 🚀 **Try out our interactive [UI playground](https://huggingface.co/spaces/Splend1dchan/BreezyVoice-Playground) now!** 🚀
🚀 **[立即體驗 BreezyVoice 語音合成](https://huggingface.co/spaces/Splend1dchan/BreezyVoice-Playground) !** 🚀
Or visit one of these resources:
- [Playground (CLI Inference)](https://www.kaggle.com/code/a24998667/breezyvoice-playground)
- [Model](https://huggingface.co/MediaTek-Research/BreezyVoice/tree/main)
- [Paper](https://arxiv.org/abs/2501.17790)
Repo Main Contributors: Chia-Chun Lin, Chan-Jan Hsu
## Features
🔥 BreezyVoice outperforms competing commercial services in terms of naturalness.
🚀 **Try out our interactive [UI playground](https://huggingface.co/spaces/Splend1dchan/BreezyVoice-Playground) now!** 🚀
🚀 **[立即體驗 BreezyVoice 語音合成](https://huggingface.co/spaces/Splend1dchan/BreezyVoice-Playground) !** 🚀
Or visit one of these resources:
- [Playground (CLI Inference)](https://www.kaggle.com/code/a24998667/breezyvoice-playground)
- [Model](https://huggingface.co/MediaTek-Research/BreezyVoice/tree/main)
- [Paper](https://arxiv.org/abs/2501.17790)
Repo Main Contributors: Chia-Chun Lin, Chan-Jan Hsu
## Features
🔥 BreezyVoice outperforms competing commercial services in terms of naturalness.
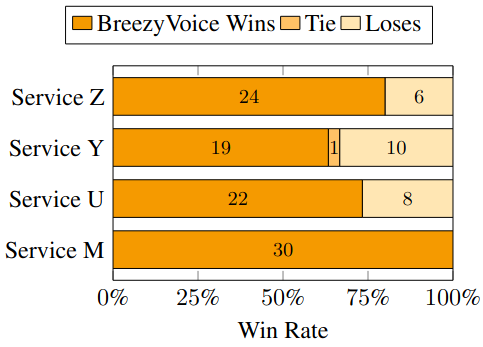 🔥 BreezyVoice is highly competitive at code-switching scenarios.
| Code-Switching Term Category | **BreezyVoice** | Z | Y | U | M |
|-------------|--------------|---|---|---|---|
| **General Words** | **8** | 5 | **8** | **8** | 7 |
| **Entities**| **9** | 6 | 4 | 7 | 4 |
| **Abbreviations** | **9** | 8 | 6 | 6 | 7 |
| **Toponyms**| 3 | 3 | **7** | 3 | 4 |
| **Full Sentences**| 7 | 7 | **8** | 5 | 3 |
🔥 BreezyVoice supports automatic 注音 annotation, as well as manual 注音 correction (See Inference).
## Install
**Clone and install**
- Clone the repo
``` sh
git clone https://github.com/mtkresearch/BreezyVoice.git
# If you failed to clone submodule due to network failures, please run following command until success
cd BreezyVoice
```
- Install Requirements (requires Python3.10)
```
pip uninstall onnxruntime # use onnxruntime-gpu instead of onnxruntime
pip install -r requirements.txt
```
(The model is runnable on CPU, please change onnxruntime-gpu to onnxruntime in `requirements.txt` if you do not have GPU in your environment)
You might need to install cudnn depending on cuda version
```
sudo apt-get -y install cudnn9-cuda-11
```
## Inference
UTF8 encoding is required:
``` sh
export PYTHONUTF8=1
```
---
**Run single_inference.py with the following arguments:**
- `--content_to_synthesize`:
- **Description**: Specifies the content that will be synthesized into speech. Phonetic symbols can optionally be included but should be used sparingly, as shown in the examples below:
- Simple text: `"今天天氣真好"`
- Text with phonetic symbols: `"今天天氣真好[:ㄏㄠ3]"`
- `--speaker_prompt_audio_path`:
- **Description**: Specifies the path to the prompt speech audio file for setting the style of the speaker. Use your custom audio file or our example file:
- Example audio: `./data/tc_speaker.wav`
- `--speaker_prompt_text_transcription` (optional):
- **Description**: Specifies the transcription of the speaker prompt audio. Providing this input is highly recommended for better accuracy. If not provided, the system will automatically transcribe the audio using Whisper.
- Example text for the audio file: `"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程才能將密文還原為正常可讀的內容。"`
- `--output_path` (optional):
- **Description**: Specifies the name and path for the output `.wav` file. If not provided, the default path is used.
- **Default Value**: `results/output.wav`
- Example: `[your_file_name].wav`
- `--model_path` (optional):
- **Description**: Specifies the pre-trained model used for speech synthesis.
- **Default Value**: `MediaTek-Research/BreezyVoice`
**Example Usage:**
``` bash
bash run_single_inference.sh
```
``` python
# python single_inference.py --text_to_speech [text to be converted into audio] --text_prompt [the prompt of that audio file] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好" --speaker_prompt_text_transcription "在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程才能將密文還原為正常可讀的內容。" --speaker_prompt_audio_path "./data/example.wav"
```
``` python
# python single_inference.py --text_to_speech [text to be converted into audio] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好[:ㄏㄠ3]" --speaker_prompt_audio_path "./data/example.wav"
```
---
**Run `batch_inference.py` with the following arguments:**
- `--csv_file`:
- **Description**: Path to the CSV file that contains the input data for batch processing.
- **Example**: `./data/batch_files.csv`
- `--speaker_prompt_audio_folder`:
- **Description**: Path to the folder containing the speaker prompt audio files. The files in this folder are used to set the style of the speaker for each synthesis task.
- **Example**: `./data`
- `--output_audio_folder`:
- **Description**: Path to the folder where the output audio files will be saved. Each processed row in the CSV will result in a synthesized audio file stored in this folder.
- **Example**: `./results`
**CSV File Structure:**
The CSV file should contain the following columns:
- **`speaker_prompt_audio_filename`**:
- **Description**: The filename (without extension) of the speaker prompt audio file that will be used to guide the style of the generated speech.
- **Example**: `example`
- **`speaker_prompt_text_transcription`**:
- **Description**: The transcription of the speaker prompt audio. This field is optional but highly recommended to improve transcription accuracy. If not provided, the system will attempt to transcribe the audio using Whisper.
- **Example**: `"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。"`
- **`content_to_synthesize`**:
- **Description**: The content that will be synthesized into speech. You can include phonetic symbols if needed, though they should be used sparingly.
- **Example**: `"今天天氣真好"`
- **`output_audio_filename`**:
- **Description**: The filename (without extension) for the generated output audio. The audio will be saved as a `.wav` file in the output folder.
- **Example**: `output`
**Example Usage:**
``` bash
bash run_batch_inference.sh
```
```bash
python batch_inference.py \
--csv_file ./data/batch_files.csv \
--speaker_prompt_audio_folder ./data \
--output_audio_folder ./results
```
### Docker and OpenAI Compatible API
``` bash
$ docker compose up -d --build
# after the container is up
$ pip install openai
$ python openai_api_inference.py
```
---
If you like our work, please cite:
```
@article{hsu2025breezyvoice,
title={BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation--Challenges and Insights},
author={Hsu, Chan-Jan and Lin, Yi-Cheng and Lin, Chia-Chun and Chen, Wei-Chih and Chung, Ho Lam and Li, Chen-An and Chen, Yi-Chang and Yu, Chien-Yu and Lee, Ming-Ji and Chen, Chien-Cheng and others},
journal={arXiv preprint arXiv:2501.17790},
year={2025}
}
@article{hsu2025breeze,
title={The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities},
author={Hsu, Chan-Jan and Liu, Chia-Sheng and Chen, Meng-Hsi and Chen, Muxi and Hsu, Po-Chun and Chen, Yi-Chang and Shiu, Da-Shan},
journal={arXiv preprint arXiv:2501.13921},
year={2025}
}
@article{du2024cosyvoice,
title={Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens},
author={Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others},
journal={arXiv preprint arXiv:2407.05407},
year={2024}
}
```
================================================
FILE: api.py
================================================
# OpenAI API Spec. Reference: https://platform.openai.com/docs/api-reference/audio/createSpeech
from contextlib import asynccontextmanager
from io import BytesIO
import torchaudio
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from g2pw import G2PWConverter
from pydantic import BaseModel, Field
from pydantic_settings import BaseSettings
from cosyvoice.utils.file_utils import load_wav
from single_inference import CustomCosyVoice, get_bopomofo_rare
class Settings(BaseSettings):
api_key: str = Field(
default="", description="Specifies the API key used to authenticate the user."
)
model_path: str = Field(
default="MediaTek-Research/BreezyVoice",
description="Specifies the model used for speech synthesis.",
)
speaker_prompt_audio_path: str = Field(
default="./data/example.wav",
description="Specifies the path to the prompt speech audio file of the speaker.",
)
speaker_prompt_text_transcription: str = Field(
default="在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程,才能將密文還原為正常可讀的內容。",
description="Specifies the transcription of the speaker prompt audio.",
)
class SpeechRequest(BaseModel):
model: str = ""
input: str = Field(
description="The content that will be synthesized into speech. You can include phonetic symbols if needed, though they should be used sparingly.",
examples=["今天天氣真好"],
)
response_format: str = ""
speed: float = 1.0
@asynccontextmanager
async def lifespan(app: FastAPI):
app.state.settings = Settings()
app.state.cosyvoice = CustomCosyVoice(app.state.settings.model_path)
app.state.bopomofo_converter = G2PWConverter()
app.state.prompt_speech_16k = load_wav(
app.state.settings.speaker_prompt_audio_path, 16000
)
yield
del app.state.cosyvoice
del app.state.bopomofo_converter
app = FastAPI(lifespan=lifespan, root_path="/v1")
@app.get("/models")
async def get_models(request: Request):
return {
"object": "list",
"data": [
{
"id": request.app.state.settings.model_path,
"object": "model",
"created": 0,
"owned_by": "local",
}
],
}
@app.post("/audio/speech")
async def speach_endpoint(request: Request, payload: SpeechRequest):
# normalization
speaker_prompt_text_transcription = (
request.app.state.cosyvoice.frontend.text_normalize_new(
request.app.state.settings.speaker_prompt_text_transcription, split=False
)
)
content_to_synthesize = request.app.state.cosyvoice.frontend.text_normalize_new(
payload.input, split=False
)
speaker_prompt_text_transcription_bopomo = get_bopomofo_rare(
speaker_prompt_text_transcription, request.app.state.bopomofo_converter
)
content_to_synthesize_bopomo = get_bopomofo_rare(
content_to_synthesize, request.app.state.bopomofo_converter
)
output = request.app.state.cosyvoice.inference_zero_shot_no_normalize(
content_to_synthesize_bopomo,
speaker_prompt_text_transcription_bopomo,
request.app.state.prompt_speech_16k,
)
audio_buffer = BytesIO()
torchaudio.save(audio_buffer, output["tts_speech"], 22050, format="wav")
audio_buffer.seek(0)
return StreamingResponse(
audio_buffer,
media_type="audio/wav",
headers={"Content-Disposition": "attachment; filename=output.wav"},
)
if __name__ == "__main__":
import uvicorn
uvicorn.run("api:app", host="0.0.0.0", port=8080)
================================================
FILE: batch_inference.py
================================================
import os
import time
import subprocess
import argparse
import pandas as pd
from datasets import Dataset
from single_inference import single_inference, CustomCosyVoice
from g2pw import G2PWConverter
def process_batch(csv_file, speaker_prompt_audio_folder, output_audio_folder, model):
# Load CSV with pandas
data = pd.read_csv(csv_file)
# Transform pandas DataFrame to HuggingFace Dataset
dataset = Dataset.from_pandas(data)
dataset = dataset.shuffle(seed = int(time.time()*1000))
cosyvoice, bopomofo_converter = model
def gen_audio(row):
speaker_prompt_audio_path = os.path.join(speaker_prompt_audio_folder, f"{row['speaker_prompt_audio_filename']}.wav")
speaker_prompt_text_transcription = row['speaker_prompt_text_transcription']
content_to_synthesize = row['content_to_synthesize']
output_audio_path = os.path.join(output_audio_folder, f"{row['output_audio_filename']}.wav")
if not os.path.exists(speaker_prompt_audio_path):
print(f"File {speaker_prompt_audio_path} does not exist")
return row #{"status": "failed", "reason": "file not found"}
if not os.path.exists(output_audio_path):
single_inference(speaker_prompt_audio_path, content_to_synthesize, output_audio_path, cosyvoice, bopomofo_converter, speaker_prompt_text_transcription)
else:
pass
# command = [
# "python", "single_inference.py",
# "--speaker_prompt_audio_path", speaker_prompt_audio_path,
# "--speaker_prompt_text_transcription", speaker_prompt_text_transcription,
# "--content_to_synthesize", content_to_synthesize,
# "--output_path", output_audio_path
# ]
# try:
# print(f"Processing: {speaker_prompt_audio_path}")
# subprocess.run(command, check=True)
# print(f"Generated: {output_audio_path}")
# return row #{"status": "success", "output": gen_voice_file_name}
# except subprocess.CalledProcessError as e:
# print(f"Failed to generate {speaker_prompt_audio_path}, error: {e}")
# return row #{"status": "failed", "reason": str(e)}
dataset = dataset.map(gen_audio, num_proc = 1)
def main():
parser = argparse.ArgumentParser(description="Batch process audio generation.")
parser.add_argument("--csv_file", required=True, help="Path to the CSV file containing input data.")
parser.add_argument("--speaker_prompt_audio_folder", required=True, help="Path to the folder containing speaker prompt audio files.")
parser.add_argument("--output_audio_folder", required=True, help="Path to the folder where results will be stored.")
parser.add_argument("--model_path", type=str, required=False, default = "MediaTek-Research/BreezyVoice-300M",help="Specifies the model used for speech synthesis.")
args = parser.parse_args()
cosyvoice = CustomCosyVoice(args.model_path)
bopomofo_converter = G2PWConverter()
os.makedirs(args.output_audio_folder, exist_ok=True)
process_batch(
csv_file=args.csv_file,
speaker_prompt_audio_folder=args.speaker_prompt_audio_folder,
output_audio_folder=args.output_audio_folder,
model = (cosyvoice, bopomofo_converter),
)
if __name__ == "__main__":
main()
================================================
FILE: compose.yaml
================================================
services:
app:
image: breezyvoice:latest
build: .
ports:
- "8080:8080"
volumes:
- hf-cache:/root/.cache/huggingface/
command: api.py
init: true
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
hf-cache:
================================================
FILE: cosyvoice/__init__.py
================================================
================================================
FILE: cosyvoice/bin/inference.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import argparse
import logging
logging.getLogger('matplotlib').setLevel(logging.WARNING)
import os
import torch
from torch.utils.data import DataLoader
import torchaudio
from hyperpyyaml import load_hyperpyyaml
from tqdm import tqdm
from cosyvoice.cli.model import CosyVoiceModel
from cosyvoice.dataset.dataset import Dataset
def get_args():
parser = argparse.ArgumentParser(description='inference with your model')
parser.add_argument('--config', required=True, help='config file')
parser.add_argument('--prompt_data', required=True, help='prompt data file')
parser.add_argument('--prompt_utt2data', required=True, help='prompt data file')
parser.add_argument('--tts_text', required=True, help='tts input file')
parser.add_argument('--llm_model', required=True, help='llm model file')
parser.add_argument('--flow_model', required=True, help='flow model file')
parser.add_argument('--hifigan_model', required=True, help='hifigan model file')
parser.add_argument('--gpu',
type=int,
default=-1,
help='gpu id for this rank, -1 for cpu')
parser.add_argument('--mode',
default='sft',
choices=['sft', 'zero_shot'],
help='inference mode')
parser.add_argument('--result_dir', required=True, help='asr result file')
args = parser.parse_args()
print(args)
return args
def main():
args = get_args()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
# Init cosyvoice models from configs
use_cuda = args.gpu >= 0 and torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
with open(args.config, 'r') as f:
configs = load_hyperpyyaml(f)
model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
model.load(args.llm_model, args.flow_model, args.hifigan_model)
test_dataset = Dataset(args.prompt_data, data_pipeline=configs['data_pipeline'], mode='inference', shuffle=False, partition=False, tts_file=args.tts_text, prompt_utt2data=args.prompt_utt2data)
test_data_loader = DataLoader(test_dataset, batch_size=None, num_workers=0)
del configs
os.makedirs(args.result_dir, exist_ok=True)
fn = os.path.join(args.result_dir, 'wav.scp')
f = open(fn, 'w')
with torch.no_grad():
for batch_idx, batch in tqdm(enumerate(test_data_loader)):
utts = batch["utts"]
assert len(utts) == 1, "inference mode only support batchsize 1"
text = batch["text"]
text_token = batch["text_token"].to(device)
text_token_len = batch["text_token_len"].to(device)
tts_text = batch["tts_text"]
tts_index = batch["tts_index"]
tts_text_token = batch["tts_text_token"].to(device)
tts_text_token_len = batch["tts_text_token_len"].to(device)
speech_token = batch["speech_token"].to(device)
speech_token_len = batch["speech_token_len"].to(device)
speech_feat = batch["speech_feat"].to(device)
speech_feat_len = batch["speech_feat_len"].to(device)
utt_embedding = batch["utt_embedding"].to(device)
spk_embedding = batch["spk_embedding"].to(device)
if args.mode == 'sft':
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'llm_embedding': spk_embedding, 'flow_embedding': spk_embedding}
else:
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'prompt_text': text_token, 'prompt_text_len': text_token_len,
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': utt_embedding, 'flow_embedding': utt_embedding}
model_output = model.inference(**model_input)
tts_key = '{}_{}'.format(utts[0], tts_index[0])
tts_fn = os.path.join(args.result_dir, '{}.wav'.format(tts_key))
torchaudio.save(tts_fn, model_output['tts_speech'], sample_rate=22050)
f.write('{} {}\n'.format(tts_key, tts_fn))
f.flush()
f.close()
logging.info('Result wav.scp saved in {}'.format(fn))
if __name__ == '__main__':
main()
================================================
FILE: cosyvoice/bin/train.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import argparse
import datetime
import logging
logging.getLogger('matplotlib').setLevel(logging.WARNING)
from copy import deepcopy
import torch
import torch.distributed as dist
import deepspeed
from hyperpyyaml import load_hyperpyyaml
from torch.distributed.elastic.multiprocessing.errors import record
from cosyvoice.utils.executor import Executor
from cosyvoice.utils.train_utils import (
init_distributed,
init_dataset_and_dataloader,
init_optimizer_and_scheduler,
init_summarywriter, save_model,
wrap_cuda_model, check_modify_and_save_config)
def get_args():
parser = argparse.ArgumentParser(description='training your network')
parser.add_argument('--train_engine',
default='torch_ddp',
choices=['torch_ddp', 'deepspeed'],
help='Engine for paralleled training')
parser.add_argument('--model', required=True, help='model which will be trained')
parser.add_argument('--config', required=True, help='config file')
parser.add_argument('--train_data', required=True, help='train data file')
parser.add_argument('--cv_data', required=True, help='cv data file')
parser.add_argument('--checkpoint', help='checkpoint model')
parser.add_argument('--model_dir', required=True, help='save model dir')
parser.add_argument('--tensorboard_dir',
default='tensorboard',
help='tensorboard log dir')
parser.add_argument('--ddp.dist_backend',
dest='dist_backend',
default='nccl',
choices=['nccl', 'gloo'],
help='distributed backend')
parser.add_argument('--num_workers',
default=0,
type=int,
help='num of subprocess workers for reading')
parser.add_argument('--prefetch',
default=100,
type=int,
help='prefetch number')
parser.add_argument('--pin_memory',
action='store_true',
default=False,
help='Use pinned memory buffers used for reading')
parser.add_argument('--deepspeed.save_states',
dest='save_states',
default='model_only',
choices=['model_only', 'model+optimizer'],
help='save model/optimizer states')
parser.add_argument('--timeout',
default=30,
type=int,
help='timeout (in seconds) of cosyvoice_join.')
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
@record
def main():
args = get_args()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
override_dict = {k: None for k in ['llm', 'flow', 'hift'] if k != args.model}
with open(args.config, 'r') as f:
configs = load_hyperpyyaml(f, overrides=override_dict)
configs['train_conf'].update(vars(args))
# Init env for ddp
init_distributed(args)
# Get dataset & dataloader
train_dataset, cv_dataset, train_data_loader, cv_data_loader = \
init_dataset_and_dataloader(args, configs)
# Do some sanity checks and save config to arsg.model_dir
configs = check_modify_and_save_config(args, configs)
# Tensorboard summary
writer = init_summarywriter(args)
# load checkpoint
model = configs[args.model]
if args.checkpoint is not None:
model.load_state_dict(torch.load(args.checkpoint, map_location='cpu'))
# Dispatch model from cpu to gpu
model = wrap_cuda_model(args, model)
# Get optimizer & scheduler
model, optimizer, scheduler = init_optimizer_and_scheduler(args, configs, model)
# Save init checkpoints
info_dict = deepcopy(configs['train_conf'])
save_model(model, 'init', info_dict)
# Get executor
executor = Executor()
# Start training loop
for epoch in range(info_dict['max_epoch']):
executor.epoch = epoch
train_dataset.set_epoch(epoch)
dist.barrier()
group_join = dist.new_group(backend="gloo", timeout=datetime.timedelta(seconds=args.timeout))
executor.train_one_epoc(model, optimizer, scheduler, train_data_loader, cv_data_loader, writer, info_dict, group_join)
dist.destroy_process_group(group_join)
if __name__ == '__main__':
main()
================================================
FILE: cosyvoice/cli/__init__.py
================================================
================================================
FILE: cosyvoice/cli/cosyvoice.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import torch
from hyperpyyaml import load_hyperpyyaml
from huggingface_hub import snapshot_download
from cosyvoice.cli.frontend import CosyVoiceFrontEnd
from cosyvoice.cli.model import CosyVoiceModel
class CosyVoice:
def __init__(self, model_dir):
instruct = True if '-Instruct' in model_dir else False
self.model_dir = model_dir
if not os.path.exists(model_dir):
model_dir = snapshot_download(model_dir)
with open('{}/cosyvoice.yaml'.format(model_dir), 'r') as f:
configs = load_hyperpyyaml(f)
self.frontend = CosyVoiceFrontEnd(configs['get_tokenizer'],
configs['feat_extractor'],
'{}/campplus.onnx'.format(model_dir),
'{}/speech_tokenizer_v1.onnx'.format(model_dir),
'{}/spk2info.pt'.format(model_dir),
instruct,
configs['allowed_special'])
self.model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
self.model.load('{}/llm.pt'.format(model_dir),
'{}/flow.pt'.format(model_dir),
'{}/hift.pt'.format(model_dir))
del configs
def list_avaliable_spks(self):
spks = list(self.frontend.spk2info.keys())
return spks
def inference_sft(self, tts_text, spk_id):
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_sft(i, spk_id)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
prompt_text = self.frontend.text_normalize(prompt_text, split=False)
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_zero_shot(i, prompt_text, prompt_speech_16k)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_cross_lingual(self, tts_text, prompt_speech_16k):
if self.frontend.instruct is True:
raise ValueError('{} do not support cross_lingual inference'.format(self.model_dir))
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_cross_lingual(i, prompt_speech_16k)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_instruct(self, tts_text, spk_id, instruct_text):
if self.frontend.instruct is False:
raise ValueError('{} do not support instruct inference'.format(self.model_dir))
instruct_text = self.frontend.text_normalize(instruct_text, split=False)
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_instruct(i, spk_id, instruct_text)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
================================================
FILE: cosyvoice/cli/frontend.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
import onnxruntime
import torch
import numpy as np
import whisper
from typing import Callable
import torchaudio.compliance.kaldi as kaldi
import torchaudio
import os
import re
import inflect
try:
import ttsfrd
use_ttsfrd = True
except ImportError:
print("failed to import ttsfrd, use WeTextProcessing instead")
from tn.chinese.normalizer import Normalizer as ZhNormalizer
from tn.english.normalizer import Normalizer as EnNormalizer
use_ttsfrd = False
from cosyvoice.utils.frontend_utils import contains_chinese, replace_blank, replace_corner_mark, remove_bracket, spell_out_number, split_paragraph
class CosyVoiceFrontEnd:
def __init__(self,
get_tokenizer: Callable,
feat_extractor: Callable,
model_dir: str,
campplus_model: str,
speech_tokenizer_model: str,
spk2info: str = '',
instruct: bool = False,
allowed_special: str = 'all'):
self.tokenizer = get_tokenizer()
self.feat_extractor = feat_extractor
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
option = onnxruntime.SessionOptions()
option.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
option.intra_op_num_threads = 1
self.campplus_session = onnxruntime.InferenceSession(campplus_model, sess_options=option, providers=["CPUExecutionProvider"])
self.speech_tokenizer_session = onnxruntime.InferenceSession(speech_tokenizer_model, sess_options=option, providers=["CUDAExecutionProvider"if torch.cuda.is_available() else "CPUExecutionProvider"])
if os.path.exists(spk2info):
self.spk2info = torch.load(spk2info, map_location=self.device)
self.instruct = instruct
self.allowed_special = allowed_special
self.inflect_parser = inflect.engine()
self.use_ttsfrd = use_ttsfrd
if self.use_ttsfrd:
self.frd = ttsfrd.TtsFrontendEngine()
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
assert self.frd.initialize('{}/CosyVoice-ttsfrd/resource'.format(model_dir)) is True, 'failed to initialize ttsfrd resource'
self.frd.set_lang_type('pinyin')
self.frd.enable_pinyin_mix(True)
self.frd.set_breakmodel_index(1)
else:
self.zh_tn_model = ZhNormalizer(remove_erhua=False, full_to_half=False)
self.en_tn_model = EnNormalizer()
def _extract_text_token(self, text):
text_token = self.tokenizer.encode(text, allowed_special=self.allowed_special)
text_token = torch.tensor([text_token], dtype=torch.int32).to(self.device)
text_token_len = torch.tensor([text_token.shape[1]], dtype=torch.int32).to(self.device)
return text_token, text_token_len
def _extract_speech_token(self, speech):
feat = whisper.log_mel_spectrogram(speech, n_mels=128)
speech_token = self.speech_tokenizer_session.run(None, {self.speech_tokenizer_session.get_inputs()[0].name: feat.detach().cpu().numpy(),
self.speech_tokenizer_session.get_inputs()[1].name: np.array([feat.shape[2]], dtype=np.int32)})[0].flatten().tolist()
speech_token = torch.tensor([speech_token], dtype=torch.int32).to(self.device)
speech_token_len = torch.tensor([speech_token.shape[1]], dtype=torch.int32).to(self.device)
return speech_token, speech_token_len
def _extract_spk_embedding(self, speech):
feat = kaldi.fbank(speech,
num_mel_bins=80,
dither=0,
sample_frequency=16000)
feat = feat - feat.mean(dim=0, keepdim=True)
embedding = self.campplus_session.run(None, {self.campplus_session.get_inputs()[0].name: feat.unsqueeze(dim=0).cpu().numpy()})[0].flatten().tolist()
embedding = torch.tensor([embedding]).to(self.device)
return embedding
def _extract_speech_feat(self, speech):
speech_feat = self.feat_extractor(speech).squeeze(dim=0).transpose(0, 1).to(self.device)
speech_feat = speech_feat.unsqueeze(dim=0)
speech_feat_len = torch.tensor([speech_feat.shape[1]], dtype=torch.int32).to(self.device)
return speech_feat, speech_feat_len
def text_normalize(self, text, split=True):
text = text.strip()
if contains_chinese(text):
if self.use_ttsfrd:
text = self.frd.get_frd_extra_info(text, 'input')
else:
text = self.zh_tn_model.normalize(text)
text = text.replace("\n", "")
text = replace_blank(text)
text = replace_corner_mark(text)
text = text.replace(".", "、")
text = text.replace(" - ", ",")
text = remove_bracket(text)
text = re.sub(r'[,,]+$', '。', text)
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "zh", token_max_n=80,
token_min_n=60, merge_len=20,
comma_split=False)]
else:
if self.use_ttsfrd:
text = self.frd.get_frd_extra_info(text, 'input')
else:
text = self.en_tn_model.normalize(text)
text = spell_out_number(text, self.inflect_parser)
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "en", token_max_n=80,
token_min_n=60, merge_len=20,
comma_split=False)]
if split is False:
return text
return texts
def frontend_sft(self, tts_text, spk_id):
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
embedding = self.spk2info[spk_id]['embedding']
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len, 'llm_embedding': embedding, 'flow_embedding': embedding}
return model_input
def frontend_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
prompt_text_token, prompt_text_token_len = self._extract_text_token(prompt_text)
prompt_speech_22050 = torchaudio.transforms.Resample(orig_freq=16000, new_freq=22050)(prompt_speech_16k)
speech_feat, speech_feat_len = self._extract_speech_feat(prompt_speech_22050)
speech_token, speech_token_len = self._extract_speech_token(prompt_speech_16k)
embedding = self._extract_spk_embedding(prompt_speech_16k)
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'prompt_text': prompt_text_token, 'prompt_text_len': prompt_text_token_len,
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': embedding, 'flow_embedding': embedding}
return model_input
def frontend_cross_lingual(self, tts_text, prompt_speech_16k):
model_input = self.frontend_zero_shot(tts_text, '', prompt_speech_16k)
# in cross lingual mode, we remove prompt in llm
del model_input['prompt_text']
del model_input['prompt_text_len']
del model_input['llm_prompt_speech_token']
del model_input['llm_prompt_speech_token_len']
return model_input
def frontend_instruct(self, tts_text, spk_id, instruct_text):
model_input = self.frontend_sft(tts_text, spk_id)
# in instruct mode, we remove spk_embedding in llm due to information leakage
del model_input['llm_embedding']
instruct_text_token, instruct_text_token_len = self._extract_text_token(instruct_text + '
🔥 BreezyVoice is highly competitive at code-switching scenarios.
| Code-Switching Term Category | **BreezyVoice** | Z | Y | U | M |
|-------------|--------------|---|---|---|---|
| **General Words** | **8** | 5 | **8** | **8** | 7 |
| **Entities**| **9** | 6 | 4 | 7 | 4 |
| **Abbreviations** | **9** | 8 | 6 | 6 | 7 |
| **Toponyms**| 3 | 3 | **7** | 3 | 4 |
| **Full Sentences**| 7 | 7 | **8** | 5 | 3 |
🔥 BreezyVoice supports automatic 注音 annotation, as well as manual 注音 correction (See Inference).
## Install
**Clone and install**
- Clone the repo
``` sh
git clone https://github.com/mtkresearch/BreezyVoice.git
# If you failed to clone submodule due to network failures, please run following command until success
cd BreezyVoice
```
- Install Requirements (requires Python3.10)
```
pip uninstall onnxruntime # use onnxruntime-gpu instead of onnxruntime
pip install -r requirements.txt
```
(The model is runnable on CPU, please change onnxruntime-gpu to onnxruntime in `requirements.txt` if you do not have GPU in your environment)
You might need to install cudnn depending on cuda version
```
sudo apt-get -y install cudnn9-cuda-11
```
## Inference
UTF8 encoding is required:
``` sh
export PYTHONUTF8=1
```
---
**Run single_inference.py with the following arguments:**
- `--content_to_synthesize`:
- **Description**: Specifies the content that will be synthesized into speech. Phonetic symbols can optionally be included but should be used sparingly, as shown in the examples below:
- Simple text: `"今天天氣真好"`
- Text with phonetic symbols: `"今天天氣真好[:ㄏㄠ3]"`
- `--speaker_prompt_audio_path`:
- **Description**: Specifies the path to the prompt speech audio file for setting the style of the speaker. Use your custom audio file or our example file:
- Example audio: `./data/tc_speaker.wav`
- `--speaker_prompt_text_transcription` (optional):
- **Description**: Specifies the transcription of the speaker prompt audio. Providing this input is highly recommended for better accuracy. If not provided, the system will automatically transcribe the audio using Whisper.
- Example text for the audio file: `"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程才能將密文還原為正常可讀的內容。"`
- `--output_path` (optional):
- **Description**: Specifies the name and path for the output `.wav` file. If not provided, the default path is used.
- **Default Value**: `results/output.wav`
- Example: `[your_file_name].wav`
- `--model_path` (optional):
- **Description**: Specifies the pre-trained model used for speech synthesis.
- **Default Value**: `MediaTek-Research/BreezyVoice`
**Example Usage:**
``` bash
bash run_single_inference.sh
```
``` python
# python single_inference.py --text_to_speech [text to be converted into audio] --text_prompt [the prompt of that audio file] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好" --speaker_prompt_text_transcription "在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程才能將密文還原為正常可讀的內容。" --speaker_prompt_audio_path "./data/example.wav"
```
``` python
# python single_inference.py --text_to_speech [text to be converted into audio] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好[:ㄏㄠ3]" --speaker_prompt_audio_path "./data/example.wav"
```
---
**Run `batch_inference.py` with the following arguments:**
- `--csv_file`:
- **Description**: Path to the CSV file that contains the input data for batch processing.
- **Example**: `./data/batch_files.csv`
- `--speaker_prompt_audio_folder`:
- **Description**: Path to the folder containing the speaker prompt audio files. The files in this folder are used to set the style of the speaker for each synthesis task.
- **Example**: `./data`
- `--output_audio_folder`:
- **Description**: Path to the folder where the output audio files will be saved. Each processed row in the CSV will result in a synthesized audio file stored in this folder.
- **Example**: `./results`
**CSV File Structure:**
The CSV file should contain the following columns:
- **`speaker_prompt_audio_filename`**:
- **Description**: The filename (without extension) of the speaker prompt audio file that will be used to guide the style of the generated speech.
- **Example**: `example`
- **`speaker_prompt_text_transcription`**:
- **Description**: The transcription of the speaker prompt audio. This field is optional but highly recommended to improve transcription accuracy. If not provided, the system will attempt to transcribe the audio using Whisper.
- **Example**: `"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。"`
- **`content_to_synthesize`**:
- **Description**: The content that will be synthesized into speech. You can include phonetic symbols if needed, though they should be used sparingly.
- **Example**: `"今天天氣真好"`
- **`output_audio_filename`**:
- **Description**: The filename (without extension) for the generated output audio. The audio will be saved as a `.wav` file in the output folder.
- **Example**: `output`
**Example Usage:**
``` bash
bash run_batch_inference.sh
```
```bash
python batch_inference.py \
--csv_file ./data/batch_files.csv \
--speaker_prompt_audio_folder ./data \
--output_audio_folder ./results
```
### Docker and OpenAI Compatible API
``` bash
$ docker compose up -d --build
# after the container is up
$ pip install openai
$ python openai_api_inference.py
```
---
If you like our work, please cite:
```
@article{hsu2025breezyvoice,
title={BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation--Challenges and Insights},
author={Hsu, Chan-Jan and Lin, Yi-Cheng and Lin, Chia-Chun and Chen, Wei-Chih and Chung, Ho Lam and Li, Chen-An and Chen, Yi-Chang and Yu, Chien-Yu and Lee, Ming-Ji and Chen, Chien-Cheng and others},
journal={arXiv preprint arXiv:2501.17790},
year={2025}
}
@article{hsu2025breeze,
title={The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities},
author={Hsu, Chan-Jan and Liu, Chia-Sheng and Chen, Meng-Hsi and Chen, Muxi and Hsu, Po-Chun and Chen, Yi-Chang and Shiu, Da-Shan},
journal={arXiv preprint arXiv:2501.13921},
year={2025}
}
@article{du2024cosyvoice,
title={Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens},
author={Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others},
journal={arXiv preprint arXiv:2407.05407},
year={2024}
}
```
================================================
FILE: api.py
================================================
# OpenAI API Spec. Reference: https://platform.openai.com/docs/api-reference/audio/createSpeech
from contextlib import asynccontextmanager
from io import BytesIO
import torchaudio
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from g2pw import G2PWConverter
from pydantic import BaseModel, Field
from pydantic_settings import BaseSettings
from cosyvoice.utils.file_utils import load_wav
from single_inference import CustomCosyVoice, get_bopomofo_rare
class Settings(BaseSettings):
api_key: str = Field(
default="", description="Specifies the API key used to authenticate the user."
)
model_path: str = Field(
default="MediaTek-Research/BreezyVoice",
description="Specifies the model used for speech synthesis.",
)
speaker_prompt_audio_path: str = Field(
default="./data/example.wav",
description="Specifies the path to the prompt speech audio file of the speaker.",
)
speaker_prompt_text_transcription: str = Field(
default="在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。只有擁有解密方法的對象,經由解密過程,才能將密文還原為正常可讀的內容。",
description="Specifies the transcription of the speaker prompt audio.",
)
class SpeechRequest(BaseModel):
model: str = ""
input: str = Field(
description="The content that will be synthesized into speech. You can include phonetic symbols if needed, though they should be used sparingly.",
examples=["今天天氣真好"],
)
response_format: str = ""
speed: float = 1.0
@asynccontextmanager
async def lifespan(app: FastAPI):
app.state.settings = Settings()
app.state.cosyvoice = CustomCosyVoice(app.state.settings.model_path)
app.state.bopomofo_converter = G2PWConverter()
app.state.prompt_speech_16k = load_wav(
app.state.settings.speaker_prompt_audio_path, 16000
)
yield
del app.state.cosyvoice
del app.state.bopomofo_converter
app = FastAPI(lifespan=lifespan, root_path="/v1")
@app.get("/models")
async def get_models(request: Request):
return {
"object": "list",
"data": [
{
"id": request.app.state.settings.model_path,
"object": "model",
"created": 0,
"owned_by": "local",
}
],
}
@app.post("/audio/speech")
async def speach_endpoint(request: Request, payload: SpeechRequest):
# normalization
speaker_prompt_text_transcription = (
request.app.state.cosyvoice.frontend.text_normalize_new(
request.app.state.settings.speaker_prompt_text_transcription, split=False
)
)
content_to_synthesize = request.app.state.cosyvoice.frontend.text_normalize_new(
payload.input, split=False
)
speaker_prompt_text_transcription_bopomo = get_bopomofo_rare(
speaker_prompt_text_transcription, request.app.state.bopomofo_converter
)
content_to_synthesize_bopomo = get_bopomofo_rare(
content_to_synthesize, request.app.state.bopomofo_converter
)
output = request.app.state.cosyvoice.inference_zero_shot_no_normalize(
content_to_synthesize_bopomo,
speaker_prompt_text_transcription_bopomo,
request.app.state.prompt_speech_16k,
)
audio_buffer = BytesIO()
torchaudio.save(audio_buffer, output["tts_speech"], 22050, format="wav")
audio_buffer.seek(0)
return StreamingResponse(
audio_buffer,
media_type="audio/wav",
headers={"Content-Disposition": "attachment; filename=output.wav"},
)
if __name__ == "__main__":
import uvicorn
uvicorn.run("api:app", host="0.0.0.0", port=8080)
================================================
FILE: batch_inference.py
================================================
import os
import time
import subprocess
import argparse
import pandas as pd
from datasets import Dataset
from single_inference import single_inference, CustomCosyVoice
from g2pw import G2PWConverter
def process_batch(csv_file, speaker_prompt_audio_folder, output_audio_folder, model):
# Load CSV with pandas
data = pd.read_csv(csv_file)
# Transform pandas DataFrame to HuggingFace Dataset
dataset = Dataset.from_pandas(data)
dataset = dataset.shuffle(seed = int(time.time()*1000))
cosyvoice, bopomofo_converter = model
def gen_audio(row):
speaker_prompt_audio_path = os.path.join(speaker_prompt_audio_folder, f"{row['speaker_prompt_audio_filename']}.wav")
speaker_prompt_text_transcription = row['speaker_prompt_text_transcription']
content_to_synthesize = row['content_to_synthesize']
output_audio_path = os.path.join(output_audio_folder, f"{row['output_audio_filename']}.wav")
if not os.path.exists(speaker_prompt_audio_path):
print(f"File {speaker_prompt_audio_path} does not exist")
return row #{"status": "failed", "reason": "file not found"}
if not os.path.exists(output_audio_path):
single_inference(speaker_prompt_audio_path, content_to_synthesize, output_audio_path, cosyvoice, bopomofo_converter, speaker_prompt_text_transcription)
else:
pass
# command = [
# "python", "single_inference.py",
# "--speaker_prompt_audio_path", speaker_prompt_audio_path,
# "--speaker_prompt_text_transcription", speaker_prompt_text_transcription,
# "--content_to_synthesize", content_to_synthesize,
# "--output_path", output_audio_path
# ]
# try:
# print(f"Processing: {speaker_prompt_audio_path}")
# subprocess.run(command, check=True)
# print(f"Generated: {output_audio_path}")
# return row #{"status": "success", "output": gen_voice_file_name}
# except subprocess.CalledProcessError as e:
# print(f"Failed to generate {speaker_prompt_audio_path}, error: {e}")
# return row #{"status": "failed", "reason": str(e)}
dataset = dataset.map(gen_audio, num_proc = 1)
def main():
parser = argparse.ArgumentParser(description="Batch process audio generation.")
parser.add_argument("--csv_file", required=True, help="Path to the CSV file containing input data.")
parser.add_argument("--speaker_prompt_audio_folder", required=True, help="Path to the folder containing speaker prompt audio files.")
parser.add_argument("--output_audio_folder", required=True, help="Path to the folder where results will be stored.")
parser.add_argument("--model_path", type=str, required=False, default = "MediaTek-Research/BreezyVoice-300M",help="Specifies the model used for speech synthesis.")
args = parser.parse_args()
cosyvoice = CustomCosyVoice(args.model_path)
bopomofo_converter = G2PWConverter()
os.makedirs(args.output_audio_folder, exist_ok=True)
process_batch(
csv_file=args.csv_file,
speaker_prompt_audio_folder=args.speaker_prompt_audio_folder,
output_audio_folder=args.output_audio_folder,
model = (cosyvoice, bopomofo_converter),
)
if __name__ == "__main__":
main()
================================================
FILE: compose.yaml
================================================
services:
app:
image: breezyvoice:latest
build: .
ports:
- "8080:8080"
volumes:
- hf-cache:/root/.cache/huggingface/
command: api.py
init: true
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
volumes:
hf-cache:
================================================
FILE: cosyvoice/__init__.py
================================================
================================================
FILE: cosyvoice/bin/inference.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import argparse
import logging
logging.getLogger('matplotlib').setLevel(logging.WARNING)
import os
import torch
from torch.utils.data import DataLoader
import torchaudio
from hyperpyyaml import load_hyperpyyaml
from tqdm import tqdm
from cosyvoice.cli.model import CosyVoiceModel
from cosyvoice.dataset.dataset import Dataset
def get_args():
parser = argparse.ArgumentParser(description='inference with your model')
parser.add_argument('--config', required=True, help='config file')
parser.add_argument('--prompt_data', required=True, help='prompt data file')
parser.add_argument('--prompt_utt2data', required=True, help='prompt data file')
parser.add_argument('--tts_text', required=True, help='tts input file')
parser.add_argument('--llm_model', required=True, help='llm model file')
parser.add_argument('--flow_model', required=True, help='flow model file')
parser.add_argument('--hifigan_model', required=True, help='hifigan model file')
parser.add_argument('--gpu',
type=int,
default=-1,
help='gpu id for this rank, -1 for cpu')
parser.add_argument('--mode',
default='sft',
choices=['sft', 'zero_shot'],
help='inference mode')
parser.add_argument('--result_dir', required=True, help='asr result file')
args = parser.parse_args()
print(args)
return args
def main():
args = get_args()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
# Init cosyvoice models from configs
use_cuda = args.gpu >= 0 and torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
with open(args.config, 'r') as f:
configs = load_hyperpyyaml(f)
model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
model.load(args.llm_model, args.flow_model, args.hifigan_model)
test_dataset = Dataset(args.prompt_data, data_pipeline=configs['data_pipeline'], mode='inference', shuffle=False, partition=False, tts_file=args.tts_text, prompt_utt2data=args.prompt_utt2data)
test_data_loader = DataLoader(test_dataset, batch_size=None, num_workers=0)
del configs
os.makedirs(args.result_dir, exist_ok=True)
fn = os.path.join(args.result_dir, 'wav.scp')
f = open(fn, 'w')
with torch.no_grad():
for batch_idx, batch in tqdm(enumerate(test_data_loader)):
utts = batch["utts"]
assert len(utts) == 1, "inference mode only support batchsize 1"
text = batch["text"]
text_token = batch["text_token"].to(device)
text_token_len = batch["text_token_len"].to(device)
tts_text = batch["tts_text"]
tts_index = batch["tts_index"]
tts_text_token = batch["tts_text_token"].to(device)
tts_text_token_len = batch["tts_text_token_len"].to(device)
speech_token = batch["speech_token"].to(device)
speech_token_len = batch["speech_token_len"].to(device)
speech_feat = batch["speech_feat"].to(device)
speech_feat_len = batch["speech_feat_len"].to(device)
utt_embedding = batch["utt_embedding"].to(device)
spk_embedding = batch["spk_embedding"].to(device)
if args.mode == 'sft':
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'llm_embedding': spk_embedding, 'flow_embedding': spk_embedding}
else:
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'prompt_text': text_token, 'prompt_text_len': text_token_len,
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': utt_embedding, 'flow_embedding': utt_embedding}
model_output = model.inference(**model_input)
tts_key = '{}_{}'.format(utts[0], tts_index[0])
tts_fn = os.path.join(args.result_dir, '{}.wav'.format(tts_key))
torchaudio.save(tts_fn, model_output['tts_speech'], sample_rate=22050)
f.write('{} {}\n'.format(tts_key, tts_fn))
f.flush()
f.close()
logging.info('Result wav.scp saved in {}'.format(fn))
if __name__ == '__main__':
main()
================================================
FILE: cosyvoice/bin/train.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import argparse
import datetime
import logging
logging.getLogger('matplotlib').setLevel(logging.WARNING)
from copy import deepcopy
import torch
import torch.distributed as dist
import deepspeed
from hyperpyyaml import load_hyperpyyaml
from torch.distributed.elastic.multiprocessing.errors import record
from cosyvoice.utils.executor import Executor
from cosyvoice.utils.train_utils import (
init_distributed,
init_dataset_and_dataloader,
init_optimizer_and_scheduler,
init_summarywriter, save_model,
wrap_cuda_model, check_modify_and_save_config)
def get_args():
parser = argparse.ArgumentParser(description='training your network')
parser.add_argument('--train_engine',
default='torch_ddp',
choices=['torch_ddp', 'deepspeed'],
help='Engine for paralleled training')
parser.add_argument('--model', required=True, help='model which will be trained')
parser.add_argument('--config', required=True, help='config file')
parser.add_argument('--train_data', required=True, help='train data file')
parser.add_argument('--cv_data', required=True, help='cv data file')
parser.add_argument('--checkpoint', help='checkpoint model')
parser.add_argument('--model_dir', required=True, help='save model dir')
parser.add_argument('--tensorboard_dir',
default='tensorboard',
help='tensorboard log dir')
parser.add_argument('--ddp.dist_backend',
dest='dist_backend',
default='nccl',
choices=['nccl', 'gloo'],
help='distributed backend')
parser.add_argument('--num_workers',
default=0,
type=int,
help='num of subprocess workers for reading')
parser.add_argument('--prefetch',
default=100,
type=int,
help='prefetch number')
parser.add_argument('--pin_memory',
action='store_true',
default=False,
help='Use pinned memory buffers used for reading')
parser.add_argument('--deepspeed.save_states',
dest='save_states',
default='model_only',
choices=['model_only', 'model+optimizer'],
help='save model/optimizer states')
parser.add_argument('--timeout',
default=30,
type=int,
help='timeout (in seconds) of cosyvoice_join.')
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
@record
def main():
args = get_args()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
override_dict = {k: None for k in ['llm', 'flow', 'hift'] if k != args.model}
with open(args.config, 'r') as f:
configs = load_hyperpyyaml(f, overrides=override_dict)
configs['train_conf'].update(vars(args))
# Init env for ddp
init_distributed(args)
# Get dataset & dataloader
train_dataset, cv_dataset, train_data_loader, cv_data_loader = \
init_dataset_and_dataloader(args, configs)
# Do some sanity checks and save config to arsg.model_dir
configs = check_modify_and_save_config(args, configs)
# Tensorboard summary
writer = init_summarywriter(args)
# load checkpoint
model = configs[args.model]
if args.checkpoint is not None:
model.load_state_dict(torch.load(args.checkpoint, map_location='cpu'))
# Dispatch model from cpu to gpu
model = wrap_cuda_model(args, model)
# Get optimizer & scheduler
model, optimizer, scheduler = init_optimizer_and_scheduler(args, configs, model)
# Save init checkpoints
info_dict = deepcopy(configs['train_conf'])
save_model(model, 'init', info_dict)
# Get executor
executor = Executor()
# Start training loop
for epoch in range(info_dict['max_epoch']):
executor.epoch = epoch
train_dataset.set_epoch(epoch)
dist.barrier()
group_join = dist.new_group(backend="gloo", timeout=datetime.timedelta(seconds=args.timeout))
executor.train_one_epoc(model, optimizer, scheduler, train_data_loader, cv_data_loader, writer, info_dict, group_join)
dist.destroy_process_group(group_join)
if __name__ == '__main__':
main()
================================================
FILE: cosyvoice/cli/__init__.py
================================================
================================================
FILE: cosyvoice/cli/cosyvoice.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import torch
from hyperpyyaml import load_hyperpyyaml
from huggingface_hub import snapshot_download
from cosyvoice.cli.frontend import CosyVoiceFrontEnd
from cosyvoice.cli.model import CosyVoiceModel
class CosyVoice:
def __init__(self, model_dir):
instruct = True if '-Instruct' in model_dir else False
self.model_dir = model_dir
if not os.path.exists(model_dir):
model_dir = snapshot_download(model_dir)
with open('{}/cosyvoice.yaml'.format(model_dir), 'r') as f:
configs = load_hyperpyyaml(f)
self.frontend = CosyVoiceFrontEnd(configs['get_tokenizer'],
configs['feat_extractor'],
'{}/campplus.onnx'.format(model_dir),
'{}/speech_tokenizer_v1.onnx'.format(model_dir),
'{}/spk2info.pt'.format(model_dir),
instruct,
configs['allowed_special'])
self.model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
self.model.load('{}/llm.pt'.format(model_dir),
'{}/flow.pt'.format(model_dir),
'{}/hift.pt'.format(model_dir))
del configs
def list_avaliable_spks(self):
spks = list(self.frontend.spk2info.keys())
return spks
def inference_sft(self, tts_text, spk_id):
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_sft(i, spk_id)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
prompt_text = self.frontend.text_normalize(prompt_text, split=False)
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_zero_shot(i, prompt_text, prompt_speech_16k)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_cross_lingual(self, tts_text, prompt_speech_16k):
if self.frontend.instruct is True:
raise ValueError('{} do not support cross_lingual inference'.format(self.model_dir))
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_cross_lingual(i, prompt_speech_16k)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
def inference_instruct(self, tts_text, spk_id, instruct_text):
if self.frontend.instruct is False:
raise ValueError('{} do not support instruct inference'.format(self.model_dir))
instruct_text = self.frontend.text_normalize(instruct_text, split=False)
tts_speeches = []
for i in self.frontend.text_normalize(tts_text, split=True):
model_input = self.frontend.frontend_instruct(i, spk_id, instruct_text)
model_output = self.model.inference(**model_input)
tts_speeches.append(model_output['tts_speech'])
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
================================================
FILE: cosyvoice/cli/frontend.py
================================================
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
import onnxruntime
import torch
import numpy as np
import whisper
from typing import Callable
import torchaudio.compliance.kaldi as kaldi
import torchaudio
import os
import re
import inflect
try:
import ttsfrd
use_ttsfrd = True
except ImportError:
print("failed to import ttsfrd, use WeTextProcessing instead")
from tn.chinese.normalizer import Normalizer as ZhNormalizer
from tn.english.normalizer import Normalizer as EnNormalizer
use_ttsfrd = False
from cosyvoice.utils.frontend_utils import contains_chinese, replace_blank, replace_corner_mark, remove_bracket, spell_out_number, split_paragraph
class CosyVoiceFrontEnd:
def __init__(self,
get_tokenizer: Callable,
feat_extractor: Callable,
model_dir: str,
campplus_model: str,
speech_tokenizer_model: str,
spk2info: str = '',
instruct: bool = False,
allowed_special: str = 'all'):
self.tokenizer = get_tokenizer()
self.feat_extractor = feat_extractor
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
option = onnxruntime.SessionOptions()
option.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
option.intra_op_num_threads = 1
self.campplus_session = onnxruntime.InferenceSession(campplus_model, sess_options=option, providers=["CPUExecutionProvider"])
self.speech_tokenizer_session = onnxruntime.InferenceSession(speech_tokenizer_model, sess_options=option, providers=["CUDAExecutionProvider"if torch.cuda.is_available() else "CPUExecutionProvider"])
if os.path.exists(spk2info):
self.spk2info = torch.load(spk2info, map_location=self.device)
self.instruct = instruct
self.allowed_special = allowed_special
self.inflect_parser = inflect.engine()
self.use_ttsfrd = use_ttsfrd
if self.use_ttsfrd:
self.frd = ttsfrd.TtsFrontendEngine()
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
assert self.frd.initialize('{}/CosyVoice-ttsfrd/resource'.format(model_dir)) is True, 'failed to initialize ttsfrd resource'
self.frd.set_lang_type('pinyin')
self.frd.enable_pinyin_mix(True)
self.frd.set_breakmodel_index(1)
else:
self.zh_tn_model = ZhNormalizer(remove_erhua=False, full_to_half=False)
self.en_tn_model = EnNormalizer()
def _extract_text_token(self, text):
text_token = self.tokenizer.encode(text, allowed_special=self.allowed_special)
text_token = torch.tensor([text_token], dtype=torch.int32).to(self.device)
text_token_len = torch.tensor([text_token.shape[1]], dtype=torch.int32).to(self.device)
return text_token, text_token_len
def _extract_speech_token(self, speech):
feat = whisper.log_mel_spectrogram(speech, n_mels=128)
speech_token = self.speech_tokenizer_session.run(None, {self.speech_tokenizer_session.get_inputs()[0].name: feat.detach().cpu().numpy(),
self.speech_tokenizer_session.get_inputs()[1].name: np.array([feat.shape[2]], dtype=np.int32)})[0].flatten().tolist()
speech_token = torch.tensor([speech_token], dtype=torch.int32).to(self.device)
speech_token_len = torch.tensor([speech_token.shape[1]], dtype=torch.int32).to(self.device)
return speech_token, speech_token_len
def _extract_spk_embedding(self, speech):
feat = kaldi.fbank(speech,
num_mel_bins=80,
dither=0,
sample_frequency=16000)
feat = feat - feat.mean(dim=0, keepdim=True)
embedding = self.campplus_session.run(None, {self.campplus_session.get_inputs()[0].name: feat.unsqueeze(dim=0).cpu().numpy()})[0].flatten().tolist()
embedding = torch.tensor([embedding]).to(self.device)
return embedding
def _extract_speech_feat(self, speech):
speech_feat = self.feat_extractor(speech).squeeze(dim=0).transpose(0, 1).to(self.device)
speech_feat = speech_feat.unsqueeze(dim=0)
speech_feat_len = torch.tensor([speech_feat.shape[1]], dtype=torch.int32).to(self.device)
return speech_feat, speech_feat_len
def text_normalize(self, text, split=True):
text = text.strip()
if contains_chinese(text):
if self.use_ttsfrd:
text = self.frd.get_frd_extra_info(text, 'input')
else:
text = self.zh_tn_model.normalize(text)
text = text.replace("\n", "")
text = replace_blank(text)
text = replace_corner_mark(text)
text = text.replace(".", "、")
text = text.replace(" - ", ",")
text = remove_bracket(text)
text = re.sub(r'[,,]+$', '。', text)
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "zh", token_max_n=80,
token_min_n=60, merge_len=20,
comma_split=False)]
else:
if self.use_ttsfrd:
text = self.frd.get_frd_extra_info(text, 'input')
else:
text = self.en_tn_model.normalize(text)
text = spell_out_number(text, self.inflect_parser)
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "en", token_max_n=80,
token_min_n=60, merge_len=20,
comma_split=False)]
if split is False:
return text
return texts
def frontend_sft(self, tts_text, spk_id):
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
embedding = self.spk2info[spk_id]['embedding']
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len, 'llm_embedding': embedding, 'flow_embedding': embedding}
return model_input
def frontend_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
prompt_text_token, prompt_text_token_len = self._extract_text_token(prompt_text)
prompt_speech_22050 = torchaudio.transforms.Resample(orig_freq=16000, new_freq=22050)(prompt_speech_16k)
speech_feat, speech_feat_len = self._extract_speech_feat(prompt_speech_22050)
speech_token, speech_token_len = self._extract_speech_token(prompt_speech_16k)
embedding = self._extract_spk_embedding(prompt_speech_16k)
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'prompt_text': prompt_text_token, 'prompt_text_len': prompt_text_token_len,
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': embedding, 'flow_embedding': embedding}
return model_input
def frontend_cross_lingual(self, tts_text, prompt_speech_16k):
model_input = self.frontend_zero_shot(tts_text, '', prompt_speech_16k)
# in cross lingual mode, we remove prompt in llm
del model_input['prompt_text']
del model_input['prompt_text_len']
del model_input['llm_prompt_speech_token']
del model_input['llm_prompt_speech_token_len']
return model_input
def frontend_instruct(self, tts_text, spk_id, instruct_text):
model_input = self.frontend_sft(tts_text, spk_id)
# in instruct mode, we remove spk_embedding in llm due to information leakage
del model_input['llm_embedding']
instruct_text_token, instruct_text_token_len = self._extract_text_token(instruct_text + '
# 🍵 Matcha-TTS: A fast TTS architecture with conditional flow matching
### [Shivam Mehta](https://www.kth.se/profile/smehta), [Ruibo Tu](https://www.kth.se/profile/ruibo), [Jonas Beskow](https://www.kth.se/profile/beskow), [Éva Székely](https://www.kth.se/profile/szekely), and [Gustav Eje Henter](https://people.kth.se/~ghe/)
[](https://www.python.org/downloads/release/python-3100/)
[](https://pytorch.org/get-started/locally/)
[](https://pytorchlightning.ai/)
[](https://hydra.cc/)
[](https://black.readthedocs.io/en/stable/)
[](https://pycqa.github.io/isort/)
> This is the official code implementation of 🍵 Matcha-TTS [ICASSP 2024].
We propose 🍵 Matcha-TTS, a new approach to non-autoregressive neural TTS, that uses [conditional flow matching](https://arxiv.org/abs/2210.02747) (similar to [rectified flows](https://arxiv.org/abs/2209.03003)) to speed up ODE-based speech synthesis. Our method:
- Is probabilistic
- Has compact memory footprint
- Sounds highly natural
- Is very fast to synthesise from
Check out our [demo page](https://shivammehta25.github.io/Matcha-TTS) and read [our ICASSP 2024 paper](https://arxiv.org/abs/2309.03199) for more details.
[Pre-trained models](https://drive.google.com/drive/folders/17C_gYgEHOxI5ZypcfE_k1piKCtyR0isJ?usp=sharing) will be automatically downloaded with the CLI or gradio interface.
You can also [try 🍵 Matcha-TTS in your browser on HuggingFace 🤗 spaces](https://huggingface.co/spaces/shivammehta25/Matcha-TTS).
## Teaser video
[](https://youtu.be/xmvJkz3bqw0)
## Installation
1. Create an environment (suggested but optional)
```
conda create -n matcha-tts python=3.10 -y
conda activate matcha-tts
```
2. Install Matcha TTS using pip or from source
```bash
pip install matcha-tts
```
from source
```bash
pip install git+https://github.com/shivammehta25/Matcha-TTS.git
cd Matcha-TTS
pip install -e .
```
3. Run CLI / gradio app / jupyter notebook
```bash
# This will download the required models
matcha-tts --text ""
```
or
```bash
matcha-tts-app
```
or open `synthesis.ipynb` on jupyter notebook
### CLI Arguments
- To synthesise from given text, run:
```bash
matcha-tts --text ""
```
- To synthesise from a file, run:
```bash
matcha-tts --file
![]()
' gr.HTML(html) with gr.Box(): radio_options = list(RADIO_OPTIONS.keys()) model_type = gr.Radio( radio_options, value=radio_options[0], label="Choose a Model", interactive=True, container=False ) with gr.Row(): gr.Markdown("# Text Input") with gr.Row(): text = gr.Textbox(value="", lines=2, label="Text to synthesise", scale=3) spk_slider = gr.Slider( minimum=0, maximum=107, step=1, value=args.spk, label="Speaker ID", interactive=True, scale=1 ) with gr.Row(): gr.Markdown("### Hyper parameters") with gr.Row(): n_timesteps = gr.Slider( label="Number of ODE steps", minimum=1, maximum=100, step=1, value=10, interactive=True, ) length_scale = gr.Slider( label="Length scale (Speaking rate)", minimum=0.5, maximum=1.5, step=0.05, value=1.0, interactive=True, ) mel_temp = gr.Slider( label="Sampling temperature", minimum=0.00, maximum=2.001, step=0.16675, value=0.667, interactive=True, ) synth_btn = gr.Button("Synthesise") with gr.Box(): with gr.Row(): gr.Markdown("### Phonetised text") phonetised_text = gr.Textbox(interactive=False, scale=10, label="Phonetised text") with gr.Box(): with gr.Row(): mel_spectrogram = gr.Image(interactive=False, label="mel spectrogram") # with gr.Row(): audio = gr.Audio(interactive=False, label="Audio") with gr.Row(visible=False) as example_row_lj_speech: examples = gr.Examples( # pylint: disable=unused-variable examples=[ [ "We propose Matcha-TTS, a new approach to non-autoregressive neural TTS, that uses conditional flow matching (similar to rectified flows) to speed up O D E-based speech synthesis.", 50, 0.677, 0.95, ], [ "The Secret Service believed that it was very doubtful that any President would ride regularly in a vehicle with a fixed top, even though transparent.", 2, 0.677, 0.95, ], [ "The Secret Service believed that it was very doubtful that any President would ride regularly in a vehicle with a fixed top, even though transparent.", 4, 0.677, 0.95, ], [ "The Secret Service believed that it was very doubtful that any President would ride regularly in a vehicle with a fixed top, even though transparent.", 10, 0.677, 0.95, ], [ "The Secret Service believed that it was very doubtful that any President would ride regularly in a vehicle with a fixed top, even though transparent.", 50, 0.677, 0.95, ], [ "The narrative of these events is based largely on the recollections of the participants.", 10, 0.677, 0.95, ], [ "The jury did not believe him, and the verdict was for the defendants.", 10, 0.677, 0.95, ], ], fn=ljspeech_example_cacher, inputs=[text, n_timesteps, mel_temp, length_scale], outputs=[phonetised_text, audio, mel_spectrogram], cache_examples=True, ) with gr.Row() as example_row_multispeaker: multi_speaker_examples = gr.Examples( # pylint: disable=unused-variable examples=[ [ "Hello everyone! I am speaker 0 and I am here to tell you that Matcha-TTS is amazing!", 10, 0.677, 0.85, 0, ], [ "Hello everyone! I am speaker 16 and I am here to tell you that Matcha-TTS is amazing!", 10, 0.677, 0.85, 16, ], [ "Hello everyone! I am speaker 44 and I am here to tell you that Matcha-TTS is amazing!", 50, 0.677, 0.85, 44, ], [ "Hello everyone! I am speaker 45 and I am here to tell you that Matcha-TTS is amazing!", 50, 0.677, 0.85, 45, ], [ "Hello everyone! I am speaker 58 and I am here to tell you that Matcha-TTS is amazing!", 4, 0.677, 0.85, 58, ], ], fn=multispeaker_example_cacher, inputs=[text, n_timesteps, mel_temp, length_scale, spk_slider], outputs=[phonetised_text, audio, mel_spectrogram], cache_examples=True, label="Multi Speaker Examples", ) model_type.change(lambda x: gr.update(interactive=False), inputs=[synth_btn], outputs=[synth_btn]).then( load_model_ui, inputs=[model_type, text], outputs=[text, synth_btn, spk_slider, example_row_lj_speech, example_row_multispeaker, length_scale], ) synth_btn.click( fn=process_text_gradio, inputs=[ text, ], outputs=[phonetised_text, processed_text, processed_text_len], api_name="matcha_tts", queue=True, ).then( fn=synthesise_mel, inputs=[processed_text, processed_text_len, n_timesteps, mel_temp, length_scale, spk_slider], outputs=[audio, mel_spectrogram], ) demo.queue().launch(share=True) if __name__ == "__main__": main() ================================================ FILE: third_party/Matcha-TTS/matcha/cli.py ================================================ import argparse import datetime as dt import os import warnings from pathlib import Path import matplotlib.pyplot as plt import numpy as np import soundfile as sf import torch from matcha.hifigan.config import v1 from matcha.hifigan.denoiser import Denoiser from matcha.hifigan.env import AttrDict from matcha.hifigan.models import Generator as HiFiGAN from matcha.models.matcha_tts import MatchaTTS from matcha.text import sequence_to_text, text_to_sequence from matcha.utils.utils import assert_model_downloaded, get_user_data_dir, intersperse MATCHA_URLS = { "matcha_ljspeech": "https://github.com/shivammehta25/Matcha-TTS-checkpoints/releases/download/v1.0/matcha_ljspeech.ckpt", "matcha_vctk": "https://github.com/shivammehta25/Matcha-TTS-checkpoints/releases/download/v1.0/matcha_vctk.ckpt", } VOCODER_URLS = { "hifigan_T2_v1": "https://github.com/shivammehta25/Matcha-TTS-checkpoints/releases/download/v1.0/generator_v1", # Old url: https://drive.google.com/file/d/14NENd4equCBLyyCSke114Mv6YR_j_uFs/view?usp=drive_link "hifigan_univ_v1": "https://github.com/shivammehta25/Matcha-TTS-checkpoints/releases/download/v1.0/g_02500000", # Old url: https://drive.google.com/file/d/1qpgI41wNXFcH-iKq1Y42JlBC9j0je8PW/view?usp=drive_link } MULTISPEAKER_MODEL = { "matcha_vctk": {"vocoder": "hifigan_univ_v1", "speaking_rate": 0.85, "spk": 0, "spk_range": (0, 107)} } SINGLESPEAKER_MODEL = {"matcha_ljspeech": {"vocoder": "hifigan_T2_v1", "speaking_rate": 0.95, "spk": None}} def plot_spectrogram_to_numpy(spectrogram, filename): fig, ax = plt.subplots(figsize=(12, 3)) im = ax.imshow(spectrogram, aspect="auto", origin="lower", interpolation="none") plt.colorbar(im, ax=ax) plt.xlabel("Frames") plt.ylabel("Channels") plt.title("Synthesised Mel-Spectrogram") fig.canvas.draw() plt.savefig(filename) def process_text(i: int, text: str, device: torch.device): print(f"[{i}] - Input text: {text}") x = torch.tensor( intersperse(text_to_sequence(text, ["english_cleaners2"]), 0), dtype=torch.long, device=device, )[None] x_lengths = torch.tensor([x.shape[-1]], dtype=torch.long, device=device) x_phones = sequence_to_text(x.squeeze(0).tolist()) print(f"[{i}] - Phonetised text: {x_phones[1::2]}") return {"x_orig": text, "x": x, "x_lengths": x_lengths, "x_phones": x_phones} def get_texts(args): if args.text: texts = [args.text] else: with open(args.file, encoding="utf-8") as f: texts = f.readlines() return texts def assert_required_models_available(args): save_dir = get_user_data_dir() if not hasattr(args, "checkpoint_path") and args.checkpoint_path is None: model_path = args.checkpoint_path else: model_path = save_dir / f"{args.model}.ckpt" assert_model_downloaded(model_path, MATCHA_URLS[args.model]) vocoder_path = save_dir / f"{args.vocoder}" assert_model_downloaded(vocoder_path, VOCODER_URLS[args.vocoder]) return {"matcha": model_path, "vocoder": vocoder_path} def load_hifigan(checkpoint_path, device): h = AttrDict(v1) hifigan = HiFiGAN(h).to(device) hifigan.load_state_dict(torch.load(checkpoint_path, map_location=device)["generator"]) _ = hifigan.eval() hifigan.remove_weight_norm() return hifigan def load_vocoder(vocoder_name, checkpoint_path, device): print(f"[!] Loading {vocoder_name}!") vocoder = None if vocoder_name in ("hifigan_T2_v1", "hifigan_univ_v1"): vocoder = load_hifigan(checkpoint_path, device) else: raise NotImplementedError( f"Vocoder {vocoder_name} not implemented! define a load_<
We provide our implementation and pretrained models as open source in this repository. **Abstract :** Several recent work on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this work, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel-spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real-time on CPU with comparable quality to an autoregressive counterpart. Visit our [demo website](https://jik876.github.io/hifi-gan-demo/) for audio samples. ## Pre-requisites 1. Python >= 3.6 2. Clone this repository. 3. Install python requirements. Please refer [requirements.txt](requirements.txt) 4. Download and extract the [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/). And move all wav files to `LJSpeech-1.1/wavs` ## Training ``` python train.py --config config_v1.json ``` To train V2 or V3 Generator, replace `config_v1.json` with `config_v2.json` or `config_v3.json`.
Checkpoints and copy of the configuration file are saved in `cp_hifigan` directory by default.
You can change the path by adding `--checkpoint_path` option. Validation loss during training with V1 generator.
 ## Pretrained Model You can also use pretrained models we provide.
[Download pretrained models](https://drive.google.com/drive/folders/1-eEYTB5Av9jNql0WGBlRoi-WH2J7bp5Y?usp=sharing)
Details of each folder are as in follows: | Folder Name | Generator | Dataset | Fine-Tuned | | ------------ | --------- | --------- | ------------------------------------------------------ | | LJ_V1 | V1 | LJSpeech | No | | LJ_V2 | V2 | LJSpeech | No | | LJ_V3 | V3 | LJSpeech | No | | LJ_FT_T2_V1 | V1 | LJSpeech | Yes ([Tacotron2](https://github.com/NVIDIA/tacotron2)) | | LJ_FT_T2_V2 | V2 | LJSpeech | Yes ([Tacotron2](https://github.com/NVIDIA/tacotron2)) | | LJ_FT_T2_V3 | V3 | LJSpeech | Yes ([Tacotron2](https://github.com/NVIDIA/tacotron2)) | | VCTK_V1 | V1 | VCTK | No | | VCTK_V2 | V2 | VCTK | No | | VCTK_V3 | V3 | VCTK | No | | UNIVERSAL_V1 | V1 | Universal | No | We provide the universal model with discriminator weights that can be used as a base for transfer learning to other datasets. ## Fine-Tuning 1. Generate mel-spectrograms in numpy format using [Tacotron2](https://github.com/NVIDIA/tacotron2) with teacher-forcing.
The file name of the generated mel-spectrogram should match the audio file and the extension should be `.npy`.
Example: ` Audio File : LJ001-0001.wav Mel-Spectrogram File : LJ001-0001.npy` 2. Create `ft_dataset` folder and copy the generated mel-spectrogram files into it.
3. Run the following command. ``` python train.py --fine_tuning True --config config_v1.json ``` For other command line options, please refer to the training section. ## Inference from wav file 1. Make `test_files` directory and copy wav files into the directory. 2. Run the following command. ` python inference.py --checkpoint_file [generator checkpoint file path]` Generated wav files are saved in `generated_files` by default.
You can change the path by adding `--output_dir` option. ## Inference for end-to-end speech synthesis 1. Make `test_mel_files` directory and copy generated mel-spectrogram files into the directory.
You can generate mel-spectrograms using [Tacotron2](https://github.com/NVIDIA/tacotron2), [Glow-TTS](https://github.com/jaywalnut310/glow-tts) and so forth. 2. Run the following command. ` python inference_e2e.py --checkpoint_file [generator checkpoint file path]` Generated wav files are saved in `generated_files_from_mel` by default.
You can change the path by adding `--output_dir` option. ## Acknowledgements We referred to [WaveGlow](https://github.com/NVIDIA/waveglow), [MelGAN](https://github.com/descriptinc/melgan-neurips) and [Tacotron2](https://github.com/NVIDIA/tacotron2) to implement this. ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/__init__.py ================================================ ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/config.py ================================================ v1 = { "resblock": "1", "num_gpus": 0, "batch_size": 16, "learning_rate": 0.0004, "adam_b1": 0.8, "adam_b2": 0.99, "lr_decay": 0.999, "seed": 1234, "upsample_rates": [8, 8, 2, 2], "upsample_kernel_sizes": [16, 16, 4, 4], "upsample_initial_channel": 512, "resblock_kernel_sizes": [3, 7, 11], "resblock_dilation_sizes": [[1, 3, 5], [1, 3, 5], [1, 3, 5]], "resblock_initial_channel": 256, "segment_size": 8192, "num_mels": 80, "num_freq": 1025, "n_fft": 1024, "hop_size": 256, "win_size": 1024, "sampling_rate": 22050, "fmin": 0, "fmax": 8000, "fmax_loss": None, "num_workers": 4, "dist_config": {"dist_backend": "nccl", "dist_url": "tcp://localhost:54321", "world_size": 1}, } ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/denoiser.py ================================================ # Code modified from Rafael Valle's implementation https://github.com/NVIDIA/waveglow/blob/5bc2a53e20b3b533362f974cfa1ea0267ae1c2b1/denoiser.py """Waveglow style denoiser can be used to remove the artifacts from the HiFiGAN generated audio.""" import torch class Denoiser(torch.nn.Module): """Removes model bias from audio produced with waveglow""" def __init__(self, vocoder, filter_length=1024, n_overlap=4, win_length=1024, mode="zeros"): super().__init__() self.filter_length = filter_length self.hop_length = int(filter_length / n_overlap) self.win_length = win_length dtype, device = next(vocoder.parameters()).dtype, next(vocoder.parameters()).device self.device = device if mode == "zeros": mel_input = torch.zeros((1, 80, 88), dtype=dtype, device=device) elif mode == "normal": mel_input = torch.randn((1, 80, 88), dtype=dtype, device=device) else: raise Exception(f"Mode {mode} if not supported") def stft_fn(audio, n_fft, hop_length, win_length, window): spec = torch.stft( audio, n_fft=n_fft, hop_length=hop_length, win_length=win_length, window=window, return_complex=True, ) spec = torch.view_as_real(spec) return torch.sqrt(spec.pow(2).sum(-1)), torch.atan2(spec[..., -1], spec[..., 0]) self.stft = lambda x: stft_fn( audio=x, n_fft=self.filter_length, hop_length=self.hop_length, win_length=self.win_length, window=torch.hann_window(self.win_length, device=device), ) self.istft = lambda x, y: torch.istft( torch.complex(x * torch.cos(y), x * torch.sin(y)), n_fft=self.filter_length, hop_length=self.hop_length, win_length=self.win_length, window=torch.hann_window(self.win_length, device=device), ) with torch.no_grad(): bias_audio = vocoder(mel_input).float().squeeze(0) bias_spec, _ = self.stft(bias_audio) self.register_buffer("bias_spec", bias_spec[:, :, 0][:, :, None]) @torch.inference_mode() def forward(self, audio, strength=0.0005): audio_spec, audio_angles = self.stft(audio) audio_spec_denoised = audio_spec - self.bias_spec.to(audio.device) * strength audio_spec_denoised = torch.clamp(audio_spec_denoised, 0.0) audio_denoised = self.istft(audio_spec_denoised, audio_angles) return audio_denoised ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/env.py ================================================ """ from https://github.com/jik876/hifi-gan """ import os import shutil class AttrDict(dict): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.__dict__ = self def build_env(config, config_name, path): t_path = os.path.join(path, config_name) if config != t_path: os.makedirs(path, exist_ok=True) shutil.copyfile(config, os.path.join(path, config_name)) ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/meldataset.py ================================================ """ from https://github.com/jik876/hifi-gan """ import math import os import random import numpy as np import torch import torch.utils.data from librosa.filters import mel as librosa_mel_fn from librosa.util import normalize from scipy.io.wavfile import read MAX_WAV_VALUE = 32768.0 def load_wav(full_path): sampling_rate, data = read(full_path) return data, sampling_rate def dynamic_range_compression(x, C=1, clip_val=1e-5): return np.log(np.clip(x, a_min=clip_val, a_max=None) * C) def dynamic_range_decompression(x, C=1): return np.exp(x) / C def dynamic_range_compression_torch(x, C=1, clip_val=1e-5): return torch.log(torch.clamp(x, min=clip_val) * C) def dynamic_range_decompression_torch(x, C=1): return torch.exp(x) / C def spectral_normalize_torch(magnitudes): output = dynamic_range_compression_torch(magnitudes) return output def spectral_de_normalize_torch(magnitudes): output = dynamic_range_decompression_torch(magnitudes) return output mel_basis = {} hann_window = {} def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False): if torch.min(y) < -1.0: print("min value is ", torch.min(y)) if torch.max(y) > 1.0: print("max value is ", torch.max(y)) global mel_basis, hann_window # pylint: disable=global-statement if fmax not in mel_basis: mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax) mel_basis[str(fmax) + "_" + str(y.device)] = torch.from_numpy(mel).float().to(y.device) hann_window[str(y.device)] = torch.hann_window(win_size).to(y.device) y = torch.nn.functional.pad( y.unsqueeze(1), (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)), mode="reflect" ) y = y.squeeze(1) spec = torch.view_as_real( torch.stft( y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[str(y.device)], center=center, pad_mode="reflect", normalized=False, onesided=True, return_complex=True, ) ) spec = torch.sqrt(spec.pow(2).sum(-1) + (1e-9)) spec = torch.matmul(mel_basis[str(fmax) + "_" + str(y.device)], spec) spec = spectral_normalize_torch(spec) return spec def get_dataset_filelist(a): with open(a.input_training_file, encoding="utf-8") as fi: training_files = [ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0 ] with open(a.input_validation_file, encoding="utf-8") as fi: validation_files = [ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0 ] return training_files, validation_files class MelDataset(torch.utils.data.Dataset): def __init__( self, training_files, segment_size, n_fft, num_mels, hop_size, win_size, sampling_rate, fmin, fmax, split=True, shuffle=True, n_cache_reuse=1, device=None, fmax_loss=None, fine_tuning=False, base_mels_path=None, ): self.audio_files = training_files random.seed(1234) if shuffle: random.shuffle(self.audio_files) self.segment_size = segment_size self.sampling_rate = sampling_rate self.split = split self.n_fft = n_fft self.num_mels = num_mels self.hop_size = hop_size self.win_size = win_size self.fmin = fmin self.fmax = fmax self.fmax_loss = fmax_loss self.cached_wav = None self.n_cache_reuse = n_cache_reuse self._cache_ref_count = 0 self.device = device self.fine_tuning = fine_tuning self.base_mels_path = base_mels_path def __getitem__(self, index): filename = self.audio_files[index] if self._cache_ref_count == 0: audio, sampling_rate = load_wav(filename) audio = audio / MAX_WAV_VALUE if not self.fine_tuning: audio = normalize(audio) * 0.95 self.cached_wav = audio if sampling_rate != self.sampling_rate: raise ValueError(f"{sampling_rate} SR doesn't match target {self.sampling_rate} SR") self._cache_ref_count = self.n_cache_reuse else: audio = self.cached_wav self._cache_ref_count -= 1 audio = torch.FloatTensor(audio) audio = audio.unsqueeze(0) if not self.fine_tuning: if self.split: if audio.size(1) >= self.segment_size: max_audio_start = audio.size(1) - self.segment_size audio_start = random.randint(0, max_audio_start) audio = audio[:, audio_start : audio_start + self.segment_size] else: audio = torch.nn.functional.pad(audio, (0, self.segment_size - audio.size(1)), "constant") mel = mel_spectrogram( audio, self.n_fft, self.num_mels, self.sampling_rate, self.hop_size, self.win_size, self.fmin, self.fmax, center=False, ) else: mel = np.load(os.path.join(self.base_mels_path, os.path.splitext(os.path.split(filename)[-1])[0] + ".npy")) mel = torch.from_numpy(mel) if len(mel.shape) < 3: mel = mel.unsqueeze(0) if self.split: frames_per_seg = math.ceil(self.segment_size / self.hop_size) if audio.size(1) >= self.segment_size: mel_start = random.randint(0, mel.size(2) - frames_per_seg - 1) mel = mel[:, :, mel_start : mel_start + frames_per_seg] audio = audio[:, mel_start * self.hop_size : (mel_start + frames_per_seg) * self.hop_size] else: mel = torch.nn.functional.pad(mel, (0, frames_per_seg - mel.size(2)), "constant") audio = torch.nn.functional.pad(audio, (0, self.segment_size - audio.size(1)), "constant") mel_loss = mel_spectrogram( audio, self.n_fft, self.num_mels, self.sampling_rate, self.hop_size, self.win_size, self.fmin, self.fmax_loss, center=False, ) return (mel.squeeze(), audio.squeeze(0), filename, mel_loss.squeeze()) def __len__(self): return len(self.audio_files) ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/models.py ================================================ """ from https://github.com/jik876/hifi-gan """ import torch import torch.nn as nn import torch.nn.functional as F from torch.nn import AvgPool1d, Conv1d, Conv2d, ConvTranspose1d from torch.nn.utils import remove_weight_norm, spectral_norm, weight_norm from .xutils import get_padding, init_weights LRELU_SLOPE = 0.1 class ResBlock1(torch.nn.Module): def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)): super().__init__() self.h = h self.convs1 = nn.ModuleList( [ weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=dilation[0], padding=get_padding(kernel_size, dilation[0]), ) ), weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=dilation[1], padding=get_padding(kernel_size, dilation[1]), ) ), weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=dilation[2], padding=get_padding(kernel_size, dilation[2]), ) ), ] ) self.convs1.apply(init_weights) self.convs2 = nn.ModuleList( [ weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=1, padding=get_padding(kernel_size, 1), ) ), weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=1, padding=get_padding(kernel_size, 1), ) ), weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=1, padding=get_padding(kernel_size, 1), ) ), ] ) self.convs2.apply(init_weights) def forward(self, x): for c1, c2 in zip(self.convs1, self.convs2): xt = F.leaky_relu(x, LRELU_SLOPE) xt = c1(xt) xt = F.leaky_relu(xt, LRELU_SLOPE) xt = c2(xt) x = xt + x return x def remove_weight_norm(self): for l in self.convs1: remove_weight_norm(l) for l in self.convs2: remove_weight_norm(l) class ResBlock2(torch.nn.Module): def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)): super().__init__() self.h = h self.convs = nn.ModuleList( [ weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=dilation[0], padding=get_padding(kernel_size, dilation[0]), ) ), weight_norm( Conv1d( channels, channels, kernel_size, 1, dilation=dilation[1], padding=get_padding(kernel_size, dilation[1]), ) ), ] ) self.convs.apply(init_weights) def forward(self, x): for c in self.convs: xt = F.leaky_relu(x, LRELU_SLOPE) xt = c(xt) x = xt + x return x def remove_weight_norm(self): for l in self.convs: remove_weight_norm(l) class Generator(torch.nn.Module): def __init__(self, h): super().__init__() self.h = h self.num_kernels = len(h.resblock_kernel_sizes) self.num_upsamples = len(h.upsample_rates) self.conv_pre = weight_norm(Conv1d(80, h.upsample_initial_channel, 7, 1, padding=3)) resblock = ResBlock1 if h.resblock == "1" else ResBlock2 self.ups = nn.ModuleList() for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)): self.ups.append( weight_norm( ConvTranspose1d( h.upsample_initial_channel // (2**i), h.upsample_initial_channel // (2 ** (i + 1)), k, u, padding=(k - u) // 2, ) ) ) self.resblocks = nn.ModuleList() for i in range(len(self.ups)): ch = h.upsample_initial_channel // (2 ** (i + 1)) for _, (k, d) in enumerate(zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)): self.resblocks.append(resblock(h, ch, k, d)) self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3)) self.ups.apply(init_weights) self.conv_post.apply(init_weights) def forward(self, x): x = self.conv_pre(x) for i in range(self.num_upsamples): x = F.leaky_relu(x, LRELU_SLOPE) x = self.ups[i](x) xs = None for j in range(self.num_kernels): if xs is None: xs = self.resblocks[i * self.num_kernels + j](x) else: xs += self.resblocks[i * self.num_kernels + j](x) x = xs / self.num_kernels x = F.leaky_relu(x) x = self.conv_post(x) x = torch.tanh(x) return x def remove_weight_norm(self): print("Removing weight norm...") for l in self.ups: remove_weight_norm(l) for l in self.resblocks: l.remove_weight_norm() remove_weight_norm(self.conv_pre) remove_weight_norm(self.conv_post) class DiscriminatorP(torch.nn.Module): def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False): super().__init__() self.period = period norm_f = weight_norm if use_spectral_norm is False else spectral_norm self.convs = nn.ModuleList( [ norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))), ] ) self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0))) def forward(self, x): fmap = [] # 1d to 2d b, c, t = x.shape if t % self.period != 0: # pad first n_pad = self.period - (t % self.period) x = F.pad(x, (0, n_pad), "reflect") t = t + n_pad x = x.view(b, c, t // self.period, self.period) for l in self.convs: x = l(x) x = F.leaky_relu(x, LRELU_SLOPE) fmap.append(x) x = self.conv_post(x) fmap.append(x) x = torch.flatten(x, 1, -1) return x, fmap class MultiPeriodDiscriminator(torch.nn.Module): def __init__(self): super().__init__() self.discriminators = nn.ModuleList( [ DiscriminatorP(2), DiscriminatorP(3), DiscriminatorP(5), DiscriminatorP(7), DiscriminatorP(11), ] ) def forward(self, y, y_hat): y_d_rs = [] y_d_gs = [] fmap_rs = [] fmap_gs = [] for _, d in enumerate(self.discriminators): y_d_r, fmap_r = d(y) y_d_g, fmap_g = d(y_hat) y_d_rs.append(y_d_r) fmap_rs.append(fmap_r) y_d_gs.append(y_d_g) fmap_gs.append(fmap_g) return y_d_rs, y_d_gs, fmap_rs, fmap_gs class DiscriminatorS(torch.nn.Module): def __init__(self, use_spectral_norm=False): super().__init__() norm_f = weight_norm if use_spectral_norm is False else spectral_norm self.convs = nn.ModuleList( [ norm_f(Conv1d(1, 128, 15, 1, padding=7)), norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)), norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)), norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)), norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)), norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)), norm_f(Conv1d(1024, 1024, 5, 1, padding=2)), ] ) self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1)) def forward(self, x): fmap = [] for l in self.convs: x = l(x) x = F.leaky_relu(x, LRELU_SLOPE) fmap.append(x) x = self.conv_post(x) fmap.append(x) x = torch.flatten(x, 1, -1) return x, fmap class MultiScaleDiscriminator(torch.nn.Module): def __init__(self): super().__init__() self.discriminators = nn.ModuleList( [ DiscriminatorS(use_spectral_norm=True), DiscriminatorS(), DiscriminatorS(), ] ) self.meanpools = nn.ModuleList([AvgPool1d(4, 2, padding=2), AvgPool1d(4, 2, padding=2)]) def forward(self, y, y_hat): y_d_rs = [] y_d_gs = [] fmap_rs = [] fmap_gs = [] for i, d in enumerate(self.discriminators): if i != 0: y = self.meanpools[i - 1](y) y_hat = self.meanpools[i - 1](y_hat) y_d_r, fmap_r = d(y) y_d_g, fmap_g = d(y_hat) y_d_rs.append(y_d_r) fmap_rs.append(fmap_r) y_d_gs.append(y_d_g) fmap_gs.append(fmap_g) return y_d_rs, y_d_gs, fmap_rs, fmap_gs def feature_loss(fmap_r, fmap_g): loss = 0 for dr, dg in zip(fmap_r, fmap_g): for rl, gl in zip(dr, dg): loss += torch.mean(torch.abs(rl - gl)) return loss * 2 def discriminator_loss(disc_real_outputs, disc_generated_outputs): loss = 0 r_losses = [] g_losses = [] for dr, dg in zip(disc_real_outputs, disc_generated_outputs): r_loss = torch.mean((1 - dr) ** 2) g_loss = torch.mean(dg**2) loss += r_loss + g_loss r_losses.append(r_loss.item()) g_losses.append(g_loss.item()) return loss, r_losses, g_losses def generator_loss(disc_outputs): loss = 0 gen_losses = [] for dg in disc_outputs: l = torch.mean((1 - dg) ** 2) gen_losses.append(l) loss += l return loss, gen_losses ================================================ FILE: third_party/Matcha-TTS/matcha/hifigan/xutils.py ================================================ """ from https://github.com/jik876/hifi-gan """ import glob import os import matplotlib import torch from torch.nn.utils import weight_norm matplotlib.use("Agg") import matplotlib.pylab as plt def plot_spectrogram(spectrogram): fig, ax = plt.subplots(figsize=(10, 2)) im = ax.imshow(spectrogram, aspect="auto", origin="lower", interpolation="none") plt.colorbar(im, ax=ax) fig.canvas.draw() plt.close() return fig def init_weights(m, mean=0.0, std=0.01): classname = m.__class__.__name__ if classname.find("Conv") != -1: m.weight.data.normal_(mean, std) def apply_weight_norm(m): classname = m.__class__.__name__ if classname.find("Conv") != -1: weight_norm(m) def get_padding(kernel_size, dilation=1): return int((kernel_size * dilation - dilation) / 2) def load_checkpoint(filepath, device): assert os.path.isfile(filepath) print(f"Loading '{filepath}'") checkpoint_dict = torch.load(filepath, map_location=device) print("Complete.") return checkpoint_dict def save_checkpoint(filepath, obj): print(f"Saving checkpoint to {filepath}") torch.save(obj, filepath) print("Complete.") def scan_checkpoint(cp_dir, prefix): pattern = os.path.join(cp_dir, prefix + "????????") cp_list = glob.glob(pattern) if len(cp_list) == 0: return None return sorted(cp_list)[-1] ================================================ FILE: third_party/Matcha-TTS/matcha/models/__init__.py ================================================ ================================================ FILE: third_party/Matcha-TTS/matcha/models/baselightningmodule.py ================================================ """ This is a base lightning module that can be used to train a model. The benefit of this abstraction is that all the logic outside of model definition can be reused for different models. """ import inspect from abc import ABC from typing import Any, Dict import torch from lightning import LightningModule from lightning.pytorch.utilities import grad_norm from matcha import utils from matcha.utils.utils import plot_tensor log = utils.get_pylogger(__name__) class BaseLightningClass(LightningModule, ABC): def update_data_statistics(self, data_statistics): if data_statistics is None: data_statistics = { "mel_mean": 0.0, "mel_std": 1.0, } self.register_buffer("mel_mean", torch.tensor(data_statistics["mel_mean"])) self.register_buffer("mel_std", torch.tensor(data_statistics["mel_std"])) def configure_optimizers(self) -> Any: optimizer = self.hparams.optimizer(params=self.parameters()) if self.hparams.scheduler not in (None, {}): scheduler_args = {} # Manage last epoch for exponential schedulers if "last_epoch" in inspect.signature(self.hparams.scheduler.scheduler).parameters: if hasattr(self, "ckpt_loaded_epoch"): current_epoch = self.ckpt_loaded_epoch - 1 else: current_epoch = -1 scheduler_args.update({"optimizer": optimizer}) scheduler = self.hparams.scheduler.scheduler(**scheduler_args) scheduler.last_epoch = current_epoch return { "optimizer": optimizer, "lr_scheduler": { "scheduler": scheduler, "interval": self.hparams.scheduler.lightning_args.interval, "frequency": self.hparams.scheduler.lightning_args.frequency, "name": "learning_rate", }, } return {"optimizer": optimizer} def get_losses(self, batch): x, x_lengths = batch["x"], batch["x_lengths"] y, y_lengths = batch["y"], batch["y_lengths"] spks = batch["spks"] dur_loss, prior_loss, diff_loss = self( x=x, x_lengths=x_lengths, y=y, y_lengths=y_lengths, spks=spks, out_size=self.out_size, ) return { "dur_loss": dur_loss, "prior_loss": prior_loss, "diff_loss": diff_loss, } def on_load_checkpoint(self, checkpoint: Dict[str, Any]) -> None: self.ckpt_loaded_epoch = checkpoint["epoch"] # pylint: disable=attribute-defined-outside-init def training_step(self, batch: Any, batch_idx: int): loss_dict = self.get_losses(batch) self.log( "step", float(self.global_step), on_step=True, prog_bar=True, logger=True, sync_dist=True, ) self.log( "sub_loss/train_dur_loss", loss_dict["dur_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) self.log( "sub_loss/train_prior_loss", loss_dict["prior_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) self.log( "sub_loss/train_diff_loss", loss_dict["diff_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) total_loss = sum(loss_dict.values()) self.log( "loss/train", total_loss, on_step=True, on_epoch=True, logger=True, prog_bar=True, sync_dist=True, ) return {"loss": total_loss, "log": loss_dict} def validation_step(self, batch: Any, batch_idx: int): loss_dict = self.get_losses(batch) self.log( "sub_loss/val_dur_loss", loss_dict["dur_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) self.log( "sub_loss/val_prior_loss", loss_dict["prior_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) self.log( "sub_loss/val_diff_loss", loss_dict["diff_loss"], on_step=True, on_epoch=True, logger=True, sync_dist=True, ) total_loss = sum(loss_dict.values()) self.log( "loss/val", total_loss, on_step=True, on_epoch=True, logger=True, prog_bar=True, sync_dist=True, ) return total_loss def on_validation_end(self) -> None: if self.trainer.is_global_zero: one_batch = next(iter(self.trainer.val_dataloaders)) if self.current_epoch == 0: log.debug("Plotting original samples") for i in range(2): y = one_batch["y"][i].unsqueeze(0).to(self.device) self.logger.experiment.add_image( f"original/{i}", plot_tensor(y.squeeze().cpu()), self.current_epoch, dataformats="HWC", ) log.debug("Synthesising...") for i in range(2): x = one_batch["x"][i].unsqueeze(0).to(self.device) x_lengths = one_batch["x_lengths"][i].unsqueeze(0).to(self.device) spks = one_batch["spks"][i].unsqueeze(0).to(self.device) if one_batch["spks"] is not None else None output = self.synthesise(x[:, :x_lengths], x_lengths, n_timesteps=10, spks=spks) y_enc, y_dec = output["encoder_outputs"], output["decoder_outputs"] attn = output["attn"] self.logger.experiment.add_image( f"generated_enc/{i}", plot_tensor(y_enc.squeeze().cpu()), self.current_epoch, dataformats="HWC", ) self.logger.experiment.add_image( f"generated_dec/{i}", plot_tensor(y_dec.squeeze().cpu()), self.current_epoch, dataformats="HWC", ) self.logger.experiment.add_image( f"alignment/{i}", plot_tensor(attn.squeeze().cpu()), self.current_epoch, dataformats="HWC", ) def on_before_optimizer_step(self, optimizer): self.log_dict({f"grad_norm/{k}": v for k, v in grad_norm(self, norm_type=2).items()}) ================================================ FILE: third_party/Matcha-TTS/matcha/models/components/__init__.py ================================================ ================================================ FILE: third_party/Matcha-TTS/matcha/models/components/decoder.py ================================================ import math from typing import Optional import torch import torch.nn as nn import torch.nn.functional as F from conformer import ConformerBlock from diffusers.models.activations import get_activation from einops import pack, rearrange, repeat from matcha.models.components.transformer import BasicTransformerBlock class SinusoidalPosEmb(torch.nn.Module): def __init__(self, dim): super().__init__() self.dim = dim assert self.dim % 2 == 0, "SinusoidalPosEmb requires dim to be even" def forward(self, x, scale=1000): if x.ndim < 1: x = x.unsqueeze(0) device = x.device half_dim = self.dim // 2 emb = math.log(10000) / (half_dim - 1) emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb) emb = scale * x.unsqueeze(1) * emb.unsqueeze(0) emb = torch.cat((emb.sin(), emb.cos()), dim=-1) return emb class Block1D(torch.nn.Module): def __init__(self, dim, dim_out, groups=8): super().__init__() self.block = torch.nn.Sequential( torch.nn.Conv1d(dim, dim_out, 3, padding=1), torch.nn.GroupNorm(groups, dim_out), nn.Mish(), ) def forward(self, x, mask): output = self.block(x * mask) return output * mask class ResnetBlock1D(torch.nn.Module): def __init__(self, dim, dim_out, time_emb_dim, groups=8): super().__init__() self.mlp = torch.nn.Sequential(nn.Mish(), torch.nn.Linear(time_emb_dim, dim_out)) self.block1 = Block1D(dim, dim_out, groups=groups) self.block2 = Block1D(dim_out, dim_out, groups=groups) self.res_conv = torch.nn.Conv1d(dim, dim_out, 1) def forward(self, x, mask, time_emb): h = self.block1(x, mask) h += self.mlp(time_emb).unsqueeze(-1) h = self.block2(h, mask) output = h + self.res_conv(x * mask) return output class Downsample1D(nn.Module): def __init__(self, dim): super().__init__() self.conv = torch.nn.Conv1d(dim, dim, 3, 2, 1) def forward(self, x): return self.conv(x) class TimestepEmbedding(nn.Module): def __init__( self, in_channels: int, time_embed_dim: int, act_fn: str = "silu", out_dim: int = None, post_act_fn: Optional[str] = None, cond_proj_dim=None, ): super().__init__() self.linear_1 = nn.Linear(in_channels, time_embed_dim) if cond_proj_dim is not None: self.cond_proj = nn.Linear(cond_proj_dim, in_channels, bias=False) else: self.cond_proj = None self.act = get_activation(act_fn) if out_dim is not None: time_embed_dim_out = out_dim else: time_embed_dim_out = time_embed_dim self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim_out) if post_act_fn is None: self.post_act = None else: self.post_act = get_activation(post_act_fn) def forward(self, sample, condition=None): if condition is not None: sample = sample + self.cond_proj(condition) sample = self.linear_1(sample) if self.act is not None: sample = self.act(sample) sample = self.linear_2(sample) if self.post_act is not None: sample = self.post_act(sample) return sample class Upsample1D(nn.Module): """A 1D upsampling layer with an optional convolution. Parameters: channels (`int`): number of channels in the inputs and outputs. use_conv (`bool`, default `False`): option to use a convolution. use_conv_transpose (`bool`, default `False`): option to use a convolution transpose. out_channels (`int`, optional): number of output channels. Defaults to `channels`. """ def __init__(self, channels, use_conv=False, use_conv_transpose=True, out_channels=None, name="conv"): super().__init__() self.channels = channels self.out_channels = out_channels or channels self.use_conv = use_conv self.use_conv_transpose = use_conv_transpose self.name = name self.conv = None if use_conv_transpose: self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1) elif use_conv: self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1) def forward(self, inputs): assert inputs.shape[1] == self.channels if self.use_conv_transpose: return self.conv(inputs) outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest") if self.use_conv: outputs = self.conv(outputs) return outputs class ConformerWrapper(ConformerBlock): def __init__( # pylint: disable=useless-super-delegation self, *, dim, dim_head=64, heads=8, ff_mult=4, conv_expansion_factor=2, conv_kernel_size=31, attn_dropout=0, ff_dropout=0, conv_dropout=0, conv_causal=False, ): super().__init__( dim=dim, dim_head=dim_head, heads=heads, ff_mult=ff_mult, conv_expansion_factor=conv_expansion_factor, conv_kernel_size=conv_kernel_size, attn_dropout=attn_dropout, ff_dropout=ff_dropout, conv_dropout=conv_dropout, conv_causal=conv_causal, ) def forward( self, hidden_states, attention_mask, encoder_hidden_states=None, encoder_attention_mask=None, timestep=None, ): return super().forward(x=hidden_states, mask=attention_mask.bool()) class Decoder(nn.Module): def __init__( self, in_channels, out_channels, channels=(256, 256), dropout=0.05, attention_head_dim=64, n_blocks=1, num_mid_blocks=2, num_heads=4, act_fn="snake", down_block_type="transformer", mid_block_type="transformer", up_block_type="transformer", ): super().__init__() channels = tuple(channels) self.in_channels = in_channels self.out_channels = out_channels self.time_embeddings = SinusoidalPosEmb(in_channels) time_embed_dim = channels[0] * 4 self.time_mlp = TimestepEmbedding( in_channels=in_channels, time_embed_dim=time_embed_dim, act_fn="silu", ) self.down_blocks = nn.ModuleList([]) self.mid_blocks = nn.ModuleList([]) self.up_blocks = nn.ModuleList([]) output_channel = in_channels for i in range(len(channels)): # pylint: disable=consider-using-enumerate input_channel = output_channel output_channel = channels[i] is_last = i == len(channels) - 1 resnet = ResnetBlock1D(dim=input_channel, dim_out=output_channel, time_emb_dim=time_embed_dim) transformer_blocks = nn.ModuleList( [ self.get_block( down_block_type, output_channel, attention_head_dim, num_heads, dropout, act_fn, ) for _ in range(n_blocks) ] ) downsample = ( Downsample1D(output_channel) if not is_last else nn.Conv1d(output_channel, output_channel, 3, padding=1) ) self.down_blocks.append(nn.ModuleList([resnet, transformer_blocks, downsample])) for i in range(num_mid_blocks): input_channel = channels[-1] out_channels = channels[-1] resnet = ResnetBlock1D(dim=input_channel, dim_out=output_channel, time_emb_dim=time_embed_dim) transformer_blocks = nn.ModuleList( [ self.get_block( mid_block_type, output_channel, attention_head_dim, num_heads, dropout, act_fn, ) for _ in range(n_blocks) ] ) self.mid_blocks.append(nn.ModuleList([resnet, transformer_blocks])) channels = channels[::-1] + (channels[0],) for i in range(len(channels) - 1): input_channel = channels[i] output_channel = channels[i + 1] is_last = i == len(channels) - 2 resnet = ResnetBlock1D( dim=2 * input_channel, dim_out=output_channel, time_emb_dim=time_embed_dim, ) transformer_blocks = nn.ModuleList( [ self.get_block( up_block_type, output_channel, attention_head_dim, num_heads, dropout, act_fn, ) for _ in range(n_blocks) ] ) upsample = ( Upsample1D(output_channel, use_conv_transpose=True) if not is_last else nn.Conv1d(output_channel, output_channel, 3, padding=1) ) self.up_blocks.append(nn.ModuleList([resnet, transformer_blocks, upsample])) self.final_block = Block1D(channels[-1], channels[-1]) self.final_proj = nn.Conv1d(channels[-1], self.out_channels, 1) self.initialize_weights() # nn.init.normal_(self.final_proj.weight) @staticmethod def get_block(block_type, dim, attention_head_dim, num_heads, dropout, act_fn): if block_type == "conformer": block = ConformerWrapper( dim=dim, dim_head=attention_head_dim, heads=num_heads, ff_mult=1, conv_expansion_factor=2, ff_dropout=dropout, attn_dropout=dropout, conv_dropout=dropout, conv_kernel_size=31, ) elif block_type == "transformer": block = BasicTransformerBlock( dim=dim, num_attention_heads=num_heads, attention_head_dim=attention_head_dim, dropout=dropout, activation_fn=act_fn, ) else: raise ValueError(f"Unknown block type {block_type}") return block def initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv1d): nn.init.kaiming_normal_(m.weight, nonlinearity="relu") if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.GroupNorm): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.kaiming_normal_(m.weight, nonlinearity="relu") if m.bias is not None: nn.init.constant_(m.bias, 0) def forward(self, x, mask, mu, t, spks=None, cond=None): """Forward pass of the UNet1DConditional model. Args: x (torch.Tensor): shape (batch_size, in_channels, time) mask (_type_): shape (batch_size, 1, time) t (_type_): shape (batch_size) spks (_type_, optional): shape: (batch_size, condition_channels). Defaults to None. cond (_type_, optional): placeholder for future use. Defaults to None. Raises: ValueError: _description_ ValueError: _description_ Returns: _type_: _description_ """ t = self.time_embeddings(t) t = self.time_mlp(t) x = pack([x, mu], "b * t")[0] if spks is not None: spks = repeat(spks, "b c -> b c t", t=x.shape[-1]) x = pack([x, spks], "b * t")[0] hiddens = [] masks = [mask] for resnet, transformer_blocks, downsample in self.down_blocks: mask_down = masks[-1] x = resnet(x, mask_down, t) x = rearrange(x, "b c t -> b t c") mask_down = rearrange(mask_down, "b 1 t -> b t") for transformer_block in transformer_blocks: x = transformer_block( hidden_states=x, attention_mask=mask_down, timestep=t, ) x = rearrange(x, "b t c -> b c t") mask_down = rearrange(mask_down, "b t -> b 1 t") hiddens.append(x) # Save hidden states for skip connections x = downsample(x * mask_down) masks.append(mask_down[:, :, ::2]) masks = masks[:-1] mask_mid = masks[-1] for resnet, transformer_blocks in self.mid_blocks: x = resnet(x, mask_mid, t) x = rearrange(x, "b c t -> b t c") mask_mid = rearrange(mask_mid, "b 1 t -> b t") for transformer_block in transformer_blocks: x = transformer_block( hidden_states=x, attention_mask=mask_mid, timestep=t, ) x = rearrange(x, "b t c -> b c t") mask_mid = rearrange(mask_mid, "b t -> b 1 t") for resnet, transformer_blocks, upsample in self.up_blocks: mask_up = masks.pop() x = resnet(pack([x, hiddens.pop()], "b * t")[0], mask_up, t) x = rearrange(x, "b c t -> b t c") mask_up = rearrange(mask_up, "b 1 t -> b t") for transformer_block in transformer_blocks: x = transformer_block( hidden_states=x, attention_mask=mask_up, timestep=t, ) x = rearrange(x, "b t c -> b c t") mask_up = rearrange(mask_up, "b t -> b 1 t") x = upsample(x * mask_up) x = self.final_block(x, mask_up) output = self.final_proj(x * mask_up) return output * mask ================================================ FILE: third_party/Matcha-TTS/matcha/models/components/flow_matching.py ================================================ from abc import ABC import torch import torch.nn.functional as F from matcha.models.components.decoder import Decoder from matcha.utils.pylogger import get_pylogger log = get_pylogger(__name__) class BASECFM(torch.nn.Module, ABC): def __init__( self, n_feats, cfm_params, n_spks=1, spk_emb_dim=128, ): super().__init__() self.n_feats = n_feats self.n_spks = n_spks self.spk_emb_dim = spk_emb_dim self.solver = cfm_params.solver if hasattr(cfm_params, "sigma_min"): self.sigma_min = cfm_params.sigma_min else: self.sigma_min = 1e-4 self.estimator = None @torch.inference_mode() def forward(self, mu, mask, n_timesteps, temperature=1.0, spks=None, cond=None): """Forward diffusion Args: mu (torch.Tensor): output of encoder shape: (batch_size, n_feats, mel_timesteps) mask (torch.Tensor): output_mask shape: (batch_size, 1, mel_timesteps) n_timesteps (int): number of diffusion steps temperature (float, optional): temperature for scaling noise. Defaults to 1.0. spks (torch.Tensor, optional): speaker ids. Defaults to None. shape: (batch_size, spk_emb_dim) cond: Not used but kept for future purposes Returns: sample: generated mel-spectrogram shape: (batch_size, n_feats, mel_timesteps) """ z = torch.randn_like(mu) * temperature t_span = torch.linspace(0, 1, n_timesteps + 1, device=mu.device) return self.solve_euler(z, t_span=t_span, mu=mu, mask=mask, spks=spks, cond=cond) def solve_euler(self, x, t_span, mu, mask, spks, cond): """ Fixed euler solver for ODEs. Args: x (torch.Tensor): random noise t_span (torch.Tensor): n_timesteps interpolated shape: (n_timesteps + 1,) mu (torch.Tensor): output of encoder shape: (batch_size, n_feats, mel_timesteps) mask (torch.Tensor): output_mask shape: (batch_size, 1, mel_timesteps) spks (torch.Tensor, optional): speaker ids. Defaults to None. shape: (batch_size, spk_emb_dim) cond: Not used but kept for future purposes """ t, _, dt = t_span[0], t_span[-1], t_span[1] - t_span[0] # I am storing this because I can later plot it by putting a debugger here and saving it to a file # Or in future might add like a return_all_steps flag sol = [] for step in range(1, len(t_span)): dphi_dt = self.estimator(x, mask, mu, t, spks, cond) x = x + dt * dphi_dt t = t + dt sol.append(x) if step < len(t_span) - 1: dt = t_span[step + 1] - t return sol[-1] def compute_loss(self, x1, mask, mu, spks=None, cond=None): """Computes diffusion loss Args: x1 (torch.Tensor): Target shape: (batch_size, n_feats, mel_timesteps) mask (torch.Tensor): target mask shape: (batch_size, 1, mel_timesteps) mu (torch.Tensor): output of encoder shape: (batch_size, n_feats, mel_timesteps) spks (torch.Tensor, optional): speaker embedding. Defaults to None. shape: (batch_size, spk_emb_dim) Returns: loss: conditional flow matching loss y: conditional flow shape: (batch_size, n_feats, mel_timesteps) """ b, _, t = mu.shape # random timestep t = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype) # sample noise p(x_0) z = torch.randn_like(x1) y = (1 - (1 - self.sigma_min) * t) * z + t * x1 u = x1 - (1 - self.sigma_min) * z loss = F.mse_loss(self.estimator(y, mask, mu, t.squeeze(), spks), u, reduction="sum") / ( torch.sum(mask) * u.shape[1] ) return loss, y class CFM(BASECFM): def __init__(self, in_channels, out_channel, cfm_params, decoder_params, n_spks=1, spk_emb_dim=64): super().__init__( n_feats=in_channels, cfm_params=cfm_params, n_spks=n_spks, spk_emb_dim=spk_emb_dim, ) in_channels = in_channels + (spk_emb_dim if n_spks > 1 else 0) # Just change the architecture of the estimator here self.estimator = Decoder(in_channels=in_channels, out_channels=out_channel, **decoder_params) ================================================ FILE: third_party/Matcha-TTS/matcha/models/components/text_encoder.py ================================================ """ from https://github.com/jaywalnut310/glow-tts """ import math import torch import torch.nn as nn from einops import rearrange import matcha.utils as utils from matcha.utils.model import sequence_mask log = utils.get_pylogger(__name__) class LayerNorm(nn.Module): def __init__(self, channels, eps=1e-4): super().__init__() self.channels = channels self.eps = eps self.gamma = torch.nn.Parameter(torch.ones(channels)) self.beta = torch.nn.Parameter(torch.zeros(channels)) def forward(self, x): n_dims = len(x.shape) mean = torch.mean(x, 1, keepdim=True) variance = torch.mean((x - mean) ** 2, 1, keepdim=True) x = (x - mean) * torch.rsqrt(variance + self.eps) shape = [1, -1] + [1] * (n_dims - 2) x = x * self.gamma.view(*shape) + self.beta.view(*shape) return x class ConvReluNorm(nn.Module): def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout): super().__init__() self.in_channels = in_channels self.hidden_channels = hidden_channels self.out_channels = out_channels self.kernel_size = kernel_size self.n_layers = n_layers self.p_dropout = p_dropout self.conv_layers = torch.nn.ModuleList() self.norm_layers = torch.nn.ModuleList() self.conv_layers.append(torch.nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size // 2)) self.norm_layers.append(LayerNorm(hidden_channels)) self.relu_drop = torch.nn.Sequential(torch.nn.ReLU(), torch.nn.Dropout(p_dropout)) for _ in range(n_layers - 1): self.conv_layers.append( torch.nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size // 2) ) self.norm_layers.append(LayerNorm(hidden_channels)) self.proj = torch.nn.Conv1d(hidden_channels, out_channels, 1) self.proj.weight.data.zero_() self.proj.bias.data.zero_() def forward(self, x, x_mask): x_org = x for i in range(self.n_layers): x = self.conv_layers[i](x * x_mask) x = self.norm_layers[i](x) x = self.relu_drop(x) x = x_org + self.proj(x) return x * x_mask class DurationPredictor(nn.Module): def __init__(self, in_channels, filter_channels, kernel_size, p_dropout): super().__init__() self.in_channels = in_channels self.filter_channels = filter_channels self.p_dropout = p_dropout self.drop = torch.nn.Dropout(p_dropout) self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size // 2) self.norm_1 = LayerNorm(filter_channels) self.conv_2 = torch.nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size // 2) self.norm_2 = LayerNorm(filter_channels) self.proj = torch.nn.Conv1d(filter_channels, 1, 1) def forward(self, x, x_mask): x = self.conv_1(x * x_mask) x = torch.relu(x) x = self.norm_1(x) x = self.drop(x) x = self.conv_2(x * x_mask) x = torch.relu(x) x = self.norm_2(x) x = self.drop(x) x = self.proj(x * x_mask) return x * x_mask class RotaryPositionalEmbeddings(nn.Module): """ ## RoPE module Rotary encoding transforms pairs of features by rotating in the 2D plane. That is, it organizes the $d$ features as $\frac{d}{2}$ pairs. Each pair can be considered a coordinate in a 2D plane, and the encoding will rotate it by an angle depending on the position of the token. """ def __init__(self, d: int, base: int = 10_000): r""" * `d` is the number of features $d$ * `base` is the constant used for calculating $\Theta$ """ super().__init__() self.base = base self.d = int(d) self.cos_cached = None self.sin_cached = None def _build_cache(self, x: torch.Tensor): r""" Cache $\cos$ and $\sin$ values """ # Return if cache is already built if self.cos_cached is not None and x.shape[0] <= self.cos_cached.shape[0]: return # Get sequence length seq_len = x.shape[0] # $\Theta = {\theta_i = 10000^{-\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$ theta = 1.0 / (self.base ** (torch.arange(0, self.d, 2).float() / self.d)).to(x.device) # Create position indexes `[0, 1, ..., seq_len - 1]` seq_idx = torch.arange(seq_len, device=x.device).float().to(x.device) # Calculate the product of position index and $\theta_i$ idx_theta = torch.einsum("n,d->nd", seq_idx, theta) # Concatenate so that for row $m$ we have # $[m \theta_0, m \theta_1, ..., m \theta_{\frac{d}{2}}, m \theta_0, m \theta_1, ..., m \theta_{\frac{d}{2}}]$ idx_theta2 = torch.cat([idx_theta, idx_theta], dim=1) # Cache them self.cos_cached = idx_theta2.cos()[:, None, None, :] self.sin_cached = idx_theta2.sin()[:, None, None, :] def _neg_half(self, x: torch.Tensor): # $\frac{d}{2}$ d_2 = self.d // 2 # Calculate $[-x^{(\frac{d}{2} + 1)}, -x^{(\frac{d}{2} + 2)}, ..., -x^{(d)}, x^{(1)}, x^{(2)}, ..., x^{(\frac{d}{2})}]$ return torch.cat([-x[:, :, :, d_2:], x[:, :, :, :d_2]], dim=-1) def forward(self, x: torch.Tensor): """ * `x` is the Tensor at the head of a key or a query with shape `[seq_len, batch_size, n_heads, d]` """ # Cache $\cos$ and $\sin$ values x = rearrange(x, "b h t d -> t b h d") self._build_cache(x) # Split the features, we can choose to apply rotary embeddings only to a partial set of features. x_rope, x_pass = x[..., : self.d], x[..., self.d :] # Calculate # $[-x^{(\frac{d}{2} + 1)}, -x^{(\frac{d}{2} + 2)}, ..., -x^{(d)}, x^{(1)}, x^{(2)}, ..., x^{(\frac{d}{2})}]$ neg_half_x = self._neg_half(x_rope) x_rope = (x_rope * self.cos_cached[: x.shape[0]]) + (neg_half_x * self.sin_cached[: x.shape[0]]) return rearrange(torch.cat((x_rope, x_pass), dim=-1), "t b h d -> b h t d") class MultiHeadAttention(nn.Module): def __init__( self, channels, out_channels, n_heads, heads_share=True, p_dropout=0.0, proximal_bias=False, proximal_init=False, ): super().__init__() assert channels % n_heads == 0 self.channels = channels self.out_channels = out_channels self.n_heads = n_heads self.heads_share = heads_share self.proximal_bias = proximal_bias self.p_dropout = p_dropout self.attn = None self.k_channels = channels // n_heads self.conv_q = torch.nn.Conv1d(channels, channels, 1) self.conv_k = torch.nn.Conv1d(channels, channels, 1) self.conv_v = torch.nn.Conv1d(channels, channels, 1) # from https://nn.labml.ai/transformers/rope/index.html self.query_rotary_pe = RotaryPositionalEmbeddings(self.k_channels * 0.5) self.key_rotary_pe = RotaryPositionalEmbeddings(self.k_channels * 0.5) self.conv_o = torch.nn.Conv1d(channels, out_channels, 1) self.drop = torch.nn.Dropout(p_dropout) torch.nn.init.xavier_uniform_(self.conv_q.weight) torch.nn.init.xavier_uniform_(self.conv_k.weight) if proximal_init: self.conv_k.weight.data.copy_(self.conv_q.weight.data) self.conv_k.bias.data.copy_(self.conv_q.bias.data) torch.nn.init.xavier_uniform_(self.conv_v.weight) def forward(self, x, c, attn_mask=None): q = self.conv_q(x) k = self.conv_k(c) v = self.conv_v(c) x, self.attn = self.attention(q, k, v, mask=attn_mask) x = self.conv_o(x) return x def attention(self, query, key, value, mask=None): b, d, t_s, t_t = (*key.size(), query.size(2)) query = rearrange(query, "b (h c) t-> b h t c", h=self.n_heads) key = rearrange(key, "b (h c) t-> b h t c", h=self.n_heads) value = rearrange(value, "b (h c) t-> b h t c", h=self.n_heads) query = self.query_rotary_pe(query) key = self.key_rotary_pe(key) scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.k_channels) if self.proximal_bias: assert t_s == t_t, "Proximal bias is only available for self-attention." scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype) if mask is not None: scores = scores.masked_fill(mask == 0, -1e4) p_attn = torch.nn.functional.softmax(scores, dim=-1) p_attn = self.drop(p_attn) output = torch.matmul(p_attn, value) output = output.transpose(2, 3).contiguous().view(b, d, t_t) return output, p_attn @staticmethod def _attention_bias_proximal(length): r = torch.arange(length, dtype=torch.float32) diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1) return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0) class FFN(nn.Module): def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0.0): super().__init__() self.in_channels = in_channels self.out_channels = out_channels self.filter_channels = filter_channels self.kernel_size = kernel_size self.p_dropout = p_dropout self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size // 2) self.conv_2 = torch.nn.Conv1d(filter_channels, out_channels, kernel_size, padding=kernel_size // 2) self.drop = torch.nn.Dropout(p_dropout) def forward(self, x, x_mask): x = self.conv_1(x * x_mask) x = torch.relu(x) x = self.drop(x) x = self.conv_2(x * x_mask) return x * x_mask class Encoder(nn.Module): def __init__( self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0.0, **kwargs, ): super().__init__() self.hidden_channels = hidden_channels self.filter_channels = filter_channels self.n_heads = n_heads self.n_layers = n_layers self.kernel_size = kernel_size self.p_dropout = p_dropout self.drop = torch.nn.Dropout(p_dropout) self.attn_layers = torch.nn.ModuleList() self.norm_layers_1 = torch.nn.ModuleList() self.ffn_layers = torch.nn.ModuleList() self.norm_layers_2 = torch.nn.ModuleList() for _ in range(self.n_layers): self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout)) self.norm_layers_1.append(LayerNorm(hidden_channels)) self.ffn_layers.append( FFN( hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout, ) ) self.norm_layers_2.append(LayerNorm(hidden_channels)) def forward(self, x, x_mask): attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1) for i in range(self.n_layers): x = x * x_mask y = self.attn_layers[i](x, x, attn_mask) y = self.drop(y) x = self.norm_layers_1[i](x + y) y = self.ffn_layers[i](x, x_mask) y = self.drop(y) x = self.norm_layers_2[i](x + y) x = x * x_mask return x class TextEncoder(nn.Module): def __init__( self, encoder_type, encoder_params, duration_predictor_params, n_vocab, n_spks=1, spk_emb_dim=128, ): super().__init__() self.encoder_type = encoder_type self.n_vocab = n_vocab self.n_feats = encoder_params.n_feats self.n_channels = encoder_params.n_channels self.spk_emb_dim = spk_emb_dim self.n_spks = n_spks self.emb = torch.nn.Embedding(n_vocab, self.n_channels) torch.nn.init.normal_(self.emb.weight, 0.0, self.n_channels**-0.5) if encoder_params.prenet: self.prenet = ConvReluNorm( self.n_channels, self.n_channels, self.n_channels, kernel_size=5, n_layers=3, p_dropout=0.5, ) else: self.prenet = lambda x, x_mask: x self.encoder = Encoder( encoder_params.n_channels + (spk_emb_dim if n_spks > 1 else 0), encoder_params.filter_channels, encoder_params.n_heads, encoder_params.n_layers, encoder_params.kernel_size, encoder_params.p_dropout, ) self.proj_m = torch.nn.Conv1d(self.n_channels + (spk_emb_dim if n_spks > 1 else 0), self.n_feats, 1) self.proj_w = DurationPredictor( self.n_channels + (spk_emb_dim if n_spks > 1 else 0), duration_predictor_params.filter_channels_dp, duration_predictor_params.kernel_size, duration_predictor_params.p_dropout, ) def forward(self, x, x_lengths, spks=None): """Run forward pass to the transformer based encoder and duration predictor Args: x (torch.Tensor): text input shape: (batch_size, max_text_length) x_lengths (torch.Tensor): text input lengths shape: (batch_size,) spks (torch.Tensor, optional): speaker ids. Defaults to None. shape: (batch_size,) Returns: mu (torch.Tensor): average output of the encoder shape: (batch_size, n_feats, max_text_length) logw (torch.Tensor): log duration predicted by the duration predictor shape: (batch_size, 1, max_text_length) x_mask (torch.Tensor): mask for the text input shape: (batch_size, 1, max_text_length) """ x = self.emb(x) * math.sqrt(self.n_channels) x = torch.transpose(x, 1, -1) x_mask = torch.unsqueeze(sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) x = self.prenet(x, x_mask) if self.n_spks > 1: x = torch.cat([x, spks.unsqueeze(-1).repeat(1, 1, x.shape[-1])], dim=1) x = self.encoder(x, x_mask) mu = self.proj_m(x) * x_mask x_dp = torch.detach(x) logw = self.proj_w(x_dp, x_mask) return mu, logw, x_mask ================================================ FILE: third_party/Matcha-TTS/matcha/models/components/transformer.py ================================================ from typing import Any, Dict, Optional import torch import torch.nn as nn from diffusers.models.attention import ( GEGLU, GELU, AdaLayerNorm, AdaLayerNormZero, ApproximateGELU, ) from diffusers.models.attention_processor import Attention from diffusers.models.lora import LoRACompatibleLinear from diffusers.utils.torch_utils import maybe_allow_in_graph class SnakeBeta(nn.Module): """ A modified Snake function which uses separate parameters for the magnitude of the periodic components Shape: - Input: (B, C, T) - Output: (B, C, T), same shape as the input Parameters: - alpha - trainable parameter that controls frequency - beta - trainable parameter that controls magnitude References: - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda: https://arxiv.org/abs/2006.08195 Examples: >>> a1 = snakebeta(256) >>> x = torch.randn(256) >>> x = a1(x) """ def __init__(self, in_features, out_features, alpha=1.0, alpha_trainable=True, alpha_logscale=True): """ Initialization. INPUT: - in_features: shape of the input - alpha - trainable parameter that controls frequency - beta - trainable parameter that controls magnitude alpha is initialized to 1 by default, higher values = higher-frequency. beta is initialized to 1 by default, higher values = higher-magnitude. alpha will be trained along with the rest of your model. """ super().__init__() self.in_features = out_features if isinstance(out_features, list) else [out_features] self.proj = LoRACompatibleLinear(in_features, out_features) # initialize alpha self.alpha_logscale = alpha_logscale if self.alpha_logscale: # log scale alphas initialized to zeros self.alpha = nn.Parameter(torch.zeros(self.in_features) * alpha) self.beta = nn.Parameter(torch.zeros(self.in_features) * alpha) else: # linear scale alphas initialized to ones self.alpha = nn.Parameter(torch.ones(self.in_features) * alpha) self.beta = nn.Parameter(torch.ones(self.in_features) * alpha) self.alpha.requires_grad = alpha_trainable self.beta.requires_grad = alpha_trainable self.no_div_by_zero = 0.000000001 def forward(self, x): """ Forward pass of the function. Applies the function to the input elementwise. SnakeBeta ∶= x + 1/b * sin^2 (xa) """ x = self.proj(x) if self.alpha_logscale: alpha = torch.exp(self.alpha) beta = torch.exp(self.beta) else: alpha = self.alpha beta = self.beta x = x + (1.0 / (beta + self.no_div_by_zero)) * torch.pow(torch.sin(x * alpha), 2) return x class FeedForward(nn.Module): r""" A feed-forward layer. Parameters: dim (`int`): The number of channels in the input. dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`. mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension. dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use. activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward. final_dropout (`bool` *optional*, defaults to False): Apply a final dropout. """ def __init__( self, dim: int, dim_out: Optional[int] = None, mult: int = 4, dropout: float = 0.0, activation_fn: str = "geglu", final_dropout: bool = False, ): super().__init__() inner_dim = int(dim * mult) dim_out = dim_out if dim_out is not None else dim if activation_fn == "gelu": act_fn = GELU(dim, inner_dim) if activation_fn == "gelu-approximate": act_fn = GELU(dim, inner_dim, approximate="tanh") elif activation_fn == "geglu": act_fn = GEGLU(dim, inner_dim) elif activation_fn == "geglu-approximate": act_fn = ApproximateGELU(dim, inner_dim) elif activation_fn == "snakebeta": act_fn = SnakeBeta(dim, inner_dim) self.net = nn.ModuleList([]) # project in self.net.append(act_fn) # project dropout self.net.append(nn.Dropout(dropout)) # project out self.net.append(LoRACompatibleLinear(inner_dim, dim_out)) # FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout if final_dropout: self.net.append(nn.Dropout(dropout)) def forward(self, hidden_states): for module in self.net: hidden_states = module(hidden_states) return hidden_states @maybe_allow_in_graph class BasicTransformerBlock(nn.Module): r""" A basic Transformer block. Parameters: dim (`int`): The number of channels in the input and output. num_attention_heads (`int`): The number of heads to use for multi-head attention. attention_head_dim (`int`): The number of channels in each head. dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use. cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention. only_cross_attention (`bool`, *optional*): Whether to use only cross-attention layers. In this case two cross attention layers are used. double_self_attention (`bool`, *optional*): Whether to use two self-attention layers. In this case no cross attention layers are used. activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward. num_embeds_ada_norm (: obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`. attention_bias (: obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter. """ def __init__( self, dim: int, num_attention_heads: int, attention_head_dim: int, dropout=0.0, cross_attention_dim: Optional[int] = None, activation_fn: str = "geglu", num_embeds_ada_norm: Optional[int] = None, attention_bias: bool = False, only_cross_attention: bool = False, double_self_attention: bool = False, upcast_attention: bool = False, norm_elementwise_affine: bool = True, norm_type: str = "layer_norm", final_dropout: bool = False, ): super().__init__() self.only_cross_attention = only_cross_attention self.use_ada_layer_norm_zero = (num_embeds_ada_norm is not None) and norm_type == "ada_norm_zero" self.use_ada_layer_norm = (num_embeds_ada_norm is not None) and norm_type == "ada_norm" if norm_type in ("ada_norm", "ada_norm_zero") and num_embeds_ada_norm is None: raise ValueError( f"`norm_type` is set to {norm_type}, but `num_embeds_ada_norm` is not defined. Please make sure to" f" define `num_embeds_ada_norm` if setting `norm_type` to {norm_type}." ) # Define 3 blocks. Each block has its own normalization layer. # 1. Self-Attn if self.use_ada_layer_norm: self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm) elif self.use_ada_layer_norm_zero: self.norm1 = AdaLayerNormZero(dim, num_embeds_ada_norm) else: self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) self.attn1 = Attention( query_dim=dim, heads=num_attention_heads, dim_head=attention_head_dim, dropout=dropout, bias=attention_bias, cross_attention_dim=cross_attention_dim if only_cross_attention else None, upcast_attention=upcast_attention, ) # 2. Cross-Attn if cross_attention_dim is not None or double_self_attention: # We currently only use AdaLayerNormZero for self attention where there will only be one attention block. # I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during # the second cross attention block. self.norm2 = ( AdaLayerNorm(dim, num_embeds_ada_norm) if self.use_ada_layer_norm else nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) ) self.attn2 = Attention( query_dim=dim, cross_attention_dim=cross_attention_dim if not double_self_attention else None, heads=num_attention_heads, dim_head=attention_head_dim, dropout=dropout, bias=attention_bias, upcast_attention=upcast_attention, # scale_qk=False, # uncomment this to not to use flash attention ) # is self-attn if encoder_hidden_states is none else: self.norm2 = None self.attn2 = None # 3. Feed-forward self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine) self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout) # let chunk size default to None self._chunk_size = None self._chunk_dim = 0 def set_chunk_feed_forward(self, chunk_size: Optional[int], dim: int): # Sets chunk feed-forward self._chunk_size = chunk_size self._chunk_dim = dim def forward( self, hidden_states: torch.FloatTensor, attention_mask: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.FloatTensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, timestep: Optional[torch.LongTensor] = None, cross_attention_kwargs: Dict[str, Any] = None, class_labels: Optional[torch.LongTensor] = None, ): # Notice that normalization is always applied before the real computation in the following blocks. # 1. Self-Attention if self.use_ada_layer_norm: norm_hidden_states = self.norm1(hidden_states, timestep) elif self.use_ada_layer_norm_zero: norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1( hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype ) else: norm_hidden_states = self.norm1(hidden_states) cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {} attn_output = self.attn1( norm_hidden_states, encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None, attention_mask=encoder_attention_mask if self.only_cross_attention else attention_mask, **cross_attention_kwargs, ) if self.use_ada_layer_norm_zero: attn_output = gate_msa.unsqueeze(1) * attn_output hidden_states = attn_output + hidden_states # 2. Cross-Attention if self.attn2 is not None: norm_hidden_states = ( self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states) ) attn_output = self.attn2( norm_hidden_states, encoder_hidden_states=encoder_hidden_states, attention_mask=encoder_attention_mask, **cross_attention_kwargs, ) hidden_states = attn_output + hidden_states # 3. Feed-forward norm_hidden_states = self.norm3(hidden_states) if self.use_ada_layer_norm_zero: norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None] if self._chunk_size is not None: # "feed_forward_chunk_size" can be used to save memory if norm_hidden_states.shape[self._chunk_dim] % self._chunk_size != 0: raise ValueError( f"`hidden_states` dimension to be chunked: {norm_hidden_states.shape[self._chunk_dim]} has to be divisible by chunk size: {self._chunk_size}. Make sure to set an appropriate `chunk_size` when calling `unet.enable_forward_chunking`." ) num_chunks = norm_hidden_states.shape[self._chunk_dim] // self._chunk_size ff_output = torch.cat( [self.ff(hid_slice) for hid_slice in norm_hidden_states.chunk(num_chunks, dim=self._chunk_dim)], dim=self._chunk_dim, ) else: ff_output = self.ff(norm_hidden_states) if self.use_ada_layer_norm_zero: ff_output = gate_mlp.unsqueeze(1) * ff_output hidden_states = ff_output + hidden_states return hidden_states ================================================ FILE: third_party/Matcha-TTS/matcha/models/matcha_tts.py ================================================ import datetime as dt import math import random import torch import matcha.utils.monotonic_align as monotonic_align from matcha import utils from matcha.models.baselightningmodule import BaseLightningClass from matcha.models.components.flow_matching import CFM from matcha.models.components.text_encoder import TextEncoder from matcha.utils.model import ( denormalize, duration_loss, fix_len_compatibility, generate_path, sequence_mask, ) log = utils.get_pylogger(__name__) class MatchaTTS(BaseLightningClass): # 🍵 def __init__( self, n_vocab, n_spks, spk_emb_dim, n_feats, encoder, decoder, cfm, data_statistics, out_size, optimizer=None, scheduler=None, prior_loss=True, ): super().__init__() self.save_hyperparameters(logger=False) self.n_vocab = n_vocab self.n_spks = n_spks self.spk_emb_dim = spk_emb_dim self.n_feats = n_feats self.out_size = out_size self.prior_loss = prior_loss if n_spks > 1: self.spk_emb = torch.nn.Embedding(n_spks, spk_emb_dim) self.encoder = TextEncoder( encoder.encoder_type, encoder.encoder_params, encoder.duration_predictor_params, n_vocab, n_spks, spk_emb_dim, ) self.decoder = CFM( in_channels=2 * encoder.encoder_params.n_feats, out_channel=encoder.encoder_params.n_feats, cfm_params=cfm, decoder_params=decoder, n_spks=n_spks, spk_emb_dim=spk_emb_dim, ) self.update_data_statistics(data_statistics) @torch.inference_mode() def synthesise(self, x, x_lengths, n_timesteps, temperature=1.0, spks=None, length_scale=1.0): """ Generates mel-spectrogram from text. Returns: 1. encoder outputs 2. decoder outputs 3. generated alignment Args: x (torch.Tensor): batch of texts, converted to a tensor with phoneme embedding ids. shape: (batch_size, max_text_length) x_lengths (torch.Tensor): lengths of texts in batch. shape: (batch_size,) n_timesteps (int): number of steps to use for reverse diffusion in decoder. temperature (float, optional): controls variance of terminal distribution. spks (bool, optional): speaker ids. shape: (batch_size,) length_scale (float, optional): controls speech pace. Increase value to slow down generated speech and vice versa. Returns: dict: { "encoder_outputs": torch.Tensor, shape: (batch_size, n_feats, max_mel_length), # Average mel spectrogram generated by the encoder "decoder_outputs": torch.Tensor, shape: (batch_size, n_feats, max_mel_length), # Refined mel spectrogram improved by the CFM "attn": torch.Tensor, shape: (batch_size, max_text_length, max_mel_length), # Alignment map between text and mel spectrogram "mel": torch.Tensor, shape: (batch_size, n_feats, max_mel_length), # Denormalized mel spectrogram "mel_lengths": torch.Tensor, shape: (batch_size,), # Lengths of mel spectrograms "rtf": float, # Real-time factor """ # For RTF computation t = dt.datetime.now() if self.n_spks > 1: # Get speaker embedding spks = self.spk_emb(spks.long()) # Get encoder_outputs `mu_x` and log-scaled token durations `logw` mu_x, logw, x_mask = self.encoder(x, x_lengths, spks) w = torch.exp(logw) * x_mask w_ceil = torch.ceil(w) * length_scale y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() y_max_length = y_lengths.max() y_max_length_ = fix_len_compatibility(y_max_length) # Using obtained durations `w` construct alignment map `attn` y_mask = sequence_mask(y_lengths, y_max_length_).unsqueeze(1).to(x_mask.dtype) attn_mask = x_mask.unsqueeze(-1) * y_mask.unsqueeze(2) attn = generate_path(w_ceil.squeeze(1), attn_mask.squeeze(1)).unsqueeze(1) # Align encoded text and get mu_y mu_y = torch.matmul(attn.squeeze(1).transpose(1, 2), mu_x.transpose(1, 2)) mu_y = mu_y.transpose(1, 2) encoder_outputs = mu_y[:, :, :y_max_length] # Generate sample tracing the probability flow decoder_outputs = self.decoder(mu_y, y_mask, n_timesteps, temperature, spks) decoder_outputs = decoder_outputs[:, :, :y_max_length] t = (dt.datetime.now() - t).total_seconds() rtf = t * 22050 / (decoder_outputs.shape[-1] * 256) return { "encoder_outputs": encoder_outputs, "decoder_outputs": decoder_outputs, "attn": attn[:, :, :y_max_length], "mel": denormalize(decoder_outputs, self.mel_mean, self.mel_std), "mel_lengths": y_lengths, "rtf": rtf, } def forward(self, x, x_lengths, y, y_lengths, spks=None, out_size=None, cond=None): """ Computes 3 losses: 1. duration loss: loss between predicted token durations and those extracted by Monotinic Alignment Search (MAS). 2. prior loss: loss between mel-spectrogram and encoder outputs. 3. flow matching loss: loss between mel-spectrogram and decoder outputs. Args: x (torch.Tensor): batch of texts, converted to a tensor with phoneme embedding ids. shape: (batch_size, max_text_length) x_lengths (torch.Tensor): lengths of texts in batch. shape: (batch_size,) y (torch.Tensor): batch of corresponding mel-spectrograms. shape: (batch_size, n_feats, max_mel_length) y_lengths (torch.Tensor): lengths of mel-spectrograms in batch. shape: (batch_size,) out_size (int, optional): length (in mel's sampling rate) of segment to cut, on which decoder will be trained. Should be divisible by 2^{num of UNet downsamplings}. Needed to increase batch size. spks (torch.Tensor, optional): speaker ids. shape: (batch_size,) """ if self.n_spks > 1: # Get speaker embedding spks = self.spk_emb(spks) # Get encoder_outputs `mu_x` and log-scaled token durations `logw` mu_x, logw, x_mask = self.encoder(x, x_lengths, spks) y_max_length = y.shape[-1] y_mask = sequence_mask(y_lengths, y_max_length).unsqueeze(1).to(x_mask) attn_mask = x_mask.unsqueeze(-1) * y_mask.unsqueeze(2) # Use MAS to find most likely alignment `attn` between text and mel-spectrogram with torch.no_grad(): const = -0.5 * math.log(2 * math.pi) * self.n_feats factor = -0.5 * torch.ones(mu_x.shape, dtype=mu_x.dtype, device=mu_x.device) y_square = torch.matmul(factor.transpose(1, 2), y**2) y_mu_double = torch.matmul(2.0 * (factor * mu_x).transpose(1, 2), y) mu_square = torch.sum(factor * (mu_x**2), 1).unsqueeze(-1) log_prior = y_square - y_mu_double + mu_square + const attn = monotonic_align.maximum_path(log_prior, attn_mask.squeeze(1)) attn = attn.detach() # Compute loss between predicted log-scaled durations and those obtained from MAS # refered to as prior loss in the paper logw_ = torch.log(1e-8 + torch.sum(attn.unsqueeze(1), -1)) * x_mask dur_loss = duration_loss(logw, logw_, x_lengths) # Cut a small segment of mel-spectrogram in order to increase batch size # - "Hack" taken from Grad-TTS, in case of Grad-TTS, we cannot train batch size 32 on a 24GB GPU without it # - Do not need this hack for Matcha-TTS, but it works with it as well if not isinstance(out_size, type(None)): max_offset = (y_lengths - out_size).clamp(0) offset_ranges = list(zip([0] * max_offset.shape[0], max_offset.cpu().numpy())) out_offset = torch.LongTensor( [torch.tensor(random.choice(range(start, end)) if end > start else 0) for start, end in offset_ranges] ).to(y_lengths) attn_cut = torch.zeros(attn.shape[0], attn.shape[1], out_size, dtype=attn.dtype, device=attn.device) y_cut = torch.zeros(y.shape[0], self.n_feats, out_size, dtype=y.dtype, device=y.device) y_cut_lengths = [] for i, (y_, out_offset_) in enumerate(zip(y, out_offset)): y_cut_length = out_size + (y_lengths[i] - out_size).clamp(None, 0) y_cut_lengths.append(y_cut_length) cut_lower, cut_upper = out_offset_, out_offset_ + y_cut_length y_cut[i, :, :y_cut_length] = y_[:, cut_lower:cut_upper] attn_cut[i, :, :y_cut_length] = attn[i, :, cut_lower:cut_upper] y_cut_lengths = torch.LongTensor(y_cut_lengths) y_cut_mask = sequence_mask(y_cut_lengths).unsqueeze(1).to(y_mask) attn = attn_cut y = y_cut y_mask = y_cut_mask # Align encoded text with mel-spectrogram and get mu_y segment mu_y = torch.matmul(attn.squeeze(1).transpose(1, 2), mu_x.transpose(1, 2)) mu_y = mu_y.transpose(1, 2) # Compute loss of the decoder diff_loss, _ = self.decoder.compute_loss(x1=y, mask=y_mask, mu=mu_y, spks=spks, cond=cond) if self.prior_loss: prior_loss = torch.sum(0.5 * ((y - mu_y) ** 2 + math.log(2 * math.pi)) * y_mask) prior_loss = prior_loss / (torch.sum(y_mask) * self.n_feats) else: prior_loss = 0 return dur_loss, prior_loss, diff_loss ================================================ FILE: third_party/Matcha-TTS/matcha/onnx/__init__.py ================================================ ================================================ FILE: third_party/Matcha-TTS/matcha/onnx/export.py ================================================ import argparse import random from pathlib import Path import numpy as np import torch from lightning import LightningModule from matcha.cli import VOCODER_URLS, load_matcha, load_vocoder DEFAULT_OPSET = 15 SEED = 1234 random.seed(SEED) np.random.seed(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False class MatchaWithVocoder(LightningModule): def __init__(self, matcha, vocoder): super().__init__() self.matcha = matcha self.vocoder = vocoder def forward(self, x, x_lengths, scales, spks=None): mel, mel_lengths = self.matcha(x, x_lengths, scales, spks) wavs = self.vocoder(mel).clamp(-1, 1) lengths = mel_lengths * 256 return wavs.squeeze(1), lengths def get_exportable_module(matcha, vocoder, n_timesteps): """ Return an appropriate `LighteningModule` and output-node names based on whether the vocoder is embedded in the final graph """ def onnx_forward_func(x, x_lengths, scales, spks=None): """ Custom forward function for accepting scaler parameters as tensors """ # Extract scaler parameters from tensors temperature = scales[0] length_scale = scales[1] output = matcha.synthesise(x, x_lengths, n_timesteps, temperature, spks, length_scale) return output["mel"], output["mel_lengths"] # Monkey-patch Matcha's forward function matcha.forward = onnx_forward_func if vocoder is None: model, output_names = matcha, ["mel", "mel_lengths"] else: model = MatchaWithVocoder(matcha, vocoder) output_names = ["wav", "wav_lengths"] return model, output_names def get_inputs(is_multi_speaker): """ Create dummy inputs for tracing """ dummy_input_length = 50 x = torch.randint(low=0, high=20, size=(1, dummy_input_length), dtype=torch.long) x_lengths = torch.LongTensor([dummy_input_length]) # Scales temperature = 0.667 length_scale = 1.0 scales = torch.Tensor([temperature, length_scale]) model_inputs = [x, x_lengths, scales] input_names = [ "x", "x_lengths", "scales", ] if is_multi_speaker: spks = torch.LongTensor([1]) model_inputs.append(spks) input_names.append("spks") return tuple(model_inputs), input_names def main(): parser = argparse.ArgumentParser(description="Export 🍵 Matcha-TTS to ONNX") parser.add_argument( "checkpoint_path", type=str, help="Path to the model checkpoint", ) parser.add_argument("output", type=str, help="Path to output `.onnx` file") parser.add_argument( "--n-timesteps", type=int, default=5, help="Number of steps to use for reverse diffusion in decoder (default 5)" ) parser.add_argument( "--vocoder-name", type=str, choices=list(VOCODER_URLS.keys()), default=None, help="Name of the vocoder to embed in the ONNX graph", ) parser.add_argument( "--vocoder-checkpoint-path", type=str, default=None, help="Vocoder checkpoint to embed in the ONNX graph for an `e2e` like experience", ) parser.add_argument("--opset", type=int, default=DEFAULT_OPSET, help="ONNX opset version to use (default 15") args = parser.parse_args() print(f"[🍵] Loading Matcha checkpoint from {args.checkpoint_path}") print(f"Setting n_timesteps to {args.n_timesteps}") checkpoint_path = Path(args.checkpoint_path) matcha = load_matcha(checkpoint_path.stem, checkpoint_path, "cpu") if args.vocoder_name or args.vocoder_checkpoint_path: assert ( args.vocoder_name and args.vocoder_checkpoint_path ), "Both vocoder_name and vocoder-checkpoint are required when embedding the vocoder in the ONNX graph." vocoder, _ = load_vocoder(args.vocoder_name, args.vocoder_checkpoint_path, "cpu") else: vocoder = None is_multi_speaker = matcha.n_spks > 1 dummy_input, input_names = get_inputs(is_multi_speaker) model, output_names = get_exportable_module(matcha, vocoder, args.n_timesteps) # Set dynamic shape for inputs/outputs dynamic_axes = { "x": {0: "batch_size", 1: "time"}, "x_lengths": {0: "batch_size"}, } if vocoder is None: dynamic_axes.update( { "mel": {0: "batch_size", 2: "time"}, "mel_lengths": {0: "batch_size"}, } ) else: print("Embedding the vocoder in the ONNX graph") dynamic_axes.update( { "wav": {0: "batch_size", 1: "time"}, "wav_lengths": {0: "batch_size"}, } ) if is_multi_speaker: dynamic_axes["spks"] = {0: "batch_size"} # Create the output directory (if not exists) Path(args.output).parent.mkdir(parents=True, exist_ok=True) model.to_onnx( args.output, dummy_input, input_names=input_names, output_names=output_names, dynamic_axes=dynamic_axes, opset_version=args.opset, export_params=True, do_constant_folding=True, ) print(f"[🍵] ONNX model exported to {args.output}") if __name__ == "__main__": main() ================================================ FILE: third_party/Matcha-TTS/matcha/onnx/infer.py ================================================ import argparse import os import warnings from pathlib import Path from time import perf_counter import numpy as np import onnxruntime as ort import soundfile as sf import torch from matcha.cli import plot_spectrogram_to_numpy, process_text def validate_args(args): assert ( args.text or args.file ), "Either text or file must be provided Matcha-T(ea)TTS need sometext to whisk the waveforms." assert args.temperature >= 0, "Sampling temperature cannot be negative" assert args.speaking_rate >= 0, "Speaking rate must be greater than 0" return args def write_wavs(model, inputs, output_dir, external_vocoder=None): if external_vocoder is None: print("The provided model has the vocoder embedded in the graph.\nGenerating waveform directly") t0 = perf_counter() wavs, wav_lengths = model.run(None, inputs) infer_secs = perf_counter() - t0 mel_infer_secs = vocoder_infer_secs = None else: print("[🍵] Generating mel using Matcha") mel_t0 = perf_counter() mels, mel_lengths = model.run(None, inputs) mel_infer_secs = perf_counter() - mel_t0 print("Generating waveform from mel using external vocoder") vocoder_inputs = {external_vocoder.get_inputs()[0].name: mels} vocoder_t0 = perf_counter() wavs = external_vocoder.run(None, vocoder_inputs)[0] vocoder_infer_secs = perf_counter() - vocoder_t0 wavs = wavs.squeeze(1) wav_lengths = mel_lengths * 256 infer_secs = mel_infer_secs + vocoder_infer_secs output_dir = Path(output_dir) output_dir.mkdir(parents=True, exist_ok=True) for i, (wav, wav_length) in enumerate(zip(wavs, wav_lengths)): output_filename = output_dir.joinpath(f"output_{i + 1}.wav") audio = wav[:wav_length] print(f"Writing audio to {output_filename}") sf.write(output_filename, audio, 22050, "PCM_24") wav_secs = wav_lengths.sum() / 22050 print(f"Inference seconds: {infer_secs}") print(f"Generated wav seconds: {wav_secs}") rtf = infer_secs / wav_secs if mel_infer_secs is not None: mel_rtf = mel_infer_secs / wav_secs print(f"Matcha RTF: {mel_rtf}") if vocoder_infer_secs is not None: vocoder_rtf = vocoder_infer_secs / wav_secs print(f"Vocoder RTF: {vocoder_rtf}") print(f"Overall RTF: {rtf}") def write_mels(model, inputs, output_dir): t0 = perf_counter() mels, mel_lengths = model.run(None, inputs) infer_secs = perf_counter() - t0 output_dir = Path(output_dir) output_dir.mkdir(parents=True, exist_ok=True) for i, mel in enumerate(mels): output_stem = output_dir.joinpath(f"output_{i + 1}") plot_spectrogram_to_numpy(mel.squeeze(), output_stem.with_suffix(".png")) np.save(output_stem.with_suffix(".numpy"), mel) wav_secs = (mel_lengths * 256).sum() / 22050 print(f"Inference seconds: {infer_secs}") print(f"Generated wav seconds: {wav_secs}") rtf = infer_secs / wav_secs print(f"RTF: {rtf}") def main(): parser = argparse.ArgumentParser( description=" 🍵 Matcha-TTS: A fast TTS architecture with conditional flow matching" ) parser.add_argument( "model", type=str, help="ONNX model to use", ) parser.add_argument("--vocoder", type=str, default=None, help="Vocoder to use (defaults to None)") parser.add_argument("--text", type=str, default=None, help="Text to synthesize") parser.add_argument("--file", type=str, default=None, help="Text file to synthesize") parser.add_argument("--spk", type=int, default=None, help="Speaker ID") parser.add_argument( "--temperature", type=float, default=0.667, help="Variance of the x0 noise (default: 0.667)", ) parser.add_argument( "--speaking-rate", type=float, default=1.0, help="change the speaking rate, a higher value means slower speaking rate (default: 1.0)", ) parser.add_argument("--gpu", action="store_true", help="Use CPU for inference (default: use GPU if available)") parser.add_argument( "--output-dir", type=str, default=os.getcwd(), help="Output folder to save results (default: current dir)", ) args = parser.parse_args() args = validate_args(args) if args.gpu: providers = ["GPUExecutionProvider"] else: providers = ["CPUExecutionProvider"] model = ort.InferenceSession(args.model, providers=providers) model_inputs = model.get_inputs() model_outputs = list(model.get_outputs()) if args.text: text_lines = args.text.splitlines() else: with open(args.file, encoding="utf-8") as file: text_lines = file.read().splitlines() processed_lines = [process_text(0, line, "cpu") for line in text_lines] x = [line["x"].squeeze() for line in processed_lines] # Pad x = torch.nn.utils.rnn.pad_sequence(x, batch_first=True) x = x.detach().cpu().numpy() x_lengths = np.array([line["x_lengths"].item() for line in processed_lines], dtype=np.int64) inputs = { "x": x, "x_lengths": x_lengths, "scales": np.array([args.temperature, args.speaking_rate], dtype=np.float32), } is_multi_speaker = len(model_inputs) == 4 if is_multi_speaker: if args.spk is None: args.spk = 0 warn = "[!] Speaker ID not provided! Using speaker ID 0" warnings.warn(warn, UserWarning) inputs["spks"] = np.repeat(args.spk, x.shape[0]).astype(np.int64) has_vocoder_embedded = model_outputs[0].name == "wav" if has_vocoder_embedded: write_wavs(model, inputs, args.output_dir) elif args.vocoder: external_vocoder = ort.InferenceSession(args.vocoder, providers=providers) write_wavs(model, inputs, args.output_dir, external_vocoder=external_vocoder) else: warn = "[!] A vocoder is not embedded in the graph nor an external vocoder is provided. The mel output will be written as numpy arrays to `*.npy` files in the output directory" warnings.warn(warn, UserWarning) write_mels(model, inputs, args.output_dir) if __name__ == "__main__": main() ================================================ FILE: third_party/Matcha-TTS/matcha/text/__init__.py ================================================ """ from https://github.com/keithito/tacotron """ from matcha.text import cleaners from matcha.text.symbols import symbols # Mappings from symbol to numeric ID and vice versa: _symbol_to_id = {s: i for i, s in enumerate(symbols)} _id_to_symbol = {i: s for i, s in enumerate(symbols)} # pylint: disable=unnecessary-comprehension def text_to_sequence(text, cleaner_names): """Converts a string of text to a sequence of IDs corresponding to the symbols in the text. Args: text: string to convert to a sequence cleaner_names: names of the cleaner functions to run the text through Returns: List of integers corresponding to the symbols in the text """ sequence = [] clean_text = _clean_text(text, cleaner_names) for symbol in clean_text: symbol_id = _symbol_to_id[symbol] sequence += [symbol_id] return sequence def cleaned_text_to_sequence(cleaned_text): """Converts a string of text to a sequence of IDs corresponding to the symbols in the text. Args: text: string to convert to a sequence Returns: List of integers corresponding to the symbols in the text """ sequence = [_symbol_to_id[symbol] for symbol in cleaned_text] return sequence def sequence_to_text(sequence): """Converts a sequence of IDs back to a string""" result = "" for symbol_id in sequence: s = _id_to_symbol[symbol_id] result += s return result def _clean_text(text, cleaner_names): for name in cleaner_names: cleaner = getattr(cleaners, name) if not cleaner: raise Exception("Unknown cleaner: %s" % name) text = cleaner(text) return text ================================================ FILE: third_party/Matcha-TTS/matcha/text/cleaners.py ================================================ """ from https://github.com/keithito/tacotron Cleaners are transformations that run over the input text at both training and eval time. Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners" hyperparameter. Some cleaners are English-specific. You'll typically want to use: 1. "english_cleaners" for English text 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using the Unidecode library (https://pypi.python.org/pypi/Unidecode) 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update the symbols in symbols.py to match your data). """ import logging import re import phonemizer import piper_phonemize from unidecode import unidecode # To avoid excessive logging we set the log level of the phonemizer package to Critical critical_logger = logging.getLogger("phonemizer") critical_logger.setLevel(logging.CRITICAL) # Intializing the phonemizer globally significantly reduces the speed # now the phonemizer is not initialising at every call # Might be less flexible, but it is much-much faster global_phonemizer = phonemizer.backend.EspeakBackend( language="en-us", preserve_punctuation=True, with_stress=True, language_switch="remove-flags", logger=critical_logger, ) # Regular expression matching whitespace: _whitespace_re = re.compile(r"\s+") # List of (regular expression, replacement) pairs for abbreviations: _abbreviations = [ (re.compile("\\b%s\\." % x[0], re.IGNORECASE), x[1]) for x in [ ("mrs", "misess"), ("mr", "mister"), ("dr", "doctor"), ("st", "saint"), ("co", "company"), ("jr", "junior"), ("maj", "major"), ("gen", "general"), ("drs", "doctors"), ("rev", "reverend"), ("lt", "lieutenant"), ("hon", "honorable"), ("sgt", "sergeant"), ("capt", "captain"), ("esq", "esquire"), ("ltd", "limited"), ("col", "colonel"), ("ft", "fort"), ] ] def expand_abbreviations(text): for regex, replacement in _abbreviations: text = re.sub(regex, replacement, text) return text def lowercase(text): return text.lower() def collapse_whitespace(text): return re.sub(_whitespace_re, " ", text) def convert_to_ascii(text): return unidecode(text) def basic_cleaners(text): """Basic pipeline that lowercases and collapses whitespace without transliteration.""" text = lowercase(text) text = collapse_whitespace(text) return text def transliteration_cleaners(text): """Pipeline for non-English text that transliterates to ASCII.""" text = convert_to_ascii(text) text = lowercase(text) text = collapse_whitespace(text) return text def english_cleaners2(text): """Pipeline for English text, including abbreviation expansion. + punctuation + stress""" text = convert_to_ascii(text) text = lowercase(text) text = expand_abbreviations(text) phonemes = global_phonemizer.phonemize([text], strip=True, njobs=1)[0] phonemes = collapse_whitespace(phonemes) return phonemes def english_cleaners_piper(text): """Pipeline for English text, including abbreviation expansion. + punctuation + stress""" text = convert_to_ascii(text) text = lowercase(text) text = expand_abbreviations(text) phonemes = "".join(piper_phonemize.phonemize_espeak(text=text, voice="en-US")[0]) phonemes = collapse_whitespace(phonemes) return phonemes ================================================ FILE: third_party/Matcha-TTS/matcha/text/numbers.py ================================================ """ from https://github.com/keithito/tacotron """ import re import inflect _inflect = inflect.engine() _comma_number_re = re.compile(r"([0-9][0-9\,]+[0-9])") _decimal_number_re = re.compile(r"([0-9]+\.[0-9]+)") _pounds_re = re.compile(r"£([0-9\,]*[0-9]+)") _dollars_re = re.compile(r"\$([0-9\.\,]*[0-9]+)") _ordinal_re = re.compile(r"[0-9]+(st|nd|rd|th)") _number_re = re.compile(r"[0-9]+") def _remove_commas(m): return m.group(1).replace(",", "") def _expand_decimal_point(m): return m.group(1).replace(".", " point ") def _expand_dollars(m): match = m.group(1) parts = match.split(".") if len(parts) > 2: return match + " dollars" dollars = int(parts[0]) if parts[0] else 0 cents = int(parts[1]) if len(parts) > 1 and parts[1] else 0 if dollars and cents: dollar_unit = "dollar" if dollars == 1 else "dollars" cent_unit = "cent" if cents == 1 else "cents" return f"{dollars} {dollar_unit}, {cents} {cent_unit}" elif dollars: dollar_unit = "dollar" if dollars == 1 else "dollars" return f"{dollars} {dollar_unit}" elif cents: cent_unit = "cent" if cents == 1 else "cents" return f"{cents} {cent_unit}" else: return "zero dollars" def _expand_ordinal(m): return _inflect.number_to_words(m.group(0)) def _expand_number(m): num = int(m.group(0)) if num > 1000 and num < 3000: if num == 2000: return "two thousand" elif num > 2000 and num < 2010: return "two thousand " + _inflect.number_to_words(num % 100) elif num % 100 == 0: return _inflect.number_to_words(num // 100) + " hundred" else: return _inflect.number_to_words(num, andword="", zero="oh", group=2).replace(", ", " ") else: return _inflect.number_to_words(num, andword="") def normalize_numbers(text): text = re.sub(_comma_number_re, _remove_commas, text) text = re.sub(_pounds_re, r"\1 pounds", text) text = re.sub(_dollars_re, _expand_dollars, text) text = re.sub(_decimal_number_re, _expand_decimal_point, text) text = re.sub(_ordinal_re, _expand_ordinal, text) text = re.sub(_number_re, _expand_number, text) return text ================================================ FILE: third_party/Matcha-TTS/matcha/text/symbols.py ================================================ """ from https://github.com/keithito/tacotron Defines the set of symbols used in text input to the model. """ _pad = "_" _punctuation = ';:,.!?¡¿—…"«»“” ' _letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" _letters_ipa = ( "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ" ) # Export all symbols: symbols = [_pad] + list(_punctuation) + list(_letters) + list(_letters_ipa) # Special symbol ids SPACE_ID = symbols.index(" ") ================================================ FILE: third_party/Matcha-TTS/matcha/train.py ================================================ from typing import Any, Dict, List, Optional, Tuple import hydra import lightning as L import rootutils from lightning import Callback, LightningDataModule, LightningModule, Trainer from lightning.pytorch.loggers import Logger from omegaconf import DictConfig from matcha import utils rootutils.setup_root(__file__, indicator=".project-root", pythonpath=True) # ------------------------------------------------------------------------------------ # # the setup_root above is equivalent to: # - adding project root dir to PYTHONPATH # (so you don't need to force user to install project as a package) # (necessary before importing any local modules e.g. `from src import utils`) # - setting up PROJECT_ROOT environment variable # (which is used as a base for paths in "configs/paths/default.yaml") # (this way all filepaths are the same no matter where you run the code) # - loading environment variables from ".env" in root dir # # you can remove it if you: # 1. either install project as a package or move entry files to project root dir # 2. set `root_dir` to "." in "configs/paths/default.yaml" # # more info: https://github.com/ashleve/rootutils # ------------------------------------------------------------------------------------ # log = utils.get_pylogger(__name__) @utils.task_wrapper def train(cfg: DictConfig) -> Tuple[Dict[str, Any], Dict[str, Any]]: """Trains the model. Can additionally evaluate on a testset, using best weights obtained during training. This method is wrapped in optional @task_wrapper decorator, that controls the behavior during failure. Useful for multiruns, saving info about the crash, etc. :param cfg: A DictConfig configuration composed by Hydra. :return: A tuple with metrics and dict with all instantiated objects. """ # set seed for random number generators in pytorch, numpy and python.random if cfg.get("seed"): L.seed_everything(cfg.seed, workers=True) log.info(f"Instantiating datamodule <{cfg.data._target_}>") # pylint: disable=protected-access datamodule: LightningDataModule = hydra.utils.instantiate(cfg.data) log.info(f"Instantiating model <{cfg.model._target_}>") # pylint: disable=protected-access model: LightningModule = hydra.utils.instantiate(cfg.model) log.info("Instantiating callbacks...") callbacks: List[Callback] = utils.instantiate_callbacks(cfg.get("callbacks")) log.info("Instantiating loggers...") logger: List[Logger] = utils.instantiate_loggers(cfg.get("logger")) log.info(f"Instantiating trainer <{cfg.trainer._target_}>") # pylint: disable=protected-access trainer: Trainer = hydra.utils.instantiate(cfg.trainer, callbacks=callbacks, logger=logger) object_dict = { "cfg": cfg, "datamodule": datamodule, "model": model, "callbacks": callbacks, "logger": logger, "trainer": trainer, } if logger: log.info("Logging hyperparameters!") utils.log_hyperparameters(object_dict) if cfg.get("train"): log.info("Starting training!") trainer.fit(model=model, datamodule=datamodule, ckpt_path=cfg.get("ckpt_path")) train_metrics = trainer.callback_metrics if cfg.get("test"): log.info("Starting testing!") ckpt_path = trainer.checkpoint_callback.best_model_path if ckpt_path == "": log.warning("Best ckpt not found! Using current weights for testing...") ckpt_path = None trainer.test(model=model, datamodule=datamodule, ckpt_path=ckpt_path) log.info(f"Best ckpt path: {ckpt_path}") test_metrics = trainer.callback_metrics # merge train and test metrics metric_dict = {**train_metrics, **test_metrics} return metric_dict, object_dict @hydra.main(version_base="1.3", config_path="../configs", config_name="train.yaml") def main(cfg: DictConfig) -> Optional[float]: """Main entry point for training. :param cfg: DictConfig configuration composed by Hydra. :return: Optional[float] with optimized metric value. """ # apply extra utilities # (e.g. ask for tags if none are provided in cfg, print cfg tree, etc.) utils.extras(cfg) # train the model metric_dict, _ = train(cfg) # safely retrieve metric value for hydra-based hyperparameter optimization metric_value = utils.get_metric_value(metric_dict=metric_dict, metric_name=cfg.get("optimized_metric")) # return optimized metric return metric_value if __name__ == "__main__": main() # pylint: disable=no-value-for-parameter ================================================ FILE: third_party/Matcha-TTS/matcha/utils/__init__.py ================================================ from matcha.utils.instantiators import instantiate_callbacks, instantiate_loggers from matcha.utils.logging_utils import log_hyperparameters from matcha.utils.pylogger import get_pylogger from matcha.utils.rich_utils import enforce_tags, print_config_tree from matcha.utils.utils import extras, get_metric_value, task_wrapper ================================================ FILE: third_party/Matcha-TTS/matcha/utils/audio.py ================================================ import numpy as np import torch import torch.utils.data from librosa.filters import mel as librosa_mel_fn from scipy.io.wavfile import read MAX_WAV_VALUE = 32768.0 def load_wav(full_path): sampling_rate, data = read(full_path) return data, sampling_rate def dynamic_range_compression(x, C=1, clip_val=1e-5): return np.log(np.clip(x, a_min=clip_val, a_max=None) * C) def dynamic_range_decompression(x, C=1): return np.exp(x) / C def dynamic_range_compression_torch(x, C=1, clip_val=1e-5): return torch.log(torch.clamp(x, min=clip_val) * C) def dynamic_range_decompression_torch(x, C=1): return torch.exp(x) / C def spectral_normalize_torch(magnitudes): output = dynamic_range_compression_torch(magnitudes) return output def spectral_de_normalize_torch(magnitudes): output = dynamic_range_decompression_torch(magnitudes) return output mel_basis = {} hann_window = {} def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False): if torch.min(y) < -1.0: print("min value is ", torch.min(y)) if torch.max(y) > 1.0: print("max value is ", torch.max(y)) global mel_basis, hann_window # pylint: disable=global-statement if f"{str(fmax)}_{str(y.device)}" not in mel_basis: mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax) mel_basis[str(fmax) + "_" + str(y.device)] = torch.from_numpy(mel).float().to(y.device) hann_window[str(y.device)] = torch.hann_window(win_size).to(y.device) y = torch.nn.functional.pad( y.unsqueeze(1), (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)), mode="reflect" ) y = y.squeeze(1) spec = torch.view_as_real( torch.stft( y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[str(y.device)], center=center, pad_mode="reflect", normalized=False, onesided=True, return_complex=True, ) ) spec = torch.sqrt(spec.pow(2).sum(-1) + (1e-9)) spec = torch.matmul(mel_basis[str(fmax) + "_" + str(y.device)], spec) spec = spectral_normalize_torch(spec) return spec ================================================ FILE: third_party/Matcha-TTS/matcha/utils/generate_data_statistics.py ================================================ r""" The file creates a pickle file where the values needed for loading of dataset is stored and the model can load it when needed. Parameters from hparam.py will be used """ import argparse import json import os import sys from pathlib import Path import rootutils import torch from hydra import compose, initialize from omegaconf import open_dict from tqdm.auto import tqdm from matcha.data.text_mel_datamodule import TextMelDataModule from matcha.utils.logging_utils import pylogger log = pylogger.get_pylogger(__name__) def compute_data_statistics(data_loader: torch.utils.data.DataLoader, out_channels: int): """Generate data mean and standard deviation helpful in data normalisation Args: data_loader (torch.utils.data.Dataloader): _description_ out_channels (int): mel spectrogram channels """ total_mel_sum = 0 total_mel_sq_sum = 0 total_mel_len = 0 for batch in tqdm(data_loader, leave=False): mels = batch["y"] mel_lengths = batch["y_lengths"] total_mel_len += torch.sum(mel_lengths) total_mel_sum += torch.sum(mels) total_mel_sq_sum += torch.sum(torch.pow(mels, 2)) data_mean = total_mel_sum / (total_mel_len * out_channels) data_std = torch.sqrt((total_mel_sq_sum / (total_mel_len * out_channels)) - torch.pow(data_mean, 2)) return {"mel_mean": data_mean.item(), "mel_std": data_std.item()} def main(): parser = argparse.ArgumentParser() parser.add_argument( "-i", "--input-config", type=str, default="vctk.yaml", help="The name of the yaml config file under configs/data", ) parser.add_argument( "-b", "--batch-size", type=int, default="256", help="Can have increased batch size for faster computation", ) parser.add_argument( "-f", "--force", action="store_true", default=False, required=False, help="force overwrite the file", ) args = parser.parse_args() output_file = Path(args.input_config).with_suffix(".json") if os.path.exists(output_file) and not args.force: print("File already exists. Use -f to force overwrite") sys.exit(1) with initialize(version_base="1.3", config_path="../../configs/data"): cfg = compose(config_name=args.input_config, return_hydra_config=True, overrides=[]) root_path = rootutils.find_root(search_from=__file__, indicator=".project-root") with open_dict(cfg): del cfg["hydra"] del cfg["_target_"] cfg["data_statistics"] = None cfg["seed"] = 1234 cfg["batch_size"] = args.batch_size cfg["train_filelist_path"] = str(os.path.join(root_path, cfg["train_filelist_path"])) cfg["valid_filelist_path"] = str(os.path.join(root_path, cfg["valid_filelist_path"])) text_mel_datamodule = TextMelDataModule(**cfg) text_mel_datamodule.setup() data_loader = text_mel_datamodule.train_dataloader() log.info("Dataloader loaded! Now computing stats...") params = compute_data_statistics(data_loader, cfg["n_feats"]) print(params) json.dump( params, open(output_file, "w"), ) if __name__ == "__main__": main() ================================================ FILE: third_party/Matcha-TTS/matcha/utils/instantiators.py ================================================ from typing import List import hydra from lightning import Callback from lightning.pytorch.loggers import Logger from omegaconf import DictConfig from matcha.utils import pylogger log = pylogger.get_pylogger(__name__) def instantiate_callbacks(callbacks_cfg: DictConfig) -> List[Callback]: """Instantiates callbacks from config. :param callbacks_cfg: A DictConfig object containing callback configurations. :return: A list of instantiated callbacks. """ callbacks: List[Callback] = [] if not callbacks_cfg: log.warning("No callback configs found! Skipping..") return callbacks if not isinstance(callbacks_cfg, DictConfig): raise TypeError("Callbacks config must be a DictConfig!") for _, cb_conf in callbacks_cfg.items(): if isinstance(cb_conf, DictConfig) and "_target_" in cb_conf: log.info(f"Instantiating callback <{cb_conf._target_}>") # pylint: disable=protected-access callbacks.append(hydra.utils.instantiate(cb_conf)) return callbacks def instantiate_loggers(logger_cfg: DictConfig) -> List[Logger]: """Instantiates loggers from config. :param logger_cfg: A DictConfig object containing logger configurations. :return: A list of instantiated loggers. """ logger: List[Logger] = [] if not logger_cfg: log.warning("No logger configs found! Skipping...") return logger if not isinstance(logger_cfg, DictConfig): raise TypeError("Logger config must be a DictConfig!") for _, lg_conf in logger_cfg.items(): if isinstance(lg_conf, DictConfig) and "_target_" in lg_conf: log.info(f"Instantiating logger <{lg_conf._target_}>") # pylint: disable=protected-access logger.append(hydra.utils.instantiate(lg_conf)) return logger ================================================ FILE: third_party/Matcha-TTS/matcha/utils/logging_utils.py ================================================ from typing import Any, Dict from lightning.pytorch.utilities import rank_zero_only from omegaconf import OmegaConf from matcha.utils import pylogger log = pylogger.get_pylogger(__name__) @rank_zero_only def log_hyperparameters(object_dict: Dict[str, Any]) -> None: """Controls which config parts are saved by Lightning loggers. Additionally saves: - Number of model parameters :param object_dict: A dictionary containing the following objects: - `"cfg"`: A DictConfig object containing the main config. - `"model"`: The Lightning model. - `"trainer"`: The Lightning trainer. """ hparams = {} cfg = OmegaConf.to_container(object_dict["cfg"]) model = object_dict["model"] trainer = object_dict["trainer"] if not trainer.logger: log.warning("Logger not found! Skipping hyperparameter logging...") return hparams["model"] = cfg["model"] # save number of model parameters hparams["model/params/total"] = sum(p.numel() for p in model.parameters()) hparams["model/params/trainable"] = sum(p.numel() for p in model.parameters() if p.requires_grad) hparams["model/params/non_trainable"] = sum(p.numel() for p in model.parameters() if not p.requires_grad) hparams["data"] = cfg["data"] hparams["trainer"] = cfg["trainer"] hparams["callbacks"] = cfg.get("callbacks") hparams["extras"] = cfg.get("extras") hparams["task_name"] = cfg.get("task_name") hparams["tags"] = cfg.get("tags") hparams["ckpt_path"] = cfg.get("ckpt_path") hparams["seed"] = cfg.get("seed") # send hparams to all loggers for logger in trainer.loggers: logger.log_hyperparams(hparams) ================================================ FILE: third_party/Matcha-TTS/matcha/utils/model.py ================================================ """ from https://github.com/jaywalnut310/glow-tts """ import numpy as np import torch def sequence_mask(length, max_length=None): if max_length is None: max_length = length.max() x = torch.arange(max_length, dtype=length.dtype, device=length.device) return x.unsqueeze(0) < length.unsqueeze(1) def fix_len_compatibility(length, num_downsamplings_in_unet=2): factor = torch.scalar_tensor(2).pow(num_downsamplings_in_unet) length = (length / factor).ceil() * factor if not torch.onnx.is_in_onnx_export(): return length.int().item() else: return length def convert_pad_shape(pad_shape): inverted_shape = pad_shape[::-1] pad_shape = [item for sublist in inverted_shape for item in sublist] return pad_shape def generate_path(duration, mask): device = duration.device b, t_x, t_y = mask.shape cum_duration = torch.cumsum(duration, 1) path = torch.zeros(b, t_x, t_y, dtype=mask.dtype).to(device=device) cum_duration_flat = cum_duration.view(b * t_x) path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype) path = path.view(b, t_x, t_y) path = path - torch.nn.functional.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1] path = path * mask return path def duration_loss(logw, logw_, lengths): loss = torch.sum((logw - logw_) ** 2) / torch.sum(lengths) return loss def normalize(data, mu, std): if not isinstance(mu, (float, int)): if isinstance(mu, list): mu = torch.tensor(mu, dtype=data.dtype, device=data.device) elif isinstance(mu, torch.Tensor): mu = mu.to(data.device) elif isinstance(mu, np.ndarray): mu = torch.from_numpy(mu).to(data.device) mu = mu.unsqueeze(-1) if not isinstance(std, (float, int)): if isinstance(std, list): std = torch.tensor(std, dtype=data.dtype, device=data.device) elif isinstance(std, torch.Tensor): std = std.to(data.device) elif isinstance(std, np.ndarray): std = torch.from_numpy(std).to(data.device) std = std.unsqueeze(-1) return (data - mu) / std def denormalize(data, mu, std): if not isinstance(mu, float): if isinstance(mu, list): mu = torch.tensor(mu, dtype=data.dtype, device=data.device) elif isinstance(mu, torch.Tensor): mu = mu.to(data.device) elif isinstance(mu, np.ndarray): mu = torch.from_numpy(mu).to(data.device) mu = mu.unsqueeze(-1) if not isinstance(std, float): if isinstance(std, list): std = torch.tensor(std, dtype=data.dtype, device=data.device) elif isinstance(std, torch.Tensor): std = std.to(data.device) elif isinstance(std, np.ndarray): std = torch.from_numpy(std).to(data.device) std = std.unsqueeze(-1) return data * std + mu ================================================ FILE: third_party/Matcha-TTS/matcha/utils/monotonic_align/__init__.py ================================================ import numpy as np import torch from matcha.utils.monotonic_align.core import maximum_path_c def maximum_path(value, mask): """Cython optimised version. value: [b, t_x, t_y] mask: [b, t_x, t_y] """ value = value * mask device = value.device dtype = value.dtype value = value.data.cpu().numpy().astype(np.float32) path = np.zeros_like(value).astype(np.int32) mask = mask.data.cpu().numpy() t_x_max = mask.sum(1)[:, 0].astype(np.int32) t_y_max = mask.sum(2)[:, 0].astype(np.int32) maximum_path_c(path, value, t_x_max, t_y_max) return torch.from_numpy(path).to(device=device, dtype=dtype) ================================================ FILE: third_party/Matcha-TTS/matcha/utils/monotonic_align/core.c ================================================ /* Generated by Cython 0.29.35 */ /* BEGIN: Cython Metadata { "distutils": { "depends": [], "name": "matcha.utils.monotonic_align.core", "sources": [ "matcha/utils/monotonic_align/core.pyx" ] }, "module_name": "matcha.utils.monotonic_align.core" } END: Cython Metadata */ #ifndef PY_SSIZE_T_CLEAN #define PY_SSIZE_T_CLEAN #endif /* PY_SSIZE_T_CLEAN */ #include "Python.h" #ifndef Py_PYTHON_H #error Python headers needed to compile C extensions, please install development version of Python. #elif PY_VERSION_HEX < 0x02060000 || (0x03000000 <= PY_VERSION_HEX && PY_VERSION_HEX < 0x03030000) #error Cython requires Python 2.6+ or Python 3.3+. #else #define CYTHON_ABI "0_29_35" #define CYTHON_HEX_VERSION 0x001D23F0 #define CYTHON_FUTURE_DIVISION 1 #include