing
while i and area_id and not country:
i -= 1
area = self.result_cache[AREA][area_id] if area_id in self.result_cache[AREA] else Area('', '', '', '', '')
country = area.country
area_id = area.parent
if not location or config.setting[OPT_AREA_DETAILS] or area.type not in EXCLUDE_AREA_TYPES:
location.append(area.name)
return country, ', '.join(location)
class AdditionalArtistsDetailsOptionsPage(OptionsPage):
"""Options page for the Additional Artists Details plugin.
"""
NAME = "additional_artists_details"
TITLE = "Additional Artists Details"
PARENT = "plugins"
options = [
config.BoolOption('setting', OPT_PROCESS_TRACKS, False),
config.BoolOption('setting', OPT_AREA_DETAILS, False),
]
def __init__(self, parent=None):
super(AdditionalArtistsDetailsOptionsPage, self).__init__(parent)
self.ui = Ui_AdditionalArtistsDetailsOptionsPage()
self.ui.setupUi(self)
# Enable external link
self.ui.format_description.setOpenExternalLinks(True)
def load(self):
"""Load the option settings.
"""
self.ui.cb_process_tracks.setChecked(config.setting[OPT_PROCESS_TRACKS])
self.ui.cb_area_details.setChecked(config.setting[OPT_AREA_DETAILS])
def save(self):
"""Save the option settings.
"""
# self._set_settings(config.setting)
config.setting[OPT_PROCESS_TRACKS] = self.ui.cb_process_tracks.isChecked()
config.setting[OPT_AREA_DETAILS] = self.ui.cb_area_details.isChecked()
plugin = ArtistDetailsPlugin()
# Register the plugin to run at a LOW priority so that other plugins that
# modify the artist information can complete their processing and this plugin
# is working with the latest updated data.
register_album_metadata_processor(plugin.make_album_vars, priority=PluginPriority.LOW)
register_track_metadata_processor(plugin.make_track_vars, priority=PluginPriority.LOW)
register_album_post_removal_processor(plugin.remove_album)
register_options_page(AdditionalArtistsDetailsOptionsPage)
================================================
FILE: plugins/additional_artists_details/docs/README.md
================================================
# Additional Artists Details
## Overview
This plugin provides specialized album and track variables with artist details such as type, gender, begin and end dates, location (begin, end and current) and country code (begin, end and current) for use in tagging and naming scripts.
***NOTE:*** This plugin makes additional calls to the MusicBrainz website api for the information, which will slow down retrieving album information from MusicBrainz. This will be particularly noticable when there are many different album or track artists, such as on a \[Various Artists\] release. There is an option to disable track artist processing, which can significantly increase the processing speed if you are only interested in album artist details.
---
## Option Settings
The plugin adds a settings page under the "Plugins" section under "Options..." from Picard's main menu. This allows you to control how the plugin operates with respect to processing track artists and detail included in the artist location variables' content.

---
## What it Does
This plugin reads the album and track metadata provided to Picard, extracts the list of associated artists, retrieves the detailed information from the MusicBrainz website, and exposes the information in a number of additional variables for use in Picard scripts.
### Variables Created
* **\_artist_\{artist_id\}_begin** - The begin date (birth date) of the artist
* **\_artist_\{artist_id\}_begin_country** - The begin two-character country code of the artist
* **\_artist_\{artist_id\}_begin_location** - The begin location of the artist
* **\_artist_\{artist_id\}_country** - The two-character country code for the artist
* **\_artist_\{artist_id\}_disambiguation** - The disambiguation information for the artist
* **\_artist_\{artist_id\}_end** - The end date (death date) of the artist
* **\_artist_\{artist_id\}_end_country** - The end two-character country code of the artist
* **\_artist_\{artist_id\}_end_location** - The end location of the artist
* **\_artist_\{artist_id\}_gender** - The gender of the artist
* **\_artist_\{artist_id\}_name** - The name of the artist
* **\_artist_\{artist_id\}_sort_name** - The sort name of the artist
* **\_artist_\{artist_id\}_type** - The type of artist (person, group, etc.)
A variable will only be created if the information is returned from MusicBrainz. For example, if a gender has not been specified in the MusicBrainz data then the **%\_artist_\{artist_id\}_gender%** variable will not be created.
---
## Example
If you load the release **Wrecking Ball** (release [8c759d7a-2ade-4201-abc2-a2a7c1a6ad6c](https://musicbrainz.org/release/8c759d7a-2ade-4201-abc2-a2a7c1a6ad6c)) by Sarah Blackwood (artist [af7e5ea9-bd58-4346-8f78-d672e9f297f7](https://musicbrainz.org/artist/af7e5ea9-bd58-4346-8f78-d672e9f297f7)), Jenni Pleau (artist [07fa21a9-c253-4ed0-b711-d63f7965b723](https://musicbrainz.org/artist/07fa21a9-c253-4ed0-b711-d63f7965b723)) & Emily Bones (artist [541d331c-f041-4895-b8f2-7db9e27dc5ab](https://musicbrainz.org/artist/541d331c-f041-4895-b8f2-7db9e27dc5ab)), the following variables will be created:
Sarah Blackwood (primary artist):
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_begin** = "1980-10-18"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_begin_country** = "CA"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_begin_location** = "Burlington, Ontario, Canada"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_country** = "CA"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_disambiguation** = "rockabilly, + "Somebody That I Used to Know""
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_gender** = "Female"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_location** = "Canada"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_name** = "Sarah Blackwood"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_sort_name** = "Blackwood, Sarah"
* **\_artist_af7e5ea9_bd58_4346_8f78_d672e9f297f7_type** = "Person"
Jenny Pleau (additional artist)
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_country** = "CA"
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_gender** = "Female"
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_location** = "Kitchener, Ontario, Canada"
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_name** = "Jenni Pleau"
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_sort_name** = "Pleau, Jenni"
* **\_artist_07fa21a9_c253_4ed0_b711_d63f7965b723_type** = "Person"
Emily Bones (additional artist)
* **\_artist_541d331c_f041_4895_b8f2_7db9e27dc5ab_gender** = "Female"
* **\_artist_541d331c_f041_4895_b8f2_7db9e27dc5ab_name** = "Emily Bones"
* **\_artist_541d331c_f041_4895_b8f2_7db9e27dc5ab_sort_name** = "Bones, Emily"
* **\_artist_541d331c_f041_4895_b8f2_7db9e27dc5ab_type** = "Person"
Note that variables will only be created for information that exists for the artist's record.
This could be used to set a **%country%** tag to the country code of the (primary) album artist with a tagging script like:
```taggerscript
$set(_tmp,_artist_$getmulti(%musicbrainz_albumartistid%,0)_)
$set(country,$if2($get(%_tmp%country),$get(%_tmp%begin_country),$get(%_tmp%end_country),xx))
```
================================================
FILE: plugins/additional_artists_details/options_additional_artists_details.ui
================================================
AdditionalArtistsDetailsOptionsPage
0
0
561
802
100
0
Form
-
QFrame::NoFrame
true
0
0
543
784
-
Additional Artists Details
-
0
0
<html><head/><body><p>These settings will determine how the <span style=" font-weight:600;">Additional Artists Details</span> plugin operates.</p><p>Please visit the repository on GitHub for <a href="https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/additional_artists_details/docs/README.md"><span style=" text-decoration: underline; color:#0000ff;">additional information</span></a>.</p></body></html>
true
-
Process Track Artists
-
<html><head/><body><p>This option determines whether or not details are retrieved for all track artists on the release. If you are only interested in details for the album artists then this should be disabled, thus significantly reducing the number of additional calls made to the MusicBrainz api and reducing the time required to load a release. Album artists are always processed.</p></body></html>
true
-
Process track artists
-
Include Area Details
-
<html><head/><body><p>This option determines whether or not County and Municipality information is included in the artist location variables created. Regardless of this setting, this information will be included if a County or Municipality is the area specified for an artist.</p></body></html>
true
-
Include area details
-
Qt::Vertical
20
40
================================================
FILE: plugins/additional_artists_details/ui_options_additional_artists_details.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file './plugins/additional_artists_details/options_additional_artists_details.ui'
#
# Created by: PyQt5 UI code generator 5.15.6
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_AdditionalArtistsDetailsOptionsPage(object):
def setupUi(self, AdditionalArtistsDetailsOptionsPage):
AdditionalArtistsDetailsOptionsPage.setObjectName("AdditionalArtistsDetailsOptionsPage")
AdditionalArtistsDetailsOptionsPage.resize(561, 802)
AdditionalArtistsDetailsOptionsPage.setMinimumSize(QtCore.QSize(100, 0))
self.verticalLayout = QtWidgets.QVBoxLayout(AdditionalArtistsDetailsOptionsPage)
self.verticalLayout.setObjectName("verticalLayout")
self.scrollArea = QtWidgets.QScrollArea(AdditionalArtistsDetailsOptionsPage)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 543, 784))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.gb_description = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_description.setObjectName("gb_description")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.gb_description)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.format_description = QtWidgets.QLabel(self.gb_description)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.format_description.sizePolicy().hasHeightForWidth())
self.format_description.setSizePolicy(sizePolicy)
self.format_description.setWordWrap(True)
self.format_description.setObjectName("format_description")
self.verticalLayout_3.addWidget(self.format_description)
self.verticalLayout_2.addWidget(self.gb_description)
self.gb_process_track_artists = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_process_track_artists.setObjectName("gb_process_track_artists")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.gb_process_track_artists)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.label = QtWidgets.QLabel(self.gb_process_track_artists)
self.label.setWordWrap(True)
self.label.setObjectName("label")
self.verticalLayout_4.addWidget(self.label)
self.cb_process_tracks = QtWidgets.QCheckBox(self.gb_process_track_artists)
self.cb_process_tracks.setObjectName("cb_process_tracks")
self.verticalLayout_4.addWidget(self.cb_process_tracks)
self.verticalLayout_2.addWidget(self.gb_process_track_artists)
self.gb_area_details = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_area_details.setObjectName("gb_area_details")
self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.gb_area_details)
self.verticalLayout_5.setObjectName("verticalLayout_5")
self.label_2 = QtWidgets.QLabel(self.gb_area_details)
self.label_2.setWordWrap(True)
self.label_2.setObjectName("label_2")
self.verticalLayout_5.addWidget(self.label_2)
self.cb_area_details = QtWidgets.QCheckBox(self.gb_area_details)
self.cb_area_details.setObjectName("cb_area_details")
self.verticalLayout_5.addWidget(self.cb_area_details)
self.verticalLayout_2.addWidget(self.gb_area_details)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(AdditionalArtistsDetailsOptionsPage)
QtCore.QMetaObject.connectSlotsByName(AdditionalArtistsDetailsOptionsPage)
def retranslateUi(self, AdditionalArtistsDetailsOptionsPage):
_translate = QtCore.QCoreApplication.translate
AdditionalArtistsDetailsOptionsPage.setWindowTitle(_translate("AdditionalArtistsDetailsOptionsPage", "Form"))
self.gb_description.setTitle(_translate("AdditionalArtistsDetailsOptionsPage", "Additional Artists Details"))
self.format_description.setText(_translate("AdditionalArtistsDetailsOptionsPage", "These settings will determine how the Additional Artists Details plugin operates.
Please visit the repository on GitHub for additional information.
"))
self.gb_process_track_artists.setTitle(_translate("AdditionalArtistsDetailsOptionsPage", "Process Track Artists"))
self.label.setText(_translate("AdditionalArtistsDetailsOptionsPage", "This option determines whether or not details are retrieved for all track artists on the release. If you are only interested in details for the album artists then this should be disabled, thus significantly reducing the number of additional calls made to the MusicBrainz api and reducing the time required to load a release. Album artists are always processed.
"))
self.cb_process_tracks.setText(_translate("AdditionalArtistsDetailsOptionsPage", "Process track artists"))
self.gb_area_details.setTitle(_translate("AdditionalArtistsDetailsOptionsPage", "Include Area Details"))
self.label_2.setText(_translate("AdditionalArtistsDetailsOptionsPage", "This option determines whether or not County and Municipality information is included in the artist location variables created. Regardless of this setting, this information will be included if a County or Municipality is the area specified for an artist.
"))
self.cb_area_details.setText(_translate("AdditionalArtistsDetailsOptionsPage", "Include area details"))
================================================
FILE: plugins/additional_artists_variables/additional_artists_variables.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2018-2023 Bob Swift (rdswift)
# Copyright (C) 2023 Ruud van Asseldonk (ruuda)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Additional Artists Variables'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides specialized album and track variables for use in
naming scripts. It is based on the "Album Artist Extension" plugin, but
expands the functionality to also include track artists. Note that it
cannot be used as a direct drop-in replacement for the "Album Artist
Extension" plugin because the variables are provided with different
names. This will require changes to existing scripts if switching to
this plugin.
Please see the user guide on GitHub for more information.
'''
PLUGIN_VERSION = '1.0'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.7', '2.9', '2.10', '2.11']
PLUGIN_LICENSE = 'GPL-2.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-2.0.html'
PLUGIN_USER_GUIDE_URL = 'https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/additional_artists_variables/docs/README.md'
from operator import itemgetter
from picard import config, log
from picard.metadata import (register_album_metadata_processor,
register_track_metadata_processor)
from picard.plugin import PluginPriority
ID_ALIASES_ARTIST_NAME = '894afba6-2816-3c24-8072-eadb66bd04bc'
ID_ALIASES_LEGAL_NAME = 'd4dcd0c0-b341-3612-a332-c0ce797b25cf'
def process_artists(album_id, source_metadata, destination_metadata, source_type):
# Test for valid metadata node.
# The 'artist-credit' key should always be there.
# This check is to avoid a runtime error if it doesn't exist for some reason.
if 'artist-credit' in source_metadata:
# Initialize variables to default values
sort_pri_artist = ''
sort_pri_artist_cred = ''
std_artist = ''
cred_artist = ''
sort_artist = ''
cred_sort_artist = ''
legal_artist = ''
additional_std_artist = ''
additional_cred_artist = ''
additional_sort_artist = ''
additional_cred_sort_artist = ''
additional_legal_artist = ''
std_artist_list = []
cred_artist_list = []
sort_artist_list = []
cred_sort_artist_list = []
legal_artist_list = []
artist_count = 0
artist_ids = []
artist_types = []
artist_join_phrases = []
for artist_credit in source_metadata['artist-credit']:
# Initialize temporary variables for each loop.
temp_std_name = ''
temp_sort_name = ''
temp_cred_name = ''
temp_cred_sort_name = ''
temp_legal_name = ''
temp_legal_sort_name = ''
temp_phrase = ''
temp_id = ''
temp_type = ''
# Check if there is a 'joinphrase' specified.
if 'joinphrase' in artist_credit:
temp_phrase = artist_credit['joinphrase']
else:
metadata_error(album_id, 'artist-credit.joinphrase', source_type)
# Check if there is a 'name' specified.
if 'name' in artist_credit:
temp_cred_name = artist_credit['name']
else:
metadata_error(album_id, 'artist-credit.name', source_type)
# Check if there is an 'artist' specified.
if 'artist' in artist_credit:
if 'id' in artist_credit['artist']:
temp_id = artist_credit['artist']['id']
else:
metadata_error(album_id, 'artist-credit.artist.id', source_type)
if 'name' in artist_credit['artist']:
temp_std_name = artist_credit['artist']['name']
else:
metadata_error(album_id, 'artist-credit.artist.name', source_type)
if 'sort-name' in artist_credit['artist']:
temp_sort_name = artist_credit['artist']['sort-name']
temp_cred_sort_name = temp_sort_name
else:
metadata_error(album_id, 'artist-credit.artist.sort-name', source_type)
if 'type' in artist_credit['artist']:
temp_type = artist_credit['artist']['type']
else:
metadata_error(album_id, 'artist-credit.artist.type', source_type)
if 'aliases' in artist_credit['artist']:
for item in artist_credit['artist']['aliases']:
if 'type-id' in item and item['type-id'] == ID_ALIASES_LEGAL_NAME:
if 'ended' in item and not item['ended']:
if 'name' in item:
temp_legal_name = item['name']
if 'sort-name' in item:
temp_legal_sort_name = item['sort-name']
if 'type-id' in item and item['type-id'] == ID_ALIASES_ARTIST_NAME:
if 'name' in item and 'sort-name' in item and str(item['name']).lower() == temp_cred_name.lower():
temp_cred_sort_name = item['sort-name']
tag_list = []
if config.setting['max_genres']:
for tag_type in ['user-genres', 'genres', 'user-tags', 'tags']:
if tag_type in artist_credit['artist']:
for item in sorted(sorted(artist_credit['artist'][tag_type], key=itemgetter('name')), key=itemgetter('count'), reverse=True):
if item['count'] > 0:
tag_list.append(item['name'])
tag_list = tag_list[:config.setting['max_genres']]
else:
# No 'artist' specified. Log as an error.
metadata_error(album_id, 'artist-credit.artist', source_type)
std_artist += temp_std_name + temp_phrase
cred_artist += temp_cred_name + temp_phrase
sort_artist += temp_sort_name + temp_phrase
cred_sort_artist += temp_cred_sort_name + temp_phrase
artist_types.append(temp_type if temp_type else 'unknown',)
artist_join_phrases.append(temp_phrase if temp_phrase else '\u200B',)
if temp_legal_name:
legal_artist += temp_legal_name + temp_phrase
legal_artist_list.append(temp_legal_name,)
else:
# Use standardized name for combined string if legal name not available
legal_artist += temp_std_name + temp_phrase
# Use 'n/a' for list if legal name not available
legal_artist_list.append('n/a',)
if temp_std_name:
std_artist_list.append(temp_std_name,)
if temp_sort_name:
sort_artist_list.append(temp_sort_name,)
if temp_cred_name:
cred_artist_list.append(temp_cred_name,)
if temp_cred_sort_name:
cred_sort_artist_list.append(temp_cred_sort_name,)
if temp_id:
artist_ids.append(temp_id,)
if artist_count < 1:
if temp_id:
destination_metadata['~artists_{0}_primary_id'.format(source_type,)] = temp_id
destination_metadata['~artists_{0}_primary_std'.format(source_type,)] = temp_std_name
destination_metadata['~artists_{0}_primary_cred'.format(source_type,)] = temp_cred_name
destination_metadata['~artists_{0}_primary_sort'.format(source_type,)] = temp_sort_name
destination_metadata['~artists_{0}_primary_cred_sort'.format(source_type,)] = temp_cred_sort_name
destination_metadata['~artists_{0}_primary_legal'.format(source_type,)] = temp_legal_name
destination_metadata['~artists_{0}_primary_sort_legal'.format(source_type,)] = temp_legal_sort_name
sort_pri_artist += temp_sort_name + temp_phrase
sort_pri_artist_cred += temp_cred_sort_name + temp_phrase
if tag_list and source_type == 'album':
destination_metadata['~artists_{0}_primary_tags'.format(source_type,)] = tag_list
else:
sort_pri_artist += temp_std_name + temp_phrase
additional_std_artist += temp_std_name + temp_phrase
additional_cred_artist += temp_cred_name + temp_phrase
additional_sort_artist += temp_sort_name + temp_phrase
if temp_legal_name:
additional_legal_artist += temp_legal_name + temp_phrase
else:
additional_legal_artist += temp_std_name + temp_phrase
if temp_cred_sort_name:
additional_cred_sort_artist += temp_cred_sort_name + temp_phrase
sort_pri_artist_cred += temp_cred_sort_name + temp_phrase
else:
additional_cred_sort_artist += temp_sort_name + temp_phrase
sort_pri_artist_cred += temp_sort_name + temp_phrase
artist_count += 1
else:
# No valid metadata found. Log as error.
metadata_error(album_id, 'artist-credit', source_type)
additional_std_artist_list = std_artist_list[1:]
additional_cred_artist_list = cred_artist_list[1:]
additional_sort_artist_list = sort_artist_list[1:]
additional_cred_sort_artist_list = cred_sort_artist_list[1:]
additional_legal_artist_list = legal_artist_list[1:]
additional_artist_ids = artist_ids[1:]
if additional_artist_ids:
destination_metadata['~artists_{0}_additional_id'.format(source_type,)] = additional_artist_ids
if additional_std_artist:
destination_metadata['~artists_{0}_additional_std'.format(source_type,)] = additional_std_artist
if additional_cred_artist:
destination_metadata['~artists_{0}_additional_cred'.format(source_type,)] = additional_cred_artist
if additional_sort_artist:
destination_metadata['~artists_{0}_additional_sort'.format(source_type,)] = additional_sort_artist
if additional_cred_sort_artist:
destination_metadata['~artists_{0}_additional_cred_sort'.format(source_type,)] = additional_cred_sort_artist
if additional_legal_artist:
destination_metadata['~artists_{0}_additional_legal'.format(source_type,)] = additional_legal_artist
if additional_std_artist_list:
destination_metadata['~artists_{0}_additional_std_multi'.format(source_type,)] = additional_std_artist_list
if additional_cred_artist_list:
destination_metadata['~artists_{0}_additional_cred_multi'.format(source_type,)] = additional_cred_artist_list
if additional_sort_artist_list:
destination_metadata['~artists_{0}_additional_sort_multi'.format(source_type,)] = additional_sort_artist_list
if additional_cred_sort_artist_list:
destination_metadata['~artists_{0}_additional_cred_sort_multi'.format(source_type,)] = additional_cred_sort_artist_list
if additional_legal_artist_list:
destination_metadata['~artists_{0}_additional_legal_multi'.format(source_type,)] = additional_legal_artist_list
if std_artist:
destination_metadata['~artists_{0}_all_std'.format(source_type,)] = std_artist
if cred_artist:
destination_metadata['~artists_{0}_all_cred'.format(source_type,)] = cred_artist
if cred_sort_artist:
destination_metadata['~artists_{0}_all_cred_sort'.format(source_type,)] = cred_sort_artist
if sort_artist:
destination_metadata['~artists_{0}_all_sort'.format(source_type,)] = sort_artist
if legal_artist:
destination_metadata['~artists_{0}_all_legal'.format(source_type,)] = legal_artist
if std_artist_list:
destination_metadata['~artists_{0}_all_std_multi'.format(source_type,)] = std_artist_list
if cred_artist_list:
destination_metadata['~artists_{0}_all_cred_multi'.format(source_type,)] = cred_artist_list
if sort_artist_list:
destination_metadata['~artists_{0}_all_sort_multi'.format(source_type,)] = sort_artist_list
if cred_sort_artist_list:
destination_metadata['~artists_{0}_all_cred_sort_multi'.format(source_type,)] = cred_sort_artist_list
if legal_artist_list:
destination_metadata['~artists_{0}_all_legal_multi'.format(source_type,)] = legal_artist_list
if sort_pri_artist:
destination_metadata['~artists_{0}_all_sort_primary'.format(source_type,)] = sort_pri_artist
if artist_types:
destination_metadata['~artists_{0}_all_types'.format(source_type,)] = artist_types
if artist_join_phrases:
destination_metadata['~artists_{0}_all_join_phrases'.format(source_type,)] = artist_join_phrases
if artist_count:
destination_metadata['~artists_{0}_all_count'.format(source_type,)] = artist_count
def make_album_vars(album, album_metadata, release_metadata):
album_id = release_metadata['id'] if release_metadata else 'No Album ID'
process_artists(album_id, release_metadata, album_metadata, 'album')
def make_track_vars(album, album_metadata, track_metadata, release_metadata):
album_id = release_metadata['id'] if release_metadata else 'No Album ID'
process_artists(album_id, track_metadata, album_metadata, 'track')
def metadata_error(album_id, metadata_element, metadata_group):
log.error("{0}: {1!r}: Missing '{2}' in {3} metadata.".format(
PLUGIN_NAME, album_id, metadata_element, metadata_group,))
# Register the plugin to run at a LOW priority so that other plugins that
# modify the artist information can complete their processing and this plugin
# is working with the latest updated data.
register_album_metadata_processor(make_album_vars, priority=PluginPriority.LOW)
register_track_metadata_processor(make_track_vars, priority=PluginPriority.LOW)
================================================
FILE: plugins/addrelease/addrelease.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "Add Cluster As Release"
PLUGIN_AUTHOR = 'Frederik "Freso" S. Olesen, Lukáš Lalinský, Philip Jägenstedt'
PLUGIN_DESCRIPTION = "Adds a plugin context menu option to clusters and single\
files to help you quickly add them as releases or standalone recordings to\
the MusicBrainz database via the website by pre-populating artists,\
track names and times."
PLUGIN_VERSION = "0.7.3"
PLUGIN_API_VERSIONS = ["2.0"]
from picard import config, log
from picard.cluster import Cluster
from picard.const import MUSICBRAINZ_SERVERS
from picard.file import File
from picard.util import webbrowser2
from picard.ui.itemviews import BaseAction, register_cluster_action, register_file_action
import os
import tempfile
HTML_HEAD = """
%s
"""
HTML_ATTR_ESCAPE = {
"&": "&",
'"': """
}
def mbserver_url(path):
host = config.setting["server_host"]
port = config.setting["server_port"]
if host in MUSICBRAINZ_SERVERS or port == 443:
urlstring = "https://%s%s" % (host, path)
elif port is None or port == 80:
urlstring = "http://%s%s" % (host, path)
else:
urlstring = "http://%s:%d%s" % (host, port, path)
return urlstring
class AddObjectAsEntity(BaseAction):
NAME = "Add Object As Entity..."
objtype = None
submit_path = '/'
def __init__(self):
super(AddObjectAsEntity, self).__init__()
self.form_values = {}
def check_object(self, objs, objtype):
"""
Checks if a given object array is valid (ie., has one item) and that
its item is an object of the given type.
Returns either False (if conditions are not met), or the object in the
array.
"""
if not isinstance(objs[0], objtype) or len(objs) != 1:
return False
else:
return objs[0]
def add_form_value(self, key, value):
"Add global (e.g., release level) name-value pair."
self.form_values[key] = value
def set_form_values(self, objdata):
return
def generate_html_file(self, form_values):
(fd, fp) = tempfile.mkstemp(suffix=".html")
with os.fdopen(fd, "w", encoding="utf-8") as f:
def esc(s):
return "".join(HTML_ATTR_ESCAPE.get(c, c) for c in s)
# add a global (release-level) name-value
def nv(n, v):
f.write(HTML_INPUT % (esc(n), esc(v)))
f.write(HTML_HEAD % (self.NAME, mbserver_url(self.submit_path)))
for key in form_values:
nv(key, form_values[key])
f.write(HTML_TAIL % (self.NAME))
return fp
def open_html_file(self, fp):
webbrowser2.open("file://" + fp)
def callback(self, objs):
objdata = self.check_object(objs, self.objtype)
try:
if objdata:
self.set_form_values(objdata)
html_file = self.generate_html_file(self.form_values)
self.open_html_file(html_file)
finally:
self.form_values.clear()
class AddClusterAsRelease(AddObjectAsEntity):
NAME = "Add Cluster As Release..."
objtype = Cluster
submit_path = '/release/add'
def __init__(self):
super().__init__()
self.discnumber_shift = -1
def extract_discnumber(self, metadata):
"""
>>> from picard.metadata import Metadata
>>> m = Metadata()
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = "boop"
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = "1"
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = 1
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = -1
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = "1/1"
>>> AddClusterAsRelease().extract_discnumber(m)
0
>>> m["discnumber"] = "2/2"
>>> AddClusterAsRelease().extract_discnumber(m)
1
>>> a = AddClusterAsRelease()
>>> m["discnumber"] = "-2/2"
>>> a.extract_discnumber(m)
0
>>> m["discnumber"] = "-1/4"
>>> a.extract_discnumber(m)
1
>>> m["discnumber"] = "1/4"
>>> a.extract_discnumber(m)
3
"""
# As per https://musicbrainz.org/doc/Development/Release_Editor_Seeding#Tracklists_data
# the medium numbers ("m") must be starting with 0.
# Maybe the existing tags don't have disc numbers in them or
# they're starting with something smaller than or equal to 0, so try
# to produce a sane disc number.
try:
discnumber = metadata.get("discnumber", "1")
# Split off any totaldiscs information
discnumber = discnumber.split("/", 1)[0]
m = int(discnumber)
if m <= 0:
# A disc number was smaller than or equal to 0 - all other
# disc numbers need to be changed to accommodate that.
self.discnumber_shift = max(self.discnumber_shift, 0 - m)
m = m + self.discnumber_shift
except ValueError as e:
# The most likely reason for an exception at this point is because
# the disc number in the tags was not a number. Just log the
# exception and assume the medium number is 0.
log.info("Trying to get the disc number of %s caused the following error: %s; assuming 0",
metadata["~filename"], e)
m = 0
return m
def set_form_values(self, cluster):
nv = self.add_form_value
nv("artist_credit.names.0.artist.name", cluster.metadata["albumartist"])
nv("name", cluster.metadata["album"])
for i, file in enumerate(cluster.files):
try:
i = int(file.metadata["tracknumber"]) - 1
except:
pass
m = self.extract_discnumber(file.metadata)
# add a track-level name-value
def tnv(n, v):
nv("mediums.%d.track.%d.%s" % (m, i, n), v)
tnv("name", file.metadata["title"])
if file.metadata["artist"] != cluster.metadata["albumartist"]:
tnv("artist_credit.names.0.name", file.metadata["artist"])
tnv("length", str(file.metadata.length))
class AddFileAsRecording(AddObjectAsEntity):
NAME = "Add File As Standalone Recording..."
objtype = File
submit_path = '/recording/create'
def set_form_values(self, track):
nv = self.add_form_value
nv("edit-recording.name", track.metadata["title"])
nv("edit-recording.artist_credit.names.0.artist.name", track.metadata["artist"])
nv("edit-recording.length", track.metadata["~length"])
class AddFileAsRelease(AddObjectAsEntity):
NAME = "Add File As Release..."
objtype = File
submit_path = '/release/add'
def set_form_values(self, track):
nv = self.add_form_value
# Main album attributes
if track.metadata["albumartist"]:
nv("artist_credit.names.0.artist.name", track.metadata["albumartist"])
else:
nv("artist_credit.names.0.artist.name", track.metadata["artist"])
if track.metadata["album"]:
nv("name", track.metadata["album"])
else:
nv("name", track.metadata["title"])
# Tracklist
nv("mediums.0.track.0.name", track.metadata["title"])
nv("mediums.0.track.0.artist_credit.names.0.name", track.metadata["artist"])
nv("mediums.0.track.0.length", str(track.metadata.length))
register_cluster_action(AddClusterAsRelease())
register_file_action(AddFileAsRecording())
register_file_action(AddFileAsRelease())
if __name__ == "__main__":
import doctest
doctest.testmod()
================================================
FILE: plugins/albumartist_website/albumartist_website.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = 'Album Artist Website'
PLUGIN_AUTHOR = 'Sophist, Sambhav Kothari, Philipp Wolfer'
PLUGIN_DESCRIPTION = '''Add's the album artist(s) Official Homepage(s)
(if they are defined in the MusicBrainz database).'''
PLUGIN_VERSION = '1.2'
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import config, log
from picard.util import LockableObject
from picard.metadata import register_track_metadata_processor
from functools import partial
class AlbumArtistWebsite:
class ArtistWebsiteQueue(LockableObject):
def __init__(self):
LockableObject.__init__(self)
self.queue = {}
def __contains__(self, name):
return name in self.queue
def __iter__(self):
return self.queue.__iter__()
def __getitem__(self, name):
self.lock_for_read()
value = self.queue[name] if name in self.queue else None
self.unlock()
return value
def __setitem__(self, name, value):
self.lock_for_write()
self.queue[name] = value
self.unlock()
def append(self, name, value):
self.lock_for_write()
if name in self.queue:
self.queue[name].append(value)
value = False
else:
self.queue[name] = [value]
value = True
self.unlock()
return value
def remove(self, name):
self.lock_for_write()
value = None
if name in self.queue:
value = self.queue[name]
del self.queue[name]
self.unlock()
return value
def __init__(self):
self.website_cache = {}
self.website_queue = self.ArtistWebsiteQueue()
def add_artist_website(self, album, track_metadata, track_node, release_node):
albumArtistIds = track_metadata.getall('musicbrainz_albumartistid')
for artistId in albumArtistIds:
# Jump through hoops to get track object!!
track = album._new_tracks[-1]
if artistId in self.website_cache:
if self.website_cache[artistId]:
self.add_websites_to_track(track, self.website_cache[artistId])
else:
self.website_add_track(album, track, artistId)
def website_add_track(self, album, track, artistId):
self.album_add_request(album)
if self.website_queue.append(artistId, (track, album)):
host = config.setting["server_host"]
port = config.setting["server_port"]
path = "/ws/2/%s/%s" % ('artist', artistId)
queryargs = {"inc": "url-rels"}
return album.tagger.webservice.get(host, port, path,
partial(self.website_process, artistId),
parse_response_type="xml", priority=True, important=False,
queryargs=queryargs)
def website_process(self, artistId, response, reply, error):
if error:
log.error("%s: %r: Network error retrieving artist record", PLUGIN_NAME, artistId)
tuples = self.website_queue.remove(artistId)
for track, album in tuples:
self.album_remove_request(album)
return
urls = self.artist_process_metadata(artistId, response)
self.website_cache[artistId] = urls
tuples = self.website_queue.remove(artistId)
for track, album in tuples:
self.add_websites_to_track(track, urls)
self.album_remove_request(album)
def add_websites_to_track(self, track, urls):
tm = track.metadata
websites = tm.getall('website')
websites += urls
websites.sort()
tm['website'] = websites
for file in track.iterfiles(True):
file.metadata['website'] = websites
def album_add_request(self, album):
album._requests += 1
def album_remove_request(self, album):
album._requests -= 1
album._finalize_loading(None)
def artist_process_metadata(self, artistId, response):
log.debug("%s: %r: Processing Artist record for official website urls: %r", PLUGIN_NAME, artistId, response)
relations = self.artist_get_relations(response)
if not relations:
log.info("%s: %r: Artist does have any associated urls.", PLUGIN_NAME, artistId)
return []
urls = []
for relation in relations:
log.debug("%s: %r: Examining: %r", PLUGIN_NAME, artistId, relation)
if 'type' in relation.attribs and relation.type == 'official homepage':
if 'target' in relation.children and len(relation.target) > 0:
if not 'ended' in relation.children or relation.ended[0].text != 'true':
log.debug("%s: Adding artist url: %s", PLUGIN_NAME, relation.target[0].text)
urls.append(relation.target[0].text)
else:
log.debug("%s: Artist url has ended: %s", PLUGIN_NAME, relation.target[0].text)
else:
log.debug("%s: No url in relation: %r", PLUGIN_NAME, relation)
if urls:
log.info("%s: %r: Artist Official Homepages: %r", PLUGIN_NAME, artistId, urls)
else:
log.info("%s: %r: Artist does not have any official website urls.", PLUGIN_NAME, artistId)
return sorted(urls)
def artist_get_relations(self, response):
log.debug("%s: artist_get_relations called", PLUGIN_NAME)
if 'metadata' in response.children and len(response.metadata) > 0:
if 'artist' in response.metadata[0].children and len(response.metadata[0].artist) > 0:
if 'relation_list' in response.metadata[0].artist[0].children and len(response.metadata[0].artist[0].relation_list) > 0:
if 'relation' in response.metadata[0].artist[0].relation_list[0].children:
log.debug("%s: artist_get_relations returning: %r", PLUGIN_NAME, response.metadata[0].artist[0].relation_list[0].relation)
return response.metadata[0].artist[0].relation_list[0].relation
else:
log.debug("%s: artist_get_relations - no relation in relation_list", PLUGIN_NAME)
else:
log.debug("%s: artist_get_relations - no relation_list in artist", PLUGIN_NAME)
else:
log.debug("%s: artist_get_relations - no artist in metadata", PLUGIN_NAME)
else:
log.debug("%s: artist_get_relations - no metadata in response", PLUGIN_NAME)
return None
register_track_metadata_processor(AlbumArtistWebsite().add_artist_website)
================================================
FILE: plugins/albumartistextension/albumartistextension.py
================================================
PLUGIN_NAME = 'AlbumArtist Extension'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides standardized, credited and sorted artist information
for the album artist. This is useful when your tagging or renaming scripts
require both the standardized artist name and the credited artist name, or
more detailed information about the album artists.
The information is provided in the following variables:
- _aaeStdAlbumArtists = The standardized version of the album artists.
- _aaeCredAlbumArtists = The credited version of the album artists.
- _aaeSortAlbumArtists = The sorted version of the album artists.
- _aaeStdPrimaryAlbumArtist = The standardized version of the first
(primary) album artist.
- _aaeCredPrimaryAlbumArtist = The credited version of the first (primary)
album artist.
- _aaeSortPrimaryAlbumArtist = The sorted version of the first (primary)
album artist.
- _aaeAlbumArtistCount = The number of artists comprising the album artist.
PLEASE NOTE: Once the plugin is installed, it automatically makes these
variables available to File Naming Scripts and other scripts in Picard.
Like other variables, you must mention them in a script for them to affect
the file name or other data.
This plugin is no longer being maintained.
Consider switching to the
[Additional Artists Variables plugin](https://github.com/rdswift/picard-plugins/tree/2.0/plugins/additional_artists_variables),
which fills this
role, and also includes additional variables. That other plugin uses different
names for the album artist names provided here, so you if you switch plugins, you
will need to update your scripts with the different names.
Version 0.6.1 of this plugin functions identically to Version 0.6. Only this
description (and the version number) has changed.
'''
PLUGIN_VERSION = "0.6.1"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import config, log
from picard.metadata import register_album_metadata_processor
from picard.plugin import PluginPriority
def add_artist_std_name(album, album_metadata, release_metadata):
album_id = release_metadata['id']
# Test for valid metadata node for the release
if 'artist-credit' in release_metadata:
# Initialize variables to default values
cred_artist = ""
std_artist = ""
sort_artist = ""
artist_count = 0
# The 'artist-credit' key should always be there.
# This check is to avoid a runtime error if it doesn't exist for some reason.
for artist_credit in release_metadata['artist-credit']:
# Initialize temporary variables for each loop.
temp_std_name = ""
temp_cred_name = ""
temp_sort_name = ""
temp_phrase = ""
# Check if there is a 'joinphrase' specified.
if 'joinphrase' in artist_credit:
temp_phrase = artist_credit['joinphrase']
else:
metadata_error(album_id, 'artist-credit.joinphrase')
# Check if there is a 'name' specified.
if 'name' in artist_credit:
temp_cred_name = artist_credit['name']
else:
metadata_error(album_id, 'artist-credit.name')
# Check if there is an 'artist' specified.
if 'artist' in artist_credit:
# Check if there is a 'name' specified.
if 'name' in artist_credit['artist']:
temp_std_name = artist_credit['artist']['name']
else:
metadata_error(album_id, 'artist-credit.artist.name')
if 'sort-name' in artist_credit['artist']:
temp_sort_name = artist_credit['artist']['sort-name']
else:
metadata_error(album_id, 'artist-credit.artist.sort-name')
else:
metadata_error(album_id, 'artist-credit.artist')
std_artist += temp_std_name + temp_phrase
cred_artist += temp_cred_name + temp_phrase
sort_artist += temp_sort_name + temp_phrase
if artist_count < 1:
album_metadata["~aaeStdPrimaryAlbumArtist"] = temp_std_name
album_metadata["~aaeCredPrimaryAlbumArtist"] = temp_cred_name
album_metadata["~aaeSortPrimaryAlbumArtist"] = temp_sort_name
artist_count += 1
else:
metadata_error(album_id, 'artist-credit')
if std_artist:
album_metadata["~aaeStdAlbumArtists"] = std_artist
if cred_artist:
album_metadata["~aaeCredAlbumArtists"] = cred_artist
if sort_artist:
album_metadata["~aaeSortAlbumArtists"] = sort_artist
if artist_count:
album_metadata["~aaeAlbumArtistCount"] = artist_count
return None
def metadata_error(album_id, metadata_element):
log.error("%s: %r: Missing '%s' in release metadata.",
PLUGIN_NAME, album_id, metadata_element)
# Register the plugin to run at a LOW priority so that other plugins that
# modify the artist information can complete their processing and this plugin
# is working with the latest updated data.
register_album_metadata_processor(add_artist_std_name, priority=PluginPriority.LOW)
================================================
FILE: plugins/amazon/amazon.py
================================================
# -*- coding: utf-8 -*-
#
# Picard, the next-generation MusicBrainz tagger
# Copyright (C) 2007 Oliver Charles
# Copyright (C) 2007-2011, 2019, 2021 Philipp Wolfer
# Copyright (C) 2007, 2010, 2011 Lukáš Lalinský
# Copyright (C) 2011 Michael Wiencek
# Copyright (C) 2011-2012 Wieland Hoffmann
# Copyright (C) 2013-2016 Laurent Monin
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
PLUGIN_NAME = 'Amazon cover art'
PLUGIN_AUTHOR = 'MusicBrainz Picard developers'
PLUGIN_DESCRIPTION = 'Use cover art from Amazon.'
PLUGIN_VERSION = "1.1"
PLUGIN_API_VERSIONS = ["2.2", "2.3", "2.4", "2.5", "2.6", "2.7"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import log
from picard.coverart.image import CoverArtImage
from picard.coverart.providers import (
CoverArtProvider,
register_cover_art_provider,
)
from picard.util import parse_amazon_url
# amazon image file names are unique on all servers and constructed like
# ..[SML]ZZZZZZZ.jpg
# A release sold on amazon.de has always = 03, for example.
# Releases not sold on amazon.com, don't have a "01"-version of the image,
# so we need to make sure we grab an existing image.
AMAZON_SERVER = {
"amazon.com": {
"server": "ec1.images-amazon.com",
"id": "01",
},
"amazon.jp": {
"server": "ec1.images-amazon.com",
"id": "09",
},
"amazon.co.jp": {
"server": "ec1.images-amazon.com",
"id": "09",
},
"amazon.co.uk": {
"server": "ec1.images-amazon.com",
"id": "02",
},
"amazon.de": {
"server": "ec2.images-amazon.com",
"id": "03",
},
"amazon.ca": {
"server": "ec1.images-amazon.com",
"id": "01", # .com and .ca are identical
},
"amazon.fr": {
"server": "ec1.images-amazon.com",
"id": "08"
},
}
AMAZON_IMAGE_PATH = '/images/P/%(asin)s.%(serverid)s.%(size)s.jpg'
# First item in the list will be tried first
AMAZON_SIZES = (
# huge size option is only available for items
# that have a ZOOMing picture on its amazon web page
# and it doesn't work for all of the domain names
# '_SCRM_', # huge size
'LZZZZZZZ', # large size, option format 1
# '_SCLZZZZZZZ_', # large size, option format 3
'MZZZZZZZ', # default image size, format 1
# '_SCMZZZZZZZ_', # medium size, option format 3
# 'TZZZZZZZ', # medium image size, option format 1
# '_SCTZZZZZZZ_', # small size, option format 3
# 'THUMBZZZ', # small size, option format 1
)
class CoverArtProviderAmazon(CoverArtProvider):
"""Use Amazon ASIN Musicbrainz relationships to get cover art"""
NAME = "Amazon"
TITLE = N_('Amazon')
def __init__(self, coverart):
super().__init__(coverart)
self._has_url_relation = False
def enabled(self):
return (super().enabled()
and not self.coverart.front_image_found)
def queue_images(self):
self.match_url_relations(('amazon asin', 'has_Amazon_ASIN'),
self._queue_from_asin_relation)
# No URL relationships loaded, try by ASIN
if not self._has_url_relation:
self._queue_from_asin()
return CoverArtProvider.FINISHED
def _queue_from_asin_relation(self, url):
"""Queue cover art images from Amazon"""
amz = parse_amazon_url(url)
if amz is None:
return
log.debug("Found ASIN relation : %s %s", amz['host'], amz['asin'])
self._has_url_relation = True
if amz['host'] in AMAZON_SERVER:
server_info = AMAZON_SERVER[amz['host']]
else:
server_info = AMAZON_SERVER['amazon.com']
self._queue_asin(server_info, amz['asin'])
def _queue_from_asin(self):
asin = self.release.get('asin')
if asin:
log.debug("Found ASIN : %s", asin)
for server_info in AMAZON_SERVER.values():
self._queue_asin(server_info, asin)
def _queue_asin(self, server_info, asin):
host = server_info['server']
for size in AMAZON_SIZES:
path = AMAZON_IMAGE_PATH % {
'asin': asin,
'serverid': server_info['id'],
'size': size
}
self.queue_put(CoverArtImage("http://%s%s" % (host, path)))
register_cover_art_provider(CoverArtProviderAmazon)
================================================
FILE: plugins/bpm/__init__.py
================================================
# -*- coding: utf-8 -*-
# Changelog:
# [2015-09-15] Initial version
# [2017-11-24] Qt5, Python3 for Picard-plugins branch 2
# [2020-12-25] Move access to config.settings outside of thread
# Dependancies:
# aubio, numpy
#
PLUGIN_NAME = "BPM Analyzer"
PLUGIN_AUTHOR = "Len Joubert, Sambhav Kothari, Philipp Wolfer"
PLUGIN_DESCRIPTION = """Calculate BPM for selected files and albums. Linux only version with dependancy on Aubio and Numpy"""
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
PLUGIN_VERSION = "1.5.2"
PLUGIN_API_VERSIONS = ["2.0"]
# PLUGIN_INCOMPATIBLE_PLATFORMS = [
# 'win32', 'cygwyn', 'darwin', 'os2', 'os2emx', 'riscos', 'atheos']
from aubio import source, tempo
from functools import partial
from numpy import median, diff
from picard.config import config, IntOption
from picard.file import File
from picard.plugins.bpm.ui_options_bpm import Ui_BPMOptionsPage
from picard.track import Track
from picard.ui.itemviews import BaseAction, register_file_action
from picard.ui.options import register_options_page, OptionsPage
from picard.util import thread
bpm_slider_settings = {
1: (44100, 1024, 512),
2: (8000, 512, 128),
3: (4000, 128, 64),
}
class FileBPM(BaseAction):
NAME = N_("Calculate BPM...")
def __init__(self):
super().__init__()
self._close = False
self.tagger.aboutToQuit.connect(self._cleanup)
def _cleanup(self):
self._close = True
def _add_file_to_queue(self, file):
settings = bpm_slider_settings[config.setting["bpm_slider_parameter"]]
thread.run_task(
partial(self._calculate_bpm, file, settings),
partial(self._calculate_bpm_callback, file))
def callback(self, objs):
for obj in objs:
if isinstance(obj, Track):
for file_ in obj.linked_files:
self._add_file_to_queue(file_)
elif isinstance(obj, File):
self._add_file_to_queue(obj)
def _calculate_bpm(self, file, settings):
self.tagger.window.set_statusbar_message(
N_('Calculating BPM for "%(filename)s"...'),
{'filename': file.filename}
)
calculated_bpm = self._get_file_bpm(file.filename, settings)
# self.tagger.log.debug('%s' % (calculated_bpm))
if self._close:
return
file.metadata["bpm"] = str(round(calculated_bpm, 1))
def _calculate_bpm_callback(self, file, result=None, error=None):
if not error:
file.update()
self.tagger.window.set_statusbar_message(
N_('BPM for "%(filename)s" successfully calculated.'),
{'filename': file.filename}
)
else:
self.tagger.window.set_statusbar_message(
N_('Could not calculate BPM for "%(filename)s".'),
{'filename': file.filename}
)
def _get_file_bpm(self, path, settings):
""" Calculate the beats per minute (bpm) of a given file.
path: path to the file
buf_size length of FFT
hop_size number of frames between two consecutive runs
samplerate sampling rate of the signal to analyze
"""
samplerate, buf_size, hop_size = settings
mediasource = source(path, samplerate, hop_size)
samplerate = mediasource.samplerate
beattracking = tempo("specdiff", buf_size, hop_size, samplerate)
# List of beats, in samples
beats = []
# Total number of frames read
total_frames = 0
while True:
if self._close:
return
samples, read = mediasource()
is_beat = beattracking(samples)
if is_beat:
this_beat = beattracking.get_last_s()
beats.append(this_beat)
total_frames += read
if read < hop_size:
break
# Convert to periods and to bpm
bpms = 60. / diff(beats)
return median(bpms)
class BPMOptionsPage(OptionsPage):
NAME = "bpm"
TITLE = "BPM"
PARENT = "plugins"
ACTIVE = True
options = [
IntOption("setting", "bpm_slider_parameter", 1)
]
def __init__(self, parent=None):
super(BPMOptionsPage, self).__init__(parent)
self.ui = Ui_BPMOptionsPage()
self.ui.setupUi(self)
self.ui.slider_parameter.valueChanged.connect(self.update_parameters)
self.update_parameters()
def load(self):
cfg = self.config.setting
self.ui.slider_parameter.setValue(cfg["bpm_slider_parameter"])
def save(self):
cfg = self.config.setting
cfg["bpm_slider_parameter"] = self.ui.slider_parameter.value()
def update_parameters(self):
val = self.ui.slider_parameter.value()
samplerate, buf_size, hop_size = [str(v) for v in
bpm_slider_settings[val]]
self.ui.samplerate_value.setText(samplerate)
self.ui.win_s_value.setText(buf_size)
self.ui.hop_s_value.setText(hop_size)
register_file_action(FileBPM())
register_options_page(BPMOptionsPage)
================================================
FILE: plugins/bpm/ui_options_bpm.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/bpm/ui_options_bpm.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_BPMOptionsPage(object):
def setupUi(self, BPMOptionsPage):
BPMOptionsPage.setObjectName("BPMOptionsPage")
BPMOptionsPage.resize(611, 273)
self.verticalLayout = QtWidgets.QVBoxLayout(BPMOptionsPage)
self.verticalLayout.setObjectName("verticalLayout")
self.bpm_options = QtWidgets.QGroupBox(BPMOptionsPage)
self.bpm_options.setObjectName("bpm_options")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.bpm_options)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.verticalWidget = QtWidgets.QWidget(self.bpm_options)
self.verticalWidget.setMaximumSize(QtCore.QSize(500, 16777215))
self.verticalWidget.setObjectName("verticalWidget")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.verticalWidget)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.slider_parameter = QtWidgets.QSlider(self.verticalWidget)
self.slider_parameter.setMinimum(1)
self.slider_parameter.setMaximum(3)
self.slider_parameter.setPageStep(1)
self.slider_parameter.setOrientation(QtCore.Qt.Horizontal)
self.slider_parameter.setTickPosition(QtWidgets.QSlider.TicksBelow)
self.slider_parameter.setTickInterval(1)
self.slider_parameter.setObjectName("slider_parameter")
self.verticalLayout_3.addWidget(self.slider_parameter)
self.slider_labels = QtWidgets.QHBoxLayout()
self.slider_labels.setSpacing(6)
self.slider_labels.setObjectName("slider_labels")
self.slider_super_fast = QtWidgets.QLabel(self.verticalWidget)
self.slider_super_fast.setLayoutDirection(QtCore.Qt.RightToLeft)
self.slider_super_fast.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignTop)
self.slider_super_fast.setObjectName("slider_super_fast")
self.slider_labels.addWidget(self.slider_super_fast)
self.slider_default = QtWidgets.QLabel(self.verticalWidget)
self.slider_default.setToolTip("")
self.slider_default.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTop|QtCore.Qt.AlignTrailing)
self.slider_default.setObjectName("slider_default")
self.slider_labels.addWidget(self.slider_default)
self.verticalLayout_3.addLayout(self.slider_labels)
self.line = QtWidgets.QFrame(self.verticalWidget)
self.line.setFrameShape(QtWidgets.QFrame.HLine)
self.line.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line.setObjectName("line")
self.verticalLayout_3.addWidget(self.line)
self.gridLayout = QtWidgets.QGridLayout()
self.gridLayout.setObjectName("gridLayout")
self.samplerate_label = QtWidgets.QLabel(self.verticalWidget)
self.samplerate_label.setObjectName("samplerate_label")
self.gridLayout.addWidget(self.samplerate_label, 2, 0, 1, 1)
self.samplerate_value = QtWidgets.QLabel(self.verticalWidget)
self.samplerate_value.setText("")
self.samplerate_value.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.samplerate_value.setObjectName("samplerate_value")
self.gridLayout.addWidget(self.samplerate_value, 2, 1, 1, 1)
self.hop_s_value = QtWidgets.QLabel(self.verticalWidget)
self.hop_s_value.setText("")
self.hop_s_value.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.hop_s_value.setObjectName("hop_s_value")
self.gridLayout.addWidget(self.hop_s_value, 1, 1, 1, 1)
self.hop_s_label = QtWidgets.QLabel(self.verticalWidget)
self.hop_s_label.setObjectName("hop_s_label")
self.gridLayout.addWidget(self.hop_s_label, 1, 0, 1, 1)
self.win_s_value = QtWidgets.QLabel(self.verticalWidget)
self.win_s_value.setText("")
self.win_s_value.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.win_s_value.setObjectName("win_s_value")
self.gridLayout.addWidget(self.win_s_value, 0, 1, 1, 1)
self.win_s_label = QtWidgets.QLabel(self.verticalWidget)
self.win_s_label.setObjectName("win_s_label")
self.gridLayout.addWidget(self.win_s_label, 0, 0, 1, 1)
self.gridLayout.setColumnStretch(0, 4)
self.verticalLayout_3.addLayout(self.gridLayout)
self.verticalLayout_2.addWidget(self.verticalWidget)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem)
self.verticalLayout.addWidget(self.bpm_options)
self.retranslateUi(BPMOptionsPage)
QtCore.QMetaObject.connectSlotsByName(BPMOptionsPage)
def retranslateUi(self, BPMOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.bpm_options.setTitle(_translate("BPMOptionsPage", "BPM Analyze Parameters:"))
self.slider_super_fast.setText(_translate("BPMOptionsPage", "Super Fast"))
self.slider_default.setText(_translate("BPMOptionsPage", "Default"))
self.samplerate_label.setText(_translate("BPMOptionsPage", "Samplerate:"))
self.hop_s_label.setText(_translate("BPMOptionsPage", "Number of frames between two consecutive runs:"))
self.win_s_label.setText(_translate("BPMOptionsPage", "Length of FFT:"))
================================================
FILE: plugins/bpm/ui_options_bpm.ui
================================================
BPMOptionsPage
0
0
611
273
-
BPM Analyze Parameters:
-
500
16777215
-
1
3
1
Qt::Horizontal
QSlider::TicksBelow
1
-
6
-
Qt::RightToLeft
Super Fast
Qt::AlignLeading|Qt::AlignLeft|Qt::AlignTop
-
Default
Qt::AlignRight|Qt::AlignTop|Qt::AlignTrailing
-
Qt::Horizontal
-
-
Samplerate:
-
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
Number of frames between two consecutive runs:
-
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
Length of FFT:
-
Qt::Vertical
20
40
================================================
FILE: plugins/classical_extras/Readme.md
================================================
# General Information
This is the documentation for version 2.0.11 of "classical\_extras". There may be beta versions later than this - check [my github site](https://github.com/MetaTunes/picard-plugins/tree/metabrainz/2.0/plugins/classical_extras) for newer releases. For further help, please review [the forum thread](https://community.metabrainz.org/t/classical-extras-2-0/394627) or post any new questions there. It only works with Picard versions 2.0 and above, **NOT** earlier versions. If you are using Picard 1.4.x, please choose the ["1.0" branch on github](https://github.com/MetaTunes/picard-plugins/tree/1.0/plugins/classical_extras) and use the latest release there - also use the [earlier forum thread](https://community.metabrainz.org/t/classical-extras-plugin/300217).
This version has only been tested with FLAC and mp3 files. It does work with m4a files, but Picard does not write all m4a tags (see further notes for iTunes users at the end of the "works and parts tab" section). "Classical Extras" populates tags and hidden variables in Picard with information from the MusicBrainz database about the recording, artists and work(s), and of any containing works, passing up through multiple work-part levels until the top is reached. The "Options" page (Options->Options->Plugins->Classical Extras) allows the user to determine how hidden variables are written to file tags, as well as a variety of other options.
This plugin is particularly designed to assist with tagging of classical music so that player or library manager software, which can display multiple work levels, different artist types and custom tags, can have access to these details.
It has two main components - "Artists" and "Works and parts" - which can be used independently or together. "Works and parts" will take at least as many seconds to process as there are works to look up (owing to MusicBrainz throttling) so users who only want the extra artist information and the tag-mapping feature, but not the work details, may turn it off (e.g. perhaps for 'popular' music). There are also two tabs - "Genres etc." and "Tag mapping" which may be used provided either "Artists" or "Works and parts" (or both) are run. Finally, an "Advanced" tab contains additional options.
Hidden metadata variables produced by this plugin are (mostly) prefixed with "\_cwp\_" or "\_cea\_" depending on which component of the plugin created them. Full details of these variables are given in a later section.
Tags are output depending on the choices specified by the user in the Options Page. Defaults are provided for these tags which can be added to / modified / deleted according to user requirements.
If the Options Page does not provide sufficient flexibility, users familiar with scripting can write Tagger Scripts to access the hidden variables directly.
## Updates
Version 2.0.11: Fix error when colons used to infer work names.
Version 2.0.10: Add hidden variable \_cwp_worktype_genres for types obtained from work (or any of its parents)
Version 2.0.9: Bug fix
Version 2.0.8: Add error trapping for certain MB database inconsistencies.
Version 2.0.7: Bug fixes for compatibility with Picard 2.2+. Ability to specify additional columns in Picard UI (see detailed notes at the end of the "Advanced" tab section). Minor enhancements.
Version 2.0.6: Fixed crash on Picard 2.2.
Version 2.0.5: Add extra error trapping for circular work references. Alpha test of release series tags if Picard provides series-rels with release lookup.
Version 2.0.4: Fix occasional regex backtracking crash. Make naming of movement tags consistent with Picard docs.
Added an option to attempt to get works and movement info from title if there are no work relationships (requires title in form "work: movement").
If Muso-specific genre processing is selected (or XML reference file is provided including classical composers) and there is no composer (because of a lack of work relationship)
then the plugin will check the listed artist against the reference list of classical composers and, if there is a match, will populate the composer metadata and set the genre to classical.
Version 2.0.3: Fix exception when references XML file does not exist
Version 2.0.2: Changed layout of tabs - the order is now Artists, Works, Genres and Tag-mapping. The help tab has been much reduced as it was of limited assistance and difficult to maintain. There is a lot of context-sensitive help and the readme file contains the latest full documentation.
Added a check-box on the genres tab to enable/disable genre filtering (previously the genre names would have to be blank to eliminate filtering and in any case this was buggy).
A general code tidy-up has led to significant performance enhancements. The only significant slowing factor is now the unavoidable MusicBrainz 1 look-up per second constraint (for looking up works).
A number of changes have been made to the way in which "extended" metadata is supplied - i.e. where title metadata is combined with the "canonical" MusicBrainz work names. Hopefully the result is a more consistent and helpful presentation. Also some minor changes to the way in which text is eliminated to arrive at part names, including a new option on the "advanced" tab to "Allow blank part names for arrangements and part recordings, if an arrangement/partial label is provided" (see documentation under the advanced tab section for more details). Plus bug fixes.
Version 2.0.1: Minor update to add _composer_lastnames variable.
Version 2.0: Major overhaul of version 0.9.4 to achieve Picard 2.0 and Python 3.7 compatibility. All webservice calls re-written for JSON rather than XmlNode responses. Periods are written to tag in date order. Addition of sub-options for inclusion of key signature information in work names. If the MB database has circular work references (i.e a parent is a descendant of itself) then these will be trapped, ignored and reported. Numerous small refinements, especially of text comparison algorithms (e.g. option to control removal of prepositions - see advanced tab). Bug fixes.
For a list of previous version changes, see the end of this document.
# Installation
Install the zip file in your plugins folder in the usual fashion.
# Usage
After installation, go to the Options Page and modify choices as required. There are 5 tabs - "Artists", "Works and parts", "Genres etc.", "Tag mapping" and "Advanced". The sections below describe each of these. If the options provided do not allow sufficient flexibility for a user's need (hopefully unlikely!) then Tagger Scripts may be used to process the hidden variables or other tags. Alternatively, it may be possible to achieve the required result by running and saving twice (or more!) with different options each time. This is not recommended for more than a one-off - a script would be better.
**Important**:
1. The plugin **will not work fully unless** "Use release relationships" and "Use track relationships" are enabled in Picard->Options->Metadata. The plugin will enable these options by default when starting Picard. However, it may be that the MusicBrainz database has conflicting data between track and release relationships, in which case you may wish to temporarily turn off one of these options, but it is better to fix the incorrect data using "Edit relationships" in MusicBrainz.
2. It is recommended only to use the plugin on one or a few release(s) at a time, particularly for initial tagging if the "Works and parts" function is being used. The plugin is not designed to do "bulk tagging" of untagged files - it may be better to use a tool such as SongKong for that and then use the plugin to enhance the results as required. However, once you have tagged files (either in Picard or another tool) such that they all have MusicBrainz IDs, you should be able to re-tag multiple releases by dragging the containing folder into Picard; this is useful to pick up changed MusicBrainz data or if you change the Classical Extras version or options (but bear in mind that the "Works and parts" function will still take at least 1 second per track.
3. **Check for error messages before saving a release**. The plugin will write out special "error message" tags which should appear prominently in the bottom Picard pane. In particular, look for "000\_major\_warning" and "001\_errors". please read the messages carefully and follow any recommended actions.
**Watch out for "002\_important\_warning" - "No file with matching trackid - IF THERE SHOULD BE ONE, TRY 'REFRESH' - (unable to process any saved options, lyrics or 'keep' tags)"; this will always occur if you load a file without MusicBrainz ids - just refresh it to pick up any existing file tags such as lyrics, if required.** This will also occur if you have manually matched files rather than used Picard's "lookup" or "scan" functions. It may also be due to Picard processing issues - more likely if the files are on a network server; if you are getting it a lot then it may be better to move the files onto local storage to do the updates.
4. If you are just changing option settings then you can usually "use cache" (see "work and parts" tab section 1) when refreshing, to avoid the 1-second per work delay. However, if the works data in MusicBrainz has been changed then obviously you will need to do a full look-up, so disable cache. If the work structure has been fundamentally changed (i.e. a different hierarchy of existing works) - either within the MusicBrainz database or by selecting/deselecting the "include collection relations", partial" or "arrangements" options - then you may need to quit and restart Picard to correctly pick up the new structure.
5. Keep a backup of your picard.ini file (C:\Users\[user name]\AppData\Roaming\MusicBrainz in Windows) in case you erase your settings or Picard crashes and loses them for you.
## Artists tab
There are five coloured sections as shown in the screen image below:

1. "Create extra artist metadata" should be selected otherwise this section will not run. This is the default.
2. "Work-artist/performer naming options".
This section deals primarily with the application of aliases and "credited as" names to replace the MusicBrainz standard names. The first box allows you to choose whether to replace MusicBrainz standard names by aliases - either for all work-artists/performers or only work-artists (writers, composers, arrangers, lyricists etc.). The second box sets the usage of "credited as" names: the first part of this lists all the places where "credited as" names can occur (really!) and the second part allows you to apply these to performing artists and/or work-artists.
Please note that, in the current version of this plugin, only aliases and "credited as" names which are in the "release XML node" are available (i.e. roughly those relating to the metadata shown in the release overview page in MusicBrainz). So, for example, if a recording is an arrangement of another work and that other work (but not the arrangement itself) has a composer linked to it, then the composer's alias will not be available (nor is the composer shown on the MB release overview page). In some cases (if appropriate) this can be remedied by adding the relevant composer relationship to the lowest-level work.
>Note regarding aliases and "credited as" names:
In a MB release, an artist can appear in one of seven contexts. Each of these is accessible in releaseXmlNode
and the track and recording contexts are also accessible in trackXmlNode.
(They are applied in sequence - e.g. track artist credit will over-ride release artist credit)
The seven contexts are:
Recording: credited-as and alias (this is applied first as it is the most general - i.e. it may apply to more than one release)
Release-group: credited-as and alias
Release: credited-as and alias
Release relationship: credited-as only (see note)
Recording relationship (direct): credited-as only (see note)
Recording relationship (via work): credited-as only (see note)
Track: credited-as and alias
Note: Aliases **may** be retrieved for "relationship" artists, but the retrieval is not reliable (MusicBrainz webservice issue)
N.B. if more than one release is loaded in Picard, any available alias names loaded so far will be available and used. However, "credited as" names will only be used from the current release. If you do not want these names to be available then you may need to restart Picard after changing the option settings (otherwise they will still be cached).
In addition to the plugin options, the main Picard options also have an effect on how 'track artists' (or any tags derived from them through tag-mapping) are displayed. In Options->Metadata, if "Translate artist names..." is selected then the alias will be used for the track artist (or failing that, a name based on the sort-name), rather than the "credited as" name. If "Use standardized artist names" is selected then neither the alias nor the "credited as" name will be used. In order to facilitate consistency, Classical Extras will save these Picard options along with its own options in specific tags (see "Advanced options" section 6).
The bottom box then (a) allows a choice as to whether aliases will over-ride "credited as" names or vice versa and (b) whether, if there are still some names in non-Latin script, these should be replaced (this will always remove middle [patronymic] names from Cyrillic-script names [but does not deal fully with other non-Latin scripts]; it is based on the sort names wherever possible).
Note that **none of this processing affects the contents of the "artist" or "album\_artist" tags, unless they are replaced by a "tag mapping" action**. These tags may be either work-artists or performing artists. Their contents are determined by the standard Picard options "translate artist names" and "use standardized artist names" in Options-->Metadata. If "translate name" is selected, the name will be the alias or (if no alias) the 'unsorted' sort-name; otherwise the name will be the MusicBrainz name if "use standardized artist names" is selected or the "credited as" name (if available) if it is not selected. Using the saved options to over-ride the displayed options has no effect on this as the processing takes place in Picard itself, not the plugin (but **over-write** will over-write all Picard and plugin options with the saved ones).
3. "Recording artist options".
In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).
Because, in classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers, by default the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadata options.
Classical Extras puts the recording artists into 'hidden variables' (as a minimum) using the chosen naming convention.
There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the 'artist', 'artists', 'artistsort' and 'artists\_sort' tags. Note that 'artist' is usually a single-valued string with a "join phrase" such as a semi-colon for multiple artists, whereas 'artists' is a list and may be multi-valued. Lists are simply merged but, because the 'artist' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s). Obviously, for classical music, if you use "merge" then the artist tag will have both the composer and the recording artists: this may be desirable for simple players (with no composer recognition) but otherwise may look odd.
Note that, if the original track artist is required in tag mapping (i.e. as it was before replacement/merge with recording artist), it is available through the hidden variable \_cea\_MB\_artists.
Note also that, if @loujin's browser script has been used to fill the recording artist data, this will be the same as the performing artists in the Recording-Artist relationship - i.e. it may be a lengthy list rather than the principal artist for the track.
4. "Other artist options":
"Modify host tags and include annotations" (Previously called "Include arrangers from all work levels"). This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag ('host' tag), with the annotation (see below) in brackets. All arranger types will also be put in a hidden variable, e.g. \_cwp\_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.
| Artist type | Host tag | Hidden variable |
| writer | composer | writers |
| lyricist | lyricist | lyricists |
| revised by | arranger | revisors |
| translator | lyricist | translators |
| arranger | arranger | arrangers |
| reconstructed by | arranger | reconstructors |
| orchestrator | arranger | orchestrators |
| instrument arranger | arranger | arrangers (with instrument type in brackets) |
| vocal arranger | arranger | arrangers (with voice type in brackets) |
| chorus master | conductor | chorusmasters |
| concertmaster | performer (with annotation as a sub-key) | leaders |
If you want to be more selective as to what is included in host tags, then disable this option and use the tag mapping section to get the data from the hidden variables. If you want to add arrangers as composers, do so in the tag mapping section also.
(Note that Picard does not normally pick up all arrangers, but that the plugin will do so, provided the "Works and parts" section is run.)
"Name album as 'Composer Last Name(s): Album Name'" will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release. MusicBrainz style is to exclude the composer name unless it is actually part of the album name, but it can be useful to add it for library organisation. The default is checked.
"Do not write 'lyricist' tag if no vocal performers". Hopefully self-evident. This applies to both the Picard 'lyricist' tag and the related internal plugin hidden variables '\_cwp\_lyricists' etc.
Note that the plugin will search for lyricists at all work levels (bottom up), but will stop after finding the first one (unless that was just a translator).
"Do not include attributes in an instrument type" (previously just referred to the attribute 'solo'). MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.
"Annotations": The chosen text will be used to annotate the artist type within the host tag (see table above for host tags), but only if "Modify host tags" is selected.
Please note that the use of the word "master" is the MusicBrainz term and is not intended to be gender-specific. Users can specify whatever text they please.
5. "Lyrics". **Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)**
Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text for a release and place it in a different tag from the text which is unique to each track.
"Split lyrics tag": enables this section.
"Incoming lyrics tag": The name of the lyrics file tag in the input file (normally just 'lyrics').
"Tag for album notes": The name of the tag where common text should be placed.
"Tag for track notes": The name of the tag where notes/lyrics unique to a track should be placed.
Note that if the 'output' tags are not specified, then internal 'hidden' variables will still be available for use in the tag-mapping section (called album\_notes and track\_notes).
## Work and parts tab
There six coloured sections as shown in the screen print below:
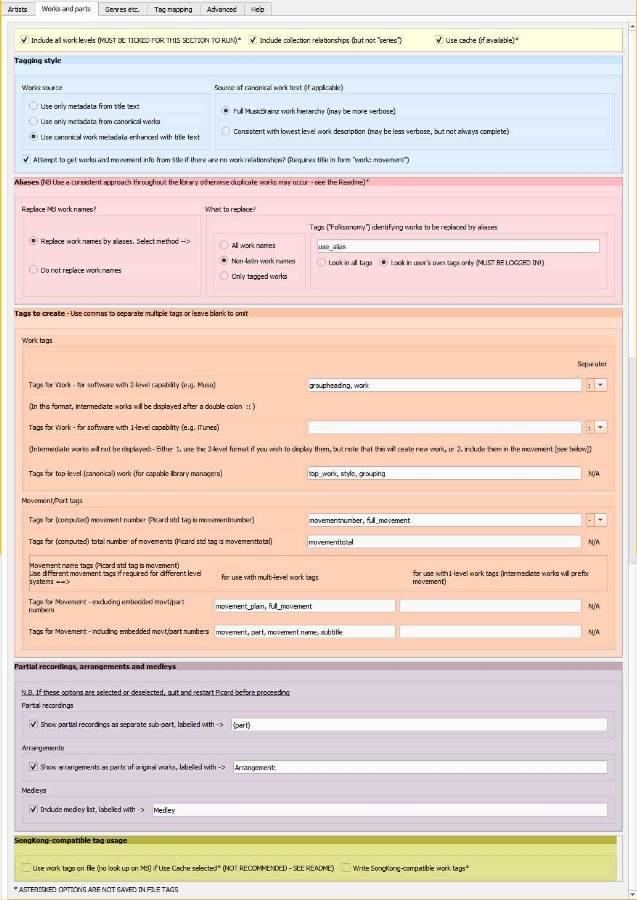
1. "Include all work levels" should be selected otherwise this section will not run. This is the default.
"Include collection relationships" (selected by default) will include parent works where the relationship has the attribute 'part of collection'. See [Discussion](https://community.metabrainz.org/t/levels-in-the-structure-of-works/293047/109) for the background to this. Note that only "work" entity types will be included, not "series" entities. If this option is changed, it will not take effect on releases already loaded in Picard - you will need to quit and restart. PLEASE BE CONSISTENT and do not use different options on albums with the same works, otherwise you may not get what you want.
"Use cache (if available)" prevents excessive look-ups of the MB database. Every look-up of a work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed. **Do not leave this option turned off** as it will make the plugin slower and may cause problems. This option will always be set on when Picard is started, regardless of how it was left when it was last closed.
2. "Tagging style". This section determines how the hierarchy of works will be sourced.
* **Works source**: There are 3 options for determing the principal source of the works metadata
- "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns, using the work structure in MusicBrainz as a guide. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
- "Use only metadata from canonical works". The names from the hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
- "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager). In this example, title text that is similar to that in the canonical text has been eliminated to make the text shorter - the mannr of doing this is controlled by settings on the Advanced tab.
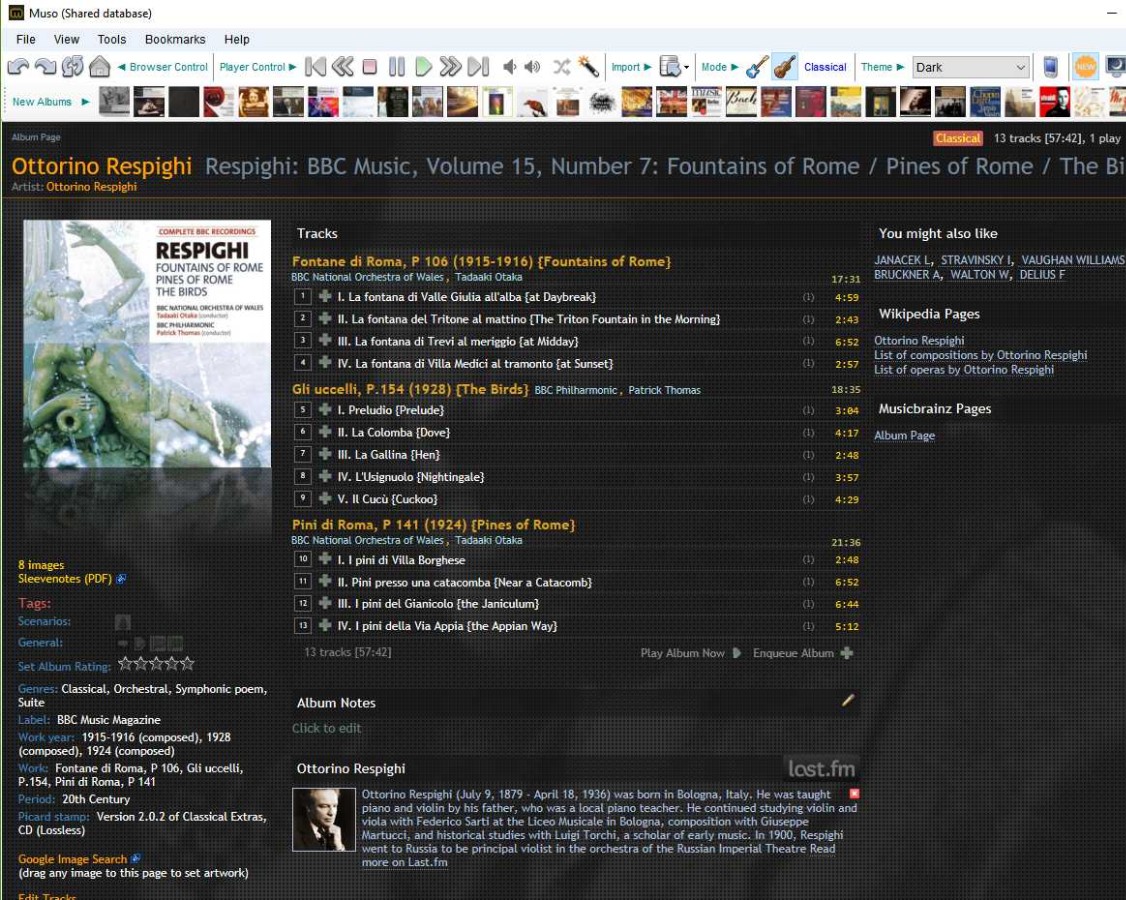
* **Source of canonical work text**. Where either of the second two options above are chosen, there is a further choice to be made:
- "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if ""Concert Fantasy for Piano and Orchestra, op. 56: I. Quasi Rondo" (level 0) is part of "Concert Fantasia, op. 56" (level 1) then that is how they will appear, since there is no repetition of text between parent and child. So, while accurate, this option might sometimes be rather verbose.
- "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. So, in the above example, "Concert Fantasy for Piano and Orchestra, op. 56" will be shown as the work and "I. Quasi Rondo" will be shown as the movement. Sometimes this may look better, but not always, **particularly if the level 0 work name does not contain all the parent work detail**. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
**Version 2.0 update**: the second option is needed less often now as there is a more sophisticated matching algorithm for the canonical work names. Text may be eliminated at places other than the start, and synonyms may be used to achieve greater matching. These options are set on the Advanced tab. Setting "Removal of common text between parent and child works" to 2 (the default) and including "Fantasia" as a synonym of "Fantasy" yields the following result:
Work: "Concert Fantasia, op. 56", Movement: "for Piano and Orchestra, … : I. Quasi Rondo"
This still repeats "for Piano and Orchestra" for each movement as this text is in level 0, not level 1 (where it only appears as disambiguation). Arguably the best way to fix this is to have consistent work names in MB. (Of course, this specific example may have been fixed in MB by now, but the principle still holds). The strategy below has been updated to reflect this
**Strategy for setting style:** *It is suggested that you start with "extended/enhanced" style and the "Full MusicBrainz work hierarchy" as the source (this is the default) and tweak the advanced settings if necessary. If this does not give acceptable results, try switching to "Consistent with lowest level work description". If the "enhanced" details in curly brackets (from the track title) give odd results then, again, try tweaking the advanced settings (see later section) or switch the style to "canonical works" only. Any remaining oddities are probably in the MusicBrainz data, which may require editing.*
* **"Attempt to get works and movement info from title if there are no work relationships? (Requires title in form "work: movement")"**.
Pretty much what it says. It may be that the track is classical, but no work relationships exist in MusicBrainz. In this case, Classical Extras will attempt to infer work and movement from the title, provided they are separated by ": " (which is the Classical Style Guideline).
In this case, the other tag style settings are irrelevant. Note that if there is no related work, then there will not be a composer metadata item in MusicBrainz. However, you can use tag mapping to set this or (better) use Muso (or and XML reference file) to determine classical composers (see Genres section).
3. "Aliases"
"Replace work names by aliases" will use **primary** aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager. The sub-options then allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be 'aliased' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone's tags ("Look in all tags") or the user's own tags. If selecting "Look in user's own tags only" you **must** be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.
4. "Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.
* **Work tags**:
- "Tags for Work - for software with 2-level capability". Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).
- "Tags for Work - for software with 1-level capability". Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).
- "Tags for top-level (canonical) work". This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable).
* **Movement/Part tags**:
(a) "Tags for (computed) movement number". This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work **on the current release**.
(For these purposes, the "parent work" is the highest level work of which the track/movement is a a part but which is not a collection)
(b) "Tags for (computed) total number of movements". This will be the total number of movements in the parent work as numbered above.
(c) "Tags for Movement - excluding embedded movt/part numbers". As below, but without the movement part/number prefix (if applicable)
(d) "Tags for Movement - including embedded movt/part numbers". This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.
For options (c) and (d), the tags can either be filled "for use with multi-level work tags" or "for use with 1-level work tags (intermediate works will prefix movement)" - or different tags for each column. The latter option will include any intermediate work levels which are missing from a single-level work tag. Use different tag names for these, from the multi-level version, otherwise both versions will be appended, creating a multi-valued tag (a warning will be given).
The default tags for (a), (b), and (c) are movementnumber, movementtotal and movement respectively - these are the standard Picard tags for these items.
Note that if a tag is included in (a) and either of (c) or (d), the movement number will be prepended at the beginning of the tag, followed by the selected separator. For more complex combinations, use the Tag Mapping tab (e.g. movementnumber + \ of + movementtotal).
If you wish to use items (a) and (b) in the tag-mapping section without populating the Picard standard tags, then use the hidden variables movt_num and movt_tot.
For more details, see the hidden variables section.
**Strategy for setting tags:** *It is suggested that initially you just use the multi-level work tag and related movement tags, even if your software only has a single-level work capability. This may result in work names being repeated in work headings, but may look better than the alternative of having work names repeated in movement names. This is the default.*
*If this does not look good you can then compare it with the alternative approach and change as required for specific releases. If your software does not have any "work" capability, then you can still get the full work details by, for example, specifying "title" as both a work and a movement tag.*
5. "Partial recordings, arrangements and medleys" gives various options where recordings are not just simply of a named complete work. These only apply if one of the two "canonical work" styles is in operation (i.e. not if "Use only metadata from title text" is selected).
* **Partial recordings**:
If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text (in the adjacent box) included in its name. Note that this text is placed at the start of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text (for "extended" style) will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2. Note that similar text between the partial work and its 'parent' will be removed which will frequently result in no text other than the specified 'partial text', unless extended metadata is used resulting in appended text in {} - this behaviour can be controlled by disabling the setting "Allow blank part names for arrangements and part recordings..." on the advanced tab.
* **Arrangements**:
If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided. Note that similar text between the arranged work and its parent will be removed unless this results in no text, in which case a stricter comparison (as for the derivation of 'part' names from works) will be used.
**Important note:** *If the Partial or Arrangement options are changed (i.e. selected/deselected) then quit and restart Picard as the work structure is fundamentally different. If the related text (only) is changed then the release can simply be refreshed.*
* **Medleys**
These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. See [Homecoming](https://musicbrainz.org/release/393913a2-7fde-4ed5-8be6-ca5c2c0ccf0d) for examples of both (tracks 8, 9 and 11). In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the **parent** work name.
6. "SongKong-compatible tag usage".
"Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, many of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. Other information, such as composed-dates will also be missing. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless you have already tagged your files with SongKong and speed is more important than quality.**
"Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data). The same caveats as those above apply.
**Note that, as from version 2.0.2, there is no significant speed difference between (basic) SongKong and Picard with Classical Extras, so this feature is only ever useful if the album has already been tagged with SongKong.**
The default for both these options is unchecked.
Note that Picard and SongKong use the tag musicbrainz\_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.
**Note for iTunes users:** *iTunes and Picard do not work well together. iTunes can display work and movement for m4a(mp4) files, but Picard does not write the movement tag. To work round this, write the movement to the "subtitle" tag assuming that is not otherwise used, and use a simple Mp3tag action to convert it to MOVEMENTNAME before importing to iTunes. If you are writing to a FLAC file which will subsequently be converted to m4a then different tag names may be required; e.g. using dBpoweramp, write the movement to "movement name". In both cases use "work" for the work. To store the top\_work, use "grouping" if writing directly to m4a, but "style" if writing to FLAC followed by dBpoweramp conversion. You can put multiple tags into the boxes described above so that your options are multi-purpose. N.B. if work tags are specified and the work has at least one level (i.e. at least work: movement), then the tag "show work movement" will be set to 1. This is used by iTunes to trigger the hierarchical display and should work both directly with m4a files and indirectly via files which are subsequently converted.*
## Genres etc. tab
This section is dependent on both the artists and workparts sections. If either of those sections are not run then this section will not operate correctly. At the very top of the tab is a checkbox "Use Muso reference database...". For [Muso](http://klarita.net/muso.html) users, selecting this enables you to use reference data for genres, composers and periods which have been entered in Muso's "Options->Classical Music" section. Regardless as to whether this is selected, there are then three main coloured sections, each with a number of subsections. The details in each section differ depending on whether the "Muso" option is selected. The screen print below shows the options assuming it is not selected (differences occurring when "Muso" is selected are discussed later):

1. "Genres". Two separate tags may be used to store genre information, a main genre tage (usually just "genre") and a sub-genre tag. These need to be specified at the top of the section. If either is left blank then the related processing will not run.
* **Source of genres**
Any or all of four sources may be selected. In each case, any values found are treated as "candidate genres" - they will only be applied to the specified genre and sub-genre tags in accordance with the criteria in the "allowed genres" section, if any (see below).
(a) "Existing file tag". The contents of the existing file tag (as specified above - main genre tag only) will be included as candidate genres. Note that, if this tag name is not "genre", then the contents of the tag "genre" will be included as well.
(b) "Folksonomy work tags". This will use the folksonomy tags for **works** (including parent works) as a possible source of genres. To use the folksonomy tags for **releases/tracks**, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) these are candidate genres, and will only be published if they match the allowed genres.
(c) "Work-type". The work-type attribute of works or parent works will be used as a candidate genre.
(d) "Infer from artist metadata". This option was on the artist tab in version 0.9.1 and prior. Owing to the additional genre processing now available, the operation of this option is slightly restricted compared to the earlier versions. It attempts to create candidate genres based on information in the artist-related tags. Values provided are:
Orchestral, Concerto, Choral, Opera, Duet,Trio, Quartet, Chamber music, Aria ('classical values') and Vocal, Song, Instrumental ('generic values'). If the track is a recorded work and the track artist is the composer (i.e. MusicBrainz 'classical style'), the candidate genre values will also include "Classical". The 'classical values' will only be included as candidate genres if the track is deemed to be 'classical' by some part of the genre processing section.
* **Allowed genres**
A check-box (ticked by default) enables this section. If it is unchecked, then no genre filtering is applied - all 'candidate genres' will be written to the genre tab.
Four boxes are provided for lists of genres which are "allowed" to appear in the specified tags. Each list should be comma-separated (and no commas in any genre name). Candidate genres matching those in a "main genre" box will be added to the specified main genre tag. Similarly for sub-genres. If a candidate genre matches a 'classical genre' (in one of the top two boxes), then the track will be deemed to be "Classical" (see next part for more details).
You may also enter a genre name to be used if no matching main genre is found (otherwise the tag will be blank).
* **"Classical" genre**
Normally (i.e. by default) a work will only be deemed to be 'classical' if it is inferred from the MusicBrainz style (see "source of genres") or if a candidate genre matches a "Classical" genre or sub-genre list. However, you may select that all tracks are 'classical' regardless. There is also an option to exclude the word "Classical" from any genre tag, but still treat the work as classical. If a work is deemed to be classical, a tag may be written with a specified value as set out in the last two boxes of this section. For example, to be consistent with SonKong/Jaikoz, you could set "is\_classical" to "1".
2. "Instruments and keys".
* **Instruments**
Specify the tag name you wish instrument names to appear in. Instruments will be sourced from performer relationships. Instrument names may either be the standard MusicBrainz names or the "credited as" names in the performer relationship, or both. Vocal types are treated similarly to instruments. (Note that, in v0.9.1 and prior, instruments were written to the same tag as inferred genres. If you wish to continue this, then you may use the same tag name here as for the genre tag.)
* **Keys**
Specify the tag name in which you wish the key signatures of works to appear. Keys will be obtained from all work levels (assuming these have been looked up): for example, Dvořák's Largo From the New World will be shown as D♭ major, C# minor (the main keys of the movement) and E minor (the home key of the overall work).
"Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák's New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)". The default sub-option is to only add these details if the key signature is missing from the work title (other sub-options are to never or to always include the information.
3. "Periods and dates".
* **Work dates**
Specify the tag name to hold work dates. Work dates will be given as a "year" value only, e.g. "1808" or a range: "1808-1810". The sources of these dates is specified in the next part. If the movement has a composed date(s), this will be used, otherwise the the dates from the parent work will be used (if available).
"Source of work dates". Select which sources to use - from composed, published and premiered, then decide whether to use them in preferential order (e.g. if "composed date" exists, then the others will not be used) or to show them all.
"Include workdate in work name ..." operates analogously to "Include key(s) in work names" described above. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).
* **Periods**
This section will use work dates, where available, to determine the "classical period" to which it belongs, by means of a "period map" (Muso users can also use composer dates - see below).
Specify the tag name to hold the period data. The period map should then be entered in the format "Period name, Start\_year, End\_year; Period name2, Start\_year, End\_year;" etc. Periods may overlap. Do not use commas or semi-colons within period names. Start and end years must be integers.
## Genres etc. tab - Muso-specific processing
Users of [Muso](http://klarita.net/muso.html) have additional capabilities, illustrated in the following screen, which appear when the option "Use Muso reference database ..." is selected at the top of the tab.
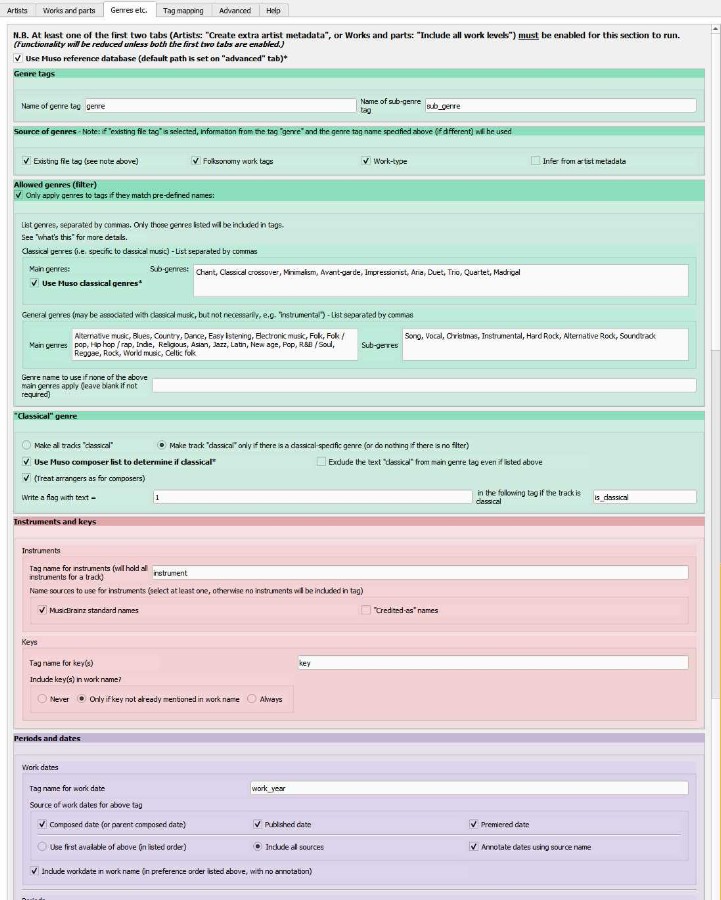
For these options to work, the path/name of the Muso reference database needs to be specified on the advanced tab. The default path is "C:\\Users\\Public\\Music\\muso\\database" and the default filename is "Reference.xml". The additional options are as follows.
1. "Use Muso classical genres". If this is selected, the box for classical main genres is eliminated and the genre list from Muso's "Tools->Options->Classical Music->Classical Music Genres" is used instead.
2. "Use Muso composer list to determine if classical". If the composer name is in Muso's list "Tools->Options->Classical Music->Composer Roster", then the work will be deemed to be classical. If this option is selected, a further option appears to "Treat arrangers as for composers" - if selected then arrangers will also be looked up in the roster.
3. "Use Muso composer dates (if no work date) to determine period". The birth date + 20 -> death dates of Muso's composer roster will be used to assign periods if no work date is available. If this option is selected, a further option appears to "Treat arrangers as for composers" - if selected then arrangers' working lives will also be used to determine periods.
(This might be replaced / supplemented by MusicBrainz in the future, but would involve another 1-second lookup per composer).
4. "Use Muso map". Replace the period map with the one in Muso at "Tools->Options->Classical Music->Classical Music Periods"
Note that non-Muso users may also use this functionality, if they wish, by manually creating a reference xml file with the relevant tags, e.g.:
Cantata
Max REGER
1873
1916
Early Romantic
1800
1850
If the Muso reference (or XML) database is selected (which includes a classical composers list) and there is no composer for the track (because of a lack of work relationship)
then the plugin will check the listed artist against the reference list of classical composers and, if there is a match, will populate the composer metadata and
(if "use Muso composer list to determine if classical" is selected) will set the genre to classical.
## Tag mapping tab
There are two coloured sections as shown in the screen image below:
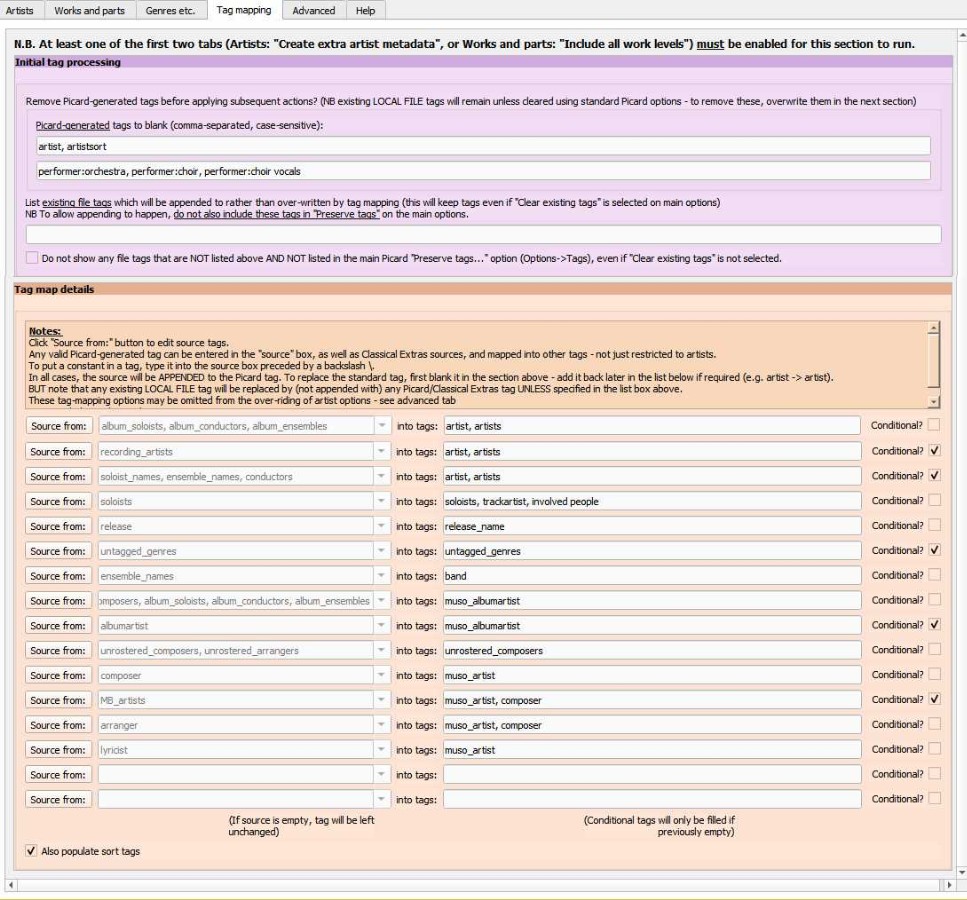
Note that either the "Create extra artist metadata" option on the Artist tab or "Include all work levels" on the Works tab needs to be selected for these sections to run.
1. "Initial tag processing": This takes place before any of the detailed tag mapping in the second section.
"Remove Picard-generated tags before applying subsequent actions?". Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.
"List existing file tags which will be appended ...": This refers to the tags which already exist on files which have been matched to MusicBrainz, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if 'Clear existing tags' is specified in the main Options->Tags screen) or keep them (if 'Preserve these tags...' is specified after the 'Clear existing tags' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below) or otherwise used. List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular "is\_classical" (which is set by SongKong to '1' if the track is deemed to be classical, based on an extensive database) is used to add 'classical' to the variable "\_cea\_worktype", if "Infer work types" is selected in the first section of the Artists tab. If you include "is\_classical" in this list then any files which have "is\_classical" = 1 will be treated as being classical, regardless of the genre tag.
**Make sure that any tags listed here are not also included in Picard's "Preserve .. tags.." option, otherwise Picard will prevent the tag from being amended**
Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the "...existing file tags..." list and does not need to be added in this section.
"Clear any previous file tags...": This operates in an almost similar way to the main Picard option (Options->Tags->"Clear existing tags"). All existing file tags will be cleared **unless** they are in the main Picard "Preserve tags..." option or the "...existing file tags..." list. The main differences from the basic Picard option are that (a) artwork is always preserved - i.e. this largely addresses [PICARD-257](https://tickets.metabrainz.org/browse/PICARD-257) and (b) the tags that are not kept are **not actually deleted or shown as deleted** in the bottom pane of Picard. They are just not displayed in the bottom pane - however, a warning tag is written.
2. "Tag map details". This section permits the contents of any hidden variable or tag to be written to one or more tags.
* **Sources**:
Some of the most useful sources are available from the drop-down list. Otherwise they can simply be typed in the box. Click on the "source from" button to enable entry (otherwise the text box / drop-down for the source is locked). Some useful names are:
- soloists : List of performers (with instruments in brackets), who are NOT ensembles or conductors, separated by semi-colons. Note they may not strictly be "soloists" in that they may be part of an ensemble.
- soloist\_names : Names of the above (i.e. no instruments).
- vocalists / instrumentalists / other\_soloists : Soloists who are vocalists, instrumentalists or not specified, respectively.
- vocalist\_names / instrumentalist\_names : Names of vocalists / instrumentalists (i.e. no instrument / voice).
- ensembles : List of performers who are ensembles (with type / instruments - e.g. "orchestra" - in brackets), separated by semi-colons.
- ensemble\_names : Names of the above (i.e. no instruments).
- album\_soloists : Sub-list of soloist\_names who are also album artists.
- album\_conductors : List of conductors who are also album artists.
- album\_ensembles: Sub-list of ensemble\_names who are also album artists.
- album\_composers : List of composers who are also album artists.
- album\_composer\_lastnames : Last names of composers, of ANY track on the album, who are also album artists. This is the source used to prefix the album name (when that option is selected).
- support\_performers : Sub-list of soloist\_names who are NOT album artists.
- composers : List of composers, after applying the naming options in the artists tab.
- conductors : List of conductors, after applying the naming options in the artists tab.
- arrangers : Includes all arrangers and instrument arrangers (except more specific roles such as orchestrators) - the standard Picard tag omits some.
- orchestrators : Arrangers who are orchestrators.
- leaders : AKA concertmasters.
- chorusmasters : as distinct from conductors (chorus masters may rehearse the choir but not conduct the performance).
Note that the Classical Extras sources for all artist types are spelled in the plural (to differentiate from the native Picard tags). Most of the names are for artist data and are sourced from hidden variables (prefixed with "\_cea\_" or "\_cwp\_"). In specifying the source, the prefix is not necessary - e.g. "arrangers" will pick up all data in \_cea\_arrangers and \_cwp\_arrangers (covering those with recording and work relationships respectively). Using the prefix will get just the specific variable.
In addition, the drop-down contains some typical combinations of multiple sources (see note on multiple sources below).
Any Picard tag names can also be typed in as sources. Any hidden variables may also be used. Any source names which are prefixed by a backslash will be treated as string constants; blanks may also be used.
It is possible to specify multiple sources. If these are separated by a comma, then each will be appended to the mapped tag(s) (if not already filled or if not "conditional"). So, for example, a source of "album\_soloists, album\_conductors, album\_ensembles" mapped to a tag of "artist" with "conditional" ticked will fill artist (if blanked) by album\_soloists, if any, otherwise album\_conductors etc. Sources separated by a + will be concatenated before being used to fill the mapped tags. The concatenated result **will only be applied if the contents of each of the sources to be concatenated is non-blank** (note that this constraint only applies to **concatenation** of multiple sources). No spaces will be added on concatenation, so these have to be added explicitly by concatenating "\ ". So, for example "ensemble\_names + \ (conducted by + conductors +\\), ensemble\_names", with "Conditional" selected, will yield something like "BBC Symphony Orchestra (conducted by Walter Weller)" or just "BBC Symphony Orchestra" if there is no conductor. **Do not use any commas in text strings**.
Another example: to add the leader's name in brackets to the tag with the performing orchestra, put "\\ (leader +leaders+\\)" in the source box and the tag containing the orchestra in the tag box. If there is no leader, the text will not be appended.
The tag mapping section is not restricted to artist metadata - any metadata or hidden variablescan be used.
* **Tags**:
Enter the (comma-separated) "destination" tag names into which the sources should be written (case sensitive). Note that this will result in the source data being APPENDED in the tag - it will not overwrite the existing contents. Check "Conditional?" if the tag is only to be updated if it is previously blank (all non-empty sources in the current line will be applied in sequence). The lines will be applied in the order shown. Users should be able to achieve most requirements via a combination of blanking tags, using the right source order and "conditional" flags. For example, to overwrite a tag sourced from "composer" with "conductor", specify "conductor" first, then "composer" as conditional. Note that, for example, to demote the MB-supplied artist to only appear if no other listed choices are present, blank the artist tag and then add it as a conditional source at the end of the list.
* **"Also populate sort tags"**:
If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Picard also writes hidden variables '\_artists\_sort' and 'albumartists\_sort' (note the plurals - these are the sort tags for multi-valued alternatives 'artists' and '\_albumartists'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. '\_arranger\_sort'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. '\_cwp\_librettists' has a matching sort variable '\_cwp\_librettists\_sort'. Therefore most artist-type sources **will** have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected - **in other words, selecting this option will cause most destination tags to have associated sort tags. Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags** (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble\_names + \; + conductors") do not have sort tags associated with them.
If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map 'conductors\_sort' to 'conductor\_sort'.
More complex operations can be built using tagger scripts. If required, these can be set to run conditionally by setting a tag or hidden variable in this section and then testing it in the script.
## Advanced tab
Hopefully, this tab should not be much used. In any case, it should not need to be changed frequently. There are six main sections as shown in the screeen print below:
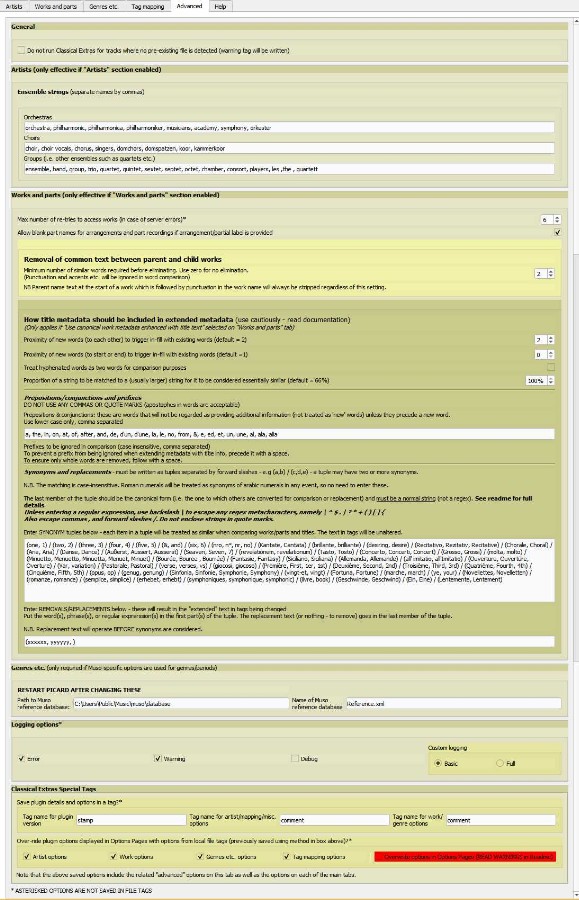
1. "General". There is only one checkbox - "Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)". This option will disable Classical Extras processing if no file is present; this means (for example) that single discs from box sets can be loaded without incurring the additional processing overhead (work look-ups etc.) for all the other discs. Also if a compilation album is loaded, where the tracks are on multiple releases, the plugin will only process the release tracks which match. If a file is present but it does not yet have a MusicBrainz trackid tag, then it will initially be treated in the same way as a non-existent file; however, after the initial loading it will (if matched by Picard) be given a MB trackid and "refreshing" the release will result in any such tracks being processed by Classical Extras, while the unmatched tracks are left untouched.
2. "Artists". This has only one subsection - "Ensemble strings" - which permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags.
If it is important that only whole words are to be matched, be sure to include a space after the string.
3. "Works and parts". This section has parameters applicable to the "works and parts" functions.
* **Max number of re-tries to access works (in case of server errors)**. Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable \_cwp\_error will be set with a message; if error logging is checked in section 5, an error message will be written to the log and the contents of \_cwp\_error will be written out to a special tag called "001\_errors" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.
* **Allow blank part names for arrangements and part recordings, if an arrangement/partial label is provided**. The default is checked (true) - in which case where an arrangement has the same name as the original work, the part will just show the arrangement/partial label (e.g. "Arrangement:"). If the option is blank (false), there will be text for the part name (which may be the same name as the parent work). Note that if "extended" metadata is being used, then blank part names will always have the title metadata added {in curly brackets} regardless of whether it is similar to the canonical part name.
* **Removal of common text between parent and child works**. This section controls the naming of parts, by stripping parent text from the work name. If the work begins with the parent name followed by punctuation then the common text will always be stripped to give the part name, even if there are punctuation or some other minor differences (synonyms will also be matched using the patterns in the next section).
However, common text which is not followed by punctuation or which is not at the start may also be stripped: to prevent this, set "Minimum number of similar words required before eliminating (other than at start)" to zero. Otherwise common text longer than the specified number of words (default = 2) will be stripped. (Note that this minimum is over-ridden by the previous option - i.e. if a smaller number of words than the minimum could be eliminated and would result in a blank part name, and that is allowed by the previous option, then the words will be removed).
* **How title metadata should be included in extended metadata**. This subsection contains various parameters affecting the processing of strings in titles, where these are used to "extend" the text in work names. This is generally only relevant if "Use canonical work metadata enhanced with title text" is selected on the "Works and parts" tab, although the "prefixes" section is also relevant if "Use only metadata from title text" is selected and the synonyms are also used in eliminating parent-child duplication as described above. Because titles are free-form, not all circumstances can be anticipated. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should largely be irrelevant, but no text from titles will be included. Some explanations are given below:
* "Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words in the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the start/end) included even if they repeat words in the work name.
* "Treat hyphenated words as two words for comparison purposes" (default = True). In comparing words, hyphenated words will be considered as separate words unless this option is deselected.
* "Proportion of a string to be matched ... for it to be considered essentially similar..." (default = 66%). If the title and work descriptions are largely the same then the title text will not be used to extend the work text, even if there are some new words.
* "Prepositions and conjunctions". Words listed here will not generally be treated as "new" (i.e. if they are in the title text but not in the work text, they will not be included in the "extended" text) unless they precede a new word which is not itself a preposition. Note that, although the term "preposition" is used here, because that is the obvious usage, any word can be listed. A group of more than one such words will be treated as new if they are not in the work text and they precede a new word which is not listed as a preposition.
* "Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomalies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" is repeated and so will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.
* "Synonyms". These words/phrases will be considered equivalent when comparing work name and title text (or parent and child text). Thus if one word/phrase appears in the work name, it and its synonyms will be removed from the title in extending the metadata (subject to the proximity setting above). Each entry should be a tuple in the form *(key word/phrase, ..., equivalent word/phrase)* - no quote marks are necessary. Each tuple should be separated by a forward slash - /. Tuples may contain multiple synonyms - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered. Spaces and punctuation are permitted, as are regular expressions, but unless entering regex, use backslash \ to escape any regex metacharacters \ ^ $ . | ? * + ( ) [ ] {
Also escape commas , and forward slashes /. Do not enclose strings in quote marks. The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison) and must be a normal string (not a regex). The sequence of synonyms within a tuple may be important, particularly if one synonym is a subset of another - always list the longer one first, as the matching will proceed in the listed order. Thus if "nro" and "nr" are synonyms of "no", then list them thus: (nro, nr, no). This will ensure that "nro" gets matched to "nro" and not to "nr".
* "Replacements". These are entered in a similar fashion to synonyms. The difference is that the last item in a tuple will be used to replace any text in earlier items in the tuple. This last element may also be left blank (after the preceding comma) in order to remove any text matching any of the earlier items.
4. "Genres etc. ...". This is only required if Muso-specific options are used for genres/periods. Specify the path and file name for the reference database (the default is the Muso default for a shared database). Note that the database is only loaded when Picard starts so you will need to restart Picard is these options are changed.
5. "Logging options". These options are in addition to the options chosen in Picard's "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown in the Picard log, the flag needs to be set here and "Debug mode" needs to be turned on in the log. **It is strongly advised to keep the "debug" flag unchecked unless debugging is required** as it slows up processing and may even cause Picard to hang if there is a large number of files (better to use the 'full' custom logging option - see below). The "error" and "warning" flags should be left checked, unless it is required to suppress messages (the messages are also written to the tags 001\_errors and 002\_warnings).
As well as the main Picard log, a custom logging function is provided. This may be either "basic" or "full". If "basic" is selected, a file "session.log" will be written (over-written each session) to a "Classical Extras" directory inside the same directory as the plugins folder. (Note - the easy way to find this directory is to select options-->plugins in Picard and the "Open plugins folder" button, then go up one level). The session log gives a processing summary for each release and includes errors, warnings and debug messages if those options have been selected.
If "full" is selected, all errors, warnings and debugs will be written, along with additional debugging messages, to a custom log file for each release processed. These files are stored in the "Classical Extras" directory inside the same directory as the plugins folder. The log file for a release is named using the release MBID. Debugging from these files requires an understanding of the source code.
Selecting "full" will slow Picard, but should not normally result in hanging or crashing.
6. "Classical Extras Special Tags". This has a number of subsections:
*"Save plugin details and options in a tag?"* can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag. All the options in the Classical Extras UI are saved **except** those which are asterisked.
The tag contents are in dict format. The options in these tags can then be used to over-ride the displayed options subsequently (see below).
N.B. The "Tag name for artist/misc. options" also saves the Picard options for 'translate\_artist\_names' and 'standardize\_artists' as these interact with the Classical Extras options.
*"Over-ride plugin options displayed in UI with options from local file tags"*. If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride.
***Note that* *very occasionally (if the tag containing the options has been corrupted) use of this option may cause an error. In such a case you will need to deselect the "over-ride" option and set the required options manually; then save the resulting tags and the corrupted tag should be over-written***
*"Overwrite options in Options Pages"*, is for **VERY CAREFUL USE ONLY**. It will cause any options read from the saved tags to over-write the options on the plugin Options Page UI. (Note that it will only operate if all the "Over-ride plugin options..." boxes are checked as well.) The intended use of this is if for some reason the user's preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, and will always be turned off when starting Picard, to prevent inadvertant use. Far better is to make a **backup copy** of the picard.ini file.
*Additional section added in v2.0.7 "Show additional tags in Picard UI"*. This enables display of any tags as columns in the Picard right-hand panel. Also tags (or groups of tags) which are different from file tags can be flagged - see the screen copy below:
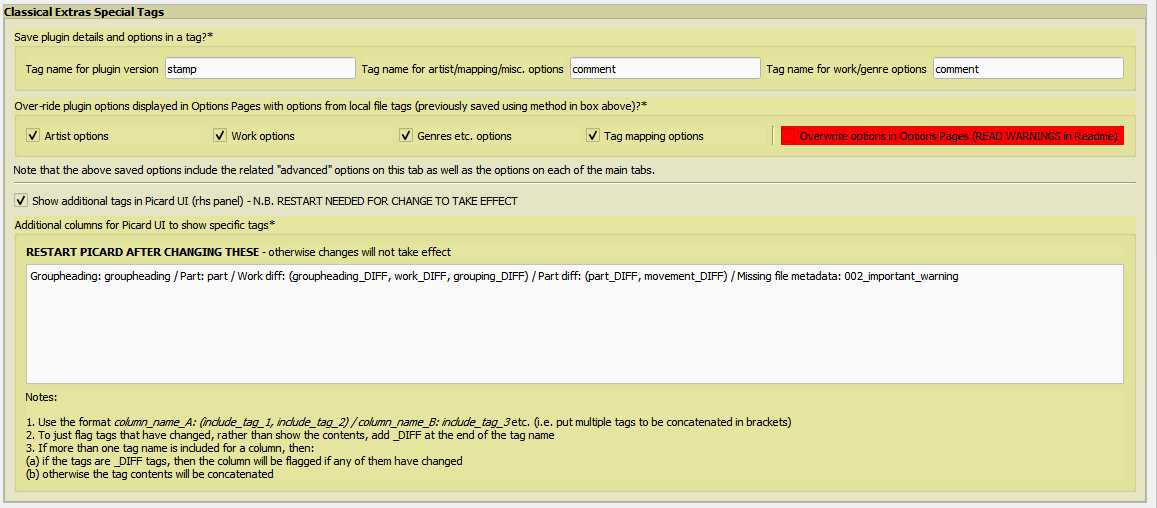
Follow the instructions on the screen to enter the options. Then, if you right-click on the column headings in the right-hand panel of Picard, you should see all the options listed from which you can select which columns to show.
# Information on hidden variables
This section is for users who want to write their own scripts, or add additional tags (in the tag mapping section) based on hidden variables. The definition and source of each hidden variable is listed. Apologies if there are errors and omissions in this section - to double check the actual hidden variables for any track, use the plugin "View script variables".
## Works and parts
- \_cwp\_work\_n, where n is an integer >=0 : The MB work name at level n. For n=0, the tag is the same as the current standard Picard tag "work"
- \_cwp\_work\_top : The top work name (i.e. for maximal n). Thus, if max n = N, \_cwp\_work\_top will be equivalent to \_cwp\_work\_N. Note, however, that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added (whereas they will be added to \_cwp\_work\_N). Nevertheless, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.
- \_cwp\_workid\_n : The matching work id for each work name. For n=0, the tag is the same as the standard Picard tag "MusicBrainz Work Id"
- \_cwp\_workid\_top : The matching work id for the top work name.
- \_cwp\_part\_n : A "stripped" version of \_cwp\_work\_n, where higher-level work text has been removed wherever possible, to avoid duplication on display.
Thus in theory, \_cwp\_work\_0 will be the same as "\_cwp\_work\_top: \_cwp\_part\_(N-1): ...: \_cwp\_part\_0" (punctuation excepted), but may differ in more complex situations where there is not an exact hierarchy of text as the work levels are traversed. (See below for the "\_X0" series which attempts to address any such inconsistencies)
- \_cwp\_part\_levels : The number of work levels attached to THIS TRACK. Should be equal to N = max(n) referred to above.
- \_cwp\_work\_part\_levels : The maximum number of levels for ANY TRACK in the album which has the same top work as this track.
- \_cwp\_single\_work\_album : A flag = 1 if there is only one top work in this album, else = 0.?
- \_cwp\_work : the level selected by the plugin to be the source of the single-level work name if "Use only metadata from canonical works" is selected (usually the top level, but one lower in the case of a single work album).
- \_cwp\_groupheading : the level selected by the plugin to be the source of the multi-level work name if "Use only metadata from canonical works" is selected.
- \_cwp\_part : The movement name derived from the MB work names (generally = \_cwp\_part\_0) and used as the source for the movement name used for "Tags for Movement - including embedded movt/part numbers".
- \_cwp\_inter\_work : Intermediate works between \_cwp\_part and \_cwp\_work (if any).
- \_cwp\_movt\_num : The number sequence of the movement track within its parent **on the current release** (see more details below).
- \_cwp\_movt\_tot : The total number of movement tracks for the parent (see more details below).
If there is more than one work any level, then \_cwp\_work\_n and \_cwp\_workid\_n will have multiple entries. Another common situation is that a "bottom level" work is spread across more than one track. Rather than artificially split the work into sub-parts, this is often shown in MusicBrainz as a track being a "partial recording of" a work. The plugin deals with this by creating a notional lowest-level with the suffix " (part)" (or other text as defined in the works and parts options tab) appended to the work it is a partial recording of. In order that this notional part can be separately identified from the full work, the musicbrainz\_recordingid is used as the identifier rather than the workid.
If there is more than one "parent" work of a lower level work, multi-valued tags are generated.
Note regarding movement numbers:
- All movements will be considered as a part of the largest grouping (on a release) to which they belong, other than as “part of collection”
- They will be numbered in the sequence in which they appear on the release
- If a track comprises more than one movement, they will be treated as one for these purposes
- If a movement is split over more than one track, then each will get a separate movement number
- One-movement works will not receive a movement number unless the movement is split over multiple tracks
- The movementtotal tag will be the total number of movements for the aforesaid grouping
- If a movement grouping is split on a release by other tracks (not part of the grouping) then they will be treated as a whole and the numbering will resume where it left off.
Items based on level 0 work data:
- \_cwp\_X0\_part\_0 : A "stripped" version of \_cwp\_work\_0 (see above), where elements of \_cwp\_work\_0 which repeat within level 1 have been stripped.
- \_cwp\_X0\_work\_n : The elements of \_cwp\_work\_0 which repeat within level n
As well as variables derived from MB's work structure, some variables are produced which are derived from the track title. Typically titles may be in the format "Work: Movement", but not always. Sometimes the title is prefixed by the name of the composer; in this case the variable
- \_cwp\_title
is provided which excludes the composer name and subsequent processing is carried out using this rather than the full title.
The plugin uses a number of methods attempt to extract the works and movement from the title. The resulting variables are:
- \_cwp\_title\_work\_n, and
- \_cwp\_title\_part\_n
which mirror those for the ones based on MB works described above.
- \_cwp\_title\_part\_levels which similarly mirrors \_cwp\_part\_levels
- \_cwp\_title\_work\_levels which similarly mirrors \_cwp\_work\_part\_levels
- \_cwp\_title\_work is the level selected by the plugin to be the source of the single-level work name if "Use only metadata from title text" is selected (usually the top level, but one lower in the case of a single work album).
- \_cwp\_title\_groupheading is similarly the level selected by the plugin to be the source of the multi-level work name if "Use only metadata from title text" is selected.
- \_cwp\_extended\_part : = \_cwp\_part with additional movement information from the title - given in {}.
- \_cwp\_extended\_groupheading : = \_cwp\_groupheading with additional work information from the title - given in {}.
- \_cwp\_extended\_work : = \_cwp\_work with additional work information from the title - given in {}.
- \_cwp\_extended\_inter\_work : = \_cwp\_inter\_work with additional work information from the title - given in {}.
The "extended" variables can be useful where the "canonical" work names in MB are in the original language and the titles are in English (say). Various heuristics are used to try and add (and only add) meaningful additional information, but oddities may occur which require manual editing.
Artist tags which derive from work-artist relationships are also set in this section:
- \_cwp\_composers & \_cwp_composers_sort
- \_cwp\_composer_lastnames
- \_cwp\_writers & \_cwp_writers_sort
- \_cwp\_arrangers : This is for arrangers of the work and also "instrument arrangers" and "vocal arrangers" with appropriate annotation for instrument and voice types. (Picard does not currently write the latter to the Arranger tag if they are part of the work-artists relationship, despite style guidance saying to use specific instrument types instead of generic arranger.)
- \_cwp\_arranger\_names & \_cwp_arrangers_sort: Just the names of the above (no annotations)
- \_cwp\_orchestrators & \_cwp_orchestrators_sort
- \_cwp\_reconstructors & \_cwp_reconstructors _sort - 'reconstructed by' relationships
- \_cwp\_revisors & \_cwp_revisors _sort - 'revised by' relationships
- \_cwp\_lyricists & \_cwp_lyricists _sort
- \_cwp\_librettists & \_cwp_librettists _sort
- \_cwp\_translators & \_cwp_translators _sort
Finally, the tags \_cwp\_error and\_cwp\_warning are provided to supply warnings and error messages to the user.
## Artists
All the additional hidden variables for artists written by Classical Extras are prefixed by \_cea\_. Note that these are generally in the plural, whereas the standard tags are singular. If the user blanks a tag then the original value is stored in the singular with the \_cea\_ prefix. Thus \_cea\_arranger would be the contents of the Picard tag "arranger" before blanking, whereas \_cea\_arrangers is hidden variable created by Classical Extras.
- \_cea\_recording\_artist : The artist credited with the recording (not necessarily the track artist). Note that this is the only "\_cea\_" tag which is singular, because it is in the same format as the 'artist' tag, whereas...
- \_cea\_recording\_artists : The list/multiple value version of the above. (This follows the approach in Picard for 'artist' and 'artists', being the track artists.)
- \_cea\_MB\_artists: The original track artists per MusicBrainz before any replacement by / merging with recording artists.
- \_cea\_soloists : List of performers (with instruments in brackets), who are NOT ensembles or conductors, separated by semi-colons. Note they may not strictly be "soloists" in that they may be part of an ensemble.
- \_cea\_recording\_artistsort : Sort names of \_cea\_recording\_artist
- \_cea\_recording\_artists\_sort : Sort names of \_cea\_recording\_artists
- \_cea\_soloist\_names : Names of the soloists (i.e. no instruments).
- \_cea\_soloists\_sort : Sort\_names of the above.
- \_cea\_vocalists : Soloists who are vocalists (with voice in brackets).
- \_cea\_vocalist\_names : Names of the above (no voice).
- \_cea\_instrumentalists : Soloists who have instruments but are not vocalists.
- \_cea\_instrumentalist\_names : Names of the above (no instrument).
- \_cea\_other\_soloists : Soloists who do not have specified instrument/voice.
- \_cea\_ensembles : List of performers which are ensembles (with type / instruments - e.g. "orchestra" - in brackets), separated by semi-colons.
- \_cea\_ensemble\_names : Names of the above (i.e. no instruments).
- \_cea\_ensembles\_sort : Sort\_names of the above.
- \_cea\_album\_soloists : Sub-list of soloist\_names who are also album artists
- \_cea\_album\_soloists\_sort : Sort\_names of the above.
- \_cea\_album\_conductors : List of conductors who are also album artists
- \_cea\_album\_conductors\_sort : Sort\_names of the above.
- \_cea\_album\_ensembles: Sub-list of ensemble\_names who are also album artists
- \_cea\_album\_ensembles\_sort : Sort\_names of the above.
- \_cea\_album\_composers : List of composers who are also album artists
- \_cea\_album\_composers\_sort : Sort\_names of the above.
- \_cea\_album\_track\_composer\_lastnames : Last names of the above. (N.B. This only includes the composers of the current track - compare with \_cea\_album\_composer\_lastnames below).
- \_cea\_album\_composer\_lastnames : Last names of composers of ANY track on the album who are also album artists. This can be used to prefix the album name if required. (cf \_cea\_album\_track\_composer\_lastnames)
- \_cea\_support\_performers : Sub-list of soloist\_names who are NOT album artists
- \_cea\_support\_performers\_sort : Sort\_names of the above.
- \_cea\_composers : Alternative to 'composer', incorporating 'naming options' on the artists tab.
- \_cea\_composer_lastnames: Last names of above.
- \_cea\_conductors : Alternative to 'conductor', incorporating 'naming options' on the artists tab.
- \_cea\_performers : Alternative to 'performer', incorporating 'naming options' on the artists tab.
- \_cea\_arrangers : All arrangers for the **recording** with instrument/voice type in brackets, if provided. If the work and parts functionality has also been selected, the arrangers of works, which Picard also currently omits will be put in \_cwp\_arrangers.
- \_cea\_orchestrators : Arrangers (per Picard) included in the MB database as type "orchestrator".
- \_cea\_chorusmasters : A person who (per Picard) is a conductor, but is "chorus master" in the MB database (i.e. not necessarily conducting the performance).
- \_cea\_leaders : The leader of the orchestra ("concertmaster" in MusicBrainz) - not created by Picard as standard.
## Genres etc.
Most of the genres, keys and date information requires the works and parts section to have been run, and so the variables are prefixed \_cwp\_, but instruments and genres which are derived from artist information and are prefixed \_cea\_.
- \_cea\_instruments : Names of all instruments on the track (MusicBrainz names)
- \_cea\_instuments\_credited : As above, but MB names replaced by as-credited names, if any
- \_cea\_instruments\_all : MB and as-credited names
- \_cea\_work\_type : The genre(s) inferred from artist information
- \_cea\_work\_type\_if\_classical : As above, but only of relevance if the work is classical
- \_cwp\_candidate\_genres : List of all tags, work types etc. found (depending on specified sources) before filtering for "allowed" genres.
- \_cwp_worktype_genres : Any "type" attribute for the work or any of its parents.
- \_cwp\_keys : keys associated with this track (from all work levels).
- \_cwp\_composed\_dates : Date composed (integer) or range (integer-integer).
- \_cwp\_published\_dates : Date published (integer) or range (integer-integer).
- \_cwp\_premiered\_dates : Date premiered (integer) or range (integer-integer).
- \_cwp\_untagged\_genres : Genres in \_cwp\_candidate\_genres which have been filtered out as they are not in any "allowed" list.
- \_cwp\_unrostered\_composers : For Muso users: composers who are not in Muso's classical composers roster.
## Special tags for ui
A number of hidden variables are created (v.2.0.7+) as part of the processing for the additional tags for the UI as described at the end of the "Advanced" tab section. The ones of the form \_tagname_OLD hold the previous value of the tag 'tagname' on the file. The ones of the form \_tagname_DIFF hold a flag '*****' if the value of 'tagname' has changed from the previous one on file (only for tags specified on the options page). The ones of the form \_columnheading_VAL hold the values to be displayed in the column 'columnheading' as specified in the options.
# Software-specific notes
Note that \_cwp\_part\_levels > 0 will indicate that the track recording is part of a work and so could be used to set other software-specific flags (e.g. for iTunes "show work movement") to indicate a multi-level "work: movement".
## SongKong
SongKong users may wish to map the \_cwp variables to tags produced by SongKong if consistency is desired, in which case the mappings are principally:
- \_cwp\_work\_0 => musicbrainz\_work\_composition
- \_cwp\_workid\_0 => musicbrainz\_work\_composition\_id
- \_cwp\_work\_n => musicbrainz\_work\_part\_leveln, for n = 1..6
- \_cwp\_workid\_n => musicbrainz\_work\_part\_leveln\_id, for n = 1..6
- \_cwp\_work\_top => musicbrainz\_work
These mappings are carried out automatically if the relevant options on the "Work and parts" tab are selected.
In addition, \_cwp\_title\_work and \_cwp\_title\_part\_0 are intended to be equivalent to SongKong's work and part tags.
(N.B. Full consistency between SongKong and Picard may also require the modification of Artist and related tags via a script, or the preservation of the related file tags)
## Muso
The tag "groupheading" should be set as the "Tags for Work - for software with 2-level capability". Muso will use this directly and extract the levels from it (split by the double colon). Muso permits a variety of import options which should be capable of combination with the tagging options in this plugin to achieve most desired effects. To avoid the use of import options in Muso, set the output tags from the plugin to be the native ones used by Muso (NB "title" may include or exclude groupheading - Muso should recognise it and extract it).
To make use of Muso's in-built classical music processing to set explicit tags in Picard, enable the "Use Muso reference database ..." option on the "Genres etc." tab.
## Players with no "work" capability
Leave the "title" tag unchanged or make it a combination of work and movement.
# Possible Enhancements
All planned functionality has been included in version 2.0. Please post any suggestions for improvements to the forum.
# Technical Matters (of possible interest to developers)
Issues were encountered with the Picard API in that there is not a documented way to let Picard know that it is still doing asynchronous tasks in the background and has not finished processing metadata. Many thanks to @dns\_server for assistance in dealing with this and to @sophist for the albumartist\_website code which I have borrowed from. I have tried to add some more comments to help any others trying the same techniques.
Also, the documentation of the XML lookup is virtually non-existent. The response is an XmlNode object (not a dict, although it is represented as one). Each node has a name with {attribs, text, children} values. The structure is more clearly understood if the web-based lookup is used (which is well documented at https://musicbrainz.org/doc/Development/XML_Web_Service/Version_2 ) as this gives an XML response. I wrote a function (parse\_data) to parse XmlNode objects, or lists thereof, for a (parameterised) hierarchy of nodes (and optional attribs value tests) in order to extract required data from the response. This may be of use to other plugin authors. The situation has been made slightly better in Picard 2.0 as the objects returned from register_track_metadata_processor are standard JSON. See https://musicbrainz.org/doc/Development/JSON_Web_Service. My parse_data function works with JSON as well as XmlNode formats, but the arguments you need to provide to it are different as the formats are structured differently. Picard 2.0 allows tagger.webservice calls to specify XML or default to JSON. This plugin has now migrated over to JSON-only.
To get the whole picture, in XML, for a release, use (for example) https://musicbrainz.org/ws/2/release/f3bb4fdd-5db0-43a8-be73-7a1747f6c2ef?inc=release-groups+media+recordings+artist-credits+artists+aliases+labels+isrcs+collections+artist-rels+release-rels+url-rels+recording-rels+work-rels+recording-level-rels+work-level-rels. (Add &fmt=json at the end to get the JSON response). This simulates the response given by Picard with the "Use release relationships" and "Use track relationships" options selected. Note that the Picard album\_metadata\_processor returns releaseXmlNode (as JSON from Picard 2.0 on) which is everything from the Release node of the XML downwards, whereas track\_metadata\_processor returns trackXmlNode which is everything from a Track node downwards (release -> medium-list -> medium -> track-list is above track). Replace all hyphens in XML with underscores when parsing the Python object (JSON uses hyphens).
Care needs to be taken when using the metadata property in Picard (e.g. as in track.metadata). This returns an object of class Metadata, which looks just like a dictionary but isn't. All values are in fact lists, which works as follows: when a value is set, it is always set as a list - i.e. a list value is entered as it is, but a string is set as a list : viz. ['string']. Then, when getting an item from the object, multiple values are joined to create a string. Thus track.metadata['item'] and track.metadata.get('item') will return list.join('; ') - i.e. a string with the list values separated by semi-colons - not the list. To get the list, you need to use track.metadata.getall('item'). The plugin stores work ids, internally and in "hidden variables" (such as _cwp_workid_0), as tuples. The Metadata class puts these into a string before setting the value in the object as a list, so the resulting value is ["(wid1, wid2, ...)"]. In order to extract the original tuple, the eval function is required.
A large variety of releases were used to test this plugin, but there may still be bugs, so further testing is welcome. The following release was particularly complex and useful for testing: https://musicbrainz.org/release/ec519fde-94ee-4812-9717-659d91be11d4. Also this release was a bit tricky - a large box set with some works appearing as originals and in arrangements: https://musicbrainz.org/release/5288f266-bab8-45bd-83e4-555730f02fa0.
# Very technical matters (probably not of interest to anyone)
I've done a bit of research and observed the following behaviour in Picard when using the `register_track_metadata_processor()` API:
1. If a new album (i.e. not yet tagged by Picard and with no MBIDs) is loaded, clustered and looked-up/scanned, resulting in the matched files being shown in the right-hand pane, then:
* `track.metadata` gives the lookup result from MB - i.e. no file information, just the track info.
* `album.tagger.files[xxxx].metadata` (where xxxx is the path/filename of the track) gives the file information (dirname etc.) and the tags on the original file.
* `album.tagger.files[xxxx].orig_metadata` gives the same as `album.tagger.files[xxxx].metadata`
2. However, if the album is then "refreshed", this does not just carry out a repeat operation, instead:
* `track.metadata` gives the same as before
* `album.tagger.files[xxxx].metadata` gives the metadata as in `track.metadata` and also includes all the file information as before.
* `album.tagger.files[xxxx].orig_metadata` gives the same as before (i.e. the original tags).
So, the 'post-refreshment' metadata is actually usable - by matching the `musicbrainz_trackid` of `track.metadata` and `album.tagger.files[xxxx].metadata`, you can get the file details of the track. Not elegant, but it works.
But why is it necessary to "refresh" to get what seems like a logical data set? Basically, the metadata process is not complete when the plugin is called, so not all metadata is available to it.
I don't know why `get_files_from_objects(objs)` doesn't work in the `register_track_metadata_processor()` API when `objs` is a list of tracks, but does provide a list of file objects when `objs` is a list of albums. Also it does work in the `register_file_action(xxx)`/`register_track_action(xxx)` API, but I assume that is because `itemsview.py` can identify that you have clicked on an item that is a track and a file (this is after the metadata processing has run).
In order to get round these problems, I have adopted a 'hack' which looks up the files for an album and finds which file matches the required track on tracknumber and discnumber. This seems to work, but there may be circumstances when it does not. As a consequence, refreshment should only be required if `get_files_from_objects(objs)` doesn't get all the album files.
# List of previous updates
Version 0.9.4: Bug fixes. The last released version for Picard 1.4 and the fork for version 2.0.
Version 0.9.3: Custom logging if enabled on "Advanced" tab - writes one log file per album in addition to standard Picard log. Also a session log with basic data is written. Performance improvements (especially for lyrics processing) and various bug fixes.
Version 0.9.2: A new tab in the options page has been created - "Genres etc." This includes special processing for genres, instruments, keys, work dates and periods. The "Infer work types" option on the "Artists" tab has been moved to this tab (but will be reset to the default of "False" and will need to be reset as required, because it operates slightly differently now that there is more control over the setting of genres). A separate section has ben added to this readme giving more details on the options in this tab.
Version 0.9.1: Bug fixes.
Version 0.9: Additional option to clear previous file tags which are not wanted, without interfering with cover art. Additional option to replace instrument names with as-credited names. Also instrument names are now saved to hidden variables tags (instruments, instruments\_credited and instruments\_all) which can be mapped to file tags as required. Sub-option added to the 'override artist options' option on the "advanced" tab - to allow tag map details to be included or not in this over-ride. Minor bug fixes and UI improvements. This is the next 'official' version after 0.7.
Version 0.8.9: Provide option (in advanced tab) to disable Classical Extras processing if no file is present; this enables (for example) single discs from box sets to be loaded without incurring the additional processing overhead for all the other discs. The settings of the main Picard options "translate\_artist\_names" and "standardize\_artists" is now saved along with the Classical Extras options so that they can be used to over-ride the displayed options. This is because they interact with the Classical Extras options in certain cases. Also:- graceful recovery from authentication failure; improved UI - more scalable; minor bug fixes.
Version 0.8.8: Fixes to allow for (1) disabling of 'use\_cache' across releases which may share works and (2) works which might appear in their own right and also have arrangements. Also, re-set certain important options to defaults on starting Picard, namely: 'use\_cache' set to True, 'log\_debug', 'log\_info' and 'options\_overwrite' set to False; the user will need to deliberately re-set these on starting Picard if required - this is to prevent inadvertently leaving these flags in an abnormal state.
Version 0.8.7: Revised treatment of "conditional" tag mapping. Previously, if multiple sources were specified for a tag mapping and the "conditional" flag set, only the first non-empty source was used. Now all sources will be mapped to a tag if it was empty before executing the current tag mapping line. This is considered to be more intuitive and leads to less complex mapping lines. However, it some cases it may be necessary to split a line from a previous version if the previous behaviour was specifically desired. Improved algorithms for extending metadata with title info. Bug fixes.
Version 0.8.6: More consistent approach to sort tags and hidden variables. Bug fixes.
Version 0.8.5: Improved handling of instruments. Bug fixes.
Version 0.8.4: Improved UI, bug fixes and code improvements.
Version 0.8.3: Ability to use aliases of work names instead of the MusicBrainz standard names. Various options to use aliases and as-credited names for performers and writers (i.e. relationship artists). Option to use recording artists as well as (or instead of) track artists. All relationship artists are now tagged for all work levels (with some special processing for lyricists). New UI layout to separate tag mapping from artist options. Option to split lyrics into common (release) and unique (track) components. Various code improvements as well as bug fixes.
Version 0.8.2: Improved algorithms and a few minor bug fixes.
Version 0.8.1: Bug fixes and minor enhancements - including revison and extension of "synonyms" section on the "advanced" tab.
Version 0.8: Handle multiple recordings and/or multiple parents of a work.
Handle multiple albumartist composers for one track.
Option to use "credited as" name for artists (inc. performers and composers) who are "release artist" or "track artist".
Option to exclude "solo" from instrument types.
Option to over-ride plugin options with those used when the album was last saved.
Option to keep (and append to) specified existing file tags - furthermore if "is\_classical" is present, the work-type variable will include "Classical".
Option to use (and write) SongKong-compatible work tags (saves processing time if SongKong is used to pre-process large numbers of files).
Include the work (and its parents) of which a work is an arrangement (as a "pseudo-parent").
Include medleys in movement/part description (as [Medley of:...] or other descriptor specified in options).
Allow for multiple parents of recordings and works (and multiple parents of those) - multiples are given as multiple tag instances, where permitted, otherwise separated by semi-colons.
Option as to whether to include parent works where the relationship attribute is "part of collection".
Plus minor enhancements and bug fixes too numerous to mention!
(Note that some old versions of the plugin may say v0.8 when they are only v0.7)
Version 0.7: Bug fixes. Pull request issued for this version.
Version 0.6.6: Bug fixes and algorithm improvements. Allow multiple sources for a tag (each will be appended) and use + as separator for concantenating sources, not a comma, to distinguish from the use of comma to separate multiples. Provide additional hidden variables ("sources") for vocalists and instrumentalists. Option to include intermediate work levels in a movement tag (for systems which cannot display multiple work levels).
Version 0.6.5: Include ability to use multiple (concatenated) sources in tag mapping (see notes under "tag mapping"). All artist "sources" using hidden variables (\_cea\_...) are now consistently in the plural, to distinguish from standard tags. Note that if "album" is used as a source in tag mapping, it will now be the revised name, where composer prefixing is used. To use the original name, use "release" as the source. Also various bug fixes, notably to ensure that all arrangers get picked up for use in tag mapping.
Version 0.6.4: Write out version number to user-specified tag. Provide default comment tags for writing ui options. Provide better m4a and iTunes compatibility (see notes). Added functionality for chorus master, orchestrator and concert master (leader). Re-arranged artist tab in ui. Various bug fixes.
Version 0.6.3: Bug fixes. Modified ui default options.
Version 0.6.2: Bug fixes. More flexible handling of artists (can blank and then add back later). Modified ui default options.
Version 0.6.1: Amended regex to permit non-Latin characters in work text.
================================================
FILE: plugins/classical_extras/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2018 Mark Evens
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = u'Classical Extras'
PLUGIN_AUTHOR = u'Mark Evens'
PLUGIN_DESCRIPTION = u"""Classical Extras provides tagging enhancements for Picard and, in particular,
utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a
user interface in Picard options->plugins. This interface provides separate sections
to enhance artist/performer tags, works and parts, genres and also allows for a generalised
"tag mapping" (simple scripting).
While it is designed to cater for the complexities of classical music tagging,
it may also be useful for other music which has more than just basic song/artist/album data.
The options screen provides five tabs for users to control the tags produced:
1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names.
Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.).
Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required.
(Note: Picard will not normally process incoming file tags).
2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or
Opera -> Act -> Number) based on the works in MusicBrainz's database. These can then be displayed in tags in a variety
of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works
are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits
look-ups to one per second.
3. Genres etc.: Options are available to customise the source and display of information relating to genres,
instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who
provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical
periods.
4. Tag mapping: in some ways, this is a simple substitute for some of Picard's scripting capability. The main advantage
is that the plugin will remember what tag mapping you use for each release (or even track).
5. Advanced: Various options to control the detailed processing of the above.
All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with
inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works
are in the composer's language and/or script).
Also existing file tags can be processed (not possible in native Picard).
See the readme file
on GitHub here for full details.
"""
########################
# DEVELOPERS NOTES: ####
########################
# This plugin contains 3 classes:
#
# I. ("EXTRA ARTISTS") Create sorted fields for all performers. Creates a number of variables with alternative values
# for "artists" and "artist".
# Creates an ensemble variable for all ensemble-type performers.
# Also creates matching sort fields for artist and artists.
# Additionally create tags for artist types which are not normally created in Picard - particularly for classical music
# (notably instrument arrangers).
#
# II. ("PART LEVELS" [aka Work Parts]) Create tags for the hierarchy of works which contain a given track recording
# - particularly for classical music'
# Variables provided for each work level, with implied part names
# Mixed metadata provided including work and title elements
#
# III. ("OPTIONS") Allows the user to set various options including what tags will be written
# (otherwise the classes above will just write outputs to "hidden variables")
#
# The main control routine is at the end of the module
PLUGIN_VERSION = '2.0.14'
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3", "2.4", "2.5", "2.6", "2.7"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard.ui.options import register_options_page, OptionsPage
from picard.plugins.classical_extras.ui_options_classical_extras import Ui_ClassicalExtrasOptionsPage
import picard.plugins.classical_extras.suffixtree
from picard import config, log
from picard.config import ConfigSection, BoolOption, IntOption, TextOption
from picard.util import LockableObject, uniqify
# note that in 2.0 picard.webservice changed to picard.util.xml
from picard.util.xml import XmlNode
from picard.util import translate_from_sortname
from picard.metadata import register_track_metadata_processor, Metadata
from functools import partial
from datetime import datetime
import collections
import re
import unicodedata
import json
import copy
import os
from PyQt5.QtCore import QXmlStreamReader
from picard.const import USER_DIR
import operator
import ast
import picard.plugins.classical_extras.const
##########################
# MODULE-WIDE COMPONENTS #
##########################
# CONSTANTS
# N.B. Constants with long definitions are set in const.py
DATE_SEP = '-'
# COMMONLY USED REGEX
ROMAN_NUMERALS = r'\b((?=[MDCLXVI])(M{0,4}(CM|CD|D?)?C{0,3}(XC|XL|L?)?X{0,3}(IX|IV|V?)?I{0,3}))(?:\.|\-|:|;|,|\s|$)'
ROMAN_NUMERALS_AT_START = r'^\W*' + ROMAN_NUMERALS
RE_ROMANS = re.compile(ROMAN_NUMERALS, re.IGNORECASE)
RE_ROMANS_AT_START = re.compile(ROMAN_NUMERALS_AT_START, re.IGNORECASE)
# KEYS
RE_NOTES = r'(\b[ABCDEFG])'
RE_ACCENTS = r'(\-sharp(?:\s+|\b)|\-flat(?:\s+|\b)|\ssharp(?:\s+|\b)|\sflat(?:\s+|\b)|\u266F(?:\s+|\b)|\u266D(?:\s+|\b)|(?:[:,.]?\s+|$|\-))'
RE_SCALES = r'(major|minor)?(?:\b|$)'
RE_KEYS = re.compile(
RE_NOTES + RE_ACCENTS + RE_SCALES,
re.UNICODE | re.IGNORECASE)
# LOGGING
# If logging occurs before any album is loaded, the startup log file will
# be written
log_files = collections.defaultdict(dict)
# entries are release-ids: to keep track of which log files are open
release_status = collections.defaultdict(dict)
# release_status[release_id]['works'] = True indicates that we are still processing works for release_id
# & similarly for 'artists'
# release_status[release_id]['start'] holds start time of release processing
# release_status[release_id]['name'] holds the album name
# release_status[release_id]['lookups'] holds number of lookups for this release
# release_status[release_id]['file_objects'] holds a cumulative list of file objects (tagger seems a bit unreliable)
# release_status[release_id]['file_found'] = False indicates that "No file
# with matching trackid" has (yet) been found
def write_log(release_id, log_type, message, *args):
"""
Custom logging function - if log_info is set, all messages will be written to a custom file in a 'Classical_Extras'
subdirectory in the same directory as the main Picard log. A different file is used for each album,
to aid in debugging - the log file is release_id.log. Any startup messages (i.e. before a release has been loaded)
are written to session.log. Summary information for each release is also written to session.log even if log_info
is not set.
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param log_type: 'error', 'warning', 'debug' or 'info'
:param message: string, e.g. 'error message for workid: %s'
:param args: arguments for parameters in string, e.g. if workId then str(workId) will replace %s in the above
:return:
"""
options = config.setting
if not isinstance(message, str):
msg = repr(message)
else:
msg = message
if args:
msg = msg % args
if options["log_info"] or log_type == "basic":
# if log_info is True, all log messages will be written to the custom log, regardless of other log_... settings
# basic session log will always be written (summary of releases and
# processing times)
filename = release_id + ".log"
log_dir = os.path.join(USER_DIR, "Classical_Extras")
if not os.path.exists(log_dir):
os.makedirs(log_dir)
if release_id not in log_files:
try:
if release_id == 'session':
log_file = open(
os.path.join(
log_dir,
filename),
'w',
encoding='utf8',
buffering=1)
# buffering=1 so that session log (low volume) is up to
# date even if not closed
else:
log_file = open(
os.path.join(
log_dir,
filename),
'w',
encoding='utf8') # , buffering=1)
# default buffering for speed, buffering = 1 for currency
log_files[release_id] = log_file
log_file.write(
PLUGIN_NAME +
' Version:' +
PLUGIN_VERSION +
'\n')
if release_id == 'session':
log_file.write('session' + '\n')
else:
log_file.write('Release id: ' + release_id + '\n')
if release_id in release_status and 'name' in release_status[release_id]:
log_file.write(
'Album name: ' + release_status[release_id]['name'] + '\n')
except IOError:
log.error('Unable to open file %s for writing log', filename)
return
else:
log_file = log_files[release_id]
try:
log_file.write(log_type[0].upper() + ': ')
log_file.write(str(datetime.now()) + ' : ')
log_file.write(msg)
log_file.write("\n")
except IOError:
log.error('Unable to write to log file %s', filename)
return
# Only debug, warning and error messages will be written to the main
# Picard log, if those options have been set
if log_type != 'info' and log_type != 'basic': # i.e. non-custom log items
message2 = PLUGIN_NAME + ': ' + message
else:
message2 = message
if log_type == 'debug' and options["log_debug"]:
if release_id in release_status and 'debug' in release_status[release_id]:
add_list_uniquely(release_status[release_id]['debug'], msg)
else:
release_status[release_id]['debug'] = [msg]
log.debug(message2, *args)
if log_type == 'warning' and options["log_warning"]:
if release_id in release_status and 'warnings' in release_status[release_id]:
add_list_uniquely(release_status[release_id]['warnings'], msg)
else:
release_status[release_id]['warnings'] = [msg]
if args:
log.warning(message2, *args)
else:
log.warning(message2)
if log_type == 'error' and options["log_error"]:
if release_id in release_status and 'errors' in release_status[release_id]:
add_list_uniquely(release_status[release_id]['errors'], msg)
else:
release_status[release_id]['errors'] = [msg]
if args:
log.error(message2, *args)
else:
log.error(message2)
def close_log(release_id, caller):
# close the custom log file if we are done
if release_id == 'session': # shouldn't happen but, just in case, don't close the session log
return
if caller in ['works', 'artists']:
release_status[release_id][caller] = False
if (caller == 'works' and release_status[release_id]['artists']) or \
(caller == 'artists' and release_status[release_id]['works']):
# log.error('exiting close_log. only %s done', caller) # debug line
return
duration = 'N/A'
lookups = 'N/A'
artists_time = 0
works_time = 0
lookup_time = 0
album_process_time = 0
if release_id in release_status:
duration = datetime.now() - release_status[release_id]['start']
lookups = release_status[release_id]['lookups']
done_lookups = release_status[release_id]['done-lookups']
lookup_time = done_lookups - release_status[release_id]['start']
album_process_time = duration - lookup_time
artists_time = release_status[release_id]['artists-done'] - \
release_status[release_id]['start']
works_time = release_status[release_id]['works-done'] - \
release_status[release_id]['start']
del release_status[release_id]['start']
del release_status[release_id]['lookups']
del release_status[release_id]['done-lookups']
del release_status[release_id]['artists-done']
del release_status[release_id]['works-done']
if release_id in log_files:
write_log(
release_id,
'info',
'Duration = %s. Number of lookups = %s.',
duration,
lookups)
write_log(release_id, 'info', 'Closing log file for %s', release_id)
log_files[release_id].close()
del log_files[release_id]
if 'session' in log_files and release_id in release_status:
write_log(
'session',
'basic',
'\n Completed processing release id %s. Details below:-',
release_id)
if 'name' in release_status[release_id]:
write_log('session', 'basic', 'Album name %s',
release_status[release_id]['name'])
if 'errors' in release_status[release_id]:
write_log(
'session',
'basic',
'-------------------- Errors --------------------')
for error in release_status[release_id]['errors']:
write_log('session', 'basic', error)
del release_status[release_id]['errors']
if 'warnings' in release_status[release_id]:
write_log(
'session',
'basic',
'-------------------- Warnings --------------------')
for warning in release_status[release_id]['warnings']:
write_log('session', 'basic', warning)
del release_status[release_id]['warnings']
if 'debug' in release_status[release_id]:
write_log(
'session',
'basic',
'-------------------- Debug log --------------------')
for debug in release_status[release_id]['debug']:
write_log('session', 'basic', debug)
del release_status[release_id]['debug']
write_log(
'session',
'basic',
'Duration = %s. Artists time = %s. Works time = %s. Of which: Lookup time = %s. '
'Album-process time = %s. Number of lookups = %s.',
duration,
artists_time,
works_time,
lookup_time,
album_process_time,
lookups)
if release_id in release_status:
del release_status[release_id]
# FILE READING AND OBJECT PARSING
_node_name_re = re.compile('[^a-zA-Z0-9]')
def _node_name(n):
return _node_name_re.sub('_', str(n))
def _read_xml(stream):
document = XmlNode()
current_node = document
path = []
while not stream.atEnd():
stream.readNext()
if stream.isStartElement():
node = XmlNode()
attrs = stream.attributes()
for i in range(attrs.count()):
attr = attrs.at(i)
node.attribs[_node_name(attr.name())] = str(attr.value())
current_node.append_child(_node_name(stream.name()), node)
path.append(current_node)
current_node = node
elif stream.isEndElement():
current_node = path.pop()
elif stream.isCharacters():
current_node.text += str(stream.text())
return document
def get_preferred_artist_language(config):
locales = config.setting["artist_locales"]
if locales:
artist_locale = locales[0]
else:
artist_locale = config.setting["artist_locale"]
if artist_locale:
return artist_locale.split('_')[0]
else:
return ''
def parse_data(release_id, obj, response_list, *match):
"""
This function takes any XmlNode object, or list thereof, or a JSON object
and extracts a list of all objects exactly matching the hierarchy listed in match.
match should contain list of each node in hierarchical sequence, with no gaps in the sequence
of nodes, to lowest level required.
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param obj: an XmlNode or JSON object, list or dictionary containing nodes
:param response_list: working memory for recursive calls
:param match: list of items to search for in node (see detailed notes below)
:return: a list of matching items (always a list, even if only one item)
Insert attribs.attribname:attribvalue in the list to select only branches where attribname
is attribvalue. (Omit the attribs prefix if the obj is JSON)
Insert childname.text:childtext in the list to select only branches where
a sibling with childname has text childtext.
(Note: childname can be a dot-list if the text is more than one level down - e.g. child1.child2
# TODO - Check this works fully )
"""
if '!log' in response_list:
DEBUG = True
INFO = True
else:
DEBUG = False
INFO = False
# Normally logging options are off as these can be VERY wordy
# They can be turned on by using !log in the call
# XmlNode instances are not iterable, so need to convert to dict
if isinstance(obj, XmlNode):
obj = obj.__dict__
if DEBUG or INFO:
write_log(release_id, 'debug', 'Parsing data - looking for %s', match)
if INFO:
write_log(release_id, 'info', 'Looking in object: %s', obj)
if isinstance(obj, list):
objlen = len(obj)
for i, item in enumerate(obj):
if isinstance(item, XmlNode):
item = item.__dict__
if INFO:
write_log(
release_id,
'info',
'Getting response for list item no.%s of %s - object is: %s',
i + 1,
objlen,
item)
parse_data(release_id, item, response_list, *match)
if INFO:
write_log(
release_id,
'info',
'response_list for list item no.%s of %s is %s',
i + 1,
objlen,
response_list)
return response_list
elif isinstance(obj, dict):
if match[0] in obj:
if len(match) == 1:
response = obj[match[0]]
if response is not None: # To prevent adding NoneTypes to list
response_list.append(response)
if INFO:
write_log(
release_id,
'info',
'response_list (last match item): %s',
response_list)
else:
match_list = list(match)
match_list.pop(0)
parse_data(release_id, obj[match[0]],
response_list, *match_list)
if INFO:
write_log(
release_id,
'info',
'response_list (passing up): %s',
response_list)
return response_list
elif ':' in match[0]:
test = match[0].split(':')
match2 = test[0].split('.')
test_data = parse_data(release_id, obj, [], *match2)
if INFO:
write_log(
release_id,
'info',
'Value comparison - looking in %s for value %s',
test_data,
test[1])
if len(test) > 1:
# latter is because Booleans are stored as such, not as
# strings, in JSON
if (test[1] in test_data) or (
(test[1] == 'True') in test_data):
if len(match) == 1:
response = obj
if response is not None:
response_list.append(response)
else:
match_list = list(match)
match_list.pop(0)
parse_data(release_id, obj, response_list, *match_list)
else:
parse_data(release_id, obj, response_list, *match2)
if INFO:
write_log(
release_id,
'info',
'response_list (from value look-up): %s',
response_list)
return response_list
else:
if 'children' in obj:
parse_data(release_id, obj['children'], response_list, *match)
if INFO:
write_log(
release_id,
'info',
'response_list (from children): %s',
response_list)
return response_list
else:
if INFO:
write_log(
release_id,
'info',
'response_list (obj is not a list or dict): %s',
response_list)
return response_list
def create_dict_from_ref_list(options, release_id, ref_list, keys, tags):
ref_dict_list = []
for refs in ref_list:
for ref in refs:
parsed_refs = [
parse_data(
release_id,
ref,
[],
t,
'text') for t in tags]
ref_dict_list.append(dict(zip(keys, parsed_refs)))
return ref_dict_list
def get_references_from_file(release_id, path, filename):
"""
Lookup Muso Reference.xml or similar
:param release_id: name of log file
:param path: Reference file path
:param filename: Reference file name
:return:
"""
options = config.setting
composer_dict_list = []
period_dict_list = []
genre_dict_list = []
xml_file = None
try:
xml_file = open(os.path.join(path, filename), encoding="utf8")
reply = xml_file.read()
xml_file.close()
document = _read_xml(QXmlStreamReader(reply))
# Composers
composer_list = parse_data(
release_id, document, [], 'ReferenceDB', 'Composer')
keys = ['name', 'sort', 'birth', 'death', 'country', 'core']
tags = ['Name', 'Sort', 'Birth', 'Death', 'CountryCode', 'Core']
composer_dict_list = create_dict_from_ref_list(
options, release_id, composer_list, keys, tags)
# Periods
period_list = parse_data(
release_id,
document,
[],
'ReferenceDB',
'ClassicalPeriod')
keys = ['name', 'start', 'end']
tags = ['Name', 'Start_x0020_Date', 'End_x0020_Date']
period_dict_list = create_dict_from_ref_list(
options, release_id, period_list, keys, tags)
# Genres
genre_list = parse_data(
release_id,
document,
[],
'ReferenceDB',
'ClassicalGenre')
keys = ['name']
tags = ['Name']
genre_dict_list = create_dict_from_ref_list(
options, release_id, genre_list, keys, tags)
except (IOError, FileNotFoundError, UnicodeDecodeError):
if options['cwp_muso_genres'] or options['cwp_muso_classical'] or options['cwp_muso_dates'] or options['cwp_muso_periods']:
write_log(
release_id,
'error',
'File %s does not exist or is corrupted',
os.path.join(
path,
filename))
finally:
if xml_file:
xml_file.close()
return {
'composers': composer_dict_list,
'periods': period_dict_list,
'genres': genre_dict_list}
# OPTIONS
def get_preserved_tags():
preserved = config.setting["preserved_tags"]
if isinstance(preserved, str):
preserved = [x.strip() for x in preserved.split(',')]
return preserved
def get_options(release_id, album, track):
"""
Get the saved options from a release and use them according to flags set on the "advanced" tab
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album: current release
:param track: current track
:return: None (result is passed via tm)
A common function for both Artist and Workparts, so that the first class to process a track will execute
this function so that the results are available to both (via a track metadata item)
"""
release_status[release_id]['done'] = False
set_options = collections.defaultdict(dict)
main_sections = ['artists', 'workparts']
all_sections = ['artists', 'tag', 'workparts', 'genres']
parent_sections = {
'artists': 'artists',
'tag': 'artists',
'workparts': 'workparts',
'genres': 'workparts'}
# The above needs to be done for legacy reasons - there are only two tags which store options - artists and workparts
# This dates from when there were only two sections
# To split these now will create compatibility issues
override = {
'artists': 'cea_override',
'tag': 'ce_tagmap_override',
'workparts': 'cwp_override',
'genres': 'ce_genres_override'}
sect_text = {'artists': 'Artists', 'workparts': 'Works'}
prefix = {'artists': 'cea', 'workparts': 'cwp'}
if album.tagger.config.setting['ce_options_overwrite'] and all(
album.tagger.config.setting[override[sect]] for sect in main_sections):
set_options[track] = album.tagger.config.setting # mutable
else:
set_options[track] = option_settings(
album.tagger.config.setting) # make a copy
if set_options[track]["log_info"]:
write_log(
release_id,
'info',
'Default (i.e. per UI) options for track %s are %r',
track,
set_options[track])
# As we use some of the main Picard options and may over-write them, save them here
# set_options[track]['translate_artist_names'] = config.setting['translate_artist_names']
# set_options[track]['standardize_artists'] = config.setting['standardize_artists']
# (not sure this is needed - TODO reconsider)
options = set_options[track]
tm = track.metadata
new_metadata = None
orig_metadata = None
# Only look up files if needed
file_options = {}
music_file = ''
music_file_found = None
release_status[release_id]['file_found'] = False
start = datetime.now()
if options["log_info"]:
write_log(release_id, 'info', 'Clock start at %s', start)
trackno = tm['tracknumber']
discno = tm['discnumber']
album_filenames = album.tagger.get_files_from_objects([album])
if options["log_info"]:
write_log(
release_id,
'info',
'No. of album files found = %s',
len(album_filenames))
# Note that sometimes Picard fails to get all the file objects, even if they are there (network issues)
# so we will cache whatever we can get!
if release_id in release_status and 'file_objects' in release_status[release_id]:
add_list_uniquely(
release_status[release_id]['file_objects'],
album_filenames)
else:
release_status[release_id]['file_objects'] = album_filenames
if options["log_info"]:
write_log(release_id, 'info', 'No. of album files cached = %s',
len(release_status[release_id]['file_objects']))
track_file = None
for album_file in release_status[release_id]['file_objects']:
if options["log_info"]:
write_log(release_id,
'info',
'Track file = %s, tracknumber = %s, discnumber = %s. Metadata trackno = %s, discno = %s',
album_file.filename,
str(album_file.tracknumber),
str(album_file.discnumber),
trackno,
discno)
if str(
album_file.tracknumber) == trackno and str(
album_file.discnumber) == discno:
if options["log_info"]:
write_log(
release_id,
'info',
'Track file found = %r',
album_file.filename)
track_file = album_file.filename
break
# Note: It would have been nice to do a rough check beforehand of total tracks,
# but ~totalalbumtracks is not yet populated
if not track_file:
album_fullnames = [
x.filename for x in release_status[release_id]['file_objects']]
if options["log_info"]:
write_log(
release_id,
'info',
'Album files found = %r',
album_fullnames)
for music_file in album_fullnames:
new_metadata = album.tagger.files[music_file].metadata
if 'musicbrainz_trackid' in new_metadata and 'musicbrainz_trackid' in tm:
if new_metadata['musicbrainz_trackid'] == tm['musicbrainz_trackid']:
track_file = music_file
break
# Nothing found...
if new_metadata and 'musicbrainz_trackid' not in new_metadata:
if options['log_warning']:
write_log(
release_id,
'warning',
'No trackid in file %s',
music_file)
if 'musicbrainz_trackid' not in tm:
if options['log_warning']:
write_log(
release_id,
'warning',
'No trackid in track %s',
track)
#
# Note that, on initial load, new_metadata == orig_metadata; but, after refresh, new_metadata will have
# the same track metadata as tm (plus the file metadata as per orig_metadata), so a trackid match
# is then possible for files that do not have musicbrainz_trackid in orig_metadata. That is why
# new_metadata is used in the above test, rather than orig_metadata, but orig_metadata is then used below
# to get the saved options.
#
# Find the tag with the options:-
if track_file:
orig_metadata = album.tagger.files[track_file].orig_metadata
music_file_found = track_file
if options['log_info']:
write_log(
release_id,
'info',
'orig_metadata for file %s is',
music_file)
write_log(release_id, 'info', orig_metadata)
for child_section in all_sections:
section = parent_sections[child_section]
if options[override[child_section]]:
if options[prefix[section] + '_options_tag'] + ':' + \
section + '_options' in orig_metadata:
file_options[section] = interpret(
orig_metadata[options[prefix[section] + '_options_tag'] + ':' + section + '_options'])
elif options[prefix[section] + '_options_tag'] in orig_metadata:
options_tag_contents = orig_metadata[options[prefix[section] + '_options_tag']]
if isinstance(options_tag_contents, list):
options_tag_contents = options_tag_contents[0]
combined_options = ''.join(options_tag_contents.split(
'(workparts_options)')).split('(artists_options)')
for i, _ in enumerate(combined_options):
combined_options[i] = interpret(
combined_options[i].lstrip('; '))
if isinstance(
combined_options[i],
dict) and 'Classical Extras' in combined_options[i]:
if sect_text[section] + \
' options' in combined_options[i]['Classical Extras']:
file_options[section] = combined_options[i]
else:
for om in orig_metadata:
if ':' + section + '_options' in om:
file_options[section] = interpret(
orig_metadata[om])
if section not in file_options or not file_options[section]:
if options['log_error']:
write_log(
release_id,
'error',
'Saved ' +
section +
' options cannot be read for file %s. Using current settings',
music_file)
append_tag(
release_id,
tm,
'~' +
prefix[section] +
'_error',
'1. Saved ' +
section +
' options cannot be read. Using current settings')
release_status[release_id]['file_found'] = True
end = datetime.now()
if options['log_info']:
write_log(release_id, 'info', 'Clock end at %s', end)
write_log(release_id, 'info', 'Duration = %s', end - start)
if not release_status[release_id]['file_found']:
if options['log_warning']:
write_log(
release_id,
'warning',
"No file with matching trackid for track %s. IF THERE SHOULD BE ONE, TRY 'REFRESH'",
track)
append_tag(
release_id,
tm,
"002_important_warning",
"No file with matching trackid - IF THERE SHOULD BE ONE, TRY 'REFRESH' - "
"(unable to process any saved options, lyrics or 'keep' tags)")
# Nothing else is done with this info as yet - ideally we need to refresh and re-run
# for all releases where, say, release_status[release_id]['file_prob']
# == True TODO?
else:
if options['log_info']:
write_log(
release_id,
'info',
'Found music file: %r',
music_file_found)
for section in all_sections:
if options[override[section]]:
parent_section = parent_sections[section]
if parent_section in file_options and file_options[parent_section]:
try:
options_dict = file_options[parent_section]['Classical Extras'][sect_text[parent_section] + ' options']
except TypeError as err:
if options['log_error']:
write_log(
release_id,
'error',
'Error: %s. Saved ' +
section +
' options cannot be read for file %s. Using current settings',
err,
music_file)
append_tag(
release_id,
tm,
'~' +
prefix[parent_section] +
'_error',
'1. Saved ' +
parent_section +
' options cannot be read. Using current settings')
break
for opt in options_dict:
if isinstance(
options_dict[opt],
dict) and options[override['tag']]: # for tag line options
# **NB tag mapping lines are the only entries of type dict**
opt_list = []
for opt_item in options_dict[opt]:
opt_list.append(
{opt + '_' + opt_item: options_dict[opt][opt_item]})
else:
opt_list = [{opt: options_dict[opt]}]
for opt_dict in opt_list:
for opt_det in opt_dict:
opt_value = opt_dict[opt_det]
addn = []
if section == 'artists':
addn = plugin_options('picard')
if section == 'tag':
addn = plugin_options('tag_detail')
for ea_opt in plugin_options(section) + addn:
displayed_option = options[ea_opt['option']]
if ea_opt['name'] == opt_det:
if 'value' in ea_opt:
if ea_opt['value'] == opt_value:
options[ea_opt['option']] = True
else:
options[ea_opt['option']
] = False
else:
options[ea_opt['option']
] = opt_value
if options[ea_opt['option']
] != displayed_option:
if options['log_debug'] or options['log_info']:
write_log(
release_id,
'info',
'Options overridden for option %s = %s',
ea_opt['option'],
opt_value)
opt_text = str(opt_value)
append_tag(
release_id, tm, '003_information:options_overridden', str(
ea_opt['name']) + ' = ' + opt_text)
if orig_metadata:
keep_list = options['cea_keep'].split(",")
if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
keep_list.append(options['cea_lyrics_tag'])
if options['cwp_genres_use_file']:
if 'genre' in orig_metadata:
append_tag(
release_id,
tm,
'~cwp_candidate_genres',
orig_metadata['genre'])
if options['cwp_genre_tag'] and options['cwp_genre_tag'] in orig_metadata:
keep_list.append(options['cwp_genre_tag'])
really_keep_list = get_preserved_tags()[:]
really_keep_list.append(
options['cwp_options_tag'] +
':workparts_options')
really_keep_list.append(
options['cea_options_tag'] +
':artists_options')
for tagx in keep_list:
tag = tagx.strip()
really_keep_list.append(tag)
if tag in orig_metadata:
append_tag(release_id, tm, tag, orig_metadata[tag])
if options['cea_clear_tags']:
delete_list = []
for tag_item in orig_metadata:
if tag_item not in really_keep_list and tag_item[0] != '~':
# the second condition is to ensure that (hidden) file variables are not deleted,
# as these are in orig_metadata, not track_metadata
delete_list.append(tag_item)
# this will be used in map_tags to delete unwanted tags
options['delete_tags'] = delete_list
## Create a "mirror" tag with the old data, for comparison purposes
mirror_tags = []
for tag_item in orig_metadata:
mirror_name = tag_item + '_OLD'
if mirror_name[0] == '~' :
mirror_name.replace('~', '_')
mirror_name = '~' + mirror_name
mirror_tags.append((mirror_name, tag_item))
append_tag(release_id, tm, mirror_name, orig_metadata[tag_item])
append_tag(release_id, tm, '~ce_mirror_tags', mirror_tags)
if not isinstance(options, dict):
options_dict = option_settings(config.setting)
write_log(
'session',
'info',
'Using option_settings(config.setting): %s',
options_dict)
else:
options_dict = options
write_log(
'session',
'info',
'Using options: %s',
options_dict)
tm['~ce_options'] = str(options_dict)
tm['~ce_file'] = music_file_found
def plugin_options(option_type):
"""
:param option_type: artists, tag, workparts, genres or other
:return: the relevant dictionary for the type
This function contains all the options data in one place - to prevent multiple repetitions elsewhere
"""
if option_type == 'artists':
return const.ARTISTS_OPTIONS
elif option_type == 'tag':
return const.TAG_OPTIONS
elif option_type == 'tag_detail':
return const.TAG_DETAIL_OPTIONS
elif option_type == 'workparts':
return const.WORKPARTS_OPTIONS
elif option_type == 'genres':
return const.GENRE_OPTIONS
elif option_type == 'picard':
return const.PICARD_OPTIONS
elif option_type == 'other':
return const.OTHER_OPTIONS
else:
return None
def option_settings(config_settings):
"""
:param config_settings: options from UI
:return: a (deep) copy of the Classical Extras options
"""
options = {}
for option in plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') + plugin_options(
'workparts') + plugin_options('genres') + plugin_options('picard') + plugin_options('other'):
options[option['option']] = copy.deepcopy(
config_settings[option['option']])
return options
def get_aliases(self, release_id, album, options, releaseXmlNode):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param self:
:param album:
:param options:
:param releaseXmlNode: all the metadata for the release
:return: Data is returned via self.artist_aliases and self.artist_credits[album]
Note regarding aliases and credited-as names:
In a MB release, an artist can appear in one of seven contexts. Each of these is accessible in releaseXmlNode
and the track and recording contexts are also accessible in trackXmlNode.
The seven contexts are:
Recording: credited-as and alias
Release-group: credited-as and alias
Release: credited-as and alias
Release relationship: credited-as and (not reliably?) alias
Recording relationship (direct): credited-as and (not reliably?) alias
Recording relationship (via work): credited-as and (not reliably?) alias
Track: credited-as and alias
(The above are applied in sequence - e.g. track artist credit will over-ride release artist credit. "Recording" gets
the lowest priority as it is more generic than the release data {may apply to multiple releases})
This function collects all the available aliases and as-credited names once (on processing the first track).
N.B. if more than one release is loaded in Picard, any available alias names loaded so far will be available
and used. However, as-credited names will only be used from the current release."""
lang = get_preferred_artist_language(config)
if lang and options['cea_aliases'] or options['cea_aliases_composer']:
# Track and recording aliases/credits are gathered by parsing the
# media, track and recording nodes
# Do the recording relationship first as it may apply to multiple releases, so release and track data
# is more specific.
media = parse_data(release_id, releaseXmlNode, [], 'media')
for m in media:
# disc_num = int(parse_data(options, m, [], 'position', 'text')[0])
# not currently used
tracks = parse_data(release_id, m, [], 'tracks')
for track in tracks:
for t in track:
# track_num = int(parse_data(options, t, [], 'number',
# 'text')[0]) # not currently used
# Recording artists
obj = parse_data(release_id, t, [], 'recording')
get_aliases_and_credits(
self,
options,
release_id,
album,
obj,
lang,
options['cea_recording_credited'])
# Get the release data before the recording relationshiops and track data
# Release group artists
obj = parse_data(release_id, releaseXmlNode, [], 'release-group')
get_aliases_and_credits(
self,
options,
release_id,
album,
obj,
lang,
options['cea_group_credited'])
# Release artists
get_aliases_and_credits(
self,
options,
release_id,
album,
releaseXmlNode,
lang,
options['cea_credited'])
# Next bit needed to identify artists who are album artists
self.release_artists_sort[album] = parse_data(
release_id, releaseXmlNode, [], 'artist-credit', 'artist', 'sort-name')
# Release relationship artists
get_relation_credits(
self,
options,
release_id,
album,
releaseXmlNode,
lang,
options['cea_release_relationship_credited'])
# Now get the rest:
for m in media:
tracks = parse_data(release_id, m, [], 'tracks')
for track in tracks:
for t in track:
# Recording relationship artists
obj = parse_data(release_id, t, [], 'recording')
get_relation_credits(
self,
options,
release_id,
album,
obj,
lang,
options['cea_recording_relationship_credited'])
# Track artists
get_aliases_and_credits(
self,
options,
release_id,
album,
t,
lang,
options['cea_track_credited'])
if options['log_info']:
write_log(release_id, 'info', 'Alias and credits info for %s', self)
write_log(release_id, 'info', 'Aliases :%s', self.artist_aliases)
write_log(
release_id,
'info',
'Credits :%s',
self.artist_credits[album])
def get_artists(options, release_id, tm, relations, relation_type):
"""
Get artist info from XML lookup
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param options:
:param tm:
:param relations:
:param relation_type: 'release', 'recording' or 'work' (NB 'work' does not pass a param for tm)
:return:
"""
if options['log_debug'] or options['log_info']:
write_log(
release_id,
'debug',
'In get_artists. relation_type: %s, relations: %s',
relation_type,
relations)
log_options = {
'log_debug': options['log_debug'],
'log_info': options['log_info']}
artists = []
instruments = []
artist_types = const.RELATION_TYPES[relation_type]
for artist_type in artist_types:
artists, instruments = create_artist_data(release_id, options, log_options, tm, relations,
relation_type, artist_type, artists, instruments)
artist_dict = {'artists': artists, 'instruments': instruments}
return artist_dict
def create_artist_data(release_id, options, log_options, tm, relations,
relation_type, artist_type, artists, instruments):
"""
Update the artists and instruments
:param release_id: the current album id
:param options:
:param log_options:
:param tm: track metadata
:param relations:
:param relation_type: release', 'recording' or 'work' (NB 'work' does not pass a param for tm)
:param artist_type: from const.RELATION_TYPES[relation_type]
:param artists: current artist list - updated with each call
:param instruments: current instruments list - updated with each call
:return: artists, instruments
"""
type_list = parse_data(
release_id,
relations,
[],
'target-type:artist',
'type:' +
artist_type)
for type_item in type_list:
artist_name_list = parse_data(
release_id, type_item, [], 'artist', 'name')
artist_sort_name_list = parse_data(
release_id, type_item, [], 'artist', 'sort-name')
if artist_type not in [
'instrument',
'vocal',
'instrument arranger',
'vocal arranger']:
instrument_list = None
credited_inst_list = None
else:
instrument_list_list = parse_data(
release_id, type_item, [], 'attributes')
if instrument_list_list:
instrument_list = instrument_list_list[0]
else:
instrument_list = []
credited_inst_list = instrument_list[:]
credited_inst_dict_list = parse_data(
release_id, type_item, [], 'attribute-credits') # keyed to insts
if credited_inst_dict_list:
credited_inst_dict = credited_inst_dict_list[0]
else:
credited_inst_dict = {}
for i, inst in enumerate(instrument_list):
if inst in credited_inst_dict:
credited_inst_list[i] = credited_inst_dict[inst]
if artist_type == 'vocal':
if not instrument_list:
instrument_list = ['vocals']
elif not any('vocals' in x for x in instrument_list):
instrument_list.append('vocals')
credited_inst_list.append('vocals')
# fill the hidden vars before we choose to use the as-credited
# version
if relation_type != 'work':
inst_tag = []
cred_tag = []
if instrument_list:
inst_tag = list(set(instrument_list))
if credited_inst_list:
cred_tag = list(set(credited_inst_list))
for attrib in ['solo', 'guest', 'additional']:
if attrib in inst_tag:
inst_tag.remove(attrib)
if attrib in cred_tag:
cred_tag.remove(attrib)
if inst_tag:
if tm['~cea_instruments']:
tm['~cea_instruments'] = add_list_uniquely(
tm['~cea_instruments'], inst_tag)
else:
tm['~cea_instruments'] = inst_tag
if cred_tag:
if tm['~cea_instruments_credited']:
tm['~cea_instruments_credited'] = add_list_uniquely(
tm['~cea_instruments_credited'], cred_tag)
else:
tm['~cea_instruments_credited'] = cred_tag
if inst_tag or cred_tag:
if tm['~cea_instruments_all']:
tm['~cea_instruments_all'] = add_list_uniquely(
tm['~cea_instruments_all'], list(set(inst_tag + cred_tag)))
else:
tm['~cea_instruments_all'] = list(
set(inst_tag + cred_tag))
if '~cea_instruments' in tm and '~cea_instruments_credited' in tm and '~cea_instruments_all' in tm:
instruments = [
tm['~cea_instruments'],
tm['~cea_instruments_credited'],
tm['~cea_instruments_all']]
if options['cea_inst_credit'] and credited_inst_list:
instrument_list = credited_inst_list
if instrument_list:
instrument_sort = 3
s_key = {
'lead vocals': 1,
'solo': 2,
'guest': 4,
'additional': 5}
for inst in s_key:
if inst in instrument_list:
instrument_sort = s_key[inst]
else:
instrument_sort = 0
if artist_type in const.ARTIST_TYPE_ORDER:
type_sort = const.ARTIST_TYPE_ORDER[artist_type]
else:
type_sort = 99
if log_options['log_error']:
write_log(
release_id,
'error',
"Error in artist type. Type '%s' is not in ARTIST_TYPE_ORDER dictionary",
artist_type)
artist = (
artist_type,
instrument_list,
artist_name_list,
artist_sort_name_list,
instrument_sort,
type_sort)
artists.append(artist)
# Sorted by sort name then instrument_sort then artist type
artists = sorted(artists, key=lambda x: (x[5], x[3], x[4], x[1]))
if log_options['log_info']:
write_log(release_id, 'info', 'sorted artists = %s', artists)
return artists, instruments
def get_series(options, release_id, relations):
"""
Get series info (depends on lookup having used inc=series-rel)
:param options:
:param release_id:
:param relations:
:return:
"""
# if options['log_debug'] or options['log_info']:
# write_log(
# release_id,
# 'debug',
# 'In get_series. relations: %s',
# relations)
# series_name_list =[]
# series_id_list = []
# for series_rels in relations:
# series_rel = parse_data(
# release_id,
# series_rels,
# [],
# 'target-type:series',
# 'type:part-of')
# if options['log_debug'] or options['log_info']:
# write_log(
# release_id,
# 'debug',
# 'series_rel = %s',
# series_rel)
# series_name_list.extend(
# parse_data(release_id, series_rel, [], 'series', 'name')
# )
# series_id_list.extend(
# parse_data(release_id, series_rel, [], 'series', 'id')
# )
type_list = parse_data(
release_id,
relations,
[],
'target-type:series',
'type:part of')
if type_list:
series_name_list = []
series_id_list = []
series_number_list = []
for type_item in type_list:
series_name_list = parse_data(
release_id, type_item, [], 'series', 'name')
series_id_list = parse_data(
release_id, type_item, [], 'series', 'id')
series_number_list = parse_data(
release_id, type_item, [], 'attribute-values', 'number')
return {'name_list': series_name_list, 'id_list': series_id_list, 'number_list': series_number_list}
else:
return None
def apply_artist_style(
options,
release_id,
lang,
a_list,
name_style,
name_tag,
sort_tag,
names_tag,
names_sort_tag):
# Get artist and apply style
for a_item in a_list:
for acs in a_item:
artistlist = parse_data(release_id, acs, [], 'name')
sortlist = parse_data(release_id, acs, [], 'artist', 'sort-name')
names = {}
if lang:
names['alias'] = parse_data(
release_id,
acs,
[],
'artist',
'aliases',
'locale:' + lang,
'primary:True',
'name')
else:
names['alias'] = []
names['credit'] = parse_data(release_id, acs, [], 'name')
pairslist = list(zip(artistlist, sortlist))
names['sort'] = [
translate_from_sortname(
*pair) for pair in pairslist]
for style in name_style:
if names[style]:
artistlist = names[style]
break
joinlist = parse_data(release_id, acs, [], 'joinphrase')
if artistlist:
name_tag.append(artistlist[0])
sort_tag.append(sortlist[0])
names_tag.append(artistlist[0])
names_sort_tag.append(sortlist[0])
if joinlist:
name_tag.append(joinlist[0])
sort_tag.append(joinlist[0])
name_tag_str = ''.join(name_tag)
sort_tag_str = ''.join(sort_tag)
return {
'artists': names_tag,
'artists_sort': names_sort_tag,
'artist': name_tag_str,
'artistsort': sort_tag_str}
def set_work_artists(self, release_id, album, track, writerList, tm, count):
"""
:param release_id:
:param self is the calling object from Artists or WorkParts
:param album: the current album
:param track: the current track
:param writerList: format [(artist_type, [instrument_list], [name list],[sort_name list]),(.....etc]
:param tm: track metadata
:param count: depth count of recursion in process_work_artists (should equate to part level)
:return:
"""
options = self.options[track]
if not options['classical_work_parts']:
caller = 'ExtraArtists'
pre = '~cea'
else:
caller = 'PartLevels'
pre = '~cwp'
write_log(
release_id,
'debug',
'Class: %s: in set_work_artists for track %s. Count (level) is %s. Writer list is %s',
caller,
track,
count,
writerList)
# tag strings are a tuple (Picard tag, cwp tag, Picard sort tag, cwp sort
# tag) (NB this is modelled on set_performer)
tag_strings = const.tag_strings(pre)
# insertions lists artist types where names in the main Picard tags may be
# updated for annotations
insertions = const.INSERTIONS
no_more_lyricists = False
if caller == 'PartLevels' and self.lyricist_filled[track]:
no_more_lyricists = True
for writer in writerList:
writer_type = writer[0]
if writer_type not in tag_strings:
break
if no_more_lyricists and (
writer_type == 'lyricist' or writer_type == 'librettist'):
break
if writer[1]:
inst_list = writer[1][:]
# take a copy of the list in case (because of list
# mutability) we need the old one
instrument = ", ".join(inst_list)
else:
instrument = None
sub_strings = { # 'instrument arranger': instrument, 'vocal arranger': instrument
}
if options['cea_arranger']:
if instrument:
arr_inst = options['cea_arranger'] + ' ' + instrument
else:
arr_inst = options['cea_arranger']
else:
arr_inst = instrument
annotations = {'writer': options['cea_writer'],
'lyricist': options['cea_lyricist'],
'librettist': options['cea_librettist'],
'revised by': options['cea_revised'],
'translator': options['cea_translator'],
'arranger': options['cea_arranger'],
'reconstructed by': options['cea_reconstructed'],
'orchestrator': options['cea_orchestrator'],
'instrument arranger': arr_inst,
'vocal arranger': arr_inst}
tag = tag_strings[writer_type][0]
sort_tag = tag_strings[writer_type][2]
cwp_tag = tag_strings[writer_type][1]
cwp_sort_tag = tag_strings[writer_type][3]
cwp_names_tag = cwp_tag[:-1] + '_names'
cwp_instrumented_tag = cwp_names_tag + '_instrumented'
if writer_type in sub_strings:
if sub_strings[writer_type]:
tag += sub_strings[writer_type]
if tag:
if '~ce_tag_cleared_' + \
tag not in tm or not tm['~ce_tag_cleared_' + tag] == "Y":
if tag in tm:
if options['log_info']:
write_log(release_id, 'info', 'delete tag %s', tag)
del tm[tag]
tm['~ce_tag_cleared_' + tag] = "Y"
if sort_tag:
if '~ce_tag_cleared_' + \
sort_tag not in tm or not tm['~ce_tag_cleared_' + sort_tag] == "Y":
if sort_tag in tm:
del tm[sort_tag]
tm['~ce_tag_cleared_' + sort_tag] = "Y"
name_list = writer[2]
for ind, name in enumerate(name_list):
sort_name = writer[3][ind]
no_credit = True
write_log(
release_id,
'info',
'In set_work_artists. Name before changes = %s',
name)
# change name to as-credited
if options['cea_composer_credited']:
if album in self.artist_credits and sort_name in self.artist_credits[album]:
no_credit = False
name = self.artist_credits[album][sort_name]
# over-ride with aliases if appropriate
if (options['cea_aliases'] or options['cea_aliases_composer']) and (
no_credit or options['cea_alias_overrides']):
if sort_name in self.artist_aliases:
name = self.artist_aliases[sort_name]
# fix cyrillic names if not already fixed
if options['cea_cyrillic']:
if not only_roman_chars(name):
name = remove_middle(unsort(sort_name))
# Only remove middle name where the existing
# performer is in non-latin script
annotated_name = name
write_log(
release_id,
'info',
'In set_work_artists. Name after changes = %s',
name)
# add annotations and write performer tags
if writer_type in annotations:
if annotations[writer_type]:
annotated_name += ' (' + annotations[writer_type] + ')'
if instrument:
instrumented_name = name + ' (' + instrument + ')'
else:
instrumented_name = name
if writer_type in insertions and options['cea_arrangers']:
self.append_tag(release_id, tm, tag, annotated_name)
else:
if options['cea_arrangers'] or writer_type == tag:
self.append_tag(release_id, tm, tag, name)
if options['cea_arrangers'] or writer_type == tag:
if sort_tag:
self.append_tag(release_id, tm, sort_tag, sort_name)
if options['cea_tag_sort'] and '~' in sort_tag:
explicit_sort_tag = sort_tag.replace('~', '')
self.append_tag(
release_id, tm, explicit_sort_tag, sort_name)
self.append_tag(release_id, tm, cwp_tag, annotated_name)
self.append_tag(release_id, tm, cwp_names_tag, name)
if instrumented_name != name:
self.append_tag(
release_id,
tm,
cwp_instrumented_tag,
instrumented_name)
if cwp_sort_tag:
self.append_tag(release_id, tm, cwp_sort_tag, sort_name)
if caller == 'PartLevels' and (
writer_type == 'lyricist' or writer_type == 'librettist'):
self.lyricist_filled[track] = True
write_log(
release_id,
'info',
'Filled lyricist for track %s. Not looking further',
track)
if writer_type == 'composer':
composerlast = sort_name.split(",")[0]
write_log(
release_id,
'info',
'composerlast = %s',
composerlast)
self.append_tag(
release_id,
tm,
pre +
'_composer_lastnames',
composerlast)
if sort_name in self.release_artists_sort[album]:
self.append_tag(
release_id, tm, '~cea_album_composers', name)
self.append_tag(
release_id, tm, '~cea_album_composers_sort', sort_name)
self.append_tag(
release_id,
tm,
'~cea_album_track_composer_lastnames',
composerlast)
composer_last_names(self, release_id, tm, album)
# Non-Latin character processing
latin_letters = {}
def is_latin(uchr):
"""Test whether character is in Latin script"""
try:
return latin_letters[uchr]
except KeyError:
return latin_letters.setdefault(
uchr, 'LATIN' in unicodedata.name(uchr))
def only_roman_chars(unistr):
"""Test whether string is in Latin script"""
return all(is_latin(uchr)
for uchr in unistr
if uchr.isalpha())
def get_roman(string):
"""Transliterate cyrillic script to Latin script"""
translit_string = ""
for index, char in enumerate(string):
if char in const.CYRILLIC_LOWER.keys():
char = const.CYRILLIC_LOWER[char]
elif char in const.CYRILLIC_UPPER.keys():
char = const.CYRILLIC_UPPER[char]
if string[index + 1] not in const.CYRILLIC_LOWER.keys():
char = char.upper()
translit_string += char
# fix multi-chars
translit_string = translit_string.replace('ks', 'x').replace('iy ', 'i ')
return translit_string
def remove_middle(performer):
"""To remove middle names of Russian composers"""
plist = performer.split()
if len(plist) == 3:
return plist[0] + ' ' + plist[2]
else:
return performer
# Sorting etc.
def unsort(performer):
"""
To take a sort field and recreate the name
Only now used for last-ditch cyrillic translation - superseded by 'translate_from_sortname'
"""
sorted_list = performer.split(', ')
sorted_list.reverse()
for i, item in enumerate(sorted_list):
if item[-1] != "'":
sorted_list[i] += ' '
return ''.join(sorted_list).strip()
def _reverse_sortname(sortname):
"""
Reverse sortnames.
Code is from picard/util/__init__.py
"""
chunks = [a.strip() for a in sortname.split(",")]
chunk_len = len(chunks)
if chunk_len == 2:
return "%s %s" % (chunks[1], chunks[0])
elif chunk_len == 3:
return "%s %s %s" % (chunks[2], chunks[1], chunks[0])
elif chunk_len == 4:
return "%s %s, %s %s" % (chunks[1], chunks[0], chunks[3], chunks[2])
else:
return sortname.strip()
def stripsir(performer):
"""
Remove honorifics from names
Also standardize hyphens and apostrophes in names
"""
performer = performer.replace(u'\u2010', u'-').replace(u'\u2019', u"'")
sir = re.compile(r'(.*)\b(Sir|Maestro|Dame)\b\s*(.*)', re.IGNORECASE)
match = sir.search(performer)
if match:
return match.group(1) + match.group(3)
else:
return performer
# def swap_prefix(performer):
# """NOT CURRENTLY USED. Create sort fields for ensembles etc., by placing the prefix (see constants) at the end"""
# prefix = '|'.join(prefixes)
# swap = re.compile(r'^(' + prefix + r')\b\s*(.*)', re.IGNORECASE)
# match = swap.search(performer)
# if match:
# return match.group(2) + ", " + match.group(1)
# else:
# return performer
def replace_roman_numerals(s):
"""Replaces roman numerals include in s, where followed by certain punctuation, by digits"""
romans = RE_ROMANS.findall(s)
for roman in romans:
if roman[0]:
numerals = str(roman[0])
digits = str(from_roman(numerals))
to_replace = r'\b' + roman[0] + r'\b'
s = re.sub(to_replace, digits, s)
return s
def from_roman(s):
romanNumeralMap = (('M', 1000),
('CM', 900),
('D', 500),
('CD', 400),
('C', 100),
('XC', 90),
('L', 50),
('XL', 40),
('X', 10),
('IX', 9),
('V', 5),
('IV', 4),
('I', 1),
('m', 1000),
('cm', 900),
('d', 500),
('cd', 400),
('c', 100),
('xc', 90),
('l', 50),
('xl', 40),
('x', 10),
('ix', 9),
('v', 5),
('iv', 4),
('i', 1))
result = 0
index = 0
for numeral, integer in romanNumeralMap:
while s[index:index + len(numeral)] == numeral:
result += integer
index += len(numeral)
return result
def turbo_lcs(release_id, multi_list):
"""
Picks the best longest common string method to use
Works with a list of lists or a list of strings
:param release_id:
:param multi_list: a list of strings or a list of lists
:return: longest common substring/list
"""
write_log(release_id, 'debug', 'In turbo_lcs')
if not isinstance(multi_list, list):
return None
list_sum = sum([len(x) for x in multi_list])
list_len = len(multi_list)
if list_len < 2:
if list_len == 1:
return multi_list[0] # Nothing to do!
else:
return []
# for big matches, use the generalised suffix tree method
if ((list_sum / list_len) ** 2) * list_len > 1000:
# heuristic: may need to tweak the 1000 in the light of results
lcs_dict = suffixtree.multi_lcs(multi_list)
# NB suffixtree may be shown as an unresolved reference in the IDE,
# but it should work provided it is included in the package
if "error" not in lcs_dict:
if "response" in lcs_dict:
write_log(
release_id,
'info',
'Longest common string was returned from suffix tree algo')
return lcs_dict['response']
## If suffix tree fails, write errors to log before proceeding with alternative
else:
write_log(
release_id,
'error',
'Suffix tree failure for release %s. Error unknown. Using standard lcs algo instead',
release_id)
else:
write_log(
release_id,
'error',
'Suffix tree failure for release %s. Error message: %s. Using standard lcs algo instead',
release_id,
lcs_dict['error'])
# otherwise, or if gst fails, use the standard algorithm
first = True
common = []
for item in multi_list:
if first:
common = item
first = False
else:
lcs = longest_common_substring(
item, common)
common = lcs['string']
write_log(release_id, 'debug', 'LCS returned from standard algo')
return common
def longest_common_substring(s1, s2):
"""
Standard lcs algo for short strings, or if suffix tree does not work
:param s1: substring 1
:param s2: substring 2
:return: {'string': the longest common substring,
'start': the start position in s1,
'length': the length of the common substring}
NB this also works on list arguments - i.e. it will find the longest common sub-list
"""
m = [[0] * (1 + len(s2)) for i in range(1 + len(s1))]
longest, x_longest = 0, 0
for x in range(1, 1 + len(s1)):
for y in range(1, 1 + len(s2)):
if s1[x - 1] == s2[y - 1]:
m[x][y] = m[x - 1][y - 1] + 1
if m[x][y] > longest:
longest = m[x][y]
x_longest = x
else:
m[x][y] = 0
return {'string': s1[x_longest - longest: x_longest],
'start': x_longest - longest, 'length': longest}
def longest_common_sequence(list1, list2, minstart=0, maxstart=0):
"""
:param list1: list 1
:param list2: list 2
:param minstart: the earliest point to start looking for a match
:param maxstart: the latest point to start looking for a match
:return: {'sequence': the common subsequence, 'length': length of subsequence}
maxstart must be >= minstart. If they are equal then the start point is fixed.
Note that this only finds subsequences starting at the same position
Use longest_common_substring for the more general problem
"""
if maxstart < minstart:
return None, 0
min_len = min(len(list1), len(list2))
longest = 0
seq = None
maxstart = min(maxstart, min_len) + 1
for k in range(minstart, maxstart):
for i in range(k, min_len + 1):
if list1[k:i] == list2[k:i] and i - k > longest:
longest = i - k
seq = list1[k:i]
return {'sequence': seq, 'length': longest}
def substart_finder(mylist, pattern):
for i, list_item in enumerate(mylist):
if list_item == pattern[0] and mylist[i:i + len(pattern)] == pattern:
return i
return len(mylist) # if nothing found
def get_ui_tags():
## Determine tags for display in ui
options = config.setting
ui_tags_raw = options['ce_ui_tags']
ui_tags = {}
ui_tags_split = [x.replace('(','').strip(') ') for x in ui_tags_raw.split('/')]
for ui_column in ui_tags_split:
if ':' in ui_column:
ui_col_parts = [x.strip() for x in ui_column.split(':')]
heading = ui_col_parts[0]
tag_names = ui_col_parts[1].split(',')
tag_names = [x.strip() for x in tag_names]
ui_tags[heading] = tuple(tag_names)
return ui_tags
def map_tags(options, release_id, album, tm):
"""
Do the common tag processing - including for the genres and tag-mapping sections
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param options: options passed from either Artists or Workparts
:param album:
:param tm: track metadata
:return: None - action is through setting tm contents
This is a common function for Artists and Workparts which should only run after both sections have completed for
a given track. If, say, Artists calls it and Workparts is not done,
then it will not execute until Workparts calls it (and vice versa).
"""
write_log(release_id, 'debug', 'In map_tags, checking readiness...')
if (options['classical_extra_artists'] and '~cea_artists_complete' not in tm) or (
options['classical_work_parts'] and '~cea_works_complete' not in tm):
write_log(release_id, 'info', '...not ready')
return
write_log(release_id, 'debug', '... processing tag mapping')
# blank tags
blank_tags = options['cea_blank_tag'].split(
",") + options['cea_blank_tag_2'].split(",")
if 'artists_sort' in [x.strip() for x in blank_tags]:
blank_tags.append('~artists_sort')
for tag in blank_tags:
if tag.strip() in tm:
# place blanked tags into hidden variables available for
# re-use
tm['~cea_' + tag.strip()] = tm[tag.strip()]
del tm[tag.strip()]
# album
if tm['~cea_album_composer_lastnames']:
last_names = str_to_list(tm['~cea_album_composer_lastnames'])
if options['cea_composer_album']:
# save it as a list to prevent splitting when appending tag
tm['~cea_release'] = [tm['album']]
new_last_names = []
for last_name in last_names:
last_name = last_name.strip()
new_last_names.append(last_name)
if len(new_last_names) > 0:
tm['album'] = "; ".join(new_last_names) + ": " + tm['album']
# remove lyricists if no vocals, according to option set
if options['cea_no_lyricists'] and not any(
[x for x in str_to_list(tm['~cea_performers']) if 'vocals' in x]):
if 'lyricist' in tm:
del tm['lyricist']
for lyricist_tag in ['lyricists', 'librettists', 'translators']:
if '~cwp_' + lyricist_tag in tm:
del tm['~cwp_' + lyricist_tag]
# genres
if config.setting['folksonomy_tags'] and 'genre' in tm:
candidate_genres = str_to_list(tm['genre'])
append_tag(release_id, tm, '~cea_candidate_genres', candidate_genres)
# to avoid confusion as it will contain unmatched folksonomy tags
del tm['genre']
else:
candidate_genres = []
is_classical = False
composers_not_found = []
composer_found = False
composer_born_list = []
composer_died_list = []
arrangers_not_found = []
arranger_found = False
arranger_born_list = []
arranger_died_list = []
no_composer_in_metadata = False
if options['cwp_use_muso_refdb'] and options['cwp_muso_classical'] or options['cwp_muso_dates']:
if COMPOSER_DICT:
composersort_list = []
if '~cwp_composer_names' in tm:
composer_list = str_to_list(tm['~cwp_composer_names'])
else:
# maybe there were no works linked,
# but it might still a classical track (based on composer name)
no_composer_in_metadata = True
composer_list = str_to_list(tm['artists'])
composersort_list = str_to_list(tm['~artists_sort'])
write_log(release_id, 'info', "No composer metadata for track %s. Using artists %r", tm['title'],
composer_list)
lc_composer_list = [c.lower() for c in composer_list]
for ind, composer in enumerate(lc_composer_list):
for classical_composer in COMPOSER_DICT:
if composer in classical_composer['lc_name']:
if options['cwp_muso_classical']:
candidate_genres.append('Classical')
is_classical = True
if options['cwp_muso_dates']:
composer_born_list = classical_composer['birth']
composer_died_list = classical_composer['death']
composer_found = True
if no_composer_in_metadata:
composersort = composersort_list[ind]
append_tag(release_id, tm, 'composer', composer_list[ind])
append_tag(release_id, tm, '~cwp_composer_names', composer_list[ind])
append_tag(release_id, tm, 'composersort', composersort)
append_tag(release_id, tm, '~cwp_composers_sort', composersort)
append_tag(release_id, tm, '~cwp_composer_lastnames', composersort.split(', ')[0])
break
if not composer_found:
composer_index = lc_composer_list.index(composer)
orig_composer = composer_list[composer_index]
composers_not_found.append(orig_composer)
append_tag(
release_id,
tm,
'~cwp_unrostered_composers',
orig_composer)
if composers_not_found:
append_tag(
release_id,
tm,
'003_information:composers',
'Composer(s) ' +
list_to_str(composers_not_found) +
' not found in reference database of classical composers')
# do the same for arrangers, if required
if options['cwp_genres_arranger_as_composer'] or options['cwp_periods_arranger_as_composer']:
arranger_list = str_to_list(
tm['~cea_arranger_names']) + str_to_list(tm['~cwp_arranger_names'])
lc_arranger_list = [c.lower() for c in arranger_list]
for arranger in lc_arranger_list:
for classical_arranger in COMPOSER_DICT:
if arranger in classical_arranger['lc_name']:
if options['cwp_muso_classical'] and options['cwp_genres_arranger_as_composer']:
candidate_genres.append('Classical')
is_classical = True
if options['cwp_muso_dates'] and options['cwp_periods_arranger_as_composer']:
arranger_born_list = classical_arranger['birth']
arranger_died_list = classical_arranger['death']
arranger_found = True
break
if not arranger_found:
arranger_index = lc_arranger_list.index(arranger)
orig_arranger = arranger_list[arranger_index]
arrangers_not_found.append(orig_arranger)
append_tag(
release_id,
tm,
'~cwp_unrostered_arrangers',
orig_arranger)
if arrangers_not_found:
append_tag(
release_id,
tm,
'003_information:arrangers',
'Arranger(s) ' +
list_to_str(arrangers_not_found) +
' not found in reference database of classical composers')
else:
append_tag(
release_id,
tm,
'001_errors:8',
'8. No composer reference file. Check log for error messages re path name.')
if options['cwp_use_muso_refdb'] and options['cwp_muso_genres'] and GENRE_DICT:
main_classical_genres_list = [list_to_str(
mg['name']).strip() for mg in GENRE_DICT]
else:
main_classical_genres_list = [
sg.strip() for sg in options['cwp_genres_classical_main'].split(',')]
sub_classical_genres_list = [
sg.strip() for sg in options['cwp_genres_classical_sub'].split(',')]
main_other_genres_list = [
sg.strip() for sg in options['cwp_genres_other_main'].split(',')]
sub_other_genres_list = [sg.strip()
for sg in options['cwp_genres_other_sub'].split(',')]
main_classical_genres = []
sub_classical_genres = []
main_other_genres = []
sub_other_genres = []
if '~cea_work_type' in tm:
candidate_genres += str_to_list(tm['~cea_work_type'])
if '~cwp_candidate_genres' in tm:
candidate_genres += str_to_list(tm['~cwp_candidate_genres'])
write_log(release_id, 'info', "Candidate genres: %r", candidate_genres)
untagged_genres = []
if candidate_genres:
main_classical_genres = [
val for val in main_classical_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
sub_classical_genres = [
val for val in sub_classical_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
if main_classical_genres or sub_classical_genres or options['cwp_genres_classical_all']:
is_classical = True
main_classical_genres.append('Classical')
candidate_genres.append('Classical')
write_log(release_id, 'info', "Main classical genres for track %s: %r", tm['title'], main_classical_genres)
candidate_genres += str_to_list(tm['~cea_work_type_if_classical'])
# next two are repeated statements, but a separate fn would be
# clumsy too!
main_classical_genres = [
val for val in main_classical_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
sub_classical_genres = [
val for val in sub_classical_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
if options['cwp_genres_classical_exclude']:
main_classical_genres = [
g for g in main_classical_genres if g.lower() != 'classical']
main_other_genres = [
val for val in main_other_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
sub_other_genres = [
val for val in sub_other_genres_list if val.lower() in [
genre.lower() for genre in candidate_genres]]
all_genres = main_classical_genres + sub_classical_genres + \
main_other_genres + sub_other_genres
untagged_genres = [
un for un in candidate_genres if un.lower() not in [
genre.lower() for genre in all_genres]]
if options['cwp_genre_tag']:
if not options['cwp_genres_filter']:
append_tag(
release_id,
tm,
options['cwp_genre_tag'],
candidate_genres)
else:
append_tag(
release_id,
tm,
options['cwp_genre_tag'],
main_classical_genres +
main_other_genres)
if options['cwp_subgenre_tag'] and options['cwp_genres_filter']:
append_tag(
release_id,
tm,
options['cwp_subgenre_tag'],
sub_classical_genres +
sub_other_genres)
if is_classical and options['cwp_genres_flag_text'] and options['cwp_genres_flag_tag']:
tm[options['cwp_genres_flag_tag']] = options['cwp_genres_flag_text']
if not (
main_classical_genres +
main_other_genres)and options['cwp_genres_filter']:
if options['cwp_genres_default']:
append_tag(
release_id,
tm,
options['cwp_genre_tag'],
options['cwp_genres_default'])
else:
if options['cwp_genre_tag'] in tm:
del tm[options['cwp_genre_tag']]
if untagged_genres and options['cwp_genres_filter']:
append_tag(
release_id,
tm,
'003_information:genres',
'Candidate genres found but not matched: ' +
list_to_str(untagged_genres))
append_tag(release_id, tm, '~cwp_untagged_genres', untagged_genres)
# instruments and keys
if options['cwp_instruments_MB_names'] and options['cwp_instruments_credited_names'] and tm['~cea_instruments_all']:
instruments = str_to_list(tm['~cea_instruments_all'])
elif options['cwp_instruments_MB_names'] and tm['~cea_instruments']:
instruments = str_to_list(tm['~cea_instruments'])
elif options['cwp_instruments_credited_names'] and tm['~cea_instruments_credited']:
instruments = str_to_list(tm['~cea_instruments_credited'])
else:
instruments = None
if instruments and options['cwp_instruments_tag']:
append_tag(release_id, tm, options['cwp_instruments_tag'], instruments)
# need to append rather than over-write as it may be the same as
# another tag (e.g. genre)
if tm['~cwp_keys'] and options['cwp_key_tag']:
append_tag(release_id, tm, options['cwp_key_tag'], tm['~cwp_keys'])
# dates
if options['cwp_workdate_annotate']:
comp = ' (composed)'
publ = ' (published)'
prem = ' (premiered)'
else:
comp = ''
publ = ''
prem = ''
tm[options['cwp_workdate_tag']] = ''
earliest_date = 9999
latest_date = -9999
found = False
if tm['~cwp_composed_dates']:
composed_dates_list = str_to_list(tm['~cwp_composed_dates'])
if len(composed_dates_list) > 1:
composed_dates_list = str_to_list(
composed_dates_list[0]) # use dates of lowest-level work
earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
for dates in composed_dates_list])
append_tag(
release_id,
tm,
options['cwp_workdate_tag'],
list_to_str(composed_dates_list) +
comp)
found = True
if tm['~cwp_published_dates'] and (
not found or options['cwp_workdate_use_all']):
if not found:
published_dates_list = str_to_list(tm['~cwp_published_dates'])
if len(published_dates_list) > 1:
published_dates_list = str_to_list(
published_dates_list[0]) # use dates of lowest-level work
earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
for dates in published_dates_list])
append_tag(
release_id,
tm,
options['cwp_workdate_tag'],
list_to_str(published_dates_list) +
publ)
found = True
if tm['~cwp_premiered_dates'] and (
not found or options['cwp_workdate_use_all']):
if not found:
premiered_dates_list = str_to_list(tm['~cwp_premiered_dates'])
if len(premiered_dates_list) > 1:
premiered_dates_list = str_to_list(
premiered_dates_list[0]) # use dates of lowest-level work
earliest_date = min([int(dates.split(DATE_SEP)[0].strip())
for dates in premiered_dates_list])
append_tag(
release_id,
tm,
options['cwp_workdate_tag'],
list_to_str(premiered_dates_list) +
prem)
# periods
PERIODS = {}
if options['cwp_period_map']:
if options['cwp_use_muso_refdb'] and options['cwp_muso_periods'] and PERIOD_DICT:
for p_item in PERIOD_DICT:
if 'start' not in p_item or p_item['start'] == []:
p_item['start'] = [u'-9999']
if 'end' not in p_item or p_item['end'] == []:
p_item['end'] = [u'2525']
if 'name' not in p_item or p_item['name'] == []:
p_item['name'] = ['NOT SPECIFIED']
PERIODS = {list_to_str(mp['name']).strip(): (
list_to_str(mp['start']),
list_to_str(mp['end']))
for mp in PERIOD_DICT}
for period in PERIODS:
if PERIODS[period][0].lstrip(
'-').isdigit() and PERIODS[period][1].lstrip('-').isdigit():
PERIODS[period] = (int(PERIODS[period][0]),
int(PERIODS[period][1]))
else:
PERIODS[period] = (
9999,
'ERROR - start and/or end of ' +
period +
' are not integers')
else:
periods = [p.strip() for p in options['cwp_period_map'].split(';')]
for p in periods:
p = p.split(',')
if len(p) == 3:
period = p[0].strip()
start = p[1].strip()
end = p[2].strip()
if start.lstrip(
'-').isdigit() and end.lstrip('-').isdigit():
PERIODS[period] = (int(start), int(end))
else:
PERIODS[period] = (
9999,
'ERROR - start and/or end of ' +
period +
' are not integers')
else:
PERIODS[p[0]] = (
9999, 'ERROR in period map - each item must contain 3 elements')
if options['cwp_period_tag'] and PERIODS:
if earliest_date == 9999: # i.e. no work date found
if options['cwp_use_muso_refdb'] and options['cwp_muso_dates']:
for composer_born in composer_born_list + arranger_born_list:
if composer_born and composer_born.isdigit():
birthdate = int(composer_born)
# productive age is taken as 20->death as per Muso
earliest_date = min(earliest_date, birthdate + 20)
for composer_died in composer_died_list + arranger_died_list:
if composer_died and composer_died.isdigit():
deathdate = int(composer_died)
latest_date = max(latest_date, deathdate)
else:
latest_date = datetime.now().year
# sort into start date order before writing tags
sorted_periods = collections.OrderedDict(
sorted(PERIODS.items(), key=lambda t: t[1]))
for period in sorted_periods:
if isinstance(
sorted_periods[period][1],
str) and 'ERROR' in sorted_periods[period][1]:
tm[options['cwp_period_tag']] = ''
append_tag(
release_id,
tm,
'001_errors:9',
'9. ' +
sorted_periods[period])
break
if earliest_date < 9999:
if sorted_periods[period][0] <= earliest_date <= sorted_periods[period][1]:
append_tag(
release_id,
tm,
options['cwp_period_tag'],
period)
if latest_date > -9999:
if sorted_periods[period][0] <= latest_date <= sorted_periods[period][1]:
append_tag(
release_id,
tm,
options['cwp_period_tag'],
period)
# generic tag mapping
sort_tags = options['cea_tag_sort']
if sort_tags:
tm['artists_sort'] = str_to_list(tm['~artists_sort'])
for i in range(0, 16):
tagline = options['cea_tag_' + str(i + 1)].split(",")
source_group = options['cea_source_' + str(i + 1)].split(",")
conditional = options['cea_cond_' + str(i + 1)]
for item, tagx in enumerate(tagline):
tag = tagx.strip()
sort = sort_suffix(tag)
if not conditional or tm[tag] == "":
for source_memberx in source_group:
source_member = source_memberx.strip()
sourceline = source_member.split("+")
if len(sourceline) > 1:
source = "\\"
for source_itemx in sourceline:
source_item = source_itemx.strip()
source_itema = source_itemx.lstrip()
write_log(
release_id, 'info', "Source_item: %s", source_item)
if "~cea_" + source_item in tm:
si = tm['~cea_' + source_item]
elif "~cwp_" + source_item in tm:
si = tm['~cwp_' + source_item]
elif source_item in tm:
si = tm[source_item]
elif len(source_itema) > 0 and source_itema[0] == "\\":
si = source_itema[1:]
else:
si = ""
if si != "" and source != "":
source = source + si
else:
source = ""
else:
source = sourceline[0]
no_names_source = re.sub('(_names)$', 's', source)
source_sort = sort_suffix(source)
write_log(
release_id,
'info',
"Tag mapping: Line: %s, Source: %s, Tag: %s, no_names_source: %s, sort: %s, item %s",
i +
1,
source,
tag,
no_names_source,
sort,
item)
if '~cea_' + source in tm or '~cwp_' + source in tm:
for prefix in ['~cea_', '~cwp_']:
if prefix + source in tm:
write_log(release_id, 'info', prefix)
append_tag(release_id, tm, tag,
tm[prefix + source], ['; '])
if sort_tags:
if prefix + no_names_source + source_sort in tm:
write_log(
release_id, 'info', prefix + " sort")
append_tag(release_id, tm, tag + sort,
tm[prefix + no_names_source + source_sort], ['; '])
elif source in tm or '~' + source in tm:
write_log(release_id, 'info', "Picard")
for p in ['', '~']:
if p + source in tm:
append_tag(release_id, tm, tag,
tm[p + source], ['; ', '/ '])
if sort_tags:
if "~" + source + source_sort in tm:
source = "~" + source
if source + source_sort in tm:
write_log(
release_id, 'info', "Picard sort")
append_tag(release_id, tm, tag + sort,
tm[source + source_sort], ['; ', '/ '])
elif len(source) > 0 and source[0] == "\\":
append_tag(release_id, tm, tag,
source[1:], ['; ', '/ '])
else:
pass
# write error messages to tags
if options['log_error'] and "~cea_error" in tm:
for error in str_to_list(tm['~cea_error']):
ecode = error[0]
append_tag(release_id, tm, '001_errors:' + ecode, error)
if options['log_warning'] and "~cea_warning" in tm:
for warning in str_to_list(tm['~cea_warning']):
wcode = warning[0]
append_tag(release_id, tm, '002_warnings:' + wcode, warning)
# delete unwanted tags
if not options['log_debug']:
if '~cea_works_complete' in tm:
del tm['~cea_works_complete']
if '~cea_artists_complete' in tm:
del tm['~cea_artists_complete']
del_list = []
for t in tm:
if 'ce_tag_cleared' in t:
del_list.append(t)
for t in del_list:
del tm[t]
# create hidden tags to flag differences
if options['ce_show_ui_tags'] and options['ce_ui_tags']:
for heading_name, tag_tuple in UI_TAGS: # UI_TAGS is already iterated in main routine, so no need for .items() method here
heading_tag = '~' + heading_name + '_VAL'
for tag in tag_tuple:
if tag[-5:] != '_DIFF':
append_tag(release_id, tm, heading_tag, tm[tag])
else:
tag = '~' + tag
mirror_tags = str_to_list((tm['~ce_mirror_tags']))
for mirror_tag in mirror_tags:
mt = interpret(mirror_tag)
st = str_to_list(mt)
(old_tag, new_tag) = tuple(st)
diff_name = old_tag.replace('OLD', 'DIFF')
if diff_name == tag and tm[old_tag] != tm[new_tag]:
tm[diff_name] = '*****'
append_tag(release_id, tm, heading_tag, '*****')
break
# if options over-write enabled, remove it after processing one album
options['ce_options_overwrite'] = False
config.setting['ce_options_overwrite'] = False
# so that options are not retained (in case of refresh with different
# options)
if '~ce_options' in tm:
del tm['~ce_options']
# remove any unwanted file tags
if '~ce_file' in tm and tm['~ce_file'] != "None":
music_file = tm['~ce_file']
orig_metadata = album.tagger.files[music_file].orig_metadata
if 'delete_tags' in options and options['delete_tags']:
warn = []
for delete_item in options['delete_tags']:
if delete_item not in tm: # keep the original for comparison if we have a new version
if delete_item in orig_metadata:
del orig_metadata[delete_item]
if delete_item != '002_warnings:7': # to avoid circularity!
warn.append(delete_item)
if warn and options['log_warning']:
append_tag(
release_id,
tm,
'002_warnings:7',
'7. Deleted tags: ' +
', '.join(warn))
write_log(
release_id,
'warning',
'Deleted tags: ' +
', '.join(warn))
def sort_suffix(tag):
"""To determine what sort suffix is appropriate for a given tag"""
if tag == "composer" or tag == "artist" or tag == "albumartist" or tag == "trackartist" or tag == "~cea_MB_artist":
sort = "sort"
else:
sort = "_sort"
return sort
def append_tag(release_id, tm, tag, source, separators=None):
"""
Update a tag
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param tm: track metadata
:param tag: tag to be appended to
:param source: item to append to tag
:param separators: characters which may be used to split string into a list
(any of the characters will be a split point)
:return: None. Action is on tm
"""
if not separators:
separators = []
if tag and tag != "":
if config.setting['log_info']:
write_log(
release_id,
'info',
'Appending source: %r to tag: %s (source is type %s) ...',
source,
tag,
type(source))
if tag in tm:
write_log(
release_id,
'info',
'... existing tag contents = %r',
tm[tag])
if source and len(source) > 0:
if isinstance(source, str):
if separators:
source = re.split('|'.join(separators), source)
else:
source = [source]
if not isinstance(source, list):
source = [source] # typically for dict items such as saved options
if all([isinstance(x, str) for x in source]): # only append if if source is a list of strings
if tag not in tm:
if tag == 'artists_sort':
# There is no artists_sort tag in Picard - just a
# hidden var ~artists_sort, so pick up those into the new tag
hidden = tm['~artists_sort']
if not isinstance(hidden, list):
if separators:
hidden = re.split(
'|'.join(separators), hidden)
for i, h in enumerate(hidden):
hidden[i] = h.strip()
else:
hidden = [hidden]
source = add_list_uniquely(source, hidden)
new_tag = True
else:
new_tag = False
for source_item in source:
if isinstance(source_item, str):
source_item = source_item.replace(u'\u2010', u'-')
source_item = source_item.replace(u'\u2011', u'-')
source_item = source_item.replace(u'\u2019', u"'")
source_item = source_item.replace(u'\u2018', u"'")
source_item = source_item.replace(u'\u201c', u'"')
source_item = source_item.replace(u'\u201d', u'"')
if new_tag:
tm[tag] = [source_item]
new_tag = False
else:
if not isinstance(tm[tag], list):
if separators:
tag_list = re.split(
'|'.join(separators), tm[tag])
for i, t in enumerate(tag_list):
tag_list[i] = t.strip()
else:
tag_list = [tm[tag]]
else:
tag_list = tm[tag]
if source_item not in tm[tag]:
tag_list.append(source_item)
tm[tag] = tag_list
# NB tag_list is used as metadata object will convert single-item lists to strings
else: # source items are not strings, so just replace
tm[tag] = source
def get_artist_credit(options, release_id, obj):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param options:
:param obj: an XmlNode
:return: a list of as-credited names
"""
name_credit_list = parse_data(release_id, obj, [], 'artist-credit')
credit_list = []
if name_credit_list:
for name_credits in name_credit_list:
for name_credit in name_credits:
credited_artist = parse_data(
release_id, name_credit, [], 'name')
if credited_artist:
name = parse_data(
release_id, name_credit, [], 'artist', 'name')
sort_name = parse_data(
release_id, name_credit, [], 'artist', 'sort-name')
credit_item = (credited_artist, name, sort_name)
credit_list.append(credit_item)
return credit_list
def get_aliases_and_credits(
self,
options,
release_id,
album,
obj,
lang,
credited):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param self: This relates to the object in the class which called this function
:param options:
:param obj: an XmlNode
:param lang: The language selected in the Picard metadata options
:param credited: The options item to determine what as-credited names are being sought
:return: None. Sets self.artist_aliases and self.artist_credits[album]
"""
name_credit_list = parse_data(release_id, obj, [], 'artist-credit')
artist_list = parse_data(release_id, name_credit_list, [], 'artist')
for artist in artist_list:
sort_names = parse_data(release_id, artist, [], 'sort-name')
if sort_names:
aliases = parse_data(release_id, artist, [], 'aliases', 'locale:' +
lang, 'primary:True', 'name')
if aliases:
self.artist_aliases[sort_names[0]] = aliases[0]
if credited:
for name_credit in name_credit_list[0]:
credited_artist = parse_data(release_id, name_credit, [], 'name')
if credited_artist:
sort_name = parse_data(
release_id, name_credit, [], 'artist', 'sort-name')
if sort_name:
self.artist_credits[album][sort_name[0]
] = credited_artist[0]
def get_relation_credits(
self,
options,
release_id,
album,
obj,
lang,
credited):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param self:
:param options: UI options
:param album: current album
:param obj: Xmlnode
:param lang: language
:param credited: credited-as name
:return: None
Note that direct recording relationships will over-ride indirect ones (via work)
"""
rels = parse_data(release_id, obj, [], 'relations', 'target-type:work',
'work', 'relations', 'target-type:artist')
for artist in rels:
sort_names = parse_data(release_id, artist, [], 'artist', 'sort-name')
if sort_names:
credited_artists = parse_data(
release_id, artist, [], 'target-credit')
if credited_artists and credited_artists[0] != '' and credited:
self.artist_credits[album][sort_names[0]
] = credited_artists[0]
aliases = parse_data(
release_id,
artist,
[],
'artist',
'aliases',
'locale:' + lang,
'primary:True',
'name')
if aliases:
self.artist_aliases[sort_names[0]] = aliases[0]
rels2 = parse_data(release_id, obj, [], 'relations', 'target-type:artist')
for artist in rels2:
sort_names = parse_data(release_id, artist, [], 'artist', 'sort-name')
if sort_names:
credited_artists = parse_data(
release_id, artist, [], 'target-credit')
if credited_artists and credited_artists[0] != '' and credited:
self.artist_credits[album][sort_names[0]
] = credited_artists[0]
aliases = parse_data(
release_id,
artist,
[],
'artist',
'aliases',
'locale:' + lang,
'primary:True',
'name')
if aliases:
self.artist_aliases[sort_names[0]] = aliases[0]
def composer_last_names(self, release_id, tm, album):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param self:
:param tm:
:param album:
:return: None
Sets composer last names for album prefixing
"""
if '~cea_album_track_composer_lastnames' in tm:
if not isinstance(tm['~cea_album_track_composer_lastnames'], list):
atc_list = re.split(
'|'.join(
self.SEPARATORS),
tm['~cea_album_track_composer_lastnames'])
else:
atc_list = str_to_list(tm['~cea_album_track_composer_lastnames'])
for atc_item in atc_list:
composer_lastnames = atc_item.strip()
if '~length' in tm and tm['~length']:
track_length = time_to_secs(tm['~length'])
else:
track_length = 0
if album in self.album_artists:
if 'composer_lastnames' in self.album_artists[album]:
if composer_lastnames not in self.album_artists[album]['composer_lastnames']:
self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
'length': track_length}
else:
self.album_artists[album]['composer_lastnames'][composer_lastnames]['length'] += track_length
else:
self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
'length': track_length}
else:
self.album_artists[album]['composer_lastnames'][composer_lastnames] = {
'length': track_length}
else:
write_log(
release_id,
'warning',
"No _cea_album_track_composer_lastnames variable available for recording \"%s\".",
tm['title'])
if 'composer' in tm:
self.append_tag(
release_id,
release_id,
tm,
'~cea_warning',
'1. Composer for this track is not in album artists and will not be available to prefix album')
else:
self.append_tag(
release_id,
release_id,
tm,
'~cea_warning',
'1. No composer for this track, but checking parent work.')
def add_list_uniquely(list_to, list_from):
"""
Adds any items in list_from to list_to, if they are not already present
If either arg is a string, it will be converted to a list, e.g. 'abc' -> ['abc']
:param list_to:
:param list_from:
:return: appends only unique elements of list 2 to list 1
"""
#
if list_to and list_from:
if not isinstance(list_to, list):
list_to = str_to_list(list_to)
if not isinstance(list_from, list):
list_from = str_to_list(list_from)
for list_item in list_from:
if list_item not in list_to:
list_to.append(list_item)
else:
if list_from:
list_to = list_from
return list_to
def str_to_list(s):
"""
:param s:
:return: list from string using ; as separator
"""
if isinstance(s, list):
return s
if not isinstance(s, str):
try:
return list(s)
except TypeError:
return []
else:
if s == '':
return []
else:
return s.split('; ')
def list_to_str(l):
"""
:param l:
:return: string from list using ; as separator
"""
if not isinstance(l, list):
return l
else:
return '; '.join(l)
def interpret(tag):
"""
:param tag:
:return: safe form of eval(tag)
"""
if isinstance(tag, str):
try:
tag = tag.strip(' \n\t')
return ast.literal_eval(tag)
except (SyntaxError, ValueError):
return tag
else:
return tag
def time_to_secs(a):
"""
:param a: string x:x:x
:return: seconds
converts string times to seconds
"""
ax = a.split(':')
ax = ax[::-1]
t = 0
for i, x in enumerate(ax):
if x.isdigit():
t += int(x) * (60 ** i)
else:
return 0
return t
def seq_last_names(self, album):
"""
Sequences composer last names for album prefix by the total lengths of their tracks
:param self:
:param album:
:return:
"""
ln = []
if album in self.album_artists and 'composer_lastnames' in self.album_artists[album]:
for x in self.album_artists[album]['composer_lastnames']:
if 'length' in self.album_artists[album]['composer_lastnames'][x]:
ln.append([x, self.album_artists[album]
['composer_lastnames'][x]['length']])
else:
return []
ln = sorted(ln, key=lambda a: a[1])
ln = ln[::-1]
return [a[0] for a in ln]
def year(date):
"""
Return YYYY portion of date(s) in YYYY-MM-DD format (may be incomplete, string or list)
:param date:
:return: YYYY
"""
if isinstance(date, list):
year_list = [blank_if_none(d).split('-')[0] for d in date]
return year_list
else:
date_list = blank_if_none(date).split('-')
return [date_list[0]]
def blank_if_none(val):
"""
Make NoneTypes strings
:param val: str or None
:return: str
"""
if not val:
return ''
else:
return val
def strip_excess_punctuation(s):
"""
remove orphan punctuation, unmatched quotes and brackets
:param s: string
:return: string
"""
if s:
s_prev = ''
counter = 0
while s != s_prev:
if counter > 100:
break # safety valve
s_prev = s
s = s.replace(' ', ' ')
s = s.strip("&.-:;, ")
s = s.lstrip("!)]}")
s = s.rstrip("([{")
s = s.lstrip(u"\u2019") # Right single quote
s = s.lstrip(u"\u201D") # Right double quote
if s.count(u"\u201E") == 0: # u201E is lower double quote (German etc.)
s = s.rstrip(u"\u201C") # Left double quote - only strip if there is no German-style lower quote present
s = s.rstrip(u"\u2018") # Left single quote
if s.count('"') % 2 != 0:
s = s.strip('"')
if s.count("'") % 2 != 0:
s = s.strip("'")
if len(s) > 0 and s[0] == u"\u201C" and s.count(u"\u201D") == 0:
s = s.lstrip(u"\u201C")
if len(s) > 0 and s[-1] == u"\u201D" and s.count(u"\u201C") == 0 and s.count(u"\u201E") == 0: # only strip if there is no German-style lower quote present
s = s.rstrip(u"\u201D")
if len(s) > 0 and s[0] == u"\u2018" and s.count(u"\u2019") == 0:
s = s.lstrip(u"\u2018")
if len(s) > 0 and s[-1] == u"\u2019" and s.count(u"\u2018") == 0:
s = s.rstrip(u"\u2019")
if s:
if s.count("\"") == 1:
s = s.replace('"', '')
if s.count("\'") == 1:
s = s.replace(" '", " ")
# s = s.replace("' ", " ") # removed to prevent removal of genuine apostrophes
if "(" in s and ")" not in s:
s = s.replace("(", "")
if ")" in s and "(" not in s:
s = s.replace(")", "")
if "[" in s and "]" not in s:
s = s.replace("[", "")
if "]" in s and "[" not in s:
s = s.replace("]", "")
if "{" in s and "}" not in s:
s = s.replace("{", "")
if "}" in s and "{" not in s:
s = s.replace("}", "")
if s:
match_chars = [("(", ")"), ("[", "]"), ("{", "}")]
last = len(s) - 1
for char_pair in match_chars:
if char_pair[0] == s[0] and char_pair[1] == s[last]:
s = s.lstrip(char_pair[0]).rstrip(char_pair[1])
counter += 1
return s
#################
#################
# EXTRA ARTISTS #
#################
#################
class ExtraArtists():
# CONSTANTS
def __init__(self):
self.album_artists = collections.defaultdict(
lambda: collections.defaultdict(dict))
# collection of artists to be applied at album level
self.track_listing = collections.defaultdict(list)
# collection of tracks - format is {album: [track 1,
# track 2, ...]}
self.options = collections.defaultdict(dict)
# collection of Classical Extras options
self.globals = collections.defaultdict(dict)
# collection of global variables for this class
self.album_performers = collections.defaultdict(
lambda: collections.defaultdict(dict))
# collection of performers who have release relationships, not track
# relationships
self.album_instruments = collections.defaultdict(
lambda: collections.defaultdict(dict))
# collection of instruments which have release relationships, not track
# relationships
self.artist_aliases = {}
# collection of alias names - format is {sort_name: alias_name, ...}
self.artist_credits = collections.defaultdict(dict)
# collection of credited-as names - format is {album: {sort_name: credit_name,
# ...}, ...}
self.release_artists_sort = collections.defaultdict(list)
# collection of release artists - format is {album: [sort_name_1,
# sort_name_2, ...]}
self.lyricist_filled = collections.defaultdict(dict)
# Boolean for each track to indicate if lyricist has been found (don't
# want to add more from higher levels)
# NB this last one is for completeness - not actually used by
# ExtraArtists, but here to remove pep8 error
self.album_series_list = collections.defaultdict(dict)
# series relationships - format is {'name_list': series names, 'id_list': series ids, 'number_list': number within series}
def add_artist_info(
self,
album,
track_metadata,
trackXmlNode,
releaseXmlNode):
"""
Main routine run for each track of release
:param album: Current release
:param track_metadata: track metadata dictionary
:param trackXmlNode: Everything in the track node downwards
:param releaseXmlNode: Everything in the release node downwards (so includes all track nodes)
:return:
"""
release_id = track_metadata['musicbrainz_albumid']
if 'start' not in release_status[release_id]:
release_status[release_id]['start'] = datetime.now()
if 'lookups' not in release_status[release_id]:
release_status[release_id]['lookups'] = 0
release_status[release_id]['name'] = track_metadata['album']
release_status[release_id]['artists'] = True
if config.setting['log_debug'] or config.setting['log_info']:
write_log(
release_id,
'debug',
'STARTING ARTIST PROCESSING FOR ALBUM %s, DISC %s, TRACK %s',
track_metadata['album'],
track_metadata['discnumber'],
track_metadata['tracknumber'] +
' ' +
track_metadata['title'])
# write_log(release_id, 'info', 'trackXmlNode = %s', trackXmlNode) # NB can crash Picard
# write_log('info', 'releaseXmlNode = %s', releaseXmlNode) # NB can crash Picard
# Jump through hoops to get track object!!
track = album._new_tracks[-1]
tm = track.metadata
# OPTIONS - OVER-RIDE IF REQUIRED
if '~ce_options' not in tm:
if config.setting['log_debug'] or config.setting['log_info']:
write_log(release_id, 'debug', 'Artists gets track first...')
get_options(release_id, album, track)
options = interpret(tm['~ce_options'])
if not options:
if config.setting["log_error"]:
write_log(
release_id,
'error',
'Artists. Failure to read saved options for track %s. options = %s',
track,
tm['~ce_options'])
options = option_settings(config.setting)
self.options[track] = options
# CONSTANTS
self.ERROR = options["log_error"]
self.WARNING = options["log_warning"]
self.ORCHESTRAS = options["cea_orchestras"].split(',')
self.CHOIRS = options["cea_choirs"].split(',')
self.GROUPS = options["cea_groups"].split(',')
self.ENSEMBLE_TYPES = self.ORCHESTRAS + self.CHOIRS + self.GROUPS
self.SEPARATORS = ['; ', '/ ', ';', '/']
# continue?
if not options["classical_extra_artists"]:
return
# album_files is not used - this is just for logging
album_files = album.tagger.get_files_from_objects([album])
if options['log_info']:
write_log(
release_id,
'info',
'ALBUM FILENAMES for album %r = %s',
album,
album_files)
if not (
options["ce_no_run"] and (
not tm['~ce_file'] or tm['~ce_file'] == "None")):
# continue
write_log(
release_id,
'debug',
"ExtraArtists - add_artist_info")
if album not in self.track_listing or track not in self.track_listing[album]:
self.track_listing[album].append(track)
# fix odd hyphens in names for consistency
field_types = ['~albumartists', '~albumartists_sort']
for field_type in field_types:
if field_type in tm:
field = tm[field_type]
if isinstance(field, list):
for x, it in enumerate(field):
field[x] = it.replace(u'\u2010', u'-')
elif isinstance(field, str):
field = field.replace(u'\u2010', u'-')
else:
pass
tm[field_type] = field
# first time for this album (reloads each refresh)
if tm['discnumber'] == '1' and tm['tracknumber'] == '1':
# get artist aliases - these are cached so can be re-used across
# releases, but are reloaded with each refresh
get_aliases(self, release_id, album, options, releaseXmlNode)
# xml_type = 'release'
# get performers etc who are related at the release level
relation_list = parse_data(
release_id, releaseXmlNode, [], 'relations')
album_performerList = get_artists(
options, release_id, tm, relation_list, 'release')['artists']
self.album_performers[album] = album_performerList
album_instrumentList = get_artists(
options, release_id, tm, relation_list, 'release')['instruments']
self.album_instruments[album] = album_instrumentList
# get series information
self.album_series_list = get_series(
options, release_id, relation_list)
else:
if album in self.album_performers:
album_performerList = self.album_performers[album]
else:
album_performerList = []
if album in self.album_instruments and self.album_instruments[album]:
tm['~cea_instruments'] = self.album_instruments[album][0]
tm['~cea_instruments_credited'] = self.album_instruments[album][1]
tm['~cea_instruments_all'] = self.album_instruments[album][2]
# Should be OK to initialise these here as recording artists
# yet to be processed
# Fill release info not given by vanilla Picard
if self.album_series_list:
tm['series'] = self.album_series_list['name_list'] if 'name_list' in self.album_series_list else None
tm['musicbrainz_seriesid'] = self.album_series_list['id_list'] if 'id_list' in self.album_series_list else None
tm['series_number'] = self.album_series_list['number_list'] if 'number_list' in self.album_series_list else None
## TODO add label id too
recording_relation_list = parse_data(
release_id, trackXmlNode, [], 'recording', 'relations')
recording_series_list = get_series(
options, release_id, recording_relation_list)
write_log(
release_id,
'info',
'Recording_series_list = %s',
recording_series_list)
track_artist_list = parse_data(
release_id, trackXmlNode, [], 'artist-credit')
if track_artist_list:
track_artist = []
track_artistsort = []
track_artists = []
track_artists_sort = []
lang = get_preferred_artist_language(config)
# Set naming option
# Put naming style into preferential list
# naming as for vanilla Picard for track artists
if options['translate_artist_names'] and lang:
name_style = ['alias', 'sort']
# documentation indicates that processing should be as below,
# but processing above appears to reflect what vanilla Picard actually does
# if options['standardize_artists']:
# name_style = ['alias', 'sort']
# else:
# name_style = ['alias', 'credit', 'sort']
else:
if not options['standardize_artists']:
name_style = ['credit']
else:
name_style = []
write_log(
release_id,
'info',
'Priority order of naming style for track artists = %s',
name_style)
styled_artists = apply_artist_style(
options,
release_id,
lang,
track_artist_list,
name_style,
track_artist,
track_artistsort,
track_artists,
track_artists_sort)
tm['artists'] = styled_artists['artists']
tm['~artists_sort'] = styled_artists['artists_sort']
tm['artist'] = styled_artists['artist']
tm['artistsort'] = styled_artists['artistsort']
if 'recording' in trackXmlNode:
self.globals[track]['is_recording'] = True
write_log(release_id, 'debug', 'Getting recording details')
recording = trackXmlNode['recording']
if not isinstance(recording, list):
recording = [recording]
for record in recording:
rec_type = type(record)
write_log(release_id, 'info', 'rec-type = %s', rec_type)
write_log(release_id, 'info', record)
# Note that the lists below reflect https://musicbrainz.org/relationships/artist-recording
# Any changes to that DB structure will require changes
# here
# get recording artists data
recording_artist_list = parse_data(
release_id, record, [], 'artist-credit')
if recording_artist_list:
recording_artist = []
recording_artistsort = []
recording_artists = []
recording_artists_sort = []
lang = get_preferred_artist_language(config)
# Set naming option
# Put naming style into preferential list
# naming as for vanilla Picard for track artists (per
# documentation rather than actual?)
if options['cea_ra_trackartist']:
if options['translate_artist_names'] and lang:
if options['standardize_artists']:
name_style = ['alias', 'sort']
else:
name_style = ['alias', 'credit', 'sort']
else:
if not options['standardize_artists']:
name_style = ['credit']
else:
name_style = []
# naming as for performers in classical extras
elif options['cea_ra_performer']:
if options['cea_aliases']:
if options['cea_alias_overrides']:
name_style = ['alias', 'credit']
else:
name_style = ['credit', 'alias']
else:
name_style = ['credit']
else:
name_style = []
write_log(
release_id,
'info',
'Priority order of naming style for recording artists = %s',
name_style)
styled_artists = apply_artist_style(
options,
release_id,
lang,
recording_artist_list,
name_style,
recording_artist,
recording_artistsort,
recording_artists,
recording_artists_sort)
self.append_tag(
release_id,
tm,
'~cea_recording_artists',
styled_artists['artists'])
self.append_tag(
release_id,
tm,
'~cea_recording_artists_sort',
styled_artists['artists_sort'])
self.append_tag(
release_id,
tm,
'~cea_recording_artist',
styled_artists['artist'])
self.append_tag(
release_id,
tm,
'~cea_recording_artistsort',
styled_artists['artistsort'])
else:
tm['~cea_recording_artists'] = ''
tm['~cea_recording_artists_sort'] = ''
tm['~cea_recording_artist'] = ''
tm['~cea_recording_artistsort'] = ''
# use recording artist options
tm['~cea_MB_artist'] = str_to_list(tm['artist'])
tm['~cea_MB_artistsort'] = str_to_list(tm['artistsort'])
tm['~cea_MB_artists'] = str_to_list(tm['artists'])
tm['~cea_MB_artists_sort'] = str_to_list(tm['~artists_sort'])
if options['cea_ra_use']:
if options['cea_ra_replace_ta']:
if tm['~cea_recording_artist']:
tm['artist'] = str_to_list(tm['~cea_recording_artist'])
tm['artistsort'] = str_to_list(tm['~cea_recording_artistsort'])
tm['artists'] = str_to_list(tm['~cea_recording_artists'])
tm['~artists_sort'] = str_to_list(tm['~cea_recording_artists_sort'])
elif not options['cea_ra_noblank_ta']:
tm['artist'] = ''
tm['artistsort'] = ''
tm['artists'] = ''
tm['~artists_sort'] = ''
elif options['cea_ra_merge_ta']:
if tm['~cea_recording_artist']:
tm['artists'] = add_list_uniquely(
tm['artists'], tm['~cea_recording_artists'])
tm['~artists_sort'] = add_list_uniquely(
tm['~artists_sort'], tm['~cea_recording_artists_sort'])
if tm['artist'] != tm['~cea_recording_artist']:
tm['artist'] = tm['artist'] + \
' (' + tm['~cea_recording_artist'] + ')'
tm['artistsort'] = tm['artistsort'] + \
' (' + tm['~cea_recording_artistsort'] + ')'
# xml_type = 'recording'
relation_list = parse_data(
release_id, record, [], 'relations')
performerList = album_performerList + \
get_artists(options, release_id, tm, relation_list, 'recording')['artists']
# returns
# [(artist type, instrument or None, artist name, artist sort name, instrument sort, type sort)]
# where instrument sort places solo ahead of additional etc.
# and type sort applies a custom sequencing to the artist
# types
if performerList:
write_log(
release_id, 'info', "Performers: %s", performerList)
self.set_performer(
release_id, album, track, performerList, tm)
if not options['classical_work_parts']:
work_artist_list = parse_data(
release_id,
record,
[],
'relations',
'target-type:work',
'type:performance',
'work',
'relations',
'target-type:artist')
work_artists = get_artists(
options, release_id, tm, work_artist_list, 'work')['artists']
set_work_artists(
self, release_id, album, track, work_artists, tm, 0)
# otherwise composers etc. will be set in work parts
else:
self.globals[track]['is_recording'] = False
else:
tm['000_major_warning'] = "WARNING: Classical Extras not run for this track as no file present - " \
"deselect the option on the advanced tab to run. If there is a file, then try 'Refresh'."
if track_metadata['tracknumber'] == track_metadata['totaltracks'] and track_metadata[
'discnumber'] == track_metadata['totaldiscs']: # last track
self.process_album(release_id, album)
release_status[release_id]['artists-done'] = datetime.now()
close_log(release_id, 'artists')
# Checks for ensembles
def ensemble_type(self, performer):
"""
Returns ensemble types
:param performer:
:return:
"""
for ensemble_name in self.ORCHESTRAS:
ensemble = re.compile(
r'(.*)\b' +
ensemble_name +
r'\b(.*)',
re.IGNORECASE)
if ensemble.search(performer):
return 'Orchestra'
for ensemble_name in self.CHOIRS:
ensemble = re.compile(
r'(.*)\b' +
ensemble_name +
r'\b(.*)',
re.IGNORECASE)
if ensemble.search(performer):
return 'Choir'
for ensemble_name in self.GROUPS:
ensemble = re.compile(
r'(.*)\b' +
ensemble_name +
r'\b(.*)',
re.IGNORECASE)
if ensemble.search(performer):
return 'Group'
return False
def process_album(self, release_id, album):
"""
Perform final processing after all tracks read
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:return:
"""
write_log(
release_id,
'debug',
'ExtraArtists: Starting process_album')
# process lyrics tags
write_log(release_id, 'debug', 'Starting lyrics processing')
common = []
tmlyrics_dict = {}
tmlyrics_sort = []
options = {}
for track in self.track_listing[album]:
options = self.options[track]
if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
tm = track.metadata
lyrics_tag = options['cea_lyrics_tag']
if tm[lyrics_tag]:
# turn text into word lists to speed processing
tmlyrics_dict[track] = tm[lyrics_tag].split()
if tmlyrics_dict:
tmlyrics_sort = sorted(
tmlyrics_dict.items(),
key=operator.itemgetter(1))
prev = None
first_track = None
unique_lyrics = []
ref_track = {}
for lyric_tuple in tmlyrics_sort: # tuple is (track, lyrics)
if lyric_tuple[1] != prev:
unique_lyrics.append(lyric_tuple[1])
first_track = lyric_tuple[0]
ref_track[lyric_tuple[0]] = first_track
prev = lyric_tuple[1]
common = turbo_lcs(
release_id,
unique_lyrics)
if common:
unique = []
for tup in tmlyrics_sort:
track = tup[0]
ref = ref_track[track]
if track == ref:
start = substart_finder(tup[1], common)
length = len(common)
end = min(start + length, len(tup[1]))
unique = tup[1][:start] + tup[1][end:]
options = self.options[track]
if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
tm = track.metadata
if unique:
tm['~cea_track_lyrics'] = ' '.join(unique)
tm['~cea_album_lyrics'] = ' '.join(common)
if options['cea_album_lyrics']:
tm[options['cea_album_lyrics']] = tm['~cea_album_lyrics']
if unique and options['cea_track_lyrics']:
tm[options['cea_track_lyrics']] = tm['~cea_track_lyrics']
else:
for track in self.track_listing[album]:
options = self.options[track]
if options['cea_split_lyrics'] and options['cea_lyrics_tag']:
tm['~cea_track_lyrics'] = tm[options['cea_lyrics_tag']]
if options['cea_track_lyrics']:
tm[options['cea_track_lyrics']] = tm['~cea_track_lyrics']
write_log(release_id, 'debug', 'Ending lyrics processing')
for track in self.track_listing[album]:
self.write_metadata(release_id, options, album, track)
self.track_listing[album] = []
write_log(
release_id,
'info',
"FINISHED Classical Extra Artists. Album: %s",
album)
def write_metadata(self, release_id, options, album, track):
"""
Write the metadata for this track
:param release_id:
:param options:
:param album:
:param track:
:return:
"""
options = self.options[track]
tm = track.metadata
tm['~cea_version'] = PLUGIN_VERSION
# set inferred genres before any tags are blanked
if options['cwp_genres_infer']:
self.infer_genres(release_id, options, track, tm)
# album
if not options['classical_work_parts']:
if 'composer_lastnames' in self.album_artists[album]:
last_names = seq_last_names(self, album)
self.append_tag(
release_id,
tm,
'~cea_album_composer_lastnames',
last_names)
# otherwise this is done in the workparts class, which has all
# composer info
# process tag mapping
tm['~cea_artists_complete'] = "Y"
map_tags(options, release_id, album, tm)
# write out options and errors/warnings to tags
if options['cea_options_tag'] != "":
self.cea_options = collections.defaultdict(
lambda: collections.defaultdict(
lambda: collections.defaultdict(dict)))
for opt in plugin_options(
'artists') + plugin_options('tag') + plugin_options('picard'):
if 'name' in opt:
if 'value' in opt:
if options[opt['option']]:
self.cea_options['Classical Extras']['Artists options'][opt['name']] = opt['value']
else:
self.cea_options['Classical Extras']['Artists options'][opt['name']
] = options[opt['option']]
for opt in plugin_options('tag_detail'):
if opt['option'] != "":
name_list = opt['name'].split("_")
self.cea_options['Classical Extras']['Artists options'][name_list[0]
][name_list[1]] = options[opt['option']]
if options['ce_version_tag'] and options['ce_version_tag'] != "":
self.append_tag(release_id, tm, options['ce_version_tag'], str(
'Version ' + tm['~cea_version'] + ' of Classical Extras'))
if options['cea_options_tag'] and options['cea_options_tag'] != "":
self.append_tag(
release_id,
tm,
options['cea_options_tag'] +
':artists_options',
json.loads(
json.dumps(
self.cea_options)))
def infer_genres(self, release_id, options, track, tm):
"""
Infer a genre from the artist/instrument metadata
:param release_id:
:param options:
:param track:
:param tm: track metadata
:return:
"""
# Note that this is now mixed in with other sources of genres in def map_tags
# ~cea_work_type_if_classical is used for types that are specifically classical
# and is only applied in map_tags if the track is deemed to be
# classical
if (self.globals[track]['is_recording'] and options['classical_work_parts']
and '~artists_sort' in tm and 'composersort' in tm
and any(x in tm['~artists_sort'] for x in tm['composersort'])
and 'writer' not in tm
and not any(x in tm['~artists_sort'] for x in tm['~cea_performers_sort'])):
self.append_tag(
release_id, tm, '~cea_work_type', 'Classical')
if isinstance(tm['~cea_soloists'], str):
soloists = re.split(
'|'.join(
self.SEPARATORS),
tm['~cea_soloists'])
else:
soloists = tm['~cea_soloists']
if '~cea_vocalists' in tm:
if isinstance(tm['~cea_vocalists'], str):
vocalists = re.split(
'|'.join(
self.SEPARATORS),
tm['~cea_vocalists'])
else:
vocalists = tm['~cea_vocalists']
else:
vocalists = []
if '~cea_ensembles' in tm:
large = False
if 'performer:orchestra' in tm:
large = True
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Orchestral')
if '~cea_soloists' in tm:
if 'vocals' in tm['~cea_instruments_all']:
self.append_tag(
release_id, tm, '~cea_work_type', 'Vocal')
if len(soloists) == 1:
if soloists != vocalists:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Concerto')
else:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Aria')
elif len(soloists) == 2:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Duet')
if not vocalists:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Concerto')
elif len(soloists) == 3:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Trio')
elif len(soloists) == 4:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Quartet')
if 'performer:choir' in tm or 'performer:choir vocals' in tm:
large = True
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Choral')
self.append_tag(
release_id, tm, '~cea_work_type', 'Vocal')
else:
if large and 'soloists' in tm and tm['soloists'].count(
'vocals') > 1:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Opera')
if not large:
if '~cea_soloists' not in tm:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
else:
if vocalists:
self.append_tag(
release_id, tm, '~cea_work_type', 'Song')
self.append_tag(
release_id, tm, '~cea_work_type', 'Vocal')
else:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
else:
if len(soloists) == 1:
if vocalists != soloists:
self.append_tag(
release_id, tm, '~cea_work_type', 'Instrumental')
else:
self.append_tag(
release_id, tm, '~cea_work_type', 'Song')
self.append_tag(
release_id, tm, '~cea_work_type', 'Vocal')
elif len(soloists) == 2:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Duet')
elif len(soloists) == 3:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Trio')
elif len(soloists) == 4:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Quartet')
else:
if not vocalists:
self.append_tag(
release_id, tm, '~cea_work_type_if_classical', 'Chamber music')
else:
self.append_tag(
release_id, tm, '~cea_work_type', 'Song')
self.append_tag(
release_id, tm, '~cea_work_type', 'Vocal')
def append_tag(self, release_id, tm, tag, source):
"""
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param tm:
:param tag:
:param source:
:return:
"""
write_log(
release_id,
'info',
"Extra Artists - appending %s to %s",
source,
tag)
append_tag(release_id, tm, tag, source, self.SEPARATORS)
def set_performer(self, release_id, album, track, performerList, tm):
"""
Sets the performer-related tags
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param track:
:param performerList: see below
:param tm:
:return:
"""
# performerList is in format [(artist_type, [instrument list],[name list],[sort_name list],
# instrument_sort, type_sort),(.....etc]
# Sorted by type_sort then sort name then instrument_sort
write_log(release_id, 'debug', "Extra Artists - set_performer")
write_log(release_id, 'info', "Performer list is:")
write_log(release_id, 'info', performerList)
options = self.options[track]
# tag strings are a tuple (Picard tag, cea tag, Picard sort tag, cea
# sort tag)
tag_strings = const.tag_strings('~cea')
# insertions lists artist types where names in the main Picard tags may be updated for annotations
# (not for performer types as Picard will write performer:inst as Performer name (inst) )
insertions = const.INSERTIONS
# First remove all existing performer tags
del_list = []
for meta in tm:
if 'performer' in meta:
del_list.append(meta)
for del_item in del_list:
del tm[del_item]
last_artist = []
last_inst_list = []
last_instrument = None
artist_inst = []
artist_inst_list = {}
for performer in performerList:
artist_type = performer[0]
if artist_type not in tag_strings:
return None
if artist_type in ['instrument', 'vocal', 'performing orchestra']:
if performer[1]:
inst_list = performer[1]
attrib_list = []
for attrib in ['solo', 'guest', 'additional']:
if attrib in inst_list:
inst_list.remove(attrib)
attrib_list.append(attrib)
attribs = " ".join(attrib_list)
instrument = ", ".join(inst_list)
if not options['cea_no_solo'] and attrib_list:
instrument = attribs + " " + instrument
if performer[3] == last_artist:
if instrument != last_instrument:
artist_inst.append(instrument)
else:
if inst_list == last_inst_list:
write_log(
release_id, 'warning', 'Duplicated performer information for %s'
' (may be in Release Relationship as well as Track Relationship).'
' Duplicates have been ignored.', performer[3])
if self.WARNING:
self.append_tag(
release_id,
tm,
'~cea_warning',
'2. Duplicated performer information for "' +
'; '.join(
performer[3]) +
'" (may be in Release Relationship as well as Track Relationship).'
' Duplicates have been ignored.')
else:
artist_inst = [instrument]
last_artist = performer[3]
last_inst_list = inst_list
last_instrument = instrument
instrument = ", ".join(artist_inst)
else:
instrument = None
if artist_type == 'performing orchestra':
instrument = 'orchestra'
artist_inst_list[tuple(performer[3])] = instrument
for performer in performerList:
artist_type = performer[0]
if artist_type not in tag_strings:
return None
performing_artist = False if artist_type in [
'arranger', 'instrument arranger', 'orchestrator', 'vocal arranger'] else True
if True and artist_type in [
'instrument',
'vocal',
'performing orchestra']: # There may be an option here (to replace 'True')
# Currently groups instruments by artist - alternative has been
# tested if required
instrument = artist_inst_list[tuple(performer[3])]
else:
if performer[1]:
inst_list = performer[1]
if options['cea_no_solo']:
for attrib in ['solo', 'guest', 'additional']:
if attrib in inst_list:
inst_list.remove(attrib)
instrument = " ".join(inst_list)
else:
instrument = None
if artist_type == 'performing orchestra':
instrument = 'orchestra'
sub_strings = {'instrument': instrument,
'vocal': instrument # ,
# 'instrument arranger': instrument,
# 'vocal arranger': instrument
}
for typ in ['concertmaster']:
if options['cea_' + typ] and options['cea_arrangers']:
sub_strings[typ] = ':' + options['cea_' + typ]
if options['cea_arranger']:
if instrument:
arr_inst = options['cea_arranger'] + ' ' + instrument
else:
arr_inst = options['cea_arranger']
else:
arr_inst = instrument
annotations = {'instrument': instrument,
'vocal': instrument,
'performing orchestra': instrument,
'chorus master': options['cea_chorusmaster'],
'concertmaster': options['cea_concertmaster'],
'arranger': options['cea_arranger'],
'instrument arranger': arr_inst,
'orchestrator': options['cea_orchestrator'],
'vocal arranger': arr_inst}
tag = tag_strings[artist_type][0]
cea_tag = tag_strings[artist_type][1]
sort_tag = tag_strings[artist_type][2]
cea_sort_tag = tag_strings[artist_type][3]
cea_names_tag = cea_tag[:-1] + '_names'
cea_instrumented_tag = cea_names_tag + '_instrumented'
if artist_type in sub_strings:
if sub_strings[artist_type]:
tag += sub_strings[artist_type]
else:
write_log(
release_id,
'warning',
'No instrument/sub-key available for artist_type %s. Performer = %s. Track is %s',
artist_type,
performer[2],
track)
if tag:
if '~ce_tag_cleared_' + \
tag not in tm or not tm['~ce_tag_cleared_' + tag] == "Y":
if tag in tm:
write_log(release_id, 'info', 'delete tag %s', tag)
del tm[tag]
tm['~ce_tag_cleared_' + tag] = "Y"
if sort_tag:
if '~ce_tag_cleared_' + \
sort_tag not in tm or not tm['~ce_tag_cleared_' + sort_tag] == "Y":
if sort_tag in tm:
del tm[sort_tag]
tm['~ce_tag_cleared_' + sort_tag] = "Y"
name_list = performer[2]
for ind, name in enumerate(name_list):
performer_type = ''
sort_name = performer[3][ind]
no_credit = True
# change name to as-credited
if (performing_artist and options['cea_performer_credited'] or
not performing_artist and options['cea_composer_credited']):
if sort_name in self.artist_credits[album]:
no_credit = False
name = self.artist_credits[album][sort_name]
# over-ride with aliases and use standard MB name (not
# as-credited) if no alias
if (options['cea_aliases'] or not performing_artist and options['cea_aliases_composer']) and (
no_credit or options['cea_alias_overrides']):
if sort_name in self.artist_aliases:
name = self.artist_aliases[sort_name]
# fix cyrillic names if not already fixed
if options['cea_cyrillic']:
if not only_roman_chars(name):
name = remove_middle(unsort(sort_name))
# Only remove middle name where the existing
# performer is in non-latin script
annotated_name = name
if instrument:
instrumented_name = name + ' (' + instrument + ')'
else:
instrumented_name = name
# add annotations and write performer tags
if artist_type in annotations:
if annotations[artist_type]:
annotated_name += ' (' + annotations[artist_type] + ')'
else:
write_log(
release_id,
'warning',
'No annotation (instrument) available for artist_type %s.'
' Performer = %s. Track is %s',
artist_type,
performer[2],
track)
if artist_type in insertions and options['cea_arrangers']:
self.append_tag(release_id, tm, tag, annotated_name)
else:
if options['cea_arrangers'] or artist_type == tag:
self.append_tag(release_id, tm, tag, name)
if options['cea_arrangers'] or artist_type == tag:
if sort_tag:
self.append_tag(release_id, tm, sort_tag, sort_name)
if options['cea_tag_sort'] and '~' in sort_tag:
explicit_sort_tag = sort_tag.replace('~', '')
self.append_tag(
release_id, tm, explicit_sort_tag, sort_name)
self.append_tag(release_id, tm, cea_tag, annotated_name)
self.append_tag(release_id, tm, cea_names_tag, name)
if instrumented_name != name:
self.append_tag(
release_id,
tm,
cea_instrumented_tag,
instrumented_name)
if cea_sort_tag:
self.append_tag(release_id, tm, cea_sort_tag, sort_name)
# differentiate soloists etc and write related tags
if artist_type == 'performing orchestra' or (
instrument and instrument in self.ENSEMBLE_TYPES) or self.ensemble_type(name):
performer_type = 'ensembles'
self.append_tag(
release_id, tm, '~cea_ensembles', instrumented_name)
self.append_tag(
release_id, tm, '~cea_ensemble_names', name)
self.append_tag(
release_id, tm, '~cea_ensembles_sort', sort_name)
elif artist_type in ['performer', 'instrument', 'vocal']:
performer_type = 'soloists'
self.append_tag(
release_id, tm, '~cea_soloists', instrumented_name)
self.append_tag(release_id, tm, '~cea_soloist_names', name)
self.append_tag(
release_id, tm, '~cea_soloists_sort', sort_name)
if artist_type == "vocal":
self.append_tag(
release_id, tm, '~cea_vocalists', instrumented_name)
self.append_tag(
release_id, tm, '~cea_vocalist_names', name)
self.append_tag(
release_id, tm, '~cea_vocalists_sort', sort_name)
elif instrument:
self.append_tag(
release_id, tm, '~cea_instrumentalists', instrumented_name)
self.append_tag(
release_id, tm, '~cea_instrumentalist_names', name)
self.append_tag(
release_id, tm, '~cea_instrumentalists_sort', sort_name)
else:
self.append_tag(
release_id, tm, '~cea_other_soloists', instrumented_name)
self.append_tag(
release_id, tm, '~cea_other_soloist_names', name)
self.append_tag(
release_id, tm, '~cea_other_soloists_sort', sort_name)
# set album artists
if performer_type or artist_type == 'conductor':
cea_album_tag = cea_tag.replace(
'cea', 'cea_album').replace(
'performers', performer_type)
cea_album_sort_tag = cea_sort_tag.replace(
'cea', 'cea_album').replace(
'performers', performer_type)
if stripsir(name) in tm['~albumartists'] or stripsir(
sort_name) in tm['~albumartists_sort']:
self.append_tag(release_id, tm, cea_album_tag, name)
self.append_tag(
release_id, tm, cea_album_sort_tag, sort_name)
else:
if performer_type:
self.append_tag(
release_id, tm, '~cea_support_performers', instrumented_name)
self.append_tag(
release_id, tm, '~cea_support_performer_names', name)
self.append_tag(
release_id, tm, '~cea_support_performers_sort', sort_name)
##############
##############
# WORK PARTS #
##############
##############
class PartLevels():
# QUEUE-HANDLING
class WorksQueue(LockableObject):
"""Object for managing the queue of lookups"""
def __init__(self):
LockableObject.__init__(self)
self.queue = {}
def __contains__(self, name):
return name in self.queue
def __iter__(self):
return self.queue.__iter__()
def __getitem__(self, name):
self.lock_for_read()
value = self.queue[name] if name in self.queue else None
self.unlock()
return value
def __setitem__(self, name, value):
self.lock_for_write()
self.queue[name] = value
self.unlock()
def append(self, name, value):
self.lock_for_write()
if name in self.queue:
self.queue[name].append(value)
value = False
else:
self.queue[name] = [value]
value = True
self.unlock()
return value
def remove(self, name):
self.lock_for_write()
value = None
if name in self.queue:
value = self.queue[name]
del self.queue[name]
self.unlock()
return value
# INITIALISATION
def __init__(self):
self.works_cache = {}
# maintains list of parent of each workid, or None if no parent found,
# so that XML lookup need only executed if no existing record
self.partof = collections.defaultdict(dict)
# the inverse of the above (immediate children of each parent)
# but note that this is specific to the album as children may vary between albums
# so format is {album1{parent1: child1, parent2:, child2},
# album2{....}}
self.works_queue = self.WorksQueue()
# lookup queue - holds track/album pairs for each queued workid (may be
# more than one pair per id, especially for higher-level parts)
self.parts = collections.defaultdict(
lambda: collections.defaultdict(dict))
# metadata collection for all parts - structure is {workid: {name: ,
# parent: , (track,album): {part_levels}}, etc}
self.top_works = collections.defaultdict(dict)
# metadata collection for top-level works for (track, album) -
# structure is {(track, album): {workId: }, etc}
self.trackback = collections.defaultdict(
lambda: collections.defaultdict(dict))
# hierarchical iterative work structure - {album: {id: , children:{id:
# , children{}, id: etc}, id: etc} }
self.child_listing = collections.defaultdict(list)
# contains list of workIds which are descendants of a given workId, to
# prevent recursion when adding new ids
self.work_listing = collections.defaultdict(list)
# contains list of workIds for each album
self.top = collections.defaultdict(list)
# self.top[album] = list of work Ids which are top-level works in album
self.options = collections.defaultdict(dict)
# active Classical Extras options for current track
self.synonyms = collections.defaultdict(dict)
# active synonym options for current track
self.replacements = collections.defaultdict(dict)
# active synonym options for current track
self.file_works = collections.defaultdict(list)
# list of works derived from SongKong-style file tags
# structure is {(album, track): [{workid: , name: }, {workid: ....}}
self.album_artists = collections.defaultdict(
lambda: collections.defaultdict(dict))
# collection of artists to be applied at album level
self.artist_aliases = {}
# collection of alias names - format is {sort_name: alias_name, ...}
self.artist_credits = collections.defaultdict(dict)
# collection of credited-as names - format is {album: {sort_name: credit_name,
# ...}, ...}
self.release_artists_sort = collections.defaultdict(list)
# collection of release artists - format is {album: [sort_name_1,
# sort_name_2, ...]}
self.lyricist_filled = collections.defaultdict(dict)
# Boolean for each track to indicate if lyricist has been found (don't
# want to add more from higher levels)
self.orphan_tracks = collections.defaultdict(list)
# To keep a list for each album of tracks which do not have works -
# format is {album: [track1, track2, ...], etc}
self.tracks = collections.defaultdict(
lambda: collections.defaultdict(dict))
# To keep a list of all tracks for the album - format is {album:
# {track1: {movement-group: movementgroup, movement-number: movementnumber},
# track2: {}, ..., etc}, album2: etc}
########################################
# SECTION 1 - Initial track processing #
########################################
def add_work_info(
self,
album,
track_metadata,
trackXmlNode,
releaseXmlNode):
"""
Main Routine - run for each track
:param album:
:param track_metadata:
:param trackXmlNode:
:param releaseXmlNode:
:return:
"""
release_id = track_metadata['musicbrainz_albumid']
if 'start' not in release_status[release_id]:
release_status[release_id]['start'] = datetime.now()
if 'lookups' not in release_status[release_id]:
release_status[release_id]['lookups'] = 0
release_status[release_id]['name'] = track_metadata['album']
release_status[release_id]['works'] = True
if config.setting['log_debug'] or config.setting['log_info']:
write_log(
release_id,
'debug',
'STARTING WORKS PROCESSING FOR ALBUM %s, DISC %s, TRACK %s',
track_metadata['album'],
track_metadata['discnumber'],
track_metadata['tracknumber'] +
' ' +
track_metadata['title'])
# clear the cache if required (if this is not done, then queue count may get out of sync)
# Jump through hoops to get track object!!
track = album._new_tracks[-1]
tm = track.metadata
if config.setting['log_debug'] or config.setting['log_info']:
write_log(
release_id,
'debug',
'Cache setting for track %s is %s',
track,
config.setting['use_cache'])
# OPTIONS - OVER-RIDE IF REQUIRED
if '~ce_options' not in tm:
if config.setting['log_debug'] or config.setting['log_info']:
write_log(release_id, 'debug', 'Workparts gets track first...')
get_options(release_id, album, track)
options = interpret(tm['~ce_options'])
if not options:
if config.setting['log_error']:
write_log(
release_id,
'error',
'Work Parts. Failure to read saved options for track %s. options = %s',
track,
tm['~ce_options'])
options = option_settings(config.setting)
self.options[track] = options
# CONSTANTS
write_log(release_id, 'basic', 'Options: %s' ,options)
self.ERROR = options["log_error"]
self.WARNING = options["log_warning"]
self.SEPARATORS = ['; ']
self.EQ = "EQ_TO_BE_REVERSED" # phrase to indicate that a synonym has been used
self.get_sk_tags(release_id, album, track, tm, options)
self.synonyms[track] = self.get_text_tuples(
release_id, track, 'synonyms') # a list of tuples
self.replacements[track] = self.get_text_tuples(
release_id, track, 'replacements') # a list of tuples
# Continue?
if not options["classical_work_parts"]:
return
# OPTION-DEPENDENT CONSTANTS:
# Maximum number of XML- lookup retries if error returned from server
self.MAX_RETRIES = options["cwp_retries"]
self.USE_CACHE = options["use_cache"]
if options["cwp_partial"] and options["cwp_partial_text"] and options["cwp_level0_works"]:
options["cwp_removewords_p"] = options["cwp_removewords"] + \
", " + options["cwp_partial_text"] + ' '
else:
options["cwp_removewords_p"] = options["cwp_removewords"]
# Explanation:
# If "Partial" is selected then the level 0 work name will have PARTIAL_TEXT appended to it.
# If a recording is split across several tracks then each sub-part (quasi-movement) will have the same name
# (with the PARTIAL_TEXT added). If level 0 is used to source work names then the level 1 work name will be
# changed to be this repeated name and will therefore also include PARTIAL_TEXT.
# So we need to add PARTIAL_TEXT to the prefixes list to ensure it is excluded from the level 1 work name.
#
write_log(
release_id,
'debug',
"PartLevels - LOAD NEW TRACK: :%s",
track)
# write_log(release_id, 'info', "trackXmlNode:") # warning - may break Picard
# first time for this album (reloads each refresh)
if tm['discnumber'] == '1' and tm['tracknumber'] == '1':
# get artist aliases - these are cached so can be re-used across
# releases, but are reloaded with each refresh
get_aliases(self, release_id, album, options, releaseXmlNode)
# fix titles which include composer name
composersort =[]
if 'compposersort' in tm:
composersort = str_to_list(['composersort'])
composerlastnames = []
for composer in composersort:
lname = re.compile(r'(.*),')
match = lname.search(composer)
if match:
composerlastnames.append(match.group(1))
else:
composerlastnames.append(composer)
title = track_metadata['title']
colons = title.count(":")
if colons > 0:
title_split = title.split(': ', 1)
test = title_split[0]
if test in composerlastnames:
track_metadata['~cwp_title'] = title_split[1]
# now process works
write_log(
release_id,
'info',
'PartLevels - add_work_info - metadata load = %r',
track_metadata)
workIds = []
if 'musicbrainz_workid' in tm:
workIds = str_to_list(tm['musicbrainz_workid'])
if workIds and not (options["ce_no_run"] and (
not tm['~ce_file'] or tm['~ce_file'] == "None")):
self.build_work_info(release_id, options, trackXmlNode, album, track, track_metadata, workIds)
else: # no work relation
write_log(
release_id,
'warning',
"WARNING - no works for this track: \"%s\"",
title)
self.append_tag(
release_id,
track_metadata,
'~cwp_warning',
'3. No works for this track')
if album in self.orphan_tracks:
if track not in self.orphan_tracks[album]:
self.orphan_tracks[album].append(track)
else:
self.orphan_tracks[album] = [track]
# Don't publish metadata yet until all album is processed
# last track
write_log(
release_id,
'debug',
'Check for last track. Requests = %s, Tracknumber = %s, Totaltracks = %s,'
' Discnumber = %s, Totaldiscs = %s',
album._requests,
track_metadata['tracknumber'],
track_metadata['totaltracks'],
track_metadata['discnumber'],
track_metadata['totaldiscs'])
if album._requests == 0 and track_metadata['tracknumber'] == track_metadata[
'totaltracks'] and track_metadata['discnumber'] == track_metadata['totaldiscs']:
self.process_album(release_id, album)
release_status[release_id]['works-done'] = datetime.now()
close_log(release_id, 'works')
def build_work_info(self, release_id, options, trackXmlNode, album, track, track_metadata, workIds):
"""
Construct the work metadata, taking into account partial recordings and medleys
:param release_id:
:param options:
:param trackXmlNode: JSON returned by the webservice
:param album:
:param track:
:param track_metadata:
:param workIds: work ids for this track
:return:
"""
work_list_info = []
keyed_workIds = {}
for i, workId in enumerate(workIds):
# sort by ordering_key, if any
match_tree = [
'recording',
'relations',
'target-type:work',
'work',
'id:' + workId]
rels = parse_data(release_id, trackXmlNode, [], *match_tree)
# for recordings which are ordered within track:-
match_tree_1 = [
'ordering-key']
# for recordings of works which are ordered as part of parent
# (may be duplicated by top-down check later):-
match_tree_2 = [
'relations',
'target-type:work',
'type:parts',
'direction:backward',
'ordering-key']
parse_result = parse_data(release_id,
rels,
[],
*match_tree_1) + parse_data(release_id,
rels,
[],
*match_tree_2)
write_log(
release_id,
'info',
'multi-works - ordering key: %s',
parse_result)
if parse_result:
if isinstance(parse_result[0], int):
key = parse_result[0]
elif isinstance(parse_result[0], str) and parse_result[0].isdigit():
key = int(parse_result[0])
else:
key = 100 + i
else:
key = 100 + i
keyed_workIds[key] = workId
partial = False
for key in sorted(keyed_workIds):
workId = keyed_workIds[key]
work_rels = parse_data(
release_id,
trackXmlNode,
[],
'recording',
'relations',
'target-type:work',
'work.id:' + workId)
write_log(release_id, 'info', 'work_rels: %s', work_rels)
work_attributes = parse_data(
release_id, work_rels, [], 'attributes')[0]
write_log(
release_id,
'info',
'work_attributes: %s',
work_attributes)
work_titles = parse_data(
release_id, work_rels, [], 'work', 'title')
work_list_info_item = {
'id': workId,
'attributes': work_attributes,
'titles': work_titles}
work_list_info.append(work_list_info_item)
work = []
for title in work_titles:
work.append(title)
if options['cwp_partial']:
# treat the recording as work level 0 and the work of which it
# is a partial recording as work level 1
if 'partial' in work_attributes:
partial = True
parentId = workId
workId = track_metadata['musicbrainz_recordingid']
works = []
for w in work:
partwork = w
works.append(partwork)
write_log(
release_id,
'info',
"Id %s is PARTIAL RECORDING OF id: %s, name: %s",
workId,
parentId,
work)
work_list_info_item = {
'id': workId,
'attributes': [],
'titles': works,
'parent': parentId}
work_list_info.append(work_list_info_item)
write_log(
release_id,
'info',
'work_list_info: %s',
work_list_info)
# we now have a list of items, where the id of each is a work id for the track or
# (multiple instances of) the recording id (for partial works)
# we need to turn this into a usable hierarchy - i.e. just one item
workId_list = []
work_list = []
parent_list = []
attribute_list = []
workId_list_p = []
work_list_p = []
attribute_list_p = []
for w in work_list_info:
if 'partial' not in w['attributes'] or not options[
'cwp_partial']: # just do the bottom-level 'works' first
workId_list.append(w['id'])
work_list += w['titles']
attribute_list += w['attributes']
if 'parent' in w:
if w['parent'] not in parent_list: # avoid duplicating parents!
parent_list.append(w['parent'])
else:
workId_list_p.append(w['id'])
work_list_p += w['titles']
attribute_list_p += w['attributes']
# de-duplicate work names
# list(set()) won't work as need to retain order
work_list = list(collections.OrderedDict.fromkeys(work_list))
work_list_p = list(collections.OrderedDict.fromkeys(work_list_p))
workId_tuple = tuple(workId_list)
workId_tuple_p = tuple(workId_list_p)
if workId_tuple not in self.work_listing[album]:
self.work_listing[album].append(workId_tuple)
if workId_tuple not in self.parts or not self.USE_CACHE:
self.parts[workId_tuple]['name'] = work_list
if parent_list:
if workId_tuple in self.works_cache:
self.works_cache[workId_tuple] += parent_list
self.parts[workId_tuple]['parent'] += parent_list
else:
self.works_cache[workId_tuple] = parent_list
self.parts[workId_tuple]['parent'] = parent_list
self.parts[workId_tuple_p]['name'] = work_list_p
if workId_tuple_p not in self.work_listing[album]:
self.work_listing[album].append(workId_tuple_p)
if 'medley' in attribute_list_p:
self.parts[workId_tuple_p]['medley'] = True
if 'medley' in attribute_list:
self.parts[workId_tuple]['medley'] = True
if partial:
self.parts[workId_tuple]['partial'] = True
self.trackback[album][workId_tuple]['id'] = workId_list
if 'meta' in self.trackback[album][workId_tuple]:
if (track,
album) not in self.trackback[album][workId_tuple]['meta']:
self.trackback[album][workId_tuple]['meta'].append(
(track, album))
else:
self.trackback[album][workId_tuple]['meta'] = [(track, album)]
write_log(
release_id,
'info',
"Trackback for %s is %s. Partial = %s",
track,
self.trackback[album][workId_tuple],
partial)
if workId_tuple in self.works_cache and (
self.USE_CACHE or partial):
write_log(
release_id,
'debug',
"GETTING WORK METADATA FROM CACHE, for work %s",
workId_tuple)
if workId_tuple not in self.work_listing[album]:
self.work_listing[album].append(workId_tuple)
not_in_cache = self.check_cache(
track_metadata, album, track, workId_tuple, [])
else:
if partial:
not_in_cache = [workId_tuple_p]
else:
not_in_cache = [workId_tuple]
for workId_tuple in not_in_cache:
if not self.USE_CACHE:
if workId_tuple in self.works_cache:
del self.works_cache[workId_tuple]
self.work_not_in_cache(release_id, album, track, workId_tuple)
def get_sk_tags(self, release_id, album, track, tm, options):
"""
Get file tags which are consistent with SongKong's metadata usage
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param track:
:param tm:
:param options:
:return:
"""
if options["cwp_use_sk"]:
if '~ce_file' in tm and interpret(tm['~ce_file']):
music_file = tm['~ce_file']
orig_metadata = album.tagger.files[music_file].orig_metadata
if 'musicbrainz_work_composition_id' in orig_metadata and 'musicbrainz_workid' in orig_metadata:
if 'musicbrainz_work_composition' in orig_metadata:
if 'musicbrainz_work' in orig_metadata:
if orig_metadata['musicbrainz_work_composition_id'] == orig_metadata[
'musicbrainz_workid'] \
and orig_metadata['musicbrainz_work_composition'] != orig_metadata[
'musicbrainz_work']:
# Picard may have overwritten SongKong tag (top
# work id) with bottom work id
write_log(
release_id,
'warning',
'File tag musicbrainz_workid incorrect? id = %s. Sourcing from MB',
orig_metadata['musicbrainz_workid'])
if self.WARNING:
self.append_tag(
release_id,
tm,
'~cwp_warning',
'4. File tag musicbrainz_workid incorrect? id = ' +
orig_metadata['musicbrainz_workid'] +
'. Sourcing from MB')
return None
write_log(
release_id,
'info',
'Read from file tag: musicbrainz_work_composition_id: %s',
orig_metadata['musicbrainz_work_composition_id'])
self.file_works[(album, track)].append({
'workid': orig_metadata['musicbrainz_work_composition_id'].split('; '),
'name': orig_metadata['musicbrainz_work_composition']})
else:
wid = orig_metadata['musicbrainz_work_composition_id']
write_log(
release_id,
'error',
"No matching work name for id tag %s",
wid)
if self.ERROR:
self.append_tag(
release_id,
tm,
'~cwp_error',
'2. No matching work name for id tag ' +
wid)
return None
n = 1
while 'musicbrainz_work_part_level' + \
str(n) + '_id' in orig_metadata:
if 'musicbrainz_work_part_level' + \
str(n) in orig_metadata:
self.file_works[(album, track)].append({
'workid': orig_metadata[
'musicbrainz_work_part_level' + str(n) + '_id'].split('; '),
'name': orig_metadata['musicbrainz_work_part_level' + str(n)]})
n += 1
else:
wid = orig_metadata['musicbrainz_work_part_level' +
str(n) + '_id']
write_log(
release_id, 'error', "No matching work name for id tag %s", wid)
if self.ERROR:
self.append_tag(
release_id,
tm,
'~cwp_error',
'2. No matching work name for id tag ' +
wid)
break
if orig_metadata['musicbrainz_work_composition_id'] != orig_metadata[
'musicbrainz_workid']:
if 'musicbrainz_work' in orig_metadata:
self.file_works[(album, track)].append({
'workid': orig_metadata['musicbrainz_workid'].split('; '),
'name': orig_metadata['musicbrainz_work']})
else:
wid = orig_metadata['musicbrainz_workid']
write_log(
release_id, 'error', "No matching work name for id tag %s", wid)
if self.ERROR:
self.append_tag(
release_id,
tm,
'~cwp_error',
'2. No matching work name for id tag ' +
wid)
return None
file_work_levels = len(self.file_works[(album, track)])
write_log(release_id,
'debug',
'Loaded works from file tags for track %s. Works: %s: ',
track,
self.file_works[(album,
track)])
for i, work in enumerate(self.file_works[(album, track)]):
workId = tuple(work['workid'])
if workId not in self.works_cache: # Use cache in preference to file tags
if workId not in self.work_listing[album]:
self.work_listing[album].append(workId)
self.parts[workId]['name'] = [work['name']]
parentId = None
parent = ''
if i < file_work_levels - 1:
parentId = self.file_works[(
album, track)][i + 1]['workid']
parent = self.file_works[(
album, track)][i + 1]['name']
if parentId:
self.works_cache[workId] = parentId
self.parts[workId]['parent'] = parentId
self.parts[tuple(parentId)]['name'] = [parent]
else:
# so we remember we looked it up and found none
self.parts[workId]['no_parent'] = True
self.top_works[(track, album)
]['workId'] = workId
if workId not in self.top[album]:
self.top[album].append(workId)
def check_cache(self, tm, album, track, workId_tuple, not_in_cache):
"""
Recursive loop to get cached works
:param tm:
:param album:
:param track:
:param workId_tuple:
:param not_in_cache:
:return:
"""
parentId_tuple = tuple(self.works_cache[workId_tuple])
if parentId_tuple not in self.work_listing[album]:
self.work_listing[album].append(parentId_tuple)
if parentId_tuple in self.works_cache:
self.check_cache(tm, album, track, parentId_tuple, not_in_cache)
else:
not_in_cache.append(parentId_tuple)
return not_in_cache
def work_not_in_cache(self, release_id, album, track, workId_tuple):
"""
Determine actions if work not in cache (is it the top or do we need to look up?)
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param track:
:param workId_tuple:
:return:
"""
write_log(
release_id,
'debug',
'Processing work_not_in_cache for workId %s',
workId_tuple)
## NB the first condition below is to prevent the side effect of assigning a dictionary entry in self.parts for workId with no details
if workId_tuple in self.parts and 'no_parent' in self.parts[workId_tuple] and (
self.USE_CACHE or self.options[track]["cwp_use_sk"]) and self.parts[workId_tuple]['no_parent']:
write_log(release_id, 'info', '%s is top work', workId_tuple)
self.top_works[(track, album)]['workId'] = workId_tuple
if album in self.top:
if workId_tuple not in self.top[album]:
self.top[album].append(workId_tuple)
else:
self.top[album] = [workId_tuple]
else:
write_log(
release_id,
'info',
'Calling work_add_track to look up parents for %s',
workId_tuple)
for workId in workId_tuple:
self.work_add_track(album, track, workId, 0)
write_log(
release_id,
'debug',
'End of work_not_in_cache for workId %s',
workId_tuple)
def work_add_track(self, album, track, workId, tries, user_data=True):
"""
Add the work to the lookup queue
:param user_data:
:param album:
:param track:
:param workId:
:param tries: number of lookup attempts
:return:
"""
release_id = track.metadata['musicbrainz_albumid']
write_log(
release_id,
'debug',
"ADDING WORK TO LOOKUP QUEUE for work %s",
workId)
self.album_add_request(release_id, album)
# to change the _requests variable to indicate that there are pending
# requests for this item and delay Picard from finalizing the album
write_log(
release_id,
'debug',
"Added lookup request for id %s. Requests = %s",
workId,
album._requests)
if self.works_queue.append(
workId,
(track,
album)): # All work combos are queued, but only new workIds are passed to XML lookup
host = config.setting["server_host"]
port = config.setting["server_port"]
path = "/ws/2/%s/%s" % ('work', workId)
if config.setting['cwp_aliases'] and config.setting['cwp_aliases_tag_text']:
if config.setting['cwp_aliases_tags_user'] and user_data:
login = True
tag_type = '+tags +user-tags'
else:
login = False
tag_type = '+tags'
else:
login = False
tag_type = ''
queryargs = {
"inc": "work-rels+artist-rels+label-rels+place-rels+aliases" +
tag_type}
write_log(
release_id,
'debug',
"Initiating XML lookup for %s......",
workId)
if release_id in release_status and 'lookups' in release_status[release_id]:
release_status[release_id]['lookups'] += 1
return album.tagger.webservice.get(
host,
port,
path,
partial(
self.work_process,
workId,
tries),
# parse_response_type="xml",
priority=True,
important=False,
mblogin=login,
queryargs=queryargs)
else:
write_log(
release_id,
'debug',
"Work is already in queue: %s",
workId)
##########################################################################
# SECTION 2 - Works processing #
# NB These functions may operate asynchronously over multiple albums (as well as multiple tracks) #
##########################################################################
def work_process(self, workId, tries, response, reply, error):
"""
Top routine to process the XML/JSON node response from the lookup
NB This function may operate over multiple albums (as well as multiple tracks)
:param workId:
:param tries:
:param response:
:param reply:
:param error:
:return:
"""
if error:
tuples = self.works_queue.remove(workId)
for track, album in tuples:
release_id = track.metadata['musicbrainz_albumid']
write_log(
release_id,
'warning',
"%r: Network error retrieving work record. Error code %r",
workId,
error)
write_log(
release_id,
'debug',
"Removed request after network error. Requests = %s",
album._requests)
if tries < self.MAX_RETRIES:
user_data = True
write_log(release_id, 'debug', "REQUEUEING...")
if str(error) == '204': # Authentication error
write_log(
release_id, 'debug', "... without user authentication")
user_data = False
self.append_tag(
release_id,
track.metadata,
'~cwp_error',
'3. Authentication failure - data retrieval omits user-specific requests')
self.work_add_track(
album, track, workId, tries + 1, user_data)
else:
write_log(
release_id,
'error',
"EXHAUSTED MAX RE-TRIES for XML lookup for track %s",
track)
if self.ERROR:
self.append_tag(
release_id,
track.metadata,
'~cwp_error',
"4. ERROR: MISSING METADATA due to network errors. Re-try or fix manually.")
self.album_remove_request(release_id, album)
return
tuples = self.works_queue.remove(workId)
if tuples:
new_queue = []
prev_album = None
album = tuples[0][1] # just added to prevent technical "reference before assignment" error
release_id = 'No_release_id'
for (track, album) in tuples:
release_id = track.metadata['musicbrainz_albumid']
# Note that this need to be set here as the work may cover
# multiple albums
if album != prev_album:
write_log(release_id, 'debug',
"Work_process. FOUND WORK: %s for album %s",
workId, album)
write_log(
release_id,
'debug',
"Requests for album %s = %s",
album,
album._requests)
prev_album = album
write_log(release_id, 'info', "RESPONSE = %s", response)
# find the id_tuple(s) key with workId in it
wid_list = []
for w in self.work_listing[album]:
if workId in w and w not in wid_list:
wid_list.append(w)
write_log(
release_id,
'info',
'wid_list for %s is %s',
workId,
wid_list)
for wid in wid_list: # wid is a tuple
write_log(
release_id,
'info',
'processing workId tuple: %r',
wid)
metaList = self.work_process_metadata(
release_id, workId, wid, track, response)
parentList = metaList[0]
# returns [[parent id], [parent name], attribute_list] or None if no parent
# found
arrangers = metaList[1]
# not just arrangers - also composers, lyricists etc.
if wid in self.parts:
if arrangers:
if 'arrangers' in self.parts[wid]:
self.parts[wid]['arrangers'] += arrangers
else:
self.parts[wid]['arrangers'] = arrangers
if parentList:
# first fix the sort order of multi-works at the prev level
# so that recordings of multiple movements of the same parent work will have the
# movements listed in the correct order (i.e.
# ordering-key, if available)
if len(wid) > 1:
for idx in wid:
if idx == workId:
match_tree = [
'relations',
'target-type:work',
'direction:backward',
'ordering-key']
parse_result = parse_data(
release_id, response, [], *match_tree)
write_log(
release_id,
'info',
'multi-works - ordering key for id %s is %s',
idx,
parse_result)
if parse_result:
if isinstance(
parse_result[0], str) and parse_result[0].isdigit():
key = int(parse_result[0])
elif isinstance(parse_result[0], int):
key = parse_result[0]
else:
key = 9999
self.parts[wid]['order'][idx] = key
parentIds = parentList[0]
parents = parentList[1]
parent_attributes = parentList[2]
write_log(
release_id,
'info',
'Parents - ids: %s, names: %s',
parentIds,
parents)
# remove any parents that are descendants of wid as
# they will result in circular references
del_list = []
for i, parentId in enumerate(parentIds):
for work_item in wid:
if work_item in self.child_listing and parentId in self.child_listing[
work_item]:
del_list.append(i)
for i in list(set(del_list)):
removed_id = parentIds.pop(i)
removed_name = parents.pop(i)
write_log(
release_id, 'error', "Found parent which is descendant of child - "
"not using, to prevent circular references. id = %s,"
" name = %s", removed_id, removed_name)
tm = track.metadata
self.append_tag(
release_id,
tm,
'~cwp_error',
'5. Found parent which which is descendant of child - not using '
'to prevent circular references. id = ' +
removed_id +
', name = ' +
removed_name)
is_collection = False
for attribute in parent_attributes:
if attribute['collection']:
is_collection = True
break
# de-dup parent ids before we start
parentIds = list(
collections.OrderedDict.fromkeys(parentIds))
# add descendants to checklist to prevent recursion
for p in parentIds:
for w in wid:
self.child_listing[p].append(w)
if w in self.child_listing:
self.child_listing[p] += self.child_listing[w]
if parentIds:
if wid in self.works_cache:
# Make sure we haven't done this
# relationship before, perhaps for another
# album
if not (set(
self.works_cache[wid]) >= set(parentIds)):
prev_ids = tuple(self.works_cache[wid])
prev_name = self.parts[prev_ids]['name']
self.works_cache[wid] = add_list_uniquely(
self.works_cache[wid], parentIds)
self.parts[wid]['parent'] = add_list_uniquely(
self.parts[wid]['parent'], parentIds)
index = self.work_listing[album].index(
prev_ids)
new_id_list = add_list_uniquely(
list(prev_ids), parentIds)
new_ids = tuple(new_id_list)
self.work_listing[album][index] = new_ids
self.parts[new_ids] = self.parts[prev_ids]
#del self.parts[prev_ids] # Removed from here to deal with multi-parent parts. De-dup now takes place in process_albums.
self.parts[new_ids]['name'] = add_list_uniquely(
prev_name, parents)
parentIds = new_id_list
write_log(
release_id,
'debug',
"In work_process. Changed wid in self.part: prev_ids = %s, new_ids = %s, prev_name = %s, new name = %s",
prev_ids,
new_ids,
prev_name,
self.parts[new_ids]['name'])
else:
self.works_cache[wid] = parentIds
self.parts[wid]['parent'] = parentIds
self.parts[tuple(parentIds)
]['name'] = parents
self.work_listing[album].append(
tuple(parentIds))
# de-duplicate the parent names
# self.parts[tuple(parentIds)]['name'] = list(
# collections.OrderedDict.fromkeys(self.parts[tuple(parentIds)]['name']))
# list(set()) won't work as need to retain order
self.parts[tuple(parentIds)]['is_collection'] = is_collection
write_log(
release_id,
'debug',
"In work_process. self.parts[%s]['is_collection']: %s",
tuple(parentIds),
self.parts[tuple(parentIds)]['is_collection'])
# de-duplicate the parent ids also, otherwise they will be treated as a separate parent
# in the trackback structure
self.parts[wid]['parent'] = list(
collections.OrderedDict.fromkeys(
self.parts[wid]['parent']))
self.works_cache[wid] = list(
collections.OrderedDict.fromkeys(
self.works_cache[wid]))
write_log(
release_id,
'info',
'Added parent ids to work_listing: %s, [Requests = %s]',
parentIds,
album._requests)
write_log(
release_id,
'info',
'work_listing after adding parents: %s',
self.work_listing[album])
# the higher-level work might already be in
# cache from another album
if tuple(
parentIds) in self.works_cache and self.USE_CACHE:
not_in_cache = self.check_cache(
track.metadata, album, track, tuple(parentIds), [])
for workId_tuple in not_in_cache:
new_queue.append(
(release_id, album, track, workId_tuple))
else:
if not self.USE_CACHE:
if tuple(
parentIds) in self.works_cache:
del self.works_cache[tuple(
parentIds)]
for parentId in parentIds:
new_queue.append(
(release_id, album, track, (parentId,)))
else:
# so we remember we looked it up and found none
self.parts[wid]['no_parent'] = True
self.top_works[(track, album)]['workId'] = wid
if wid not in self.top[album]:
self.top[album].append(wid)
write_log(
release_id, 'info', "TOP[album]: %s", self.top[album])
else:
# so we remember we looked it up and found none
self.parts[wid]['no_parent'] = True
self.top_works[(track, album)]['workId'] = wid
self.top[album].append(wid)
write_log(
release_id,
'debug',
"End of tuple processing for workid %s in album %s, track %s,"
" requests remaining = %s, new queue is %r",
workId,
album,
track,
album._requests,
new_queue)
self.album_remove_request(release_id, album)
for queued_item in new_queue:
write_log(
release_id,
'info',
'Have a new queue: queued_item = %r',
queued_item)
write_log(
release_id,
'debug',
'Penultimate end of work_process for %s (subject to parent lookups in "new_queue")',
workId)
for queued_item in new_queue:
self.work_not_in_cache(
queued_item[0],
queued_item[1],
queued_item[2],
queued_item[3])
write_log(release_id, 'debug',
'Ultimate end of work_process for %s', workId)
if album._requests == 0:
self.process_album(release_id, album)
album._finalize_loading(None)
release_status[release_id]['works-done'] = datetime.now()
close_log(release_id, 'works')
def work_process_metadata(self, release_id, workId, wid, track, response):
"""
Process XML node
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
NB release_id may be from a different album than the original, if works lookups are identical
:param workId:
:param wid: The work id tuple of which workId is a member
:param track:
:param response:
:return:
"""
write_log(release_id, 'debug', "In work_process_metadata")
all_tags = parse_data(release_id, response, [], 'tags', 'name')
self.parts[wid]['folks_genres'] = all_tags
self.parts[wid]['worktype_genres'] = parse_data(
release_id, response, [], 'type')
key = parse_data(
release_id,
response,
[],
'attributes',
'type:Key',
'value')
self.parts[wid]['key'] = key
composed_begin_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:artist',
'type:composer',
'begin'))
composed_end_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:artist',
'type:composer',
'end'))
if composed_begin_dates == composed_end_dates:
composed_dates = composed_begin_dates
else:
composed_dates = list(
zip(composed_begin_dates, composed_end_dates))
composed_dates = [y + DATE_SEP + z if y != z else y for y, z in composed_dates]
self.parts[wid]['composed_dates'] = composed_dates
published_begin_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:label',
'type:publishing',
'begin'))
published_end_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:label',
'type:publishing',
'end'))
if published_begin_dates == published_end_dates:
published_dates = published_begin_dates
else:
published_dates = list(
zip(published_begin_dates, published_end_dates))
published_dates = [x + DATE_SEP + y for x, y in published_dates]
self.parts[wid]['published_dates'] = published_dates
premiered_begin_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:place',
'type:premiere',
'begin'))
premiered_end_dates = year(
parse_data(
release_id,
response,
[],
'relations',
'target-type:place',
'type:premiere',
'end'))
if premiered_begin_dates == premiered_end_dates:
premiered_dates = premiered_begin_dates
else:
premiered_dates = list(
zip(premiered_begin_dates, premiered_end_dates))
premiered_dates = [x + DATE_SEP + y for x, y in premiered_dates]
self.parts[wid]['premiered_dates'] = premiered_dates
lang = get_preferred_artist_language(config)
if lang:
alias = parse_data(release_id, response, [], 'aliases',
'locale:' + lang, 'primary:True', 'name')
user_tags = parse_data(
release_id, response, [], 'user-tags', 'name')
if config.setting['cwp_aliases_tags_user']:
tags = user_tags
else:
tags = all_tags
if alias:
self.parts[wid]['alias'] = self.parts[wid]['name'][:]
self.parts[wid]['tags'] = tags
for ind, w in enumerate(wid):
if w == workId:
# alias should be a one item list but just in case it isn't...
if len(self.parts[wid]['alias']) > ind:
# The condition here is just to trap errors caused by database inconsistencies
# (e.g. a part is shown as a recording of two works, one of which is an arrangement
# of the other - this can create a two-item wid with a one-item self.parts[wid]['name']
self.parts[wid]['alias'][ind] = '; '.join(
alias)
relation_list = parse_data(release_id, response, [], 'relations')
return self.work_process_relations(
release_id, track, workId, wid, relation_list)
def work_process_relations(
self,
release_id,
track,
workId,
wid,
relations):
"""
Find the parents etc.
NB track is just the last album/track for this work - used as being
representative for options identification. If this is inconsistent (e.g. different collections
option for albums with the same works) then the latest added track will over-ride others' settings).
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param track:
:param workId:
:param wid:
:param relations:
:return:
"""
write_log(
release_id,
'debug',
"In work_process_relations. Relations--> %s",
relations)
if track:
options = self.options[track]
else:
options = config.setting
new_workIds = []
new_works = []
attributes_list = []
relation_attributes = parse_data(
release_id,
relations,
[],
'target-type:work',
'type:parts',
'direction:backward',
'attributes')
new_work_list = []
write_log(
release_id,
'debug',
"relation_attributes--> %s",
relation_attributes)
for relation_attribute in relation_attributes:
if (
'part of collection' not in relation_attribute) or options['cwp_collections']:
new_work_list += parse_data(release_id,
relations,
[],
'target-type:work',
'type:parts',
'direction:backward',
'work')
attributes_dict = {'collection' : ('part of collection' in relation_attribute),
'movements' : ('movement' in relation_attribute),
'acts' : ('act' in relation_attribute),
'numbers' : ('number' in relation_attribute)}
attributes_list += [attributes_dict]
if (
'part of collection' in relation_attribute) and not options['cwp_collections']:
write_log(
release_id,
'info',
'Not getting parent work because relationship is "part of collection" and option not selected')
if new_work_list:
write_log(
release_id,
'info',
'new_work_list: %s',
new_work_list)
new_workIds = parse_data(release_id, new_work_list, [], 'id')
new_works = parse_data(release_id, new_work_list, [], 'title')
else:
arrangement_of = parse_data(
release_id,
relations,
[],
'target-type:work',
'type:arrangement',
'direction:backward',
'work')
if arrangement_of and options['cwp_arrangements']:
new_workIds = parse_data(release_id, arrangement_of, [], 'id')
new_works = parse_data(release_id, arrangement_of, [], 'title')
self.parts[wid]['arrangement'] = True
else:
medley_of = parse_data(
release_id,
relations,
[],
'target-type:work',
'type:medley',
'work')
direction = parse_data(
release_id,
relations,
[],
'target-type:work',
'type:medley',
'direction')
if 'backward' not in direction:
write_log(
release_id, 'info', 'Medley_of: %s', medley_of)
if medley_of and options['cwp_medley']:
medley_list = []
medley_id_list = []
for medley_item in medley_of:
medley_list = medley_list + \
parse_data(release_id, medley_item, [], 'title')
medley_id_list = medley_id_list + \
parse_data(release_id, medley_item, [], 'id')
# (parse_data is a list...)
new_workIds = medley_id_list
new_works = medley_list
write_log(
release_id, 'info', 'Medley_list: %s', medley_list)
self.parts[wid]['medley_list'] = medley_list
write_log(
release_id,
'info',
'New works: ids: %s, names: %s, attributes: %s',
new_workIds,
new_works,
attributes_list)
artists = get_artists(
options,
release_id,
{},
relations,
'work')['artists']
# artist_types = ['arranger', 'instrument arranger', 'orchestrator', 'composer', 'writer', 'lyricist',
# 'librettist', 'revised by', 'translator', 'reconstructed by', 'vocal arranger']
write_log(release_id, 'info', "ARTISTS %s", artists)
workItems = (new_workIds, new_works, attributes_list)
itemsFound = [workItems, artists]
return itemsFound
@staticmethod
def album_add_request(release_id, album):
"""
To keep track as to whether all lookups have been processed
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:return:
"""
album._requests += 1
write_log(
release_id,
'debug',
"Added album request - requests: %s",
album._requests)
@staticmethod
def album_remove_request(release_id, album):
"""
To keep track as to whether all lookups have been processed
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:return:
"""
album._requests -= 1
write_log(
release_id,
'debug',
"Removed album request - requests: %s",
album._requests)
##################################################
# SECTION 3 - Organise tracks and works in album #
##################################################
def process_album(self, release_id, album):
"""
Top routine to run end-of-album processes
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:return:
"""
write_log(release_id, 'debug', "PROCESS ALBUM %s", album)
release_status[release_id]['done-lookups'] = datetime.now()
# De-duplicate names in self.parts, maintaining order (in case part names have been arrived at via multiple paths)
for part_item in self.parts:
if 'name' in self.parts[part_item]:
self.parts[part_item]['name'] = list(collections.OrderedDict.fromkeys(str_to_list(self.parts[part_item]['name'])))
# populate the inverse hierarchy
write_log(release_id, 'info', "Cache: %s", self.works_cache)
write_log(release_id, 'info', "Work listing %s", self.work_listing)
alias_tag_list = config.setting['cwp_aliases_tag_text'].split(',')
for i, tag_item in enumerate(alias_tag_list):
alias_tag_list[i] = tag_item.strip()
for workId in self.work_listing[album]:
if workId in self.parts:
write_log(
release_id,
'info',
'Processing workid: %s',
workId)
write_log(
release_id,
'info',
'self.work_listing[album]: %s',
self.work_listing[album])
if len(workId) > 1:
# fix the order of names using ordering keys gathered in
# work_process
if 'order' in self.parts[workId]:
seq = []
for idx in workId:
if idx in self.parts[workId]['order']:
seq.append(self.parts[workId]['order'][idx])
else:
# for the possibility of workids not part of
# the same parent and not all ordered
seq.append(999)
zipped_names = zip(self.parts[workId]['name'], seq)
sorted_tups = sorted(zipped_names, key=lambda x: x[1])
self.parts[workId]['name'] = [x[0]
for x in sorted_tups]
# use aliases where appropriate
# name is a list - need a string to test for Latin chars
name_string = '; '.join(self.parts[workId]['name'])
if config.setting['cwp_aliases']:
if config.setting['cwp_aliases_all'] or (
config.setting['cwp_aliases_greek'] and not only_roman_chars(name_string)) or (
'tags' in self.parts[workId] and any(
x in self.parts[workId]['tags'] for x in alias_tag_list)):
if 'alias' in self.parts[workId] and self.parts[workId]['alias']:
self.parts[workId]['name'] = self.parts[workId]['alias'][:]
topId = None
write_log(
release_id,
'info',
'Works_cache: %s',
self.works_cache)
if workId in self.works_cache:
parentIds = tuple(self.works_cache[workId])
# for parentId in parentIds:
write_log(
release_id,
'debug',
"Create inverses: %s, %s",
workId,
parentIds)
if parentIds in self.partof[album]:
if workId not in self.partof[album][parentIds]:
self.partof[album][parentIds].append(workId)
else:
self.partof[album][parentIds] = [workId]
write_log(release_id, 'info', "Partof: %s",
self.partof[album][parentIds])
if 'no_parent' in self.parts[parentIds]:
# to handle case if album includes works already in
# cache from a different album
if self.parts[parentIds]['no_parent']:
topId = parentIds
else:
topId = workId
if topId:
if album in self.top:
if topId not in self.top[album]:
self.top[album].append(topId)
else:
self.top[album] = [topId]
# work out the full hierarchy and part levels
height = 0
write_log(
release_id,
'info',
"TOP: %s, \nALBUM: %s, \nTOP[ALBUM]: %s",
self.top,
album,
self.top[album])
if len(self.top[album]) > 1:
single_work_album = 0
else:
single_work_album = 1
for topId in self.top[album]:
self.create_trackback(release_id, album, topId)
write_log(
release_id,
'info',
"Top id = %s, Name = %s",
topId,
self.parts[topId]['name'])
write_log(
release_id,
'info',
"Trackback before levels: %s",
self.trackback[album][topId])
work_part_levels = self.level_calc(
release_id, self.trackback[album][topId], height)
write_log(
release_id,
'info',
"Trackback after levels: %s",
self.trackback[album][topId])
# determine the level which will be the principal 'work' level
if work_part_levels >= 3:
ref_level = work_part_levels - single_work_album
else:
ref_level = work_part_levels
# extended metadata scheme won't display more than 3 work levels
# ref_level = min(3, ref_level)
ref_height = work_part_levels - ref_level
top_info = {
'levels': work_part_levels,
'id': topId,
'name': self.parts[topId]['name'],
'single': single_work_album}
# set the metadata in sequence defined by the work structure
answer = self.process_trackback(
release_id,
album,
self.trackback[album][topId],
ref_height,
top_info)
##
# trackback is a tree in the form {album: {id: , children:{id: , children{},
# id: etc},
# id: etc} }
# process_trackback uses the trackback tree to derive title and level_0 based hierarchies
# from the structure. It also returns a tuple (id, tracks), where tracks has the structure
# {'track': [(track, height), (track, height), ...tuples...]
# 'work': [[worknames], [worknames], ...lists...]
# 'tracknumber': [num, num, ...floats of form n.nnn = disc.track...]
# 'title': [title, title, ...strings...]}
# each list is the same length - i.e. the number of tracks for the top work
# there can be more than one workname for a track
# height is the number of part levels for the related track
##
if answer:
tracks = sorted(zip(answer[1]['track'], answer[1]['tracknumber']), key=lambda x: x[1])
# need them in tracknumber sequence for the movement numbers to be correct
write_log(release_id, 'info', "TRACKS: %s", tracks)
# work_part_levels = self.trackback[album][topId]['depth']
movement_count = 0
prev_movementgroup = None
for track, _ in tracks:
movement_count += 1
track_meta = track[0]
tm = track_meta.metadata
if '~cwp_workid_0' in tm:
workIds = tuple(str_to_list(tm['~cwp_workid_0']))
if workIds:
count = 0
self.process_work_artists(
release_id, album, track_meta, workIds, tm, count)
title_work_levels = 0
if '~cwp_title_work_levels' in tm:
title_work_levels = int(tm['~cwp_title_work_levels'])
movementgroup = self.extend_metadata(
release_id,
top_info,
track_meta,
ref_height,
title_work_levels) # revise for new data
if track_meta not in self.tracks[album]:
self.tracks[album][track_meta] = {}
if movementgroup:
if movementgroup != prev_movementgroup:
movement_count = 1
write_log(
release_id,
'debug',
"processing movements for track: %s - movement-group is %s",
track, movementgroup)
self.tracks[album][track_meta]['movement-group'] = movementgroup
self.tracks[album][track_meta]['movement-number'] = movement_count
self.parts[tuple(movementgroup)]['movement-total'] = movement_count
prev_movementgroup = movementgroup
write_log(
release_id,
'debug',
"FINISHED TRACK PROCESSING FOR Top work id: %s",
topId)
# Need to redo the loop so that all album-wide tm is updated before
# publishing
for track, movement_info in self.tracks[album].items():
self.publish_metadata(release_id, album, track, movement_info)
# #
# The messages below are normally commented out as they get VERY long if there are a lot of albums loaded
# For extreme debugging, remove the comments and just run one or a few albums
# Do not forget to comment out again.
# #
# write_log(release_id, 'info', 'Self.parts: %s', self.parts)
# write_log(release_id, 'info', 'Self.trackback: %s', self.trackback)
# tidy up
self.trackback[album].clear()
# Finally process the orphan tracks
if album in self.orphan_tracks:
for track in self.orphan_tracks[album]:
tm = track.metadata
options = self.options[track]
if options['cwp_derive_works_from_title']:
work, movt, inter_work = self.derive_from_title(release_id, track, tm['title'])
tm['~cwp_extended_work'] = tm['~cwp_extended_groupheading'] = tm['~cwp_title_work'] = \
tm['~cwp_title_groupheading'] = tm['~cwp_work'] = tm['~cwp_groupheading']= work
tm['~cwp_part'] = tm['~cwp_extended_part'] = tm['~cwp_title_part_0'] = movt
tm['~cwp_inter_work'] = tm['~cwp_extended_inter_work'] = tm['~cwp_inter_title_work'] = inter_work
self.publish_metadata(release_id, album, track)
write_log(release_id, 'debug', "PROCESS ALBUM function complete")
def create_trackback(self, release_id, album, parentId):
"""
Create an inverse listing of the work-parent relationships
:param release_id:
:param album:
:param parentId:
:return: trackback for a given parentId
"""
write_log(release_id, 'debug', "Create trackback for %s", parentId)
if parentId in self.partof[album]: # NB parentId is a tuple
for child in self.partof[album][parentId]: # NB child is a tuple
if child in self.partof[album]:
child_trackback = self.create_trackback(
release_id, album, child)
self.append_trackback(
release_id, album, parentId, child_trackback)
else:
self.append_trackback(
release_id, album, parentId, self.trackback[album][child])
return self.trackback[album][parentId]
else:
return self.trackback[album][parentId]
def append_trackback(self, release_id, album, parentId, child):
"""
Recursive process to populate trackback
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param parentId:
:param child:
:return:
"""
write_log(release_id, 'debug', "In append_trackback...")
if parentId in self.trackback[album]: # NB parentId is a tuple
if 'children' in self.trackback[album][parentId]:
if child not in self.trackback[album][parentId]['children']:
write_log(release_id, 'info', "TRYING TO APPEND...")
self.trackback[album][parentId]['children'].append(child)
write_log(
release_id,
'info',
"...PARENT %s - ADDED %s as child",
self.parts[parentId]['name'],
child)
else:
write_log(
release_id,
'info',
"Parent %s already has %s as child",
parentId,
child)
else:
self.trackback[album][parentId]['children'] = [child]
write_log(
release_id,
'info',
"Existing PARENT %s - ADDED %s as child",
self.parts[parentId]['name'],
child)
else:
self.trackback[album][parentId]['id'] = parentId
self.trackback[album][parentId]['children'] = [child]
write_log(
release_id,
'info',
"New PARENT %s - ADDED %s as child",
self.parts[parentId]['name'],
child)
write_log(
release_id,
'info',
"APPENDED TRACKBACK: %s",
self.trackback[album][parentId])
return self.trackback[album][parentId]
def level_calc(self, release_id, trackback, height):
"""
Recursive process to determine the max level for a work
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param trackback:
:param height: number of levels above this one
:return:
"""
write_log(release_id, 'debug', 'In level_calc process')
if 'children' not in trackback:
write_log(release_id, 'info', "Got to bottom")
trackback['height'] = height
trackback['depth'] = 0
return 0
else:
trackback['height'] = height
height += 1
max_depth = 0
for child in trackback['children']:
write_log(release_id, 'info', "CHILD: %s", child)
depth = self.level_calc(release_id, child, height) + 1
write_log(release_id, 'info', "DEPTH: %s", depth)
max_depth = max(depth, max_depth)
trackback['depth'] = max_depth
return max_depth
###########################################
# SECTION 4 - Process tracks within album #
###########################################
def process_trackback(
self,
release_id,
album_req,
trackback,
ref_height,
top_info):
"""
Set work structure metadata & govern other metadata-setting processes
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album_req:
:param trackback:
:param ref_height:
:param top_info:
:return:
"""
write_log(
release_id,
'debug',
"IN PROCESS_TRACKBACK. Trackback = %s",
trackback)
tracks = collections.defaultdict(dict)
process_now = False
if 'meta' in trackback:
for track, album in trackback['meta']:
if album_req == album:
process_now = True
if process_now or 'children' not in trackback:
if 'meta' in trackback and 'id' in trackback and 'depth' in trackback and 'height' in trackback:
write_log(release_id, 'info', "Processing level 0")
depth = trackback['depth']
height = trackback['height']
workId = tuple(trackback['id'])
if depth != 0:
if 'children' in trackback:
child_response = self.process_trackback_children(
release_id, album_req, trackback, ref_height, top_info, tracks)
tracks = child_response[1]
write_log(
release_id,
'info',
'Bottom level for this trackback is higher level elsewhere - adjusting levels')
depth = 0
write_log(release_id, 'info', "WorkId: %s, Work name: %s", workId, self.parts[workId]['name'])
for track, album in trackback['meta']:
if album == album_req:
write_log(release_id, 'info', "Track: %s", track)
tm = track.metadata
write_log(
release_id, 'info', "Track metadata = %s", tm)
tm['~cwp_workid_' + str(depth)] = workId
self.write_tags(release_id, track, tm, workId)
self.make_annotations(release_id, track, workId)
# strip leading and trailing spaces from work names
if isinstance(self.parts[workId]['name'], str):
worktemp = self.parts[workId]['name'].strip()
else:
for index, it in enumerate(
self.parts[workId]['name']):
self.parts[workId]['name'][index] = it.strip()
worktemp = self.parts[workId]['name']
if isinstance(top_info['name'], str):
toptemp = top_info['name'].strip()
else:
for index, it in enumerate(top_info['name']):
top_info['name'][index] = it.strip()
toptemp = top_info['name']
tm['~cwp_work_' + str(depth)] = worktemp
tm['~cwp_part_levels'] = str(height)
tm['~cwp_work_part_levels'] = str(top_info['levels'])
tm['~cwp_workid_top'] = top_info['id']
tm['~cwp_work_top'] = toptemp
tm['~cwp_single_work_album'] = top_info['single']
write_log(
release_id, 'info', "Track metadata = %s", tm)
if 'track' in tracks:
tracks['track'].append((track, height))
else:
tracks['track'] = [(track, height)]
tracks['tracknumber'] = [int(tm['discnumber']) + (int(tm['tracknumber']) / 1000)]
# Hopefully no more than 999 tracks per disc!
write_log(release_id, 'info', "Tracks: %s", tracks)
response = (workId, tracks)
write_log(release_id, 'debug', "LEAVING PROCESS_TRACKBACK")
write_log(
release_id,
'info',
"depth %s Response = %s",
depth,
response)
return response
else:
return None
else:
response = self.process_trackback_children(
release_id, album_req, trackback, ref_height, top_info, tracks)
return response
def process_trackback_children(
self,
release_id,
album_req,
trackback,
ref_height,
top_info,
tracks):
"""
TODO add some better documentation!
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album_req:
:param trackback:
:param ref_height:
:param top_info:
:param tracks:
:return:
"""
if 'id' in trackback and 'depth' in trackback and 'height' in trackback:
write_log(
release_id,
'debug',
'In process_children_trackback for trackback %s',
trackback)
depth = trackback['depth']
height = trackback['height']
parentId = tuple(trackback['id'])
parent = self.parts[parentId]['name']
width = 0
for child in trackback['children']:
width += 1
write_log(
release_id,
'info',
"child trackback = %s",
child)
answer = self.process_trackback(
release_id, album_req, child, ref_height, top_info)
if answer:
workId = answer[0]
child_tracks = answer[1]['track']
for track in child_tracks:
track_meta = track[0]
track_height = track[1]
part_level = track_height - height
write_log(
release_id,
'debug',
"Calling set metadata %s",
(part_level,
workId,
parentId,
parent,
track_meta))
self.set_metadata(
release_id, part_level, workId, parentId, parent, track_meta)
if 'track' in tracks:
tracks['track'].append(
(track_meta, track_height))
else:
tracks['track'] = [(track_meta, track_height)]
tm = track_meta.metadata
# ~cwp_title if composer had to be removed
title = tm['~cwp_title'] or tm['title']
if 'title' in tracks:
tracks['title'].append(title)
else:
tracks['title'] = [title]
# to make sure we get it as a list
work = tm.getall('~cwp_work_0')
if 'work' in tracks:
tracks['work'].append(work)
else:
tracks['work'] = [work]
if 'tracknumber' not in tm:
tm['tracknumber'] = 0
if 'discnumber' not in tm:
tm['discnumber'] = 0
if 'tracknumber' in tracks:
tracks['tracknumber'].append(
int(tm['discnumber']) + (int(tm['tracknumber']) / 1000))
else:
tracks['tracknumber'] = [
int(tm['discnumber']) + (int(tm['tracknumber']) / 1000)]
if tracks and 'track' in tracks:
track = tracks['track'][0][0]
# NB this will only be the first track of tracks, but its
# options will be used for the structure
self.derive_from_structure(
release_id, top_info, tracks, height, depth, width, 'title')
if self.options[track]["cwp_level0_works"]:
# replace hierarchical works with those from work_0 (for
# consistency)
self.derive_from_structure(
release_id, top_info, tracks, height, depth, width, 'work')
write_log(
release_id,
'info',
"Trackback result for %s = %s",
parentId,
tracks)
response = parentId, tracks
write_log(
release_id,
'debug',
"LEAVING PROCESS_CHILD_TRACKBACK depth %s Response = %s",
depth,
response)
return response
else:
return None
else:
return None
def derive_from_structure(
self,
release_id,
top_info,
tracks,
height,
depth,
width,
name_type):
"""
Derive title (or work level-0) components from MB hierarchical work structure
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param top_info:
{'levels': work_part_levels,'id': topId,'name': self.parts[topId]['name'],'single': single_work_album}
:param tracks:
{'track':[(track1, height1), (track2, height2), ...], 'work': [work1, work2,...],
'title': [title1, title2, ...], 'tracknumber': [tracknumber1, tracknumber2, ...]}
where height is the number of levels in total in the branch for that track (i.e. height 1 => work_0 & work_1)
:param height: number of levels above the current one
:param depth: maximum number of levels
:param width: number of siblings
:param name_type: work or title
:return:
"""
if 'track' in tracks:
track = tracks['track'][0][0]
# NB this will only be the first track of tracks, but its
# options will be used for the structure
single_work_track = False # default
write_log(
release_id,
'debug',
"Deriving info for %s from structure for tracks %s",
name_type,
tracks['track'])
write_log(
release_id,
'info',
'%ss are %r',
name_type,
tracks[name_type])
if 'tracknumber' in tracks:
sorted_tracknumbers = sorted(tracks['tracknumber'])
else:
sorted_tracknumbers = None
write_log(
release_id,
'info',
"SORTED TRACKNUMBERS: %s",
sorted_tracknumbers)
common_len = 0
if name_type in tracks:
meta_str = "_title" if name_type == 'title' else "_X0"
# in case of works, could be a list of lists
name_list = tracks[name_type]
write_log(
release_id,
'info',
"%s list %s",
name_type,
name_list)
if len(name_list) == 1: # only one track in this work so try and extract using colons
single_work_track = True
track_height = tracks['track'][0][1]
if track_height - height > 0: # track_height - height == part_level
if name_type == 'title':
write_log(
release_id,
'debug',
"Single track work. Deriving directly from title text: %s",
track)
ti = name_list[0]
common_subset = self.derive_from_title(
release_id, track, ti)[0]
else:
common_subset = ""
else:
common_subset = name_list[0]
write_log(
release_id,
'info',
"%s is single-track work. common_subset is set to %s",
tracks['track'][0][0],
common_subset)
if common_subset:
common_len = len(common_subset)
else:
common_len = 0
else: # NB if names are lists of lists, we'll assume they all start the same way
if isinstance(name_list[0], list):
compare = name_list[0][0].split()
else:
# a list of the words in the first name
compare = name_list[0].split()
for name_item in name_list:
if isinstance(name_item, list):
name = name_item[0]
else:
name = name_item
lcs = longest_common_sequence(compare, name.split())
compare = lcs['sequence']
if not compare:
common_len = 0
break
if lcs['length'] > 0:
common_subset = " ".join(compare)
write_log(
release_id,
'info',
"Common subset from %ss at level %s, item name %s ..........",
name_type,
tracks['track'][0][1] -
height,
name)
write_log(
release_id, 'info', "..........is %s", common_subset)
common_len = len(common_subset)
write_log(
release_id,
'info',
"checked for common sequence - length is %s",
common_len)
for track_index, track_item in enumerate(tracks['track']):
track_meta = track_item[0]
tm = track_meta.metadata
top_level = int(tm['~cwp_part_levels'])
part_level = track_item[1] - height
if common_len > 0:
self.create_work_levels(release_id, name_type, tracks, track, track_index,
track_meta, tm, meta_str, part_level, depth, width, common_len)
else: # (no common substring at this level)
if name_type == 'work':
write_log(release_id, 'info',
'single track work - indicator = %s. track = %s, part_level = %s, top_level = %s',
single_work_track, track_item, part_level, top_level)
if part_level >= top_level: # so it won't be covered by top-down action
for level in range(
0, part_level + 1): # fill in the missing work names from the canonical list
if '~cwp' + meta_str + '_work_' + \
str(level) not in tm:
tm['~cwp' +
meta_str +
'_work_' +
str(level)] = tm['~cwp_work_' +
str(level)]
if level > 0:
self.level0_warn(release_id, tm, level)
if '~cwp' + meta_str + '_part_' + \
str(level) not in tm and '~cwp_part_' + str(level) in tm:
tm['~cwp' +
meta_str +
'_part_' +
str(level)] = tm['~cwp_part_' +
str(level)]
if level > 0:
self.level0_warn(release_id, tm, level)
def create_work_levels(self, release_id, name_type, tracks, track, track_index,
track_meta, tm, meta_str, part_level, depth, width, common_len):
"""
For a group of tracks with common metadata in the title/level0 work, create the work structure
for that metadata, using the structure in the MB database
:param release_id:
:param name_type: title or work
:param tracks: {'track':[(track1, height1), (track2, height2), ...], 'work': [work1, work2,...],
'title': [title1, title2, ...], 'tracknumber': [tracknumber1, tracknumber2, ...]}
where height is the number of levels in total in the branch for that track (i.e. height 1 => work_0 & work_1)
:param track:
:param track_index: index of track in tracks
:param track_meta:
:param tm: track meta (dup?)
:param meta_str: string created from name_type
:param part_level: The level of the current item in the works hierarchy
:param depth: The number of levels below the current item
:param width: The number of children of the current item
:param common_len: length of the common text
:return:
"""
allow_repeats = True
write_log(
release_id,
'info',
"Use %s info for track: %s at level %s",
name_type,
track_meta,
part_level)
name = tracks[name_type][track_index]
if isinstance(name, list):
work = name[0][:common_len]
else:
work = name[:common_len]
work = work.rstrip(":,.;- ")
if self.options[track]["cwp_removewords_p"]:
removewords = self.options[track]["cwp_removewords_p"].split(
',')
else:
removewords = []
write_log(
release_id,
'info',
"Prefixes (in %s) = %s",
name_type,
removewords)
for prefix in removewords:
prefix2 = str(prefix).lower().rstrip()
if prefix2[0] != " ":
prefix2 = " " + prefix2
write_log(
release_id, 'info', "checking prefix %s", prefix2)
if work.lower().endswith(prefix2):
if len(prefix2) > 0:
work = work[:-len(prefix2)]
common_len = len(work)
work = work.rstrip(":,.;- ")
if work.lower() == prefix2.strip():
work = ''
common_len = 0
write_log(
release_id,
'info',
"work after prefix strip %s",
work)
write_log(release_id, 'info', "Prefixes checked")
tm['~cwp' + meta_str + '_work_' +
str(part_level)] = work
if part_level > 0 and name_type == "work":
write_log(
release_id,
'info',
'checking if %s is repeated name at part_level = %s',
work,
part_level)
write_log(release_id, 'info', 'lower work name is %s',
tm['~cwp' + meta_str + '_work_' + str(part_level - 1)])
# fill in missing names caused by no common string at lower levels
# count the missing levels and push the current name
# down to the lowest missing level
missing_levels = 0
fill_level = part_level - 1
while '~cwp' + meta_str + '_work_' + \
str(fill_level) not in tm:
missing_levels += 1
fill_level -= 1
if fill_level < 0:
break
write_log(
release_id,
'info',
'there is/are %s missing level(s)',
missing_levels)
if missing_levels > 0:
allow_repeats = True
for lev in range(
part_level - missing_levels, part_level):
if lev > 0: # not filled_lowest and lev > 0:
tm['~cwp' + meta_str +
'_work_' + str(lev)] = work
tm['~cwp' +
meta_str +
'_part_' +
str(lev - 1)] = self.strip_parent_from_work(track,
release_id,
interpret(tm['~cwp' + meta_str + '_work_'
+ str(lev - 1)]),
tm['~cwp' + meta_str + '_work_' + str(lev)],
lev - 1, False)[0]
else:
tm['~cwp' + meta_str + '_work_' + str(lev)] = tm['~cwp_work_' + str(lev)]
if missing_levels > 0:
write_log(release_id, 'info', 'lower work name is now %r', tm.getall(
'~cwp' + meta_str + '_work_' + str(part_level - 1)))
# now fix the repeated work name at this level
if work == tm['~cwp' + meta_str + '_work_' +
str(part_level - 1)] and not allow_repeats:
tm['~cwp' +
meta_str +
'_work_' +
str(part_level)] = tm['~cwp_work_' +
str(part_level)]
self.level0_warn(release_id, tm, part_level)
tm['~cwp' +
meta_str +
'_part_' +
str(part_level -
1)] = self.strip_parent_from_work(track,
release_id,
tm.getall('~cwp' + meta_str + '_work_' + str(part_level - 1)),
tm['~cwp' + meta_str + '_work_' + str(part_level)],
part_level - 1, False)[0]
if part_level == 1:
if isinstance(name, list):
movt = [x[common_len:].strip().lstrip(":,.;- ")
for x in name]
else:
movt = name[common_len:].strip().lstrip(":,.;- ")
write_log(
release_id, 'info', "%s - movt = %s", name_type, movt)
tm['~cwp' + meta_str + '_part_0'] = movt
write_log(
release_id,
'info',
"%s Work part_level = %s",
name_type,
part_level)
if name_type == 'title':
if '~cwp_title_work_' + str(part_level - 1) in tm and tm['~cwp_title_work_' + str(
part_level)] == tm['~cwp_title_work_' + str(part_level - 1)] and width == 1:
pass # don't count higher part-levels which are not distinct from lower ones
# when the parent work has only one child
else:
tm['~cwp_title_work_levels'] = depth
tm['~cwp_title_part_levels'] = part_level
write_log(
release_id,
'info',
"Set new metadata for %s OK",
name_type)
def level0_warn(self, release_id, tm, level):
"""
Issue warnings if inadequate level 0 data
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param tm:
:param level:
:return:
"""
write_log(
release_id,
'warning',
'Unable to use level 0 as work name source in level %s - using hierarchy instead',
level)
if self.WARNING:
self.append_tag(
release_id,
tm,
'~cwp_warning',
'5. Unable to use level 0 as work name source in level ' +
str(level) +
' - using hierarchy instead')
def set_metadata(
self,
release_id,
part_level,
workId,
parentId,
parent,
track):
"""
Set the names of works and parts
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param part_level:
:param workId:
:param parentId:
:param parent:
:param track:
:return:
"""
write_log(
release_id,
'debug',
"SETTING METADATA FOR TRACK = %r, parent = %s, part_level = %s",
track,
parent,
part_level)
tm = track.metadata
if parentId:
self.write_tags(release_id, track, tm, parentId)
self.make_annotations(release_id, track, parentId)
if 'annotations' in self.parts[workId]:
work_annotations = self.parts[workId]['annotations']
self.parts[workId]['stripped_annotations'] = work_annotations
else:
work_annotations = []
if 'annotations' in self.parts[parentId]:
parent_annotations = self.parts[parentId]['annotations']
else:
parent_annotations = []
if parent_annotations:
work_annotations = [
z for z in work_annotations if z not in parent_annotations]
self.parts[workId]['stripped_annotations'] = work_annotations
tm['~cwp_workid_' + str(part_level)] = parentId
tm['~cwp_work_' + str(part_level)] = parent
# maybe more than one work name
work = self.parts[workId]['name']
write_log(release_id, 'info', "Set work name to: %s", work)
works = []
# in case there is only one and it isn't in a list
if isinstance(work, str):
works.append(work)
else:
works = work[:]
stripped_works = []
for work in works:
extend = True
strip = self.strip_parent_from_work(
track, release_id, work, parent, part_level, extend, parentId, workId)
stripped_works.append(strip[0])
write_log(
release_id,
'info',
"Parent: %s, Stripped works = %s",
parent,
stripped_works)
# now == parent, after removing full_parent logic
full_parent = strip[1]
if full_parent != parent:
tm['~cwp_work_' +
str(part_level)] = full_parent.strip()
self.parts[parentId]['name'] = full_parent
if 'no_parent' in self.parts[parentId]:
if self.parts[parentId]['no_parent']:
tm['~cwp_work_top'] = full_parent.strip()
tm['~cwp_part_' + str(part_level - 1)] = stripped_works
self.parts[workId]['stripped_name'] = stripped_works
write_log(release_id, 'debug', "GOT TO END OF SET_METADATA")
def write_tags(self, release_id, track, tm, workId):
"""
write genre-related tags from internal variables
:param track:
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param tm: track metadata
:param workId: MBID of current work
:return: None - just writes tags
"""
options = self.options[track]
candidate_genres = []
if options['cwp_genres_use_folks'] and 'folks_genres' in self.parts[workId]:
candidate_genres += self.parts[workId]['folks_genres']
if options['cwp_genres_use_worktype'] and 'worktype_genres' in self.parts[workId]:
candidate_genres += self.parts[workId]['worktype_genres']
self.append_tag(
release_id,
tm,
'~cwp_worktype_genres',
self.parts[workId]['worktype_genres'])
self.append_tag(
release_id,
tm,
'~cwp_candidate_genres',
candidate_genres)
self.append_tag(release_id, tm, '~cwp_keys', self.parts[workId]['key'])
self.append_tag(release_id, tm, '~cwp_composed_dates',
self.parts[workId]['composed_dates'])
self.append_tag(release_id, tm, '~cwp_published_dates',
self.parts[workId]['published_dates'])
self.append_tag(release_id, tm, '~cwp_premiered_dates',
self.parts[workId]['premiered_dates'])
def make_annotations(self, release_id, track, wid):
"""
create an 'annotations' entry in the 'parts' dict, as dictated by options, from dates and keys
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param track: the current track
:param wid: the current work MBID
:return:
"""
write_log(
release_id,
'debug',
"Starting module %s",
'make_annotations')
options = self.options[track]
if options['cwp_workdate_include']:
if options['cwp_workdate_source_composed'] and 'composed_dates' in self.parts[wid] and self.parts[wid]['composed_dates']:
workdates = self.parts[wid]['composed_dates']
elif options['cwp_workdate_source_published'] and 'published_dates' in self.parts[wid] and self.parts[wid]['published_dates']:
workdates = self.parts[wid]['published_dates']
elif options['cwp_workdate_source_premiered'] and 'premiered_dates' in self.parts[wid] and self.parts[wid]['premiered_dates']:
workdates = self.parts[wid]['premiered_dates']
else:
workdates = []
else:
workdates = []
keys = []
if options['cwp_key_include'] and 'key' in self.parts[wid] and self.parts[wid]['key']:
keys = self.parts[wid]['key']
elif options['cwp_key_contingent_include'] and 'key' in self.parts[wid] and self.parts[wid]['key']\
and 'name' in self.parts[wid]:
write_log(
release_id,
'info',
'checking for key. keys = %s, names = %s',
self.parts[wid]['key'],
self.parts[wid]['name'])
# add all the parent names to the string for checking -
work_name = list_to_str(self.parts[wid]['name'])
work_chk = wid
while work_chk in self.works_cache:
parent_chk = tuple(self.works_cache[work_chk])
if parent_chk in self.parts and self.parts[parent_chk] and 'name' in self.parts[parent_chk] and self.parts[parent_chk]['name']:
parent_name = list_to_str(self.parts[parent_chk]['name'])
p_name_orig = self.parts[parent_chk]['name']
p_chk = self.parts[parent_chk]
work_name = parent_name + ': ' + work_name
work_chk = parent_chk
# now see if the key has been mentioned in the work or its parents
for key in self.parts[wid]['key']:
# if not any([key.lower() in x.lower() for x in
# str_to_list(work_name)]): # TODO remove
if not key.lower() in work_name.lower():
keys.append(key)
annotations = keys + workdates
if annotations:
self.parts[wid]['annotations'] = annotations
else:
if 'annotations' in self.parts[wid]:
del self.parts[wid]['annotations']
write_log(
release_id,
'info',
'make annotations has set id %s on track %s with annotation %s',
wid,
track,
annotations)
write_log(
release_id,
'debug',
"Ending module %s",
'make_annotations')
@staticmethod
def derive_from_title(release_id, track, title):
"""
Attempt to parse title to get components
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param track:
:param title:
:return:
"""
write_log(
release_id,
'info',
"DERIVING METADATA FROM TITLE for track: %s",
track)
tm = track.metadata
movt = title
work = ""
colons = title.count(": ")
inter_work = None
if '~cwp_part_levels' in tm:
part_levels = int(tm['~cwp_part_levels'])
if int(tm['~cwp_work_part_levels']
) > 0: # we have a work with movements
if colons > 0:
title_split = title.split(': ', 1)
title_rsplit = title.rsplit(': ', 1)
if part_levels >= colons:
work = title_rsplit[0]
movt = title_rsplit[1]
else:
work = title_split[0]
movt = title_split[1]
else:
# No works found so try and just get parts from title
if colons > 0:
title_split = title.rsplit(': ', 1)
work = title_split[0]
if colons > 1:
colon_ind = work.rfind(':')
inter_work = work[colon_ind + 1:].strip()
work = work[:colon_ind]
movt = title_split[1]
write_log(release_id, 'info', "Work %s, Movt %s", work, movt)
return work, movt, inter_work
def process_work_artists(
self,
release_id,
album,
track,
workIds,
tm,
count):
"""
Carry out the artist processing that needs to be done in the PartLevels class
as it requires XML lookups of the works
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param track:
:param workIds:
:param tm:
:param count:
:return:
"""
if not self.options[track]['classical_extra_artists']:
write_log(
release_id,
'debug',
'Not processing work_artists as ExtraArtists not selected to be run')
return None
write_log(
release_id,
'debug',
'In process_work_artists for track: %s, workIds: %s',
track,
workIds)
write_log(
release_id,
'debug',
'In process_work_artists for track: %s, self.parts: %s',
track,
self.parts)
if workIds in self.parts and 'arrangers' in self.parts[workIds]:
write_log(
release_id,
'info',
'Arrangers = %s',
self.parts[workIds]['arrangers'])
set_work_artists(
self,
release_id,
album,
track,
self.parts[workIds]['arrangers'],
tm,
count)
if workIds in self.works_cache:
count += 1
self.process_work_artists(release_id, album, track, tuple(
self.works_cache[workIds]), tm, count)
#################################################
# SECTION 5 - Extend work metadata using titles #
#################################################
def extend_metadata(self, release_id, top_info, track, ref_height, depth):
"""
Combine MB work and title data according to user options
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param top_info:
:param track:
:param ref_height:
:param depth:
:return:
"""
write_log(release_id, 'debug', 'IN EXTEND_METADATA')
tm = track.metadata
options = self.options[track]
movementgroup = ()
if '~cwp_part_levels' not in tm:
write_log(
release_id,
'debug',
'NO PART LEVELS. Metadata = %s',
tm)
return None
part_levels = int(tm['~cwp_part_levels'])
write_log(
release_id,
'debug',
"Extending metadata for track: %s, ref_height: %s, depth: %s, part_levels: %s",
track,
ref_height,
depth,
part_levels)
write_log(release_id, 'info', "Metadata = %s", tm)
# previously: ref_height = work_part_levels - ref_level,
# where this ref-level is the level for the top-named work
# so ref_height is effectively the "single work album" indicator (1 or 0) -
# i.e. where all tracks are part of one work which is implicitly the album
# without there being a groupheading for it
ref_level = part_levels - ref_height
# work_ref_level = work_part_levels - ref_height # not currently used
# replace works and parts by those derived from the level 0 work, where
# required, available and appropriate, but only use work names based on
# level 0 text if it doesn't cause ambiguity
# before embellishing with partial / arrangement etc
vanilla_part = tm['~cwp_part_0']
# Fix text for arrangements, partials and medleys (Done here so that
# cache can be used)
if options['cwp_arrangements'] and options["cwp_arrangements_text"]:
for lev in range(
0,
ref_level): # top level will not be an arrangement else there would be a higher level
# needs to be a tuple to match
if '~cwp_workid_' + str(lev) in tm:
tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
if 'arrangement' in self.parts[tup_id] and self.parts[tup_id]['arrangement']:
update_list = ['~cwp_work_', '~cwp_part_']
if options["cwp_level0_works"] and '~cwp_X0_work_' + \
str(lev) in tm:
update_list += ['~cwp_X0_work_', '~cwp_X0_part_']
for item in update_list:
tm[item + str(lev)] = options["cwp_arrangements_text"] + \
' ' + tm[item + str(lev)]
if options['cwp_partial'] and options["cwp_partial_text"]:
if '~cwp_workid_0' in tm:
work0_id = tuple(str_to_list(tm['~cwp_workid_0']))
if 'partial' in self.parts[work0_id] and self.parts[work0_id]['partial']:
update_list = ['~cwp_work_0', '~cwp_part_0']
if options["cwp_level0_works"] and '~cwp_X0_work_0' in tm:
update_list += ['~cwp_X0_work_0', '~cwp_X0_part_0']
for item in update_list:
meta_item = tm.getall(item)
if isinstance(
meta_item, list): # it should be a list as I think getall always returns a list
if meta_item == []:
meta_item.append(options["cwp_partial_text"])
else:
for ind, w in enumerate(meta_item):
meta_item[ind] = options["cwp_partial_text"] + ' ' + w
write_log(
release_id, 'info', 'now meta item is %s', meta_item)
tm[item] = meta_item
else:
tm[item] = options["cwp_partial_text"] + \
' ' + tm[item]
write_log(
release_id, 'info', 'meta item is not a list')
# fix "type 1" medley text
if options['cwp_medley']:
for lev in range(0, ref_level + 1):
if '~cwp_workid_' + str(lev) in tm:
tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
if 'medley_list' in self.parts[tup_id] and self.parts[tup_id]['medley_list']:
medley_list = self.parts[tup_id]['medley_list']
tm['~cwp_work_' + str(lev)] += " (" + options["cwp_medley_text"] + \
': ' + ', '.join(medley_list) + ")"
if '~cwp_part_' + str(lev) in tm:
tm['~cwp_part_' + str(
lev)] = "(" + options["cwp_medley_text"] + ") " + tm['~cwp_part_' + str(lev)]
# add any annotations for dates and keys
if options['cwp_workdate_include'] or options['cwp_key_include'] or options['cwp_key_contingent_include']:
if options["cwp_titles"] and part_levels == 0:
# ~cwp_title_work_0 will not have been set, but need it to hold any annotations
tm['~cwp_title_work_0'] = tm['~cwp_title'] or tm['title']
for lev in range(0, part_levels + 1):
if '~cwp_workid_' + str(lev) in tm:
tup_id = tuple(str_to_list(tm['~cwp_workid_' + str(lev)]))
if 'annotations' in self.parts[tup_id]:
write_log(
release_id,
'info',
'in extend_metadata, annotations for id %s on track %s are %s',
tup_id,
track,
self.parts[tup_id]['annotations'])
tm['~cwp_work_' + str(lev)] += " (" + \
', '.join(self.parts[tup_id]['annotations']) + ")"
if options["cwp_level0_works"] and '~cwp_X0_work_' + \
str(lev) in tm:
tm['~cwp_X0_work_' + str(lev)] += " (" + ', '.join(
self.parts[tup_id]['annotations']) + ")"
if options["cwp_titles"] and '~cwp_title_work_' + \
str(lev) in tm:
tm['~cwp_title_work_' + str(lev)] += " (" + ', '.join(
self.parts[tup_id]['annotations']) + ")"
if lev < part_levels:
if 'stripped_annotations' in self.parts[tup_id]:
if self.parts[tup_id]['stripped_annotations']:
tm['~cwp_part_' + str(lev)] += " (" + ', '.join(
self.parts[tup_id]['stripped_annotations']) + ")"
if options["cwp_level0_works"] and '~cwp_X0_part_' + \
str(lev) in tm:
tm['~cwp_X0_part_' + str(lev)] += " (" + ', '.join(
self.parts[tup_id]['stripped_annotations']) + ")"
if options["cwp_titles"] and '~cwp_title_part_' + \
str(lev) in tm:
tm['~cwp_title_part' + str(lev)] += " (" + ', '.join(
self.parts[tup_id]['stripped_annotations']) + ")"
part = []
work = []
for level in range(0, part_levels):
part.append(tm['~cwp_part_' + str(level)])
work.append(tm['~cwp_work_' + str(level)])
work.append(tm['~cwp_work_' + str(part_levels)])
# Use level_0-derived names if applicable
if options["cwp_level0_works"]:
for level in range(0, part_levels + 1):
if '~cwp_X0_work_' + str(level) in tm:
work[level] = tm['~cwp_X0_work_' + str(level)]
else:
if level != 0:
work[level] = ''
if part and len(part) > level:
if '~cwp_X0_part_' + str(level) in tm:
part[level] = tm['~cwp_X0_part_' + str(level)]
else:
if level != 0:
part[level] = ''
# set up group heading and part
if part_levels > 0:
groupheading = work[1]
work_main = work[ref_level]
inter_work = None
work_titles = tm['~cwp_title_work_' + str(ref_level)]
if ref_level > 1:
for r in range(1, ref_level):
if inter_work:
inter_work = ': ' + inter_work
inter_work = part[r] + (inter_work or '')
groupheading = work[ref_level] + ':: ' + (inter_work or '')
else:
groupheading = work[0]
work_main = groupheading
inter_work = None
work_titles = None
# determine movement grouping (highest level that is not a collection)
if '~cwp_workid_top' in tm:
movementgroup = tuple(str_to_list(tm['~cwp_workid_top']))
n = part_levels
write_log(
release_id,
'debug',
"In extend. self.parts[%s]['is_collection']: %s",
movementgroup,
self.parts[movementgroup]['is_collection'])
while self.parts[movementgroup]['is_collection']:
n -= 1
if n < 0:
# shouldn't happen in theory as bottom level can't be a collection, but just in case...
break
if '~cwp_workid_' + str(n) in tm:
movementgroup = tuple(str_to_list(tm['~cwp_workid_' + str(n)]))
else:
break
# set part text (initially)
if part:
part_main = part[0]
else:
part_main = work[0]
tm['~cwp_part'] = part_main
# fix medley text for "type 2" medleys
type2_medley = False
if self.parts[tuple(str_to_list(tm['~cwp_workid_0']))
]['medley'] and options['cwp_medley']:
if options["cwp_medley_text"]:
if part_levels > 0:
medleyheading = groupheading + ':: ' + part[0]
else:
medleyheading = groupheading
groupheading = medleyheading + \
' (' + options["cwp_medley_text"] + ')'
type2_medley = True
tm['~cwp_groupheading'] = groupheading
tm['~cwp_work'] = work_main
tm['~cwp_inter_work'] = inter_work
tm['~cwp_title_work'] = work_titles
write_log(
release_id,
'debug',
"Groupheading set to: %s",
groupheading)
# extend group heading from title metadata
if groupheading:
ext_groupheading = groupheading
title_groupheading = None
ext_work = work_main
ext_inter_work = inter_work
inter_title_work = ""
if '~cwp_title_work_levels' in tm:
title_depth = int(tm['~cwp_title_work_levels'])
write_log(
release_id,
'info',
"Title_depth: %s",
title_depth)
diff_work = [""] * ref_level
diff_part = [""] * ref_level
title_tag = [""]
# level 0 work for title # was 'x' # to avoid errors, reset
# before used
tw_str_lower = 'title'
max_d = min(ref_level, title_depth) + 1
for d in range(1, max_d):
tw_str = '~cwp_title_work_' + str(d)
write_log(release_id, 'info', "TW_STR = %s", tw_str)
if tw_str in tm:
title_tag.append(tm[tw_str])
title_work = title_tag[d]
work_main = ''
for w in range(d, ref_level + 1):
work_main += (work[w] + ' ')
diff_work[d - 1] = self.diff_pair(
release_id, track, tm, work_main, title_work)
if diff_work[d - 1]:
diff_work[d - 1] = diff_work[d - 1].strip('.;:-,')
if diff_work[d - 1] == '…':
diff_work[d - 1] = ''
if d > 1 and tw_str_lower in tm:
title_part = self.strip_parent_from_work(
track, release_id, tm[tw_str_lower], tm[tw_str], 0, False)[0]
if title_part:
title_part = title_part.strip(' .;:-,')
tm['~cwp_title_part_' +
str(d - 1)] = title_part
part_n = part[d - 1]
diff_part[d - 1] = self.diff_pair(
release_id, track, tm, part_n, title_part) or ""
if diff_part[d - 1] == '…':
diff_part[d - 1] = ''
else:
title_tag.append('')
tw_str_lower = tw_str
# remove duplicate items at lower levels in diff_work:
for w in range(ref_level - 2, -1, -1):
for higher in range(1, ref_level - w):
if diff_work[w] and diff_work[w + higher]:
diff_work[w] = diff_work[w].replace(
diff_work[w + higher], '').strip(' .;:-,\u2026')
# if diff_work[w] == '…':
# diff_work[w] = ''
write_log(
release_id,
'info',
"diff list for works: %s",
diff_work)
write_log(
release_id,
'info',
"diff list for parts: %s",
diff_part)
if not diff_work or len(diff_work) == 0:
if part_levels > 0:
ext_groupheading = groupheading
else:
write_log(
release_id,
'debug',
"Now calc extended groupheading...")
write_log(
release_id,
'info',
"depth = %s, ref_level = %s, title_depth = %s",
depth,
ref_level,
title_depth)
write_log(
release_id,
'info',
"diff_work = %s, diff_part = %s",
diff_work,
diff_part)
# remove duplications:
for lev in range(1, ref_level):
for diff_list in [diff_work, diff_part]:
if diff_list[lev] and diff_list[lev - 1]:
diff_list[lev - 1] = self.diff_pair(
release_id, track, tm, diff_list[lev], diff_list[lev - 1])
if diff_list[lev - 1] == '…':
diff_list[lev - 1] = ''
write_log(
release_id,
'info',
"Removed duplication. Revised diff_work = %s, diff_part = %s",
diff_work,
diff_part)
if part_levels > 0 and depth >= 1:
addn_work = []
addn_part = []
for stripped_work in diff_work:
if stripped_work:
write_log(
release_id, 'info', "Stripped work = %s", stripped_work)
addn_work.append(" {" + stripped_work + "}")
else:
addn_work.append("")
for stripped_part in diff_part:
if stripped_part and stripped_part != "":
write_log(release_id, 'info', "Stripped part = %s", stripped_part)
addn_part.append(" {" + stripped_part + "}")
else:
addn_part.append("")
write_log(
release_id,
'info',
"addn_work = %s, addn_part = %s",
addn_work,
addn_part)
ext_groupheading = work[1] + addn_work[0]
ext_work = work[ref_level] + addn_work[ref_level - 1]
ext_inter_work = ""
inter_title_work = ""
title_groupheading = tm['~cwp_title_work_1']
if ref_level > 1:
for r in range(1, ref_level):
if ext_inter_work:
ext_inter_work = ': ' + ext_inter_work
ext_inter_work = part[r] + \
addn_work[r - 1] + ext_inter_work
ext_groupheading = work[ref_level] + \
addn_work[ref_level - 1] + ':: ' + ext_inter_work
if title_depth > 1 and ref_level > 1:
for r in range(1, min(title_depth, ref_level)):
if inter_title_work:
inter_title_work = ': ' + inter_title_work
inter_title_work = tm['~cwp_title_part_' +
str(r)] + inter_title_work
title_groupheading = tm['~cwp_title_work_' + str(
min(title_depth, ref_level))] + ':: ' + inter_title_work
else:
ext_groupheading = groupheading # title will be in part
ext_work = work_main
ext_inter_work = inter_work
inter_title_work = ""
write_log(release_id, 'debug', ".... ext_groupheading done")
if ext_groupheading:
write_log(
release_id,
'info',
"EXTENDED GROUPHEADING: %s",
ext_groupheading)
tm['~cwp_extended_groupheading'] = ext_groupheading
tm['~cwp_extended_work'] = ext_work
if ext_inter_work:
tm['~cwp_extended_inter_work'] = ext_inter_work
if inter_title_work:
tm['~cwp_inter_title_work'] = inter_title_work
if title_groupheading:
tm['~cwp_title_groupheading'] = title_groupheading
write_log(
release_id,
'info',
"title_groupheading = %s",
title_groupheading)
# extend part from title metadata
write_log(
release_id,
'debug',
"NOW EXTEND PART...(part = %s)",
part_main)
if part_main:
if '~cwp_title_part_0' in tm:
movement = tm['~cwp_title_part_0']
else:
movement = tm['~cwp_title_part_0'] or tm['~cwp_title'] or tm['title']
if '~cwp_extended_groupheading' in tm:
work_compare = tm['~cwp_extended_groupheading'] + \
': ' + part_main
elif '~cwp_work_1' in tm:
work_compare = work[1] + ': ' + part_main
else:
work_compare = work[0]
diff = self.diff_pair(
release_id, track, tm, work_compare, movement)
# compare with the fullest possible work name, not the stripped one
# - to maximise the duplication elimination
reverse_diff = self.diff_pair(
release_id, track, tm, movement, vanilla_part)
# for the reverse comparison use the part name without any work details or annotation
if diff and reverse_diff and self.parts[tuple(str_to_list(tm['~cwp_workid_0']))]['partial']:
diff = movement
# for partial tracks, do not eliminate the title text as it is
# frequently deliberately a component of the the overall work txt
# (unless it is identical)
fill_part = options['cwp_fill_part']
# To fill part with title text if it
# would otherwise have no text other than arrangement or partial
# annotations
if not diff and not vanilla_part and part_levels > 0 and fill_part:
# In other words the movement will have no text other than
# arrangement or partial annotations
diff = movement
write_log(release_id, 'info', "DIFF PART - MOVT. ti =%s", diff)
write_log(release_id,
'info',
'medley indicator for %s is %s',
tm['~cwp_workid_0'],
self.parts[tuple(str_to_list(tm['~cwp_workid_0']))]['medley'])
if type2_medley:
tm['~cwp_extended_part'] = "{" + movement + "}"
else:
if diff:
tm['~cwp_extended_part'] = part_main + \
" {" + diff.strip() + "}"
else:
tm['~cwp_extended_part'] = part_main
if part_levels == 0:
if tm['~cwp_extended_groupheading']:
del tm['~cwp_extended_groupheading']
# remove unwanted groupheadings (needed them up to now for adding
# extensions)
if '~cwp_groupheading' in tm and tm['~cwp_groupheading'] == tm['~cwp_part']:
del tm['~cwp_groupheading']
if '~cwp_title_groupheading' in tm and tm['~cwp_title_groupheading'] == tm['~cwp_title_part']:
del tm['~cwp_title_groupheading']
# clean up groupheadings (may be stray separators if level 0 or title
# options used)
if '~cwp_groupheading' in tm:
tm['~cwp_groupheading'] = tm['~cwp_groupheading'].strip(
':').strip(
options['cwp_single_work_sep']).strip(
options['cwp_multi_work_sep'])
if '~cwp_extended_groupheading' in tm:
tm['~cwp_extended_groupheading'] = tm['~cwp_extended_groupheading'].strip(
':').strip(
options['cwp_single_work_sep']).strip(
options['cwp_multi_work_sep'])
if '~cwp_title_groupheading' in tm:
tm['~cwp_title_groupheading'] = tm['~cwp_title_groupheading'].strip(
':').strip(
options['cwp_single_work_sep']).strip(
options['cwp_multi_work_sep'])
write_log(release_id, 'debug', "....done")
return movementgroup
##########################################################
# SECTION 6- Write metadata to tags according to options #
##########################################################
def publish_metadata(self, release_id, album, track, movement_info={}):
"""
Write out the metadata according to user options
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param album:
:param track:
:param movement_info: format is {'movement-group': movementgroup, 'movement-number': movementnumber}
:return:
"""
write_log(release_id, 'debug', "IN PUBLISH METADATA for %s", track)
options = self.options[track]
tm = track.metadata
tm['~cwp_version'] = PLUGIN_VERSION
# set movement grouping tags (hidden vars)
if movement_info:
movementtotal = self.parts[tuple(movement_info['movement-group'])]['movement-total']
if movementtotal > 1:
tm['~cwp_movt_num'] = movement_info['movement-number']
tm['~cwp_movt_tot'] = movementtotal
# album composers needed by map_tags (set in set_work_artists)
if 'composer_lastnames' in self.album_artists[album]:
last_names = seq_last_names(self, album)
self.append_tag(
release_id,
tm,
'~cea_album_composer_lastnames',
last_names)
write_log(release_id, 'info', "Check options")
if options["cwp_titles"]:
write_log(release_id, 'info', "titles")
part = tm['~cwp_title_part_0'] or tm['~cwp_title_work_0']or tm['~cwp_title'] or tm['title']
# for multi-level work display
groupheading = tm['~cwp_title_groupheading'] or ""
# for single-level work display
work = tm['~cwp_title_work'] or ""
inter_work = tm['~cwp_inter_title_work'] or ""
elif options["cwp_works"]:
write_log(release_id, 'info', "works")
part = tm['~cwp_part']
groupheading = tm['~cwp_groupheading'] or ""
work = tm['~cwp_work'] or ""
inter_work = tm['~cwp_inter_work'] or ""
else:
# options["cwp_extended"]
write_log(release_id, 'info', "extended")
part = tm['~cwp_extended_part']
groupheading = tm['~cwp_extended_groupheading'] or ""
work = tm['~cwp_extended_work'] or ""
inter_work = tm['~cwp_extended_inter_work'] or ""
write_log(release_id, 'info', "Done options")
p1 = RE_ROMANS_AT_START
# Matches positive integers with punctuation
p2 = re.compile(r'^\W*\d+[.):-]')
movt = part
for _ in range(
0, 5): # in case of multiple levels
movt = p2.sub('', p1.sub('', movt)).strip()
write_log(release_id, 'info', "Done movt")
movt_inc_tags = options["cwp_movt_tag_inc"].split(",")
movt_inc_tags = [x.strip(' ') for x in movt_inc_tags]
movt_exc_tags = options["cwp_movt_tag_exc"].split(",")
movt_exc_tags = [x.strip(' ') for x in movt_exc_tags]
movt_inc_1_tags = options["cwp_movt_tag_inc1"].split(",")
movt_inc_1_tags = [x.strip(' ') for x in movt_inc_1_tags]
movt_exc_1_tags = options["cwp_movt_tag_exc1"].split(",")
movt_exc_1_tags = [x.strip(' ') for x in movt_exc_1_tags]
movt_no_tags = options["cwp_movt_no_tag"].split(",")
movt_no_tags = [x.strip(' ') for x in movt_no_tags]
movt_no_sep = options["cwp_movt_no_sep"]
movt_tot_tags = options["cwp_movt_tot_tag"].split(",")
movt_tot_tags = [x.strip(' ') for x in movt_tot_tags]
gh_tags = options["cwp_work_tag_multi"].split(",")
gh_tags = [x.strip(' ') for x in gh_tags]
gh_sep = options["cwp_multi_work_sep"]
work_tags = options["cwp_work_tag_single"].split(",")
work_tags = [x.strip(' ') for x in work_tags]
work_sep = options["cwp_single_work_sep"]
top_tags = options["cwp_top_tag"].split(",")
top_tags = [x.strip(' ') for x in top_tags]
write_log(
release_id,
'info',
"Done splits. gh_tags: %s, work_tags: %s, movt_inc_tags: %s, movt_exc_tags: %s, movt_no_tags: %s",
gh_tags,
work_tags,
movt_inc_tags,
movt_exc_tags,
movt_no_tags)
for tag in gh_tags + work_tags + movt_inc_tags + movt_exc_tags + movt_no_tags:
tm[tag] = ""
for tag in gh_tags:
if tag in movt_inc_tags + movt_exc_tags + movt_no_tags:
self.append_tag(release_id, tm, tag, groupheading, gh_sep)
else:
self.append_tag(release_id, tm, tag, groupheading)
for tag in work_tags:
if tag in movt_inc_1_tags + movt_exc_1_tags + movt_no_tags:
self.append_tag(release_id, tm, tag, work, work_sep)
else:
self.append_tag(release_id, tm, tag, work)
if '~cwp_part_levels' in tm and int(tm['~cwp_part_levels']) > 0:
self.append_tag(
release_id,
tm,
'show work movement',
'1') # original tag for iTunes, kept for backwards compatibility
self.append_tag(
release_id,
tm,
'showmovement',
'1') # new tag for iTunes & MusicBee, consistent with Picard tag docs
for tag in top_tags:
if '~cwp_work_top' in tm:
self.append_tag(release_id, tm, tag, tm['~cwp_work_top'])
if '~cwp_movt_num' in tm and len(tm['~cwp_movt_num']) > 0:
movt_num_punc = tm['~cwp_movt_num'] + movt_no_sep + ' '
else:
movt_num_punc = ''
for tag in movt_no_tags:
if tag not in movt_inc_tags + movt_exc_tags + movt_inc_1_tags + movt_exc_1_tags:
self.append_tag(release_id, tm, tag, tm['~cwp_movt_num'])
for tag in movt_tot_tags:
self.append_tag(release_id, tm, tag, tm['~cwp_movt_tot'])
for tag in movt_exc_tags:
if tag in movt_no_tags:
movt = movt_num_punc + movt
self.append_tag(release_id, tm, tag, movt)
for tag in movt_inc_tags:
if tag in movt_no_tags:
part = movt_num_punc + part
self.append_tag(release_id, tm, tag, part)
for tag in movt_inc_1_tags + movt_exc_1_tags:
if tag in movt_inc_1_tags:
pt = part
else:
pt = movt
if tag in movt_no_tags:
pt = movt_num_punc + pt
if inter_work and inter_work != "":
if tag in movt_exc_tags + movt_inc_tags and tag != "":
write_log(
release_id,
'warning',
"Tag %s will have multiple contents",
tag)
if self.WARNING:
self.append_tag(release_id, tm, '~cwp_warning', '6. Tag ' +
tag +
' has multiple contents')
self.append_tag(
release_id,
tm,
tag,
inter_work +
work_sep +
" " +
pt)
else:
self.append_tag(release_id, tm, tag, pt)
for tag in movt_exc_tags + movt_inc_tags + movt_exc_1_tags + movt_inc_1_tags:
if tag in movt_no_tags:
# i.e treat as one item, not multiple
tm[tag] = "".join(re.split('|'.join(self.SEPARATORS), tm[tag]))
# write "SongKong" tags
if options['cwp_write_sk']:
write_log(release_id, 'debug', "Writing SongKong work tags")
if '~cwp_part_levels' in tm:
part_levels = int(tm['~cwp_part_levels'])
for n in range(0, part_levels + 1):
if '~cwp_work_' + \
str(n) in tm and '~cwp_workid_' + str(n) in tm:
source = tm['~cwp_work_' + str(n)]
source_id = list(
tuple(str_to_list(tm['~cwp_workid_' + str(n)])))
if n == 0:
self.append_tag(
release_id, tm, 'musicbrainz_work_composition', source)
for source_id_item in source_id:
self.append_tag(
release_id, tm, 'musicbrainz_work_composition_id', source_id_item)
if n == part_levels:
self.append_tag(
release_id, tm, 'musicbrainz_work', source)
if 'musicbrainz_workid' in tm:
del tm['musicbrainz_workid']
# Delete the Picard version of this tag before
# replacing it with the SongKong version
for source_id_item in source_id:
self.append_tag(
release_id, tm, 'musicbrainz_workid', source_id_item)
if n != 0 and n != part_levels:
self.append_tag(
release_id, tm, 'musicbrainz_work_part_level' + str(n), source)
for source_id_item in source_id:
self.append_tag(
release_id,
tm,
'musicbrainz_work_part_level' +
str(n) +
'_id',
source_id_item)
# carry out tag mapping
tm['~cea_works_complete'] = "Y"
map_tags(options, release_id, album, tm)
write_log(release_id, 'debug', "Published metadata for %s", track)
if options['cwp_options_tag'] != "":
self.cwp_options = collections.defaultdict(
lambda: collections.defaultdict(dict))
for opt in plugin_options('workparts') + plugin_options('genres'):
if 'name' in opt:
if 'value' in opt:
if options[opt['option']]:
self.cwp_options['Classical Extras']['Works options'][opt['name']] = opt['value']
else:
self.cwp_options['Classical Extras']['Works options'][opt['name']
] = options[opt['option']]
write_log(release_id, 'info', "Options %s", self.cwp_options)
if options['ce_version_tag'] and options['ce_version_tag'] != "":
self.append_tag(release_id, tm, options['ce_version_tag'], str(
'Version ' + tm['~cwp_version'] + ' of Classical Extras'))
if options['cwp_options_tag'] and options['cwp_options_tag'] != "":
self.append_tag(release_id, tm, options['cwp_options_tag'] +
':workparts_options', json.loads(
json.dumps(
self.cwp_options)))
if self.ERROR and "~cwp_error" in tm:
for error in str_to_list(tm['~cwp_error']):
code = error[0]
self.append_tag(release_id, tm, '001_errors:' + code, error)
if self.WARNING and "~cwp_warning" in tm:
for warning in str_to_list(tm['~cwp_warning']):
wcode = warning[0]
self.append_tag(release_id, tm, '002_warnings:' + wcode, warning)
def append_tag(self, release_id, tm, tag, source, sep=None):
"""
pass to main append routine
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param tm:
:param tag:
:param source:
:param sep: separators may be used to split string into list on appending
:return:
"""
write_log(
release_id,
'info',
"In append_tag (Work parts). tag = %s, source = %s, sep =%s",
tag,
source,
sep)
append_tag(release_id, tm, tag, source, self.SEPARATORS)
write_log(
release_id,
'info',
"Appended. Resulting contents of tag: %s are: %s",
tag,
tm[tag])
################################################
# SECTION 7 - Common string handling functions #
################################################
def strip_parent_from_work(
self,
track,
release_id,
work,
parent,
part_level,
extend,
parentId=None,
workId=None):
"""
Remove common text
:param track:
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param work: could be a list of works, all of which require stripping
:param parent:
:param part_level:
:param extend:
:param parentId:
:param workId:
:return:
"""
# extend=True is used [ NO LONGER to find "full_parent" names] + (with parentId)
# to trigger recursion if unable to strip parent name from work and also to look for common subsequences
# extend=False is used when this routine is called for other purposes
# than strict work: parent relationships
options = self.options[track]
write_log(
release_id,
'debug',
"STRIPPING HIGHER LEVEL WORK TEXT FROM PART NAMES")
write_log(
release_id,
'info',
'PARAMS: WORK = %r, PARENT = %s, PART_LEVEL = %s, EXTEND= %s',
work,
parent,
part_level,
extend)
if isinstance(work, list):
result = []
for w, work_item in enumerate(work):
if workId and isinstance(workId, list):
sub_workId = workId[w]
else:
sub_workId = workId
result.append(
self.strip_parent_from_work(
track,
release_id,
work_item,
parent,
part_level,
extend,
parentId,
sub_workId)[0])
return result, parent
if not isinstance(parent, str):
# in case it is a list - make sure it is a string
parent = '; '.join(parent)
if not isinstance(work, str):
work = '; '.join(work)
# replace any punctuation or numbers, with a space (to remove any
# inconsistent punctuation and numbering) - (?u) specifies the
# re.UNICODE flag in sub
clean_parent = re.sub("(?u)[\W]", ' ', parent)
# now allow the spaces to be filled with up to 2 non-letters
pattern_parent = clean_parent.replace(" ", "\W{0,2}")
pattern_parent = "(^|.*?\s)(\W*" + pattern_parent + "\W?)(.*)"
# (removed previous alternative pattern for extend=true, owing to catastrophic backtracking)
write_log(
release_id,
'info',
"Pattern parent: %s, Work: %s",
pattern_parent,
work)
p = re.compile(pattern_parent, re.IGNORECASE | re.UNICODE)
m = p.search(work)
if m:
write_log(release_id, 'info', "Matched...")
if m.group(1):
stripped_work = m.group(1) + u"\u2026" + m.group(3)
else:
stripped_work = m.group(3)
# may not have a full work name in the parent (missing op. no.
# etc.)
stripped_work = stripped_work.lstrip(":;,.- ")
else:
write_log(release_id, 'info', "No match...")
stripped_work = work
if extend and options['cwp_common_chars'] > 0:
# try stripping out a common substring (multiple times until
# nothing more stripped)
prev_stripped_work = ''
counter = 1
while prev_stripped_work != stripped_work:
if counter > 20:
break # in case something went awry
prev_stripped_work = stripped_work
parent_tuples = self.listify(release_id, track, parent)
parent_words = parent_tuples['s_tuple']
clean_parent_words = list(parent_tuples['s_test_tuple'])
for w, word in enumerate(clean_parent_words):
clean_parent_words[w] = self.boil(release_id, word)
work_tuples = self.listify(
release_id, track, stripped_work)
work_words = work_tuples['s_tuple']
clean_work_words = list(work_tuples['s_test_tuple'])
for w, word in enumerate(clean_work_words):
clean_work_words[w] = self.boil(release_id, word)
common_dets = longest_common_substring(
clean_work_words, clean_parent_words)
# this is actually a list, not a string, since list
# arguments were supplied
common_seq = common_dets['string']
seq_length = common_dets['length']
seq_start = common_dets['start']
# the original items (before 'cleaning')
full_common_seq = [
x.group() for x in work_words[seq_start:seq_start + seq_length]]
# number of words in common_seq
full_seq_length = sum([len(x.split())
for x in full_common_seq])
write_log(
release_id,
'info',
'Checking common sequence between parent and work, iteration %s ... parent_words = %s',
counter,
parent_words)
write_log(
release_id,
'info',
'... longest common sequence = %s',
common_seq)
if full_seq_length > 0:
potential_stripped_work = stripped_work
if seq_start > 0:
ellipsis = ' ' + u"\u2026" + ' '
else:
ellipsis = ''
if counter > 1:
potential_stripped_work = stripped_work.rstrip(
' :,-\u2026')
potential_stripped_work = potential_stripped_work.replace(
'(\u2026)', '').rstrip()
potential_stripped_work = potential_stripped_work[:work_words[seq_start].start(
)] + ellipsis + potential_stripped_work[work_words[seq_start + seq_length - 1].end():]
potential_stripped_work = potential_stripped_work.lstrip(
' :,-')
potential_stripped_work = re.sub(
r'(\W*…\W*)(\W*…\W*)', ' … ', potential_stripped_work)
potential_stripped_work = strip_excess_punctuation(
potential_stripped_work)
if full_seq_length >= options['cwp_common_chars'] \
or potential_stripped_work == '' and options['cwp_allow_empty_parts']:
# Make sure it is more than the required min (it will be > 0 anyway)
# unless a full strip will result anyway (and blank
# part names are allowed)
stripped_work = potential_stripped_work
if not stripped_work or stripped_work == '':
if workId and \
('arrangement' in self.parts[workId] and self.parts[workId]['arrangement']
and options['cwp_arrangements'] and options['cwp_arrangements_text']) \
or ('partial' in self.parts[workId] and self.parts[workId]['partial']
and options['cwp_partial'] and options['cwp_partial_text']) \
and options['cwp_allow_empty_parts']:
pass
else:
stripped_work = prev_stripped_work # do not allow empty parts
counter += 1
stripped_work = strip_excess_punctuation(stripped_work)
write_log(
release_id,
'info',
'stripped_work = %s',
stripped_work)
if extend and parentId and parentId in self.works_cache:
write_log(
release_id,
'info',
"Looking for match at next level up")
grandparentIds = tuple(self.works_cache[parentId])
grandparent = self.parts[grandparentIds]['name']
stripped_work = self.strip_parent_from_work(
track,
release_id,
stripped_work,
grandparent,
part_level,
True,
grandparentIds,
workId)[0]
write_log(
release_id,
'info',
"Finished strip_parent_from_work, Work: %s",
work)
write_log(release_id, 'info', "Stripped work: %s", stripped_work)
# Changed full_parent to parent after removal of 'extend' logic above
stripped_work = strip_excess_punctuation(stripped_work)
write_log(release_id, 'info', "Stripped work after punctuation removal: %s", stripped_work)
return stripped_work, parent
def diff_pair(
self,
release_id,
track,
tm,
mb_item,
title_item,
remove_numbers=True):
"""
Removes common text (or synonyms) from title item
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param track:
:param tm:
:param mb_item:
:param title_item:
:param remove_numbers: remove movement numbers when comparing (not currently called with False by anything)
:return: Reduced title item
"""
write_log(release_id, 'debug', "Inside DIFF_PAIR")
mb = mb_item.strip()
write_log(release_id, 'info', "mb = %s", mb)
write_log(release_id, 'info', "title_item = %s", title_item)
if not mb:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
ti = title_item.strip(" :;-.,")
if ti.count('"') == 1:
ti = ti.strip('"')
if ti.count("'") == 1:
ti = ti.strip("'")
write_log(release_id, 'info', "ti (amended) = %s", ti)
if not ti:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
if self.options[track]["cwp_removewords_p"]:
removewords = self.options[track]["cwp_removewords_p"].split(',')
else:
removewords = []
write_log(release_id, 'info', "Prefixes = %s", removewords)
# remove numbers, roman numerals, part etc and punctuation from the
# start
write_log(release_id, 'info', "checking prefixes")
found_prefix = True
i = 0
while found_prefix:
if i > 20:
break # safety valve
found_prefix = False
for prefix in removewords:
if prefix[0] != " ":
prefix2 = str(prefix).lower().lstrip()
write_log(
release_id, 'info', "checking prefix %s", prefix2)
if mb.lower().startswith(prefix2):
found_prefix = True
mb = mb[len(prefix2):]
if ti.lower().startswith(prefix2):
found_prefix = True
ti = ti[len(prefix2):]
mb = mb.strip()
ti = ti.strip()
i += 1
write_log(
release_id,
'info',
"pairs after prefix strip iteration %s. mb = %s, ti = %s",
i,
mb,
ti)
write_log(release_id, 'info', "Prefixes checked")
# replacements
replacements = self.replacements[track]
write_log(release_id, 'info', "Replacement: %s", replacements)
for tup in replacements:
for ind in range(0, len(tup) - 1):
ti = re.sub(tup[ind], tup[-1], ti, flags=re.IGNORECASE)
write_log(
release_id,
'debug',
'Looking for any new words in the title')
write_log(
release_id,
'info',
"Check before splitting: mb = %s, ti = %s",
mb,
ti)
ti_tuples = self.listify(release_id, track, ti)
ti_tuple = ti_tuples['s_tuple']
ti_test_tuple = ti_tuples['s_test_tuple']
mb_tuples = self.listify(release_id, track, mb)
mb_test_tuple = mb_tuples['s_test_tuple']
write_log(
release_id,
'info',
"Check after splitting: mb_test = %s, ti = %s, ti_test = %s",
mb_test_tuple,
ti_tuple,
ti_test_tuple)
ti_stencil = self.stencil(release_id, ti_tuple, ti)
ti_list = ti_stencil['match list']
ti_list_punc = ti_stencil['gap list']
ti_test_list = list(ti_test_tuple)
if ti_stencil['dummy']:
# to deal with case where stencil has added a dummy item at the
# start
ti_test_list.insert(0, '')
write_log(release_id, 'info', 'ti_test_list = %r', ti_test_list)
# zip is an iterable, not a list in Python 3, so make it re-usable
ti_zip_list = list(zip(ti_list, ti_list_punc))
# len(ti_list) should be = len(ti_test_list) as only difference should
# be synonyms which are each one 'word'
# However, because of the grouping of some words via regex, it is possible that inconsistencies might arise
# Therefore, there is a test here to check for equality and produce an
# error message (but continue processing)
if len(ti_list) != len(ti_test_list):
write_log(
release_id,
'error',
'Mismatch in title list after canonization/synonymization')
write_log(
release_id,
'error',
'Orig. title list = %r. Test list = %r',
ti_list,
ti_test_list)
# mb_test_tuple = self.listify(release_id, track, mb_test)
mb_list2 = list(mb_test_tuple)
for index, mb_bit2 in enumerate(mb_list2):
mb_list2[index] = self.boil(release_id, mb_bit2)
write_log(
release_id,
'info',
"mb_list2[%s] = %s",
index,
mb_list2[index])
ti_new = []
ti_rich_list = []
for i, ti_bit_test in enumerate(ti_test_list):
if i <= len(ti_list) - 1:
ti_bit = ti_zip_list[i]
# NB ti_bit is a tuple where the word (1st item) is grouped
# with its following punctuation (2nd item)
else:
ti_bit = ('', '')
write_log(
release_id,
'info',
"i = %s, ti_bit_test = %s, ti_bit = %s",
i,
ti_bit_test,
ti_bit)
ti_rich_list.append((ti_bit, True))
# Boolean to indicate whether ti_bit is a new word
if ti_bit_test == '':
ti_rich_list[i] = (ti_bit, False)
else:
if self.boil(release_id, ti_bit_test) in mb_list2:
ti_rich_list[i] = (ti_bit, False)
if remove_numbers: # Only remove numbers at the start if they are not new items
p0 = re.compile(r'\b\w+\b')
p1 = RE_ROMANS
p2 = re.compile(r'^\d+') # Matches positive integers
starts_with_numeral = True
while starts_with_numeral:
starts_with_numeral = False
if ti_rich_list and p0.match(ti_rich_list[0][0][0]):
start_word = p0.match(ti_rich_list[0][0][0]).group()
if p1.match(start_word) or p2.match(start_word):
if not ti_rich_list[0][1]:
starts_with_numeral = True
ti_rich_list.pop(0)
ti_test_list.pop(0)
write_log(
release_id,
'info',
"ti_rich_list before removing singletons = %s. length = %s",
ti_rich_list,
len(ti_rich_list))
s = 0
index = 0
change = ()
for i, (t, n) in enumerate(ti_rich_list):
if n:
s += 1
index = i
change = t # NB this is a tuple
p = self.options[track]["cwp_proximity"]
ep = self.options[track]["cwp_end_proximity"]
# NB these may be modified later
if s == 1:
if 0 < index < len(ti_rich_list) - 1:
# ignore singleton new words in middle of title unless they are
# within "cwp_end_proximity" from the start or end
write_log(
release_id, 'info', 'item length is %s', len(
change[0].split()))
# also make sure that the item is just one word before
# eliminating
if ep < index < len(ti_rich_list) - ep - \
1 and len(change[0].split()) == 1:
ti_rich_list[index] = (change, False)
s = 0
# remove prepositions
write_log(
release_id,
'info',
"ti_rich_list before removing prepositions = %s. length = %s",
ti_rich_list,
len(ti_rich_list))
if self.options[track]["cwp_prepositions"]:
prepositions_fat = self.options[track]["cwp_prepositions"].split(
',')
prepositions = [w.strip() for w in prepositions_fat]
for i, ti_bit_test in enumerate(
reversed(ti_test_list)): # Need to reverse it to check later prepositions first
if ti_bit_test.lower().strip() in prepositions:
# NB i is counting up while traversing the list backwards
j = len(ti_rich_list) - i - 1
if i == 0 or not ti_rich_list[j + 1][1]:
# Don't make it false if it is preceded by a
# non-preposition new word
if not (j > 0 and ti_rich_list[j -
1][1] and ti_test_list[j -
1].lower() not in prepositions):
ti_rich_list[j] = (ti_rich_list[j][0], False)
# create comparison for later usage
compare_string = ''
for item in ti_rich_list:
if item[1]:
compare_string += item[0][0]
ti_compare = self.boil(release_id, compare_string)
compare_length = len(ti_compare)
write_log(
release_id,
'info',
"ti_rich_list before gapping (True indicates a word in title not in MB work) = %s. length = %s",
ti_rich_list,
len(ti_rich_list))
if s > 0:
d = p - ep
start = True # To keep track of new words at the start of the title
for i, (ti_bit, new) in enumerate(ti_rich_list):
if not new:
write_log(
release_id,
'info',
"item(i = %s) val = %s - not new. proximity param = %s, end_proximity param = %s",
i,
ti_bit,
p,
ep)
if start:
prox_test = ep
else:
prox_test = p
if prox_test > 0:
for j in range(0, prox_test + 1):
write_log(release_id, 'info', "item(i) = %s, look-ahead(j) = %s", i, j)
if i + j < len(ti_rich_list):
if ti_rich_list[i + j][1]:
write_log(
release_id, 'info', "Set to true..")
ti_rich_list[i] = (ti_bit, True)
write_log(
release_id, 'info', "...set OK")
else:
if j <= p - d:
ti_rich_list[i] = (ti_bit, True)
else:
p = self.options[track]["cwp_proximity"]
start = False
if not ti_rich_list[i][1]:
p -= 1
ep -= 1
write_log(
release_id,
'info',
"ti_rich_list after gapping (True indicates new words plus infills) = %s",
ti_rich_list)
nothing_new = True
for (ti_bit, new) in ti_rich_list:
if new:
nothing_new = False
new_prev = True
break
if nothing_new:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
else:
new_prev = False
for i, (ti_bit, new) in enumerate(ti_rich_list):
write_log(release_id, 'info', "Create new for %s?", ti_bit)
if new:
write_log(release_id, 'info', "Yes for %s", ti_bit)
if not new_prev:
if i > 0:
# check to see if the last char of the prev
# punctuation group needs to be added first
if len(ti_rich_list[i - 1][0][1]) > 1:
# i.e. ti_bit[1][-1] of previous loop
ti_new.append(ti_rich_list[i - 1][0][1][-1])
ti_new.append(ti_bit[0])
if len(ti_bit[1]) > 1:
if i < len(ti_rich_list) - 1:
if ti_rich_list[i + 1][1]:
ti_new.append(ti_bit[1])
else:
ti_new.append(ti_bit[1][:-1])
else:
ti_new.append(ti_bit[1])
else:
ti_new.append(ti_bit[1])
write_log(
release_id,
'info',
"appended %s. ti_new is now %s",
ti_bit,
ti_new)
else:
write_log(release_id, 'info', "Not for %s", ti_bit)
if new != new_prev:
ti_new.append(u"\u2026" + ' ')
new_prev = new
if ti_new:
write_log(release_id, 'info', "ti_new %s", ti_new)
ti = ''.join(ti_new)
write_log(release_id, 'info', "New text from title = %s", ti)
else:
write_log(release_id, 'info', "New text empty")
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
# see if there is any significant difference between the strings
if ti:
nopunc_ti = ti_compare # was = self.boil(release_id, ti)
# not necessary as already set?
nopunc_mb = self.boil(release_id, mb)
# ti_len = len(nopunc_ti) use compare_length instead (= len before
# removals and additions)
substring_proportion = float(
self.options[track]["cwp_substring_match"]) / 100
sub_len = compare_length * substring_proportion
if substring_proportion < 1:
write_log(release_id, 'info', "test sub....")
lcs = longest_common_substring(nopunc_mb, nopunc_ti)['string']
write_log(
release_id,
'info',
"Longest common substring is: %s. Threshold length is %s",
lcs,
sub_len)
if len(lcs) >= sub_len:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
write_log(release_id, 'info', "...done, ti =%s", ti)
# remove duplicate successive words (and remove first word of title
# item if it duplicates last word of mb item)
if ti:
ti_list_new = re.split(' ', ti)
ti_list_ref = ti_list_new
ti_bit_prev = None
for i, ti_bit in enumerate(ti_list_ref):
if ti_bit != "...":
if i > 1:
if self.boil(
release_id, ti_bit) == self.boil(
release_id, ti_bit_prev):
dup = ti_list_new.pop(i)
write_log(release_id, 'info', "...removed dup %s", dup)
ti_bit_prev = ti_bit
if ti_list_new and mb_list2:
write_log(release_id,
'info',
"1st word of ti = %s. Last word of mb = %s",
ti_list_new[0],
mb_list2[-1])
if self.boil(release_id, ti_list_new[0]) == mb_list2[-1]:
write_log(release_id, 'info', "Removing 1st word from ti...")
first = ti_list_new.pop(0)
write_log(release_id, 'info', "...removed %s", first)
else:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
if ti_list_new:
ti = ' '.join(ti_list_new)
else:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
# remove excess brackets and punctuation
if ti:
ti = strip_excess_punctuation(ti)
write_log(release_id, 'info', "stripped punc ok. ti = %s", ti)
write_log(
release_id,
'debug',
"DIFF_PAIR is returning ti = %s",
ti)
if ti and len(ti) > 0:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
ti)
return ti
else:
write_log(
release_id,
'info',
'End of DIFF_PAIR. Returning %s',
None)
return None
@staticmethod
def canonize_opus(release_id, track, s):
"""
make opus numbers etc. into one-word items
:param release_id:
:param track:
:param s: A string
:return:
"""
write_log(release_id, 'debug', 'Canonizing: %s', s)
# Canonize catalogue & opus numbers (e.g. turn K. 126 into K126 or K
# 345a into K345a or op. 144 into op144):
regex = re.compile(
r'\b((?:op|no|k|kk|kv|L|B|Hob|S|D|M)|\w+WV)\W?\s?(\d+\-?\u2013?\u2014?\d*\w*)\b',
re.IGNORECASE)
regex_match = regex.search(s)
s_canon = s
if regex_match and len(regex_match.groups()) == 2:
pt1 = regex_match.group(1) or ''
pt2 = regex_match.group(2) or ''
if regex_match.group(1) and regex_match.group(2):
pt1 = re.sub(
r'^\W*no\b',
'',
regex_match.group(1),
flags=re.IGNORECASE)
s_canon = pt1 + pt2
write_log(release_id, 'info', 'canonized item = %s', s_canon)
return s_canon
@staticmethod
def canonize_key(release_id, track, s):
"""
make keys into standardized one-word items
:param release_id:
:param track:
:param s: A string
:return:
"""
write_log(release_id, 'debug', 'Canonizing: %s', s)
match = RE_KEYS.search(s)
s_canon = s
if match:
if match.group(2):
k2 = re.sub(
r'\-sharp|\u266F',
'sharp',
match.group(2),
flags=re.IGNORECASE)
k2 = re.sub(r'\-flat|\u266D', 'flat', k2, flags=re.IGNORECASE)
k2 = k2.replace('-', '')
else:
k2 = ''
if not match.group(3) or match.group(
3).strip() == '': # if the scale is not given, assume it is the major key
if match.group(1).isupper(
) or k2 != '': # but only if it is upper case or has an accent
k3 = 'major'
else:
k3 = ''
else:
k3 = match.group(3).strip()
s_canon = match.group(1).strip() + k2.strip() + k3
write_log(release_id, 'info', 'canonized item = %s', s_canon)
return s_canon
@staticmethod
def canonize_synonyms(release_id, tuples, s):
"""
make synonyms equal
:param release_id:
:param tuples
:param s: A string
:return:
"""
write_log(release_id, 'debug', 'Canonizing: %s', s)
s_canon = s
syn_patterns = []
syn_subs = []
for syn_tup in tuples:
syn_pattern = r'((?:^|\W)' + \
r'(?:$|\W)|(?:^|\W)'.join(syn_tup) + r'(?:$|\W))'
syn_patterns.append(syn_pattern)
# to get the last synonym in the tuple - the canonical form
syn_sub = syn_tup[-1:][0]
syn_subs.append(syn_sub)
for syn_ind, pattern in enumerate(syn_patterns):
regex = re.compile(pattern, re.IGNORECASE)
regex_match = regex.search(s)
if regex_match:
test_reg = regex_match.group().strip()
s_canon = s_canon.replace(test_reg, syn_subs[syn_ind])
write_log(release_id, 'info', 'canonized item = %s', s_canon)
return s_canon
def find_synonyms(self, release_id, track, reg_item):
"""
extend regex item to include synonyms
:param release_id:
:param track:
:param reg_item: A regex portion
:return: reg_new: A replacement for reg_item that includes all its synonyms
(if reg_item matches the last in a synonym tuple)
"""
write_log(release_id, 'debug', 'Finding synonyms of: %s', reg_item)
syn_others = []
syn_all = []
for syn_tup in self.synonyms[track]:
# to get the last synonym in the tuple - the canonical form
syn_last = syn_tup[-1:][0]
if re.match(r'^\s*' + reg_item + r'\s*$', syn_last, re.IGNORECASE):
syn_others += syn_tup[:-1]
syn_all += syn_tup
if syn_others:
reg_item = '(?:' + ')|(?:'.join(syn_others) + \
')|(?:' + reg_item + ')'
write_log(release_id, 'info', 'new regex item = %s', reg_item)
return reg_item, syn_all
def listify(self, release_id, track, s):
"""
Turn a string into a list of 'words', where words may also be phrases which
are then 'canonized' - i.e. turned into equivalents for comparison purposes
:param release_id:
:param track:
:param s: string
:return: s_tuple: a tuple of all the **match objects** (re words and defined phrases)
s_test_tuple: a tuple of the matched and canonized words and phrases (i.e. a tuple of strings, not objects)
"""
tuples = self.synonyms[track]
# just list anything that is a synonym (with word boundary markers)
syn_pattern = '|'.join(
[r'(?:^|\W|\b)' + x + r'(?:$|\W)' for y in self.synonyms[track] for x in y])
op = self.find_synonyms(
release_id,
track,
r'(?:op|no|k|kk|kv|L|B|Hob|S|D|M|\w+WV)')
op_groups = op[0]
op_all = op[1]
notes = self.find_synonyms(release_id, track, r'[ABCDEFG]')
notes_groups = notes[0]
notes_all = notes[1]
sharp = self.find_synonyms(release_id, track, r'sharp')
sharp_groups = sharp[0]
sharp_all = sharp[1]
flat = self.find_synonyms(release_id, track, r'flat')
flat_groups = flat[0]
flat_all = flat[1]
major = self.find_synonyms(release_id, track, r'major')
major_groups = major[0]
major_all = major[1]
minor = self.find_synonyms(release_id, track, r'minor')
minor_groups = minor[0]
minor_all = minor[1]
opus_pattern = r"(?:\b((?:(" + op_groups + \
r"))\W?\s?\d+\-?\u2013?\u2014?\d*\w*)\b)"
note_pattern = r"(\b" + notes_groups + r")"
accent_pattern = r"(?:\-(" + sharp_groups + r")(?:\s+|\b)|\-(" + flat_groups + r")(?:\s+|\b)|\s(" + sharp_groups + \
r")(?:\s+|\b)|\s(" + flat_groups + r")(?:\s+|\b)|\u266F(?:\s+|\b)|\u266D(?:\s+|\b)|(?:[:,.]?\s+|$|\-))"
scale_pattern = r"(?:((" + major_groups + \
r")|(" + minor_groups + r"))?\b)"
key_pattern = note_pattern + accent_pattern + scale_pattern
hyphen_split_pattern = r"(?:\b|\"|\')(\w+['’]?\w*)|(?:\b\w+\b)|(\B\&\B)"
# treat em-dash and en-dash as hyphens
hyphen_embed_pattern = r"(?:\b|\"|\')(\w+['’\-\u2013\u2014]?\w*)|(?:\b\w+\b)|(\B\&\B)"
# The regex is split into two iterations as putting it all together can have unpredictable consequences
# - may match synonyms before op's even though that is later in the string
# First match the op's and keys
regex_1 = opus_pattern + r"|(" + key_pattern + r")"
matches_1 = re.finditer(regex_1, s, re.UNICODE | re.IGNORECASE)
s_list = []
s_test_list = []
s_scrubbed = s
all_synonyms_lists = [
op_all,
notes_all,
sharp_all,
flat_all,
sharp_all,
flat_all,
major_all,
minor_all]
matches_list = [2, 4, 5, 6, 7, 8, 10, 11]
for match in matches_1:
test_a = match.group()
match_a = []
match_a.append(match.group())
for j in range(1, 12):
match_a.append(match.group(j))
# 0. overall match
# 1. overall opus match
# 2. 2-char op match
# 3. overall key match
# 4. note match
# 5. hyphenated sharp match
# 6. hyphenated flat match
# 7. non-hyphenated sharp match
# 8. non-hyphenated flat match
# 9. overall scale match
# 10. major match
# 11. minor match
for i, all_synonyms_list in enumerate(all_synonyms_lists):
if all_synonyms_list and match_a[matches_list[i]]:
match_regex = [re.match(pattern, match_a[matches_list[i]], re.IGNORECASE).group()
for pattern in all_synonyms_list
if re.match(pattern, match_a[matches_list[i]], re.IGNORECASE)]
if match_regex:
match_a[matches_list[i]] = self.canonize_synonyms(
release_id, tuples, match_a[matches_list[i]])
test_a = re.sub(r"\b" + match_regex[0] + r"(?:\b|$|\s|\.)",
match_a[matches_list[i]],
test_a, flags=re.IGNORECASE)
if match_a[1]:
clean_opus = test_a.strip(' ,.:;/-?"')
test_a = re.sub(
re.escape(clean_opus),
self.canonize_opus(
release_id,
track,
clean_opus),
test_a,
flags=re.IGNORECASE)
if match_a[3]:
clean_key = test_a.strip(' ,.:;/-?"')
test_a = re.sub(
re.escape(clean_key),
self.canonize_key(
release_id,
track,
clean_key),
test_a,
flags=re.IGNORECASE)
s_test_list.append(test_a)
s_list.append(match)
s_scrubbed_list = list(s_scrubbed)
for char in range(match.start(), match.end()):
if len(s_scrubbed_list) >= match.end(): # belt and braces
s_scrubbed_list[char] = '#'
s_scrubbed = ''.join(s_scrubbed_list)
# Then match the synonyms and remaining words
if self.options[track]["cwp_split_hyphenated"]:
regex_2 = r"(" + syn_pattern + r")|" + hyphen_split_pattern
# allow ampersands and non-latin characters as word characters. Treat apostrophes as part of words.
# Treat opus and catalogue entries - e.g. K. 657 or OP.5 or op. 35a or CD 144 or BWV 243a - as one word
# also treat ranges of opus numbers (connected by dash, en dash or
# em dash) as one word
else:
regex_2 = r"(" + syn_pattern + r")|" + hyphen_embed_pattern
# as previous but also treat embedded hyphens as part of words.
matches_2 = re.finditer(
regex_2, s_scrubbed, re.UNICODE | re.IGNORECASE)
for match in matches_2:
if match.group(1) and match.group(1) == match.group():
s_test_list.append(
self.canonize_synonyms(
release_id,
tuples,
match.group(1))) # synonym
else:
s_test_list.append(match.group())
s_list.append(match)
if s_list:
s_zip = list(zip(s_list, s_test_list))
s_list, s_test_list = zip(
*sorted(s_zip, key=lambda tup: tup[0].start()))
s_tuple = tuple(s_list)
s_test_tuple = tuple(s_test_list)
return {'s_tuple': s_tuple, 's_test_tuple': s_test_tuple}
def get_text_tuples(self, release_id, track, text_type):
"""
Return synonym or 'replacement' tuples
:param release_id:
:param track:
:param text_type: 'replacements' or 'synonyms'
Note that code in this method refers to synonyms (as that was written first), but applies equally to replacements and ui_tags
:return:
"""
tm = track.metadata
strsyns = re.split(r'(?= 2:
for i, ts in enumerate(tup):
tup[i] = ts.strip("' ").strip('"')
if len(
tup[i]) > 4 and tup[i][0] == "!" and tup[i][1] == "!" and tup[i][-1] == "!" and tup[i][-2] == "!":
# we have a reg ex inside - this deals with legacy
# replacement text where enclosure in double-shouts was
# required
tup[i] = tup[i][2:-2]
if (i < len(tup) - 1 or text_type ==
'synonyms') and not tup[i]:
write_log(
release_id,
'warning',
'%s: entries must not be blank - error in %s',
text_type,
syn)
if self.WARNING:
self.append_tag(
release_id,
tm,
'~cwp_warning',
'7. ' + text_type + ': entries must not be blank - error in ' + syn)
tup[i] = "**BAD**"
elif [tup for t in synonyms if tup[i] in t]:
write_log(
release_id,
'warning',
'%s: keys cannot duplicate any in existing %s - error in %s '
'- omitted from %s. To fix, place all %s in one tuple.',
text_type,
text_type,
syn,
text_type,
text_type)
if self.WARNING:
self.append_tag(release_id, tm, '~cwp_warning',
'7. ' + text_type + ': keys cannot duplicate any in existing ' + text_type + ' - error in ' +
syn + ' - omitted from ' + text_type + '. To fix, place all ' + text_type + ' in one tuple.')
tup[i] = "**BAD**"
if "**BAD**" in tup:
continue
else:
synonyms.append(tup)
else:
write_log(
release_id,
'warning',
'Error in %s format for %s',
text_type,
syn)
if self.WARNING:
self.append_tag(
release_id,
tm,
'~cwp_warning',
'7. Error in ' +
text_type +
' format for ' +
syn)
write_log(release_id, 'info', "%s: %s", text_type, synonyms)
return synonyms
@staticmethod
def stencil(release_id, matches_tuple, test_string):
"""
Produce lists of matching items, AND the items in between, in equal length lists
:param release_id:
:param matches_tuple: tuple of regex matches
:param test_string: original string used in regex
:return: 'match list' - list of matched strings, 'gap list' - list of strings in gaps between matches
"""
match_items = []
gap_items = []
dummy = False
pointer = 0
write_log(
release_id,
'debug',
'In fn stencil. test_string = %s. matches_tuple = %s',
test_string,
matches_tuple)
for match_num, match in enumerate(matches_tuple):
start = match.start()
end = match.end()
if start > pointer:
if pointer == 0:
# add a null word item at start to keep the lists the same
# length
match_items.append('')
dummy = True
gap_items.append(test_string[pointer:start])
else:
if pointer > 0:
# shouldn't happen, but just in case there are two word
# items with no gap
gap_items.append('')
match_items.append(test_string[start:end])
pointer = end
if match_num + 1 == len(matches_tuple):
# pick up any punc items at end
gap_items.append(test_string[pointer:])
return {
'match list': match_items,
'gap list': gap_items,
'dummy': dummy}
def boil(self, release_id, s):
"""
Remove punctuation, spaces, capitals and accents for string comparisons
:param release_id: name for log file - usually =musicbrainz_albumid
unless called outside metadata processor
:param s:
:return:
"""
write_log(release_id, 'debug', "boiling %s", s)
s = s.lower()
s = replace_roman_numerals(s)
s = s.replace('sch', 'sh')\
.replace(u'\xdf', 'ss')\
.replace('sz', 'ss')\
.replace(u'\u0153', 'oe')\
.replace('oe', 'o')\
.replace(u'\u00fc', 'ue')\
.replace('ue', 'u')\
.replace(u'\u00e6', 'ae')\
.replace('ae', 'a')\
.replace(u'\u266F', 'sharp')\
.replace(u'\u266D', 'flat')\
.replace(u'\u2013', '-')\
.replace(u'\u2014', '-')
# first term above is to remove the markers used for synonyms, to
# enable a true comparison
punc = re.compile(r'\W*', re.ASCII)
s = ''.join(
c for c in unicodedata.normalize(
'NFD',
s) if unicodedata.category(c) != 'Mn')
boiled = punc.sub('', s).strip().lower().rstrip("s'")
write_log(release_id, 'debug', "boiled result = %s", boiled)
return boiled
################
# OPTIONS PAGE #
################
class ClassicalExtrasOptionsPage(OptionsPage):
NAME = "classical_extras"
TITLE = "Classical Extras"
PARENT = "plugins"
HELP_URL = "http://music.highmossergate.co.uk/symphony/tagging/classical-extras/"
opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
options = [
IntOption("persist", 'ce_tab', 0)
]
# custom logging for non-album-related messages is written to session.log
for opt in opts:
if 'type' in opt:
if 'default' in opt:
default = opt['default']
else:
default = ""
if opt['type'] == 'Boolean':
options.append(BoolOption("setting", opt['option'], default))
elif opt['type'] == 'Text' or opt['type'] == 'Combo' or opt['type'] == 'PlainText':
options.append(TextOption("setting", opt['option'], default))
elif opt['type'] == 'Integer':
options.append(IntOption("setting", opt['option'], default))
else:
write_log(
"session",
'error',
"Error in setting options for option = %s",
opt['option'])
def __init__(self, parent=None):
super(ClassicalExtrasOptionsPage, self).__init__(parent)
self.ui = Ui_ClassicalExtrasOptionsPage()
self.ui.setupUi(self)
def load(self):
"""
Load the options - NB all options are set in plugin_options, so this just parses that
:return:
"""
opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
# To force a toggle so that signal given
toggle_list = ['use_cwp',
'use_cea',
'cea_override',
'cwp_override',
'cea_ra_use',
'cea_split_lyrics',
'cwp_partial',
'cwp_arrangements',
'cwp_medley',
'cwp_use_muso_refdb',
'ce_show_ui_tags',]
# open at last used tab
if 'ce_tab' in config.persist:
cfg_val = config.persist['ce_tab'] or 0
if 0 <= cfg_val <= 5:
self.ui.tabWidget.setCurrentIndex(cfg_val)
else:
self.ui.tabWidget.setCurrentIndex(0)
for opt in opts:
if opt['option'] == 'classical_work_parts':
ui_name = 'use_cwp'
elif opt['option'] == 'classical_extra_artists':
ui_name = 'use_cea'
else:
ui_name = opt['option']
if ui_name in toggle_list:
not_setting = not self.config.setting[opt['option']]
self.ui.__dict__[ui_name].setChecked(not_setting)
if opt['type'] == 'Boolean':
self.ui.__dict__[ui_name].setChecked(
self.config.setting[opt['option']])
elif opt['type'] == 'Text':
self.ui.__dict__[ui_name].setText(
self.config.setting[opt['option']])
elif opt['type'] == 'PlainText':
self.ui.__dict__[ui_name].setPlainText(
self.config.setting[opt['option']])
elif opt['type'] == 'Combo':
self.ui.__dict__[ui_name].setEditText(
self.config.setting[opt['option']])
elif opt['type'] == 'Integer':
self.ui.__dict__[ui_name].setValue(
self.config.setting[opt['option']])
else:
write_log(
'session',
'error',
"Error in loading options for option = %s",
opt['option'])
def save(self):
opts = plugin_options('artists') + plugin_options('tag') + plugin_options('tag_detail') +\
plugin_options('workparts') + plugin_options('genres') + plugin_options('other')
# save tab setting
config.persist['ce_tab'] = self.ui.tabWidget.currentIndex()
for opt in opts:
if opt['option'] == 'classical_work_parts':
ui_name = 'use_cwp'
elif opt['option'] == 'classical_extra_artists':
ui_name = 'use_cea'
else:
ui_name = opt['option']
if opt['type'] == 'Boolean':
self.config.setting[opt['option']] = self.ui.__dict__[
ui_name].isChecked()
elif opt['type'] == 'Text':
self.config.setting[opt['option']] = str(
self.ui.__dict__[ui_name].text())
elif opt['type'] == 'PlainText':
self.config.setting[opt['option']] = str(
self.ui.__dict__[ui_name].toPlainText())
elif opt['type'] == 'Combo':
self.config.setting[opt['option']] = str(
self.ui.__dict__[ui_name].currentText())
elif opt['type'] == 'Integer':
self.config.setting[opt['option']
] = self.ui.__dict__[ui_name].value()
else:
write_log(
'session',
'error',
"Error in saving options for option = %s",
opt['option'])
#################
# MAIN ROUTINE #
#################
# custom logging for non-album-related messages is written to session.log
write_log('session', 'basic', 'Loading ' + PLUGIN_NAME)
# SET UI COLUMNS FOR PICARD RHS
if config.setting['ce_show_ui_tags'] and config.setting['ce_ui_tags']:
from picard.ui.itemviews import MainPanel
UI_TAGS = get_ui_tags().items()
for heading, tag_names in UI_TAGS:
heading_tag = '~' + heading + '_VAL'
MainPanel.columns.append((N_(heading), heading_tag))
write_log('session', 'info', 'UI_TAGS')
write_log('session', 'info', UI_TAGS)
# set defaults for certain options that MUST be manually changed by the
# user each time they are to be over-ridden
config.setting['use_cache'] = True
config.setting['ce_options_overwrite'] = False
config.setting['track_ars'] = True
config.setting['release_ars'] = True
# REFERENCE DATA
REF_DICT = get_references_from_file(
'session',
config.setting['cwp_muso_path'],
config.setting['cwp_muso_refdb'])
write_log('session', 'info', 'External references (Muso):')
write_log('session', 'info', REF_DICT)
COMPOSER_DICT = REF_DICT['composers']
if config.setting['cwp_muso_classical'] and not COMPOSER_DICT:
write_log('session', 'error', 'No composer roster found')
for cd in COMPOSER_DICT:
cd['lc_name'] = [c.lower() for c in cd['name']]
cd['lc_sort'] = [c.lower() for c in cd['sort']]
PERIOD_DICT = REF_DICT['periods']
if (config.setting['cwp_muso_dates']
or config.setting['cwp_muso_periods']) and not PERIOD_DICT:
write_log('session', 'error', 'No period map found')
GENRE_DICT = REF_DICT['genres']
if config.setting['cwp_muso_genres'] and not GENRE_DICT:
write_log('session', 'error', 'No classical genre list found')
# API CALLS
register_track_metadata_processor(PartLevels().add_work_info)
register_track_metadata_processor(ExtraArtists().add_artist_info)
register_options_page(ClassicalExtrasOptionsPage)
# END
write_log('session', 'basic', 'Finished intialisation')
================================================
FILE: plugins/classical_extras/const.py
================================================
# -*- coding: utf-8 -*-
"""
Declare constants for Picard Classical Extras plugin
v2.0.2
"""
# Copyright (C) 2018 Mark Evens
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
RELATION_TYPES = {
'work': [
'arranger',
'instrument arranger',
'orchestrator',
'composer',
'writer',
'lyricist',
'librettist',
'revised by',
'translator',
'reconstructed by',
'vocal arranger'],
'release': [
'instrument',
'performer',
'vocal',
'performing orchestra',
'conductor',
'chorus master',
'concertmaster',
'arranger',
'instrument arranger',
'orchestrator',
'vocal arranger'],
'recording': [
'instrument',
'performer',
'vocal',
'performing orchestra',
'conductor',
'chorus master',
'concertmaster',
'arranger',
'instrument arranger',
'orchestrator',
'vocal arranger']}
ARTISTS_OPTIONS = [
{'option': 'classical_extra_artists',
'name': 'run extra artists',
'type': 'Boolean',
'default': True
},
{'option': 'cea_orchestras',
'name': 'orchestra strings',
'type': 'Text',
'default': 'orchestra, philharmonic, philharmonica, philharmoniker, musicians, academy, symphony, orkester'
},
{'option': 'cea_choirs',
'name': 'choir strings',
'type': 'Text',
'default': 'choir, choir vocals, chorus, singers, domchors, domspatzen, koor, kammerkoor'
},
{'option': 'cea_groups',
'name': 'group strings',
'type': 'Text',
'default': 'ensemble, band, group, trio, quartet, quintet, sextet, septet, octet, chamber, consort, players, '
'les ,the , quartett'
},
{'option': 'cea_aliases',
'name': 'replace artist name with alias?',
'value': 'replace',
'type': 'Boolean',
'default': True
},
{'option': 'cea_aliases_composer',
'name': 'replace artist name with alias?',
'value': 'composer',
'type': 'Boolean',
'default': False
},
{'option': 'cea_no_aliases',
'name': 'replace artist name with alias?',
'value': 'no replace',
'type': 'Boolean',
'default': False
},
{'option': 'cea_alias_overrides',
'name': 'alias vs credited-as',
'value': 'alias over-rides',
'type': 'Boolean',
'default': True
},
{'option': 'cea_credited_overrides',
'name': 'alias vs credited-as',
'value': 'credited-as over-rides',
'type': 'Boolean',
'default': False
},
{'option': 'cea_ra_use',
'name': 'use recording artist',
'type': 'Boolean',
'default': False
},
{'option': 'cea_ra_trackartist',
'name': 'recording artist name style',
'value': 'track artist',
'type': 'Boolean',
'default': False
},
{'option': 'cea_ra_performer',
'name': 'recording artist name style',
'value': 'performer',
'type': 'Boolean',
'default': True
},
{'option': 'cea_ra_replace_ta',
'name': 'recording artist effect on track artist',
'value': 'replace',
'type': 'Boolean',
'default': False
},
{'option': 'cea_ra_noblank_ta',
'name': 'disallow blank recording artist',
'type': 'Boolean',
'default': False
},
{'option': 'cea_ra_merge_ta',
'name': 'recording artist effect on track artist',
'value': 'merge',
'type': 'Boolean',
'default': True
},
{'option': 'cea_composer_album',
'name': 'Album prefix',
# 'value': 'Composer', # Can't use 'value' if there is only one option, otherwise False will revert to default
'type': 'Boolean',
'default': True
},
{'option': 'cea_arrangers',
'name': 'include arrangers',
'type': 'Boolean',
'default': True
},
{'option': 'cea_no_lyricists',
'name': 'exclude lyricists if no vocals',
'type': 'Boolean',
'default': True
},
{'option': 'cea_cyrillic',
'name': 'fix cyrillic',
'type': 'Boolean',
'default': True
},
# {'option': 'cea_genres',
# 'name': 'infer work types',
# 'type': 'Boolean',
# 'default': True
# },
# Note that the above is no longer used - replaced by cwp_genres_infer from v0.9.2
{'option': 'cea_credited',
'name': 'use release credited-as name',
'type': 'Boolean',
'default': True
},
{'option': 'cea_release_relationship_credited',
'name': 'use release relationship credited-as name',
'type': 'Boolean',
'default': True
},
{'option': 'cea_group_credited',
'name': 'use release-group credited-as name',
'type': 'Boolean',
'default': True
},
{'option': 'cea_recording_credited',
'name': 'use recording credited-as name',
'type': 'Boolean',
'default': False
},
{'option': 'cea_recording_relationship_credited',
'name': 'use recording relationship credited-as name',
'type': 'Boolean',
'default': True
},
{'option': 'cea_track_credited',
'name': 'use track credited-as name',
'type': 'Boolean',
'default': True
},
{'option': 'cea_performer_credited',
'name': 'use credited-as name for performer',
'type': 'Boolean',
'default': True
},
{'option': 'cea_composer_credited',
'name': 'use credited-as name for composer',
'type': 'Boolean',
'default': False
},
{'option': 'cea_inst_credit',
'name': 'use credited instrument',
'type': 'Boolean',
'default': True
},
{'option': 'cea_no_solo',
'name': 'exclude solo',
'type': 'Boolean',
'default': True
},
{'option': 'cea_chorusmaster',
'name': 'chorusmaster',
'type': 'Text',
'default': 'choirmaster'
},
{'option': 'cea_orchestrator',
'name': 'orchestrator',
'type': 'Text',
'default': 'orch.'
},
{'option': 'cea_concertmaster',
'name': 'concertmaster',
'type': 'Text',
'default': 'leader'
},
{'option': 'cea_lyricist',
'name': 'lyricist',
'type': 'Text',
'default': 'lyrics'
},
{'option': 'cea_librettist',
'name': 'librettist',
'type': 'Text',
'default': 'libretto'
},
{'option': 'cea_writer',
'name': 'writer',
'type': 'Text',
'default': 'writer'
},
{'option': 'cea_arranger',
'name': 'arranger',
'type': 'Text',
'default': 'arr.'
},
{'option': 'cea_reconstructed',
'name': 'reconstructed by',
'type': 'Text',
'default': 'reconstructed'
},
{'option': 'cea_revised',
'name': 'revised by',
'type': 'Text',
'default': 'revised'
},
{'option': 'cea_translator',
'name': 'translator',
'type': 'Text',
'default': 'trans.'
},
{'option': 'cea_split_lyrics',
'name': 'split lyrics',
'type': 'Boolean',
'default': True
},
{'option': 'cea_lyrics_tag',
'name': 'lyrics',
'type': 'Text',
'default': 'lyrics'
},
{'option': 'cea_album_lyrics',
'name': 'album lyrics',
'type': 'Text',
'default': 'albumnotes'
},
{'option': 'cea_track_lyrics',
'name': 'track lyrics',
'type': 'Text',
'default': 'tracknotes'
}
]
TAG_OPTIONS = [
{'option': 'cea_blank_tag',
'name': 'Tags to blank',
'type': 'Text',
'default': 'artist, artistsort'
},
{'option': 'cea_blank_tag_2',
'name': 'Tags to blank 2',
'type': 'Text',
'default': 'performer:orchestra, performer:choir, performer:choir vocals'
},
{'option': 'cea_keep',
'name': 'File tags to keep',
'type': 'Text',
'default': ''
},
{'option': 'cea_clear_tags',
'name': 'Clear previous tags',
'type': 'Boolean',
'default': False
},
{'option': 'cea_tag_sort',
'name': 'populate sort tags',
'type': 'Boolean',
'default': True
}
]
# (tag mapping detail lines)
default_list = [
('album_soloists, album_ensembles, album_conductors', 'artist, artists', False),
('recording_artists', 'artist, artists', True),
('soloist_names, ensemble_names, conductors', 'artist, artists', True),
('soloists', 'soloists, trackartist, involved people', False),
('release', 'release_name', False),
('ensemble_names', 'band', False),
('composers', 'artist', True),
('MB_artists', 'composer', True),
('arranger', 'composer', True)
]
TAG_DETAIL_OPTIONS = []
for i in range(0, 16):
if i < len(default_list):
default_source, default_tag, default_cond = default_list[i]
else:
default_source = ''
default_tag = ''
default_cond = False
TAG_DETAIL_OPTIONS.append({'option': 'cea_source_' + str(i + 1),
'name': 'line ' + str(i + 1) + '_source',
'type': 'Combo',
'default': default_source
})
TAG_DETAIL_OPTIONS.append({'option': 'cea_tag_' + str(i + 1),
'name': 'line ' + str(i + 1) + '_tag',
'type': 'Text',
'default': default_tag
})
TAG_DETAIL_OPTIONS.append({'option': 'cea_cond_' + str(i + 1),
'name': 'line ' + str(i + 1) + '_conditional',
'type': 'Boolean',
'default': default_cond
})
WORKPARTS_OPTIONS = [
{'option': 'classical_work_parts',
'name': 'run work parts',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_collections',
'name': 'include collection relations',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_allow_empty_parts',
# allow parts to be blank if there is arrangement or partial text label
# checked = split
'name': 'allow-empty-parts',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_common_chars',
# for use in strip_parent_from_work
# where no match exists and substring elimination is used
# this sets the minimum number of matching 'words' (words followed by punctuation/spaces or EOL)
# required before they will be eliminated
# 0 => no elimination
# default is 2 words
'name': 'min common words to eliminate',
'type': 'Integer',
'default': 2
},
{'option': 'cwp_proximity',
# proximity of new words in title comparison which will result in
# infill words being included as well. 2 means 2-word 'gaps' of
# existing words between new words will be treated as 'new'
'name': 'in-string proximity trigger',
'type': 'Integer',
'default': 2
},
{'option': 'cwp_end_proximity',
# proximity measure to be used when infilling to the end of the title
'name': 'end-string proximity trigger',
'type': 'Integer',
'default': 1
},
{'option': 'cwp_split_hyphenated',
# splitting of hyphenated words for matching purposes
# checked = split
'name': 'hyphen-splitting',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_substring_match',
# Proportion of a string to be matched to a (usually larger) string for
# it to be considered essentially similar
'name': 'similarity threshold',
'type': 'Integer',
'default': 100
},
{'option': 'cwp_fill_part',
# Fill part name with title text if it would otherwise
# have no text other than arrangement or partial annotations
'name': 'disallow empty part names',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_prepositions',
'name': 'prepositions',
'type': 'Text',
'default': "a, the, in, on, at, of, after, and, de, d'un, d'une, la, le, no, from, &, e, ed, et, un,"
" une, al, ala, alla"
},
{'option': 'cwp_removewords',
'name': 'ignore prefixes',
'type': 'Text',
'default': ' part , act , scene, movement, movt, no. , no , n., n , nr., nr , book , the , a , la , le , un ,'
' une , el , il , tableau, from , KV ,Concerto in, Concerto'
},
{'option': 'cwp_synonyms',
'name': 'synonyms',
'type': 'PlainText',
'default': '(1, one) / (2, two) / (3, three) / (&, and) / (Rezitativ, Recitativo, Recitative) / '
'(Sinfonia, Sinfonie, Symphonie, Symphony) / (Arie, Aria) / '
'(Minuetto, Menuetto, Minuetta, Menuet, Minuet) / (Bourée, Bouree , Bourrée)'
},
{'option': 'cwp_replacements',
'name': 'replacements',
'type': 'Text',
'default': '(words to be replaced, replacement words) / (please blank me, ) / (etc, etc)'
},
{'option': 'cwp_titles',
'name': 'Style',
'value': 'Titles',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_works',
'name': 'Style',
'value': 'Works',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_extended',
'name': 'Style',
'value': 'Extended',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_hierarchical_works',
'name': 'Work source',
'value': 'Hierarchy',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_level0_works',
'name': 'Work source',
'value': 'Level_0',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_derive_works_from_title',
'name': 'Derive works from title',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_movt_tag_inc',
'name': 'movement tag inc num',
'type': 'Text',
'default': 'part, movement, subtitle'
},
{'option': 'cwp_movt_tag_exc',
'name': 'movement tag exc num',
'type': 'Text',
'default': ''
},
{'option': 'cwp_movt_tag_inc1',
'name': '1-level movement tag inc num',
'type': 'Text',
'default': 'movement'
},
{'option': 'cwp_movt_tag_exc1',
'name': '1-level movement tag exc num',
'type': 'Text',
'default': ''
},
{'option': 'cwp_movt_no_tag',
'name': 'movement num tag',
'type': 'Text',
'default': 'movementnumber'
},
{'option': 'cwp_movt_tot_tag',
'name': 'movement tot tag',
'type': 'Text',
'default': 'movementtotal'
},
{'option': 'cwp_work_tag_multi',
'name': 'multi-level work tag',
'type': 'Text',
'default': 'groupheading, work'
},
{'option': 'cwp_work_tag_single',
'name': 'single level work tag',
'type': 'Text',
'default': ''
},
{'option': 'cwp_top_tag',
'name': 'top level work tag',
'type': 'Text',
'default': 'top_work, style, grouping'
},
{'option': 'cwp_multi_work_sep',
'name': 'multi-level work separator',
'type': 'Combo',
'default': ':'
},
{'option': 'cwp_single_work_sep',
'name': 'single level work separator',
'type': 'Combo',
'default': ':'
},
{'option': 'cwp_movt_no_sep',
'name': 'movement number separator',
'type': 'Combo',
'default': '.'
},
{'option': 'cwp_partial',
'name': 'show partial recordings',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_partial_text',
'name': 'partial text',
'type': 'Text',
'default': '(part)'
},
{'option': 'cwp_arrangements',
'name': 'include arrangement of',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_arrangements_text',
'name': 'arrangements text',
'type': 'Text',
'default': 'Arrangement:'
},
{'option': 'cwp_medley',
'name': 'list medleys',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_medley_text',
'name': 'medley text',
'type': 'Text',
'default': 'Medley'
}
]
# Options on "Genres etc." tab
GENRE_OPTIONS = [
{'option': 'cwp_genre_tag',
'name': 'main genre tag',
'type': 'Text',
'default': 'genre'
},
{'option': 'cwp_subgenre_tag',
'name': 'sub-genre tag',
'type': 'Text',
'default': 'sub-genre'
},
{'option': 'cwp_genres_use_file',
'name': 'source genre from file',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_use_folks',
'name': 'source genre from folksonomy tags',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_use_worktype',
'name': 'source genre from work-type(s)',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_infer',
'name': 'infer genre from artist details(s)',
'type': 'Boolean',
'default': False
},
# Note that the "infer from artists" option was in the "artists"
# section - legacy from v0.9.1 & prior
{'option': 'cwp_genres_filter',
'name': 'apply filter to genres',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_classical_main',
'name': 'classical main genres',
'type': 'PlainText',
'default': 'Classical, Chamber music, Concerto, Symphony, Opera, Orchestral, Sonata, Choral, Aria, Ballet, '
'Oratorio, Motet, Symphonic poem, Suite, Partita, Song-cycle, Overture, '
'Mass, Cantata'
},
{'option': 'cwp_genres_classical_sub',
'name': 'classical sub-genres',
'type': 'PlainText',
'default': 'Chant, Classical crossover, Minimalism, Avant-garde, Impressionist, Aria, Duet, Trio, Quartet'
},
{'option': 'cwp_genres_other_main',
'name': 'general main genres',
'type': 'PlainText',
'default': 'Alternative music, Blues, Country, Dance, Easy listening, Electronic music, Folk, Folk / pop, '
'Hip hop / rap, Indie, Religious, Asian, Jazz, Latin, New age, Pop, R&B / Soul, Reggae, Rock, '
'World music, Celtic folk, French Medieval'
},
{'option': 'cwp_genres_other_sub',
'name': 'general sub-genres',
'type': 'PlainText',
'default': 'Song, Vocal, Christmas, Instrumental'
},
{'option': 'cwp_genres_arranger_as_composer',
'name': 'treat arranger as for composer for genre-setting',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_classical_all',
'name': 'make tracks classical',
'value': 'all',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_genres_classical_selective',
'name': 'make tracks classical',
'value': 'selective',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_genres_classical_exclude',
'name': 'exclude "classical" from main genre tag',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_genres_flag_text',
'name': 'classical flag',
'type': 'Text',
'default': '1'
},
{'option': 'cwp_genres_flag_tag',
'name': 'classical flag tag',
'type': 'Text',
'default': 'is_classical'
},
{'option': 'cwp_genres_default',
'name': 'default genre',
'type': 'Text',
'default': 'Other'
},
{'option': 'cwp_instruments_tag',
'name': 'instruments tag',
'type': 'Text',
'default': 'instrument'
},
{'option': 'cwp_instruments_MB_names',
'name': 'use MB instrument names',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_instruments_credited_names',
'name': 'use credited instrument names',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_key_tag',
'name': 'key tag',
'type': 'Text',
'default': 'key'
},
{'option': 'cwp_key_contingent_include',
'name': 'contingent include key in workname',
'value': 'contingent',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_key_never_include',
'name': 'never include key in workname',
'value': 'never',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_key_include',
'name': 'include key in workname',
'value': 'always',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_workdate_tag',
'name': 'workdate tag',
'type': 'Text',
'default': 'work_year'
},
{'option': 'cwp_workdate_source_composed',
'name': 'use composed for workdate',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_workdate_source_published',
'name': 'use published for workdate',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_workdate_source_premiered',
'name': 'use premiered for workdate',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_workdate_use_first',
'name': 'use workdate sources sequentially',
'value': 'sequence',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_workdate_use_all',
'name': 'use all workdate sources',
'value': 'all',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_workdate_annotate',
'name': 'annotate dates',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_workdate_include',
'name': 'include workdate in workname',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_period_tag',
'name': 'period tag',
'type': 'Text',
'default': 'period'
},
{'option': 'cwp_periods_arranger_as_composer',
'name': 'treat arranger as for composer for period-setting',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_period_map',
'name': 'period map',
'type': 'PlainText',
'default': 'Early, -3000,800; Medieval, 800,1400; Renaissance, 1400, 1600; Baroque, 1600,1750; '
'Classical, 1750,1820; Early Romantic, 1800,1850; Late Romantic, 1850,1910; '
'20th Century, 1910,1975; Contemporary, 1975,2525'
}
]
# Picard options which are also saved (NB only affects plugin processing - not main Picard processing)
PICARD_OPTIONS = [
{'option': 'standardize_artists',
'name': 'standardize artists',
'type': 'Boolean',
'default': False
},
{'option': 'translate_artist_names',
'name': 'translate artist names',
'type': 'Boolean',
'default': True
},
]
# other options (not saved in file tags)
OTHER_OPTIONS = [
{'option': 'use_cache',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_aliases',
'name': 'replace with alias?',
'value': 'replace',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_no_aliases',
'name': 'replace with alias?',
'value': 'no replace',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_aliases_all',
'name': 'alias replacement type',
'value': 'all',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_aliases_greek',
'name': 'alias replacement type',
'value': 'non-latin',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_aliases_tagged',
'name': 'alias replacement type',
'value': 'tagged works',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_aliases_tag_text',
'name': 'use_alias tag text',
'type': 'Text',
'default': 'use_alias'
},
{'option': 'cwp_aliases_tags_all',
'name': 'use_alias tags all',
'type': 'Boolean',
'default': True
},
{'option': 'cwp_aliases_tags_user',
'name': 'use_alias tags user',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_use_sk',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_write_sk',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_retries',
'type': 'Integer',
'default': 6
},
{'option': 'cwp_use_muso_refdb',
'name': 'use Muso ref database',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_muso_genres',
'name': 'use Muso classical genres',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_muso_classical',
'name': 'use Muso classical composers',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_muso_dates',
'name': 'use Muso composer dates',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_muso_periods',
'name': 'use Muso periods',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_muso_path',
'name': 'path to Muso database',
'type': 'Text',
'default': 'C:\\Users\\Public\\Music\\muso\\database'
},
{'option': 'cwp_muso_refdb',
'name': 'name of Muso reference database',
'type': 'Text',
'default': 'Reference.xml'
},
{'option': 'log_error',
'type': 'Boolean',
'default': True
},
{'option': 'log_warning',
'type': 'Boolean',
'default': True
},
{'option': 'log_debug',
'type': 'Boolean',
'default': False
},
{'option': 'log_basic',
'type': 'Boolean',
'default': True
},
{'option': 'log_info',
'type': 'Boolean',
'default': False
},
{'option': 'ce_version_tag',
'type': 'Text',
'default': 'stamp'
},
{'option': 'cea_options_tag',
'type': 'Text',
'default': 'comment'
},
{'option': 'cwp_options_tag',
'type': 'Text',
'default': 'comment'
},
{'option': 'cea_override',
'type': 'Boolean',
'default': False
},
{'option': 'ce_tagmap_override',
'type': 'Boolean',
'default': False
},
{'option': 'cwp_override',
'type': 'Boolean',
'default': False
},
{'option': 'ce_genres_override',
'type': 'Boolean',
'default': False
},
{'option': 'ce_options_overwrite',
'type': 'Boolean',
'default': False
},
{'option': 'ce_no_run',
'type': 'Boolean',
'default': False
},
{'option': 'ce_show_ui_tags',
'type': 'Boolean',
'default': False
},
{'option': 'ce_ui_tags',
## Note that this is not just for work parts (although that is the main use),
# but cwp prefix is to make use of code for synonyms
'name': 'tags for ui columns',
'type': 'PlainText',
'default': 'Work diff: (groupheading_DIFF, work_DIFF, top_work_DIFF, grouping_DIFF) / Part diff: (part_DIFF, movement_DIFF) / Missing file metadata: 002_important_warning'
}
]
ARTIST_TYPE_ORDER = {'vocal': 1,
'instrument': 1,
'performer': 0,
'performing orchestra': 2,
'concertmaster': 3,
'conductor': 4,
'chorus master': 5,
'composer': 6,
'writer': 7,
'reconstructed by': 8,
'instrument arranger': 9,
'vocal arranger': 9,
'arranger': 11,
'orchestrator': 12,
'revised by': 13,
'lyricist': 14,
'librettist': 15,
'translator': 16
}
CYRILLIC_UPPER = {
u'А': u'A',
u'Б': u'B',
u'В': u'V',
u'Г': u'G',
u'Д': u'D',
u'Е': u'E',
u'Ё': u'E',
u'Ж': u'Zh',
u'З': u'Z',
u'И': u'I',
u'Й': u'Y',
u'К': u'K',
u'Л': u'L',
u'М': u'M',
u'Н': u'N',
u'О': u'O',
u'П': u'P',
u'Р': u'R',
u'С': u'S',
u'Т': u'T',
u'У': u'U',
u'Ф': u'F',
u'Х': u'H',
u'Ц': u'Ts',
u'Ч': u'Ch',
u'Ш': u'Sh',
u'Щ': u'Sch',
u'Ъ': u'',
u'Ы': u'Y',
u'Ь': u'',
u'Э': u'E',
u'Ю': u'Yu',
u'Я': u'Ya'
}
CYRILLIC_LOWER = {
u'а': u'a',
u'б': u'b',
u'в': u'v',
u'г': u'g',
u'д': u'd',
u'е': u'e',
u'ё': u'e',
u'ж': u'zh',
u'з': u'z',
u'и': u'i',
u'й': u'y',
u'к': u'k',
u'л': u'l',
u'м': u'm',
u'н': u'n',
u'о': u'o',
u'п': u'p',
u'р': u'r',
u'с': u's',
u'т': u't',
u'у': u'u',
u'ф': u'f',
u'х': u'h',
u'ц': u'ts',
u'ч': u'ch',
u'ш': u'sh',
u'щ': u'sch',
u'ъ': u'',
u'ы': u'y',
u'ь': u'',
u'э': u'e',
u'ю': u'yu',
u'я': u'ya'
}
def tag_strings(pre):
TAG_STRINGS = {
'writer': (
'composer',
pre + '_writers',
'composersort',
pre + '_writers_sort'),
'composer': (
'composer',
pre + '_composers',
'composersort',
pre + '_composers_sort'),
'lyricist': (
'lyricist',
pre + '_lyricists',
'~lyricists_sort',
pre + '_lyricists_sort'),
'librettist': (
'lyricist',
pre + '_librettists',
'~lyricists_sort',
pre + '_librettists_sort'),
'revised by': (
'arranger',
pre + '_revisors',
'~arranger_sort',
pre + '_revisors_sort'),
'translator': (
'lyricist',
pre + '_translators',
'~lyricists_sort',
pre + '_translators_sort'),
'reconstructed by': (
'arranger',
pre + '_reconstructors',
'~arranger_sort',
pre + '_reconstructors_sort'),
'arranger': (
'arranger',
pre + '_arrangers',
'~arranger_sort',
pre + '_arrangers_sort'),
'instrument arranger': (
'arranger',
pre + '_arrangers',
'~arranger_sort',
pre + '_arrangers_sort'),
'orchestrator': (
'arranger',
pre + '_orchestrators',
'~arranger_sort',
pre + '_orchestrators_sort'),
'vocal arranger': (
'arranger',
pre + '_arrangers',
'~arranger_sort',
pre + '_arrangers_sort'),
'performer': (
'performer:',
pre + '_performers',
'~performer_sort',
pre + '_performers_sort'),
'instrument': (
'performer:',
pre + '_performers',
'~performer_sort',
pre + '_performers_sort'),
'vocal': (
'performer:',
pre + '_performers',
'~performer_sort',
pre + '_performers_sort'),
'performing orchestra': (
'performer:orchestra',
pre + '_ensembles',
'~performer_sort',
pre + '_ensembles_sort'),
'conductor': (
'conductor',
pre + '_conductors',
'~conductor_sort',
pre + '_conductors_sort'),
'chorus master': (
'conductor',
pre + '_chorusmasters',
'~conductor_sort',
pre + '_chorusmasters_sort'),
'concertmaster': (
'performer',
pre + '~_leaders',
'~performer_sort',
pre + '_leaders_sort')}
return TAG_STRINGS
INSERTIONS = ['writer',
'lyricist',
'librettist',
'revised by',
'translator',
'arranger',
'reconstructed by',
'orchestrator',
'instrument arranger',
'vocal arranger',
'chorus master']
================================================
FILE: plugins/classical_extras/options_classical_extras.ui
================================================
ClassicalExtrasOptionsPage
0
0
1145
918
0
0
Qt::DefaultContextMenu
false
6
9
-
0
0
1200
1200
false
4
<html><head/><body><p><br/></p></body></html>
Artists
-
0
0
Qt::WheelFocus
QFrame::NoFrame
QFrame::Plain
1
true
0
0
1086
1071
false
-
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
false
background-color: rgb(255, 255, 222);
QFrame::StyledPanel
QFrame::Raised
-
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
<html><head/><body><p>should be selected otherwise this section will not run</p></body></html>
Create extra artist metadata (MUST BE TICKED FOR THIS SECTION TO RUN)
-
(Note that the "infer work-types" option has moved to the "genres" tab)
-
Qt::Horizontal
-
<html><head/><body><p><span style=" font-weight:600; font-style:italic;">The naming style for 'artist' tags is set in the main Picard Options->Metadata section</span></p></body></html>
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(176, 220, 192);
<html><head/><body><p><span style=" font-weight:600;">Work-artist / performer naming options</span></p></body></html>
-
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
UpArrowCursor
<html><head/><body><p>"Work-artists" are types such as composer, writer, arranger and lyricist who belong to the MusicBrainz Work-Artist relationship</p><p>"Performers" are types such as performer and conductor who belong to the MusicBrainz Recording-Artist relationship</p></body></html>
false
background-color: rgb(211, 248, 224);
QFrame::NoFrame
QFormLayout::AllNonFixedFieldsGrow
6
9
0
9
-
<html><head/><body><p>This section does not change the contents of "artist" or "album artist" tags - it only affects writer (composer etc.) and peformer tags, by using as-credited/alias names from the artist data for the release.</p></body></html>
-
<html><head/><body><p><br/></p></body></html>
Credited-as options:-
-
<html><head/><body><p>Select the source for 'as-credited' names - whether these are applied depends on the sub-options choices.</p></body></html>
false
background-color: rgb(250, 250, 250);
Names to use...
-
Qt::RightToLeft
Use "credited as" name for work-artists/performers who are recording artists
-
Qt::RightToLeft
false
and/or release group artists
-
<html><head/><body><p><br/></p></body></html>
Qt::RightToLeft
and/or release artists
-
Qt::RightToLeft
and/or release relationship artists
-
Qt::RightToLeft
and/or recording relationship artists
-
<html><head/><body><p><br/></p></body></html>
Qt::RightToLeft
and/or track artists
-
Qt::RightToLeft
The above are applied in sequence - e.g. track artist credit will over-ride release artist credit.
-
Names are cached. A restart is necessary if any of the above name sources are removed.
-
<html><head/><body><p>Select the tag types where any 'as-credited' names will be applied - whether these are applied depends on the sub-options choices.</p></body></html>
background-color: rgb(250, 250, 250);
Places to use them ...
QLayout::SetDefaultConstraint
9
-
Qt::RightToLeft
Use for performing artists
-
Qt::RightToLeft
Use for work-artists
-
background-color: rgb(250, 250, 250);
Sub-options
-
<html><head/><body><p>Alias (if it exists) will over-ride as-credited</p></body></html>
Alias over-rides credited-as
-
<html><head/><body><p>As-credited (if it exists) will over-ride alias</p></body></html>
Credited-as over-rides MB/Alias
-
<html><head/><body><p>Will be based on sort names. For cyrillic script names, patronyms will be removed.</p></body></html>
Fix non-Latin text in names (where possible and if not fixed by other naming options)
-
background-color: rgb(211, 248, 224);
MusicBrainz standard names and Aliases
-
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Do not use aliases (but may be replaced by as-credited name)</p></body></html>
Use MB standard names
-
<html><head/><body><p>Alias will only be available for use if the work-artist/performer is also a release artist, recording artist or track artist.</p></body></html>
Use alias for all work-artists/performers
-
<html><head/><body><p>Only use alias (if available) for work-artists (writers, composers, arrangers, lyricists etc.)</p></body></html>
Use alias for work-artists only
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(176, 220, 192);
<html><head/><body><p><span style=" font-weight:600;">Recording artist options</span></p></body></html>
-
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
<html><head/><body><p>Select recording artist options (see "What's this")</p></body></html>
<html><head/><body><p>In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).</p><p>Classical Extras puts the recording artists into 'hidden variables' (as a minimum) using the chosen naming convention.</p><p>There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the 'artist', 'artists', 'artistsort' and 'artists_sort' tags. Note that 'artist' is a single-valued string whereas 'artists' is a list and may be multi-valued. Lists are properly merged, but because the 'artist' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s).</p></body></html>
false
background-color: rgb(211, 248, 224);
-
<html><head/><body><p>In classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers. By default, the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadat options.</p></body></html>
background-color: rgb(250, 250, 250);
Naming convention as for ...
-
...track artist (set in Picard options)
-
... perfomers (set above)
-
Qt::Vertical
-
Use recording artists to update track artists ->
-
0
0
background-color: rgb(250, 250, 250);
Replace/merge options
-
Replace track artist by recording artist
-
0
0
Qt::LeftToRight
Only replace if rec. artist exists
-
Merge track artist and recording artist
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(176, 220, 192);
<html><head/><body><p><span style=" font-weight:600;">Other artist options</span></p></body></html>
-
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
211
248
224
false
background-color: rgb(211, 248, 224);
6
-
<html><head/><body><p>Enter text to appear in annotations. Do not use any quotation marks.</p></body></html>
background-color: rgba(250, 250, 250, 250);
Annotations - performers and lyricists
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
6
QLayout::SetDefaultConstraint
1
9
-
<html><head/><body><p>Annotation to include with "chorus master" in conductor tag.</p></body></html>
Chorus Master
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
1
-
<html><head/><body><p>Annotation to include for "concert master" in performer tag.</p></body></html>
Concert Master
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>Annotation for lyricist, to include in lyricist tag</p></body></html>
Lyricist
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>Annotation for librettist, to include in lyricist tag</p></body></html>
Librettist
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>Annotation for translator, to include in lyricist tag</p></body></html>
Translator
-
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Select as required. See "What's this" for details.</p></body></html>
background-color: rgba(250, 250, 250, 250);
6
-
<html><head/><body><p><br/></p></body></html>
<html><head/><body><p>This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag ('host' tag), with the annotation (see details to right of this box) in brackets. All arranger types will also be put in a hidden variable, e.g. _cwp_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.</p><p>| Artist type | Host tag | Hidden variable |</p><p>| ----------------- | ------------------| -------------------------------------- |</p><p>| writer | composer | writers |</p><p>| lyricist | lyricist | lyricists |</p><p>| librettist | lyricist | librettists |</p><p>| revised by | arranger | revisors |</p><p>| translator | lyricist | translators |</p><p>| arranger | arranger | arrangers |</p><p>| reconstructed by | arranger | reconstructors |</p><p>| orchestrator | arranger | orchestrators |</p><p>| instrument arranger | arranger | arrangers (with instrument type in brackets) |</p><p>| vocal arranger | arranger | arrangers (with voice type in brackets) |</p><p>| chorus master | conductor | chorusmasters |</p><p>| concertmaster | performer (with annotation as a sub-key) | leaders |</p></body></html>
Modify host tags and include annotations (see =>)
-
<html><head/><body><p><br/></p></body></html>
<html><head/><body><p>This will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release.</p></body></html>
Name album as "Composer Last Name(s): Album Name"
-
<html><head/><body><p>This applies to both the Picard 'lyricist' tag and the related internal plugin hidden variables '_cwp_lyricists' etc.</p></body></html>
Do not write 'lyricist' tag if no vocal performers
-
Use "credited-as" name for instrument
-
<html><head/><body><p>Select to eliminate "additional", "solo" or "guest" from instrument description</p></body></html>
<html><head/><body><p>MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.</p></body></html>
Do not include attributes (e.g. 'solo') in an instrument type
-
<html><head/><body><p>Enter text to appear in annotations. Do not use any quotation marks.</p></body></html>
background-color: rgb(250, 250, 250);
Annotations - writers and arrangers
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
Writer
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
Arranger
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
1
-
<html><head/><body><p>Text with which to annotate orchestrator in the arranger tag.</p></body></html>
Orchestrator
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>Annotation for "reconstructed by", to include in arranger tag</p></body></html>
Reconstructed by
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(211, 248, 224);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>Annotation for "revised by", to include in arranger tag tag</p></body></html>
Revised by
-
background-color: rgb(250, 250, 250);
-
1
Qt::Horizontal
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(204, 168, 161);
<html><head/><body><p><span style=" font-weight:600;">Lyrics</span></p></body></html>
-
230
215
211
230
215
211
230
215
211
230
215
211
230
215
211
230
215
211
230
215
211
230
215
211
230
215
211
<html><head/><body><p><span style=" font-weight:600;">Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)</span></p><p> Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text and place it in a different tag from the text which is unique to each track.</p></body></html>
false
background-color: rgb(230, 215, 211);
-
<html><head/><body><p>enables this section</p></body></html>
Split lyrics tag into track and album levels
-
<html><head/><body><p>Enter a valid tag name (no spaces, punctuation or special charcaters other than underline; use lower case)</p></body></html>
-
background-color: rgb(204, 168, 161);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>The name of the lyrics file tag in the input file (normally just 'lyrics')</p></body></html>
Incoming lyrics tag (i.e. file tag)
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(204, 168, 161);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>The name of the tag where common text should be placed</p></body></html>
Tag for album notes / lyrics
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(204, 168, 161);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>The name of the tag where notes/lyrics unique to a track should be placed</p></body></html>
Tag for track notes / lyrics
-
background-color: rgb(250, 250, 250);
-
Qt::Vertical
20
40
Works and parts
-
0
0
true
0
0
1084
1086
0
0
-
0
0
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
255
255
222
false
background-color: rgb(255, 255, 222);
QFrame::StyledPanel
QFrame::Raised
-
<html><head/><body><p>"Include all work levels" should be selected otherwise this section will not run.</p></body></html>
Include all work levels (MUST BE TICKED FOR THIS SECTION TO RUN)*
-
<html><head/><body><p>This will include parent works where the relationship has the attribute 'part of collection'.<br/>PLEASE BE CONSISTENT and do not use different options on albums with the same works, or the results may be unexpected.</p></body></html>
Include collection relationships (but not "series")
-
<html><head/><body><p>Select to use cached works. Deselect to refesh from MusicBrainz.</p></body></html>
<html><head/><body><p>"Use cache" prevents excessive look-ups of the MB database. Every look-up of a parent work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed.</p></body></html>
Use cache (if available)*
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(205, 230, 255);
<html><head/><body><p><span style=" font-weight:600;">Tagging style</span></p></body></html>
-
0
0
225
240
255
225
240
255
225
240
255
225
240
255
225
240
255
225
240
255
225
240
255
225
240
255
225
240
255
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:400; font-style:normal;">
<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Tagging style". This section determines how the hierarchy of works will be sourced. </p>
<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Works source</span>: There are 3 options for determing the principal source of the works metadata </p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided. </p>
<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><br /></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below). </p>
<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><br /></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles <span style=" font-weight:600;">where it is significantly different</span>. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations.</p>
<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Source of canonical work text</span>. Where either of the second two options above are chosen, there is a further choice to be made: </p>
<p style=" margin-top:12px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose. </p>
<p style=" margin-top:12px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">"Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag. </p>
<p style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600;">Strategy for setting style:</span> <span style=" font-style:italic;">It is suggested that you start with "extended/enhanced" style and the "Consistent with lowest level work description" as the source (this is the default). If this does not give acceptable results, try switching to "Full MusicBrainz work hierarchy". If the "enhanced" details in curly brackets (from the track title) give odd results then switch the style to "canonical works" only. Any remaining oddities are then probably in the MusicBrainz data, which may require editing.</span> </p></body></html>
false
background-color: rgb(225, 240, 255);
-
<html><head/><body><p>There are 3 options for determing the principal source of the works metadata</p><p> - "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.</p><p> - "Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will be in the language of the release.</p><p> - "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles <span style=" font-weight:600;">where it is significantly different</span>. The supplementary data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager).</p></body></html>
Works source
-
<html><head/><body><p>"Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.</p></body></html>
Use only metadata from title text
-
<html><head/><body><p>"Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).</p></body></html>
Use only metadata from canonical works
-
<html><head/><body><p>"Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations</p></body></html>
Use canonical work metadata enhanced with title text
-
true
<html><head/><body><p>Where either of the second two options above are chosen, there is a further choice to be made:</p><p> - "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.</p><p> - "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.</p></body></html>
Source of canonical work text (if applicable)
-
<html><head/><body><p>"Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.</p></body></html>
Full MusicBrainz work hierarchy (may be more verbose)
-
<html><head/><body><p>"Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, <span style=" font-weight:600;">particularly if the level 0 work name does not contain all the parent work detail</span>. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.</p></body></html>
Consistent with lowest level work description (may be less verbose, but not always complete)
-
Attempt to get works and movement info from title if there are no work relationships? (Requires title in form "work: movement")
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(255, 186, 189);
<html><head/><body><p><span style=" font-weight:600;">Aliases</span> (NB Use a consistent approach throughout the library otherwise duplicate works may occur - see the Readme)*</p></body></html>
-
255
220
222
255
220
222
255
220
222
255
220
222
255
220
222
255
220
222
255
220
222
255
220
222
255
220
222
<html><head/><body><p>"Replace work names by aliases" will use <span style=" font-weight:600;">primary</span> aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager. </p><p>The sub-options allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be 'aliased' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone's tags ("Look in all tags") or the user's own tags. If selecting "Look in user's own tags only" you <span style=" font-weight:600;">must</span> be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.</p></body></html>
false
background-color: rgb(255, 220, 222);
-
Replace MB work names?
-
<html><head/><body><p>Use primary aliases for the chosen locale instead of standard MusicBrainz work names.</p></body></html>
Replace work names by aliases. Select method -->
-
Do not replace work names
-
What to replace?
-
-
All work names
-
Non-latin work names
-
Only tagged works
-
Tags ("Folksonomy") identifying works to be replaced by aliases
-
Look in all tags
-
Look in user's own tags only (MUST BE LOGGED IN!)
-
<html><head/><body><p>Separate multiple tags by commas</p></body></html>
background-color: rgb(250, 250, 250);
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(255, 194, 158);
<html><head/><body><p><span style=" font-weight:600;">Tags to create</span> - Use commas to separate multiple tags or leave blank to omit</p></body></html>
-
0
0
255
221
201
255
221
201
255
221
201
255
221
201
255
221
201
255
221
201
255
221
201
255
221
201
255
221
201
<html><head/><body><p>Separate multiple tags by commas.</p></body></html>
<html><head/><body><p>"Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.</p></body></html>
false
background-color: rgb(255, 221, 201);
-
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
false
background-color: rgb(255, 209, 182);
Work tags
-
Separator
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
6
0
-
0
0
<html><head/><body><p>Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).</p></body></html>
<html><head/><body><p>Tags for Work - for software with 2-level capability (e.g. Muso)</p></body></html>
-
background-color: rgb(250, 250, 250);
-
true
-
-
;
-
:
-
.
-
,
-
-
-
(In this format, intermediate works will be displayed after a double colon :: )
-
6
0
-
0
0
<html><head/><body><p>Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).</p></body></html>
<html><head/><body><p>Tags for Work - for software with 1-level capability (e.g. iTunes)</p></body></html>
-
background-color: rgb(250, 250, 250);
-
true
-
-
;
-
:
-
.
-
,
-
-
-
(Intermediate works will not be displayed:- Either 1. use the 2-level format if you wish to display them, but note that this will ceate new work, or 2. include them in the movement [see below])
-
6
0
-
0
0
<html><head/><body><p>This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable). Note that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added. However, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.</p></body></html>
<html><head/><body><p>Tags for top-level (canonical) work (for capable library managers)</p></body></html>
-
background-color: rgb(250, 250, 250);
-
N/A
-
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
255
209
182
false
background-color: rgb(255, 209, 182);
Movement/Part tags
-
6
0
-
0
0
<html><head/><body><p>The Picard standard tag is 'movementnumber' - include that or other(s) of your choice</p></body></html>
<html><head/><body><p>This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work <span style=" font-weight:600;">on the current release</span>.</p></body></html>
<html><head/><body><p>Tags for (computed) movement number (Picard std tag is movementnumber)</p></body></html>
-
background-color: rgb(250, 250, 250);
-
true
-
-
;
-
:
-
.
-
,
-
-
-
6
0
-
0
0
<html><head/><body><p>The Picard tag 'movementtotal' will be populated in any case - no need to specify it</p></body></html>
<html><head/><body><p>This is not necessarily the total number of movements in the parent work, but is the total number of movement tracks within the parent work <span style=" font-weight:600;">on the current release</span>.</p></body></html>
<html><head/><body><p>Tags for (computed) total number of movements (Picard std tag is movementtotal)</p></body></html>
-
background-color: rgb(250, 250, 250);
-
N/A
-
QFrame::StyledPanel
QFrame::Raised
0
-
<html><head/><body><p>Movement name tags (Picard std tag is movement)<br/>Use different movement tags if required for different level systems ==></p></body></html>
-
<html><head/><body><p><br/>for use with multi-level work tags</p></body></html>
-
<html><head/><body><p><br/>for use with1-level work tags (intermediate works will prefix movement)</p></body></html>
-
6
0
-
0
0
<html><head/><body><p>The Picard standard tag is 'movement' - include that or other(s) of your choice</p></body></html>
<html><head/><body><p>As below, but without the movement part/number prefix (if applicable)</p></body></html>
<html><head/><body><p>Tags for Movement - excluding embedded movt/part numbers</p></body></html>
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(250, 250, 250);
-
N/A
-
6
0
-
0
0
<html><head/><body><p>The Picard standard tag is 'movement' - include that or other(s) of your choice</p></body></html>
<html><head/><body><p>This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.</p></body></html>
<html><head/><body><p>Tags for Movement - including embedded movt/part numbers</p></body></html>
-
background-color: rgb(250, 250, 250);
-
background-color: rgb(250, 250, 250);
-
N/A
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(195, 168, 179);
<html><head/><body><p><span style=" font-weight:600;">Partial recordings, arrangements and medleys</span></p></body></html>
-
221
209
221
221
209
221
221
209
221
221
209
221
221
209
221
221
209
221
221
209
221
221
209
221
221
209
221
<html><head/><body><p>Enter text - do not use any quotation marks</p></body></html>
false
background-color: rgb(221, 209, 221);
-
font: 75 8pt "MS Shell Dlg 2";
text-decoration: underline;
N.B. If these options are selected or deselected, quit and restart Picard before proceeding
-
<html><head/><body><p>If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text included in its name. Note that this text is at the end of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2.</p></body></html>
Partial recordings
-
Show partial recordings as separate sub-part, labelled with ->
-
true
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided.</p></body></html>
Arrangements
-
Show arrangements as parts of original works, labelled with ->
-
true
background-color: rgb(250, 250, 250);
false
-
Medleys
-
<html><head/><body><p><span style=" font-weight:600;">Medleys</span></p><p> These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the parent work name.</p><p><br/></p></body></html>
Include medley list, labelled with ->
-
true
background-color: rgb(250, 250, 250);
-
QFrame::StyledPanel
QFrame::Raised
0
0
0
0
-
background-color: rgb(182, 182, 62);
<html><head/><body><p><span style=" font-weight:600;">SongKong-compatible tag usage</span></p></body></html>
-
227
227
143
227
227
143
227
227
143
227
227
143
227
227
143
227
227
143
227
227
143
227
227
143
227
227
143
<html><head/><body><p>See "What's this"</p></body></html>
<html><head/><body><p> "Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, some of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless speed is more important than quality.**</p><p><br/></p><p> "Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data).</p><p><br/></p><p>Note that Picard and SongKong use the tag musicbrainz_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.</p></body></html>
false
background-color: rgb(227, 227, 143);
-
Use work tags on file (no look up on MB) if Use Cache selected* (NOT RECOMMENDED - SEE README)
-
Write SongKong-compatible work tags*
-
* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
Genres etc.
-
true
0
-26
1084
1310
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(138, 222, 187);
<html><head/><body><p><span style=" font-weight:600;">Genre tags</span></p></body></html>
-
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
false
background-color: rgb(207, 236, 225);
-
Name of genre tag
-
Name of sub-genre tag
-
background-color: rgb(250,250,250);
-
background-color: rgb(250,250,250);
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(138, 222, 187);
<html><head/><body><p><span style=" font-weight:600;">"Classical" genre </span></p></body></html>
-
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
false
background-color: rgb(207, 236, 225);
-
Exclude the text "classical" from main genre tag even if listed above
-
Make track "classical" only if there is a classical-specific genre (or do nothing if there is no filter)
-
75
true
Use Muso composer list to determine if classical*
-
Make all tracks "classical"
-
Write a flag with text =
-
background-color: rgb(250, 250, 250);
-
in the following tag if the track is classical
-
background-color: rgb(250, 250, 250);
-
(Treat arrangers as for composers)
-
* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
-
75
true
Use Muso reference database (default path is set on "advanced" tab)*
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(225, 168, 171);
<html><head/><body><p><span style=" font-weight:600;">Instruments and keys</span></p></body></html>
-
245
224
226
245
224
226
245
224
226
245
224
226
245
224
226
245
224
226
245
224
226
245
224
226
245
224
226
false
background-color: rgb(245, 224, 226);
-
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
false
background-color: rgb(245, 210, 213);
Instruments
-
Tag name for instruments (will hold all instruments for a track)
-
background-color: rgb(250, 250, 250);
-
Name sources to use for instruments (select at least one, otherwise no instruments will be included in tag)
-
MusicBrainz standard names
-
"Credited-as" names
-
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
245
210
213
false
background-color: rgb(245, 210, 213);
Keys
-
Tag name for key(s)
-
background-color: rgb(250, 250, 250);
-
Include key(s) in work name?
-
Never
-
Only if key not already mentioned in work name
-
<html><head/><body><p>"Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák's New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)"</p></body></html>
Always
-
QFrame::StyledPanel
QFrame::Raised
1
0
0
0
-
background-color: rgb(138, 222, 187);
<html><head/><body><p><span style=" font-weight:600;">Allowed genres (filter)</span></p></body></html>
-
Qt::LeftToRight
background-color: rgb(138, 222, 187);
Only apply genres to tags if they match pre-defined names:
-
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
<html><head/><body><p><span style=" font-weight:600;">Explanation of genre-matching:</span></p><p><br/></p><p>Only genres matching those in the boxes will be placed in the genre or sub-genre tags.</p><p><br/></p><p>If there is a matching genre found in the "classical main genres" or "classical sub-genres" box, then the track will be treated as being classical.</p></body></html>
false
background-color: rgb(207, 236, 225);
-
background-color: rgb(190, 236, 219);
Classical genres (i.e. specific to classical music) - List separated by commas
-
Main genres:
-
16777215
50
background-color: rgb(250,250,250);
-
Sub-genres:
-
0
0
16777215
50
background-color: rgb(250,250,250);
-
75
true
<html><head/><body><p>Select this to use the "classical genres" in Muso options as the "Main classical genres" here.</p></body></html>
Use Muso classical genres*
-
background-color: rgb(190, 236, 219);
General genres (may be associated with classical music, but not necessarily, e.g. "instrumental") - List separated by commas
-
Main genres
-
16777215
50
background-color: rgb(250,250,250);
-
Sub-genres
-
16777215
50
background-color: rgb(250,250,250);
cwp_genres_other_main
cwp_genres_other_sub
label_62
label_76
-
Genre name to use if none of the above main genres apply (leave blank if not required)
-
background-color: rgb(250,250,250);
-
List genres, separated by commas. Only those genres listed will be included in tags.
-
See "what's this" for more details.
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(138, 222, 187);
<html><head/><body><p><span style=" font-weight:600;">Source of genres</span> - Note: if "existing file tag" is selected, information from the tag "genre" and the genre tag name specified above (if different) will be used</p></body></html>
-
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
207
236
225
false
background-color: rgb(207, 236, 225);
-
<html><head/><body><p>NB: This will use the contents of the file tag with the name given above (usually 'genre').</p></body></html>
Existing file tag (see note above)
-
<html><head/><body><p>This will use the folksonomy tags for <span style=" font-weight:600;">works</span> as a possible source of genres (if they match one of the lists below).</p><p><br/></p><p>To use the folksonomy tags for <span style=" font-weight:600;">releases/tracks</span>, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) they will only be used by this plugin if they match one of the lists below.</p></body></html>
Folksonomy work tags
-
Work-type
-
Infer from artist metadata
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(195, 183, 213);
<html><head/><body><p><span style=" font-weight:600;">Periods and dates</span></p></body></html>
-
229
224
236
229
224
236
229
224
236
229
224
236
229
224
236
229
224
236
229
224
236
229
224
236
229
224
236
false
background-color: rgb(229, 224, 236);
-
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
false
background-color: rgb(222, 212, 236);
Work dates
-
Source of work dates for above tag
-
Composed date (or parent composed date)
-
Published date
-
Premiered date
-
Qt::Horizontal
-
Use first available of above (in listed order)
-
Include all sources
-
Annotate dates using source name
-
Tag name for work date
-
<html><head/><body><p>"Includeworkdate in work names" gives the option to include the 'work year' for a work in brackets after the name of the work in the metadata. Dates (years) will be added in the appropriate levels: e.g. Smetana's 'Má vlast' will get (1874-1879) at the work level, but the movements with different dates will be annotated viz. "Vyšehrad, JB 1:112/1 (1874)". If the dates are the same, there should be no repitetion at the movement level. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).</p></body></html>
Include workdate in work name (in preference order listed above, with no annotation)
-
background-color: rgb(250, 250, 250);
-
0
Qt::Horizontal
-
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
222
212
236
false
background-color: rgb(222, 212, 236);
Periods
-
Tag name for period
-
75
true
Use Muso map*
-
75
true
Use Muso composer dates (if no work date) to determine period*
-
background-color: rgb(250, 250, 250);
-
Period map:
-
background-color: rgb(250, 250, 250);
-
(Period name, Start year, End year; Period name2, ... etc.) - periods may overlap [Do not use commas or semi-colons within period name]
-
(Treat arrangers as for composers)
-
<html><head/><body><p><span style=" font-size:9pt; font-weight:600;">N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") </span><span style=" font-size:9pt; font-weight:600; text-decoration: underline;">must</span><span style=" font-size:9pt; font-weight:600;"> be enabled for this section to run.<br/></span><span style=" font-weight:600; font-style:italic;">(Functionality will be reduced unless both the first two tabs are enabled.) </span></p></body></html>
Tag mapping
-
0
0
Qt::ScrollBarAsNeeded
true
0
0
1084
917
-
<html><head/><body><p><span style=" font-size:9pt; font-weight:600;">N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") </span><span style=" font-size:9pt; font-weight:600; text-decoration: underline;">must</span><span style=" font-size:9pt; font-weight:600;"> be enabled for this section to run. </span></p></body></html>
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(209, 171, 222);
<html><head/><body><p><span style=" font-weight:600;">Initial tag processing</span></p></body></html>
-
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
<html><head/><body><p><br/></p></body></html>
false
background-color: rgb(242, 221, 245);
-
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
242
221
245
<html><head/><body><p>Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.</p></body></html>
false
Remove Picard-generated tags before applying subsequent actions? (NB existing LOCAL FILE tags will remain unless cleared using standard Picard options - to remove these, overwrite them in the next section)
-
<html><head/><body><p><span style=" text-decoration: underline;">Picard-generated</span> tags to blank (comma-separated, case-sensitive):</p></body></html>
-
<html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
background-color: rgb(250, 250, 250);
-
<html><head/><body><p><br/></p></body></html>
<html><head/><body><p>List <span style=" text-decoration: underline;">existing file tags</span> which will be appended to rather than over-written by tag mapping (this will keep tags even if "Clear existing tags" is selected on main options)<br/>NB To allow appending to happen, <span style=" text-decoration: underline;">do not also include these tags in "Preserve tags"</span> on the main options.</p></body></html>
-
<html><head/><body><p>Enter file tag names, separated by commas</p></body></html>
<html><head/><body><p>This refers to the tags which already exist on files which have been matched to MusicBrainz in the right-hand panel, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if 'Clear existing tags' is specified in the main Options->Tags screen) or keep them (if 'Preserve these tags...' is specified after the 'Clear existing tags' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below). List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular genre-related tags (see the Genres etc. options tab for more).</p><p>Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the 'Keep file tags' list and does not need to be added in this section.</p></body></html>
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Note that the main Picard option "Clear existing tags" should be <span style=" text-decoration: underline;">unchecked</span> for this option to operate in preference to that Picard option. The difference is that this option <span style=" text-decoration: underline;">will not intefere with cover art</span>, whereas the main Picard option will remove previous cover art.</p></body></html>
<html><head/><body><p>If selected: the bottom pane of Picard will only show tags which have been generated from the MusicBrainz lookups plus any existing file tags which are listed above or in the main options "Preserve tags...".</p><p>This does not mean that the file tags will be removed when saving the file. For that to happen, "Clear existing tags" needs to be selected in the main options.</p></body></html>
Do not show any file tags that are NOT listed above AND NOT listed in the main Picard "Preserve tags..." option (Options->Tags), even if "Clear existing tags" is not selected.
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(229, 174, 142);
<html><head/><body><p><span style=" font-weight:600;">Tag map details</span></p></body></html>
-
0
0
255
229
214
255
229
214
255
229
214
255
229
214
255
229
214
255
229
214
255
229
214
255
229
214
255
229
214
Qt::NoFocus
<html><head/><body><p>Enter tags, separated by commas.</p></body></html>
false
font: 75 8pt "MS Shell Dlg 2";
background-color: rgb(255, 229, 214);
-
0
0
16777215
100
background-color: rgb(249, 215, 187);
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:72; font-style:normal;">
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-weight:600; text-decoration: underline;">Notes: </span></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Click "Source from:" button to edit source tags.</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Any valid Picard-generated tag can be entered in the "source" box, as well as Classical Extras sources, and mapped into other tags - not just restricted to artists.</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">To put a constant in a tag, type it into the source box preceded by a backslash \.</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">In all cases, the source will be APPENDED to the Picard tag. To replace the standard tag, first blank it in the section above - add it back later in the list below if required (e.g. artist -> artist).</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">BUT note that any existing LOCAL FILE tag will be replaced by (not appended with) any Picard/Classical Extras tag UNLESS specified in the list box above.</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">These tag-mapping options may be omitted from the over-riding of artist options - see advanced tab</p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">For more help seethe readme.</p></body></html>
-
6
QLayout::SetDefaultConstraint
1
-
Click to edit sources
false
Source from:
true
Qt::ToolButtonIconOnly
false
-
false
0
0
false
Qt::StrongFocus
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
QComboBox::AdjustToContents
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
Click to edit sources
Source from:
true
-
false
Click button to edit. See notes above.
background-color: rgb(250, 250, 250);
true
-
-
album_soloists, album_conductors, album_ensembles
-
soloists, conductors, ensembles, album_composers, composers
-
album_soloists
-
album_conductors
-
album_ensembles
-
album_composers
-
album_composer_lastnames
-
soloists
-
soloist_names
-
ensembles
-
ensemble_names
-
composers
-
arrangers
-
orchestrators
-
conductors
-
chorusmasters
-
leaders
-
support_performers
-
work_type
-
release
-
into tags:
-
Enter comma-separated list of tags
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Conditional?
-
6
0
-
0
0
Qt::LeftToRight
1
(If source is empty, tag will be left unchanged)
Qt::AlignLeading|Qt::AlignLeft|Qt::AlignVCenter
-
0
0
Qt::RightToLeft
(Conditional tags will only be filled if previously empty)
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
<html><head/><body><p>Select to include sort-tags, where available. See<span style=" font-style:italic;"> "What's this?"</span> for more details.</p></body></html>
<html><head/><body><p>If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Piacrd also writes hidden variables '_artists_sort' and 'albumartists_sort' (note the plurals - these are the sort tags for multi-valued alternatives 'artists' and '_albumartists'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. '_arranger_sort'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. '_cwp_librettists' has a matching sort variable '_cwp_librettists_sort'. Therefore most artist-type sources <span style=" font-weight:600;">will</span> have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected -<span style=" font-weight:600;"> in other words, selecting this option will cause most destination tags to have associated sort tags</span>.<span style=" font-weight:600;"> Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags</span> (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble_names + \; + conductors") do not have sort tags associated with them.</p><p><br/></p><p>If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map 'conductors_sort' to 'conductor_sort'.</p></body></html>
Qt::LeftToRight
Also populate sort tags
Advanced
-
0
0
true
0
-853
1084
1707
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">General</span></p></body></html>
-
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
false
background-color: rgb(229, 229, 197);
-
Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">Artists (only effective if "Artists" section enabled)</span></p></body></html>
-
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
<html><head/><body><p>Separate multiple names by commas. Do not use any quotation marks.</p></body></html>
<html><head/><body><p>Permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags. </p><p>If it is important that only whole words are to be matched, be sure to include a space after the string.</p></body></html>
false
background-color: rgb(229, 229, 197);
-
<html><head/><body><p><span style=" font-weight:600;">Ensemble strings</span> (separate names by commas)</p></body></html>
-
2
9
-
Orchestras
-
background-color: rgb(250, 250, 250);
-
Choirs
-
background-color: rgb(250, 250, 250);
-
Groups (i.e. other ensembles such as quartets etc.)
-
background-color: rgb(250, 250, 250);
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">Works and parts (only effective if "Works and parts" section enabled)</span></p></body></html>
-
0
0
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
false
background-color: rgb(229, 229, 197);
-
6
0
-
0
0
<html><head/><body><p>Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable _cwp_error will be set with a message; if error logging is checked in section 4, an error message will be written to the log and the contents of _cwp_error will be written out to a special tag called "An_error_has_occurred" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.</p></body></html>
<html><head/><body><p>Max number of re-tries to access works (in case of server errors)*</p></body></html>
cwp_retries
-
background-color: rgb(250, 250, 250);
0
20
-
6
0
-
0
0
<html><head/><body><p>Allow blank part names for arrangements and part recordings if arrangement/partial label is provided</p></body></html>
cwp_retries
-
Qt::RightToLeft
-
241
241
167
241
241
167
241
241
167
241
241
167
241
241
167
241
241
167
241
241
167
241
241
167
241
241
167
false
background-color: rgb(241, 241, 167);
-
<html><head/><body><p><span style=" font-size:10pt; font-weight:600;">Removal of common text between parent and child works</span></p></body></html>
-
6
0
-
0
0
<html><head/><body><p>Minimum number of similar words required before eliminating. Use zero for no elimination.<br/>(Punctuation and accents etc. will be ignored in word comparison)</p></body></html>
cwp_retries
-
background-color: rgb(250, 250, 250);
0
99
-
<html><head/><body><p>NB Parent name text at the start of a work which is followed by punctuation in the work name will always be stripped regardless of this setting.<br/>Synonyms in the next section also apply.</p></body></html>
-
202
202
140
202
202
140
202
202
140
202
202
140
202
202
140
202
202
140
202
202
140
202
202
140
202
202
140
<html><head/><body><p>This subsection contains various parameters affecting the processing of strings in titles. Because titles are free-form, not all circumstances can be anticipated. Detailed documentation of these is beyond the scope of this Readme as the effects can be quite complex and subtle and may require an understanding of the plugin code (which is of course open-source) to acsertain them. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should be irrelevant, but no text from titles will be included. Some explanations are given below:</p><p> "Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words between the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the end) included even if they repeat words in the work name.</p><p> "Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomolies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.</p><p> "Synonyms". These words will be considered equivalent when comparing work name and title text. Thus if one word appears in the work name, that and its synonym will be removed from the title in extending the metadata (subject to the proximity setting above).</p><p> "Replacements". These words/phrases will be replaced in the title text in extended metadata, regardless of the text in the work name.</p></body></html>
false
background-color: rgb(202, 202, 140);
-
<html><head/><body><p><span style=" font-size:10pt; font-weight:600;">How title metadata should be included in extended metadata</span><span style=" font-size:10pt;"> (use cautiously - read documentation)</span><br/><span style=" font-style:italic;">(Mostly only applies if "Use canonical work metadata enhanced with title text" selected on "Works and parts" tab. </span><span style=" font-weight:600; font-style:italic;">However synonyms also apply to parent/child text removal</span><span style=" font-style:italic;">.)</span></p></body></html>
-
6
0
-
0
0
<html><head/><body><p>Proximity of new words (to each other) to trigger in-fill with existing words (default = 2)</p></body></html>
cwp_retries
-
background-color: rgb(250, 250, 250);
99
-
6
0
-
0
0
<html><head/><body><p>Proximity of new words (to start or end) to trigger in-fill with existing words (default =1)</p></body></html>
cwp_retries
-
background-color: rgb(250, 250, 250);
99
-
6
0
-
0
0
<html><head/><body><p>Treat hyphenated words as two words for comparison purposes</p></body></html>
cwp_retries
-
Qt::RightToLeft
-
6
0
-
0
0
<html><head/><body><p>Proportion of a string to be matched to a (usually larger) string for it to be considered essentially similar (default = 66%)</p></body></html>
cwp_retries
-
background-color: rgb(250, 250, 250);
%
100
-
6
0
-
0
0
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8pt; font-weight:400; font-style:normal;">
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;">Fill part name with title text if it would otherwise have no text other than arrangement or partial annotations</p></body></html>
cwp_retries
-
Qt::RightToLeft
-
Qt::Horizontal
-
<html><head/><body><p><span style=" font-weight:600; font-style:italic;">Prepositions/conjunctions and prefixes</span><span style=" font-weight:600;"><br/></span>DO NOT USE ANY COMMAS OR QUOTE MARKS (apostophes in words are acceptable)</p></body></html>
-
<html><head/><body><p>Prepositions & conjunctions: these are words that will not be regarded as providing additional information (not treated as 'new' words) unless they precede a new word.<br/>Use lower case only, comma separated</p></body></html>
-
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Prefixes to be ignored in comparison (case insensitive, comma separated)<br/>To prevent a prefix from being ignored when extending metadata with title info, precede it with a space. <br/>To ensure only whole words are removed, follow with a space.</p></body></html>
-
<html><head/><body><p>Separate multiple names by commas. Do not use any quotation marks.</p></body></html>
background-color: rgb(250, 250, 250);
-
Qt::Horizontal
-
<html><head/><body><p><span style=" font-weight:600; font-style:italic;">Synonyms and replacements</span> - must be written as tuples separated by forward slashes - e.g (a,b) / (c,d,e) - a tuple may have two or more synonyms.</p><p>N.B. The matching is case-insensitive. Roman numerals will be treated as synonyms of arabic numerals in any event, so no need to enter these.</p><p>The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison or replacement) and <span style=" text-decoration: underline;">must be a normal strin</span>g (not a regex). <span style=" font-weight:600;">See readme for full details</span>.<br/><span style=" font-weight:600; font-style:italic;">Unless entering a regular expression, use backslash \ to escape any regex metacharacters, namely \ ^ $ . | ? * + ( ) [ ] { <br/>Also escape commas , and forward slashes /. Do not enclose strings in quote marks.</span></p><p>Enter SYNONYM tuples below - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered.</p></body></html>
-
16777215
120
background-color: rgb(250, 250, 250);
-
<html><head/><body><p>Enter REMOVALS/REPLACEMENTS below - these will result in the "extended" text in tags being changed<br/>Put the word(s), phrase(s), or regular exprerssion(s) in the first part(s) of the tuple. The replacement text (or nothing - to remove) goes in the last member of the tuple.</p><p>N.B. Replacement text will operate BEFORE synonyms are considered.</p></body></html>
-
<html><head/><body><p>Entries must be 2-tuples, e.g. (Replace this, with this). Separate multiple tuples by forward slash. Do not use any quotation marks. Spaces are acceptable. The first item of a tuple may be a regular expression - enclose it with double exclamation marks - e.g.(!!regex here!!, replacement text here).</p></body></html>
background-color: rgb(250, 250, 250);
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">Genres etc.</span> (only required if Muso-specific options are used for genres/periods)</p></body></html>
-
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
false
background-color: rgb(229, 229, 197);
-
Path to Muso reference database:
-
background-color: rgb(250, 250, 250);
-
Name of Muso reference database
-
background-color: rgb(250, 250, 250);
-
<html><head/><body><p><span style=" font-weight:600;">RESTART PICARD AFTER CHANGING THESE</span></p></body></html>
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">Logging options</span>*</p></body></html>
-
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
<html><head/><body><p>These options are in addition to the options chosen in Picard's "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown, the flag needs to be set here and "Debug mode" needs to be turned on in the log. It is strongly advised to keep the "debug" and "info" flags unchecked unless debugging is required as they slow up processing significantly and may even cause Picard to crash on large releases. The "error" and "warning" flags should be left checked, unless it is required to suppress messages written out to tags (the default is to write messages to the tags 001_errors and 002_warnings).</p></body></html>
Qt::LeftToRight
false
background-color: rgb(229, 229, 197);
-
Error
-
Warning
-
Debug
-
background-color: rgb(229, 229, 159);
Custom logging
-
Basic
-
Full
-
QFrame::StyledPanel
QFrame::Raised
0
0
-
background-color: rgb(208, 208, 156);
<html><head/><body><p><span style=" font-weight:600;">Classical Extras Special Tags</span></p></body></html>
-
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
229
229
197
false
background-color: rgb(229, 229, 197);
QFrame::StyledPanel
QFrame::Raised
-
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
<html><head/><body><p>This can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag. </p></body></html>
false
background-color: rgb(229, 229, 159);
Save plugin details and options in a tag?*
-
Tag name for plugin version
-
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Tag name for artist/mapping/misc. options
-
Qt::RightToLeft
background-color: rgb(250, 250, 250);
-
Qt::RightToLeft
Tag name for work/genre options
-
Qt::RightToLeft
background-color: rgb(250, 250, 250);
-
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
229
229
159
<html><head/><body><p>If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride. If artist options over-ride is chosen, then tag map detail options may be included or not in the override.</p><p><br/></p><p>The last checkbox, "Overwrite options in Options Pages", is for <span style=" font-weight:600;">VERY CAREFUL USE ONLY</span>. It will cause any options read from the saved tags (if the relevant box has been ticked) to over-write the options on the plugin Options Page UI. The intended use of this is if for some reason the user's preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, to prevent inadvertant use. Far better is to make a <span style=" font-weight:600;">backup copy</span> of the picard.ini file.</p></body></html>
false
background-color: rgb(229, 229, 159);
Over-ride plugin options displayed in Options Pages with options from local file tags (previously saved using method in box above)?*
-
Artist options
-
Work options
-
true
Genres etc. options
-
true
<html><head/><body><p>Will not over-ride displayed options unless artist options over-ride is also selected</p></body></html>
Tag mapping options
-
Qt::Vertical
-
background-color: rgb(255, 0, 0);
Overwrite options in Options Pages (READ WARNINGS in Readme)
-
Note that the above saved options include the related "advanced" options on this tab as well as the options on each of the main tabs.
-
Qt::Horizontal
-
Show additional tags in Picard UI (rhs panel) - N.B. RESTART NEEDED FOR CHANGE TO TAKE EFFECT
-
background-color: rgb(229, 229, 159);
Additional columns for Picard UI to show specific tags*
-
<html><head/><body><p><span style=" font-weight:600;">RESTART PICARD AFTER CHANGING THESE</span> - otherwise changes will not take effect</p></body></html>
-
0
0
16777215
120
background-color: rgb(250, 250, 250);
-
0
0
<html><head/><body><p>Notes:</p><p>1. Use the format <span style=" font-style:italic;">column_name_A: (include_tag_1, include_tag_2) / column_name_B: include_tag_3 </span> etc. (i.e. put multiple tags to be concatenated in brackets)<br/>2. To just flag tags that have changed, rather than show the contents, add _DIFF at the end of the tag name<br/>3. If more than one tag name is included for a column, then:<br/>(a) if the tags are _DIFF tags, then the column will be flagged if any of them have changed<br/>(b) otherwise the tag contents will be concatenated</p></body></html>
-
* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS
Help
0
-10
671
561
0
0
true
0
0
669
559
9
109
641
421
0
0
Qt::ScrollBarAsNeeded
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8.25pt; font-weight:400; font-style:normal;">
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt; font-weight:600; text-decoration: underline;">General description</span></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:8pt;">Classical Extras provides tagging enhancements for Picard and, in particular, utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a user interface in Picard options->plugins. This interface provides separate sections to enhance artist/performer tags, works and parts, genres and also allows for a generalised "tag mapping" (simple scripting). While it is designed to cater for the complexities of classical music tagging, it may also be useful for other music which has more than just basic song/artist/album data. <br /><br />The options screen provides five tabs for users to control the tags produced: <br /><br />1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names. Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.). Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required. (Note: Picard will not normally process incoming file tags). <br /><br />2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or Opera -> Act -> Number) based on the works in MusicBrainz's database. These can then be displayed in tags in a variety of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits look-ups to one per second. <br /><br />3. Genres etc.: Options are available to customise the source and display of information relating to genres, instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical periods. <br /><br />4. Tag mapping: in some ways, this is a simple substitute for some of Picard's scripting capability. The main advantage is that the plugin will remember what tag mapping you use for each release (or even track). <br /><br />5. Advanced: Various options to control the detailed processing of the above. <br /><br />All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works are in the composer's language and/or script). Also existing file tags can be processed (not possible in native Picard). </span></p></body></html>
true
9
9
471
16
0
0
9
28
641
81
0
0
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body style=" font-family:'MS Shell Dlg 2'; font-size:8.25pt; font-weight:400; font-style:normal;">
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:12pt; font-weight:600;">Please see</span><span style=" font-size:14pt; font-weight:600;"> </span><a href="http://music.highmossergate.co.uk/symphony/tagging/classical-extras/"><span style=" font-size:14pt; text-decoration: underline; color:#0000ff;">my website</span></a><span style=" font-size:14pt; font-weight:600;"> </span><span style=" font-size:12pt; font-weight:600;">for full details of this plugin and how to use it.</span></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt;">This help page now has only general information.</span></p>
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-size:10pt;">There are extensive tooltips and "What's This" popups (right click for them)</span></p></body></html>
true
cea_ra_use
toggled(bool)
ra_replace_merge_options_box
setEnabled(bool)
515
552
1085
511
cea_ra_replace_ta
toggled(bool)
cea_ra_noblank_ta
setEnabled(bool)
1075
536
704
559
use_cea
toggled(bool)
lyrics_frame
setEnabled(bool)
158
59
562
933
use_cwp
toggled(bool)
cwp_collections
setEnabled(bool)
94
60
508
76
cea_split_lyrics
toggled(bool)
lyrics_and_notes_tags_frame
setEnabled(bool)
160
1016
610
947
use_cwp
toggled(bool)
use_cache
setEnabled(bool)
124
60
850
76
use_cea
toggled(bool)
other_artist_options_frame
setEnabled(bool)
158
59
562
682
cea_arrangers
toggled(bool)
annotations_lh_box
setEnabled(bool)
180
680
468
663
cea_arrangers
toggled(bool)
annotations_rh_box
setEnabled(bool)
180
680
830
663
toolButton_1
toggled(bool)
cea_source_1
setEnabled(bool)
116
439
450
440
toolButton_2
toggled(bool)
cea_source_2
setEnabled(bool)
116
467
191
468
toolButton_3
toggled(bool)
cea_source_3
setEnabled(bool)
116
495
191
496
toolButton_4
toggled(bool)
cea_source_4
setEnabled(bool)
116
523
191
524
toolButton_5
toggled(bool)
cea_source_5
setEnabled(bool)
116
551
191
552
toolButton_6
toggled(bool)
cea_source_6
setEnabled(bool)
116
579
191
580
toolButton_7
toggled(bool)
cea_source_7
setEnabled(bool)
116
607
191
608
toolButton_8
toggled(bool)
cea_source_8
setEnabled(bool)
116
635
191
636
toolButton_9
toggled(bool)
cea_source_9
setEnabled(bool)
116
663
191
664
toolButton_10
toggled(bool)
cea_source_10
setEnabled(bool)
116
691
298
710
toolButton_11
toggled(bool)
cea_source_11
setEnabled(bool)
119
742
298
740
toolButton_12
toggled(bool)
cea_source_12
setEnabled(bool)
119
772
298
770
toolButton_13
toggled(bool)
cea_source_13
setEnabled(bool)
119
802
298
800
toolButton_14
toggled(bool)
cea_source_14
setEnabled(bool)
119
832
298
830
toolButton_15
toggled(bool)
cea_source_15
setEnabled(bool)
119
862
298
860
toolButton_16
toggled(bool)
cea_source_16
setEnabled(bool)
119
892
298
890
use_cea
toggled(bool)
advanced_artists_frame
setEnabled(bool)
158
59
573
-721
use_cwp
toggled(bool)
advanced_workparts_frame
setEnabled(bool)
139
76
573
-228
use_cea
toggled(bool)
naming_options_frame
setEnabled(bool)
158
59
128
149
use_cea
toggled(bool)
recording_artists_options_frame
setEnabled(bool)
158
59
572
499
use_cwp
toggled(bool)
work_style_frame
setEnabled(bool)
47
63
562
158
use_cwp
toggled(bool)
work_aliases_frame
setEnabled(bool)
139
76
562
305
use_cwp
toggled(bool)
works_parts_tags_frame
setEnabled(bool)
139
76
562
566
use_cwp
toggled(bool)
songkong_frame
setEnabled(bool)
139
76
573
1047
cwp_use_muso_refdb
toggled(bool)
cwp_muso_genres
setVisible(bool)
89
-357
136
-94
cwp_use_muso_refdb
toggled(bool)
cwp_muso_genres
setChecked(bool)
120
-357
169
-94
cwp_use_muso_refdb
toggled(bool)
cwp_muso_classical
setVisible(bool)
161
-357
173
126
cwp_use_muso_refdb
toggled(bool)
cwp_muso_classical
setChecked(bool)
180
-357
219
126
cwp_use_muso_refdb
toggled(bool)
cwp_muso_dates
setVisible(bool)
584
-357
626
726
cwp_use_muso_refdb
toggled(bool)
cwp_muso_periods
setVisible(bool)
584
-357
213
826
cwp_use_muso_refdb
toggled(bool)
cwp_muso_dates
setChecked(bool)
584
-357
626
726
cwp_use_muso_refdb
toggled(bool)
cwp_muso_periods
setChecked(bool)
584
-357
213
826
cwp_muso_genres
toggled(bool)
cwp_genres_classical_main
setHidden(bool)
226
-94
618
-80
cwp_muso_classical
toggled(bool)
cwp_genres_arranger_as_composer
setVisible(bool)
130
126
143
149
cwp_muso_dates
toggled(bool)
cwp_periods_arranger_as_composer
setVisible(bool)
130
726
140
749
cwp_muso_periods
toggled(bool)
cwp_period_map
setHidden(bool)
207
826
777
826
cwp_muso_periods
toggled(bool)
period_map_annotation_label
setHidden(bool)
150
826
780
845
cwp_genres_filter
toggled(bool)
genre_filters_frame
setVisible(bool)
53
-201
50
-120
use_cwp
toggled(bool)
partial_arrangements_medleys_frame
setEnabled(bool)
139
76
234
816
cwp_titles
toggled(bool)
source_of_canonical_box
setDisabled(bool)
135
146
582
137
cwp_titles
toggled(bool)
partial_arrangements_medleys_frame
setHidden(bool)
263
150
562
864
use_cache
toggled(bool)
cwp_use_sk
setEnabled(bool)
918
68
320
1071
ce_show_ui_tags
toggled(bool)
groupBox
setVisible(bool)
55
529
42
563
================================================
FILE: plugins/classical_extras/suffixtree.py
================================================
# -*- coding: utf-8
"""
Search longest common substrings using generalized suffix trees built with Ukkonen's algorithm
Author: Ilya Stepanov
(c) 2013
Modified by Mark Evens as part of Picard Classical Extras project
Not for stand-alone use - use the original code
Accepts list or string inputs, but returns list outputs
Changed to allow a range of different special characters in case $ is in a string
(c) 2018
"""
import sys
END_OF_STRING = sys.maxsize
class SuffixTreeNode:
"""
Suffix tree node class. Actually, it also respresents a tree edge that points to this node.
"""
new_identifier = 0
def __init__(self, start=0, end=END_OF_STRING):
self.identifier = SuffixTreeNode.new_identifier
SuffixTreeNode.new_identifier += 1
# suffix link is required by Ukkonen's algorithm
self.suffix_link = None
# child edges/nodes, each dict key represents the first letter of an edge
self.edges = {}
# stores reference to parent
self.parent = None
# bit vector shows to which strings this node belongs
self.bit_vector = 0
# edge info: start index and end index
self.start = start
self.end = end
def add_child(self, key, start, end):
"""
Create a new child node
Agrs:
key: a char that will be used during active edge searching
start, end: node's edge start and end indices
Returns:
created child node
"""
child = SuffixTreeNode(start=start, end=end)
child.parent = self
self.edges[key] = child
return child
def add_exisiting_node_as_child(self, key, node):
"""
Add an existing node as a child
Args:
key: a char that will be used during active edge searching
node: a node that will be added as a child
"""
node.parent = self
self.edges[key] = node
def get_edge_length(self, current_index):
"""
Get length of an edge that points to this node
Args:
current_index: index of current processing symbol (usefull for leaf nodes that have "infinity" end index)
"""
return min(self.end, current_index + 1) - self.start
def __str__(self):
return 'id=' + str(self.identifier)
class SuffixTree:
"""
Generalized suffix tree
"""
def __init__(self):
# the root node
self.root = SuffixTreeNode()
# all strings are concatenaited together. Tree's nodes stores only indices
self.input_string = []
# number of strings stored by this tree
self.strings_count = 0
# list of tree leaves
self.leaves = []
def append_string(self, input_string, special_char):
"""
Add new string to the suffix tree
"""
start_index = len(self.input_string)
current_string_index = self.strings_count
# each sting should have a unique ending
input_string += special_char + str(current_string_index)
# gathering 'em all together
self.input_string += input_string
self.strings_count += 1
# these 3 variables represents current "active point"
active_node = self.root
active_edge = 0
active_length = 0
# shows how many
remainder = 0
# new leaves appended to tree
new_leaves = []
# main circle
for index in range(start_index, len(self.input_string)):
previous_node = None
remainder += 1
while remainder > 0:
if active_length == 0:
active_edge = index
if self.input_string[active_edge] not in active_node.edges:
# no edge starting with current char, so creating a new leaf node
leaf_node = active_node.add_child(self.input_string[active_edge], index, END_OF_STRING)
# a leaf node will always be leaf node belonging to only one string
# (because each string has different termination)
leaf_node.bit_vector = 1 << current_string_index
new_leaves.append(leaf_node)
# doing suffix link magic
if previous_node is not None:
previous_node.suffix_link = active_node
previous_node = active_node
else:
# ok, we've got an active edge
next_node = active_node.edges[self.input_string[active_edge]]
# walking down through edges (if active_length is bigger than edge length)
next_edge_length = next_node.get_edge_length(index)
if active_length >= next_node.get_edge_length(index):
active_edge += next_edge_length
active_length -= next_edge_length
active_node = next_node
continue
# current edge already contains the suffix we need to insert.
# Increase the active_length and go forward
if self.input_string[next_node.start + active_length] == self.input_string[index]:
active_length += 1
if previous_node is not None:
previous_node.suffix_link = active_node
previous_node = active_node
break
# splitting edge
split_node = active_node.add_child(
self.input_string[active_edge],
next_node.start,
next_node.start + active_length
)
next_node.start += active_length
split_node.add_exisiting_node_as_child(self.input_string[next_node.start], next_node)
leaf_node = split_node.add_child(self.input_string[index], index, END_OF_STRING)
leaf_node.bit_vector = 1 << current_string_index
new_leaves.append(leaf_node)
# suffix link magic again
if previous_node is not None:
previous_node.suffix_link = split_node
previous_node = split_node
remainder -= 1
# follow suffix link (if exists) or go to root
if active_node == self.root and active_length > 0:
active_length -= 1
active_edge = index - remainder + 1
else:
active_node = active_node.suffix_link if active_node.suffix_link is not None else self.root
# update leaves ends from "infinity" to actual string end
for leaf in new_leaves:
leaf.end = len(self.input_string)
self.leaves.extend(new_leaves)
def find_longest_common_substrings(self, special_char):
"""
Search longest common substrings in the tree by locating lowest common ancestors that belong to all strings
"""
# all bits are set
success_bit_vector = 2 ** self.strings_count - 1
lowest_common_ancestors = []
# going up to the root
for leaf in self.leaves:
node = leaf
while node.parent is not None:
if node.bit_vector != success_bit_vector:
# updating parent's bit vector
node.parent.bit_vector |= node.bit_vector
node = node.parent
else:
# hey, we've found a lowest common ancestor!
lowest_common_ancestors.append(node)
break
longest_common_substrings = []
longest_length = 0
# need to filter the result array and get the longest common strings
for common_ancestor in lowest_common_ancestors:
common_substring = []
node = common_ancestor
while node.parent is not None:
label = self.input_string[node.start:node.end]
common_substring = label + common_substring
node = node.parent
# remove unique endings (), we don't need them anymore ...
if special_char in common_substring:
common_substring = common_substring[:common_substring.index(special_char)]
# ... also in input strings to avoid mutation problems
if len(common_substring) > longest_length:
longest_length = len(common_substring)
longest_common_substrings = [common_substring]
elif len(common_substring) == longest_length and common_substring not in longest_common_substrings:
longest_common_substrings.append(common_substring)
return longest_common_substrings
def multi_lcs(strings_list):
"""
Returns longest common string (or list) for a list of strings (or lists)
:param strings_list: a list of lists or a list of strings
:return: a list of longest common strings (or lists)
(more than one is possible if they are distinct and of the same length)
"""
if not isinstance(strings_list, list):
return {'response': [], 'error': 'Argument is not a list'}
arg_type = type(strings_list[0])
for item in strings_list:
if not isinstance(item, arg_type):
return {'response': [], 'error': 'List members are not of the same type'}
if arg_type is not list and arg_type is not str:
return {'response': [], 'error': 'List members are not lists or strings'}
suffix_tree = SuffixTree()
special_char = None
for char in ['|', '$', '#', '%', '@', '_']:
test_strings = [x for x in strings_list if char in x]
if not test_strings:
special_char = char
break
if special_char:
# print special_char
for s in strings_list:
if arg_type is list:
s_copy = s[:] # to avoid mutating input lists
else:
s_copy = s
suffix_tree.append_string(s_copy, special_char)
lcs = suffix_tree.find_longest_common_substrings(special_char)
else:
return {'response': [], 'error': 'Too many special characters'}
if arg_type is list:
if lcs:
return {'response': lcs[0]}
else:
return {'response': [], 'error': 'Internal suffix tree problems'}
else:
if lcs:
return {'response': [''.join(x) for x in lcs[0]]}
else:
return {'response': [], 'error': 'Internal suffix tree problems'}
================================================
FILE: plugins/classical_extras/ui_options_classical_extras.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'M:\Documents\Mark's documents\Music\Picard 230\Classical Extras development\classical_extras\options_classical_extras.ui'
#
# Created by: PyQt5 UI code generator 5.11.2
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_ClassicalExtrasOptionsPage(object):
def setupUi(self, ClassicalExtrasOptionsPage):
ClassicalExtrasOptionsPage.setObjectName("ClassicalExtrasOptionsPage")
ClassicalExtrasOptionsPage.resize(1145, 918)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(ClassicalExtrasOptionsPage.sizePolicy().hasHeightForWidth())
ClassicalExtrasOptionsPage.setSizePolicy(sizePolicy)
ClassicalExtrasOptionsPage.setContextMenuPolicy(QtCore.Qt.DefaultContextMenu)
ClassicalExtrasOptionsPage.setAcceptDrops(False)
self.vboxlayout = QtWidgets.QVBoxLayout(ClassicalExtrasOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.tabWidget = QtWidgets.QTabWidget(ClassicalExtrasOptionsPage)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.MinimumExpanding, QtWidgets.QSizePolicy.MinimumExpanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.tabWidget.sizePolicy().hasHeightForWidth())
self.tabWidget.setSizePolicy(sizePolicy)
self.tabWidget.setMaximumSize(QtCore.QSize(1200, 1200))
palette = QtGui.QPalette()
self.tabWidget.setPalette(palette)
self.tabWidget.setAutoFillBackground(False)
self.tabWidget.setStyleSheet("")
self.tabWidget.setObjectName("tabWidget")
self.Artists = QtWidgets.QWidget()
self.Artists.setObjectName("Artists")
self.verticalLayout_10 = QtWidgets.QVBoxLayout(self.Artists)
self.verticalLayout_10.setObjectName("verticalLayout_10")
self.scrollArea = QtWidgets.QScrollArea(self.Artists)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea.sizePolicy().hasHeightForWidth())
self.scrollArea.setSizePolicy(sizePolicy)
self.scrollArea.setFocusPolicy(QtCore.Qt.WheelFocus)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setFrameShadow(QtWidgets.QFrame.Plain)
self.scrollArea.setLineWidth(1)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 1086, 1071))
self.scrollAreaWidgetContents.setAcceptDrops(False)
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_13 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_13.setObjectName("verticalLayout_13")
self.artists_run_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.artists_run_frame.setPalette(palette)
self.artists_run_frame.setAutoFillBackground(False)
self.artists_run_frame.setStyleSheet("background-color: rgb(255, 255, 222);")
self.artists_run_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.artists_run_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.artists_run_frame.setObjectName("artists_run_frame")
self.horizontalLayout_9 = QtWidgets.QHBoxLayout(self.artists_run_frame)
self.horizontalLayout_9.setObjectName("horizontalLayout_9")
self.use_cea = QtWidgets.QCheckBox(self.artists_run_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.use_cea.setPalette(palette)
self.use_cea.setStyleSheet("")
self.use_cea.setObjectName("use_cea")
self.horizontalLayout_9.addWidget(self.use_cea)
self.infer_worktypes_old_label = QtWidgets.QLabel(self.artists_run_frame)
self.infer_worktypes_old_label.setObjectName("infer_worktypes_old_label")
self.horizontalLayout_9.addWidget(self.infer_worktypes_old_label)
self.verticalLayout_13.addWidget(self.artists_run_frame)
self.line_4 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.line_4.setFrameShape(QtWidgets.QFrame.HLine)
self.line_4.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_4.setObjectName("line_4")
self.verticalLayout_13.addWidget(self.line_4)
self.naming_style_note_label = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.naming_style_note_label.setObjectName("naming_style_note_label")
self.verticalLayout_13.addWidget(self.naming_style_note_label)
self.naming_options_frame_2 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.naming_options_frame_2.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.naming_options_frame_2.setFrameShadow(QtWidgets.QFrame.Raised)
self.naming_options_frame_2.setObjectName("naming_options_frame_2")
self.verticalLayout_36 = QtWidgets.QVBoxLayout(self.naming_options_frame_2)
self.verticalLayout_36.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_36.setSpacing(0)
self.verticalLayout_36.setObjectName("verticalLayout_36")
self.naming_options_label = QtWidgets.QLabel(self.naming_options_frame_2)
self.naming_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
self.naming_options_label.setObjectName("naming_options_label")
self.verticalLayout_36.addWidget(self.naming_options_label)
self.naming_options_frame = QtWidgets.QFrame(self.naming_options_frame_2)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.naming_options_frame.setPalette(palette)
self.naming_options_frame.setCursor(QtGui.QCursor(QtCore.Qt.UpArrowCursor))
self.naming_options_frame.setAutoFillBackground(False)
self.naming_options_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.naming_options_frame.setFrameShape(QtWidgets.QFrame.NoFrame)
self.naming_options_frame.setObjectName("naming_options_frame")
self.formLayout_3 = QtWidgets.QFormLayout(self.naming_options_frame)
self.formLayout_3.setFieldGrowthPolicy(QtWidgets.QFormLayout.AllNonFixedFieldsGrow)
self.formLayout_3.setContentsMargins(9, 0, 9, -1)
self.formLayout_3.setVerticalSpacing(6)
self.formLayout_3.setObjectName("formLayout_3")
self.label_22 = QtWidgets.QLabel(self.naming_options_frame)
self.label_22.setObjectName("label_22")
self.formLayout_3.setWidget(2, QtWidgets.QFormLayout.SpanningRole, self.label_22)
self.credited_as_options_box = QtWidgets.QGroupBox(self.naming_options_frame)
self.credited_as_options_box.setObjectName("credited_as_options_box")
self.horizontalLayout_18 = QtWidgets.QHBoxLayout(self.credited_as_options_box)
self.horizontalLayout_18.setObjectName("horizontalLayout_18")
self.names_to_use_box = QtWidgets.QGroupBox(self.credited_as_options_box)
self.names_to_use_box.setAutoFillBackground(False)
self.names_to_use_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.names_to_use_box.setObjectName("names_to_use_box")
self.verticalLayout_26 = QtWidgets.QVBoxLayout(self.names_to_use_box)
self.verticalLayout_26.setObjectName("verticalLayout_26")
self.cea_recording_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_recording_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_recording_credited.setObjectName("cea_recording_credited")
self.verticalLayout_26.addWidget(self.cea_recording_credited)
self.cea_group_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_group_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_group_credited.setAutoFillBackground(False)
self.cea_group_credited.setStyleSheet("")
self.cea_group_credited.setObjectName("cea_group_credited")
self.verticalLayout_26.addWidget(self.cea_group_credited)
self.cea_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_credited.setObjectName("cea_credited")
self.verticalLayout_26.addWidget(self.cea_credited)
self.cea_release_relationship_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_release_relationship_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_release_relationship_credited.setObjectName("cea_release_relationship_credited")
self.verticalLayout_26.addWidget(self.cea_release_relationship_credited)
self.cea_recording_relationship_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_recording_relationship_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_recording_relationship_credited.setObjectName("cea_recording_relationship_credited")
self.verticalLayout_26.addWidget(self.cea_recording_relationship_credited)
self.cea_track_credited = QtWidgets.QCheckBox(self.names_to_use_box)
self.cea_track_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_track_credited.setObjectName("cea_track_credited")
self.verticalLayout_26.addWidget(self.cea_track_credited)
self.label_24 = QtWidgets.QLabel(self.names_to_use_box)
self.label_24.setLayoutDirection(QtCore.Qt.RightToLeft)
self.label_24.setObjectName("label_24")
self.verticalLayout_26.addWidget(self.label_24)
self.label_88 = QtWidgets.QLabel(self.names_to_use_box)
self.label_88.setObjectName("label_88")
self.verticalLayout_26.addWidget(self.label_88)
self.horizontalLayout_18.addWidget(self.names_to_use_box)
self.places_to_use_them_box = QtWidgets.QGroupBox(self.credited_as_options_box)
self.places_to_use_them_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.places_to_use_them_box.setObjectName("places_to_use_them_box")
self.verticalLayout_27 = QtWidgets.QVBoxLayout(self.places_to_use_them_box)
self.verticalLayout_27.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
self.verticalLayout_27.setContentsMargins(9, -1, -1, -1)
self.verticalLayout_27.setObjectName("verticalLayout_27")
self.cea_performer_credited = QtWidgets.QCheckBox(self.places_to_use_them_box)
self.cea_performer_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_performer_credited.setObjectName("cea_performer_credited")
self.verticalLayout_27.addWidget(self.cea_performer_credited)
self.cea_composer_credited = QtWidgets.QCheckBox(self.places_to_use_them_box)
self.cea_composer_credited.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_composer_credited.setObjectName("cea_composer_credited")
self.verticalLayout_27.addWidget(self.cea_composer_credited)
self.horizontalLayout_18.addWidget(self.places_to_use_them_box)
self.formLayout_3.setWidget(3, QtWidgets.QFormLayout.FieldRole, self.credited_as_options_box)
self.naming_sub_options_box = QtWidgets.QGroupBox(self.naming_options_frame)
self.naming_sub_options_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.naming_sub_options_box.setObjectName("naming_sub_options_box")
self.horizontalLayout_11 = QtWidgets.QHBoxLayout(self.naming_sub_options_box)
self.horizontalLayout_11.setObjectName("horizontalLayout_11")
self.cea_alias_overrides = QtWidgets.QRadioButton(self.naming_sub_options_box)
self.cea_alias_overrides.setObjectName("cea_alias_overrides")
self.horizontalLayout_11.addWidget(self.cea_alias_overrides)
self.cea_credited_overrides = QtWidgets.QRadioButton(self.naming_sub_options_box)
self.cea_credited_overrides.setObjectName("cea_credited_overrides")
self.horizontalLayout_11.addWidget(self.cea_credited_overrides)
self.cea_cyrillic = QtWidgets.QCheckBox(self.naming_sub_options_box)
self.cea_cyrillic.setObjectName("cea_cyrillic")
self.horizontalLayout_11.addWidget(self.cea_cyrillic)
self.formLayout_3.setWidget(4, QtWidgets.QFormLayout.SpanningRole, self.naming_sub_options_box)
self.MB_std_names_aliases_box_outer = QtWidgets.QGroupBox(self.naming_options_frame)
self.MB_std_names_aliases_box_outer.setStyleSheet("background-color: rgb(211, 248, 224);")
self.MB_std_names_aliases_box_outer.setObjectName("MB_std_names_aliases_box_outer")
self.verticalLayout_24 = QtWidgets.QVBoxLayout(self.MB_std_names_aliases_box_outer)
self.verticalLayout_24.setObjectName("verticalLayout_24")
self.MB_std_names_aliases_box_inner = QtWidgets.QGroupBox(self.MB_std_names_aliases_box_outer)
self.MB_std_names_aliases_box_inner.setStyleSheet("background-color: rgb(250, 250, 250);")
self.MB_std_names_aliases_box_inner.setTitle("")
self.MB_std_names_aliases_box_inner.setObjectName("MB_std_names_aliases_box_inner")
self.verticalLayout_40 = QtWidgets.QVBoxLayout(self.MB_std_names_aliases_box_inner)
self.verticalLayout_40.setObjectName("verticalLayout_40")
self.cea_no_aliases = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
self.cea_no_aliases.setObjectName("cea_no_aliases")
self.verticalLayout_40.addWidget(self.cea_no_aliases)
self.cea_aliases = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
self.cea_aliases.setObjectName("cea_aliases")
self.verticalLayout_40.addWidget(self.cea_aliases)
self.cea_aliases_composer = QtWidgets.QRadioButton(self.MB_std_names_aliases_box_inner)
self.cea_aliases_composer.setObjectName("cea_aliases_composer")
self.verticalLayout_40.addWidget(self.cea_aliases_composer)
self.verticalLayout_24.addWidget(self.MB_std_names_aliases_box_inner)
self.formLayout_3.setWidget(3, QtWidgets.QFormLayout.LabelRole, self.MB_std_names_aliases_box_outer)
self.verticalLayout_36.addWidget(self.naming_options_frame)
self.verticalLayout_13.addWidget(self.naming_options_frame_2)
self.recording_artists_options_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.recording_artists_options_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.recording_artists_options_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.recording_artists_options_frame.setObjectName("recording_artists_options_frame")
self.verticalLayout_37 = QtWidgets.QVBoxLayout(self.recording_artists_options_frame)
self.verticalLayout_37.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_37.setSpacing(0)
self.verticalLayout_37.setObjectName("verticalLayout_37")
self.recording_artist_options_label = QtWidgets.QLabel(self.recording_artists_options_frame)
self.recording_artist_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
self.recording_artist_options_label.setObjectName("recording_artist_options_label")
self.verticalLayout_37.addWidget(self.recording_artist_options_label)
self.recording_artists_options_box = QtWidgets.QGroupBox(self.recording_artists_options_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.recording_artists_options_box.setPalette(palette)
self.recording_artists_options_box.setAutoFillBackground(False)
self.recording_artists_options_box.setStyleSheet("background-color: rgb(211, 248, 224);")
self.recording_artists_options_box.setTitle("")
self.recording_artists_options_box.setObjectName("recording_artists_options_box")
self.horizontalLayout_24 = QtWidgets.QHBoxLayout(self.recording_artists_options_box)
self.horizontalLayout_24.setObjectName("horizontalLayout_24")
self.naming_convention_box = QtWidgets.QGroupBox(self.recording_artists_options_box)
self.naming_convention_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.naming_convention_box.setObjectName("naming_convention_box")
self.verticalLayout_31 = QtWidgets.QVBoxLayout(self.naming_convention_box)
self.verticalLayout_31.setObjectName("verticalLayout_31")
self.cea_ra_trackartist = QtWidgets.QRadioButton(self.naming_convention_box)
self.cea_ra_trackartist.setObjectName("cea_ra_trackartist")
self.verticalLayout_31.addWidget(self.cea_ra_trackartist)
self.cea_ra_performer = QtWidgets.QRadioButton(self.naming_convention_box)
self.cea_ra_performer.setObjectName("cea_ra_performer")
self.verticalLayout_31.addWidget(self.cea_ra_performer)
self.horizontalLayout_24.addWidget(self.naming_convention_box)
self.line_7 = QtWidgets.QFrame(self.recording_artists_options_box)
self.line_7.setFrameShape(QtWidgets.QFrame.VLine)
self.line_7.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_7.setObjectName("line_7")
self.horizontalLayout_24.addWidget(self.line_7)
self.cea_ra_use = QtWidgets.QCheckBox(self.recording_artists_options_box)
self.cea_ra_use.setObjectName("cea_ra_use")
self.horizontalLayout_24.addWidget(self.cea_ra_use)
self.ra_replace_merge_options_box = QtWidgets.QGroupBox(self.recording_artists_options_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.MinimumExpanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.ra_replace_merge_options_box.sizePolicy().hasHeightForWidth())
self.ra_replace_merge_options_box.setSizePolicy(sizePolicy)
self.ra_replace_merge_options_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.ra_replace_merge_options_box.setObjectName("ra_replace_merge_options_box")
self.verticalLayout_29 = QtWidgets.QVBoxLayout(self.ra_replace_merge_options_box)
self.verticalLayout_29.setObjectName("verticalLayout_29")
self.cea_ra_replace_ta = QtWidgets.QRadioButton(self.ra_replace_merge_options_box)
self.cea_ra_replace_ta.setObjectName("cea_ra_replace_ta")
self.verticalLayout_29.addWidget(self.cea_ra_replace_ta)
self.cea_ra_noblank_ta = QtWidgets.QCheckBox(self.ra_replace_merge_options_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.cea_ra_noblank_ta.sizePolicy().hasHeightForWidth())
self.cea_ra_noblank_ta.setSizePolicy(sizePolicy)
self.cea_ra_noblank_ta.setLayoutDirection(QtCore.Qt.LeftToRight)
self.cea_ra_noblank_ta.setObjectName("cea_ra_noblank_ta")
self.verticalLayout_29.addWidget(self.cea_ra_noblank_ta)
self.cea_ra_merge_ta = QtWidgets.QRadioButton(self.ra_replace_merge_options_box)
self.cea_ra_merge_ta.setObjectName("cea_ra_merge_ta")
self.verticalLayout_29.addWidget(self.cea_ra_merge_ta)
self.horizontalLayout_24.addWidget(self.ra_replace_merge_options_box)
self.verticalLayout_37.addWidget(self.recording_artists_options_box)
self.verticalLayout_13.addWidget(self.recording_artists_options_frame)
self.other_artist_options_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.other_artist_options_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.other_artist_options_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.other_artist_options_frame.setObjectName("other_artist_options_frame")
self.verticalLayout_38 = QtWidgets.QVBoxLayout(self.other_artist_options_frame)
self.verticalLayout_38.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_38.setSpacing(0)
self.verticalLayout_38.setObjectName("verticalLayout_38")
self.other_artist_options_label = QtWidgets.QLabel(self.other_artist_options_frame)
self.other_artist_options_label.setStyleSheet("background-color: rgb(176, 220, 192);")
self.other_artist_options_label.setObjectName("other_artist_options_label")
self.verticalLayout_38.addWidget(self.other_artist_options_label)
self.other_artist_options_box = QtWidgets.QGroupBox(self.other_artist_options_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(211, 248, 224))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.other_artist_options_box.setPalette(palette)
self.other_artist_options_box.setAutoFillBackground(False)
self.other_artist_options_box.setStyleSheet("background-color: rgb(211, 248, 224);")
self.other_artist_options_box.setTitle("")
self.other_artist_options_box.setObjectName("other_artist_options_box")
self.gridLayout = QtWidgets.QGridLayout(self.other_artist_options_box)
self.gridLayout.setVerticalSpacing(6)
self.gridLayout.setObjectName("gridLayout")
self.annotations_lh_box = QtWidgets.QGroupBox(self.other_artist_options_box)
self.annotations_lh_box.setStyleSheet("background-color: rgba(250, 250, 250, 250);")
self.annotations_lh_box.setObjectName("annotations_lh_box")
self.verticalLayout_15 = QtWidgets.QVBoxLayout(self.annotations_lh_box)
self.verticalLayout_15.setObjectName("verticalLayout_15")
self.chorusmaster_frame = QtWidgets.QFrame(self.annotations_lh_box)
self.chorusmaster_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.chorusmaster_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.chorusmaster_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.chorusmaster_frame.setObjectName("chorusmaster_frame")
self.horizontalLayout_8 = QtWidgets.QHBoxLayout(self.chorusmaster_frame)
self.horizontalLayout_8.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
self.horizontalLayout_8.setContentsMargins(-1, 1, -1, 9)
self.horizontalLayout_8.setSpacing(6)
self.horizontalLayout_8.setObjectName("horizontalLayout_8")
self.label_44 = QtWidgets.QLabel(self.chorusmaster_frame)
self.label_44.setObjectName("label_44")
self.horizontalLayout_8.addWidget(self.label_44)
self.cea_chorusmaster = QtWidgets.QLineEdit(self.chorusmaster_frame)
self.cea_chorusmaster.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_chorusmaster.setObjectName("cea_chorusmaster")
self.horizontalLayout_8.addWidget(self.cea_chorusmaster)
self.verticalLayout_15.addWidget(self.chorusmaster_frame)
self.concertmaster_frame = QtWidgets.QFrame(self.annotations_lh_box)
self.concertmaster_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.concertmaster_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.concertmaster_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.concertmaster_frame.setObjectName("concertmaster_frame")
self.horizontalLayout_6 = QtWidgets.QHBoxLayout(self.concertmaster_frame)
self.horizontalLayout_6.setContentsMargins(-1, 1, -1, -1)
self.horizontalLayout_6.setObjectName("horizontalLayout_6")
self.label_46 = QtWidgets.QLabel(self.concertmaster_frame)
self.label_46.setObjectName("label_46")
self.horizontalLayout_6.addWidget(self.label_46)
self.cea_concertmaster = QtWidgets.QLineEdit(self.concertmaster_frame)
self.cea_concertmaster.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_concertmaster.setObjectName("cea_concertmaster")
self.horizontalLayout_6.addWidget(self.cea_concertmaster)
self.verticalLayout_15.addWidget(self.concertmaster_frame)
self.lyricist_frame = QtWidgets.QFrame(self.annotations_lh_box)
self.lyricist_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.lyricist_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.lyricist_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.lyricist_frame.setObjectName("lyricist_frame")
self.horizontalLayout_23 = QtWidgets.QHBoxLayout(self.lyricist_frame)
self.horizontalLayout_23.setObjectName("horizontalLayout_23")
self.label_34 = QtWidgets.QLabel(self.lyricist_frame)
self.label_34.setObjectName("label_34")
self.horizontalLayout_23.addWidget(self.label_34)
self.cea_lyricist = QtWidgets.QLineEdit(self.lyricist_frame)
self.cea_lyricist.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_lyricist.setObjectName("cea_lyricist")
self.horizontalLayout_23.addWidget(self.cea_lyricist)
self.verticalLayout_15.addWidget(self.lyricist_frame)
self.librettist_frame = QtWidgets.QFrame(self.annotations_lh_box)
self.librettist_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.librettist_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.librettist_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.librettist_frame.setObjectName("librettist_frame")
self.horizontalLayout_19 = QtWidgets.QHBoxLayout(self.librettist_frame)
self.horizontalLayout_19.setObjectName("horizontalLayout_19")
self.label_26 = QtWidgets.QLabel(self.librettist_frame)
self.label_26.setObjectName("label_26")
self.horizontalLayout_19.addWidget(self.label_26)
self.cea_librettist = QtWidgets.QLineEdit(self.librettist_frame)
self.cea_librettist.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_librettist.setObjectName("cea_librettist")
self.horizontalLayout_19.addWidget(self.cea_librettist)
self.verticalLayout_15.addWidget(self.librettist_frame)
self.translator_frame = QtWidgets.QFrame(self.annotations_lh_box)
self.translator_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.translator_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.translator_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.translator_frame.setObjectName("translator_frame")
self.horizontalLayout_21 = QtWidgets.QHBoxLayout(self.translator_frame)
self.horizontalLayout_21.setObjectName("horizontalLayout_21")
self.label_30 = QtWidgets.QLabel(self.translator_frame)
self.label_30.setObjectName("label_30")
self.horizontalLayout_21.addWidget(self.label_30)
self.cea_translator = QtWidgets.QLineEdit(self.translator_frame)
self.cea_translator.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_translator.setObjectName("cea_translator")
self.horizontalLayout_21.addWidget(self.cea_translator)
self.verticalLayout_15.addWidget(self.translator_frame)
self.gridLayout.addWidget(self.annotations_lh_box, 0, 1, 1, 1)
self.other_artist_checkboxes_box = QtWidgets.QGroupBox(self.other_artist_options_box)
self.other_artist_checkboxes_box.setStyleSheet("background-color: rgba(250, 250, 250, 250);")
self.other_artist_checkboxes_box.setTitle("")
self.other_artist_checkboxes_box.setObjectName("other_artist_checkboxes_box")
self.verticalLayout_14 = QtWidgets.QVBoxLayout(self.other_artist_checkboxes_box)
self.verticalLayout_14.setSpacing(6)
self.verticalLayout_14.setObjectName("verticalLayout_14")
self.cea_arrangers = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
self.cea_arrangers.setObjectName("cea_arrangers")
self.verticalLayout_14.addWidget(self.cea_arrangers)
self.cea_composer_album = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
self.cea_composer_album.setObjectName("cea_composer_album")
self.verticalLayout_14.addWidget(self.cea_composer_album)
self.cea_no_lyricists = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
self.cea_no_lyricists.setObjectName("cea_no_lyricists")
self.verticalLayout_14.addWidget(self.cea_no_lyricists)
self.cea_inst_credit = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
self.cea_inst_credit.setObjectName("cea_inst_credit")
self.verticalLayout_14.addWidget(self.cea_inst_credit)
self.cea_no_solo = QtWidgets.QCheckBox(self.other_artist_checkboxes_box)
self.cea_no_solo.setObjectName("cea_no_solo")
self.verticalLayout_14.addWidget(self.cea_no_solo)
self.gridLayout.addWidget(self.other_artist_checkboxes_box, 0, 0, 1, 1)
self.annotations_rh_box = QtWidgets.QGroupBox(self.other_artist_options_box)
self.annotations_rh_box.setStyleSheet("background-color: rgb(250, 250, 250);")
self.annotations_rh_box.setObjectName("annotations_rh_box")
self.verticalLayout_21 = QtWidgets.QVBoxLayout(self.annotations_rh_box)
self.verticalLayout_21.setObjectName("verticalLayout_21")
self.writer_frame = QtWidgets.QFrame(self.annotations_rh_box)
self.writer_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.writer_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.writer_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.writer_frame.setObjectName("writer_frame")
self.horizontalLayout_30 = QtWidgets.QHBoxLayout(self.writer_frame)
self.horizontalLayout_30.setObjectName("horizontalLayout_30")
self.label_56 = QtWidgets.QLabel(self.writer_frame)
self.label_56.setObjectName("label_56")
self.horizontalLayout_30.addWidget(self.label_56)
self.cea_writer = QtWidgets.QLineEdit(self.writer_frame)
self.cea_writer.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_writer.setObjectName("cea_writer")
self.horizontalLayout_30.addWidget(self.cea_writer)
self.verticalLayout_21.addWidget(self.writer_frame)
self.arranger_frame = QtWidgets.QFrame(self.annotations_rh_box)
self.arranger_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.arranger_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.arranger_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.arranger_frame.setObjectName("arranger_frame")
self.horizontalLayout_29 = QtWidgets.QHBoxLayout(self.arranger_frame)
self.horizontalLayout_29.setObjectName("horizontalLayout_29")
self.label_54 = QtWidgets.QLabel(self.arranger_frame)
self.label_54.setObjectName("label_54")
self.horizontalLayout_29.addWidget(self.label_54)
self.cea_arranger = QtWidgets.QLineEdit(self.arranger_frame)
self.cea_arranger.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_arranger.setObjectName("cea_arranger")
self.horizontalLayout_29.addWidget(self.cea_arranger)
self.verticalLayout_21.addWidget(self.arranger_frame)
self.orchestrator_frame = QtWidgets.QFrame(self.annotations_rh_box)
self.orchestrator_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.orchestrator_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.orchestrator_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.orchestrator_frame.setObjectName("orchestrator_frame")
self.horizontalLayout_7 = QtWidgets.QHBoxLayout(self.orchestrator_frame)
self.horizontalLayout_7.setContentsMargins(-1, 1, -1, -1)
self.horizontalLayout_7.setObjectName("horizontalLayout_7")
self.label_45 = QtWidgets.QLabel(self.orchestrator_frame)
self.label_45.setObjectName("label_45")
self.horizontalLayout_7.addWidget(self.label_45)
self.cea_orchestrator = QtWidgets.QLineEdit(self.orchestrator_frame)
self.cea_orchestrator.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_orchestrator.setObjectName("cea_orchestrator")
self.horizontalLayout_7.addWidget(self.cea_orchestrator)
self.verticalLayout_21.addWidget(self.orchestrator_frame)
self.reconstructed_frame = QtWidgets.QFrame(self.annotations_rh_box)
self.reconstructed_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.reconstructed_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.reconstructed_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.reconstructed_frame.setObjectName("reconstructed_frame")
self.horizontalLayout_22 = QtWidgets.QHBoxLayout(self.reconstructed_frame)
self.horizontalLayout_22.setObjectName("horizontalLayout_22")
self.label_32 = QtWidgets.QLabel(self.reconstructed_frame)
self.label_32.setObjectName("label_32")
self.horizontalLayout_22.addWidget(self.label_32)
self.cea_reconstructed = QtWidgets.QLineEdit(self.reconstructed_frame)
self.cea_reconstructed.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_reconstructed.setObjectName("cea_reconstructed")
self.horizontalLayout_22.addWidget(self.cea_reconstructed)
self.verticalLayout_21.addWidget(self.reconstructed_frame)
self.revised_frame = QtWidgets.QFrame(self.annotations_rh_box)
self.revised_frame.setStyleSheet("background-color: rgb(211, 248, 224);")
self.revised_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.revised_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.revised_frame.setObjectName("revised_frame")
self.horizontalLayout_20 = QtWidgets.QHBoxLayout(self.revised_frame)
self.horizontalLayout_20.setObjectName("horizontalLayout_20")
self.label_28 = QtWidgets.QLabel(self.revised_frame)
self.label_28.setObjectName("label_28")
self.horizontalLayout_20.addWidget(self.label_28)
self.cea_revised = QtWidgets.QLineEdit(self.revised_frame)
self.cea_revised.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_revised.setObjectName("cea_revised")
self.horizontalLayout_20.addWidget(self.cea_revised)
self.verticalLayout_21.addWidget(self.revised_frame)
self.gridLayout.addWidget(self.annotations_rh_box, 0, 2, 1, 1)
self.verticalLayout_38.addWidget(self.other_artist_options_box)
self.verticalLayout_13.addWidget(self.other_artist_options_frame)
self.line_3 = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.line_3.setLineWidth(1)
self.line_3.setFrameShape(QtWidgets.QFrame.HLine)
self.line_3.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_3.setObjectName("line_3")
self.verticalLayout_13.addWidget(self.line_3)
self.lyrics_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.lyrics_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.lyrics_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.lyrics_frame.setObjectName("lyrics_frame")
self.verticalLayout_39 = QtWidgets.QVBoxLayout(self.lyrics_frame)
self.verticalLayout_39.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_39.setSpacing(0)
self.verticalLayout_39.setObjectName("verticalLayout_39")
self.lyrics_label = QtWidgets.QLabel(self.lyrics_frame)
self.lyrics_label.setStyleSheet("background-color: rgb(204, 168, 161);")
self.lyrics_label.setObjectName("lyrics_label")
self.verticalLayout_39.addWidget(self.lyrics_label)
self.lyrics_box = QtWidgets.QGroupBox(self.lyrics_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(230, 215, 211))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.lyrics_box.setPalette(palette)
self.lyrics_box.setAutoFillBackground(False)
self.lyrics_box.setStyleSheet("background-color: rgb(230, 215, 211);")
self.lyrics_box.setTitle("")
self.lyrics_box.setObjectName("lyrics_box")
self.horizontalLayout_25 = QtWidgets.QHBoxLayout(self.lyrics_box)
self.horizontalLayout_25.setObjectName("horizontalLayout_25")
self.cea_split_lyrics = QtWidgets.QCheckBox(self.lyrics_box)
self.cea_split_lyrics.setObjectName("cea_split_lyrics")
self.horizontalLayout_25.addWidget(self.cea_split_lyrics)
self.lyrics_and_notes_tags_frame = QtWidgets.QGroupBox(self.lyrics_box)
self.lyrics_and_notes_tags_frame.setTitle("")
self.lyrics_and_notes_tags_frame.setObjectName("lyrics_and_notes_tags_frame")
self.verticalLayout_30 = QtWidgets.QVBoxLayout(self.lyrics_and_notes_tags_frame)
self.verticalLayout_30.setObjectName("verticalLayout_30")
self.lyrics_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
self.lyrics_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
self.lyrics_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.lyrics_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.lyrics_tags_frame.setObjectName("lyrics_tags_frame")
self.horizontalLayout_26 = QtWidgets.QHBoxLayout(self.lyrics_tags_frame)
self.horizontalLayout_26.setObjectName("horizontalLayout_26")
self.label_50 = QtWidgets.QLabel(self.lyrics_tags_frame)
self.label_50.setObjectName("label_50")
self.horizontalLayout_26.addWidget(self.label_50)
self.cea_lyrics_tag = QtWidgets.QLineEdit(self.lyrics_tags_frame)
self.cea_lyrics_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_lyrics_tag.setObjectName("cea_lyrics_tag")
self.horizontalLayout_26.addWidget(self.cea_lyrics_tag)
self.verticalLayout_30.addWidget(self.lyrics_tags_frame)
self.album_notes_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
self.album_notes_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
self.album_notes_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.album_notes_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.album_notes_tags_frame.setObjectName("album_notes_tags_frame")
self.horizontalLayout_27 = QtWidgets.QHBoxLayout(self.album_notes_tags_frame)
self.horizontalLayout_27.setObjectName("horizontalLayout_27")
self.label_51 = QtWidgets.QLabel(self.album_notes_tags_frame)
self.label_51.setObjectName("label_51")
self.horizontalLayout_27.addWidget(self.label_51)
self.cea_album_lyrics = QtWidgets.QLineEdit(self.album_notes_tags_frame)
self.cea_album_lyrics.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_album_lyrics.setObjectName("cea_album_lyrics")
self.horizontalLayout_27.addWidget(self.cea_album_lyrics)
self.verticalLayout_30.addWidget(self.album_notes_tags_frame)
self.track_notes_tags_frame = QtWidgets.QFrame(self.lyrics_and_notes_tags_frame)
self.track_notes_tags_frame.setStyleSheet("background-color: rgb(204, 168, 161);")
self.track_notes_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.track_notes_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.track_notes_tags_frame.setObjectName("track_notes_tags_frame")
self.horizontalLayout_28 = QtWidgets.QHBoxLayout(self.track_notes_tags_frame)
self.horizontalLayout_28.setObjectName("horizontalLayout_28")
self.label_52 = QtWidgets.QLabel(self.track_notes_tags_frame)
self.label_52.setObjectName("label_52")
self.horizontalLayout_28.addWidget(self.label_52)
self.cea_track_lyrics = QtWidgets.QLineEdit(self.track_notes_tags_frame)
self.cea_track_lyrics.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_track_lyrics.setObjectName("cea_track_lyrics")
self.horizontalLayout_28.addWidget(self.cea_track_lyrics)
self.verticalLayout_30.addWidget(self.track_notes_tags_frame)
self.horizontalLayout_25.addWidget(self.lyrics_and_notes_tags_frame)
self.verticalLayout_39.addWidget(self.lyrics_box)
self.verticalLayout_13.addWidget(self.lyrics_frame)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_13.addItem(spacerItem)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout_10.addWidget(self.scrollArea)
self.tabWidget.addTab(self.Artists, "")
self.Works = QtWidgets.QWidget()
self.Works.setObjectName("Works")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.Works)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.scrollArea_3 = QtWidgets.QScrollArea(self.Works)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea_3.sizePolicy().hasHeightForWidth())
self.scrollArea_3.setSizePolicy(sizePolicy)
self.scrollArea_3.setWidgetResizable(True)
self.scrollArea_3.setObjectName("scrollArea_3")
self.scrollAreaWidgetContents_3 = QtWidgets.QWidget()
self.scrollAreaWidgetContents_3.setGeometry(QtCore.QRect(0, 0, 1084, 1086))
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollAreaWidgetContents_3.sizePolicy().hasHeightForWidth())
self.scrollAreaWidgetContents_3.setSizePolicy(sizePolicy)
self.scrollAreaWidgetContents_3.setObjectName("scrollAreaWidgetContents_3")
self.verticalLayout_25 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_3)
self.verticalLayout_25.setObjectName("verticalLayout_25")
self.works_run_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.works_run_frame.sizePolicy().hasHeightForWidth())
self.works_run_frame.setSizePolicy(sizePolicy)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 255, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.works_run_frame.setPalette(palette)
self.works_run_frame.setAutoFillBackground(False)
self.works_run_frame.setStyleSheet("background-color: rgb(255, 255, 222);")
self.works_run_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.works_run_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.works_run_frame.setObjectName("works_run_frame")
self.horizontalLayout_3 = QtWidgets.QHBoxLayout(self.works_run_frame)
self.horizontalLayout_3.setObjectName("horizontalLayout_3")
self.use_cwp = QtWidgets.QCheckBox(self.works_run_frame)
self.use_cwp.setObjectName("use_cwp")
self.horizontalLayout_3.addWidget(self.use_cwp)
self.cwp_collections = QtWidgets.QCheckBox(self.works_run_frame)
self.cwp_collections.setObjectName("cwp_collections")
self.horizontalLayout_3.addWidget(self.cwp_collections)
self.use_cache = QtWidgets.QCheckBox(self.works_run_frame)
self.use_cache.setObjectName("use_cache")
self.horizontalLayout_3.addWidget(self.use_cache)
self.verticalLayout_25.addWidget(self.works_run_frame)
self.work_style_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
self.work_style_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.work_style_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.work_style_frame.setObjectName("work_style_frame")
self.verticalLayout_44 = QtWidgets.QVBoxLayout(self.work_style_frame)
self.verticalLayout_44.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_44.setSpacing(0)
self.verticalLayout_44.setObjectName("verticalLayout_44")
self.work_style_label = QtWidgets.QLabel(self.work_style_frame)
self.work_style_label.setStyleSheet("background-color: rgb(205, 230, 255);")
self.work_style_label.setObjectName("work_style_label")
self.verticalLayout_44.addWidget(self.work_style_label)
self.work_style_box = QtWidgets.QGroupBox(self.work_style_frame)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.work_style_box.sizePolicy().hasHeightForWidth())
self.work_style_box.setSizePolicy(sizePolicy)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(225, 240, 255))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.work_style_box.setPalette(palette)
self.work_style_box.setAutoFillBackground(False)
self.work_style_box.setStyleSheet("background-color: rgb(225, 240, 255);")
self.work_style_box.setTitle("")
self.work_style_box.setObjectName("work_style_box")
self.formLayout_2 = QtWidgets.QFormLayout(self.work_style_box)
self.formLayout_2.setObjectName("formLayout_2")
self.works_source_box = QtWidgets.QGroupBox(self.work_style_box)
self.works_source_box.setObjectName("works_source_box")
self.verticalLayout_11 = QtWidgets.QVBoxLayout(self.works_source_box)
self.verticalLayout_11.setObjectName("verticalLayout_11")
self.cwp_titles = QtWidgets.QRadioButton(self.works_source_box)
self.cwp_titles.setObjectName("cwp_titles")
self.verticalLayout_11.addWidget(self.cwp_titles)
self.cwp_works = QtWidgets.QRadioButton(self.works_source_box)
self.cwp_works.setObjectName("cwp_works")
self.verticalLayout_11.addWidget(self.cwp_works)
self.cwp_extended = QtWidgets.QRadioButton(self.works_source_box)
self.cwp_extended.setObjectName("cwp_extended")
self.verticalLayout_11.addWidget(self.cwp_extended)
self.formLayout_2.setWidget(0, QtWidgets.QFormLayout.LabelRole, self.works_source_box)
self.source_of_canonical_box = QtWidgets.QGroupBox(self.work_style_box)
self.source_of_canonical_box.setEnabled(True)
self.source_of_canonical_box.setObjectName("source_of_canonical_box")
self.verticalLayout_6 = QtWidgets.QVBoxLayout(self.source_of_canonical_box)
self.verticalLayout_6.setObjectName("verticalLayout_6")
self.cwp_hierarchical_works = QtWidgets.QRadioButton(self.source_of_canonical_box)
self.cwp_hierarchical_works.setObjectName("cwp_hierarchical_works")
self.verticalLayout_6.addWidget(self.cwp_hierarchical_works)
self.cwp_level0_works = QtWidgets.QRadioButton(self.source_of_canonical_box)
self.cwp_level0_works.setObjectName("cwp_level0_works")
self.verticalLayout_6.addWidget(self.cwp_level0_works)
self.formLayout_2.setWidget(0, QtWidgets.QFormLayout.FieldRole, self.source_of_canonical_box)
self.cwp_derive_works_from_title = QtWidgets.QCheckBox(self.work_style_box)
self.cwp_derive_works_from_title.setObjectName("cwp_derive_works_from_title")
self.formLayout_2.setWidget(1, QtWidgets.QFormLayout.SpanningRole, self.cwp_derive_works_from_title)
self.verticalLayout_44.addWidget(self.work_style_box)
self.verticalLayout_25.addWidget(self.work_style_frame)
self.work_aliases_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
self.work_aliases_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.work_aliases_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.work_aliases_frame.setObjectName("work_aliases_frame")
self.verticalLayout_45 = QtWidgets.QVBoxLayout(self.work_aliases_frame)
self.verticalLayout_45.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_45.setSpacing(0)
self.verticalLayout_45.setObjectName("verticalLayout_45")
self.work_aliases_label = QtWidgets.QLabel(self.work_aliases_frame)
self.work_aliases_label.setStyleSheet("background-color: rgb(255, 186, 189);")
self.work_aliases_label.setObjectName("work_aliases_label")
self.verticalLayout_45.addWidget(self.work_aliases_label)
self.work_aliases_box = QtWidgets.QGroupBox(self.work_aliases_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 220, 222))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.work_aliases_box.setPalette(palette)
self.work_aliases_box.setAutoFillBackground(False)
self.work_aliases_box.setStyleSheet("background-color: rgb(255, 220, 222);")
self.work_aliases_box.setTitle("")
self.work_aliases_box.setObjectName("work_aliases_box")
self.horizontalLayout_16 = QtWidgets.QHBoxLayout(self.work_aliases_box)
self.horizontalLayout_16.setObjectName("horizontalLayout_16")
self.replace_MBworknames_box = QtWidgets.QGroupBox(self.work_aliases_box)
self.replace_MBworknames_box.setObjectName("replace_MBworknames_box")
self.verticalLayout_22 = QtWidgets.QVBoxLayout(self.replace_MBworknames_box)
self.verticalLayout_22.setObjectName("verticalLayout_22")
self.cwp_aliases = QtWidgets.QRadioButton(self.replace_MBworknames_box)
self.cwp_aliases.setObjectName("cwp_aliases")
self.verticalLayout_22.addWidget(self.cwp_aliases)
self.cwp_no_aliases = QtWidgets.QRadioButton(self.replace_MBworknames_box)
self.cwp_no_aliases.setObjectName("cwp_no_aliases")
self.verticalLayout_22.addWidget(self.cwp_no_aliases)
self.horizontalLayout_16.addWidget(self.replace_MBworknames_box)
self.what_to_replace_outer_box = QtWidgets.QGroupBox(self.work_aliases_box)
self.what_to_replace_outer_box.setStyleSheet("")
self.what_to_replace_outer_box.setObjectName("what_to_replace_outer_box")
self.horizontalLayout_17 = QtWidgets.QHBoxLayout(self.what_to_replace_outer_box)
self.horizontalLayout_17.setObjectName("horizontalLayout_17")
self.what_to_replace_radios_box = QtWidgets.QGroupBox(self.what_to_replace_outer_box)
self.what_to_replace_radios_box.setTitle("")
self.what_to_replace_radios_box.setObjectName("what_to_replace_radios_box")
self.verticalLayout_23 = QtWidgets.QVBoxLayout(self.what_to_replace_radios_box)
self.verticalLayout_23.setObjectName("verticalLayout_23")
self.cwp_aliases_all = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
self.cwp_aliases_all.setObjectName("cwp_aliases_all")
self.verticalLayout_23.addWidget(self.cwp_aliases_all)
self.cwp_aliases_greek = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
self.cwp_aliases_greek.setObjectName("cwp_aliases_greek")
self.verticalLayout_23.addWidget(self.cwp_aliases_greek)
self.cwp_aliases_tagged = QtWidgets.QRadioButton(self.what_to_replace_radios_box)
self.cwp_aliases_tagged.setObjectName("cwp_aliases_tagged")
self.verticalLayout_23.addWidget(self.cwp_aliases_tagged)
self.horizontalLayout_17.addWidget(self.what_to_replace_radios_box)
self.works_alias_tags_box = QtWidgets.QGroupBox(self.what_to_replace_outer_box)
self.works_alias_tags_box.setObjectName("works_alias_tags_box")
self.formLayout = QtWidgets.QFormLayout(self.works_alias_tags_box)
self.formLayout.setObjectName("formLayout")
self.cwp_aliases_tags_all = QtWidgets.QRadioButton(self.works_alias_tags_box)
self.cwp_aliases_tags_all.setObjectName("cwp_aliases_tags_all")
self.formLayout.setWidget(1, QtWidgets.QFormLayout.LabelRole, self.cwp_aliases_tags_all)
self.cwp_aliases_tags_user = QtWidgets.QRadioButton(self.works_alias_tags_box)
self.cwp_aliases_tags_user.setObjectName("cwp_aliases_tags_user")
self.formLayout.setWidget(1, QtWidgets.QFormLayout.FieldRole, self.cwp_aliases_tags_user)
self.cwp_aliases_tag_text = QtWidgets.QLineEdit(self.works_alias_tags_box)
self.cwp_aliases_tag_text.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_aliases_tag_text.setObjectName("cwp_aliases_tag_text")
self.formLayout.setWidget(0, QtWidgets.QFormLayout.SpanningRole, self.cwp_aliases_tag_text)
self.horizontalLayout_17.addWidget(self.works_alias_tags_box)
self.horizontalLayout_16.addWidget(self.what_to_replace_outer_box)
self.verticalLayout_45.addWidget(self.work_aliases_box)
self.verticalLayout_25.addWidget(self.work_aliases_frame)
self.works_parts_tags_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
self.works_parts_tags_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.works_parts_tags_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.works_parts_tags_frame.setObjectName("works_parts_tags_frame")
self.verticalLayout_46 = QtWidgets.QVBoxLayout(self.works_parts_tags_frame)
self.verticalLayout_46.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_46.setSpacing(0)
self.verticalLayout_46.setObjectName("verticalLayout_46")
self.work_parts_tags_label = QtWidgets.QLabel(self.works_parts_tags_frame)
self.work_parts_tags_label.setStyleSheet("background-color: rgb(255, 194, 158);")
self.work_parts_tags_label.setObjectName("work_parts_tags_label")
self.verticalLayout_46.addWidget(self.work_parts_tags_label)
self.works_parts_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_frame)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.MinimumExpanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.works_parts_tags_box.sizePolicy().hasHeightForWidth())
self.works_parts_tags_box.setSizePolicy(sizePolicy)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 221, 201))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.works_parts_tags_box.setPalette(palette)
self.works_parts_tags_box.setAutoFillBackground(False)
self.works_parts_tags_box.setStyleSheet("background-color: rgb(255, 221, 201);")
self.works_parts_tags_box.setTitle("")
self.works_parts_tags_box.setObjectName("works_parts_tags_box")
self.verticalLayout_9 = QtWidgets.QVBoxLayout(self.works_parts_tags_box)
self.verticalLayout_9.setObjectName("verticalLayout_9")
self.works_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.works_tags_box.setPalette(palette)
self.works_tags_box.setAutoFillBackground(False)
self.works_tags_box.setStyleSheet("background-color: rgb(255, 209, 182);")
self.works_tags_box.setObjectName("works_tags_box")
self.verticalLayout_8 = QtWidgets.QVBoxLayout(self.works_tags_box)
self.verticalLayout_8.setObjectName("verticalLayout_8")
self.label_40 = QtWidgets.QLabel(self.works_tags_box)
self.label_40.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.label_40.setObjectName("label_40")
self.verticalLayout_8.addWidget(self.label_40)
self._8 = QtWidgets.QHBoxLayout()
self._8.setContentsMargins(0, 0, 0, 0)
self._8.setSpacing(6)
self._8.setObjectName("_8")
self.label_11 = QtWidgets.QLabel(self.works_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_11.sizePolicy().hasHeightForWidth())
self.label_11.setSizePolicy(sizePolicy)
self.label_11.setObjectName("label_11")
self._8.addWidget(self.label_11)
self.cwp_work_tag_multi = QtWidgets.QLineEdit(self.works_tags_box)
self.cwp_work_tag_multi.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_work_tag_multi.setObjectName("cwp_work_tag_multi")
self._8.addWidget(self.cwp_work_tag_multi)
self.cwp_multi_work_sep = QtWidgets.QComboBox(self.works_tags_box)
self.cwp_multi_work_sep.setEditable(True)
self.cwp_multi_work_sep.setObjectName("cwp_multi_work_sep")
self.cwp_multi_work_sep.addItem("")
self.cwp_multi_work_sep.setItemText(0, "")
self.cwp_multi_work_sep.addItem("")
self.cwp_multi_work_sep.addItem("")
self.cwp_multi_work_sep.addItem("")
self.cwp_multi_work_sep.addItem("")
self.cwp_multi_work_sep.addItem("")
self._8.addWidget(self.cwp_multi_work_sep)
self.verticalLayout_8.addLayout(self._8)
self.label = QtWidgets.QLabel(self.works_tags_box)
self.label.setObjectName("label")
self.verticalLayout_8.addWidget(self.label)
self._12 = QtWidgets.QHBoxLayout()
self._12.setContentsMargins(0, 0, 0, 0)
self._12.setSpacing(6)
self._12.setObjectName("_12")
self.label_15 = QtWidgets.QLabel(self.works_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_15.sizePolicy().hasHeightForWidth())
self.label_15.setSizePolicy(sizePolicy)
self.label_15.setObjectName("label_15")
self._12.addWidget(self.label_15)
self.cwp_work_tag_single = QtWidgets.QLineEdit(self.works_tags_box)
self.cwp_work_tag_single.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_work_tag_single.setObjectName("cwp_work_tag_single")
self._12.addWidget(self.cwp_work_tag_single)
self.cwp_single_work_sep = QtWidgets.QComboBox(self.works_tags_box)
self.cwp_single_work_sep.setEditable(True)
self.cwp_single_work_sep.setObjectName("cwp_single_work_sep")
self.cwp_single_work_sep.addItem("")
self.cwp_single_work_sep.setItemText(0, "")
self.cwp_single_work_sep.addItem("")
self.cwp_single_work_sep.addItem("")
self.cwp_single_work_sep.addItem("")
self.cwp_single_work_sep.addItem("")
self.cwp_single_work_sep.addItem("")
self._12.addWidget(self.cwp_single_work_sep)
self.verticalLayout_8.addLayout(self._12)
self.label_2 = QtWidgets.QLabel(self.works_tags_box)
self.label_2.setObjectName("label_2")
self.verticalLayout_8.addWidget(self.label_2)
self._9 = QtWidgets.QHBoxLayout()
self._9.setContentsMargins(0, 0, 0, 0)
self._9.setSpacing(6)
self._9.setObjectName("_9")
self.label_12 = QtWidgets.QLabel(self.works_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_12.sizePolicy().hasHeightForWidth())
self.label_12.setSizePolicy(sizePolicy)
self.label_12.setObjectName("label_12")
self._9.addWidget(self.label_12)
self.cwp_top_tag = QtWidgets.QLineEdit(self.works_tags_box)
self.cwp_top_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_top_tag.setObjectName("cwp_top_tag")
self._9.addWidget(self.cwp_top_tag)
self.label_10 = QtWidgets.QLabel(self.works_tags_box)
self.label_10.setObjectName("label_10")
self._9.addWidget(self.label_10)
self.verticalLayout_8.addLayout(self._9)
self.verticalLayout_9.addWidget(self.works_tags_box)
self.parts_tags_box = QtWidgets.QGroupBox(self.works_parts_tags_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 209, 182))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.parts_tags_box.setPalette(palette)
self.parts_tags_box.setAutoFillBackground(False)
self.parts_tags_box.setStyleSheet("background-color: rgb(255, 209, 182);")
self.parts_tags_box.setObjectName("parts_tags_box")
self.verticalLayout_7 = QtWidgets.QVBoxLayout(self.parts_tags_box)
self.verticalLayout_7.setObjectName("verticalLayout_7")
self._10 = QtWidgets.QHBoxLayout()
self._10.setContentsMargins(0, 0, 0, 0)
self._10.setSpacing(6)
self._10.setObjectName("_10")
self.label_13 = QtWidgets.QLabel(self.parts_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_13.sizePolicy().hasHeightForWidth())
self.label_13.setSizePolicy(sizePolicy)
self.label_13.setObjectName("label_13")
self._10.addWidget(self.label_13)
self.cwp_movt_no_tag = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_no_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_no_tag.setObjectName("cwp_movt_no_tag")
self._10.addWidget(self.cwp_movt_no_tag)
self.cwp_movt_no_sep = QtWidgets.QComboBox(self.parts_tags_box)
self.cwp_movt_no_sep.setEditable(True)
self.cwp_movt_no_sep.setObjectName("cwp_movt_no_sep")
self.cwp_movt_no_sep.addItem("")
self.cwp_movt_no_sep.setItemText(0, "")
self.cwp_movt_no_sep.addItem("")
self.cwp_movt_no_sep.addItem("")
self.cwp_movt_no_sep.addItem("")
self.cwp_movt_no_sep.addItem("")
self.cwp_movt_no_sep.addItem("")
self._10.addWidget(self.cwp_movt_no_sep)
self.verticalLayout_7.addLayout(self._10)
self._24 = QtWidgets.QHBoxLayout()
self._24.setContentsMargins(0, 0, 0, 0)
self._24.setSpacing(6)
self._24.setObjectName("_24")
self.label_43 = QtWidgets.QLabel(self.parts_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_43.sizePolicy().hasHeightForWidth())
self.label_43.setSizePolicy(sizePolicy)
self.label_43.setObjectName("label_43")
self._24.addWidget(self.label_43)
self.cwp_movt_tot_tag = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_tot_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_tot_tag.setObjectName("cwp_movt_tot_tag")
self._24.addWidget(self.cwp_movt_tot_tag)
self.label_79 = QtWidgets.QLabel(self.parts_tags_box)
self.label_79.setObjectName("label_79")
self._24.addWidget(self.label_79)
self.verticalLayout_7.addLayout(self._24)
self.frame = QtWidgets.QFrame(self.parts_tags_box)
self.frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.frame.setObjectName("frame")
self.horizontalLayout_5 = QtWidgets.QHBoxLayout(self.frame)
self.horizontalLayout_5.setContentsMargins(0, -1, -1, -1)
self.horizontalLayout_5.setObjectName("horizontalLayout_5")
self.label_49 = QtWidgets.QLabel(self.frame)
self.label_49.setObjectName("label_49")
self.horizontalLayout_5.addWidget(self.label_49)
self.label_47 = QtWidgets.QLabel(self.frame)
self.label_47.setObjectName("label_47")
self.horizontalLayout_5.addWidget(self.label_47)
self.label_48 = QtWidgets.QLabel(self.frame)
self.label_48.setObjectName("label_48")
self.horizontalLayout_5.addWidget(self.label_48)
self.verticalLayout_7.addWidget(self.frame)
self._11 = QtWidgets.QHBoxLayout()
self._11.setContentsMargins(0, 0, 0, 0)
self._11.setSpacing(6)
self._11.setObjectName("_11")
self.label_14 = QtWidgets.QLabel(self.parts_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_14.sizePolicy().hasHeightForWidth())
self.label_14.setSizePolicy(sizePolicy)
self.label_14.setObjectName("label_14")
self._11.addWidget(self.label_14)
self.cwp_movt_tag_exc = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_tag_exc.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_tag_exc.setObjectName("cwp_movt_tag_exc")
self._11.addWidget(self.cwp_movt_tag_exc)
self.cwp_movt_tag_exc1 = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_tag_exc1.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_tag_exc1.setObjectName("cwp_movt_tag_exc1")
self._11.addWidget(self.cwp_movt_tag_exc1)
self.label_39 = QtWidgets.QLabel(self.parts_tags_box)
self.label_39.setObjectName("label_39")
self._11.addWidget(self.label_39)
self.verticalLayout_7.addLayout(self._11)
self._6 = QtWidgets.QHBoxLayout()
self._6.setContentsMargins(0, 0, 0, 0)
self._6.setSpacing(6)
self._6.setObjectName("_6")
self.label_9 = QtWidgets.QLabel(self.parts_tags_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_9.sizePolicy().hasHeightForWidth())
self.label_9.setSizePolicy(sizePolicy)
self.label_9.setObjectName("label_9")
self._6.addWidget(self.label_9)
self.cwp_movt_tag_inc = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_tag_inc.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_tag_inc.setObjectName("cwp_movt_tag_inc")
self._6.addWidget(self.cwp_movt_tag_inc)
self.cwp_movt_tag_inc1 = QtWidgets.QLineEdit(self.parts_tags_box)
self.cwp_movt_tag_inc1.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_movt_tag_inc1.setObjectName("cwp_movt_tag_inc1")
self._6.addWidget(self.cwp_movt_tag_inc1)
self.label_37 = QtWidgets.QLabel(self.parts_tags_box)
self.label_37.setObjectName("label_37")
self._6.addWidget(self.label_37)
self.verticalLayout_7.addLayout(self._6)
self.verticalLayout_9.addWidget(self.parts_tags_box)
self.verticalLayout_46.addWidget(self.works_parts_tags_box)
self.verticalLayout_25.addWidget(self.works_parts_tags_frame)
self.partial_arrangements_medleys_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
self.partial_arrangements_medleys_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.partial_arrangements_medleys_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.partial_arrangements_medleys_frame.setObjectName("partial_arrangements_medleys_frame")
self.verticalLayout_47 = QtWidgets.QVBoxLayout(self.partial_arrangements_medleys_frame)
self.verticalLayout_47.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_47.setSpacing(0)
self.verticalLayout_47.setObjectName("verticalLayout_47")
self.partial_arrangements_medleys_label = QtWidgets.QLabel(self.partial_arrangements_medleys_frame)
self.partial_arrangements_medleys_label.setStyleSheet("background-color: rgb(195, 168, 179);")
self.partial_arrangements_medleys_label.setObjectName("partial_arrangements_medleys_label")
self.verticalLayout_47.addWidget(self.partial_arrangements_medleys_label)
self.partial_arrangements_medleys_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(221, 209, 221))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.partial_arrangements_medleys_box.setPalette(palette)
self.partial_arrangements_medleys_box.setAutoFillBackground(False)
self.partial_arrangements_medleys_box.setStyleSheet("background-color: rgb(221, 209, 221);")
self.partial_arrangements_medleys_box.setTitle("")
self.partial_arrangements_medleys_box.setObjectName("partial_arrangements_medleys_box")
self.verticalLayout_19 = QtWidgets.QVBoxLayout(self.partial_arrangements_medleys_box)
self.verticalLayout_19.setObjectName("verticalLayout_19")
self.label_20 = QtWidgets.QLabel(self.partial_arrangements_medleys_box)
self.label_20.setStyleSheet("font: 75 8pt \"MS Shell Dlg 2\";\n"
"text-decoration: underline;")
self.label_20.setObjectName("label_20")
self.verticalLayout_19.addWidget(self.label_20)
self.partial_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
self.partial_box.setObjectName("partial_box")
self.horizontalLayout_13 = QtWidgets.QHBoxLayout(self.partial_box)
self.horizontalLayout_13.setObjectName("horizontalLayout_13")
self.cwp_partial = QtWidgets.QCheckBox(self.partial_box)
self.cwp_partial.setObjectName("cwp_partial")
self.horizontalLayout_13.addWidget(self.cwp_partial)
self.cwp_partial_text = QtWidgets.QLineEdit(self.partial_box)
self.cwp_partial_text.setEnabled(True)
self.cwp_partial_text.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_partial_text.setObjectName("cwp_partial_text")
self.horizontalLayout_13.addWidget(self.cwp_partial_text)
self.verticalLayout_19.addWidget(self.partial_box)
self.arrangements_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
self.arrangements_box.setObjectName("arrangements_box")
self.horizontalLayout_15 = QtWidgets.QHBoxLayout(self.arrangements_box)
self.horizontalLayout_15.setObjectName("horizontalLayout_15")
self.cwp_arrangements = QtWidgets.QCheckBox(self.arrangements_box)
self.cwp_arrangements.setObjectName("cwp_arrangements")
self.horizontalLayout_15.addWidget(self.cwp_arrangements)
self.cwp_arrangements_text = QtWidgets.QLineEdit(self.arrangements_box)
self.cwp_arrangements_text.setEnabled(True)
self.cwp_arrangements_text.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_arrangements_text.setDragEnabled(False)
self.cwp_arrangements_text.setObjectName("cwp_arrangements_text")
self.horizontalLayout_15.addWidget(self.cwp_arrangements_text)
self.verticalLayout_19.addWidget(self.arrangements_box)
self.medleys_box = QtWidgets.QGroupBox(self.partial_arrangements_medleys_box)
self.medleys_box.setObjectName("medleys_box")
self.horizontalLayout_12 = QtWidgets.QHBoxLayout(self.medleys_box)
self.horizontalLayout_12.setObjectName("horizontalLayout_12")
self.cwp_medley = QtWidgets.QCheckBox(self.medleys_box)
self.cwp_medley.setObjectName("cwp_medley")
self.horizontalLayout_12.addWidget(self.cwp_medley)
self.cwp_medley_text = QtWidgets.QLineEdit(self.medleys_box)
self.cwp_medley_text.setEnabled(True)
self.cwp_medley_text.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_medley_text.setObjectName("cwp_medley_text")
self.horizontalLayout_12.addWidget(self.cwp_medley_text)
self.verticalLayout_19.addWidget(self.medleys_box)
self.verticalLayout_47.addWidget(self.partial_arrangements_medleys_box)
self.verticalLayout_25.addWidget(self.partial_arrangements_medleys_frame)
self.songkong_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_3)
self.songkong_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.songkong_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.songkong_frame.setObjectName("songkong_frame")
self.verticalLayout_48 = QtWidgets.QVBoxLayout(self.songkong_frame)
self.verticalLayout_48.setContentsMargins(0, 0, -1, 0)
self.verticalLayout_48.setSpacing(0)
self.verticalLayout_48.setObjectName("verticalLayout_48")
self.songkong_label = QtWidgets.QLabel(self.songkong_frame)
self.songkong_label.setStyleSheet("background-color: rgb(182, 182, 62);")
self.songkong_label.setObjectName("songkong_label")
self.verticalLayout_48.addWidget(self.songkong_label)
self.songkong_box = QtWidgets.QGroupBox(self.songkong_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(227, 227, 143))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.songkong_box.setPalette(palette)
self.songkong_box.setAutoFillBackground(False)
self.songkong_box.setStyleSheet("background-color: rgb(227, 227, 143);")
self.songkong_box.setTitle("")
self.songkong_box.setObjectName("songkong_box")
self.horizontalLayout_14 = QtWidgets.QHBoxLayout(self.songkong_box)
self.horizontalLayout_14.setObjectName("horizontalLayout_14")
self.cwp_use_sk = QtWidgets.QCheckBox(self.songkong_box)
self.cwp_use_sk.setObjectName("cwp_use_sk")
self.horizontalLayout_14.addWidget(self.cwp_use_sk)
self.cwp_write_sk = QtWidgets.QCheckBox(self.songkong_box)
self.cwp_write_sk.setObjectName("cwp_write_sk")
self.horizontalLayout_14.addWidget(self.cwp_write_sk)
self.verticalLayout_48.addWidget(self.songkong_box)
self.verticalLayout_25.addWidget(self.songkong_frame)
self.label_82 = QtWidgets.QLabel(self.scrollAreaWidgetContents_3)
self.label_82.setObjectName("label_82")
self.verticalLayout_25.addWidget(self.label_82)
self.scrollArea_3.setWidget(self.scrollAreaWidgetContents_3)
self.verticalLayout_4.addWidget(self.scrollArea_3)
self.tabWidget.addTab(self.Works, "")
self.Genres = QtWidgets.QWidget()
self.Genres.setObjectName("Genres")
self.gridLayout_2 = QtWidgets.QGridLayout(self.Genres)
self.gridLayout_2.setObjectName("gridLayout_2")
self.scrollArea_6 = QtWidgets.QScrollArea(self.Genres)
self.scrollArea_6.setWidgetResizable(True)
self.scrollArea_6.setObjectName("scrollArea_6")
self.scrollAreaWidgetContents_5 = QtWidgets.QWidget()
self.scrollAreaWidgetContents_5.setGeometry(QtCore.QRect(0, -26, 1084, 1310))
self.scrollAreaWidgetContents_5.setObjectName("scrollAreaWidgetContents_5")
self.gridLayout_13 = QtWidgets.QGridLayout(self.scrollAreaWidgetContents_5)
self.gridLayout_13.setObjectName("gridLayout_13")
self.genre_tag_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.genre_tag_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.genre_tag_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.genre_tag_frame.setObjectName("genre_tag_frame")
self.verticalLayout_52 = QtWidgets.QVBoxLayout(self.genre_tag_frame)
self.verticalLayout_52.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_52.setSpacing(0)
self.verticalLayout_52.setObjectName("verticalLayout_52")
self.genre_tag_label = QtWidgets.QLabel(self.genre_tag_frame)
self.genre_tag_label.setStyleSheet("background-color: rgb(138, 222, 187);")
self.genre_tag_label.setObjectName("genre_tag_label")
self.verticalLayout_52.addWidget(self.genre_tag_label)
self.genre_tag_box = QtWidgets.QGroupBox(self.genre_tag_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.genre_tag_box.setPalette(palette)
self.genre_tag_box.setAutoFillBackground(False)
self.genre_tag_box.setStyleSheet("background-color: rgb(207, 236, 225);")
self.genre_tag_box.setTitle("")
self.genre_tag_box.setObjectName("genre_tag_box")
self.gridLayout_5 = QtWidgets.QGridLayout(self.genre_tag_box)
self.gridLayout_5.setObjectName("gridLayout_5")
self.label_73 = QtWidgets.QLabel(self.genre_tag_box)
self.label_73.setObjectName("label_73")
self.gridLayout_5.addWidget(self.label_73, 0, 0, 1, 1)
self.label_74 = QtWidgets.QLabel(self.genre_tag_box)
self.label_74.setObjectName("label_74")
self.gridLayout_5.addWidget(self.label_74, 0, 2, 1, 1)
self.cwp_subgenre_tag = QtWidgets.QLineEdit(self.genre_tag_box)
self.cwp_subgenre_tag.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_subgenre_tag.setObjectName("cwp_subgenre_tag")
self.gridLayout_5.addWidget(self.cwp_subgenre_tag, 0, 3, 1, 1)
self.cwp_genre_tag = QtWidgets.QLineEdit(self.genre_tag_box)
self.cwp_genre_tag.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genre_tag.setObjectName("cwp_genre_tag")
self.gridLayout_5.addWidget(self.cwp_genre_tag, 0, 1, 1, 1)
self.verticalLayout_52.addWidget(self.genre_tag_box)
self.gridLayout_13.addWidget(self.genre_tag_frame, 2, 0, 1, 1)
self.classical_genre_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.classical_genre_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.classical_genre_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.classical_genre_frame.setObjectName("classical_genre_frame")
self.verticalLayout_51 = QtWidgets.QVBoxLayout(self.classical_genre_frame)
self.verticalLayout_51.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_51.setSpacing(0)
self.verticalLayout_51.setObjectName("verticalLayout_51")
self.classical_genre_label = QtWidgets.QLabel(self.classical_genre_frame)
self.classical_genre_label.setStyleSheet("background-color: rgb(138, 222, 187);")
self.classical_genre_label.setObjectName("classical_genre_label")
self.verticalLayout_51.addWidget(self.classical_genre_label)
self.classical_genre_box = QtWidgets.QGroupBox(self.classical_genre_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.classical_genre_box.setPalette(palette)
self.classical_genre_box.setAutoFillBackground(False)
self.classical_genre_box.setStyleSheet("background-color: rgb(207, 236, 225);")
self.classical_genre_box.setTitle("")
self.classical_genre_box.setObjectName("classical_genre_box")
self.gridLayout_3 = QtWidgets.QGridLayout(self.classical_genre_box)
self.gridLayout_3.setObjectName("gridLayout_3")
self.cwp_genres_classical_exclude = QtWidgets.QCheckBox(self.classical_genre_box)
self.cwp_genres_classical_exclude.setObjectName("cwp_genres_classical_exclude")
self.gridLayout_3.addWidget(self.cwp_genres_classical_exclude, 1, 3, 1, 2)
self.cwp_genres_classical_selective = QtWidgets.QRadioButton(self.classical_genre_box)
self.cwp_genres_classical_selective.setObjectName("cwp_genres_classical_selective")
self.gridLayout_3.addWidget(self.cwp_genres_classical_selective, 0, 2, 1, 2)
self.cwp_muso_classical = QtWidgets.QCheckBox(self.classical_genre_box)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.cwp_muso_classical.setFont(font)
self.cwp_muso_classical.setObjectName("cwp_muso_classical")
self.gridLayout_3.addWidget(self.cwp_muso_classical, 1, 0, 1, 3)
self.cwp_genres_classical_all = QtWidgets.QRadioButton(self.classical_genre_box)
self.cwp_genres_classical_all.setObjectName("cwp_genres_classical_all")
self.gridLayout_3.addWidget(self.cwp_genres_classical_all, 0, 0, 1, 2)
self.label_64 = QtWidgets.QLabel(self.classical_genre_box)
self.label_64.setObjectName("label_64")
self.gridLayout_3.addWidget(self.label_64, 3, 0, 1, 1)
self.cwp_genres_flag_text = QtWidgets.QLineEdit(self.classical_genre_box)
self.cwp_genres_flag_text.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_genres_flag_text.setObjectName("cwp_genres_flag_text")
self.gridLayout_3.addWidget(self.cwp_genres_flag_text, 3, 1, 1, 3)
self.label_71 = QtWidgets.QLabel(self.classical_genre_box)
self.label_71.setObjectName("label_71")
self.gridLayout_3.addWidget(self.label_71, 3, 4, 1, 1)
self.cwp_genres_flag_tag = QtWidgets.QLineEdit(self.classical_genre_box)
self.cwp_genres_flag_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_genres_flag_tag.setObjectName("cwp_genres_flag_tag")
self.gridLayout_3.addWidget(self.cwp_genres_flag_tag, 3, 5, 1, 1)
self.cwp_genres_arranger_as_composer = QtWidgets.QCheckBox(self.classical_genre_box)
self.cwp_genres_arranger_as_composer.setObjectName("cwp_genres_arranger_as_composer")
self.gridLayout_3.addWidget(self.cwp_genres_arranger_as_composer, 2, 0, 1, 1)
self.verticalLayout_51.addWidget(self.classical_genre_box)
self.gridLayout_13.addWidget(self.classical_genre_frame, 5, 0, 1, 1)
self.label_81 = QtWidgets.QLabel(self.scrollAreaWidgetContents_5)
self.label_81.setObjectName("label_81")
self.gridLayout_13.addWidget(self.label_81, 8, 0, 1, 1)
self.cwp_use_muso_refdb = QtWidgets.QCheckBox(self.scrollAreaWidgetContents_5)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.cwp_use_muso_refdb.setFont(font)
self.cwp_use_muso_refdb.setObjectName("cwp_use_muso_refdb")
self.gridLayout_13.addWidget(self.cwp_use_muso_refdb, 1, 0, 1, 1)
self.instruments_keys_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.instruments_keys_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.instruments_keys_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.instruments_keys_frame.setObjectName("instruments_keys_frame")
self.verticalLayout_53 = QtWidgets.QVBoxLayout(self.instruments_keys_frame)
self.verticalLayout_53.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_53.setSpacing(0)
self.verticalLayout_53.setObjectName("verticalLayout_53")
self.instruments_keys_label = QtWidgets.QLabel(self.instruments_keys_frame)
self.instruments_keys_label.setStyleSheet("background-color: rgb(225, 168, 171);")
self.instruments_keys_label.setObjectName("instruments_keys_label")
self.verticalLayout_53.addWidget(self.instruments_keys_label)
self.instruments_keys_box = QtWidgets.QGroupBox(self.instruments_keys_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 224, 226))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.instruments_keys_box.setPalette(palette)
self.instruments_keys_box.setAutoFillBackground(False)
self.instruments_keys_box.setStyleSheet("background-color: rgb(245, 224, 226);")
self.instruments_keys_box.setTitle("")
self.instruments_keys_box.setObjectName("instruments_keys_box")
self.verticalLayout_34 = QtWidgets.QVBoxLayout(self.instruments_keys_box)
self.verticalLayout_34.setObjectName("verticalLayout_34")
self.instruments_box = QtWidgets.QGroupBox(self.instruments_keys_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.instruments_box.setPalette(palette)
self.instruments_box.setAutoFillBackground(False)
self.instruments_box.setStyleSheet("background-color: rgb(245, 210, 213);")
self.instruments_box.setObjectName("instruments_box")
self.gridLayout_11 = QtWidgets.QGridLayout(self.instruments_box)
self.gridLayout_11.setObjectName("gridLayout_11")
self.label_66 = QtWidgets.QLabel(self.instruments_box)
self.label_66.setObjectName("label_66")
self.gridLayout_11.addWidget(self.label_66, 0, 0, 1, 1)
self.cwp_instruments_tag = QtWidgets.QLineEdit(self.instruments_box)
self.cwp_instruments_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_instruments_tag.setObjectName("cwp_instruments_tag")
self.gridLayout_11.addWidget(self.cwp_instruments_tag, 0, 1, 1, 1)
self.instruments_source_box = QtWidgets.QGroupBox(self.instruments_box)
self.instruments_source_box.setObjectName("instruments_source_box")
self.horizontalLayout_33 = QtWidgets.QHBoxLayout(self.instruments_source_box)
self.horizontalLayout_33.setObjectName("horizontalLayout_33")
self.cwp_instruments_MB_names = QtWidgets.QCheckBox(self.instruments_source_box)
self.cwp_instruments_MB_names.setObjectName("cwp_instruments_MB_names")
self.horizontalLayout_33.addWidget(self.cwp_instruments_MB_names)
self.cwp_instruments_credited_names = QtWidgets.QCheckBox(self.instruments_source_box)
self.cwp_instruments_credited_names.setObjectName("cwp_instruments_credited_names")
self.horizontalLayout_33.addWidget(self.cwp_instruments_credited_names)
self.gridLayout_11.addWidget(self.instruments_source_box, 1, 0, 1, 2)
self.verticalLayout_34.addWidget(self.instruments_box)
self.keys_box = QtWidgets.QGroupBox(self.instruments_keys_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(245, 210, 213))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.keys_box.setPalette(palette)
self.keys_box.setAutoFillBackground(False)
self.keys_box.setStyleSheet("background-color: rgb(245, 210, 213);")
self.keys_box.setObjectName("keys_box")
self.gridLayout_4 = QtWidgets.QGridLayout(self.keys_box)
self.gridLayout_4.setObjectName("gridLayout_4")
self.label_72 = QtWidgets.QLabel(self.keys_box)
self.label_72.setObjectName("label_72")
self.gridLayout_4.addWidget(self.label_72, 0, 0, 1, 1)
self.cwp_key_tag = QtWidgets.QLineEdit(self.keys_box)
self.cwp_key_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_key_tag.setObjectName("cwp_key_tag")
self.gridLayout_4.addWidget(self.cwp_key_tag, 0, 2, 1, 1)
self.keys_include_box = QtWidgets.QGroupBox(self.keys_box)
self.keys_include_box.setObjectName("keys_include_box")
self.horizontalLayout_35 = QtWidgets.QHBoxLayout(self.keys_include_box)
self.horizontalLayout_35.setObjectName("horizontalLayout_35")
self.cwp_key_never_include = QtWidgets.QRadioButton(self.keys_include_box)
self.cwp_key_never_include.setObjectName("cwp_key_never_include")
self.horizontalLayout_35.addWidget(self.cwp_key_never_include)
self.cwp_key_contingent_include = QtWidgets.QRadioButton(self.keys_include_box)
self.cwp_key_contingent_include.setObjectName("cwp_key_contingent_include")
self.horizontalLayout_35.addWidget(self.cwp_key_contingent_include)
self.cwp_key_include = QtWidgets.QRadioButton(self.keys_include_box)
self.cwp_key_include.setObjectName("cwp_key_include")
self.horizontalLayout_35.addWidget(self.cwp_key_include)
self.gridLayout_4.addWidget(self.keys_include_box, 1, 0, 1, 2)
self.verticalLayout_34.addWidget(self.keys_box)
self.verticalLayout_53.addWidget(self.instruments_keys_box)
self.gridLayout_13.addWidget(self.instruments_keys_frame, 6, 0, 1, 1)
self.allowed_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.allowed_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.allowed_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.allowed_genres_frame.setLineWidth(1)
self.allowed_genres_frame.setMidLineWidth(0)
self.allowed_genres_frame.setObjectName("allowed_genres_frame")
self.verticalLayout_50 = QtWidgets.QVBoxLayout(self.allowed_genres_frame)
self.verticalLayout_50.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_50.setSpacing(0)
self.verticalLayout_50.setObjectName("verticalLayout_50")
self.allowed_filters_label = QtWidgets.QLabel(self.allowed_genres_frame)
self.allowed_filters_label.setStyleSheet("background-color: rgb(138, 222, 187);")
self.allowed_filters_label.setObjectName("allowed_filters_label")
self.verticalLayout_50.addWidget(self.allowed_filters_label)
self.cwp_genres_filter = QtWidgets.QCheckBox(self.allowed_genres_frame)
self.cwp_genres_filter.setLayoutDirection(QtCore.Qt.LeftToRight)
self.cwp_genres_filter.setStyleSheet("background-color: rgb(138, 222, 187);")
self.cwp_genres_filter.setObjectName("cwp_genres_filter")
self.verticalLayout_50.addWidget(self.cwp_genres_filter)
self.genre_filters_frame = QtWidgets.QGroupBox(self.allowed_genres_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.genre_filters_frame.setPalette(palette)
self.genre_filters_frame.setAutoFillBackground(False)
self.genre_filters_frame.setStyleSheet("background-color: rgb(207, 236, 225);")
self.genre_filters_frame.setTitle("")
self.genre_filters_frame.setObjectName("genre_filters_frame")
self.gridLayout_6 = QtWidgets.QGridLayout(self.genre_filters_frame)
self.gridLayout_6.setObjectName("gridLayout_6")
self.classical_genres_box = QtWidgets.QGroupBox(self.genre_filters_frame)
self.classical_genres_box.setStyleSheet("background-color: rgb(190, 236, 219);")
self.classical_genres_box.setObjectName("classical_genres_box")
self.gridLayout_9 = QtWidgets.QGridLayout(self.classical_genres_box)
self.gridLayout_9.setObjectName("gridLayout_9")
self.label_60 = QtWidgets.QLabel(self.classical_genres_box)
self.label_60.setObjectName("label_60")
self.gridLayout_9.addWidget(self.label_60, 0, 0, 1, 1)
self.cwp_genres_classical_main = QtWidgets.QPlainTextEdit(self.classical_genres_box)
self.cwp_genres_classical_main.setMaximumSize(QtCore.QSize(16777215, 50))
self.cwp_genres_classical_main.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genres_classical_main.setObjectName("cwp_genres_classical_main")
self.gridLayout_9.addWidget(self.cwp_genres_classical_main, 0, 1, 3, 1)
self.label_75 = QtWidgets.QLabel(self.classical_genres_box)
self.label_75.setObjectName("label_75")
self.gridLayout_9.addWidget(self.label_75, 0, 2, 1, 1)
self.cwp_genres_classical_sub = QtWidgets.QPlainTextEdit(self.classical_genres_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.cwp_genres_classical_sub.sizePolicy().hasHeightForWidth())
self.cwp_genres_classical_sub.setSizePolicy(sizePolicy)
self.cwp_genres_classical_sub.setMaximumSize(QtCore.QSize(16777215, 50))
self.cwp_genres_classical_sub.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genres_classical_sub.setObjectName("cwp_genres_classical_sub")
self.gridLayout_9.addWidget(self.cwp_genres_classical_sub, 0, 3, 3, 1)
self.cwp_muso_genres = QtWidgets.QCheckBox(self.classical_genres_box)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.cwp_muso_genres.setFont(font)
self.cwp_muso_genres.setObjectName("cwp_muso_genres")
self.gridLayout_9.addWidget(self.cwp_muso_genres, 1, 0, 1, 1)
self.gridLayout_6.addWidget(self.classical_genres_box, 2, 0, 1, 2)
self.general_genres_box = QtWidgets.QGroupBox(self.genre_filters_frame)
self.general_genres_box.setStyleSheet("background-color: rgb(190, 236, 219);")
self.general_genres_box.setObjectName("general_genres_box")
self.horizontalLayout_36 = QtWidgets.QHBoxLayout(self.general_genres_box)
self.horizontalLayout_36.setObjectName("horizontalLayout_36")
self.label_62 = QtWidgets.QLabel(self.general_genres_box)
self.label_62.setObjectName("label_62")
self.horizontalLayout_36.addWidget(self.label_62)
self.cwp_genres_other_main = QtWidgets.QPlainTextEdit(self.general_genres_box)
self.cwp_genres_other_main.setMaximumSize(QtCore.QSize(16777215, 50))
self.cwp_genres_other_main.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genres_other_main.setObjectName("cwp_genres_other_main")
self.horizontalLayout_36.addWidget(self.cwp_genres_other_main)
self.label_76 = QtWidgets.QLabel(self.general_genres_box)
self.label_76.setObjectName("label_76")
self.horizontalLayout_36.addWidget(self.label_76)
self.cwp_genres_other_sub = QtWidgets.QPlainTextEdit(self.general_genres_box)
self.cwp_genres_other_sub.setMaximumSize(QtCore.QSize(16777215, 50))
self.cwp_genres_other_sub.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genres_other_sub.setObjectName("cwp_genres_other_sub")
self.horizontalLayout_36.addWidget(self.cwp_genres_other_sub)
self.cwp_genres_other_main.raise_()
self.cwp_genres_other_sub.raise_()
self.label_62.raise_()
self.label_76.raise_()
self.gridLayout_6.addWidget(self.general_genres_box, 3, 0, 1, 2)
self.label_80 = QtWidgets.QLabel(self.genre_filters_frame)
self.label_80.setObjectName("label_80")
self.gridLayout_6.addWidget(self.label_80, 4, 0, 1, 1)
self.cwp_genres_default = QtWidgets.QLineEdit(self.genre_filters_frame)
self.cwp_genres_default.setStyleSheet("background-color: rgb(250,250,250);")
self.cwp_genres_default.setObjectName("cwp_genres_default")
self.gridLayout_6.addWidget(self.cwp_genres_default, 4, 1, 1, 1)
self.label_77 = QtWidgets.QLabel(self.genre_filters_frame)
self.label_77.setObjectName("label_77")
self.gridLayout_6.addWidget(self.label_77, 0, 0, 1, 2)
self.label_78 = QtWidgets.QLabel(self.genre_filters_frame)
self.label_78.setObjectName("label_78")
self.gridLayout_6.addWidget(self.label_78, 1, 0, 1, 1)
self.verticalLayout_50.addWidget(self.genre_filters_frame)
self.gridLayout_13.addWidget(self.allowed_genres_frame, 4, 0, 1, 1)
self.source_of_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.source_of_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.source_of_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.source_of_genres_frame.setObjectName("source_of_genres_frame")
self.verticalLayout_49 = QtWidgets.QVBoxLayout(self.source_of_genres_frame)
self.verticalLayout_49.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_49.setSpacing(0)
self.verticalLayout_49.setObjectName("verticalLayout_49")
self.source_of_genres_label = QtWidgets.QLabel(self.source_of_genres_frame)
self.source_of_genres_label.setStyleSheet("background-color: rgb(138, 222, 187);")
self.source_of_genres_label.setObjectName("source_of_genres_label")
self.verticalLayout_49.addWidget(self.source_of_genres_label)
self.source_of_genres_box = QtWidgets.QGroupBox(self.source_of_genres_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(207, 236, 225))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.source_of_genres_box.setPalette(palette)
self.source_of_genres_box.setAutoFillBackground(False)
self.source_of_genres_box.setStyleSheet("background-color: rgb(207, 236, 225);")
self.source_of_genres_box.setTitle("")
self.source_of_genres_box.setObjectName("source_of_genres_box")
self.horizontalLayout_32 = QtWidgets.QHBoxLayout(self.source_of_genres_box)
self.horizontalLayout_32.setObjectName("horizontalLayout_32")
self.cwp_genres_use_file = QtWidgets.QCheckBox(self.source_of_genres_box)
self.cwp_genres_use_file.setObjectName("cwp_genres_use_file")
self.horizontalLayout_32.addWidget(self.cwp_genres_use_file)
self.cwp_genres_use_folks = QtWidgets.QCheckBox(self.source_of_genres_box)
self.cwp_genres_use_folks.setObjectName("cwp_genres_use_folks")
self.horizontalLayout_32.addWidget(self.cwp_genres_use_folks)
self.cwp_genres_use_worktype = QtWidgets.QCheckBox(self.source_of_genres_box)
self.cwp_genres_use_worktype.setObjectName("cwp_genres_use_worktype")
self.horizontalLayout_32.addWidget(self.cwp_genres_use_worktype)
self.cwp_genres_infer = QtWidgets.QCheckBox(self.source_of_genres_box)
self.cwp_genres_infer.setObjectName("cwp_genres_infer")
self.horizontalLayout_32.addWidget(self.cwp_genres_infer)
self.verticalLayout_49.addWidget(self.source_of_genres_box)
self.gridLayout_13.addWidget(self.source_of_genres_frame, 3, 0, 1, 1)
self.periods_dates_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_5)
self.periods_dates_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.periods_dates_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.periods_dates_frame.setObjectName("periods_dates_frame")
self.verticalLayout_54 = QtWidgets.QVBoxLayout(self.periods_dates_frame)
self.verticalLayout_54.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_54.setSpacing(0)
self.verticalLayout_54.setObjectName("verticalLayout_54")
self.label_109 = QtWidgets.QLabel(self.periods_dates_frame)
self.label_109.setStyleSheet("background-color: rgb(195, 183, 213);")
self.label_109.setObjectName("label_109")
self.verticalLayout_54.addWidget(self.label_109)
self.periods_dates_box = QtWidgets.QGroupBox(self.periods_dates_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 224, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.periods_dates_box.setPalette(palette)
self.periods_dates_box.setAutoFillBackground(False)
self.periods_dates_box.setStyleSheet("background-color: rgb(229, 224, 236);")
self.periods_dates_box.setTitle("")
self.periods_dates_box.setObjectName("periods_dates_box")
self.verticalLayout_32 = QtWidgets.QVBoxLayout(self.periods_dates_box)
self.verticalLayout_32.setObjectName("verticalLayout_32")
self.dates_box = QtWidgets.QGroupBox(self.periods_dates_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.dates_box.setPalette(palette)
self.dates_box.setAutoFillBackground(False)
self.dates_box.setStyleSheet("background-color: rgb(222, 212, 236);")
self.dates_box.setObjectName("dates_box")
self.gridLayout_10 = QtWidgets.QGridLayout(self.dates_box)
self.gridLayout_10.setObjectName("gridLayout_10")
self.dates_box_inner = QtWidgets.QGroupBox(self.dates_box)
self.dates_box_inner.setObjectName("dates_box_inner")
self.gridLayout_7 = QtWidgets.QGridLayout(self.dates_box_inner)
self.gridLayout_7.setObjectName("gridLayout_7")
self.cwp_workdate_source_composed = QtWidgets.QCheckBox(self.dates_box_inner)
self.cwp_workdate_source_composed.setObjectName("cwp_workdate_source_composed")
self.gridLayout_7.addWidget(self.cwp_workdate_source_composed, 0, 0, 1, 1)
self.cwp_workdate_source_published = QtWidgets.QCheckBox(self.dates_box_inner)
self.cwp_workdate_source_published.setObjectName("cwp_workdate_source_published")
self.gridLayout_7.addWidget(self.cwp_workdate_source_published, 0, 1, 1, 1)
self.cwp_workdate_source_premiered = QtWidgets.QCheckBox(self.dates_box_inner)
self.cwp_workdate_source_premiered.setObjectName("cwp_workdate_source_premiered")
self.gridLayout_7.addWidget(self.cwp_workdate_source_premiered, 0, 2, 1, 1)
self.line_9 = QtWidgets.QFrame(self.dates_box_inner)
self.line_9.setFrameShape(QtWidgets.QFrame.HLine)
self.line_9.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_9.setObjectName("line_9")
self.gridLayout_7.addWidget(self.line_9, 1, 0, 1, 3)
self.cwp_workdate_use_first = QtWidgets.QRadioButton(self.dates_box_inner)
self.cwp_workdate_use_first.setObjectName("cwp_workdate_use_first")
self.gridLayout_7.addWidget(self.cwp_workdate_use_first, 2, 0, 1, 1)
self.cwp_workdate_use_all = QtWidgets.QRadioButton(self.dates_box_inner)
self.cwp_workdate_use_all.setObjectName("cwp_workdate_use_all")
self.gridLayout_7.addWidget(self.cwp_workdate_use_all, 2, 1, 1, 1)
self.cwp_workdate_annotate = QtWidgets.QCheckBox(self.dates_box_inner)
self.cwp_workdate_annotate.setObjectName("cwp_workdate_annotate")
self.gridLayout_7.addWidget(self.cwp_workdate_annotate, 2, 2, 1, 1)
self.gridLayout_10.addWidget(self.dates_box_inner, 1, 0, 1, 3)
self.label_68 = QtWidgets.QLabel(self.dates_box)
self.label_68.setObjectName("label_68")
self.gridLayout_10.addWidget(self.label_68, 0, 0, 1, 1)
self.cwp_workdate_include = QtWidgets.QCheckBox(self.dates_box)
self.cwp_workdate_include.setObjectName("cwp_workdate_include")
self.gridLayout_10.addWidget(self.cwp_workdate_include, 2, 0, 1, 2)
self.cwp_workdate_tag = QtWidgets.QLineEdit(self.dates_box)
self.cwp_workdate_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_workdate_tag.setObjectName("cwp_workdate_tag")
self.gridLayout_10.addWidget(self.cwp_workdate_tag, 0, 1, 1, 2)
self.verticalLayout_32.addWidget(self.dates_box)
self.line_5 = QtWidgets.QFrame(self.periods_dates_box)
self.line_5.setMidLineWidth(0)
self.line_5.setFrameShape(QtWidgets.QFrame.HLine)
self.line_5.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_5.setObjectName("line_5")
self.verticalLayout_32.addWidget(self.line_5)
self.periods_box = QtWidgets.QGroupBox(self.periods_dates_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(222, 212, 236))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.periods_box.setPalette(palette)
self.periods_box.setAutoFillBackground(False)
self.periods_box.setStyleSheet("background-color: rgb(222, 212, 236);")
self.periods_box.setObjectName("periods_box")
self.gridLayout_12 = QtWidgets.QGridLayout(self.periods_box)
self.gridLayout_12.setObjectName("gridLayout_12")
self.label_69 = QtWidgets.QLabel(self.periods_box)
self.label_69.setObjectName("label_69")
self.gridLayout_12.addWidget(self.label_69, 0, 0, 1, 1)
self.cwp_muso_periods = QtWidgets.QCheckBox(self.periods_box)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.cwp_muso_periods.setFont(font)
self.cwp_muso_periods.setObjectName("cwp_muso_periods")
self.gridLayout_12.addWidget(self.cwp_muso_periods, 4, 0, 1, 2)
self.cwp_muso_dates = QtWidgets.QCheckBox(self.periods_box)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.cwp_muso_dates.setFont(font)
self.cwp_muso_dates.setObjectName("cwp_muso_dates")
self.gridLayout_12.addWidget(self.cwp_muso_dates, 1, 0, 1, 3)
self.cwp_period_tag = QtWidgets.QLineEdit(self.periods_box)
self.cwp_period_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_period_tag.setObjectName("cwp_period_tag")
self.gridLayout_12.addWidget(self.cwp_period_tag, 0, 1, 1, 2)
self.label_70 = QtWidgets.QLabel(self.periods_box)
self.label_70.setObjectName("label_70")
self.gridLayout_12.addWidget(self.label_70, 3, 0, 1, 1)
self.cwp_period_map = QtWidgets.QPlainTextEdit(self.periods_box)
self.cwp_period_map.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_period_map.setObjectName("cwp_period_map")
self.gridLayout_12.addWidget(self.cwp_period_map, 3, 2, 2, 1)
self.period_map_annotation_label = QtWidgets.QLabel(self.periods_box)
self.period_map_annotation_label.setObjectName("period_map_annotation_label")
self.gridLayout_12.addWidget(self.period_map_annotation_label, 5, 2, 1, 1)
self.cwp_periods_arranger_as_composer = QtWidgets.QCheckBox(self.periods_box)
self.cwp_periods_arranger_as_composer.setObjectName("cwp_periods_arranger_as_composer")
self.gridLayout_12.addWidget(self.cwp_periods_arranger_as_composer, 2, 0, 1, 1)
self.verticalLayout_32.addWidget(self.periods_box)
self.verticalLayout_54.addWidget(self.periods_dates_box)
self.gridLayout_13.addWidget(self.periods_dates_frame, 7, 0, 1, 1)
self.label_119 = QtWidgets.QLabel(self.scrollAreaWidgetContents_5)
self.label_119.setObjectName("label_119")
self.gridLayout_13.addWidget(self.label_119, 0, 0, 1, 1)
self.scrollArea_6.setWidget(self.scrollAreaWidgetContents_5)
self.gridLayout_2.addWidget(self.scrollArea_6, 1, 0, 1, 1)
self.tabWidget.addTab(self.Genres, "")
self.Tag_mapping = QtWidgets.QWidget()
self.Tag_mapping.setObjectName("Tag_mapping")
self.verticalLayout_28 = QtWidgets.QVBoxLayout(self.Tag_mapping)
self.verticalLayout_28.setObjectName("verticalLayout_28")
self.scrollArea_4 = QtWidgets.QScrollArea(self.Tag_mapping)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea_4.sizePolicy().hasHeightForWidth())
self.scrollArea_4.setSizePolicy(sizePolicy)
self.scrollArea_4.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded)
self.scrollArea_4.setWidgetResizable(True)
self.scrollArea_4.setObjectName("scrollArea_4")
self.scrollAreaWidgetContents_8 = QtWidgets.QWidget()
self.scrollAreaWidgetContents_8.setGeometry(QtCore.QRect(0, 0, 1084, 917))
self.scrollAreaWidgetContents_8.setObjectName("scrollAreaWidgetContents_8")
self.verticalLayout_33 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_8)
self.verticalLayout_33.setObjectName("verticalLayout_33")
self.label_18 = QtWidgets.QLabel(self.scrollAreaWidgetContents_8)
self.label_18.setStyleSheet("")
self.label_18.setObjectName("label_18")
self.verticalLayout_33.addWidget(self.label_18)
self.initial_tag_processing_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_8)
self.initial_tag_processing_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.initial_tag_processing_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.initial_tag_processing_frame.setObjectName("initial_tag_processing_frame")
self.verticalLayout_41 = QtWidgets.QVBoxLayout(self.initial_tag_processing_frame)
self.verticalLayout_41.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_41.setSpacing(0)
self.verticalLayout_41.setObjectName("verticalLayout_41")
self.label_97 = QtWidgets.QLabel(self.initial_tag_processing_frame)
self.label_97.setStyleSheet("background-color: rgb(209, 171, 222);\n"
"")
self.label_97.setObjectName("label_97")
self.verticalLayout_41.addWidget(self.label_97)
self.initial_tag_processing_box = QtWidgets.QGroupBox(self.initial_tag_processing_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.initial_tag_processing_box.setPalette(palette)
self.initial_tag_processing_box.setAutoFillBackground(False)
self.initial_tag_processing_box.setStyleSheet("background-color: rgb(242, 221, 245);")
self.initial_tag_processing_box.setTitle("")
self.initial_tag_processing_box.setObjectName("initial_tag_processing_box")
self.verticalLayout_17 = QtWidgets.QVBoxLayout(self.initial_tag_processing_box)
self.verticalLayout_17.setObjectName("verticalLayout_17")
self.tags_to_blank = QtWidgets.QGroupBox(self.initial_tag_processing_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(242, 221, 245))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.tags_to_blank.setPalette(palette)
self.tags_to_blank.setAutoFillBackground(False)
self.tags_to_blank.setStyleSheet("")
self.tags_to_blank.setObjectName("tags_to_blank")
self.verticalLayout_12 = QtWidgets.QVBoxLayout(self.tags_to_blank)
self.verticalLayout_12.setObjectName("verticalLayout_12")
self.label_3 = QtWidgets.QLabel(self.tags_to_blank)
self.label_3.setObjectName("label_3")
self.verticalLayout_12.addWidget(self.label_3)
self.cea_blank_tag = QtWidgets.QLineEdit(self.tags_to_blank)
self.cea_blank_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_blank_tag.setObjectName("cea_blank_tag")
self.verticalLayout_12.addWidget(self.cea_blank_tag)
self.cea_blank_tag_2 = QtWidgets.QLineEdit(self.tags_to_blank)
self.cea_blank_tag_2.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_blank_tag_2.setObjectName("cea_blank_tag_2")
self.verticalLayout_12.addWidget(self.cea_blank_tag_2)
self.verticalLayout_17.addWidget(self.tags_to_blank)
self.label_19 = QtWidgets.QLabel(self.initial_tag_processing_box)
self.label_19.setObjectName("label_19")
self.verticalLayout_17.addWidget(self.label_19)
self.cea_keep = QtWidgets.QLineEdit(self.initial_tag_processing_box)
self.cea_keep.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_keep.setObjectName("cea_keep")
self.verticalLayout_17.addWidget(self.cea_keep)
self.cea_clear_tags = QtWidgets.QCheckBox(self.initial_tag_processing_box)
self.cea_clear_tags.setObjectName("cea_clear_tags")
self.verticalLayout_17.addWidget(self.cea_clear_tags)
self.verticalLayout_41.addWidget(self.initial_tag_processing_box)
self.verticalLayout_33.addWidget(self.initial_tag_processing_frame)
self.tagmap_details_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_8)
self.tagmap_details_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.tagmap_details_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.tagmap_details_frame.setObjectName("tagmap_details_frame")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.tagmap_details_frame)
self.verticalLayout_3.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_3.setSpacing(0)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.label_98 = QtWidgets.QLabel(self.tagmap_details_frame)
self.label_98.setStyleSheet("background-color: rgb(229, 174, 142);")
self.label_98.setObjectName("label_98")
self.verticalLayout_3.addWidget(self.label_98)
self.tagmap_details_box = QtWidgets.QGroupBox(self.tagmap_details_frame)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Expanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.tagmap_details_box.sizePolicy().hasHeightForWidth())
self.tagmap_details_box.setSizePolicy(sizePolicy)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(255, 229, 214))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.tagmap_details_box.setPalette(palette)
self.tagmap_details_box.setFocusPolicy(QtCore.Qt.NoFocus)
self.tagmap_details_box.setAutoFillBackground(False)
self.tagmap_details_box.setStyleSheet("font: 75 8pt \"MS Shell Dlg 2\";\n"
"background-color: rgb(255, 229, 214);")
self.tagmap_details_box.setTitle("")
self.tagmap_details_box.setObjectName("tagmap_details_box")
self.gridLayout_14 = QtWidgets.QGridLayout(self.tagmap_details_box)
self.gridLayout_14.setObjectName("gridLayout_14")
self.textBrowser = QtWidgets.QTextBrowser(self.tagmap_details_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.textBrowser.sizePolicy().hasHeightForWidth())
self.textBrowser.setSizePolicy(sizePolicy)
self.textBrowser.setMaximumSize(QtCore.QSize(16777215, 100))
self.textBrowser.setStyleSheet("background-color: rgb(249, 215, 187);")
self.textBrowser.setObjectName("textBrowser")
self.gridLayout_14.addWidget(self.textBrowser, 0, 0, 1, 1)
self.frame_25 = QtWidgets.QFrame(self.tagmap_details_box)
self.frame_25.setObjectName("frame_25")
self._14 = QtWidgets.QHBoxLayout(self.frame_25)
self._14.setSizeConstraint(QtWidgets.QLayout.SetDefaultConstraint)
self._14.setContentsMargins(1, 1, 1, 1)
self._14.setSpacing(6)
self._14.setObjectName("_14")
self.toolButton_1 = QtWidgets.QToolButton(self.frame_25)
self.toolButton_1.setAutoFillBackground(False)
self.toolButton_1.setStyleSheet("")
self.toolButton_1.setCheckable(True)
self.toolButton_1.setToolButtonStyle(QtCore.Qt.ToolButtonIconOnly)
self.toolButton_1.setAutoRaise(False)
self.toolButton_1.setObjectName("toolButton_1")
self._14.addWidget(self.toolButton_1)
self.cea_source_1 = QtWidgets.QComboBox(self.frame_25)
self.cea_source_1.setEnabled(False)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.cea_source_1.sizePolicy().hasHeightForWidth())
self.cea_source_1.setSizePolicy(sizePolicy)
self.cea_source_1.setMouseTracking(False)
self.cea_source_1.setFocusPolicy(QtCore.Qt.StrongFocus)
self.cea_source_1.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_1.setEditable(True)
self.cea_source_1.setSizeAdjustPolicy(QtWidgets.QComboBox.AdjustToContents)
self.cea_source_1.setObjectName("cea_source_1")
self.cea_source_1.addItem("")
self.cea_source_1.setItemText(0, "")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self.cea_source_1.addItem("")
self._14.addWidget(self.cea_source_1)
self.label_21 = QtWidgets.QLabel(self.frame_25)
self.label_21.setObjectName("label_21")
self._14.addWidget(self.label_21)
self.cea_tag_1 = QtWidgets.QLineEdit(self.frame_25)
self.cea_tag_1.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_1.setObjectName("cea_tag_1")
self._14.addWidget(self.cea_tag_1)
self.cea_cond_1 = QtWidgets.QCheckBox(self.frame_25)
self.cea_cond_1.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_1.setObjectName("cea_cond_1")
self._14.addWidget(self.cea_cond_1)
self.gridLayout_14.addWidget(self.frame_25, 1, 0, 1, 1)
self._15 = QtWidgets.QHBoxLayout()
self._15.setContentsMargins(0, 0, 0, 0)
self._15.setSpacing(6)
self._15.setObjectName("_15")
self.toolButton_2 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_2.setStyleSheet("")
self.toolButton_2.setCheckable(True)
self.toolButton_2.setObjectName("toolButton_2")
self._15.addWidget(self.toolButton_2)
self.cea_source_2 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_2.setEnabled(False)
self.cea_source_2.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_2.setEditable(True)
self.cea_source_2.setObjectName("cea_source_2")
self.cea_source_2.addItem("")
self.cea_source_2.setItemText(0, "")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self.cea_source_2.addItem("")
self._15.addWidget(self.cea_source_2)
self.label_23 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_23.setObjectName("label_23")
self._15.addWidget(self.label_23)
self.cea_tag_2 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_2.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_2.setObjectName("cea_tag_2")
self._15.addWidget(self.cea_tag_2)
self.cea_cond_2 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_2.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_2.setObjectName("cea_cond_2")
self._15.addWidget(self.cea_cond_2)
self.gridLayout_14.addLayout(self._15, 2, 0, 1, 1)
self._16 = QtWidgets.QHBoxLayout()
self._16.setContentsMargins(0, 0, 0, 0)
self._16.setSpacing(6)
self._16.setObjectName("_16")
self.toolButton_3 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_3.setStyleSheet("")
self.toolButton_3.setCheckable(True)
self.toolButton_3.setObjectName("toolButton_3")
self._16.addWidget(self.toolButton_3)
self.cea_source_3 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_3.setEnabled(False)
self.cea_source_3.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_3.setEditable(True)
self.cea_source_3.setObjectName("cea_source_3")
self.cea_source_3.addItem("")
self.cea_source_3.setItemText(0, "")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self.cea_source_3.addItem("")
self._16.addWidget(self.cea_source_3)
self.label_25 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_25.setObjectName("label_25")
self._16.addWidget(self.label_25)
self.cea_tag_3 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_3.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_3.setObjectName("cea_tag_3")
self._16.addWidget(self.cea_tag_3)
self.cea_cond_3 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_3.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_3.setObjectName("cea_cond_3")
self._16.addWidget(self.cea_cond_3)
self.gridLayout_14.addLayout(self._16, 3, 0, 1, 1)
self._17 = QtWidgets.QHBoxLayout()
self._17.setContentsMargins(0, 0, 0, 0)
self._17.setSpacing(6)
self._17.setObjectName("_17")
self.toolButton_4 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_4.setStyleSheet("")
self.toolButton_4.setCheckable(True)
self.toolButton_4.setObjectName("toolButton_4")
self._17.addWidget(self.toolButton_4)
self.cea_source_4 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_4.setEnabled(False)
self.cea_source_4.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_4.setEditable(True)
self.cea_source_4.setObjectName("cea_source_4")
self.cea_source_4.addItem("")
self.cea_source_4.setItemText(0, "")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self.cea_source_4.addItem("")
self._17.addWidget(self.cea_source_4)
self.label_27 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_27.setObjectName("label_27")
self._17.addWidget(self.label_27)
self.cea_tag_4 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_4.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_4.setObjectName("cea_tag_4")
self._17.addWidget(self.cea_tag_4)
self.cea_cond_4 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_4.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_4.setObjectName("cea_cond_4")
self._17.addWidget(self.cea_cond_4)
self.gridLayout_14.addLayout(self._17, 4, 0, 1, 1)
self._18 = QtWidgets.QHBoxLayout()
self._18.setContentsMargins(0, 0, 0, 0)
self._18.setSpacing(6)
self._18.setObjectName("_18")
self.toolButton_5 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_5.setStyleSheet("")
self.toolButton_5.setCheckable(True)
self.toolButton_5.setObjectName("toolButton_5")
self._18.addWidget(self.toolButton_5)
self.cea_source_5 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_5.setEnabled(False)
self.cea_source_5.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_5.setEditable(True)
self.cea_source_5.setObjectName("cea_source_5")
self.cea_source_5.addItem("")
self.cea_source_5.setItemText(0, "")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self.cea_source_5.addItem("")
self._18.addWidget(self.cea_source_5)
self.label_29 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_29.setObjectName("label_29")
self._18.addWidget(self.label_29)
self.cea_tag_5 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_5.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_5.setObjectName("cea_tag_5")
self._18.addWidget(self.cea_tag_5)
self.cea_cond_5 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_5.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_5.setObjectName("cea_cond_5")
self._18.addWidget(self.cea_cond_5)
self.gridLayout_14.addLayout(self._18, 5, 0, 1, 1)
self._19 = QtWidgets.QHBoxLayout()
self._19.setContentsMargins(0, 0, 0, 0)
self._19.setSpacing(6)
self._19.setObjectName("_19")
self.toolButton_6 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_6.setStyleSheet("")
self.toolButton_6.setCheckable(True)
self.toolButton_6.setObjectName("toolButton_6")
self._19.addWidget(self.toolButton_6)
self.cea_source_6 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_6.setEnabled(False)
self.cea_source_6.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_6.setEditable(True)
self.cea_source_6.setObjectName("cea_source_6")
self.cea_source_6.addItem("")
self.cea_source_6.setItemText(0, "")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self.cea_source_6.addItem("")
self._19.addWidget(self.cea_source_6)
self.label_31 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_31.setObjectName("label_31")
self._19.addWidget(self.label_31)
self.cea_tag_6 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_6.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_6.setObjectName("cea_tag_6")
self._19.addWidget(self.cea_tag_6)
self.cea_cond_6 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_6.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_6.setObjectName("cea_cond_6")
self._19.addWidget(self.cea_cond_6)
self.gridLayout_14.addLayout(self._19, 6, 0, 1, 1)
self._20 = QtWidgets.QHBoxLayout()
self._20.setContentsMargins(0, 0, 0, 0)
self._20.setSpacing(6)
self._20.setObjectName("_20")
self.toolButton_7 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_7.setStyleSheet("")
self.toolButton_7.setCheckable(True)
self.toolButton_7.setObjectName("toolButton_7")
self._20.addWidget(self.toolButton_7)
self.cea_source_7 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_7.setEnabled(False)
self.cea_source_7.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_7.setEditable(True)
self.cea_source_7.setObjectName("cea_source_7")
self.cea_source_7.addItem("")
self.cea_source_7.setItemText(0, "")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self.cea_source_7.addItem("")
self._20.addWidget(self.cea_source_7)
self.label_33 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_33.setObjectName("label_33")
self._20.addWidget(self.label_33)
self.cea_tag_7 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_7.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_7.setObjectName("cea_tag_7")
self._20.addWidget(self.cea_tag_7)
self.cea_cond_7 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_7.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_7.setObjectName("cea_cond_7")
self._20.addWidget(self.cea_cond_7)
self.gridLayout_14.addLayout(self._20, 7, 0, 1, 1)
self._21 = QtWidgets.QHBoxLayout()
self._21.setContentsMargins(0, 0, 0, 0)
self._21.setSpacing(6)
self._21.setObjectName("_21")
self.toolButton_8 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_8.setStyleSheet("")
self.toolButton_8.setCheckable(True)
self.toolButton_8.setObjectName("toolButton_8")
self._21.addWidget(self.toolButton_8)
self.cea_source_8 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_8.setEnabled(False)
self.cea_source_8.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_8.setEditable(True)
self.cea_source_8.setObjectName("cea_source_8")
self.cea_source_8.addItem("")
self.cea_source_8.setItemText(0, "")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self.cea_source_8.addItem("")
self._21.addWidget(self.cea_source_8)
self.label_35 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_35.setObjectName("label_35")
self._21.addWidget(self.label_35)
self.cea_tag_8 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_8.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_8.setObjectName("cea_tag_8")
self._21.addWidget(self.cea_tag_8)
self.cea_cond_8 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_8.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_8.setObjectName("cea_cond_8")
self._21.addWidget(self.cea_cond_8)
self.gridLayout_14.addLayout(self._21, 8, 0, 1, 1)
self._30 = QtWidgets.QHBoxLayout()
self._30.setContentsMargins(0, 0, 0, 0)
self._30.setSpacing(6)
self._30.setObjectName("_30")
self.toolButton_9 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_9.setStyleSheet("")
self.toolButton_9.setCheckable(True)
self.toolButton_9.setObjectName("toolButton_9")
self._30.addWidget(self.toolButton_9)
self.cea_source_9 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_9.setEnabled(False)
self.cea_source_9.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_9.setEditable(True)
self.cea_source_9.setObjectName("cea_source_9")
self.cea_source_9.addItem("")
self.cea_source_9.setItemText(0, "")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self.cea_source_9.addItem("")
self._30.addWidget(self.cea_source_9)
self.label_53 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_53.setObjectName("label_53")
self._30.addWidget(self.label_53)
self.cea_tag_9 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_9.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_9.setObjectName("cea_tag_9")
self._30.addWidget(self.cea_tag_9)
self.cea_cond_9 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_9.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_9.setObjectName("cea_cond_9")
self._30.addWidget(self.cea_cond_9)
self.gridLayout_14.addLayout(self._30, 9, 0, 1, 1)
self._31 = QtWidgets.QHBoxLayout()
self._31.setContentsMargins(0, 0, 0, 0)
self._31.setSpacing(6)
self._31.setObjectName("_31")
self.toolButton_10 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_10.setStyleSheet("")
self.toolButton_10.setCheckable(True)
self.toolButton_10.setObjectName("toolButton_10")
self._31.addWidget(self.toolButton_10)
self.cea_source_10 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_10.setEnabled(False)
self.cea_source_10.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_10.setEditable(True)
self.cea_source_10.setObjectName("cea_source_10")
self.cea_source_10.addItem("")
self.cea_source_10.setItemText(0, "")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self.cea_source_10.addItem("")
self._31.addWidget(self.cea_source_10)
self.label_55 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_55.setObjectName("label_55")
self._31.addWidget(self.label_55)
self.cea_tag_10 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_10.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_10.setObjectName("cea_tag_10")
self._31.addWidget(self.cea_tag_10)
self.cea_cond_10 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_10.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_10.setObjectName("cea_cond_10")
self._31.addWidget(self.cea_cond_10)
self.gridLayout_14.addLayout(self._31, 10, 0, 1, 1)
self._32 = QtWidgets.QHBoxLayout()
self._32.setContentsMargins(0, 0, 0, 0)
self._32.setSpacing(6)
self._32.setObjectName("_32")
self.toolButton_11 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_11.setStyleSheet("")
self.toolButton_11.setCheckable(True)
self.toolButton_11.setObjectName("toolButton_11")
self._32.addWidget(self.toolButton_11)
self.cea_source_11 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_11.setEnabled(False)
self.cea_source_11.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_11.setEditable(True)
self.cea_source_11.setObjectName("cea_source_11")
self.cea_source_11.addItem("")
self.cea_source_11.setItemText(0, "")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self.cea_source_11.addItem("")
self._32.addWidget(self.cea_source_11)
self.label_57 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_57.setObjectName("label_57")
self._32.addWidget(self.label_57)
self.cea_tag_11 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_11.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_11.setObjectName("cea_tag_11")
self._32.addWidget(self.cea_tag_11)
self.cea_cond_11 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_11.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_11.setObjectName("cea_cond_11")
self._32.addWidget(self.cea_cond_11)
self.gridLayout_14.addLayout(self._32, 11, 0, 1, 1)
self._33 = QtWidgets.QHBoxLayout()
self._33.setContentsMargins(0, 0, 0, 0)
self._33.setSpacing(6)
self._33.setObjectName("_33")
self.toolButton_12 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_12.setStyleSheet("")
self.toolButton_12.setCheckable(True)
self.toolButton_12.setObjectName("toolButton_12")
self._33.addWidget(self.toolButton_12)
self.cea_source_12 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_12.setEnabled(False)
self.cea_source_12.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_12.setEditable(True)
self.cea_source_12.setObjectName("cea_source_12")
self.cea_source_12.addItem("")
self.cea_source_12.setItemText(0, "")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self.cea_source_12.addItem("")
self._33.addWidget(self.cea_source_12)
self.label_59 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_59.setObjectName("label_59")
self._33.addWidget(self.label_59)
self.cea_tag_12 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_12.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_12.setObjectName("cea_tag_12")
self._33.addWidget(self.cea_tag_12)
self.cea_cond_12 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_12.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_12.setObjectName("cea_cond_12")
self._33.addWidget(self.cea_cond_12)
self.gridLayout_14.addLayout(self._33, 12, 0, 1, 1)
self._34 = QtWidgets.QHBoxLayout()
self._34.setContentsMargins(0, 0, 0, 0)
self._34.setSpacing(6)
self._34.setObjectName("_34")
self.toolButton_13 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_13.setStyleSheet("")
self.toolButton_13.setCheckable(True)
self.toolButton_13.setObjectName("toolButton_13")
self._34.addWidget(self.toolButton_13)
self.cea_source_13 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_13.setEnabled(False)
self.cea_source_13.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_13.setEditable(True)
self.cea_source_13.setObjectName("cea_source_13")
self.cea_source_13.addItem("")
self.cea_source_13.setItemText(0, "")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self.cea_source_13.addItem("")
self._34.addWidget(self.cea_source_13)
self.label_61 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_61.setObjectName("label_61")
self._34.addWidget(self.label_61)
self.cea_tag_13 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_13.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_13.setObjectName("cea_tag_13")
self._34.addWidget(self.cea_tag_13)
self.cea_cond_13 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_13.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_13.setObjectName("cea_cond_13")
self._34.addWidget(self.cea_cond_13)
self.gridLayout_14.addLayout(self._34, 13, 0, 1, 1)
self._35 = QtWidgets.QHBoxLayout()
self._35.setContentsMargins(0, 0, 0, 0)
self._35.setSpacing(6)
self._35.setObjectName("_35")
self.toolButton_14 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_14.setStyleSheet("")
self.toolButton_14.setCheckable(True)
self.toolButton_14.setObjectName("toolButton_14")
self._35.addWidget(self.toolButton_14)
self.cea_source_14 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_14.setEnabled(False)
self.cea_source_14.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_14.setEditable(True)
self.cea_source_14.setObjectName("cea_source_14")
self.cea_source_14.addItem("")
self.cea_source_14.setItemText(0, "")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self.cea_source_14.addItem("")
self._35.addWidget(self.cea_source_14)
self.label_63 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_63.setObjectName("label_63")
self._35.addWidget(self.label_63)
self.cea_tag_14 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_14.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_14.setObjectName("cea_tag_14")
self._35.addWidget(self.cea_tag_14)
self.cea_cond_14 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_14.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_14.setObjectName("cea_cond_14")
self._35.addWidget(self.cea_cond_14)
self.gridLayout_14.addLayout(self._35, 14, 0, 1, 1)
self._36 = QtWidgets.QHBoxLayout()
self._36.setContentsMargins(0, 0, 0, 0)
self._36.setSpacing(6)
self._36.setObjectName("_36")
self.toolButton_15 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_15.setStyleSheet("")
self.toolButton_15.setCheckable(True)
self.toolButton_15.setObjectName("toolButton_15")
self._36.addWidget(self.toolButton_15)
self.cea_source_15 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_15.setEnabled(False)
self.cea_source_15.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_15.setEditable(True)
self.cea_source_15.setObjectName("cea_source_15")
self.cea_source_15.addItem("")
self.cea_source_15.setItemText(0, "")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self.cea_source_15.addItem("")
self._36.addWidget(self.cea_source_15)
self.label_65 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_65.setObjectName("label_65")
self._36.addWidget(self.label_65)
self.cea_tag_15 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_15.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_15.setObjectName("cea_tag_15")
self._36.addWidget(self.cea_tag_15)
self.cea_cond_15 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_15.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_15.setObjectName("cea_cond_15")
self._36.addWidget(self.cea_cond_15)
self.gridLayout_14.addLayout(self._36, 15, 0, 1, 1)
self._37 = QtWidgets.QHBoxLayout()
self._37.setContentsMargins(0, 0, 0, 0)
self._37.setSpacing(6)
self._37.setObjectName("_37")
self.toolButton_16 = QtWidgets.QToolButton(self.tagmap_details_box)
self.toolButton_16.setStyleSheet("")
self.toolButton_16.setCheckable(True)
self.toolButton_16.setObjectName("toolButton_16")
self._37.addWidget(self.toolButton_16)
self.cea_source_16 = QtWidgets.QComboBox(self.tagmap_details_box)
self.cea_source_16.setEnabled(False)
self.cea_source_16.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_source_16.setEditable(True)
self.cea_source_16.setObjectName("cea_source_16")
self.cea_source_16.addItem("")
self.cea_source_16.setItemText(0, "")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self.cea_source_16.addItem("")
self._37.addWidget(self.cea_source_16)
self.label_67 = QtWidgets.QLabel(self.tagmap_details_box)
self.label_67.setObjectName("label_67")
self._37.addWidget(self.label_67)
self.cea_tag_16 = QtWidgets.QLineEdit(self.tagmap_details_box)
self.cea_tag_16.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_tag_16.setObjectName("cea_tag_16")
self._37.addWidget(self.cea_tag_16)
self.cea_cond_16 = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_cond_16.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_cond_16.setObjectName("cea_cond_16")
self._37.addWidget(self.cea_cond_16)
self.gridLayout_14.addLayout(self._37, 16, 0, 1, 1)
self._38 = QtWidgets.QHBoxLayout()
self._38.setContentsMargins(0, 0, 0, 0)
self._38.setSpacing(6)
self._38.setObjectName("_38")
self.label_42 = QtWidgets.QLabel(self.tagmap_details_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_42.sizePolicy().hasHeightForWidth())
self.label_42.setSizePolicy(sizePolicy)
self.label_42.setLayoutDirection(QtCore.Qt.LeftToRight)
self.label_42.setLineWidth(1)
self.label_42.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignVCenter)
self.label_42.setObjectName("label_42")
self._38.addWidget(self.label_42)
self.label_17 = QtWidgets.QLabel(self.tagmap_details_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_17.sizePolicy().hasHeightForWidth())
self.label_17.setSizePolicy(sizePolicy)
self.label_17.setLayoutDirection(QtCore.Qt.RightToLeft)
self.label_17.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.label_17.setObjectName("label_17")
self._38.addWidget(self.label_17)
self.gridLayout_14.addLayout(self._38, 17, 0, 1, 1)
self.cea_tag_sort = QtWidgets.QCheckBox(self.tagmap_details_box)
self.cea_tag_sort.setLayoutDirection(QtCore.Qt.LeftToRight)
self.cea_tag_sort.setObjectName("cea_tag_sort")
self.gridLayout_14.addWidget(self.cea_tag_sort, 18, 0, 1, 1)
self.verticalLayout_3.addWidget(self.tagmap_details_box)
self.verticalLayout_33.addWidget(self.tagmap_details_frame)
self.scrollArea_4.setWidget(self.scrollAreaWidgetContents_8)
self.verticalLayout_28.addWidget(self.scrollArea_4)
self.tabWidget.addTab(self.Tag_mapping, "")
self.Advanced = QtWidgets.QWidget()
self.Advanced.setObjectName("Advanced")
self.horizontalLayout_31 = QtWidgets.QHBoxLayout(self.Advanced)
self.horizontalLayout_31.setObjectName("horizontalLayout_31")
self.scrollArea_2 = QtWidgets.QScrollArea(self.Advanced)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea_2.sizePolicy().hasHeightForWidth())
self.scrollArea_2.setSizePolicy(sizePolicy)
self.scrollArea_2.setWidgetResizable(True)
self.scrollArea_2.setObjectName("scrollArea_2")
self.scrollAreaWidgetContents_2 = QtWidgets.QWidget()
self.scrollAreaWidgetContents_2.setGeometry(QtCore.QRect(0, -853, 1084, 1707))
self.scrollAreaWidgetContents_2.setObjectName("scrollAreaWidgetContents_2")
self.verticalLayout_18 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents_2)
self.verticalLayout_18.setObjectName("verticalLayout_18")
self.advanced_general_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.advanced_general_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.advanced_general_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.advanced_general_frame.setObjectName("advanced_general_frame")
self.verticalLayout_55 = QtWidgets.QVBoxLayout(self.advanced_general_frame)
self.verticalLayout_55.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_55.setSpacing(0)
self.verticalLayout_55.setObjectName("verticalLayout_55")
self.label_110 = QtWidgets.QLabel(self.advanced_general_frame)
self.label_110.setStyleSheet("background-color: rgb(208, 208, 156);")
self.label_110.setObjectName("label_110")
self.verticalLayout_55.addWidget(self.label_110)
self.advanced_general_box = QtWidgets.QGroupBox(self.advanced_general_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.advanced_general_box.setPalette(palette)
self.advanced_general_box.setAutoFillBackground(False)
self.advanced_general_box.setStyleSheet("background-color: rgb(229, 229, 197);")
self.advanced_general_box.setTitle("")
self.advanced_general_box.setObjectName("advanced_general_box")
self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.advanced_general_box)
self.verticalLayout_5.setObjectName("verticalLayout_5")
self.ce_no_run = QtWidgets.QCheckBox(self.advanced_general_box)
self.ce_no_run.setObjectName("ce_no_run")
self.verticalLayout_5.addWidget(self.ce_no_run)
self.verticalLayout_55.addWidget(self.advanced_general_box)
self.verticalLayout_18.addWidget(self.advanced_general_frame)
self.advanced_artists_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.advanced_artists_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.advanced_artists_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.advanced_artists_frame.setObjectName("advanced_artists_frame")
self.verticalLayout_56 = QtWidgets.QVBoxLayout(self.advanced_artists_frame)
self.verticalLayout_56.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_56.setSpacing(0)
self.verticalLayout_56.setObjectName("verticalLayout_56")
self.advanced_artists_label = QtWidgets.QLabel(self.advanced_artists_frame)
self.advanced_artists_label.setStyleSheet("background-color: rgb(208, 208, 156);")
self.advanced_artists_label.setObjectName("advanced_artists_label")
self.verticalLayout_56.addWidget(self.advanced_artists_label)
self.advanced_artists_box = QtWidgets.QGroupBox(self.advanced_artists_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.advanced_artists_box.setPalette(palette)
self.advanced_artists_box.setAutoFillBackground(False)
self.advanced_artists_box.setStyleSheet("background-color: rgb(229, 229, 197);")
self.advanced_artists_box.setTitle("")
self.advanced_artists_box.setObjectName("advanced_artists_box")
self.verticalLayout_20 = QtWidgets.QVBoxLayout(self.advanced_artists_box)
self.verticalLayout_20.setObjectName("verticalLayout_20")
self.ensemble_strings_label = QtWidgets.QLabel(self.advanced_artists_box)
self.ensemble_strings_label.setObjectName("ensemble_strings_label")
self.verticalLayout_20.addWidget(self.ensemble_strings_label)
self.ensemble_strings_box = QtWidgets.QGroupBox(self.advanced_artists_box)
self.ensemble_strings_box.setTitle("")
self.ensemble_strings_box.setObjectName("ensemble_strings_box")
self._13 = QtWidgets.QVBoxLayout(self.ensemble_strings_box)
self._13.setContentsMargins(9, 9, 9, 9)
self._13.setSpacing(2)
self._13.setObjectName("_13")
self.cea_orchestras_2 = QtWidgets.QLabel(self.ensemble_strings_box)
self.cea_orchestras_2.setObjectName("cea_orchestras_2")
self._13.addWidget(self.cea_orchestras_2)
self.cea_orchestras = QtWidgets.QLineEdit(self.ensemble_strings_box)
self.cea_orchestras.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_orchestras.setObjectName("cea_orchestras")
self._13.addWidget(self.cea_orchestras)
self.cea_choirs_2 = QtWidgets.QLabel(self.ensemble_strings_box)
self.cea_choirs_2.setObjectName("cea_choirs_2")
self._13.addWidget(self.cea_choirs_2)
self.cea_choirs = QtWidgets.QLineEdit(self.ensemble_strings_box)
self.cea_choirs.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_choirs.setObjectName("cea_choirs")
self._13.addWidget(self.cea_choirs)
self.cea_groups_2 = QtWidgets.QLabel(self.ensemble_strings_box)
self.cea_groups_2.setObjectName("cea_groups_2")
self._13.addWidget(self.cea_groups_2)
self.cea_groups = QtWidgets.QLineEdit(self.ensemble_strings_box)
self.cea_groups.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_groups.setObjectName("cea_groups")
self._13.addWidget(self.cea_groups)
self.verticalLayout_20.addWidget(self.ensemble_strings_box)
self.verticalLayout_56.addWidget(self.advanced_artists_box)
self.verticalLayout_18.addWidget(self.advanced_artists_frame)
self.advanced_workparts_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.advanced_workparts_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.advanced_workparts_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.advanced_workparts_frame.setObjectName("advanced_workparts_frame")
self.verticalLayout_57 = QtWidgets.QVBoxLayout(self.advanced_workparts_frame)
self.verticalLayout_57.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_57.setSpacing(0)
self.verticalLayout_57.setObjectName("verticalLayout_57")
self.advanced_workparts_label = QtWidgets.QLabel(self.advanced_workparts_frame)
self.advanced_workparts_label.setStyleSheet("background-color: rgb(208, 208, 156);")
self.advanced_workparts_label.setObjectName("advanced_workparts_label")
self.verticalLayout_57.addWidget(self.advanced_workparts_label)
self.advanced_workparts_box = QtWidgets.QGroupBox(self.advanced_workparts_frame)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.advanced_workparts_box.sizePolicy().hasHeightForWidth())
self.advanced_workparts_box.setSizePolicy(sizePolicy)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.advanced_workparts_box.setPalette(palette)
self.advanced_workparts_box.setAutoFillBackground(False)
self.advanced_workparts_box.setStyleSheet("background-color: rgb(229, 229, 197);")
self.advanced_workparts_box.setTitle("")
self.advanced_workparts_box.setObjectName("advanced_workparts_box")
self.verticalLayout = QtWidgets.QVBoxLayout(self.advanced_workparts_box)
self.verticalLayout.setObjectName("verticalLayout")
self._2 = QtWidgets.QHBoxLayout()
self._2.setContentsMargins(0, 0, 0, 0)
self._2.setSpacing(6)
self._2.setObjectName("_2")
self.label_4 = QtWidgets.QLabel(self.advanced_workparts_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())
self.label_4.setSizePolicy(sizePolicy)
self.label_4.setObjectName("label_4")
self._2.addWidget(self.label_4)
self.cwp_retries = QtWidgets.QSpinBox(self.advanced_workparts_box)
self.cwp_retries.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_retries.setSuffix("")
self.cwp_retries.setMinimum(0)
self.cwp_retries.setMaximum(20)
self.cwp_retries.setObjectName("cwp_retries")
self._2.addWidget(self.cwp_retries)
self.verticalLayout.addLayout(self._2)
self._23 = QtWidgets.QHBoxLayout()
self._23.setContentsMargins(0, 0, 0, 0)
self._23.setSpacing(6)
self._23.setObjectName("_23")
self.label_120 = QtWidgets.QLabel(self.advanced_workparts_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_120.sizePolicy().hasHeightForWidth())
self.label_120.setSizePolicy(sizePolicy)
self.label_120.setObjectName("label_120")
self._23.addWidget(self.label_120)
self.cwp_allow_empty_parts = QtWidgets.QCheckBox(self.advanced_workparts_box)
self.cwp_allow_empty_parts.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cwp_allow_empty_parts.setText("")
self.cwp_allow_empty_parts.setObjectName("cwp_allow_empty_parts")
self._23.addWidget(self.cwp_allow_empty_parts)
self.verticalLayout.addLayout(self._23)
self.parent_child_text_box = QtWidgets.QGroupBox(self.advanced_workparts_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(241, 241, 167))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.parent_child_text_box.setPalette(palette)
self.parent_child_text_box.setAutoFillBackground(False)
self.parent_child_text_box.setStyleSheet("background-color: rgb(241, 241, 167);")
self.parent_child_text_box.setTitle("")
self.parent_child_text_box.setObjectName("parent_child_text_box")
self.verticalLayout_35 = QtWidgets.QVBoxLayout(self.parent_child_text_box)
self.verticalLayout_35.setObjectName("verticalLayout_35")
self.label_114 = QtWidgets.QLabel(self.parent_child_text_box)
self.label_114.setObjectName("label_114")
self.verticalLayout_35.addWidget(self.label_114)
self._22 = QtWidgets.QHBoxLayout()
self._22.setContentsMargins(0, 0, 0, 0)
self._22.setSpacing(6)
self._22.setObjectName("_22")
self.label_90 = QtWidgets.QLabel(self.parent_child_text_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_90.sizePolicy().hasHeightForWidth())
self.label_90.setSizePolicy(sizePolicy)
self.label_90.setObjectName("label_90")
self._22.addWidget(self.label_90)
self.cwp_common_chars = QtWidgets.QSpinBox(self.parent_child_text_box)
self.cwp_common_chars.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_common_chars.setSuffix("")
self.cwp_common_chars.setMinimum(0)
self.cwp_common_chars.setMaximum(99)
self.cwp_common_chars.setObjectName("cwp_common_chars")
self._22.addWidget(self.cwp_common_chars)
self.verticalLayout_35.addLayout(self._22)
self.label_89 = QtWidgets.QLabel(self.parent_child_text_box)
self.label_89.setObjectName("label_89")
self.verticalLayout_35.addWidget(self.label_89)
self.verticalLayout.addWidget(self.parent_child_text_box)
self.title_metadata_box = QtWidgets.QGroupBox(self.advanced_workparts_box)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(202, 202, 140))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.title_metadata_box.setPalette(palette)
self.title_metadata_box.setAutoFillBackground(False)
self.title_metadata_box.setStyleSheet("background-color: rgb(202, 202, 140);")
self.title_metadata_box.setTitle("")
self.title_metadata_box.setObjectName("title_metadata_box")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.title_metadata_box)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.label_115 = QtWidgets.QLabel(self.title_metadata_box)
self.label_115.setObjectName("label_115")
self.verticalLayout_2.addWidget(self.label_115)
self._3 = QtWidgets.QHBoxLayout()
self._3.setContentsMargins(0, 0, 0, 0)
self._3.setSpacing(6)
self._3.setObjectName("_3")
self.label_6 = QtWidgets.QLabel(self.title_metadata_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_6.sizePolicy().hasHeightForWidth())
self.label_6.setSizePolicy(sizePolicy)
self.label_6.setObjectName("label_6")
self._3.addWidget(self.label_6)
self.cwp_proximity = QtWidgets.QSpinBox(self.title_metadata_box)
self.cwp_proximity.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_proximity.setSuffix("")
self.cwp_proximity.setMaximum(99)
self.cwp_proximity.setObjectName("cwp_proximity")
self._3.addWidget(self.cwp_proximity)
self.verticalLayout_2.addLayout(self._3)
self._4 = QtWidgets.QHBoxLayout()
self._4.setContentsMargins(0, 0, 0, 0)
self._4.setSpacing(6)
self._4.setObjectName("_4")
self.label_7 = QtWidgets.QLabel(self.title_metadata_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_7.sizePolicy().hasHeightForWidth())
self.label_7.setSizePolicy(sizePolicy)
self.label_7.setObjectName("label_7")
self._4.addWidget(self.label_7)
self.cwp_end_proximity = QtWidgets.QSpinBox(self.title_metadata_box)
self.cwp_end_proximity.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_end_proximity.setSuffix("")
self.cwp_end_proximity.setMaximum(99)
self.cwp_end_proximity.setObjectName("cwp_end_proximity")
self._4.addWidget(self.cwp_end_proximity)
self.verticalLayout_2.addLayout(self._4)
self._5 = QtWidgets.QHBoxLayout()
self._5.setContentsMargins(0, 0, 0, 0)
self._5.setSpacing(6)
self._5.setObjectName("_5")
self.label_5 = QtWidgets.QLabel(self.title_metadata_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_5.sizePolicy().hasHeightForWidth())
self.label_5.setSizePolicy(sizePolicy)
self.label_5.setObjectName("label_5")
self._5.addWidget(self.label_5)
self.cwp_split_hyphenated = QtWidgets.QCheckBox(self.title_metadata_box)
self.cwp_split_hyphenated.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cwp_split_hyphenated.setText("")
self.cwp_split_hyphenated.setObjectName("cwp_split_hyphenated")
self._5.addWidget(self.cwp_split_hyphenated)
self.verticalLayout_2.addLayout(self._5)
self._25 = QtWidgets.QHBoxLayout()
self._25.setContentsMargins(0, 0, 0, 0)
self._25.setSpacing(6)
self._25.setObjectName("_25")
self.label_93 = QtWidgets.QLabel(self.title_metadata_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_93.sizePolicy().hasHeightForWidth())
self.label_93.setSizePolicy(sizePolicy)
self.label_93.setObjectName("label_93")
self._25.addWidget(self.label_93)
self.cwp_substring_match = QtWidgets.QSpinBox(self.title_metadata_box)
self.cwp_substring_match.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_substring_match.setMaximum(100)
self.cwp_substring_match.setObjectName("cwp_substring_match")
self._25.addWidget(self.cwp_substring_match)
self.verticalLayout_2.addLayout(self._25)
self._7 = QtWidgets.QHBoxLayout()
self._7.setContentsMargins(0, 0, 0, 0)
self._7.setSpacing(6)
self._7.setObjectName("_7")
self.label_87 = QtWidgets.QLabel(self.title_metadata_box)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_87.sizePolicy().hasHeightForWidth())
self.label_87.setSizePolicy(sizePolicy)
self.label_87.setObjectName("label_87")
self._7.addWidget(self.label_87)
self.cwp_fill_part = QtWidgets.QCheckBox(self.title_metadata_box)
self.cwp_fill_part.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cwp_fill_part.setText("")
self.cwp_fill_part.setObjectName("cwp_fill_part")
self._7.addWidget(self.cwp_fill_part)
self.verticalLayout_2.addLayout(self._7)
self.line_8 = QtWidgets.QFrame(self.title_metadata_box)
self.line_8.setFrameShape(QtWidgets.QFrame.HLine)
self.line_8.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_8.setObjectName("line_8")
self.verticalLayout_2.addWidget(self.line_8)
self.label_92 = QtWidgets.QLabel(self.title_metadata_box)
self.label_92.setObjectName("label_92")
self.verticalLayout_2.addWidget(self.label_92)
self.label_91 = QtWidgets.QLabel(self.title_metadata_box)
self.label_91.setObjectName("label_91")
self.verticalLayout_2.addWidget(self.label_91)
self.cwp_prepositions = QtWidgets.QLineEdit(self.title_metadata_box)
self.cwp_prepositions.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_prepositions.setObjectName("cwp_prepositions")
self.verticalLayout_2.addWidget(self.cwp_prepositions)
self.cwp_removewords_2 = QtWidgets.QLabel(self.title_metadata_box)
self.cwp_removewords_2.setObjectName("cwp_removewords_2")
self.verticalLayout_2.addWidget(self.cwp_removewords_2)
self.cwp_removewords = QtWidgets.QLineEdit(self.title_metadata_box)
self.cwp_removewords.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_removewords.setObjectName("cwp_removewords")
self.verticalLayout_2.addWidget(self.cwp_removewords)
self.line = QtWidgets.QFrame(self.title_metadata_box)
self.line.setFrameShape(QtWidgets.QFrame.HLine)
self.line.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line.setObjectName("line")
self.verticalLayout_2.addWidget(self.line)
self.cwp_synonyms_2 = QtWidgets.QLabel(self.title_metadata_box)
self.cwp_synonyms_2.setObjectName("cwp_synonyms_2")
self.verticalLayout_2.addWidget(self.cwp_synonyms_2)
self.cwp_synonyms = QtWidgets.QTextEdit(self.title_metadata_box)
self.cwp_synonyms.setMaximumSize(QtCore.QSize(16777215, 120))
self.cwp_synonyms.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_synonyms.setObjectName("cwp_synonyms")
self.verticalLayout_2.addWidget(self.cwp_synonyms)
self.label_16 = QtWidgets.QLabel(self.title_metadata_box)
self.label_16.setObjectName("label_16")
self.verticalLayout_2.addWidget(self.label_16)
self.cwp_replacements = QtWidgets.QLineEdit(self.title_metadata_box)
self.cwp_replacements.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_replacements.setObjectName("cwp_replacements")
self.verticalLayout_2.addWidget(self.cwp_replacements)
self.verticalLayout.addWidget(self.title_metadata_box)
self.verticalLayout_57.addWidget(self.advanced_workparts_box)
self.verticalLayout_18.addWidget(self.advanced_workparts_frame)
self.advanced_genres_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.advanced_genres_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.advanced_genres_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.advanced_genres_frame.setObjectName("advanced_genres_frame")
self.verticalLayout_58 = QtWidgets.QVBoxLayout(self.advanced_genres_frame)
self.verticalLayout_58.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_58.setSpacing(0)
self.verticalLayout_58.setObjectName("verticalLayout_58")
self.advanced_genres_label = QtWidgets.QLabel(self.advanced_genres_frame)
self.advanced_genres_label.setStyleSheet("background-color: rgb(208, 208, 156);")
self.advanced_genres_label.setObjectName("advanced_genres_label")
self.verticalLayout_58.addWidget(self.advanced_genres_label)
self.advanced_genres_box = QtWidgets.QGroupBox(self.advanced_genres_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.advanced_genres_box.setPalette(palette)
self.advanced_genres_box.setAutoFillBackground(False)
self.advanced_genres_box.setStyleSheet("background-color: rgb(229, 229, 197);")
self.advanced_genres_box.setTitle("")
self.advanced_genres_box.setObjectName("advanced_genres_box")
self.gridLayout_8 = QtWidgets.QGridLayout(self.advanced_genres_box)
self.gridLayout_8.setObjectName("gridLayout_8")
self.label_85 = QtWidgets.QLabel(self.advanced_genres_box)
self.label_85.setObjectName("label_85")
self.gridLayout_8.addWidget(self.label_85, 1, 0, 1, 1)
self.cwp_muso_refdb = QtWidgets.QLineEdit(self.advanced_genres_box)
self.cwp_muso_refdb.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_muso_refdb.setObjectName("cwp_muso_refdb")
self.gridLayout_8.addWidget(self.cwp_muso_refdb, 1, 3, 1, 1)
self.label_84 = QtWidgets.QLabel(self.advanced_genres_box)
self.label_84.setObjectName("label_84")
self.gridLayout_8.addWidget(self.label_84, 1, 2, 1, 1)
self.cwp_muso_path = QtWidgets.QLineEdit(self.advanced_genres_box)
self.cwp_muso_path.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_muso_path.setObjectName("cwp_muso_path")
self.gridLayout_8.addWidget(self.cwp_muso_path, 1, 1, 1, 1)
self.label_86 = QtWidgets.QLabel(self.advanced_genres_box)
self.label_86.setObjectName("label_86")
self.gridLayout_8.addWidget(self.label_86, 0, 0, 1, 2)
self.verticalLayout_58.addWidget(self.advanced_genres_box)
self.verticalLayout_18.addWidget(self.advanced_genres_frame)
self.logging_frame = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.logging_frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.logging_frame.setFrameShadow(QtWidgets.QFrame.Raised)
self.logging_frame.setObjectName("logging_frame")
self.verticalLayout_59 = QtWidgets.QVBoxLayout(self.logging_frame)
self.verticalLayout_59.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_59.setSpacing(0)
self.verticalLayout_59.setObjectName("verticalLayout_59")
self.label_117 = QtWidgets.QLabel(self.logging_frame)
self.label_117.setStyleSheet("background-color: rgb(208, 208, 156);")
self.label_117.setObjectName("label_117")
self.verticalLayout_59.addWidget(self.label_117)
self.logging_box = QtWidgets.QGroupBox(self.logging_frame)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.logging_box.setPalette(palette)
self.logging_box.setLayoutDirection(QtCore.Qt.LeftToRight)
self.logging_box.setAutoFillBackground(False)
self.logging_box.setStyleSheet("background-color: rgb(229, 229, 197);")
self.logging_box.setTitle("")
self.logging_box.setObjectName("logging_box")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout(self.logging_box)
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.log_error = QtWidgets.QCheckBox(self.logging_box)
self.log_error.setObjectName("log_error")
self.horizontalLayout_2.addWidget(self.log_error)
self.log_warning = QtWidgets.QCheckBox(self.logging_box)
self.log_warning.setObjectName("log_warning")
self.horizontalLayout_2.addWidget(self.log_warning)
self.log_debug = QtWidgets.QCheckBox(self.logging_box)
self.log_debug.setObjectName("log_debug")
self.horizontalLayout_2.addWidget(self.log_debug)
self.custom_logging_box = QtWidgets.QGroupBox(self.logging_box)
self.custom_logging_box.setStyleSheet("background-color: rgb(229, 229, 159);")
self.custom_logging_box.setObjectName("custom_logging_box")
self.horizontalLayout_34 = QtWidgets.QHBoxLayout(self.custom_logging_box)
self.horizontalLayout_34.setObjectName("horizontalLayout_34")
self.log_basic = QtWidgets.QRadioButton(self.custom_logging_box)
self.log_basic.setObjectName("log_basic")
self.horizontalLayout_34.addWidget(self.log_basic)
self.log_info = QtWidgets.QRadioButton(self.custom_logging_box)
self.log_info.setObjectName("log_info")
self.horizontalLayout_34.addWidget(self.log_info)
self.horizontalLayout_2.addWidget(self.custom_logging_box)
self.verticalLayout_59.addWidget(self.logging_box)
self.verticalLayout_18.addWidget(self.logging_frame)
self.special_tags_frame_outer = QtWidgets.QFrame(self.scrollAreaWidgetContents_2)
self.special_tags_frame_outer.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.special_tags_frame_outer.setFrameShadow(QtWidgets.QFrame.Raised)
self.special_tags_frame_outer.setObjectName("special_tags_frame_outer")
self.verticalLayout_60 = QtWidgets.QVBoxLayout(self.special_tags_frame_outer)
self.verticalLayout_60.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_60.setSpacing(0)
self.verticalLayout_60.setObjectName("verticalLayout_60")
self.label_118 = QtWidgets.QLabel(self.special_tags_frame_outer)
self.label_118.setStyleSheet("background-color: rgb(208, 208, 156);")
self.label_118.setObjectName("label_118")
self.verticalLayout_60.addWidget(self.label_118)
self.special_tags_frame_inner = QtWidgets.QFrame(self.special_tags_frame_outer)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 197))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.special_tags_frame_inner.setPalette(palette)
self.special_tags_frame_inner.setAutoFillBackground(False)
self.special_tags_frame_inner.setStyleSheet("background-color: rgb(229, 229, 197);")
self.special_tags_frame_inner.setFrameShape(QtWidgets.QFrame.StyledPanel)
self.special_tags_frame_inner.setFrameShadow(QtWidgets.QFrame.Raised)
self.special_tags_frame_inner.setObjectName("special_tags_frame_inner")
self.verticalLayout_16 = QtWidgets.QVBoxLayout(self.special_tags_frame_inner)
self.verticalLayout_16.setObjectName("verticalLayout_16")
self.save_options_box = QtWidgets.QGroupBox(self.special_tags_frame_inner)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.save_options_box.setPalette(palette)
self.save_options_box.setAutoFillBackground(False)
self.save_options_box.setStyleSheet("background-color: rgb(229, 229, 159);")
self.save_options_box.setObjectName("save_options_box")
self.horizontalLayout_4 = QtWidgets.QHBoxLayout(self.save_options_box)
self.horizontalLayout_4.setObjectName("horizontalLayout_4")
self.label_41 = QtWidgets.QLabel(self.save_options_box)
self.label_41.setObjectName("label_41")
self.horizontalLayout_4.addWidget(self.label_41)
self.ce_version_tag = QtWidgets.QLineEdit(self.save_options_box)
self.ce_version_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.ce_version_tag.setObjectName("ce_version_tag")
self.horizontalLayout_4.addWidget(self.ce_version_tag)
self.label_36 = QtWidgets.QLabel(self.save_options_box)
self.label_36.setLayoutDirection(QtCore.Qt.RightToLeft)
self.label_36.setObjectName("label_36")
self.horizontalLayout_4.addWidget(self.label_36)
self.cea_options_tag = QtWidgets.QLineEdit(self.save_options_box)
self.cea_options_tag.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cea_options_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cea_options_tag.setObjectName("cea_options_tag")
self.horizontalLayout_4.addWidget(self.cea_options_tag)
self.label_38 = QtWidgets.QLabel(self.save_options_box)
self.label_38.setLayoutDirection(QtCore.Qt.RightToLeft)
self.label_38.setObjectName("label_38")
self.horizontalLayout_4.addWidget(self.label_38)
self.cwp_options_tag = QtWidgets.QLineEdit(self.save_options_box)
self.cwp_options_tag.setLayoutDirection(QtCore.Qt.RightToLeft)
self.cwp_options_tag.setStyleSheet("background-color: rgb(250, 250, 250);")
self.cwp_options_tag.setObjectName("cwp_options_tag")
self.horizontalLayout_4.addWidget(self.cwp_options_tag)
self.verticalLayout_16.addWidget(self.save_options_box)
self.override_box = QtWidgets.QGroupBox(self.special_tags_frame_inner)
palette = QtGui.QPalette()
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)
brush = QtGui.QBrush(QtGui.QColor(229, 229, 159))
brush.setStyle(QtCore.Qt.SolidPattern)
palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)
self.override_box.setPalette(palette)
self.override_box.setAutoFillBackground(False)
self.override_box.setStyleSheet("background-color: rgb(229, 229, 159);")
self.override_box.setObjectName("override_box")
self.horizontalLayout_10 = QtWidgets.QHBoxLayout(self.override_box)
self.horizontalLayout_10.setObjectName("horizontalLayout_10")
self.cea_override = QtWidgets.QCheckBox(self.override_box)
self.cea_override.setObjectName("cea_override")
self.horizontalLayout_10.addWidget(self.cea_override)
self.cwp_override = QtWidgets.QCheckBox(self.override_box)
self.cwp_override.setObjectName("cwp_override")
self.horizontalLayout_10.addWidget(self.cwp_override)
self.ce_genres_override = QtWidgets.QCheckBox(self.override_box)
self.ce_genres_override.setEnabled(True)
self.ce_genres_override.setObjectName("ce_genres_override")
self.horizontalLayout_10.addWidget(self.ce_genres_override)
self.ce_tagmap_override = QtWidgets.QCheckBox(self.override_box)
self.ce_tagmap_override.setEnabled(True)
self.ce_tagmap_override.setObjectName("ce_tagmap_override")
self.horizontalLayout_10.addWidget(self.ce_tagmap_override)
self.line_11 = QtWidgets.QFrame(self.override_box)
self.line_11.setFrameShape(QtWidgets.QFrame.VLine)
self.line_11.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_11.setObjectName("line_11")
self.horizontalLayout_10.addWidget(self.line_11)
self.ce_options_overwrite = QtWidgets.QCheckBox(self.override_box)
self.ce_options_overwrite.setStyleSheet("background-color: rgb(255, 0, 0);")
self.ce_options_overwrite.setObjectName("ce_options_overwrite")
self.horizontalLayout_10.addWidget(self.ce_options_overwrite)
self.verticalLayout_16.addWidget(self.override_box)
self.label_121 = QtWidgets.QLabel(self.special_tags_frame_inner)
self.label_121.setObjectName("label_121")
self.verticalLayout_16.addWidget(self.label_121)
self.line_2 = QtWidgets.QFrame(self.special_tags_frame_inner)
self.line_2.setFrameShape(QtWidgets.QFrame.HLine)
self.line_2.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line_2.setObjectName("line_2")
self.verticalLayout_16.addWidget(self.line_2)
self.ce_show_ui_tags = QtWidgets.QCheckBox(self.special_tags_frame_inner)
self.ce_show_ui_tags.setObjectName("ce_show_ui_tags")
self.verticalLayout_16.addWidget(self.ce_show_ui_tags)
self.groupBox = QtWidgets.QGroupBox(self.special_tags_frame_inner)
self.groupBox.setStyleSheet("background-color: rgb(229, 229, 159);")
self.groupBox.setObjectName("groupBox")
self.verticalLayout_42 = QtWidgets.QVBoxLayout(self.groupBox)
self.verticalLayout_42.setObjectName("verticalLayout_42")
self.label_94 = QtWidgets.QLabel(self.groupBox)
self.label_94.setObjectName("label_94")
self.verticalLayout_42.addWidget(self.label_94)
self.ce_ui_tags = QtWidgets.QTextEdit(self.groupBox)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.ce_ui_tags.sizePolicy().hasHeightForWidth())
self.ce_ui_tags.setSizePolicy(sizePolicy)
self.ce_ui_tags.setMaximumSize(QtCore.QSize(16777215, 120))
self.ce_ui_tags.setStyleSheet("background-color: rgb(250, 250, 250);")
self.ce_ui_tags.setObjectName("ce_ui_tags")
self.verticalLayout_42.addWidget(self.ce_ui_tags)
self.label_8 = QtWidgets.QLabel(self.groupBox)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_8.sizePolicy().hasHeightForWidth())
self.label_8.setSizePolicy(sizePolicy)
self.label_8.setObjectName("label_8")
self.verticalLayout_42.addWidget(self.label_8)
self.verticalLayout_16.addWidget(self.groupBox)
self.verticalLayout_60.addWidget(self.special_tags_frame_inner)
self.verticalLayout_18.addWidget(self.special_tags_frame_outer)
self.label_83 = QtWidgets.QLabel(self.scrollAreaWidgetContents_2)
self.label_83.setObjectName("label_83")
self.verticalLayout_18.addWidget(self.label_83)
self.scrollArea_2.setWidget(self.scrollAreaWidgetContents_2)
self.horizontalLayout_31.addWidget(self.scrollArea_2)
self.tabWidget.addTab(self.Advanced, "")
self.Help = QtWidgets.QWidget()
self.Help.setObjectName("Help")
self.scrollArea_5 = QtWidgets.QScrollArea(self.Help)
self.scrollArea_5.setGeometry(QtCore.QRect(0, -10, 671, 561))
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea_5.sizePolicy().hasHeightForWidth())
self.scrollArea_5.setSizePolicy(sizePolicy)
self.scrollArea_5.setWidgetResizable(True)
self.scrollArea_5.setObjectName("scrollArea_5")
self.scrollAreaWidgetContents_4 = QtWidgets.QWidget()
self.scrollAreaWidgetContents_4.setGeometry(QtCore.QRect(0, 0, 669, 559))
self.scrollAreaWidgetContents_4.setObjectName("scrollAreaWidgetContents_4")
self.textBrowser_2 = QtWidgets.QTextBrowser(self.scrollAreaWidgetContents_4)
self.textBrowser_2.setGeometry(QtCore.QRect(9, 109, 641, 421))
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Expanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.textBrowser_2.sizePolicy().hasHeightForWidth())
self.textBrowser_2.setSizePolicy(sizePolicy)
self.textBrowser_2.setHorizontalScrollBarPolicy(QtCore.Qt.ScrollBarAsNeeded)
self.textBrowser_2.setOpenExternalLinks(True)
self.textBrowser_2.setObjectName("textBrowser_2")
self.label_58 = QtWidgets.QLabel(self.scrollAreaWidgetContents_4)
self.label_58.setGeometry(QtCore.QRect(9, 9, 471, 16))
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Maximum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_58.sizePolicy().hasHeightForWidth())
self.label_58.setSizePolicy(sizePolicy)
self.label_58.setText("")
self.label_58.setObjectName("label_58")
self.textBrowser_3 = QtWidgets.QTextBrowser(self.scrollAreaWidgetContents_4)
self.textBrowser_3.setGeometry(QtCore.QRect(9, 28, 641, 81))
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Expanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.textBrowser_3.sizePolicy().hasHeightForWidth())
self.textBrowser_3.setSizePolicy(sizePolicy)
self.textBrowser_3.setOpenExternalLinks(True)
self.textBrowser_3.setObjectName("textBrowser_3")
self.scrollArea_5.setWidget(self.scrollAreaWidgetContents_4)
self.tabWidget.addTab(self.Help, "")
self.vboxlayout.addWidget(self.tabWidget)
self.label_4.setBuddy(self.cwp_retries)
self.label_120.setBuddy(self.cwp_retries)
self.label_90.setBuddy(self.cwp_retries)
self.label_6.setBuddy(self.cwp_retries)
self.label_7.setBuddy(self.cwp_retries)
self.label_5.setBuddy(self.cwp_retries)
self.label_93.setBuddy(self.cwp_retries)
self.label_87.setBuddy(self.cwp_retries)
self.retranslateUi(ClassicalExtrasOptionsPage)
self.tabWidget.setCurrentIndex(4)
self.cea_ra_use.toggled['bool'].connect(self.ra_replace_merge_options_box.setEnabled)
self.cea_ra_replace_ta.toggled['bool'].connect(self.cea_ra_noblank_ta.setEnabled)
self.use_cea.toggled['bool'].connect(self.lyrics_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.cwp_collections.setEnabled)
self.cea_split_lyrics.toggled['bool'].connect(self.lyrics_and_notes_tags_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.use_cache.setEnabled)
self.use_cea.toggled['bool'].connect(self.other_artist_options_frame.setEnabled)
self.cea_arrangers.toggled['bool'].connect(self.annotations_lh_box.setEnabled)
self.cea_arrangers.toggled['bool'].connect(self.annotations_rh_box.setEnabled)
self.toolButton_1.toggled['bool'].connect(self.cea_source_1.setEnabled)
self.toolButton_2.toggled['bool'].connect(self.cea_source_2.setEnabled)
self.toolButton_3.toggled['bool'].connect(self.cea_source_3.setEnabled)
self.toolButton_4.toggled['bool'].connect(self.cea_source_4.setEnabled)
self.toolButton_5.toggled['bool'].connect(self.cea_source_5.setEnabled)
self.toolButton_6.toggled['bool'].connect(self.cea_source_6.setEnabled)
self.toolButton_7.toggled['bool'].connect(self.cea_source_7.setEnabled)
self.toolButton_8.toggled['bool'].connect(self.cea_source_8.setEnabled)
self.toolButton_9.toggled['bool'].connect(self.cea_source_9.setEnabled)
self.toolButton_10.toggled['bool'].connect(self.cea_source_10.setEnabled)
self.toolButton_11.toggled['bool'].connect(self.cea_source_11.setEnabled)
self.toolButton_12.toggled['bool'].connect(self.cea_source_12.setEnabled)
self.toolButton_13.toggled['bool'].connect(self.cea_source_13.setEnabled)
self.toolButton_14.toggled['bool'].connect(self.cea_source_14.setEnabled)
self.toolButton_15.toggled['bool'].connect(self.cea_source_15.setEnabled)
self.toolButton_16.toggled['bool'].connect(self.cea_source_16.setEnabled)
self.use_cea.toggled['bool'].connect(self.advanced_artists_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.advanced_workparts_frame.setEnabled)
self.use_cea.toggled['bool'].connect(self.naming_options_frame.setEnabled)
self.use_cea.toggled['bool'].connect(self.recording_artists_options_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.work_style_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.work_aliases_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.works_parts_tags_frame.setEnabled)
self.use_cwp.toggled['bool'].connect(self.songkong_frame.setEnabled)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_genres.setVisible)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_genres.setChecked)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_classical.setVisible)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_classical.setChecked)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_dates.setVisible)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_periods.setVisible)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_dates.setChecked)
self.cwp_use_muso_refdb.toggled['bool'].connect(self.cwp_muso_periods.setChecked)
self.cwp_muso_genres.toggled['bool'].connect(self.cwp_genres_classical_main.setHidden)
self.cwp_muso_classical.toggled['bool'].connect(self.cwp_genres_arranger_as_composer.setVisible)
self.cwp_muso_dates.toggled['bool'].connect(self.cwp_periods_arranger_as_composer.setVisible)
self.cwp_muso_periods.toggled['bool'].connect(self.cwp_period_map.setHidden)
self.cwp_muso_periods.toggled['bool'].connect(self.period_map_annotation_label.setHidden)
self.cwp_genres_filter.toggled['bool'].connect(self.genre_filters_frame.setVisible)
self.use_cwp.toggled['bool'].connect(self.partial_arrangements_medleys_frame.setEnabled)
self.cwp_titles.toggled['bool'].connect(self.source_of_canonical_box.setDisabled)
self.cwp_titles.toggled['bool'].connect(self.partial_arrangements_medleys_frame.setHidden)
self.use_cache.toggled['bool'].connect(self.cwp_use_sk.setEnabled)
self.ce_show_ui_tags.toggled['bool'].connect(self.groupBox.setVisible)
QtCore.QMetaObject.connectSlotsByName(ClassicalExtrasOptionsPage)
def retranslateUi(self, ClassicalExtrasOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.Artists.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.use_cea.setToolTip(_translate("ClassicalExtrasOptionsPage", "should be selected otherwise this section will not run
"))
self.use_cea.setText(_translate("ClassicalExtrasOptionsPage", "Create extra artist metadata (MUST BE TICKED FOR THIS SECTION TO RUN)"))
self.infer_worktypes_old_label.setText(_translate("ClassicalExtrasOptionsPage", "(Note that the \"infer work-types\" option has moved to the \"genres\" tab)"))
self.naming_style_note_label.setText(_translate("ClassicalExtrasOptionsPage", "The naming style for \'artist\' tags is set in the main Picard Options->Metadata section
"))
self.naming_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Work-artist / performer naming options
"))
self.naming_options_frame.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Work-artists" are types such as composer, writer, arranger and lyricist who belong to the MusicBrainz Work-Artist relationship
"Performers" are types such as performer and conductor who belong to the MusicBrainz Recording-Artist relationship
"))
self.label_22.setText(_translate("ClassicalExtrasOptionsPage", "This section does not change the contents of "artist" or "album artist" tags - it only affects writer (composer etc.) and peformer tags, by using as-credited/alias names from the artist data for the release.
"))
self.credited_as_options_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.credited_as_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Credited-as options:-"))
self.names_to_use_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select the source for \'as-credited\' names - whether these are applied depends on the sub-options choices.
"))
self.names_to_use_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Names to use..."))
self.cea_recording_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use \"credited as\" name for work-artists/performers who are recording artists"))
self.cea_group_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release group artists"))
self.cea_credited.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.cea_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release artists"))
self.cea_release_relationship_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or release relationship artists"))
self.cea_recording_relationship_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or recording relationship artists"))
self.cea_track_credited.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.cea_track_credited.setText(_translate("ClassicalExtrasOptionsPage", "and/or track artists"))
self.label_24.setText(_translate("ClassicalExtrasOptionsPage", "The above are applied in sequence - e.g. track artist credit will over-ride release artist credit."))
self.label_88.setText(_translate("ClassicalExtrasOptionsPage", "Names are cached. A restart is necessary if any of the above name sources are removed."))
self.places_to_use_them_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select the tag types where any \'as-credited\' names will be applied - whether these are applied depends on the sub-options choices.
"))
self.places_to_use_them_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Places to use them ..."))
self.cea_performer_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use for performing artists"))
self.cea_composer_credited.setText(_translate("ClassicalExtrasOptionsPage", "Use for work-artists"))
self.naming_sub_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Sub-options"))
self.cea_alias_overrides.setToolTip(_translate("ClassicalExtrasOptionsPage", "Alias (if it exists) will over-ride as-credited
"))
self.cea_alias_overrides.setText(_translate("ClassicalExtrasOptionsPage", "Alias over-rides credited-as"))
self.cea_credited_overrides.setToolTip(_translate("ClassicalExtrasOptionsPage", "As-credited (if it exists) will over-ride alias
"))
self.cea_credited_overrides.setText(_translate("ClassicalExtrasOptionsPage", "Credited-as over-rides MB/Alias"))
self.cea_cyrillic.setToolTip(_translate("ClassicalExtrasOptionsPage", "Will be based on sort names. For cyrillic script names, patronyms will be removed.
"))
self.cea_cyrillic.setText(_translate("ClassicalExtrasOptionsPage", "Fix non-Latin text in names (where possible and if not fixed by other naming options)"))
self.MB_std_names_aliases_box_outer.setTitle(_translate("ClassicalExtrasOptionsPage", "MusicBrainz standard names and Aliases"))
self.cea_no_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Do not use aliases (but may be replaced by as-credited name)
"))
self.cea_no_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Use MB standard names"))
self.cea_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Alias will only be available for use if the work-artist/performer is also a release artist, recording artist or track artist.
"))
self.cea_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Use alias for all work-artists/performers"))
self.cea_aliases_composer.setToolTip(_translate("ClassicalExtrasOptionsPage", "Only use alias (if available) for work-artists (writers, composers, arrangers, lyricists etc.)
"))
self.cea_aliases_composer.setText(_translate("ClassicalExtrasOptionsPage", "Use alias for work-artists only"))
self.recording_artist_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Recording artist options
"))
self.recording_artists_options_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select recording artist options (see "What\'s this")
"))
self.recording_artists_options_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "In MusicBrainz, the recording artist may be different from the track artist. For classical music, the MusicBrainz guidelines state that the track artist should be the composer; however the recording artist(s) is/are usually the principal performer(s).
Classical Extras puts the recording artists into \'hidden variables\' (as a minimum) using the chosen naming convention.
There is also option to allow you to replace the track artist by the recording artist (or to merge them). The chosen action will be applied to the \'artist\', \'artists\', \'artistsort\' and \'artists_sort\' tags. Note that \'artist\' is a single-valued string whereas \'artists\' is a list and may be multi-valued. Lists are properly merged, but because the \'artist\' string may have different join-phrases etc, a merged tag may have the recording artist(s) in brackets after the track artist(s).
"))
self.naming_convention_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "In classical music (in MusicBrainz), recording artists will usually be performers whereas track artists are composers. By default, the naming convention for performers (set in the previous section) will be used (although only the as-credited name set for the recording artist will be applied). Alternatively, the naming convention for track artists can be used - which is determined by the main Picard metadat options.
"))
self.naming_convention_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Naming convention as for ..."))
self.cea_ra_trackartist.setText(_translate("ClassicalExtrasOptionsPage", "...track artist (set in Picard options)"))
self.cea_ra_performer.setText(_translate("ClassicalExtrasOptionsPage", "... perfomers (set above)"))
self.cea_ra_use.setText(_translate("ClassicalExtrasOptionsPage", "Use recording artists to update track artists ->"))
self.ra_replace_merge_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Replace/merge options"))
self.cea_ra_replace_ta.setText(_translate("ClassicalExtrasOptionsPage", "Replace track artist by recording artist"))
self.cea_ra_noblank_ta.setText(_translate("ClassicalExtrasOptionsPage", "Only replace if rec. artist exists"))
self.cea_ra_merge_ta.setText(_translate("ClassicalExtrasOptionsPage", "Merge track artist and recording artist"))
self.other_artist_options_label.setText(_translate("ClassicalExtrasOptionsPage", "Other artist options
"))
self.annotations_lh_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text to appear in annotations. Do not use any quotation marks.
"))
self.annotations_lh_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Annotations - performers and lyricists"))
self.label_44.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation to include with "chorus master" in conductor tag.
"))
self.label_44.setText(_translate("ClassicalExtrasOptionsPage", "Chorus Master"))
self.label_46.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation to include for "concert master" in performer tag.
"))
self.label_46.setText(_translate("ClassicalExtrasOptionsPage", "Concert Master"))
self.label_34.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for lyricist, to include in lyricist tag
"))
self.label_34.setText(_translate("ClassicalExtrasOptionsPage", "Lyricist"))
self.label_26.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for librettist, to include in lyricist tag
"))
self.label_26.setText(_translate("ClassicalExtrasOptionsPage", "Librettist"))
self.label_30.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for translator, to include in lyricist tag
"))
self.label_30.setText(_translate("ClassicalExtrasOptionsPage", "Translator"))
self.other_artist_checkboxes_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select as required. See "What\'s this" for details.
"))
self.cea_arrangers.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.cea_arrangers.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will gather together, for example, any arranger-type information from the recording, work or parent works and place it in the "arranger" tag (\'host\' tag), with the annotation (see details to right of this box) in brackets. All arranger types will also be put in a hidden variable, e.g. _cwp_orchestrators. The table below shows the artist types, host tag and hidden variable for each artist type.
| Artist type | Host tag | Hidden variable |
| ----------------- | ------------------| -------------------------------------- |
| writer | composer | writers |
| lyricist | lyricist | lyricists |
| librettist | lyricist | librettists |
| revised by | arranger | revisors |
| translator | lyricist | translators |
| arranger | arranger | arrangers |
| reconstructed by | arranger | reconstructors |
| orchestrator | arranger | orchestrators |
| instrument arranger | arranger | arrangers (with instrument type in brackets) |
| vocal arranger | arranger | arrangers (with voice type in brackets) |
| chorus master | conductor | chorusmasters |
| concertmaster | performer (with annotation as a sub-key) | leaders |
"))
self.cea_arrangers.setText(_translate("ClassicalExtrasOptionsPage", "Modify host tags and include annotations (see =>)"))
self.cea_composer_album.setToolTip(_translate("ClassicalExtrasOptionsPage", "
"))
self.cea_composer_album.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will add the composer(s) last name(s) before the album name, if they are listed as album artists. If there is more than one composer, they will be listed in the descending order of the length of their music on the release.
"))
self.cea_composer_album.setText(_translate("ClassicalExtrasOptionsPage", "Name album as \"Composer Last Name(s): Album Name\""))
self.cea_no_lyricists.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This applies to both the Picard \'lyricist\' tag and the related internal plugin hidden variables \'_cwp_lyricists\' etc.
"))
self.cea_no_lyricists.setText(_translate("ClassicalExtrasOptionsPage", "Do not write \'lyricist\' tag if no vocal performers"))
self.cea_inst_credit.setText(_translate("ClassicalExtrasOptionsPage", "Use \"credited-as\" name for instrument"))
self.cea_no_solo.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to eliminate "additional", "solo" or "guest" from instrument description
"))
self.cea_no_solo.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "MusicBrainz permits the use of "solo", "guest" and "additional" as instrument attributes although, for classical music, its use should be fairly rare - usually only if explicitly stated as a "solo" on the the sleevenotes. Classical Extras provides the option to exclude these attributes (the default), but you may wish to enable them for certain releases or non-Classical / cross-over releases.
"))
self.cea_no_solo.setText(_translate("ClassicalExtrasOptionsPage", "Do not include attributes (e.g. \'solo\') in an instrument type"))
self.annotations_rh_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text to appear in annotations. Do not use any quotation marks.
"))
self.annotations_rh_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Annotations - writers and arrangers"))
self.label_56.setText(_translate("ClassicalExtrasOptionsPage", "Writer"))
self.label_54.setText(_translate("ClassicalExtrasOptionsPage", "Arranger"))
self.label_45.setToolTip(_translate("ClassicalExtrasOptionsPage", "Text with which to annotate orchestrator in the arranger tag.
"))
self.label_45.setText(_translate("ClassicalExtrasOptionsPage", "Orchestrator"))
self.label_32.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for "reconstructed by", to include in arranger tag
"))
self.label_32.setText(_translate("ClassicalExtrasOptionsPage", "Reconstructed by"))
self.label_28.setToolTip(_translate("ClassicalExtrasOptionsPage", "Annotation for "revised by", to include in arranger tag tag
"))
self.label_28.setText(_translate("ClassicalExtrasOptionsPage", "Revised by"))
self.lyrics_label.setText(_translate("ClassicalExtrasOptionsPage", "Lyrics
"))
self.lyrics_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Please note that this section operates on the underlying input file tags, not the Picard-generated tags (MusicBrainz does not have lyrics)
Sometimes "lyrics" tags can contain album notes (repeated for every track in an album) as well as track notes and lyrics. This section will filter out the common text and place it in a different tag from the text which is unique to each track.
"))
self.cea_split_lyrics.setToolTip(_translate("ClassicalExtrasOptionsPage", "enables this section
"))
self.cea_split_lyrics.setText(_translate("ClassicalExtrasOptionsPage", "Split lyrics tag into track and album levels"))
self.lyrics_and_notes_tags_frame.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter a valid tag name (no spaces, punctuation or special charcaters other than underline; use lower case)
"))
self.label_50.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the lyrics file tag in the input file (normally just \'lyrics\')
"))
self.label_50.setText(_translate("ClassicalExtrasOptionsPage", "Incoming lyrics tag (i.e. file tag)"))
self.label_51.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the tag where common text should be placed
"))
self.label_51.setText(_translate("ClassicalExtrasOptionsPage", "Tag for album notes / lyrics"))
self.label_52.setToolTip(_translate("ClassicalExtrasOptionsPage", "The name of the tag where notes/lyrics unique to a track should be placed
"))
self.label_52.setText(_translate("ClassicalExtrasOptionsPage", "Tag for track notes / lyrics"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Artists), _translate("ClassicalExtrasOptionsPage", "Artists"))
self.use_cwp.setToolTip(_translate("ClassicalExtrasOptionsPage", ""Include all work levels" should be selected otherwise this section will not run.
"))
self.use_cwp.setText(_translate("ClassicalExtrasOptionsPage", "Include all work levels (MUST BE TICKED FOR THIS SECTION TO RUN)*"))
self.cwp_collections.setToolTip(_translate("ClassicalExtrasOptionsPage", "This will include parent works where the relationship has the attribute \'part of collection\'.
PLEASE BE CONSISTENT and do not use different options on albums with the same works, or the results may be unexpected.
"))
self.cwp_collections.setText(_translate("ClassicalExtrasOptionsPage", "Include collection relationships (but not \"series\")"))
self.use_cache.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to use cached works. Deselect to refesh from MusicBrainz.
"))
self.use_cache.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use cache" prevents excessive look-ups of the MB database. Every look-up of a parent work needs to be performed separately (hopefully the MB database might make this easier some day). Network usage constraints by MB means that each look-up takes a minimum of 1 second. Once a release has been looked-up, the works are retained in cache, significantly reducing the time required if, say, the options are changed and the data refreshed. However, if the user edits the works in the MB database then the cache will need to be turned off temporarily for the refresh to find the new/changed works. Also some types of work (e.g. arrangements) will require a full look-up if options have been changed.
"))
self.use_cache.setText(_translate("ClassicalExtrasOptionsPage", "Use cache (if available)*"))
self.work_style_label.setText(_translate("ClassicalExtrasOptionsPage", "Tagging style
"))
self.work_style_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "\n"
"\n"
""Tagging style". This section determines how the hierarchy of works will be sourced.
\n"
"Works source: There are 3 options for determing the principal source of the works metadata
\n"
""Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
\n"
"
\n"
""Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
\n"
"
\n"
""Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles where it is significantly different. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations.
\n"
"Source of canonical work text. Where either of the second two options above are chosen, there is a further choice to be made:
\n"
""Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
\n"
""Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
\n"
"Strategy for setting style: It is suggested that you start with "extended/enhanced" style and the "Consistent with lowest level work description" as the source (this is the default). If this does not give acceptable results, try switching to "Full MusicBrainz work hierarchy". If the "enhanced" details in curly brackets (from the track title) give odd results then switch the style to "canonical works" only. Any remaining oddities are then probably in the MusicBrainz data, which may require editing.
"))
self.works_source_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "There are 3 options for determing the principal source of the works metadata
- "Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
- "Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will be in the language of the release.
- "Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles where it is significantly different. The supplementary data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations - see image below for an example (using the Muso library manager).
"))
self.works_source_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Works source"))
self.cwp_titles.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use only metadata from title text". The plugin will attempt to extract the hierarchy of works from the track title by looking for repetitions and patterns. If the title does not contain all the work names in the hierarchy then obviously this will limit what can be provided.
"))
self.cwp_titles.setText(_translate("ClassicalExtrasOptionsPage", "Use only metadata from title text"))
self.cwp_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use only metadata from canonical works". The hierarchy in the MB database will be used. Assuming the work is correctly entered in MB, this should provide all the data. However the text may differ from the track titles and will be the same for all recordings. It may also be in the language of the composer whereas the titles will probably be in the language of the release. (This language issue can also be addressed by using aliases - see below).
"))
self.cwp_works.setText(_translate("ClassicalExtrasOptionsPage", "Use only metadata from canonical works"))
self.cwp_extended.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Use canonical work metadata enhanced with title text". This supplements the canonical data with text from the titles **where it is significantly different**. The supplementary title data will be in curly brackets. This is clearly the most complete metadata style of the three but may lead to long descriptions. It is particularly useful for providing translations
"))
self.cwp_extended.setText(_translate("ClassicalExtrasOptionsPage", "Use canonical work metadata enhanced with title text"))
self.source_of_canonical_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Where either of the second two options above are chosen, there is a further choice to be made:
- "Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
- "Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
"))
self.source_of_canonical_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Source of canonical work text (if applicable)"))
self.cwp_hierarchical_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Full MusicBrainz work hierarchy". The names of each level of work are used to populate the relevant tags. E.g. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast, JB 1:112", not "Má vlast". So, while accurate, this option might be more verbose.
"))
self.cwp_hierarchical_works.setText(_translate("ClassicalExtrasOptionsPage", "Full MusicBrainz work hierarchy (may be more verbose)"))
self.cwp_level0_works.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Consistent with lowest level work description". The names of the level 0 work are used to populate the relevant tags. I.e. if "Má vlast: I. Vyšehrad, JB 1:112/1" (level 0) is part of "Má vlast, JB 1:112" (level 1) then the parent work will be tagged as "Má vlast", not "Má vlast, JB 1:112". This frequently looks better, but not always, particularly if the level 0 work name does not contain all the parent work detail. If the full structure is not implicit in the level 0 name then a warning will be logged and written to the "warning" tag.
"))
self.cwp_level0_works.setText(_translate("ClassicalExtrasOptionsPage", "Consistent with lowest level work description (may be less verbose, but not always complete)"))
self.cwp_derive_works_from_title.setText(_translate("ClassicalExtrasOptionsPage", "Attempt to get works and movement info from title if there are no work relationships? (Requires title in form \"work: movement\")"))
self.work_aliases_label.setText(_translate("ClassicalExtrasOptionsPage", "Aliases (NB Use a consistent approach throughout the library otherwise duplicate works may occur - see the Readme)*
"))
self.work_aliases_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Replace work names by aliases" will use primary aliases for the chosen locale instead of standard MusicBrainz work names. To choose the locale, use the drop-down under "translate artist names" in the main Picard Options-->Metadata page. Note that this option is not saved as a file tag since, if different choices are made for different releases, different work names may be stored and therefore cannot be grouped together in your player/library manager.
The sub-options allow either the replacement of all work names, where a primary alias exists, just the replacement of work names which are in non-Latin script, or only replace those which are flagged with user "Folksonomy" tags. The tag text needs to be included in the text box, in which case flagged works will be \'aliased\' as well as non-Latin script works, if the second sub-option is chosen. Note that the tags may either be anyone\'s tags ("Look in all tags") or the user\'s own tags. If selecting "Look in user\'s own tags only" you must be logged in to your MusicBrainz user account (in the Picard Options->General page), otherwise repeated dialogue boxes may be generated and you may need to force restart Picard.
"))
self.replace_MBworknames_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Replace MB work names?"))
self.cwp_aliases.setToolTip(_translate("ClassicalExtrasOptionsPage", "Use primary aliases for the chosen locale instead of standard MusicBrainz work names.
"))
self.cwp_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Replace work names by aliases. Select method -->"))
self.cwp_no_aliases.setText(_translate("ClassicalExtrasOptionsPage", "Do not replace work names"))
self.what_to_replace_outer_box.setTitle(_translate("ClassicalExtrasOptionsPage", "What to replace?"))
self.cwp_aliases_all.setText(_translate("ClassicalExtrasOptionsPage", "All work names"))
self.cwp_aliases_greek.setText(_translate("ClassicalExtrasOptionsPage", "Non-latin work names"))
self.cwp_aliases_tagged.setText(_translate("ClassicalExtrasOptionsPage", "Only tagged works"))
self.works_alias_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Tags (\"Folksonomy\") identifying works to be replaced by aliases"))
self.cwp_aliases_tags_all.setText(_translate("ClassicalExtrasOptionsPage", "Look in all tags"))
self.cwp_aliases_tags_user.setText(_translate("ClassicalExtrasOptionsPage", "Look in user\'s own tags only (MUST BE LOGGED IN!)"))
self.cwp_aliases_tag_text.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple tags by commas
"))
self.work_parts_tags_label.setText(_translate("ClassicalExtrasOptionsPage", "Tags to create - Use commas to separate multiple tags or leave blank to omit
"))
self.works_parts_tags_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple tags by commas.
"))
self.works_parts_tags_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Tags to create" sets the names of the tags that will be created from the sources described above. All these tags will be blanked before filling as specified. Tags specified against more than one source will have later sources appended in the sequence specified, separated by separators as specified.
"))
self.works_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Work tags"))
self.label_40.setText(_translate("ClassicalExtrasOptionsPage", "Separator"))
self.label_11.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Some software (notably Muso) can display a 2-level work hierarchy as well as the work-movement hierarchy. This tag can be use to store the 2-level work name (a double colon :: is used to separate the levels within the tag).
"))
self.label_11.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Work - for software with 2-level capability (e.g. Muso)
"))
self.cwp_multi_work_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
self.cwp_multi_work_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
self.cwp_multi_work_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
self.cwp_multi_work_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
self.cwp_multi_work_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
self.label.setText(_translate("ClassicalExtrasOptionsPage", "(In this format, intermediate works will be displayed after a double colon :: )"))
self.label_15.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Software which can display a movement and work (but no higher levels) could use any tags specified here. Note that if there are multiple work levels, the intermediate levels will not be tagged. Users wanting all the information should use the tags from the previous option (but it may cause some breaks in the display if levels change) - alternatively the missing work levels can be included in a movement tag (see below).
"))
self.label_15.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Work - for software with 1-level capability (e.g. iTunes)
"))
self.cwp_single_work_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
self.cwp_single_work_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
self.cwp_single_work_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
self.cwp_single_work_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
self.cwp_single_work_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
self.label_2.setText(_translate("ClassicalExtrasOptionsPage", "(Intermediate works will not be displayed:- Either 1. use the 2-level format if you wish to display them, but note that this will ceate new work, or 2. include them in the movement [see below])"))
self.label_12.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is the top-level work held in MB. This can be useful for cataloguing and searching (if the library software is capable). Note that this will always be the "canonical" MB name, not one derived from titles or the lowest level work name and that no annotations (e.g. key or work year) will be added. However, if "replace work names by aliases" has been selected and is applicable, the relevant alias will be used.
"))
self.label_12.setText(_translate("ClassicalExtrasOptionsPage", "Tags for top-level (canonical) work (for capable library managers)
"))
self.label_10.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
self.parts_tags_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Movement/Part tags"))
self.label_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movementnumber\' - include that or other(s) of your choice
"))
self.label_13.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is not necessarily the embedded movt/part number, but is the sequence number of the movement within its parent work on the current release.
"))
self.label_13.setText(_translate("ClassicalExtrasOptionsPage", "Tags for (computed) movement number (Picard std tag is movementnumber)
"))
self.cwp_movt_no_sep.setItemText(1, _translate("ClassicalExtrasOptionsPage", "; "))
self.cwp_movt_no_sep.setItemText(2, _translate("ClassicalExtrasOptionsPage", ": "))
self.cwp_movt_no_sep.setItemText(3, _translate("ClassicalExtrasOptionsPage", ". "))
self.cwp_movt_no_sep.setItemText(4, _translate("ClassicalExtrasOptionsPage", ", "))
self.cwp_movt_no_sep.setItemText(5, _translate("ClassicalExtrasOptionsPage", "- "))
self.label_43.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard tag \'movementtotal\' will be populated in any case - no need to specify it
"))
self.label_43.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This is not necessarily the total number of movements in the parent work, but is the total number of movement tracks within the parent work on the current release.
"))
self.label_43.setText(_translate("ClassicalExtrasOptionsPage", "Tags for (computed) total number of movements (Picard std tag is movementtotal)
"))
self.label_79.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
self.label_49.setText(_translate("ClassicalExtrasOptionsPage", "Movement name tags (Picard std tag is movement)
Use different movement tags if required for different level systems ==>
"))
self.label_47.setText(_translate("ClassicalExtrasOptionsPage", "
for use with multi-level work tags
"))
self.label_48.setText(_translate("ClassicalExtrasOptionsPage", "
for use with1-level work tags (intermediate works will prefix movement)
"))
self.label_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movement\' - include that or other(s) of your choice
"))
self.label_14.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "As below, but without the movement part/number prefix (if applicable)
"))
self.label_14.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Movement - excluding embedded movt/part numbers
"))
self.label_39.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
self.label_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "The Picard standard tag is \'movement\' - include that or other(s) of your choice
"))
self.label_9.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This tag(s) will contain the full lowest-level part name extracted from the lowest-level work name, according to the chosen tagging style.
"))
self.label_9.setText(_translate("ClassicalExtrasOptionsPage", "Tags for Movement - including embedded movt/part numbers
"))
self.label_37.setText(_translate("ClassicalExtrasOptionsPage", " N/A "))
self.partial_arrangements_medleys_label.setText(_translate("ClassicalExtrasOptionsPage", "Partial recordings, arrangements and medleys
"))
self.partial_arrangements_medleys_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter text - do not use any quotation marks
"))
self.label_20.setText(_translate("ClassicalExtrasOptionsPage", "N.B. If these options are selected or deselected, quit and restart Picard before proceeding"))
self.partial_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If this option is selected, partial recordings will be treated as a sub-part of the whole recording and will have the related text included in its name. Note that this text is at the end of the canonical name, but the latter will probably be stripped from the sub-part as it duplicates the recording work name; any title text will be appended to the whole. Note that, if "Consistent with lowest level work description" is chosen in section 2, the text may be treated as a "prefix" similar to those in the "Advanced" tab. If this eliminates other similar prefixes and has unwanted effects, then either change the desired text slightly (e.g. surround with brackets) or use the "Full MusicBrainz work hierarchy" option in section 2.
"))
self.partial_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Partial recordings"))
self.cwp_partial.setText(_translate("ClassicalExtrasOptionsPage", "Show partial recordings as separate sub-part, labelled with ->"))
self.arrangements_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If this option is selected, works which are arrangements of other works will have the latter treated in the same manner as "parent" works, except that the arrangement work name will be prefixed by the text provided.
"))
self.arrangements_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Arrangements"))
self.cwp_arrangements.setText(_translate("ClassicalExtrasOptionsPage", "Show arrangements as parts of original works, labelled with ->"))
self.medleys_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Medleys"))
self.cwp_medley.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Medleys
These can occur in two ways in MusicBrainz: (a) the recording is described as a "medley of" a number of works and (b) the track is described as (more than one) "medley including a recording of" a work. In the first case, the specified text will be included in brackets after the work name, whereas in the second case, the track will be treated as a recording of multiple works and the specified text will appear in the parent work name.
"))
self.cwp_medley.setText(_translate("ClassicalExtrasOptionsPage", "Include medley list, labelled with ->"))
self.songkong_label.setText(_translate("ClassicalExtrasOptionsPage", "SongKong-compatible tag usage
"))
self.songkong_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "See "What\'s this"
"))
self.songkong_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", " "Use work tags on file (no look up on MB) if Use Cache selected": This will enable the existing work tags on the file to be used in preference to looking up on MusicBrainz, if those tags are SongKong-compatible (which should be the case if SongKong has been used or if the SongKong tags have been previously written by this plugin). If present, this can speed up processing considerably, but obviously any new data on MusicBrainz will be missed. For the option to operate, "Use cache" also needs to be selected. Although faster, some of the subtleties of a full look-up will be missed - for example, parent works which are arrangements will not be highlighted as such, some arrangers or composers of original works may be omitted and some medley information may be missed. **In general, therefore, the use of this option will result in poorer metadata than allowing the full database look-up to run. It is not recommended unless speed is more important than quality.**
"Write SongKong-compatible work tags" does what it says. These can then be used by the previous option, if the release is subsequently reloaded into Picard, to speed things up (assuming the reload was not to pick up new work data).
Note that Picard and SongKong use the tag musicbrainz_workid to mean different things. If Picard has overwritten the SongKong tag (not a problem if this plugin is used) then a warning will be given and the works will be looked up on MusicBrainz. Also note that once a release is loaded, subsequent refreshes will use the cache (if option is ticked) in preference to the file tags.
"))
self.cwp_use_sk.setText(_translate("ClassicalExtrasOptionsPage", "Use work tags on file (no look up on MB) if Use Cache selected* (NOT RECOMMENDED - SEE README)"))
self.cwp_write_sk.setText(_translate("ClassicalExtrasOptionsPage", "Write SongKong-compatible work tags*"))
self.label_82.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Works), _translate("ClassicalExtrasOptionsPage", "Works and parts"))
self.genre_tag_label.setText(_translate("ClassicalExtrasOptionsPage", "Genre tags
"))
self.label_73.setText(_translate("ClassicalExtrasOptionsPage", "Name of genre tag"))
self.label_74.setText(_translate("ClassicalExtrasOptionsPage", "Name of sub-genre tag"))
self.classical_genre_label.setText(_translate("ClassicalExtrasOptionsPage", ""Classical" genre
"))
self.cwp_genres_classical_exclude.setText(_translate("ClassicalExtrasOptionsPage", "Exclude the text \"classical\" from main genre tag even if listed above"))
self.cwp_genres_classical_selective.setText(_translate("ClassicalExtrasOptionsPage", "Make track \"classical\" only if there is a classical-specific genre (or do nothing if there is no filter)"))
self.cwp_muso_classical.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso composer list to determine if classical*"))
self.cwp_genres_classical_all.setText(_translate("ClassicalExtrasOptionsPage", "Make all tracks \"classical\""))
self.label_64.setText(_translate("ClassicalExtrasOptionsPage", "Write a flag with text ="))
self.label_71.setText(_translate("ClassicalExtrasOptionsPage", " in the following tag if the track is classical"))
self.cwp_genres_arranger_as_composer.setText(_translate("ClassicalExtrasOptionsPage", "(Treat arrangers as for composers)"))
self.label_81.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
self.cwp_use_muso_refdb.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso reference database (default path is set on \"advanced\" tab)*"))
self.instruments_keys_label.setText(_translate("ClassicalExtrasOptionsPage", "Instruments and keys
"))
self.instruments_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Instruments"))
self.label_66.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for instruments (will hold all instruments for a track)"))
self.instruments_source_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Name sources to use for instruments (select at least one, otherwise no instruments will be included in tag)"))
self.cwp_instruments_MB_names.setText(_translate("ClassicalExtrasOptionsPage", "MusicBrainz standard names"))
self.cwp_instruments_credited_names.setText(_translate("ClassicalExtrasOptionsPage", "\"Credited-as\" names"))
self.keys_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Keys"))
self.label_72.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for key(s)"))
self.keys_include_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Include key(s) in work name?"))
self.cwp_key_never_include.setText(_translate("ClassicalExtrasOptionsPage", "Never"))
self.cwp_key_contingent_include.setText(_translate("ClassicalExtrasOptionsPage", "Only if key not already mentioned in work name"))
self.cwp_key_include.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Include key(s) in work names" gives the option to include the key signature for a work in brackets after the name of the work in the metadata. Keys will be added in the appropriate levels: e.g. Dvořák\'s New World Symphony will get (E minor) at the work level, but only movements with different keys will be annotated viz. "II. Largo (D-flat major, C-Sharp minor)"
"))
self.cwp_key_include.setText(_translate("ClassicalExtrasOptionsPage", "Always"))
self.allowed_filters_label.setText(_translate("ClassicalExtrasOptionsPage", "Allowed genres (filter)
"))
self.cwp_genres_filter.setText(_translate("ClassicalExtrasOptionsPage", "Only apply genres to tags if they match pre-defined names:"))
self.genre_filters_frame.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Explanation of genre-matching:
Only genres matching those in the boxes will be placed in the genre or sub-genre tags.
If there is a matching genre found in the "classical main genres" or "classical sub-genres" box, then the track will be treated as being classical.
"))
self.classical_genres_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Classical genres (i.e. specific to classical music) - List separated by commas"))
self.label_60.setText(_translate("ClassicalExtrasOptionsPage", "Main genres:"))
self.label_75.setText(_translate("ClassicalExtrasOptionsPage", "Sub-genres:"))
self.cwp_muso_genres.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select this to use the "classical genres" in Muso options as the "Main classical genres" here.
"))
self.cwp_muso_genres.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso classical genres*"))
self.general_genres_box.setTitle(_translate("ClassicalExtrasOptionsPage", "General genres (may be associated with classical music, but not necessarily, e.g. \"instrumental\") - List separated by commas"))
self.label_62.setText(_translate("ClassicalExtrasOptionsPage", "Main genres"))
self.label_76.setText(_translate("ClassicalExtrasOptionsPage", "Sub-genres"))
self.label_80.setText(_translate("ClassicalExtrasOptionsPage", "Genre name to use if none of the above main genres apply (leave blank if not required)"))
self.label_77.setText(_translate("ClassicalExtrasOptionsPage", "List genres, separated by commas. Only those genres listed will be included in tags."))
self.label_78.setText(_translate("ClassicalExtrasOptionsPage", "See \"what\'s this\" for more details."))
self.source_of_genres_label.setText(_translate("ClassicalExtrasOptionsPage", "Source of genres - Note: if "existing file tag" is selected, information from the tag "genre" and the genre tag name specified above (if different) will be used
"))
self.cwp_genres_use_file.setToolTip(_translate("ClassicalExtrasOptionsPage", "NB: This will use the contents of the file tag with the name given above (usually \'genre\').
"))
self.cwp_genres_use_file.setText(_translate("ClassicalExtrasOptionsPage", "Existing file tag (see note above)"))
self.cwp_genres_use_folks.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This will use the folksonomy tags for works as a possible source of genres (if they match one of the lists below).
To use the folksonomy tags for releases/tracks, select the main Picard option in Options->Metadata->"Use folksonomy tags as genre". Again (unlike vanilla Picard) they will only be used by this plugin if they match one of the lists below.
"))
self.cwp_genres_use_folks.setText(_translate("ClassicalExtrasOptionsPage", "Folksonomy work tags"))
self.cwp_genres_use_worktype.setText(_translate("ClassicalExtrasOptionsPage", "Work-type"))
self.cwp_genres_infer.setText(_translate("ClassicalExtrasOptionsPage", "Infer from artist metadata"))
self.label_109.setText(_translate("ClassicalExtrasOptionsPage", "Periods and dates
"))
self.dates_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Work dates"))
self.dates_box_inner.setTitle(_translate("ClassicalExtrasOptionsPage", "Source of work dates for above tag"))
self.cwp_workdate_source_composed.setText(_translate("ClassicalExtrasOptionsPage", "Composed date (or parent composed date)"))
self.cwp_workdate_source_published.setText(_translate("ClassicalExtrasOptionsPage", "Published date"))
self.cwp_workdate_source_premiered.setText(_translate("ClassicalExtrasOptionsPage", "Premiered date"))
self.cwp_workdate_use_first.setText(_translate("ClassicalExtrasOptionsPage", "Use first available of above (in listed order)"))
self.cwp_workdate_use_all.setText(_translate("ClassicalExtrasOptionsPage", "Include all sources"))
self.cwp_workdate_annotate.setText(_translate("ClassicalExtrasOptionsPage", "Annotate dates using source name"))
self.label_68.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for work date"))
self.cwp_workdate_include.setWhatsThis(_translate("ClassicalExtrasOptionsPage", ""Includeworkdate in work names" gives the option to include the \'work year\' for a work in brackets after the name of the work in the metadata. Dates (years) will be added in the appropriate levels: e.g. Smetana\'s \'Má vlast\' will get (1874-1879) at the work level, but the movements with different dates will be annotated viz. "Vyšehrad, JB 1:112/1 (1874)". If the dates are the same, there should be no repitetion at the movement level. (Work dates will be used in preference order, i.e. composed - published - premiered, with only the first available date being shown).
"))
self.cwp_workdate_include.setText(_translate("ClassicalExtrasOptionsPage", "Include workdate in work name (in preference order listed above, with no annotation)"))
self.periods_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Periods"))
self.label_69.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for period"))
self.cwp_muso_periods.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso map*"))
self.cwp_muso_dates.setText(_translate("ClassicalExtrasOptionsPage", "Use Muso composer dates (if no work date) to determine period*"))
self.label_70.setText(_translate("ClassicalExtrasOptionsPage", "Period map:"))
self.period_map_annotation_label.setText(_translate("ClassicalExtrasOptionsPage", " (Period name, Start year, End year; Period name2, ... etc.) - periods may overlap [Do not use commas or semi-colons within period name]"))
self.cwp_periods_arranger_as_composer.setText(_translate("ClassicalExtrasOptionsPage", "(Treat arrangers as for composers)"))
self.label_119.setText(_translate("ClassicalExtrasOptionsPage", "N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") must be enabled for this section to run.
(Functionality will be reduced unless both the first two tabs are enabled.)
"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Genres), _translate("ClassicalExtrasOptionsPage", "Genres etc."))
self.label_18.setText(_translate("ClassicalExtrasOptionsPage", "N.B. At least one of the first two tabs (Artists: "Create extra artist metadata", or Works and parts: "Include all work levels") must be enabled for this section to run.
"))
self.label_97.setText(_translate("ClassicalExtrasOptionsPage", "Initial tag processing
"))
self.initial_tag_processing_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "
"))
self.tags_to_blank.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Any tags specified in the next two rows will be blanked before applying the tag sources described in the following section. NB this applies only to Picard-generated tags, not to other tags which might pre-exist on the file: to blank those, use the main Options->Tags page. Comma-separate the tag names within the rows and note that these names are case-sensitive.
"))
self.tags_to_blank.setTitle(_translate("ClassicalExtrasOptionsPage", "Remove Picard-generated tags before applying subsequent actions? (NB existing LOCAL FILE tags will remain unless cleared using standard Picard options - to remove these, overwrite them in the next section)"))
self.label_3.setText(_translate("ClassicalExtrasOptionsPage", "Picard-generated tags to blank (comma-separated, case-sensitive):
"))
self.cea_blank_tag.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
self.cea_blank_tag_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
self.label_19.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "
"))
self.label_19.setText(_translate("ClassicalExtrasOptionsPage", "List existing file tags which will be appended to rather than over-written by tag mapping (this will keep tags even if "Clear existing tags" is selected on main options)
NB To allow appending to happen, do not also include these tags in "Preserve tags" on the main options.
"))
self.cea_keep.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter file tag names, separated by commas
"))
self.cea_keep.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This refers to the tags which already exist on files which have been matched to MusicBrainz in the right-hand panel, not the tags generated by Picard from the MusicBrainz database. Normally, Picard cannot process these tags - either it will overwrite them (if it creates a similarly named tag), clear them (if \'Clear existing tags\' is specified in the main Options->Tags screen) or keep them (if \'Preserve these tags...\' is specified after the \'Clear existing tags\' option). Classical Extras allows a further option - for the tags to be appended to in the tag mapping section (see below). List file tags which will be appended to rather than over-written by tag mapping (NB this will keep tags even if "Clear existing tags" is selected on main options). In addition, certain existing tags may be used by Classical Extras - in particular genre-related tags (see the Genres etc. options tab for more).
Note that if "Split lyrics tag" is specified (see the Artists tab), then the tag named there will be included in the \'Keep file tags\' list and does not need to be added in this section.
"))
self.cea_clear_tags.setToolTip(_translate("ClassicalExtrasOptionsPage", "Note that the main Picard option "Clear existing tags" should be unchecked for this option to operate in preference to that Picard option. The difference is that this option will not intefere with cover art, whereas the main Picard option will remove previous cover art.
"))
self.cea_clear_tags.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If selected: the bottom pane of Picard will only show tags which have been generated from the MusicBrainz lookups plus any existing file tags which are listed above or in the main options "Preserve tags...".
This does not mean that the file tags will be removed when saving the file. For that to happen, "Clear existing tags" needs to be selected in the main options.
"))
self.cea_clear_tags.setText(_translate("ClassicalExtrasOptionsPage", "Do not show any file tags that are NOT listed above AND NOT listed in the main Picard \"Preserve tags...\" option (Options->Tags), even if \"Clear existing tags\" is not selected."))
self.label_98.setText(_translate("ClassicalExtrasOptionsPage", "Tag map details
"))
self.tagmap_details_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter tags, separated by commas.
"))
self.textBrowser.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
"\n"
"Notes:
\n"
"Click "Source from:" button to edit source tags.
\n"
"Any valid Picard-generated tag can be entered in the "source" box, as well as Classical Extras sources, and mapped into other tags - not just restricted to artists.
\n"
"To put a constant in a tag, type it into the source box preceded by a backslash \\.
\n"
"In all cases, the source will be APPENDED to the Picard tag. To replace the standard tag, first blank it in the section above - add it back later in the list below if required (e.g. artist -> artist).
\n"
"BUT note that any existing LOCAL FILE tag will be replaced by (not appended with) any Picard/Classical Extras tag UNLESS specified in the list box above.
\n"
"These tag-mapping options may be omitted from the over-riding of artist options - see advanced tab
\n"
"For more help seethe readme.
"))
self.toolButton_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_1.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_1.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_1.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_1.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_1.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_1.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_1.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_1.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_1.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_1.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_1.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_1.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_1.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_1.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_1.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_1.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_1.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_1.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_1.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_1.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_1.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_21.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_1.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_1.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_2.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_2.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_2.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_2.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_2.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_2.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_2.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_2.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_2.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_2.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_2.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_2.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_2.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_2.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_2.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_2.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_2.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_2.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_2.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_2.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_2.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_23.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_2.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_2.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_3.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_3.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_3.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_3.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_3.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_3.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_3.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_3.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_3.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_3.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_3.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_3.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_3.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_3.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_3.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_3.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_3.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_3.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_3.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_3.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_3.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_25.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_3.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_3.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_4.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_4.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_4.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_4.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_4.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_4.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_4.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_4.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_4.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_4.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_4.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_4.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_4.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_4.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_4.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_4.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_4.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_4.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_4.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_4.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_4.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_27.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_4.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_4.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_5.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_5.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_5.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_5.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_5.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_5.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_5.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_5.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_5.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_5.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_5.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_5.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_5.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_5.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_5.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_5.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_5.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_5.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_5.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_5.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_5.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_29.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_5.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_5.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_6.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_6.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_6.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_6.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_6.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_6.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_6.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_6.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_6.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_6.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_6.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_6.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_6.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_6.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_6.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_6.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_6.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_6.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_6.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_6.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_6.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_31.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_6.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_6.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_7.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_7.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_7.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_7.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_7.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_7.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_7.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_7.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_7.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_7.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_7.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_7.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_7.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_7.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_7.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_7.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_7.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_7.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_7.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_7.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_7.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_33.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_7.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_7.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_8.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_8.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_8.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_8.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_8.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_8.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_8.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_8.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_8.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_8.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_8.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_8.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_8.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_8.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_8.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_8.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_8.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_8.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_8.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_8.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_8.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_35.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_8.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_8.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_9.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_9.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_9.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_9.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_9.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_9.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_9.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_9.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_9.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_9.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_9.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_9.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_9.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_9.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_9.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_9.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_9.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_9.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_9.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_9.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_9.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_53.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_9.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_9.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_10.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_10.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_10.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_10.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_10.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_10.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_10.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_10.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_10.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_10.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_10.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_10.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_10.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_10.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_10.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_10.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_10.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_10.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_10.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_10.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_10.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_55.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_10.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_10.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_11.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_11.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_11.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_11.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_11.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_11.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_11.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_11.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_11.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_11.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_11.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_11.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_11.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_11.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_11.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_11.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_11.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_11.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_11.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_11.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_11.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_57.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_11.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_11.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_12.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_12.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_12.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_12.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_12.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_12.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_12.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_12.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_12.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_12.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_12.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_12.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_12.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_12.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_12.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_12.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_12.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_12.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_12.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_12.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_12.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_59.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_12.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_12.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_13.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_13.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_13.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_13.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_13.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_13.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_13.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_13.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_13.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_13.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_13.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_13.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_13.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_13.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_13.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_13.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_13.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_13.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_13.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_13.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_13.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_61.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_13.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_13.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_14.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_14.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_14.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_14.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_14.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_14.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_14.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_14.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_14.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_14.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_14.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_14.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_14.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_14.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_14.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_14.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_14.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_14.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_14.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_14.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_14.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_63.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_14.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_14.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_15.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_15.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_15.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_15.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_15.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_15.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_15.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_15.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_15.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_15.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_15.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_15.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_15.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_15.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_15.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_15.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_15.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_15.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_15.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_15.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_15.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_65.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_15.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_15.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.toolButton_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click to edit sources"))
self.toolButton_16.setText(_translate("ClassicalExtrasOptionsPage", "Source from:"))
self.cea_source_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Click button to edit. See notes above."))
self.cea_source_16.setItemText(1, _translate("ClassicalExtrasOptionsPage", "album_soloists, album_conductors, album_ensembles"))
self.cea_source_16.setItemText(2, _translate("ClassicalExtrasOptionsPage", "soloists, conductors, ensembles, album_composers, composers"))
self.cea_source_16.setItemText(3, _translate("ClassicalExtrasOptionsPage", "album_soloists"))
self.cea_source_16.setItemText(4, _translate("ClassicalExtrasOptionsPage", "album_conductors"))
self.cea_source_16.setItemText(5, _translate("ClassicalExtrasOptionsPage", "album_ensembles"))
self.cea_source_16.setItemText(6, _translate("ClassicalExtrasOptionsPage", "album_composers"))
self.cea_source_16.setItemText(7, _translate("ClassicalExtrasOptionsPage", "album_composer_lastnames"))
self.cea_source_16.setItemText(8, _translate("ClassicalExtrasOptionsPage", "soloists"))
self.cea_source_16.setItemText(9, _translate("ClassicalExtrasOptionsPage", "soloist_names"))
self.cea_source_16.setItemText(10, _translate("ClassicalExtrasOptionsPage", "ensembles"))
self.cea_source_16.setItemText(11, _translate("ClassicalExtrasOptionsPage", "ensemble_names"))
self.cea_source_16.setItemText(12, _translate("ClassicalExtrasOptionsPage", "composers"))
self.cea_source_16.setItemText(13, _translate("ClassicalExtrasOptionsPage", "arrangers"))
self.cea_source_16.setItemText(14, _translate("ClassicalExtrasOptionsPage", "orchestrators"))
self.cea_source_16.setItemText(15, _translate("ClassicalExtrasOptionsPage", "conductors"))
self.cea_source_16.setItemText(16, _translate("ClassicalExtrasOptionsPage", "chorusmasters"))
self.cea_source_16.setItemText(17, _translate("ClassicalExtrasOptionsPage", "leaders"))
self.cea_source_16.setItemText(18, _translate("ClassicalExtrasOptionsPage", "support_performers"))
self.cea_source_16.setItemText(19, _translate("ClassicalExtrasOptionsPage", "work_type"))
self.cea_source_16.setItemText(20, _translate("ClassicalExtrasOptionsPage", "release"))
self.label_67.setText(_translate("ClassicalExtrasOptionsPage", "into tags:"))
self.cea_tag_16.setToolTip(_translate("ClassicalExtrasOptionsPage", "Enter comma-separated list of tags"))
self.cea_cond_16.setText(_translate("ClassicalExtrasOptionsPage", "Conditional?"))
self.label_42.setText(_translate("ClassicalExtrasOptionsPage", "(If source is empty, tag will be left unchanged) "))
self.label_17.setText(_translate("ClassicalExtrasOptionsPage", "(Conditional tags will only be filled if previously empty)"))
self.cea_tag_sort.setToolTip(_translate("ClassicalExtrasOptionsPage", "Select to include sort-tags, where available. See "What\'s this?" for more details.
"))
self.cea_tag_sort.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If a sort tag is associated with the source tag then the sort names will be placed in a sort tag corresponding to the destination tag. Note that the only explicit sort tags written by Picard are for artist, albumartist and composer. Piacrd also writes hidden variables \'_artists_sort\' and \'albumartists_sort\' (note the plurals - these are the sort tags for multi-valued alternatives \'artists\' and \'_albumartists\'). To be consistent with this approach, the plugin writes hidden variables for other tags - e.g. \'_arranger_sort\'. The plugin also writes hidden sort variables for the various hidden artist variables - e.g. \'_cwp_librettists\' has a matching sort variable \'_cwp_librettists_sort\'. Therefore most artist-type sources will have a sort tag/variable associated with them and these will be placed in a destination sort tag if this option is selected - in other words, selecting this option will cause most destination tags to have associated sort tags. Furthermore, any hidden sort variables associated with tags which are not listed explicitly in the tag mapping section will also be written out as tags (i.e. even if the related tags are not included as destination tags). Note, however, that composite sources (e.g. " ensemble_names + \\; + conductors") do not have sort tags associated with them.
If this option is not selected, no additional sort tags will be written, but the hidden variables will still be available, so if a sort tag is required explicitly, just map the sort tag directly - e.g. map \'conductors_sort\' to \'conductor_sort\'.
"))
self.cea_tag_sort.setText(_translate("ClassicalExtrasOptionsPage", "Also populate sort tags"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Tag_mapping), _translate("ClassicalExtrasOptionsPage", "Tag mapping"))
self.label_110.setText(_translate("ClassicalExtrasOptionsPage", "General
"))
self.ce_no_run.setText(_translate("ClassicalExtrasOptionsPage", "Do not run Classical Extras for tracks where no pre-existing file is detected (warning tag will be written)"))
self.advanced_artists_label.setText(_translate("ClassicalExtrasOptionsPage", "Artists (only effective if \"Artists\" section enabled)
"))
self.advanced_artists_box.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple names by commas. Do not use any quotation marks.
"))
self.advanced_artists_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Permits the listing of strings by which ensembles of different types may be identified. This is used by the plugin to place performer details in the relevant hidden variables and thus make them available for use in the "Tag mapping" tab as sources for any required tags.
If it is important that only whole words are to be matched, be sure to include a space after the string.
"))
self.ensemble_strings_label.setText(_translate("ClassicalExtrasOptionsPage", "Ensemble strings (separate names by commas)
"))
self.cea_orchestras_2.setText(_translate("ClassicalExtrasOptionsPage", "Orchestras"))
self.cea_choirs_2.setText(_translate("ClassicalExtrasOptionsPage", "Choirs"))
self.cea_groups_2.setText(_translate("ClassicalExtrasOptionsPage", "Groups (i.e. other ensembles such as quartets etc.)"))
self.advanced_workparts_label.setText(_translate("ClassicalExtrasOptionsPage", "Works and parts (only effective if \"Works and parts\" section enabled)
"))
self.label_4.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "Sometimes MB lookups fail. Unfortunately Picard (currently) has no automatic "retry" function. The plugin will attempt to retry for the specified number of attempts. If it still fails, the hidden variable _cwp_error will be set with a message; if error logging is checked in section 4, an error message will be written to the log and the contents of _cwp_error will be written out to a special tag called "An_error_has_occurred" which should appear prominently in the bottom pane of Picard. The problem may be resolved by refreshing, otherwise there may be a problem with the MB database availability. It is unlikely to be a software problem with the plugin.
"))
self.label_4.setText(_translate("ClassicalExtrasOptionsPage", "Max number of re-tries to access works (in case of server errors)*
"))
self.label_120.setText(_translate("ClassicalExtrasOptionsPage", "Allow blank part names for arrangements and part recordings if arrangement/partial label is provided
"))
self.label_114.setText(_translate("ClassicalExtrasOptionsPage", "Removal of common text between parent and child works
"))
self.label_90.setText(_translate("ClassicalExtrasOptionsPage", "Minimum number of similar words required before eliminating. Use zero for no elimination.
(Punctuation and accents etc. will be ignored in word comparison)
"))
self.label_89.setText(_translate("ClassicalExtrasOptionsPage", "NB Parent name text at the start of a work which is followed by punctuation in the work name will always be stripped regardless of this setting.
Synonyms in the next section also apply.
"))
self.title_metadata_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This subsection contains various parameters affecting the processing of strings in titles. Because titles are free-form, not all circumstances can be anticipated. Detailed documentation of these is beyond the scope of this Readme as the effects can be quite complex and subtle and may require an understanding of the plugin code (which is of course open-source) to acsertain them. If pure canonical works are used ("Use only metadata from canonical works" and, if necessary, "Full MusicBrainz work hierarchy" on the Works and parts tab, section 2) then this processing should be irrelevant, but no text from titles will be included. Some explanations are given below:
"Proximity of new words". When using extended metadata - i.e. "metadata enhanced with title text", the plugin will attempt to remove similar words between the canonical work name (in MusicBrainz) and the title before extending the canonical name. After removing such words, a rather "bitty" result may occur. To avoid this, any new words with the specified proximity will have the words between them (or up to the end) included even if they repeat words in the work name.
"Prefixes". When using "metadata from titles" or extended metadata, the structure of the works in MusicBrainz is used to infer the structure in the title text, so strings that are repeated between tracks which are part of the same MusicBrainz work will be treated as "higher level". This can lead to anomolies if, for instance, the titles are "Work name: Part 1", "Work name: Part 2", "Part" will be treated as part of the parent work name. Specifying such words in "Prefixes" will prevent this.
"Synonyms". These words will be considered equivalent when comparing work name and title text. Thus if one word appears in the work name, that and its synonym will be removed from the title in extending the metadata (subject to the proximity setting above).
"Replacements". These words/phrases will be replaced in the title text in extended metadata, regardless of the text in the work name.
"))
self.label_115.setText(_translate("ClassicalExtrasOptionsPage", "How title metadata should be included in extended metadata (use cautiously - read documentation)
(Mostly only applies if "Use canonical work metadata enhanced with title text" selected on "Works and parts" tab. However synonyms also apply to parent/child text removal.)
"))
self.label_6.setText(_translate("ClassicalExtrasOptionsPage", "Proximity of new words (to each other) to trigger in-fill with existing words (default = 2)
"))
self.label_7.setText(_translate("ClassicalExtrasOptionsPage", "Proximity of new words (to start or end) to trigger in-fill with existing words (default =1)
"))
self.label_5.setText(_translate("ClassicalExtrasOptionsPage", "Treat hyphenated words as two words for comparison purposes
"))
self.label_93.setText(_translate("ClassicalExtrasOptionsPage", "Proportion of a string to be matched to a (usually larger) string for it to be considered essentially similar (default = 66%)
"))
self.cwp_substring_match.setSuffix(_translate("ClassicalExtrasOptionsPage", "%"))
self.label_87.setText(_translate("ClassicalExtrasOptionsPage", "\n"
"\n"
"Fill part name with title text if it would otherwise have no text other than arrangement or partial annotations
"))
self.label_92.setText(_translate("ClassicalExtrasOptionsPage", "Prepositions/conjunctions and prefixes
DO NOT USE ANY COMMAS OR QUOTE MARKS (apostophes in words are acceptable)
"))
self.label_91.setText(_translate("ClassicalExtrasOptionsPage", "Prepositions & conjunctions: these are words that will not be regarded as providing additional information (not treated as \'new\' words) unless they precede a new word.
Use lower case only, comma separated
"))
self.cwp_removewords_2.setText(_translate("ClassicalExtrasOptionsPage", "Prefixes to be ignored in comparison (case insensitive, comma separated)
To prevent a prefix from being ignored when extending metadata with title info, precede it with a space.
To ensure only whole words are removed, follow with a space.
"))
self.cwp_removewords.setToolTip(_translate("ClassicalExtrasOptionsPage", "Separate multiple names by commas. Do not use any quotation marks.
"))
self.cwp_synonyms_2.setText(_translate("ClassicalExtrasOptionsPage", "Synonyms and replacements - must be written as tuples separated by forward slashes - e.g (a,b) / (c,d,e) - a tuple may have two or more synonyms.
N.B. The matching is case-insensitive. Roman numerals will be treated as synonyms of arabic numerals in any event, so no need to enter these.
The last member of the tuple should be the canonical form (i.e. the one to which others are converted for comparison or replacement) and must be a normal string (not a regex). See readme for full details.
Unless entering a regular expression, use backslash \\ to escape any regex metacharacters, namely \\ ^ $ . | ? * + ( ) [ ] {
Also escape commas , and forward slashes /. Do not enclose strings in quote marks.
Enter SYNONYM tuples below - each item in a tuple will be treated as similar when comparing works/parts and titles. The text in tags will be unaltered.
"))
self.label_16.setText(_translate("ClassicalExtrasOptionsPage", "Enter REMOVALS/REPLACEMENTS below - these will result in the "extended" text in tags being changed
Put the word(s), phrase(s), or regular exprerssion(s) in the first part(s) of the tuple. The replacement text (or nothing - to remove) goes in the last member of the tuple.
N.B. Replacement text will operate BEFORE synonyms are considered.
"))
self.cwp_replacements.setToolTip(_translate("ClassicalExtrasOptionsPage", "Entries must be 2-tuples, e.g. (Replace this, with this). Separate multiple tuples by forward slash. Do not use any quotation marks. Spaces are acceptable. The first item of a tuple may be a regular expression - enclose it with double exclamation marks - e.g.(!!regex here!!, replacement text here).
"))
self.advanced_genres_label.setText(_translate("ClassicalExtrasOptionsPage", "Genres etc. (only required if Muso-specific options are used for genres/periods)
"))
self.label_85.setText(_translate("ClassicalExtrasOptionsPage", "Path to Muso reference database:"))
self.label_84.setText(_translate("ClassicalExtrasOptionsPage", "Name of Muso reference database"))
self.label_86.setText(_translate("ClassicalExtrasOptionsPage", "RESTART PICARD AFTER CHANGING THESE
"))
self.label_117.setText(_translate("ClassicalExtrasOptionsPage", "Logging options*
"))
self.logging_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "These options are in addition to the options chosen in Picard\'s "Help->View error/debug log" settings. They only affect messages written by this plugin. To enable debug messages to be shown, the flag needs to be set here and "Debug mode" needs to be turned on in the log. It is strongly advised to keep the "debug" and "info" flags unchecked unless debugging is required as they slow up processing significantly and may even cause Picard to crash on large releases. The "error" and "warning" flags should be left checked, unless it is required to suppress messages written out to tags (the default is to write messages to the tags 001_errors and 002_warnings).
"))
self.log_error.setText(_translate("ClassicalExtrasOptionsPage", "Error"))
self.log_warning.setText(_translate("ClassicalExtrasOptionsPage", "Warning"))
self.log_debug.setText(_translate("ClassicalExtrasOptionsPage", "Debug"))
self.custom_logging_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Custom logging"))
self.log_basic.setText(_translate("ClassicalExtrasOptionsPage", "Basic"))
self.log_info.setText(_translate("ClassicalExtrasOptionsPage", "Full"))
self.label_118.setText(_translate("ClassicalExtrasOptionsPage", "Classical Extras Special Tags
"))
self.save_options_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "This can be used so that the user has a record of the version of Classical Extras which generated the tags and which options were selected to achieve the resulting tags. Note that the tags will be blanked first so this will only show the last options used on a particular file. The same tag can be used for both sets of options, resulting in a multi-valued tag.
"))
self.save_options_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Save plugin details and options in a tag?*"))
self.label_41.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for plugin version"))
self.label_36.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for artist/mapping/misc. options"))
self.label_38.setText(_translate("ClassicalExtrasOptionsPage", "Tag name for work/genre options"))
self.override_box.setWhatsThis(_translate("ClassicalExtrasOptionsPage", "If options have previously been saved (see above), selecting these will cause the saved options to be used in preference to the displayed options. The displayed options will not be affected and will be used if no saved options are present. The default is for no over-ride. If artist options over-ride is chosen, then tag map detail options may be included or not in the override.
The last checkbox, "Overwrite options in Options Pages", is for VERY CAREFUL USE ONLY. It will cause any options read from the saved tags (if the relevant box has been ticked) to over-write the options on the plugin Options Page UI. The intended use of this is if for some reason the user\'s preferred options have been erased/reverted to default - by using this option, the previously-used choices from a reliable filed album can be used to populate the Options Page. The box will automatically be unticked after loading/refreshing one album, to prevent inadvertant use. Far better is to make a backup copy of the picard.ini file.
"))
self.override_box.setTitle(_translate("ClassicalExtrasOptionsPage", "Over-ride plugin options displayed in Options Pages with options from local file tags (previously saved using method in box above)?*"))
self.cea_override.setText(_translate("ClassicalExtrasOptionsPage", "Artist options"))
self.cwp_override.setText(_translate("ClassicalExtrasOptionsPage", "Work options"))
self.ce_genres_override.setText(_translate("ClassicalExtrasOptionsPage", "Genres etc. options"))
self.ce_tagmap_override.setToolTip(_translate("ClassicalExtrasOptionsPage", "Will not over-ride displayed options unless artist options over-ride is also selected
"))
self.ce_tagmap_override.setText(_translate("ClassicalExtrasOptionsPage", "Tag mapping options"))
self.ce_options_overwrite.setText(_translate("ClassicalExtrasOptionsPage", "Overwrite options in Options Pages (READ WARNINGS in Readme)"))
self.label_121.setText(_translate("ClassicalExtrasOptionsPage", "Note that the above saved options include the related \"advanced\" options on this tab as well as the options on each of the main tabs."))
self.ce_show_ui_tags.setText(_translate("ClassicalExtrasOptionsPage", "Show additional tags in Picard UI (rhs panel) - N.B. RESTART NEEDED FOR CHANGE TO TAKE EFFECT"))
self.groupBox.setTitle(_translate("ClassicalExtrasOptionsPage", "Additional columns for Picard UI to show specific tags*"))
self.label_94.setText(_translate("ClassicalExtrasOptionsPage", "RESTART PICARD AFTER CHANGING THESE - otherwise changes will not take effect
"))
self.label_8.setText(_translate("ClassicalExtrasOptionsPage", "Notes:
1. Use the format column_name_A: (include_tag_1, include_tag_2) / column_name_B: include_tag_3 etc. (i.e. put multiple tags to be concatenated in brackets)
2. To just flag tags that have changed, rather than show the contents, add _DIFF at the end of the tag name
3. If more than one tag name is included for a column, then:
(a) if the tags are _DIFF tags, then the column will be flagged if any of them have changed
(b) otherwise the tag contents will be concatenated
"))
self.label_83.setText(_translate("ClassicalExtrasOptionsPage", "* ASTERISKED OPTIONS ARE NOT SAVED IN FILE TAGS"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Advanced), _translate("ClassicalExtrasOptionsPage", "Advanced"))
self.textBrowser_2.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
"\n"
"General description
\n"
"Classical Extras provides tagging enhancements for Picard and, in particular, utilises MusicBrainz’s hierarchy of works to provide work/movement tags. All options are set through a user interface in Picard options->plugins. This interface provides separate sections to enhance artist/performer tags, works and parts, genres and also allows for a generalised "tag mapping" (simple scripting). While it is designed to cater for the complexities of classical music tagging, it may also be useful for other music which has more than just basic song/artist/album data.
The options screen provides five tabs for users to control the tags produced:
1. Artists: Options as to whether artist tags will contain standard MB names, aliases or as-credited names. Ability to include and annotate names for specialist roles (chorus master, arranger, lyricist etc.). Ability to read lyrics tags on the file which has been loaded and assign them to track and album levels if required. (Note: Picard will not normally process incoming file tags).
2. Works and parts: The plugin will build a hierarchy of works and parts (e.g. Work -> Part -> Movement or Opera -> Act -> Number) based on the works in MusicBrainz\'s database. These can then be displayed in tags in a variety of ways according to user preferences. Furthermore partial recordings, medleys, arrangements and collections of works are all handled according to user choices. There is a processing overhead for this at present because MusicBrainz limits look-ups to one per second.
3. Genres etc.: Options are available to customise the source and display of information relating to genres, instruments, keys, work dates and periods. Additional capabilities are provided for users of Muso (or others who provide the relevant XML files) to use pre-existing databases of classical genres, classical composers and classical periods.
4. Tag mapping: in some ways, this is a simple substitute for some of Picard\'s scripting capability. The main advantage is that the plugin will remember what tag mapping you use for each release (or even track).
5. Advanced: Various options to control the detailed processing of the above.
All user options can be saved on a per-album (or even per-track) basis so that tweaks can be used to deal with inconsistencies in the MusicBrainz data (e.g. include English titles from the track listing where the MusicBrainz works are in the composer\'s language and/or script). Also existing file tags can be processed (not possible in native Picard).
"))
self.textBrowser_3.setHtml(_translate("ClassicalExtrasOptionsPage", "\n"
"\n"
"Please see my website for full details of this plugin and how to use it.
\n"
"This help page now has only general information.
\n"
"There are extensive tooltips and "What\'s This" popups (right click for them)
"))
self.tabWidget.setTabText(self.tabWidget.indexOf(self.Help), _translate("ClassicalExtrasOptionsPage", "Help"))
================================================
FILE: plugins/classicdiscnumber/classicdiscnumber.py
================================================
PLUGIN_NAME = 'Classic Disc Numbers'
PLUGIN_AUTHOR = 'Lukas Lalinsky'
PLUGIN_DESCRIPTION = '''Moves disc numbers and subtitles from the separate tags to album titles.'''
PLUGIN_VERSION = "0.2"
PLUGIN_API_VERSIONS = ["0.15", "2.0"]
from picard.metadata import register_track_metadata_processor
import re
def add_discnumbers(tagger, metadata, track, release):
if int(metadata["totaldiscs"] or "0") > 1:
if "discsubtitle" in metadata:
metadata["album"] = "%s (disc %s: %s)" % (
metadata["album"], metadata["discnumber"],
metadata["discsubtitle"])
else:
metadata["album"] = "%s (disc %s)" % (
metadata["album"], metadata["discnumber"])
register_track_metadata_processor(add_discnumbers)
================================================
FILE: plugins/collect_artists/collect_artists.py
================================================
PLUGIN_NAME = "Collect Album Artists"
PLUGIN_AUTHOR = "johbi"
PLUGIN_DESCRIPTION = "Adds a context menu shortcut to collect all track artists from a release and format them as the releases album artist."
PLUGIN_VERSION = '0.1'
PLUGIN_API_VERSIONS = ['2.1', '2.2']
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl.txt"
from picard.album import Album
from picard.ui.itemviews import BaseAction, register_album_action
class CollectArtists(BaseAction):
NAME = 'Replace release artist with &track artists...'
def callback(self, objs):
for album in objs:
if isinstance(album, Album):
trackartists = []
for track in album.tracks:
if "artists" in track.metadata:
artists = track.metadata.getall("artists")
elif "artist" in track.metadata:
artists = track.metadata.getall("artist")
else:
continue
for artist in artists:
if artist not in trackartists:
trackartists.append(artist)
if len(trackartists) >= 2:
albumartist = (", ").join(trackartists[:-1]) + ' & ' + trackartists[-1]
elif len(trackartists) == 1:
albumartist = trackartists[0]
else:
self.tagger.window.set_statusbar_message("Could not find any artists for the album: \"" + album.metadata['album'] + "\"")
continue
album.metadata.set("albumartist", albumartist)
for track in album.tracks:
track.metadata.set("albumartist", albumartist)
for files in track.linked_files:
track.update_file_metadata(files)
album.update()
register_album_action(CollectArtists())
================================================
FILE: plugins/compatible_TXXX/compatible_TXXX.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = u"Compatible TXXX frames"
PLUGIN_AUTHOR = u'Tungol'
PLUGIN_DESCRIPTION = """This plugin improves the compatibility of ID3 tags \
by using only a single value for TXXX frames. Multiple value TXXX frames \
technically don't comply with the ID3 specification."""
PLUGIN_VERSION = "0.1"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import config
from picard.formats import register_format
from picard.formats.id3 import MP3File, TrueAudioFile, DSFFile, AiffFile
from mutagen import id3
id3v24_join_with = '; '
def build_compliant_TXXX(self, encoding, desc, values):
"""Return a TXXX frame with only a single value.
Use id3v23_join_with as the sperator if using id3v2.3, otherwise the value
set in this plugin (default "; ").
"""
if config.setting['write_id3v23']:
sep = config.setting['id3v23_join_with']
else:
sep = id3v24_join_with
joined_values = [sep.join(values)]
return id3.TXXX(encoding=encoding, desc=desc, text=joined_values)
# I can't actually remove the original MP3File et al formats once they're
# registered. This depends on the name of the replacements sorting after the
# name of the originals, because picard.formats.guess_format picks the last
# item from a sorted list.
class MP3FileCompliant(MP3File):
"""Alternate MP3 format class which uses single-value TXXX frames."""
build_TXXX = build_compliant_TXXX
class TrueAudioFileCompliant(TrueAudioFile):
"""Alternate TTA format class which uses single-value TXXX frames."""
build_TXXX = build_compliant_TXXX
class DSFFileCompliant(DSFFile):
"""Alternate DSF format class which uses single-value TXXX frames."""
build_TXXX = build_compliant_TXXX
class AiffFileCompliant(AiffFile):
"""Alternate AIFF format class which uses single-value TXXX frames."""
build_TXXX = build_compliant_TXXX
register_format(MP3FileCompliant)
register_format(TrueAudioFileCompliant)
register_format(DSFFileCompliant)
register_format(AiffFileCompliant)
================================================
FILE: plugins/critiquebrainz/critiquebrainz.py
================================================
# -*- coding: utf-8 -*-
# Critiquebrainz plugin for Picard
# Copyright (C) 2022 Tobias Sarner
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License version 2 as
# published by the Free Software Foundation.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License along
# with this program; if not, write to the Free Software Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
#
PLUGIN_NAME = 'Critiquebrainz Review Comment'
PLUGIN_AUTHOR = 'Tobias Sarner'
PLUGIN_DESCRIPTION = '''Uses Critiquebrainz for comment as review or rating.
WARNING: Experimental plugin. All guarantees voided by use.
Example: Taylor Swift
Release: Midnights
https://musicbrainz.org/release/e348fdd6-f73b-47fe-94c4-670bfee26a39 ,
https://critiquebrainz.org/release-group/0dcc84fb-c592-46e9-ba92-a52bb44dd553
Recording:
https://musicbrainz.org/recording/93113326-93e9-409c-a3d6-5ec91864ba30 ,
https://critiquebrainz.org/recording/93113326-93e9-409c-a3d6-5ec91864ba30'''
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
PLUGIN_VERSION = "1.0.2"
PLUGIN_API_VERSIONS = ["2.0"]
from functools import partial
from picard import log
from picard.metadata import register_album_metadata_processor
from picard.metadata import register_track_metadata_processor
from picard.webservice import ratecontrol
from picard.util import load_json
CRITIQUEBRAINZ_HOST = "critiquebrainz.org"
CRITIQUEBRAINZ_PORT = 80
ratecontrol.set_minimum_delay((CRITIQUEBRAINZ_HOST, CRITIQUEBRAINZ_PORT), 50)
def result_review(album, metadata, data, reply, error):
if error:
album._requests -= 1
album._finalize_loading(None)
return
try:
reviews = load_json(data).get("reviews")
if reviews:
for review in reviews:
if "last_revision" in review:
ident = (review["entity_type"].replace("_", "-") + "_review_" + review["published_on"] + "_" + review["user"]["display_name"] + "_" + review["language"]).lower()
if review["last_revision"]["text"] is not None:
review_text = review["last_revision"]["text"] + "\n\nEine Bewertung mit " + str(review["last_revision"]["rating"]) + " von 5 Sternen veröffentlich durch " + review["user"]["display_name"] + " am " + review["published_on"] + " lizensiert unter " + review["full_name"] + ".";
if "comment:" + ident in metadata:
metadata["comment:" + ident] = review_text
else:
metadata.add("comment:" + ident, review_text)
review_url = "https://critiquebrainz.org/review/" + review["id"]
if "website:" + ident in metadata:
metadata["website:" + ident] = review_url
else:
metadata.add("website:" + ident, review_url)
log.debug("%s: success parsing %s reviews (%s) from response", PLUGIN_NAME, reviews["count"], metadata["albumtitle"])
except Exception as e:
log.error("%s: error parsing review (%s) from response: %s", PLUGIN_NAME, metadata["albumtitle"], str(e))
finally:
album._requests -= 1
album._finalize_loading(None)
def process_releasegroup(album, metadata, release):
queryargs = {
"entity_id": metadata["musicbrainz_releasegroupid"],
"entity_type": "release_group"
}
album.tagger.webservice.get(
CRITIQUEBRAINZ_HOST,
CRITIQUEBRAINZ_PORT,
"/ws/1/review",
partial(result_review, album, metadata),
priority=True,
parse_response_type=None,
queryargs=queryargs
)
album._requests += 1
def process_recording(album, metadata, track, release):
queryargs = {
"entity_id": metadata["musicbrainz_recordingid"],
"entity_type": "recording"
}
album.tagger.webservice.get(
CRITIQUEBRAINZ_HOST,
CRITIQUEBRAINZ_PORT,
"/ws/1/review",
partial(result_review, album, metadata),
priority=True,
parse_response_type=None,
queryargs=queryargs
)
album._requests += 1
register_album_metadata_processor(process_releasegroup)
register_track_metadata_processor(process_recording)
================================================
FILE: plugins/cuesheet/cuesheet.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "Generate Cuesheet"
PLUGIN_AUTHOR = "Lukáš Lalinský, Sambhav Kothari"
PLUGIN_DESCRIPTION = "Generate cuesheet (.cue file) from an album."
PLUGIN_VERSION = "1.2.2"
PLUGIN_API_VERSIONS = ["2.0"]
import os.path
import re
from PyQt5 import QtCore, QtWidgets
from picard.util import find_existing_path, encode_filename
from picard.ui.itemviews import BaseAction, register_album_action
_whitespace_re = re.compile(r'\s', re.UNICODE)
_split_re = re.compile(r'\s*("[^"]*"|[^ ]+)\s*', re.UNICODE)
def msfToMs(msf):
msf = msf.split(":")
return ((int(msf[0]) * 60 + int(msf[1])) * 75 + int(msf[2])) * 1000 / 75
class CuesheetTrack(list):
def __init__(self, cuesheet, index):
list.__init__(self)
self.cuesheet = cuesheet
self.index = index
def set(self, *args):
self.append(args)
def find(self, prefix):
return [i for i in self if tuple(i[:len(prefix)]) == tuple(prefix)]
def getTrackNumber(self):
return self.index
def getLength(self):
try:
nextTrack = self.cuesheet.tracks[self.index + 1]
index0 = self.find(("INDEX", "01"))
index1 = nextTrack.find(("INDEX", "01"))
return msfToMs(index1[0][2]) - msfToMs(index0[0][2])
except IndexError:
return 0
def getField(self, prefix):
try:
return self.find(prefix)[0][len(prefix)]
except IndexError:
return ""
def getArtist(self):
return self.getField(("PERFORMER",))
def getTitle(self):
return self.getField(("TITLE",))
def setArtist(self, artist):
found = False
for item in self:
if item[0] == "PERFORMER":
if not found:
item[1] = artist
found = True
else:
del item
if not found:
self.append(("PERFORMER", artist))
artist = property(getArtist, setArtist)
class Cuesheet(object):
def __init__(self, filename):
self.filename = filename
self.tracks = []
def read(self):
with open(encode_filename(self.filename)) as f:
self.parse(f.readlines())
def unquote(self, string):
if string.startswith('"'):
if string.endswith('"'):
return string[1:-1]
else:
return string[1:]
return string
def quote(self, string):
if _whitespace_re.search(string):
return '"' + string.replace('"', '\'') + '"'
return string
def parse(self, lines):
track = CuesheetTrack(self, 0)
self.tracks = [track]
isUnicode = False
for line in lines:
# remove BOM
if line.startswith('\xfe\xff'):
isUnicode = True
line = line[1:]
# decode to unicode string
line = line.strip()
if isUnicode:
line = line.decode('UTF-8', 'replace')
else:
line = line.decode('ISO-8859-1', 'replace')
# parse the line
split = [self.unquote(s) for s in _split_re.findall(line)]
keyword = split[0].upper()
if keyword == 'TRACK':
trackNum = int(split[1])
track = CuesheetTrack(self, trackNum)
self.tracks.append(track)
track.append(split)
def write(self):
lines = []
for track in self.tracks:
num = track.index
for line in track:
indent = 0
if num > 0:
if line[0] == "TRACK":
indent = 2
elif line[0] != "FILE":
indent = 4
line2 = " ".join([self.quote(s) for s in line])
line2 = " " * indent + line2 + "\n"
lines.append(line2.encode("UTF-8"))
with open(encode_filename(self.filename), "wb") as f:
f.writelines(lines)
class GenerateCuesheet(BaseAction):
NAME = "Generate &Cuesheet..."
def callback(self, objs):
album = objs[0]
current_directory = self.config.persist["current_directory"] or QtCore.QDir.homePath()
current_directory = find_existing_path(str(current_directory))
filename, selected_format = QtWidgets.QFileDialog.getSaveFileName(
None, "", current_directory, "Cuesheet (*.cue)")
if filename:
cuesheet = Cuesheet(filename)
#try: cuesheet.read()
#except IOError: pass
while len(cuesheet.tracks) <= len(album.tracks):
track = CuesheetTrack(cuesheet, len(cuesheet.tracks))
cuesheet.tracks.append(track)
#if len(cuesheet.tracks) > len(album.tracks) - 1:
# cuesheet.tracks = cuesheet.tracks[0:len(album.tracks)+1]
t = cuesheet.tracks[0]
t.set("PERFORMER", album.metadata["albumartist"])
t.set("TITLE", album.metadata["album"])
t.set("REM", "MUSICBRAINZ_ALBUM_ID", album.metadata["musicbrainz_albumid"])
t.set("REM", "MUSICBRAINZ_ALBUM_ARTIST_ID", album.metadata["musicbrainz_albumartistid"])
if "date" in album.metadata:
t.set("REM", "DATE", album.metadata["date"])
index = 0.0
for i, track in enumerate(album.tracks):
mm = index / 60.0
ss = (mm - int(mm)) * 60.0
ff = (ss - int(ss)) * 75.0
index += track.metadata.length / 1000.0
t = cuesheet.tracks[i + 1]
t.set("TRACK", "%02d" % (i + 1), "AUDIO")
t.set("PERFORMER", track.metadata["artist"])
t.set("TITLE", track.metadata["title"])
t.set("REM", "MUSICBRAINZ_TRACK_ID", track.metadata["musicbrainz_trackid"])
t.set("REM", "MUSICBRAINZ_ARTIST_ID", track.metadata["musicbrainz_artistid"])
t.set("INDEX", "01", "%02d:%02d:%02d" % (mm, ss, ff))
for file in track.linked_files:
audio_filename = file.filename
extension = audio_filename.split(".")[-1].lower()
if os.path.dirname(filename) == os.path.dirname(audio_filename):
audio_filename = os.path.basename(audio_filename)
if extension in ["mp3", "mp2", "m2a"]:
file_type = "MP3"
elif extension in ["aiff", "aif", "aifc"]:
file_type = "AIFF"
else:
file_type = "WAVE"
cuesheet.tracks[i].set("FILE", audio_filename, file_type)
cuesheet.write()
action = GenerateCuesheet()
register_album_action(action)
================================================
FILE: plugins/decade/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2019 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Decade function'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = ('Add a $decade(date) function to get the decade '
'from a year. E.g. $decade(1994-04-05) will give "90s". '
'By default decades between 1920 and 2000 will be '
'shortened to two digits. You can disable this with '
'setting the second parameter to 0, e.g. '
'$decade(1994,0) will give "1990s".')
PLUGIN_VERSION = "1.0"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard.script import register_script_function
def decade(date, shorten=True):
"""
>>> decade("1970-09-18")
'70s'
>>> decade("1994")
'90s'
>>> decade("1994-04")
'90s'
>>> decade("1994-04-05")
'90s'
>>> decade("1994-04-05", shorten=False)
'1990s'
>>> decade("1901")
'1900s'
>>> decade("1917-08-22")
'1910s'
>>> decade("1921-10-10")
'20s'
>>> decade("1770-12-16")
'1770s'
>>> decade("2017-07-20")
'2010s'
>>> decade("2020")
'2020s'
>>> decade("992")
'990s'
>>> decade("992-01")
'990s'
>>> decade("")
''
>>> decade(None)
''
>>> decade("foo")
''
"""
try:
year = int(date.split('-')[0])
except (AttributeError, ValueError):
return ""
decade = year // 10 * 10
if shorten and 1920 <= decade < 2000:
decade -= 1900
return "%ds" % decade
def script_decade(parser, value, shorten=True):
return decade(value, shorten and shorten != '0')
register_script_function(script_decade, name="decade")
================================================
FILE: plugins/decode_cyrillic/decode_cyrillic.py
================================================
# -*- coding: utf-8 -*-
# This is the Decode Cyrillic plugin for MusicBrainz Picard.
# Copyright (C) 2015 aeontech
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
from __future__ import print_function
PLUGIN_NAME = "Decode Cyrillic"
PLUGIN_AUTHOR = "aeontech"
PLUGIN_DESCRIPTION = '''
This plugin helps you quickly convert mis-encoded cyrillic Windows-1251 tags
to proper UTF-8 encoded strings. If your track/album names look something like
"Àëèñà â ñò›àíå ÷óäåñ", run this plugin from the context menu
before running the "Lookup" or "Scan" tools
'''
PLUGIN_VERSION = "1.1"
PLUGIN_API_VERSIONS = ["1.0", "2.0"]
PLUGIN_LICENSE = "MIT"
PLUGIN_LICENSE_URL = "https://opensource.org/licenses/MIT"
from picard import log
from picard.cluster import Cluster
from picard.ui.itemviews import BaseAction, register_cluster_action
_decode_tags = [
'title',
'albumartist',
'artist',
'album',
'artistsort'
]
# _from_encoding = "latin1"
# _to_encoding = "cp1251"
# TODO:
# - extend to support multiple codepage decoding, not just cp1251->latin1
# instead, try the common variations, and show a dialog to the user,
# allowing him to select the correct transcoding. See 2cyr.com for example.
# - also see http://stackoverflow.com/questions/23326531/how-to-decode-cp1252-string
class DecodeCyrillic(BaseAction):
NAME = "Unmangle cyrillic metadata"
def unmangle(self, tag, value):
try:
print(value, value.encode('latin1'))
unmangled_value = value.encode('latin1').decode('cp1251')
except UnicodeError:
unmangled_value = value
log.debug("%s: could not unmangle tag %s; original value: %s" % (PLUGIN_NAME, tag, value))
return unmangled_value
def callback(self, objs):
for cluster in objs:
if not isinstance(cluster, Cluster):
continue
for tag in _decode_tags:
if not (tag in cluster.metadata):
continue
cluster.metadata[tag] = self.unmangle(tag, cluster.metadata[tag])
log.debug("cluster name is %s by %s" % (cluster.metadata['album'], cluster.metadata['albumartist']))
for i, file in enumerate(cluster.files):
log.debug("%s: Trying to unmangle file - original metadata %s" % (PLUGIN_NAME, file.orig_metadata))
for tag in _decode_tags:
if not (tag in file.metadata):
continue
unmangled_tag = self.unmangle(tag, file.metadata[tag])
file.orig_metadata[tag] = unmangled_tag
file.metadata[tag] = unmangled_tag
file.orig_metadata.changed = True
file.metadata.changed = True
file.update(signal=True)
cluster.update()
register_cluster_action(DecodeCyrillic())
================================================
FILE: plugins/decode_greek_cyrillic/decode_greek1253.py
================================================
# -*- coding: utf-8 -*-
#This is not my work. I just changed the language to Greek.
#All the credits goes to the original coder.
# This is the Decode Greek plugin for MusicBrainz Picard.
# Copyright (C) 2015 aeontech
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
from __future__ import print_function
PLUGIN_NAME = "Decode Cyrillic Greek"
PLUGIN_AUTHOR = "aeontech, Lefteris NeNpO"
PLUGIN_VERSION = "1.3"
PLUGIN_API_VERSIONS = ["1.0", "2.0"]
PLUGIN_LICENSE = "MIT"
PLUGIN_LICENSE_URL = "https://opensource.org/licenses/MIT"
PLUGIN_DESCRIPTION = '''
This plugin helps you quickly convert mis-encoded Greek Windows-1253 tags
to proper UTF-8 encoded strings. If your track/album names look something like
"Àëèñà â ñò›àíå ÷óäåñ", run this plugin from the context menu
before running the "Lookup" or "Scan" tools
'''
from picard import log
from picard.cluster import Cluster
from picard.ui.itemviews import BaseAction, register_cluster_action
_decode_tags = [
'title',
'albumartist',
'albumartistsort',
'artist',
'artistsort',
'album',
'comment:',
'comment:ID3v1 Comment'
]
class DecodeGreek(BaseAction):
NAME = "Unmangle Greek metadata"
def unmangle(self, tag, value):
try:
log.debug("%s: %s => %r" % (PLUGIN_NAME, value, value.encode('latin1')))
unmangled_value = value.encode('latin1').decode('cp1253')
except UnicodeError:
unmangled_value = value
log.debug("%s: could not unmangle tag %s; original value: %s" % (PLUGIN_NAME, tag, value))
return unmangled_value
def callback(self, objs):
for cluster in objs:
if not isinstance(cluster, Cluster):
continue
for tag in _decode_tags:
if not (tag in cluster.metadata):
continue
cluster.metadata[tag] = self.unmangle(tag, cluster.metadata[tag])
log.debug("cluster name is %s by %s" % (cluster.metadata['album'], cluster.metadata['albumartist']))
for file in cluster.files:
log.debug("%s: Trying to unmangle file - original metadata %s" % (PLUGIN_NAME, file.orig_metadata))
for tag in _decode_tags:
if not (tag in file.metadata):
continue
unmangled_tag = self.unmangle(tag, file.metadata[tag])
file.orig_metadata[tag] = unmangled_tag
file.metadata[tag] = unmangled_tag
file.orig_metadata.changed = True
file.metadata.changed = True
file.update(signal=True)
cluster.update()
register_cluster_action(DecodeGreek())
================================================
FILE: plugins/deezerart/__init__.py
================================================
PLUGIN_NAME = "Deezer cover art"
PLUGIN_AUTHOR = "Fabio Forni "
PLUGIN_DESCRIPTION = "Fetch cover arts from Deezer"
PLUGIN_VERSION = '1.2.2'
PLUGIN_API_VERSIONS = ['2.5']
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-3.0.html"
from typing import Any, List, Optional
from urllib.parse import urlsplit
import picard
from picard import config
from picard.coverart import providers
from picard.coverart.image import CoverArtImage
from picard.util.astrcmp import astrcmp
from PyQt5 import QtNetwork as QtNet
from .deezer import Client, SearchOptions, obj
from .options import Ui_Form
__version__ = PLUGIN_VERSION
DEFAULT_SIMILARITY_THRESHOLD = 0.6
def is_similar(str1: str, str2: str, min_similarity: float = DEFAULT_SIMILARITY_THRESHOLD) -> bool:
if str1 in str2:
return True
return astrcmp(str1, str2) >= min_similarity
def is_deezer_url(url: str) -> bool:
return 'deezer.com' in urlsplit(url).netloc
class OptionsPage(providers.ProviderOptions):
NAME = 'Deezer'
TITLE = 'Deezer'
options = [
config.TextOption('setting', 'deezerart_size', obj.CoverSize.BIG.value),
config.FloatOption('setting', 'deezerart_min_similarity', DEFAULT_SIMILARITY_THRESHOLD),
]
_options_ui = Ui_Form
def load(self):
for s in obj.CoverSize:
self.ui.size.addItem(str(s.name).title(), userData=s.value)
self.ui.size.setCurrentIndex(self.ui.size.findData(config.setting['deezerart_size']))
self.ui.min_similarity.setValue(int(config.setting["deezerart_min_similarity"] * 100))
def save(self):
config.setting['deezerart_size'] = self.ui.size.currentData()
config.setting['deezerart_min_similarity'] = float(self.ui.min_similarity.value()) / 100.0
class Provider(providers.CoverArtProvider):
NAME = 'Deezer'
OPTIONS = OptionsPage
_log_prefix = 'Deezerart: '
def __init__(self, coverart):
super().__init__(coverart)
self.client = Client(self.album.tagger.webservice)
self._has_url_relation = False
self._retry_search = False
# Override.
def queue_images(self):
self.match_url_relations(['free streaming'], self._url_callback)
if not self._has_url_relation:
if not self._retry_search:
search_opts = SearchOptions(artist=self._artist(), album=self.metadata['album'])
else:
try:
track = self.release['media'][0]['tracks'][1]['title']
except (IndexError, KeyError):
self.error('cannot find a track name to retry a search. No cover found')
return self.FINISHED
else:
search_opts = SearchOptions(artist=self._artist(), track=track)
self.client.advanced_search(search_opts, self._queue_from_search)
self.album._requests += 1
return self.WAIT
# Override.
def error(self, msg):
super().error(self._log_prefix + msg)
def log_debug(self, msg: Any, *args):
picard.log.debug(self._log_prefix + msg, *args)
def _url_callback(self, url: str):
if is_deezer_url(url):
self._has_url_relation = True
self.client.obj_from_url(url, self._queue_from_url)
def _queue_from_url(self, album: obj.APIObject, error: QtNet.QNetworkReply.NetworkError):
self.album._requests -= 1
try:
if error:
self.error('could not get Deezer API object: {}'.format(error))
return
if not isinstance(album, obj.Album):
self.error('API object is not an album')
return
cover_url = album.cover_url(obj.CoverSize(config.setting['deezerart_size']))
self.queue_put(CoverArtImage(cover_url))
self.log_debug('queued cover using an URL relation')
finally:
self.next_in_queue()
def _queue_from_search(self, results: List[obj.APIObject], error: Optional[QtNet.QNetworkReply.NetworkError]):
self.album._requests -= 1
try:
if error:
self.error('could not fetch search results: {}'.format(error))
return
if len(results) == 0:
if self._retry_search:
self.error('no results found')
return
self._retry_search = True
self.queue_images()
return
artist = self._artist()
album = self.metadata['album']
min_similarity = config.setting['deezerart_min_similarity']
for result in results:
if not isinstance(result, obj.Track):
continue
if not is_similar(artist, result.artist.name, min_similarity):
self.log_debug('artist similarity below threshold: %r ~ %r', artist, result.artist.name)
continue
if not is_similar(album, result.album.title, min_similarity):
self.log_debug('album similarity below threshold: %r ~ %r', album, result.album.title)
continue
cover_url = result.album.cover_url(obj.CoverSize(config.setting['deezerart_size']))
self.queue_put(CoverArtImage(cover_url))
self.log_debug('queued cover using a Deezer search')
return
self.error('no result matched the criteria')
finally:
self.next_in_queue()
def _artist(self) -> str:
# If there are many artists, we want to search
# the album in Deezer with just one as keyword.
# Deezerart may not specify all the artists
# MusicBrainz does, or it may use different separators.
return self.metadata.getraw('~albumartists')[0]
providers.register_cover_art_provider(Provider)
================================================
FILE: plugins/deezerart/deezer/__init__.py
================================================
from .client import Client, SearchOptions
================================================
FILE: plugins/deezerart/deezer/client.py
================================================
import json
from functools import partial
from typing import Callable, List, NamedTuple, Optional, TypeVar
from urllib.parse import urlsplit, urlunsplit
from picard.webservice import WebService
from PyQt5.QtCore import QByteArray
from PyQt5.QtNetwork import QNetworkReply
from . import obj
DEEZER_HOST = 'api.deezer.com'
DEEZER_PORT = 443
T = TypeVar('T', bound=obj.APIObject)
SearchCallback = Callable[[List[T], Optional[QNetworkReply.NetworkError]], None]
APIURLCallback = Callable[[Optional[T], Optional[QNetworkReply.NetworkError]], None]
class SearchOptions(NamedTuple('SearchOptions', [('artist', str), ('album', str), ('track', str), ('label', str)])):
"""
Options for the advanced search.
"""
def __str__(self):
options = ['{}:"{}"'.format(k, v) for k, v in self._asdict().items() if v]
return ' '.join(options)
# Python 3.5 cannot set defaults values in an othodox way.
SearchOptions.__new__.__defaults__ = ('',) * len(SearchOptions._fields)
class Client:
def __init__(self, webservice: WebService):
self.webservice = webservice
self._get = partial(self.webservice.get, DEEZER_HOST, DEEZER_PORT)
def advanced_search(self, options: SearchOptions, callback: SearchCallback[obj.APIObject]):
path = '/search'
def handler(document: QByteArray, _: QNetworkReply, error: Optional[QNetworkReply.NetworkError]):
try:
parsed_doc = json.loads(str(document, 'utf-8'))
except json.JSONDecodeError:
callback([], error)
else:
result = []
error = None
if 'data' in parsed_doc:
result = [obj.parse_json(dct) for dct in parsed_doc['data']]
elif 'error' in parsed_doc:
error = parsed_doc['error'].get('message', 'Deezer responded with an unknown error')
else:
error = 'Deezer returned an unexpected response'
callback(result, error)
self._get(path,
queryargs={'q': str(options)},
parse_response_type=None,
handler=handler)
def obj_from_url(self, url: str, callback: APIURLCallback[obj.APIObject]):
def handler(document: QByteArray, _: QNetworkReply, error: Optional[QNetworkReply.NetworkError]):
try:
deezer_obj = obj.parse_json(str(document, 'utf-8'))
except json.JSONDecodeError:
deezer_obj = None
finally:
callback(deezer_obj, error)
self._get(self._remove_language_path(urlsplit(url).path),
parse_response_type=None,
handler=handler)
@staticmethod
def api_url(url: str) -> str:
parsed = urlsplit(url)
path = Client._remove_language_path(parsed.path)
return urlunsplit((parsed.scheme, DEEZER_HOST, path, parsed.query, parsed.fragment))
@staticmethod
def _remove_language_path(path: str) -> str:
# Deezer has a 2-letter language path, e.g. /us/track/123.
lang_len = 2
paths = path[1:].split('/', maxsplit=1)
return path[lang_len + 1:] if len(paths[0]) == lang_len else path
================================================
FILE: plugins/deezerart/deezer/obj.py
================================================
import enum
import json
from typing import Any, List, Mapping, Optional, Union
# This module is a perfect target for dataclasses.
# Picard though supports Python 3.5+, so we cannot
# use dataclasses for compatibility reasons.
class APIObject:
"""
Base class from Deezer API objects.
"""
fields = [] # type: List[str]
def __init__(self, **kwargs):
if len(self.fields) == 0:
raise NotImplementedError(type(self).__name__ + ' cannot have an empty field list')
for field in self.fields:
setattr(self, field, kwargs.get(field))
def __eq__(self, other):
for field in self.fields:
if getattr(self, field) != getattr(other, field):
return False
return True
class Artist(APIObject):
"""
The Artist API object.
"""
fields = ['name']
class CoverSize(enum.Enum):
"""
Cover size selector.
"""
THUMBNAIL = 'small'
SMALL = ''
MEDIUM = 'medium'
BIG = 'big'
LARGE = 'xl'
class Album(APIObject):
"""
The Album API object.
"""
fields = ['title', 'cover']
def cover_url(self, cover_size: CoverSize) -> str:
"""
Get the album cover URL based on the size wanted.
"""
return '{}?size={}'.format(self.cover, cover_size.value)
class Track(APIObject):
"""
The Track API object.
"""
fields = ['album', 'artist']
available_objects = {c.__name__.lower(): c for c in APIObject.__subclasses__()}
def parse_json(data: Union[str, Mapping[str, Any]]) -> APIObject:
if isinstance(data, str):
return json.loads(data, object_hook=_dict_to_object)
def convert_inner(data: Mapping[str, Any]):
"""
Traverse the dictionaries with post-order
algorithm to convert dict objects in Object instances.
"""
for k, v in data.items():
if isinstance(v, dict):
data[k] = convert_inner(v)
return _dict_to_object(data)
convert_inner(data)
return _dict_to_object(data)
def _dict_to_object(data: Mapping[str, Any]) -> Optional[APIObject]:
try:
obj_type = data['type']
obj_class = available_objects[obj_type]
except KeyError:
return None
else:
return obj_class(**data)
================================================
FILE: plugins/deezerart/options.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/deezerart/options.ui'
#
# Created by: PyQt5 UI code generator 5.15.9
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_Form(object):
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(420, 320)
self.gridLayout = QtWidgets.QGridLayout(Form)
self.gridLayout.setObjectName("gridLayout")
self.sizeLabel = QtWidgets.QLabel(Form)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.sizeLabel.sizePolicy().hasHeightForWidth())
self.sizeLabel.setSizePolicy(sizePolicy)
self.sizeLabel.setObjectName("sizeLabel")
self.gridLayout.addWidget(self.sizeLabel, 0, 0, 1, 1)
self.size = QtWidgets.QComboBox(Form)
self.size.setObjectName("size")
self.gridLayout.addWidget(self.size, 0, 2, 1, 1)
self.min_similarity_label = QtWidgets.QLabel(Form)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.min_similarity_label.sizePolicy().hasHeightForWidth())
self.min_similarity_label.setSizePolicy(sizePolicy)
self.min_similarity_label.setObjectName("min_similarity_label")
self.gridLayout.addWidget(self.min_similarity_label, 1, 0, 1, 2)
self.min_similarity = QtWidgets.QSpinBox(Form)
self.min_similarity.setMaximum(100)
self.min_similarity.setObjectName("min_similarity")
self.gridLayout.addWidget(self.min_similarity, 1, 2, 1, 1)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.gridLayout.addItem(spacerItem, 2, 1, 1, 1)
self.retranslateUi(Form)
QtCore.QMetaObject.connectSlotsByName(Form)
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "Form"))
self.sizeLabel.setText(_translate("Form", "Cover size:"))
self.min_similarity_label.setText(_translate("Form", "Minimal similarity for matches:"))
self.min_similarity.setSuffix(_translate("Form", " %"))
self.min_similarity.setPrefix(_translate("Form", " "))
================================================
FILE: plugins/deezerart/options.ui
================================================
Form
0
0
420
320
Form
-
0
0
Cover size:
-
-
0
0
Minimal similarity for matches:
-
%
100
-
Qt::Vertical
20
40
================================================
FILE: plugins/discnumber/discnumber.py
================================================
PLUGIN_NAME = 'Disc Numbers'
PLUGIN_AUTHOR = 'Lukas Lalinsky'
PLUGIN_DESCRIPTION = '''Moves disc numbers and subtitles from album titles to separate tags. For example:
"Aerial (disc 1: A Sea of Honey)"
- album = "Aerial"
- discnumber = "1"
- discsubtitle = "A Sea of Honey"
'''
PLUGIN_VERSION = "0.1"
PLUGIN_API_VERSIONS = ["0.9.0", "0.10", "0.15", "2.0"]
from picard.metadata import register_album_metadata_processor
import re
_discnumber_re = re.compile(r"\s+\(disc (\d+)(?::\s+([^)]+))?\)")
def remove_discnumbers(tagger, metadata, release):
matches = _discnumber_re.search(metadata["album"])
if matches:
metadata["discnumber"] = matches.group(1)
if matches.group(2):
metadata["discsubtitle"] = matches.group(2)
metadata["album"] = _discnumber_re.sub('', metadata["album"])
register_album_metadata_processor(remove_discnumbers)
================================================
FILE: plugins/enhanced_titles/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2024 Giorgio Fontanive (twodoorcoupe)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Enhanced Titles"
PLUGIN_AUTHOR = "Giorgio Fontanive"
PLUGIN_DESCRIPTION = """
This plugin sets the albumsort and titlesort tags. It also provides the script
functions $swapprefix_lang, $delprefix_lang and $title_lang. The languages
included at the moment are English, Spanish, Italian, German, French and Portuguese.
The functions do the same thing as their original counterparts, but take
multiple languages as parameters. If no languages are provided, all the available ones are
included. Languages are provided with ISO 639-3 codes: eng, spa, ita, fra, deu, por.
Tagging and checking aliases can be disabled in the plugin's options page, found
under "plugins". Checking aliases will slow down processing.
If you wish to add your own language or to change the words that are not capitalized,
please feel free to code the changes and submit a pull request along with links to web
pages that give definitive language-specific title-case rules.
"""
PLUGIN_VERSION = "0.1"
PLUGIN_API_VERSIONS = ["2.10"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import log, config
from picard.plugin import PluginPriority
from picard.metadata import register_album_metadata_processor, register_track_metadata_processor
from picard.script import register_script_function
from picard.script.functions import func_swapprefix, func_delprefix
from picard.webservice.api_helpers import MBAPIHelper
from picard.ui.options import OptionsPage, register_options_page
from .ui_options_enhanced_titles import Ui_EnhancedTitlesOptions
from functools import partial
import re
# Options.
KEEP_ALLCAPS = "et_keep_allcaps"
ENABLE_TAGGING = "et_enable_tagging"
CHECK_ALBUM = "et_check_album_aliases"
CHECK_TRACK = "et_check_track_aliases"
_articles = {
"eng": {"the", "a", "an"},
"spa": {"el", "los", "la", "las", "lo", "un", "unos", "una", "unas"},
"ita": {"il", "l'", "la", "i", "gli", "le", "un", "uno", "una", "un'"},
"fra": {"le", "la", "les", "un", "une", "des", "l'"},
"deu": {"der", "den", "die", "das", "dem", "des", "den"},
"por": {"o", "os", "a", "as", "um", "uns", "uma", "umas"}
}
# Prepositions and conjunctions with 3 letters or fewer.
# These will stay in lower case when doing title case.
_other_minor_words = {
"eng": {"so", "yet", "as", "at", "by", "for", "in", "of", "off", "on", "per",
"to", "up", "via", "and", "as", "but", "for", "if", "nor", "or", "en", "via", "vs"},
"spa": {"mas", "que", "en", "con", "por", "de", "y", "e", "o", "u", "si", "ni"},
"ita": {"di", "a", "da", "in", "con", "su", "per", "tra", "fra", "e", "o", "ma", "se"},
"fra": {"à", "de", "en", "par", "sur", "et", "ou", "que", "si"},
"deu": {"bis", "für", "um", "an", "auf", "in", "vor", "aus", "bei", "mit",
"von", "zu", "la", "so", "daß", "als", "ob", "ehe"},
"por": {"dem", "em", "por", "ao", "à", "aos", "às", "do", "da", "dos", "das",
"no", "na", "nos", "nas", "num", "dum", "e", "mas", "até", "em", "ou",
"que", "se", "por"}
}
def flatten_values(dictionary):
l = list()
for v in dictionary.values():
l += v
return set(l)
_articles_langs = set(_articles)
_all_articles = flatten_values(_articles)
_all_other_minor_words = flatten_values(_other_minor_words)
class ReleaseGroupHelper(MBAPIHelper):
"""API Helper to retrieve release group information.
"""
def get_release_group_by_id(self, release_id, handler, inc = None):
"""Gets the information for a release group.
"""
return self._get_by_id("release-group", release_id, handler, inc)
class SortTagger:
"""Sets the titlesort and albumsort tags.
First, it checks if there is already a sort name available in one of the
aliases. If it does not find any, it swaps the prefix if there is one in
the title.
"""
def _select_alias(self, aliases, name):
"""Selects the first alias where the names match and the sort name is
different.
Args:
aliases (list): One dictionary for each alias available.
name (str): Title of the album/track.
Returns:
(str): The sort name of the first useful alias it finds. None if
none are found.
For example, the album "The Beatles" has alias "Le Double Blanc" with
sort name "Double Blanc, Le", so it's not considered. But it also has alias
"The Beatles" with sort name "Beatles, The", so this one is chosen.
Another example, "The Continuing Story of Bungalow Bill" has an alias
with the sort name equal to the title, this is not considered because
it makes more sense to swap the prefix.
"""
name_casefold = name.casefold()
for alias in aliases:
sortname = alias["sort-name"]
if (alias["name"].casefold() == name_casefold and
not sortname.casefold() == name_casefold):
log.info('Enhanced Titles: sort name found for "%s", "%s".', name, sortname)
return sortname
log.info('Enhanced Titles: no proper sort name found for "%s".', name)
return None
def _response_handler(self, document, reply, error, metadata = None, field = None):
"""Handles the response from MusicBrainz.
Args:
metadata (MetaData): The object that needs to be updated.
field (str): Either "title" or "album", depending on what is being
updated.
"""
sortname = None
try:
if document:
if error:
log.error("Enhanced Titles: information retrieval error.")
if document["aliases"]:
sortname = self._select_alias(document["aliases"], metadata[field])
else:
log.info('Enhanced Titles: no aliases found for "%s".', metadata[field])
finally:
sortfield = field + "sort"
if sortname:
metadata[sortfield] = sortname
else:
metadata[sortfield] = self._swapprefix(metadata, field)
def _swapprefix(self, metadata, field):
"""Swaps the prefix of the title based on the album/track language.
If none of the languages are available, it just copies the title.
Otherwise, if no language information is found, then it uses all languages available.
Otherwise, it uses exclusively the languages that are also available.
"""
languages = lang_functions.find_languages(metadata)
if not languages: # None of the languages found are available.
return metadata[field]
prefixes = lang_functions.find_prefixes(languages)
return func_swapprefix(None, metadata[field], *prefixes)
def set_track_titlesort(self, album, metadata, track, release):
"""Sets the track's titlesort field.
"""
if config.setting[ENABLE_TAGGING]:
handler = partial(self._response_handler, metadata = metadata, field = "title")
if config.setting[CHECK_TRACK]:
MBAPIHelper(album.tagger.webservice).get_track_by_id(
metadata["musicbrainz_recordingid"],
handler,
inc = ["aliases"]
)
else:
metadata["titlesort"] = self._swapprefix(metadata, "title")
def set_album_titlesort(self, album, metadata, release):
"""Sets the album's albumsort field.
"""
if config.setting[ENABLE_TAGGING]:
handler = partial(self._response_handler, metadata = metadata, field = "album")
if config.setting[CHECK_ALBUM]:
ReleaseGroupHelper(album.tagger.webservice).get_release_group_by_id(
metadata["musicbrainz_releasegroupid"],
handler,
inc = ["aliases"]
)
else:
metadata["albumsort"] = self._swapprefix(metadata, "album")
class LangFunctions:
"""Provides scripting functions swapprefix_lang, delprefix_lang, and title_lang.
Combinations of languages and their prefixes/minor words are stored after
they're used at least once.
"""
prefixes_cache = {}
minor_words_cache = {}
def __init__(self):
all_articles = set(_all_articles | set(article.capitalize() for article in _all_articles))
all_minor_words = set(_all_articles | _all_other_minor_words)
self.prefixes_cache[""] = all_articles
self.minor_words_cache[""] = all_minor_words
def _format_languages(self, languages):
"""Filters out the languages that are not available.
It returns a tuple to be used as key for the two cache dictionaries.
"""
languages = set(lang[:3].lower() for lang in languages)
return tuple(languages.intersection(_articles_langs))
def _create_prefixes_list(self, languages = None, is_title = False):
"""Creates a list of all the prefixes or minor words for all the given languages.
Args:
languages (set): All the languages to be considered.
is_title (bool): If true, only articles are included, with a lower case
and a capitalized copy for each. This is because the
swapprefix and delprefix functions are case sensitive.
If false, also prepositions and conjunctions are included,
all in lowercase.
Returns:
(set): The set of prefixes or minor words.
The available languages are saved with ISO 639-3 codes.
"""
prefixes = []
for language in languages:
prefixes.extend(_articles[language])
if is_title:
prefixes.extend(_other_minor_words[language])
else:
prefixes.extend([article.capitalize() for article in _articles[language]])
return set(prefixes)
def _title_case(self, text, lower_case_words):
"""Returns the text in titlecase.
If a word has an apostrophe and the segment to its left is an article,
it capitalizes only the word on the right. Otherwise it capitalizes
only the word on the left.
For example, "let's groove" becomes "Let's Groove", but "voglio l'anima"
becomes "Voglio l'Anima".
"""
new_text = []
words = re.split(r"([\w']+)", text.strip().lower().replace("’", "'"))
words = [word for word in words if word]
for word in words:
if "'" in word: # Apply the rule described above
split = word.split("'")
if split[0] + "'" in lower_case_words:
split[1] = split[1].capitalize()
else:
split[0] = split[0].capitalize()
word = "'".join(split)
elif word not in lower_case_words:
word = word.capitalize()
new_text.append(word)
if new_text:
new_text[0] = new_text[0].capitalize()
return "".join(new_text)
else:
return ""
def find_languages(self, metadata):
"""Finds the languages from the metadata.
Returns a set with only an empty string if no language information is found.
Returns None if the languages found are not available.
"""
languages = (metadata["language"], metadata["_releaselanguage"])
languages = set(language for language in languages if language)
if not languages:
return {""} # No language information is found.
languages = languages.intersection(_articles_langs)
if not languages:
return None # None of the languages found are available.
return languages
def find_prefixes(self, languages):
"""Returns the list of prefixes for the given languages.
If the same combination was previously used, it finds the values stored
to avoid recreating the same list twice.
"""
if not languages or "" in languages:
return self.prefixes_cache[""]
combination = self._format_languages(languages)
if combination in self.prefixes_cache:
return self.prefixes_cache[combination]
prefixes = self._create_prefixes_list(combination)
self.prefixes_cache[combination] = prefixes
return prefixes
def find_minor_words(self, languages):
"""Returns the list of minor words for the given languages.
If the same combination was previously used, it finds the values stored
to avoid recreating the same list twice.
"""
if not languages or "" in languages:
return self.minor_words_cache[""]
combination = self._format_languages(languages)
if combination in self.minor_words_cache:
return self.minor_words_cache[combination]
minor_words = self._create_prefixes_list(combination, True)
self.minor_words_cache[combination] = minor_words
return minor_words
swapprefix_lang_documentation = N_(
"""`$swapprefix_lang(text,language1,language2,...)`
Moves the prefix to the end of the text. It uses a list prefixes
taken from the specified languages.
Multiple languages can be added as seperate parameters.
If none are provided, it uses all the available ones.
""")
def swapprefix_lang(self, parser, text, *languages):
"""
>>> lf = LangFunctions()
>>> lf.swapprefix_lang(None, "The prefix is swapped")
'prefix is swapped, The'
>>> lf.swapprefix_lang(None, "the is swapped also in lower case")
'is swapped also in lower case, the'
>>> lf.swapprefix_lang(None, "the prefix is not in Spanish", "spa")
'the prefix is not in Spanish'
>>> lf.swapprefix_lang(None, "Il prefisso è scambiato", "ita")
'prefisso è scambiato, Il'
>>> lf.swapprefix_lang(None, "the-prefix-is-not-swapped")
'the-prefix-is-not-swapped'
>>> lf.swapprefix_lang(None, "the")
'the'
"""
if parser and not languages:
languages = self.find_languages(parser.context)
prefixes = self.find_prefixes(languages)
return func_swapprefix(parser, text, *prefixes)
delprefix_lang_documentation = N_(
"""`$delprefix_lang(text,language1,language2,...)`
Deletes the prefix from the text. It uses a list prefixes
taken from the specified languages.
Multiple languages can be added as seperate parameters.
If none are provided, it uses all the available ones.
""")
def delprefix_lang(self, parser, text, *languages):
"""
>>> lf = LangFunctions()
>>> lf.delprefix_lang(None, "The prefix is deleted")
'prefix is deleted'
>>> lf.delprefix_lang(None, "the is deleted also in lower case")
'is deleted also in lower case'
>>> lf.delprefix_lang(None, "the prefix is not in Spanish", "spa")
'the prefix is not in Spanish'
>>> lf.delprefix_lang(None, "Il prefisso è eliminato", "ita")
'prefisso è eliminato'
>>> lf.delprefix_lang(None, "the-prefix-is-not-deleted")
'the-prefix-is-not-deleted'
>>> lf.delprefix_lang(None, "the")
'the'
"""
if parser and not languages:
languages = self.find_languages(parser.context)
prefixes = self.find_prefixes(languages)
return func_delprefix(parser, text, *prefixes)
title_lang_documentation = N_(
"""`$title_lang(text,language1,language2,...)`
Makes the text title case based on the minor words of the specified languages.
Multiple languages can be added as separate parameters.
If none are provided, it uses all the available ones.
""")
def title_lang(self, parser, text, *languages):
"""
>>> lf = LangFunctions()
>>> lf.title_lang(None, "title case")
'Title Case'
>>> lf.title_lang(None, "prepositions and/or conjunctions")
'Prepositions and/or Conjunctions'
>>> lf.title_lang(None, "(random-punctuation/and.symbols@")
'(Random-Punctuation/and.Symbols@'
>>> lf.title_lang(None, "only in english: and, or, but...", "eng")
'Only in English: and, or, but...'
>>> lf.title_lang(None, "only in spanish: and, or, but...", "spa")
'Only In Spanish: And, Or, But...'
>>> lf.title_lang(None, "Also in other languages, con altre lingue", "eng", "ita")
'Also in Other Languages, con Altre Lingue'
>>> lf.title_lang(None, "with no valid language", "aaa")
'With No Valid Language'
>>> lf.title_lang(None, "let's groove")
"Let's Groove"
>>> lf.title_lang(None, "voglio l'anima")
"Voglio l'Anima"
>>> lf.title_lang(None, "casiopea, カシオペア")
'Casiopea, カシオペア'
"""
if text.upper() == text and config.setting[KEEP_ALLCAPS]:
return text
if parser and not languages:
languages = self.find_languages(parser.context)
minor_words = self.find_minor_words(languages)
return self._title_case(text, minor_words)
class EnhancedTitlesOptions(OptionsPage):
"""Options page found under the "plugins" page.
"""
NAME = "enhanced_titles"
TITLE = "Enhanced Titles"
PARENT = "plugins"
options = [
config.BoolOption("setting", KEEP_ALLCAPS, False),
config.BoolOption("setting", ENABLE_TAGGING, True),
config.BoolOption("setting", CHECK_ALBUM, True),
config.BoolOption("setting", CHECK_TRACK, False),
]
def __init__(self, parent = None):
super(EnhancedTitlesOptions, self).__init__(parent)
self.ui = Ui_EnhancedTitlesOptions()
self.ui.setupUi(self)
def load(self):
self.ui.check_allcaps.setChecked(config.setting[KEEP_ALLCAPS])
self.ui.check_tagging.setChecked(config.setting[ENABLE_TAGGING])
self.ui.check_album_aliases.setChecked(config.setting[CHECK_ALBUM])
self.ui.check_track_aliases.setChecked(config.setting[CHECK_TRACK])
def save(self):
config.setting[KEEP_ALLCAPS] = self.ui.check_allcaps.isChecked()
config.setting[ENABLE_TAGGING] = self.ui.check_tagging.isChecked()
config.setting[CHECK_ALBUM] = self.ui.check_album_aliases.isChecked()
config.setting[CHECK_TRACK] = self.ui.check_track_aliases.isChecked()
sort_tagger = SortTagger()
lang_functions = LangFunctions()
register_track_metadata_processor(sort_tagger.set_track_titlesort, priority = PluginPriority.LOW)
register_album_metadata_processor(sort_tagger.set_album_titlesort, priority = PluginPriority.LOW)
register_script_function(lang_functions.swapprefix_lang, check_argcount = False, documentation = lang_functions.swapprefix_lang_documentation)
register_script_function(lang_functions.delprefix_lang, check_argcount = False, documentation = lang_functions.delprefix_lang_documentation)
register_script_function(lang_functions.title_lang, check_argcount = False, documentation = lang_functions.title_lang_documentation)
register_options_page(EnhancedTitlesOptions)
================================================
FILE: plugins/enhanced_titles/options_enhanced_titles.ui
================================================
EnhancedTitlesOptions
100
0
Form
-
QFrame::NoFrame
true
0
0
379
502
-
Titles in All Caps
-
true
If this option is enabled, text in all caps will not be affected by the $title_lang script function.
true
-
Ignore titles in all caps.
-
Tagging
-
<html><head/><body><p>If this option is enabled, the fields albumsort and titlesort will be filled. If you are only interested in the scripting functions, then disable this to reduce the time it takes to load releases.</p></body></html>
true
-
Tag albumsort and titlesort fields
true
-
<html><head/><body><p>If this option is enabled, the plugin will first check if there are any sort names already available in MusicBrainz. Otherwise, it will swap the title's prefix directly. Enabling this option will increase the time it takes to load releases, especially for tracks.</p></body></html>
true
-
Check for album aliases
true
true
-
Check for track aliases
-
Qt::Vertical
20
40
================================================
FILE: plugins/enhanced_titles/ui_options_enhanced_titles.py
================================================
# -*- coding: utf-8 -*-
################################################################################
## Form generated from reading UI file 'options_enhanced_titles.ui'
##
## Created by: Qt User Interface Compiler version 6.6.1
##
## WARNING! All changes made in this file will be lost when recompiling UI file!
################################################################################
from PyQt5.QtCore import (QCoreApplication, QDate, QDateTime, QLocale,
QMetaObject, QObject, QPoint, QRect,
QSize, QTime, QUrl, Qt)
from PyQt5.QtGui import (QBrush, QColor, QConicalGradient, QCursor,
QFont, QFontDatabase, QGradient, QIcon,
QImage, QKeySequence, QLinearGradient, QPainter,
QPalette, QPixmap, QRadialGradient, QTransform)
from PyQt5.QtWidgets import (QApplication, QCheckBox, QFrame, QGroupBox,
QLabel, QScrollArea, QSizePolicy, QSpacerItem,
QVBoxLayout, QWidget)
class Ui_EnhancedTitlesOptions(object):
def setupUi(self, EnhancedTitlesOptions):
if not EnhancedTitlesOptions.objectName():
EnhancedTitlesOptions.setObjectName(u"EnhancedTitlesOptions")
EnhancedTitlesOptions.setMinimumSize(QSize(100, 0))
self.verticalLayout = QVBoxLayout(EnhancedTitlesOptions)
self.verticalLayout.setObjectName(u"verticalLayout")
self.scrollArea = QScrollArea(EnhancedTitlesOptions)
self.scrollArea.setObjectName(u"scrollArea")
self.scrollArea.setFrameShape(QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollAreaWidgetContents = QWidget()
self.scrollAreaWidgetContents.setObjectName(u"scrollAreaWidgetContents")
self.scrollAreaWidgetContents.setGeometry(QRect(0, 0, 379, 502))
self.verticalLayout_2 = QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setObjectName(u"verticalLayout_2")
self.titles_all_caps = QGroupBox(self.scrollAreaWidgetContents)
self.titles_all_caps.setObjectName(u"titles_all_caps")
self.verticalLayout_6 = QVBoxLayout(self.titles_all_caps)
self.verticalLayout_6.setObjectName(u"verticalLayout_6")
self.label_4 = QLabel(self.titles_all_caps)
self.label_4.setObjectName(u"label_4")
self.label_4.setMouseTracking(True)
self.label_4.setWordWrap(True)
self.verticalLayout_6.addWidget(self.label_4)
self.check_allcaps = QCheckBox(self.titles_all_caps)
self.check_allcaps.setObjectName(u"check_allcaps")
self.verticalLayout_6.addWidget(self.check_allcaps)
self.verticalLayout_2.addWidget(self.titles_all_caps)
self.check_for_sort_names = QGroupBox(self.scrollAreaWidgetContents)
self.check_for_sort_names.setObjectName(u"check_for_sort_names")
self.verticalLayout_3 = QVBoxLayout(self.check_for_sort_names)
self.verticalLayout_3.setObjectName(u"verticalLayout_3")
self.label = QLabel(self.check_for_sort_names)
self.label.setObjectName(u"label")
self.label.setWordWrap(True)
self.verticalLayout_3.addWidget(self.label)
self.check_tagging = QCheckBox(self.check_for_sort_names)
self.check_tagging.setObjectName(u"check_tagging")
self.check_tagging.setChecked(True)
self.verticalLayout_3.addWidget(self.check_tagging)
self.label_2 = QLabel(self.check_for_sort_names)
self.label_2.setObjectName(u"label_2")
self.label_2.setWordWrap(True)
self.verticalLayout_3.addWidget(self.label_2)
self.check_album_aliases = QCheckBox(self.check_for_sort_names)
self.check_album_aliases.setObjectName(u"check_album_aliases")
self.check_album_aliases.setCheckable(True)
self.check_album_aliases.setChecked(True)
self.verticalLayout_3.addWidget(self.check_album_aliases)
self.check_track_aliases = QCheckBox(self.check_for_sort_names)
self.check_track_aliases.setObjectName(u"check_track_aliases")
self.verticalLayout_3.addWidget(self.check_track_aliases)
self.verticalLayout_2.addWidget(self.check_for_sort_names)
self.verticalSpacer = QSpacerItem(20, 40, QSizePolicy.Minimum, QSizePolicy.Expanding)
self.verticalLayout_2.addItem(self.verticalSpacer)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(EnhancedTitlesOptions)
QMetaObject.connectSlotsByName(EnhancedTitlesOptions)
# setupUi
def retranslateUi(self, EnhancedTitlesOptions):
EnhancedTitlesOptions.setWindowTitle(QCoreApplication.translate("EnhancedTitlesOptions", u"Form", None))
self.titles_all_caps.setTitle(QCoreApplication.translate("EnhancedTitlesOptions", u"Titles in All Caps", None))
self.label_4.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"If this option is enabled, text in all caps will not be affected by the $title_lang script function.", None))
self.check_allcaps.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"Ignore titles in all caps.", None))
self.check_for_sort_names.setTitle(QCoreApplication.translate("EnhancedTitlesOptions", u"Tagging", None))
self.label.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"If this option is enabled, the fields albumsort and titlesort will be filled. If you are only interested in the scripting functions, then disable this to reduce the time it takes to load releases.
", None))
self.check_tagging.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"Tag albumsort and titlesort fields", None))
self.label_2.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"If this option is enabled, the plugin will first check if there are any sort names already available in MusicBrainz. Otherwise, it will swap the title's prefix directly. Enabling this option will increase the time it takes to load releases, especially for tracks.
", None))
self.check_album_aliases.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"Check for album aliases", None))
self.check_track_aliases.setText(QCoreApplication.translate("EnhancedTitlesOptions", u"Check for track aliases", None))
# retranslateUi
================================================
FILE: plugins/fanarttv/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2015-2021 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'fanart.tv cover art'
PLUGIN_AUTHOR = 'Philipp Wolfer, Sambhav Kothari'
PLUGIN_DESCRIPTION = ('Use cover art from fanart.tv.
'
'To use this plugin you have to register a personal API key on '
'fanart.tv.')
PLUGIN_VERSION = "1.6.3"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3", "2.4", "2.5", "2.6"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from functools import partial
from PyQt5.QtCore import QUrl
from PyQt5.QtNetwork import QNetworkReply
from picard import config, log
from picard.coverart.providers import (
CoverArtProvider,
ProviderOptions,
register_cover_art_provider,
)
from picard.coverart.image import CoverArtImage
from picard.config import TextOption
from .ui_options_fanarttv import Ui_FanartTvOptionsPage
FANART_HOST = "webservice.fanart.tv"
FANART_PORT = 443
FANART_APIKEY = "21305dd1589766f4d544535ad4df12f4"
OPTION_CDART_ALWAYS = "always"
OPTION_CDART_NEVER = "never"
OPTION_CDART_NOALBUMART = "noalbumart"
def cover_sort_key(cover):
"""For sorting a list of cover arts by likes."""
try:
return int(cover["likes"]) if "likes" in cover else 0
except ValueError:
return 0
def encode_queryarg(arg):
return bytes(QUrl.toPercentEncoding(arg)).decode()
class FanartTvOptionsPage(ProviderOptions):
_options_ui = Ui_FanartTvOptionsPage
options = [
TextOption("setting", "fanarttv_client_key", ""),
TextOption("setting", "fanarttv_use_cdart", OPTION_CDART_NOALBUMART),
]
def load(self):
setting = config.setting
self.ui.fanarttv_client_key.setText(setting["fanarttv_client_key"])
if setting["fanarttv_use_cdart"] == OPTION_CDART_ALWAYS:
self.ui.fanarttv_cdart_use_always.setChecked(True)
elif setting["fanarttv_use_cdart"] == OPTION_CDART_NEVER:
self.ui.fanarttv_cdart_use_never.setChecked(True)
elif setting["fanarttv_use_cdart"] == OPTION_CDART_NOALBUMART:
self.ui.fanarttv_cdart_use_if_no_albumcover.setChecked(True)
def save(self):
setting = config.setting
setting["fanarttv_client_key"] = self.ui.fanarttv_client_key.text()
if self.ui.fanarttv_cdart_use_always.isChecked():
setting["fanarttv_use_cdart"] = OPTION_CDART_ALWAYS
elif self.ui.fanarttv_cdart_use_never.isChecked():
setting["fanarttv_use_cdart"] = OPTION_CDART_NEVER
elif self.ui.fanarttv_cdart_use_if_no_albumcover.isChecked():
setting["fanarttv_use_cdart"] = OPTION_CDART_NOALBUMART
class FanartTvCoverArtImage(CoverArtImage):
"""Image from fanart.tv"""
support_types = True
sourceprefix = "FATV"
class CoverArtProviderFanartTv(CoverArtProvider):
"""Use fanart.tv to get cover art"""
NAME = "fanart.tv"
TITLE = "fanart.tv"
OPTIONS = FanartTvOptionsPage
def enabled(self):
return (self._client_key and super().enabled()
and not self.coverart.front_image_found)
def queue_images(self):
release_group_id = self.metadata["musicbrainz_releasegroupid"]
path = "/v3/music/albums/%s" % (release_group_id, )
queryargs = {
"api_key": encode_queryarg(FANART_APIKEY),
"client_key": encode_queryarg(self._client_key),
}
log.debug("CoverArtProviderFanartTv.queue_downloads: %s" % path)
self.album.tagger.webservice.get(
FANART_HOST,
FANART_PORT,
path,
partial(self._json_downloaded, release_group_id),
priority=True,
important=False,
parse_response_type='json',
queryargs=queryargs)
self.album._requests += 1
return CoverArtProvider.WAIT
@property
def _client_key(self):
return config.setting["fanarttv_client_key"]
def _json_downloaded(self, release_group_id, data, reply, error):
self.album._requests -= 1
if error:
if error != QNetworkReply.ContentNotFoundError:
error_level = log.error
else:
error_level = log.debug
error_level("Problem requesting metadata in fanart.tv plugin: %s",
error)
else:
try:
release = data["albums"][release_group_id]
has_cover = "albumcover" in release
has_cdart = "cdart" in release
use_cdart = config.setting["fanarttv_use_cdart"]
if has_cover:
covers = release["albumcover"]
self._select_and_add_cover_art(covers, ["front"])
if has_cdart and (use_cdart == OPTION_CDART_ALWAYS
or (use_cdart == OPTION_CDART_NOALBUMART
and not has_cover)):
covers = release["cdart"]
types = ["medium"]
if not has_cover:
types.append("front")
self._select_and_add_cover_art(covers, types)
except (AttributeError, KeyError, TypeError):
log.error("Problem processing downloaded metadata in fanart.tv plugin", exc_info=True)
self.next_in_queue()
def _select_and_add_cover_art(self, covers, types):
covers = sorted(covers, key=cover_sort_key, reverse=True)
url = covers[0]["url"]
log.debug("CoverArtProviderFanartTv found artwork %s" % url)
self.queue_put(FanartTvCoverArtImage(url, types=types))
register_cover_art_provider(CoverArtProviderFanartTv)
================================================
FILE: plugins/fanarttv/ui_options_fanarttv.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/fanarttv/ui_options_fanarttv.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_FanartTvOptionsPage(object):
def setupUi(self, FanartTvOptionsPage):
FanartTvOptionsPage.setObjectName("FanartTvOptionsPage")
FanartTvOptionsPage.resize(340, 317)
self.vboxlayout = QtWidgets.QVBoxLayout(FanartTvOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.groupBox = QtWidgets.QGroupBox(FanartTvOptionsPage)
self.groupBox.setObjectName("groupBox")
self.vboxlayout1 = QtWidgets.QVBoxLayout(self.groupBox)
self.vboxlayout1.setContentsMargins(9, 9, 9, 9)
self.vboxlayout1.setSpacing(2)
self.vboxlayout1.setObjectName("vboxlayout1")
self.label = QtWidgets.QLabel(self.groupBox)
self.label.setTextFormat(QtCore.Qt.RichText)
self.label.setWordWrap(True)
self.label.setOpenExternalLinks(True)
self.label.setObjectName("label")
self.vboxlayout1.addWidget(self.label)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout1.addItem(spacerItem)
self.label_2 = QtWidgets.QLabel(self.groupBox)
self.label_2.setObjectName("label_2")
self.vboxlayout1.addWidget(self.label_2)
self.fanarttv_client_key = QtWidgets.QLineEdit(self.groupBox)
self.fanarttv_client_key.setObjectName("fanarttv_client_key")
self.vboxlayout1.addWidget(self.fanarttv_client_key)
self.vboxlayout.addWidget(self.groupBox)
self.verticalGroupBox = QtWidgets.QGroupBox(FanartTvOptionsPage)
self.verticalGroupBox.setObjectName("verticalGroupBox")
self.verticalLayout = QtWidgets.QVBoxLayout(self.verticalGroupBox)
self.verticalLayout.setObjectName("verticalLayout")
self.fanarttv_cdart_use_always = QtWidgets.QRadioButton(self.verticalGroupBox)
self.fanarttv_cdart_use_always.setObjectName("fanarttv_cdart_use_always")
self.verticalLayout.addWidget(self.fanarttv_cdart_use_always)
self.fanarttv_cdart_use_if_no_albumcover = QtWidgets.QRadioButton(self.verticalGroupBox)
self.fanarttv_cdart_use_if_no_albumcover.setObjectName("fanarttv_cdart_use_if_no_albumcover")
self.verticalLayout.addWidget(self.fanarttv_cdart_use_if_no_albumcover)
self.fanarttv_cdart_use_never = QtWidgets.QRadioButton(self.verticalGroupBox)
self.fanarttv_cdart_use_never.setObjectName("fanarttv_cdart_use_never")
self.verticalLayout.addWidget(self.fanarttv_cdart_use_never)
self.vboxlayout.addWidget(self.verticalGroupBox)
spacerItem1 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem1)
spacerItem2 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem2)
self.retranslateUi(FanartTvOptionsPage)
QtCore.QMetaObject.connectSlotsByName(FanartTvOptionsPage)
def retranslateUi(self, FanartTvOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.groupBox.setTitle(_translate("FanartTvOptionsPage", "fanart.tv cover art"))
self.label.setText(_translate("FanartTvOptionsPage", "\n"
"\n"
"This plugin loads cover art from fanart.tv. If you want to improve the results of this plugin please contribute.
\n"
"In order to use this plugin you have to register a personal API key on
https://fanart.tv/get-an-api-key/
"))
self.label_2.setText(_translate("FanartTvOptionsPage", "Enter your personal API key here:"))
self.verticalGroupBox.setTitle(_translate("FanartTvOptionsPage", "Medium images"))
self.fanarttv_cdart_use_always.setText(_translate("FanartTvOptionsPage", "Always load medium images"))
self.fanarttv_cdart_use_if_no_albumcover.setText(_translate("FanartTvOptionsPage", "Load only if no front cover is available"))
self.fanarttv_cdart_use_never.setText(_translate("FanartTvOptionsPage", "Never load medium images"))
================================================
FILE: plugins/fanarttv/ui_options_fanarttv.ui
================================================
FanartTvOptionsPage
0
0
340
317
6
9
9
9
9
-
fanart.tv cover art
2
9
9
9
9
-
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /></head><body>
<p>This plugin loads cover art from <a href="http://fanart.tv/">fanart.tv</a>. If you want to improve the results of this plugin please contribute.</p>
<p>In order to use this plugin you have to register a personal API key on<br /><a href="https://fanart.tv/get-an-api-key/">https://fanart.tv/get-an-api-key/</a></p></body></html>
Qt::RichText
true
true
-
Qt::Vertical
QSizePolicy::Expanding
20
40
-
Enter your personal API key here:
-
-
Medium images
-
Always load medium images
-
Load only if no front cover is available
-
Never load medium images
-
Qt::Vertical
20
40
-
Qt::Vertical
20
40
================================================
FILE: plugins/featartist/featartist.py
================================================
PLUGIN_NAME = 'Feat. Artists Removed'
PLUGIN_AUTHOR = 'Lukas Lalinsky, Bryan Toth'
PLUGIN_DESCRIPTION = 'Removes feat. artists from track titles. Substitution is case insensitive.'
PLUGIN_VERSION = "0.4"
PLUGIN_API_VERSIONS = ["0.9.0", "0.10", "0.15", "0.16", "2.0"]
from picard.metadata import register_track_metadata_processor
import re
_feat_re = re.compile(r"\s+\(feat\. [^)]*\)", re.IGNORECASE)
def remove_featartists(tagger, metadata, track, release):
metadata["title"] = _feat_re.sub("", metadata["title"])
register_track_metadata_processor(remove_featartists)
================================================
FILE: plugins/featartistsintitles/featartistsintitles.py
================================================
PLUGIN_NAME = 'Feat. Artists in Titles'
PLUGIN_AUTHOR = 'Lukas Lalinsky, Michael Wiencek, Bryan Toth, JeromyNix (NobahdiAtoll)'
PLUGIN_DESCRIPTION = 'Move "feat." from artist names to album and track titles. Match is case insensitive.'
PLUGIN_VERSION = "0.5"
PLUGIN_API_VERSIONS = ["0.9.0", "0.10", "0.15", "0.16", "2.0"]
from picard.metadata import register_album_metadata_processor, register_track_metadata_processor
import re
_feat_re = re.compile(r"([\s\S]+) feat\.([\s\S]+)", re.IGNORECASE)
def move_album_featartists(tagger, metadata, release):
match = _feat_re.match(metadata["albumartist"])
if match:
metadata["albumartist"] = match.group(1)
metadata["album"] += " (feat.%s)" % match.group(2)
match = _feat_re.match(metadata["albumartistsort"])
if match:
metadata["albumartistsort"] = match.group(1)
def move_track_featartists(tagger, metadata, track, release):
match = _feat_re.match(metadata["artist"])
if match:
metadata["artist"] = match.group(1)
metadata["title"] += " (feat.%s)" % match.group(2)
match = _feat_re.match(metadata["artistsort"])
if match:
metadata["artistsort"] = match.group(1)
register_album_metadata_processor(move_album_featartists)
register_track_metadata_processor(move_track_featartists)
================================================
FILE: plugins/fix_tracknums/fix_tracknums.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Fix Track Numbers plugin for MusicBrainz Picard
# Copyright (C) 2017 Jonathan Bradley Whited
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see .
PLUGIN_NAME = 'Fix Track Numbers'
PLUGIN_AUTHOR = 'Jonathan Bradley Whited'
PLUGIN_DESCRIPTION = '''
Fix the track numbers in a cluster by either using the track titles (1) or sequential order (2).
-
The title should contain something like "#-#" (number dash number) and be unique.
All non-numbers and non-dashes will be removed when comparing the titles.
This is especially useful for Language Audio Lessons, like this:
- Title: "Unit 1 - Lesson 10"
For example, take the following titles and track numbers:
- Title: "Unit 1 - Lesson 1" - Track #1
- Title: "Unit 1 - Lesson 2" - Track #1
- Title: "Unit 2 - Lesson 10" - Track #2
- Title: "Unit 2 - Lesson 1" - Track #2
The track numbers will be changed to: 1, 2, 4, 3
The 3rd one will be changed to Track #4 because Lesson 1 < Lesson 10.
The titles will remain unchanged.
- The track numbers will be set based on the sequential order they appear within the cluster.
How to use:
- Cluster a group of files
- Right click on the cluster
-
Then click one:
- Plugins => Fix track numbers using titles
- Plugins => Fix track numbers using sequence
'''
PLUGIN_VERSION = '0.2.1'
PLUGIN_API_VERSIONS = ['0.15', '1.0', '2.0']
PLUGIN_LICENSE = 'GPL-3.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl.txt'
from picard import log
from picard.cluster import Cluster
from picard.ui.itemviews import BaseAction, register_cluster_action
import re
# FIXME: for Python 3.0 and Picard 2.0, use String.format(...) instead of %?
class FixedTrack:
def __init__(self, tracknumber=0, title=None, title_num1=0, title_num2=0):
self.title = title
self.title_num1 = title_num1
self.title_num2 = title_num2
self.tracknumber = tracknumber
class FixTrackNumsUsingTitles(BaseAction):
NAME = 'Fix track numbers using titles'
TITLE_REGEX = re.compile(r"[^\d\-]+") # Only digits and '-' allowed
def callback(self, objs):
log.debug('[FixTrackNumsUsingTitles]')
for cluster in objs:
if not isinstance(cluster, Cluster) or not cluster.files:
continue
tracks = [] # Sorted list of FixedTrack
for i, f in enumerate(cluster.files):
if not f or not f.metadata or 'title' not in f.metadata:
log.debug('No file/metadata/title for [%i]' % (i))
continue
track = FixedTrack(i + 1, f.metadata['title'])
if not track.title:
log.debug('No title for [%i]' % (i))
continue
title_nums = self.TITLE_REGEX.sub('', track.title)
dash_index = title_nums.find('-')
if dash_index < 0:
log.debug('No dash in [%i][%s]' % (i, title_nums))
continue
try:
track.title_num1 = int(title_nums[:dash_index])
track.title_num2 = int(title_nums[dash_index + 1:])
except ValueError:
log.debug('Invalid ints in [%i][%s]' % (i, title_nums))
continue
was_added = False
# Not empty?
if tracks:
# Justin Timberlake?
for j, t in enumerate(tracks):
if was_added:
# Increment all track numbers above last added one
t.tracknumber += 1
# Don't do "<=" on title_num2 to preserve sequence
# - Case 1: "2-10" < "3-1"
# - Case 2: "2-1" < "2-10"
elif ((track.title_num1 < t.title_num1) or
(track.title_num1 == t.title_num1 and
track.title_num2 < t.title_num2)):
# t.tracknumber will be updated in next loop cycle
track.tracknumber = t.tracknumber
tracks.insert(j, track)
was_added = True # Don't break
if not was_added:
tracks.append(track)
# Let's build a dictionary of the new (fixed) track numbers
new_tracks = {}
for i, t in enumerate(tracks):
# Assume title is unique
new_tracks[t.title] = str(t.tracknumber)
for i, f in enumerate(cluster.files):
if not f or not f.metadata or 'title' not in f.metadata:
# Already logged
continue
key = f.metadata['title']
if not key:
# Already logged
continue
if key not in new_tracks:
log.debug('No new track for [%i][%s]' % (i, key))
continue
new_track = new_tracks[key]
log.debug('Change [%s]=>[%s]' % (key, new_track))
f.metadata['tracknumber'] = new_track
f.metadata.changed = True
f.update(signal=True)
cluster.update()
class FixTrackNumsUsingSeq(BaseAction):
NAME = 'Fix track numbers using sequence'
def callback(self, objs):
log.debug('[FixTrackNumsUsingSeq]')
for cluster in objs:
if not isinstance(cluster, Cluster) or not cluster.files:
continue
for i, f in enumerate(cluster.files):
if not f or not f.metadata:
log.debug('No file/metadata for [%i]' % (i))
continue
new_track = str(i + 1)
if 'title' in f.metadata and f.metadata['title']:
log.debug('Change [%s]=>[%s]' %
(f.metadata['title'], new_track))
f.metadata['tracknumber'] = new_track
f.metadata.changed = True
f.update(signal=True)
cluster.update()
register_cluster_action(FixTrackNumsUsingTitles())
register_cluster_action(FixTrackNumsUsingSeq())
================================================
FILE: plugins/format_performer_tags/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2018 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Format Performer Tags'
PLUGIN_AUTHOR = 'Bob Swift, Philipp Wolfer'
PLUGIN_DESCRIPTION = '''
This plugin provides options with respect to the formatting of performer
tags. It has been developed using the 'Standardise Performers' plugin by
Sophist as the basis for retrieving and processing the performer data for
each of the tracks. The format of the resulting tags can be customized
in the option settings page.
'''
PLUGIN_VERSION = "0.8.2"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
PLUGIN_USER_GUIDE_URL = "https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/format_performer_tags/docs/README.md"
import re
from picard import config, log
from picard.metadata import Metadata, register_track_metadata_processor
from picard.plugin import PluginPriority
from picard.ui.options import register_options_page, OptionsPage
from picard.plugins.format_performer_tags.ui_options_format_performer_tags import Ui_FormatPerformerTagsOptionsPage
performers_split = re.compile(r", | and ").split
WORD_LIST = ['guest', 'solo', 'additional']
def get_word_dict(settings):
word_dict = {}
for word in WORD_LIST:
word_dict[word] = settings['format_group_' + word]
return word_dict
def rewrite_tag(key, values, metadata, word_dict, settings):
if ':' not in key:
mainkey = key
subkey = ''
else:
mainkey, subkey = key.split(':', 1)
log.debug("%s: Removing key: '%s'", PLUGIN_NAME, key,)
metadata.delete(key)
log.debug("%s: Formatting Performer [%s: %s]", PLUGIN_NAME, subkey, values,)
if not subkey:
instruments = []
else:
instruments = performers_split(subkey)
if instruments:
for instrument in instruments:
groups = { 1: [], 2: [], 3: [], 4: [], }
vocals = ''
if instrument:
instrument_key = ''
words = instrument.split()
for word in words[:]:
if word in WORD_LIST:
groups[word_dict[word]].append(word)
words.remove(word)
display_group = {}
for group_number in range(1, 5):
if groups[group_number]:
group_separator = settings["format_group_{0}_sep_char".format(group_number)]
if not group_separator:
group_separator = " "
display_group[group_number] = settings["format_group_{0}_start_char".format(group_number)] \
+ group_separator.join(groups[group_number]) \
+ settings["format_group_{0}_end_char".format(group_number)]
else:
display_group[group_number] = ""
if words:
instrument_key = ' '.join(words)
if (len(words) > 1) and (words[-1] in ["vocal", "vocals",]):
vocals = " ".join(words[:-1])
instrument_key = words[-1]
else:
instrument_key = ''
if vocals:
group_number = settings["format_group_vocals"]
temp_group = groups[group_number][:]
if group_number < 2:
temp_group.append(vocals)
else:
temp_group.insert(0, vocals)
group_separator = settings["format_group_{0}_sep_char".format(group_number)]
if not group_separator:
group_separator = " "
display_group[group_number] = settings["format_group_{0}_start_char".format(group_number)] \
+ group_separator.join(temp_group) \
+ settings["format_group_{0}_end_char".format(group_number)]
newkey = ('%s:%s%s%s%s' % (mainkey, display_group[1], instrument_key, display_group[2], display_group[3],))
log.debug("%s: newkey: %s", PLUGIN_NAME, newkey,)
for value in values:
metadata.add_unique(newkey, (value + display_group[4]))
else:
newkey = '%s:' % (mainkey,)
log.debug("%s: newkey: %s", PLUGIN_NAME, newkey,)
for value in values:
metadata.add_unique(newkey, value)
def format_performer_tags(album, metadata, *args):
word_dict = get_word_dict(config.setting)
for key, values in list(filter(lambda filter_tuple: filter_tuple[0].startswith('performer') or filter_tuple[0].startswith('~performersort'), metadata.rawitems())):
rewrite_tag(key, values, metadata, word_dict, config.setting)
class FormatPerformerTagsOptionsPage(OptionsPage):
NAME = "format_performer_tags"
TITLE = "Format Performer Tags"
PARENT = "plugins"
HELP_URL = "https://github.com/metabrainz/picard-plugins/blob/2.0/plugins/format_performer_tags/docs/README.md"
options = [
config.IntOption("setting", "format_group_additional", 3),
config.IntOption("setting", "format_group_guest", 4),
config.IntOption("setting", "format_group_solo", 3),
config.IntOption("setting", "format_group_vocals", 2),
config.TextOption("setting", "format_group_1_start_char", ''),
config.TextOption("setting", "format_group_1_end_char", ' '),
config.TextOption("setting", "format_group_1_sep_char", ''),
config.TextOption("setting", "format_group_2_start_char", ', '),
config.TextOption("setting", "format_group_2_end_char", ''),
config.TextOption("setting", "format_group_2_sep_char", ''),
config.TextOption("setting", "format_group_3_start_char", ' ('),
config.TextOption("setting", "format_group_3_end_char", ')'),
config.TextOption("setting", "format_group_3_sep_char", ''),
config.TextOption("setting", "format_group_4_start_char", ' ('),
config.TextOption("setting", "format_group_4_end_char", ')'),
config.TextOption("setting", "format_group_4_sep_char", ''),
]
def __init__(self, parent=None):
super(FormatPerformerTagsOptionsPage, self).__init__(parent)
self.ui = Ui_FormatPerformerTagsOptionsPage()
self.ui.setupUi(self)
self.ui.additional_rb_1.clicked.connect(self.update_examples)
self.ui.additional_rb_2.clicked.connect(self.update_examples)
self.ui.additional_rb_3.clicked.connect(self.update_examples)
self.ui.additional_rb_4.clicked.connect(self.update_examples)
self.ui.guest_rb_1.clicked.connect(self.update_examples)
self.ui.guest_rb_2.clicked.connect(self.update_examples)
self.ui.guest_rb_3.clicked.connect(self.update_examples)
self.ui.guest_rb_4.clicked.connect(self.update_examples)
self.ui.solo_rb_1.clicked.connect(self.update_examples)
self.ui.solo_rb_2.clicked.connect(self.update_examples)
self.ui.solo_rb_3.clicked.connect(self.update_examples)
self.ui.solo_rb_4.clicked.connect(self.update_examples)
self.ui.vocals_rb_1.clicked.connect(self.update_examples)
self.ui.vocals_rb_2.clicked.connect(self.update_examples)
self.ui.vocals_rb_3.clicked.connect(self.update_examples)
self.ui.vocals_rb_4.clicked.connect(self.update_examples)
self.ui.format_group_1_start_char.editingFinished.connect(self.update_examples)
self.ui.format_group_2_start_char.editingFinished.connect(self.update_examples)
self.ui.format_group_3_start_char.editingFinished.connect(self.update_examples)
self.ui.format_group_4_start_char.editingFinished.connect(self.update_examples)
self.ui.format_group_1_sep_char.editingFinished.connect(self.update_examples)
self.ui.format_group_2_sep_char.editingFinished.connect(self.update_examples)
self.ui.format_group_3_sep_char.editingFinished.connect(self.update_examples)
self.ui.format_group_4_sep_char.editingFinished.connect(self.update_examples)
self.ui.format_group_1_end_char.editingFinished.connect(self.update_examples)
self.ui.format_group_2_end_char.editingFinished.connect(self.update_examples)
self.ui.format_group_3_end_char.editingFinished.connect(self.update_examples)
self.ui.format_group_4_end_char.editingFinished.connect(self.update_examples)
def load(self):
# Enable external link
self.ui.format_description.setOpenExternalLinks(True)
# Settings for Keyword: additional
temp = config.setting["format_group_additional"]
if temp > 3:
self.ui.additional_rb_4.setChecked(True)
elif temp > 2:
self.ui.additional_rb_3.setChecked(True)
elif temp > 1:
self.ui.additional_rb_2.setChecked(True)
else:
self.ui.additional_rb_1.setChecked(True)
# Settings for Keyword: guest
temp = config.setting["format_group_guest"]
if temp > 3:
self.ui.guest_rb_4.setChecked(True)
elif temp > 2:
self.ui.guest_rb_3.setChecked(True)
elif temp > 1:
self.ui.guest_rb_2.setChecked(True)
else:
self.ui.guest_rb_1.setChecked(True)
# Settings for Keyword: solo
temp = config.setting["format_group_solo"]
if temp > 3:
self.ui.solo_rb_4.setChecked(True)
elif temp > 2:
self.ui.solo_rb_3.setChecked(True)
elif temp > 1:
self.ui.solo_rb_2.setChecked(True)
else:
self.ui.solo_rb_1.setChecked(True)
# Settings for all vocal keywords
temp = config.setting["format_group_vocals"]
if temp > 3:
self.ui.vocals_rb_4.setChecked(True)
elif temp > 2:
self.ui.vocals_rb_3.setChecked(True)
elif temp > 1:
self.ui.vocals_rb_2.setChecked(True)
else:
self.ui.vocals_rb_1.setChecked(True)
# Settings for word group 1
self.ui.format_group_1_start_char.setText(config.setting["format_group_1_start_char"])
self.ui.format_group_1_end_char.setText(config.setting["format_group_1_end_char"])
self.ui.format_group_1_sep_char.setText(config.setting["format_group_1_sep_char"])
# Settings for word group 2
self.ui.format_group_2_start_char.setText(config.setting["format_group_2_start_char"])
self.ui.format_group_2_end_char.setText(config.setting["format_group_2_end_char"])
self.ui.format_group_2_sep_char.setText(config.setting["format_group_2_sep_char"])
# Settings for word group 3
self.ui.format_group_3_start_char.setText(config.setting["format_group_3_start_char"])
self.ui.format_group_3_end_char.setText(config.setting["format_group_3_end_char"])
self.ui.format_group_3_sep_char.setText(config.setting["format_group_3_sep_char"])
# Settings for word group 4
self.ui.format_group_4_start_char.setText(config.setting["format_group_4_start_char"])
self.ui.format_group_4_end_char.setText(config.setting["format_group_4_end_char"])
self.ui.format_group_4_sep_char.setText(config.setting["format_group_4_sep_char"])
self.update_examples()
# TODO: Modify self.format_description in ui_options_format_performer_tags.py to include a placeholder
# such as {user_guide_url} so that the translated string can be formatted to include the value
# of PLUGIN_USER_GUIDE_URL to dynamically set the link while not requiring retranslation if the
# link changes. Preliminary code something like:
#
# temp = (self.ui.format_description.text).format(user_guide_url=PLUGIN_USER_GUIDE_URL,)
# self.ui.format_description.setText(temp)
def save(self):
self._set_settings(config.setting)
def restore_defaults(self):
super().restore_defaults()
self.update_examples()
def _set_settings(self, settings):
# Process 'additional' keyword settings
temp = 1
if self.ui.additional_rb_2.isChecked(): temp = 2
if self.ui.additional_rb_3.isChecked(): temp = 3
if self.ui.additional_rb_4.isChecked(): temp = 4
settings["format_group_additional"] = temp
# Process 'guest' keyword settings
temp = 1
if self.ui.guest_rb_2.isChecked(): temp = 2
if self.ui.guest_rb_3.isChecked(): temp = 3
if self.ui.guest_rb_4.isChecked(): temp = 4
settings["format_group_guest"] = temp
# Process 'solo' keyword settings
temp = 1
if self.ui.solo_rb_2.isChecked(): temp = 2
if self.ui.solo_rb_3.isChecked(): temp = 3
if self.ui.solo_rb_4.isChecked(): temp = 4
settings["format_group_solo"] = temp
# Process all vocal keyword settings
temp = 1
if self.ui.vocals_rb_2.isChecked(): temp = 2
if self.ui.vocals_rb_3.isChecked(): temp = 3
if self.ui.vocals_rb_4.isChecked(): temp = 4
settings["format_group_vocals"] = temp
# Settings for word group 1
settings["format_group_1_start_char"] = self.ui.format_group_1_start_char.text()
settings["format_group_1_end_char"] = self.ui.format_group_1_end_char.text()
settings["format_group_1_sep_char"] = self.ui.format_group_1_sep_char.text()
# Settings for word group 2
settings["format_group_2_start_char"] = self.ui.format_group_2_start_char.text()
settings["format_group_2_end_char"] = self.ui.format_group_2_end_char.text()
settings["format_group_2_sep_char"] = self.ui.format_group_2_sep_char.text()
# Settings for word group 3
settings["format_group_3_start_char"] = self.ui.format_group_3_start_char.text()
settings["format_group_3_end_char"] = self.ui.format_group_3_end_char.text()
settings["format_group_3_sep_char"] = self.ui.format_group_3_sep_char.text()
# Settings for word group 4
settings["format_group_4_start_char"] = self.ui.format_group_4_start_char.text()
settings["format_group_4_end_char"] = self.ui.format_group_4_end_char.text()
settings["format_group_4_sep_char"] = self.ui.format_group_4_sep_char.text()
def update_examples(self):
settings = {}
self._set_settings(settings)
word_dict = get_word_dict(settings)
instruments_credits = {
"guitar": ["Johnny Flux", "John Watson"],
"guest guitar": ["Jimmy Page"],
"additional guest solo guitar": ["Jimmy Page"],
}
instruments_example = self.build_example(instruments_credits, word_dict, settings)
self.ui.example_instruments.setText(instruments_example)
vocals_credits = {
"additional solo lead vocals": ["Robert Plant"],
"additional solo guest lead vocals": ["Sandy Denny"],
}
vocals_example = self.build_example(vocals_credits, word_dict, settings)
self.ui.example_vocals.setText(vocals_example)
@staticmethod
def build_example(credits, word_dict, settings):
prefix = "performer:"
metadata = Metadata()
for key, values in credits.items():
rewrite_tag(prefix + key, values, metadata, word_dict, settings)
examples = []
for key, values in metadata.rawitems():
credit = "%s: %s" % (key, ", ".join(values))
if credit.startswith(prefix):
credit = credit[len(prefix):]
examples.append(credit)
return "\n".join(examples)
# Register the plugin to run at a LOW priority.
register_track_metadata_processor(format_performer_tags, priority=PluginPriority.LOW)
register_options_page(FormatPerformerTagsOptionsPage)
================================================
FILE: plugins/format_performer_tags/docs/HISTORY.md
================================================
# Format Performer Tags
## Contributors
The following people have contributed to the development of this plugin.
* Bob Swift ([rdswift](https://github.com/rdswift/))
* Philipp Wolfer ([phw](https://github.com/phw/))
---
## Revision History
The following identifies the development history of the plugin, in reverse chronological order. Each version lists the changes made for that version, along with the author of each change.
### Version 0.7
* Test that instrument is in the list before trying to remove it. (Issue #256: ValueError Exception in Format Performer Tags) \[rdswift\]
* Properly handle unspecified performer types (i.e.: with no instrument, vocal, etc. specified). \[rdswift\]
### Version 0.6
* Update the user interface. Add live examples when settings are changed. \[phw\]
* Update plugin metadata. \[phw\]
* Add `HISTORY.md` file containing the contributors list and revision history. \[rdswift\]
### Version 0.5
* Reformat long lines. \[rdswift\]
* Add TODO note about language translation. \[rdswift\]
### Version 0.4
* Remove code to strip extra whitespace from key and value strings. \[rdswift\]
### Version 0.3
* Update to use four user-defined sections. \[rdswift\]
* Add user guide. \[rdswift\]
### Version 0.2
* Fix bug that caused some performer records to be missed in the processing. \[rdswift\]
* Add vocals performer processing. \[rdswift\]
### Version 0.1
* Initial testing release. \[rdswift\]
---
================================================
FILE: plugins/format_performer_tags/docs/README.md
================================================
# Format Performer Tags \[[Download](https://github.com/rdswift/picard-plugins/raw/2.0_RDS_Plugins/plugins/format_performer_tags/format_performer_tags.zip)\]
## Overview
This plugin allows the user to configure the way that instrument and vocal performer tags are written. Once
installed a settings page will be added to Picard's options, which is where the plugin is configured.
---
## What it Does
This plugin serves two purposes.
### First:
Picard will by default try to order the performer/instrument credits by the name of the performers, summing up all instruments for that performer in one line.
This plugin will order the performer/instrument credits by instrument, summing up all performers that play them.
So instead of this:
```
background vocals and drums: Wayne Gretzky
bass and background vocals: Leslie Nielsen
guitar, keyboard and synthesizer: Edward Hopper
guitar and vocals: Vladimir Nabokov
keyboard and lead vocals: Bianca Castafiore
```
It will be displayed like this:
```
background vocals: Wayne Gretzky, Leslie Nielsen
bass: Leslie Nielsen
drums: Wayne Gretzky
guitar: Edward Hopper, Vladimir Nabokov
keyboard: Edward Hopper, Bianca Castafiore
lead vocals: Bianca Castafiore
synthesizer: Edward Hopper
vocals: Vladimir Nabokov
```
### Second:
This plugin allows fine-tuned organization of how instruments, performers and additional descriptions (keywords) are displayed in the instrument/performer tags.
Here is some background information about these keywords:
MusicBrainz' database allows to add and store keywords (attributes) that will refine or additionally describe the role of a performer for a recording.
For an artist performing music on an instrument, these are the three attributes (keywords) that MusicBrainz can store, and offer Picard:
* additional
* guest
* solo
For an artist performing with his/her voice, MusicBrainz has this restricted list of keywords describing the role or the register of the voice:
* background vocals
* choir vocals
* lead vocals
* alto vocals
* baritone vocals
* bass vocals
* bass-baritone vocals
* contralto vocals
* countertenor vocals
* mezzo-soprano vocals
* soprano vocals
* tenor vocals
* treble vocals
* other vocals
* spoken vocals
Picard can retrieve and display these keywords and will list them all together in front of the performer.
The result will be something like this:
```
guitar and solo guitar: Bob 'Swift' Fingers
additional drums: Rob Reiner (guest)
additional baritone vocals: Hermann Rorschach
guest soprano vocals: Bianca Castafiore
```
The problem with this is that it is a bit indistinct if these keywords say something about the instrument, the artist and their performing role, the voice's register, or the persons relation to the group/orchestra.
For instance:
* 'additional' is referring to instrumentation. For example 'additional percussion'.
* 'guest' is referring to the performer as a person. Indicating that they are a guest in that band/orchestra instead of a regular member.
* 'solo' is referring to a specific role a musician performs in a composition. For example a musician performing a guitar solo.
* 'soprano vocals' is saying something about the register of a performer's voice.
So you might want to attach 'solo' to the instrument, 'baritone' to the vocals, and 'guest' to the performer.
This plugin allows you to do that, so you could have something like this as a result:
```
guitar [solo]: Bob 'Swift' Fingers
drums ‹additional› : Rob Reiner (guest)
vocals, baritone ‹additional› : Hermann Rorschach
vocals, soprano: Bianca Castafiore (guest)
```
---
## How it Works
This is the concept behind the workings of this plugin:
The basic structure of a performer tag such as Picard produces it is:
[Keywords] Instrument / Vocals: Performer
This plugin makes four different 'Sections' at fixed positions in these tags available.
Their positions are:
[Section 1]Instrument / Vocals[Section 2][Section 3]: Performer[Section 4]
In the settings panel you can define in what section (at what location) you want each of the available keywords to be displayed.
You can do that by simply selecting the section number for that (group of) keyword(s).
You can also define what characters you want to use for delimiting or surrounding the keywords.
For some situations you might want to use the more common parenthesis brackets ( ), or maybe you prefer less common brackets such as \[ \] or ‹ ›.
Note that using default parenthesis might confuse possible subsequent tagging formulas in the music player/manager of your choice.
You can also just leave them blank, or use commas, spaces, etc.
Note that the plugin does not add any spaces as separators by default, so you will need to define those to your personal liking.
---
## Settings
The first group of settings is the **Keyword Section Assignments**. This is where you select the section in
which each of the keywords will be displayed. Selection is made by clicking the radio button corresponding
to the desired section for each of the keywords.
The second group of settings is the **Section Display Settings**. This is where you configure the text
included at the beginning and end of each section displayed, and the characters used to separate multiple
items within a section. Note that leading or trailing spaces must be included in the settings and will not
be automatically added. If no separator characters are entered, the items will be automatically separated
by a single space.
The initial default settings are:

These settings will produce tags such as:
```
rhodes piano (solo): Billy Preston (guest)
percussion: Steve Berlin (guest), Kris MacFarlane, Séan McCann
vocals, background: Jeen (guest)
```
---
## Examples
The following are some examples using actual information from MusicBrainz:
### Example 1:
(add example)
### Example 2:
(add example)
### Example 3:
(add example)
---
## Credits
Special thank-you to [hiccup](https://musicbrainz.org/user/hiccup) for improvement suggestions and extensive testing during
the development of this plugin, and for providing the write-up and examples that formed the basis for this User Guide.
================================================
FILE: plugins/format_performer_tags/ui_options_format_performer_tags.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/format_performer_tags/ui_options_format_performer_tags.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_FormatPerformerTagsOptionsPage(object):
def setupUi(self, FormatPerformerTagsOptionsPage):
FormatPerformerTagsOptionsPage.setObjectName("FormatPerformerTagsOptionsPage")
FormatPerformerTagsOptionsPage.resize(561, 802)
FormatPerformerTagsOptionsPage.setMinimumSize(QtCore.QSize(360, 0))
self.verticalLayout = QtWidgets.QVBoxLayout(FormatPerformerTagsOptionsPage)
self.verticalLayout.setObjectName("verticalLayout")
self.scrollArea = QtWidgets.QScrollArea(FormatPerformerTagsOptionsPage)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, -13, 529, 848))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.gb_description = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_description.setObjectName("gb_description")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.gb_description)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.format_description = QtWidgets.QLabel(self.gb_description)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.format_description.sizePolicy().hasHeightForWidth())
self.format_description.setSizePolicy(sizePolicy)
self.format_description.setWordWrap(True)
self.format_description.setObjectName("format_description")
self.verticalLayout_3.addWidget(self.format_description)
self.verticalLayout_2.addWidget(self.gb_description)
self.gb_word_groups = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_word_groups.setObjectName("gb_word_groups")
self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.gb_word_groups)
self.verticalLayout_5.setObjectName("verticalLayout_5")
self.group_additonal = QtWidgets.QGroupBox(self.gb_word_groups)
self.group_additonal.setObjectName("group_additonal")
self.horizontalLayout = QtWidgets.QHBoxLayout(self.group_additonal)
self.horizontalLayout.setContentsMargins(1, 1, 1, 1)
self.horizontalLayout.setObjectName("horizontalLayout")
self.additional_rb_1 = QtWidgets.QRadioButton(self.group_additonal)
self.additional_rb_1.setMaximumSize(QtCore.QSize(40, 16777215))
self.additional_rb_1.setObjectName("additional_rb_1")
self.horizontalLayout.addWidget(self.additional_rb_1)
self.additional_rb_2 = QtWidgets.QRadioButton(self.group_additonal)
self.additional_rb_2.setMaximumSize(QtCore.QSize(40, 16777215))
self.additional_rb_2.setObjectName("additional_rb_2")
self.horizontalLayout.addWidget(self.additional_rb_2)
self.additional_rb_3 = QtWidgets.QRadioButton(self.group_additonal)
self.additional_rb_3.setMaximumSize(QtCore.QSize(40, 16777215))
self.additional_rb_3.setObjectName("additional_rb_3")
self.horizontalLayout.addWidget(self.additional_rb_3)
self.additional_rb_4 = QtWidgets.QRadioButton(self.group_additonal)
self.additional_rb_4.setMaximumSize(QtCore.QSize(40, 16777215))
self.additional_rb_4.setObjectName("additional_rb_4")
self.horizontalLayout.addWidget(self.additional_rb_4)
self.verticalLayout_5.addWidget(self.group_additonal)
self.group_guest = QtWidgets.QGroupBox(self.gb_word_groups)
self.group_guest.setObjectName("group_guest")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout(self.group_guest)
self.horizontalLayout_2.setContentsMargins(1, 1, 1, 1)
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.guest_rb_1 = QtWidgets.QRadioButton(self.group_guest)
self.guest_rb_1.setMaximumSize(QtCore.QSize(40, 16777215))
self.guest_rb_1.setObjectName("guest_rb_1")
self.horizontalLayout_2.addWidget(self.guest_rb_1)
self.guest_rb_2 = QtWidgets.QRadioButton(self.group_guest)
self.guest_rb_2.setMaximumSize(QtCore.QSize(40, 16777215))
self.guest_rb_2.setObjectName("guest_rb_2")
self.horizontalLayout_2.addWidget(self.guest_rb_2)
self.guest_rb_3 = QtWidgets.QRadioButton(self.group_guest)
self.guest_rb_3.setMaximumSize(QtCore.QSize(40, 16777215))
self.guest_rb_3.setObjectName("guest_rb_3")
self.horizontalLayout_2.addWidget(self.guest_rb_3)
self.guest_rb_4 = QtWidgets.QRadioButton(self.group_guest)
self.guest_rb_4.setMaximumSize(QtCore.QSize(40, 16777215))
self.guest_rb_4.setObjectName("guest_rb_4")
self.horizontalLayout_2.addWidget(self.guest_rb_4)
self.verticalLayout_5.addWidget(self.group_guest)
self.group_solo = QtWidgets.QGroupBox(self.gb_word_groups)
self.group_solo.setObjectName("group_solo")
self.horizontalLayout_3 = QtWidgets.QHBoxLayout(self.group_solo)
self.horizontalLayout_3.setContentsMargins(1, 1, 1, 1)
self.horizontalLayout_3.setObjectName("horizontalLayout_3")
self.solo_rb_1 = QtWidgets.QRadioButton(self.group_solo)
self.solo_rb_1.setMaximumSize(QtCore.QSize(40, 16777215))
self.solo_rb_1.setObjectName("solo_rb_1")
self.horizontalLayout_3.addWidget(self.solo_rb_1)
self.solo_rb_2 = QtWidgets.QRadioButton(self.group_solo)
self.solo_rb_2.setMaximumSize(QtCore.QSize(40, 16777215))
self.solo_rb_2.setObjectName("solo_rb_2")
self.horizontalLayout_3.addWidget(self.solo_rb_2)
self.solo_rb_3 = QtWidgets.QRadioButton(self.group_solo)
self.solo_rb_3.setMaximumSize(QtCore.QSize(40, 16777215))
self.solo_rb_3.setObjectName("solo_rb_3")
self.horizontalLayout_3.addWidget(self.solo_rb_3)
self.solo_rb_4 = QtWidgets.QRadioButton(self.group_solo)
self.solo_rb_4.setMaximumSize(QtCore.QSize(40, 16777215))
self.solo_rb_4.setObjectName("solo_rb_4")
self.horizontalLayout_3.addWidget(self.solo_rb_4)
self.verticalLayout_5.addWidget(self.group_solo)
self.group_vocals = QtWidgets.QGroupBox(self.gb_word_groups)
self.group_vocals.setObjectName("group_vocals")
self.horizontalLayout_4 = QtWidgets.QHBoxLayout(self.group_vocals)
self.horizontalLayout_4.setContentsMargins(1, 1, 1, 1)
self.horizontalLayout_4.setObjectName("horizontalLayout_4")
self.vocals_rb_1 = QtWidgets.QRadioButton(self.group_vocals)
self.vocals_rb_1.setMinimumSize(QtCore.QSize(40, 20))
self.vocals_rb_1.setMaximumSize(QtCore.QSize(40, 16777215))
self.vocals_rb_1.setObjectName("vocals_rb_1")
self.horizontalLayout_4.addWidget(self.vocals_rb_1)
self.vocals_rb_2 = QtWidgets.QRadioButton(self.group_vocals)
self.vocals_rb_2.setMaximumSize(QtCore.QSize(40, 16777215))
self.vocals_rb_2.setObjectName("vocals_rb_2")
self.horizontalLayout_4.addWidget(self.vocals_rb_2)
self.vocals_rb_3 = QtWidgets.QRadioButton(self.group_vocals)
self.vocals_rb_3.setMaximumSize(QtCore.QSize(40, 16777215))
self.vocals_rb_3.setObjectName("vocals_rb_3")
self.horizontalLayout_4.addWidget(self.vocals_rb_3)
self.vocals_rb_4 = QtWidgets.QRadioButton(self.group_vocals)
self.vocals_rb_4.setMaximumSize(QtCore.QSize(40, 16777215))
self.vocals_rb_4.setObjectName("vocals_rb_4")
self.horizontalLayout_4.addWidget(self.vocals_rb_4)
self.verticalLayout_5.addWidget(self.group_vocals)
self.verticalLayout_2.addWidget(self.gb_word_groups)
self.gb_group_settings = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_group_settings.setObjectName("gb_group_settings")
self.verticalLayout_6 = QtWidgets.QVBoxLayout(self.gb_group_settings)
self.verticalLayout_6.setObjectName("verticalLayout_6")
self.gridLayout = QtWidgets.QGridLayout()
self.gridLayout.setVerticalSpacing(1)
self.gridLayout.setObjectName("gridLayout")
self.label_2 = QtWidgets.QLabel(self.gb_group_settings)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_2.sizePolicy().hasHeightForWidth())
self.label_2.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_2.setFont(font)
self.label_2.setObjectName("label_2")
self.gridLayout.addWidget(self.label_2, 2, 0, 1, 1, QtCore.Qt.AlignLeft)
self.label_3 = QtWidgets.QLabel(self.gb_group_settings)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_3.sizePolicy().hasHeightForWidth())
self.label_3.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_3.setFont(font)
self.label_3.setObjectName("label_3")
self.gridLayout.addWidget(self.label_3, 3, 0, 1, 1, QtCore.Qt.AlignLeft)
self.format_group_1_start_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_1_start_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_1_start_char.setObjectName("format_group_1_start_char")
self.gridLayout.addWidget(self.format_group_1_start_char, 1, 1, 1, 1, QtCore.Qt.AlignHCenter)
self.label = QtWidgets.QLabel(self.gb_group_settings)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label.sizePolicy().hasHeightForWidth())
self.label.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label.setFont(font)
self.label.setObjectName("label")
self.gridLayout.addWidget(self.label, 1, 0, 1, 1, QtCore.Qt.AlignLeft)
self.label_4 = QtWidgets.QLabel(self.gb_group_settings)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())
self.label_4.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_4.setFont(font)
self.label_4.setObjectName("label_4")
self.gridLayout.addWidget(self.label_4, 4, 0, 1, 1, QtCore.Qt.AlignLeft)
self.format_group_1_sep_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_1_sep_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_1_sep_char.setObjectName("format_group_1_sep_char")
self.gridLayout.addWidget(self.format_group_1_sep_char, 1, 2, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_1_end_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_1_end_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_1_end_char.setObjectName("format_group_1_end_char")
self.gridLayout.addWidget(self.format_group_1_end_char, 1, 3, 1, 1, QtCore.Qt.AlignHCenter)
self.label_5 = QtWidgets.QLabel(self.gb_group_settings)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_5.setFont(font)
self.label_5.setObjectName("label_5")
self.gridLayout.addWidget(self.label_5, 0, 1, 1, 1, QtCore.Qt.AlignHCenter)
self.label_6 = QtWidgets.QLabel(self.gb_group_settings)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_6.setFont(font)
self.label_6.setObjectName("label_6")
self.gridLayout.addWidget(self.label_6, 0, 2, 1, 1, QtCore.Qt.AlignHCenter)
self.label_7 = QtWidgets.QLabel(self.gb_group_settings)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_7.setFont(font)
self.label_7.setObjectName("label_7")
self.gridLayout.addWidget(self.label_7, 0, 3, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_2_start_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_2_start_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_2_start_char.setObjectName("format_group_2_start_char")
self.gridLayout.addWidget(self.format_group_2_start_char, 2, 1, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_3_start_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_3_start_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_3_start_char.setObjectName("format_group_3_start_char")
self.gridLayout.addWidget(self.format_group_3_start_char, 3, 1, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_4_start_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_4_start_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_4_start_char.setObjectName("format_group_4_start_char")
self.gridLayout.addWidget(self.format_group_4_start_char, 4, 1, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_2_sep_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_2_sep_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_2_sep_char.setObjectName("format_group_2_sep_char")
self.gridLayout.addWidget(self.format_group_2_sep_char, 2, 2, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_3_sep_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_3_sep_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_3_sep_char.setObjectName("format_group_3_sep_char")
self.gridLayout.addWidget(self.format_group_3_sep_char, 3, 2, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_4_sep_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_4_sep_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_4_sep_char.setObjectName("format_group_4_sep_char")
self.gridLayout.addWidget(self.format_group_4_sep_char, 4, 2, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_2_end_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_2_end_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_2_end_char.setObjectName("format_group_2_end_char")
self.gridLayout.addWidget(self.format_group_2_end_char, 2, 3, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_3_end_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_3_end_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_3_end_char.setObjectName("format_group_3_end_char")
self.gridLayout.addWidget(self.format_group_3_end_char, 3, 3, 1, 1, QtCore.Qt.AlignHCenter)
self.format_group_4_end_char = QtWidgets.QLineEdit(self.gb_group_settings)
self.format_group_4_end_char.setMaximumSize(QtCore.QSize(50, 16777215))
self.format_group_4_end_char.setObjectName("format_group_4_end_char")
self.gridLayout.addWidget(self.format_group_4_end_char, 4, 3, 1, 1, QtCore.Qt.AlignHCenter)
self.verticalLayout_6.addLayout(self.gridLayout)
self.verticalLayout_2.addWidget(self.gb_group_settings)
self.gb_examples = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_examples.setObjectName("gb_examples")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.gb_examples)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.example_instruments = QtWidgets.QLabel(self.gb_examples)
self.example_instruments.setText("")
self.example_instruments.setObjectName("example_instruments")
self.verticalLayout_4.addWidget(self.example_instruments)
self.example_vocals = QtWidgets.QLabel(self.gb_examples)
self.example_vocals.setText("")
self.example_vocals.setObjectName("example_vocals")
self.verticalLayout_4.addWidget(self.example_vocals)
self.verticalLayout_2.addWidget(self.gb_examples)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(FormatPerformerTagsOptionsPage)
QtCore.QMetaObject.connectSlotsByName(FormatPerformerTagsOptionsPage)
def retranslateUi(self, FormatPerformerTagsOptionsPage):
_translate = QtCore.QCoreApplication.translate
FormatPerformerTagsOptionsPage.setWindowTitle(_translate("FormatPerformerTagsOptionsPage", "Form"))
self.gb_description.setTitle(_translate("FormatPerformerTagsOptionsPage", "Format Performer Tags"))
self.format_description.setText(_translate("FormatPerformerTagsOptionsPage", "These settings will determine the format for any Performer tags prepared. The format is divided into six parts: the performer; the instrument or "vocals"; and four user selectable sections for the extra information. This is set out as:
[Section 1]Instrument/Vocals[Section 2][Section 3]: Performer[Section 4]
You can select the section in which each of the extra information words appears.
For each of the sections you can select the starting character(s), the character(s) separating entries, and the ending character(s). Note that leading or trailing spaces must be included in the settings and will not be automatically added. If no separator characters are entered, the items within a section will be automatically separated by a single space.
Please visit the repository on GitHub for additional information.
"))
self.gb_word_groups.setTitle(_translate("FormatPerformerTagsOptionsPage", "Keyword Sections Assignment"))
self.group_additonal.setTitle(_translate("FormatPerformerTagsOptionsPage", "Keyword: additional"))
self.additional_rb_1.setText(_translate("FormatPerformerTagsOptionsPage", "1"))
self.additional_rb_2.setText(_translate("FormatPerformerTagsOptionsPage", "2"))
self.additional_rb_3.setText(_translate("FormatPerformerTagsOptionsPage", "3"))
self.additional_rb_4.setText(_translate("FormatPerformerTagsOptionsPage", "4"))
self.group_guest.setTitle(_translate("FormatPerformerTagsOptionsPage", "Keyword: guest"))
self.guest_rb_1.setText(_translate("FormatPerformerTagsOptionsPage", "1"))
self.guest_rb_2.setText(_translate("FormatPerformerTagsOptionsPage", "2"))
self.guest_rb_3.setText(_translate("FormatPerformerTagsOptionsPage", "3"))
self.guest_rb_4.setText(_translate("FormatPerformerTagsOptionsPage", "4"))
self.group_solo.setTitle(_translate("FormatPerformerTagsOptionsPage", "Keyword: solo"))
self.solo_rb_1.setText(_translate("FormatPerformerTagsOptionsPage", "1"))
self.solo_rb_2.setText(_translate("FormatPerformerTagsOptionsPage", "2"))
self.solo_rb_3.setText(_translate("FormatPerformerTagsOptionsPage", "3"))
self.solo_rb_4.setText(_translate("FormatPerformerTagsOptionsPage", "4"))
self.group_vocals.setTitle(_translate("FormatPerformerTagsOptionsPage", "All vocal type keywords"))
self.vocals_rb_1.setText(_translate("FormatPerformerTagsOptionsPage", "1"))
self.vocals_rb_2.setText(_translate("FormatPerformerTagsOptionsPage", "2"))
self.vocals_rb_3.setText(_translate("FormatPerformerTagsOptionsPage", "3"))
self.vocals_rb_4.setText(_translate("FormatPerformerTagsOptionsPage", "4"))
self.gb_group_settings.setTitle(_translate("FormatPerformerTagsOptionsPage", "Section Display Settings"))
self.label_2.setText(_translate("FormatPerformerTagsOptionsPage", "Section 2"))
self.label_3.setText(_translate("FormatPerformerTagsOptionsPage", "Section 3"))
self.format_group_1_start_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.label.setText(_translate("FormatPerformerTagsOptionsPage", "Section 1"))
self.label_4.setText(_translate("FormatPerformerTagsOptionsPage", "Section 4"))
self.format_group_1_sep_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_1_end_char.setText(_translate("FormatPerformerTagsOptionsPage", " "))
self.format_group_1_end_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.label_5.setText(_translate("FormatPerformerTagsOptionsPage", "Start Char(s)"))
self.label_6.setText(_translate("FormatPerformerTagsOptionsPage", "Sep Char(s)"))
self.label_7.setText(_translate("FormatPerformerTagsOptionsPage", "End Char(s)"))
self.format_group_2_start_char.setText(_translate("FormatPerformerTagsOptionsPage", ", "))
self.format_group_2_start_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_3_start_char.setText(_translate("FormatPerformerTagsOptionsPage", " ("))
self.format_group_3_start_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_4_start_char.setText(_translate("FormatPerformerTagsOptionsPage", " ("))
self.format_group_4_start_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_2_sep_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_3_sep_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_4_sep_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_2_end_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_3_end_char.setText(_translate("FormatPerformerTagsOptionsPage", ")"))
self.format_group_3_end_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.format_group_4_end_char.setText(_translate("FormatPerformerTagsOptionsPage", ")"))
self.format_group_4_end_char.setPlaceholderText(_translate("FormatPerformerTagsOptionsPage", "(blank)"))
self.gb_examples.setTitle(_translate("FormatPerformerTagsOptionsPage", "Examples"))
================================================
FILE: plugins/format_performer_tags/ui_options_format_performer_tags.ui
================================================
FormatPerformerTagsOptionsPage
0
0
561
802
360
0
Form
-
QFrame::NoFrame
true
0
-13
529
848
-
Format Performer Tags
-
0
0
<html><head/><body><p>These settings will determine the format for any <span style=" font-weight:600;">Performer</span> tags prepared. The format is divided into six parts: the performer; the instrument or "vocals"; and four user selectable sections for the extra information. This is set out as:</p><p align="center"><span style=" font-weight:600;">[Section 1]</span>Instrument/Vocals<span style=" font-weight:600;">[Section 2][Section 3]</span>: Performer<span style=" font-weight:600;">[Section 4]</span></p><p>You can select the section in which each of the extra information words appears.</p><p>For each of the sections you can select the starting character(s), the character(s) separating entries, and the ending character(s). Note that leading or trailing spaces must be included in the settings and will not be automatically added. If no separator characters are entered, the items within a section will be automatically separated by a single space.</p><p>Please visit the repository on GitHub for <a href="https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/format_performer_tags/docs/README.md"><span style=" text-decoration: underline; color:#0000ff;">additional information</span></a>.</p></body></html>
true
-
Keyword Sections Assignment
-
Keyword: additional
1
1
1
1
-
40
16777215
1
-
40
16777215
2
-
40
16777215
3
-
40
16777215
4
-
Keyword: guest
1
1
1
1
-
40
16777215
1
-
40
16777215
2
-
40
16777215
3
-
40
16777215
4
-
Keyword: solo
1
1
1
1
-
40
16777215
1
-
40
16777215
2
-
40
16777215
3
-
40
16777215
4
-
All vocal type keywords
1
1
1
1
-
40
20
40
16777215
1
-
40
16777215
2
-
40
16777215
3
-
40
16777215
4
-
Section Display Settings
-
1
-
0
0
75
true
Section 2
-
0
0
75
true
Section 3
-
50
16777215
(blank)
-
0
0
75
true
Section 1
-
0
0
75
true
Section 4
-
50
16777215
(blank)
-
50
16777215
(blank)
-
75
true
Start Char(s)
-
75
true
Sep Char(s)
-
75
true
End Char(s)
-
50
16777215
,
(blank)
-
50
16777215
(
(blank)
-
50
16777215
(
(blank)
-
50
16777215
(blank)
-
50
16777215
(blank)
-
50
16777215
(blank)
-
50
16777215
(blank)
-
50
16777215
)
(blank)
-
50
16777215
)
(blank)
-
Examples
-
-
-
Qt::Vertical
20
40
================================================
FILE: plugins/genre_mapper/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2022-2024 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Genre Mapper'
PLUGIN_AUTHOR = 'Bob Swift'
PLUGIN_DESCRIPTION = '''
This plugin provides the ability to standardize genres in the "genre"
tag by matching the genres as found to a standard genre as defined in
the genre replacement mapping configuration option. Once installed a
settings page will be added to Picard's options, which is where the
plugin is configured.
Please see the user guide on GitHub for more information.
'''
PLUGIN_VERSION = '0.6'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3', '2.6', '2.7', '2.8', '2.9', '2.10', '2.11']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
import re
from picard import (
config,
log,
)
from picard.metadata import (
MULTI_VALUED_JOINER,
register_track_metadata_processor,
)
from picard.plugin import PluginPriority
from picard.plugins.genre_mapper.ui_options_genre_mapper import (
Ui_GenreMapperOptionsPage,
)
from picard.ui.options import (
OptionsPage,
register_options_page,
)
pairs_split = re.compile(r"\r\n|\n\r|\n").split
OPT_GENRE_SEPARATOR = 'join_genres'
OPT_MATCH_ENABLED = 'genre_mapper_enabled'
OPT_MATCH_PAIRS = 'genre_mapper_replacement_pairs'
OPT_MATCH_FIRST = 'genre_mapper_apply_first_match_only'
OPT_MATCH_REGEX = 'genre_mapper_use_regex'
class GenreMappingPairs():
pairs = []
@classmethod
def refresh(cls):
log.debug("%s: Refreshing the genre replacement maps processing pairs using '%s' translation.",
PLUGIN_NAME, 'RegEx' if config.Option.exists("setting", OPT_MATCH_REGEX) and config.setting[OPT_MATCH_REGEX] else 'Simple',)
if not config.Option.exists("setting", OPT_MATCH_PAIRS):
log.warning("%s: Unable to read the '%s' setting.", PLUGIN_NAME, OPT_MATCH_PAIRS,)
return
def _make_re(map_string):
# Replace period with temporary placeholder character (newline)
re_string = str(map_string).strip().replace('.', '\n')
# Convert wildcard characters to regular expression equivalents
re_string = re_string.replace('*', '.*').replace('?', '.')
# Escape carat and dollar sign for regular expression
re_string = re_string.replace('^', '\\^').replace('$', '\\$')
# Replace temporary placeholder characters with escaped periods
re_string = '^' + re_string.replace('\n', '\\.') + '$'
# Return regular expression with carat and dollar sign to force match condition on full string
return re_string
cls.pairs = []
for pair in pairs_split(config.setting[OPT_MATCH_PAIRS]):
if "=" not in pair:
continue
original, replacement = pair.split('=', 1)
original = original.strip()
if not original:
continue
replacement = replacement.strip()
cls.pairs.append((original if config.setting[OPT_MATCH_REGEX] else _make_re(original), replacement))
log.debug('%s: Add genre mapping pair: "%s" = "%s"', PLUGIN_NAME, original, replacement,)
if not cls.pairs:
log.debug("%s: No genre replacement maps defined.", PLUGIN_NAME,)
class GenreMapperOptionsPage(OptionsPage):
NAME = "genre_mapper"
TITLE = "Genre Mapper"
PARENT = "plugins"
options = [
config.TextOption("setting", OPT_MATCH_PAIRS, ''),
config.BoolOption("setting", OPT_MATCH_FIRST, False),
config.BoolOption("setting", OPT_MATCH_ENABLED, False),
config.BoolOption("setting", OPT_MATCH_REGEX, False),
]
def __init__(self, parent=None):
super().__init__(parent)
self.ui = Ui_GenreMapperOptionsPage()
self.ui.setupUi(self)
def load(self):
# Enable external link
self.ui.format_description.setOpenExternalLinks(True)
self.ui.genre_mapper_replacement_pairs.setPlainText(config.setting[OPT_MATCH_PAIRS])
self.ui.genre_mapper_first_match_only.setChecked(config.setting[OPT_MATCH_FIRST])
self.ui.cb_enable_genre_mapping.setChecked(config.setting[OPT_MATCH_ENABLED])
self.ui.cb_use_regex.setChecked(config.setting[OPT_MATCH_REGEX])
self.ui.cb_enable_genre_mapping.stateChanged.connect(self._set_enabled_state)
self._set_enabled_state()
def save(self):
config.setting[OPT_MATCH_PAIRS] = self.ui.genre_mapper_replacement_pairs.toPlainText()
config.setting[OPT_MATCH_FIRST] = self.ui.genre_mapper_first_match_only.isChecked()
config.setting[OPT_MATCH_ENABLED] = self.ui.cb_enable_genre_mapping.isChecked()
config.setting[OPT_MATCH_REGEX] = self.ui.cb_use_regex.isChecked()
GenreMappingPairs.refresh()
def _set_enabled_state(self, *args):
self.ui.gm_replacement_pairs.setEnabled(self.ui.cb_enable_genre_mapping.isChecked())
def track_genre_mapper(album, metadata, *args):
if not config.setting[OPT_MATCH_ENABLED]:
return
if 'genre' not in metadata or not metadata['genre']:
log.debug('%s: No genres found for: "%s"', PLUGIN_NAME, metadata['title'],)
return
genre_joiner = config.setting[OPT_GENRE_SEPARATOR] if config.setting[OPT_GENRE_SEPARATOR] else MULTI_VALUED_JOINER
genres = set()
metadata_genres = str(metadata['genre']).split(genre_joiner)
for genre in metadata_genres:
for (original, replacement) in GenreMappingPairs.pairs:
try:
if genre and re.search(original, genre, re.IGNORECASE):
genre = replacement
if config.setting[OPT_MATCH_FIRST]:
break
except re.error:
log.error('%s: Invalid regular expression ignored: "%s"', PLUGIN_NAME, original,)
if genre:
genres.add(genre.title())
genres = sorted(genres)
log.debug('%s: Genres updated from %s to %s', PLUGIN_NAME, metadata_genres, genres,)
metadata['genre'] = genres
# Register the plugin to run at a LOW priority.
register_track_metadata_processor(track_genre_mapper, priority=PluginPriority.LOW)
register_options_page(GenreMapperOptionsPage)
GenreMappingPairs.refresh()
================================================
FILE: plugins/genre_mapper/options_genre_mapper.ui
================================================
GenreMapperOptionsPage
0
0
398
568
0
0
16
-
-
0
0
0
50
75
true
Genre Mapper
9
9
9
1
-
0
0
50
false
<html><head/><body><p>These are the original / replacement pairs used to map one genre entry to another. Each pair must be entered on a separate line in the form:</p><p><span style=" font-weight:600;">[genre match test string]=[replacement genre]</span></p><p>Unless the "regular expressions" option is enabled, supported wildcards in the test string part of the mapping include '*' and '?' to match any number of characters and a single character respectively. An example for mapping all types of Rock genres (e.g. Country Rock, Hard Rock, Progressive Rock) to "Rock" would be done using the following line:</p><p><span style=" font-family:'Courier New'; font-size:10pt; font-weight:600;">*rock*=Rock</span></p><p>Blank lines and lines beginning with an equals sign (=) will be ignored. Case-insensitive tests are used when matching. Replacements will be made in the order they are found in the list.</p><p>For more information please see the <a href="https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/genre_mapper/docs/README.md"><span style=" text-decoration: underline; color:#0000ff;">User Guide</span></a> on GitHub.<br/></p></body></html>
Qt::AlignLeading|Qt::AlignLeft|Qt::AlignTop
true
-
Enable genre mapping
-
true
0
0
0
50
75
true
Replacement Pairs
-
50
false
Match tests are entered as regular expressions
-
50
false
Apply only the first matching replacement
false
-
0
0
0
50
Courier New
10
true
QPlainTextEdit::NoWrap
Enter replacement pairs (one per line)
cb_enable_genre_mapping
cb_use_regex
genre_mapper_first_match_only
genre_mapper_replacement_pairs
================================================
FILE: plugins/genre_mapper/ui_options_genre_mapper.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file '.\plugins\genre_mapper\options_genre_mapper.ui'
#
# Created by: PyQt5 UI code generator 5.14.1
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_GenreMapperOptionsPage(object):
def setupUi(self, GenreMapperOptionsPage):
GenreMapperOptionsPage.setObjectName("GenreMapperOptionsPage")
GenreMapperOptionsPage.resize(398, 568)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(GenreMapperOptionsPage.sizePolicy().hasHeightForWidth())
GenreMapperOptionsPage.setSizePolicy(sizePolicy)
self.vboxlayout = QtWidgets.QVBoxLayout(GenreMapperOptionsPage)
self.vboxlayout.setSpacing(16)
self.vboxlayout.setObjectName("vboxlayout")
self.verticalLayout_4 = QtWidgets.QVBoxLayout()
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.gm_description = QtWidgets.QGroupBox(GenreMapperOptionsPage)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.gm_description.sizePolicy().hasHeightForWidth())
self.gm_description.setSizePolicy(sizePolicy)
self.gm_description.setMinimumSize(QtCore.QSize(0, 50))
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.gm_description.setFont(font)
self.gm_description.setObjectName("gm_description")
self.verticalLayout = QtWidgets.QVBoxLayout(self.gm_description)
self.verticalLayout.setContentsMargins(9, 9, 9, 1)
self.verticalLayout.setObjectName("verticalLayout")
self.format_description = QtWidgets.QLabel(self.gm_description)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.format_description.sizePolicy().hasHeightForWidth())
self.format_description.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(False)
font.setWeight(50)
self.format_description.setFont(font)
self.format_description.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignTop)
self.format_description.setWordWrap(True)
self.format_description.setObjectName("format_description")
self.verticalLayout.addWidget(self.format_description)
self.verticalLayout_4.addWidget(self.gm_description)
self.cb_enable_genre_mapping = QtWidgets.QCheckBox(GenreMapperOptionsPage)
self.cb_enable_genre_mapping.setObjectName("cb_enable_genre_mapping")
self.verticalLayout_4.addWidget(self.cb_enable_genre_mapping)
self.gm_replacement_pairs = QtWidgets.QGroupBox(GenreMapperOptionsPage)
self.gm_replacement_pairs.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.MinimumExpanding)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.gm_replacement_pairs.sizePolicy().hasHeightForWidth())
self.gm_replacement_pairs.setSizePolicy(sizePolicy)
self.gm_replacement_pairs.setMinimumSize(QtCore.QSize(0, 50))
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.gm_replacement_pairs.setFont(font)
self.gm_replacement_pairs.setObjectName("gm_replacement_pairs")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.gm_replacement_pairs)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.cb_use_regex = QtWidgets.QCheckBox(self.gm_replacement_pairs)
font = QtGui.QFont()
font.setBold(False)
font.setWeight(50)
self.cb_use_regex.setFont(font)
self.cb_use_regex.setObjectName("cb_use_regex")
self.verticalLayout_3.addWidget(self.cb_use_regex)
self.genre_mapper_first_match_only = QtWidgets.QCheckBox(self.gm_replacement_pairs)
font = QtGui.QFont()
font.setBold(False)
font.setWeight(50)
self.genre_mapper_first_match_only.setFont(font)
self.genre_mapper_first_match_only.setChecked(False)
self.genre_mapper_first_match_only.setObjectName("genre_mapper_first_match_only")
self.verticalLayout_3.addWidget(self.genre_mapper_first_match_only)
self.genre_mapper_replacement_pairs = QtWidgets.QPlainTextEdit(self.gm_replacement_pairs)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.genre_mapper_replacement_pairs.sizePolicy().hasHeightForWidth())
self.genre_mapper_replacement_pairs.setSizePolicy(sizePolicy)
self.genre_mapper_replacement_pairs.setMinimumSize(QtCore.QSize(0, 50))
font = QtGui.QFont()
font.setFamily("Courier New")
font.setPointSize(10)
self.genre_mapper_replacement_pairs.setFont(font)
self.genre_mapper_replacement_pairs.setTabChangesFocus(True)
self.genre_mapper_replacement_pairs.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)
self.genre_mapper_replacement_pairs.setObjectName("genre_mapper_replacement_pairs")
self.verticalLayout_3.addWidget(self.genre_mapper_replacement_pairs)
self.verticalLayout_4.addWidget(self.gm_replacement_pairs)
self.vboxlayout.addLayout(self.verticalLayout_4)
self.retranslateUi(GenreMapperOptionsPage)
QtCore.QMetaObject.connectSlotsByName(GenreMapperOptionsPage)
GenreMapperOptionsPage.setTabOrder(self.cb_enable_genre_mapping, self.cb_use_regex)
GenreMapperOptionsPage.setTabOrder(self.cb_use_regex, self.genre_mapper_first_match_only)
GenreMapperOptionsPage.setTabOrder(self.genre_mapper_first_match_only, self.genre_mapper_replacement_pairs)
def retranslateUi(self, GenreMapperOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.gm_description.setTitle(_translate("GenreMapperOptionsPage", "Genre Mapper"))
self.format_description.setText(_translate("GenreMapperOptionsPage", "These are the original / replacement pairs used to map one genre entry to another. Each pair must be entered on a separate line in the form:
[genre match test string]=[replacement genre]
Unless the "regular expressions" option is enabled, supported wildcards in the test string part of the mapping include \'*\' and \'?\' to match any number of characters and a single character respectively. An example for mapping all types of Rock genres (e.g. Country Rock, Hard Rock, Progressive Rock) to "Rock" would be done using the following line:
*rock*=Rock
Blank lines and lines beginning with an equals sign (=) will be ignored. Case-insensitive tests are used when matching. Replacements will be made in the order they are found in the list.
For more information please see the User Guide on GitHub.
"))
self.cb_enable_genre_mapping.setText(_translate("GenreMapperOptionsPage", "Enable genre mapping"))
self.gm_replacement_pairs.setTitle(_translate("GenreMapperOptionsPage", "Replacement Pairs"))
self.cb_use_regex.setText(_translate("GenreMapperOptionsPage", "Match tests are entered as regular expressions"))
self.genre_mapper_first_match_only.setText(_translate("GenreMapperOptionsPage", "Apply only the first matching replacement"))
self.genre_mapper_replacement_pairs.setPlaceholderText(_translate("GenreMapperOptionsPage", "Enter replacement pairs (one per line)"))
================================================
FILE: plugins/haikuattrs/haikuattrs.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (c) 2019, 2021 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Haiku BFS Attributes'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Save and load metadata to/from Haiku BFS attributes.'
PLUGIN_VERSION = "1.3"
PLUGIN_API_VERSIONS = ["2.2", "2.3", "2.4", "2.5", "2.6"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import os
import struct
import sys
from collections import namedtuple
from ctypes import (CDLL, POINTER, Structure, byref, c_char_p, c_int, c_long,
c_longlong, c_size_t, c_ssize_t, c_uint32, c_void_p, cast)
from ctypes.util import find_library
from functools import partial
from picard import log
from picard.file import (
register_file_post_load_processor,
register_file_post_save_processor,
)
from picard.util import thread
if sys.platform[:5] == 'haiku':
class AttrInfo(Structure):
_fields_ = [
('type', c_uint32),
('size', c_size_t)]
def __repr__(self):
return 'AttrInfo(type=%r, size=%r)' % (self.type, self.size)
try:
libbe_path = find_library('be') or 'libbe.so'
be = CDLL(libbe_path, use_errno=True)
be.fs_stat_attr.restype = c_int
be.fs_stat_attr.argtypes = [c_int, c_char_p, POINTER(AttrInfo)]
be.fs_read_attr.restype = c_ssize_t
be.fs_read_attr.argtypes = [c_int, c_char_p, c_uint32, c_size_t,
c_void_p, c_size_t]
be.fs_remove_attr.restype = c_int
be.fs_remove_attr.argtypes = [c_int, c_char_p]
be.fs_write_attr.restype = c_ssize_t
be.fs_write_attr.argtypes = [c_int, c_char_p, c_uint32, c_size_t,
c_void_p, c_size_t]
except OSError:
log.error('haikuattrs: unable to load libbe', exc_info=True)
be = None
else:
log.warning('haikuattrs: this plugin is only for the Haiku operating system')
be = None
if be:
Attr = namedtuple('Attr', ['type', 'name'])
attr_map = {
'artist' : Attr(b'CSTR', b'Audio:Artist'),
'album' : Attr(b'CSTR', b'Audio:Album'),
'title' : Attr(b'CSTR', b'Media:Title'),
'date' : Attr(b'LONG', b'Media:Year'),
'comment:' : Attr(b'CSTR', b'Media:Comment'),
'tracknumber': Attr(b'LONG', b'Audio:Track'),
'genre' : Attr(b'CSTR', b'Media:Genre'),
'composer' : Attr(b'CSTR', b'Audio:Composer'),
'~rating' : Attr(b'LONG', b'Media:Rating'),
'~length' : Attr(b'LLNG', b'Media:Length'),
'~bitrate' : Attr(b'CSTR', b'Audio:Bitrate'),
}
def get_numeric_type(attr):
return struct.unpack('>I', attr.type)[0]
def read_attr(fd, attr):
info = AttrInfo()
if be.fs_stat_attr(fd, attr.name, byref(info)) == -1:
return None
buffer = b'\0' * info.size
bytes_read = be.fs_read_attr(fd, attr.name, info.type, 0,
buffer, len(buffer))
result = None
if bytes_read > -1:
buffer = buffer[:bytes_read]
if attr.type == b'LONG':
result = str(struct.unpack('=l', buffer)[0])
elif attr.type == b'LLNG':
result = str(struct.unpack('=q', buffer)[0])
elif attr.type == b'CSTR':
result = buffer.decode('utf-8', errors='replace')
else:
raise ValueError('Unsupported attribute type %s' % attr.type)
log.debug("haikuattrs: fs_read_attr(%r, %r, %r, %r, %r, %r) -> %r: %r" % (
fd, attr.name, info.type, 0, buffer, len(buffer), bytes_read, result))
return result
def remove_attr(fd, attr):
return be.fs_remove_attr(fd, attr.name) == 0
def write_attr(fd, attr, attr_value):
if attr.type in (b'LONG', b'LLNG'):
try:
attr_value = int(attr_value)
except ValueError:
return False
length = 4
c_type = c_long if attr.type == b'LONG' else c_longlong
buffer = byref(c_type(attr_value))
elif attr.type == b'CSTR':
attr_value = attr_value.encode('utf-8')
length = len(attr_value)
buffer = cast(attr_value, c_char_p)
else:
raise ValueError('Unsupported attribute type %s' % attr.type)
int_type = get_numeric_type(attr)
ret_val = be.fs_write_attr(fd, attr.name, int_type, 0, buffer, length)
log.debug("haikuattrs: fs_write_attr(%r, %r, %r, %r, %r, %r) -> %r" % (
fd, attr.name, int_type, 0, buffer, length, ret_val))
return ret_val >= 0
def get_attribute_value(tag, file):
metadata = file.orig_metadata
value = metadata[tag]
if value:
if tag == 'date':
value = value[:4]
elif tag == '~length':
# Haiku expects the Media:Length attribute in nanoseconds
value = metadata.length * 1000
elif tag == '~bitrate':
value = '%s kbps' % value
elif tag == '~rating':
# Haiku's ratings are internally repesented by integers between 1 and 10
value = int(value * 2)
return value
def set_attrs_from_metadata(file):
log.debug('haikuattrs: setting attributes for %s' % file.filename)
fd = os.open(file.filename, os.O_RDWR)
try:
for tag, attr in attr_map.items():
try:
value = get_attribute_value(tag, file)
except (TypeError, ValueError) as err:
log.warning(
'haikuattrs: failed converting tag %s with value %r for %s: %r',
tag, value, file.filename, err)
continue
if value:
if not write_attr(fd, attr, value):
log.error('haikuattrs: setting %s=%s for %s failed' % (
attr.name, value, file.filename))
else:
remove_attr(fd, attr)
finally:
os.close(fd)
def set_attrs_from_metadata_finished(file, result=None, error=None):
if error:
log.error('haikuattrs: setting attributes for %s failed: %r' % (
file.filename, error))
else:
log.debug('haikuattrs: attributes set for %s' % file.filename)
def load_attrs_to_metadata(file):
fd = os.open(file.filename, os.O_RDONLY)
filename, _ = os.path.splitext(file.base_filename)
try:
for tag, attr in attr_map.items():
# Technical variables that are loaded directly from the file
if tag in ('~bitrate', '~length'):
continue
# Ignore tags for which metadata is included in the file.
# But ignore the special case where the title has been set to
# the filename.
value = file.metadata[tag]
if value and not (tag == 'title' and value == filename):
continue
value = read_attr(fd, attr)
if value:
file.metadata[tag] = value
file.orig_metadata[tag] = value
finally:
os.close(fd)
def load_attrs_to_metadata_finished(file, result=None, error=None):
if error:
log.error('haikuattrs: loading attributes for %s failed: %r' % (
file.filename, error))
else:
log.debug('haikuattrs: attributes loaded for %s' % file.filename)
file.update()
def on_file_load_processor(file):
thread.run_task(
partial(load_attrs_to_metadata, file),
partial(load_attrs_to_metadata_finished, file))
def on_file_save_processor(file):
thread.run_task(
partial(set_attrs_from_metadata, file),
partial(set_attrs_from_metadata_finished, file))
register_file_post_load_processor(on_file_load_processor)
register_file_post_save_processor(on_file_save_processor)
================================================
FILE: plugins/happidev_lyrics/happidev_lyrics.py
================================================
from functools import partial
from urllib.parse import (
quote,
urlencode,
urlparse,
)
from PyQt5 import QtWidgets
from PyQt5.QtNetwork import QNetworkRequest
from picard import (
config,
log,
)
from picard.config import TextOption
from picard.metadata import register_track_metadata_processor
from picard.ui.options import (
OptionsPage,
register_options_page,
)
from picard.webservice import ratecontrol
PLUGIN_NAME = 'Happi.dev Lyrics'
PLUGIN_AUTHOR = 'Andrea Avallone, Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Fetch lyrics from Happi.dev Lyrics, which provides millions of lyrics from artist all around the world. ' \
'Lyrics provided are for educational purposes and personal use only. Commercial use is not allowed.
' \
'In order to use Happi.dev you need to get a free API key at happi.dev'
PLUGIN_VERSION = '2.1.2'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3', '2.4', '2.5', '2.6']
PLUGIN_LICENSE = 'MIT'
PLUGIN_LICENSE_URL = 'https://opensource.org/licenses/MIT'
class HappidevLyricsMetadataProcessor:
happidev_host = 'api.happi.dev'
happidev_port = 443
happidev_delay = int(60 * 1000 / 60) # 60 requests per minute
def __init__(self):
super().__init__()
ratecontrol.set_minimum_delay(
(self.happidev_host, self.happidev_port), self.happidev_delay)
def process_metadata(self, album, metadata, track, release):
if not config.setting['happidev_apikey']:
error = 'API key is missing, please provide a valid value'
log.warning('{}: {}'.format(PLUGIN_NAME, error))
return
artist = metadata['artist']
title = metadata['title']
if not (artist and title):
log.debug(
'{}: both artist and title are required to obtain lyrics'.format(PLUGIN_NAME))
return
path = '/v1/music'
queryargs = {
'q': '"{}" "{}"'.format(artist, title),
'lyrics': 'true',
'type': 'track',
}
album._requests += 1
log.debug('{}: GET {}?{}'.format(PLUGIN_NAME, quote(path), urlencode(queryargs)))
self._request(album.tagger.webservice, path,
partial(self.process_search_response, album, metadata), queryargs)
def _request(self, ws, path, callback, queryargs=None, important=False):
if not queryargs:
queryargs = {}
queryargs['apikey'] = config.setting['happidev_apikey']
ws.get(self.happidev_host, self.happidev_port, path, callback,
parse_response_type='json', priority=True, important=important,
queryargs=queryargs, cacheloadcontrol=QNetworkRequest.PreferCache)
def process_search_response(self, album, metadata, response, reply, error):
if self._handle_error(album, error, response):
log.warning('{}: lyrics NOT found for track "{}" by {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist']))
return
try:
lyrics_url = response['result'][0]['api_lyrics']
log.debug('{}: lyrics found for track "{}" by {} at {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist'], lyrics_url))
path = urlparse(lyrics_url).path
except (TypeError, KeyError, ValueError):
log.warn('{}: failed parsing search response for "{}" by {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist']), exc_info=True)
album._requests -= 1
album._finalize_loading(None)
return
self._request(album.tagger.webservice, path,
partial(self.process_lyrics_response, album, metadata),
important=True)
def process_lyrics_response(self, album, metadata, response, reply, error):
if self._handle_error(album, error, response):
log.warning('{}: lyrics NOT loaded for track "{}" by {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist']))
return
try:
lyrics = response['result']['lyrics']
metadata['lyrics'] = lyrics
log.debug('{}: lyrics loaded for track "{}" by {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist']))
except (TypeError, KeyError):
log.warn('{}: failed parsing search response for "{}" by {}'.format(
PLUGIN_NAME, metadata['title'], metadata['artist']), exc_info=True)
finally:
album._requests -= 1
album._finalize_loading(None)
@staticmethod
def _handle_error(album, error, response):
if error or (response and (not response.get('success', False) or not response.get('length', 0))):
album._requests -= 1
album._finalize_loading(None)
return True
return False
class HappidevLyricsOptionsPage(OptionsPage):
NAME = 'apiseeds_lyrics'
TITLE = 'Happi.dev Lyrics'
PARENT = 'plugins'
options = [TextOption('setting', 'happidev_apikey', '')]
def __init__(self, parent=None):
super().__init__(parent)
self.box = QtWidgets.QVBoxLayout(self)
self.label = QtWidgets.QLabel(self)
self.label.setText('Apiseeds API key')
self.box.addWidget(self.label)
self.description = QtWidgets.QLabel(self)
self.description.setText('Happi.dev Music provides millions of lyrics from artist all around the world. '
'Lyrics provided are for educational purposes and personal use only. Commercial use is not allowed. '
'In order to use Happi.dev Music you need to get a free API key here.')
self.description.setOpenExternalLinks(True)
self.box.addWidget(self.description)
self.input = QtWidgets.QLineEdit(self)
self.box.addWidget(self.input)
self.spacer = QtWidgets.QSpacerItem(
0, 0, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.box.addItem(self.spacer)
def load(self):
self.input.setText(config.setting['happidev_apikey'])
def save(self):
config.setting['happidev_apikey'] = self.input.text()
register_track_metadata_processor(HappidevLyricsMetadataProcessor().process_metadata)
register_options_page(HappidevLyricsOptionsPage)
================================================
FILE: plugins/hyphen_unicode/hyphen_unicode.py
================================================
# -*- coding: utf-8 -*-
# Copyright (C) 2016 Anderson Mesquita
# Copyright (C) 2019 Alan Swanson
#
# This program is free software: you can redistribute it and/or modify it under
# the terms of the GNU General Public License as published by the Free Software
# Foundation, either version 3 of the License, or (at your option) any later
# version.
#
# This program is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
# details.
#
# You should have received a copy of the GNU General Public License along with
# this program. If not, see .
from picard import metadata
PLUGIN_NAME = "Hyphen unicode"
PLUGIN_AUTHOR = "Alan Swanson "
PLUGIN_VERSION = "1.0.1"
PLUGIN_API_VERSIONS = ["0.9", "0.10", "0.11", "0.15", "2.0"]
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://gnu.org/licenses/gpl.html"
PLUGIN_DESCRIPTION = '''Replaces unicode character HYPHEN (U+2010) [0xE2 0x80
0x90] with typographically identical HYPHEN-MINUS (U+002D) [0x2D] for fonts
that do not support HYPHEN and to prevent visually duplicate filenames
differentiated only by their hyphens.
Unicode duplicated hyphen from ASCII as an unambiguous way to designate a
hyphen from a minus whilst still being typographically indentical. Since
text processing on music tags is rare so choice is purely pedantic esepcially
as keyboards only have HYPHEN-MINUS.
Replaces character on "album", "title", "artist", "artists", "artistsort",
"albumartist", "albumartists" and "albumartistsort" tags.'''
# Based on Non-ASCII Equivalents plugin.
# Musicbrainz form discussion on HYPHEN versus HYPHEN-MINUS at;
# https://community.metabrainz.org/t/correct-hyphen-unicode-hyphen-or-hyphen-minus/19610
CHAR_TABLE = {
# HYPHEN to HYPHEN-MINUS
"‐": "-",
}
FILTER_TAGS = [
"title",
"artist",
"artists",
"artistsort",
"album",
"albumsort",
"albumartist",
"albumartists",
"albumartistsort",
]
def sanitize(char):
if char in CHAR_TABLE:
return CHAR_TABLE[char]
return char
def ascii(word):
return "".join(sanitize(char) for char in word)
def main(tagger, metadata, *args):
for name, value in metadata.rawitems():
if name in FILTER_TAGS:
metadata[name] = [ascii(x) for x in value]
metadata.register_track_metadata_processor(main)
metadata.register_album_metadata_processor(main)
================================================
FILE: plugins/instruments/instruments.py
================================================
# MusicBrainz Picard plugin to add an ~instruments tag.
# Copyright (C) 2019 David Mandelberg
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see .
PLUGIN_NAME = 'Instruments'
PLUGIN_AUTHOR = 'David Mandelberg'
PLUGIN_DESCRIPTION = """\
Adds a multi-valued tag (~instruments) containing all the instruments (including vocals),
for use in scripts.
"""
PLUGIN_VERSION = '1.0.1'
PLUGIN_API_VERSIONS = ['2.0']
PLUGIN_LICENSE = 'GPL-3.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-3.0.html'
from typing import Generator, Optional
from picard import metadata
from picard import plugin
def _iterate_instruments(instrument_list: str) -> Generator[str, None, None]:
"""Yields individual instruments from a string listing them.
Args:
instrument_list: List of instruments in the form 'A, B and C'.
"""
remaining = instrument_list
while remaining:
instrument, _, remaining = remaining.partition(', ')
if not remaining:
instrument, _, remaining = instrument.partition(' and ')
if ' and ' in remaining:
raise ValueError('Instrument list contains multiple \'and\'s: {!r}'
.format(instrument_list))
yield instrument
def _strip_instrument_prefixes(instrument: str) -> Optional[str]:
"""Returns the instrument name without qualifying prefixes, or None.
Args:
instrument: Potentially prefixed instrument name, e.g., 'solo bassoon'.
Returns:
The instrument name with all prefixes stripped, or None if there's nothing
other than prefixes. The all-prefixes case can happen with relationships
like 'guest performer'.
"""
instrument_prefixes = {
'additional',
'guest',
'solo',
}
remaining = instrument
while remaining:
prefix, sep, remaining = remaining.partition(' ')
if prefix not in instrument_prefixes:
return ''.join((prefix, sep, remaining))
return None
def add_instruments(tagger, metadata_, *args):
key_prefix = 'performer:'
instruments = set()
for key in metadata_.keys():
if not key.startswith(key_prefix):
continue
for instrument in _iterate_instruments(key[len(key_prefix):]):
instrument = _strip_instrument_prefixes(instrument)
if instrument:
instruments.add(instrument)
metadata_['~instruments'] = list(instruments)
metadata.register_track_metadata_processor(
add_instruments, priority=plugin.PluginPriority.HIGH)
================================================
FILE: plugins/keep/keep.py
================================================
PLUGIN_NAME = "Keep tags"
PLUGIN_AUTHOR = "Wieland Hoffmann"
PLUGIN_DESCRIPTION = """
Adds a $keep() function to delete all tags except the ones that you want.
Tags beginning with `musicbrainz_` are kept automatically, as are tags
beginning with `_`.
To keep all tags that can have a description (like `comment`, lyrics` and
`performer`), add `<tagname without description>` (not including `:`) to the
list of tags to keep."""
PLUGIN_VERSION = "1.2.1"
PLUGIN_API_VERSIONS = ["0.15.0", "0.15.1", "0.16.0", "1.0.0", "1.1.0", "1.2.0",
"1.3.0", "2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard.script import register_script_function
@register_script_function
def keep(parser, *keeptags):
tags = list(parser.context.keys())
for tag in tags:
if (tag in keeptags or
tag.startswith("musicbrainz_") or
tag.startswith("~")):
continue
if ":" in tag:
tag_without_description = tag.split(":")[0]
if tag_without_description in keeptags:
continue
parser.context.pop(tag, None)
return ""
================================================
FILE: plugins/key_wheel_converter/key_wheel_converter.py
================================================
# -*- coding: utf-8 -*-
"""Key Wheel Converter Plugin
"""
#
# Copyright (C) 2022-2025 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
# pylint: disable=C0413 (wrong-import-position)
# pylint: disable=W0613 (unused-argument)
PLUGIN_NAME = 'Key Wheel Converter'
PLUGIN_AUTHOR = 'Bob Swift'
PLUGIN_DESCRIPTION = '''
Adds functions to convert between 'standard', 'camelot', 'open key' and 'traktor' key formats.
'''
PLUGIN_VERSION = '1.2'
PLUGIN_API_VERSIONS = ['2.3', '2.4', '2.6', '2.7', '2.13']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
import re
try:
from picard import log
except ModuleNotFoundError:
class log():
"""Mocked logger for testing
"""
# pylint: disable=invalid-name
# pylint: disable=too-few-public-methods
@staticmethod
def debug(*args, **kwargs):
"""Mocked degug logger
"""
return
try:
from picard.script import register_script_function
except ModuleNotFoundError:
def register_script_function(*args, **kwargs):
"""Mocked function for testing
"""
return
class KeyMap():
"""
Class to hold the mapping dictionary. The dictionary is
stored as a class variable so that it is only generated once.
"""
# pylint: disable=too-few-public-methods
# Circle of Fifths reference:
# https://www.circleoffifths.com
# Key Wheel references:
# https://i.imgur.com/p9Kdevi.jpg
# http://www.quanta.com.br/wp-content/uploads/2013/07/traktor-key-wheel_alta.jpg
# List of tuples of:
# 'camelot key',
# 'open key',
# 'standard key /w symbols',
# 'standard key /w text'
# 'traktor key'
_keys = [
('1A', '6m', 'A♭ Minor', 'A-Flat Minor', 'Abm'),
('1B', '6d', 'B Major', 'B Major', 'B'),
('2A', '7m', 'E♭ Minor', 'E-Flat Minor', 'Ebm'),
('2B', '7d', 'F# Major', 'F-Sharp Major', 'F#'),
('3A', '8m', 'B♭ Minor', 'B-Flat Minor', 'Bbm'),
('3B', '8d', 'D♭ Major', 'D-Flat Major', 'Db'),
('4A', '9m', 'F Minor', 'F Minor', 'Fm'),
('4B', '9d', 'A♭ Major', 'A-Flat Major', 'Ab'),
('5A', '10m', 'C Minor', 'C Minor', 'Cm'),
('5B', '10d', 'E♭ Major', 'E-Flat Major', 'Eb'),
('6A', '11m', 'G Minor', 'G Minor', 'Gm'),
('6B', '11d', 'B♭ Major', 'B-Flat Major', 'Bb'),
('7A', '12m', 'D Minor', 'D Minor', 'Dm'),
('7B', '12d', 'F Major', 'F Major', 'F'),
('8A', '1m', 'A Minor', 'A Minor', 'Am'),
('8B', '1d', 'C Major', 'C Major', 'C'),
('9A', '2m', 'E Minor', 'E Minor', 'Em'),
('9B', '2d', 'G Major', 'G Major', 'G'),
('10A', '3m', 'B Minor', 'B Minor', 'Bm'),
('10B', '3d', 'D Major', 'D Major', 'D'),
('11A', '4m', 'G♭ Minor', 'G-Flat Minor', 'Gbm'),
('11B', '4d', 'A Major', 'A Major', 'A'),
('12A', '5m', 'D♭ Minor', 'D-Flat Minor', 'Dbm'),
('12B', '5d', 'E Major', 'E Major', 'E'),
]
# Build mapping dictionary with 'camelot', 'standard with text'
# and 'traktor' keys.
keys = {}
for item in _keys:
for i in [0, 3, 4]:
keys[item[i]] = {
'camelot': item[0],
'open': item[1],
'standard_s': item[2],
'standard_t': item[3],
'traktor': item[4],
}
# Alternate mapping for standard keys
s_alt = {
'G-Flat Major': 'F-Sharp Major',
'D-Sharp Minor': 'E-Flat Minor',
}
# Alternate mapping for traktor keys
t_alt = {
'G#': 'Ab',
'A#': 'Bb',
'C#': 'Db',
'D#': 'Eb',
'G#m': 'Abm',
'A#m': 'Bbm',
'C#m': 'Dbm',
'D#m': 'Ebm',
'F#m': 'Gbm',
}
def _matcher(text, out_type):
"""Helper function that performs the actual key lookup.
Args:
text (str): Key provided by the user.
out_type (str): Output format to use for the return value
Returns:
str: Value mapped to the key for the specified output type
"""
# pylint: disable=consider-using-f-string
match_text = _parse_input(text)
if match_text not in KeyMap.keys:
log.debug("{0}: Unable to match key: '{1}'".format(PLUGIN_NAME, text,))
return ''
return KeyMap.keys[match_text][out_type]
def _parse_input(text):
"""Helper function to parse the input argument to try to match
one of the supported formats used for the mapping keys.
Args:
text (str): Input argument provided by the user
Returns:
str: Argument converted to supported key format (if possible)
"""
# pylint: disable=too-many-return-statements
text = text.strip()
if not text:
return ''
if re.match("[0-9]{1,2}[ABab]$", text):
# Matches camelot key. Fix capitalization for lookup.
return text.upper()
if re.match("[0-9]{1,2}[dmDM]$", text):
# Matches open key format. Convert to camelot key for lookup.
temp = int(text[0:-1])
if 0 < temp < 13:
_num = ((temp + 6) % 12) + 1
_char = text[-1:].lower().replace('m', 'A').replace('d', 'B')
return "{0}{1}".format(_num, _char,)
# if re.match("[a-gA-G][#bB♭]?[mM]?$", text):
if re.match("[a-gA-G][#Bb]?[mM]?$", text):
# Matches Traktor key format. Fix capitalization for lookup.
temp = text[0:1].upper() + text[1:].replace('♭', 'b').lower()
# Handle cases where there are multiple entries for the item
if temp in KeyMap.t_alt:
return KeyMap.t_alt[temp]
return temp
# Parse as standard key
# Add missing hyphens before 'Flat' and 'Sharp'
text = text.lower().replace(' s', '-s').replace(' f', '-f')
# Convert symbols to text for lookup.
parts = text.replace('♭', '-Flat').replace('#', '-Sharp').split()
for (i, part) in enumerate(parts):
parts[i] = part[0:1].upper() + part[1:]
temp = ' '.join(parts).replace('-s', '-S').replace('-f', '-F')
# Handle cases where there are multiple entries for the item
if temp in KeyMap.s_alt:
return KeyMap.s_alt[temp]
return temp
def key2camelot(parser, text):
"""Any key to camelot format converter.
Args:
parser (object): Picard parser object
text (str): Key to convert
Returns:
str: Converted key value
Tests:
>>> key2camelot(None, '1A')
'1A'
>>> key2camelot(None, '6m')
'1A'
>>> key2camelot(None, 'A♭ Minor')
'1A'
>>> key2camelot(None, 'A-Flat Minor')
'1A'
>>> key2camelot(None, '1a')
'1A'
>>> key2camelot(None, '6M')
'1A'
>>> key2camelot(None, 'A-FLAT MINOR')
'1A'
>>> key2camelot(None, 'a-flat minor')
'1A'
>>> key2camelot(None, ' 1A')
'1A'
>>> key2camelot(None, '1A ')
'1A'
>>> key2camelot(None, 'ABm')
'1A'
>>> key2camelot(None, '')
''
>>> key2camelot(None, 'A-Flat Minor x')
''
>>> key2camelot(None, 'H-Flat Minor')
''
>>> key2camelot(None, '1-Flat Minor')
''
>>> key2camelot(None, 'A-Flat')
''
>>> key2camelot(None, 'A♭')
''
>>> key2camelot(None, '0a')
''
>>> key2camelot(None, '13a')
''
>>> key2camelot(None, '0m')
''
>>> key2camelot(None, '13m')
''
>>> key2camelot(None, '1x')
''
>>> key2camelot(None, 'A#')
'6B'
>>> key2camelot(None, 'A#M')
'3A'
>>> key2camelot(None, 'C#')
'3B'
>>> key2camelot(None, 'C#M')
'12A'
>>> key2camelot(None, 'D#')
'5B'
>>> key2camelot(None, 'D#M')
'2A'
>>> key2camelot(None, 'F#M')
'11A'
>>> key2camelot(None, 'G#')
'4B'
>>> key2camelot(None, 'G#M')
'1A'
>>> key2camelot(None, 'c')
'8B'
>>> key2camelot(None, 'dB')
'3B'
>>> key2camelot(None, 'd#M')
'2A'
>>> key2camelot(None, 'D#M')
'2A'
"""
return _matcher(text, 'camelot')
def key2openkey(parser, text):
"""Any key to open key format converter.
Args:
parser (object): Picard parser object
text (str): Key to convert
Returns:
str: Converted key value
Tests:
>>> key2openkey(None, '1A')
'6m'
>>> key2openkey(None, '6m')
'6m'
>>> key2openkey(None, 'A♭ Minor')
'6m'
>>> key2openkey(None, 'A-Flat Minor')
'6m'
>>> key2openkey(None, '1a')
'6m'
>>> key2openkey(None, '6M')
'6m'
>>> key2openkey(None, 'A-FLAT MINOR')
'6m'
>>> key2openkey(None, 'a-flat minor')
'6m'
>>> key2openkey(None, ' 1A')
'6m'
>>> key2openkey(None, '1A ')
'6m'
>>> key2openkey(None, '')
''
>>> key2openkey(None, 'A-Flat Minor x')
''
>>> key2openkey(None, 'H-Flat Minor')
''
>>> key2openkey(None, '1-Flat Minor')
''
>>> key2openkey(None, 'A-Flat')
''
>>> key2openkey(None, 'A♭')
''
>>> key2openkey(None, '0a')
''
>>> key2openkey(None, '13a')
''
>>> key2openkey(None, '0m')
''
>>> key2openkey(None, '13m')
''
>>> key2openkey(None, '1x')
''
"""
return _matcher(text, 'open')
def key2standard(parser, text, use_symbol=''):
"""Any key to standard key format converter.
Args:
parser (object): Picard parser object
text (str): Key to convert
use_symbol (str, optional): Use '♭' and '#' symbols. Defaults to False.
Returns:
str: Converted key value
Tests:
>>> key2standard(None, '1A')
'A-Flat Minor'
>>> key2standard(None, '6m')
'A-Flat Minor'
>>> key2standard(None, 'A♭ Minor')
'A-Flat Minor'
>>> key2standard(None, 'A-Flat Minor')
'A-Flat Minor'
>>> key2standard(None, '1a')
'A-Flat Minor'
>>> key2standard(None, '6M')
'A-Flat Minor'
>>> key2standard(None, 'A-FLAT MINOR')
'A-Flat Minor'
>>> key2standard(None, 'a-flat minor')
'A-Flat Minor'
>>> key2standard(None, ' 1A')
'A-Flat Minor'
>>> key2standard(None, '1A ')
'A-Flat Minor'
>>> key2standard(None, '')
''
>>> key2standard(None, 'A-Flat Minor x')
''
>>> key2standard(None, 'H-Flat Minor')
''
>>> key2standard(None, '1-Flat Minor')
''
>>> key2standard(None, 'A-Flat')
''
>>> key2standard(None, 'A♭')
''
>>> key2standard(None, '0a')
''
>>> key2standard(None, '13a')
''
>>> key2standard(None, '0m')
''
>>> key2standard(None, '13m')
''
>>> key2standard(None, '1x')
''
>>> key2standard(None, '1A', 'x')
'A♭ Minor'
>>> key2standard(None, '6m', 'x')
'A♭ Minor'
>>> key2standard(None, 'A♭ Minor', 'x')
'A♭ Minor'
>>> key2standard(None, 'A-Flat Minor', 'x')
'A♭ Minor'
>>> key2standard(None, '1a', 'x')
'A♭ Minor'
>>> key2standard(None, '6M', 'x')
'A♭ Minor'
>>> key2standard(None, 'A-FLAT MINOR', 'x')
'A♭ Minor'
>>> key2standard(None, 'a-flat minor', 'x')
'A♭ Minor'
>>> key2standard(None, ' 1A', 'x')
'A♭ Minor'
>>> key2standard(None, '1A ', 'x')
'A♭ Minor'
>>> key2standard(None, '1A ', ' ')
'A♭ Minor'
>>> key2standard(None, '', 'x')
''
>>> key2standard(None, 'A-Flat Minor x', 'x')
''
>>> key2standard(None, 'H-Flat Minor', 'x')
''
>>> key2standard(None, '1-Flat Minor', 'x')
''
>>> key2standard(None, 'A-Flat', 'x')
''
>>> key2standard(None, 'A♭', 'x')
''
>>> key2standard(None, '0a', 'x')
''
>>> key2standard(None, '13a', 'x')
''
>>> key2standard(None, '0m', 'x')
''
>>> key2standard(None, '13m', 'x')
''
>>> key2standard(None, '1x', 'x')
''
>>> key2standard(None, 'A Flat Minor')
'A-Flat Minor'
>>> key2standard(None, 'F Sharp Major')
'F-Sharp Major'
>>> key2standard(None, 'G♭ Major')
'F-Sharp Major'
>>> key2standard(None, 'D# Minor')
'E-Flat Minor'
"""
if use_symbol:
return _matcher(text, 'standard_s')
return _matcher(text, 'standard_t')
def key2traktor(parser, text):
"""Any key to traktor key format converter.
Args:
parser (object): Picard parser object
text (str): Key to convert
Returns:
str: Converted key value
Tests:
>>> key2traktor(None, '1A')
'Abm'
>>> key2traktor(None, '6m')
'Abm'
>>> key2traktor(None, 'A♭ Minor')
'Abm'
>>> key2traktor(None, 'A-Flat Minor')
'Abm'
>>> key2traktor(None, 'c#')
'Db'
>>> key2traktor(None, 'gBM')
'Gbm'
>>> key2traktor(None, 'gbM')
'Gbm'
>>> key2traktor(None, 'g♭M')
''
>>> key2traktor(None, '')
''
"""
return _matcher(text, 'traktor')
register_script_function(
key2camelot,
name='key2camelot',
documentation="""`$key2camelot(key)`
Returns the key string `key` in camelot key format.
The `key` argument can be entered in any of the supported formats, such as
'2B' (camelot), '6d' (open key), 'A♭ Minor' (standard with symbols),
'A-Flat Minor' (standard with text) or 'C#' (traktor). If the `key` argument
is not recognized as one of the standard keys in the supported formats, then
an empty string will be returned.""")
register_script_function(
key2openkey,
name='key2openkey',
documentation="""`$key2openkey(key)`
Returns the key string `key` in open key format.
The `key` argument can be entered in any of the supported formats, such as
'2B' (camelot), '6d' (open key), 'A♭ Minor' (standard with symbols),
'A-Flat Minor' (standard with text) or 'C#' (traktor). If the `key` argument
is not recognized as one of the standard keys in the supported formats, then
an empty string will be returned.""")
register_script_function(
key2standard,
name='key2standard',
documentation="""`$key2standard(key[,symbols])`
Returns the key string `key` in standard key format. If the optional argument
`symbols` is set, then the '♭' and '#' symbols will be used, rather than
spelling out '-Flat' and '-Sharp'.
The `key` argument can be entered in any of the supported formats, such as
'2B' (camelot), '6d' (open key), 'A♭ Minor' (standard with symbols),
'A-Flat Minor' (standard with text) or 'C#' (traktor). If the `key` argument
is not recognized as one of the standard keys in the supported formats, then
an empty string will be returned.""")
register_script_function(
key2traktor,
name='key2traktor',
documentation="""`$key2traktor(key)`
Returns the key string `key` in traktor key format.
The `key` argument can be entered in any of the supported formats, such as
'2B' (camelot), '6d' (open key), 'A♭ Minor' (standard with symbols),
'A-Flat Minor' (standard with text) or 'C#' (traktor). If the `key` argument
is not recognized as one of the standard keys in the supported formats, then
an empty string will be returned.""")
if __name__ == "__main__":
import doctest
doctest.testmod()
================================================
FILE: plugins/lastfm/__init__.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = 'Last.fm'
PLUGIN_AUTHOR = 'Lukáš Lalinský, Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Use tags from Last.fm as genre.'
PLUGIN_VERSION = "0.10.1"
PLUGIN_API_VERSIONS = ["2.0"]
import re
from functools import partial
from PyQt5 import QtCore
from picard import config, log
from picard.config import BoolOption, IntOption, TextOption
from picard.metadata import register_track_metadata_processor
from picard.plugins.lastfm.ui_options_lastfm import Ui_LastfmOptionsPage
from picard.ui.options import register_options_page, OptionsPage
from picard.util import build_qurl
from picard.webservice import ratecontrol
LASTFM_HOST = 'ws.audioscrobbler.com'
LASTFM_PORT = 80
LASTFM_PATH = '/2.0/'
LASTFM_API_KEY = '0a210a4a6741f2ec8f27a791b9d5d971'
# From https://www.last.fm/api/tos, 2018-09-04
# 4.4 […] You will not make more than 5 requests per originating IP address per
# second, averaged over a 5 minute period, without prior written consent. […]
ratecontrol.set_minimum_delay((LASTFM_HOST, LASTFM_PORT), 200)
# Cache for Tags to avoid re-requesting tags within same Picard session
_cache = {}
# Keeps track of requests for tags made to webservice API but not yet returned
# (to avoid re-requesting the same URIs)
_pending_requests = {}
# TODO: move this to an options page
TRANSLATE_TAGS = {
"hip hop": "Hip-Hop",
"synth-pop": "Synthpop",
"electronica": "Electronic",
}
TITLE_CASE = True
def parse_ignored_tags(ignore_tags_setting):
ignore_tags = []
for tag in ignore_tags_setting.lower().split(','):
tag = tag.strip()
if tag.startswith('/') and tag.endswith('/'):
try:
tag = re.compile(tag[1:-1])
except re.error:
log.error(
'Error parsing ignored tag "%s"', tag, exc_info=True)
ignore_tags.append(tag)
return ignore_tags
def matches_ignored(ignore_tags, tag):
tag = tag.lower().strip()
for pattern in ignore_tags:
if hasattr(pattern, 'match'):
match = pattern.match(tag)
else:
match = pattern == tag
if match:
return True
return False
def _tags_finalize(album, metadata, tags, next_):
if next_:
next_(tags)
else:
tags = list(set(tags))
if tags:
join_tags = config.setting["lastfm_join_tags"]
if join_tags:
tags = join_tags.join(tags)
metadata["genre"] = tags
def _tags_downloaded(album, metadata, min_usage, ignore, next_, current, data,
reply, error):
if error:
album._requests -= 1
album._finalize_loading(None)
return
try:
try:
intags = data.lfm[0].toptags[0].tag
except AttributeError:
intags = []
tags = []
for tag in intags:
name = tag.name[0].text.strip()
try:
count = int(tag.count[0].text.strip())
except ValueError:
count = 0
if count < min_usage:
break
try:
name = TRANSLATE_TAGS[name]
except KeyError:
pass
if not matches_ignored(ignore, name):
tags.append(name.title())
url = reply.url().toString()
_cache[url] = tags
_tags_finalize(album, metadata, current + tags, next_)
# Process any pending requests for the same URL
if url in _pending_requests:
pending = _pending_requests[url]
del _pending_requests[url]
for delayed_call in pending:
delayed_call()
except Exception:
log.error('Problem processing download tags', exc_info=True)
finally:
album._requests -= 1
album._finalize_loading(None)
def get_tags(album, metadata, queryargs, min_usage, ignore, next_, current):
"""Get tags from an URL."""
url = build_qurl(
LASTFM_HOST, LASTFM_PORT, LASTFM_PATH, queryargs).toString()
if url in _cache:
_tags_finalize(album, metadata, current + _cache[url], next_)
else:
# If we have already sent a request for this URL, delay this call
if url in _pending_requests:
_pending_requests[url].append(
partial(get_tags, album, metadata, queryargs, min_usage,
ignore, next_, current))
else:
_pending_requests[url] = []
album._requests += 1
album.tagger.webservice.get(
LASTFM_HOST, LASTFM_PORT, LASTFM_PATH,
partial(_tags_downloaded, album, metadata, min_usage, ignore,
next_, current),
queryargs=queryargs, parse_response_type='xml',
priority=True, important=True)
def encode_str(s):
s = QtCore.QUrl.toPercentEncoding(s)
return bytes(s).decode()
def get_queryargs(queryargs):
queryargs = {k: encode_str(v) for (k, v) in queryargs.items()}
queryargs['api_key'] = LASTFM_API_KEY
return queryargs
def get_track_tags(album, metadata, artist, track, min_usage,
ignore, next_, current):
"""Get track top tags."""
queryargs = get_queryargs({
'method': 'Track.getTopTags',
'artist': artist,
'track': track,
})
get_tags(album, metadata, queryargs, min_usage, ignore, next_, current)
def get_artist_tags(album, metadata, artist, min_usage,
ignore, next_, current):
"""Get artist top tags."""
queryargs = get_queryargs({
'method': 'Artist.getTopTags',
'artist': artist,
})
get_tags(album, metadata, queryargs, min_usage, ignore, next_, current)
def process_track(album, metadata, track, release):
use_track_tags = config.setting["lastfm_use_track_tags"]
use_artist_tags = config.setting["lastfm_use_artist_tags"]
min_tag_usage = config.setting["lastfm_min_tag_usage"]
ignore_tags = parse_ignored_tags(config.setting["lastfm_ignore_tags"])
if use_track_tags or use_artist_tags:
artist = metadata["artist"]
title = metadata["title"]
if artist:
if use_artist_tags:
get_artist_tags_func = partial(get_artist_tags, album,
metadata, artist, min_tag_usage,
ignore_tags, None)
else:
get_artist_tags_func = None
if title and use_track_tags:
get_track_tags(album, metadata, artist, title, min_tag_usage,
ignore_tags, get_artist_tags_func, [])
elif get_artist_tags_func:
get_artist_tags_func([])
class LastfmOptionsPage(OptionsPage):
NAME = "lastfm"
TITLE = "Last.fm"
PARENT = "plugins"
options = [
BoolOption("setting", "lastfm_use_track_tags", False),
BoolOption("setting", "lastfm_use_artist_tags", False),
IntOption("setting", "lastfm_min_tag_usage", 90),
TextOption("setting", "lastfm_ignore_tags",
"seen live, favorites, /\\d+ of \\d+ stars/"),
TextOption("setting", "lastfm_join_tags", ""),
]
def __init__(self, parent=None):
super(LastfmOptionsPage, self).__init__(parent)
self.ui = Ui_LastfmOptionsPage()
self.ui.setupUi(self)
def load(self):
setting = config.setting
self.ui.use_track_tags.setChecked(setting["lastfm_use_track_tags"])
self.ui.use_artist_tags.setChecked(setting["lastfm_use_artist_tags"])
self.ui.min_tag_usage.setValue(setting["lastfm_min_tag_usage"])
self.ui.ignore_tags.setText(setting["lastfm_ignore_tags"])
self.ui.join_tags.setEditText(setting["lastfm_join_tags"])
def save(self):
global _cache
setting = config.setting
if setting["lastfm_min_tag_usage"] != self.ui.min_tag_usage.value() \
or setting["lastfm_ignore_tags"] != str(self.ui.ignore_tags.text()):
_cache = {}
setting["lastfm_use_track_tags"] = self.ui.use_track_tags.isChecked()
setting["lastfm_use_artist_tags"] = self.ui.use_artist_tags.isChecked()
setting["lastfm_min_tag_usage"] = self.ui.min_tag_usage.value()
setting["lastfm_ignore_tags"] = str(self.ui.ignore_tags.text())
setting["lastfm_join_tags"] = str(self.ui.join_tags.currentText())
register_track_metadata_processor(process_track)
register_options_page(LastfmOptionsPage)
================================================
FILE: plugins/lastfm/ui_options_lastfm.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/lastfm/ui_options_lastfm.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_LastfmOptionsPage(object):
def setupUi(self, LastfmOptionsPage):
LastfmOptionsPage.setObjectName("LastfmOptionsPage")
LastfmOptionsPage.resize(305, 317)
self.vboxlayout = QtWidgets.QVBoxLayout(LastfmOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.rename_files = QtWidgets.QGroupBox(LastfmOptionsPage)
self.rename_files.setObjectName("rename_files")
self.vboxlayout1 = QtWidgets.QVBoxLayout(self.rename_files)
self.vboxlayout1.setContentsMargins(9, 9, 9, 9)
self.vboxlayout1.setSpacing(2)
self.vboxlayout1.setObjectName("vboxlayout1")
self.use_track_tags = QtWidgets.QCheckBox(self.rename_files)
self.use_track_tags.setObjectName("use_track_tags")
self.vboxlayout1.addWidget(self.use_track_tags)
self.use_artist_tags = QtWidgets.QCheckBox(self.rename_files)
self.use_artist_tags.setObjectName("use_artist_tags")
self.vboxlayout1.addWidget(self.use_artist_tags)
self.vboxlayout.addWidget(self.rename_files)
self.rename_files_2 = QtWidgets.QGroupBox(LastfmOptionsPage)
self.rename_files_2.setObjectName("rename_files_2")
self.vboxlayout2 = QtWidgets.QVBoxLayout(self.rename_files_2)
self.vboxlayout2.setContentsMargins(9, 9, 9, 9)
self.vboxlayout2.setSpacing(2)
self.vboxlayout2.setObjectName("vboxlayout2")
self.ignore_tags_2 = QtWidgets.QLabel(self.rename_files_2)
self.ignore_tags_2.setObjectName("ignore_tags_2")
self.vboxlayout2.addWidget(self.ignore_tags_2)
self.ignore_tags = QtWidgets.QLineEdit(self.rename_files_2)
self.ignore_tags.setObjectName("ignore_tags")
self.vboxlayout2.addWidget(self.ignore_tags)
self.hboxlayout = QtWidgets.QHBoxLayout()
self.hboxlayout.setContentsMargins(0, 0, 0, 0)
self.hboxlayout.setSpacing(6)
self.hboxlayout.setObjectName("hboxlayout")
self.ignore_tags_4 = QtWidgets.QLabel(self.rename_files_2)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(4)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.ignore_tags_4.sizePolicy().hasHeightForWidth())
self.ignore_tags_4.setSizePolicy(sizePolicy)
self.ignore_tags_4.setObjectName("ignore_tags_4")
self.hboxlayout.addWidget(self.ignore_tags_4)
self.join_tags = QtWidgets.QComboBox(self.rename_files_2)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(1)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.join_tags.sizePolicy().hasHeightForWidth())
self.join_tags.setSizePolicy(sizePolicy)
self.join_tags.setEditable(True)
self.join_tags.setObjectName("join_tags")
self.join_tags.addItem("")
self.join_tags.setItemText(0, "")
self.join_tags.addItem("")
self.join_tags.addItem("")
self.hboxlayout.addWidget(self.join_tags)
self.vboxlayout2.addLayout(self.hboxlayout)
self.hboxlayout1 = QtWidgets.QHBoxLayout()
self.hboxlayout1.setContentsMargins(0, 0, 0, 0)
self.hboxlayout1.setSpacing(6)
self.hboxlayout1.setObjectName("hboxlayout1")
self.label_4 = QtWidgets.QLabel(self.rename_files_2)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())
self.label_4.setSizePolicy(sizePolicy)
self.label_4.setObjectName("label_4")
self.hboxlayout1.addWidget(self.label_4)
self.min_tag_usage = QtWidgets.QSpinBox(self.rename_files_2)
self.min_tag_usage.setMaximum(100)
self.min_tag_usage.setObjectName("min_tag_usage")
self.hboxlayout1.addWidget(self.min_tag_usage)
self.vboxlayout2.addLayout(self.hboxlayout1)
self.vboxlayout.addWidget(self.rename_files_2)
spacerItem = QtWidgets.QSpacerItem(263, 21, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.label_4.setBuddy(self.min_tag_usage)
self.retranslateUi(LastfmOptionsPage)
QtCore.QMetaObject.connectSlotsByName(LastfmOptionsPage)
LastfmOptionsPage.setTabOrder(self.use_track_tags, self.ignore_tags)
def retranslateUi(self, LastfmOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.rename_files.setTitle(_translate("LastfmOptionsPage", "Last.fm"))
self.use_track_tags.setText(_translate("LastfmOptionsPage", "Use track tags"))
self.use_artist_tags.setText(_translate("LastfmOptionsPage", "Use artist tags"))
self.rename_files_2.setTitle(_translate("LastfmOptionsPage", "Tags"))
self.ignore_tags_2.setText(_translate("LastfmOptionsPage", "Ignore tags:"))
self.ignore_tags_4.setText(_translate("LastfmOptionsPage", "Join multiple tags with:"))
self.join_tags.setItemText(1, _translate("LastfmOptionsPage", " / "))
self.join_tags.setItemText(2, _translate("LastfmOptionsPage", ", "))
self.label_4.setText(_translate("LastfmOptionsPage", "Minimal tag usage:"))
self.min_tag_usage.setSuffix(_translate("LastfmOptionsPage", " %"))
================================================
FILE: plugins/lastfm/ui_options_lastfm.ui
================================================
LastfmOptionsPage
0
0
305
317
6
9
9
9
9
-
Last.fm
2
9
9
9
9
-
Use track tags
-
Use artist tags
-
Tags
2
9
9
9
9
-
Ignore tags:
-
-
6
0
0
0
0
-
4
0
Join multiple tags with:
-
1
0
true
-
-
/
-
,
-
6
0
0
0
0
-
0
0
Minimal tag usage:
min_tag_usage
-
%
100
-
Qt::Vertical
263
21
use_track_tags
ignore_tags
================================================
FILE: plugins/loadasnat/loadasnat.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2017, 2019, 2021 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = "Load as non-album track"
PLUGIN_AUTHOR = "Philipp Wolfer"
PLUGIN_DESCRIPTION = ("Allows loading selected tracks as non-album tracks. "
"Useful for tagging single tracks where you do not care "
"about the album.")
PLUGIN_VERSION = "0.4"
PLUGIN_API_VERSIONS = ["1.4.0", "2.0", "2.1", "2.2"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard import log
from picard.track import Track
from picard.ui.itemviews import (
BaseAction,
register_track_action,
)
class LoadAsNat(BaseAction):
NAME = "Load as non-album track..."
def callback(self, objs):
for track in (t for t in objs if isinstance(t, Track)):
nat = self.tagger.load_nat(
track.metadata['musicbrainz_recordingid'])
for file in list(track.linked_files):
file.move(nat)
metadata = file.metadata
metadata.delete('albumartist')
metadata.delete('albumartistsort')
metadata.delete('albumsort')
metadata.delete('asin')
metadata.delete('barcode')
metadata.delete('catalognumber')
metadata.delete('discnumber')
metadata.delete('discsubtitle')
metadata.delete('media')
metadata.delete('musicbrainz_albumartistid')
metadata.delete('musicbrainz_albumid')
metadata.delete('musicbrainz_discid')
metadata.delete('musicbrainz_releasegroupid')
metadata.delete('releasecountry')
metadata.delete('releasestatus')
metadata.delete('releasetype')
metadata.delete('totaldiscs')
metadata.delete('totaltracks')
metadata.delete('tracknumber')
log.debug("[LoadAsNat] deleted tags: %r", metadata.deleted_tags)
register_track_action(LoadAsNat())
================================================
FILE: plugins/losslessfuncs/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2014, 2017, 2021, 2023-2024 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
PLUGIN_NAME = 'Tagger script functions $is_lossless() and $is_lossy()'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Tagger script functions to detect if a file is lossless or lossy'
PLUGIN_VERSION = "0.3"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3", "2.4", "2.5", "2.6", "2.7", "2.8", "2.9", "2.10", "2.11"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
LOSSLESS_EXTENSIONS = {'flac', 'oggflac', 'ape', 'ofr', 'tak', 'wv', 'tta',
'aiff', 'aif', 'wav'}
from picard.script import register_script_function
def is_lossless(parser):
"""
Returns true, if the file processed is a lossless audio format.
Note: This depends mainly on the file extension and does not look inside the
file to detect the codec.
"""
if parser.context['~extension'] in LOSSLESS_EXTENSIONS:
return "1"
elif parser.context['~extension'] == 'm4a':
# Mutagen < 1.26 fails to detect the bitrate for Apple Lossless Audio Codec.
if not parser.context['~bitrate']:
return "1"
else:
try:
bitrate = float(parser.context['~bitrate'])
return "1" if bitrate > 1000 else ""
except (TypeError, ValueError):
return ""
else:
return ""
def is_lossy(parser):
"""Returns true, if the file processed is a lossy audio format."""
return "" if is_lossless(parser) == "1" else "1"
register_script_function(is_lossless)
register_script_function(is_lossy)
================================================
FILE: plugins/lrclib_lyrics/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2024 Giorgio Fontanive (twodoorcoupe)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Lrclib Lyrics"
PLUGIN_AUTHOR = "Giorgio Fontanive"
PLUGIN_DESCRIPTION = """
Fetches lyrics from lrclib.net
Also allows to export lyrics to an .lrc file or import them from one.
"""
PLUGIN_VERSION = "0.3"
PLUGIN_API_VERSIONS = ["2.12"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import os
import re
from functools import partial
from picard import config, log
from picard.file import register_file_post_save_processor, register_file_post_addition_to_track_processor
from picard.track import Track
from picard.ui.itemviews import BaseAction, register_track_action
from picard.ui.options import OptionsPage, register_options_page
from picard.webservice import ratecontrol
from .option_lrclib_lyrics import Ui_OptionLrclibLyrics
URL = "https://lrclib.net/api/get"
REQUESTS_DELAY = 100
# Options
ADD_UNSYNCED_LYRICS = "add_unsynced_lyrics"
ADD_SYNCED_LYRICS = "add_synced_lyrics"
NEVER_REPLACE_LYRICS = "never_replace_lyrics"
LRC_FILENAME = "exported_lrc_filename"
LRC_AS_SIDECAR = "lrc_as_sidecar"
EXPORT_LRC = "exported_lrc"
NEVER_REPLACE_LRC = "never_replace_lrc"
lyrics_cache = {}
synced_lyrics_pattern = re.compile(r"(\[\d\d:\d\d\.\d\d\d]|<\d\d:\d\d\.\d\d\d>)")
tags_pattern = re.compile(r"%(\w+)%")
extra_file_variables = {
"filepath": lambda file: file,
"folderpath": lambda file: os.path.dirname(file), # pylint: disable=unnecessary-lambda
"filename": lambda file: os.path.splitext(os.path.basename(file))[0],
"filename_ext": lambda file: os.path.basename(file), # pylint: disable=unnecessary-lambda
"directory": lambda file: os.path.basename(os.path.dirname(file))
}
def get_lyrics(track, file):
album = track.album
metadata = file.metadata
if not (config.setting[ADD_UNSYNCED_LYRICS] or config.setting[ADD_SYNCED_LYRICS]):
return
if not (metadata.get("title") and metadata.get("artist")):
log.debug(f"Skipping fetching lyrics for track in {album} as both title and artist are required")
return
if config.setting[NEVER_REPLACE_LYRICS] and metadata.get("lyrics"):
log.debug(f"Skipping fetching lyrics for {metadata['title']} as lyrics are already embedded")
return
args = {
"track_name": metadata["title"],
"artist_name": metadata["artist"],
}
if metadata.get("album"):
args["album_name"] = metadata["album"]
handler = partial(response_handler, metadata)
album.tagger.webservice.get_url(
method="GET",
handler=handler,
parse_response_type='json',
url=URL,
unencoded_queryargs=args
)
def response_handler(metadata, document, reply, error):
if document and not error:
unsynced_lyrics = document.get("plainLyrics")
synced_lyrics = document.get("syncedLyrics")
if unsynced_lyrics:
lyrics_cache[metadata["title"]] = unsynced_lyrics
if ((not config.setting[ADD_UNSYNCED_LYRICS]) or
(config.setting[NEVER_REPLACE_LYRICS] and metadata.get("lyrics"))):
return
metadata["lyrics"] = unsynced_lyrics
if synced_lyrics:
lyrics_cache[metadata["title"]] = synced_lyrics
# Support for the syncedlyrics tag is not available yet
# if (not config.setting[ADD_SYNCED_LYRICS] or
# (config.setting[NEVER_REPLACE_LYRICS] and metadata.get("syncedlyrics"))):
# return
# metadata["syncedlyrics"] = syncedlyrics
else:
log.debug(f"Could not fetch lyrics for {metadata['title']}")
def get_lrc_file_name(file):
filename = f"{tags_pattern.sub('{}', config.setting[LRC_FILENAME])}"
# If sidecar option is selected, override any pattern
if config.setting[LRC_AS_SIDECAR]:
filename = f"{os.path.splitext(file.filename)[0]}.lrc"
log.debug(f"LRC sidecar filename for {file.metadata['title']}: {filename}")
return filename
# Otherwise, parse the pattern
tags = tags_pattern.findall(config.setting[LRC_FILENAME])
values = []
for tag in tags:
if tag in extra_file_variables:
values.append(extra_file_variables[tag](file.filename))
else:
values.append(file.metadata.get(tag, f"%{tag}%"))
return filename.format(*values)
def export_lrc_file(file):
if config.setting[EXPORT_LRC]:
metadata = file.metadata
# If no lyrics were downloaded, try to export the lyrics already embedded
lyrics = lyrics_cache.pop(metadata["title"], metadata.get("lyrics"))
if lyrics:
filename = get_lrc_file_name(file)
if config.setting[NEVER_REPLACE_LRC] and os.path.exists(filename):
return
try:
with open(filename, 'w') as file:
file.write(lyrics)
log.debug(f"Created new lyrics file at {filename}")
except OSError:
log.debug(f"Could not create the lrc file for {metadata['title']}")
else:
log.debug(f"Could not export any lyrics for {metadata['title']}")
class ImportLrc(BaseAction):
NAME = 'Import lyrics from lrc files'
def callback(self, objs):
for track in objs:
if isinstance(track, Track):
file = track.files[0]
filename = get_lrc_file_name(file)
try:
with open(filename, 'r') as lyrics_file:
lyrics = lyrics_file.read()
if synced_lyrics_pattern.search(lyrics):
# Support for syncedlyrics is not available yet
# file.metadata["syncedlyrics"] = lyrics
pass
else:
file.metadata["lyrics"] = lyrics
except FileNotFoundError:
log.debug(f"Could not find matching lrc file for {file.metadata['title']}")
class LrclibLyricsOptions(OptionsPage):
NAME = "lrclib_lyrics"
TITLE = "Lrclib Lyrics"
PARENT = "plugins"
# By default, use a path for the LRC file in the same folder as
# the music file so as not to store the LRC files "somewhere"
__default_naming = f"%folderpath%{os.sep}%filename%.lrc"
options = [
config.BoolOption("setting", ADD_UNSYNCED_LYRICS, True),
config.BoolOption("setting", ADD_SYNCED_LYRICS, False),
config.BoolOption("setting", NEVER_REPLACE_LYRICS, False),
config.BoolOption("setting", LRC_AS_SIDECAR, True),
config.TextOption("setting", LRC_FILENAME, __default_naming),
config.BoolOption("setting", EXPORT_LRC, False),
config.BoolOption("setting", NEVER_REPLACE_LRC, False),
]
def __init__(self, parent=None):
super(LrclibLyricsOptions, self).__init__(parent)
self.ui = Ui_OptionLrclibLyrics()
self.ui.setupUi(self)
def load(self):
self.ui.lyrics.setChecked(config.setting[ADD_UNSYNCED_LYRICS])
self.ui.syncedlyrics.setChecked(config.setting[ADD_SYNCED_LYRICS])
self.ui.replace_embedded.setChecked(config.setting[NEVER_REPLACE_LYRICS])
self.ui.lrc_name.setText(config.setting[LRC_FILENAME])
self.ui.lrc_as_sidecar.setChecked(config.setting[LRC_AS_SIDECAR])
self.ui.export_lyrics.setChecked(config.setting[EXPORT_LRC])
self.ui.replace_exported.setChecked(config.setting[NEVER_REPLACE_LRC])
# Initialize the LRC filename field state
self.update_lrc_name_field_state()
# Connect the sidecar checkbox to update the filename field state
self.ui.lrc_as_sidecar.toggled.connect(self.update_lrc_name_field_state())
def save(self):
config.setting[ADD_UNSYNCED_LYRICS] = self.ui.lyrics.isChecked()
config.setting[ADD_SYNCED_LYRICS] = self.ui.syncedlyrics.isChecked()
config.setting[NEVER_REPLACE_LYRICS] = self.ui.replace_embedded.isChecked()
config.setting[LRC_FILENAME] = self.ui.lrc_name.text()
config.setting[LRC_AS_SIDECAR] = self.ui.lrc_as_sidecar.isChecked()
config.setting[EXPORT_LRC] = self.ui.export_lyrics.isChecked()
config.setting[NEVER_REPLACE_LRC] = self.ui.replace_exported.isChecked()
def update_lrc_name_field_state(self):
"""Enable or disable the LRC filename field based on the sidecar option."""
self.ui.lrc_name.setEnabled(not self.ui.lrc_as_sidecar.isChecked())
ratecontrol.set_minimum_delay_for_url(URL, REQUESTS_DELAY)
register_file_post_addition_to_track_processor(get_lyrics)
register_file_post_save_processor(export_lrc_file)
register_track_action(ImportLrc())
register_options_page(LrclibLyricsOptions)
================================================
FILE: plugins/lrclib_lyrics/option_lrclib_lyrics.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'option_lrclib_lyrics.ui'
#
# Created by: PyQt5 UI code generator 5.15.10
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtWidgets
class Ui_OptionLrclibLyrics(object):
def setupUi(self, OptionLrclibLyrics):
OptionLrclibLyrics.setObjectName("OptionLrclibLyrics")
OptionLrclibLyrics.resize(432, 368)
self.verticalLayout = QtWidgets.QVBoxLayout(OptionLrclibLyrics)
self.verticalLayout.setObjectName("verticalLayout")
self.groupBox = QtWidgets.QGroupBox(OptionLrclibLyrics)
self.groupBox.setObjectName("groupBox")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.groupBox)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.lyrics = QtWidgets.QCheckBox(self.groupBox)
self.lyrics.setObjectName("lyrics")
self.verticalLayout_2.addWidget(self.lyrics)
self.syncedlyrics = QtWidgets.QCheckBox(self.groupBox)
self.syncedlyrics.setEnabled(False)
self.syncedlyrics.setCheckable(False)
self.syncedlyrics.setObjectName("syncedlyrics")
self.verticalLayout_2.addWidget(self.syncedlyrics)
self.replace_embedded = QtWidgets.QCheckBox(self.groupBox)
self.replace_embedded.setObjectName("replace_embedded")
self.verticalLayout_2.addWidget(self.replace_embedded)
self.verticalLayout.addWidget(self.groupBox)
self.groupBox_2 = QtWidgets.QGroupBox(OptionLrclibLyrics)
self.groupBox_2.setObjectName("groupBox_2")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.groupBox_2)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.export_lyrics = QtWidgets.QCheckBox(self.groupBox_2)
self.export_lyrics.setObjectName("export_lyrics")
self.verticalLayout_3.addWidget(self.export_lyrics)
self.lrc_as_sidecar = QtWidgets.QCheckBox(self.groupBox_2)
self.lrc_as_sidecar.setObjectName("lrc_as_sidecar")
self.verticalLayout_3.addWidget(self.lrc_as_sidecar)
self.label = QtWidgets.QLabel(self.groupBox_2)
self.label.setObjectName("label")
self.verticalLayout_3.addWidget(self.label)
self.lrc_name = QtWidgets.QLineEdit(self.groupBox_2)
self.lrc_name.setObjectName("lrc_name")
self.verticalLayout_3.addWidget(self.lrc_name)
self.replace_exported = QtWidgets.QCheckBox(self.groupBox_2)
self.replace_exported.setObjectName("replace_exported")
self.verticalLayout_3.addWidget(self.replace_exported)
self.verticalLayout.addWidget(self.groupBox_2)
spacerItem = QtWidgets.QSpacerItem(20, 23, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout.addItem(spacerItem)
self.retranslateUi(OptionLrclibLyrics)
QtCore.QMetaObject.connectSlotsByName(OptionLrclibLyrics)
def retranslateUi(self, OptionLrclibLyrics):
_translate = QtCore.QCoreApplication.translate
OptionLrclibLyrics.setWindowTitle(_translate("OptionLrclibLyrics", "Form"))
self.groupBox.setTitle(_translate("OptionLrclibLyrics", "Embedded Lyrics Options"))
self.lyrics.setText(_translate("OptionLrclibLyrics", "Download and embed unsynced lyrics"))
self.syncedlyrics.setText(_translate("OptionLrclibLyrics", "Download and embed synced lyrics"))
self.replace_embedded.setText(_translate("OptionLrclibLyrics", "Never replace any embedded lyrics if already present"))
self.groupBox_2.setTitle(_translate("OptionLrclibLyrics", "Lrc Files Options"))
self.export_lyrics.setText(_translate("OptionLrclibLyrics", "Export lyrics to lrc file when saving (priority to synced lyrics)"))
self.lrc_as_sidecar.setText(_translate("OptionLrclibLyrics", "Save the LRC file as a sidecar file to the audio file or"))
self.label.setText(_translate("OptionLrclibLyrics", "use the following name pattern for lrc files:"))
self.replace_exported.setText(_translate("OptionLrclibLyrics", "Never replace lrc files if already present"))
================================================
FILE: plugins/lrclib_lyrics/option_lrclib_lyrics.ui
================================================
OptionLrclibLyrics
0
0
432
368
Form
-
Embedded Lyrics Options
-
Download and embed unsynced lyrics
-
false
Download and embed synced lyrics
false
-
Never replace any embedded lyrics if already present
-
Lrc Files Options
-
Export lyrics to lrc file when saving (priority to synced lyrics)
-
Save the LRC file as a sidecar file to the audio file or
-
use the following name pattern for lrc files:
-
-
Never replace lrc files if already present
-
Qt::Vertical
20
23
================================================
FILE: plugins/matroska_tagger/matroska_tagger.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "Matroska Tagger"
PLUGIN_AUTHOR = "Ben McLean"
PLUGIN_VERSION = "0.1"
PLUGIN_API_VERSIONS = [
"2.0",
"2.1",
"2.2",
"2.3",
"2.4",
"2.5",
"2.6",
"2.7",
"2.8",
"2.9",
"2.10",
"2.11",
"2.12",
"2.13",
]
PLUGIN_DESCRIPTION = (
"Adds support for reading and writing tags in Matroska (.mkv, .mka) files via MKVToolNix "
"(https://mkvtoolnix.download)."
)
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import json
import os
import subprocess
import sys
import tempfile
from picard import config, log
from picard.config import BoolOption, TextOption
from picard.file import File
from picard.formats import register_format
from picard.metadata import Metadata
from picard.ui.options import register_options_page, OptionsPage
from PyQt5.QtWidgets import (
QCheckBox,
QFileDialog,
QFormLayout,
QHBoxLayout,
QLabel,
QLineEdit,
QPushButton,
QVBoxLayout,
)
from PyQt5.QtCore import (
QBuffer,
QFile,
QIODevice,
QXmlStreamReader,
QXmlStreamWriter,
Qt,
)
_AlignTop = Qt.AlignTop
# ---------------------------------------------------------------------------
# Tag mappings
# ---------------------------------------------------------------------------
# Picard internal name → Matroska tag name, for track-level tags (TargetTypeValue=30)
_TRACK_TAGS = {
"title": "TITLE",
"artist": "ARTIST",
"comment": "COMMENT",
"lyrics": "LYRICS",
"isrc": "ISRC",
"bpm": "BPM",
"key": "INITIAL_KEY",
"language": "LANGUAGE", # undocumented in spec but used by MP3Tag
"subtitle": "SUBTITLE",
"remixer": "REMIXED_BY",
"conductor": "CONDUCTOR",
"lyricist": "LYRICIST",
"composer": "COMPOSER",
"engineer": "SOUND_ENGINEER",
"mixer": "MIXED_BY",
"djmixer": "DJMIXED_BY",
"producer": "PRODUCER",
"mood": "MOOD",
"artists": "ARTISTS",
"grouping": "GROUPING",
# titlesort/artistsort/composersort emitted as SORT_WITH nested inside TITLE/ARTIST/COMPOSER
"website": "WEBSITE",
"license": "LICENSE",
"copyright": "COPYRIGHT",
# originalartist emitted as ORIGINAL/ARTIST nested structure
"musicbrainz_recordingid": "MUSICBRAINZ_RECORDINGID",
"musicbrainz_trackid": "MUSICBRAINZ_RELEASETRACKID",
"musicbrainz_workid": "MUSICBRAINZ_WORKID",
"musicbrainz_artistid": "MUSICBRAINZ_ARTISTID",
"musicbrainz_composerid": "MUSICBRAINZ_COMPOSERID",
"musicbrainz_originalartistid": "MUSICBRAINZ_ORIGINALARTISTID",
"acoustid_id": "ACOUSTID_ID",
"acoustid_fingerprint": "ACOUSTID_FINGERPRINT",
"replaygain_track_gain": "REPLAYGAIN_GAIN",
"replaygain_track_peak": "REPLAYGAIN_PEAK",
"replaygain_track_range": "REPLAYGAIN_TRACK_RANGE",
"genre": "GENRE",
}
# Picard internal name → Matroska tag name, for album-level tags (TargetTypeValue=50)
_ALBUM_TAGS = {
"album": "TITLE",
"albumartist": "ARTIST",
"date": "DATE_RELEASED",
"label": "LABEL",
"catalognumber": "CATALOG_NUMBER",
"barcode": "BARCODE",
"script": "SCRIPT",
"media": "ORIGINAL_MEDIA_TYPE",
"releasestatus": "RELEASE_STATUS",
"releasecountry": "RELEASE_COUNTRY",
"releasetype": "RELEASE_TYPE",
"asin": "ASIN",
"compilation": "COMPILATION",
# albumsort/albumartistsort emitted as SORT_WITH nested inside TITLE/ARTIST
"musicbrainz_albumid": "MUSICBRAINZ_ALBUMID",
"musicbrainz_releasegroupid": "MUSICBRAINZ_RELEASEGROUPID",
"musicbrainz_albumartistid": "MUSICBRAINZ_ALBUMARTISTID",
"musicbrainz_discid": "MUSICBRAINZ_DISCID",
"musicbrainz_originalalbumid": "MUSICBRAINZ_ORIGINALALBUMID",
"replaygain_album_gain": "REPLAYGAIN_GAIN",
"replaygain_album_peak": "REPLAYGAIN_PEAK",
"replaygain_album_range": "REPLAYGAIN_ALBUM_RANGE",
"replaygain_reference_loudness": "REPLAYGAIN_REFERENCE_LOUDNESS",
}
# Picard internal name → Matroska tag name, for disc-level tags (TargetTypeValue=60)
_DISC_TAGS = {
"discnumber": "PART_NUMBER",
"totaldiscs": "TOTAL_PARTS",
}
# Sort companions: maps the main Picard field to its sort field, per level.
# These are emitted as SORT_WITH nested inside the parent Simple element.
_TRACK_SORT = {"title": "titlesort", "artist": "artistsort", "composer": "composersort"}
_ALBUM_SORT = {"album": "albumsort", "albumartist": "albumartistsort"}
# Reverse maps for loading: Matroska tag name → Picard internal name (per level)
_R_TRACK_TAGS = {v: k for k, v in _TRACK_TAGS.items()}
_R_ALBUM_TAGS = {v: k for k, v in _ALBUM_TAGS.items()}
_R_DISC_TAGS = {v: k for k, v in _DISC_TAGS.items()}
# All Picard internal tag names that this format can store.
_SUPPORTED_TAGS = (
set(_TRACK_TAGS)
| set(_ALBUM_TAGS)
| set(_DISC_TAGS)
| set(_TRACK_SORT.values()) # titlesort, artistsort, composersort
| set(_ALBUM_SORT.values()) # albumsort, albumartistsort
| {"tracknumber", "totaltracks", "originalartist", "originaldate"}
)
# ---------------------------------------------------------------------------
# Tool path helpers
# ---------------------------------------------------------------------------
def _tool_path(name, tooldir):
"""Return the full path to a MKVToolNix executable."""
if sys.platform == "win32":
name = name + ".exe"
if tooldir:
return os.path.join(tooldir, name)
return name # rely on PATH
def _subprocess_flags():
"""Return extra kwargs for subprocess.run to suppress console windows on Windows."""
flags = {}
if sys.platform == "win32":
flags["creationflags"] = subprocess.CREATE_NO_WINDOW
return flags
def _run(args, **kwargs):
"""Run a subprocess, returning CompletedProcess. Raises on non-zero exit."""
log.debug("MkvPlugin: running %r", args)
already_captured = "capture_output" in kwargs or "stdout" in kwargs
if not already_captured:
kwargs["capture_output"] = True
result = subprocess.run(args, check=True, **_subprocess_flags(), **kwargs)
if not already_captured:
if result.stdout:
for line in result.stdout.decode("utf-8", errors="replace").splitlines():
log.debug("MkvPlugin stdout: %s", line)
if result.stderr:
for line in result.stderr.decode("utf-8", errors="replace").splitlines():
log.debug("MkvPlugin stderr: %s", line)
return result
def _get_tooldir():
return config.setting["mkvtoolnix_dir"].strip()
# ---------------------------------------------------------------------------
# XML generation (Picard Metadata → Matroska tags XML)
# ---------------------------------------------------------------------------
def _write_simple(w, name, value):
w.writeStartElement("Simple")
w.writeTextElement("Name", name)
w.writeTextElement("String", str(value))
w.writeEndElement()
def _write_simple_with_sort(w, name, value, sort_value=None):
"""Write a Simple element, with an optional nested SORT_WITH child."""
w.writeStartElement("Simple")
w.writeTextElement("Name", name)
w.writeTextElement("String", str(value))
if sort_value:
w.writeStartElement("Simple")
w.writeTextElement("Name", "SORT_WITH")
w.writeTextElement("String", str(sort_value))
w.writeEndElement()
w.writeEndElement()
def _write_original_artist(w, value):
"""Write originalartist as a nested ORIGINAL/ARTIST structure per spec."""
w.writeStartElement("Simple")
w.writeTextElement("Name", "ORIGINAL")
w.writeStartElement("Simple")
w.writeTextElement("Name", "ARTIST")
w.writeTextElement("String", str(value))
w.writeEndElement()
w.writeEndElement()
def _sort_field_for(mkv_name, target_type_value):
"""Return the Picard sort field for a SORT_WITH element nested under mkv_name."""
if target_type_value < 50:
return {
"TITLE": "titlesort",
"ARTIST": "artistsort",
"COMPOSER": "composersort",
}.get(mkv_name)
if target_type_value < 60:
return {"TITLE": "albumsort", "ARTIST": "albumartistsort"}.get(mkv_name)
return None
def _tags_xml(metadata):
"""Combined XML with level-50 (album), level-60 (disc), and level-30 (track) Tag blocks.
All blocks have no UID in their Targets, which is the spec-correct form for
a single-track file. mkvpropedit writes them via --tags global:, and FFmpeg
routes all no-UID tags to s->metadata regardless of TargetTypeValue.
Because the level-30 block is written last, level-30 TITLE/ARTIST overwrite
the level-50 values in fctx->metadata — giving Kodi the track title and track
artist in its title/artist fields as desired.
ALBUM, ALBUM_ARTIST, and DATE are Kodi compatibility aliases. They have no
level-30 counterparts, so they survive in fctx->metadata after level-30
processing. Kodi reads these case-insensitively and maps them to its album,
albumartist, and date fields respectively.
TargetType string is omitted from all blocks: FFmpeg uses it as a key prefix
on global tags (e.g. "ALBUM/TITLE"), which breaks Kodi's exact-match lookup.
TargetTypeValue is still written for spec-compliant readers.
"""
buf = QBuffer()
buf.open(QIODevice.WriteOnly)
w = QXmlStreamWriter(buf)
w.setAutoFormatting(True)
w.writeStartDocument()
w.writeStartElement("Tags")
# --- Level 50: album ---
w.writeStartElement("Tag")
w.writeStartElement("Targets")
w.writeTextElement("TargetTypeValue", "50")
w.writeEndElement() # Targets
for picard_name, mkv_name in _ALBUM_TAGS.items():
sort_key = _ALBUM_SORT.get(picard_name)
sort_val = metadata.get(sort_key, "") if sort_key else ""
for value in metadata.getall(picard_name):
if value:
_write_simple_with_sort(w, mkv_name, value, sort_val or None)
for value in metadata.getall("totaltracks"):
if value:
_write_simple(w, "TOTAL_PARTS", value)
# Kodi compat aliases: no level-30 equivalents so they persist in fctx->metadata
for value in metadata.getall("album"):
if value:
_write_simple(w, "ALBUM", value)
for value in metadata.getall("albumartist"):
if value:
_write_simple(w, "ALBUM_ARTIST", value)
_date_field = "originaldate" if config.setting["mkv_use_original_date"] else "date"
for value in metadata.getall(_date_field):
if value:
_write_simple(w, "DATE", value)
w.writeEndElement() # Tag (album)
# --- Level 60: disc (omitted when no disc data is present) ---
disc_num = metadata.get("discnumber", "")
total_discs = metadata.get("totaldiscs", "")
if disc_num or total_discs:
w.writeStartElement("Tag")
w.writeStartElement("Targets")
w.writeTextElement("TargetTypeValue", "60")
w.writeEndElement() # Targets
if disc_num:
_write_simple(w, "PART_NUMBER", disc_num)
if total_discs:
_write_simple(w, "TOTAL_PARTS", total_discs)
w.writeEndElement() # Tag (disc)
# --- Level 30: track ---
w.writeStartElement("Tag")
w.writeStartElement("Targets")
w.writeTextElement("TargetTypeValue", "30")
w.writeEndElement() # Targets
for picard_name, mkv_name in _TRACK_TAGS.items():
sort_key = _TRACK_SORT.get(picard_name)
sort_val = metadata.get(sort_key, "") if sort_key else ""
for value in metadata.getall(picard_name):
if value:
_write_simple_with_sort(w, mkv_name, value, sort_val or None)
for value in metadata.getall("originalartist"):
if value:
_write_original_artist(w, value)
for value in metadata.getall("tracknumber"):
if value:
_write_simple(w, "PART_NUMBER", value)
w.writeEndElement() # Tag (track)
w.writeEndElement() # Tags
w.writeEndDocument()
buf.close()
return bytes(buf.data()).decode("utf-8")
# ---------------------------------------------------------------------------
# XML parsing (Matroska tags XML → Picard Metadata)
# ---------------------------------------------------------------------------
def _parse_tags_xml(xml_path, metadata):
"""Read a Matroska tags XML file and populate a Metadata object."""
f = QFile(xml_path)
if not f.open(QIODevice.ReadOnly):
log.warning("MkvPlugin: failed to open tags XML %r", xml_path)
return
reader = QXmlStreamReader(f)
target_type_value = 50
in_tag = False
in_targets = False
in_ttv = False
ttv_text = ""
# Stack of open Simple elements; each frame: {name, value, reading_name, reading_string}
simple_stack = []
while not reader.atEnd():
token = reader.readNext()
if token == QXmlStreamReader.StartElement:
el = reader.name()
if el == "Tag":
in_tag = True
target_type_value = 50
elif el == "Targets" and in_tag:
in_targets = True
elif el == "TargetTypeValue" and in_targets:
in_ttv = True
ttv_text = ""
elif el == "Simple" and in_tag:
simple_stack.append(
{
"name": "",
"value": "",
"reading_name": False,
"reading_string": False,
}
)
elif el == "Name" and simple_stack:
simple_stack[-1]["reading_name"] = True
elif el == "String" and simple_stack:
simple_stack[-1]["reading_string"] = True
elif token == QXmlStreamReader.EndElement:
el = reader.name()
if el == "Tag":
in_tag = False
simple_stack.clear()
elif el == "Targets":
in_targets = False
elif el == "TargetTypeValue":
in_ttv = False
try:
target_type_value = int(ttv_text)
except ValueError:
pass
elif el == "Name" and simple_stack:
simple_stack[-1]["reading_name"] = False
elif el == "String" and simple_stack:
simple_stack[-1]["reading_string"] = False
elif el == "Simple" and simple_stack:
frame = simple_stack.pop()
mkv_name = frame["name"].upper()
value = frame["value"]
if simple_stack:
# Nested Simple: handle SORT_WITH and ORIGINAL/ARTIST
parent_name = simple_stack[-1]["name"].upper()
if mkv_name == "SORT_WITH" and value:
sort_field = _sort_field_for(parent_name, target_type_value)
if sort_field:
metadata.add(sort_field, value)
elif parent_name == "ORIGINAL" and mkv_name == "ARTIST" and value:
metadata.add("originalartist", value)
else:
# Top-level Simple
if target_type_value >= 60:
if value and mkv_name in _R_DISC_TAGS:
metadata.add(_R_DISC_TAGS[mkv_name], value)
elif target_type_value >= 50:
if value:
if mkv_name == "TOTAL_PARTS":
metadata.add("totaltracks", value)
elif mkv_name in _R_ALBUM_TAGS:
metadata.add(_R_ALBUM_TAGS[mkv_name], value)
else:
if mkv_name == "PART_NUMBER":
if value:
if "/" in value:
parts = value.split("/", 1)
metadata.add("tracknumber", parts[0].strip())
metadata.add("totaltracks", parts[1].strip())
else:
metadata.add("tracknumber", value)
elif value and mkv_name in _R_TRACK_TAGS:
metadata.add(_R_TRACK_TAGS[mkv_name], value)
elif token == QXmlStreamReader.Characters:
text = reader.text()
if in_ttv:
ttv_text += text
elif simple_stack:
frame = simple_stack[-1]
if frame["reading_name"]:
frame["name"] += text
elif frame["reading_string"]:
frame["value"] += text
f.close()
if reader.hasError():
log.warning(
"MkvPlugin: failed to parse tags XML %r: %s", xml_path, reader.errorString()
)
# ---------------------------------------------------------------------------
# Matroska file format base class
# ---------------------------------------------------------------------------
class _MatroskaFileBase(File):
"""
Handles both reading and writing of Matroska tags via MKVToolNix.
_load() uses mkvmerge --identify for duration/codec info and mkvextract tags for existing tag values.
_save() generates a Matroska tags XML and feeds it to mkvpropedit.
"""
@classmethod
def supports_tag(cls, name):
return name in _SUPPORTED_TAGS
def _load(self, filename):
log.debug("MkvPlugin: loading %r", filename)
tooldir = _get_tooldir()
metadata = Metadata()
# Read file info (duration, codec) via mkvmerge --identify
mkvmerge = _tool_path("mkvmerge", tooldir)
try:
result = _run(
[mkvmerge, "--identify", "--identification-format", "json", filename],
capture_output=True,
text=True,
encoding="utf-8",
)
info = json.loads(result.stdout)
duration_ns = (
info.get("container", {}).get("properties", {}).get("duration", 0)
)
if duration_ns:
metadata.length = duration_ns // 1_000_000 # ns → ms
except FileNotFoundError:
raise Exception(
f"mkvmerge not found at {mkvmerge!r}. "
"Install MKVToolNix and set the folder path in "
"Options > Plugins > Matroska Tagger."
)
except subprocess.CalledProcessError as e:
log.warning("MkvPlugin: mkvmerge failed on %r: %s", filename, e)
except (json.JSONDecodeError, KeyError) as e:
log.warning(
"MkvPlugin: could not parse mkvmerge output for %r: %s", filename, e
)
# Read existing tags via mkvextract tags
mkvextract = _tool_path("mkvextract", tooldir)
tmp_fd, tmp_path = tempfile.mkstemp(suffix=".xml", prefix="picard_mkv_")
os.close(tmp_fd)
try:
# mkvextract returns 0 (clean) or 1 (warnings but still valid output).
# check=True would treat exit code 1 as failure, so we check manually.
result = subprocess.run(
[mkvextract, filename, "tags", tmp_path],
capture_output=True,
**_subprocess_flags(),
)
if result.returncode >= 2:
raise subprocess.CalledProcessError(result.returncode, result.args)
if os.path.getsize(tmp_path) > 0:
_parse_tags_xml(tmp_path, metadata)
except FileNotFoundError:
raise Exception(
f"mkvextract not found at {mkvextract!r}. "
"Install MKVToolNix and set the folder path in "
"Options > Plugins > Matroska Tagger."
)
except subprocess.CalledProcessError as e:
log.warning("MkvPlugin: mkvextract failed on %r: %s", filename, e)
finally:
try:
os.unlink(tmp_path)
except OSError:
pass
return metadata
def _save(self, filename, metadata):
log.debug("MkvPlugin: saving %r", filename)
tooldir = _get_tooldir()
mkvpropedit = _tool_path("mkvpropedit", tooldir)
tags_xml = _tags_xml(metadata)
log.debug("MkvPlugin: tags XML: %s", tags_xml)
tags_fd, tags_path = tempfile.mkstemp(suffix=".xml", prefix="picard_mkv_")
try:
with os.fdopen(tags_fd, "w", encoding="utf-8") as f:
f.write(tags_xml)
try:
if config.setting["mkv_strip_chapters"]:
_run([mkvpropedit, filename, "--chapters", ""])
title = metadata.get("title", "")
_run(
[
mkvpropedit,
filename,
"--edit",
"info",
"--set",
f"title={title}",
"--edit",
"track:a1",
"--set",
f"name={title}",
"--tags",
"all:",
"--tags",
f"global:{tags_path}",
]
)
except FileNotFoundError:
raise Exception(
f"mkvpropedit not found at {mkvpropedit!r}. "
"Install MKVToolNix and set the folder path in "
"Options > Plugins > Matroska Tagger."
)
except subprocess.CalledProcessError as e:
raise Exception(f"mkvpropedit failed: {e}")
finally:
try:
os.unlink(tags_path)
except OSError:
pass
# ---------------------------------------------------------------------------
# Concrete format classes — one per extension so Picard treats them separately
# ---------------------------------------------------------------------------
class MKVFile(_MatroskaFileBase):
NAME = "Matroska Video (MKV)"
EXTENSIONS = [".mkv"]
class MKAFile(_MatroskaFileBase):
NAME = "Matroska Audio (MKA)"
EXTENSIONS = [".mka"]
# ---------------------------------------------------------------------------
# Options page
# ---------------------------------------------------------------------------
class _MkvOptionsPage(OptionsPage):
NAME = "matroska_tagger"
TITLE = "Matroska Tagger"
PARENT = "plugins"
SORT_ORDER = 100
def __init__(self, parent=None):
super().__init__(parent)
layout = QVBoxLayout(self)
layout.setAlignment(_AlignTop)
desc = QLabel(
"Path to the folder containing MKVToolNix executables "
"(mkvpropedit, mkvmerge, mkvextract). "
"Leave empty to use the system PATH."
)
desc.setWordWrap(True)
layout.addWidget(desc)
form = QFormLayout()
path_row = QHBoxLayout()
self._path_edit = QLineEdit()
if sys.platform == "win32":
self._path_edit.setPlaceholderText(r"e.g. C:\Program Files\MKVToolNix")
else:
self._path_edit.setPlaceholderText("e.g. /usr/bin (leave empty for PATH)")
path_row.addWidget(self._path_edit)
browse_btn = QPushButton("Browse…")
browse_btn.clicked.connect(self._browse)
path_row.addWidget(browse_btn)
form.addRow("MKVToolNix folder:", path_row)
layout.addLayout(form)
test_row = QHBoxLayout()
self._test_btn = QPushButton("Test")
self._test_btn.clicked.connect(self._test_tools)
test_row.addWidget(self._test_btn)
self._test_label = QLabel("")
test_row.addWidget(self._test_label)
test_row.addStretch()
layout.addLayout(test_row)
self._strip_chapters_cb = QCheckBox("Remove chapter data when saving")
layout.addWidget(self._strip_chapters_cb)
self._use_original_date_cb = QCheckBox(
"Use original release date as DATE tag (instead of this release's date)"
)
layout.addWidget(self._use_original_date_cb)
def _browse(self):
folder = QFileDialog.getExistingDirectory(
self, "Select MKVToolNix folder", self._path_edit.text()
)
if folder:
self._path_edit.setText(folder)
def _test_tools(self):
tooldir = self._path_edit.text().strip()
results = []
for name in ("mkvpropedit", "mkvmerge", "mkvextract"):
path = _tool_path(name, tooldir)
try:
_run([path, "--version"], capture_output=True)
results.append(f"✓ {name}")
except FileNotFoundError:
results.append(f"✗ {name} not found")
except subprocess.CalledProcessError as e:
results.append(f"✗ {name} error ({e.returncode})")
self._test_label.setText(" ".join(results))
def load(self):
self._path_edit.setText(config.setting["mkvtoolnix_dir"])
self._strip_chapters_cb.setChecked(config.setting["mkv_strip_chapters"])
self._use_original_date_cb.setChecked(config.setting["mkv_use_original_date"])
def save(self):
config.setting["mkvtoolnix_dir"] = self._path_edit.text().strip()
config.setting["mkv_strip_chapters"] = self._strip_chapters_cb.isChecked()
config.setting["mkv_use_original_date"] = self._use_original_date_cb.isChecked()
# ---------------------------------------------------------------------------
# Registration
# ---------------------------------------------------------------------------
def _default_tooldir():
if sys.platform == "win32":
prog_files = os.environ.get("ProgramFiles", r"C:\Program Files")
candidate = os.path.join(prog_files, "MKVToolNix")
if os.path.isdir(candidate):
return candidate
return ""
TextOption("setting", "mkvtoolnix_dir", _default_tooldir())
BoolOption("setting", "mkv_strip_chapters", False)
BoolOption("setting", "mkv_use_original_date", True)
register_format(MKVFile)
register_format(MKAFile)
register_options_page(_MkvOptionsPage)
log.info("MkvPlugin: Matroska Tagger enabled (MKV + MKA)")
================================================
FILE: plugins/mod/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2022, 2025 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
# For Python 3.8 compatibility
from __future__ import annotations
PLUGIN_NAME = 'MOD files'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = (
'Support for loading and renaming various tracker module formats '
'(.mod, .xm, .it, .mptm, .ahx, .mtm, .med, .s3m, .ult, .699, .okt). '
'There is limited support for writing the title tag as track name for '
'some formats.'
)
PLUGIN_VERSION = "0.2.1"
PLUGIN_API_VERSIONS = ["2.8"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from collections import namedtuple
from enum import Enum
from io import RawIOBase
import struct
from mutagen._util import resize_bytes
from picard import log
from picard.file import File
from picard.formats import register_format
from picard.metadata import Metadata
from picard.util.textencoding import asciipunct
class FieldAccess(Enum):
READ_ONLY = 0
READ_WRITE = 1
StaticField = namedtuple('StaticField', 'name offset length access fillchar', defaults=(' ',))
class MagicBytes(bytes):
offset: int = 0
def __new__(cls, value, offset: int = 0):
self = super().__new__(cls, value)
self.offset = offset
return self
class ModuleFile(File):
# Allows to specify a magic number to identify the file format.
# Re-implement _ensure_format for more complex cases.
_magic_bytes: tuple[MagicBytes] = None
# Specify the encoding for the format.
# There is not much info about encoding, most files seem to be limited
# to ASCII. But cp850 seems to be a solid default for the few files that
# use 8-bit characters.
_encoding = 'cp850' # or cp437?
# List of StaticField. Most fields in mod files
# have static position and fixed size.
_static_text_fields: tuple[StaticField] = ()
@classmethod
def supports_tag(cls, name: str) -> bool:
return name in {field.name for field in cls._static_text_fields}
def _load(self, filename: str) -> Metadata:
log.debug('Loading file %r', filename)
metadata = Metadata()
self._add_path_to_metadata(metadata)
metadata['~format'] = self.NAME
with open(filename, 'rb') as f:
magic = self._ensure_format(f)
self._parse_file(f, metadata, magic)
return metadata
def _save(self, filename: str, metadata: Metadata):
log.debug('Saving file %r', filename)
with open(filename, 'rb+') as f:
self._ensure_format(f)
self._write_file(f, metadata)
def _ensure_format(self, f: RawIOBase) -> MagicBytes:
if not self._magic_bytes:
raise NotImplementedError('_magic_bytes not set or method not implemented')
for magic in self._magic_bytes:
if self._magic_matches(f, magic):
return magic
# None of the magic byte sequences matched, fail loading
raise ValueError('Not a %s file' % self.NAME)
def _magic_matches(self, f: RawIOBase, magic: MagicBytes) -> bool:
f.seek(magic.offset)
file_id = f.read(len(magic))
return file_id == magic
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
for field in self._static_text_fields:
f.seek(field.offset)
metadata[field.name] = self._decode_text(f.read(field.length))
def _write_file(self, f: RawIOBase, metadata: Metadata):
for field in self._static_text_fields:
if field.access == FieldAccess.READ_WRITE and not field.name.startswith('~'):
f.seek(field.offset)
f.write(self._encode_text(metadata[field.name], field.length, field.fillchar))
def _decode_text(self, data: bytes) -> str:
return data.decode(self._encoding, errors='replace').strip().strip('\0')
def _encode_text(self, text: str, length: int = None, fillchar: str = ' ') -> bytes:
if length:
text = text[:length].ljust(length, fillchar)
return asciipunct(text).encode(self._encoding, errors='replace')
class MODFile(ModuleFile):
EXTENSIONS = ['.mod']
NAME = 'MOD'
# https://www.ocf.berkeley.edu/~eek/index.html/tiny_examples/ptmod/ap12.html
_magic_bytes = (MagicBytes(b'M\x2eK\x2e', offset=1080),)
_static_text_fields = (
StaticField('title', 0, 20, FieldAccess.READ_WRITE),
)
class ExtendedModuleFile(ModuleFile):
EXTENSIONS = ['.xm']
NAME = 'Extended Module'
# https://github.com/milkytracker/MilkyTracker/blob/master/resources/reference/xm-form.txt
_magic_bytes = (MagicBytes(b'Extended Module: '),)
_static_text_fields = (
StaticField('title', 17, 20, FieldAccess.READ_WRITE),
StaticField('encodedby', 38, 20, FieldAccess.READ_WRITE),
)
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
super()._parse_file(f, metadata, magic)
# OpenMPT seems to use iso-8859-1 encoding.
if metadata['encodedby'].startswith('OpenMPT'):
self._encoding = 'iso-8859-1'
super()._parse_file(f, metadata, magic)
f.seek(68)
metadata['~channels'] = struct.unpack(' bool:
return name in {'title'}
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
self._seek_names_offset(f)
metadata['title'] = self._decode_text(self._read_string(f))
def _write_file(self, f: RawIOBase, metadata: Metadata):
# Write the title (first null terminated string after the samples)
names_offset = self._seek_names_offset(f)
old_title = self._read_string(f)
new_title = self._encode_text(metadata['title'])
resize_bytes(f, len(old_title), len(new_title), names_offset)
f.seek(names_offset)
f.write(new_title)
def _seek_names_offset(self, f: RawIOBase) -> int:
f.seek(6)
len_ = struct.unpack('>H', f.read(2))[0] & 0xfff
f.seek(10)
trl, trk, smp, ss = struct.unpack('BBBB', f.read(4))
samples_offset = 14 + ss*2 + len_*8 + (trk+1)*trl*3
f.seek(samples_offset)
self._skip_samples(f, count=smp)
return f.tell()
def _skip_samples(self, f: RawIOBase, count: int):
while count:
f.seek(f.tell() + 21)
plen = struct.unpack('B', f.read(1))[0]
f.seek(f.tell() + plen*4)
count -= 1
def _read_string(self, f: RawIOBase) -> bytes:
"""Reads a null terminated string from the current position."""
result = b''
char = f.read(1)
while char and char != b'\0':
result += char
char = f.read(1)
return result
class MEDFile(ModuleFile):
EXTENSIONS = ['.med']
NAME = 'MED'
# https://github.com/dv1/ion_player/blob/master/extern/uade-2.13/amigasrc/players/med/MMD_FileFormat.doc
_magic_bytes = (
MagicBytes(b'MMD0'),
MagicBytes(b'MMD1'),
MagicBytes(b'MMD2'),
MagicBytes(b'MMD3'),
)
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
# TODO: Extract songname
super()._parse_file(f, metadata, magic)
metadata['~format'] = '%s (%s)' % (self.NAME, self._decode_text(magic))
class MTMFile(ModuleFile):
EXTENSIONS = ['.mtm']
NAME = 'MTM'
# https://www.fileformat.info/format/mtm/corion.htm
_magic_bytes = (MagicBytes(b'MTM'),)
_static_text_fields = (
StaticField('title', 4, 20, FieldAccess.READ_WRITE, '\0'),
)
class S3MFile(ModuleFile):
EXTENSIONS = ['.s3m']
NAME = 'S3M'
# https://www.fileformat.info/format/screamtracker/corion.htm
_magic_bytes = (MagicBytes(b'\x1a', offset=28),)
_static_text_fields = (
StaticField('title', 0, 20, FieldAccess.READ_WRITE, '\0'),
StaticField('encodedby', 20, 8, FieldAccess.READ_WRITE, '\0'),
)
class ULTFile(ModuleFile):
EXTENSIONS = ['.ult']
NAME = 'ULT'
# http://www.textfiles.com/programming/FORMATS/ultform.pro
# http://www.textfiles.com/programming/FORMATS/ultform14.pro
_magic_bytes = (
MagicBytes(b'MAS_UTrack_V001'),
MagicBytes(b'MAS_UTrack_V002'),
MagicBytes(b'MAS_UTrack_V003'),
MagicBytes(b'MAS_UTrack_V004'),
)
_static_text_fields = (
StaticField('title', 15, 32, FieldAccess.READ_WRITE),
)
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
super()._parse_file(f, metadata, magic)
metadata['~format'] = '%s (%s)' % (self.NAME, self._decode_text(magic))
class Composer669File(ModuleFile):
EXTENSIONS = ['.669']
NAME = 'Composer 669'
# http://www.textfiles.com/programming/FORMATS/669-form.pro
_magic_bytes = (
MagicBytes(b'if'),
MagicBytes(b'JN'), # Extended 669
)
_static_text_fields = (
StaticField('comment', 2, 108, FieldAccess.READ_WRITE),
)
def _parse_file(self, f: RawIOBase, metadata: Metadata, magic: MagicBytes):
super()._parse_file(f, metadata, magic)
if magic == b'JN':
metadata['~format'] = 'Extended Composer 669'
class OktalyzerFile(ModuleFile):
EXTENSIONS = ['.okt']
NAME = 'Oktalyzer'
# http://www.vgmpf.com/Wiki/index.php?title=OKT
_magic_bytes = (MagicBytes(b'OKTASONGCMOD'),)
register_format(MODFile)
register_format(ExtendedModuleFile)
register_format(ImpulseTrackerFile)
register_format(AHXFile)
register_format(MEDFile)
register_format(MTMFile)
register_format(S3MFile)
register_format(ULTFile)
register_format(Composer669File)
register_format(OktalyzerFile)
================================================
FILE: plugins/moodbars/__init__.py
================================================
# -*- coding: utf-8 -*-
# Changelog:
# [2015-09-24] Initial version with support for Ogg Vorbis, FLAC, WAV and MP3, tested MP3 and FLAC
# [2017-11-21] Amended to Python3 & Qt5
# [2017-11-21] removed unicode, replaced str with string_ and untrusted input on check_call addressed
PLUGIN_NAME = "Moodbars"
PLUGIN_AUTHOR = "Len Joubert, Sambhav Kothari"
PLUGIN_DESCRIPTION = """Calculate Moodbars for selected files and albums.
According to WikiPedia
a "Moodbar is a computer visualization used for navigating within a piece of music or any other recording on a digital audio track.
This is done with a commonly horizontal bar that is divided into vertical stripes.
Each stripe has a colour combination showing the "mood" within a short part of the audio track."
To use this plugin you will need to download special executables to create the moodbars -
at the time of writing, executables are only available for various Linux distributions
(see the Amarok Moodbar page for details).
"""
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
PLUGIN_VERSION = "2.3.3"
PLUGIN_API_VERSIONS = ["2.0"]
# PLUGIN_INCOMPATIBLE_PLATFORMS = [
# 'win32', 'cygwyn', 'darwin', 'os2', 'os2emx', 'riscos', 'atheos']
import os.path
from functools import partial
from collections import defaultdict
from subprocess import check_call
from picard.album import Album, NatAlbum
from picard.track import Track
from picard.file import File
from picard.util import encode_filename, decode_filename, thread
from picard.ui.options import register_options_page, OptionsPage
from picard.config import TextOption
from picard.ui.itemviews import (BaseAction, register_file_action,
register_album_action)
from picard.plugins.moodbars.ui_options_moodbar import Ui_MoodbarOptionsPage
# Path to various moodbar tools. There must be a tool for every supported
# audio file format.
MOODBAR_COMMANDS = {
"Ogg Vorbis": ("moodbar_vorbis_command", "moodbar_vorbis_options"),
"MPEG-1 Audio": ("moodbar_mp3_command", "moodbar_mp3_options"),
"FLAC": ("moodbar_flac_command", "moodbar_flac_options"),
"WavPack": ("moodbar_wav_command", "moodbar_wav_options"),
}
def generate_moodbar_for_files(files, format, tagger):
"""Generate the moodfiles for a list of files in album mode."""
# python3 list for subprocess
command_to_execute = []
file_list = [files]
for mood_file in file_list:
new_filename = os.path.join(os.path.dirname(
mood_file), '.' + os.path.splitext(os.path.basename(mood_file))[0] + '.mood')
# file format to make it compaitble with Amarok and hidden in linux
file_list_mood = ['%s' % new_filename]
file_list_music = ['%s' % file_list[0]]
if format in MOODBAR_COMMANDS \
and tagger.config.setting[MOODBAR_COMMANDS[format][0]]:
command = tagger.config.setting[MOODBAR_COMMANDS[format][0]]
options = tagger.config.setting[
MOODBAR_COMMANDS[format][1]].split(' ')
# tagger.log.debug('My debug file_list_mood >>> %s' %
# (file_list_mood))
#tagger.log.debug('My debug file_list >>> %s' % (file_list_music))
#tagger.log.debug('My debug command >>> %s' % (command))
#tagger.log.debug('My debug options >>> %s' % (options))
# tagger.log.debug(
# '%s %s %s %s' % (command, decode_filename(' '.join(file_list)), ' '.join(options), decode_filename(' '.join(file_list_mood))))
# command args order corrected for new moodbar
command_to_execute.append(command)
command_to_execute = command_to_execute + options
# need to decode the file string and appand to the list
command_to_execute.append(file_list_mood[0])
command_to_execute = command_to_execute + file_list_music
tagger.log.debug('My debug command to execute >>> %s' %
(command_to_execute))
check_call(command_to_execute, shell=False)
# check_call([command] + options + file_list_mood + file_list)
else:
raise Exception('Moodbar: Unsupported format %s' % (format))
class MoodBar(BaseAction):
NAME = N_("Generate Moodbar &file...")
def _add_file_to_queue(self, file):
thread.run_task(
partial(self._generate_moodbar, file),
partial(self._moodbar_callback, file))
def callback(self, objs):
for obj in objs:
if isinstance(obj, Track):
for file_ in obj.linked_files:
self._add_file_to_queue(file_)
elif isinstance(obj, File):
self._add_file_to_queue(obj)
def _generate_moodbar(self, file):
self.tagger.window.set_statusbar_message(
N_('Calculating moodbar for "%(filename)s"...'),
{'filename': file.filename}
)
generate_moodbar_for_files(file.filename, file.NAME, self.tagger)
def _moodbar_callback(self, file, result=None, error=None):
if not error:
self.tagger.window.set_statusbar_message(
N_('Moodbar for "%(filename)s" successfully generated.'),
{'filename': file.filename}
)
else:
self.tagger.window.set_statusbar_message(
N_('Could not generate moodbar for "%(filename)s".'),
{'filename': file.filename}
)
class MoodbarOptionsPage(OptionsPage):
NAME = "Moodbars"
TITLE = "Moodbars"
PARENT = "plugins"
options = [
TextOption("setting", "moodbar_vorbis_command", "moodbar"),
TextOption("setting", "moodbar_vorbis_options", "-o"),
TextOption("setting", "moodbar_mp3_command", "moodbar"),
TextOption("setting", "moodbar_mp3_options", "-o"),
TextOption("setting", "moodbar_flac_command", "moodbar"),
TextOption("setting", "moodbar_flac_options", "-o"),
TextOption("setting", "moodbar_wav_command", "moodbar"),
TextOption("setting", "moodbar_wav_options", "-o")
]
def __init__(self, parent=None):
super(MoodbarOptionsPage, self).__init__(parent)
self.ui = Ui_MoodbarOptionsPage()
self.ui.setupUi(self)
def load(self):
self.ui.vorbis_command.setText(
self.config.setting["moodbar_vorbis_command"])
self.ui.mp3_command.setText(
self.config.setting["moodbar_mp3_command"])
self.ui.flac_command.setText(
self.config.setting["moodbar_flac_command"])
self.ui.wav_command.setText(
self.config.setting["moodbar_wav_command"])
def save(self):
self.config.setting["moodbar_vorbis_command"] = self.ui.vorbis_command.text()
self.config.setting["moodbar_mp3_command"] = self.ui.mp3_command.text()
self.config.setting["moodbar_flac_command"] = self.ui.flac_command.text()
self.config.setting["moodbar_wav_command"] = self.ui.wav_command.text()
register_file_action(MoodBar())
register_options_page(MoodbarOptionsPage)
================================================
FILE: plugins/moodbars/ui_options_moodbar.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/moodbars/ui_options_moodbar.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_MoodbarOptionsPage(object):
def setupUi(self, MoodbarOptionsPage):
MoodbarOptionsPage.setObjectName("MoodbarOptionsPage")
MoodbarOptionsPage.resize(305, 317)
self.vboxlayout = QtWidgets.QVBoxLayout(MoodbarOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.moodbar_group = QtWidgets.QGroupBox(MoodbarOptionsPage)
self.moodbar_group.setObjectName("moodbar_group")
self.vboxlayout1 = QtWidgets.QVBoxLayout(self.moodbar_group)
self.vboxlayout1.setContentsMargins(9, 9, 9, 9)
self.vboxlayout1.setSpacing(2)
self.vboxlayout1.setObjectName("vboxlayout1")
self.label = QtWidgets.QLabel(self.moodbar_group)
self.label.setObjectName("label")
self.vboxlayout1.addWidget(self.label)
self.vorbis_command = QtWidgets.QLineEdit(self.moodbar_group)
self.vorbis_command.setObjectName("vorbis_command")
self.vboxlayout1.addWidget(self.vorbis_command)
self.label_2 = QtWidgets.QLabel(self.moodbar_group)
self.label_2.setObjectName("label_2")
self.vboxlayout1.addWidget(self.label_2)
self.mp3_command = QtWidgets.QLineEdit(self.moodbar_group)
self.mp3_command.setObjectName("mp3_command")
self.vboxlayout1.addWidget(self.mp3_command)
self.label_3 = QtWidgets.QLabel(self.moodbar_group)
self.label_3.setObjectName("label_3")
self.vboxlayout1.addWidget(self.label_3)
self.flac_command = QtWidgets.QLineEdit(self.moodbar_group)
self.flac_command.setObjectName("flac_command")
self.vboxlayout1.addWidget(self.flac_command)
self.label_4 = QtWidgets.QLabel(self.moodbar_group)
self.label_4.setObjectName("label_4")
self.vboxlayout1.addWidget(self.label_4)
self.wav_command = QtWidgets.QLineEdit(self.moodbar_group)
self.wav_command.setObjectName("wav_command")
self.vboxlayout1.addWidget(self.wav_command)
self.vboxlayout.addWidget(self.moodbar_group)
spacerItem = QtWidgets.QSpacerItem(263, 21, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.retranslateUi(MoodbarOptionsPage)
QtCore.QMetaObject.connectSlotsByName(MoodbarOptionsPage)
def retranslateUi(self, MoodbarOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.moodbar_group.setTitle(_translate("MoodbarOptionsPage", "Moodbar"))
self.label.setText(_translate("MoodbarOptionsPage", "Path to Ogg Vorbis moodbar tool:"))
self.label_2.setText(_translate("MoodbarOptionsPage", "Path to MP3 moodbar tool:"))
self.label_3.setText(_translate("MoodbarOptionsPage", "Path to FLAC moodbar tool:"))
self.label_4.setText(_translate("MoodbarOptionsPage", "Path to WAV moodbar tool:"))
================================================
FILE: plugins/moodbars/ui_options_moodbar.ui
================================================
MoodbarOptionsPage
0
0
305
317
6
9
-
Moodbar
2
9
-
Path to Ogg Vorbis moodbar tool:
-
-
Path to MP3 moodbar tool:
-
-
Path to FLAC moodbar tool:
-
-
Path to WAV moodbar tool:
-
-
Qt::Vertical
263
21
================================================
FILE: plugins/musixmatch/README
================================================
Installation:
Obtain API key from Musixmatch (https://developer.musixmatch.com)
================================================
FILE: plugins/musixmatch/__init__.py
================================================
PLUGIN_NAME = 'Musixmatch Lyrics'
PLUGIN_AUTHOR = 'm-yn, Sambhav Kothari, Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Fetch first 30% of lyrics from Musixmatch'
PLUGIN_VERSION = '1.1.1'
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from functools import partial
from picard import config, log
from picard.metadata import register_track_metadata_processor
from picard.ui.options import register_options_page, OptionsPage
from .ui_options_musixmatch import Ui_MusixmatchOptionsPage
MUSIXMATCH_HOST = 'api.musixmatch.com'
MUSIXMATCH_PORT = 80
def handle_result(album, metadata, data, reply, error):
try:
if error:
log.error(error)
return
message = data.get('message', {})
header = message.get('header')
if header.get('status_code') != 200:
log.warning('MusixMatch: Server returned no result: %s', data)
return
result = message.get('body', {}).get('lyrics')
if result:
lyrics = result.get('lyrics_body')
if lyrics:
metadata['lyrics:description'] = lyrics
except AttributeError:
log.error('MusixMatch: Error handling server response %s',
data, exc_info=True)
finally:
album._requests -= 1
album._finalize_loading(error)
def process_track(album, metadata, track, release):
apikey = config.setting['musixmatch_api_key']
if not apikey:
log.warning('MusixMatch: No API key configured')
return
if metadata['language'] == 'zxx':
log.debug('MusixMatch: Track %s has no lyrics, skipping query',
metadata['musicbrainz_recordingid'])
return
queryargs = {
'apikey': apikey,
'track_mbid': metadata['musicbrainz_recordingid']
}
album.tagger.webservice.get(
MUSIXMATCH_HOST,
MUSIXMATCH_PORT,
"/ws/1.1/track.lyrics.get",
partial(handle_result, album, metadata),
parse_response_type='json',
queryargs=queryargs
)
album._requests += 1
class MusixmatchOptionsPage(OptionsPage):
NAME = 'musixmatch'
TITLE = 'Musixmatch API Key'
PARENT = "plugins"
options = [
config.TextOption("setting", "musixmatch_api_key", "")
]
def __init__(self, parent=None):
super(MusixmatchOptionsPage, self).__init__(parent)
self.ui = Ui_MusixmatchOptionsPage()
self.ui.setupUi(self)
def load(self):
self.ui.api_key.setText(config.setting["musixmatch_api_key"])
def save(self):
self.config.setting["musixmatch_api_key"] = self.ui.api_key.text()
register_track_metadata_processor(process_track)
register_options_page(MusixmatchOptionsPage)
================================================
FILE: plugins/musixmatch/ui_options_musixmatch.py
================================================
from PyQt5 import QtCore, QtWidgets
class Ui_MusixmatchOptionsPage(object):
def setupUi(self, MusixmatchOptionsPage):
MusixmatchOptionsPage.setObjectName("MusixmatchOptionsPage")
MusixmatchOptionsPage.resize(305, 317)
self.vboxlayout = QtWidgets.QVBoxLayout(MusixmatchOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.api_key_group = QtWidgets.QGroupBox(MusixmatchOptionsPage)
self.api_key_group.setObjectName("api_key_group")
self.vboxlayout2 = QtWidgets.QVBoxLayout(self.api_key_group)
self.vboxlayout2.setContentsMargins(9, 9, 9, 9)
self.vboxlayout2.setSpacing(2)
self.vboxlayout2.setObjectName("vboxlayout2")
self.api_key_label = QtWidgets.QLabel(self.api_key_group)
self.api_key_label.setObjectName("api_key_label")
self.vboxlayout2.addWidget(self.api_key_label)
self.api_key = QtWidgets.QLineEdit(self.api_key_group)
self.api_key.setObjectName("api_key")
self.vboxlayout2.addWidget(self.api_key)
self.vboxlayout.addWidget(self.api_key_group)
spacerItem = QtWidgets.QSpacerItem(263, 21, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.retranslateUi(MusixmatchOptionsPage)
QtCore.QMetaObject.connectSlotsByName(MusixmatchOptionsPage)
def retranslateUi(self, MusixmatchOptionsPage):
self.api_key_label.setText(_("Musixmatch API Key"))
================================================
FILE: plugins/no_release/no_release.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = 'No release'
PLUGIN_AUTHOR = 'Johannes Weißl, Philipp Wolfer'
PLUGIN_DESCRIPTION = '''Do not store specific release information in releases of unknown origin.'''
PLUGIN_VERSION = '0.3'
PLUGIN_API_VERSIONS = ['2.0']
from PyQt5 import QtCore, QtGui, QtWidgets
from picard import config
from picard.album import Album
from picard.metadata import register_album_metadata_processor, register_track_metadata_processor
from picard.ui.options import register_options_page, OptionsPage
from picard.ui.itemviews import BaseAction, register_album_action
from picard.config import BoolOption, TextOption
class Ui_NoReleaseOptionsPage(object):
def setupUi(self, NoReleaseOptionsPage):
NoReleaseOptionsPage.setObjectName('NoReleaseOptionsPage')
NoReleaseOptionsPage.resize(394, 300)
self.verticalLayout = QtWidgets.QVBoxLayout(NoReleaseOptionsPage)
self.verticalLayout.setObjectName('verticalLayout')
self.groupBox = QtWidgets.QGroupBox(NoReleaseOptionsPage)
self.groupBox.setObjectName('groupBox')
self.vboxlayout = QtWidgets.QVBoxLayout(self.groupBox)
self.vboxlayout.setObjectName('vboxlayout')
self.norelease_enable = QtWidgets.QCheckBox(self.groupBox)
self.norelease_enable.setObjectName('norelease_enable')
self.vboxlayout.addWidget(self.norelease_enable)
self.label = QtWidgets.QLabel(self.groupBox)
self.label.setObjectName('label')
self.vboxlayout.addWidget(self.label)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName('horizontalLayout')
self.norelease_strip_tags = QtWidgets.QLineEdit(self.groupBox)
self.norelease_strip_tags.setObjectName('norelease_strip_tags')
self.horizontalLayout.addWidget(self.norelease_strip_tags)
self.vboxlayout.addLayout(self.horizontalLayout)
self.verticalLayout.addWidget(self.groupBox)
spacerItem = QtWidgets.QSpacerItem(368, 187, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout.addItem(spacerItem)
self.retranslateUi(NoReleaseOptionsPage)
QtCore.QMetaObject.connectSlotsByName(NoReleaseOptionsPage)
def retranslateUi(self, NoReleaseOptionsPage):
self.groupBox.setTitle(QtWidgets.QApplication.translate('NoReleaseOptionsPage', 'No release'))
self.norelease_enable.setText(QtWidgets.QApplication.translate('NoReleaseOptionsPage', _('Enable plugin for all releases by default')))
self.label.setText(QtWidgets.QApplication.translate('NoReleaseOptionsPage', _('Tags to strip (comma-separated)')))
def strip_release_specific_metadata(metadata):
strip_tags = config.setting['norelease_strip_tags']
strip_tags = [tag.strip() for tag in strip_tags.split(',')]
for tag in strip_tags:
metadata.delete(tag)
class NoReleaseAction(BaseAction):
NAME = _('Remove specific release information...')
def callback(self, objs):
for album in objs:
if isinstance(album, Album):
strip_release_specific_metadata(album.metadata)
for track in album.tracks:
strip_release_specific_metadata(track.metadata)
for file in track.linked_files:
track.update_file_metadata(file)
album.update()
class NoReleaseOptionsPage(OptionsPage):
NAME = 'norelease'
TITLE = 'No release'
PARENT = 'plugins'
options = [
BoolOption('setting', 'norelease_enable', False),
TextOption('setting', 'norelease_strip_tags', 'asin,barcode,catalognumber,date,label,media,releasecountry,releasestatus'),
]
def __init__(self, parent=None):
super(NoReleaseOptionsPage, self).__init__(parent)
self.ui = Ui_NoReleaseOptionsPage()
self.ui.setupUi(self)
def load(self):
self.ui.norelease_strip_tags.setText(config.setting['norelease_strip_tags'])
self.ui.norelease_enable.setChecked(config.setting['norelease_enable'])
def save(self):
config.setting['norelease_strip_tags'] = str(self.ui.norelease_strip_tags.text())
config.setting['norelease_enable'] = self.ui.norelease_enable.isChecked()
def no_release_album_processor(tagger, metadata, release):
if config.setting['norelease_enable']:
strip_release_specific_metadata(metadata)
def no_release_track_processor(tagger, metadata, track, release):
if config.setting['norelease_enable']:
strip_release_specific_metadata(metadata)
register_album_metadata_processor(no_release_album_processor)
register_track_metadata_processor(no_release_track_processor)
register_album_action(NoReleaseAction())
register_options_page(NoReleaseOptionsPage)
================================================
FILE: plugins/non_ascii_equivalents/non_ascii_equivalents.py
================================================
# -*- coding: utf-8 -*-
# Copyright (C) 2016 Anderson Mesquita
#
# This program is free software: you can redistribute it and/or modify it under
# the terms of the GNU General Public License as published by the Free Software
# Foundation, either version 3 of the License, or (at your option) any later
# version.
#
# This program is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
# details.
#
# You should have received a copy of the GNU General Public License along with
# this program. If not, see .
from picard import metadata
from picard.util.textencoding import unaccent
PLUGIN_NAME = "Non-ASCII Equivalents"
PLUGIN_AUTHOR = "Anderson Mesquita , Konrad Marciniak"
PLUGIN_VERSION = "0.5"
PLUGIN_API_VERSIONS = ["0.9", "0.10", "0.11", "0.15", "2.0"]
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://gnu.org/licenses/gpl.html"
PLUGIN_DESCRIPTION = '''Replaces accented and otherwise non-ASCII characters
with a somewhat equivalent version of their ASCII counterparts. This allows old
devices to be able to display song artists and titles somewhat correctly,
instead of displaying weird or blank symbols. It's an attempt to do a little
better than Musicbrainz's native "Replace non-ASCII characters" option.
Currently replaces characters on "album", "albumartist", "albumartists", "albumartistsort", "albumsort", "artist", "artists", "artistsort" and "title" tags.'''
CHAR_TABLE = {
# Misc Letters
"Å": "AA",
"å": "aa",
"Æ": "AE",
"æ": "ae",
"Œ": "OE",
"œ": "oe",
"ẞ": "ss",
"ß": "ss",
"Ø": "O",
"ø": "o",
"Ł": "L",
"ł": "l",
"Þ": "Th", # Thorn
"þ": "th",
"Ð": "D", # Eth
"ð": "d",
# Punctuation
"¡": "!",
"¿": "?",
"–": "--",
"—": "--",
"―": "--",
"«": "<<",
"»": ">>",
"‘": "'",
"’": "'",
"‚": ",",
"‛": "'",
"“": '"',
"”": '"',
"„": ",,",
"‟": '"',
"‹": "<",
"›": ">",
"⹂": ",,",
"「": "|-",
"」": "-|",
"『": "|-",
"』": "-|",
"〝": '"',
"〞": '"',
"〟": ",,",
"﹁": "-|",
"﹂": "|-",
"﹃": "-|",
"﹄": "|-",
"「": "|-",
"」": "-|",
"・": ".", # Katakana middle dot
# Mathematics
"≠": "!=",
"≤": "<=",
"≥": ">=",
"±": "+-",
"∓": "-+",
"×": "x",
"·": ".",
"÷": "/",
"√": "\\/",
"∑": "E",
"≪": "<<", # these are different
"≫": ">>", # from the quotation marks
# Misc
"°": "o",
"µ": "u",
"ı": "i",
"†": "t",
"©": "(c)",
"®": "(R)",
"♥": "<3",
"→": "-->",
"☆": "*",
"★": "*",
}
FILTER_TAGS = [
"album",
"albumartist",
"albumartists",
"albumartistsort",
"albumsort",
"artist",
"artists",
"artistsort",
"title",
]
def sanitize(char):
if char in CHAR_TABLE:
return CHAR_TABLE[char]
return unaccent(char)
def to_ascii(word):
return "".join(sanitize(char) for char in word)
def main(tagger, metadata, *args):
for name, value in metadata.rawitems():
if name in FILTER_TAGS:
metadata[name] = [to_ascii(x) for x in value]
metadata.register_track_metadata_processor(main)
metadata.register_album_metadata_processor(main)
================================================
FILE: plugins/padded/padded.py
================================================
PLUGIN_NAME = "Padded disc and tracknumbers"
PLUGIN_AUTHOR = "Wieland Hoffmann"
PLUGIN_DESCRIPTION = """
Adds padded disc- and tracknumbers so the length of all disc- and tracknumbers
is the same. They are stored in the `_paddedtracknumber` and `_paddeddiscnumber`
tags."""
PLUGIN_VERSION = "1.0.1"
PLUGIN_API_VERSIONS = ["0.15.0", "0.15.1", "0.16.0", "1.0.0", "1.1.0", "1.2.0",
"1.3.0", "2.0", ]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard.metadata import register_track_metadata_processor
@register_track_metadata_processor
def add_padded_tn(album, metadata, track, release):
maxlength = len(metadata["totaltracks"])
islength = len(metadata["tracknumber"])
metadata["~paddedtracknumber"] = (int(maxlength - islength) * "0" +
metadata["tracknumber"])
@register_track_metadata_processor
def add_padded_dn(album, metadata, track, release):
maxlength = len(metadata["totaldiscs"])
islength = len(metadata["discnumber"])
metadata["~paddeddiscnumber"] = (int(maxlength - islength) * "0" +
metadata["discnumber"])
================================================
FILE: plugins/papercdcase/papercdcase.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2015, 2019 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Paper CD case'
PLUGIN_AUTHOR = 'Philipp Wolfer, Sambhav Kothari'
PLUGIN_DESCRIPTION = ('Create a paper CD case from an album or cluster '
'using http://papercdcase.com')
PLUGIN_VERSION = "1.2.1"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from PyQt5.QtCore import QUrl, QUrlQuery
from picard.album import Album
from picard.cluster import Cluster
from picard.ui.itemviews import (
BaseAction,
register_album_action,
register_cluster_action,
)
from picard.util import webbrowser2
from picard.util import textencoding
PAPERCDCASE_URL = 'http://papercdcase.com/advanced.php'
URLENCODE_ASCII_CHARS = [ord(' '), ord('%'), ord('&'), ord('/'), ord('?')]
def urlencode(s):
chars = []
for c in s:
n = ord(c)
if (n < 128 or n > 255) and n not in URLENCODE_ASCII_CHARS:
chars.append(c)
else:
chars.append('%' + hex(n)[2:].upper())
return ''.join(chars)
def build_papercdcase_url(artist, album, tracks):
url = QUrl(PAPERCDCASE_URL)
# papercdcase.com does not deal well with unicode characters :(
url_query = QUrlQuery()
url_query.addQueryItem('artist',
urlencode(textencoding.asciipunct(artist)))
url_query.addQueryItem('title',
urlencode(textencoding.asciipunct(album)))
i = 1
for track in tracks:
url_query.addQueryItem('track' + str(i),
urlencode(textencoding.asciipunct(track)))
i += 1
url.setQuery(url_query)
return url.toString(QUrl.FullyEncoded)
class PaperCdCase(BaseAction):
NAME = 'Create paper CD case'
def callback(self, objs):
for obj in objs:
if isinstance(obj, Album) or isinstance(obj, Cluster):
artist = obj.metadata['albumartist']
album = obj.metadata['album']
if isinstance(obj, Album):
tracks = [track.metadata['title'] for track in obj.tracks]
else:
tracks = [file.metadata['title'] for file in obj.files]
url = build_papercdcase_url(artist, album, tracks)
webbrowser2.open(url)
paperCdCase = PaperCdCase()
register_album_action(paperCdCase)
register_cluster_action(paperCdCase)
================================================
FILE: plugins/performer_tag_replace/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2018-2025 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
import re
from picard import config, log
from picard.metadata import register_track_metadata_processor
from picard.plugins.performer_tag_replace.ui_options_performer_tag_replace import \
Ui_PerformerTagReplaceOptionsPage
from picard.ui.options import OptionsPage, register_options_page
PLUGIN_NAME = 'Performer Tag Replace'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides the ability to replace text in performer tags. It
has been developed using the 'Standardise Performers' plugin by Sophist
as the basis for retrieving and processing the performer data for each
of the tracks. The original/replacement pairs used can be customized
in the option settings page.
Please see the user
guide on GitHub for more information.
'''
PLUGIN_VERSION = "0.03"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0 or later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
PLUGIN_USER_GUIDE_URL = "https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/performer_tag_replace/docs/README.md"
DEV_TESTING = False
pairs_split = re.compile(r"\r\n|\n\r|\n").split
def _update_track_metadata(track_metadata, replacements):
if 'recording' not in track_metadata or 'relations' not in track_metadata['recording']:
return
relations = []
for relation in track_metadata['recording']['relations']:
if 'type' in relation and relation['type'] in ['instrument', 'vocal']:
if 'attributes' in relation:
attributes = []
for attribute in relation['attributes']:
for (original, replacement) in replacements:
attribute = attribute.replace(original, replacement)
attributes.append(attribute)
relation['attributes'] = attributes
if 'attribute-ids' in relation:
attribute_ids = {}
for key, value in relation['attribute-ids'].items():
for (original, replacement) in replacements:
key = key.replace(original, replacement)
attribute_ids[key] = value
relation['attribute-ids'] = attribute_ids
if 'attribute-credits' in relation:
attribute_credits = {}
for key, value in relation['attribute-credits'].items():
for (original, replacement) in replacements:
key = key.replace(original, replacement)
attribute_credits[key] = value
relation['attribute-credits'] = attribute_credits
relations.append(relation)
track_metadata['recording']['relations'] = relations
return
def performer_tag_replace(album, metadata, track_metadata, *args):
replacements = []
for pair in pairs_split(config.setting["performer_tag_replacement_pairs"]):
if "=" not in pair:
continue
original, replacement = pair.split('=', 1)
if original:
replacements.append((original, replacement))
if DEV_TESTING:
log.debug("%s: Add pair: '%s' = '%s'", PLUGIN_NAME, original, replacement,)
if replacements:
_update_track_metadata(track_metadata, replacements)
for key, values in list(metadata.rawitems()):
if not key.startswith('performer:') and not key.startswith('~performersort:'):
continue
mainkey, subkey = key.split(':', 1)
if not subkey:
continue
log.debug("%s: Original key: '%s'", PLUGIN_NAME, subkey,)
for (original, replacement) in replacements:
subkey = subkey.replace(original, replacement)
if DEV_TESTING:
log.debug("%s: Applying pair: '%s' = '%s'", PLUGIN_NAME, original, replacement,)
log.debug("%s: Updated key: '%s'", PLUGIN_NAME, subkey,)
log.debug("%s: Replacement key: '%s'", PLUGIN_NAME, subkey,)
del metadata[key]
newkey = ('%s:%s' % (mainkey, subkey,)).strip()
for value in values:
if config.setting["performer_tag_replace_performers"]:
log.debug("%s: Original value: '%s'", PLUGIN_NAME, subkey,)
for (original, replacement) in replacements:
value = value.replace(original, replacement)
if DEV_TESTING:
log.debug("%s: Applying pair: '%s' = '%s'", PLUGIN_NAME, original, replacement,)
log.debug("%s: Updated value: '%s'", PLUGIN_NAME, value,)
log.debug("%s: Replacement value: '%s'", PLUGIN_NAME, value,)
metadata.add_unique(newkey, value)
else:
log.debug("%s: No replacement pairs found.", PLUGIN_NAME,)
class PerformerTagReplaceOptionsPage(OptionsPage):
NAME = "performer_tag_replace"
TITLE = "Performer Tag Replacement"
PARENT = "plugins"
options = [
config.TextOption("setting", "performer_tag_replacement_pairs", ''),
config.BoolOption("setting", "performer_tag_replace_performers", False),
]
def __init__(self, parent=None):
super(PerformerTagReplaceOptionsPage, self).__init__(parent)
self.ui = Ui_PerformerTagReplaceOptionsPage()
self.ui.setupUi(self)
def load(self):
# Enable external link
self.ui.format_description.setOpenExternalLinks(True)
# Replacement settings
self.ui.performer_tag_replacement_pairs.setPlainText(config.setting["performer_tag_replacement_pairs"])
self.ui.performer_tag_replace_performers.setChecked(config.setting["performer_tag_replace_performers"])
def save(self):
# Replacement settings
config.setting["performer_tag_replacement_pairs"] = self.ui.performer_tag_replacement_pairs.toPlainText()
config.setting["performer_tag_replace_performers"] = self.ui.performer_tag_replace_performers.isChecked()
# Register the plugin to run at a priority slightly higher than NORMAL to help ensure that
# the replacements are applied before most other metadata processing plugins are executed.
register_track_metadata_processor(performer_tag_replace, priority=10)
register_options_page(PerformerTagReplaceOptionsPage)
================================================
FILE: plugins/performer_tag_replace/options_performer_tag_replace.ui
================================================
PerformerTagReplaceOptionsPage
0
0
398
568
0
0
16
-
0
0
380
550
QFrame::NoFrame
true
Qt::AlignLeading|Qt::AlignLeft|Qt::AlignTop
0
0
380
550
-
0
0
0
50
75
true
Performer Tag Replacement
9
9
9
1
-
0
0
50
false
<html><head/><body><p>These are the original / replacement pairs used to modify the keys for the performer tags. Each pair must be entered on a separate line in the form:</p><p><span style=" font-weight:600;">original character string=replacement character string</span></p><p>Blank lines and lines beginning with an equals sign (=) will be ignored. Replacements will be made in the order they are found in the list. An example for removing "family" from instrument names would be done using the following two lines:</p><pre style=" margin-top:12px; margin-bottom:12px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;"><span style=" font-family:'Courier New'; font-size:10pt; font-weight:600;">s family=ses<br/> family=s</span></pre><p>Note that the second line begins with a single space.</p><p>For more information please see the <a href="https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/performer_tag_replace/docs/README.md"><span style=" text-decoration: underline; color:#0000ff;">User Guide</span></a> on GitHub.<br/></p></body></html>
Qt::AlignLeading|Qt::AlignLeft|Qt::AlignTop
true
-
75
true
Replacement Pairs
-
Courier New
10
Enter replacement pairs (one per line)
-
Apply replacements to performers as well as instruments && vocals
false
-
Qt::Vertical
20
0
scrollArea
================================================
FILE: plugins/performer_tag_replace/ui_options_performer_tag_replace.py
================================================
# -*- coding: utf-8 -*-
# Automatically generated - don't edit.
# Use `python setup.py build_ui` to update it.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_PerformerTagReplaceOptionsPage(object):
def setupUi(self, PerformerTagReplaceOptionsPage):
PerformerTagReplaceOptionsPage.setObjectName("PerformerTagReplaceOptionsPage")
PerformerTagReplaceOptionsPage.resize(398, 568)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(PerformerTagReplaceOptionsPage.sizePolicy().hasHeightForWidth())
PerformerTagReplaceOptionsPage.setSizePolicy(sizePolicy)
self.vboxlayout = QtWidgets.QVBoxLayout(PerformerTagReplaceOptionsPage)
self.vboxlayout.setSpacing(16)
self.vboxlayout.setObjectName("vboxlayout")
self.scrollArea = QtWidgets.QScrollArea(PerformerTagReplaceOptionsPage)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.scrollArea.sizePolicy().hasHeightForWidth())
self.scrollArea.setSizePolicy(sizePolicy)
self.scrollArea.setMinimumSize(QtCore.QSize(380, 550))
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignTop)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 380, 550))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.gb_description = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.gb_description.sizePolicy().hasHeightForWidth())
self.gb_description.setSizePolicy(sizePolicy)
self.gb_description.setMinimumSize(QtCore.QSize(0, 50))
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.gb_description.setFont(font)
self.gb_description.setObjectName("gb_description")
self.verticalLayout = QtWidgets.QVBoxLayout(self.gb_description)
self.verticalLayout.setContentsMargins(9, 9, 9, 1)
self.verticalLayout.setObjectName("verticalLayout")
self.format_description = QtWidgets.QLabel(self.gb_description)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.format_description.sizePolicy().hasHeightForWidth())
self.format_description.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(False)
font.setWeight(50)
self.format_description.setFont(font)
self.format_description.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignTop)
self.format_description.setWordWrap(True)
self.format_description.setObjectName("format_description")
self.verticalLayout.addWidget(self.format_description)
self.verticalLayout_2.addWidget(self.gb_description)
self.gb_replacement_pairs = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.gb_replacement_pairs.setFont(font)
self.gb_replacement_pairs.setObjectName("gb_replacement_pairs")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.gb_replacement_pairs)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.performer_tag_replacement_pairs = QtWidgets.QPlainTextEdit(self.gb_replacement_pairs)
font = QtGui.QFont()
font.setFamily("Courier New")
font.setPointSize(10)
self.performer_tag_replacement_pairs.setFont(font)
self.performer_tag_replacement_pairs.setObjectName("performer_tag_replacement_pairs")
self.verticalLayout_3.addWidget(self.performer_tag_replacement_pairs)
self.verticalLayout_2.addWidget(self.gb_replacement_pairs, 0, QtCore.Qt.AlignTop)
self.performer_tag_replace_performers = QtWidgets.QCheckBox(self.scrollAreaWidgetContents)
self.performer_tag_replace_performers.setChecked(False)
self.performer_tag_replace_performers.setObjectName("performer_tag_replace_performers")
self.verticalLayout_2.addWidget(self.performer_tag_replace_performers)
spacerItem = QtWidgets.QSpacerItem(20, 0, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.vboxlayout.addWidget(self.scrollArea, 0, QtCore.Qt.AlignTop)
self.retranslateUi(PerformerTagReplaceOptionsPage)
QtCore.QMetaObject.connectSlotsByName(PerformerTagReplaceOptionsPage)
def retranslateUi(self, PerformerTagReplaceOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.gb_description.setTitle(_("Performer Tag Replacement"))
self.format_description.setText(_("These are the original / replacement pairs used to modify the keys for the performer tags. Each pair must be entered on a separate line in the form:
original character string=replacement character string
Blank lines and lines beginning with an equals sign (=) will be ignored. Replacements will be made in the order they are found in the list. An example for removing "family" from instrument names would be done using the following two lines:
s family=ses
family=s
Note that the second line begins with a single space.
For more information please see the User Guide on GitHub.
"))
self.gb_replacement_pairs.setTitle(_("Replacement Pairs"))
self.performer_tag_replacement_pairs.setPlaceholderText(_("Enter replacement pairs (one per line)"))
self.performer_tag_replace_performers.setText(_("Apply replacements to performers as well as instruments && vocals"))
================================================
FILE: plugins/persistent_variables/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2022 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
# "Persistent variables display" context is based on the code from
# the "View Script Variables" plugin.
PLUGIN_NAME = 'Persistent Variables'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides the ability to store and retrieve script variables that persist across tracks and albums.
This allows things like finding and storing the earliest recording date of all of the tracks on an album.
There are two types of persistent variables maintained - album variables and session variables. Album variables
persist across all tracks on an album. Each album's information is stored separately, and is reset when the
album is refreshed. The information is cleared when an album is removed. Session variables persist across all
albums and tracks, and are cleared when Picard is shut down or restarted.
This plugin adds eight new scripting functions to allow management of persistent script variables:
- $set_a(name,value) : Sets the album persistent variable name to value.
- $unset_a(name) : Unsets the album persistent variable name.
- $get_a(name) : Gets the album persistent variable name.
- $clear_a() : Clears all album persistent variables.
- $set_s(name,value) : Sets the session persistent variable name to value.
- $unset_s(name) : Unsets the session persistent variable name.
- $get_s(name) : Gets the session persistent variable name.
- $clear_s() : Clears all session persistent variables.
Please see the user guide on GitHub for more information.
'''
PLUGIN_VERSION = '1.1'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3', '2.4', '2.6', '2.7']
PLUGIN_LICENSE = 'GPL-2.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-2.0.html'
PLUGIN_USER_GUIDE_URL = 'https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/persistent_variables/docs/README.md'
from PyQt5 import QtWidgets
from picard import log
from picard.album import (
Album,
register_album_post_removal_processor,
)
from picard.file import File
from picard.metadata import register_album_metadata_processor
from picard.plugin import PluginPriority
from picard.plugins.persistent_variables.ui_variables_dialog import (
Ui_VariablesDialog,
)
from picard.script import register_script_function
from picard.script.parser import normalize_tagname
from picard.track import Track
from picard.ui.itemviews import (
BaseAction,
register_album_action,
register_file_action,
register_track_action,
)
class PersistentVariables:
album_variables = {}
session_variables = {}
@classmethod
def clear_album_vars(cls, album):
if album:
cls.album_variables[album] = {}
@classmethod
def set_album_var(cls, album, key, value):
if album:
if album not in cls.album_variables:
cls.clear_album_vars(album)
if key:
cls.album_variables[album][key] = value
@classmethod
def unset_album_var(cls, album, key):
if album and album in cls.album_variables:
cls.album_variables[album].pop(key, None)
@classmethod
def unset_album_dict(cls, album):
if album:
cls.album_variables.pop(album, None)
@classmethod
def get_album_var(cls, album, key):
if album in cls.album_variables:
return cls.album_variables[album][key] if key in cls.album_variables[album] else ""
return ""
@classmethod
def clear_session_vars(cls):
cls.session_variables = {}
@classmethod
def set_session_var(cls, key, value):
if key:
cls.session_variables[key] = value
@classmethod
def unset_session_var(cls, key):
cls.session_variables.pop(key, None)
@classmethod
def get_session_var(cls, key):
return cls.session_variables[key] if key in cls.session_variables else ""
@classmethod
def get_album_dict(cls, album):
if album and album in cls.album_variables:
return cls.album_variables[album]
return {}
@classmethod
def get_session_dict(cls):
return cls.session_variables
def _get_album_id(parser):
file = parser.file
if file:
if file.parent and hasattr(file.parent, 'album') and file.parent.album:
return str(file.parent.album.id)
else:
return ""
# Fall back to parser context to allow processing on albums newly retrieved from MusicBrainz
return parser.context['musicbrainz_albumid']
def func_set_s(parser, name, value):
if value:
PersistentVariables.set_session_var(normalize_tagname(name), value)
else:
func_unset_s(parser, name)
return ""
def func_unset_s(parser, name):
PersistentVariables.unset_session_var(normalize_tagname(name))
return ""
def func_get_s(parser, name):
return PersistentVariables.get_session_var(normalize_tagname(name))
def func_clear_s(parser):
PersistentVariables.clear_session_vars()
return ""
def func_unset_a(parser, name):
album_id = _get_album_id(parser)
log.debug("{0}: Unsetting album '{1}' variable '{2}'".format(PLUGIN_NAME, album_id, normalize_tagname(name),))
if album_id:
PersistentVariables.unset_album_var(album_id, normalize_tagname(name))
return ""
def func_set_a(parser, name, value):
album_id = _get_album_id(parser)
log.debug("{0}: Setting album '{1}' persistent variable '{2}' to '{3}'".format(PLUGIN_NAME, album_id, normalize_tagname(name), value,))
if album_id:
PersistentVariables.set_album_var(album_id, normalize_tagname(name), value)
return ""
def func_get_a(parser, name):
album_id = _get_album_id(parser)
log.debug("{0}: Getting album '{1}' persistent variable '{2}'".format(PLUGIN_NAME, album_id, normalize_tagname(name),))
if album_id:
return PersistentVariables.get_album_var(album_id, normalize_tagname(name))
return ""
def func_clear_a(parser):
album_id = _get_album_id(parser)
log.debug("{0}: Clearing album '{1}' persistent variables dictionary".format(PLUGIN_NAME, album_id,))
if album_id:
PersistentVariables.clear_album_vars(album_id)
return ""
def initialize_album_dict(album, album_metadata, release_metadata):
album_id = str(album.id)
log.debug("{0}: Initializing album '{1}' persistent variables dictionary".format(PLUGIN_NAME, album_id,))
PersistentVariables.clear_album_vars(album_id)
def destroy_album_dict(album):
album_id = str(album.id)
log.debug("{0}: Destroying album '{1}' persistent variables dictionary".format(PLUGIN_NAME, album_id,))
PersistentVariables.unset_album_dict(album_id)
class ViewVariables(BaseAction):
NAME = 'View persistent variables'
def callback(self, objs):
obj = objs[0]
files = self.tagger.get_files_from_objects(objs)
if files:
obj = files[0]
dialog = ViewVariablesDialog(obj)
dialog.exec_()
class ViewVariablesDialog(QtWidgets.QDialog):
def __init__(self, obj, parent=None):
QtWidgets.QDialog.__init__(self, parent)
self.ui = Ui_VariablesDialog()
self.ui.setupUi(self)
self.ui.buttonBox.accepted.connect(self.accept)
self.album_id = ""
self.setWindowTitle("Persistent Variables")
if isinstance(obj, Album):
self.album_id = str(obj.id)
if isinstance(obj, File):
if obj.parent and hasattr(obj.parent, 'album') and obj.parent.album:
self.album_id = str(obj.parent.album.id)
elif isinstance(obj, Track):
if obj.album:
self.album_id = str(obj.album.id)
album_dict = PersistentVariables.get_album_dict(self.album_id)
album_count = len(album_dict)
session_dict = PersistentVariables.get_session_dict()
session_count = len(session_dict)
table = self.ui.metadata_table
key_example, value_example = self.get_table_items(table, 0)
self.key_flags = key_example.flags()
self.value_flags = value_example.flags()
table.setRowCount(album_count + session_count + 2)
i = 0
self.add_separator_row(table, i, "Album Variables", album_count)
i += 1
for key in sorted(album_dict.keys()):
key_item, value_item = self.get_table_items(table, i)
key_item.setText(key)
value_item.setText(album_dict[key])
i += 1
self.add_separator_row(table, i, "Session Variables", session_count)
i += 1
for key in sorted(session_dict.keys()):
key_item, value_item = self.get_table_items(table, i)
key_item.setText(key)
value_item.setText(session_dict[key])
i += 1
def add_separator_row(self, table, i, title, count):
key_item, value_item = self.get_table_items(table, i)
font = key_item.font()
font.setBold(True)
key_item.setFont(font)
key_item.setText(title)
value_item.setText("{0} item{1}".format(count, "" if count == 1 else "s",))
def get_table_items(self, table, i):
key_item = table.item(i, 0)
value_item = table.item(i, 1)
if not key_item:
key_item = QtWidgets.QTableWidgetItem()
key_item.setFlags(self.key_flags)
table.setItem(i, 0, key_item)
if not value_item:
value_item = QtWidgets.QTableWidgetItem()
value_item.setFlags(self.value_flags)
table.setItem(i, 1, value_item)
return key_item, value_item
viewer = ViewVariables()
# Register the new functions
register_script_function(func_set_a, name='set_a',
documentation="""`$set_a(name,value)`
Sets the album persistent variable `name` to `value`.""")
register_script_function(func_unset_a, name='unset_a',
documentation="""`$unset_a(name)`
Unsets the album persistent variable `name`.""")
register_script_function(func_get_a, name='get_a',
documentation="""`$get_a(name)`
Gets the album persistent variable `name`.""")
register_script_function(func_clear_a, name='clear_a',
documentation="""`$clear_a()`
Clears all album persistent variables.""")
register_script_function(func_set_s, name='set_s',
documentation="""`$set_s(name,value)`
Sets the session persistent variable `name` to `value`.""")
register_script_function(func_unset_s, name='unset_s',
documentation="""`$unset_s(name)`
Unsets the session persistent variable `name`.""")
register_script_function(func_get_s, name='get_s',
documentation="""`$get_s(name)`
Gets the session persistent variable `name`.""")
register_script_function(func_clear_s, name='clear_s',
documentation="""`$clear_s()`
Clears all session persistent variables.""")
# Register the processers
register_album_metadata_processor(initialize_album_dict, priority=PluginPriority.HIGH)
register_album_post_removal_processor(destroy_album_dict)
# Register context actions
register_file_action(viewer)
register_track_action(viewer)
register_album_action(viewer)
================================================
FILE: plugins/persistent_variables/ui_variables_dialog.py
================================================
# -*- coding: utf-8 -*-
# Form based on that used for the "View Script Variables" plugin
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_VariablesDialog(object):
def setupUi(self, VariablesDialog):
VariablesDialog.setObjectName("VariablesDialog")
VariablesDialog.resize(600, 450)
self.verticalLayout = QtWidgets.QVBoxLayout(VariablesDialog)
self.verticalLayout.setObjectName("verticalLayout")
self.metadata_table = QtWidgets.QTableWidget(VariablesDialog)
self.metadata_table.setAutoFillBackground(False)
self.metadata_table.setSelectionMode(QtWidgets.QAbstractItemView.ContiguousSelection)
self.metadata_table.setRowCount(1)
self.metadata_table.setColumnCount(2)
self.metadata_table.setObjectName("metadata_table")
item = QtWidgets.QTableWidgetItem()
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
item.setFont(font)
self.metadata_table.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
item.setFont(font)
self.metadata_table.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
item.setFlags(QtCore.Qt.ItemIsSelectable|QtCore.Qt.ItemIsEnabled)
self.metadata_table.setItem(0, 0, item)
item = QtWidgets.QTableWidgetItem()
item.setFlags(QtCore.Qt.ItemIsSelectable|QtCore.Qt.ItemIsEnabled)
self.metadata_table.setItem(0, 1, item)
self.metadata_table.horizontalHeader().setDefaultSectionSize(150)
self.metadata_table.horizontalHeader().setSortIndicatorShown(False)
self.metadata_table.horizontalHeader().setStretchLastSection(True)
self.metadata_table.verticalHeader().setVisible(False)
self.metadata_table.verticalHeader().setDefaultSectionSize(20)
self.metadata_table.verticalHeader().setMinimumSectionSize(20)
self.verticalLayout.addWidget(self.metadata_table)
self.buttonBox = QtWidgets.QDialogButtonBox(VariablesDialog)
self.buttonBox.setStandardButtons(QtWidgets.QDialogButtonBox.Ok)
self.buttonBox.setObjectName("buttonBox")
self.verticalLayout.addWidget(self.buttonBox)
self.retranslateUi(VariablesDialog)
QtCore.QMetaObject.connectSlotsByName(VariablesDialog)
def retranslateUi(self, VariablesDialog):
_translate = QtCore.QCoreApplication.translate
item = self.metadata_table.horizontalHeaderItem(0)
item.setText(_translate("VariablesDialog", "Variable"))
item = self.metadata_table.horizontalHeaderItem(1)
item.setText(_translate("VariablesDialog", "Value"))
__sortingEnabled = self.metadata_table.isSortingEnabled()
self.metadata_table.setSortingEnabled(False)
self.metadata_table.setSortingEnabled(__sortingEnabled)
================================================
FILE: plugins/playlist/playlist.py
================================================
#!/usr/bin/python
# -*- coding: utf-8 -*-
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Generate M3U playlist"
PLUGIN_AUTHOR = "Francis Chin, Sambhav Kothari, Chris Hylen"
PLUGIN_DESCRIPTION = """Generate an Extended M3U playlist (.m3u8 file, UTF8
encoded text). Relative pathnames are used where audio files are in the same
directory as the playlist, otherwise absolute (full) pathnames are used."""
PLUGIN_VERSION = "1.2.1"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import os.path
from PyQt5 import QtCore, QtWidgets
from picard import log
from picard.const import VARIOUS_ARTISTS_ID
from picard.util import find_existing_path, encode_filename
from picard.ui.itemviews import BaseAction, register_album_action
_debug_level = 0
def get_safe_filename(filename):
_valid_chars = " .,_-:+&!()"
_safe_filename = "".join(
c if (c.isalnum() or c in _valid_chars) else "_" for c in filename
).rstrip()
return _safe_filename
class PlaylistEntry(list):
def __init__(self, playlist, index):
list.__init__(self)
self.playlist = playlist
self.index = index
def add(self, entry_row):
self.append(entry_row + "\n")
class Playlist(object):
def __init__(self, filename):
self.filename = filename
self.entries = []
self.headers = []
def add_header(self, header):
self.headers.append(header + "\n")
def write(self):
b_lines = []
for header in self.headers:
b_lines.append(header.encode("utf-8"))
for entry in self.entries:
for row in entry:
b_lines.append(row.encode("utf-8"))
with open(encode_filename(self.filename), "wb") as f:
f.writelines(b_lines)
class GeneratePlaylist(BaseAction):
NAME = "Generate &Playlist..."
def callback(self, objs):
# Find common path of all files to default where to save playlist
files = []
for album in objs:
for track in album.tracks:
if track.linked_files:
files.append(track.linked_files[0].filename)
try:
current_directory = os.path.commonpath(files)
except ValueError:
current_directory = ""
# Default playlist filename set as "%albumartist% - %album%.m3u8",
# except where "Various Artists" is suppressed
if _debug_level > 1:
log.debug("{}: VARIOUS_ARTISTS_ID is {}, musicbrainz_albumartistid is {}".format(
PLUGIN_NAME, VARIOUS_ARTISTS_ID,
objs[0].metadata["musicbrainz_albumartistid"]))
if objs[0].metadata["musicbrainz_albumartistid"] != VARIOUS_ARTISTS_ID:
default_filename = get_safe_filename(
objs[0].metadata["albumartist"] + " - "
+ objs[0].metadata["album"] + ".m3u8"
)
else:
default_filename = get_safe_filename(
objs[0].metadata["album"] + ".m3u8"
)
if _debug_level > 1:
log.debug("{}: default playlist filename sanitized to {}".format(
PLUGIN_NAME, default_filename))
filename, selected_format = QtWidgets.QFileDialog.getSaveFileName(
None, "Save new playlist",
os.path.join(current_directory, default_filename),
"Playlist (*.m3u8 *.m3u)"
)
if filename:
playlist = Playlist(filename)
playlist.add_header("#EXTM3U")
for album in objs:
for track in album.tracks:
if track.linked_files:
entry = PlaylistEntry(playlist, len(playlist.entries))
playlist.entries.append(entry)
# M3U EXTINF row
track_length_seconds = int(round(track.metadata.length / 1000.0))
# EXTINF format assumed to be fixed as follows:
entry.add("#EXTINF:{duration:d},{artist} - {title}".format(
duration=track_length_seconds,
artist=track.metadata["artist"],
title=track.metadata["title"]
)
)
# M3U URL row - assumes only one file per track
audio_filename = track.linked_files[0].filename
if _debug_level > 1:
for i, file in enumerate(track.linked_files):
log.debug("{}: linked_file {}: {}".format(
PLUGIN_NAME, i, str(file)))
# If playlist is in same directory as audio files, then use
# local (relative) pathname, otherwise use absolute pathname
if _debug_level > 1:
log.debug("{}: audio_filename: {}, selected dir: {}".format(
PLUGIN_NAME, audio_filename, os.path.dirname(filename)))
try:
audio_filename = os.path.relpath(audio_filename, os.path.dirname(filename))
except ValueError:
pass
entry.add(str(audio_filename))
playlist.write()
register_album_action(GeneratePlaylist())
================================================
FILE: plugins/post_tagging_actions/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2024 Giorgio Fontanive (twodoorcoupe)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Post Tagging Actions"
PLUGIN_AUTHOR = "Giorgio Fontanive"
PLUGIN_DESCRIPTION = """
This plugin lets you set up actions that run with a context menu click.
An action consists in a command line executed for each album or each track along
with a few options to tweak the behaviour.
This can be used to run external programs and pass some variables to it.
"""
PLUGIN_VERSION = "0.1"
PLUGIN_API_VERSIONS = ["2.10", "2.11"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
PLUGIN_USER_GUIDE_URL = "https://github.com/metabrainz/picard-plugins/tree/2.0/plugins/post_tagging_actions/docs/guide.md"
from picard.album import Album
from picard.track import Track
from picard.ui.options import OptionsPage, register_options_page
from picard.ui.itemviews import BaseAction, register_album_action, register_track_action
from picard.ui import mainwindow
from picard import log, config
from picard.const import sys
from picard.util import thread
from picard.script import parser
from .options_post_tagging_actions import Ui_PostTaggingActions
from .actions_status import Ui_ActionsStatus
from PyQt5 import QtCore, QtWidgets, QtGui
from collections import namedtuple
from queue import PriorityQueue
from threading import Thread, Lock
from concurrent import futures
from os import path, cpu_count
import re
import shlex
import subprocess # nosec B404
import time
WIDGET_UPDATE_INTERVAL = 0.5
# Additional special variables.
TRACK_SPECIAL_VARIABLES = {
"filepath": lambda file: file,
"folderpath": lambda file: path.dirname(file), # pylint: disable=unnecessary-lambda
"filename": lambda file: path.splitext(path.basename(file))[0],
"filename_ext": lambda file: path.basename(file), # pylint: disable=unnecessary-lambda
"directory": lambda file: path.basename(path.dirname(file))
}
ALBUM_SPECIAL_VARIABLES = {
"get_num_matched_tracks",
"get_num_unmatched_files",
"get_num_total_files",
"get_num_unsaved_files",
"is_complete",
"is_modified"
}
# Settings.
CANCEL = "pta_cancel"
MAX_WORKERS = "pta_max_workers"
OPTIONS = ("pta_command", "pta_wait_for_exit", "pta_execute_for_tracks", "pta_refresh_tags")
Options = namedtuple("Options", ("variables", *[option[4:] for option in OPTIONS]))
Action = namedtuple("Action", ("commands", "album", "options"))
PriorityAction = namedtuple("PriorityAction", ("priority", "counter", "action"))
action_queue = PriorityQueue()
variables_pattern = re.compile(r'%.*?%')
class ActionLoader:
"""Adds actions to the execution queue.
Attributes:
action_options (list): Stores the actions' information loaded from the options page.
action_counter (int): The count of actions that have been added to the queue, used for priority.
"""
def __init__(self):
self.action_options = []
self.action_counter = 0
self.load_actions()
def _create_options(self, command, *other_options):
"""Finds the variables in the command and adds the options to the action options list.
"""
variables = [parser.normalize_tagname(variable[1:-1]) for variable in variables_pattern.findall(command)]
command = variables_pattern.sub('{}', command)
options = Options(variables, command, *other_options)
self.action_options.append(options)
def _create_action(self, priority, commands, album, options):
"""Adds an action with the given parameters to the execution queue.
If the os is not windows, the command is split as suggested by the subprocess
module documentation.
"""
if not sys.IS_WIN:
commands = [shlex.split(command) for command in commands]
action = Action(commands, album, options)
priority_action = PriorityAction(priority, self.action_counter, action)
action_queue.put(priority_action)
self.action_counter += 1
def _replace_variables(self, variables, item):
"""Returns a list where each variable is replaced with its value.
Item is either an album or a track. For track special variables,
it uses the path of the first file of the given item.
If the variable is not found anywhere, it remains as in the original text.
"""
values = []
album = item.album if isinstance(item, Track) else item
first_file_path = next(item.iterfiles()).filename
for variable in variables:
if variable in ALBUM_SPECIAL_VARIABLES:
values.append(getattr(album, variable)())
elif variable in TRACK_SPECIAL_VARIABLES:
values.append(TRACK_SPECIAL_VARIABLES[variable](first_file_path))
else:
values.append(item.metadata.get(variable, f"%{variable}%"))
return values
def add_actions(self, album, tracks):
"""Adds one action to the execution queue for each tuple in the action options list.
Actions meant to be executed once for each track are considered as a single
action. This way, the other options are more consistent.
"""
for priority, options in enumerate(self.action_options):
if options.execute_for_tracks:
values_list = [self._replace_variables(options.variables, track) for track in tracks]
else:
values_list = [self._replace_variables(options.variables, album)]
commands = [options.command.format(*values) for values in values_list]
self._create_action(priority, commands, album, options)
def load_actions(self):
"""Loads the information from the options and saves it in the action options list.
This gets called when the plugin is loaded or when the user saves the options.
"""
self.action_options = []
option_tuples = zip(*[config.setting[name] for name in OPTIONS])
for option_tuple in option_tuples:
command = option_tuple[0]
other_options = [eval(option) for option in option_tuple[1:]] # nosec B307
self._create_options(command, *other_options)
class ActionRunner:
"""Runs actions in the execution queue.
Attributes:
action_thread_pool (ThreadPoolExecutor): Pool used to run processes with the subprocess module.
refresh_tags_pool (ThreadPoolExecutor): Pool used to reload tags from files and refresh albums.
worker (Thread): Worker thread that picks actions from the execution queue.
update_widget (Thread): Thread that updates the number of pending actions in the status bar.
"""
def __init__(self):
self.action_thread_pool = futures.ThreadPoolExecutor(config.setting[MAX_WORKERS])
self.refresh_tags_pool = futures.ThreadPoolExecutor(1)
self.worker = Thread(target = self._execute)
self.update_widget = Thread(target = self._update_widget)
self.worker.start()
self.keep_updating = True
self.currently_executing = 0
self.currently_executing_lock = Lock()
self.status_widget = ActionsStatus()
# This is used to register functions that run when the application is being closed.
# The stop function makes the background threads return.
tagger = QtCore.QCoreApplication.instance()
tagger.register_cleanup(self.stop)
# This checks whether the tagger has already created the main window.
# It should happen only when the plugin is installed through the options menu,
# otherwise the plugins are loaded before the main window is created.
if hasattr(tagger, "window"):
self._create_widget(tagger.window)
else:
# This is used to register functions that run after the main window has finished loading.
mainwindow.register_ui_init(self._create_widget)
def _create_widget(self, window):
"""Adds the pending actions widget to the right of the other icons in the statusbar.
"""
window.statusBar().insertPermanentWidget(1, self.status_widget)
self.update_widget.start()
def _update_widget(self):
"""Updates the number of pending actions in the status bar at regular intervals.
"""
while self.keep_updating:
number_of_actions = action_queue.qsize() + self.currently_executing
thread.to_main(self.status_widget.update_actions_count, number_of_actions)
time.sleep(WIDGET_UPDATE_INTERVAL)
def _refresh_tags(self, future_objects, album):
"""Reloads tags from the album's files and refreshes the album.
First, it makes sure that the action has finished running. This is used for
when an external process changes a file's tags.
"""
futures.wait(future_objects, return_when = futures.ALL_COMPLETED)
for file in album.iterfiles():
file.set_pending()
file.load(lambda file: None)
thread.to_main(album.load, priority = True, refresh = True)
def _run_process(self, command):
"""Runs the process and waits for it to finish.
"""
process = subprocess.Popen(
command,
text = True,
stdout = subprocess.PIPE,
stderr = subprocess.PIPE
) # nosec B603
answer = process.communicate()
if answer[0]:
log.info("Action output:\n%s", answer[0])
if answer[1]:
log.error("Action error:\n%s", answer[1])
def _update_executing_count(self, future_objects):
"""Decrements the count of executing actions once the given action finishes.
"""
futures.wait(future_objects, return_when = futures.ALL_COMPLETED)
with self.currently_executing_lock:
self.currently_executing -= 1
def _execute(self):
"""Takes actions from the execution queue and runs them.
If it finds an action with priority -1, the loop stops. When the loop
stops, both ThreadPoolExecutors are shutdown.
"""
while True:
priority_action = action_queue.get()
if priority_action.priority == -1:
break
with self.currently_executing_lock:
self.currently_executing += 1
next_action = priority_action.action
commands = next_action.commands
future_objects = {self.action_thread_pool.submit(self._run_process, command) for command in commands}
if next_action.options.wait_for_exit:
futures.wait(future_objects, return_when = futures.ALL_COMPLETED)
if next_action.options.refresh_tags:
self.refresh_tags_pool.submit(self._refresh_tags, future_objects, next_action.album)
self.refresh_tags_pool.submit(self._update_executing_count, future_objects)
action_queue.task_done()
self.action_thread_pool.shutdown(wait = False, cancel_futures = True)
self.refresh_tags_pool.shutdown(wait = False, cancel_futures = True)
def stop(self):
"""Makes the worker thread exit its loop.
This gets called when Picard is closed. It waits for the processes that
are still executing to finish before exiting.
"""
if not config.setting[CANCEL]:
action_queue.join()
action_queue.put(PriorityAction(-1, -1, None))
self.keep_updating = False
if self.update_widget.is_alive():
self.update_widget.join()
self.worker.join()
class ExecuteAlbumActions(BaseAction):
NAME = "Run actions for highlighted albums"
def callback(self, objs):
albums = {obj for obj in objs if isinstance(obj, Album)}
for album in albums:
action_loader.add_actions(album, album.tracks)
class ExecuteTrackActions(BaseAction):
NAME = "Run actions for highlighted tracks"
def callback(self, objs):
tracks = {obj for obj in objs if isinstance(obj, Track)}
albums = {track.album for track in tracks}
for album in albums:
album_tracks = tracks.intersection(album.tracks)
action_loader.add_actions(album, album_tracks)
class PostTaggingActionsOptions(OptionsPage):
"""Options page found under the "plugins" page.
"""
NAME = "post_tagging_actions"
TITLE = "Post Tagging Actions"
PARENT = "plugins"
action_options = [config.ListOption("setting", name, []) for name in OPTIONS]
options = [
config.BoolOption("setting", CANCEL, True),
config.IntOption("setting", MAX_WORKERS, min(32, cpu_count() + 4)),
*action_options
]
def __init__(self, parent = None):
super(PostTaggingActionsOptions, self).__init__(parent)
self.ui = Ui_PostTaggingActions()
self.ui.setupUi(self)
self._reset_ui()
header = self.ui.table.horizontalHeader()
header.setSectionResizeMode(0, QtWidgets.QHeaderView.ResizeMode.Stretch)
for column in range(1, header.count()):
header.setSectionResizeMode(column, QtWidgets.QHeaderView.ResizeMode.ResizeToContents)
self.ui.add_file_path.clicked.connect(self._open_file_dialog)
self.ui.add_action.clicked.connect(self._add_action_to_table)
self.ui.remove_action.clicked.connect(self._remove_action_from_table)
self.ui.up.clicked.connect(self._move_action_up)
self.ui.down.clicked.connect(self._move_action_down)
self.get_table_columns_values = [
self.ui.action.text,
self.ui.wait.isChecked,
self.ui.tracks.isChecked,
self.ui.refresh.isChecked
]
def _open_file_dialog(self):
"""Adds the selected file's path to the command line text box.
"""
file = QtWidgets.QFileDialog.getOpenFileName(self)[0]
cursor_position = self.ui.action.cursorPosition()
current_text = self.ui.action.text()
if not sys.IS_WIN:
file = shlex.quote(file)
new_text = current_text[:cursor_position] + file + current_text[cursor_position:]
self.ui.action.setText(new_text)
def _reset_ui(self):
self.ui.action.setText("")
self.ui.wait.setChecked(False)
self.ui.refresh.setChecked(False)
self.ui.albums.setChecked(True)
def _add_action_to_table(self):
if not self.ui.action.text():
return
row_position = self.ui.table.rowCount()
self.ui.table.insertRow(row_position)
for column in range(self.ui.table.columnCount()):
value = self.get_table_columns_values[column]()
value = str(value)
widget = QtWidgets.QTableWidgetItem(value)
self.ui.table.setItem(row_position, column, widget)
self._reset_ui()
def _remove_action_from_table(self):
current_row = self.ui.table.currentRow()
if current_row != -1:
self.ui.table.removeRow(current_row)
def _move_action_up(self):
current_row = self.ui.table.currentRow()
new_row = current_row - 1
if current_row > 0:
self._swap_table_rows(current_row, new_row)
self.ui.table.setCurrentCell(new_row, 0)
def _move_action_down(self):
current_row = self.ui.table.currentRow()
new_row = current_row + 1
if current_row < self.ui.table.rowCount() - 1:
self._swap_table_rows(current_row, new_row)
self.ui.table.setCurrentCell(new_row, 0)
def _swap_table_rows(self, row1, row2):
for column in range(self.ui.table.columnCount()):
item1 = self.ui.table.takeItem(row1, column)
item2 = self.ui.table.takeItem(row2, column)
self.ui.table.setItem(row1, column, item2)
self.ui.table.setItem(row2, column, item1)
def load(self):
"""Puts the plugin's settings into the actions table.
"""
settings = zip(*[config.setting[name] for name in OPTIONS])
for row, values in enumerate(settings):
self.ui.table.insertRow(row)
for column in range(self.ui.table.columnCount()):
widget = QtWidgets.QTableWidgetItem(values[column])
self.ui.table.setItem(row, column, widget)
self.ui.cancel.setChecked(config.setting[CANCEL])
self.ui.max_workers.setValue(config.setting[MAX_WORKERS])
def save(self):
"""Saves the actions table items in the settings.
"""
settings = []
for column in range(self.ui.table.columnCount()):
settings.append([])
for row in range(self.ui.table.rowCount()):
setting = self.ui.table.item(row, column).text()
settings[column].append(setting)
config.setting[OPTIONS[column]] = settings[column]
config.setting[CANCEL] = self.ui.cancel.isChecked()
config.setting[MAX_WORKERS] = self.ui.max_workers.value()
action_loader.load_actions()
class ActionsStatus(QtWidgets.QWidget, Ui_ActionsStatus):
"""An icon and a label that displays the number of pending actions.
The widget is only visible when there are pending actions. This is placed
in the statusbar to the left of the other icons.
"""
def __init__(self):
QtWidgets.QWidget.__init__(self)
Ui_ActionsStatus.__init__(self)
self.setupUi(self)
self.hide()
# Creates the icon to the right of the label.
size = QtCore.QSize(16, 16)
icon = QtGui.QIcon(":/images/16x16/applications-system.png")
self.label.setPixmap(icon.pixmap(size))
def update_actions_count(self, count):
self.actions_count.setText(f"{count}")
self.setVisible(count > 0)
action_loader = ActionLoader()
action_runner = ActionRunner()
register_album_action(ExecuteAlbumActions())
register_track_action(ExecuteTrackActions())
register_options_page(PostTaggingActionsOptions)
================================================
FILE: plugins/post_tagging_actions/actions_status.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/post_tagging_actions/actions_status.ui'
#
# Created by: PyQt5 UI code generator 5.15.10
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtWidgets
class Ui_ActionsStatus(object):
def setupUi(self, ActionsStatus):
ActionsStatus.setObjectName("ActionsStatus")
ActionsStatus.resize(94, 18)
self.horizontalLayout = QtWidgets.QHBoxLayout(ActionsStatus)
self.horizontalLayout.setContentsMargins(0, 0, 0, 0)
self.horizontalLayout.setSpacing(2)
self.horizontalLayout.setObjectName("horizontalLayout")
self.actions_count = QtWidgets.QLabel(ActionsStatus)
self.actions_count.setMinimumSize(QtCore.QSize(35, 0))
self.actions_count.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)
self.actions_count.setObjectName("actions_count")
self.horizontalLayout.addWidget(self.actions_count)
self.label = QtWidgets.QLabel(ActionsStatus)
self.label.setText("")
self.label.setObjectName("label")
self.horizontalLayout.addWidget(self.label)
self.retranslateUi(ActionsStatus)
QtCore.QMetaObject.connectSlotsByName(ActionsStatus)
def retranslateUi(self, ActionsStatus):
_translate = QtCore.QCoreApplication.translate
ActionsStatus.setWindowTitle(_translate("ActionsStatus", "Form"))
self.actions_count.setText(_translate("ActionsStatus", "0"))
self.label.setToolTip(_translate("ActionsStatus", "Remaining Actions"))
================================================
FILE: plugins/post_tagging_actions/actions_status.ui
================================================
ActionsStatus
0
0
94
18
Form
2
0
0
0
0
-
35
0
0
Qt::AlignRight|Qt::AlignTrailing|Qt::AlignVCenter
-
Remaining Actions
================================================
FILE: plugins/post_tagging_actions/docs/guide.md
================================================
# Post Tagging Actions
This plugin lets you set up actions that run with a context menu click.
An action consists in a command line executed for each album or each track along with a few options to tweak the behaviour. This can be used to run external programs and pass some variables to it. Environment variables do not work.
To run the actions,
- First move the albums or tracks you are interested in to the right hand pane.
- Then highlight all the items you want the actions to run for.
- Right click, go to plugins, then click "Run Actions for highlighted albums/tracks".
### Adding an action
In the options page, you will find "Post Tagging Actions" under "Plugins". You will be greeted by this:

1. Enter the command to run in the text box, choose your options, then click "Add action".
2. You can click on "Add file" to search for a file and add its path to the text box.
3. Once you add an action, it will appear in the table at the bottom of the page. You can reorder actions with the arrows above the table.
## Options
- `Wait for process to finish` will make the next command in the queue execute only after this one has finished.
- `Refresh tags after process finishes` will reload the files once the command finishes. This is useful when an external program changes files' tags.
- `Execute for albums/tracks` lets you choose whether the command will be executed once for each track or each album highlighted.
The order of the actions in the table represents the order of execution: the top most action will be executed first.
## Variables
You can use variables in the commands just like in scripting. For example:
```
python /path/script.py --album %album% --artist %albumartist%
```
The variables `%album%` and `%albumartist%` will be replaced with their value for each album.
For actions that execute once per album, only variables in the album's metadata can be used. Same thing for actions that execute once per track, only variables in the track's metadata can be used.
### Special variables
There are also extra variables that can be used.
The following are used to get files' information:
- `%filepath%`: The full path of the file.
- `%folderpath%`: The path of the folder in which the file is located.
- `%filename%`: The name of the file, without the extension.
- `%filename_ext%`: The name of the file, with the extension.
- `%directory%`: The name of the folder in which the file is located.
When these are used with album actions, the first file found is considered. For example, if you keep all tracks in the same folder, using `%folderpath%` will give you the path to that folder.
The following apply to each album:
- `%gen_num_matched_tracks%`: The number of tracks which have a matching file.
- `%gen_num_unmatched_tracks%`: The number of tracks without any matching files.
- `%gen_num_total_files%`: The number of files added.
- `%gen_num_unsaed_files%`: The number of files that have unsaved changes.
- `%is_complete%`: "True" if every track is matched, "False" otherwise. (Shown with a gold disc in Picard)
- `%is_modified%`: "True" if the album has some changes to apply, "False" otherwise. (Shown with a red star on the disc)
When these are used with track actions, the album to which the track belongs to is considered.
================================================
FILE: plugins/post_tagging_actions/options_post_tagging_actions.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/post_tagging_actions/options_post_tagging_actions.ui'
#
# Created by: PyQt5 UI code generator 5.15.10
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtWidgets
class Ui_PostTaggingActions(object):
def setupUi(self, PostTaggingActions):
PostTaggingActions.setObjectName("PostTaggingActions")
PostTaggingActions.resize(638, 450)
PostTaggingActions.setMinimumSize(QtCore.QSize(100, 0))
self.verticalLayout = QtWidgets.QVBoxLayout(PostTaggingActions)
self.verticalLayout.setObjectName("verticalLayout")
self.scrollArea = QtWidgets.QScrollArea(PostTaggingActions)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, -70, 606, 502))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.vboxlayout = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.vboxlayout.setObjectName("vboxlayout")
self.action_widget = QtWidgets.QWidget(self.scrollAreaWidgetContents)
self.action_widget.setObjectName("action_widget")
self._2 = QtWidgets.QVBoxLayout(self.action_widget)
self._2.setObjectName("_2")
self.widget_2 = QtWidgets.QWidget(self.action_widget)
self.widget_2.setObjectName("widget_2")
self.horizontalLayout_3 = QtWidgets.QHBoxLayout(self.widget_2)
self.horizontalLayout_3.setObjectName("horizontalLayout_3")
self.label_3 = QtWidgets.QLabel(self.widget_2)
self.label_3.setObjectName("label_3")
self.horizontalLayout_3.addWidget(self.label_3)
self.add_file_path = QtWidgets.QPushButton(self.widget_2)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.add_file_path.sizePolicy().hasHeightForWidth())
self.add_file_path.setSizePolicy(sizePolicy)
self.add_file_path.setCheckable(False)
self.add_file_path.setObjectName("add_file_path")
self.horizontalLayout_3.addWidget(self.add_file_path)
self._2.addWidget(self.widget_2)
self.action = QtWidgets.QLineEdit(self.action_widget)
self.action.setObjectName("action")
self._2.addWidget(self.action)
self.wait = QtWidgets.QCheckBox(self.action_widget)
self.wait.setObjectName("wait")
self._2.addWidget(self.wait)
self.refresh = QtWidgets.QCheckBox(self.action_widget)
self.refresh.setObjectName("refresh")
self._2.addWidget(self.refresh)
self.widget_3 = QtWidgets.QWidget(self.action_widget)
self.widget_3.setObjectName("widget_3")
self.horizontalLayout_6 = QtWidgets.QHBoxLayout(self.widget_3)
self.horizontalLayout_6.setObjectName("horizontalLayout_6")
self.albums = QtWidgets.QRadioButton(self.widget_3)
self.albums.setObjectName("albums")
self.horizontalLayout_6.addWidget(self.albums)
self.tracks = QtWidgets.QRadioButton(self.widget_3)
self.tracks.setObjectName("tracks")
self.horizontalLayout_6.addWidget(self.tracks)
self._2.addWidget(self.widget_3)
self.vboxlayout.addWidget(self.action_widget)
self.table_commands = QtWidgets.QWidget(self.scrollAreaWidgetContents)
self.table_commands.setObjectName("table_commands")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout(self.table_commands)
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.widget = QtWidgets.QWidget(self.table_commands)
self.widget.setObjectName("widget")
self.horizontalLayout_5 = QtWidgets.QHBoxLayout(self.widget)
self.horizontalLayout_5.setObjectName("horizontalLayout_5")
self.add_action = QtWidgets.QPushButton(self.widget)
self.add_action.setObjectName("add_action")
self.horizontalLayout_5.addWidget(self.add_action)
self.remove_action = QtWidgets.QPushButton(self.widget)
self.remove_action.setObjectName("remove_action")
self.horizontalLayout_5.addWidget(self.remove_action)
self.horizontalLayout_2.addWidget(self.widget)
self.widget1 = QtWidgets.QWidget(self.table_commands)
self.widget1.setObjectName("widget1")
self.horizontalLayout_4 = QtWidgets.QHBoxLayout(self.widget1)
self.horizontalLayout_4.setObjectName("horizontalLayout_4")
self.up = QtWidgets.QToolButton(self.widget1)
self.up.setText("")
self.up.setArrowType(QtCore.Qt.UpArrow)
self.up.setObjectName("up")
self.horizontalLayout_4.addWidget(self.up)
self.down = QtWidgets.QToolButton(self.widget1)
self.down.setText("")
self.down.setArrowType(QtCore.Qt.DownArrow)
self.down.setObjectName("down")
self.horizontalLayout_4.addWidget(self.down)
self.horizontalLayout_2.addWidget(self.widget1, 0, QtCore.Qt.AlignRight)
self.vboxlayout.addWidget(self.table_commands)
self.table = QtWidgets.QTableWidget(self.scrollAreaWidgetContents)
self.table.setSizeAdjustPolicy(QtWidgets.QAbstractScrollArea.AdjustToContents)
self.table.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)
self.table.setSelectionMode(QtWidgets.QAbstractItemView.SingleSelection)
self.table.setSelectionBehavior(QtWidgets.QAbstractItemView.SelectRows)
self.table.setObjectName("table")
self.table.setColumnCount(4)
self.table.setRowCount(0)
item = QtWidgets.QTableWidgetItem()
self.table.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
self.table.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
self.table.setHorizontalHeaderItem(2, item)
item = QtWidgets.QTableWidgetItem()
self.table.setHorizontalHeaderItem(3, item)
self.table.horizontalHeader().setDefaultSectionSize(150)
self.vboxlayout.addWidget(self.table)
self.line = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.line.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line.setFrameShape(QtWidgets.QFrame.HLine)
self.line.setObjectName("line")
self.vboxlayout.addWidget(self.line)
self.frame = QtWidgets.QFrame(self.scrollAreaWidgetContents)
self.frame.setObjectName("frame")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.frame)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.cancel = QtWidgets.QCheckBox(self.frame)
self.cancel.setObjectName("cancel")
self.verticalLayout_2.addWidget(self.cancel)
self.widget_4 = QtWidgets.QWidget(self.frame)
self.widget_4.setObjectName("widget_4")
self.horizontalLayout = QtWidgets.QHBoxLayout(self.widget_4)
self.horizontalLayout.setObjectName("horizontalLayout")
self.max_workers = QtWidgets.QSpinBox(self.widget_4)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.max_workers.sizePolicy().hasHeightForWidth())
self.max_workers.setSizePolicy(sizePolicy)
self.max_workers.setMinimum(1)
self.max_workers.setMaximum(64)
self.max_workers.setObjectName("max_workers")
self.horizontalLayout.addWidget(self.max_workers)
self.label_2 = QtWidgets.QLabel(self.widget_4)
self.label_2.setObjectName("label_2")
self.horizontalLayout.addWidget(self.label_2)
self.verticalLayout_2.addWidget(self.widget_4)
self.label = QtWidgets.QLabel(self.frame)
self.label.setOpenExternalLinks(True)
self.label.setObjectName("label")
self.verticalLayout_2.addWidget(self.label)
self.vboxlayout.addWidget(self.frame)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(PostTaggingActions)
QtCore.QMetaObject.connectSlotsByName(PostTaggingActions)
def retranslateUi(self, PostTaggingActions):
_translate = QtCore.QCoreApplication.translate
PostTaggingActions.setWindowTitle(_translate("PostTaggingActions", "Form"))
self.label_3.setText(_translate("PostTaggingActions", "Insert action"))
self.add_file_path.setToolTip(_translate("PostTaggingActions", "Add a file path to the command line."))
self.add_file_path.setText(_translate("PostTaggingActions", "Add file"))
self.wait.setToolTip(_translate("PostTaggingActions", "If checked, the next action runs immediately."))
self.wait.setText(_translate("PostTaggingActions", " Wait for process to finish"))
self.refresh.setToolTip(_translate("PostTaggingActions", "If checked, the album will "refresh" after this action finishes.
"))
self.refresh.setText(_translate("PostTaggingActions", " Refresh tags after process finishes"))
self.albums.setToolTip(_translate("PostTaggingActions", "Makes the action execute once for each album tagged."))
self.albums.setText(_translate("PostTaggingActions", "Execute for albums"))
self.tracks.setToolTip(_translate("PostTaggingActions", "Makes the action run once for each track tagged."))
self.tracks.setText(_translate("PostTaggingActions", "Execute for tracks"))
self.add_action.setToolTip(_translate("PostTaggingActions", "Add the action at the bottom of the queue."))
self.add_action.setText(_translate("PostTaggingActions", "Add action"))
self.remove_action.setToolTip(_translate("PostTaggingActions", "Remove the selected action."))
self.remove_action.setText(_translate("PostTaggingActions", "Remove action"))
self.table.setToolTip(_translate("PostTaggingActions", "Actions at the top of the list run first. Use the buttons on the right to reorder the selected action."))
item = self.table.horizontalHeaderItem(0)
item.setText(_translate("PostTaggingActions", "Action"))
item = self.table.horizontalHeaderItem(1)
item.setText(_translate("PostTaggingActions", " Wait for exit "))
item = self.table.horizontalHeaderItem(2)
item.setText(_translate("PostTaggingActions", " Execute for tracks "))
item = self.table.horizontalHeaderItem(3)
item.setText(_translate("PostTaggingActions", " Refresh tags "))
self.cancel.setToolTip(_translate("PostTaggingActions", "If not checked, when Picard is closed, it will wait for the actions to finish in the background.
"))
self.cancel.setText(_translate("PostTaggingActions", "Cancel actions in the queue when Picard is closed"))
self.label_2.setToolTip(_translate("PostTaggingActions", "Sets the number of background threads executing the actions"))
self.label_2.setText(_translate("PostTaggingActions", " Maximum number of worker threads (Requires Picard restart)"))
self.label.setText(_translate("PostTaggingActions", "Hover over each item to know more, or take a peek at the user guide here.
"))
================================================
FILE: plugins/post_tagging_actions/options_post_tagging_actions.ui
================================================
PostTaggingActions
0
0
638
450
100
0
Form
-
QFrame::NoFrame
true
0
-70
606
502
-
-
-
Insert action
-
0
0
Add a file path to the command line.
Add file
false
-
-
If checked, the next action runs immediately.
Wait for process to finish
-
<html><head/><body><p>If checked, the album will "refresh" after this action finishes.</p></body></html>
Refresh tags after process finishes
-
-
Makes the action execute once for each album tagged.
Execute for albums
-
Makes the action run once for each track tagged.
Execute for tracks
-
-
-
Add the action at the bottom of the queue.
Add action
-
Remove the selected action.
Remove action
-
-
Qt::UpArrow
-
Qt::DownArrow
-
Actions at the top of the list run first. Use the buttons on the right to reorder the selected action.
QAbstractScrollArea::AdjustToContents
QAbstractItemView::NoEditTriggers
QAbstractItemView::SingleSelection
QAbstractItemView::SelectRows
150
Action
Wait for exit
Execute for tracks
Refresh tags
-
QFrame::Sunken
Qt::Horizontal
-
-
<html><head/><body><p>If <span style=" font-weight:700;">not </span>checked, when Picard is closed, it will wait for the actions to finish in the background.</p></body></html>
Cancel actions in the queue when Picard is closed
-
-
0
0
1
64
-
Sets the number of background threads executing the actions
Maximum number of worker threads (Requires Picard restart)
-
<html><head/><body><p>Hover over each item to know more, or take a peek at the user guide <a href="https://github.com/metabrainz/picard-plugins/tree/2.0/plugins/post_tagging_actions/docs/guide.md"><span style=" text-decoration: underline; color:#3584e4;">here.</span></a></p></body></html>
true
-
Qt::Vertical
20
40
================================================
FILE: plugins/release_type/release_type.py
================================================
PLUGIN_NAME = 'Release Type'
PLUGIN_AUTHOR = 'Elliot Chance'
PLUGIN_DESCRIPTION = 'Appends information to EPs and Singles'
PLUGIN_VERSION = '1.4'
PLUGIN_API_VERSIONS = ["0.9.0", "0.10", "0.15", "2.0"]
from picard.metadata import register_album_metadata_processor
RELEASE_TYPE_MAPPING = {
"ep": " EP",
"single": " (single)"
}
def add_release_type(tagger, metadata, release):
# make sure "EP" (or "single", ...) is not already a word in the name
words = metadata["album"].lower().split(" ")
for word in ["ep", "e.p.", "single", "(single)"]:
if word in words:
return
# check release type
for releasetype, text in RELEASE_TYPE_MAPPING.items():
if (metadata["~primaryreleasetype"] == releasetype) or (
metadata["releasetype"].startswith(releasetype)):
rs = text
break
else:
rs = ""
# append title
metadata["album"] = metadata["album"] + rs
register_album_metadata_processor(add_release_type)
================================================
FILE: plugins/releasetag_aggregations/releasetag_aggregations.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Release tag aggregation functions'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = ('Add functions to aggregate tags on a release:'
''
'- $album_all(name)
'
'- $album_avg(name, precision=2)
'
'- $album_max(name, precision=2)
'
'- $album_min(name, precision=2)
'
'- $album_mode(name)
'
'- $album_distinct(name, separator=; )
'
'- $album_multi_avg(name, precision=2)
'
'- $album_multi_max(name, precision=2)
'
'- $album_multi_min(name, precision=2)
'
'- $album_multi_mode(name)
'
'- $album_multi_distinct(name, separator=; )
'
'
'
'The functions work only in file naming scripts and '
'the files should either be part of a release or cluster!')
PLUGIN_VERSION = "0.4"
PLUGIN_API_VERSIONS = ["2.5", "2.6"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from functools import partial
from picard.cluster import Cluster
from picard.metadata import MULTI_VALUED_JOINER
from picard.script import script_function
from picard.script.parser import normalize_tagname
def get_parent_release(file):
if file.parent:
if isinstance(file.parent, Cluster):
return file.parent
elif hasattr(file.parent, 'album') and file.parent.album:
return file.parent.album
return None
def iter_release_values(name, file):
parent = get_parent_release(file)
if parent:
for file in parent.iterfiles(save=True):
yield file.metadata.get(name, '')
else:
yield file.metadata.get(name, '')
def iter_release_values_multi(name, file):
parent = get_parent_release(file)
if parent:
for file in parent.iterfiles(save=True):
yield from file.metadata.getall(name)
else:
yield from file.metadata.getall(name)
def try_iter_numeric(values, skip_non_numeric=False):
for value in values:
# First try treating the value as an integer, if this fails try float
try:
yield int(value)
except (TypeError, ValueError):
try:
yield float(value)
except (TypeError, ValueError):
if not skip_non_numeric:
yield value
def aggregate_release_tags(parser, name, aggregate_func, multi=False):
name = normalize_tagname(name)
file = parser.file
if file:
iter_func = iter_release_values_multi if multi else iter_release_values
return aggregate_func(iter_func(name, file))
else: # Nothing to aggregate, return base value
return parser.context.get(name, '')
def format_number(value, precision=2):
try:
precision = int(precision)
except (TypeError, ValueError):
precision = 0
if isinstance(value, int):
return str(value)
elif isinstance(value, float):
fmt = '{:.' + str(precision) + 'f}'
return fmt.format(value)
elif not value:
return ''
else:
return str(value)
def mode(values):
"""Returns the mode, the value with the most occurrences, from values."""
l = list(values)
if not l:
return ''
return max(set(l), key=l.count)
def average(values, precision=2):
"""Returns the arithmetic average of all numeric elements in values.
Non-numeric elements are ignored.
"""
numbers = list(try_iter_numeric(values, skip_non_numeric=True))
if not numbers:
return ''
return format_number(sum(numbers) / len(numbers), precision=precision)
def natsort_min(values, precision=2):
"""Returns the smallest value from values, treats numeric strings as numbers."""
return format_number(max(try_iter_numeric(values)), precision=precision)
def natsort_max(values, precision=2):
"""Returns the largest value from values, treats numeric strings as numbers."""
return format_number(max(try_iter_numeric(values)), precision=precision)
def distinct(values, separator=MULTI_VALUED_JOINER):
return separator.join(set(values))
@script_function(documentation="""`$album_all(name)`
Returns the value of the tag name if all files on the album have the same
value for this tag. Otherwise returns empty.
**Only works in File Naming scripts.**""")
def func_album_all(parser, name):
def aggregate_func(values):
common_value = ''
for value in values:
if not common_value:
common_value = value
if common_value != value:
return ''
return common_value
return aggregate_release_tags(parser, name, aggregate_func)
@script_function(documentation="""`$album_mode(name)`
Returns the value with the most occurrences over all the files on the release for the given tag.
**Only works in File Naming scripts.**""")
def func_album_mode(parser, name):
return aggregate_release_tags(parser, name, mode)
@script_function(documentation="""`$album_multi_mode(name)`
Returns the value with the most occurrences over all the files on the release for the given tag.
Similar to $album_mode(), but considers each value of multi-value tags separately.
**Only works in File Naming scripts.**""")
def func_album_multi_mode(parser, name):
return aggregate_release_tags(parser, name, mode, multi=True)
@script_function(documentation="""`$album_min(name, precision=2)`
Returns the minimum value of all the files on the release for the given tag.
**Only works in File Naming scripts.**""")
def func_album_min(parser, name, precision="2"):
aggregate_func = partial(natsort_min, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func)
@script_function(documentation="""`$album_multi_min(name, precision=2)`
Returns the minimum value of all the files on the release for the given tag.
Similar to $album_min(), but considers each value of multi-value tags separately.
**Only works in File Naming scripts.**""")
def releasetag_multi_min(parser, name, precision="2"):
aggregate_func = partial(natsort_min, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func, multi=True)
@script_function(documentation="""`$album_max(name, precision=2)`
Returns the maximum value of all the files on the release for the given tag.
**Only works in File Naming scripts.**""")
def func_album_max(parser, name, precision="2"):
aggregate_func = partial(natsort_max, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func)
@script_function(documentation="""`$album_multi_max(name, precision=2)`
Returns the maximum value of all the files on the release for the given tag.
Similar to $album_max(), but considers each value of multi-value tags separately.
**Only works in File Naming scripts.**""")
def releasetag_multi_max(parser, name, precision="2"):
aggregate_func = partial(natsort_max, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func, multi=True)
@script_function(documentation="""`$album_avg(name, precision=2)`
Returns the arithmetical average value of all the files on the release for the given tag.
Non-numeric values are ignored. Returns empty if no numeric value is present.
**Only works in File Naming scripts.**""")
def func_album_avg(parser, name, precision="2"):
aggregate_func = partial(average, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func)
@script_function(documentation="""`$album_multi_avg(name, precision=2)`
Returns the arithmetical average value of all the files on the release for the given tag.
Non-numeric values are ignored. Returns empty if no numeric value is present.
Similar to $album_avg(), but considers each value of multi-value tags separately.
**Only works in File Naming scripts.**""")
def func_album_multi_avg(parser, name, precision="2"):
aggregate_func = partial(average, precision=precision)
return aggregate_release_tags(parser, name, aggregate_func, multi=True)
@script_function(documentation="""`$album_distinct(name, separator=; )`
Returns a multi-value tag with all distinct values of tag across all the files on the release.
**Only works in File Naming scripts.**""")
def func_album_distinct(parser, name, separator=MULTI_VALUED_JOINER):
aggregate_func = partial(distinct, separator=separator)
return aggregate_release_tags(parser, name, aggregate_func)
@script_function(documentation="""`$album_multi_distinct(name, separator=; )`
Returns a multi-value tag with all distinct values of tag across all the files on the release.
Similar to $album_distinct(), but considers each value of multi-value tags separately.
**Only works in File Naming scripts.**""")
def func_album_multi_distinct(parser, name, separator=MULTI_VALUED_JOINER):
aggregate_func = partial(distinct, separator=separator)
return aggregate_release_tags(parser, name, aggregate_func, multi=True)
================================================
FILE: plugins/remove_perfect_albums/remove_perfect_albums.py
================================================
PLUGIN_NAME = 'Remove Perfect Albums'
PLUGIN_AUTHOR = 'ichneumon, hrglgrmpf'
PLUGIN_DESCRIPTION = '''Remove all perfectly matched albums from the selection.'''
PLUGIN_VERSION = '0.3'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from PyQt5.QtCore import QCoreApplication
from picard.album import Album
from picard.ui.itemviews import BaseAction, register_album_action
class RemovePerfectAlbums(BaseAction):
NAME = 'Remove perfect albums'
def callback(self, objs):
for album in objs:
if (isinstance(album, Album) and album.loaded
and album.is_complete() and album.get_num_unsaved_files() == 0):
self.tagger.remove_album(album)
QCoreApplication.processEvents()
register_album_action(RemovePerfectAlbums())
================================================
FILE: plugins/reorder_sides/reorder_sides.py
================================================
# MusicBrainz Picard plugin to re-order sides of a release.
# Copyright (C) 2016 David Mandelberg
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see .
PLUGIN_NAME = 'Re-order sides of a release'
PLUGIN_AUTHOR = 'David Mandelberg, Sambhav Kothari'
PLUGIN_DESCRIPTION = """\
Split mediums and re-order sides to match side order rather than
medium order. E.g., if a release has two mediums with track numbers
A1, A2, ..., D1, D2, ... and B1, B2, ..., C1, C2,
..., this plugin will split the release into four mediums and
reorder the new mediums so that the track numbers are A1, A2,
..., B1, B2, ..., C1, C2, ..., D1, D2, ...
This is primarily intended to make vinyl records designed for record
changers
(https://en.wikipedia.org/wiki/Record_changer#Automatic_sequencing)
play in the correct order."""
PLUGIN_VERSION = '1.2'
PLUGIN_API_VERSIONS = ['2.0']
PLUGIN_LICENSE = 'GPL-3.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-3.0.html'
import collections
from picard.metadata import \
register_album_metadata_processor, register_track_metadata_processor
# List of strings that represent the medium side of a track when the
# track number is one of these strings followed by digits. The order of
# this list specifies the order of the sides.
SIDE_PREFIXES = [
'A',
'B',
'C',
'D',
'E',
'F',
'G',
'H',
'I',
'J',
'K',
'L',
'M',
'N',
'O',
'P',
'Q',
'R',
'S',
'T',
'U',
'V',
'W',
'X',
'Y',
'Z',
]
# Map from release MBID to information that we can use to re-group and
# re-order the tracks. The per-release info (value of this map) is an
# OrderedDict mapping side name to a sequence of (discnumber of the
# side, first tracknumber of the side, last tracknumber of the side).
# The order of the OrderedDict specifies the intended order of the
# sides.
release_to_side_info = {}
def tracknumber_to_side(tracknumber):
"""Given a track "number", return the side, or None"""
for side_prefix in SIDE_PREFIXES:
if not tracknumber.startswith(side_prefix):
continue
number_in_side = tracknumber[len(side_prefix):]
try:
int(number_in_side)
except ValueError:
continue
return side_prefix
return None
def get_side_info(release):
"""Return side info (see release_to_side_info), or None if we don't
want to reorder the sides."""
side_info = collections.OrderedDict()
for medium in release['media']:
current_side = None
for track in medium['tracks']:
tracknumber = track['number']
trackside = tracknumber_to_side(tracknumber)
try:
int_tracknumber = int(track['position'])
except ValueError:
# Non-integer tracknumber, so give up.
return None
if trackside is None:
# If any track has no side information, we don't reorder
# anything.
return None
if current_side is not None and current_side == trackside:
# Another track of the same side as before, so just update the
# last tracknumber for this side.
if int_tracknumber > side_info[current_side][2]:
side_info[current_side][2] = int_tracknumber
continue
# At this point, we're on the first track of a new side.
current_side = trackside
if current_side in side_info:
# We've already seen this side somewhere else, so give up.
return None
try:
side_info[current_side] = [
int(medium['position']),
int_tracknumber,
int_tracknumber,
]
except ValueError:
# Non-integer position, so give up.
return None
# At this point, we know that all tracknumbers include side
# information, and no sides appear in more than one place (every
# side is contiguous).
sides_in_order_of_appearance = list(side_info.keys())
sides_in_intended_order = sorted(
sides_in_order_of_appearance,
key=lambda s: SIDE_PREFIXES.index(s),
)
if sides_in_order_of_appearance == sides_in_intended_order:
# Sides are already in the right order, so we don't need to do
# anything.
return None
# Re-order side_info to match the intended order.
side_info_ordered = collections.OrderedDict()
for side in sides_in_intended_order:
side_info_ordered[side] = side_info[side]
side_info = side_info_ordered
return side_info
def find_side(side_info, metadata):
"""Given side info and track metadata, return the side that the
track belongs to."""
orig_discnumber = int(metadata['discnumber'])
orig_tracknumber = int(metadata['tracknumber'])
for side_item in side_info.items():
(
side,
(
side_discnumber,
side_first_tracknumber,
side_last_tracknumber,
),
) = side_item
if side_discnumber == orig_discnumber \
and side_first_tracknumber <= orig_tracknumber \
and orig_tracknumber <= side_last_tracknumber:
return side
raise RuntimeError('Unable to find side for track: ' + metadata)
def analyze_release(tagger, metadata, release):
"""Analyze a release to determine if its sides should be
re-ordered"""
side_info = get_side_info(release)
if side_info is not None:
release_to_side_info[metadata['musicbrainz_albumid']] = side_info
register_album_metadata_processor(analyze_release)
def reorder_sides(tagger, metadata, *args):
"""Re-order sides of a release, using the information in
release_to_side_info."""
if metadata['musicbrainz_albumid'] not in release_to_side_info:
return
side_info = release_to_side_info[metadata['musicbrainz_albumid']]
all_sides = list(side_info.keys())
side = find_side(side_info, metadata)
side_first_tracknumber = side_info[side][1]
side_last_tracknumber = side_info[side][2]
metadata['totaldiscs'] = str(len(all_sides))
metadata['discnumber'] = str(all_sides.index(side) + 1)
metadata['totaltracks'] = \
str(side_last_tracknumber - side_first_tracknumber + 1)
metadata['tracknumber'] = \
str(int(metadata['tracknumber']) - side_first_tracknumber + 1)
register_track_metadata_processor(reorder_sides)
================================================
FILE: plugins/replace_forbidden_symbols/replace_forbidden_symbols.py
================================================
# -*- coding: utf-8 -*-
# Copyright (C) 2019 Alex Rustler
#
# This program is free software: you can redistribute it and/or modify it under
# the terms of the GNU General Public License as published by the Free Software
# Foundation, either version 3 of the License, or (at your option) any later
# version.
#
# This program is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
# details.
#
# You should have received a copy of the GNU General Public License along with
# this program. If not, see .
from picard import metadata
from picard.script import register_script_function
PLUGIN_NAME = "Replace Forbidden Symbols"
PLUGIN_AUTHOR = "Alex Rustler "
PLUGIN_VERSION = "0.3"
PLUGIN_API_VERSIONS = ["0.9", "0.10", "0.11", "0.15", "2.0", "2.2"]
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://gnu.org/licenses/gpl.html"
PLUGIN_DESCRIPTION = '''Replaces Windows forbidden symbols: :, /, *, ?, ", ., | etc.
with a similar UNICODE version.
Currently replaces characters on "album", "artist",
"title", "albumartist", "releasetype", "label" tags.
Also add $replace_forbidden() function for Tagger.
Example: $set(composer,$script_forbidden(%composer%))
'''
CHAR_TABLE = {
# forbidden
":": "∶",
"/": "⁄",
"*": "∗",
"?": "?",
'"': '″',
'\\': '⧵',
'.': '․',
'|': 'ǀ',
'<': '‹',
'>': '›'
}
FILTER_TAGS = [
"album",
"artist",
"title",
"albumartist",
"releasetype",
"label",
]
def sanitize(char):
if char in CHAR_TABLE:
return CHAR_TABLE[char]
return char
def fix_forbidden(word):
return "".join(sanitize(char) for char in word)
def replace_forbidden(value):
return [fix_forbidden(x) for x in value]
def script_replace_forbidden(parser, value):
return fix_forbidden(value)
def main(tagger, metadata, *args):
for name, value in metadata.rawitems():
if name in FILTER_TAGS:
metadata[name] = replace_forbidden(value)
metadata.register_track_metadata_processor(main)
metadata.register_album_metadata_processor(main)
register_script_function(script_replace_forbidden, name="replace_forbidden")
================================================
FILE: plugins/replaygain2/__init__.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "ReplayGain 2.0"
PLUGIN_AUTHOR = "complexlogic"
PLUGIN_DESCRIPTION = '''
Calculates ReplayGain information for tracks and albums according to the
[ReplayGain 2.0 specification](https://wiki.hydrogenaud.io/index.php?title=ReplayGain_2.0_specification).
This plugin depends on the ReplayGain utility [rsgain](https://github.com/complexlogic/rsgain). Users
are required to install rsgain and set its path in the plugin settings before use.
#### Usage
Select one or more tracks, albums, or clusters then right click and select Plugin->Calculate ReplayGain.
The plugin will calculate ReplayGain information for the selected items and display the results in the
metadata window. Click the save button to write the tags to file.
The following file formats are supported:
- MP3 (.mp3)
- FLAC (.flac)
- Ogg (.ogg, .oga, spx)
- Opus (.opus)
- MPEG-4 Audio (.m4a, .mp4)
- Wavpack (.wv)
- Monkey's Audio (.ape)
- WMA (.wma)
- MP2 (.mp2)
- WAV (.wav)
- AIFF (.aiff)
- TAK (.tak)
- MusePack *(Stream Version 8 only)* (.mpc)
This plugin is based on the original ReplayGain plugin by Philipp Wolfer and Sophist.
'''
PLUGIN_VERSION = "1.8"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from enum import IntEnum
from functools import partial
import subprocess # nosec: B404
import shutil
import os
from PyQt5.QtWidgets import QFileDialog
from picard import log
from picard.formats import (
AiffFile,
ASFFile,
FLACFile,
MonkeysAudioFile,
MP3File,
MP4File,
MusepackFile,
OggFLACFile,
OggOpusFile,
OggSpeexFile,
OggTheoraFile,
OggVorbisFile,
TAKFile,
WAVFile,
WavPackFile,
)
from picard.album import Album
from picard.track import Track, NonAlbumTrack
from picard.file import File
from picard.cluster import Cluster
from picard.util import thread
from picard.ui.options import register_options_page, OptionsPage
from picard.config import TextOption, BoolOption, IntOption, config
from picard.ui.itemviews import (BaseAction, register_track_action,
register_album_action, register_cluster_action)
from picard.plugins.replaygain2.ui_options_replaygain2 import Ui_ReplayGain2OptionsPage
CLIP_MODE_DISABLED = 0
CLIP_MODE_POSITIVE = 1
CLIP_MODE_ALWAYS = 2
CLIP_MODE_MAP = (
"n",
"p",
"a"
)
SUPPORTED_FORMATS = (
AiffFile,
ASFFile,
FLACFile,
MonkeysAudioFile,
MP3File,
MP4File,
MusepackFile,
OggFLACFile,
OggOpusFile,
OggSpeexFile,
OggTheoraFile,
OggVorbisFile,
TAKFile,
WAVFile,
WavPackFile,
)
TABLE_HEADER = (
"filename",
"loudness",
"gain",
"peak",
"peak_db",
"peak_type",
"clipping_adjustment"
)
TAGS = (
"replaygain_album_gain",
"replaygain_album_peak",
"replaygain_album_range",
"replaygain_reference_loudness",
"replaygain_track_gain",
"replaygain_track_peak",
"replaygain_track_range",
"r128_album_gain",
"r128_track_gain"
)
class OpusMode(IntEnum):
STANDARD = 0
R128 = 1
BOTH = 2
# Make sure the rsgain executable exists
def rsgain_found(rsgain_command, window):
if not os.path.exists(rsgain_command) and shutil.which(rsgain_command) is None:
window.set_statusbar_message("Failed to locate rsgain. Enter the path in the plugin settings.")
return False
return True
# Convert Picard settings dict to rsgain command line options
def build_options(config):
options = ["custom", "-O", "-s", "s"]
if (config.setting["album_tags"]):
options.append("-a")
if (config.setting["true_peak"]):
options.append("-t")
options += ["-l", str(config.setting["target_loudness"])]
options += ["-c", CLIP_MODE_MAP[config.setting["clip_mode"]]]
options += ["-m", str(config.setting["max_peak"])]
return options
# Convert table row to result dict
def parse_result(line):
result = dict()
columns = line.split("\t")
if len(columns) != len(TABLE_HEADER):
return None
for i, column in enumerate(columns):
result[TABLE_HEADER[i]] = column
return result
# Format the gain as a Q7.8 fixed point number per RFC 7845
# see: https://datatracker.ietf.org/doc/html/rfc7845
def format_r128(result, config):
gain = float(result["gain"])
if config.setting["opus_m23"]:
gain += float(-23 - config.setting["target_loudness"])
return str(int(round(gain * 256.0)))
def update_metadata(metadata, track_result, album_result, is_nat, opus_mode):
for tag in TAGS:
metadata.delete(tag)
# Opus R128 tags
if opus_mode in (OpusMode.R128, OpusMode.BOTH):
metadata.set("r128_track_gain", format_r128(track_result, config))
if album_result is not None:
metadata.set("r128_album_gain", format_r128(album_result, config))
# Standard ReplayGain tags
if opus_mode in (OpusMode.STANDARD, OpusMode.BOTH):
metadata.set("replaygain_track_gain", track_result["gain"] + " dB")
metadata.set("replaygain_track_peak", track_result["peak"])
if config.setting["album_tags"]:
if is_nat:
metadata.set("replaygain_album_gain", track_result["gain"] + " dB")
metadata.set("replaygain_album_peak", track_result["peak"])
elif album_result is not None:
metadata.set("replaygain_album_gain", album_result["gain"] + " dB")
metadata.set("replaygain_album_peak", album_result["peak"])
if config.setting["reference_loudness"]:
metadata.set("replaygain_reference_loudness", f"{float(config.setting['target_loudness']):.2f} LUFS")
def calculate_replaygain(input_objs, options):
# Make sure files are of supported type, build file list
files = list()
valid_list = list()
for obj in input_objs:
if isinstance(obj, Track):
if not obj.files:
continue
file = obj.files[0]
elif isinstance(obj, File):
file = obj
else:
raise Exception(f"ReplayGain 2.0: Object {obj} is not a Track or File")
if not isinstanceany(file, SUPPORTED_FORMATS):
raise Exception(f"ReplayGain 2.0: File '{file.filename}' is of unsupported format")
files.append(file.filename)
valid_list.append(obj)
call = [config.setting["rsgain_command"]] + options + files
for item in call:
item.encode("utf-8")
# Prevent an unwanted console spawn in Windows
si = None
if (os.name == "nt"):
si = subprocess.STARTUPINFO()
si.dwFlags = subprocess.STARTF_USESHOWWINDOW
si.wShowWindow = subprocess.SW_HIDE
# Execute the scan with rsgain
lines = list()
with subprocess.Popen( # nosec: B603
call,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
startupinfo=si,
encoding="utf-8",
text=True
) as process:
(output, _unused) = process.communicate()
rc = process.poll()
if rc:
raise Exception(f'ReplayGain 2.0: rsgain returned non-zero code ({rc})')
log.debug(output)
lines = output.splitlines()
album_tags = config.setting["album_tags"]
# Make sure the number of rows in the output is what we expected
if (len(lines) !=
1 # Table header
+ len(valid_list) # 1 row per track
+ 1 if album_tags else 0): # Album result
raise Exception(f"ReplayGain 2.0: Unexpected output from rsgain: {lines}")
lines.pop(0) # Don't care about the table header
# Parse album result
album_result = None
if album_tags:
album_result = parse_result(lines[-1])
lines.pop(-1)
# Parse track results
results = list()
for line in lines:
result = parse_result(line)
if result is None:
raise Exception("ReplayGain 2.0: Failed to parse result")
results.append(result)
# Update track metadata with results
for i, item in enumerate(valid_list):
if isinstance(item, Track):
filelist = item.files
else: # is a file
filelist = [item]
for file in filelist:
if isinstance(file, OggOpusFile):
opus_mode = config.setting["opus_mode"]
else:
opus_mode = OpusMode.STANDARD
update_metadata(
file.metadata,
results[i],
album_result,
isinstance(item, NonAlbumTrack),
opus_mode
)
def isinstanceany(obj, types):
return any(isinstance(obj, t) for t in types)
class ScanCluster(BaseAction):
NAME = "Calculate Cluster Replay&Gain as Album..."
def callback(self, objs):
if not rsgain_found(self.config.setting["rsgain_command"], self.tagger.window):
return
clusters = list(filter(lambda o: isinstance(o, Cluster), objs))
self.options = build_options(self.config)
num_clusters = len(clusters)
if num_clusters == 1:
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for %s...', clusters[0].metadata['album']
)
else:
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for %i clusters...', num_clusters
)
for cluster in clusters:
thread.run_task(
partial(calculate_replaygain, cluster.files, self.options),
partial(self._replaygain_callback, cluster.files)
)
def _replaygain_callback(self, files, result=None, error=None):
if error is None:
for file in files:
file.update()
self.tagger.window.set_statusbar_message('ReplayGain successfully calculated.')
else:
self.tagger.window.set_statusbar_message('Could not calculate ReplayGain.')
class ScanTracks(BaseAction):
NAME = "Calculate Replay&Gain..."
def callback(self, objs):
if not rsgain_found(self.config.setting["rsgain_command"], self.tagger.window):
return
tracks = list(filter(lambda o: isinstance(o, Track), objs))
self.options = build_options(self.config)
num_tracks = len(tracks)
if num_tracks == 1:
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for %s...', {tracks[0].files[0].filename}
)
else:
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for %i tracks...', num_tracks
)
thread.run_task(
partial(calculate_replaygain, tracks, self.options),
partial(self._replaygain_callback, tracks)
)
def _replaygain_callback(self, tracks, result=None, error=None):
if error is None:
for track in tracks:
for file in track.files:
file.update()
track.update()
self.tagger.window.set_statusbar_message('ReplayGain successfully calculated.')
else:
self.tagger.window.set_statusbar_message('Could not calculate ReplayGain.')
class ScanAlbums(BaseAction):
NAME = "Calculate Replay&Gain..."
def callback(self, objs):
if not rsgain_found(self.config.setting["rsgain_command"], self.tagger.window):
return
self.options = build_options(self.config)
albums = list(filter(lambda o: isinstance(o, Album), objs))
self.num_albums = len(albums)
self.current = 0
if (self.num_albums == 1):
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for "%s"...', albums[0].metadata['album']
)
else:
self.tagger.window.set_statusbar_message(
'Calculating ReplayGain for %i albums...', self.num_albums
)
for album in albums:
thread.run_task(
partial(calculate_replaygain, album.tracks, self.options),
partial(self._albumgain_callback, album)
)
def _format_progress(self):
if self.num_albums == 1:
return ""
else:
self.current += 1
return f" ({self.current}/{self.num_albums})"
def _albumgain_callback(self, album, result=None, error=None):
progress = self._format_progress()
if error is None:
for track in album.tracks:
for file in track.files:
file.update()
track.update()
album.update()
self.tagger.window.set_statusbar_message(
'Successfully calculated ReplayGain for "%(album)s"%(progress)s.',
{
'album': album.metadata['album'],
'progress': progress,
}
)
else:
self.tagger.window.set_statusbar_message(
'Failed to calculate ReplayGain for "%(album)s"%(progress)s.',
{
'album': album.metadata['album'],
'progress': progress,
}
)
class ReplayGain2OptionsPage(OptionsPage):
NAME = "replaygain2"
TITLE = "ReplayGain 2.0"
PARENT = "plugins"
options = [
TextOption("setting", "rsgain_command", "rsgain"),
BoolOption("setting", "album_tags", True),
BoolOption("setting", "true_peak", False),
BoolOption("setting", "reference_loudness", False),
IntOption("setting", "target_loudness", -18),
IntOption("setting", "clip_mode", CLIP_MODE_POSITIVE),
IntOption("setting", "max_peak", 0),
IntOption("setting", "opus_mode", OpusMode.STANDARD),
BoolOption("setting", "opus_m23", False)
]
def __init__(self, parent=None):
super(ReplayGain2OptionsPage, self).__init__(parent)
self.ui = Ui_ReplayGain2OptionsPage()
self.ui.setupUi(self)
self.ui.clip_mode.addItems([
"Disabled",
"Enabled for positive gain values only",
"Always enabled"
])
self.ui.opus_mode.addItems([
"Write standard ReplayGain tags",
"Write R128_*_GAIN tags",
"Write both standard and R128 tags"
])
self.ui.rsgain_command_browse.clicked.connect(self.rsgain_command_browse)
def load(self):
self.ui.rsgain_command.setText(self.config.setting["rsgain_command"])
self.ui.album_tags.setChecked(self.config.setting["album_tags"])
self.ui.true_peak.setChecked(self.config.setting["true_peak"])
self.ui.reference_loudness.setChecked(self.config.setting["reference_loudness"])
self.ui.target_loudness.setValue(self.config.setting["target_loudness"])
self.ui.clip_mode.setCurrentIndex(self.config.setting["clip_mode"])
self.ui.max_peak.setValue(self.config.setting["max_peak"])
self.ui.opus_mode.setCurrentIndex(self.config.setting["opus_mode"])
self.ui.opus_m23.setChecked(self.config.setting["opus_m23"])
def save(self):
self.config.setting["rsgain_command"] = self.ui.rsgain_command.text()
self.config.setting["album_tags"] = self.ui.album_tags.isChecked()
self.config.setting["true_peak"] = self.ui.true_peak.isChecked()
self.config.setting["reference_loudness"] = self.ui.reference_loudness.isChecked()
self.config.setting["target_loudness"] = self.ui.target_loudness.value()
self.config.setting["clip_mode"] = self.ui.clip_mode.currentIndex()
self.config.setting["max_peak"] = self.ui.max_peak.value()
self.config.setting["opus_mode"] = self.ui.opus_mode.currentIndex()
self.config.setting["opus_m23"] = self.ui.opus_m23.isChecked()
def rsgain_command_browse(self):
path, _filter = QFileDialog.getOpenFileName(self, "", self.ui.rsgain_command.text())
if path:
path = os.path.normpath(path)
self.ui.rsgain_command.setText(path)
register_track_action(ScanTracks())
register_album_action(ScanAlbums())
register_cluster_action(ScanCluster())
register_options_page(ReplayGain2OptionsPage)
================================================
FILE: plugins/replaygain2/ui_options_replaygain2.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/replaygain2/ui_options_replaygain2.ui'
#
# Created by: PyQt5 UI code generator 5.15.10
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_ReplayGain2OptionsPage(object):
def setupUi(self, ReplayGain2OptionsPage):
ReplayGain2OptionsPage.setObjectName("ReplayGain2OptionsPage")
ReplayGain2OptionsPage.resize(477, 577)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(ReplayGain2OptionsPage.sizePolicy().hasHeightForWidth())
ReplayGain2OptionsPage.setSizePolicy(sizePolicy)
self.vboxlayout = QtWidgets.QVBoxLayout(ReplayGain2OptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.replay_gain = QtWidgets.QGroupBox(ReplayGain2OptionsPage)
self.replay_gain.setObjectName("replay_gain")
self.vboxlayout1 = QtWidgets.QVBoxLayout(self.replay_gain)
self.vboxlayout1.setContentsMargins(9, 9, 9, 9)
self.vboxlayout1.setSpacing(2)
self.vboxlayout1.setObjectName("vboxlayout1")
self.label = QtWidgets.QLabel(self.replay_gain)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label.setFont(font)
self.label.setObjectName("label")
self.vboxlayout1.addWidget(self.label)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.rsgain_command = QtWidgets.QLineEdit(self.replay_gain)
self.rsgain_command.setObjectName("rsgain_command")
self.horizontalLayout.addWidget(self.rsgain_command)
self.rsgain_command_browse = QtWidgets.QToolButton(self.replay_gain)
self.rsgain_command_browse.setObjectName("rsgain_command_browse")
self.horizontalLayout.addWidget(self.rsgain_command_browse)
self.vboxlayout1.addLayout(self.horizontalLayout)
self.label_6 = QtWidgets.QLabel(self.replay_gain)
self.label_6.setOpenExternalLinks(True)
self.label_6.setTextInteractionFlags(QtCore.Qt.TextBrowserInteraction)
self.label_6.setObjectName("label_6")
self.vboxlayout1.addWidget(self.label_6)
self.album_tags = QtWidgets.QCheckBox(self.replay_gain)
self.album_tags.setChecked(True)
self.album_tags.setObjectName("album_tags")
self.vboxlayout1.addWidget(self.album_tags)
self.true_peak = QtWidgets.QCheckBox(self.replay_gain)
self.true_peak.setObjectName("true_peak")
self.vboxlayout1.addWidget(self.true_peak)
self.reference_loudness = QtWidgets.QCheckBox(self.replay_gain)
self.reference_loudness.setObjectName("reference_loudness")
self.vboxlayout1.addWidget(self.reference_loudness)
self.label_5 = QtWidgets.QLabel(self.replay_gain)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_5.setFont(font)
self.label_5.setObjectName("label_5")
self.vboxlayout1.addWidget(self.label_5)
self.target_loudness = QtWidgets.QSpinBox(self.replay_gain)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.target_loudness.sizePolicy().hasHeightForWidth())
self.target_loudness.setSizePolicy(sizePolicy)
self.target_loudness.setMinimum(-30)
self.target_loudness.setMaximum(-5)
self.target_loudness.setProperty("value", -18)
self.target_loudness.setObjectName("target_loudness")
self.vboxlayout1.addWidget(self.target_loudness)
self.label_2 = QtWidgets.QLabel(self.replay_gain)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_2.setFont(font)
self.label_2.setObjectName("label_2")
self.vboxlayout1.addWidget(self.label_2)
self.clip_mode = QtWidgets.QComboBox(self.replay_gain)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.clip_mode.sizePolicy().hasHeightForWidth())
self.clip_mode.setSizePolicy(sizePolicy)
self.clip_mode.setMaxCount(3)
self.clip_mode.setObjectName("clip_mode")
self.vboxlayout1.addWidget(self.clip_mode)
self.label_3 = QtWidgets.QLabel(self.replay_gain)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Maximum, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.label_3.sizePolicy().hasHeightForWidth())
self.label_3.setSizePolicy(sizePolicy)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_3.setFont(font)
self.label_3.setObjectName("label_3")
self.vboxlayout1.addWidget(self.label_3)
self.max_peak = QtWidgets.QSpinBox(self.replay_gain)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.max_peak.sizePolicy().hasHeightForWidth())
self.max_peak.setSizePolicy(sizePolicy)
self.max_peak.setMinimum(-5)
self.max_peak.setMaximum(0)
self.max_peak.setObjectName("max_peak")
self.vboxlayout1.addWidget(self.max_peak)
self.label_4 = QtWidgets.QLabel(self.replay_gain)
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
self.label_4.setFont(font)
self.label_4.setObjectName("label_4")
self.vboxlayout1.addWidget(self.label_4)
self.opus_mode = QtWidgets.QComboBox(self.replay_gain)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.opus_mode.sizePolicy().hasHeightForWidth())
self.opus_mode.setSizePolicy(sizePolicy)
self.opus_mode.setMaxCount(3)
self.opus_mode.setObjectName("opus_mode")
self.vboxlayout1.addWidget(self.opus_mode)
self.opus_m23 = QtWidgets.QCheckBox(self.replay_gain)
self.opus_m23.setObjectName("opus_m23")
self.vboxlayout1.addWidget(self.opus_m23)
self.vboxlayout.addWidget(self.replay_gain)
spacerItem = QtWidgets.QSpacerItem(263, 21, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.retranslateUi(ReplayGain2OptionsPage)
self.opus_mode.setCurrentIndex(-1)
QtCore.QMetaObject.connectSlotsByName(ReplayGain2OptionsPage)
def retranslateUi(self, ReplayGain2OptionsPage):
_translate = QtCore.QCoreApplication.translate
self.replay_gain.setTitle(_translate("ReplayGain2OptionsPage", "ReplayGain 2.0 Settings"))
self.label.setText(_translate("ReplayGain2OptionsPage", "Path to rsgain:"))
self.rsgain_command.setText(_translate("ReplayGain2OptionsPage", "rsgain"))
self.rsgain_command_browse.setText(_translate("ReplayGain2OptionsPage", "Browse..."))
self.label_6.setText(_translate("ReplayGain2OptionsPage", "Download rsgain"))
self.album_tags.setText(_translate("ReplayGain2OptionsPage", "Calculate album gain/peak"))
self.true_peak.setWhatsThis(_translate("ReplayGain2OptionsPage", "Use more accurate true peak calculations (trade for performance)"))
self.true_peak.setText(_translate("ReplayGain2OptionsPage", "Use true peak"))
self.reference_loudness.setText(_translate("ReplayGain2OptionsPage", "Write reference loudness tags"))
self.label_5.setText(_translate("ReplayGain2OptionsPage", "Target Loudness (LUFS)"))
self.label_2.setText(_translate("ReplayGain2OptionsPage", "Clipping Protection"))
self.label_3.setText(_translate("ReplayGain2OptionsPage", "Max Peak (dB)"))
self.label_4.setText(_translate("ReplayGain2OptionsPage", "Opus Files"))
self.opus_m23.setText(_translate("ReplayGain2OptionsPage", "Always reference Opus R128_*_GAIN tags to -23 LUFS"))
================================================
FILE: plugins/replaygain2/ui_options_replaygain2.ui
================================================
ReplayGain2OptionsPage
0
0
477
577
0
0
6
9
9
9
9
-
ReplayGain 2.0 Settings
2
9
9
9
9
-
75
true
Path to rsgain:
-
-
rsgain
-
Browse...
-
<a href="https://github.com/complexlogic/rsgain">Download rsgain</a>
true
Qt::TextBrowserInteraction
-
Calculate album gain/peak
true
-
Use more accurate true peak calculations (trade for performance)
Use true peak
-
Write reference loudness tags
-
75
true
Target Loudness (LUFS)
-
0
0
-30
-5
-18
-
75
true
Clipping Protection
-
0
0
3
-
0
0
75
true
Max Peak (dB)
-
0
0
-5
0
-
75
true
Opus Files
-
0
0
-1
3
-
Always reference Opus R128_*_GAIN tags to -23 LUFS
-
Qt::Vertical
263
21
================================================
FILE: plugins/save_and_rewrite_header/save_and_rewrite_header.py
================================================
#!/usr/bin/python
# -*- coding: utf-8 -*-
#
# This source code is a plugin for MusicBrainz Picard.
# It adds a context menu action to save files and rewrite their header.
# Copyright (C) 2015 Nicolas Cenerario
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see .
from __future__ import unicode_literals
PLUGIN_NAME = "Save and rewrite header"
PLUGIN_AUTHOR = "Nicolas Cenerario"
PLUGIN_DESCRIPTION = "This plugin adds a context menu action to save files and rewrite their header."
PLUGIN_VERSION = "0.3"
PLUGIN_API_VERSIONS = ["0.9.0", "0.10", "0.15", "2.0"]
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "http://www.gnu.org/licenses/gpl-3.0.txt"
from _functools import partial
from mutagen import File as MFile
from picard.ui.itemviews import (BaseAction, register_album_action,
register_cluster_action,
register_clusterlist_action,
register_track_action, register_file_action)
from picard.metadata import Metadata
from picard.util import thread
class save_and_rewrite_header(BaseAction):
NAME = "Save and rewrite header"
def __init__(self):
super(save_and_rewrite_header, self).__init__()
register_file_action(self)
register_track_action(self)
register_album_action(self)
register_cluster_action(self)
register_clusterlist_action(self)
def callback(self, obj):
def save(pf):
metadata = Metadata()
metadata.copy(pf.metadata)
mf = MFile(pf.filename)
if mf is not None:
mf.delete()
return pf._save_and_rename(pf.filename, metadata)
for f in self.tagger.get_files_from_objects(obj, save=True):
f.set_pending()
thread.run_task(partial(save, f), f._saving_finished,
priority=2, thread_pool=f.tagger.save_thread_pool)
save_and_rewrite_header()
================================================
FILE: plugins/script_logger/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2023 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
# pylint: disable=missing-module-docstring, wrong-import-position, line-too-long
PLUGIN_NAME = 'Script Logger'
PLUGIN_AUTHOR = 'Bob Swift (rdswift)'
PLUGIN_DESCRIPTION = '''
This plugin provides a new script function `$logline()` to write entries
to Picard's system log. By default, the log level is set at `Info`, but
any level can be used by providing the level as an optional second
parameter to the function.
The function is used as:
`$logline(text[,level])`
where `text` is the text to write to the log. The entry will be written
at log level `Info` by default, but this can be changed by specifying a
different level as an optional second parameter. Allowable log levels are:
- E (Error)
- W (Warning)
- I (Info)
- D (Debug)
If an unknown level is entered, the function will use the default `Info`
level.
'''
PLUGIN_VERSION = '0.1'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3', '2.6', '2.9']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
PLUGIN_USER_GUIDE_URL = "https://github.com/rdswift/picard-plugins/blob/2.0_RDS_Plugins/plugins/script_logger/docs/README.md"
DOCUMENTATION = """\
`$logline(text[,level])`
where `text` is the text to write to the log. The entry will be written
at log level `Info` by default, but this can be changed by specifying a
different level as an optional second parameter. Allowable log levels are:
- E (Error)
- W (Warning)
- I (Info)
- D (Debug)
If an unknown level is entered, the function will use the default `Info`
level.
"""
from picard import log
from picard.script import register_script_function
LEVELS = {
'E': log.error,
'W': log.warning,
'I': log.info,
'D': log.debug,
}
def logline(_parser, text: str, level=None):
"""Logs text to the Picard log.
Args:
_parser (parser): Script parser
text (str): Text message to log
level (str, optional): Level to use for logging ('E', 'W', 'I' or 'D'). Defaults to 'I'.
"""
if level:
_level = (str(level).strip().upper() + 'I')[0]
else:
_level = 'I'
if _level not in LEVELS:
_level = 'I'
LEVELS[_level](text.strip())
return ''
register_script_function(logline, documentation=DOCUMENTATION)
================================================
FILE: plugins/search_engine_lookup/README.md
================================================
# Search Engine Lookup \[[Download](https://github.com/rdswift/picard-plugins/raw/2.0_RDS_Plugins/plugins/search_engine_lookup/search_engine_lookup.zip)\]
## Overview
This plugin adds a right click option on a cluster, providing the ability to lookup the cluster using a search engine in a browser window.
It also provides a right click option on album and track items in the right-hand Album pane, allowing a search engine lookup for the cover art
associated with the selected album or track.
When you right-click on the cluster, album or track, the lookup option is found under the "Plugins" section of the context list.
## Settings
A settings screen is available in Picard's options settings, under the Plugins section. This allows the user to select their preferred
search engine provider, and any additional words to provide with the cluster search. You can also add, edit or remove search engine providers.

When adding or editing a provider, checkmarks to the right of each field indicate whether or not the information in the field is valid.
The title is valid when it contains at least two non-space characters, does not begin or end with a space, and is not the same as the
title of another existing provider. The URL is valid when it contains the search replacement parameter ``%search%`` and does not begin
or end with, or contain any spaces. The "Save" button will be disabled until both fields are valid.

---
================================================
FILE: plugins/search_engine_lookup/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2020-2021, 2026 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Search Engine Lookup'
PLUGIN_AUTHOR = 'Bob Swift'
PLUGIN_DESCRIPTION = '''
Adds a right click option on a cluster to look up album information using a search engine in a browser window.
Adds a right click option on an album or track to look up cover art for the selected album or title.
'''
PLUGIN_VERSION = '2.1.1'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
import re
from urllib.parse import quote_plus
from uuid import uuid4
from PyQt5 import QtCore, QtWidgets
from picard import config, log
from picard.cluster import Cluster
from picard.plugins.search_engine_lookup.ui_options_search_engine_editor import Ui_SearchEngineEditorDialog
from picard.plugins.search_engine_lookup.ui_options_search_engine_lookup import Ui_SearchEngineLookupOptionsPage
from picard.ui.itemviews import BaseAction, register_cluster_action, register_album_action, register_track_action
from picard.ui.options import OptionsPage, register_options_page
from picard.util.webbrowser2 import open as _open
DEFAULT_PROVIDERS = {
'ea520f49-36bc-4821-a16a-38bf0340d1f3': {'name': _('Google'), 'url': r'https://www.google.com/search?q=%search%'},
'7b93d4b5-34d9-49a7-901c-ed0914f07aee': {'name': _('Bing'), 'url': r'https://www.bing.com/search?q=%search%'},
'37be75d9-5fc5-4858-87fc-b5db0896a163': {'name': _('DuckDuckGo'), 'url': r'https://duckduckgo.com/?q=%search%'},
}
DEFAULT_PROVIDER = 'ea520f49-36bc-4821-a16a-38bf0340d1f3'
DEFAULT_EXTRA_WORDS = 'album'
RE_VALIDATE_TITLE = re.compile(r'^[^\s"|][^"|]*[^\s"|]$')
RE_VALIDATE_URL = re.compile(r'^[^\s"]*%search%[^\s"]*$')
KEY_PROVIDER = 'search_engine_lookup_provider'
KEY_PROVIDERS = 'search_engine_lookup_providers'
KEY_EXTRA = 'search_engine_lookup_extra_words'
def show_popup(title='', content='', window=None):
QtWidgets.QMessageBox.information(
window,
title,
content,
QtWidgets.QMessageBox.Ok,
QtWidgets.QMessageBox.Ok
)
def lookup_error():
log.error("{0}: No existing metadata to lookup.".format(PLUGIN_NAME,))
show_popup(_('Lookup Error'), _('There is no existing data to use for a search.'))
def do_lookup(text):
provider = config.setting[KEY_PROVIDER]
providers = config.setting[KEY_PROVIDERS]
base_url = providers[provider]['url'] if provider in providers else DEFAULT_PROVIDERS[DEFAULT_PROVIDER]['url']
url = base_url.replace(r'%search%', quote_plus(text))
log.debug("{0}: Looking up {1}".format(PLUGIN_NAME, url,))
_open(url)
def lookup_cover_art(title, artist):
text = "{0} by {1} album cover".format(title, artist)
do_lookup(text)
class SearchEngineLookupTest(BaseAction):
NAME = 'Search engine lookup'
def callback(self, cluster_list):
extra = config.setting[KEY_EXTRA].split()
for cluster in cluster_list:
if isinstance(cluster, Cluster):
parts = []
if 'albumartist' in cluster.metadata and cluster.metadata['albumartist']:
parts.extend(cluster.metadata['albumartist'].split())
if 'album' in cluster.metadata and cluster.metadata['albumartist']:
parts.extend(cluster.metadata['album'].split())
if parts:
if extra:
parts.extend(extra)
text = ' '.join(parts)
do_lookup(text)
else:
lookup_error()
else:
log.error("{0}: Argument is not a cluster. {1}".format(PLUGIN_NAME, cluster,))
show_popup(_('Lookup Error'), _('There was a problem with the information provided for the cluster.'))
class AlbumCoverArtLookup(BaseAction):
NAME = 'Album cover art lookup'
def callback(self, album):
metadata = album[0].metadata
if 'album' in metadata and 'albumartist' in metadata:
lookup_cover_art(metadata['album'], metadata['albumartist'])
else:
lookup_error()
class TrackCoverArtLookup(BaseAction):
NAME = 'Track cover art lookup'
def callback(self, track):
metadata = track[0].metadata
if 'title' in metadata and 'artist' in metadata:
lookup_cover_art(metadata['title'], metadata['artist'])
else:
lookup_error()
class SearchEngineEditDialog(QtWidgets.QDialog):
def __init__(self, parent=None, edit_provider='', edit_url='', titles=None):
super().__init__(parent)
self.parent = parent
self.output = None
self.edit_provider = edit_provider
self.edit_url = edit_url
self.providers = titles if titles else []
self.valid_no = QtWidgets.QApplication.style().standardIcon(QtWidgets.QStyle.SP_DialogCancelButton).pixmap(16, 16)
self.valid_yes = QtWidgets.QApplication.style().standardIcon(QtWidgets.QStyle.SP_DialogApplyButton).pixmap(16, 16)
self.ui = Ui_SearchEngineEditorDialog()
self.ui.setupUi(self)
self.ui.le_title.setText(self.edit_provider)
self.ui.le_url.setText(self.edit_url)
self.setup_actions()
self.check_validation()
def setup_actions(self):
self.ui.le_title.textChanged.connect(self.title_text_changed)
self.ui.le_url.textChanged.connect(self.url_text_changed)
self.ui.pb_save.clicked.connect(self.accept)
self.ui.pb_cancel.clicked.connect(self.reject)
def check_validation(self):
valid_title = re.match(RE_VALIDATE_TITLE, self.edit_provider) and self.edit_provider not in self.providers
self.ui.img_valid_title.setPixmap(self.valid_yes if valid_title else self.valid_no)
valid_url = re.match(RE_VALIDATE_URL, self.edit_url)
self.ui.img_valid_url.setPixmap(self.valid_yes if valid_url else self.valid_no)
# Note that this needs to be forced to a bool to avoid Qt crashing Picard
self.ui.pb_save.setEnabled(bool(valid_title and valid_url))
def get_output(self):
return self.output
def accept(self):
self.output = (self.edit_provider.strip(), self.edit_url.strip())
super().accept()
def title_text_changed(self, text):
self.edit_provider = text
self.check_validation()
def url_text_changed(self, text):
self.edit_url = text
self.check_validation()
class SearchEngineLookupOptionsPage(OptionsPage):
NAME = "search_engine_lookup_options"
TITLE = "Search Engine Lookup"
PARENT = "plugins"
HELP_URL = "https://github.com/metabrainz/picard-plugins/blob/2.0/plugins/search_engine_lookup/README.md"
options = [
config.Option("setting", KEY_PROVIDERS, DEFAULT_PROVIDERS.copy()),
config.TextOption("setting", KEY_PROVIDER, DEFAULT_PROVIDER),
config.TextOption("setting", KEY_EXTRA, DEFAULT_EXTRA_WORDS),
]
def __init__(self, parent=None):
super(SearchEngineLookupOptionsPage, self).__init__(parent)
self.ui = Ui_SearchEngineLookupOptionsPage()
self.ui.setupUi(self)
self.setup_actions()
self.provider = ''
self.providers = {}
self.additional_words = ''
def setup_actions(self):
self.ui.list_providers.itemChanged.connect(self.select_provider)
self.ui.pb_add.clicked.connect(self.add_provider)
self.ui.pb_edit.clicked.connect(self.edit_provider)
self.ui.pb_delete.clicked.connect(self.delete_provider)
self.ui.pb_test.clicked.connect(self.test_provider)
self.ui.le_additional_words.textChanged.connect(self.additional_words_changed)
def additional_words_changed(self, text):
self.additional_words = text
def load(self):
# Settings for search engine providers
self.providers = config.setting[KEY_PROVIDERS] or DEFAULT_PROVIDERS.copy()
# Settings for search engine provider
self.provider = config.setting[KEY_PROVIDER]
if self.provider not in self.providers:
# Assign an arbitrary valid value to self.provider
self.provider = list(self.providers)[0]
# Settings for search extra words
self.additional_words = config.setting[KEY_EXTRA]
self.ui.le_additional_words.setText(self.additional_words)
# Display list of providers
self.update_list()
def select_provider(self, list_item):
if list_item.checkState() == QtCore.Qt.Checked:
# New provider selected
self.provider = list_item.data(QtCore.Qt.UserRole)
self.update_list(current_item=self.provider)
else:
# Attempt to deselect the current provider leaving none selected
list_item.setCheckState(QtCore.Qt.Checked)
def add_provider(self):
provider_id = str(uuid4())
self.edit_provider_dialog(provider_id)
def edit_provider(self):
current_item = self.ui.list_providers.currentItem()
provider = current_item.text()
provider_id = current_item.data(QtCore.Qt.UserRole)
url = self.providers[provider_id]['url']
self.edit_provider_dialog(provider_id, provider, url)
def edit_provider_dialog(self, provider_id='', provider='', url=''):
# List of titles currently used and not allowed. Omit current title from the list when editing.
titles = [x['name'] for x in self.providers.values() if x['name'] != provider]
dialog = SearchEngineEditDialog(self, provider, url, titles)
temp = dialog.exec_()
if temp == QtWidgets.QDialog.Accepted:
data = dialog.get_output()
if data:
new_provider, new_url = data
self.providers[provider_id] = {'name': new_provider, 'url': new_url}
self.update_list(provider_id)
def delete_provider(self):
current_item = self.ui.list_providers.currentItem()
provider = current_item.text()
provider_id = current_item.data(QtCore.Qt.UserRole)
if current_item.checkState() or provider_id == self.provider:
QtWidgets.QMessageBox.critical(
self,
_('Deletion Error'),
_('You cannot delete the currently selected search provider.'),
QtWidgets.QMessageBox.Ok,
QtWidgets.QMessageBox.Ok
)
else:
if QtWidgets.QMessageBox.warning(
self,
_('Confirm Deletion'),
_('You are about to permanently delete the search provider "{provider_name}". Continue?').format(provider_name=provider),
QtWidgets.QMessageBox.Ok | QtWidgets.QMessageBox.Cancel,
QtWidgets.QMessageBox.Cancel
) == QtWidgets.QMessageBox.Ok:
self.providers.pop(provider_id, None)
self.update_list()
def test_provider(self):
current_item = self.ui.list_providers.currentItem()
parts = ('The Beatles Abby Road ' + self.additional_words).strip().split()
url = self.providers[current_item.data(QtCore.Qt.UserRole)]['url'].replace(r'%search%', quote_plus(' '.join(parts)))
_open(url)
def update_list(self, current_item=None):
current_row = -1
self.ui.list_providers.clear()
for counter, provider_id in enumerate(self.providers):
item = QtWidgets.QListWidgetItem()
item.setFlags(item.flags() | QtCore.Qt.ItemIsUserCheckable)
item.setText(self.providers[provider_id]['name'])
item.setCheckState(QtCore.Qt.Checked if provider_id == self.provider else QtCore.Qt.Unchecked)
item.setData(QtCore.Qt.UserRole, provider_id)
self.ui.list_providers.addItem(item)
if current_item and provider_id == current_item:
current_row = counter
current_row = max(current_row, 0)
self.ui.list_providers.setCurrentRow(current_row)
self.ui.list_providers.sortItems()
def save(self):
self._set_settings(config.setting)
def _set_settings(self, settings):
settings[KEY_PROVIDER] = self.provider.strip()
settings[KEY_EXTRA] = self.additional_words.strip()
settings[KEY_PROVIDERS] = self.providers or DEFAULT_PROVIDERS.copy()
register_cluster_action(SearchEngineLookupTest())
register_options_page(SearchEngineLookupOptionsPage)
register_album_action(AlbumCoverArtLookup())
register_track_action(TrackCoverArtLookup())
================================================
FILE: plugins/search_engine_lookup/ui_options_search_engine_editor.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/search_engine_lookup/ui_options_search_engine_editor.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_SearchEngineEditorDialog(object):
def setupUi(self, SearchEngineEditorDialog):
SearchEngineEditorDialog.setObjectName("SearchEngineEditorDialog")
SearchEngineEditorDialog.setWindowModality(QtCore.Qt.ApplicationModal)
SearchEngineEditorDialog.resize(560, 205)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(SearchEngineEditorDialog.sizePolicy().hasHeightForWidth())
SearchEngineEditorDialog.setSizePolicy(sizePolicy)
SearchEngineEditorDialog.setMinimumSize(QtCore.QSize(560, 205))
SearchEngineEditorDialog.setMaximumSize(QtCore.QSize(560, 300))
self.verticalLayout = QtWidgets.QVBoxLayout(SearchEngineEditorDialog)
self.verticalLayout.setObjectName("verticalLayout")
self.scrollArea = QtWidgets.QScrollArea(SearchEngineEditorDialog)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 542, 187))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.label_4 = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.label_4.setWordWrap(True)
self.label_4.setObjectName("label_4")
self.verticalLayout_2.addWidget(self.label_4)
spacerItem = QtWidgets.QSpacerItem(20, 5, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem)
self.gridLayout = QtWidgets.QGridLayout()
self.gridLayout.setContentsMargins(-1, -1, -1, 0)
self.gridLayout.setObjectName("gridLayout")
self.label_2 = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.label_2.setObjectName("label_2")
self.gridLayout.addWidget(self.label_2, 0, 0, 1, 1)
self.label_3 = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.label_3.setObjectName("label_3")
self.gridLayout.addWidget(self.label_3, 1, 0, 1, 1)
self.le_title = QtWidgets.QLineEdit(self.scrollAreaWidgetContents)
font = QtGui.QFont()
font.setPointSize(9)
self.le_title.setFont(font)
self.le_title.setToolTipDuration(-1)
self.le_title.setObjectName("le_title")
self.gridLayout.addWidget(self.le_title, 0, 1, 1, 1)
self.le_url = QtWidgets.QLineEdit(self.scrollAreaWidgetContents)
font = QtGui.QFont()
font.setPointSize(9)
self.le_url.setFont(font)
self.le_url.setObjectName("le_url")
self.gridLayout.addWidget(self.le_url, 1, 1, 1, 1)
self.img_valid_title = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.img_valid_title.setMinimumSize(QtCore.QSize(16, 16))
self.img_valid_title.setText("")
self.img_valid_title.setObjectName("img_valid_title")
self.gridLayout.addWidget(self.img_valid_title, 0, 2, 1, 1)
self.img_valid_url = QtWidgets.QLabel(self.scrollAreaWidgetContents)
self.img_valid_url.setMinimumSize(QtCore.QSize(16, 16))
self.img_valid_url.setText("")
self.img_valid_url.setObjectName("img_valid_url")
self.gridLayout.addWidget(self.img_valid_url, 1, 2, 1, 1)
self.verticalLayout_2.addLayout(self.gridLayout)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setContentsMargins(-1, 5, -1, 0)
self.horizontalLayout.setObjectName("horizontalLayout")
spacerItem1 = QtWidgets.QSpacerItem(40, 20, QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Minimum)
self.horizontalLayout.addItem(spacerItem1)
self.pb_save = QtWidgets.QPushButton(self.scrollAreaWidgetContents)
self.pb_save.setObjectName("pb_save")
self.horizontalLayout.addWidget(self.pb_save)
self.pb_cancel = QtWidgets.QPushButton(self.scrollAreaWidgetContents)
self.pb_cancel.setObjectName("pb_cancel")
self.horizontalLayout.addWidget(self.pb_cancel)
self.verticalLayout_2.addLayout(self.horizontalLayout)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(SearchEngineEditorDialog)
QtCore.QMetaObject.connectSlotsByName(SearchEngineEditorDialog)
def retranslateUi(self, SearchEngineEditorDialog):
_translate = QtCore.QCoreApplication.translate
SearchEngineEditorDialog.setWindowTitle(_translate("SearchEngineEditorDialog", "Edit Search Engine Provider"))
self.label_4.setText(_translate("SearchEngineEditorDialog", "Enter the title and URL for the search engine provider. Titles must be at least two non-space characters long, and must not be the same as the title of an existing provider.
When entering the URL the macro %search% must be included. This will be replaced by the list of search words separated by plus signs when the url is sent to your browser for display.
"))
self.label_2.setText(_translate("SearchEngineEditorDialog", "Title:"))
self.label_3.setText(_translate("SearchEngineEditorDialog", "URL:"))
self.le_title.setToolTip(_translate("SearchEngineEditorDialog", "The title to show in the list for the search engine provider"))
self.le_url.setToolTip(_translate("SearchEngineEditorDialog", "The URL to use for the search engine provider"))
self.pb_save.setText(_translate("SearchEngineEditorDialog", "Save"))
self.pb_cancel.setText(_translate("SearchEngineEditorDialog", "Cancel"))
================================================
FILE: plugins/search_engine_lookup/ui_options_search_engine_editor.ui
================================================
SearchEngineEditorDialog
Qt::ApplicationModal
0
0
560
205
0
0
560
205
560
300
Edit Search Engine Provider
-
QFrame::NoFrame
true
0
0
542
187
-
<html><head/><body><p>Enter the title and URL for the search engine provider. Titles must be at least two non-space characters long, and must not be the same as the title of an existing provider.</p><p>When entering the URL the macro <span style="font-weight:600;">%search%</span> must be included. This will be replaced by the list of search words separated by plus signs when the url is sent to your browser for display.</p></body></html>
true
-
Qt::Vertical
20
5
-
0
-
Title:
-
URL:
-
9
The title to show in the list for the search engine provider
-1
-
9
The URL to use for the search engine provider
-
16
16
-
16
16
-
5
0
-
Qt::Horizontal
40
20
-
Save
-
Cancel
================================================
FILE: plugins/search_engine_lookup/ui_options_search_engine_lookup.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/search_engine_lookup/ui_options_search_engine_lookup.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_SearchEngineLookupOptionsPage(object):
def setupUi(self, SearchEngineLookupOptionsPage):
SearchEngineLookupOptionsPage.setObjectName("SearchEngineLookupOptionsPage")
SearchEngineLookupOptionsPage.resize(561, 802)
SearchEngineLookupOptionsPage.setMinimumSize(QtCore.QSize(360, 0))
self.verticalLayout = QtWidgets.QVBoxLayout(SearchEngineLookupOptionsPage)
self.verticalLayout.setObjectName("verticalLayout")
self.scrollArea = QtWidgets.QScrollArea(SearchEngineLookupOptionsPage)
self.scrollArea.setFrameShape(QtWidgets.QFrame.NoFrame)
self.scrollArea.setWidgetResizable(True)
self.scrollArea.setObjectName("scrollArea")
self.scrollAreaWidgetContents = QtWidgets.QWidget()
self.scrollAreaWidgetContents.setGeometry(QtCore.QRect(0, 0, 543, 784))
self.scrollAreaWidgetContents.setObjectName("scrollAreaWidgetContents")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.scrollAreaWidgetContents)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.gb_description = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_description.setObjectName("gb_description")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.gb_description)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.format_description = QtWidgets.QLabel(self.gb_description)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Minimum)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.format_description.sizePolicy().hasHeightForWidth())
self.format_description.setSizePolicy(sizePolicy)
self.format_description.setWordWrap(True)
self.format_description.setObjectName("format_description")
self.verticalLayout_3.addWidget(self.format_description)
self.verticalLayout_2.addWidget(self.gb_description)
self.gb_search_engine = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.gb_search_engine.setMinimumSize(QtCore.QSize(0, 0))
self.gb_search_engine.setObjectName("gb_search_engine")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.gb_search_engine)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.list_providers = QtWidgets.QListWidget(self.gb_search_engine)
self.list_providers.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)
self.list_providers.setObjectName("list_providers")
self.verticalLayout_4.addWidget(self.list_providers)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setContentsMargins(-1, -1, -1, 0)
self.horizontalLayout.setObjectName("horizontalLayout")
spacerItem = QtWidgets.QSpacerItem(40, 20, QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Minimum)
self.horizontalLayout.addItem(spacerItem)
self.pb_add = QtWidgets.QPushButton(self.gb_search_engine)
self.pb_add.setObjectName("pb_add")
self.horizontalLayout.addWidget(self.pb_add)
self.pb_edit = QtWidgets.QPushButton(self.gb_search_engine)
self.pb_edit.setObjectName("pb_edit")
self.horizontalLayout.addWidget(self.pb_edit)
self.pb_delete = QtWidgets.QPushButton(self.gb_search_engine)
self.pb_delete.setObjectName("pb_delete")
self.horizontalLayout.addWidget(self.pb_delete)
self.pb_test = QtWidgets.QPushButton(self.gb_search_engine)
self.pb_test.setObjectName("pb_test")
self.horizontalLayout.addWidget(self.pb_test)
self.verticalLayout_4.addLayout(self.horizontalLayout)
self.verticalLayout_2.addWidget(self.gb_search_engine)
self.groupBox = QtWidgets.QGroupBox(self.scrollAreaWidgetContents)
self.groupBox.setMinimumSize(QtCore.QSize(0, 0))
self.groupBox.setObjectName("groupBox")
self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.groupBox)
self.verticalLayout_5.setObjectName("verticalLayout_5")
self.label = QtWidgets.QLabel(self.groupBox)
self.label.setWordWrap(True)
self.label.setObjectName("label")
self.verticalLayout_5.addWidget(self.label)
self.le_additional_words = QtWidgets.QLineEdit(self.groupBox)
self.le_additional_words.setObjectName("le_additional_words")
self.verticalLayout_5.addWidget(self.le_additional_words)
self.verticalLayout_2.addWidget(self.groupBox)
spacerItem1 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem1)
self.scrollArea.setWidget(self.scrollAreaWidgetContents)
self.verticalLayout.addWidget(self.scrollArea)
self.retranslateUi(SearchEngineLookupOptionsPage)
QtCore.QMetaObject.connectSlotsByName(SearchEngineLookupOptionsPage)
def retranslateUi(self, SearchEngineLookupOptionsPage):
_translate = QtCore.QCoreApplication.translate
SearchEngineLookupOptionsPage.setWindowTitle(_translate("SearchEngineLookupOptionsPage", "Form"))
self.gb_description.setTitle(_translate("SearchEngineLookupOptionsPage", "Search Engine Lookup"))
self.format_description.setText(_translate("SearchEngineLookupOptionsPage", "The Search Engine Lookup plugin allows you to initiate a search engine lookup in your browser for a cluster from the menu displayed when right-clicking the cluster. These settings allow you select which search engine to use for the lookup, as well as any additional search terms.
"))
self.gb_search_engine.setTitle(_translate("SearchEngineLookupOptionsPage", "Search Engine Providers"))
self.pb_add.setText(_translate("SearchEngineLookupOptionsPage", "Add"))
self.pb_edit.setText(_translate("SearchEngineLookupOptionsPage", "Edit"))
self.pb_delete.setText(_translate("SearchEngineLookupOptionsPage", "Delete"))
self.pb_test.setText(_translate("SearchEngineLookupOptionsPage", "Test"))
self.groupBox.setTitle(_translate("SearchEngineLookupOptionsPage", "Additional Search Words"))
self.label.setText(_translate("SearchEngineLookupOptionsPage", "By default, the search parameters used are the artist name and album name if they are available in the metadata. You have the option of specifying additional words to be added to the search parameters (e.g.: album).
Additional words are entered below and should be separated by spaces.
"))
================================================
FILE: plugins/search_engine_lookup/ui_options_search_engine_lookup.ui
================================================
SearchEngineLookupOptionsPage
0
0
561
802
360
0
Form
-
QFrame::NoFrame
true
0
0
543
784
-
Search Engine Lookup
-
0
0
<html><head/><body><p>The Search Engine Lookup plugin allows you to initiate a search engine lookup in your browser for a cluster from the menu displayed when right-clicking the cluster. These settings allow you select which search engine to use for the lookup, as well as any additional search terms.</p></body></html>
true
-
0
0
Search Engine Providers
-
QAbstractItemView::NoEditTriggers
-
0
-
Qt::Horizontal
40
20
-
Add
-
Edit
-
Delete
-
Test
-
0
0
Additional Search Words
-
<html><head/><body><p>By default, the search parameters used are the artist name and album name if they are available in the metadata. You have the option of specifying additional words to be added to the search parameters (e.g.: album).</p><p>Additional words are entered below and should be separated by spaces.</p></body></html>
true
-
-
Qt::Vertical
20
40
================================================
FILE: plugins/smart_title_case/smart_title_case.py
================================================
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# This is the Smart Title Case plugin for MusicBrainz Picard.
# Copyright (C) 2017 Sophist.
#
# Updated for use with Picard v2.0 by Bob Swift (rdswift).
#
# It is based on the Title Case plugin by Javier Kohen
# Copyright 2007 Javier Kohen
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Smart Title Case"
PLUGIN_AUTHOR = "Sophist based on an earlier plugin by Javier Kohen"
PLUGIN_DESCRIPTION = """
Capitalize First Character In Every Word Of Album/Track Title/Artist.
Leaves words containing embedded uppercase as-is i.e. USA or DoA.
For Artist/AlbumArtist, title cases only artists not join phrases
e.g. The Beatles feat. The Who.
"""
PLUGIN_VERSION = "0.4.2"
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-3.0.html"
import re, unicodedata
from picard import log
from picard.metadata import (
register_track_metadata_processor,
register_album_metadata_processor,
)
title_tags = ['title', 'album']
artist_tags = [
('artist', 'artists'),
('artistsort', '~artists_sort'),
('albumartist', '~albumartists'),
('albumartistsort', '~albumartists_sort'),
]
title_re = re.compile(r'\w[^-,/\s\u2010\u2011]*')
def match_word(match):
word = match.group(0)
if word == word.lower():
word = word[0].upper() + word[1:]
return word
def string_title_match(match_word, string):
return title_re.sub(match_word, string)
def string_cleanup(string):
if not string:
return ""
return unicodedata.normalize("NFKC", string)
def string_title_case(string):
"""Title-case a string using a less destructive method than str.title.
>>> string_title_case('make title case')
'Make Title Case'
>>> string_title_case('Already Title Case')
'Already Title Case'
>>> string_title_case('mIxEd cAsE')
'mIxEd cAsE'
>>> string_title_case('a')
'A'
>>> string_title_case("apostrophe's apostrophe's")
"Apostrophe's Apostrophe's"
>>> string_title_case('(bracketed text)')
'(Bracketed Text)'
>>> string_title_case("'single quotes'")
"'Single Quotes'"
>>> string_title_case('"double quotes"')
'"Double Quotes"'
>>> string_title_case('a,b')
'A,B'
>>> string_title_case('a-b')
'A-B'
>>> string_title_case('a/b')
'A/B'
>>> string_title_case('flügel')
'Flügel'
>>> string_title_case('HARVEST STORY by 杉山清貴')
'HARVEST STORY By 杉山清貴'
"""
return string_title_match(match_word, string_cleanup(string))
def artist_title_case(text, artists, artists_upper):
"""
Use the array of artists and the joined string
to identify artists to make title case
and the join strings to leave as-is.
>>> artist_title_case('the beatles feat. the who', ['the beatles', 'the who'], ['The Beatles', 'The Who'])
'The Beatles feat. The Who'
>>> artist_title_case('kesha feat. 3OH!3', ['kesha', '3OH!3'], ['Kesha', '3OH!3'])
'Kesha feat. 3OH!3'
"""
find = "^(" + r")(\s+\S+?\s+)(".join((map(re.escape, map(string_cleanup,artists)))) + ")(.*$)"
replace = "".join([r"%s\g<%d>" % (a, x*2 + 2) for x, a in enumerate(artists_upper)])
result = re.sub(find, replace, string_cleanup(text))
return result
def title_case(tagger, metadata, *args):
for name in title_tags:
if name in metadata:
values = metadata.getall(name)
new_values = [string_title_case(v) for v in values]
if values != new_values:
log.debug("SmartTitleCase: %s: %r replaced with %r", name, values, new_values)
metadata[name] = new_values
for artist_string, artists_list in artist_tags:
if artist_string in metadata and artists_list in metadata:
artist = metadata.getall(artist_string)
artists = metadata.getall(artists_list)
new_artists = list(map(string_title_case, artists))
new_artist = [artist_title_case(x, artists, new_artists) for x in artist]
if artists != new_artists and artist != new_artist:
log.debug("SmartTitleCase: %s: %s replaced with %s", artist_string, artist, new_artist)
log.debug("SmartTitleCase: %s: %r replaced with %r", artists_list, artists, new_artists)
metadata[artist_string] = new_artist
metadata[artists_list] = new_artists
elif artists != new_artists or artist != new_artist:
if artists != new_artists:
log.warning("SmartTitleCase: %s changed, %s wasn't", artists_list, artist_string)
log.warning("SmartTitleCase: %s: %r changed to %r", artists_list, artists, new_artists)
log.warning("SmartTitleCase: %s: %r unchanged", artist_string, artist)
else:
log.warning("SmartTitleCase: %s changed, %s wasn't", artist_string, artists_list)
log.warning("SmartTitleCase: %s: %r changed to %r", artist_string, artist, new_artist)
log.warning("SmartTitleCase: %s: %r unchanged", artists_list, artists)
register_track_metadata_processor(title_case)
register_album_metadata_processor(title_case)
================================================
FILE: plugins/sort_multivalue_tags/sort_multivalue_tags.py
================================================
# -*- coding: utf-8 -*-
# This is the Sort Multivalue Tags plugin for MusicBrainz Picard.
# Copyright (C) 2013 Sophist
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
PLUGIN_NAME = "Sort Multi-Value Tags"
PLUGIN_AUTHOR = "Sophist"
PLUGIN_DESCRIPTION = '''
This plugin sorts multi-value tags e.g. Performers alphabetically.
Note: Some multi-value tags are excluded for the following reasons:
- Sequence is important e.g. Artists
- The sequence of one tag is linked to the sequence of another e.g. Label and Catalogue number.
'''
PLUGIN_VERSION = "1.1"
PLUGIN_API_VERSIONS = ["0.15", "2.0"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from picard.metadata import register_track_metadata_processor
from picard.plugin import PluginPriority
from picard import log
# Define tags where sort order is important
_sort_multivalue_tags_exclude = (
'artists', '~artists_sort', 'musicbrainz_artistid',
'~albumartists', '~albumartists_sort', 'musicbrainz_albumartistid',
'work', 'musicbrainz_workid',
'label', 'catalognumber',
'country', 'date',
'releasetype',
'mood',
)
# Possible future enhancement:
# Sort linked tags e.g. work so that the sequence in related tags e.g. workid retains the relationship between
# e.g. work and workid.
def sort_multivalue_tags(tagger, metadata, track, release):
for tag in list(metadata.keys()):
if tag in _sort_multivalue_tags_exclude:
continue
data = metadata.getall(tag)
if len(data) > 1:
sorted_data = sorted(data)
if data != sorted_data:
metadata.set(tag, sorted_data)
log.debug("%s: Tag sorted: %s = %s", PLUGIN_NAME, tag, sorted_data)
register_track_metadata_processor(sort_multivalue_tags, priority=PluginPriority.LOW)
================================================
FILE: plugins/soundtrack/soundtrack.py
================================================
# -*- coding: utf-8 -*-
# Copyright © 2015 Samir Benmendil
# This work is free. You can redistribute it and/or modify it under the
# terms of the Do What The Fuck You Want To Public License, Version 2,
# as published by Sam Hocevar. See http://www.wtfpl.net/ for more details.
PLUGIN_NAME = 'Soundtrack'
PLUGIN_AUTHOR = 'Samir Benmendil'
PLUGIN_LICENSE = 'WTFPL'
PLUGIN_LICENSE_URL = 'http://www.wtfpl.net/'
PLUGIN_DESCRIPTION = '''Sets the albumartist to "Soundtrack" if releasetype is a soundtrack.'''
PLUGIN_VERSION = "0.2"
PLUGIN_API_VERSIONS = ["1.0", "2.0"]
from picard.metadata import register_album_metadata_processor
def soundtrack(tagger, metadata, release):
if "soundtrack" in metadata["releasetype"]:
metadata["albumartist"] = "Soundtrack"
metadata["albumartistsort"] = "Soundtrack"
register_album_metadata_processor(soundtrack)
================================================
FILE: plugins/standardise_feat/standardise_feat.py
================================================
PLUGIN_NAME = 'Standardise Feat.'
PLUGIN_AUTHOR = 'Sambhav Kothari'
PLUGIN_DESCRIPTION = 'Standardises "featuring" join phrases for artists to "feat."'
PLUGIN_VERSION = "0.3"
PLUGIN_API_VERSIONS = ["1.4", "2.0", "2.1", "2.2", "2.3"]
PLUGIN_LICENSE = "GPL-3.0"
PLUGIN_LICENSE_URL = "http://www.gnu.org/licenses/gpl-3.0.txt"
import re
from picard import log
from picard.metadata import register_track_metadata_processor, register_album_metadata_processor
from picard.plugin import PluginPriority
_feat_re = re.compile(r" f(ea)?t(\.|uring)? ", re.IGNORECASE)
def standardise_feat(artists_str, artists_list):
"""
>>> standardise_feat("The A", ["The A"])
'The A'
>>> standardise_feat("The A ft. B", ["The A", "B"])
'The A feat. B'
>>> standardise_feat("The A & B featuring C", ["The A", "B", "C"])
'The A & B feat. C'
>>> standardise_feat("The A featuring B (and C)", ["The A", "B", "C"])
'The A feat. B (and C)'
"""
match_exp = r"(\s*.*\s*)".join((map(re.escape, artists_list))) + r"(\s*.*$)"
try:
join_phrases = re.match(match_exp, artists_str).groups()
except AttributeError:
log.debug("Unable to standardise artists: %r", artists_str)
return artists_str
else:
standardised_join_phrases = [_feat_re.sub(" feat. ", phrase)
for phrase in join_phrases]
# Add a blank string at the end to allow zipping of
# join phrases and artists_list since there is one less join phrase
standardised_join_phrases.append("")
return "".join([artist + join_phrase for artist, join_phrase in
zip(artists_list, standardised_join_phrases)])
def standardise_track_artist(tagger, metadata, track, release):
metadata["artist"] = standardise_feat(metadata["artist"], metadata.getall("artists"))
metadata["artistsort"] = standardise_feat(metadata["artistsort"], metadata.getall("~artists_sort"))
def standardise_album_artist(tagger, metadata, release):
metadata["albumartist"] = standardise_feat(metadata["albumartist"], metadata.getall("~albumartists"))
metadata["albumartistsort"] = standardise_feat(metadata["albumartistsort"], metadata.getall("~albumartists_sort"))
register_track_metadata_processor(standardise_track_artist, priority=PluginPriority.HIGH)
register_album_metadata_processor(standardise_album_artist, priority=PluginPriority.HIGH)
================================================
FILE: plugins/standardise_performers/standardise_performers.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = 'Standardise Performers'
PLUGIN_AUTHOR = 'Sophist'
PLUGIN_DESCRIPTION = '''Splits multi-instrument performer tags into single
instruments and combines names so e.g. (from 10cc by 10cc track 1):
Performer [acoustic guitar, bass, dobro, electric guitar and tambourine]: Graham Gouldman
Performer [acoustic guitar, electric guitar, grand piano and synthesizer]: Lol Creme
Performer [electric guitar, moog and slide guitar]: Eric Stewart
becomes:
Performer [acoustic guitar]: Graham Gouldman; Lol Creme
Performer [bass]: Graham Gouldman
Performer [dobro]: Graham Gouldman
Performer [electric guitar]: Eric Stewart; Graham Gouldman; Lol Creme
Performer [grand piano]: Lol Creme
Performer [moog]: Eric Stewart
Performer [slide guitar]: Eric Stewart
Performer [synthesizer]: Lol Creme
Performer [tambourine]: Graham Gouldman
Update: This version now sorts the performer tags in order to maintain a consistent value and avoid tags appearing to change even though the base data is equivalent.
'''
PLUGIN_VERSION = '1.0'
PLUGIN_API_VERSIONS = ["2.0"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import re
from picard import log
from picard.metadata import register_track_metadata_processor
standardise_performers_split = re.compile(r", | and ").split
def standardise_performers(album, metadata, *args):
for key, values in list(metadata.rawitems()):
if not key.startswith('performer:') \
and not key.startswith('~performersort:'):
continue
mainkey, subkey = key.split(':', 1)
if not subkey:
continue
instruments = standardise_performers_split(subkey)
if len(instruments) == 1:
continue
log.debug("%s: Splitting Performer [%s] into separate performers",
PLUGIN_NAME,
subkey,
)
prefixes = []
words = instruments[0].split()
for word in words[:]:
if not word in ['guest', 'solo', 'additional', 'minor']:
break
prefixes.append(word)
words.remove(word)
instruments[0] = " ".join(words)
prefix = " ".join(prefixes) + " " if prefixes else ""
for instrument in instruments:
newkey = '%s:%s%s' % (mainkey, prefix, instrument)
for value in values:
metadata.add_unique(newkey, value)
del metadata[key]
# Sort performer metdata to avoid changes in processing sequence creating false changes in metadata
for key, values in list(metadata.rawitems()):
if key.startswith('performer:') or key.startswith('~performersort:'):
metadata[key] = sorted(values)
from picard.plugin import PluginPriority
register_track_metadata_processor(standardise_performers,
priority=PluginPriority.HIGH)
================================================
FILE: plugins/submit_folksonomy_tags/README.md
================================================
# Submit Folksonomy Tags - Picard Plugin
A plugin that lets the user submit tags from their tracks' tags - defaults to `genre` and `mood` - to their respective MusicBrainz pages' folksonomy tags via MusicBrainz Picard. Useful for music geeks who are meticulous with their genre tagging.
**This plugin requires that you log into MusicBrainz via Picard.** The option to do so is in _Options > Options > General_.
To use, right click on a track or release, then go to _Plugins > Submit **x** tags to MusicBrainz_ - there are multiple options depending on if you want to submit tags to the recording, release, release group or release artist associated with the track/s or album/s you've right-clicked. The tags will be applied from the track tags you have configured.
Uses code from rswift's "Submit ISRC" plugin (specifically, the handling of the network response)
## Features
It does what it says on the tin: submits any tags you have in the genre tags of whichever files you drop into Picard to the respective pages. Right now the following entities are supported:
- recordings
- releases
- release groups
- artists (by release)
The plugin can also replace certain tags if your tags don't match up with MusicBrainz's standard tags, notably with their allowed genre list (e.g. if you use "synthpop" and not "synth-pop", or you use the full name "electronic dance music" and not the abbreviated "edm").
## Limitations
Right now, this plugin only submits tags. No tags are _retrieved_ for comparison yet, meaning I've opted to implement two modes based on how the MusicBrainz API works: maintain the tags that are already saved or overwrite _all_ of your tags. For anyone using the MusicBrainz API, choosing to keep your tags is basically sending the "upvote" attribute with every user tag, and choosing to overwrite doesn't do that, which MusicBrainz will respond by clearing old tags. See the [tags section of the MusicBrainz API for more details.](https://musicbrainz.org/doc/MusicBrainz_API#tags)
Submitting for releases, release artists and release groups will also trigger an alert if your tags are not consistently the same across all tracks in an album. This is to prevent spamming of tags, purposeful or accidental, and is based on the standard already set for years by digital music sites and CD ripper utilities where an album would have the same genres tagged across all tracks.
================================================
FILE: plugins/submit_folksonomy_tags/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2023 Flaky
# Copyright (C) 2023 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = "Submit Folksonomy Tags"
PLUGIN_AUTHOR = "Flaky"
PLUGIN_DESCRIPTION = """
A plugin allowing submission of specific tags on tracks you own (defaults to genre and mood) as folksonomy tags on MusicBrainz. Supports submitting to recording, release, release group and release artist entities.
A MusicBrainz login is required to use this plugin. Log in first by going to the General options. Then, to use, right click on a track or release then go to Plugins and depending on what you want to submit, choose the option you want.
Uses code from rdswift's "Submit ISRC" plugin (specifically, the handling of the network response)
"""
PLUGIN_VERSION = '0.3'
PLUGIN_API_VERSIONS = ['2.2', '2.9']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
from picard import config, log, PICARD_VERSION
from picard.album import Album, Track
from picard.ui.itemviews import (BaseAction,
register_album_action,
register_track_action
)
from picard.ui.options import OptionsPage, register_options_page
from picard.version import Version
from picard.webservice.api_helpers import MBAPIHelper, _wrap_xml_metadata
from .ui_config import TagSubmitPluginOptionsUI
import re
import functools
from xml.sax.saxutils import escape
from PyQt5 import QtCore
from PyQt5.QtWidgets import QMessageBox
NEW_MBAPIHelper = (PICARD_VERSION >= Version(2, 9, 0, 'beta', 2))
# List of Qt network error codes.
# From "Submit ISRC" plugin - credit to rdswift.
q_error_codes = {
0: 'No error',
1: "The remote server refused the connection (the server is not accepting requests).",
2: "The remote server closed the connection prematurely, before the entire reply was received and processed.",
3: "The remote host name was not found (invalid hostname).",
4: "The connection to the remote server timed out.",
5: "The operation was canceled via calls to abort() or close() before it was finished.",
6: "The SSL/TLS handshake failed and the encrypted channel could not be established. The sslErrors() signal should have been emitted.",
7: "The connection was broken due to disconnection from the network, however the system has initiated roaming to another access point. The request should be resubmitted and will be processed as soon as the connection is re-established.",
8: "The connection was broken due to disconnection from the network or failure to start the network.",
9: "The background request is not currently allowed due to platform policy.",
10: "While following redirects, the maximum limit was reached.",
11: "While following redirects, the network access API detected a redirect from a encrypted protocol (https) to an unencrypted one (http).",
99: "An unknown network-related error was detected.",
101: "The connection to the proxy server was refused (the proxy server is not accepting requests).",
102: "The proxy server closed the connection prematurely, before the entire reply was received and processed.",
103: "The proxy host name was not found (invalid proxy hostname).",
104: "The connection to the proxy timed out or the proxy did not reply in time to the request sent.",
105: "The proxy requires authentication in order to honour the request but did not accept any credentials offered (if any).",
199: "An unknown proxy-related error was detected.",
201: "The access to the remote content was denied (similar to HTTP error 403).",
202: "The operation requested on the remote content is not permitted.",
203: "The remote content was not found at the server (similar to HTTP error 404).",
204: "The remote server requires authentication to serve the content but the credentials provided were not accepted (if any).",
205: "The request needed to be sent again, but this failed for example because the upload data could not be read a second time.",
206: "The request could not be completed due to a conflict with the current state of the resource.",
207: "The requested resource is no longer available at the server.",
299: "An unknown error related to the remote content was detected.",
301: "The Network Access API cannot honor the request because the protocol is not known.",
302: "The requested operation is invalid for this protocol.",
399: "A breakdown in protocol was detected (parsing error, invalid or unexpected responses, etc.).",
401: "The server encountered an unexpected condition which prevented it from fulfilling the request.",
402: "The server does not support the functionality required to fulfill the request.",
403: "The server is unable to handle the request at this time.",
499: "An unknown error related to the server response was detected.",
}
# Some internal settings.
# Don't change these unless you know what you're doing.
# You can change the tags you want to submit in the settings.
client_params = {
"client": f"picard_plugin_{PLUGIN_NAME.replace(' ', '_')}-v{PLUGIN_VERSION}"
}
default_tags_to_submit = ['genre', 'mood']
# The options as saved in Picard.ini
config.BoolOption("setting", 'tag_submit_plugin_destructive', False)
config.BoolOption("setting", 'tag_submit_plugin_destructive_alert_acknowledged', False)
config.BoolOption("setting", 'tag_submit_plugin_aliases_enabled', False)
config.ListOption("setting", 'tag_submit_plugin_alias_list', [])
config.ListOption("setting", 'tag_submit_plugin_tags_to_submit', default_tags_to_submit)
def tag_submit_handler(document, reply, error, tagger):
"""
The function handling the network response from MusicBrainz
or QtNetwork, showing a message box if an error had occurred.
Uses the network response handler code from rdswift's "Submit ISRC"
plugin.
"""
if error:
# Error handling from rdswift's Submit ISRC plugin
xml_text = str(document, 'UTF-8') if isinstance(document, (bytes, bytearray, QtCore.QByteArray)) else str(document)
# Build error text message from returned xml payload
err_text = ''
matches = re.findall(r'(.*?)', xml_text)
if matches:
err_text = '\n'.join(matches)
else:
err_text = ''
if not err_text:
err_text = q_error_codes[error] if error in q_error_codes else 'There was no error message provided.'
error = QMessageBox()
error.setStandardButtons(QMessageBox.Ok)
error.setDefaultButton(QMessageBox.Ok)
error.setIcon(QMessageBox.Critical)
error.setText(f"An error has occurred submitting the tags to MusicBrainz.
{err_text}
")
error.exec_()
else:
tagger.window.set_statusbar_message(
"Successfully submitted tags to MusicBrainz."
)
def process_tag_aliases(tag_input):
"""
Retrieves a string as input, and searches the tag alias tuple list
for a match.
"""
matched_tag_index = next(
(tag for tag,
tag_tuple in enumerate(config.setting['tag_submit_plugin_alias_list'])
if tag_tuple[0] == tag_input.lower()),
None
)
if matched_tag_index is not None:
resolved_tag = config.setting['tag_submit_plugin_alias_list'][matched_tag_index][1]
return resolved_tag
else:
return tag_input
def process_objs_to_track_list(objs):
"""
Creates a track list out of Album/Track objects
"""
track_list = []
for item in objs:
if isinstance(item, Track):
track_list.append(item)
elif isinstance(item, Album):
if len(item.tracks) > 0:
for track in item.tracks:
track_list.append(track)
return track_list
# TODO handle artist
def handle_submit_process(tagger, track_list, target_tag):
"""
Does some pre-processing before submitting tags. Handles tag deduplication
and halting when inconsistent tagging is detected (i.e. the user is trying
to submit tags to a release with the submitted track tags not being
consistent.)
"""
dict_key = ""
tags_to_search = config.setting['tag_submit_plugin_tags_to_submit']
# Variable to enable when inconsistent tagging is detected, which can be problematic for anything other than recordings.
alert_inconsistent = True
inconsistent_detected = False
# Variable to enable alert if multiple MBIDs are associated, must be toggled.
alert_multiple_mbids = False
# TODO when Windows Picard updates with Python 3.10, use case/switch.
if target_tag == "musicbrainz_recordingid":
dict_key = "recording"
alert_inconsistent = False
elif target_tag == "musicbrainz_albumid":
dict_key = "release"
elif target_tag == "musicbrainz_releasegroupid":
dict_key = "release-group"
elif target_tag == "musicbrainz_albumartistid" or target_tag == "musicbrainz_artistid":
dict_key = "artist"
data = {dict_key: {}}
last_tags = {"mbid": ""}
banned_mbids = {
# Any artist entities that can be applied to multiple artists go here.
# SPAs generally fit the bill here.
"f731ccc4-e22a-43af-a747-64213329e088", # artist: [anonymous]
"33cf029c-63b0-41a0-9855-be2a3665fb3b", # artist: [data]
"314e1c25-dde7-4e4d-b2f4-0a7b9f7c56dc", # artist: [dialogue]
"eec63d3c-3b81-4ad4-b1e4-7c147d4d2b61", # artist: [no artist]
"9be7f096-97ec-4615-8957-8d40b5dcbc41", # artist: [traditional]
"125ec42a-7229-4250-afc5-e057484327fe", # artist: [unknown]
"89ad4ac3-39f7-470e-963a-56509c546377", # artist: Various Artists
"66ea0139-149f-4a0c-8fbf-5ea9ec4a6e49", # artist: [Disney]
"a0ef7e1d-44ff-4039-9435-7d5fefdeecc9", # artist: [theatre]
"80a8851f-444c-4539-892b-ad2a49292aa9", # artist: [language instruction]
"", # blank
}
for track in track_list:
if track.files:
for file in track.files:
mbid_list = file.metadata.getall(target_tag)
if len(mbid_list) > 1:
alert_multiple_mbids = True
for mbid in mbid_list:
if mbid not in banned_mbids:
processed_tags = []
for tag in tags_to_search:
if file.metadata[tag]:
if tag not in last_tags:
pass
else:
# Flip the switch when current tag didn't match last tag on current mbid, on an entity that needs this checked.
if (last_tags[tag] != file.metadata[tag]) and (last_tags["mbid"] == file.metadata[target_tag]) and alert_inconsistent:
inconsistent_detected = True
# in any case, process the tags in case the user intends to go with it.
processed_tags.extend([tag.strip().lower() for tag
in re.split(";|/|,", file.metadata[tag])])
last_tags[tag] = file.metadata[tag]
last_tags["mbid"] = file.metadata[target_tag]
# If a track has multiple files associated to it, there may be duplicate tags.
processed_tags = list(set(processed_tags))
if processed_tags and mbid in data[dict_key]:
data[dict_key][mbid].extend(processed_tags)
else:
data[dict_key][mbid] = processed_tags
else:
log.info(f"Not submitting MBID {track.metadata[target_tag]} as it was found on 'do not submit' MBID set.")
# Send an alert when, at the end of it all, inconsistent tagging was detected.
if inconsistent_detected or alert_multiple_mbids:
warning = QMessageBox()
warning.setStandardButtons(QMessageBox.Ok|QMessageBox.Cancel)
warning.setDefaultButton(QMessageBox.Cancel)
warning.setIcon(QMessageBox.Warning)
if inconsistent_detected and alert_multiple_mbids:
warning.setText("""
WARNING: INCONSISTENT TAGGING AND SUBMISSION TO MULTIPLE MBIDS DETECTED.
You are trying to apply different tags to multiple MusicBrainz entities.
This isn't a use case this plugin supports whatsoever due to the potential for
wrong tags to be unintentionally assigned, but detects and warns just in case.
If this was intentional, click OK. Otherwise, click Cancel.
""")
elif inconsistent_detected:
warning.setText("""
WARNING: INCONSISTENT TAGGING DETECTED.
You are trying to apply multiple tags to one entity, which benefits more from
having the same tags across all tracks when submitting tags via this plugin.
If you intended to have tracks in a release to have different submitted tags,
it's better to cancel this attempt and choose the recording option.
If you didn't, you should apply the same tag across all tracks.
If this was intentional, click OK. Otherwise, click Cancel.
""")
elif alert_multiple_mbids:
warning.setText("""
MULTIPLE MBIDS DETECTED.
You are trying to apply a tag to multiple MusicBrainz entities.
This isn't a use case this plugin supports whatsoever due to the potential for
wrong tags to be unintentionally assigned, but detects and warns just in case.
If this was intentional, click OK. Otherwise, click Cancel.
""")
result = warning.exec_()
if result == QMessageBox.Ok:
upload_tags_to_mbz(data, tagger)
else:
tagger.window.set_statusbar_message(
"Tag submission halted by user request."
)
else:
upload_tags_to_mbz(data, tagger)
def upload_tags_to_mbz(data, tagger):
"""
Generates the XML from the data retrieved, and then uploads it to MusicBrainz.
"""
helper = MBAPIHelper(tagger.webservice)
empty_data = {
"",
"",
"",
""
}
xml_data = []
upvote_tag_fill = ' vote="upvote"' if not config.setting['tag_submit_plugin_destructive'] else ''
for key in data:
# start the list
xml_data.append(f"<{key}-list>")
for mbid in data[key]:
# deduplicate the list of genres so no redundant tags are sent.
data[key][mbid] = list(set(data[key][mbid]))
# start the user tag list
xml_data.extend([f'<{key} id="{mbid}">', ""])
# add the tags
for tag in data[key][mbid]:
xml_data.append(f'{escape(process_tag_aliases(tag.lower()))}')
# close the user tag list
xml_data.extend(["", f""])
# close the list
xml_data.append(f"")
# make the string that would become our submitted XML.
final_xml = ''.join(xml_data)
log.info(final_xml)
if final_xml not in empty_data:
# post it to MusicBrainz
tagger.window.set_statusbar_message(
"Submitting tags to MusicBrainz..."
)
submitted_xml = _wrap_xml_metadata(''.join(xml_data))
path = '/tag' if NEW_MBAPIHelper else ['tag']
helper.post(
path,
submitted_xml,
functools.partial(tag_submit_handler, tagger=tagger),
priority=True,
queryargs=client_params,
parse_response_type="xml",
request_mimetype="application/xml; charset=utf-8"
)
else:
tagger.window.set_statusbar_message(
"Not submitting to MusicBrainz due to empty data."
)
class TagSubmitPlugin_OptionsPage(OptionsPage):
NAME = "tag_submit_plugin"
TITLE = "Tag Submission Plugin"
PARENT = "plugins"
HELP_URL = ""
def __init__(self, parent=None):
super().__init__()
self.ui = TagSubmitPluginOptionsUI(self)
self.destructive_acknowledgement = config.setting['tag_submit_plugin_destructive_alert_acknowledged']
self.ui.overwrite_radio_button.clicked.connect(self.on_destructive_selected)
def on_destructive_selected(self):
if not config.setting['tag_submit_plugin_destructive_alert_acknowledged']:
warning = QMessageBox()
warning.setStandardButtons(QMessageBox.Ok)
warning.setDefaultButton(QMessageBox.Ok)
warning.setIcon(QMessageBox.Warning)
warning.setText("WARNING: BY SELECTING TO OVERWRITE ALL TAGS, THIS MEANS ALL TAGS.
By enabling this option, you acknowledge that you may lose the tags already saved online from the tracks you process via this plugin. This alert will only be displayed once before you save.
If you do not want this behaviour, select the maintain option.
")
warning.exec_()
config.setting['tag_submit_plugin_destructive_alert_acknowledged'] = True
def load(self):
# Destructive option
if config.setting['tag_submit_plugin_destructive']:
self.ui.overwrite_radio_button.setChecked(True)
else:
self.ui.keep_radio_button.setChecked(True)
self.ui.tags_to_save_textbox.setText(
'; '.join(config.setting['tag_submit_plugin_tags_to_submit'])
)
# Aliases enabled option
self.ui.tag_alias_groupbox.setChecked(
config.setting['tag_submit_plugin_aliases_enabled']
)
# Alias list
if 'tag_submit_plugin_alias_list' in config.setting:
log.info("Alias list exists! Let's populate the table.")
for alias_tuple in config.setting['tag_submit_plugin_alias_list']:
self.ui.add_row(alias_tuple[0], alias_tuple[1])
self.ui.tag_alias_table.resizeColumnsToContents()
config.setting['tag_submit_plugin_destructive_alert_acknowledged'] = self.destructive_acknowledgement
def save(self):
config.setting['tag_submit_plugin_destructive'] = self.ui.overwrite_radio_button.isChecked()
config.setting['tag_submit_plugin_aliases_enabled'] = self.ui.tag_alias_groupbox.isChecked()
tag_textbox_text = self.ui.tags_to_save_textbox.text()
if tag_textbox_text:
config.setting['tag_submit_plugin_tags_to_submit'] = [
tag.strip() for tag in tag_textbox_text.split(';')
]
else:
config.setting['tag_submit_plugin_tags_to_submit'] = default_tags_to_submit
if config.setting['tag_submit_plugin_aliases_enabled']:
new_alias_list = self.ui.rows_to_tuple_list()
log.info(new_alias_list)
config.setting['tag_submit_plugin_alias_list'] = new_alias_list
class SubmitTrackTagsMenuAction(BaseAction):
NAME = 'Submit tags to MusicBrainz (recording)'
def callback(self, objs):
handle_submit_process(
objs[0].tagger,
process_objs_to_track_list(objs),
"musicbrainz_recordingid"
)
class SubmitReleaseTagsMenuAction(BaseAction):
NAME = 'Submit tags to MusicBrainz (release)'
def callback(self, objs):
handle_submit_process(
objs[0].tagger,
process_objs_to_track_list(objs),
"musicbrainz_albumid"
)
class SubmitRGTagsMenuAction(BaseAction):
NAME = 'Submit tags to MusicBrainz (release group)'
def callback(self, objs):
handle_submit_process(
objs[0].tagger,
process_objs_to_track_list(objs),
"musicbrainz_releasegroupid"
)
class SubmitRATagsMenuAction(BaseAction):
NAME = 'Submit tags to MusicBrainz (release artist)'
def callback(self, objs):
handle_submit_process(
objs[0].tagger,
process_objs_to_track_list(objs),
"musicbrainz_albumartistid"
)
register_options_page(TagSubmitPlugin_OptionsPage)
register_album_action(SubmitTrackTagsMenuAction())
register_track_action(SubmitTrackTagsMenuAction())
register_album_action(SubmitReleaseTagsMenuAction())
register_track_action(SubmitReleaseTagsMenuAction())
register_album_action(SubmitRGTagsMenuAction())
register_track_action(SubmitRGTagsMenuAction())
register_album_action(SubmitRATagsMenuAction())
register_track_action(SubmitRATagsMenuAction())
================================================
FILE: plugins/submit_folksonomy_tags/ui_config.py
================================================
from PyQt5.QtCore import (
QSize,
Qt
)
from PyQt5.QtWidgets import (
QGridLayout,
QGroupBox,
QHBoxLayout,
QLabel,
QPushButton,
QRadioButton,
QSizePolicy,
QTableWidget,
QTableWidgetItem,
QVBoxLayout,
QAbstractItemView,
QLineEdit
)
class TagSubmitPluginOptionsUI():
def __init__(self, page):
self.main_container = QVBoxLayout()
sizePolicy = QSizePolicy(QSizePolicy.Preferred, QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
# Group box: tag saving
self.tag_save_groupbox = QGroupBox()
sizePolicy.setHeightForWidth(self.tag_save_groupbox.sizePolicy().hasHeightForWidth())
self.tag_save_groupbox.setSizePolicy(sizePolicy)
self.tag_save_groupbox_layout = QGridLayout(self.tag_save_groupbox)
# Label: tag saving description
self.tag_save_description = QLabel(self.tag_save_groupbox)
sizePolicy.setHeightForWidth(self.tag_save_description.sizePolicy().hasHeightForWidth())
self.tag_save_description.setSizePolicy(sizePolicy)
self.tag_save_description.setMinimumSize(QSize(0, 56))
self.tag_save_description.setWordWrap(True)
self.tag_save_groupbox_layout.addWidget(self.tag_save_description, 0, 0, 1, 1)
self.tag_save_groupbox.setTitle("Tag Saving")
self.tag_save_description.setText(u"There are two modes to tag saving via this plugin right now: keep all existing saved tags (only adding on tags) or overwrite them. If you are not in a position where replacing your saved tags online is a good idea, it is recommended to keep this option unchanged.
")
self.main_container.addWidget(self.tag_save_groupbox)
self.tag_save_groupbox_layout.addWidget(self.tag_save_description, 0, 0, 1, 1)
self.tags_to_save_groupbox = QGroupBox()
sizePolicy.setHeightForWidth(self.tags_to_save_groupbox.sizePolicy().hasHeightForWidth())
self.tags_to_save_groupbox.setSizePolicy(sizePolicy)
self.tags_to_save_groupbox_layout = QGridLayout(self.tags_to_save_groupbox)
self.tags_to_save_groupbox.setTitle("Tags to Submit")
self.tags_to_save_description = QLabel(self.tags_to_save_groupbox)
sizePolicy.setHeightForWidth(self.tags_to_save_description.sizePolicy().hasHeightForWidth())
self.tags_to_save_textbox = QLineEdit()
self.tags_to_save_description.setText("List the tags that you want to submit to MusicBrainz via the plugin in the text box below. Separate each tag with a semi-colon. (e.g. genre; mood)
")
self.tags_to_save_groupbox_layout.addWidget(self.tags_to_save_description)
self.tags_to_save_textbox.setPlaceholderText("Tags you want to submit (separated by semicolons - e.g. genre; mood)")
self.tags_to_save_groupbox_layout.addWidget(self.tags_to_save_textbox)
self.main_container.addWidget(self.tags_to_save_groupbox)
# Radio buttons for tag saving options (on the plugin as "destructive")
self.keep_radio_button = QRadioButton(self.tag_save_groupbox)
self.keep_radio_button.setText("Keep existing online saved tags")
self.tag_save_groupbox_layout.addWidget(self.keep_radio_button, 1, 0, 1, 1)
self.overwrite_radio_button = QRadioButton(self.tag_save_groupbox)
self.overwrite_radio_button.setText("Overwrite all online saved tags")
self.tag_save_groupbox_layout.addWidget(self.overwrite_radio_button, 2, 0, 1, 1)
# Group box: tag aliases
self.tag_alias_groupbox = QGroupBox()
sizePolicy1 = QSizePolicy(QSizePolicy.Preferred, QSizePolicy.Expanding)
sizePolicy1.setHorizontalStretch(0)
sizePolicy1.setVerticalStretch(0)
sizePolicy1.setHeightForWidth(self.tag_alias_groupbox.sizePolicy().hasHeightForWidth())
self.tag_alias_groupbox.setSizePolicy(sizePolicy1)
self.tag_alias_groupbox.setCheckable(True)
self.tag_alias_groupbox.setChecked(False)
self.tag_alias_groupbox_layout = QVBoxLayout(self.tag_alias_groupbox)
self.tag_alias_groupbox.setTitle("Tag Aliases")
self.tag_alias_description = QLabel()
self.tag_alias_description.setText("There may be cases where you prefer one tag on your files to be saved as another on MusicBrainz (e.g. if your genre tags don't align with MusicBrainz's standard genre tags). In such cases, the plugin can substitute your tags with whichever tags you want when submitting.
Anything listed here is case-insensitive, as MusicBrainz will process them in lowercase anyway.
")
self.tag_alias_description.setMinimumSize(QSize(0, 42))
self.tag_alias_description.setWordWrap(True)
self.tag_alias_groupbox_layout.addWidget(self.tag_alias_description)
# Tag alias table
self.tag_alias_table = QTableWidget()
self.tag_alias_table.setColumnCount(2)
__find_column = QTableWidgetItem()
__find_column.setText("Find...")
self.tag_alias_table.setHorizontalHeaderItem(0, __find_column)
__replace_column = QTableWidgetItem()
__replace_column.setText("Replace...")
self.tag_alias_table.setHorizontalHeaderItem(1, __replace_column)
self.tag_alias_table.setSelectionBehavior(QAbstractItemView.SelectionBehavior.SelectRows)
self.tag_alias_groupbox_layout.addWidget(self.tag_alias_table)
# Tag alias buttons
self.table_button_layout = QHBoxLayout()
self.add_row_button = QPushButton()
self.delete_row_button = QPushButton()
self.add_row_button.setText("Add tag alias")
self.add_row_button.clicked.connect(self.add_row)
self.delete_row_button.setText("Delete selected tag aliases")
self.delete_row_button.clicked.connect(self.delete_rows)
self.table_button_layout.addWidget(self.add_row_button)
self.table_button_layout.addWidget(self.delete_row_button)
self.tag_alias_groupbox_layout.addLayout(self.table_button_layout)
self.main_container.addWidget(self.tag_alias_groupbox)
page.setLayout(self.main_container)
def add_row(self, find_entry="", replace_entry=""):
"""
Adds a row to the table. Accepts input.
"""
row_pos = self.tag_alias_table.rowCount()
self.tag_alias_table.insertRow(row_pos)
find_tableitem = QTableWidgetItem(find_entry)
replace_tableitem = QTableWidgetItem(replace_entry)
self.tag_alias_table.setItem(row_pos, 0, find_tableitem)
self.tag_alias_table.setItem(row_pos, 1, replace_tableitem)
def delete_rows(self):
"""
Self-explanatory - removes the selected rows.
"""
for row in self.tag_alias_table.selectionModel().selectedRows():
self.tag_alias_table.removeRow(row.row())
def rows_to_tuple_list(self):
"""
Converts filled in rows to a list of tuples for the alias list setting.
"""
tuple_list = []
row_count = self.tag_alias_table.rowCount()
for row in range(row_count):
find_tableitem = self.tag_alias_table.item(row, 0).text()
replace_tableitem = self.tag_alias_table.item(row, 1).text()
if find_tableitem and replace_tableitem:
tuple_list.append((find_tableitem, replace_tableitem))
return tuple_list
================================================
FILE: plugins/submit_isrc/README.md
================================================
# Submit ISRC
## Overview
This plugin adds a right click option on an album to submit the ISRCs to the MusicBrainz server specified in the Option settings.
To use this function, you must first match your files to the appropriate tracks for a release. Once this is done, but before you save your files if you have Picard set to overwrite the `isrc` tag in your files, right-click the release and select "Submit ISRCs" in the "Plugins" section. For each file that has a single valid ISRC in its metadata, the ISRC will be added to the recording on the release if it does not already exist. Once all tracks for the release have been processed, the missing ISRCs will be submitted to MusicBrainz.
If a file's metadata contains multiple ISRCs, such as if the file has already been tagged, then no ISRCs will be submitted for that file.
If one of the files contains an invalid ISRC, or if the same ISRC appears in the metadata for two or more files, then a notice will be displayed and the submission process will be aborted.
When ISRCs have been submitted, a notice will be displayed showing whether or not the submission was successful.
---
================================================
FILE: plugins/submit_isrc/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2020-2021, 2023 Bob Swift (rdswift)
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Submit ISRC'
PLUGIN_AUTHOR = 'Bob Swift'
PLUGIN_DESCRIPTION = '''
Adds a right click option on an album to submit the ISRCs to the MusicBrainz server
specified in the Options.
To use this function, you must first match your files to the appropriate tracks for
a release. Once this is done, but before you save your files if you have Picard set
to overwrite the 'isrc' tag in your files, right-click the release and select "Submit
ISRCs" in the "Plugins" section. For each file that has a single valid ISRC in its
metadata, the ISRC will be added to the recording on the release if it does not
already exist. Once all tracks for the release have been processed, the missing
ISRCs will be submitted to MusicBrainz.
If a file's metadata contains multiple ISRCs, such as if the file has already been
tagged, then no ISRCs will be submitted for that file.
If one of the files contains an invalid ISRC, or if the same ISRC appears in the
metadata for two or more files, then a notice will be displayed and the submission
process will be aborted.
When ISRCs have been submitted, a notice will be displayed showing whether or not
the submission was successful.
'''
PLUGIN_VERSION = '1.1'
PLUGIN_API_VERSIONS = ['2.0', '2.1', '2.2', '2.3', '2.6', '2.9']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.txt"
import re
from picard import log, PICARD_VERSION
from picard.ui.itemviews import BaseAction, register_album_action
from picard.version import Version
from picard.webservice.api_helpers import MBAPIHelper, _wrap_xml_metadata
from PyQt5 import QtCore, QtWidgets
RE_VALIDATE_ISRC = re.compile(r'^[A-Z]{2}[A-Z0-9]{3}[0-9]{7}$')
NEW_MBAPIHelper = (PICARD_VERSION >= Version(2, 9, 0, 'beta', 2))
XML_HEADER = ''
XML_TEMPLATE = ''
XML_FOOTER = ''
Q_ERROR_CODES = {
0: 'No error',
1: "The remote server refused the connection (the server is not accepting requests).",
2: "The remote server closed the connection prematurely, before the entire reply was received and processed.",
3: "The remote host name was not found (invalid hostname).",
4: "The connection to the remote server timed out.",
5: "The operation was canceled via calls to abort() or close() before it was finished.",
6: "The SSL/TLS handshake failed and the encrypted channel could not be established. The sslErrors() signal should have been emitted.",
7: "The connection was broken due to disconnection from the network, however the system has initiated roaming to another access point. The request should be resubmitted and will be processed as soon as the connection is re-established.",
8: "The connection was broken due to disconnection from the network or failure to start the network.",
9: "The background request is not currently allowed due to platform policy.",
10: "While following redirects, the maximum limit was reached.",
11: "While following redirects, the network access API detected a redirect from a encrypted protocol (https) to an unencrypted one (http).",
99: "An unknown network-related error was detected.",
101: "The connection to the proxy server was refused (the proxy server is not accepting requests).",
102: "The proxy server closed the connection prematurely, before the entire reply was received and processed.",
103: "The proxy host name was not found (invalid proxy hostname).",
104: "The connection to the proxy timed out or the proxy did not reply in time to the request sent.",
105: "The proxy requires authentication in order to honour the request but did not accept any credentials offered (if any).",
199: "An unknown proxy-related error was detected.",
201: "The access to the remote content was denied (similar to HTTP error 403).",
202: "The operation requested on the remote content is not permitted.",
203: "The remote content was not found at the server (similar to HTTP error 404).",
204: "The remote server requires authentication to serve the content but the credentials provided were not accepted (if any).",
205: "The request needed to be sent again, but this failed for example because the upload data could not be read a second time.",
206: "The request could not be completed due to a conflict with the current state of the resource.",
207: "The requested resource is no longer available at the server.",
299: "An unknown error related to the remote content was detected.",
301: "The Network Access API cannot honor the request because the protocol is not known.",
302: "The requested operation is invalid for this protocol.",
399: "A breakdown in protocol was detected (parsing error, invalid or unexpected responses, etc.).",
401: "The server encountered an unexpected condition which prevented it from fulfilling the request.",
402: "The server does not support the functionality required to fulfill the request.",
403: "The server is unable to handle the request at this time.",
499: "An unknown error related to the server response was detected.",
}
def validate_isrc(isrc):
"""Verify that the provided ISRC matches the standard pattern for a valid ISRC.
Args:
isrc (str): ISRC to validate
Returns:
str: Properly formatted ISRC (upper case with no spaces or hyphens) if valid, otherwise None
"""
formatted_isrc = str(isrc).upper().replace(' ', '').replace('-', '')
if re.match(RE_VALIDATE_ISRC, formatted_isrc):
return formatted_isrc
return None
def show_popup(title, content, window=None):
"""Display a pop-up dialog.
Args:
title (str): Title for the pop-up dialog.
content (str): Test to be displayed in the pop-up dialog..
window (object, optional): Parent object for the dialog. Defaults to None.
"""
QtWidgets.QMessageBox.information(
window,
title,
content,
QtWidgets.QMessageBox.Ok,
QtWidgets.QMessageBox.Ok
)
class SubmitAlbumISRCs(BaseAction):
NAME = 'Submit ISRCs'
def callback(self, album):
if not album:
log.error("{0}: No album specified for submitting ISRCs.".format(PLUGIN_NAME,))
return
log.info("{0}: Submitting ISRCs for: {1}".format(PLUGIN_NAME, album[0].metadata['album'],))
if not album[0].tracks:
log.debug("{0}: No tracks found in album: {1}".format(PLUGIN_NAME, album[0].metadata['album'],))
show_popup('Error', 'No tracks found in the album.')
return
isrcs = {}
multi_isrcs = []
for track in album[0].tracks:
if not track.files:
continue
audio_file = track.files[0]
metadata = track.metadata
file_metadata = audio_file.orig_metadata
# No ISRC found in the file
if 'isrc' not in file_metadata:
continue
# Get string of existing ISRCs on MusicBrainz
if 'isrc' in metadata:
mb_isrc = metadata['isrc'].upper()
else:
mb_isrc = ''
# Get ISRC string from the file
file_isrc = file_metadata['isrc']
# Multiple ISRCs found in the file (don't process)
if ';' in file_isrc:
multi_isrcs.append(' {0} - {1}'.format(metadata['tracknumber'], metadata['title']))
log.info("{0}: Multiple ISRCs found on track {1} (not processed): {2}".format(PLUGIN_NAME, metadata['tracknumber'], file_isrc))
continue
isrc = validate_isrc(file_isrc)
# ISRC does not pass validation test
if not isrc:
log.debug("{0}: Invalid ISRC found on track {1}: {2}".format(PLUGIN_NAME, metadata['tracknumber'], file_isrc))
show_popup('Error', "Invalid ISRC found on track {0}: '{1}'".format(metadata['tracknumber'], file_isrc))
return
# ISRC already found on another track for this album
if isrc in isrcs:
log.debug("{0}: Duplicate ISRC found on track {1}: {2}".format(PLUGIN_NAME, metadata['tracknumber'], file_isrc))
show_popup('Error', "Duplicate ISRC found on track {0}: '{1}'".format(metadata['tracknumber'], file_isrc))
return
# ISRC already associated with that track (MusicBrainz recording)
if isrc in mb_isrc:
continue
# New ISRC added for submission
log.debug("{0}: Adding ISRC '{1}' for track {2} - \"{3}\"".format(PLUGIN_NAME, isrc, metadata['tracknumber'], metadata['title'],))
isrcs[isrc] = metadata['musicbrainz_recordingid']
if multi_isrcs:
multiple_msg = '\n\nThe following track audio files contained multiple ISRCs (not submitted):\n' + '\n'.join(multi_isrcs)
else:
multiple_msg = ''
# Save count of new ISRCs to display in success message
self.isrc_count = len(isrcs)
# Nothing to submit
if not isrcs:
log.debug("{0}: No new ISRCs found in album: {1}".format(PLUGIN_NAME, album[0].metadata['album'],))
show_popup('Error', 'No new ISRCs found for the tracks in the album.{0}'.format(multiple_msg,))
return
if multiple_msg:
show_popup('Submitting', 'Submitting {0} ISRC{1}.{2}'.format(self.isrc_count, '' if self.isrc_count == 1 else 's', multiple_msg,))
# Build the xml data payload
xml_items = [XML_HEADER]
for isrc, recording in isrcs.items():
xml_items.append(XML_TEMPLATE.format(recording, isrc))
xml_items.append(XML_FOOTER)
data = _wrap_xml_metadata(''.join(xml_items))
# Initialize the MusicBrainz API Helper
webservice = album[0].tagger.webservice
helper = MBAPIHelper(webservice)
# Set up parameters for the helper
client_string = 'Picard_Plugin_{0}-v{1}'.format(PLUGIN_NAME, PLUGIN_VERSION).replace(' ', '_')
handler = self.submission_handler
path = '/recording' if NEW_MBAPIHelper else ['recording']
params = {"client": client_string}
return helper.post(path, data, handler, priority=True,
queryargs=params, parse_response_type="xml",
request_mimetype="application/xml; charset=utf-8")
def submission_handler(self, document, reply, error):
if not error:
show_popup('Success', 'Successfully submitted {0} ISRC{1}.'.format(
self.isrc_count,
'' if self.isrc_count == 1 else 's',
))
return
# Decode response if necessary.
xml_text = str(document, 'UTF-8') if isinstance(document, (bytes, bytearray, QtCore.QByteArray)) else str(document)
# Build error text message from returned xml payload
err_text = ''
matches = re.findall(r'(.*?)', xml_text)
if matches:
err_text = '\n'.join(matches)
else:
err_text = ''
# Use standard QNetworkReply error messages if no message was provided in the xml payload
if not err_text:
err_text = Q_ERROR_CODES[error] if error in Q_ERROR_CODES else 'There was no error message provided.'
show_popup('Error', "There was an error processing the ISRC submission. Please try again.\n\nError Code: {0}\n\n{1}".format(error, err_text))
register_album_action(SubmitAlbumISRCs())
================================================
FILE: plugins/tangoinfo/README.md
================================================
# tango.info plugin for MusicBrainz Picard
Automatically get *genre, date and singers* from **tango.info**, right inside of MusicBrainz Picard.
## Usage
Then open Picard, navigate to `Options -> Options -> Plugins` and enable
the one called `Tango.info Adapter`, then restart and use Picard
like you usually would.
If(and **only if**) there is a valid `barcode` tag for your files, the plugin
will try to look up the corresponding album on *tango.info* and fill in the
`genre`(capitalized), `vocal`(for Singers) and `date` tags for you.
## How it works
The plugin looks up the barcode of an album, constructs the url for the corresponding
*tango.info* album('product'/'TINP') page, parses the HTML, looks for the
`tracks` table and extracts `genre`, `Perf date` and `Vocalist(s)`.
## What is a TINT
See [tango.info wiki: TINT](https://tango.info/wiki/TINT)
`--`, example: `TINT:00743216335725-1-5`.
[tango.info wiki: TINP](https://tango.info/wiki/TINP) - *Tango Info Number
for a Product* is a 14-digit numeric tango.info code used by tango.info and
others.
## Future
Provided tango.info's [Tobias Conradi](https://tango.info/tangoinfo/eng/contact)
does not change the page structure in a manner that breaks this plugin, you
might be able to map instrumentalists and vocalists to the id3 tags of your
liking, or download cover art. Just construct the respective regex and change a
few lines.
## License: GPLv2
Copyright (C) 2016-2022 **Felix Elsner**, Sambhav Kothari, Philipp Wolfer
With help from **Sophist-UK**, whose albumartist_website plugin, to be found
[here](https://github.com/Sophist-UK/sophist-picard-plugins),
this work heavily draws upon
This program is free software; you can redistribute it and/or
modify it under the terms of the GNU General Public License
as published by the Free Software Foundation; either version 2
of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
================================================
FILE: plugins/tangoinfo/__init__.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "Tango.info Adapter"
PLUGIN_AUTHOR = "Felix Elsner, Sambhav Kothari, Philipp Wolfer"
PLUGIN_DESCRIPTION = """
Load genre, date and vocalist tags for latin dance music
from tango.info.
"""
PLUGIN_VERSION = "0.2.0"
PLUGIN_API_VERSIONS = ["2.6", "2.7"]
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import re
from functools import partial
from picard import log
from picard.util import LockableObject
from picard.metadata import register_track_metadata_processor
table_regex = re.compile(
r'
tr_regex = re.compile(r"((?!
).+?)") # Match elements
td_regex = re.compile(r"]*>((?!).+?)") # Match elements
tint_regex = re.compile(r"TINT:([0-9]+-[0-9]{1,2}-[0-9]{1,2})")
TANGO_INFO_HOST = "tango.info"
TANGO_INFO_PORT = 443
# FIXME Remove all this
# This is all just a hack to get around server issues at tango.info
# The server will reply with an empty body if the Host header is set to
# "tango.info:443", but just "tango.info" is fine.
# Picard 2.8+ will by default not append the port to the Host header and thus
# not need this workaround
from picard import PICARD_VERSION
from picard.version import Version
host_workaround_needed = False
if PICARD_VERSION < Version(2, 8, 0, 'dev', 1):
log.warning("%s: Picard version is older than 2.8, using workaround for "
"tango.info Host header issue", PLUGIN_NAME)
host_workaround_needed = True
if host_workaround_needed:
from picard.webservice import WSGetRequest
from PyQt5.QtCore import QUrl
class WrappedWSGetRequest(WSGetRequest): # noqa
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
url_without_port = QUrl(self.url().url())
# -1 is QUrl defaultPort
url_without_port.setPort(-1)
self.setUrl(url_without_port)
class TangoInfoTagger:
class TangoInfoScrapeQueue(LockableObject):
def __init__(self):
LockableObject.__init__(self)
self.queue = {}
def __contains__(self, name):
return name in self.queue
def __iter__(self):
return self.queue.__iter__()
def __getitem__(self, name):
self.lock_for_read()
value = self.queue.get(name)
self.unlock()
return value
def __setitem__(self, name, value):
self.lock_for_write()
self.queue[name] = value
self.unlock()
def append(self, name, value):
self.lock_for_write()
if name in self.queue:
self.queue[name].append(value)
value = False
else:
self.queue[name] = [value]
value = True
self.unlock()
return value
def pop(self, name):
self.lock_for_write()
value = None
if name in self.queue:
value = self.queue[name]
del self.queue[name]
self.unlock()
return value
def __init__(self):
self.albumpage_cache = {}
self.albumpage_queue = self.TangoInfoScrapeQueue()
def add_tangoinfo_data(self, album, track_metadata, track, release):
# Look for BARCODE or barcode tag
if track_metadata.get("barcode"):
barcode = str(track_metadata["barcode"])
elif track_metadata.get("BARCODE"):
barcode = str(track_metadata["BARCODE"])
else:
# Abort if no barcode in track_metadata
return
# https://tango.info/wiki/TINT = --
# https://tango.info/wiki/TINP - "Tango Info Number for a Product" is a
# 14-digit numeric tango.info code used by tango.info and others.
# Example: TINT:00743216335725-1-5
# This plugin normalizes TINTs by stripping all zeros from the left
tint = "%s-%s-%s" % (
barcode.lstrip("0"),
str(track_metadata.get("discnumber", "1")),
str(track_metadata.get("tracknumber")),
)
if barcode in self.albumpage_cache:
if self.albumpage_cache[barcode].get(tint):
for field in ("genre", "date", "vocal"):
# Do no overwrite with empty data
if not self.albumpage_cache[barcode][tint].get(field):
continue
track_metadata[field] = \
self.albumpage_cache[barcode][tint][field]
else:
log.debug(
"%s: No information on tango.info for barcode %s",
PLUGIN_NAME, barcode)
else:
self.website_add_track(album, album._new_tracks[-1], barcode, tint)
def website_add_track(self, album, track, barcode, tint, zeros=0):
"""
:param zeros: Number of zeros that have been prepended to the barcode
"""
self.album_add_request(album)
if self.albumpage_queue.append(barcode, (track, album, tint)):
# Barcode, zero-padded as needed
path = "/%s" % ("0" * zeros) + barcode
log.debug("%s: Downloading from tango.info: track %s, album %s "
"with TINT %s from %s",
PLUGIN_NAME, str(track), str(album), tint,
"https://%s%s" % (TANGO_INFO_HOST, path))
# FIXME: Remove this
if host_workaround_needed:
ws = album.tagger.webservice
def get_patched(self, *args, **kwargs): # noqa
request = WrappedWSGetRequest(self, *args, **kwargs)
return ws.add_request(request)
ws.get_patched = get_patched
return ws.get_patched(
TANGO_INFO_HOST,
TANGO_INFO_PORT,
path,
partial(self.website_process, barcode, zeros),
priority=False,
important=False,
parse_response_type=None,
queryargs=None,
)
# Call website_process() as a partial func
return album.tagger.webservice.get(
TANGO_INFO_HOST,
TANGO_INFO_PORT,
path,
partial(self.website_process, barcode, zeros),
priority=False,
important=False,
parse_response_type=None,
queryargs=None,
)
def website_process(self, barcode, zeros, response_bytes, reply, error):
"""
response_bytes: PyQt5.QtCore.QByteArray, equals reply.readAll()
reply: PyQt5.QtNetwork.QNetworkReply
error: PyQt5.QtNetwork.QNetworkReply.NetworkError (optional)
"""
if error:
log.warning("%s: Network error retrieving info for barcode %s",
PLUGIN_NAME, barcode)
track_triple = self.albumpage_queue.pop(barcode)
for track, album, tint in track_triple:
self.album_remove_request(album)
return
# Decode QByteArray into unicode
response_decoded = response_bytes.data().decode('utf-8')
tangoinfo_albumdata = self.extract_data(barcode, response_decoded)
self.albumpage_cache[barcode] = tangoinfo_albumdata
track_triple = self.albumpage_queue.pop(barcode)
if tangoinfo_albumdata:
if zeros:
log.debug("%s: tango.info does not seem to have data for "
"barcode %s. "
"However, retrying with barcode %s (i.e. the same "
"with %s prepended) was successful. "
"This most likely means either MusicBrainz or "
"tango.info has stored a wrong barcode for this "
"release. You might want to investigate this "
"discrepancy and report it.",
PLUGIN_NAME, barcode, ("0" * zeros) + barcode,
("a zero" if zeros == 1 else "%d zeros" % zeros))
for track, album, tint in track_triple:
tm = track.metadata
if not self.albumpage_cache[barcode].get(tint):
self.album_remove_request(album)
continue
for field in ("genre", "date", "vocal"):
# Write track metadata
if self.albumpage_cache[barcode][tint].get(field):
tm[field] = self.albumpage_cache[barcode][tint][field]
for file in track.iterfiles():
fm = file.metadata
for field in ("genre", "date", "vocal"):
if not self.albumpage_cache[barcode][tint].get(field):
continue
# Write file metadata
fm[field] = self.albumpage_cache[barcode][tint][field]
self.album_remove_request(album)
else:
if zeros >= 2:
log.debug("%s: Could not load album with barcode %s even with "
"zero prepended(%s). This most likely means "
"tango.info does not have a release for this "
"barcode (or MusicBrainz has a wrong barcode)",
PLUGIN_NAME, barcode, ("0" * zeros) + barcode)
for track, album, tint in track_triple:
self.album_remove_request(album)
return
log.debug("%s: Retrying with 0-padded barcode for barcode %s",
PLUGIN_NAME, barcode)
for track, album, tint in track_triple:
# Try again with zero-prepended barcode, but at most two times
self.website_add_track(
album, track, barcode, tint, zeros=(zeros + 1)
)
self.album_remove_request(album)
def album_add_request(self, album):
album._requests += 1
def album_remove_request(self, album):
album._requests -= 1
album._finalize_loading(None)
def extract_data(self, barcode, response):
# Check whether we have a concealed 404 and get the homepage
if "Contents - tango.info" in response:
log.debug("%s: No album with barcode %s on tango.info",
PLUGIN_NAME, barcode)
return
table = re.findall(table_regex, response)
if not table:
log.warning("%s: Could not extract table from album webpage - "
"regex failed or page structure changed", PLUGIN_NAME)
return
table = table[0] # re.findall() returns a list
# Content inside of elements
trcontent = (match.groups()[0] for match in tr_regex.finditer(table))
page_structure_warned = False # Ratelimit warnings
albuminfo = {}
for tr in trcontent:
# Content inside of | elements
trackinfo = [m.groups()[0] for m in td_regex.finditer(tr)]
# Example of expected structure:
# |
# | 1 |
# 6 |
# Ese sos vos |
# tango |
# Ricardo Tanturi |
# Alberto Castillo |
# 1941-12-23 |
# 02:38 |
# info
|
#
# Sanity checks
if not trackinfo:
# Check if list is empty, e.g. contains a for table header
continue
if len(trackinfo) < 9:
if not page_structure_warned: # Only warn once per |
log.warning("%s: Table ' ' structure on webpage "
"unexpected for barcode %s",
PLUGIN_NAME, barcode)
page_structure_warned = True
# Bail out early
continue
# Get tango.info TINT, e.g.
#
tint = re.findall(tint_regex, trackinfo[8])
if tint:
# Normalize TINT by stripping all leading slashes and zeros
tint = tint[0].lstrip("/").lstrip("0")
albuminfo[tint] = {}
else:
# This really shouldn't happen
log.warning("%s: No TINT found on webpage for barcode %s",
PLUGIN_NAME, barcode)
continue
# Get genre, e.g.
# tango
if trackinfo[3] != "-":
genre = re.split("<|>", trackinfo[3])[2].title()
albuminfo[tint]['genre'] = genre
# Get date, e.g.
# 1941-08-14
if trackinfo[6] != "-":
date = re.split("<|>", trackinfo[6])[2]
albuminfo[tint]['date'] = date
# Get singers, e.g.
# Alberto Castillo
if trackinfo[5] != "-":
# Catch and strip tags
vocal = re.sub("<[^>]*>", "", trackinfo[5])
albuminfo[tint]['vocal'] = vocal
return albuminfo or None
tagger = TangoInfoTagger()
register_track_metadata_processor(tagger.add_tangoinfo_data)
================================================
FILE: plugins/theaudiodb/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (c) 2015-2020 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'TheAudioDB cover art'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = 'Use cover art from TheAudioDB.'
PLUGIN_VERSION = "1.3.1"
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2", "2.3", "2.4", "2.5", "2.6"]
PLUGIN_LICENSE = "GPL-2.0-or-later"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from base64 import b64decode
from PyQt5.QtCore import QUrl
from PyQt5.QtNetwork import QNetworkReply
from picard import config, log
from picard.coverart.providers import (
CoverArtProvider,
ProviderOptions,
register_cover_art_provider,
)
from picard.coverart.image import CoverArtImage
from picard.config import (
BoolOption,
TextOption,
)
from picard.webservice import ratecontrol
from .ui_options_theaudiodb import Ui_TheAudioDbOptionsPage
THEAUDIODB_HOST = "www.theaudiodb.com"
THEAUDIODB_PORT = 443
THEAUDIODB_APIKEY = 'MWQ2NTY1NjQ2OTRmMTM0ZDY1NjU2NA=='
OPTION_CDART_ALWAYS = "always"
OPTION_CDART_NEVER = "never"
OPTION_CDART_NOALBUMART = "noalbumart"
# No rate limit for TheAudioDB.
ratecontrol.set_minimum_delay((THEAUDIODB_HOST, THEAUDIODB_PORT), 0)
class TheAudioDbOptionsPage(ProviderOptions):
_options_ui = Ui_TheAudioDbOptionsPage
options = [
TextOption("setting", "theaudiodb_use_cdart", OPTION_CDART_NOALBUMART),
BoolOption("setting", "theaudiodb_use_high_quality", False),
]
def load(self):
if config.setting["theaudiodb_use_cdart"] == OPTION_CDART_ALWAYS:
self.ui.theaudiodb_cdart_use_always.setChecked(True)
elif config.setting["theaudiodb_use_cdart"] == OPTION_CDART_NEVER:
self.ui.theaudiodb_cdart_use_never.setChecked(True)
elif config.setting["theaudiodb_use_cdart"] == OPTION_CDART_NOALBUMART:
self.ui.theaudiodb_cdart_use_if_no_albumcover.setChecked(True)
self.ui.theaudiodb_use_high_quality.setChecked(
config.setting['theaudiodb_use_high_quality'])
def save(self):
if self.ui.theaudiodb_cdart_use_always.isChecked():
config.setting["theaudiodb_use_cdart"] = OPTION_CDART_ALWAYS
elif self.ui.theaudiodb_cdart_use_never.isChecked():
config.setting["theaudiodb_use_cdart"] = OPTION_CDART_NEVER
elif self.ui.theaudiodb_cdart_use_if_no_albumcover.isChecked():
config.setting["theaudiodb_use_cdart"] = OPTION_CDART_NOALBUMART
config.setting['theaudiodb_use_high_quality'] = self.ui.theaudiodb_use_high_quality.isChecked()
class TheAudioDbCoverArtImage(CoverArtImage):
"""Image from The Audio DB"""
support_types = True
sourceprefix = "AUDIODB"
def parse_url(self, url):
super().parse_url(url)
# Workaround for Picard always returning port 80 regardless of the
# scheme. No longer necessary for Picard >= 2.1.3
self.port = self.url.port(443 if self.url.scheme() == 'https' else 80)
class CoverArtProviderTheAudioDb(CoverArtProvider):
"""Use TheAudioDB to get cover art"""
NAME = "TheAudioDB"
TITLE = "TheAudioDB"
OPTIONS = TheAudioDbOptionsPage
def __init__(self, coverart):
super().__init__(coverart)
self.__api_key = b64decode(THEAUDIODB_APIKEY).decode()
def enabled(self):
return super().enabled() and not self.coverart.front_image_found
def queue_images(self):
release_group_id = self.metadata["musicbrainz_releasegroupid"]
path = "/api/v1/json/%s/album-mb.php" % self.__api_key
queryargs = {
"i": bytes(QUrl.toPercentEncoding(release_group_id)).decode()
}
log.debug("TheAudioDB: Queued download: %s?i=%s", path, queryargs["i"])
self.album.tagger.webservice.get(
THEAUDIODB_HOST,
THEAUDIODB_PORT,
path,
self._json_downloaded,
priority=True,
important=False,
parse_response_type='json',
queryargs=queryargs)
self.album._requests += 1
return CoverArtProvider.WAIT
def _json_downloaded(self, data, reply, error):
self.album._requests -= 1
if error:
if error != QNetworkReply.ContentNotFoundError:
error_level = log.error
else:
error_level = log.debug
error_level("TheAudioDB: Problem requesting metadata: %s", error)
else:
try:
releases = data.get("album")
if not releases:
log.debug("TheAudioDB: No cover art found for %s",
reply.url().url())
return
release = releases[0]
albumart_url = None
if config.setting['theaudiodb_use_high_quality']:
albumart_url = release.get("strAlbumThumbHQ")
if not albumart_url:
albumart_url = release.get("strAlbumThumb")
cdart_url = release.get("strAlbumCDart")
use_cdart = config.setting["theaudiodb_use_cdart"]
if albumart_url:
self._select_and_add_cover_art(albumart_url, ["front"])
if cdart_url and (use_cdart == OPTION_CDART_ALWAYS
or (use_cdart == OPTION_CDART_NOALBUMART
and not albumart_url)):
types = ["medium"]
if not albumart_url:
types.append("front")
self._select_and_add_cover_art(cdart_url, types)
except (TypeError):
log.error("TheAudioDB: Problem processing downloaded metadata", exc_info=True)
finally:
self.next_in_queue()
def _select_and_add_cover_art(self, url, types):
log.debug("TheAudioDB: Found artwork %s" % url)
self.queue_put(TheAudioDbCoverArtImage(url, types=types))
register_cover_art_provider(CoverArtProviderTheAudioDb)
================================================
FILE: plugins/theaudiodb/ui_options_theaudiodb.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/theaudiodb/ui_options_theaudiodb.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_TheAudioDbOptionsPage(object):
def setupUi(self, TheAudioDbOptionsPage):
TheAudioDbOptionsPage.setObjectName("TheAudioDbOptionsPage")
TheAudioDbOptionsPage.resize(442, 364)
self.vboxlayout = QtWidgets.QVBoxLayout(TheAudioDbOptionsPage)
self.vboxlayout.setContentsMargins(9, 9, 9, 9)
self.vboxlayout.setSpacing(6)
self.vboxlayout.setObjectName("vboxlayout")
self.groupBox = QtWidgets.QGroupBox(TheAudioDbOptionsPage)
self.groupBox.setObjectName("groupBox")
self.vboxlayout1 = QtWidgets.QVBoxLayout(self.groupBox)
self.vboxlayout1.setContentsMargins(9, 9, 9, 9)
self.vboxlayout1.setSpacing(2)
self.vboxlayout1.setObjectName("vboxlayout1")
self.label = QtWidgets.QLabel(self.groupBox)
self.label.setTextFormat(QtCore.Qt.RichText)
self.label.setWordWrap(True)
self.label.setOpenExternalLinks(True)
self.label.setObjectName("label")
self.vboxlayout1.addWidget(self.label)
self.vboxlayout.addWidget(self.groupBox)
self.verticalGroupBox = QtWidgets.QGroupBox(TheAudioDbOptionsPage)
self.verticalGroupBox.setObjectName("verticalGroupBox")
self.verticalLayout = QtWidgets.QVBoxLayout(self.verticalGroupBox)
self.verticalLayout.setObjectName("verticalLayout")
self.theaudiodb_cdart_use_always = QtWidgets.QRadioButton(self.verticalGroupBox)
self.theaudiodb_cdart_use_always.setObjectName("theaudiodb_cdart_use_always")
self.verticalLayout.addWidget(self.theaudiodb_cdart_use_always)
self.theaudiodb_cdart_use_if_no_albumcover = QtWidgets.QRadioButton(self.verticalGroupBox)
self.theaudiodb_cdart_use_if_no_albumcover.setObjectName("theaudiodb_cdart_use_if_no_albumcover")
self.verticalLayout.addWidget(self.theaudiodb_cdart_use_if_no_albumcover)
self.theaudiodb_cdart_use_never = QtWidgets.QRadioButton(self.verticalGroupBox)
self.theaudiodb_cdart_use_never.setObjectName("theaudiodb_cdart_use_never")
self.verticalLayout.addWidget(self.theaudiodb_cdart_use_never)
self.vboxlayout.addWidget(self.verticalGroupBox)
self.theaudiodb_use_high_quality = QtWidgets.QCheckBox(TheAudioDbOptionsPage)
self.theaudiodb_use_high_quality.setObjectName("theaudiodb_use_high_quality")
self.vboxlayout.addWidget(self.theaudiodb_use_high_quality)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.vboxlayout.addItem(spacerItem)
self.retranslateUi(TheAudioDbOptionsPage)
QtCore.QMetaObject.connectSlotsByName(TheAudioDbOptionsPage)
def retranslateUi(self, TheAudioDbOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.groupBox.setTitle(_translate("TheAudioDbOptionsPage", "TheAudioDB cover art"))
self.label.setText(_translate("TheAudioDbOptionsPage", "\n"
"\n"
"This plugin loads cover art from TheAudioDB. TheAudioDB is a community Database of audio artwork and data. Their content is only possible thanks to the hard work of volunteer editors. If you like this plugin, please consider registering as an editor or supporting the TheAudioDB patreon campaign. "))
self.verticalGroupBox.setTitle(_translate("TheAudioDbOptionsPage", "Medium images"))
self.theaudiodb_cdart_use_always.setText(_translate("TheAudioDbOptionsPage", "Always load medium images"))
self.theaudiodb_cdart_use_if_no_albumcover.setText(_translate("TheAudioDbOptionsPage", "Load only if no front cover is available"))
self.theaudiodb_cdart_use_never.setText(_translate("TheAudioDbOptionsPage", "Never load medium images"))
self.theaudiodb_use_high_quality.setText(_translate("TheAudioDbOptionsPage", "Use high resolution images, if available"))
================================================
FILE: plugins/theaudiodb/ui_options_theaudiodb.ui
================================================
TheAudioDbOptionsPage
0
0
442
364
6
9
9
9
9
-
TheAudioDB cover art
2
9
9
9
9
-
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta name="qrichtext" content="1" /></head><body>
<p>This plugin loads cover art from <a href="https://www.theaudiodb.com">TheAudioDB</a>. TheAudioDB is a community Database of audio artwork and data. Their content is only possible thanks to the hard work of volunteer editors. If you like this plugin, please consider <a href="https://www.theaudiodb.com/user_register_now.php">registering</a> as an editor or supporting the TheAudioDB <a href="https://www.patreon.com/thedatadb">patreon campaign</a>.</p></body></html>
Qt::RichText
true
true
-
Medium images
-
Always load medium images
-
Load only if no front cover is available
-
Never load medium images
-
Use high resolution images, if available
-
Qt::Vertical
20
40
================================================
FILE: plugins/titlecase/titlecase.py
================================================
# -*- coding: utf-8 -*-
# Copyright 2007 Javier Kohen
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License version 2 as
# published by the Free Software Foundation
PLUGIN_NAME = "Title Case"
PLUGIN_AUTHOR = "Javier Kohen, Sambhav Kothari"
PLUGIN_DESCRIPTION = "Capitalize First Character In Every Word Of A Title"
PLUGIN_VERSION = "1.0.2"
PLUGIN_API_VERSIONS = ['2.0']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
import unicodedata
from picard.plugin import PluginPriority
def iswbound(char):
"""Returns whether the given character is a word boundary."""
category = unicodedata.category(char)
# If it's a space separator or punctuation
return 'Zs' == category or 'Sk' == category or 'P' == category[0]
def utitle(string):
"""Title-case a string using a less destructive method than str.title."""
new_string = string[0].capitalize()
cap = False
for i in range(1, len(string)):
s = string[i]
# Special case apostrophe in the middle of a word.
if s in "’'" and string[i - 1].isalpha():
cap = False
elif iswbound(s):
cap = True
elif cap and s.isalpha():
cap = False
s = s.capitalize()
else:
cap = False
new_string += s
return new_string
def title(string):
"""Title-case a string using a less destructive method than str.title."""
if not string:
return ""
# if the string is all uppercase, lowercase it - Erich/Javier
# Lots of Japanese songs use entirely upper-case English titles,
# so I don't like this change... - JoeW
#if string == string.upper(): string = string.lower()
return utitle(str(string))
from picard.metadata import (
register_track_metadata_processor,
register_album_metadata_processor,
)
def title_case(tagger, metadata, *args):
for name, value in metadata.rawitems():
if name in ["title", "album", "artist"]:
metadata[name] = [title(x) for x in value]
register_track_metadata_processor(title_case, priority=PluginPriority.LOW)
register_album_metadata_processor(title_case, priority=PluginPriority.LOW)
================================================
FILE: plugins/tracks2clipboard/tracks2clipboard.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = "Copy Cluster to Clipboard"
PLUGIN_AUTHOR = "Michael Elsdörfer, Sambhav Kothari"
PLUGIN_DESCRIPTION = "Exports a cluster's tracks to the clipboard, so it can be copied into the tracklist field on MusicBrainz"
PLUGIN_VERSION = "1.0"
PLUGIN_API_VERSIONS = ["2.0"]
from PyQt5 import QtWidgets
from picard.cluster import Cluster
from picard.util import format_time
from picard.ui.itemviews import BaseAction, register_cluster_action
class CopyClusterToClipboard(BaseAction):
NAME = "Copy Cluster to Clipboard..."
def callback(self, objs):
if len(objs) != 1 or not isinstance(objs[0], Cluster):
return
cluster = objs[0]
artists = set()
for i, file in enumerate(cluster.files):
artists.add(file.metadata["artist"])
tracks = []
for i, file in enumerate(cluster.files):
try:
i = int(file.metadata["tracknumber"])
except:
i += 1
if len(artists) > 1:
tracks.append((i, "%s. %s - %s (%s)" % (
i,
file.metadata["title"],
file.metadata["artist"],
format_time(file.metadata.length))))
else:
tracks.append((i, "%s. %s (%s)" % (
i,
file.metadata["title"],
format_time(file.metadata.length))))
clipboard = QtWidgets.QApplication.clipboard()
clipboard.setText("\n".join([x[1] for x in sorted(tracks)]))
register_cluster_action(CopyClusterToClipboard())
================================================
FILE: plugins/viewvariables/__init__.py
================================================
# -*- coding: utf-8 -*-
PLUGIN_NAME = 'View script variables'
PLUGIN_AUTHOR = 'Sophist'
PLUGIN_DESCRIPTION = '''Display a dialog box listing the metadata variables for the track / file.
This allows you to see metadata variables beginning with "~" which are not normally visible in the metadata
pane of the main Picard window, which can be useful when you are writing tagging or file naming scripts.
'''
PLUGIN_VERSION = '0.7.2'
PLUGIN_API_VERSIONS = ['2.0']
PLUGIN_LICENSE = "GPL-2.0"
PLUGIN_LICENSE_URL = "https://www.gnu.org/licenses/gpl-2.0.html"
from PyQt5 import QtWidgets, QtCore
try:
from picard.util.tags import PRESERVED_TAGS
except ImportError:
from picard.file import File
PRESERVED_TAGS = File._default_preserved_tags
from picard.file import File
from picard.track import Track
from picard.ui.itemviews import BaseAction, register_file_action, register_track_action
from picard.plugins.viewvariables.ui_variables_dialog import Ui_VariablesDialog
class ViewVariables(BaseAction):
NAME = 'View script variables'
def callback(self, objs):
obj = objs[0]
files = self.tagger.get_files_from_objects(objs)
if files:
obj = files[0]
dialog = ViewVariablesDialog(obj)
dialog.exec_()
class ViewVariablesDialog(QtWidgets.QDialog):
def __init__(self, obj, parent=None):
QtWidgets.QDialog.__init__(self, parent)
self.ui = Ui_VariablesDialog()
self.ui.setupUi(self)
self.ui.buttonBox.accepted.connect(self.accept)
self.ui.buttonBox.rejected.connect(self.reject)
metadata = obj.metadata
if isinstance(obj, File):
self.setWindowTitle(_("File: %s") % obj.base_filename)
elif isinstance(obj, Track):
tn = metadata['tracknumber']
if len(tn) == 1:
tn = "0" + tn
self.setWindowTitle(_("Track: %s %s ") % (tn, metadata['title']))
else:
self.setWindowTitle(_("Variables"))
self._display_metadata(metadata)
def _display_metadata(self, metadata):
keys = metadata.keys()
keys = sorted(keys, key=lambda key:
'0' + key if key in PRESERVED_TAGS and key.startswith('~') else
'1' + key if key.startswith('~') else
'2' + key)
media = hidden = album = False
table = self.ui.metadata_table
key_example, value_example = self.get_table_items(table, 0)
self.key_flags = key_example.flags()
self.value_flags = value_example.flags()
table.setRowCount(len(keys) + 3)
i = 0
for key in keys:
if key in PRESERVED_TAGS and key.startswith('~'):
if not media:
self.add_separator_row(table, i, _("File variables"))
i += 1
media = True
elif key.startswith('~'):
if not hidden:
self.add_separator_row(table, i, _("Hidden variables"))
i += 1
hidden = True
else:
if not album:
self.add_separator_row(table, i, _("Tag variables"))
i += 1
album = True
key_item, value_item = self.get_table_items(table, i)
i += 1
key_item.setText("_" + key[1:] if key.startswith('~') else key)
if key in metadata:
value = metadata.getall(key)
if len(value) == 1 and value[0] != '':
value = value[0]
else:
value = repr(value)
value_item.setText(value)
def add_separator_row(self, table, i, title):
key_item, value_item = self.get_table_items(table, i)
font = key_item.font()
font.setBold(True)
key_item.setFont(font)
key_item.setText(title)
def get_table_items(self, table, i):
key_item = table.item(i, 0)
value_item = table.item(i, 1)
if not key_item:
key_item = QtWidgets.QTableWidgetItem()
key_item.setFlags(self.key_flags)
table.setItem(i, 0, key_item)
if not value_item:
value_item = QtWidgets.QTableWidgetItem()
value_item.setFlags(self.value_flags)
table.setItem(i, 1, value_item)
return key_item, value_item
vv = ViewVariables()
register_file_action(vv)
register_track_action(vv)
================================================
FILE: plugins/viewvariables/ui_variables_dialog.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/viewvariables/ui_variables_dialog.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_VariablesDialog(object):
def setupUi(self, VariablesDialog):
VariablesDialog.setObjectName("VariablesDialog")
VariablesDialog.resize(600, 450)
self.verticalLayout = QtWidgets.QVBoxLayout(VariablesDialog)
self.verticalLayout.setObjectName("verticalLayout")
self.metadata_table = QtWidgets.QTableWidget(VariablesDialog)
self.metadata_table.setAutoFillBackground(False)
self.metadata_table.setSelectionMode(QtWidgets.QAbstractItemView.ContiguousSelection)
self.metadata_table.setRowCount(1)
self.metadata_table.setColumnCount(2)
self.metadata_table.setObjectName("metadata_table")
item = QtWidgets.QTableWidgetItem()
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
item.setFont(font)
self.metadata_table.setHorizontalHeaderItem(0, item)
item = QtWidgets.QTableWidgetItem()
font = QtGui.QFont()
font.setBold(True)
font.setWeight(75)
item.setFont(font)
self.metadata_table.setHorizontalHeaderItem(1, item)
item = QtWidgets.QTableWidgetItem()
item.setFlags(QtCore.Qt.ItemIsSelectable|QtCore.Qt.ItemIsEnabled)
self.metadata_table.setItem(0, 0, item)
item = QtWidgets.QTableWidgetItem()
item.setFlags(QtCore.Qt.ItemIsSelectable|QtCore.Qt.ItemIsEnabled)
self.metadata_table.setItem(0, 1, item)
self.metadata_table.horizontalHeader().setDefaultSectionSize(150)
self.metadata_table.horizontalHeader().setSortIndicatorShown(False)
self.metadata_table.horizontalHeader().setStretchLastSection(True)
self.metadata_table.verticalHeader().setVisible(False)
self.metadata_table.verticalHeader().setDefaultSectionSize(20)
self.metadata_table.verticalHeader().setMinimumSectionSize(20)
self.verticalLayout.addWidget(self.metadata_table)
self.buttonBox = QtWidgets.QDialogButtonBox(VariablesDialog)
self.buttonBox.setStandardButtons(QtWidgets.QDialogButtonBox.Cancel|QtWidgets.QDialogButtonBox.Ok)
self.buttonBox.setObjectName("buttonBox")
self.verticalLayout.addWidget(self.buttonBox)
self.retranslateUi(VariablesDialog)
QtCore.QMetaObject.connectSlotsByName(VariablesDialog)
def retranslateUi(self, VariablesDialog):
_translate = QtCore.QCoreApplication.translate
item = self.metadata_table.horizontalHeaderItem(0)
item.setText(_translate("VariablesDialog", "Variable"))
item = self.metadata_table.horizontalHeaderItem(1)
item.setText(_translate("VariablesDialog", "Value"))
__sortingEnabled = self.metadata_table.isSortingEnabled()
self.metadata_table.setSortingEnabled(False)
self.metadata_table.setSortingEnabled(__sortingEnabled)
================================================
FILE: plugins/viewvariables/ui_variables_dialog.ui
================================================
VariablesDialog
0
0
600
450
-
false
QAbstractItemView::ContiguousSelection
1
2
150
false
true
false
20
20
|
Variable
75
true
Value
75
true
-
ItemIsSelectable|ItemIsEnabled
-
ItemIsSelectable|ItemIsEnabled
-
QDialogButtonBox::Cancel|QDialogButtonBox::Ok
buttonBox
================================================
FILE: plugins/wikidata/__init__.py
================================================
# -*- coding: utf-8 -*-
# Copyright © 2016 Daniel sobey
# This work is free. You can redistribute it and/or modify it under the
# terms of the Do What The Fuck You Want To Public License, Version 2,
# as published by Sam Hocevar. See http://www.wtfpl.net/ for more details.
PLUGIN_NAME = 'Wikidata Genre'
PLUGIN_AUTHOR = 'Daniel Sobey, Sambhav Kothari'
PLUGIN_DESCRIPTION = 'Query wikidata to get genre tags'
PLUGIN_VERSION = '1.4.5'
PLUGIN_API_VERSIONS = ["2.0", "2.1", "2.2"]
PLUGIN_LICENSE = 'WTFPL'
PLUGIN_LICENSE_URL = 'http://www.wtfpl.net/'
import re
from functools import partial
from picard import config, log
from picard.metadata import register_track_metadata_processor
from picard.plugins.wikidata.ui_options_wikidata import Ui_WikidataOptionsPage
from picard.ui.options import register_options_page, OptionsPage
from picard.webservice import ratecontrol
WIKIDATA_HOST = 'www.wikidata.org'
WIKIDATA_PORT = 443
ratecontrol.set_minimum_delay((WIKIDATA_HOST, WIKIDATA_PORT), 0)
def parse_ignored_tags(ignore_tags_setting):
ignore_tags = []
for tag in ignore_tags_setting.lower().split(','):
if not tag:
break
tag = tag.strip()
if tag.startswith('/') and tag.endswith('/'):
try:
tag = re.compile(tag[1:-1])
except re.error:
log.error(
'Error parsing ignored tag "%s"', tag, exc_info=True)
ignore_tags.append(tag)
return ignore_tags
def matches_ignored(ignore_tags, tag):
if ignore_tags:
tag = tag.lower().strip()
for pattern in ignore_tags:
if hasattr(pattern, 'match'):
match = pattern.match(tag)
else:
match = pattern == tag
if match:
return True
return False
class Wikidata:
RELEASE_GROUP = 1
ARTIST = 2
WORK = 3
def __init__(self):
# Key: mbid, value: List of metadata entries to be updated when we have parsed everything
self.requests = {}
# Key: mbid, value: List of items to track the number of outstanding requests
self.itemAlbums = {}
# cache, items that have been found
# key: mbid, value: list of strings containing the genre's
self.cache = {}
# metabrainz url
self.mb_host = ''
self.mb_port = ''
# web service & logger
self.ws = None
self.log = None
# settings from options, options
self.use_release_group_genres = False
self.use_artist_genres = False
self.use_artist_only_if_no_release = False
self.ignore_genres_from_these_artists = ''
self.ignore_genres_from_these_artists_list = []
self.use_work_genres = True
self.ignore_these_genres = ''
self.ignore_these_genres_list = []
self.genre_delimiter = ''
# not used
def process_release(self, album, metadata, release):
self.ws = album.tagger.webservice
self.log = album.log
item_id = metadata.getall('musicbrainz_releasegroupid')[0]
log.info('WIKIDATA: Processing release group %s ' % item_id)
self.process_request(metadata, album, item_id, item_type='release-group')
for artist in metadata.getall('musicbrainz_albumartistid'):
item_id = artist
log.info('WIKIDATA: Processing release artist %s' % item_id)
self.process_request(metadata, album, item_id, item_type='artist')
# Main processing function
# First see if we have already found what we need in the cache, finalize loading
# Next see if we are already looking for the item
# If we are, add this item to the list of items to be updated once we find what we are looking for.
# Otherwise we are the first one to look up this item, start a new request
# metadata, map containing the new metadata
#
def process_request(self, metadata, album, item_id, item_type):
log.debug('WIKIDATA: Looking up cache for item: %s' % item_id)
log.debug('WIKIDATA: Album request count: %s' % album._requests)
log.debug('WIKIDATA: Item type %s' % item_type)
if item_id in self.cache:
log.debug('WIKIDATA: Found item in cache')
genre_list = self.cache[item_id]
new_genre = set(metadata.getall("genre"))
new_genre.update(genre_list)
#sort the new genre list so that they don't appear as new entries (not a change) next time
metadata["genre"] = self.genre_delimiter.join(sorted(new_genre))
return
else:
# pending requests are handled by adding the metadata object to a
# list of things to be updated when the genre is found
if item_id in self.itemAlbums:
log.debug(
'WIKIDATA: Request already pending, add it to the list of items to update once this has been'
'found')
self.requests[item_id].append(metadata)
else:
self.requests[item_id] = [metadata]
self.itemAlbums[item_id] = album
album._requests += 1
log.debug('WIKIDATA: First request for this item')
log.debug('WIKIDATA: About to call Musicbrainz to look up %s ' % item_id)
path = '/ws/2/%s/%s' % (item_type, item_id)
queryargs = {"inc": "url-rels"}
self.ws.get(self.mb_host, self.mb_port, path, partial(self.musicbrainz_release_lookup, item_id,
metadata),
parse_response_type="xml", priority=False, important=False, queryargs=queryargs)
def musicbrainz_release_lookup(self, item_id, metadata, response, reply, error):
found = False
if error:
log.error('WIKIDATA: Error retrieving release group info')
else:
if 'metadata' in response.children:
if 'release_group' in response.metadata[0].children and self.use_release_group_genres:
if 'relation_list' in response.metadata[0].release_group[0].children:
for relation in response.metadata[0].release_group[0].relation_list[0].relation:
if relation.type == 'wikidata' and 'target' in relation.children:
found = True
wikidata_url = relation.target[0].text
log.debug('WIKIDATA: wikidata url found for RELEASE_GROUP: %s ', wikidata_url)
self.process_wikidata(Wikidata.RELEASE_GROUP, wikidata_url, item_id)
if 'artist' in response.metadata[0].children and self.use_artist_genres:
if 'relation_list' in response.metadata[0].artist[0].children:
for relation in response.metadata[0].artist[0].relation_list[0].relation:
if relation.type == 'wikidata' and 'target' in relation.children:
found = True
wikidata_url = relation.target[0].text
self.process_wikidata(Wikidata.ARTIST, wikidata_url, item_id)
log.debug('WIKIDATA: wikidata url found for ARTIST: %s ', wikidata_url)
if 'work' in response.metadata[0].children and self.use_work_genres:
if 'relation_list' in response.metadata[0].work[0].children:
for relation in response.metadata[0].work[0].relation_list[0].relation:
if relation.type == 'wikidata' and 'target' in relation.children:
found = True
wikidata_url = relation.target[0].text
log.debug('WIKIDATA: wikidata url found for WORK: %s ', wikidata_url)
self.process_wikidata(Wikidata.WORK, wikidata_url, item_id)
if not found:
log.debug('WIKIDATA: No wikidata url found for item_id: %s ', item_id)
album = self.itemAlbums[item_id]
album._requests -= 1
if not album._requests:
self.itemAlbums = {k: v for k, v in self.itemAlbums.items() if v != album}
album._finalize_loading(None)
log.info('WIKIDATA: Total remaining requests: %s' % album._requests)
if not self.itemAlbums:
self.requests.clear()
log.info('WIKIDATA: Finished (A)')
def process_wikidata(self, genre_source_type, wikidata_url, item_id):
album = self.itemAlbums[item_id]
album._requests += 1
item = wikidata_url.split('/')[4]
path = "/wiki/Special:EntityData/" + item + ".rdf"
log.debug('WIKIDATA: Fetching from wikidata.org%s' % path)
self.ws.get(WIKIDATA_HOST, WIKIDATA_PORT, path,
partial(self.parse_wikidata_response, item, item_id, genre_source_type),
parse_response_type="xml", priority=False, important=False)
def parse_wikidata_response(self, item, item_id, genre_source_type, response, reply, error):
genre_entries = []
genre_list = []
if error:
log.error('WIKIDATA: error getting data from wikidata.org')
else:
if 'RDF' in response.children:
node = response.RDF[0]
for node1 in node.Description:
if 'about' in node1.attribs:
if node1.attribs.get('about') == 'http://www.wikidata.org/entity/%s' % item:
for key, val in list(node1.children.items()):
if key == 'P136':
for i in val:
if 'resource' in i.attribs:
tmp = i.attribs.get('resource')
if 'entity' == tmp.split('/')[3] and len(tmp.split('/')) == 5:
genre_id = tmp.split('/')[4]
log.debug(
'WIKIDATA: Found the wikidata id for the genre: %s' % genre_id)
genre_entries.append(tmp)
else:
for tmp in genre_entries:
if tmp == node1.attribs.get('about'):
list1 = node1.children.get('name')
if not list1:
log.warning('WIKIDATA: Response does not contain a name field')
else:
for node2 in list1:
if node2.attribs.get('lang') == 'en':
genre = node2.text.title()
if not matches_ignored(self.ignore_these_genres_list, genre):
genre_list.append(genre)
log.debug('New genre has been found and ALLOWED: %s' % genre)
else:
log.debug('New genre has been found, but IGNORED: %s' % genre)
if len(genre_list) > 0:
log.debug('WIKIDATA: item_id: %s' % item_id)
log.debug('WIKIDATA: Final list of wikidata id found: %s' % genre_entries)
log.debug('WIKIDATA: Final list of genre: %s' % genre_list)
log.info('WIKIDATA: Total items to update: %d ' % len(self.requests[item_id]))
for metadata in self.requests[item_id]:
if genre_source_type == Wikidata.RELEASE_GROUP:
metadata['~release_group_genre_sourced'] = True
elif genre_source_type == Wikidata.ARTIST:
if self.use_artist_only_if_no_release and metadata['~release_group_genre_sourced'] or \
matches_ignored(self.ignore_genres_from_these_artists_list, metadata.get("artist")):
if item_id not in self.cache:
self.cache[item_id] = []
log.debug('WIKIDATA: NOT setting Artist-sourced genre: %s ' % genre_list)
continue
else:
log.debug('WIKIDATA: Setting Artist-sourced genre: %s ' % genre_list)
# getall doesn't handle delimiters so we need to check-n-parse here
old_genre_metadata = metadata.getall("genre")
old_genre_list = []
for genre in old_genre_metadata:
if self.genre_delimiter and self.genre_delimiter in genre:
old_genre_list.extend(genre.split(self.genre_delimiter))
else:
old_genre_list.append(genre)
new_genre = set(old_genre_list)
new_genre.update(genre_list)
# Sort the new genre list so that they don't appear as new entries (not a change) next time
log.debug('WIKIDATA: setting metadata genre to : %s ' % new_genre)
if self.genre_delimiter:
metadata["genre"] = self.genre_delimiter.join(sorted(new_genre))
else:
metadata["genre"] = sorted(new_genre)
log.debug('WIKIDATA: setting cache genre to : %s ' % genre_list)
self.cache[item_id] = genre_list
else:
log.debug('WIKIDATA: genre not found in wikidata')
log.debug('WIKIDATA: seeing if we can finalize tags...')
album = self.itemAlbums[item_id]
album._requests -= 1
if not album._requests:
self.itemAlbums = {k: v for k, v in self.itemAlbums.items() if v != album}
album._finalize_loading(None)
log.info('WIKIDATA: total remaining requests: %s' % album._requests)
if not self.itemAlbums:
self.requests.clear()
log.info('WIKIDATA: Finished (B)')
def process_track(self, album, metadata, track, release):
self.update_settings()
self.ws = album.tagger.webservice
self.log = album.log
log.info('WIKIDATA: Processing Track...')
if self.use_release_group_genres:
for release_group in metadata.getall('musicbrainz_releasegroupid'):
log.debug('WIKIDATA: Looking up release group metadata for %s ' % release_group)
self.process_request(metadata, album, release_group, item_type='release-group')
if self.use_artist_genres:
for artist in metadata.getall('musicbrainz_albumartistid'):
log.debug('WIKIDATA: Processing release artist %s' % artist)
self.process_request(metadata, album, artist, item_type='artist')
if self.use_artist_genres:
for artist in metadata.getall('musicbrainz_artistid'):
log.debug('WIKIDATA: Processing track artist %s' % artist)
self.process_request(metadata, album, artist, item_type='artist')
if self.use_work_genres:
for workid in metadata.getall('musicbrainz_workid'):
log.debug('WIKIDATA: Processing track artist %s' % workid)
self.process_request(metadata, album, workid, item_type='work')
def update_settings(self):
self.mb_host = config.setting["server_host"]
self.mb_port = config.setting["server_port"]
self.use_release_group_genres = config.setting[""]
self.use_work_genres = config.setting["wikidata_use_work_genres"]
# Some changed settings could invalidate the cache, so clear it to be safe
if self.use_release_group_genres != config.setting["wikidata_use_release_group_genres"]:
self.use_release_group_genres = config.setting["wikidata_use_release_group_genres"]
self.cache.clear()
if self.use_artist_genres != config.setting["wikidata_use_artist_genres"]:
self.use_artist_genres = config.setting["wikidata_use_artist_genres"]
self.cache.clear()
if self.use_artist_only_if_no_release != config.setting["wikidata_use_artist_only_if_no_release"]:
self.use_artist_only_if_no_release = config.setting["wikidata_use_artist_only_if_no_release"]
self.cache.clear()
if self.ignore_genres_from_these_artists != parse_ignored_tags(
config.setting["wikidata_ignore_genres_from_these_artists"]):
self.ignore_genres_from_these_artists_list = parse_ignored_tags(
config.setting["wikidata_ignore_genres_from_these_artists"])
self.cache.clear()
if self.use_work_genres != config.setting["wikidata_use_work_genres"]:
self.use_work_genres = config.setting["wikidata_use_work_genres"]
self.cache.clear()
if self.ignore_these_genres != parse_ignored_tags(config.setting["wikidata_ignore_these_genres"]):
self.ignore_these_genres = parse_ignored_tags(config.setting["wikidata_ignore_these_genres"])
self.ignore_these_genres_list = parse_ignored_tags(
config.setting["wikidata_ignore_these_genres"])
self.cache.clear()
if config.setting["write_id3v23"]:
self.genre_delimiter = config.setting["wikidata_genre_delimiter"]
class WikidataOptionsPage(OptionsPage):
NAME = "wikidata"
TITLE = "Wikidata Genre"
PARENT = "plugins"
options = [
config.BoolOption("setting", "wikidata_use_release_group_genres", True),
config.BoolOption("setting", "wikidata_use_artist_genres", True),
config.BoolOption("setting", "wikidata_use_artist_only_if_no_release", True),
config.TextOption("setting", "wikidata_ignore_genres_from_these_artists", ""),
config.BoolOption("setting", "wikidata_use_work_genres", True),
config.TextOption("setting", "wikidata_ignore_these_genres", "seen live, favorites, /\\d+ of \\d+ stars/"),
config.TextOption("setting", "wikidata_genre_delimiter", "; "),
]
def __init__(self, parent=None):
super(WikidataOptionsPage, self).__init__(parent)
self.ui = Ui_WikidataOptionsPage()
self.ui.setupUi(self)
if not config.setting["write_id3v23"]:
self.ui.genre_delimiter.setEnabled(False);
self.ui.genre_delimiter_label.setEnabled(False);
else:
self.ui.genre_delimiter.setEnabled(True);
self.ui.genre_delimiter_label.setEnabled(True);
def load(self):
setting = config.setting
self.ui.use_release_group_genres.setChecked(setting["wikidata_use_release_group_genres"])
self.ui.use_artist_genres.setChecked(setting["wikidata_use_artist_genres"])
self.ui.use_artist_only_if_no_release.setChecked(setting["wikidata_use_artist_only_if_no_release"])
self.ui.ignore_genres_from_these_artists.setText(setting["wikidata_ignore_genres_from_these_artists"])
self.ui.use_work_genres.setChecked(setting["wikidata_use_work_genres"])
self.ui.ignore_these_genres.setText(setting["wikidata_ignore_these_genres"])
if config.setting["write_id3v23"]:
self.ui.genre_delimiter.setEditText(setting["wikidata_genre_delimiter"])
def save(self):
setting = config.setting
setting["wikidata_use_release_group_genres"] = self.ui.use_release_group_genres.isChecked()
setting["wikidata_use_artist_genres"] = self.ui.use_artist_genres.isChecked()
setting["wikidata_use_artist_only_if_no_release"] = self.ui.use_artist_only_if_no_release.isChecked()
setting["wikidata_ignore_genres_from_these_artists"] = str(self.ui.ignore_genres_from_these_artists.text())
setting["wikidata_use_work_genres"] = self.ui.use_work_genres.isChecked()
setting["wikidata_ignore_these_genres"] = str(self.ui.ignore_these_genres.text())
if config.setting["write_id3v23"]:
setting["wikidata_genre_delimiter"] = str(self.ui.genre_delimiter.currentText())
wikidata = Wikidata()
register_track_metadata_processor(wikidata.process_track)
register_options_page(WikidataOptionsPage)
================================================
FILE: plugins/wikidata/ui_options_wikidata.py
================================================
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'plugins/wikidata/ui_options_wikidata.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_WikidataOptionsPage(object):
def setupUi(self, WikidataOptionsPage):
WikidataOptionsPage.setObjectName("WikidataOptionsPage")
WikidataOptionsPage.resize(602, 512)
self.verticalLayout_2 = QtWidgets.QVBoxLayout(WikidataOptionsPage)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.releaseGroup_groupBox = QtWidgets.QGroupBox(WikidataOptionsPage)
self.releaseGroup_groupBox.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.releaseGroup_groupBox.sizePolicy().hasHeightForWidth())
self.releaseGroup_groupBox.setSizePolicy(sizePolicy)
self.releaseGroup_groupBox.setMinimumSize(QtCore.QSize(0, 0))
self.releaseGroup_groupBox.setObjectName("releaseGroup_groupBox")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.releaseGroup_groupBox)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.use_release_group_genres = QtWidgets.QCheckBox(self.releaseGroup_groupBox)
self.use_release_group_genres.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.use_release_group_genres.sizePolicy().hasHeightForWidth())
self.use_release_group_genres.setSizePolicy(sizePolicy)
self.use_release_group_genres.setChecked(True)
self.use_release_group_genres.setObjectName("use_release_group_genres")
self.verticalLayout_4.addWidget(self.use_release_group_genres)
self.verticalLayout_2.addWidget(self.releaseGroup_groupBox)
self.artist_groupBox = QtWidgets.QGroupBox(WikidataOptionsPage)
self.artist_groupBox.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.artist_groupBox.sizePolicy().hasHeightForWidth())
self.artist_groupBox.setSizePolicy(sizePolicy)
self.artist_groupBox.setMinimumSize(QtCore.QSize(0, 0))
self.artist_groupBox.setObjectName("artist_groupBox")
self.verticalLayout_8 = QtWidgets.QVBoxLayout(self.artist_groupBox)
self.verticalLayout_8.setObjectName("verticalLayout_8")
self.use_artist_genres = QtWidgets.QCheckBox(self.artist_groupBox)
self.use_artist_genres.setObjectName("use_artist_genres")
self.verticalLayout_8.addWidget(self.use_artist_genres)
self.hLayout_use_artist_no_release = QtWidgets.QHBoxLayout()
self.hLayout_use_artist_no_release.setObjectName("hLayout_use_artist_no_release")
spacerItem = QtWidgets.QSpacerItem(20, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.hLayout_use_artist_no_release.addItem(spacerItem)
self.use_artist_only_if_no_release = QtWidgets.QCheckBox(self.artist_groupBox)
self.use_artist_only_if_no_release.setEnabled(False)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.use_artist_only_if_no_release.sizePolicy().hasHeightForWidth())
self.use_artist_only_if_no_release.setSizePolicy(sizePolicy)
self.use_artist_only_if_no_release.setCheckable(True)
self.use_artist_only_if_no_release.setChecked(False)
self.use_artist_only_if_no_release.setObjectName("use_artist_only_if_no_release")
self.hLayout_use_artist_no_release.addWidget(self.use_artist_only_if_no_release)
self.verticalLayout_8.addLayout(self.hLayout_use_artist_no_release)
self.hLayout_ignore_genres_from_artists_label = QtWidgets.QHBoxLayout()
self.hLayout_ignore_genres_from_artists_label.setObjectName("hLayout_ignore_genres_from_artists_label")
spacerItem1 = QtWidgets.QSpacerItem(20, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.hLayout_ignore_genres_from_artists_label.addItem(spacerItem1)
self.ignore_genres_from_these_artists_label = QtWidgets.QLabel(self.artist_groupBox)
self.ignore_genres_from_these_artists_label.setEnabled(False)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.ignore_genres_from_these_artists_label.sizePolicy().hasHeightForWidth())
self.ignore_genres_from_these_artists_label.setSizePolicy(sizePolicy)
self.ignore_genres_from_these_artists_label.setObjectName("ignore_genres_from_these_artists_label")
self.hLayout_ignore_genres_from_artists_label.addWidget(self.ignore_genres_from_these_artists_label)
self.verticalLayout_8.addLayout(self.hLayout_ignore_genres_from_artists_label)
self.hLayout_ignore_genres_from_artists = QtWidgets.QHBoxLayout()
self.hLayout_ignore_genres_from_artists.setObjectName("hLayout_ignore_genres_from_artists")
spacerItem2 = QtWidgets.QSpacerItem(20, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.hLayout_ignore_genres_from_artists.addItem(spacerItem2)
self.ignore_genres_from_these_artists = QtWidgets.QLineEdit(self.artist_groupBox)
self.ignore_genres_from_these_artists.setEnabled(False)
self.ignore_genres_from_these_artists.setObjectName("ignore_genres_from_these_artists")
self.hLayout_ignore_genres_from_artists.addWidget(self.ignore_genres_from_these_artists)
self.verticalLayout_8.addLayout(self.hLayout_ignore_genres_from_artists)
self.verticalLayout_2.addWidget(self.artist_groupBox)
self.work_groupBox = QtWidgets.QGroupBox(WikidataOptionsPage)
self.work_groupBox.setEnabled(True)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.work_groupBox.sizePolicy().hasHeightForWidth())
self.work_groupBox.setSizePolicy(sizePolicy)
self.work_groupBox.setObjectName("work_groupBox")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.work_groupBox)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.use_work_genres = QtWidgets.QCheckBox(self.work_groupBox)
self.use_work_genres.setChecked(True)
self.use_work_genres.setObjectName("use_work_genres")
self.verticalLayout_3.addWidget(self.use_work_genres)
self.verticalLayout_2.addWidget(self.work_groupBox)
self.generalSettings_groupBox = QtWidgets.QGroupBox(WikidataOptionsPage)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.generalSettings_groupBox.sizePolicy().hasHeightForWidth())
self.generalSettings_groupBox.setSizePolicy(sizePolicy)
self.generalSettings_groupBox.setMinimumSize(QtCore.QSize(0, 120))
self.generalSettings_groupBox.setObjectName("generalSettings_groupBox")
self.verticalLayout = QtWidgets.QVBoxLayout(self.generalSettings_groupBox)
self.verticalLayout.setObjectName("verticalLayout")
self.ignore_genres_label = QtWidgets.QLabel(self.generalSettings_groupBox)
self.ignore_genres_label.setObjectName("ignore_genres_label")
self.verticalLayout.addWidget(self.ignore_genres_label)
self.hLayout_ignore_these_genres = QtWidgets.QHBoxLayout()
self.hLayout_ignore_these_genres.setObjectName("hLayout_ignore_these_genres")
spacerItem3 = QtWidgets.QSpacerItem(20, 20, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.hLayout_ignore_these_genres.addItem(spacerItem3)
self.ignore_these_genres = QtWidgets.QLineEdit(self.generalSettings_groupBox)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.ignore_these_genres.sizePolicy().hasHeightForWidth())
self.ignore_these_genres.setSizePolicy(sizePolicy)
self.ignore_these_genres.setObjectName("ignore_these_genres")
self.hLayout_ignore_these_genres.addWidget(self.ignore_these_genres)
self.verticalLayout.addLayout(self.hLayout_ignore_these_genres)
self.genre_delimiter_label = QtWidgets.QLabel(self.generalSettings_groupBox)
self.genre_delimiter_label.setEnabled(False)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.genre_delimiter_label.sizePolicy().hasHeightForWidth())
self.genre_delimiter_label.setSizePolicy(sizePolicy)
self.genre_delimiter_label.setWordWrap(False)
self.genre_delimiter_label.setObjectName("genre_delimiter_label")
self.verticalLayout.addWidget(self.genre_delimiter_label)
self.hLayout_genre_delimiter = QtWidgets.QHBoxLayout()
self.hLayout_genre_delimiter.setObjectName("hLayout_genre_delimiter")
spacerItem4 = QtWidgets.QSpacerItem(20, 17, QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Minimum)
self.hLayout_genre_delimiter.addItem(spacerItem4)
self.genre_delimiter = QtWidgets.QComboBox(self.generalSettings_groupBox)
self.genre_delimiter.setEnabled(False)
sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Fixed, QtWidgets.QSizePolicy.Fixed)
sizePolicy.setHorizontalStretch(0)
sizePolicy.setVerticalStretch(0)
sizePolicy.setHeightForWidth(self.genre_delimiter.sizePolicy().hasHeightForWidth())
self.genre_delimiter.setSizePolicy(sizePolicy)
self.genre_delimiter.setEditable(True)
self.genre_delimiter.setObjectName("genre_delimiter")
self.genre_delimiter.addItem("")
self.genre_delimiter.setItemText(0, " / ")
self.genre_delimiter.addItem("")
self.genre_delimiter.addItem("")
self.genre_delimiter.setItemText(2, ";")
self.genre_delimiter.addItem("")
self.genre_delimiter.addItem("")
self.genre_delimiter.setItemText(4, ", ")
self.hLayout_genre_delimiter.addWidget(self.genre_delimiter)
spacerItem5 = QtWidgets.QSpacerItem(40, 20, QtWidgets.QSizePolicy.Expanding, QtWidgets.QSizePolicy.Minimum)
self.hLayout_genre_delimiter.addItem(spacerItem5)
self.verticalLayout.addLayout(self.hLayout_genre_delimiter)
self.verticalLayout_2.addWidget(self.generalSettings_groupBox)
spacerItem6 = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Expanding)
self.verticalLayout_2.addItem(spacerItem6)
self.retranslateUi(WikidataOptionsPage)
self.use_artist_genres.toggled['bool'].connect(self.ignore_genres_from_these_artists_label.setEnabled)
self.use_artist_genres.toggled['bool'].connect(self.use_artist_only_if_no_release.setEnabled)
self.use_artist_genres.toggled['bool'].connect(self.ignore_genres_from_these_artists.setEnabled)
QtCore.QMetaObject.connectSlotsByName(WikidataOptionsPage)
def retranslateUi(self, WikidataOptionsPage):
_translate = QtCore.QCoreApplication.translate
self.releaseGroup_groupBox.setTitle(_translate("WikidataOptionsPage", "Release Group Genre Settings"))
self.use_release_group_genres.setText(_translate("WikidataOptionsPage", "Use Release Group genres"))
self.artist_groupBox.setTitle(_translate("WikidataOptionsPage", "Artist Genre Settings"))
self.use_artist_genres.setText(_translate("WikidataOptionsPage", "Use Artist genres"))
self.use_artist_only_if_no_release.setText(_translate("WikidataOptionsPage", "Use Artist genres only if no Release Group genres exist"))
self.ignore_genres_from_these_artists_label.setText(_translate("WikidataOptionsPage", "Ignore Artist genres from these Artist(s): (comma separated regular expressions)"))
self.work_groupBox.setTitle(_translate("WikidataOptionsPage", "Work Genre Settings"))
self.use_work_genres.setText(_translate("WikidataOptionsPage", "Use Work genres, when applicable"))
self.generalSettings_groupBox.setTitle(_translate("WikidataOptionsPage", "General Settings"))
self.ignore_genres_label.setText(_translate("WikidataOptionsPage", "Ignore these genres: (comma separated regular expressions)"))
self.genre_delimiter_label.setText(_translate("WikidataOptionsPage", "Genre Delimiter: (only applicable to ID3v2.3 tags)"))
self.genre_delimiter.setItemText(1, _translate("WikidataOptionsPage", "; "))
self.genre_delimiter.setItemText(3, _translate("WikidataOptionsPage", " ; "))
================================================
FILE: plugins/wikidata/ui_options_wikidata.ui
================================================
WikidataOptionsPage
0
0
602
512
-
true
0
0
0
0
Release Group Genre Settings
-
true
0
0
Use Release Group genres
true
-
true
0
0
0
0
Artist Genre Settings
-
Use Artist genres
-
-
Qt::Horizontal
QSizePolicy::Fixed
20
20
-
false
0
0
Use Artist genres only if no Release Group genres exist
true
false
-
-
Qt::Horizontal
QSizePolicy::Fixed
20
20
-
false
0
0
Ignore Artist genres from these Artist(s): (comma separated regular expressions)
-
-
Qt::Horizontal
QSizePolicy::Fixed
20
20
-
false
-
true
0
0
Work Genre Settings
-
Use Work genres, when applicable
true
-
0
0
0
120
General Settings
-
Ignore these genres: (comma separated regular expressions)
-
-
Qt::Horizontal
QSizePolicy::Fixed
20
20
-
0
0
-
false
0
0
Genre Delimiter: (only applicable to ID3v2.3 tags)
false
-
-
Qt::Horizontal
QSizePolicy::Fixed
20
17
-
false
0
0
true
-
/
-
;
-
;
-
;
-
,
-
Qt::Horizontal
40
20
-
Qt::Vertical
20
40
use_artist_genres
toggled(bool)
ignore_genres_from_these_artists_label
setEnabled(bool)
300
58
313
111
use_artist_genres
toggled(bool)
use_artist_only_if_no_release
setEnabled(bool)
300
58
313
83
use_artist_genres
toggled(bool)
ignore_genres_from_these_artists
setEnabled(bool)
300
58
313
139
================================================
FILE: plugins/workandmovement/__init__.py
================================================
# -*- coding: utf-8 -*-
#
# Copyright (C) 2018-2019, 2021-2022 Philipp Wolfer
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA
# 02110-1301, USA.
PLUGIN_NAME = 'Work & Movement'
PLUGIN_AUTHOR = 'Philipp Wolfer'
PLUGIN_DESCRIPTION = '''Set work and movement based on work relationships.
This plugin attempts to set the `movement` and `movementnumber` tags, but only
if the work linked to the recording is part of a larger work. The `work` tag
then gets set to the work of which the movement is a part of.
If the recording is only linked to a simple work without separate parts then it
is not considered a proper work and the work and movement related tags will be
cleared.
The plugin will always set the original values, as loaded from MusicBrainz, of
the `work` and `musicbrainz_workid` tags into the variables `%%recording_work%`
and `%%recording_workid%` to be used in scripting.
'''
PLUGIN_VERSION = '1.1'
PLUGIN_API_VERSIONS = ['2.1', '2.2', '2.3', '2.4', '2.5', '2.6', '2.7', '2.8']
PLUGIN_LICENSE = 'GPL-2.0-or-later'
PLUGIN_LICENSE_URL = 'https://www.gnu.org/licenses/gpl-2.0.html'
import re
from .roman import (
fromRoman,
RomanError,
)
from picard import log
from picard.metadata import register_track_metadata_processor
_re_work_title = re.compile(r'(?P.*):\s+(?P[IVXLCDM]+)\.\s[\s,:;./]*(?P.*)')
_re_part_number = re.compile(r'(?P[0-9IVXLCDM]+)\.?\s[\s,:;./]*')
_re_separators = re.compile(r'^[\s,:;./-]+')
class Work:
def __init__(self, title, mbid=None):
self.mbid = mbid
self.title = title
self.is_movement = False
self.is_work = False
self.part_number = 0
self.parent = None
def __str__(self):
s = []
if self.parent:
s.append(str(self.parent))
if self.is_movement:
work_type = 'Movement'
elif self.is_work:
work_type = 'Work'
else:
work_type = 'Unknown'
s.append('%s %i: %s' % (work_type, self.part_number, self.title))
return '\n'.join(s)
def is_performance_work(rel):
return (rel['target-type'] == 'work'
and rel['direction'] == 'forward'
and rel['type'] == 'performance')
def is_parent_work(rel):
return (rel['target-type'] == 'work'
and rel['direction'] == 'backward'
and rel['type'] == 'parts')
def is_movement_like(rel):
return ('movement' in rel['attributes']
or 'act' in rel['attributes']
or 'ordering-key' in rel)
def is_child_work(rel):
return (rel['target-type'] == 'work'
and rel['direction'] == 'forward'
and rel['type'] == 'parts')
def number_to_int(s):
"""
Converts a numeric string to int. `s` can also be a Roman numeral.
"""
try:
return int(s)
except ValueError:
try:
return fromRoman(s)
except RomanError as e:
raise ValueError(e)
def parse_work_name(title):
return _re_work_title.search(title)
def create_work_and_movement_from_title(work):
"""
Attempts to parse work.title in the form ": . ",
where is in Roman numerals.
Sets the `is_movement` and `part_number` properties on `work` and creates
a `parent` work if not already present.
"""
title = work.title
match = parse_work_name(title)
if match:
work.title = match.group('movement')
work.is_movement = True
try:
number = number_to_int(match.group('movementnumber'))
except ValueError as e:
log.error(e)
number = 0
if not work.part_number:
work.part_number = number
elif work.part_number != number:
log.warning('Movement number mismatch for "%s": %s != %i',
title, match.group('movementnumber'), work.part_number)
if not work.parent:
work.parent = Work(match.group('work'))
work.parent.is_work = True
elif work.parent.title != match.group('work'):
log.warning('Movement work name mismatch for "%s": "%s" != "%s"',
title, match.group('work'), work.parent.title)
return work
def normalize_movement_title(work):
"""
Removes the parent work title and part number from the beginning of
`work.title`. This ensures movement names don't contain duplicated
information even if they do not follow the strict naming format used by
`create_work_and_movement_from_title`.
"""
movement_title = work.title
if work.parent:
work_title = work.parent.title
if movement_title.startswith(work_title):
movement_title = movement_title[len(work_title):]
movement_title = _re_separators.sub('', movement_title)
match = _re_part_number.match(movement_title)
if match:
# Only remove the number if it matches the part_number
try:
number = number_to_int(match.group('number'))
if number == work.part_number:
movement_title = _re_part_number.sub('', movement_title)
except ValueError as e:
log.warning(e)
return movement_title
def parse_work(work_rel):
work = Work(work_rel['title'], work_rel['id'])
if 'relations' in work_rel:
for rel in work_rel['relations']:
# If this work has parents and is linked to those as 'movement' or
# 'act' we consider it a part of a larger work and store it
# in the movement tag. The parent will be set as the work.
if is_parent_work(rel):
if is_movement_like(rel):
work.is_movement = True
work.part_number = rel.get('ordering-key')
if 'work' in rel:
work.parent = parse_work(rel['work'])
work.parent.is_work = True
work.title = normalize_movement_title(work)
else:
# Not a movement, but still part of a larger work.
# Mark it as a work.
work.is_work = True
# If this work has any parts, we consider it a proper work.
# This is a recording directly linked to a larger work.
if is_child_work(rel):
work.is_work = True
return work
def unset_work(metadata):
metadata.delete('work')
metadata.delete('musicbrainz_workid')
metadata.delete('movement')
metadata.delete('movementnumber')
metadata.delete('movementtotal')
metadata.delete('showmovement')
def set_work(metadata, work):
metadata['work'] = work.title
metadata['musicbrainz_workid'] = work.mbid
metadata['showmovement'] = 1
def process_track(album, metadata, track, release):
if 'recording' in track:
recording = track['recording']
else:
recording = track
if 'relations' not in recording:
return
# Remember original work and work ID
metadata['~recording_work'] = metadata.getall('work')
metadata['~recording_workid'] = metadata.getall('musicbrainz_workid')
# Try to find a suitable work linked to the recording.
# As a fallback try to get work + movement information by parsing
# the recording title.
work = Work(recording['title'])
for rel in recording['relations']:
if is_performance_work(rel):
work = parse_work(rel['work'])
# Only use the first work that qualifies as a work or movement
log.debug('Found work:\n%s', work)
if work.is_movement or work.is_work:
break
unset_work(metadata)
if not work.is_movement:
work = create_work_and_movement_from_title(work)
if work.is_movement and work.parent and work.parent.is_work:
metadata['movement'] = work.title
if work.part_number:
metadata['movementnumber'] = work.part_number
set_work(metadata, work.parent)
elif work.is_work:
set_work(metadata, work)
register_track_metadata_processor(process_track)
================================================
FILE: plugins/workandmovement/roman.py
================================================
"""Convert to and from Roman numerals"""
__author__ = "Mark Pilgrim (f8dy@diveintopython.org)"
__version__ = "1.4"
__date__ = "8 August 2001"
__copyright__ = """Copyright (c) 2001 Mark Pilgrim
This program is part of "Dive Into Python", a free Python tutorial for
experienced programmers. Visit http://diveintopython.org/ for the
latest version.
This program is free software; you can redistribute it and/or modify
it under the terms of the Python 2.1.1 license, available at
http://www.python.org/2.1.1/license.html
"""
import re
#Define exceptions
class RomanError(Exception): pass
class OutOfRangeError(RomanError): pass
class NotIntegerError(RomanError): pass
class InvalidRomanNumeralError(RomanError): pass
#Define digit mapping
romanNumeralMap = (('M', 1000),
('CM', 900),
('D', 500),
('CD', 400),
('C', 100),
('XC', 90),
('L', 50),
('XL', 40),
('X', 10),
('IX', 9),
('V', 5),
('IV', 4),
('I', 1))
def toRoman(n):
"""convert integer to Roman numeral"""
if not isinstance(n, int):
raise NotIntegerError("decimals can not be converted")
if not (0 < n < 5000):
raise OutOfRangeError("number out of range (must be 1..4999)")
result = ""
for numeral, integer in romanNumeralMap:
while n >= integer:
result += numeral
n -= integer
return result
#Define pattern to detect valid Roman numerals
romanNumeralPattern = re.compile("""
^ # beginning of string
M{0,4} # thousands - 0 to 4 M's
(CM|CD|D?C{0,3}) # hundreds - 900 (CM), 400 (CD), 0-300 (0 to 3 C's),
# or 500-800 (D, followed by 0 to 3 C's)
(XC|XL|L?X{0,3}) # tens - 90 (XC), 40 (XL), 0-30 (0 to 3 X's),
# or 50-80 (L, followed by 0 to 3 X's)
(IX|IV|V?I{0,3}) # ones - 9 (IX), 4 (IV), 0-3 (0 to 3 I's),
# or 5-8 (V, followed by 0 to 3 I's)
$ # end of string
""" ,re.VERBOSE)
def fromRoman(s):
"""convert Roman numeral to integer"""
if not s:
raise InvalidRomanNumeralError('Input can not be blank')
if not romanNumeralPattern.search(s):
raise InvalidRomanNumeralError('Invalid Roman numeral: %s' % s)
result = 0
index = 0
for numeral, integer in romanNumeralMap:
while s[index:index+len(numeral)] == numeral:
result += integer
index += len(numeral)
return result
================================================
FILE: setup.cfg
================================================
[flake8]
# E127: continuation line over-indented for visual indent
# E128: continuation line under-indented for visual indent
# E129: visually indented line with same indent as next logical line
# E226: missing whitespace around arithmetic operator
# E241: multiple spaces after ','
# E402: module level import not at top of file
# E501: line too long (xx > 79 characters)
# W503: line break occurred before a binary operator
ignore = E127,E128,E129,E226,E241,E402,E501,W503
builtins = _,N_,ngettext,gettext_attributes,pgettext_attributes,gettext_countries
exclude = ui_*.py
================================================
FILE: test/__init__.py
================================================
================================================
FILE: test/plugin_test_case.py
================================================
# -*- coding: utf-8 -*-
#
# Picard, the next-generation MusicBrainz tagger
#
# Copyright (C) 2018 Wieland Hoffmann
# Copyright (C) 2019-2023 Philipp Wolfer
# Copyright (C) 2020-2021 Laurent Monin
# Copyright (C) 2021 Bob Swift
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
import importlib
import logging
import os
import shutil
import sys
import unittest
from tempfile import mkdtemp, mkstemp
from types import ModuleType
from typing import Any, Callable, Optional
from unittest.mock import Mock, patch
import picard
from picard import config, log
from picard.i18n import setup_gettext
from picard.plugin import _PLUGIN_MODULE_PREFIX, _unregister_module_extensions
from picard.pluginmanager import PluginManager
from picard.releasegroup import ReleaseGroup
from PyQt5 import QtCore
class FakeThreadPool(QtCore.QObject):
def start(self, runnable, priority):
runnable.run()
class FakeTagger(QtCore.QObject):
tagger_stats_changed = QtCore.pyqtSignal()
def __init__(self):
QtCore.QObject.__init__(self)
QtCore.QObject.config = config
QtCore.QObject.log = log
self.tagger_stats_changed.connect(self.emit)
self.exit_cleanup = []
self.files = {}
self.stopping = False
self.thread_pool = FakeThreadPool()
self.priority_thread_pool = FakeThreadPool()
self.save_thread_pool = FakeThreadPool()
self.mb_api = Mock()
def register_cleanup(self, func: Callable[[], Any]) -> None:
self.exit_cleanup.append(func)
def run_cleanup(self) -> None:
for f in self.exit_cleanup:
f()
def emit(self, *args) -> None:
pass
def get_release_group_by_id(self, rg_id: str) -> ReleaseGroup:
return ReleaseGroup(rg_id)
class PluginTestCase(unittest.TestCase):
def setUp(self) -> None:
log.set_level(logging.DEBUG)
setup_gettext(None, "C")
self.tagger = FakeTagger()
QtCore.QObject.tagger = self.tagger
QtCore.QCoreApplication.instance = lambda: self.tagger
self.addCleanup(self.tagger.run_cleanup)
self.init_config()
self.tmp_directory = self.mktmpdir()
# return tmp_directory from pluginmanager.plugin_dirs
self.patchers = [
patch(
"picard.pluginmanager.plugin_dirs", return_value=[self.tmp_directory]
).start(),
patch(
"picard.util.thread.to_main",
side_effect=lambda func, *args, **kwargs: func(*args, **kwargs),
).start(),
]
def tearDown(self) -> None:
for patcher in self.patchers:
patcher.stop()
@staticmethod
def init_config() -> None:
fake_config = Mock()
fake_config.setting = {}
fake_config.persist = {}
fake_config.profiles = {}
# Make config object available for legacy use
config.config = fake_config
config.setting = fake_config.setting
config.persist = fake_config.persist
config.profiles = fake_config.profiles
@staticmethod
def set_config_values(
setting: Optional[dict] = None,
persist: Optional[dict] = None,
profiles: Optional[dict] = None,
) -> None:
if setting:
for key, value in setting.items():
config.config.setting[key] = value
if persist:
for key, value in persist.items():
config.config.persist[key] = value
if profiles:
for key, value in profiles.items():
config.config.profiles[key] = value
def mktmpdir(self, ignore_errors: bool = False) -> None:
tmpdir = mkdtemp(suffix=self.__class__.__name__)
self.addCleanup(shutil.rmtree, tmpdir, ignore_errors=ignore_errors)
return tmpdir
def copy_file_tmp(self, filepath: str, ext: Optional[str] = None) -> str:
fd, copy = mkstemp(suffix=ext)
os.close(fd)
self.addCleanup(self.remove_file_tmp, copy)
shutil.copy(filepath, copy)
return copy
@staticmethod
def remove_file_tmp(filepath: str) -> None:
if os.path.isfile(filepath):
os.unlink(filepath)
def _test_plugin_install(self, name: str, module: str) -> ModuleType:
self.unload_plugin(module)
with self.assertRaises(ImportError):
importlib.import_module(f"picard.plugins.{module}")
pm = PluginManager(plugins_directory=self.tmp_directory)
msg = f"install_plugin: {name} from {module}"
pm.install_plugin(os.path.join("plugins", module))
self.assertEqual(len(pm.plugins), 1, msg)
self.assertEqual(pm.plugins[0].name, name, msg)
self.set_config_values(setting={"enabled_plugins": [module]})
# if module is properly loaded, this should work
return importlib.import_module(f"picard.plugins.{module}")
def unload_plugin(self, plugin_name: str) -> None:
"""for testing purposes"""
_unregister_module_extensions(plugin_name)
if hasattr(picard.plugins, plugin_name):
delattr(picard.plugins, plugin_name)
key = _PLUGIN_MODULE_PREFIX + plugin_name
if key in sys.modules:
del sys.modules[key]
================================================
FILE: test/test_add_to_collection.py
================================================
import os
from itertools import chain
from test.plugin_test_case import PluginTestCase
from typing import Union
from unittest.mock import ANY, patch
from picard.collection import Collection, user_collections
from picard.file import File
from picard.file import _file_post_save_processors as post_save_processors
from picard.ui.options import _pages as option_pages
class TestAddToCollection(PluginTestCase):
SAVE_FILE_SETTINGS = {
"dont_write_tags": True,
"rename_files": False,
"move_files": False,
"delete_empty_dirs": False,
"save_images_to_files": False,
"clear_existing_tags": False,
"compare_ignore_tags": [],
}
def install_plugin(self) -> None:
self.plugin = self._test_plugin_install(
"Add to Collection", "add_to_collection"
)
def create_file(self, file_name: str, album_id: Union[str, None] = None) -> File:
file_path = os.path.join(self.tmp_directory, file_name)
file = File(file_path)
if album_id:
file.metadata["musicbrainz_albumid"] = album_id
self.tagger.files[file_path] = file
return file
def tearDown(self) -> None:
user_collections.clear()
return super().tearDown()
def test_hooks_installed(self) -> None:
self.install_plugin()
self.assertIn(
self.plugin.post_save_processor.post_save_processor,
list(chain.from_iterable(post_save_processors.functions.values())),
)
self.assertIn(
self.plugin.options.AddToCollectionOptionsPage, list(option_pages)
)
def test_file_save(self) -> None:
self.install_plugin()
self.set_config_values(
setting={
**self.SAVE_FILE_SETTINGS,
"add_to_collection_id": "test_collection_id",
}
)
file = self.create_file(file_name="test.mp3", album_id="test_album_id")
user_collections["test_collection_id"] = Collection(
collection_id="test_collection_id", name="Test Collection", size=0
)
with patch("picard.collection.Collection.add_releases") as add_releases:
file.save()
add_releases.assert_called_with(set(["test_album_id"]), callback=ANY)
def test_two_files_save(self) -> None:
self.install_plugin()
self.set_config_values(
setting={
**self.SAVE_FILE_SETTINGS,
"add_to_collection_id": "test_collection_id",
}
)
collection = Collection(
collection_id="test_collection_id", name="Test Collection", size=0
)
user_collections["test_collection_id"] = collection
with patch(
"picard.collection.Collection.add_releases",
side_effect=lambda ids, callback: collection.releases.update(ids),
) as add_releases:
for i in range(2):
file = self.create_file(
file_name=f"test{i}.mp3", album_id="test_album_id"
)
file.save()
# only added once
add_releases.assert_called_once_with(set(["test_album_id"]), callback=ANY)
def test_no_collection_id_setting(self) -> None:
self.install_plugin()
self.set_config_values(setting=self.SAVE_FILE_SETTINGS)
file = self.create_file(file_name="test.mp3", album_id="test_album_id")
user_collections["test_collection_id"] = Collection(
collection_id="test_collection_id", name="Test Collection", size=0
)
with patch("picard.collection.Collection.add_releases") as add_releases:
file.save()
add_releases.assert_not_called()
def test_no_user_collection(self) -> None:
self.install_plugin()
self.set_config_values(
setting={
**self.SAVE_FILE_SETTINGS,
"add_to_collection_id": "test_collection_id",
}
)
file = self.create_file(file_name="test.mp3", album_id="test_album_id")
with patch("picard.collection.Collection.add_releases") as add_releases:
file.save()
add_releases.assert_not_called()
def test_no_release(self) -> None:
self.install_plugin()
self.set_config_values(
setting={
**self.SAVE_FILE_SETTINGS,
"add_to_collection_id": "test_collection_id",
}
)
file = self.create_file(file_name="test.mp3")
with patch("picard.collection.Collection.add_releases") as add_releases:
file.save()
add_releases.assert_not_called()
================================================
FILE: test/test_doctest.py
================================================
import doctest
def load_tests(loader, tests, ignore):
from plugins.addrelease import addrelease
tests.addTests(doctest.DocTestSuite(addrelease))
from plugins import decade
tests.addTests(doctest.DocTestSuite(decade))
from plugins.smart_title_case import smart_title_case
tests.addTests(doctest.DocTestSuite(smart_title_case))
from plugins.standardise_feat import standardise_feat
tests.addTests(doctest.DocTestSuite(standardise_feat))
from plugins.key_wheel_converter import key_wheel_converter
tests.addTests(doctest.DocTestSuite(key_wheel_converter))
from plugins import enhanced_titles
tests.addTests(doctest.DocTestSuite(enhanced_titles))
return tests
================================================
FILE: test/test_generate.py
================================================
import doctest
import os
import glob
import json
import shutil
import tempfile
import unittest
from contextlib import redirect_stdout
from io import StringIO
from generate import build_json, zip_files
class GenerateTestCase(unittest.TestCase):
"""Run tests"""
# The file that contains json data
PLUGIN_FILE = "plugins.json"
# The directory which contains plugin files
PLUGIN_DIR = "plugins"
def setUp(self):
# Destination directory
self.dest_dir = tempfile.mkdtemp()
self.addCleanup(shutil.rmtree, self.dest_dir)
self.plugin_file = os.path.join(self.dest_dir, self.PLUGIN_FILE)
@staticmethod
def with_suppressed_stdout(func, *args, **kwargs):
out = StringIO()
try:
with redirect_stdout(out):
func(*args, **kwargs)
except Exception:
print(out.getvalue())
raise
def test_generate_json(self):
"""
Generates the json data from all the plugins
and asserts that all plugins are accounted for.
"""
self.with_suppressed_stdout(build_json, self.dest_dir)
# Load the json file
with open(self.plugin_file, "r") as in_file:
plugin_json = json.load(in_file)["plugins"]
# All top level directories in plugin_dir
plugin_folders = next(os.walk(self.PLUGIN_DIR))[1]
# Number of entries in the json should be equal to the
# number of folders in plugin_dir
self.assertEqual(len(plugin_json), len(plugin_folders))
def test_generate_zip(self):
"""
Generates zip files for all folders and asserts
that all folders are accounted for.
"""
self.with_suppressed_stdout(zip_files, self.dest_dir)
# All zip files in plugin_dir
plugin_zips = glob.glob(os.path.join(self.dest_dir, "*.zip"))
# All top level directories in plugin_dir
plugin_folders = next(os.walk(self.PLUGIN_DIR))[1]
# Number of folders should be equal to number of zips
self.assertEqual(len(plugin_zips), len(plugin_folders))
def test_valid_json(self):
"""
Asserts that the json data contains all the fields
for all the plugins.
"""
self.with_suppressed_stdout(build_json, self.dest_dir)
# Load the json file
with open(self.plugin_file, "r") as in_file:
plugin_json = json.load(in_file)["plugins"]
# All plugins should contain all required fields
for module_name, data in plugin_json.items():
self.assertIsInstance(data['name'], str)
self.assertIsInstance(data['api_versions'], list)
self.assertIsInstance(data['author'], str)
self.assertIsInstance(data['description'], str)
self.assertIsInstance(data['version'], str)
================================================
FILE: test/test_keep.py
================================================
#!/usr/bin/env python
# coding: utf-8
import unittest
from picard.metadata import Metadata
from picard.script import ScriptParser
from plugins.keep.keep import keep # noqa: F401 pylint: disable=unused-import
class TestKeep(unittest.TestCase):
def setUp(self):
self.parser = ScriptParser()
def test_keep_simple(self):
meta = Metadata(
{
"foo": "foo",
"bar": "bar"
})
sc = """$keep(bar)"""
self.parser.eval(sc, meta)
self.assertEqual(meta["bar"], "bar")
self.assertEqual(len(meta.keys()), 1)
self.assertNotIn("foo", meta)
def test_keep_mbid(self):
meta = Metadata(
{
"foo": "foo",
"bar": "bar",
"musicbrainz_albumid": "albumid",
})
sc = """$keep(bar)"""
self.parser.eval(sc, meta)
self.assertEqual(meta["musicbrainz_albumid"], "albumid")
self.assertEqual(len(meta.keys()), 2)
def test_keep_nonfiletags(self):
meta = Metadata(
{
"foo": "foo",
"bar": "bar",
"~baz": "baz",
})
sc = """$keep(bar)"""
self.parser.eval(sc, meta)
self.assertEqual(meta["~baz"], "baz")
self.assertEqual(len(meta.keys()), 2)
def _description_test(self, tagname):
meta = Metadata(
{
"foo": "foo",
"bar": "bar",
tagname: tagname
})
tag_without_description = tagname.split(":")[0]
sc = """$keep({tag})""".format(tag=tag_without_description)
self.parser.eval(sc, meta)
self.assertEqual(meta[tagname], tagname)
self.assertEqual(len(meta.keys()), 1)
def test_keep_performer(self):
self._description_test("performer:vocal")
self._description_test("performer:")
def test_keep_lyrics(self):
self._description_test("lyrics:foo")
self._description_test("lyrics:")
def test_keep_comment(self):
self._description_test("comment:foo")
self._description_test("comment:")
def test_keep_with_description(self):
meta = Metadata(
{
"foo": "foo",
"bar": "bar",
"performer:vocal": "performer:vocal",
"performer:guitar": "performer:guitar"
})
sc = """$keep(performer:vocal)"""
self.parser.eval(sc, meta)
self.assertEqual(meta["performer:vocal"], "performer:vocal")
self.assertEqual(len(meta.keys()), 1)
|